

Commit
·
7756290
1
Parent(s):
46d4891
Update parquet files (step 19 of 121)
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- spaces/1acneusushi/gradio-2dmoleculeeditor/data/Don 2 UPDATED Full Hindi Movie Hd With English Subtitles.md +0 -18
- spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/APKPure How to Get Marvel Contest of Champions APK for Free.md +0 -113
- spaces/1phancelerku/anime-remove-background/Download Anime Kamen Rider W The Legendary Tokusatsu Series.md +0 -123
- spaces/1toTree/lora_test/ppdiffusers/pipelines/stable_diffusion/pipeline_fastdeploy_stable_diffusion.py +0 -460
- spaces/2ndelement/voicevox/test/test_core_version_utility.py +0 -40
- spaces/801artistry/RVC801/infer/modules/vc/utils.py +0 -42
- spaces/A666sxr/Genshin_TTS/text/japanese.py +0 -153
- spaces/AI-Dashboards/AI.Dashboard.Streamlit.Index.For.Assessments/app.py +0 -453
- spaces/AIConsultant/MusicGen/README.md +0 -13
- spaces/AIGC-Audio/Make_An_Audio/ldm/modules/encoders/open_clap/htsat.py +0 -1022
- spaces/ALSv/midjourney-v4-1/app.py +0 -3
- spaces/Ababababababbababa/Ashaar/app.py +0 -151
- spaces/Ababababababbababa/Sha3bor_Aragpt2_Base/README.md +0 -12
- spaces/Abhaykoul/BardCookies-AI_Query/app.py +0 -36
- spaces/AgentVerse/agentVerse/agentverse/registry.py +0 -27
- spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/oval/Factory.js +0 -13
- spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/easemove/EaseMove.ts +0 -2
- spaces/Al-Chan/Vits_League_of_Legends_Yuumi_TTS/monotonic_align/__init__.py +0 -19
- spaces/Ameaou/academic-chatgpt3.1/docs/README_EN.md +0 -291
- spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/examples/research_projects/intel_opts/README.md +0 -37
- spaces/Andy1621/uniformer_image_detection/configs/foveabox/fovea_align_r50_fpn_gn-head_4x4_2x_coco.py +0 -10
- spaces/Andy1621/uniformer_image_segmentation/configs/nonlocal_net/nonlocal_r101-d8_512x1024_40k_cityscapes.py +0 -2
- spaces/Andy1621/uniformer_image_segmentation/configs/pspnet/pspnet_r50-d8_769x769_40k_cityscapes.py +0 -9
- spaces/AndySAnker/DeepStruc/models/README.md +0 -5
- spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmcv/ops/cc_attention.py +0 -83
- spaces/Ariharasudhan/YoloV5/utils/__init__.py +0 -80
- spaces/Arnaudding001/FrenchTranslationAI/README.md +0 -12
- spaces/Arnx/MusicGenXvAKN/tests/modules/test_seanet.py +0 -115
- spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/rich/file_proxy.py +0 -57
- spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/_vendor/importlib_metadata/_text.py +0 -99
- spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/command/build_clib.py +0 -101
- spaces/CVPR/LIVE/thrust/dependencies/cub/experimental/histogram/histogram_gmem_atomics.h +0 -185
- spaces/CVPR/LIVE/thrust/thrust/system/detail/generic/find.h +0 -63
- spaces/CYSD/AI-image-detector/app.py +0 -14
- spaces/CarperAI/pile-v2-eda/README.md +0 -10
- spaces/ChandraMohanNayal/AutoGPT/autogpt/app.py +0 -330
- spaces/ChandraMohanNayal/AutoGPT/autogpt/workspace.py +0 -47
- spaces/Chris4K/llms_compare/Aloo Chaat Hd Movie Download 1080p __TOP__.md +0 -56
- spaces/ChrisPreston/diff-svc_minato_aqua/infer_tools/f0_static.py +0 -116
- spaces/CikeyQI/Yunzai/Yunzai/plugins/ws-plugin/index.js +0 -103
- spaces/CodingBillionaire/bark-voice-cloning/README.md +0 -16
- spaces/CofAI/chat.b4/client/js/highlight.min.js +0 -0
- spaces/CofAI/chat.b4/g4f/Provider/Providers/Mishalsgpt.py +0 -23
- spaces/CofAI/chat.b4/server/website.py +0 -32
- spaces/Cong723/gpt-academic-public/crazy_functions/test_project/latex/attention/parameter_attention.tex +0 -45
- spaces/Cropinky/esrgan/realesrgan/__init__.py +0 -6
- spaces/Cvandi/remake/realesrgan/archs/srvgg_arch.py +0 -69
- spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/aiofiles/tempfile/__init__.py +0 -263
- spaces/Dauzy/whisper-webui/src/hooks/subTaskProgressListener.py +0 -37
- spaces/Dauzy/whisper-webui/src/whisper/whisperFactory.py +0 -19
spaces/1acneusushi/gradio-2dmoleculeeditor/data/Don 2 UPDATED Full Hindi Movie Hd With English Subtitles.md
DELETED
|
@@ -1,18 +0,0 @@
|
|
| 1 |
-
<br />
|
| 2 |
-
<h1>Don 2: A Thrilling Sequel to the 2006 Action Hit</h1>
|
| 3 |
-
<p>If you are looking for a fast-paced and exciting movie to watch, you might want to check out <strong>Don 2</strong>, a sequel to the 2006 Indian action thriller <em>Don</em>. The movie stars <strong>Shah Rukh Khan</strong> as the international gangster Don, who has conquered the Asian underworld and now sets his sights on Europe. Along the way, he faces challenges from the Interpol, the mob bosses of each nation, and his own former allies.</p>
|
| 4 |
-
<p>The movie is directed by <strong>Farhan Akhtar</strong>, who also co-wrote the screenplay with <strong>Ameet Mehta</strong> and <strong>Amrish Shah</strong>. The movie also features <strong>Priyanka Chopra Jonas</strong> as Roma, an Interpol officer who is obsessed with catching Don; <strong>Boman Irani</strong> as Vardhan, Don's former enemy who joins forces with him; <strong>Kunal Kapoor</strong> as Sameer, Don's trusted friend; and <strong>Lara Dutta</strong> as Ayesha, Don's girlfriend.</p>
|
| 5 |
-
<h2>don 2 full hindi movie hd with english subtitles</h2><br /><p><b><b>Download</b> ❤❤❤ <a href="https://byltly.com/2uKvZg">https://byltly.com/2uKvZg</a></b></p><br /><br />
|
| 6 |
-
<p>The movie was released in 2011 and was a huge commercial and critical success. It was praised for its stylish cinematography, stunning action sequences, and charismatic performances by the lead actors. The movie also features a catchy soundtrack composed by <strong>Shankar-Ehsaan-Loy</strong>, with lyrics by <strong>Javed Akhtar</strong>.</p>
|
| 7 |
-
<p>If you want to watch <strong>Don 2</strong>, you can find it on various streaming platforms such as Netflix and Prime Video. The movie is available in Hindi with English subtitles, as well as in other languages such as German, Spanish, French, Italian, Korean, Chinese, and more. You can also rent or buy the movie on Amazon or other online platforms.</p>
|
| 8 |
-
<p>So what are you waiting for? Grab some popcorn and enjoy this thrilling ride with Don and his gang!</p>
|
| 9 |
-
|
| 10 |
-
<h2>Don 2: The Plot</h2>
|
| 11 |
-
<p>The movie begins with Don (Shah Rukh Khan) narrating his rise to power in the Asian underworld, after killing his lookalike Vijay and escaping from the Interpol. He reveals that he has a master plan to rob the currency printing plates from a bank in Berlin, Germany. To do this, he needs the help of Vardhan (Boman Irani), who is imprisoned in Malaysia.</p>
|
| 12 |
-
<p>Don surrenders himself to the Interpol in Malaysia, hoping to get close to Vardhan and break him out of jail. However, he is confronted by Roma (Priyanka Chopra Jonas), who has not forgotten her personal vendetta against him. She tries to stop him from escaping, but Don manages to outsmart her and frees Vardhan. They then fly to Zurich, Switzerland, where they meet Sameer (Kunal Kapoor), Don's friend and partner in crime.</p>
|
| 13 |
-
<p></p>
|
| 14 |
-
<p>In Zurich, Don also meets Ayesha (Lara Dutta), his girlfriend and accomplice. She helps him get in touch with Diwan (Alyy Khan), a hacker who can access the bank's security system. Don also recruits Jabbar (Nawab Shah), an assassin who can eliminate any obstacles in his way. With his team ready, Don sets his plan in motion.</p>
|
| 15 |
-
<p>However, things are not as easy as they seem. Don has to deal with the ruthless mob boss of Europe, Arjun Khanna (Om Puri), who does not want anyone to interfere with his business. He also has to face Malik (Florian Lukas), a German police officer who is determined to catch him. And most importantly, he has to watch out for Roma and her team, who are hot on his trail.</p>
|
| 16 |
-
<p>Will Don succeed in his daring heist? Will Roma finally get her revenge? Will Don's allies remain loyal to him? Watch <strong>Don 2</strong> to find out!</p> 7b8c122e87<br />
|
| 17 |
-
<br />
|
| 18 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/APKPure How to Get Marvel Contest of Champions APK for Free.md
DELETED
|
@@ -1,113 +0,0 @@
|
|
| 1 |
-
|
| 2 |
-
<h1>Marvel Contest of Champions Apkpure: A Superhero Fighting Game for Your Mobile Device</h1>
|
| 3 |
-
<p>Do you love Marvel comics and movies? Do you enjoy fighting games with simple controls and stunning graphics? If you answered yes to both questions, then you should check out Marvel Contest of Champions apkpure, a free-to-play mobile game that lets you collect and battle with your favorite Marvel characters. In this article, we will tell you everything you need to know about Marvel Contest of Champions apkpure, including how to play it, who are the characters, what are the tips, and what are the reviews.</p>
|
| 4 |
-
<h2>How to Play Marvel Contest of Champions Apkpure</h2>
|
| 5 |
-
<p>Marvel Contest of Champions apkpure is a fighting game that pits Marvel heroes and villains against each other in epic duels. You can download the game from [ApkCombo](^1^), a website that provides free APK files for Android devices. The game requires an internet connection and about 1.5 GB of storage space.</p>
|
| 6 |
-
<h2>marvel contest of champions apkpure</h2><br /><p><b><b>Download Zip</b> ————— <a href="https://urlin.us/2uSUZm">https://urlin.us/2uSUZm</a></b></p><br /><br />
|
| 7 |
-
<p>The game has a simple touchscreen interface that allows you to control your character's movements and attacks. You can tap to perform light attacks, swipe to perform medium attacks, press and hold to perform heavy attacks, and swipe back to dodge or block. You can also unleash powerful special attacks when your power meter is full, which is indicated by the blue bars at the bottom of the screen.</p>
|
| 8 |
-
<p>The game has several features and modes that make it fun and engaging. You can play through a story mode that follows a comic book-inspired plot, where you have to fight against the Collector, Thanos, Kang, and other villains who want to destroy the Marvel universe. You can also join an alliance with other players and participate in alliance events, quests, and wars, where you can cooperate or compete with other alliances for rewards and glory. You can also enter various arenas and tournaments, where you can test your skills against other players from around the world.</p>
|
| 9 |
-
<h2>Who Are the Characters in Marvel Contest of Champions Apkpure</h2>
|
| 10 |
-
<p>Marvel Contest of Champions apkpure features over 250 playable characters from the Marvel universe, including Spider-Man, Iron Man, Wolverine, Captain America, Black Widow, Thor, Hulk, Deadpool, Doctor Strange, Captain Marvel, Black Panther, Thanos, Ultron, Venom, and many more. You can obtain new characters by opening crystals that you earn or buy with in-game currency or real money.</p>
|
| 11 |
-
<p>The characters belong to different classes that have advantages and disadvantages against each other. The classes are Mutant, Skill, Science, Mystic, Cosmic, and Tech. For example, Mutants are strong against Skill but weak against Tech, while Techs are strong against Mutants but weak against Cosmic. You can see the class relationships by tapping on the class icons at the top of the screen.</p>
|
| 12 |
-
<p>Each character has a unique set of stats, abilities, and special moves that reflect their comic book counterparts. For example, Spider-Man can web-sling, evade attacks, and stun enemies with his spider-sense; Iron Man can fire repulsor blasts, boost his armor, and unleash a unibeam; Wolverine can heal himself, slash enemies with his claws, and go berserk; and so on. You can upgrade your characters by leveling them up with ISO-8 crystals or ranking them up with catalysts. You can also unlock their signature abilities by obtaining duplicate copies of them from crystals.</p>
|
| 13 |
-
<h2>How to Improve Your Skills and Strategies in Marvel Contest of Champions Apkpure</h2>
|
| 14 |
-
<p>If you want to become a better player in Marvel Contest of Champions apkpure, here are some tips that you should follow:</p>
|
| 15 |
-
<p>marvel contest of champions apk download apkpure<br />
|
| 16 |
-
marvel contest of champions mod apk apkpure<br />
|
| 17 |
-
marvel contest of champions hack apk apkpure<br />
|
| 18 |
-
marvel contest of champions latest version apkpure<br />
|
| 19 |
-
marvel contest of champions update apkpure<br />
|
| 20 |
-
marvel contest of champions offline apkpure<br />
|
| 21 |
-
marvel contest of champions apk obb apkpure<br />
|
| 22 |
-
marvel contest of champions apk data apkpure<br />
|
| 23 |
-
marvel contest of champions apk mirror apkpure<br />
|
| 24 |
-
marvel contest of champions apk pure download<br />
|
| 25 |
-
marvel contest of champions apk pure mod<br />
|
| 26 |
-
marvel contest of champions apk pure hack<br />
|
| 27 |
-
marvel contest of champions apk pure latest version<br />
|
| 28 |
-
marvel contest of champions apk pure update<br />
|
| 29 |
-
marvel contest of champions apk pure offline<br />
|
| 30 |
-
marvel contest of champions apk pure obb<br />
|
| 31 |
-
marvel contest of champions apk pure data<br />
|
| 32 |
-
marvel contest of champions apk pure mirror<br />
|
| 33 |
-
download marvel contest of champions apkpure<br />
|
| 34 |
-
download marvel contest of champions mod apkpure<br />
|
| 35 |
-
download marvel contest of champions hack apkpure<br />
|
| 36 |
-
download marvel contest of champions latest version apkpure<br />
|
| 37 |
-
download marvel contest of champions update apkpure<br />
|
| 38 |
-
download marvel contest of champions offline apkpure<br />
|
| 39 |
-
download marvel contest of champions obb apkpure<br />
|
| 40 |
-
download marvel contest of champions data apkpure<br />
|
| 41 |
-
download marvel contest of champions mirror apkpure<br />
|
| 42 |
-
how to install marvel contest of champions apkpure<br />
|
| 43 |
-
how to play marvel contest of champions apkpure<br />
|
| 44 |
-
how to update marvel contest of champions apkpure<br />
|
| 45 |
-
how to hack marvel contest of champions apkpure<br />
|
| 46 |
-
how to mod marvel contest of champions apkpure<br />
|
| 47 |
-
how to download obb for marvel contest of champions apkpure<br />
|
| 48 |
-
how to download data for marvel contest of champions apkpure<br />
|
| 49 |
-
how to fix error in marvel contest of champions apkpure<br />
|
| 50 |
-
is marvel contest of champions available on apkpure<br />
|
| 51 |
-
is marvel contest of champions safe on apkpure<br />
|
| 52 |
-
is marvel contest of champions offline on apkpure<br />
|
| 53 |
-
is marvel contest of champions modded on apkpure<br />
|
| 54 |
-
is marvel contest of champions hacked on apkpure</p>
|
| 55 |
-
<ul>
|
| 56 |
-
<li>Build a balanced team of characters with different classes and synergies. Synergies are bonuses that you get when you pair up certain characters based on their comic book relationships or affiliations. For example, pairing up Spider-Man and Venom gives you a bonus to critical rate; - Pairing up Iron Man and Captain America gives you a bonus to armor and block proficiency. You can see the synergies by tapping on the team icon at the bottom of the screen.</li>
|
| 57 |
-
<li>Learn the strengths and weaknesses of each character and use them to your advantage. For example, if you are facing a Mystic character, you can use a Cosmic character to deal more damage and avoid their debuffs; if you are facing a Tech character, you can use a Mutant character to bypass their armor and power drain.</li>
|
| 58 |
-
<li>Master the basic combat mechanics and practice your timing and reflexes. You should know when to attack, when to block, when to dodge, and when to use your special attacks. You should also learn how to parry, which is a technique that allows you to stun your opponent by blocking right before they hit you. Parrying is very useful for creating openings and preventing damage.</li>
|
| 59 |
-
<li>Use your special attacks wisely and strategically. You should not waste your power meter on weak or ineffective special attacks, but save it for the ones that can deal more damage, inflict debuffs, or trigger effects. You should also be aware of your opponent's power meter and avoid getting hit by their special attacks, especially the third one, which is usually the most powerful and cannot be blocked.</li>
|
| 60 |
-
<li>Explore the different game modes and quests and complete the objectives and challenges. You can earn rewards such as gold, units, crystals, ISO-8, catalysts, and more by playing the game regularly and completing various tasks. You can also unlock new characters, arenas, and stories by progressing through the game.</li>
|
| 61 |
-
</ul>
|
| 62 |
-
<h2>What Are the Pros and Cons of Marvel Contest of Champions Apkpure</h2>
|
| 63 |
-
<p>Marvel Contest of Champions apkpure is a popular and well-received game that has many positive aspects, but also some negative ones. Here are some of the pros and cons of Marvel Contest of Champions apkpure:</p>
|
| 64 |
-
<table>
|
| 65 |
-
<tr>
|
| 66 |
-
<th>Pros</th>
|
| 67 |
-
<th>Cons</th>
|
| 68 |
-
</tr>
|
| 69 |
-
<tr>
|
| 70 |
-
<td>- The game has amazing graphics and animations that make the characters look realistic and lifelike.</td>
|
| 71 |
-
<td>- The game can be repetitive and grindy at times, especially when you have to farm for resources or fight the same opponents over and over.</td>
|
| 72 |
-
</tr>
|
| 73 |
-
<tr>
|
| 74 |
-
<td>- The game has a large and diverse roster of characters that appeal to Marvel fans of all ages and preferences.</td>
|
| 75 |
-
<td>- The game can be frustrating and unfair at times, especially when you face opponents that are much stronger or have annoying abilities or buffs.</td>
|
| 76 |
-
</tr>
|
| 77 |
-
<tr>
|
| 78 |
-
<td>- The game has a simple and intuitive control system that makes it easy to play for anyone.</td>
|
| 79 |
-
<td>- The game can be expensive and pay-to-win at times, especially when you have to buy crystals or units to get better characters or items.</td>
|
| 80 |
-
</tr>
|
| 81 |
-
<tr>
|
| 82 |
-
<td>- The game has a fun and engaging story mode that follows an original plot with twists and surprises.</td>
|
| 83 |
-
<td>- The game can be buggy and glitchy at times, especially when it crashes or freezes during gameplay or loading screens.</td>
|
| 84 |
-
</tr>
|
| 85 |
-
<tr>
|
| 86 |
-
<td>- The game has a social and competitive aspect that allows you to interact with other players and join alliances.</td>
|
| 87 |
-
<td>- The game can be addictive and time-consuming at times, especially when you have to keep up with the events and quests or maintain your alliance status.</td>
|
| 88 |
-
</tr>
|
| 89 |
-
</table>
|
| 90 |
-
<h2>Conclusion: Is Marvel Contest of Champions Apkpure Worth Playing?</h2>
|
| 91 |
-
<p>In conclusion, Marvel Contest of Champions apkpure is a great game for Marvel fans and fighting game enthusiasts who want to enjoy a thrilling and immersive experience on their mobile devices. The game has many advantages such as stunning graphics, diverse characters, simple controls, engaging story, and social features. However, the game also has some drawbacks such as repetitiveness, frustration, expense, bugs, and addiction. Therefore, we recommend that you play Marvel Contest of Champions apkpure with moderation and caution, and only if you are willing to accept its flaws. If you are looking for a superhero fighting game that is fun, easy, and free to play, then Marvel Contest of Champions apkpure is definitely worth trying.</p>
|
| 92 |
-
<h2>FAQs: Frequently Asked Questions About Marvel Contest of Champions Apkpure</h2>
|
| 93 |
-
<p>Here are some of the most common questions that people ask about Marvel Contest of Champions apkpure:</p>
|
| 94 |
-
<h3>Q: What is apkpure?</h3>
|
| 95 |
-
<p>A: Apkpure is a website that provides free APK files for Android devices. APK files are application packages that contain all the files needed to install an app on your device. Apkpure allows you to download APK files from various sources without any restrictions or limitations.</p>
|
| 96 |
-
<h3>Q: Is Marvel Contest of Champions apkpure safe?</h <p>A: Marvel Contest of Champions apkpure is generally safe to download and play, as long as you get it from a trusted source like ApkCombo. However, you should always be careful when downloading APK files from unknown or unverified sources, as they may contain malware or viruses that can harm your device or compromise your privacy. You should also make sure that your device meets the minimum requirements and has enough storage space to run the game smoothly.</p>
|
| 97 |
-
<h3>Q: How do I update Marvel Contest of Champions apkpure?</h3>
|
| 98 |
-
<p>A: Marvel Contest of Champions apkpure is updated regularly with new features, characters, events, and bug fixes. You can update the game by downloading the latest APK file from ApkCombo and installing it over the existing one. You can also enable the auto-update option in the settings of your device or the ApkCombo app to get notified and download the updates automatically.</p>
|
| 99 |
-
<h3>Q: How do I get more crystals in Marvel Contest of Champions apkpure?</h3>
|
| 100 |
-
<p>A: Crystals are items that you can use to obtain new characters, items, or resources in Marvel Contest of Champions apkpure. You can get crystals by completing quests, participating in events, opening chests, spinning wheels, watching ads, or buying them with real money. You can also get free crystals every day by logging in to the game and claiming your daily rewards.</p>
|
| 101 |
-
<h3>Q: How do I contact the support team of Marvel Contest of Champions apkpure?</h3>
|
| 102 |
-
<p>A: If you have any issues, questions, or feedback regarding Marvel Contest of Champions apkpure, you can contact the support team by tapping on the gear icon at the top left corner of the screen, then tapping on "Support". You can also visit the official website of Marvel Contest of Champions or follow their social media accounts for more information and updates.</p>
|
| 103 |
-
<h3>Q: What are some similar games to Marvel Contest of Champions apkpure?</h3>
|
| 104 |
-
<p>A: If you like Marvel Contest of Champions apkpure, you might also enjoy some other games that are similar in genre or theme. Some examples are:</p>
|
| 105 |
-
<ul>
|
| 106 |
-
<li>Marvel Future Fight: A role-playing game that lets you create and customize your own team of Marvel heroes and villains and fight against various enemies and bosses.</li>
|
| 107 |
-
<li>Injustice 2: A fighting game that features characters from DC comics and movies and allows you to upgrade and customize them with gear and abilities.</li>
|
| 108 |
-
<li>Mortal Kombat X: A fighting game that features characters from the Mortal Kombat franchise and allows you to perform brutal fatalities and x-ray moves.</li>
|
| 109 |
-
<li>Marvel Strike Force: A turn-based strategy game that lets you assemble and command a squad of Marvel characters and fight against various threats.</li>
|
| 110 |
-
<li>Marvel Puzzle Quest: A match-3 puzzle game that lets you collect and use Marvel characters in battles and events.</li>
|
| 111 |
-
</ul></p> 197e85843d<br />
|
| 112 |
-
<br />
|
| 113 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1phancelerku/anime-remove-background/Download Anime Kamen Rider W The Legendary Tokusatsu Series.md
DELETED
|
@@ -1,123 +0,0 @@
|
|
| 1 |
-
|
| 2 |
-
<h1>Download Anime Kamen Rider W: A Guide for Fans</h1>
|
| 3 |
-
<p>If you are a fan of tokusatsu, superhero, action, or detective genres, you might have heard of <strong>anime kamen rider w</strong>. This is a Japanese live-action TV series that aired from 2009 to 2010, as part of the long-running Kamen Rider franchise. It is also known as Kamen Rider Double, because it features two protagonists who can combine into one Kamen Rider. Anime kamen rider w is widely regarded as one of the best Kamen Rider series in the Heisei era, and has spawned a manga sequel, an anime adaptation, and various merchandise and games. In this article, we will give you an overview of anime kamen rider w, its plot and characters, its reception and popularity, its merchandise and games, and the best sites to download it.</p>
|
| 4 |
-
<h2>Plot and Characters</h2>
|
| 5 |
-
<p>Anime kamen rider w is set in the ecologically-minded city of Futo (the "Windy City"), where windmills power almost everything. However, the city is also plagued by crimes committed by Dopants, monsters created by using Gaia Memories, mysterious USB-like devices that contain the essence of the Earth. The Gaia Memories are sold by the Sonozaki Family, a powerful crime syndicate that also controls the Museum, a secret organization that researches the Gaia Memories.</p>
|
| 6 |
-
<h2>download anime kamen rider w</h2><br /><p><b><b>Download File</b> ↔ <a href="https://jinyurl.com/2uNMJr">https://jinyurl.com/2uNMJr</a></b></p><br /><br />
|
| 7 |
-
<p>The main protagonists of anime kamen rider w are Shotaro Hidari and Philip. Shotaro is a private detective who runs the Narumi Detective Agency, which specializes in Dopant cases. He is also a self-proclaimed "hard-boiled" detective who likes to wear a fedora and a trench coat. Philip is a mysterious young man who has no memories of his past, but possesses a vast knowledge of the Gaia Memories. He lives in a secret room in the agency, where he accesses a library-like database called the Gaia Library. Together, they can transform into Kamen Rider W (or Double), using two Gaia Memories and a belt called the Double Driver. By combining different Gaia Memories, they can access various forms with different powers and weapons.</p>
