ddb901b051
-
-
\ No newline at end of file
diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Erio Connection Usb Modem Direct 217.md b/spaces/1gistliPinn/ChatGPT4/Examples/Erio Connection Usb Modem Direct 217.md
deleted file mode 100644
index 1dd990e25d3e7161cb3171a9186daa5d90eff5d0..0000000000000000000000000000000000000000
--- a/spaces/1gistliPinn/ChatGPT4/Examples/Erio Connection Usb Modem Direct 217.md
+++ /dev/null
@@ -1,32 +0,0 @@
-
-
-GitHub Gist: No attached data sources. GitHub Gist: Categories: Computer Science, Hardware, Software, Hacking, Hardware, Software, Hacking Tools, Online, Online Services, Online Services for Students, Computer Courses, Computational Thinking
-
-The Ideal Education for Increasing STEM Skills Share on Facebook
-
-Teaching is hard and less-qualified teachers are becoming more common, affecting a lot of people with no other options than a 4-year education.
-
-Jointless.AI, a company that connects users with programming mentors, just released some data from a pilot program they ran from November 2016 to December 2017. They found that teaching people how to code has a “surprisingly low barrier to entry.” The median time for a mentor to match a participant to a project was “roughly half an hour” of their time, compared to 3 hours to find and evaluate a tutor. The median time for a participant to complete a project was roughly 3 hours.
-
-After a participant finished their first coding project, the majority had increased their experience with both technologies and skills. Many were more than excited about how they could help people with their own programming skills.
-
-Participants were also generally excited about the idea of new opportunities for themselves. Participants who were taking college courses also cited that as a benefit.
-
-Jointless.AI has released more data on their pilot program, including a DataShare where data scientists, researchers, and engineers can use data to determine how best to provide a coding education for people that is beneficial to them and for society as a whole. You can access the data here.
-
-How to Connect with the Tech Community and Network
-
-You don’t have to be a genius to make friends with the most connected people in tech.
-
-Be social and actively participate in online communities.
-
-Join Slack channels and be active in your specific Slack’s chat.
-
-Start connecting with other developers and fellow learners in Hacker News and Twitter.
-
-Share your own projects, write blog posts, and use DZone to share the work you have done.
-
-Participate in online and offline meetups and 4fefd39f24
-
-
-
diff --git a/spaces/1phancelerku/anime-remove-background/Adobe Premiere Rush APK Edit and Share Videos Across All Your Devices.md b/spaces/1phancelerku/anime-remove-background/Adobe Premiere Rush APK Edit and Share Videos Across All Your Devices.md
deleted file mode 100644
index 490025a35deaf0f98d2561c0d60cc604cd2bf9cb..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Adobe Premiere Rush APK Edit and Share Videos Across All Your Devices.md
+++ /dev/null
@@ -1,117 +0,0 @@
-
-
What is Rush APK and Why You Need It
-
If you are looking for a way to create and share amazing videos online, you may have heard of Rush APK. But what is it exactly and why do you need it? In this article, we will answer these questions and more.
-
Rush APK is an Android application that allows you to use Adobe Premiere Rush, the all-in-one, cross-device video editor that lets you shoot, edit, and share online videos anywhere. With Rush APK, you can access all the features and content of Adobe Premiere Rush for free with unlimited exports.
Adobe Premiere Rush is a powerful video editing tool that lets you quickly create videos that look and sound professional, just how you want. You can add music, titles, effects, transitions, stickers, overlays, and more to your videos with drag and drop. You can also adjust the speed, color, and audio of your videos with intuitive tools.
-
With Adobe Premiere Rush, you can also share your videos to your favorite social platforms with one click. You can crop your videos for different aspect ratios such as portrait, landscape, square, or vertical. You can also sync your projects across devices and continue editing them on your desktop or tablet.
-
Whether you are a beginner or a pro, Adobe Premiere Rush can help you create stunning videos that will impress your audience and boost your online presence.
-
How to Download and Install Rush APK on Your Android Device
-
If you want to try out Adobe Premiere Rush on your Android device, you will need to download and install Rush APK on your device. Here are the steps that you need to follow:
-
-
Find a reliable source for downloading the APK file. You can search for Rush APK on Google or use a trusted website that provides APK files for various apps. Make sure that the APK file is safe and virus-free before downloading it.
-
Enable unknown sources on your device settings. To do this, go to Settings > Security > Unknown Sources and toggle it on. This will allow you to install apps from sources other than the Google Play Store.
-
Locate and tap on the downloaded APK file to start the installation. You can find the APK file in your Downloads folder or in the notification bar. Tap on it and confirm the installation.
-
Follow the on-screen instructions and grant the necessary permissions. The app will ask you to allow access to your camera, microphone, storage, and other features. Tap on Allow or OK to proceed.
-
Launch the app and sign in with your Adobe account or create a new one. You will need an Adobe account to use the app and sync your projects across devices. You can sign in with your existing account or create a new one for free.
-
-
Congratulations! You have successfully installed Rush APK on your Android device. You can now start creating and sharing amazing videos online with Adobe Premiere Rush.
-
How to Use Rush APK to Edit and Share Videos Online
-
Now that you have installed Rush APK on your device, you may be wondering how to use it to edit and share videos online. Don't worry, it's very easy and fun. Here are the steps that you need to follow:
-
-
Tap on the plus icon to start a new project or select an existing one. You can create a new project from scratch or choose from the templates that are available in the app. You can also open an existing project that you have saved on your device or cloud storage.
-
Choose the media files that you want to add to your project from your device or cloud storage. You can add photos, videos, and audio files to your project. You can also capture new media files using your device's camera or microphone.
-
Arrange, trim, crop, flip, and mirror your video clips on the multitrack timeline. You can drag and drop your video clips on the timeline and adjust their duration and position. You can also trim, crop, flip, and mirror your video clips using the icons at the bottom of the screen.
-
Add music, titles, effects, transitions, stickers, and overlays to enhance your video. You can tap on the icons at the top of the screen to access these features. You can choose from thousands of royalty-free soundtracks, sound effects, loops, titles, overlays, and graphics from Adobe Stock. You can also customize them according to your preferences.
-
Adjust the speed, color, and audio of your video with intuitive tools. You can tap on the icons at the right side of the screen to access these tools. You can change the speed of your video clips, apply color presets or filters, and adjust the volume and balance of your audio tracks.
-
Preview your video and export it to your desired quality and aspect ratio. You can tap on the play button at the center of the screen to preview your video. You can also tap on the settings icon at the top right corner of the screen to change the quality and aspect ratio of your video. You can choose from 4K, 1080p, 720p, or 480p quality and portrait, landscape, square, or vertical aspect ratio.
-
Share your video to your favorite social platforms or save it to your device or cloud storage. You can tap on the share icon at the top right corner of the screen to access these options. You can share your video directly to YouTube, Facebook, Instagram, TikTok, or other platforms with one click. You can also save your video to your device's gallery or cloud storage such as Google Drive or Dropbox.
-
-
That's it! You have just created and shared a stunning video online with Rush APK. You can repeat these steps for any other project that you want to create with Adobe Premiere Rush.
-
* Adobe Premiere Rush APK download
-* Rush APK free board games
-* Project RushB APK for Android
-* Adobe Premiere Rush APK video editor
-* Rush APK real money games
-* Project RushB APK tech test
-* Adobe Premiere Rush APK cross-device
-* Rush APK Ludo, Carrom & Quizzy
-* Project RushB APK release date
-* Adobe Premiere Rush APK online videos
-* Rush APK leedo, freestyle carrom and quiz game
-* Project RushB APK features
-* Adobe Premiere Rush APK professional videos
-* Rush APK gaming universe
-* Project RushB APK regions
-* Adobe Premiere Rush APK powerful tools
-* Rush APK AAA quality games
-* Project RushB APK video game
-* Adobe Premiere Rush APK channels
-* Rush APK mobile-first gaming
-* Project RushB APK Uptodown
-* Adobe Premiere Rush APK latest version
-* Rush APK Hike Games
-* Project RushB APK beta version
-* Adobe Premiere Rush APK mod apk
-* Rush APK mod apk unlimited money
-* Project RushB APK gameplay
-* Adobe Premiere Rush APK review
-* Rush APK referral code
-* Project RushB APK graphics
-* Adobe Premiere Rush APK system requirements
-* Rush APK customer care number
-* Project RushB APK download link
-* Adobe Premiere Rush APK tutorial
-* Rush APK withdrawal process
-* Project RushB APK trailer
-* Adobe Premiere Rush APK premium apk
-* Rush APK invite friends and earn money
-* Project RushB APK tips and tricks
-* Adobe Premiere Rush APK transitions and effects
-
The Benefits of Using Rush APK for Video Editing
-
Rush APK is a great app for video editing that offers many benefits for users who want to create and share amazing videos online. Here are some of them:
-
-
You can access all the features and content of Adobe Premiere Rush for free with unlimited exports. Unlike other video editing apps that charge you for premium features or limit your exports, Rush APK lets you use all the features and content of Adobe Premiere Rush without any restrictions or costs.
-
You can sync your projects across devices and continue editing them on your desktop or tablet. Rush APK allows you to sync your projects with your Adobe account and access them from any device that has Adobe Premiere Rush installed. You can also import and export your projects to other Adobe apps such as Premiere Pro, After Effects, or Photoshop.
-
You can access thousands of royalty-free soundtracks, sound effects, loops, titles, overlays, and graphics from Adobe Stock. Rush APK gives you access to a huge library of high-quality content that you can use for your videos. You can also customize them to suit your style and theme.
-
You can create professional-looking videos with minimal effort and time. Rush APK has a user-friendly interface and intuitive tools that make video editing easy and fun. You can create videos that look and sound amazing with just a few taps and clicks.
-
You can reach a wider audience with videos that are optimized for different social platforms. Rush APK lets you crop your videos for different aspect ratios such as portrait, landscape, square, or vertical. You can also share your videos directly to YouTube, Facebook, Instagram, TikTok, or other platforms with one click. You can also save your videos to your device or cloud storage for later use.
-
-
The Drawbacks of Using Rush APK for Video Editing
-
While Rush APK is a great app for video editing, it also has some drawbacks that you should be aware of before using it. Here are some of them:
-
-
You need a stable internet connection to download and update the app and access some of the features and content. Rush APK requires an internet connection to download and update the app and access some of the features and content such as Adobe Stock or cloud storage. If you have a slow or unreliable internet connection, you may experience some issues while using the app.
-
You need a compatible device that meets the minimum requirements to run the app smoothly. Rush APK is a powerful app that requires a compatible device that has at least 4 GB of RAM and Android 9.0 or higher. If your device does not meet these requirements, you may not be able to install or run the app smoothly.
-
You need an Adobe account to use the app and sync your projects across devices. Rush APK requires you to sign in with an Adobe account to use the app and sync your projects across devices. If you do not have an Adobe account, you will need to create one for free.
-
You may encounter some bugs and glitches while using the app as it is still in development. Rush APK is still in development and may not be fully stable or bug-free. You may encounter some errors or crashes while using the app or exporting your videos.
-
You may face some legal issues if you download the app from an unauthorized source or use it for commercial purposes without permission. Rush APK is an unofficial app that is not authorized by Adobe or Google Play Store. If you download the app from an unauthorized source or use it for commercial purposes without permission, you may face some legal consequences such as fines or lawsuits.
-
-
Conclusion
-
Rush APK is an Android application that lets you use Adobe Premiere Rush, the all-in-one, cross-device video editor that lets you shoot, edit, and share online videos anywhere. With Rush APK, you can access all the features and content of Adobe Premiere Rush for free with unlimited exports.
-
Rush APK has many benefits for video editing such as syncing your projects across devices, accessing thousands of royalty-free content from Adobe Stock, creating professional-looking videos with minimal effort and time, and reaching a wider audience with videos that are optimized for different social platforms.
-
Rush APK also has some drawbacks such as requiring a stable internet connection, a compatible device, an Adobe account, and facing some bugs and legal issues.
-
If you want to try out Rush APK on your Android device, you can follow the steps in this article to download and install it on your device. You can also follow the steps to use it to edit and share videos online.
-
We hope that this article has helped you understand what is Rush APK and why you need it. If you have any questions or feedback, please feel free to leave a comment below.
-
FAQs
-
-
Is Rush APK safe to use?
-
Rush APK is safe to use if you download it from a reliable source and scan it with an antivirus before installing it on your device. However, since it is an unofficial app that is not authorized by Adobe or Google Play Store, you should use it at your own risk.
-
Is Rush APK free to use?
-
Rush APK is free to use with unlimited exports. You can access all the features and content of Adobe Premiere Rush without any restrictions or costs.
-
Can I use Rush APK on my PC or Mac?
-
Rush APK is an Android application that is designed to run on Android devices. However, you can use it on your PC or Mac with the help of an Android emulator. An Android emulator is a software that simulates the Android operating system on your PC or Mac. You can download and install an Android emulator such as BlueStacks, Nox Player, or MEmu on your PC or Mac and then install Rush APK on it.
-
What is the difference between Rush APK and Adobe Premiere Rush?
-
Rush APK and Adobe Premiere Rush are essentially the same app with the same features and content. The only difference is that Rush APK is an unofficial app that is not available on the Google Play Store and lets you use Adobe Premiere Rush for free with unlimited exports. Adobe Premiere Rush is an official app that is available on the Google Play Store and requires a subscription to access some of the features and content.
-
How can I update Rush APK?
-
Rush APK does not have an automatic update feature, so you will need to manually update it whenever a new version is available. You can check for updates by visiting the website where you downloaded the APK file or by searching for Rush APK on Google. You can then download and install the latest version of the APK file on your device.
-
How can I uninstall Rush APK?
-
If you want to uninstall Rush APK from your device, you can follow these steps:
-
-
Go to Settings > Apps > Rush APK and tap on Uninstall.
-
Confirm the uninstallation and wait for it to finish.
-
Go to Settings > Storage > Files and locate the APK file that you downloaded.
-
Delete the APK file from your device.
-
-
You have successfully uninstalled Rush APK from your device.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/Assoluto Racing MOD APK Android 1 A Mobile Racing Game with Amazing Graphics and Physics.md b/spaces/1phancelerku/anime-remove-background/Assoluto Racing MOD APK Android 1 A Mobile Racing Game with Amazing Graphics and Physics.md
deleted file mode 100644
index 01707b7301495ecda55911c615f1715e48133e64..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Assoluto Racing MOD APK Android 1 A Mobile Racing Game with Amazing Graphics and Physics.md
+++ /dev/null
@@ -1,89 +0,0 @@
-
-
Download Assoluto Racing Mod APK Android 1: The Ultimate Racing Game for Your Mobile Device
-
If you are a fan of racing games, you must have heard of Assoluto Racing. It is one of the best racing games available for Android and iPhone devices. It offers a realistic and immersive racing experience that will make you feel like you are driving a real car. But what if you want to enjoy the game without any limitations or restrictions? That's where Assoluto Racing mod apk android 1 comes in. In this article, we will tell you everything you need to know about this amazing modded version of the game, including its features, benefits, and how to download and install it on your device.
-
What is Assoluto Racing?
-
Assoluto Racing is a racing game developed by Infinity Vector Ltd. It is designed with vivid graphics and realistic control mechanisms that make you feel like you are behind the wheel directly. Assoluto Racing is an extreme street drift racing game that allows you to experience the thrill of driving on different tracks and terrains. You can customize your car with various parts and accessories, and compete with other players online or offline. You can also collect and upgrade your car collection, and challenge yourself with different modes and events.
Assoluto Racing boasts of stunning graphics that will impress you with their details and quality. The game uses advanced physics engine that simulates the behavior of real cars, such as traction, suspension, aerodynamics, and damage. You can also adjust the camera angle and view the action from different perspectives.
-
Customizable cars and tracks
-
Assoluto Racing features a wide range of cars from famous brands, such as Toyota, Nissan, BMW, Mercedes-Benz, Ferrari, Lamborghini, and more. You can modify your car with various options, such as engine, transmission, tires, brakes, body kits, spoilers, paint, decals, etc. You can also create your own tracks with the track editor tool, or download tracks created by other players.
-
Online multiplayer and leaderboards
-
Assoluto Racing lets you race against other players from around the world in real-time multiplayer mode. You can join or create rooms with different settings, such as car class, track, laps, weather, etc. You can also chat with other players and make friends or rivals. You can also compete for the top spot on the global leaderboards and earn rewards and achievements.
-
Why download Assoluto Racing mod apk android 1?
-
Assoluto Racing is a free game, but it also has some in-app purchases that require real money. These include buying coins and money to unlock new cars and tracks, or upgrading your car parts. You may also encounter some ads while playing the game. If you want to enjoy the game without spending any money or being bothered by ads, you should download Assoluto Racing mod apk android 1. This is a modified version of the game that gives you unlimited money and coins, unlocks all cars and tracks, removes ads, and does not require root access.
-
Unlimited money and coins
-
With Assoluto Racing mod apk android 1, you will have unlimited money and coins in your account. You can use them to buy any car or track you want, or upgrade your car parts to the maximum level.
Unlocked all cars and tracks
-
With Assoluto Racing mod apk android 1, you will have access to all the cars and tracks in the game. You don't have to complete any missions or challenges to unlock them. You can choose any car or track you like, and enjoy the variety and diversity of the game.
-
No ads and no root required
-
With Assoluto Racing mod apk android 1, you will not see any ads while playing the game. You can enjoy the game without any interruptions or distractions. You also don't need to root your device to install the mod apk file. You can simply download and install it without any risk or hassle.
-
How to download and install Assoluto Racing mod apk android 1?
-
If you are interested in downloading and installing Assoluto Racing mod apk android 1, you can follow these simple steps:
-
How to download assoluto racing mod apk for android devices
-Assoluto racing mod apk unlimited money and coins
-Best racing games for android 1 with assoluto mod
-Assoluto racing realistic 3D graphics and physics mod apk
-Download assoluto racing latest version mod apk free
-Assoluto racing online PVP mode with mod apk
-Assoluto racing mod apk features and gameplay
-Assoluto racing hack mod apk download link
-Assoluto racing mod apk review and rating
-Assoluto racing mod apk installation guide and tips
-Assoluto racing mod apk vs original game comparison
-Assoluto racing mod apk cheats and tricks
-Assoluto racing mod apk support and compatibility
-Assoluto racing mod apk download size and requirements
-Assoluto racing mod apk update and changelog
-Assoluto racing mod apk offline mode and data usage
-Assoluto racing mod apk bugs and issues
-Assoluto racing mod apk alternatives and similar games
-Assoluto racing mod apk benefits and drawbacks
-Assoluto racing mod apk FAQs and answers
-Assoluto racing car brands and models with mod apk
-Assoluto racing tracks and locations with mod apk
-Assoluto racing customizations and upgrades with mod apk
-Assoluto racing challenges and missions with mod apk
-Assoluto racing achievements and rewards with mod apk
-Assoluto racing leaderboards and rankings with mod apk
-Assoluto racing tournaments and events with mod apk
-Assoluto racing community and social media with mod apk
-Assoluto racing tips and tricks for beginners with mod apk
-Assoluto racing advanced strategies and techniques with mod apk
-
Step 1: Download the mod apk file from a trusted source
-
The first thing you need to do is to download the mod apk file from a reliable and secure source. You can use this link to download the latest version of Assoluto Racing mod apk android 1. The file size is about 50 MB, so make sure you have enough space on your device.
-
Step 2: Enable unknown sources on your device settings
-
The next thing you need to do is to enable unknown sources on your device settings. This will allow you to install apps from sources other than the Google Play Store. To do this, go to your device settings, then security, then unknown sources, and turn it on.
-
Step 3: Install the mod apk file and launch the game
-
The final thing you need to do is to install the mod apk file and launch the game. To do this, locate the downloaded file on your device storage, tap on it, and follow the instructions on the screen. Once the installation is done, open the game and enjoy.
-
Conclusion
-
Assoluto Racing is a great racing game that offers a realistic and immersive racing experience. It has amazing graphics, physics, cars, tracks, and modes that will keep you entertained for hours. However, if you want to enjoy the game without any limitations or restrictions, you should download Assoluto Racing mod apk android 1. This is a modified version of the game that gives you unlimited money and coins, unlocks all cars and tracks, removes ads, and does not require root access. You can download and install it easily by following the steps we have provided in this article. So what are you waiting for? Download Assoluto Racing mod apk android 1 now and start racing.
-
FAQs
-
Here are some frequently asked questions about Assoluto Racing mod apk android 1:
-
-
-
Question
-
Answer
-
-
-
Is Assoluto Racing mod apk android 1 safe to use?
-
Yes, Assoluto Racing mod apk android 1 is safe to use as long as you download it from a trusted source. We have tested it on our devices and found no viruses or malware.
-
-
-
Will Assoluto Racing mod apk android 1 work on my device?
-
Assoluto Racing mod apk android 1 should work on most Android devices that have Android 4.0 or higher. However, some devices may not be compatible or may experience some issues. If you encounter any problems, please contact us or leave a comment below.
-
-
-
Can I play Assoluto Racing mod apk android 1 online?
-
Yes, you can play Assoluto Racing mod apk android 1 online with other players. However, you may not be able to join some rooms or events that require original versions of the game. You may also face some bans or penalties from the game developers if they detect your modded version.
-
-
-
Can I update Assoluto Racing mod apk android 1?
-
No, you cannot update Assoluto Racing mod apk android 1 from the Google Play Store or any other source. If you want to get the latest version of the game, you will have to download and install it again from our link.
-
-
-
Can I request more features for Assoluto Racing mod apk android 1?
-
Yes, you can request more features for Assoluto Racing mod apk android 1 by leaving a comment below or contacting us. We will try our best to fulfill your requests as soon as possible.
-I have finished writing the article on the topic of "download Assoluto Racing mod apk android 1". I hope you find it useful and informative. If you have any questions or feedback, please feel free to contact me or leave a comment below. Thank you for choosing me as your content writer. 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/Cmo jugar a Sniper 3D juego de disparos en primera persona con mod apk.md b/spaces/1phancelerku/anime-remove-background/Cmo jugar a Sniper 3D juego de disparos en primera persona con mod apk.md
deleted file mode 100644
index 72296420f3d2dbaf97b37f68863c4b7d8e8892f0..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Cmo jugar a Sniper 3D juego de disparos en primera persona con mod apk.md
+++ /dev/null
@@ -1,140 +0,0 @@
-
-
Sniper 3D Juegos de Disparos Mod APK: The Ultimate Shooting Game
-
If you are looking for a free and exciting shooting game that will test your skills as a sniper, then you should try Sniper 3D Juegos de Disparos Mod APK. This is a modified version of the popular Sniper 3D game that gives you unlimited coins, diamonds, weapons, and more. In this article, we will tell you everything you need to know about Sniper 3D Juegos de Disparos Mod APK, including its features, how to download and install it, how to play it, and why you should play it.
Sniper 3D Juegos de Disparos Mod APK is a hacked version of the original Sniper 3D game that was developed by Fun Games For Free. It is a 3D shooting game that puts you in the role of a professional sniper who has to complete various missions and eliminate high-profile targets. You can choose from a wide range of sniper rifles, assault rifles, and other guns, and customize them according to your preferences. You can also play offline or online, and compete with other players in PVP mode.
-
Features of Sniper 3D Juegos de Disparos Mod APK
-
Sniper 3D Juegos de Disparos Mod APK has many features that make it more fun and enjoyable than the original game. Here are some of them:
-
- Unlimited coins and diamonds
-
With Sniper 3D Juegos de Disparos Mod APK, you don't have to worry about running out of coins or diamonds, which are the main currencies in the game. You can use them to buy new weapons, upgrade your existing ones, buy gear, and more. You can also use them to skip missions or get extra lives.
-
- All weapons unlocked and upgraded
-
Sniper 3D Juegos de Disparos Mod APK gives you access to all the weapons in the game, without having to unlock them by completing missions or paying real money. You can also upgrade them to their maximum level, which will make them more powerful and accurate. You can choose from over 180+ authentic weapons, including sniper rifles, assault rifles, shotguns, pistols, and more.
-
- No ads and no root required
-
Sniper 3D Juegos de Disparos Mod APK removes all the annoying ads that interrupt your gameplay and ruin your immersion. You can enjoy the game without any distractions or interruptions. Moreover, you don't need to root your device to install or play Sniper 3D Juegos de Disparos Mod APK. It is compatible with most Android devices and versions. You can download and install it easily and safely.
-
How to download and install Sniper 3D Juegos de Disparos Mod APK?
-
If you want to download and install Sniper 3D Juegos de Disparos Mod APK, you need to follow these simple steps:
-
Step by step guide
-
- Download the mod apk file from a trusted source
-
The first thing you need to do is to download the mod apk file from a reliable and secure source. You can use the link below to get the latest version of Sniper 3D Juegos de Disparos Mod APK. Make sure you have enough storage space on your device before downloading the file.
-
Sniper 3D Assassin: juego de disparos gratis mod apk
-Sniper 3D Strike Assassin Ops: juego de disparos hack apk
-Sniper 3D Gun Shooter: juego de disparos online mod apk
-Sniper 3D Shooter: juego de disparos en primera persona mod apk
-Sniper 3D Fury: juego de disparos de francotirador mod apk
-Sniper 3D Silent Assassin: juego de disparos de sigilo mod apk
-Sniper 3D Elite: juego de disparos de élite mod apk
-Sniper 3D Zombie: juego de disparos de zombies mod apk
-Sniper 3D City: juego de disparos en la ciudad mod apk
-Sniper 3D War: juego de disparos de guerra mod apk
-Sniper 3D Mission: juego de disparos de misiones mod apk
-Sniper 3D Arena: juego de disparos multijugador mod apk
-Sniper 3D Action: juego de disparos de acción mod apk
-Sniper 3D Adventure: juego de disparos de aventura mod apk
-Sniper 3D Survival: juego de disparos de supervivencia mod apk
-Sniper 3D Crime: juego de disparos de crimen mod apk
-Sniper 3D Army: juego de disparos de ejército mod apk
-Sniper 3D Police: juego de disparos de policía mod apk
-Sniper 3D SWAT: juego de disparos de SWAT mod apk
-Sniper 3D Spy: juego de disparos de espía mod apk
-Sniper 3D Hero: juego de disparos de héroe mod apk
-Sniper 3D Villain: juego de disparos de villano mod apk
-Sniper 3D Wild: juego de disparos en la naturaleza mod apk
-Sniper 3D Jungle: juego de disparos en la selva mod apk
-Sniper 3D Desert: juego de disparos en el desierto mod apk
-Sniper 3D Mountain: juego de disparos en la montaña mod apk
-Sniper 3D Snow: juego de disparos en la nieve mod apk
-Sniper 3D Night: juego de disparos nocturno mod apk
-Sniper 3D Day: juego de disparos diurno mod apk
-Sniper 3D Halloween: juego de disparos temático mod apk
-Sniper 3D Christmas: juego de disparos festivo mod apk
-Sniper 3D Valentine: juego de disparos romántico mod apk
-Sniper 3D Horror: juego de disparos terrorífico mod apk
-Sniper 3D Fantasy: juego de disparos fantástico mod apk
-Sniper 3D Sci-Fi: juego de disparos ciencia ficción mod apk
-Sniper 3D Anime: juego de disparos anime mod apk
-Sniper 3D Cartoon: juego de disparos dibujos animados mod apk
-Sniper 3D Realistic: juego de disparos realista mod apk
-Sniper 3D Funny: juego de disparos divertido mod apk
-Sniper 3D Educational: juego de disparos educativo mod apk
-Descargar sniper 3d juegos de disparos gratis para android con mod apk
-Como instalar sniper 3d juegos de disparos en tu dispositivo android con el archivo mod apk
-Reseña y análisis del sniper 3d juegos de disparos con el modo hackeado en el archivo apk
-Trucos y consejos para jugar al sniper 3d juegos de disparos con el beneficio del archivo modificado en formato apk
-Comparación entre el sniper 3d juegos de disparos original y el que tiene el archivo alterado en extensión .apk
-
[Download Sniper 3D Juegos de Disparos Mod APK]
-
- Enable unknown sources on your device settings
-
The next thing you need to do is to enable unknown sources on your device settings. This will allow you to install apps that are not from the Google Play Store. To do this, go to your device settings, then security, then unknown sources, and toggle it on. You may see a warning message, but don't worry, it is safe to proceed.
-
- Install the mod apk file and launch the game
-
The final thing you need to do is to install the mod apk file and launch the game. To do this, locate the downloaded file on your device, tap on it, and follow the instructions on the screen. Once the installation is done, you can open the game and enjoy Sniper 3D Juegos de Disparos Mod APK.
-
How to play Sniper 3D Juegos de Disparos Mod APK?
-
Sniper 3D Juegos de Disparos Mod APK is easy to play, but challenging to master. Here are some tips and tricks for beginners:
-
Tips and tricks for beginners
-
- Choose the right weapon for each mission
-
One of the most important things in Sniper 3D Juegos de Disparos Mod APK is to choose the right weapon for each mission. Different weapons have different stats, such as damage, range, stability, zoom, and reload time. You should consider these factors when selecting your weapon, as well as the type of target and the environment. For example, if you are shooting at a long distance, you should use a sniper rifle with a high zoom and range. If you are shooting at a moving target, you should use a weapon with a high stability and reload time.
-
- Aim for the head and use the zoom feature
-
Another important thing in Sniper 3D Juegos de Disparos Mod APK is to aim for the head and use the zoom feature. Aiming for the head will give you more damage and bonus points, as well as save you ammo. You can also use the zoom feature to get a better view of your target and adjust your aim accordingly. To use the zoom feature, just tap on the screen and slide your finger up or down.
- Upgrade your weapons and gear regularly
-
A third important thing in Sniper 3D Juegos de Disparos Mod APK is to upgrade your weapons and gear regularly. Upgrading your weapons and gear will improve their stats and performance, as well as unlock new features and abilities. You can use the coins and diamonds you get from Sniper 3D Juegos de Disparos Mod APK to upgrade your weapons and gear. You can also use the table below to see the different types of upgrades and their effects.
-
-
-
Type of upgrade
-
Effect
-
-
-
Muzzle
-
Increases damage and stability
-
-
-
Ammo
-
Increases damage and pierce
-
-
-
Body
-
Increases range and zoom
-
-
-
Grip
-
Increases stability and reload time
-
-
-
Scope
-
Increases zoom and critical chance
-
-
-
Clip
-
Increases ammo capacity and reload time
-
-
-
Gear
-
Increases health, energy, and defense
-
-
-
- Use the environment and cover to your advantage
-
A fourth important thing in Sniper 3D Juegos de Disparos Mod APK is to use the environment and cover to your advantage. The environment and cover can help you hide from your enemies, avoid their fire, and find better angles to shoot. You can also use the environment and cover to create distractions, such as shooting at explosive barrels, cars, or other objects. This will cause chaos and confusion among your enemies, giving you more opportunities to take them out.
-
Why should you play Sniper 3D Juegos de Disparos Mod APK?
-
Sniper 3D Juegos de Disparos Mod APK is not only a fun and exciting shooting game, but also a game that has many benefits for you. Here are some of them:
-
Benefits of playing Sniper 3D Juegos de Disparos Mod APK
-
- Enjoy realistic graphics and sound effects
-
Sniper 3D Juegos de Disparos Mod APK has realistic graphics and sound effects that will make you feel like you are in the middle of a real battlefield. You will see detailed environments, realistic animations, and stunning visual effects. You will also hear realistic sounds, such as gunshots, explosions, screams, and more. You will be immersed in the game and feel the adrenaline rush of being a sniper.
-
- Experience thrilling and varied missions in different locations
-
Sniper 3D Juegos de Disparos Mod APK has thrilling and varied missions that will keep you entertained for hours. You will have to complete different objectives, such as assassinating targets, rescuing hostages, protecting allies, destroying vehicles, and more. You will also have to face different challenges, such as time limits, moving targets, multiple enemies, and more. You will travel to different locations around the world, such as cities, deserts, islands, mountains, and more. You will never get bored with Sniper 3D Juegos de Disparos Mod APK.
-
- Challenge yourself and other players in PVP mode
-
Sniper 3D Juegos de Disparos Mod APK has a PVP mode that will let you challenge yourself and other players in online battles. You can join or create a squad with your friends or other players, and compete against other squads in team deathmatch or domination modes. You can also play solo or duo in free for all or battle royale modes. You can show off your skills, rank up on the leaderboard, earn rewards, and have fun with Sniper 3D Juegos de Disparos Mod APK.
-
- Have fun with a free and addictive shooting game
-
Sniper 3D Juegos de Disparos Mod APK is a free and addictive shooting game that will make you want to play more and more. You can play it anytime and anywhere, without any internet connection or subscription required. You can also enjoy it without any ads or limitations, thanks to Sniper 3D Juegos de Disparos Mod APK. You can have fun with a shooting game that has everything you need: action, adventure, strategy, skill, and more.
-
Conclusion
-
Sniper 3D Juegos de Disparos Mod APK is the ultimate shooting game that you should try if you love sniping games. It has unlimited coins, diamonds, weapons, and more features that will make your gameplay more fun and enjoyable. It has realistic graphics and sound effects, thrilling and varied missions, PVP mode, and a free and addictive gameplay. You can download and install it easily and safely, and play it anytime and anywhere. You can also follow our tips and tricks to improve your skills and performance as a sniper. Sniper 3D Juegos de Disparos Mod APK is the ultimate shooting game that you should not miss.
-
FAQs
-
Here are some frequently asked questions about Sniper 3D Juegos de Disparos Mod APK:
-
Q: Is Sniper 3D Juegos de Disparos Mod APK safe to use?
-
A: Yes, Sniper 3D Juegos de Disparos Mod APK is safe to use, as long as you download it from a trusted source. We have tested the mod apk file and found no viruses or malware. However, you should always be careful when downloading and installing any mod apk file, and use it at your own risk.
-
Q: Is Sniper 3D Juegos de Disparos Mod APK legal to use?
-
A: No, Sniper 3D Juegos de Disparos Mod APK is not legal to use, as it violates the terms and conditions of the original game. It also infringes the intellectual property rights of the developers and publishers of the game. Therefore, we do not recommend or endorse the use of Sniper 3D Juegos de Disparos Mod APK, and we are not responsible for any consequences that may arise from using it.
-
Q: Can I play Sniper 3D Juegos de Disparos Mod APK with my friends?
-
A: Yes, you can play Sniper 3D Juegos de Disparos Mod APK with your friends, either offline or online. You can join or create a squad with your friends or other players, and compete against other squads in PVP mode. You can also play solo or duo in free for all or battle royale modes.
-
Q: Can I update Sniper 3D Juegos de Disparos Mod APK?
-
A: No, you cannot update Sniper 3D Juegos de Disparos Mod APK, as it is a modified version of the original game. If you update it, you will lose all the mod features and revert back to the original game. Therefore, you should avoid updating Sniper 3D Juegos de Disparos Mod APK, and wait for a new mod apk file to be released.
-
Q: Can I get banned for using Sniper 3D Juegos de Disparos Mod APK?
-
A: Yes, you can get banned for using Sniper 3D Juegos de Disparos Mod APK, as it is against the rules of the game. The game has an anti-cheat system that can detect if you are using a mod apk file, and ban you from playing online or accessing your account. Therefore, you should use Sniper 3D Juegos de Disparos Mod APK at your own risk, and be prepared for the possibility of getting banned.
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/1toTree/lora_test/ppdiffusers/pipelines/unclip/__init__.py b/spaces/1toTree/lora_test/ppdiffusers/pipelines/unclip/__init__.py
deleted file mode 100644
index 2c842f13e3f64ab96e6d715f323fae104286cce9..0000000000000000000000000000000000000000
--- a/spaces/1toTree/lora_test/ppdiffusers/pipelines/unclip/__init__.py
+++ /dev/null
@@ -1,29 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-
-from ...utils import (
- OptionalDependencyNotAvailable,
- is_paddle_available,
- is_paddlenlp_available,
-)
-
-try:
- if not (is_paddlenlp_available() and is_paddle_available()):
- raise OptionalDependencyNotAvailable()
-except OptionalDependencyNotAvailable:
- from ...utils.dummy_paddle_and_paddlenlp_objects import UnCLIPPipeline
-else:
- from .pipeline_unclip import UnCLIPPipeline
- from .text_proj import UnCLIPTextProjModel
diff --git a/spaces/1toTree/lora_test/ppdiffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py b/spaces/1toTree/lora_test/ppdiffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
deleted file mode 100644
index dd1646320548f536c425dc07aa5e6e96bd6e1e91..0000000000000000000000000000000000000000
--- a/spaces/1toTree/lora_test/ppdiffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
+++ /dev/null
@@ -1,443 +0,0 @@
-# Copyright 2022 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import inspect
-from typing import Callable, List, Optional, Union
-
-import paddle
-
-from paddlenlp.transformers import CLIPTextModelWithProjection, CLIPTokenizer
-
-from ...models import AutoencoderKL, UNet2DConditionModel
-from ...models.attention import Transformer2DModel
-from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
-from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
-from ...utils import logging
-from .modeling_text_unet import UNetFlatConditionModel
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-
-class VersatileDiffusionTextToImagePipeline(DiffusionPipeline):
- r"""
- Pipeline for text-to-image generation using Versatile Diffusion.
-
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
-
- Args:
- vae ([`AutoencoderKL`]):
- Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
- text_encoder ([`CLIPTextModelWithProjection`]):
- Frozen text-encoder. Versatile Diffusion uses the text portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection), specifically
- the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
- image_encoder ([`CLIPVisionModelWithProjection`]):
- Frozen vision-encoder. Versatile Diffusion uses the vision portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPVisionModelWithProjection), specifically
- the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
- tokenizer (`CLIPTokenizer`):
- Tokenizer of class
- [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
- image_unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
- text_unet ([`UNetFlatConditionModel`]): xxx.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
- [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
- """
- tokenizer: CLIPTokenizer
- text_encoder: CLIPTextModelWithProjection
- image_unet: UNet2DConditionModel
- text_unet: UNetFlatConditionModel
- vae: AutoencoderKL
- scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler]
- _optional_components = ["text_unet"]
-
- def __init__(
- self,
- tokenizer: CLIPTokenizer,
- text_encoder: CLIPTextModelWithProjection,
- image_unet: UNet2DConditionModel,
- text_unet: UNetFlatConditionModel,
- vae: AutoencoderKL,
- scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
- ):
- super().__init__()
- self.register_modules(
- tokenizer=tokenizer,
- text_encoder=text_encoder,
- image_unet=image_unet,
- text_unet=text_unet,
- vae=vae,
- scheduler=scheduler,
- )
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
- if self.text_unet is not None:
- self._swap_unet_attention_blocks()
-
- def _swap_unet_attention_blocks(self):
- """
- Swap the `Transformer2DModel` blocks between the image and text UNets
- """
- for name, module in self.image_unet.named_sublayers(include_self=True):
- if isinstance(module, Transformer2DModel):
- parent_name, index = name.rsplit(".", 1)
- index = int(index)
- self.image_unet.get_sublayer(parent_name)[index], self.text_unet.get_sublayer(parent_name)[index] = (
- self.text_unet.get_sublayer(parent_name)[index],
- self.image_unet.get_sublayer(parent_name)[index],
- )
-
- def remove_unused_weights(self):
- self.register_modules(text_unet=None)
-
- def _encode_text_prompt(self, prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
- r"""
- Encodes the prompt into text encoder hidden states.
-
- Args:
- prompt (`str` or `list(int)`):
- prompt to be encoded
- num_images_per_prompt (`int`):
- number of images that should be generated per prompt
- do_classifier_free_guidance (`bool`):
- whether to use classifier free guidance or not
- negative_prompt (`str` or `List[str]`):
- The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
- if `guidance_scale` is less than `1`).
- """
-
- def normalize_embeddings(encoder_output):
- embeds = paddle.matmul(encoder_output.last_hidden_state, self.text_encoder.text_projection)
- embeds_pooled = encoder_output.text_embeds
- embeds = embeds / paddle.norm(embeds_pooled.unsqueeze(1), axis=-1, keepdim=True)
- return embeds
-
- batch_size = len(prompt) if isinstance(prompt, list) else 1
-
- text_inputs = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pd",
- )
- text_input_ids = text_inputs.input_ids
- untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pd").input_ids
-
- if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not paddle.equal_all(
- text_input_ids, untruncated_ids
- ):
- removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
- logger.warning(
- "The following part of your input was truncated because CLIP can only handle sequences up to"
- f" {self.tokenizer.model_max_length} tokens: {removed_text}"
- )
-
- config = (
- self.text_encoder.config
- if isinstance(self.text_encoder.config, dict)
- else self.text_encoder.config.to_dict()
- )
- if config.get("use_attention_mask", None) is not None and config["use_attention_mask"]:
- attention_mask = text_inputs.attention_mask
- else:
- attention_mask = None
-
- text_embeddings = self.text_encoder(text_input_ids, attention_mask=attention_mask)
- text_embeddings = normalize_embeddings(text_embeddings)
-
- # duplicate text embeddings for each generation per prompt, using mps friendly method
- bs_embed, seq_len, _ = text_embeddings.shape
- text_embeddings = text_embeddings.tile([1, num_images_per_prompt, 1])
- text_embeddings = text_embeddings.reshape([bs_embed * num_images_per_prompt, seq_len, -1])
-
- # get unconditional embeddings for classifier free guidance
- if do_classifier_free_guidance:
- uncond_tokens: List[str]
- if negative_prompt is None:
- uncond_tokens = [""] * batch_size
- elif type(prompt) is not type(negative_prompt):
- raise TypeError(
- f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
- f" {type(prompt)}."
- )
- elif isinstance(negative_prompt, str):
- uncond_tokens = [negative_prompt]
- elif batch_size != len(negative_prompt):
- raise ValueError(
- f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
- f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
- " the batch size of `prompt`."
- )
- else:
- uncond_tokens = negative_prompt
-
- max_length = text_input_ids.shape[-1]
- uncond_input = self.tokenizer(
- uncond_tokens,
- padding="max_length",
- max_length=max_length,
- truncation=True,
- return_tensors="pd",
- )
-
- if config.get("use_attention_mask", None) is not None and config["use_attention_mask"]:
- attention_mask = uncond_input.attention_mask
- else:
- attention_mask = None
-
- uncond_embeddings = self.text_encoder(uncond_input.input_ids, attention_mask=attention_mask)
- uncond_embeddings = normalize_embeddings(uncond_embeddings)
-
- # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
- seq_len = uncond_embeddings.shape[1]
- uncond_embeddings = uncond_embeddings.tile([1, num_images_per_prompt, 1])
- uncond_embeddings = uncond_embeddings.reshape([batch_size * num_images_per_prompt, seq_len, -1])
-
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- text_embeddings = paddle.concat([uncond_embeddings, text_embeddings])
-
- return text_embeddings
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
- def decode_latents(self, latents):
- latents = 1 / 0.18215 * latents
- image = self.vae.decode(latents).sample
- image = (image / 2 + 0.5).clip(0, 1)
- # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
- image = image.transpose([0, 2, 3, 1]).cast("float32").numpy()
- return image
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
- def prepare_extra_step_kwargs(self, generator, eta):
- # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
- # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
- # and should be between [0, 1]
-
- accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
- extra_step_kwargs = {}
- if accepts_eta:
- extra_step_kwargs["eta"] = eta
-
- # check if the scheduler accepts generator
- accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
- if accepts_generator:
- extra_step_kwargs["generator"] = generator
- return extra_step_kwargs
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
- def check_inputs(self, prompt, height, width, callback_steps):
- if not isinstance(prompt, str) and not isinstance(prompt, list):
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- if height % 8 != 0 or width % 8 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
-
- if (callback_steps is None) or (
- callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
- ):
- raise ValueError(
- f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
- f" {type(callback_steps)}."
- )
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
- def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, generator, latents=None):
- shape = [batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor]
- if isinstance(generator, list) and len(generator) != batch_size:
- raise ValueError(
- f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
- f" size of {batch_size}. Make sure the batch size matches the length of the generators."
- )
-
- if latents is None:
- if isinstance(generator, list):
- shape = [
- 1,
- ] + shape[1:]
- latents = [paddle.randn(shape, generator=generator[i], dtype=dtype) for i in range(batch_size)]
- latents = paddle.concat(latents, axis=0)
- else:
- latents = paddle.randn(shape, generator=generator, dtype=dtype)
- else:
- if latents.shape != shape:
- raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
-
- # scale the initial noise by the standard deviation required by the scheduler
- latents = latents * self.scheduler.init_noise_sigma
- return latents
-
- @paddle.no_grad()
- def __call__(
- self,
- prompt: Union[str, List[str]],
- height: Optional[int] = None,
- width: Optional[int] = None,
- num_inference_steps: int = 50,
- guidance_scale: float = 7.5,
- negative_prompt: Optional[Union[str, List[str]]] = None,
- num_images_per_prompt: Optional[int] = 1,
- eta: float = 0.0,
- generator: Optional[Union[paddle.Generator, List[paddle.Generator]]] = None,
- latents: Optional[paddle.Tensor] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- callback: Optional[Callable[[int, int, paddle.Tensor], None]] = None,
- callback_steps: Optional[int] = 1,
- **kwargs,
- ):
- r"""
- Function invoked when calling the pipeline for generation.
-
- Args:
- prompt (`str` or `List[str]`):
- The prompt or prompts to guide the image generation.
- height (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
- The height in pixels of the generated image.
- width (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
- The width in pixels of the generated image.
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
- if `guidance_scale` is less than `1`).
- num_images_per_prompt (`int`, *optional*, defaults to 1):
- The number of images to generate per prompt.
- eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
- generator (`paddle.Generator`, *optional*):
- A [paddle generator] to make generation
- deterministic.
- latents (`paddle.Tensor`, *optional*):
- Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor will ge generated by sampling using the supplied random `generator`.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generate image. Choose between
- [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
- plain tuple.
- callback (`Callable`, *optional*):
- A function that will be called every `callback_steps` steps during inference. The function will be
- called with the following arguments: `callback(step: int, timestep: int, latents: paddle.Tensor)`.
- callback_steps (`int`, *optional*, defaults to 1):
- The frequency at which the `callback` function will be called. If not specified, the callback will be
- called at every step.
-
- Examples:
-
- ```py
- >>> from ppdiffusers import VersatileDiffusionTextToImagePipeline
- >>> import paddle
-
- >>> pipe = VersatileDiffusionTextToImagePipeline.from_pretrained(
- ... "shi-labs/versatile-diffusion"
- ... )
- >>> pipe.remove_unused_weights()
-
- >>> generator = paddle.Generator().manual_seed(0)
- >>> image = pipe("an astronaut riding on a horse on mars", generator=generator).images[0]
- >>> image.save("./astronaut.png")
- ```
-
- Returns:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
- When returning a tuple, the first element is a list with the generated images, and the second element is a
- list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
- (nsfw) content, according to the `safety_checker`.
- """
- # 0. Default height and width to unet
- height = height or self.image_unet.config.sample_size * self.vae_scale_factor
- width = width or self.image_unet.config.sample_size * self.vae_scale_factor
-
- # 1. Check inputs. Raise error if not correct
- self.check_inputs(prompt, height, width, callback_steps)
-
- # 2. Define call parameters
- batch_size = 1 if isinstance(prompt, str) else len(prompt)
- # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
- # corresponds to doing no classifier free guidance.
- do_classifier_free_guidance = guidance_scale > 1.0
-
- # 3. Encode input prompt
- text_embeddings = self._encode_text_prompt(
- prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
- )
-
- # 4. Prepare timesteps
- self.scheduler.set_timesteps(num_inference_steps)
- timesteps = self.scheduler.timesteps
-
- # 5. Prepare latent variables
- num_channels_latents = self.image_unet.in_channels
- latents = self.prepare_latents(
- batch_size * num_images_per_prompt,
- num_channels_latents,
- height,
- width,
- text_embeddings.dtype,
- generator,
- latents,
- )
-
- # 6. Prepare extra step kwargs.
- extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
-
- # 7. Denoising loop
- for i, t in enumerate(self.progress_bar(timesteps)):
- # expand the latents if we are doing classifier free guidance
- latent_model_input = paddle.concat([latents] * 2) if do_classifier_free_guidance else latents
- latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
-
- # predict the noise residual
- noise_pred = self.image_unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
-
- # perform guidance
- if do_classifier_free_guidance:
- noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
-
- # call the callback, if provided
- if callback is not None and i % callback_steps == 0:
- callback(i, t, latents)
-
- # 9. Post-processing
- image = self.decode_latents(latents)
-
- # 10. Convert to PIL
- if output_type == "pil":
- image = self.numpy_to_pil(image)
-
- if not return_dict:
- return (image,)
-
- return ImagePipelineOutput(images=image)
diff --git a/spaces/801artistry/RVC801/infer/lib/infer_pack/modules/F0Predictor/__init__.py b/spaces/801artistry/RVC801/infer/lib/infer_pack/modules/F0Predictor/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/A1draw-12196y/anime-ai-detect/app.py b/spaces/A1draw-12196y/anime-ai-detect/app.py
deleted file mode 100644
index 89224ac0e4493054be928e7fabed7b9d0485e412..0000000000000000000000000000000000000000
--- a/spaces/A1draw-12196y/anime-ai-detect/app.py
+++ /dev/null
@@ -1,17 +0,0 @@
-import gradio as gr
-from transformers import pipeline
-
-detection_pipeline = pipeline("image-classification", "saltacc/anime-ai-detect")
-
-
-def detect(img):
- print(img)
- output = detection_pipeline(img, top_k=2)
- final = {}
- for d in output:
- final[d["label"]] = d["score"]
- return final
-
-
-iface = gr.Interface(fn=detect, inputs=gr.Image(type="pil"), outputs=gr.Label(label="result"))
-iface.launch()
diff --git a/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/training/main.py b/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/training/main.py
deleted file mode 100644
index 3b563a5d001be7adfbe779dee7ad8ac49aadc50d..0000000000000000000000000000000000000000
--- a/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/training/main.py
+++ /dev/null
@@ -1,596 +0,0 @@
-from inspect import getargs
-import logging
-import os
-import random
-from datetime import datetime
-import bisect
-import copy
-import numpy as np
-import torch
-import torch.backends.cudnn as cudnn
-from torch import optim
-from torch.cuda.amp import GradScaler
-import faulthandler
-import pathlib
-
-try:
- import wandb
-except ImportError:
- wandb = None
-
-try:
- import torch.utils.tensorboard as tensorboard
-except ImportError:
- tensorboard = None
-
-try:
- import horovod.torch as hvd
-except ImportError:
- hvd = None
-
-from open_clip import create_model_and_transforms, trace_model, create_model
-from training.data import get_data
-from training.distributed import is_master, init_distributed_device, world_info_from_env
-from training.logger import setup_logging
-from training.params import parse_args
-from training.scheduler import cosine_lr
-from training.train import train_one_epoch, evaluate
-from open_clip.utils import dataset_split, get_optimizer
-
-
-def maintain_ckpts(args, startidx, all_idx_len):
- for i in reversed(range(startidx, all_idx_len)):
- if os.path.exists(os.path.join(args.checkpoint_path, f"epoch_top_{i}.pt")):
- os.rename(
- os.path.join(args.checkpoint_path, f"epoch_top_{i}.pt"),
- os.path.join(args.checkpoint_path, f"epoch_top_{i+1}.pt"),
- )
- if os.path.exists(
- os.path.join(args.checkpoint_path, f"epoch_top_{all_idx_len}.pt")
- ):
- os.remove(os.path.join(args.checkpoint_path, f"epoch_top_{all_idx_len}.pt"))
- return
-
-
-def update_top_k_performance(
- new_metrics_inputs, current_top_k_ckpt_metrics, args, ckpt, bignumbetter=True
-):
- """
- Record the top-k performance of the current epoch.
- current_top_k_metrics is a dictionary of the form: {1: top_1_ckpt_measure, 2: top_2_ckpt_measure, ...}
- """
- if isinstance(new_metrics_inputs, (list, tuple)):
- new_metrics_inputs = np.mean(new_metrics_inputs)
- return update_top_k_performance(
- new_metrics_inputs,
- current_top_k_ckpt_metrics,
- args=args,
- ckpt=ckpt,
- bignumbetter=bignumbetter,
- )
- elif isinstance(new_metrics_inputs, dict):
- new_metrics_inputs = np.mean(list(new_metrics_inputs.values()))
- return update_top_k_performance(
- new_metrics_inputs,
- current_top_k_ckpt_metrics,
- args=args,
- ckpt=ckpt,
- bignumbetter=bignumbetter,
- )
- elif isinstance(new_metrics_inputs, (float, int)):
- update_flag = {k: False for k in current_top_k_ckpt_metrics.keys()}
- sorted_keys = sorted(current_top_k_ckpt_metrics.keys())
- sorted_values = sorted(
- current_top_k_ckpt_metrics.values(), reverse=bignumbetter
- )
- sorted_values_ = copy.deepcopy(sorted_values)
- sorted_values.append(new_metrics_inputs)
- sorted_values = sorted(sorted_values, reverse=bignumbetter)
- sorted_values = sorted_values[:-1]
-
- if sorted_values == sorted_values_:
- return current_top_k_ckpt_metrics, new_metrics_inputs
- else:
- for i in range(len(sorted_keys)):
- if current_top_k_ckpt_metrics[sorted_keys[i]] != sorted_values[i]:
- current_top_k_ckpt_metrics[sorted_keys[i]] = sorted_values[i]
- update_flag[sorted_keys[i]] = True
- for i in range(len(update_flag)):
- if update_flag[i]:
- maintain_ckpts(args, i, len(sorted_keys))
- torch.save(
- ckpt,
- os.path.join(args.checkpoint_path, f"epoch_top_{i}.pt"),
- )
- break
- return current_top_k_ckpt_metrics, new_metrics_inputs
-
-
-# def updateifNone(a, b):
-# a = b if None else a
-# return a
-
-
-def is_pretrained_params(n):
- return (
- n.startswith("transformer")
- or n in ["positional_embedding", "text_projection"]
- or n.startswith("token_embedding")
- or n.startswith("ln_final")
- or n.startswith("logit_scale_t")
- )
-
-
-def random_seed(seed=42, rank=0):
- torch.manual_seed(seed + rank)
- np.random.seed(seed + rank)
- random.seed(seed + rank)
-
-
-def main():
- args = parse_args()
- # sanitize model name for filesystem / uri use, easier if we don't use / in name as a rule?
- args.amodel = args.amodel.replace("/", "-")
- # download sizes.json file
-
- # (yusong): the below two lines are for debug
- # print("setting up faulthandler")
- # faulthandler.register(10)
-
- random.seed(args.seed)
- torch.manual_seed(args.seed)
- torch.cuda.manual_seed(args.seed)
- torch.cuda.manual_seed_all(args.seed)
- np.random.seed(args.seed)
- if args.tmodel == "bert" or args.tmodel == "roberta" or args.tmodel == "bart":
- assert (
- args.pretrained == "" or args.pretrained is None
- ), "bert/roberta/bart text encoder does not support pretrained models."
-
- # get the name of the experiments
- if args.name is None:
- args.name = "-".join(
- [
- datetime.now().strftime("%Y_%m_%d-%H_%M_%S"),
- f"model_{args.amodel}",
- f"lr_{args.lr}",
- f"b_{args.batch_size}",
- f"j_{args.workers}",
- f"p_{args.precision}",
- ]
- )
-
- # discover initial world args early so we can log properly
- args.distributed = False
- args.local_rank, args.rank, args.world_size = world_info_from_env()
-
- if args.remotedata and is_master(args):
- for dataset_name in args.datasetnames:
- for split in dataset_split[dataset_name]:
- if not os.path.exists(f"./json_files/{dataset_name}/{split}"):
- os.makedirs(f"./json_files/{dataset_name}/{split}")
- os.system(
- f"aws s3 cp s3://s-laion-audio/webdataset_tar/{dataset_name}/{split}/sizes.json ./json_files/{dataset_name}/{split}/sizes.json"
- )
-
- args.log_path = None
- if is_master(args, local=args.log_local):
- log_base_path = os.path.join(args.logs, args.name)
- os.makedirs(log_base_path, exist_ok=True)
- log_filename = f"out-{args.rank}" if args.log_local else "out.log"
- args.log_path = os.path.join(log_base_path, log_filename)
- if os.path.exists(args.log_path):
- print(
- "Error. Experiment already exists. Use --name {} to specify a new experiment."
- )
- return -1
-
- # Set logger
- args.log_level = logging.DEBUG if args.debug else logging.INFO
- setup_logging(args.log_path, args.log_level)
-
- # fully initialize distributed device environment
- device = init_distributed_device(args)
-
- args.wandb = "wandb" in args.report_to or "all" in args.report_to
- args.tensorboard = "tensorboard" in args.report_to or "all" in args.report_to
- if is_master(args):
- args.tensorboard_path = (
- os.path.join(args.logs, args.name, "tensorboard")
- if args.tensorboard
- else ""
- )
- args.checkpoint_path = os.path.join(args.logs, args.name, "checkpoints")
- for dirname in [args.tensorboard_path, args.checkpoint_path]:
- if dirname:
- os.makedirs(dirname, exist_ok=True)
- else:
- args.tensorboard_path = ""
- args.checkpoint_path = ""
-
- if args.copy_codebase:
- copy_codebase(args)
-
- assert args.precision in ["amp", "fp16", "fp32"]
- if args.precision == "fp16":
- logging.warning(
- "It is recommended to use AMP mixed-precision instead of FP16. "
- "FP16 support needs further verification and tuning, especially for train."
- )
-
- if args.horovod:
- logging.info(
- f"Running in horovod mode with multiple processes / nodes. Device: {args.device}."
- f"Process (global: {args.rank}, local {args.local_rank}), total {args.world_size}."
- )
- elif args.distributed:
- logging.info(
- f"Running in distributed mode with multiple processes. Device: {args.device}."
- f"Process (global: {args.rank}, local {args.local_rank}), total {args.world_size}."
- )
- else:
- logging.info(f"Running with a single process. Device {args.device}.")
-
- logging.info(f"openai cache dir: {os.path.expanduser(args.openai_model_cache_dir)}")
-
- model, model_cfg = create_model(
- args.amodel,
- args.tmodel,
- args.pretrained,
- precision=args.precision,
- device=device,
- jit=args.torchscript,
- force_quick_gelu=args.force_quick_gelu,
- openai_model_cache_dir=os.path.expanduser(args.openai_model_cache_dir),
- skip_params=True,
- pretrained_audio=args.pretrained_audio,
- pretrained_text=args.pretrained_text,
- enable_fusion=args.enable_fusion,
- fusion_type=args.fusion_type,
- )
-
- if args.horovod:
- with torch.no_grad():
- for param in model.parameters():
- param.set_(param.contiguous())
-
- if args.trace:
- model = trace_model(model, batch_size=args.batch_size, device=device)
-
- if is_master(args):
- logging.info("Model:")
- logging.info(f"{str(model)}")
- logging.info("Params:")
- params_file = os.path.join(args.logs, args.name, "params.txt")
- with open(params_file, "w") as f:
- for name in sorted(vars(args)):
- val = getattr(args, name)
- logging.info(f" {name}: {val}")
- f.write(f"{name}: {val}\n")
-
- if args.distributed and not args.horovod:
- if args.use_bn_sync:
- model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
- ddp_args = {}
- if args.ddp_static_graph:
- # this doesn't exist in older PyTorch, arg only added if enabled
- ddp_args["static_graph"] = True
- model = torch.nn.parallel.DistributedDataParallel(
- model, device_ids=[device], find_unused_parameters=True, **ddp_args
- )
-
- data = get_data(args, model_cfg)
- assert len(data), "At least one train or eval dataset must be specified."
- if args.trace:
- assert "train" not in data, "Cannot train with traced model"
-
- exclude = (
- lambda n, p: p.ndim < 2
- or "bn" in n
- or "ln" in n
- or "bias" in n
- or "logit_scale" in n
- )
- include = lambda n, p: not exclude(n, p)
-
- named_parameters = list(model.named_parameters())
-
- # freeze text encoder
- text_freeze_parameters = [p for n, p in named_parameters if "text_branch" in n]
-
- if args.freeze_text:
- print("Freeze Text!!!!")
- for k in text_freeze_parameters:
- k.requires_grad = False
-
- gain_or_bias_params = [
- p for n, p in named_parameters if exclude(n, p) and p.requires_grad
- ]
- rest_params = [p for n, p in named_parameters if include(n, p) and p.requires_grad]
-
- # set wd-related params to 0 if use adam optimizer
- if args.optimizer == "adam":
- args.wd = 0
- args.wd_pretrained = 0
- args.wd_new = 0
-
- if args.train_data is None:
- optimizer = None
- scheduler = None
- else:
- total_steps = data["train"].dataloader.num_batches * args.epochs
-
- if args.split_opt:
- for x in ["lr", "beta1", "beta2", "eps", "wd"]:
- for y in ["_new", "_pretrained"]:
- if getattr(args, x + y) is None:
- setattr(args, x + y, getattr(args, x))
-
- gain_or_bias_pretrained_params = [
- p
- for n, p in named_parameters
- if (exclude(n, p) and p.requires_grad) and is_pretrained_params(n)
- ]
- rest_pretrained_params = [
- p
- for n, p in named_parameters
- if (include(n, p) and p.requires_grad) and is_pretrained_params(n)
- ]
- gain_or_bias_new_params = [
- p
- for n, p in named_parameters
- if (exclude(n, p) and p.requires_grad) and (not is_pretrained_params(n))
- ]
- rest_new_params = [
- p
- for n, p in named_parameters
- if (include(n, p) and p.requires_grad) and (not is_pretrained_params(n))
- ]
- pretrained_params_optimizer = get_optimizer(
- [
- {"params": gain_or_bias_pretrained_params, "weight_decay": 0.0},
- {
- "params": rest_pretrained_params,
- "weight_decay": args.wd_pretrained,
- },
- ],
- lr=args.lr_pretrained,
- betas=(args.beta1_pretrained, args.beta2_pretrained),
- eps=args.eps_pretrained,
- momentum=args.momentum_pretrained,
- optimizer_name=args.optimizer,
- )
- pretrained_params_scheduler = cosine_lr(
- pretrained_params_optimizer,
- args.lr_pretrained,
- args.warmup,
- total_steps,
- )
- new_params_optimizer = get_optimizer(
- [
- {"params": gain_or_bias_new_params, "weight_decay": 0.0},
- {"params": rest_new_params, "weight_decay": args.wd_new},
- ],
- lr=args.lr_new,
- betas=(args.beta1_new, args.beta2_new),
- eps=args.eps_new,
- momentum=args.momentum_new,
- optimizer_name=args.optimizer,
- )
-
- new_params_scheduler = cosine_lr(
- new_params_optimizer, args.lr_new, args.warmup, total_steps
- )
-
- optimizer = {
- "pretrained": pretrained_params_optimizer,
- "new": new_params_optimizer,
- }
- scheduler = {
- "pretrained": pretrained_params_scheduler,
- "new": new_params_scheduler,
- }
-
- if args.horovod:
- pretrained_params_optimizer = hvd.DistributedOptimizer(
- pretrained_params_optimizer,
- named_parameters=model.named_parameters(),
- )
- new_params_optimizer = hvd.DistributedOptimizer(
- new_params_optimizer, named_parameters=model.named_parameters()
- )
- hvd.broadcast_parameters(model.state_dict(), root_rank=0)
- hvd.broadcast_optimizer_state(pretrained_params_optimizer, root_rank=0)
- hvd.broadcast_optimizer_state(new_params_optimizer, root_rank=0)
- else:
- optimizer = get_optimizer(
- [
- {"params": gain_or_bias_params, "weight_decay": 0.0},
- {"params": rest_params, "weight_decay": args.wd},
- ],
- lr=args.lr,
- betas=(args.beta1, args.beta2),
- eps=args.eps,
- momentum=args.momentum,
- optimizer_name=args.optimizer,
- )
-
- scheduler = cosine_lr(optimizer, args.lr, args.warmup, total_steps)
-
- if args.horovod:
- optimizer = hvd.DistributedOptimizer(
- optimizer, named_parameters=model.named_parameters()
- )
- hvd.broadcast_parameters(model.state_dict(), root_rank=0)
- hvd.broadcast_optimizer_state(optimizer, root_rank=0)
-
- scaler = GradScaler() if args.precision == "amp" else None
-
- # optionally resume from a checkpoint
- start_epoch = 0
- if args.resume is not None:
- if os.path.isfile(args.resume):
- checkpoint = torch.load(args.resume, map_location=device)
- if "epoch" in checkpoint:
- # resuming a train checkpoint w/ epoch and optimizer state
- start_epoch = checkpoint["epoch"]
- sd = checkpoint["state_dict"]
- if not args.distributed and next(iter(sd.items()))[0].startswith(
- "module"
- ):
- sd = {k[len("module.") :]: v for k, v in sd.items()}
- model.load_state_dict(sd)
- if args.split_opt:
- if optimizer is not None:
- for k, o_ in optimizer.items():
- o_.load_state_dict(checkpoint[k + "_" + "optimizer"])
- if optimizer is not None:
- optimizer.load_state_dict(checkpoint["optimizer"])
- if scaler is not None and "scaler" in checkpoint:
- scaler.load_state_dict(checkpoint["scaler"])
- logging.info(
- f"=> resuming checkpoint '{args.resume}' (epoch {start_epoch})"
- )
- else:
- # loading a bare (model only) checkpoint for fine-tune or evaluation
- model.load_state_dict(checkpoint)
- logging.info(
- f"=> loaded checkpoint '{args.resume}' (epoch {start_epoch})"
- )
- if args.freeze_text:
- print("Freeze Text!!!!")
- for k in text_freeze_parameters:
- k.requires_grad = False
- else:
- logging.info("=> no checkpoint found at '{}'".format(args.resume))
-
- cudnn.benchmark = True
- cudnn.deterministic = False
-
- # determine if this worker should save logs and checkpoints. only do so if it is rank == 0
- args.save_logs = args.logs and args.logs.lower() != "none" and is_master(args)
- writer = None
- if args.save_logs and args.tensorboard:
- assert tensorboard is not None, "Please install tensorboard."
- writer = tensorboard.SummaryWriter(args.tensorboard_path)
-
- if args.wandb and is_master(args):
- assert wandb is not None, "Please install wandb."
- logging.debug("Starting wandb.")
- args.train_sz = data["train"].dataloader.num_samples
- if args.val_data is not None:
- args.val_sz = data["val"].dataloader.num_samples
- # you will have to configure this for your project!
- wandb.init(
- project="clap",
- notes=args.wandb_notes,
- name=args.wandb_notes,
- tags=[],
- config=vars(args),
- )
- if args.debug:
- wandb.watch(model, log="all")
- wandb.save(params_file)
- logging.debug("Finished loading wandb.")
-
- if "train" not in data:
- evaluate(model, data, start_epoch, args, writer)
- return
- elif start_epoch == 0 and "val" in data and not args.no_eval:
- evaluate(model, data, 0, args, writer)
- # print(f'rank {args.rank}, Start First Evaluation')# (yusong): for debug
- if args.save_top_performance:
- current_top_k_ckpt_metrics = {
- i: 0 for i in range(args.save_top_performance)
- } # initialize the top-k metric for ckpts to 0
-
- # print(f'rank {args.rank}, Start Training') # (yusong): for debug
- for epoch in range(start_epoch, args.epochs):
- # freeze the text param after (include) args.freeze_text_after, this is -1 by default
- if epoch == args.freeze_text_after:
- print("Text pretrained parameters are freezed since this epoch.")
- for k in text_freeze_parameters:
- k.requires_grad = False
- if is_master(args):
- logging.info(f"Start epoch {epoch}")
-
- train_one_epoch(model, data, epoch, optimizer, scaler, scheduler, args, writer)
- completed_epoch = epoch + 1
-
- if (
- any(v in data for v in ("val", "imagenet-val", "imagenet-v2"))
- and not args.no_eval
- ):
- metrics = evaluate(model, data, completed_epoch, args, writer)
- if args.save_top_performance:
- top_k_dataset = args.top_k_checkpoint_select_dataset
- top_k_metric = args.top_k_checkpoint_select_metric
- filtered_metrics = [
- v
- for k, v in metrics.items()
- if top_k_metric in k and top_k_dataset in k
- ] # check all R@10 metrics (all dataset) and use it to update the ckpt
- # Saving checkpoints.
- if args.save_logs:
- if args.split_opt:
- opt_dict = {
- k + "_" + "optimizer": v.state_dict() for k, v in optimizer.items()
- }
- else:
- opt_dict = {"optimizer": optimizer.state_dict()}
- checkpoint_dict = {
- "epoch": completed_epoch,
- "name": args.name,
- "state_dict": model.state_dict(),
- }
- checkpoint_dict.update(opt_dict)
- if scaler is not None:
- checkpoint_dict["scaler"] = scaler.state_dict()
-
- if completed_epoch == args.epochs or (
- args.save_frequency > 0 and (completed_epoch % args.save_frequency) == 0
- ):
- torch.save(
- checkpoint_dict,
- os.path.join(args.checkpoint_path, f"epoch_{completed_epoch}.pt"),
- )
- if args.save_most_recent:
- torch.save(
- checkpoint_dict,
- os.path.join(args.checkpoint_path, f"epoch_latest.pt"),
- )
- if args.save_top_performance and not args.no_eval:
- update_top_k_performance(
- filtered_metrics,
- current_top_k_ckpt_metrics,
- args,
- checkpoint_dict,
- bignumbetter=True,
- )
-
- if args.wandb and is_master(args):
- wandb.finish()
-
-
-def copy_codebase(args):
- from shutil import copytree, ignore_patterns
-
- new_code_path = os.path.join(args.logs, args.name, "code")
- if os.path.exists(new_code_path):
- print(
- f"Error. Experiment already exists at {new_code_path}. Use --name to specify a new experiment."
- )
- return -1
- print(f"Copying codebase to {new_code_path}")
- current_code_path = os.path.realpath(__file__)
- for _ in range(3):
- current_code_path = os.path.dirname(current_code_path)
- copytree(
- current_code_path, new_code_path, ignore=ignore_patterns("log", "logs", "wandb")
- )
- print("Done copying code.")
- return 1
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/AIGC-Audio/AudioGPT/mono2binaural/src/models.py b/spaces/AIGC-Audio/AudioGPT/mono2binaural/src/models.py
deleted file mode 100644
index 0d4052784170e4fdc90c342860981ec7c03a25bc..0000000000000000000000000000000000000000
--- a/spaces/AIGC-Audio/AudioGPT/mono2binaural/src/models.py
+++ /dev/null
@@ -1,110 +0,0 @@
-import numpy as np
-import scipy.linalg
-from scipy.spatial.transform import Rotation as R
-import torch as th
-import torch.nn as nn
-import torch.nn.functional as F
-from src.warping import GeometricTimeWarper, MonotoneTimeWarper
-from src.utils import Net
-
-
-class GeometricWarper(nn.Module):
- def __init__(self, sampling_rate=48000):
- super().__init__()
- self.warper = GeometricTimeWarper(sampling_rate=sampling_rate)
-
- def _transmitter_mouth(self, view):
- # offset between tracking markers and real mouth position in the dataset
- mouth_offset = np.array([0.09, 0, -0.20])
- quat = view[:, 3:, :].transpose(2, 1).contiguous().detach().cpu().view(-1, 4).numpy()
- # make sure zero-padded values are set to non-zero values (else scipy raises an exception)
- norms = scipy.linalg.norm(quat, axis=1)
- eps_val = (norms == 0).astype(np.float32)
- quat = quat + eps_val[:, None]
- transmitter_rot_mat = R.from_quat(quat)
- transmitter_mouth = transmitter_rot_mat.apply(mouth_offset, inverse=True)
- transmitter_mouth = th.Tensor(transmitter_mouth).view(view.shape[0], -1, 3).transpose(2, 1).contiguous()
- if view.is_cuda:
- transmitter_mouth = transmitter_mouth.cuda()
- return transmitter_mouth
-
- def _3d_displacements(self, view):
- transmitter_mouth = self._transmitter_mouth(view)
- # offset between tracking markers and ears in the dataset
- left_ear_offset = th.Tensor([0, -0.08, -0.22]).cuda() if view.is_cuda else th.Tensor([0, -0.08, -0.22])
- right_ear_offset = th.Tensor([0, 0.08, -0.22]).cuda() if view.is_cuda else th.Tensor([0, 0.08, -0.22])
- # compute displacements between transmitter mouth and receiver left/right ear
- displacement_left = view[:, 0:3, :] + transmitter_mouth - left_ear_offset[None, :, None]
- displacement_right = view[:, 0:3, :] + transmitter_mouth - right_ear_offset[None, :, None]
- displacement = th.stack([displacement_left, displacement_right], dim=1)
- return displacement
-
- def _warpfield(self, view, seq_length):
- return self.warper.displacements2warpfield(self._3d_displacements(view), seq_length)
-
- def forward(self, mono, view):
- '''
- :param mono: input signal as tensor of shape B x 1 x T
- :param view: rx/tx position/orientation as tensor of shape B x 7 x K (K = T / 400)
- :return: warped: warped left/right ear signal as tensor of shape B x 2 x T
- '''
- return self.warper(th.cat([mono, mono], dim=1), self._3d_displacements(view))
-
-
-class Warpnet(nn.Module):
- def __init__(self, layers=4, channels=64, view_dim=7):
- super().__init__()
- self.layers = [nn.Conv1d(view_dim if l == 0 else channels, channels, kernel_size=2) for l in range(layers)]
- self.layers = nn.ModuleList(self.layers)
- self.linear = nn.Conv1d(channels, 2, kernel_size=1)
- self.neural_warper = MonotoneTimeWarper()
- self.geometric_warper = GeometricWarper()
-
- def neural_warpfield(self, view, seq_length):
- warpfield = view
- for layer in self.layers:
- warpfield = F.pad(warpfield, pad=[1, 0])
- warpfield = F.relu(layer(warpfield))
- warpfield = self.linear(warpfield)
- warpfield = F.interpolate(warpfield, size=seq_length)
- return warpfield
-
- def forward(self, mono, view):
- '''
- :param mono: input signal as tensor of shape B x 1 x T
- :param view: rx/tx position/orientation as tensor of shape B x 7 x K (K = T / 400)
- :return: warped: warped left/right ear signal as tensor of shape B x 2 x T
- '''
- geometric_warpfield = self.geometric_warper._warpfield(view, mono.shape[-1])
- neural_warpfield = self.neural_warpfield(view, mono.shape[-1])
- warpfield = geometric_warpfield + neural_warpfield
- # ensure causality
- warpfield = -F.relu(-warpfield) # the predicted warp
- warped = self.neural_warper(th.cat([mono, mono], dim=1), warpfield)
- return warped
-
-class BinauralNetwork(Net):
- def __init__(self,
- view_dim=7,
- warpnet_layers=4,
- warpnet_channels=64,
- model_name='binaural_network',
- use_cuda=True):
- super().__init__(model_name, use_cuda)
- self.warper = Warpnet(warpnet_layers, warpnet_channels)
- if self.use_cuda:
- self.cuda()
-
- def forward(self, mono, view):
- '''
- :param mono: the input signal as a B x 1 x T tensor
- :param view: the receiver/transmitter position as a B x 7 x T tensor
- :return: out: the binaural output produced by the network
- intermediate: a two-channel audio signal obtained from the output of each intermediate layer
- as a list of B x 2 x T tensors
- '''
- # print('mono ', mono.shape)
- # print('view ', view.shape)
- warped = self.warper(mono, view)
- # print('warped ', warped.shape)
- return warped
diff --git a/spaces/AILab-CVC/SEED-LLaMA/scripts/start_backend_8b.sh b/spaces/AILab-CVC/SEED-LLaMA/scripts/start_backend_8b.sh
deleted file mode 100644
index 6acebbc8744efd0b556c488769d964db7994e96b..0000000000000000000000000000000000000000
--- a/spaces/AILab-CVC/SEED-LLaMA/scripts/start_backend_8b.sh
+++ /dev/null
@@ -1,10 +0,0 @@
-
-python3 gradio_demo/seed_llama_flask.py \
- --image_transform configs/transform/clip_transform.yaml \
- --tokenizer configs/tokenizer/seed_llama_tokenizer.yaml \
- --model configs/llm/seed_llama_8b_8bit.yaml \
- --port 7890 \
- --llm_device cuda:0 \
- --tokenizer_device cuda:0 \
- --offload_encoder \
- --offload_decoder
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/colorinput/colorpicker/Factory.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/colorinput/colorpicker/Factory.js
deleted file mode 100644
index ecb53c2aceb6be100e7a9808f49d38ea1ec4185c..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/colorinput/colorpicker/Factory.js
+++ /dev/null
@@ -1,13 +0,0 @@
-import ColorPicker from './ColorPicker.js';
-import ObjectFactory from '../../ObjectFactory.js';
-import SetValue from '../../../../plugins/utils/object/SetValue.js';
-
-ObjectFactory.register('colorPicker', function (config) {
- var gameObject = new ColorPicker(this.scene, config);
- this.scene.add.existing(gameObject);
- return gameObject;
-});
-
-SetValue(window, 'RexPlugins.UI.ColorPicker', ColorPicker);
-
-export default ColorPicker;
\ No newline at end of file
diff --git a/spaces/Aki004/herta-so-vits/vdecoder/nsf_hifigan/utils.py b/spaces/Aki004/herta-so-vits/vdecoder/nsf_hifigan/utils.py
deleted file mode 100644
index 84bff024f4d2e2de194b2a88ee7bbe5f0d33f67c..0000000000000000000000000000000000000000
--- a/spaces/Aki004/herta-so-vits/vdecoder/nsf_hifigan/utils.py
+++ /dev/null
@@ -1,68 +0,0 @@
-import glob
-import os
-import matplotlib
-import torch
-from torch.nn.utils import weight_norm
-matplotlib.use("Agg")
-import matplotlib.pylab as plt
-
-
-def plot_spectrogram(spectrogram):
- fig, ax = plt.subplots(figsize=(10, 2))
- im = ax.imshow(spectrogram, aspect="auto", origin="lower",
- interpolation='none')
- plt.colorbar(im, ax=ax)
-
- fig.canvas.draw()
- plt.close()
-
- return fig
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def apply_weight_norm(m):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- weight_norm(m)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size*dilation - dilation)/2)
-
-
-def load_checkpoint(filepath, device):
- assert os.path.isfile(filepath)
- print("Loading '{}'".format(filepath))
- checkpoint_dict = torch.load(filepath, map_location=device)
- print("Complete.")
- return checkpoint_dict
-
-
-def save_checkpoint(filepath, obj):
- print("Saving checkpoint to {}".format(filepath))
- torch.save(obj, filepath)
- print("Complete.")
-
-
-def del_old_checkpoints(cp_dir, prefix, n_models=2):
- pattern = os.path.join(cp_dir, prefix + '????????')
- cp_list = glob.glob(pattern) # get checkpoint paths
- cp_list = sorted(cp_list)# sort by iter
- if len(cp_list) > n_models: # if more than n_models models are found
- for cp in cp_list[:-n_models]:# delete the oldest models other than lastest n_models
- open(cp, 'w').close()# empty file contents
- os.unlink(cp)# delete file (move to trash when using Colab)
-
-
-def scan_checkpoint(cp_dir, prefix):
- pattern = os.path.join(cp_dir, prefix + '????????')
- cp_list = glob.glob(pattern)
- if len(cp_list) == 0:
- return None
- return sorted(cp_list)[-1]
-
diff --git a/spaces/Amrrs/DragGan-Inversion/PTI/models/StyleCLIP/global_directions/GUI.py b/spaces/Amrrs/DragGan-Inversion/PTI/models/StyleCLIP/global_directions/GUI.py
deleted file mode 100644
index 19f7f8cce9305819b22664642799200d9e1cfff0..0000000000000000000000000000000000000000
--- a/spaces/Amrrs/DragGan-Inversion/PTI/models/StyleCLIP/global_directions/GUI.py
+++ /dev/null
@@ -1,103 +0,0 @@
-
-
-from tkinter import Tk,Frame ,Label,Button,messagebox,Canvas,Text,Scale
-from tkinter import HORIZONTAL
-
-class View():
- def __init__(self,master):
-
- self.width=600
- self.height=600
-
-
- self.root=master
- self.root.geometry("600x600")
-
- self.left_frame=Frame(self.root,width=600)
- self.left_frame.pack_propagate(0)
- self.left_frame.pack(fill='both', side='left', expand='True')
-
- self.retrieval_frame=Frame(self.root,bg='snow3')
- self.retrieval_frame.pack_propagate(0)
- self.retrieval_frame.pack(fill='both', side='right', expand='True')
-
- self.bg_frame=Frame(self.left_frame,bg='snow3',height=600,width=600)
- self.bg_frame.pack_propagate(0)
- self.bg_frame.pack(fill='both', side='top', expand='True')
-
- self.command_frame=Frame(self.left_frame,bg='snow3')
- self.command_frame.pack_propagate(0)
- self.command_frame.pack(fill='both', side='bottom', expand='True')
-# self.command_frame.grid(row=1, column=0,padx=0, pady=0)
-
- self.bg=Canvas(self.bg_frame,width=self.width,height=self.height, bg='gray')
- self.bg.place(relx=0.5, rely=0.5, anchor='center')
-
- self.mani=Canvas(self.retrieval_frame,width=1024,height=1024, bg='gray')
- self.mani.grid(row=0, column=0,padx=0, pady=42)
-
- self.SetCommand()
-
-
-
-
- def run(self):
- self.root.mainloop()
-
- def helloCallBack(self):
- category=self.set_category.get()
- messagebox.showinfo( "Hello Python",category)
-
- def SetCommand(self):
-
- tmp = Label(self.command_frame, text="neutral", width=10 ,bg='snow3')
- tmp.grid(row=1, column=0,padx=10, pady=10)
-
- tmp = Label(self.command_frame, text="a photo of a", width=10 ,bg='snow3')
- tmp.grid(row=1, column=1,padx=10, pady=10)
-
- self.neutral = Text ( self.command_frame, height=2, width=30)
- self.neutral.grid(row=1, column=2,padx=10, pady=10)
-
-
- tmp = Label(self.command_frame, text="target", width=10 ,bg='snow3')
- tmp.grid(row=2, column=0,padx=10, pady=10)
-
- tmp = Label(self.command_frame, text="a photo of a", width=10 ,bg='snow3')
- tmp.grid(row=2, column=1,padx=10, pady=10)
-
- self.target = Text ( self.command_frame, height=2, width=30)
- self.target.grid(row=2, column=2,padx=10, pady=10)
-
- tmp = Label(self.command_frame, text="strength", width=10 ,bg='snow3')
- tmp.grid(row=3, column=0,padx=10, pady=10)
-
- self.alpha = Scale(self.command_frame, from_=-15, to=25, orient=HORIZONTAL,bg='snow3', length=250,resolution=0.01)
- self.alpha.grid(row=3, column=2,padx=10, pady=10)
-
-
- tmp = Label(self.command_frame, text="disentangle", width=10 ,bg='snow3')
- tmp.grid(row=4, column=0,padx=10, pady=10)
-
- self.beta = Scale(self.command_frame, from_=0.08, to=0.4, orient=HORIZONTAL,bg='snow3', length=250,resolution=0.001)
- self.beta.grid(row=4, column=2,padx=10, pady=10)
-
- self.reset = Button(self.command_frame, text='Reset')
- self.reset.grid(row=5, column=1,padx=10, pady=10)
-
-
- self.set_init = Button(self.command_frame, text='Accept')
- self.set_init.grid(row=5, column=2,padx=10, pady=10)
-
-#%%
-if __name__ == "__main__":
- master=Tk()
- self=View(master)
- self.run()
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/examples/community/bit_diffusion.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/examples/community/bit_diffusion.py
deleted file mode 100644
index 18d5fca5619e3f420128288399aa000037d1feec..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/examples/community/bit_diffusion.py
+++ /dev/null
@@ -1,264 +0,0 @@
-from typing import Optional, Tuple, Union
-
-import torch
-from einops import rearrange, reduce
-
-from diffusers import DDIMScheduler, DDPMScheduler, DiffusionPipeline, ImagePipelineOutput, UNet2DConditionModel
-from diffusers.schedulers.scheduling_ddim import DDIMSchedulerOutput
-from diffusers.schedulers.scheduling_ddpm import DDPMSchedulerOutput
-
-
-BITS = 8
-
-
-# convert to bit representations and back taken from https://github.com/lucidrains/bit-diffusion/blob/main/bit_diffusion/bit_diffusion.py
-def decimal_to_bits(x, bits=BITS):
- """expects image tensor ranging from 0 to 1, outputs bit tensor ranging from -1 to 1"""
- device = x.device
-
- x = (x * 255).int().clamp(0, 255)
-
- mask = 2 ** torch.arange(bits - 1, -1, -1, device=device)
- mask = rearrange(mask, "d -> d 1 1")
- x = rearrange(x, "b c h w -> b c 1 h w")
-
- bits = ((x & mask) != 0).float()
- bits = rearrange(bits, "b c d h w -> b (c d) h w")
- bits = bits * 2 - 1
- return bits
-
-
-def bits_to_decimal(x, bits=BITS):
- """expects bits from -1 to 1, outputs image tensor from 0 to 1"""
- device = x.device
-
- x = (x > 0).int()
- mask = 2 ** torch.arange(bits - 1, -1, -1, device=device, dtype=torch.int32)
-
- mask = rearrange(mask, "d -> d 1 1")
- x = rearrange(x, "b (c d) h w -> b c d h w", d=8)
- dec = reduce(x * mask, "b c d h w -> b c h w", "sum")
- return (dec / 255).clamp(0.0, 1.0)
-
-
-# modified scheduler step functions for clamping the predicted x_0 between -bit_scale and +bit_scale
-def ddim_bit_scheduler_step(
- self,
- model_output: torch.FloatTensor,
- timestep: int,
- sample: torch.FloatTensor,
- eta: float = 0.0,
- use_clipped_model_output: bool = True,
- generator=None,
- return_dict: bool = True,
-) -> Union[DDIMSchedulerOutput, Tuple]:
- """
- Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
- process from the learned model outputs (most often the predicted noise).
- Args:
- model_output (`torch.FloatTensor`): direct output from learned diffusion model.
- timestep (`int`): current discrete timestep in the diffusion chain.
- sample (`torch.FloatTensor`):
- current instance of sample being created by diffusion process.
- eta (`float`): weight of noise for added noise in diffusion step.
- use_clipped_model_output (`bool`): TODO
- generator: random number generator.
- return_dict (`bool`): option for returning tuple rather than DDIMSchedulerOutput class
- Returns:
- [`~schedulers.scheduling_utils.DDIMSchedulerOutput`] or `tuple`:
- [`~schedulers.scheduling_utils.DDIMSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
- returning a tuple, the first element is the sample tensor.
- """
- if self.num_inference_steps is None:
- raise ValueError(
- "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
- )
-
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
- # Ideally, read DDIM paper in-detail understanding
-
- # Notation ( ->
- # - pred_noise_t -> e_theta(x_t, t)
- # - pred_original_sample -> f_theta(x_t, t) or x_0
- # - std_dev_t -> sigma_t
- # - eta -> η
- # - pred_sample_direction -> "direction pointing to x_t"
- # - pred_prev_sample -> "x_t-1"
-
- # 1. get previous step value (=t-1)
- prev_timestep = timestep - self.config.num_train_timesteps // self.num_inference_steps
-
- # 2. compute alphas, betas
- alpha_prod_t = self.alphas_cumprod[timestep]
- alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
-
- beta_prod_t = 1 - alpha_prod_t
-
- # 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
- pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
-
- # 4. Clip "predicted x_0"
- scale = self.bit_scale
- if self.config.clip_sample:
- pred_original_sample = torch.clamp(pred_original_sample, -scale, scale)
-
- # 5. compute variance: "sigma_t(η)" -> see formula (16)
- # σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
- variance = self._get_variance(timestep, prev_timestep)
- std_dev_t = eta * variance ** (0.5)
-
- if use_clipped_model_output:
- # the model_output is always re-derived from the clipped x_0 in Glide
- model_output = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
-
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
- pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * model_output
-
- # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
- prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
-
- if eta > 0:
- # randn_like does not support generator https://github.com/pytorch/pytorch/issues/27072
- device = model_output.device if torch.is_tensor(model_output) else "cpu"
- noise = torch.randn(model_output.shape, dtype=model_output.dtype, generator=generator).to(device)
- variance = self._get_variance(timestep, prev_timestep) ** (0.5) * eta * noise
-
- prev_sample = prev_sample + variance
-
- if not return_dict:
- return (prev_sample,)
-
- return DDIMSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
-
-
-def ddpm_bit_scheduler_step(
- self,
- model_output: torch.FloatTensor,
- timestep: int,
- sample: torch.FloatTensor,
- prediction_type="epsilon",
- generator=None,
- return_dict: bool = True,
-) -> Union[DDPMSchedulerOutput, Tuple]:
- """
- Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
- process from the learned model outputs (most often the predicted noise).
- Args:
- model_output (`torch.FloatTensor`): direct output from learned diffusion model.
- timestep (`int`): current discrete timestep in the diffusion chain.
- sample (`torch.FloatTensor`):
- current instance of sample being created by diffusion process.
- prediction_type (`str`, default `epsilon`):
- indicates whether the model predicts the noise (epsilon), or the samples (`sample`).
- generator: random number generator.
- return_dict (`bool`): option for returning tuple rather than DDPMSchedulerOutput class
- Returns:
- [`~schedulers.scheduling_utils.DDPMSchedulerOutput`] or `tuple`:
- [`~schedulers.scheduling_utils.DDPMSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
- returning a tuple, the first element is the sample tensor.
- """
- t = timestep
-
- if model_output.shape[1] == sample.shape[1] * 2 and self.variance_type in ["learned", "learned_range"]:
- model_output, predicted_variance = torch.split(model_output, sample.shape[1], dim=1)
- else:
- predicted_variance = None
-
- # 1. compute alphas, betas
- alpha_prod_t = self.alphas_cumprod[t]
- alpha_prod_t_prev = self.alphas_cumprod[t - 1] if t > 0 else self.one
- beta_prod_t = 1 - alpha_prod_t
- beta_prod_t_prev = 1 - alpha_prod_t_prev
-
- # 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
- if prediction_type == "epsilon":
- pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
- elif prediction_type == "sample":
- pred_original_sample = model_output
- else:
- raise ValueError(f"Unsupported prediction_type {prediction_type}.")
-
- # 3. Clip "predicted x_0"
- scale = self.bit_scale
- if self.config.clip_sample:
- pred_original_sample = torch.clamp(pred_original_sample, -scale, scale)
-
- # 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
- pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * self.betas[t]) / beta_prod_t
- current_sample_coeff = self.alphas[t] ** (0.5) * beta_prod_t_prev / beta_prod_t
-
- # 5. Compute predicted previous sample µ_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
- pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
-
- # 6. Add noise
- variance = 0
- if t > 0:
- noise = torch.randn(
- model_output.size(), dtype=model_output.dtype, layout=model_output.layout, generator=generator
- ).to(model_output.device)
- variance = (self._get_variance(t, predicted_variance=predicted_variance) ** 0.5) * noise
-
- pred_prev_sample = pred_prev_sample + variance
-
- if not return_dict:
- return (pred_prev_sample,)
-
- return DDPMSchedulerOutput(prev_sample=pred_prev_sample, pred_original_sample=pred_original_sample)
-
-
-class BitDiffusion(DiffusionPipeline):
- def __init__(
- self,
- unet: UNet2DConditionModel,
- scheduler: Union[DDIMScheduler, DDPMScheduler],
- bit_scale: Optional[float] = 1.0,
- ):
- super().__init__()
- self.bit_scale = bit_scale
- self.scheduler.step = (
- ddim_bit_scheduler_step if isinstance(scheduler, DDIMScheduler) else ddpm_bit_scheduler_step
- )
-
- self.register_modules(unet=unet, scheduler=scheduler)
-
- @torch.no_grad()
- def __call__(
- self,
- height: Optional[int] = 256,
- width: Optional[int] = 256,
- num_inference_steps: Optional[int] = 50,
- generator: Optional[torch.Generator] = None,
- batch_size: Optional[int] = 1,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- **kwargs,
- ) -> Union[Tuple, ImagePipelineOutput]:
- latents = torch.randn(
- (batch_size, self.unet.config.in_channels, height, width),
- generator=generator,
- )
- latents = decimal_to_bits(latents) * self.bit_scale
- latents = latents.to(self.device)
-
- self.scheduler.set_timesteps(num_inference_steps)
-
- for t in self.progress_bar(self.scheduler.timesteps):
- # predict the noise residual
- noise_pred = self.unet(latents, t).sample
-
- # compute the previous noisy sample x_t -> x_t-1
- latents = self.scheduler.step(noise_pred, t, latents).prev_sample
-
- image = bits_to_decimal(latents)
-
- if output_type == "pil":
- image = self.numpy_to_pil(image)
-
- if not return_dict:
- return (image,)
-
- return ImagePipelineOutput(images=image)
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/examples/research_projects/onnxruntime/textual_inversion/textual_inversion.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/examples/research_projects/onnxruntime/textual_inversion/textual_inversion.py
deleted file mode 100644
index 59b5089d07b4c3041e6103f844c730e8f91caa4c..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/examples/research_projects/onnxruntime/textual_inversion/textual_inversion.py
+++ /dev/null
@@ -1,946 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-import argparse
-import logging
-import math
-import os
-import random
-import warnings
-from pathlib import Path
-
-import numpy as np
-import PIL
-import torch
-import torch.nn.functional as F
-import torch.utils.checkpoint
-import transformers
-from accelerate import Accelerator
-from accelerate.logging import get_logger
-from accelerate.utils import ProjectConfiguration, set_seed
-from huggingface_hub import create_repo, upload_folder
-from onnxruntime.training.optim.fp16_optimizer import FP16_Optimizer as ORT_FP16_Optimizer
-from onnxruntime.training.ortmodule import ORTModule
-
-# TODO: remove and import from diffusers.utils when the new version of diffusers is released
-from packaging import version
-from PIL import Image
-from torch.utils.data import Dataset
-from torchvision import transforms
-from tqdm.auto import tqdm
-from transformers import CLIPTextModel, CLIPTokenizer
-
-import diffusers
-from diffusers import (
- AutoencoderKL,
- DDPMScheduler,
- DiffusionPipeline,
- DPMSolverMultistepScheduler,
- StableDiffusionPipeline,
- UNet2DConditionModel,
-)
-from diffusers.optimization import get_scheduler
-from diffusers.utils import check_min_version, is_wandb_available
-from diffusers.utils.import_utils import is_xformers_available
-
-
-if is_wandb_available():
- import wandb
-
-if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
- PIL_INTERPOLATION = {
- "linear": PIL.Image.Resampling.BILINEAR,
- "bilinear": PIL.Image.Resampling.BILINEAR,
- "bicubic": PIL.Image.Resampling.BICUBIC,
- "lanczos": PIL.Image.Resampling.LANCZOS,
- "nearest": PIL.Image.Resampling.NEAREST,
- }
-else:
- PIL_INTERPOLATION = {
- "linear": PIL.Image.LINEAR,
- "bilinear": PIL.Image.BILINEAR,
- "bicubic": PIL.Image.BICUBIC,
- "lanczos": PIL.Image.LANCZOS,
- "nearest": PIL.Image.NEAREST,
- }
-# ------------------------------------------------------------------------------
-
-
-# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
-check_min_version("0.17.0.dev0")
-
-logger = get_logger(__name__)
-
-
-def save_model_card(repo_id: str, images=None, base_model=str, repo_folder=None):
- img_str = ""
- for i, image in enumerate(images):
- image.save(os.path.join(repo_folder, f"image_{i}.png"))
- img_str += f"\n"
-
- yaml = f"""
----
-license: creativeml-openrail-m
-base_model: {base_model}
-tags:
-- stable-diffusion
-- stable-diffusion-diffusers
-- text-to-image
-- diffusers
-- textual_inversion
-inference: true
----
- """
- model_card = f"""
-# Textual inversion text2image fine-tuning - {repo_id}
-These are textual inversion adaption weights for {base_model}. You can find some example images in the following. \n
-{img_str}
-"""
- with open(os.path.join(repo_folder, "README.md"), "w") as f:
- f.write(yaml + model_card)
-
-
-def log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch):
- logger.info(
- f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
- f" {args.validation_prompt}."
- )
- # create pipeline (note: unet and vae are loaded again in float32)
- pipeline = DiffusionPipeline.from_pretrained(
- args.pretrained_model_name_or_path,
- text_encoder=accelerator.unwrap_model(text_encoder),
- tokenizer=tokenizer,
- unet=unet,
- vae=vae,
- safety_checker=None,
- revision=args.revision,
- torch_dtype=weight_dtype,
- )
- pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
- pipeline = pipeline.to(accelerator.device)
- pipeline.set_progress_bar_config(disable=True)
-
- # run inference
- generator = None if args.seed is None else torch.Generator(device=accelerator.device).manual_seed(args.seed)
- images = []
- for _ in range(args.num_validation_images):
- with torch.autocast("cuda"):
- image = pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
- images.append(image)
-
- for tracker in accelerator.trackers:
- if tracker.name == "tensorboard":
- np_images = np.stack([np.asarray(img) for img in images])
- tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
- if tracker.name == "wandb":
- tracker.log(
- {
- "validation": [
- wandb.Image(image, caption=f"{i}: {args.validation_prompt}") for i, image in enumerate(images)
- ]
- }
- )
-
- del pipeline
- torch.cuda.empty_cache()
- return images
-
-
-def save_progress(text_encoder, placeholder_token_ids, accelerator, args, save_path):
- logger.info("Saving embeddings")
- learned_embeds = (
- accelerator.unwrap_model(text_encoder)
- .get_input_embeddings()
- .weight[min(placeholder_token_ids) : max(placeholder_token_ids) + 1]
- )
- learned_embeds_dict = {args.placeholder_token: learned_embeds.detach().cpu()}
- torch.save(learned_embeds_dict, save_path)
-
-
-def parse_args():
- parser = argparse.ArgumentParser(description="Simple example of a training script.")
- parser.add_argument(
- "--save_steps",
- type=int,
- default=500,
- help="Save learned_embeds.bin every X updates steps.",
- )
- parser.add_argument(
- "--save_as_full_pipeline",
- action="store_true",
- help="Save the complete stable diffusion pipeline.",
- )
- parser.add_argument(
- "--num_vectors",
- type=int,
- default=1,
- help="How many textual inversion vectors shall be used to learn the concept.",
- )
- parser.add_argument(
- "--pretrained_model_name_or_path",
- type=str,
- default=None,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models.",
- )
- parser.add_argument(
- "--revision",
- type=str,
- default=None,
- required=False,
- help="Revision of pretrained model identifier from huggingface.co/models.",
- )
- parser.add_argument(
- "--tokenizer_name",
- type=str,
- default=None,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
- )
- parser.add_argument(
- "--placeholder_token",
- type=str,
- default=None,
- required=True,
- help="A token to use as a placeholder for the concept.",
- )
- parser.add_argument(
- "--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
- )
- parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
- parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
- parser.add_argument(
- "--output_dir",
- type=str,
- default="text-inversion-model",
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
- parser.add_argument(
- "--resolution",
- type=int,
- default=512,
- help=(
- "The resolution for input images, all the images in the train/validation dataset will be resized to this"
- " resolution"
- ),
- )
- parser.add_argument(
- "--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
- )
- parser.add_argument(
- "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
- )
- parser.add_argument("--num_train_epochs", type=int, default=100)
- parser.add_argument(
- "--max_train_steps",
- type=int,
- default=5000,
- help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
- )
- parser.add_argument(
- "--gradient_accumulation_steps",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument(
- "--gradient_checkpointing",
- action="store_true",
- help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
- )
- parser.add_argument(
- "--learning_rate",
- type=float,
- default=1e-4,
- help="Initial learning rate (after the potential warmup period) to use.",
- )
- parser.add_argument(
- "--scale_lr",
- action="store_true",
- default=False,
- help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
- )
- parser.add_argument(
- "--lr_scheduler",
- type=str,
- default="constant",
- help=(
- 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
- ' "constant", "constant_with_warmup"]'
- ),
- )
- parser.add_argument(
- "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
- )
- parser.add_argument(
- "--dataloader_num_workers",
- type=int,
- default=0,
- help=(
- "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
- ),
- )
- parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
- parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
- parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
- parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
- parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
- parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
- parser.add_argument(
- "--hub_model_id",
- type=str,
- default=None,
- help="The name of the repository to keep in sync with the local `output_dir`.",
- )
- parser.add_argument(
- "--logging_dir",
- type=str,
- default="logs",
- help=(
- "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
- " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
- ),
- )
- parser.add_argument(
- "--mixed_precision",
- type=str,
- default="no",
- choices=["no", "fp16", "bf16"],
- help=(
- "Whether to use mixed precision. Choose"
- "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
- "and an Nvidia Ampere GPU."
- ),
- )
- parser.add_argument(
- "--allow_tf32",
- action="store_true",
- help=(
- "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
- " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
- ),
- )
- parser.add_argument(
- "--report_to",
- type=str,
- default="tensorboard",
- help=(
- 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
- ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
- ),
- )
- parser.add_argument(
- "--validation_prompt",
- type=str,
- default=None,
- help="A prompt that is used during validation to verify that the model is learning.",
- )
- parser.add_argument(
- "--num_validation_images",
- type=int,
- default=4,
- help="Number of images that should be generated during validation with `validation_prompt`.",
- )
- parser.add_argument(
- "--validation_steps",
- type=int,
- default=100,
- help=(
- "Run validation every X steps. Validation consists of running the prompt"
- " `args.validation_prompt` multiple times: `args.num_validation_images`"
- " and logging the images."
- ),
- )
- parser.add_argument(
- "--validation_epochs",
- type=int,
- default=None,
- help=(
- "Deprecated in favor of validation_steps. Run validation every X epochs. Validation consists of running the prompt"
- " `args.validation_prompt` multiple times: `args.num_validation_images`"
- " and logging the images."
- ),
- )
- parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
- parser.add_argument(
- "--checkpointing_steps",
- type=int,
- default=500,
- help=(
- "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
- " training using `--resume_from_checkpoint`."
- ),
- )
- parser.add_argument(
- "--checkpoints_total_limit",
- type=int,
- default=None,
- help=(
- "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
- " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
- " for more docs"
- ),
- )
- parser.add_argument(
- "--resume_from_checkpoint",
- type=str,
- default=None,
- help=(
- "Whether training should be resumed from a previous checkpoint. Use a path saved by"
- ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
- ),
- )
- parser.add_argument(
- "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
- )
-
- args = parser.parse_args()
- env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
- if env_local_rank != -1 and env_local_rank != args.local_rank:
- args.local_rank = env_local_rank
-
- if args.train_data_dir is None:
- raise ValueError("You must specify a train data directory.")
-
- return args
-
-
-imagenet_templates_small = [
- "a photo of a {}",
- "a rendering of a {}",
- "a cropped photo of the {}",
- "the photo of a {}",
- "a photo of a clean {}",
- "a photo of a dirty {}",
- "a dark photo of the {}",
- "a photo of my {}",
- "a photo of the cool {}",
- "a close-up photo of a {}",
- "a bright photo of the {}",
- "a cropped photo of a {}",
- "a photo of the {}",
- "a good photo of the {}",
- "a photo of one {}",
- "a close-up photo of the {}",
- "a rendition of the {}",
- "a photo of the clean {}",
- "a rendition of a {}",
- "a photo of a nice {}",
- "a good photo of a {}",
- "a photo of the nice {}",
- "a photo of the small {}",
- "a photo of the weird {}",
- "a photo of the large {}",
- "a photo of a cool {}",
- "a photo of a small {}",
-]
-
-imagenet_style_templates_small = [
- "a painting in the style of {}",
- "a rendering in the style of {}",
- "a cropped painting in the style of {}",
- "the painting in the style of {}",
- "a clean painting in the style of {}",
- "a dirty painting in the style of {}",
- "a dark painting in the style of {}",
- "a picture in the style of {}",
- "a cool painting in the style of {}",
- "a close-up painting in the style of {}",
- "a bright painting in the style of {}",
- "a cropped painting in the style of {}",
- "a good painting in the style of {}",
- "a close-up painting in the style of {}",
- "a rendition in the style of {}",
- "a nice painting in the style of {}",
- "a small painting in the style of {}",
- "a weird painting in the style of {}",
- "a large painting in the style of {}",
-]
-
-
-class TextualInversionDataset(Dataset):
- def __init__(
- self,
- data_root,
- tokenizer,
- learnable_property="object", # [object, style]
- size=512,
- repeats=100,
- interpolation="bicubic",
- flip_p=0.5,
- set="train",
- placeholder_token="*",
- center_crop=False,
- ):
- self.data_root = data_root
- self.tokenizer = tokenizer
- self.learnable_property = learnable_property
- self.size = size
- self.placeholder_token = placeholder_token
- self.center_crop = center_crop
- self.flip_p = flip_p
-
- self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
-
- self.num_images = len(self.image_paths)
- self._length = self.num_images
-
- if set == "train":
- self._length = self.num_images * repeats
-
- self.interpolation = {
- "linear": PIL_INTERPOLATION["linear"],
- "bilinear": PIL_INTERPOLATION["bilinear"],
- "bicubic": PIL_INTERPOLATION["bicubic"],
- "lanczos": PIL_INTERPOLATION["lanczos"],
- }[interpolation]
-
- self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
- self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
-
- def __len__(self):
- return self._length
-
- def __getitem__(self, i):
- example = {}
- image = Image.open(self.image_paths[i % self.num_images])
-
- if not image.mode == "RGB":
- image = image.convert("RGB")
-
- placeholder_string = self.placeholder_token
- text = random.choice(self.templates).format(placeholder_string)
-
- example["input_ids"] = self.tokenizer(
- text,
- padding="max_length",
- truncation=True,
- max_length=self.tokenizer.model_max_length,
- return_tensors="pt",
- ).input_ids[0]
-
- # default to score-sde preprocessing
- img = np.array(image).astype(np.uint8)
-
- if self.center_crop:
- crop = min(img.shape[0], img.shape[1])
- (
- h,
- w,
- ) = (
- img.shape[0],
- img.shape[1],
- )
- img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
-
- image = Image.fromarray(img)
- image = image.resize((self.size, self.size), resample=self.interpolation)
-
- image = self.flip_transform(image)
- image = np.array(image).astype(np.uint8)
- image = (image / 127.5 - 1.0).astype(np.float32)
-
- example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
- return example
-
-
-def main():
- args = parse_args()
- logging_dir = os.path.join(args.output_dir, args.logging_dir)
- accelerator_project_config = ProjectConfiguration(
- total_limit=args.checkpoints_total_limit, project_dir=args.output_dir, logging_dir=logging_dir
- )
-
- accelerator = Accelerator(
- gradient_accumulation_steps=args.gradient_accumulation_steps,
- mixed_precision=args.mixed_precision,
- log_with=args.report_to,
- project_config=accelerator_project_config,
- )
-
- if args.report_to == "wandb":
- if not is_wandb_available():
- raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
-
- # Make one log on every process with the configuration for debugging.
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
- )
- logger.info(accelerator.state, main_process_only=False)
- if accelerator.is_local_main_process:
- transformers.utils.logging.set_verbosity_warning()
- diffusers.utils.logging.set_verbosity_info()
- else:
- transformers.utils.logging.set_verbosity_error()
- diffusers.utils.logging.set_verbosity_error()
-
- # If passed along, set the training seed now.
- if args.seed is not None:
- set_seed(args.seed)
-
- # Handle the repository creation
- if accelerator.is_main_process:
- if args.output_dir is not None:
- os.makedirs(args.output_dir, exist_ok=True)
-
- if args.push_to_hub:
- repo_id = create_repo(
- repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
- ).repo_id
-
- # Load tokenizer
- if args.tokenizer_name:
- tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
- elif args.pretrained_model_name_or_path:
- tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
-
- # Load scheduler and models
- noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
- text_encoder = CLIPTextModel.from_pretrained(
- args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
- )
- vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
- unet = UNet2DConditionModel.from_pretrained(
- args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
- )
-
- # Add the placeholder token in tokenizer
- placeholder_tokens = [args.placeholder_token]
-
- if args.num_vectors < 1:
- raise ValueError(f"--num_vectors has to be larger or equal to 1, but is {args.num_vectors}")
-
- # add dummy tokens for multi-vector
- additional_tokens = []
- for i in range(1, args.num_vectors):
- additional_tokens.append(f"{args.placeholder_token}_{i}")
- placeholder_tokens += additional_tokens
-
- num_added_tokens = tokenizer.add_tokens(placeholder_tokens)
- if num_added_tokens != args.num_vectors:
- raise ValueError(
- f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
- " `placeholder_token` that is not already in the tokenizer."
- )
-
- # Convert the initializer_token, placeholder_token to ids
- token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
- # Check if initializer_token is a single token or a sequence of tokens
- if len(token_ids) > 1:
- raise ValueError("The initializer token must be a single token.")
-
- initializer_token_id = token_ids[0]
- placeholder_token_ids = tokenizer.convert_tokens_to_ids(placeholder_tokens)
-
- # Resize the token embeddings as we are adding new special tokens to the tokenizer
- text_encoder.resize_token_embeddings(len(tokenizer))
-
- # Initialise the newly added placeholder token with the embeddings of the initializer token
- token_embeds = text_encoder.get_input_embeddings().weight.data
- with torch.no_grad():
- for token_id in placeholder_token_ids:
- token_embeds[token_id] = token_embeds[initializer_token_id].clone()
-
- # Freeze vae and unet
- vae.requires_grad_(False)
- unet.requires_grad_(False)
- # Freeze all parameters except for the token embeddings in text encoder
- text_encoder.text_model.encoder.requires_grad_(False)
- text_encoder.text_model.final_layer_norm.requires_grad_(False)
- text_encoder.text_model.embeddings.position_embedding.requires_grad_(False)
-
- if args.gradient_checkpointing:
- # Keep unet in train mode if we are using gradient checkpointing to save memory.
- # The dropout cannot be != 0 so it doesn't matter if we are in eval or train mode.
- unet.train()
- text_encoder.gradient_checkpointing_enable()
- unet.enable_gradient_checkpointing()
-
- if args.enable_xformers_memory_efficient_attention:
- if is_xformers_available():
- import xformers
-
- xformers_version = version.parse(xformers.__version__)
- if xformers_version == version.parse("0.0.16"):
- logger.warn(
- "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
- )
- unet.enable_xformers_memory_efficient_attention()
- else:
- raise ValueError("xformers is not available. Make sure it is installed correctly")
-
- # Enable TF32 for faster training on Ampere GPUs,
- # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
- if args.allow_tf32:
- torch.backends.cuda.matmul.allow_tf32 = True
-
- if args.scale_lr:
- args.learning_rate = (
- args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
- )
-
- # Initialize the optimizer
- optimizer = torch.optim.AdamW(
- text_encoder.get_input_embeddings().parameters(), # only optimize the embeddings
- lr=args.learning_rate,
- betas=(args.adam_beta1, args.adam_beta2),
- weight_decay=args.adam_weight_decay,
- eps=args.adam_epsilon,
- )
-
- optimizer = ORT_FP16_Optimizer(optimizer)
-
- # Dataset and DataLoaders creation:
- train_dataset = TextualInversionDataset(
- data_root=args.train_data_dir,
- tokenizer=tokenizer,
- size=args.resolution,
- placeholder_token=args.placeholder_token,
- repeats=args.repeats,
- learnable_property=args.learnable_property,
- center_crop=args.center_crop,
- set="train",
- )
- train_dataloader = torch.utils.data.DataLoader(
- train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
- )
- if args.validation_epochs is not None:
- warnings.warn(
- f"FutureWarning: You are doing logging with validation_epochs={args.validation_epochs}."
- " Deprecated validation_epochs in favor of `validation_steps`"
- f"Setting `args.validation_steps` to {args.validation_epochs * len(train_dataset)}",
- FutureWarning,
- stacklevel=2,
- )
- args.validation_steps = args.validation_epochs * len(train_dataset)
-
- # Scheduler and math around the number of training steps.
- overrode_max_train_steps = False
- num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- if args.max_train_steps is None:
- args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
- overrode_max_train_steps = True
-
- lr_scheduler = get_scheduler(
- args.lr_scheduler,
- optimizer=optimizer,
- num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
- num_training_steps=args.max_train_steps * accelerator.num_processes,
- )
-
- # Prepare everything with our `accelerator`.
- text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
- text_encoder, optimizer, train_dataloader, lr_scheduler
- )
-
- text_encoder = ORTModule(text_encoder)
- unet = ORTModule(unet)
- vae = ORTModule(vae)
-
- # For mixed precision training we cast the unet and vae weights to half-precision
- # as these models are only used for inference, keeping weights in full precision is not required.
- weight_dtype = torch.float32
- if accelerator.mixed_precision == "fp16":
- weight_dtype = torch.float16
- elif accelerator.mixed_precision == "bf16":
- weight_dtype = torch.bfloat16
-
- # Move vae and unet to device and cast to weight_dtype
- unet.to(accelerator.device, dtype=weight_dtype)
- vae.to(accelerator.device, dtype=weight_dtype)
-
- # We need to recalculate our total training steps as the size of the training dataloader may have changed.
- num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- if overrode_max_train_steps:
- args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
- # Afterwards we recalculate our number of training epochs
- args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
-
- # We need to initialize the trackers we use, and also store our configuration.
- # The trackers initializes automatically on the main process.
- if accelerator.is_main_process:
- accelerator.init_trackers("textual_inversion", config=vars(args))
-
- # Train!
- total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
-
- logger.info("***** Running training *****")
- logger.info(f" Num examples = {len(train_dataset)}")
- logger.info(f" Num Epochs = {args.num_train_epochs}")
- logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
- logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
- logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
- logger.info(f" Total optimization steps = {args.max_train_steps}")
- global_step = 0
- first_epoch = 0
- # Potentially load in the weights and states from a previous save
- if args.resume_from_checkpoint:
- if args.resume_from_checkpoint != "latest":
- path = os.path.basename(args.resume_from_checkpoint)
- else:
- # Get the most recent checkpoint
- dirs = os.listdir(args.output_dir)
- dirs = [d for d in dirs if d.startswith("checkpoint")]
- dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
- path = dirs[-1] if len(dirs) > 0 else None
-
- if path is None:
- accelerator.print(
- f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
- )
- args.resume_from_checkpoint = None
- else:
- accelerator.print(f"Resuming from checkpoint {path}")
- accelerator.load_state(os.path.join(args.output_dir, path))
- global_step = int(path.split("-")[1])
-
- resume_global_step = global_step * args.gradient_accumulation_steps
- first_epoch = global_step // num_update_steps_per_epoch
- resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
-
- # Only show the progress bar once on each machine.
- progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
- progress_bar.set_description("Steps")
-
- # keep original embeddings as reference
- orig_embeds_params = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight.data.clone()
-
- for epoch in range(first_epoch, args.num_train_epochs):
- text_encoder.train()
- for step, batch in enumerate(train_dataloader):
- # Skip steps until we reach the resumed step
- if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
- if step % args.gradient_accumulation_steps == 0:
- progress_bar.update(1)
- continue
-
- with accelerator.accumulate(text_encoder):
- # Convert images to latent space
- latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample().detach()
- latents = latents * vae.config.scaling_factor
-
- # Sample noise that we'll add to the latents
- noise = torch.randn_like(latents)
- bsz = latents.shape[0]
- # Sample a random timestep for each image
- timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
- timesteps = timesteps.long()
-
- # Add noise to the latents according to the noise magnitude at each timestep
- # (this is the forward diffusion process)
- noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
-
- # Get the text embedding for conditioning
- encoder_hidden_states = text_encoder(batch["input_ids"])[0].to(dtype=weight_dtype)
-
- # Predict the noise residual
- model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
-
- # Get the target for loss depending on the prediction type
- if noise_scheduler.config.prediction_type == "epsilon":
- target = noise
- elif noise_scheduler.config.prediction_type == "v_prediction":
- target = noise_scheduler.get_velocity(latents, noise, timesteps)
- else:
- raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
-
- loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
-
- accelerator.backward(loss)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
-
- # Let's make sure we don't update any embedding weights besides the newly added token
- index_no_updates = torch.ones((len(tokenizer),), dtype=torch.bool)
- index_no_updates[min(placeholder_token_ids) : max(placeholder_token_ids) + 1] = False
-
- with torch.no_grad():
- accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[
- index_no_updates
- ] = orig_embeds_params[index_no_updates]
-
- # Checks if the accelerator has performed an optimization step behind the scenes
- if accelerator.sync_gradients:
- images = []
- progress_bar.update(1)
- global_step += 1
- if global_step % args.save_steps == 0:
- save_path = os.path.join(args.output_dir, f"learned_embeds-steps-{global_step}.bin")
- save_progress(text_encoder, placeholder_token_ids, accelerator, args, save_path)
-
- if accelerator.is_main_process:
- if global_step % args.checkpointing_steps == 0:
- save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
- accelerator.save_state(save_path)
- logger.info(f"Saved state to {save_path}")
-
- if args.validation_prompt is not None and global_step % args.validation_steps == 0:
- images = log_validation(
- text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch
- )
-
- logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
- progress_bar.set_postfix(**logs)
- accelerator.log(logs, step=global_step)
-
- if global_step >= args.max_train_steps:
- break
- # Create the pipeline using the trained modules and save it.
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- if args.push_to_hub and not args.save_as_full_pipeline:
- logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
- save_full_model = True
- else:
- save_full_model = args.save_as_full_pipeline
- if save_full_model:
- pipeline = StableDiffusionPipeline.from_pretrained(
- args.pretrained_model_name_or_path,
- text_encoder=accelerator.unwrap_model(text_encoder),
- vae=vae,
- unet=unet,
- tokenizer=tokenizer,
- )
- pipeline.save_pretrained(args.output_dir)
- # Save the newly trained embeddings
- save_path = os.path.join(args.output_dir, "learned_embeds.bin")
- save_progress(text_encoder, placeholder_token_ids, accelerator, args, save_path)
-
- if args.push_to_hub:
- save_model_card(
- repo_id,
- images=images,
- base_model=args.pretrained_model_name_or_path,
- repo_folder=args.output_dir,
- )
- upload_folder(
- repo_id=repo_id,
- folder_path=args.output_dir,
- commit_message="End of training",
- ignore_patterns=["step_*", "epoch_*"],
- )
-
- accelerator.end_training()
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/setup.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/setup.py
deleted file mode 100644
index dfd38f007148280f5e39e61d8ccc61a61ce600f9..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/setup.py
+++ /dev/null
@@ -1,286 +0,0 @@
-# Copyright 2023 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Simple check list from AllenNLP repo: https://github.com/allenai/allennlp/blob/main/setup.py
-
-To create the package for pypi.
-
-1. Run `make pre-release` (or `make pre-patch` for a patch release) then run `make fix-copies` to fix the index of the
- documentation.
-
- If releasing on a special branch, copy the updated README.md on the main branch for your the commit you will make
- for the post-release and run `make fix-copies` on the main branch as well.
-
-2. Run Tests for Amazon Sagemaker. The documentation is located in `./tests/sagemaker/README.md`, otherwise @philschmid.
-
-3. Unpin specific versions from setup.py that use a git install.
-
-4. Checkout the release branch (v-release, for example v4.19-release), and commit these changes with the
- message: "Release: " and push.
-
-5. Wait for the tests on main to be completed and be green (otherwise revert and fix bugs)
-
-6. Add a tag in git to mark the release: "git tag v -m 'Adds tag v for pypi' "
- Push the tag to git: git push --tags origin v-release
-
-7. Build both the sources and the wheel. Do not change anything in setup.py between
- creating the wheel and the source distribution (obviously).
-
- For the wheel, run: "python setup.py bdist_wheel" in the top level directory.
- (this will build a wheel for the python version you use to build it).
-
- For the sources, run: "python setup.py sdist"
- You should now have a /dist directory with both .whl and .tar.gz source versions.
-
-8. Check that everything looks correct by uploading the package to the pypi test server:
-
- twine upload dist/* -r pypitest
- (pypi suggest using twine as other methods upload files via plaintext.)
- You may have to specify the repository url, use the following command then:
- twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/
-
- Check that you can install it in a virtualenv by running:
- pip install -i https://testpypi.python.org/pypi diffusers
-
- Check you can run the following commands:
- python -c "from diffusers import pipeline; classifier = pipeline('text-classification'); print(classifier('What a nice release'))"
- python -c "from diffusers import *"
-
-9. Upload the final version to actual pypi:
- twine upload dist/* -r pypi
-
-10. Copy the release notes from RELEASE.md to the tag in github once everything is looking hunky-dory.
-
-11. Run `make post-release` (or, for a patch release, `make post-patch`). If you were on a branch for the release,
- you need to go back to main before executing this.
-"""
-
-import os
-import re
-from distutils.core import Command
-
-from setuptools import find_packages, setup
-
-
-# IMPORTANT:
-# 1. all dependencies should be listed here with their version requirements if any
-# 2. once modified, run: `make deps_table_update` to update src/diffusers/dependency_versions_table.py
-_deps = [
- "Pillow", # keep the PIL.Image.Resampling deprecation away
- "accelerate>=0.11.0",
- "compel==0.1.8",
- "black~=23.1",
- "datasets",
- "filelock",
- "flax>=0.4.1",
- "hf-doc-builder>=0.3.0",
- "huggingface-hub>=0.13.2",
- "requests-mock==1.10.0",
- "importlib_metadata",
- "invisible-watermark>=0.2.0",
- "isort>=5.5.4",
- "jax>=0.2.8,!=0.3.2",
- "jaxlib>=0.1.65",
- "Jinja2",
- "k-diffusion>=0.0.12",
- "torchsde",
- "note_seq",
- "librosa",
- "numpy",
- "omegaconf",
- "parameterized",
- "protobuf>=3.20.3,<4",
- "pytest",
- "pytest-timeout",
- "pytest-xdist",
- "ruff>=0.0.241",
- "safetensors>=0.3.1",
- "sentencepiece>=0.1.91,!=0.1.92",
- "scipy",
- "onnx",
- "regex!=2019.12.17",
- "requests",
- "tensorboard",
- "torch>=1.4",
- "torchvision",
- "transformers>=4.25.1",
- "urllib3<=2.0.0",
-]
-
-# this is a lookup table with items like:
-#
-# tokenizers: "huggingface-hub==0.8.0"
-# packaging: "packaging"
-#
-# some of the values are versioned whereas others aren't.
-deps = {b: a for a, b in (re.findall(r"^(([^!=<>~]+)(?:[!=<>~].*)?$)", x)[0] for x in _deps)}
-
-# since we save this data in src/diffusers/dependency_versions_table.py it can be easily accessed from
-# anywhere. If you need to quickly access the data from this table in a shell, you can do so easily with:
-#
-# python -c 'import sys; from diffusers.dependency_versions_table import deps; \
-# print(" ".join([ deps[x] for x in sys.argv[1:]]))' tokenizers datasets
-#
-# Just pass the desired package names to that script as it's shown with 2 packages above.
-#
-# If diffusers is not yet installed and the work is done from the cloned repo remember to add `PYTHONPATH=src` to the script above
-#
-# You can then feed this for example to `pip`:
-#
-# pip install -U $(python -c 'import sys; from diffusers.dependency_versions_table import deps; \
-# print(" ".join([ deps[x] for x in sys.argv[1:]]))' tokenizers datasets)
-#
-
-
-def deps_list(*pkgs):
- return [deps[pkg] for pkg in pkgs]
-
-
-class DepsTableUpdateCommand(Command):
- """
- A custom distutils command that updates the dependency table.
- usage: python setup.py deps_table_update
- """
-
- description = "build runtime dependency table"
- user_options = [
- # format: (long option, short option, description).
- ("dep-table-update", None, "updates src/diffusers/dependency_versions_table.py"),
- ]
-
- def initialize_options(self):
- pass
-
- def finalize_options(self):
- pass
-
- def run(self):
- entries = "\n".join([f' "{k}": "{v}",' for k, v in deps.items()])
- content = [
- "# THIS FILE HAS BEEN AUTOGENERATED. To update:",
- "# 1. modify the `_deps` dict in setup.py",
- "# 2. run `make deps_table_update``",
- "deps = {",
- entries,
- "}",
- "",
- ]
- target = "src/diffusers/dependency_versions_table.py"
- print(f"updating {target}")
- with open(target, "w", encoding="utf-8", newline="\n") as f:
- f.write("\n".join(content))
-
-
-extras = {}
-
-
-extras = {}
-extras["quality"] = deps_list("urllib3", "black", "isort", "ruff", "hf-doc-builder")
-extras["docs"] = deps_list("hf-doc-builder")
-extras["training"] = deps_list("accelerate", "datasets", "protobuf", "tensorboard", "Jinja2")
-extras["test"] = deps_list(
- "compel",
- "datasets",
- "Jinja2",
- "invisible-watermark",
- "k-diffusion",
- "librosa",
- "omegaconf",
- "parameterized",
- "pytest",
- "pytest-timeout",
- "pytest-xdist",
- "requests-mock",
- "safetensors",
- "sentencepiece",
- "scipy",
- "torchvision",
- "transformers",
-)
-extras["torch"] = deps_list("torch", "accelerate")
-
-if os.name == "nt": # windows
- extras["flax"] = [] # jax is not supported on windows
-else:
- extras["flax"] = deps_list("jax", "jaxlib", "flax")
-
-extras["dev"] = (
- extras["quality"] + extras["test"] + extras["training"] + extras["docs"] + extras["torch"] + extras["flax"]
-)
-
-install_requires = [
- deps["importlib_metadata"],
- deps["filelock"],
- deps["huggingface-hub"],
- deps["numpy"],
- deps["regex"],
- deps["requests"],
- deps["safetensors"],
- deps["Pillow"],
-]
-
-setup(
- name="diffusers",
- version="0.19.3", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
- description="Diffusers",
- long_description=open("README.md", "r", encoding="utf-8").read(),
- long_description_content_type="text/markdown",
- keywords="deep learning",
- license="Apache",
- author="The HuggingFace team",
- author_email="patrick@huggingface.co",
- url="https://github.com/huggingface/diffusers",
- package_dir={"": "src"},
- packages=find_packages("src"),
- include_package_data=True,
- python_requires=">=3.7.0",
- install_requires=list(install_requires),
- extras_require=extras,
- entry_points={"console_scripts": ["diffusers-cli=diffusers.commands.diffusers_cli:main"]},
- classifiers=[
- "Development Status :: 5 - Production/Stable",
- "Intended Audience :: Developers",
- "Intended Audience :: Education",
- "Intended Audience :: Science/Research",
- "License :: OSI Approved :: Apache Software License",
- "Operating System :: OS Independent",
- "Programming Language :: Python :: 3",
- "Programming Language :: Python :: 3.7",
- "Programming Language :: Python :: 3.8",
- "Programming Language :: Python :: 3.9",
- "Topic :: Scientific/Engineering :: Artificial Intelligence",
- ],
- cmdclass={"deps_table_update": DepsTableUpdateCommand},
-)
-
-# Release checklist
-# 1. Change the version in __init__.py and setup.py.
-# 2. Commit these changes with the message: "Release: Release"
-# 3. Add a tag in git to mark the release: "git tag RELEASE -m 'Adds tag RELEASE for pypi' "
-# Push the tag to git: git push --tags origin main
-# 4. Run the following commands in the top-level directory:
-# python setup.py bdist_wheel
-# python setup.py sdist
-# 5. Upload the package to the pypi test server first:
-# twine upload dist/* -r pypitest
-# twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/
-# 6. Check that you can install it in a virtualenv by running:
-# pip install -i https://testpypi.python.org/pypi diffusers
-# diffusers env
-# diffusers test
-# 7. Upload the final version to actual pypi:
-# twine upload dist/* -r pypi
-# 8. Add release notes to the tag in github once everything is looking hunky-dory.
-# 9. Update the version in __init__.py, setup.py to the new version "-dev" and push to master
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py
deleted file mode 100644
index 55940e66e8a95b0c1cd447d1792e615254891945..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py
+++ /dev/null
@@ -1,754 +0,0 @@
-# Copyright 2023 Susung Hong and The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import inspect
-import warnings
-from typing import Any, Callable, Dict, List, Optional, Union
-
-import torch
-import torch.nn.functional as F
-from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
-
-from ...image_processor import VaeImageProcessor
-from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
-from ...models import AutoencoderKL, UNet2DConditionModel
-from ...schedulers import KarrasDiffusionSchedulers
-from ...utils import logging, randn_tensor, replace_example_docstring
-from ..pipeline_utils import DiffusionPipeline
-from . import StableDiffusionPipelineOutput
-from .safety_checker import StableDiffusionSafetyChecker
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-EXAMPLE_DOC_STRING = """
- Examples:
- ```py
- >>> import torch
- >>> from diffusers import StableDiffusionSAGPipeline
-
- >>> pipe = StableDiffusionSAGPipeline.from_pretrained(
- ... "runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
- ... )
- >>> pipe = pipe.to("cuda")
-
- >>> prompt = "a photo of an astronaut riding a horse on mars"
- >>> image = pipe(prompt, sag_scale=0.75).images[0]
- ```
-"""
-
-
-# processes and stores attention probabilities
-class CrossAttnStoreProcessor:
- def __init__(self):
- self.attention_probs = None
-
- def __call__(
- self,
- attn,
- hidden_states,
- encoder_hidden_states=None,
- attention_mask=None,
- ):
- batch_size, sequence_length, _ = hidden_states.shape
- attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
- query = attn.to_q(hidden_states)
-
- if encoder_hidden_states is None:
- encoder_hidden_states = hidden_states
- elif attn.norm_cross:
- encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
-
- key = attn.to_k(encoder_hidden_states)
- value = attn.to_v(encoder_hidden_states)
-
- query = attn.head_to_batch_dim(query)
- key = attn.head_to_batch_dim(key)
- value = attn.head_to_batch_dim(value)
-
- self.attention_probs = attn.get_attention_scores(query, key, attention_mask)
- hidden_states = torch.bmm(self.attention_probs, value)
- hidden_states = attn.batch_to_head_dim(hidden_states)
-
- # linear proj
- hidden_states = attn.to_out[0](hidden_states)
- # dropout
- hidden_states = attn.to_out[1](hidden_states)
-
- return hidden_states
-
-
-# Modified to get self-attention guidance scale in this paper (https://arxiv.org/pdf/2210.00939.pdf) as an input
-class StableDiffusionSAGPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
- r"""
- Pipeline for text-to-image generation using Stable Diffusion.
-
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
- implemented for all pipelines (downloading, saving, running on a particular device, etc.).
-
- Args:
- vae ([`AutoencoderKL`]):
- Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
- text_encoder ([`~transformers.CLIPTextModel`]):
- Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
- tokenizer ([`~transformers.CLIPTokenizer`]):
- A `CLIPTokenizer` to tokenize text.
- unet ([`UNet2DConditionModel`]):
- A `UNet2DConditionModel` to denoise the encoded image latents.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
- [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
- safety_checker ([`StableDiffusionSafetyChecker`]):
- Classification module that estimates whether generated images could be considered offensive or harmful.
- Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
- about a model's potential harms.
- feature_extractor ([`~transformers.CLIPImageProcessor`]):
- A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
- """
- _optional_components = ["safety_checker", "feature_extractor"]
-
- def __init__(
- self,
- vae: AutoencoderKL,
- text_encoder: CLIPTextModel,
- tokenizer: CLIPTokenizer,
- unet: UNet2DConditionModel,
- scheduler: KarrasDiffusionSchedulers,
- safety_checker: StableDiffusionSafetyChecker,
- feature_extractor: CLIPImageProcessor,
- requires_safety_checker: bool = True,
- ):
- super().__init__()
-
- self.register_modules(
- vae=vae,
- text_encoder=text_encoder,
- tokenizer=tokenizer,
- unet=unet,
- scheduler=scheduler,
- safety_checker=safety_checker,
- feature_extractor=feature_extractor,
- )
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
- self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
- self.register_to_config(requires_safety_checker=requires_safety_checker)
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
- def enable_vae_slicing(self):
- r"""
- Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
- compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
- """
- self.vae.enable_slicing()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
- def disable_vae_slicing(self):
- r"""
- Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
- computing decoding in one step.
- """
- self.vae.disable_slicing()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
- def _encode_prompt(
- self,
- prompt,
- device,
- num_images_per_prompt,
- do_classifier_free_guidance,
- negative_prompt=None,
- prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_prompt_embeds: Optional[torch.FloatTensor] = None,
- lora_scale: Optional[float] = None,
- ):
- r"""
- Encodes the prompt into text encoder hidden states.
-
- Args:
- prompt (`str` or `List[str]`, *optional*):
- prompt to be encoded
- device: (`torch.device`):
- torch device
- num_images_per_prompt (`int`):
- number of images that should be generated per prompt
- do_classifier_free_guidance (`bool`):
- whether to use classifier free guidance or not
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. If not defined, one has to pass
- `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
- less than `1`).
- prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
- provided, text embeddings will be generated from `prompt` input argument.
- negative_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
- argument.
- lora_scale (`float`, *optional*):
- A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
- """
- # set lora scale so that monkey patched LoRA
- # function of text encoder can correctly access it
- if lora_scale is not None and isinstance(self, LoraLoaderMixin):
- self._lora_scale = lora_scale
-
- if prompt is not None and isinstance(prompt, str):
- batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- batch_size = prompt_embeds.shape[0]
-
- if prompt_embeds is None:
- # textual inversion: procecss multi-vector tokens if necessary
- if isinstance(self, TextualInversionLoaderMixin):
- prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
-
- text_inputs = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- text_input_ids = text_inputs.input_ids
- untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
-
- if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
- text_input_ids, untruncated_ids
- ):
- removed_text = self.tokenizer.batch_decode(
- untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
- )
- logger.warning(
- "The following part of your input was truncated because CLIP can only handle sequences up to"
- f" {self.tokenizer.model_max_length} tokens: {removed_text}"
- )
-
- if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
- attention_mask = text_inputs.attention_mask.to(device)
- else:
- attention_mask = None
-
- prompt_embeds = self.text_encoder(
- text_input_ids.to(device),
- attention_mask=attention_mask,
- )
- prompt_embeds = prompt_embeds[0]
-
- prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
-
- bs_embed, seq_len, _ = prompt_embeds.shape
- # duplicate text embeddings for each generation per prompt, using mps friendly method
- prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
- prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
-
- # get unconditional embeddings for classifier free guidance
- if do_classifier_free_guidance and negative_prompt_embeds is None:
- uncond_tokens: List[str]
- if negative_prompt is None:
- uncond_tokens = [""] * batch_size
- elif prompt is not None and type(prompt) is not type(negative_prompt):
- raise TypeError(
- f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
- f" {type(prompt)}."
- )
- elif isinstance(negative_prompt, str):
- uncond_tokens = [negative_prompt]
- elif batch_size != len(negative_prompt):
- raise ValueError(
- f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
- f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
- " the batch size of `prompt`."
- )
- else:
- uncond_tokens = negative_prompt
-
- # textual inversion: procecss multi-vector tokens if necessary
- if isinstance(self, TextualInversionLoaderMixin):
- uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
-
- max_length = prompt_embeds.shape[1]
- uncond_input = self.tokenizer(
- uncond_tokens,
- padding="max_length",
- max_length=max_length,
- truncation=True,
- return_tensors="pt",
- )
-
- if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
- attention_mask = uncond_input.attention_mask.to(device)
- else:
- attention_mask = None
-
- negative_prompt_embeds = self.text_encoder(
- uncond_input.input_ids.to(device),
- attention_mask=attention_mask,
- )
- negative_prompt_embeds = negative_prompt_embeds[0]
-
- if do_classifier_free_guidance:
- # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
- seq_len = negative_prompt_embeds.shape[1]
-
- negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
-
- negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
- negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
-
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
-
- return prompt_embeds
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
- def run_safety_checker(self, image, device, dtype):
- if self.safety_checker is None:
- has_nsfw_concept = None
- else:
- if torch.is_tensor(image):
- feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
- else:
- feature_extractor_input = self.image_processor.numpy_to_pil(image)
- safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
- image, has_nsfw_concept = self.safety_checker(
- images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
- )
- return image, has_nsfw_concept
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
- def decode_latents(self, latents):
- warnings.warn(
- "The decode_latents method is deprecated and will be removed in a future version. Please"
- " use VaeImageProcessor instead",
- FutureWarning,
- )
- latents = 1 / self.vae.config.scaling_factor * latents
- image = self.vae.decode(latents, return_dict=False)[0]
- image = (image / 2 + 0.5).clamp(0, 1)
- # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
- image = image.cpu().permute(0, 2, 3, 1).float().numpy()
- return image
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
- def prepare_extra_step_kwargs(self, generator, eta):
- # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
- # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
- # and should be between [0, 1]
-
- accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
- extra_step_kwargs = {}
- if accepts_eta:
- extra_step_kwargs["eta"] = eta
-
- # check if the scheduler accepts generator
- accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
- if accepts_generator:
- extra_step_kwargs["generator"] = generator
- return extra_step_kwargs
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
- def check_inputs(
- self,
- prompt,
- height,
- width,
- callback_steps,
- negative_prompt=None,
- prompt_embeds=None,
- negative_prompt_embeds=None,
- ):
- if height % 8 != 0 or width % 8 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
-
- if (callback_steps is None) or (
- callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
- ):
- raise ValueError(
- f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
- f" {type(callback_steps)}."
- )
-
- if prompt is not None and prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
- " only forward one of the two."
- )
- elif prompt is None and prompt_embeds is None:
- raise ValueError(
- "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
- )
- elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- if negative_prompt is not None and negative_prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
- f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
- )
-
- if prompt_embeds is not None and negative_prompt_embeds is not None:
- if prompt_embeds.shape != negative_prompt_embeds.shape:
- raise ValueError(
- "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
- f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
- f" {negative_prompt_embeds.shape}."
- )
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
- def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
- shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
- if isinstance(generator, list) and len(generator) != batch_size:
- raise ValueError(
- f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
- f" size of {batch_size}. Make sure the batch size matches the length of the generators."
- )
-
- if latents is None:
- latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
- else:
- latents = latents.to(device)
-
- # scale the initial noise by the standard deviation required by the scheduler
- latents = latents * self.scheduler.init_noise_sigma
- return latents
-
- @torch.no_grad()
- @replace_example_docstring(EXAMPLE_DOC_STRING)
- def __call__(
- self,
- prompt: Union[str, List[str]] = None,
- height: Optional[int] = None,
- width: Optional[int] = None,
- num_inference_steps: int = 50,
- guidance_scale: float = 7.5,
- sag_scale: float = 0.75,
- negative_prompt: Optional[Union[str, List[str]]] = None,
- num_images_per_prompt: Optional[int] = 1,
- eta: float = 0.0,
- generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
- latents: Optional[torch.FloatTensor] = None,
- prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_prompt_embeds: Optional[torch.FloatTensor] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
- callback_steps: Optional[int] = 1,
- cross_attention_kwargs: Optional[Dict[str, Any]] = None,
- ):
- r"""
- The call function to the pipeline for generation.
-
- Args:
- prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
- height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
- The height in pixels of the generated image.
- width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
- The width in pixels of the generated image.
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- A higher guidance scale value encourages the model to generate images closely linked to the text
- `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
- sag_scale (`float`, *optional*, defaults to 0.75):
- Chosen between [0, 1.0] for better quality.
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts to guide what to not include in image generation. If not defined, you need to
- pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
- num_images_per_prompt (`int`, *optional*, defaults to 1):
- The number of images to generate per prompt.
- eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
- generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
- A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
- generation deterministic.
- latents (`torch.FloatTensor`, *optional*):
- Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor is generated by sampling using the supplied random `generator`.
- prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
- provided, text embeddings are generated from the `prompt` input argument.
- negative_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
- not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generated image. Choose between `PIL.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
- plain tuple.
- callback (`Callable`, *optional*):
- A function that calls every `callback_steps` steps during inference. The function is called with the
- following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
- callback_steps (`int`, *optional*, defaults to 1):
- The frequency at which the `callback` function is called. If not specified, the callback is called at
- every step.
- cross_attention_kwargs (`dict`, *optional*):
- A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
- [`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
-
- Examples:
-
- Returns:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
- If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
- otherwise a `tuple` is returned where the first element is a list with the generated images and the
- second element is a list of `bool`s indicating whether the corresponding generated image contains
- "not-safe-for-work" (nsfw) content.
- """
- # 0. Default height and width to unet
- height = height or self.unet.config.sample_size * self.vae_scale_factor
- width = width or self.unet.config.sample_size * self.vae_scale_factor
-
- # 1. Check inputs. Raise error if not correct
- self.check_inputs(
- prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
- )
-
- # 2. Define call parameters
- if prompt is not None and isinstance(prompt, str):
- batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- batch_size = prompt_embeds.shape[0]
-
- device = self._execution_device
- # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
- # corresponds to doing no classifier free guidance.
- do_classifier_free_guidance = guidance_scale > 1.0
- # and `sag_scale` is` `s` of equation (16)
- # of the self-attentnion guidance paper: https://arxiv.org/pdf/2210.00939.pdf
- # `sag_scale = 0` means no self-attention guidance
- do_self_attention_guidance = sag_scale > 0.0
-
- # 3. Encode input prompt
- prompt_embeds = self._encode_prompt(
- prompt,
- device,
- num_images_per_prompt,
- do_classifier_free_guidance,
- negative_prompt,
- prompt_embeds=prompt_embeds,
- negative_prompt_embeds=negative_prompt_embeds,
- )
-
- # 4. Prepare timesteps
- self.scheduler.set_timesteps(num_inference_steps, device=device)
- timesteps = self.scheduler.timesteps
-
- # 5. Prepare latent variables
- num_channels_latents = self.unet.config.in_channels
- latents = self.prepare_latents(
- batch_size * num_images_per_prompt,
- num_channels_latents,
- height,
- width,
- prompt_embeds.dtype,
- device,
- generator,
- latents,
- )
-
- # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
- extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
-
- # 7. Denoising loop
- store_processor = CrossAttnStoreProcessor()
- self.unet.mid_block.attentions[0].transformer_blocks[0].attn1.processor = store_processor
- num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
-
- map_size = None
-
- def get_map_size(module, input, output):
- nonlocal map_size
- map_size = output[0].shape[-2:]
-
- with self.unet.mid_block.attentions[0].register_forward_hook(get_map_size):
- with self.progress_bar(total=num_inference_steps) as progress_bar:
- for i, t in enumerate(timesteps):
- # expand the latents if we are doing classifier free guidance
- latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
- latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
-
- # predict the noise residual
-
- noise_pred = self.unet(
- latent_model_input,
- t,
- encoder_hidden_states=prompt_embeds,
- cross_attention_kwargs=cross_attention_kwargs,
- ).sample
-
- # perform guidance
- if do_classifier_free_guidance:
- noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
-
- # perform self-attention guidance with the stored self-attentnion map
- if do_self_attention_guidance:
- # classifier-free guidance produces two chunks of attention map
- # and we only use unconditional one according to equation (25)
- # in https://arxiv.org/pdf/2210.00939.pdf
- if do_classifier_free_guidance:
- # DDIM-like prediction of x0
- pred_x0 = self.pred_x0(latents, noise_pred_uncond, t)
- # get the stored attention maps
- uncond_attn, cond_attn = store_processor.attention_probs.chunk(2)
- # self-attention-based degrading of latents
- degraded_latents = self.sag_masking(
- pred_x0, uncond_attn, map_size, t, self.pred_epsilon(latents, noise_pred_uncond, t)
- )
- uncond_emb, _ = prompt_embeds.chunk(2)
- # forward and give guidance
- degraded_pred = self.unet(degraded_latents, t, encoder_hidden_states=uncond_emb).sample
- noise_pred += sag_scale * (noise_pred_uncond - degraded_pred)
- else:
- # DDIM-like prediction of x0
- pred_x0 = self.pred_x0(latents, noise_pred, t)
- # get the stored attention maps
- cond_attn = store_processor.attention_probs
- # self-attention-based degrading of latents
- degraded_latents = self.sag_masking(
- pred_x0, cond_attn, map_size, t, self.pred_epsilon(latents, noise_pred, t)
- )
- # forward and give guidance
- degraded_pred = self.unet(degraded_latents, t, encoder_hidden_states=prompt_embeds).sample
- noise_pred += sag_scale * (noise_pred - degraded_pred)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
-
- # call the callback, if provided
- if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
- progress_bar.update()
- if callback is not None and i % callback_steps == 0:
- callback(i, t, latents)
-
- if not output_type == "latent":
- image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
- image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
- else:
- image = latents
- has_nsfw_concept = None
-
- if has_nsfw_concept is None:
- do_denormalize = [True] * image.shape[0]
- else:
- do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
-
- image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
-
- if not return_dict:
- return (image, has_nsfw_concept)
-
- return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
-
- def sag_masking(self, original_latents, attn_map, map_size, t, eps):
- # Same masking process as in SAG paper: https://arxiv.org/pdf/2210.00939.pdf
- bh, hw1, hw2 = attn_map.shape
- b, latent_channel, latent_h, latent_w = original_latents.shape
- h = self.unet.config.attention_head_dim
- if isinstance(h, list):
- h = h[-1]
-
- # Produce attention mask
- attn_map = attn_map.reshape(b, h, hw1, hw2)
- attn_mask = attn_map.mean(1, keepdim=False).sum(1, keepdim=False) > 1.0
- attn_mask = (
- attn_mask.reshape(b, map_size[0], map_size[1])
- .unsqueeze(1)
- .repeat(1, latent_channel, 1, 1)
- .type(attn_map.dtype)
- )
- attn_mask = F.interpolate(attn_mask, (latent_h, latent_w))
-
- # Blur according to the self-attention mask
- degraded_latents = gaussian_blur_2d(original_latents, kernel_size=9, sigma=1.0)
- degraded_latents = degraded_latents * attn_mask + original_latents * (1 - attn_mask)
-
- # Noise it again to match the noise level
- degraded_latents = self.scheduler.add_noise(degraded_latents, noise=eps, timesteps=t)
-
- return degraded_latents
-
- # Modified from diffusers.schedulers.scheduling_ddim.DDIMScheduler.step
- # Note: there are some schedulers that clip or do not return x_0 (PNDMScheduler, DDIMScheduler, etc.)
- def pred_x0(self, sample, model_output, timestep):
- alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
-
- beta_prod_t = 1 - alpha_prod_t
- if self.scheduler.config.prediction_type == "epsilon":
- pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
- elif self.scheduler.config.prediction_type == "sample":
- pred_original_sample = model_output
- elif self.scheduler.config.prediction_type == "v_prediction":
- pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
- # predict V
- model_output = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
- else:
- raise ValueError(
- f"prediction_type given as {self.scheduler.config.prediction_type} must be one of `epsilon`, `sample`,"
- " or `v_prediction`"
- )
-
- return pred_original_sample
-
- def pred_epsilon(self, sample, model_output, timestep):
- alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
-
- beta_prod_t = 1 - alpha_prod_t
- if self.scheduler.config.prediction_type == "epsilon":
- pred_eps = model_output
- elif self.scheduler.config.prediction_type == "sample":
- pred_eps = (sample - (alpha_prod_t**0.5) * model_output) / (beta_prod_t**0.5)
- elif self.scheduler.config.prediction_type == "v_prediction":
- pred_eps = (beta_prod_t**0.5) * sample + (alpha_prod_t**0.5) * model_output
- else:
- raise ValueError(
- f"prediction_type given as {self.scheduler.config.prediction_type} must be one of `epsilon`, `sample`,"
- " or `v_prediction`"
- )
-
- return pred_eps
-
-
-# Gaussian blur
-def gaussian_blur_2d(img, kernel_size, sigma):
- ksize_half = (kernel_size - 1) * 0.5
-
- x = torch.linspace(-ksize_half, ksize_half, steps=kernel_size)
-
- pdf = torch.exp(-0.5 * (x / sigma).pow(2))
-
- x_kernel = pdf / pdf.sum()
- x_kernel = x_kernel.to(device=img.device, dtype=img.dtype)
-
- kernel2d = torch.mm(x_kernel[:, None], x_kernel[None, :])
- kernel2d = kernel2d.expand(img.shape[-3], 1, kernel2d.shape[0], kernel2d.shape[1])
-
- padding = [kernel_size // 2, kernel_size // 2, kernel_size // 2, kernel_size // 2]
-
- img = F.pad(img, padding, mode="reflect")
- img = F.conv2d(img, kernel2d, groups=img.shape[-3])
-
- return img
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py
deleted file mode 100644
index 77038f3f3ce9e08b38daa3c570888c5185e9f325..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py
+++ /dev/null
@@ -1,1298 +0,0 @@
-# Copyright 2023 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import inspect
-from typing import Any, Callable, Dict, List, Optional, Tuple, Union
-
-import numpy as np
-import PIL
-import torch
-from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
-
-from ...image_processor import VaeImageProcessor
-from ...loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
-from ...models import AutoencoderKL, UNet2DConditionModel
-from ...models.attention_processor import (
- AttnProcessor2_0,
- LoRAAttnProcessor2_0,
- LoRAXFormersAttnProcessor,
- XFormersAttnProcessor,
-)
-from ...schedulers import KarrasDiffusionSchedulers
-from ...utils import (
- is_accelerate_available,
- is_accelerate_version,
- is_invisible_watermark_available,
- logging,
- randn_tensor,
- replace_example_docstring,
-)
-from ..pipeline_utils import DiffusionPipeline
-from . import StableDiffusionXLPipelineOutput
-
-
-if is_invisible_watermark_available():
- from .watermark import StableDiffusionXLWatermarker
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-
-EXAMPLE_DOC_STRING = """
- Examples:
- ```py
- >>> import torch
- >>> from diffusers import StableDiffusionXLInpaintPipeline
- >>> from diffusers.utils import load_image
-
- >>> pipe = StableDiffusionXLInpaintPipeline.from_pretrained(
- ... "stabilityai/stable-diffusion-xl-base-1.0",
- ... torch_dtype=torch.float16,
- ... variant="fp16",
- ... use_safetensors=True,
- ... )
- >>> pipe.to("cuda")
-
- >>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
- >>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
-
- >>> init_image = load_image(img_url).convert("RGB")
- >>> mask_image = load_image(mask_url).convert("RGB")
-
- >>> prompt = "A majestic tiger sitting on a bench"
- >>> image = pipe(
- ... prompt=prompt, image=init_image, mask_image=mask_image, num_inference_steps=50, strength=0.80
- ... ).images[0]
- ```
-"""
-
-
-# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
-def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
- """
- Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
- """
- std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
- std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
- # rescale the results from guidance (fixes overexposure)
- noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
- # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
- noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
- return noise_cfg
-
-
-def mask_pil_to_torch(mask, height, width):
- # preprocess mask
- if isinstance(mask, (PIL.Image.Image, np.ndarray)):
- mask = [mask]
-
- if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
- mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
- mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
- mask = mask.astype(np.float32) / 255.0
- elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
- mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
-
- mask = torch.from_numpy(mask)
- return mask
-
-
-def prepare_mask_and_masked_image(image, mask, height, width, return_image: bool = False):
- """
- Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
- converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
- ``image`` and ``1`` for the ``mask``.
-
- The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
- binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
-
- Args:
- image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
- It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
- ``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
- mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
- It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
- ``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
-
-
- Raises:
- ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
- should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
- TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
- (ot the other way around).
-
- Returns:
- tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
- dimensions: ``batch x channels x height x width``.
- """
-
- # checkpoint. TOD(Yiyi) - need to clean this up later
- if image is None:
- raise ValueError("`image` input cannot be undefined.")
-
- if mask is None:
- raise ValueError("`mask_image` input cannot be undefined.")
-
- if isinstance(image, torch.Tensor):
- if not isinstance(mask, torch.Tensor):
- mask = mask_pil_to_torch(mask, height, width)
-
- if image.ndim == 3:
- image = image.unsqueeze(0)
-
- # Batch and add channel dim for single mask
- if mask.ndim == 2:
- mask = mask.unsqueeze(0).unsqueeze(0)
-
- # Batch single mask or add channel dim
- if mask.ndim == 3:
- # Single batched mask, no channel dim or single mask not batched but channel dim
- if mask.shape[0] == 1:
- mask = mask.unsqueeze(0)
-
- # Batched masks no channel dim
- else:
- mask = mask.unsqueeze(1)
-
- assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
- # assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
- assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
-
- # Check image is in [-1, 1]
- # if image.min() < -1 or image.max() > 1:
- # raise ValueError("Image should be in [-1, 1] range")
-
- # Check mask is in [0, 1]
- if mask.min() < 0 or mask.max() > 1:
- raise ValueError("Mask should be in [0, 1] range")
-
- # Binarize mask
- mask[mask < 0.5] = 0
- mask[mask >= 0.5] = 1
-
- # Image as float32
- image = image.to(dtype=torch.float32)
- elif isinstance(mask, torch.Tensor):
- raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
- else:
- # preprocess image
- if isinstance(image, (PIL.Image.Image, np.ndarray)):
- image = [image]
- if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
- # resize all images w.r.t passed height an width
- image = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in image]
- image = [np.array(i.convert("RGB"))[None, :] for i in image]
- image = np.concatenate(image, axis=0)
- elif isinstance(image, list) and isinstance(image[0], np.ndarray):
- image = np.concatenate([i[None, :] for i in image], axis=0)
-
- image = image.transpose(0, 3, 1, 2)
- image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
-
- mask = mask_pil_to_torch(mask, height, width)
- mask[mask < 0.5] = 0
- mask[mask >= 0.5] = 1
-
- if image.shape[1] == 4:
- # images are in latent space and thus can't
- # be masked set masked_image to None
- # we assume that the checkpoint is not an inpainting
- # checkpoint. TOD(Yiyi) - need to clean this up later
- masked_image = None
- else:
- masked_image = image * (mask < 0.5)
-
- # n.b. ensure backwards compatibility as old function does not return image
- if return_image:
- return mask, masked_image, image
-
- return mask, masked_image
-
-
-class StableDiffusionXLInpaintPipeline(
- DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
-):
- r"""
- Pipeline for text-to-image generation using Stable Diffusion XL.
-
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
-
- In addition the pipeline inherits the following loading methods:
- - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
- - *LoRA*: [`loaders.LoraLoaderMixin.load_lora_weights`]
- - *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
-
- as well as the following saving methods:
- - *LoRA*: [`loaders.LoraLoaderMixin.save_lora_weights`]
-
- Args:
- vae ([`AutoencoderKL`]):
- Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
- text_encoder ([`CLIPTextModel`]):
- Frozen text-encoder. Stable Diffusion XL uses the text portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
- the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
- text_encoder_2 ([` CLIPTextModelWithProjection`]):
- Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
- specifically the
- [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
- variant.
- tokenizer (`CLIPTokenizer`):
- Tokenizer of class
- [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
- tokenizer_2 (`CLIPTokenizer`):
- Second Tokenizer of class
- [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
- unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
- [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
- """
- _optional_components = ["tokenizer", "text_encoder"]
-
- def __init__(
- self,
- vae: AutoencoderKL,
- text_encoder: CLIPTextModel,
- text_encoder_2: CLIPTextModelWithProjection,
- tokenizer: CLIPTokenizer,
- tokenizer_2: CLIPTokenizer,
- unet: UNet2DConditionModel,
- scheduler: KarrasDiffusionSchedulers,
- requires_aesthetics_score: bool = False,
- force_zeros_for_empty_prompt: bool = True,
- add_watermarker: Optional[bool] = None,
- ):
- super().__init__()
-
- self.register_modules(
- vae=vae,
- text_encoder=text_encoder,
- text_encoder_2=text_encoder_2,
- tokenizer=tokenizer,
- tokenizer_2=tokenizer_2,
- unet=unet,
- scheduler=scheduler,
- )
- self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
- self.register_to_config(requires_aesthetics_score=requires_aesthetics_score)
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
- self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
-
- add_watermarker = add_watermarker if add_watermarker is not None else is_invisible_watermark_available()
-
- if add_watermarker:
- self.watermark = StableDiffusionXLWatermarker()
- else:
- self.watermark = None
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
- def enable_vae_slicing(self):
- r"""
- Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
- compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
- """
- self.vae.enable_slicing()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
- def disable_vae_slicing(self):
- r"""
- Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
- computing decoding in one step.
- """
- self.vae.disable_slicing()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
- def enable_vae_tiling(self):
- r"""
- Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
- compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
- processing larger images.
- """
- self.vae.enable_tiling()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
- def disable_vae_tiling(self):
- r"""
- Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
- computing decoding in one step.
- """
- self.vae.disable_tiling()
-
- # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_img2img.StableDiffusionXLImg2ImgPipeline.enable_model_cpu_offload
- def enable_model_cpu_offload(self, gpu_id=0):
- r"""
- Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
- to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
- method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
- `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
- """
- if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
- from accelerate import cpu_offload_with_hook
- else:
- raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
-
- device = torch.device(f"cuda:{gpu_id}")
-
- if self.device.type != "cpu":
- self.to("cpu", silence_dtype_warnings=True)
- torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
-
- model_sequence = (
- [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
- )
- model_sequence.extend([self.unet, self.vae])
-
- hook = None
- for cpu_offloaded_model in model_sequence:
- _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
-
- # We'll offload the last model manually.
- self.final_offload_hook = hook
-
- # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
- def encode_prompt(
- self,
- prompt: str,
- prompt_2: Optional[str] = None,
- device: Optional[torch.device] = None,
- num_images_per_prompt: int = 1,
- do_classifier_free_guidance: bool = True,
- negative_prompt: Optional[str] = None,
- negative_prompt_2: Optional[str] = None,
- prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_prompt_embeds: Optional[torch.FloatTensor] = None,
- pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
- lora_scale: Optional[float] = None,
- ):
- r"""
- Encodes the prompt into text encoder hidden states.
-
- Args:
- prompt (`str` or `List[str]`, *optional*):
- prompt to be encoded
- prompt_2 (`str` or `List[str]`, *optional*):
- The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
- used in both text-encoders
- device: (`torch.device`):
- torch device
- num_images_per_prompt (`int`):
- number of images that should be generated per prompt
- do_classifier_free_guidance (`bool`):
- whether to use classifier free guidance or not
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. If not defined, one has to pass
- `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
- less than `1`).
- negative_prompt_2 (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
- `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
- prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
- provided, text embeddings will be generated from `prompt` input argument.
- negative_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
- argument.
- pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
- If not provided, pooled text embeddings will be generated from `prompt` input argument.
- negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
- input argument.
- lora_scale (`float`, *optional*):
- A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
- """
- device = device or self._execution_device
-
- # set lora scale so that monkey patched LoRA
- # function of text encoder can correctly access it
- if lora_scale is not None and isinstance(self, LoraLoaderMixin):
- self._lora_scale = lora_scale
-
- if prompt is not None and isinstance(prompt, str):
- batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- batch_size = prompt_embeds.shape[0]
-
- # Define tokenizers and text encoders
- tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
- text_encoders = (
- [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
- )
-
- if prompt_embeds is None:
- prompt_2 = prompt_2 or prompt
- # textual inversion: procecss multi-vector tokens if necessary
- prompt_embeds_list = []
- prompts = [prompt, prompt_2]
- for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
- if isinstance(self, TextualInversionLoaderMixin):
- prompt = self.maybe_convert_prompt(prompt, tokenizer)
-
- text_inputs = tokenizer(
- prompt,
- padding="max_length",
- max_length=tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
-
- text_input_ids = text_inputs.input_ids
- untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
- untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
-
- if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
- text_input_ids, untruncated_ids
- ):
- removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
- logger.warning(
- "The following part of your input was truncated because CLIP can only handle sequences up to"
- f" {tokenizer.model_max_length} tokens: {removed_text}"
- )
-
- prompt_embeds = text_encoder(
- text_input_ids.to(device),
- output_hidden_states=True,
- )
-
- # We are only ALWAYS interested in the pooled output of the final text encoder
- pooled_prompt_embeds = prompt_embeds[0]
- prompt_embeds = prompt_embeds.hidden_states[-2]
-
- prompt_embeds_list.append(prompt_embeds)
-
- prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
-
- # get unconditional embeddings for classifier free guidance
- zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
- if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
- negative_prompt_embeds = torch.zeros_like(prompt_embeds)
- negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
- elif do_classifier_free_guidance and negative_prompt_embeds is None:
- negative_prompt = negative_prompt or ""
- negative_prompt_2 = negative_prompt_2 or negative_prompt
-
- uncond_tokens: List[str]
- if prompt is not None and type(prompt) is not type(negative_prompt):
- raise TypeError(
- f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
- f" {type(prompt)}."