|
| 8 |
-
<p>Some of their allies include Akiko Narumi, Shotaro's boss and the daughter of his mentor Sokichi Narumi, who was killed by a Dopant; Ryu Terui, a police officer who becomes Kamen Rider Accel to avenge his family; Shun Makura, a journalist who helps them with information; Watcherman, a blogger who reports on Dopant incidents; Santa-chan, a former thief who runs a souvenir shop; Queen and Elizabeth, two teenage girls who are fans of Kamen Rider W; and Jinno and Makura, two police officers who often assist Shotaro.</p>
|
| 9 |
-
<p>Some of their enemies include Ryubee Sonozaki, the head of the Sonozaki Family and the Museum; Saeko Sonozaki, his eldest daughter who becomes the Taboo Dopant; Wakana Sonozaki, his youngest daughter who becomes the Clay Doll Dopant; Kirihiko Sudo, Saeko's husband who becomes the Nasca Dopant; Shinkuro Isaka, a doctor who becomes the Weather Dopant; Jun Kazu, a politician who becomes the Utopia Dopant; Katsumi Daido, the leader of NEVER, a group of undead soldiers who becomes the Eternal Dopant; and Foundation X, a mysterious organization that funds the Museum.</p>
|
| 10 |
-
<h2>Reception and Popularity</h2>
|
| 11 |
-
<p>Anime kamen rider w was well-received by both critics and fans when it aired. It was praised for its engaging plot, likable characters, creative designs, catchy music, humorous moments, emotional scenes, and thrilling action. It also won several awards, such as the Tokyo Anime Award for Best Domestic Feature <h2>Merchandise and Games</h2>
|
| 12 |
-
<p>Anime kamen rider w has a lot of merchandise and games for fans to enjoy. Some of the most popular products include the Gaia Memories, the Double Driver, the Accel Driver, the Lost Driver, and the various weapons and gadgets used by the Kamen Riders. These are sold as toys that can be used to recreate the transformations and attacks from the show. Some of them also have sounds and lights that match the ones in the show.</p>
|
| 13 |
-
<p>There are also several video games based on anime kamen rider w, such as Kamen Rider: Climax Heroes W, Kamen Rider: Climax Heroes OOO, Kamen Rider: Super Climax Heroes, Kamen Rider: Battride War, Kamen Rider: Battride War II, Kamen Rider: Battride War Genesis, Kamen Rider: Memory of Heroez, and Kamen Rider Battle: Ganbarizing. These games allow players to control various Kamen Riders from anime kamen rider w and other series, and fight against enemies and bosses in different stages. Some of them also have story modes that follow the plot of the show or original scenarios.</p>
|
| 14 |
-
<p>For fans who prefer more casual games, there are also some mobile games and web games related to anime kamen rider w, such as Kamen Rider City Wars, Kamen Rider Battle Rush, Kamen Rider Transcend Heroes, Kamen Rider Break Joker, and Futo Detectives. These games feature anime kamen rider w characters and elements in various genres, such as city-building, card battle, action RPG, puzzle, and adventure.</p>
|
| 15 |
-
<p>download kamen rider w episodes free<br />
|
| 16 |
-
kamen rider w blu-ray download<br />
|
| 17 |
-
kamen rider w internet archive download<br />
|
| 18 |
-
download kamen rider w movie war 2010<br />
|
| 19 |
-
kamen rider w bd box download<br />
|
| 20 |
-
download kamen rider w sub indo<br />
|
| 21 |
-
kamen rider w tokushare download<br />
|
| 22 |
-
download kamen rider w gaia memory encyclopedia<br />
|
| 23 |
-
kamen rider w donburi's α download<br />
|
| 24 |
-
download kamen rider w english subtitles<br />
|
| 25 |
-
kamen rider w ozc-live download<br />
|
| 26 |
-
download kamen rider w mp4 format<br />
|
| 27 |
-
kamen rider w over-time subs download<br />
|
| 28 |
-
download kamen rider w 720p quality<br />
|
| 29 |
-
kamen rider w streaming and download<br />
|
| 30 |
-
download kamen rider w soundtrack<br />
|
| 31 |
-
kamen rider w opening song download<br />
|
| 32 |
-
download kamen rider w cyclone effect<br />
|
| 33 |
-
kamen rider w finger on the trigger download<br />
|
| 34 |
-
download kamen rider w nobody's perfect<br />
|
| 35 |
-
kamen rider w extreme dream download<br />
|
| 36 |
-
download kamen rider w love wars<br />
|
| 37 |
-
kamen rider w naturally download<br />
|
| 38 |
-
download kamen rider w goodbye to the tears<br />
|
| 39 |
-
kamen rider w free your heat download<br />
|
| 40 |
-
download kamen rider w theme songs collection<br />
|
| 41 |
-
kamen rider w character songs album download<br />
|
| 42 |
-
download kamen rider w gaia memory soundboard<br />
|
| 43 |
-
kamen rider w driver app download<br />
|
| 44 |
-
download kamen rider w android game<br />
|
| 45 |
-
kamen rider w memory of heroines game download<br />
|
| 46 |
-
download kamen rider w climax heroes game<br />
|
| 47 |
-
kamen rider w all riders vs dai-shocker game download<br />
|
| 48 |
-
download kamen rider w manga scanlation<br />
|
| 49 |
-
kamen rider w fuuto detectives manga download<br />
|
| 50 |
-
download kamen rider w novel translation<br />
|
| 51 |
-
kamen rider w returns movie download<br />
|
| 52 |
-
download kamen rider eternal movie<br />
|
| 53 |
-
kamen rider accel movie download<br />
|
| 54 |
-
download kamen rider joker movie<br />
|
| 55 |
-
kamen rider skull movie core download<br />
|
| 56 |
-
download fuuto pi drama cd series <br />
|
| 57 |
-
fuuto tantei drama cd special file 3.5 - the man who was too loved by the wind - featuring shotaro hirudo and philip - guest starring akiko narumi and ryu terui - a story that takes place after the events of the tv series - a must-listen for fans of the hard-boiled detective duo - available for digital purchase and streaming on various platforms - don't miss it! (This is a parody of the actual drama cd title)</p>
|
| 58 |
-
<p>If you are looking for anime kamen rider w gifts and merchandise, you can check out some online stores that sell them, such as Redbubble, Amazon, eBay, Mandarake, and AmiAmi. These sites offer a wide range of products, such as T-shirts, posters, stickers, mugs, keychains, figures, cosplay items, and more. You can also find some fan-made items that are unique and creative.</p>
|
| 59 |
-
<h2>Best Sites to Download Anime Kamen Rider W</h2>
|
| 60 |
-
<p>If you want to watch or rewatch anime kamen rider w on your devices, you might be wondering where to download it. There are many sites that offer anime kamen rider w for download, but not all of them are reliable and safe. Some of them might have low-quality videos, broken links, malware, or illegal content. To avoid these problems, you should only use trusted and reputable sites that have good reviews and ratings from other users.</p>
|
| 61 |
-
<p>Here are some of the best sites to download anime kamen rider w:</p>
|
| 62 |
-
<table>
|
| 63 |
-
<tr>
|
| 64 |
-
<th>Site</th>
|
| 65 |
-
<th>Pros</th>
|
| 66 |
-
<th>Cons</th>
|
| 67 |
-
</tr>
|
| 68 |
-
<tr>
|
| 69 |
-
<td>[Internet Archive](^7^)</td>
|
| 70 |
-
<td>- Free and legal<br>- High-quality videos<br>- All episodes and movies available<br>- No ads or pop-ups</td>
|
| 71 |
-
<td>- Slow download speed<br>- Limited formats and subtitles</td>
|
| 72 |
-
</tr>
|
| 73 |
-
<tr>
|
| 74 |
-
<td>[Nyaa](^8^)</td>
|
| 75 |
-
<td>- Free and fast<br>- High-quality videos<br>- Various formats and subtitles<br>- Multiple sources and seeds</td>
|
| 76 |
-
<td>- Not legal<br>- Requires torrent client<br>- May contain malware or viruses<br>- May be blocked by some ISPs</td>
|
| 77 |
-
</tr>
|
| 78 |
-
<tr>
|
| 79 |
-
<td>[KissAsian](^9^)</td>
|
| 80 |
-
<td>- Free and easy<br>- High-quality videos<br>- Various formats and subtitles<br>- Streaming option available</td>
|
| 81 |
-
<td>- Not legal<br>- Contains ads and pop-ups<br>- May redirect to other sites<br>- May require registration or verification</td>
|
| 82 |
-
</tr>
|
| 83 |
-
<tr>
|
| 84 |
-
<td>[Over-Time]</td>
|
| 85 |
-
<td>- Free and legal<br>- High-quality videos<br>- Various formats and subtitles<br>- Official fansub group</td>
|
| 86 |
-
<td>- Slow download speed<br>- Requires torrent client or file hosting service<br>- Only episodes available<br>- No streaming option</td>
|
| 87 |
-
</tr>
|
| 88 |
-
<tr>
|
| 89 |
-
<td>[OZC-Live]</td>
|
| 90 |
-
<td>- Free and legal<br>- High-quality videos<br>- Various formats and subtitles<br>- Official fansub group</td>
|
| 91 |
-
<td>- Slow download speed<br>- Requires torrent client or file hosting service<br>- Only episodes available<br>- No streaming option</td>
|
| 92 |
-
</tr>
|
| 93 |
-
</table>
|
| 94 |
-
<h2>Conclusion</h2>
|
| 95 |
-
<p>Anime kamen rider w is a great series that deserves to be watched by anyone who likes tokusatsu, superhero, action, or detective genres. It has a captivating plot, charming characters, creative designs, catchy music, humorous moments, emotional scenes, and thrilling action. It also has a lot of merchandise and games for fans to enjoy. If you want to download anime kamen rider w, you can use one of the sites we recommended, or find other ones that suit your preferences. Just make sure to be careful and responsible when downloading, and respect the rights of the creators and owners of the content.</p>
|
| 96 |
-
<p>We hope this article has helped you learn more about anime kamen rider w, and why it is such a popular and beloved series. If you have not watched it yet, we highly recommend you to give it a try. You will not regret it. Anime kamen rider w is a series that will make you laugh, cry, cheer, and feel inspired. It is a series that will stay with you for a long time.</p>
|
| 97 |
-
<h2>FAQs</h2>
|
| 98 |
-
<p>Here are some frequently asked questions and answers about anime kamen rider w:</p>
|
| 99 |
-
<h3>Q: How many episodes and movies are there in anime kamen rider w?</h3>
|
| 100 |
-
<p>A: Anime kamen rider w has 49 episodes and 3 movies. The episodes are divided into 26 two-part cases, each with a different title that follows the W theme (e.g. The W Search/Two Detectives in One). The movies are Kamen Rider × Kamen Rider W & Decade: Movie War 2010, Kamen Rider W Forever: A to Z/The Gaia Memories of Fate, and Kamen Rider W Returns.</p>
|
| 101 |
-
<h3>Q: What is the difference between the live-action and the anime versions of anime kamen rider w?</h3>
|
| 102 |
-
<p>A: The live-action version of anime kamen rider w is the original TV series that aired from 2009 to 2010. The anime version of anime kamen rider w is an adaptation that was released in 2018 as part of the Toei Animation's 60th anniversary project. The anime version follows the same plot and characters as the live-action version, but with some changes and additions, such as new scenes, new forms, new enemies, and new voice actors.</p>
|
| 103 |
-
<h3>Q: What is the meaning of the W in anime kamen rider w?</h3>
|
| 104 |
-
<p>A: The W in anime kamen rider w has multiple meanings. It stands for Double, because it represents the two protagonists who can combine into one Kamen Rider. It also stands for Windy City, because it is the nickname of Futo, where the series takes place. It also stands for Words, because it relates to the names of the Gaia Memories and the titles of the cases. It also stands for Wonders, because it reflects the mysterious and amazing nature of the series.</p>
|
| 105 |
-
<h3>Q: Who are the voice actors of anime kamen rider w?</h3>
|
| 106 |
-
<p>A: The voice actors of anime kamen rider w are as follows:</p>
|
| 107 |
-
<ul>
|
| 108 |
-
<li>Shotaro Hidari: Renn Kiriyama (live-action), Mamoru Miyano (anime)</li>
|
| 109 |
-
<li>Philip: Masaki Suda (live-action), Ryo Yoshizawa (anime)</li>
|
| 110 |
-
<li>Akiko Narumi: Hikaru Yamamoto (live-action), Aoi Yuuki (anime)</li>
|
| 111 |
-
<li>Ryu Terui: Minehiro Kinomoto (live-action), Hiroshi Kamiya (anime)</li>
|
| 112 |
-
<li>Shun Makura: Tomomi Itano (live-action), Kana Hanazawa (anime)</li>
|
| 113 |
-
<li>Watcherman: Shingo Yanagisawa (live-action), Tomokazu Sugita (anime)</li>
|
| 114 |
-
<li>Santa-chan: Mark Okita (live-action), Jun Fukuyama (anime)</li>
|
| 115 |
-
<li>Queen: Rin Asuka (live-action), Nana Mizuki (anime)</li>
|
| 116 |
-
<li>Elizabeth: Minami Tsukui (live-action), Yui Horie (anime)</li>
|
| 117 |
-
<li>Jinno: Takeshi Nadagi (live-action), Daisuke Ono (anime)</li>
|
| 118 |
-
<li>Makura: Akira Date (live-action), Yuichi Nakamura (anime)</li>
|
| 119 |
-
</ul>
|
| 120 |
-
<h3>Q: Where can I read the manga sequel of anime kamen rider w?</h3>
|
| 121 |
-
<p>A: The manga sequel of anime kamen rider w is called Futo Detectives, and it is written by Riku Sanjo and drawn by Masaki Sato. It continues the story of Shotaro and Philip after the events of the TV series, as they face new cases and enemies in Futo. You can read it online on some manga sites, such as MangaDex, MangaRock, or MangaFox. You can also buy the physical volumes on some online stores, such as Amazon, CDJapan, or YesAsia.</p> 197e85843d<br />
|
| 122 |
-
<br />
|
| 123 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1toTree/lora_test/ppdiffusers/pipelines/stable_diffusion/pipeline_fastdeploy_stable_diffusion.py
DELETED
|
@@ -1,460 +0,0 @@
|
|
| 1 |
-
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
|
| 2 |
-
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
| 3 |
-
#
|
| 4 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
-
# you may not use this file except in compliance with the License.
|
| 6 |
-
# You may obtain a copy of the License at
|
| 7 |
-
#
|
| 8 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
-
#
|
| 10 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
-
# See the License for the specific language governing permissions and
|
| 14 |
-
# limitations under the License.
|
| 15 |
-
|
| 16 |
-
import inspect
|
| 17 |
-
import time
|
| 18 |
-
from typing import Callable, List, Optional, Union
|
| 19 |
-
|
| 20 |
-
import numpy as np
|
| 21 |
-
import paddle
|
| 22 |
-
|
| 23 |
-
from paddlenlp.transformers import CLIPFeatureExtractor, CLIPTokenizer
|
| 24 |
-
|
| 25 |
-
from ...fastdeploy_utils import FastDeployRuntimeModel
|
| 26 |
-
from ...pipeline_utils import DiffusionPipeline
|
| 27 |
-
from ...schedulers import (
|
| 28 |
-
DDIMScheduler,
|
| 29 |
-
DPMSolverMultistepScheduler,
|
| 30 |
-
EulerAncestralDiscreteScheduler,
|
| 31 |
-
EulerDiscreteScheduler,
|
| 32 |
-
LMSDiscreteScheduler,
|
| 33 |
-
PNDMScheduler,
|
| 34 |
-
)
|
| 35 |
-
from ...schedulers.preconfig import (
|
| 36 |
-
PreconfigEulerAncestralDiscreteScheduler,
|
| 37 |
-
PreconfigLMSDiscreteScheduler,
|
| 38 |
-
)
|
| 39 |
-
from ...utils import logging
|
| 40 |
-
from . import StableDiffusionPipelineOutput
|
| 41 |
-
|
| 42 |
-
logger = logging.get_logger(__name__)
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
class FastDeployStableDiffusionPipeline(DiffusionPipeline):
|
| 46 |
-
r"""
|
| 47 |
-
Pipeline for text-to-image generation using Stable Diffusion.
|
| 48 |
-
|
| 49 |
-
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
| 50 |
-
library implements for all the pipelines (such as downloading or saving etc.)
|
| 51 |
-
|
| 52 |
-
Args:
|
| 53 |
-
vae_encoder ([`FastDeployRuntimeModel`]):
|
| 54 |
-
Variational Auto-Encoder (VAE) Model to encode images to latent representations.
|
| 55 |
-
vae_decoder ([`FastDeployRuntimeModel`]):
|
| 56 |
-
Variational Auto-Encoder (VAE) Model to decode images from latent representations.
|
| 57 |
-
text_encoder ([`FastDeployRuntimeModel`]):
|
| 58 |
-
Frozen text-encoder. Stable Diffusion uses the text portion of
|
| 59 |
-
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
|
| 60 |
-
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
|
| 61 |
-
tokenizer (`CLIPTokenizer`):
|
| 62 |
-
Tokenizer of class
|
| 63 |
-
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
|
| 64 |
-
unet ([`FastDeployRuntimeModel`]): Conditional U-Net architecture to denoise the encoded image latents.
|
| 65 |
-
scheduler ([`SchedulerMixin`]):
|
| 66 |
-
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
|
| 67 |
-
[`DDIMScheduler`], [`LMSDiscreteScheduler`], [`PNDMScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`]
|
| 68 |
-
or [`DPMSolverMultistepScheduler`].
|
| 69 |
-
safety_checker ([`FastDeployRuntimeModel`]):
|
| 70 |
-
Classification module that estimates whether generated images could be considered offensive or harmful.
|
| 71 |
-
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
|
| 72 |
-
feature_extractor ([`CLIPFeatureExtractor`]):
|
| 73 |
-
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
|
| 74 |
-
"""
|
| 75 |
-
_optional_components = ["vae_encoder", "safety_checker", "feature_extractor"]
|
| 76 |
-
|
| 77 |
-
def __init__(
|
| 78 |
-
self,
|
| 79 |
-
vae_encoder: FastDeployRuntimeModel,
|
| 80 |
-
vae_decoder: FastDeployRuntimeModel,
|
| 81 |
-
text_encoder: FastDeployRuntimeModel,
|
| 82 |
-
tokenizer: CLIPTokenizer,
|
| 83 |
-
unet: FastDeployRuntimeModel,
|
| 84 |
-
scheduler: Union[
|
| 85 |
-
DDIMScheduler,
|
| 86 |
-
PNDMScheduler,
|
| 87 |
-
LMSDiscreteScheduler,
|
| 88 |
-
PreconfigLMSDiscreteScheduler,
|
| 89 |
-
EulerDiscreteScheduler,
|
| 90 |
-
EulerAncestralDiscreteScheduler,
|
| 91 |
-
PreconfigEulerAncestralDiscreteScheduler,
|
| 92 |
-
DPMSolverMultistepScheduler,
|
| 93 |
-
],
|
| 94 |
-
safety_checker: FastDeployRuntimeModel,
|
| 95 |
-
feature_extractor: CLIPFeatureExtractor,
|
| 96 |
-
requires_safety_checker: bool = True,
|
| 97 |
-
):
|
| 98 |
-
super().__init__()
|
| 99 |
-
if safety_checker is None and requires_safety_checker:
|
| 100 |
-
logger.warning(
|
| 101 |
-
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
|
| 102 |
-
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
|
| 103 |
-
" results in services or applications open to the public. PaddleNLP team, diffusers team and Hugging Face"
|
| 104 |
-
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
|
| 105 |
-
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
|
| 106 |
-
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
|
| 107 |
-
)
|
| 108 |
-
if safety_checker is not None and feature_extractor is None:
|
| 109 |
-
raise ValueError(
|
| 110 |
-
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
|
| 111 |
-
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
|
| 112 |
-
)
|
| 113 |
-
|
| 114 |
-
self.register_modules(
|
| 115 |
-
vae_encoder=vae_encoder,
|
| 116 |
-
vae_decoder=vae_decoder,
|
| 117 |
-
text_encoder=text_encoder,
|
| 118 |
-
tokenizer=tokenizer,
|
| 119 |
-
unet=unet,
|
| 120 |
-
scheduler=scheduler,
|
| 121 |
-
safety_checker=safety_checker,
|
| 122 |
-
feature_extractor=feature_extractor,
|
| 123 |
-
)
|
| 124 |
-
self.register_to_config(requires_safety_checker=requires_safety_checker)
|
| 125 |
-
|
| 126 |
-
def _encode_prompt(self, prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
|
| 127 |
-
r"""
|
| 128 |
-
Encodes the prompt into text encoder hidden states.
|
| 129 |
-
|
| 130 |
-
Args:
|
| 131 |
-
prompt (`str` or `list(int)`):
|
| 132 |
-
prompt to be encoded
|
| 133 |
-
num_images_per_prompt (`int`):
|
| 134 |
-
number of images that should be generated per prompt
|
| 135 |
-
do_classifier_free_guidance (`bool`):
|
| 136 |
-
whether to use classifier free guidance or not
|
| 137 |
-
negative_prompt (`str` or `List[str]`):
|
| 138 |
-
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
| 139 |
-
if `guidance_scale` is less than `1`).
|
| 140 |
-
"""
|
| 141 |
-
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
| 142 |
-
|
| 143 |
-
# get prompt text embeddings
|
| 144 |
-
text_inputs = self.tokenizer(
|
| 145 |
-
prompt,
|
| 146 |
-
padding="max_length",
|
| 147 |
-
max_length=self.tokenizer.model_max_length,
|
| 148 |
-
truncation=True,
|
| 149 |
-
return_tensors="np",
|
| 150 |
-
)
|
| 151 |
-
text_input_ids = text_inputs.input_ids
|
| 152 |
-
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="np").input_ids
|
| 153 |
-
|
| 154 |
-
if not np.array_equal(text_input_ids, untruncated_ids):
|
| 155 |
-
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
| 156 |
-
logger.warning(
|
| 157 |
-
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
| 158 |
-
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
| 159 |
-
)
|
| 160 |
-
|
| 161 |
-
text_embeddings = self.text_encoder(input_ids=text_input_ids.astype(np.int64))[0]
|
| 162 |
-
text_embeddings = np.repeat(text_embeddings, num_images_per_prompt, axis=0)
|
| 163 |
-
# get unconditional embeddings for classifier free guidance
|
| 164 |
-
if do_classifier_free_guidance:
|
| 165 |
-
uncond_tokens: List[str]
|
| 166 |
-
if negative_prompt is None:
|
| 167 |
-
uncond_tokens = [""] * batch_size
|
| 168 |
-
elif type(prompt) is not type(negative_prompt):
|
| 169 |
-
raise TypeError(
|
| 170 |
-
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
| 171 |
-
f" {type(prompt)}."
|
| 172 |
-
)
|
| 173 |
-
elif isinstance(negative_prompt, str):
|
| 174 |
-
uncond_tokens = [negative_prompt] * batch_size
|
| 175 |
-
elif batch_size != len(negative_prompt):
|
| 176 |
-
raise ValueError(
|
| 177 |
-
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
| 178 |
-
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
| 179 |
-
" the batch size of `prompt`."
|
| 180 |
-
)
|
| 181 |
-
else:
|
| 182 |
-
uncond_tokens = negative_prompt
|
| 183 |
-
|
| 184 |
-
max_length = text_input_ids.shape[-1]
|
| 185 |
-
uncond_input = self.tokenizer(
|
| 186 |
-
uncond_tokens,
|
| 187 |
-
padding="max_length",
|
| 188 |
-
max_length=max_length,
|
| 189 |
-
truncation=True,
|
| 190 |
-
return_tensors="np",
|
| 191 |
-
)
|
| 192 |
-
uncond_embeddings = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int64))[0]
|
| 193 |
-
uncond_embeddings = np.repeat(uncond_embeddings, num_images_per_prompt, axis=0)
|
| 194 |
-
|
| 195 |
-
# For classifier free guidance, we need to do two forward passes.
|
| 196 |
-
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 197 |
-
# to avoid doing two forward passes
|
| 198 |
-
text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
|
| 199 |
-
|
| 200 |
-
return text_embeddings
|
| 201 |
-
|
| 202 |
-
def run_safety_checker(self, image, dtype):
|
| 203 |
-
if self.safety_checker is not None:
|
| 204 |
-
safety_checker_input = self.feature_extractor(
|
| 205 |
-
self.numpy_to_pil(image), return_tensors="np"
|
| 206 |
-
).pixel_values.astype(dtype)
|
| 207 |
-
# There will throw an error if use safety_checker batchsize>1
|
| 208 |
-
images, has_nsfw_concept = [], []
|
| 209 |
-
for i in range(image.shape[0]):
|
| 210 |
-
image_i, has_nsfw_concept_i = self.safety_checker(
|
| 211 |
-
clip_input=safety_checker_input[i : i + 1], images=image[i : i + 1]
|
| 212 |
-
)
|
| 213 |
-
images.append(image_i)
|
| 214 |
-
has_nsfw_concept.append(has_nsfw_concept_i[0])
|
| 215 |
-
image = np.concatenate(images)
|
| 216 |
-
else:
|
| 217 |
-
has_nsfw_concept = None
|
| 218 |
-
return image, has_nsfw_concept
|
| 219 |
-
|
| 220 |
-
def decode_latents(self, latents):
|
| 221 |
-
latents = 1 / 0.18215 * latents
|
| 222 |
-
latents_shape = latents.shape
|
| 223 |
-
vae_output_shape = [latents_shape[0], 3, latents_shape[2] * 8, latents_shape[3] * 8]
|
| 224 |
-
images_vae = paddle.zeros(vae_output_shape, dtype="float32")
|
| 225 |
-
|
| 226 |
-
vae_input_name = self.vae_decoder.model.get_input_info(0).name
|
| 227 |
-
vae_output_name = self.vae_decoder.model.get_output_info(0).name
|
| 228 |
-
|
| 229 |
-
self.vae_decoder.zero_copy_infer(
|
| 230 |
-
prebinded_inputs={vae_input_name: latents},
|
| 231 |
-
prebinded_outputs={vae_output_name: images_vae},
|
| 232 |
-
share_with_raw_ptr=True,
|
| 233 |
-
)
|
| 234 |
-
|
| 235 |
-
images_vae = paddle.clip(images_vae / 2 + 0.5, 0, 1)
|
| 236 |
-
images = images_vae.transpose([0, 2, 3, 1])
|
| 237 |
-
return images.numpy()
|
| 238 |
-
|
| 239 |
-
def prepare_extra_step_kwargs(self, eta):
|
| 240 |
-
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
| 241 |
-
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
| 242 |
-
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
| 243 |
-
# and should be between [0, 1]
|
| 244 |
-
|
| 245 |
-
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 246 |
-
extra_step_kwargs = {}
|
| 247 |
-
if accepts_eta:
|
| 248 |
-
extra_step_kwargs["eta"] = eta
|
| 249 |
-
return extra_step_kwargs
|
| 250 |
-
|
| 251 |
-
def check_var_kwargs_of_scheduler_func(self, scheduler_func):
|
| 252 |
-
sig = inspect.signature(scheduler_func)
|
| 253 |
-
params = sig.parameters.values()
|
| 254 |
-
has_kwargs = any([True for p in params if p.kind == p.VAR_KEYWORD])
|
| 255 |
-
return has_kwargs
|
| 256 |
-
|
| 257 |
-
def check_inputs(self, prompt, height, width, callback_steps):
|
| 258 |
-
if not isinstance(prompt, str) and not isinstance(prompt, list):
|
| 259 |
-
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
| 260 |
-
|
| 261 |
-
if height % 8 != 0 or width % 8 != 0:
|
| 262 |
-
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
|
| 263 |
-
|
| 264 |
-
if (callback_steps is None) or (
|
| 265 |
-
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
|
| 266 |
-
):
|
| 267 |
-
raise ValueError(
|
| 268 |
-
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
|
| 269 |
-
f" {type(callback_steps)}."
|
| 270 |
-
)
|
| 271 |
-
|
| 272 |
-
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, generator, latents=None):
|
| 273 |
-
if generator is None:
|
| 274 |
-
generator = np.random
|
| 275 |
-
|
| 276 |
-
latents_shape = (batch_size, num_channels_latents, height // 8, width // 8)
|
| 277 |
-
if latents is None:
|
| 278 |
-
latents = generator.randn(*latents_shape).astype(dtype)
|
| 279 |
-
elif latents.shape != latents_shape:
|
| 280 |
-
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
|
| 281 |
-
|
| 282 |
-
# scale the initial noise by the standard deviation required by the scheduler
|
| 283 |
-
latents = latents * float(self.scheduler.init_noise_sigma)
|
| 284 |
-
return latents
|
| 285 |
-
|
| 286 |
-
def __call__(
|
| 287 |
-
self,
|
| 288 |
-
prompt: Union[str, List[str]],
|
| 289 |
-
height: Optional[int] = 512,
|
| 290 |
-
width: Optional[int] = 512,
|
| 291 |
-
num_inference_steps: Optional[int] = 50,
|
| 292 |
-
guidance_scale: Optional[float] = 7.5,
|
| 293 |
-
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 294 |
-
num_images_per_prompt: Optional[int] = 1,
|
| 295 |
-
eta: Optional[float] = 0.0,
|
| 296 |
-
generator: Optional[np.random.RandomState] = None,
|
| 297 |
-
latents: Optional[np.ndarray] = None,
|
| 298 |
-
output_type: Optional[str] = "pil",
|
| 299 |
-
return_dict: bool = True,
|
| 300 |
-
callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
|
| 301 |
-
callback_steps: Optional[int] = 1,
|
| 302 |
-
):
|
| 303 |
-
r"""
|
| 304 |
-
Function invoked when calling the pipeline for generation.
|
| 305 |
-
|
| 306 |
-
Args:
|
| 307 |
-
prompt (`str` or `List[str]`):
|
| 308 |
-
The prompt or prompts to guide the image generation.
|
| 309 |
-
height (`int`, *optional*, 512):
|
| 310 |
-
The height in pixels of the generated image.
|
| 311 |
-
width (`int`, *optional*, 512):
|
| 312 |
-
The width in pixels of the generated image.
|
| 313 |
-
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 314 |
-
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 315 |
-
expense of slower inference.
|
| 316 |
-
guidance_scale (`float`, *optional*, defaults to 7.5):
|
| 317 |
-
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
| 318 |
-
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
| 319 |
-
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
| 320 |
-
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
| 321 |
-
usually at the expense of lower image quality.
|
| 322 |
-
negative_prompt (`str` or `List[str]`, *optional*):
|
| 323 |
-
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
| 324 |
-
if `guidance_scale` is less than `1`).
|
| 325 |
-
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 326 |
-
The number of images to generate per prompt.
|
| 327 |
-
eta (`float`, *optional*, defaults to 0.0):
|
| 328 |
-
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
|
| 329 |
-
[`schedulers.DDIMScheduler`], will be ignored for others.
|
| 330 |
-
generator (`np.random.RandomState`, *optional*):
|
| 331 |
-
A np.random.RandomState to make generation deterministic.
|
| 332 |
-
latents (`np.ndarray`, *optional*):
|
| 333 |
-
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
| 334 |
-
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 335 |
-
tensor will ge generated by sampling using the supplied random `generator`.
|
| 336 |
-
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 337 |
-
The output format of the generate image. Choose between
|
| 338 |
-
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
|
| 339 |
-
return_dict (`bool`, *optional*, defaults to `True`):
|
| 340 |
-
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
| 341 |
-
plain tuple.
|
| 342 |
-
callback (`Callable`, *optional*):
|
| 343 |
-
A function that will be called every `callback_steps` steps during inference. The function will be
|
| 344 |
-
called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
|
| 345 |
-
callback_steps (`int`, *optional*, defaults to 1):
|
| 346 |
-
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
| 347 |
-
called at every step.
|
| 348 |
-
|
| 349 |
-
Returns:
|
| 350 |
-
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
|
| 351 |
-
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
|
| 352 |
-
When returning a tuple, the first element is a list with the generated images, and the second element is a
|
| 353 |
-
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
|
| 354 |
-
(nsfw) content, according to the `safety_checker`.
|
| 355 |
-
"""
|
| 356 |
-
# 1. Check inputs. Raise error if not correct
|
| 357 |
-
self.check_inputs(prompt, height, width, callback_steps)
|
| 358 |
-
|
| 359 |
-
# 2. Define call parameters
|
| 360 |
-
batch_size = 1 if isinstance(prompt, str) else len(prompt)
|
| 361 |
-
|
| 362 |
-
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 363 |
-
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 364 |
-
# corresponds to doing no classifier free guidance.
|
| 365 |
-
do_classifier_free_guidance = guidance_scale > 1.0
|
| 366 |
-
|
| 367 |
-
# 3. Encode input prompt
|
| 368 |
-
start_time_encode_prompt = time.perf_counter()
|
| 369 |
-
text_embeddings = self._encode_prompt(
|
| 370 |
-
prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
| 371 |
-
)
|
| 372 |
-
print("_encode_prompt latency:", time.perf_counter() - start_time_encode_prompt)
|
| 373 |
-
# 4. Prepare timesteps
|
| 374 |
-
timesteps = self.scheduler.timesteps
|
| 375 |
-
|
| 376 |
-
# 5. Prepare latent variables
|
| 377 |
-
num_channels_latents = 4
|
| 378 |
-
latents = self.prepare_latents(
|
| 379 |
-
batch_size * num_images_per_prompt,
|
| 380 |
-
num_channels_latents,
|
| 381 |
-
height,
|
| 382 |
-
width,
|
| 383 |
-
text_embeddings.dtype,
|
| 384 |
-
generator,
|
| 385 |
-
latents,
|
| 386 |
-
)
|
| 387 |
-
if isinstance(latents, np.ndarray):
|
| 388 |
-
latents = paddle.to_tensor(latents)
|
| 389 |
-
# 6. Prepare extra step kwargs.
|
| 390 |
-
extra_step_kwargs = self.prepare_extra_step_kwargs(eta)
|
| 391 |
-
# 7. Denoising loop
|
| 392 |
-
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 393 |
-
scheduler_support_kwagrs_scale_input = self.check_var_kwargs_of_scheduler_func(
|
| 394 |
-
self.scheduler.scale_model_input
|
| 395 |
-
)
|
| 396 |
-
scheduler_support_kwagrs_step = self.check_var_kwargs_of_scheduler_func(self.scheduler.step)
|
| 397 |
-
|
| 398 |
-
unet_output_name = self.unet.model.get_output_info(0).name
|
| 399 |
-
unet_input_names = [self.unet.model.get_input_info(i).name for i in range(self.unet.model.num_inputs())]
|
| 400 |
-
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 401 |
-
text_embeddings = paddle.to_tensor(text_embeddings, dtype="float32")
|
| 402 |
-
for i, t in enumerate(timesteps):
|
| 403 |
-
noise_pred_unet = paddle.zeros(
|
| 404 |
-
[2 * batch_size * num_images_per_prompt, 4, height // 8, width // 8], dtype="float32"
|
| 405 |
-
)
|
| 406 |
-
# expand the latents if we are doing classifier free guidance
|
| 407 |
-
latent_model_input = paddle.concat([latents] * 2) if do_classifier_free_guidance else latents
|
| 408 |
-
if scheduler_support_kwagrs_scale_input:
|
| 409 |
-
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t, step_index=i)
|
| 410 |
-
else:
|
| 411 |
-
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 412 |
-
|
| 413 |
-
# predict the noise residual
|
| 414 |
-
self.unet.zero_copy_infer(
|
| 415 |
-
prebinded_inputs={
|
| 416 |
-
unet_input_names[0]: latent_model_input,
|
| 417 |
-
unet_input_names[1]: t,
|
| 418 |
-
unet_input_names[2]: text_embeddings,
|
| 419 |
-
},
|
| 420 |
-
prebinded_outputs={unet_output_name: noise_pred_unet},
|
| 421 |
-
share_with_raw_ptr=True,
|
| 422 |
-
)
|
| 423 |
-
# perform guidance
|
| 424 |
-
if do_classifier_free_guidance:
|
| 425 |
-
noise_pred_uncond, noise_pred_text = noise_pred_unet.chunk(2)
|
| 426 |
-
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 427 |
-
# compute the previous noisy sample x_t -> x_t-1
|
| 428 |
-
if scheduler_support_kwagrs_step:
|
| 429 |
-
scheduler_output = self.scheduler.step(
|
| 430 |
-
noise_pred, t, latents, step_index=i, return_pred_original_sample=False, **extra_step_kwargs
|
| 431 |
-
)
|
| 432 |
-
else:
|
| 433 |
-
scheduler_output = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs)
|
| 434 |
-
latents = scheduler_output.prev_sample
|
| 435 |
-
if i == num_inference_steps - 1:
|
| 436 |
-
# sync for accuracy it/s measure
|
| 437 |
-
paddle.device.cuda.synchronize()
|
| 438 |
-
# call the callback, if provided
|
| 439 |
-
if i == num_inference_steps - 1 or (
|
| 440 |
-
(i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0
|
| 441 |
-
):
|
| 442 |
-
progress_bar.update()
|
| 443 |
-
if callback is not None and i % callback_steps == 0:
|
| 444 |
-
callback(i, t, latents)
|
| 445 |
-
|
| 446 |
-
# 8. Post-processing
|
| 447 |
-
time_start_decoder = time.perf_counter()
|
| 448 |
-
image = self.decode_latents(latents)
|
| 449 |
-
print("decoder latency:", time.perf_counter() - time_start_decoder)
|
| 450 |
-
# 9. Run safety checker
|
| 451 |
-
image, has_nsfw_concept = self.run_safety_checker(image, text_embeddings.dtype)
|
| 452 |
-
|
| 453 |
-
# 10. Convert to PIL
|
| 454 |
-
if output_type == "pil":
|
| 455 |
-
image = self.numpy_to_pil(image)
|
| 456 |
-
|
| 457 |
-
if not return_dict:
|
| 458 |
-
return (image, has_nsfw_concept)
|
| 459 |
-
|
| 460 |
-
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/2ndelement/voicevox/test/test_core_version_utility.py
DELETED
|
@@ -1,40 +0,0 @@
|
|
| 1 |
-
from unittest import TestCase
|
| 2 |
-
|
| 3 |
-
from voicevox_engine.utility import get_latest_core_version, parse_core_version
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
class TestCoreVersion(TestCase):
|
| 7 |
-
def test_parse_core_version(self):
|
| 8 |
-
parse_core_version("0.0.0")
|
| 9 |
-
parse_core_version("0.1.0")
|
| 10 |
-
parse_core_version("0.10.0")
|
| 11 |
-
parse_core_version("0.10.0-preview.1")
|
| 12 |
-
parse_core_version("0.14.0")
|
| 13 |
-
parse_core_version("0.14.0-preview.1")
|
| 14 |
-
parse_core_version("0.14.0-preview.10")
|
| 15 |
-
|
| 16 |
-
def test_get_latest_core_version(self):
|
| 17 |
-
self.assertEqual(
|
| 18 |
-
get_latest_core_version(
|
| 19 |
-
versions=[
|
| 20 |
-
"0.0.0",
|
| 21 |
-
"0.1.0",
|
| 22 |
-
"0.10.0",
|
| 23 |
-
"0.10.0-preview.1",
|
| 24 |
-
"0.14.0",
|
| 25 |
-
"0.14.0-preview.1",
|
| 26 |
-
"0.14.0-preview.10",
|
| 27 |
-
]
|
| 28 |
-
),
|
| 29 |
-
"0.14.0",
|
| 30 |
-
)
|
| 31 |
-
|
| 32 |
-
self.assertEqual(
|
| 33 |
-
get_latest_core_version(
|
| 34 |
-
versions=[
|
| 35 |
-
"0.14.0",
|
| 36 |
-
"0.15.0-preview.1",
|
| 37 |
-
]
|
| 38 |
-
),
|
| 39 |
-
"0.15.0-preview.1",
|
| 40 |
-
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/801artistry/RVC801/infer/modules/vc/utils.py
DELETED
|
@@ -1,42 +0,0 @@
|
|
| 1 |
-
import os
|
| 2 |
-
import re
|
| 3 |
-
from fairseq import checkpoint_utils
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
def get_index_path_from_model(sid):
|
| 7 |
-
sid0strip = re.sub(r'\.pth|\.onnx$', '', sid)
|
| 8 |
-
sid0name = os.path.split(sid0strip)[-1] # Extract only the name, not the directory
|
| 9 |
-
|
| 10 |
-
# Check if the sid0strip has the specific ending format _eXXX_sXXX
|
| 11 |
-
if re.match(r'.+_e\d+_s\d+$', sid0name):
|
| 12 |
-
base_model_name = sid0name.rsplit('_', 2)[0]
|
| 13 |
-
else:
|
| 14 |
-
base_model_name = sid0name
|
| 15 |
-
|
| 16 |
-
return next(
|
| 17 |
-
(
|
| 18 |
-
f
|
| 19 |
-
for f in [
|
| 20 |
-
os.path.join(root, name)
|
| 21 |
-
for root, _, files in os.walk(os.getenv("index_root"), topdown=False)
|
| 22 |
-
for name in files
|
| 23 |
-
if name.endswith(".index") and "trained" not in name
|
| 24 |
-
]
|
| 25 |
-
if base_model_name in f
|
| 26 |
-
),
|
| 27 |
-
"",
|
| 28 |
-
)
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
def load_hubert(config):
|
| 32 |
-
models, _, _ = checkpoint_utils.load_model_ensemble_and_task(
|
| 33 |
-
["assets/hubert/hubert_base.pt"],
|
| 34 |
-
suffix="",
|
| 35 |
-
)
|
| 36 |
-
hubert_model = models[0]
|
| 37 |
-
hubert_model = hubert_model.to(config.device)
|
| 38 |
-
if config.is_half:
|
| 39 |
-
hubert_model = hubert_model.half()
|
| 40 |
-
else:
|
| 41 |
-
hubert_model = hubert_model.float()
|
| 42 |
-
return hubert_model.eval()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/A666sxr/Genshin_TTS/text/japanese.py
DELETED
|
@@ -1,153 +0,0 @@
|
|
| 1 |
-
import re
|
| 2 |
-
from unidecode import unidecode
|
| 3 |
-
import pyopenjtalk
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
# Regular expression matching Japanese without punctuation marks:
|
| 7 |
-
_japanese_characters = re.compile(
|
| 8 |
-
r'[A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
|
| 9 |
-
|
| 10 |
-
# Regular expression matching non-Japanese characters or punctuation marks:
|
| 11 |
-
_japanese_marks = re.compile(
|
| 12 |
-
r'[^A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
|
| 13 |
-
|
| 14 |
-
# List of (symbol, Japanese) pairs for marks:
|
| 15 |
-
_symbols_to_japanese = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 16 |
-
('%', 'パーセント')
|
| 17 |
-
]]
|
| 18 |
-
|
| 19 |
-
# List of (romaji, ipa) pairs for marks:
|
| 20 |
-
_romaji_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 21 |
-
('ts', 'ʦ'),
|
| 22 |
-
('u', 'ɯ'),
|
| 23 |
-
('j', 'ʥ'),
|
| 24 |
-
('y', 'j'),
|
| 25 |
-
('ni', 'n^i'),
|
| 26 |
-
('nj', 'n^'),
|
| 27 |
-
('hi', 'çi'),
|
| 28 |
-
('hj', 'ç'),
|
| 29 |
-
('f', 'ɸ'),
|
| 30 |
-
('I', 'i*'),
|
| 31 |
-
('U', 'ɯ*'),
|
| 32 |
-
('r', 'ɾ')
|
| 33 |
-
]]
|
| 34 |
-
|
| 35 |
-
# List of (romaji, ipa2) pairs for marks:
|
| 36 |
-
_romaji_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 37 |
-
('u', 'ɯ'),
|
| 38 |
-
('ʧ', 'tʃ'),
|
| 39 |
-
('j', 'dʑ'),
|
| 40 |
-
('y', 'j'),
|
| 41 |
-
('ni', 'n^i'),
|
| 42 |
-
('nj', 'n^'),
|
| 43 |
-
('hi', 'çi'),
|
| 44 |
-
('hj', 'ç'),
|
| 45 |
-
('f', 'ɸ'),
|
| 46 |
-
('I', 'i*'),
|
| 47 |
-
('U', 'ɯ*'),
|
| 48 |
-
('r', 'ɾ')
|
| 49 |
-
]]
|
| 50 |
-
|
| 51 |
-
# List of (consonant, sokuon) pairs:
|
| 52 |
-
_real_sokuon = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 53 |
-
(r'Q([↑↓]*[kg])', r'k#\1'),
|
| 54 |
-
(r'Q([↑↓]*[tdjʧ])', r't#\1'),
|
| 55 |
-
(r'Q([↑↓]*[sʃ])', r's\1'),
|
| 56 |
-
(r'Q([↑↓]*[pb])', r'p#\1')
|
| 57 |
-
]]
|
| 58 |
-
|
| 59 |
-
# List of (consonant, hatsuon) pairs:
|
| 60 |
-
_real_hatsuon = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 61 |
-
(r'N([↑↓]*[pbm])', r'm\1'),
|
| 62 |
-
(r'N([↑↓]*[ʧʥj])', r'n^\1'),
|
| 63 |
-
(r'N([↑↓]*[tdn])', r'n\1'),
|
| 64 |
-
(r'N([↑↓]*[kg])', r'ŋ\1')
|
| 65 |
-
]]
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
def symbols_to_japanese(text):
|
| 69 |
-
for regex, replacement in _symbols_to_japanese:
|
| 70 |
-
text = re.sub(regex, replacement, text)
|
| 71 |
-
return text
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
def japanese_to_romaji_with_accent(text):
|
| 75 |
-
'''Reference https://r9y9.github.io/ttslearn/latest/notebooks/ch10_Recipe-Tacotron.html'''
|
| 76 |
-
text = symbols_to_japanese(text)
|
| 77 |
-
sentences = re.split(_japanese_marks, text)
|
| 78 |
-
marks = re.findall(_japanese_marks, text)
|
| 79 |
-
text = ''
|
| 80 |
-
for i, sentence in enumerate(sentences):
|
| 81 |
-
if re.match(_japanese_characters, sentence):
|
| 82 |
-
if text != '':
|
| 83 |
-
text += ' '
|
| 84 |
-
labels = pyopenjtalk.extract_fullcontext(sentence)
|
| 85 |
-
for n, label in enumerate(labels):
|
| 86 |
-
phoneme = re.search(r'\-([^\+]*)\+', label).group(1)
|
| 87 |
-
if phoneme not in ['sil', 'pau']:
|
| 88 |
-
text += phoneme.replace('ch', 'ʧ').replace('sh',
|
| 89 |
-
'ʃ').replace('cl', 'Q')
|
| 90 |
-
else:
|
| 91 |
-
continue
|
| 92 |
-
# n_moras = int(re.search(r'/F:(\d+)_', label).group(1))
|
| 93 |
-
a1 = int(re.search(r"/A:(\-?[0-9]+)\+", label).group(1))
|
| 94 |
-
a2 = int(re.search(r"\+(\d+)\+", label).group(1))
|
| 95 |
-
a3 = int(re.search(r"\+(\d+)/", label).group(1))
|
| 96 |
-
if re.search(r'\-([^\+]*)\+', labels[n + 1]).group(1) in ['sil', 'pau']:
|
| 97 |
-
a2_next = -1
|
| 98 |
-
else:
|
| 99 |
-
a2_next = int(
|
| 100 |
-
re.search(r"\+(\d+)\+", labels[n + 1]).group(1))
|
| 101 |
-
# Accent phrase boundary
|
| 102 |
-
if a3 == 1 and a2_next == 1:
|
| 103 |
-
text += ' '
|
| 104 |
-
# Falling
|
| 105 |
-
elif a1 == 0 and a2_next == a2 + 1:
|
| 106 |
-
text += '↓'
|
| 107 |
-
# Rising
|
| 108 |
-
elif a2 == 1 and a2_next == 2:
|
| 109 |
-
text += '↑'
|
| 110 |
-
if i < len(marks):
|
| 111 |
-
text += unidecode(marks[i]).replace(' ', '')
|
| 112 |
-
return text
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
def get_real_sokuon(text):
|
| 116 |
-
for regex, replacement in _real_sokuon:
|
| 117 |
-
text = re.sub(regex, replacement, text)
|
| 118 |
-
return text
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
def get_real_hatsuon(text):
|
| 122 |
-
for regex, replacement in _real_hatsuon:
|
| 123 |
-
text = re.sub(regex, replacement, text)
|
| 124 |
-
return text
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
def japanese_to_ipa(text):
|
| 128 |
-
text = japanese_to_romaji_with_accent(text).replace('...', '…')
|
| 129 |
-
text = re.sub(
|
| 130 |
-
r'([aiueo])\1+', lambda x: x.group(0)[0]+'ː'*(len(x.group(0))-1), text)
|
| 131 |
-
text = get_real_sokuon(text)
|
| 132 |
-
text = get_real_hatsuon(text)
|
| 133 |
-
for regex, replacement in _romaji_to_ipa:
|
| 134 |
-
text = re.sub(regex, replacement, text)
|
| 135 |
-
return text
|
| 136 |
-
|
| 137 |
-
|
| 138 |
-
def japanese_to_ipa2(text):
|
| 139 |
-
text = japanese_to_romaji_with_accent(text).replace('...', '…')
|
| 140 |
-
text = get_real_sokuon(text)
|
| 141 |
-
text = get_real_hatsuon(text)
|
| 142 |
-
for regex, replacement in _romaji_to_ipa2:
|
| 143 |
-
text = re.sub(regex, replacement, text)
|
| 144 |
-
return text
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
def japanese_to_ipa3(text):
|
| 148 |
-
text = japanese_to_ipa2(text).replace('n^', 'ȵ').replace(
|
| 149 |
-
'ʃ', 'ɕ').replace('*', '\u0325').replace('#', '\u031a')
|
| 150 |
-
text = re.sub(
|
| 151 |
-
r'([aiɯeo])\1+', lambda x: x.group(0)[0]+'ː'*(len(x.group(0))-1), text)
|
| 152 |
-
text = re.sub(r'((?:^|\s)(?:ts|tɕ|[kpt]))', r'\1ʰ', text)
|
| 153 |
-
return text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AI-Dashboards/AI.Dashboard.Streamlit.Index.For.Assessments/app.py
DELETED
|
@@ -1,453 +0,0 @@
|
|
| 1 |
-
import streamlit as st
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
st.markdown("""
|
| 5 |
-
|
| 6 |
-
## FHIR - CT - Graph
|
| 7 |
-
|
| 8 |
-
# FHIR:
|
| 9 |
-
https://huggingface.co/spaces/awacke1/Clinical-Terminology-FHIR-Assessment
|
| 10 |
-
https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Observation-SDKs
|
| 11 |
-
https://huggingface.co/spaces/awacke1/SMART-FHIR-Kits-SDC-HL7
|
| 12 |
-
https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Blood-Pressure
|
| 13 |
-
https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Exercise
|
| 14 |
-
|
| 15 |
-
# Clinical Terminology:
|
| 16 |
-
https://huggingface.co/spaces/awacke1/Ontology-Gradio
|
| 17 |
-
https://huggingface.co/spaces/awacke1/Biomed-NLP-AI-Clinical-Terminology
|
| 18 |
-
https://huggingface.co/spaces/awacke1/ClinicalTerminologyNER-Refactored
|
| 19 |
-
https://huggingface.co/spaces/awacke1/ClinicalTerminologyAISearch
|
| 20 |
-
https://huggingface.co/spaces/awacke1/ClinicalTerminologyAISearch1215
|
| 21 |
-
|
| 22 |
-
# Graph, Clinical Terminology, FHIR Apps and Services:
|
| 23 |
-
https://huggingface.co/spaces/awacke1/Git-GPG-Git-Actions-01-GraphViz
|
| 24 |
-
https://huggingface.co/spaces/awacke1/Dice-Roll-Treemap-Plotly
|
| 25 |
-
https://huggingface.co/spaces/awacke1/GraphVis3
|
| 26 |
-
https://huggingface.co/spaces/awacke1/GraphViz-Demo
|
| 27 |
-
https://huggingface.co/spaces/awacke1/StreamlitGraphViz
|
| 28 |
-
https://huggingface.co/spaces/awacke1/CardGameActivity-GraphViz
|
| 29 |
-
|
| 30 |
-
# CP Matplotlib, NetworkX, Streamlit, PyVis, st-click0detector, graphviz:
|
| 31 |
-
https://huggingface.co/spaces/awacke1/CPVisGraph
|
| 32 |
-
|
| 33 |
-
# OMS and LOCUS:
|
| 34 |
-
https://huggingface.co/spaces/awacke1/NLPGraphOMSandLOCUS
|
| 35 |
-
|
| 36 |
-
# Technical Architecture - Open Source Graph ML Libraries:
|
| 37 |
-
NetworkX: https://networkx.org/
|
| 38 |
-
PyTorch GNN: https://github.com/microsoft/ptgnn
|
| 39 |
-
Jraph: https://github.com/deepmind/jraph
|
| 40 |
-
Spektral: https://graphneural.network/
|
| 41 |
-
Graph Nets: https://github.com/deepmind/graph_nets
|
| 42 |
-
Deep Graph Library (DGL): https://github.com/dmlc
|
| 43 |
-
PyTorch Geometric: https://github.com/pyg-team/pytorch_geometric
|
| 44 |
-
|
| 45 |
-
# Provider Graph - Maps of Hospitals
|
| 46 |
-
|
| 47 |
-
https://huggingface.co/spaces/awacke1/MN.Map.Hospitals.Top.Five
|
| 48 |
-

|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
# Graph, Clinical Terminology, FHIR Apps and Services:
|
| 53 |
-
|
| 54 |
-
CP Matplotlib, NetworkX, Streamlit, PyVis, st-click0detector, graphviz:
|
| 55 |
-
https://huggingface.co/spaces/awacke1/CPVisGraph
|
| 56 |
-
|
| 57 |
-
OMS and LOCUS:
|
| 58 |
-
https://huggingface.co/spaces/awacke1/NLPGraphOMSandLOCUS
|
| 59 |
-
|
| 60 |
-
https://huggingface.co/spaces/awacke1/Git-GPG-Git-Actions-01-GraphViz
|
| 61 |
-
https://huggingface.co/spaces/awacke1/Dice-Roll-Treemap-Plotly
|
| 62 |
-
https://huggingface.co/spaces/awacke1/GraphVis3
|
| 63 |
-
https://huggingface.co/spaces/awacke1/GraphViz-Demo
|
| 64 |
-
https://huggingface.co/spaces/awacke1/StreamlitGraphViz
|
| 65 |
-
https://huggingface.co/spaces/awacke1/CardGameActivity-GraphViz
|
| 66 |
-
|
| 67 |
-
Technical Architecture - Open Source Graph ML Libraries:
|
| 68 |
-
|
| 69 |
-
NetworkX: https://networkx.org/
|
| 70 |
-
PyTorch GNN: https://github.com/microsoft/ptgnn
|
| 71 |
-
Jraph: https://github.com/deepmind/jraph
|
| 72 |
-
Spektral: https://graphneural.network/
|
| 73 |
-
Graph Nets: https://github.com/deepmind/graph_nets
|
| 74 |
-
Deep Graph Library (DGL): https://github.com/dmlc
|
| 75 |
-
PyTorch Geometric: https://github.com/pyg-team/pytorch_geometric
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
# Clinical Terminology:
|
| 80 |
-
# FHIR:
|
| 81 |
-
https://huggingface.co/spaces/awacke1/Clinical-Terminology-FHIR-Assessment
|
| 82 |
-
https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Observation-SDKs
|
| 83 |
-
https://huggingface.co/spaces/awacke1/SMART-FHIR-Kits-SDC-HL7
|
| 84 |
-
https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Blood-Pressure
|
| 85 |
-
https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Exercise
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
# Clinical Terminology:
|
| 89 |
-
https://huggingface.co/spaces/awacke1/Ontology-Gradio
|
| 90 |
-
https://huggingface.co/spaces/awacke1/Biomed-NLP-AI-Clinical-Terminology
|
| 91 |
-
https://huggingface.co/spaces/awacke1/ClinicalTerminologyNER-Refactored
|
| 92 |
-
https://huggingface.co/spaces/awacke1/ClinicalTerminologyAISearch
|
| 93 |
-
https://huggingface.co/spaces/awacke1/ClinicalTerminologyAISearch1215
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
# Saturday Evening:
|
| 99 |
-
https://huggingface.co/spaces/awacke1/MN.Map.Hospitals.Top.Five
|
| 100 |
-

|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
# Iceland Myths - Places to See - https://huggingface.co/spaces/awacke1/Maps.Markers.Honor.Iceland
|
| 104 |
-

|
| 105 |
-
|
| 106 |
-
Ásbyrgi: Thor, trying to prove his strength, challenged Sleipnir to a race. Odin agreed, but secretly fed Sleipnir his favorite snack, lightning bolts. With each step, Sleipnir left a massive print, and thus, Ásbyrgi was formed.