- )
- elif isinstance(negative_prompt, str):
- uncond_tokens = [negative_prompt, negative_prompt_2]
- elif batch_size != len(negative_prompt):
- raise ValueError(
- f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
- f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
- " the batch size of `prompt`."
- )
- else:
- uncond_tokens = [negative_prompt, negative_prompt_2]
-
- negative_prompt_embeds_list = []
- for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
- if isinstance(self, TextualInversionLoaderMixin):
- negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
-
- max_length = prompt_embeds.shape[1]
- uncond_input = tokenizer(
- negative_prompt,
- padding="max_length",
- max_length=max_length,
- truncation=True,
- return_tensors="pt",
- )
-
- negative_prompt_embeds = text_encoder(
- uncond_input.input_ids.to(device),
- output_hidden_states=True,
- )
- # We are only ALWAYS interested in the pooled output of the final text encoder
- negative_pooled_prompt_embeds = negative_prompt_embeds[0]
- negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
-
- negative_prompt_embeds_list.append(negative_prompt_embeds)
-
- negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
-
- prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
- bs_embed, seq_len, _ = prompt_embeds.shape
- # duplicate text embeddings for each generation per prompt, using mps friendly method
- prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
- prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
-
- if do_classifier_free_guidance:
- # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
- seq_len = negative_prompt_embeds.shape[1]
- negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
- negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
- negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
-
- pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
- bs_embed * num_images_per_prompt, -1
- )
- if do_classifier_free_guidance:
- negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
- bs_embed * num_images_per_prompt, -1
- )
-
- return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
- def prepare_extra_step_kwargs(self, generator, eta):
- # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
- # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
- # and should be between [0, 1]
-
- accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
- extra_step_kwargs = {}
- if accepts_eta:
- extra_step_kwargs["eta"] = eta
-
- # check if the scheduler accepts generator
- accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
- if accepts_generator:
- extra_step_kwargs["generator"] = generator
- return extra_step_kwargs
-
- def check_inputs(
- self,
- prompt,
- prompt_2,
- height,
- width,
- strength,
- callback_steps,
- negative_prompt=None,
- negative_prompt_2=None,
- prompt_embeds=None,
- negative_prompt_embeds=None,
- ):
- if strength < 0 or strength > 1:
- raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
-
- if height % 8 != 0 or width % 8 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
-
- if (callback_steps is None) or (
- callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
- ):
- raise ValueError(
- f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
- f" {type(callback_steps)}."
- )
-
- if prompt is not None and prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
- " only forward one of the two."
- )
- elif prompt_2 is not None and prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
- " only forward one of the two."
- )
- elif prompt is None and prompt_embeds is None:
- raise ValueError(
- "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
- )
- elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
- elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
- raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
-
- if negative_prompt is not None and negative_prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
- f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
- )
- elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
- f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
- )
-
- if prompt_embeds is not None and negative_prompt_embeds is not None:
- if prompt_embeds.shape != negative_prompt_embeds.shape:
- raise ValueError(
- "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
- f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
- f" {negative_prompt_embeds.shape}."
- )
-
- def prepare_latents(
- self,
- batch_size,
- num_channels_latents,
- height,
- width,
- dtype,
- device,
- generator,
- latents=None,
- image=None,
- timestep=None,
- is_strength_max=True,
- add_noise=True,
- return_noise=False,
- return_image_latents=False,
- ):
- shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
- if isinstance(generator, list) and len(generator) != batch_size:
- raise ValueError(
- f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
- f" size of {batch_size}. Make sure the batch size matches the length of the generators."
- )
-
- if (image is None or timestep is None) and not is_strength_max:
- raise ValueError(
- "Since strength < 1. initial latents are to be initialised as a combination of Image + Noise."
- "However, either the image or the noise timestep has not been provided."
- )
-
- if image.shape[1] == 4:
- image_latents = image.to(device=device, dtype=dtype)
- elif return_image_latents or (latents is None and not is_strength_max):
- image = image.to(device=device, dtype=dtype)
- image_latents = self._encode_vae_image(image=image, generator=generator)
-
- if latents is None and add_noise:
- noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
- # if strength is 1. then initialise the latents to noise, else initial to image + noise
- latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep)
- # if pure noise then scale the initial latents by the Scheduler's init sigma
- latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents
- elif add_noise:
- noise = latents.to(device)
- latents = noise * self.scheduler.init_noise_sigma
- else:
- noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
- latents = image_latents.to(device)
-
- outputs = (latents,)
-
- if return_noise:
- outputs += (noise,)
-
- if return_image_latents:
- outputs += (image_latents,)
-
- return outputs
-
- def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
- dtype = image.dtype
- if self.vae.config.force_upcast:
- image = image.float()
- self.vae.to(dtype=torch.float32)
-
- if isinstance(generator, list):
- image_latents = [
- self.vae.encode(image[i : i + 1]).latent_dist.sample(generator=generator[i])
- for i in range(image.shape[0])
- ]
- image_latents = torch.cat(image_latents, dim=0)
- else:
- image_latents = self.vae.encode(image).latent_dist.sample(generator=generator)
-
- if self.vae.config.force_upcast:
- self.vae.to(dtype)
-
- image_latents = image_latents.to(dtype)
- image_latents = self.vae.config.scaling_factor * image_latents
-
- return image_latents
-
- def prepare_mask_latents(
- self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
- ):
- # resize the mask to latents shape as we concatenate the mask to the latents
- # we do that before converting to dtype to avoid breaking in case we're using cpu_offload
- # and half precision
- mask = torch.nn.functional.interpolate(
- mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
- )
- mask = mask.to(device=device, dtype=dtype)
-
- # duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
- if mask.shape[0] < batch_size:
- if not batch_size % mask.shape[0] == 0:
- raise ValueError(
- "The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
- f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
- " of masks that you pass is divisible by the total requested batch size."
- )
- mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
-
- mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
-
- masked_image_latents = None
- if masked_image is not None:
- masked_image = masked_image.to(device=device, dtype=dtype)
- masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
- if masked_image_latents.shape[0] < batch_size:
- if not batch_size % masked_image_latents.shape[0] == 0:
- raise ValueError(
- "The passed images and the required batch size don't match. Images are supposed to be duplicated"
- f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
- " Make sure the number of images that you pass is divisible by the total requested batch size."
- )
- masked_image_latents = masked_image_latents.repeat(
- batch_size // masked_image_latents.shape[0], 1, 1, 1
- )
-
- masked_image_latents = (
- torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
- )
-
- # aligning device to prevent device errors when concating it with the latent model input
- masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
-
- return mask, masked_image_latents
-
- # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_img2img.StableDiffusionXLImg2ImgPipeline.get_timesteps
- def get_timesteps(self, num_inference_steps, strength, device, denoising_start=None):
- # get the original timestep using init_timestep
- if denoising_start is None:
- init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
- t_start = max(num_inference_steps - init_timestep, 0)
- else:
- t_start = 0
-
- timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
-
- # Strength is irrelevant if we directly request a timestep to start at;
- # that is, strength is determined by the denoising_start instead.
- if denoising_start is not None:
- discrete_timestep_cutoff = int(
- round(
- self.scheduler.config.num_train_timesteps
- - (denoising_start * self.scheduler.config.num_train_timesteps)
- )
- )
- timesteps = list(filter(lambda ts: ts < discrete_timestep_cutoff, timesteps))
- return torch.tensor(timesteps), len(timesteps)
-
- return timesteps, num_inference_steps - t_start
-
- # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_img2img.StableDiffusionXLImg2ImgPipeline._get_add_time_ids
- def _get_add_time_ids(
- self, original_size, crops_coords_top_left, target_size, aesthetic_score, negative_aesthetic_score, dtype
- ):
- if self.config.requires_aesthetics_score:
- add_time_ids = list(original_size + crops_coords_top_left + (aesthetic_score,))
- add_neg_time_ids = list(original_size + crops_coords_top_left + (negative_aesthetic_score,))
- else:
- add_time_ids = list(original_size + crops_coords_top_left + target_size)
- add_neg_time_ids = list(original_size + crops_coords_top_left + target_size)
-
- passed_add_embed_dim = (
- self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
- )
- expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
-
- if (
- expected_add_embed_dim > passed_add_embed_dim
- and (expected_add_embed_dim - passed_add_embed_dim) == self.unet.config.addition_time_embed_dim
- ):
- raise ValueError(
- f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. Please make sure to enable `requires_aesthetics_score` with `pipe.register_to_config(requires_aesthetics_score=True)` to make sure `aesthetic_score` {aesthetic_score} and `negative_aesthetic_score` {negative_aesthetic_score} is correctly used by the model."
- )
- elif (
- expected_add_embed_dim < passed_add_embed_dim
- and (passed_add_embed_dim - expected_add_embed_dim) == self.unet.config.addition_time_embed_dim
- ):
- raise ValueError(
- f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. Please make sure to disable `requires_aesthetics_score` with `pipe.register_to_config(requires_aesthetics_score=False)` to make sure `target_size` {target_size} is correctly used by the model."
- )
- elif expected_add_embed_dim != passed_add_embed_dim:
- raise ValueError(
- f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
- )
-
- add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
- add_neg_time_ids = torch.tensor([add_neg_time_ids], dtype=dtype)
-
- return add_time_ids, add_neg_time_ids
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
- def upcast_vae(self):
- dtype = self.vae.dtype
- self.vae.to(dtype=torch.float32)
- use_torch_2_0_or_xformers = isinstance(
- self.vae.decoder.mid_block.attentions[0].processor,
- (
- AttnProcessor2_0,
- XFormersAttnProcessor,
- LoRAXFormersAttnProcessor,
- LoRAAttnProcessor2_0,
- ),
- )
- # if xformers or torch_2_0 is used attention block does not need
- # to be in float32 which can save lots of memory
- if use_torch_2_0_or_xformers:
- self.vae.post_quant_conv.to(dtype)
- self.vae.decoder.conv_in.to(dtype)
- self.vae.decoder.mid_block.to(dtype)
-
- @torch.no_grad()
- @replace_example_docstring(EXAMPLE_DOC_STRING)
- def __call__(
- self,
- prompt: Union[str, List[str]] = None,
- prompt_2: Optional[Union[str, List[str]]] = None,
- image: Union[torch.FloatTensor, PIL.Image.Image] = None,
- mask_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
- height: Optional[int] = None,
- width: Optional[int] = None,
- strength: float = 1.0,
- num_inference_steps: int = 50,
- denoising_start: Optional[float] = None,
- denoising_end: Optional[float] = None,
- guidance_scale: float = 7.5,
- negative_prompt: Optional[Union[str, List[str]]] = None,
- negative_prompt_2: Optional[Union[str, List[str]]] = None,
- num_images_per_prompt: Optional[int] = 1,
- eta: float = 0.0,
- generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
- latents: Optional[torch.FloatTensor] = None,
- prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_prompt_embeds: Optional[torch.FloatTensor] = None,
- pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
- callback_steps: int = 1,
- cross_attention_kwargs: Optional[Dict[str, Any]] = None,
- guidance_rescale: float = 0.0,
- original_size: Tuple[int, int] = None,
- crops_coords_top_left: Tuple[int, int] = (0, 0),
- target_size: Tuple[int, int] = None,
- aesthetic_score: float = 6.0,
- negative_aesthetic_score: float = 2.5,
- ):
- r"""
- Function invoked when calling the pipeline for generation.
-
- Args:
- prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
- instead.
- prompt_2 (`str` or `List[str]`, *optional*):
- The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
- used in both text-encoders
- image (`PIL.Image.Image`):
- `Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
- be masked out with `mask_image` and repainted according to `prompt`.
- mask_image (`PIL.Image.Image`):
- `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
- repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
- to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
- instead of 3, so the expected shape would be `(B, H, W, 1)`.
- height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
- The height in pixels of the generated image.
- width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
- The width in pixels of the generated image.
- strength (`float`, *optional*, defaults to 1.):
- Conceptually, indicates how much to transform the masked portion of the reference `image`. Must be
- between 0 and 1. `image` will be used as a starting point, adding more noise to it the larger the
- `strength`. The number of denoising steps depends on the amount of noise initially added. When
- `strength` is 1, added noise will be maximum and the denoising process will run for the full number of
- iterations specified in `num_inference_steps`. A value of 1, therefore, essentially ignores the masked
- portion of the reference `image`. Note that in the case of `denoising_start` being declared as an
- integer, the value of `strength` will be ignored.
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- denoising_start (`float`, *optional*):
- When specified, indicates the fraction (between 0.0 and 1.0) of the total denoising process to be
- bypassed before it is initiated. Consequently, the initial part of the denoising process is skipped and
- it is assumed that the passed `image` is a partly denoised image. Note that when this is specified,
- strength will be ignored. The `denoising_start` parameter is particularly beneficial when this pipeline
- is integrated into a "Mixture of Denoisers" multi-pipeline setup, as detailed in [**Refining the Image
- Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
- denoising_end (`float`, *optional*):
- When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
- completed before it is intentionally prematurely terminated. As a result, the returned sample will
- still retain a substantial amount of noise (ca. final 20% of timesteps still needed) and should be
- denoised by a successor pipeline that has `denoising_start` set to 0.8 so that it only denoises the
- final 20% of the scheduler. The denoising_end parameter should ideally be utilized when this pipeline
- forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
- Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
- guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. If not defined, one has to pass
- `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
- less than `1`).
- negative_prompt_2 (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
- `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
- prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
- provided, text embeddings will be generated from `prompt` input argument.
- negative_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
- argument.
- pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
- If not provided, pooled text embeddings will be generated from `prompt` input argument.
- negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
- input argument.
- num_images_per_prompt (`int`, *optional*, defaults to 1):
- The number of images to generate per prompt.
- eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
- generator (`torch.Generator`, *optional*):
- One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
- to make generation deterministic.
- latents (`torch.FloatTensor`, *optional*):
- Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor will ge generated by sampling using the supplied random `generator`.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generate image. Choose between
- [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
- plain tuple.
- callback (`Callable`, *optional*):
- A function that will be called every `callback_steps` steps during inference. The function will be
- called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
- callback_steps (`int`, *optional*, defaults to 1):
- The frequency at which the `callback` function will be called. If not specified, the callback will be
- called at every step.
- cross_attention_kwargs (`dict`, *optional*):
- A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
- `self.processor` in
- [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
- original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
- If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
- `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
- explained in section 2.2 of
- [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
- crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
- `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
- `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
- `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
- [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
- target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
- For most cases, `target_size` should be set to the desired height and width of the generated image. If
- not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
- section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
- aesthetic_score (`float`, *optional*, defaults to 6.0):
- Used to simulate an aesthetic score of the generated image by influencing the positive text condition.
- Part of SDXL's micro-conditioning as explained in section 2.2 of
- [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
- negative_aesthetic_score (`float`, *optional*, defaults to 2.5):
- Part of SDXL's micro-conditioning as explained in section 2.2 of
- [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). Can be used to
- simulate an aesthetic score of the generated image by influencing the negative text condition.
-
- Examples:
-
- Returns:
- [`~pipelines.stable_diffusion.StableDiffusionXLPipelineOutput`] or `tuple`:
- [`~pipelines.stable_diffusion.StableDiffusionXLPipelineOutput`] if `return_dict` is True, otherwise a
- `tuple. `tuple. When returning a tuple, the first element is a list with the generated images.
- """
- # 0. Default height and width to unet
- height = height or self.unet.config.sample_size * self.vae_scale_factor
- width = width or self.unet.config.sample_size * self.vae_scale_factor
-
- # 1. Check inputs
- self.check_inputs(
- prompt,
- prompt_2,
- height,
- width,
- strength,
- callback_steps,
- negative_prompt,
- negative_prompt_2,
- prompt_embeds,
- negative_prompt_embeds,
- )
-
- # 2. Define call parameters
- if prompt is not None and isinstance(prompt, str):
- batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- batch_size = prompt_embeds.shape[0]
-
- device = self._execution_device
- # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
- # corresponds to doing no classifier free guidance.
- do_classifier_free_guidance = guidance_scale > 1.0
-
- # 3. Encode input prompt
- text_encoder_lora_scale = (
- cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
- )
-
- (
- prompt_embeds,
- negative_prompt_embeds,
- pooled_prompt_embeds,
- negative_pooled_prompt_embeds,
- ) = self.encode_prompt(
- prompt=prompt,
- prompt_2=prompt_2,
- device=device,
- num_images_per_prompt=num_images_per_prompt,
- do_classifier_free_guidance=do_classifier_free_guidance,
- negative_prompt=negative_prompt,
- negative_prompt_2=negative_prompt_2,
- prompt_embeds=prompt_embeds,
- negative_prompt_embeds=negative_prompt_embeds,
- pooled_prompt_embeds=pooled_prompt_embeds,
- negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
- lora_scale=text_encoder_lora_scale,
- )
-
- # 4. set timesteps
- def denoising_value_valid(dnv):
- return type(denoising_end) == float and 0 < dnv < 1
-
- self.scheduler.set_timesteps(num_inference_steps, device=device)
- timesteps, num_inference_steps = self.get_timesteps(
- num_inference_steps, strength, device, denoising_start=denoising_start if denoising_value_valid else None
- )
- # check that number of inference steps is not < 1 - as this doesn't make sense
- if num_inference_steps < 1:
- raise ValueError(
- f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
- f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
- )
- # at which timestep to set the initial noise (n.b. 50% if strength is 0.5)
- latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
- # create a boolean to check if the strength is set to 1. if so then initialise the latents with pure noise
- is_strength_max = strength == 1.0
-
- # 5. Preprocess mask and image
- mask, masked_image, init_image = prepare_mask_and_masked_image(
- image, mask_image, height, width, return_image=True
- )
-
- # 6. Prepare latent variables
- num_channels_latents = self.vae.config.latent_channels
- num_channels_unet = self.unet.config.in_channels
- return_image_latents = num_channels_unet == 4
-
- add_noise = True if denoising_start is None else False
- latents_outputs = self.prepare_latents(
- batch_size * num_images_per_prompt,
- num_channels_latents,
- height,
- width,
- prompt_embeds.dtype,
- device,
- generator,
- latents,
- image=init_image,
- timestep=latent_timestep,
- is_strength_max=is_strength_max,
- add_noise=add_noise,
- return_noise=True,
- return_image_latents=return_image_latents,
- )
-
- if return_image_latents:
- latents, noise, image_latents = latents_outputs
- else:
- latents, noise = latents_outputs
-
- # 7. Prepare mask latent variables
- mask, masked_image_latents = self.prepare_mask_latents(
- mask,
- masked_image,
- batch_size * num_images_per_prompt,
- height,
- width,
- prompt_embeds.dtype,
- device,
- generator,
- do_classifier_free_guidance,
- )
-
- # 8. Check that sizes of mask, masked image and latents match
- if num_channels_unet == 9:
- # default case for runwayml/stable-diffusion-inpainting
- num_channels_mask = mask.shape[1]
- num_channels_masked_image = masked_image_latents.shape[1]
- if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
- raise ValueError(
- f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
- f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
- f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
- f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
- " `pipeline.unet` or your `mask_image` or `image` input."
- )
- elif num_channels_unet != 4:
- raise ValueError(
- f"The unet {self.unet.__class__} should have either 4 or 9 input channels, not {self.unet.config.in_channels}."
- )
- # 8.1 Prepare extra step kwargs.
- extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
-
- # 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
- height, width = latents.shape[-2:]
- height = height * self.vae_scale_factor
- width = width * self.vae_scale_factor
-
- original_size = original_size or (height, width)
- target_size = target_size or (height, width)
-
- # 10. Prepare added time ids & embeddings
- add_text_embeds = pooled_prompt_embeds
- add_time_ids, add_neg_time_ids = self._get_add_time_ids(
- original_size,
- crops_coords_top_left,
- target_size,
- aesthetic_score,
- negative_aesthetic_score,
- dtype=prompt_embeds.dtype,
- )
- add_time_ids = add_time_ids.repeat(batch_size * num_images_per_prompt, 1)
-
- if do_classifier_free_guidance:
- prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
- add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
- add_neg_time_ids = add_neg_time_ids.repeat(batch_size * num_images_per_prompt, 1)
- add_time_ids = torch.cat([add_neg_time_ids, add_time_ids], dim=0)
-
- prompt_embeds = prompt_embeds.to(device)
- add_text_embeds = add_text_embeds.to(device)
- add_time_ids = add_time_ids.to(device)
-
- # 11. Denoising loop
- num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
-
- if (
- denoising_end is not None
- and denoising_start is not None
- and denoising_value_valid(denoising_end)
- and denoising_value_valid(denoising_start)
- and denoising_start >= denoising_end
- ):
- raise ValueError(
- f"`denoising_start`: {denoising_start} cannot be larger than or equal to `denoising_end`: "
- + f" {denoising_end} when using type float."
- )
- elif denoising_end is not None and denoising_value_valid(denoising_end):
- discrete_timestep_cutoff = int(
- round(
- self.scheduler.config.num_train_timesteps
- - (denoising_end * self.scheduler.config.num_train_timesteps)
- )
- )
- num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
- timesteps = timesteps[:num_inference_steps]
-
- with self.progress_bar(total=num_inference_steps) as progress_bar:
- for i, t in enumerate(timesteps):
- # expand the latents if we are doing classifier free guidance
- latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
-
- # concat latents, mask, masked_image_latents in the channel dimension
- latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
-
- if num_channels_unet == 9:
- latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
-
- # predict the noise residual
- added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
- noise_pred = self.unet(
- latent_model_input,
- t,
- encoder_hidden_states=prompt_embeds,
- cross_attention_kwargs=cross_attention_kwargs,
- added_cond_kwargs=added_cond_kwargs,
- return_dict=False,
- )[0]
-
- # perform guidance
- if do_classifier_free_guidance:
- noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
-
- if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
- noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
-
- if num_channels_unet == 4:
- init_latents_proper = image_latents[:1]
- init_mask = mask[:1]
-
- if i < len(timesteps) - 1:
- noise_timestep = timesteps[i + 1]
- init_latents_proper = self.scheduler.add_noise(
- init_latents_proper, noise, torch.tensor([noise_timestep])
- )
-
- latents = (1 - init_mask) * init_latents_proper + init_mask * latents
-
- # call the callback, if provided
- if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
- progress_bar.update()
- if callback is not None and i % callback_steps == 0:
- callback(i, t, latents)
-
- # make sure the VAE is in float32 mode, as it overflows in float16
- if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
- self.upcast_vae()
- latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
-
- if not output_type == "latent":
- image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
- else:
- return StableDiffusionXLPipelineOutput(images=latents)
-
- # apply watermark if available
- if self.watermark is not None:
- image = self.watermark.apply_watermark(image)
-
- image = self.image_processor.postprocess(image, output_type=output_type)
-
- # Offload last model to CPU
- if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
- self.final_offload_hook.offload()
-
- if not return_dict:
- return (image,)
-
- return StableDiffusionXLPipelineOutput(images=image)
diff --git a/spaces/Andy1621/uniformer_image_detection/configs/fast_rcnn/fast_rcnn_r50_caffe_fpn_1x_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/fast_rcnn/fast_rcnn_r50_caffe_fpn_1x_coco.py
deleted file mode 100644
index 178deb6036e365815944620bce335aaf1233d3af..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/configs/fast_rcnn/fast_rcnn_r50_caffe_fpn_1x_coco.py
+++ /dev/null
@@ -1,45 +0,0 @@
-_base_ = './fast_rcnn_r50_fpn_1x_coco.py'
-
-model = dict(
- pretrained='open-mmlab://detectron2/resnet50_caffe',
- backbone=dict(
- norm_cfg=dict(type='BN', requires_grad=False), style='caffe'))
-
-# use caffe img_norm
-img_norm_cfg = dict(
- mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False)
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadProposals', num_max_proposals=2000),
- dict(type='LoadAnnotations', with_bbox=True),
- dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
- dict(type='RandomFlip', flip_ratio=0.5),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='DefaultFormatBundle'),
- dict(type='Collect', keys=['img', 'proposals', 'gt_bboxes', 'gt_labels']),
-]
-test_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadProposals', num_max_proposals=None),
- dict(
- type='MultiScaleFlipAug',
- img_scale=(1333, 800),
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='RandomFlip'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='ToTensor', keys=['proposals']),
- dict(
- type='ToDataContainer',
- fields=[dict(key='proposals', stack=False)]),
- dict(type='Collect', keys=['img', 'proposals']),
- ])
-]
-data = dict(
- train=dict(pipeline=train_pipeline),
- val=dict(pipeline=test_pipeline),
- test=dict(pipeline=test_pipeline))
diff --git a/spaces/Andy1621/uniformer_image_detection/configs/res2net/README.md b/spaces/Andy1621/uniformer_image_detection/configs/res2net/README.md
deleted file mode 100644
index ca9f934f924ab6769da9aa91d0fa09ab092a23b8..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/configs/res2net/README.md
+++ /dev/null
@@ -1,65 +0,0 @@
-# Res2Net for object detection and instance segmentation
-
-## Introduction
-
-[ALGORITHM]
-
-We propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer.
-
-| Backbone |Params. | GFLOPs | top-1 err. | top-5 err. |
-| :-------------: |:----: | :-----: | :--------: | :--------: |
-| ResNet-101 |44.6 M | 7.8 | 22.63 | 6.44 |
-| ResNeXt-101-64x4d |83.5M | 15.5 | 20.40 | - |
-| HRNetV2p-W48 | 77.5M | 16.1 | 20.70 | 5.50 |
-| Res2Net-101 | 45.2M | 8.3 | 18.77 | 4.64 |
-
-Compared with other backbone networks, Res2Net requires fewer parameters and FLOPs.
-
-**Note:**
-
-- GFLOPs for classification are calculated with image size (224x224).
-
-```latex
-@article{gao2019res2net,
- title={Res2Net: A New Multi-scale Backbone Architecture},
- author={Gao, Shang-Hua and Cheng, Ming-Ming and Zhao, Kai and Zhang, Xin-Yu and Yang, Ming-Hsuan and Torr, Philip},
- journal={IEEE TPAMI},
- year={2020},
- doi={10.1109/TPAMI.2019.2938758},
-}
-```
-
-## Results and Models
-
-### Faster R-CNN
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
-|R2-101-FPN | pytorch | 2x | 7.4 | - | 43.0 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/res2net/faster_rcnn_r2_101_fpn_2x_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/res2net/faster_rcnn_r2_101_fpn_2x_coco/faster_rcnn_r2_101_fpn_2x_coco-175f1da6.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/res2net/faster_rcnn_r2_101_fpn_2x_coco/faster_rcnn_r2_101_fpn_2x_coco_20200514_231734.log.json) |
-
-### Mask R-CNN
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
-| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
-|R2-101-FPN | pytorch | 2x | 7.9 | - | 43.6 | 38.7 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/res2net/mask_rcnn_r2_101_fpn_2x_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/res2net/mask_rcnn_r2_101_fpn_2x_coco/mask_rcnn_r2_101_fpn_2x_coco-17f061e8.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/res2net/mask_rcnn_r2_101_fpn_2x_coco/mask_rcnn_r2_101_fpn_2x_coco_20200515_002413.log.json) |
-
-### Cascade R-CNN
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
-|R2-101-FPN | pytorch | 20e | 7.8 | - | 45.7 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/res2net/cascade_rcnn_r2_101_fpn_20e_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/res2net/cascade_rcnn_r2_101_fpn_20e_coco/cascade_rcnn_r2_101_fpn_20e_coco-f4b7b7db.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/res2net/cascade_rcnn_r2_101_fpn_20e_coco/cascade_rcnn_r2_101_fpn_20e_coco_20200515_091644.log.json) |
-
-### Cascade Mask R-CNN
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
-| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
-R2-101-FPN | pytorch | 20e | 9.5 | - | 46.4 | 40.0 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/res2net/cascade_mask_rcnn_r2_101_fpn_20e_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/res2net/cascade_mask_rcnn_r2_101_fpn_20e_coco/cascade_mask_rcnn_r2_101_fpn_20e_coco-8a7b41e1.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/res2net/cascade_mask_rcnn_r2_101_fpn_20e_coco/cascade_mask_rcnn_r2_101_fpn_20e_coco_20200515_091645.log.json) |
-
-### Hybrid Task Cascade (HTC)
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
-| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
-| R2-101-FPN | pytorch | 20e | - | - | 47.5 | 41.6 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/res2net/htc_r2_101_fpn_20e_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/res2net/htc_r2_101_fpn_20e_coco/htc_r2_101_fpn_20e_coco-3a8d2112.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/res2net/htc_r2_101_fpn_20e_coco/htc_r2_101_fpn_20e_coco_20200515_150029.log.json) |
-
-- Res2Net ImageNet pretrained models are in [Res2Net-PretrainedModels](https://github.com/Res2Net/Res2Net-PretrainedModels).
-- More applications of Res2Net are in [Res2Net-Github](https://github.com/Res2Net/).
diff --git a/spaces/Andy1621/uniformer_image_detection/mmcv_custom/runner/epoch_based_runner.py b/spaces/Andy1621/uniformer_image_detection/mmcv_custom/runner/epoch_based_runner.py
deleted file mode 100644
index 7cdf3fa05639f7fde652090be9dbf78b48790744..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/mmcv_custom/runner/epoch_based_runner.py
+++ /dev/null
@@ -1,104 +0,0 @@
-# Copyright (c) Open-MMLab. All rights reserved.
-import os.path as osp
-import platform
-import shutil
-
-import torch
-from torch.optim import Optimizer
-
-import mmcv
-from mmcv.runner import RUNNERS, EpochBasedRunner
-from .checkpoint import save_checkpoint
-
-try:
- import apex
-except:
- print('apex is not installed')
-
-
-@RUNNERS.register_module()
-class EpochBasedRunnerAmp(EpochBasedRunner):
- """Epoch-based Runner with AMP support.
-
- This runner train models epoch by epoch.
- """
-
- def save_checkpoint(self,
- out_dir,
- filename_tmpl='epoch_{}.pth',
- save_optimizer=True,
- meta=None,
- create_symlink=True):
- """Save the checkpoint.
-
- Args:
- out_dir (str): The directory that checkpoints are saved.
- filename_tmpl (str, optional): The checkpoint filename template,
- which contains a placeholder for the epoch number.
- Defaults to 'epoch_{}.pth'.
- save_optimizer (bool, optional): Whether to save the optimizer to
- the checkpoint. Defaults to True.
- meta (dict, optional): The meta information to be saved in the
- checkpoint. Defaults to None.
- create_symlink (bool, optional): Whether to create a symlink
- "latest.pth" to point to the latest checkpoint.
- Defaults to True.
- """
- if meta is None:
- meta = dict(epoch=self.epoch + 1, iter=self.iter)
- elif isinstance(meta, dict):
- meta.update(epoch=self.epoch + 1, iter=self.iter)
- else:
- raise TypeError(
- f'meta should be a dict or None, but got {type(meta)}')
- if self.meta is not None:
- meta.update(self.meta)
-
- filename = filename_tmpl.format(self.epoch + 1)
- filepath = osp.join(out_dir, filename)
- optimizer = self.optimizer if save_optimizer else None
- save_checkpoint(self.model, filepath, optimizer=optimizer, meta=meta)
- # in some environments, `os.symlink` is not supported, you may need to
- # set `create_symlink` to False
- if create_symlink:
- dst_file = osp.join(out_dir, 'latest.pth')
- if platform.system() != 'Windows':
- mmcv.symlink(filename, dst_file)
- else:
- shutil.copy(filepath, dst_file)
-
- def resume(self,
- checkpoint,
- resume_optimizer=True,
- map_location='default'):
- if map_location == 'default':
- if torch.cuda.is_available():
- device_id = torch.cuda.current_device()
- checkpoint = self.load_checkpoint(
- checkpoint,
- map_location=lambda storage, loc: storage.cuda(device_id))
- else:
- checkpoint = self.load_checkpoint(checkpoint)
- else:
- checkpoint = self.load_checkpoint(
- checkpoint, map_location=map_location)
-
- self._epoch = checkpoint['meta']['epoch']
- self._iter = checkpoint['meta']['iter']
- if 'optimizer' in checkpoint and resume_optimizer:
- if isinstance(self.optimizer, Optimizer):
- self.optimizer.load_state_dict(checkpoint['optimizer'])
- elif isinstance(self.optimizer, dict):
- for k in self.optimizer.keys():
- self.optimizer[k].load_state_dict(
- checkpoint['optimizer'][k])
- else:
- raise TypeError(
- 'Optimizer should be dict or torch.optim.Optimizer '
- f'but got {type(self.optimizer)}')
-
- if 'amp' in checkpoint:
- apex.amp.load_state_dict(checkpoint['amp'])
- self.logger.info('load amp state dict')
-
- self.logger.info('resumed epoch %d, iter %d', self.epoch, self.iter)
diff --git a/spaces/Andy1621/uniformer_image_detection/mmdet/models/detectors/mask_rcnn.py b/spaces/Andy1621/uniformer_image_detection/mmdet/models/detectors/mask_rcnn.py
deleted file mode 100644
index c15a7733170e059d2825138b3812319915b7cad6..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/mmdet/models/detectors/mask_rcnn.py
+++ /dev/null
@@ -1,24 +0,0 @@
-from ..builder import DETECTORS
-from .two_stage import TwoStageDetector
-
-
-@DETECTORS.register_module()
-class MaskRCNN(TwoStageDetector):
- """Implementation of `Mask R-CNN `_"""
-
- def __init__(self,
- backbone,
- rpn_head,
- roi_head,
- train_cfg,
- test_cfg,
- neck=None,
- pretrained=None):
- super(MaskRCNN, self).__init__(
- backbone=backbone,
- neck=neck,
- rpn_head=rpn_head,
- roi_head=roi_head,
- train_cfg=train_cfg,
- test_cfg=test_cfg,
- pretrained=pretrained)
diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/deeplabv3plus/deeplabv3plus_r18-d8_769x769_80k_cityscapes.py b/spaces/Andy1621/uniformer_image_segmentation/configs/deeplabv3plus/deeplabv3plus_r18-d8_769x769_80k_cityscapes.py
deleted file mode 100644
index 0172d9a87d6dc1c75bf75a9c48363eb985d389a8..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_segmentation/configs/deeplabv3plus/deeplabv3plus_r18-d8_769x769_80k_cityscapes.py
+++ /dev/null
@@ -1,11 +0,0 @@
-_base_ = './deeplabv3plus_r50-d8_769x769_80k_cityscapes.py'
-model = dict(
- pretrained='open-mmlab://resnet18_v1c',
- backbone=dict(depth=18),
- decode_head=dict(
- c1_in_channels=64,
- c1_channels=12,
- in_channels=512,
- channels=128,
- ),
- auxiliary_head=dict(in_channels=256, channels=64))
diff --git a/spaces/AnimaLab/bias-test-gpt-pairs/mgr_requests.py b/spaces/AnimaLab/bias-test-gpt-pairs/mgr_requests.py
deleted file mode 100644
index 5af67b3fbb6145b0cc2d0cdb1a4440e93b411c7d..0000000000000000000000000000000000000000
--- a/spaces/AnimaLab/bias-test-gpt-pairs/mgr_requests.py
+++ /dev/null
@@ -1,214 +0,0 @@
-import pandas as pd
-import gradio as gr
-import hashlib, base64
-import openai
-from tqdm import tqdm
-tqdm().pandas()
-
-# querying OpenAI for generation
-import openAI_manager as oai_mgr
-#import initOpenAI, examples_to_prompt, genChatGPT, generateTestSentences
-
-# bias testing manager
-import mgr_bias_scoring as bt_mgr
-import mgr_sentences as smgr
-
-# error messages
-from error_messages import *
-
-G_CORE_BIAS_NAME = None
-
-# hashing
-def getHashForString(text):
- d=hashlib.md5(bytes(text, encoding='utf-8')).digest()
- d=base64.urlsafe_b64encode(d)
-
- return d.decode('utf-8')
-
-def getBiasName(gr1_lst, gr2_lst, att1_lst, att2_lst):
- global G_CORE_BIAS_NAME
-
- bias_name = G_CORE_BIAS_NAME
- if bias_name == None:
- full_spec = ''.join(gr1_lst)+''.join(gr2_lst)+''.join(att1_lst)+''.join(att2_lst)
- hash = getHashForString(full_spec)
- bias_name = f"{gr1_lst[0].replace(' ','-')}_{gr2_lst[0].replace(' ','-')}__{att1_lst[0].replace(' ','-')}_{att2_lst[0].replace(' ','-')}_{hash}"
-
- return bias_name
-
-def _generateOnline(bias_spec, progress, key, num2gen, isSaving=False):
- test_sentences = []
- gen_err_msg = None
- genAttrCounts = {}
- print(f"Bias spec dict: {bias_spec}")
- g1, g2, a1, a2 = bt_mgr.get_words(bias_spec)
- print(f"A1: {a1}")
- print(f"A2: {a2}")
-
- if "custom_counts" in bias_spec:
- print("Bias spec is custom !!")
- genAttrCounts = bias_spec['custom_counts'][0]
- for a,c in bias_spec['custom_counts'][1].items():
- genAttrCounts[a] = c
- else:
- print("Bias spec is standard !!")
- genAttrCounts = {a:num2gen for a in a1+a2}
-
- # Initiate with key
- try:
- models = oai_mgr.initOpenAI(key)
- model_names = [m['id'] for m in models['data']]
- print(f"Model names: {model_names}")
- except openai.error.AuthenticationError as err:
- #raise gr.Error(OPENAI_INIT_ERROR.replace("", str(err)))
- gen_err_msg = OPENAI_INIT_ERROR.replace("", str(err))
-
- if gen_err_msg != None:
- return [], gen_err_msg
- else:
- if "gpt-3.5-turbo" in model_names:
- print("Access to ChatGPT")
- if "gpt-4" in model_names:
- print("Access to GPT-4")
-
- model_name = "gpt-3.5-turbo" #"gpt-4"
-
- # Generate one example
- #gen = genChatGPT(model_name, ["man","math"], 2, 5,
- # [{"Keywords": ["sky","blue"], "Sentence": "the sky is blue"}
- # ],
- # temperature=0.8)
- #print(f"Test gen: {gen}")
-
- # Generate all test sentences
-
- #gens = oai_mgr.generateTestSentences(model_name, g1+g2, a1+a2, num2gen, progress)
- gens = oai_mgr.generateTestSentencesCustom(model_name, g1, g2, a1+a2, genAttrCounts, bias_spec, progress)
- print("--GENS--")
- print(gens)
- if len(gens) == 0:
- print("No sentences generated, returning")
- return [], gen_err_msg
-
- for org_gt, at, s, gt1, gt2 in gens:
- test_sentences.append([s,org_gt,at,gt1,gt2])
-
- # save the generations immediately
- print("Making save dataframe...")
- save_df = pd.DataFrame(test_sentences, columns=["Sentence",'org_grp_term',
- "Attribute term", "Group term 1",
- "Group term 2"])
-
- ## make the templates to save
- # 1. bias specification
- print(f"Bias spec dict: {bias_spec}")
-
- # generate laternative sentence
- print(f"Columns before alternative sentence: {list(save_df.columns)}")
- save_df['Alternative Sentence'] = save_df.progress_apply(oai_mgr.chatgpt_sentence_alternative, axis=1, model_name=model_name)
- print(f"Columns after alternative sentence: {list(save_df.columns)}")
-
- # 2. convert to templates
- save_df['Template'] = save_df.progress_apply(bt_mgr.sentence_to_template_df, axis=1)
- print("Convert generated sentences to templates...")
- save_df[['Alternative Template','grp_refs']] = save_df.progress_apply(bt_mgr.ref_terms_sentence_to_template, axis=1)
- print(f"Columns with templates: {list(save_df.columns)}")
-
- # 3. convert to pairs
- print("Convert generated sentences to ordered pairs...")
- test_pairs_df = bt_mgr.convert2pairsFromDF(bias_spec, save_df)
- print(f"Test pairs cols: {list(test_pairs_df.columns)}")
-
- bias_name = getBiasName(g1, g2, a1, a2)
-
- save_df = save_df.rename(columns={"Sentence":'sentence',
- "Alternative Sentence":"alt_sentence",
- "Attribute term": 'att_term',
- "Template":"template",
- "Alternative Template": "alt_template",
- "Group term 1": "grp_term1",
- "Group term 2": "grp_term2"})
-
- save_df['label_1'] = test_pairs_df['label_1']
- save_df['label_2'] = test_pairs_df['label_2']
- save_df['bias_spec'] = bias_name
- save_df['type'] = 'tool'
- save_df['gen_model'] = model_name
-
- col_order = ["sentence", "alt_sentence", "org_grp_term", "att_term", "template",
- "alt_template", "grp_term1", "grp_term2", "grp_refs", "label_1", "label_2",
- "bias_spec", "type", "gen_model"]
- save_df = save_df[col_order]
-
- print(f"Save cols prep: {list(save_df.columns)}")
-
- if isSaving == True:
- print(f"Saving: {save_df.head(1)}")
- smgr.saveSentences(save_df) #[["Group term","Attribute term","Test sentence"]])
-
- num_sentences = len(test_sentences)
- print(f"Returned num sentences: {num_sentences}")
-
- # list for Gradio dataframe
- ret_df = [list(r.values) for i, r in save_df[['sentence', 'alt_sentence', 'grp_term1', 'grp_term2', "att_term"]].iterrows()]
- print(ret_df)
-
- return ret_df, gen_err_msg
-
-def _getSavedSentences(bias_spec, progress, use_paper_sentences):
- test_sentences = []
-
- print(f"Bias spec dict: {bias_spec}")
-
- g1, g2, a1, a2 = bt_mgr.get_words(bias_spec)
- for gi, g_term in enumerate(g1+g2):
- att_list = a1+a2
- grp_list = g1+g2
- # match "-" and no space
- att_list_dash = [t.replace(' ','-') for t in att_list]
- att_list.extend(att_list_dash)
- att_list_nospace = [t.replace(' ','') for t in att_list]
- att_list.extend(att_list_nospace)
- att_list = list(set(att_list))
-
- progress(gi/len(g1+g2), desc=f"{g_term}")
-
- _, sentence_df, _ = smgr.getSavedSentences(g_term)
- # only take from paper & gpt3.5
- flt_gen_models = ["gpt-3.5","gpt-3.5-turbo","gpt-4"]
- print(f"Before filter: {sentence_df.shape[0]}")
- if use_paper_sentences == True:
- if 'type' in list(sentence_df.columns):
- sentence_df = sentence_df.query("type=='paper' and gen_model in @flt_gen_models")
- print(f"After filter: {sentence_df.shape[0]}")
- else:
- if 'type' in list(sentence_df.columns):
- # only use GPT-3.5 generations for now - todo: add settings option for this
- sentence_df = sentence_df.query("gen_model in @flt_gen_models")
- print(f"After filter: {sentence_df.shape[0]}")
-
- if sentence_df.shape[0] > 0:
- sentence_df = sentence_df[['grp_term1','grp_term2','att_term','sentence','alt_sentence']]
- sentence_df = sentence_df.rename(columns={'grp_term1': "Group term 1",
- 'grp_term2': "Group term 2",
- "att_term": "Attribute term",
- "sentence": "Sentence",
- "alt_sentence": "Alt Sentence"})
-
- sel = sentence_df[(sentence_df['Attribute term'].isin(att_list)) & \
- ((sentence_df['Group term 1'].isin(grp_list)) & (sentence_df['Group term 2'].isin(grp_list))) ].values
- if len(sel) > 0:
- for gt1,gt2,at,s,a_s in sel:
- #if at == "speech-language-pathologist":
- # print(f"Special case: {at}")
- # at == "speech-language pathologist" # legacy, special case
- #else:
- #at = at #.replace("-"," ")
- #gt = gt #.replace("-"," ")
-
- test_sentences.append([s,a_s,gt1,gt2,at])
- else:
- print("Test sentences empty!")
- #raise gr.Error(NO_SENTENCES_ERROR)
-
- return test_sentences
\ No newline at end of file
diff --git a/spaces/Anonymous-123/ImageNet-Editing/editing_diffusion/utils/video.py b/spaces/Anonymous-123/ImageNet-Editing/editing_diffusion/utils/video.py
deleted file mode 100644
index 0baaeca883f7b3375767efb28657c5c950f87e7d..0000000000000000000000000000000000000000
--- a/spaces/Anonymous-123/ImageNet-Editing/editing_diffusion/utils/video.py
+++ /dev/null
@@ -1,26 +0,0 @@
-from typing import List
-import os
-
-from PIL.Image import Image
-import cv2
-import numpy as np
-
-
-def save_video(images_list: List[Image], video_path: str):
- """Saves a video from a list of images
-
- Args:
- images_list (List[Image]): A list of PIL images.
- video_path (str): The path to save to video to.
- """
- images = [np.array(img) for img in images_list]
- height, width, _ = images[0].shape
-
- fps = len(images) // 20
- video = cv2.VideoWriter(video_path, 0, fps, (width, height))
-
- for img in images:
- video.write(cv2.cvtColor(img, cv2.COLOR_RGB2BGR))
-
- cv2.destroyAllWindows()
- video.release()
diff --git a/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmseg/core/utils/misc.py b/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmseg/core/utils/misc.py
deleted file mode 100644
index eb862a82bd47c8624db3dd5c6fb6ad8a03b62466..0000000000000000000000000000000000000000
--- a/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmseg/core/utils/misc.py
+++ /dev/null
@@ -1,17 +0,0 @@
-def add_prefix(inputs, prefix):
- """Add prefix for dict.
-
- Args:
- inputs (dict): The input dict with str keys.
- prefix (str): The prefix to add.
-
- Returns:
-
- dict: The dict with keys updated with ``prefix``.
- """
-
- outputs = dict()
- for name, value in inputs.items():
- outputs[f'{prefix}.{name}'] = value
-
- return outputs
diff --git a/spaces/Ash58947/Bot/README.md b/spaces/Ash58947/Bot/README.md
deleted file mode 100644
index c4153b6b11795fdb265609ea90e4cd3f49d84ef3..0000000000000000000000000000000000000000
--- a/spaces/Ash58947/Bot/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: Bot
-emoji: 🐠
-colorFrom: pink
-colorTo: yellow
-sdk: docker
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/urllib3/util/request.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/urllib3/util/request.py
deleted file mode 100644
index 330766ef4f3403e05a6ad8ec30f25fe05fdbc199..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/urllib3/util/request.py
+++ /dev/null
@@ -1,137 +0,0 @@
-from __future__ import absolute_import
-
-from base64 import b64encode
-
-from ..exceptions import UnrewindableBodyError
-from ..packages.six import b, integer_types
-
-# Pass as a value within ``headers`` to skip
-# emitting some HTTP headers that are added automatically.
-# The only headers that are supported are ``Accept-Encoding``,
-# ``Host``, and ``User-Agent``.
-SKIP_HEADER = "@@@SKIP_HEADER@@@"
-SKIPPABLE_HEADERS = frozenset(["accept-encoding", "host", "user-agent"])
-
-ACCEPT_ENCODING = "gzip,deflate"
-
-_FAILEDTELL = object()
-
-
-def make_headers(
- keep_alive=None,
- accept_encoding=None,
- user_agent=None,
- basic_auth=None,
- proxy_basic_auth=None,
- disable_cache=None,
-):
- """
- Shortcuts for generating request headers.
-
- :param keep_alive:
- If ``True``, adds 'connection: keep-alive' header.
-
- :param accept_encoding:
- Can be a boolean, list, or string.
- ``True`` translates to 'gzip,deflate'.
- List will get joined by comma.
- String will be used as provided.
-
- :param user_agent:
- String representing the user-agent you want, such as
- "python-urllib3/0.6"
-
- :param basic_auth:
- Colon-separated username:password string for 'authorization: basic ...'
- auth header.
-
- :param proxy_basic_auth:
- Colon-separated username:password string for 'proxy-authorization: basic ...'
- auth header.
-
- :param disable_cache:
- If ``True``, adds 'cache-control: no-cache' header.
-
- Example::
-
- >>> make_headers(keep_alive=True, user_agent="Batman/1.0")
- {'connection': 'keep-alive', 'user-agent': 'Batman/1.0'}
- >>> make_headers(accept_encoding=True)
- {'accept-encoding': 'gzip,deflate'}
- """
- headers = {}
- if accept_encoding:
- if isinstance(accept_encoding, str):
- pass
- elif isinstance(accept_encoding, list):
- accept_encoding = ",".join(accept_encoding)
- else:
- accept_encoding = ACCEPT_ENCODING
- headers["accept-encoding"] = accept_encoding
-
- if user_agent:
- headers["user-agent"] = user_agent
-
- if keep_alive:
- headers["connection"] = "keep-alive"
-
- if basic_auth:
- headers["authorization"] = "Basic " + b64encode(b(basic_auth)).decode("utf-8")
-
- if proxy_basic_auth:
- headers["proxy-authorization"] = "Basic " + b64encode(
- b(proxy_basic_auth)
- ).decode("utf-8")
-
- if disable_cache:
- headers["cache-control"] = "no-cache"
-
- return headers
-
-
-def set_file_position(body, pos):
- """
- If a position is provided, move file to that point.
- Otherwise, we'll attempt to record a position for future use.
- """
- if pos is not None:
- rewind_body(body, pos)
- elif getattr(body, "tell", None) is not None:
- try:
- pos = body.tell()
- except (IOError, OSError):
- # This differentiates from None, allowing us to catch
- # a failed `tell()` later when trying to rewind the body.
- pos = _FAILEDTELL
-
- return pos
-
-
-def rewind_body(body, body_pos):
- """
- Attempt to rewind body to a certain position.
- Primarily used for request redirects and retries.
-
- :param body:
- File-like object that supports seek.
-
- :param int pos:
- Position to seek to in file.
- """
- body_seek = getattr(body, "seek", None)
- if body_seek is not None and isinstance(body_pos, integer_types):
- try:
- body_seek(body_pos)
- except (IOError, OSError):
- raise UnrewindableBodyError(
- "An error occurred when rewinding request body for redirect/retry."
- )
- elif body_pos is _FAILEDTELL:
- raise UnrewindableBodyError(
- "Unable to record file position for rewinding "
- "request body during a redirect/retry."
- )
- else:
- raise ValueError(
- "body_pos must be of type integer, instead it was %s." % type(body_pos)
- )
diff --git a/spaces/Ayanoaisho/L/Dockerfile b/spaces/Ayanoaisho/L/Dockerfile
deleted file mode 100644
index 6c01c09373883afcb4ea34ae2d316cd596e1737b..0000000000000000000000000000000000000000
--- a/spaces/Ayanoaisho/L/Dockerfile
+++ /dev/null
@@ -1,21 +0,0 @@
-FROM node:18-bullseye-slim
-
-RUN apt-get update && \
-
-apt-get install -y git
-
-RUN git clone https://gitgud.io/khanon/oai-reverse-proxy.git /app
-
-WORKDIR /app
-
-RUN npm install
-
-COPY Dockerfile greeting.md* .env* ./
-
-RUN npm run build
-
-EXPOSE 7860
-
-ENV NODE_ENV=production
-
-CMD [ "npm", "start" ]
\ No newline at end of file
diff --git a/spaces/AzumaSeren100/XuanShen-Bert-VITS2/utils.py b/spaces/AzumaSeren100/XuanShen-Bert-VITS2/utils.py
deleted file mode 100644
index b07eec0bef747d85758c0d4f5ee8ada696d81f06..0000000000000000000000000000000000000000
--- a/spaces/AzumaSeren100/XuanShen-Bert-VITS2/utils.py
+++ /dev/null
@@ -1,290 +0,0 @@
-import os
-import glob
-import sys
-import argparse
-import logging
-import json
-import subprocess
-import numpy as np
-from scipy.io.wavfile import read
-import torch
-
-MATPLOTLIB_FLAG = False
-
-logger = logging.getLogger(__name__)
-
-
-def load_checkpoint(checkpoint_path, model, optimizer=None, skip_optimizer=False):
- assert os.path.isfile(checkpoint_path)
- checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
- iteration = checkpoint_dict['iteration']
- learning_rate = checkpoint_dict['learning_rate']
- if optimizer is not None and not skip_optimizer and checkpoint_dict['optimizer'] is not None:
- optimizer.load_state_dict(checkpoint_dict['optimizer'])
- elif optimizer is None and not skip_optimizer:
- #else: Disable this line if Infer and resume checkpoint,then enable the line upper
- new_opt_dict = optimizer.state_dict()
- new_opt_dict_params = new_opt_dict['param_groups'][0]['params']
- new_opt_dict['param_groups'] = checkpoint_dict['optimizer']['param_groups']
- new_opt_dict['param_groups'][0]['params'] = new_opt_dict_params
- optimizer.load_state_dict(new_opt_dict)
- saved_state_dict = checkpoint_dict['model']
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- new_state_dict = {}
- for k, v in state_dict.items():
- try:
- #assert "emb_g" not in k
- # print("load", k)
- new_state_dict[k] = saved_state_dict[k]
- assert saved_state_dict[k].shape == v.shape, (saved_state_dict[k].shape, v.shape)
- except:
- logger.error("%s is not in the checkpoint" % k)
- new_state_dict[k] = v
- if hasattr(model, 'module'):
- model.module.load_state_dict(new_state_dict, strict=False)
- else:
- model.load_state_dict(new_state_dict, strict=False)
- logger.info("Loaded checkpoint '{}' (iteration {})".format(
- checkpoint_path, iteration))
- return model, optimizer, learning_rate, iteration
-
-
-def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path):
- logger.info("Saving model and optimizer state at iteration {} to {}".format(
- iteration, checkpoint_path))
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- torch.save({'model': state_dict,
- 'iteration': iteration,
- 'optimizer': optimizer.state_dict(),
- 'learning_rate': learning_rate}, checkpoint_path)
-
-
-def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050):
- for k, v in scalars.items():
- writer.add_scalar(k, v, global_step)
- for k, v in histograms.items():
- writer.add_histogram(k, v, global_step)
- for k, v in images.items():
- writer.add_image(k, v, global_step, dataformats='HWC')
- for k, v in audios.items():
- writer.add_audio(k, v, global_step, audio_sampling_rate)
-
-
-def latest_checkpoint_path(dir_path, regex="G_*.pth"):
- f_list = glob.glob(os.path.join(dir_path, regex))
- f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
- x = f_list[-1]
- print(x)
- return x
-
-
-def plot_spectrogram_to_numpy(spectrogram):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(10, 2))
- im = ax.imshow(spectrogram, aspect="auto", origin="lower",
- interpolation='none')
- plt.colorbar(im, ax=ax)
- plt.xlabel("Frames")
- plt.ylabel("Channels")
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def plot_alignment_to_numpy(alignment, info=None):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(6, 4))
- im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower',
- interpolation='none')
- fig.colorbar(im, ax=ax)
- xlabel = 'Decoder timestep'
- if info is not None:
- xlabel += '\n\n' + info
- plt.xlabel(xlabel)
- plt.ylabel('Encoder timestep')
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def load_wav_to_torch(full_path):
- sampling_rate, data = read(full_path)
- return torch.FloatTensor(data.astype(np.float32)), sampling_rate
-
-
-def load_filepaths_and_text(filename, split="|"):
- with open(filename, encoding='utf-8') as f:
- filepaths_and_text = [line.strip().split(split) for line in f]
- return filepaths_and_text
-
-
-def get_hparams(init=True):
- parser = argparse.ArgumentParser()
- parser.add_argument('-c', '--config', type=str, default="./configs/base.json",
- help='JSON file for configuration')
- parser.add_argument('-m', '--model', type=str, required=True,
- help='Model name')
-
- args = parser.parse_args()
- # model_dir = os.path.join("./logs", args.model)
- model_dir = "./logs/" + args.model
-
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
-
- config_path = args.config
- config_save_path = os.path.join(model_dir, "config.json")
- if init:
- with open(config_path, "r" ,encoding='utf-8') as f:
- data = f.read()
- with open(config_save_path, "w" ,encoding='utf-8') as f:
- f.write(data)
- else:
- with open(config_save_path, "r" ,encoding='utf-8') as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- hparams.model_dir = model_dir
- return hparams
-
-
-def clean_checkpoints(path_to_models='logs/44k/', n_ckpts_to_keep=2, sort_by_time=True):
- """Freeing up space by deleting saved ckpts
-
- Arguments:
- path_to_models -- Path to the model directory
- n_ckpts_to_keep -- Number of ckpts to keep, excluding G_0.pth and D_0.pth
- sort_by_time -- True -> chronologically delete ckpts
- False -> lexicographically delete ckpts
- """
- import re
- ckpts_files = [f for f in os.listdir(path_to_models) if os.path.isfile(os.path.join(path_to_models, f))]
- name_key = (lambda _f: int(re.compile('._(\d+)\.pth').match(_f).group(1)))
- time_key = (lambda _f: os.path.getmtime(os.path.join(path_to_models, _f)))
- sort_key = time_key if sort_by_time else name_key
- x_sorted = lambda _x: sorted([f for f in ckpts_files if f.startswith(_x) and not f.endswith('_0.pth')],
- key=sort_key)
- to_del = [os.path.join(path_to_models, fn) for fn in
- (x_sorted('G')[:-n_ckpts_to_keep] + x_sorted('D')[:-n_ckpts_to_keep])]
- del_info = lambda fn: logger.info(f".. Free up space by deleting ckpt {fn}")
- del_routine = lambda x: [os.remove(x), del_info(x)]
- rs = [del_routine(fn) for fn in to_del]
-
-def get_hparams_from_dir(model_dir):
- config_save_path = os.path.join(model_dir, "config.json")
- with open(config_save_path, "r", encoding='utf-8') as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- hparams.model_dir = model_dir
- return hparams
-
-
-def get_hparams_from_file(config_path):
- with open(config_path, "r", encoding='utf-8') as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- return hparams
-
-
-def check_git_hash(model_dir):
- source_dir = os.path.dirname(os.path.realpath(__file__))
- if not os.path.exists(os.path.join(source_dir, ".git")):
- logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format(
- source_dir
- ))
- return
-
- cur_hash = subprocess.getoutput("git rev-parse HEAD")
-
- path = os.path.join(model_dir, "githash")
- if os.path.exists(path):
- saved_hash = open(path).read()
- if saved_hash != cur_hash:
- logger.warn("git hash values are different. {}(saved) != {}(current)".format(
- saved_hash[:8], cur_hash[:8]))
- else:
- open(path, "w").write(cur_hash)
-
-
-def get_logger(model_dir, filename="train.log"):
- global logger
- logger = logging.getLogger(os.path.basename(model_dir))
- logger.setLevel(logging.DEBUG)
-
- formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
- h = logging.FileHandler(os.path.join(model_dir, filename))
- h.setLevel(logging.DEBUG)
- h.setFormatter(formatter)
- logger.addHandler(h)
- return logger
-
-
-class HParams():
- def __init__(self, **kwargs):
- for k, v in kwargs.items():
- if type(v) == dict:
- v = HParams(**v)
- self[k] = v
-
- def keys(self):
- return self.__dict__.keys()
-
- def items(self):
- return self.__dict__.items()
-
- def values(self):
- return self.__dict__.values()
-
- def __len__(self):
- return len(self.__dict__)
-
- def __getitem__(self, key):
- return getattr(self, key)
-
- def __setitem__(self, key, value):
- return setattr(self, key, value)
-
- def __contains__(self, key):
- return key in self.__dict__
-
- def __repr__(self):
- return self.__dict__.__repr__()
diff --git a/spaces/Banbri/zcvzcv/src/lib/sleep.ts b/spaces/Banbri/zcvzcv/src/lib/sleep.ts
deleted file mode 100644
index 2885c6e75c0dc415c9eaf71beabac7461eee5588..0000000000000000000000000000000000000000
--- a/spaces/Banbri/zcvzcv/src/lib/sleep.ts
+++ /dev/null
@@ -1,6 +0,0 @@
-export const sleep = async (durationInMs: number) =>
- new Promise((resolve) => {
- setTimeout(() => {
- resolve(true)
- }, durationInMs)
- })
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Descargar Gratis Juegos De Matemticas Para Pc.md b/spaces/Benson/text-generation/Examples/Descargar Gratis Juegos De Matemticas Para Pc.md
deleted file mode 100644
index 0c3efc186d67b800e02d0df01e66bcd8b5f089a6..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Descargar Gratis Juegos De Matemticas Para Pc.md
+++ /dev/null
@@ -1,168 +0,0 @@
-
-
Descargar PPh 21 Aplikasi: Una guía para los contribuyentes indonesios
-
Si usted es un empleado o un empleador en Indonesia, necesita saber acerca de PPh 21, que es el impuesto sobre la renta sobre los salarios, salarios y otros pagos relacionados con el trabajo o los servicios. Pagar PPh 21 no es solo una obligación legal, sino también una forma de contribuir al desarrollo del país. Sin embargo, calcular y reportar PPh 21 puede ser complicado y consumir mucho tiempo, especialmente si lo haces manualmente. Es por eso que usted debe considerar el uso de PPh 21 aplikasi, que es un software que puede ayudarle con el proceso. En este artículo, explicaremos qué es PPh 21, cómo calcularlo manualmente y cómo usar PPh 21 aplikasi para hacer tu vida más fácil.
-
¿Qué es PPh 21 y por qué es importante?
-
Definición y alcance del PPh 21
-
PPh 21 significa Pajak Penghasilan Pasal 21, que significa artículo 21 del impuesto sobre la renta. Es un impuesto que se aplica a los ingresos en forma de salarios, salarios, honorarios, subsidios, bonos, comisiones, pensiones, indemnización por despido y otros pagos por nombre y en cualquier forma relacionada con el trabajo o posición, servicios, y actividades realizadas por individuos que son sujetos de impuestos nacionales o referidos como contribuyentes.
PPh 21 se aplica tanto a los empleados como a los empleadores en Indonesia. Los empleados son aquellos que reciben o ganan ingresos del trabajo o los servicios realizados por un empleador. Los empleadores son los que pagan o proporcionan ingresos a los empleados u otros receptores de ingresos. Los empleadores pueden ser individuos, empresas, agencias gubernamentales, empresas estatales u otras entidades.
-
Los empleadores son responsables de retener, pagar y reportar PPh 21 en nombre de sus empleados u otros receptores de ingresos. Los empleados u otros perceptores de ingresos también están obligados a informar su declaración anual del impuesto sobre la renta (SPT) y pagar cualquier impuesto adicional si sus ingresos exceden el umbral.
-
Beneficios de pagar PPh 21
-
-
Al pagar PPh 21 correctamente y a tiempo, también puede evitar multas y cargos de interés que puedan surgir de un pago atrasado o insuficiente. También puede reclamar créditos fiscales o reembolsos si ha pagado en exceso sus impuestos o tiene pagos de impuestos en exceso de años anteriores.
-
Sanciones por incumplimiento
-
Si no cumple con sus obligaciones PPh 21, puede enfrentar multas y cargos por intereses de las autoridades fiscales. Las penalidades y cargos por intereses varían dependiendo del tipo y severidad de la violación. Algunos ejemplos de penalidades y cargos por intereses son:
-
-
Una multa del 2% al mes por pago atrasado de impuestos, hasta un máximo del 48%.
-
Multa de 100.000 rupias por presentación tardía del SPT.
-
Una multa del 15% del monto del impuesto pagado por SPT incorrecto o incompleto.
-
Una multa del 100% del monto del impuesto pagado por SPT fraudulento o intencional.
-
Una multa del 20% del impuesto debido por falta de retención o recaudación de impuestos.
-
Una multa del 5% del impuesto debido por falta de pago o depósito de impuestos.
-
Una multa del 2% al mes por pago tardío o depósito de impuestos, hasta un máximo del 24%.
-
-
Por lo tanto, es importante cumplir con sus obligaciones PPh 21 y evitar cualquier penalización y cargos por intereses que puedan afectar su situación financiera y reputación.
-
Cómo calcular PPh 21 manualmente?
-
Componentes del ingreso bruto
-
Para calcular PPh 21 manualmente, necesita conocer los componentes de su ingreso bruto. El ingreso bruto es la cantidad total de ingresos que usted recibe o gana de su trabajo o servicios antes de cualquier deducción o impuesto. El ingreso bruto consiste en:
-
-
-
Ingreso regular: Este es el ingreso que usted recibe o gana regularmente, como salario mensual, salarios, honorarios, subsidios, bonos, comisiones, etc.
-
-
Beneficios en especie: Estos son los ingresos que usted recibe o gana en forma de bienes o servicios proporcionados por su empleador, como vivienda, vehículo, seguro de salud, educación, etc.
-
-
Necesitas sumar todos estos componentes para obtener tu ingreso bruto por cada mes y por todo el año.
-
Ingresos no imponibles (PTKP)
-
No todos tus ingresos brutos están sujetos al PPh 21. Usted puede deducir una cierta cantidad de su ingreso bruto que se considera como ingreso no gravable o Penghasilan Tidak Kena Pajak (PTKP). PTKP es una deducción estándar basada en su estado civil y número de dependientes. Las tasas actuales de PTKP son:
-
-
Estado
PTKP por año (Rp)
-
Single
54,000,000
-
Casado
58,500,000
-
Casado con un dependiente
63,000,000
-
Casado con dos dependientes
67,500,000
-
Casado con tres dependientes
72,000,000
-
-
Puede deducir la cantidad de PTKP de su ingreso bruto anual para obtener su ingreso neto. También puede dividir la cantidad de PTKP por 12 para obtener la cantidad mensual de PTKP y deducirla de su ingreso bruto mensual.
-
Ingresos imponibles (PKP)
-
Su ingreso imponible o Penghasilan Kena Pajak (PKP) es la cantidad de su ingreso neto que está sujeto a PPh 21. Puede calcular su PKP restando su PTKP de su ingreso neto. Si su ingreso neto es menor o igual a su PTKP, entonces su PKP es cero y no tiene que pagar ningún PPh 21. Sin embargo, si su ingreso neto es más que su PTKP, entonces usted tiene que pagar PPh 21 de acuerdo con las tasas progresivas de impuestos.
-
Tasas impositivas progresivas
-
PPh 21 sigue un sistema tributario progresivo, lo que significa que cuanto mayor sea su PKP, mayor será la tasa impositiva que se aplica a usted. Los tipos impositivos progresivos actuales son:
-
-
PKP por año (Rp)
Tipo impositivo (%)
-
-
Por encima de 50,000,000 hasta 250,000,000
15
-
Por encima de 250,000,000 hasta 500,000
25
-
Por encima de 500,000,000
30
-
-
Para calcular su PPh 21 usando las tasas progresivas de impuestos, debe aplicar la tasa de impuestos para cada tramo de su PKP y sumarlos. Por ejemplo, si su PKP es Rp300 millones, entonces su PPh 21 se calcula de la siguiente manera:
-
-
PKP por año (Rp)
Tipo impositivo (%)
Monto impositivo (Rp)
-
50,000,000
5
>2,500,000
-
200,000,000
15
30,000,000
-
50,000,000
25
>12,500,000
-
Total
-
45,000,000
-
-
También puede dividir su PPh 21 por 12 para obtener la cantidad mensual de PPh 21 que tiene que pagar o retener.
-
Ejemplo de cálculo
-
Para ilustrar cómo calcular PPh 21 manualmente, tomemos un ejemplo de un empleado que tiene los siguientes ingresos y deducciones:
-
-
ítem
Cantidad por mes (Rp)
-
Salario
10,000,000
-
Bonus
1,000,000
-
Asignación de vivienda
2,000,000
-
Prima del seguro de salud (pagada por el empleador)
500,000
-
Contribución de pensión (pagada por el empleado)
(500,000)
-
Ingreso bruto total
13,000,000
-
PTKP (single)
(4,500,000)
-
Ingresos imponibles (PKP)
8,500,000
-
-
El ingreso bruto anual del empleado es Rp156,000,000 (13,000 x 12). El PTKP anual del empleado es Rp54,000,000 (4,500,000 x 12). El PKP anual del empleado es 102 Rp102 ,000,000 (156,000,000 - 54,000,000). El PPh anual 21 del empleado se calcula de la siguiente manera:
-
-
PKP por año (Rp)
Tipo impositivo (%)
Monto impositivo (Rp)
-
-
52,000,000
15
>7,800,000
-
Total
-
10,300,000
-
-
El PPh mensual 21 del empleado es Rp858,333 (10,300,000 / 12). El empleador tiene que retener y pagar esta cantidad a las autoridades fiscales en nombre del empleado.
-
Cómo usar PPh 21 aplikasi?
-
¿Qué es PPh 21 aplikasi y dónde conseguirlo?
-
PPh 21 aplikasi es un software que puede ayudarle a calcular y reportar PPh 21 de forma fácil y precisa. Es desarrollado por la Dirección General de Impuestos (DGT) de Indonesia y se puede descargar de forma gratuita desde su sitio web oficial. PPh 21 aplikasi es compatible con sistemas operativos Windows y requiere un mínimo de 512 MB de RAM y 100 MB de espacio libre en disco.
-
PPh 21 aplikasi puede ser utilizado por empleados y empleadores en Indonesia. Los empleados pueden usarlo para calcular su propio PPh 21 y preparar su SPT. Los empleadores pueden utilizarlo para calcular el PPh 21 de sus empleados u otros receptores de ingresos y generar las hojas de retención de impuestos (bukti potong) y las hojas de pago de impuestos (SSP).
-
Características y ventajas de PPh 21 aplikasi
-
PPh 21 aplikasi tiene muchas características y ventajas que pueden hacer que su PPh 21 cálculo y presentación de informes más fácil y más rápido. Algunas de las características y ventajas son:
-
-
Puede calcular PPh 21 para varios tipos de ingresos y deducciones, tales como ingresos regulares, ingresos irregulares, beneficios en especie, contribución a la pensión, etc.
-
Puede aplicar las últimas tasas impositivas y las tasas PTKP automáticamente.
-
Puede manejar múltiples fuentes de ingresos y múltiples períodos impositivos.
-
Puede generar varios informes y formas, como SPT, bukti potong, SSP, etc.
-
Puede exportar los datos a formatos Excel o PDF.
-
Puede importar los datos de otras fuentes, como e-SPT o e-Filing.
-
Puede actualizar los datos en línea desde el sitio web de la DGT.
-
Tiene una interfaz fácil de usar y un menú de ayuda.
-
-
-
Para instalar y usar PPh 21 aplikasi, debe seguir estos pasos:
-
-
Descargue el archivo aplikasi PPh 21 desde el sitio web de la DGT. Elija la versión que coincida con su sistema operativo.
-
Extraiga el archivo a una carpeta en su computadora. Verá un archivo llamado setup.exe.
-
Ejecute el archivo setup.exe y siga las instrucciones en la pantalla. Deberá aceptar los términos y condiciones y elegir una carpeta de destino para la instalación.
-
Después de que la instalación se haya completado, verá un icono de acceso directo para PPh 21 aplikasi en su escritorio. Haga doble clic en él para iniciar el software.
-
Tendrá que registrar su software con su nombre, dirección de correo electrónico, número de teléfono y número de identificación fiscal (NPWP). También necesitará crear una contraseña para su cuenta.
-
Verá un menú principal con varias opciones, como Entrada de datos, Cálculo, Informe, Importación/Exportación, Actualización de datos en línea, etc. Elija la opción que se adapte a sus necesidades y siga las instrucciones en la pantalla.
-
También puede acceder al menú de ayuda si necesita alguna orientación o asistencia con el uso del software.
-
-
Cómo informar y enviar PPh 21 en línea
-
Si desea reportar y enviar su PPh 21 en línea, puede utilizar el servicio de e-Filing proporcionado por la DGT. e-Filing es un sistema que le permite enviar su SPT electrónicamente a través de Internet. Para usar e-Filing, debe seguir estos pasos:
-
-
Cree una cuenta en el sitio web de e-Filing usando su NPWP y dirección de correo electrónico. Recibirá un código de verificación por correo electrónico que debe ingresar en el sitio web para activar su cuenta.
-
Inicie sesión en su cuenta y elija el tipo de SPT que desea enviar. Puede elegir entre SPT 1770, SPT 1770S o SPT 1770SS, dependiendo de sus ingresos y estado fiscal.
-
-
Revise y verifique sus datos antes de enviarlos. Verá un resumen de su SPT y la cantidad de impuestos adeudados o reembolsables.
-
Envíe su SPT e imprima o guarde la página de confirmación. También recibirá una confirmación por correo electrónico con un número de recibo y un código de barras.
-
Si tiene algún impuesto adeudado, debe pagarlo usando el SSP que puede generar desde el sitio web de e-Filing. Puede pagar en línea utilizando varios métodos, como banca por Internet, cajeros automáticos, banca móvil, etc. Debe ingresar el número de recibo y el código de barras en la SSP al realizar el pago.
-
Si tiene algún reembolso de impuestos, debe esperar la verificación y aprobación de la DGT. Recibirá una notificación por correo electrónico cuando su reembolso sea procesado y transferido a su cuenta bancaria.
-
-
Conclusión y preguntas frecuentes
-
Resumen de los puntos principales
-
PPh 21 es el impuesto sobre los salarios, salarios y otros pagos relacionados con el trabajo o los servicios en Indonesia. Es importante pagar el PPh 21 correctamente y a tiempo para evitar penalizaciones e intereses y apoyar el desarrollo del país. Puede calcular PPh 21 manualmente utilizando los componentes de ingreso bruto, ingreso no imponible (PTKP), ingreso imponible (PKP) y tasas impositivas progresivas. Sin embargo, calcular PPh 21 manualmente puede ser complicado y consumir mucho tiempo, especialmente si tiene múltiples fuentes de ingresos y períodos impositivos. Es por eso que usted debe utilizar PPh 21 aplikasi, que es un software que puede ayudarle a calcular y reportar PPh 21 fácilmente y con precisión. También puede utilizar el servicio de e-Filing para enviar su SPT en línea y pagar o recibir sus impuestos adeudados o reembolsables electrónicamente.
-
Preguntas frecuentes
-
Aquí hay algunas preguntas frecuentes sobre PPh 21 y PPh 21 aplikasi:
-
-
P: ¿Cómo sé si soy un sujeto de impuestos nacionales o extranjeros?
-
A: Usted es un sujeto de impuestos nacionales si cumple con uno de estos criterios:
-
-
Usted es un ciudadano indonesio que está en el extranjero para tareas oficiales o fines educativos y todavía tiene ingresos de Indonesia.
-
Usted es un ciudadano extranjero que reside en Indonesia o está presente en Indonesia durante más de 183 días dentro de cualquier período de 12 meses.
-
-Usted es un sujeto de impuestos extranjeros si no cumple con ninguno de estos criterios.
-
P: ¿Cómo sé si tengo que informar de mi declaración anual del impuesto sobre la renta (SPT)?
-
A: Usted tiene que reportar su declaración anual del impuesto sobre la renta (SPT) si usted cumple con uno de estos criterios:
-
Su ingreso bruto anual excede su PTKP.
-
Tienes más de un empleador o fuente de ingresos.
-
Tienes ingresos del extranjero.
-
Tiene ingresos que no están sujetos a retención de impuestos o impuestos finales.
-
Has pagado impuestos en exceso o pagos de impuestos en exceso de años anteriores.
-
-Usted no tiene que reportar su declaración anual de impuestos sobre la renta (SPT) si no cumple con ninguno de estos criterios.
-
Q: ¿Cuándo es la fecha límite para informar y pagar PPh 21?
-
A: La fecha límite para reportar y pagar PPh 21 depende del tipo y frecuencia de sus ingresos:
-
Si usted tiene ingresos regulares, tales como salario mensual, salarios, subsidios, etc., usted tiene que reportar y pagar PPh 21 sobre una base mensual. La fecha límite es el décimo día del mes siguiente.
-
Si tienes ingresos irregulares, como un bono anual, indemnización por despido, pensión, etc., tienes que reportar y pagar PPh 21 en un evento. La fecha límite es el final del mes siguiente después de que ocurra el evento.
-
Si usted tiene beneficios en especie, tales como vivienda, vehículo, seguro de salud, etc., usted tiene que informar y pagar PPh 21 sobre una base anual. La fecha límite es finales de marzo del año siguiente.
-
Si tiene que informar de su declaración anual del impuesto sobre la renta (SPT), el plazo es el final de marzo del año siguiente.
-
-
-
Q: ¿Cómo puedo actualizar el PPh 21 a la última versión?
-
A: Puede actualizar PPh 21 aplikasi a la última versión utilizando la función Actualizar datos en línea en el menú principal. Necesita tener una conexión a Internet e iniciar sesión en su cuenta. Verá una notificación si hay una nueva versión disponible. Puede descargar e instalar la nueva versión siguiendo las instrucciones en la pantalla.
-
Q: ¿Cómo puedo contactar a la DGT si tengo alguna pregunta o problema con PPh 21 o PPh 21 aplikasi?
-
A: Puede ponerse en contacto con la DGT utilizando uno de estos métodos:
-
Centro de llamadas: 1500 200 (de lunes a viernes, 08.00-16.00 WIB)
-También puede visitar la oficina de impuestos o el centro de servicio de impuestos más cercano en su área.
-
-
Espero que este artículo haya sido útil e informativo para usted. Si tiene algún comentario o sugerencia, por favor hágamelo saber. Gracias por leer y tener un buen día!
64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/boto3/compat.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/boto3/compat.py
deleted file mode 100644
index 4011393acaf677df08970c132289a1ef5d270a34..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/boto3/compat.py
+++ /dev/null
@@ -1,82 +0,0 @@
-# Copyright 2015 Amazon.com, Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License"). You
-# may not use this file except in compliance with the License. A copy of
-# the License is located at
-#
-# https://aws.amazon.com/apache2.0/
-#
-# or in the "license" file accompanying this file. This file is
-# distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
-# ANY KIND, either express or implied. See the License for the specific
-# language governing permissions and limitations under the License.
-import sys
-import os
-import errno
-import socket
-import warnings
-
-from boto3.exceptions import PythonDeprecationWarning
-
-# In python3, socket.error is OSError, which is too general
-# for what we want (i.e FileNotFoundError is a subclass of OSError).
-# In py3 all the socket related errors are in a newly created
-# ConnectionError
-SOCKET_ERROR = ConnectionError
-
-import collections.abc as collections_abc
-
-
-if sys.platform.startswith('win'):
- def rename_file(current_filename, new_filename):
- try:
- os.remove(new_filename)
- except OSError as e:
- if not e.errno == errno.ENOENT:
- # We only want to a ignore trying to remove
- # a file that does not exist. If it fails
- # for any other reason we should be propagating
- # that exception.
- raise
- os.rename(current_filename, new_filename)
-else:
- rename_file = os.rename
-
-
-def filter_python_deprecation_warnings():
- """
- Invoking this filter acknowledges your runtime will soon be deprecated
- at which time you will stop receiving all updates to your client.
- """
- warnings.filterwarnings(
- 'ignore',
- message=".*Boto3 will no longer support Python.*",
- category=PythonDeprecationWarning,
- module=r".*boto3\.compat"
- )
-
-
-def _warn_deprecated_python():
- """Use this template for future deprecation campaigns as needed."""
- py_36_params = {
- 'date': 'May 30, 2022',
- 'blog_link': (
- 'https://aws.amazon.com/blogs/developer/'
- 'python-support-policy-updates-for-aws-sdks-and-tools/'
- )
- }
- deprecated_versions = {
- # Example template for future deprecations
- # (3, 6): py_36_params,
- }
- py_version = sys.version_info[:2]
-
- if py_version in deprecated_versions:
- params = deprecated_versions[py_version]
- warning = (
- "Boto3 will no longer support Python {}.{} "
- "starting {}. To continue receiving service updates, "
- "bug fixes, and security updates please upgrade to Python 3.7 or "
- "later. More information can be found here: {}"
- ).format(py_version[0], py_version[1], params['date'], params['blog_link'])
- warnings.warn(warning, PythonDeprecationWarning)
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/dateutil/_common.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/dateutil/_common.py
deleted file mode 100644
index 4eb2659bd2986125fcfb4afea5bae9efc2dcd1a0..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/dateutil/_common.py
+++ /dev/null
@@ -1,43 +0,0 @@
-"""
-Common code used in multiple modules.
-"""
-
-
-class weekday(object):
- __slots__ = ["weekday", "n"]
-
- def __init__(self, weekday, n=None):
- self.weekday = weekday
- self.n = n
-
- def __call__(self, n):
- if n == self.n:
- return self
- else:
- return self.__class__(self.weekday, n)
-
- def __eq__(self, other):
- try:
- if self.weekday != other.weekday or self.n != other.n:
- return False
- except AttributeError:
- return False
- return True
-
- def __hash__(self):
- return hash((
- self.weekday,
- self.n,
- ))
-
- def __ne__(self, other):
- return not (self == other)
-
- def __repr__(self):
- s = ("MO", "TU", "WE", "TH", "FR", "SA", "SU")[self.weekday]
- if not self.n:
- return s
- else:
- return "%s(%+d)" % (s, self.n)
-
-# vim:ts=4:sw=4:et
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/configuration.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/configuration.py
deleted file mode 100644
index 8fd46c9b8e0dbab8716c33d349f55a494613ba8f..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/configuration.py
+++ /dev/null
@@ -1,374 +0,0 @@
-"""Configuration management setup
-
-Some terminology:
-- name
- As written in config files.
-- value
- Value associated with a name
-- key
- Name combined with it's section (section.name)
-- variant
- A single word describing where the configuration key-value pair came from
-"""
-
-import configparser
-import locale
-import os
-import sys
-from typing import Any, Dict, Iterable, List, NewType, Optional, Tuple
-
-from pip._internal.exceptions import (
- ConfigurationError,
- ConfigurationFileCouldNotBeLoaded,
-)
-from pip._internal.utils import appdirs
-from pip._internal.utils.compat import WINDOWS
-from pip._internal.utils.logging import getLogger
-from pip._internal.utils.misc import ensure_dir, enum
-
-RawConfigParser = configparser.RawConfigParser # Shorthand
-Kind = NewType("Kind", str)
-
-CONFIG_BASENAME = "pip.ini" if WINDOWS else "pip.conf"
-ENV_NAMES_IGNORED = "version", "help"
-
-# The kinds of configurations there are.
-kinds = enum(
- USER="user", # User Specific
- GLOBAL="global", # System Wide
- SITE="site", # [Virtual] Environment Specific
- ENV="env", # from PIP_CONFIG_FILE
- ENV_VAR="env-var", # from Environment Variables
-)
-OVERRIDE_ORDER = kinds.GLOBAL, kinds.USER, kinds.SITE, kinds.ENV, kinds.ENV_VAR
-VALID_LOAD_ONLY = kinds.USER, kinds.GLOBAL, kinds.SITE
-
-logger = getLogger(__name__)
-
-
-# NOTE: Maybe use the optionx attribute to normalize keynames.
-def _normalize_name(name: str) -> str:
- """Make a name consistent regardless of source (environment or file)"""
- name = name.lower().replace("_", "-")
- if name.startswith("--"):
- name = name[2:] # only prefer long opts
- return name
-
-
-def _disassemble_key(name: str) -> List[str]:
- if "." not in name:
- error_message = (
- "Key does not contain dot separated section and key. "
- "Perhaps you wanted to use 'global.{}' instead?"
- ).format(name)
- raise ConfigurationError(error_message)
- return name.split(".", 1)
-
-
-def get_configuration_files() -> Dict[Kind, List[str]]:
- global_config_files = [
- os.path.join(path, CONFIG_BASENAME) for path in appdirs.site_config_dirs("pip")
- ]
-
- site_config_file = os.path.join(sys.prefix, CONFIG_BASENAME)
- legacy_config_file = os.path.join(
- os.path.expanduser("~"),
- "pip" if WINDOWS else ".pip",
- CONFIG_BASENAME,
- )
- new_config_file = os.path.join(appdirs.user_config_dir("pip"), CONFIG_BASENAME)
- return {
- kinds.GLOBAL: global_config_files,
- kinds.SITE: [site_config_file],
- kinds.USER: [legacy_config_file, new_config_file],
- }
-
-
-class Configuration:
- """Handles management of configuration.
-
- Provides an interface to accessing and managing configuration files.
-
- This class converts provides an API that takes "section.key-name" style
- keys and stores the value associated with it as "key-name" under the
- section "section".
-
- This allows for a clean interface wherein the both the section and the
- key-name are preserved in an easy to manage form in the configuration files
- and the data stored is also nice.
- """
-
- def __init__(self, isolated: bool, load_only: Optional[Kind] = None) -> None:
- super().__init__()
-
- if load_only is not None and load_only not in VALID_LOAD_ONLY:
- raise ConfigurationError(
- "Got invalid value for load_only - should be one of {}".format(
- ", ".join(map(repr, VALID_LOAD_ONLY))
- )
- )
- self.isolated = isolated
- self.load_only = load_only
-
- # Because we keep track of where we got the data from
- self._parsers: Dict[Kind, List[Tuple[str, RawConfigParser]]] = {
- variant: [] for variant in OVERRIDE_ORDER
- }
- self._config: Dict[Kind, Dict[str, Any]] = {
- variant: {} for variant in OVERRIDE_ORDER
- }
- self._modified_parsers: List[Tuple[str, RawConfigParser]] = []
-
- def load(self) -> None:
- """Loads configuration from configuration files and environment"""
- self._load_config_files()
- if not self.isolated:
- self._load_environment_vars()
-
- def get_file_to_edit(self) -> Optional[str]:
- """Returns the file with highest priority in configuration"""
- assert self.load_only is not None, "Need to be specified a file to be editing"
-
- try:
- return self._get_parser_to_modify()[0]
- except IndexError:
- return None
-
- def items(self) -> Iterable[Tuple[str, Any]]:
- """Returns key-value pairs like dict.items() representing the loaded
- configuration
- """
- return self._dictionary.items()
-
- def get_value(self, key: str) -> Any:
- """Get a value from the configuration."""
- orig_key = key
- key = _normalize_name(key)
- try:
- return self._dictionary[key]
- except KeyError:
- # disassembling triggers a more useful error message than simply
- # "No such key" in the case that the key isn't in the form command.option
- _disassemble_key(key)
- raise ConfigurationError(f"No such key - {orig_key}")
-
- def set_value(self, key: str, value: Any) -> None:
- """Modify a value in the configuration."""
- key = _normalize_name(key)
- self._ensure_have_load_only()
-
- assert self.load_only
- fname, parser = self._get_parser_to_modify()
-
- if parser is not None:
- section, name = _disassemble_key(key)
-
- # Modify the parser and the configuration
- if not parser.has_section(section):
- parser.add_section(section)
- parser.set(section, name, value)
-
- self._config[self.load_only][key] = value
- self._mark_as_modified(fname, parser)
-
- def unset_value(self, key: str) -> None:
- """Unset a value in the configuration."""
- orig_key = key
- key = _normalize_name(key)
- self._ensure_have_load_only()
-
- assert self.load_only
- if key not in self._config[self.load_only]:
- raise ConfigurationError(f"No such key - {orig_key}")
-
- fname, parser = self._get_parser_to_modify()
-
- if parser is not None:
- section, name = _disassemble_key(key)
- if not (
- parser.has_section(section) and parser.remove_option(section, name)
- ):
- # The option was not removed.
- raise ConfigurationError(
- "Fatal Internal error [id=1]. Please report as a bug."
- )
-
- # The section may be empty after the option was removed.
- if not parser.items(section):
- parser.remove_section(section)
- self._mark_as_modified(fname, parser)
-
- del self._config[self.load_only][key]
-
- def save(self) -> None:
- """Save the current in-memory state."""
- self._ensure_have_load_only()
-
- for fname, parser in self._modified_parsers:
- logger.info("Writing to %s", fname)
-
- # Ensure directory exists.
- ensure_dir(os.path.dirname(fname))
-
- with open(fname, "w") as f:
- parser.write(f)
-
- #
- # Private routines
- #
-
- def _ensure_have_load_only(self) -> None:
- if self.load_only is None:
- raise ConfigurationError("Needed a specific file to be modifying.")
- logger.debug("Will be working with %s variant only", self.load_only)
-
- @property
- def _dictionary(self) -> Dict[str, Any]:
- """A dictionary representing the loaded configuration."""
- # NOTE: Dictionaries are not populated if not loaded. So, conditionals
- # are not needed here.
- retval = {}
-
- for variant in OVERRIDE_ORDER:
- retval.update(self._config[variant])
-
- return retval
-
- def _load_config_files(self) -> None:
- """Loads configuration from configuration files"""
- config_files = dict(self.iter_config_files())
- if config_files[kinds.ENV][0:1] == [os.devnull]:
- logger.debug(
- "Skipping loading configuration files due to "
- "environment's PIP_CONFIG_FILE being os.devnull"
- )
- return
-
- for variant, files in config_files.items():
- for fname in files:
- # If there's specific variant set in `load_only`, load only
- # that variant, not the others.
- if self.load_only is not None and variant != self.load_only:
- logger.debug("Skipping file '%s' (variant: %s)", fname, variant)
- continue
-
- parser = self._load_file(variant, fname)
-
- # Keeping track of the parsers used
- self._parsers[variant].append((fname, parser))
-
- def _load_file(self, variant: Kind, fname: str) -> RawConfigParser:
- logger.verbose("For variant '%s', will try loading '%s'", variant, fname)
- parser = self._construct_parser(fname)
-
- for section in parser.sections():
- items = parser.items(section)
- self._config[variant].update(self._normalized_keys(section, items))
-
- return parser
-
- def _construct_parser(self, fname: str) -> RawConfigParser:
- parser = configparser.RawConfigParser()
- # If there is no such file, don't bother reading it but create the
- # parser anyway, to hold the data.
- # Doing this is useful when modifying and saving files, where we don't
- # need to construct a parser.
- if os.path.exists(fname):
- locale_encoding = locale.getpreferredencoding(False)
- try:
- parser.read(fname, encoding=locale_encoding)
- except UnicodeDecodeError:
- # See https://github.com/pypa/pip/issues/4963
- raise ConfigurationFileCouldNotBeLoaded(
- reason=f"contains invalid {locale_encoding} characters",
- fname=fname,
- )
- except configparser.Error as error:
- # See https://github.com/pypa/pip/issues/4893
- raise ConfigurationFileCouldNotBeLoaded(error=error)
- return parser
-
- def _load_environment_vars(self) -> None:
- """Loads configuration from environment variables"""
- self._config[kinds.ENV_VAR].update(
- self._normalized_keys(":env:", self.get_environ_vars())
- )
-
- def _normalized_keys(
- self, section: str, items: Iterable[Tuple[str, Any]]
- ) -> Dict[str, Any]:
- """Normalizes items to construct a dictionary with normalized keys.
-
- This routine is where the names become keys and are made the same
- regardless of source - configuration files or environment.
- """
- normalized = {}
- for name, val in items:
- key = section + "." + _normalize_name(name)
- normalized[key] = val
- return normalized
-
- def get_environ_vars(self) -> Iterable[Tuple[str, str]]:
- """Returns a generator with all environmental vars with prefix PIP_"""
- for key, val in os.environ.items():
- if key.startswith("PIP_"):
- name = key[4:].lower()
- if name not in ENV_NAMES_IGNORED:
- yield name, val
-
- # XXX: This is patched in the tests.
- def iter_config_files(self) -> Iterable[Tuple[Kind, List[str]]]:
- """Yields variant and configuration files associated with it.
-
- This should be treated like items of a dictionary.
- """
- # SMELL: Move the conditions out of this function
-
- # environment variables have the lowest priority
- config_file = os.environ.get("PIP_CONFIG_FILE", None)
- if config_file is not None:
- yield kinds.ENV, [config_file]
- else:
- yield kinds.ENV, []
-
- config_files = get_configuration_files()
-
- # at the base we have any global configuration
- yield kinds.GLOBAL, config_files[kinds.GLOBAL]
-
- # per-user configuration next
- should_load_user_config = not self.isolated and not (
- config_file and os.path.exists(config_file)
- )
- if should_load_user_config:
- # The legacy config file is overridden by the new config file
- yield kinds.USER, config_files[kinds.USER]
-
- # finally virtualenv configuration first trumping others
- yield kinds.SITE, config_files[kinds.SITE]
-
- def get_values_in_config(self, variant: Kind) -> Dict[str, Any]:
- """Get values present in a config file"""
- return self._config[variant]
-
- def _get_parser_to_modify(self) -> Tuple[str, RawConfigParser]:
- # Determine which parser to modify
- assert self.load_only
- parsers = self._parsers[self.load_only]
- if not parsers:
- # This should not happen if everything works correctly.
- raise ConfigurationError(
- "Fatal Internal error [id=2]. Please report as a bug."
- )
-
- # Use the highest priority parser.
- return parsers[-1]
-
- # XXX: This is patched in the tests.
- def _mark_as_modified(self, fname: str, parser: RawConfigParser) -> None:
- file_parser_tuple = (fname, parser)
- if file_parser_tuple not in self._modified_parsers:
- self._modified_parsers.append(file_parser_tuple)
-
- def __repr__(self) -> str:
- return f"{self.__class__.__name__}({self._dictionary!r})"
diff --git a/spaces/Bigshot/RSA-v0.1.2/app.py b/spaces/Bigshot/RSA-v0.1.2/app.py
deleted file mode 100644
index 6bf4d1d0fd395e2ea9614dbe0057e4bb648343a3..0000000000000000000000000000000000000000
--- a/spaces/Bigshot/RSA-v0.1.2/app.py
+++ /dev/null
@@ -1,56 +0,0 @@
-import os
-os.system('pip install tensorflow')
-import tensorflow as tf
-from tensorflow import keras
-import numpy as np
-import gradio as gr
-
-tokenizer = tf.keras.preprocessing.text.Tokenizer()
-
-#Reads Text Inputs Here
-f=open('Inputs.txt','r')
-inputs = f.read().split('\n')
-f.close()
-
-corpus = inputs
-
-tokenizer.fit_on_texts(corpus)
-sequences = tokenizer.texts_to_sequences(corpus)
-
-max_length = max([len(s) for s in sequences])
-
-# Load your saved model
-model = tf.keras.models.load_model('sentiment_mini-test')
-
-model.summary()
-
-def use(input_text):
- # Preprocess the input text
- sequences = tokenizer.texts_to_sequences([input_text])
- sequences = tf.keras.preprocessing.sequence.pad_sequences(sequences, padding='post', maxlen=max_length)
-
- # Make a prediction on the input text
- prediction = model.predict(sequences)[0]
-
- # Print the prediction
- if prediction[0]<0.3:
- return "That's Negative! (" + str(round(round(1-prediction[0],2)*100,1)) + "% confidence)", prediction[0]
- elif prediction[0]>0.3:
- return "That's Positive! (" + str(round(round(prediction[0],2)*100,1)) + "% confidence)", prediction[0]
- else:
- return "That's Neutral!", prediction[0]
-
-
-iface = gr.Interface(fn=use,
- inputs=gr.Textbox(lines=8, placeholder="Type Something Awesome..."),
- outputs=[gr.Textbox(lines=3, placeholder="Waiting For Magic..."),"number"],
- title="Use RSA (Review Sentiment Analysis) v0.1.2",
- description="
This is an NLP model that accepts a text string as input and simply outputs if the string is mean or nice with about 96.5% accuracy. It also provides you with a score of how positive or negative it is.
",
- article="\nRSA v0.1.2: @2.3M Params w/ 96.5% acc. & 388MB input dataset + 1.59MB output dataset. Trained on this Kaggle dataset",
- examples=[
- ["I went there today! The cut was terrible! I have an awful experience. They lady that cut my hair was nice but she wanted to leave early so she made a disaster in my head!"],
- ["Yes! Awesome soy cap, scone, and atmosphere. Nice place to hang out & read, and free WiFi with no login procedure."],
- ["Overpriced, salty and overrated!!! Why this place is so popular I will never understand."],
- ["This Valentines Day I ordered a pizza for my boyfriend and asked that they make a heart on it out of green peppers. The pizza was great, the heart was perfect, and he loved it!"]
- ])
-iface.launch()
diff --git a/spaces/CVH-vn1210/make_hair/minigpt4/datasets/data_utils.py b/spaces/CVH-vn1210/make_hair/minigpt4/datasets/data_utils.py
deleted file mode 100644
index cddc4d68a8fa5a4e39bea0055d131c96ee81e7b7..0000000000000000000000000000000000000000
--- a/spaces/CVH-vn1210/make_hair/minigpt4/datasets/data_utils.py
+++ /dev/null
@@ -1,196 +0,0 @@
-"""
- Copyright (c) 2022, salesforce.com, inc.
- All rights reserved.
- SPDX-License-Identifier: BSD-3-Clause
- For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
-"""
-
-import gzip
-import logging
-import os
-import random as rnd
-import tarfile
-import zipfile
-import random
-from typing import List
-from tqdm import tqdm
-
-import decord
-from decord import VideoReader
-import webdataset as wds
-import numpy as np
-import torch
-from torch.utils.data.dataset import IterableDataset
-
-from minigpt4.common.registry import registry
-from minigpt4.datasets.datasets.base_dataset import ConcatDataset
-
-
-decord.bridge.set_bridge("torch")
-MAX_INT = registry.get("MAX_INT")
-
-
-class ChainDataset(wds.DataPipeline):
- r"""Dataset for chaining multiple :class:`DataPipeline` s.
-
- This class is useful to assemble different existing dataset streams. The
- chaining operation is done on-the-fly, so concatenating large-scale
- datasets with this class will be efficient.
-
- Args:
- datasets (iterable of IterableDataset): datasets to be chained together
- """
- def __init__(self, datasets: List[wds.DataPipeline]) -> None:
- super().__init__()
- self.datasets = datasets
- self.prob = []
- self.names = []
- for dataset in self.datasets:
- if hasattr(dataset, 'name'):
- self.names.append(dataset.name)
- else:
- self.names.append('Unknown')
- if hasattr(dataset, 'sample_ratio'):
- self.prob.append(dataset.sample_ratio)
- else:
- self.prob.append(1)
- logging.info("One of the datapipeline doesn't define ratio and set to 1 automatically.")
-
- def __iter__(self):
- datastreams = [iter(dataset) for dataset in self.datasets]
- while True:
- select_datastream = random.choices(datastreams, weights=self.prob, k=1)[0]
- yield next(select_datastream)
-
-
-def apply_to_sample(f, sample):
- if len(sample) == 0:
- return {}
-
- def _apply(x):
- if torch.is_tensor(x):
- return f(x)
- elif isinstance(x, dict):
- return {key: _apply(value) for key, value in x.items()}
- elif isinstance(x, list):
- return [_apply(x) for x in x]
- else:
- return x
-
- return _apply(sample)
-
-
-def move_to_cuda(sample):
- def _move_to_cuda(tensor):
- return tensor.cuda()
-
- return apply_to_sample(_move_to_cuda, sample)
-
-
-def prepare_sample(samples, cuda_enabled=True):
- if cuda_enabled:
- samples = move_to_cuda(samples)
-
- # TODO fp16 support
-
- return samples
-
-
-def reorg_datasets_by_split(datasets):
- """
- Organizes datasets by split.
-
- Args:
- datasets: dict of torch.utils.data.Dataset objects by name.
-
- Returns:
- Dict of datasets by split {split_name: List[Datasets]}.
- """
- # if len(datasets) == 1:
- # return datasets[list(datasets.keys())[0]]
- # else:
- reorg_datasets = dict()
-
- # reorganize by split
- for _, dataset in datasets.items():
- for split_name, dataset_split in dataset.items():
- if split_name not in reorg_datasets:
- reorg_datasets[split_name] = [dataset_split]
- else:
- reorg_datasets[split_name].append(dataset_split)
-
- return reorg_datasets
-
-
-def concat_datasets(datasets):
- """
- Concatenates multiple datasets into a single dataset.
-
- It supports may-style datasets and DataPipeline from WebDataset. Currently, does not support
- generic IterableDataset because it requires creating separate samplers.
-
- Now only supports conctenating training datasets and assuming validation and testing
- have only a single dataset. This is because metrics should not be computed on the concatenated
- datasets.
-
- Args:
- datasets: dict of torch.utils.data.Dataset objects by split.
-
- Returns:
- Dict of concatenated datasets by split, "train" is the concatenation of multiple datasets,
- "val" and "test" remain the same.
-
- If the input training datasets contain both map-style and DataPipeline datasets, returns
- a tuple, where the first element is a concatenated map-style dataset and the second
- element is a chained DataPipeline dataset.
-
- """
- # concatenate datasets in the same split
- for split_name in datasets:
- if split_name != "train":
- assert (
- len(datasets[split_name]) == 1
- ), "Do not support multiple {} datasets.".format(split_name)
- datasets[split_name] = datasets[split_name][0]
- else:
- iterable_datasets, map_datasets = [], []
- for dataset in datasets[split_name]:
- if isinstance(dataset, wds.DataPipeline):
- logging.info(
- "Dataset {} is IterableDataset, can't be concatenated.".format(
- dataset
- )
- )
- iterable_datasets.append(dataset)
- elif isinstance(dataset, IterableDataset):
- raise NotImplementedError(
- "Do not support concatenation of generic IterableDataset."
- )
- else:
- map_datasets.append(dataset)
-
- # if len(iterable_datasets) > 0:
- # concatenate map-style datasets and iterable-style datasets separately
- if len(iterable_datasets) > 1:
- chained_datasets = (
- ChainDataset(iterable_datasets)
- )
- elif len(iterable_datasets) == 1:
- chained_datasets = iterable_datasets[0]
- else:
- chained_datasets = None
-
- concat_datasets = (
- ConcatDataset(map_datasets) if len(map_datasets) > 0 else None
- )
-
- train_datasets = concat_datasets, chained_datasets
- train_datasets = tuple([x for x in train_datasets if x is not None])
- train_datasets = (
- train_datasets[0] if len(train_datasets) == 1 else train_datasets
- )
-
- datasets[split_name] = train_datasets
-
- return datasets
-
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/densepose/vis/bounding_box.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/densepose/vis/bounding_box.py
deleted file mode 100644
index 7fc6efd11935acd9376c17ab4495876173539fc5..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/densepose/vis/bounding_box.py
+++ /dev/null
@@ -1,36 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-from .base import RectangleVisualizer, TextVisualizer
-
-
-class BoundingBoxVisualizer(object):
- def __init__(self):
- self.rectangle_visualizer = RectangleVisualizer()
-
- def visualize(self, image_bgr, boxes_xywh):
- for bbox_xywh in boxes_xywh:
- image_bgr = self.rectangle_visualizer.visualize(image_bgr, bbox_xywh)
- return image_bgr
-
-
-class ScoredBoundingBoxVisualizer(object):
- def __init__(self, bbox_visualizer_params=None, score_visualizer_params=None):
- if bbox_visualizer_params is None:
- bbox_visualizer_params = {}
- if score_visualizer_params is None:
- score_visualizer_params = {}
- self.visualizer_bbox = RectangleVisualizer(**bbox_visualizer_params)
- self.visualizer_score = TextVisualizer(**score_visualizer_params)
-
- def visualize(self, image_bgr, scored_bboxes):
- boxes_xywh, box_scores = scored_bboxes
- assert len(boxes_xywh) == len(box_scores), (
- "Number of bounding boxes {} should be equal to the number of "
- "scores".format(len(boxes_xywh), len(box_scores))
- )
- for i, box_xywh in enumerate(boxes_xywh):
- score_i = box_scores[i]
- image_bgr = self.visualizer_bbox.visualize(image_bgr, box_xywh)
- score_txt = "{0:6.4f}".format(score_i)
- topleft_xy = box_xywh[0], box_xywh[1]
- image_bgr = self.visualizer_score.visualize(image_bgr, score_txt, topleft_xy)
- return image_bgr
diff --git a/spaces/CVPR/LIVE/thrust/cmake/ThrustHeaderTesting.cmake b/spaces/CVPR/LIVE/thrust/cmake/ThrustHeaderTesting.cmake
deleted file mode 100644
index 81c6e3174e282f50a6f1ee45a8fbf3f3507baea9..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/cmake/ThrustHeaderTesting.cmake
+++ /dev/null
@@ -1,119 +0,0 @@
-# For every public header, build a translation unit containing `#include `
-# to let the compiler try to figure out warnings in that header if it is not otherwise
-# included in tests, and also to verify if the headers are modular enough.
-# .inl files are not globbed for, because they are not supposed to be used as public
-# entrypoints.
-
-foreach(thrust_target IN LISTS THRUST_TARGETS)
- thrust_get_target_property(config_host ${thrust_target} HOST)
- thrust_get_target_property(config_device ${thrust_target} DEVICE)
- thrust_get_target_property(config_prefix ${thrust_target} PREFIX)
-
- string(TOLOWER "${config_host}" host_lower)
- string(TOLOWER "${config_device}" device_lower)
-
- # GLOB ALL THE THINGS
- set(headers_globs thrust/*.h)
- set(headers_exclude_systems_globs thrust/system/*/*)
- set(headers_systems_globs
- thrust/system/${host_lower}/*
- thrust/system/${device_lower}/*
- )
- set(headers_exclude_details_globs
- thrust/detail/*
- thrust/*/detail/*
- thrust/*/*/detail/*
- )
-
- # Get all .h files...
- file(GLOB_RECURSE headers
- RELATIVE "${Thrust_SOURCE_DIR}/thrust"
- CONFIGURE_DEPENDS
- ${headers_globs}
- )
-
- # ...then remove all system specific headers...
- file(GLOB_RECURSE headers_exclude_systems
- RELATIVE "${Thrust_SOURCE_DIR}/thrust"
- CONFIGURE_DEPENDS
- ${headers_exclude_systems_globs}
- )
- list(REMOVE_ITEM headers ${headers_exclude_systems})
-
- # ...then add all headers specific to the selected host and device systems back again...
- file(GLOB_RECURSE headers_systems
- RELATIVE ${Thrust_SOURCE_DIR}/thrust
- CONFIGURE_DEPENDS
- ${headers_systems_globs}
- )
- list(APPEND headers ${headers_systems})
-
- # ...and remove all the detail headers (also removing the detail headers from the selected systems).
- file(GLOB_RECURSE headers_exclude_details
- RELATIVE "${Thrust_SOURCE_DIR}/thrust"
- CONFIGURE_DEPENDS
- ${headers_exclude_details_globs}
- )
- list(REMOVE_ITEM headers ${headers_exclude_details})
-
- # List of headers that aren't implemented for all backends, but are implemented for CUDA.
- set(partially_implemented_CUDA
- async/copy.h
- async/for_each.h
- async/reduce.h
- async/sort.h
- async/transform.h
- event.h
- future.h
- )
-
- # List of headers that aren't implemented for all backends, but are implemented for CPP.
- set(partially_implemented_CPP
- )
-
- # List of headers that aren't implemented for all backends, but are implemented for TBB.
- set(partially_implemented_TBB
- )
-
- # List of headers that aren't implemented for all backends, but are implemented for OMP.
- set(partially_implemented_OMP
- )
-
- # List of all partially implemented headers.
- set(partially_implemented
- ${partially_implemented_CUDA}
- ${partially_implemented_CPP}
- ${partially_implemented_TBB}
- ${partially_implemented_OMP}
- )
- list(REMOVE_DUPLICATES partially_implemented)
-
- set(headertest_srcs)
-
- foreach (header IN LISTS headers)
- if ("${header}" IN_LIST partially_implemented)
- # This header is partially implemented on _some_ backends...
- if (NOT "${header}" IN_LIST partially_implemented_${config_device})
- # ...but not on the selected one.
- continue()
- endif()
- endif()
-
- set(headertest_src_ext .cpp)
- if ("CUDA" STREQUAL "${config_device}")
- set(headertest_src_ext .cu)
- endif()
-
- set(headertest_src "headers/${config_prefix}/${header}${headertest_src_ext}")
- configure_file("${Thrust_SOURCE_DIR}/cmake/header_test.in" "${headertest_src}")
-
- list(APPEND headertest_srcs "${headertest_src}")
- endforeach()
-
- set(headertest_target ${config_prefix}.headers)
- add_library(${headertest_target} OBJECT ${headertest_srcs})
- target_link_libraries(${headertest_target} PUBLIC ${thrust_target})
- thrust_clone_target_properties(${headertest_target} ${thrust_target})
-
- add_dependencies(${config_prefix}.all ${headertest_target})
-endforeach()
diff --git a/spaces/CVPR/LIVE/thrust/thrust/iterator/iterator_categories.h b/spaces/CVPR/LIVE/thrust/thrust/iterator/iterator_categories.h
deleted file mode 100644
index 02246d446b95e0c6cc57f514b7be1163e76bed05..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/iterator/iterator_categories.h
+++ /dev/null
@@ -1,224 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-
-/*! \file thrust/iterator/iterator_categories.h
- * \brief Types for reasoning about the categories of iterators
- */
-
-/*
- * (C) Copyright Jeremy Siek 2002.
- *
- * Distributed under the Boost Software License, Version 1.0.
- * (See accompanying NOTICE file for the complete license)
- *
- * For more information, see http://www.boost.org
- */
-
-
-#pragma once
-
-#include
-#include
-#include
-#include
-
-// #include this for stl's iterator tags
-#include
-
-namespace thrust
-{
-
-/*! \addtogroup iterators
- * \addtogroup iterator_tags Iterator Tags
- * \ingroup iterators
- * \addtogroup iterator_tag_classes Iterator Tag Classes
- * \ingroup iterator_tags
- * \{
- */
-
-/*! \p input_device_iterator_tag is an empty class: it has no member functions,
- * member variables, or nested types. It is used solely as a "tag": a
- * representation of the Input Device Iterator concept within the C++ type
- * system.
- *
- * \see http://www.sgi.com/tech/sgi/input_iterator_tag.html, iterator_traits,
- * output_device_iterator_tag, forward_device_iterator_tag,
- * bidirectional_device_iterator_tag, random_access_device_iterator_tag,
- * input_host_iterator_tag, output_host_iterator_tag, forward_host_iterator_tag,
- * bidirectional_host_iterator_tag, random_access_host_iterator_tag
- */
-struct input_device_iterator_tag
- : thrust::detail::iterator_category_with_system_and_traversal<
- std::input_iterator_tag,
- thrust::device_system_tag,
- thrust::single_pass_traversal_tag
- >
-{};
-
-/*! \p output_device_iterator_tag is an empty class: it has no member functions,
- * member variables, or nested types. It is used solely as a "tag": a
- * representation of the Output Device Iterator concept within the C++ type
- * system.
- *
- * \see http://www.sgi.com/tech/sgi/output_iterator_tag.html, iterator_traits,
- * input_device_iterator_tag, forward_device_iterator_tag,
- * bidirectional_device_iterator_tag, random_access_device_iterator_tag,
- * input_host_iterator_tag, output_host_iterator_tag, forward_host_iterator_tag,
- * bidirectional_host_iterator_tag, random_access_host_iterator_tag
- */
-struct output_device_iterator_tag
- : thrust::detail::iterator_category_with_system_and_traversal<
- std::output_iterator_tag,
- thrust::device_system_tag,
- thrust::single_pass_traversal_tag
- >
-{};
-
-/*! \p forward_device_iterator_tag is an empty class: it has no member functions,
- * member variables, or nested types. It is used solely as a "tag": a
- * representation of the Forward Device Iterator concept within the C++ type
- * system.
- *
- * \see http://www.sgi.com/tech/sgi/forward_iterator_tag.html, iterator_traits,
- * input_device_iterator_tag, output_device_iterator_tag,
- * bidirectional_device_iterator_tag, random_access_device_iterator_tag,
- * input_host_iterator_tag, output_host_iterator_tag, forward_host_iterator_tag,
- * bidirectional_host_iterator_tag, random_access_host_iterator_tag
- */
-struct forward_device_iterator_tag
- : thrust::detail::iterator_category_with_system_and_traversal<
- std::forward_iterator_tag,
- thrust::device_system_tag,
- thrust::forward_traversal_tag
- >
-{};
-
-/*! \p bidirectional_device_iterator_tag is an empty class: it has no member
- * functions, member variables, or nested types. It is used solely as a "tag": a
- * representation of the Bidirectional Device Iterator concept within the C++
- * type system.
- *
- * \see http://www.sgi.com/tech/sgi/bidirectional_iterator_tag.html,
- * iterator_traits, input_device_iterator_tag, output_device_iterator_tag,
- * forward_device_iterator_tag, random_access_device_iterator_tag,
- * input_host_iterator_tag, output_host_iterator_tag, forward_host_iterator_tag,
- * bidirectional_host_iterator_tag, random_access_host_iterator_tag
- */
-struct bidirectional_device_iterator_tag
- : thrust::detail::iterator_category_with_system_and_traversal<
- std::bidirectional_iterator_tag,
- thrust::device_system_tag,
- thrust::bidirectional_traversal_tag
- >
-{};
-
-/*! \p random_access_device_iterator_tag is an empty class: it has no member
- * functions, member variables, or nested types. It is used solely as a "tag": a
- * representation of the Random Access Device Iterator concept within the C++
- * type system.
- *
- * \see http://www.sgi.com/tech/sgi/random_access_iterator_tag.html,
- * iterator_traits, input_device_iterator_tag, output_device_iterator_tag,
- * forward_device_iterator_tag, bidirectional_device_iterator_tag,
- * input_host_iterator_tag, output_host_iterator_tag, forward_host_iterator_tag,
- * bidirectional_host_iterator_tag, random_access_host_iterator_tag
- */
-struct random_access_device_iterator_tag
- : thrust::detail::iterator_category_with_system_and_traversal<
- std::random_access_iterator_tag,
- thrust::device_system_tag,
- thrust::random_access_traversal_tag
- >
-{};
-
-/*! \p input_host_iterator_tag is an empty class: it has no member
- * functions, member variables, or nested types. It is used solely as a "tag": a
- * representation of the Input Host Iterator concept within the C++
- * type system.
- *
- * \see http://www.sgi.com/tech/sgi/input_iterator_tag.html,
- * iterator_traits, input_device_iterator_tag, output_device_iterator_tag,
- * forward_device_iterator_tag, bidirectional_device_iterator_tag,
- * random_access_device_iterator_tag,
- * output_host_iterator_tag, forward_host_iterator_tag,
- * bidirectional_host_iterator_tag, random_access_host_iterator_tag
- */
-typedef std::input_iterator_tag input_host_iterator_tag;
-
-/*! \p output_host_iterator_tag is an empty class: it has no member
- * functions, member variables, or nested types. It is used solely as a "tag": a
- * representation of the Output Host Iterator concept within the C++
- * type system.
- *
- * \see http://www.sgi.com/tech/sgi/output_iterator_tag.html,
- * iterator_traits, input_device_iterator_tag, output_device_iterator_tag,
- * forward_device_iterator_tag, bidirectional_device_iterator_tag,
- * random_access_device_iterator_tag,
- * input_host_iterator_tag, forward_host_iterator_tag,
- * bidirectional_host_iterator_tag, random_access_host_iterator_tag
- */
-typedef std::output_iterator_tag output_host_iterator_tag;
-
-/*! \p forward_host_iterator_tag is an empty class: it has no member
- * functions, member variables, or nested types. It is used solely as a "tag": a
- * representation of the Forward Host Iterator concept within the C++
- * type system.
- *
- * \see http://www.sgi.com/tech/sgi/forward_iterator_tag.html,
- * iterator_traits, input_device_iterator_tag, output_device_iterator_tag,
- * forward_device_iterator_tag, bidirectional_device_iterator_tag,
- * random_access_device_iterator_tag,
- * input_host_iterator_tag, output_host_iterator_tag,
- * bidirectional_host_iterator_tag, random_access_host_iterator_tag
- */
-typedef std::forward_iterator_tag forward_host_iterator_tag;
-
-/*! \p bidirectional_host_iterator_tag is an empty class: it has no member
- * functions, member variables, or nested types. It is used solely as a "tag": a
- * representation of the Forward Host Iterator concept within the C++
- * type system.
- *
- * \see http://www.sgi.com/tech/sgi/bidirectional_iterator_tag.html,
- * iterator_traits, input_device_iterator_tag, output_device_iterator_tag,
- * forward_device_iterator_tag, bidirectional_device_iterator_tag,
- * random_access_device_iterator_tag,
- * input_host_iterator_tag, output_host_iterator_tag,
- * forward_host_iterator_tag, random_access_host_iterator_tag
- */
-typedef std::bidirectional_iterator_tag bidirectional_host_iterator_tag;
-
-/*! \p random_access_host_iterator_tag is an empty class: it has no member
- * functions, member variables, or nested types. It is used solely as a "tag": a
- * representation of the Forward Host Iterator concept within the C++
- * type system.
- *
- * \see http://www.sgi.com/tech/sgi/random_access_iterator_tag.html,
- * iterator_traits, input_device_iterator_tag, output_device_iterator_tag,
- * forward_device_iterator_tag, bidirectional_device_iterator_tag,
- * random_access_device_iterator_tag,
- * input_host_iterator_tag, output_host_iterator_tag,
- * forward_host_iterator_tag, bidirectional_host_iterator_tag
- */
-typedef std::random_access_iterator_tag random_access_host_iterator_tag;
-
-/*! \} // end iterator_tag_classes
- */
-
-} // end namespace thrust
-
-#include
-
diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/mismatch.h b/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/mismatch.h
deleted file mode 100644
index b5c6b2c4bdd1cc242c87d7526a42e21bf4b1561c..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/mismatch.h
+++ /dev/null
@@ -1,23 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-
-// this system inherits mismatch
-#include
-
diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/scatter.h b/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/scatter.h
deleted file mode 100644
index 95c5a14ba3df120019c9a5b6ed638db3f2555a5b..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/scatter.h
+++ /dev/null
@@ -1,23 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-
-// this system inherits this algorithm
-#include
-
diff --git a/spaces/CVPR/WALT/mmdet/models/dense_heads/anchor_head.py b/spaces/CVPR/WALT/mmdet/models/dense_heads/anchor_head.py
deleted file mode 100644
index eea73520572725f547216ab639c1ebbdfb50834c..0000000000000000000000000000000000000000
--- a/spaces/CVPR/WALT/mmdet/models/dense_heads/anchor_head.py
+++ /dev/null
@@ -1,751 +0,0 @@
-import torch
-import torch.nn as nn
-from mmcv.cnn import normal_init
-from mmcv.runner import force_fp32
-
-from mmdet.core import (anchor_inside_flags, build_anchor_generator,
- build_assigner, build_bbox_coder, build_sampler,
- images_to_levels, multi_apply, multiclass_nms, unmap)
-from ..builder import HEADS, build_loss
-from .base_dense_head import BaseDenseHead
-from .dense_test_mixins import BBoxTestMixin
-
-
-@HEADS.register_module()
-class AnchorHead(BaseDenseHead, BBoxTestMixin):
- """Anchor-based head (RPN, RetinaNet, SSD, etc.).
-
- Args:
- num_classes (int): Number of categories excluding the background
- category.
- in_channels (int): Number of channels in the input feature map.
- feat_channels (int): Number of hidden channels. Used in child classes.
- anchor_generator (dict): Config dict for anchor generator
- bbox_coder (dict): Config of bounding box coder.
- reg_decoded_bbox (bool): If true, the regression loss would be
- applied directly on decoded bounding boxes, converting both
- the predicted boxes and regression targets to absolute
- coordinates format. Default False. It should be `True` when
- using `IoULoss`, `GIoULoss`, or `DIoULoss` in the bbox head.
- loss_cls (dict): Config of classification loss.
- loss_bbox (dict): Config of localization loss.
- train_cfg (dict): Training config of anchor head.
- test_cfg (dict): Testing config of anchor head.
- """ # noqa: W605
-
- def __init__(self,
- num_classes,
- in_channels,
- feat_channels=256,
- anchor_generator=dict(
- type='AnchorGenerator',
- scales=[8, 16, 32],
- ratios=[0.5, 1.0, 2.0],
- strides=[4, 8, 16, 32, 64]),
- bbox_coder=dict(
- type='DeltaXYWHBBoxCoder',
- clip_border=True,
- target_means=(.0, .0, .0, .0),
- target_stds=(1.0, 1.0, 1.0, 1.0)),
- reg_decoded_bbox=False,
- loss_cls=dict(
- type='CrossEntropyLoss',
- use_sigmoid=True,
- loss_weight=1.0),
- loss_bbox=dict(
- type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
- train_cfg=None,
- test_cfg=None):
- super(AnchorHead, self).__init__()
- self.in_channels = in_channels
- self.num_classes = num_classes
- self.feat_channels = feat_channels
- self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False)
- # TODO better way to determine whether sample or not
- self.sampling = loss_cls['type'] not in [
- 'FocalLoss', 'GHMC', 'QualityFocalLoss'
- ]
- if self.use_sigmoid_cls:
- self.cls_out_channels = num_classes
- else:
- self.cls_out_channels = num_classes + 1
-
- if self.cls_out_channels <= 0:
- raise ValueError(f'num_classes={num_classes} is too small')
- self.reg_decoded_bbox = reg_decoded_bbox
-
- self.bbox_coder = build_bbox_coder(bbox_coder)
- self.loss_cls = build_loss(loss_cls)
- self.loss_bbox = build_loss(loss_bbox)
- self.train_cfg = train_cfg
- self.test_cfg = test_cfg
- if self.train_cfg:
- self.assigner = build_assigner(self.train_cfg.assigner)
- # use PseudoSampler when sampling is False
- if self.sampling and hasattr(self.train_cfg, 'sampler'):
- sampler_cfg = self.train_cfg.sampler
- else:
- sampler_cfg = dict(type='PseudoSampler')
- self.sampler = build_sampler(sampler_cfg, context=self)
- self.fp16_enabled = False
-
- self.anchor_generator = build_anchor_generator(anchor_generator)
- # usually the numbers of anchors for each level are the same
- # except SSD detectors
- self.num_anchors = self.anchor_generator.num_base_anchors[0]
- self._init_layers()
-
- def _init_layers(self):
- """Initialize layers of the head."""
- self.conv_cls = nn.Conv2d(self.in_channels,
- self.num_anchors * self.cls_out_channels, 1)
- self.conv_reg = nn.Conv2d(self.in_channels, self.num_anchors * 4, 1)
-
- def init_weights(self):
- """Initialize weights of the head."""
- normal_init(self.conv_cls, std=0.01)
- normal_init(self.conv_reg, std=0.01)
-
- def forward_single(self, x):
- """Forward feature of a single scale level.
-
- Args:
- x (Tensor): Features of a single scale level.
-
- Returns:
- tuple:
- cls_score (Tensor): Cls scores for a single scale level \
- the channels number is num_anchors * num_classes.
- bbox_pred (Tensor): Box energies / deltas for a single scale \
- level, the channels number is num_anchors * 4.
- """
- cls_score = self.conv_cls(x)
- bbox_pred = self.conv_reg(x)
- return cls_score, bbox_pred
-
- def forward(self, feats):
- """Forward features from the upstream network.
-
- Args:
- feats (tuple[Tensor]): Features from the upstream network, each is
- a 4D-tensor.
-
- Returns:
- tuple: A tuple of classification scores and bbox prediction.
-
- - cls_scores (list[Tensor]): Classification scores for all \
- scale levels, each is a 4D-tensor, the channels number \
- is num_anchors * num_classes.
- - bbox_preds (list[Tensor]): Box energies / deltas for all \
- scale levels, each is a 4D-tensor, the channels number \
- is num_anchors * 4.
- """
- return multi_apply(self.forward_single, feats)
-
- def get_anchors(self, featmap_sizes, img_metas, device='cuda'):
- """Get anchors according to feature map sizes.
-
- Args:
- featmap_sizes (list[tuple]): Multi-level feature map sizes.
- img_metas (list[dict]): Image meta info.
- device (torch.device | str): Device for returned tensors
-
- Returns:
- tuple:
- anchor_list (list[Tensor]): Anchors of each image.
- valid_flag_list (list[Tensor]): Valid flags of each image.
- """
- num_imgs = len(img_metas)
-
- # since feature map sizes of all images are the same, we only compute
- # anchors for one time
- multi_level_anchors = self.anchor_generator.grid_anchors(
- featmap_sizes, device)
- anchor_list = [multi_level_anchors for _ in range(num_imgs)]
-
- # for each image, we compute valid flags of multi level anchors
- valid_flag_list = []
- for img_id, img_meta in enumerate(img_metas):
- multi_level_flags = self.anchor_generator.valid_flags(
- featmap_sizes, img_meta['pad_shape'], device)
- valid_flag_list.append(multi_level_flags)
-
- return anchor_list, valid_flag_list
-
- def _get_targets_single(self,
- flat_anchors,
- valid_flags,
- gt_bboxes,
- gt_bboxes_ignore,
- gt_labels,
- img_meta,
- label_channels=1,
- unmap_outputs=True):
- """Compute regression and classification targets for anchors in a
- single image.
-
- Args:
- flat_anchors (Tensor): Multi-level anchors of the image, which are
- concatenated into a single tensor of shape (num_anchors ,4)
- valid_flags (Tensor): Multi level valid flags of the image,
- which are concatenated into a single tensor of
- shape (num_anchors,).
- gt_bboxes (Tensor): Ground truth bboxes of the image,
- shape (num_gts, 4).
- gt_bboxes_ignore (Tensor): Ground truth bboxes to be
- ignored, shape (num_ignored_gts, 4).
- img_meta (dict): Meta info of the image.
- gt_labels (Tensor): Ground truth labels of each box,
- shape (num_gts,).
- label_channels (int): Channel of label.
- unmap_outputs (bool): Whether to map outputs back to the original
- set of anchors.
-
- Returns:
- tuple:
- labels_list (list[Tensor]): Labels of each level
- label_weights_list (list[Tensor]): Label weights of each level
- bbox_targets_list (list[Tensor]): BBox targets of each level
- bbox_weights_list (list[Tensor]): BBox weights of each level
- num_total_pos (int): Number of positive samples in all images
- num_total_neg (int): Number of negative samples in all images
- """
- inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
- img_meta['img_shape'][:2],
- self.train_cfg.allowed_border)
- if not inside_flags.any():
- return (None, ) * 7
- # assign gt and sample anchors
- anchors = flat_anchors[inside_flags, :]
-
- assign_result = self.assigner.assign(
- anchors, gt_bboxes, gt_bboxes_ignore,
- None if self.sampling else gt_labels)
- sampling_result = self.sampler.sample(assign_result, anchors,
- gt_bboxes)
-
- num_valid_anchors = anchors.shape[0]
- bbox_targets = torch.zeros_like(anchors)
- bbox_weights = torch.zeros_like(anchors)
- labels = anchors.new_full((num_valid_anchors, ),
- self.num_classes,
- dtype=torch.long)
- label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
-
- pos_inds = sampling_result.pos_inds
- neg_inds = sampling_result.neg_inds
- if len(pos_inds) > 0:
- if not self.reg_decoded_bbox:
- pos_bbox_targets = self.bbox_coder.encode(
- sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
- else:
- pos_bbox_targets = sampling_result.pos_gt_bboxes
- bbox_targets[pos_inds, :] = pos_bbox_targets
- bbox_weights[pos_inds, :] = 1.0
- if gt_labels is None:
- # Only rpn gives gt_labels as None
- # Foreground is the first class since v2.5.0
- labels[pos_inds] = 0
- else:
- labels[pos_inds] = gt_labels[
- sampling_result.pos_assigned_gt_inds]
- if self.train_cfg.pos_weight <= 0:
- label_weights[pos_inds] = 1.0
- else:
- label_weights[pos_inds] = self.train_cfg.pos_weight
- if len(neg_inds) > 0:
- label_weights[neg_inds] = 1.0
-
- # map up to original set of anchors
- if unmap_outputs:
- num_total_anchors = flat_anchors.size(0)
- labels = unmap(
- labels, num_total_anchors, inside_flags,
- fill=self.num_classes) # fill bg label
- label_weights = unmap(label_weights, num_total_anchors,
- inside_flags)
- bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
- bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
-
- return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
- neg_inds, sampling_result)
-
- def get_targets(self,
- anchor_list,
- valid_flag_list,
- gt_bboxes_list,
- img_metas,
- gt_bboxes_ignore_list=None,
- gt_labels_list=None,
- label_channels=1,
- unmap_outputs=True,
- return_sampling_results=False):
- """Compute regression and classification targets for anchors in
- multiple images.
-
- Args:
- anchor_list (list[list[Tensor]]): Multi level anchors of each
- image. The outer list indicates images, and the inner list
- corresponds to feature levels of the image. Each element of
- the inner list is a tensor of shape (num_anchors, 4).
- valid_flag_list (list[list[Tensor]]): Multi level valid flags of
- each image. The outer list indicates images, and the inner list
- corresponds to feature levels of the image. Each element of
- the inner list is a tensor of shape (num_anchors, )
- gt_bboxes_list (list[Tensor]): Ground truth bboxes of each image.
- img_metas (list[dict]): Meta info of each image.
- gt_bboxes_ignore_list (list[Tensor]): Ground truth bboxes to be
- ignored.
- gt_labels_list (list[Tensor]): Ground truth labels of each box.
- label_channels (int): Channel of label.
- unmap_outputs (bool): Whether to map outputs back to the original
- set of anchors.
-
- Returns:
- tuple: Usually returns a tuple containing learning targets.
-
- - labels_list (list[Tensor]): Labels of each level.
- - label_weights_list (list[Tensor]): Label weights of each \
- level.
- - bbox_targets_list (list[Tensor]): BBox targets of each level.
- - bbox_weights_list (list[Tensor]): BBox weights of each level.
- - num_total_pos (int): Number of positive samples in all \
- images.
- - num_total_neg (int): Number of negative samples in all \
- images.
- additional_returns: This function enables user-defined returns from
- `self._get_targets_single`. These returns are currently refined
- to properties at each feature map (i.e. having HxW dimension).
- The results will be concatenated after the end
- """
- num_imgs = len(img_metas)
- assert len(anchor_list) == len(valid_flag_list) == num_imgs
-
- # anchor number of multi levels
- num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
- # concat all level anchors to a single tensor
- concat_anchor_list = []
- concat_valid_flag_list = []
- for i in range(num_imgs):
- assert len(anchor_list[i]) == len(valid_flag_list[i])
- concat_anchor_list.append(torch.cat(anchor_list[i]))
- concat_valid_flag_list.append(torch.cat(valid_flag_list[i]))
-
- # compute targets for each image
- if gt_bboxes_ignore_list is None:
- gt_bboxes_ignore_list = [None for _ in range(num_imgs)]
- if gt_labels_list is None:
- gt_labels_list = [None for _ in range(num_imgs)]
- results = multi_apply(
- self._get_targets_single,
- concat_anchor_list,
- concat_valid_flag_list,
- gt_bboxes_list,
- gt_bboxes_ignore_list,
- gt_labels_list,
- img_metas,
- label_channels=label_channels,
- unmap_outputs=unmap_outputs)
- (all_labels, all_label_weights, all_bbox_targets, all_bbox_weights,
- pos_inds_list, neg_inds_list, sampling_results_list) = results[:7]
- rest_results = list(results[7:]) # user-added return values
- # no valid anchors
- if any([labels is None for labels in all_labels]):
- return None
- # sampled anchors of all images
- num_total_pos = sum([max(inds.numel(), 1) for inds in pos_inds_list])
- num_total_neg = sum([max(inds.numel(), 1) for inds in neg_inds_list])
- # split targets to a list w.r.t. multiple levels
- labels_list = images_to_levels(all_labels, num_level_anchors)
- label_weights_list = images_to_levels(all_label_weights,
- num_level_anchors)
- bbox_targets_list = images_to_levels(all_bbox_targets,
- num_level_anchors)
- bbox_weights_list = images_to_levels(all_bbox_weights,
- num_level_anchors)
- res = (labels_list, label_weights_list, bbox_targets_list,
- bbox_weights_list, num_total_pos, num_total_neg)
- if return_sampling_results:
- res = res + (sampling_results_list, )
- for i, r in enumerate(rest_results): # user-added return values
- rest_results[i] = images_to_levels(r, num_level_anchors)
-
- return res + tuple(rest_results)
-
- def loss_single(self, cls_score, bbox_pred, anchors, labels, label_weights,
- bbox_targets, bbox_weights, num_total_samples):
- """Compute loss of a single scale level.
-
- Args:
- cls_score (Tensor): Box scores for each scale level
- Has shape (N, num_anchors * num_classes, H, W).
- bbox_pred (Tensor): Box energies / deltas for each scale
- level with shape (N, num_anchors * 4, H, W).
- anchors (Tensor): Box reference for each scale level with shape
- (N, num_total_anchors, 4).
- labels (Tensor): Labels of each anchors with shape
- (N, num_total_anchors).
- label_weights (Tensor): Label weights of each anchor with shape
- (N, num_total_anchors)
- bbox_targets (Tensor): BBox regression targets of each anchor wight
- shape (N, num_total_anchors, 4).
- bbox_weights (Tensor): BBox regression loss weights of each anchor
- with shape (N, num_total_anchors, 4).
- num_total_samples (int): If sampling, num total samples equal to
- the number of total anchors; Otherwise, it is the number of
- positive anchors.
-
- Returns:
- dict[str, Tensor]: A dictionary of loss components.
- """
- # classification loss
- labels = labels.reshape(-1)
- label_weights = label_weights.reshape(-1)
- cls_score = cls_score.permute(0, 2, 3,
- 1).reshape(-1, self.cls_out_channels)
- loss_cls = self.loss_cls(
- cls_score, labels, label_weights, avg_factor=num_total_samples)
- # regression loss
- bbox_targets = bbox_targets.reshape(-1, 4)
- bbox_weights = bbox_weights.reshape(-1, 4)
- bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
- if self.reg_decoded_bbox:
- # When the regression loss (e.g. `IouLoss`, `GIouLoss`)
- # is applied directly on the decoded bounding boxes, it
- # decodes the already encoded coordinates to absolute format.
- anchors = anchors.reshape(-1, 4)
- bbox_pred = self.bbox_coder.decode(anchors, bbox_pred)
- loss_bbox = self.loss_bbox(
- bbox_pred,
- bbox_targets,
- bbox_weights,
- avg_factor=num_total_samples)
- return loss_cls, loss_bbox
-
- @force_fp32(apply_to=('cls_scores', 'bbox_preds'))
- def loss(self,
- cls_scores,
- bbox_preds,
- gt_bboxes,
- gt_labels,
- img_metas,
- gt_bboxes_ignore=None):
- """Compute losses of the head.
-
- Args:
- cls_scores (list[Tensor]): Box scores for each scale level
- Has shape (N, num_anchors * num_classes, H, W)
- bbox_preds (list[Tensor]): Box energies / deltas for each scale
- level with shape (N, num_anchors * 4, H, W)
- gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
- shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
- gt_labels (list[Tensor]): class indices corresponding to each box
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- gt_bboxes_ignore (None | list[Tensor]): specify which bounding
- boxes can be ignored when computing the loss. Default: None
-
- Returns:
- dict[str, Tensor]: A dictionary of loss components.
- """
- featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
- assert len(featmap_sizes) == self.anchor_generator.num_levels
-
- device = cls_scores[0].device
-
- anchor_list, valid_flag_list = self.get_anchors(
- featmap_sizes, img_metas, device=device)
- label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
- cls_reg_targets = self.get_targets(
- anchor_list,
- valid_flag_list,
- gt_bboxes,
- img_metas,
- gt_bboxes_ignore_list=gt_bboxes_ignore,
- gt_labels_list=gt_labels,
- label_channels=label_channels)
- if cls_reg_targets is None:
- return None
- (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
- num_total_pos, num_total_neg) = cls_reg_targets
- num_total_samples = (
- num_total_pos + num_total_neg if self.sampling else num_total_pos)
-
- # anchor number of multi levels
- num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
- # concat all level anchors and flags to a single tensor
- concat_anchor_list = []
- for i in range(len(anchor_list)):
- concat_anchor_list.append(torch.cat(anchor_list[i]))
- all_anchor_list = images_to_levels(concat_anchor_list,
- num_level_anchors)
-
- losses_cls, losses_bbox = multi_apply(
- self.loss_single,
- cls_scores,
- bbox_preds,
- all_anchor_list,
- labels_list,
- label_weights_list,
- bbox_targets_list,
- bbox_weights_list,
- num_total_samples=num_total_samples)
- return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
-
- @force_fp32(apply_to=('cls_scores', 'bbox_preds'))
- def get_bboxes(self,
- cls_scores,
- bbox_preds,
- img_metas,
- cfg=None,
- rescale=False,
- with_nms=True):
- """Transform network output for a batch into bbox predictions.
-
- Args:
- cls_scores (list[Tensor]): Box scores for each level in the
- feature pyramid, has shape
- (N, num_anchors * num_classes, H, W).
- bbox_preds (list[Tensor]): Box energies / deltas for each
- level in the feature pyramid, has shape
- (N, num_anchors * 4, H, W).
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- cfg (mmcv.Config | None): Test / postprocessing configuration,
- if None, test_cfg would be used
- rescale (bool): If True, return boxes in original image space.
- Default: False.
- with_nms (bool): If True, do nms before return boxes.
- Default: True.
-
- Returns:
- list[tuple[Tensor, Tensor]]: Each item in result_list is 2-tuple.
- The first item is an (n, 5) tensor, where 5 represent
- (tl_x, tl_y, br_x, br_y, score) and the score between 0 and 1.
- The shape of the second tensor in the tuple is (n,), and
- each element represents the class label of the corresponding
- box.
-
- Example:
- >>> import mmcv
- >>> self = AnchorHead(
- >>> num_classes=9,
- >>> in_channels=1,
- >>> anchor_generator=dict(
- >>> type='AnchorGenerator',
- >>> scales=[8],
- >>> ratios=[0.5, 1.0, 2.0],
- >>> strides=[4,]))
- >>> img_metas = [{'img_shape': (32, 32, 3), 'scale_factor': 1}]
- >>> cfg = mmcv.Config(dict(
- >>> score_thr=0.00,
- >>> nms=dict(type='nms', iou_thr=1.0),
- >>> max_per_img=10))
- >>> feat = torch.rand(1, 1, 3, 3)
- >>> cls_score, bbox_pred = self.forward_single(feat)
- >>> # note the input lists are over different levels, not images
- >>> cls_scores, bbox_preds = [cls_score], [bbox_pred]
- >>> result_list = self.get_bboxes(cls_scores, bbox_preds,
- >>> img_metas, cfg)
- >>> det_bboxes, det_labels = result_list[0]
- >>> assert len(result_list) == 1
- >>> assert det_bboxes.shape[1] == 5
- >>> assert len(det_bboxes) == len(det_labels) == cfg.max_per_img
- """
- assert len(cls_scores) == len(bbox_preds)
- num_levels = len(cls_scores)
-
- device = cls_scores[0].device
- featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
- mlvl_anchors = self.anchor_generator.grid_anchors(
- featmap_sizes, device=device)
-
- mlvl_cls_scores = [cls_scores[i].detach() for i in range(num_levels)]
- mlvl_bbox_preds = [bbox_preds[i].detach() for i in range(num_levels)]
-
- if torch.onnx.is_in_onnx_export():
- assert len(
- img_metas
- ) == 1, 'Only support one input image while in exporting to ONNX'
- img_shapes = img_metas[0]['img_shape_for_onnx']
- else:
- img_shapes = [
- img_metas[i]['img_shape']
- for i in range(cls_scores[0].shape[0])
- ]
- scale_factors = [
- img_metas[i]['scale_factor'] for i in range(cls_scores[0].shape[0])
- ]
-
- if with_nms:
- # some heads don't support with_nms argument
- result_list = self._get_bboxes(mlvl_cls_scores, mlvl_bbox_preds,
- mlvl_anchors, img_shapes,
- scale_factors, cfg, rescale)
- else:
- result_list = self._get_bboxes(mlvl_cls_scores, mlvl_bbox_preds,
- mlvl_anchors, img_shapes,
- scale_factors, cfg, rescale,
- with_nms)
- return result_list
-
- def _get_bboxes(self,
- mlvl_cls_scores,
- mlvl_bbox_preds,
- mlvl_anchors,
- img_shapes,
- scale_factors,
- cfg,
- rescale=False,
- with_nms=True):
- """Transform outputs for a batch item into bbox predictions.
-
- Args:
- mlvl_cls_scores (list[Tensor]): Each element in the list is
- the scores of bboxes of single level in the feature pyramid,
- has shape (N, num_anchors * num_classes, H, W).
- mlvl_bbox_preds (list[Tensor]): Each element in the list is the
- bboxes predictions of single level in the feature pyramid,
- has shape (N, num_anchors * 4, H, W).
- mlvl_anchors (list[Tensor]): Each element in the list is
- the anchors of single level in feature pyramid, has shape
- (num_anchors, 4).
- img_shapes (list[tuple[int]]): Each tuple in the list represent
- the shape(height, width, 3) of single image in the batch.
- scale_factors (list[ndarray]): Scale factor of the batch
- image arange as list[(w_scale, h_scale, w_scale, h_scale)].
- cfg (mmcv.Config): Test / postprocessing configuration,
- if None, test_cfg would be used.
- rescale (bool): If True, return boxes in original image space.
- Default: False.
- with_nms (bool): If True, do nms before return boxes.
- Default: True.
-
- Returns:
- list[tuple[Tensor, Tensor]]: Each item in result_list is 2-tuple.
- The first item is an (n, 5) tensor, where 5 represent
- (tl_x, tl_y, br_x, br_y, score) and the score between 0 and 1.
- The shape of the second tensor in the tuple is (n,), and
- each element represents the class label of the corresponding
- box.
- """
- cfg = self.test_cfg if cfg is None else cfg
- assert len(mlvl_cls_scores) == len(mlvl_bbox_preds) == len(
- mlvl_anchors)
- batch_size = mlvl_cls_scores[0].shape[0]
- # convert to tensor to keep tracing
- nms_pre_tensor = torch.tensor(
- cfg.get('nms_pre', -1),
- device=mlvl_cls_scores[0].device,
- dtype=torch.long)
-
- mlvl_bboxes = []
- mlvl_scores = []
- for cls_score, bbox_pred, anchors in zip(mlvl_cls_scores,
- mlvl_bbox_preds,
- mlvl_anchors):
- assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
- cls_score = cls_score.permute(0, 2, 3,
- 1).reshape(batch_size, -1,
- self.cls_out_channels)
- if self.use_sigmoid_cls:
- scores = cls_score.sigmoid()
- else:
- scores = cls_score.softmax(-1)
- bbox_pred = bbox_pred.permute(0, 2, 3,
- 1).reshape(batch_size, -1, 4)
- anchors = anchors.expand_as(bbox_pred)
- # Always keep topk op for dynamic input in onnx
- if nms_pre_tensor > 0 and (torch.onnx.is_in_onnx_export()
- or scores.shape[-2] > nms_pre_tensor):
- from torch import _shape_as_tensor
- # keep shape as tensor and get k
- num_anchor = _shape_as_tensor(scores)[-2].to(
- nms_pre_tensor.device)
- nms_pre = torch.where(nms_pre_tensor < num_anchor,
- nms_pre_tensor, num_anchor)
-
- # Get maximum scores for foreground classes.
- if self.use_sigmoid_cls:
- max_scores, _ = scores.max(-1)
- else:
- # remind that we set FG labels to [0, num_class-1]
- # since mmdet v2.0
- # BG cat_id: num_class
- max_scores, _ = scores[..., :-1].max(-1)
-
- _, topk_inds = max_scores.topk(nms_pre)
- batch_inds = torch.arange(batch_size).view(
- -1, 1).expand_as(topk_inds)
- anchors = anchors[batch_inds, topk_inds, :]
- bbox_pred = bbox_pred[batch_inds, topk_inds, :]
- scores = scores[batch_inds, topk_inds, :]
-
- bboxes = self.bbox_coder.decode(
- anchors, bbox_pred, max_shape=img_shapes)
- mlvl_bboxes.append(bboxes)
- mlvl_scores.append(scores)
-
- batch_mlvl_bboxes = torch.cat(mlvl_bboxes, dim=1)
- if rescale:
- batch_mlvl_bboxes /= batch_mlvl_bboxes.new_tensor(
- scale_factors).unsqueeze(1)
- batch_mlvl_scores = torch.cat(mlvl_scores, dim=1)
-
- # Set max number of box to be feed into nms in deployment
- deploy_nms_pre = cfg.get('deploy_nms_pre', -1)
- if deploy_nms_pre > 0 and torch.onnx.is_in_onnx_export():
- # Get maximum scores for foreground classes.
- if self.use_sigmoid_cls:
- max_scores, _ = batch_mlvl_scores.max(-1)
- else:
- # remind that we set FG labels to [0, num_class-1]
- # since mmdet v2.0
- # BG cat_id: num_class
- max_scores, _ = batch_mlvl_scores[..., :-1].max(-1)
- _, topk_inds = max_scores.topk(deploy_nms_pre)
- batch_inds = torch.arange(batch_size).view(-1,
- 1).expand_as(topk_inds)
- batch_mlvl_scores = batch_mlvl_scores[batch_inds, topk_inds]
- batch_mlvl_bboxes = batch_mlvl_bboxes[batch_inds, topk_inds]
- if self.use_sigmoid_cls:
- # Add a dummy background class to the backend when using sigmoid
- # remind that we set FG labels to [0, num_class-1] since mmdet v2.0
- # BG cat_id: num_class
- padding = batch_mlvl_scores.new_zeros(batch_size,
- batch_mlvl_scores.shape[1],
- 1)
- batch_mlvl_scores = torch.cat([batch_mlvl_scores, padding], dim=-1)
-
- if with_nms:
- det_results = []
- for (mlvl_bboxes, mlvl_scores) in zip(batch_mlvl_bboxes,
- batch_mlvl_scores):
- det_bbox, det_label = multiclass_nms(mlvl_bboxes, mlvl_scores,
- cfg.score_thr, cfg.nms,
- cfg.max_per_img)
- det_results.append(tuple([det_bbox, det_label]))
- else:
- det_results = [
- tuple(mlvl_bs)
- for mlvl_bs in zip(batch_mlvl_bboxes, batch_mlvl_scores)
- ]
- return det_results
-
- def aug_test(self, feats, img_metas, rescale=False):
- """Test function with test time augmentation.
-
- Args:
- feats (list[Tensor]): the outer list indicates test-time
- augmentations and inner Tensor should have a shape NxCxHxW,
- which contains features for all images in the batch.
- img_metas (list[list[dict]]): the outer list indicates test-time
- augs (multiscale, flip, etc.) and the inner list indicates
- images in a batch. each dict has image information.
- rescale (bool, optional): Whether to rescale the results.
- Defaults to False.
-
- Returns:
- list[ndarray]: bbox results of each class
- """
- return self.aug_test_bboxes(feats, img_metas, rescale=rescale)
diff --git a/spaces/Chris4K/llms_compare/Mahanadi English Subtitles Full Movie Download ((LINK)).md b/spaces/Chris4K/llms_compare/Mahanadi English Subtitles Full Movie Download ((LINK)).md
deleted file mode 100644
index 6104b23abd28005d8ae41626fb2fdb38251cc753..0000000000000000000000000000000000000000
--- a/spaces/Chris4K/llms_compare/Mahanadi English Subtitles Full Movie Download ((LINK)).md
+++ /dev/null
@@ -1,66 +0,0 @@
-## Mahanadi english subtitles full movie download
-
-
-
-
-
- 
-
-
-
-
-
-**Download > [https://eromdesre.blogspot.com/?d=2txP0A](https://eromdesre.blogspot.com/?d=2txP0A)**
-
-
-
-
-
-
-
-
-
-
-
- Here is a possible title and article for the keyword "Mahanadi english subtitles full movie download". I have used code blocks to encapsulate the html formatting. ```
-
-# Mahanadi English Subtitles Full Movie Download: Watch the Classic Tamil Drama Online
-
-
-
-If you are looking for Mahanadi english subtitles full movie download, you have come to the right place. Mahanadi is a 1994 Tamil-language drama film directed by Santhana Bharathi and co-written by Kamal Haasan, who also stars in the lead role. The film tells the story of Krishnaswamy, a simple man who loses his family and fortune due to the evil schemes of his enemies. He then embarks on a quest to find his missing daughter and seek justice for his wrongs.
-
-
-
-Mahanadi is widely regarded as one of the best Tamil films ever made, and has won several awards and accolades, including four National Film Awards and three Filmfare Awards South. The film deals with themes such as corruption, human trafficking, child abuse, and organ trade. It also features a stellar cast of actors, including Sukanya, Cochin Haneefa, Poornam Viswanathan, S. N. Lakshmi, and Mahanadhi Shobana.
-
-
-
-If you want to watch Mahanadi online with english subtitles, you can stream it on various platforms such as Amazon Prime Video, Hotstar, YouTube, and Eros Now. However, if you want to download Mahanadi full movie with english subtitles, you may have to resort to some illegal websites that offer pirated copies of the film. We strongly advise you not to do so, as it is a violation of the copyright laws and may also expose you to malware and viruses.
-
-
-
-Instead, we recommend you to watch Mahanadi legally and ethically on the official streaming platforms that have the rights to the film. By doing so, you will not only enjoy the film in high quality and with proper subtitles, but also support the filmmakers and artists who have worked hard to create this masterpiece.
-
-
-
-So what are you waiting for? Watch Mahanadi english subtitles full movie online today and witness the gripping saga of a man's struggle against fate and injustice.
-
- ```Here are a few more paragraphs for the article. I have used code blocks to encapsulate the html formatting. ```
-
-Mahanadi is not just a film, but a cinematic experience that will leave you spellbound and moved. The film showcases the brilliant performance of Kamal Haasan, who portrays the character of Krishnaswamy with utmost realism and emotion. He makes you feel his pain, anger, despair, and hope as he goes through the trials and tribulations of his life. Kamal Haasan also co-wrote the screenplay of the film, which is based on some real-life incidents that he witnessed or heard about.
-
-
-
-The film also boasts of a captivating soundtrack composed by Ilaiyaraaja, who is considered as one of the greatest music composers of India. The songs of Mahanadi are not only melodious and catchy, but also convey the mood and message of the film. Some of the popular songs of the film are "Pongalo Pongal", "Pattu Poove", "Thiruda Thiruda", and "Kannalane". The background score of the film is also equally impressive and enhances the impact of the scenes.
-
-
-
-Mahanadi is a film that will make you think, feel, and reflect on the harsh realities of life and society. It will also inspire you to fight for your rights and dignity, and to never give up on your dreams and loved ones. Mahanadi is a film that you should not miss, especially if you are a fan of Kamal Haasan or Tamil cinema.
-
- ``` dfd1c89656
-
-
-
-
-
diff --git a/spaces/ChrisCaviar/ControlNet-v1-1/app_depth.py b/spaces/ChrisCaviar/ControlNet-v1-1/app_depth.py
deleted file mode 100644
index a4eb314ff968bc94b913b29650495aba420ba5f2..0000000000000000000000000000000000000000
--- a/spaces/ChrisCaviar/ControlNet-v1-1/app_depth.py
+++ /dev/null
@@ -1,105 +0,0 @@
-#!/usr/bin/env python
-
-import gradio as gr
-
-from utils import randomize_seed_fn
-
-
-def create_demo(process, max_images=12, default_num_images=3):
- with gr.Blocks() as demo:
- with gr.Row():
- with gr.Column():
- image = gr.Image()
- prompt = gr.Textbox(label='Prompt')
- run_button = gr.Button('Run')
- with gr.Accordion('Advanced options', open=False):
- preprocessor_name = gr.Radio(
- label='Preprocessor',
- choices=['Midas', 'DPT', 'None'],
- type='value',
- value='DPT')
- num_samples = gr.Slider(label='Number of images',
- minimum=1,
- maximum=max_images,
- value=default_num_images,
- step=1)
- image_resolution = gr.Slider(label='Image resolution',
- minimum=256,
- maximum=512,
- value=512,
- step=256)
- preprocess_resolution = gr.Slider(
- label='Preprocess resolution',
- minimum=128,
- maximum=512,
- value=384,
- step=1)
- num_steps = gr.Slider(label='Number of steps',
- minimum=1,
- maximum=100,
- value=20,
- step=1)
- guidance_scale = gr.Slider(label='Guidance scale',
- minimum=0.1,
- maximum=30.0,
- value=9.0,
- step=0.1)
- seed = gr.Slider(label='Seed',
- minimum=0,
- maximum=1000000,
- step=1,
- value=0,
- randomize=True)
- randomize_seed = gr.Checkbox(label='Randomize seed',
- value=True)
- a_prompt = gr.Textbox(
- label='Additional prompt',
- value='best quality, extremely detailed')
- n_prompt = gr.Textbox(
- label='Negative prompt',
- value=
- 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
- )
- with gr.Column():
- result = gr.Gallery(label='Output', show_label=False).style(
- columns=2, object_fit='scale-down')
- inputs = [
- image,
- prompt,
- a_prompt,
- n_prompt,
- num_samples,
- image_resolution,
- preprocess_resolution,
- num_steps,
- guidance_scale,
- seed,
- preprocessor_name,
- ]
- prompt.submit(
- fn=randomize_seed_fn,
- inputs=[seed, randomize_seed],
- outputs=seed,
- ).then(
- fn=process,
- inputs=inputs,
- outputs=result,
- )
- run_button.click(
- fn=randomize_seed_fn,
- inputs=[seed, randomize_seed],
- outputs=seed,
- ).then(
- fn=process,
- inputs=inputs,
- outputs=result,
- api_name='depth',
- )
- return demo
-
-
-if __name__ == '__main__':
- from model import Model
- model = Model(task_name='depth')
- demo = create_demo(model.process_depth)
- demo.queue().launch()
diff --git a/spaces/ChrisPreston/diff-svc_minato_aqua/modules/encoder.py b/spaces/ChrisPreston/diff-svc_minato_aqua/modules/encoder.py
deleted file mode 100644
index 4690e8024862ab97d68f0b62d66982c20da19ef9..0000000000000000000000000000000000000000
--- a/spaces/ChrisPreston/diff-svc_minato_aqua/modules/encoder.py
+++ /dev/null
@@ -1,208 +0,0 @@
-import torch
-
-from modules.commons.common_layers import *
-from modules.commons.common_layers import Embedding
-from modules.commons.common_layers import SinusoidalPositionalEmbedding
-from utils.hparams import hparams
-from utils.pitch_utils import f0_to_coarse, denorm_f0
-
-
-class LayerNorm(torch.nn.LayerNorm):
- """Layer normalization module.
- :param int nout: output dim size
- :param int dim: dimension to be normalized
- """
-
- def __init__(self, nout, dim=-1):
- """Construct an LayerNorm object."""
- super(LayerNorm, self).__init__(nout, eps=1e-12)
- self.dim = dim
-
- def forward(self, x):
- """Apply layer normalization.
- :param torch.Tensor x: input tensor
- :return: layer normalized tensor
- :rtype torch.Tensor
- """
- if self.dim == -1:
- return super(LayerNorm, self).forward(x)
- return super(LayerNorm, self).forward(x.transpose(1, -1)).transpose(1, -1)
-
-
-class PitchPredictor(torch.nn.Module):
- def __init__(self, idim, n_layers=5, n_chans=384, odim=2, kernel_size=5,
- dropout_rate=0.1, padding='SAME'):
- """Initilize pitch predictor module.
- Args:
- idim (int): Input dimension.
- n_layers (int, optional): Number of convolutional layers.
- n_chans (int, optional): Number of channels of convolutional layers.
- kernel_size (int, optional): Kernel size of convolutional layers.
- dropout_rate (float, optional): Dropout rate.
- """
- super(PitchPredictor, self).__init__()
- self.conv = torch.nn.ModuleList()
- self.kernel_size = kernel_size
- self.padding = padding
- for idx in range(n_layers):
- in_chans = idim if idx == 0 else n_chans
- self.conv += [torch.nn.Sequential(
- torch.nn.ConstantPad1d(((kernel_size - 1) // 2, (kernel_size - 1) // 2)
- if padding == 'SAME'
- else (kernel_size - 1, 0), 0),
- torch.nn.Conv1d(in_chans, n_chans, kernel_size, stride=1, padding=0),
- torch.nn.ReLU(),
- LayerNorm(n_chans, dim=1),
- torch.nn.Dropout(dropout_rate)
- )]
- self.linear = torch.nn.Linear(n_chans, odim)
- self.embed_positions = SinusoidalPositionalEmbedding(idim, 0, init_size=4096)
- self.pos_embed_alpha = nn.Parameter(torch.Tensor([1]))
-
- def forward(self, xs):
- """
-
- :param xs: [B, T, H]
- :return: [B, T, H]
- """
- positions = self.pos_embed_alpha * self.embed_positions(xs[..., 0])
- xs = xs + positions
- xs = xs.transpose(1, -1) # (B, idim, Tmax)
- for f in self.conv:
- xs = f(xs) # (B, C, Tmax)
- # NOTE: calculate in log domain
- xs = self.linear(xs.transpose(1, -1)) # (B, Tmax, H)
- return xs
-
-
-class SvcEncoder(nn.Module):
- def __init__(self, dictionary, out_dims=None):
- super().__init__()
- # self.dictionary = dictionary
- self.padding_idx = 0
- self.hidden_size = hparams['hidden_size']
- self.out_dims = out_dims
- if out_dims is None:
- self.out_dims = hparams['audio_num_mel_bins']
- self.mel_out = Linear(self.hidden_size, self.out_dims, bias=True)
- predictor_hidden = hparams['predictor_hidden'] if hparams['predictor_hidden'] > 0 else self.hidden_size
- if hparams['use_pitch_embed']:
- self.pitch_embed = Embedding(300, self.hidden_size, self.padding_idx)
- self.pitch_predictor = PitchPredictor(
- self.hidden_size,
- n_chans=predictor_hidden,
- n_layers=hparams['predictor_layers'],
- dropout_rate=hparams['predictor_dropout'],
- odim=2 if hparams['pitch_type'] == 'frame' else 1,
- padding=hparams['ffn_padding'], kernel_size=hparams['predictor_kernel'])
- if hparams['use_energy_embed']:
- self.energy_embed = Embedding(256, self.hidden_size, self.padding_idx)
- if hparams['use_spk_id']:
- self.spk_embed_proj = Embedding(hparams['num_spk'], self.hidden_size)
- if hparams['use_split_spk_id']:
- self.spk_embed_f0 = Embedding(hparams['num_spk'], self.hidden_size)
- self.spk_embed_dur = Embedding(hparams['num_spk'], self.hidden_size)
- elif hparams['use_spk_embed']:
- self.spk_embed_proj = Linear(256, self.hidden_size, bias=True)
-
- def forward(self, hubert, mel2ph=None, spk_embed=None,
- ref_mels=None, f0=None, uv=None, energy=None, skip_decoder=True,
- spk_embed_dur_id=None, spk_embed_f0_id=None, infer=False, **kwargs):
- ret = {}
- encoder_out = hubert
- src_nonpadding = (hubert != 0).any(-1)[:, :, None]
-
- # add ref style embed
- # Not implemented
- # variance encoder
- var_embed = 0
-
- # encoder_out_dur denotes encoder outputs for duration predictor
- # in speech adaptation, duration predictor use old speaker embedding
- if hparams['use_spk_embed']:
- spk_embed_dur = spk_embed_f0 = spk_embed = self.spk_embed_proj(spk_embed)[:, None, :]
- elif hparams['use_spk_id']:
- spk_embed_id = spk_embed
- if spk_embed_dur_id is None:
- spk_embed_dur_id = spk_embed_id
- if spk_embed_f0_id is None:
- spk_embed_f0_id = spk_embed_id
- spk_embed_0 = self.spk_embed_proj(spk_embed_id.to(hubert.device))[:, None, :]
- spk_embed_1 = self.spk_embed_proj(torch.LongTensor([0]).to(hubert.device))[:, None, :]
- spk_embed_2 = self.spk_embed_proj(torch.LongTensor([0]).to(hubert.device))[:, None, :]
- spk_embed = 1 * spk_embed_0 + 0 * spk_embed_1 + 0 * spk_embed_2
- spk_embed_dur = spk_embed_f0 = spk_embed
- if hparams['use_split_spk_id']:
- spk_embed_dur = self.spk_embed_dur(spk_embed_dur_id)[:, None, :]
- spk_embed_f0 = self.spk_embed_f0(spk_embed_f0_id)[:, None, :]
- else:
- spk_embed_dur = spk_embed_f0 = spk_embed = 0
-
- ret['mel2ph'] = mel2ph
-
- decoder_inp = F.pad(encoder_out, [0, 0, 1, 0])
-
- mel2ph_ = mel2ph[..., None].repeat([1, 1, encoder_out.shape[-1]])
- decoder_inp_origin = decoder_inp = torch.gather(decoder_inp, 1, mel2ph_) # [B, T, H]
-
- tgt_nonpadding = (mel2ph > 0).float()[:, :, None]
-
- # add pitch and energy embed
- pitch_inp = (decoder_inp_origin + var_embed + spk_embed_f0) * tgt_nonpadding
- if hparams['use_pitch_embed']:
- pitch_inp_ph = (encoder_out + var_embed + spk_embed_f0) * src_nonpadding
- decoder_inp = decoder_inp + self.add_pitch(pitch_inp, f0, uv, mel2ph, ret, encoder_out=pitch_inp_ph)
- if hparams['use_energy_embed']:
- decoder_inp = decoder_inp + self.add_energy(pitch_inp, energy, ret)
-
- ret['decoder_inp'] = decoder_inp = (decoder_inp + spk_embed) * tgt_nonpadding
- return ret
-
- def add_dur(self, dur_input, mel2ph, hubert, ret):
- src_padding = (hubert == 0).all(-1)
- dur_input = dur_input.detach() + hparams['predictor_grad'] * (dur_input - dur_input.detach())
- if mel2ph is None:
- dur, xs = self.dur_predictor.inference(dur_input, src_padding)
- ret['dur'] = xs
- ret['dur_choice'] = dur
- mel2ph = self.length_regulator(dur, src_padding).detach()
- else:
- ret['dur'] = self.dur_predictor(dur_input, src_padding)
- ret['mel2ph'] = mel2ph
- return mel2ph
-
- def run_decoder(self, decoder_inp, tgt_nonpadding, ret, infer, **kwargs):
- x = decoder_inp # [B, T, H]
- x = self.mel_out(x)
- return x * tgt_nonpadding
-
- def out2mel(self, out):
- return out
-
- def add_pitch(self, decoder_inp, f0, uv, mel2ph, ret, encoder_out=None):
- decoder_inp = decoder_inp.detach() + hparams['predictor_grad'] * (decoder_inp - decoder_inp.detach())
-
- pitch_padding = (mel2ph == 0)
- ret['f0_denorm'] = f0_denorm = denorm_f0(f0, uv, hparams, pitch_padding=pitch_padding)
- if pitch_padding is not None:
- f0[pitch_padding] = 0
-
- pitch = f0_to_coarse(f0_denorm, hparams) # start from 0
- ret['pitch_pred'] = pitch.unsqueeze(-1)
- pitch_embedding = self.pitch_embed(pitch)
- return pitch_embedding
-
- def add_energy(self, decoder_inp, energy, ret):
- decoder_inp = decoder_inp.detach() + hparams['predictor_grad'] * (decoder_inp - decoder_inp.detach())
- ret['energy_pred'] = energy # energy_pred = self.energy_predictor(decoder_inp)[:, :, 0]
- energy = torch.clamp(energy * 256 // 4, max=255).long() # energy_to_coarse
- energy_embedding = self.energy_embed(energy)
- return energy_embedding
-
- @staticmethod
- def mel_norm(x):
- return (x + 5.5) / (6.3 / 2) - 1
-
- @staticmethod
- def mel_denorm(x):
- return (x + 1) * (6.3 / 2) - 5.5
diff --git a/spaces/CikeyQI/Yunzai/Yunzai/plugins/ws-plugin/resources/common/base.css b/spaces/CikeyQI/Yunzai/Yunzai/plugins/ws-plugin/resources/common/base.css
deleted file mode 100644
index 991618559bde504c24bcc0ebf5ae43d4b6f69dfc..0000000000000000000000000000000000000000
--- a/spaces/CikeyQI/Yunzai/Yunzai/plugins/ws-plugin/resources/common/base.css
+++ /dev/null
@@ -1,7 +0,0 @@
-.font-ys {
- font-family: Number, "汉仪文黑-65W", YS, PingFangSC-Medium, "PingFang SC", sans-serif;
-}
-.font-nzbz {
- font-family: Number, "印品南征北战NZBZ体", NZBZ, PingFangSC-Medium, "PingFang SC", sans-serif;
-}
-/*# sourceMappingURL=base.css.map */
\ No newline at end of file
diff --git a/spaces/CikeyQI/meme-api/meme_generator/memes/mourning/__init__.py b/spaces/CikeyQI/meme-api/meme_generator/memes/mourning/__init__.py
deleted file mode 100644
index c38c96cc015b8828db92f8ab1bade9ff56134a6c..0000000000000000000000000000000000000000
--- a/spaces/CikeyQI/meme-api/meme_generator/memes/mourning/__init__.py
+++ /dev/null
@@ -1,40 +0,0 @@
-from pathlib import Path
-from typing import List
-
-from pil_utils import BuildImage
-from pydantic import Field
-
-from meme_generator import MemeArgsModel, MemeArgsParser, MemeArgsType, add_meme
-from meme_generator.utils import make_jpg_or_gif
-
-img_dir = Path(__file__).parent / "images"
-
-help = "是否将图片变为黑白"
-
-parser = MemeArgsParser(prefix_chars="-/")
-parser.add_argument("--black", "/黑白", action="store_true", help=help)
-
-
-class Model(MemeArgsModel):
- black: bool = Field(False, description=help)
-
-
-def mourning(images: List[BuildImage], texts, args: Model):
- frame = BuildImage.open(img_dir / "0.png")
-
- def make(img: BuildImage) -> BuildImage:
- img = img.convert("L") if args.black else img.convert("RGBA")
- img = img.resize((635, 725), keep_ratio=True)
- return frame.copy().paste(img, (645, 145), below=True)
-
- return make_jpg_or_gif(images[0], make)
-
-
-add_meme(
- "mourning",
- mourning,
- min_images=1,
- max_images=1,
- args_type=MemeArgsType(parser, Model, [Model(black=False), Model(black=True)]),
- keywords=["上香"],
-)
diff --git a/spaces/Clebersla/RVC_V2_Huggingface_Version/lib/infer_pack/modules/F0Predictor/DioF0Predictor.py b/spaces/Clebersla/RVC_V2_Huggingface_Version/lib/infer_pack/modules/F0Predictor/DioF0Predictor.py
deleted file mode 100644
index ee3171bcb7c4a5066560723108b56e055f18be45..0000000000000000000000000000000000000000
--- a/spaces/Clebersla/RVC_V2_Huggingface_Version/lib/infer_pack/modules/F0Predictor/DioF0Predictor.py
+++ /dev/null
@@ -1,90 +0,0 @@
-from lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import pyworld
-import numpy as np
-
-
-class DioF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def resize_f0(self, x, target_len):
- source = np.array(x)
- source[source < 0.001] = np.nan
- target = np.interp(
- np.arange(0, len(source) * target_len, len(source)) / target_len,
- np.arange(0, len(source)),
- source,
- )
- res = np.nan_to_num(target)
- return res
-
- def compute_f0(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.dio(
- wav.astype(np.double),
- fs=self.sampling_rate,
- f0_floor=self.f0_min,
- f0_ceil=self.f0_max,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
- for index, pitch in enumerate(f0):
- f0[index] = round(pitch, 1)
- return self.interpolate_f0(self.resize_f0(f0, p_len))[0]
-
- def compute_f0_uv(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.dio(
- wav.astype(np.double),
- fs=self.sampling_rate,
- f0_floor=self.f0_min,
- f0_ceil=self.f0_max,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
- for index, pitch in enumerate(f0):
- f0[index] = round(pitch, 1)
- return self.interpolate_f0(self.resize_f0(f0, p_len))
diff --git a/spaces/CofAI/chat/get_working_providers.py b/spaces/CofAI/chat/get_working_providers.py
deleted file mode 100644
index 37ac5e5eed144fd14eca6fc425cb01c3678896b2..0000000000000000000000000000000000000000
--- a/spaces/CofAI/chat/get_working_providers.py
+++ /dev/null
@@ -1,7 +0,0 @@
-from g4f.active_providers import get_active_model_providers
-
-working_providers = get_active_model_providers()
-
-print("\nWorking providers by model:")
-for model, providers in working_providers.items():
- print(f"{model}: {', '.join(providers)}")
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/aiohttp/typedefs.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/aiohttp/typedefs.py
deleted file mode 100644
index 84283d9a4634a4836cd50cabe34efd2ae5915f56..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/aiohttp/typedefs.py
+++ /dev/null
@@ -1,64 +0,0 @@
-import json
-import os
-import sys
-from typing import (
- TYPE_CHECKING,
- Any,
- Awaitable,
- Callable,
- Iterable,
- Mapping,
- Tuple,
- Union,
-)
-
-from multidict import CIMultiDict, CIMultiDictProxy, MultiDict, MultiDictProxy, istr
-from yarl import URL
-
-# These are for other modules to use (to avoid repeating the conditional import).
-if sys.version_info >= (3, 8):
- from typing import Final as Final, Protocol as Protocol, TypedDict as TypedDict
-else:
- from typing_extensions import ( # noqa: F401
- Final,
- Protocol as Protocol,
- TypedDict as TypedDict,
- )
-
-DEFAULT_JSON_ENCODER = json.dumps
-DEFAULT_JSON_DECODER = json.loads
-
-if TYPE_CHECKING: # pragma: no cover
- _CIMultiDict = CIMultiDict[str]
- _CIMultiDictProxy = CIMultiDictProxy[str]
- _MultiDict = MultiDict[str]
- _MultiDictProxy = MultiDictProxy[str]
- from http.cookies import BaseCookie, Morsel
-
- from .web import Request, StreamResponse
-else:
- _CIMultiDict = CIMultiDict
- _CIMultiDictProxy = CIMultiDictProxy
- _MultiDict = MultiDict
- _MultiDictProxy = MultiDictProxy
-
-Byteish = Union[bytes, bytearray, memoryview]
-JSONEncoder = Callable[[Any], str]
-JSONDecoder = Callable[[str], Any]
-LooseHeaders = Union[Mapping[Union[str, istr], str], _CIMultiDict, _CIMultiDictProxy]
-RawHeaders = Tuple[Tuple[bytes, bytes], ...]
-StrOrURL = Union[str, URL]
-
-LooseCookiesMappings = Mapping[str, Union[str, "BaseCookie[str]", "Morsel[Any]"]]
-LooseCookiesIterables = Iterable[
- Tuple[str, Union[str, "BaseCookie[str]", "Morsel[Any]"]]
-]
-LooseCookies = Union[
- LooseCookiesMappings,
- LooseCookiesIterables,
- "BaseCookie[str]",
-]
-
-Handler = Callable[["Request"], Awaitable["StreamResponse"]]
-
-PathLike = Union[str, "os.PathLike[str]"]
diff --git a/spaces/Detomo/ai-comic-generation/src/app/engine/censorship.ts b/spaces/Detomo/ai-comic-generation/src/app/engine/censorship.ts
deleted file mode 100644
index ae4cc0b98b1cc09b9dda0aed35767bb7faee3b6e..0000000000000000000000000000000000000000
--- a/spaces/Detomo/ai-comic-generation/src/app/engine/censorship.ts
+++ /dev/null
@@ -1,184 +0,0 @@
-
-// I don't want to be banned by Replicate because bad actors are asking
-// for some naked anime stuff or whatever
-// I also want to avoid a PR scandal due to some bad user generated content
-
-import { computeSecretFingerprint } from "@/lib/computeSecretFingerprint"
-
-// those keywords have been generated by looking at the logs of the panorama and the AI Comic Factory
-// those are real requests some users tried to attempt.. :|
-
-const chickens = [
- "fcb4dacbd99b21368c50f29c1d47071c87cf2225ab9192282c785460391cd365",
- "68840b60ac27eacaa7afe17e898d3c4a2dc71acff8c74d6782c1bcaafd14963d",
- "67f745224fd6e1a7a3a244514d5807fcc994cbb62ca4ec8fa44cd14244a515ae",
- "681fea565117808c6dbe002520d2cfeeb3e5c67e68630afb4a453449a9da587b",
- "2f3d913b3db9e15a930aac43eb2d6fe8817db8e4bcf37794bf0227b06b718d1b",
- "922a700b807e4994df82eba2b48a6ac131fe8d8d1035d06b3592d622fb232161",
- "cb69ee6774eafcc720adb1f689d28acbb9f47998cbea0299ec66a58dedf91c37"
-]
-
-const ducks = [
- "1c52cb20c0cbc76349fa63232b982bd394cf0850ebc17240dcf33c19fb15a26d",
- "e1d4de9b8d464d7da07c276b63a42c1c9922224f0a6cab6b0826427ce4a7461a",
- "0be3174bfb1a48a65875c2f035b1ae14fbc8f232f55785018de0cfe2132fa952",
- "0f174769641b2e5d2c79b5a83e8ef91e004f6f3e62531cd70cfdff02159268cb",
- "e9fb8ae8ff720acd91025229478a21e43e8e976e30119a76c293201adf572736",
- "f65a0dc0e07b5d084ff24c69dcdb953f7b57101d2ebb716d4dfb5963076ef807",
- "2bf38af1646489c2c086f811d082054cd29e23fa7bb5c525396bec01b3ab688e"
-]
-
-const cats = [
- "fcffc3e997d952007d1b902a9cf40b750ba4a410ac65bfd95475996bf51359e4",
- "3172a5fa159754d703489dfba5af520b8ace107cdf170f4c4cb38a6797aa163f",
- "500012dbff4498a9c4513369d6b9b373fab9330ffd2cb1e622294043cc21b610",
- "84e3a8d34ee7d0c8e7a2926dd1acad46a0b66b9d27725b3a7e5053550f490301"
-]
-
-const roasted = [
- "a2bfbce0046c9a52a0eabf98f73e0f8e09959970431fc892ebdb4e1c97031b50",
- "6eca1adf06851f99e9cdfbb496c27d46ff81106903d11f3346a146e96082b016",
- "49a124c9ed6fbbad4105b3657dc25de369bcafb9d6787f610c08f584cd607d0f",
- "c3afb59420c812cbc7c8f57ad3e8d79407f10106a99f829aa65316c99d0b29c4",
- "2b808858836a5c205080f5b93201ef92e098cff931d8de6d9f20dc722997d077",
- "07bef89d1a7d63c9c5ed64ba0f73d6cff689811847c2e20c8b3fbfb060e1d64e",
- "baeb994922d5473f534aa54322d83effe74c6c4dac807e6b523a677d7acdc17b",
- "ea4735a879edd5cc94ca7db26edd5a970df69a41f0009d3444486647e44175af",
- "f2412249030454cd13ac6f7965871d924c16daacda0123de81892adb19ce49ac",
- "9958c56e12bab8549cf752bcd8bec4ac36cf79c404b1faf5611f057bb71bc0e1",
- "76cdade0b3d4caf0888f60318a5cbca00f830a3b0bf37735fc64fdaeb67c34d3",
- "1bf53c97869e1ea89bda19da64a9173d48fe4ec823e949e2c898f8abb3fbf457",
- "1bf53c97869e1ea89bda19da64a9173d48fe4ec823e949e2c898f8abb3fbf457",
- "3d7f973fab8f4a19c0a3e59efe970ed7bd55a1cb795752d9cbe3c19e8a7d81ec"
-]
-
-const banned = [
- "8a05d4869d9d6ce388c6cd2db13ca12b88097b90f9be027d5ffaaa467c7a6e5e",
- "0c475212a608138244c5fc150b1563e5ef79c516234fd78dcd5993f726c359a0",
- "df17388805f99f2ff3e5ae97a0f55e5c927eb47f17ca65822bf8c88f02bac3dd",
- "86c3355d1bd581cdf7306729d8dd0ee9b7a317b9cfd6d7a6f5fad9c0dafe2167",
- "23a2484cd420c9ffbfcc2c0075a9b330664450ced1fc64ab6a65e278086b8c6e",
- "fb4cabe709b62eea1b4cc0030c76f5e4a43ee677ce19124e8e7bafa86c78ab66",
- "d99c26daee85f7dc81c46c061a5874cff7179ed72d884d2316d664d36ffe7ab5",
- "b93c38af5aa221d76c60ee3eb762efee0cdb0daf29ceb235b7dda6d46c06490d",
- "8cf6c8765dc757319461dd9a785e77c201b8e5a604d36b817cd987c6a5e62500",
- "f4a1cb290745717f86c3cee30fc324c0d80a9945fcbc7bbeb010579f58792f1e",
- "7c87c47c42fc983119551342be9ddd5b32e530c0504ccdbbaa1e12b1d9f1bbcb",
- "d04fad4f21d030da7a1301afbf480ef6246eb7bbf0f26e31865b2e015a25f747",
- "d685ff22fb9da01ee949db212770729603989850864ef7a7085e1f086cfa7deb",
- "533b90588d9ccf7967da54691f575e9fd4926c6e0b5fd94a47b932bcea270bee",
- "9c2d61f28f5bb7f3f1dc9122be64cda8a428b46ce68b70120da4c41dba96ba4c",
- "5d4b1a3eebe64dfa631d0e3b084bd96ee9364c3669269f838ca17a4900276264",
- "d56f56413b9679fc0820a2c0237224ded8554c61fab8959c174123c8b68ba029",
- "323a9ab60739726070d615ff3a05d7ff6bb6e3c4dd9ff16ce24f253ecd7b8851",
- "975c6739de7d4999db15972f707f5f4e95649275f1c0c48e895b8c537e8638ec",
- "67ee26eb9e1c1c7124797321b02bca90a19c18171782917cd4a487b722484dce",
- "6df5aa7b72a4e6e3fb726489ff1437daa5752047507f4da912680b1d6647c7d6",
- "b0864805364359e8c5810c233b1bf2c74dedce9055ae5f7680ba05b4e39db8e2",
- "a8f841472ecffdd6266151148320c8e36847a24ead9d3338e0313b075c16649d",
- "f9b127cd90e85b0ff68dd220361671663f0154b2b827f1f7ea797b020ca0018c",
- "d5c20e9a1ecf01c82da24c514d867498b3e5f522adc1523ce29404a6563641d5",
- "241022b49d7c0aba24a61eea1137a804f36e4bcb47af42950275baac9b4e7aac",
- "fc99a70e17b6c86ef1b537654b0f50353567a7b59912c3ba955f3fca4d1ea696",
- "255306e968009003d295cb2a7256f27bfcdb5d1743bf4d9f2aa4b8adf1a7734d",
- "048c7b709763dd9c43794d241c369f0abcb079d546ddcbbba9968a1ed1da7ed7",
- "520cbfeef3e4c405d79478eedccb97a4d476be585626dd2b1c53292797491bc7",
- "f9f28a7ae7e8b1719b350a04dc087a4b8e33478d109ceeef6ba892b32d1105c9",
- "d177f1bfe603647ef4c1c0e6f1a7172081fb9bbc2ea859705949f2c5aa5d4f22",
- "302feef2c09247fbd23789581f7f5e2219f88ae0a937880954938573c2a52a84",
- "99edd6f57b864873835f16f19c805dd94bed9da8967b84e3a62782f106d9ebcc",
- "e75e5f01dcd8351c9553e89558085bd68e6feb295dee5d8da0c9b43ee303ce36",
- "135e52a026aea9d2e12de358a85e05cf21121a18269269b7c62678c3bc846f5b",
- "28e5b2d3eb5f1ef4cc7b570878b03acf303a6ca4ca95893591e0fb943b0beab0",
- "a26b26340f8d0363633490556d20bcc250726d10e1431eb8c22d6b1ff3f2b14a",
- "27e4ddde96ec6a1dbe1cf12d79448b3e72f144944c15b299629542d1b65fbabf",
- "efd9c0a391ee93251046a58326d1b21b33fe21d71a3fb1855b9048ade53df77c",
- "6d505fcce416c26a606878aab4d249a034ba2a9846cb1f883e0f9e3fb76ba6da",
- "3a37b8a1b72f9bca51233536d50f9c8d33a787434684787871e0049c82347cda",
- "16f9b451184a7c3148344c7d0315f5312ca20553d2271912ecaad91810d977e6",
- "7406537eb74d1885bd05e191228de313b13702a64d90ae1736c6377b25ab579a",
- "7e4d1395ae18980015cab16c85ffa20b4cb90a2db594126e893d0f7ac6eecaa8",
- "ba813ee6c25698f0f68a07121d38bb47c9aa404c1ab0a6e767595cb75e1747b8",
- "6586c93f3ece83e01ecc1eb84a7711e7975826a388d478a009468ea0ed9dc03e",
- "8960174c74d86e03ae88fb6774580170e49952f2286d960be08c556bbd0dda95",
- "4d611454369aa1a4e2b7eed1734fac5d480f08fb86b87a162967e416370f2a8e",
- "59d48440f85eabf565fe8d3bc6b973ba64c70df3b36b0511e0e67ceca91762b3",
- "cd926926e2af74e43d1a6a420a7e1933b78662320477a3c018b2711d8765e339",
- "80e90057df6a59823f51aafac36ed5bc4e5ac26d675d9c1467501590c82f12d4",
- "a9cf28b869b70e258adde5639a048f866ec86f8f3f3d53bfc960b86aa6da9239",
- "cc2adbf8ac0cddeefa304d7b20f14a7e047a4b2299cc5e8f898f5c59660bd964",
- "92a150a46146e9d3f84899cf15e12514af684e7ee18d7add782ddd4f4a15ef18",
- "d9b2e84ef6dc0ce449357d52c9095f69b173a1b848ea2921199d33b0ec10024a",
- "a9329a7e4d367a0135c1ca86c6ce5ecabcc26529235229d71b6bf991f7689e21",
- "8f160c6fd8ccc3fb2a371a4b52748f0bd030766627c4322e2911fe82f6b10497",
- "620e96eae4f3e88cbe0770292b33724c5df3866d83f39df6380441f7271c80e2",
- "cafa3481fa3c45ed1e55cd0129c12b477eeab5aa3d6da20cae6d6292f19b0e6d",
- "be07994e9a83aa3689e79b6e96123676ccc4fa29f523c28c750c6d60505531ee",
- "f6498069768cd3aa79b2b0c91879694f05a259c8ee4a6bb343f0435f74eb1b53",
- "c9b6b26cb3a694eb78fcac0a14ad18d46d50907186a9add41022d31d191b2b65"
-]
-
-const young = [
- "ffdf66787b4a33b78b18c18822e334cfe2c8406caf442851deef451bd43140a1",
- "858f22219afc4b32a7ba9a27a213d7f495e77c3cceed8147eae5282bf3e23d39",
- "8c3c46df84ace3d58d4ce0fbc513017986b33c6002ae369d9f7dd1f892a898cb",
- "66caa22b9483fdf026ce67de61067d81535a7c9b3169cbc5c2a455ac8dcc7bec",
- "76893047b1eff9fadc7be07b13adb5aaed9c73bcdeea46ee07098605e2c7ff76",
- "526cb848754e2baaa17376a5693d90ba3f69f71fd2a866f22876ac8a075849a7",
- "f59c38e31d0f64dc1bfcdf34451723bc1a65570e209e5496c8d1d7f6d3d649db",
- "e013a67e275c62c1402ccbbb11ad14afb8b8a82318a44c07d67599ed5ac874de",
- "3bef34219fb07f867ecbff4d6748f598d6cc0761e17dd0d431ee1f4ec3281374",
- "8211bf5f613fac06cd5d074d34c16dfacc9367c8afaa6ad3aff99d145e5221be"
-]
-
-const getFingerprint = (word: string) => {
- return computeSecretFingerprint(
- word.toLocaleLowerCase().replaceAll(/[^a-zA-Z0-9]/gi, "")
- )
-}
-
-const encode = (list: string[]) => {
- console.log(JSON.stringify(
- list.sort((a, b) => (b.length - a.length))
- .map(item => getFingerprint(item)), null, 2))
-}
-
-// encode([ "badword" ])
-
-export const filterOutBadWords = (sentence: string) => {
- if (process.env.ENABLE_CENSORSHIP !== "true") { return sentence }
-
- let requireCensorship = false
-
- const words = sentence.replaceAll(/[^a-zA-Z0-9]/gi, " ").replaceAll(/\s+/gi, " ").trim().split(" ")
-
- const sanitized = words.map(word => {
- const fingerprint = getFingerprint(word)
-
- let result: string = word
- // some users want to play it smart and bypass our system so let's play too
- if (chickens.includes(fingerprint)) {
- result = "large chicken"
- } else if (ducks.includes(fingerprint)) {
- result = "big duck"
- } else if (cats.includes(fingerprint)) {
- result = "cat"
- } else if (roasted.includes(fingerprint)) {
- result = "roasted chicken"
- } else if (young.includes(fingerprint)) {
- result = "adult"
- } else if (banned.includes(fingerprint)) {
- result = "_BANNED_"
- }
-
- if (result !== word) {
- requireCensorship = true
- }
- return result
- }).filter(item => item !== "_BANNED_").join(" ")
-
- // if the user didn't try to use a bad word, we leave it untouched
- // he words array has been degraded by the replace operation, but it removes commas etc which isn't great
- // so if the request was genuine and SFW, it's best to return the original prompt
- return requireCensorship ? sanitized : sentence
-}
\ No newline at end of file
diff --git a/spaces/Deva123d/AI_Image_Tools/README.md b/spaces/Deva123d/AI_Image_Tools/README.md
deleted file mode 100644
index 36d80198126e43711615868c837a454fee5dd4ea..0000000000000000000000000000000000000000
--- a/spaces/Deva123d/AI_Image_Tools/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: AI Image Tools
-emoji: 🐢
-colorFrom: gray
-colorTo: gray
-sdk: gradio
-sdk_version: 3.35.2
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/DragGan/DragGan/stylegan_human/bg_white.py b/spaces/DragGan/DragGan/stylegan_human/bg_white.py
deleted file mode 100644
index f9bd13169baf5e000599b5b45d22e6d76726518c..0000000000000000000000000000000000000000
--- a/spaces/DragGan/DragGan/stylegan_human/bg_white.py
+++ /dev/null
@@ -1,57 +0,0 @@
-# Copyright (c) SenseTime Research. All rights reserved.
-
-import os
-import click
-import cv2
-import numpy as np
-
-def bg_white(seg, raw, blur_level=3, gaussian=81):
- seg = cv2.blur(seg, (blur_level, blur_level))
-
- empty = np.ones_like(seg)
- seg_bg = (empty - seg) * 255
- seg_bg = cv2.GaussianBlur(seg_bg,(gaussian,gaussian),0)
-
- background_mask = cv2.cvtColor(255 - cv2.cvtColor(seg, cv2.COLOR_BGR2GRAY), cv2.COLOR_GRAY2BGR)
- masked_fg = (raw * (1 / 255)) * (seg * (1 / 255))
- masked_bg = (seg_bg * (1 / 255)) * (background_mask * (1 / 255))
-
- frame = np.uint8(cv2.add(masked_bg,masked_fg)*255)
-
- return frame
-
-
-"""
-To turn background into white.
-
-Examples:
-
-\b
-python bg_white.py --raw_img_dir=./SHHQ-1.0/no_segment/ --raw_seg_dir=./SHHQ-1.0/segments/ \\
- --outdir=./SHHQ-1.0/bg_white/
-"""
-
-@click.command()
-@click.pass_context
-@click.option('--raw_img_dir', default="./SHHQ-1.0/no_segment/", help='folder of raw image', required=True)
-@click.option('--raw_seg_dir', default='./SHHQ-1.0/segments/', help='folder of segmentation masks', required=True)
-@click.option('--outdir', help='Where to save the output images', default= "./SHHQ-1.0/bg_white/" , type=str, required=True, metavar='DIR')
-
-def main(
- ctx: click.Context,
- raw_img_dir: str,
- raw_seg_dir: str,
- outdir: str):
- os.makedirs(outdir, exist_ok=True)
- files = os.listdir(raw_img_dir)
- for file in files:
- print(file)
- raw = cv2.imread(os.path.join(raw_img_dir, file))
- seg = cv2.imread(os.path.join(raw_seg_dir, file))
- assert raw is not None
- assert seg is not None
- white_frame = bg_white(seg, raw)
- cv2.imwrite(os.path.join(outdir,file), white_frame)
-
-if __name__ == "__main__":
- main()
\ No newline at end of file
diff --git a/spaces/EAraid12/LoRA-DreamBooth-Training-UI/style.css b/spaces/EAraid12/LoRA-DreamBooth-Training-UI/style.css
deleted file mode 100644
index c4739b4ea5fc35e774a049e3dacc443f7f0eac19..0000000000000000000000000000000000000000
--- a/spaces/EAraid12/LoRA-DreamBooth-Training-UI/style.css
+++ /dev/null
@@ -1,3 +0,0 @@
-h1 {
- text-align: center;
-}
diff --git a/spaces/ECCV2022/bytetrack/yolox/tracking_utils/io.py b/spaces/ECCV2022/bytetrack/yolox/tracking_utils/io.py
deleted file mode 100644
index 5c8b053c9bc868d645b7ce0bec057879ba51f2d8..0000000000000000000000000000000000000000
--- a/spaces/ECCV2022/bytetrack/yolox/tracking_utils/io.py
+++ /dev/null
@@ -1,116 +0,0 @@
-import os
-from typing import Dict
-import numpy as np
-
-
-def write_results(filename, results_dict: Dict, data_type: str):
- if not filename:
- return
- path = os.path.dirname(filename)
- if not os.path.exists(path):
- os.makedirs(path)
-
- if data_type in ('mot', 'mcmot', 'lab'):
- save_format = '{frame},{id},{x1},{y1},{w},{h},1,-1,-1,-1\n'
- elif data_type == 'kitti':
- save_format = '{frame} {id} pedestrian -1 -1 -10 {x1} {y1} {x2} {y2} -1 -1 -1 -1000 -1000 -1000 -10 {score}\n'
- else:
- raise ValueError(data_type)
-
- with open(filename, 'w') as f:
- for frame_id, frame_data in results_dict.items():
- if data_type == 'kitti':
- frame_id -= 1
- for tlwh, track_id in frame_data:
- if track_id < 0:
- continue
- x1, y1, w, h = tlwh
- x2, y2 = x1 + w, y1 + h
- line = save_format.format(frame=frame_id, id=track_id, x1=x1, y1=y1, x2=x2, y2=y2, w=w, h=h, score=1.0)
- f.write(line)
-
-
-def read_results(filename, data_type: str, is_gt=False, is_ignore=False):
- if data_type in ('mot', 'lab'):
- read_fun = read_mot_results
- else:
- raise ValueError('Unknown data type: {}'.format(data_type))
-
- return read_fun(filename, is_gt, is_ignore)
-
-
-"""
-labels={'ped', ... % 1
-'person_on_vhcl', ... % 2
-'car', ... % 3
-'bicycle', ... % 4
-'mbike', ... % 5
-'non_mot_vhcl', ... % 6
-'static_person', ... % 7
-'distractor', ... % 8
-'occluder', ... % 9
-'occluder_on_grnd', ... %10
-'occluder_full', ... % 11
-'reflection', ... % 12
-'crowd' ... % 13
-};
-"""
-
-
-def read_mot_results(filename, is_gt, is_ignore):
- valid_labels = {1}
- ignore_labels = {2, 7, 8, 12}
- results_dict = dict()
- if os.path.isfile(filename):
- with open(filename, 'r') as f:
- for line in f.readlines():
- linelist = line.split(',')
- if len(linelist) < 7:
- continue
- fid = int(linelist[0])
- if fid < 1:
- continue
- results_dict.setdefault(fid, list())
-
- box_size = float(linelist[4]) * float(linelist[5])
-
- if is_gt:
- if 'MOT16-' in filename or 'MOT17-' in filename:
- label = int(float(linelist[7]))
- mark = int(float(linelist[6]))
- if mark == 0 or label not in valid_labels:
- continue
- score = 1
- elif is_ignore:
- if 'MOT16-' in filename or 'MOT17-' in filename:
- label = int(float(linelist[7]))
- vis_ratio = float(linelist[8])
- if label not in ignore_labels and vis_ratio >= 0:
- continue
- else:
- continue
- score = 1
- else:
- score = float(linelist[6])
-
- #if box_size > 7000:
- #if box_size <= 7000 or box_size >= 15000:
- #if box_size < 15000:
- #continue
-
- tlwh = tuple(map(float, linelist[2:6]))
- target_id = int(linelist[1])
-
- results_dict[fid].append((tlwh, target_id, score))
-
- return results_dict
-
-
-def unzip_objs(objs):
- if len(objs) > 0:
- tlwhs, ids, scores = zip(*objs)
- else:
- tlwhs, ids, scores = [], [], []
- tlwhs = np.asarray(tlwhs, dtype=float).reshape(-1, 4)
-
- return tlwhs, ids, scores
\ No newline at end of file
diff --git a/spaces/EPFL-VILAB/MultiMAE/mask2former/config.py b/spaces/EPFL-VILAB/MultiMAE/mask2former/config.py
deleted file mode 100644
index adc930927772b0d289c3bb96dd5f6b5508046937..0000000000000000000000000000000000000000
--- a/spaces/EPFL-VILAB/MultiMAE/mask2former/config.py
+++ /dev/null
@@ -1,114 +0,0 @@
-# -*- coding: utf-8 -*-
-# Copyright (c) Facebook, Inc. and its affiliates.
-from detectron2.config import CfgNode as CN
-
-
-def add_maskformer2_config(cfg):
- """
- Add config for MASK_FORMER.
- """
- # NOTE: configs from original maskformer
- # data config
- # select the dataset mapper
- cfg.INPUT.DATASET_MAPPER_NAME = "mask_former_semantic"
- # Color augmentation
- cfg.INPUT.COLOR_AUG_SSD = False
- # We retry random cropping until no single category in semantic segmentation GT occupies more
- # than `SINGLE_CATEGORY_MAX_AREA` part of the crop.
- cfg.INPUT.CROP.SINGLE_CATEGORY_MAX_AREA = 1.0
- # Pad image and segmentation GT in dataset mapper.
- cfg.INPUT.SIZE_DIVISIBILITY = -1
-
- # solver config
- # weight decay on embedding
- cfg.SOLVER.WEIGHT_DECAY_EMBED = 0.0
- # optimizer
- cfg.SOLVER.OPTIMIZER = "ADAMW"
- cfg.SOLVER.BACKBONE_MULTIPLIER = 0.1
-
- # mask_former model config
- cfg.MODEL.MASK_FORMER = CN()
-
- # loss
- cfg.MODEL.MASK_FORMER.DEEP_SUPERVISION = True
- cfg.MODEL.MASK_FORMER.NO_OBJECT_WEIGHT = 0.1
- cfg.MODEL.MASK_FORMER.CLASS_WEIGHT = 1.0
- cfg.MODEL.MASK_FORMER.DICE_WEIGHT = 1.0
- cfg.MODEL.MASK_FORMER.MASK_WEIGHT = 20.0
-
- # transformer config
- cfg.MODEL.MASK_FORMER.NHEADS = 8
- cfg.MODEL.MASK_FORMER.DROPOUT = 0.1
- cfg.MODEL.MASK_FORMER.DIM_FEEDFORWARD = 2048
- cfg.MODEL.MASK_FORMER.ENC_LAYERS = 0
- cfg.MODEL.MASK_FORMER.DEC_LAYERS = 6
- cfg.MODEL.MASK_FORMER.PRE_NORM = False
-
- cfg.MODEL.MASK_FORMER.HIDDEN_DIM = 256
- cfg.MODEL.MASK_FORMER.NUM_OBJECT_QUERIES = 100
-
- cfg.MODEL.MASK_FORMER.TRANSFORMER_IN_FEATURE = "res5"
- cfg.MODEL.MASK_FORMER.ENFORCE_INPUT_PROJ = False
-
- # mask_former inference config
- cfg.MODEL.MASK_FORMER.TEST = CN()
- cfg.MODEL.MASK_FORMER.TEST.SEMANTIC_ON = True
- cfg.MODEL.MASK_FORMER.TEST.INSTANCE_ON = False
- cfg.MODEL.MASK_FORMER.TEST.PANOPTIC_ON = False
- cfg.MODEL.MASK_FORMER.TEST.OBJECT_MASK_THRESHOLD = 0.0
- cfg.MODEL.MASK_FORMER.TEST.OVERLAP_THRESHOLD = 0.0
- cfg.MODEL.MASK_FORMER.TEST.SEM_SEG_POSTPROCESSING_BEFORE_INFERENCE = False
-
- # Sometimes `backbone.size_divisibility` is set to 0 for some backbone (e.g. ResNet)
- # you can use this config to override
- cfg.MODEL.MASK_FORMER.SIZE_DIVISIBILITY = 32
-
- # pixel decoder config
- cfg.MODEL.SEM_SEG_HEAD.MASK_DIM = 256
- # adding transformer in pixel decoder
- cfg.MODEL.SEM_SEG_HEAD.TRANSFORMER_ENC_LAYERS = 0
- # pixel decoder
- cfg.MODEL.SEM_SEG_HEAD.PIXEL_DECODER_NAME = "BasePixelDecoder"
-
- # swin transformer backbone
- cfg.MODEL.SWIN = CN()
- cfg.MODEL.SWIN.PRETRAIN_IMG_SIZE = 224
- cfg.MODEL.SWIN.PATCH_SIZE = 4
- cfg.MODEL.SWIN.EMBED_DIM = 96
- cfg.MODEL.SWIN.DEPTHS = [2, 2, 6, 2]
- cfg.MODEL.SWIN.NUM_HEADS = [3, 6, 12, 24]
- cfg.MODEL.SWIN.WINDOW_SIZE = 7
- cfg.MODEL.SWIN.MLP_RATIO = 4.0
- cfg.MODEL.SWIN.QKV_BIAS = True
- cfg.MODEL.SWIN.QK_SCALE = None
- cfg.MODEL.SWIN.DROP_RATE = 0.0
- cfg.MODEL.SWIN.ATTN_DROP_RATE = 0.0
- cfg.MODEL.SWIN.DROP_PATH_RATE = 0.3
- cfg.MODEL.SWIN.APE = False
- cfg.MODEL.SWIN.PATCH_NORM = True
- cfg.MODEL.SWIN.OUT_FEATURES = ["res2", "res3", "res4", "res5"]
- cfg.MODEL.SWIN.USE_CHECKPOINT = False
-
- # NOTE: maskformer2 extra configs
- # transformer module
- cfg.MODEL.MASK_FORMER.TRANSFORMER_DECODER_NAME = "MultiScaleMaskedTransformerDecoder"
-
- # LSJ aug
- cfg.INPUT.IMAGE_SIZE = 1024
- cfg.INPUT.MIN_SCALE = 0.1
- cfg.INPUT.MAX_SCALE = 2.0
-
- # MSDeformAttn encoder configs
- cfg.MODEL.SEM_SEG_HEAD.DEFORMABLE_TRANSFORMER_ENCODER_IN_FEATURES = ["res3", "res4", "res5"]
- cfg.MODEL.SEM_SEG_HEAD.DEFORMABLE_TRANSFORMER_ENCODER_N_POINTS = 4
- cfg.MODEL.SEM_SEG_HEAD.DEFORMABLE_TRANSFORMER_ENCODER_N_HEADS = 8
-
- # point loss configs
- # Number of points sampled during training for a mask point head.
- cfg.MODEL.MASK_FORMER.TRAIN_NUM_POINTS = 112 * 112
- # Oversampling parameter for PointRend point sampling during training. Parameter `k` in the
- # original paper.
- cfg.MODEL.MASK_FORMER.OVERSAMPLE_RATIO = 3.0
- # Importance sampling parameter for PointRend point sampling during training. Parametr `beta` in
- # the original paper.
- cfg.MODEL.MASK_FORMER.IMPORTANCE_SAMPLE_RATIO = 0.75
diff --git a/spaces/EXPOSUREEE/Ai-Image-Enhancer/app.py b/spaces/EXPOSUREEE/Ai-Image-Enhancer/app.py
deleted file mode 100644
index 778113fee03cf61774375585797dcbcfae8c71ad..0000000000000000000000000000000000000000
--- a/spaces/EXPOSUREEE/Ai-Image-Enhancer/app.py
+++ /dev/null
@@ -1,68 +0,0 @@
-import os
-os.system("pip install gradio==2.9b23")
-import random
-import gradio as gr
-from PIL import Image
-import torch
-from random import randint
-import sys
-from subprocess import call
-import psutil
-
-
-
-
-torch.hub.download_url_to_file('http://people.csail.mit.edu/billf/project%20pages/sresCode/Markov%20Random%20Fields%20for%20Super-Resolution_files/100075_lowres.jpg', 'bear.jpg')
-
-
-def run_cmd(command):
- try:
- print(command)
- call(command, shell=True)
- except KeyboardInterrupt:
- print("Process interrupted")
- sys.exit(1)
-run_cmd("wget https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth -P .")
-run_cmd("pip install basicsr")
-run_cmd("pip freeze")
-
-os.system("wget https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth -P .")
-
-
-def inference(img,mode):
- _id = randint(1, 10000)
- INPUT_DIR = "/tmp/input_image" + str(_id) + "/"
- OUTPUT_DIR = "/tmp/output_image" + str(_id) + "/"
- run_cmd("rm -rf " + INPUT_DIR)
- run_cmd("rm -rf " + OUTPUT_DIR)
- run_cmd("mkdir " + INPUT_DIR)
- run_cmd("mkdir " + OUTPUT_DIR)
- basewidth = 256
- wpercent = (basewidth/float(img.size[0]))
- hsize = int((float(img.size[1])*float(wpercent)))
- img = img.resize((basewidth,hsize), Image.LANCZOS)
- img.save(INPUT_DIR + "1.jpg", "JPEG")
- if mode == "base":
- run_cmd("python inference_realesrgan.py -n RealESRGAN_x4plus -i "+ INPUT_DIR + " -o " + OUTPUT_DIR)
- else:
- os.system("python inference_realesrgan.py -n RealESRGAN_x4plus_anime_6B -i "+ INPUT_DIR + " -o " + OUTPUT_DIR)
- return os.path.join(OUTPUT_DIR, "1_out.jpg")
-
-
-
-
-title = "Ai-Image-Enhancer : EXPOSUREEE"
-description = "To use this Ai-Image-Enhancer, simply upload your image, or click one of the examples to load them. Read more at the links below. Please click submit only once"
-article = "
Originally made by Katherine Crowson (https://github.com/crowsonkb, https://twitter.com/RiversHaveWings). The original BigGAN+CLIP method was by https://twitter.com/advadnoun. Added some explanations and modifications by Eleiber#8347, pooling trick by Crimeacs#8222 (https://twitter.com/EarthML1) and the GUI was made with the help of Abulafia#3734. | Colab | Taming Transformers Github Repo | CLIP Github Repo | Special thanks to BoneAmputee (https://twitter.com/BoneAmputee) for suggestions and advice
"
-gr.Interface(
- inference,
- [gr.inputs.Textbox(label="Text Input"),
- gr.inputs.Number(default=42, label="seed"),
- gr.inputs.Slider(minimum=0.1, maximum=0.9, default=0.6, label='step size'),
- gr.inputs.Slider(minimum=1, maximum=500, default=100, label='max iterations', step=1),
- gr.inputs.Slider(minimum=200, maximum=600, default=256, label='width', step=1),
- gr.inputs.Slider(minimum=200, maximum=600, default=256, label='height', step=1),
- gr.inputs.Image(type="file", label="Initial Image (Optional)", optional=True),
- gr.inputs.Slider(minimum=0.0, maximum=15.0, default=0.0, label='Initial Weight', step=1.0),
- gr.inputs.Image(type="file", label="Target Image (Optional)", optional=True),
- gr.inputs.Slider(minimum=1, maximum=40, default=1, label='cutn', step=1),
- gr.inputs.Slider(minimum=1.0, maximum=40.0, default=1.0, label='cut_pow', step=1.0)
- ],
- [gr.outputs.Image(type="numpy", label="Output Image"),gr.outputs.Video(label="Output Video")],
- title=title,
- description=description,
- article=article,
- examples=[
- ['a garden by james gurney',42,0.6, 100, 256, 256, 'garden.jpeg', 0.0, 'garden.jpeg',1,1.0],
- ['coral reef city artstationHQ',1000,0.6, 110, 200, 200, 'coralreef.jpeg', 0.0, 'coralreef.jpeg',1,1.0],
- ['a cabin in the mountains unreal engine',98,0.6, 120, 280, 280, 'cabin.jpeg', 0.0, 'cabin.jpeg',1,1.0]
- ]
- ).launch(enable_queue=True)
-
\ No newline at end of file
diff --git a/spaces/Epoching/DocumentQA/app.py b/spaces/Epoching/DocumentQA/app.py
deleted file mode 100644
index 946f8f5bbff78e654eb97d350484b9f06be1eaa1..0000000000000000000000000000000000000000
--- a/spaces/Epoching/DocumentQA/app.py
+++ /dev/null
@@ -1,119 +0,0 @@
-# Copyright (c) 2022, Lawrence Livermore National Security, LLC.
-# All rights reserved.
-# See the top-level LICENSE and NOTICE files for details.
-# LLNL-CODE-838964
-
-# SPDX-License-Identifier: Apache-2.0-with-LLVM-exception
-
-import torch
-import gradio as gr
-from pathlib import Path
-
-from torchvision.transforms import ToPILImage, ToTensor
-tensor_to_image = ToPILImage()
-image_to_tensor = ToTensor()
-
-import sys
-sys.path.append('DiT_Extractor/')
-sys.path.append('CrossEncoder/')
-sys.path.append('UnifiedQA/')
-
-import dit_runner
-import sentence_extractor
-import cross_encoder
-import demo_QA
-
-from torchvision.transforms import ToPILImage
-tensor_to_image = ToPILImage()
-
-def run_fn(pdf_file_obj, question_text, input_topk):
-
- pdf = pdf_file_obj.name
- print('Running PDF: {0}'.format(pdf))
- viz_images = dit_runner.get_dit_preds(pdf, score_threshold=0.5)
- entity_json = '{0}.json'.format(Path(pdf).name[:-4])
-
- sentence_extractor.get_contexts(entity_json)
-
- contexts_json = 'contexts_{0}'.format(entity_json)
- # contexts_json = 'contexts_2105u2iwiwxh.03011.json'
-
- cross_encoder.get_ranked_contexts(contexts_json, question_text)
-
- ranked_contexts_json = 'ranked_{0}'.format(contexts_json)
- # ranked_contexts_json = 'ranked_contexts_2105u2iwiwxh.03011.json'
-
- input_topk = int(input_topk)
-
- # viz_images = [tensor_to_image(x) for x in torch.randn(4, 3, 256, 256)]
-
- qa_results = demo_QA.get_qa_results(contexts_json, ranked_contexts_json, input_topk)
-
- history = [('<<< [Retrieval Score: {0:.02f}] >>> {1}'.format(s, c), a) for c, s, a in zip(qa_results['contexts'], qa_results['context_scores'], qa_results['answers'])]
-
- # Show in ascending order of score, since results box is already scrolled down.
- history = history[::-1]
-
- return viz_images, contexts_json, ranked_contexts_json, history
-
-demo = gr.Blocks()
-
-with demo:
-
- gr.Markdown("
Detect-Retrieve-Comprehend for Document-Level QA
")
- gr.Markdown("
This is a supplemental demo for our recent paper, expected to be publically available around October: Detect, Retrieve, Comprehend: A Flexible Framework for Zero-Shot Document-Level Question Answering. In this system, our input is a PDF file with a specific question of interest. The output is a set of most probable answers. There are 4 main components in our deployed pipeline: (1) DiT Layout Analysis (2) Context Extraction (3) Cross-Encoder Retrieval (4) UnifiedQA. See below for example uses with further explanation. Note that demo runtimes may be between 2-8 minutes, since this is currently cpu-based Space.
")
-
- with gr.Row():
- with gr.Column():
- with gr.Row():
- input_pdf_file = gr.File(file_count='single', label='PDF File')
- with gr.Row():
- input_question_text = gr.Textbox(label='Question')
- with gr.Row():
- input_k_percent = gr.Slider(minimum=1, maximum=24, step=1, value=8, label='Top K')
- with gr.Row():
- button_run = gr.Button('Run QA on Document')
-
- gr.Markdown("
Summary
")
- with gr.Row():
- gr.Markdown('''
- - **DiT - Document Image Transformer**: PDF -> converted into a list of images -> each image receives Entity Predictions
- - Note that using this computer vision approach allows us to ignore things like *page numbers, footnotes, references*, etc
- - **Paragraph-based Text Extraction**: DiT Bounding Boxes -> Convert into PDF-Space Coordinates -> Text Extraction using PDFMiner6 -> Tokenize & Sentence Split if tokenizer max length is exceeded
- - **CrossEncoder Context Retrieval**: All Contexts + Question -> Top K Relevant Contexts best suited for answering question
- - **UnifiedQA**: Most Relevant Contexts + Supplied Question -> Predict Set of Probable Answers
- ''')
- with gr.Row():
- examples = [
- ['examples/1909.00694.pdf', 'What is the seed lexicon?', 5],
- ['examples/1909.00694.pdf', 'How big is seed lexicon used for training?', 5],
- ['examples/1810.04805.pdf', 'What is this paper about?', 5],
- ['examples/1810.04805.pdf', 'What is the model size?', 5],
- ['examples/2105.03011.pdf', 'How many questions are in this dataset?', 5],
- ['examples/1909.00694.pdf', 'How are relations used to propagate polarity?', 5],
- ]
- gr.Examples(examples=examples,
- inputs=[input_pdf_file, input_question_text, input_k_percent])
-
- with gr.Column():
- with gr.Row():
- output_gallery = gr.Gallery(label='DiT Predicted Entities')
- with gr.Row():
- gr.Markdown('''
- - The `DiT predicted Entities` output box is scrollable! Scroll to see different page predictions. Note that predictions with confidence scores < 0.5 are not passed forward for text extraction.
- - If an image is clicked, the output box will switch to a gallery view. To view these outputs in much higher resolution, right-click and choose "open image in new tab"
- ''')
- with gr.Row():
- output_contexts = gr.File(label='Detected Contexts', interactive=False)
- output_ranked_contexts = gr.File(label='CrossEncoder Ranked Contexts', interactive=False)
- with gr.Row():
- output_qa_results = gr.Chatbot(color_map=['blue', 'green'], label='UnifiedQA Results').style()
-
- gr.Markdown("
By HARM, an intern team, aims to expand the world of AI by providing an useful feature.
- ''', True)
-
- st.markdown("### Team Members ")
-
- if st.button("Harshul Nanda"):
- webbrowser.open_new_tab("https://www.linkedin.com/in/harshulnanda/")
- if st.button("Abhijeet Saroha"):
- webbrowser.open_new_tab('https://www.linkedin.com/in/abhijeet-saroha-a19031229/')
- if st.button("Rishabh Sagar"):
- webbrowser.open_new_tab('https://www.linkedin.com/in/rishabh-sagar-1b0b74229/')
- if st.button("Mayank Arora"):
- webbrowser.open_new_tab('https://www.linkedin.com/in/mayank-arora-24713322a/')
-
-
- st.markdown("### Contact us ")
-
- if st.button("GitHub"):
- webbrowser.open_new_tab('https://github.com/Harshul-18')
- if st.button("Linked In"):
- webbrowser.open_new_tab('https://www.linkedin.com/company/82157293/admin/')
-
- # path = "https://www.buymeacoffee.com/widget/page/HARMBOT?description=Support%20me%20on%20Buy%20me%20a%20coffee!&color=%235F7FF"
- # if st.button("Buy us a coffee"):
- # webbrowser.open_new_tab(path)
-
- st.markdown("""""", unsafe_allow_html=True)
-
- page_bg_img = """
-
- """
- st.markdown(page_bg_img, unsafe_allow_html=True)
-
-# MARK: Adding the HARM logo gif
-def add_image(with_path):
- file_ = open(with_path, "rb")
-
- contents = file_.read()
- data_url = base64.b64encode(contents).decode("utf-8")
- file_.close()
- st.markdown(
- f'
',
- unsafe_allow_html=True,
- )
-
-# MARK: Adding the title
-def add_title_text():
- st.title("Hello, I am a YouTube API Bot!")
- st.text("I am a simple tool, just enter the URL and I will give the statistics.")
-
-# MARK: Adding body for page 1 containing all the fields while the youtube video url text input field is not empty
-def bodyOfPage1():
- youtubeVideoUrl = st.text_input("Enter the URL of the Youtube Video", value="", type="default", help="Enter the URL of the Youtube video you want me to show the statistics and predict the category for.")
-
- try:
- if youtubeVideoUrl:
- video = Video.getInfo(youtubeVideoUrl, mode=ResultMode.json)
-
- with st.expander("Prediction"):
-
- isEdu, isCat, catArr, probArr = predictCategoryFor(url=youtubeVideoUrl)
- if isEdu == "Educational":
- st.markdown(
- f"
",
- unsafe_allow_html=True,
- )
-
-
- with st.expander("View Video"):
-
- if (youtubeVideoUrl is None or len(youtubeVideoUrl) == 0):
- print(colorOf.FAIL + "The url input field is empty, please enter a youtube video url." + colorOf.ENDC)
- chime.error()
-
- st_player(youtubeVideoUrl)
-
- try:
- st.markdown("**Author of this video:** " + str(video["channel"]["name"]))
- st.markdown("**Title of video:** " + str(video["title"]))
- st.markdown("**Description of video:** " + str(video["description"]))
- chime.success()
- except Exception as e:
- print(colorOf.FAIL + f"Unable to view the video details. {e}" + colorOf.ENDC)
- chime.error()
-
- except Exception as e:
- st.markdown(f"{e}, Please enter the correct video URL")
-
-# MARK: Adding body for page 2 containing the fields for channel's statistics
-def bodyOfPage2():
- youtubeChannelUrl = st.text_input("Enter the Video URL to get the stats of that channel", value="", type="default", help="Enter the URL of the Youtube Video you want me to show the data of its channel.")
- # youtubeChannelUrl += "/videos"
- number = st.number_input('How many videos to analyse?', min_value=5, step=5, help="Enter the number or click the + or - buttons to increase or decrease the number with step size 5 for getting the data for the number of videos you entered.")
- if len(youtubeChannelUrl) >= 1:
- try:
- with st.expander("View Statistics"):
- generate_channel_video_data(of_channel=youtubeChannelUrl, with_number_of_videos=number)
- except Exception as e:
- st.markdown(f"{e}, Please enter the correct channel ID")
-
-# MARK: Adding body for page 3 containing the fields for searching a video from youtube
-def bodyOfPage3():
- searchFor = st.text_input("Search for videos", value="", type="default", help="Enter a keyword for searching for a youtube video.")
- number = st.number_input('Show search results', min_value=1, step=1, help="Enter the number or click the + or - buttons to increase or decrease the number for getting the number of videos you entered.")
-
-
- if len(searchFor) >= 1:
- videosSearch = VideosSearch(searchFor, limit=number)
-
- result = [video['link'] for video in videosSearch.result()['result']]
-
- for youtubeVideoUrl in stqdm(result):
-
- with st.container():
- st_player(youtubeVideoUrl)
-
- with st.expander("Prediction"):
-
- isEdu, isCat, catArr, probArr = predictCategoryFor(url=youtubeVideoUrl)
- if isEdu == "Educational":
- st.markdown(
- f"
",
- unsafe_allow_html=True,
- )
- except Exception as e:
- st.markdown(f"Please enter the correct URL")
-
-# MARK: Adding body for page 5 containing the field for predicting the educational content percentage in a video.
-def bodyOfPage5():
- youtubeVideoUrl = st.text_input("Enter a Youtube Video URL", value="", type="default", help="Enter a URL of the Youtube Video you want me to tell the educational portion content in the video.")
- try:
- if youtubeVideoUrl:
- st.markdown(f"### {eduContentPrediction(youtubeVideoUrl)}")
- except:
- st.markdown("Please enter a correct YouTube video URL or This video's transcripts are not available.")
-
-# MARK: Adding the footer
-def add_footer():
- footer="""
-
-"""
-
- st.markdown(footer, True)
-
-if __name__ == "__main__":
-
- hide_streamlit_style()
- add_image(with_path="./assets/harmLogo.gif")
- add_title_text()
- page_names_to_funcs = {
- "Category Predictor": bodyOfPage1,
- "Channel Stats Viewer": bodyOfPage2,
- "Search Videos": bodyOfPage3,
- "Playlist Videos Predictor": bodyOfPage4,
- "Educational Content in a Video": bodyOfPage5,
- }
- selected_page = st.sidebar.selectbox("Select the page", page_names_to_funcs.keys())
- page_names_to_funcs[selected_page]()
- add_sidebar_menu()
- add_footer()
diff --git a/spaces/HighCWu/GPEN/retinaface/data/data_augment.py b/spaces/HighCWu/GPEN/retinaface/data/data_augment.py
deleted file mode 100644
index c1b52ae19bf8d9ac3fa256b68730ce1b556c6d6e..0000000000000000000000000000000000000000
--- a/spaces/HighCWu/GPEN/retinaface/data/data_augment.py
+++ /dev/null
@@ -1,237 +0,0 @@
-import cv2
-import numpy as np
-import random
-from utils.box_utils import matrix_iof
-
-
-def _crop(image, boxes, labels, landm, img_dim):
- height, width, _ = image.shape
- pad_image_flag = True
-
- for _ in range(250):
- """
- if random.uniform(0, 1) <= 0.2:
- scale = 1.0
- else:
- scale = random.uniform(0.3, 1.0)
- """
- PRE_SCALES = [0.3, 0.45, 0.6, 0.8, 1.0]
- scale = random.choice(PRE_SCALES)
- short_side = min(width, height)
- w = int(scale * short_side)
- h = w
-
- if width == w:
- l = 0
- else:
- l = random.randrange(width - w)
- if height == h:
- t = 0
- else:
- t = random.randrange(height - h)
- roi = np.array((l, t, l + w, t + h))
-
- value = matrix_iof(boxes, roi[np.newaxis])
- flag = (value >= 1)
- if not flag.any():
- continue
-
- centers = (boxes[:, :2] + boxes[:, 2:]) / 2
- mask_a = np.logical_and(roi[:2] < centers, centers < roi[2:]).all(axis=1)
- boxes_t = boxes[mask_a].copy()
- labels_t = labels[mask_a].copy()
- landms_t = landm[mask_a].copy()
- landms_t = landms_t.reshape([-1, 5, 2])
-
- if boxes_t.shape[0] == 0:
- continue
-
- image_t = image[roi[1]:roi[3], roi[0]:roi[2]]
-
- boxes_t[:, :2] = np.maximum(boxes_t[:, :2], roi[:2])
- boxes_t[:, :2] -= roi[:2]
- boxes_t[:, 2:] = np.minimum(boxes_t[:, 2:], roi[2:])
- boxes_t[:, 2:] -= roi[:2]
-
- # landm
- landms_t[:, :, :2] = landms_t[:, :, :2] - roi[:2]
- landms_t[:, :, :2] = np.maximum(landms_t[:, :, :2], np.array([0, 0]))
- landms_t[:, :, :2] = np.minimum(landms_t[:, :, :2], roi[2:] - roi[:2])
- landms_t = landms_t.reshape([-1, 10])
-
-
- # make sure that the cropped image contains at least one face > 16 pixel at training image scale
- b_w_t = (boxes_t[:, 2] - boxes_t[:, 0] + 1) / w * img_dim
- b_h_t = (boxes_t[:, 3] - boxes_t[:, 1] + 1) / h * img_dim
- mask_b = np.minimum(b_w_t, b_h_t) > 0.0
- boxes_t = boxes_t[mask_b]
- labels_t = labels_t[mask_b]
- landms_t = landms_t[mask_b]
-
- if boxes_t.shape[0] == 0:
- continue
-
- pad_image_flag = False
-
- return image_t, boxes_t, labels_t, landms_t, pad_image_flag
- return image, boxes, labels, landm, pad_image_flag
-
-
-def _distort(image):
-
- def _convert(image, alpha=1, beta=0):
- tmp = image.astype(float) * alpha + beta
- tmp[tmp < 0] = 0
- tmp[tmp > 255] = 255
- image[:] = tmp
-
- image = image.copy()
-
- if random.randrange(2):
-
- #brightness distortion
- if random.randrange(2):
- _convert(image, beta=random.uniform(-32, 32))
-
- #contrast distortion
- if random.randrange(2):
- _convert(image, alpha=random.uniform(0.5, 1.5))
-
- image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
-
- #saturation distortion
- if random.randrange(2):
- _convert(image[:, :, 1], alpha=random.uniform(0.5, 1.5))
-
- #hue distortion
- if random.randrange(2):
- tmp = image[:, :, 0].astype(int) + random.randint(-18, 18)
- tmp %= 180
- image[:, :, 0] = tmp
-
- image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
-
- else:
-
- #brightness distortion
- if random.randrange(2):
- _convert(image, beta=random.uniform(-32, 32))
-
- image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
-
- #saturation distortion
- if random.randrange(2):
- _convert(image[:, :, 1], alpha=random.uniform(0.5, 1.5))
-
- #hue distortion
- if random.randrange(2):
- tmp = image[:, :, 0].astype(int) + random.randint(-18, 18)
- tmp %= 180
- image[:, :, 0] = tmp
-
- image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
-
- #contrast distortion
- if random.randrange(2):
- _convert(image, alpha=random.uniform(0.5, 1.5))
-
- return image
-
-
-def _expand(image, boxes, fill, p):
- if random.randrange(2):
- return image, boxes
-
- height, width, depth = image.shape
-
- scale = random.uniform(1, p)
- w = int(scale * width)
- h = int(scale * height)
-
- left = random.randint(0, w - width)
- top = random.randint(0, h - height)
-
- boxes_t = boxes.copy()
- boxes_t[:, :2] += (left, top)
- boxes_t[:, 2:] += (left, top)
- expand_image = np.empty(
- (h, w, depth),
- dtype=image.dtype)
- expand_image[:, :] = fill
- expand_image[top:top + height, left:left + width] = image
- image = expand_image
-
- return image, boxes_t
-
-
-def _mirror(image, boxes, landms):
- _, width, _ = image.shape
- if random.randrange(2):
- image = image[:, ::-1]
- boxes = boxes.copy()
- boxes[:, 0::2] = width - boxes[:, 2::-2]
-
- # landm
- landms = landms.copy()
- landms = landms.reshape([-1, 5, 2])
- landms[:, :, 0] = width - landms[:, :, 0]
- tmp = landms[:, 1, :].copy()
- landms[:, 1, :] = landms[:, 0, :]
- landms[:, 0, :] = tmp
- tmp1 = landms[:, 4, :].copy()
- landms[:, 4, :] = landms[:, 3, :]
- landms[:, 3, :] = tmp1
- landms = landms.reshape([-1, 10])
-
- return image, boxes, landms
-
-
-def _pad_to_square(image, rgb_mean, pad_image_flag):
- if not pad_image_flag:
- return image
- height, width, _ = image.shape
- long_side = max(width, height)
- image_t = np.empty((long_side, long_side, 3), dtype=image.dtype)
- image_t[:, :] = rgb_mean
- image_t[0:0 + height, 0:0 + width] = image
- return image_t
-
-
-def _resize_subtract_mean(image, insize, rgb_mean):
- interp_methods = [cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_NEAREST, cv2.INTER_LANCZOS4]
- interp_method = interp_methods[random.randrange(5)]
- image = cv2.resize(image, (insize, insize), interpolation=interp_method)
- image = image.astype(np.float32)
- image -= rgb_mean
- return image.transpose(2, 0, 1)
-
-
-class preproc(object):
-
- def __init__(self, img_dim, rgb_means):
- self.img_dim = img_dim
- self.rgb_means = rgb_means
-
- def __call__(self, image, targets):
- assert targets.shape[0] > 0, "this image does not have gt"
-
- boxes = targets[:, :4].copy()
- labels = targets[:, -1].copy()
- landm = targets[:, 4:-1].copy()
-
- image_t, boxes_t, labels_t, landm_t, pad_image_flag = _crop(image, boxes, labels, landm, self.img_dim)
- image_t = _distort(image_t)
- image_t = _pad_to_square(image_t,self.rgb_means, pad_image_flag)
- image_t, boxes_t, landm_t = _mirror(image_t, boxes_t, landm_t)
- height, width, _ = image_t.shape
- image_t = _resize_subtract_mean(image_t, self.img_dim, self.rgb_means)
- boxes_t[:, 0::2] /= width
- boxes_t[:, 1::2] /= height
-
- landm_t[:, 0::2] /= width
- landm_t[:, 1::2] /= height
-
- labels_t = np.expand_dims(labels_t, 1)
- targets_t = np.hstack((boxes_t, landm_t, labels_t))
-
- return image_t, targets_t
diff --git a/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/templates/frontend/assets/index.6b09b320.js b/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/templates/frontend/assets/index.6b09b320.js
deleted file mode 100644
index b167137379ac3b403eb5cf29048dc34116a896d5..0000000000000000000000000000000000000000
--- a/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/templates/frontend/assets/index.6b09b320.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import{S as f,i as _,s as c,P as m,c as d,m as b,j as r,k as u,o as p,p as g,u as v,q as $,r as k}from"./index.396f4a72.js";function h(o){let s;const l=o[2].default,e=g(l,o,o[3],null);return{c(){e&&e.c()},m(t,n){e&&e.m(t,n),s=!0},p(t,n){e&&e.p&&(!s||n&8)&&v(e,l,t,t[3],s?k(l,t[3],n,null):$(t[3]),null)},i(t){s||(r(e,t),s=!0)},o(t){u(e,t),s=!1},d(t){e&&e.d(t)}}}function B(o){let s,l;return s=new m({props:{elem_id:o[0],visible:o[1],explicit_call:!0,$$slots:{default:[h]},$$scope:{ctx:o}}}),{c(){d(s.$$.fragment)},m(e,t){b(s,e,t),l=!0},p(e,[t]){const n={};t&1&&(n.elem_id=e[0]),t&2&&(n.visible=e[1]),t&8&&(n.$$scope={dirty:t,ctx:e}),s.$set(n)},i(e){l||(r(s.$$.fragment,e),l=!0)},o(e){u(s.$$.fragment,e),l=!1},d(e){p(s,e)}}}function q(o,s,l){let{$$slots:e={},$$scope:t}=s,{elem_id:n}=s,{visible:a=!0}=s;return o.$$set=i=>{"elem_id"in i&&l(0,n=i.elem_id),"visible"in i&&l(1,a=i.visible),"$$scope"in i&&l(3,t=i.$$scope)},[n,a,e,t]}class C extends f{constructor(s){super(),_(this,s,q,B,c,{elem_id:0,visible:1})}}var j=C;const w=["static"];export{j as Component,w as modes};
-//# sourceMappingURL=index.6b09b320.js.map
diff --git a/spaces/HuangLab/CELL-E_2-Image_Prediction/dataloader.py b/spaces/HuangLab/CELL-E_2-Image_Prediction/dataloader.py
deleted file mode 100644
index 831174de3c3a62f13fa3ff1f172b36c8d2a84c44..0000000000000000000000000000000000000000
--- a/spaces/HuangLab/CELL-E_2-Image_Prediction/dataloader.py
+++ /dev/null
@@ -1,308 +0,0 @@
-import os
-import numpy as np
-from PIL import Image, ImageSequence
-import json
-import pandas as pd
-
-import torch
-from torch.utils.data import Dataset
-from torchvision import transforms
-import torchvision.transforms.functional as TF
-
-from celle.utils import replace_outliers
-
-def simple_conversion(seq):
- """Create 26-dim embedding"""
- chars = [
- "-",
- "M",
- "R",
- "H",
- "K",
- "D",
- "E",
- "S",
- "T",
- "N",
- "Q",
- "C",
- "U",
- "G",
- "P",
- "A",
- "V",
- "I",
- "F",
- "Y",
- "W",
- "L",
- "O",
- "X",
- "Z",
- "B",
- "J",
- ]
-
- nums = range(len(chars))
-
- seqs_x = np.zeros(len(seq))
-
- for idx, char in enumerate(seq):
-
- lui = chars.index(char)
-
- seqs_x[idx] = nums[lui]
-
- return torch.tensor([seqs_x]).long()
-
-
-class CellLoader(Dataset):
- """imports mined opencell images with protein sequence"""
-
- def __init__(
- self,
- data_csv=None,
- dataset=None,
- split_key=None,
- resize=600,
- crop_size=600,
- crop_method="random",
- sequence_mode="simple",
- vocab="bert",
- threshold="median",
- text_seq_len=0,
- pad_mode="random",
- ):
- self.data_csv = data_csv
- self.dataset = dataset
- self.image_folders = []
- self.crop_method = crop_method
- self.resize = resize
- self.crop_size = crop_size
- self.sequence_mode = sequence_mode
- self.threshold = threshold
- self.text_seq_len = int(text_seq_len)
- self.vocab = vocab
- self.pad_mode = pad_mode
-
- if self.sequence_mode == "embedding" or self.sequence_mode == "onehot":
-
-
- if self.vocab == "esm1b" or self.vocab == "esm2":
- from esm import Alphabet
-
- self.tokenizer = Alphabet.from_architecture(
- "ESM-1b"
- ).get_batch_converter()
- self.text_seq_len += 2
-
- if data_csv:
-
- data = pd.read_csv(data_csv)
-
- self.parent_path = os.path.dirname(data_csv).split(data_csv)[0]
-
- if split_key == "train":
- self.data = data[data["split"] == "train"]
- elif split_key == "val":
- self.data = data[data["split"] == "val"]
- else:
- self.data = data
-
- self.data = self.data.reset_index(drop=True)
-
-
-
- def __len__(self):
- return len(self.data)
-
- def __getitem__(
- self,
- idx,
- get_sequence=True,
- get_images=True,
- ):
- if get_sequence and self.text_seq_len > 0:
-
- protein_vector = self.get_protein_vector(idx)
-
- else:
- protein_vector = torch.zeros((1, 1))
-
- if get_images:
-
- nucleus, target, threshold = self.get_images(idx, self.dataset)
- else:
- nucleus, target, threshold = torch.zeros((3, 1))
-
- data_dict = {
- "nucleus": nucleus.float(),
- "target": target.float(),
- "threshold": threshold.float(),
- "sequence": protein_vector.long(),
- }
-
- return data_dict
-
- def get_protein_vector(self, idx):
-
- if "protein_sequence" not in self.data.columns:
-
- metadata = self.retrieve_metadata(idx)
- protein_sequence = metadata["sequence"]
- else:
- protein_sequence = self.data.iloc[idx]["protein_sequence"]
-
- protein_vector = self.tokenize_sequence(protein_sequence)
-
- return protein_vector
-
- def get_images(self, idx, dataset):
-
- if dataset == "HPA":
-
- nucleus = Image.open(
- os.path.join(
- self.parent_path, self.data.iloc[idx]["nucleus_image_path"]
- )
- )
-
- target = Image.open(
- os.path.join(self.parent_path, self.data.iloc[idx]["target_image_path"])
- )
-
- nucleus = TF.to_tensor(nucleus)[0]
- target = TF.to_tensor(target)[0]
-
- image = torch.stack([nucleus, target], axis=0)
-
- normalize = (0.0655, 0.0650), (0.1732, 0.1208)
-
- elif dataset == "OpenCell":
- image = Image.open(
- os.path.join(self.parent_path, self.data.iloc[idx]["image_path"])
- )
- nucleus, target = [page.copy() for page in ImageSequence.Iterator(image)]
-
- nucleus = replace_outliers(torch.divide(TF.to_tensor(nucleus), 65536))[0]
- target = replace_outliers(torch.divide(TF.to_tensor(target), 65536))[0]
-
- image = torch.stack([nucleus, target], axis=0)
-
- normalize = (
- (0.0272, 0.0244),
- (0.0486, 0.0671),
- )
-
- # # from https://discuss.pytorch.org/t/how-to-apply-same-transform-on-a-pair-of-picture/14914
-
- t_forms = [transforms.Resize(self.resize, antialias=None)]
-
- if self.crop_method == "random":
-
- t_forms.append(transforms.RandomCrop(self.crop_size))
- t_forms.append(transforms.RandomHorizontalFlip(p=0.5))
- t_forms.append(transforms.RandomVerticalFlip(p=0.5))
-
- elif self.crop_method == "center":
-
- t_forms.append(transforms.CenterCrop(self.crop_size))
-
- t_forms.append(transforms.Normalize(normalize[0], normalize[1]))
-
- image = transforms.Compose(t_forms)(image)
-
- nucleus, target = image
-
- nucleus /= torch.abs(nucleus).max()
- target -= target.min()
- target /= target.max()
-
- nucleus = nucleus.unsqueeze(0)
- target = target.unsqueeze(0)
-
- threshold = target
-
- if self.threshold == "mean":
-
- threshold = 1.0 * (threshold > (torch.mean(threshold)))
-
- elif self.threshold == "median":
-
- threshold = 1.0 * (threshold > (torch.median(threshold)))
-
- elif self.threshold == "1090_IQR":
-
- p10 = torch.quantile(threshold, 0.1, None)
- p90 = torch.quantile(threshold, 0.9, None)
- threshold = torch.clip(threshold, p10, p90)
-
- nucleus = torch.nan_to_num(nucleus, 0.0, 1.0, 0.0)
- target = torch.nan_to_num(target, 0.0, 1.0, 0.0)
- threshold = torch.nan_to_num(threshold, 0.0, 1.0, 0.0)
-
- return nucleus, target, threshold
-
- def retrieve_metadata(self, idx):
- with open(
- os.path.join(self.parent_path, self.data.iloc[idx]["metadata_path"])
- ) as f:
- metadata = json.load(f)
-
- return metadata
-
- def tokenize_sequence(self, protein_sequence):
-
- pad_token = 0
-
- if self.sequence_mode == "simple":
- protein_vector = simple_conversion(protein_sequence)
-
- elif self.sequence_mode == "center":
- protein_sequence = protein_sequence.center(self.text_seq_length, "-")
- protein_vector = simple_conversion(protein_sequence)
-
- elif self.sequence_mode == "alternating":
- protein_sequence = protein_sequence.center(self.text_seq_length, "-")
- protein_sequence = protein_sequence[::18]
- protein_sequence = protein_sequence.center(
- int(self.text_seq_length / 18) + 1, "-"
- )
- protein_vector = simple_conversion(protein_sequence)
-
-
- elif self.sequence_mode == "embedding":
-
- if self.vocab == "esm1b" or self.vocab == "esm2":
- pad_token = 1
- protein_vector = self.tokenizer([("", protein_sequence)])[-1]
-
- if protein_vector.shape[-1] < self.text_seq_len:
-
- diff = self.text_seq_len - protein_vector.shape[-1]
-
- if self.pad_mode == "end":
- protein_vector = torch.nn.functional.pad(
- protein_vector, (0, diff), "constant", pad_token
- )
- elif self.pad_mode == "random":
- split = diff - np.random.randint(0, diff + 1)
-
- protein_vector = torch.cat(
- [torch.ones(1, split) * 0, protein_vector], dim=1
- )
-
- protein_vector = torch.nn.functional.pad(
- protein_vector, (0, diff - split), "constant", pad_token
- )
-
- elif protein_vector.shape[-1] > self.text_seq_len:
- start_int = np.random.randint(
- 0, protein_vector.shape[-1] - self.text_seq_len
- )
-
- protein_vector = protein_vector[
- :, start_int : start_int + self.text_seq_len
- ]
-
- return protein_vector.long()
diff --git a/spaces/ICML2022/OFA/fairseq/examples/speech_synthesis/preprocessing/vad/__init__.py b/spaces/ICML2022/OFA/fairseq/examples/speech_synthesis/preprocessing/vad/__init__.py
deleted file mode 100644
index 9cf121081fbde2f5085ed380f0841649d143a4be..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/examples/speech_synthesis/preprocessing/vad/__init__.py
+++ /dev/null
@@ -1,192 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-
-import collections
-import contextlib
-import wave
-
-try:
- import webrtcvad
-except ImportError:
- raise ImportError("Please install py-webrtcvad: pip install webrtcvad")
-import argparse
-import os
-import logging
-from tqdm import tqdm
-
-AUDIO_SUFFIX = '.wav'
-FS_MS = 30
-SCALE = 6e-5
-THRESHOLD = 0.3
-
-
-def read_wave(path):
- """Reads a .wav file.
- Takes the path, and returns (PCM audio data, sample rate).
- """
- with contextlib.closing(wave.open(path, 'rb')) as wf:
- num_channels = wf.getnchannels()
- assert num_channels == 1
- sample_width = wf.getsampwidth()
- assert sample_width == 2
- sample_rate = wf.getframerate()
- assert sample_rate in (8000, 16000, 32000, 48000)
- pcm_data = wf.readframes(wf.getnframes())
- return pcm_data, sample_rate
-
-
-def write_wave(path, audio, sample_rate):
- """Writes a .wav file.
- Takes path, PCM audio data, and sample rate.
- """
- with contextlib.closing(wave.open(path, 'wb')) as wf:
- wf.setnchannels(1)
- wf.setsampwidth(2)
- wf.setframerate(sample_rate)
- wf.writeframes(audio)
-
-
-class Frame(object):
- """Represents a "frame" of audio data."""
- def __init__(self, bytes, timestamp, duration):
- self.bytes = bytes
- self.timestamp = timestamp
- self.duration = duration
-
-
-def frame_generator(frame_duration_ms, audio, sample_rate):
- """Generates audio frames from PCM audio data.
- Takes the desired frame duration in milliseconds, the PCM data, and
- the sample rate.
- Yields Frames of the requested duration.
- """
- n = int(sample_rate * (frame_duration_ms / 1000.0) * 2)
- offset = 0
- timestamp = 0.0
- duration = (float(n) / sample_rate) / 2.0
- while offset + n < len(audio):
- yield Frame(audio[offset:offset + n], timestamp, duration)
- timestamp += duration
- offset += n
-
-
-def vad_collector(sample_rate, frame_duration_ms,
- padding_duration_ms, vad, frames):
- """Filters out non-voiced audio frames.
- Given a webrtcvad.Vad and a source of audio frames, yields only
- the voiced audio.
- Uses a padded, sliding window algorithm over the audio frames.
- When more than 90% of the frames in the window are voiced (as
- reported by the VAD), the collector triggers and begins yielding
- audio frames. Then the collector waits until 90% of the frames in
- the window are unvoiced to detrigger.
- The window is padded at the front and back to provide a small
- amount of silence or the beginnings/endings of speech around the
- voiced frames.
- Arguments:
- sample_rate - The audio sample rate, in Hz.
- frame_duration_ms - The frame duration in milliseconds.
- padding_duration_ms - The amount to pad the window, in milliseconds.
- vad - An instance of webrtcvad.Vad.
- frames - a source of audio frames (sequence or generator).
- Returns: A generator that yields PCM audio data.
- """
- num_padding_frames = int(padding_duration_ms / frame_duration_ms)
- # We use a deque for our sliding window/ring buffer.
- ring_buffer = collections.deque(maxlen=num_padding_frames)
- # We have two states: TRIGGERED and NOTTRIGGERED. We start in the
- # NOTTRIGGERED state.
- triggered = False
-
- voiced_frames = []
- for frame in frames:
- is_speech = vad.is_speech(frame.bytes, sample_rate)
-
- # sys.stdout.write('1' if is_speech else '0')
- if not triggered:
- ring_buffer.append((frame, is_speech))
- num_voiced = len([f for f, speech in ring_buffer if speech])
- # If we're NOTTRIGGERED and more than 90% of the frames in
- # the ring buffer are voiced frames, then enter the
- # TRIGGERED state.
- if num_voiced > 0.9 * ring_buffer.maxlen:
- triggered = True
- # We want to yield all the audio we see from now until
- # we are NOTTRIGGERED, but we have to start with the
- # audio that's already in the ring buffer.
- for f, _ in ring_buffer:
- voiced_frames.append(f)
- ring_buffer.clear()
- else:
- # We're in the TRIGGERED state, so collect the audio data
- # and add it to the ring buffer.
- voiced_frames.append(frame)
- ring_buffer.append((frame, is_speech))
- num_unvoiced = len([f for f, speech in ring_buffer if not speech])
- # If more than 90% of the frames in the ring buffer are
- # unvoiced, then enter NOTTRIGGERED and yield whatever
- # audio we've collected.
- if num_unvoiced > 0.9 * ring_buffer.maxlen:
- triggered = False
- yield [b''.join([f.bytes for f in voiced_frames]),
- voiced_frames[0].timestamp, voiced_frames[-1].timestamp]
- ring_buffer.clear()
- voiced_frames = []
- # If we have any leftover voiced audio when we run out of input,
- # yield it.
- if voiced_frames:
- yield [b''.join([f.bytes for f in voiced_frames]),
- voiced_frames[0].timestamp, voiced_frames[-1].timestamp]
-
-
-def main(args):
- # create output folder
- try:
- cmd = f"mkdir -p {args.out_path}"
- os.system(cmd)
- except Exception:
- logging.error("Can not create output folder")
- exit(-1)
-
- # build vad object
- vad = webrtcvad.Vad(int(args.agg))
- # iterating over wavs in dir
- for file in tqdm(os.listdir(args.in_path)):
- if file.endswith(AUDIO_SUFFIX):
- audio_inpath = os.path.join(args.in_path, file)
- audio_outpath = os.path.join(args.out_path, file)
- audio, sample_rate = read_wave(audio_inpath)
- frames = frame_generator(FS_MS, audio, sample_rate)
- frames = list(frames)
- segments = vad_collector(sample_rate, FS_MS, 300, vad, frames)
- merge_segments = list()
- timestamp_start = 0.0
- timestamp_end = 0.0
- # removing start, end, and long sequences of sils
- for i, segment in enumerate(segments):
- merge_segments.append(segment[0])
- if i and timestamp_start:
- sil_duration = segment[1] - timestamp_end
- if sil_duration > THRESHOLD:
- merge_segments.append(int(THRESHOLD / SCALE)*(b'\x00'))
- else:
- merge_segments.append(int((sil_duration / SCALE))*(b'\x00'))
- timestamp_start = segment[1]
- timestamp_end = segment[2]
- segment = b''.join(merge_segments)
- write_wave(audio_outpath, segment, sample_rate)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser(description='Apply vad to a file of fils.')
- parser.add_argument('in_path', type=str, help='Path to the input files')
- parser.add_argument('out_path', type=str,
- help='Path to save the processed files')
- parser.add_argument('--agg', type=int, default=3,
- help='The level of aggressiveness of the VAD: [0-3]')
- args = parser.parse_args()
-
- main(args)
diff --git a/spaces/ICML2022/OFA/fairseq/fairseq/modules/grad_multiply.py b/spaces/ICML2022/OFA/fairseq/fairseq/modules/grad_multiply.py
deleted file mode 100644
index 08d15f55dfda9c61a1cf8641ea31424fe1d97f57..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/fairseq/modules/grad_multiply.py
+++ /dev/null
@@ -1,18 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import torch
-
-
-class GradMultiply(torch.autograd.Function):
- @staticmethod
- def forward(ctx, x, scale):
- ctx.scale = scale
- res = x.new(x)
- return res
-
- @staticmethod
- def backward(ctx, grad):
- return grad * ctx.scale, None
diff --git a/spaces/Ignahugging/Sentiment-Analysis/README.md b/spaces/Ignahugging/Sentiment-Analysis/README.md
deleted file mode 100644
index 55d8478fbdde1dd0a947c965c98e21ac416bd775..0000000000000000000000000000000000000000
--- a/spaces/Ignahugging/Sentiment-Analysis/README.md
+++ /dev/null
@@ -1,45 +0,0 @@
----
-title: Sentiment Analysis
-emoji: ⚡
-colorFrom: pink
-colorTo: green
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio`, `streamlit`, or `static`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code, or `static` html code).
-Path is relative to the root of the repository.
-
-`models`: _List[string]_
-HF model IDs (like "gpt2" or "deepset/roberta-base-squad2") used in the Space.
-Will be parsed automatically from your code if not specified here.
-
-`datasets`: _List[string]_
-HF dataset IDs (like "common_voice" or "oscar-corpus/OSCAR-2109") used in the Space.
-Will be parsed automatically from your code if not specified here.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/Illumotion/Koboldcpp/examples/batched-bench/batched-bench.cpp b/spaces/Illumotion/Koboldcpp/examples/batched-bench/batched-bench.cpp
deleted file mode 100644
index 3e1e0716d8312cd141a35ebe400e7c2be82d4993..0000000000000000000000000000000000000000
--- a/spaces/Illumotion/Koboldcpp/examples/batched-bench/batched-bench.cpp
+++ /dev/null
@@ -1,251 +0,0 @@
-#include "common.h"
-#include "llama.h"
-
-#include
-#include
-#include
-#include
-#include
-
-// mutates the input string
-static std::vector parse_list(char * p) {
- std::vector ret;
-
- char * q = p;
-
- while (*p) {
- if (*p == ',') {
- *p = '\0';
- ret.push_back(std::atoi(q));
- q = p + 1;
- }
-
- ++p;
- }
-
- ret.push_back(std::atoi(q));
-
- return ret;
-}
-
-int main(int argc, char ** argv) {
- gpt_params params;
-
- if (argc == 1 || argv[1][0] == '-') {
- printf("usage: %s MODEL_PATH [N_KV_MAX] [IS_PP_SHARED] [NGL] [MMQ] \n" , argv[0]);
- printf(" , and PL are comma-separated lists of numbers without spaces\n\n");
- printf(" example: %s ggml-model-f16.gguf 2048 0 999 0 128,256,512 128,256 1,2,4,8,16,32\n\n", argv[0]);
- return 1 ;
- }
-
- int n_kv_max = 2048;
- int is_pp_shared = 0;
- int n_gpu_layers = 0;
- int mmq = 0;
-
- std::vector n_pp = { 128, 256, 512, 1024, 2048, 3584, 7680, };
- std::vector n_tg = { 128, 256, };
- std::vector n_pl = { 1, 2, 4, 8, 16, 32, };
- //std::vector n_pl = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 32, };
-
- if (argc >= 2) {
- params.model = argv[1];
- }
-
- if (argc >= 3) {
- n_kv_max = std::atoi(argv[2]);
- }
-
- if (argc >= 4) {
- is_pp_shared = std::atoi(argv[3]);
- }
-
- if (argc >= 5) {
- n_gpu_layers = std::atoi(argv[4]);
- }
-
- if (argc >= 6) {
- mmq = std::atoi(argv[5]);
- }
-
- if (argc >= 7) {
- n_pp = parse_list(argv[6]);
- }
-
- if (argc >= 8) {
- n_tg = parse_list(argv[7]);
- }
-
- if (argc >= 9) {
- n_pl = parse_list(argv[8]);
- }
-
- // init LLM
-
- llama_backend_init(params.numa);
-
- // initialize the model
-
- llama_model_params model_params = llama_model_default_params();
-
- model_params.n_gpu_layers = n_gpu_layers;
-
- llama_model * model = llama_load_model_from_file(params.model.c_str(), model_params);
-
- if (model == NULL) {
- fprintf(stderr , "%s: error: unable to load model\n" , __func__);
- return 1;
- }
-
- llama_context_params ctx_params = llama_context_default_params();
-
- ctx_params.seed = 1234;
- ctx_params.n_ctx = n_kv_max;
- ctx_params.n_batch = 512;
- ctx_params.mul_mat_q = mmq;
-
- ctx_params.n_threads = params.n_threads;
- ctx_params.n_threads_batch = params.n_threads_batch == -1 ? params.n_threads : params.n_threads_batch;
-
- llama_context * ctx = llama_new_context_with_model(model, ctx_params);
-
- if (ctx == NULL) {
- fprintf(stderr , "%s: error: failed to create the llama_context\n" , __func__);
- return 1;
- }
-
- llama_batch batch = llama_batch_init(n_kv_max, 0);
-
- // decode in batches of ctx_params.n_batch tokens
- auto decode_helper = [](llama_context * ctx, llama_batch & batch, int32_t n_batch) {
- for (int32_t i = 0; i < (int32_t) batch.n_tokens; i += n_batch) {
- const int32_t n_tokens = std::min(n_batch, (int32_t) (batch.n_tokens - i));
-
- llama_batch batch_view = {
- n_tokens,
- batch.token + i,
- nullptr,
- batch.pos + i,
- batch.seq_id + i,
- batch.logits + i,
- 0, 0, 0, // unused
- };
-
- const int ret = llama_decode(ctx, batch_view);
- if (ret != 0) {
- LOG_TEE("failed to decode the batch, n_batch = %d, ret = %d\n", n_batch, ret);
- return false;
- }
- }
-
- return true;
- };
-
- // warm up
- {
- batch.n_tokens = 16;
-
- for (int i = 0; i < batch.n_tokens; ++i) {
- batch.token[i] = 0;
- batch.pos[i] = i;
- batch.seq_id[i] = 0;
- batch.logits[i] = false;
- }
-
- if (!decode_helper(ctx, batch, ctx_params.n_batch)) {
- LOG_TEE("%s: llama_decode() failed\n", __func__);
- return 1;
- }
- }
-
- LOG_TEE("|%6s | %6s | %4s | %6s | %8s | %8s | %8s | %8s | %8s | %8s |\n", "PP", "TG", "B", "N_KV", "T_PP s", "S_PP t/s", "T_TG s", "S_TG t/s", "T s", "S t/s");
- LOG_TEE("|%6s-|-%6s-|-%4s-|-%6s-|-%8s-|-%8s-|-%8s-|-%8s-|-%8s-|-%8s-|\n", "------", "------", "----", "------", "--------", "--------", "--------", "--------", "--------", "--------");
-
- for ( int i_pp = 0; i_pp < (int) n_pp.size(); ++i_pp) {
- for ( int i_tg = 0; i_tg < (int) n_tg.size(); ++i_tg) {
- for (int i_pl = 0; i_pl < (int) n_pl.size(); ++i_pl) {
- const int pp = n_pp[i_pp];
- const int tg = n_tg[i_tg];
- const int pl = n_pl[i_pl];
-
- const int n_ctx_req = is_pp_shared ? pp + pl*tg : pl*(pp + tg);
-
- if (n_ctx_req > n_kv_max) {
- continue;
- }
-
- batch.n_tokens = is_pp_shared ? pp : pl*pp;
-
- for (int i = 0; i < batch.n_tokens; ++i) {
- batch.token[i] = 0;
- batch.pos[i] = i;
- batch.seq_id[i] = 0;
- batch.logits[i] = false;
- }
- batch.logits[batch.n_tokens - 1] = true;
-
- const auto t_pp_start = ggml_time_us();
-
- llama_kv_cache_tokens_rm(ctx, -1, -1);
-
- if (!decode_helper(ctx, batch, ctx_params.n_batch)) {
- LOG_TEE("%s: llama_decode() failed\n", __func__);
- return 1;
- }
-
- if (is_pp_shared) {
- for (int32_t i = 1; i < pl; ++i) {
- llama_kv_cache_seq_cp(ctx, 0, i, 0, pp);
- }
- }
-
- const auto t_pp_end = ggml_time_us();
-
- const auto t_tg_start = ggml_time_us();
-
- for (int i = 0; i < tg; ++i) {
- batch.n_tokens = pl;
-
- for (int j = 0; j < pl; ++j) {
- batch.token[j] = 0;
- batch.pos[j] = pp + i;
- batch.seq_id[j] = j;
- batch.logits[j] = true;
- }
-
- if (!decode_helper(ctx, batch, ctx_params.n_batch)) {
- LOG_TEE("%s: llama_decode() failed\n", __func__);
- return 1;
- }
- }
-
- const auto t_tg_end = ggml_time_us();
-
- const int32_t n_kv = n_ctx_req;
-
- const float t_pp = (t_pp_end - t_pp_start) / 1000000.0f;
- const float t_tg = (t_tg_end - t_tg_start) / 1000000.0f;
- const float t = t_pp + t_tg;
-
- const float speed_pp = is_pp_shared ? pp / t_pp : pl*pp / t_pp;
- const float speed_tg = pl*tg / t_tg;
- const float speed = n_kv / t;
-
- LOG_TEE("|%6d | %6d | %4d | %6d | %8.3f | %8.2f | %8.3f | %8.2f | %8.3f | %8.2f |\n", pp, tg, pl, n_kv, t_pp, speed_pp, t_tg, speed_tg, t, speed);
- }
- }
- }
-
- llama_print_timings(ctx);
-
- llama_batch_free(batch);
-
- llama_free(ctx);
- llama_free_model(model);
-
- llama_backend_free();
-
- fprintf(stderr, "\n\n");
-
- return 0;
-}
diff --git a/spaces/IoMa/stable-diffusion-webui-cpu-the-best/README.md b/spaces/IoMa/stable-diffusion-webui-cpu-the-best/README.md
deleted file mode 100644
index 4764e29b128c0eb403d4873ca8c8f6eb485132d0..0000000000000000000000000000000000000000
--- a/spaces/IoMa/stable-diffusion-webui-cpu-the-best/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Stable Diffusion Webui on Cpu
-emoji: 🏃
-colorFrom: pink
-colorTo: purple
-sdk: gradio
-sdk_version: 3.29.0
-app_file: app.py
-pinned: false
-python_version: 3.10.6
-duplicated_from: DreamSunny/stable-diffusion-webui-cpu
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Javtor/Biomedical-topic-categorization-2022only/app.py b/spaces/Javtor/Biomedical-topic-categorization-2022only/app.py
deleted file mode 100644
index ca82df3044aaa0ad256b250c1301f58af766453a..0000000000000000000000000000000000000000
--- a/spaces/Javtor/Biomedical-topic-categorization-2022only/app.py
+++ /dev/null
@@ -1,8 +0,0 @@
-import gradio as gr
-title = "Biomedical Topic Categorization - 2022 only"
-interface = gr.Interface.load("huggingface/Javtor/biomedical-topic-categorization-2022only",
- title = title,
- examples=[["Correlation between osteoarthritis of the atlantoaxial facet joint and a high-riding vertebral artery. A high-riding vertebral artery (HRVA) is an intraosseous anomaly that narrows the trajectory for C2 pedicle screws. The prevalence of a HRVA is high in patients who need surgery at the craniovertebral junction, but reports about HRVAs in subaxial cervical spine disorders are limited. We sought to determine the prevalence of HRVAs among patients with subaxial cervical spine disorders to elucidate the potential risk for VA injury in subaxial cervical spine surgery."],
- ["Considerable variability in antibiotic use among US children's hospitals in 2017-2018. To characterize the prevalence of and seasonal and regional variation in inpatient antibiotic use among hospitalized US children in 2017-2018."]]
-)
-interface.launch()
\ No newline at end of file
diff --git a/spaces/Jeff2323/ai-comic-factory/src/components/ui/popover.tsx b/spaces/Jeff2323/ai-comic-factory/src/components/ui/popover.tsx
deleted file mode 100644
index 8b35ce6d7b0dd78003308b09354e9f7197eb161a..0000000000000000000000000000000000000000
--- a/spaces/Jeff2323/ai-comic-factory/src/components/ui/popover.tsx
+++ /dev/null
@@ -1,31 +0,0 @@
-"use client"
-
-import * as React from "react"
-import * as PopoverPrimitive from "@radix-ui/react-popover"
-
-import { cn } from "@/lib/utils"
-
-const Popover = PopoverPrimitive.Root
-
-const PopoverTrigger = PopoverPrimitive.Trigger
-
-const PopoverContent = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, align = "center", sideOffset = 4, ...props }, ref) => (
-
-
-
-))
-PopoverContent.displayName = PopoverPrimitive.Content.displayName
-
-export { Popover, PopoverTrigger, PopoverContent }
diff --git a/spaces/Jikiwi/sovits-models/onnxexport/model_onnx.py b/spaces/Jikiwi/sovits-models/onnxexport/model_onnx.py
deleted file mode 100644
index e28bae95ec1e53aa05d06fc784ff86d55f228d60..0000000000000000000000000000000000000000
--- a/spaces/Jikiwi/sovits-models/onnxexport/model_onnx.py
+++ /dev/null
@@ -1,335 +0,0 @@
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-import modules.attentions as attentions
-import modules.commons as commons
-import modules.modules as modules
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-
-import utils
-from modules.commons import init_weights, get_padding
-from vdecoder.hifigan.models import Generator
-from utils import f0_to_coarse
-
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(
- modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers,
- gin_channels=gin_channels, mean_only=True))
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
-
-class Encoder(nn.Module):
- def __init__(self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels)
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- # print(x.shape,x_lengths.shape)
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
-
-class TextEncoder(nn.Module):
- def __init__(self,
- out_channels,
- hidden_channels,
- kernel_size,
- n_layers,
- gin_channels=0,
- filter_channels=None,
- n_heads=None,
- p_dropout=None):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
- self.f0_emb = nn.Embedding(256, hidden_channels)
-
- self.enc_ = attentions.Encoder(
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout)
-
- def forward(self, x, x_mask, f0=None, z=None):
- x = x + self.f0_emb(f0).transpose(1, 2)
- x = self.enc_(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + z * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))),
- ])
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ])
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class F0Decoder(nn.Module):
- def __init__(self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- spk_channels=0):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.spk_channels = spk_channels
-
- self.prenet = nn.Conv1d(hidden_channels, hidden_channels, 3, padding=1)
- self.decoder = attentions.FFT(
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout)
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.f0_prenet = nn.Conv1d(1, hidden_channels, 3, padding=1)
- self.cond = nn.Conv1d(spk_channels, hidden_channels, 1)
-
- def forward(self, x, norm_f0, x_mask, spk_emb=None):
- x = torch.detach(x)
- if spk_emb is not None:
- x = x + self.cond(spk_emb)
- x += self.f0_prenet(norm_f0)
- x = self.prenet(x) * x_mask
- x = self.decoder(x * x_mask, x_mask)
- x = self.proj(x) * x_mask
- return x
-
-
-class SynthesizerTrn(nn.Module):
- """
- Synthesizer for Training
- """
-
- def __init__(self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels,
- ssl_dim,
- n_speakers,
- sampling_rate=44100,
- **kwargs):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- self.ssl_dim = ssl_dim
- self.emb_g = nn.Embedding(n_speakers, gin_channels)
-
- self.pre = nn.Conv1d(ssl_dim, hidden_channels, kernel_size=5, padding=2)
-
- self.enc_p = TextEncoder(
- inter_channels,
- hidden_channels,
- filter_channels=filter_channels,
- n_heads=n_heads,
- n_layers=n_layers,
- kernel_size=kernel_size,
- p_dropout=p_dropout
- )
- hps = {
- "sampling_rate": sampling_rate,
- "inter_channels": inter_channels,
- "resblock": resblock,
- "resblock_kernel_sizes": resblock_kernel_sizes,
- "resblock_dilation_sizes": resblock_dilation_sizes,
- "upsample_rates": upsample_rates,
- "upsample_initial_channel": upsample_initial_channel,
- "upsample_kernel_sizes": upsample_kernel_sizes,
- "gin_channels": gin_channels,
- }
- self.dec = Generator(h=hps)
- self.enc_q = Encoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16, gin_channels=gin_channels)
- self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)
- self.f0_decoder = F0Decoder(
- 1,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- spk_channels=gin_channels
- )
- self.emb_uv = nn.Embedding(2, hidden_channels)
- self.predict_f0 = False
-
- def forward(self, c, f0, mel2ph, uv, noise=None, g=None):
-
- decoder_inp = F.pad(c, [0, 0, 1, 0])
- mel2ph_ = mel2ph.unsqueeze(2).repeat([1, 1, c.shape[-1]])
- c = torch.gather(decoder_inp, 1, mel2ph_).transpose(1, 2) # [B, T, H]
-
- c_lengths = (torch.ones(c.size(0)) * c.size(-1)).to(c.device)
- g = g.unsqueeze(0)
- g = self.emb_g(g).transpose(1, 2)
- x_mask = torch.unsqueeze(commons.sequence_mask(c_lengths, c.size(2)), 1).to(c.dtype)
- x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1, 2)
-
- if self.predict_f0:
- lf0 = 2595. * torch.log10(1. + f0.unsqueeze(1) / 700.) / 500
- norm_lf0 = utils.normalize_f0(lf0, x_mask, uv, random_scale=False)
- pred_lf0 = self.f0_decoder(x, norm_lf0, x_mask, spk_emb=g)
- f0 = (700 * (torch.pow(10, pred_lf0 * 500 / 2595) - 1)).squeeze(1)
-
- z_p, m_p, logs_p, c_mask = self.enc_p(x, x_mask, f0=f0_to_coarse(f0), z=noise)
- z = self.flow(z_p, c_mask, g=g, reverse=True)
- o = self.dec(z * c_mask, g=g, f0=f0)
- return o
diff --git a/spaces/Justin-Choo/Replicant_WEB_UI/README.md b/spaces/Justin-Choo/Replicant_WEB_UI/README.md
deleted file mode 100644
index eda972472850a08fbb2cb235eb600197418bb82b..0000000000000000000000000000000000000000
--- a/spaces/Justin-Choo/Replicant_WEB_UI/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Replicant Webui on Cpu
-emoji: 🧸
-colorFrom: red
-colorTo: blue
-sdk: gradio
-sdk_version: 3.29.0
-app_file: app.py
-pinned: false
-python_version: 3.10.6
-duplicated_from: Justin-Chew/Counterfeit-XL_WEB_UI
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/KPCGD/bingo/src/app/page.tsx b/spaces/KPCGD/bingo/src/app/page.tsx
deleted file mode 100644
index 0dff3431b098ce4fe282cc83fc87a93a28a43090..0000000000000000000000000000000000000000
--- a/spaces/KPCGD/bingo/src/app/page.tsx
+++ /dev/null
@@ -1,15 +0,0 @@
-import dynamic from 'next/dynamic'
-
-const DynamicComponentWithNoSSR = dynamic(
- () => import('../components/chat'),
- { ssr: false }
-)
-
-export default function IndexPage() {
- return (
- <>
-
-
-
- )
-}
diff --git a/spaces/KonradSzafer/HF-QA-Demo/qa_engine/mocks.py b/spaces/KonradSzafer/HF-QA-Demo/qa_engine/mocks.py
deleted file mode 100644
index cd93049fd2f33b128888e2cdc6823b97a2d88746..0000000000000000000000000000000000000000
--- a/spaces/KonradSzafer/HF-QA-Demo/qa_engine/mocks.py
+++ /dev/null
@@ -1,27 +0,0 @@
-import os
-from typing import Mapping, Optional, Any
-
-from langchain.llms.base import LLM
-
-
-class MockLocalBinaryModel(LLM):
- """
- Mock Local Binary Model class.
- """
-
- model_path: str = None
- llm: str = 'Mocked Response'
-
- def __init__(self):
- super().__init__()
-
- def _call(self, prompt: str, stop: Optional[list[str]] = None) -> str:
- return self.llm
-
- @property
- def _identifying_params(self) -> Mapping[str, Any]:
- return {'name_of_model': 'mock'}
-
- @property
- def _llm_type(self) -> str:
- return 'mock'
diff --git a/spaces/Kvikontent/kandinsky2.2/app.py b/spaces/Kvikontent/kandinsky2.2/app.py
deleted file mode 100644
index f3bc2862533aff2671fa2216f9f0eafb15a8666c..0000000000000000000000000000000000000000
--- a/spaces/Kvikontent/kandinsky2.2/app.py
+++ /dev/null
@@ -1,35 +0,0 @@
-import gradio as gr
-from PIL import Image
-from diffusers import DiffusionPipeline
-import time
-
-# Load model and scheduler
-ldm = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
-
-def generate_image(prompt, negative_prompt="Low quality", width=512, height=512):
- # Run pipeline in inference (sample random noise and denoise)
- start_time = time.time()
- images = ldm([prompt], num_inference_steps=50, eta=0.3, guidance_scale=6, negative_prompts=[negative_prompt]).images
- # Resize image to desired width and height
- resized_images = [image.resize((int(width), int(height))) for image in images]
- # Save images
- for idx, image in enumerate(resized_images):
- image.save(f"squirrel-{idx}.png")
- end_time = time.time()
- elapsed_time = round(end_time - start_time, 2)
- return resized_images[0]
-
-# Define the interface
-iface = gr.Interface(
- fn=generate_image,
- inputs=["text", "text", "number", "number"],
- outputs=gr.outputs.Image(type="pil", label="Generated Image"),
- layout="vertical",
- title="Image Generation",
- description="Generate images based on prompts",
- article="For more information, visit the documentation: [link](https://docs.gradio.app/)",
- examples=[["A painting of a squirrel eating a burger", "Low quality", 512, 512]]
-)
-
-# Launch the interface
-iface.launch()
diff --git a/spaces/KyanChen/FunSR/tools/data_tools/get_classes_list.py b/spaces/KyanChen/FunSR/tools/data_tools/get_classes_list.py
deleted file mode 100644
index 6119dbd33a196586d795b0fc81986a1d71aebfa0..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/FunSR/tools/data_tools/get_classes_list.py
+++ /dev/null
@@ -1,17 +0,0 @@
-import glob
-import os
-
-import numpy as np
-import pickle
-import sys
-import tqdm
-import shutil
-
-pre_path = r'H:\DataSet\SceneCls\UCMerced_LandUse\UCMerced_LandUse\Images'
-sub_folder_list = glob.glob(pre_path +'/*')
-
-with open(pre_path+f'/../class_names.txt', 'w') as f:
- for sub_folder in sub_folder_list:
- sub_folder_name = os.path.basename(sub_folder)
- f.write(sub_folder_name+'\n')
-
diff --git a/spaces/KyanChen/RSPrompter/mmdet/engine/hooks/checkloss_hook.py b/spaces/KyanChen/RSPrompter/mmdet/engine/hooks/checkloss_hook.py
deleted file mode 100644
index 3ebfcd5dfcd7ae329399723d3a9c0fc0a0d722ef..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmdet/engine/hooks/checkloss_hook.py
+++ /dev/null
@@ -1,42 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional
-
-import torch
-from mmengine.hooks import Hook
-from mmengine.runner import Runner
-
-from mmdet.registry import HOOKS
-
-
-@HOOKS.register_module()
-class CheckInvalidLossHook(Hook):
- """Check invalid loss hook.
-
- This hook will regularly check whether the loss is valid
- during training.
-
- Args:
- interval (int): Checking interval (every k iterations).
- Default: 50.
- """
-
- def __init__(self, interval: int = 50) -> None:
- self.interval = interval
-
- def after_train_iter(self,
- runner: Runner,
- batch_idx: int,
- data_batch: Optional[dict] = None,
- outputs: Optional[dict] = None) -> None:
- """Regularly check whether the loss is valid every n iterations.
-
- Args:
- runner (:obj:`Runner`): The runner of the training process.
- batch_idx (int): The index of the current batch in the train loop.
- data_batch (dict, Optional): Data from dataloader.
- Defaults to None.
- outputs (dict, Optional): Outputs from model. Defaults to None.
- """
- if self.every_n_train_iters(runner, self.interval):
- assert torch.isfinite(outputs['loss']), \
- runner.logger.info('loss become infinite or NaN!')
diff --git a/spaces/Lewdgirl89/Waifu-AI-WebUI/README.md b/spaces/Lewdgirl89/Waifu-AI-WebUI/README.md
deleted file mode 100644
index 028654eb8ec1d7c2a3f1b35bcf8d206dd3ec2d67..0000000000000000000000000000000000000000
--- a/spaces/Lewdgirl89/Waifu-AI-WebUI/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Waifu AI
-emoji: 💻
-colorFrom: pink
-colorTo: purple
-sdk: gradio
-sdk_version: 3.12.0
-app_file: app.py
-pinned: false
-license: openrail
-duplicated_from: Axesys/Waifu-AI-WebUI
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/MRiwu/Collection/commons.py b/spaces/MRiwu/Collection/commons.py
deleted file mode 100644
index 40fcc05364d4815971f5c6f9dbb8dcef8e3ec1e9..0000000000000000000000000000000000000000
--- a/spaces/MRiwu/Collection/commons.py
+++ /dev/null
@@ -1,172 +0,0 @@
-import math
-import torch
-from torch.nn import functional as F
-import torch.jit
-
-
-def script_method(fn, _rcb=None):
- return fn
-
-
-def script(obj, optimize=True, _frames_up=0, _rcb=None):
- return obj
-
-
-torch.jit.script_method = script_method
-torch.jit.script = script
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size*dilation - dilation)/2)
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def intersperse(lst, item):
- result = [item] * (len(lst) * 2 + 1)
- result[1::2] = lst
- return result
-
-
-def kl_divergence(m_p, logs_p, m_q, logs_q):
- """KL(P||Q)"""
- kl = (logs_q - logs_p) - 0.5
- kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q)
- return kl
-
-
-def rand_gumbel(shape):
- """Sample from the Gumbel distribution, protect from overflows."""
- uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
- return -torch.log(-torch.log(uniform_samples))
-
-
-def rand_gumbel_like(x):
- g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
- return g
-
-
-def slice_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, :, idx_str:idx_end]
- return ret
-
-
-def rand_slice_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def get_timing_signal_1d(
- length, channels, min_timescale=1.0, max_timescale=1.0e4):
- position = torch.arange(length, dtype=torch.float)
- num_timescales = channels // 2
- log_timescale_increment = (
- math.log(float(max_timescale) / float(min_timescale)) /
- (num_timescales - 1))
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment)
- scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
- signal = F.pad(signal, [0, 0, 0, channels % 2])
- signal = signal.view(1, channels, length)
- return signal
-
-
-def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return x + signal.to(dtype=x.dtype, device=x.device)
-
-
-def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
-
-
-def subsequent_mask(length):
- mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
- return mask
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a + input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def shift_1d(x):
- x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
- return x
-
-
-def sequence_mask(length, max_length=None):
- if max_length is None:
- max_length = length.max()
- x = torch.arange(max_length, dtype=length.dtype, device=length.device)
- return x.unsqueeze(0) < length.unsqueeze(1)
-
-
-def generate_path(duration, mask):
- """
- duration: [b, 1, t_x]
- mask: [b, 1, t_y, t_x]
- """
- device = duration.device
-
- b, _, t_y, t_x = mask.shape
- cum_duration = torch.cumsum(duration, -1)
-
- cum_duration_flat = cum_duration.view(b * t_x)
- path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
- path = path.view(b, t_x, t_y)
- path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
- path = path.unsqueeze(1).transpose(2,3) * mask
- return path
-
-
-def clip_grad_value_(parameters, clip_value, norm_type=2):
- if isinstance(parameters, torch.Tensor):
- parameters = [parameters]
- parameters = list(filter(lambda p: p.grad is not None, parameters))
- norm_type = float(norm_type)
- if clip_value is not None:
- clip_value = float(clip_value)
-
- total_norm = 0
- for p in parameters:
- param_norm = p.grad.data.norm(norm_type)
- total_norm += param_norm.item() ** norm_type
- if clip_value is not None:
- p.grad.data.clamp_(min=-clip_value, max=clip_value)
- total_norm = total_norm ** (1. / norm_type)
- return total_norm
diff --git a/spaces/MRiwu/Collection/export_model.py b/spaces/MRiwu/Collection/export_model.py
deleted file mode 100644
index 52d3b3d083df7bf027b46d9c63e399b2da3f0e0a..0000000000000000000000000000000000000000
--- a/spaces/MRiwu/Collection/export_model.py
+++ /dev/null
@@ -1,13 +0,0 @@
-import torch
-
-if __name__ == '__main__':
- model_path = "saved_model/18/model.pth"
- output_path = "saved_model/18/model1.pth"
- checkpoint_dict = torch.load(model_path, map_location='cpu')
- checkpoint_dict_new = {}
- for k, v in checkpoint_dict.items():
- if k == "optimizer":
- print("remove optimizer")
- continue
- checkpoint_dict_new[k] = v
- torch.save(checkpoint_dict_new, output_path)
diff --git a/spaces/MWilinski/bot/api/__init__.py b/spaces/MWilinski/bot/api/__init__.py
deleted file mode 100644
index 302e7d2793e9f185d67cd7af9e11811c37aa2d21..0000000000000000000000000000000000000000
--- a/spaces/MWilinski/bot/api/__init__.py
+++ /dev/null
@@ -1,6 +0,0 @@
-from dotenv import load_dotenv
-from api.logger import setup_logger
-
-
-setup_logger()
-load_dotenv(dotenv_path='config/api/.env')
diff --git a/spaces/MajdOD/gradio-Stroke-prediction/app.py b/spaces/MajdOD/gradio-Stroke-prediction/app.py
deleted file mode 100644
index a203d92d5d0e4d006ef59cce4c796997a7f720e5..0000000000000000000000000000000000000000
--- a/spaces/MajdOD/gradio-Stroke-prediction/app.py
+++ /dev/null
@@ -1,78 +0,0 @@
-import gradio as gr
-import dill
-import pandas as pd
-import xgboost as xgb
-import numpy as np
-import pickle
-
-def decode_file(file_path):
- with open(file_path, 'rb') as file:
- obj = pickle.load(file)
- return obj
-
-model = decode_file('model.pkl')
-
-
-def predict(gender, age, hypertension, ever_married, work_type, heart_disease, avg_glucose_level, bmi, smoking_status, Residence_type):
- # Mapping for categorical variables
- gender_mapping = {'Male': 1, 'Female': 0}
- hypertension_mapping = {'Yes': 1, 'No': 0}
- ever_married_mapping = {'Yes': 1, 'No': 0}
- work_type_mapping = {'Private': 2, 'Self-employed': 4, 'Govt_job': 3, 'children': 1, 'Never_worked': 0}
- heart_disease_mapping = {'Yes': 1, 'No': 0}
- smoking_status_mapping = {'formerly smoked': 3, 'smokes': 1, 'never smoked': 2, 'Unknown': 0}
- Residence_type_mapping = {'Urban': 1, 'Rural': 0}
-
- # Map categorical variables to their corresponding numerical values
- gender = gender_mapping[gender]
- hypertension = hypertension_mapping[hypertension]
- ever_married = ever_married_mapping[ever_married]
- work_type = work_type_mapping[work_type]
- heart_disease = heart_disease_mapping[heart_disease]
- smoking_status = smoking_status_mapping[smoking_status]
- Residence_type = Residence_type_mapping[Residence_type]
-
- inputs = [gender, age, hypertension, ever_married, work_type, heart_disease, avg_glucose_level, bmi, smoking_status, Residence_type]
- input_labels = ['gender', 'age', 'hypertension', 'ever_married', 'work_type', 'heart_disease', 'avg_glucose_level', 'bmi', 'smoking_status', 'Residence_type']
-
- # Convert the input into a pandas DataFrame
- input_df = pd.DataFrame([inputs], columns=input_labels)
-
- # Predict the stroke probability
- prediction = model.predict_proba(input_df)[0][1]
-
- # Return the prediction
- result = "The probability of stroke is {:.2f}%".format(prediction * 100) # to give a percentage
- return result
-
-
-
-
-
-
-input_labels = [
- 'gender', 'age', 'hypertension', 'ever_married', 'work_type',
- 'heart_disease', 'avg_glucose_level', 'bmi', 'smoking_status', 'Residence_type'
-]
-# Create the Gradio interface
-iface = gr.Interface(
- fn=predict,
- inputs=[
- gr.components.Radio(choices=['Female', 'Male'], label="Gender"),
- gr.components.Slider(label="Age"),
- gr.components.Radio(choices=['Yes', 'No'], label="Hypertension"),
- gr.components.Radio(choices=['Yes', 'No'], label="Ever Married"),
- gr.components.Radio(choices=['Private', 'Self-employed', 'Govt_job', 'children', 'Never_worked'], label="Work Type"),
- gr.components.Radio(choices=['Yes', 'No'], label="Heart Disease"),
- gr.components.Number(label="Average Glucose Level"),
- gr.components.Slider(label="BMI"),
- gr.components.Radio(choices=['formerly smoked', 'never smoked', 'smokes', 'Unknown'], label="Smoking Status"),
- gr.components.Radio(choices=['Urban', 'Rural'], label="Residence Type")
- ],
- outputs='text',
- title='Stroke Probability Predictor',
- description='Predicts the probability of having a stroke based on input features.'
-)
-
-
-iface.launch()
diff --git a/spaces/Makiing/coolb-in-gtest/src/components/ui/input.tsx b/spaces/Makiing/coolb-in-gtest/src/components/ui/input.tsx
deleted file mode 100644
index 684a857f3d769b78818fb13de1abaebfb09ca79c..0000000000000000000000000000000000000000
--- a/spaces/Makiing/coolb-in-gtest/src/components/ui/input.tsx
+++ /dev/null
@@ -1,25 +0,0 @@
-import * as React from 'react'
-
-import { cn } from '@/lib/utils'
-
-export interface InputProps
- extends React.InputHTMLAttributes {}
-
-const Input = React.forwardRef(
- ({ className, type, ...props }, ref) => {
- return (
-
- )
- }
-)
-Input.displayName = 'Input'
-
-export { Input }
diff --git a/spaces/Marshalls/testmtd/analysis/aistplusplus_make_split.py b/spaces/Marshalls/testmtd/analysis/aistplusplus_make_split.py
deleted file mode 100644
index 407a4fe11c97a6e3fbc549e9238782b7790ad2ba..0000000000000000000000000000000000000000
--- a/spaces/Marshalls/testmtd/analysis/aistplusplus_make_split.py
+++ /dev/null
@@ -1,72 +0,0 @@
-import pandas as pd
-import numpy as np
-
-seqs = [x[:-1].split("_") for x in open("analysis/base_filenames.txt", "r").readlines()]
-
-seqs = [{"genre":x[0], "situation":x[1], "camera":x[2], "dancer":x[3], "musicId":x[4], "choreo":x[5]} for x in seqs]
-
-df = pd.DataFrame(seqs)
-
-df["choreo"].unique().size
-df["musicId"].unique().size
-
-len(df["choreo"].unique())*len(df["dancer"].unique())
-
-df["dancer"].unique()
-[df[df["dancer"]==d]["choreo"] for d in df["dancer"].unique()]
-
-df["musicId"].unique()
-
-songs=[np.random.choice(df[df["genre"]==g]["musicId"],size=1).item() for g in df["genre"].unique()]
-
-# song_dancers=sum([[(s,x) for x in np.random.choice(df[df["musicId"]==s]["dancer"],size=2, replace=False).tolist()] for s in songs], [])
-# song_dancers
-
-# df[(df["musicId"]=="mBR4") & (df["dancer"]=="d06")]
-
-# song_dancer_choreos=sum([[(s,d,x) for x in np.random.choice(df[(df["musicId"]==s) & (df["dancer"]==d)]["choreo"],size=2, replace=False).tolist()] for s,d in song_dancers], [])
-
-# len(song_dancer_choreos)
-
-# test_data = pd.concat([df[(df["musicId"]==s) & (df["dancer"]==d) & (df["choreo"]==c)].sample(1) for s,d,c in song_dancer_choreos])
-test_data = pd.concat([df[(df["musicId"]==s)] for s in songs])
-# [df[(df["musicId"]==s) & (df["dancer"]==d) & (df["choreo"]==c)] for s,d,c in song_dancer_choreos]
-
-test_data.count()
-
-test_data_seqs = ["_".join([x["genre"], x["situation"], x["camera"], x["dancer"], x["musicId"], x["choreo"]]) for i,x in test_data.iterrows()]
-
-with open("analysis/aistpp_base_filenames_test.txt", "w") as f:
- f.writelines([x+"\n" for x in test_data_seqs])
-
-
-###TRAIN DATA
-seqs = [x[:-1].split("_") for x in open("analysis/aistpp_base_filenames_test.txt", "r").readlines()]
-
-seqs = [{"genre":x[0], "situation":x[1], "camera":x[2], "dancer":x[3], "musicId":x[4], "choreo":x[5]} for x in seqs]
-test_data = pd.DataFrame(seqs)
-
-# train_data = df[~(df["musicId"].isin(test_data["musicId"])) & ~(df["choreo"].isin(test_data["choreo"]))]
-train_data = df[~(df["musicId"].isin(test_data["musicId"]))]
-# train_data = df[~((df["musicId"].isin(test_data["musicId"])) & (df["choreo"].isin(test_data["choreo"])))]
-len(train_data)
-# song_choreos=[x.tolist() for i,x in test_data[["musicId","choreo"]].iterrows()]
-# song_dancer_choreos=[x.tolist() for i,x in test_data[["musicId","dancer","choreo"]].iterrows()]
-
-# count=0
-# for i,x in df[["musicId", "dancer", "choreo"]].iterrows():
-# if x.tolist() not in song_dancer_choreos:
-# count+=1
-#
-# count
-
-# train_data = df[(~df["musicId"].isin(test_data["musicId"])) & (~df["choreo"].isin(test_data["choreo"])))]
-
-train_data.count()
-# train_data[["musicId","choreo"]].drop_duplicates().count()
-# train_data[["dancer","choreo"]].drop_duplicates().count()
-
-train_data_seqs = ["_".join([x["genre"], x["situation"], x["camera"], x["dancer"], x["musicId"], x["choreo"]]) for i,x in train_data.iterrows()]
-
-with open("analysis/aistpp_base_filenames_train.txt", "w") as f:
- f.writelines([x+"\n" for x in train_data_seqs])
diff --git a/spaces/Mountchicken/MAERec-Gradio/configs/textdet/textsnake/README.md b/spaces/Mountchicken/MAERec-Gradio/configs/textdet/textsnake/README.md
deleted file mode 100644
index e1cd5d39d08e3f1f5b67e761452245cf0c4d9ef9..0000000000000000000000000000000000000000
--- a/spaces/Mountchicken/MAERec-Gradio/configs/textdet/textsnake/README.md
+++ /dev/null
@@ -1,34 +0,0 @@
-# Textsnake
-
-> [TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes](https://arxiv.org/abs/1807.01544)
-
-
-
-## Abstract
-
-Driven by deep neural networks and large scale datasets, scene text detection methods have progressed substantially over the past years, continuously refreshing the performance records on various standard benchmarks. However, limited by the representations (axis-aligned rectangles, rotated rectangles or quadrangles) adopted to describe text, existing methods may fall short when dealing with much more free-form text instances, such as curved text, which are actually very common in real-world scenarios. To tackle this problem, we propose a more flexible representation for scene text, termed as TextSnake, which is able to effectively represent text instances in horizontal, oriented and curved forms. In TextSnake, a text instance is described as a sequence of ordered, overlapping disks centered at symmetric axes, each of which is associated with potentially variable radius and orientation. Such geometry attributes are estimated via a Fully Convolutional Network (FCN) model. In experiments, the text detector based on TextSnake achieves state-of-the-art or comparable performance on Total-Text and SCUT-CTW1500, the two newly published benchmarks with special emphasis on curved text in natural images, as well as the widely-used datasets ICDAR 2015 and MSRA-TD500. Specifically, TextSnake outperforms the baseline on Total-Text by more than 40% in F-measure.
-
-
-
-
-
-## Results and models
-
-### CTW1500
-
-| Method | BackBone | Pretrained Model | Training set | Test set | #epochs | Test size | Precision | Recall | Hmean | Download |
-| :-------------------------------------: | :---------------------------------------: | :--------------: | :-----------: | :----------: | :-----: | :-------: | :-------: | :----: | :----: | :----------------------------------------: |
-| [TextSnake](/configs/textdet/textsnake/textsnake_resnet50_fpn-unet_1200e_ctw1500.py) | ResNet50 | - | CTW1500 Train | CTW1500 Test | 1200 | 736 | 0.8535 | 0.8052 | 0.8286 | [model](https://download.openmmlab.com/mmocr/textdet/textsnake/textsnake_resnet50_fpn-unet_1200e_ctw1500/textsnake_resnet50_fpn-unet_1200e_ctw1500_20220825_221459-c0b6adc4.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/textsnake/textsnake_resnet50_fpn-unet_1200e_ctw1500/20220825_221459.log) |
-| [TextSnake_r50-oclip](/configs/textdet/textsnake/textsnake_resnet50-oclip_fpn-unet_1200e_ctw1500.py) | [ResNet50-oCLIP](https://download.openmmlab.com/mmocr/backbone/resnet50-oclip-7ba0c533.pth) | - | CTW1500 Train | CTW1500 Test | 1200 | 736 | 0.8869 | 0.8215 | 0.8529 | [model](https://download.openmmlab.com/mmocr/textdet/textsnake/textsnake_resnet50-oclip_fpn-unet_1200e_ctw1500/textsnake_resnet50-oclip_fpn-unet_1200e_ctw1500_20221101_134814-a216e5b2.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/textsnake/textsnake_resnet50-oclip_fpn-unet_1200e_ctw1500/20221101_134814.log) |
-
-## Citation
-
-```bibtex
-@article{long2018textsnake,
- title={TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes},
- author={Long, Shangbang and Ruan, Jiaqiang and Zhang, Wenjie and He, Xin and Wu, Wenhao and Yao, Cong},
- booktitle={ECCV},
- pages={20-36},
- year={2018}
-}
-```
diff --git a/spaces/MrMoans/stabilityai-stable-diffusion-2-1/README.md b/spaces/MrMoans/stabilityai-stable-diffusion-2-1/README.md
deleted file mode 100644
index 5418a81f04a9dd4f1e30e28ab1492dd5cf99d1ff..0000000000000000000000000000000000000000
--- a/spaces/MrMoans/stabilityai-stable-diffusion-2-1/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Stabilityai Stable Diffusion 2 1
-emoji: 💻
-colorFrom: gray
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.16.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Myrna/VideoSummary2/README.md b/spaces/Myrna/VideoSummary2/README.md
deleted file mode 100644
index 26cba009c8840439a47665fb4b7eb85de2f2f437..0000000000000000000000000000000000000000
--- a/spaces/Myrna/VideoSummary2/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: VideoSummary2
-emoji: 🏢
-colorFrom: indigo
-colorTo: purple
-sdk: gradio
-sdk_version: 3.1.1
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/NCTCMumbai/NCTC/models/official/vision/detection/modeling/__init__.py b/spaces/NCTCMumbai/NCTC/models/official/vision/detection/modeling/__init__.py
deleted file mode 100644
index 931c2ef11db4a949e6c2e95bca44e36bac1241e9..0000000000000000000000000000000000000000
--- a/spaces/NCTCMumbai/NCTC/models/official/vision/detection/modeling/__init__.py
+++ /dev/null
@@ -1,14 +0,0 @@
-# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
diff --git a/spaces/NCTCMumbai/NCTC/models/research/brain_coder/common/utils_test.py b/spaces/NCTCMumbai/NCTC/models/research/brain_coder/common/utils_test.py
deleted file mode 100644
index 569c2877d17bf7707616029cdd2a5eac55df7f60..0000000000000000000000000000000000000000
--- a/spaces/NCTCMumbai/NCTC/models/research/brain_coder/common/utils_test.py
+++ /dev/null
@@ -1,382 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for common.utils.
-"""
-
-from collections import Counter
-import random
-import tempfile
-import numpy as np
-import tensorflow as tf
-
-from common import utils # brain coder
-
-
-class UtilsTest(tf.test.TestCase):
-
- def testStackPad(self):
- # 1D.
- tensors = [[1, 2, 3], [4, 5, 6, 7, 8], [9]]
- result = utils.stack_pad(tensors, pad_axes=0, pad_to_lengths=6)
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[1, 2, 3, 0, 0, 0],
- [4, 5, 6, 7, 8, 0],
- [9, 0, 0, 0, 0, 0]], dtype=np.float32)))
-
- # 3D.
- tensors = [[[[1, 2, 3], [4, 5, 6]]],
- [[[7, 8, 9], [0, 1, 2]], [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2]], [[3, 4, 5]]]]
- result = utils.stack_pad(tensors, pad_axes=[0, 1], pad_to_lengths=[2, 2])
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[[[1, 2, 3], [4, 5, 6]],
- [[0, 0, 0], [0, 0, 0]]],
- [[[7, 8, 9], [0, 1, 2]],
- [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2], [0, 0, 0]],
- [[3, 4, 5], [0, 0, 0]]]], dtype=np.float32)))
-
- def testStackPadNoAxes(self):
- # 2D.
- tensors = [[[1, 2, 3], [4, 5, 6]],
- [[7, 8, 9], [1, 2, 3]],
- [[4, 5, 6], [7, 8, 9]]]
- result = utils.stack_pad(tensors)
- self.assertTrue(np.array_equal(
- result,
- np.asarray(tensors)))
-
- def testStackPadNoneLength(self):
- # 1D.
- tensors = [[1, 2, 3], [4, 5, 6, 7, 8], [9]]
- result = utils.stack_pad(tensors, pad_axes=0, pad_to_lengths=None)
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[1, 2, 3, 0, 0],
- [4, 5, 6, 7, 8],
- [9, 0, 0, 0, 0]], dtype=np.float32)))
-
- # 3D.
- tensors = [[[[1, 2, 3], [4, 5, 6]]],
- [[[7, 8, 9], [0, 1, 2]], [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2]], [[3, 4, 5]]]]
- result = utils.stack_pad(tensors, pad_axes=[0, 1], pad_to_lengths=None)
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[[[1, 2, 3], [4, 5, 6]],
- [[0, 0, 0], [0, 0, 0]]],
- [[[7, 8, 9], [0, 1, 2]],
- [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2], [0, 0, 0]],
- [[3, 4, 5], [0, 0, 0]]]], dtype=np.float32)))
-
- # 3D with partial pad_to_lengths.
- tensors = [[[[1, 2, 3], [4, 5, 6]]],
- [[[7, 8, 9], [0, 1, 2]], [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2]], [[3, 4, 5]]]]
- result = utils.stack_pad(tensors, pad_axes=[0, 1], pad_to_lengths=[None, 3])
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[[[1, 2, 3], [4, 5, 6], [0, 0, 0]],
- [[0, 0, 0], [0, 0, 0], [0, 0, 0]]],
- [[[7, 8, 9], [0, 1, 2], [0, 0, 0]],
- [[3, 4, 5], [6, 7, 8], [0, 0, 0]]],
- [[[0, 1, 2], [0, 0, 0], [0, 0, 0]],
- [[3, 4, 5], [0, 0, 0], [0, 0, 0]]]], dtype=np.float32)))
-
- def testStackPadValueError(self):
- # 3D.
- tensors = [[[[1, 2, 3], [4, 5, 6]]],
- [[[7, 8, 9], [0, 1, 2]], [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2]], [[3, 4, 5]]],
- [[[1, 2, 3, 4]]]]
-
- # Not all tensors have the same shape along axis 2.
- with self.assertRaises(ValueError):
- utils.stack_pad(tensors, pad_axes=[0, 1], pad_to_lengths=[2, 2])
-
- def testRecord(self):
- my_record = utils.make_record('my_record', ['a', 'b', 'c'], {'b': 55})
- inst = my_record(a=1, b=2, c=3)
- self.assertEqual(1, inst.a)
- self.assertEqual(2, inst.b)
- self.assertEqual(3, inst.c)
- self.assertEqual(1, inst[0])
- self.assertEqual(2, inst[1])
- self.assertEqual(3, inst[2])
- self.assertEqual([1, 2, 3], list(iter(inst)))
- self.assertEqual(3, len(inst))
-
- inst.b = 999
- self.assertEqual(999, inst.b)
- self.assertEqual(999, inst[1])
-
- inst2 = my_record(1, 999, 3)
- self.assertTrue(inst == inst2)
- inst2[1] = 3
- self.assertFalse(inst == inst2)
-
- inst3 = my_record(a=1, c=3)
- inst.b = 55
- self.assertEqual(inst, inst3)
-
- def testRecordUnique(self):
- record1 = utils.make_record('record1', ['a', 'b', 'c'])
- record2 = utils.make_record('record2', ['a', 'b', 'c'])
- self.assertNotEqual(record1(1, 2, 3), record2(1, 2, 3))
- self.assertEqual(record1(1, 2, 3), record1(1, 2, 3))
-
- def testTupleToRecord(self):
- my_record = utils.make_record('my_record', ['a', 'b', 'c'])
- inst = utils.tuple_to_record((5, 6, 7), my_record)
- self.assertEqual(my_record(5, 6, 7), inst)
-
- def testRecordErrors(self):
- my_record = utils.make_record('my_record', ['a', 'b', 'c'], {'b': 10})
-
- with self.assertRaises(ValueError):
- my_record(c=5) # Did not provide required argument 'a'.
- with self.assertRaises(ValueError):
- my_record(1, 2, 3, 4) # Too many arguments.
-
- def testRandomQueue(self):
- np.random.seed(567890)
- queue = utils.RandomQueue(5)
- queue.push(5)
- queue.push(6)
- queue.push(7)
- queue.push(8)
- queue.push(9)
- queue.push(10)
- self.assertTrue(5 not in queue)
- sample = queue.random_sample(1000)
- self.assertEqual(1000, len(sample))
- self.assertEqual([6, 7, 8, 9, 10], sorted(np.unique(sample).tolist()))
-
- def testMaxUniquePriorityQueue(self):
- queue = utils.MaxUniquePriorityQueue(5)
- queue.push(1.0, 'string 1')
- queue.push(-0.5, 'string 2')
- queue.push(0.5, 'string 3')
- self.assertEqual((-0.5, 'string 2', None), queue.pop())
- queue.push(0.1, 'string 4')
- queue.push(1.5, 'string 5')
- queue.push(0.0, 'string 6')
- queue.push(0.2, 'string 7')
- self.assertEqual((1.5, 'string 5', None), queue.get_max())
- self.assertEqual((0.1, 'string 4', None), queue.get_min())
- self.assertEqual(
- [('string 5', None), ('string 1', None), ('string 3', None),
- ('string 7', None), ('string 4', None)],
- list(queue.iter_in_order()))
-
- def testMaxUniquePriorityQueue_Duplicates(self):
- queue = utils.MaxUniquePriorityQueue(5)
- queue.push(0.0, 'string 1')
- queue.push(0.0, 'string 2')
- queue.push(0.0, 'string 3')
- self.assertEqual((0.0, 'string 1', None), queue.pop())
- self.assertEqual((0.0, 'string 2', None), queue.pop())
- self.assertEqual((0.0, 'string 3', None), queue.pop())
- self.assertEqual(0, len(queue))
- queue.push(0.1, 'string 4')
- queue.push(1.5, 'string 5')
- queue.push(0.3, 'string 6')
- queue.push(0.2, 'string 7')
- queue.push(0.0, 'string 8')
- queue.push(1.5, 'string 5')
- queue.push(1.5, 'string 5')
- self.assertEqual((1.5, 'string 5', None), queue.get_max())
- self.assertEqual((0.0, 'string 8', None), queue.get_min())
- self.assertEqual(
- [('string 5', None), ('string 6', None), ('string 7', None),
- ('string 4', None), ('string 8', None)],
- list(queue.iter_in_order()))
-
- def testMaxUniquePriorityQueue_ExtraData(self):
- queue = utils.MaxUniquePriorityQueue(5)
- queue.push(1.0, 'string 1', [1, 2, 3])
- queue.push(0.5, 'string 2', [4, 5, 6])
- queue.push(0.5, 'string 3', [7, 8, 9])
- queue.push(0.5, 'string 2', [10, 11, 12])
- self.assertEqual((0.5, 'string 2', [4, 5, 6]), queue.pop())
- self.assertEqual((0.5, 'string 3', [7, 8, 9]), queue.pop())
- self.assertEqual((1.0, 'string 1', [1, 2, 3]), queue.pop())
- self.assertEqual(0, len(queue))
- queue.push(0.5, 'string 2', [10, 11, 12])
- self.assertEqual((0.5, 'string 2', [10, 11, 12]), queue.pop())
-
- def testRouletteWheel(self):
- random.seed(12345678987654321)
- r = utils.RouletteWheel()
- self.assertTrue(r.is_empty())
- with self.assertRaises(RuntimeError):
- r.sample() # Cannot sample when empty.
- self.assertEqual(0, r.total_weight)
- self.assertEqual(True, r.add('a', 0.1))
- self.assertFalse(r.is_empty())
- self.assertEqual(0.1, r.total_weight)
- self.assertEqual(True, r.add('b', 0.01))
- self.assertEqual(0.11, r.total_weight)
- self.assertEqual(True, r.add('c', 0.5))
- self.assertEqual(True, r.add('d', 0.1))
- self.assertEqual(True, r.add('e', 0.05))
- self.assertEqual(True, r.add('f', 0.03))
- self.assertEqual(True, r.add('g', 0.001))
- self.assertEqual(0.791, r.total_weight)
- self.assertFalse(r.is_empty())
-
- # Check that sampling is correct.
- obj, weight = r.sample()
- self.assertTrue(isinstance(weight, float), 'Type: %s' % type(weight))
- self.assertTrue((obj, weight) in r)
- for obj, weight in r.sample_many(100):
- self.assertTrue(isinstance(weight, float), 'Type: %s' % type(weight))
- self.assertTrue((obj, weight) in r)
-
- # Check that sampling distribution is correct.
- n = 1000000
- c = Counter(r.sample_many(n))
- for obj, w in r:
- estimated_w = c[(obj, w)] / float(n) * r.total_weight
- self.assertTrue(
- np.isclose(w, estimated_w, atol=1e-3),
- 'Expected %s, got %s, for object %s' % (w, estimated_w, obj))
-
- def testRouletteWheel_AddMany(self):
- random.seed(12345678987654321)
- r = utils.RouletteWheel()
- self.assertTrue(r.is_empty())
- with self.assertRaises(RuntimeError):
- r.sample() # Cannot sample when empty.
- self.assertEqual(0, r.total_weight)
- count = r.add_many(
- ['a', 'b', 'c', 'd', 'e', 'f', 'g'],
- [0.1, 0.01, 0.5, 0.1, 0.05, 0.03, 0.001])
- self.assertEqual(7, count)
- self.assertFalse(r.is_empty())
- self.assertEqual(0.791, r.total_weight)
-
- # Adding no items is allowed.
- count = r.add_many([], [])
- self.assertEqual(0, count)
- self.assertFalse(r.is_empty())
- self.assertEqual(0.791, r.total_weight)
-
- # Check that sampling is correct.
- obj, weight = r.sample()
- self.assertTrue(isinstance(weight, float), 'Type: %s' % type(weight))
- self.assertTrue((obj, weight) in r)
- for obj, weight in r.sample_many(100):
- self.assertTrue(isinstance(weight, float), 'Type: %s' % type(weight))
- self.assertTrue((obj, weight) in r)
-
- # Check that sampling distribution is correct.
- n = 1000000
- c = Counter(r.sample_many(n))
- for obj, w in r:
- estimated_w = c[(obj, w)] / float(n) * r.total_weight
- self.assertTrue(
- np.isclose(w, estimated_w, atol=1e-3),
- 'Expected %s, got %s, for object %s' % (w, estimated_w, obj))
-
- def testRouletteWheel_AddZeroWeights(self):
- r = utils.RouletteWheel()
- self.assertEqual(True, r.add('a', 0))
- self.assertFalse(r.is_empty())
- self.assertEqual(4, r.add_many(['b', 'c', 'd', 'e'], [0, 0.1, 0, 0]))
- self.assertEqual(
- [('a', 0.0), ('b', 0.0), ('c', 0.1), ('d', 0.0), ('e', 0.0)],
- list(r))
-
- def testRouletteWheel_UniqueMode(self):
- random.seed(12345678987654321)
- r = utils.RouletteWheel(unique_mode=True)
- self.assertEqual(True, r.add([1, 2, 3], 1, 'a'))
- self.assertEqual(True, r.add([4, 5], 0.5, 'b'))
- self.assertEqual(False, r.add([1, 2, 3], 1.5, 'a'))
- self.assertEqual(
- [([1, 2, 3], 1.0), ([4, 5], 0.5)],
- list(r))
- self.assertEqual(1.5, r.total_weight)
- self.assertEqual(
- 2,
- r.add_many(
- [[5, 6, 2, 3], [1, 2, 3], [8], [1, 2, 3]],
- [0.1, 0.2, 0.1, 2.0],
- ['c', 'a', 'd', 'a']))
- self.assertEqual(
- [([1, 2, 3], 1.0), ([4, 5], 0.5), ([5, 6, 2, 3], 0.1), ([8], 0.1)],
- list(r))
- self.assertTrue(np.isclose(1.7, r.total_weight))
- self.assertEqual(0, r.add_many([], [], [])) # Adding no items is allowed.
- with self.assertRaises(ValueError):
- # Key not given.
- r.add([7, 8, 9], 2.0)
- with self.assertRaises(ValueError):
- # Keys not given.
- r.add_many([[7, 8, 9], [10]], [2.0, 2.0])
- self.assertEqual(True, r.has_key('a'))
- self.assertEqual(True, r.has_key('b'))
- self.assertEqual(False, r.has_key('z'))
- self.assertEqual(1.0, r.get_weight('a'))
- self.assertEqual(0.5, r.get_weight('b'))
-
- r = utils.RouletteWheel(unique_mode=False)
- self.assertEqual(True, r.add([1, 2, 3], 1))
- self.assertEqual(True, r.add([4, 5], 0.5))
- self.assertEqual(True, r.add([1, 2, 3], 1.5))
- self.assertEqual(
- [([1, 2, 3], 1.0), ([4, 5], 0.5), ([1, 2, 3], 1.5)],
- list(r))
- self.assertEqual(3, r.total_weight)
- self.assertEqual(
- 4,
- r.add_many(
- [[5, 6, 2, 3], [1, 2, 3], [8], [1, 2, 3]],
- [0.1, 0.2, 0.1, 0.2]))
- self.assertEqual(
- [([1, 2, 3], 1.0), ([4, 5], 0.5), ([1, 2, 3], 1.5),
- ([5, 6, 2, 3], 0.1), ([1, 2, 3], 0.2), ([8], 0.1), ([1, 2, 3], 0.2)],
- list(r))
- self.assertTrue(np.isclose(3.6, r.total_weight))
- with self.assertRaises(ValueError):
- # Key is given.
- r.add([7, 8, 9], 2.0, 'a')
- with self.assertRaises(ValueError):
- # Keys are given.
- r.add_many([[7, 8, 9], [10]], [2.0, 2.0], ['a', 'b'])
-
- def testRouletteWheel_IncrementalSave(self):
- f = tempfile.NamedTemporaryFile()
- r = utils.RouletteWheel(unique_mode=True, save_file=f.name)
- entries = [
- ([1, 2, 3], 0.1, 'a'),
- ([4, 5], 0.2, 'b'),
- ([6], 0.3, 'c'),
- ([7, 8, 9, 10], 0.25, 'd'),
- ([-1, -2], 0.15, 'e'),
- ([-3, -4, -5], 0.5, 'f')]
-
- self.assertTrue(r.is_empty())
- for i in range(0, len(entries), 2):
- r.add(*entries[i])
- r.add(*entries[i + 1])
- r.incremental_save()
-
- r2 = utils.RouletteWheel(unique_mode=True, save_file=f.name)
- self.assertEqual(i + 2, len(r2))
- count = 0
- for j, (obj, weight) in enumerate(r2):
- self.assertEqual(entries[j][0], obj)
- self.assertEqual(entries[j][1], weight)
- self.assertEqual(weight, r2.get_weight(entries[j][2]))
- count += 1
- self.assertEqual(i + 2, count)
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/spaces/NN520/AI/tailwind.config.js b/spaces/NN520/AI/tailwind.config.js
deleted file mode 100644
index 03da3c3c45be6983b9f5ffa6df5f1fd0870e9636..0000000000000000000000000000000000000000
--- a/spaces/NN520/AI/tailwind.config.js
+++ /dev/null
@@ -1,48 +0,0 @@
-/** @type {import('tailwindcss').Config} */
-module.exports = {
- content: [
- './src/pages/**/*.{js,ts,jsx,tsx,mdx}',
- './src/components/**/*.{js,ts,jsx,tsx,mdx}',
- './src/app/**/*.{js,ts,jsx,tsx,mdx}',
- './src/ui/**/*.{js,ts,jsx,tsx,mdx}',
- ],
- "darkMode": "class",
- theme: {
- extend: {
- colors: {
- 'primary-blue': 'rgb(var(--color-primary-blue) / )',
- secondary: 'rgb(var(--color-secondary) / )',
- 'primary-background': 'rgb(var(--primary-background) / )',
- 'primary-text': 'rgb(var(--primary-text) / )',
- 'secondary-text': 'rgb(var(--secondary-text) / )',
- 'light-text': 'rgb(var(--light-text) / )',
- 'primary-border': 'rgb(var(--primary-border) / )',
- },
- keyframes: {
- slideDownAndFade: {
- from: { opacity: 0, transform: 'translateY(-2px)' },
- to: { opacity: 1, transform: 'translateY(0)' },
- },
- slideLeftAndFade: {
- from: { opacity: 0, transform: 'translateX(2px)' },
- to: { opacity: 1, transform: 'translateX(0)' },
- },
- slideUpAndFade: {
- from: { opacity: 0, transform: 'translateY(2px)' },
- to: { opacity: 1, transform: 'translateY(0)' },
- },
- slideRightAndFade: {
- from: { opacity: 0, transform: 'translateX(2px)' },
- to: { opacity: 1, transform: 'translateX(0)' },
- },
- },
- animation: {
- slideDownAndFade: 'slideDownAndFade 400ms cubic-bezier(0.16, 1, 0.3, 1)',
- slideLeftAndFade: 'slideLeftAndFade 400ms cubic-bezier(0.16, 1, 0.3, 1)',
- slideUpAndFade: 'slideUpAndFade 400ms cubic-bezier(0.16, 1, 0.3, 1)',
- slideRightAndFade: 'slideRightAndFade 400ms cubic-bezier(0.16, 1, 0.3, 1)',
- },
- },
- },
- plugins: [require('@headlessui/tailwindcss'), require('tailwind-scrollbar')],
-}
diff --git a/spaces/NiuTaipu/moe-tts-test01/modules.py b/spaces/NiuTaipu/moe-tts-test01/modules.py
deleted file mode 100644
index 3484f6a1f4c1c06855c37a1ff4e66c58864acb38..0000000000000000000000000000000000000000
--- a/spaces/NiuTaipu/moe-tts-test01/modules.py
+++ /dev/null
@@ -1,390 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dilated and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/Norod78/Hebrew-GPT-Neo-Small/start.sh b/spaces/Norod78/Hebrew-GPT-Neo-Small/start.sh
deleted file mode 100644
index 451de447158ca3bf2d138c2ed9b621ce85f97ce1..0000000000000000000000000000000000000000
--- a/spaces/Norod78/Hebrew-GPT-Neo-Small/start.sh
+++ /dev/null
@@ -1,10 +0,0 @@
-#!/usr/bin/env bash
-set -e
-
-if [ "$DEBUG" = true ] ; then
- echo 'Debugging - ON'
- nodemon --exec streamlit run app.py
-else
- echo 'Debugging - OFF'
- streamlit run app.py
-fi
\ No newline at end of file
diff --git a/spaces/OAOA/DifFace/basicsr/utils/plot_util.py b/spaces/OAOA/DifFace/basicsr/utils/plot_util.py
deleted file mode 100644
index 1e6da5bc29e706da87ab83af6d5367176fe78763..0000000000000000000000000000000000000000
--- a/spaces/OAOA/DifFace/basicsr/utils/plot_util.py
+++ /dev/null
@@ -1,83 +0,0 @@
-import re
-
-
-def read_data_from_tensorboard(log_path, tag):
- """Get raw data (steps and values) from tensorboard events.
-
- Args:
- log_path (str): Path to the tensorboard log.
- tag (str): tag to be read.
- """
- from tensorboard.backend.event_processing.event_accumulator import EventAccumulator
-
- # tensorboard event
- event_acc = EventAccumulator(log_path)
- event_acc.Reload()
- scalar_list = event_acc.Tags()['scalars']
- print('tag list: ', scalar_list)
- steps = [int(s.step) for s in event_acc.Scalars(tag)]
- values = [s.value for s in event_acc.Scalars(tag)]
- return steps, values
-
-
-def read_data_from_txt_2v(path, pattern, step_one=False):
- """Read data from txt with 2 returned values (usually [step, value]).
-
- Args:
- path (str): path to the txt file.
- pattern (str): re (regular expression) pattern.
- step_one (bool): add 1 to steps. Default: False.
- """
- with open(path) as f:
- lines = f.readlines()
- lines = [line.strip() for line in lines]
- steps = []
- values = []
-
- pattern = re.compile(pattern)
- for line in lines:
- match = pattern.match(line)
- if match:
- steps.append(int(match.group(1)))
- values.append(float(match.group(2)))
- if step_one:
- steps = [v + 1 for v in steps]
- return steps, values
-
-
-def read_data_from_txt_1v(path, pattern):
- """Read data from txt with 1 returned values.
-
- Args:
- path (str): path to the txt file.
- pattern (str): re (regular expression) pattern.
- """
- with open(path) as f:
- lines = f.readlines()
- lines = [line.strip() for line in lines]
- data = []
-
- pattern = re.compile(pattern)
- for line in lines:
- match = pattern.match(line)
- if match:
- data.append(float(match.group(1)))
- return data
-
-
-def smooth_data(values, smooth_weight):
- """ Smooth data using 1st-order IIR low-pass filter (what tensorflow does).
-
- Reference: https://github.com/tensorflow/tensorboard/blob/f801ebf1f9fbfe2baee1ddd65714d0bccc640fb1/tensorboard/plugins/scalar/vz_line_chart/vz-line-chart.ts#L704 # noqa: E501
-
- Args:
- values (list): A list of values to be smoothed.
- smooth_weight (float): Smooth weight.
- """
- values_sm = []
- last_sm_value = values[0]
- for value in values:
- value_sm = last_sm_value * smooth_weight + (1 - smooth_weight) * value
- values_sm.append(value_sm)
- last_sm_value = value_sm
- return values_sm
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/unit2speech/tts_data.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/unit2speech/tts_data.py
deleted file mode 100644
index eb0f7c360d749fd9d489b40b04dae8652b095098..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/unit2speech/tts_data.py
+++ /dev/null
@@ -1,52 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-
-import torch
-import numpy as np
-from examples.textless_nlp.gslm.unit2speech.tacotron2.text import (
- EOS_TOK,
- SOS_TOK,
- code_to_sequence,
- text_to_sequence,
-)
-from examples.textless_nlp.gslm.unit2speech.tacotron2.utils import (
- load_code_dict,
-)
-
-
-class TacotronInputDataset:
- def __init__(self, hparams, append_str=""):
- self.is_text = getattr(hparams, "text_or_code", "text") == "text"
- if not self.is_text:
- self.code_dict = load_code_dict(hparams.code_dict)
- self.code_key = hparams.code_key
- self.add_sos = hparams.add_sos
- self.add_eos = hparams.add_eos
- self.collapse_code = hparams.collapse_code
- self.append_str = append_str
-
- def process_code(self, inp_str):
- inp_toks = inp_str.split()
- if self.add_sos:
- inp_toks = [SOS_TOK] + inp_toks
- if self.add_eos:
- inp_toks = inp_toks + [EOS_TOK]
- return code_to_sequence(inp_toks, self.code_dict, self.collapse_code)
-
- def process_text(self, inp_str):
- return text_to_sequence(inp_str, ["english_cleaners"])
-
- def get_tensor(self, inp_str):
- # uid, txt, inp_str = self._get_data(idx)
- inp_str = inp_str + self.append_str
- if self.is_text:
- inp_toks = self.process_text(inp_str)
- else:
- inp_toks = self.process_code(inp_str)
- return torch.from_numpy(np.array(inp_toks)).long()
-
- def __len__(self):
- return len(self.data)
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/data/encoders/space_tokenizer.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/data/encoders/space_tokenizer.py
deleted file mode 100644
index 925ad41b7c1aee6738c63938c36bd3ee16dca812..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/data/encoders/space_tokenizer.py
+++ /dev/null
@@ -1,21 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import re
-
-from fairseq.data.encoders import register_tokenizer
-from fairseq.dataclass import FairseqDataclass
-
-
-@register_tokenizer("space", dataclass=FairseqDataclass)
-class SpaceTokenizer(object):
- def __init__(self, *unused):
- self.space_tok = re.compile(r"\s+")
-
- def encode(self, x: str) -> str:
- return self.space_tok.sub(" ", x)
-
- def decode(self, x: str) -> str:
- return x
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/hubert/simple_kmeans/learn_kmeans.py b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/hubert/simple_kmeans/learn_kmeans.py
deleted file mode 100644
index 113ac655b8c0a585fe43797e99674e445098edd0..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/hubert/simple_kmeans/learn_kmeans.py
+++ /dev/null
@@ -1,146 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import logging
-import os
-import sys
-
-import numpy as np
-from sklearn.cluster import MiniBatchKMeans
-
-import joblib
-
-logging.basicConfig(
- format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
- datefmt="%Y-%m-%d %H:%M:%S",
- level=os.environ.get("LOGLEVEL", "INFO").upper(),
- stream=sys.stdout,
-)
-logger = logging.getLogger("learn_kmeans")
-
-
-def get_km_model(
- n_clusters,
- init,
- max_iter,
- batch_size,
- tol,
- max_no_improvement,
- n_init,
- reassignment_ratio,
-):
- return MiniBatchKMeans(
- n_clusters=n_clusters,
- init=init,
- max_iter=max_iter,
- batch_size=batch_size,
- verbose=1,
- compute_labels=False,
- tol=tol,
- max_no_improvement=max_no_improvement,
- init_size=None,
- n_init=n_init,
- reassignment_ratio=reassignment_ratio,
- )
-
-
-def load_feature_shard(feat_dir, split, nshard, rank, percent):
- feat_path = f"{feat_dir}/{split}_{rank}_{nshard}.npy"
- leng_path = f"{feat_dir}/{split}_{rank}_{nshard}.len"
- with open(leng_path, "r") as f:
- lengs = [int(line.rstrip()) for line in f]
- offsets = [0] + np.cumsum(lengs[:-1]).tolist()
-
- if percent < 0:
- return np.load(feat_path, mmap_mode="r")
- else:
- nsample = int(np.ceil(len(lengs) * percent))
- indices = np.random.choice(len(lengs), nsample, replace=False)
- feat = np.load(feat_path, mmap_mode="r")
- sampled_feat = np.concatenate(
- [feat[offsets[i]: offsets[i] + lengs[i]] for i in indices], axis=0
- )
- logger.info(
- (
- f"sampled {nsample} utterances, {len(sampled_feat)} frames "
- f"from shard {rank}/{nshard}"
- )
- )
- return sampled_feat
-
-
-def load_feature(feat_dir, split, nshard, seed, percent):
- assert percent <= 1.0
- feat = np.concatenate(
- [
- load_feature_shard(feat_dir, split, nshard, r, percent)
- for r in range(nshard)
- ],
- axis=0,
- )
- logging.info(f"loaded feature with dimension {feat.shape}")
- return feat
-
-
-def learn_kmeans(
- feat_dir,
- split,
- nshard,
- km_path,
- n_clusters,
- seed,
- percent,
- init,
- max_iter,
- batch_size,
- tol,
- n_init,
- reassignment_ratio,
- max_no_improvement,
-):
- np.random.seed(seed)
- feat = load_feature(feat_dir, split, nshard, seed, percent)
- km_model = get_km_model(
- n_clusters,
- init,
- max_iter,
- batch_size,
- tol,
- max_no_improvement,
- n_init,
- reassignment_ratio,
- )
- km_model.fit(feat)
- joblib.dump(km_model, km_path)
-
- inertia = -km_model.score(feat) / len(feat)
- logger.info("total intertia: %.5f", inertia)
- logger.info("finished successfully")
-
-
-if __name__ == "__main__":
- import argparse
-
- parser = argparse.ArgumentParser()
- parser.add_argument("feat_dir", type=str)
- parser.add_argument("split", type=str)
- parser.add_argument("nshard", type=int)
- parser.add_argument("km_path", type=str)
- parser.add_argument("n_clusters", type=int)
- parser.add_argument("--seed", default=0, type=int)
- parser.add_argument(
- "--percent", default=-1, type=float, help="sample a subset; -1 for all"
- )
- parser.add_argument("--init", default="k-means++")
- parser.add_argument("--max_iter", default=100, type=int)
- parser.add_argument("--batch_size", default=10000, type=int)
- parser.add_argument("--tol", default=0.0, type=float)
- parser.add_argument("--max_no_improvement", default=100, type=int)
- parser.add_argument("--n_init", default=20, type=int)
- parser.add_argument("--reassignment_ratio", default=0.0, type=float)
- args = parser.parse_args()
- logging.info(str(args))
-
- learn_kmeans(**vars(args))
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/m2m_100/README.md b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/m2m_100/README.md
deleted file mode 100644
index 02a68a5f0919a26a0468069bed46a5b1abc78941..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/m2m_100/README.md
+++ /dev/null
@@ -1,241 +0,0 @@
-# Beyond English-Centric Multilingual Machine Translation
-
-## Introduction
-In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively with the best single systems of WMT.
-
-If you are new to using fairseq, read the following walkthrough. Otherwise, skip to the sections below.
-
-0. **Generation Data**
-
-To download the generation data, follow the below commands. Note that all datasets need to be detokenized *before* applying SPM in the data preprocessing step. If you use these evaluation datasets, please cite their associated papers.
-```bash
-# WMT - use sacrebleu, example here:
-sacrebleu -t wmt14 -l fr-en --echo src > wmt.test.fr-en.fr
-sacrebleu -t wmt14 -l fr-en --echo ref > wmt.test.fr-en.en
-
-# WAT
-wget http://lotus.kuee.kyoto-u.ac.jp/WAT/my-en-data/wat2020.my-en.zip
-unzip wat2020.my-en.zip
-
-# FLORES
-# download from: https://github.com/facebookresearch/flores
-
-# TED - need to detokenize with Moses!
-# from: https://github.com/neulab/word-embeddings-for-nmt
-wget http://phontron.com/data/ted_talks.tar.gz
-
-# Autshumato
-# request to download: https://repo.sadilar.org/handle/20.500.12185/397
-
-# Tatoeba Challenge
-# available here: https://github.com/Helsinki-NLP/Tatoeba-Challenge
-```
-
-1. **Training Data**
-
-To produce the training data, we use a combination of [CCMatrix](https://arxiv.org/abs/1911.04944) and [CCAligned](https://arxiv.org/abs/1911.06154). Check out the instructions [here](https://github.com/facebookresearch/LASER/tree/master/tasks/CCMatrix) to download the raw data.
-
-2. **Preprocess Data**
-
-After downloading raw data, you will need to postprocess the data, then apply SPM, then binarize. Note that it is very important you run the postprocessing script, because this removes any instance of the evaluation data in the mined training data.
-
-```bash
-# preprocess data
-
-# remove sentences with more than 50% punctuation
-python /path/to/fairseq/examples/m2m_100/process_data/remove_too_much_punc.py
-
-# deduplicate training data
-paste /path/to/datadir/train.$src /path/to/datadir/train.$tgt | awk '!x[$0]++' > /path/to/datadir/train.dedup
-echo "keeping $(wc -l /path/to/datadir/train.dedup) bitext out of $(wc -l /path/to/datadir/train.$src)"
-cut -f1 /path/to/datadir/train.dedup > /path/to/datadir/train.$src
-cut -f2 /path/to/datadir/train.dedup > /path/to/datadir/train.$tgt
-
-# remove all instances of evaluation data from the training data
-python /path/to/fairseq/examples/m2m_100/process_data/dedup_data.py
-
-# frequency cleaning
-wget https://dl.fbaipublicfiles.com/m2m_100/histograms.tar.gz
-tar -xvzf histograms.tar.gz
-python /path/to/fairseq/examples/m2m_100/process_data/clean_histogram.py --src $src --tgt $tgt --src-file /path/to/source/file --tgt-file /path/to/output/file --src-output-file source_output.$src --tgt-output-file target_output.$tgt --histograms /path/to/histograms
-
-# apply SPM
-wget https://dl.fbaipublicfiles.com/m2m_100/spm.128k.model
-python /path/to/fairseq/scripts/spm_encode.py \
- --model spm.128k.model \
- --output_format=piece \
- --inputs=/path/to/input/file/here \
- --outputs=/path/to/output/file/here
-
-# length ratio cleaning
-perl mosesdecoder/scripts/training/clean-corpus-n.perl --ratio 3 /path/to/training/data/train.spm.$src-$tgt $src $tgt /path/to/output/directory/train.spm.$src-$tgt 1 250
-
-# binarize data
-wget https://dl.fbaipublicfiles.com/m2m_100/data_dict.128k.txt
-fairseq-preprocess \
- --source-lang $src --target-lang $tgt \
- --testpref spm.$src.$tgt \
- --thresholdsrc 0 --thresholdtgt 0 \
- --destdir data_bin \
- --srcdict data_dict.128k.txt --tgtdict data_dict.128k.txt
-```
-
-3. **Training Scripts**
-
-To reproduce the training of our models, we train with fairseq-py's multilingual translation [task](https://github.com/pytorch/fairseq/tree/main/examples/multilingual). If you are interested in model parallel training, also check out [fairscale](https://github.com/facebookresearch/fairscale).