|
| 107 |
-
|
| 108 |
-

|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
# Saturday
|
| 113 |
-
write a streamlit python program that uses functions and user interface elements of a textbox, a dial, a four direction button array for up down left right and display a folium map with the data in python list dictionaries with these values: Aurora Spottings, Notifications on Nerthern Lights, Northern lights map location cities and countries for Iceland on a map written with folium for latitude and longitude of top ten places to view Northern Lights. Cite References as urls.
|
| 114 |
-
|
| 115 |
-
# Maps
|
| 116 |
-
|
| 117 |
-
Space | URL
|
| 118 |
-
-------------------------------------------------------------------------------------------------------------------------------------------
|
| 119 |
-
awacke1/VizLib-TopLargeHospitalsNewJersey-03-09-2023 | https://huggingface.co/spaces/awacke1/VizLib-TopLargeHospitalsNewJersey-03-09-2023
|
| 120 |
-
awacke1/Bird-Species-Migration-Month-Map | https://huggingface.co/spaces/awacke1/Bird-Species-Migration-Month-Map
|
| 121 |
-
⚗️🧠🔬🧬 Clinical Terminology Auto Mapper AI 👩⚕️🩺⚕️🙋 | https://huggingface.co/spaces/awacke1/SNOMED-LOINC-eCQM
|
| 122 |
-
awacke1/Visualization-Plotly-Sunbursts-Treemaps-and-WebGL | https://huggingface.co/spaces/awacke1/Visualization-Plotly-Sunbursts-Treemaps-and-WebGL
|
| 123 |
-
awacke1/HTML5-Aframe-3D-Maps | https://huggingface.co/spaces/awacke1/HTML5-Aframe-3D-Maps
|
| 124 |
-
awacke1/HTML5-Aframe-3dMap-Flight | https://huggingface.co/spaces/awacke1/HTML5-Aframe-3dMap-Flight
|
| 125 |
-
|
| 126 |
-
Figures:
|
| 127 |
-

|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
# Top Ten Board Games
|
| 132 |
-
## Map-Making-Strategy
|
| 133 |
-
https://huggingface.co/spaces/awacke1/Top-Ten-Board-Games-Map-Making-Strategy
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
# MediaPipe
|
| 138 |
-
### A cross language SDK for AI that is real time, 3d, camera responsive, and on any device for nearly any language
|
| 139 |
-
#### Vision
|
| 140 |
-
#### Natural Language
|
| 141 |
-
#### Audio
|
| 142 |
-
|
| 143 |
-
Mediapipe has fast and flexible AI/ML pipelines.
|
| 144 |
-
Examples with Javascript Links!
|
| 145 |
-
|
| 146 |
-
1. Image Classifier: https://mediapipe-studio.webapps.google.com/demo/image_classifier
|
| 147 |
-
2. Object Detector: https://mediapipe-studio.webapps.google.com/demo/object_detector
|
| 148 |
-
3. Text Classification: https://mediapipe-studio.webapps.google.com/demo/text_classifier
|
| 149 |
-
4. Gesture Recognizer: https://mediapipe-studio.webapps.google.com/demo/gesture_recognizer
|
| 150 |
-
5. Hand Landmark Detection: https://mediapipe-studio.webapps.google.com/demo/hand_landmarker
|
| 151 |
-
6. Audio Classifier: https://mediapipe-studio.webapps.google.com/demo/audio_classifier
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
Get started with just Javascript!!
|
| 155 |
-
Getting Started: https://google.github.io/mediapipe/getting_started/javascript.html
|
| 156 |
-
|
| 157 |
-
Javascript Solutions - Ready to Demo:
|
| 158 |
-
1. Face Mesh: https://codepen.io/mediapipe/full/KKgVaPJ
|
| 159 |
-
2. Face Detection: https://codepen.io/mediapipe/full/dyOzvZM
|
| 160 |
-
3. Hands: https://codepen.io/mediapipe/full/RwGWYJw
|
| 161 |
-
4. Face, Hands, Body: https://codepen.io/mediapipe/full/LYRRYEw
|
| 162 |
-
5. Objectron: https://codepen.io/mediapipe/full/BaWvzdY
|
| 163 |
-
6. Full Skeletal Pose: https://codepen.io/mediapipe/full/jOMbvxw
|
| 164 |
-
7. Self Segmentation From Background: https://codepen.io/mediapipe/full/wvJyQpq
|
| 165 |
-
|
| 166 |
-
Demonstration in Action with Screenshots:
|
| 167 |
-
|
| 168 |
-
Self Segmentation From Background:
|
| 169 |
-
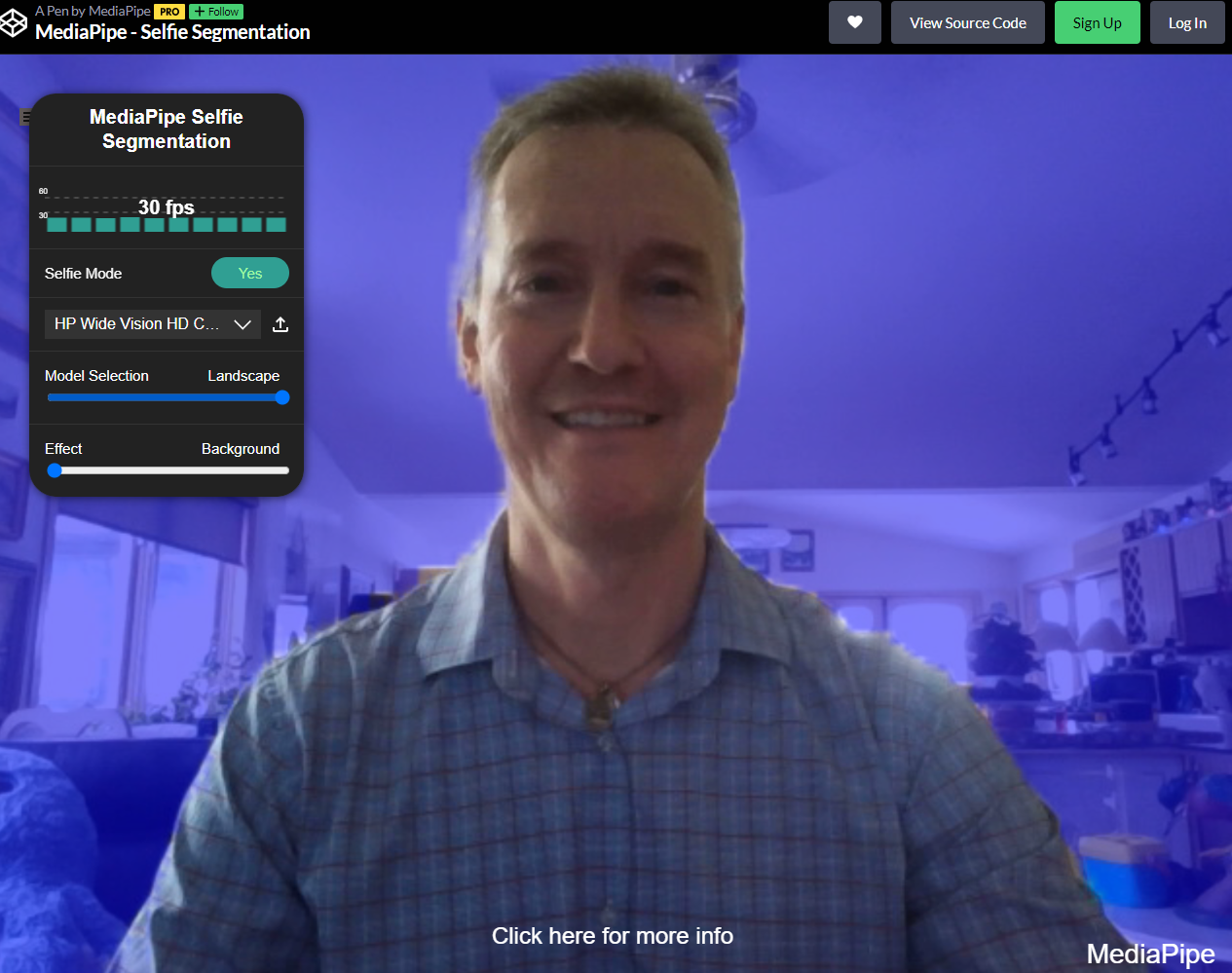
|
| 170 |
-
|
| 171 |
-
Full Skeletal Pose:
|
| 172 |
-
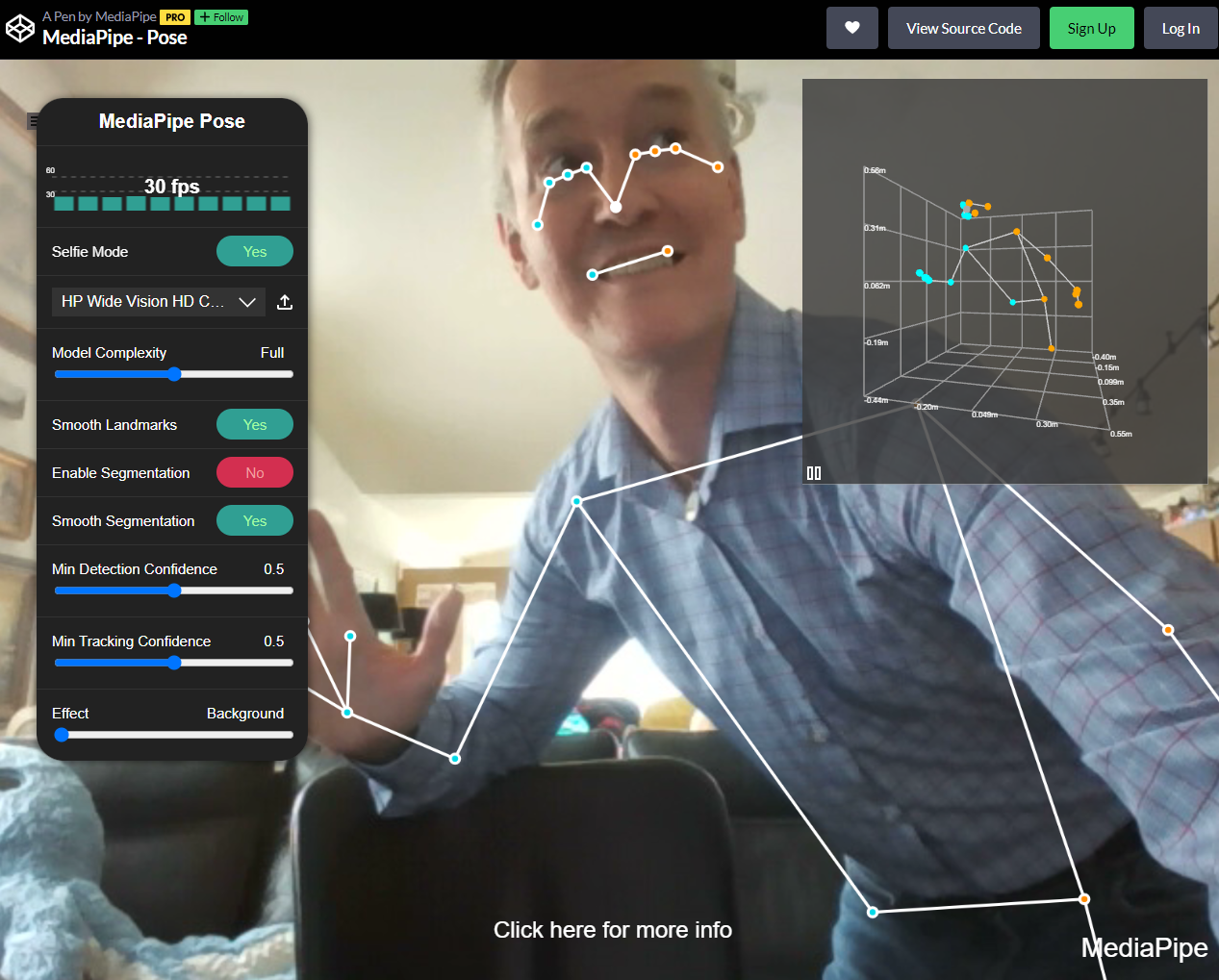
|
| 173 |
-
|
| 174 |
-
Hands - Both in 3D Projection even hidden surface vertices - Mahalo:
|
| 175 |
-
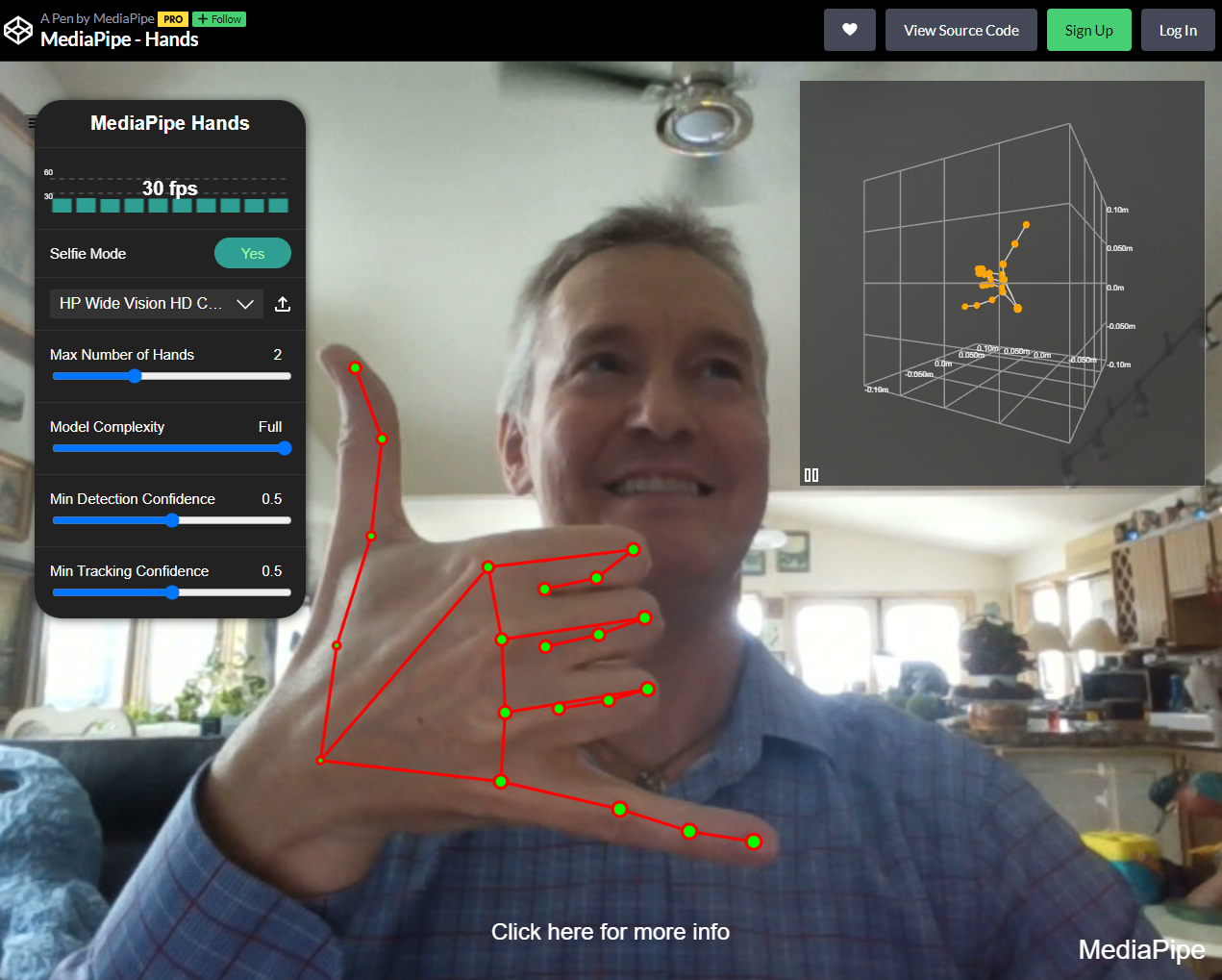
|
| 176 |
-
|
| 177 |
-
Holistic - Face, Hands, Body:
|
| 178 |
-
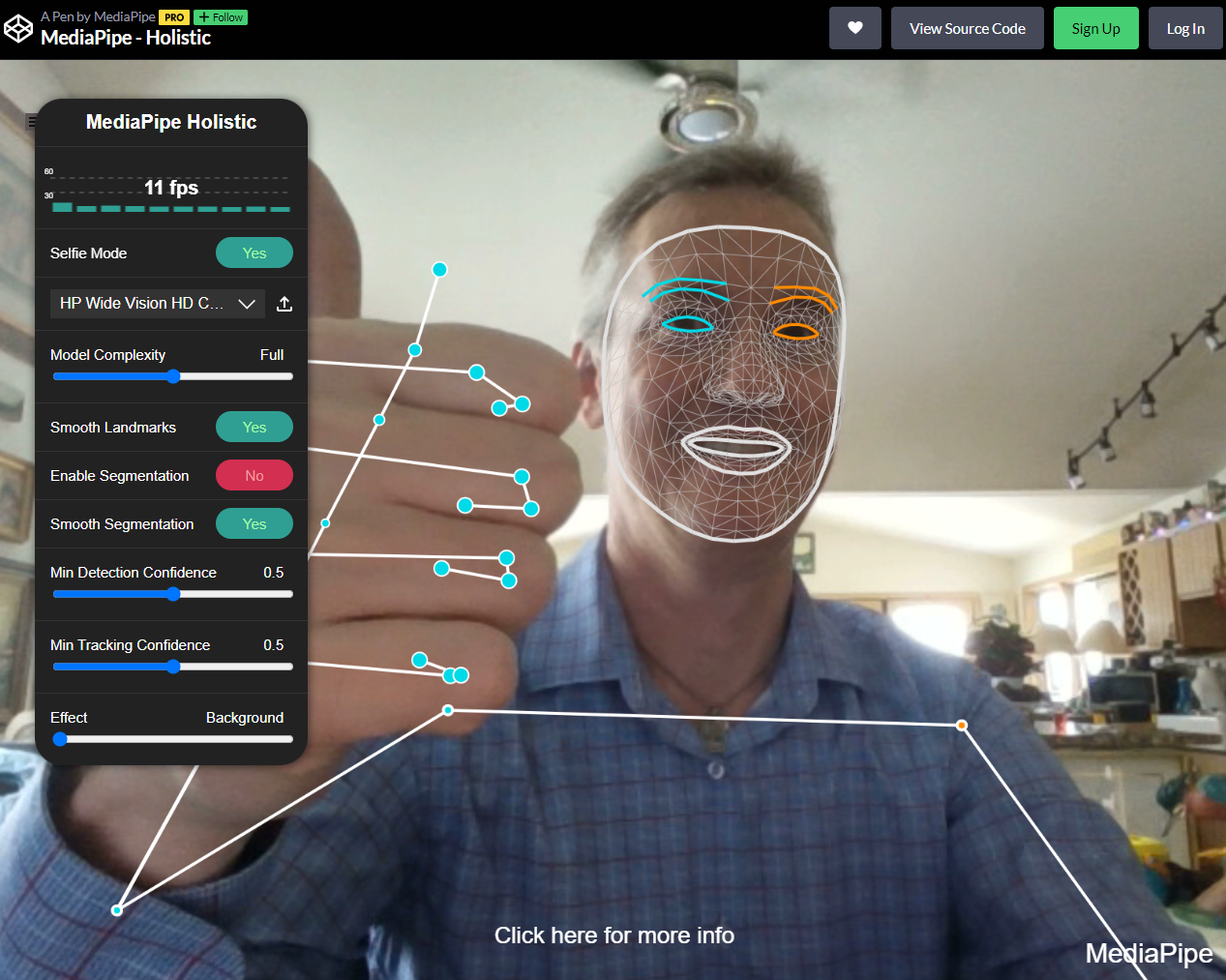
|
| 179 |
-
|
| 180 |
-
Face Detection:
|
| 181 |
-
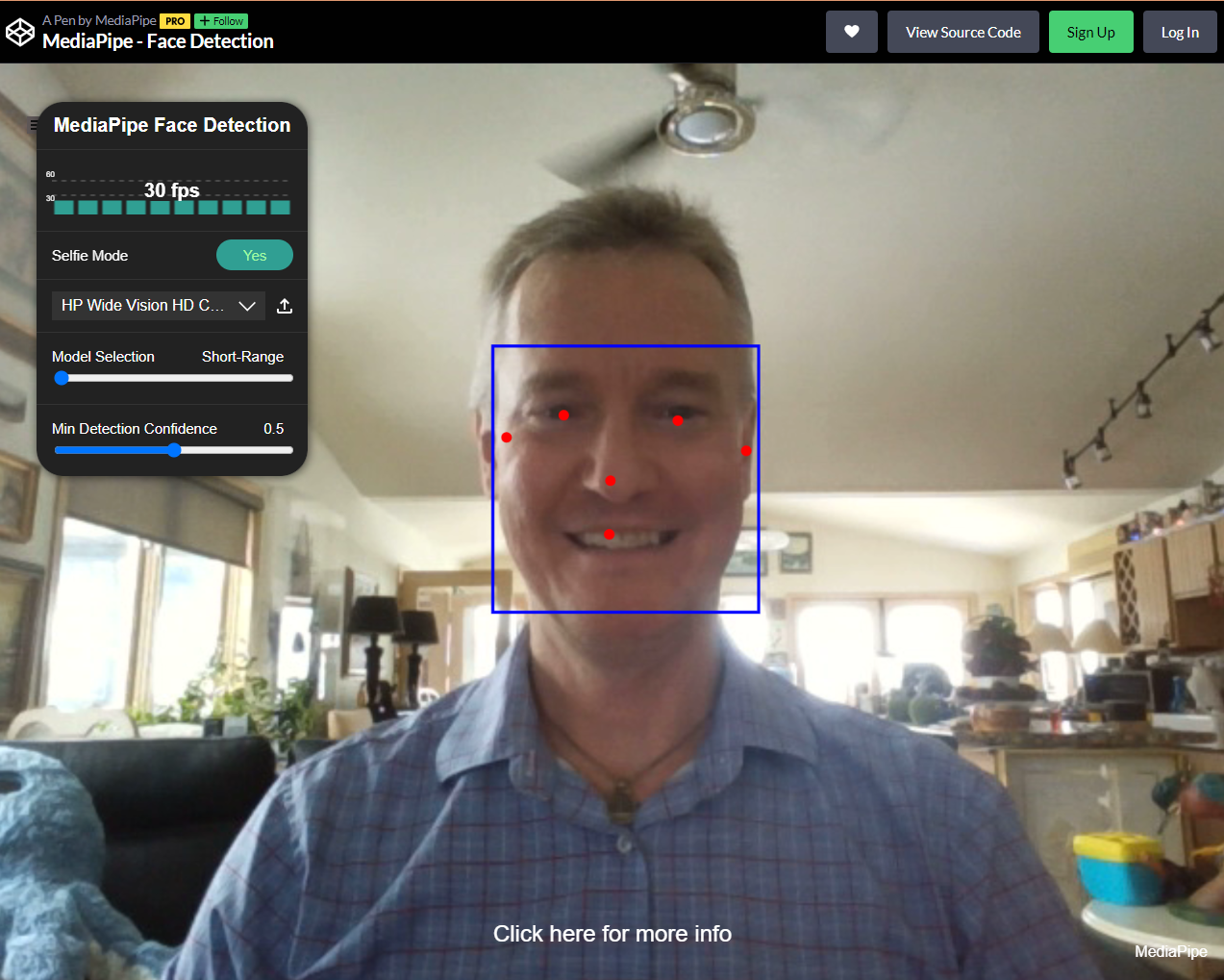
|
| 182 |
-
|
| 183 |
-
Face Mesh Real Time - 30 Frames per second!