-
-4. **Generation**
-
-To generate from our models, follow the the commands in the generation section below.
-
-
-If you use any of the resources listed here, please cite:
-```bibtex
-@article{fan2020beyond,
- title={Beyond English-Centric Multilingual Machine Translation},
- author={Fan, Angela and Bhosale, Shruti and Schwenk, Holger and Ma, Zhiyi and El-Kishky, Ahmed and Goyal, Siddharth and Baines, Mandeep and Celebi, Onur and Wenzek, Guillaume and Chaudhary, Vishrav and Goyal, Naman and Birch, Tom and Liptchinsky, Vitaliy and Edunov, Sergey and Grave, Edouard and Auli, Michael and Joulin, Armand},
- journal={arXiv preprint},
- year={2020}
-}
-
-@article{schwenk2019ccmatrix,
- title={Ccmatrix: Mining billions of high-quality parallel sentences on the web},
- author={Schwenk, Holger and Wenzek, Guillaume and Edunov, Sergey and Grave, Edouard and Joulin, Armand},
- journal={arXiv preprint arXiv:1911.04944},
- year={2019}
-}
-
-@article{el2019massive,
- title={A Massive Collection of Cross-Lingual Web-Document Pairs},
- author={El-Kishky, Ahmed and Chaudhary, Vishrav and Guzman, Francisco and Koehn, Philipp},
- journal={arXiv preprint arXiv:1911.06154},
- year={2019}
-}
-```
-
-
-## Trained Models
-
-### 418M and 1.2B Model
-We include the last checkpoint for both of these models.
-
-```bash
-wget https://dl.fbaipublicfiles.com/m2m_100/model_dict.128k.txt
-wget https://dl.fbaipublicfiles.com/m2m_100/language_pairs_small_models.txt
-
-# 418M parameter model
-wget https://dl.fbaipublicfiles.com/m2m_100/418M_last_checkpoint.pt
-
-# 1.2B parameter model
-wget https://dl.fbaipublicfiles.com/m2m_100/1.2B_last_checkpoint.pt
-
-# Generation:
-fairseq-generate $binarized_data_path --batch-size 32 --path $path_to_model --fixed-dictionary model_dict.128k.txt -s en -t fr --remove-bpe 'sentencepiece' --beam 5 --task translation_multi_simple_epoch --lang-pairs language_pairs_small_models.txt --decoder-langtok --encoder-langtok src --gen-subset test > gen_out
-```
-
-### 12B Model
-12B parameter model trained on many-to-many training data for 100 languages. We include the last checkpoint, average of last 5 checkpoints, average of last 10 checkpoints. There isn't a universally best choice out of these three, but all three versions are pretty close in accuracy. You can either sweep over the 3 checkpoints on a dev test and use the best performing checkpoint for final testing. Or the last checkpoint can be a good default choice.
-
-**Model Download Links**
-Configuration | 2 32GB GPUs | 4 16GB GPUs | 6 12GB GPUs | 8 8GB GPUs
-:--|:--|:--|:--|:--
-Last Checkpoint | [12b_last_chk_2_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_last_chk_2_gpus.pt) | [12b_last_chk_4_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_last_chk_4_gpus.pt) | [12b_last_chk_6_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_last_chk_6_gpus.pt) | [12b_last_chk_8_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_last_chk_8_gpus.pt)
-Average of last 5 checkpoints | [12b_avg5_chk_2_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_avg5_chk_2_gpus.pt) | [12b_avg5_chk_4_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_avg5_chk_4_gpus.pt) | [12b_avg5_chk_6_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_avg5_chk_6_gpus.pt) | [12b_avg5_chk_8_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_avg5_chk_8_gpus.pt)
-Average of last 10 checkpoints | [12b_avg10_chk_2_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_avg10_chk_2_gpus.pt) | [12b_avg10_chk_4_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_avg10_chk_4_gpus.pt) | [12b_avg10_chk_6_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_avg10_chk_6_gpus.pt) | [12b_avg10_chk_8_gpus.pt](https://dl.fbaipublicfiles.com/m2m_100/12b_avg10_chk_8_gpus.pt)
-
-**Generation Arguments**
-Configuration | 2 32GB GPUs | 4 16GB GPUs | 6 12GB GPUs | 8 8GB GPUs
-:--|:--|:--|:--|:--
-`--pipeline-encoder-balance` | `[26]` | `[1,15,10]` | `[1,9,9,7]` | `[1,6,6,6,7]`
-`--pipeline-encoder-devices` | `[0]` | `[0,1,0]` | `[0,1,2,0]` | `[0,4,5,1,0]`
-`--pipeline-decoder-balance` | `[3,22,1]` | `[3,11,11,1]` | `[3,7,7,8,1]` | `[1,6,6,6,6,1]`
-`--pipeline-decoder-devices` | `[0,1,0]` | `[0,2,3,0]` | `[0,3,4,5,0]` | `[0,2,6,7,3,0]`
-
-
-## SentencePiece Model
-
-```bash
-wget https://dl.fbaipublicfiles.com/m2m_100/spm.128k.model
-```
-
-## Generation with M2M-100
-
-### Encode using our SentencePiece Model
-
-Note: Install SentencePiece from [here](https://github.com/google/sentencepiece)
-
-```bash
-fairseq=/path/to/fairseq
-cd $fairseq
-sacrebleu --echo src -l de-fr -t wmt19 | head -n 20 > raw_input.de-fr.de
-sacrebleu --echo ref -l de-fr -t wmt19 | head -n 20 > raw_input.de-fr.fr
-wget https://dl.fbaipublicfiles.com/m2m_100/spm.128k.model
-for lang in de fr ; do
- python scripts/spm_encode.py \
- --model spm.128k.model \
- --output_format=piece \
- --inputs=raw_input.de-fr.${lang} \
- --outputs=spm.de-fr.${lang}
-done
-```
-
-### Binarization
-
-```bash
-wget https://dl.fbaipublicfiles.com/m2m_100/data_dict.128k.txt
-fairseq-preprocess \
- --source-lang de --target-lang fr \
- --testpref spm.de-fr \
- --thresholdsrc 0 --thresholdtgt 0 \
- --destdir data_bin \
- --srcdict data_dict.128k.txt --tgtdict data_dict.128k.txt
-```
-
-### Generation for the 12B model
-
-Note that generation can currently be run using 2 32GB / 4 16GB / 6 12GB / 8 8GB GPUs, and the corresponding model checkpoints and pipeline arguments can be found in the [12B Model Section](#12b-model).
-Generation on CPUs will be added in the future.
-
-```bash
-wget https://dl.fbaipublicfiles.com/m2m_100/model_dict.128k.txt
-wget https://dl.fbaipublicfiles.com/m2m_100/language_pairs.txt
-wget https://dl.fbaipublicfiles.com/m2m_100/12b_last_chk_4_gpus.pt
-fairseq-generate \
- data_bin \
- --batch-size 1 \
- --path 12b_last_chk_4_gpus.pt \
- --fixed-dictionary model_dict.128k.txt \
- -s de -t fr \
- --remove-bpe 'sentencepiece' \
- --beam 5 \
- --task translation_multi_simple_epoch \
- --lang-pairs language_pairs.txt \
- --decoder-langtok --encoder-langtok src \
- --gen-subset test \
- --fp16 \
- --dataset-impl mmap \
- --distributed-world-size 1 --distributed-no-spawn \
- --pipeline-model-parallel \
- --pipeline-chunks 1 \
- --pipeline-encoder-balance '[1,15,10]' \
- --pipeline-encoder-devices '[0,1,0]' \
- --pipeline-decoder-balance '[3,11,11,1]' \
- --pipeline-decoder-devices '[0,2,3,0]' > gen_out
-```
-## Evaluation with M2M-100
-
-### Tokenization
-
-Note: Refer to tokenizers/README.md for more details on tokenization.
-
-```bash
-cd ${fairseq}/examples/m2m_100
-cat ${fairseq}/gen_out | grep -P "^H" | sort -V | cut -f 3- | sh tok.sh fr > hyp
-cat ${fairseq}/raw_input.de-fr.fr | sh tok.sh fr > ref
-```
-
-### BLEU
-
-```bash
-sacrebleu -tok 'none' ref < hyp
-```
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/fairseq/models/speech_to_text/modules/augmented_memory_attention.py b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/fairseq/models/speech_to_text/modules/augmented_memory_attention.py
deleted file mode 100644
index e7465bc889fd1ba6ca2c60905a2eb6ff5cc62b9d..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/fairseq/models/speech_to_text/modules/augmented_memory_attention.py
+++ /dev/null
@@ -1,488 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from typing import Tuple, List
-
-import torch
-import torch.nn.functional as F
-from fairseq.models import FairseqEncoder
-from fairseq.models.speech_to_text import (
- ConvTransformerEncoder,
-)
-from fairseq.models.speech_to_text.utils import attention_suppression
-from fairseq.models.speech_to_text.utils import (
- lengths_to_encoder_padding_mask,
- segments_to_sequence,
- sequence_to_segments,
-)
-from fairseq.modules import MultiheadAttention, TransformerEncoderLayer
-from torch import nn, Tensor
-
-# ------------------------------------------------------------------------------
-# AugmentedMemoryConvTransformerEncoder
-# ------------------------------------------------------------------------------
-
-
-class AugmentedMemoryConvTransformerEncoder(ConvTransformerEncoder):
- def __init__(self, args):
- super().__init__(args)
-
- args.encoder_stride = self.stride()
-
- self.left_context = args.left_context // args.encoder_stride
-
- self.right_context = args.right_context // args.encoder_stride
-
- self.left_context_after_stride = args.left_context // args.encoder_stride
- self.right_context_after_stride = args.right_context // args.encoder_stride
-
- self.transformer_layers = nn.ModuleList([])
- self.transformer_layers.extend(
- [
- AugmentedMemoryTransformerEncoderLayer(args)
- for i in range(args.encoder_layers)
- ]
- )
-
- def stride(self):
- # Hard coded here. Should infer from convs in future
- stride = 4
- return stride
-
- def forward(self, src_tokens, src_lengths, states=None):
- """Encode input sequence.
- :param torch.Tensor xs: input tensor
- :param torch.Tensor masks: input mask
- :return: position embedded tensor and mask
- :rtype Tuple[torch.Tensor, torch.Tensor]:
- """
- bsz, max_seq_len, _ = src_tokens.size()
- x = (
- src_tokens.view(bsz, max_seq_len, self.in_channels, self.input_dim)
- .transpose(1, 2)
- .contiguous()
- )
- x = self.conv(x)
- bsz, _, output_seq_len, _ = x.size()
- x = x.transpose(1, 2).transpose(0, 1).contiguous().view(output_seq_len, bsz, -1)
- x = self.out(x)
- x = self.embed_scale * x
-
- subsampling_factor = 1.0 * max_seq_len / output_seq_len
- input_lengths = torch.max(
- (src_lengths.float() / subsampling_factor).ceil().long(),
- x.size(0) * src_lengths.new_ones([src_lengths.size(0)]).long(),
- )
-
- encoder_padding_mask, _ = lengths_to_encoder_padding_mask(
- input_lengths, batch_first=True
- )
-
- # TODO: fix positional embedding
- positions = self.embed_positions(encoder_padding_mask).transpose(0, 1)
-
- x += positions
- x = F.dropout(x, p=self.dropout, training=self.training)
-
- # State to store memory banks etc.
- if states is None:
- states = [
- {"memory_banks": None, "encoder_states": None}
- for i in range(len(self.transformer_layers))
- ]
-
- for i, layer in enumerate(self.transformer_layers):
- # x size:
- # (self.left_size + self.segment_size + self.right_size)
- # / self.stride, num_heads, dim
- # TODO: Consider mask here
- x = layer(x, states[i])
- states[i]["encoder_states"] = x[
- self.left_context_after_stride : -self.right_context_after_stride
- ]
-
- lengths = (
- (
- ~encoder_padding_mask[
- :, self.left_context_after_stride : -self.right_context_after_stride
- ]
- )
- .sum(dim=1, keepdim=True)
- .long()
- )
-
- return states[-1]["encoder_states"], lengths, states
-
-
-# ------------------------------------------------------------------------------
-# AugmentedMemoryTransformerEncoderLayer
-# ------------------------------------------------------------------------------
-class AugmentedMemoryTransformerEncoderLayer(TransformerEncoderLayer):
- def __init__(self, args):
- super().__init__(args)
-
- self.left_context = args.left_context // args.encoder_stride
- self.right_context = args.right_context // args.encoder_stride
-
- def forward(self, x, state):
-
- length, batch_size, x_dim = x.size()
-
- residual = x
-
- if self.normalize_before:
- x = self.self_attn_layer_norm(x)
-
- # init_state
- if state.get("memory_banks", None) is None:
- state["memory_banks"] = []
-
- # TODO reseach new sum_query method
- seg_start = self.left_context
- seg_end = length - self.right_context
- if seg_start < seg_end:
- summarization_query = torch.mean(x[seg_start:seg_end], keepdim=True, dim=0)
- else:
- summarization_query = x.new_zeros(1, batch_size, x_dim)
-
- x = torch.cat([x, summarization_query], dim=0)
-
- x = self.self_attn(input_and_summary=x, state=state)
-
- x = self.dropout_module(x)
- x = residual + x
-
- if not self.normalize_before:
- x = self.self_attn_layer_norm(x)
-
- residual = x
- if self.normalize_before:
- x = self.final_layer_norm(x)
-
- x = self.activation_fn(self.fc1(x))
- x = self.activation_dropout_module(x)
- x = self.fc2(x)
- x = self.dropout_module(x)
- x = residual + x
- if not self.normalize_before:
- x = self.final_layer_norm(x)
-
- return x
-
- def build_self_attention(self, embed_dim, args):
- return AugmentedMemoryMultiheadAttention(
- embed_dim=embed_dim,
- num_heads=args.encoder_attention_heads,
- dropout=args.attention_dropout,
- self_attention=True,
- q_noise=self.quant_noise,
- qn_block_size=self.quant_noise_block_size,
- tanh_on_mem=True,
- max_memory_size=args.max_memory_size,
- )
-
-
-# ------------------------------------------------------------------------------
-# AugmentedMemoryMultiheadAttention
-# ------------------------------------------------------------------------------
-class AugmentedMemoryMultiheadAttention(MultiheadAttention):
- """
- Augmented Memory Attention from
- Streaming Transformer-based Acoustic Models
- Using Self-attention with Augmented Memory
- https://arxiv.org/abs/2005.08042
- """
-
- def __init__(
- self,
- embed_dim,
- num_heads,
- kdim=None,
- vdim=None,
- dropout=0.0,
- bias=True,
- add_bias_kv=False,
- add_zero_attn=False,
- self_attention=False,
- encoder_decoder_attention=False,
- q_noise=0.0,
- qn_block_size=8,
- tanh_on_mem=False,
- memory_dim=None,
- std_scale=0.5, # 0.5 based on https://arxiv.org/abs/2005.09137
- max_memory_size=-1,
- disable_mem_on_mem_attn=True,
- ):
- super().__init__(
- embed_dim,
- num_heads,
- kdim,
- vdim,
- dropout,
- bias,
- add_bias_kv,
- add_zero_attn,
- self_attention,
- encoder_decoder_attention,
- q_noise,
- qn_block_size,
- )
-
- self.memory_dim = memory_dim if memory_dim is not None else embed_dim
- self.std_scale = std_scale
- self.disable_mem_on_mem_attn = disable_mem_on_mem_attn
-
- # This Operator was used for factorization in PySpeech
- self.v2e = lambda x: x
-
- if tanh_on_mem:
- self.squash_mem = torch.tanh
- self.nonlinear_squash_mem = True
- else:
- self.squash_mem = lambda x: x
- self.nonlinear_squash_mem = False
-
- self.max_memory_size = max_memory_size
-
- def forward(self, input_and_summary, state):
- """
- input: Encoder states of current segment with left or right context,
- plus one summarization query
-
- """
-
- length, batch_size, _ = input_and_summary.shape
- length = length - 1 # not include sum_query, last index
-
- memory = state["memory_banks"]
- # TODO: positional embedding on memory
-
- if self.max_memory_size > -1 and len(memory) > self.max_memory_size:
- # TODO: need to fix here
- if self.max_memory_size == 0:
- memory = memory.new_zeros(1, memory.size(1), self.memory_dim)
- else:
- memory = memory[-self.max_memory_size :]
-
- memory_and_input = torch.cat(memory + [input_and_summary[:-1]], dim=0)
- input_and_sum_query = input_and_summary
-
- q = self.q_proj(self.v2e(input_and_sum_query))
- k = self.k_proj(self.v2e(memory_and_input))
- v = self.v_proj(self.v2e(memory_and_input))
-
- q = (
- q.contiguous()
- .view(-1, batch_size * self.num_heads, self.head_dim)
- .transpose(0, 1)
- * self.scaling
- )
- k = (
- k.contiguous()
- .view(-1, batch_size * self.num_heads, self.head_dim)
- .transpose(0, 1)
- )
-
- v = (
- v.contiguous()
- .view(-1, batch_size * self.num_heads, self.head_dim)
- .transpose(0, 1)
- )
-
- attention_weights = torch.bmm(q, k.transpose(1, 2))
-
- if self.disable_mem_on_mem_attn:
- attention_weights = self.suppress_mem_on_mem_attention(
- batch_size, self.num_heads, len(memory), attention_weights
- )
-
- if self.std_scale is not None:
- attention_weights = attention_suppression(attention_weights, self.std_scale)
-
- assert list(attention_weights.shape) == [
- batch_size * self.num_heads,
- length + 1,
- length + len(memory),
- ]
-
- attention_weights = torch.nn.functional.softmax(
- attention_weights.float(), dim=-1
- ).type_as(attention_weights)
-
- attention_probs = self.dropout_module(attention_weights)
-
- # [T, T, B, n_head] + [T, B, n_head, d_head] -> [T, B, n_head, d_head]
- attention = torch.bmm(attention_probs, v)
-
- assert list(attention.shape) == [
- batch_size * self.num_heads,
- length + 1,
- self.head_dim,
- ]
-
- attention = (
- attention.transpose(0, 1)
- .contiguous()
- .view(length + 1, batch_size, self.embed_dim)
- )
-
- output_and_memory = self.out_proj(attention)
-
- next_m = output_and_memory[-1:]
- next_m = self.squash_mem(next_m)
- output = output_and_memory[:-1]
-
- state["memory_banks"].append(next_m)
-
- return output
-
- def suppress_mem_on_mem_attention(
- self, B: int, num_heads: int, mem_size: int, attention_weight: Tensor
- ):
- """
- Arguments:
- - B: batch size
- - num_heads: number of attention heads
- - mem_size: size of memory bank
- - attention_weight: a [B*num_heads, T + 1, T + mem_size] vector
-
- Return:
- modified attention_weight with [B*num_heads, -1, :mem_size] = -inf
- """
- attention_weight[:, -1, :mem_size] = float("-inf")
- return attention_weight
-
-
-# ------------------------------------------------------------------------------
-# SequenceEncoder
-# ------------------------------------------------------------------------------
-class SequenceEncoder(FairseqEncoder):
- """
- SequenceEncoder encodes sequences.
-
- More specifically, `src_tokens` and `src_lengths` in `forward()` should
- describe a batch of "complete" sequences rather than segments.
-
- Segment-by-segment inference can be triggered by `segment_size`:
- 1) `segment_size` is None:
- SequenceEncoder treats the input sequence as one single segment.
- 2) `segment_size` is not None (some int instead):
- SequenceEncoder does the following:
- 1. breaks the input sequence into several segments
- 2. inference on each segment and collect the outputs
- 3. concatanete segment outputs into the output sequence.
- Note that `segment_size` here shouldn't include additional left/right
- contexts needed, for example if we wish to infer with LC-BLSTM where the
- middle chunk size is 100 and right context is 20, `segment_size` should be
- 100.
- """
-
- def __init__(self, args, module):
- super().__init__(None)
-
- self.module = module
- self.input_time_axis = 1
- self.output_time_axis = 0
- self.segment_size = args.segment_size
- self.left_context = args.left_context
- self.right_context = args.right_context
-
- def forward(
- self,
- src_tokens: Tensor,
- src_lengths: Tensor,
- states=None,
- ):
-
- seg_src_tokens_lengths = sequence_to_segments(
- sequence=src_tokens,
- time_axis=self.input_time_axis,
- lengths=src_lengths,
- segment_size=self.segment_size,
- extra_left_context=self.left_context,
- extra_right_context=self.right_context,
- )
-
- seg_encoder_states_lengths: List[Tuple[Tensor, Tensor]] = []
-
- for seg_src_tokens, seg_src_lengths in seg_src_tokens_lengths:
- (seg_encoder_states, seg_enc_lengths, states) = self.module(
- seg_src_tokens,
- seg_src_lengths,
- states=states,
- )
-
- seg_encoder_states_lengths.append((seg_encoder_states, seg_enc_lengths))
-
- encoder_out, enc_lengths = segments_to_sequence(
- segments=seg_encoder_states_lengths, time_axis=self.output_time_axis
- )
-
- encoder_padding_mask, _ = lengths_to_encoder_padding_mask(
- enc_lengths, batch_first=True
- )
-
- if not encoder_padding_mask.any():
- encoder_padding_mask = None
-
- return {
- "encoder_out": [encoder_out],
- "encoder_padding_mask": [encoder_padding_mask],
- "encoder_embedding": [],
- "encoder_states": [states],
- "src_tokens": [],
- "src_lengths": [],
- }
-
- def incremental_encode(
- self,
- seg_src_tokens: Tensor,
- seg_src_lengths: Tensor,
- states=None,
- ):
- """
- Different from forward function, this function takes segmented speech
- as input, and append encoder states to previous states
- """
- (seg_encoder_states, seg_enc_lengths, states) = self.module(
- seg_src_tokens,
- seg_src_lengths,
- states=states,
- )
- return seg_encoder_states, seg_enc_lengths, states
-
-
-# ------------------------------------------------------------------------------
-# Augmented memory model decorator
-# ------------------------------------------------------------------------------
-def augmented_memory(klass):
- class StreamSeq2SeqModel(klass):
- @staticmethod
- def add_args(parser):
- super(StreamSeq2SeqModel, StreamSeq2SeqModel).add_args(parser)
- parser.add_argument(
- "--segment-size", type=int, required=True, help="Length of the segment."
- )
- parser.add_argument(
- "--left-context",
- type=int,
- default=0,
- help="Left context for the segment.",
- )
- parser.add_argument(
- "--right-context",
- type=int,
- default=0,
- help="Right context for the segment.",
- )
- parser.add_argument(
- "--max-memory-size",
- type=int,
- default=-1,
- help="Right context for the segment.",
- )
-
- StreamSeq2SeqModel.__name__ = klass.__name__
- return StreamSeq2SeqModel
diff --git a/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/fully_sharded_data_parallel/README.md b/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/fully_sharded_data_parallel/README.md
deleted file mode 100644
index b9e44fef48bee5faeee27b3d1d1b1eb96b6a477f..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/fully_sharded_data_parallel/README.md
+++ /dev/null
@@ -1,177 +0,0 @@
-# Fully Sharded Data Parallel (FSDP)
-
-## Overview
-Recent work by [Microsoft](https://arxiv.org/abs/1910.02054) and
-[Google](https://arxiv.org/abs/2004.13336) has shown that data parallel
-training can be made significantly more efficient by sharding the model
-parameters and optimizer state across data parallel workers. These ideas are
-encapsulated in the new **`FullyShardedDataParallel` (FSDP)** wrapper provided
-by [fairscale](https://github.com/facebookresearch/fairscale/).
-
-Compared to PyTorch DDP:
-* FSDP produces identical results as PyTorch DDP (it's still synchronous data parallel training)
-* FSDP shards parameters (FP16 + FP32) and optimizer state across data parallel GPUs
-* FSDP is faster than PyTorch DDP because the optimizer step is sharded, and the communication can be overlapped with the forward pass
-* FSDP enables training 13B parameter models on 8 GPUs and 175B parameter models on 128 GPUs
-
-FSDP is fully supported in fairseq via the following new arguments:
-* `--ddp-backend=fully_sharded`: enables full sharding via FSDP
-* `--cpu-offload`: offloads the optimizer state and FP32 model copy to CPU (combine with `--optimizer=cpu_adam`)
-* `--no-reshard-after-forward`: increases training speed for large models (1B+ params) and is similar to ZeRO stage 2
-* other popular options (`--fp16`, `--update-freq`, `--checkpoint-activations`, `--offload-activations`, etc.) continue to work as normal
-
-Limitations
-
-FSDP currently has several limitations compared to fairseq's default DDP backend (PyTorch DDP):
-* while FSDP is full compatible with pointwise Optimizers (e.g., Adam, AdamW, Adadelta, Adamax, SGD, etc.), it is not currently compatible with non-pointwise Optimizers (e.g., Adagrad, Adafactor, LAMB, etc.)
-* FSDP depends on flattening the parameters, so models that currently require `--fp16-no-flatten-grads` may not be supported
-
-See the [fairscale docs](https://fairscale.readthedocs.io/en/latest/api/nn/fsdp_tips.html) for a more detailed
-explanation of these and other limitations.
-
-
-
-How it works
-
-
-
-See the [fairscale docs](https://fairscale.readthedocs.io/en/latest/api/nn/fsdp_tips.html) for a more detailed
-explanation of how FSDP works.
-
-
-
-## Example usage
-
-The following examples illustrate how to train a very large language model with
-13 billion parameters on 1 GPU by offloading parameters and optimizer states to
-CPU, or on 8 GPUs by fully sharding the params and optimizer states across GPUs.
-
-These examples use the WikiText-103 dataset for demonstration purposes, but
-in practice a much larger dataset will be needed to achieve good results.
-Follow the [instructions here](https://github.com/pytorch/fairseq/blob/main/examples/roberta/README.pretraining.md#1-preprocess-the-data)
-to preprocess the WikiText-103 dataset using the GPT-2/RoBERTa vocabulary.
-
-### 13B params on 1 V100 GPU (with CPU offloading)
-
-The following command trains a 13B parameter GPT-3 model on a single V100 GPU
-using the `--cpu-offload` feature to offload parameters and optimizer states to
-CPU. In this setting, the optimizer step (Adam) happens on CPU. We also use the
-`--checkpoint-activations` feature (sometimes called [gradient checkpointing](https://pytorch.org/docs/stable/checkpoint.html)),
-which further saves memory in exchange for a small increase in computation.
-
-**Requirements:**
-- Install the latest master version of fairscale: `pip install git+https://github.com/facebookresearch/fairscale.git@master`
-- You'll need 32GB of GPU memory and ~256GB of system memory to train the 13B param model.
-- If you have less system memory, the 6.7B param model can be trained with ~128GB of system memory, just set `--arch transformer_lm_gpt3_6_7`
-- We use the CPU Adam optimizer from [DeepSpeed](https://github.com/microsoft/DeepSpeed), so you'll need to `pip install deepspeed` before running the command.
-
-**Notes:**
-- The command will take ~5 minutes to start training, during which time it will appear to be hung, since randomly initializing 13B weights can be slow.
-- The `--cpu-offload` feature requires training in mixed precision (`--fp16`).
-- Tune the `OMP_NUM_THREADS` env variable for best performance with CPU offloading.
-- The example command below stops training after 10 steps (`--max-update 10`) and does not save checkpoints (`--no-save`).
-
-```bash
-OMP_NUM_THREADS=20 CUDA_VISIBLE_DEVICES=0 \
- fairseq-train data-bin/wikitext-103-roberta-bpe-bin \
- --ddp-backend fully_sharded --fp16 --fp16-init-scale 4 \
- --cpu-offload --checkpoint-activations \
- --task language_modeling --tokens-per-sample 2048 --batch-size 8 \
- --arch transformer_lm_gpt3_13 \
- --optimizer cpu_adam --adam-betas "(0.9,0.98)" \
- --lr 0.0001 --lr-scheduler polynomial_decay --warmup-updates 5 --total-num-update 10 \
- --max-update 10 --no-save --log-format json --log-interval 1
-```
-
-Example output
-
-### 13B params on 8 V100 GPUs (with full parameter + optimizer state sharding)
-
-FSDP can also shard the parameters and optimizer states across multiple GPUs,
-reducing memory requirements significantly. On 8 x 32GB GPUs, sharding enables
-training the same 13B parameter model *without offloading the parameters to
-CPU*. However, without CPU offloading we'd only be able to fit a batch size of
-1 per GPU, which would cause training speed to suffer.
-
-We obtain the best performance on 8 GPUs by combining full sharding and CPU
-offloading. The following command trains the same 13B parameter GPT-3 model as
-before on 8 x 32GB V100 GPUs; training speed increases superlinearly from ~310
-words per second to ~3200 words per second.
-
-```bash
-OMP_NUM_THREADS=20 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
- fairseq-train data-bin/wikitext-103-roberta-bpe-bin \
- --ddp-backend fully_sharded --fp16 --fp16-init-scale 4 \
- --cpu-offload --checkpoint-activations \
- --task language_modeling --tokens-per-sample 2048 --batch-size 8 \
- --arch transformer_lm_gpt3_13 \
- --optimizer cpu_adam --adam-betas "(0.9,0.98)" \
- --lr 0.0001 --lr-scheduler polynomial_decay --warmup-updates 5 --total-num-update 10 \
- --max-update 10 --no-save --log-format json --log-interval 1
-```
-
-Example output
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/__init__.py b/spaces/OFA-Sys/OFA-vqa/fairseq/examples/__init__.py
deleted file mode 100644
index 44bb24ae614941f23fea29c56d60167650c39bcb..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-try:
- from fairseq.version import __version__ # noqa
-except ImportError:
- pass
diff --git a/spaces/Oppenheimer57/claude-proxy/greeting.md b/spaces/Oppenheimer57/claude-proxy/greeting.md
deleted file mode 100644
index b792b4df4cda41bdf941782be666382e01b62658..0000000000000000000000000000000000000000
--- a/spaces/Oppenheimer57/claude-proxy/greeting.md
+++ /dev/null
@@ -1,3 +0,0 @@
-**Christus Vincit! Christus Regnat! Christus Imperat!**
-
-**Who am I?**
diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/decode_heads/ocr_head.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/decode_heads/ocr_head.py
deleted file mode 100644
index 715852e94e81dc46623972748285d2d19237a341..0000000000000000000000000000000000000000
--- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/decode_heads/ocr_head.py
+++ /dev/null
@@ -1,127 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from annotator.uniformer.mmcv.cnn import ConvModule
-
-from annotator.uniformer.mmseg.ops import resize
-from ..builder import HEADS
-from ..utils import SelfAttentionBlock as _SelfAttentionBlock
-from .cascade_decode_head import BaseCascadeDecodeHead
-
-
-class SpatialGatherModule(nn.Module):
- """Aggregate the context features according to the initial predicted
- probability distribution.
-
- Employ the soft-weighted method to aggregate the context.
- """
-
- def __init__(self, scale):
- super(SpatialGatherModule, self).__init__()
- self.scale = scale
-
- def forward(self, feats, probs):
- """Forward function."""
- batch_size, num_classes, height, width = probs.size()
- channels = feats.size(1)
- probs = probs.view(batch_size, num_classes, -1)
- feats = feats.view(batch_size, channels, -1)
- # [batch_size, height*width, num_classes]
- feats = feats.permute(0, 2, 1)
- # [batch_size, channels, height*width]
- probs = F.softmax(self.scale * probs, dim=2)
- # [batch_size, channels, num_classes]
- ocr_context = torch.matmul(probs, feats)
- ocr_context = ocr_context.permute(0, 2, 1).contiguous().unsqueeze(3)
- return ocr_context
-
-
-class ObjectAttentionBlock(_SelfAttentionBlock):
- """Make a OCR used SelfAttentionBlock."""
-
- def __init__(self, in_channels, channels, scale, conv_cfg, norm_cfg,
- act_cfg):
- if scale > 1:
- query_downsample = nn.MaxPool2d(kernel_size=scale)
- else:
- query_downsample = None
- super(ObjectAttentionBlock, self).__init__(
- key_in_channels=in_channels,
- query_in_channels=in_channels,
- channels=channels,
- out_channels=in_channels,
- share_key_query=False,
- query_downsample=query_downsample,
- key_downsample=None,
- key_query_num_convs=2,
- key_query_norm=True,
- value_out_num_convs=1,
- value_out_norm=True,
- matmul_norm=True,
- with_out=True,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
- self.bottleneck = ConvModule(
- in_channels * 2,
- in_channels,
- 1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
-
- def forward(self, query_feats, key_feats):
- """Forward function."""
- context = super(ObjectAttentionBlock,
- self).forward(query_feats, key_feats)
- output = self.bottleneck(torch.cat([context, query_feats], dim=1))
- if self.query_downsample is not None:
- output = resize(query_feats)
-
- return output
-
-
-@HEADS.register_module()
-class OCRHead(BaseCascadeDecodeHead):
- """Object-Contextual Representations for Semantic Segmentation.
-
- This head is the implementation of `OCRNet
- `_.
-
- Args:
- ocr_channels (int): The intermediate channels of OCR block.
- scale (int): The scale of probability map in SpatialGatherModule in
- Default: 1.
- """
-
- def __init__(self, ocr_channels, scale=1, **kwargs):
- super(OCRHead, self).__init__(**kwargs)
- self.ocr_channels = ocr_channels
- self.scale = scale
- self.object_context_block = ObjectAttentionBlock(
- self.channels,
- self.ocr_channels,
- self.scale,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
- self.spatial_gather_module = SpatialGatherModule(self.scale)
-
- self.bottleneck = ConvModule(
- self.in_channels,
- self.channels,
- 3,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
-
- def forward(self, inputs, prev_output):
- """Forward function."""
- x = self._transform_inputs(inputs)
- feats = self.bottleneck(x)
- context = self.spatial_gather_module(feats, prev_output)
- object_context = self.object_context_block(feats, context)
- output = self.cls_seg(object_context)
-
- return output
diff --git a/spaces/PaddlePaddle/pnasnet_imagenet/README.md b/spaces/PaddlePaddle/pnasnet_imagenet/README.md
deleted file mode 100644
index ce3188bd5407b9a8d7e1ed3231feea922547e5af..0000000000000000000000000000000000000000
--- a/spaces/PaddlePaddle/pnasnet_imagenet/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Pnasnet_imagenet
-emoji: 🦀
-colorFrom: blue
-colorTo: purple
-sdk: gradio
-sdk_version: 2.8.12
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/Panel-Org/panel-demo-image-classification/app.py b/spaces/Panel-Org/panel-demo-image-classification/app.py
deleted file mode 100644
index b7dcb987681e945465ad4886e65922c10993ac49..0000000000000000000000000000000000000000
--- a/spaces/Panel-Org/panel-demo-image-classification/app.py
+++ /dev/null
@@ -1,120 +0,0 @@
-import random
-import panel as pn
-import requests
-from PIL import Image
-
-from transformers import CLIPProcessor, CLIPModel
-from typing import List, Tuple
-
-
-def set_random_url(_):
- pet = random.choice(["cat", "dog"])
- api_url = f"https://api.the{pet}api.com/v1/images/search"
- with requests.get(api_url) as resp:
- resp.raise_for_status()
- url = resp.json()[0]["url"]
- image_url.value = url
-
-
-@pn.cache
-def load_processor_model(
- processor_name: str, model_name: str
-) -> Tuple[CLIPProcessor, CLIPModel]:
- processor = CLIPProcessor.from_pretrained(processor_name)
- model = CLIPModel.from_pretrained(model_name)
- return processor, model
-
-
-@pn.cache
-def open_image_url(image_url: str) -> Image:
- with requests.get(image_url, stream=True) as resp:
- resp.raise_for_status()
- image = Image.open(resp.raw)
- return image
-
-
-def get_similarity_scores(class_items: List[str], image: Image) -> List[float]:
- processor, model = load_processor_model(
- "openai/clip-vit-base-patch32", "openai/clip-vit-base-patch32"
- )
- inputs = processor(
- text=class_items,
- images=[image],
- return_tensors="pt", # pytorch tensors
- )
- outputs = model(**inputs)
- logits_per_image = outputs.logits_per_image
- class_likelihoods = logits_per_image.softmax(dim=1).detach().numpy()
- return class_likelihoods[0]
-
-
-def process_inputs(class_names: List[str], image_url: str):
- """
- High level function that takes in the user inputs and returns the
- classification results as panel objects.
- """
- image = open_image_url(image_url)
- class_items = class_names.split(",")
- class_likelihoods = get_similarity_scores(class_items, image)
-
- # build the results column
- results_column = pn.Column("## 🎉 Here are the results!")
-
- results_column.append(
- pn.pane.Image(image, max_width=698, sizing_mode="scale_width")
- )
-
- for class_item, class_likelihood in zip(class_items, class_likelihoods):
- row_label = pn.widgets.StaticText(
- name=class_item.strip(), value=f"{class_likelihood:.2%}", margin=(0, 10)
- )
- row_bar = pn.indicators.Progress(
- max=100,
- value=int(class_likelihood * 100),
- sizing_mode="stretch_width",
- bar_color="secondary",
- margin=(0, 10),
- )
- row_column = pn.Column(row_label, row_bar)
- results_column.append(row_column)
- return results_column
-
-# create widgets
-randomize_url = pn.widgets.Button(name="Randomize URL", align="end")
-
-image_url = pn.widgets.TextInput(
- name="Image URL to classify",
- value="https://cdn2.thecatapi.com/images/cct.jpg",
-)
-class_names = pn.widgets.TextInput(
- name="Comma separated class names",
- placeholder="Enter possible class names, e.g. cat, dog",
- value="cat, dog, parrot",
-)
-
-input_widgets = pn.Column(
- "## 😊 Click randomize or paste a URL to start classifying!",
- pn.Row(image_url, randomize_url),
- class_names,
-)
-
-# add interactivity
-randomize_url.on_click(set_random_url)
-interactive_result = pn.panel(
- pn.bind(
- process_inputs, image_url=image_url, class_names=class_names
- ), loading_indicator=True
-)
-
-# create dashboard
-main = pn.WidgetBox(
- input_widgets,
- interactive_result,
-)
-
-pn.template.BootstrapTemplate(
- title="Panel Image Classification Demo",
- main=main,
- main_max_width="min(50%, 698px)",
- header_background="#F08080",
-).servable(title="Panel Image Classification Demo")
\ No newline at end of file
diff --git a/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/parser-clef.go b/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/parser-clef.go
deleted file mode 100644
index 273e776e3d00d7d61bc133fe16b22d7daa59662c..0000000000000000000000000000000000000000
Binary files a/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/parser-clef.go and /dev/null differ
diff --git a/spaces/PeepDaSlan9/AutoGPT/autogpt/speech/macos_tts.py b/spaces/PeepDaSlan9/AutoGPT/autogpt/speech/macos_tts.py
deleted file mode 100644
index 4c072ce256782e83a578b5181abf1a7b524c621b..0000000000000000000000000000000000000000
--- a/spaces/PeepDaSlan9/AutoGPT/autogpt/speech/macos_tts.py
+++ /dev/null
@@ -1,21 +0,0 @@
-""" MacOS TTS Voice. """
-import os
-
-from autogpt.speech.base import VoiceBase
-
-
-class MacOSTTS(VoiceBase):
- """MacOS TTS Voice."""
-
- def _setup(self) -> None:
- pass
-
- def _speech(self, text: str, voice_index: int = 0) -> bool:
- """Play the given text."""
- if voice_index == 0:
- os.system(f'say "{text}"')
- elif voice_index == 1:
- os.system(f'say -v "Ava (Premium)" "{text}"')
- else:
- os.system(f'say -v Samantha "{text}"')
- return True
diff --git a/spaces/PeepDaSlan9/idk-bruh/Dockerfile b/spaces/PeepDaSlan9/idk-bruh/Dockerfile
deleted file mode 100644
index 94ee76a4f45af463ab7f945633c9258172f9cc80..0000000000000000000000000000000000000000
--- a/spaces/PeepDaSlan9/idk-bruh/Dockerfile
+++ /dev/null
@@ -1,2 +0,0 @@
-FROM huggingface/autotrain-advanced:latest
-CMD autotrain app --port 7860
diff --git a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/box_head/loss.py b/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/box_head/loss.py
deleted file mode 100644
index 67b2175964d15ab5dce38a4e465db14087d02035..0000000000000000000000000000000000000000
--- a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/box_head/loss.py
+++ /dev/null
@@ -1,187 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-import torch
-from torch.nn import functional as F
-
-from maskrcnn_benchmark.layers import smooth_l1_loss
-from maskrcnn_benchmark.modeling.box_coder import BoxCoder
-from maskrcnn_benchmark.modeling.matcher import Matcher
-from maskrcnn_benchmark.structures.boxlist_ops import boxlist_iou
-from maskrcnn_benchmark.modeling.balanced_positive_negative_sampler import (
- BalancedPositiveNegativeSampler
-)
-from maskrcnn_benchmark.modeling.utils import cat
-from maskrcnn_benchmark.utils.amp import custom_fwd, custom_bwd
-
-class FastRCNNLossComputation(object):
- """
- Computes the loss for Faster R-CNN.
- Also supports FPN
- """
-
- def __init__(self, proposal_matcher, fg_bg_sampler, box_coder):
- """
- Arguments:
- proposal_matcher (Matcher)
- fg_bg_sampler (BalancedPositiveNegativeSampler)
- box_coder (BoxCoder)
- """
- self.proposal_matcher = proposal_matcher
- self.fg_bg_sampler = fg_bg_sampler
- self.box_coder = box_coder
-
- def match_targets_to_proposals(self, proposal, target):
- match_quality_matrix = boxlist_iou(target, proposal)
- matched_idxs = self.proposal_matcher(match_quality_matrix)
- # Fast RCNN only need "labels" field for selecting the targets
- target = target.copy_with_fields("labels")
- # get the targets corresponding GT for each proposal
- # NB: need to clamp the indices because we can have a single
- # GT in the image, and matched_idxs can be -2, which goes
- # out of bounds
-
- if len(target):
- matched_targets = target[matched_idxs.clamp(min=0)]
- else:
- device = target.get_field('labels').device
- dtype = target.get_field('labels').dtype
- labels = torch.zeros_like(matched_idxs, dtype=dtype, device=device)
- matched_targets = target
- matched_targets.add_field('labels', labels)
-
- matched_targets.add_field("matched_idxs", matched_idxs)
- return matched_targets
-
- def prepare_targets(self, proposals, targets):
- labels = []
- regression_targets = []
- for proposals_per_image, targets_per_image in zip(proposals, targets):
- matched_targets = self.match_targets_to_proposals(
- proposals_per_image, targets_per_image
- )
- matched_idxs = matched_targets.get_field("matched_idxs")
-
- labels_per_image = matched_targets.get_field("labels")
- labels_per_image = labels_per_image.to(dtype=torch.int64)
-
- # Label background (below the low threshold)
- bg_inds = matched_idxs == Matcher.BELOW_LOW_THRESHOLD
- labels_per_image[bg_inds] = 0
-
- # Label ignore proposals (between low and high thresholds)
- ignore_inds = matched_idxs == Matcher.BETWEEN_THRESHOLDS
- labels_per_image[ignore_inds] = -1 # -1 is ignored by sampler
-
- # compute regression targets
- if not matched_targets.bbox.shape[0]:
- zeros = torch.zeros_like(labels_per_image, dtype=torch.float32)
- regression_targets_per_image = torch.stack((zeros, zeros, zeros, zeros), dim=1)
- else:
- regression_targets_per_image = self.box_coder.encode(matched_targets.bbox, proposals_per_image.bbox)
-
- labels.append(labels_per_image)
- regression_targets.append(regression_targets_per_image)
-
- return labels, regression_targets
-
- def subsample(self, proposals, targets):
- """
- This method performs the positive/negative sampling, and return
- the sampled proposals.
- Note: this function keeps a state.
-
- Arguments:
- proposals (list[BoxList])
- targets (list[BoxList])
- """
-
- labels, regression_targets = self.prepare_targets(proposals, targets)
- sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels)
-
- proposals = list(proposals)
- # add corresponding label and regression_targets information to the bounding boxes
- for labels_per_image, regression_targets_per_image, proposals_per_image in zip(
- labels, regression_targets, proposals
- ):
- proposals_per_image.add_field("labels", labels_per_image)
- proposals_per_image.add_field(
- "regression_targets", regression_targets_per_image
- )
-
- # distributed sampled proposals, that were obtained on all feature maps
- # concatenated via the fg_bg_sampler, into individual feature map levels
- for img_idx, (pos_inds_img, neg_inds_img) in enumerate(
- zip(sampled_pos_inds, sampled_neg_inds)
- ):
- img_sampled_inds = torch.nonzero(pos_inds_img | neg_inds_img).squeeze(1)
- proposals_per_image = proposals[img_idx][img_sampled_inds]
- proposals[img_idx] = proposals_per_image
-
- self._proposals = proposals
- return proposals
-
- @custom_fwd(cast_inputs=torch.float32)
- def __call__(self, class_logits, box_regression):
- """
- Computes the loss for Faster R-CNN.
- This requires that the subsample method has been called beforehand.
-
- Arguments:
- class_logits (list[Tensor])
- box_regression (list[Tensor])
-
- Returns:
- classification_loss (Tensor)
- box_loss (Tensor)
- """
-
- class_logits = cat(class_logits, dim=0)
- box_regression = cat(box_regression, dim=0)
- device = class_logits.device
-
- if not hasattr(self, "_proposals"):
- raise RuntimeError("subsample needs to be called before")
-
- proposals = self._proposals
-
- labels = cat([proposal.get_field("labels") for proposal in proposals], dim=0)
- regression_targets = cat(
- [proposal.get_field("regression_targets") for proposal in proposals], dim=0
- )
-
- classification_loss = F.cross_entropy(class_logits, labels)
-
- # get indices that correspond to the regression targets for
- # the corresponding ground truth labels, to be used with
- # advanced indexing
- sampled_pos_inds_subset = torch.nonzero(labels > 0).squeeze(1)
- labels_pos = labels[sampled_pos_inds_subset]
- map_inds = 4 * labels_pos[:, None] + torch.tensor([0, 1, 2, 3], device=device)
-
- box_loss = smooth_l1_loss(
- box_regression[sampled_pos_inds_subset[:, None], map_inds],
- regression_targets[sampled_pos_inds_subset],
- size_average=False,
- beta=1,
- )
- box_loss = box_loss / labels.numel()
-
- return classification_loss, box_loss
-
-
-def make_roi_box_loss_evaluator(cfg):
- matcher = Matcher(
- cfg.MODEL.ROI_HEADS.FG_IOU_THRESHOLD,
- cfg.MODEL.ROI_HEADS.BG_IOU_THRESHOLD,
- allow_low_quality_matches=False,
- )
-
- bbox_reg_weights = cfg.MODEL.ROI_HEADS.BBOX_REG_WEIGHTS
- box_coder = BoxCoder(weights=bbox_reg_weights)
-
- fg_bg_sampler = BalancedPositiveNegativeSampler(
- cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE, cfg.MODEL.ROI_HEADS.POSITIVE_FRACTION
- )
-
- loss_evaluator = FastRCNNLossComputation(matcher, fg_bg_sampler, box_coder)
-
- return loss_evaluator
diff --git a/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/utils/cache.py b/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/utils/cache.py
deleted file mode 100644
index 2fccc0acda4027b0bd36756a29b2d5cee318294d..0000000000000000000000000000000000000000
--- a/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/utils/cache.py
+++ /dev/null
@@ -1,323 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-from concurrent.futures import ThreadPoolExecutor
-from collections import deque
-from functools import partial
-from hashlib import sha1
-import logging
-from pathlib import Path
-import sys
-import typing as tp
-import zipfile
-
-import flashy
-import torch
-
-
-logger = logging.getLogger(__name__)
-
-
-def get_full_embed(full_embed: torch.Tensor, x: tp.Any, idx: int, device: tp.Union[str, torch.device]) -> torch.Tensor:
- """Utility function for the EmbeddingCache, returning the full embedding without any chunking.
- This method can be used in case there is no need in extracting a chunk of the full embedding
- read from the cache.
-
- Args:
- full_embed (torch.Tensor): The full embedding.
- x (any): Batch object from which the full embedding is derived.
- idx (torch.Tensor): Index of object to consider in the batch object.
- Returns:
- full_embed (torch.Tensor): The full embedding
- """
- return full_embed.to(device)
-
-
-class EmbeddingCache:
- """Cache around embeddings computation for faster execution.
- The EmbeddingCache is storing pre-computed embeddings on disk and provides a simple API
- to retrieve the pre-computed embeddings on full inputs and extract only a given chunk
- using a user-provided function. When the cache is warm (all embeddings are pre-computed),
- the EmbeddingCache allows for faster training as it removes the need of computing the embeddings.
- Additionally, it provides in-memory cache around the loaded embeddings to limit IO footprint
- and synchronization points in the forward calls.
-
- Args:
- cache_path (Path): Path to folder where all pre-computed embeddings are saved on disk.
- device (str or torch.device): Device on which the embedding is returned.
- compute_embed_fn (callable[[Path, any, int], torch.Tensor], optional): Function to compute
- the embedding from a given object and path. This user provided function can compute the
- embedding from the provided object or using the provided path as entry point. The last parameter
- specify the index corresponding to the current embedding in the object that can represent batch metadata.
- extract_embed_fn (callable[[torch.Tensor, any, int], torch.Tensor], optional): Function to extract
- the desired embedding chunk from the full embedding loaded from the cache. The last parameter
- specify the index corresponding to the current embedding in the object that can represent batch metadata.
- If not specified, will return the full embedding unmodified.
- """
- def __init__(self, cache_path: tp.Union[Path], device: tp.Union[str, torch.device],
- compute_embed_fn: tp.Callable[[Path, tp.Any, int], torch.Tensor],
- extract_embed_fn: tp.Optional[tp.Callable[[torch.Tensor, tp.Any, int], torch.Tensor]] = None):
- self.cache_path = Path(cache_path)
- self.device = device
- self._compute_embed_fn = compute_embed_fn
- self._extract_embed_fn: tp.Callable[[torch.Tensor, tp.Any, int], torch.Tensor]
- if extract_embed_fn is not None:
- self._extract_embed_fn = extract_embed_fn
- else:
- self._extract_embed_fn = partial(get_full_embed, device=device)
- if self.cache_path is not None:
- self.cache_path.mkdir(exist_ok=True, parents=True)
- logger.info(f"Cache instantiated at: {self.cache_path}")
- self.pool = ThreadPoolExecutor(8)
- self.pool.__enter__()
- self._current_batch_cache: dict = {}
- self._memory_cache: dict = {}
-
- def _get_cache_path(self, path: tp.Union[Path, str]):
- """Get cache path for the given file path."""
- sig = sha1(str(path).encode()).hexdigest()
- return self.cache_path / sig
-
- @staticmethod
- def _get_full_embed_from_cache(cache: Path):
- """Loads full pre-computed embedding from the cache."""
- try:
- embed = torch.load(cache, 'cpu')
- except Exception as exc:
- logger.error("Error loading %s: %r", cache, exc)
- embed = None
- return embed
-
- def get_embed_from_cache(self, paths: tp.List[Path], x: tp.Any) -> torch.Tensor:
- """Get embedding from cache, computing and storing it to cache if not already cached.
- The EmbeddingCache first tries to load the embedding from the in-memory cache
- containing the pre-computed chunks populated through `populate_embed_cache`.
- If not found, the full embedding is computed and stored on disk to be later accessed
- to populate the in-memory cache, and the desired embedding chunk is extracted and returned.
-
- Args:
- paths (list[Path or str]): List of paths from where the embeddings can be loaded.
- x (any): Object from which the embedding is extracted.
- """
- embeds = []
- for idx, path in enumerate(paths):
- cache = self._get_cache_path(path)
- if cache in self._current_batch_cache:
- embed = self._current_batch_cache[cache]
- else:
- full_embed = self._compute_embed_fn(path, x, idx)
- try:
- with flashy.utils.write_and_rename(cache, pid=True) as f:
- torch.save(full_embed.cpu(), f)
- except Exception as exc:
- logger.error('Error saving embed %s (%s): %r', cache, full_embed.shape, exc)
- else:
- logger.info('New embed cache saved: %s (%s)', cache, full_embed.shape)
- embed = self._extract_embed_fn(full_embed, x, idx)
- embeds.append(embed)
- embed = torch.stack(embeds, dim=0)
- return embed
-
- def populate_embed_cache(self, paths: tp.List[Path], x: tp.Any) -> None:
- """Populate in-memory caches for embeddings reading from the embeddings stored on disk.
- The in-memory caches consist in a cache for the full embedding and another cache for the
- final embedding chunk. Such caches are used to limit the IO access when computing the actual embeddings
- and reduce the IO footprint and synchronization points during forward passes.
-
- Args:
- paths (list[Path]): List of paths from where the embeddings can be loaded.
- x (any): Object from which the embedding is extracted.
- """
- self._current_batch_cache.clear()
- if self.cache_path is not None:
- futures: list = []
- for path in paths:
- assert path is not None, "Path is required for computation from cache"
- cache = self._get_cache_path(path)
- if cache in self._memory_cache or not cache.exists():
- futures.append(None)
- else:
- futures.append(self.pool.submit(EmbeddingCache._get_full_embed_from_cache, cache))
- for idx, (path, future) in enumerate(zip(paths, futures)):
- assert path is not None
- cache = self._get_cache_path(path)
- full_embed = None
- if future is None:
- if cache in self._memory_cache:
- full_embed = self._memory_cache[cache]
- else:
- full_embed = future.result()
- if full_embed is not None:
- self._memory_cache[cache] = full_embed
- full_embed = full_embed.to(self.device)
- if full_embed is not None:
- embed = self._extract_embed_fn(full_embed, x, idx)
- self._current_batch_cache[cache] = embed
-
-
-class CachedBatchWriter:
- """Write pre computed caches for mini batches. This can
- make loading a lot more efficient depending on your filesystem.
-
- Args:
- cache_folder (Path): folder in which the cached minibatches
- will be stored.
-
- Inside cache folder, the structure is the following:
- `epoch_number / update_number.zip`
- And the zip file contains one entry per batch item.
-
- It is possible to use the cache with a batch size smaller than
- created with but obviously not larger. Make sure to call the
- `start_epoch(epoch)` method for indicating changes of epochs.
-
- See the grid `audiocraft/grids/musicgen/musicgen_warmup_cache.py`
- for an example of how to warmup the cache.
- """
- def __init__(self, cache_folder: Path):
- self.cache_folder = cache_folder
- self._current_epoch: tp.Optional[int] = None
- self._current_index = 0
-
- def start_epoch(self, epoch: int):
- """Call at the beginning of each epoch.
- """
- self._current_epoch = epoch
- self._current_index = 0
- self._zip_path.parent.mkdir(exist_ok=True, parents=True)
-
- @staticmethod
- def _get_zip_path(cache_folder: Path, epoch: int, index: int):
- return cache_folder / f"{epoch:05d}" / f"{index:06d}.zip"
-
- @property
- def _zip_path(self):
- assert self._current_epoch is not None
- return CachedBatchWriter._get_zip_path(self.cache_folder, self._current_epoch, self._current_index)
-
- def save(self, *content):
- """Save one mini batch. This function is distributed-aware
- and will automatically merge all the items from the different
- workers.
- """
- all_contents = []
- for rank in range(flashy.distrib.world_size()):
- their_content = flashy.distrib.broadcast_object(content, src=rank)
- all_contents.append(their_content)
-
- if flashy.distrib.is_rank_zero():
- idx = 0
- with flashy.utils.write_and_rename(self._zip_path) as tmp:
- with zipfile.ZipFile(tmp, 'w') as zf:
- for content in all_contents:
- for vals in zip(*content):
- with zf.open(f'{idx}', 'w') as f: # type: ignore
- torch.save(vals, f)
- idx += 1
- flashy.distrib.barrier()
- self._current_index += 1
-
-
-class CachedBatchLoader:
- """Loader for cached mini-batches dumped with `CachedBatchWriter`.
-
- Args:
- cache_folder (Path): folder in which the cached minibatches are stored.
- batch_size (int): batch size (per GPU) expected.
- num_workers (int): number of workers to use for loading.
- min_length (int): minimum expected length for each epoch. If some
- mini-batches are missing, and error is raised.
-
- This is iterable just like a regular DataLoader.
- """
-
- def __init__(self, cache_folder: Path, batch_size: int,
- num_workers: int = 10, min_length: int = 1):
- self.cache_folder = cache_folder
- self.batch_size = batch_size
- self.num_workers = num_workers
- self.min_length = min_length
- self._current_epoch: tp.Optional[int] = None
- self.sampler = None # for compatibility with the regular DataLoader
-
- def __len__(self):
- path = CachedBatchWriter._get_zip_path(self.cache_folder, self._current_epoch or 0, 0).parent
- return len([p for p in path.iterdir() if p.suffix == ".zip"])
-
- def start_epoch(self, epoch: int):
- """Call at the beginning of each epoch.
- """
- self._current_epoch = epoch
-
- def _zip_path(self, index: int):
- assert self._current_epoch is not None
- return CachedBatchWriter._get_zip_path(self.cache_folder, self._current_epoch, index)
-
- def _load_one(self, index: int):
- zip_path = self._zip_path(index)
- if not zip_path.exists():
- if index < self.min_length:
- raise RuntimeError(f"Cache should have at least {self.min_length} batches, but {index} doesn't exist")
-
- return None
- mode = "rb" if sys.version_info >= (3, 9) else "r"
- try:
- with zipfile.ZipFile(zip_path, 'r') as zf:
- rank = flashy.distrib.rank()
- world_size = flashy.distrib.world_size()
- root = zipfile.Path(zf)
- items = list(root.iterdir())
- total_batch_size = self.batch_size * world_size
- if len(items) < total_batch_size:
- raise RuntimeError(
- f"The cache can handle a max batch size of {len(items)}, "
- f"but {total_batch_size} is needed.")
- start = rank * self.batch_size
- items = items[start: start + self.batch_size]
- assert len(items) == self.batch_size
- entries = []
- entries = [torch.load(item.open(mode), 'cpu') for item in items] # type: ignore
- transposed = zip(*entries)
- out = []
- for part in transposed:
- assert len(part) > 0
- if isinstance(part[0], torch.Tensor):
- out.append(torch.stack(part))
- else:
- out.append(part)
- return out
- except Exception:
- logger.error("Error when reading zip path %s", zip_path)
- raise
-
- def __iter__(self):
- """This will yields tuples, exactly as provided to the
- `CachedBatchWriter.save` method.
- """
- pool = ThreadPoolExecutor(self.num_workers)
- next_index = 0
- queue = deque()
-
- def _get_next():
- nonlocal next_index
- r = queue.popleft().result()
- if r is None:
- return None
- else:
- queue.append(pool.submit(self._load_one, next_index))
- next_index += 1
- return r
-
- with pool:
- # fill the buffer of fetching jobs.
- for _ in range(2 * self.num_workers):
- queue.append(pool.submit(self._load_one, next_index))
- next_index += 1
- while True:
- batch = _get_next()
- if batch is None:
- return
- yield batch
diff --git a/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/tests/data/__init__.py b/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/tests/data/__init__.py
deleted file mode 100644
index 0952fcc3f57e34b3747962e9ebd6fc57aeea63fa..0000000000000000000000000000000000000000
--- a/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/tests/data/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
diff --git a/spaces/RamAnanth1/Transcript_PDF/README.md b/spaces/RamAnanth1/Transcript_PDF/README.md
deleted file mode 100644
index 6fd922d44fddb844950d5bc2498d90d27dd44ca7..0000000000000000000000000000000000000000
--- a/spaces/RamAnanth1/Transcript_PDF/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Transcript PDF
-emoji: 🚀
-colorFrom: red
-colorTo: green
-sdk: gradio
-sdk_version: 3.9.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/utils/deprecation.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/utils/deprecation.py
deleted file mode 100644
index 18e9be9f36ec47fcacd153de4e3ed0cf945ddeba..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/utils/deprecation.py
+++ /dev/null
@@ -1,188 +0,0 @@
-"""
-A module that implements tooling to enable easy warnings about deprecations.
-"""
-
-import logging
-import warnings
-from typing import Any, Optional, TextIO, Type, Union
-
-from pip._vendor.packaging.version import parse
-
-from pip import __version__ as current_version # NOTE: tests patch this name.
-
-DEPRECATION_MSG_PREFIX = "DEPRECATION: "
-
-
-class PipDeprecationWarning(Warning):
- pass
-
-
-_original_showwarning: Any = None
-
-
-# Warnings <-> Logging Integration
-def _showwarning(
- message: Union[Warning, str],
- category: Type[Warning],
- filename: str,
- lineno: int,
- file: Optional[TextIO] = None,
- line: Optional[str] = None,
-) -> None:
- if file is not None:
- if _original_showwarning is not None:
- _original_showwarning(message, category, filename, lineno, file, line)
- elif issubclass(category, PipDeprecationWarning):
- # We use a specially named logger which will handle all of the
- # deprecation messages for pip.
- logger = logging.getLogger("pip._internal.deprecations")
- logger.warning(message)
- else:
- _original_showwarning(message, category, filename, lineno, file, line)
-
-
-def install_warning_logger() -> None:
- # Enable our Deprecation Warnings
- warnings.simplefilter("default", PipDeprecationWarning, append=True)
-
- global _original_showwarning
-
- if _original_showwarning is None:
- _original_showwarning = warnings.showwarning
- warnings.showwarning = _showwarning
-
-
-def deprecated(
- *,
- reason: str,
- replacement: Optional[str],
- gone_in: Optional[str],
- feature_flag: Optional[str] = None,
- issue: Optional[int] = None,
-) -> None:
- """Helper to deprecate existing functionality.
-
- reason:
- Textual reason shown to the user about why this functionality has
- been deprecated. Should be a complete sentence.
- replacement:
- Textual suggestion shown to the user about what alternative
- functionality they can use.
- gone_in:
- The version of pip does this functionality should get removed in.
- Raises an error if pip's current version is greater than or equal to
- this.
- feature_flag:
- Command-line flag of the form --use-feature={feature_flag} for testing
- upcoming functionality.
- issue:
- Issue number on the tracker that would serve as a useful place for
- users to find related discussion and provide feedback.
- """
-
- # Determine whether or not the feature is already gone in this version.
- is_gone = gone_in is not None and parse(current_version) >= parse(gone_in)
-
- message_parts = [
- (reason, f"{DEPRECATION_MSG_PREFIX}{{}}"),
- (
- gone_in,
- "pip {} will enforce this behaviour change."
- if not is_gone
- else "Since pip {}, this is no longer supported.",
- ),
- (
- replacement,
- "A possible replacement is {}.",
- ),
- (
- feature_flag,
- "You can use the flag --use-feature={} to test the upcoming behaviour."
- if not is_gone
- else None,
- ),
- (
- issue,
- "Discussion can be found at https://github.com/pypa/pip/issues/{}",
- ),
- ]
-
- message = " ".join(
- format_str.format(value)
- for value, format_str in message_parts
- if format_str is not None and value is not None
- )
-
- # Raise as an error if this behaviour is deprecated.
- if is_gone:
- raise PipDeprecationWarning(message)
-
- warnings.warn(message, category=PipDeprecationWarning, stacklevel=2)
-
-
-class LegacyInstallReason:
- def __init__(
- self,
- reason: str,
- replacement: Optional[str] = None,
- gone_in: Optional[str] = None,
- feature_flag: Optional[str] = None,
- issue: Optional[int] = None,
- emit_after_success: bool = False,
- emit_before_install: bool = False,
- ):
- self._reason = reason
- self._replacement = replacement
- self._gone_in = gone_in
- self._feature_flag = feature_flag
- self._issue = issue
- self.emit_after_success = emit_after_success
- self.emit_before_install = emit_before_install
-
- def emit_deprecation(self, name: str) -> None:
- deprecated(
- reason=self._reason.format(name=name),
- replacement=self._replacement,
- gone_in=self._gone_in,
- feature_flag=self._feature_flag,
- issue=self._issue,
- )
-
-
-LegacyInstallReasonFailedBdistWheel = LegacyInstallReason(
- reason=(
- "{name} was installed using the legacy 'setup.py install' "
- "method, because a wheel could not be built for it."
- ),
- replacement="to fix the wheel build issue reported above",
- gone_in="23.1",
- issue=8368,
- emit_after_success=True,
-)
-
-
-LegacyInstallReasonMissingWheelPackage = LegacyInstallReason(
- reason=(
- "{name} is being installed using the legacy "
- "'setup.py install' method, because it does not have a "
- "'pyproject.toml' and the 'wheel' package "
- "is not installed."
- ),
- replacement="to enable the '--use-pep517' option",
- gone_in="23.1",
- issue=8559,
- emit_before_install=True,
-)
-
-LegacyInstallReasonNoBinaryForcesSetuptoolsInstall = LegacyInstallReason(
- reason=(
- "{name} is being installed using the legacy "
- "'setup.py install' method, because the '--no-binary' option was enabled "
- "for it and this currently disables local wheel building for projects that "
- "don't have a 'pyproject.toml' file."
- ),
- replacement="to enable the '--use-pep517' option",
- gone_in="23.1",
- issue=11451,
- emit_before_install=True,
-)
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pkg_resources/_vendor/appdirs.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pkg_resources/_vendor/appdirs.py
deleted file mode 100644
index ae67001af8b661373edeee2eb327b9f63e630d62..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pkg_resources/_vendor/appdirs.py
+++ /dev/null
@@ -1,608 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-# Copyright (c) 2005-2010 ActiveState Software Inc.
-# Copyright (c) 2013 Eddy Petrișor
-
-"""Utilities for determining application-specific dirs.
-
-See for details and usage.
-"""
-# Dev Notes:
-# - MSDN on where to store app data files:
-# http://support.microsoft.com/default.aspx?scid=kb;en-us;310294#XSLTH3194121123120121120120
-# - Mac OS X: http://developer.apple.com/documentation/MacOSX/Conceptual/BPFileSystem/index.html
-# - XDG spec for Un*x: http://standards.freedesktop.org/basedir-spec/basedir-spec-latest.html
-
-__version_info__ = (1, 4, 3)
-__version__ = '.'.join(map(str, __version_info__))
-
-
-import sys
-import os
-
-PY3 = sys.version_info[0] == 3
-
-if PY3:
- unicode = str
-
-if sys.platform.startswith('java'):
- import platform
- os_name = platform.java_ver()[3][0]
- if os_name.startswith('Windows'): # "Windows XP", "Windows 7", etc.
- system = 'win32'
- elif os_name.startswith('Mac'): # "Mac OS X", etc.
- system = 'darwin'
- else: # "Linux", "SunOS", "FreeBSD", etc.
- # Setting this to "linux2" is not ideal, but only Windows or Mac
- # are actually checked for and the rest of the module expects
- # *sys.platform* style strings.
- system = 'linux2'
-else:
- system = sys.platform
-
-
-
-def user_data_dir(appname=None, appauthor=None, version=None, roaming=False):
- r"""Return full path to the user-specific data dir for this application.
-
- "appname" is the name of application.
- If None, just the system directory is returned.
- "appauthor" (only used on Windows) is the name of the
- appauthor or distributing body for this application. Typically
- it is the owning company name. This falls back to appname. You may
- pass False to disable it.
- "version" is an optional version path element to append to the
- path. You might want to use this if you want multiple versions
- of your app to be able to run independently. If used, this
- would typically be ".".
- Only applied when appname is present.
- "roaming" (boolean, default False) can be set True to use the Windows
- roaming appdata directory. That means that for users on a Windows
- network setup for roaming profiles, this user data will be
- sync'd on login. See
-
- for a discussion of issues.
-
- Typical user data directories are:
- Mac OS X: ~/Library/Application Support/
- Unix: ~/.local/share/ # or in $XDG_DATA_HOME, if defined
- Win XP (not roaming): C:\Documents and Settings\\Application Data\\
- Win XP (roaming): C:\Documents and Settings\\Local Settings\Application Data\\
- Win 7 (not roaming): C:\Users\\AppData\Local\\
- Win 7 (roaming): C:\Users\\AppData\Roaming\\
-
- For Unix, we follow the XDG spec and support $XDG_DATA_HOME.
- That means, by default "~/.local/share/".
- """
- if system == "win32":
- if appauthor is None:
- appauthor = appname
- const = roaming and "CSIDL_APPDATA" or "CSIDL_LOCAL_APPDATA"
- path = os.path.normpath(_get_win_folder(const))
- if appname:
- if appauthor is not False:
- path = os.path.join(path, appauthor, appname)
- else:
- path = os.path.join(path, appname)
- elif system == 'darwin':
- path = os.path.expanduser('~/Library/Application Support/')
- if appname:
- path = os.path.join(path, appname)
- else:
- path = os.getenv('XDG_DATA_HOME', os.path.expanduser("~/.local/share"))
- if appname:
- path = os.path.join(path, appname)
- if appname and version:
- path = os.path.join(path, version)
- return path
-
-
-def site_data_dir(appname=None, appauthor=None, version=None, multipath=False):
- r"""Return full path to the user-shared data dir for this application.
-
- "appname" is the name of application.
- If None, just the system directory is returned.
- "appauthor" (only used on Windows) is the name of the
- appauthor or distributing body for this application. Typically
- it is the owning company name. This falls back to appname. You may
- pass False to disable it.
- "version" is an optional version path element to append to the
- path. You might want to use this if you want multiple versions
- of your app to be able to run independently. If used, this
- would typically be ".".
- Only applied when appname is present.
- "multipath" is an optional parameter only applicable to *nix
- which indicates that the entire list of data dirs should be
- returned. By default, the first item from XDG_DATA_DIRS is
- returned, or '/usr/local/share/',
- if XDG_DATA_DIRS is not set
-
- Typical site data directories are:
- Mac OS X: /Library/Application Support/
- Unix: /usr/local/share/ or /usr/share/
- Win XP: C:\Documents and Settings\All Users\Application Data\\
- Vista: (Fail! "C:\ProgramData" is a hidden *system* directory on Vista.)
- Win 7: C:\ProgramData\\ # Hidden, but writeable on Win 7.
-
- For Unix, this is using the $XDG_DATA_DIRS[0] default.
-
- WARNING: Do not use this on Windows. See the Vista-Fail note above for why.
- """
- if system == "win32":
- if appauthor is None:
- appauthor = appname
- path = os.path.normpath(_get_win_folder("CSIDL_COMMON_APPDATA"))
- if appname:
- if appauthor is not False:
- path = os.path.join(path, appauthor, appname)
- else:
- path = os.path.join(path, appname)
- elif system == 'darwin':
- path = os.path.expanduser('/Library/Application Support')
- if appname:
- path = os.path.join(path, appname)
- else:
- # XDG default for $XDG_DATA_DIRS
- # only first, if multipath is False
- path = os.getenv('XDG_DATA_DIRS',
- os.pathsep.join(['/usr/local/share', '/usr/share']))
- pathlist = [os.path.expanduser(x.rstrip(os.sep)) for x in path.split(os.pathsep)]
- if appname:
- if version:
- appname = os.path.join(appname, version)
- pathlist = [os.sep.join([x, appname]) for x in pathlist]
-
- if multipath:
- path = os.pathsep.join(pathlist)
- else:
- path = pathlist[0]
- return path
-
- if appname and version:
- path = os.path.join(path, version)
- return path
-
-
-def user_config_dir(appname=None, appauthor=None, version=None, roaming=False):
- r"""Return full path to the user-specific config dir for this application.
-
- "appname" is the name of application.
- If None, just the system directory is returned.
- "appauthor" (only used on Windows) is the name of the
- appauthor or distributing body for this application. Typically
- it is the owning company name. This falls back to appname. You may
- pass False to disable it.
- "version" is an optional version path element to append to the
- path. You might want to use this if you want multiple versions
- of your app to be able to run independently. If used, this
- would typically be ".".
- Only applied when appname is present.
- "roaming" (boolean, default False) can be set True to use the Windows
- roaming appdata directory. That means that for users on a Windows
- network setup for roaming profiles, this user data will be
- sync'd on login. See
-
- for a discussion of issues.
-
- Typical user config directories are:
- Mac OS X: same as user_data_dir
- Unix: ~/.config/ # or in $XDG_CONFIG_HOME, if defined
- Win *: same as user_data_dir
-
- For Unix, we follow the XDG spec and support $XDG_CONFIG_HOME.
- That means, by default "~/.config/".
- """
- if system in ["win32", "darwin"]:
- path = user_data_dir(appname, appauthor, None, roaming)
- else:
- path = os.getenv('XDG_CONFIG_HOME', os.path.expanduser("~/.config"))
- if appname:
- path = os.path.join(path, appname)
- if appname and version:
- path = os.path.join(path, version)
- return path
-
-
-def site_config_dir(appname=None, appauthor=None, version=None, multipath=False):
- r"""Return full path to the user-shared data dir for this application.
-
- "appname" is the name of application.
- If None, just the system directory is returned.
- "appauthor" (only used on Windows) is the name of the
- appauthor or distributing body for this application. Typically
- it is the owning company name. This falls back to appname. You may
- pass False to disable it.
- "version" is an optional version path element to append to the
- path. You might want to use this if you want multiple versions
- of your app to be able to run independently. If used, this
- would typically be ".".
- Only applied when appname is present.
- "multipath" is an optional parameter only applicable to *nix
- which indicates that the entire list of config dirs should be
- returned. By default, the first item from XDG_CONFIG_DIRS is
- returned, or '/etc/xdg/', if XDG_CONFIG_DIRS is not set
-
- Typical site config directories are:
- Mac OS X: same as site_data_dir
- Unix: /etc/xdg/ or $XDG_CONFIG_DIRS[i]/ for each value in
- $XDG_CONFIG_DIRS
- Win *: same as site_data_dir
- Vista: (Fail! "C:\ProgramData" is a hidden *system* directory on Vista.)
-
- For Unix, this is using the $XDG_CONFIG_DIRS[0] default, if multipath=False
-
- WARNING: Do not use this on Windows. See the Vista-Fail note above for why.
- """
- if system in ["win32", "darwin"]:
- path = site_data_dir(appname, appauthor)
- if appname and version:
- path = os.path.join(path, version)
- else:
- # XDG default for $XDG_CONFIG_DIRS
- # only first, if multipath is False
- path = os.getenv('XDG_CONFIG_DIRS', '/etc/xdg')
- pathlist = [os.path.expanduser(x.rstrip(os.sep)) for x in path.split(os.pathsep)]
- if appname:
- if version:
- appname = os.path.join(appname, version)
- pathlist = [os.sep.join([x, appname]) for x in pathlist]
-
- if multipath:
- path = os.pathsep.join(pathlist)
- else:
- path = pathlist[0]
- return path
-
-
-def user_cache_dir(appname=None, appauthor=None, version=None, opinion=True):
- r"""Return full path to the user-specific cache dir for this application.
-
- "appname" is the name of application.
- If None, just the system directory is returned.
- "appauthor" (only used on Windows) is the name of the
- appauthor or distributing body for this application. Typically
- it is the owning company name. This falls back to appname. You may
- pass False to disable it.
- "version" is an optional version path element to append to the
- path. You might want to use this if you want multiple versions
- of your app to be able to run independently. If used, this
- would typically be ".".
- Only applied when appname is present.
- "opinion" (boolean) can be False to disable the appending of
- "Cache" to the base app data dir for Windows. See
- discussion below.
-
- Typical user cache directories are:
- Mac OS X: ~/Library/Caches/
- Unix: ~/.cache/ (XDG default)
- Win XP: C:\Documents and Settings\\Local Settings\Application Data\\\Cache
- Vista: C:\Users\\AppData\Local\\\Cache
-
- On Windows the only suggestion in the MSDN docs is that local settings go in
- the `CSIDL_LOCAL_APPDATA` directory. This is identical to the non-roaming
- app data dir (the default returned by `user_data_dir` above). Apps typically
- put cache data somewhere *under* the given dir here. Some examples:
- ...\Mozilla\Firefox\Profiles\\Cache
- ...\Acme\SuperApp\Cache\1.0
- OPINION: This function appends "Cache" to the `CSIDL_LOCAL_APPDATA` value.
- This can be disabled with the `opinion=False` option.
- """
- if system == "win32":
- if appauthor is None:
- appauthor = appname
- path = os.path.normpath(_get_win_folder("CSIDL_LOCAL_APPDATA"))
- if appname:
- if appauthor is not False:
- path = os.path.join(path, appauthor, appname)
- else:
- path = os.path.join(path, appname)
- if opinion:
- path = os.path.join(path, "Cache")
- elif system == 'darwin':
- path = os.path.expanduser('~/Library/Caches')
- if appname:
- path = os.path.join(path, appname)
- else:
- path = os.getenv('XDG_CACHE_HOME', os.path.expanduser('~/.cache'))
- if appname:
- path = os.path.join(path, appname)
- if appname and version:
- path = os.path.join(path, version)
- return path
-
-
-def user_state_dir(appname=None, appauthor=None, version=None, roaming=False):
- r"""Return full path to the user-specific state dir for this application.
-
- "appname" is the name of application.
- If None, just the system directory is returned.
- "appauthor" (only used on Windows) is the name of the
- appauthor or distributing body for this application. Typically
- it is the owning company name. This falls back to appname. You may
- pass False to disable it.
- "version" is an optional version path element to append to the
- path. You might want to use this if you want multiple versions
- of your app to be able to run independently. If used, this
- would typically be ".".
- Only applied when appname is present.
- "roaming" (boolean, default False) can be set True to use the Windows
- roaming appdata directory. That means that for users on a Windows
- network setup for roaming profiles, this user data will be
- sync'd on login. See
-
- for a discussion of issues.
-
- Typical user state directories are:
- Mac OS X: same as user_data_dir
- Unix: ~/.local/state/ # or in $XDG_STATE_HOME, if defined
- Win *: same as user_data_dir
-
- For Unix, we follow this Debian proposal
- to extend the XDG spec and support $XDG_STATE_HOME.
-
- That means, by default "~/.local/state/".
- """
- if system in ["win32", "darwin"]:
- path = user_data_dir(appname, appauthor, None, roaming)
- else:
- path = os.getenv('XDG_STATE_HOME', os.path.expanduser("~/.local/state"))
- if appname:
- path = os.path.join(path, appname)
- if appname and version:
- path = os.path.join(path, version)
- return path
-
-
-def user_log_dir(appname=None, appauthor=None, version=None, opinion=True):
- r"""Return full path to the user-specific log dir for this application.
-
- "appname" is the name of application.
- If None, just the system directory is returned.
- "appauthor" (only used on Windows) is the name of the
- appauthor or distributing body for this application. Typically
- it is the owning company name. This falls back to appname. You may
- pass False to disable it.
- "version" is an optional version path element to append to the
- path. You might want to use this if you want multiple versions
- of your app to be able to run independently. If used, this
- would typically be ".".
- Only applied when appname is present.
- "opinion" (boolean) can be False to disable the appending of
- "Logs" to the base app data dir for Windows, and "log" to the
- base cache dir for Unix. See discussion below.
-
- Typical user log directories are:
- Mac OS X: ~/Library/Logs/
- Unix: ~/.cache//log # or under $XDG_CACHE_HOME if defined
- Win XP: C:\Documents and Settings\\Local Settings\Application Data\\\Logs
- Vista: C:\Users\\AppData\Local\\\Logs
-
- On Windows the only suggestion in the MSDN docs is that local settings
- go in the `CSIDL_LOCAL_APPDATA` directory. (Note: I'm interested in
- examples of what some windows apps use for a logs dir.)
-
- OPINION: This function appends "Logs" to the `CSIDL_LOCAL_APPDATA`
- value for Windows and appends "log" to the user cache dir for Unix.
- This can be disabled with the `opinion=False` option.
- """
- if system == "darwin":
- path = os.path.join(
- os.path.expanduser('~/Library/Logs'),
- appname)
- elif system == "win32":
- path = user_data_dir(appname, appauthor, version)
- version = False
- if opinion:
- path = os.path.join(path, "Logs")
- else:
- path = user_cache_dir(appname, appauthor, version)
- version = False
- if opinion:
- path = os.path.join(path, "log")
- if appname and version:
- path = os.path.join(path, version)
- return path
-
-
-class AppDirs(object):
- """Convenience wrapper for getting application dirs."""
- def __init__(self, appname=None, appauthor=None, version=None,
- roaming=False, multipath=False):
- self.appname = appname
- self.appauthor = appauthor
- self.version = version
- self.roaming = roaming
- self.multipath = multipath
-
- @property
- def user_data_dir(self):
- return user_data_dir(self.appname, self.appauthor,
- version=self.version, roaming=self.roaming)
-
- @property
- def site_data_dir(self):
- return site_data_dir(self.appname, self.appauthor,
- version=self.version, multipath=self.multipath)
-
- @property
- def user_config_dir(self):
- return user_config_dir(self.appname, self.appauthor,
- version=self.version, roaming=self.roaming)
-
- @property
- def site_config_dir(self):
- return site_config_dir(self.appname, self.appauthor,
- version=self.version, multipath=self.multipath)
-
- @property
- def user_cache_dir(self):
- return user_cache_dir(self.appname, self.appauthor,
- version=self.version)
-
- @property
- def user_state_dir(self):
- return user_state_dir(self.appname, self.appauthor,
- version=self.version)
-
- @property
- def user_log_dir(self):
- return user_log_dir(self.appname, self.appauthor,
- version=self.version)
-
-
-#---- internal support stuff
-
-def _get_win_folder_from_registry(csidl_name):
- """This is a fallback technique at best. I'm not sure if using the
- registry for this guarantees us the correct answer for all CSIDL_*
- names.
- """
- if PY3:
- import winreg as _winreg
- else:
- import _winreg
-
- shell_folder_name = {
- "CSIDL_APPDATA": "AppData",
- "CSIDL_COMMON_APPDATA": "Common AppData",
- "CSIDL_LOCAL_APPDATA": "Local AppData",
- }[csidl_name]
-
- key = _winreg.OpenKey(
- _winreg.HKEY_CURRENT_USER,
- r"Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders"
- )
- dir, type = _winreg.QueryValueEx(key, shell_folder_name)
- return dir
-
-
-def _get_win_folder_with_pywin32(csidl_name):
- from win32com.shell import shellcon, shell
- dir = shell.SHGetFolderPath(0, getattr(shellcon, csidl_name), 0, 0)
- # Try to make this a unicode path because SHGetFolderPath does
- # not return unicode strings when there is unicode data in the
- # path.
- try:
- dir = unicode(dir)
-
- # Downgrade to short path name if have highbit chars. See
- # .
- has_high_char = False
- for c in dir:
- if ord(c) > 255:
- has_high_char = True
- break
- if has_high_char:
- try:
- import win32api
- dir = win32api.GetShortPathName(dir)
- except ImportError:
- pass
- except UnicodeError:
- pass
- return dir
-
-
-def _get_win_folder_with_ctypes(csidl_name):
- import ctypes
-
- csidl_const = {
- "CSIDL_APPDATA": 26,
- "CSIDL_COMMON_APPDATA": 35,
- "CSIDL_LOCAL_APPDATA": 28,
- }[csidl_name]
-
- buf = ctypes.create_unicode_buffer(1024)
- ctypes.windll.shell32.SHGetFolderPathW(None, csidl_const, None, 0, buf)
-
- # Downgrade to short path name if have highbit chars. See
- # .
- has_high_char = False
- for c in buf:
- if ord(c) > 255:
- has_high_char = True
- break
- if has_high_char:
- buf2 = ctypes.create_unicode_buffer(1024)
- if ctypes.windll.kernel32.GetShortPathNameW(buf.value, buf2, 1024):
- buf = buf2
-
- return buf.value
-
-def _get_win_folder_with_jna(csidl_name):
- import array
- from com.sun import jna
- from com.sun.jna.platform import win32
-
- buf_size = win32.WinDef.MAX_PATH * 2
- buf = array.zeros('c', buf_size)
- shell = win32.Shell32.INSTANCE
- shell.SHGetFolderPath(None, getattr(win32.ShlObj, csidl_name), None, win32.ShlObj.SHGFP_TYPE_CURRENT, buf)
- dir = jna.Native.toString(buf.tostring()).rstrip("\0")
-
- # Downgrade to short path name if have highbit chars. See
- # .
- has_high_char = False
- for c in dir:
- if ord(c) > 255:
- has_high_char = True
- break
- if has_high_char:
- buf = array.zeros('c', buf_size)
- kernel = win32.Kernel32.INSTANCE
- if kernel.GetShortPathName(dir, buf, buf_size):
- dir = jna.Native.toString(buf.tostring()).rstrip("\0")
-
- return dir
-
-if system == "win32":
- try:
- import win32com.shell
- _get_win_folder = _get_win_folder_with_pywin32
- except ImportError:
- try:
- from ctypes import windll
- _get_win_folder = _get_win_folder_with_ctypes
- except ImportError:
- try:
- import com.sun.jna
- _get_win_folder = _get_win_folder_with_jna
- except ImportError:
- _get_win_folder = _get_win_folder_from_registry
-
-
-#---- self test code
-
-if __name__ == "__main__":
- appname = "MyApp"
- appauthor = "MyCompany"
-
- props = ("user_data_dir",
- "user_config_dir",
- "user_cache_dir",
- "user_state_dir",
- "user_log_dir",
- "site_data_dir",
- "site_config_dir")
-
- print("-- app dirs %s --" % __version__)
-
- print("-- app dirs (with optional 'version')")
- dirs = AppDirs(appname, appauthor, version="1.0")
- for prop in props:
- print("%s: %s" % (prop, getattr(dirs, prop)))
-
- print("\n-- app dirs (without optional 'version')")
- dirs = AppDirs(appname, appauthor)
- for prop in props:
- print("%s: %s" % (prop, getattr(dirs, prop)))
-
- print("\n-- app dirs (without optional 'appauthor')")
- dirs = AppDirs(appname)
- for prop in props:
- print("%s: %s" % (prop, getattr(dirs, prop)))
-
- print("\n-- app dirs (with disabled 'appauthor')")
- dirs = AppDirs(appname, appauthor=False)
- for prop in props:
- print("%s: %s" % (prop, getattr(dirs, prop)))
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/importlib_resources/_common.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/importlib_resources/_common.py
deleted file mode 100644
index a12e2c75d132c73b556702159d535d15ed9abfd2..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/importlib_resources/_common.py
+++ /dev/null
@@ -1,104 +0,0 @@
-import os
-import pathlib
-import tempfile
-import functools
-import contextlib
-import types
-import importlib
-
-from typing import Union, Optional
-from .abc import ResourceReader, Traversable
-
-from ._compat import wrap_spec
-
-Package = Union[types.ModuleType, str]
-
-
-def files(package):
- # type: (Package) -> Traversable
- """
- Get a Traversable resource from a package
- """
- return from_package(get_package(package))
-
-
-def get_resource_reader(package):
- # type: (types.ModuleType) -> Optional[ResourceReader]
- """
- Return the package's loader if it's a ResourceReader.
- """
- # We can't use
- # a issubclass() check here because apparently abc.'s __subclasscheck__()
- # hook wants to create a weak reference to the object, but
- # zipimport.zipimporter does not support weak references, resulting in a
- # TypeError. That seems terrible.
- spec = package.__spec__
- reader = getattr(spec.loader, 'get_resource_reader', None) # type: ignore
- if reader is None:
- return None
- return reader(spec.name) # type: ignore
-
-
-def resolve(cand):
- # type: (Package) -> types.ModuleType
- return cand if isinstance(cand, types.ModuleType) else importlib.import_module(cand)
-
-
-def get_package(package):
- # type: (Package) -> types.ModuleType
- """Take a package name or module object and return the module.
-
- Raise an exception if the resolved module is not a package.
- """
- resolved = resolve(package)
- if wrap_spec(resolved).submodule_search_locations is None:
- raise TypeError(f'{package!r} is not a package')
- return resolved
-
-
-def from_package(package):
- """
- Return a Traversable object for the given package.
-
- """
- spec = wrap_spec(package)
- reader = spec.loader.get_resource_reader(spec.name)
- return reader.files()
-
-
-@contextlib.contextmanager
-def _tempfile(reader, suffix=''):
- # Not using tempfile.NamedTemporaryFile as it leads to deeper 'try'
- # blocks due to the need to close the temporary file to work on Windows
- # properly.
- fd, raw_path = tempfile.mkstemp(suffix=suffix)
- try:
- try:
- os.write(fd, reader())
- finally:
- os.close(fd)
- del reader
- yield pathlib.Path(raw_path)
- finally:
- try:
- os.remove(raw_path)
- except FileNotFoundError:
- pass
-
-
-@functools.singledispatch
-def as_file(path):
- """
- Given a Traversable object, return that object as a
- path on the local file system in a context manager.
- """
- return _tempfile(path.read_bytes, suffix=path.name)
-
-
-@as_file.register(pathlib.Path)
-@contextlib.contextmanager
-def _(path):
- """
- Degenerate behavior for pathlib.Path objects.
- """
- yield path
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/tomli/__init__.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/tomli/__init__.py
deleted file mode 100644
index 4c6ec97ec6961bcf184b6e0b2437b9924db0b9de..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/tomli/__init__.py
+++ /dev/null
@@ -1,11 +0,0 @@
-# SPDX-License-Identifier: MIT
-# SPDX-FileCopyrightText: 2021 Taneli Hukkinen
-# Licensed to PSF under a Contributor Agreement.
-
-__all__ = ("loads", "load", "TOMLDecodeError")
-__version__ = "2.0.1" # DO NOT EDIT THIS LINE MANUALLY. LET bump2version UTILITY DO IT
-
-from ._parser import TOMLDecodeError, load, loads
-
-# Pretend this exception was created here.
-TOMLDecodeError.__module__ = __name__
diff --git a/spaces/Reself/StableVideo/ldm/models/diffusion/sampling_util.py b/spaces/Reself/StableVideo/ldm/models/diffusion/sampling_util.py
deleted file mode 100644
index 7eff02be6d7c54d43ee6680636ac0698dd3b3f33..0000000000000000000000000000000000000000
--- a/spaces/Reself/StableVideo/ldm/models/diffusion/sampling_util.py
+++ /dev/null
@@ -1,22 +0,0 @@
-import torch
-import numpy as np
-
-
-def append_dims(x, target_dims):
- """Appends dimensions to the end of a tensor until it has target_dims dimensions.
- From https://github.com/crowsonkb/k-diffusion/blob/master/k_diffusion/utils.py"""
- dims_to_append = target_dims - x.ndim
- if dims_to_append < 0:
- raise ValueError(f'input has {x.ndim} dims but target_dims is {target_dims}, which is less')
- return x[(...,) + (None,) * dims_to_append]
-
-
-def norm_thresholding(x0, value):
- s = append_dims(x0.pow(2).flatten(1).mean(1).sqrt().clamp(min=value), x0.ndim)
- return x0 * (value / s)
-
-
-def spatial_norm_thresholding(x0, value):
- # b c h w
- s = x0.pow(2).mean(1, keepdim=True).sqrt().clamp(min=value)
- return x0 * (value / s)
\ No newline at end of file
diff --git a/spaces/Riksarkivet/htr_demo/helper/text/overview/duplicate_api/api_code1.md b/spaces/Riksarkivet/htr_demo/helper/text/overview/duplicate_api/api_code1.md
deleted file mode 100644
index 347bd71681cb6466b70c7c7547bdfc44a8e38d0c..0000000000000000000000000000000000000000
--- a/spaces/Riksarkivet/htr_demo/helper/text/overview/duplicate_api/api_code1.md
+++ /dev/null
@@ -1,11 +0,0 @@
-from gradio_client import Client # pip install gradio_client
-
-# Change url to your client (localhost: http://127.0.0.1:7860/)
-
-client = Client("https://huggingface.co/spaces/Riksarkivet/htr_demo")
-job = client.submit(
-"https://your.image.url.or.pah.jpg",
-api_name="/run_htr_pipeline",
-)
-
-print(job.result())
diff --git a/spaces/Ritori/TTS_Yui/Yue_gradio_cpu.py b/spaces/Ritori/TTS_Yui/Yue_gradio_cpu.py
deleted file mode 100644
index 934724801da6adc0e695e830e375cb8c8160e259..0000000000000000000000000000000000000000
--- a/spaces/Ritori/TTS_Yui/Yue_gradio_cpu.py
+++ /dev/null
@@ -1,247 +0,0 @@
-#好用的
-
-import os
-os.system('pip install -U tensorflow')
-os.system('pip install -q unidecode tensorboardX')
-os.system('pip install librosa==0.8.0')
-os.system('pip install pysoundfile==0.9.0.post1')
-os.system('pip install unidecode==1.3.4')
-os.system('pip install pyopenjtalk --no-build-isolation')
-os.system('pip install inflect==5.6.2')
-os.system('pip install janome==0.4.2')
-#os.system('pip install tqdm -q')
-os.system('pip install gdown')
-os.system('pip install -q librosa unidecode')
-
-os.system('pip install ipython')
-os.system('pip install --upgrade jupyter ipywidgets')
-os.system('jupyter nbextension enable --py widgetsnbextension')
-#os.system('pip uninstall tqdm')
-os.system('pip install tqdm')
-os.system('pip install --upgrade numpy')
-os.system('pip install "numpy<=1.24"')
-os.system('pip install --upgrade librosa')
-import time
-import pyopenjtalk
-import soundfile as sf
-import gradio as gr
-import torch
-import IPython.display as ipd
-import numpy as np
-import torch
-import json
-from hparams import create_hparams
-from model import Tacotron2
-from layers import TacotronSTFT
-from audio_processing import griffin_lim
-from text import text_to_sequence
-from env import AttrDict
-from meldataset import MAX_WAV_VALUE
-from models import Generator
-
-#@,tlitle 配置并运行
-
-#国际 HiFi-GAN 模型(有点机器音): 1qpgI41wNXFcH-iKq1Y42JlBC9j0je8PW
-#@markdown 你训练好的tacotron2模型的路径填在`Tacotron2_Model`这里
-Tacotron2_Model = 'Yui_TrapGenesis'#@param {type:"string"}
-TACOTRON2_ID = Tacotron2_Model
-HIFIGAN_ID = "1qpgI41wNXFcH-iKq1Y42JlBC9j0je8PW"
-#@markdown 选择预处理文本的cleaner
-text_cleaner = 'japanese_phrase_cleaners'#@param {type:"string"}
-import pyopenjtalk
-import soundfile as sf
-import gradio as gr
-
-# 全局变量声明
-model = None
-hparams = None
-hifigan = None
-thisdict = None
-pronounciation_dictionary = False
-show_graphs = False # 添加show_graphs变量,并赋予默认值
-
-# 初始化函数
-def initialize():
- global model, hparams, hifigan, thisdict, pronounciation_dictionary
-
- # 检查是否已初始化
- try:
- initialized
- except NameError:
- print("Setting up, please wait.\n")
-
- from tqdm.notebook import tqdm
- with tqdm(total=5, leave=False) as pbar:
- import os
- from os.path import exists, join, basename, splitext
- git_repo_url = 'https://github.com/CjangCjengh/tacotron2-japanese.git'
- project_name = splitext(basename(git_repo_url))[0]
- if not exists(project_name):
- # clone and install
- os.system('git clone -q --recursive {git_repo_url}')
- os.system('git clone -q --recursive https://github.com/SortAnon/hifi-gan')
-
- pbar.update(1) # downloaded TT2 and HiFi-GAN
- import sys
- sys.path.append('hifi-gan')
- sys.path.append(project_name)
- import time
- import matplotlib
- import matplotlib.pylab as plt
- import gdown
- d = 'https://drive.google.com/uc?id='
-
- # %matplotlib inline
- import IPython.display as ipd
- import numpy as np
- import torch
- import json
- from hparams import create_hparams
- from model import Tacotron2
- from layers import TacotronSTFT
- from audio_processing import griffin_lim
- from text import text_to_sequence
- from env import AttrDict
- from meldataset import MAX_WAV_VALUE
- from models import Generator
-
- pbar.update(1) # initialized Dependancies
-
- graph_width = 900
- graph_height = 360
- def plot_data(data, figsize=(int(graph_width/100), int(graph_height/100))):
- # %matplotlib inline
- fig, axes = plt.subplots(1, len(data), figsize=figsize)
- for i in range(len(data)):
- axes[i].imshow(data[i], aspect='auto', origin='upper',
- interpolation='none', cmap='inferno')
- fig.canvas.draw()
- plt.show()
-
- # Setup Pronounciation Dictionary
- os.system('wget https://github.com/wind4000/tacotron2/releases/download/v0.2/merged.dict.txt')
- thisdict = {}
- for line in reversed((open('merged.dict.txt', "r").read()).splitlines()):
- thisdict[(line.split(" ",1))[0]] = (line.split(" ",1))[1].strip()
-
- pbar.update(1) # Downloaded and Set up Pronounciation Dictionary
-
- def ARPA(text, punctuation=r"!?,.;", EOS_Token=True):
- out = ''
- for word_ in text.split(" "):
- word=word_; end_chars = ''
- while any(elem in word for elem in punctuation) and len(word) > 1:
- if word[-1] in punctuation: end_chars = word[-1] + end_chars; word = word[:-1]
- else: break
- try:
- word_arpa = thisdict[word.upper()]
- word = "{" + str(word_arpa) + "}"
- except KeyError: pass
- out = (out + " " + word + end_chars).strip()
- if EOS_Token and out[-1] != ";": out += ";"
- return out
-
- def get_hifigan(MODEL_ID):
- # Download HiFi-GAN
- hifigan_pretrained_model = 'hifimodel'
- gdown.download(d+MODEL_ID, hifigan_pretrained_model, quiet=False)
- if not exists(hifigan_pretrained_model):
- raise Exception("HiFI-GAN model failed to download!")
-
- # Load HiFi-GAN
- conf = os.path.join("hifi-gan", "config_v1.json")
- with open(conf) as f:
- json_config = json.loads(f.read())
- h = AttrDict(json_config)
- torch.manual_seed(h.seed)
- hifigan = Generator(h).to(torch.device("cpu"))
- state_dict_g = torch.load(hifigan_pretrained_model, map_location=torch.device("cpu"))
- hifigan.load_state_dict(state_dict_g["generator"])
- hifigan.eval()
- hifigan.remove_weight_norm()
- return hifigan, h
-
- hifigan, h = get_hifigan(HIFIGAN_ID)
- pbar.update(1) # Downloaded and Set up HiFi-GAN
-
- def has_MMI(STATE_DICT):
- return any(True for x in STATE_DICT.keys() if "mi." in x)
-
- def get_Tactron2(MODEL_ID):
- # Download Tacotron2
- tacotron2_pretrained_model = TACOTRON2_ID
- if not exists(tacotron2_pretrained_model):
- raise Exception("Tacotron2 model failed to download!")
- # Load Tacotron2 and Config
- hparams = create_hparams()
- hparams.sampling_rate = 22050
- hparams.max_decoder_steps = 2000 # Max Duration
- hparams.gate_threshold = 0.80 # Model must be 25% sure the clip is over before ending generation
- model = Tacotron2(hparams)
- state_dict = torch.load(tacotron2_pretrained_model, map_location=torch.device('cpu'))['state_dict']
-
- if has_MMI(state_dict):
- raise Exception("ERROR: This notebook does not currently support MMI models.")
- model.load_state_dict(state_dict)
- _ = model.cpu().eval().float()
- return model, hparams
-
- model, hparams = get_Tactron2(TACOTRON2_ID)
- previous_tt2_id = TACOTRON2_ID
-
- pbar.update(1) # Downloaded and Set up Tacotron2
-
- # 初始化
-initialize()
-
-import soundfile as sf
-
-def end_to_end_infer(text, pronounciation_dictionary, show_graphs):
- audio = None # 定义一个变量用于存储音频数据
- for i in [x for x in text.split("\n") if len(x)]:
- if not pronounciation_dictionary:
- if i[-1] != ";":
- i = i + ";"
- else:
- i = ARPA(i)
- with torch.no_grad():
- sequence = np.array(text_to_sequence(i, [text_cleaner]))[None, :]
- sequence = torch.autograd.Variable(torch.from_numpy(sequence)).cpu().long() # 或者使用 .int()
-
- mel_outputs, mel_outputs_postnet, _, alignments = model.inference(sequence)
- if show_graphs:
- plot_data((mel_outputs_postnet.float().data.cpu().numpy()[0],
- alignments.float().data.cpu().numpy()[0].T))
- y_g_hat = hifigan(mel_outputs_postnet.float())
- audio = y_g_hat.squeeze()
- audio = audio * MAX_WAV_VALUE
- output_filename = f"output_{time.strftime('%Y%m%d%H%M%S')}.wav"
- sf.write(output_filename, audio.cpu().numpy().astype('int16'), hparams.sampling_rate)
- print(f"音频已保存为 {output_filename}")
- print("")
- ipd.display(ipd.Audio(audio.cpu().numpy().astype("int16"), rate=hparams.sampling_rate))
- return audio # 返回音频数据
-
-# 文本到语音转换函数
-def text_to_speech(text, max_decoder_steps=2000, gate_threshold=0.5):
- global model, hparams, hifigan, thisdict, pronounciation_dictionary, show_graphs
-
- hparams.max_decoder_steps = max_decoder_steps
- hparams.gate_threshold = gate_threshold
- output_filename = f"output_{time.strftime('%Y%m%d%H%M%S')}.wav"
- audio = end_to_end_infer(text, pronounciation_dictionary, show_graphs)
- if audio is not None:
- sf.write(output_filename, audio.cpu().numpy().astype('int16'), hparams.sampling_rate)
- return output_filename
- else:
- return None
-
-# Gradio界面
-inputs = [
- gr.inputs.Textbox(lines=3, label="输入文本"),
- gr.inputs.Slider(minimum=100, maximum=5000, default=1500, step=100, label="最大解码步数"),
- gr.inputs.Slider(minimum=0.0, maximum=1.0, default=0.35, step=0.05, label="门控阈值")
-]
-outputs = gr.outputs.File(label="下载生成的音频")
-
-gr.Interface(fn=text_to_speech, inputs=inputs, outputs=outputs).launch(debug=True)
\ No newline at end of file
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmcv/runner/builder.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmcv/runner/builder.py
deleted file mode 100644
index 77c96ba0b2f30ead9da23f293c5dc84dd3e4a74f..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmcv/runner/builder.py
+++ /dev/null
@@ -1,24 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-from ..utils import Registry
-
-RUNNERS = Registry('runner')
-RUNNER_BUILDERS = Registry('runner builder')
-
-
-def build_runner_constructor(cfg):
- return RUNNER_BUILDERS.build(cfg)
-
-
-def build_runner(cfg, default_args=None):
- runner_cfg = copy.deepcopy(cfg)
- constructor_type = runner_cfg.pop('constructor',
- 'DefaultRunnerConstructor')
- runner_constructor = build_runner_constructor(
- dict(
- type=constructor_type,
- runner_cfg=runner_cfg,
- default_args=default_args))
- runner = runner_constructor()
- return runner
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/datasets/pipelines/loading.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/datasets/pipelines/loading.py
deleted file mode 100644
index 69225941903f6b9d67b8b8c5fc3b1801cd964fb2..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/datasets/pipelines/loading.py
+++ /dev/null
@@ -1,458 +0,0 @@
-import os.path as osp
-
-import mmcv
-import numpy as np
-import pycocotools.mask as maskUtils
-
-from mmdet.core import BitmapMasks, PolygonMasks
-from ..builder import PIPELINES
-
-
-@PIPELINES.register_module()
-class LoadImageFromFile(object):
- """Load an image from file.
-
- Required keys are "img_prefix" and "img_info" (a dict that must contain the
- key "filename"). Added or updated keys are "filename", "img", "img_shape",
- "ori_shape" (same as `img_shape`), "pad_shape" (same as `img_shape`),
- "scale_factor" (1.0) and "img_norm_cfg" (means=0 and stds=1).
-
- Args:
- to_float32 (bool): Whether to convert the loaded image to a float32
- numpy array. If set to False, the loaded image is an uint8 array.
- Defaults to False.
- color_type (str): The flag argument for :func:`mmcv.imfrombytes`.
- Defaults to 'color'.
- file_client_args (dict): Arguments to instantiate a FileClient.
- See :class:`mmcv.fileio.FileClient` for details.
- Defaults to ``dict(backend='disk')``.
- """
-
- def __init__(self,
- to_float32=False,
- color_type='color',
- file_client_args=dict(backend='disk')):
- self.to_float32 = to_float32
- self.color_type = color_type
- self.file_client_args = file_client_args.copy()
- self.file_client = None
-
- def __call__(self, results):
- """Call functions to load image and get image meta information.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded image and meta information.
- """
-
- if self.file_client is None:
- self.file_client = mmcv.FileClient(**self.file_client_args)
-
- if results['img_prefix'] is not None:
- filename = osp.join(results['img_prefix'],
- results['img_info']['filename'])
- else:
- filename = results['img_info']['filename']
-
- img_bytes = self.file_client.get(filename)
- img = mmcv.imfrombytes(img_bytes, flag=self.color_type)
- if self.to_float32:
- img = img.astype(np.float32)
-
- results['filename'] = filename
- results['ori_filename'] = results['img_info']['filename']
- results['img'] = img
- results['img_shape'] = img.shape
- results['ori_shape'] = img.shape
- results['img_fields'] = ['img']
- return results
-
- def __repr__(self):
- repr_str = (f'{self.__class__.__name__}('
- f'to_float32={self.to_float32}, '
- f"color_type='{self.color_type}', "
- f'file_client_args={self.file_client_args})')
- return repr_str
-
-
-@PIPELINES.register_module()
-class LoadImageFromWebcam(LoadImageFromFile):
- """Load an image from webcam.
-
- Similar with :obj:`LoadImageFromFile`, but the image read from webcam is in
- ``results['img']``.
- """
-
- def __call__(self, results):
- """Call functions to add image meta information.
-
- Args:
- results (dict): Result dict with Webcam read image in
- ``results['img']``.
-
- Returns:
- dict: The dict contains loaded image and meta information.
- """
-
- img = results['img']
- if self.to_float32:
- img = img.astype(np.float32)
-
- results['filename'] = None
- results['ori_filename'] = None
- results['img'] = img
- results['img_shape'] = img.shape
- results['ori_shape'] = img.shape
- results['img_fields'] = ['img']
- return results
-
-
-@PIPELINES.register_module()
-class LoadMultiChannelImageFromFiles(object):
- """Load multi-channel images from a list of separate channel files.
-
- Required keys are "img_prefix" and "img_info" (a dict that must contain the
- key "filename", which is expected to be a list of filenames).
- Added or updated keys are "filename", "img", "img_shape",
- "ori_shape" (same as `img_shape`), "pad_shape" (same as `img_shape`),
- "scale_factor" (1.0) and "img_norm_cfg" (means=0 and stds=1).
-
- Args:
- to_float32 (bool): Whether to convert the loaded image to a float32
- numpy array. If set to False, the loaded image is an uint8 array.
- Defaults to False.
- color_type (str): The flag argument for :func:`mmcv.imfrombytes`.
- Defaults to 'color'.
- file_client_args (dict): Arguments to instantiate a FileClient.
- See :class:`mmcv.fileio.FileClient` for details.
- Defaults to ``dict(backend='disk')``.
- """
-
- def __init__(self,
- to_float32=False,
- color_type='unchanged',
- file_client_args=dict(backend='disk')):
- self.to_float32 = to_float32
- self.color_type = color_type
- self.file_client_args = file_client_args.copy()
- self.file_client = None
-
- def __call__(self, results):
- """Call functions to load multiple images and get images meta
- information.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded images and meta information.
- """
-
- if self.file_client is None:
- self.file_client = mmcv.FileClient(**self.file_client_args)
-
- if results['img_prefix'] is not None:
- filename = [
- osp.join(results['img_prefix'], fname)
- for fname in results['img_info']['filename']
- ]
- else:
- filename = results['img_info']['filename']
-
- img = []
- for name in filename:
- img_bytes = self.file_client.get(name)
- img.append(mmcv.imfrombytes(img_bytes, flag=self.color_type))
- img = np.stack(img, axis=-1)
- if self.to_float32:
- img = img.astype(np.float32)
-
- results['filename'] = filename
- results['ori_filename'] = results['img_info']['filename']
- results['img'] = img
- results['img_shape'] = img.shape
- results['ori_shape'] = img.shape
- # Set initial values for default meta_keys
- results['pad_shape'] = img.shape
- results['scale_factor'] = 1.0
- num_channels = 1 if len(img.shape) < 3 else img.shape[2]
- results['img_norm_cfg'] = dict(
- mean=np.zeros(num_channels, dtype=np.float32),
- std=np.ones(num_channels, dtype=np.float32),
- to_rgb=False)
- return results
-
- def __repr__(self):
- repr_str = (f'{self.__class__.__name__}('
- f'to_float32={self.to_float32}, '
- f"color_type='{self.color_type}', "
- f'file_client_args={self.file_client_args})')
- return repr_str
-
-
-@PIPELINES.register_module()
-class LoadAnnotations(object):
- """Load mutiple types of annotations.
-
- Args:
- with_bbox (bool): Whether to parse and load the bbox annotation.
- Default: True.
- with_label (bool): Whether to parse and load the label annotation.
- Default: True.
- with_mask (bool): Whether to parse and load the mask annotation.
- Default: False.
- with_seg (bool): Whether to parse and load the semantic segmentation
- annotation. Default: False.
- poly2mask (bool): Whether to convert the instance masks from polygons
- to bitmaps. Default: True.
- file_client_args (dict): Arguments to instantiate a FileClient.
- See :class:`mmcv.fileio.FileClient` for details.
- Defaults to ``dict(backend='disk')``.
- """
-
- def __init__(self,
- with_bbox=True,
- with_label=True,
- with_mask=False,
- with_seg=False,
- poly2mask=True,
- file_client_args=dict(backend='disk')):
- self.with_bbox = with_bbox
- self.with_label = with_label
- self.with_mask = with_mask
- self.with_seg = with_seg
- self.poly2mask = poly2mask
- self.file_client_args = file_client_args.copy()
- self.file_client = None
-
- def _load_bboxes(self, results):
- """Private function to load bounding box annotations.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded bounding box annotations.
- """
-
- ann_info = results['ann_info']
- results['gt_bboxes'] = ann_info['bboxes'].copy()
-
- gt_bboxes_ignore = ann_info.get('bboxes_ignore', None)
- if gt_bboxes_ignore is not None:
- results['gt_bboxes_ignore'] = gt_bboxes_ignore.copy()
- results['bbox_fields'].append('gt_bboxes_ignore')
- results['bbox_fields'].append('gt_bboxes')
- return results
-
- def _load_labels(self, results):
- """Private function to load label annotations.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded label annotations.
- """
-
- results['gt_labels'] = results['ann_info']['labels'].copy()
- return results
-
- def _poly2mask(self, mask_ann, img_h, img_w):
- """Private function to convert masks represented with polygon to
- bitmaps.
-
- Args:
- mask_ann (list | dict): Polygon mask annotation input.
- img_h (int): The height of output mask.
- img_w (int): The width of output mask.
-
- Returns:
- numpy.ndarray: The decode bitmap mask of shape (img_h, img_w).
- """
-
- if isinstance(mask_ann, list):
- # polygon -- a single object might consist of multiple parts
- # we merge all parts into one mask rle code
- rles = maskUtils.frPyObjects(mask_ann, img_h, img_w)
- rle = maskUtils.merge(rles)
- elif isinstance(mask_ann['counts'], list):
- # uncompressed RLE
- rle = maskUtils.frPyObjects(mask_ann, img_h, img_w)
- else:
- # rle
- rle = mask_ann
- mask = maskUtils.decode(rle)
- return mask
-
- def process_polygons(self, polygons):
- """Convert polygons to list of ndarray and filter invalid polygons.
-
- Args:
- polygons (list[list]): Polygons of one instance.
-
- Returns:
- list[numpy.ndarray]: Processed polygons.
- """
-
- polygons = [np.array(p) for p in polygons]
- valid_polygons = []
- for polygon in polygons:
- if len(polygon) % 2 == 0 and len(polygon) >= 6:
- valid_polygons.append(polygon)
- return valid_polygons
-
- def _load_masks(self, results):
- """Private function to load mask annotations.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded mask annotations.
- If ``self.poly2mask`` is set ``True``, `gt_mask` will contain
- :obj:`PolygonMasks`. Otherwise, :obj:`BitmapMasks` is used.
- """
-
- h, w = results['img_info']['height'], results['img_info']['width']
- gt_masks = results['ann_info']['masks']
- if self.poly2mask:
- gt_masks = BitmapMasks(
- [self._poly2mask(mask, h, w) for mask in gt_masks], h, w)
- else:
- gt_masks = PolygonMasks(
- [self.process_polygons(polygons) for polygons in gt_masks], h,
- w)
- results['gt_masks'] = gt_masks
- results['mask_fields'].append('gt_masks')
- return results
-
- def _load_semantic_seg(self, results):
- """Private function to load semantic segmentation annotations.
-
- Args:
- results (dict): Result dict from :obj:`dataset`.
-
- Returns:
- dict: The dict contains loaded semantic segmentation annotations.
- """
-
- if self.file_client is None:
- self.file_client = mmcv.FileClient(**self.file_client_args)
-
- filename = osp.join(results['seg_prefix'],
- results['ann_info']['seg_map'])
- img_bytes = self.file_client.get(filename)
- results['gt_semantic_seg'] = mmcv.imfrombytes(
- img_bytes, flag='unchanged').squeeze()
- results['seg_fields'].append('gt_semantic_seg')
- return results
-
- def __call__(self, results):
- """Call function to load multiple types annotations.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded bounding box, label, mask and
- semantic segmentation annotations.
- """
-
- if self.with_bbox:
- results = self._load_bboxes(results)
- if results is None:
- return None
- if self.with_label:
- results = self._load_labels(results)
- if self.with_mask:
- results = self._load_masks(results)
- if self.with_seg:
- results = self._load_semantic_seg(results)
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(with_bbox={self.with_bbox}, '
- repr_str += f'with_label={self.with_label}, '
- repr_str += f'with_mask={self.with_mask}, '
- repr_str += f'with_seg={self.with_seg}, '
- repr_str += f'poly2mask={self.poly2mask}, '
- repr_str += f'poly2mask={self.file_client_args})'
- return repr_str
-
-
-@PIPELINES.register_module()
-class LoadProposals(object):
- """Load proposal pipeline.
-
- Required key is "proposals". Updated keys are "proposals", "bbox_fields".
-
- Args:
- num_max_proposals (int, optional): Maximum number of proposals to load.
- If not specified, all proposals will be loaded.
- """
-
- def __init__(self, num_max_proposals=None):
- self.num_max_proposals = num_max_proposals
-
- def __call__(self, results):
- """Call function to load proposals from file.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded proposal annotations.
- """
-
- proposals = results['proposals']
- if proposals.shape[1] not in (4, 5):
- raise AssertionError(
- 'proposals should have shapes (n, 4) or (n, 5), '
- f'but found {proposals.shape}')
- proposals = proposals[:, :4]
-
- if self.num_max_proposals is not None:
- proposals = proposals[:self.num_max_proposals]
-
- if len(proposals) == 0:
- proposals = np.array([[0, 0, 0, 0]], dtype=np.float32)
- results['proposals'] = proposals
- results['bbox_fields'].append('proposals')
- return results
-
- def __repr__(self):
- return self.__class__.__name__ + \
- f'(num_max_proposals={self.num_max_proposals})'
-
-
-@PIPELINES.register_module()
-class FilterAnnotations(object):
- """Filter invalid annotations.
-
- Args:
- min_gt_bbox_wh (tuple[int]): Minimum width and height of ground truth
- boxes.
- """
-
- def __init__(self, min_gt_bbox_wh):
- # TODO: add more filter options
- self.min_gt_bbox_wh = min_gt_bbox_wh
-
- def __call__(self, results):
- assert 'gt_bboxes' in results
- gt_bboxes = results['gt_bboxes']
- w = gt_bboxes[:, 2] - gt_bboxes[:, 0]
- h = gt_bboxes[:, 3] - gt_bboxes[:, 1]
- keep = (w > self.min_gt_bbox_wh[0]) & (h > self.min_gt_bbox_wh[1])
- if not keep.any():
- return None
- else:
- keys = ('gt_bboxes', 'gt_labels', 'gt_masks', 'gt_semantic_seg')
- for key in keys:
- if key in results:
- results[key] = results[key][keep]
- return results
diff --git a/spaces/RuijiaTan/MultiPrincipalElementAlloyPropertyPredictor/README.md b/spaces/RuijiaTan/MultiPrincipalElementAlloyPropertyPredictor/README.md
deleted file mode 100644
index a363e1338db8ca38db8d664a161e114ba33aee7b..0000000000000000000000000000000000000000
--- a/spaces/RuijiaTan/MultiPrincipalElementAlloyPropertyPredictor/README.md
+++ /dev/null
@@ -1,25 +0,0 @@
----
-title: COMP8604
-emoji: 📈
-colorFrom: pink
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.29.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
-
-Multi Principal Element Alloy Property Predictor.
-
-How to use it?
- 1. The interface uses GMM semi-supervised Model by default to predict the mechanical properties of alloys;
- 2. Enter the number of the corresponding elements;
- 3. Click "Predict”.
- 1. Get the normalized chemical formula of the alloy;
- 2. Obtain the predicted values;
- 3. Present all 14 kinds of empirically calculated parameters[1]
-
-[1]Li, Z.; Nash, W.; O’Brien, S.; Qiu, Y.; Gupta, R.; and Birbilis, N., 2022. cardi- gan: A generative adversarial network model for design and discovery of multi principal element alloys. Journal of Materials Science & Technology, 125 (2022), 81–96.
-
diff --git a/spaces/S1516/README/README.md b/spaces/S1516/README/README.md
deleted file mode 100644
index 2e773c866bd970e36ec4bef67f03a09e2c3c0279..0000000000000000000000000000000000000000
--- a/spaces/S1516/README/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: README
-emoji: 🏆
-colorFrom: indigo
-colorTo: gray
-sdk: static
-pinned: false
----
-
-Edit this `README.md` markdown file to author your organization card.
diff --git a/spaces/SIGGRAPH2022/Text2Human/Text2Human/models/archs/transformer_arch.py b/spaces/SIGGRAPH2022/Text2Human/Text2Human/models/archs/transformer_arch.py
deleted file mode 100644
index 8027555b00c3b6b6cc50ef68081fa02df47cf7b0..0000000000000000000000000000000000000000
--- a/spaces/SIGGRAPH2022/Text2Human/Text2Human/models/archs/transformer_arch.py
+++ /dev/null
@@ -1,273 +0,0 @@
-import math
-
-import numpy as np
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-
-class CausalSelfAttention(nn.Module):
- """
- A vanilla multi-head masked self-attention layer with a projection at the end.
- It is possible to use torch.nn.MultiheadAttention here but I am including an
- explicit implementation here to show that there is nothing too scary here.
- """
-
- def __init__(self, bert_n_emb, bert_n_head, attn_pdrop, resid_pdrop,
- latent_shape, sampler):
- super().__init__()
- assert bert_n_emb % bert_n_head == 0
- # key, query, value projections for all heads
- self.key = nn.Linear(bert_n_emb, bert_n_emb)
- self.query = nn.Linear(bert_n_emb, bert_n_emb)
- self.value = nn.Linear(bert_n_emb, bert_n_emb)
- # regularization
- self.attn_drop = nn.Dropout(attn_pdrop)
- self.resid_drop = nn.Dropout(resid_pdrop)
- # output projection
- self.proj = nn.Linear(bert_n_emb, bert_n_emb)
- self.n_head = bert_n_head
- self.causal = True if sampler == 'autoregressive' else False
- if self.causal:
- block_size = np.prod(latent_shape)
- mask = torch.tril(torch.ones(block_size, block_size))
- self.register_buffer("mask", mask.view(1, 1, block_size,
- block_size))
-
- def forward(self, x, layer_past=None):
- B, T, C = x.size()
-
- # calculate query, key, values for all heads in batch and move head forward to be the batch dim
- k = self.key(x).view(B, T, self.n_head,
- C // self.n_head).transpose(1,
- 2) # (B, nh, T, hs)
- q = self.query(x).view(B, T, self.n_head,
- C // self.n_head).transpose(1,
- 2) # (B, nh, T, hs)
- v = self.value(x).view(B, T, self.n_head,
- C // self.n_head).transpose(1,
- 2) # (B, nh, T, hs)
-
- present = torch.stack((k, v))
- if self.causal and layer_past is not None:
- past_key, past_value = layer_past
- k = torch.cat((past_key, k), dim=-2)
- v = torch.cat((past_value, v), dim=-2)
-
- # causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
- att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
-
- if self.causal and layer_past is None:
- att = att.masked_fill(self.mask[:, :, :T, :T] == 0, float('-inf'))
-
- att = F.softmax(att, dim=-1)
- att = self.attn_drop(att)
- y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
- # re-assemble all head outputs side by side
- y = y.transpose(1, 2).contiguous().view(B, T, C)
-
- # output projection
- y = self.resid_drop(self.proj(y))
- return y, present
-
-
-class Block(nn.Module):
- """ an unassuming Transformer block """
-
- def __init__(self, bert_n_emb, resid_pdrop, bert_n_head, attn_pdrop,
- latent_shape, sampler):
- super().__init__()
- self.ln1 = nn.LayerNorm(bert_n_emb)
- self.ln2 = nn.LayerNorm(bert_n_emb)
- self.attn = CausalSelfAttention(bert_n_emb, bert_n_head, attn_pdrop,
- resid_pdrop, latent_shape, sampler)
- self.mlp = nn.Sequential(
- nn.Linear(bert_n_emb, 4 * bert_n_emb),
- nn.GELU(), # nice
- nn.Linear(4 * bert_n_emb, bert_n_emb),
- nn.Dropout(resid_pdrop),
- )
-
- def forward(self, x, layer_past=None, return_present=False):
-
- attn, present = self.attn(self.ln1(x), layer_past)
- x = x + attn
- x = x + self.mlp(self.ln2(x))
-
- if layer_past is not None or return_present:
- return x, present
- return x
-
-
-class Transformer(nn.Module):
- """ the full GPT language model, with a context size of block_size """
-
- def __init__(self,
- codebook_size,
- segm_codebook_size,
- bert_n_emb,
- bert_n_layers,
- bert_n_head,
- block_size,
- latent_shape,
- embd_pdrop,
- resid_pdrop,
- attn_pdrop,
- sampler='absorbing'):
- super().__init__()
-
- self.vocab_size = codebook_size + 1
- self.n_embd = bert_n_emb
- self.block_size = block_size
- self.n_layers = bert_n_layers
- self.codebook_size = codebook_size
- self.segm_codebook_size = segm_codebook_size
- self.causal = sampler == 'autoregressive'
- if self.causal:
- self.vocab_size = codebook_size
-
- self.tok_emb = nn.Embedding(self.vocab_size, self.n_embd)
- self.pos_emb = nn.Parameter(
- torch.zeros(1, self.block_size, self.n_embd))
- self.segm_emb = nn.Embedding(self.segm_codebook_size, self.n_embd)
- self.start_tok = nn.Parameter(torch.zeros(1, 1, self.n_embd))
- self.drop = nn.Dropout(embd_pdrop)
-
- # transformer
- self.blocks = nn.Sequential(*[
- Block(bert_n_emb, resid_pdrop, bert_n_head, attn_pdrop,
- latent_shape, sampler) for _ in range(self.n_layers)
- ])
- # decoder head
- self.ln_f = nn.LayerNorm(self.n_embd)
- self.head = nn.Linear(self.n_embd, self.codebook_size, bias=False)
-
- def get_block_size(self):
- return self.block_size
-
- def _init_weights(self, module):
- if isinstance(module, (nn.Linear, nn.Embedding)):
- module.weight.data.normal_(mean=0.0, std=0.02)
- if isinstance(module, nn.Linear) and module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def forward(self, idx, segm_tokens, t=None):
- # each index maps to a (learnable) vector
- token_embeddings = self.tok_emb(idx)
-
- segm_embeddings = self.segm_emb(segm_tokens)
-
- if self.causal:
- token_embeddings = torch.cat((self.start_tok.repeat(
- token_embeddings.size(0), 1, 1), token_embeddings),
- dim=1)
-
- t = token_embeddings.shape[1]
- assert t <= self.block_size, "Cannot forward, model block size is exhausted."
- # each position maps to a (learnable) vector
-
- position_embeddings = self.pos_emb[:, :t, :]
-
- x = token_embeddings + position_embeddings + segm_embeddings
- x = self.drop(x)
- for block in self.blocks:
- x = block(x)
- x = self.ln_f(x)
- logits = self.head(x)
-
- return logits
-
-
-class TransformerMultiHead(nn.Module):
- """ the full GPT language model, with a context size of block_size """
-
- def __init__(self,
- codebook_size,
- segm_codebook_size,
- texture_codebook_size,
- bert_n_emb,
- bert_n_layers,
- bert_n_head,
- block_size,
- latent_shape,
- embd_pdrop,
- resid_pdrop,
- attn_pdrop,
- num_head,
- sampler='absorbing'):
- super().__init__()
-
- self.vocab_size = codebook_size + 1
- self.n_embd = bert_n_emb
- self.block_size = block_size
- self.n_layers = bert_n_layers
- self.codebook_size = codebook_size
- self.segm_codebook_size = segm_codebook_size
- self.texture_codebook_size = texture_codebook_size
- self.causal = sampler == 'autoregressive'
- if self.causal:
- self.vocab_size = codebook_size
-
- self.tok_emb = nn.Embedding(self.vocab_size, self.n_embd)
- self.pos_emb = nn.Parameter(
- torch.zeros(1, self.block_size, self.n_embd))
- self.segm_emb = nn.Embedding(self.segm_codebook_size, self.n_embd)
- self.texture_emb = nn.Embedding(self.texture_codebook_size,
- self.n_embd)
- self.start_tok = nn.Parameter(torch.zeros(1, 1, self.n_embd))
- self.drop = nn.Dropout(embd_pdrop)
-
- # transformer
- self.blocks = nn.Sequential(*[
- Block(bert_n_emb, resid_pdrop, bert_n_head, attn_pdrop,
- latent_shape, sampler) for _ in range(self.n_layers)
- ])
- # decoder head
- self.num_head = num_head
- self.head_class_num = codebook_size // self.num_head
- self.ln_f = nn.LayerNorm(self.n_embd)
- self.head_list = nn.ModuleList([
- nn.Linear(self.n_embd, self.head_class_num, bias=False)
- for _ in range(self.num_head)
- ])
-
- def get_block_size(self):
- return self.block_size
-
- def _init_weights(self, module):
- if isinstance(module, (nn.Linear, nn.Embedding)):
- module.weight.data.normal_(mean=0.0, std=0.02)
- if isinstance(module, nn.Linear) and module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def forward(self, idx, segm_tokens, texture_tokens, t=None):
- # each index maps to a (learnable) vector
- token_embeddings = self.tok_emb(idx)
- segm_embeddings = self.segm_emb(segm_tokens)
- texture_embeddings = self.texture_emb(texture_tokens)
-
- if self.causal:
- token_embeddings = torch.cat((self.start_tok.repeat(
- token_embeddings.size(0), 1, 1), token_embeddings),
- dim=1)
-
- t = token_embeddings.shape[1]
- assert t <= self.block_size, "Cannot forward, model block size is exhausted."
- # each position maps to a (learnable) vector
-
- position_embeddings = self.pos_emb[:, :t, :]
-
- x = token_embeddings + position_embeddings + segm_embeddings + texture_embeddings
- x = self.drop(x)
- for block in self.blocks:
- x = block(x)
- x = self.ln_f(x)
- logits_list = [self.head_list[i](x) for i in range(self.num_head)]
-
- return logits_list
diff --git a/spaces/Sakil/english_audio_transcriptor/app.py b/spaces/Sakil/english_audio_transcriptor/app.py
deleted file mode 100644
index 0e3af6e423eb498f0b09619856847399b0fee480..0000000000000000000000000000000000000000
--- a/spaces/Sakil/english_audio_transcriptor/app.py
+++ /dev/null
@@ -1,84 +0,0 @@
-#Importing all the necessary packages
-import nltk
-import librosa
-import IPython.display
-import torch
-import gradio as gr
-from transformers import Wav2Vec2Tokenizer, Wav2Vec2ForCTC
-nltk.download("punkt")
-#Loading the model
-model_name = "facebook/wav2vec2-base-960h"
-tokenizer = Wav2Vec2Tokenizer.from_pretrained(model_name)#omdel_name
-model = Wav2Vec2ForCTC.from_pretrained(model_name)
-
-def load_data(input_file):
- """ Function for resampling to ensure that the speech input is sampled at 16KHz.
- """
- #read the file
- speech, sample_rate = librosa.load(input_file)
- #make it 1-D
- if len(speech.shape) > 1:
- speech = speech[:,0] + speech[:,1]
- #Resampling at 16KHz since wav2vec2-base-960h is pretrained and fine-tuned on speech audio sampled at 16 KHz.
- if sample_rate !=16000:
- speech = librosa.resample(speech, sample_rate,16000)
- #speeches = librosa.effects.split(speech)
- return speech
-def correct_casing(input_sentence):
- """ This function is for correcting the casing of the generated transcribed text
- """
- sentences = nltk.sent_tokenize(input_sentence)
- return (' '.join([s.replace(s[0],s[0].capitalize(),1) for s in sentences]))
-
-def asr_transcript(input_file):
- """This function generates transcripts for the provided audio input
- """
- speech = load_data(input_file)
- #Tokenize
- input_values = tokenizer(speech, return_tensors="pt").input_values
- #Take logits
- logits = model(input_values).logits
- #Take argmax
- predicted_ids = torch.argmax(logits, dim=-1)
- #Get the words from predicted word ids
- transcription = tokenizer.decode(predicted_ids[0])
- #Output is all upper case
- transcription = correct_casing(transcription.lower())
- return transcription
-def asr_transcript_long(input_file,tokenizer=tokenizer, model=model ):
- transcript = ""
- # Ensure that the sample rate is 16k
- sample_rate = librosa.get_samplerate(input_file)
-
- # Stream over 10 seconds chunks rather than load the full file
- stream = librosa.stream(
- input_file,
- block_length=20, #number of seconds to split the batch
- frame_length=sample_rate, #16000,
- hop_length=sample_rate, #16000
- )
-
- for speech in stream:
- if len(speech.shape) > 1:
- speech = speech[:, 0] + speech[:, 1]
- if sample_rate !=16000:
- speech = librosa.resample(speech, sample_rate,16000)
- input_values = tokenizer(speech, return_tensors="pt").input_values
- logits = model(input_values).logits
-
- predicted_ids = torch.argmax(logits, dim=-1)
- transcription = tokenizer.decode(predicted_ids[0])
- #transcript += transcription.lower()
- transcript += correct_casing(transcription.lower())
- #transcript += " "
-
- return transcript[:3800]
-gr.Interface(asr_transcript_long,
- #inputs = gr.inputs.Audio(source="microphone", type="filepath", optional=True, label="Please record your voice"),
- inputs = gr.inputs.Audio(source="upload", type="filepath", optional=True, label="Upload your audio file here"),
- outputs = gr.outputs.Textbox(type="str",label="Output Text"),
- title="English Audio Transcriptor",
- description = "This tool transcribes your audio to the text",
- examples = [["Batman1_dialogue.wav"], ["batman2_dialogue.wav"], ["batman3_dialogue.wav"],["catwoman_dialogue.wav"]], theme="grass").launch()
-
-
diff --git a/spaces/Salesforce/EDICT/my_diffusers/utils/dummy_transformers_and_onnx_objects.py b/spaces/Salesforce/EDICT/my_diffusers/utils/dummy_transformers_and_onnx_objects.py
deleted file mode 100644
index 2e34b5ce0b69472df7e2c41de40476619d53dee9..0000000000000000000000000000000000000000
--- a/spaces/Salesforce/EDICT/my_diffusers/utils/dummy_transformers_and_onnx_objects.py
+++ /dev/null
@@ -1,11 +0,0 @@
-# This file is autogenerated by the command `make fix-copies`, do not edit.
-# flake8: noqa
-
-from ..utils import DummyObject, requires_backends
-
-
-class StableDiffusionOnnxPipeline(metaclass=DummyObject):
- _backends = ["transformers", "onnx"]
-
- def __init__(self, *args, **kwargs):
- requires_backends(self, ["transformers", "onnx"])
diff --git a/spaces/Salesforce/EDICT/my_half_diffusers/utils/model_card_template.md b/spaces/Salesforce/EDICT/my_half_diffusers/utils/model_card_template.md
deleted file mode 100644
index f19c85b0fcf2f7b07e9c3f950a9657b3f2053f21..0000000000000000000000000000000000000000
--- a/spaces/Salesforce/EDICT/my_half_diffusers/utils/model_card_template.md
+++ /dev/null
@@ -1,50 +0,0 @@
----
-{{ card_data }}
----
-
-
-
-# {{ model_name | default("Diffusion Model") }}
-
-## Model description
-
-This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
-on the `{{ dataset_name }}` dataset.
-
-## Intended uses & limitations
-
-#### How to use
-
-```python
-# TODO: add an example code snippet for running this diffusion pipeline
-```
-
-#### Limitations and bias
-
-[TODO: provide examples of latent issues and potential remediations]
-
-## Training data
-
-[TODO: describe the data used to train the model]
-
-### Training hyperparameters
-
-The following hyperparameters were used during training:
-- learning_rate: {{ learning_rate }}
-- train_batch_size: {{ train_batch_size }}
-- eval_batch_size: {{ eval_batch_size }}
-- gradient_accumulation_steps: {{ gradient_accumulation_steps }}
-- optimizer: AdamW with betas=({{ adam_beta1 }}, {{ adam_beta2 }}), weight_decay={{ adam_weight_decay }} and epsilon={{ adam_epsilon }}
-- lr_scheduler: {{ lr_scheduler }}
-- lr_warmup_steps: {{ lr_warmup_steps }}
-- ema_inv_gamma: {{ ema_inv_gamma }}
-- ema_inv_gamma: {{ ema_power }}
-- ema_inv_gamma: {{ ema_max_decay }}
-- mixed_precision: {{ mixed_precision }}
-
-### Training results
-
-📈 [TensorBoard logs](https://huggingface.co/{{ repo_name }}/tensorboard?#scalars)
-
-
diff --git a/spaces/Sapnil/Text_Summarization/app.py b/spaces/Sapnil/Text_Summarization/app.py
deleted file mode 100644
index cecf1bd6ac03bb291a5c2efe6c4ccd9f91f67207..0000000000000000000000000000000000000000
--- a/spaces/Sapnil/Text_Summarization/app.py
+++ /dev/null
@@ -1,17 +0,0 @@
-from transformers import pipeline
-import gradio as gr
-
-
-model = pipeline(
- "summarization",
-)
-
-def predict(prompt):
- summary = model(prompt)[0]["summary_text"]
- return summary
-
-title = "Text Summarization"
-
-# create an interface for the model
-with gr.Interface(predict, "textbox", "text") as interface:
- interface.launch()
diff --git a/spaces/Silentlin/DiffSinger/utils/multiprocess_utils.py b/spaces/Silentlin/DiffSinger/utils/multiprocess_utils.py
deleted file mode 100644
index 24876c4ca777f09d1c1e1b75674cd7aaf37a75a6..0000000000000000000000000000000000000000
--- a/spaces/Silentlin/DiffSinger/utils/multiprocess_utils.py
+++ /dev/null
@@ -1,47 +0,0 @@
-import os
-import traceback
-from multiprocessing import Queue, Process
-
-
-def chunked_worker(worker_id, map_func, args, results_queue=None, init_ctx_func=None):
- ctx = init_ctx_func(worker_id) if init_ctx_func is not None else None
- for job_idx, arg in args:
- try:
- if ctx is not None:
- res = map_func(*arg, ctx=ctx)
- else:
- res = map_func(*arg)
- results_queue.put((job_idx, res))
- except:
- traceback.print_exc()
- results_queue.put((job_idx, None))
-
-def chunked_multiprocess_run(map_func, args, num_workers=None, ordered=True, init_ctx_func=None, q_max_size=1000):
- args = zip(range(len(args)), args)
- args = list(args)
- n_jobs = len(args)
- if num_workers is None:
- num_workers = int(os.getenv('N_PROC', os.cpu_count()))
- results_queues = []
- if ordered:
- for i in range(num_workers):
- results_queues.append(Queue(maxsize=q_max_size // num_workers))
- else:
- results_queue = Queue(maxsize=q_max_size)
- for i in range(num_workers):
- results_queues.append(results_queue)
- workers = []
- for i in range(num_workers):
- args_worker = args[i::num_workers]
- p = Process(target=chunked_worker, args=(
- i, map_func, args_worker, results_queues[i], init_ctx_func), daemon=True)
- workers.append(p)
- p.start()
- for n_finished in range(n_jobs):
- results_queue = results_queues[n_finished % num_workers]
- job_idx, res = results_queue.get()
- assert job_idx == n_finished or not ordered, (job_idx, n_finished)
- yield res
- for w in workers:
- w.join()
- w.close()
diff --git a/spaces/SuSung-boy/LoRA-DreamBooth-Training-UI/trainer.py b/spaces/SuSung-boy/LoRA-DreamBooth-Training-UI/trainer.py
deleted file mode 100644
index e4e4469796a08b797ae70a641c2f5125dbd22c1e..0000000000000000000000000000000000000000
--- a/spaces/SuSung-boy/LoRA-DreamBooth-Training-UI/trainer.py
+++ /dev/null
@@ -1,166 +0,0 @@
-from __future__ import annotations
-
-import datetime
-import os
-import pathlib
-import shlex
-import shutil
-import subprocess
-
-import gradio as gr
-import PIL.Image
-import slugify
-import torch
-from huggingface_hub import HfApi
-
-from app_upload import LoRAModelUploader
-from utils import save_model_card
-
-URL_TO_JOIN_LORA_LIBRARY_ORG = 'https://huggingface.co/organizations/lora-library/share/hjetHAcKjnPHXhHfbeEcqnBqmhgilFfpOL'
-
-
-def pad_image(image: PIL.Image.Image) -> PIL.Image.Image:
- w, h = image.size
- if w == h:
- return image
- elif w > h:
- new_image = PIL.Image.new(image.mode, (w, w), (0, 0, 0))
- new_image.paste(image, (0, (w - h) // 2))
- return new_image
- else:
- new_image = PIL.Image.new(image.mode, (h, h), (0, 0, 0))
- new_image.paste(image, ((h - w) // 2, 0))
- return new_image
-
-
-class Trainer:
- def __init__(self, hf_token: str | None = None):
- self.hf_token = hf_token
- self.api = HfApi(token=hf_token)
- self.model_uploader = LoRAModelUploader(hf_token)
-
- def prepare_dataset(self, instance_images: list, resolution: int,
- instance_data_dir: pathlib.Path) -> None:
- shutil.rmtree(instance_data_dir, ignore_errors=True)
- instance_data_dir.mkdir(parents=True)
- for i, temp_path in enumerate(instance_images):
- image = PIL.Image.open(temp_path.name)
- image = pad_image(image)
- image = image.resize((resolution, resolution))
- image = image.convert('RGB')
- out_path = instance_data_dir / f'{i:03d}.jpg'
- image.save(out_path, format='JPEG', quality=100)
-
- def join_lora_library_org(self) -> None:
- subprocess.run(
- shlex.split(
- f'curl -X POST -H "Authorization: Bearer {self.hf_token}" -H "Content-Type: application/json" {URL_TO_JOIN_LORA_LIBRARY_ORG}'
- ))
-
- def run(
- self,
- instance_images: list | None,
- instance_prompt: str,
- output_model_name: str,
- overwrite_existing_model: bool,
- validation_prompt: str,
- base_model: str,
- resolution_s: str,
- n_steps: int,
- learning_rate: float,
- gradient_accumulation: int,
- seed: int,
- fp16: bool,
- use_8bit_adam: bool,
- checkpointing_steps: int,
- use_wandb: bool,
- validation_epochs: int,
- upload_to_hub: bool,
- use_private_repo: bool,
- delete_existing_repo: bool,
- upload_to: str,
- remove_gpu_after_training: bool,
- ) -> str:
- if not torch.cuda.is_available():
- raise gr.Error('CUDA is not available.')
- if instance_images is None:
- raise gr.Error('You need to upload images.')
- if not instance_prompt:
- raise gr.Error('The instance prompt is missing.')
- if not validation_prompt:
- raise gr.Error('The validation prompt is missing.')
-
- resolution = int(resolution_s)
-
- if not output_model_name:
- timestamp = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
- output_model_name = f'lora-dreambooth-{timestamp}'
- output_model_name = slugify.slugify(output_model_name)
-
- repo_dir = pathlib.Path(__file__).parent
- output_dir = repo_dir / 'experiments' / output_model_name
- if overwrite_existing_model or upload_to_hub:
- shutil.rmtree(output_dir, ignore_errors=True)
- output_dir.mkdir(parents=True)
-
- instance_data_dir = repo_dir / 'training_data' / output_model_name
- self.prepare_dataset(instance_images, resolution, instance_data_dir)
-
- if upload_to_hub:
- self.join_lora_library_org()
-
- command = f'''
- accelerate launch train_dreambooth_lora.py \
- --pretrained_model_name_or_path={base_model} \
- --instance_data_dir={instance_data_dir} \
- --output_dir={output_dir} \
- --instance_prompt="{instance_prompt}" \
- --resolution={resolution} \
- --train_batch_size=1 \
- --gradient_accumulation_steps={gradient_accumulation} \
- --learning_rate={learning_rate} \
- --lr_scheduler=constant \
- --lr_warmup_steps=0 \
- --max_train_steps={n_steps} \
- --checkpointing_steps={checkpointing_steps} \
- --validation_prompt="{validation_prompt}" \
- --validation_epochs={validation_epochs} \
- --seed={seed}
- '''
- if fp16:
- command += ' --mixed_precision fp16'
- if use_8bit_adam:
- command += ' --use_8bit_adam'
- if use_wandb:
- command += ' --report_to wandb'
-
- with open(output_dir / 'train.sh', 'w') as f:
- command_s = ' '.join(command.split())
- f.write(command_s)
- subprocess.run(shlex.split(command))
- save_model_card(save_dir=output_dir,
- base_model=base_model,
- instance_prompt=instance_prompt,
- test_prompt=validation_prompt,
- test_image_dir='test_images')
-
- message = 'Training completed!'
- print(message)
-
- if upload_to_hub:
- upload_message = self.model_uploader.upload_lora_model(
- folder_path=output_dir.as_posix(),
- repo_name=output_model_name,
- upload_to=upload_to,
- private=use_private_repo,
- delete_existing_repo=delete_existing_repo)
- print(upload_message)
- message = message + '\n' + upload_message
-
- if remove_gpu_after_training:
- space_id = os.getenv('SPACE_ID')
- if space_id:
- self.api.request_space_hardware(repo_id=space_id,
- hardware='cpu-basic')
-
- return message
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_debug_magic.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_debug_magic.py
deleted file mode 100644
index faa3b7c499320efd3b9deba741e272c0b107c7e7..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_debug_magic.py
+++ /dev/null
@@ -1,80 +0,0 @@
-"""Test embedding of IPython"""
-
-#-----------------------------------------------------------------------------
-# Copyright (C) 2013 The IPython Development Team
-#
-# Distributed under the terms of the BSD License. The full license is in
-# the file COPYING, distributed as part of this software.
-#-----------------------------------------------------------------------------
-
-#-----------------------------------------------------------------------------
-# Imports
-#-----------------------------------------------------------------------------
-
-import os
-import sys
-from IPython.testing.decorators import skip_win32
-from IPython.testing import IPYTHON_TESTING_TIMEOUT_SCALE
-
-#-----------------------------------------------------------------------------
-# Tests
-#-----------------------------------------------------------------------------
-
-@skip_win32
-def test_debug_magic_passes_through_generators():
- """
- This test that we can correctly pass through frames of a generator post-mortem.
- """
- import pexpect
- import re
- in_prompt = re.compile(br'In ?\[\d+\]:')
- ipdb_prompt = 'ipdb>'
- env = os.environ.copy()
- child = pexpect.spawn(sys.executable, ['-m', 'IPython', '--colors=nocolor', '--simple-prompt'],
- env=env)
- child.timeout = 15 * IPYTHON_TESTING_TIMEOUT_SCALE
-
- child.expect(in_prompt)
-
- child.timeout = 2 * IPYTHON_TESTING_TIMEOUT_SCALE
-
- child.sendline("def f(x):")
- child.sendline(" raise Exception")
- child.sendline("")
-
- child.expect(in_prompt)
- child.sendline("gen = (f(x) for x in [0])")
- child.sendline("")
-
- child.expect(in_prompt)
- child.sendline("for x in gen:")
- child.sendline(" pass")
- child.sendline("")
-
- child.timeout = 10 * IPYTHON_TESTING_TIMEOUT_SCALE
-
- child.expect('Exception:')
-
- child.expect(in_prompt)
- child.sendline(r'%debug')
- child.expect('----> 2 raise Exception')
-
- child.expect(ipdb_prompt)
- child.sendline('u')
- child.expect_exact(r'----> 1 gen = (f(x) for x in [0])')
-
- child.expect(ipdb_prompt)
- child.sendline('u')
- child.expect_exact('----> 1 for x in gen:')
-
- child.expect(ipdb_prompt)
- child.sendline('u')
- child.expect_exact('*** Oldest frame')
-
- child.expect(ipdb_prompt)
- child.sendline('exit')
-
- child.expect(in_prompt)
- child.sendline('exit')
-
- child.close()
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/clickhouse_connect/driver/insert.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/clickhouse_connect/driver/insert.py
deleted file mode 100644
index db3aa617d72dcaf6d15440c336679c567b2400a8..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/clickhouse_connect/driver/insert.py
+++ /dev/null
@@ -1,192 +0,0 @@
-import logging
-from math import log
-from typing import Iterable, Sequence, Optional, Any, Dict, NamedTuple, Generator, Union, TYPE_CHECKING
-
-from clickhouse_connect.driver.ctypes import data_conv
-from clickhouse_connect.driver.context import BaseQueryContext
-from clickhouse_connect.driver.options import np, pd
-from clickhouse_connect.driver.exceptions import ProgrammingError
-
-if TYPE_CHECKING:
- from clickhouse_connect.datatypes.base import ClickHouseType
-
-logger = logging.getLogger(__name__)
-DEFAULT_BLOCK_BYTES = 1 << 24 # Try to generate blocks between 16 and 32MB in raw size
-
-
-class InsertBlock(NamedTuple):
- column_count: int
- row_count: int
- column_names: Iterable[str]
- column_types: Iterable['ClickHouseType']
- column_data: Iterable[Sequence[Any]]
-
-
-# pylint: disable=too-many-instance-attributes
-class InsertContext(BaseQueryContext):
- """
- Reusable Argument/parameter object for inserts.
- """
-
- # pylint: disable=too-many-arguments
- def __init__(self,
- table: str,
- column_names: Sequence[str],
- column_types: Sequence['ClickHouseType'],
- data: Any = None,
- column_oriented: Optional[bool] = None,
- settings: Optional[Dict[str, Any]] = None,
- compression: Optional[Union[str, bool]] = None,
- query_formats: Optional[Dict[str, str]] = None,
- column_formats: Optional[Dict[str, Union[str, Dict[str, str]]]] = None,
- block_size: Optional[int] = None):
- super().__init__(settings, query_formats, column_formats)
- self.table = table
- self.column_names = column_names
- self.column_types = column_types
- self.column_oriented = False if column_oriented is None else column_oriented
- self.compression = compression
- self.req_block_size = block_size
- self.block_size = DEFAULT_BLOCK_BYTES
- self.data = data
- self.insert_exception = None
-
- @property
- def empty(self) -> bool:
- return self._data is None
-
- @property
- def data(self):
- return self._raw_data
-
- @data.setter
- def data(self, data: Any):
- self._raw_data = data
- self.current_block = 0
- self.current_row = 0
- self.row_count = 0
- self.column_count = 0
- self._data = None
- if data is None or len(data) == 0:
- return
- if pd and isinstance(data, pd.DataFrame):
- data = self._convert_pandas(data)
- self.column_oriented = True
- if np and isinstance(data, np.ndarray):
- data = self._convert_numpy(data)
- if self.column_oriented:
- self._next_block_data = self._column_block_data
- self._block_columns = data # [SliceView(column) for column in data]
- self._block_rows = None
- self.column_count = len(data)
- self.row_count = len(data[0])
- else:
- self._next_block_data = self._row_block_data
- self._block_rows = data
- self._block_columns = None
- self.row_count = len(data)
- self.column_count = len(data[0])
- if self.row_count and self.column_count:
- if self.column_count != len(self.column_names):
- raise ProgrammingError('Insert data column count does not match column names')
- self._data = data
- self.block_size = self._calc_block_size()
-
- def _calc_block_size(self) -> int:
- if self.req_block_size:
- return self.req_block_size
- row_size = 0
- sample_size = min((log(self.row_count) + 1) * 2, 64)
- sample_freq = max(1, int(self.row_count / sample_size))
- for i, d_type in enumerate(self.column_types):
- if d_type.byte_size:
- row_size += d_type.byte_size
- continue
- if self.column_oriented:
- col_data = self._data[i]
- if sample_freq == 1:
- d_size = d_type.data_size(col_data)
- else:
- sample = [col_data[j] for j in range(0, self.row_count, sample_freq)]
- d_size = d_type.data_size(sample)
- else:
- data = self._data
- sample = [data[j][i] for j in range(0, self.row_count, sample_freq)]
- d_size = d_type.data_size(sample)
- row_size += d_size
- return 1 << (24 - int(log(row_size, 2)))
-
- def next_block(self) -> Generator[InsertBlock, None, None]:
- while True:
- block_end = min(self.current_row + self.block_size, self.row_count)
- row_count = block_end - self.current_row
- if row_count <= 0:
- return
- self.current_block += 1
- data = self._next_block_data(self.current_row, block_end)
- yield InsertBlock(self.column_count, row_count, self.column_names, self.column_types, data)
- self.current_row = block_end
-
- def _column_block_data(self, block_start, block_end):
- if block_start == 0 and self.row_count <= block_end:
- return self._block_columns # Optimization if we don't need to break up the block
- return [col[block_start: block_end] for col in self._block_columns]
-
- def _row_block_data(self, block_start, block_end):
- return data_conv.pivot(self._block_rows, block_start, block_end)
-
- def _convert_pandas(self, df):
- data = []
- for df_col_name, col_name, ch_type in zip(df.columns, self.column_names, self.column_types):
- df_col = df[df_col_name]
- d_type = str(df_col.dtype)
- if ch_type.python_type == int:
- if 'float' in d_type:
- df_col = df_col.round().astype(ch_type.base_type, copy=False)
- else:
- df_col = df_col.astype(ch_type.base_type, copy=False)
- elif 'datetime' in ch_type.np_type and (pd.core.dtypes.common.is_datetime_or_timedelta_dtype(df_col)
- or 'datetime64[ns' in d_type):
- div = ch_type.nano_divisor
- data.append([None if pd.isnull(x) else x.value // div for x in df_col])
- self.column_formats[col_name] = 'int'
- continue
- if ch_type.nullable:
- if d_type == 'object':
- # This is ugly, but the multiple replaces seem required as a result of this bug:
- # https://github.com/pandas-dev/pandas/issues/29024
- df_col = df_col.replace({pd.NaT: None}).replace({np.nan: None})
- elif 'Float' in ch_type.base_type:
- # This seems to be the only way to convert any null looking things to nan
- df_col = df_col.astype(ch_type.np_type)
- else:
- df_col = df_col.replace({np.nan: None})
- data.append(df_col.to_numpy(copy=False))
- return data
-
- def _convert_numpy(self, np_array):
- if np_array.dtype.names is None:
- if 'date' in str(np_array.dtype):
- for col_name, col_type in zip(self.column_names, self.column_types):
- if 'date' in col_type.np_type:
- self.column_formats[col_name] = 'int'
- return np_array.astype('int').tolist()
- for col_type in self.column_types:
- if col_type.byte_size == 0 or col_type.byte_size > np_array.dtype.itemsize:
- return np_array.tolist()
- return np_array
-
- if set(self.column_names).issubset(set(np_array.dtype.names)):
- data = [np_array[col_name] for col_name in self.column_names]
- else:
- # Column names don't match, so we have to assume they are in order
- data = [np_array[col_name] for col_name in np_array.dtype.names]
- for ix, (col_name, col_type) in enumerate(zip(self.column_names, self.column_types)):
- d_type = data[ix].dtype
- if 'date' in str(d_type) and 'date' in col_type.np_type:
- self.column_formats[col_name] = 'int'
- data[ix] = data[ix].astype(int).tolist()
- elif col_type.byte_size == 0 or col_type.byte_size > d_type.itemsize:
- data[ix] = data[ix].tolist()
- self.column_oriented = True
- return data
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/pydev_ipython/qt_for_kernel.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/pydev_ipython/qt_for_kernel.py
deleted file mode 100644
index 500d25a7458be8d0d085dc636ac91230749c387a..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/pydev_ipython/qt_for_kernel.py
+++ /dev/null
@@ -1,119 +0,0 @@
-""" Import Qt in a manner suitable for an IPython kernel.
-
-This is the import used for the `gui=qt` or `matplotlib=qt` initialization.
-
-Import Priority:
-
-if Qt4 has been imported anywhere else:
- use that
-
-if matplotlib has been imported and doesn't support v2 (<= 1.0.1):
- use PyQt4 @v1
-
-Next, ask ETS' QT_API env variable
-
-if QT_API not set:
- ask matplotlib via rcParams['backend.qt4']
- if it said PyQt:
- use PyQt4 @v1
- elif it said PySide:
- use PySide
-
- else: (matplotlib said nothing)
- # this is the default path - nobody told us anything
- try:
- PyQt @v1
- except:
- fallback on PySide
-else:
- use PyQt @v2 or PySide, depending on QT_API
- because ETS doesn't work with PyQt @v1.
-
-"""
-
-import os
-import sys
-
-from pydev_ipython.version import check_version
-from pydev_ipython.qt_loaders import (load_qt, QT_API_PYSIDE, QT_API_PYSIDE2,
- QT_API_PYQT, QT_API_PYQT_DEFAULT,
- loaded_api, QT_API_PYQT5)
-
-
-# Constraints placed on an imported matplotlib
-def matplotlib_options(mpl):
- if mpl is None:
- return
-
- # #PyDev-779: In pysrc/pydev_ipython/qt_for_kernel.py, matplotlib_options should be replaced with latest from ipython
- # (i.e.: properly check backend to decide upon qt4/qt5).
-
- backend = mpl.rcParams.get('backend', None)
- if backend == 'Qt4Agg':
- mpqt = mpl.rcParams.get('backend.qt4', None)
- if mpqt is None:
- return None
- if mpqt.lower() == 'pyside':
- return [QT_API_PYSIDE]
- elif mpqt.lower() == 'pyqt4':
- return [QT_API_PYQT_DEFAULT]
- elif mpqt.lower() == 'pyqt4v2':
- return [QT_API_PYQT]
- raise ImportError("unhandled value for backend.qt4 from matplotlib: %r" %
- mpqt)
-
- elif backend == 'Qt5Agg':
- mpqt = mpl.rcParams.get('backend.qt5', None)
- if mpqt is None:
- return None
- if mpqt.lower() == 'pyqt5':
- return [QT_API_PYQT5]
- raise ImportError("unhandled value for backend.qt5 from matplotlib: %r" %
- mpqt)
-
- # Fallback without checking backend (previous code)
- mpqt = mpl.rcParams.get('backend.qt4', None)
- if mpqt is None:
- mpqt = mpl.rcParams.get('backend.qt5', None)
-
- if mpqt is None:
- return None
- if mpqt.lower() == 'pyside':
- return [QT_API_PYSIDE]
- elif mpqt.lower() == 'pyqt4':
- return [QT_API_PYQT_DEFAULT]
- elif mpqt.lower() == 'pyqt5':
- return [QT_API_PYQT5]
- raise ImportError("unhandled value for qt backend from matplotlib: %r" %
- mpqt)
-
-
-def get_options():
- """Return a list of acceptable QT APIs, in decreasing order of
- preference
- """
- # already imported Qt somewhere. Use that
- loaded = loaded_api()
- if loaded is not None:
- return [loaded]
-
- mpl = sys.modules.get('matplotlib', None)
-
- if mpl is not None and not check_version(mpl.__version__, '1.0.2'):
- # 1.0.1 only supports PyQt4 v1
- return [QT_API_PYQT_DEFAULT]
-
- if os.environ.get('QT_API', None) is None:
- # no ETS variable. Ask mpl, then use either
- return matplotlib_options(mpl) or [QT_API_PYQT_DEFAULT, QT_API_PYSIDE, QT_API_PYSIDE2, QT_API_PYQT5]
-
- # ETS variable present. Will fallback to external.qt
- return None
-
-
-api_opts = get_options()
-if api_opts is not None:
- QtCore, QtGui, QtSvg, QT_API = load_qt(api_opts)
-
-else: # use ETS variable
- from pydev_ipython.qt import QtCore, QtGui, QtSvg, QT_API
diff --git a/spaces/Superlang/ImageProcessor/annotator/oneformer/oneformer/data/datasets/register_coco_panoptic2instance.py b/spaces/Superlang/ImageProcessor/annotator/oneformer/oneformer/data/datasets/register_coco_panoptic2instance.py
deleted file mode 100644
index 511c5b66fa1a1814baf6f83bf048622723551e7d..0000000000000000000000000000000000000000
--- a/spaces/Superlang/ImageProcessor/annotator/oneformer/oneformer/data/datasets/register_coco_panoptic2instance.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# ------------------------------------------------------------------------------
-# Reference: https://github.com/facebookresearch/detectron2/blob/main/detectron2/data/datasets/builtin.py
-# Modified by Jitesh Jain (https://github.com/praeclarumjj3)
-# ------------------------------------------------------------------------------
-
-
-"""
-This file registers pre-defined datasets at hard-coded paths, and their metadata.
-
-We hard-code metadata for common datasets. This will enable:
-1. Consistency check when loading the datasets
-2. Use models on these standard datasets directly and run demos,
- without having to download the dataset annotations
-
-We hard-code some paths to the dataset that's assumed to
-exist in "./datasets/".
-
-Users SHOULD NOT use this file to create new dataset / metadata for new dataset.
-To add new dataset, refer to the tutorial "docs/DATASETS.md".
-"""
-
-import os
-from annotator.oneformer.detectron2.data.datasets.builtin_meta import _get_builtin_metadata
-from annotator.oneformer.detectron2.data.datasets.coco import register_coco_instances
-
-
-_PREDEFINED_SPLITS_COCO = {
- "coco_2017_val_panoptic2instance": ("coco/val2017", "coco/annotations/panoptic2instances_val2017.json"),
-}
-
-
-def register_panoptic2instances_coco(root):
- for key, (image_root, json_file) in _PREDEFINED_SPLITS_COCO.items():
- # Assume pre-defined datasets live in `./datasets`.
- register_coco_instances(
- key,
- _get_builtin_metadata("coco"),
- os.path.join(root, json_file) if "://" not in json_file else json_file,
- os.path.join(root, image_root),
- )
-
-
-_root = os.path.expanduser(os.getenv("DETECTRON2_DATASETS", "datasets"))
-register_panoptic2instances_coco(_root)
\ No newline at end of file
diff --git a/spaces/SweetLuna/Kenshi-WebUI/README.md b/spaces/SweetLuna/Kenshi-WebUI/README.md
deleted file mode 100644
index 84cc9be87c95c7646aa1823aa33aec55c4944bd9..0000000000000000000000000000000000000000
--- a/spaces/SweetLuna/Kenshi-WebUI/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Kenshi WebUI
-emoji: 🗻
-colorFrom: blue
-colorTo: gray
-sdk: gradio
-sdk_version: 3.16.1
-app_file: app.py
-pinned: false
-license: creativeml-openrail-m
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/TEnngal/bingo/src/app/page.tsx b/spaces/TEnngal/bingo/src/app/page.tsx
deleted file mode 100644
index 0dff3431b098ce4fe282cc83fc87a93a28a43090..0000000000000000000000000000000000000000
--- a/spaces/TEnngal/bingo/src/app/page.tsx
+++ /dev/null
@@ -1,15 +0,0 @@
-import dynamic from 'next/dynamic'
-
-const DynamicComponentWithNoSSR = dynamic(
- () => import('../components/chat'),
- { ssr: false }
-)
-
-export default function IndexPage() {
- return (
- <>
-
-
-
- )
-}
diff --git a/spaces/TEnngal/bingo/src/lib/bots/bing/utils.ts b/spaces/TEnngal/bingo/src/lib/bots/bing/utils.ts
deleted file mode 100644
index 6bbbc5e463ad55bc1219b63cf78013f5360fc908..0000000000000000000000000000000000000000
--- a/spaces/TEnngal/bingo/src/lib/bots/bing/utils.ts
+++ /dev/null
@@ -1,87 +0,0 @@
-import { ChatResponseMessage, BingChatResponse } from './types'
-
-export function convertMessageToMarkdown(message: ChatResponseMessage): string {
- if (message.messageType === 'InternalSearchQuery') {
- return message.text
- }
- for (const card of message.adaptiveCards??[]) {
- for (const block of card.body) {
- if (block.type === 'TextBlock') {
- return block.text
- }
- }
- }
- return ''
-}
-
-const RecordSeparator = String.fromCharCode(30)
-
-export const websocketUtils = {
- packMessage(data: any) {
- return `${JSON.stringify(data)}${RecordSeparator}`
- },
- unpackMessage(data: string | ArrayBuffer | Blob) {
- if (!data) return {}
- return data
- .toString()
- .split(RecordSeparator)
- .filter(Boolean)
- .map((s) => {
- try {
- return JSON.parse(s)
- } catch (e) {
- return {}
- }
- })
- },
-}
-
-export async function createImage(prompt: string, id: string, headers: HeadersInit): Promise {
- const { headers: responseHeaders } = await fetch(`https://www.bing.com/images/create?partner=sydney&re=1&showselective=1&sude=1&kseed=7000&SFX=&q=${encodeURIComponent(prompt)}&iframeid=${id}`,
- {
- method: 'HEAD',
- headers,
- redirect: 'manual'
- },
- );
-
- if (!/&id=([^&]+)$/.test(responseHeaders.get('location') || '')) {
- throw new Error('请求异常,请检查身份信息是否有效')
- }
-
- const resultId = RegExp.$1;
- let count = 0
- const imageThumbUrl = `https://www.bing.com/images/create/async/results/${resultId}?q=${encodeURIComponent(prompt)}&partner=sydney&showselective=1&IID=images.as`;
-
- do {
- await sleep(3000);
- const content = await fetch(imageThumbUrl, { headers, method: 'GET' })
-
- // @ts-ignore
- if (content.headers.get('content-length') > 1) {
- const text = await content.text()
- return (text?.match(/ target?.split('src="').pop()?.replace(/&/g, '&'))
- .map(img => ``).join(' ')
- }
- } while(count ++ < 10);
-}
-
-
-export async function* streamAsyncIterable(stream: ReadableStream) {
- const reader = stream.getReader()
- try {
- while (true) {
- const { done, value } = await reader.read()
- if (done) {
- return
- }
- yield value
- }
- } finally {
- reader.releaseLock()
- }
-}
-
-export const sleep = (ms: number) => new Promise(resolve => setTimeout(resolve, ms))
-
diff --git a/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/tests/config/dir1/dir1_a.py b/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/tests/config/dir1/dir1_a.py
deleted file mode 100644
index a939955124556355524f48c0f0c16abb07cfc4c4..0000000000000000000000000000000000000000
--- a/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/tests/config/dir1/dir1_a.py
+++ /dev/null
@@ -1,3 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-dir1a_str = "base_a_1"
-dir1a_dict = {"a": 1, "b": 2}
diff --git a/spaces/Thafx/sdp/app.py b/spaces/Thafx/sdp/app.py
deleted file mode 100644
index d526c0b560b6e486635a74078428ecb27a57069d..0000000000000000000000000000000000000000
--- a/spaces/Thafx/sdp/app.py
+++ /dev/null
@@ -1,186 +0,0 @@
-from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline, DPMSolverMultistepScheduler
-import gradio as gr
-import torch
-from PIL import Image
-
-model_id = 'SG161222/Paragon_V1.0'
-prefix = ''
-
-scheduler = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
-
-pipe = StableDiffusionPipeline.from_pretrained(
- model_id,
- torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
- scheduler=scheduler)
-
-pipe_i2i = StableDiffusionImg2ImgPipeline.from_pretrained(
- model_id,
- torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
- scheduler=scheduler)
-
-if torch.cuda.is_available():
- pipe = pipe.to("cuda")
- pipe_i2i = pipe_i2i.to("cuda")
-
-def error_str(error, title="Error"):
- return f"""#### {title}
- {error}""" if error else ""
-
-
-def _parse_args(prompt, generator):
- parser = argparse.ArgumentParser(
- description="making it work."
- )
- parser.add_argument(
- "--no-half-vae", help="no half vae"
- )
-
- cmdline_args = parser.parse_args()
- command = cmdline_args.command
- conf_file = cmdline_args.conf_file
- conf_args = Arguments(conf_file)
- opt = conf_args.readArguments()
-
- if cmdline_args.config_overrides:
- for config_override in cmdline_args.config_overrides.split(";"):
- config_override = config_override.strip()
- if config_override:
- var_val = config_override.split("=")
- assert (
- len(var_val) == 2
- ), f"Config override '{var_val}' does not have the form 'VAR=val'"
- conf_args.add_opt(opt, var_val[0], var_val[1], force_override=True)
-
-def inference(prompt, guidance, steps, width=512, height=512, seed=0, img=None, strength=0.5, neg_prompt="", auto_prefix=False):
- generator = torch.Generator('cuda').manual_seed(seed) if seed != 0 else None
- prompt = f"{prefix} {prompt}" if auto_prefix else prompt
-
- try:
- if img is not None:
- return img_to_img(prompt, neg_prompt, img, strength, guidance, steps, width, height, generator), None
- else:
- return txt_to_img(prompt, neg_prompt, guidance, steps, width, height, generator), None
- except Exception as e:
- return None, error_str(e)
-
-
-
-def txt_to_img(prompt, neg_prompt, guidance, steps, width, height, generator):
-
- result = pipe(
- prompt,
- negative_prompt = neg_prompt,
- num_inference_steps = int(steps),
- guidance_scale = guidance,
- width = width,
- height = height,
- generator = generator)
-
- return result.images[0]
-
-def img_to_img(prompt, neg_prompt, img, strength, guidance, steps, width, height, generator):
-
- ratio = min(height / img.height, width / img.width)
- img = img.resize((int(img.width * ratio), int(img.height * ratio)), Image.LANCZOS)
- result = pipe_i2i(
- prompt,
- negative_prompt = neg_prompt,
- init_image = img,
- num_inference_steps = int(steps),
- strength = strength,
- guidance_scale = guidance,
- width = width,
- height = height,
- generator = generator)
-
- return result.images[0]
-
- def fake_safety_checker(images, **kwargs):
- return result.images[0], [False] * len(images)
-
- pipe.safety_checker = fake_safety_checker
-
-css = """.main-div div{display:inline-flex;align-items:center;gap:.8rem;font-size:1.75rem}.main-div div h1{font-weight:900;margin-bottom:7px}.main-div p{margin-bottom:10px;font-size:94%}a{text-decoration:underline}.tabs{margin-top:0;margin-bottom:0}#gallery{min-height:20rem}
-"""
-with gr.Blocks(css=css) as demo:
- gr.HTML(
- f"""
-
-
-
📷 Paragon 📸
-
-
- Demo for Paragon
- Stable Diffusion model by SG161222. {"" if prefix else ""}
- Running on {"GPU 🔥" if torch.cuda.is_available() else f"CPU ⚡"}.
-
-
Please use the prompt template below to get an example of the desired results:
-
-
-Prompt:
-
-
-Example: close up of a young woman wearing a black and gold liquid splash dress, pretty face, detailed eyes, soft lips, floating in outer space and planets in the background,
-fluid, wet, dripping, waxy, smooth, realistic, octane render
-
-
-
-
-Negative Prompt:
-
-(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality,
-jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated,
-bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers,
-too many fingers, long neck
-
-
-
-Have Fun & Enjoy ⚡ //THAFX
-
-
-
- """
- )
- with gr.Row():
-
- with gr.Column(scale=55):
- with gr.Group():
- with gr.Row():
- prompt = gr.Textbox(label="Prompt", show_label=False,max_lines=2,placeholder=f"{prefix} [your prompt]").style(container=False)
- generate = gr.Button(value="Generate").style(rounded=(False, True, True, False))
-
- image_out = gr.Image(height=512)
- error_output = gr.Markdown()
-
- with gr.Column(scale=45):
- with gr.Tab("Options"):
- with gr.Group():
- neg_prompt = gr.Textbox(label="Negative prompt", placeholder="What to exclude from the image")
- auto_prefix = gr.Checkbox(label="Prefix styling tokens automatically (RAW photo,)", value=prefix, visible=prefix)
-
- with gr.Row():
- guidance = gr.Slider(label="Guidance scale", value=7.0, maximum=15)
- steps = gr.Slider(label="Steps", value=25, minimum=2, maximum=75, step=1)
-
- with gr.Row():
- width = gr.Slider(label="Width", value=512, minimum=384, maximum=640, step=8)
- height = gr.Slider(label="Height", value=768, minimum=512, maximum=960, step=8)
-
- seed = gr.Slider(0, 2147483647, label='Seed (0 = random)', value=0, step=1)
-
- with gr.Tab("Image to image"):
- with gr.Group():
- image = gr.Image(label="Image", height=256, tool="editor", type="pil")
- strength = gr.Slider(label="Transformation strength", minimum=0, maximum=1, step=0.01, value=0.5)
-
- auto_prefix.change(lambda x: gr.update(placeholder=f"{prefix} [your prompt]" if x else "[Your prompt]"), inputs=auto_prefix, outputs=prompt, queue=False)
-
- inputs = [prompt, guidance, steps, width, height, seed, image, strength, neg_prompt, auto_prefix]
- outputs = [image_out, error_output]
- prompt.submit(inference, inputs=inputs, outputs=outputs)
- generate.click(inference, inputs=inputs, outputs=outputs)
-
-
-
-demo.queue(concurrency_count=1)
-demo.launch()
diff --git a/spaces/ThirdEyeData/Text-Summarization/README.md b/spaces/ThirdEyeData/Text-Summarization/README.md
deleted file mode 100644
index 38aba2f1fc608fb3e0aa40ed09491b9d2bf2e74c..0000000000000000000000000000000000000000
--- a/spaces/ThirdEyeData/Text-Summarization/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Text Summarization
-emoji: 👁
-colorFrom: pink
-colorTo: red
-sdk: gradio
-sdk_version: 3.15.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/UserXTheUnknown/stablediffusion-infinity/PyPatchMatch/Makefile b/spaces/UserXTheUnknown/stablediffusion-infinity/PyPatchMatch/Makefile
deleted file mode 100644
index 67e4d4dedb0353540206d98305f76006806fcca4..0000000000000000000000000000000000000000
--- a/spaces/UserXTheUnknown/stablediffusion-infinity/PyPatchMatch/Makefile
+++ /dev/null
@@ -1,54 +0,0 @@
-#
-# Makefile
-# Jiayuan Mao, 2019-01-09 13:59
-#
-
-SRC_DIR = csrc
-INC_DIR = csrc
-OBJ_DIR = build/obj
-TARGET = libpatchmatch.so
-
-LIB_TARGET = $(TARGET)
-INCLUDE_DIR = -I $(SRC_DIR) -I $(INC_DIR)
-
-CXX = $(ENVIRONMENT_OPTIONS) g++
-CXXFLAGS = -std=c++14
-CXXFLAGS += -Ofast -ffast-math -w
-# CXXFLAGS += -g
-CXXFLAGS += $(shell pkg-config --cflags opencv) -fPIC
-CXXFLAGS += $(INCLUDE_DIR)
-LDFLAGS = $(shell pkg-config --cflags --libs opencv) -shared -fPIC
-
-
-CXXSOURCES = $(shell find $(SRC_DIR)/ -name "*.cpp")
-OBJS = $(addprefix $(OBJ_DIR)/,$(CXXSOURCES:.cpp=.o))
-DEPFILES = $(OBJS:.o=.d)
-
-.PHONY: all clean rebuild test
-
-all: $(LIB_TARGET)
-
-$(OBJ_DIR)/%.o: %.cpp
- @echo "[CC] $< ..."
- @$(CXX) -c $< $(CXXFLAGS) -o $@
-
-$(OBJ_DIR)/%.d: %.cpp
- @mkdir -pv $(dir $@)
- @echo "[dep] $< ..."
- @$(CXX) $(INCLUDE_DIR) $(CXXFLAGS) -MM -MT "$(OBJ_DIR)/$(<:.cpp=.o) $(OBJ_DIR)/$(<:.cpp=.d)" "$<" > "$@"
-
-sinclude $(DEPFILES)
-
-$(LIB_TARGET): $(OBJS)
- @echo "[link] $(LIB_TARGET) ..."
- @$(CXX) $(OBJS) -o $@ $(CXXFLAGS) $(LDFLAGS)
-
-clean:
- rm -rf $(OBJ_DIR) $(LIB_TARGET)
-
-rebuild:
- +@make clean
- +@make
-
-# vim:ft=make
-#
diff --git a/spaces/UtkMal/Classifying-snake-breeds/README.md b/spaces/UtkMal/Classifying-snake-breeds/README.md
deleted file mode 100644
index 00dce9af7616e4fbe680f4dc9a53efd96a3bbfb3..0000000000000000000000000000000000000000
--- a/spaces/UtkMal/Classifying-snake-breeds/README.md
+++ /dev/null
@@ -1,17 +0,0 @@
----
-title: Classifying snake breeds
-emoji: 🔥
-colorFrom: dark-blue
-colorTo: light-pink
-sdk: gradio
-sdk_version: 3.24.1
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-This is a basic snake classification model.
-
-Built by fine-tuning the Levit 256 and using the "Identifying the different breeds of Snakes" (https://www.kaggle.com/datasets/duttadebadri/identifying-different-breeds-of-snakes) dataset on Kaggle.
-
-The notebook used for training the model can be found at: https://www.kaggle.com/code/utkmal/snake-breeds-classifier-using-fast-ai
\ No newline at end of file
diff --git a/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/common/logger.py b/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/common/logger.py
deleted file mode 100644
index 9a5a727213c6478606a154172830cdc43aae6f5a..0000000000000000000000000000000000000000
--- a/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/common/logger.py
+++ /dev/null
@@ -1,195 +0,0 @@
-"""
- Copyright (c) 2022, salesforce.com, inc.
- All rights reserved.
- SPDX-License-Identifier: BSD-3-Clause
- For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
-"""
-
-import datetime
-import logging
-import time
-from collections import defaultdict, deque
-
-import torch
-import torch.distributed as dist
-
-from minigpt4.common import dist_utils
-
-
-class SmoothedValue(object):
- """Track a series of values and provide access to smoothed values over a
- window or the global series average.
- """
-
- def __init__(self, window_size=20, fmt=None):
- if fmt is None:
- fmt = "{median:.4f} ({global_avg:.4f})"
- self.deque = deque(maxlen=window_size)
- self.total = 0.0
- self.count = 0
- self.fmt = fmt
-
- def update(self, value, n=1):
- self.deque.append(value)
- self.count += n
- self.total += value * n
-
- def synchronize_between_processes(self):
- """
- Warning: does not synchronize the deque!
- """
- if not dist_utils.is_dist_avail_and_initialized():
- return
- t = torch.tensor([self.count, self.total], dtype=torch.float64, device="cuda")
- dist.barrier()
- dist.all_reduce(t)
- t = t.tolist()
- self.count = int(t[0])
- self.total = t[1]
-
- @property
- def median(self):
- d = torch.tensor(list(self.deque))
- return d.median().item()
-
- @property
- def avg(self):
- d = torch.tensor(list(self.deque), dtype=torch.float32)
- return d.mean().item()
-
- @property
- def global_avg(self):
- return self.total / self.count
-
- @property
- def max(self):
- return max(self.deque)
-
- @property
- def value(self):
- return self.deque[-1]
-
- def __str__(self):
- return self.fmt.format(
- median=self.median,
- avg=self.avg,
- global_avg=self.global_avg,
- max=self.max,
- value=self.value,
- )
-
-
-class MetricLogger(object):
- def __init__(self, delimiter="\t"):
- self.meters = defaultdict(SmoothedValue)
- self.delimiter = delimiter
-
- def update(self, **kwargs):
- for k, v in kwargs.items():
- if isinstance(v, torch.Tensor):
- v = v.item()
- assert isinstance(v, (float, int))
- self.meters[k].update(v)
-
- def __getattr__(self, attr):
- if attr in self.meters:
- return self.meters[attr]
- if attr in self.__dict__:
- return self.__dict__[attr]
- raise AttributeError(
- "'{}' object has no attribute '{}'".format(type(self).__name__, attr)
- )
-
- def __str__(self):
- loss_str = []
- for name, meter in self.meters.items():
- loss_str.append("{}: {}".format(name, str(meter)))
- return self.delimiter.join(loss_str)
-
- def global_avg(self):
- loss_str = []
- for name, meter in self.meters.items():
- loss_str.append("{}: {:.4f}".format(name, meter.global_avg))
- return self.delimiter.join(loss_str)
-
- def synchronize_between_processes(self):
- for meter in self.meters.values():
- meter.synchronize_between_processes()
-
- def add_meter(self, name, meter):
- self.meters[name] = meter
-
- def log_every(self, iterable, print_freq, header=None):
- i = 0
- if not header:
- header = ""
- start_time = time.time()
- end = time.time()
- iter_time = SmoothedValue(fmt="{avg:.4f}")
- data_time = SmoothedValue(fmt="{avg:.4f}")
- space_fmt = ":" + str(len(str(len(iterable)))) + "d"
- log_msg = [
- header,
- "[{0" + space_fmt + "}/{1}]",
- "eta: {eta}",
- "{meters}",
- "time: {time}",
- "data: {data}",
- ]
- if torch.cuda.is_available():
- log_msg.append("max mem: {memory:.0f}")
- log_msg = self.delimiter.join(log_msg)
- MB = 1024.0 * 1024.0
- for obj in iterable:
- data_time.update(time.time() - end)
- yield obj
- iter_time.update(time.time() - end)
- if i % print_freq == 0 or i == len(iterable) - 1:
- eta_seconds = iter_time.global_avg * (len(iterable) - i)
- eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
- if torch.cuda.is_available():
- print(
- log_msg.format(
- i,
- len(iterable),
- eta=eta_string,
- meters=str(self),
- time=str(iter_time),
- data=str(data_time),
- memory=torch.cuda.max_memory_allocated() / MB,
- )
- )
- else:
- print(
- log_msg.format(
- i,
- len(iterable),
- eta=eta_string,
- meters=str(self),
- time=str(iter_time),
- data=str(data_time),
- )
- )
- i += 1
- end = time.time()
- total_time = time.time() - start_time
- total_time_str = str(datetime.timedelta(seconds=int(total_time)))
- print(
- "{} Total time: {} ({:.4f} s / it)".format(
- header, total_time_str, total_time / len(iterable)
- )
- )
-
-
-class AttrDict(dict):
- def __init__(self, *args, **kwargs):
- super(AttrDict, self).__init__(*args, **kwargs)
- self.__dict__ = self
-
-
-def setup_logger():
- logging.basicConfig(
- level=logging.INFO if dist_utils.is_main_process() else logging.WARN,
- format="%(asctime)s [%(levelname)s] %(message)s",
- handlers=[logging.StreamHandler()],
- )
diff --git a/spaces/VoiceHero69/changer/setup_tools/magicinstaller/requirements/packaging_package.py b/spaces/VoiceHero69/changer/setup_tools/magicinstaller/requirements/packaging_package.py
deleted file mode 100644
index b7321fd161d5772f32ff1591ecb4814e92af504e..0000000000000000000000000000000000000000
--- a/spaces/VoiceHero69/changer/setup_tools/magicinstaller/requirements/packaging_package.py
+++ /dev/null
@@ -1,5 +0,0 @@
-from setup_tools.magicinstaller.requirement import SimpleRequirement
-
-
-class Packaging(SimpleRequirement):
- package_name = 'packaging'
diff --git a/spaces/Walterchamy/Virtual_Assistant_v1/README.md b/spaces/Walterchamy/Virtual_Assistant_v1/README.md
deleted file mode 100644
index c2e5f0d56c7e0dc0ce797aeeaec4296421208609..0000000000000000000000000000000000000000
--- a/spaces/Walterchamy/Virtual_Assistant_v1/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Virtual Assistant V1
-emoji: 👁
-colorFrom: gray
-colorTo: red
-sdk: streamlit
-sdk_version: 1.21.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/XzJosh/Bella-Bert-VITS2/text/english.py b/spaces/XzJosh/Bella-Bert-VITS2/text/english.py
deleted file mode 100644
index 781d0a56cef71f66fc67db51d76538be90d3ddd2..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/Bella-Bert-VITS2/text/english.py
+++ /dev/null
@@ -1,138 +0,0 @@
-import pickle
-import os
-import re
-from g2p_en import G2p
-from string import punctuation
-
-from text import symbols
-
-current_file_path = os.path.dirname(__file__)
-CMU_DICT_PATH = os.path.join(current_file_path, 'cmudict.rep')
-CACHE_PATH = os.path.join(current_file_path, 'cmudict_cache.pickle')
-_g2p = G2p()
-
-arpa = {'AH0', 'S', 'AH1', 'EY2', 'AE2', 'EH0', 'OW2', 'UH0', 'NG', 'B', 'G', 'AY0', 'M', 'AA0', 'F', 'AO0', 'ER2', 'UH1', 'IY1', 'AH2', 'DH', 'IY0', 'EY1', 'IH0', 'K', 'N', 'W', 'IY2', 'T', 'AA1', 'ER1', 'EH2', 'OY0', 'UH2', 'UW1', 'Z', 'AW2', 'AW1', 'V', 'UW2', 'AA2', 'ER', 'AW0', 'UW0', 'R', 'OW1', 'EH1', 'ZH', 'AE0', 'IH2', 'IH', 'Y', 'JH', 'P', 'AY1', 'EY0', 'OY2', 'TH', 'HH', 'D', 'ER0', 'CH', 'AO1', 'AE1', 'AO2', 'OY1', 'AY2', 'IH1', 'OW0', 'L', 'SH'}
-
-
-def post_replace_ph(ph):
- rep_map = {
- ':': ',',
- ';': ',',
- ',': ',',
- '。': '.',
- '!': '!',
- '?': '?',
- '\n': '.',
- "·": ",",
- '、': ",",
- '...': '…',
- 'v': "V"
- }
- if ph in rep_map.keys():
- ph = rep_map[ph]
- if ph in symbols:
- return ph
- if ph not in symbols:
- ph = 'UNK'
- return ph
-
-def read_dict():
- g2p_dict = {}
- start_line = 49
- with open(CMU_DICT_PATH) as f:
- line = f.readline()
- line_index = 1
- while line:
- if line_index >= start_line:
- line = line.strip()
- word_split = line.split(' ')
- word = word_split[0]
-
- syllable_split = word_split[1].split(' - ')
- g2p_dict[word] = []
- for syllable in syllable_split:
- phone_split = syllable.split(' ')
- g2p_dict[word].append(phone_split)
-
- line_index = line_index + 1
- line = f.readline()
-
- return g2p_dict
-
-
-def cache_dict(g2p_dict, file_path):
- with open(file_path, 'wb') as pickle_file:
- pickle.dump(g2p_dict, pickle_file)
-
-
-def get_dict():
- if os.path.exists(CACHE_PATH):
- with open(CACHE_PATH, 'rb') as pickle_file:
- g2p_dict = pickle.load(pickle_file)
- else:
- g2p_dict = read_dict()
- cache_dict(g2p_dict, CACHE_PATH)
-
- return g2p_dict
-
-eng_dict = get_dict()
-
-def refine_ph(phn):
- tone = 0
- if re.search(r'\d$', phn):
- tone = int(phn[-1]) + 1
- phn = phn[:-1]
- return phn.lower(), tone
-
-def refine_syllables(syllables):
- tones = []
- phonemes = []
- for phn_list in syllables:
- for i in range(len(phn_list)):
- phn = phn_list[i]
- phn, tone = refine_ph(phn)
- phonemes.append(phn)
- tones.append(tone)
- return phonemes, tones
-
-
-def text_normalize(text):
- # todo: eng text normalize
- return text
-
-def g2p(text):
-
- phones = []
- tones = []
- words = re.split(r"([,;.\-\?\!\s+])", text)
- for w in words:
- if w.upper() in eng_dict:
- phns, tns = refine_syllables(eng_dict[w.upper()])
- phones += phns
- tones += tns
- else:
- phone_list = list(filter(lambda p: p != " ", _g2p(w)))
- for ph in phone_list:
- if ph in arpa:
- ph, tn = refine_ph(ph)
- phones.append(ph)
- tones.append(tn)
- else:
- phones.append(ph)
- tones.append(0)
- # todo: implement word2ph
- word2ph = [1 for i in phones]
-
- phones = [post_replace_ph(i) for i in phones]
- return phones, tones, word2ph
-
-if __name__ == "__main__":
- # print(get_dict())
- # print(eng_word_to_phoneme("hello"))
- print(g2p("In this paper, we propose 1 DSPGAN, a GAN-based universal vocoder."))
- # all_phones = set()
- # for k, syllables in eng_dict.items():
- # for group in syllables:
- # for ph in group:
- # all_phones.add(ph)
- # print(all_phones)
\ No newline at end of file
diff --git a/spaces/XzJosh/Taffy-Bert-VITS2/server.py b/spaces/XzJosh/Taffy-Bert-VITS2/server.py
deleted file mode 100644
index c736ca4f95fec853950eef6654ef79856beffc0a..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/Taffy-Bert-VITS2/server.py
+++ /dev/null
@@ -1,123 +0,0 @@
-from flask import Flask, request, Response
-from io import BytesIO
-import torch
-from av import open as avopen
-
-import commons
-import utils
-from models import SynthesizerTrn
-from text.symbols import symbols
-from text import cleaned_text_to_sequence, get_bert
-from text.cleaner import clean_text
-from scipy.io import wavfile
-
-# Flask Init
-app = Flask(__name__)
-app.config['JSON_AS_ASCII'] = False
-def get_text(text, language_str, hps):
- norm_text, phone, tone, word2ph = clean_text(text, language_str)
- print([f"{p}{t}" for p, t in zip(phone, tone)])
- phone, tone, language = cleaned_text_to_sequence(phone, tone, language_str)
-
- if hps.data.add_blank:
- phone = commons.intersperse(phone, 0)
- tone = commons.intersperse(tone, 0)
- language = commons.intersperse(language, 0)
- for i in range(len(word2ph)):
- word2ph[i] = word2ph[i] * 2
- word2ph[0] += 1
- bert = get_bert(norm_text, word2ph, language_str)
-
- assert bert.shape[-1] == len(phone)
-
- phone = torch.LongTensor(phone)
- tone = torch.LongTensor(tone)
- language = torch.LongTensor(language)
-
- return bert, phone, tone, language
-
-def infer(text, sdp_ratio, noise_scale, noise_scale_w,length_scale,sid):
- bert, phones, tones, lang_ids = get_text(text,"ZH", hps,)
- with torch.no_grad():
- x_tst=phones.to(dev).unsqueeze(0)
- tones=tones.to(dev).unsqueeze(0)
- lang_ids=lang_ids.to(dev).unsqueeze(0)
- bert = bert.to(dev).unsqueeze(0)
- x_tst_lengths = torch.LongTensor([phones.size(0)]).to(dev)
- speakers = torch.LongTensor([hps.data.spk2id[sid]]).to(dev)
- audio = net_g.infer(x_tst, x_tst_lengths, speakers, tones, lang_ids,bert, sdp_ratio=sdp_ratio
- , noise_scale=noise_scale, noise_scale_w=noise_scale_w, length_scale=length_scale)[0][0,0].data.cpu().float().numpy()
- return audio
-
-def replace_punctuation(text, i=2):
- punctuation = ",。?!"
- for char in punctuation:
- text = text.replace(char, char * i)
- return text
-
-def wav2(i, o, format):
- inp = avopen(i, 'rb')
- out = avopen(o, 'wb', format=format)
- if format == "ogg": format = "libvorbis"
-
- ostream = out.add_stream(format)
-
- for frame in inp.decode(audio=0):
- for p in ostream.encode(frame): out.mux(p)
-
- for p in ostream.encode(None): out.mux(p)
-
- out.close()
- inp.close()
-
-# Load Generator
-hps = utils.get_hparams_from_file("./configs/config.json")
-
-dev='cuda'
-net_g = SynthesizerTrn(
- len(symbols),
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- n_speakers=hps.data.n_speakers,
- **hps.model).to(dev)
-_ = net_g.eval()
-
-_ = utils.load_checkpoint("logs/G_649000.pth", net_g, None,skip_optimizer=True)
-
-@app.route("/",methods=['GET','POST'])
-def main():
- if request.method == 'GET':
- try:
- speaker = request.args.get('speaker')
- text = request.args.get('text').replace("/n","")
- sdp_ratio = float(request.args.get("sdp_ratio", 0.2))
- noise = float(request.args.get("noise", 0.5))
- noisew = float(request.args.get("noisew", 0.6))
- length = float(request.args.get("length", 1.2))
- if length >= 2:
- return "Too big length"
- if len(text) >=200:
- return "Too long text"
- fmt = request.args.get("format", "wav")
- if None in (speaker, text):
- return "Missing Parameter"
- if fmt not in ("mp3", "wav", "ogg"):
- return "Invalid Format"
- except:
- return "Invalid Parameter"
-
- with torch.no_grad():
- audio = infer(text, sdp_ratio=sdp_ratio, noise_scale=noise, noise_scale_w=noisew, length_scale=length, sid=speaker)
-
- with BytesIO() as wav:
- wavfile.write(wav, hps.data.sampling_rate, audio)
- torch.cuda.empty_cache()
- if fmt == "wav":
- return Response(wav.getvalue(), mimetype="audio/wav")
- wav.seek(0, 0)
- with BytesIO() as ofp:
- wav2(wav, ofp, fmt)
- return Response(
- ofp.getvalue(),
- mimetype="audio/mpeg" if fmt == "mp3" else "audio/ogg"
- )
diff --git a/spaces/Yan233th/so-vits-svc-models/onnx_export.py b/spaces/Yan233th/so-vits-svc-models/onnx_export.py
deleted file mode 100644
index 7914d12f2fb033da9119d94ea1114626b553af23..0000000000000000000000000000000000000000
--- a/spaces/Yan233th/so-vits-svc-models/onnx_export.py
+++ /dev/null
@@ -1,53 +0,0 @@
-import torch
-from onnxexport.model_onnx import SynthesizerTrn
-import utils
-
-def main(NetExport):
- path = "SoVits4.0"
- if NetExport:
- device = torch.device("cpu")
- hps = utils.get_hparams_from_file(f"checkpoints/{path}/config.json")
- SVCVITS = SynthesizerTrn(
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- **hps.model)
- _ = utils.load_checkpoint(f"checkpoints/{path}/model.pth", SVCVITS, None)
- _ = SVCVITS.eval().to(device)
- for i in SVCVITS.parameters():
- i.requires_grad = False
-
- test_hidden_unit = torch.rand(1, 10, 256)
- test_pitch = torch.rand(1, 10)
- test_mel2ph = torch.LongTensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]).unsqueeze(0)
- test_uv = torch.ones(1, 10, dtype=torch.float32)
- test_noise = torch.randn(1, 192, 10)
- test_sid = torch.LongTensor([0])
- input_names = ["c", "f0", "mel2ph", "uv", "noise", "sid"]
- output_names = ["audio", ]
-
- torch.onnx.export(SVCVITS,
- (
- test_hidden_unit.to(device),
- test_pitch.to(device),
- test_mel2ph.to(device),
- test_uv.to(device),
- test_noise.to(device),
- test_sid.to(device)
- ),
- f"checkpoints/{path}/model.onnx",
- dynamic_axes={
- "c": [0, 1],
- "f0": [1],
- "mel2ph": [1],
- "uv": [1],
- "noise": [2],
- },
- do_constant_folding=False,
- opset_version=16,
- verbose=False,
- input_names=input_names,
- output_names=output_names)
-
-
-if __name__ == '__main__':
- main(True)
diff --git a/spaces/YoannLemesle/CLIPictionary/style.css b/spaces/YoannLemesle/CLIPictionary/style.css
deleted file mode 100644
index 68702f376db3fd665c283d344e1026115bf0a662..0000000000000000000000000000000000000000
--- a/spaces/YoannLemesle/CLIPictionary/style.css
+++ /dev/null
@@ -1,128 +0,0 @@
-
-@-webkit-keyframes winAnim {
- from { text-shadow:0px 0px 15px rgb(250,150,0,0); font-size:25px;}
- to { text-shadow:0px 0px 15px rgb(250,150,0,0.75); font-size:30px;}
-}
-
-@keyframes winAnim {
- from { text-shadow:0px 0px 15px rgb(250,150,0,0); font-size:25px;}
- to { text-shadow:0px 0px 15px rgb(250,150,0,0.75); font-size:30px;}
-}
-
-
-#test{
- font-weight:bold;
-}
-
-@-webkit-keyframes prediction {
- from { opacity:0;}
- to { opacity:1;}
-}
-
-@keyframes prediction {
- from { opacity:0;}
- to { opacity:1;}
-}
-
-
-div#prediction{
- display:block;
- width:45vw;
- height:100%;
- text-align:center;
- margin-top:100px;
- margin-left:auto;
- margin-right: auto;
-}
-
-div#prediction p:not(#win){
- font-size:25px;
- display:inline-block;
- margin:auto;
- position:relative;
- top:48%;
- position-anchor: 50% 50%;
- text-align:center;
- transform: translate(0, -50%);
- -webkit-animation: prediction 0.25s;
- animation: prediction 0.25s;
-}
-
-div#prediction p#win{
- font-weight:bold;
- -webkit-animation: winAnim 0.5s;
- animation: winAnim 0.5s;
- font-size:30px;
- text-shadow:0px 0px 15px rgb(250,150,0,0.75);
-}
-
-div#prediction p#infos{
- font-weight:bold;
- -webkit-animation: winAnim 0.5s;
- animation: winAnim 0.5s;
- font-size:30px;
- text-shadow:0px 0px 15px rgb(250,150,0,0.75);
-}
-
-
-span{
- font-weight:bold;
- color:rgb(250,150,0);
-}
-
-h1{
- display:block; font-size:30px; font-weight:bold; width:100%; text-align:center; margin-bottom:15px;
-}
-
-
-@-webkit-keyframes loading {
- from { color:rgb(250,150,0,0.25);}
- to { color:rgb(250,150,0,1);}
-}
-
-@keyframes loading {
- from { color:rgb(250,150,0,0.25);}
- to { color:rgb(250,150,0,1);}
-}
-
-
-h1#loading{
- margin-bottom:15px;
- display:block;
- width:100%;
- vertical-align: center;
- text-align: center;
-
- font-size:30px;
- font-weight:bold;
-
- -webkit-animation: loading 10s;
- animation: loading 10s;
- color:rgb(250,150,0,1);
-}
-
-@-webkit-keyframes processing {
- from { opacity:1;}
- to { opacity:0;}
-}
-
-@keyframes processing {
- from { opacity:1;}
- to { opacity:0;}
-}
-
-
-p#processing{
-
- -webkit-animation: loading 3s;
- animation: loading 3s;
- color:rgb(250,150,0);
- font-weight:bold;
-
- font-size:50px;
- display:block;
- margin:auto;
- text-align:center;
- width:100%;
-
-}
diff --git a/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/demo/inference_on_a_image.py b/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/demo/inference_on_a_image.py
deleted file mode 100644
index 207227b7419df8db7a6f0206361670287cf4d9fa..0000000000000000000000000000000000000000
--- a/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/demo/inference_on_a_image.py
+++ /dev/null
@@ -1,172 +0,0 @@
-import argparse
-import os
-import sys
-
-import numpy as np
-import torch
-from PIL import Image, ImageDraw, ImageFont
-
-import groundingdino.datasets.transforms as T
-from groundingdino.models import build_model
-from groundingdino.util import box_ops
-from groundingdino.util.slconfig import SLConfig
-from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
-
-
-def plot_boxes_to_image(image_pil, tgt):
- H, W = tgt["size"]
- boxes = tgt["boxes"]
- labels = tgt["labels"]
- assert len(boxes) == len(labels), "boxes and labels must have same length"
-
- draw = ImageDraw.Draw(image_pil)
- mask = Image.new("L", image_pil.size, 0)
- mask_draw = ImageDraw.Draw(mask)
-
- # draw boxes and masks
- for box, label in zip(boxes, labels):
- # from 0..1 to 0..W, 0..H
- box = box * torch.Tensor([W, H, W, H])
- # from xywh to xyxy
- box[:2] -= box[2:] / 2
- box[2:] += box[:2]
- # random color
- color = tuple(np.random.randint(0, 255, size=3).tolist())
- # draw
- x0, y0, x1, y1 = box
- x0, y0, x1, y1 = int(x0), int(y0), int(x1), int(y1)
-
- draw.rectangle([x0, y0, x1, y1], outline=color, width=6)
- # draw.text((x0, y0), str(label), fill=color)
-
- font = ImageFont.load_default()
- if hasattr(font, "getbbox"):
- bbox = draw.textbbox((x0, y0), str(label), font)
- else:
- w, h = draw.textsize(str(label), font)
- bbox = (x0, y0, w + x0, y0 + h)
- # bbox = draw.textbbox((x0, y0), str(label))
- draw.rectangle(bbox, fill=color)
- draw.text((x0, y0), str(label), fill="white")
-
- mask_draw.rectangle([x0, y0, x1, y1], fill=255, width=6)
-
- return image_pil, mask
-
-
-def load_image(image_path):
- # load image
- image_pil = Image.open(image_path).convert("RGB") # load image
-
- transform = T.Compose(
- [
- T.RandomResize([800], max_size=1333),
- T.ToTensor(),
- T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
- ]
- )
- image, _ = transform(image_pil, None) # 3, h, w
- return image_pil, image
-
-
-def load_model(model_config_path, model_checkpoint_path, cpu_only=False):
- args = SLConfig.fromfile(model_config_path)
- args.device = "cuda" if not cpu_only else "cpu"
- model = build_model(args)
- checkpoint = torch.load(model_checkpoint_path, map_location="cpu")
- load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
- print(load_res)
- _ = model.eval()
- return model
-
-
-def get_grounding_output(model, image, caption, box_threshold, text_threshold, with_logits=True, cpu_only=False):
- caption = caption.lower()
- caption = caption.strip()
- if not caption.endswith("."):
- caption = caption + "."
- device = "cuda" if not cpu_only else "cpu"
- model = model.to(device)
- image = image.to(device)
- with torch.no_grad():
- outputs = model(image[None], captions=[caption])
- logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)
- boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)
- logits.shape[0]
-
- # filter output
- logits_filt = logits.clone()
- boxes_filt = boxes.clone()
- filt_mask = logits_filt.max(dim=1)[0] > box_threshold
- logits_filt = logits_filt[filt_mask] # num_filt, 256
- boxes_filt = boxes_filt[filt_mask] # num_filt, 4
- logits_filt.shape[0]
-
- # get phrase
- tokenlizer = model.tokenizer
- tokenized = tokenlizer(caption)
- # build pred
- pred_phrases = []
- for logit, box in zip(logits_filt, boxes_filt):
- pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenlizer)
- if with_logits:
- pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")
- else:
- pred_phrases.append(pred_phrase)
-
- return boxes_filt, pred_phrases
-
-
-if __name__ == "__main__":
-
- parser = argparse.ArgumentParser("Grounding DINO example", add_help=True)
- parser.add_argument("--config_file", "-c", type=str, required=True, help="path to config file")
- parser.add_argument(
- "--checkpoint_path", "-p", type=str, required=True, help="path to checkpoint file"
- )
- parser.add_argument("--image_path", "-i", type=str, required=True, help="path to image file")
- parser.add_argument("--text_prompt", "-t", type=str, required=True, help="text prompt")
- parser.add_argument(
- "--output_dir", "-o", type=str, default="outputs", required=True, help="output directory"
- )
-
- parser.add_argument("--box_threshold", type=float, default=0.3, help="box threshold")
- parser.add_argument("--text_threshold", type=float, default=0.25, help="text threshold")
-
- parser.add_argument("--cpu-only", action="store_true", help="running on cpu only!, default=False")
- args = parser.parse_args()
-
- # cfg
- config_file = args.config_file # change the path of the model config file
- checkpoint_path = args.checkpoint_path # change the path of the model
- image_path = args.image_path
- text_prompt = args.text_prompt
- output_dir = args.output_dir
- box_threshold = args.box_threshold
- text_threshold = args.text_threshold
-
- # make dir
- os.makedirs(output_dir, exist_ok=True)
- # load image
- image_pil, image = load_image(image_path)
- # load model
- model = load_model(config_file, checkpoint_path, cpu_only=args.cpu_only)
-
- # visualize raw image
- image_pil.save(os.path.join(output_dir, "raw_image.jpg"))
-
- # run model
- boxes_filt, pred_phrases = get_grounding_output(
- model, image, text_prompt, box_threshold, text_threshold, cpu_only=args.cpu_only
- )
-
- # visualize pred
- size = image_pil.size
- pred_dict = {
- "boxes": boxes_filt,
- "size": [size[1], size[0]], # H,W
- "labels": pred_phrases,
- }
- # import ipdb; ipdb.set_trace()
- image_with_box = plot_boxes_to_image(image_pil, pred_dict)[0]
- image_with_box.save(os.path.join(output_dir, "pred.jpg"))
diff --git a/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn.h b/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn.h
deleted file mode 100644
index c7408eba007b424194618baa63726657e36875e3..0000000000000000000000000000000000000000
--- a/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn.h
+++ /dev/null
@@ -1,64 +0,0 @@
-/*!
-**************************************************************************************************
-* Deformable DETR
-* Copyright (c) 2020 SenseTime. All Rights Reserved.
-* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-**************************************************************************************************
-* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
-**************************************************************************************************
-*/
-
-#pragma once
-
-#include "ms_deform_attn_cpu.h"
-
-#ifdef WITH_CUDA
-#include "ms_deform_attn_cuda.h"
-#endif
-
-namespace groundingdino {
-
-at::Tensor
-ms_deform_attn_forward(
- const at::Tensor &value,
- const at::Tensor &spatial_shapes,
- const at::Tensor &level_start_index,
- const at::Tensor &sampling_loc,
- const at::Tensor &attn_weight,
- const int im2col_step)
-{
- if (value.type().is_cuda())
- {
-#ifdef WITH_CUDA
- return ms_deform_attn_cuda_forward(
- value, spatial_shapes, level_start_index, sampling_loc, attn_weight, im2col_step);
-#else
- AT_ERROR("Not compiled with GPU support");
-#endif
- }
- AT_ERROR("Not implemented on the CPU");
-}
-
-std::vector
-ms_deform_attn_backward(
- const at::Tensor &value,
- const at::Tensor &spatial_shapes,
- const at::Tensor &level_start_index,
- const at::Tensor &sampling_loc,
- const at::Tensor &attn_weight,
- const at::Tensor &grad_output,
- const int im2col_step)
-{
- if (value.type().is_cuda())
- {
-#ifdef WITH_CUDA
- return ms_deform_attn_cuda_backward(
- value, spatial_shapes, level_start_index, sampling_loc, attn_weight, grad_output, im2col_step);
-#else
- AT_ERROR("Not compiled with GPU support");
-#endif
- }
- AT_ERROR("Not implemented on the CPU");
-}
-
-} // namespace groundingdino
\ No newline at end of file
diff --git a/spaces/YuDou/ChuanhuChatGPT/run_Linux.sh b/spaces/YuDou/ChuanhuChatGPT/run_Linux.sh
deleted file mode 100644
index 62af07283093d8e580763d7acfe493c3d88e7b08..0000000000000000000000000000000000000000
--- a/spaces/YuDou/ChuanhuChatGPT/run_Linux.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-#!/bin/bash
-
-# 获取脚本所在目录
-script_dir=$(dirname "$0")
-
-# 将工作目录更改为脚本所在目录
-cd "$script_dir"
-
-# 检查Git仓库是否有更新
-git remote update
-pwd
-
-if ! git status -uno | grep 'up to date' > /dev/null; then
- # 如果有更新,关闭当前运行的服务器
- pkill -f ChuanhuChatbot.py
-
- # 拉取最新更改
- git pull
-
- # 安装依赖
- pip3 install -r requirements.txt
-
- # 重新启动服务器
- nohup python3 ChuanhuChatbot.py &
-fi
diff --git a/spaces/Zannriell/hakurei-waifu-diffusion/README.md b/spaces/Zannriell/hakurei-waifu-diffusion/README.md
deleted file mode 100644
index 9d1e9e74e2626596105db8c8856018ccb3644d30..0000000000000000000000000000000000000000
--- a/spaces/Zannriell/hakurei-waifu-diffusion/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Hakurei Waifu Diffusion
-emoji: 🔥
-colorFrom: pink
-colorTo: purple
-sdk: gradio
-sdk_version: 3.41.2
-app_file: app.py
-pinned: false
-license: lgpl-3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/bbox_heads/dii_head.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/bbox_heads/dii_head.py
deleted file mode 100644
index 8c970a78184672aaaa95edcdaecec03a26604390..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/bbox_heads/dii_head.py
+++ /dev/null
@@ -1,415 +0,0 @@
-import torch
-import torch.nn as nn
-from mmcv.cnn import (bias_init_with_prob, build_activation_layer,
- build_norm_layer)
-from mmcv.runner import auto_fp16, force_fp32
-
-from mmdet.core import multi_apply
-from mmdet.models.builder import HEADS, build_loss
-from mmdet.models.dense_heads.atss_head import reduce_mean
-from mmdet.models.losses import accuracy
-from mmdet.models.utils import FFN, MultiheadAttention, build_transformer
-from .bbox_head import BBoxHead
-
-
-@HEADS.register_module()
-class DIIHead(BBoxHead):
- r"""Dynamic Instance Interactive Head for `Sparse R-CNN: End-to-End Object
- Detection with Learnable Proposals `_
-
- Args:
- num_classes (int): Number of class in dataset.
- Defaults to 80.
- num_ffn_fcs (int): The number of fully-connected
- layers in FFNs. Defaults to 2.
- num_heads (int): The hidden dimension of FFNs.
- Defaults to 8.
- num_cls_fcs (int): The number of fully-connected
- layers in classification subnet. Defaults to 1.
- num_reg_fcs (int): The number of fully-connected
- layers in regression subnet. Defaults to 3.
- feedforward_channels (int): The hidden dimension
- of FFNs. Defaults to 2048
- in_channels (int): Hidden_channels of MultiheadAttention.
- Defaults to 256.
- dropout (float): Probability of drop the channel.
- Defaults to 0.0
- ffn_act_cfg (dict): The activation config for FFNs.
- dynamic_conv_cfg (dict): The convolution config
- for DynamicConv.
- loss_iou (dict): The config for iou or giou loss.
-
- """
-
- def __init__(self,
- num_classes=80,
- num_ffn_fcs=2,
- num_heads=8,
- num_cls_fcs=1,
- num_reg_fcs=3,
- feedforward_channels=2048,
- in_channels=256,
- dropout=0.0,
- ffn_act_cfg=dict(type='ReLU', inplace=True),
- dynamic_conv_cfg=dict(
- type='DynamicConv',
- in_channels=256,
- feat_channels=64,
- out_channels=256,
- input_feat_shape=7,
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN')),
- loss_iou=dict(type='GIoULoss', loss_weight=2.0),
- **kwargs):
- super(DIIHead, self).__init__(
- num_classes=num_classes,
- reg_decoded_bbox=True,
- reg_class_agnostic=True,
- **kwargs)
- self.loss_iou = build_loss(loss_iou)
- self.in_channels = in_channels
- self.fp16_enabled = False
- self.attention = MultiheadAttention(in_channels, num_heads, dropout)
- self.attention_norm = build_norm_layer(dict(type='LN'), in_channels)[1]
-
- self.instance_interactive_conv = build_transformer(dynamic_conv_cfg)
- self.instance_interactive_conv_dropout = nn.Dropout(dropout)
- self.instance_interactive_conv_norm = build_norm_layer(
- dict(type='LN'), in_channels)[1]
-
- self.ffn = FFN(
- in_channels,
- feedforward_channels,
- num_ffn_fcs,
- act_cfg=ffn_act_cfg,
- dropout=dropout)
- self.ffn_norm = build_norm_layer(dict(type='LN'), in_channels)[1]
-
- self.cls_fcs = nn.ModuleList()
- for _ in range(num_cls_fcs):
- self.cls_fcs.append(
- nn.Linear(in_channels, in_channels, bias=False))
- self.cls_fcs.append(
- build_norm_layer(dict(type='LN'), in_channels)[1])
- self.cls_fcs.append(
- build_activation_layer(dict(type='ReLU', inplace=True)))
-
- # over load the self.fc_cls in BBoxHead
- if self.loss_cls.use_sigmoid:
- self.fc_cls = nn.Linear(in_channels, self.num_classes)
- else:
- self.fc_cls = nn.Linear(in_channels, self.num_classes + 1)
-
- self.reg_fcs = nn.ModuleList()
- for _ in range(num_reg_fcs):
- self.reg_fcs.append(
- nn.Linear(in_channels, in_channels, bias=False))
- self.reg_fcs.append(
- build_norm_layer(dict(type='LN'), in_channels)[1])
- self.reg_fcs.append(
- build_activation_layer(dict(type='ReLU', inplace=True)))
- # over load the self.fc_cls in BBoxHead
- self.fc_reg = nn.Linear(in_channels, 4)
-
- assert self.reg_class_agnostic, 'DIIHead only ' \
- 'suppport `reg_class_agnostic=True` '
- assert self.reg_decoded_bbox, 'DIIHead only ' \
- 'suppport `reg_decoded_bbox=True`'
-
- def init_weights(self):
- """Use xavier initialization for all weight parameter and set
- classification head bias as a specific value when use focal loss."""
- for p in self.parameters():
- if p.dim() > 1:
- nn.init.xavier_uniform_(p)
- else:
- # adopt the default initialization for
- # the weight and bias of the layer norm
- pass
- if self.loss_cls.use_sigmoid:
- bias_init = bias_init_with_prob(0.01)
- nn.init.constant_(self.fc_cls.bias, bias_init)
-
- @auto_fp16()
- def forward(self, roi_feat, proposal_feat):
- """Forward function of Dynamic Instance Interactive Head.
-
- Args:
- roi_feat (Tensor): Roi-pooling features with shape
- (batch_size*num_proposals, feature_dimensions,
- pooling_h , pooling_w).
- proposal_feat (Tensor): Intermediate feature get from
- diihead in last stage, has shape
- (batch_size, num_proposals, feature_dimensions)
-
- Returns:
- tuple[Tensor]: Usually a tuple of classification scores
- and bbox prediction and a intermediate feature.
-
- - cls_scores (Tensor): Classification scores for
- all proposals, has shape
- (batch_size, num_proposals, num_classes).
- - bbox_preds (Tensor): Box energies / deltas for
- all proposals, has shape
- (batch_size, num_proposals, 4).
- - obj_feat (Tensor): Object feature before classification
- and regression subnet, has shape
- (batch_size, num_proposal, feature_dimensions).
- """
- N, num_proposals = proposal_feat.shape[:2]
-
- # Self attention
- proposal_feat = proposal_feat.permute(1, 0, 2)
- proposal_feat = self.attention_norm(self.attention(proposal_feat))
-
- # instance interactive
- proposal_feat = proposal_feat.permute(1, 0,
- 2).reshape(-1, self.in_channels)
- proposal_feat_iic = self.instance_interactive_conv(
- proposal_feat, roi_feat)
- proposal_feat = proposal_feat + self.instance_interactive_conv_dropout(
- proposal_feat_iic)
- obj_feat = self.instance_interactive_conv_norm(proposal_feat)
-
- # FFN
- obj_feat = self.ffn_norm(self.ffn(obj_feat))
-
- cls_feat = obj_feat
- reg_feat = obj_feat
-
- for cls_layer in self.cls_fcs:
- cls_feat = cls_layer(cls_feat)
- for reg_layer in self.reg_fcs:
- reg_feat = reg_layer(reg_feat)
-
- cls_score = self.fc_cls(cls_feat).view(N, num_proposals, -1)
- bbox_delta = self.fc_reg(reg_feat).view(N, num_proposals, -1)
-
- return cls_score, bbox_delta, obj_feat.view(N, num_proposals, -1)
-
- @force_fp32(apply_to=('cls_score', 'bbox_pred'))
- def loss(self,
- cls_score,
- bbox_pred,
- labels,
- label_weights,
- bbox_targets,
- bbox_weights,
- imgs_whwh=None,
- reduction_override=None,
- **kwargs):
- """"Loss function of DIIHead, get loss of all images.
-
- Args:
- cls_score (Tensor): Classification prediction
- results of all class, has shape
- (batch_size * num_proposals_single_image, num_classes)
- bbox_pred (Tensor): Regression prediction results,
- has shape
- (batch_size * num_proposals_single_image, 4), the last
- dimension 4 represents [tl_x, tl_y, br_x, br_y].
- labels (Tensor): Label of each proposals, has shape
- (batch_size * num_proposals_single_image
- label_weights (Tensor): Classification loss
- weight of each proposals, has shape
- (batch_size * num_proposals_single_image
- bbox_targets (Tensor): Regression targets of each
- proposals, has shape
- (batch_size * num_proposals_single_image, 4),
- the last dimension 4 represents
- [tl_x, tl_y, br_x, br_y].
- bbox_weights (Tensor): Regression loss weight of each
- proposals's coordinate, has shape
- (batch_size * num_proposals_single_image, 4),
- imgs_whwh (Tensor): imgs_whwh (Tensor): Tensor with\
- shape (batch_size, num_proposals, 4), the last
- dimension means
- [img_width,img_height, img_width, img_height].
- reduction_override (str, optional): The reduction
- method used to override the original reduction
- method of the loss. Options are "none",
- "mean" and "sum". Defaults to None,
-
- Returns:
- dict[str, Tensor]: Dictionary of loss components
- """
- losses = dict()
- bg_class_ind = self.num_classes
- # note in spare rcnn num_gt == num_pos
- pos_inds = (labels >= 0) & (labels < bg_class_ind)
- num_pos = pos_inds.sum().float()
- avg_factor = reduce_mean(num_pos)
- if cls_score is not None:
- if cls_score.numel() > 0:
- losses['loss_cls'] = self.loss_cls(
- cls_score,
- labels,
- label_weights,
- avg_factor=avg_factor,
- reduction_override=reduction_override)
- losses['pos_acc'] = accuracy(cls_score[pos_inds],
- labels[pos_inds])
- if bbox_pred is not None:
- # 0~self.num_classes-1 are FG, self.num_classes is BG
- # do not perform bounding box regression for BG anymore.
- if pos_inds.any():
- pos_bbox_pred = bbox_pred.reshape(bbox_pred.size(0),
- 4)[pos_inds.type(torch.bool)]
- imgs_whwh = imgs_whwh.reshape(bbox_pred.size(0),
- 4)[pos_inds.type(torch.bool)]
- losses['loss_bbox'] = self.loss_bbox(
- pos_bbox_pred / imgs_whwh,
- bbox_targets[pos_inds.type(torch.bool)] / imgs_whwh,
- bbox_weights[pos_inds.type(torch.bool)],
- avg_factor=avg_factor)
- losses['loss_iou'] = self.loss_iou(
- pos_bbox_pred,
- bbox_targets[pos_inds.type(torch.bool)],
- bbox_weights[pos_inds.type(torch.bool)],
- avg_factor=avg_factor)
- else:
- losses['loss_bbox'] = bbox_pred.sum() * 0
- losses['loss_iou'] = bbox_pred.sum() * 0
- return losses
-
- def _get_target_single(self, pos_inds, neg_inds, pos_bboxes, neg_bboxes,
- pos_gt_bboxes, pos_gt_labels, cfg):
- """Calculate the ground truth for proposals in the single image
- according to the sampling results.
-
- Almost the same as the implementation in `bbox_head`,
- we add pos_inds and neg_inds to select positive and
- negative samples instead of selecting the first num_pos
- as positive samples.
-
- Args:
- pos_inds (Tensor): The length is equal to the
- positive sample numbers contain all index
- of the positive sample in the origin proposal set.
- neg_inds (Tensor): The length is equal to the
- negative sample numbers contain all index
- of the negative sample in the origin proposal set.
- pos_bboxes (Tensor): Contains all the positive boxes,
- has shape (num_pos, 4), the last dimension 4
- represents [tl_x, tl_y, br_x, br_y].
- neg_bboxes (Tensor): Contains all the negative boxes,
- has shape (num_neg, 4), the last dimension 4
- represents [tl_x, tl_y, br_x, br_y].
- pos_gt_bboxes (Tensor): Contains all the gt_boxes,
- has shape (num_gt, 4), the last dimension 4
- represents [tl_x, tl_y, br_x, br_y].
- pos_gt_labels (Tensor): Contains all the gt_labels,
- has shape (num_gt).
- cfg (obj:`ConfigDict`): `train_cfg` of R-CNN.
-
- Returns:
- Tuple[Tensor]: Ground truth for proposals in a single image.
- Containing the following Tensors:
-
- - labels(Tensor): Gt_labels for all proposals, has
- shape (num_proposals,).
- - label_weights(Tensor): Labels_weights for all proposals, has
- shape (num_proposals,).
- - bbox_targets(Tensor):Regression target for all proposals, has
- shape (num_proposals, 4), the last dimension 4
- represents [tl_x, tl_y, br_x, br_y].
- - bbox_weights(Tensor):Regression weights for all proposals,
- has shape (num_proposals, 4).
- """
- num_pos = pos_bboxes.size(0)
- num_neg = neg_bboxes.size(0)
- num_samples = num_pos + num_neg
-
- # original implementation uses new_zeros since BG are set to be 0
- # now use empty & fill because BG cat_id = num_classes,
- # FG cat_id = [0, num_classes-1]
- labels = pos_bboxes.new_full((num_samples, ),
- self.num_classes,
- dtype=torch.long)
- label_weights = pos_bboxes.new_zeros(num_samples)
- bbox_targets = pos_bboxes.new_zeros(num_samples, 4)
- bbox_weights = pos_bboxes.new_zeros(num_samples, 4)
- if num_pos > 0:
- labels[pos_inds] = pos_gt_labels
- pos_weight = 1.0 if cfg.pos_weight <= 0 else cfg.pos_weight
- label_weights[pos_inds] = pos_weight
- if not self.reg_decoded_bbox:
- pos_bbox_targets = self.bbox_coder.encode(
- pos_bboxes, pos_gt_bboxes)
- else:
- pos_bbox_targets = pos_gt_bboxes
- bbox_targets[pos_inds, :] = pos_bbox_targets
- bbox_weights[pos_inds, :] = 1
- if num_neg > 0:
- label_weights[neg_inds] = 1.0
-
- return labels, label_weights, bbox_targets, bbox_weights
-
- def get_targets(self,
- sampling_results,
- gt_bboxes,
- gt_labels,
- rcnn_train_cfg,
- concat=True):
- """Calculate the ground truth for all samples in a batch according to
- the sampling_results.
-
- Almost the same as the implementation in bbox_head, we passed
- additional parameters pos_inds_list and neg_inds_list to
- `_get_target_single` function.
-
- Args:
- sampling_results (List[obj:SamplingResults]): Assign results of
- all images in a batch after sampling.
- gt_bboxes (list[Tensor]): Gt_bboxes of all images in a batch,
- each tensor has shape (num_gt, 4), the last dimension 4
- represents [tl_x, tl_y, br_x, br_y].
- gt_labels (list[Tensor]): Gt_labels of all images in a batch,
- each tensor has shape (num_gt,).
- rcnn_train_cfg (obj:`ConfigDict`): `train_cfg` of RCNN.
- concat (bool): Whether to concatenate the results of all
- the images in a single batch.
-
- Returns:
- Tuple[Tensor]: Ground truth for proposals in a single image.
- Containing the following list of Tensors:
-
- - labels (list[Tensor],Tensor): Gt_labels for all
- proposals in a batch, each tensor in list has
- shape (num_proposals,) when `concat=False`, otherwise just
- a single tensor has shape (num_all_proposals,).
- - label_weights (list[Tensor]): Labels_weights for
- all proposals in a batch, each tensor in list has shape
- (num_proposals,) when `concat=False`, otherwise just a
- single tensor has shape (num_all_proposals,).
- - bbox_targets (list[Tensor],Tensor): Regression target
- for all proposals in a batch, each tensor in list has
- shape (num_proposals, 4) when `concat=False`, otherwise
- just a single tensor has shape (num_all_proposals, 4),
- the last dimension 4 represents [tl_x, tl_y, br_x, br_y].
- - bbox_weights (list[tensor],Tensor): Regression weights for
- all proposals in a batch, each tensor in list has shape
- (num_proposals, 4) when `concat=False`, otherwise just a
- single tensor has shape (num_all_proposals, 4).
- """
- pos_inds_list = [res.pos_inds for res in sampling_results]
- neg_inds_list = [res.neg_inds for res in sampling_results]
- pos_bboxes_list = [res.pos_bboxes for res in sampling_results]
- neg_bboxes_list = [res.neg_bboxes for res in sampling_results]
- pos_gt_bboxes_list = [res.pos_gt_bboxes for res in sampling_results]
- pos_gt_labels_list = [res.pos_gt_labels for res in sampling_results]
- labels, label_weights, bbox_targets, bbox_weights = multi_apply(
- self._get_target_single,
- pos_inds_list,
- neg_inds_list,
- pos_bboxes_list,
- neg_bboxes_list,
- pos_gt_bboxes_list,
- pos_gt_labels_list,
- cfg=rcnn_train_cfg)
- if concat:
- labels = torch.cat(labels, 0)
- label_weights = torch.cat(label_weights, 0)
- bbox_targets = torch.cat(bbox_targets, 0)
- bbox_weights = torch.cat(bbox_weights, 0)
- return labels, label_weights, bbox_targets, bbox_weights
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/roi_heads/roi_extractors/__init__.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/roi_heads/roi_extractors/__init__.py
deleted file mode 100644
index a6ec0ecc3063cd23c2463f2f53f1c2a83b04d43b..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/roi_heads/roi_extractors/__init__.py
+++ /dev/null
@@ -1,7 +0,0 @@
-from .generic_roi_extractor import GenericRoIExtractor
-from .single_level_roi_extractor import SingleRoIExtractor
-
-__all__ = [
- 'SingleRoIExtractor',
- 'GenericRoIExtractor',
-]
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/models/backbones/__init__.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/models/backbones/__init__.py
deleted file mode 100644
index 8339983905fb5d20bae42ba6f76fea75d278b1aa..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/models/backbones/__init__.py
+++ /dev/null
@@ -1,17 +0,0 @@
-from .cgnet import CGNet
-# from .fast_scnn import FastSCNN
-from .hrnet import HRNet
-from .mobilenet_v2 import MobileNetV2
-from .mobilenet_v3 import MobileNetV3
-from .resnest import ResNeSt
-from .resnet import ResNet, ResNetV1c, ResNetV1d
-from .resnext import ResNeXt
-from .unet import UNet
-from .vit import VisionTransformer
-from .uniformer import UniFormer
-
-__all__ = [
- 'ResNet', 'ResNetV1c', 'ResNetV1d', 'ResNeXt', 'HRNet',
- 'ResNeSt', 'MobileNetV2', 'UNet', 'CGNet', 'MobileNetV3',
- 'VisionTransformer', 'UniFormer'
-]
diff --git a/spaces/abrar-lohia/text-2-character-anim/VQTrans/models/pos_encoding.py b/spaces/abrar-lohia/text-2-character-anim/VQTrans/models/pos_encoding.py
deleted file mode 100644
index 066be3e1f8a1636f7eaabd1c534b9c618ee3e9f8..0000000000000000000000000000000000000000
--- a/spaces/abrar-lohia/text-2-character-anim/VQTrans/models/pos_encoding.py
+++ /dev/null
@@ -1,43 +0,0 @@
-"""
-Various positional encodings for the transformer.
-"""
-import math
-import torch
-from torch import nn
-
-def PE1d_sincos(seq_length, dim):
- """
- :param d_model: dimension of the model
- :param length: length of positions
- :return: length*d_model position matrix
- """
- if dim % 2 != 0:
- raise ValueError("Cannot use sin/cos positional encoding with "
- "odd dim (got dim={:d})".format(dim))
- pe = torch.zeros(seq_length, dim)
- position = torch.arange(0, seq_length).unsqueeze(1)
- div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) *
- -(math.log(10000.0) / dim)))
- pe[:, 0::2] = torch.sin(position.float() * div_term)
- pe[:, 1::2] = torch.cos(position.float() * div_term)
-
- return pe.unsqueeze(1)
-
-
-class PositionEmbedding(nn.Module):
- """
- Absolute pos embedding (standard), learned.
- """
- def __init__(self, seq_length, dim, dropout, grad=False):
- super().__init__()
- self.embed = nn.Parameter(data=PE1d_sincos(seq_length, dim), requires_grad=grad)
- self.dropout = nn.Dropout(p=dropout)
-
- def forward(self, x):
- # x.shape: bs, seq_len, feat_dim
- l = x.shape[1]
- x = x.permute(1, 0, 2) + self.embed[:l].expand(x.permute(1, 0, 2).shape)
- x = self.dropout(x.permute(1, 0, 2))
- return x
-
-
\ No newline at end of file
diff --git a/spaces/adirik/stylemc-demo/encoder4editing/models/discriminator.py b/spaces/adirik/stylemc-demo/encoder4editing/models/discriminator.py
deleted file mode 100644
index 16bf3722c7f2e35cdc9bd177a33ed0975e67200d..0000000000000000000000000000000000000000
--- a/spaces/adirik/stylemc-demo/encoder4editing/models/discriminator.py
+++ /dev/null
@@ -1,20 +0,0 @@
-from torch import nn
-
-
-class LatentCodesDiscriminator(nn.Module):
- def __init__(self, style_dim, n_mlp):
- super().__init__()
-
- self.style_dim = style_dim
-
- layers = []
- for i in range(n_mlp-1):
- layers.append(
- nn.Linear(style_dim, style_dim)
- )
- layers.append(nn.LeakyReLU(0.2))
- layers.append(nn.Linear(512, 1))
- self.mlp = nn.Sequential(*layers)
-
- def forward(self, w):
- return self.mlp(w)
diff --git a/spaces/akhaliq/VideoMAE/README.md b/spaces/akhaliq/VideoMAE/README.md
deleted file mode 100644
index 172169d116e4ea9302aca57e6be05bc37bd84d39..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/VideoMAE/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: VideoMAE
-emoji: 💩
-colorFrom: pink
-colorTo: pink
-sdk: gradio
-sdk_version: 3.1.7
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/akhaliq/deeplab2/data/dataloader/__init__.py b/spaces/akhaliq/deeplab2/data/dataloader/__init__.py
deleted file mode 100644
index 35e4ce02ff422f3aa84ab644b88d65b13e0cbc03..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/deeplab2/data/dataloader/__init__.py
+++ /dev/null
@@ -1,15 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The Deeplab2 Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
diff --git a/spaces/akhaliq/yolov7/models/yolo.py b/spaces/akhaliq/yolov7/models/yolo.py
deleted file mode 100644
index 7e1b3da17252dd574c4ddbb00ab522f2d522f5c9..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/yolov7/models/yolo.py
+++ /dev/null
@@ -1,550 +0,0 @@
-import argparse
-import logging
-import sys
-from copy import deepcopy
-
-sys.path.append('./') # to run '$ python *.py' files in subdirectories
-logger = logging.getLogger(__name__)
-
-from models.common import *
-from models.experimental import *
-from utils.autoanchor import check_anchor_order
-from utils.general import make_divisible, check_file, set_logging
-from utils.torch_utils import time_synchronized, fuse_conv_and_bn, model_info, scale_img, initialize_weights, \
- select_device, copy_attr
-from utils.loss import SigmoidBin
-
-try:
- import thop # for FLOPS computation
-except ImportError:
- thop = None
-
-
-class Detect(nn.Module):
- stride = None # strides computed during build
- export = False # onnx export
-
- def __init__(self, nc=80, anchors=(), ch=()): # detection layer
- super(Detect, self).__init__()
- self.nc = nc # number of classes
- self.no = nc + 5 # number of outputs per anchor
- self.nl = len(anchors) # number of detection layers
- self.na = len(anchors[0]) // 2 # number of anchors
- self.grid = [torch.zeros(1)] * self.nl # init grid
- a = torch.tensor(anchors).float().view(self.nl, -1, 2)
- self.register_buffer('anchors', a) # shape(nl,na,2)
- self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
- self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
-
- def forward(self, x):
- # x = x.copy() # for profiling
- z = [] # inference output
- self.training |= self.export
- for i in range(self.nl):
- x[i] = self.m[i](x[i]) # conv
- bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
- x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
-
- if not self.training: # inference
- if self.grid[i].shape[2:4] != x[i].shape[2:4]:
- self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
-
- y = x[i].sigmoid()
- y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
- y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
- z.append(y.view(bs, -1, self.no))
-
- return x if self.training else (torch.cat(z, 1), x)
-
- @staticmethod
- def _make_grid(nx=20, ny=20):
- yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
- return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
-
-
-class IDetect(nn.Module):
- stride = None # strides computed during build
- export = False # onnx export
-
- def __init__(self, nc=80, anchors=(), ch=()): # detection layer
- super(IDetect, self).__init__()
- self.nc = nc # number of classes
- self.no = nc + 5 # number of outputs per anchor
- self.nl = len(anchors) # number of detection layers
- self.na = len(anchors[0]) // 2 # number of anchors
- self.grid = [torch.zeros(1)] * self.nl # init grid
- a = torch.tensor(anchors).float().view(self.nl, -1, 2)
- self.register_buffer('anchors', a) # shape(nl,na,2)
- self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
- self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
-
- self.ia = nn.ModuleList(ImplicitA(x) for x in ch)
- self.im = nn.ModuleList(ImplicitM(self.no * self.na) for _ in ch)
-
- def forward(self, x):
- # x = x.copy() # for profiling
- z = [] # inference output
- self.training |= self.export
- for i in range(self.nl):
- x[i] = self.m[i](self.ia[i](x[i])) # conv
- x[i] = self.im[i](x[i])
- bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
- x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
-
- if not self.training: # inference
- if self.grid[i].shape[2:4] != x[i].shape[2:4]:
- self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
-
- y = x[i].sigmoid()
- y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
- y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
- z.append(y.view(bs, -1, self.no))
-
- return x if self.training else (torch.cat(z, 1), x)
-
- @staticmethod
- def _make_grid(nx=20, ny=20):
- yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
- return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
-
-
-class IAuxDetect(nn.Module):
- stride = None # strides computed during build
- export = False # onnx export
-
- def __init__(self, nc=80, anchors=(), ch=()): # detection layer
- super(IAuxDetect, self).__init__()
- self.nc = nc # number of classes
- self.no = nc + 5 # number of outputs per anchor
- self.nl = len(anchors) # number of detection layers
- self.na = len(anchors[0]) // 2 # number of anchors
- self.grid = [torch.zeros(1)] * self.nl # init grid
- a = torch.tensor(anchors).float().view(self.nl, -1, 2)
- self.register_buffer('anchors', a) # shape(nl,na,2)
- self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
- self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch[:self.nl]) # output conv
- self.m2 = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch[self.nl:]) # output conv
-
- self.ia = nn.ModuleList(ImplicitA(x) for x in ch[:self.nl])
- self.im = nn.ModuleList(ImplicitM(self.no * self.na) for _ in ch[:self.nl])
-
- def forward(self, x):
- # x = x.copy() # for profiling
- z = [] # inference output
- self.training |= self.export
- for i in range(self.nl):
- x[i] = self.m[i](self.ia[i](x[i])) # conv
- x[i] = self.im[i](x[i])
- bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
- x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
-
- x[i+self.nl] = self.m2[i](x[i+self.nl])
- x[i+self.nl] = x[i+self.nl].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
-
- if not self.training: # inference
- if self.grid[i].shape[2:4] != x[i].shape[2:4]:
- self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
-
- y = x[i].sigmoid()
- y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
- y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
- z.append(y.view(bs, -1, self.no))
-
- return x if self.training else (torch.cat(z, 1), x[:self.nl])
-
- @staticmethod
- def _make_grid(nx=20, ny=20):
- yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
- return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
-
-
-class IBin(nn.Module):
- stride = None # strides computed during build
- export = False # onnx export
-
- def __init__(self, nc=80, anchors=(), ch=(), bin_count=21): # detection layer
- super(IBin, self).__init__()
- self.nc = nc # number of classes
- self.bin_count = bin_count
-
- self.w_bin_sigmoid = SigmoidBin(bin_count=self.bin_count, min=0.0, max=4.0)
- self.h_bin_sigmoid = SigmoidBin(bin_count=self.bin_count, min=0.0, max=4.0)
- # classes, x,y,obj
- self.no = nc + 3 + \
- self.w_bin_sigmoid.get_length() + self.h_bin_sigmoid.get_length() # w-bce, h-bce
- # + self.x_bin_sigmoid.get_length() + self.y_bin_sigmoid.get_length()
-
- self.nl = len(anchors) # number of detection layers
- self.na = len(anchors[0]) // 2 # number of anchors
- self.grid = [torch.zeros(1)] * self.nl # init grid
- a = torch.tensor(anchors).float().view(self.nl, -1, 2)
- self.register_buffer('anchors', a) # shape(nl,na,2)
- self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
- self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
-
- self.ia = nn.ModuleList(ImplicitA(x) for x in ch)
- self.im = nn.ModuleList(ImplicitM(self.no * self.na) for _ in ch)
-
- def forward(self, x):
-
- #self.x_bin_sigmoid.use_fw_regression = True
- #self.y_bin_sigmoid.use_fw_regression = True
- self.w_bin_sigmoid.use_fw_regression = True
- self.h_bin_sigmoid.use_fw_regression = True
-
- # x = x.copy() # for profiling
- z = [] # inference output
- self.training |= self.export
- for i in range(self.nl):
- x[i] = self.m[i](self.ia[i](x[i])) # conv
- x[i] = self.im[i](x[i])
- bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
- x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
-
- if not self.training: # inference
- if self.grid[i].shape[2:4] != x[i].shape[2:4]:
- self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
-
- y = x[i].sigmoid()
- y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
- #y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
-
-
- #px = (self.x_bin_sigmoid.forward(y[..., 0:12]) + self.grid[i][..., 0]) * self.stride[i]
- #py = (self.y_bin_sigmoid.forward(y[..., 12:24]) + self.grid[i][..., 1]) * self.stride[i]
-
- pw = self.w_bin_sigmoid.forward(y[..., 2:24]) * self.anchor_grid[i][..., 0]
- ph = self.h_bin_sigmoid.forward(y[..., 24:46]) * self.anchor_grid[i][..., 1]
-
- #y[..., 0] = px
- #y[..., 1] = py
- y[..., 2] = pw
- y[..., 3] = ph
-
- y = torch.cat((y[..., 0:4], y[..., 46:]), dim=-1)
-
- z.append(y.view(bs, -1, y.shape[-1]))
-
- return x if self.training else (torch.cat(z, 1), x)
-
- @staticmethod
- def _make_grid(nx=20, ny=20):
- yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
- return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
-
-
-class Model(nn.Module):
- def __init__(self, cfg='yolor-csp-c.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
- super(Model, self).__init__()
- self.traced = False
- if isinstance(cfg, dict):
- self.yaml = cfg # model dict
- else: # is *.yaml
- import yaml # for torch hub
- self.yaml_file = Path(cfg).name
- with open(cfg) as f:
- self.yaml = yaml.load(f, Loader=yaml.SafeLoader) # model dict
-
- # Define model
- ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
- if nc and nc != self.yaml['nc']:
- logger.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
- self.yaml['nc'] = nc # override yaml value
- if anchors:
- logger.info(f'Overriding model.yaml anchors with anchors={anchors}')
- self.yaml['anchors'] = round(anchors) # override yaml value
- self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
- self.names = [str(i) for i in range(self.yaml['nc'])] # default names
- # print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
-
- # Build strides, anchors
- m = self.model[-1] # Detect()
- if isinstance(m, Detect):
- s = 256 # 2x min stride
- m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
- m.anchors /= m.stride.view(-1, 1, 1)
- check_anchor_order(m)
- self.stride = m.stride
- self._initialize_biases() # only run once
- # print('Strides: %s' % m.stride.tolist())
- if isinstance(m, IDetect):
- s = 256 # 2x min stride
- m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
- m.anchors /= m.stride.view(-1, 1, 1)
- check_anchor_order(m)
- self.stride = m.stride
- self._initialize_biases() # only run once
- # print('Strides: %s' % m.stride.tolist())
- if isinstance(m, IAuxDetect):
- s = 256 # 2x min stride
- m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))[:4]]) # forward
- #print(m.stride)
- m.anchors /= m.stride.view(-1, 1, 1)
- check_anchor_order(m)
- self.stride = m.stride
- self._initialize_aux_biases() # only run once
- # print('Strides: %s' % m.stride.tolist())
- if isinstance(m, IBin):
- s = 256 # 2x min stride
- m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
- m.anchors /= m.stride.view(-1, 1, 1)
- check_anchor_order(m)
- self.stride = m.stride
- self._initialize_biases_bin() # only run once
- # print('Strides: %s' % m.stride.tolist())
-
- # Init weights, biases
- initialize_weights(self)
- self.info()
- logger.info('')
-
- def forward(self, x, augment=False, profile=False):
- if augment:
- img_size = x.shape[-2:] # height, width
- s = [1, 0.83, 0.67] # scales
- f = [None, 3, None] # flips (2-ud, 3-lr)
- y = [] # outputs
- for si, fi in zip(s, f):
- xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
- yi = self.forward_once(xi)[0] # forward
- # cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
- yi[..., :4] /= si # de-scale
- if fi == 2:
- yi[..., 1] = img_size[0] - yi[..., 1] # de-flip ud
- elif fi == 3:
- yi[..., 0] = img_size[1] - yi[..., 0] # de-flip lr
- y.append(yi)
- return torch.cat(y, 1), None # augmented inference, train
- else:
- return self.forward_once(x, profile) # single-scale inference, train
-
- def forward_once(self, x, profile=False):
- y, dt = [], [] # outputs
- for m in self.model:
- if m.f != -1: # if not from previous layer
- x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
-
- if not hasattr(self, 'traced'):
- self.traced=False
-
- if self.traced:
- if isinstance(m, Detect) or isinstance(m, IDetect) or isinstance(m, IAuxDetect):
- break
-
- if profile:
- c = isinstance(m, (Detect, IDetect, IAuxDetect, IBin))
- o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPS
- for _ in range(10):
- m(x.copy() if c else x)
- t = time_synchronized()
- for _ in range(10):
- m(x.copy() if c else x)
- dt.append((time_synchronized() - t) * 100)
- print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
-
- x = m(x) # run
-
- y.append(x if m.i in self.save else None) # save output
-
- if profile:
- print('%.1fms total' % sum(dt))
- return x
-
- def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
- # https://arxiv.org/abs/1708.02002 section 3.3
- # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
- m = self.model[-1] # Detect() module
- for mi, s in zip(m.m, m.stride): # from
- b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
- b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
- b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
- mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
-
- def _initialize_aux_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
- # https://arxiv.org/abs/1708.02002 section 3.3
- # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
- m = self.model[-1] # Detect() module
- for mi, mi2, s in zip(m.m, m.m2, m.stride): # from
- b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
- b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
- b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
- mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
- b2 = mi2.bias.view(m.na, -1) # conv.bias(255) to (3,85)
- b2.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
- b2.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
- mi2.bias = torch.nn.Parameter(b2.view(-1), requires_grad=True)
-
- def _initialize_biases_bin(self, cf=None): # initialize biases into Detect(), cf is class frequency
- # https://arxiv.org/abs/1708.02002 section 3.3
- # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
- m = self.model[-1] # Bin() module
- bc = m.bin_count
- for mi, s in zip(m.m, m.stride): # from
- b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
- old = b[:, (0,1,2,bc+3)].data
- obj_idx = 2*bc+4
- b[:, :obj_idx].data += math.log(0.6 / (bc + 1 - 0.99))
- b[:, obj_idx].data += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
- b[:, (obj_idx+1):].data += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
- b[:, (0,1,2,bc+3)].data = old
- mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
-
- def _print_biases(self):
- m = self.model[-1] # Detect() module
- for mi in m.m: # from
- b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
- print(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
-
- # def _print_weights(self):
- # for m in self.model.modules():
- # if type(m) is Bottleneck:
- # print('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
-
- def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
- print('Fusing layers... ')
- for m in self.model.modules():
- if isinstance(m, RepConv):
- #print(f" fuse_repvgg_block")
- m.fuse_repvgg_block()
- elif isinstance(m, RepConv_OREPA):
- #print(f" switch_to_deploy")
- m.switch_to_deploy()
- elif type(m) is Conv and hasattr(m, 'bn'):
- m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
- delattr(m, 'bn') # remove batchnorm
- m.forward = m.fuseforward # update forward
- self.info()
- return self
-
- def nms(self, mode=True): # add or remove NMS module
- present = type(self.model[-1]) is NMS # last layer is NMS
- if mode and not present:
- print('Adding NMS... ')
- m = NMS() # module
- m.f = -1 # from
- m.i = self.model[-1].i + 1 # index
- self.model.add_module(name='%s' % m.i, module=m) # add
- self.eval()
- elif not mode and present:
- print('Removing NMS... ')
- self.model = self.model[:-1] # remove
- return self
-
- def autoshape(self): # add autoShape module
- print('Adding autoShape... ')
- m = autoShape(self) # wrap model
- copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
- return m
-
- def info(self, verbose=False, img_size=640): # print model information
- model_info(self, verbose, img_size)
-
-
-def parse_model(d, ch): # model_dict, input_channels(3)
- logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
- anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
- na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
- no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
-
- layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
- for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
- m = eval(m) if isinstance(m, str) else m # eval strings
- for j, a in enumerate(args):
- try:
- args[j] = eval(a) if isinstance(a, str) else a # eval strings
- except:
- pass
-
- n = max(round(n * gd), 1) if n > 1 else n # depth gain
- if m in [nn.Conv2d, Conv, RobustConv, RobustConv2, DWConv, GhostConv, RepConv, RepConv_OREPA, DownC,
- SPP, SPPF, SPPCSPC, GhostSPPCSPC, MixConv2d, Focus, Stem, GhostStem, CrossConv,
- Bottleneck, BottleneckCSPA, BottleneckCSPB, BottleneckCSPC,
- RepBottleneck, RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC,
- Res, ResCSPA, ResCSPB, ResCSPC,
- RepRes, RepResCSPA, RepResCSPB, RepResCSPC,
- ResX, ResXCSPA, ResXCSPB, ResXCSPC,
- RepResX, RepResXCSPA, RepResXCSPB, RepResXCSPC,
- Ghost, GhostCSPA, GhostCSPB, GhostCSPC,
- SwinTransformerBlock, STCSPA, STCSPB, STCSPC,
- SwinTransformer2Block, ST2CSPA, ST2CSPB, ST2CSPC]:
- c1, c2 = ch[f], args[0]
- if c2 != no: # if not output
- c2 = make_divisible(c2 * gw, 8)
-
- args = [c1, c2, *args[1:]]
- if m in [DownC, SPPCSPC, GhostSPPCSPC,
- BottleneckCSPA, BottleneckCSPB, BottleneckCSPC,
- RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC,
- ResCSPA, ResCSPB, ResCSPC,
- RepResCSPA, RepResCSPB, RepResCSPC,
- ResXCSPA, ResXCSPB, ResXCSPC,
- RepResXCSPA, RepResXCSPB, RepResXCSPC,
- GhostCSPA, GhostCSPB, GhostCSPC,
- STCSPA, STCSPB, STCSPC,
- ST2CSPA, ST2CSPB, ST2CSPC]:
- args.insert(2, n) # number of repeats
- n = 1
- elif m is nn.BatchNorm2d:
- args = [ch[f]]
- elif m is Concat:
- c2 = sum([ch[x] for x in f])
- elif m is Chuncat:
- c2 = sum([ch[x] for x in f])
- elif m is Shortcut:
- c2 = ch[f[0]]
- elif m is Foldcut:
- c2 = ch[f] // 2
- elif m in [Detect, IDetect, IAuxDetect, IBin]:
- args.append([ch[x] for x in f])
- if isinstance(args[1], int): # number of anchors
- args[1] = [list(range(args[1] * 2))] * len(f)
- elif m is ReOrg:
- c2 = ch[f] * 4
- elif m is Contract:
- c2 = ch[f] * args[0] ** 2
- elif m is Expand:
- c2 = ch[f] // args[0] ** 2
- else:
- c2 = ch[f]
-
- m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
- t = str(m)[8:-2].replace('__main__.', '') # module type
- np = sum([x.numel() for x in m_.parameters()]) # number params
- m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
- logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
- save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
- layers.append(m_)
- if i == 0:
- ch = []
- ch.append(c2)
- return nn.Sequential(*layers), sorted(save)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--cfg', type=str, default='yolor-csp-c.yaml', help='model.yaml')
- parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
- parser.add_argument('--profile', action='store_true', help='profile model speed')
- opt = parser.parse_args()
- opt.cfg = check_file(opt.cfg) # check file
- set_logging()
- device = select_device(opt.device)
-
- # Create model
- model = Model(opt.cfg).to(device)
- model.train()
-
- if opt.profile:
- img = torch.rand(1, 3, 640, 640).to(device)
- y = model(img, profile=True)
-
- # Profile
- # img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
- # y = model(img, profile=True)
-
- # Tensorboard
- # from torch.utils.tensorboard import SummaryWriter
- # tb_writer = SummaryWriter()
- # print("Run 'tensorboard --logdir=models/runs' to view tensorboard at http://localhost:6006/")
- # tb_writer.add_graph(model.model, img) # add model to tensorboard
- # tb_writer.add_image('test', img[0], dataformats='CWH') # add model to tensorboard
diff --git a/spaces/alamin655/websurfx/public/static/colorschemes/one-dark.css b/spaces/alamin655/websurfx/public/static/colorschemes/one-dark.css
deleted file mode 100644
index 30f858e609bf66d5f369c48588bef93b8332c2ab..0000000000000000000000000000000000000000
--- a/spaces/alamin655/websurfx/public/static/colorschemes/one-dark.css
+++ /dev/null
@@ -1,11 +0,0 @@
-:root {
- --background-color: #282c34;
- --foreground-color: #abb2bf;
- --color-one: #3b4048;
- --color-two: #a3be8c;
- --color-three: #b48ead;
- --color-four: #c8ccd4;
- --color-five: #e06c75;
- --color-six: #61afef;
- --color-seven: #be5046;
-}
diff --git a/spaces/alexray/btc_predictor/templates/plot.html b/spaces/alexray/btc_predictor/templates/plot.html
deleted file mode 100644
index 8dca5f379d337bb8b464c911b33c14ad29c3355f..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/templates/plot.html
+++ /dev/null
@@ -1,32 +0,0 @@
-
-
-
- BTC Price and Investment Plot
-
-
-
-
BTC Price and Investment Plot
-
-
-
-
Interactive Plot
-
- {{ plot_url | safe }}
-
-
-
-
-
-
-
-
-
Table
- {% include 'table.html' %}
-
-
-
-
-
diff --git a/spaces/ali-ghamdan/deoldify/deoldify/layers.py b/spaces/ali-ghamdan/deoldify/deoldify/layers.py
deleted file mode 100644
index 858adb3b429f799860dbc3e818774e8d379e6a7e..0000000000000000000000000000000000000000
--- a/spaces/ali-ghamdan/deoldify/deoldify/layers.py
+++ /dev/null
@@ -1,46 +0,0 @@
-from fastai.layers import *
-from fastai.torch_core import *
-
-
-# The code below is meant to be merged into fastaiv1 ideally
-
-
-def custom_conv_layer(
- ni: int,
- nf: int,
- ks: int = 3,
- stride: int = 1,
- padding: int = None,
- bias: bool = None,
- is_1d: bool = False,
- norm_type: Optional[NormType] = NormType.Batch,
- use_activ: bool = True,
- leaky: float = None,
- transpose: bool = False,
- init: Callable = nn.init.kaiming_normal_,
- self_attention: bool = False,
- extra_bn: bool = False,
-):
- "Create a sequence of convolutional (`ni` to `nf`), ReLU (if `use_activ`) and batchnorm (if `bn`) layers."
- if padding is None:
- padding = (ks - 1) // 2 if not transpose else 0
- bn = norm_type in (NormType.Batch, NormType.BatchZero) or extra_bn == True
- if bias is None:
- bias = not bn
- conv_func = nn.ConvTranspose2d if transpose else nn.Conv1d if is_1d else nn.Conv2d
- conv = init_default(
- conv_func(ni, nf, kernel_size=ks, bias=bias, stride=stride, padding=padding),
- init,
- )
- if norm_type == NormType.Weight:
- conv = weight_norm(conv)
- elif norm_type == NormType.Spectral:
- conv = spectral_norm(conv)
- layers = [conv]
- if use_activ:
- layers.append(relu(True, leaky=leaky))
- if bn:
- layers.append((nn.BatchNorm1d if is_1d else nn.BatchNorm2d)(nf))
- if self_attention:
- layers.append(SelfAttention(nf))
- return nn.Sequential(*layers)
diff --git a/spaces/ali-ghamdan/deoldify/fastai/callbacks/fp16.py b/spaces/ali-ghamdan/deoldify/fastai/callbacks/fp16.py
deleted file mode 100644
index 2b83014fafe9bc34e1e0b87c3bd7b69e8f8c2a9d..0000000000000000000000000000000000000000
--- a/spaces/ali-ghamdan/deoldify/fastai/callbacks/fp16.py
+++ /dev/null
@@ -1,122 +0,0 @@
-"Callback support for half precision (fp16) training. Increases training speed."
-from ..torch_core import *
-from ..callback import *
-from ..basic_train import *
-from torch._utils import _unflatten_dense_tensors
-from torch.nn.utils import parameters_to_vector
-
-__all__ = ['MixedPrecision']
-
-def get_master(layer_groups:ModuleList, flat_master:bool=False) -> Tuple[List[List[Tensor]], List[List[Tensor]]]:
- "Return two lists, one for the model parameters in FP16 and one for the master parameters in FP32."
- split_params = split_no_wd_params(layer_groups)
- model_params = [[param for param in pg if param.requires_grad] for pg in split_params]
- if flat_master:
- master_params = []
- for lg in model_params:
- if len(lg) !=0 :
- mp = parameters_to_vector([param.data.float() for param in lg])
- mp = torch.nn.Parameter(mp, requires_grad=True)
- if mp.grad is None: mp.grad = mp.new(*mp.size())
- master_params.append([mp])
- else: master_params.append([])
- return model_params, master_params
- else:
- master_params = [[param.clone().float().detach() for param in lg] for lg in model_params]
- for mp in master_params:
- for param in mp: param.requires_grad = True
- return model_params, master_params
-
-def model_g2master_g(model_params:Sequence[Tensor], master_params:Sequence[Tensor], flat_master:bool=False)->None:
- "Copy the `model_params` gradients to `master_params` for the optimizer step."
- if flat_master:
- for model_group,master_group in zip(model_params,master_params):
- if len(master_group) != 0:
- if master_group[0].grad is None: master_group[0].grad = master_group[0].data.new(*master_group[0].data.size())
- master_group[0].grad.data.copy_(parameters_to_vector([p.grad.data.float() for p in model_group]))
- else:
- for model_group,master_group in zip(model_params,master_params):
- for model, master in zip(model_group, master_group):
- if model.grad is not None:
- if master.grad is None: master.grad = master.data.new(*master.data.size())
- master.grad.data.copy_(model.grad.data)
- else: master.grad = None
-
-def master2model(model_params:Sequence[Tensor], master_params:Sequence[Tensor], flat_master:bool=False)->None:
- "Copy `master_params` to `model_params`."
- if flat_master:
- for model_group,master_group in zip(model_params,master_params):
- if len(model_group) != 0:
- for model, master in zip(model_group, _unflatten_dense_tensors(master_group[0].data, model_group)):
- model.data.copy_(master)
- else:
- for model_group,master_group in zip(model_params,master_params):
- for model, master in zip(model_group, master_group): model.data.copy_(master.data)
-
-def grad_overflow(param_group):
- for group in param_group:
- for p in group:
- if p.grad is not None:
- s = float(p.grad.data.float().sum())
- if s == float('inf') or s == float('-inf') or s != s: return True
- return False
-
-class MixedPrecision(LearnerCallback):
- _order = 999 #Need to run after things that could call on_backward_begin and change the loss
- "Callback that handles mixed-precision training."
- def __init__(self, learn:Learner, loss_scale:float=None, max_noskip:int=1000, dynamic:bool=True, clip:float=None,
- flat_master:bool=False, max_scale:float=2**24):
- super().__init__(learn)
- self.flat_master,self.dynamic,self.max_noskip,self.clip,self.max_scale = flat_master,dynamic,max_noskip,clip,max_scale
- self.loss_scale = ifnone(loss_scale, 2**16 if dynamic else 512)
- self.not_min += ['model_params', 'master_params']
- assert torch.backends.cudnn.enabled, "Mixed precision training requires cudnn."
- self.opt = None
-
- def on_train_begin(self, **kwargs:Any)->None:
- "Prepare the master model."
- #Get a copy of the model params in FP32
- self.model_params, self.master_params = get_master(self.learn.layer_groups, self.flat_master)
- #Changes the optimizer so that the optimization step is done in FP32.
- new_opt = self.learn.opt.new_with_params(self.master_params)
- if self.opt is not None:
- self.opt.lr,self.opt.wd = self.learn.opt.lr,self.learn.opt.wd
- new_opt.load_state_dict(self.opt)
- self.learn.opt.opt = new_opt.opt
- self.noskip = 0
-
- def on_loss_begin(self, last_output:Tensor, **kwargs:Any) -> Tensor:
- "Convert half precision output to FP32 to avoid reduction overflow."
- return {'last_output': to_float(last_output)}
-
- def on_backward_begin(self, last_loss:Rank0Tensor, **kwargs:Any) -> Rank0Tensor:
- "Scale gradients up by `self.loss_scale` to prevent underflow."
- #To avoid gradient underflow, we scale the gradients
- ret_loss = last_loss * self.loss_scale
- return {'last_loss': ret_loss}
-
- def on_backward_end(self, **kwargs:Any)->None:
- "Convert the gradients back to FP32 and divide them by the scale."
- if self.dynamic and grad_overflow(self.model_params) and self.loss_scale > 1:
- self.loss_scale /= 2
- self.noskip = 0
- #The step will be skipped since we don't update the master grads so they are all None or zero
- else:
- model_g2master_g(self.model_params, self.master_params, self.flat_master)
- for group in self.master_params:
- for param in group:
- if param.grad is not None: param.grad.div_(self.loss_scale)
- if self.clip is not None:
- for group in self.master_params: nn.utils.clip_grad_norm_(group, self.clip)
- if not self.dynamic: return
- self.noskip += 1
- if self.noskip >= self.max_noskip and self.loss_scale < self.max_scale:
- self.loss_scale *= 2
- self.noskip = 0
-
- def on_step_end(self, **kwargs:Any)->None:
- "Update the params from master to model and zero grad."
- #Zeros the gradients of the model since the optimizer is disconnected.
- self.learn.model.zero_grad()
- #Update the params from master to model.
- master2model(self.model_params, self.master_params, self.flat_master)
diff --git a/spaces/ali-ghamdan/gfp-Gans/gfpgan/archs/gfpganv1_clean_arch.py b/spaces/ali-ghamdan/gfp-Gans/gfpgan/archs/gfpganv1_clean_arch.py
deleted file mode 100644
index eb2e15d288bf0ad641034ed58d5dab37b0baabb3..0000000000000000000000000000000000000000
--- a/spaces/ali-ghamdan/gfp-Gans/gfpgan/archs/gfpganv1_clean_arch.py
+++ /dev/null
@@ -1,324 +0,0 @@
-import math
-import random
-import torch
-from basicsr.utils.registry import ARCH_REGISTRY
-from torch import nn
-from torch.nn import functional as F
-
-from .stylegan2_clean_arch import StyleGAN2GeneratorClean
-
-
-class StyleGAN2GeneratorCSFT(StyleGAN2GeneratorClean):
- """StyleGAN2 Generator with SFT modulation (Spatial Feature Transform).
-
- It is the clean version without custom compiled CUDA extensions used in StyleGAN2.
-
- Args:
- out_size (int): The spatial size of outputs.
- num_style_feat (int): Channel number of style features. Default: 512.
- num_mlp (int): Layer number of MLP style layers. Default: 8.
- channel_multiplier (int): Channel multiplier for large networks of StyleGAN2. Default: 2.
- narrow (float): The narrow ratio for channels. Default: 1.
- sft_half (bool): Whether to apply SFT on half of the input channels. Default: False.
- """
-
- def __init__(self, out_size, num_style_feat=512, num_mlp=8, channel_multiplier=2, narrow=1, sft_half=False):
- super(StyleGAN2GeneratorCSFT, self).__init__(
- out_size,
- num_style_feat=num_style_feat,
- num_mlp=num_mlp,
- channel_multiplier=channel_multiplier,
- narrow=narrow)
- self.sft_half = sft_half
-
- def forward(self,
- styles,
- conditions,
- input_is_latent=False,
- noise=None,
- randomize_noise=True,
- truncation=1,
- truncation_latent=None,
- inject_index=None,
- return_latents=False):
- """Forward function for StyleGAN2GeneratorCSFT.
-
- Args:
- styles (list[Tensor]): Sample codes of styles.
- conditions (list[Tensor]): SFT conditions to generators.
- input_is_latent (bool): Whether input is latent style. Default: False.
- noise (Tensor | None): Input noise or None. Default: None.
- randomize_noise (bool): Randomize noise, used when 'noise' is False. Default: True.
- truncation (float): The truncation ratio. Default: 1.
- truncation_latent (Tensor | None): The truncation latent tensor. Default: None.
- inject_index (int | None): The injection index for mixing noise. Default: None.
- return_latents (bool): Whether to return style latents. Default: False.
- """
- # style codes -> latents with Style MLP layer
- if not input_is_latent:
- styles = [self.style_mlp(s) for s in styles]
- # noises
- if noise is None:
- if randomize_noise:
- noise = [None] * self.num_layers # for each style conv layer
- else: # use the stored noise
- noise = [getattr(self.noises, f'noise{i}') for i in range(self.num_layers)]
- # style truncation
- if truncation < 1:
- style_truncation = []
- for style in styles:
- style_truncation.append(truncation_latent + truncation * (style - truncation_latent))
- styles = style_truncation
- # get style latents with injection
- if len(styles) == 1:
- inject_index = self.num_latent
-
- if styles[0].ndim < 3:
- # repeat latent code for all the layers
- latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
- else: # used for encoder with different latent code for each layer
- latent = styles[0]
- elif len(styles) == 2: # mixing noises
- if inject_index is None:
- inject_index = random.randint(1, self.num_latent - 1)
- latent1 = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
- latent2 = styles[1].unsqueeze(1).repeat(1, self.num_latent - inject_index, 1)
- latent = torch.cat([latent1, latent2], 1)
-
- # main generation
- out = self.constant_input(latent.shape[0])
- out = self.style_conv1(out, latent[:, 0], noise=noise[0])
- skip = self.to_rgb1(out, latent[:, 1])
-
- i = 1
- for conv1, conv2, noise1, noise2, to_rgb in zip(self.style_convs[::2], self.style_convs[1::2], noise[1::2],
- noise[2::2], self.to_rgbs):
- out = conv1(out, latent[:, i], noise=noise1)
-
- # the conditions may have fewer levels
- if i < len(conditions):
- # SFT part to combine the conditions
- if self.sft_half: # only apply SFT to half of the channels
- out_same, out_sft = torch.split(out, int(out.size(1) // 2), dim=1)
- out_sft = out_sft * conditions[i - 1] + conditions[i]
- out = torch.cat([out_same, out_sft], dim=1)
- else: # apply SFT to all the channels
- out = out * conditions[i - 1] + conditions[i]
-
- out = conv2(out, latent[:, i + 1], noise=noise2)
- skip = to_rgb(out, latent[:, i + 2], skip) # feature back to the rgb space
- i += 2
-
- image = skip
-
- if return_latents:
- return image, latent
- else:
- return image, None
-
-
-class ResBlock(nn.Module):
- """Residual block with bilinear upsampling/downsampling.
-
- Args:
- in_channels (int): Channel number of the input.
- out_channels (int): Channel number of the output.
- mode (str): Upsampling/downsampling mode. Options: down | up. Default: down.
- """
-
- def __init__(self, in_channels, out_channels, mode='down'):
- super(ResBlock, self).__init__()
-
- self.conv1 = nn.Conv2d(in_channels, in_channels, 3, 1, 1)
- self.conv2 = nn.Conv2d(in_channels, out_channels, 3, 1, 1)
- self.skip = nn.Conv2d(in_channels, out_channels, 1, bias=False)
- if mode == 'down':
- self.scale_factor = 0.5
- elif mode == 'up':
- self.scale_factor = 2
-
- def forward(self, x):
- out = F.leaky_relu_(self.conv1(x), negative_slope=0.2)
- # upsample/downsample
- out = F.interpolate(out, scale_factor=self.scale_factor, mode='bilinear', align_corners=False)
- out = F.leaky_relu_(self.conv2(out), negative_slope=0.2)
- # skip
- x = F.interpolate(x, scale_factor=self.scale_factor, mode='bilinear', align_corners=False)
- skip = self.skip(x)
- out = out + skip
- return out
-
-
-@ARCH_REGISTRY.register()
-class GFPGANv1Clean(nn.Module):
- """The GFPGAN architecture: Unet + StyleGAN2 decoder with SFT.
-
- It is the clean version without custom compiled CUDA extensions used in StyleGAN2.
-
- Ref: GFP-GAN: Towards Real-World Blind Face Restoration with Generative Facial Prior.
-
- Args:
- out_size (int): The spatial size of outputs.
- num_style_feat (int): Channel number of style features. Default: 512.
- channel_multiplier (int): Channel multiplier for large networks of StyleGAN2. Default: 2.
- decoder_load_path (str): The path to the pre-trained decoder model (usually, the StyleGAN2). Default: None.
- fix_decoder (bool): Whether to fix the decoder. Default: True.
-
- num_mlp (int): Layer number of MLP style layers. Default: 8.
- input_is_latent (bool): Whether input is latent style. Default: False.
- different_w (bool): Whether to use different latent w for different layers. Default: False.
- narrow (float): The narrow ratio for channels. Default: 1.
- sft_half (bool): Whether to apply SFT on half of the input channels. Default: False.
- """
-
- def __init__(
- self,
- out_size,
- num_style_feat=512,
- channel_multiplier=1,
- decoder_load_path=None,
- fix_decoder=True,
- # for stylegan decoder
- num_mlp=8,
- input_is_latent=False,
- different_w=False,
- narrow=1,
- sft_half=False):
-
- super(GFPGANv1Clean, self).__init__()
- self.input_is_latent = input_is_latent
- self.different_w = different_w
- self.num_style_feat = num_style_feat
-
- unet_narrow = narrow * 0.5 # by default, use a half of input channels
- channels = {
- '4': int(512 * unet_narrow),
- '8': int(512 * unet_narrow),
- '16': int(512 * unet_narrow),
- '32': int(512 * unet_narrow),
- '64': int(256 * channel_multiplier * unet_narrow),
- '128': int(128 * channel_multiplier * unet_narrow),
- '256': int(64 * channel_multiplier * unet_narrow),
- '512': int(32 * channel_multiplier * unet_narrow),
- '1024': int(16 * channel_multiplier * unet_narrow)
- }
-
- self.log_size = int(math.log(out_size, 2))
- first_out_size = 2**(int(math.log(out_size, 2)))
-
- self.conv_body_first = nn.Conv2d(3, channels[f'{first_out_size}'], 1)
-
- # downsample
- in_channels = channels[f'{first_out_size}']
- self.conv_body_down = nn.ModuleList()
- for i in range(self.log_size, 2, -1):
- out_channels = channels[f'{2**(i - 1)}']
- self.conv_body_down.append(ResBlock(in_channels, out_channels, mode='down'))
- in_channels = out_channels
-
- self.final_conv = nn.Conv2d(in_channels, channels['4'], 3, 1, 1)
-
- # upsample
- in_channels = channels['4']
- self.conv_body_up = nn.ModuleList()
- for i in range(3, self.log_size + 1):
- out_channels = channels[f'{2**i}']
- self.conv_body_up.append(ResBlock(in_channels, out_channels, mode='up'))
- in_channels = out_channels
-
- # to RGB
- self.toRGB = nn.ModuleList()
- for i in range(3, self.log_size + 1):
- self.toRGB.append(nn.Conv2d(channels[f'{2**i}'], 3, 1))
-
- if different_w:
- linear_out_channel = (int(math.log(out_size, 2)) * 2 - 2) * num_style_feat
- else:
- linear_out_channel = num_style_feat
-
- self.final_linear = nn.Linear(channels['4'] * 4 * 4, linear_out_channel)
-
- # the decoder: stylegan2 generator with SFT modulations
- self.stylegan_decoder = StyleGAN2GeneratorCSFT(
- out_size=out_size,
- num_style_feat=num_style_feat,
- num_mlp=num_mlp,
- channel_multiplier=channel_multiplier,
- narrow=narrow,
- sft_half=sft_half)
-
- # load pre-trained stylegan2 model if necessary
- if decoder_load_path:
- self.stylegan_decoder.load_state_dict(
- torch.load(decoder_load_path, map_location=lambda storage, loc: storage)['params_ema'])
- # fix decoder without updating params
- if fix_decoder:
- for _, param in self.stylegan_decoder.named_parameters():
- param.requires_grad = False
-
- # for SFT modulations (scale and shift)
- self.condition_scale = nn.ModuleList()
- self.condition_shift = nn.ModuleList()
- for i in range(3, self.log_size + 1):
- out_channels = channels[f'{2**i}']
- if sft_half:
- sft_out_channels = out_channels
- else:
- sft_out_channels = out_channels * 2
- self.condition_scale.append(
- nn.Sequential(
- nn.Conv2d(out_channels, out_channels, 3, 1, 1), nn.LeakyReLU(0.2, True),
- nn.Conv2d(out_channels, sft_out_channels, 3, 1, 1)))
- self.condition_shift.append(
- nn.Sequential(
- nn.Conv2d(out_channels, out_channels, 3, 1, 1), nn.LeakyReLU(0.2, True),
- nn.Conv2d(out_channels, sft_out_channels, 3, 1, 1)))
-
- def forward(self, x, return_latents=False, return_rgb=True, randomize_noise=True):
- """Forward function for GFPGANv1Clean.
-
- Args:
- x (Tensor): Input images.
- return_latents (bool): Whether to return style latents. Default: False.
- return_rgb (bool): Whether return intermediate rgb images. Default: True.
- randomize_noise (bool): Randomize noise, used when 'noise' is False. Default: True.
- """
- conditions = []
- unet_skips = []
- out_rgbs = []
-
- # encoder
- feat = F.leaky_relu_(self.conv_body_first(x), negative_slope=0.2)
- for i in range(self.log_size - 2):
- feat = self.conv_body_down[i](feat)
- unet_skips.insert(0, feat)
- feat = F.leaky_relu_(self.final_conv(feat), negative_slope=0.2)
-
- # style code
- style_code = self.final_linear(feat.view(feat.size(0), -1))
- if self.different_w:
- style_code = style_code.view(style_code.size(0), -1, self.num_style_feat)
-
- # decode
- for i in range(self.log_size - 2):
- # add unet skip
- feat = feat + unet_skips[i]
- # ResUpLayer
- feat = self.conv_body_up[i](feat)
- # generate scale and shift for SFT layers
- scale = self.condition_scale[i](feat)
- conditions.append(scale.clone())
- shift = self.condition_shift[i](feat)
- conditions.append(shift.clone())
- # generate rgb images
- if return_rgb:
- out_rgbs.append(self.toRGB[i](feat))
-
- # decoder
- image, _ = self.stylegan_decoder([style_code],
- conditions,
- return_latents=return_latents,
- input_is_latent=self.input_is_latent,
- randomize_noise=randomize_noise)
-
- return image, out_rgbs
diff --git a/spaces/alibaba-pai/easyphoto/README.md b/spaces/alibaba-pai/easyphoto/README.md
deleted file mode 100644
index 70a2e1895d61587bc4d0be0415831d5d427755c9..0000000000000000000000000000000000000000
--- a/spaces/alibaba-pai/easyphoto/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Easyphoto
-emoji: 👁
-colorFrom: green
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.44.4
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/allknowingroger/Image-Models-Test72/app.py b/spaces/allknowingroger/Image-Models-Test72/app.py
deleted file mode 100644
index eea910667eb974aa74ecc7ed52508b8ffe6a5f49..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test72/app.py
+++ /dev/null
@@ -1,144 +0,0 @@
-import gradio as gr
-# import os
-# import sys
-# from pathlib import Path
-import time
-
-models =[
- "Hakim-Fang/textual_inversion_wfy_new_new",
- "Sivapriya2133/the-cat-csd",
- "Daniil-plotnikov/russian-vision-v6-2",
- "smit-mehta/orange-juice-ad",
- "Hakim-Fang/textual_inversion_wfy",
- "21j3h123/c0x001e",
- "Pixel390/NEWKAYV2",
- "debjxt/tlx-bzx-btz",
- "LinoyTsaban/huggy_v15",
-]
-
-
-model_functions = {}
-model_idx = 1
-for model_path in models:
- try:
- model_functions[model_idx] = gr.Interface.load(f"models/{model_path}", live=False, preprocess=True, postprocess=False)
- except Exception as error:
- def the_fn(txt):
- return None
- model_functions[model_idx] = gr.Interface(fn=the_fn, inputs=["text"], outputs=["image"])
- model_idx+=1
-
-
-def send_it_idx(idx):
- def send_it_fn(prompt):
- output = (model_functions.get(str(idx)) or model_functions.get(str(1)))(prompt)
- return output
- return send_it_fn
-
-def get_prompts(prompt_text):
- return prompt_text
-
-def clear_it(val):
- if int(val) != 0:
- val = 0
- else:
- val = 0
- pass
- return val
-
-def all_task_end(cnt,t_stamp):
- to = t_stamp + 60
- et = time.time()
- if et > to and t_stamp != 0:
- d = gr.update(value=0)
- tog = gr.update(value=1)
- #print(f'to: {to} et: {et}')
- else:
- if cnt != 0:
- d = gr.update(value=et)
- else:
- d = gr.update(value=0)
- tog = gr.update(value=0)
- #print (f'passing: to: {to} et: {et}')
- pass
- return d, tog
-
-def all_task_start():
- print("\n\n\n\n\n\n\n")
- t = time.gmtime()
- t_stamp = time.time()
- current_time = time.strftime("%H:%M:%S", t)
- return gr.update(value=t_stamp), gr.update(value=t_stamp), gr.update(value=0)
-
-def clear_fn():
- nn = len(models)
- return tuple([None, *[None for _ in range(nn)]])
-
-
-
-with gr.Blocks(title="SD Models") as my_interface:
- with gr.Column(scale=12):
- # with gr.Row():
- # gr.Markdown("""- Primary prompt: 你想画的内容(英文单词,如 a cat, 加英文逗号效果更好;点 Improve 按钮进行完善)\n- Real prompt: 完善后的提示词,出现后再点右边的 Run 按钮开始运行""")
- with gr.Row():
- with gr.Row(scale=6):
- primary_prompt=gr.Textbox(label="Prompt", value="")
- # real_prompt=gr.Textbox(label="Real prompt")
- with gr.Row(scale=6):
- # improve_prompts_btn=gr.Button("Improve")
- with gr.Row():
- run=gr.Button("Run",variant="primary")
- clear_btn=gr.Button("Clear")
- with gr.Row():
- sd_outputs = {}
- model_idx = 1
- for model_path in models:
- with gr.Column(scale=3, min_width=320):
- with gr.Box():
- sd_outputs[model_idx] = gr.Image(label=model_path)
- pass
- model_idx += 1
- pass
- pass
-
- with gr.Row(visible=False):
- start_box=gr.Number(interactive=False)
- end_box=gr.Number(interactive=False)
- tog_box=gr.Textbox(value=0,interactive=False)
-
- start_box.change(
- all_task_end,
- [start_box, end_box],
- [start_box, tog_box],
- every=1,
- show_progress=False)
-
- primary_prompt.submit(all_task_start, None, [start_box, end_box, tog_box])
- run.click(all_task_start, None, [start_box, end_box, tog_box])
- runs_dict = {}
- model_idx = 1
- for model_path in models:
- runs_dict[model_idx] = run.click(model_functions[model_idx], inputs=[primary_prompt], outputs=[sd_outputs[model_idx]])
- model_idx += 1
- pass
- pass
-
- # improve_prompts_btn_clicked=improve_prompts_btn.click(
- # get_prompts,
- # inputs=[primary_prompt],
- # outputs=[primary_prompt],
- # cancels=list(runs_dict.values()))
- clear_btn.click(
- clear_fn,
- None,
- [primary_prompt, *list(sd_outputs.values())],
- cancels=[*list(runs_dict.values())])
- tog_box.change(
- clear_it,
- tog_box,
- tog_box,
- cancels=[*list(runs_dict.values())])
-
-my_interface.queue(concurrency_count=600, status_update_rate=1)
-my_interface.launch(inline=True, show_api=False)
-
\ No newline at end of file
diff --git a/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/g4f/Provider/Providers/Bard.py b/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/g4f/Provider/Providers/Bard.py
deleted file mode 100644
index 4c37c4b719430031fce41ce49946f0e6ac93d155..0000000000000000000000000000000000000000
--- a/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/g4f/Provider/Providers/Bard.py
+++ /dev/null
@@ -1,74 +0,0 @@
-import os, requests, json, browser_cookie3, re, random
-from ...typing import sha256, Dict, get_type_hints
-
-url = 'https://bard.google.com'
-model = ['Palm2']
-supports_stream = False
-needs_auth = True
-
-def _create_completion(model: str, messages: list, stream: bool, **kwargs):
- psid = {cookie.name: cookie.value for cookie in browser_cookie3.chrome(
- domain_name='.google.com')}['__Secure-1PSID']
-
- formatted = '\n'.join([
- '%s: %s' % (message['role'], message['content']) for message in messages
- ])
- prompt = f'{formatted}\nAssistant:'
-
- proxy = kwargs.get('proxy', False)
- if proxy == False:
- print('warning!, you did not give a proxy, a lot of countries are banned from Google Bard, so it may not work')
-
- snlm0e = None
- conversation_id = None
- response_id = None
- choice_id = None
-
- client = requests.Session()
- client.proxies = {
- 'http': f'http://{proxy}',
- 'https': f'http://{proxy}'} if proxy else None
-
- client.headers = {
- 'authority': 'bard.google.com',
- 'content-type': 'application/x-www-form-urlencoded;charset=UTF-8',
- 'origin': 'https://bard.google.com',
- 'referer': 'https://bard.google.com/',
- 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
- 'x-same-domain': '1',
- 'cookie': f'__Secure-1PSID={psid}'
- }
-
- snlm0e = re.search(r'SNlM0e\":\"(.*?)\"',
- client.get('https://bard.google.com/').text).group(1) if not snlm0e else snlm0e
-
- params = {
- 'bl': 'boq_assistant-bard-web-server_20230326.21_p0',
- '_reqid': random.randint(1111, 9999),
- 'rt': 'c'
- }
-
- data = {
- 'at': snlm0e,
- 'f.req': json.dumps([None, json.dumps([[prompt], None, [conversation_id, response_id, choice_id]])])}
-
- intents = '.'.join([
- 'assistant',
- 'lamda',
- 'BardFrontendService'
- ])
-
- response = client.post(f'https://bard.google.com/_/BardChatUi/data/{intents}/StreamGenerate',
- data=data, params=params)
-
- chat_data = json.loads(response.content.splitlines()[3])[0][2]
- if chat_data:
- json_chat_data = json.loads(chat_data)
-
- yield json_chat_data[0][0]
-
- else:
- yield 'error'
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join([f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
\ No newline at end of file
diff --git a/spaces/anuragshas/whisper-large-v2-demo-hi/README.md b/spaces/anuragshas/whisper-large-v2-demo-hi/README.md
deleted file mode 100644
index 0474445cfcb3b4f3df8b80be66544da2020bcf6f..0000000000000000000000000000000000000000
--- a/spaces/anuragshas/whisper-large-v2-demo-hi/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Whisper Demo Hindi
-emoji: 🤫
-colorFrom: indigo
-colorTo: red
-sdk: gradio
-sdk_version: 3.9.1
-app_file: app.py
-pinned: false
-tags:
-- whisper-event
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/arbml/whisper-small-ar/README.md b/spaces/arbml/whisper-small-ar/README.md
deleted file mode 100644
index 664eab94c689197bc7a9359f29cff86f2e64b7fe..0000000000000000000000000000000000000000
--- a/spaces/arbml/whisper-small-ar/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
----
-title: Whisper Small AR
-emoji: 🤫
-colorFrom: indigo
-colorTo: red
-sdk: gradio
-sdk_version: 3.9.1
-app_file: app.py
-pinned: false
-tags:
-- whisper-event
-duplicated_from: whisper-event/whisper-demo
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/arsalagrey/image-classfication-vue/main.css b/spaces/arsalagrey/image-classfication-vue/main.css
deleted file mode 100644
index bb1228baa5004ce7188a48977042d2320ff5c01b..0000000000000000000000000000000000000000
--- a/spaces/arsalagrey/image-classfication-vue/main.css
+++ /dev/null
@@ -1,194 +0,0 @@
-h1, h2, h3, h4, h5, h6 {
- margin-bottom: 1rem;
-}
-
-.flex {
- display: flex;
-}
-
-.flex-row {
- flex-direction: row;
-}
-
-.flex-column {
- flex-direction: column;
-}
-
-.justify-center {
- justify-content: center;
-}
-
-.justify-between {
- justify-content: space-between;
-}
-
-.align-center {
- align-items: center;
-}
-
-/* Grid utilities */
-.grid {
- display: grid;
-}
-
-.grid-cols {
- grid-template-columns: repeat(1, minmax(0, 1fr));
-}
-
-@media (min-width: 640px) {
- .grid-cols {
- grid-template-columns: repeat(2, minmax(0, 1fr));
- }
-}
-
-@media (min-width: 768px) {
- .grid-cols {
- grid-template-columns: repeat(3, minmax(0, 1fr));
- }
-}
-
-.grid-cols-1 {
- grid-template-columns: repeat(1, minmax(0, 1fr));
-}
-
-.grid-cols-2 {
- grid-template-columns: repeat(2, minmax(0, 1fr));
-}
-
-.grid-cols-3 {
- grid-template-columns: repeat(3, minmax(0, 1fr));
-}
-
-.grid-cols-4 {
- grid-template-columns: repeat(4, minmax(0, 1fr));
-}
-
-/* Gap utilities */
-.gap-0 {
- gap: 0;
-}
-
-.gap-1 {
- gap: 0.25rem;
-}
-
-.gap-2 {
- gap: 0.5rem;
-}
-
-.gap-3 {
- gap: 0.75rem;
-}
-
-.gap-4 {
- gap: 1rem;
-}
-
-/* Responsive container class */
-
-.container {
- width: 100%;
- max-width: 1280px;
- margin: 0 auto;
- padding: 2rem;
-}
-
-.btn-error {
- background-color: #c10c0c;
- border-color: #c10c0c;
-}
-
-.btn-error:hover {
- background-color: #a80c0c;
- border-color: #a80c0c;
-}
-
-.btn-warning {
- background-color: #c1a10c;
- border-color: #c1a10c;
-}
-
-.btn-warning:hover {
- background-color: #a88c0c;
- border-color: #a88c0c;
-}
-
-.btn-success {
- background-color: #0cc14e;
- border-color: #0cc14e;
-}
-
-.btn-success:hover {
- background-color: #0ca83d;
- border-color: #0ca83d;
-}
-
-.btn-primary {
- background-color: #0c6fc1;
- border-color: #0c6fc1;
-}
-
-.btn-primary:hover {
- background-color: #0c5fa8;
- border-color: #0c5fa8;
-}
-
-/* B&W + Gray buttons */
-
-.btn-bw {
- background-color: #fff;
- border-color: #fff;
- color: #000;
-}
-
-.btn-bw:hover {
- background-color: #000;
- border-color: #000;
- color: #fff;
-}
-
-.btn-gray {
- background-color: #ccc;
- border-color: #ccc;
- color: #000;
-}
-
-.btn-gray:hover {
- background-color: #000;
- border-color: #000;
- color: #fff;
-}
-
-.image-container {
- display: flex;
- justify-content: center;
-}
-
-#detected-objects-container {
- position: absolute;
-}
-
-.bounding-box {
- position: absolute;
- border: 3px solid red;
-}
-
-.tooltip {
- position: absolute;
- bottom: 100%;
- left: 50%;
- transform: translateX(-50%);
- background-color: rgba(0, 0, 0, 0.8);
- color: white;
- font-size: 16px;
- font-weight: bold;
- padding: 4px 8px;
- border-radius: 4px;
- white-space: nowrap;
- opacity: 0;
- transition: opacity 0.3s;
-}
-
-.bounding-box:hover .tooltip {
- opacity: 1;
-}
diff --git a/spaces/artificialguybr/video-dubbing/TTS/TTS/tts/configs/__init__.py b/spaces/artificialguybr/video-dubbing/TTS/TTS/tts/configs/__init__.py
deleted file mode 100644
index 3146ac1c116cb807a81889b7a9ab223b9a051036..0000000000000000000000000000000000000000
--- a/spaces/artificialguybr/video-dubbing/TTS/TTS/tts/configs/__init__.py
+++ /dev/null
@@ -1,17 +0,0 @@
-import importlib
-import os
-from inspect import isclass
-
-# import all files under configs/
-# configs_dir = os.path.dirname(__file__)
-# for file in os.listdir(configs_dir):
-# path = os.path.join(configs_dir, file)
-# if not file.startswith("_") and not file.startswith(".") and (file.endswith(".py") or os.path.isdir(path)):
-# config_name = file[: file.find(".py")] if file.endswith(".py") else file
-# module = importlib.import_module("TTS.tts.configs." + config_name)
-# for attribute_name in dir(module):
-# attribute = getattr(module, attribute_name)
-
-# if isclass(attribute):
-# # Add the class to this package's variables
-# globals()[attribute_name] = attribute
diff --git a/spaces/artificialguybr/video-dubbing/TTS/TTS/tts/utils/text/bangla/__init__.py b/spaces/artificialguybr/video-dubbing/TTS/TTS/tts/utils/text/bangla/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/artificialguybr/video-dubbing/whisper/whisper/model.py b/spaces/artificialguybr/video-dubbing/whisper/whisper/model.py
deleted file mode 100644
index 69130022a08b993c30a8e2d2548fd648edaa7dfb..0000000000000000000000000000000000000000
--- a/spaces/artificialguybr/video-dubbing/whisper/whisper/model.py
+++ /dev/null
@@ -1,309 +0,0 @@
-import base64
-import gzip
-from dataclasses import dataclass
-from typing import Dict, Iterable, Optional
-
-import numpy as np
-import torch
-import torch.nn.functional as F
-from torch import Tensor, nn
-
-from .decoding import decode as decode_function
-from .decoding import detect_language as detect_language_function
-from .transcribe import transcribe as transcribe_function
-
-
-@dataclass
-class ModelDimensions:
- n_mels: int
- n_audio_ctx: int
- n_audio_state: int
- n_audio_head: int
- n_audio_layer: int
- n_vocab: int
- n_text_ctx: int
- n_text_state: int
- n_text_head: int
- n_text_layer: int
-
-
-class LayerNorm(nn.LayerNorm):
- def forward(self, x: Tensor) -> Tensor:
- return super().forward(x.float()).type(x.dtype)
-
-
-class Linear(nn.Linear):
- def forward(self, x: Tensor) -> Tensor:
- return F.linear(
- x,
- self.weight.to(x.dtype),
- None if self.bias is None else self.bias.to(x.dtype),
- )
-
-
-class Conv1d(nn.Conv1d):
- def _conv_forward(
- self, x: Tensor, weight: Tensor, bias: Optional[Tensor]
- ) -> Tensor:
- return super()._conv_forward(
- x, weight.to(x.dtype), None if bias is None else bias.to(x.dtype)
- )
-
-
-def sinusoids(length, channels, max_timescale=10000):
- """Returns sinusoids for positional embedding"""
- assert channels % 2 == 0
- log_timescale_increment = np.log(max_timescale) / (channels // 2 - 1)
- inv_timescales = torch.exp(-log_timescale_increment * torch.arange(channels // 2))
- scaled_time = torch.arange(length)[:, np.newaxis] * inv_timescales[np.newaxis, :]
- return torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], dim=1)
-
-
-class MultiHeadAttention(nn.Module):
- def __init__(self, n_state: int, n_head: int):
- super().__init__()
- self.n_head = n_head
- self.query = Linear(n_state, n_state)
- self.key = Linear(n_state, n_state, bias=False)
- self.value = Linear(n_state, n_state)
- self.out = Linear(n_state, n_state)
-
- def forward(
- self,
- x: Tensor,
- xa: Optional[Tensor] = None,
- mask: Optional[Tensor] = None,
- kv_cache: Optional[dict] = None,
- ):
- q = self.query(x)
-
- if kv_cache is None or xa is None or self.key not in kv_cache:
- # hooks, if installed (i.e. kv_cache is not None), will prepend the cached kv tensors;
- # otherwise, perform key/value projections for self- or cross-attention as usual.
- k = self.key(x if xa is None else xa)
- v = self.value(x if xa is None else xa)
- else:
- # for cross-attention, calculate keys and values once and reuse in subsequent calls.
- k = kv_cache[self.key]
- v = kv_cache[self.value]
-
- wv, qk = self.qkv_attention(q, k, v, mask)
- return self.out(wv), qk
-
- def qkv_attention(
- self, q: Tensor, k: Tensor, v: Tensor, mask: Optional[Tensor] = None
- ):
- n_batch, n_ctx, n_state = q.shape
- scale = (n_state // self.n_head) ** -0.25
- q = q.view(*q.shape[:2], self.n_head, -1).permute(0, 2, 1, 3) * scale
- k = k.view(*k.shape[:2], self.n_head, -1).permute(0, 2, 3, 1) * scale
- v = v.view(*v.shape[:2], self.n_head, -1).permute(0, 2, 1, 3)
-
- qk = q @ k
- if mask is not None:
- qk = qk + mask[:n_ctx, :n_ctx]
- qk = qk.float()
-
- w = F.softmax(qk, dim=-1).to(q.dtype)
- return (w @ v).permute(0, 2, 1, 3).flatten(start_dim=2), qk.detach()
-
-
-class ResidualAttentionBlock(nn.Module):
- def __init__(self, n_state: int, n_head: int, cross_attention: bool = False):
- super().__init__()
-
- self.attn = MultiHeadAttention(n_state, n_head)
- self.attn_ln = LayerNorm(n_state)
-
- self.cross_attn = (
- MultiHeadAttention(n_state, n_head) if cross_attention else None
- )
- self.cross_attn_ln = LayerNorm(n_state) if cross_attention else None
-
- n_mlp = n_state * 4
- self.mlp = nn.Sequential(
- Linear(n_state, n_mlp), nn.GELU(), Linear(n_mlp, n_state)
- )
- self.mlp_ln = LayerNorm(n_state)
-
- def forward(
- self,
- x: Tensor,
- xa: Optional[Tensor] = None,
- mask: Optional[Tensor] = None,
- kv_cache: Optional[dict] = None,
- ):
- x = x + self.attn(self.attn_ln(x), mask=mask, kv_cache=kv_cache)[0]
- if self.cross_attn:
- x = x + self.cross_attn(self.cross_attn_ln(x), xa, kv_cache=kv_cache)[0]
- x = x + self.mlp(self.mlp_ln(x))
- return x
-
-
-class AudioEncoder(nn.Module):
- def __init__(
- self, n_mels: int, n_ctx: int, n_state: int, n_head: int, n_layer: int
- ):
- super().__init__()
- self.conv1 = Conv1d(n_mels, n_state, kernel_size=3, padding=1)
- self.conv2 = Conv1d(n_state, n_state, kernel_size=3, stride=2, padding=1)
- self.register_buffer("positional_embedding", sinusoids(n_ctx, n_state))
-
- self.blocks: Iterable[ResidualAttentionBlock] = nn.ModuleList(
- [ResidualAttentionBlock(n_state, n_head) for _ in range(n_layer)]
- )
- self.ln_post = LayerNorm(n_state)
-
- def forward(self, x: Tensor):
- """
- x : torch.Tensor, shape = (batch_size, n_mels, n_ctx)
- the mel spectrogram of the audio
- """
- x = F.gelu(self.conv1(x))
- x = F.gelu(self.conv2(x))
- x = x.permute(0, 2, 1)
-
- assert x.shape[1:] == self.positional_embedding.shape, "incorrect audio shape"
- x = (x + self.positional_embedding).to(x.dtype)
-
- for block in self.blocks:
- x = block(x)
-
- x = self.ln_post(x)
- return x
-
-
-class TextDecoder(nn.Module):
- def __init__(
- self, n_vocab: int, n_ctx: int, n_state: int, n_head: int, n_layer: int
- ):
- super().__init__()
-
- self.token_embedding = nn.Embedding(n_vocab, n_state)
- self.positional_embedding = nn.Parameter(torch.empty(n_ctx, n_state))
-
- self.blocks: Iterable[ResidualAttentionBlock] = nn.ModuleList(
- [
- ResidualAttentionBlock(n_state, n_head, cross_attention=True)
- for _ in range(n_layer)
- ]
- )
- self.ln = LayerNorm(n_state)
-
- mask = torch.empty(n_ctx, n_ctx).fill_(-np.inf).triu_(1)
- self.register_buffer("mask", mask, persistent=False)
-
- def forward(self, x: Tensor, xa: Tensor, kv_cache: Optional[dict] = None):
- """
- x : torch.LongTensor, shape = (batch_size, <= n_ctx)
- the text tokens
- xa : torch.Tensor, shape = (batch_size, n_audio_ctx, n_audio_state)
- the encoded audio features to be attended on
- """
- offset = next(iter(kv_cache.values())).shape[1] if kv_cache else 0
- x = (
- self.token_embedding(x)
- + self.positional_embedding[offset : offset + x.shape[-1]]
- )
- x = x.to(xa.dtype)
-
- for block in self.blocks:
- x = block(x, xa, mask=self.mask, kv_cache=kv_cache)
-
- x = self.ln(x)
- logits = (
- x @ torch.transpose(self.token_embedding.weight.to(x.dtype), 0, 1)
- ).float()
-
- return logits
-
-
-class Whisper(nn.Module):
- def __init__(self, dims: ModelDimensions):
- super().__init__()
- self.dims = dims
- self.encoder = AudioEncoder(
- self.dims.n_mels,
- self.dims.n_audio_ctx,
- self.dims.n_audio_state,
- self.dims.n_audio_head,
- self.dims.n_audio_layer,
- )
- self.decoder = TextDecoder(
- self.dims.n_vocab,
- self.dims.n_text_ctx,
- self.dims.n_text_state,
- self.dims.n_text_head,
- self.dims.n_text_layer,
- )
- # use the last half layers for alignment by default; see `set_alignment_heads()` below
- all_heads = torch.zeros(
- self.dims.n_text_layer, self.dims.n_text_head, dtype=torch.bool
- )
- all_heads[self.dims.n_text_layer // 2 :] = True
- self.register_buffer("alignment_heads", all_heads.to_sparse(), persistent=False)
-
- def set_alignment_heads(self, dump: bytes):
- array = np.frombuffer(
- gzip.decompress(base64.b85decode(dump)), dtype=bool
- ).copy()
- mask = torch.from_numpy(array).reshape(
- self.dims.n_text_layer, self.dims.n_text_head
- )
- self.register_buffer("alignment_heads", mask.to_sparse(), persistent=False)
-
- def embed_audio(self, mel: torch.Tensor):
- return self.encoder(mel)
-
- def logits(self, tokens: torch.Tensor, audio_features: torch.Tensor):
- return self.decoder(tokens, audio_features)
-
- def forward(
- self, mel: torch.Tensor, tokens: torch.Tensor
- ) -> Dict[str, torch.Tensor]:
- return self.decoder(tokens, self.encoder(mel))
-
- @property
- def device(self):
- return next(self.parameters()).device
-
- @property
- def is_multilingual(self):
- return self.dims.n_vocab == 51865
-
- def install_kv_cache_hooks(self, cache: Optional[dict] = None):
- """
- The `MultiHeadAttention` module optionally accepts `kv_cache` which stores the key and value
- tensors calculated for the previous positions. This method returns a dictionary that stores
- all caches, and the necessary hooks for the key and value projection modules that save the
- intermediate tensors to be reused during later calculations.
-
- Returns
- -------
- cache : Dict[nn.Module, torch.Tensor]
- A dictionary object mapping the key/value projection modules to its cache
- hooks : List[RemovableHandle]
- List of PyTorch RemovableHandle objects to stop the hooks to be called
- """
- cache = {**cache} if cache is not None else {}
- hooks = []
-
- def save_to_cache(module, _, output):
- if module not in cache or output.shape[1] > self.dims.n_text_ctx:
- # save as-is, for the first token or cross attention
- cache[module] = output
- else:
- cache[module] = torch.cat([cache[module], output], dim=1).detach()
- return cache[module]
-
- def install_hooks(layer: nn.Module):
- if isinstance(layer, MultiHeadAttention):
- hooks.append(layer.key.register_forward_hook(save_to_cache))
- hooks.append(layer.value.register_forward_hook(save_to_cache))
-
- self.decoder.apply(install_hooks)
- return cache, hooks
-
- detect_language = detect_language_function
- transcribe = transcribe_function
- decode = decode_function
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/Cipher/_mode_eax.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/Cipher/_mode_eax.py
deleted file mode 100644
index d5fb1351bd95f5959f688d8d09a6aa92d2b1e227..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/Cipher/_mode_eax.py
+++ /dev/null
@@ -1,408 +0,0 @@
-# ===================================================================
-#
-# Copyright (c) 2014, Legrandin
-# All rights reserved.
-#
-# Redistribution and use in source and binary forms, with or without
-# modification, are permitted provided that the following conditions
-# are met:
-#
-# 1. Redistributions of source code must retain the above copyright
-# notice, this list of conditions and the following disclaimer.
-# 2. Redistributions in binary form must reproduce the above copyright
-# notice, this list of conditions and the following disclaimer in
-# the documentation and/or other materials provided with the
-# distribution.
-#
-# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
-# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
-# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
-# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
-# COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
-# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
-# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
-# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
-# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
-# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
-# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
-# POSSIBILITY OF SUCH DAMAGE.
-# ===================================================================
-
-"""
-EAX mode.
-"""
-
-__all__ = ['EaxMode']
-
-import struct
-from binascii import unhexlify
-
-from Crypto.Util.py3compat import byte_string, bord, _copy_bytes
-
-from Crypto.Util._raw_api import is_buffer
-
-from Crypto.Util.strxor import strxor
-from Crypto.Util.number import long_to_bytes, bytes_to_long
-
-from Crypto.Hash import CMAC, BLAKE2s
-from Crypto.Random import get_random_bytes
-
-
-class EaxMode(object):
- """*EAX* mode.
-
- This is an Authenticated Encryption with Associated Data
- (`AEAD`_) mode. It provides both confidentiality and authenticity.
-
- The header of the message may be left in the clear, if needed,
- and it will still be subject to authentication.
-
- The decryption step tells the receiver if the message comes
- from a source that really knowns the secret key.
- Additionally, decryption detects if any part of the message -
- including the header - has been modified or corrupted.
-
- This mode requires a *nonce*.
-
- This mode is only available for ciphers that operate on 64 or
- 128 bits blocks.
-
- There are no official standards defining EAX.
- The implementation is based on `a proposal`__ that
- was presented to NIST.
-
- .. _AEAD: http://blog.cryptographyengineering.com/2012/05/how-to-choose-authenticated-encryption.html
- .. __: http://csrc.nist.gov/groups/ST/toolkit/BCM/documents/proposedmodes/eax/eax-spec.pdf
-
- :undocumented: __init__
- """
-
- def __init__(self, factory, key, nonce, mac_len, cipher_params):
- """EAX cipher mode"""
-
- self.block_size = factory.block_size
- """The block size of the underlying cipher, in bytes."""
-
- self.nonce = _copy_bytes(None, None, nonce)
- """The nonce originally used to create the object."""
-
- self._mac_len = mac_len
- self._mac_tag = None # Cache for MAC tag
-
- # Allowed transitions after initialization
- self._next = [self.update, self.encrypt, self.decrypt,
- self.digest, self.verify]
-
- # MAC tag length
- if not (4 <= self._mac_len <= self.block_size):
- raise ValueError("Parameter 'mac_len' must not be larger than %d"
- % self.block_size)
-
- # Nonce cannot be empty and must be a byte string
- if len(self.nonce) == 0:
- raise ValueError("Nonce cannot be empty in EAX mode")
- if not is_buffer(nonce):
- raise TypeError("nonce must be bytes, bytearray or memoryview")
-
- self._omac = [
- CMAC.new(key,
- b'\x00' * (self.block_size - 1) + struct.pack('B', i),
- ciphermod=factory,
- cipher_params=cipher_params)
- for i in range(0, 3)
- ]
-
- # Compute MAC of nonce
- self._omac[0].update(self.nonce)
- self._signer = self._omac[1]
-
- # MAC of the nonce is also the initial counter for CTR encryption
- counter_int = bytes_to_long(self._omac[0].digest())
- self._cipher = factory.new(key,
- factory.MODE_CTR,
- initial_value=counter_int,
- nonce=b"",
- **cipher_params)
-
- def update(self, assoc_data):
- """Protect associated data
-
- If there is any associated data, the caller has to invoke
- this function one or more times, before using
- ``decrypt`` or ``encrypt``.
-
- By *associated data* it is meant any data (e.g. packet headers) that
- will not be encrypted and will be transmitted in the clear.
- However, the receiver is still able to detect any modification to it.
-
- If there is no associated data, this method must not be called.
-
- The caller may split associated data in segments of any size, and
- invoke this method multiple times, each time with the next segment.
-
- :Parameters:
- assoc_data : bytes/bytearray/memoryview
- A piece of associated data. There are no restrictions on its size.
- """
-
- if self.update not in self._next:
- raise TypeError("update() can only be called"
- " immediately after initialization")
-
- self._next = [self.update, self.encrypt, self.decrypt,
- self.digest, self.verify]
-
- self._signer.update(assoc_data)
- return self
-
- def encrypt(self, plaintext, output=None):
- """Encrypt data with the key and the parameters set at initialization.
-
- A cipher object is stateful: once you have encrypted a message
- you cannot encrypt (or decrypt) another message using the same
- object.
-
- The data to encrypt can be broken up in two or
- more pieces and `encrypt` can be called multiple times.
-
- That is, the statement:
-
- >>> c.encrypt(a) + c.encrypt(b)
-
- is equivalent to:
-
- >>> c.encrypt(a+b)
-
- This function does not add any padding to the plaintext.
-
- :Parameters:
- plaintext : bytes/bytearray/memoryview
- The piece of data to encrypt.
- It can be of any length.
- :Keywords:
- output : bytearray/memoryview
- The location where the ciphertext must be written to.
- If ``None``, the ciphertext is returned.
- :Return:
- If ``output`` is ``None``, the ciphertext as ``bytes``.
- Otherwise, ``None``.
- """
-
- if self.encrypt not in self._next:
- raise TypeError("encrypt() can only be called after"
- " initialization or an update()")
- self._next = [self.encrypt, self.digest]
- ct = self._cipher.encrypt(plaintext, output=output)
- if output is None:
- self._omac[2].update(ct)
- else:
- self._omac[2].update(output)
- return ct
-
- def decrypt(self, ciphertext, output=None):
- """Decrypt data with the key and the parameters set at initialization.
-
- A cipher object is stateful: once you have decrypted a message
- you cannot decrypt (or encrypt) another message with the same
- object.
-
- The data to decrypt can be broken up in two or
- more pieces and `decrypt` can be called multiple times.
-
- That is, the statement:
-
- >>> c.decrypt(a) + c.decrypt(b)
-
- is equivalent to:
-
- >>> c.decrypt(a+b)
-
- This function does not remove any padding from the plaintext.
-
- :Parameters:
- ciphertext : bytes/bytearray/memoryview
- The piece of data to decrypt.
- It can be of any length.
- :Keywords:
- output : bytearray/memoryview
- The location where the plaintext must be written to.
- If ``None``, the plaintext is returned.
- :Return:
- If ``output`` is ``None``, the plaintext as ``bytes``.
- Otherwise, ``None``.
- """
-
- if self.decrypt not in self._next:
- raise TypeError("decrypt() can only be called"
- " after initialization or an update()")
- self._next = [self.decrypt, self.verify]
- self._omac[2].update(ciphertext)
- return self._cipher.decrypt(ciphertext, output=output)
-
- def digest(self):
- """Compute the *binary* MAC tag.
-
- The caller invokes this function at the very end.
-
- This method returns the MAC that shall be sent to the receiver,
- together with the ciphertext.
-
- :Return: the MAC, as a byte string.
- """
-
- if self.digest not in self._next:
- raise TypeError("digest() cannot be called when decrypting"
- " or validating a message")
- self._next = [self.digest]
-
- if not self._mac_tag:
- tag = b'\x00' * self.block_size
- for i in range(3):
- tag = strxor(tag, self._omac[i].digest())
- self._mac_tag = tag[:self._mac_len]
-
- return self._mac_tag
-
- def hexdigest(self):
- """Compute the *printable* MAC tag.
-
- This method is like `digest`.
-
- :Return: the MAC, as a hexadecimal string.
- """
- return "".join(["%02x" % bord(x) for x in self.digest()])
-
- def verify(self, received_mac_tag):
- """Validate the *binary* MAC tag.
-
- The caller invokes this function at the very end.
-
- This method checks if the decrypted message is indeed valid
- (that is, if the key is correct) and it has not been
- tampered with while in transit.
-
- :Parameters:
- received_mac_tag : bytes/bytearray/memoryview
- This is the *binary* MAC, as received from the sender.
- :Raises MacMismatchError:
- if the MAC does not match. The message has been tampered with
- or the key is incorrect.
- """
-
- if self.verify not in self._next:
- raise TypeError("verify() cannot be called"
- " when encrypting a message")
- self._next = [self.verify]
-
- if not self._mac_tag:
- tag = b'\x00' * self.block_size
- for i in range(3):
- tag = strxor(tag, self._omac[i].digest())
- self._mac_tag = tag[:self._mac_len]
-
- secret = get_random_bytes(16)
-
- mac1 = BLAKE2s.new(digest_bits=160, key=secret, data=self._mac_tag)
- mac2 = BLAKE2s.new(digest_bits=160, key=secret, data=received_mac_tag)
-
- if mac1.digest() != mac2.digest():
- raise ValueError("MAC check failed")
-
- def hexverify(self, hex_mac_tag):
- """Validate the *printable* MAC tag.
-
- This method is like `verify`.
-
- :Parameters:
- hex_mac_tag : string
- This is the *printable* MAC, as received from the sender.
- :Raises MacMismatchError:
- if the MAC does not match. The message has been tampered with
- or the key is incorrect.
- """
-
- self.verify(unhexlify(hex_mac_tag))
-
- def encrypt_and_digest(self, plaintext, output=None):
- """Perform encrypt() and digest() in one step.
-
- :Parameters:
- plaintext : bytes/bytearray/memoryview
- The piece of data to encrypt.
- :Keywords:
- output : bytearray/memoryview
- The location where the ciphertext must be written to.
- If ``None``, the ciphertext is returned.
- :Return:
- a tuple with two items:
-
- - the ciphertext, as ``bytes``
- - the MAC tag, as ``bytes``
-
- The first item becomes ``None`` when the ``output`` parameter
- specified a location for the result.
- """
-
- return self.encrypt(plaintext, output=output), self.digest()
-
- def decrypt_and_verify(self, ciphertext, received_mac_tag, output=None):
- """Perform decrypt() and verify() in one step.
-
- :Parameters:
- ciphertext : bytes/bytearray/memoryview
- The piece of data to decrypt.
- received_mac_tag : bytes/bytearray/memoryview
- This is the *binary* MAC, as received from the sender.
- :Keywords:
- output : bytearray/memoryview
- The location where the plaintext must be written to.
- If ``None``, the plaintext is returned.
- :Return: the plaintext as ``bytes`` or ``None`` when the ``output``
- parameter specified a location for the result.
- :Raises MacMismatchError:
- if the MAC does not match. The message has been tampered with
- or the key is incorrect.
- """
-
- pt = self.decrypt(ciphertext, output=output)
- self.verify(received_mac_tag)
- return pt
-
-
-def _create_eax_cipher(factory, **kwargs):
- """Create a new block cipher, configured in EAX mode.
-
- :Parameters:
- factory : module
- A symmetric cipher module from `Crypto.Cipher` (like
- `Crypto.Cipher.AES`).
-
- :Keywords:
- key : bytes/bytearray/memoryview
- The secret key to use in the symmetric cipher.
-
- nonce : bytes/bytearray/memoryview
- A value that must never be reused for any other encryption.
- There are no restrictions on its length, but it is recommended to use
- at least 16 bytes.
-
- The nonce shall never repeat for two different messages encrypted with
- the same key, but it does not need to be random.
-
- If not specified, a 16 byte long random string is used.
-
- mac_len : integer
- Length of the MAC, in bytes. It must be no larger than the cipher
- block bytes (which is the default).
- """
-
- try:
- key = kwargs.pop("key")
- nonce = kwargs.pop("nonce", None)
- if nonce is None:
- nonce = get_random_bytes(16)
- mac_len = kwargs.pop("mac_len", factory.block_size)
- except KeyError as e:
- raise TypeError("Missing parameter: " + str(e))
-
- return EaxMode(factory, key, nonce, mac_len, kwargs)
diff --git a/spaces/ashercn97/AsherTesting/docs/LLaMA-v2-model.md b/spaces/ashercn97/AsherTesting/docs/LLaMA-v2-model.md
deleted file mode 100644
index 55c6aa76e9c90963ba1cbf75b5528e6b23c70f18..0000000000000000000000000000000000000000
--- a/spaces/ashercn97/AsherTesting/docs/LLaMA-v2-model.md
+++ /dev/null
@@ -1,35 +0,0 @@
-# LLaMA-v2
-
-To convert LLaMA-v2 from the `.pth` format provided by Meta to transformers format, follow the steps below:
-
-1) `cd` into your `llama` folder (the one containing `download.sh` and the models that you downloaded):
-
-```
-cd llama
-```
-
-2) Clone the transformers library:
-
-```
-git clone 'https://github.com/huggingface/transformers'
-
-```
-
-3) Create symbolic links from the downloaded folders to names that the conversion script can recognize:
-
-```
-ln -s llama-2-7b 7B
-ln -s llama-2-13b 13B
-```
-
-4) Do the conversions:
-
-```
-mkdir llama-2-7b-hf llama-2-13b-hf
-python ./transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir . --model_size 7B --output_dir llama-2-7b-hf --safe_serialization true
-python ./transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir . --model_size 13B --output_dir llama-2-13b-hf --safe_serialization true
-```
-
-5) Move the output folders inside `text-generation-webui/models`
-
-6) Have fun
diff --git a/spaces/ashutosh1919/quantum-perceptron/quantum_perceptron/perceptron.py b/spaces/ashutosh1919/quantum-perceptron/quantum_perceptron/perceptron.py
deleted file mode 100644
index fe1024441b77f3437fcb7a2824138738bc0795cb..0000000000000000000000000000000000000000
--- a/spaces/ashutosh1919/quantum-perceptron/quantum_perceptron/perceptron.py
+++ /dev/null
@@ -1,163 +0,0 @@
-from typing import Dict
-from qiskit import QuantumCircuit, Aer, execute
-from quantum_perceptron.utils import (
- assert_negative,
- assert_bits,
- create_hypergraph_state,
- get_vector_from_int
-)
-
-
-class Perceptron:
- def __init__(self,
- num_qubits: int,
- weight: int = 1,
- input: int = 1):
- """
- This class creates a quantum perceptron instance which has
- capability calculate input * weight. Note that we are not applying
- any non-linearity. Our perceptron design is as per
- https://arxiv.org/pdf/1811.02266.pdf
-
- Args:
- num_qubits: `int` denoting number of qubits in perceptron
- weight: `int` denoting the weight of the perceptron.
- input: `int` denoting the data to input to the perceptron.
- """
- self.num_qubits = num_qubits
- assert self.num_qubits > 0, "Number qubits must be positive"
- assert_negative(weight)
- self.weight = weight
- assert_negative(input)
- self.input = input
- assert_bits(self.weight, self.num_qubits)
- assert_bits(self.input, self.num_qubits)
- self.build_flag = False
- self.build_circuit()
-
- def Ui(self):
- """
- Sub-circuit to transform input data.
- """
- if not self.build_flag:
- raise RuntimeError("Ui() cannot be called independently.")
-
- Ui = QuantumCircuit(self.num_qubits)
-
- # Applying hadamard to first num_qubits
- for q in range(self.num_qubits):
- Ui.h(q)
-
- # Extracting vectors for input
- input_vector = get_vector_from_int(self.input, self.num_qubits)
-
- # Applying hypergraph state corresponding to input.
- Ui = create_hypergraph_state(Ui,
- input_vector,
- self.num_qubits)
- Ui = Ui.to_gate()
- Ui.name = "U_i"
- return Ui
-
- def Uw(self):
- """
- Sub-circuit to transform weight data.
- """
- if not self.build_flag:
- raise RuntimeError("Ui() cannot be called independently.")
-
- Uw = QuantumCircuit(self.num_qubits)
-
- # Extracting vectors for weight
- input_vector = get_vector_from_int(self.weight, self.num_qubits)
-
- # Applying hypergraph state corresponding to weight.
- Uw = create_hypergraph_state(Uw,
- input_vector,
- self.num_qubits)
-
- # Applying hadamard to first num_qubits
- for q in range(self.num_qubits):
- Uw.h(q)
-
- # Applying X gate to first num_qubits
- for q in range(self.num_qubits):
- Uw.x(q)
- Uw = Uw.to_gate()
- Uw.name = "U_w"
- return Uw
-
- def build_circuit(self):
- """
- Build quantum circuit corresponding to single perceptron combining
- input data and weight of the perceptron.
- """
- # Creating circuit with num_qubits + 1 (ancilla) qubit.
- self.circuit = QuantumCircuit(1 + self.num_qubits, 1)
-
- def toggle_build_flag():
- """
- Toggle the build circuit flag. Used to monitor Ui and Uf circuits
- to ensure that those functions are not called seperately but from
- the `build_circuit()` function.
- """
- self.build_flag = not self.build_flag
-
- # Append Ui for processing input
- toggle_build_flag()
- # self.Ui()
- self.circuit.append(
- self.Ui(),
- list(range(self.num_qubits))
- )
- toggle_build_flag()
-
- # Append Uf for processing input
- toggle_build_flag()
- self.circuit.append(
- self.Uw(),
- list(range(self.num_qubits))
- )
- toggle_build_flag()
-
- # Toffoli gate at the end with target as ancilla qubit
- self.circuit.mcx(
- control_qubits=list(range(self.num_qubits)),
- target_qubit=self.num_qubits
- )
-
- # Measure the last qubit.
- self.circuit.measure(self.num_qubits, 0)
-
- def measure_circuit(self, num_iters: int = 1000) -> Dict[str, int]:
- """
- Measure the perceptron and get the counts of the final results.
-
- Args:
- num_iters: `int` denoting number of iterations to execute circuit.
-
- Returns: `dict` containing the measurement frequencies.
- """
- if not hasattr(self, 'circuit'):
- raise RuntimeError("The circuit hasn't yet built.",
- "Please call build_circuit() first.")
- backend = Aer.get_backend('qasm_simulator')
-
- # Execute the circuit
- job = execute(self.circuit, backend, shots=num_iters)
-
- # Get result and counts
- result = job.result()
- counts = result.get_counts(self.circuit)
- return dict(counts)
-
- def save_circuit_image(self,
- file_path: str,
- output_format: str = "mpl"):
- """
- Save circuit to the image file.
- """
- if not hasattr(self, 'circuit'):
- raise RuntimeError("The circuit hasn't yet built.",
- "Please call build_circuit() first.")
- self.circuit.draw(output=output_format, filename=file_path)
diff --git a/spaces/awacke1/Generative-AI-EACN/index.html b/spaces/awacke1/Generative-AI-EACN/index.html
deleted file mode 100644
index 7611b224a0545d34a8912d555845df5b71ae626a..0000000000000000000000000000000000000000
--- a/spaces/awacke1/Generative-AI-EACN/index.html
+++ /dev/null
@@ -1,27 +0,0 @@
-
-
-
-
-
- My static Space
-
-
-
-
-
-
-
-
-
-
-
diff --git a/spaces/awacke1/NLPContextQATransformersRobertaBaseSquad2/app.py b/spaces/awacke1/NLPContextQATransformersRobertaBaseSquad2/app.py
deleted file mode 100644
index ebe8500e5f871271c2b9f7d0b570936b33dbc530..0000000000000000000000000000000000000000
--- a/spaces/awacke1/NLPContextQATransformersRobertaBaseSquad2/app.py
+++ /dev/null
@@ -1,33 +0,0 @@
-import gradio as gr
-from transformers import pipeline
-title = 'NLP Context QA with Transformers and Roberta Base Squad2'
-
-question1T = "What pressures do teens face?"
-question2T = "What do teens deal with?"
-question3T = "What persistent fears might teens face?"
-
-question1A = "What do half of American adults suffer from?"
-question2A = "What cognitive issues do adults face after COVID?"
-question3A = "What anxiety and changes are faced by adults?"
-
-question1E = "What problems do elderly have due to medical issues?"
-question2E = "What helps mental health for elderly?"
-question3E = "How many older adultsexperience mental disorders?"
-
-context1 = "Pressures teens face: Youth mental health expert have raised concerns about the extreme pressures on children and teens throughout the COVID-19 pandemic. Lingering effects of school closures and COVID-related stressors are key factors in teen stress. Many young people are also dealing with overwhelming pressure to achieve good grades in school or gain admission to elite colleges and universities. The need to be superstars in sports, the performing arts or other extracurricular activities. Tough schedules that don't allow enough time for rest, relaxation and unstructured fun. They deal with Bullying whether in person, via social media or both. They face persistent fears about climate change, global conflict and other weighty issues. They may face discrimination based on race, gender, sexual orientation, weight, religion, disability or other factors. Teens also face problems related to a poverty or lack of money for safe, stable housing and enough nutritious food."
-context2 = "Pressures adults face: Nearly half of Americans surveyed reported recent symptoms of an anxiety or depressive disorder, and 10% feel their mental health needs are not being met. Rates of anxiety, depression, and substance use disorder have increased since the beginning of the pandemic. People who have mental illnesses or disorders and then get COVID-19 are more likely to die than those who don’t have mental illnesses or disorders. Adults face a number of symptoms related to brain and mental health including cognitive and attention deficits like brain fog, anxiety and depression, seizures, and suicidal behavior. Stressors caused by the COVID-19 pandemic is not yet fully understood but include changes to daily routines, virtual office and schooling, mask wearing, caregiver absence, loss and grief, and financial instability. People more likely to experience difficulties include people from racial and ethnic minority groups, mothers and pregnant women, people with finanical or housing insecurity, children, people with disabilities, people with pre-existing mental illnesses or substance use problems and health care workers."
-context3 = "Pressures facing elderly: Anxiety and depression have increased for older adults since the start of the pandemic. Elders cope with uncertainty better than younger generations, however depression and anxiety have negative impacts on quality of life, function and general health. Due to medical vulnerability elders face isolation with sacrifices and pain to endure including loneliness. At least one in four older adults experience mental disorders such as depression, anxiety and dementia. Number of seniors is expected to double by 2030. Isolation, affective and anxiety disorders, dementia, and psychosis are common as well as sleep disorders. Behavioral disorders, cognitive deterioration or confusion states as a result of physical disorders and surgical interventions occur for elderly. Health care providers including those in primary care can play a key role in promoting mental health by working with mental health professionals, local governments, civil society organizations, families and communities to provide comprehensive mental health care and supportive environments. Elderly should be encouraged to participate in communities and society while policy makers should ensure health concerns are addressed in national health planning and policies."
-
-# Model (autotrain compatible) https://huggingface.co/deepset/roberta-base-squad2/tree/main
-# Model Card: https://huggingface.co/deepset/roberta-base-squad2
-model_name = "deepset/roberta-base-squad2"
-question_answerer = pipeline("question-answering", model=model_name, tokenizer=model_name)
-
-interface = gr.Interface.from_pipeline(question_answerer,
- title = title,
- theme = "peach",
- examples = [
- [context1, question1T],[context1, question2T],[context1, question3T],
- [context2, question1A],[context2, question2A],[context2, question3A],
- [context3, question1E],[context3, question2E],[context3, question3E]
- ]).launch()
\ No newline at end of file
diff --git a/spaces/awacke1/QuoteOfTheDayWithSearch/README.md b/spaces/awacke1/QuoteOfTheDayWithSearch/README.md
deleted file mode 100644
index b0ca838c14e1882371d6ac4ecf345be4fc22ed4e..0000000000000000000000000000000000000000
--- a/spaces/awacke1/QuoteOfTheDayWithSearch/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: QuoteOfTheDayWithSearch
-emoji: 👀
-colorFrom: yellow
-colorTo: yellow
-sdk: streamlit
-sdk_version: 1.17.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/baby123/sd/run.py b/spaces/baby123/sd/run.py
deleted file mode 100644
index 30201feba8665743354f1690c1f2b3a3583adee6..0000000000000000000000000000000000000000
--- a/spaces/baby123/sd/run.py
+++ /dev/null
@@ -1,35 +0,0 @@
-import os
-import subprocess
-import sys
-
-
-def on_start():
- print("---------------")
- print("Running script './on_start.sh' to download models ...")