|
| 184 |
-
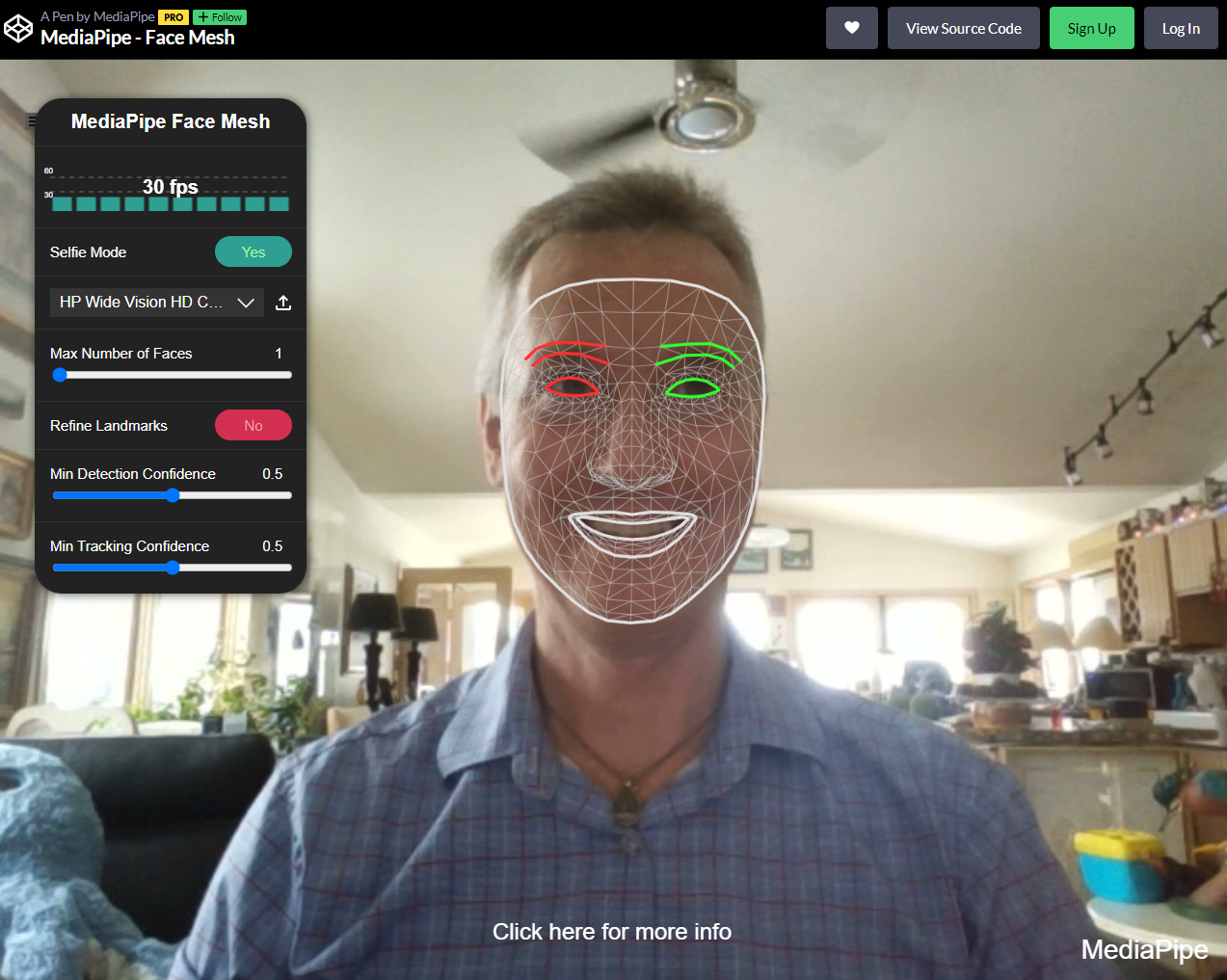
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
|
| 188 |
-
# ASR Voice and Virtual Assistants With Avatars
|
| 189 |
-
1. https://huggingface.co/spaces/awacke1/ASR-openai-whisper-large
|
| 190 |
-
2. https://huggingface.co/spaces/awacke1/ASR-voidful-wav2vec2-xlsr-multilingual-56
|
| 191 |
-
3. https://huggingface.co/spaces/awacke1/ASR-nvidia-stt_en_conformer_ctc_large
|
| 192 |
-
4. https://huggingface.co/spaces/awacke1/ASR-facebook-hubert-large-ls960-ft
|
| 193 |
-
5. https://huggingface.co/spaces/awacke1/ASR-openai-whisper-tiny.en
|
| 194 |
-
6. https://huggingface.co/spaces/awacke1/ASR-openai-whisper-tiny
|
| 195 |
-
7. https://huggingface.co/spaces/awacke1/ASR-openai-whisper-medium
|
| 196 |
-
8. https://huggingface.co/spaces/awacke1/ASR-nvidia-stt_en_conformer_transducer_xlarge
|
| 197 |
-
9. https://huggingface.co/spaces/awacke1/ASR-openai-whisper-base
|
| 198 |
-
10. https://huggingface.co/spaces/awacke1/ASR-facebook-wav2vec2-large-960h-lv60-self
|
| 199 |
-
11. https://huggingface.co/spaces/awacke1/ASR-facebook-wav2vec2-base-960h
|
| 200 |
-
12. https://huggingface.co/spaces/awacke1/ASR-High-Accuracy-Test
|
| 201 |
-
13. https://huggingface.co/spaces/awacke1/ASRGenerateStory
|
| 202 |
-
14. https://huggingface.co/spaces/awacke1/TTS-STT-Blocks
|
| 203 |
-
15. https://huggingface.co/spaces/awacke1/2-LiveASR
|
| 204 |
-
16. https://huggingface.co/spaces/awacke1/CloneAnyVoice
|
| 205 |
-
17. https://huggingface.co/spaces/awacke1/ASR-SOTA-NvidiaSTTMozilla
|
| 206 |
-
18. https://huggingface.co/spaces/awacke1/ASRSpeechRecognition1
|
| 207 |
-
19. https://huggingface.co/spaces/awacke1/1110-ASRLiveExample
|
| 208 |
-
20. https://huggingface.co/spaces/awacke1/Z1-ASRLiveSpeechRecognition-GR
|
| 209 |
-
21. https://huggingface.co/spaces/awacke1/PrivateASRWithMemory
|
| 210 |
-
22. https://huggingface.co/spaces/awacke1/TimerASRLive
|
| 211 |
-
|
| 212 |
-
# Best Voice Apps - HF:
|
| 213 |
-
1. https://huggingface.co/spaces/BilalSardar/Voice-Cloning
|
| 214 |
-
2. https://huggingface.co/spaces/RamAnanth1/chatGPT_voice
|
| 215 |
-
3. https://huggingface.co/spaces/Voicemod/speech-synthesis-demo
|
| 216 |
-
4. https://huggingface.co/spaces/ysharma/Voice-to-Youtube
|
| 217 |
-
5. https://huggingface.co/spaces/ramkamal2000/voice-conversion-yourtts
|
| 218 |
-
6. https://huggingface.co/spaces/RamAnanth1/co_chat_voice
|
| 219 |
-
7. https://huggingface.co/spaces/ysharma/Voice-to-jokes
|
| 220 |
-
8. https://huggingface.co/spaces/jayesh95/Voice-QA
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
# Supervised Learning (SL) for ML and Reinforcement Learning with Human Feedback (RLHF):
|
| 225 |
-
|
| 226 |
-
For human imitation we use reinforcement learning for fine tuning since feedback based on rewards shapes the quality of output where an agent completes a task and then observes a result. SL works on ranks not responses so is good for modifying elements at the token level however RLHF is trained to estimate the quality of the response with cumulative rewards for coherent conversation. RLHF considers context and coherence of entire conversation. Supervised learning is used to teach the model initially where the model learns basic structure and content. In the RLHF stage the model is refined with responses that represent improved accuracy.
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
# Mermaid Model for Core NLP Tasks:
|
| 233 |
-
|
| 234 |
-
```mermaid
|
| 235 |
-
graph LR;
|
| 236 |
-
A[Reader]-->B[Classifier];
|
| 237 |
-
A-->C[Retriever];
|
| 238 |
-
A-->D[Summarizer];
|
| 239 |
-
B-->E[Ranker];
|
| 240 |
-
B-->F[Query Classifier];
|
| 241 |
-
D-->G[Generator];
|
| 242 |
-
F-->H[Question Generator];
|
| 243 |
-
H-->G;
|
| 244 |
-
I[File Converter]-->J[Preprocessor];
|
| 245 |
-
J-->A;
|
| 246 |
-
I-->C;
|
| 247 |
-
K[Snowflake]-->B;
|
| 248 |
-
L[Oracle]-->B;
|
| 249 |
-
M[Pandas CSV]-->A;
|
| 250 |
-
N[Index]-->C;
|
| 251 |
-
N-->E;
|
| 252 |
-
O[Query with Filters]-->F;
|
| 253 |
-
P[Evaluation]-->E;
|
| 254 |
-
P-->F;
|
| 255 |
-
Q[Retraining]-->B;
|
| 256 |
-
Q-->E;
|
| 257 |
-
R[Annotation]-->B;
|
| 258 |
-
```
|
| 259 |
-
|
| 260 |
-
# Core NLP Task Model for QA
|
| 261 |
-
|
| 262 |
-
Tasks:
|
| 263 |
-
1. Reader
|
| 264 |
-
2. Summarizer
|
| 265 |
-
3. Classifier
|
| 266 |
-
4. Retriever
|
| 267 |
-
5. Ranker
|
| 268 |
-
6. Query Classifier
|
| 269 |
-
7. Question Generator
|
| 270 |
-
8. Generator
|
| 271 |
-
|
| 272 |
-
Connectors:
|
| 273 |
-
1. File Converter
|
| 274 |
-
2. Preprocessor
|
| 275 |
-
3. Snowflake
|
| 276 |
-
4. Oracle
|
| 277 |
-
5. Pandas CSV
|
| 278 |
-
|
| 279 |
-
Supported Workflow:
|
| 280 |
-
1. Index
|
| 281 |
-
2. Query with Filters
|
| 282 |
-
3. Evaluation
|
| 283 |
-
4. Retraining
|
| 284 |
-
5. Annotation
|
| 285 |
-
|
| 286 |
-
# QA Model Spaces:
|
| 287 |
-
|
| 288 |
-
QA use cases include QA, Semantic Document and FAQ Search.
|
| 289 |
-
|
| 290 |
-
1. Streamlit Question Answering w Hugging Face: https://huggingface.co/spaces/awacke1/Question-answering
|
| 291 |
-
2. Seq2Seq:
|
| 292 |
-
- https://huggingface.co/spaces/awacke1/4-Seq2SeqQAT5
|
| 293 |
-
- https://huggingface.co/spaces/awacke1/AW-04-GR-Seq-2-Seq-QA-Auto-Gen
|
| 294 |
-
-
|
| 295 |
-
3. BioGPT: https://huggingface.co/spaces/awacke1/microsoft-BioGPT-Large-PubMedQA
|
| 296 |
-
4. NLP QA Context: https://huggingface.co/spaces/awacke1/NLPContextQATransformersRobertaBaseSquad2
|
| 297 |
-
- https://huggingface.co/spaces/awacke1/SOTA-Plan
|
| 298 |
-
5. https://huggingface.co/spaces/awacke1/Question-answering
|
| 299 |
-
6. QA MLM: https://huggingface.co/spaces/awacke1/SOTA-MedEntity
|
| 300 |
-
|
| 301 |
-
# 🤖 QA Models and Datasets:
|
| 302 |
-
|
| 303 |
-
- Reader model extracts answers from text using QA pairs. SQuAD is the primary dataset.
|
| 304 |
-
- Transformers (huggingface) has research momentum and solves real business problems.
|
| 305 |
-
|
| 306 |
-
## 💻 Process:
|
| 307 |
-
|
| 308 |
-
1. Best practices for QA systems: https://www.youtube.com/playlist?list=PLHgX2IExbFotW6WgDZ-cMzpDBUNKCMBbF
|
| 309 |
-
2. Optimize Question/Answer Heads for SQuAD.
|
| 310 |
-
3. QA search to ask questions to textual kb.
|
| 311 |
-
4. Return text sections as answers.
|
| 312 |
-
5. Organize text collection.
|
| 313 |
-
6. Find similar documents to given input.
|
| 314 |
-
7. Perform semantic and comprehensive word matching.
|
| 315 |
-
8. Match incoming questions to FAQ KB dataset.
|
| 316 |
-
|
| 317 |
-
## 📋 Tasks:
|
| 318 |
-
|
| 319 |
-
1. Visual,
|
| 320 |
-
2. Document, and
|
| 321 |
-
3. Table QA.
|
| 322 |
-
4. Zero Shot Classification.
|
| 323 |
-
5. Translation.
|
| 324 |
-
6. Conversational/Chat.
|
| 325 |
-
7. Text2Text Generation.
|
| 326 |
-
8. ASR/TTS.
|
| 327 |
-
|
| 328 |
-
# Mermaid model
|
| 329 |
-
|
| 330 |
-
```mermaid
|
| 331 |
-
graph LR;
|
| 332 |
-
A[Reader model]-->B[SQuAD];
|
| 333 |
-
C[Transformers from Huggingface]-->D[Real Business Problems];
|
| 334 |
-
E[Best practices for QA systems]-->F[Optimize Question/Answer Heads for SQuAD];
|
| 335 |
-
G[QA search]-->H[Textual KB];
|
| 336 |
-
H-->I[Return text sections as answers];
|
| 337 |
-
J[Organize text collection]-->K[Find similar documents to given input];
|
| 338 |
-
K-->I;
|
| 339 |
-
L[Perform semantic and comprehensive word matching]-->I;
|
| 340 |
-
M[Match incoming questions to FAQ KB dataset]-->I;
|
| 341 |
-
N[Visual QA]-->O[Document QA];
|
| 342 |
-
N-->P[Table QA];
|
| 343 |
-
Q[Zero Shot Classification]-->I;
|
| 344 |
-
R[Translation]-->I;
|
| 345 |
-
S[Conversational/Chat]-->I;
|
| 346 |
-
T[Text2Text Generation]-->I;
|
| 347 |
-
U[ASR/TTS]-->I;
|
| 348 |
-
|
| 349 |
-
```
|
| 350 |
-
|
| 351 |
-
# Top 50 Assessments in Physical and Mental Health
|
| 352 |
-
|
| 353 |
-
Below are the top 50 mental and physical health assessments.
|
| 354 |
-
1. **Patient Health Questionnaire (PHQ-9)** 🧠 - Major depressive disorder (ICD-10: F32)
|
| 355 |
-
2. **Generalized Anxiety Disorder 7-item Scale (GAD-7)** 😰 - Generalized anxiety disorder (ICD-10: F41.1)
|
| 356 |
-
3. **Hamilton Rating Scale for Depression (HRSD)** 🧠 - Major depressive disorder (ICD-10: F32)
|
| 357 |
-
4. **World Health Organization Disability Assessment Schedule 2.0 (WHODAS 2.0)** 🧠💪 - Physical and mental disability (ICD-10: Z73.1)
|
| 358 |
-
5. **Short Form-36 Health Survey (SF-36)** 💪🧠 - Health-related quality of life (CPT: 99499)
|
| 359 |
-
6. **Health Assessment Questionnaire (HAQ)** 💪 - Functional status assessment (CPT: 97750)
|
| 360 |
-
7. **EuroQol-5D (EQ-5D)** 💪🧠 - Health-related quality of life (LOINC: 83792-6)
|
| 361 |
-
8. **Geriatric Depression Scale (GDS)** 🧑🦳🧠 - Depression in older adults (ICD-10: F32.1)
|
| 362 |
-
9. **Mini-Mental State Examination (MMSE)** 🧑🦳💭 - Cognitive impairment (ICD-10: F06.7)
|
| 363 |
-
10. **Pain Catastrophizing Scale (PCS)** 💔 - Chronic pain (LOINC: 86351-6)
|
| 364 |
-
11. **Oswestry Disability Index (ODI)** 💪💔 - Back pain (CPT: 97750)
|
| 365 |
-
12. **Fibromyalgia Impact Questionnaire (FIQ)** 💔😩 - Fibromyalgia (SNOMED: 316962002)
|
| 366 |
-
13. **Beck Depression Inventory (BDI)** 🧠 - Depression (ICD-10: F32)
|
| 367 |
-
14. **Posttraumatic Stress Disorder Checklist (PCL)** 😰😞 - Posttraumatic stress disorder (ICD-10: F43.1)
|
| 368 |
-
15. **Alcohol Use Disorders Identification Test (AUDIT)** 🍻 - Alcohol use disorder (ICD-10: F10)
|
| 369 |
-
16. **Drug Abuse Screening Test (DAST)** 💊 - Substance use disorder (ICD-10: F19)
|
| 370 |
-
17. **Eating Attitudes Test (EAT)** 🍴 - Eating disorders (ICD-10: F50)
|
| 371 |
-
18. **Adolescent Eating Disorder Examination (ADE)** 🍴👩🦰 - Eating disorders in adolescents (ICD-10: F50)
|
| 372 |
-
19. **Child Behavior Checklist (CBCL)** 👧🧒 - Child behavior problems (ICD-10: F90)
|
| 373 |
-
20. **Autism Spectrum Quotient (AQ)** 🧑🦱 - Autism spectrum disorder (ICD-10: F84.0)
|
| 374 |
-
21. **Columbia-Suicide Severity Rating Scale (C-SSRS)** 🩸 - Suicide risk (ICD-10: Z65.8)
|
| 375 |
-
22. **Perceived Stress Scale (PSS)** 😩 - Stress (LOINC: 75217-3)
|
| 376 |
-
23. **Satisfaction with Life Scale (SWLS)** 😊 - Life satisfaction (LOINC: 69406-9)
|
| 377 |
-
24. **Health Belief Model Scale (HBM)** 💊💉 - Health beliefs (LOINC: 88018)
|
| 378 |
-
25. **Multidimensional Health Locus of Control Scale (MHLC)** 💊💉 - Health locus of control (LOINC: 87561-7)
|
| 379 |
-
26. **Life Orientation Test-Revised (LOT-R)** 😃 - Optimism (LOINC: 75315-5)
|
| 380 |
-
27. **State-Trait Anxiety Inventory (STAI)** 😰 - Anxiety (LOINC: 71092-3)
|
| 381 |
-
28. **Multidimensional Scale of Perceived Social Support (MSPSS)** 👥 - Social support (LOINC: 86649-4)
|
| 382 |
-
29. **Job Content Questionnaire (JCQ)** 💼 - Job stress (LOINC: 76554-9)
|
| 383 |
-
30. **Burnout Measure (BO)** 🔥 - Burnout (LOINC: 89049-8)
|
| 384 |
-
31. **Family Assessment Device (FAD)** 👨👩👧 - Family functioning (LOINC: 84113-2)
|
| 385 |
-
32. **Perceived Control Scale (PCS)** 💪 - Perceived control (LOINC: 86447-0)
|
| 386 |
-
33. **General Self-Efficacy Scale (GSES)** 💪 - Self-efficacy (LOINC: 76563-0)
|
| 387 |
-
34. **Coping Strategies Inventory (CSI)** 😓 - Coping strategies (LOINC: 89057-1)
|
| 388 |
-
35. **Acceptance and Action Questionnaire (AAQ-II)** 🧘 - Acceptance and commitment therapy (LOINC: 88027-2)
|
| 389 |
-
36. **Attention Deficit Hyperactivity Disorder Self-Report Scale (ASRS)** 👧🧒 - ADHD (ICD-10: F90)
|
| 390 |
-
37. **Impact of Event Scale-Revised (IES-R)** 😔😞 - Trauma (LOINC: 86237-7)
|
| 391 |
-
38. **Insomnia Severity Index (ISI)** 💤 - Insomnia (LOINC: 82451-5)
|
| 392 |
-
39. **Social Phobia Inventory (SPIN)** 😰 - Social anxiety disorder (ICD-10: F40.1)
|
| 393 |
-
40. **Panic Disorder Severity Scale (PDSS)** 😰 - Panic disorder (ICD-10: F41.0)
|
| 394 |
-
41. **Yale-Brown Obsessive Compulsive Scale (Y-BOCS)** 🤔 - Obsessive-compulsive disorder (ICD-10: F42)
|
| 395 |
-
42. **Social Interaction Anxiety Scale (SIAS)** 😰 - Social anxiety disorder (ICD-10: F40.1)
|
| 396 |
-
43. **Generalized Anxiety Disorder Scale (GADS)** 😰 - Generalized anxiety disorder (ICD-10: F41.1)
|
| 397 |
-
44. **Postpartum Depression Screening Scale (PDSS)** 🤱🧠 - Postpartum depression (ICD-10: F53.0)
|
| 398 |
-
45. **Child and Adolescent Symptom Inventory (CASI)** 👧🧒🧠 - Child and adolescent mental health (ICD-10: F90)
|
| 399 |
-
46. **Strengths and Difficulties Questionnaire (SDQ)** 👧🧒🧠 - Child and adolescent mental health (ICD-10: F90)
|
| 400 |
-
47. **Kessler Psychological Distress Scale (K10)** 🧠 - Psychological distress (LOINC: 76550-6)
|
| 401 |
-
48. **World Health Organization Quality of Life Scale (WHOQOL)** 💪🧠 - Quality of life (LOINC: 88055-2)
|
| 402 |
-
49. **Multidimensional Pain Inventory (MPI)** 💔 - Chronic pain (LOINC: 71808-8)
|
| 403 |
-
50. **Cornell Scale for Depression in Dementia (CSDD)** 👴👵🧠 - Depression in dementia patients (ICD-10: F03.90)
|
| 404 |
-
|
| 405 |
-
|
| 406 |
-
# SMART/FHIR/SDC Survey-Assess-Plan
|
| 407 |
-
|
| 408 |
-
These SMART/FHIR/SDC compatible Surveys demonstrate how to build and conducct surveys with EMR/EHR Compliance Standards
|
| 409 |
-
|
| 410 |
-
1. Smart FHIR Connect and Test BMI Calculator: https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-BMI
|
| 411 |
-
2. Smart FHIR Kits SDC HL7: https://huggingface.co/spaces/awacke1/SMART-FHIR-Kits-SDC-HL7
|
| 412 |
-
3. Smart FHIR Assessment Exercise: https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Exercise
|
| 413 |
-
4. Smart FHIR Assessment Blood Pressure: https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Blood-Pressure
|
| 414 |
-
5. Smart FHIR - Observations-Assessments-Rules-Referrals-Providers-Programs-Fulfillment-Alerrts-Notes-SDOH: https://huggingface.co/spaces/awacke1/SMART-FHIR-Assessment-Observation-SDKs
|
| 415 |
-
|
| 416 |
-
|
| 417 |
-
# Graphs Survey-Assess-Plan-Goals
|
| 418 |
-
|
| 419 |
-
These top 5 graph examples introduce visual ideas to use to survey, assess, plan and reach goals.