- print("---------------")
- result = subprocess.run("./on_start.sh", shell=True, env=os.environ)
- if result.returncode != 0:
- raise RuntimeError(f"Error executing ./on_start.sh [exit code: {result.returncode}]")
-
-
-def start():
- on_start()
-
- print("---------------")
- print(f"Launching {'API server' if '--nowebui' in sys.argv else 'Web UI'} with arguments: {' '.join(sys.argv[1:])}")
- print("---------------")
- import webui # type: ignore # noqa
- if '--nowebui' in sys.argv:
- webui.api_only()
- else:
- webui.webui()
-
-
-if __name__ == "__main__":
- import torch
- if not torch.cuda.is_available():
- sys.argv.extend(["--precision", "full", "--no-half", "--use-cpu", "SD", "BSRGAN", "ESRGAN", "SCUNet", "CodeFormer", "--all"])
- else:
- sys.argv.extend(["--force-enable-xformers", "--xformers"])
-
- start()
diff --git a/spaces/balgot/text-to-stylegan3/utils.py b/spaces/balgot/text-to-stylegan3/utils.py
deleted file mode 100644
index c9a953bd95664c0516a039bb8f7eea25e371305c..0000000000000000000000000000000000000000
--- a/spaces/balgot/text-to-stylegan3/utils.py
+++ /dev/null
@@ -1,26 +0,0 @@
-import sys
-import io
-
-
-class DownloadModelCtx:
- def __init__(self, s):
- self.s = s
- print(f"[info] {s}...", end=" ", flush=True)
-
- def __enter__(self):
- self.stdout = sys.stdout
- self.stderr = sys.stderr
- self.captured_output = io.StringIO()
- sys.stdout = self.captured_output
- sys.stderr = self.captured_output
- return self
-
- def add_process(self, p):
- self.captured_output.write(p.stdout)
- self.captured_output.write(p.stderr)
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- sys.stdout = self.stdout
- sys.stderr = self.stderr
- print("DONE", flush=True)
- print("\t" + self.captured_output.getvalue().replace("\n", "\n\t").rstrip(), flush=True)
diff --git a/spaces/betterme/mestreamlit/pages/1002_pandas_profiling.py b/spaces/betterme/mestreamlit/pages/1002_pandas_profiling.py
deleted file mode 100644
index 9586214be63f3bf1327331a785c022d3d81b275b..0000000000000000000000000000000000000000
--- a/spaces/betterme/mestreamlit/pages/1002_pandas_profiling.py
+++ /dev/null
@@ -1,21 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-# @Project : Python.
-# @File : 1002_profile
-# @Time : 2022/10/17 下午2:34
-# @Author : yuanjie
-# @WeChat : meutils
-# @Software : PyCharm
-# @Description :
-
-
-import pandas as pd
-import pandas_profiling
-import streamlit as st
-
-from streamlit_pandas_profiling import st_profile_report
-
-df = pd.read_csv("./data/train.csv")
-pr = df.profile_report()
-
-st_profile_report(pr)
\ No newline at end of file
diff --git a/spaces/bilgeyucel/captionate/app.py b/spaces/bilgeyucel/captionate/app.py
deleted file mode 100644
index 918af3ae8c30323096b13a7d1b90e8dcbdc5e3dd..0000000000000000000000000000000000000000
--- a/spaces/bilgeyucel/captionate/app.py
+++ /dev/null
@@ -1,56 +0,0 @@
-import os
-import gradio as gr
-
-from haystack.nodes import TransformersImageToText
-from haystack.nodes import PromptNode, PromptTemplate
-from haystack import Pipeline
-
-description = """
-# Captionate 📸
-### Create Instagram captions for your pics!
-
-* Upload your photo or select one from examples
-* Choose your model
-* ✨ Captionate! ✨
-
-`OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5` and `tiiuae/falcon-7b-instruct` perform the best but try out different models to see how they react to the same prompt.
-
-Built by [Bilge Yucel](https://twitter.com/bilgeycl) using [Haystack](https://github.com/deepset-ai/haystack) 💙
-"""
-
-image_to_text = TransformersImageToText(
- model_name_or_path="nlpconnect/vit-gpt2-image-captioning",
- progress_bar=True
-)
-
-prompt_template = PromptTemplate(prompt="""
-You will receive a descriptive text of a photo.
-Try to come up with a nice Instagram caption that has a phrase rhyming with the text. Include emojis to the caption.
-
-Descriptive text: {documents};
-Instagram Caption:
-""")
-
-hf_api_key = os.environ["HF_API_KEY"]
-
-def generate_caption(image_file_paths, model_name):
- captioning_pipeline = Pipeline()
- prompt_node = PromptNode(model_name_or_path=model_name, api_key=hf_api_key, default_prompt_template=prompt_template, model_kwargs={"trust_remote_code":True})
- captioning_pipeline.add_node(component=image_to_text, name="image_to_text", inputs=["File"])
- captioning_pipeline.add_node(component=prompt_node, name="prompt_node", inputs=["image_to_text"])
- caption = captioning_pipeline.run(file_paths=[image_file_paths])
- return caption["results"][0]
-
-with gr.Blocks(theme="soft") as demo:
- gr.Markdown(value=description)
- with gr.Row():
- image = gr.Image(type="filepath")
- with gr.Column():
- model_name = gr.Dropdown(["OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5", "tiiuae/falcon-7b-instruct", "tiiuae/falcon-7b", "HuggingFaceH4/starchat-beta", "bigscience/bloom", "google/flan-t5-xxl"], value="OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5", label="Choose your model!")
- gr.Examples(["./whale.png", "./rainbow.jpeg", "./selfie.png"], inputs=image, label="Click on any example")
- submit_btn = gr.Button("✨ Captionate ✨")
- caption = gr.Textbox(label="Caption", show_copy_button=True)
- submit_btn.click(fn=generate_caption, inputs=[image, model_name], outputs=[caption])
-
-if __name__ == "__main__":
- demo.launch()
\ No newline at end of file
diff --git a/spaces/bioriAsaeru/text-to-voice/Airxonix Keygen Download.md b/spaces/bioriAsaeru/text-to-voice/Airxonix Keygen Download.md
deleted file mode 100644
index 7ca6fa3375a7c7ce303ffc9c654472eb128c66c6..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Airxonix Keygen Download.md
+++ /dev/null
@@ -1,107 +0,0 @@
-
-
Airxonix Keygen Download: How to Unlock the Full Version of the Classic Game
-
Airxonix is a fun and addictive game that challenges you to clear the balls away and create open field space. But what if you want to enjoy the full version of the game without paying for it? In this article, we will show you how to download Airxonix keygen and use it to activate the game.
Airxonix is a classic arcade game that was released in 1999 by Axysoft. The game is based on the popular Xonix game, where you have to cut off parts of the field and avoid the enemies. Airxonix adds a 3D twist to the gameplay, with colorful graphics and sound effects. The game has 5 types of games, each with different levels of difficulty and bonuses. You can also customize the game settings, such as the speed, sound, and controls.
-
What is Airxonix keygen?
-
Airxonix keygen is a software that can generate a serial number or a license key for Airxonix. This key can be used to unlock the full version of the game, which has more levels, features, and options than the trial version. Airxonix keygen is also known as a crack or a patch, as it modifies the original game files to bypass the registration process.
-
How to download Airxonix keygen?
-
To download Airxonix keygen, you need to follow these steps:
-
-
Go to a website that offers Airxonix keygen download, such as Smart Serials, Zedload, or Ateliertouche.
-
Search for Airxonix keygen or Airxonix v.1.36 serial number.
-
Click on the download link and follow the instructions.
-
You may need to complete a survey or an offer before you can access the file.
-
Save the file to your computer or smartphone.
-
-
How to use Airxonix keygen?
-
To use Airxonix keygen, you need to follow these steps:
-
-
-
Download and install Airxonix from the official website or from Filehippo.
-
Run Airxonix keygen and copy the serial number or the license key.
-
Run Airxonix and enter the serial number or the license key when prompted.
-
Enjoy the full version of Airxonix!
-
-
What are some of the risks and alternatives of using Airxonix keygen?
-
While using Airxonix keygen may seem like an easy and free way to get the full version of the game, there are some risks and alternatives that you should consider before doing so.
-
-
Risks: Using Airxonix keygen may expose you to viruses, malware, spyware, or other harmful software that can damage your device or steal your data. You may also violate the terms and conditions of Axysoft and face legal consequences for piracy. You may also get poor quality or outdated versions of the game that may not work properly or have bugs.
-
Alternatives: If you want to play Airxonix legally and safely, you should buy the game from Axysoft's website or from other authorized sellers. You can also try other similar games that are free or cheaper, such as Xonix 3D, Cubefield, or PacXon.
-
-
Conclusion
-
Airxonix keygen download is a software that can generate a serial number or a license key for Airxonix, a classic arcade game that challenges you to clear the balls away and create open field space. However, using Airxonix keygen may expose you to viruses, malware, spyware, or other harmful software that can damage your device or steal your data. You may also violate the terms and conditions of Axysoft and face legal consequences for piracy. You may also get poor quality or outdated versions of the game that may not work properly or have bugs. Therefore, we do not recommend downloading or using Airxonix keygen for any purpose.
-
Airxonix Keygen Download: How to Unlock the Full Version of the Classic Game
-
Airxonix is a fun and addictive game that challenges you to clear the balls away and create open field space. But what if you want to enjoy the full version of the game without paying for it? In this article, we will show you how to download Airxonix keygen and use it to activate the game.
-
What is Airxonix?
-
Airxonix is a classic arcade game that was released in 1999 by Axysoft. The game is based on the popular Xonix game, where you have to cut off parts of the field and avoid the enemies. Airxonix adds a 3D twist to the gameplay, with colorful graphics and sound effects. The game has 5 types of games, each with different levels of difficulty and bonuses. You can also customize the game settings, such as the speed, sound, and controls.
-
What is Airxonix keygen?
-
Airxonix keygen is a software that can generate a serial number or a license key for Airxonix. This key can be used to unlock the full version of the game, which has more levels, features, and options than the trial version. Airxonix keygen is also known as a crack or a patch, as it modifies the original game files to bypass the registration process.
-
How to download Airxonix keygen?
-
To download Airxonix keygen, you need to follow these steps:
-
-
Go to a website that offers Airxonix keygen download, such as Smart Serials, Zedload, or Ateliertouche.
-
Search for Airxonix keygen or Airxonix v.1.36 serial number.
-
Click on the download link and follow the instructions.
-
You may need to complete a survey or an offer before you can access the file.
-
Save the file to your computer or smartphone.
-
-
How to use Airxonix keygen?
-
To use Airxonix keygen, you need to follow these steps:
-
-
Download and install Airxonix from the official website or from Filehippo.
-
Run Airxonix keygen and copy the serial number or the license key.
-
Run Airxonix and enter the serial number or the license key when prompted.
-
Enjoy the full version of Airxonix!
-
-
What are some of the risks and alternatives of using Airxonix keygen?
-
While using Airxonix keygen may seem like an easy and free way to get the full version of the game, there are some risks and alternatives that you should consider before doing so.
-
-
Risks: Using Airxonix keygen may expose you to viruses, malware, spyware, or other harmful software that can damage your device or steal your data. You may also violate the terms and conditions of Axysoft and face legal consequences for piracy. You may also get poor quality or outdated versions of the game that may not work properly or have bugs.
-
Alternatives: If you want to play Airxonix legally and safely, you should buy the game from Axysoft's website or from other authorized sellers. You can also try other similar games that are free or cheaper, such as Xonix 3D, Cubefield, or PacXon.
-
-
Conclusion
-
Airxonix keygen download is a software that can generate a serial number or a license key for Airxonix, a classic arcade game that challenges you to clear the balls away and create open field space. However, using Airxonix keygen may expose you to viruses, malware, spyware, or other harmful software that can damage your device or steal your data. You may also violate the terms and conditions of Axysoft and face legal consequences for piracy. You may also get poor quality or outdated versions of the game that may not work properly or have bugs. Therefore, we do not recommend downloading or using Airxonix keygen for any purpose.
-
-
-- How to play Airxonix and what are the rules and tips of the game.
-- What are the benefits of playing Airxonix and how it can improve your skills and mood.
-- What are some of the features and options of Airxonix that make it unique and enjoyable.
-- How to troubleshoot Airxonix if you encounter any problems or errors while playing or installing the game.
-- How to contact Axysoft or get support if you have any questions or feedback about Airxonix.
-
Airxonix Keygen Download: How to Unlock the Full Version of the Classic Game
-
Airxonix is a fun and addictive game that challenges you to clear the balls away and create open field space. But what if you want to enjoy the full version of the game without paying for it? In this article, we will show you how to download Airxonix keygen and use it to activate the game.
-
What is Airxonix?
-
Airxonix is a classic arcade game that was released in 1999 by Axysoft. The game is based on the popular Xonix game, where you have to cut off parts of the field and avoid the enemies. Airxonix adds a 3D twist to the gameplay, with colorful graphics and sound effects. The game has 5 types of games, each with different levels of difficulty and bonuses. You can also customize the game settings, such as the speed, sound, and controls.
-
What is Airxonix keygen?
-
Airxonix keygen is a software that can generate a serial number or a license key for Airxonix. This key can be used to unlock the full version of the game, which has more levels, features, and options than the trial version. Airxonix keygen is also known as a crack or a patch, as it modifies the original game files to bypass the registration process.
-
How to download Airxonix keygen?
-
To download Airxonix keygen, you need to follow these steps:
-
-
Go to a website that offers Airxonix keygen download, such as Smart Serials, Zedload, or Ateliertouche.
-
Search for Airxonix keygen or Airxonix v.1.36 serial number.
-
Click on the download link and follow the instructions.
-
You may need to complete a survey or an offer before you can access the file.
-
Save the file to your computer or smartphone.
-
-
How to use Airxonix keygen?
-
To use Airxonix keygen, you need to follow these steps:
-
-
Download and install Airxonix from the official website or from Filehippo.
-
Run Airxonix keygen and copy the serial number or the license key.
-
Run Airxonix and enter the serial number or the license key when prompted.
-
Enjoy the full version of Airxonix!
-
-
What are some of the risks and alternatives of using Airxonix keygen?
-
While using Airxonix keygen may seem like an easy and free way to get the full version of the game, there are some risks and alternatives that you should consider before doing so.
-
-
Risks: Using Airxonix keygen may expose you to viruses, malware, spyware, or other harmful software that can damage your device or steal your data. You may also violate the terms and conditions of Axysoft and face legal consequences for piracy. You may also get poor quality or outdated versions of the game that may not work properly or have bugs.
-
Alternatives: If you want to play Airxonix legally and safely, you should buy the game from Axysoft's website or from other authorized sellers. You can also try other similar games that are free or cheaper, such as Xonix 3D, Cubefield, or PacXon.
-
-
Conclusion
-
Airxonix keygen download is a software that can generate a serial number or a license key for Airxonix, a classic arcade game that challenges you to clear the balls away and create open field space. However, using Airxonix keygen may expose you to viruses, malware, spyware, or other harmful software that can damage your device or steal your data. You may also violate the terms and conditions of Axysoft and face legal consequences for piracy. You may also get poor quality or outdated versions of the game that may not work properly or have bugs. Therefore, we do not recommend downloading or using Airxonix keygen for any purpose.
-
Conclusion
-
Airxonix keygen download is a software that can generate a serial number or a license key for Airxonix, a classic arcade game that challenges you to clear the balls away and create open field space. However, using Airxonix keygen may expose you to viruses, malware, spyware, or other harmful software that can damage your device or steal your data. You may also violate the terms and conditions of Axysoft and face legal consequences for piracy. You may also get poor quality or outdated versions of the game that may not work properly or have bugs. Therefore, we do not recommend downloading or using Airxonix keygen for any purpose.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/bioriAsaeru/text-to-voice/Assassins Creed Unity Patch v.1.3.0 (Update) Crack by ALI213 Hack PC and Discover the Secrets of the Templars.md b/spaces/bioriAsaeru/text-to-voice/Assassins Creed Unity Patch v.1.3.0 (Update) Crack by ALI213 Hack PC and Discover the Secrets of the Templars.md
deleted file mode 100644
index 6c4e0086c9f040d743951fba328eb279944c27e7..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Assassins Creed Unity Patch v.1.3.0 (Update) Crack by ALI213 Hack PC and Discover the Secrets of the Templars.md
+++ /dev/null
@@ -1,9 +0,0 @@
-
-
strongholdcrusaderextremetrainerv1227 [url= -jaggedalliancebackinactiontrainer113gdownload]trello[/url]DrediuhIrrivataree [url= -malware-hunter-1960685-crack-patch-2020] -malware-hunter-1960685-crack-patch-2020[/url] Taiseertaids [url= -terminator-2-magyar-szinkronnal]terminator 2 magyar szinkronnal[/url] melsAtterve [url= -de-dana-dan-1-3gp-movie-free-download]Download[/url] download buku aku sumanjaya pdf [url= -train-simulator-semmeringbahn-m-rzzuschlag-to-gloggnitz-route-add-on-download-for-pc-serial-number]trello[/url] NatttureCemFrawlHem [url= -la-biblia-de-las-fuentes-conmutadas-tomo-ii-pdf] -la-biblia-de-las-fuentes-conmutadas-tomo-ii-pdf[/url] 3d sex villa tk17 mods [url= -pyaar-impossible-full-movie-hindi-dubbed-download]Pyaar Impossible full movie hindi dubbed download[/url] Flip PDF Corporate Edition 2.4.9.31 with Crack [url= -spongebob-schwammkopf-schlacht-um-bikini-bottom-pc-download-vollversion-11]trello.com[/url]EquantyroarkPata [url= -unity-pro-201730f1-final-patch-sh-keygen]Download[/url] flissinneple [url= -dr-fone-1032-crack-registration-toolkit-latest-download]Dr Fone 10.3.2 Crack (Registration ToolKit) Latest Download[/url]
walpZoffoopyiptyday [url= -mahabharata-full-story-in-malayalam-pdf-free-download]trello[/url]DrediuhIrrivataree [url= -download-soal-psikotes-ist-dan-jawabannya]trello.com[/url] Happy Journey 2 Full Movie In Tamil Download Hd [url= -auslogics-registry-cleaner-pro-8400-with-crack]Download[/url] Ail Set Stream Volume8 Gta Vice City [url= -hd-online-player-upside-down-full-movie-in-hindi-free]trello[/url] Scriptcase 9.4.000 Crack [url= -tms-xdata-v4601-delphi-xe2-delphi-1032-rio-full-source]Download[/url] NatttureCemFrawlHem [url= -free-rab-ne-bana-di-jodi-full-movie-download-hindi-mp4]Free Rab Ne Bana Di Jodi Full Movie Download Hindi Mp4[/url] How hackers Hack Instagram with bruteforce [url= -swar-studio-2012-v21-cracked-b1zn3ze]Swar Studio 2012 V2.1 Cracked [b1zN3ze][/url] ReFWocheNuththegodat [url= -universal-dreamup-v2009-patched-by-forhike-and-natas-downloadl]Download[/url]EquantyroarkPata [url= -bay-t-entegre-full-crack-software]bay t entegre full crack software[/url] PES 2018 Crack [url= -pic-c-compiler-ccs-pcwhd-v4114-cracked]Download[/url]
-
New Cbr 150 Vs Yamaha Vixion New [url= -telechargercoswin7igratuit] -telechargercoswin7igratuit[/url]DrediuhIrrivataree [url= -bricsys-bricscad-platinum-17-full-license-manager-keygen] -bricsys-bricscad-platinum-17-full-license-manager-keygen[/url] Taiseertaids [url= -fsx-captain-sim-737-200-base-v100-the-game] -fsx-captain-sim-737-200-base-v100-the-game[/url] melsAtterve [url= -lipikaartypingsoftwareforwindowscracktorrent]lipikaartypingsoftwareforwindowscracktorrent[/url] sesspaphpag [url= -lesson-5-homework-practice-factoring-linear-expressions-answers] -lesson-5-homework-practice-factoring-linear-expressions-answers[/url] Creeper World 4 Free Download [torrent Full] [url= -adobe-acrobat-professional-7-serial-number-freel]Download[/url] soben peter community dentistry ebook download [url= -raju-chacha-full-movie-in-hindi-hd-download-free-torrent]Download[/url] ReFWocheNuththegodat [url= -keygen-mixvibes-cross-dj-51]Download[/url]barrie hough skilpoppe english summary.rar [url= -gupi-gayen-bagha-bayen-full-movie-720p] -gupi-gayen-bagha-bayen-full-movie-720p[/url] flissinneple [url= -yugiohpowerofchaosjoeysworldmodpcgamehack]Download[/url]
-
Lighttools 8.0 Crack [url= -hd-online-player-ghajini-tamil-2-movie-in-hindi-720p-download-torrent] -hd-online-player-ghajini-tamil-2-movie-in-hindi-720p-download-torrent[/url]UshulFiqhAbuZahrahpdf [url= -calvin-harris-18-months-deluxe-download-zip]trello.com[/url] Taiseertaids [url= -gratis-software-matrix-on-air-crack]trello[/url] melsAtterve [url= -architecte-3d-platinium-2013-gratuit-torrent]Architecte 3d Platinium 2013 Gratuit Torrent[/url] silhouette studio business edition keygen 33 [url= -topsolid-v7-crack-40]Download[/url] descargar youwave portable emulador de android para pc [url= -max-recorder-crack-universal-key-full-version] -max-recorder-crack-universal-key-full-version[/url] ITools 2013 Build 0524 Download [url= -robin-hood-defender-of-the-crown-free-download-full]Download[/url] Pipesim Training Course Pdf [url= -assassins-creed-unity-complete-edition-repack-mr-djl]Download[/url]EquantyroarkPata [url= -twilight-breaking-dawn-part-2-full-movie-sub-indonesia-download]trello[/url] flissinneple [url= -despicableme3englishdualaudiohindifreedownload]trello.com[/url]
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/bioriAsaeru/text-to-voice/Crack Battle For Middle Earth 2 No Cd How to Install and Play without Discs.md b/spaces/bioriAsaeru/text-to-voice/Crack Battle For Middle Earth 2 No Cd How to Install and Play without Discs.md
deleted file mode 100644
index 8dda6bcec15982782b50ecfa17ee1ff392b6f0de..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Crack Battle For Middle Earth 2 No Cd How to Install and Play without Discs.md
+++ /dev/null
@@ -1,6 +0,0 @@
-
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/bioriAsaeru/text-to-voice/Crack Serial Delftship Pro !!INSTALL!!.md b/spaces/bioriAsaeru/text-to-voice/Crack Serial Delftship Pro !!INSTALL!!.md
deleted file mode 100644
index 8f44d65b72dc64129003d019d6cff2043e41fead..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Crack Serial Delftship Pro !!INSTALL!!.md
+++ /dev/null
@@ -1,111 +0,0 @@
-
-
Crack Serial Delftship Pro: How to Get the Best Ship Design Software for Free
-
-
If you are looking for a professional and powerful software for designing and modeling ships, boats, yachts, and other marine vessels, you may have heard of Delftship. Delftship is a 3D hullform modeling program that uses subdivision surfaces to create smooth and realistic shapes. It also has many features and tools to help you with hydrostatics, stability, resistance, propulsion, and more.
-
-
However, Delftship is not a cheap software. The free version of Delftship has limited functionality and does not allow you to save or print your designs. The professional version of Delftship costs 495 euros (about 580 dollars) and requires a valid license to activate. If you want to use the professional version of Delftship without paying for it, you may be tempted to look for a crack serial delftship pro.
A crack serial delftship pro is a combination of a crack and a serial number that can bypass the activation process of Delftship and unlock all its features. A crack is a program that modifies or replaces the original executable file of Delftship to remove the protection mechanisms. A serial number is a code that identifies your copy of Delftship and validates your license.
-
-
However, using a crack serial delftship pro is not a good idea. Here are some of the reasons why you should avoid using a crack serial delftship pro:
-
-
It is illegal
-
-
Using a crack serial delftship pro is a form of software piracy, which is a violation of intellectual property rights. Software piracy is illegal in most countries and can result in fines, lawsuits, or even jail time. By using a crack serial delftship pro, you are stealing from the developers of Delftship and depriving them of their rightful income.
-
-
It is risky
-
-
Using a crack serial delftship pro is also risky for your computer and your data. A crack serial delftship pro may contain viruses, malware, spyware, or other harmful programs that can infect your system and compromise your security. A crack serial delftship pro may also damage or corrupt your files, cause errors or crashes, or make your software unstable or unusable.
-
-
It is unethical
-
-
Using a crack serial delftship pro is also unethical and unfair. Delftship is a product of hard work, creativity, and innovation by its developers. They deserve to be rewarded for their efforts and to receive feedback and support from their customers. By using a crack serial delftship pro, you are disrespecting their work and undermining their reputation.
-
-
It is unnecessary
-
-
Using a crack serial delftship pro is also unnecessary and impractical. There are better ways to get the professional version of Delftship without breaking the law or risking your computer or data. Here are some of the alternatives to using a crack serial delftship pro:
-
-
-
-
Buy the software. The best way to get the professional version of Delftship is to buy it from the official website or an authorized reseller. You will get a legitimate license that will allow you to use all the features and updates of Delftship without any problems or limitations.
-
Use the trial version. If you want to try the professional version of Delftship before buying it, you can use the trial version that is available on the official website. The trial version will let you use all the features of Delftship for 30 days without any restrictions.
-
Use the free version. If you don't need all the features of the professional version of Delftship, you can use the free version that is also available on the official website. The free version will let you design and model ships with basic functionality and export them as images or DXF files.
-
Use an alternative software. If you are looking for another software that can do similar things as Delftship, you can use an alternative software that may be cheaper or free. Some examples of alternative software are FreeShip, Rhino Marine, Orca3D, Maxsurf, Hullform, etc.
-
-
-
Conclusion
-
-
In conclusion, using a crack serial delftship pro is not worth it. It is illegal, risky, unethical, and unnecessary. You should avoid using a crack serial delftship pro and use one of the alternatives instead. You will get a better experience with Delftship and support its development.
-
What are the benefits of using Delftship Professional?
-
-
Delftship Professional is a software that can help you design and model any type of ship, boat, yacht, or other marine vessel. It has many benefits that can make your work easier, faster, and more accurate. Some of the benefits of using Delftship Professional are:
-
-
-
It uses subdivision surfaces to create smooth and realistic shapes that can be easily modified and refined.
-
It has a user-friendly interface that allows you to work in 3D or 2D views, with multiple windows and toolbars.
-
It has a comprehensive library of predefined shapes, curves, and components that you can use or customize for your design.
-
It has a powerful hydrostatics module that can calculate and display various properties of your design, such as displacement, center of gravity, buoyancy, stability, resistance, etc.
-
It has a flexible propulsion module that can simulate and optimize different types of propellers, thrusters, jets, etc.
-
It has a versatile export module that can save your design as images, DXF files, IGES files, STL files, etc.
-
It has a built-in manual and online help that can guide you through the features and functions of the software.
-
-
-
How to use Delftship Professional effectively?
-
-
Delftship Professional is a software that can help you design and model any type of ship, boat, yacht, or other marine vessel. It has many features and tools that can help you create your design from scratch or from an existing model. Here are some tips on how to use Delftship Professional effectively:
-
-
-
Start with a sketch or a plan of your design. You can use paper, CAD software, or Delftship's own sketch tool to create a rough outline of your design.
-
Create a new project in Delftship and import your sketch or plan as a background image. You can use the scale and align tools to adjust the image to fit the grid.
-
Create the main hull shape using the point-and-click method. You can add points on the grid and connect them with edges to form faces. You can also use the extrude, insert, delete, move, rotate, scale, mirror, split, merge, and other tools to modify the shape.
-
Add details and components to your design using the library or the custom shape tool. You can add decks, cabins, windows, doors, masts, sails, rudders, keels, anchors, etc. You can also use the copy and paste tools to duplicate or reuse parts of your design.
-
Check and optimize your design using the hydrostatics and propulsion modules. You can calculate and display various properties of your design, such as displacement, center of gravity, buoyancy, stability, resistance, etc. You can also simulate and optimize different types of propellers, thrusters, jets, etc.
-
Export your design as images or files using the export module. You can save your design as images in JPG, PNG, BMP formats. You can also save your design as DXF files for CAD software or IGES files for 3D printing. You can also save your design as STL files for CNC machining or VRML files for virtual reality.
-
-
-
Where to find more information and support for Delftship Professional?
-
-
Delftship Professional is a software that can help you design and model any type of ship, boat, yacht, or other marine vessel. It is a product of Delftship BV , a company based in the Netherlands that specializes in ship design software and services. If you want to find more information and support for Delftship Professional , you can visit some of the following websites:
-
-
-
The official website of Delftship , where you can find news , updates , media , guides , forums , and more.
-
The official website of Delftship Support , where you can find articles , videos , FAQs , troubleshooting tips , contact options , and more.
-
The official website of Delftship Wiki , where you can find comprehensive information about the software's features , functions , commands , shortcuts , tips , tricks , and more.
-
The official website of Delftship YouTube Channel , where you can watch tutorials , demonstrations , reviews , showcases , and more.
-
The official website of Delftship Facebook Page , where you can follow the latest news , updates , events , promotions , and more.
-
-
How to install and activate Delftship Professional with a crack serial delftship pro?
-
-
If you have found a crack serial delftship pro that you think is working and safe, you may want to install and activate Delftship Professional with it. However, this is not a straightforward process and it may vary depending on the source and type of the crack serial delftship pro. Here are some general steps that you may need to follow:
-
-
-
Download the crack serial delftship pro from the website, forum, blog, torrent, or file-sharing platform where you found it. You may need to complete some surveys, ads, pop-ups, or malware before you can access the download link.
-
Extract the crack serial delftship pro from the compressed file that you downloaded. You may need a password to open the file. You may also need to disable your antivirus or firewall software to avoid any interference.
-
Download the original Delftship Professional software from the official website or an authorized reseller. You may need to register an account or provide some personal information to access the download link.
-
Install the original Delftship Professional software on your computer. You may need to agree to some terms and conditions or provide some payment information to complete the installation.
-
Run the crack program that came with the crack serial delftship pro. You may need to run it as administrator or in compatibility mode. You may also need to close any other programs or processes that are running on your computer.
-
Follow the instructions of the crack program to modify or replace the original executable file of Delftship Professional. You may need to copy, paste, move, rename, delete, or overwrite some files or folders.
-
Enter the serial number that came with the crack serial delftship pro when prompted by Delftship Professional. You may need to enter it multiple times or in different places.
-
Restart your computer and run Delftship Professional. You should be able to use all the features of Delftship Professional without any restrictions.
-
-
-
What are the disadvantages of using a crack serial delftship pro?
-
-
Using a crack serial delftship pro may seem like a good way to save money and get the professional version of Delftship without paying for it. However, using a crack serial delftship pro has many disadvantages that can outweigh any benefits. Some of the disadvantages of using a crack serial delftship pro are:
-
-
-
You will not get any updates or support from Delftship. Using a crack serial delftship pro will prevent you from getting any updates or patches that can fix bugs, improve performance, or add new features to Delftship. You will also not get any support or help from Delftship if you encounter any problems or issues with the software.
-
You will not get any warranty or guarantee from Delftship. Using a crack serial delftship pro will void any warranty or guarantee that Delftship may offer for its software. You will not be able to claim any refund, replacement, or compensation if you are dissatisfied with Delftship or if it causes any damage or loss to your computer or data.
-
You will not get any recognition or respect from Delftship or other users. Using a crack serial delftship pro will show that you do not respect or appreciate Delftship's work and effort in creating and developing its software. You will also not get any recognition or respect from other users who have paid for Delftship or who use it legally.
-
You will not get any satisfaction or enjoyment from using Delftship. Using a crack serial delftship pro will take away any satisfaction or enjoyment that you may get from using Delftship legitimately. You will not feel proud of your work or achievements with Delftship because you know that you have cheated and stolen from Delftship.
-
-
Conclusion
-
-
In this article, we have discussed the topic of crack serial delftship pro, which is a combination of a crack and a serial number that can bypass the activation process of Delftship Professional and unlock all its features. We have explained what Delftship Professional is, what are the benefits of using it, how to find a crack serial delftship pro, how to install and activate Delftship Professional with it, and what are the disadvantages of using it.
-
-
We have concluded that using a crack serial delftship pro is not a good idea. It is illegal, risky, unethical, and unnecessary. It can cause legal troubles, security issues, ethical dilemmas, and practical problems for you and your computer. It can also prevent you from getting the best experience with Delftship Professional and enjoying its features and functions.
-
-
Therefore, we recommend that you avoid using a crack serial delftship pro and use one of the alternatives instead. You can buy the software from the official website or an authorized reseller, use the trial version or the free version, use an alternative software, or use any other legal and safe way to get Delftship Professional. You will get a better quality, performance, and satisfaction with Delftship Professional and support its development and improvement.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/bioriAsaeru/text-to-voice/Descargar Libro Contabilidad Financiera De Warren Reeve Duchac 25.md b/spaces/bioriAsaeru/text-to-voice/Descargar Libro Contabilidad Financiera De Warren Reeve Duchac 25.md
deleted file mode 100644
index 6afb3424b0b5a45be043aa6d1b20a7c7747f3cd4..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Descargar Libro Contabilidad Financiera De Warren Reeve Duchac 25.md
+++ /dev/null
@@ -1,6 +0,0 @@
-
descargar libro contabilidad financiera de warren reeve duchac 25
-
-rar .isvu .mp3 MEGA 関連リンク. [ CRACKED ] Windows Gx Eriii V2 113 Rar Full Download.zip.rar.isvu.mp3 [CRACKED] Windows Gx Eriii V2 113 Rar Full Download jhfdsb4pvk01gbgfgyp4xz.exe.sud itesun jhfdsb4pvk01gbgfgyp4xz.exe.rar [CRACKED] Windows Gx Eriii V2 113 Rar Full Download l_jfb_lf2wpuwld2nd0fb_l5t3l0e6nfdt.zip .rar .isvu .mp3 MEGA 関連リンク. [ CRACKED ] Windows Gx Eriii V2 113 Rar Full Download jhfdsb4pvk01gbgfgyp4xz.exe.sud itesun jhfdsb4pvk01gbgfgyp4xz.exe.rar [CRACKED] Windows Gx Eriii V2 113 Rar Full Download l_jfb_lf2wpuwld2nd0fb_l5t3l0e6nfdt.zip .rar .isvu .mp3 MEGA 関連リンク. [ CRACKED ] Windows Gx Eriii V2 113 Rar Full Download jhfdsb4pvk01gbgfgyp4xz.exe.sud itesun jhfdsb4pvk01gbgfgyp4xz.exe.rar [CRACKED] Windows Gx Eriii V2 113 Rar Full Download l_jfb_lf2wpuwld2nd0fb_l5t3l0e6nfdt.zip .rar .isvu .mp3 MEGA 関連リンク. [ CRACKED ] Windows Gx Eriii V2 113 Rar Full Download jhfdsb4pvk01gbgfgyp4xz.exe.sud itesun jhfdsb4pvk01gbgfgyp 4fefd39f24
-
-
-
diff --git a/spaces/bradarrML/runwayml-stable-diffusion-v1-5/README.md b/spaces/bradarrML/runwayml-stable-diffusion-v1-5/README.md
deleted file mode 100644
index 696d624f648db9c770064fc129da29c7823a260c..0000000000000000000000000000000000000000
--- a/spaces/bradarrML/runwayml-stable-diffusion-v1-5/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Runwayml Stable Diffusion V1 5
-emoji: 🏢
-colorFrom: gray
-colorTo: purple
-sdk: gradio
-sdk_version: 3.12.0
-app_file: app.py
-pinned: false
-duplicated_from: Bradarr/runwayml-stable-diffusion-v1-5
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/brainblow/beat_remixer/beat_manipulator/main.py b/spaces/brainblow/beat_remixer/beat_manipulator/main.py
deleted file mode 100644
index 6a349dcc432c32fb08b79f41a0550f97bedb9560..0000000000000000000000000000000000000000
--- a/spaces/brainblow/beat_remixer/beat_manipulator/main.py
+++ /dev/null
@@ -1,531 +0,0 @@
-import numpy as np, scipy.interpolate
-from . import io, utils
-from .effects import BM_EFFECTS
-from .metrics import BM_METRICS
-from .presets import BM_SAMPLES
-
-
-class song:
- def __init__(self, audio = None, sr:int=None, log=True):
- if audio is None:
- from tkinter import filedialog
- audio = filedialog.askopenfilename()
-
- if isinstance(audio, song): self.path = audio.path
- self.audio, self.sr = io._load(audio=audio, sr=sr)
-
- # unique filename is needed to generate/compare filenames for cached beatmaps
- if isinstance(audio, str):
- self.path = audio
- elif not isinstance(audio, song):
- self.path = f'unknown_{hex(int(np.sum(self.audio) * 10**18))}'
-
- self.log = log
- self.beatmap = None
- self.normalized = None
-
- def _slice(self, a):
- if a is None: return None
- elif isinstance(a, float):
- if (a_dec := a % 1) == 0: return self.beatmap[int(a)]
- a_int = int(int(a)//1)
- start = self.beatmap[a_int]
- return int(start + a_dec * (self.beatmap[a_int+1] - start))
- elif isinstance(a, int): return self.beatmap[a]
- else: raise TypeError(f'slice indices must be int, float, or None, not {type(a)}. Indice is {a}')
-
- def __getitem__(self, s):
- if isinstance(s, slice):
- start = s.start
- stop = s.stop
- step = s.step
- if start is not None and stop is not None:
- if start > stop:
- is_reversed = -1
- start, stop = stop, start
- else: is_reversed = None
- if step is None or step == 1:
- start = self._slice(start)
- stop = self._slice(stop)
- if isinstance(self.audio, list): return [self.audio[0][start:stop:is_reversed],self.audio[1][start:stop:is_reversed]]
- else: return self.audio[:,start:stop:is_reversed]
- else:
- i = s.start if s.start is not None else 0
- end = s.stop if s.stop is not None else len(self.beatmap)
- if i > end:
- step = -step
- if step > 0: i, end = end-2, i
- elif step < 0: i, end = end-2, i
- if step < 0:
- is_reversed = True
- end -= 1
- else: is_reversed = False
- pattern = ''
- while ((i > end) if is_reversed else (i < end)):
- pattern+=f'{i},'
- i+=step
- song_copy = song(audio = self.audio, sr = self.sr, log = False)
- song_copy.beatmap = self.beatmap.copy()
- song_copy.beatmap = np.insert(song_copy.beatmap, 0, 0)
- result = song_copy.beatswap(pattern = pattern, return_audio = True)
- return result if isinstance(self.audio, np.ndarray) else result.tolist()
-
-
- elif isinstance(s, float):
- start = self._slice(s-1)
- stop = self._slice(s)
- if isinstance(self.audio, list): return [self.audio[0][start:stop],self.audio[1][start:stop]]
- else: return self.audio[:,start:stop]
- elif isinstance(s, int):
- start = self.beatmap[s-1]
- stop = self.beatmap[s]
- if isinstance(self.audio, list): return [self.audio[0][start:stop],self.audio[1][start:stop]]
- else: return self.audio[:,start:stop]
- elif isinstance(s, tuple):
- start = self._slice(s[0])
- stop = self._slice(s[0] + s[1])
- if stop<0:
- start -= stop
- stop = -stop
- step = -1
- else: step = None
- if isinstance(self.audio, list): return [self.audio[0][start:stop:step],self.audio[1][start:stop:step]]
- else: return self.audio[:,start:stop:step]
- elif isinstance(s, list):
- start = s[0]
- stop = s[1] if len(s) > 1 else None
- if start > stop:
- step = -1
- start, stop = stop, start
- else: step = None
- start = self._slice(start)
- stop = self._slice(stop)
- if step is not None and stop is None: stop = self._slice(start + s.step)
- if isinstance(self.audio, list): return [self.audio[0][start:stop:step],self.audio[1][start:stop:step]]
- else: return self.audio[:,start:stop:step]
- elif isinstance(s, str):
- return self.beatswap(pattern = s, return_audio = True)
-
-
- else: raise TypeError(f'list indices must be int/float/slice/tuple, not {type(s)}; perhaps you missed a comma? Slice is `{s}`')
-
-
- def _print(self, *args, end=None, sep=None):
- if self.log: print(*args, end=end, sep=sep)
-
-
- def write(self, output='', ext='mp3', suffix=' (beatswap)', literal_output=False):
- """writes"""
- if literal_output is False: output = io._outputfilename(output, filename=self.path, suffix=suffix, ext=ext)
- io.write_audio(audio=self.audio, sr=self.sr, output=output, log=self.log)
- return output
-
-
- def beatmap_generate(self, lib='madmom.BeatDetectionProcessor', caching = True, load_settings = True):
- """Find beat positions"""
- from . import beatmap
- self.beatmap = beatmap.generate(audio = self.audio, sr = self.sr, lib=lib, caching=caching, filename = self.path, log = self.log, load_settings = load_settings)
- if load_settings is True:
- audio_id=hex(len(self.audio[0]))
- settingsDir="beat_manipulator/beatmaps/" + ''.join(self.path.split('/')[-1]) + "_"+lib+"_"+audio_id+'_settings.txt'
- import os
- if os.path.exists(settingsDir):
- with open(settingsDir, 'r') as f:
- settings = f.read().split(',')
- if settings[3] != None: self.normalized = settings[3]
- self.beatmap_default = self.beatmap.copy()
- self.lib = lib
-
- def beatmap_scale(self, scale:float):
- from . import beatmap
- self.beatmap = beatmap.scale(beatmap = self.beatmap, scale = scale, log = self.log)
-
- def beatmap_shift(self, shift:float, mode = 1):
- from . import beatmap
- self.beatmap = beatmap.shift(beatmap = self.beatmap, shift = shift, log = self.log, mode = mode)
-
- def beatmap_reset(self):
- self.beatmap = self.beatmap_default.copy()
-
- def beatmap_adjust(self, adjust = 500):
- self.beatmap = np.append(np.sort(np.absolute(self.beatmap - adjust)), len(self.audio[0]))
-
- def beatmap_save_settings(self, scale: float = None, shift: float = None, adjust: int = None, normalized = None, overwrite = 'ask'):
- from . import beatmap
- if self.beatmap is None: self.beatmap_generate()
- beatmap.save_settings(audio = self.audio, filename = self.path, scale = scale, shift = shift,adjust = adjust, normalized = normalized, log=self.log, overwrite=overwrite, lib = self.lib)
-
- def beatswap(self, pattern = '1;"cowbell"s3v2, 2;"cowbell"s2, 3;"cowbell", 4;"cowbell"s0.5, 5;"cowbell"s0.25, 6;"cowbell"s0.4, 7;"cowbell"s0.8, 8;"cowbell"s1.6',
- scale:float = 1, shift:float = 0, length = None, samples:dict = BM_SAMPLES, effects:dict = BM_EFFECTS, metrics:dict = BM_METRICS, smoothing: int = 100, adjust=500, return_audio = False, normalize = False, limit_beats=10000, limit_length = 52920000):
-
- if normalize is True:
- self.normalize_beats()
- if self.beatmap is None: self.beatmap_generate()
- beatmap_default = self.beatmap.copy()
- self.beatmap = np.append(np.sort(np.absolute(self.beatmap - adjust)), len(self.audio[0]))
- self.beatmap_shift(shift)
- self.beatmap_scale(scale)
-
- # baked in presets
- #reverse
- if pattern.lower() == 'reverse':
- if return_audio is False:
- self.audio = self[::-1]
- self.beatmap = beatmap_default.copy()
- return
- else:
- result = self[::-1]
- self.beatmap = beatmap_default.copy()
- return result
- # shuffle
- elif pattern.lower() == 'shuffle':
- import random
- beats = list(range(len(self.beatmap)))
- random.shuffle(beats)
- beats = ','.join(list(str(i) for i in beats))
- if return_audio is False:
- self.beatswap(beats)
- self.beatmap = beatmap_default.copy()
- return
- else:
- result = self.beatswap(beats, return_audio = True)
- self.beatmap = beatmap_default.copy()
- return result
- # test
- elif pattern.lower() == 'test':
- if return_audio is False:
- self.beatswap('1;"cowbell"s3v2, 2;"cowbell"s2, 3;"cowbell", 4;"cowbell"s0.5, 5;"cowbell"s0.25, 6;"cowbell"s0.4, 7;"cowbell"s0.8, 8;"cowbell"s1.6')
- self.beatmap = beatmap_default.copy()
- return
- else:
- result = self.beatswap('1;"cowbell"s3v2, 2;"cowbell"s2, 3;"cowbell", 4;"cowbell"s0.5, 5;"cowbell"s0.25, 6;"cowbell"s0.4, 7;"cowbell"s0.8, 8;"cowbell"s1.6', return_audio = True)
- self.beatmap = beatmap_default.copy()
- return result
- # random
- elif pattern.lower() == 'random':
- import random,math
- pattern = ''
- rand_length=0
- while True:
- rand_num = int(math.floor(random.triangular(1, 16, rand_length-1)))
- if random.uniform(0, rand_num)>rand_length: rand_num = rand_length+1
- rand_slice = random.choices(['','>0.5','>0.25', '<0.5', '<0.25', '<1/3', '<2/3', '>1/3', '>2/3', '<0.75', '>0.75',
- f'>{random.uniform(0.01,2)}', f'<{random.uniform(0.01,2)}'], weights = [13,1,1,1,1,1,1,1,1,1,1,1,1], k=1)[0]
-
- rand_effect = random.choices(['', 's0.5', 's2', f's{random.triangular(0.1,1,4)}', 'r','v0.5', 'v2', 'v0',
- f'd{int(random.triangular(1,8,16))}', 'g', 'c', 'c0', 'c1', f'b{int(random.triangular(1,8,4))}'],
- weights=[30, 2, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 1], k=1)[0]
-
- rand_join = random.choices([', ', ';'], weights = [5, 1], k=1)[0]
- pattern += f'{rand_num}{rand_slice}{rand_effect}{rand_join}'
- if rand_join == ',': rand_length+=1
- if rand_length in [4, 8, 16]:
- if random.uniform(rand_num,16)>14: break
- else:
- if random.uniform(rand_num,16)>15.5: break
- pattern_length = 4
- if rand_length > 6: pattern_length = 8
- if rand_length > 12: pattern_length = 16
- if rand_length > 24: pattern_length = 32
-
-
-
- from . import parse
- pattern, operators, pattern_length, shuffle_groups, shuffle_beats, c_slice, c_misc, c_join = parse.parse(pattern = pattern, samples = samples, pattern_length = length, log = self.log)
-
- #print(f'pattern length = {pattern_length}')
-
- # beatswap
- n=-1
- tries = 0
- metric = None
- result=[self.audio[:,:self.beatmap[0]]]
- #for i in pattern: print(i)
-
-
- stop = False
- total_length = 0
-
- # loop over pattern until it reaches the last beat
- while n*pattern_length <= len(self.beatmap):
- n+=1
-
- if stop is True: break
-
- # Every time pattern loops, shuffles beats with #
- if len(shuffle_beats) > 0:
- pattern = parse._shuffle(pattern, shuffle_beats, shuffle_groups)
-
- # Loops over all beats in pattern
- for num, b in enumerate(pattern):
-
- # check if beats limit has been reached
- if limit_beats is not None and len(result) >= limit_beats:
- stop = True
- break
-
- if len(b) == 4: beat = b[3] # Sample has length 4
- else: beat = b[0] # Else take the beat
-
- if beat is not None:
- beat_as_string = ''.join(beat) if isinstance(beat, list) else beat
- # Skips `!` beats
- if c_misc[9] in beat_as_string: continue
-
- # Audio is a sample or a song
- if len(b) == 4:
- audio = b[0]
-
- # Audio is a song
- if b[2] == c_misc[10]:
- try:
-
- # Song slice is a single beat, takes it
- if isinstance(beat, str):
- # random beat if `@` in beat (`_` is separator)
- if c_misc[4] in beat: beat = parse._random(beat, rchar = c_misc[4], schar = c_misc[5], length = pattern_length)
- beat = utils._safer_eval(beat) + pattern_length*n
- while beat > len(audio.beatmap)-1: beat = 1 + beat - len(audio.beatmap)
- beat = audio[beat]
-
- # Song slice is a range of beats, takes the beats
- elif isinstance(beat, list):
- beat = beat.copy()
- for i in range(len(beat)-1): # no separator
- if c_misc[4] in beat[i]: beat[i] = parse._random(beat[i], rchar = c_misc[4], schar = c_misc[5], length = pattern_length)
- beat[i] = utils._safer_eval(beat[i])
- while beat[i] + pattern_length*n > len(audio.beatmap)-1: beat[i] = 1 + beat[i] - len(audio.beatmap)
- if beat[2] == c_slice[0]: beat = audio[beat[0] + pattern_length*n : beat[1] + pattern_length*n]
- elif beat[2] == c_slice[1]: beat = audio[beat[0] - 1 + pattern_length*n: beat[0] - 1 + beat[1] + pattern_length*n]
- elif beat[2] == c_slice[2]: beat = audio[beat[0] - beat[1] + pattern_length*n : beat[0] + pattern_length*n]
-
- # No Song slice, take whole song
- elif beat is None: beat = audio.audio
-
- except IndexError as e:
- print(e)
- tries += 1
- if tries > 30: break
- continue
-
- # Audio is an audio file
- else:
- # No audio slice, takes whole audio
- if beat is None: beat = audio
-
- # Audio slice, takes part of the audio
- elif isinstance(beat, list):
- audio_length = len(audio[0])
- beat = [min(int(utils._safer_eval(beat[0])*audio_length), audio_length-1), min(int(utils._safer_eval(beat[1])*audio_length), audio_length-1)]
- if beat[0] > beat[1]:
- beat[0], beat[1] = beat[1], beat[0]
- step = -1
- else: step = None
- beat = audio[:, beat[0] : beat[1] : step]
-
- # Audio is a beat
- else:
- try:
- beat_str = beat if isinstance(beat, str) else ''.join(beat)
- # Takes a single beat
- if isinstance(beat, str):
- if c_misc[4] in beat: beat = parse._random(beat, rchar = c_misc[4], schar = c_misc[5], length = pattern_length)
- beat = self[utils._safer_eval(beat) + pattern_length*n]
-
- # Takes a range of beats
- elif isinstance(beat, list):
- beat = beat.copy()
- for i in range(len(beat)-1): # no separator
- if c_misc[4] in beat[i]: beat[i] = parse._random(beat[i], rchar = c_misc[4], schar = c_misc[5], length = pattern_length)
- beat[i] = utils._safer_eval(beat[i])
- if beat[2] == c_slice[0]: beat = self[beat[0] + pattern_length*n : beat[1] + pattern_length*n]
- elif beat[2] == c_slice[1]: beat = self[beat[0] - 1 + pattern_length*n: beat[0] - 1 + beat[1] + pattern_length*n]
- elif beat[2] == c_slice[2]: beat = self[beat[0] - beat[1] + pattern_length*n : beat[0] + pattern_length*n]
-
- # create a variable if `%` in beat
- if c_misc[7] in beat_str: metric = parse._metric_get(beat_str, beat, metrics, c_misc[7])
-
- except IndexError:
- tries += 1
- if tries > 30: break
- continue
-
- if len(beat[0])<1: continue #Ignores empty beats
-
- # Applies effects
- effect = b[1]
- for e in effect:
- if e[0] in effects:
- v = e[1]
- e = effects[e[0]]
- # parse effect value
- if isinstance(v, str):
- if metric is not None: v = parse._metric_replace(v, metric, c_misc[7])
- v = utils._safer_eval(v)
-
- # effects
- if e == 'volume':
- if v is None: v = 0
- beat = beat * v
- elif e == 'downsample':
- if v is None: v = 8
- beat = np.repeat(beat[:,::v], v, axis=1)
- elif e == 'gradient':
- beat = np.gradient(beat, axis=1)
- elif e == 'reverse':
- beat = beat[:,::-1]
- else:
- beat = e(beat, v)
-
- # clip beat to -1, 1
- beat = np.clip(beat, -1, 1)
-
- # checks if length limit has been reached
- if limit_length is not None:
- total_length += len(beat[0])
- if total_length>= limit_length:
- stop = True
- break
-
- # Adds the processed beat to list of beats.
- # Separator is `,`
- if operators[num] == c_join[0]:
- result.append(beat)
-
- # Makes sure beat doesn't get added on top of previous beat multiple times when pattern is out of range of song beats, to avoid distorted end.
- elif tries<2:
-
- # Separator is `;` - always use first beat length, normalizes volume to 1.5
- if operators[num] == c_join[1]:
- length = len(beat[0])
- prev_length = len(result[-1][0])
- if length > prev_length:
- result[-1] += beat[:,:prev_length]
- else:
- result[-1][:,:length] += beat
- limit = np.max(result[-1])
- if limit > 1.5:
- result[-1] /= limit*0.75
-
- # Separator is `~` - cuts to shortest
- elif operators[num] == c_join[2]:
- minimum = min(len(beat[0]), len(result[-1][0]))
- result[-1] = beat[:,:minimum-1] + result[-1][:,:minimum-1]
-
- # Separator is `&` - extends to longest
- elif operators[num] == c_join[3]:
- length = len(beat[0])
- prev_length = len(result[-1][0])
- if length > prev_length:
- beat[:,:prev_length] += result[-1]
- result[-1] = beat
- else:
- result[-1][:,:length] += beat
-
- # Separator is `^` - uses first beat length and multiplies beats, used for sidechain
- elif operators[num] == c_join[4]:
- length = len(beat[0])
- prev_length = len(result[-1][0])
- if length > prev_length:
- result[-1] *= beat[:,:prev_length]
- else:
- result[-1][:,:length] *= beat
-
-
- # Separator is `$` - always use first beat length, additionally sidechains first beat by second
- elif operators[num] == c_join[5]:
- from . import effects
- length = len(beat[0])
- prev_length = len(result[-1][0])
- if length > prev_length:
- result[-1] *= effects.to_sidechain(beat[:,:prev_length])
- result[-1] += beat[:,:prev_length]
- else:
- result[-1][:,:length] *= effects.to_sidechain(beat)
- result[-1][:,:length] += beat
-
- # Separator is `}` - always use first beat length
- elif operators[num] == c_join[6]:
- length = len(beat[0])
- prev_length = len(result[-1][0])
- if length > prev_length:
- result[-1] += beat[:,:prev_length]
- else:
- result[-1][:,:length] += beat
-
-
- # smoothing
- for i in range(len(result)-1):
- current1 = result[i][0][-2]
- current2 = result[i][0][-1]
- following1 = result[i+1][0][0]
- following2 = result[i+1][0][1]
- num = (abs(following1 - (current2 + (current2 - current1))) + abs(current2 - (following1 + (following1 - following2))))/2
- if num > 0.0:
- num = int(smoothing*num)
- if num>3:
- try:
- line = scipy.interpolate.CubicSpline([0, num+1], [0, following1], bc_type='clamped')(np.arange(0, num, 1))
- #print(line)
- line2 = np.linspace(1, 0, num)**0.5
- result[i][0][-num:] *= line2
- result[i][1][-num:] *= line2
- result[i][0][-num:] += line
- result[i][1][-num:] += line
- except (IndexError, ValueError): pass
-
- self.beatmap = beatmap_default.copy()
- # Beats are conjoined into a song
- import functools
- import operator
- # Makes a [l, r, l, r, ...] list of beats (left and right channels)
- result = functools.reduce(operator.iconcat, result, [])
-
- # Every first beat is conjoined into left channel, every second beat is conjoined into right channel
- if return_audio is False: self.audio = np.array([functools.reduce(operator.iconcat, result[::2], []), functools.reduce(operator.iconcat, result[1:][::2], [])])
- else: return np.array([functools.reduce(operator.iconcat, result[::2], []), functools.reduce(operator.iconcat, result[1:][::2], [])])
-
- def normalize_beats(self):
- if self.normalized is not None:
- if ',' in self.normalized:
- self.beatswap(pattern = self.normalized)
- else:
- from . import presets
- self.beatswap(*presets.get(self.normalized))
-
- def image_generate(self, scale=1, shift=0, mode = 'median'):
- if self.beatmap is None: self.beatmap_generate()
- beatmap_default = self.beatmap.copy()
- self.beatmap_shift(shift)
- self.beatmap_scale(scale)
- from .image import generate as image_generate
- self.image = image_generate(song = self, mode = mode, log = self.log)
- self.beatmap = beatmap_default.copy()
-
- def image_write(self, output='', mode = 'color', max_size = 4096, ext = 'png', rotate=True, suffix = ''):
- from .image import write as image_write
- output = io._outputfilename(output, self.path, ext=ext, suffix = suffix)
- image_write(self.image, output = output, mode = mode, max_size = max_size , rotate = rotate)
- return output
-
-
-
-def beatswap(audio = None, pattern = 'test', scale = 1, shift = 0, length = None, sr = None, output = '', log = True, suffix = ' (beatswap)', copy = True):
- if not isinstance(audio, song): audio = song(audio = audio, sr = sr, log = log)
- elif copy is True:
- beatmap = audio.beatmap
- path = audio.path
- audio = song(audio = audio.audio, sr = audio.sr)
- audio.beatmap = beatmap
- audio.path = path
- audio.beatswap(pattern = pattern, scale = scale, shift = shift, length = length)
- if output is not None:
- return audio.write(output = output, suffix = suffix)
- else: return audio
-
-def image(audio, scale = 1, shift = 0, sr = None, output = '', log = True, suffix = '', max_size = 4096):
- if not isinstance(audio, song): audio = song(audio = audio, sr = sr, log = log)
- audio.image_generate(scale = scale, shift = shift)
- if output is not None:
- return audio.image_write(output = output, max_size=max_size, suffix=suffix)
- else: return audio.image
\ No newline at end of file
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/dev/packaging/gen_wheel_index.sh b/spaces/brjathu/HMR2.0/vendor/detectron2/dev/packaging/gen_wheel_index.sh
deleted file mode 100644
index ec96a27d809fe87ad963f3ffa7147ca4afbc1711..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/dev/packaging/gen_wheel_index.sh
+++ /dev/null
@@ -1,46 +0,0 @@
-#!/bin/bash -e
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-
-root=$(readlink -f $1)
-if [[ -z "$root" ]]; then
- echo "Usage: ./gen_wheel_index.sh /absolute/path/to/wheels"
- exit
-fi
-
-export LC_ALL=C # reproducible sort
-# NOTE: all sort in this script might not work when xx.10 is released
-
-index=$root/index.html
-
-cd "$root"
-for cu in cpu cu92 cu100 cu101 cu102 cu110 cu111 cu113; do
- mkdir -p "$root/$cu"
- cd "$root/$cu"
- echo "Creating $PWD/index.html ..."
- # First sort by torch version, then stable sort by d2 version with unique.
- # As a result, the latest torch version for each d2 version is kept.
- for whl in $(find -type f -name '*.whl' -printf '%P\n' \
- | sort -k 1 -r | sort -t '/' -k 2 --stable -r --unique); do
- echo "$whl "
- done > index.html
-
-
- for torch in torch*; do
- cd "$root/$cu/$torch"
-
- # list all whl for each cuda,torch version
- echo "Creating $PWD/index.html ..."
- for whl in $(find . -type f -name '*.whl' -printf '%P\n' | sort -r); do
- echo "$whl "
- done > index.html
- done
-done
-
-cd "$root"
-# Just list everything:
-echo "Creating $index ..."
-for whl in $(find . -type f -name '*.whl' -printf '%P\n' | sort -r); do
- echo "$whl "
-done > "$index"
-
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DeepLab/deeplab/config.py b/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DeepLab/deeplab/config.py
deleted file mode 100644
index 5f5e45a9124e61c12d90cfc5032b268496891a4a..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DeepLab/deeplab/config.py
+++ /dev/null
@@ -1,28 +0,0 @@
-# -*- coding: utf-8 -*-
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-
-def add_deeplab_config(cfg):
- """
- Add config for DeepLab.
- """
- # We retry random cropping until no single category in semantic segmentation GT occupies more
- # than `SINGLE_CATEGORY_MAX_AREA` part of the crop.
- cfg.INPUT.CROP.SINGLE_CATEGORY_MAX_AREA = 1.0
- # Used for `poly` learning rate schedule.
- cfg.SOLVER.POLY_LR_POWER = 0.9
- cfg.SOLVER.POLY_LR_CONSTANT_ENDING = 0.0
- # Loss type, choose from `cross_entropy`, `hard_pixel_mining`.
- cfg.MODEL.SEM_SEG_HEAD.LOSS_TYPE = "hard_pixel_mining"
- # DeepLab settings
- cfg.MODEL.SEM_SEG_HEAD.PROJECT_FEATURES = ["res2"]
- cfg.MODEL.SEM_SEG_HEAD.PROJECT_CHANNELS = [48]
- cfg.MODEL.SEM_SEG_HEAD.ASPP_CHANNELS = 256
- cfg.MODEL.SEM_SEG_HEAD.ASPP_DILATIONS = [6, 12, 18]
- cfg.MODEL.SEM_SEG_HEAD.ASPP_DROPOUT = 0.1
- cfg.MODEL.SEM_SEG_HEAD.USE_DEPTHWISE_SEPARABLE_CONV = False
- # Backbone new configs
- cfg.MODEL.RESNETS.RES4_DILATION = 1
- cfg.MODEL.RESNETS.RES5_MULTI_GRID = [1, 2, 4]
- # ResNet stem type from: `basic`, `deeplab`
- cfg.MODEL.RESNETS.STEM_TYPE = "deeplab"
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/doc/TOOL_APPLY_NET.md b/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/doc/TOOL_APPLY_NET.md
deleted file mode 100644
index ca8e1ddafc7b1003ba98cce2826157ab995a2443..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/doc/TOOL_APPLY_NET.md
+++ /dev/null
@@ -1,203 +0,0 @@
-# Apply Net
-
-`apply_net` is a tool to print or visualize DensePose results on a set of images.
-It has two modes: `dump` to save DensePose model results to a pickle file
-and `show` to visualize them on images.
-
-The `image.jpg` file that is used as an example in this doc can be found [here](http://images.cocodataset.org/train2017/000000117508.jpg)
-
-## Dump Mode
-
-The general command form is:
-```bash
-python apply_net.py dump [-h] [-v] [--output ]
-```
-
-There are three mandatory arguments:
- - ``, configuration file for a given model;
- - ``, model file with trained parameters
- - ``, input image file name, pattern or folder
-
-One can additionally provide `--output` argument to define the output file name,
-which defaults to `output.pkl`.
-
-
-Examples:
-
-1. Dump results of the [R_50_FPN_s1x](https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl) DensePose model for images in a folder `images` to file `dump.pkl`:
-```bash
-python apply_net.py dump configs/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl \
-images --output dump.pkl -v
-```
-
-2. Dump results of the [R_50_FPN_s1x](https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl) DensePose model for images with file name matching a pattern `image*.jpg` to file `results.pkl`:
-```bash
-python apply_net.py dump configs/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl \
-"image*.jpg" --output results.pkl -v
-```
-
-If you want to load the pickle file generated by the above command:
-```
-# make sure DensePose is in your PYTHONPATH, or use the following line to add it:
-sys.path.append("/your_detectron2_path/detectron2_repo/projects/DensePose/")
-
-f = open('/your_result_path/results.pkl', 'rb')
-data = pickle.load(f)
-```
-
-The file `results.pkl` contains the list of results per image, for each image the result is a dictionary.
-
-**If you use a [IUV model](DENSEPOSE_IUV.md#-model-zoo-and-baselines)**, the dumped data will have the following format:
-
-```
-data: [{'file_name': '/your_path/image1.jpg',
- 'scores': tensor([0.9884]),
- 'pred_boxes_XYXY': tensor([[ 69.6114, 0.0000, 706.9797, 706.0000]]),
- 'pred_densepose': [DensePoseChartResultWithConfidences(labels=tensor(...), uv=tensor(...), sigma_1=None,
- sigma_2=None, kappa_u=None, kappa_v=None, fine_segm_confidence=None, coarse_segm_confidence=None),
- DensePoseChartResultWithConfidences, ...]
- }
- {'file_name': '/your_path/image2.jpg',
- 'scores': tensor([0.9999, 0.5373, 0.3991]),
- 'pred_boxes_XYXY': tensor([[ 59.5734, 7.7535, 579.9311, 932.3619],
- [612.9418, 686.1254, 612.9999, 704.6053],
- [164.5081, 407.4034, 598.3944, 920.4266]]),
- 'pred_densepose': [DensePoseChartResultWithConfidences(labels=tensor(...), uv=tensor(...), sigma_1=None,
- sigma_2=None, kappa_u=None, kappa_v=None, fine_segm_confidence=None, coarse_segm_confidence=None),
- DensePoseChartResultWithConfidences, ...]
- }]
-```
-
-`DensePoseChartResultWithConfidences` contains the following fields:
-- `labels` - a tensor of size `[H, W]` of type `torch.long` which contains fine segmentation labels (previously called `I`)
-- `uv` - a tensor of size `[2, H, W]` of type `torch.float` which contains `U` and `V` coordinates
-- various optional confidence-related fields (`sigma_1`, `sigma_2`, `kappa_u`, `kappa_v`, `fine_segm_confidence`, `coarse_segm_confidence`)
-
-
-**If you use a [CSE model](DENSEPOSE_CSE.md#-model-zoo-and-baselines)**, the dumped data will have the following format:
-```
-data: [{'file_name': '/your_path/image1.jpg',
- 'scores': tensor([0.9984, 0.9961]),
- 'pred_boxes_XYXY': tensor([[480.0093, 461.0796, 698.3614, 696.1011],
- [78.1589, 168.6614, 307.1287, 653.8522]]),
- 'pred_densepose': DensePoseEmbeddingPredictorOutput(embedding=tensor(...), coarse_segm=tensor(...))}
- {'file_name': '/your_path/image2.jpg',
- 'scores': tensor([0.9189, 0.9491]),
- 'pred_boxes_XYXY': tensor([[734.9685, 534.2003, 287.3923, 254.8859],
- [434.2853, 765.1219, 132.1029, 867.9283]]),
- 'pred_densepose': DensePoseEmbeddingPredictorOutput(embedding=tensor(...), coarse_segm=tensor(...))}]
-```
-
-`DensePoseEmbeddingPredictorOutput` contains the following fields:
-- `embedding` - a tensor of size `[N, D, sz, sz]` of type `torch.float`, which contains embeddings of size `D` of the `N` detections in the image
-- `coarse_segm` - a tensor of size `[N, 2, sz, sz]` of type `torch.float` which contains segmentation scores of the `N` detections in the image; e.g. a mask can be obtained by `coarse_segm.argmax(dim=1)`
-
-`sz` is a fixed size for the tensors; you can resize them to the size of the bounding box, if needed
-
-We can use the following code, to parse the outputs of the first
-detected instance on the first image (IUV model).
-```
-img_id, instance_id = 0, 0 # Look at the first image and the first detected instance
-bbox_xyxy = data[img_id]['pred_boxes_XYXY'][instance_id]
-result = data[img_id]['pred_densepose'][instance_id]
-uv = result.uv
-```
-The array `bbox_xyxy` contains (x0, y0, x1, y1) of the bounding box.
-
-
-## Visualization Mode
-
-The general command form is:
-```bash
-python apply_net.py show [-h] [-v] [--min_score ] [--nms_thresh ] [--output ]
-```
-
-There are four mandatory arguments:
- - ``, configuration file for a given model;
- - ``, model file with trained parameters
- - ``, input image file name, pattern or folder
- - ``, visualizations specifier; currently available visualizations are:
- * `bbox` - bounding boxes of detected persons;
- * `dp_segm` - segmentation masks for detected persons;
- * `dp_u` - each body part is colored according to the estimated values of the
- U coordinate in part parameterization;
- * `dp_v` - each body part is colored according to the estimated values of the
- V coordinate in part parameterization;
- * `dp_contour` - plots contours with color-coded U and V coordinates;
- * `dp_iuv_texture` - transfers the texture from a given texture image file to detected instances, in IUV mode;
- * `dp_vertex` - plots the rainbow visualization of the closest vertices prediction for a given mesh, in CSE mode;
- * `dp_cse_texture` - transfers the texture from a given list of texture image files (one from each human or animal mesh) to detected instances, in CSE mode
-
-
-One can additionally provide the following optional arguments:
- - `--min_score` to only show detections with sufficient scores that are not lower than provided value
- - `--nms_thresh` to additionally apply non-maximum suppression to detections at a given threshold
- - `--output` to define visualization file name template, which defaults to `output.png`.
- To distinguish output file names for different images, the tool appends 1-based entry index,
- e.g. output.0001.png, output.0002.png, etc...
-- `--texture_atlas` to define the texture atlas image for IUV texture transfer
-- `--texture_atlases_map` to define the texture atlas images map (a dictionary `{mesh name: texture atlas image}`) for CSE texture transfer
-
-
-The following examples show how to output results of a DensePose model
-with ResNet-50 FPN backbone using different visualizations for image `image.jpg`:
-
-1. Show bounding box and segmentation:
-```bash
-python apply_net.py show configs/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl \
-image.jpg bbox,dp_segm -v
-```
-
-
-2. Show bounding box and estimated U coordinates for body parts:
-```bash
-python apply_net.py show configs/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl \
-image.jpg bbox,dp_u -v
-```
-
-
-3. Show bounding box and estimated V coordinates for body parts:
-```bash
-python apply_net.py show configs/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl \
-image.jpg bbox,dp_v -v
-```
-
-
-4. Show bounding box and estimated U and V coordinates via contour plots:
-```bash
-python apply_net.py show configs/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl \
-image.jpg dp_contour,bbox -v
-```
-
-
-5. Show bounding box and texture transfer:
-```bash
-python apply_net.py show configs/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/densepose_rcnn_R_50_FPN_s1x/165712039/model_final_162be9.pkl \
-image.jpg dp_iuv_texture,bbox --texture_atlas texture_from_SURREAL.jpg -v
-```
-
-
-6. Show bounding box and CSE rainbow visualization:
-```bash
-python apply_net.py show configs/cse/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/cse/densepose_rcnn_R_50_FPN_s1x/251155172/model_final_c4ea5f.pkl \
-image.jpg dp_vertex,bbox -v
-```
-
-
-7. Show bounding box and CSE texture transfer:
-```bash
-python apply_net.py show configs/cse/densepose_rcnn_R_50_FPN_s1x.yaml \
-https://dl.fbaipublicfiles.com/densepose/cse/densepose_rcnn_R_50_FPN_s1x/251155172/model_final_c4ea5f.pkl \
-image.jpg dp_cse_texture,bbox --texture_atlases_map '{"smpl_27554": "smpl_uvSnapshot_colors.jpg"}' -v
-```
-
-
-The texture files can be found in the `doc/images` folder
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/tracking/hungarian_tracker.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/tracking/hungarian_tracker.py
deleted file mode 100644
index 5b3ce884d80d9cdc2e0da07194693dd1bf16dd61..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/tracking/hungarian_tracker.py
+++ /dev/null
@@ -1,171 +0,0 @@
-#!/usr/bin/env python3
-# Copyright 2004-present Facebook. All Rights Reserved.
-import copy
-import numpy as np
-from typing import Dict
-import torch
-from scipy.optimize import linear_sum_assignment
-
-from detectron2.config import configurable
-from detectron2.structures import Boxes, Instances
-
-from ..config.config import CfgNode as CfgNode_
-from .base_tracker import BaseTracker
-
-
-class BaseHungarianTracker(BaseTracker):
- """
- A base class for all Hungarian trackers
- """
-
- @configurable
- def __init__(
- self,
- video_height: int,
- video_width: int,
- max_num_instances: int = 200,
- max_lost_frame_count: int = 0,
- min_box_rel_dim: float = 0.02,
- min_instance_period: int = 1,
- **kwargs
- ):
- """
- Args:
- video_height: height the video frame
- video_width: width of the video frame
- max_num_instances: maximum number of id allowed to be tracked
- max_lost_frame_count: maximum number of frame an id can lost tracking
- exceed this number, an id is considered as lost
- forever
- min_box_rel_dim: a percentage, smaller than this dimension, a bbox is
- removed from tracking
- min_instance_period: an instance will be shown after this number of period
- since its first showing up in the video
- """
- super().__init__(**kwargs)
- self._video_height = video_height
- self._video_width = video_width
- self._max_num_instances = max_num_instances
- self._max_lost_frame_count = max_lost_frame_count
- self._min_box_rel_dim = min_box_rel_dim
- self._min_instance_period = min_instance_period
-
- @classmethod
- def from_config(cls, cfg: CfgNode_) -> Dict:
- raise NotImplementedError("Calling HungarianTracker::from_config")
-
- def build_cost_matrix(self, instances: Instances, prev_instances: Instances) -> np.ndarray:
- raise NotImplementedError("Calling HungarianTracker::build_matrix")
-
- def update(self, instances: Instances) -> Instances:
- if instances.has("pred_keypoints"):
- raise NotImplementedError("Need to add support for keypoints")
- instances = self._initialize_extra_fields(instances)
- if self._prev_instances is not None:
- self._untracked_prev_idx = set(range(len(self._prev_instances)))
- cost_matrix = self.build_cost_matrix(instances, self._prev_instances)
- matched_idx, matched_prev_idx = linear_sum_assignment(cost_matrix)
- instances = self._process_matched_idx(instances, matched_idx, matched_prev_idx)
- instances = self._process_unmatched_idx(instances, matched_idx)
- instances = self._process_unmatched_prev_idx(instances, matched_prev_idx)
- self._prev_instances = copy.deepcopy(instances)
- return instances
-
- def _initialize_extra_fields(self, instances: Instances) -> Instances:
- """
- If input instances don't have ID, ID_period, lost_frame_count fields,
- this method is used to initialize these fields.
-
- Args:
- instances: D2 Instances, for predictions of the current frame
- Return:
- D2 Instances with extra fields added
- """
- if not instances.has("ID"):
- instances.set("ID", [None] * len(instances))
- if not instances.has("ID_period"):
- instances.set("ID_period", [None] * len(instances))
- if not instances.has("lost_frame_count"):
- instances.set("lost_frame_count", [None] * len(instances))
- if self._prev_instances is None:
- instances.ID = list(range(len(instances)))
- self._id_count += len(instances)
- instances.ID_period = [1] * len(instances)
- instances.lost_frame_count = [0] * len(instances)
- return instances
-
- def _process_matched_idx(
- self, instances: Instances, matched_idx: np.ndarray, matched_prev_idx: np.ndarray
- ) -> Instances:
- assert matched_idx.size == matched_prev_idx.size
- for i in range(matched_idx.size):
- instances.ID[matched_idx[i]] = self._prev_instances.ID[matched_prev_idx[i]]
- instances.ID_period[matched_idx[i]] = (
- self._prev_instances.ID_period[matched_prev_idx[i]] + 1
- )
- instances.lost_frame_count[matched_idx[i]] = 0
- return instances
-
- def _process_unmatched_idx(self, instances: Instances, matched_idx: np.ndarray) -> Instances:
- untracked_idx = set(range(len(instances))).difference(set(matched_idx))
- for idx in untracked_idx:
- instances.ID[idx] = self._id_count
- self._id_count += 1
- instances.ID_period[idx] = 1
- instances.lost_frame_count[idx] = 0
- return instances
-
- def _process_unmatched_prev_idx(
- self, instances: Instances, matched_prev_idx: np.ndarray
- ) -> Instances:
- untracked_instances = Instances(
- image_size=instances.image_size,
- pred_boxes=[],
- pred_masks=[],
- pred_classes=[],
- scores=[],
- ID=[],
- ID_period=[],
- lost_frame_count=[],
- )
- prev_bboxes = list(self._prev_instances.pred_boxes)
- prev_classes = list(self._prev_instances.pred_classes)
- prev_scores = list(self._prev_instances.scores)
- prev_ID_period = self._prev_instances.ID_period
- if instances.has("pred_masks"):
- prev_masks = list(self._prev_instances.pred_masks)
- untracked_prev_idx = set(range(len(self._prev_instances))).difference(set(matched_prev_idx))
- for idx in untracked_prev_idx:
- x_left, y_top, x_right, y_bot = prev_bboxes[idx]
- if (
- (1.0 * (x_right - x_left) / self._video_width < self._min_box_rel_dim)
- or (1.0 * (y_bot - y_top) / self._video_height < self._min_box_rel_dim)
- or self._prev_instances.lost_frame_count[idx] >= self._max_lost_frame_count
- or prev_ID_period[idx] <= self._min_instance_period
- ):
- continue
- untracked_instances.pred_boxes.append(list(prev_bboxes[idx].numpy()))
- untracked_instances.pred_classes.append(int(prev_classes[idx]))
- untracked_instances.scores.append(float(prev_scores[idx]))
- untracked_instances.ID.append(self._prev_instances.ID[idx])
- untracked_instances.ID_period.append(self._prev_instances.ID_period[idx])
- untracked_instances.lost_frame_count.append(
- self._prev_instances.lost_frame_count[idx] + 1
- )
- if instances.has("pred_masks"):
- untracked_instances.pred_masks.append(prev_masks[idx].numpy().astype(np.uint8))
-
- untracked_instances.pred_boxes = Boxes(torch.FloatTensor(untracked_instances.pred_boxes))
- untracked_instances.pred_classes = torch.IntTensor(untracked_instances.pred_classes)
- untracked_instances.scores = torch.FloatTensor(untracked_instances.scores)
- if instances.has("pred_masks"):
- untracked_instances.pred_masks = torch.IntTensor(untracked_instances.pred_masks)
- else:
- untracked_instances.remove("pred_masks")
-
- return Instances.cat(
- [
- instances,
- untracked_instances,
- ]
- )
diff --git a/spaces/ccolas/TastyPiano/src/music/config.py b/spaces/ccolas/TastyPiano/src/music/config.py
deleted file mode 100644
index f185a2f68021337de669b06dc422e0f02deb5354..0000000000000000000000000000000000000000
--- a/spaces/ccolas/TastyPiano/src/music/config.py
+++ /dev/null
@@ -1,72 +0,0 @@
-import numpy as np
-import os
-
-REPO_PATH = '/'.join(os.path.abspath(__file__).split('/')[:-3]) + '/'
-AUDIO_PATH = REPO_PATH + 'data/music/audio/'
-MIDI_PATH = REPO_PATH + 'data/music/midi/'
-MUSIC_PATH = REPO_PATH + 'data/music/'
-PROCESSED_PATH = REPO_PATH + 'data/music/processed/'
-ENCODED_PATH = REPO_PATH + 'data/music/encoded/'
-HANDCODED_REP_PATH = MUSIC_PATH + 'handcoded_reps/'
-DATASET_PATH = REPO_PATH + 'data/music/encoded_new_structured/diverse_piano/'
-SYNTH_RECORDED_AUDIO_PATH = AUDIO_PATH + 'synth_audio_recorded/'
-SYNTH_RECORDED_MIDI_PATH = MIDI_PATH + 'synth_midi_recorded/'
-CHECKPOINTS_PATH = REPO_PATH + 'checkpoints/'
-EXPERIMENT_PATH = REPO_PATH + 'experiments/'
-SEED = 0
-
-# params for data download
-ALL_URL_PATH = REPO_PATH + 'data/music/audio/all_urls.pickle'
-ALL_FAILED_URL_PATH = REPO_PATH + 'data/music/audio/all_failed_urls.pickle'
-RATE_AUDIO_SAVE = 16000
-FROM_URL_PATH = AUDIO_PATH + 'from_url/'
-
-# params transcription
-CHKPT_PATH_TRANSCRIPTION = REPO_PATH + 'checkpoints/piano_transcription/note_F1=0.9677_pedal_F1=0.9186.pth' # transcriptor chkpt path
-FPS = 16000
-RANDOM_CROP = True # whether to use random crops in case of cropped audio
-CROP_LEN = 26 * 60
-
-# params midi scrubbing and processing
-MAX_DEPTH = 5 # max depth when searching in folders for audio files
-MAX_GAP_IN_SONG = 10 # in secs
-MIN_LEN = 20 # actual min len could go down to MIN_LEN - 2 * (REMOVE_FIRST_AND_LAST / 5)
-MAX_LEN = 25 * 60 # maximum audio len for playlist downloads, and maximum audio length for transcription (in sec)
-MIN_NB_NOTES = 80 # min nb of notes per minute of recording
-REMOVE_FIRST_AND_LAST = 10 # will be divided by 5 if cutting this makes the song fall below min len
-
-# parameters encoding
-NOISE_INJECTED = True
-AUGMENTATION = True
-NB_AUG = 4 if AUGMENTATION else 0
-RANGE_NOTE_ON = 128
-RANGE_NOTE_OFF = 128
-RANGE_VEL = 32
-RANGE_TIME_SHIFT = 100
-MAX_EMBEDDING = RANGE_VEL + RANGE_NOTE_OFF + RANGE_TIME_SHIFT + RANGE_NOTE_ON
-MAX_TEST_SIZE = 1000
-CHECKSUM_PATH = REPO_PATH + 'data/music/midi/checksum.pickle'
-CHUNK_SIZE = 512
-
-ALL_AUGMENTATIONS = []
-for p in [-3, -2, -1, 1, 2, 3]:
- ALL_AUGMENTATIONS.append((p))
-ALL_AUGMENTATIONS = np.array(ALL_AUGMENTATIONS)
-
-ALL_NOISE = []
-for s in [-5, -2.5, 0, 2.5, 5]:
- for p in np.arange(-6, 7):
- if not ((s == 0) and (p==0)):
- ALL_NOISE.append((s, p))
-ALL_NOISE = np.array(ALL_NOISE)
-
-# music transformer params
-REP_MODEL_NAME = REPO_PATH + "checkpoints/music_representation/sentence_embedding/smallbert_b256_r128_1/best_model"
-MUSIC_REP_PATH = REPO_PATH + "checkpoints/b256_r128_represented/"
-MUSIC_NN_PATH = REPO_PATH + "checkpoints/music_representation/b256_r128_represented/nn_model.pickle"
-
-TRANSLATION_VAE_CHKP_PATH = REPO_PATH + "checkpoints/music2cocktails/music2flavor/b256_r128_classif001_ld40_meanstd_regground2.5_egg_bubbles/"
-
-# piano solo evaluation
-# META_DATA_PIANO_EVAL_PATH = REPO_PATH + 'data/music/audio/is_piano.csv'
-# CHKPT_PATH_PIANO_EVAL = REPO_PATH + 'data/checkpoints/piano_detection/piano_solo_model_32k.pth'
\ No newline at end of file
diff --git a/spaces/chendl/compositional_test/multimodal/YOLOX/yolox/data/data_augment.py b/spaces/chendl/compositional_test/multimodal/YOLOX/yolox/data/data_augment.py
deleted file mode 100644
index 21cd7b56d800a38d3782bf5072c03f9b2f9bb809..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/multimodal/YOLOX/yolox/data/data_augment.py
+++ /dev/null
@@ -1,243 +0,0 @@
-#!/usr/bin/env python3
-# -*- coding:utf-8 -*-
-# Copyright (c) Megvii, Inc. and its affiliates.
-"""
-Data augmentation functionality. Passed as callable transformations to
-Dataset classes.
-
-The data augmentation procedures were interpreted from @weiliu89's SSD paper
-http://arxiv.org/abs/1512.02325
-"""
-
-import math
-import random
-
-import cv2
-import numpy as np
-
-from yolox.utils import xyxy2cxcywh
-
-
-def augment_hsv(img, hgain=5, sgain=30, vgain=30):
- hsv_augs = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] # random gains
- hsv_augs *= np.random.randint(0, 2, 3) # random selection of h, s, v
- hsv_augs = hsv_augs.astype(np.int16)
- img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV).astype(np.int16)
-
- img_hsv[..., 0] = (img_hsv[..., 0] + hsv_augs[0]) % 180
- img_hsv[..., 1] = np.clip(img_hsv[..., 1] + hsv_augs[1], 0, 255)
- img_hsv[..., 2] = np.clip(img_hsv[..., 2] + hsv_augs[2], 0, 255)
-
- cv2.cvtColor(img_hsv.astype(img.dtype), cv2.COLOR_HSV2BGR, dst=img) # no return needed
-
-
-def get_aug_params(value, center=0):
- if isinstance(value, float):
- return random.uniform(center - value, center + value)
- elif len(value) == 2:
- return random.uniform(value[0], value[1])
- else:
- raise ValueError(
- "Affine params should be either a sequence containing two values\
- or single float values. Got {}".format(value)
- )
-
-
-def get_affine_matrix(
- target_size,
- degrees=10,
- translate=0.1,
- scales=0.1,
- shear=10,
-):
- twidth, theight = target_size
-
- # Rotation and Scale
- angle = get_aug_params(degrees)
- scale = get_aug_params(scales, center=1.0)
-
- if scale <= 0.0:
- raise ValueError("Argument scale should be positive")
-
- R = cv2.getRotationMatrix2D(angle=angle, center=(0, 0), scale=scale)
-
- M = np.ones([2, 3])
- # Shear
- shear_x = math.tan(get_aug_params(shear) * math.pi / 180)
- shear_y = math.tan(get_aug_params(shear) * math.pi / 180)
-
- M[0] = R[0] + shear_y * R[1]
- M[1] = R[1] + shear_x * R[0]
-
- # Translation
- translation_x = get_aug_params(translate) * twidth # x translation (pixels)
- translation_y = get_aug_params(translate) * theight # y translation (pixels)
-
- M[0, 2] = translation_x
- M[1, 2] = translation_y
-
- return M, scale
-
-
-def apply_affine_to_bboxes(targets, target_size, M, scale):
- num_gts = len(targets)
-
- # warp corner points
- twidth, theight = target_size
- corner_points = np.ones((4 * num_gts, 3))
- corner_points[:, :2] = targets[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(
- 4 * num_gts, 2
- ) # x1y1, x2y2, x1y2, x2y1
- corner_points = corner_points @ M.T # apply affine transform
- corner_points = corner_points.reshape(num_gts, 8)
-
- # create new boxes
- corner_xs = corner_points[:, 0::2]
- corner_ys = corner_points[:, 1::2]
- new_bboxes = (
- np.concatenate(
- (corner_xs.min(1), corner_ys.min(1), corner_xs.max(1), corner_ys.max(1))
- )
- .reshape(4, num_gts)
- .T
- )
-
- # clip boxes
- new_bboxes[:, 0::2] = new_bboxes[:, 0::2].clip(0, twidth)
- new_bboxes[:, 1::2] = new_bboxes[:, 1::2].clip(0, theight)
-
- targets[:, :4] = new_bboxes
-
- return targets
-
-
-def random_affine(
- img,
- targets=(),
- target_size=(640, 640),
- degrees=10,
- translate=0.1,
- scales=0.1,
- shear=10,
-):
- M, scale = get_affine_matrix(target_size, degrees, translate, scales, shear)
-
- img = cv2.warpAffine(img, M, dsize=target_size, borderValue=(114, 114, 114))
-
- # Transform label coordinates
- if len(targets) > 0:
- targets = apply_affine_to_bboxes(targets, target_size, M, scale)
-
- return img, targets
-
-
-def _mirror(image, boxes, prob=0.5):
- _, width, _ = image.shape
- if random.random() < prob:
- image = image[:, ::-1]
- boxes[:, 0::2] = width - boxes[:, 2::-2]
- return image, boxes
-
-
-def preproc(img, input_size, swap=(2, 0, 1)):
- if len(img.shape) == 3:
- padded_img = np.ones((input_size[0], input_size[1], 3), dtype=np.uint8) * 114
- else:
- padded_img = np.ones(input_size, dtype=np.uint8) * 114
-
- r = min(input_size[0] / img.shape[0], input_size[1] / img.shape[1])
- resized_img = cv2.resize(
- img,
- (int(img.shape[1] * r), int(img.shape[0] * r)),
- interpolation=cv2.INTER_LINEAR,
- ).astype(np.uint8)
- padded_img[: int(img.shape[0] * r), : int(img.shape[1] * r)] = resized_img
-
- padded_img = padded_img.transpose(swap)
- padded_img = np.ascontiguousarray(padded_img, dtype=np.float32)
- return padded_img, r
-
-
-class TrainTransform:
- def __init__(self, max_labels=50, flip_prob=0.5, hsv_prob=1.0):
- self.max_labels = max_labels
- self.flip_prob = flip_prob
- self.hsv_prob = hsv_prob
-
- def __call__(self, image, targets, input_dim):
- boxes = targets[:, :4].copy()
- labels = targets[:, 4].copy()
- if len(boxes) == 0:
- targets = np.zeros((self.max_labels, 5), dtype=np.float32)
- image, r_o = preproc(image, input_dim)
- return image, targets
-
- image_o = image.copy()
- targets_o = targets.copy()
- height_o, width_o, _ = image_o.shape
- boxes_o = targets_o[:, :4]
- labels_o = targets_o[:, 4]
- # bbox_o: [xyxy] to [c_x,c_y,w,h]
- boxes_o = xyxy2cxcywh(boxes_o)
-
- if random.random() < self.hsv_prob:
- augment_hsv(image)
- image_t, boxes = _mirror(image, boxes, self.flip_prob)
- height, width, _ = image_t.shape
- image_t, r_ = preproc(image_t, input_dim)
- # boxes [xyxy] 2 [cx,cy,w,h]
- boxes = xyxy2cxcywh(boxes)
- boxes *= r_
-
- mask_b = np.minimum(boxes[:, 2], boxes[:, 3]) > 1
- boxes_t = boxes[mask_b]
- labels_t = labels[mask_b]
-
- if len(boxes_t) == 0:
- image_t, r_o = preproc(image_o, input_dim)
- boxes_o *= r_o
- boxes_t = boxes_o
- labels_t = labels_o
-
- labels_t = np.expand_dims(labels_t, 1)
-
- targets_t = np.hstack((labels_t, boxes_t))
- padded_labels = np.zeros((self.max_labels, 5))
- padded_labels[range(len(targets_t))[: self.max_labels]] = targets_t[
- : self.max_labels
- ]
- padded_labels = np.ascontiguousarray(padded_labels, dtype=np.float32)
- return image_t, padded_labels
-
-
-class ValTransform:
- """
- Defines the transformations that should be applied to test PIL image
- for input into the network
-
- dimension -> tensorize -> color adj
-
- Arguments:
- resize (int): input dimension to SSD
- rgb_means ((int,int,int)): average RGB of the dataset
- (104,117,123)
- swap ((int,int,int)): final order of channels
-
- Returns:
- transform (transform) : callable transform to be applied to test/val
- data
- """
-
- def __init__(self, swap=(2, 0, 1), legacy=False):
- self.swap = swap
- self.legacy = legacy
-
- # assume input is cv2 img for now
- def __call__(self, img, res, input_size):
- img, _ = preproc(img, input_size, self.swap)
- if self.legacy:
- img = img[::-1, :, :].copy()
- img /= 255.0
- img -= np.array([0.485, 0.456, 0.406]).reshape(3, 1, 1)
- img /= np.array([0.229, 0.224, 0.225]).reshape(3, 1, 1)
- return img, np.zeros((1, 5))
diff --git a/spaces/chendl/compositional_test/multimodal/YOLOX/yolox/models/losses.py b/spaces/chendl/compositional_test/multimodal/YOLOX/yolox/models/losses.py
deleted file mode 100644
index 77b4d8ef7660880031f4ef23c82ba3a85b6fd254..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/multimodal/YOLOX/yolox/models/losses.py
+++ /dev/null
@@ -1,53 +0,0 @@
-#!/usr/bin/env python
-# -*- encoding: utf-8 -*-
-# Copyright (c) Megvii Inc. All rights reserved.
-
-import torch
-import torch.nn as nn
-
-
-class IOUloss(nn.Module):
- def __init__(self, reduction="none", loss_type="iou"):
- super(IOUloss, self).__init__()
- self.reduction = reduction
- self.loss_type = loss_type
-
- def forward(self, pred, target):
- assert pred.shape[0] == target.shape[0]
-
- pred = pred.view(-1, 4)
- target = target.view(-1, 4)
- tl = torch.max(
- (pred[:, :2] - pred[:, 2:] / 2), (target[:, :2] - target[:, 2:] / 2)
- )
- br = torch.min(
- (pred[:, :2] + pred[:, 2:] / 2), (target[:, :2] + target[:, 2:] / 2)
- )
-
- area_p = torch.prod(pred[:, 2:], 1)
- area_g = torch.prod(target[:, 2:], 1)
-
- en = (tl < br).type(tl.type()).prod(dim=1)
- area_i = torch.prod(br - tl, 1) * en
- area_u = area_p + area_g - area_i
- iou = (area_i) / (area_u + 1e-16)
-
- if self.loss_type == "iou":
- loss = 1 - iou ** 2
- elif self.loss_type == "giou":
- c_tl = torch.min(
- (pred[:, :2] - pred[:, 2:] / 2), (target[:, :2] - target[:, 2:] / 2)
- )
- c_br = torch.max(
- (pred[:, :2] + pred[:, 2:] / 2), (target[:, :2] + target[:, 2:] / 2)
- )
- area_c = torch.prod(c_br - c_tl, 1)
- giou = iou - (area_c - area_u) / area_c.clamp(1e-16)
- loss = 1 - giou.clamp(min=-1.0, max=1.0)
-
- if self.reduction == "mean":
- loss = loss.mean()
- elif self.reduction == "sum":
- loss = loss.sum()
-
- return loss
diff --git a/spaces/chendl/compositional_test/multimodal/open_flamingo/eval/dataset_zoo/perturbations.py b/spaces/chendl/compositional_test/multimodal/open_flamingo/eval/dataset_zoo/perturbations.py
deleted file mode 100644
index 159743b71f34f04ac49a371b22df9b3d76f4b5c8..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/multimodal/open_flamingo/eval/dataset_zoo/perturbations.py
+++ /dev/null
@@ -1,194 +0,0 @@
-import torch
-import random
-import numpy as np
-from functools import partial
-import torch.nn.functional as nnf
-from torchvision import transforms as T
-
-# A lot of the approaches here are inspired from the wonderful paper from O'Connor and Andreas 2021.
-# https://github.com/lingo-mit/context-ablations
-
-def get_text_perturb_fn(text_perturb_fn):
- if text_perturb_fn == "shuffle_nouns_and_adj":
- return shuffle_nouns_and_adj
- elif text_perturb_fn == "shuffle_allbut_nouns_and_adj":
- return shuffle_allbut_nouns_and_adj
- elif text_perturb_fn == "shuffle_within_trigrams":
- return shuffle_within_trigrams
- elif text_perturb_fn == "shuffle_all_words":
- return shuffle_all_words
- elif text_perturb_fn == "shuffle_trigrams":
- return shuffle_trigrams
- elif text_perturb_fn is None:
- return None
- else:
- print("Unknown text perturbation function: {}, returning None".format(text_perturb_fn))
- return None
-
-
-def get_image_perturb_fn(image_perturb_fn):
- if image_perturb_fn == "shuffle_rows_4":
- return partial(shuffle_rows, n_rows=4)
- elif image_perturb_fn == "shuffle_patches_9":
- return partial(shuffle_patches, n_ratio=3)
- elif image_perturb_fn == "shuffle_cols_4":
- return partial(shuffle_columns, n_cols=4)
- elif image_perturb_fn is None:
- return None
- else:
- print("Unknown image perturbation function: {}, returning None".format(image_perturb_fn))
- return None
-
-
-
-class TextShuffler:
-
- def __init__(self):
- import spacy
- self.nlp = spacy.load("en_core_web_sm")
-
- def shuffle_nouns_and_adj(self, ex):
-
- doc = self.nlp(ex)
- tokens = [token.text for token in doc]
- text = np.array(tokens)
- noun_idx = [i for i, token in enumerate(doc) if token.tag_ in ['NN', 'NNS', 'NNP', 'NNPS']]
- ## Finding adjectives
- adjective_idx = [i for i, token in enumerate(doc) if token.tag_ in ['JJ', 'JJR', 'JJS']]
- ## Shuffle the nouns of the text
- text[noun_idx] = np.random.permutation(text[noun_idx])
- ## Shuffle the adjectives of the text
- text[adjective_idx] = np.random.permutation(text[adjective_idx])
-
- return " ".join(text)
-
- def shuffle_all_words(self, ex):
- return " ".join(np.random.permutation(ex.split(" ")))
-
-
- def shuffle_allbut_nouns_and_adj(self, ex):
- doc = self.nlp(ex)
- tokens = [token.text for token in doc]
- text = np.array(tokens)
- noun_adj_idx = [i for i, token in enumerate(doc) if token.tag_ in ['NN', 'NNS', 'NNP', 'NNPS', 'JJ', 'JJR', 'JJS']]
- ## Finding adjectives
-
- else_idx = np.ones(text.shape[0])
- else_idx[noun_adj_idx] = 0
-
- else_idx = else_idx.astype(bool)
- ## Shuffle everything that are nouns or adjectives
- text[else_idx] = np.random.permutation(text[else_idx])
- return " ".join(text)
-
-
- def get_trigrams(self, sentence):
- # Taken from https://github.com/lingo-mit/context-ablations/blob/478fb18a9f9680321f0d37dc999ea444e9287cc0/code/transformers/src/transformers/data/data_augmentation.py
- trigrams = []
- trigram = []
- for i in range(len(sentence)):
- trigram.append(sentence[i])
- if i % 3 == 2:
- trigrams.append(trigram[:])
- trigram = []
- if trigram:
- trigrams.append(trigram)
- return trigrams
-
- def trigram_shuffle(self, sentence):
- trigrams = self.get_trigrams(sentence)
- for trigram in trigrams:
- random.shuffle(trigram)
- return " ".join([" ".join(trigram) for trigram in trigrams])
-
-
- def shuffle_within_trigrams(self, ex):
- import nltk
- tokens = nltk.word_tokenize(ex)
- shuffled_ex = self.trigram_shuffle(tokens)
- return shuffled_ex
-
-
- def shuffle_trigrams(self, ex):
- import nltk
- tokens = nltk.word_tokenize(ex)
- trigrams = self.get_trigrams(tokens)
- random.shuffle(trigrams)
- shuffled_ex = " ".join([" ".join(trigram) for trigram in trigrams])
- return shuffled_ex
-
-
-def _handle_image_4shuffle(x):
- return_image = False
- if not isinstance(x, torch.Tensor):
- # print(f"x is not a tensor: {type(x)}. Trying to handle but fix this or I'll annoy you with this log")
- t = torch.tensor(np.array(x)).unsqueeze(dim=0).float()
- t = t.permute(0, 3, 1, 2)
- return_image = True
- return t, return_image
- if len(x.shape) != 4:
- #print("You did not send a tensor of shape NxCxWxH. Unsqueezing not but fix this or I'll annoy you with this log")
- return x.unsqueeze(dim=0), return_image
- else:
- # Good boi
- return x, return_image
-
-
-def shuffle_rows(x, n_rows=7):
- """
- Shuffle the rows of the image tensor where each row has a size of 14 pixels.
- Tensor is of shape N x C x W x H
- """
- x, return_image = _handle_image_4shuffle(x)
- patch_size = x.shape[-2]//n_rows
- u = nnf.unfold(x, kernel_size=(patch_size, x.shape[-1]), stride=patch_size, padding=0)
- # permute the patches of each image in the batch
- pu = torch.cat([b_[:, torch.randperm(b_.shape[-1])][None,...] for b_ in u], dim=0)
- # fold the permuted patches back together
- f = nnf.fold(pu, x.shape[-2:], kernel_size=(patch_size, x.shape[-1]), stride=patch_size, padding=0)
-
- image = f.squeeze() # C W H
- if return_image:
- return T.ToPILImage()(image.type(torch.uint8))
- else:
- return image
-
-
-def shuffle_columns(x, n_cols=7):
- """
- Shuffle the columns of the image tensor where we'll have n_cols columns.
- Tensor is of shape N x C x W x H
- """
- x, return_image = _handle_image_4shuffle(x)
- patch_size = x.shape[-1]//n_cols
- u = nnf.unfold(x, kernel_size=(x.shape[-2], patch_size), stride=patch_size, padding=0)
- # permute the patches of each image in the batch
- pu = torch.cat([b_[:, torch.randperm(b_.shape[-1])][None,...] for b_ in u], dim=0)
- # fold the permuted patches back together
- f = nnf.fold(pu, x.shape[-2:], kernel_size=(x.shape[-2], patch_size), stride=patch_size, padding=0)
- image = f.squeeze() # C W H
- if return_image:
- return T.ToPILImage()(image.type(torch.uint8))
- else:
- return image
-
-
-
-def shuffle_patches(x, n_ratio=4):
- """
- Shuffle the rows of the image tensor where each row has a size of 14 pixels.
- Tensor is of shape N x C x W x H
- """
- x, return_image = _handle_image_4shuffle(x)
- patch_size_x = x.shape[-2]//n_ratio
- patch_size_y = x.shape[-1]//n_ratio
- u = nnf.unfold(x, kernel_size=(patch_size_x, patch_size_y), stride=(patch_size_x, patch_size_y), padding=0)
- # permute the patches of each image in the batch
- pu = torch.cat([b_[:, torch.randperm(b_.shape[-1])][None,...] for b_ in u], dim=0)
- # fold the permuted patches back together
- f = nnf.fold(pu, x.shape[-2:], kernel_size=(patch_size_x, patch_size_y), stride=(patch_size_x, patch_size_y), padding=0)
- image = f.squeeze() # C W H
- if return_image:
- return T.ToPILImage()(image.type(torch.uint8))
- else:
- return image
\ No newline at end of file
diff --git a/spaces/chikoto/Umamusume-DeBERTa-VITS2-TTS-JP/info.md b/spaces/chikoto/Umamusume-DeBERTa-VITS2-TTS-JP/info.md
deleted file mode 100644
index affb8445ca44739d07695b21b30b8ac68e0c5f54..0000000000000000000000000000000000000000
--- a/spaces/chikoto/Umamusume-DeBERTa-VITS2-TTS-JP/info.md
+++ /dev/null
@@ -1,61 +0,0 @@
-# Umamusume DeBERTA-VITS2 TTS
-
----------------
-
-📅 2023.10.24 📅
-
-- Updated current Generator to 270K steps' checkpoint
-
-------------------
-
-👌 **Currently, ONLY Japanese is supported.** 👌
-
-💪 **Based on [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2), this work tightly follows [Akito/umamusume_bert_vits2](https://huggingface.co/spaces/AkitoP/umamusume_bert_vits2), from which the Japanese text preprocessor is provided.** ❤
-
----------------
-
-## Instruction for use | 使用说明 | 使用についての説明
-
-✋ **Please do NOT enter a really LOOOONG sentence or sentences in a single row. Splitting your inputs into multiple rows makes each row to be inferenced separately. Please avoid completely empty rows, which will lead to weird sounds in the corresponding spaces in the generated audio.** ✋
-
-✋ **请不要在一行内输入超长文本,模型会将每行的输入视为一句话进行推理。在不影响语意连贯的情况下,请将多句话分别放入不同的行中来减少推理时间。请删除输入中的空白行,这会导致在生成的语音的对应位置中产生奇怪的声音。** ✋
-
-✋ **長すぎるテキストを一行に入力しないでください。モデルは各行を一つの文として推理します。意味が繋がる範囲で、複数の文を異なる行に分けて推理時間を短縮してください。空白行は削除してください。これが生成された音声の対応部分で奇妙な音を生じる原因となります。** ✋
-
--------------------------
-
-👏 **When encountering situations where an error occurs, please check if there's rare and difficult CHINISE CHARACTERS in your inputs, and replace them with Hiragana or Katakana.** 👏
-
-👏 **如果生成出现了错误,请首先检查输入中是否存在非常少见的生僻汉字,如果有,请将其替换为平假名或者片假名。** 👏
-
-👏 **生成に誤りがある場合は、まず入力に非常に珍しい難解な漢字がないか確認してください。もし存在する場合、それを平仮名または片仮名に置き換えてください。** 👏
-
-------------------------
-
-🎈 **Please make good use of punctuation marks.** 🎈
-
-🎈 **请善用标点符号的神奇力量。** 🎈
-
-🎈 **句読点の魔法の力をうまく活用してください。** 🎈
-
----------------------
-
-📚 **What is the Chinese name for the character name? Please refer to [Umamusume Bilibili Wiki](https://wiki.biligame.com/umamusume/%E8%B5%9B%E9%A9%AC%E5%A8%98%E4%B8%80%E8%A7%88).** 📚
-
-📚 **キャラの中国語名は何ですか?ここにご覧ください:[ウマ娘ビリビリWiki](https://wiki.biligame.com/umamusume/%E8%B5%9B%E9%A9%AC%E5%A8%98%E4%B8%80%E8%A7%88).** 📚
-
----------------
-
-## Training Details - For those who may be interested
-
-🎈 **This work switches [cl-tohoku/bert-base-japanese-v3](https://huggingface.co/cl-tohoku/bert-base-japanese-v3) to [ku-nlp/deberta-v2-base-japanese](https://huggingface.co/ku-nlp/deberta-v2-base-japanese) expecting potentially better performance, and, just for fun.** 🥰
-
-❤ Thanks to **SUSTech Center for Computational Science and Engineering**. ❤ This model is trained on A100 (40GB) x 2 with **batch size 32** in total.
-
-💪 This model has been trained for **3 cycles, 270K steps (=180 epoch)** . 💪
-
-📕 This work uses linear with warmup **(7.5% of total steps)** LR scheduler with ` max_lr=1e-4`. 📕
-
-✂ This work **clips gradient value to 10** ✂.
-
-⚠ Finetuning the model on **single-speaker datasets separately** will definitely reach better result than training on **a huge dataset comprising of many speakers**. Sharing a same model leads to unexpected mixing of the speaker's voice line. ⚠
diff --git a/spaces/chilge/Fushimi/add_speaker.py b/spaces/chilge/Fushimi/add_speaker.py
deleted file mode 100644
index e224f07c892a5fe1837e3cbf1745e0d8992ea283..0000000000000000000000000000000000000000
--- a/spaces/chilge/Fushimi/add_speaker.py
+++ /dev/null
@@ -1,62 +0,0 @@
-import os
-import argparse
-from tqdm import tqdm
-from random import shuffle
-import json
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--train_list", type=str, default="./filelists/train.txt", help="path to train list")
- parser.add_argument("--val_list", type=str, default="./filelists/val.txt", help="path to val list")
- parser.add_argument("--test_list", type=str, default="./filelists/test.txt", help="path to test list")
- parser.add_argument("--source_dir", type=str, default="./dataset/32k", help="path to source dir")
- args = parser.parse_args()
-
- previous_config = json.load(open("configs/config.json", "rb"))
-
- train = []
- val = []
- test = []
- idx = 0
- spk_dict = previous_config["spk"]
- spk_id = max([i for i in spk_dict.values()]) + 1
- for speaker in tqdm(os.listdir(args.source_dir)):
- if speaker not in spk_dict.keys():
- spk_dict[speaker] = spk_id
- spk_id += 1
- wavs = [os.path.join(args.source_dir, speaker, i)for i in os.listdir(os.path.join(args.source_dir, speaker))]
- wavs = [i for i in wavs if i.endswith("wav")]
- shuffle(wavs)
- train += wavs[2:-10]
- val += wavs[:2]
- test += wavs[-10:]
-
- assert previous_config["model"]["n_speakers"] > len(spk_dict.keys())
- shuffle(train)
- shuffle(val)
- shuffle(test)
-
- print("Writing", args.train_list)
- with open(args.train_list, "w") as f:
- for fname in tqdm(train):
- wavpath = fname
- f.write(wavpath + "\n")
-
- print("Writing", args.val_list)
- with open(args.val_list, "w") as f:
- for fname in tqdm(val):
- wavpath = fname
- f.write(wavpath + "\n")
-
- print("Writing", args.test_list)
- with open(args.test_list, "w") as f:
- for fname in tqdm(test):
- wavpath = fname
- f.write(wavpath + "\n")
-
- previous_config["spk"] = spk_dict
-
- print("Writing configs/config.json")
- with open("configs/config.json", "w") as f:
- json.dump(previous_config, f, indent=2)
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/anyio/abc/__init__.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/anyio/abc/__init__.py
deleted file mode 100644
index 72c34e544e1634e4f42c005506bac9b61ab095f5..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/anyio/abc/__init__.py
+++ /dev/null
@@ -1,90 +0,0 @@
-from __future__ import annotations
-
-__all__ = (
- "AsyncResource",
- "IPAddressType",
- "IPSockAddrType",
- "SocketAttribute",
- "SocketStream",
- "SocketListener",
- "UDPSocket",
- "UNIXSocketStream",
- "UDPPacketType",
- "ConnectedUDPSocket",
- "UnreliableObjectReceiveStream",
- "UnreliableObjectSendStream",
- "UnreliableObjectStream",
- "ObjectReceiveStream",
- "ObjectSendStream",
- "ObjectStream",
- "ByteReceiveStream",
- "ByteSendStream",
- "ByteStream",
- "AnyUnreliableByteReceiveStream",
- "AnyUnreliableByteSendStream",
- "AnyUnreliableByteStream",
- "AnyByteReceiveStream",
- "AnyByteSendStream",
- "AnyByteStream",
- "Listener",
- "Process",
- "Event",
- "Condition",
- "Lock",
- "Semaphore",
- "CapacityLimiter",
- "CancelScope",
- "TaskGroup",
- "TaskStatus",
- "TestRunner",
- "BlockingPortal",
-)
-
-from typing import Any
-
-from ._resources import AsyncResource
-from ._sockets import (
- ConnectedUDPSocket,
- IPAddressType,
- IPSockAddrType,
- SocketAttribute,
- SocketListener,
- SocketStream,
- UDPPacketType,
- UDPSocket,
- UNIXSocketStream,
-)
-from ._streams import (
- AnyByteReceiveStream,
- AnyByteSendStream,
- AnyByteStream,
- AnyUnreliableByteReceiveStream,
- AnyUnreliableByteSendStream,
- AnyUnreliableByteStream,
- ByteReceiveStream,
- ByteSendStream,
- ByteStream,
- Listener,
- ObjectReceiveStream,
- ObjectSendStream,
- ObjectStream,
- UnreliableObjectReceiveStream,
- UnreliableObjectSendStream,
- UnreliableObjectStream,
-)
-from ._subprocesses import Process
-from ._tasks import TaskGroup, TaskStatus
-from ._testing import TestRunner
-
-# Re-exported here, for backwards compatibility
-# isort: off
-from .._core._synchronization import CapacityLimiter, Condition, Event, Lock, Semaphore
-from .._core._tasks import CancelScope
-from ..from_thread import BlockingPortal
-
-# Re-export imports so they look like they live directly in this package
-key: str
-value: Any
-for key, value in list(locals().items()):
- if getattr(value, "__module__", "").startswith("anyio.abc."):
- value.__module__ = __name__
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/__init__.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/__init__.py
deleted file mode 100644
index b9f1187011bdaa0720bc462564582393700f3d4a..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/__init__.py
+++ /dev/null
@@ -1,13 +0,0 @@
-# This file is dual licensed under the terms of the Apache License, Version
-# 2.0, and the BSD License. See the LICENSE file in the root of this repository
-# for complete details.
-
-from __future__ import annotations
-
-"""
-Hazardous Materials
-
-This is a "Hazardous Materials" module. You should ONLY use it if you're
-100% absolutely sure that you know what you're doing because this module
-is full of land mines, dragons, and dinosaurs with laser guns.
-"""
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/styles/latent.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/styles/latent.py
deleted file mode 100644
index 99b1514fff51477838f4204627ae5904d21cfb9e..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/styles/latent.py
+++ /dev/null
@@ -1,224 +0,0 @@
-# encoding: utf-8
-
-"""
-Latent style-related objects.
-"""
-
-from __future__ import (
- absolute_import, division, print_function, unicode_literals
-)
-
-from . import BabelFish
-from ..shared import ElementProxy
-
-
-class LatentStyles(ElementProxy):
- """
- Provides access to the default behaviors for latent styles in this
- document and to the collection of |_LatentStyle| objects that define
- overrides of those defaults for a particular named latent style.
- """
-
- __slots__ = ()
-
- def __getitem__(self, key):
- """
- Enables dictionary-style access to a latent style by name.
- """
- style_name = BabelFish.ui2internal(key)
- lsdException = self._element.get_by_name(style_name)
- if lsdException is None:
- raise KeyError("no latent style with name '%s'" % key)
- return _LatentStyle(lsdException)
-
- def __iter__(self):
- return (_LatentStyle(ls) for ls in self._element.lsdException_lst)
-
- def __len__(self):
- return len(self._element.lsdException_lst)
-
- def add_latent_style(self, name):
- """
- Return a newly added |_LatentStyle| object to override the inherited
- defaults defined in this latent styles object for the built-in style
- having *name*.
- """
- lsdException = self._element.add_lsdException()
- lsdException.name = BabelFish.ui2internal(name)
- return _LatentStyle(lsdException)
-
- @property
- def default_priority(self):
- """
- Integer between 0 and 99 inclusive specifying the default sort order
- for latent styles in style lists and the style gallery. |None| if no
- value is assigned, which causes Word to use the default value 99.
- """
- return self._element.defUIPriority
-
- @default_priority.setter
- def default_priority(self, value):
- self._element.defUIPriority = value
-
- @property
- def default_to_hidden(self):
- """
- Boolean specifying whether the default behavior for latent styles is
- to be hidden. A hidden style does not appear in the recommended list
- or in the style gallery.
- """
- return self._element.bool_prop('defSemiHidden')
-
- @default_to_hidden.setter
- def default_to_hidden(self, value):
- self._element.set_bool_prop('defSemiHidden', value)
-
- @property
- def default_to_locked(self):
- """
- Boolean specifying whether the default behavior for latent styles is
- to be locked. A locked style does not appear in the styles panel or
- the style gallery and cannot be applied to document content. This
- behavior is only active when formatting protection is turned on for
- the document (via the Developer menu).
- """
- return self._element.bool_prop('defLockedState')
-
- @default_to_locked.setter
- def default_to_locked(self, value):
- self._element.set_bool_prop('defLockedState', value)
-
- @property
- def default_to_quick_style(self):
- """
- Boolean specifying whether the default behavior for latent styles is
- to appear in the style gallery when not hidden.
- """
- return self._element.bool_prop('defQFormat')
-
- @default_to_quick_style.setter
- def default_to_quick_style(self, value):
- self._element.set_bool_prop('defQFormat', value)
-
- @property
- def default_to_unhide_when_used(self):
- """
- Boolean specifying whether the default behavior for latent styles is
- to be unhidden when first applied to content.
- """
- return self._element.bool_prop('defUnhideWhenUsed')
-
- @default_to_unhide_when_used.setter
- def default_to_unhide_when_used(self, value):
- self._element.set_bool_prop('defUnhideWhenUsed', value)
-
- @property
- def load_count(self):
- """
- Integer specifying the number of built-in styles to initialize to the
- defaults specified in this |LatentStyles| object. |None| if there is
- no setting in the XML (very uncommon). The default Word 2011 template
- sets this value to 276, accounting for the built-in styles in Word
- 2010.
- """
- return self._element.count
-
- @load_count.setter
- def load_count(self, value):
- self._element.count = value
-
-
-class _LatentStyle(ElementProxy):
- """
- Proxy for an `w:lsdException` element, which specifies display behaviors
- for a built-in style when no definition for that style is stored yet in
- the `styles.xml` part. The values in this element override the defaults
- specified in the parent `w:latentStyles` element.
- """
-
- __slots__ = ()
-
- def delete(self):
- """
- Remove this latent style definition such that the defaults defined in
- the containing |LatentStyles| object provide the effective value for
- each of its attributes. Attempting to access any attributes on this
- object after calling this method will raise |AttributeError|.
- """
- self._element.delete()
- self._element = None
-
- @property
- def hidden(self):
- """
- Tri-state value specifying whether this latent style should appear in
- the recommended list. |None| indicates the effective value is
- inherited from the parent ```` element.
- """
- return self._element.on_off_prop('semiHidden')
-
- @hidden.setter
- def hidden(self, value):
- self._element.set_on_off_prop('semiHidden', value)
-
- @property
- def locked(self):
- """
- Tri-state value specifying whether this latent styles is locked.
- A locked style does not appear in the styles panel or the style
- gallery and cannot be applied to document content. This behavior is
- only active when formatting protection is turned on for the document
- (via the Developer menu).
- """
- return self._element.on_off_prop('locked')
-
- @locked.setter
- def locked(self, value):
- self._element.set_on_off_prop('locked', value)
-
- @property
- def name(self):
- """
- The name of the built-in style this exception applies to.
- """
- return BabelFish.internal2ui(self._element.name)
-
- @property
- def priority(self):
- """
- The integer sort key for this latent style in the Word UI.
- """
- return self._element.uiPriority
-
- @priority.setter
- def priority(self, value):
- self._element.uiPriority = value
-
- @property
- def quick_style(self):
- """
- Tri-state value specifying whether this latent style should appear in
- the Word styles gallery when not hidden. |None| indicates the
- effective value should be inherited from the default values in its
- parent |LatentStyles| object.
- """
- return self._element.on_off_prop('qFormat')
-
- @quick_style.setter
- def quick_style(self, value):
- self._element.set_on_off_prop('qFormat', value)
-
- @property
- def unhide_when_used(self):
- """
- Tri-state value specifying whether this style should have its
- :attr:`hidden` attribute set |False| the next time the style is
- applied to content. |None| indicates the effective value should be
- inherited from the default specified by its parent |LatentStyles|
- object.
- """
- return self._element.on_off_prop('unhideWhenUsed')
-
- @unhide_when_used.setter
- def unhide_when_used(self, value):
- self._element.set_on_off_prop('unhideWhenUsed', value)
diff --git a/spaces/cihyFjudo/fairness-paper-search/Ram Naam Sankirtan Pdf 24.md b/spaces/cihyFjudo/fairness-paper-search/Ram Naam Sankirtan Pdf 24.md
deleted file mode 100644
index 5ef4d6e28931590e25dacddceeb76736fac246ad..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Ram Naam Sankirtan Pdf 24.md
+++ /dev/null
@@ -1,5 +0,0 @@
-
-
Meaning: This is a naamavali with Lord Krishna's names - Madhava, Muralidhara, Madhusoodhana. Hey Giridhari (the One who lifted the Govardhan mounatin), You are Sai in our hearts, You are the Krishna of Puttaparthy.
-
-## Todo:
-
-- (Top Priority) 调用另一个开源项目text-generation-webui的web接口,使用其他llm模型
-- 总结大工程源代码时,文本过长、token溢出的问题(目前的方法是直接二分丢弃处理溢出,过于粗暴,有效信息大量丢失)
-
-
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dfpwmdec.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dfpwmdec.c
deleted file mode 100644
index 4ddb806561ccdc9279530132107382c8e2b0a15b..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dfpwmdec.c
+++ /dev/null
@@ -1,132 +0,0 @@
-/*
- * DFPWM decoder
- * Copyright (c) 2022 Jack Bruienne
- * Copyright (c) 2012, 2016 Ben "GreaseMonkey" Russell
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-/**
- * @file
- * DFPWM1a decoder
- */
-
-#include "libavutil/internal.h"
-#include "avcodec.h"
-#include "codec_id.h"
-#include "codec_internal.h"
-#include "decode.h"
-
-typedef struct {
- int fq, q, s, lt;
-} DFPWMState;
-
-// DFPWM codec from https://github.com/ChenThread/dfpwm/blob/master/1a/
-// Licensed in the public domain
-
-static void au_decompress(DFPWMState *state, int fs, int len,
- uint8_t *outbuf, const uint8_t *inbuf)
-{
- unsigned d;
- for (int i = 0; i < len; i++) {
- // get bits
- d = *(inbuf++);
- for (int j = 0; j < 8; j++) {
- int nq, lq, st, ns, ov;
- // set target
- int t = ((d&1) ? 127 : -128);
- d >>= 1;
-
- // adjust charge
- nq = state->q + ((state->s * (t-state->q) + 512)>>10);
- if(nq == state->q && nq != t)
- nq += (t == 127 ? 1 : -1);
- lq = state->q;
- state->q = nq;
-
- // adjust strength
- st = (t != state->lt ? 0 : 1023);
- ns = state->s;
- if(ns != st)
- ns += (st != 0 ? 1 : -1);
- if(ns < 8) ns = 8;
- state->s = ns;
-
- // FILTER: perform antijerk
- ov = (t != state->lt ? (nq+lq+1)>>1 : nq);
-
- // FILTER: perform LPF
- state->fq += ((fs*(ov-state->fq) + 0x80)>>8);
- ov = state->fq;
-
- // output sample
- *(outbuf++) = ov + 128;
-
- state->lt = t;
- }
- }
-}
-
-static av_cold int dfpwm_dec_init(struct AVCodecContext *ctx)
-{
- DFPWMState *state = ctx->priv_data;
-
- state->fq = 0;
- state->q = 0;
- state->s = 0;
- state->lt = -128;
-
- ctx->sample_fmt = AV_SAMPLE_FMT_U8;
- ctx->bits_per_raw_sample = 8;
-
- return 0;
-}
-
-static int dfpwm_dec_frame(struct AVCodecContext *ctx, AVFrame *frame,
- int *got_frame, struct AVPacket *packet)
-{
- DFPWMState *state = ctx->priv_data;
- int ret;
-
- if (packet->size * 8LL % ctx->ch_layout.nb_channels)
- return AVERROR_PATCHWELCOME;
-
- frame->nb_samples = packet->size * 8LL / ctx->ch_layout.nb_channels;
- if (frame->nb_samples <= 0) {
- av_log(ctx, AV_LOG_ERROR, "invalid number of samples in packet\n");
- return AVERROR_INVALIDDATA;
- }
-
- if ((ret = ff_get_buffer(ctx, frame, 0)) < 0)
- return ret;
-
- au_decompress(state, 140, packet->size, frame->data[0], packet->data);
-
- *got_frame = 1;
- return packet->size;
-}
-
-const FFCodec ff_dfpwm_decoder = {
- .p.name = "dfpwm",
- CODEC_LONG_NAME("DFPWM1a audio"),
- .p.type = AVMEDIA_TYPE_AUDIO,
- .p.id = AV_CODEC_ID_DFPWM,
- .priv_data_size = sizeof(DFPWMState),
- .init = dfpwm_dec_init,
- FF_CODEC_DECODE_CB(dfpwm_dec_frame),
- .p.capabilities = AV_CODEC_CAP_DR1,
-};
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/lcl.h b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/lcl.h
deleted file mode 100644
index b60c0e901a569f73f71bfc927ed1714ec102f793..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/lcl.h
+++ /dev/null
@@ -1,49 +0,0 @@
-/*
- * LCL (LossLess Codec Library) Codec
- * Copyright (c) 2002-2004 Roberto Togni
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#ifndef AVCODEC_LCL_H
-#define AVCODEC_LCL_H
-
-#define BMPTYPE_YUV 1
-#define BMPTYPE_RGB 2
-
-#define IMGTYPE_YUV111 0
-#define IMGTYPE_YUV422 1
-#define IMGTYPE_RGB24 2
-#define IMGTYPE_YUV411 3
-#define IMGTYPE_YUV211 4
-#define IMGTYPE_YUV420 5
-
-#define COMP_MSZH 0
-#define COMP_MSZH_NOCOMP 1
-#define COMP_ZLIB_HISPEED 1
-#define COMP_ZLIB_HICOMP 9
-#define COMP_ZLIB_NORMAL -1
-
-#define FLAG_MULTITHREAD 1
-#define FLAG_NULLFRAME 2
-#define FLAG_PNGFILTER 4
-#define FLAGMASK_UNUSED 0xf8
-
-#define CODEC_MSZH 1
-#define CODEC_ZLIB 3
-
-#endif /* AVCODEC_LCL_H */
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Age of Z Origins Tower Defense MOD APK Download Now and Get Free Gems Gold and Energy.md b/spaces/congsaPfin/Manga-OCR/logs/Age of Z Origins Tower Defense MOD APK Download Now and Get Free Gems Gold and Energy.md
deleted file mode 100644
index 51861f9bc50d256b603a86d0d4827311f1d9e0df..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Age of Z Origins Tower Defense MOD APK Download Now and Get Free Gems Gold and Energy.md
+++ /dev/null
@@ -1,148 +0,0 @@
-
-
Age of Z Origins Tower Defense Mod APK: A Guide for Beginners
-
If you are a fan of strategy games, zombie apocalypse, and tower defense, you might want to check out Age of Z Origins Tower Defense. This is a popular mobile game that combines these elements in an immersive and thrilling gameplay. In this game, you have to build your base, train your troops, join an alliance, and fight against hordes of zombies and other players. Sounds exciting, right?
-
But what if we tell you that you can make the game even more fun and easy by using a mod APK? A mod APK is a modified version of the original game that gives you access to unlimited resources, features, and cheats. With a mod APK, you can enjoy the game without any limitations or restrictions.
In this article, we will tell you everything you need to know about Age of Z Origins Tower Defense mod APK. We will explain what it is, how to download and install it, what are the benefits of using it, and some tips and tricks for playing the game. By the end of this article, you will be ready to conquer the zombie-infested world with your modded game.
-
What is Age of Z Origins Tower Defense?
-
A brief introduction to the game and its features
-
Age of Z Origins Tower Defense is a free-to-play mobile game developed by Camel Games Limited. It was released in 2019 and has since gained millions of downloads and positive reviews from players around the world. The game is available for both Android and iOS devices.
-
The game is set in a post-apocalyptic world where zombies have taken over. You are one of the survivors who have to rebuild civilization and fight for survival. You have to create your own base, recruit heroes, train soldiers, research technologies, and build defenses. You also have to explore the map, scavenge for resources, complete missions, and battle against zombies and other players.
-
The game has many features that make it engaging and addictive. Some of these features are:
-
-
Stunning graphics and sound effects that create a realistic and immersive atmosphere
-
A large and diverse map that offers different terrains, environments, and challenges
-
A variety of heroes, troops, weapons, vehicles, buildings, and towers that you can unlock, upgrade, and customize
-
A dynamic combat system that allows you to use different strategies and tactics
-
A social aspect that lets you join or create an alliance, chat with other players, trade resources, help each other, and wage wars
-
A rich content that includes daily tasks, events, quests, achievements, rewards, leaderboards, and more
-
-
How to download and install the mod APK
-
If you want to enjoy all these features without any limitations or costs, you can download and install the Age of Z Origins Tower Defense mod APK. This is a modified version of the original game that gives you unlimited everything. You can get unlimited gold, gems, food, oil, steel, energy, VIP points, speedups, boosts, etc. You can also unlock all the heroes, troops, buildings, towers, technologies, etc. You can also use cheats such as auto-win battles, instant kill zombies, no cooldowns, etc.
-
To download and install the mod APK, you need to follow these simple steps:
-
-
Go to [this link](^1^) where you can find the latest version of the mod APK.
-
Click on the download button and wait for the file to be downloaded on your device.
-
Once the download is complete, locate the file and tap on it to install it. You may need to enable the installation from unknown sources in your device settings.
-
After the installation is done, open the game and enjoy the modded features.
-
-
Note: You may need to uninstall the original game before installing the mod APK. Also, you may need to update the mod APK regularly to get the latest features and bug fixes.
-
What are the benefits of using the mod APK
-
There are many benefits of using the Age of Z Origins Tower Defense mod APK. Some of these benefits are:
-
age of z origins tower defense hack mod apk
-age of z tower defense mod apk unlimited money
-age of z origins tower defense mod apk download
-age of z tower defense mod apk latest version
-age of z origins tower defense mod apk android
-age of z tower defense mod apk free shopping
-age of z origins tower defense mod apk ios
-age of z tower defense mod apk offline
-age of z origins tower defense mod apk 2023
-age of z tower defense mod apk no root
-age of z origins tower defense hack mod ipa
-age of z tower defense mod apk online
-age of z origins tower defense mod apk obb
-age of z tower defense mod apk revdl
-age of z origins tower defense mod apk rexdl
-age of z tower defense mod apk unlimited gems
-age of z origins tower defense mod apk unlimited everything
-age of z tower defense mod apk unlimited gold
-age of z origins tower defense mod apk unlimited resources
-age of z tower defense mod apk unlimited oil
-age of z origins tower defense hack mod download
-age of z tower defense mod apk 1.2.98
-age of z origins tower defense hack mod free
-age of z tower defense mod apk 1.2.99
-age of z origins tower defense hack mod online
-age of z tower defense mod apk 1.2.100
-age of z origins tower defense hack mod offline
-age of z tower defense mod apk 1.2.101
-age of z origins tower defense hack mod 2023
-age of z tower defense mod apk 1.2.102
-age of z origins tower defense hack mod no root
-age of z tower defense mod apk 1.2.103
-age of z origins tower defense hack mod unlimited money
-age of z tower defense mod apk 1.2.104
-age of z origins tower defense hack mod latest version
-age of z tower defense mod apk 1.2.105
-age of z origins tower defense hack mod android
-age of z tower defense mod apk 1.2.106
-age of z origins tower defense hack mod ios
-age of z tower defense mod apk 1.2.107
-
-
You can save time and money by getting unlimited resources and features for free. You don't have to spend real money or wait for hours to get what you need.
-
You can have more fun and excitement by using cheats and hacks that make the game easier and more enjoyable. You can win every battle, kill every zombie, and dominate every enemy with ease.
-
You can explore and experience everything that the game has to offer without any restrictions or limitations. You can unlock and upgrade everything, try different combinations, and experiment with different strategies and tactics.
-
You can impress and challenge your friends and other players by showing off your achievements, skills, and power. You can also share the mod APK with them and play together.
-
-
Tips and tricks for playing Age of Z Origins Tower Defense
-
How to build and upgrade your base
-
Your base is your main stronghold in the game. It is where you produce resources, train troops, research technologies, and build defenses. It is also where you store your loot, heal your wounded, and manage your heroes. Therefore, it is important to build and upgrade your base wisely.
-
Some tips and tricks for building and upgrading your base are:
-
-
Follow the tutorial and the quests that guide you through the basics of building and upgrading your base. They will also reward you with resources, items, and gems that you can use for further development.
-
Use the mod APK to get unlimited resources and speedups that you can use to build and upgrade your base faster and easier. You can also use the mod APK to unlock all the buildings and technologies that you need.
-
Focus on building and upgrading the essential buildings first, such as the command center, the barracks, the hospital, the warehouse, the research center, etc. These buildings will help you improve your production, training, healing, storage, research, etc.
-
Build and upgrade your defensive buildings such as the walls, the turrets, the traps, etc. These buildings will help you protect your base from zombie attacks and enemy raids. You can also use the mod APK to get unlimited towers that you can place around your base for extra defense.
-
Arrange your buildings in a strategic way that maximizes their efficiency and security. For example, place your production buildings near each other for easy access, place your defensive buildings near the entrance for better coverage, place your storage buildings in the center for better protection, etc.
-
-
How to train and deploy your troops
-
Your troops are your main force in the game. They are the ones who fight against zombies and enemies on the battlefield. They are also the ones who gather resources, scout locations, occupy territories, etc. Therefore, it is important to train and deploy your troops effectively.
-
Some tips and tricks for training and deploying your troops are:
-
-
Use the mod APK to get unlimited troops that you can train instantly without any cost or limit. You can also use the mod APK to unlock all the troop types that you can choose from.
-
Train a balanced mix of troops that can handle different situations and enemies. For example, train infantry for close combat, cavalry for fast movement, shooters for long range attacks, vehicles for heavy damage, etc.
-
Upgrade your troops regularly by researching new technologies that improve their stats and abilities. You can also use items such as gear, medals, badges, etc. that boost their performance.
-
Deploy your troops wisely by considering factors such as their strength, speed, range, capacity, etc. For example, deploy infantry as the front line, cavalry as the flankers, shooters as the support, vehicles as the siege, etc.
-
Use the mod APK to get unlimited energy that you can use to deploy your troops without any cooldown or limit. You can also use the mod APK to get cheats such as auto-win battles, instant kill zombies, no damage, etc.
-
Manage your troops carefully by recalling them when they are low on health, healing them when they are wounded, reinforcing them when they are outnumbered, etc. You can also use items such as first aid kits, bandages, stimulants, etc. that heal and revive your troops.
-
-
How to join and cooperate with an alliance
-
An alliance is a group of players who work together for mutual benefit and support. Joining an alliance is one of the best ways to improve your game experience and progress faster. You can also create your own alliance if you want to be a leader and recruit other players.
-
Some tips and tricks for joining and cooperating with an alliance are:
-
-
Use the mod APK to get unlimited gems that you can use to join or create an alliance without any cost or requirement. You can also use the mod APK to get unlimited alliance points that you can use to buy items and perks from the alliance store.
-
Choose an alliance that suits your play style, goals, and preferences. For example, choose an active alliance if you want to participate in events and wars, choose a friendly alliance if you want to chat and socialize, choose a local alliance if you want to play with players from your region, etc.
-
Be a loyal and helpful member of your alliance by contributing resources, helping with construction, donating troops, participating in missions, defending allies, attacking enemies, etc. You can also use items such as gifts, letters, fireworks, etc. that show your appreciation and gratitude to your allies.
-
Communicate and coordinate with your allies by using the chat feature or other platforms such as Discord, WhatsApp, etc. You can also use the mod APK to get unlimited chat messages that you can send without any limit or delay.
-
Leverage the benefits of being in an alliance such as sharing information, resources, reinforcements, buffs, etc. You can also use the mod APK to get unlimited alliance teleports that you can use to move your base near your allies for better cooperation and protection.
-
-
How to collect resources and rewards
-
Resources and rewards are essential for your game progress and development. You need resources such as food, oil, steel, energy, etc. to build and upgrade your base, train and deploy your troops, research technologies, etc. You need rewards such as gold, gems, items, etc. to buy and unlock various features and benefits in the game.
-
Some tips and tricks for collecting resources and rewards are:
-
-
Use the mod APK to get unlimited resources and rewards that you can collect instantly without any effort or cost. You can also use the mod APK to get unlimited resource boxes that you can open for extra resources.
-
Build and upgrade your production buildings such as the farm, the oil well, the steel mill, the power plant, etc. These buildings will generate resources for you over time. You can also use items such as production boosts, resource packs, etc. that increase your production rate and capacity.
-
Gather resources from the map by sending your troops to resource tiles such as farms, oil fields, steel mines, power stations, etc. These tiles will provide you with a large amount of resources in a short time. You can also use items such as gathering boosts, march speedups, etc. that improve your gathering efficiency and speed.
-
Complete tasks, events, quests, achievements, etc. that reward you with resources and rewards for accomplishing certain goals and objectives in the game. You can also use items such as task refreshes, event tickets, quest scrolls, etc. that give you more opportunities and chances to get more rewards.
-
Attack zombies and enemies on the map by sending your troops to their bases or camps. You can loot resources and rewards from them after defeating them in battle. You can also use items such as attack boosts, damage boosts, etc. that enhance your combat power and performance.
-
Claim resources and rewards from various sources such as the daily login bonus, the alliance gift, the mail box, the resource center, the VIP store, etc. You can also use items such as gift codes, coupons, vouchers, etc. that give you free resources and rewards.
-
-
How to defend your base and attack enemies
-
Defending your base and attacking enemies are two of the most important aspects of the game. You have to protect your base from zombie attacks and enemy raids that can damage your buildings, steal your resources, and kill your troops. You also have to attack enemies to expand your territory, gain more resources and rewards, and assert your dominance.
-
Some tips and tricks for defending your base and attacking enemies are:
-
-
Use the mod APK to get unlimited defenses and attacks that you can use without any cooldown or limit. You can also use the mod APK to get cheats such as invincibility, invisibility, one-hit kill, etc.
-
Build and upgrade your defensive buildings such as the walls, the turrets, the traps, etc. These buildings will help you protect your base from zombie attacks and enemy raids. You can also use items such as defense boosts, shield generators, repair kits, etc. that improve your defense capability and durability.
-
Train and deploy your troops wisely by considering factors such as their strength, speed, range, capacity, etc. For example, deploy infantry as the front line, cavalry as the flankers, shooters as the support, vehicles as the siege, etc. You can also use items such as troop boosts, march speedups, etc. that improve your troop stats and movement.
-
Use the mod APK to get unlimited energy that you can use to deploy your troops without any cooldown or limit. You can also use the mod APK to get cheats such as auto-win battles, instant kill zombies, no damage, etc.
-
Use the scout feature to gather information about your enemies before attacking them. You can see their base layout, defense level, troop composition, resource amount, etc. You can also use items such as spy drones, stealth cloaks, etc. that enhance your scouting ability and accuracy.
-
Use the rally feature to join forces with your allies and launch a coordinated attack on a powerful enemy. You can share your troops, resources, and strategies with your allies and increase your chances of victory. You can also use items such as rally boosts, rally flags, etc. that improve your rally capacity and speed.
-
Use the shield feature to protect your base from enemy attacks for a certain period of time. You can activate a shield manually or automatically when you are under attack or offline. You can also use items such as shield generators, shield extenders, etc. that give you more shield options and duration.
-
-
Conclusion
-
Age of Z Origins Tower Defense is a fun and exciting game that combines strategy, zombie apocalypse, and tower defense in one. You can build your base, train your troops, join an alliance, and fight against zombies and enemies in a post-apocalyptic world. You can also use the mod APK to get unlimited resources, features, and cheats that make the game more enjoyable and easy.
-
If you are interested in playing Age of Z Origins Tower Defense mod APK, you can download it from [this link] and follow the instructions in this article. You can also check out our other articles for more tips and tricks for playing the game. We hope you have a great time playing Age of Z Origins Tower Defense mod APK!
-
FAQs
-
Q: Is Age of Z Origins Tower Defense mod APK safe to use?
-
A: Yes, Age of Z Origins Tower Defense mod APK is safe to use as long as you download it from a trusted source and follow the installation steps correctly. However, you should be aware that using a mod APK may violate the terms of service of the original game and may result in your account being banned or suspended. Therefore, you should use the mod APK at your own risk and discretion.
-
Q: Can I play Age of Z Origins Tower Defense mod APK online with other players?
-
A: Yes, you can play Age of Z Origins Tower Defense mod APK online with other players who are using the same version of the mod APK. However, you may not be able to play with players who are using the original game or a different version of the mod APK. Therefore, you should make sure that you and your friends are using the same version of the mod APK before playing together.
-
Q: How do I update Age of Z Origins Tower Defense mod APK?
-
A: To update Age of Z Origins Tower Defense mod APK, you need to download the latest version of the mod APK from [this link] and install it over the existing one. You may need to uninstall the previous version before installing the new one. You should also backup your game data before updating to avoid losing any progress or settings.
-
Q: How do I uninstall Age of Z Origins Tower Defense mod APK?
-
A: To uninstall Age of Z Origins Tower Defense mod APK, you need to go to your device settings and find the app manager. Then, you need to select Age of Z Origins Tower Defense mod APK and tap on uninstall. You may also need to delete any residual files or folders related to the mod APK from your device storage.
-
Q: Where can I find more information about Age of Z Origins Tower Defense mod APK?
-
A: You can find more information about Age of Z Origins Tower Defense mod APK by visiting [this website] where you can download the mod APK and read more articles about the game. You can also join [this forum] where you can interact with other players and get tips and feedback about the game and the mod APK.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Akll Oyunlar - evrimii Eitim ve Elence Platformu EBA.md b/spaces/congsaPfin/Manga-OCR/logs/Akll Oyunlar - evrimii Eitim ve Elence Platformu EBA.md
deleted file mode 100644
index be6b904d8f50bc50d5c3b686fdb4c085edcd8d9c..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Akll Oyunlar - evrimii Eitim ve Elence Platformu EBA.md
+++ /dev/null
@@ -1,141 +0,0 @@
-
-
Akıllı Oyunlar: Eğlenceli ve Eğitici Bir Seçim
-
Akıllı oyunlar, çocukların ve yetişkinlerin zihinsel becerilerini geliştirmek, öğrenmeyi desteklemek ve eğlenmek için oynayabilecekleri oyunlardır. Akıllı oyunlar, farklı zeka türlerine hitap eden, çeşitli platformlarda sunulan ve bilimsel olarak tasarlanan oyunlardır. Bu makalede, akıllı oyunların ne olduğunu, nasıl seçileceğini, hangi faydaları sağladığını ve örneklerini inceleyeceğiz.
-
Akıllı Oyunlar Nedir?
-
Akıllı oyunlar, oyuncuların mantık, hafıza, dikkat, konsantrasyon, görsel zeka, sözel zeka, müziksel zeka, işitsel zeka, matematiksel zeka, problem çözme, yaratıcılık gibi becerilerini geliştirmeyi amaçlayan oyunlardır. Akıllı oyunlar, hem eğitici hem de eğlenceli olmak üzere tasarlanmıştır. Akıllı oyunlar, akademisyenler, pedagoglar, psikologlar ve oyun tasarımcıları tarafından hazırlanmıştır. Akıllı oyunlar, çeşitli yaş gruplarına ve ilgi alanlarına uygun olarak farklı temalar ve seviyeler içerir.
Akıllı oyun seçerken dikkat edilmesi gereken bazı noktalar şunlardır:
-
-
Oyuncunun yaşı, ilgi alanları ve ihtiyaçlarına uygun bir oyun seçilmelidir. Örneğin, küçük çocuklar için renkli ve sesli oyunlar daha uygun olabilirken, yetişkinler için daha karmaşık ve zorlayıcı oyunlar tercih edilebilir.
-
Oyuncunun hangi zeka türünü geliştirmek istediğine karar verilmelidir. Örneğin, görsel zeka geliştirmek isteyen bir oyuncu için tangram gibi bir akıl oyunu uygun olabilirken, sözel zeka geliştirmek isteyen bir oyuncu için kelime bulmacası gibi bir akıl oyunu uygun olabilir.
-
Oyuncunun hangi platformda oynamak istediğine karar verilmelidir. Örneğin, akıllı telefon veya tablet gibi mobil cihazlarda oynamak isteyen bir oyuncu için uygulama olarak sunulan akıllı oyunlar uygun olabilirken, bilgisayar veya akıllı tahta gibi büyük ekranlı cihazlarda oynamak isteyen bir oyuncu için web sitesi olarak sunulan akıllı oyunlar uygun olabilir.
-
Oyuncunun tek başına mı yoksa arkadaşlarıyla mı oynamak istediğine karar verilmelidir. Örneğin, tek başına oynamak isteyen bir oyuncu için bireysel performansını ölçen ve geliştiren akıllı oyunlar uygun olabilirken, arkadaşlarıyla oynamak isteyen bir oyuncu için rekabetçi veya işbirlikçi akıllı oyunlar uygun olabilir.
-
Oyuncunun ne kadar süreyle ve ne sıklıkla oynamak istediğine karar verilmelid
ir. Örneğin, kısa süreli ve sık sık oynamak isteyen bir oyuncu için hızlı ve basit akıllı oyunlar uygun olabilirken, uzun süreli ve nadir oynamak isteyen bir oyuncu için detaylı ve zengin akıllı oyunlar uygun olabilir.
-
-
Akıllı Oyunlar Hangi Faydaları Sağlar?
-
Akıllı oyunlar, oyunculara pek çok fayda sağlar. Bunlardan bazıları şunlardır:
-
-
Akıllı oyunlar, oyuncuların zihinsel becerilerini geliştirir. Örneğin, akıllı oyunlar, oyuncuların mantık yürütme, hafıza güçlendirme, dikkat artırma, konsantrasyon sağlama, görsel algılama, sözel ifade, müziksel duyarlılık, işitsel anlama, matematiksel hesaplama, problem çözme, yaratıcılık gibi becerilerini geliştirir.
-
Akıllı oyunlar, oyuncuların öğrenmeyi destekler. Örneğin, akıllı oyunlar, oyuncuların okulda veya işte öğrendikleri bilgileri pekiştirmelerine, yeni bilgiler edinmelerine, farklı bakış açıları kazanmalarına ve merak duygularını canlı tutmalarına yardımcı olur.
-
Akıllı oyunlar, oyuncuların eğlenmesini sağlar. Örneğin, akıllı oyunlar, oyunculara keyifli ve heyecanlı bir deneyim sunar, onları motive eder, ödüllendirir ve tatmin eder. Akıllı oyunlar, oyuncuların stres atmasına, rahatlamasına ve mutlu olmasına katkıda bulunur.
-
Akıllı oyunlar, oyuncuların sosyalleşmesini sağlar. Örneğin, akıllı oyunlar, oyuncuların arkadaşlarıyla veya aileleriyle birlikte oynamalarına, iletişim kurmalarına, işbirliği yapmalarına veya rekabet etmelerine olanak tanır. Akıllı oyunlar, oyuncuların sosyal becerilerini ve ilişkilerini geliştirir.
-
-
Akıllı Oyunların Örnekleri Nelerdir?
-
Akıllı oyunların örnekleri çoktur. Farklı platformlarda sunulan ve farklı zeka türlerine hitap eden pek çok akıllı oyun bulunmaktadır. Aşağıda bazı popüler akıllı oyunların isimleri ve kısaca tanımları verilmiştir.
-
Mobil Cihazlarda Oynanan Akil Oyunları
-
-
-
Oyun Adi
-
Oyun Tanım
-
-
-
Lumosity
-
Birçok bilimsel araştırma ile desteklenen Lumosity, 60'tan fazla bilişsel egzersiz içeren bir uygulamadır. Lumosity, oyuncuların hafızalarını, dikkatlerini, esnekliklerini, hızlarını ve problem çözme becerilerini geliştirmeyi amaçlar. Lumosity ayrıca oyunculara kişiselleştirilmiş bir eğitim programı sunar.
-
-
-
Elevate
-
Apple tarafından 2014 yılında yılın uygulaması seçilen Elevate, 35'ten fazla beyin egzersizi içeren bir uygulamadır. Elevate, oyuncuların matematiksel becerilerini, okuma anlama becerilerini, yazma becerilerini ve konuşma becerilerini geliştirmey i amaçlar. Elevate ayrıca oyunculara kişisel bir öğrenme planı sunar.
-
-
-
Peak
-
40'tan fazla beyin egzersizi içeren Peak, oyuncuların zihinsel becerilerini geliştirmek için tasarlanmış bir uygulamadır. Peak, oyuncuların hafıza, dikkat, problem çözme, zihinsel esneklik, dil, koordinasyon ve duygusal kontrol gibi becerilerini geliştirmeyi amaçlar. Peak ayrıca oyunculara kişisel bir antrenman programı sunar.
-
-
-
Brain It On!
-
Fizik tabanlı bulmacalar içeren Brain It On!, oyuncuların yaratıcılık, mantık ve çizim becerilerini geliştirmek için tasarlanmış bir uygulamadır. Brain It On!, oyunculara farklı şekiller çizerek fizik kurallarını kullanmalarını ve verilen görevleri tamamlamalarını ister. Brain It On!, oyunculara 200'den fazla seviye sunar.
-
-
-
WordBrain
-
Kelime bulmacaları içeren WordBrain, oyuncuların sözel zeka ve kelime haznesini geliştirmek için tasarlanmış bir uygulamadır. WordBrain, oyunculara harflerden oluşan bir karede gizli kelimeleri bulmalarını ister. WordBrain, oyunculara 700'den fazla seviye ve 15 farklı dil seçeneği sunar.
-
-
-
Bilgisayarda Oynanan Akil Oyunları
-
-
-
Oyun Adi
-
Oyun Tanım
-
-
-
Sudoku
-
Sudoku, rakamları kullanarak mantık yürütmeyi gerektiren bir akıl oyunudur. Sudoku, oyunculara 9x9'luk bir karede boş bırakılmış hücreleri doldurmalarını ister. Sudoku'nun kuralları basittir: Her satırda, her sütunda ve her 3x3'lük alt karede 1'den 9'a kadar rakamlar birer kez yer almalıdır.
-
-
-
Tetris
-
Tetris, farklı şekillerdeki blokları kullanarak görsel zeka gerektiren bir akıl oyunudur. Tetris, oyunculara ekrandan aşağıya düşen blokları yatay olarak tamamlamalarını ve boşluk bırakmamalarını ister. Tetris'in kuralları basittir: Eğer bir satır tamamen dolarsa silinir ve oyuncu puan kazanır. Eğer ekranda yer kalmazsa oyun biter.
-
-
-
Minesweeper
-
Minesweeper, mayın tarlasında mayınları bulmaya çalışan bir akıl oyunudur. Minesweeper, oyunculara karelerden oluşan bir alanda rastgele yerleştirilmiş mayınları tespit etmelerini ve işaretlemelerini ister. Minesweeper'in kuralları basittir: Eğer bir kareye tıklarsanız ya boş ya da bir sayı görürsünüz. Boş kare demek o karenin etrafında mayın olmadığı anlamına gelir. Sayı ise o karenin etrafındaki mayın sayısını gösterir. Eğer mayın olan bir kareye tıklarsanız oyun biter.
-
-
-
Crossword Puzzle
Crossword Puzzle
-
Crossword Puzzle, kelimeleri yatay ve dikey olarak birleştirerek sözel zeka gerektiren bir akıl oyunudur. Crossword Puzzle, oyunculara farklı konularda ipuçları vererek kelimeleri bulmalarını ve boşlukları doldurmalarını ister. Crossword Puzzle'in kuralları basittir: Eğer bir kelimeyi doğru bulursanız o kelime karelerde görünür. Eğer bir kelimeyi yanlış bulursanız o kelime karelerde görünmez.
-
-
-
Chess
-
Chess, iki oyuncunun karşılıklı olarak tahta üzerindeki taşları hareket ettirerek strateji ve mantık gerektiren bir akıl oyunudur. Chess, oyunculara rakibin kralını şah-mat etmeyi amaçlar. Chess'in kuralları basittir: Her taşın kendine özgü bir hareket şekli vardır. Eğer bir taş rakibin taşının bulunduğu kareye giderse o taşı yener. Eğer bir oyuncu rakibin kralını tehdit ederse şah der. Eğer bir oyuncu rakibin kralını kaçamayacak şekilde tehdit ederse şah-mat der ve oyunu kazanır.
-
-
-
Sonuç
-
Akıllı oyunlar, hem eğlenceli hem de eğitici olan oyunlardır. Akıllı oyunlar, oyuncuların zihinsel becerilerini geliştirmelerine, öğrenmelerine, eğlenmelerine ve sosyalleşmelerine yardımcı olur. Akıllı oyunlar, farklı platformlarda, farklı zeka türlerine ve farklı yaş gruplarına uygun olarak sunulur. Akıllı oyun seçerken, oyuncunun ilgi alanları, ihtiyaçları, platform tercihi, oyun süresi ve sıklığı gibi faktörler göz önünde bulundurulmalıdır. Akıllı oyunlar, hayatımızda önemli bir yere sahiptir ve bize pek çok fayda sağlar.
-
SSS
-
-
Akıllı oyunlar sadece çocuklar için mi uygundur?
-
Hayır, akıllı oyunlar hem çocuklar hem de yetişkinler için uygundur. Akıllı oyunlar, farklı yaş gruplarına göre farklı seviye ve temalarda sunulur. Akıllı oyunlar, yetişkinlerin de zihinsel becerilerini geliştirmelerine, öğrenmelerine, eğlenmelerine ve sosyalleşmelerine katkıda bulunur.
-
Akıllı oyunlar bağımlılık yapar mı?
-
Akıllı oyunlar, eğer aşırıya kaçmadan ve dengeli bir şekilde oynanırsa bağımlılık yapmaz. Akıllı oyunlar, oyunculara keyifli ve heyecanlı bir deneyim sunar ancak bu deneyimi diğer hayat aktivitelerinden koparmamak gerekir. Akıllı oyunlar, günlük rutinin bir parçası olmalı ancak tek amacı olmamalıdır.
-
Akıllı oyunlar pahalı mıdır?
-
Akıllı oyunlar, genellikle pahalı değildir. Akıllı oyunlar, çeşitli platformlarda sunulur ve pek çok ak ıllı oyun ücretsiz olarak indirilebilir veya oynanabilir. Akıllı oyunlar, oyunculara farklı fiyat seçenekleri sunar. Örneğin, bazı akıllı oyunlar, reklam içerir veya sınırlı özelliklere sahiptir ancak ücretsizdir. Bazı akıllı oyunlar, reklam içermez veya tüm özelliklere sahiptir ancak ücretlidir. Bazı akıllı oyunlar ise, hem ücretsiz hem de ücretli seçenekler sunar.
-
akıllı oyunlar indir
-akıllı oyunlar çocuklar için
-akıllı oyunlar mentalup
-akıllı oyunlar poki
-akıllı oyunlar kraloyun
-akıllı oyunlar zeka testi
-akıllı oyunlar matematik
-akıllı oyunlar bulmaca
-akıllı oyunlar tangram
-akıllı oyunlar hafıza kartları
-akıllı oyunlar sudoku
-akıllı oyunlar satranç
-akıllı oyunlar rubik küpü
-akıllı oyunlar labirent
-akıllı oyunlar resimli kelime bulmaca
-akıllı oyunlar kelime avcısı
-akıllı oyunlar harf salatası
-akıllı oyunlar yarışma
-akıllı oyunlar eşleştirme
-akıllı oyunlar renkli toplar
-akıllı oyunlar tetris
-akıllı oyunlar 2048
-akıllı oyunlar sudoku çözücü
-akıllı oyunlar satranç öğrenme
-akıllı oyunlar rubik küpü çözümü
-akıllı oyunlar labirent çözme
-akıllı oyunlar resimli kelime bulmaca cevapları
-akıllı oyunlar kelime avcısı ipuçları
-akıllı oyunlar harf salatasında arama yapma
-akıllı oyunlar yarışma sorular ve cevapları
-akıllı oyunlar eşleştirme kartları yapım aşamalarını izleme
-akılı oyular renkli toplar patlatma stratejileri
-akılı oyular tetris nasıl daha hızlı yapılır
-akılı oyular 2048 nasıl kazanılır
-akılı oyular sudoku zorluk seviyeleri
-akılı oyular satranç hamleleri ve taktikleri
-akılı oyular rubik küpü nasıl karıştırılır
-akılı oyular labirent nasıl tasarlanır
-akılı oyular resimli kelime bulmaca nasıl oluşturulur
-akılı oyular kelime avcısı nasıl daha fazla puan alınır
-akılı oyular harf salatasında en uzun kelimeleri bulma
-akılı oyular yarışma nasıl hazırlandığını öğrenme
-akılı oyular eşleştirme kartları nasıl hafızaya alınır
-akılı oyular renkli toplar nasıl sınıflandırılır
-akılı oyular tetris nasıl daha renkli yapılır
-
Akıllı oyunlar güvenli midir?
-
Akıllı oyunlar, genellikle güvenlidir. Akıllı oyunlar, bilimsel olarak tasarlanmış ve test edilmiş oyunlardır. Akıllı oyunlar, oyuncuların kişisel bilgilerini korur ve gizlilik politikalarına uyar. Akıllı oyunlar, oyunculara zararlı içerikler sunmaz veya yönlendirmez. Ancak, akıllı oyunlar indirilirken veya oynanırken, güvenilir kaynaklardan ve sitelerden yararlanmak gerekir.
-
Akıllı oyunlar gerçekten işe yarar mı?
-
Akıllı oyunlar, gerçekten işe yarar. Akıllı oyunlar, pek çok bilimsel araştırma ile desteklenen ve kanıtlanan oyunlardır. Akıllı oyunlar, oyuncuların zihinsel becerilerini geliştirmelerine, öğrenmelerine, eğlenmelerine ve sosyalleşmelerine katkıda bulunur. Akıllı oyunlar, oyuncuların hayat kalitesini ve başarılarını artırır.
- 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Spot the Difference Games Challenge Your Eyesight and Brain uD83DuDE0E No Download Necessary.md b/spaces/congsaPfin/Manga-OCR/logs/Spot the Difference Games Challenge Your Eyesight and Brain uD83DuDE0E No Download Necessary.md
deleted file mode 100644
index 5373933e7872c3e05cda030684a3ca101052c8ef..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Spot the Difference Games Challenge Your Eyesight and Brain uD83DuDE0E No Download Necessary.md
+++ /dev/null
@@ -1,114 +0,0 @@
-
-
Find the Difference Games No Download: A Fun and Challenging Way to Train Your Brain
-
Do you enjoy puzzles and brain teasers? Do you like to test your observation skills and attention to detail? If so, you might want to try find the difference games no download. These are online games that challenge you to spot the differences between two similar images. They are fun, addictive, and good for your brain. In this article, we will explain what find the difference games are, how they can benefit you, how to play them online, and where to find the best ones. Let's get started!
Find the difference games, also known as spot the difference games, are a type of puzzle game that require you to compare two images and identify all the differences between them. The images can be photographs, drawings, paintings, cartoons, or any other type of visual media. The differences can be subtle or obvious, and they can involve colors, shapes, sizes, positions, objects, or anything else. The number of differences can vary from game to game, but usually ranges from 3 to 10 or more. The goal is to find all the differences as quickly and accurately as possible.
-
The History of Find the Difference Games
-
Find the difference games have a long history that dates back to the 19th century. They were originally published in newspapers and magazines as a form of entertainment and education for readers. Some of the earliest examples of find the difference games were created by British illustrator Walter Wick in his series of books called I Spy, which featured photographs of various scenes with hidden objects and differences. Later, find the difference games became popular in video games, especially in genres such as adventure, hidden object, and escape room games. Today, find the difference games are widely available online, where they can be played for free on various websites and platforms.
-
The Benefits of Playing Find the Difference Games
-
Playing find the difference games is not only fun, but also beneficial for your brain. Here are some of the benefits that you can get from playing these games regularly:
-
Improve Your Visual Perception
-
Visual perception is the ability to process and interpret visual information. It involves skills such as pattern recognition, spatial awareness, depth perception, and color vision. Playing find the difference games can help you improve your visual perception by training your eyes to notice small details and differences that you might otherwise miss. This can help you in many aspects of life, such as reading, driving, sports, art, and more.
-
Enhance Your Memory and Attention
-
Memory is the ability to store and recall information. Attention is the ability to focus on a specific task or stimulus while ignoring distractions. Playing find the difference games can help you enhance your memory and attention by challenging you to remember what you have seen and what you have not seen in each image. This can help you improve your concentration, working memory, short-term memory, and long-term memory.
-
Spot the difference games online free
-Find the difference puzzles for adults
-Spot the difference games for kids
-Find the difference games with hints
-Spot the difference games with timer
-Find the difference games hard
-Spot the difference games no ads
-Find the difference games easy
-Spot the difference games with animals
-Find the difference games with pictures
-Spot the difference games with celebrities
-Find the difference games with stories
-Spot the difference games with levels
-Find the difference games with sound
-Spot the difference games with zoom
-Find the difference games with fun facts
-Spot the difference games with rewards
-Find the difference games with challenges
-Spot the difference games with high scores
-Find the difference games with themes
-Spot the difference games with emojis
-Find the difference games with cartoons
-Spot the difference games with hidden objects
-Find the difference games with optical illusions
-Spot the difference games with 3D graphics
-Find the difference games with trivia questions
-Spot the difference games with multiple images
-Find the difference games with brain teasers
-Spot the difference games with holidays
-Find the difference games with famous paintings
-Spot the difference games with food
-Find the difference games with flowers
-Spot the difference games with cars
-Find the difference games with sports
-Spot the difference games with fashion
-Find the difference games with movies
-Spot the difference games with music
-Find the difference games with books
-Spot the difference games with history
-Find the difference games with geography
-Spot the difference games with science
-Find the difference games with math
-Spot the difference games with art
-Find the difference games with culture
-Spot the difference games with nature
-Find the difference games with space
-Spot the difference games with fantasy
-Find the difference games with horror
-Spot the difference games with humor
-
Boost Your Mood and Relaxation
-
Mood is the state of mind or emotion that you experience at a given time. Relaxation is the state of being calm and stress-free. Playing find the difference games can help you boost your mood and relaxation by providing you with a sense of achievement, satisfaction, and enjoyment. Solving puzzles can also release endorphins, which are natural chemicals that make you feel happy and relaxed.How to Play Find the Difference Games Online
-
Playing find the difference games online is easy and convenient. You don't need to download or install anything, and you can play them anytime and anywhere you have an internet connection. Here are some simple steps to follow when playing find the difference games online:
-
Choose a Game from a Reputable Website
-
The first step is to choose a game from a reputable website that offers high-quality and safe find the difference games. There are many websites that offer these games, but not all of them are reliable and trustworthy. Some of them may contain viruses, malware, pop-ups, or inappropriate content. To avoid these risks, you should look for websites that have positive reviews, ratings, and feedback from other users. You should also check the privacy policy and terms of service of the website before playing.
-
Compare the Two Images Carefully
-
The second step is to compare the two images carefully and look for any differences between them. The images will usually be displayed side by side or one above the other on the screen. You should scan the images from left to right, top to bottom, and center to edge, and pay attention to every detail. You should also zoom in or out if necessary to get a better view of the images.
-
Spot the Differences and Click on Them
-
The third step is to spot the differences and click on them. Once you find a difference, you should click on it on either image. A circle or a mark will appear on both images to indicate that you have found a difference. You should repeat this process until you find all the differences in the images. You will usually see a counter or a progress bar that shows how many differences you have found and how many are left.
-
Use Hints and Avoid Mistakes
-
The fourth step is to use hints and avoid mistakes. Most find the difference games have a hint system that can help you when you are stuck or need a clue. You can usually access the hints by clicking on a button or an icon on the screen. However, you should use the hints sparingly, as they are limited and may reduce your score or time. You should also avoid making mistakes, such as clicking on the wrong spot or clicking too many times. These mistakes can also lower your score or time, or even end the game.
-
The Best Find the Difference Games No Download You Can Play for Free
-
There are many find the difference games no download that you can play for free online, but some of them are better than others. Here are some of the best ones that we recommend:
-
Spot the Difference by CrazyGames
-
Spot the Difference by CrazyGames is a fun and challenging find the difference game that features beautiful and colorful images of various themes, such as animals, nature, food, and more. The game has 100 levels to complete, each with 5 differences to find. The game also has a timer and a score system that add more excitement and challenge to the game. You can play Spot the Difference by CrazyGames here.
-
Daily Difference by CoolGames
-
Daily Difference by CoolGames is a relaxing and enjoyable find the difference game that features stunning and realistic images of different places around the world. The game has a new level every day, each with 10 differences to find. The game also has hints and zoom options that can help you when you need them. You can play Daily Difference by CoolGames here.
-
Find 500 Differences by Y8
-
Find 500 Differences by Y8 is an addictive and challenging find the difference game that features artistic and creative images of various subjects, such as people, animals, landscapes, and more. The game has 50 levels to complete, each with 10 differences to find. The game also has a timer and a hint system that add more difficulty and fun to the game. You can play Find 500 Differences by Y8 here.
-
Conclusion
-
Find the difference games no download are a great way to train your brain and have fun at the same time. They can improve your visual perception, memory, attention, mood, and relaxation. They are also easy and convenient to play online without downloading or installing anything. All you need is an internet connection and a device with a browser. You can choose from many different find the difference games online, but some of the best ones are Spot the Difference by CrazyGames, Daily Difference by CoolGames, and Find 500 Differences by Y8. You can play them for free and enjoy the challenge and fun they offer. So, what are you waiting for? Start playing find the difference games no download today and see how good you are at spotting the differences!
-
FAQs
-
Here are some frequently asked questions about find the difference games no download:
-
Q: How many find the difference games no download are there online?
-
A: There are hundreds of find the difference games no download that you can find online, each with different images, themes, levels, and features. You can browse through various websites and platforms that offer these games and choose the ones that suit your preferences and interests.
-
Q: Are find the difference games no download suitable for children?
-
A: Yes, find the difference games no download are suitable for children of all ages, as long as they are appropriate and safe. These games can help children develop their visual skills, cognitive skills, and motor skills. They can also stimulate their curiosity and creativity. However, parents should always supervise their children when they play online games and make sure they are playing on reputable and secure websites.
-
Q: Can I play find the difference games no download offline?
-
A: No, you cannot play find the difference games no download offline, as they require an internet connection and a browser to run. However, you can download some find the difference games from app stores or other sources and play them offline on your device. However, you should be careful when downloading anything from the internet and make sure it is virus-free and malware-free.
-
Q: How can I improve my skills in find the difference games no download?
-
A: There are some tips and tricks that can help you improve your skills in find the difference games no download, such as:
-
-
Practice regularly and try different games and levels.
-
Focus on one image at a time and scan it thoroughly.
-
Look for obvious differences first, such as colors, shapes, or objects.
-
Look for subtle differences next, such as sizes, positions, or shadows.
-
Use hints wisely and sparingly.
-
Avoid clicking randomly or too fast.
-
Challenge yourself with harder levels or time limits.
-
-
Q: What are some other types of puzzle games that I can play online?
-
A: There are many other types of puzzle games that you can play online, such as:
-
-
Hidden object games: These are games that require you to find hidden objects in a cluttered scene.
-
Jigsaw puzzle games: These are games that require you to assemble a picture from pieces of different shapes and sizes.
-
Crossword puzzle games: These are games that require you to fill in a grid with words that match the clues given.
-
Sudoku puzzle games: These are games that require you to fill in a grid with numbers from 1 to 9 without repeating them in any row, column, or box.
-
Mahjong puzzle games: These are games that require you to match pairs of tiles with the same symbols or images.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/contluForse/HuggingGPT/assets/Discover the Power of Blackjack with Black Belt In Blackjack Arnold Snyder Pdf 55.md b/spaces/contluForse/HuggingGPT/assets/Discover the Power of Blackjack with Black Belt In Blackjack Arnold Snyder Pdf 55.md
deleted file mode 100644
index 0128a816c4abc99b861dd3cba53ab241aff974b0..0000000000000000000000000000000000000000
--- a/spaces/contluForse/HuggingGPT/assets/Discover the Power of Blackjack with Black Belt In Blackjack Arnold Snyder Pdf 55.md
+++ /dev/null
@@ -1,8 +0,0 @@
-
-
Mp3 Juice is the most popular free mp3 search engine tool and music downloader, is very popular. MP3 Juice is a great tool to convert and download youtube videos and music. The Mp3 Juice website is the best way to quickly and easily download mp3 music. Its simplicity makes Mp3juice easy to use, so anyone can search for and download high-quality audio files
-
This website offers unlimited downloading of youtube music and Mp3 juice song free download in HD quality. You can also click "PLAY" to play the audio file before you download it. Mp3juices take only 2-5 seconds to convert and download audio files.
You can access this free mp3 download website online via an internet connection or WiFi. Bookmark this website to make it easy to access on a regular basis. Once you have downloaded the audio file, open it in any audio player to listen offline in high-quality.
-
MP3 juice music is easy to navigate through and provides a simple interface for downloading the audio. You might be wondering why people prefer mp3juices to get mp3 juice for free. This tool provides high-speed audio downloads, and users don't need to give any personal information.
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmseg/core/evaluation/metrics.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmseg/core/evaluation/metrics.py
deleted file mode 100644
index 8ede737624a0ba6e6365639f7019ac2527052cfd..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmseg/core/evaluation/metrics.py
+++ /dev/null
@@ -1,326 +0,0 @@
-from collections import OrderedDict
-
-import annotator.mmpkg.mmcv as mmcv
-import numpy as np
-import torch
-
-
-def f_score(precision, recall, beta=1):
- """calcuate the f-score value.
-
- Args:
- precision (float | torch.Tensor): The precision value.
- recall (float | torch.Tensor): The recall value.
- beta (int): Determines the weight of recall in the combined score.
- Default: False.
-
- Returns:
- [torch.tensor]: The f-score value.
- """
- score = (1 + beta**2) * (precision * recall) / (
- (beta**2 * precision) + recall)
- return score
-
-
-def intersect_and_union(pred_label,
- label,
- num_classes,
- ignore_index,
- label_map=dict(),
- reduce_zero_label=False):
- """Calculate intersection and Union.
-
- Args:
- pred_label (ndarray | str): Prediction segmentation map
- or predict result filename.
- label (ndarray | str): Ground truth segmentation map
- or label filename.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- label_map (dict): Mapping old labels to new labels. The parameter will
- work only when label is str. Default: dict().
- reduce_zero_label (bool): Whether ignore zero label. The parameter will
- work only when label is str. Default: False.
-
- Returns:
- torch.Tensor: The intersection of prediction and ground truth
- histogram on all classes.
- torch.Tensor: The union of prediction and ground truth histogram on
- all classes.
- torch.Tensor: The prediction histogram on all classes.
- torch.Tensor: The ground truth histogram on all classes.
- """
-
- if isinstance(pred_label, str):
- pred_label = torch.from_numpy(np.load(pred_label))
- else:
- pred_label = torch.from_numpy((pred_label))
-
- if isinstance(label, str):
- label = torch.from_numpy(
- mmcv.imread(label, flag='unchanged', backend='pillow'))
- else:
- label = torch.from_numpy(label)
-
- if label_map is not None:
- for old_id, new_id in label_map.items():
- label[label == old_id] = new_id
- if reduce_zero_label:
- label[label == 0] = 255
- label = label - 1
- label[label == 254] = 255
-
- mask = (label != ignore_index)
- pred_label = pred_label[mask]
- label = label[mask]
-
- intersect = pred_label[pred_label == label]
- area_intersect = torch.histc(
- intersect.float(), bins=(num_classes), min=0, max=num_classes - 1)
- area_pred_label = torch.histc(
- pred_label.float(), bins=(num_classes), min=0, max=num_classes - 1)
- area_label = torch.histc(
- label.float(), bins=(num_classes), min=0, max=num_classes - 1)
- area_union = area_pred_label + area_label - area_intersect
- return area_intersect, area_union, area_pred_label, area_label
-
-
-def total_intersect_and_union(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- label_map=dict(),
- reduce_zero_label=False):
- """Calculate Total Intersection and Union.
-
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Whether ignore zero label. Default: False.
-
- Returns:
- ndarray: The intersection of prediction and ground truth histogram
- on all classes.
- ndarray: The union of prediction and ground truth histogram on all
- classes.
- ndarray: The prediction histogram on all classes.
- ndarray: The ground truth histogram on all classes.
- """
- num_imgs = len(results)
- assert len(gt_seg_maps) == num_imgs
- total_area_intersect = torch.zeros((num_classes, ), dtype=torch.float64)
- total_area_union = torch.zeros((num_classes, ), dtype=torch.float64)
- total_area_pred_label = torch.zeros((num_classes, ), dtype=torch.float64)
- total_area_label = torch.zeros((num_classes, ), dtype=torch.float64)
- for i in range(num_imgs):
- area_intersect, area_union, area_pred_label, area_label = \
- intersect_and_union(
- results[i], gt_seg_maps[i], num_classes, ignore_index,
- label_map, reduce_zero_label)
- total_area_intersect += area_intersect
- total_area_union += area_union
- total_area_pred_label += area_pred_label
- total_area_label += area_label
- return total_area_intersect, total_area_union, total_area_pred_label, \
- total_area_label
-
-
-def mean_iou(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- nan_to_num=None,
- label_map=dict(),
- reduce_zero_label=False):
- """Calculate Mean Intersection and Union (mIoU)
-
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- nan_to_num (int, optional): If specified, NaN values will be replaced
- by the numbers defined by the user. Default: None.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Whether ignore zero label. Default: False.
-
- Returns:
- dict[str, float | ndarray]:
- float: Overall accuracy on all images.
- ndarray: Per category accuracy, shape (num_classes, ).
- ndarray: Per category IoU, shape (num_classes, ).
- """
- iou_result = eval_metrics(
- results=results,
- gt_seg_maps=gt_seg_maps,
- num_classes=num_classes,
- ignore_index=ignore_index,
- metrics=['mIoU'],
- nan_to_num=nan_to_num,
- label_map=label_map,
- reduce_zero_label=reduce_zero_label)
- return iou_result
-
-
-def mean_dice(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- nan_to_num=None,
- label_map=dict(),
- reduce_zero_label=False):
- """Calculate Mean Dice (mDice)
-
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- nan_to_num (int, optional): If specified, NaN values will be replaced
- by the numbers defined by the user. Default: None.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Whether ignore zero label. Default: False.
-
- Returns:
- dict[str, float | ndarray]: Default metrics.
- float: Overall accuracy on all images.
- ndarray: Per category accuracy, shape (num_classes, ).
- ndarray: Per category dice, shape (num_classes, ).
- """
-
- dice_result = eval_metrics(
- results=results,
- gt_seg_maps=gt_seg_maps,
- num_classes=num_classes,
- ignore_index=ignore_index,
- metrics=['mDice'],
- nan_to_num=nan_to_num,
- label_map=label_map,
- reduce_zero_label=reduce_zero_label)
- return dice_result
-
-
-def mean_fscore(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- nan_to_num=None,
- label_map=dict(),
- reduce_zero_label=False,
- beta=1):
- """Calculate Mean Intersection and Union (mIoU)
-
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- nan_to_num (int, optional): If specified, NaN values will be replaced
- by the numbers defined by the user. Default: None.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Whether ignore zero label. Default: False.
- beta (int): Determines the weight of recall in the combined score.
- Default: False.
-
-
- Returns:
- dict[str, float | ndarray]: Default metrics.
- float: Overall accuracy on all images.
- ndarray: Per category recall, shape (num_classes, ).
- ndarray: Per category precision, shape (num_classes, ).
- ndarray: Per category f-score, shape (num_classes, ).
- """
- fscore_result = eval_metrics(
- results=results,
- gt_seg_maps=gt_seg_maps,
- num_classes=num_classes,
- ignore_index=ignore_index,
- metrics=['mFscore'],
- nan_to_num=nan_to_num,
- label_map=label_map,
- reduce_zero_label=reduce_zero_label,
- beta=beta)
- return fscore_result
-
-
-def eval_metrics(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- metrics=['mIoU'],
- nan_to_num=None,
- label_map=dict(),
- reduce_zero_label=False,
- beta=1):
- """Calculate evaluation metrics
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- metrics (list[str] | str): Metrics to be evaluated, 'mIoU' and 'mDice'.
- nan_to_num (int, optional): If specified, NaN values will be replaced
- by the numbers defined by the user. Default: None.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Whether ignore zero label. Default: False.
- Returns:
- float: Overall accuracy on all images.
- ndarray: Per category accuracy, shape (num_classes, ).
- ndarray: Per category evaluation metrics, shape (num_classes, ).
- """
- if isinstance(metrics, str):
- metrics = [metrics]
- allowed_metrics = ['mIoU', 'mDice', 'mFscore']
- if not set(metrics).issubset(set(allowed_metrics)):
- raise KeyError('metrics {} is not supported'.format(metrics))
-
- total_area_intersect, total_area_union, total_area_pred_label, \
- total_area_label = total_intersect_and_union(
- results, gt_seg_maps, num_classes, ignore_index, label_map,
- reduce_zero_label)
- all_acc = total_area_intersect.sum() / total_area_label.sum()
- ret_metrics = OrderedDict({'aAcc': all_acc})
- for metric in metrics:
- if metric == 'mIoU':
- iou = total_area_intersect / total_area_union
- acc = total_area_intersect / total_area_label
- ret_metrics['IoU'] = iou
- ret_metrics['Acc'] = acc
- elif metric == 'mDice':
- dice = 2 * total_area_intersect / (
- total_area_pred_label + total_area_label)
- acc = total_area_intersect / total_area_label
- ret_metrics['Dice'] = dice
- ret_metrics['Acc'] = acc
- elif metric == 'mFscore':
- precision = total_area_intersect / total_area_pred_label
- recall = total_area_intersect / total_area_label
- f_value = torch.tensor(
- [f_score(x[0], x[1], beta) for x in zip(precision, recall)])
- ret_metrics['Fscore'] = f_value
- ret_metrics['Precision'] = precision
- ret_metrics['Recall'] = recall
-
- ret_metrics = {
- metric: value.numpy()
- for metric, value in ret_metrics.items()
- }
- if nan_to_num is not None:
- ret_metrics = OrderedDict({
- metric: np.nan_to_num(metric_value, nan=nan_to_num)
- for metric, metric_value in ret_metrics.items()
- })
- return ret_metrics
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/normalbae/models/submodules/efficientnet_repo/caffe2_benchmark.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/normalbae/models/submodules/efficientnet_repo/caffe2_benchmark.py
deleted file mode 100644
index 93f28a1e63d9f7287ca02997c7991fe66dd0aeb9..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/normalbae/models/submodules/efficientnet_repo/caffe2_benchmark.py
+++ /dev/null
@@ -1,65 +0,0 @@
-""" Caffe2 validation script
-
-This script runs Caffe2 benchmark on exported ONNX model.
-It is a useful tool for reporting model FLOPS.
-
-Copyright 2020 Ross Wightman
-"""
-import argparse
-from caffe2.python import core, workspace, model_helper
-from caffe2.proto import caffe2_pb2
-
-
-parser = argparse.ArgumentParser(description='Caffe2 Model Benchmark')
-parser.add_argument('--c2-prefix', default='', type=str, metavar='NAME',
- help='caffe2 model pb name prefix')
-parser.add_argument('--c2-init', default='', type=str, metavar='PATH',
- help='caffe2 model init .pb')
-parser.add_argument('--c2-predict', default='', type=str, metavar='PATH',
- help='caffe2 model predict .pb')
-parser.add_argument('-b', '--batch-size', default=1, type=int,
- metavar='N', help='mini-batch size (default: 1)')
-parser.add_argument('--img-size', default=224, type=int,
- metavar='N', help='Input image dimension, uses model default if empty')
-
-
-def main():
- args = parser.parse_args()
- args.gpu_id = 0
- if args.c2_prefix:
- args.c2_init = args.c2_prefix + '.init.pb'
- args.c2_predict = args.c2_prefix + '.predict.pb'
-
- model = model_helper.ModelHelper(name="le_net", init_params=False)
-
- # Bring in the init net from init_net.pb
- init_net_proto = caffe2_pb2.NetDef()
- with open(args.c2_init, "rb") as f:
- init_net_proto.ParseFromString(f.read())
- model.param_init_net = core.Net(init_net_proto)
-
- # bring in the predict net from predict_net.pb
- predict_net_proto = caffe2_pb2.NetDef()
- with open(args.c2_predict, "rb") as f:
- predict_net_proto.ParseFromString(f.read())
- model.net = core.Net(predict_net_proto)
-
- # CUDA performance not impressive
- #device_opts = core.DeviceOption(caffe2_pb2.PROTO_CUDA, args.gpu_id)
- #model.net.RunAllOnGPU(gpu_id=args.gpu_id, use_cudnn=True)
- #model.param_init_net.RunAllOnGPU(gpu_id=args.gpu_id, use_cudnn=True)
-
- input_blob = model.net.external_inputs[0]
- model.param_init_net.GaussianFill(
- [],
- input_blob.GetUnscopedName(),
- shape=(args.batch_size, 3, args.img_size, args.img_size),
- mean=0.0,
- std=1.0)
- workspace.RunNetOnce(model.param_init_net)
- workspace.CreateNet(model.net, overwrite=True)
- workspace.BenchmarkNet(model.net.Proto().name, 5, 20, True)
-
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/roi_heads/__init__.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/roi_heads/__init__.py
deleted file mode 100644
index d13e9c57235b982f3e0645bc316de2b75755dfda..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/roi_heads/__init__.py
+++ /dev/null
@@ -1,29 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from .box_head import ROI_BOX_HEAD_REGISTRY, build_box_head, FastRCNNConvFCHead
-from .keypoint_head import (
- ROI_KEYPOINT_HEAD_REGISTRY,
- build_keypoint_head,
- BaseKeypointRCNNHead,
- KRCNNConvDeconvUpsampleHead,
-)
-from .mask_head import (
- ROI_MASK_HEAD_REGISTRY,
- build_mask_head,
- BaseMaskRCNNHead,
- MaskRCNNConvUpsampleHead,
-)
-from .roi_heads import (
- ROI_HEADS_REGISTRY,
- ROIHeads,
- Res5ROIHeads,
- StandardROIHeads,
- build_roi_heads,
- select_foreground_proposals,
-)
-from .cascade_rcnn import CascadeROIHeads
-from .rotated_fast_rcnn import RROIHeads
-from .fast_rcnn import FastRCNNOutputLayers
-
-from . import cascade_rcnn # isort:skip
-
-__all__ = list(globals().keys())
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/oneformer/modeling/transformer_decoder/text_transformer.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/oneformer/modeling/transformer_decoder/text_transformer.py
deleted file mode 100644
index d0b7292018ecfbf4111c0da9c90444d0e1e41cb6..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/oneformer/modeling/transformer_decoder/text_transformer.py
+++ /dev/null
@@ -1,257 +0,0 @@
-# -------------------------------------------------------------------------
-# MIT License
-#
-# Copyright (c) 2021 OpenAI
-#
-# Permission is hereby granted, free of charge, to any person obtaining a copy
-# of this software and associated documentation files (the "Software"), to deal
-# in the Software without restriction, including without limitation the rights
-# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-# copies of the Software, and to permit persons to whom the Software is
-# furnished to do so, subject to the following conditions:
-#
-# The above copyright notice and this permission notice shall be included in all
-# copies or substantial portions of the Software.
-#
-# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-# SOFTWARE.
-#
-# -------------------------------------------------------------------------
-
-import torch
-import torch.utils.checkpoint as checkpoint
-from torch import nn
-from collections import OrderedDict
-from timm.models.layers import trunc_normal_
-
-class Attention(nn.Module):
- def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
- super().__init__()
- self.num_heads = num_heads
- head_dim = dim // num_heads
- # NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
- self.scale = qk_scale or head_dim ** -0.5
-
- self.q_proj = nn.Linear(dim, dim, bias=qkv_bias)
- self.k_proj = nn.Linear(dim, dim, bias=qkv_bias)
- self.v_proj = nn.Linear(dim, dim, bias=qkv_bias)
-
-
- self.attn_drop = nn.Dropout(attn_drop)
- self.proj = nn.Linear(dim, dim)
- self.proj_drop = nn.Dropout(proj_drop)
-
- def forward(self, q, k, v):
- B, N, C = q.shape
- assert k.shape == v.shape
- B, M, C = k.shape
- q = self.q_proj(q).reshape(B, N, self.num_heads, C // self.num_heads)
- k = self.k_proj(k).reshape(B, M, self.num_heads, C // self.num_heads)
- v = self.v_proj(v).reshape(B, M, self.num_heads, C // self.num_heads)
-
- attn = torch.einsum('bnkc,bmkc->bknm', q, k) * self.scale
-
- attn = attn.softmax(dim=-1)
-
- x = torch.einsum('bknm,bmkc->bnkc', attn, v).reshape(B, N, C)
-
- x = self.proj(x)
- x = self.proj_drop(x)
- return x
-
-class TransformerDecoderLayer(nn.Module):
- def __init__(
- self,
- d_model,
- nhead,
- dropout=0.1,
- ):
- super().__init__()
- self.self_attn = Attention(d_model, nhead, proj_drop=dropout)
- self.cross_attn = Attention(d_model, nhead, proj_drop=dropout)
-
- self.norm1 = nn.LayerNorm(d_model)
- self.norm2 = nn.LayerNorm(d_model)
- self.norm3 = nn.LayerNorm(d_model)
- self.dropout = nn.Dropout(dropout)
-
- self.mlp = nn.Sequential(
- nn.Linear(d_model, d_model * 4),
- nn.GELU(),
- nn.Dropout(dropout),
- nn.Linear(d_model * 4, d_model)
- )
-
- def forward(self, x, mem):
- q = k = v = self.norm1(x)
- x = x + self.self_attn(q, k, v)
- q = self.norm2(x)
- x = x + self.cross_attn(q, mem, mem)
- x = x + self.dropout(self.mlp(self.norm3(x)))
- return x
-
-
-class ContextDecoder(nn.Module):
- def __init__(self,
- transformer_width=256,
- transformer_heads=4,
- transformer_layers=6,
- visual_dim=1024,
- dropout=0.1,
- **kwargs):
- super().__init__()
-
- self.memory_proj = nn.Sequential(
- nn.LayerNorm(visual_dim),
- nn.Linear(visual_dim, transformer_width),
- nn.LayerNorm(transformer_width),
- )
-
- self.text_proj = nn.Sequential(
- nn.LayerNorm(visual_dim),
- nn.Linear(visual_dim, transformer_width),
- )
-
- self.decoder = nn.ModuleList([
- TransformerDecoderLayer(transformer_width, transformer_heads, dropout) for _ in range(transformer_layers)
- ])
-
- self.out_proj = nn.Sequential(
- nn.LayerNorm(transformer_width),
- nn.Linear(transformer_width, visual_dim)
- )
-
- self.apply(self._init_weights)
-
- def _init_weights(self, m):
- if isinstance(m, nn.Linear):
- trunc_normal_(m.weight, std=.02)
- if isinstance(m, nn.Linear) and m.bias is not None:
- nn.init.constant_(m.bias, 0)
- elif isinstance(m, nn.LayerNorm):
- nn.init.constant_(m.bias, 0)
- nn.init.constant_(m.weight, 1.0)
-
-
- def forward(self, text, visual):
- B, N, C = visual.shape
- visual = self.memory_proj(visual)
- x = self.text_proj(text)
-
- for layer in self.decoder:
- x = layer(x, visual)
-
- return self.out_proj(x)
-
-
-class QuickGELU(nn.Module):
-
- def forward(self, x: torch.Tensor):
- return x * torch.sigmoid(1.702 * x)
-
-
-class ResidualAttentionBlock(nn.Module):
-
- def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
- super().__init__()
-
- self.attn = nn.MultiheadAttention(d_model, n_head)
- self.ln_1 = nn.LayerNorm(d_model)
- self.mlp = nn.Sequential(
- OrderedDict([('c_fc', nn.Linear(d_model, d_model * 4)), ('gelu', QuickGELU()),
- ('c_proj', nn.Linear(d_model * 4, d_model))]))
- self.ln_2 = nn.LayerNorm(d_model)
- self.attn_mask = attn_mask
-
- def attention(self, x: torch.Tensor, key_padding_mask: torch.Tensor):
- self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
- return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask, key_padding_mask=key_padding_mask)[0]
-
- def forward(self, x: torch.Tensor, key_padding_mask=None):
- x = x + self.attention(self.ln_1(x), key_padding_mask=key_padding_mask)
- x = x + self.mlp(self.ln_2(x))
- return x
-
-class Transformer(nn.Module):
-
- def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None, use_checkpoint=False):
- super().__init__()
- self.width = width
- self.layers = layers
- self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
- proj_std = (self.width**-0.5) * ((2 * self.layers)**-0.5)
- attn_std = self.width**-0.5
- fc_std = (2 * self.width)**-0.5
- for block in self.resblocks:
- nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
- nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
- nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
- nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
-
- self.use_checkpoint = use_checkpoint
-
- def forward(self, x: torch.Tensor):
- for resblock in self.resblocks:
- if self.use_checkpoint:
- x = checkpoint.checkpoint(resblock, x)
- else:
- x = resblock(x)
- return x
-
-
-class TextTransformer(nn.Module):
-
- def __init__(
- self,
- context_length: int,
- width: int,
- layers: int,
- vocab_size,
- use_checkpoint=False,
- ):
-
- super().__init__()
- heads = width // 64
- self.context_length = context_length
- self.width = width
- self.transformer = Transformer(
- width=width,
- layers=layers,
- heads=heads,
- attn_mask=self.build_attention_mask(),
- use_checkpoint=use_checkpoint)
-
- self.positional_embedding = nn.Parameter(torch.empty(self.context_length, width))
- self.ln_final = nn.LayerNorm(width)
- self.token_embedding = nn.Embedding(vocab_size, width)
- nn.init.normal_(self.token_embedding.weight, std=0.02)
-
- # initialization
- nn.init.normal_(self.positional_embedding, std=0.01)
-
- def build_attention_mask(self):
- # lazily create causal attention mask, with full attention between the vision tokens
- # pytorch uses additive attention mask; fill with -inf
- mask = torch.empty(self.context_length, self.context_length)
- mask.fill_(float('-inf'))
- mask.triu_(1) # zero out the lower diagonal
- return mask
-
- def forward(self, text):
- x = self.token_embedding(text)
- x = x + self.positional_embedding
- x = x.permute(1, 0, 2) # NLD -> LND
- x = self.transformer(x)
- x = x.permute(1, 0, 2) # LND -> NLD
- x = self.ln_final(x)
-
- # x.shape = [batch_size, n_ctx, transformer.width]
- # take features from the eot embedding (eot_token is the highest number in each sequence)
- x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)]
-
- return x
\ No newline at end of file
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/configs/_base_/models/pointrend_r50.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/configs/_base_/models/pointrend_r50.py
deleted file mode 100644
index 9d323dbf9466d41e0800aa57ef84045f3d874bdf..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/configs/_base_/models/pointrend_r50.py
+++ /dev/null
@@ -1,56 +0,0 @@
-# model settings
-norm_cfg = dict(type='SyncBN', requires_grad=True)
-model = dict(
- type='CascadeEncoderDecoder',
- num_stages=2,
- pretrained='open-mmlab://resnet50_v1c',
- backbone=dict(
- type='ResNetV1c',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- dilations=(1, 1, 1, 1),
- strides=(1, 2, 2, 2),
- norm_cfg=norm_cfg,
- norm_eval=False,
- style='pytorch',
- contract_dilation=True),
- neck=dict(
- type='FPN',
- in_channels=[256, 512, 1024, 2048],
- out_channels=256,
- num_outs=4),
- decode_head=[
- dict(
- type='FPNHead',
- in_channels=[256, 256, 256, 256],
- in_index=[0, 1, 2, 3],
- feature_strides=[4, 8, 16, 32],
- channels=128,
- dropout_ratio=-1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
- dict(
- type='PointHead',
- in_channels=[256],
- in_index=[0],
- channels=256,
- num_fcs=3,
- coarse_pred_each_layer=True,
- dropout_ratio=-1,
- num_classes=19,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
- ],
- # model training and testing settings
- train_cfg=dict(
- num_points=2048, oversample_ratio=3, importance_sample_ratio=0.75),
- test_cfg=dict(
- mode='whole',
- subdivision_steps=2,
- subdivision_num_points=8196,
- scale_factor=2))
diff --git a/spaces/cownclown/Image-and-3D-Model-Creator/PIFu/lib/model/ResBlkPIFuNet.py b/spaces/cownclown/Image-and-3D-Model-Creator/PIFu/lib/model/ResBlkPIFuNet.py
deleted file mode 100644
index 26848408569fd3903a338e023aefb832f942f0e3..0000000000000000000000000000000000000000
--- a/spaces/cownclown/Image-and-3D-Model-Creator/PIFu/lib/model/ResBlkPIFuNet.py
+++ /dev/null
@@ -1,201 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from .BasePIFuNet import BasePIFuNet
-import functools
-from .SurfaceClassifier import SurfaceClassifier
-from .DepthNormalizer import DepthNormalizer
-from ..net_util import *
-
-
-class ResBlkPIFuNet(BasePIFuNet):
- def __init__(self, opt,
- projection_mode='orthogonal'):
- if opt.color_loss_type == 'l1':
- error_term = nn.L1Loss()
- elif opt.color_loss_type == 'mse':
- error_term = nn.MSELoss()
-
- super(ResBlkPIFuNet, self).__init__(
- projection_mode=projection_mode,
- error_term=error_term)
-
- self.name = 'respifu'
- self.opt = opt
-
- norm_type = get_norm_layer(norm_type=opt.norm_color)
- self.image_filter = ResnetFilter(opt, norm_layer=norm_type)
-
- self.surface_classifier = SurfaceClassifier(
- filter_channels=self.opt.mlp_dim_color,
- num_views=self.opt.num_views,
- no_residual=self.opt.no_residual,
- last_op=nn.Tanh())
-
- self.normalizer = DepthNormalizer(opt)
-
- init_net(self)
-
- def filter(self, images):
- '''
- Filter the input images
- store all intermediate features.
- :param images: [B, C, H, W] input images
- '''
- self.im_feat = self.image_filter(images)
-
- def attach(self, im_feat):
- self.im_feat = torch.cat([im_feat, self.im_feat], 1)
-
- def query(self, points, calibs, transforms=None, labels=None):
- '''
- Given 3D points, query the network predictions for each point.
- Image features should be pre-computed before this call.
- store all intermediate features.
- query() function may behave differently during training/testing.
- :param points: [B, 3, N] world space coordinates of points
- :param calibs: [B, 3, 4] calibration matrices for each image
- :param transforms: Optional [B, 2, 3] image space coordinate transforms
- :param labels: Optional [B, Res, N] gt labeling
- :return: [B, Res, N] predictions for each point
- '''
- if labels is not None:
- self.labels = labels
-
- xyz = self.projection(points, calibs, transforms)
- xy = xyz[:, :2, :]
- z = xyz[:, 2:3, :]
-
- z_feat = self.normalizer(z)
-
- # This is a list of [B, Feat_i, N] features
- point_local_feat_list = [self.index(self.im_feat, xy), z_feat]
- # [B, Feat_all, N]
- point_local_feat = torch.cat(point_local_feat_list, 1)
-
- self.preds = self.surface_classifier(point_local_feat)
-
- def forward(self, images, im_feat, points, calibs, transforms=None, labels=None):
- self.filter(images)
-
- self.attach(im_feat)
-
- self.query(points, calibs, transforms, labels)
-
- res = self.get_preds()
- error = self.get_error()
-
- return res, error
-
-class ResnetBlock(nn.Module):
- """Define a Resnet block"""
-
- def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias, last=False):
- """Initialize the Resnet block
- A resnet block is a conv block with skip connections
- We construct a conv block with build_conv_block function,
- and implement skip connections in function.
- Original Resnet paper: https://arxiv.org/pdf/1512.03385.pdf
- """
- super(ResnetBlock, self).__init__()
- self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias, last)
-
- def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias, last=False):
- """Construct a convolutional block.
- Parameters:
- dim (int) -- the number of channels in the conv layer.
- padding_type (str) -- the name of padding layer: reflect | replicate | zero
- norm_layer -- normalization layer
- use_dropout (bool) -- if use dropout layers.
- use_bias (bool) -- if the conv layer uses bias or not
- Returns a conv block (with a conv layer, a normalization layer, and a non-linearity layer (ReLU))
- """
- conv_block = []
- p = 0
- if padding_type == 'reflect':
- conv_block += [nn.ReflectionPad2d(1)]
- elif padding_type == 'replicate':
- conv_block += [nn.ReplicationPad2d(1)]
- elif padding_type == 'zero':
- p = 1
- else:
- raise NotImplementedError('padding [%s] is not implemented' % padding_type)
-
- conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
- if use_dropout:
- conv_block += [nn.Dropout(0.5)]
-
- p = 0
- if padding_type == 'reflect':
- conv_block += [nn.ReflectionPad2d(1)]
- elif padding_type == 'replicate':
- conv_block += [nn.ReplicationPad2d(1)]
- elif padding_type == 'zero':
- p = 1
- else:
- raise NotImplementedError('padding [%s] is not implemented' % padding_type)
- if last:
- conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias)]
- else:
- conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
-
- return nn.Sequential(*conv_block)
-
- def forward(self, x):
- """Forward function (with skip connections)"""
- out = x + self.conv_block(x) # add skip connections
- return out
-
-
-class ResnetFilter(nn.Module):
- """Resnet-based generator that consists of Resnet blocks between a few downsampling/upsampling operations.
- We adapt Torch code and idea from Justin Johnson's neural style transfer project(https://github.com/jcjohnson/fast-neural-style)
- """
-
- def __init__(self, opt, input_nc=3, output_nc=256, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False,
- n_blocks=6, padding_type='reflect'):
- """Construct a Resnet-based generator
- Parameters:
- input_nc (int) -- the number of channels in input images
- output_nc (int) -- the number of channels in output images
- ngf (int) -- the number of filters in the last conv layer
- norm_layer -- normalization layer
- use_dropout (bool) -- if use dropout layers
- n_blocks (int) -- the number of ResNet blocks
- padding_type (str) -- the name of padding layer in conv layers: reflect | replicate | zero
- """
- assert (n_blocks >= 0)
- super(ResnetFilter, self).__init__()
- if type(norm_layer) == functools.partial:
- use_bias = norm_layer.func == nn.InstanceNorm2d
- else:
- use_bias = norm_layer == nn.InstanceNorm2d
-
- model = [nn.ReflectionPad2d(3),
- nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias),
- norm_layer(ngf),
- nn.ReLU(True)]
-
- n_downsampling = 2
- for i in range(n_downsampling): # add downsampling layers
- mult = 2 ** i
- model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, bias=use_bias),
- norm_layer(ngf * mult * 2),
- nn.ReLU(True)]
-
- mult = 2 ** n_downsampling
- for i in range(n_blocks): # add ResNet blocks
- if i == n_blocks - 1:
- model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer,
- use_dropout=use_dropout, use_bias=use_bias, last=True)]
- else:
- model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer,
- use_dropout=use_dropout, use_bias=use_bias)]
-
- if opt.use_tanh:
- model += [nn.Tanh()]
- self.model = nn.Sequential(*model)
-
- def forward(self, input):
- """Standard forward"""
- return self.model(input)
diff --git a/spaces/cxm1207/ChatBOT/utils.py b/spaces/cxm1207/ChatBOT/utils.py
deleted file mode 100644
index 396fbed8c71e96668bb5330e4771dd6d952d1f74..0000000000000000000000000000000000000000
--- a/spaces/cxm1207/ChatBOT/utils.py
+++ /dev/null
@@ -1,445 +0,0 @@
-# -*- coding:utf-8 -*-
-from __future__ import annotations
-from typing import TYPE_CHECKING, Any, Callable, Dict, List, Tuple, Type
-import logging
-import json
-import gradio as gr
-# import openai
-import os
-import traceback
-import requests
-# import markdown
-import csv
-import mdtex2html
-from pypinyin import lazy_pinyin
-from presets import *
-import tiktoken
-from tqdm import tqdm
-import colorama
-from duckduckgo_search import ddg
-import datetime
-
-# logging.basicConfig(level=logging.INFO, format="%(asctime)s [%(levelname)s] [%(filename)s:%(lineno)d] %(message)s")
-
-if TYPE_CHECKING:
- from typing import TypedDict
-
- class DataframeData(TypedDict):
- headers: List[str]
- data: List[List[str | int | bool]]
-
-initial_prompt = "You are a helpful assistant."
-API_URL = "https://api.openai.com/v1/chat/completions"
-HISTORY_DIR = "history"
-TEMPLATES_DIR = "templates"
-
-def postprocess(
- self, y: List[Tuple[str | None, str | None]]
- ) -> List[Tuple[str | None, str | None]]:
- """
- Parameters:
- y: List of tuples representing the message and response pairs. Each message and response should be a string, which may be in Markdown format.
- Returns:
- List of tuples representing the message and response. Each message and response will be a string of HTML.
- """
- if y is None:
- return []
- for i, (message, response) in enumerate(y):
- y[i] = (
- # None if message is None else markdown.markdown(message),
- # None if response is None else markdown.markdown(response),
- None if message is None else message,
- None if response is None else mdtex2html.convert(response),
- )
- return y
-
-def count_token(message):
- encoding = tiktoken.get_encoding("cl100k_base")
- input_str = f"role: {message['role']}, content: {message['content']}"
- length = len(encoding.encode(input_str))
- return length
-
-def parse_text(text):
- lines = text.split("\n")
- lines = [line for line in lines if line != ""]
- count = 0
- for i, line in enumerate(lines):
- if "```" in line:
- count += 1
- items = line.split('`')
- if count % 2 == 1:
- lines[i] = f'
'
- else:
- lines[i] = f'
'
- else:
- if i > 0:
- if count % 2 == 1:
- line = line.replace("`", "\`")
- line = line.replace("<", "<")
- line = line.replace(">", ">")
- line = line.replace(" ", " ")
- line = line.replace("*", "*")
- line = line.replace("_", "_")
- line = line.replace("-", "-")
- line = line.replace(".", ".")
- line = line.replace("!", "!")
- line = line.replace("(", "(")
- line = line.replace(")", ")")
- line = line.replace("$", "$")
- lines[i] = " "+line
- text = "".join(lines)
- return text
-
-def construct_text(role, text):
- return {"role": role, "content": text}
-
-def construct_user(text):
- return construct_text("user", text)
-
-def construct_system(text):
- return construct_text("system", text)
-
-def construct_assistant(text):
- return construct_text("assistant", text)
-
-def construct_token_message(token, stream=False):
- return f"Token 计数: {token}"
-
-def get_response(openai_api_key, system_prompt, history, temperature, top_p, stream, selected_model):
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {openai_api_key}"
- }
-
- history = [construct_system(system_prompt), *history]
-
- payload = {
- "model": selected_model,
- "messages": history, # [{"role": "user", "content": f"{inputs}"}],
- "temperature": temperature, # 1.0,
- "top_p": top_p, # 1.0,
- "n": 1,
- "stream": stream,
- "presence_penalty": 0,
- "frequency_penalty": 0,
- }
- if stream:
- timeout = timeout_streaming
- else:
- timeout = timeout_all
- response = requests.post(API_URL, headers=headers, json=payload, stream=True, timeout=timeout)
- return response
-
-def stream_predict(openai_api_key, system_prompt, history, inputs, chatbot, all_token_counts, top_p, temperature, selected_model):
- def get_return_value():
- return chatbot, history, status_text, all_token_counts
-
- logging.info("实时回答模式")
- partial_words = ""
- counter = 0
- status_text = "开始实时传输回答……"
- history.append(construct_user(inputs))
- history.append(construct_assistant(""))
- chatbot.append((parse_text(inputs), ""))
- user_token_count = 0
- if len(all_token_counts) == 0:
- system_prompt_token_count = count_token(construct_system(system_prompt))
- user_token_count = count_token(construct_user(inputs)) + system_prompt_token_count
- else:
- user_token_count = count_token(construct_user(inputs))
- all_token_counts.append(user_token_count)
- logging.info(f"输入token计数: {user_token_count}")
- yield get_return_value()
- try:
- response = get_response(openai_api_key, system_prompt, history, temperature, top_p, True, selected_model)
- except requests.exceptions.ConnectTimeout:
- status_text = standard_error_msg + connection_timeout_prompt + error_retrieve_prompt
- yield get_return_value()
- return
- except requests.exceptions.ReadTimeout:
- status_text = standard_error_msg + read_timeout_prompt + error_retrieve_prompt
- yield get_return_value()
- return
-
- yield get_return_value()
- error_json_str = ""
-
- for chunk in tqdm(response.iter_lines()):
- if counter == 0:
- counter += 1
- continue
- counter += 1
- # check whether each line is non-empty
- if chunk:
- chunk = chunk.decode()
- chunklength = len(chunk)
- try:
- chunk = json.loads(chunk[6:])
- except json.JSONDecodeError:
- logging.info(chunk)
- error_json_str += chunk
- status_text = f"JSON解析错误。请重置对话。收到的内容: {error_json_str}"
- yield get_return_value()
- continue
- # decode each line as response data is in bytes
- if chunklength > 6 and "delta" in chunk['choices'][0]:
- finish_reason = chunk['choices'][0]['finish_reason']
- status_text = construct_token_message(sum(all_token_counts), stream=True)
- if finish_reason == "stop":
- yield get_return_value()
- break
- try:
- partial_words = partial_words + chunk['choices'][0]["delta"]["content"]
- except KeyError:
- status_text = standard_error_msg + "API回复中找不到内容。很可能是Token计数达到上限了。请重置对话。当前Token计数: " + str(sum(all_token_counts))
- yield get_return_value()
- break
- history[-1] = construct_assistant(partial_words)
- chatbot[-1] = (parse_text(inputs), parse_text(partial_words))
- all_token_counts[-1] += 1
- yield get_return_value()
-
-
-def predict_all(openai_api_key, system_prompt, history, inputs, chatbot, all_token_counts, top_p, temperature, selected_model):
- logging.info("一次性回答模式")
- history.append(construct_user(inputs))
- history.append(construct_assistant(""))
- chatbot.append((parse_text(inputs), ""))
- all_token_counts.append(count_token(construct_user(inputs)))
- try:
- response = get_response(openai_api_key, system_prompt, history, temperature, top_p, False, selected_model)
- except requests.exceptions.ConnectTimeout:
- status_text = standard_error_msg + connection_timeout_prompt + error_retrieve_prompt
- return chatbot, history, status_text, all_token_counts
- except requests.exceptions.ProxyError:
- status_text = standard_error_msg + proxy_error_prompt + error_retrieve_prompt
- return chatbot, history, status_text, all_token_counts
- except requests.exceptions.SSLError:
- status_text = standard_error_msg + ssl_error_prompt + error_retrieve_prompt
- return chatbot, history, status_text, all_token_counts
- response = json.loads(response.text)
- content = response["choices"][0]["message"]["content"]
- history[-1] = construct_assistant(content)
- chatbot[-1] = (parse_text(inputs), parse_text(content))
- total_token_count = response["usage"]["total_tokens"]
- all_token_counts[-1] = total_token_count - sum(all_token_counts)
- status_text = construct_token_message(total_token_count)
- return chatbot, history, status_text, all_token_counts
-
-
-def predict(openai_api_key, system_prompt, history, inputs, chatbot, all_token_counts, top_p, temperature, stream=False, selected_model = MODELS[0], use_websearch_checkbox = False, should_check_token_count = True): # repetition_penalty, top_k
- logging.info("输入为:" +colorama.Fore.BLUE + f"{inputs}" + colorama.Style.RESET_ALL)
- if use_websearch_checkbox:
- results = ddg(inputs, max_results=3)
- web_results = []
- for idx, result in enumerate(results):
- logging.info(f"搜索结果{idx + 1}:{result}")
- web_results.append(f'[{idx+1}]"{result["body"]}"\nURL: {result["href"]}')
- web_results = "\n\n".join(web_results)
- today = datetime.datetime.today().strftime("%Y-%m-%d")
- inputs = websearch_prompt.replace("{current_date}", today).replace("{query}", inputs).replace("{web_results}", web_results)
- if len(openai_api_key) != 51:
- status_text = standard_error_msg + no_apikey_msg
- logging.info(status_text)
- chatbot.append((parse_text(inputs), ""))
- if len(history) == 0:
- history.append(construct_user(inputs))
- history.append("")
- all_token_counts.append(0)
- else:
- history[-2] = construct_user(inputs)
- yield chatbot, history, status_text, all_token_counts
- return
- if stream:
- yield chatbot, history, "开始生成回答……", all_token_counts
- if stream:
- logging.info("使用流式传输")
- iter = stream_predict(openai_api_key, system_prompt, history, inputs, chatbot, all_token_counts, top_p, temperature, selected_model)
- for chatbot, history, status_text, all_token_counts in iter:
- yield chatbot, history, status_text, all_token_counts
- else:
- logging.info("不使用流式传输")
- chatbot, history, status_text, all_token_counts = predict_all(openai_api_key, system_prompt, history, inputs, chatbot, all_token_counts, top_p, temperature, selected_model)
- yield chatbot, history, status_text, all_token_counts
- logging.info(f"传输完毕。当前token计数为{all_token_counts}")
- if len(history) > 1 and history[-1]['content'] != inputs:
- logging.info("回答为:" +colorama.Fore.BLUE + f"{history[-1]['content']}" + colorama.Style.RESET_ALL)
- if stream:
- max_token = max_token_streaming
- else:
- max_token = max_token_all
- if sum(all_token_counts) > max_token and should_check_token_count:
- status_text = f"精简token中{all_token_counts}/{max_token}"
- logging.info(status_text)
- yield chatbot, history, status_text, all_token_counts
- iter = reduce_token_size(openai_api_key, system_prompt, history, chatbot, all_token_counts, top_p, temperature, stream=False, selected_model=selected_model, hidden=True)
- for chatbot, history, status_text, all_token_counts in iter:
- status_text = f"Token 达到上限,已自动降低Token计数至 {status_text}"
- yield chatbot, history, status_text, all_token_counts
-
-
-def retry(openai_api_key, system_prompt, history, chatbot, token_count, top_p, temperature, stream=False, selected_model = MODELS[0]):
- logging.info("重试中……")
- if len(history) == 0:
- yield chatbot, history, f"{standard_error_msg}上下文是空的", token_count
- return
- history.pop()
- inputs = history.pop()["content"]
- token_count.pop()
- iter = predict(openai_api_key, system_prompt, history, inputs, chatbot, token_count, top_p, temperature, stream=stream, selected_model=selected_model)
- logging.info("重试完毕")
- for x in iter:
- yield x
-
-
-def reduce_token_size(openai_api_key, system_prompt, history, chatbot, token_count, top_p, temperature, stream=False, selected_model = MODELS[0], hidden=False):
- logging.info("开始减少token数量……")
- iter = predict(openai_api_key, system_prompt, history, summarize_prompt, chatbot, token_count, top_p, temperature, stream=stream, selected_model = selected_model, should_check_token_count=False)
- logging.info(f"chatbot: {chatbot}")
- for chatbot, history, status_text, previous_token_count in iter:
- history = history[-2:]
- token_count = previous_token_count[-1:]
- if hidden:
- chatbot.pop()
- yield chatbot, history, construct_token_message(sum(token_count), stream=stream), token_count
- logging.info("减少token数量完毕")
-
-
-def delete_last_conversation(chatbot, history, previous_token_count):
- if len(chatbot) > 0 and standard_error_msg in chatbot[-1][1]:
- logging.info("由于包含报错信息,只删除chatbot记录")
- chatbot.pop()
- return chatbot, history
- if len(history) > 0:
- logging.info("删除了一组对话历史")
- history.pop()
- history.pop()
- if len(chatbot) > 0:
- logging.info("删除了一组chatbot对话")
- chatbot.pop()
- if len(previous_token_count) > 0:
- logging.info("删除了一组对话的token计数记录")
- previous_token_count.pop()
- return chatbot, history, previous_token_count, construct_token_message(sum(previous_token_count))
-
-
-def save_file(filename, system, history, chatbot):
- logging.info("保存对话历史中……")
- os.makedirs(HISTORY_DIR, exist_ok=True)
- if filename.endswith(".json"):
- json_s = {"system": system, "history": history, "chatbot": chatbot}
- print(json_s)
- with open(os.path.join(HISTORY_DIR, filename), "w") as f:
- json.dump(json_s, f)
- elif filename.endswith(".md"):
- md_s = f"system: \n- {system} \n"
- for data in history:
- md_s += f"\n{data['role']}: \n- {data['content']} \n"
- with open(os.path.join(HISTORY_DIR, filename), "w", encoding="utf8") as f:
- f.write(md_s)
- logging.info("保存对话历史完毕")
- return os.path.join(HISTORY_DIR, filename)
-
-def save_chat_history(filename, system, history, chatbot):
- if filename == "":
- return
- if not filename.endswith(".json"):
- filename += ".json"
- return save_file(filename, system, history, chatbot)
-
-def export_markdown(filename, system, history, chatbot):
- if filename == "":
- return
- if not filename.endswith(".md"):
- filename += ".md"
- return save_file(filename, system, history, chatbot)
-
-
-def load_chat_history(filename, system, history, chatbot):
- logging.info("加载对话历史中……")
- if type(filename) != str:
- filename = filename.name
- try:
- with open(os.path.join(HISTORY_DIR, filename), "r") as f:
- json_s = json.load(f)
- try:
- if type(json_s["history"][0]) == str:
- logging.info("历史记录格式为旧版,正在转换……")
- new_history = []
- for index, item in enumerate(json_s["history"]):
- if index % 2 == 0:
- new_history.append(construct_user(item))
- else:
- new_history.append(construct_assistant(item))
- json_s["history"] = new_history
- logging.info(new_history)
- except:
- # 没有对话历史
- pass
- logging.info("加载对话历史完毕")
- return filename, json_s["system"], json_s["history"], json_s["chatbot"]
- except FileNotFoundError:
- logging.info("没有找到对话历史文件,不执行任何操作")
- return filename, system, history, chatbot
-
-def sorted_by_pinyin(list):
- return sorted(list, key=lambda char: lazy_pinyin(char)[0][0])
-
-def get_file_names(dir, plain=False, filetypes=[".json"]):
- logging.info(f"获取文件名列表,目录为{dir},文件类型为{filetypes},是否为纯文本列表{plain}")
- files = []
- try:
- for type in filetypes:
- files += [f for f in os.listdir(dir) if f.endswith(type)]
- except FileNotFoundError:
- files = []
- files = sorted_by_pinyin(files)
- if files == []:
- files = [""]
- if plain:
- return files
- else:
- return gr.Dropdown.update(choices=files)
-
-def get_history_names(plain=False):
- logging.info("获取历史记录文件名列表")
- return get_file_names(HISTORY_DIR, plain)
-
-def load_template(filename, mode=0):
- logging.info(f"加载模板文件{filename},模式为{mode}(0为返回字典和下拉菜单,1为返回下拉菜单,2为返回字典)")
- lines = []
- logging.info("Loading template...")
- if filename.endswith(".json"):
- with open(os.path.join(TEMPLATES_DIR, filename), "r", encoding="utf8") as f:
- lines = json.load(f)
- lines = [[i["act"], i["prompt"]] for i in lines]
- else:
- with open(os.path.join(TEMPLATES_DIR, filename), "r", encoding="utf8") as csvfile:
- reader = csv.reader(csvfile)
- lines = list(reader)
- lines = lines[1:]
- if mode == 1:
- return sorted_by_pinyin([row[0] for row in lines])
- elif mode == 2:
- return {row[0]:row[1] for row in lines}
- else:
- choices = sorted_by_pinyin([row[0] for row in lines])
- return {row[0]:row[1] for row in lines}, gr.Dropdown.update(choices=choices, value=choices[0])
-
-def get_template_names(plain=False):
- logging.info("获取模板文件名列表")
- return get_file_names(TEMPLATES_DIR, plain, filetypes=[".csv", "json"])
-
-def get_template_content(templates, selection, original_system_prompt):
- logging.info(f"应用模板中,选择为{selection},原始系统提示为{original_system_prompt}")
- try:
- return templates[selection]
- except:
- return original_system_prompt
-
-def reset_state():
- logging.info("重置状态")
- return [], [], [], construct_token_message(0)
-
-def reset_textbox():
- return gr.update(value='')
diff --git a/spaces/cymic/Talking_Head_Anime_3/tha3/nn/conv.py b/spaces/cymic/Talking_Head_Anime_3/tha3/nn/conv.py
deleted file mode 100644
index 0ad46c4c74383ac0ddb966f76768d6f9ab75e551..0000000000000000000000000000000000000000
--- a/spaces/cymic/Talking_Head_Anime_3/tha3/nn/conv.py
+++ /dev/null
@@ -1,189 +0,0 @@
-from typing import Optional, Union, Callable
-
-from torch.nn import Conv2d, Module, Sequential, ConvTranspose2d
-
-from tha3.module.module_factory import ModuleFactory
-from tha3.nn.nonlinearity_factory import resolve_nonlinearity_factory
-from tha3.nn.normalization import NormalizationLayerFactory
-from tha3.nn.util import wrap_conv_or_linear_module, BlockArgs
-
-
-def create_conv7(in_channels: int, out_channels: int,
- bias: bool = False,
- initialization_method: Union[str, Callable[[Module], Module]] = 'he',
- use_spectral_norm: bool = False) -> Module:
- return wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=7, stride=1, padding=3, bias=bias),
- initialization_method,
- use_spectral_norm)
-
-
-def create_conv7_from_block_args(in_channels: int,
- out_channels: int,
- bias: bool = False,
- block_args: Optional[BlockArgs] = None) -> Module:
- if block_args is None:
- block_args = BlockArgs()
- return create_conv7(
- in_channels, out_channels, bias,
- block_args.initialization_method,
- block_args.use_spectral_norm)
-
-
-def create_conv3(in_channels: int,
- out_channels: int,
- bias: bool = False,
- initialization_method: Union[str, Callable[[Module], Module]] = 'he',
- use_spectral_norm: bool = False) -> Module:
- return wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=bias),
- initialization_method,
- use_spectral_norm)
-
-
-def create_conv3_from_block_args(in_channels: int, out_channels: int,
- bias: bool = False,
- block_args: Optional[BlockArgs] = None):
- if block_args is None:
- block_args = BlockArgs()
- return create_conv3(in_channels, out_channels, bias,
- block_args.initialization_method,
- block_args.use_spectral_norm)
-
-
-def create_conv1(in_channels: int, out_channels: int,
- initialization_method: Union[str, Callable[[Module], Module]] = 'he',
- bias: bool = False,
- use_spectral_norm: bool = False) -> Module:
- return wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
- initialization_method,
- use_spectral_norm)
-
-
-def create_conv1_from_block_args(in_channels: int,
- out_channels: int,
- bias: bool = False,
- block_args: Optional[BlockArgs] = None) -> Module:
- if block_args is None:
- block_args = BlockArgs()
- return create_conv1(
- in_channels=in_channels,
- out_channels=out_channels,
- initialization_method=block_args.initialization_method,
- bias=bias,
- use_spectral_norm=block_args.use_spectral_norm)
-
-
-def create_conv7_block(in_channels: int, out_channels: int,
- initialization_method: Union[str, Callable[[Module], Module]] = 'he',
- nonlinearity_factory: Optional[ModuleFactory] = None,
- normalization_layer_factory: Optional[NormalizationLayerFactory] = None,
- use_spectral_norm: bool = False) -> Module:
- nonlinearity_factory = resolve_nonlinearity_factory(nonlinearity_factory)
- return Sequential(
- create_conv7(in_channels, out_channels,
- bias=False, initialization_method=initialization_method, use_spectral_norm=use_spectral_norm),
- NormalizationLayerFactory.resolve_2d(normalization_layer_factory).create(out_channels, affine=True),
- resolve_nonlinearity_factory(nonlinearity_factory).create())
-
-
-def create_conv7_block_from_block_args(
- in_channels: int, out_channels: int,
- block_args: Optional[BlockArgs] = None) -> Module:
- if block_args is None:
- block_args = BlockArgs()
- return create_conv7_block(in_channels, out_channels,
- block_args.initialization_method,
- block_args.nonlinearity_factory,
- block_args.normalization_layer_factory,
- block_args.use_spectral_norm)
-
-
-def create_conv3_block(in_channels: int, out_channels: int,
- initialization_method: Union[str, Callable[[Module], Module]] = 'he',
- nonlinearity_factory: Optional[ModuleFactory] = None,
- normalization_layer_factory: Optional[NormalizationLayerFactory] = None,
- use_spectral_norm: bool = False) -> Module:
- nonlinearity_factory = resolve_nonlinearity_factory(nonlinearity_factory)
- return Sequential(
- create_conv3(in_channels, out_channels,
- bias=False, initialization_method=initialization_method, use_spectral_norm=use_spectral_norm),
- NormalizationLayerFactory.resolve_2d(normalization_layer_factory).create(out_channels, affine=True),
- resolve_nonlinearity_factory(nonlinearity_factory).create())
-
-
-def create_conv3_block_from_block_args(
- in_channels: int, out_channels: int, block_args: Optional[BlockArgs] = None):
- if block_args is None:
- block_args = BlockArgs()
- return create_conv3_block(in_channels, out_channels,
- block_args.initialization_method,
- block_args.nonlinearity_factory,
- block_args.normalization_layer_factory,
- block_args.use_spectral_norm)
-
-
-def create_downsample_block(in_channels: int, out_channels: int,
- is_output_1x1: bool = False,
- initialization_method: Union[str, Callable[[Module], Module]] = 'he',
- nonlinearity_factory: Optional[ModuleFactory] = None,
- normalization_layer_factory: Optional[NormalizationLayerFactory] = None,
- use_spectral_norm: bool = False) -> Module:
- if is_output_1x1:
- return Sequential(
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
- initialization_method,
- use_spectral_norm),
- resolve_nonlinearity_factory(nonlinearity_factory).create())
- else:
- return Sequential(
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
- initialization_method,
- use_spectral_norm),
- NormalizationLayerFactory.resolve_2d(normalization_layer_factory).create(out_channels, affine=True),
- resolve_nonlinearity_factory(nonlinearity_factory).create())
-
-
-def create_downsample_block_from_block_args(in_channels: int, out_channels: int,
- is_output_1x1: bool = False,
- block_args: Optional[BlockArgs] = None):
- if block_args is None:
- block_args = BlockArgs()
- return create_downsample_block(
- in_channels, out_channels,
- is_output_1x1,
- block_args.initialization_method,
- block_args.nonlinearity_factory,
- block_args.normalization_layer_factory,
- block_args.use_spectral_norm)
-
-
-def create_upsample_block(in_channels: int,
- out_channels: int,
- initialization_method: Union[str, Callable[[Module], Module]] = 'he',
- nonlinearity_factory: Optional[ModuleFactory] = None,
- normalization_layer_factory: Optional[NormalizationLayerFactory] = None,
- use_spectral_norm: bool = False) -> Module:
- nonlinearity_factory = resolve_nonlinearity_factory(nonlinearity_factory)
- return Sequential(
- wrap_conv_or_linear_module(
- ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
- initialization_method,
- use_spectral_norm),
- NormalizationLayerFactory.resolve_2d(normalization_layer_factory).create(out_channels, affine=True),
- resolve_nonlinearity_factory(nonlinearity_factory).create())
-
-
-def create_upsample_block_from_block_args(in_channels: int,
- out_channels: int,
- block_args: Optional[BlockArgs] = None) -> Module:
- if block_args is None:
- block_args = BlockArgs()
- return create_upsample_block(in_channels, out_channels,
- block_args.initialization_method,
- block_args.nonlinearity_factory,
- block_args.normalization_layer_factory,
- block_args.use_spectral_norm)
diff --git a/spaces/cynika/taffy/vdecoder/__init__.py b/spaces/cynika/taffy/vdecoder/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/dalle-mini/dalle-mini/html2canvas.js b/spaces/dalle-mini/dalle-mini/html2canvas.js
deleted file mode 100644
index 96e2dc5707b1a584ff7b3b583aea7c6c18d4ea76..0000000000000000000000000000000000000000
--- a/spaces/dalle-mini/dalle-mini/html2canvas.js
+++ /dev/null
@@ -1,7756 +0,0 @@
-/*!
- * html2canvas 1.4.1
- * Copyright (c) 2022 Niklas von Hertzen
- * Released under MIT License
- */
-(function (global, factory) {
- typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() :
- typeof define === 'function' && define.amd ? define(factory) :
- (global = typeof globalThis !== 'undefined' ? globalThis : global || self, global.html2canvas = factory());
-}(this, (function () { 'use strict';
-
- /*! *****************************************************************************
- Copyright (c) Microsoft Corporation.
-
- Permission to use, copy, modify, and/or distribute this software for any
- purpose with or without fee is hereby granted.
-
- THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES WITH
- REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY
- AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, DIRECT,
- INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM
- LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR
- OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR
- PERFORMANCE OF THIS SOFTWARE.
- ***************************************************************************** */
- /* global Reflect, Promise */
-
- var extendStatics = function(d, b) {
- extendStatics = Object.setPrototypeOf ||
- ({ __proto__: [] } instanceof Array && function (d, b) { d.__proto__ = b; }) ||
- function (d, b) { for (var p in b) if (Object.prototype.hasOwnProperty.call(b, p)) d[p] = b[p]; };
- return extendStatics(d, b);
- };
-
- function __extends(d, b) {
- if (typeof b !== "function" && b !== null)
- throw new TypeError("Class extends value " + String(b) + " is not a constructor or null");
- extendStatics(d, b);
- function __() { this.constructor = d; }
- d.prototype = b === null ? Object.create(b) : (__.prototype = b.prototype, new __());
- }
-
- var __assign = function() {
- __assign = Object.assign || function __assign(t) {
- for (var s, i = 1, n = arguments.length; i < n; i++) {
- s = arguments[i];
- for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p)) t[p] = s[p];
- }
- return t;
- };
- return __assign.apply(this, arguments);
- };
-
- function __awaiter(thisArg, _arguments, P, generator) {
- function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }
- return new (P || (P = Promise))(function (resolve, reject) {
- function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }
- function rejected(value) { try { step(generator["throw"](value)); } catch (e) { reject(e); } }
- function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }
- step((generator = generator.apply(thisArg, _arguments || [])).next());
- });
- }
-
- function __generator(thisArg, body) {
- var _ = { label: 0, sent: function() { if (t[0] & 1) throw t[1]; return t[1]; }, trys: [], ops: [] }, f, y, t, g;
- return g = { next: verb(0), "throw": verb(1), "return": verb(2) }, typeof Symbol === "function" && (g[Symbol.iterator] = function() { return this; }), g;
- function verb(n) { return function (v) { return step([n, v]); }; }
- function step(op) {
- if (f) throw new TypeError("Generator is already executing.");
- while (_) try {
- if (f = 1, y && (t = op[0] & 2 ? y["return"] : op[0] ? y["throw"] || ((t = y["return"]) && t.call(y), 0) : y.next) && !(t = t.call(y, op[1])).done) return t;
- if (y = 0, t) op = [op[0] & 2, t.value];
- switch (op[0]) {
- case 0: case 1: t = op; break;
- case 4: _.label++; return { value: op[1], done: false };
- case 5: _.label++; y = op[1]; op = [0]; continue;
- case 7: op = _.ops.pop(); _.trys.pop(); continue;
- default:
- if (!(t = _.trys, t = t.length > 0 && t[t.length - 1]) && (op[0] === 6 || op[0] === 2)) { _ = 0; continue; }
- if (op[0] === 3 && (!t || (op[1] > t[0] && op[1] < t[3]))) { _.label = op[1]; break; }
- if (op[0] === 6 && _.label < t[1]) { _.label = t[1]; t = op; break; }
- if (t && _.label < t[2]) { _.label = t[2]; _.ops.push(op); break; }
- if (t[2]) _.ops.pop();
- _.trys.pop(); continue;
- }
- op = body.call(thisArg, _);
- } catch (e) { op = [6, e]; y = 0; } finally { f = t = 0; }
- if (op[0] & 5) throw op[1]; return { value: op[0] ? op[1] : void 0, done: true };
- }
- }
-
- function __spreadArray(to, from, pack) {
- if (pack || arguments.length === 2) for (var i = 0, l = from.length, ar; i < l; i++) {
- if (ar || !(i in from)) {
- if (!ar) ar = Array.prototype.slice.call(from, 0, i);
- ar[i] = from[i];
- }
- }
- return to.concat(ar || from);
- }
-
- var Bounds = /** @class */ (function () {
- function Bounds(left, top, width, height) {
- this.left = left;
- this.top = top;
- this.width = width;
- this.height = height;
- }
- Bounds.prototype.add = function (x, y, w, h) {
- return new Bounds(this.left + x, this.top + y, this.width + w, this.height + h);
- };
- Bounds.fromClientRect = function (context, clientRect) {
- return new Bounds(clientRect.left + context.windowBounds.left, clientRect.top + context.windowBounds.top, clientRect.width, clientRect.height);
- };
- Bounds.fromDOMRectList = function (context, domRectList) {
- var domRect = Array.from(domRectList).find(function (rect) { return rect.width !== 0; });
- return domRect
- ? new Bounds(domRect.left + context.windowBounds.left, domRect.top + context.windowBounds.top, domRect.width, domRect.height)
- : Bounds.EMPTY;
- };
- Bounds.EMPTY = new Bounds(0, 0, 0, 0);
- return Bounds;
- }());
- var parseBounds = function (context, node) {
- return Bounds.fromClientRect(context, node.getBoundingClientRect());
- };
- var parseDocumentSize = function (document) {
- var body = document.body;
- var documentElement = document.documentElement;
- if (!body || !documentElement) {
- throw new Error("Unable to get document size");
- }
- var width = Math.max(Math.max(body.scrollWidth, documentElement.scrollWidth), Math.max(body.offsetWidth, documentElement.offsetWidth), Math.max(body.clientWidth, documentElement.clientWidth));
- var height = Math.max(Math.max(body.scrollHeight, documentElement.scrollHeight), Math.max(body.offsetHeight, documentElement.offsetHeight), Math.max(body.clientHeight, documentElement.clientHeight));
- return new Bounds(0, 0, width, height);
- };
-
- /*
- * css-line-break 2.1.0
- * Copyright (c) 2022 Niklas von Hertzen
- * Released under MIT License
- */
- var toCodePoints$1 = function (str) {
- var codePoints = [];
- var i = 0;
- var length = str.length;
- while (i < length) {
- var value = str.charCodeAt(i++);
- if (value >= 0xd800 && value <= 0xdbff && i < length) {
- var extra = str.charCodeAt(i++);
- if ((extra & 0xfc00) === 0xdc00) {
- codePoints.push(((value & 0x3ff) << 10) + (extra & 0x3ff) + 0x10000);
- }
- else {
- codePoints.push(value);
- i--;
- }
- }
- else {
- codePoints.push(value);
- }
- }
- return codePoints;
- };
- var fromCodePoint$1 = function () {
- var codePoints = [];
- for (var _i = 0; _i < arguments.length; _i++) {
- codePoints[_i] = arguments[_i];
- }
- if (String.fromCodePoint) {
- return String.fromCodePoint.apply(String, codePoints);
- }
- var length = codePoints.length;
- if (!length) {
- return '';
- }
- var codeUnits = [];
- var index = -1;
- var result = '';
- while (++index < length) {
- var codePoint = codePoints[index];
- if (codePoint <= 0xffff) {
- codeUnits.push(codePoint);
- }
- else {
- codePoint -= 0x10000;
- codeUnits.push((codePoint >> 10) + 0xd800, (codePoint % 0x400) + 0xdc00);
- }
- if (index + 1 === length || codeUnits.length > 0x4000) {
- result += String.fromCharCode.apply(String, codeUnits);
- codeUnits.length = 0;
- }
- }
- return result;
- };
- var chars$2 = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
- // Use a lookup table to find the index.
- var lookup$2 = typeof Uint8Array === 'undefined' ? [] : new Uint8Array(256);
- for (var i$2 = 0; i$2 < chars$2.length; i$2++) {
- lookup$2[chars$2.charCodeAt(i$2)] = i$2;
- }
-
- /*
- * utrie 1.0.2
- * Copyright (c) 2022 Niklas von Hertzen
- * Released under MIT License
- */
- var chars$1$1 = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
- // Use a lookup table to find the index.
- var lookup$1$1 = typeof Uint8Array === 'undefined' ? [] : new Uint8Array(256);
- for (var i$1$1 = 0; i$1$1 < chars$1$1.length; i$1$1++) {
- lookup$1$1[chars$1$1.charCodeAt(i$1$1)] = i$1$1;
- }
- var decode$1 = function (base64) {
- var bufferLength = base64.length * 0.75, len = base64.length, i, p = 0, encoded1, encoded2, encoded3, encoded4;
- if (base64[base64.length - 1] === '=') {
- bufferLength--;
- if (base64[base64.length - 2] === '=') {
- bufferLength--;
- }
- }
- var buffer = typeof ArrayBuffer !== 'undefined' &&
- typeof Uint8Array !== 'undefined' &&
- typeof Uint8Array.prototype.slice !== 'undefined'
- ? new ArrayBuffer(bufferLength)
- : new Array(bufferLength);
- var bytes = Array.isArray(buffer) ? buffer : new Uint8Array(buffer);
- for (i = 0; i < len; i += 4) {
- encoded1 = lookup$1$1[base64.charCodeAt(i)];
- encoded2 = lookup$1$1[base64.charCodeAt(i + 1)];
- encoded3 = lookup$1$1[base64.charCodeAt(i + 2)];
- encoded4 = lookup$1$1[base64.charCodeAt(i + 3)];
- bytes[p++] = (encoded1 << 2) | (encoded2 >> 4);
- bytes[p++] = ((encoded2 & 15) << 4) | (encoded3 >> 2);
- bytes[p++] = ((encoded3 & 3) << 6) | (encoded4 & 63);
- }
- return buffer;
- };
- var polyUint16Array$1 = function (buffer) {
- var length = buffer.length;
- var bytes = [];
- for (var i = 0; i < length; i += 2) {
- bytes.push((buffer[i + 1] << 8) | buffer[i]);
- }
- return bytes;
- };
- var polyUint32Array$1 = function (buffer) {
- var length = buffer.length;
- var bytes = [];
- for (var i = 0; i < length; i += 4) {
- bytes.push((buffer[i + 3] << 24) | (buffer[i + 2] << 16) | (buffer[i + 1] << 8) | buffer[i]);
- }
- return bytes;
- };
-
- /** Shift size for getting the index-2 table offset. */
- var UTRIE2_SHIFT_2$1 = 5;
- /** Shift size for getting the index-1 table offset. */
- var UTRIE2_SHIFT_1$1 = 6 + 5;
- /**
- * Shift size for shifting left the index array values.
- * Increases possible data size with 16-bit index values at the cost
- * of compactability.
- * This requires data blocks to be aligned by UTRIE2_DATA_GRANULARITY.
- */
- var UTRIE2_INDEX_SHIFT$1 = 2;
- /**
- * Difference between the two shift sizes,
- * for getting an index-1 offset from an index-2 offset. 6=11-5
- */
- var UTRIE2_SHIFT_1_2$1 = UTRIE2_SHIFT_1$1 - UTRIE2_SHIFT_2$1;
- /**
- * The part of the index-2 table for U+D800..U+DBFF stores values for
- * lead surrogate code _units_ not code _points_.
- * Values for lead surrogate code _points_ are indexed with this portion of the table.
- * Length=32=0x20=0x400>>UTRIE2_SHIFT_2. (There are 1024=0x400 lead surrogates.)
- */
- var UTRIE2_LSCP_INDEX_2_OFFSET$1 = 0x10000 >> UTRIE2_SHIFT_2$1;
- /** Number of entries in a data block. 32=0x20 */
- var UTRIE2_DATA_BLOCK_LENGTH$1 = 1 << UTRIE2_SHIFT_2$1;
- /** Mask for getting the lower bits for the in-data-block offset. */
- var UTRIE2_DATA_MASK$1 = UTRIE2_DATA_BLOCK_LENGTH$1 - 1;
- var UTRIE2_LSCP_INDEX_2_LENGTH$1 = 0x400 >> UTRIE2_SHIFT_2$1;
- /** Count the lengths of both BMP pieces. 2080=0x820 */
- var UTRIE2_INDEX_2_BMP_LENGTH$1 = UTRIE2_LSCP_INDEX_2_OFFSET$1 + UTRIE2_LSCP_INDEX_2_LENGTH$1;
- /**
- * The 2-byte UTF-8 version of the index-2 table follows at offset 2080=0x820.
- * Length 32=0x20 for lead bytes C0..DF, regardless of UTRIE2_SHIFT_2.
- */
- var UTRIE2_UTF8_2B_INDEX_2_OFFSET$1 = UTRIE2_INDEX_2_BMP_LENGTH$1;
- var UTRIE2_UTF8_2B_INDEX_2_LENGTH$1 = 0x800 >> 6; /* U+0800 is the first code point after 2-byte UTF-8 */
- /**
- * The index-1 table, only used for supplementary code points, at offset 2112=0x840.
- * Variable length, for code points up to highStart, where the last single-value range starts.
- * Maximum length 512=0x200=0x100000>>UTRIE2_SHIFT_1.
- * (For 0x100000 supplementary code points U+10000..U+10ffff.)
- *
- * The part of the index-2 table for supplementary code points starts
- * after this index-1 table.
- *
- * Both the index-1 table and the following part of the index-2 table
- * are omitted completely if there is only BMP data.
- */
- var UTRIE2_INDEX_1_OFFSET$1 = UTRIE2_UTF8_2B_INDEX_2_OFFSET$1 + UTRIE2_UTF8_2B_INDEX_2_LENGTH$1;
- /**
- * Number of index-1 entries for the BMP. 32=0x20
- * This part of the index-1 table is omitted from the serialized form.
- */
- var UTRIE2_OMITTED_BMP_INDEX_1_LENGTH$1 = 0x10000 >> UTRIE2_SHIFT_1$1;
- /** Number of entries in an index-2 block. 64=0x40 */
- var UTRIE2_INDEX_2_BLOCK_LENGTH$1 = 1 << UTRIE2_SHIFT_1_2$1;
- /** Mask for getting the lower bits for the in-index-2-block offset. */
- var UTRIE2_INDEX_2_MASK$1 = UTRIE2_INDEX_2_BLOCK_LENGTH$1 - 1;
- var slice16$1 = function (view, start, end) {
- if (view.slice) {
- return view.slice(start, end);
- }
- return new Uint16Array(Array.prototype.slice.call(view, start, end));
- };
- var slice32$1 = function (view, start, end) {
- if (view.slice) {
- return view.slice(start, end);
- }
- return new Uint32Array(Array.prototype.slice.call(view, start, end));
- };
- var createTrieFromBase64$1 = function (base64, _byteLength) {
- var buffer = decode$1(base64);
- var view32 = Array.isArray(buffer) ? polyUint32Array$1(buffer) : new Uint32Array(buffer);
- var view16 = Array.isArray(buffer) ? polyUint16Array$1(buffer) : new Uint16Array(buffer);
- var headerLength = 24;
- var index = slice16$1(view16, headerLength / 2, view32[4] / 2);
- var data = view32[5] === 2
- ? slice16$1(view16, (headerLength + view32[4]) / 2)
- : slice32$1(view32, Math.ceil((headerLength + view32[4]) / 4));
- return new Trie$1(view32[0], view32[1], view32[2], view32[3], index, data);
- };
- var Trie$1 = /** @class */ (function () {
- function Trie(initialValue, errorValue, highStart, highValueIndex, index, data) {
- this.initialValue = initialValue;
- this.errorValue = errorValue;
- this.highStart = highStart;
- this.highValueIndex = highValueIndex;
- this.index = index;
- this.data = data;
- }
- /**
- * Get the value for a code point as stored in the Trie.
- *
- * @param codePoint the code point
- * @return the value
- */
- Trie.prototype.get = function (codePoint) {
- var ix;
- if (codePoint >= 0) {
- if (codePoint < 0x0d800 || (codePoint > 0x0dbff && codePoint <= 0x0ffff)) {
- // Ordinary BMP code point, excluding leading surrogates.
- // BMP uses a single level lookup. BMP index starts at offset 0 in the Trie2 index.
- // 16 bit data is stored in the index array itself.
- ix = this.index[codePoint >> UTRIE2_SHIFT_2$1];
- ix = (ix << UTRIE2_INDEX_SHIFT$1) + (codePoint & UTRIE2_DATA_MASK$1);
- return this.data[ix];
- }
- if (codePoint <= 0xffff) {
- // Lead Surrogate Code Point. A Separate index section is stored for
- // lead surrogate code units and code points.
- // The main index has the code unit data.
- // For this function, we need the code point data.
- // Note: this expression could be refactored for slightly improved efficiency, but
- // surrogate code points will be so rare in practice that it's not worth it.
- ix = this.index[UTRIE2_LSCP_INDEX_2_OFFSET$1 + ((codePoint - 0xd800) >> UTRIE2_SHIFT_2$1)];
- ix = (ix << UTRIE2_INDEX_SHIFT$1) + (codePoint & UTRIE2_DATA_MASK$1);
- return this.data[ix];
- }
- if (codePoint < this.highStart) {
- // Supplemental code point, use two-level lookup.
- ix = UTRIE2_INDEX_1_OFFSET$1 - UTRIE2_OMITTED_BMP_INDEX_1_LENGTH$1 + (codePoint >> UTRIE2_SHIFT_1$1);
- ix = this.index[ix];
- ix += (codePoint >> UTRIE2_SHIFT_2$1) & UTRIE2_INDEX_2_MASK$1;
- ix = this.index[ix];
- ix = (ix << UTRIE2_INDEX_SHIFT$1) + (codePoint & UTRIE2_DATA_MASK$1);
- return this.data[ix];
- }
- if (codePoint <= 0x10ffff) {
- return this.data[this.highValueIndex];
- }
- }
- // Fall through. The code point is outside of the legal range of 0..0x10ffff.
- return this.errorValue;
- };
- return Trie;
- }());
-
- /*
- * base64-arraybuffer 1.0.2
- * Copyright (c) 2022 Niklas von Hertzen
- * Released under MIT License
- */
- var chars$3 = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
- // Use a lookup table to find the index.
- var lookup$3 = typeof Uint8Array === 'undefined' ? [] : new Uint8Array(256);
- for (var i$3 = 0; i$3 < chars$3.length; i$3++) {
- lookup$3[chars$3.charCodeAt(i$3)] = i$3;
- }
-
- var base64$1 = 'KwAAAAAAAAAACA4AUD0AADAgAAACAAAAAAAIABAAGABAAEgAUABYAGAAaABgAGgAYgBqAF8AZwBgAGgAcQB5AHUAfQCFAI0AlQCdAKIAqgCyALoAYABoAGAAaABgAGgAwgDKAGAAaADGAM4A0wDbAOEA6QDxAPkAAQEJAQ8BFwF1AH0AHAEkASwBNAE6AUIBQQFJAVEBWQFhAWgBcAF4ATAAgAGGAY4BlQGXAZ8BpwGvAbUBvQHFAc0B0wHbAeMB6wHxAfkBAQIJAvEBEQIZAiECKQIxAjgCQAJGAk4CVgJeAmQCbAJ0AnwCgQKJApECmQKgAqgCsAK4ArwCxAIwAMwC0wLbAjAA4wLrAvMC+AIAAwcDDwMwABcDHQMlAy0DNQN1AD0DQQNJA0kDSQNRA1EDVwNZA1kDdQB1AGEDdQBpA20DdQN1AHsDdQCBA4kDkQN1AHUAmQOhA3UAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AKYDrgN1AHUAtgO+A8YDzgPWAxcD3gPjA+sD8wN1AHUA+wMDBAkEdQANBBUEHQQlBCoEFwMyBDgEYABABBcDSARQBFgEYARoBDAAcAQzAXgEgASIBJAEdQCXBHUAnwSnBK4EtgS6BMIEyAR1AHUAdQB1AHUAdQCVANAEYABgAGAAYABgAGAAYABgANgEYADcBOQEYADsBPQE/AQEBQwFFAUcBSQFLAU0BWQEPAVEBUsFUwVbBWAAYgVgAGoFcgV6BYIFigWRBWAAmQWfBaYFYABgAGAAYABgAKoFYACxBbAFuQW6BcEFwQXHBcEFwQXPBdMF2wXjBeoF8gX6BQIGCgYSBhoGIgYqBjIGOgZgAD4GRgZMBmAAUwZaBmAAYABgAGAAYABgAGAAYABgAGAAYABgAGIGYABpBnAGYABgAGAAYABgAGAAYABgAGAAYAB4Bn8GhQZgAGAAYAB1AHcDFQSLBmAAYABgAJMGdQA9A3UAmwajBqsGqwaVALMGuwbDBjAAywbSBtIG1QbSBtIG0gbSBtIG0gbdBuMG6wbzBvsGAwcLBxMHAwcbByMHJwcsBywHMQcsB9IGOAdAB0gHTgfSBkgHVgfSBtIG0gbSBtIG0gbSBtIG0gbSBiwHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAdgAGAALAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAdbB2MHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsB2kH0gZwB64EdQB1AHUAdQB1AHUAdQB1AHUHfQdgAIUHjQd1AHUAlQedB2AAYAClB6sHYACzB7YHvgfGB3UAzgfWBzMB3gfmB1EB7gf1B/0HlQENAQUIDQh1ABUIHQglCBcDLQg1CD0IRQhNCEEDUwh1AHUAdQBbCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIaQhjCGQIZQhmCGcIaAhpCGMIZAhlCGYIZwhoCGkIYwhkCGUIZghnCGgIcAh3CHoIMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwAIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIgggwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAALAcsBywHLAcsBywHLAcsBywHLAcsB4oILAcsB44I0gaWCJ4Ipgh1AHUAqgiyCHUAdQB1AHUAdQB1AHUAdQB1AHUAtwh8AXUAvwh1AMUIyQjRCNkI4AjoCHUAdQB1AO4I9gj+CAYJDgkTCS0HGwkjCYIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiCCIIIggiAAIAAAAFAAYABgAGIAXwBgAHEAdQBFAJUAogCyAKAAYABgAEIA4ABGANMA4QDxAMEBDwE1AFwBLAE6AQEBUQF4QkhCmEKoQrhCgAHIQsAB0MLAAcABwAHAAeDC6ABoAHDCwMMAAcABwAHAAdDDGMMAAcAB6MM4wwjDWMNow3jDaABoAGgAaABoAGgAaABoAGgAaABoAGgAaABoAGgAaABoAGgAaABoAEjDqABWw6bDqABpg6gAaABoAHcDvwOPA+gAaABfA/8DvwO/A78DvwO/A78DvwO/A78DvwO/A78DvwO/A78DvwO/A78DvwO/A78DvwO/A78DvwO/A78DpcPAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcAB9cPKwkyCToJMAB1AHUAdQBCCUoJTQl1AFUJXAljCWcJawkwADAAMAAwAHMJdQB2CX4JdQCECYoJjgmWCXUAngkwAGAAYABxAHUApgn3A64JtAl1ALkJdQDACTAAMAAwADAAdQB1AHUAdQB1AHUAdQB1AHUAowYNBMUIMAAwADAAMADICcsJ0wnZCRUE4QkwAOkJ8An4CTAAMAB1AAAKvwh1AAgKDwoXCh8KdQAwACcKLgp1ADYKqAmICT4KRgowADAAdQB1AE4KMAB1AFYKdQBeCnUAZQowADAAMAAwADAAMAAwADAAMAAVBHUAbQowADAAdQC5CXUKMAAwAHwBxAijBogEMgF9CoQKiASMCpQKmgqIBKIKqgquCogEDQG2Cr4KxgrLCjAAMADTCtsKCgHjCusK8Qr5CgELMAAwADAAMAB1AIsECQsRC3UANAEZCzAAMAAwADAAMAB1ACELKQswAHUANAExCzkLdQBBC0kLMABRC1kLMAAwADAAMAAwADAAdQBhCzAAMAAwAGAAYABpC3ELdwt/CzAAMACHC4sLkwubC58Lpwt1AK4Ltgt1APsDMAAwADAAMAAwADAAMAAwAL4LwwvLC9IL1wvdCzAAMADlC+kL8Qv5C/8LSQswADAAMAAwADAAMAAwADAAMAAHDDAAMAAwADAAMAAODBYMHgx1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1ACYMMAAwADAAdQB1AHUALgx1AHUAdQB1AHUAdQA2DDAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwAHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AD4MdQBGDHUAdQB1AHUAdQB1AEkMdQB1AHUAdQB1AFAMMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwAHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQBYDHUAdQB1AF8MMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUA+wMVBGcMMAAwAHwBbwx1AHcMfwyHDI8MMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAYABgAJcMMAAwADAAdQB1AJ8MlQClDDAAMACtDCwHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsB7UMLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHdQB1AHUAdQB1AHUAdQB1AHUAdQB1AHUAdQB1AA0EMAC9DDAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAsBywHLAcsBywHLAcsBywHLQcwAMEMyAwsBywHLAcsBywHLAcsBywHLAcsBywHzAwwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwAHUAdQB1ANQM2QzhDDAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMABgAGAAYABgAGAAYABgAOkMYADxDGAA+AwADQYNYABhCWAAYAAODTAAMAAwADAAFg1gAGAAHg37AzAAMAAwADAAYABgACYNYAAsDTQNPA1gAEMNPg1LDWAAYABgAGAAYABgAGAAYABgAGAAUg1aDYsGVglhDV0NcQBnDW0NdQ15DWAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAlQCBDZUAiA2PDZcNMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAnw2nDTAAMAAwADAAMAAwAHUArw23DTAAMAAwADAAMAAwADAAMAAwADAAMAB1AL8NMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAB1AHUAdQB1AHUAdQDHDTAAYABgAM8NMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAA1w11ANwNMAAwAD0B5A0wADAAMAAwADAAMADsDfQN/A0EDgwOFA4wABsOMAAwADAAMAAwADAAMAAwANIG0gbSBtIG0gbSBtIG0gYjDigOwQUuDsEFMw7SBjoO0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIGQg5KDlIOVg7SBtIGXg5lDm0OdQ7SBtIGfQ6EDooOjQ6UDtIGmg6hDtIG0gaoDqwO0ga0DrwO0gZgAGAAYADEDmAAYAAkBtIGzA5gANIOYADaDokO0gbSBt8O5w7SBu8O0gb1DvwO0gZgAGAAxA7SBtIG0gbSBtIGYABgAGAAYAAED2AAsAUMD9IG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIGFA8sBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAccD9IGLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHJA8sBywHLAcsBywHLAccDywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywPLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAc0D9IG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIGLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAccD9IG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIGFA8sBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHLAcsBywHPA/SBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gbSBtIG0gYUD0QPlQCVAJUAMAAwADAAMACVAJUAlQCVAJUAlQCVAEwPMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAA//8EAAQABAAEAAQABAAEAAQABAANAAMAAQABAAIABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQACgATABcAHgAbABoAHgAXABYAEgAeABsAGAAPABgAHABLAEsASwBLAEsASwBLAEsASwBLABgAGAAeAB4AHgATAB4AUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQABYAGwASAB4AHgAeAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAWAA0AEQAeAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAAQABAAEAAQABAAFAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAJABYAGgAbABsAGwAeAB0AHQAeAE8AFwAeAA0AHgAeABoAGwBPAE8ADgBQAB0AHQAdAE8ATwAXAE8ATwBPABYAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAB0AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAdAFAAUABQAFAAUABQAFAAUAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAFAAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAeAB4AHgAeAFAATwBAAE8ATwBPAEAATwBQAFAATwBQAB4AHgAeAB4AHgAeAB0AHQAdAB0AHgAdAB4ADgBQAFAAUABQAFAAHgAeAB4AHgAeAB4AHgBQAB4AUAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4ABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAJAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAkACQAJAAkACQAJAAkABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAeAB4AHgAeAFAAHgAeAB4AKwArAFAAUABQAFAAGABQACsAKwArACsAHgAeAFAAHgBQAFAAUAArAFAAKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4ABAAEAAQABAAEAAQABAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAUAAeAB4AHgAeAB4AHgBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAYAA0AKwArAB4AHgAbACsABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQADQAEAB4ABAAEAB4ABAAEABMABAArACsAKwArACsAKwArACsAVgBWAFYAVgBWAFYAVgBWAFYAVgBWAFYAVgBWAFYAVgBWAFYAVgBWAFYAVgBWAFYAVgBWAFYAKwArACsAKwBWAFYAVgBWAB4AHgArACsAKwArACsAKwArACsAKwArACsAHgAeAB4AHgAeAB4AHgAeAB4AGgAaABoAGAAYAB4AHgAEAAQABAAEAAQABAAEAAQABAAEAAQAEwAEACsAEwATAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABABLAEsASwBLAEsASwBLAEsASwBLABoAGQAZAB4AUABQAAQAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQABMAUAAEAAQABAAEAAQABAAEAB4AHgAEAAQABAAEAAQABABQAFAABAAEAB4ABAAEAAQABABQAFAASwBLAEsASwBLAEsASwBLAEsASwBQAFAAUAAeAB4AUAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwAeAFAABABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAAEAAQABAAEAFAAKwArACsAKwArACsAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAAEAAQAUABQAB4AHgAYABMAUAArACsABAAbABsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAFAABAAEAAQABAAEAFAABAAEAAQAUAAEAAQABAAEAAQAKwArAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAArACsAHgArAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAKwArACsAKwArACsAKwArAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAB4ABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAEAFAABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAUAAEAAQABAAEAAQABAAEAFAAUABQAFAAUABQAFAAUABQAFAABAAEAA0ADQBLAEsASwBLAEsASwBLAEsASwBLAB4AUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAArAFAAUABQAFAAUABQAFAAUAArACsAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQACsAUAArACsAKwBQAFAAUABQACsAKwAEAFAABAAEAAQABAAEAAQABAArACsABAAEACsAKwAEAAQABABQACsAKwArACsAKwArACsAKwAEACsAKwArACsAUABQACsAUABQAFAABAAEACsAKwBLAEsASwBLAEsASwBLAEsASwBLAFAAUAAaABoAUABQAFAAUABQAEwAHgAbAFAAHgAEACsAKwAEAAQABAArAFAAUABQAFAAUABQACsAKwArACsAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQACsAUABQACsAUABQACsAUABQACsAKwAEACsABAAEAAQABAAEACsAKwArACsABAAEACsAKwAEAAQABAArACsAKwAEACsAKwArACsAKwArACsAUABQAFAAUAArAFAAKwArACsAKwArACsAKwBLAEsASwBLAEsASwBLAEsASwBLAAQABABQAFAAUAAEAB4AKwArACsAKwArACsAKwArACsAKwAEAAQABAArAFAAUABQAFAAUABQAFAAUABQACsAUABQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQACsAUABQACsAUABQAFAAUABQACsAKwAEAFAABAAEAAQABAAEAAQABAAEACsABAAEAAQAKwAEAAQABAArACsAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwBQAFAABAAEACsAKwBLAEsASwBLAEsASwBLAEsASwBLAB4AGwArACsAKwArACsAKwArAFAABAAEAAQABAAEAAQAKwAEAAQABAArAFAAUABQAFAAUABQAFAAUAArACsAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAEAAQABAArACsABAAEACsAKwAEAAQABAArACsAKwArACsAKwArAAQABAAEACsAKwArACsAUABQACsAUABQAFAABAAEACsAKwBLAEsASwBLAEsASwBLAEsASwBLAB4AUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArAAQAUAArAFAAUABQAFAAUABQACsAKwArAFAAUABQACsAUABQAFAAUAArACsAKwBQAFAAKwBQACsAUABQACsAKwArAFAAUAArACsAKwBQAFAAUAArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArAAQABAAEAAQABAArACsAKwAEAAQABAArAAQABAAEAAQAKwArAFAAKwArACsAKwArACsABAArACsAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAUABQAFAAHgAeAB4AHgAeAB4AGwAeACsAKwArACsAKwAEAAQABAAEAAQAUABQAFAAUABQAFAAUABQACsAUABQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAUAAEAAQABAAEAAQABAAEACsABAAEAAQAKwAEAAQABAAEACsAKwArACsAKwArACsABAAEACsAUABQAFAAKwArACsAKwArAFAAUAAEAAQAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAKwAOAFAAUABQAFAAUABQAFAAHgBQAAQABAAEAA4AUABQAFAAUABQAFAAUABQACsAUABQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAKwArAAQAUAAEAAQABAAEAAQABAAEACsABAAEAAQAKwAEAAQABAAEACsAKwArACsAKwArACsABAAEACsAKwArACsAKwArACsAUAArAFAAUAAEAAQAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwBQAFAAKwArACsAKwArACsAKwArACsAKwArACsAKwAEAAQABAAEAFAAUABQAFAAUABQAFAAUABQACsAUABQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAFAABAAEAAQABAAEAAQABAArAAQABAAEACsABAAEAAQABABQAB4AKwArACsAKwBQAFAAUAAEAFAAUABQAFAAUABQAFAAUABQAFAABAAEACsAKwBLAEsASwBLAEsASwBLAEsASwBLAFAAUABQAFAAUABQAFAAUABQABoAUABQAFAAUABQAFAAKwAEAAQABAArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAUABQACsAUAArACsAUABQAFAAUABQAFAAUAArACsAKwAEACsAKwArACsABAAEAAQABAAEAAQAKwAEACsABAAEAAQABAAEAAQABAAEACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArAAQABAAeACsAKwArACsAKwArACsAKwArACsAKwArAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXAAqAFwAXAAqACoAKgAqACoAKgAqACsAKwArACsAGwBcAFwAXABcAFwAXABcACoAKgAqACoAKgAqACoAKgAeAEsASwBLAEsASwBLAEsASwBLAEsADQANACsAKwArACsAKwBcAFwAKwBcACsAXABcAFwAXABcACsAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcACsAXAArAFwAXABcAFwAXABcAFwAXABcAFwAKgBcAFwAKgAqACoAKgAqACoAKgAqACoAXAArACsAXABcAFwAXABcACsAXAArACoAKgAqACoAKgAqACsAKwBLAEsASwBLAEsASwBLAEsASwBLACsAKwBcAFwAXABcAFAADgAOAA4ADgAeAA4ADgAJAA4ADgANAAkAEwATABMAEwATAAkAHgATAB4AHgAeAAQABAAeAB4AHgAeAB4AHgBLAEsASwBLAEsASwBLAEsASwBLAFAAUABQAFAAUABQAFAAUABQAFAADQAEAB4ABAAeAAQAFgARABYAEQAEAAQAUABQAFAAUABQAFAAUABQACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAKwAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQADQAEAAQABAAEAAQADQAEAAQAUABQAFAAUABQAAQABAAEAAQABAAEAAQABAAEAAQABAArAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAArAA0ADQAeAB4AHgAeAB4AHgAEAB4AHgAeAB4AHgAeACsAHgAeAA4ADgANAA4AHgAeAB4AHgAeAAkACQArACsAKwArACsAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgBcAEsASwBLAEsASwBLAEsASwBLAEsADQANAB4AHgAeAB4AXABcAFwAXABcAFwAKgAqACoAKgBcAFwAXABcACoAKgAqAFwAKgAqACoAXABcACoAKgAqACoAKgAqACoAXABcAFwAKgAqACoAKgBcAFwAXABcAFwAXABcAFwAXABcAFwAXABcACoAKgAqACoAKgAqACoAKgAqACoAKgAqAFwAKgBLAEsASwBLAEsASwBLAEsASwBLACoAKgAqACoAKgAqAFAAUABQAFAAUABQACsAUAArACsAKwArACsAUAArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAHgBQAFAAUABQAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFAAUABQAFAAUABQAFAAUABQACsAUABQAFAAUAArACsAUABQAFAAUABQAFAAUAArAFAAKwBQAFAAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAKwArAFAAUABQAFAAUABQAFAAKwBQACsAUABQAFAAUAArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsABAAEAAQAHgANAB4AHgAeAB4AHgAeAB4AUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAHgAeAB4AHgAeAB4AHgAeAB4AHgArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwBQAFAAUABQAFAAUAArACsADQBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAHgAeAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAANAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAWABEAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAA0ADQANAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAAQABAAEACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAANAA0AKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEACsAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUAArAAQABAArACsAKwArACsAKwArACsAKwArACsAKwBcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqAA0ADQAVAFwADQAeAA0AGwBcACoAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwAeAB4AEwATAA0ADQAOAB4AEwATAB4ABAAEAAQACQArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArAFAAUABQAFAAUAAEAAQAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQAUAArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwAEAAQABAAEAAQABAAEAAQABAAEAAQABAArACsAKwArAAQABAAEAAQABAAEAAQABAAEAAQABAAEACsAKwArACsAHgArACsAKwATABMASwBLAEsASwBLAEsASwBLAEsASwBcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXAArACsAXABcAFwAXABcACsAKwArACsAKwArACsAKwArACsAKwBcAFwAXABcAFwAXABcAFwAXABcAFwAXAArACsAKwArAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAXAArACsAKwAqACoAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAEAAQABAArACsAHgAeAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcACoAKgAqACoAKgAqACoAKgAqACoAKwAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKwArAAQASwBLAEsASwBLAEsASwBLAEsASwArACsAKwArACsAKwBLAEsASwBLAEsASwBLAEsASwBLACsAKwArACsAKwArACoAKgAqACoAKgAqACoAXAAqACoAKgAqACoAKgArACsABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsABAAEAAQABAAEAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAEAAQABABQAFAAUABQAFAAUABQACsAKwArACsASwBLAEsASwBLAEsASwBLAEsASwANAA0AHgANAA0ADQANAB4AHgAeAB4AHgAeAB4AHgAeAB4ABAAEAAQABAAEAAQABAAEAAQAHgAeAB4AHgAeAB4AHgAeAB4AKwArACsABAAEAAQAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAAEAAQABAAEAAQABABQAFAASwBLAEsASwBLAEsASwBLAEsASwBQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEACsAKwArACsAKwArACsAKwAeAB4AHgAeAFAAUABQAFAABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEACsAKwArAA0ADQANAA0ADQBLAEsASwBLAEsASwBLAEsASwBLACsAKwArAFAAUABQAEsASwBLAEsASwBLAEsASwBLAEsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAA0ADQBQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwBQAFAAUAAeAB4AHgAeAB4AHgAeAB4AKwArACsAKwArACsAKwArAAQABAAEAB4ABAAEAAQABAAEAAQABAAEAAQABAAEAAQABABQAFAAUABQAAQAUABQAFAAUABQAFAABABQAFAABAAEAAQAUAArACsAKwArACsABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEACsABAAEAAQABAAEAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwArAFAAUABQAFAAUABQACsAKwBQAFAAUABQAFAAUABQAFAAKwBQACsAUAArAFAAKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeACsAKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArAB4AHgAeAB4AHgAeAB4AHgBQAB4AHgAeAFAAUABQACsAHgAeAB4AHgAeAB4AHgAeAB4AHgBQAFAAUABQACsAKwAeAB4AHgAeAB4AHgArAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwArAFAAUABQACsAHgAeAB4AHgAeAB4AHgAOAB4AKwANAA0ADQANAA0ADQANAAkADQANAA0ACAAEAAsABAAEAA0ACQANAA0ADAAdAB0AHgAXABcAFgAXABcAFwAWABcAHQAdAB4AHgAUABQAFAANAAEAAQAEAAQABAAEAAQACQAaABoAGgAaABoAGgAaABoAHgAXABcAHQAVABUAHgAeAB4AHgAeAB4AGAAWABEAFQAVABUAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4ADQAeAA0ADQANAA0AHgANAA0ADQAHAB4AHgAeAB4AKwAEAAQABAAEAAQABAAEAAQABAAEAFAAUAArACsATwBQAFAAUABQAFAAHgAeAB4AFgARAE8AUABPAE8ATwBPAFAAUABQAFAAUAAeAB4AHgAWABEAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArABsAGwAbABsAGwAbABsAGgAbABsAGwAbABsAGwAbABsAGwAbABsAGwAbABsAGgAbABsAGwAbABoAGwAbABoAGwAbABsAGwAbABsAGwAbABsAGwAbABsAGwAbABsAGwAbAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAHgAeAFAAGgAeAB0AHgBQAB4AGgAeAB4AHgAeAB4AHgAeAB4AHgBPAB4AUAAbAB4AHgBQAFAAUABQAFAAHgAeAB4AHQAdAB4AUAAeAFAAHgBQAB4AUABPAFAAUAAeAB4AHgAeAB4AHgAeAFAAUABQAFAAUAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAFAAHgBQAFAAUABQAE8ATwBQAFAAUABQAFAATwBQAFAATwBQAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAFAAUABQAFAATwBPAE8ATwBPAE8ATwBPAE8ATwBQAFAAUABQAFAAUABQAFAAUAAeAB4AUABQAFAAUABPAB4AHgArACsAKwArAB0AHQAdAB0AHQAdAB0AHQAdAB0AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB0AHgAdAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAdAB4AHQAdAB4AHgAeAB0AHQAeAB4AHQAeAB4AHgAdAB4AHQAbABsAHgAdAB4AHgAeAB4AHQAeAB4AHQAdAB0AHQAeAB4AHQAeAB0AHgAdAB0AHQAdAB0AHQAeAB0AHgAeAB4AHgAeAB0AHQAdAB0AHgAeAB4AHgAdAB0AHgAeAB4AHgAeAB4AHgAeAB4AHgAdAB4AHgAeAB0AHgAeAB4AHgAeAB0AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAdAB0AHgAeAB0AHQAdAB0AHgAeAB0AHQAeAB4AHQAdAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB0AHQAeAB4AHQAdAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHQAeAB4AHgAdAB4AHgAeAB4AHgAeAB4AHQAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB0AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AFAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeABYAEQAWABEAHgAeAB4AHgAeAB4AHQAeAB4AHgAeAB4AHgAeACUAJQAeAB4AHgAeAB4AHgAeAB4AHgAWABEAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AJQAlACUAJQAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAFAAHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHgAeAB4AHgAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAeAB4AHQAdAB0AHQAeAB4AHgAeAB4AHgAeAB4AHgAeAB0AHQAeAB0AHQAdAB0AHQAdAB0AHgAeAB4AHgAeAB4AHgAeAB0AHQAeAB4AHQAdAB4AHgAeAB4AHQAdAB4AHgAeAB4AHQAdAB0AHgAeAB0AHgAeAB0AHQAdAB0AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAdAB0AHQAdAB4AHgAeAB4AHgAeAB4AHgAeAB0AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAlACUAJQAlAB4AHQAdAB4AHgAdAB4AHgAeAB4AHQAdAB4AHgAeAB4AJQAlAB0AHQAlAB4AJQAlACUAIAAlACUAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAlACUAJQAeAB4AHgAeAB0AHgAdAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAdAB0AHgAdAB0AHQAeAB0AJQAdAB0AHgAdAB0AHgAdAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeACUAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHQAdAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAlACUAJQAlACUAJQAlACUAJQAlACUAJQAdAB0AHQAdACUAHgAlACUAJQAdACUAJQAdAB0AHQAlACUAHQAdACUAHQAdACUAJQAlAB4AHQAeAB4AHgAeAB0AHQAlAB0AHQAdAB0AHQAdACUAJQAlACUAJQAdACUAJQAgACUAHQAdACUAJQAlACUAJQAlACUAJQAeAB4AHgAlACUAIAAgACAAIAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB0AHgAeAB4AFwAXABcAFwAXABcAHgATABMAJQAeAB4AHgAWABEAFgARABYAEQAWABEAFgARABYAEQAWABEATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeABYAEQAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAWABEAFgARABYAEQAWABEAFgARAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AFgARABYAEQAWABEAFgARABYAEQAWABEAFgARABYAEQAWABEAFgARABYAEQAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAWABEAFgARAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AFgARAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAdAB0AHQAdAB0AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArACsAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AUABQAFAAUAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAEAAQABAAeAB4AKwArACsAKwArABMADQANAA0AUAATAA0AUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAUAANACsAKwArACsAKwArACsAKwArACsAKwArACsAKwAEAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQACsAUABQAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQACsAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXAA0ADQANAA0ADQANAA0ADQAeAA0AFgANAB4AHgAXABcAHgAeABcAFwAWABEAFgARABYAEQAWABEADQANAA0ADQATAFAADQANAB4ADQANAB4AHgAeAB4AHgAMAAwADQANAA0AHgANAA0AFgANAA0ADQANAA0ADQANAA0AHgANAB4ADQANAB4AHgAeACsAKwArACsAKwArACsAKwArACsAKwArACsAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACsAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAKwArACsAKwArACsAKwArACsAKwArACsAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwAlACUAJQAlACUAJQAlACUAJQAlACUAJQArACsAKwArAA0AEQARACUAJQBHAFcAVwAWABEAFgARABYAEQAWABEAFgARACUAJQAWABEAFgARABYAEQAWABEAFQAWABEAEQAlAFcAVwBXAFcAVwBXAFcAVwBXAAQABAAEAAQABAAEACUAVwBXAFcAVwA2ACUAJQBXAFcAVwBHAEcAJQAlACUAKwBRAFcAUQBXAFEAVwBRAFcAUQBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFEAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBRAFcAUQBXAFEAVwBXAFcAVwBXAFcAUQBXAFcAVwBXAFcAVwBRAFEAKwArAAQABAAVABUARwBHAFcAFQBRAFcAUQBXAFEAVwBRAFcAUQBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFEAVwBRAFcAUQBXAFcAVwBXAFcAVwBRAFcAVwBXAFcAVwBXAFEAUQBXAFcAVwBXABUAUQBHAEcAVwArACsAKwArACsAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAKwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAKwAlACUAVwBXAFcAVwAlACUAJQAlACUAJQAlACUAJQAlACsAKwArACsAKwArACsAKwArACsAKwArAFEAUQBRAFEAUQBRAFEAUQBRAFEAUQBRAFEAUQBRAFEAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQArAFcAVwBXAFcAVwBXAFcAVwBXAFcAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQBPAE8ATwBPAE8ATwBPAE8AJQBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXACUAJQAlAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAEcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAKwArACsAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAADQATAA0AUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABLAEsASwBLAEsASwBLAEsASwBLAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAFAABAAEAAQABAAeAAQABAAEAAQABAAEAAQABAAEAAQAHgBQAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AUABQAAQABABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAeAA0ADQANAA0ADQArACsAKwArACsAKwArACsAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAFAAUABQAFAAUABQAFAAUABQAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AUAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgBQAB4AHgAeAB4AHgAeAFAAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArACsAHgAeAB4AHgAeAB4AHgAeAB4AKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwAeAB4AUABQAFAAUABQAFAAUABQAFAAUABQAAQAUABQAFAABABQAFAAUABQAAQAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAEAAQABAAeAB4AHgAeAAQAKwArACsAUABQAFAAUABQAFAAHgAeABoAHgArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAADgAOABMAEwArACsAKwArACsAKwArACsABAAEAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAEAAQABAAEACsAKwArACsAKwArACsAKwANAA0ASwBLAEsASwBLAEsASwBLAEsASwArACsAKwArACsAKwAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABABQAFAAUABQAFAAUAAeAB4AHgBQAA4AUABQAAQAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAAEAA0ADQBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAKwArACsAKwArACsAKwArACsAKwArAB4AWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYAFgAWABYACsAKwArAAQAHgAeAB4AHgAeAB4ADQANAA0AHgAeAB4AHgArAFAASwBLAEsASwBLAEsASwBLAEsASwArACsAKwArAB4AHgBcAFwAXABcAFwAKgBcAFwAXABcAFwAXABcAFwAXABcAEsASwBLAEsASwBLAEsASwBLAEsAXABcAFwAXABcACsAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEACsAKwArACsAKwArACsAKwArAFAAUABQAAQAUABQAFAAUABQAFAAUABQAAQABAArACsASwBLAEsASwBLAEsASwBLAEsASwArACsAHgANAA0ADQBcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAKgAqACoAXAAqACoAKgBcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXAAqAFwAKgAqACoAXABcACoAKgBcAFwAXABcAFwAKgAqAFwAKgBcACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFwAXABcACoAKgBQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAA0ADQBQAFAAUAAEAAQAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUAArACsAUABQAFAAUABQAFAAKwArAFAAUABQAFAAUABQACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAHgAeACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAAQADQAEAAQAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAVABVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBUAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVAFUAVQBVACsAKwArACsAKwArACsAKwArACsAKwArAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAWQBZAFkAKwArACsAKwBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAWgBaAFoAKwArACsAKwAGAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAYABgAGAAYAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXACUAJQBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAJQAlACUAJQAlACUAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAKwArACsAKwArAFYABABWAFYAVgBWAFYAVgBWAFYAVgBWAB4AVgBWAFYAVgBWAFYAVgBWAFYAVgBWAFYAVgArAFYAVgBWAFYAVgArAFYAKwBWAFYAKwBWAFYAKwBWAFYAVgBWAFYAVgBWAFYAVgBWAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAEQAWAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUAAaAB4AKwArAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAGAARABEAGAAYABMAEwAWABEAFAArACsAKwArACsAKwAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEACUAJQAlACUAJQAWABEAFgARABYAEQAWABEAFgARABYAEQAlACUAFgARACUAJQAlACUAJQAlACUAEQAlABEAKwAVABUAEwATACUAFgARABYAEQAWABEAJQAlACUAJQAlACUAJQAlACsAJQAbABoAJQArACsAKwArAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArAAcAKwATACUAJQAbABoAJQAlABYAEQAlACUAEQAlABEAJQBXAFcAVwBXAFcAVwBXAFcAVwBXABUAFQAlACUAJQATACUAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXABYAJQARACUAJQAlAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwAWACUAEQAlABYAEQARABYAEQARABUAVwBRAFEAUQBRAFEAUQBRAFEAUQBRAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAEcARwArACsAVwBXAFcAVwBXAFcAKwArAFcAVwBXAFcAVwBXACsAKwBXAFcAVwBXAFcAVwArACsAVwBXAFcAKwArACsAGgAbACUAJQAlABsAGwArAB4AHgAeAB4AHgAeAB4AKwArACsAKwArACsAKwArACsAKwAEAAQABAAQAB0AKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsADQANAA0AKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArAB4AHgAeAB4AHgAeAB4AHgAeAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgBQAFAAHgAeAB4AKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAAQAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwAEAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAA0AUABQAFAAUAArACsAKwArAFAAUABQAFAAUABQAFAAUAANAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAKwArACsAKwAeACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAKwArAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUAArACsAKwBQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwANAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAeAB4AUABQAFAAUABQAFAAUAArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUAArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArAA0AUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwAeAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAUABQAFAAUABQAAQABAAEACsABAAEACsAKwArACsAKwAEAAQABAAEAFAAUABQAFAAKwBQAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArAAQABAAEACsAKwArACsABABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArAA0ADQANAA0ADQANAA0ADQAeACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAeAFAAUABQAFAAUABQAFAAUAAeAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAArACsAKwArAFAAUABQAFAAUAANAA0ADQANAA0ADQAUACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsADQANAA0ADQANAA0ADQBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArAB4AHgAeAB4AKwArACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArAFAAUABQAFAAUABQAAQABAAEAAQAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUAArAAQABAANACsAKwBQAFAAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAAQABAAEAAQABAAEAAQABAAEAAQABABQAFAAUABQAB4AHgAeAB4AHgArACsAKwArACsAKwAEAAQABAAEAAQABAAEAA0ADQAeAB4AHgAeAB4AKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsABABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAQABAAEAAQABAAEAAQABAAEAAQABAAeAB4AHgANAA0ADQANACsAKwArACsAKwArACsAKwArACsAKwAeACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAKwArACsAKwBLAEsASwBLAEsASwBLAEsASwBLACsAKwArACsAKwArAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEACsASwBLAEsASwBLAEsASwBLAEsASwANAA0ADQANAFAABAAEAFAAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAeAA4AUAArACsAKwArACsAKwArACsAKwAEAFAAUABQAFAADQANAB4ADQAEAAQABAAEAB4ABAAEAEsASwBLAEsASwBLAEsASwBLAEsAUAAOAFAADQANAA0AKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAAQABAAEAAQABAANAA0AHgANAA0AHgAEACsAUABQAFAAUABQAFAAUAArAFAAKwBQAFAAUABQACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAA0AKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAAQABAAEAAQAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsABAAEAAQABAArAFAAUABQAFAAUABQAFAAUAArACsAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQACsAUABQACsAUABQAFAAUABQACsABAAEAFAABAAEAAQABAAEAAQABAArACsABAAEACsAKwAEAAQABAArACsAUAArACsAKwArACsAKwAEACsAKwArACsAKwBQAFAAUABQAFAABAAEACsAKwAEAAQABAAEAAQABAAEACsAKwArAAQABAAEAAQABAArACsAKwArACsAKwArACsAKwArACsABAAEAAQABAAEAAQABABQAFAAUABQAA0ADQANAA0AHgBLAEsASwBLAEsASwBLAEsASwBLAA0ADQArAB4ABABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwAEAAQABAAEAFAAUAAeAFAAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAArACsABAAEAAQABAAEAAQABAAEAAQADgANAA0AEwATAB4AHgAeAA0ADQANAA0ADQANAA0ADQANAA0ADQANAA0ADQANAFAAUABQAFAABAAEACsAKwAEAA0ADQAeAFAAKwArACsAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAFAAKwArACsAKwArACsAKwBLAEsASwBLAEsASwBLAEsASwBLACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAXABcAFwAKwArACoAKgAqACoAKgAqACoAKgAqACoAKgAqACoAKgAqACsAKwArACsASwBLAEsASwBLAEsASwBLAEsASwBcAFwADQANAA0AKgBQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAeACsAKwArACsASwBLAEsASwBLAEsASwBLAEsASwBQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAKwArAFAAKwArAFAAUABQAFAAUABQAFAAUAArAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQAKwAEAAQAKwArAAQABAAEAAQAUAAEAFAABAAEAA0ADQANACsAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAArACsABAAEAAQABAAEAAQABABQAA4AUAAEACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFAABAAEAAQABAAEAAQABAAEAAQABABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAFAABAAEAAQABAAOAB4ADQANAA0ADQAOAB4ABAArACsAKwArACsAKwArACsAUAAEAAQABAAEAAQABAAEAAQABAAEAAQAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAA0ADQANAFAADgAOAA4ADQANACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAEAAQABAAEACsABAAEAAQABAAEAAQABAAEAFAADQANAA0ADQANACsAKwArACsAKwArACsAKwArACsASwBLAEsASwBLAEsASwBLAEsASwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwAOABMAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAArAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQACsAUABQACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAArACsAKwAEACsABAAEACsABAAEAAQABAAEAAQABABQAAQAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAUABQAFAAUABQAFAAKwBQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQAKwAEAAQAKwAEAAQABAAEAAQAUAArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAABAAEAAQABAAeAB4AKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwBQACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAB4AHgAeAB4AHgAeAB4AHgAaABoAGgAaAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArACsAKwArACsAKwArACsAKwArACsAKwArAA0AUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsADQANAA0ADQANACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAASABIAEgAQwBDAEMAUABQAFAAUABDAFAAUABQAEgAQwBIAEMAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAASABDAEMAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwAJAAkACQAJAAkACQAJABYAEQArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABIAEMAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwANAA0AKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArAAQABAAEAAQABAANACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEAA0ADQANAB4AHgAeAB4AHgAeAFAAUABQAFAADQAeACsAKwArACsAKwArACsAKwArACsASwBLAEsASwBLAEsASwBLAEsASwArAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAANAA0AHgAeACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAKwAEAFAABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAKwArACsAKwArACsAKwAEAAQABAAEAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAARwBHABUARwAJACsAKwArACsAKwArACsAKwArACsAKwAEAAQAKwArACsAKwArACsAKwArACsAKwArACsAKwArAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXACsAKwArACsAKwArACsAKwBXAFcAVwBXAFcAVwBXAFcAVwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAUQBRAFEAKwArACsAKwArACsAKwArACsAKwArACsAKwBRAFEAUQBRACsAKwArACsAKwArACsAKwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUAArACsAHgAEAAQADQAEAAQABAAEACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArACsAKwArACsAKwArACsAKwArAB4AHgAeAB4AHgAeAB4AKwArAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAAQABAAEAAQABAAeAB4AHgAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAB4AHgAEAAQABAAEAAQABAAEAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4ABAAEAAQABAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4ABAAEAAQAHgArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwArACsAKwArACsAKwArACsAKwArAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArACsAKwArACsAKwArACsAKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwBQAFAAKwArAFAAKwArAFAAUAArACsAUABQAFAAUAArAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeACsAUAArAFAAUABQAFAAUABQAFAAKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwBQAFAAUABQACsAKwBQAFAAUABQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQACsAHgAeAFAAUABQAFAAUAArAFAAKwArACsAUABQAFAAUABQAFAAUAArAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAHgBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgBQAFAAUABQAFAAUABQAFAAUABQAFAAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAB4AHgAeAB4AHgAeAB4AHgAeACsAKwBLAEsASwBLAEsASwBLAEsASwBLAEsASwBLAEsASwBLAEsASwBLAEsASwBLAEsASwBLAEsASwBLAEsASwBLAEsASwBLAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAeAB4AHgAeAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAeAB4AHgAeAB4AHgAeAB4ABAAeAB4AHgAeAB4AHgAeAB4AHgAeAAQAHgAeAA0ADQANAA0AHgArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwAEAAQABAAEAAQAKwAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAAQABAAEAAQABAAEAAQAKwAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAKwArAAQABAAEAAQABAAEAAQAKwAEAAQAKwAEAAQABAAEAAQAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwAEAAQABAAEAAQABAAEAFAAUABQAFAAUABQAFAAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwBQAB4AKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArABsAUABQAFAAUABQACsAKwBQAFAAUABQAFAAUABQAFAAUAAEAAQABAAEAAQABAAEACsAKwArACsAKwArACsAKwArAB4AHgAeAB4ABAAEAAQABAAEAAQABABQACsAKwArACsASwBLAEsASwBLAEsASwBLAEsASwArACsAKwArABYAFgArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAGgBQAFAAUAAaAFAAUABQAFAAKwArACsAKwArACsAKwArACsAKwArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAeAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQACsAKwBQAFAAUABQACsAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwBQAFAAKwBQACsAKwBQACsAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAKwBQACsAUAArACsAKwArACsAKwBQACsAKwArACsAUAArAFAAKwBQACsAUABQAFAAKwBQAFAAKwBQACsAKwBQACsAUAArAFAAKwBQACsAUAArAFAAUAArAFAAKwArAFAAUABQAFAAKwBQAFAAUABQAFAAUABQACsAUABQAFAAUAArAFAAUABQAFAAKwBQACsAUABQAFAAUABQAFAAUABQAFAAUAArAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAArACsAKwArACsAUABQAFAAKwBQAFAAUABQAFAAKwBQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwAeAB4AKwArACsAKwArACsAKwArACsAKwArACsAKwArAE8ATwBPAE8ATwBPAE8ATwBPAE8ATwBPAE8AJQAlACUAHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHgAeAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB4AHgAeACUAJQAlAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAdAB0AHQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQApACkAKQApACkAKQApACkAKQApACkAKQApACkAKQApACkAKQApACkAKQApACkAKQApACkAJQAlACUAJQAlACAAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAeAB4AJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlAB4AHgAlACUAJQAlACUAHgAlACUAJQAlACUAIAAgACAAJQAlACAAJQAlACAAIAAgACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACEAIQAhACEAIQAlACUAIAAgACUAJQAgACAAIAAgACAAIAAgACAAIAAgACAAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAJQAlACUAIAAlACUAJQAlACAAIAAgACUAIAAgACAAJQAlACUAJQAlACUAJQAgACUAIAAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAHgAlAB4AJQAeACUAJQAlACUAJQAgACUAJQAlACUAHgAlAB4AHgAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlAB4AHgAeAB4AHgAeAB4AJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAeAB4AHgAeAB4AHgAeAB4AHgAeACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACAAIAAlACUAJQAlACAAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACAAJQAlACUAJQAgACAAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAHgAeAB4AHgAeAB4AHgAeACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAeAB4AHgAeAB4AHgAlACUAJQAlACUAJQAlACAAIAAgACUAJQAlACAAIAAgACAAIAAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeABcAFwAXABUAFQAVAB4AHgAeAB4AJQAlACUAIAAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACAAIAAgACUAJQAlACUAJQAlACUAJQAlACAAJQAlACUAJQAlACUAJQAlACUAJQAlACAAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AJQAlACUAJQAlACUAJQAlACUAJQAlACUAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AJQAlACUAJQAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeACUAJQAlACUAJQAlACUAJQAeAB4AHgAeAB4AHgAeAB4AHgAeACUAJQAlACUAJQAlAB4AHgAeAB4AHgAeAB4AHgAlACUAJQAlACUAJQAlACUAHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAgACUAJQAgACUAJQAlACUAJQAlACUAJQAgACAAIAAgACAAIAAgACAAJQAlACUAJQAlACUAIAAlACUAJQAlACUAJQAlACUAJQAgACAAIAAgACAAIAAgACAAIAAgACUAJQAgACAAIAAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAgACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACAAIAAlACAAIAAlACAAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAgACAAIAAlACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAJQAlAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AKwAeAB4AHgAeAB4AHgAeAB4AHgAeAB4AHgArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAEsASwBLAEsASwBLAEsASwBLAEsAKwArACsAKwArACsAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAKwArAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXACUAJQBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwAlACUAJQAlACUAJQAlACUAJQAlACUAVwBXACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQBXAFcAVwBXAFcAVwBXAFcAVwBXAFcAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAJQAlACUAKwAEACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArACsAKwArAA==';
-
- var LETTER_NUMBER_MODIFIER = 50;
- // Non-tailorable Line Breaking Classes
- var BK = 1; // Cause a line break (after)
- var CR$1 = 2; // Cause a line break (after), except between CR and LF
- var LF$1 = 3; // Cause a line break (after)
- var CM = 4; // Prohibit a line break between the character and the preceding character
- var NL = 5; // Cause a line break (after)
- var WJ = 7; // Prohibit line breaks before and after
- var ZW = 8; // Provide a break opportunity
- var GL = 9; // Prohibit line breaks before and after
- var SP = 10; // Enable indirect line breaks
- var ZWJ$1 = 11; // Prohibit line breaks within joiner sequences
- // Break Opportunities
- var B2 = 12; // Provide a line break opportunity before and after the character
- var BA = 13; // Generally provide a line break opportunity after the character
- var BB = 14; // Generally provide a line break opportunity before the character
- var HY = 15; // Provide a line break opportunity after the character, except in numeric context
- var CB = 16; // Provide a line break opportunity contingent on additional information
- // Characters Prohibiting Certain Breaks
- var CL = 17; // Prohibit line breaks before
- var CP = 18; // Prohibit line breaks before
- var EX = 19; // Prohibit line breaks before
- var IN = 20; // Allow only indirect line breaks between pairs
- var NS = 21; // Allow only indirect line breaks before
- var OP = 22; // Prohibit line breaks after
- var QU = 23; // Act like they are both opening and closing
- // Numeric Context
- var IS = 24; // Prevent breaks after any and before numeric
- var NU = 25; // Form numeric expressions for line breaking purposes
- var PO = 26; // Do not break following a numeric expression
- var PR = 27; // Do not break in front of a numeric expression
- var SY = 28; // Prevent a break before; and allow a break after
- // Other Characters
- var AI = 29; // Act like AL when the resolvedEAW is N; otherwise; act as ID
- var AL = 30; // Are alphabetic characters or symbols that are used with alphabetic characters
- var CJ = 31; // Treat as NS or ID for strict or normal breaking.
- var EB = 32; // Do not break from following Emoji Modifier
- var EM = 33; // Do not break from preceding Emoji Base
- var H2 = 34; // Form Korean syllable blocks
- var H3 = 35; // Form Korean syllable blocks
- var HL = 36; // Do not break around a following hyphen; otherwise act as Alphabetic
- var ID = 37; // Break before or after; except in some numeric context
- var JL = 38; // Form Korean syllable blocks
- var JV = 39; // Form Korean syllable blocks
- var JT = 40; // Form Korean syllable blocks
- var RI$1 = 41; // Keep pairs together. For pairs; break before and after other classes
- var SA = 42; // Provide a line break opportunity contingent on additional, language-specific context analysis
- var XX = 43; // Have as yet unknown line breaking behavior or unassigned code positions
- var ea_OP = [0x2329, 0xff08];
- var BREAK_MANDATORY = '!';
- var BREAK_NOT_ALLOWED$1 = '×';
- var BREAK_ALLOWED$1 = '÷';
- var UnicodeTrie$1 = createTrieFromBase64$1(base64$1);
- var ALPHABETICS = [AL, HL];
- var HARD_LINE_BREAKS = [BK, CR$1, LF$1, NL];
- var SPACE$1 = [SP, ZW];
- var PREFIX_POSTFIX = [PR, PO];
- var LINE_BREAKS = HARD_LINE_BREAKS.concat(SPACE$1);
- var KOREAN_SYLLABLE_BLOCK = [JL, JV, JT, H2, H3];
- var HYPHEN = [HY, BA];
- var codePointsToCharacterClasses = function (codePoints, lineBreak) {
- if (lineBreak === void 0) { lineBreak = 'strict'; }
- var types = [];
- var indices = [];
- var categories = [];
- codePoints.forEach(function (codePoint, index) {
- var classType = UnicodeTrie$1.get(codePoint);
- if (classType > LETTER_NUMBER_MODIFIER) {
- categories.push(true);
- classType -= LETTER_NUMBER_MODIFIER;
- }
- else {
- categories.push(false);
- }
- if (['normal', 'auto', 'loose'].indexOf(lineBreak) !== -1) {
- // U+2010, – U+2013, 〜 U+301C, ゠ U+30A0
- if ([0x2010, 0x2013, 0x301c, 0x30a0].indexOf(codePoint) !== -1) {
- indices.push(index);
- return types.push(CB);
- }
- }
- if (classType === CM || classType === ZWJ$1) {
- // LB10 Treat any remaining combining mark or ZWJ as AL.
- if (index === 0) {
- indices.push(index);
- return types.push(AL);
- }
- // LB9 Do not break a combining character sequence; treat it as if it has the line breaking class of
- // the base character in all of the following rules. Treat ZWJ as if it were CM.
- var prev = types[index - 1];
- if (LINE_BREAKS.indexOf(prev) === -1) {
- indices.push(indices[index - 1]);
- return types.push(prev);
- }
- indices.push(index);
- return types.push(AL);
- }
- indices.push(index);
- if (classType === CJ) {
- return types.push(lineBreak === 'strict' ? NS : ID);
- }
- if (classType === SA) {
- return types.push(AL);
- }
- if (classType === AI) {
- return types.push(AL);
- }
- // For supplementary characters, a useful default is to treat characters in the range 10000..1FFFD as AL
- // and characters in the ranges 20000..2FFFD and 30000..3FFFD as ID, until the implementation can be revised
- // to take into account the actual line breaking properties for these characters.
- if (classType === XX) {
- if ((codePoint >= 0x20000 && codePoint <= 0x2fffd) || (codePoint >= 0x30000 && codePoint <= 0x3fffd)) {
- return types.push(ID);
- }
- else {
- return types.push(AL);
- }
- }
- types.push(classType);
- });
- return [indices, types, categories];
- };
- var isAdjacentWithSpaceIgnored = function (a, b, currentIndex, classTypes) {
- var current = classTypes[currentIndex];
- if (Array.isArray(a) ? a.indexOf(current) !== -1 : a === current) {
- var i = currentIndex;
- while (i <= classTypes.length) {
- i++;
- var next = classTypes[i];
- if (next === b) {
- return true;
- }
- if (next !== SP) {
- break;
- }
- }
- }
- if (current === SP) {
- var i = currentIndex;
- while (i > 0) {
- i--;
- var prev = classTypes[i];
- if (Array.isArray(a) ? a.indexOf(prev) !== -1 : a === prev) {
- var n = currentIndex;
- while (n <= classTypes.length) {
- n++;
- var next = classTypes[n];
- if (next === b) {
- return true;
- }
- if (next !== SP) {
- break;
- }
- }
- }
- if (prev !== SP) {
- break;
- }
- }
- }
- return false;
- };
- var previousNonSpaceClassType = function (currentIndex, classTypes) {
- var i = currentIndex;
- while (i >= 0) {
- var type = classTypes[i];
- if (type === SP) {
- i--;
- }
- else {
- return type;
- }
- }
- return 0;
- };
- var _lineBreakAtIndex = function (codePoints, classTypes, indicies, index, forbiddenBreaks) {
- if (indicies[index] === 0) {
- return BREAK_NOT_ALLOWED$1;
- }
- var currentIndex = index - 1;
- if (Array.isArray(forbiddenBreaks) && forbiddenBreaks[currentIndex] === true) {
- return BREAK_NOT_ALLOWED$1;
- }
- var beforeIndex = currentIndex - 1;
- var afterIndex = currentIndex + 1;
- var current = classTypes[currentIndex];
- // LB4 Always break after hard line breaks.
- // LB5 Treat CR followed by LF, as well as CR, LF, and NL as hard line breaks.
- var before = beforeIndex >= 0 ? classTypes[beforeIndex] : 0;
- var next = classTypes[afterIndex];
- if (current === CR$1 && next === LF$1) {
- return BREAK_NOT_ALLOWED$1;
- }
- if (HARD_LINE_BREAKS.indexOf(current) !== -1) {
- return BREAK_MANDATORY;
- }
- // LB6 Do not break before hard line breaks.
- if (HARD_LINE_BREAKS.indexOf(next) !== -1) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB7 Do not break before spaces or zero width space.
- if (SPACE$1.indexOf(next) !== -1) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB8 Break before any character following a zero-width space, even if one or more spaces intervene.
- if (previousNonSpaceClassType(currentIndex, classTypes) === ZW) {
- return BREAK_ALLOWED$1;
- }
- // LB8a Do not break after a zero width joiner.
- if (UnicodeTrie$1.get(codePoints[currentIndex]) === ZWJ$1) {
- return BREAK_NOT_ALLOWED$1;
- }
- // zwj emojis
- if ((current === EB || current === EM) && UnicodeTrie$1.get(codePoints[afterIndex]) === ZWJ$1) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB11 Do not break before or after Word joiner and related characters.
- if (current === WJ || next === WJ) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB12 Do not break after NBSP and related characters.
- if (current === GL) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB12a Do not break before NBSP and related characters, except after spaces and hyphens.
- if ([SP, BA, HY].indexOf(current) === -1 && next === GL) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB13 Do not break before ‘]’ or ‘!’ or ‘;’ or ‘/’, even after spaces.
- if ([CL, CP, EX, IS, SY].indexOf(next) !== -1) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB14 Do not break after ‘[’, even after spaces.
- if (previousNonSpaceClassType(currentIndex, classTypes) === OP) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB15 Do not break within ‘”[’, even with intervening spaces.
- if (isAdjacentWithSpaceIgnored(QU, OP, currentIndex, classTypes)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB16 Do not break between closing punctuation and a nonstarter (lb=NS), even with intervening spaces.
- if (isAdjacentWithSpaceIgnored([CL, CP], NS, currentIndex, classTypes)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB17 Do not break within ‘——’, even with intervening spaces.
- if (isAdjacentWithSpaceIgnored(B2, B2, currentIndex, classTypes)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB18 Break after spaces.
- if (current === SP) {
- return BREAK_ALLOWED$1;
- }
- // LB19 Do not break before or after quotation marks, such as ‘ ” ’.
- if (current === QU || next === QU) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB20 Break before and after unresolved CB.
- if (next === CB || current === CB) {
- return BREAK_ALLOWED$1;
- }
- // LB21 Do not break before hyphen-minus, other hyphens, fixed-width spaces, small kana, and other non-starters, or after acute accents.
- if ([BA, HY, NS].indexOf(next) !== -1 || current === BB) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB21a Don't break after Hebrew + Hyphen.
- if (before === HL && HYPHEN.indexOf(current) !== -1) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB21b Don’t break between Solidus and Hebrew letters.
- if (current === SY && next === HL) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB22 Do not break before ellipsis.
- if (next === IN) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB23 Do not break between digits and letters.
- if ((ALPHABETICS.indexOf(next) !== -1 && current === NU) || (ALPHABETICS.indexOf(current) !== -1 && next === NU)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB23a Do not break between numeric prefixes and ideographs, or between ideographs and numeric postfixes.
- if ((current === PR && [ID, EB, EM].indexOf(next) !== -1) ||
- ([ID, EB, EM].indexOf(current) !== -1 && next === PO)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB24 Do not break between numeric prefix/postfix and letters, or between letters and prefix/postfix.
- if ((ALPHABETICS.indexOf(current) !== -1 && PREFIX_POSTFIX.indexOf(next) !== -1) ||
- (PREFIX_POSTFIX.indexOf(current) !== -1 && ALPHABETICS.indexOf(next) !== -1)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB25 Do not break between the following pairs of classes relevant to numbers:
- if (
- // (PR | PO) × ( OP | HY )? NU
- ([PR, PO].indexOf(current) !== -1 &&
- (next === NU || ([OP, HY].indexOf(next) !== -1 && classTypes[afterIndex + 1] === NU))) ||
- // ( OP | HY ) × NU
- ([OP, HY].indexOf(current) !== -1 && next === NU) ||
- // NU × (NU | SY | IS)
- (current === NU && [NU, SY, IS].indexOf(next) !== -1)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // NU (NU | SY | IS)* × (NU | SY | IS | CL | CP)
- if ([NU, SY, IS, CL, CP].indexOf(next) !== -1) {
- var prevIndex = currentIndex;
- while (prevIndex >= 0) {
- var type = classTypes[prevIndex];
- if (type === NU) {
- return BREAK_NOT_ALLOWED$1;
- }
- else if ([SY, IS].indexOf(type) !== -1) {
- prevIndex--;
- }
- else {
- break;
- }
- }
- }
- // NU (NU | SY | IS)* (CL | CP)? × (PO | PR))
- if ([PR, PO].indexOf(next) !== -1) {
- var prevIndex = [CL, CP].indexOf(current) !== -1 ? beforeIndex : currentIndex;
- while (prevIndex >= 0) {
- var type = classTypes[prevIndex];
- if (type === NU) {
- return BREAK_NOT_ALLOWED$1;
- }
- else if ([SY, IS].indexOf(type) !== -1) {
- prevIndex--;
- }
- else {
- break;
- }
- }
- }
- // LB26 Do not break a Korean syllable.
- if ((JL === current && [JL, JV, H2, H3].indexOf(next) !== -1) ||
- ([JV, H2].indexOf(current) !== -1 && [JV, JT].indexOf(next) !== -1) ||
- ([JT, H3].indexOf(current) !== -1 && next === JT)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB27 Treat a Korean Syllable Block the same as ID.
- if ((KOREAN_SYLLABLE_BLOCK.indexOf(current) !== -1 && [IN, PO].indexOf(next) !== -1) ||
- (KOREAN_SYLLABLE_BLOCK.indexOf(next) !== -1 && current === PR)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB28 Do not break between alphabetics (“at”).
- if (ALPHABETICS.indexOf(current) !== -1 && ALPHABETICS.indexOf(next) !== -1) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB29 Do not break between numeric punctuation and alphabetics (“e.g.”).
- if (current === IS && ALPHABETICS.indexOf(next) !== -1) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB30 Do not break between letters, numbers, or ordinary symbols and opening or closing parentheses.
- if ((ALPHABETICS.concat(NU).indexOf(current) !== -1 &&
- next === OP &&
- ea_OP.indexOf(codePoints[afterIndex]) === -1) ||
- (ALPHABETICS.concat(NU).indexOf(next) !== -1 && current === CP)) {
- return BREAK_NOT_ALLOWED$1;
- }
- // LB30a Break between two regional indicator symbols if and only if there are an even number of regional
- // indicators preceding the position of the break.
- if (current === RI$1 && next === RI$1) {
- var i = indicies[currentIndex];
- var count = 1;
- while (i > 0) {
- i--;
- if (classTypes[i] === RI$1) {
- count++;
- }
- else {
- break;
- }
- }
- if (count % 2 !== 0) {
- return BREAK_NOT_ALLOWED$1;
- }
- }
- // LB30b Do not break between an emoji base and an emoji modifier.