|
| 420 |
-
|
| 421 |
-
1. Graph OMS and LOCUS Standards and Quality Metrics: https://huggingface.co/spaces/awacke1/NLPGraphOMSandLOCUS
|
| 422 |
-
2. Graph Pain and High Medium Low Confidence: https://huggingface.co/spaces/awacke1/VISNLP-Graph
|
| 423 |
-
3. Graph Action Mechanics: https://huggingface.co/spaces/awacke1/CardGameActivity-GraphViz
|
| 424 |
-
4. Graph - OMS, MH, Charts, Maps, DOT lang for Pyvis VisJS: https://huggingface.co/spaces/awacke1/CPVisGraph
|
| 425 |
-
5. Graph - Plan and Assess: https://huggingface.co/spaces/awacke1/Git-GPG-Git-Actions-01-GraphViz
|
| 426 |
-
|
| 427 |
-
# ICD10, CPT, LOINC, SNOMED, HCPCS, OMS Codes for Top Health Conditions and Treatment Preferences Assessment
|
| 428 |
-
|
| 429 |
-
Assess Topic| Assess Metric | Code Emoji | Code Topic | Code Type | Code
|
| 430 |
-
------------|---------------|------------|------------|------------|-----------
|
| 431 |
-
Childhood Immunization| % of children immunized by age two |🧒💉 | Clinical Code| ICD10 | Z28.2
|
| 432 |
-
Breast Cancer Screening| % of women with mammogram in past 2 yrs |🩺🎀 | Clinical Code| CPT| 77067
|
| 433 |
-
Colorectal Cancer Screening| % of adults screened for colorectal cancer| 🩺💩 | Clinical Code| CPT| 82274
|
| 434 |
-
Comprehensive Diabetes Care| % of diabetic patients who had all recommended tests| 🩺🩹 | Clinical Code| LOINC| 4548-4
|
| 435 |
-
Controlling High Blood Pressure| % of patients with controlled blood pressure| 🩺💊 | Clinical Code| ICD10|I10
|
| 436 |
-
Medication Management for Asthma| % of asthma patients with proper meds| 💊🌬️ | Clinical Code| SNOMED|195967001
|
| 437 |
-
Follow-up After Mental Illness Hospitalization| % of patients with follow-up care| 🩺🏥 | Clinical Code| HCPCS|G0181
|
| 438 |
-
Prenatal & Postpartum Care| % of pregnant women with proper care |🤰🩺 | Clinical Code| ICD10|Z34
|
| 439 |
-
Comprehensive Eye Exam| % of diabetic patients with eye exam |🩺👀 | Clinical Code| CPT| 92014
|
| 440 |
-
Childhood Weight Assessment| % of children with BMI assessment |🧒📏 | Clinical Code| ICD10| Z00.121
|
| 441 |
-
Chlamydia Screening in Women| % of sexually active women screened| 🩺👩 | Clinical Code| CPT|87491
|
| 442 |
-
Avoidance of Antibiotic Treatment for Acute Bronchitis| % of patients without antibiotics |🩺💊 | Clinical Code| ICD10|J20.9
|
| 443 |
-
Osteoporosis Management in Women|% of women with bone density test |🩺💪 | Clinical Code| CPT|77080
|
| 444 |
-
Use of High-Risk Medications in the Elderly| % of elderly with safe meds |💊👴👵 | Clinical Code| HCPCS |G9612
|
| 445 |
-
Diabetes Screening for Schizophrenia or Bipolar Disorder| % of patients with mental illness screened |🧠🩺 | Clinical Code| SNOMED| 169609005
|
| 446 |
-
All-Cause Readmissions| % of patients readmitted within 30 days |🩺🏥 | Clinical Code| ICD10| Z51.5
|
| 447 |
-
Antidepressant Medication Management| % of depressed patients with proper meds & follow-up |🩺🧠 | Clinical Code| CPT|96127
|
| 448 |
-
Follow-up Care for Children Prescribed ADHD Medication|% of children with follow-up care |🩺🧒 | Clinical Code| ICD10|F90
|
| 449 |
-
Imaging Studies for Low Back Pain| % of patients without imaging studies|🩺📊 | Clinical Code| ICD10|M54.5
|
| 450 |
-
Spirometry Testing for COPD|% of COPD patients with spirometry testing |🩺🫁 | Clinical Code|CPT|94010
|
| 451 |
-
|
| 452 |
-
|
| 453 |
-
""")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AIConsultant/MusicGen/README.md
DELETED
|
@@ -1,13 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: AudioCraft Plus v2.0.0a (MusicGen + AudioGen)
|
| 3 |
-
emoji: 🎶
|
| 4 |
-
colorFrom: yellow
|
| 5 |
-
colorTo: green
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.39.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: true
|
| 10 |
-
license: mit
|
| 11 |
-
---
|
| 12 |
-
|
| 13 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AIGC-Audio/Make_An_Audio/ldm/modules/encoders/open_clap/htsat.py
DELETED
|
@@ -1,1022 +0,0 @@
|
|
| 1 |
-
# Ke Chen
|
| 2 | |
| 3 |
-
# HTS-AT: A HIERARCHICAL TOKEN-SEMANTIC AUDIO TRANSFORMER FOR SOUND CLASSIFICATION AND DETECTION
|
| 4 |
-
# Some layers designed on the model
|
| 5 |
-
# below codes are based and referred from https://github.com/microsoft/Swin-Transformer
|
| 6 |
-
# Swin Transformer for Computer Vision: https://arxiv.org/pdf/2103.14030.pdf
|
| 7 |
-
|
| 8 |
-
import torch
|
| 9 |
-
import torch.nn as nn
|
| 10 |
-
import torch.nn.functional as F
|
| 11 |
-
from itertools import repeat
|
| 12 |
-
import collections.abc
|
| 13 |
-
import math
|
| 14 |
-
import warnings
|
| 15 |
-
|
| 16 |
-
from torch.nn.init import _calculate_fan_in_and_fan_out
|
| 17 |
-
import torch.utils.checkpoint as checkpoint
|
| 18 |
-
|
| 19 |
-
import random
|
| 20 |
-
|
| 21 |
-
from torchlibrosa.stft import Spectrogram, LogmelFilterBank
|
| 22 |
-
from torchlibrosa.augmentation import SpecAugmentation
|
| 23 |
-
|
| 24 |
-
from itertools import repeat
|
| 25 |
-
from .utils import do_mixup, interpolate
|
| 26 |
-
|
| 27 |
-
from .feature_fusion import iAFF, AFF, DAF
|
| 28 |
-
|
| 29 |
-
# from PyTorch internals
|
| 30 |
-
def _ntuple(n):
|
| 31 |
-
def parse(x):
|
| 32 |
-
if isinstance(x, collections.abc.Iterable):
|
| 33 |
-
return x
|
| 34 |
-
return tuple(repeat(x, n))
|
| 35 |
-
return parse
|
| 36 |
-
|
| 37 |
-
to_1tuple = _ntuple(1)
|
| 38 |
-
to_2tuple = _ntuple(2)
|
| 39 |
-
to_3tuple = _ntuple(3)
|
| 40 |
-
to_4tuple = _ntuple(4)
|
| 41 |
-
to_ntuple = _ntuple
|
| 42 |
-
|
| 43 |
-
def drop_path(x, drop_prob: float = 0., training: bool = False):
|
| 44 |
-
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
|
| 45 |
-
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
|
| 46 |
-
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
|
| 47 |
-
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
|
| 48 |
-
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
|
| 49 |
-
'survival rate' as the argument.
|
| 50 |
-
"""
|
| 51 |
-
if drop_prob == 0. or not training:
|
| 52 |
-
return x
|
| 53 |
-
keep_prob = 1 - drop_prob
|
| 54 |
-
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
|
| 55 |
-
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
|
| 56 |
-
random_tensor.floor_() # binarize
|
| 57 |
-
output = x.div(keep_prob) * random_tensor
|
| 58 |
-
return output
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
class DropPath(nn.Module):
|
| 62 |
-
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
|
| 63 |
-
"""
|
| 64 |
-
def __init__(self, drop_prob=None):
|
| 65 |
-
super(DropPath, self).__init__()
|
| 66 |
-
self.drop_prob = drop_prob
|
| 67 |
-
|
| 68 |
-
def forward(self, x):
|
| 69 |
-
return drop_path(x, self.drop_prob, self.training)
|
| 70 |
-
|
| 71 |
-
class PatchEmbed(nn.Module):
|
| 72 |
-
""" 2D Image to Patch Embedding
|
| 73 |
-
"""
|
| 74 |
-
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True, patch_stride = 16,
|
| 75 |
-
enable_fusion=False, fusion_type='None'):
|
| 76 |
-
super().__init__()
|
| 77 |
-
img_size = to_2tuple(img_size)
|
| 78 |
-
patch_size = to_2tuple(patch_size)
|
| 79 |
-
patch_stride = to_2tuple(patch_stride)
|
| 80 |
-
self.img_size = img_size
|
| 81 |
-
self.patch_size = patch_size
|
| 82 |
-
self.patch_stride = patch_stride
|
| 83 |
-
self.grid_size = (img_size[0] // patch_stride[0], img_size[1] // patch_stride[1])
|
| 84 |
-
self.num_patches = self.grid_size[0] * self.grid_size[1]
|
| 85 |
-
self.flatten = flatten
|
| 86 |
-
self.in_chans = in_chans
|
| 87 |
-
self.embed_dim = embed_dim
|
| 88 |
-
|
| 89 |
-
self.enable_fusion = enable_fusion
|
| 90 |
-
self.fusion_type = fusion_type
|
| 91 |
-
|
| 92 |
-
padding = ((patch_size[0] - patch_stride[0]) // 2, (patch_size[1] - patch_stride[1]) // 2)
|
| 93 |
-
|
| 94 |
-
if (self.enable_fusion) and (self.fusion_type == 'channel_map'):
|
| 95 |
-
self.proj = nn.Conv2d(in_chans*4, embed_dim, kernel_size=patch_size, stride=patch_stride, padding=padding)
|
| 96 |
-
else:
|
| 97 |
-
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, padding=padding)
|
| 98 |
-
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
|
| 99 |
-
|
| 100 |
-
if (self.enable_fusion) and (self.fusion_type in ['daf_2d','aff_2d','iaff_2d']):
|
| 101 |
-
self.mel_conv2d = nn.Conv2d(in_chans, embed_dim, kernel_size=(patch_size[0], patch_size[1]*3), stride=(patch_stride[0], patch_stride[1] * 3), padding=padding)
|
| 102 |
-
if self.fusion_type == 'daf_2d':
|
| 103 |
-
self.fusion_model = DAF()
|
| 104 |
-
elif self.fusion_type == 'aff_2d':
|
| 105 |
-
self.fusion_model = AFF(channels=embed_dim, type='2D')
|
| 106 |
-
elif self.fusion_type == 'iaff_2d':
|
| 107 |
-
self.fusion_model = iAFF(channels=embed_dim, type='2D')
|
| 108 |
-
def forward(self, x, longer_idx = None):
|
| 109 |
-
if (self.enable_fusion) and (self.fusion_type in ['daf_2d','aff_2d','iaff_2d']):
|
| 110 |
-
global_x = x[:,0:1,:,:]
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
# global processing
|
| 114 |
-
B, C, H, W = global_x.shape
|
| 115 |
-
assert H == self.img_size[0] and W == self.img_size[1], \
|
| 116 |
-
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
|
| 117 |
-
global_x = self.proj(global_x)
|
| 118 |
-
TW = global_x.size(-1)
|
| 119 |
-
if len(longer_idx) > 0:
|
| 120 |
-
# local processing
|
| 121 |
-
local_x = x[longer_idx,1:,:,:].contiguous()
|
| 122 |
-
B, C, H, W = local_x.shape
|
| 123 |
-
local_x = local_x.view(B*C,1,H,W)
|
| 124 |
-
local_x = self.mel_conv2d(local_x)
|
| 125 |
-
local_x = local_x.view(B,C,local_x.size(1),local_x.size(2),local_x.size(3))
|
| 126 |
-
local_x = local_x.permute((0,2,3,1,4)).contiguous().flatten(3)
|
| 127 |
-
TB,TC,TH,_ = local_x.size()
|
| 128 |
-
if local_x.size(-1) < TW:
|
| 129 |
-
local_x = torch.cat([local_x, torch.zeros((TB,TC,TH,TW-local_x.size(-1)), device=global_x.device)], dim=-1)
|
| 130 |
-
else:
|
| 131 |
-
local_x = local_x[:,:,:,:TW]
|
| 132 |
-
|
| 133 |
-
global_x[longer_idx] = self.fusion_model(global_x[longer_idx],local_x)
|
| 134 |
-
x = global_x
|
| 135 |
-
else:
|
| 136 |
-
B, C, H, W = x.shape
|
| 137 |
-
assert H == self.img_size[0] and W == self.img_size[1], \
|
| 138 |
-
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
|
| 139 |
-
x = self.proj(x)
|
| 140 |
-
|
| 141 |
-
if self.flatten:
|
| 142 |
-
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
|
| 143 |
-
x = self.norm(x)
|
| 144 |
-
return x
|
| 145 |
-
|
| 146 |
-
class Mlp(nn.Module):
|
| 147 |
-
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
|
| 148 |
-
"""
|
| 149 |
-
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
|
| 150 |
-
super().__init__()
|
| 151 |
-
out_features = out_features or in_features
|
| 152 |
-
hidden_features = hidden_features or in_features
|
| 153 |
-
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 154 |
-
self.act = act_layer()
|
| 155 |
-
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 156 |
-
self.drop = nn.Dropout(drop)
|
| 157 |
-
|
| 158 |
-
def forward(self, x):
|
| 159 |
-
x = self.fc1(x)
|
| 160 |
-
x = self.act(x)
|
| 161 |
-
x = self.drop(x)
|
| 162 |
-
x = self.fc2(x)
|
| 163 |
-
x = self.drop(x)
|
| 164 |
-
return x
|
| 165 |
-
|
| 166 |
-
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
|
| 167 |
-
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 168 |
-
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 169 |
-
def norm_cdf(x):
|
| 170 |
-
# Computes standard normal cumulative distribution function
|
| 171 |
-
return (1. + math.erf(x / math.sqrt(2.))) / 2.
|
| 172 |
-
|
| 173 |
-
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 174 |
-
warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 175 |
-
"The distribution of values may be incorrect.",
|
| 176 |
-
stacklevel=2)
|
| 177 |
-
|
| 178 |
-
with torch.no_grad():
|
| 179 |
-
# Values are generated by using a truncated uniform distribution and
|
| 180 |
-
# then using the inverse CDF for the normal distribution.
|
| 181 |
-
# Get upper and lower cdf values
|
| 182 |
-
l = norm_cdf((a - mean) / std)
|
| 183 |
-
u = norm_cdf((b - mean) / std)
|
| 184 |
-
|
| 185 |
-
# Uniformly fill tensor with values from [l, u], then translate to
|
| 186 |
-
# [2l-1, 2u-1].
|
| 187 |
-
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 188 |
-
|
| 189 |
-
# Use inverse cdf transform for normal distribution to get truncated
|
| 190 |
-
# standard normal
|
| 191 |
-
tensor.erfinv_()
|
| 192 |
-
|
| 193 |
-
# Transform to proper mean, std
|
| 194 |
-
tensor.mul_(std * math.sqrt(2.))
|
| 195 |
-
tensor.add_(mean)
|
| 196 |
-
|
| 197 |
-
# Clamp to ensure it's in the proper range
|
| 198 |
-
tensor.clamp_(min=a, max=b)
|
| 199 |
-
return tensor
|
| 200 |
-
|
| 201 |
-
|
| 202 |
-
def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
|
| 203 |
-
# type: (Tensor, float, float, float, float) -> Tensor
|
| 204 |
-
r"""Fills the input Tensor with values drawn from a truncated
|
| 205 |
-
normal distribution. The values are effectively drawn from the
|
| 206 |
-
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 207 |
-
with values outside :math:`[a, b]` redrawn until they are within
|
| 208 |
-
the bounds. The method used for generating the random values works
|
| 209 |
-
best when :math:`a \leq \text{mean} \leq b`.
|
| 210 |
-
Args:
|
| 211 |
-
tensor: an n-dimensional `torch.Tensor`
|
| 212 |
-
mean: the mean of the normal distribution
|
| 213 |
-
std: the standard deviation of the normal distribution
|
| 214 |
-
a: the minimum cutoff value
|
| 215 |
-
b: the maximum cutoff value
|
| 216 |
-
Examples:
|
| 217 |
-
>>> w = torch.empty(3, 5)
|
| 218 |
-
>>> nn.init.trunc_normal_(w)
|
| 219 |
-
"""
|
| 220 |
-
return _no_grad_trunc_normal_(tensor, mean, std, a, b)
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
def variance_scaling_(tensor, scale=1.0, mode='fan_in', distribution='normal'):
|
| 224 |
-
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
|
| 225 |
-
if mode == 'fan_in':
|
| 226 |
-
denom = fan_in
|
| 227 |
-
elif mode == 'fan_out':
|
| 228 |
-
denom = fan_out
|
| 229 |
-
elif mode == 'fan_avg':
|
| 230 |
-
denom = (fan_in + fan_out) / 2
|
| 231 |
-
|
| 232 |
-
variance = scale / denom
|
| 233 |
-
|
| 234 |
-
if distribution == "truncated_normal":
|
| 235 |
-
# constant is stddev of standard normal truncated to (-2, 2)
|
| 236 |
-
trunc_normal_(tensor, std=math.sqrt(variance) / .87962566103423978)
|
| 237 |
-
elif distribution == "normal":
|
| 238 |
-
tensor.normal_(std=math.sqrt(variance))
|
| 239 |
-
elif distribution == "uniform":
|
| 240 |
-
bound = math.sqrt(3 * variance)
|
| 241 |
-
tensor.uniform_(-bound, bound)
|
| 242 |
-
else:
|
| 243 |
-
raise ValueError(f"invalid distribution {distribution}")
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
def lecun_normal_(tensor):
|
| 247 |
-
variance_scaling_(tensor, mode='fan_in', distribution='truncated_normal')
|
| 248 |
-
|
| 249 |
-
def window_partition(x, window_size):
|
| 250 |
-
"""
|
| 251 |
-
Args:
|
| 252 |
-
x: (B, H, W, C)
|
| 253 |
-
window_size (int): window size
|
| 254 |
-
Returns:
|
| 255 |
-
windows: (num_windows*B, window_size, window_size, C)
|
| 256 |
-
"""
|
| 257 |
-
B, H, W, C = x.shape
|
| 258 |
-
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
|
| 259 |
-
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
|
| 260 |
-
return windows
|
| 261 |
-
|
| 262 |
-
|
| 263 |
-
def window_reverse(windows, window_size, H, W):
|
| 264 |
-
"""
|
| 265 |
-
Args:
|
| 266 |
-
windows: (num_windows*B, window_size, window_size, C)
|
| 267 |
-
window_size (int): Window size
|
| 268 |
-
H (int): Height of image
|
| 269 |
-
W (int): Width of image
|
| 270 |
-
Returns:
|
| 271 |
-
x: (B, H, W, C)
|
| 272 |
-
"""
|
| 273 |
-
B = int(windows.shape[0] / (H * W / window_size / window_size))
|
| 274 |
-
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
|
| 275 |
-
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
|
| 276 |
-
return x
|
| 277 |
-
|
| 278 |
-
|
| 279 |
-
class WindowAttention(nn.Module):
|
| 280 |
-
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
|
| 281 |
-
It supports both of shifted and non-shifted window.
|
| 282 |
-
Args:
|
| 283 |
-
dim (int): Number of input channels.
|
| 284 |
-
window_size (tuple[int]): The height and width of the window.
|
| 285 |
-
num_heads (int): Number of attention heads.
|
| 286 |
-
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 287 |
-
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
|
| 288 |
-
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
|
| 289 |
-
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
|
| 290 |
-
"""
|
| 291 |
-
|
| 292 |
-
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
|
| 293 |
-
|
| 294 |
-
super().__init__()
|
| 295 |
-
self.dim = dim
|
| 296 |
-
self.window_size = window_size # Wh, Ww
|
| 297 |
-
self.num_heads = num_heads
|
| 298 |
-
head_dim = dim // num_heads
|
| 299 |
-
self.scale = qk_scale or head_dim ** -0.5
|
| 300 |
-
|
| 301 |
-
# define a parameter table of relative position bias
|
| 302 |
-
self.relative_position_bias_table = nn.Parameter(
|
| 303 |
-
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
|
| 304 |
-
|
| 305 |
-
# get pair-wise relative position index for each token inside the window
|
| 306 |
-
coords_h = torch.arange(self.window_size[0])
|
| 307 |
-
coords_w = torch.arange(self.window_size[1])
|
| 308 |
-
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
|
| 309 |
-
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
|
| 310 |
-
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
|
| 311 |
-
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
|
| 312 |
-
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
|
| 313 |
-
relative_coords[:, :, 1] += self.window_size[1] - 1
|
| 314 |
-
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
|
| 315 |
-
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
|
| 316 |
-
self.register_buffer("relative_position_index", relative_position_index)
|
| 317 |
-
|
| 318 |
-
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 319 |
-
self.attn_drop = nn.Dropout(attn_drop)
|
| 320 |
-
self.proj = nn.Linear(dim, dim)
|
| 321 |
-
self.proj_drop = nn.Dropout(proj_drop)
|
| 322 |
-
|
| 323 |
-
trunc_normal_(self.relative_position_bias_table, std=.02)
|
| 324 |
-
self.softmax = nn.Softmax(dim=-1)
|
| 325 |
-
|
| 326 |
-
def forward(self, x, mask=None):
|
| 327 |
-
"""
|
| 328 |
-
Args:
|
| 329 |
-
x: input features with shape of (num_windows*B, N, C)
|
| 330 |
-
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
|
| 331 |
-
"""
|
| 332 |
-
B_, N, C = x.shape
|
| 333 |
-
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 334 |
-
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
|
| 335 |
-
|
| 336 |
-
q = q * self.scale
|
| 337 |
-
attn = (q @ k.transpose(-2, -1))
|
| 338 |
-
|
| 339 |
-
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
|
| 340 |
-
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
|
| 341 |
-
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
|
| 342 |
-
attn = attn + relative_position_bias.unsqueeze(0)
|
| 343 |
-
|
| 344 |
-
if mask is not None:
|
| 345 |
-
nW = mask.shape[0]
|
| 346 |
-
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
|
| 347 |
-
attn = attn.view(-1, self.num_heads, N, N)
|
| 348 |
-
attn = self.softmax(attn)
|
| 349 |
-
else:
|
| 350 |
-
attn = self.softmax(attn)
|
| 351 |
-
|
| 352 |
-
attn = self.attn_drop(attn)
|
| 353 |
-
|
| 354 |
-
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
|
| 355 |
-
x = self.proj(x)
|
| 356 |
-
x = self.proj_drop(x)
|
| 357 |
-
return x, attn
|
| 358 |
-
|
| 359 |
-
def extra_repr(self):
|
| 360 |
-
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
|
| 361 |
-
|
| 362 |
-
|
| 363 |
-
# We use the model based on Swintransformer Block, therefore we can use the swin-transformer pretrained model
|
| 364 |
-
class SwinTransformerBlock(nn.Module):
|
| 365 |
-
r""" Swin Transformer Block.
|
| 366 |
-
Args:
|
| 367 |
-
dim (int): Number of input channels.
|
| 368 |
-
input_resolution (tuple[int]): Input resulotion.
|
| 369 |
-
num_heads (int): Number of attention heads.
|
| 370 |
-
window_size (int): Window size.
|
| 371 |
-
shift_size (int): Shift size for SW-MSA.
|
| 372 |
-
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 373 |
-
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 374 |
-
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
|
| 375 |
-
drop (float, optional): Dropout rate. Default: 0.0
|
| 376 |
-
attn_drop (float, optional): Attention dropout rate. Default: 0.0
|
| 377 |
-
drop_path (float, optional): Stochastic depth rate. Default: 0.0
|
| 378 |
-
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
|
| 379 |
-
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 380 |
-
"""
|
| 381 |
-
|
| 382 |
-
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
|
| 383 |
-
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
|
| 384 |
-
act_layer=nn.GELU, norm_layer=nn.LayerNorm, norm_before_mlp='ln'):
|
| 385 |
-
super().__init__()
|
| 386 |
-
self.dim = dim
|
| 387 |
-
self.input_resolution = input_resolution
|
| 388 |
-
self.num_heads = num_heads
|
| 389 |
-
self.window_size = window_size
|
| 390 |
-
self.shift_size = shift_size
|
| 391 |
-
self.mlp_ratio = mlp_ratio
|
| 392 |
-
self.norm_before_mlp = norm_before_mlp
|
| 393 |
-
if min(self.input_resolution) <= self.window_size:
|
| 394 |
-
# if window size is larger than input resolution, we don't partition windows
|
| 395 |
-
self.shift_size = 0
|
| 396 |
-
self.window_size = min(self.input_resolution)
|
| 397 |
-
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
|
| 398 |
-
|
| 399 |
-
self.norm1 = norm_layer(dim)
|
| 400 |
-
self.attn = WindowAttention(
|
| 401 |
-
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
|
| 402 |
-
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
|
| 403 |
-
|
| 404 |
-
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
| 405 |
-
if self.norm_before_mlp == 'ln':
|
| 406 |
-
self.norm2 = nn.LayerNorm(dim)
|
| 407 |
-
elif self.norm_before_mlp == 'bn':
|
| 408 |
-
self.norm2 = lambda x: nn.BatchNorm1d(dim)(x.transpose(1, 2)).transpose(1, 2)
|
| 409 |
-
else:
|
| 410 |
-
raise NotImplementedError
|
| 411 |
-
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 412 |
-
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
|
| 413 |
-
|
| 414 |
-
if self.shift_size > 0:
|
| 415 |
-
# calculate attention mask for SW-MSA
|
| 416 |
-
H, W = self.input_resolution
|
| 417 |
-
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
|
| 418 |
-
h_slices = (slice(0, -self.window_size),
|
| 419 |
-
slice(-self.window_size, -self.shift_size),
|
| 420 |
-
slice(-self.shift_size, None))
|
| 421 |
-
w_slices = (slice(0, -self.window_size),
|
| 422 |
-
slice(-self.window_size, -self.shift_size),
|
| 423 |
-
slice(-self.shift_size, None))
|
| 424 |
-
cnt = 0
|
| 425 |
-
for h in h_slices:
|
| 426 |
-
for w in w_slices:
|
| 427 |
-
img_mask[:, h, w, :] = cnt
|
| 428 |
-
cnt += 1
|
| 429 |
-
|
| 430 |
-
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
|
| 431 |
-
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
|
| 432 |
-
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
|
| 433 |
-
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
|
| 434 |
-
else:
|
| 435 |
-
attn_mask = None
|
| 436 |
-
|
| 437 |
-
self.register_buffer("attn_mask", attn_mask)
|
| 438 |
-
|
| 439 |
-
def forward(self, x):
|
| 440 |
-
# pdb.set_trace()
|
| 441 |
-
H, W = self.input_resolution
|
| 442 |
-
# print("H: ", H)
|
| 443 |
-
# print("W: ", W)
|
| 444 |
-
# pdb.set_trace()
|
| 445 |
-
B, L, C = x.shape
|
| 446 |
-
# assert L == H * W, "input feature has wrong size"
|
| 447 |
-
|
| 448 |
-
shortcut = x
|
| 449 |
-
x = self.norm1(x)
|
| 450 |
-
x = x.view(B, H, W, C)
|
| 451 |
-
|
| 452 |
-
# cyclic shift
|
| 453 |
-
if self.shift_size > 0:
|
| 454 |
-
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
|
| 455 |
-
else:
|
| 456 |
-
shifted_x = x
|
| 457 |
-
|
| 458 |
-
# partition windows
|
| 459 |
-
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
|
| 460 |
-
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
|
| 461 |
-
|
| 462 |
-
# W-MSA/SW-MSA
|
| 463 |
-
attn_windows, attn = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
|
| 464 |
-
|
| 465 |
-
# merge windows
|
| 466 |
-
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
|
| 467 |
-
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
|
| 468 |
-
|
| 469 |
-
# reverse cyclic shift
|
| 470 |
-
if self.shift_size > 0:
|
| 471 |
-
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
|
| 472 |
-
else:
|
| 473 |
-
x = shifted_x
|
| 474 |
-
x = x.view(B, H * W, C)
|
| 475 |
-
|
| 476 |
-
# FFN
|
| 477 |
-
x = shortcut + self.drop_path(x)
|
| 478 |
-
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 479 |
-
|
| 480 |
-
return x, attn
|
| 481 |
-
|
| 482 |
-
def extra_repr(self):
|
| 483 |
-
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
|
| 484 |
-
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
|
| 485 |
-
|
| 486 |
-
|
| 487 |
-
|
| 488 |
-
class PatchMerging(nn.Module):
|
| 489 |
-
r""" Patch Merging Layer.