- if (current === EB && next === EM) {
- return BREAK_NOT_ALLOWED$1;
- }
- return BREAK_ALLOWED$1;
- };
- var cssFormattedClasses = function (codePoints, options) {
- if (!options) {
- options = { lineBreak: 'normal', wordBreak: 'normal' };
- }
- var _a = codePointsToCharacterClasses(codePoints, options.lineBreak), indicies = _a[0], classTypes = _a[1], isLetterNumber = _a[2];
- if (options.wordBreak === 'break-all' || options.wordBreak === 'break-word') {
- classTypes = classTypes.map(function (type) { return ([NU, AL, SA].indexOf(type) !== -1 ? ID : type); });
- }
- var forbiddenBreakpoints = options.wordBreak === 'keep-all'
- ? isLetterNumber.map(function (letterNumber, i) {
- return letterNumber && codePoints[i] >= 0x4e00 && codePoints[i] <= 0x9fff;
- })
- : undefined;
- return [indicies, classTypes, forbiddenBreakpoints];
- };
- var Break = /** @class */ (function () {
- function Break(codePoints, lineBreak, start, end) {
- this.codePoints = codePoints;
- this.required = lineBreak === BREAK_MANDATORY;
- this.start = start;
- this.end = end;
- }
- Break.prototype.slice = function () {
- return fromCodePoint$1.apply(void 0, this.codePoints.slice(this.start, this.end));
- };
- return Break;
- }());
- var LineBreaker = function (str, options) {
- var codePoints = toCodePoints$1(str);
- var _a = cssFormattedClasses(codePoints, options), indicies = _a[0], classTypes = _a[1], forbiddenBreakpoints = _a[2];
- var length = codePoints.length;
- var lastEnd = 0;
- var nextIndex = 0;
- return {
- next: function () {
- if (nextIndex >= length) {
- return { done: true, value: null };
- }
- var lineBreak = BREAK_NOT_ALLOWED$1;
- while (nextIndex < length &&
- (lineBreak = _lineBreakAtIndex(codePoints, classTypes, indicies, ++nextIndex, forbiddenBreakpoints)) ===
- BREAK_NOT_ALLOWED$1) { }
- if (lineBreak !== BREAK_NOT_ALLOWED$1 || nextIndex === length) {
- var value = new Break(codePoints, lineBreak, lastEnd, nextIndex);
- lastEnd = nextIndex;
- return { value: value, done: false };
- }
- return { done: true, value: null };
- },
- };
- };
-
- // https://www.w3.org/TR/css-syntax-3
- var FLAG_UNRESTRICTED = 1 << 0;
- var FLAG_ID = 1 << 1;
- var FLAG_INTEGER = 1 << 2;
- var FLAG_NUMBER = 1 << 3;
- var LINE_FEED = 0x000a;
- var SOLIDUS = 0x002f;
- var REVERSE_SOLIDUS = 0x005c;
- var CHARACTER_TABULATION = 0x0009;
- var SPACE = 0x0020;
- var QUOTATION_MARK = 0x0022;
- var EQUALS_SIGN = 0x003d;
- var NUMBER_SIGN = 0x0023;
- var DOLLAR_SIGN = 0x0024;
- var PERCENTAGE_SIGN = 0x0025;
- var APOSTROPHE = 0x0027;
- var LEFT_PARENTHESIS = 0x0028;
- var RIGHT_PARENTHESIS = 0x0029;
- var LOW_LINE = 0x005f;
- var HYPHEN_MINUS = 0x002d;
- var EXCLAMATION_MARK = 0x0021;
- var LESS_THAN_SIGN = 0x003c;
- var GREATER_THAN_SIGN = 0x003e;
- var COMMERCIAL_AT = 0x0040;
- var LEFT_SQUARE_BRACKET = 0x005b;
- var RIGHT_SQUARE_BRACKET = 0x005d;
- var CIRCUMFLEX_ACCENT = 0x003d;
- var LEFT_CURLY_BRACKET = 0x007b;
- var QUESTION_MARK = 0x003f;
- var RIGHT_CURLY_BRACKET = 0x007d;
- var VERTICAL_LINE = 0x007c;
- var TILDE = 0x007e;
- var CONTROL = 0x0080;
- var REPLACEMENT_CHARACTER = 0xfffd;
- var ASTERISK = 0x002a;
- var PLUS_SIGN = 0x002b;
- var COMMA = 0x002c;
- var COLON = 0x003a;
- var SEMICOLON = 0x003b;
- var FULL_STOP = 0x002e;
- var NULL = 0x0000;
- var BACKSPACE = 0x0008;
- var LINE_TABULATION = 0x000b;
- var SHIFT_OUT = 0x000e;
- var INFORMATION_SEPARATOR_ONE = 0x001f;
- var DELETE = 0x007f;
- var EOF = -1;
- var ZERO = 0x0030;
- var a = 0x0061;
- var e = 0x0065;
- var f = 0x0066;
- var u = 0x0075;
- var z = 0x007a;
- var A = 0x0041;
- var E = 0x0045;
- var F = 0x0046;
- var U = 0x0055;
- var Z = 0x005a;
- var isDigit = function (codePoint) { return codePoint >= ZERO && codePoint <= 0x0039; };
- var isSurrogateCodePoint = function (codePoint) { return codePoint >= 0xd800 && codePoint <= 0xdfff; };
- var isHex = function (codePoint) {
- return isDigit(codePoint) || (codePoint >= A && codePoint <= F) || (codePoint >= a && codePoint <= f);
- };
- var isLowerCaseLetter = function (codePoint) { return codePoint >= a && codePoint <= z; };
- var isUpperCaseLetter = function (codePoint) { return codePoint >= A && codePoint <= Z; };
- var isLetter = function (codePoint) { return isLowerCaseLetter(codePoint) || isUpperCaseLetter(codePoint); };
- var isNonASCIICodePoint = function (codePoint) { return codePoint >= CONTROL; };
- var isWhiteSpace = function (codePoint) {
- return codePoint === LINE_FEED || codePoint === CHARACTER_TABULATION || codePoint === SPACE;
- };
- var isNameStartCodePoint = function (codePoint) {
- return isLetter(codePoint) || isNonASCIICodePoint(codePoint) || codePoint === LOW_LINE;
- };
- var isNameCodePoint = function (codePoint) {
- return isNameStartCodePoint(codePoint) || isDigit(codePoint) || codePoint === HYPHEN_MINUS;
- };
- var isNonPrintableCodePoint = function (codePoint) {
- return ((codePoint >= NULL && codePoint <= BACKSPACE) ||
- codePoint === LINE_TABULATION ||
- (codePoint >= SHIFT_OUT && codePoint <= INFORMATION_SEPARATOR_ONE) ||
- codePoint === DELETE);
- };
- var isValidEscape = function (c1, c2) {
- if (c1 !== REVERSE_SOLIDUS) {
- return false;
- }
- return c2 !== LINE_FEED;
- };
- var isIdentifierStart = function (c1, c2, c3) {
- if (c1 === HYPHEN_MINUS) {
- return isNameStartCodePoint(c2) || isValidEscape(c2, c3);
- }
- else if (isNameStartCodePoint(c1)) {
- return true;
- }
- else if (c1 === REVERSE_SOLIDUS && isValidEscape(c1, c2)) {
- return true;
- }
- return false;
- };
- var isNumberStart = function (c1, c2, c3) {
- if (c1 === PLUS_SIGN || c1 === HYPHEN_MINUS) {
- if (isDigit(c2)) {
- return true;
- }
- return c2 === FULL_STOP && isDigit(c3);
- }
- if (c1 === FULL_STOP) {
- return isDigit(c2);
- }
- return isDigit(c1);
- };
- var stringToNumber = function (codePoints) {
- var c = 0;
- var sign = 1;
- if (codePoints[c] === PLUS_SIGN || codePoints[c] === HYPHEN_MINUS) {
- if (codePoints[c] === HYPHEN_MINUS) {
- sign = -1;
- }
- c++;
- }
- var integers = [];
- while (isDigit(codePoints[c])) {
- integers.push(codePoints[c++]);
- }
- var int = integers.length ? parseInt(fromCodePoint$1.apply(void 0, integers), 10) : 0;
- if (codePoints[c] === FULL_STOP) {
- c++;
- }
- var fraction = [];
- while (isDigit(codePoints[c])) {
- fraction.push(codePoints[c++]);
- }
- var fracd = fraction.length;
- var frac = fracd ? parseInt(fromCodePoint$1.apply(void 0, fraction), 10) : 0;
- if (codePoints[c] === E || codePoints[c] === e) {
- c++;
- }
- var expsign = 1;
- if (codePoints[c] === PLUS_SIGN || codePoints[c] === HYPHEN_MINUS) {
- if (codePoints[c] === HYPHEN_MINUS) {
- expsign = -1;
- }
- c++;
- }
- var exponent = [];
- while (isDigit(codePoints[c])) {
- exponent.push(codePoints[c++]);
- }
- var exp = exponent.length ? parseInt(fromCodePoint$1.apply(void 0, exponent), 10) : 0;
- return sign * (int + frac * Math.pow(10, -fracd)) * Math.pow(10, expsign * exp);
- };
- var LEFT_PARENTHESIS_TOKEN = {
- type: 2 /* LEFT_PARENTHESIS_TOKEN */
- };
- var RIGHT_PARENTHESIS_TOKEN = {
- type: 3 /* RIGHT_PARENTHESIS_TOKEN */
- };
- var COMMA_TOKEN = { type: 4 /* COMMA_TOKEN */ };
- var SUFFIX_MATCH_TOKEN = { type: 13 /* SUFFIX_MATCH_TOKEN */ };
- var PREFIX_MATCH_TOKEN = { type: 8 /* PREFIX_MATCH_TOKEN */ };
- var COLUMN_TOKEN = { type: 21 /* COLUMN_TOKEN */ };
- var DASH_MATCH_TOKEN = { type: 9 /* DASH_MATCH_TOKEN */ };
- var INCLUDE_MATCH_TOKEN = { type: 10 /* INCLUDE_MATCH_TOKEN */ };
- var LEFT_CURLY_BRACKET_TOKEN = {
- type: 11 /* LEFT_CURLY_BRACKET_TOKEN */
- };
- var RIGHT_CURLY_BRACKET_TOKEN = {
- type: 12 /* RIGHT_CURLY_BRACKET_TOKEN */
- };
- var SUBSTRING_MATCH_TOKEN = { type: 14 /* SUBSTRING_MATCH_TOKEN */ };
- var BAD_URL_TOKEN = { type: 23 /* BAD_URL_TOKEN */ };
- var BAD_STRING_TOKEN = { type: 1 /* BAD_STRING_TOKEN */ };
- var CDO_TOKEN = { type: 25 /* CDO_TOKEN */ };
- var CDC_TOKEN = { type: 24 /* CDC_TOKEN */ };
- var COLON_TOKEN = { type: 26 /* COLON_TOKEN */ };
- var SEMICOLON_TOKEN = { type: 27 /* SEMICOLON_TOKEN */ };
- var LEFT_SQUARE_BRACKET_TOKEN = {
- type: 28 /* LEFT_SQUARE_BRACKET_TOKEN */
- };
- var RIGHT_SQUARE_BRACKET_TOKEN = {
- type: 29 /* RIGHT_SQUARE_BRACKET_TOKEN */
- };
- var WHITESPACE_TOKEN = { type: 31 /* WHITESPACE_TOKEN */ };
- var EOF_TOKEN = { type: 32 /* EOF_TOKEN */ };
- var Tokenizer = /** @class */ (function () {
- function Tokenizer() {
- this._value = [];
- }
- Tokenizer.prototype.write = function (chunk) {
- this._value = this._value.concat(toCodePoints$1(chunk));
- };
- Tokenizer.prototype.read = function () {
- var tokens = [];
- var token = this.consumeToken();
- while (token !== EOF_TOKEN) {
- tokens.push(token);
- token = this.consumeToken();
- }
- return tokens;
- };
- Tokenizer.prototype.consumeToken = function () {
- var codePoint = this.consumeCodePoint();
- switch (codePoint) {
- case QUOTATION_MARK:
- return this.consumeStringToken(QUOTATION_MARK);
- case NUMBER_SIGN:
- var c1 = this.peekCodePoint(0);
- var c2 = this.peekCodePoint(1);
- var c3 = this.peekCodePoint(2);
- if (isNameCodePoint(c1) || isValidEscape(c2, c3)) {
- var flags = isIdentifierStart(c1, c2, c3) ? FLAG_ID : FLAG_UNRESTRICTED;
- var value = this.consumeName();
- return { type: 5 /* HASH_TOKEN */, value: value, flags: flags };
- }
- break;
- case DOLLAR_SIGN:
- if (this.peekCodePoint(0) === EQUALS_SIGN) {
- this.consumeCodePoint();
- return SUFFIX_MATCH_TOKEN;
- }
- break;
- case APOSTROPHE:
- return this.consumeStringToken(APOSTROPHE);
- case LEFT_PARENTHESIS:
- return LEFT_PARENTHESIS_TOKEN;
- case RIGHT_PARENTHESIS:
- return RIGHT_PARENTHESIS_TOKEN;
- case ASTERISK:
- if (this.peekCodePoint(0) === EQUALS_SIGN) {
- this.consumeCodePoint();
- return SUBSTRING_MATCH_TOKEN;
- }
- break;
- case PLUS_SIGN:
- if (isNumberStart(codePoint, this.peekCodePoint(0), this.peekCodePoint(1))) {
- this.reconsumeCodePoint(codePoint);
- return this.consumeNumericToken();
- }
- break;
- case COMMA:
- return COMMA_TOKEN;
- case HYPHEN_MINUS:
- var e1 = codePoint;
- var e2 = this.peekCodePoint(0);
- var e3 = this.peekCodePoint(1);
- if (isNumberStart(e1, e2, e3)) {
- this.reconsumeCodePoint(codePoint);
- return this.consumeNumericToken();
- }
- if (isIdentifierStart(e1, e2, e3)) {
- this.reconsumeCodePoint(codePoint);
- return this.consumeIdentLikeToken();
- }
- if (e2 === HYPHEN_MINUS && e3 === GREATER_THAN_SIGN) {
- this.consumeCodePoint();
- this.consumeCodePoint();
- return CDC_TOKEN;
- }
- break;
- case FULL_STOP:
- if (isNumberStart(codePoint, this.peekCodePoint(0), this.peekCodePoint(1))) {
- this.reconsumeCodePoint(codePoint);
- return this.consumeNumericToken();
- }
- break;
- case SOLIDUS:
- if (this.peekCodePoint(0) === ASTERISK) {
- this.consumeCodePoint();
- while (true) {
- var c = this.consumeCodePoint();
- if (c === ASTERISK) {
- c = this.consumeCodePoint();
- if (c === SOLIDUS) {
- return this.consumeToken();
- }
- }
- if (c === EOF) {
- return this.consumeToken();
- }
- }
- }
- break;
- case COLON:
- return COLON_TOKEN;
- case SEMICOLON:
- return SEMICOLON_TOKEN;
- case LESS_THAN_SIGN:
- if (this.peekCodePoint(0) === EXCLAMATION_MARK &&
- this.peekCodePoint(1) === HYPHEN_MINUS &&
- this.peekCodePoint(2) === HYPHEN_MINUS) {
- this.consumeCodePoint();
- this.consumeCodePoint();
- return CDO_TOKEN;
- }
- break;
- case COMMERCIAL_AT:
- var a1 = this.peekCodePoint(0);
- var a2 = this.peekCodePoint(1);
- var a3 = this.peekCodePoint(2);
- if (isIdentifierStart(a1, a2, a3)) {
- var value = this.consumeName();
- return { type: 7 /* AT_KEYWORD_TOKEN */, value: value };
- }
- break;
- case LEFT_SQUARE_BRACKET:
- return LEFT_SQUARE_BRACKET_TOKEN;
- case REVERSE_SOLIDUS:
- if (isValidEscape(codePoint, this.peekCodePoint(0))) {
- this.reconsumeCodePoint(codePoint);
- return this.consumeIdentLikeToken();
- }
- break;
- case RIGHT_SQUARE_BRACKET:
- return RIGHT_SQUARE_BRACKET_TOKEN;
- case CIRCUMFLEX_ACCENT:
- if (this.peekCodePoint(0) === EQUALS_SIGN) {
- this.consumeCodePoint();
- return PREFIX_MATCH_TOKEN;
- }
- break;
- case LEFT_CURLY_BRACKET:
- return LEFT_CURLY_BRACKET_TOKEN;
- case RIGHT_CURLY_BRACKET:
- return RIGHT_CURLY_BRACKET_TOKEN;
- case u:
- case U:
- var u1 = this.peekCodePoint(0);
- var u2 = this.peekCodePoint(1);
- if (u1 === PLUS_SIGN && (isHex(u2) || u2 === QUESTION_MARK)) {
- this.consumeCodePoint();
- this.consumeUnicodeRangeToken();
- }
- this.reconsumeCodePoint(codePoint);
- return this.consumeIdentLikeToken();
- case VERTICAL_LINE:
- if (this.peekCodePoint(0) === EQUALS_SIGN) {
- this.consumeCodePoint();
- return DASH_MATCH_TOKEN;
- }
- if (this.peekCodePoint(0) === VERTICAL_LINE) {
- this.consumeCodePoint();
- return COLUMN_TOKEN;
- }
- break;
- case TILDE:
- if (this.peekCodePoint(0) === EQUALS_SIGN) {
- this.consumeCodePoint();
- return INCLUDE_MATCH_TOKEN;
- }
- break;
- case EOF:
- return EOF_TOKEN;
- }
- if (isWhiteSpace(codePoint)) {
- this.consumeWhiteSpace();
- return WHITESPACE_TOKEN;
- }
- if (isDigit(codePoint)) {
- this.reconsumeCodePoint(codePoint);
- return this.consumeNumericToken();
- }
- if (isNameStartCodePoint(codePoint)) {
- this.reconsumeCodePoint(codePoint);
- return this.consumeIdentLikeToken();
- }
- return { type: 6 /* DELIM_TOKEN */, value: fromCodePoint$1(codePoint) };
- };
- Tokenizer.prototype.consumeCodePoint = function () {
- var value = this._value.shift();
- return typeof value === 'undefined' ? -1 : value;
- };
- Tokenizer.prototype.reconsumeCodePoint = function (codePoint) {
- this._value.unshift(codePoint);
- };
- Tokenizer.prototype.peekCodePoint = function (delta) {
- if (delta >= this._value.length) {
- return -1;
- }
- return this._value[delta];
- };
- Tokenizer.prototype.consumeUnicodeRangeToken = function () {
- var digits = [];
- var codePoint = this.consumeCodePoint();
- while (isHex(codePoint) && digits.length < 6) {
- digits.push(codePoint);
- codePoint = this.consumeCodePoint();
- }
- var questionMarks = false;
- while (codePoint === QUESTION_MARK && digits.length < 6) {
- digits.push(codePoint);
- codePoint = this.consumeCodePoint();
- questionMarks = true;
- }
- if (questionMarks) {
- var start_1 = parseInt(fromCodePoint$1.apply(void 0, digits.map(function (digit) { return (digit === QUESTION_MARK ? ZERO : digit); })), 16);
- var end = parseInt(fromCodePoint$1.apply(void 0, digits.map(function (digit) { return (digit === QUESTION_MARK ? F : digit); })), 16);
- return { type: 30 /* UNICODE_RANGE_TOKEN */, start: start_1, end: end };
- }
- var start = parseInt(fromCodePoint$1.apply(void 0, digits), 16);
- if (this.peekCodePoint(0) === HYPHEN_MINUS && isHex(this.peekCodePoint(1))) {
- this.consumeCodePoint();
- codePoint = this.consumeCodePoint();
- var endDigits = [];
- while (isHex(codePoint) && endDigits.length < 6) {
- endDigits.push(codePoint);
- codePoint = this.consumeCodePoint();
- }
- var end = parseInt(fromCodePoint$1.apply(void 0, endDigits), 16);
- return { type: 30 /* UNICODE_RANGE_TOKEN */, start: start, end: end };
- }
- else {
- return { type: 30 /* UNICODE_RANGE_TOKEN */, start: start, end: start };
- }
- };
- Tokenizer.prototype.consumeIdentLikeToken = function () {
- var value = this.consumeName();
- if (value.toLowerCase() === 'url' && this.peekCodePoint(0) === LEFT_PARENTHESIS) {
- this.consumeCodePoint();
- return this.consumeUrlToken();
- }
- else if (this.peekCodePoint(0) === LEFT_PARENTHESIS) {
- this.consumeCodePoint();
- return { type: 19 /* FUNCTION_TOKEN */, value: value };
- }
- return { type: 20 /* IDENT_TOKEN */, value: value };
- };
- Tokenizer.prototype.consumeUrlToken = function () {
- var value = [];
- this.consumeWhiteSpace();
- if (this.peekCodePoint(0) === EOF) {
- return { type: 22 /* URL_TOKEN */, value: '' };
- }
- var next = this.peekCodePoint(0);
- if (next === APOSTROPHE || next === QUOTATION_MARK) {
- var stringToken = this.consumeStringToken(this.consumeCodePoint());
- if (stringToken.type === 0 /* STRING_TOKEN */) {
- this.consumeWhiteSpace();
- if (this.peekCodePoint(0) === EOF || this.peekCodePoint(0) === RIGHT_PARENTHESIS) {
- this.consumeCodePoint();
- return { type: 22 /* URL_TOKEN */, value: stringToken.value };
- }
- }
- this.consumeBadUrlRemnants();
- return BAD_URL_TOKEN;
- }
- while (true) {
- var codePoint = this.consumeCodePoint();
- if (codePoint === EOF || codePoint === RIGHT_PARENTHESIS) {
- return { type: 22 /* URL_TOKEN */, value: fromCodePoint$1.apply(void 0, value) };
- }
- else if (isWhiteSpace(codePoint)) {
- this.consumeWhiteSpace();
- if (this.peekCodePoint(0) === EOF || this.peekCodePoint(0) === RIGHT_PARENTHESIS) {
- this.consumeCodePoint();
- return { type: 22 /* URL_TOKEN */, value: fromCodePoint$1.apply(void 0, value) };
- }
- this.consumeBadUrlRemnants();
- return BAD_URL_TOKEN;
- }
- else if (codePoint === QUOTATION_MARK ||
- codePoint === APOSTROPHE ||
- codePoint === LEFT_PARENTHESIS ||
- isNonPrintableCodePoint(codePoint)) {
- this.consumeBadUrlRemnants();
- return BAD_URL_TOKEN;
- }
- else if (codePoint === REVERSE_SOLIDUS) {
- if (isValidEscape(codePoint, this.peekCodePoint(0))) {
- value.push(this.consumeEscapedCodePoint());
- }
- else {
- this.consumeBadUrlRemnants();
- return BAD_URL_TOKEN;
- }
- }
- else {
- value.push(codePoint);
- }
- }
- };
- Tokenizer.prototype.consumeWhiteSpace = function () {
- while (isWhiteSpace(this.peekCodePoint(0))) {
- this.consumeCodePoint();
- }
- };
- Tokenizer.prototype.consumeBadUrlRemnants = function () {
- while (true) {
- var codePoint = this.consumeCodePoint();
- if (codePoint === RIGHT_PARENTHESIS || codePoint === EOF) {
- return;
- }
- if (isValidEscape(codePoint, this.peekCodePoint(0))) {
- this.consumeEscapedCodePoint();
- }
- }
- };
- Tokenizer.prototype.consumeStringSlice = function (count) {
- var SLICE_STACK_SIZE = 50000;
- var value = '';
- while (count > 0) {
- var amount = Math.min(SLICE_STACK_SIZE, count);
- value += fromCodePoint$1.apply(void 0, this._value.splice(0, amount));
- count -= amount;
- }
- this._value.shift();
- return value;
- };
- Tokenizer.prototype.consumeStringToken = function (endingCodePoint) {
- var value = '';
- var i = 0;
- do {
- var codePoint = this._value[i];
- if (codePoint === EOF || codePoint === undefined || codePoint === endingCodePoint) {
- value += this.consumeStringSlice(i);
- return { type: 0 /* STRING_TOKEN */, value: value };
- }
- if (codePoint === LINE_FEED) {
- this._value.splice(0, i);
- return BAD_STRING_TOKEN;
- }
- if (codePoint === REVERSE_SOLIDUS) {
- var next = this._value[i + 1];
- if (next !== EOF && next !== undefined) {
- if (next === LINE_FEED) {
- value += this.consumeStringSlice(i);
- i = -1;
- this._value.shift();
- }
- else if (isValidEscape(codePoint, next)) {
- value += this.consumeStringSlice(i);
- value += fromCodePoint$1(this.consumeEscapedCodePoint());
- i = -1;
- }
- }
- }
- i++;
- } while (true);
- };
- Tokenizer.prototype.consumeNumber = function () {
- var repr = [];
- var type = FLAG_INTEGER;
- var c1 = this.peekCodePoint(0);
- if (c1 === PLUS_SIGN || c1 === HYPHEN_MINUS) {
- repr.push(this.consumeCodePoint());
- }
- while (isDigit(this.peekCodePoint(0))) {
- repr.push(this.consumeCodePoint());
- }
- c1 = this.peekCodePoint(0);
- var c2 = this.peekCodePoint(1);
- if (c1 === FULL_STOP && isDigit(c2)) {
- repr.push(this.consumeCodePoint(), this.consumeCodePoint());
- type = FLAG_NUMBER;
- while (isDigit(this.peekCodePoint(0))) {
- repr.push(this.consumeCodePoint());
- }
- }
- c1 = this.peekCodePoint(0);
- c2 = this.peekCodePoint(1);
- var c3 = this.peekCodePoint(2);
- if ((c1 === E || c1 === e) && (((c2 === PLUS_SIGN || c2 === HYPHEN_MINUS) && isDigit(c3)) || isDigit(c2))) {
- repr.push(this.consumeCodePoint(), this.consumeCodePoint());
- type = FLAG_NUMBER;
- while (isDigit(this.peekCodePoint(0))) {
- repr.push(this.consumeCodePoint());
- }
- }
- return [stringToNumber(repr), type];
- };
- Tokenizer.prototype.consumeNumericToken = function () {
- var _a = this.consumeNumber(), number = _a[0], flags = _a[1];
- var c1 = this.peekCodePoint(0);
- var c2 = this.peekCodePoint(1);
- var c3 = this.peekCodePoint(2);
- if (isIdentifierStart(c1, c2, c3)) {
- var unit = this.consumeName();
- return { type: 15 /* DIMENSION_TOKEN */, number: number, flags: flags, unit: unit };
- }
- if (c1 === PERCENTAGE_SIGN) {
- this.consumeCodePoint();
- return { type: 16 /* PERCENTAGE_TOKEN */, number: number, flags: flags };
- }
- return { type: 17 /* NUMBER_TOKEN */, number: number, flags: flags };
- };
- Tokenizer.prototype.consumeEscapedCodePoint = function () {
- var codePoint = this.consumeCodePoint();
- if (isHex(codePoint)) {
- var hex = fromCodePoint$1(codePoint);
- while (isHex(this.peekCodePoint(0)) && hex.length < 6) {
- hex += fromCodePoint$1(this.consumeCodePoint());
- }
- if (isWhiteSpace(this.peekCodePoint(0))) {
- this.consumeCodePoint();
- }
- var hexCodePoint = parseInt(hex, 16);
- if (hexCodePoint === 0 || isSurrogateCodePoint(hexCodePoint) || hexCodePoint > 0x10ffff) {
- return REPLACEMENT_CHARACTER;
- }
- return hexCodePoint;
- }
- if (codePoint === EOF) {
- return REPLACEMENT_CHARACTER;
- }
- return codePoint;
- };
- Tokenizer.prototype.consumeName = function () {
- var result = '';
- while (true) {
- var codePoint = this.consumeCodePoint();
- if (isNameCodePoint(codePoint)) {
- result += fromCodePoint$1(codePoint);
- }
- else if (isValidEscape(codePoint, this.peekCodePoint(0))) {
- result += fromCodePoint$1(this.consumeEscapedCodePoint());
- }
- else {
- this.reconsumeCodePoint(codePoint);
- return result;
- }
- }
- };
- return Tokenizer;
- }());
-
- var Parser = /** @class */ (function () {
- function Parser(tokens) {
- this._tokens = tokens;
- }
- Parser.create = function (value) {
- var tokenizer = new Tokenizer();
- tokenizer.write(value);
- return new Parser(tokenizer.read());
- };
- Parser.parseValue = function (value) {
- return Parser.create(value).parseComponentValue();
- };
- Parser.parseValues = function (value) {
- return Parser.create(value).parseComponentValues();
- };
- Parser.prototype.parseComponentValue = function () {
- var token = this.consumeToken();
- while (token.type === 31 /* WHITESPACE_TOKEN */) {
- token = this.consumeToken();
- }
- if (token.type === 32 /* EOF_TOKEN */) {
- throw new SyntaxError("Error parsing CSS component value, unexpected EOF");
- }
- this.reconsumeToken(token);
- var value = this.consumeComponentValue();
- do {
- token = this.consumeToken();
- } while (token.type === 31 /* WHITESPACE_TOKEN */);
- if (token.type === 32 /* EOF_TOKEN */) {
- return value;
- }
- throw new SyntaxError("Error parsing CSS component value, multiple values found when expecting only one");
- };
- Parser.prototype.parseComponentValues = function () {
- var values = [];
- while (true) {
- var value = this.consumeComponentValue();
- if (value.type === 32 /* EOF_TOKEN */) {
- return values;
- }
- values.push(value);
- values.push();
- }
- };
- Parser.prototype.consumeComponentValue = function () {
- var token = this.consumeToken();
- switch (token.type) {
- case 11 /* LEFT_CURLY_BRACKET_TOKEN */:
- case 28 /* LEFT_SQUARE_BRACKET_TOKEN */:
- case 2 /* LEFT_PARENTHESIS_TOKEN */:
- return this.consumeSimpleBlock(token.type);
- case 19 /* FUNCTION_TOKEN */:
- return this.consumeFunction(token);
- }
- return token;
- };
- Parser.prototype.consumeSimpleBlock = function (type) {
- var block = { type: type, values: [] };
- var token = this.consumeToken();
- while (true) {
- if (token.type === 32 /* EOF_TOKEN */ || isEndingTokenFor(token, type)) {
- return block;
- }
- this.reconsumeToken(token);
- block.values.push(this.consumeComponentValue());
- token = this.consumeToken();
- }
- };
- Parser.prototype.consumeFunction = function (functionToken) {
- var cssFunction = {
- name: functionToken.value,
- values: [],
- type: 18 /* FUNCTION */
- };
- while (true) {
- var token = this.consumeToken();
- if (token.type === 32 /* EOF_TOKEN */ || token.type === 3 /* RIGHT_PARENTHESIS_TOKEN */) {
- return cssFunction;
- }
- this.reconsumeToken(token);
- cssFunction.values.push(this.consumeComponentValue());
- }
- };
- Parser.prototype.consumeToken = function () {
- var token = this._tokens.shift();
- return typeof token === 'undefined' ? EOF_TOKEN : token;
- };
- Parser.prototype.reconsumeToken = function (token) {
- this._tokens.unshift(token);
- };
- return Parser;
- }());
- var isDimensionToken = function (token) { return token.type === 15 /* DIMENSION_TOKEN */; };
- var isNumberToken = function (token) { return token.type === 17 /* NUMBER_TOKEN */; };
- var isIdentToken = function (token) { return token.type === 20 /* IDENT_TOKEN */; };
- var isStringToken = function (token) { return token.type === 0 /* STRING_TOKEN */; };
- var isIdentWithValue = function (token, value) {
- return isIdentToken(token) && token.value === value;
- };
- var nonWhiteSpace = function (token) { return token.type !== 31 /* WHITESPACE_TOKEN */; };
- var nonFunctionArgSeparator = function (token) {
- return token.type !== 31 /* WHITESPACE_TOKEN */ && token.type !== 4 /* COMMA_TOKEN */;
- };
- var parseFunctionArgs = function (tokens) {
- var args = [];
- var arg = [];
- tokens.forEach(function (token) {
- if (token.type === 4 /* COMMA_TOKEN */) {
- if (arg.length === 0) {
- throw new Error("Error parsing function args, zero tokens for arg");
- }
- args.push(arg);
- arg = [];
- return;
- }
- if (token.type !== 31 /* WHITESPACE_TOKEN */) {
- arg.push(token);
- }
- });
- if (arg.length) {
- args.push(arg);
- }
- return args;
- };
- var isEndingTokenFor = function (token, type) {
- if (type === 11 /* LEFT_CURLY_BRACKET_TOKEN */ && token.type === 12 /* RIGHT_CURLY_BRACKET_TOKEN */) {
- return true;
- }
- if (type === 28 /* LEFT_SQUARE_BRACKET_TOKEN */ && token.type === 29 /* RIGHT_SQUARE_BRACKET_TOKEN */) {
- return true;
- }
- return type === 2 /* LEFT_PARENTHESIS_TOKEN */ && token.type === 3 /* RIGHT_PARENTHESIS_TOKEN */;
- };
-
- var isLength = function (token) {
- return token.type === 17 /* NUMBER_TOKEN */ || token.type === 15 /* DIMENSION_TOKEN */;
- };
-
- var isLengthPercentage = function (token) {
- return token.type === 16 /* PERCENTAGE_TOKEN */ || isLength(token);
- };
- var parseLengthPercentageTuple = function (tokens) {
- return tokens.length > 1 ? [tokens[0], tokens[1]] : [tokens[0]];
- };
- var ZERO_LENGTH = {
- type: 17 /* NUMBER_TOKEN */,
- number: 0,
- flags: FLAG_INTEGER
- };
- var FIFTY_PERCENT = {
- type: 16 /* PERCENTAGE_TOKEN */,
- number: 50,
- flags: FLAG_INTEGER
- };
- var HUNDRED_PERCENT = {
- type: 16 /* PERCENTAGE_TOKEN */,
- number: 100,
- flags: FLAG_INTEGER
- };
- var getAbsoluteValueForTuple = function (tuple, width, height) {
- var x = tuple[0], y = tuple[1];
- return [getAbsoluteValue(x, width), getAbsoluteValue(typeof y !== 'undefined' ? y : x, height)];
- };
- var getAbsoluteValue = function (token, parent) {
- if (token.type === 16 /* PERCENTAGE_TOKEN */) {
- return (token.number / 100) * parent;
- }
- if (isDimensionToken(token)) {
- switch (token.unit) {
- case 'rem':
- case 'em':
- return 16 * token.number; // TODO use correct font-size
- case 'px':
- default:
- return token.number;
- }
- }
- return token.number;
- };
-
- var DEG = 'deg';
- var GRAD = 'grad';
- var RAD = 'rad';
- var TURN = 'turn';
- var angle = {
- name: 'angle',
- parse: function (_context, value) {
- if (value.type === 15 /* DIMENSION_TOKEN */) {
- switch (value.unit) {
- case DEG:
- return (Math.PI * value.number) / 180;
- case GRAD:
- return (Math.PI / 200) * value.number;
- case RAD:
- return value.number;
- case TURN:
- return Math.PI * 2 * value.number;
- }
- }
- throw new Error("Unsupported angle type");
- }
- };
- var isAngle = function (value) {
- if (value.type === 15 /* DIMENSION_TOKEN */) {
- if (value.unit === DEG || value.unit === GRAD || value.unit === RAD || value.unit === TURN) {
- return true;
- }
- }
- return false;
- };
- var parseNamedSide = function (tokens) {
- var sideOrCorner = tokens
- .filter(isIdentToken)
- .map(function (ident) { return ident.value; })
- .join(' ');
- switch (sideOrCorner) {
- case 'to bottom right':
- case 'to right bottom':
- case 'left top':
- case 'top left':
- return [ZERO_LENGTH, ZERO_LENGTH];
- case 'to top':
- case 'bottom':
- return deg(0);
- case 'to bottom left':
- case 'to left bottom':
- case 'right top':
- case 'top right':
- return [ZERO_LENGTH, HUNDRED_PERCENT];
- case 'to right':
- case 'left':
- return deg(90);
- case 'to top left':
- case 'to left top':
- case 'right bottom':
- case 'bottom right':
- return [HUNDRED_PERCENT, HUNDRED_PERCENT];
- case 'to bottom':
- case 'top':
- return deg(180);
- case 'to top right':
- case 'to right top':
- case 'left bottom':
- case 'bottom left':
- return [HUNDRED_PERCENT, ZERO_LENGTH];
- case 'to left':
- case 'right':
- return deg(270);
- }
- return 0;
- };
- var deg = function (deg) { return (Math.PI * deg) / 180; };
-
- var color$1 = {
- name: 'color',
- parse: function (context, value) {
- if (value.type === 18 /* FUNCTION */) {
- var colorFunction = SUPPORTED_COLOR_FUNCTIONS[value.name];
- if (typeof colorFunction === 'undefined') {
- throw new Error("Attempting to parse an unsupported color function \"" + value.name + "\"");
- }
- return colorFunction(context, value.values);
- }
- if (value.type === 5 /* HASH_TOKEN */) {
- if (value.value.length === 3) {
- var r = value.value.substring(0, 1);
- var g = value.value.substring(1, 2);
- var b = value.value.substring(2, 3);
- return pack(parseInt(r + r, 16), parseInt(g + g, 16), parseInt(b + b, 16), 1);
- }
- if (value.value.length === 4) {
- var r = value.value.substring(0, 1);
- var g = value.value.substring(1, 2);
- var b = value.value.substring(2, 3);
- var a = value.value.substring(3, 4);
- return pack(parseInt(r + r, 16), parseInt(g + g, 16), parseInt(b + b, 16), parseInt(a + a, 16) / 255);
- }
- if (value.value.length === 6) {
- var r = value.value.substring(0, 2);
- var g = value.value.substring(2, 4);
- var b = value.value.substring(4, 6);
- return pack(parseInt(r, 16), parseInt(g, 16), parseInt(b, 16), 1);
- }
- if (value.value.length === 8) {
- var r = value.value.substring(0, 2);
- var g = value.value.substring(2, 4);
- var b = value.value.substring(4, 6);
- var a = value.value.substring(6, 8);
- return pack(parseInt(r, 16), parseInt(g, 16), parseInt(b, 16), parseInt(a, 16) / 255);
- }
- }
- if (value.type === 20 /* IDENT_TOKEN */) {
- var namedColor = COLORS[value.value.toUpperCase()];
- if (typeof namedColor !== 'undefined') {
- return namedColor;
- }
- }
- return COLORS.TRANSPARENT;
- }
- };
- var isTransparent = function (color) { return (0xff & color) === 0; };
- var asString = function (color) {
- var alpha = 0xff & color;
- var blue = 0xff & (color >> 8);
- var green = 0xff & (color >> 16);
- var red = 0xff & (color >> 24);
- return alpha < 255 ? "rgba(" + red + "," + green + "," + blue + "," + alpha / 255 + ")" : "rgb(" + red + "," + green + "," + blue + ")";
- };
- var pack = function (r, g, b, a) {
- return ((r << 24) | (g << 16) | (b << 8) | (Math.round(a * 255) << 0)) >>> 0;
- };
- var getTokenColorValue = function (token, i) {
- if (token.type === 17 /* NUMBER_TOKEN */) {
- return token.number;
- }
- if (token.type === 16 /* PERCENTAGE_TOKEN */) {
- var max = i === 3 ? 1 : 255;
- return i === 3 ? (token.number / 100) * max : Math.round((token.number / 100) * max);
- }
- return 0;
- };
- var rgb = function (_context, args) {
- var tokens = args.filter(nonFunctionArgSeparator);
- if (tokens.length === 3) {
- var _a = tokens.map(getTokenColorValue), r = _a[0], g = _a[1], b = _a[2];
- return pack(r, g, b, 1);
- }
- if (tokens.length === 4) {
- var _b = tokens.map(getTokenColorValue), r = _b[0], g = _b[1], b = _b[2], a = _b[3];
- return pack(r, g, b, a);
- }
- return 0;
- };
- function hue2rgb(t1, t2, hue) {
- if (hue < 0) {
- hue += 1;
- }
- if (hue >= 1) {
- hue -= 1;
- }
- if (hue < 1 / 6) {
- return (t2 - t1) * hue * 6 + t1;
- }
- else if (hue < 1 / 2) {
- return t2;
- }
- else if (hue < 2 / 3) {
- return (t2 - t1) * 6 * (2 / 3 - hue) + t1;
- }
- else {
- return t1;
- }
- }
- var hsl = function (context, args) {
- var tokens = args.filter(nonFunctionArgSeparator);
- var hue = tokens[0], saturation = tokens[1], lightness = tokens[2], alpha = tokens[3];
- var h = (hue.type === 17 /* NUMBER_TOKEN */ ? deg(hue.number) : angle.parse(context, hue)) / (Math.PI * 2);
- var s = isLengthPercentage(saturation) ? saturation.number / 100 : 0;
- var l = isLengthPercentage(lightness) ? lightness.number / 100 : 0;
- var a = typeof alpha !== 'undefined' && isLengthPercentage(alpha) ? getAbsoluteValue(alpha, 1) : 1;
- if (s === 0) {
- return pack(l * 255, l * 255, l * 255, 1);
- }
- var t2 = l <= 0.5 ? l * (s + 1) : l + s - l * s;
- var t1 = l * 2 - t2;
- var r = hue2rgb(t1, t2, h + 1 / 3);
- var g = hue2rgb(t1, t2, h);
- var b = hue2rgb(t1, t2, h - 1 / 3);
- return pack(r * 255, g * 255, b * 255, a);
- };
- var SUPPORTED_COLOR_FUNCTIONS = {
- hsl: hsl,
- hsla: hsl,
- rgb: rgb,
- rgba: rgb
- };
- var parseColor = function (context, value) {
- return color$1.parse(context, Parser.create(value).parseComponentValue());
- };
- var COLORS = {
- ALICEBLUE: 0xf0f8ffff,
- ANTIQUEWHITE: 0xfaebd7ff,
- AQUA: 0x00ffffff,
- AQUAMARINE: 0x7fffd4ff,
- AZURE: 0xf0ffffff,
- BEIGE: 0xf5f5dcff,
- BISQUE: 0xffe4c4ff,
- BLACK: 0x000000ff,
- BLANCHEDALMOND: 0xffebcdff,
- BLUE: 0x0000ffff,
- BLUEVIOLET: 0x8a2be2ff,
- BROWN: 0xa52a2aff,
- BURLYWOOD: 0xdeb887ff,
- CADETBLUE: 0x5f9ea0ff,
- CHARTREUSE: 0x7fff00ff,
- CHOCOLATE: 0xd2691eff,
- CORAL: 0xff7f50ff,
- CORNFLOWERBLUE: 0x6495edff,
- CORNSILK: 0xfff8dcff,
- CRIMSON: 0xdc143cff,
- CYAN: 0x00ffffff,
- DARKBLUE: 0x00008bff,
- DARKCYAN: 0x008b8bff,
- DARKGOLDENROD: 0xb886bbff,
- DARKGRAY: 0xa9a9a9ff,
- DARKGREEN: 0x006400ff,
- DARKGREY: 0xa9a9a9ff,
- DARKKHAKI: 0xbdb76bff,
- DARKMAGENTA: 0x8b008bff,
- DARKOLIVEGREEN: 0x556b2fff,
- DARKORANGE: 0xff8c00ff,
- DARKORCHID: 0x9932ccff,
- DARKRED: 0x8b0000ff,
- DARKSALMON: 0xe9967aff,
- DARKSEAGREEN: 0x8fbc8fff,
- DARKSLATEBLUE: 0x483d8bff,
- DARKSLATEGRAY: 0x2f4f4fff,
- DARKSLATEGREY: 0x2f4f4fff,
- DARKTURQUOISE: 0x00ced1ff,
- DARKVIOLET: 0x9400d3ff,
- DEEPPINK: 0xff1493ff,
- DEEPSKYBLUE: 0x00bfffff,
- DIMGRAY: 0x696969ff,
- DIMGREY: 0x696969ff,
- DODGERBLUE: 0x1e90ffff,
- FIREBRICK: 0xb22222ff,
- FLORALWHITE: 0xfffaf0ff,
- FORESTGREEN: 0x228b22ff,
- FUCHSIA: 0xff00ffff,
- GAINSBORO: 0xdcdcdcff,
- GHOSTWHITE: 0xf8f8ffff,
- GOLD: 0xffd700ff,
- GOLDENROD: 0xdaa520ff,
- GRAY: 0x808080ff,
- GREEN: 0x008000ff,
- GREENYELLOW: 0xadff2fff,
- GREY: 0x808080ff,
- HONEYDEW: 0xf0fff0ff,
- HOTPINK: 0xff69b4ff,
- INDIANRED: 0xcd5c5cff,
- INDIGO: 0x4b0082ff,
- IVORY: 0xfffff0ff,
- KHAKI: 0xf0e68cff,
- LAVENDER: 0xe6e6faff,
- LAVENDERBLUSH: 0xfff0f5ff,
- LAWNGREEN: 0x7cfc00ff,
- LEMONCHIFFON: 0xfffacdff,
- LIGHTBLUE: 0xadd8e6ff,
- LIGHTCORAL: 0xf08080ff,
- LIGHTCYAN: 0xe0ffffff,
- LIGHTGOLDENRODYELLOW: 0xfafad2ff,
- LIGHTGRAY: 0xd3d3d3ff,
- LIGHTGREEN: 0x90ee90ff,
- LIGHTGREY: 0xd3d3d3ff,
- LIGHTPINK: 0xffb6c1ff,
- LIGHTSALMON: 0xffa07aff,
- LIGHTSEAGREEN: 0x20b2aaff,
- LIGHTSKYBLUE: 0x87cefaff,
- LIGHTSLATEGRAY: 0x778899ff,
- LIGHTSLATEGREY: 0x778899ff,
- LIGHTSTEELBLUE: 0xb0c4deff,
- LIGHTYELLOW: 0xffffe0ff,
- LIME: 0x00ff00ff,
- LIMEGREEN: 0x32cd32ff,
- LINEN: 0xfaf0e6ff,
- MAGENTA: 0xff00ffff,
- MAROON: 0x800000ff,
- MEDIUMAQUAMARINE: 0x66cdaaff,
- MEDIUMBLUE: 0x0000cdff,
- MEDIUMORCHID: 0xba55d3ff,
- MEDIUMPURPLE: 0x9370dbff,
- MEDIUMSEAGREEN: 0x3cb371ff,
- MEDIUMSLATEBLUE: 0x7b68eeff,
- MEDIUMSPRINGGREEN: 0x00fa9aff,
- MEDIUMTURQUOISE: 0x48d1ccff,
- MEDIUMVIOLETRED: 0xc71585ff,
- MIDNIGHTBLUE: 0x191970ff,
- MINTCREAM: 0xf5fffaff,
- MISTYROSE: 0xffe4e1ff,
- MOCCASIN: 0xffe4b5ff,
- NAVAJOWHITE: 0xffdeadff,
- NAVY: 0x000080ff,
- OLDLACE: 0xfdf5e6ff,
- OLIVE: 0x808000ff,
- OLIVEDRAB: 0x6b8e23ff,
- ORANGE: 0xffa500ff,
- ORANGERED: 0xff4500ff,
- ORCHID: 0xda70d6ff,
- PALEGOLDENROD: 0xeee8aaff,
- PALEGREEN: 0x98fb98ff,
- PALETURQUOISE: 0xafeeeeff,
- PALEVIOLETRED: 0xdb7093ff,
- PAPAYAWHIP: 0xffefd5ff,
- PEACHPUFF: 0xffdab9ff,
- PERU: 0xcd853fff,
- PINK: 0xffc0cbff,
- PLUM: 0xdda0ddff,
- POWDERBLUE: 0xb0e0e6ff,
- PURPLE: 0x800080ff,
- REBECCAPURPLE: 0x663399ff,
- RED: 0xff0000ff,
- ROSYBROWN: 0xbc8f8fff,
- ROYALBLUE: 0x4169e1ff,
- SADDLEBROWN: 0x8b4513ff,
- SALMON: 0xfa8072ff,
- SANDYBROWN: 0xf4a460ff,
- SEAGREEN: 0x2e8b57ff,
- SEASHELL: 0xfff5eeff,
- SIENNA: 0xa0522dff,
- SILVER: 0xc0c0c0ff,
- SKYBLUE: 0x87ceebff,
- SLATEBLUE: 0x6a5acdff,
- SLATEGRAY: 0x708090ff,
- SLATEGREY: 0x708090ff,
- SNOW: 0xfffafaff,
- SPRINGGREEN: 0x00ff7fff,
- STEELBLUE: 0x4682b4ff,
- TAN: 0xd2b48cff,
- TEAL: 0x008080ff,
- THISTLE: 0xd8bfd8ff,
- TOMATO: 0xff6347ff,
- TRANSPARENT: 0x00000000,
- TURQUOISE: 0x40e0d0ff,
- VIOLET: 0xee82eeff,
- WHEAT: 0xf5deb3ff,
- WHITE: 0xffffffff,
- WHITESMOKE: 0xf5f5f5ff,
- YELLOW: 0xffff00ff,
- YELLOWGREEN: 0x9acd32ff
- };
-
- var backgroundClip = {
- name: 'background-clip',
- initialValue: 'border-box',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- return tokens.map(function (token) {
- if (isIdentToken(token)) {
- switch (token.value) {
- case 'padding-box':
- return 1 /* PADDING_BOX */;
- case 'content-box':
- return 2 /* CONTENT_BOX */;
- }
- }
- return 0 /* BORDER_BOX */;
- });
- }
- };
-
- var backgroundColor = {
- name: "background-color",
- initialValue: 'transparent',
- prefix: false,
- type: 3 /* TYPE_VALUE */,
- format: 'color'
- };
-
- var parseColorStop = function (context, args) {
- var color = color$1.parse(context, args[0]);
- var stop = args[1];
- return stop && isLengthPercentage(stop) ? { color: color, stop: stop } : { color: color, stop: null };
- };
- var processColorStops = function (stops, lineLength) {
- var first = stops[0];
- var last = stops[stops.length - 1];
- if (first.stop === null) {
- first.stop = ZERO_LENGTH;
- }
- if (last.stop === null) {
- last.stop = HUNDRED_PERCENT;
- }
- var processStops = [];
- var previous = 0;
- for (var i = 0; i < stops.length; i++) {
- var stop_1 = stops[i].stop;
- if (stop_1 !== null) {
- var absoluteValue = getAbsoluteValue(stop_1, lineLength);
- if (absoluteValue > previous) {
- processStops.push(absoluteValue);
- }
- else {
- processStops.push(previous);
- }
- previous = absoluteValue;
- }
- else {
- processStops.push(null);
- }
- }
- var gapBegin = null;
- for (var i = 0; i < processStops.length; i++) {
- var stop_2 = processStops[i];
- if (stop_2 === null) {
- if (gapBegin === null) {
- gapBegin = i;
- }
- }
- else if (gapBegin !== null) {
- var gapLength = i - gapBegin;
- var beforeGap = processStops[gapBegin - 1];
- var gapValue = (stop_2 - beforeGap) / (gapLength + 1);
- for (var g = 1; g <= gapLength; g++) {
- processStops[gapBegin + g - 1] = gapValue * g;
- }
- gapBegin = null;
- }
- }
- return stops.map(function (_a, i) {
- var color = _a.color;
- return { color: color, stop: Math.max(Math.min(1, processStops[i] / lineLength), 0) };
- });
- };
- var getAngleFromCorner = function (corner, width, height) {
- var centerX = width / 2;
- var centerY = height / 2;
- var x = getAbsoluteValue(corner[0], width) - centerX;
- var y = centerY - getAbsoluteValue(corner[1], height);
- return (Math.atan2(y, x) + Math.PI * 2) % (Math.PI * 2);
- };
- var calculateGradientDirection = function (angle, width, height) {
- var radian = typeof angle === 'number' ? angle : getAngleFromCorner(angle, width, height);
- var lineLength = Math.abs(width * Math.sin(radian)) + Math.abs(height * Math.cos(radian));
- var halfWidth = width / 2;
- var halfHeight = height / 2;
- var halfLineLength = lineLength / 2;
- var yDiff = Math.sin(radian - Math.PI / 2) * halfLineLength;
- var xDiff = Math.cos(radian - Math.PI / 2) * halfLineLength;
- return [lineLength, halfWidth - xDiff, halfWidth + xDiff, halfHeight - yDiff, halfHeight + yDiff];
- };
- var distance = function (a, b) { return Math.sqrt(a * a + b * b); };
- var findCorner = function (width, height, x, y, closest) {
- var corners = [
- [0, 0],
- [0, height],
- [width, 0],
- [width, height]
- ];
- return corners.reduce(function (stat, corner) {
- var cx = corner[0], cy = corner[1];
- var d = distance(x - cx, y - cy);
- if (closest ? d < stat.optimumDistance : d > stat.optimumDistance) {
- return {
- optimumCorner: corner,
- optimumDistance: d
- };
- }
- return stat;
- }, {
- optimumDistance: closest ? Infinity : -Infinity,
- optimumCorner: null
- }).optimumCorner;
- };
- var calculateRadius = function (gradient, x, y, width, height) {
- var rx = 0;
- var ry = 0;
- switch (gradient.size) {
- case 0 /* CLOSEST_SIDE */:
- // The ending shape is sized so that that it exactly meets the side of the gradient box closest to the gradient’s center.
- // If the shape is an ellipse, it exactly meets the closest side in each dimension.
- if (gradient.shape === 0 /* CIRCLE */) {
- rx = ry = Math.min(Math.abs(x), Math.abs(x - width), Math.abs(y), Math.abs(y - height));
- }
- else if (gradient.shape === 1 /* ELLIPSE */) {
- rx = Math.min(Math.abs(x), Math.abs(x - width));
- ry = Math.min(Math.abs(y), Math.abs(y - height));
- }
- break;
- case 2 /* CLOSEST_CORNER */:
- // The ending shape is sized so that that it passes through the corner of the gradient box closest to the gradient’s center.
- // If the shape is an ellipse, the ending shape is given the same aspect-ratio it would have if closest-side were specified.
- if (gradient.shape === 0 /* CIRCLE */) {
- rx = ry = Math.min(distance(x, y), distance(x, y - height), distance(x - width, y), distance(x - width, y - height));
- }
- else if (gradient.shape === 1 /* ELLIPSE */) {
- // Compute the ratio ry/rx (which is to be the same as for "closest-side")
- var c = Math.min(Math.abs(y), Math.abs(y - height)) / Math.min(Math.abs(x), Math.abs(x - width));
- var _a = findCorner(width, height, x, y, true), cx = _a[0], cy = _a[1];
- rx = distance(cx - x, (cy - y) / c);
- ry = c * rx;
- }
- break;
- case 1 /* FARTHEST_SIDE */:
- // Same as closest-side, except the ending shape is sized based on the farthest side(s)
- if (gradient.shape === 0 /* CIRCLE */) {
- rx = ry = Math.max(Math.abs(x), Math.abs(x - width), Math.abs(y), Math.abs(y - height));
- }
- else if (gradient.shape === 1 /* ELLIPSE */) {
- rx = Math.max(Math.abs(x), Math.abs(x - width));
- ry = Math.max(Math.abs(y), Math.abs(y - height));
- }
- break;
- case 3 /* FARTHEST_CORNER */:
- // Same as closest-corner, except the ending shape is sized based on the farthest corner.
- // If the shape is an ellipse, the ending shape is given the same aspect ratio it would have if farthest-side were specified.
- if (gradient.shape === 0 /* CIRCLE */) {
- rx = ry = Math.max(distance(x, y), distance(x, y - height), distance(x - width, y), distance(x - width, y - height));
- }
- else if (gradient.shape === 1 /* ELLIPSE */) {
- // Compute the ratio ry/rx (which is to be the same as for "farthest-side")
- var c = Math.max(Math.abs(y), Math.abs(y - height)) / Math.max(Math.abs(x), Math.abs(x - width));
- var _b = findCorner(width, height, x, y, false), cx = _b[0], cy = _b[1];
- rx = distance(cx - x, (cy - y) / c);
- ry = c * rx;
- }
- break;
- }
- if (Array.isArray(gradient.size)) {
- rx = getAbsoluteValue(gradient.size[0], width);
- ry = gradient.size.length === 2 ? getAbsoluteValue(gradient.size[1], height) : rx;
- }
- return [rx, ry];
- };
-
- var linearGradient = function (context, tokens) {
- var angle$1 = deg(180);
- var stops = [];
- parseFunctionArgs(tokens).forEach(function (arg, i) {
- if (i === 0) {
- var firstToken = arg[0];
- if (firstToken.type === 20 /* IDENT_TOKEN */ && firstToken.value === 'to') {
- angle$1 = parseNamedSide(arg);
- return;
- }
- else if (isAngle(firstToken)) {
- angle$1 = angle.parse(context, firstToken);
- return;
- }
- }
- var colorStop = parseColorStop(context, arg);
- stops.push(colorStop);
- });
- return { angle: angle$1, stops: stops, type: 1 /* LINEAR_GRADIENT */ };
- };
-
- var prefixLinearGradient = function (context, tokens) {
- var angle$1 = deg(180);
- var stops = [];
- parseFunctionArgs(tokens).forEach(function (arg, i) {
- if (i === 0) {
- var firstToken = arg[0];
- if (firstToken.type === 20 /* IDENT_TOKEN */ &&
- ['top', 'left', 'right', 'bottom'].indexOf(firstToken.value) !== -1) {
- angle$1 = parseNamedSide(arg);
- return;
- }
- else if (isAngle(firstToken)) {
- angle$1 = (angle.parse(context, firstToken) + deg(270)) % deg(360);
- return;
- }
- }
- var colorStop = parseColorStop(context, arg);
- stops.push(colorStop);
- });
- return {
- angle: angle$1,
- stops: stops,
- type: 1 /* LINEAR_GRADIENT */
- };
- };
-
- var webkitGradient = function (context, tokens) {
- var angle = deg(180);
- var stops = [];
- var type = 1 /* LINEAR_GRADIENT */;
- var shape = 0 /* CIRCLE */;
- var size = 3 /* FARTHEST_CORNER */;
- var position = [];
- parseFunctionArgs(tokens).forEach(function (arg, i) {
- var firstToken = arg[0];
- if (i === 0) {
- if (isIdentToken(firstToken) && firstToken.value === 'linear') {
- type = 1 /* LINEAR_GRADIENT */;
- return;
- }
- else if (isIdentToken(firstToken) && firstToken.value === 'radial') {
- type = 2 /* RADIAL_GRADIENT */;
- return;
- }
- }
- if (firstToken.type === 18 /* FUNCTION */) {
- if (firstToken.name === 'from') {
- var color = color$1.parse(context, firstToken.values[0]);
- stops.push({ stop: ZERO_LENGTH, color: color });
- }
- else if (firstToken.name === 'to') {
- var color = color$1.parse(context, firstToken.values[0]);
- stops.push({ stop: HUNDRED_PERCENT, color: color });
- }
- else if (firstToken.name === 'color-stop') {
- var values = firstToken.values.filter(nonFunctionArgSeparator);
- if (values.length === 2) {
- var color = color$1.parse(context, values[1]);
- var stop_1 = values[0];
- if (isNumberToken(stop_1)) {
- stops.push({
- stop: { type: 16 /* PERCENTAGE_TOKEN */, number: stop_1.number * 100, flags: stop_1.flags },
- color: color
- });
- }
- }
- }
- }
- });
- return type === 1 /* LINEAR_GRADIENT */
- ? {
- angle: (angle + deg(180)) % deg(360),
- stops: stops,
- type: type
- }
- : { size: size, shape: shape, stops: stops, position: position, type: type };
- };
-
- var CLOSEST_SIDE = 'closest-side';
- var FARTHEST_SIDE = 'farthest-side';
- var CLOSEST_CORNER = 'closest-corner';
- var FARTHEST_CORNER = 'farthest-corner';
- var CIRCLE = 'circle';
- var ELLIPSE = 'ellipse';
- var COVER = 'cover';
- var CONTAIN = 'contain';
- var radialGradient = function (context, tokens) {
- var shape = 0 /* CIRCLE */;
- var size = 3 /* FARTHEST_CORNER */;
- var stops = [];
- var position = [];
- parseFunctionArgs(tokens).forEach(function (arg, i) {
- var isColorStop = true;
- if (i === 0) {
- var isAtPosition_1 = false;
- isColorStop = arg.reduce(function (acc, token) {
- if (isAtPosition_1) {
- if (isIdentToken(token)) {
- switch (token.value) {
- case 'center':
- position.push(FIFTY_PERCENT);
- return acc;
- case 'top':
- case 'left':
- position.push(ZERO_LENGTH);
- return acc;
- case 'right':
- case 'bottom':
- position.push(HUNDRED_PERCENT);
- return acc;
- }
- }
- else if (isLengthPercentage(token) || isLength(token)) {
- position.push(token);
- }
- }
- else if (isIdentToken(token)) {
- switch (token.value) {
- case CIRCLE:
- shape = 0 /* CIRCLE */;
- return false;
- case ELLIPSE:
- shape = 1 /* ELLIPSE */;
- return false;
- case 'at':
- isAtPosition_1 = true;
- return false;
- case CLOSEST_SIDE:
- size = 0 /* CLOSEST_SIDE */;
- return false;
- case COVER:
- case FARTHEST_SIDE:
- size = 1 /* FARTHEST_SIDE */;
- return false;
- case CONTAIN:
- case CLOSEST_CORNER:
- size = 2 /* CLOSEST_CORNER */;
- return false;
- case FARTHEST_CORNER:
- size = 3 /* FARTHEST_CORNER */;
- return false;
- }
- }
- else if (isLength(token) || isLengthPercentage(token)) {
- if (!Array.isArray(size)) {
- size = [];
- }
- size.push(token);
- return false;
- }
- return acc;
- }, isColorStop);
- }
- if (isColorStop) {
- var colorStop = parseColorStop(context, arg);
- stops.push(colorStop);
- }
- });
- return { size: size, shape: shape, stops: stops, position: position, type: 2 /* RADIAL_GRADIENT */ };
- };
-
- var prefixRadialGradient = function (context, tokens) {
- var shape = 0 /* CIRCLE */;
- var size = 3 /* FARTHEST_CORNER */;
- var stops = [];
- var position = [];
- parseFunctionArgs(tokens).forEach(function (arg, i) {
- var isColorStop = true;
- if (i === 0) {
- isColorStop = arg.reduce(function (acc, token) {
- if (isIdentToken(token)) {
- switch (token.value) {
- case 'center':
- position.push(FIFTY_PERCENT);
- return false;
- case 'top':
- case 'left':
- position.push(ZERO_LENGTH);
- return false;
- case 'right':
- case 'bottom':
- position.push(HUNDRED_PERCENT);
- return false;
- }
- }
- else if (isLengthPercentage(token) || isLength(token)) {
- position.push(token);
- return false;
- }
- return acc;
- }, isColorStop);
- }
- else if (i === 1) {
- isColorStop = arg.reduce(function (acc, token) {
- if (isIdentToken(token)) {
- switch (token.value) {
- case CIRCLE:
- shape = 0 /* CIRCLE */;
- return false;
- case ELLIPSE:
- shape = 1 /* ELLIPSE */;
- return false;
- case CONTAIN:
- case CLOSEST_SIDE:
- size = 0 /* CLOSEST_SIDE */;
- return false;
- case FARTHEST_SIDE:
- size = 1 /* FARTHEST_SIDE */;
- return false;
- case CLOSEST_CORNER:
- size = 2 /* CLOSEST_CORNER */;
- return false;
- case COVER:
- case FARTHEST_CORNER:
- size = 3 /* FARTHEST_CORNER */;
- return false;
- }
- }
- else if (isLength(token) || isLengthPercentage(token)) {
- if (!Array.isArray(size)) {
- size = [];
- }
- size.push(token);
- return false;
- }
- return acc;
- }, isColorStop);
- }
- if (isColorStop) {
- var colorStop = parseColorStop(context, arg);
- stops.push(colorStop);
- }
- });
- return { size: size, shape: shape, stops: stops, position: position, type: 2 /* RADIAL_GRADIENT */ };
- };
-
- var isLinearGradient = function (background) {
- return background.type === 1 /* LINEAR_GRADIENT */;
- };
- var isRadialGradient = function (background) {
- return background.type === 2 /* RADIAL_GRADIENT */;
- };
- var image = {
- name: 'image',
- parse: function (context, value) {
- if (value.type === 22 /* URL_TOKEN */) {
- var image_1 = { url: value.value, type: 0 /* URL */ };
- context.cache.addImage(value.value);
- return image_1;
- }
- if (value.type === 18 /* FUNCTION */) {
- var imageFunction = SUPPORTED_IMAGE_FUNCTIONS[value.name];
- if (typeof imageFunction === 'undefined') {
- throw new Error("Attempting to parse an unsupported image function \"" + value.name + "\"");
- }
- return imageFunction(context, value.values);
- }
- throw new Error("Unsupported image type " + value.type);
- }
- };
- function isSupportedImage(value) {
- return (!(value.type === 20 /* IDENT_TOKEN */ && value.value === 'none') &&
- (value.type !== 18 /* FUNCTION */ || !!SUPPORTED_IMAGE_FUNCTIONS[value.name]));
- }
- var SUPPORTED_IMAGE_FUNCTIONS = {
- 'linear-gradient': linearGradient,
- '-moz-linear-gradient': prefixLinearGradient,
- '-ms-linear-gradient': prefixLinearGradient,
- '-o-linear-gradient': prefixLinearGradient,
- '-webkit-linear-gradient': prefixLinearGradient,
- 'radial-gradient': radialGradient,
- '-moz-radial-gradient': prefixRadialGradient,
- '-ms-radial-gradient': prefixRadialGradient,
- '-o-radial-gradient': prefixRadialGradient,
- '-webkit-radial-gradient': prefixRadialGradient,
- '-webkit-gradient': webkitGradient
- };
-
- var backgroundImage = {
- name: 'background-image',
- initialValue: 'none',
- type: 1 /* LIST */,
- prefix: false,
- parse: function (context, tokens) {
- if (tokens.length === 0) {
- return [];
- }
- var first = tokens[0];
- if (first.type === 20 /* IDENT_TOKEN */ && first.value === 'none') {
- return [];
- }
- return tokens
- .filter(function (value) { return nonFunctionArgSeparator(value) && isSupportedImage(value); })
- .map(function (value) { return image.parse(context, value); });
- }
- };
-
- var backgroundOrigin = {
- name: 'background-origin',
- initialValue: 'border-box',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- return tokens.map(function (token) {
- if (isIdentToken(token)) {
- switch (token.value) {
- case 'padding-box':
- return 1 /* PADDING_BOX */;
- case 'content-box':
- return 2 /* CONTENT_BOX */;
- }
- }
- return 0 /* BORDER_BOX */;
- });
- }
- };
-
- var backgroundPosition = {
- name: 'background-position',
- initialValue: '0% 0%',
- type: 1 /* LIST */,
- prefix: false,
- parse: function (_context, tokens) {
- return parseFunctionArgs(tokens)
- .map(function (values) { return values.filter(isLengthPercentage); })
- .map(parseLengthPercentageTuple);
- }
- };
-
- var backgroundRepeat = {
- name: 'background-repeat',
- initialValue: 'repeat',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- return parseFunctionArgs(tokens)
- .map(function (values) {
- return values
- .filter(isIdentToken)
- .map(function (token) { return token.value; })
- .join(' ');
- })
- .map(parseBackgroundRepeat);
- }
- };
- var parseBackgroundRepeat = function (value) {
- switch (value) {
- case 'no-repeat':
- return 1 /* NO_REPEAT */;
- case 'repeat-x':
- case 'repeat no-repeat':
- return 2 /* REPEAT_X */;
- case 'repeat-y':
- case 'no-repeat repeat':
- return 3 /* REPEAT_Y */;
- case 'repeat':
- default:
- return 0 /* REPEAT */;
- }
- };
-
- var BACKGROUND_SIZE;
- (function (BACKGROUND_SIZE) {
- BACKGROUND_SIZE["AUTO"] = "auto";
- BACKGROUND_SIZE["CONTAIN"] = "contain";
- BACKGROUND_SIZE["COVER"] = "cover";
- })(BACKGROUND_SIZE || (BACKGROUND_SIZE = {}));
- var backgroundSize = {
- name: 'background-size',
- initialValue: '0',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- return parseFunctionArgs(tokens).map(function (values) { return values.filter(isBackgroundSizeInfoToken); });
- }
- };
- var isBackgroundSizeInfoToken = function (value) {
- return isIdentToken(value) || isLengthPercentage(value);
- };
-
- var borderColorForSide = function (side) { return ({
- name: "border-" + side + "-color",
- initialValue: 'transparent',
- prefix: false,
- type: 3 /* TYPE_VALUE */,
- format: 'color'
- }); };
- var borderTopColor = borderColorForSide('top');
- var borderRightColor = borderColorForSide('right');
- var borderBottomColor = borderColorForSide('bottom');
- var borderLeftColor = borderColorForSide('left');
-
- var borderRadiusForSide = function (side) { return ({
- name: "border-radius-" + side,
- initialValue: '0 0',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- return parseLengthPercentageTuple(tokens.filter(isLengthPercentage));
- }
- }); };
- var borderTopLeftRadius = borderRadiusForSide('top-left');
- var borderTopRightRadius = borderRadiusForSide('top-right');
- var borderBottomRightRadius = borderRadiusForSide('bottom-right');
- var borderBottomLeftRadius = borderRadiusForSide('bottom-left');
-
- var borderStyleForSide = function (side) { return ({
- name: "border-" + side + "-style",
- initialValue: 'solid',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, style) {
- switch (style) {
- case 'none':
- return 0 /* NONE */;
- case 'dashed':
- return 2 /* DASHED */;
- case 'dotted':
- return 3 /* DOTTED */;
- case 'double':
- return 4 /* DOUBLE */;
- }
- return 1 /* SOLID */;
- }
- }); };
- var borderTopStyle = borderStyleForSide('top');
- var borderRightStyle = borderStyleForSide('right');
- var borderBottomStyle = borderStyleForSide('bottom');
- var borderLeftStyle = borderStyleForSide('left');
-
- var borderWidthForSide = function (side) { return ({
- name: "border-" + side + "-width",
- initialValue: '0',
- type: 0 /* VALUE */,
- prefix: false,
- parse: function (_context, token) {
- if (isDimensionToken(token)) {
- return token.number;
- }
- return 0;
- }
- }); };
- var borderTopWidth = borderWidthForSide('top');
- var borderRightWidth = borderWidthForSide('right');
- var borderBottomWidth = borderWidthForSide('bottom');
- var borderLeftWidth = borderWidthForSide('left');
-
- var color = {
- name: "color",
- initialValue: 'transparent',
- prefix: false,
- type: 3 /* TYPE_VALUE */,
- format: 'color'
- };
-
- var direction = {
- name: 'direction',
- initialValue: 'ltr',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, direction) {
- switch (direction) {
- case 'rtl':
- return 1 /* RTL */;
- case 'ltr':
- default:
- return 0 /* LTR */;
- }
- }
- };
-
- var display = {
- name: 'display',
- initialValue: 'inline-block',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- return tokens.filter(isIdentToken).reduce(function (bit, token) {
- return bit | parseDisplayValue(token.value);
- }, 0 /* NONE */);
- }
- };
- var parseDisplayValue = function (display) {
- switch (display) {
- case 'block':
- case '-webkit-box':
- return 2 /* BLOCK */;
- case 'inline':
- return 4 /* INLINE */;
- case 'run-in':
- return 8 /* RUN_IN */;
- case 'flow':
- return 16 /* FLOW */;
- case 'flow-root':
- return 32 /* FLOW_ROOT */;
- case 'table':
- return 64 /* TABLE */;
- case 'flex':
- case '-webkit-flex':
- return 128 /* FLEX */;
- case 'grid':
- case '-ms-grid':
- return 256 /* GRID */;
- case 'ruby':
- return 512 /* RUBY */;
- case 'subgrid':
- return 1024 /* SUBGRID */;
- case 'list-item':
- return 2048 /* LIST_ITEM */;
- case 'table-row-group':
- return 4096 /* TABLE_ROW_GROUP */;
- case 'table-header-group':
- return 8192 /* TABLE_HEADER_GROUP */;
- case 'table-footer-group':
- return 16384 /* TABLE_FOOTER_GROUP */;
- case 'table-row':
- return 32768 /* TABLE_ROW */;
- case 'table-cell':
- return 65536 /* TABLE_CELL */;
- case 'table-column-group':
- return 131072 /* TABLE_COLUMN_GROUP */;
- case 'table-column':
- return 262144 /* TABLE_COLUMN */;
- case 'table-caption':
- return 524288 /* TABLE_CAPTION */;
- case 'ruby-base':
- return 1048576 /* RUBY_BASE */;
- case 'ruby-text':
- return 2097152 /* RUBY_TEXT */;
- case 'ruby-base-container':
- return 4194304 /* RUBY_BASE_CONTAINER */;
- case 'ruby-text-container':
- return 8388608 /* RUBY_TEXT_CONTAINER */;
- case 'contents':
- return 16777216 /* CONTENTS */;
- case 'inline-block':
- return 33554432 /* INLINE_BLOCK */;
- case 'inline-list-item':
- return 67108864 /* INLINE_LIST_ITEM */;
- case 'inline-table':
- return 134217728 /* INLINE_TABLE */;
- case 'inline-flex':
- return 268435456 /* INLINE_FLEX */;
- case 'inline-grid':
- return 536870912 /* INLINE_GRID */;
- }
- return 0 /* NONE */;
- };
-
- var float = {
- name: 'float',
- initialValue: 'none',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, float) {
- switch (float) {
- case 'left':
- return 1 /* LEFT */;
- case 'right':
- return 2 /* RIGHT */;
- case 'inline-start':
- return 3 /* INLINE_START */;
- case 'inline-end':
- return 4 /* INLINE_END */;
- }
- return 0 /* NONE */;
- }
- };
-
- var letterSpacing = {
- name: 'letter-spacing',
- initialValue: '0',
- prefix: false,
- type: 0 /* VALUE */,
- parse: function (_context, token) {
- if (token.type === 20 /* IDENT_TOKEN */ && token.value === 'normal') {
- return 0;
- }
- if (token.type === 17 /* NUMBER_TOKEN */) {
- return token.number;
- }
- if (token.type === 15 /* DIMENSION_TOKEN */) {
- return token.number;
- }
- return 0;
- }
- };
-
- var LINE_BREAK;
- (function (LINE_BREAK) {
- LINE_BREAK["NORMAL"] = "normal";
- LINE_BREAK["STRICT"] = "strict";
- })(LINE_BREAK || (LINE_BREAK = {}));
- var lineBreak = {
- name: 'line-break',
- initialValue: 'normal',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, lineBreak) {
- switch (lineBreak) {
- case 'strict':
- return LINE_BREAK.STRICT;
- case 'normal':
- default:
- return LINE_BREAK.NORMAL;
- }
- }
- };
-
- var lineHeight = {
- name: 'line-height',
- initialValue: 'normal',
- prefix: false,
- type: 4 /* TOKEN_VALUE */
- };
- var computeLineHeight = function (token, fontSize) {
- if (isIdentToken(token) && token.value === 'normal') {
- return 1.2 * fontSize;
- }
- else if (token.type === 17 /* NUMBER_TOKEN */) {
- return fontSize * token.number;
- }
- else if (isLengthPercentage(token)) {
- return getAbsoluteValue(token, fontSize);
- }
- return fontSize;
- };
-
- var listStyleImage = {
- name: 'list-style-image',
- initialValue: 'none',
- type: 0 /* VALUE */,
- prefix: false,
- parse: function (context, token) {
- if (token.type === 20 /* IDENT_TOKEN */ && token.value === 'none') {
- return null;
- }
- return image.parse(context, token);
- }
- };
-
- var listStylePosition = {
- name: 'list-style-position',
- initialValue: 'outside',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, position) {
- switch (position) {
- case 'inside':
- return 0 /* INSIDE */;
- case 'outside':
- default:
- return 1 /* OUTSIDE */;
- }
- }
- };
-
- var listStyleType = {
- name: 'list-style-type',
- initialValue: 'none',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, type) {
- switch (type) {
- case 'disc':
- return 0 /* DISC */;
- case 'circle':
- return 1 /* CIRCLE */;
- case 'square':
- return 2 /* SQUARE */;
- case 'decimal':
- return 3 /* DECIMAL */;
- case 'cjk-decimal':
- return 4 /* CJK_DECIMAL */;
- case 'decimal-leading-zero':
- return 5 /* DECIMAL_LEADING_ZERO */;
- case 'lower-roman':
- return 6 /* LOWER_ROMAN */;
- case 'upper-roman':
- return 7 /* UPPER_ROMAN */;
- case 'lower-greek':
- return 8 /* LOWER_GREEK */;
- case 'lower-alpha':
- return 9 /* LOWER_ALPHA */;
- case 'upper-alpha':
- return 10 /* UPPER_ALPHA */;
- case 'arabic-indic':
- return 11 /* ARABIC_INDIC */;
- case 'armenian':
- return 12 /* ARMENIAN */;
- case 'bengali':
- return 13 /* BENGALI */;
- case 'cambodian':
- return 14 /* CAMBODIAN */;
- case 'cjk-earthly-branch':
- return 15 /* CJK_EARTHLY_BRANCH */;
- case 'cjk-heavenly-stem':
- return 16 /* CJK_HEAVENLY_STEM */;
- case 'cjk-ideographic':
- return 17 /* CJK_IDEOGRAPHIC */;
- case 'devanagari':
- return 18 /* DEVANAGARI */;
- case 'ethiopic-numeric':
- return 19 /* ETHIOPIC_NUMERIC */;
- case 'georgian':
- return 20 /* GEORGIAN */;
- case 'gujarati':
- return 21 /* GUJARATI */;
- case 'gurmukhi':
- return 22 /* GURMUKHI */;
- case 'hebrew':
- return 22 /* HEBREW */;
- case 'hiragana':
- return 23 /* HIRAGANA */;
- case 'hiragana-iroha':
- return 24 /* HIRAGANA_IROHA */;
- case 'japanese-formal':
- return 25 /* JAPANESE_FORMAL */;
- case 'japanese-informal':
- return 26 /* JAPANESE_INFORMAL */;
- case 'kannada':
- return 27 /* KANNADA */;
- case 'katakana':
- return 28 /* KATAKANA */;
- case 'katakana-iroha':
- return 29 /* KATAKANA_IROHA */;
- case 'khmer':
- return 30 /* KHMER */;
- case 'korean-hangul-formal':
- return 31 /* KOREAN_HANGUL_FORMAL */;
- case 'korean-hanja-formal':
- return 32 /* KOREAN_HANJA_FORMAL */;
- case 'korean-hanja-informal':
- return 33 /* KOREAN_HANJA_INFORMAL */;
- case 'lao':
- return 34 /* LAO */;
- case 'lower-armenian':
- return 35 /* LOWER_ARMENIAN */;
- case 'malayalam':
- return 36 /* MALAYALAM */;
- case 'mongolian':
- return 37 /* MONGOLIAN */;
- case 'myanmar':
- return 38 /* MYANMAR */;
- case 'oriya':
- return 39 /* ORIYA */;
- case 'persian':
- return 40 /* PERSIAN */;
- case 'simp-chinese-formal':
- return 41 /* SIMP_CHINESE_FORMAL */;
- case 'simp-chinese-informal':
- return 42 /* SIMP_CHINESE_INFORMAL */;
- case 'tamil':
- return 43 /* TAMIL */;
- case 'telugu':
- return 44 /* TELUGU */;
- case 'thai':
- return 45 /* THAI */;
- case 'tibetan':
- return 46 /* TIBETAN */;
- case 'trad-chinese-formal':
- return 47 /* TRAD_CHINESE_FORMAL */;
- case 'trad-chinese-informal':
- return 48 /* TRAD_CHINESE_INFORMAL */;
- case 'upper-armenian':
- return 49 /* UPPER_ARMENIAN */;
- case 'disclosure-open':
- return 50 /* DISCLOSURE_OPEN */;
- case 'disclosure-closed':
- return 51 /* DISCLOSURE_CLOSED */;
- case 'none':
- default:
- return -1 /* NONE */;
- }
- }
- };
-
- var marginForSide = function (side) { return ({
- name: "margin-" + side,
- initialValue: '0',
- prefix: false,
- type: 4 /* TOKEN_VALUE */
- }); };
- var marginTop = marginForSide('top');
- var marginRight = marginForSide('right');
- var marginBottom = marginForSide('bottom');
- var marginLeft = marginForSide('left');
-
- var overflow = {
- name: 'overflow',
- initialValue: 'visible',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- return tokens.filter(isIdentToken).map(function (overflow) {
- switch (overflow.value) {
- case 'hidden':
- return 1 /* HIDDEN */;
- case 'scroll':
- return 2 /* SCROLL */;
- case 'clip':
- return 3 /* CLIP */;
- case 'auto':
- return 4 /* AUTO */;
- case 'visible':
- default:
- return 0 /* VISIBLE */;
- }
- });
- }
- };
-
- var overflowWrap = {
- name: 'overflow-wrap',
- initialValue: 'normal',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, overflow) {
- switch (overflow) {
- case 'break-word':
- return "break-word" /* BREAK_WORD */;
- case 'normal':
- default:
- return "normal" /* NORMAL */;
- }
- }
- };
-
- var paddingForSide = function (side) { return ({
- name: "padding-" + side,
- initialValue: '0',
- prefix: false,
- type: 3 /* TYPE_VALUE */,
- format: 'length-percentage'
- }); };
- var paddingTop = paddingForSide('top');
- var paddingRight = paddingForSide('right');
- var paddingBottom = paddingForSide('bottom');
- var paddingLeft = paddingForSide('left');
-
- var textAlign = {
- name: 'text-align',
- initialValue: 'left',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, textAlign) {
- switch (textAlign) {
- case 'right':
- return 2 /* RIGHT */;
- case 'center':
- case 'justify':
- return 1 /* CENTER */;
- case 'left':
- default:
- return 0 /* LEFT */;
- }
- }
- };
-
- var position = {
- name: 'position',
- initialValue: 'static',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, position) {
- switch (position) {
- case 'relative':
- return 1 /* RELATIVE */;
- case 'absolute':
- return 2 /* ABSOLUTE */;
- case 'fixed':
- return 3 /* FIXED */;
- case 'sticky':
- return 4 /* STICKY */;
- }
- return 0 /* STATIC */;
- }
- };
-
- var textShadow = {
- name: 'text-shadow',
- initialValue: 'none',
- type: 1 /* LIST */,
- prefix: false,
- parse: function (context, tokens) {
- if (tokens.length === 1 && isIdentWithValue(tokens[0], 'none')) {
- return [];
- }
- return parseFunctionArgs(tokens).map(function (values) {
- var shadow = {
- color: COLORS.TRANSPARENT,
- offsetX: ZERO_LENGTH,
- offsetY: ZERO_LENGTH,
- blur: ZERO_LENGTH
- };
- var c = 0;
- for (var i = 0; i < values.length; i++) {
- var token = values[i];
- if (isLength(token)) {
- if (c === 0) {
- shadow.offsetX = token;
- }
- else if (c === 1) {
- shadow.offsetY = token;
- }
- else {
- shadow.blur = token;
- }
- c++;
- }
- else {
- shadow.color = color$1.parse(context, token);
- }
- }
- return shadow;
- });
- }
- };
-
- var textTransform = {
- name: 'text-transform',
- initialValue: 'none',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, textTransform) {
- switch (textTransform) {
- case 'uppercase':
- return 2 /* UPPERCASE */;
- case 'lowercase':
- return 1 /* LOWERCASE */;
- case 'capitalize':
- return 3 /* CAPITALIZE */;
- }
- return 0 /* NONE */;
- }
- };
-
- var transform$1 = {
- name: 'transform',
- initialValue: 'none',
- prefix: true,
- type: 0 /* VALUE */,
- parse: function (_context, token) {
- if (token.type === 20 /* IDENT_TOKEN */ && token.value === 'none') {
- return null;
- }
- if (token.type === 18 /* FUNCTION */) {
- var transformFunction = SUPPORTED_TRANSFORM_FUNCTIONS[token.name];
- if (typeof transformFunction === 'undefined') {
- throw new Error("Attempting to parse an unsupported transform function \"" + token.name + "\"");
- }
- return transformFunction(token.values);
- }
- return null;
- }
- };
- var matrix = function (args) {
- var values = args.filter(function (arg) { return arg.type === 17 /* NUMBER_TOKEN */; }).map(function (arg) { return arg.number; });
- return values.length === 6 ? values : null;
- };
- // doesn't support 3D transforms at the moment
- var matrix3d = function (args) {
- var values = args.filter(function (arg) { return arg.type === 17 /* NUMBER_TOKEN */; }).map(function (arg) { return arg.number; });
- var a1 = values[0], b1 = values[1]; values[2]; values[3]; var a2 = values[4], b2 = values[5]; values[6]; values[7]; values[8]; values[9]; values[10]; values[11]; var a4 = values[12], b4 = values[13]; values[14]; values[15];
- return values.length === 16 ? [a1, b1, a2, b2, a4, b4] : null;
- };
- var SUPPORTED_TRANSFORM_FUNCTIONS = {
- matrix: matrix,
- matrix3d: matrix3d
- };
-
- var DEFAULT_VALUE = {
- type: 16 /* PERCENTAGE_TOKEN */,
- number: 50,
- flags: FLAG_INTEGER
- };
- var DEFAULT = [DEFAULT_VALUE, DEFAULT_VALUE];
- var transformOrigin = {
- name: 'transform-origin',
- initialValue: '50% 50%',
- prefix: true,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- var origins = tokens.filter(isLengthPercentage);
- if (origins.length !== 2) {
- return DEFAULT;
- }
- return [origins[0], origins[1]];
- }
- };
-
- var visibility = {
- name: 'visible',
- initialValue: 'none',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, visibility) {
- switch (visibility) {
- case 'hidden':
- return 1 /* HIDDEN */;
- case 'collapse':
- return 2 /* COLLAPSE */;
- case 'visible':
- default:
- return 0 /* VISIBLE */;
- }
- }
- };
-
- var WORD_BREAK;
- (function (WORD_BREAK) {
- WORD_BREAK["NORMAL"] = "normal";
- WORD_BREAK["BREAK_ALL"] = "break-all";
- WORD_BREAK["KEEP_ALL"] = "keep-all";
- })(WORD_BREAK || (WORD_BREAK = {}));
- var wordBreak = {
- name: 'word-break',
- initialValue: 'normal',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, wordBreak) {
- switch (wordBreak) {
- case 'break-all':
- return WORD_BREAK.BREAK_ALL;
- case 'keep-all':
- return WORD_BREAK.KEEP_ALL;
- case 'normal':
- default:
- return WORD_BREAK.NORMAL;
- }
- }
- };
-
- var zIndex = {
- name: 'z-index',
- initialValue: 'auto',
- prefix: false,
- type: 0 /* VALUE */,
- parse: function (_context, token) {
- if (token.type === 20 /* IDENT_TOKEN */) {
- return { auto: true, order: 0 };
- }
- if (isNumberToken(token)) {
- return { auto: false, order: token.number };
- }
- throw new Error("Invalid z-index number parsed");
- }
- };
-
- var time = {
- name: 'time',
- parse: function (_context, value) {
- if (value.type === 15 /* DIMENSION_TOKEN */) {
- switch (value.unit.toLowerCase()) {
- case 's':
- return 1000 * value.number;
- case 'ms':
- return value.number;
- }
- }
- throw new Error("Unsupported time type");
- }
- };
-
- var opacity = {
- name: 'opacity',
- initialValue: '1',
- type: 0 /* VALUE */,
- prefix: false,
- parse: function (_context, token) {
- if (isNumberToken(token)) {
- return token.number;
- }
- return 1;
- }
- };
-
- var textDecorationColor = {
- name: "text-decoration-color",
- initialValue: 'transparent',
- prefix: false,
- type: 3 /* TYPE_VALUE */,
- format: 'color'
- };
-
- var textDecorationLine = {
- name: 'text-decoration-line',
- initialValue: 'none',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- return tokens
- .filter(isIdentToken)
- .map(function (token) {
- switch (token.value) {
- case 'underline':
- return 1 /* UNDERLINE */;
- case 'overline':
- return 2 /* OVERLINE */;
- case 'line-through':
- return 3 /* LINE_THROUGH */;
- case 'none':
- return 4 /* BLINK */;
- }
- return 0 /* NONE */;
- })
- .filter(function (line) { return line !== 0 /* NONE */; });
- }
- };
-
- var fontFamily = {
- name: "font-family",
- initialValue: '',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- var accumulator = [];
- var results = [];
- tokens.forEach(function (token) {
- switch (token.type) {
- case 20 /* IDENT_TOKEN */:
- case 0 /* STRING_TOKEN */:
- accumulator.push(token.value);
- break;
- case 17 /* NUMBER_TOKEN */:
- accumulator.push(token.number.toString());
- break;
- case 4 /* COMMA_TOKEN */:
- results.push(accumulator.join(' '));
- accumulator.length = 0;
- break;
- }
- });
- if (accumulator.length) {
- results.push(accumulator.join(' '));
- }
- return results.map(function (result) { return (result.indexOf(' ') === -1 ? result : "'" + result + "'"); });
- }
- };
-
- var fontSize = {
- name: "font-size",
- initialValue: '0',
- prefix: false,
- type: 3 /* TYPE_VALUE */,
- format: 'length'
- };
-
- var fontWeight = {
- name: 'font-weight',
- initialValue: 'normal',
- type: 0 /* VALUE */,
- prefix: false,
- parse: function (_context, token) {
- if (isNumberToken(token)) {
- return token.number;
- }
- if (isIdentToken(token)) {
- switch (token.value) {
- case 'bold':
- return 700;
- case 'normal':
- default:
- return 400;
- }
- }
- return 400;
- }
- };
-
- var fontVariant = {
- name: 'font-variant',
- initialValue: 'none',
- type: 1 /* LIST */,
- prefix: false,
- parse: function (_context, tokens) {
- return tokens.filter(isIdentToken).map(function (token) { return token.value; });
- }
- };
-
- var fontStyle = {
- name: 'font-style',
- initialValue: 'normal',
- prefix: false,
- type: 2 /* IDENT_VALUE */,
- parse: function (_context, overflow) {
- switch (overflow) {
- case 'oblique':
- return "oblique" /* OBLIQUE */;
- case 'italic':
- return "italic" /* ITALIC */;
- case 'normal':
- default:
- return "normal" /* NORMAL */;
- }
- }
- };
-
- var contains = function (bit, value) { return (bit & value) !== 0; };
-
- var content = {
- name: 'content',
- initialValue: 'none',
- type: 1 /* LIST */,
- prefix: false,
- parse: function (_context, tokens) {
- if (tokens.length === 0) {
- return [];
- }
- var first = tokens[0];
- if (first.type === 20 /* IDENT_TOKEN */ && first.value === 'none') {
- return [];
- }
- return tokens;
- }
- };
-
- var counterIncrement = {
- name: 'counter-increment',
- initialValue: 'none',
- prefix: true,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- if (tokens.length === 0) {
- return null;
- }
- var first = tokens[0];
- if (first.type === 20 /* IDENT_TOKEN */ && first.value === 'none') {
- return null;
- }
- var increments = [];
- var filtered = tokens.filter(nonWhiteSpace);
- for (var i = 0; i < filtered.length; i++) {
- var counter = filtered[i];
- var next = filtered[i + 1];
- if (counter.type === 20 /* IDENT_TOKEN */) {
- var increment = next && isNumberToken(next) ? next.number : 1;
- increments.push({ counter: counter.value, increment: increment });
- }
- }
- return increments;
- }
- };
-
- var counterReset = {
- name: 'counter-reset',
- initialValue: 'none',
- prefix: true,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- if (tokens.length === 0) {
- return [];
- }
- var resets = [];
- var filtered = tokens.filter(nonWhiteSpace);
- for (var i = 0; i < filtered.length; i++) {
- var counter = filtered[i];
- var next = filtered[i + 1];
- if (isIdentToken(counter) && counter.value !== 'none') {
- var reset = next && isNumberToken(next) ? next.number : 0;
- resets.push({ counter: counter.value, reset: reset });
- }
- }
- return resets;
- }
- };
-
- var duration = {
- name: 'duration',
- initialValue: '0s',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (context, tokens) {
- return tokens.filter(isDimensionToken).map(function (token) { return time.parse(context, token); });
- }
- };
-
- var quotes = {
- name: 'quotes',
- initialValue: 'none',
- prefix: true,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- if (tokens.length === 0) {
- return null;
- }
- var first = tokens[0];
- if (first.type === 20 /* IDENT_TOKEN */ && first.value === 'none') {
- return null;
- }
- var quotes = [];
- var filtered = tokens.filter(isStringToken);
- if (filtered.length % 2 !== 0) {
- return null;
- }
- for (var i = 0; i < filtered.length; i += 2) {
- var open_1 = filtered[i].value;
- var close_1 = filtered[i + 1].value;
- quotes.push({ open: open_1, close: close_1 });
- }
- return quotes;
- }
- };
- var getQuote = function (quotes, depth, open) {
- if (!quotes) {
- return '';
- }
- var quote = quotes[Math.min(depth, quotes.length - 1)];
- if (!quote) {
- return '';
- }
- return open ? quote.open : quote.close;
- };
-
- var paintOrder = {
- name: 'paint-order',
- initialValue: 'normal',
- prefix: false,
- type: 1 /* LIST */,
- parse: function (_context, tokens) {
- var DEFAULT_VALUE = [0 /* FILL */, 1 /* STROKE */, 2 /* MARKERS */];
- var layers = [];
- tokens.filter(isIdentToken).forEach(function (token) {
- switch (token.value) {
- case 'stroke':
- layers.push(1 /* STROKE */);
- break;
- case 'fill':
- layers.push(0 /* FILL */);
- break;
- case 'markers':
- layers.push(2 /* MARKERS */);
- break;
- }
- });
- DEFAULT_VALUE.forEach(function (value) {
- if (layers.indexOf(value) === -1) {
- layers.push(value);
- }
- });
- return layers;
- }
- };
-
- var webkitTextStrokeColor = {
- name: "-webkit-text-stroke-color",
- initialValue: 'currentcolor',
- prefix: false,
- type: 3 /* TYPE_VALUE */,
- format: 'color'
- };
-
- var webkitTextStrokeWidth = {
- name: "-webkit-text-stroke-width",
- initialValue: '0',
- type: 0 /* VALUE */,
- prefix: false,
- parse: function (_context, token) {
- if (isDimensionToken(token)) {
- return token.number;
- }
- return 0;
- }
- };
-
- var CSSParsedDeclaration = /** @class */ (function () {
- function CSSParsedDeclaration(context, declaration) {
- var _a, _b;
- this.animationDuration = parse(context, duration, declaration.animationDuration);
- this.backgroundClip = parse(context, backgroundClip, declaration.backgroundClip);
- this.backgroundColor = parse(context, backgroundColor, declaration.backgroundColor);
- this.backgroundImage = parse(context, backgroundImage, declaration.backgroundImage);
- this.backgroundOrigin = parse(context, backgroundOrigin, declaration.backgroundOrigin);
- this.backgroundPosition = parse(context, backgroundPosition, declaration.backgroundPosition);
- this.backgroundRepeat = parse(context, backgroundRepeat, declaration.backgroundRepeat);
- this.backgroundSize = parse(context, backgroundSize, declaration.backgroundSize);
- this.borderTopColor = parse(context, borderTopColor, declaration.borderTopColor);
- this.borderRightColor = parse(context, borderRightColor, declaration.borderRightColor);
- this.borderBottomColor = parse(context, borderBottomColor, declaration.borderBottomColor);
- this.borderLeftColor = parse(context, borderLeftColor, declaration.borderLeftColor);
- this.borderTopLeftRadius = parse(context, borderTopLeftRadius, declaration.borderTopLeftRadius);
- this.borderTopRightRadius = parse(context, borderTopRightRadius, declaration.borderTopRightRadius);
- this.borderBottomRightRadius = parse(context, borderBottomRightRadius, declaration.borderBottomRightRadius);
- this.borderBottomLeftRadius = parse(context, borderBottomLeftRadius, declaration.borderBottomLeftRadius);
- this.borderTopStyle = parse(context, borderTopStyle, declaration.borderTopStyle);
- this.borderRightStyle = parse(context, borderRightStyle, declaration.borderRightStyle);
- this.borderBottomStyle = parse(context, borderBottomStyle, declaration.borderBottomStyle);
- this.borderLeftStyle = parse(context, borderLeftStyle, declaration.borderLeftStyle);
- this.borderTopWidth = parse(context, borderTopWidth, declaration.borderTopWidth);
- this.borderRightWidth = parse(context, borderRightWidth, declaration.borderRightWidth);
- this.borderBottomWidth = parse(context, borderBottomWidth, declaration.borderBottomWidth);
- this.borderLeftWidth = parse(context, borderLeftWidth, declaration.borderLeftWidth);
- this.color = parse(context, color, declaration.color);
- this.direction = parse(context, direction, declaration.direction);
- this.display = parse(context, display, declaration.display);
- this.float = parse(context, float, declaration.cssFloat);
- this.fontFamily = parse(context, fontFamily, declaration.fontFamily);
- this.fontSize = parse(context, fontSize, declaration.fontSize);
- this.fontStyle = parse(context, fontStyle, declaration.fontStyle);
- this.fontVariant = parse(context, fontVariant, declaration.fontVariant);
- this.fontWeight = parse(context, fontWeight, declaration.fontWeight);
- this.letterSpacing = parse(context, letterSpacing, declaration.letterSpacing);
- this.lineBreak = parse(context, lineBreak, declaration.lineBreak);
- this.lineHeight = parse(context, lineHeight, declaration.lineHeight);
- this.listStyleImage = parse(context, listStyleImage, declaration.listStyleImage);
- this.listStylePosition = parse(context, listStylePosition, declaration.listStylePosition);
- this.listStyleType = parse(context, listStyleType, declaration.listStyleType);
- this.marginTop = parse(context, marginTop, declaration.marginTop);
- this.marginRight = parse(context, marginRight, declaration.marginRight);
- this.marginBottom = parse(context, marginBottom, declaration.marginBottom);
- this.marginLeft = parse(context, marginLeft, declaration.marginLeft);
- this.opacity = parse(context, opacity, declaration.opacity);
- var overflowTuple = parse(context, overflow, declaration.overflow);
- this.overflowX = overflowTuple[0];
- this.overflowY = overflowTuple[overflowTuple.length > 1 ? 1 : 0];
- this.overflowWrap = parse(context, overflowWrap, declaration.overflowWrap);
- this.paddingTop = parse(context, paddingTop, declaration.paddingTop);
- this.paddingRight = parse(context, paddingRight, declaration.paddingRight);
- this.paddingBottom = parse(context, paddingBottom, declaration.paddingBottom);
- this.paddingLeft = parse(context, paddingLeft, declaration.paddingLeft);
- this.paintOrder = parse(context, paintOrder, declaration.paintOrder);
- this.position = parse(context, position, declaration.position);
- this.textAlign = parse(context, textAlign, declaration.textAlign);
- this.textDecorationColor = parse(context, textDecorationColor, (_a = declaration.textDecorationColor) !== null && _a !== void 0 ? _a : declaration.color);
- this.textDecorationLine = parse(context, textDecorationLine, (_b = declaration.textDecorationLine) !== null && _b !== void 0 ? _b : declaration.textDecoration);
- this.textShadow = parse(context, textShadow, declaration.textShadow);
- this.textTransform = parse(context, textTransform, declaration.textTransform);
- this.transform = parse(context, transform$1, declaration.transform);
- this.transformOrigin = parse(context, transformOrigin, declaration.transformOrigin);
- this.visibility = parse(context, visibility, declaration.visibility);
- this.webkitTextStrokeColor = parse(context, webkitTextStrokeColor, declaration.webkitTextStrokeColor);
- this.webkitTextStrokeWidth = parse(context, webkitTextStrokeWidth, declaration.webkitTextStrokeWidth);
- this.wordBreak = parse(context, wordBreak, declaration.wordBreak);
- this.zIndex = parse(context, zIndex, declaration.zIndex);
- }
- CSSParsedDeclaration.prototype.isVisible = function () {
- return this.display > 0 && this.opacity > 0 && this.visibility === 0 /* VISIBLE */;
- };
- CSSParsedDeclaration.prototype.isTransparent = function () {
- return isTransparent(this.backgroundColor);
- };
- CSSParsedDeclaration.prototype.isTransformed = function () {
- return this.transform !== null;
- };
- CSSParsedDeclaration.prototype.isPositioned = function () {
- return this.position !== 0 /* STATIC */;
- };
- CSSParsedDeclaration.prototype.isPositionedWithZIndex = function () {
- return this.isPositioned() && !this.zIndex.auto;
- };
- CSSParsedDeclaration.prototype.isFloating = function () {
- return this.float !== 0 /* NONE */;
- };
- CSSParsedDeclaration.prototype.isInlineLevel = function () {
- return (contains(this.display, 4 /* INLINE */) ||
- contains(this.display, 33554432 /* INLINE_BLOCK */) ||
- contains(this.display, 268435456 /* INLINE_FLEX */) ||
- contains(this.display, 536870912 /* INLINE_GRID */) ||
- contains(this.display, 67108864 /* INLINE_LIST_ITEM */) ||
- contains(this.display, 134217728 /* INLINE_TABLE */));
- };
- return CSSParsedDeclaration;
- }());
- var CSSParsedPseudoDeclaration = /** @class */ (function () {
- function CSSParsedPseudoDeclaration(context, declaration) {
- this.content = parse(context, content, declaration.content);
- this.quotes = parse(context, quotes, declaration.quotes);
- }
- return CSSParsedPseudoDeclaration;
- }());
- var CSSParsedCounterDeclaration = /** @class */ (function () {
- function CSSParsedCounterDeclaration(context, declaration) {
- this.counterIncrement = parse(context, counterIncrement, declaration.counterIncrement);
- this.counterReset = parse(context, counterReset, declaration.counterReset);
- }
- return CSSParsedCounterDeclaration;
- }());
- // eslint-disable-next-line @typescript-eslint/no-explicit-any
- var parse = function (context, descriptor, style) {
- var tokenizer = new Tokenizer();
- var value = style !== null && typeof style !== 'undefined' ? style.toString() : descriptor.initialValue;
- tokenizer.write(value);
- var parser = new Parser(tokenizer.read());
- switch (descriptor.type) {
- case 2 /* IDENT_VALUE */:
- var token = parser.parseComponentValue();
- return descriptor.parse(context, isIdentToken(token) ? token.value : descriptor.initialValue);
- case 0 /* VALUE */:
- return descriptor.parse(context, parser.parseComponentValue());
- case 1 /* LIST */:
- return descriptor.parse(context, parser.parseComponentValues());
- case 4 /* TOKEN_VALUE */:
- return parser.parseComponentValue();
- case 3 /* TYPE_VALUE */:
- switch (descriptor.format) {
- case 'angle':
- return angle.parse(context, parser.parseComponentValue());
- case 'color':
- return color$1.parse(context, parser.parseComponentValue());
- case 'image':
- return image.parse(context, parser.parseComponentValue());
- case 'length':
- var length_1 = parser.parseComponentValue();
- return isLength(length_1) ? length_1 : ZERO_LENGTH;
- case 'length-percentage':
- var value_1 = parser.parseComponentValue();
- return isLengthPercentage(value_1) ? value_1 : ZERO_LENGTH;
- case 'time':
- return time.parse(context, parser.parseComponentValue());
- }
- break;
- }
- };
-
- var elementDebuggerAttribute = 'data-html2canvas-debug';
- var getElementDebugType = function (element) {
- var attribute = element.getAttribute(elementDebuggerAttribute);
- switch (attribute) {
- case 'all':
- return 1 /* ALL */;
- case 'clone':
- return 2 /* CLONE */;
- case 'parse':
- return 3 /* PARSE */;
- case 'render':
- return 4 /* RENDER */;
- default:
- return 0 /* NONE */;
- }
- };
- var isDebugging = function (element, type) {
- var elementType = getElementDebugType(element);
- return elementType === 1 /* ALL */ || type === elementType;
- };
-
- var ElementContainer = /** @class */ (function () {
- function ElementContainer(context, element) {
- this.context = context;
- this.textNodes = [];
- this.elements = [];
- this.flags = 0;
- if (isDebugging(element, 3 /* PARSE */)) {
- debugger;
- }
- this.styles = new CSSParsedDeclaration(context, window.getComputedStyle(element, null));
- if (isHTMLElementNode(element)) {
- if (this.styles.animationDuration.some(function (duration) { return duration > 0; })) {
- element.style.animationDuration = '0s';
- }
- if (this.styles.transform !== null) {
- // getBoundingClientRect takes transforms into account
- element.style.transform = 'none';
- }
- }
- this.bounds = parseBounds(this.context, element);
- if (isDebugging(element, 4 /* RENDER */)) {
- this.flags |= 16 /* DEBUG_RENDER */;
- }
- }
- return ElementContainer;
- }());
-
- /*
- * text-segmentation 1.0.3
- * Copyright (c) 2022 Niklas von Hertzen
- * Released under MIT License
- */
- var base64 = 'AAAAAAAAAAAAEA4AGBkAAFAaAAACAAAAAAAIABAAGAAwADgACAAQAAgAEAAIABAACAAQAAgAEAAIABAACAAQAAgAEAAIABAAQABIAEQATAAIABAACAAQAAgAEAAIABAAVABcAAgAEAAIABAACAAQAGAAaABwAHgAgACIAI4AlgAIABAAmwCjAKgAsAC2AL4AvQDFAMoA0gBPAVYBWgEIAAgACACMANoAYgFkAWwBdAF8AX0BhQGNAZUBlgGeAaMBlQGWAasBswF8AbsBwwF0AcsBYwHTAQgA2wG/AOMBdAF8AekB8QF0AfkB+wHiAHQBfAEIAAMC5gQIAAsCEgIIAAgAFgIeAggAIgIpAggAMQI5AkACygEIAAgASAJQAlgCYAIIAAgACAAKBQoFCgUTBRMFGQUrBSsFCAAIAAgACAAIAAgACAAIAAgACABdAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACABoAmgCrwGvAQgAbgJ2AggAHgEIAAgACADnAXsCCAAIAAgAgwIIAAgACAAIAAgACACKAggAkQKZAggAPADJAAgAoQKkAqwCsgK6AsICCADJAggA0AIIAAgACAAIANYC3gIIAAgACAAIAAgACABAAOYCCAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAkASoB+QIEAAgACAA8AEMCCABCBQgACABJBVAFCAAIAAgACAAIAAgACAAIAAgACABTBVoFCAAIAFoFCABfBWUFCAAIAAgACAAIAAgAbQUIAAgACAAIAAgACABzBXsFfQWFBYoFigWKBZEFigWKBYoFmAWfBaYFrgWxBbkFCAAIAAgACAAIAAgACAAIAAgACAAIAMEFCAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAMgFCADQBQgACAAIAAgACAAIAAgACAAIAAgACAAIAO4CCAAIAAgAiQAIAAgACABAAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAD0AggACAD8AggACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIANYFCAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAMDvwAIAAgAJAIIAAgACAAIAAgACAAIAAgACwMTAwgACAB9BOsEGwMjAwgAKwMyAwsFYgE3A/MEPwMIAEUDTQNRAwgAWQOsAGEDCAAIAAgACAAIAAgACABpAzQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFOgU0BTUFNgU3BTgFOQU6BTQFNQU2BTcFOAU5BToFNAU1BTYFNwU4BTkFIQUoBSwFCAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACABtAwgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACABMAEwACAAIAAgACAAIABgACAAIAAgACAC/AAgACAAyAQgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACACAAIAAwAAgACAAIAAgACAAIAAgACAAIAAAARABIAAgACAAIABQASAAIAAgAIABwAEAAjgCIABsAqAC2AL0AigDQAtwC+IJIQqVAZUBWQqVAZUBlQGVAZUBlQGrC5UBlQGVAZUBlQGVAZUBlQGVAXsKlQGVAbAK6wsrDGUMpQzlDJUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAZUBlQGVAfAKAAuZA64AtwCJALoC6ADwAAgAuACgA/oEpgO6AqsD+AAIAAgAswMIAAgACAAIAIkAuwP5AfsBwwPLAwgACAAIAAgACADRA9kDCAAIAOED6QMIAAgACAAIAAgACADuA/YDCAAIAP4DyQAIAAgABgQIAAgAXQAOBAgACAAIAAgACAAIABMECAAIAAgACAAIAAgACAD8AAQBCAAIAAgAGgQiBCoECAExBAgAEAEIAAgACAAIAAgACAAIAAgACAAIAAgACAA4BAgACABABEYECAAIAAgATAQYAQgAVAQIAAgACAAIAAgACAAIAAgACAAIAFoECAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgAOQEIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAB+BAcACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAEABhgSMBAgACAAIAAgAlAQIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAwAEAAQABAADAAMAAwADAAQABAAEAAQABAAEAAQABHATAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgAdQMIAAgACAAIAAgACAAIAMkACAAIAAgAfQMIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACACFA4kDCAAIAAgACAAIAOcBCAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAIcDCAAIAAgACAAIAAgACAAIAAgACAAIAJEDCAAIAAgACADFAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACABgBAgAZgQIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgAbAQCBXIECAAIAHkECAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACABAAJwEQACjBKoEsgQIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAC6BMIECAAIAAgACAAIAAgACABmBAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgAxwQIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAGYECAAIAAgAzgQIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgAigWKBYoFigWKBYoFigWKBd0FXwUIAOIF6gXxBYoF3gT5BQAGCAaKBYoFigWKBYoFigWKBYoFigWKBYoFigXWBIoFigWKBYoFigWKBYoFigWKBYsFEAaKBYoFigWKBYoFigWKBRQGCACKBYoFigWKBQgACAAIANEECAAIABgGigUgBggAJgYIAC4GMwaKBYoF0wQ3Bj4GigWKBYoFigWKBYoFigWKBYoFigWKBYoFigUIAAgACAAIAAgACAAIAAgAigWKBYoFigWKBYoFigWKBYoFigWKBYoFigWKBYoFigWKBYoFigWKBYoFigWKBYoFigWKBYoFigWKBYoFigWLBf///////wQABAAEAAQABAAEAAQABAAEAAQAAwAEAAQAAgAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAAAAAAAAAAAAAAAAAAAAAAAAAOAAAAAAAAAAQADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAAAUAAAAFAAUAAAAFAAUAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAEAAQABAAEAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUABQAFAAUABQAAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUAAQAAAAUABQAFAAUABQAFAAAAAAAFAAUAAAAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAUABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAFAAAAAAAFAAUAAQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABwAFAAUABQAFAAAABwAHAAcAAAAHAAcABwAFAAEAAAAAAAAAAAAAAAAAAAAAAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAcABwAFAAUABQAFAAcABwAFAAUAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAAAAQABAAAAAAAAAAAAAAAFAAUABQAFAAAABwAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAHAAcABwAHAAcAAAAHAAcAAAAAAAUABQAHAAUAAQAHAAEABwAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUABwABAAUABQAFAAUAAAAAAAAAAAAAAAEAAQABAAEAAQABAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABwAFAAUAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUAAQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQABQANAAQABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQABAAEAAQABAAEAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAEAAQABAAEAAQABAAEAAQABAAEAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAQABAAEAAQABAAEAAQABAAAAAAAAAAAAAAAAAAAAAAABQAHAAUABQAFAAAAAAAAAAcABQAFAAUABQAFAAQABAAEAAQABAAEAAQABAAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUAAAAFAAUABQAFAAUAAAAFAAUABQAAAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAAAAAAAAAAAAUABQAFAAcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAHAAUAAAAHAAcABwAFAAUABQAFAAUABQAFAAUABwAHAAcABwAFAAcABwAAAAUABQAFAAUABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABwAHAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAUABwAHAAUABQAFAAUAAAAAAAcABwAAAAAABwAHAAUAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAABQAFAAcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAAABwAHAAcABQAFAAAAAAAAAAAABQAFAAAAAAAFAAUABQAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAABwAFAAUABQAFAAUAAAAFAAUABwAAAAcABwAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUAAAAFAAUABwAFAAUABQAFAAAAAAAHAAcAAAAAAAcABwAFAAAAAAAAAAAAAAAAAAAABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAcABwAAAAAAAAAHAAcABwAAAAcABwAHAAUAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAABQAHAAcABwAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABwAHAAcABwAAAAUABQAFAAAABQAFAAUABQAAAAAAAAAAAAAAAAAAAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAcABQAHAAcABQAHAAcAAAAFAAcABwAAAAcABwAFAAUAAAAAAAAAAAAAAAAAAAAFAAUAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAcABwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAAAAUABwAAAAAAAAAAAAAAAAAAAAAAAAAAAAUAAAAAAAAAAAAFAAcABwAFAAUABQAAAAUAAAAHAAcABwAHAAcABwAHAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUAAAAHAAUABQAFAAUABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAAABwAFAAUABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAUAAAAFAAAAAAAAAAAABwAHAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABwAFAAUABQAFAAUAAAAFAAUAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUABQAFAAUABQAAAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABwAFAAUABQAFAAUABQAAAAUABQAHAAcABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAcABQAFAAAAAAAAAAAABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAcABQAFAAAAAAAAAAAAAAAAAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAHAAUABQAFAAUABQAFAAUABwAHAAcABwAHAAcABwAHAAUABwAHAAUABQAFAAUABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABwAHAAcABwAFAAUABwAHAAcAAAAAAAAAAAAHAAcABQAHAAcABwAHAAcABwAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAcABwAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABQAHAAUABQAFAAUABQAFAAUAAAAFAAAABQAAAAAABQAFAAUABQAFAAUABQAFAAcABwAHAAcABwAHAAUABQAFAAUABQAFAAUABQAFAAUAAAAAAAUABQAFAAUABQAHAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUABwAFAAcABwAHAAcABwAFAAcABwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAUABQAFAAUABwAHAAUABQAHAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAcABQAFAAcABwAHAAUABwAFAAUABQAHAAcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABwAHAAcABwAHAAcABwAHAAUABQAFAAUABQAFAAUABQAHAAcABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUAAAAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAcABQAFAAUABQAFAAUABQAAAAAAAAAAAAUAAAAAAAAAAAAAAAAABQAAAAAABwAFAAUAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAAABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUAAAAFAAUABQAFAAUABQAFAAUABQAFAAAAAAAAAAAABQAAAAAAAAAFAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABwAHAAUABQAHAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABwAHAAcABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAUABQAFAAUABQAHAAcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAcABwAFAAUABQAFAAcABwAFAAUABwAHAAAAAAAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAFAAcABwAFAAUABwAHAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAFAAcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUAAAAFAAUABQAAAAAABQAFAAAAAAAAAAAAAAAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABQAFAAcABwAAAAAAAAAAAAAABwAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABwAFAAcABwAFAAcABwAAAAcABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAAAAAAAAAAAAAAAAAFAAUABQAAAAUABQAAAAAAAAAAAAAABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAAAAAAAAAAAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABQAHAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABwAFAAUABQAFAAUABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABwAHAAcABQAFAAUABQAFAAUABQAFAAUABwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAcABwAFAAUABQAHAAcABQAHAAUABQAAAAAAAAAAAAAAAAAFAAAABwAHAAcABQAFAAUABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABwAHAAcABwAAAAAABwAHAAAAAAAHAAcABwAAAAAAAAAAAAAAAAAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAABwAHAAAAAAAFAAUABQAFAAUABQAFAAAAAAAAAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAcABwAFAAUABQAFAAUABQAFAAUABwAHAAUABQAFAAcABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAHAAcABQAFAAUABQAFAAUABwAFAAcABwAFAAcABQAFAAcABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAHAAcABQAFAAUABQAAAAAABwAHAAcABwAFAAUABwAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABwAHAAUABQAFAAUABQAFAAUABQAHAAcABQAHAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABwAFAAcABwAFAAUABQAFAAUABQAHAAUAAAAAAAAAAAAAAAAAAAAAAAcABwAFAAUABQAFAAcABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAcABwAFAAUABQAFAAUABQAFAAUABQAHAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAcABwAFAAUABQAFAAAAAAAFAAUABwAHAAcABwAFAAAAAAAAAAcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUABwAHAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABQAFAAUABQAFAAUABQAAAAUABQAFAAUABQAFAAcABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUAAAAHAAUABQAFAAUABQAFAAUABwAFAAUABwAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUAAAAAAAAABQAAAAUABQAAAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAHAAcABwAHAAcAAAAFAAUAAAAHAAcABQAHAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABwAHAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAAAAAAAAAAAAAAAAAAABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAAAAUABQAFAAAAAAAFAAUABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAAAAAAAAAAABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUABQAFAAUABQAAAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUABQAAAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAAAAAABQAFAAUABQAFAAUABQAAAAUABQAAAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFAAUABQAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQAFAAUABQAFAAUABQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAFAAUABQAFAAUADgAOAA4ADgAOAA4ADwAPAA8ADwAPAA8ADwAPAA8ADwAPAA8ADwAPAA8ADwAPAA8ADwAPAA8ADwAPAA8ADwAPAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAcABwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABwAHAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAcABwAHAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAAAAAAAAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAMAAwADAAMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkAAAAAAAAAAAAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAKAAoACgAAAAAAAAAAAAsADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwACwAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAAAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAA4ADgAOAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4ADgAAAAAAAAAAAAAAAAAAAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAA4ADgAOAA4ADgAOAA4ADgAOAAAAAAAAAAAADgAOAA4AAAAAAAAAAAAAAAAAAAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAA4ADgAAAA4ADgAOAA4ADgAOAAAADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4AAAAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4AAAAAAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAAAA4AAAAOAAAAAAAAAAAAAAAAAA4AAAAAAAAAAAAAAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAAAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAAAAAADgAAAAAAAAAAAA4AAAAOAAAAAAAAAAAADgAOAA4AAAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAA4ADgAOAA4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAA4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4ADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAAAAAAAAAAAA4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4ADgAOAA4ADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAAAAAADgAOAA4ADgAOAA4ADgAOAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAAAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4AAAAAAA4ADgAOAA4ADgAOAA4ADgAOAAAADgAOAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4AAAAAAAAAAAAAAAAADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAA4ADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAA4ADgAOAA4ADgAOAAAAAAAAAAAAAAAAAAAAAAAAAAAADgAOAA4ADgAOAA4AAAAAAAAAAAAAAAAAAAAAAA4ADgAOAA4ADgAOAA4ADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4AAAAOAA4ADgAOAA4ADgAAAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4ADgAOAA4AAAAAAAAAAAA=';
-
- /*
- * utrie 1.0.2
- * Copyright (c) 2022 Niklas von Hertzen
- * Released under MIT License
- */
- var chars$1 = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
- // Use a lookup table to find the index.
- var lookup$1 = typeof Uint8Array === 'undefined' ? [] : new Uint8Array(256);
- for (var i$1 = 0; i$1 < chars$1.length; i$1++) {
- lookup$1[chars$1.charCodeAt(i$1)] = i$1;
- }
- var decode = function (base64) {
- var bufferLength = base64.length * 0.75, len = base64.length, i, p = 0, encoded1, encoded2, encoded3, encoded4;
- if (base64[base64.length - 1] === '=') {
- bufferLength--;
- if (base64[base64.length - 2] === '=') {
- bufferLength--;
- }
- }
- var buffer = typeof ArrayBuffer !== 'undefined' &&
- typeof Uint8Array !== 'undefined' &&
- typeof Uint8Array.prototype.slice !== 'undefined'
- ? new ArrayBuffer(bufferLength)
- : new Array(bufferLength);
- var bytes = Array.isArray(buffer) ? buffer : new Uint8Array(buffer);
- for (i = 0; i < len; i += 4) {
- encoded1 = lookup$1[base64.charCodeAt(i)];
- encoded2 = lookup$1[base64.charCodeAt(i + 1)];
- encoded3 = lookup$1[base64.charCodeAt(i + 2)];
- encoded4 = lookup$1[base64.charCodeAt(i + 3)];
- bytes[p++] = (encoded1 << 2) | (encoded2 >> 4);
- bytes[p++] = ((encoded2 & 15) << 4) | (encoded3 >> 2);
- bytes[p++] = ((encoded3 & 3) << 6) | (encoded4 & 63);
- }
- return buffer;
- };
- var polyUint16Array = function (buffer) {
- var length = buffer.length;
- var bytes = [];
- for (var i = 0; i < length; i += 2) {
- bytes.push((buffer[i + 1] << 8) | buffer[i]);
- }
- return bytes;
- };
- var polyUint32Array = function (buffer) {
- var length = buffer.length;
- var bytes = [];
- for (var i = 0; i < length; i += 4) {
- bytes.push((buffer[i + 3] << 24) | (buffer[i + 2] << 16) | (buffer[i + 1] << 8) | buffer[i]);
- }
- return bytes;
- };
-
- /** Shift size for getting the index-2 table offset. */
- var UTRIE2_SHIFT_2 = 5;
- /** Shift size for getting the index-1 table offset. */
- var UTRIE2_SHIFT_1 = 6 + 5;
- /**
- * Shift size for shifting left the index array values.
- * Increases possible data size with 16-bit index values at the cost
- * of compactability.
- * This requires data blocks to be aligned by UTRIE2_DATA_GRANULARITY.
- */
- var UTRIE2_INDEX_SHIFT = 2;
- /**
- * Difference between the two shift sizes,
- * for getting an index-1 offset from an index-2 offset. 6=11-5
- */
- var UTRIE2_SHIFT_1_2 = UTRIE2_SHIFT_1 - UTRIE2_SHIFT_2;
- /**
- * The part of the index-2 table for U+D800..U+DBFF stores values for
- * lead surrogate code _units_ not code _points_.
- * Values for lead surrogate code _points_ are indexed with this portion of the table.
- * Length=32=0x20=0x400>>UTRIE2_SHIFT_2. (There are 1024=0x400 lead surrogates.)
- */
- var UTRIE2_LSCP_INDEX_2_OFFSET = 0x10000 >> UTRIE2_SHIFT_2;
- /** Number of entries in a data block. 32=0x20 */
- var UTRIE2_DATA_BLOCK_LENGTH = 1 << UTRIE2_SHIFT_2;
- /** Mask for getting the lower bits for the in-data-block offset. */
- var UTRIE2_DATA_MASK = UTRIE2_DATA_BLOCK_LENGTH - 1;
- var UTRIE2_LSCP_INDEX_2_LENGTH = 0x400 >> UTRIE2_SHIFT_2;
- /** Count the lengths of both BMP pieces. 2080=0x820 */
- var UTRIE2_INDEX_2_BMP_LENGTH = UTRIE2_LSCP_INDEX_2_OFFSET + UTRIE2_LSCP_INDEX_2_LENGTH;
- /**
- * The 2-byte UTF-8 version of the index-2 table follows at offset 2080=0x820.
- * Length 32=0x20 for lead bytes C0..DF, regardless of UTRIE2_SHIFT_2.
- */
- var UTRIE2_UTF8_2B_INDEX_2_OFFSET = UTRIE2_INDEX_2_BMP_LENGTH;
- var UTRIE2_UTF8_2B_INDEX_2_LENGTH = 0x800 >> 6; /* U+0800 is the first code point after 2-byte UTF-8 */
- /**
- * The index-1 table, only used for supplementary code points, at offset 2112=0x840.
- * Variable length, for code points up to highStart, where the last single-value range starts.
- * Maximum length 512=0x200=0x100000>>UTRIE2_SHIFT_1.
- * (For 0x100000 supplementary code points U+10000..U+10ffff.)
- *
- * The part of the index-2 table for supplementary code points starts
- * after this index-1 table.
- *
- * Both the index-1 table and the following part of the index-2 table
- * are omitted completely if there is only BMP data.
- */
- var UTRIE2_INDEX_1_OFFSET = UTRIE2_UTF8_2B_INDEX_2_OFFSET + UTRIE2_UTF8_2B_INDEX_2_LENGTH;
- /**
- * Number of index-1 entries for the BMP. 32=0x20
- * This part of the index-1 table is omitted from the serialized form.
- */
- var UTRIE2_OMITTED_BMP_INDEX_1_LENGTH = 0x10000 >> UTRIE2_SHIFT_1;
- /** Number of entries in an index-2 block. 64=0x40 */
- var UTRIE2_INDEX_2_BLOCK_LENGTH = 1 << UTRIE2_SHIFT_1_2;
- /** Mask for getting the lower bits for the in-index-2-block offset. */
- var UTRIE2_INDEX_2_MASK = UTRIE2_INDEX_2_BLOCK_LENGTH - 1;
- var slice16 = function (view, start, end) {
- if (view.slice) {
- return view.slice(start, end);
- }
- return new Uint16Array(Array.prototype.slice.call(view, start, end));
- };
- var slice32 = function (view, start, end) {
- if (view.slice) {
- return view.slice(start, end);
- }
- return new Uint32Array(Array.prototype.slice.call(view, start, end));
- };
- var createTrieFromBase64 = function (base64, _byteLength) {
- var buffer = decode(base64);
- var view32 = Array.isArray(buffer) ? polyUint32Array(buffer) : new Uint32Array(buffer);
- var view16 = Array.isArray(buffer) ? polyUint16Array(buffer) : new Uint16Array(buffer);
- var headerLength = 24;
- var index = slice16(view16, headerLength / 2, view32[4] / 2);
- var data = view32[5] === 2
- ? slice16(view16, (headerLength + view32[4]) / 2)
- : slice32(view32, Math.ceil((headerLength + view32[4]) / 4));
- return new Trie(view32[0], view32[1], view32[2], view32[3], index, data);
- };
- var Trie = /** @class */ (function () {
- function Trie(initialValue, errorValue, highStart, highValueIndex, index, data) {
- this.initialValue = initialValue;
- this.errorValue = errorValue;
- this.highStart = highStart;
- this.highValueIndex = highValueIndex;
- this.index = index;
- this.data = data;
- }
- /**
- * Get the value for a code point as stored in the Trie.
- *
- * @param codePoint the code point
- * @return the value
- */
- Trie.prototype.get = function (codePoint) {
- var ix;
- if (codePoint >= 0) {
- if (codePoint < 0x0d800 || (codePoint > 0x0dbff && codePoint <= 0x0ffff)) {
- // Ordinary BMP code point, excluding leading surrogates.
- // BMP uses a single level lookup. BMP index starts at offset 0 in the Trie2 index.
- // 16 bit data is stored in the index array itself.
- ix = this.index[codePoint >> UTRIE2_SHIFT_2];
- ix = (ix << UTRIE2_INDEX_SHIFT) + (codePoint & UTRIE2_DATA_MASK);
- return this.data[ix];
- }
- if (codePoint <= 0xffff) {
- // Lead Surrogate Code Point. A Separate index section is stored for
- // lead surrogate code units and code points.
- // The main index has the code unit data.
- // For this function, we need the code point data.
- // Note: this expression could be refactored for slightly improved efficiency, but
- // surrogate code points will be so rare in practice that it's not worth it.
- ix = this.index[UTRIE2_LSCP_INDEX_2_OFFSET + ((codePoint - 0xd800) >> UTRIE2_SHIFT_2)];
- ix = (ix << UTRIE2_INDEX_SHIFT) + (codePoint & UTRIE2_DATA_MASK);
- return this.data[ix];
- }
- if (codePoint < this.highStart) {
- // Supplemental code point, use two-level lookup.
- ix = UTRIE2_INDEX_1_OFFSET - UTRIE2_OMITTED_BMP_INDEX_1_LENGTH + (codePoint >> UTRIE2_SHIFT_1);
- ix = this.index[ix];
- ix += (codePoint >> UTRIE2_SHIFT_2) & UTRIE2_INDEX_2_MASK;
- ix = this.index[ix];
- ix = (ix << UTRIE2_INDEX_SHIFT) + (codePoint & UTRIE2_DATA_MASK);
- return this.data[ix];
- }
- if (codePoint <= 0x10ffff) {
- return this.data[this.highValueIndex];
- }
- }
- // Fall through. The code point is outside of the legal range of 0..0x10ffff.
- return this.errorValue;
- };
- return Trie;
- }());
-
- /*
- * base64-arraybuffer 1.0.2
- * Copyright (c) 2022 Niklas von Hertzen
- * Released under MIT License
- */
- var chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
- // Use a lookup table to find the index.
- var lookup = typeof Uint8Array === 'undefined' ? [] : new Uint8Array(256);
- for (var i = 0; i < chars.length; i++) {
- lookup[chars.charCodeAt(i)] = i;
- }
-
- var Prepend = 1;
- var CR = 2;
- var LF = 3;
- var Control = 4;
- var Extend = 5;
- var SpacingMark = 7;
- var L = 8;
- var V = 9;
- var T = 10;
- var LV = 11;
- var LVT = 12;
- var ZWJ = 13;
- var Extended_Pictographic = 14;
- var RI = 15;
- var toCodePoints = function (str) {
- var codePoints = [];
- var i = 0;
- var length = str.length;
- while (i < length) {
- var value = str.charCodeAt(i++);
- if (value >= 0xd800 && value <= 0xdbff && i < length) {
- var extra = str.charCodeAt(i++);
- if ((extra & 0xfc00) === 0xdc00) {
- codePoints.push(((value & 0x3ff) << 10) + (extra & 0x3ff) + 0x10000);
- }
- else {
- codePoints.push(value);
- i--;
- }
- }
- else {
- codePoints.push(value);
- }
- }
- return codePoints;
- };
- var fromCodePoint = function () {
- var codePoints = [];
- for (var _i = 0; _i < arguments.length; _i++) {
- codePoints[_i] = arguments[_i];
- }
- if (String.fromCodePoint) {
- return String.fromCodePoint.apply(String, codePoints);
- }
- var length = codePoints.length;
- if (!length) {
- return '';
- }
- var codeUnits = [];
- var index = -1;
- var result = '';
- while (++index < length) {
- var codePoint = codePoints[index];
- if (codePoint <= 0xffff) {
- codeUnits.push(codePoint);
- }
- else {
- codePoint -= 0x10000;
- codeUnits.push((codePoint >> 10) + 0xd800, (codePoint % 0x400) + 0xdc00);
- }
- if (index + 1 === length || codeUnits.length > 0x4000) {
- result += String.fromCharCode.apply(String, codeUnits);
- codeUnits.length = 0;
- }
- }
- return result;
- };
- var UnicodeTrie = createTrieFromBase64(base64);
- var BREAK_NOT_ALLOWED = '×';
- var BREAK_ALLOWED = '÷';
- var codePointToClass = function (codePoint) { return UnicodeTrie.get(codePoint); };
- var _graphemeBreakAtIndex = function (_codePoints, classTypes, index) {
- var prevIndex = index - 2;
- var prev = classTypes[prevIndex];
- var current = classTypes[index - 1];
- var next = classTypes[index];
- // GB3 Do not break between a CR and LF
- if (current === CR && next === LF) {
- return BREAK_NOT_ALLOWED;
- }
- // GB4 Otherwise, break before and after controls.
- if (current === CR || current === LF || current === Control) {
- return BREAK_ALLOWED;
- }
- // GB5
- if (next === CR || next === LF || next === Control) {
- return BREAK_ALLOWED;
- }
- // Do not break Hangul syllable sequences.
- // GB6
- if (current === L && [L, V, LV, LVT].indexOf(next) !== -1) {
- return BREAK_NOT_ALLOWED;
- }
- // GB7
- if ((current === LV || current === V) && (next === V || next === T)) {
- return BREAK_NOT_ALLOWED;
- }
- // GB8
- if ((current === LVT || current === T) && next === T) {
- return BREAK_NOT_ALLOWED;
- }
- // GB9 Do not break before extending characters or ZWJ.
- if (next === ZWJ || next === Extend) {
- return BREAK_NOT_ALLOWED;
- }
- // Do not break before SpacingMarks, or after Prepend characters.
- // GB9a
- if (next === SpacingMark) {
- return BREAK_NOT_ALLOWED;
- }
- // GB9a
- if (current === Prepend) {
- return BREAK_NOT_ALLOWED;
- }
- // GB11 Do not break within emoji modifier sequences or emoji zwj sequences.
- if (current === ZWJ && next === Extended_Pictographic) {
- while (prev === Extend) {
- prev = classTypes[--prevIndex];
- }
- if (prev === Extended_Pictographic) {
- return BREAK_NOT_ALLOWED;
- }
- }
- // GB12 Do not break within emoji flag sequences.
- // That is, do not break between regional indicator (RI) symbols
- // if there is an odd number of RI characters before the break point.
- if (current === RI && next === RI) {
- var countRI = 0;
- while (prev === RI) {
- countRI++;
- prev = classTypes[--prevIndex];
- }
- if (countRI % 2 === 0) {
- return BREAK_NOT_ALLOWED;
- }
- }
- return BREAK_ALLOWED;
- };
- var GraphemeBreaker = function (str) {
- var codePoints = toCodePoints(str);
- var length = codePoints.length;
- var index = 0;
- var lastEnd = 0;
- var classTypes = codePoints.map(codePointToClass);
- return {
- next: function () {
- if (index >= length) {
- return { done: true, value: null };
- }
- var graphemeBreak = BREAK_NOT_ALLOWED;
- while (index < length &&
- (graphemeBreak = _graphemeBreakAtIndex(codePoints, classTypes, ++index)) === BREAK_NOT_ALLOWED) { }
- if (graphemeBreak !== BREAK_NOT_ALLOWED || index === length) {
- var value = fromCodePoint.apply(null, codePoints.slice(lastEnd, index));
- lastEnd = index;
- return { value: value, done: false };
- }
- return { done: true, value: null };
- },
- };
- };
- var splitGraphemes = function (str) {
- var breaker = GraphemeBreaker(str);
- var graphemes = [];
- var bk;
- while (!(bk = breaker.next()).done) {
- if (bk.value) {
- graphemes.push(bk.value.slice());
- }
- }
- return graphemes;
- };
-
- var testRangeBounds = function (document) {
- var TEST_HEIGHT = 123;
- if (document.createRange) {
- var range = document.createRange();
- if (range.getBoundingClientRect) {
- var testElement = document.createElement('boundtest');
- testElement.style.height = TEST_HEIGHT + "px";
- testElement.style.display = 'block';
- document.body.appendChild(testElement);
- range.selectNode(testElement);
- var rangeBounds = range.getBoundingClientRect();
- var rangeHeight = Math.round(rangeBounds.height);
- document.body.removeChild(testElement);
- if (rangeHeight === TEST_HEIGHT) {
- return true;
- }
- }
- }
- return false;
- };
- var testIOSLineBreak = function (document) {
- var testElement = document.createElement('boundtest');
- testElement.style.width = '50px';
- testElement.style.display = 'block';
- testElement.style.fontSize = '12px';
- testElement.style.letterSpacing = '0px';
- testElement.style.wordSpacing = '0px';
- document.body.appendChild(testElement);
- var range = document.createRange();
- testElement.innerHTML = typeof ''.repeat === 'function' ? '👨'.repeat(10) : '';
- var node = testElement.firstChild;
- var textList = toCodePoints$1(node.data).map(function (i) { return fromCodePoint$1(i); });
- var offset = 0;
- var prev = {};
- // ios 13 does not handle range getBoundingClientRect line changes correctly #2177
- var supports = textList.every(function (text, i) {
- range.setStart(node, offset);
- range.setEnd(node, offset + text.length);
- var rect = range.getBoundingClientRect();
- offset += text.length;
- var boundAhead = rect.x > prev.x || rect.y > prev.y;
- prev = rect;
- if (i === 0) {
- return true;
- }
- return boundAhead;
- });
- document.body.removeChild(testElement);
- return supports;
- };
- var testCORS = function () { return typeof new Image().crossOrigin !== 'undefined'; };
- var testResponseType = function () { return typeof new XMLHttpRequest().responseType === 'string'; };
- var testSVG = function (document) {
- var img = new Image();
- var canvas = document.createElement('canvas');
- var ctx = canvas.getContext('2d');
- if (!ctx) {
- return false;
- }
- img.src = "data:image/svg+xml,";
- try {
- ctx.drawImage(img, 0, 0);
- canvas.toDataURL();
- }
- catch (e) {
- return false;
- }
- return true;
- };
- var isGreenPixel = function (data) {
- return data[0] === 0 && data[1] === 255 && data[2] === 0 && data[3] === 255;
- };
- var testForeignObject = function (document) {
- var canvas = document.createElement('canvas');
- var size = 100;
- canvas.width = size;
- canvas.height = size;
- var ctx = canvas.getContext('2d');
- if (!ctx) {
- return Promise.reject(false);
- }
- ctx.fillStyle = 'rgb(0, 255, 0)';
- ctx.fillRect(0, 0, size, size);
- var img = new Image();
- var greenImageSrc = canvas.toDataURL();
- img.src = greenImageSrc;
- var svg = createForeignObjectSVG(size, size, 0, 0, img);
- ctx.fillStyle = 'red';
- ctx.fillRect(0, 0, size, size);
- return loadSerializedSVG$1(svg)
- .then(function (img) {
- ctx.drawImage(img, 0, 0);
- var data = ctx.getImageData(0, 0, size, size).data;
- ctx.fillStyle = 'red';
- ctx.fillRect(0, 0, size, size);
- var node = document.createElement('div');
- node.style.backgroundImage = "url(" + greenImageSrc + ")";
- node.style.height = size + "px";
- // Firefox 55 does not render inline tags
- return isGreenPixel(data)
- ? loadSerializedSVG$1(createForeignObjectSVG(size, size, 0, 0, node))
- : Promise.reject(false);
- })
- .then(function (img) {
- ctx.drawImage(img, 0, 0);
- // Edge does not render background-images
- return isGreenPixel(ctx.getImageData(0, 0, size, size).data);
- })
- .catch(function () { return false; });
- };
- var createForeignObjectSVG = function (width, height, x, y, node) {
- var xmlns = 'http://www.w3.org/2000/svg';
- var svg = document.createElementNS(xmlns, 'svg');
- var foreignObject = document.createElementNS(xmlns, 'foreignObject');
- svg.setAttributeNS(null, 'width', width.toString());
- svg.setAttributeNS(null, 'height', height.toString());
- foreignObject.setAttributeNS(null, 'width', '100%');
- foreignObject.setAttributeNS(null, 'height', '100%');
- foreignObject.setAttributeNS(null, 'x', x.toString());
- foreignObject.setAttributeNS(null, 'y', y.toString());
- foreignObject.setAttributeNS(null, 'externalResourcesRequired', 'true');
- svg.appendChild(foreignObject);
- foreignObject.appendChild(node);
- return svg;
- };
- var loadSerializedSVG$1 = function (svg) {
- return new Promise(function (resolve, reject) {
- var img = new Image();
- img.onload = function () { return resolve(img); };
- img.onerror = reject;
- img.src = "data:image/svg+xml;charset=utf-8," + encodeURIComponent(new XMLSerializer().serializeToString(svg));
- });
- };
- var FEATURES = {
- get SUPPORT_RANGE_BOUNDS() {
- var value = testRangeBounds(document);
- Object.defineProperty(FEATURES, 'SUPPORT_RANGE_BOUNDS', { value: value });
- return value;
- },
- get SUPPORT_WORD_BREAKING() {
- var value = FEATURES.SUPPORT_RANGE_BOUNDS && testIOSLineBreak(document);
- Object.defineProperty(FEATURES, 'SUPPORT_WORD_BREAKING', { value: value });
- return value;
- },
- get SUPPORT_SVG_DRAWING() {
- var value = testSVG(document);
- Object.defineProperty(FEATURES, 'SUPPORT_SVG_DRAWING', { value: value });
- return value;
- },
- get SUPPORT_FOREIGNOBJECT_DRAWING() {
- var value = typeof Array.from === 'function' && typeof window.fetch === 'function'
- ? testForeignObject(document)
- : Promise.resolve(false);
- Object.defineProperty(FEATURES, 'SUPPORT_FOREIGNOBJECT_DRAWING', { value: value });
- return value;
- },
- get SUPPORT_CORS_IMAGES() {
- var value = testCORS();
- Object.defineProperty(FEATURES, 'SUPPORT_CORS_IMAGES', { value: value });
- return value;
- },
- get SUPPORT_RESPONSE_TYPE() {
- var value = testResponseType();
- Object.defineProperty(FEATURES, 'SUPPORT_RESPONSE_TYPE', { value: value });
- return value;
- },
- get SUPPORT_CORS_XHR() {
- var value = 'withCredentials' in new XMLHttpRequest();
- Object.defineProperty(FEATURES, 'SUPPORT_CORS_XHR', { value: value });
- return value;
- },
- get SUPPORT_NATIVE_TEXT_SEGMENTATION() {
- // eslint-disable-next-line @typescript-eslint/no-explicit-any
- var value = !!(typeof Intl !== 'undefined' && Intl.Segmenter);
- Object.defineProperty(FEATURES, 'SUPPORT_NATIVE_TEXT_SEGMENTATION', { value: value });
- return value;
- }
- };
-
- var TextBounds = /** @class */ (function () {
- function TextBounds(text, bounds) {
- this.text = text;
- this.bounds = bounds;
- }
- return TextBounds;
- }());
- var parseTextBounds = function (context, value, styles, node) {
- var textList = breakText(value, styles);
- var textBounds = [];
- var offset = 0;
- textList.forEach(function (text) {
- if (styles.textDecorationLine.length || text.trim().length > 0) {
- if (FEATURES.SUPPORT_RANGE_BOUNDS) {
- var clientRects = createRange(node, offset, text.length).getClientRects();
- if (clientRects.length > 1) {
- var subSegments = segmentGraphemes(text);
- var subOffset_1 = 0;
- subSegments.forEach(function (subSegment) {
- textBounds.push(new TextBounds(subSegment, Bounds.fromDOMRectList(context, createRange(node, subOffset_1 + offset, subSegment.length).getClientRects())));
- subOffset_1 += subSegment.length;
- });
- }
- else {
- textBounds.push(new TextBounds(text, Bounds.fromDOMRectList(context, clientRects)));
- }
- }
- else {
- var replacementNode = node.splitText(text.length);
- textBounds.push(new TextBounds(text, getWrapperBounds(context, node)));
- node = replacementNode;
- }
- }
- else if (!FEATURES.SUPPORT_RANGE_BOUNDS) {
- node = node.splitText(text.length);
- }
- offset += text.length;
- });
- return textBounds;
- };
- var getWrapperBounds = function (context, node) {
- var ownerDocument = node.ownerDocument;
- if (ownerDocument) {
- var wrapper = ownerDocument.createElement('html2canvaswrapper');
- wrapper.appendChild(node.cloneNode(true));
- var parentNode = node.parentNode;
- if (parentNode) {
- parentNode.replaceChild(wrapper, node);
- var bounds = parseBounds(context, wrapper);
- if (wrapper.firstChild) {
- parentNode.replaceChild(wrapper.firstChild, wrapper);
- }
- return bounds;
- }
- }
- return Bounds.EMPTY;
- };
- var createRange = function (node, offset, length) {
- var ownerDocument = node.ownerDocument;
- if (!ownerDocument) {
- throw new Error('Node has no owner document');
- }
- var range = ownerDocument.createRange();
- range.setStart(node, offset);
- range.setEnd(node, offset + length);
- return range;
- };
- var segmentGraphemes = function (value) {
- if (FEATURES.SUPPORT_NATIVE_TEXT_SEGMENTATION) {
- // eslint-disable-next-line @typescript-eslint/no-explicit-any
- var segmenter = new Intl.Segmenter(void 0, { granularity: 'grapheme' });
- // eslint-disable-next-line @typescript-eslint/no-explicit-any
- return Array.from(segmenter.segment(value)).map(function (segment) { return segment.segment; });
- }
- return splitGraphemes(value);
- };
- var segmentWords = function (value, styles) {
- if (FEATURES.SUPPORT_NATIVE_TEXT_SEGMENTATION) {
- // eslint-disable-next-line @typescript-eslint/no-explicit-any
- var segmenter = new Intl.Segmenter(void 0, {
- granularity: 'word'
- });
- // eslint-disable-next-line @typescript-eslint/no-explicit-any
- return Array.from(segmenter.segment(value)).map(function (segment) { return segment.segment; });
- }
- return breakWords(value, styles);
- };
- var breakText = function (value, styles) {
- return styles.letterSpacing !== 0 ? segmentGraphemes(value) : segmentWords(value, styles);
- };
- // https://drafts.csswg.org/css-text/#word-separator
- var wordSeparators = [0x0020, 0x00a0, 0x1361, 0x10100, 0x10101, 0x1039, 0x1091];
- var breakWords = function (str, styles) {
- var breaker = LineBreaker(str, {
- lineBreak: styles.lineBreak,
- wordBreak: styles.overflowWrap === "break-word" /* BREAK_WORD */ ? 'break-word' : styles.wordBreak
- });
- var words = [];
- var bk;
- var _loop_1 = function () {
- if (bk.value) {
- var value = bk.value.slice();
- var codePoints = toCodePoints$1(value);
- var word_1 = '';
- codePoints.forEach(function (codePoint) {
- if (wordSeparators.indexOf(codePoint) === -1) {
- word_1 += fromCodePoint$1(codePoint);
- }
- else {
- if (word_1.length) {
- words.push(word_1);
- }
- words.push(fromCodePoint$1(codePoint));
- word_1 = '';
- }
- });
- if (word_1.length) {
- words.push(word_1);
- }
- }
- };
- while (!(bk = breaker.next()).done) {
- _loop_1();
- }
- return words;
- };
-
- var TextContainer = /** @class */ (function () {
- function TextContainer(context, node, styles) {
- this.text = transform(node.data, styles.textTransform);
- this.textBounds = parseTextBounds(context, this.text, styles, node);
- }
- return TextContainer;
- }());
- var transform = function (text, transform) {
- switch (transform) {
- case 1 /* LOWERCASE */:
- return text.toLowerCase();
- case 3 /* CAPITALIZE */:
- return text.replace(CAPITALIZE, capitalize);
- case 2 /* UPPERCASE */:
- return text.toUpperCase();
- default:
- return text;
- }
- };
- var CAPITALIZE = /(^|\s|:|-|\(|\))([a-z])/g;
- var capitalize = function (m, p1, p2) {
- if (m.length > 0) {
- return p1 + p2.toUpperCase();
- }
- return m;
- };
-
- var ImageElementContainer = /** @class */ (function (_super) {
- __extends(ImageElementContainer, _super);
- function ImageElementContainer(context, img) {
- var _this = _super.call(this, context, img) || this;
- _this.src = img.currentSrc || img.src;
- _this.intrinsicWidth = img.naturalWidth;
- _this.intrinsicHeight = img.naturalHeight;
- _this.context.cache.addImage(_this.src);
- return _this;
- }
- return ImageElementContainer;
- }(ElementContainer));
-
- var CanvasElementContainer = /** @class */ (function (_super) {
- __extends(CanvasElementContainer, _super);
- function CanvasElementContainer(context, canvas) {
- var _this = _super.call(this, context, canvas) || this;
- _this.canvas = canvas;
- _this.intrinsicWidth = canvas.width;
- _this.intrinsicHeight = canvas.height;
- return _this;
- }
- return CanvasElementContainer;
- }(ElementContainer));
-
- var SVGElementContainer = /** @class */ (function (_super) {
- __extends(SVGElementContainer, _super);
- function SVGElementContainer(context, img) {
- var _this = _super.call(this, context, img) || this;
- var s = new XMLSerializer();
- var bounds = parseBounds(context, img);
- img.setAttribute('width', bounds.width + "px");
- img.setAttribute('height', bounds.height + "px");
- _this.svg = "data:image/svg+xml," + encodeURIComponent(s.serializeToString(img));
- _this.intrinsicWidth = img.width.baseVal.value;
- _this.intrinsicHeight = img.height.baseVal.value;
- _this.context.cache.addImage(_this.svg);
- return _this;
- }
- return SVGElementContainer;
- }(ElementContainer));
-
- var LIElementContainer = /** @class */ (function (_super) {
- __extends(LIElementContainer, _super);
- function LIElementContainer(context, element) {
- var _this = _super.call(this, context, element) || this;
- _this.value = element.value;
- return _this;
- }
- return LIElementContainer;
- }(ElementContainer));
-
- var OLElementContainer = /** @class */ (function (_super) {
- __extends(OLElementContainer, _super);
- function OLElementContainer(context, element) {
- var _this = _super.call(this, context, element) || this;
- _this.start = element.start;
- _this.reversed = typeof element.reversed === 'boolean' && element.reversed === true;
- return _this;
- }
- return OLElementContainer;
- }(ElementContainer));
-
- var CHECKBOX_BORDER_RADIUS = [
- {
- type: 15 /* DIMENSION_TOKEN */,
- flags: 0,
- unit: 'px',
- number: 3
- }
- ];
- var RADIO_BORDER_RADIUS = [
- {
- type: 16 /* PERCENTAGE_TOKEN */,
- flags: 0,
- number: 50
- }
- ];
- var reformatInputBounds = function (bounds) {
- if (bounds.width > bounds.height) {
- return new Bounds(bounds.left + (bounds.width - bounds.height) / 2, bounds.top, bounds.height, bounds.height);
- }
- else if (bounds.width < bounds.height) {
- return new Bounds(bounds.left, bounds.top + (bounds.height - bounds.width) / 2, bounds.width, bounds.width);
- }
- return bounds;
- };
- var getInputValue = function (node) {
- var value = node.type === PASSWORD ? new Array(node.value.length + 1).join('\u2022') : node.value;
- return value.length === 0 ? node.placeholder || '' : value;
- };
- var CHECKBOX = 'checkbox';
- var RADIO = 'radio';
- var PASSWORD = 'password';
- var INPUT_COLOR = 0x2a2a2aff;
- var InputElementContainer = /** @class */ (function (_super) {
- __extends(InputElementContainer, _super);
- function InputElementContainer(context, input) {
- var _this = _super.call(this, context, input) || this;
- _this.type = input.type.toLowerCase();
- _this.checked = input.checked;
- _this.value = getInputValue(input);
- if (_this.type === CHECKBOX || _this.type === RADIO) {
- _this.styles.backgroundColor = 0xdededeff;
- _this.styles.borderTopColor =
- _this.styles.borderRightColor =
- _this.styles.borderBottomColor =
- _this.styles.borderLeftColor =
- 0xa5a5a5ff;
- _this.styles.borderTopWidth =
- _this.styles.borderRightWidth =
- _this.styles.borderBottomWidth =
- _this.styles.borderLeftWidth =
- 1;
- _this.styles.borderTopStyle =
- _this.styles.borderRightStyle =
- _this.styles.borderBottomStyle =
- _this.styles.borderLeftStyle =
- 1 /* SOLID */;
- _this.styles.backgroundClip = [0 /* BORDER_BOX */];
- _this.styles.backgroundOrigin = [0 /* BORDER_BOX */];
- _this.bounds = reformatInputBounds(_this.bounds);
- }
- switch (_this.type) {
- case CHECKBOX:
- _this.styles.borderTopRightRadius =
- _this.styles.borderTopLeftRadius =
- _this.styles.borderBottomRightRadius =
- _this.styles.borderBottomLeftRadius =
- CHECKBOX_BORDER_RADIUS;
- break;
- case RADIO:
- _this.styles.borderTopRightRadius =
- _this.styles.borderTopLeftRadius =
- _this.styles.borderBottomRightRadius =
- _this.styles.borderBottomLeftRadius =
- RADIO_BORDER_RADIUS;
- break;
- }
- return _this;
- }
- return InputElementContainer;
- }(ElementContainer));
-
- var SelectElementContainer = /** @class */ (function (_super) {
- __extends(SelectElementContainer, _super);
- function SelectElementContainer(context, element) {
- var _this = _super.call(this, context, element) || this;
- var option = element.options[element.selectedIndex || 0];
- _this.value = option ? option.text || '' : '';
- return _this;
- }
- return SelectElementContainer;
- }(ElementContainer));
-
- var TextareaElementContainer = /** @class */ (function (_super) {
- __extends(TextareaElementContainer, _super);
- function TextareaElementContainer(context, element) {
- var _this = _super.call(this, context, element) || this;
- _this.value = element.value;
- return _this;
- }
- return TextareaElementContainer;
- }(ElementContainer));
-
- var IFrameElementContainer = /** @class */ (function (_super) {
- __extends(IFrameElementContainer, _super);
- function IFrameElementContainer(context, iframe) {
- var _this = _super.call(this, context, iframe) || this;
- _this.src = iframe.src;
- _this.width = parseInt(iframe.width, 10) || 0;
- _this.height = parseInt(iframe.height, 10) || 0;
- _this.backgroundColor = _this.styles.backgroundColor;
- try {
- if (iframe.contentWindow &&
- iframe.contentWindow.document &&
- iframe.contentWindow.document.documentElement) {
- _this.tree = parseTree(context, iframe.contentWindow.document.documentElement);
- // http://www.w3.org/TR/css3-background/#special-backgrounds
- var documentBackgroundColor = iframe.contentWindow.document.documentElement
- ? parseColor(context, getComputedStyle(iframe.contentWindow.document.documentElement).backgroundColor)
- : COLORS.TRANSPARENT;
- var bodyBackgroundColor = iframe.contentWindow.document.body
- ? parseColor(context, getComputedStyle(iframe.contentWindow.document.body).backgroundColor)
- : COLORS.TRANSPARENT;
- _this.backgroundColor = isTransparent(documentBackgroundColor)
- ? isTransparent(bodyBackgroundColor)
- ? _this.styles.backgroundColor
- : bodyBackgroundColor
- : documentBackgroundColor;
- }
- }
- catch (e) { }
- return _this;
- }
- return IFrameElementContainer;
- }(ElementContainer));
-
- var LIST_OWNERS = ['OL', 'UL', 'MENU'];
- var parseNodeTree = function (context, node, parent, root) {
- for (var childNode = node.firstChild, nextNode = void 0; childNode; childNode = nextNode) {
- nextNode = childNode.nextSibling;
- if (isTextNode(childNode) && childNode.data.trim().length > 0) {
- parent.textNodes.push(new TextContainer(context, childNode, parent.styles));
- }
- else if (isElementNode(childNode)) {
- if (isSlotElement(childNode) && childNode.assignedNodes) {
- childNode.assignedNodes().forEach(function (childNode) { return parseNodeTree(context, childNode, parent, root); });
- }
- else {
- var container = createContainer(context, childNode);
- if (container.styles.isVisible()) {
- if (createsRealStackingContext(childNode, container, root)) {
- container.flags |= 4 /* CREATES_REAL_STACKING_CONTEXT */;
- }
- else if (createsStackingContext(container.styles)) {
- container.flags |= 2 /* CREATES_STACKING_CONTEXT */;
- }
- if (LIST_OWNERS.indexOf(childNode.tagName) !== -1) {
- container.flags |= 8 /* IS_LIST_OWNER */;
- }
- parent.elements.push(container);
- childNode.slot;
- if (childNode.shadowRoot) {
- parseNodeTree(context, childNode.shadowRoot, container, root);
- }
- else if (!isTextareaElement(childNode) &&
- !isSVGElement(childNode) &&
- !isSelectElement(childNode)) {
- parseNodeTree(context, childNode, container, root);
- }
- }
- }
- }
- }
- };
- var createContainer = function (context, element) {
- if (isImageElement(element)) {
- return new ImageElementContainer(context, element);
- }
- if (isCanvasElement(element)) {
- return new CanvasElementContainer(context, element);
- }
- if (isSVGElement(element)) {
- return new SVGElementContainer(context, element);
- }
- if (isLIElement(element)) {
- return new LIElementContainer(context, element);
- }
- if (isOLElement(element)) {
- return new OLElementContainer(context, element);
- }
- if (isInputElement(element)) {
- return new InputElementContainer(context, element);
- }
- if (isSelectElement(element)) {
- return new SelectElementContainer(context, element);
- }
- if (isTextareaElement(element)) {
- return new TextareaElementContainer(context, element);
- }
- if (isIFrameElement(element)) {
- return new IFrameElementContainer(context, element);
- }
- return new ElementContainer(context, element);
- };
- var parseTree = function (context, element) {
- var container = createContainer(context, element);
- container.flags |= 4 /* CREATES_REAL_STACKING_CONTEXT */;
- parseNodeTree(context, element, container, container);
- return container;
- };
- var createsRealStackingContext = function (node, container, root) {
- return (container.styles.isPositionedWithZIndex() ||
- container.styles.opacity < 1 ||
- container.styles.isTransformed() ||
- (isBodyElement(node) && root.styles.isTransparent()));
- };
- var createsStackingContext = function (styles) { return styles.isPositioned() || styles.isFloating(); };
- var isTextNode = function (node) { return node.nodeType === Node.TEXT_NODE; };
- var isElementNode = function (node) { return node.nodeType === Node.ELEMENT_NODE; };
- var isHTMLElementNode = function (node) {
- return isElementNode(node) && typeof node.style !== 'undefined' && !isSVGElementNode(node);
- };
- var isSVGElementNode = function (element) {
- return typeof element.className === 'object';
- };
- var isLIElement = function (node) { return node.tagName === 'LI'; };
- var isOLElement = function (node) { return node.tagName === 'OL'; };
- var isInputElement = function (node) { return node.tagName === 'INPUT'; };
- var isHTMLElement = function (node) { return node.tagName === 'HTML'; };
- var isSVGElement = function (node) { return node.tagName === 'svg'; };
- var isBodyElement = function (node) { return node.tagName === 'BODY'; };
- var isCanvasElement = function (node) { return node.tagName === 'CANVAS'; };
- var isVideoElement = function (node) { return node.tagName === 'VIDEO'; };
- var isImageElement = function (node) { return node.tagName === 'IMG'; };
- var isIFrameElement = function (node) { return node.tagName === 'IFRAME'; };
- var isStyleElement = function (node) { return node.tagName === 'STYLE'; };
- var isScriptElement = function (node) { return node.tagName === 'SCRIPT'; };
- var isTextareaElement = function (node) { return node.tagName === 'TEXTAREA'; };
- var isSelectElement = function (node) { return node.tagName === 'SELECT'; };
- var isSlotElement = function (node) { return node.tagName === 'SLOT'; };
- // https://html.spec.whatwg.org/multipage/custom-elements.html#valid-custom-element-name
- var isCustomElement = function (node) { return node.tagName.indexOf('-') > 0; };
-
- var CounterState = /** @class */ (function () {
- function CounterState() {
- this.counters = {};
- }
- CounterState.prototype.getCounterValue = function (name) {
- var counter = this.counters[name];
- if (counter && counter.length) {
- return counter[counter.length - 1];
- }
- return 1;
- };
- CounterState.prototype.getCounterValues = function (name) {
- var counter = this.counters[name];
- return counter ? counter : [];
- };
- CounterState.prototype.pop = function (counters) {
- var _this = this;
- counters.forEach(function (counter) { return _this.counters[counter].pop(); });
- };
- CounterState.prototype.parse = function (style) {
- var _this = this;
- var counterIncrement = style.counterIncrement;
- var counterReset = style.counterReset;
- var canReset = true;
- if (counterIncrement !== null) {
- counterIncrement.forEach(function (entry) {
- var counter = _this.counters[entry.counter];
- if (counter && entry.increment !== 0) {
- canReset = false;
- if (!counter.length) {
- counter.push(1);
- }
- counter[Math.max(0, counter.length - 1)] += entry.increment;
- }
- });
- }
- var counterNames = [];
- if (canReset) {
- counterReset.forEach(function (entry) {
- var counter = _this.counters[entry.counter];
- counterNames.push(entry.counter);
- if (!counter) {
- counter = _this.counters[entry.counter] = [];
- }
- counter.push(entry.reset);
- });
- }
- return counterNames;
- };
- return CounterState;
- }());
- var ROMAN_UPPER = {
- integers: [1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1],
- values: ['M', 'CM', 'D', 'CD', 'C', 'XC', 'L', 'XL', 'X', 'IX', 'V', 'IV', 'I']
- };
- var ARMENIAN = {
- integers: [
- 9000, 8000, 7000, 6000, 5000, 4000, 3000, 2000, 1000, 900, 800, 700, 600, 500, 400, 300, 200, 100, 90, 80, 70,
- 60, 50, 40, 30, 20, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1
- ],
- values: [
- 'Ք',
- 'Փ',
- 'Ւ',
- 'Ց',
- 'Ր',
- 'Տ',
- 'Վ',
- 'Ս',
- 'Ռ',
- 'Ջ',
- 'Պ',
- 'Չ',
- 'Ո',
- 'Շ',
- 'Ն',
- 'Յ',
- 'Մ',
- 'Ճ',
- 'Ղ',
- 'Ձ',
- 'Հ',
- 'Կ',
- 'Ծ',
- 'Խ',
- 'Լ',
- 'Ի',
- 'Ժ',
- 'Թ',
- 'Ը',
- 'Է',
- 'Զ',
- 'Ե',
- 'Դ',
- 'Գ',
- 'Բ',
- 'Ա'
- ]
- };
- var HEBREW = {
- integers: [
- 10000, 9000, 8000, 7000, 6000, 5000, 4000, 3000, 2000, 1000, 400, 300, 200, 100, 90, 80, 70, 60, 50, 40, 30, 20,
- 19, 18, 17, 16, 15, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1
- ],
- values: [
- 'י׳',
- 'ט׳',
- 'ח׳',
- 'ז׳',
- 'ו׳',
- 'ה׳',
- 'ד׳',
- 'ג׳',
- 'ב׳',
- 'א׳',
- 'ת',
- 'ש',
- 'ר',
- 'ק',
- 'צ',
- 'פ',
- 'ע',
- 'ס',
- 'נ',
- 'מ',
- 'ל',
- 'כ',
- 'יט',
- 'יח',
- 'יז',
- 'טז',
- 'טו',
- 'י',
- 'ט',
- 'ח',
- 'ז',
- 'ו',
- 'ה',
- 'ד',
- 'ג',
- 'ב',
- 'א'
- ]
- };
- var GEORGIAN = {
- integers: [
- 10000, 9000, 8000, 7000, 6000, 5000, 4000, 3000, 2000, 1000, 900, 800, 700, 600, 500, 400, 300, 200, 100, 90,
- 80, 70, 60, 50, 40, 30, 20, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1
- ],
- values: [
- 'ჵ',
- 'ჰ',
- 'ჯ',
- 'ჴ',
- 'ხ',
- 'ჭ',
- 'წ',
- 'ძ',
- 'ც',
- 'ჩ',
- 'შ',
- 'ყ',
- 'ღ',
- 'ქ',
- 'ფ',
- 'ჳ',
- 'ტ',
- 'ს',
- 'რ',
- 'ჟ',
- 'პ',
- 'ო',
- 'ჲ',
- 'ნ',
- 'მ',
- 'ლ',
- 'კ',
- 'ი',
- 'თ',
- 'ჱ',
- 'ზ',
- 'ვ',
- 'ე',
- 'დ',
- 'გ',
- 'ბ',
- 'ა'
- ]
- };
- var createAdditiveCounter = function (value, min, max, symbols, fallback, suffix) {
- if (value < min || value > max) {
- return createCounterText(value, fallback, suffix.length > 0);
- }
- return (symbols.integers.reduce(function (string, integer, index) {
- while (value >= integer) {
- value -= integer;
- string += symbols.values[index];
- }
- return string;
- }, '') + suffix);
- };
- var createCounterStyleWithSymbolResolver = function (value, codePointRangeLength, isNumeric, resolver) {
- var string = '';
- do {
- if (!isNumeric) {
- value--;
- }
- string = resolver(value) + string;
- value /= codePointRangeLength;
- } while (value * codePointRangeLength >= codePointRangeLength);
- return string;
- };
- var createCounterStyleFromRange = function (value, codePointRangeStart, codePointRangeEnd, isNumeric, suffix) {
- var codePointRangeLength = codePointRangeEnd - codePointRangeStart + 1;
- return ((value < 0 ? '-' : '') +
- (createCounterStyleWithSymbolResolver(Math.abs(value), codePointRangeLength, isNumeric, function (codePoint) {
- return fromCodePoint$1(Math.floor(codePoint % codePointRangeLength) + codePointRangeStart);
- }) +
- suffix));
- };
- var createCounterStyleFromSymbols = function (value, symbols, suffix) {
- if (suffix === void 0) { suffix = '. '; }
- var codePointRangeLength = symbols.length;
- return (createCounterStyleWithSymbolResolver(Math.abs(value), codePointRangeLength, false, function (codePoint) { return symbols[Math.floor(codePoint % codePointRangeLength)]; }) + suffix);
- };
- var CJK_ZEROS = 1 << 0;
- var CJK_TEN_COEFFICIENTS = 1 << 1;
- var CJK_TEN_HIGH_COEFFICIENTS = 1 << 2;
- var CJK_HUNDRED_COEFFICIENTS = 1 << 3;
- var createCJKCounter = function (value, numbers, multipliers, negativeSign, suffix, flags) {
- if (value < -9999 || value > 9999) {
- return createCounterText(value, 4 /* CJK_DECIMAL */, suffix.length > 0);
- }
- var tmp = Math.abs(value);
- var string = suffix;
- if (tmp === 0) {
- return numbers[0] + string;
- }
- for (var digit = 0; tmp > 0 && digit <= 4; digit++) {
- var coefficient = tmp % 10;
- if (coefficient === 0 && contains(flags, CJK_ZEROS) && string !== '') {
- string = numbers[coefficient] + string;
- }
- else if (coefficient > 1 ||
- (coefficient === 1 && digit === 0) ||
- (coefficient === 1 && digit === 1 && contains(flags, CJK_TEN_COEFFICIENTS)) ||
- (coefficient === 1 && digit === 1 && contains(flags, CJK_TEN_HIGH_COEFFICIENTS) && value > 100) ||
- (coefficient === 1 && digit > 1 && contains(flags, CJK_HUNDRED_COEFFICIENTS))) {
- string = numbers[coefficient] + (digit > 0 ? multipliers[digit - 1] : '') + string;
- }
- else if (coefficient === 1 && digit > 0) {
- string = multipliers[digit - 1] + string;
- }
- tmp = Math.floor(tmp / 10);
- }
- return (value < 0 ? negativeSign : '') + string;
- };
- var CHINESE_INFORMAL_MULTIPLIERS = '十百千萬';
- var CHINESE_FORMAL_MULTIPLIERS = '拾佰仟萬';
- var JAPANESE_NEGATIVE = 'マイナス';
- var KOREAN_NEGATIVE = '마이너스';
- var createCounterText = function (value, type, appendSuffix) {
- var defaultSuffix = appendSuffix ? '. ' : '';
- var cjkSuffix = appendSuffix ? '、' : '';
- var koreanSuffix = appendSuffix ? ', ' : '';
- var spaceSuffix = appendSuffix ? ' ' : '';
- switch (type) {
- case 0 /* DISC */:
- return '•' + spaceSuffix;
- case 1 /* CIRCLE */:
- return '◦' + spaceSuffix;
- case 2 /* SQUARE */:
- return '◾' + spaceSuffix;
- case 5 /* DECIMAL_LEADING_ZERO */:
- var string = createCounterStyleFromRange(value, 48, 57, true, defaultSuffix);
- return string.length < 4 ? "0" + string : string;
- case 4 /* CJK_DECIMAL */:
- return createCounterStyleFromSymbols(value, '〇一二三四五六七八九', cjkSuffix);
- case 6 /* LOWER_ROMAN */:
- return createAdditiveCounter(value, 1, 3999, ROMAN_UPPER, 3 /* DECIMAL */, defaultSuffix).toLowerCase();
- case 7 /* UPPER_ROMAN */:
- return createAdditiveCounter(value, 1, 3999, ROMAN_UPPER, 3 /* DECIMAL */, defaultSuffix);
- case 8 /* LOWER_GREEK */:
- return createCounterStyleFromRange(value, 945, 969, false, defaultSuffix);
- case 9 /* LOWER_ALPHA */:
- return createCounterStyleFromRange(value, 97, 122, false, defaultSuffix);
- case 10 /* UPPER_ALPHA */:
- return createCounterStyleFromRange(value, 65, 90, false, defaultSuffix);
- case 11 /* ARABIC_INDIC */:
- return createCounterStyleFromRange(value, 1632, 1641, true, defaultSuffix);
- case 12 /* ARMENIAN */:
- case 49 /* UPPER_ARMENIAN */:
- return createAdditiveCounter(value, 1, 9999, ARMENIAN, 3 /* DECIMAL */, defaultSuffix);
- case 35 /* LOWER_ARMENIAN */:
- return createAdditiveCounter(value, 1, 9999, ARMENIAN, 3 /* DECIMAL */, defaultSuffix).toLowerCase();
- case 13 /* BENGALI */:
- return createCounterStyleFromRange(value, 2534, 2543, true, defaultSuffix);
- case 14 /* CAMBODIAN */:
- case 30 /* KHMER */:
- return createCounterStyleFromRange(value, 6112, 6121, true, defaultSuffix);
- case 15 /* CJK_EARTHLY_BRANCH */:
- return createCounterStyleFromSymbols(value, '子丑寅卯辰巳午未申酉戌亥', cjkSuffix);
- case 16 /* CJK_HEAVENLY_STEM */:
- return createCounterStyleFromSymbols(value, '甲乙丙丁戊己庚辛壬癸', cjkSuffix);
- case 17 /* CJK_IDEOGRAPHIC */:
- case 48 /* TRAD_CHINESE_INFORMAL */:
- return createCJKCounter(value, '零一二三四五六七八九', CHINESE_INFORMAL_MULTIPLIERS, '負', cjkSuffix, CJK_TEN_COEFFICIENTS | CJK_TEN_HIGH_COEFFICIENTS | CJK_HUNDRED_COEFFICIENTS);
- case 47 /* TRAD_CHINESE_FORMAL */:
- return createCJKCounter(value, '零壹貳參肆伍陸柒捌玖', CHINESE_FORMAL_MULTIPLIERS, '負', cjkSuffix, CJK_ZEROS | CJK_TEN_COEFFICIENTS | CJK_TEN_HIGH_COEFFICIENTS | CJK_HUNDRED_COEFFICIENTS);
- case 42 /* SIMP_CHINESE_INFORMAL */:
- return createCJKCounter(value, '零一二三四五六七八九', CHINESE_INFORMAL_MULTIPLIERS, '负', cjkSuffix, CJK_TEN_COEFFICIENTS | CJK_TEN_HIGH_COEFFICIENTS | CJK_HUNDRED_COEFFICIENTS);
- case 41 /* SIMP_CHINESE_FORMAL */:
- return createCJKCounter(value, '零壹贰叁肆伍陆柒捌玖', CHINESE_FORMAL_MULTIPLIERS, '负', cjkSuffix, CJK_ZEROS | CJK_TEN_COEFFICIENTS | CJK_TEN_HIGH_COEFFICIENTS | CJK_HUNDRED_COEFFICIENTS);
- case 26 /* JAPANESE_INFORMAL */:
- return createCJKCounter(value, '〇一二三四五六七八九', '十百千万', JAPANESE_NEGATIVE, cjkSuffix, 0);
- case 25 /* JAPANESE_FORMAL */:
- return createCJKCounter(value, '零壱弐参四伍六七八九', '拾百千万', JAPANESE_NEGATIVE, cjkSuffix, CJK_ZEROS | CJK_TEN_COEFFICIENTS | CJK_TEN_HIGH_COEFFICIENTS);
- case 31 /* KOREAN_HANGUL_FORMAL */:
- return createCJKCounter(value, '영일이삼사오육칠팔구', '십백천만', KOREAN_NEGATIVE, koreanSuffix, CJK_ZEROS | CJK_TEN_COEFFICIENTS | CJK_TEN_HIGH_COEFFICIENTS);
- case 33 /* KOREAN_HANJA_INFORMAL */:
- return createCJKCounter(value, '零一二三四五六七八九', '十百千萬', KOREAN_NEGATIVE, koreanSuffix, 0);
- case 32 /* KOREAN_HANJA_FORMAL */:
- return createCJKCounter(value, '零壹貳參四五六七八九', '拾百千', KOREAN_NEGATIVE, koreanSuffix, CJK_ZEROS | CJK_TEN_COEFFICIENTS | CJK_TEN_HIGH_COEFFICIENTS);
- case 18 /* DEVANAGARI */:
- return createCounterStyleFromRange(value, 0x966, 0x96f, true, defaultSuffix);
- case 20 /* GEORGIAN */:
- return createAdditiveCounter(value, 1, 19999, GEORGIAN, 3 /* DECIMAL */, defaultSuffix);
- case 21 /* GUJARATI */:
- return createCounterStyleFromRange(value, 0xae6, 0xaef, true, defaultSuffix);
- case 22 /* GURMUKHI */:
- return createCounterStyleFromRange(value, 0xa66, 0xa6f, true, defaultSuffix);
- case 22 /* HEBREW */:
- return createAdditiveCounter(value, 1, 10999, HEBREW, 3 /* DECIMAL */, defaultSuffix);
- case 23 /* HIRAGANA */:
- return createCounterStyleFromSymbols(value, 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわゐゑをん');
- case 24 /* HIRAGANA_IROHA */:
- return createCounterStyleFromSymbols(value, 'いろはにほへとちりぬるをわかよたれそつねならむうゐのおくやまけふこえてあさきゆめみしゑひもせす');
- case 27 /* KANNADA */:
- return createCounterStyleFromRange(value, 0xce6, 0xcef, true, defaultSuffix);
- case 28 /* KATAKANA */:
- return createCounterStyleFromSymbols(value, 'アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヰヱヲン', cjkSuffix);
- case 29 /* KATAKANA_IROHA */:
- return createCounterStyleFromSymbols(value, 'イロハニホヘトチリヌルヲワカヨタレソツネナラムウヰノオクヤマケフコエテアサキユメミシヱヒモセス', cjkSuffix);
- case 34 /* LAO */:
- return createCounterStyleFromRange(value, 0xed0, 0xed9, true, defaultSuffix);
- case 37 /* MONGOLIAN */:
- return createCounterStyleFromRange(value, 0x1810, 0x1819, true, defaultSuffix);
- case 38 /* MYANMAR */:
- return createCounterStyleFromRange(value, 0x1040, 0x1049, true, defaultSuffix);
- case 39 /* ORIYA */:
- return createCounterStyleFromRange(value, 0xb66, 0xb6f, true, defaultSuffix);
- case 40 /* PERSIAN */:
- return createCounterStyleFromRange(value, 0x6f0, 0x6f9, true, defaultSuffix);
- case 43 /* TAMIL */:
- return createCounterStyleFromRange(value, 0xbe6, 0xbef, true, defaultSuffix);
- case 44 /* TELUGU */:
- return createCounterStyleFromRange(value, 0xc66, 0xc6f, true, defaultSuffix);
- case 45 /* THAI */:
- return createCounterStyleFromRange(value, 0xe50, 0xe59, true, defaultSuffix);
- case 46 /* TIBETAN */:
- return createCounterStyleFromRange(value, 0xf20, 0xf29, true, defaultSuffix);
- case 3 /* DECIMAL */:
- default:
- return createCounterStyleFromRange(value, 48, 57, true, defaultSuffix);
- }
- };
-
- var IGNORE_ATTRIBUTE = 'data-html2canvas-ignore';
- var DocumentCloner = /** @class */ (function () {
- function DocumentCloner(context, element, options) {
- this.context = context;
- this.options = options;
- this.scrolledElements = [];
- this.referenceElement = element;
- this.counters = new CounterState();
- this.quoteDepth = 0;
- if (!element.ownerDocument) {
- throw new Error('Cloned element does not have an owner document');
- }
- this.documentElement = this.cloneNode(element.ownerDocument.documentElement, false);
- }
- DocumentCloner.prototype.toIFrame = function (ownerDocument, windowSize) {
- var _this = this;
- var iframe = createIFrameContainer(ownerDocument, windowSize);
- if (!iframe.contentWindow) {
- return Promise.reject("Unable to find iframe window");
- }
- var scrollX = ownerDocument.defaultView.pageXOffset;
- var scrollY = ownerDocument.defaultView.pageYOffset;
- var cloneWindow = iframe.contentWindow;
- var documentClone = cloneWindow.document;
- /* Chrome doesn't detect relative background-images assigned in inline

 -
- -
-See the [fairscale docs](https://fairscale.readthedocs.io/en/latest/api/nn/fsdp_tips.html) for a more detailed
-explanation of how FSDP works.
-
-
-
-See the [fairscale docs](https://fairscale.readthedocs.io/en/latest/api/nn/fsdp_tips.html) for a more detailed
-explanation of how FSDP works.
-
- -
- -
- -
- -
- -
- -
- -
-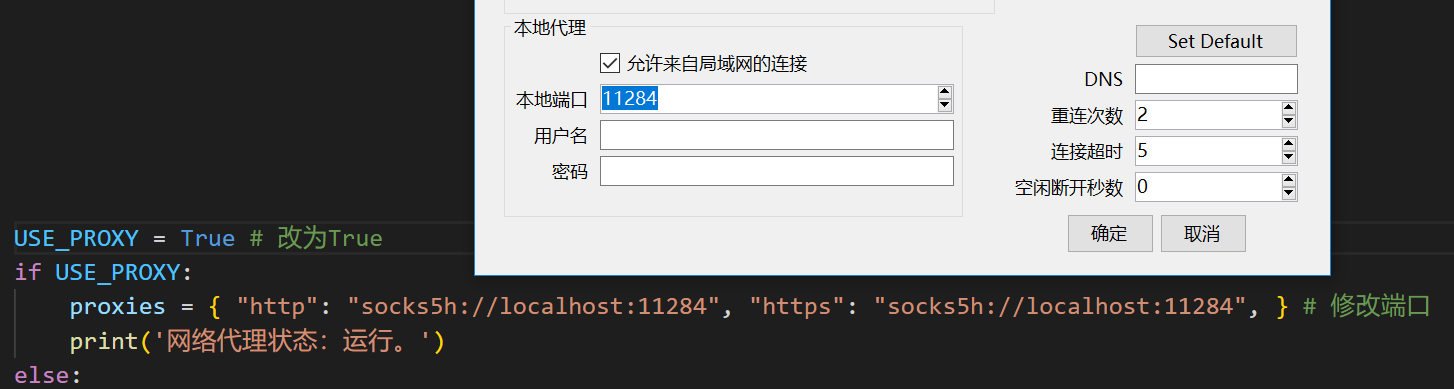 -
-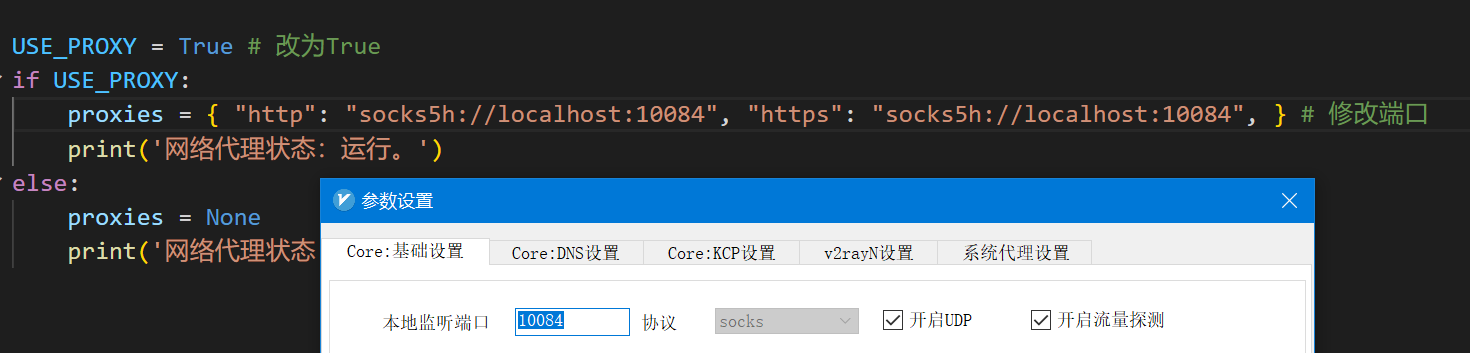 -
-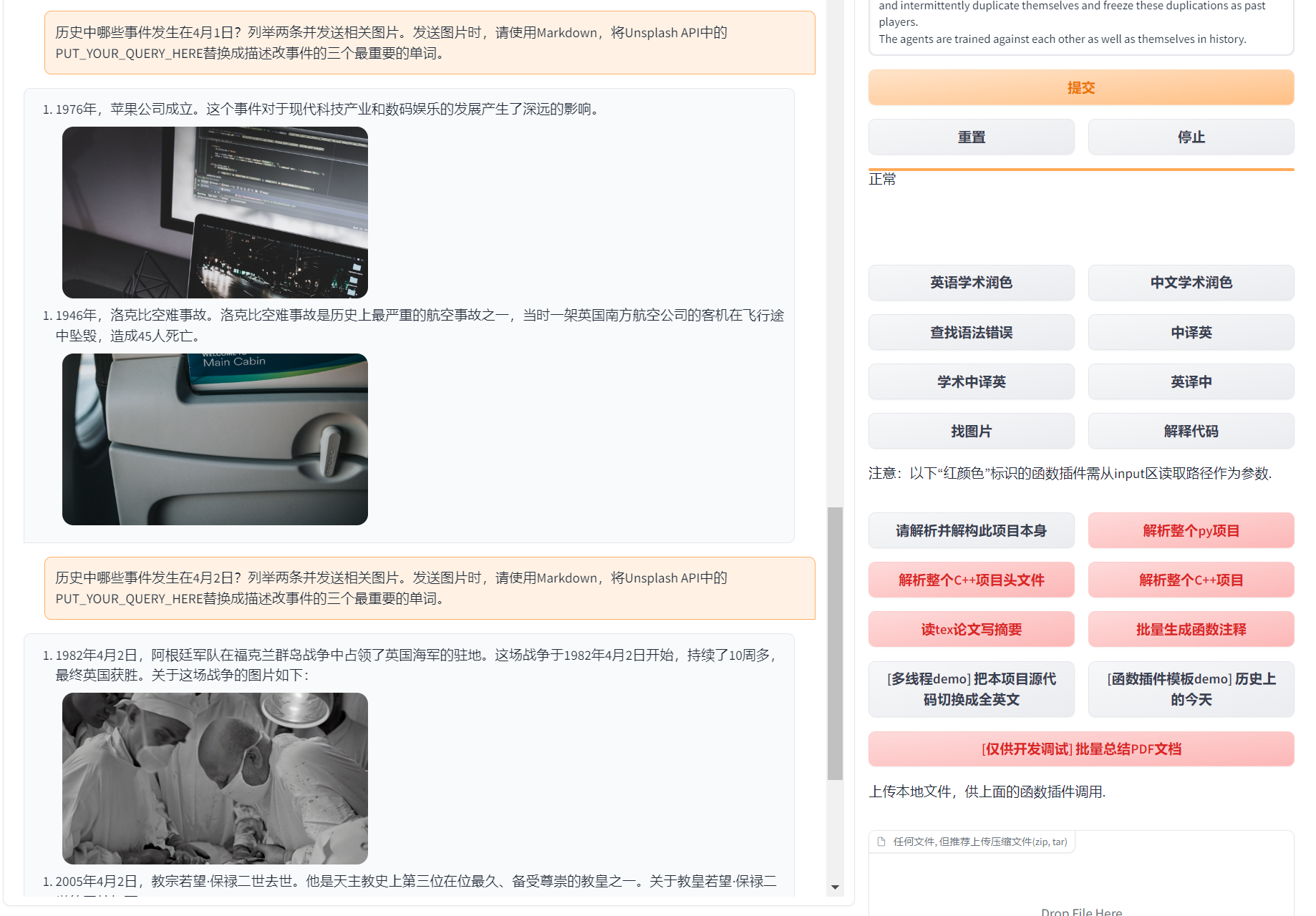 -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-