|
| 490 |
-
Args:
|
| 491 |
-
input_resolution (tuple[int]): Resolution of input feature.
|
| 492 |
-
dim (int): Number of input channels.
|
| 493 |
-
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 494 |
-
"""
|
| 495 |
-
|
| 496 |
-
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
|
| 497 |
-
super().__init__()
|
| 498 |
-
self.input_resolution = input_resolution
|
| 499 |
-
self.dim = dim
|
| 500 |
-
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
|
| 501 |
-
self.norm = norm_layer(4 * dim)
|
| 502 |
-
|
| 503 |
-
def forward(self, x):
|
| 504 |
-
"""
|
| 505 |
-
x: B, H*W, C
|
| 506 |
-
"""
|
| 507 |
-
H, W = self.input_resolution
|
| 508 |
-
B, L, C = x.shape
|
| 509 |
-
assert L == H * W, "input feature has wrong size"
|
| 510 |
-
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
|
| 511 |
-
|
| 512 |
-
x = x.view(B, H, W, C)
|
| 513 |
-
|
| 514 |
-
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
|
| 515 |
-
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
|
| 516 |
-
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
|
| 517 |
-
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
|
| 518 |
-
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
|
| 519 |
-
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
|
| 520 |
-
|
| 521 |
-
x = self.norm(x)
|
| 522 |
-
x = self.reduction(x)
|
| 523 |
-
|
| 524 |
-
return x
|
| 525 |
-
|
| 526 |
-
def extra_repr(self):
|
| 527 |
-
return f"input_resolution={self.input_resolution}, dim={self.dim}"
|
| 528 |
-
|
| 529 |
-
|
| 530 |
-
class BasicLayer(nn.Module):
|
| 531 |
-
""" A basic Swin Transformer layer for one stage.
|
| 532 |
-
Args:
|
| 533 |
-
dim (int): Number of input channels.
|
| 534 |
-
input_resolution (tuple[int]): Input resolution.
|
| 535 |
-
depth (int): Number of blocks.
|
| 536 |
-
num_heads (int): Number of attention heads.
|
| 537 |
-
window_size (int): Local window size.
|
| 538 |
-
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 539 |
-
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 540 |
-
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
|
| 541 |
-
drop (float, optional): Dropout rate. Default: 0.0
|
| 542 |
-
attn_drop (float, optional): Attention dropout rate. Default: 0.0
|
| 543 |
-
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
|
| 544 |
-
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 545 |
-
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
|
| 546 |
-
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
|
| 547 |
-
"""
|
| 548 |
-
|
| 549 |
-
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
|
| 550 |
-
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
|
| 551 |
-
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
|
| 552 |
-
norm_before_mlp='ln'):
|
| 553 |
-
|
| 554 |
-
super().__init__()
|
| 555 |
-
self.dim = dim
|
| 556 |
-
self.input_resolution = input_resolution
|
| 557 |
-
self.depth = depth
|
| 558 |
-
self.use_checkpoint = use_checkpoint
|
| 559 |
-
|
| 560 |
-
# build blocks
|
| 561 |
-
self.blocks = nn.ModuleList([
|
| 562 |
-
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
|
| 563 |
-
num_heads=num_heads, window_size=window_size,
|
| 564 |
-
shift_size=0 if (i % 2 == 0) else window_size // 2,
|
| 565 |
-
mlp_ratio=mlp_ratio,
|
| 566 |
-
qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 567 |
-
drop=drop, attn_drop=attn_drop,
|
| 568 |
-
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
|
| 569 |
-
norm_layer=norm_layer, norm_before_mlp=norm_before_mlp)
|
| 570 |
-
for i in range(depth)])
|
| 571 |
-
|
| 572 |
-
# patch merging layer
|
| 573 |
-
if downsample is not None:
|
| 574 |
-
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
|
| 575 |
-
else:
|
| 576 |
-
self.downsample = None
|
| 577 |
-
|
| 578 |
-
def forward(self, x):
|
| 579 |
-
attns = []
|
| 580 |
-
for blk in self.blocks:
|
| 581 |
-
if self.use_checkpoint:
|
| 582 |
-
x = checkpoint.checkpoint(blk, x)
|
| 583 |
-
else:
|
| 584 |
-
x, attn = blk(x)
|
| 585 |
-
if not self.training:
|
| 586 |
-
attns.append(attn.unsqueeze(0))
|
| 587 |
-
if self.downsample is not None:
|
| 588 |
-
x = self.downsample(x)
|
| 589 |
-
if not self.training:
|
| 590 |
-
attn = torch.cat(attns, dim = 0)
|
| 591 |
-
attn = torch.mean(attn, dim = 0)
|
| 592 |
-
return x, attn
|
| 593 |
-
|
| 594 |
-
def extra_repr(self):
|
| 595 |
-
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
|
| 596 |
-
|
| 597 |
-
|
| 598 |
-
# The Core of HTSAT
|
| 599 |
-
class HTSAT_Swin_Transformer(nn.Module):
|
| 600 |
-
r"""HTSAT based on the Swin Transformer
|
| 601 |
-
Args:
|
| 602 |
-
spec_size (int | tuple(int)): Input Spectrogram size. Default 256
|
| 603 |
-
patch_size (int | tuple(int)): Patch size. Default: 4
|
| 604 |
-
path_stride (iot | tuple(int)): Patch Stride for Frequency and Time Axis. Default: 4
|
| 605 |
-
in_chans (int): Number of input image channels. Default: 1 (mono)
|
| 606 |
-
num_classes (int): Number of classes for classification head. Default: 527
|
| 607 |
-
embed_dim (int): Patch embedding dimension. Default: 96
|
| 608 |
-
depths (tuple(int)): Depth of each HTSAT-Swin Transformer layer.
|
| 609 |
-
num_heads (tuple(int)): Number of attention heads in different layers.
|
| 610 |
-
window_size (int): Window size. Default: 8
|
| 611 |
-
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
|
| 612 |
-
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
|
| 613 |
-
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
|
| 614 |
-
drop_rate (float): Dropout rate. Default: 0
|
| 615 |
-
attn_drop_rate (float): Attention dropout rate. Default: 0
|
| 616 |
-
drop_path_rate (float): Stochastic depth rate. Default: 0.1
|
| 617 |
-
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
|
| 618 |
-
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
|
| 619 |
-
patch_norm (bool): If True, add normalization after patch embedding. Default: True
|
| 620 |
-
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
|
| 621 |
-
config (module): The configuration Module from config.py
|
| 622 |
-
"""
|
| 623 |
-
|
| 624 |
-
def __init__(self, spec_size=256, patch_size=4, patch_stride=(4,4),
|
| 625 |
-
in_chans=1, num_classes=527,
|
| 626 |
-
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[4, 8, 16, 32],
|
| 627 |
-
window_size=8, mlp_ratio=4., qkv_bias=True, qk_scale=None,
|
| 628 |
-
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
|
| 629 |
-
norm_layer=nn.LayerNorm,
|
| 630 |
-
ape=False, patch_norm=True,
|
| 631 |
-
use_checkpoint=False, norm_before_mlp='ln', config = None,
|
| 632 |
-
enable_fusion = False, fusion_type = 'None', **kwargs):
|
| 633 |
-
super(HTSAT_Swin_Transformer, self).__init__()
|
| 634 |
-
|
| 635 |
-
self.config = config
|
| 636 |
-
self.spec_size = spec_size
|
| 637 |
-
self.patch_stride = patch_stride
|
| 638 |
-
self.patch_size = patch_size
|
| 639 |
-
self.window_size = window_size
|
| 640 |
-
self.embed_dim = embed_dim
|
| 641 |
-
self.depths = depths
|
| 642 |
-
self.ape = ape
|
| 643 |
-
self.in_chans = in_chans
|
| 644 |
-
self.num_classes = num_classes
|
| 645 |
-
self.num_heads = num_heads
|
| 646 |
-
self.num_layers = len(self.depths)
|
| 647 |
-
self.num_features = int(self.embed_dim * 2 ** (self.num_layers - 1))
|
| 648 |
-
|
| 649 |
-
self.drop_rate = drop_rate
|
| 650 |
-
self.attn_drop_rate = attn_drop_rate
|
| 651 |
-
self.drop_path_rate = drop_path_rate
|
| 652 |
-
|
| 653 |
-
self.qkv_bias = qkv_bias
|
| 654 |
-
self.qk_scale = None
|
| 655 |
-
|
| 656 |
-
self.patch_norm = patch_norm
|
| 657 |
-
self.norm_layer = norm_layer if self.patch_norm else None
|
| 658 |
-
self.norm_before_mlp = norm_before_mlp
|
| 659 |
-
self.mlp_ratio = mlp_ratio
|
| 660 |
-
|
| 661 |
-
self.use_checkpoint = use_checkpoint
|
| 662 |
-
|
| 663 |
-
self.enable_fusion = enable_fusion
|
| 664 |
-
self.fusion_type = fusion_type
|
| 665 |
-
|
| 666 |
-
# process mel-spec ; used only once
|
| 667 |
-
self.freq_ratio = self.spec_size // self.config.mel_bins
|
| 668 |
-
window = 'hann'
|
| 669 |
-
center = True
|
| 670 |
-
pad_mode = 'reflect'
|
| 671 |
-
ref = 1.0
|
| 672 |
-
amin = 1e-10
|
| 673 |
-
top_db = None
|
| 674 |
-
self.interpolate_ratio = 32 # Downsampled ratio
|
| 675 |
-
# Spectrogram extractor
|
| 676 |
-
self.spectrogram_extractor = Spectrogram(n_fft=config.window_size, hop_length=config.hop_size,
|
| 677 |
-
win_length=config.window_size, window=window, center=center, pad_mode=pad_mode,
|
| 678 |
-
freeze_parameters=True)
|
| 679 |
-
# Logmel feature extractor
|
| 680 |
-
self.logmel_extractor = LogmelFilterBank(sr=config.sample_rate, n_fft=config.window_size,
|
| 681 |
-
n_mels=config.mel_bins, fmin=config.fmin, fmax=config.fmax, ref=ref, amin=amin, top_db=top_db,
|
| 682 |
-
freeze_parameters=True)
|
| 683 |
-
# Spec augmenter
|
| 684 |
-
self.spec_augmenter = SpecAugmentation(time_drop_width=64, time_stripes_num=2,
|
| 685 |
-
freq_drop_width=8, freq_stripes_num=2) # 2 2
|
| 686 |
-
self.bn0 = nn.BatchNorm2d(self.config.mel_bins)
|
| 687 |
-
|
| 688 |
-
|
| 689 |
-
# split spctrogram into non-overlapping patches
|
| 690 |
-
self.patch_embed = PatchEmbed(
|
| 691 |
-
img_size=self.spec_size, patch_size=self.patch_size, in_chans=self.in_chans,
|
| 692 |
-
embed_dim=self.embed_dim, norm_layer=self.norm_layer, patch_stride = patch_stride,
|
| 693 |
-
enable_fusion=self.enable_fusion, fusion_type=self.fusion_type
|
| 694 |
-
)
|
| 695 |
-
|
| 696 |
-
num_patches = self.patch_embed.num_patches
|
| 697 |
-
patches_resolution = self.patch_embed.grid_size
|
| 698 |
-
self.patches_resolution = patches_resolution
|
| 699 |
-
|
| 700 |
-
# absolute position embedding
|
| 701 |
-
if self.ape:
|
| 702 |
-
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, self.embed_dim))
|
| 703 |
-
trunc_normal_(self.absolute_pos_embed, std=.02)
|
| 704 |
-
|
| 705 |
-
self.pos_drop = nn.Dropout(p=self.drop_rate)
|
| 706 |
-
|
| 707 |
-
# stochastic depth
|
| 708 |
-
dpr = [x.item() for x in torch.linspace(0, self.drop_path_rate, sum(self.depths))] # stochastic depth decay rule
|
| 709 |
-
|
| 710 |
-
# build layers
|
| 711 |
-
self.layers = nn.ModuleList()
|
| 712 |
-
for i_layer in range(self.num_layers):
|
| 713 |
-
layer = BasicLayer(dim=int(self.embed_dim * 2 ** i_layer),
|
| 714 |
-
input_resolution=(patches_resolution[0] // (2 ** i_layer),
|
| 715 |
-
patches_resolution[1] // (2 ** i_layer)),
|
| 716 |
-
depth=self.depths[i_layer],
|
| 717 |
-
num_heads=self.num_heads[i_layer],
|
| 718 |
-
window_size=self.window_size,
|
| 719 |
-
mlp_ratio=self.mlp_ratio,
|
| 720 |
-
qkv_bias=self.qkv_bias, qk_scale=self.qk_scale,
|
| 721 |
-
drop=self.drop_rate, attn_drop=self.attn_drop_rate,
|
| 722 |
-
drop_path=dpr[sum(self.depths[:i_layer]):sum(self.depths[:i_layer + 1])],
|
| 723 |
-
norm_layer=self.norm_layer,
|
| 724 |
-
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
|
| 725 |
-
use_checkpoint=use_checkpoint,
|
| 726 |
-
norm_before_mlp=self.norm_before_mlp)
|
| 727 |
-
self.layers.append(layer)
|
| 728 |
-
|
| 729 |
-
self.norm = self.norm_layer(self.num_features)
|
| 730 |
-
self.avgpool = nn.AdaptiveAvgPool1d(1)
|
| 731 |
-
self.maxpool = nn.AdaptiveMaxPool1d(1)
|
| 732 |
-
|
| 733 |
-
SF = self.spec_size // (2 ** (len(self.depths) - 1)) // self.patch_stride[0] // self.freq_ratio
|
| 734 |
-
self.tscam_conv = nn.Conv2d(
|
| 735 |
-
in_channels = self.num_features,
|
| 736 |
-
out_channels = self.num_classes,
|
| 737 |
-
kernel_size = (SF,3),
|
| 738 |
-
padding = (0,1)
|
| 739 |
-
)
|
| 740 |
-
self.head = nn.Linear(num_classes, num_classes)
|
| 741 |
-
|
| 742 |
-
if (self.enable_fusion) and (self.fusion_type in ['daf_1d','aff_1d','iaff_1d']):
|
| 743 |
-
self.mel_conv1d = nn.Sequential(
|
| 744 |
-
nn.Conv1d(64, 64, kernel_size=5, stride=3, padding=2),
|
| 745 |
-
nn.BatchNorm1d(64)
|
| 746 |
-
)
|
| 747 |
-
if self.fusion_type == 'daf_1d':
|
| 748 |
-
self.fusion_model = DAF()
|
| 749 |
-
elif self.fusion_type == 'aff_1d':
|
| 750 |
-
self.fusion_model = AFF(channels=64, type='1D')
|
| 751 |
-
elif self.fusion_type == 'iaff_1d':
|
| 752 |
-
self.fusion_model = iAFF(channels=64, type='1D')
|
| 753 |
-
|
| 754 |
-
self.apply(self._init_weights)
|
| 755 |
-
|
| 756 |
-
def _init_weights(self, m):
|
| 757 |
-
if isinstance(m, nn.Linear):
|
| 758 |
-
trunc_normal_(m.weight, std=.02)
|
| 759 |
-
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 760 |
-
nn.init.constant_(m.bias, 0)
|
| 761 |
-
elif isinstance(m, nn.LayerNorm):
|
| 762 |
-
nn.init.constant_(m.bias, 0)
|
| 763 |
-
nn.init.constant_(m.weight, 1.0)
|
| 764 |
-
|
| 765 |
-
@torch.jit.ignore
|
| 766 |
-
def no_weight_decay(self):
|
| 767 |
-
return {'absolute_pos_embed'}
|
| 768 |
-
|
| 769 |
-
@torch.jit.ignore
|
| 770 |
-
def no_weight_decay_keywords(self):
|
| 771 |
-
return {'relative_position_bias_table'}
|
| 772 |
-
|
| 773 |
-
|
| 774 |
-
def forward_features(self, x, longer_idx = None):
|
| 775 |
-
# A deprecated optimization for using a hierarchical output from different blocks
|
| 776 |
-
|
| 777 |
-
frames_num = x.shape[2]
|
| 778 |
-
x = self.patch_embed(x, longer_idx = longer_idx)
|
| 779 |
-
if self.ape:
|
| 780 |
-
x = x + self.absolute_pos_embed
|
| 781 |
-
x = self.pos_drop(x)
|
| 782 |
-
for i, layer in enumerate(self.layers):
|
| 783 |
-
x, attn = layer(x)
|
| 784 |
-
# for x
|
| 785 |
-
x = self.norm(x)
|
| 786 |
-
B, N, C = x.shape
|
| 787 |
-
SF = frames_num // (2 ** (len(self.depths) - 1)) // self.patch_stride[0]
|
| 788 |
-
ST = frames_num // (2 ** (len(self.depths) - 1)) // self.patch_stride[1]
|
| 789 |
-
x = x.permute(0,2,1).contiguous().reshape(B, C, SF, ST)
|
| 790 |
-
B, C, F, T = x.shape
|
| 791 |
-
# group 2D CNN
|
| 792 |
-
c_freq_bin = F // self.freq_ratio
|
| 793 |
-
x = x.reshape(B, C, F // c_freq_bin, c_freq_bin, T)
|
| 794 |
-
x = x.permute(0,1,3,2,4).contiguous().reshape(B, C, c_freq_bin, -1)
|
| 795 |
-
# get latent_output
|
| 796 |
-
fine_grained_latent_output = torch.mean(x, dim = 2)
|
| 797 |
-
fine_grained_latent_output = interpolate(fine_grained_latent_output.permute(0,2,1).contiguous(), 8 * self.patch_stride[1])
|
| 798 |
-
|
| 799 |
-
latent_output = self.avgpool(torch.flatten(x,2))
|
| 800 |
-
latent_output = torch.flatten(latent_output, 1)
|
| 801 |
-
|
| 802 |
-
# display the attention map, if needed
|
| 803 |
-
|
| 804 |
-
x = self.tscam_conv(x)
|
| 805 |
-
x = torch.flatten(x, 2) # B, C, T
|
| 806 |
-
|
| 807 |
-
fpx = interpolate(torch.sigmoid(x).permute(0,2,1).contiguous(), 8 * self.patch_stride[1])
|
| 808 |
-
|
| 809 |
-
x = self.avgpool(x)
|
| 810 |
-
x = torch.flatten(x, 1)
|
| 811 |
-
|
| 812 |
-
output_dict = {
|
| 813 |
-
'framewise_output': fpx, # already sigmoided
|
| 814 |
-
'clipwise_output': torch.sigmoid(x),
|
| 815 |
-
'fine_grained_embedding': fine_grained_latent_output,
|
| 816 |
-
'embedding': latent_output
|
| 817 |
-
}
|
| 818 |
-
|
| 819 |
-
return output_dict
|
| 820 |
-
|
| 821 |
-
def crop_wav(self, x, crop_size, spe_pos = None):
|
| 822 |
-
time_steps = x.shape[2]
|
| 823 |
-
tx = torch.zeros(x.shape[0], x.shape[1], crop_size, x.shape[3]).to(x.device)
|
| 824 |
-
for i in range(len(x)):
|
| 825 |
-
if spe_pos is None:
|
| 826 |
-
crop_pos = random.randint(0, time_steps - crop_size - 1)
|
| 827 |
-
else:
|
| 828 |
-
crop_pos = spe_pos
|
| 829 |
-
tx[i][0] = x[i, 0, crop_pos:crop_pos + crop_size,:]
|
| 830 |
-
return tx
|
| 831 |
-
|
| 832 |
-
# Reshape the wavform to a img size, if you want to use the pretrained swin transformer model
|
| 833 |
-
def reshape_wav2img(self, x):
|
| 834 |
-
B, C, T, F = x.shape
|
| 835 |
-
target_T = int(self.spec_size * self.freq_ratio)
|
| 836 |
-
target_F = self.spec_size // self.freq_ratio
|
| 837 |
-
assert T <= target_T and F <= target_F, "the wav size should less than or equal to the swin input size"
|
| 838 |
-
# to avoid bicubic zero error
|
| 839 |
-
if T < target_T:
|
| 840 |
-
x = nn.functional.interpolate(x, (target_T, x.shape[3]), mode="bicubic", align_corners=True)
|
| 841 |
-
if F < target_F:
|
| 842 |
-
x = nn.functional.interpolate(x, (x.shape[2], target_F), mode="bicubic", align_corners=True)
|
| 843 |
-
x = x.permute(0,1,3,2).contiguous()
|
| 844 |
-
x = x.reshape(x.shape[0], x.shape[1], x.shape[2], self.freq_ratio, x.shape[3] // self.freq_ratio)
|
| 845 |
-
# print(x.shape)
|
| 846 |
-
x = x.permute(0,1,3,2,4).contiguous()
|
| 847 |
-
x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3], x.shape[4])
|
| 848 |
-
return x
|
| 849 |
-
|
| 850 |
-
# Repeat the wavform to a img size, if you want to use the pretrained swin transformer model
|
| 851 |
-
def repeat_wat2img(self, x, cur_pos):
|
| 852 |
-
B, C, T, F = x.shape
|
| 853 |
-
target_T = int(self.spec_size * self.freq_ratio)
|
| 854 |
-
target_F = self.spec_size // self.freq_ratio
|
| 855 |
-
assert T <= target_T and F <= target_F, "the wav size should less than or equal to the swin input size"
|
| 856 |
-
# to avoid bicubic zero error
|
| 857 |
-
if T < target_T:
|
| 858 |
-
x = nn.functional.interpolate(x, (target_T, x.shape[3]), mode="bicubic", align_corners=True)
|
| 859 |
-
if F < target_F:
|
| 860 |
-
x = nn.functional.interpolate(x, (x.shape[2], target_F), mode="bicubic", align_corners=True)
|
| 861 |
-
x = x.permute(0,1,3,2).contiguous() # B C F T
|
| 862 |
-
x = x[:,:,:,cur_pos:cur_pos + self.spec_size]
|
| 863 |
-
x = x.repeat(repeats = (1,1,4,1))
|
| 864 |
-
return x
|
| 865 |
-
|
| 866 |
-
def forward(self, x: torch.Tensor, mixup_lambda = None, infer_mode = False, device=None):# out_feat_keys: List[str] = None):
|
| 867 |
-
|
| 868 |
-
if self.enable_fusion and x["longer"].sum() == 0:
|
| 869 |
-
# if no audio is longer than 10s, then randomly select one audio to be longer
|
| 870 |
-
x["longer"][torch.randint(0, x["longer"].shape[0], (1,))] = True
|
| 871 |
-
|
| 872 |
-
if not self.enable_fusion:
|
| 873 |
-
x = x["waveform"].to(device=device, non_blocking=True)
|
| 874 |
-
x = self.spectrogram_extractor(x) # (batch_size, 1, time_steps, freq_bins)
|
| 875 |
-
x = self.logmel_extractor(x) # (batch_size, 1, time_steps, mel_bins)
|
| 876 |
-
x = x.transpose(1, 3)
|
| 877 |
-
x = self.bn0(x)
|
| 878 |
-
x = x.transpose(1, 3)
|
| 879 |
-
if self.training:
|
| 880 |
-
x = self.spec_augmenter(x)
|
| 881 |
-
|
| 882 |
-
if self.training and mixup_lambda is not None:
|
| 883 |
-
x = do_mixup(x, mixup_lambda)
|
| 884 |
-
|
| 885 |
-
x = self.reshape_wav2img(x)
|
| 886 |
-
output_dict = self.forward_features(x)
|
| 887 |
-
else:
|
| 888 |
-
longer_list = x["longer"].to(device=device, non_blocking=True)
|
| 889 |
-
x = x["mel_fusion"].to(device=device, non_blocking=True)
|
| 890 |
-
x = x.transpose(1, 3)
|
| 891 |
-
x = self.bn0(x)
|
| 892 |
-
x = x.transpose(1, 3)
|
| 893 |
-
longer_list_idx = torch.where(longer_list)[0]
|
| 894 |
-
if self.fusion_type in ['daf_1d','aff_1d','iaff_1d']:
|
| 895 |
-
new_x = x[:,0:1,:,:].clone().contiguous()
|
| 896 |
-
if len(longer_list_idx) > 0:
|
| 897 |
-
# local processing
|
| 898 |
-
fusion_x_local = x[longer_list_idx,1:,:,:].clone().contiguous()
|
| 899 |
-
FB,FC,FT,FF = fusion_x_local.size()
|
| 900 |
-
fusion_x_local = fusion_x_local.view(FB * FC, FT, FF)
|
| 901 |
-
fusion_x_local = torch.permute(fusion_x_local, (0,2,1)).contiguous()
|
| 902 |
-
fusion_x_local = self.mel_conv1d(fusion_x_local)
|
| 903 |
-
fusion_x_local = fusion_x_local.view(FB,FC,FF,fusion_x_local.size(-1))
|
| 904 |
-
fusion_x_local = torch.permute(fusion_x_local, (0,2,1,3)).contiguous().flatten(2)
|
| 905 |
-
if fusion_x_local.size(-1) < FT:
|
| 906 |
-
fusion_x_local = torch.cat([fusion_x_local, torch.zeros((FB,FF,FT- fusion_x_local.size(-1)), device=device)], dim=-1)
|
| 907 |
-
else:
|
| 908 |
-
fusion_x_local = fusion_x_local[:,:,:FT]
|
| 909 |
-
# 1D fusion
|
| 910 |
-
new_x = new_x.squeeze(1).permute((0,2,1)).contiguous()
|
| 911 |
-
new_x[longer_list_idx] = self.fusion_model(new_x[longer_list_idx], fusion_x_local)
|
| 912 |
-
x = new_x.permute((0,2,1)).contiguous()[:,None,:,:]
|
| 913 |
-
else:
|
| 914 |
-
x = new_x
|
| 915 |
-
|
| 916 |
-
elif self.fusion_type in ['daf_2d','aff_2d','iaff_2d','channel_map']:
|
| 917 |
-
x = x # no change
|
| 918 |
-
|
| 919 |
-
if self.training:
|
| 920 |
-
x = self.spec_augmenter(x)
|
| 921 |
-
if self.training and mixup_lambda is not None:
|
| 922 |
-
x = do_mixup(x, mixup_lambda)
|
| 923 |
-
|
| 924 |
-
x = self.reshape_wav2img(x)
|
| 925 |
-
output_dict = self.forward_features(x, longer_idx = longer_list_idx)
|
| 926 |
-
|
| 927 |
-
# if infer_mode:
|
| 928 |
-
# # in infer mode. we need to handle different length audio input
|
| 929 |
-
# frame_num = x.shape[2]
|
| 930 |
-
# target_T = int(self.spec_size * self.freq_ratio)
|
| 931 |
-
# repeat_ratio = math.floor(target_T / frame_num)
|
| 932 |
-
# x = x.repeat(repeats=(1,1,repeat_ratio,1))
|
| 933 |
-
# x = self.reshape_wav2img(x)
|
| 934 |
-
# output_dict = self.forward_features(x)
|
| 935 |
-
# else:
|
| 936 |
-
# if x.shape[2] > self.freq_ratio * self.spec_size:
|
| 937 |
-
# if self.training:
|
| 938 |
-
# x = self.crop_wav(x, crop_size=self.freq_ratio * self.spec_size)
|
| 939 |
-
# x = self.reshape_wav2img(x)
|
| 940 |
-
# output_dict = self.forward_features(x)
|
| 941 |
-
# else:
|
| 942 |
-
# # Change: Hard code here
|
| 943 |
-
# overlap_size = (x.shape[2] - 1) // 4
|
| 944 |
-
# output_dicts = []
|
| 945 |
-
# crop_size = (x.shape[2] - 1) // 2
|
| 946 |
-
# for cur_pos in range(0, x.shape[2] - crop_size - 1, overlap_size):
|
| 947 |
-
# tx = self.crop_wav(x, crop_size = crop_size, spe_pos = cur_pos)
|
| 948 |
-
# tx = self.reshape_wav2img(tx)
|
| 949 |
-
# output_dicts.append(self.forward_features(tx))
|
| 950 |
-
# clipwise_output = torch.zeros_like(output_dicts[0]["clipwise_output"]).float().to(x.device)
|
| 951 |
-
# framewise_output = torch.zeros_like(output_dicts[0]["framewise_output"]).float().to(x.device)
|
| 952 |
-
# for d in output_dicts:
|
| 953 |
-
# clipwise_output += d["clipwise_output"]
|
| 954 |
-
# framewise_output += d["framewise_output"]
|
| 955 |
-
# clipwise_output = clipwise_output / len(output_dicts)
|
| 956 |
-
# framewise_output = framewise_output / len(output_dicts)
|
| 957 |
-
# output_dict = {
|
| 958 |
-
# 'framewise_output': framewise_output,
|
| 959 |
-
# 'clipwise_output': clipwise_output
|
| 960 |
-
# }
|
| 961 |
-
# else: # this part is typically used, and most easy one
|
| 962 |
-
# x = self.reshape_wav2img(x)
|
| 963 |
-
# output_dict = self.forward_features(x)
|
| 964 |
-
# x = self.head(x)
|
| 965 |
-
|
| 966 |
-
# We process the data in the dataloader part, in that here we only consider the input_T < fixed_T
|
| 967 |
-
|
| 968 |
-
|
| 969 |
-
|
| 970 |
-
return output_dict
|
| 971 |
-
|
| 972 |
-
def create_htsat_model(audio_cfg, enable_fusion=False, fusion_type='None'):
|
| 973 |
-
try:
|
| 974 |
-
|
| 975 |
-
assert audio_cfg.model_name in ["tiny", "base", "large"], "model name for HTS-AT is wrong!"
|
| 976 |
-
if audio_cfg.model_name == "tiny":
|
| 977 |
-
model = HTSAT_Swin_Transformer(
|
| 978 |
-
spec_size=256,
|
| 979 |
-
patch_size=4,
|
| 980 |
-
patch_stride=(4,4),
|
| 981 |
-
num_classes=audio_cfg.class_num,
|
| 982 |
-
embed_dim=96,
|
| 983 |
-
depths=[2,2,6,2],
|
| 984 |
-
num_heads=[4,8,16,32],
|
| 985 |
-
window_size=8,
|
| 986 |
-
config = audio_cfg,
|
| 987 |
-
enable_fusion = enable_fusion,
|
| 988 |
-
fusion_type = fusion_type
|
| 989 |
-
)
|
| 990 |
-
elif audio_cfg.model_name == "base":
|
| 991 |
-
model = HTSAT_Swin_Transformer(
|
| 992 |
-
spec_size=256,
|
| 993 |
-
patch_size=4,
|
| 994 |
-
patch_stride=(4,4),
|
| 995 |
-
num_classes=audio_cfg.class_num,
|
| 996 |
-
embed_dim=128,
|
| 997 |
-
depths=[2,2,12,2],
|
| 998 |
-
num_heads=[4,8,16,32],
|
| 999 |
-
window_size=8,
|
| 1000 |
-
config = audio_cfg,
|
| 1001 |
-
enable_fusion = enable_fusion,
|
| 1002 |
-
fusion_type = fusion_type
|
| 1003 |
-
)
|
| 1004 |
-
elif audio_cfg.model_name == "large":
|
| 1005 |
-
model = HTSAT_Swin_Transformer(
|
| 1006 |
-
spec_size=256,
|
| 1007 |
-
patch_size=4,
|
| 1008 |
-
patch_stride=(4,4),
|
| 1009 |
-
num_classes=audio_cfg.class_num,
|
| 1010 |
-
embed_dim=256,
|
| 1011 |
-
depths=[2,2,12,2],
|
| 1012 |
-
num_heads=[4,8,16,32],
|
| 1013 |
-
window_size=8,
|
| 1014 |
-
config = audio_cfg,
|
| 1015 |
-
enable_fusion = enable_fusion,
|
| 1016 |
-
fusion_type = fusion_type
|
| 1017 |
-
)
|
| 1018 |
-
|
| 1019 |
-
return model
|
| 1020 |
-
except:
|
| 1021 |
-
raise RuntimeError(f'Import Model for {audio_cfg.model_name} not found, or the audio cfg parameters are not enough.')
|
| 1022 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/ALSv/midjourney-v4-1/app.py
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
import gradio as gr
|
| 2 |
-
|
| 3 |
-
gr.Interface.load("models/Joeythemonster/anything-midjourney-v-4-1").launch()
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ababababababbababa/Ashaar/app.py
DELETED
|
@@ -1,151 +0,0 @@
|
|
| 1 |
-
import os
|
| 2 |
-
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
|
| 3 |
-
import gradio as gr
|
| 4 |
-
from transformers import pipeline
|
| 5 |
-
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 6 |
-
from Ashaar.utils import get_output_df, get_highlighted_patterns_html
|
| 7 |
-
from Ashaar.bait_analysis import BaitAnalysis
|
| 8 |
-
from langs import *
|
| 9 |
-
import sys
|
| 10 |
-
import json
|
| 11 |
-
import argparse
|
| 12 |
-
|
| 13 |
-
arg_parser = argparse.ArgumentParser()
|
| 14 |
-
arg_parser.add_argument('--lang', type = str, default = 'ar')
|
| 15 |
-
args = arg_parser.parse_args()
|
| 16 |
-
lang = args.lang
|
| 17 |
-
|
| 18 |
-
if lang == 'ar':
|
| 19 |
-
TITLE = TITLE_ar
|
| 20 |
-
DESCRIPTION = DESCRIPTION_ar
|
| 21 |
-
textbox_trg_text = textbox_trg_text_ar
|
| 22 |
-
textbox_inp_text = textbox_inp_text_ar
|
| 23 |
-
btn_trg_text = btn_trg_text_ar
|
| 24 |
-
btn_inp_text = btn_inp_text_ar
|
| 25 |
-
css = """ #textbox{ direction: RTL;}"""
|
| 26 |
-
|
| 27 |
-
else:
|
| 28 |
-
TITLE = TITLE_en
|
| 29 |
-
DESCRIPTION = DESCRIPTION_en
|
| 30 |
-
textbox_trg_text = textbox_trg_text_en
|
| 31 |
-
textbox_inp_text = textbox_inp_text_en
|
| 32 |
-
btn_trg_text = btn_trg_text_en
|
| 33 |
-
btn_inp_text = btn_inp_text_en
|
| 34 |
-
css = ""
|
| 35 |
-
|
| 36 |
-
gpt_tokenizer = AutoTokenizer.from_pretrained('arbml/ashaar_tokenizer')
|
| 37 |
-
model = AutoModelForCausalLM.from_pretrained('arbml/Ashaar_model')
|
| 38 |
-
|
| 39 |
-
theme_to_token = json.load(open("extra/theme_tokens.json", "r"))
|
| 40 |
-
token_to_theme = {t:m for m,t in theme_to_token.items()}
|
| 41 |
-
meter_to_token = json.load(open("extra/meter_tokens.json", "r"))
|
| 42 |
-
token_to_meter = {t:m for m,t in meter_to_token.items()}
|
| 43 |
-
|
| 44 |
-
analysis = BaitAnalysis()
|
| 45 |
-
meter, theme, qafiyah = "", "", ""
|
| 46 |
-
|
| 47 |
-
def analyze(poem):
|
| 48 |
-
global meter,theme,qafiyah, generate_btn
|
| 49 |
-
shatrs = poem.split("\n")
|
| 50 |
-
baits = [' # '.join(shatrs[2*i:2*i+2]) for i in range(len(shatrs)//2)]
|
| 51 |
-
output = analysis.analyze(baits,override_tashkeel=True)
|
| 52 |
-
meter = output['meter']
|
| 53 |
-
qafiyah = output['qafiyah'][0]
|
| 54 |
-
theme = output['theme'][-1]
|
| 55 |
-
df = get_output_df(output)
|
| 56 |
-
return get_highlighted_patterns_html(df), gr.Button.update(interactive=True)
|
| 57 |
-
|
| 58 |
-
def generate(inputs, top_p = 3):
|
| 59 |
-
baits = inputs.split('\n')
|
| 60 |
-
if len(baits) % 2 !=0:
|
| 61 |
-
baits = baits[:-1]
|
| 62 |
-
poem = ' '.join(['<|bsep|> '+baits[i]+' <|vsep|> '+baits[i+1]+' </|bsep|>' for i in range(0, len(baits), 2)])
|
| 63 |
-
prompt = f"""
|
| 64 |
-
{meter_to_token[meter]} {qafiyah} {theme_to_token[theme]}
|
| 65 |
-
<|psep|>
|
| 66 |
-
{poem}
|
| 67 |
-
""".strip()
|
| 68 |
-
print(prompt)
|
| 69 |
-
encoded_input = gpt_tokenizer(prompt, return_tensors='pt')
|
| 70 |
-
output = model.generate(**encoded_input, max_length = 512, top_p = 3, do_sample=True)
|
| 71 |
-
|
| 72 |
-
result = ""
|
| 73 |
-
prev_token = ""
|
| 74 |
-
line_cnts = 0
|
| 75 |
-
for i, beam in enumerate(output[:, len(encoded_input.input_ids[0]):]):
|
| 76 |
-
if line_cnts >= 10:
|
| 77 |
-
break
|
| 78 |
-
for token in beam:
|
| 79 |
-
if line_cnts >= 10:
|
| 80 |
-
break
|
| 81 |
-
decoded = gpt_tokenizer.decode(token)
|
| 82 |
-
if 'meter' in decoded or 'theme' in decoded:
|
| 83 |
-
break
|
| 84 |
-
if decoded in ["<|vsep|>", "</|bsep|>"]:
|
| 85 |
-
result += "\n"
|
| 86 |
-
line_cnts+=1
|
| 87 |
-
elif decoded in ['<|bsep|>', '<|psep|>', '</|psep|>']:
|
| 88 |
-
pass
|
| 89 |
-
else:
|
| 90 |
-
result += decoded
|
| 91 |
-
prev_token = decoded
|
| 92 |
-
else:
|
| 93 |
-
break
|
| 94 |
-
# return theme+" "+ f"من بحر {meter} مع قافية بحر ({qafiyah})" + "\n" +result
|
| 95 |
-
return result, gr.Button.update(interactive=False)
|
| 96 |
-
|
| 97 |
-
examples = [
|
| 98 |
-
[
|
| 99 |
-
"""القلب أعلم يا عذول بدائه
|
| 100 |
-
وأحق منك بجفنه وبمائه"""
|
| 101 |
-
],
|
| 102 |
-
[
|
| 103 |
-
"""رمتِ الفؤادَ مليحة عذراءُ
|
| 104 |
-
بسهامِ لحظٍ ما لهنَّ دواءُ"""
|
| 105 |
-
],
|
| 106 |
-
[
|
| 107 |
-
"""أذَلَّ الحِرْصُ والطَّمَعُ الرِّقابَا
|
| 108 |
-
وقَد يَعفو الكَريمُ، إذا استَرَابَا"""
|
| 109 |
-
]
|
| 110 |
-
]
|
| 111 |
-
|
| 112 |
-
with gr.Blocks(theme=gr.themes.Soft(), css=css) as demo:
|
| 113 |
-
with gr.Row():
|
| 114 |
-
with gr.Column():
|
| 115 |
-
gr.HTML(TITLE)
|
| 116 |
-
gr.HTML(DESCRIPTION)
|
| 117 |
-
|
| 118 |
-
with gr.Row():
|
| 119 |
-
with gr.Column():
|
| 120 |
-
textbox_output = gr.Textbox(lines=10, label=textbox_trg_text, elem_id="textbox")
|
| 121 |
-
with gr.Column():
|
| 122 |
-
inputs = gr.Textbox(lines=10, label=textbox_inp_text, elem_id="textbox")
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
with gr.Row():
|
| 126 |
-
with gr.Column():
|
| 127 |
-
if lang == 'ar':
|
| 128 |
-
trg_btn = gr.Button(btn_trg_text, interactive=False)
|
| 129 |
-
else:
|
| 130 |
-
trg_btn = gr.Button(btn_trg_text)
|
| 131 |
-
|
| 132 |
-
with gr.Column():
|
| 133 |
-
if lang == 'ar':
|
| 134 |
-
inp_btn = gr.Button(btn_inp_text)
|
| 135 |
-
else:
|
| 136 |
-
inp_btn = gr.Button(btn_inp_text, interactive = False)
|
| 137 |
-
|
| 138 |
-
with gr.Row():
|
| 139 |
-
html_output = gr.HTML()
|
| 140 |
-
|
| 141 |
-
if lang == 'en':
|
| 142 |
-
gr.Examples(examples, textbox_output)
|
| 143 |
-
inp_btn.click(generate, inputs = textbox_output, outputs=[inputs, inp_btn])
|
| 144 |
-
trg_btn.click(analyze, inputs = textbox_output, outputs=[html_output,inp_btn])
|
| 145 |
-
else:
|
| 146 |
-
gr.Examples(examples, inputs)
|
| 147 |
-
trg_btn.click(generate, inputs = inputs, outputs=[textbox_output, trg_btn])
|
| 148 |
-
inp_btn.click(analyze, inputs = inputs, outputs=[html_output,trg_btn] )
|
| 149 |
-
|
| 150 |
-
# demo.launch(server_name = '0.0.0.0', share=True)
|
| 151 |
-
demo.launch()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ababababababbababa/Sha3bor_Aragpt2_Base/README.md
DELETED
|
@@ -1,12 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: Sha3bor Aragpt2 Base
|
| 3 |
-
emoji: 🏆
|
| 4 |
-
colorFrom: gray
|
| 5 |
-
colorTo: red
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.29.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
---
|
| 11 |
-
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Abhaykoul/BardCookies-AI_Query/app.py
DELETED
|
@@ -1,36 +0,0 @@
|
|
| 1 |
-
from bardapi import BardCookies
|
| 2 |
-
import requests
|
| 3 |
-
from requests.exceptions import ReadTimeout
|
| 4 |
-
import gradio as gr
|
| 5 |
-
|
| 6 |
-
def get_bard_response(Secure_1PSID, Secure_1PSIDTS, Secure_1PSIDCC, Query):
|
| 7 |
-
cookie_dict = {
|
| 8 |
-
"__Secure-1PSID": Secure_1PSID,
|
| 9 |
-
"__Secure-1PSIDTS": Secure_1PSIDTS,
|
| 10 |
-
"__Secure-1PSIDCC": Secure_1PSIDCC
|
| 11 |
-
}
|
| 12 |
-
|
| 13 |
-
bard = BardCookies(cookie_dict=cookie_dict)
|
| 14 |
-
retries = 3 # Number of retries
|
| 15 |
-
for _ in range(retries):
|
| 16 |
-
try:
|
| 17 |
-
Reply = bard.get_answer(Query)['content']
|
| 18 |
-
return Reply
|
| 19 |
-
except ReadTimeout:
|
| 20 |
-
continue
|
| 21 |
-
return "Failed to fetch data after multiple retries."
|
| 22 |
-
|
| 23 |
-
iface = gr.Interface(
|
| 24 |
-
fn=get_bard_response,
|
| 25 |
-
inputs=[
|
| 26 |
-
gr.components.Textbox(label="__Secure-1PSID"),
|
| 27 |
-
gr.components.Textbox(label="__Secure-1PSIDTS"),
|
| 28 |
-
gr.components.Textbox(label="__Secure-1PSIDCC"),
|
| 29 |
-
gr.components.Textbox(label="Query")
|
| 30 |
-
],
|
| 31 |
-
outputs="text",
|
| 32 |
-
title="BardCookies - AI Query",
|
| 33 |
-
description = "Enter your cookies and a query to get a response from BardCookies. If you need help with cookies, check out the <a href='https://chrome.google.com/webstore/detail/editthiscookie/fngmhnnpilhplaeedifhccceomclgfbg?utm_source=ext_app_menu' target='_blank'>Chrome extension</a> for managing cookies. Go to bard.google.com and then use EditThisCookie extension and copy Secure_1PSID, Secure_1PSIDTS, Secure_1PSIDCC from it. <a href='https://bard.google.com/chat' target='_blank'>Bard Chat</a>."
|
| 34 |
-
)
|
| 35 |
-
|
| 36 |
-
iface.launch()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AgentVerse/agentVerse/agentverse/registry.py
DELETED
|
@@ -1,27 +0,0 @@
|
|
| 1 |
-
from typing import Dict
|
| 2 |
-
|
| 3 |
-
from pydantic import BaseModel
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
class Registry(BaseModel):
|
| 7 |
-
"""Registry for storing and building classes."""
|
| 8 |
-
|
| 9 |
-
name: str
|
| 10 |
-
entries: Dict = {}
|
| 11 |
-
|
| 12 |
-
def register(self, key: str):
|
| 13 |
-
def decorator(class_builder):
|
| 14 |
-
self.entries[key] = class_builder
|
| 15 |
-
return class_builder
|
| 16 |
-
|
| 17 |
-
return decorator
|
| 18 |
-
|
| 19 |
-
def build(self, type: str, **kwargs):
|
| 20 |
-
if type not in self.entries:
|
| 21 |
-
raise ValueError(
|
| 22 |
-
f'{type} is not registered. Please register with the .register("{type}") method provided in {self.name} registry'
|
| 23 |
-
)
|
| 24 |
-
return self.entries[type](**kwargs)
|
| 25 |
-
|
| 26 |
-
def get_all_entries(self):
|
| 27 |
-
return self.entries
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/oval/Factory.js
DELETED
|
@@ -1,13 +0,0 @@
|
|
| 1 |
-
import Oval from './Oval.js';
|
| 2 |
-
import ObjectFactory from '../ObjectFactory.js';
|
| 3 |
-
import SetValue from '../../../plugins/utils/object/SetValue.js';
|
| 4 |
-
|
| 5 |
-
ObjectFactory.register('oval', function (config) {
|
| 6 |
-
var gameObject = new Oval(this.scene, config);
|
| 7 |
-
this.scene.add.existing(gameObject);
|
| 8 |
-
return gameObject;
|
| 9 |
-
});
|
| 10 |
-
|
| 11 |
-
SetValue(window, 'RexPlugins.Spinner.Oval', Oval);
|
| 12 |
-
|
| 13 |
-
export default Oval;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/easemove/EaseMove.ts
DELETED
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
import { EaseMove, EaseMoveTo, EaseMoveFrom } from '../../../plugins/easemove';
|
| 2 |
-
export { EaseMove, EaseMoveTo, EaseMoveFrom };
|
|
|
|
|
|
|
|
|
spaces/Al-Chan/Vits_League_of_Legends_Yuumi_TTS/monotonic_align/__init__.py
DELETED
|
@@ -1,19 +0,0 @@
|
|
| 1 |
-
import numpy as np
|
| 2 |
-
import torch
|
| 3 |
-
from .monotonic_align.core import maximum_path_c
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
def maximum_path(neg_cent, mask):
|
| 7 |
-
""" Cython optimized version.
|
| 8 |
-
neg_cent: [b, t_t, t_s]
|
| 9 |
-
mask: [b, t_t, t_s]
|
| 10 |
-
"""
|
| 11 |
-
device = neg_cent.device
|
| 12 |
-
dtype = neg_cent.dtype
|
| 13 |
-
neg_cent = neg_cent.data.cpu().numpy().astype(np.float32)
|
| 14 |
-
path = np.zeros(neg_cent.shape, dtype=np.int32)
|
| 15 |
-
|
| 16 |
-
t_t_max = mask.sum(1)[:, 0].data.cpu().numpy().astype(np.int32)
|
| 17 |
-
t_s_max = mask.sum(2)[:, 0].data.cpu().numpy().astype(np.int32)
|
| 18 |
-
maximum_path_c(path, neg_cent, t_t_max, t_s_max)
|
| 19 |
-
return torch.from_numpy(path).to(device=device, dtype=dtype)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ameaou/academic-chatgpt3.1/docs/README_EN.md
DELETED
|
@@ -1,291 +0,0 @@
|
|
| 1 |
-
> **Note**
|
| 2 |
-
>
|
| 3 |
-
> This English README is automatically generated by the markdown translation plugin in this project, and may not be 100% correct.
|
| 4 |
-
>
|
| 5 |
-
|
| 6 |
-
# <img src="logo.png" width="40" > ChatGPT Academic Optimization
|
| 7 |
-
|
| 8 |
-
**If you like this project, please give it a Star. If you've come up with more useful academic shortcuts or functional plugins, feel free to open an issue or pull request. We also have a [README in English](docs/README_EN.md) translated by this project itself.**
|
| 9 |
-
|
| 10 |
-
> **Note**
|
| 11 |
-
>
|
| 12 |
-
> 1. Please note that only **functions with red color** supports reading files, some functions are located in the **dropdown menu** of plugins. Additionally, we welcome and prioritize any new plugin PRs with **highest priority**!
|
| 13 |
-
>
|
| 14 |
-
> 2. The functionality of each file in this project is detailed in the self-translation report [`self_analysis.md`](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) of the project. With the iteration of the version, you can also click on the relevant function plugins at any time to call GPT to regenerate the self-analysis report of the project. The FAQ summary is in the [`wiki`](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98) section.
|
| 15 |
-
>
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
<div align="center">
|
| 19 |
-
|
| 20 |
-
Function | Description
|
| 21 |
-
--- | ---
|
| 22 |
-
One-Click Polish | Supports one-click polishing and finding grammar errors in academic papers.
|
| 23 |
-
One-Key Translation Between Chinese and English | One-click translation between Chinese and English.
|
| 24 |
-
One-Key Code Interpretation | Can correctly display and interpret code.
|
| 25 |
-
[Custom Shortcut Keys](https://www.bilibili.com/video/BV14s4y1E7jN) | Supports custom shortcut keys.
|
| 26 |
-
[Configure Proxy Server](https://www.bilibili.com/video/BV1rc411W7Dr) | Supports configuring proxy servers.
|
| 27 |
-
Modular Design | Supports custom high-order function plugins and [function plugins], and plugins support [hot updates](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
|
| 28 |
-
[Self-programming Analysis](https://www.bilibili.com/video/BV1cj411A7VW) | [Function Plugin] [One-Key Read] (https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) The source code of this project is analyzed.
|
| 29 |
-
[Program Analysis](https://www.bilibili.com/video/BV1cj411A7VW) | [Function Plugin] One-click can analyze the project tree of other Python/C/C++/Java/Lua/... projects
|
| 30 |
-
Read the Paper | [Function Plugin] One-click interpretation of the full text of latex paper and generation of abstracts
|
| 31 |
-
Latex Full Text Translation, Proofreading | [Function Plugin] One-click translation or proofreading of latex papers.
|
| 32 |
-
Batch Comment Generation | [Function Plugin] One-click batch generation of function comments
|
| 33 |
-
Chat Analysis Report Generation | [Function Plugin] After running, an automatic summary report will be generated
|
| 34 |
-
[Arxiv Assistant](https://www.bilibili.com/video/BV1LM4y1279X) | [Function Plugin] Enter the arxiv article url to translate the abstract and download the PDF with one click
|
| 35 |
-
[Full-text Translation Function of PDF Paper](https://www.bilibili.com/video/BV1KT411x7Wn) | [Function Plugin] Extract the title & abstract of the PDF paper + translate the full text (multithreading)
|
| 36 |
-
[Google Scholar Integration Assistant](https://www.bilibili.com/video/BV19L411U7ia) | [Function Plugin] Given any Google Scholar search page URL, let gpt help you choose interesting articles.
|
| 37 |
-
Formula / Picture / Table Display | Can display both the tex form and the rendering form of formulas at the same time, support formula and code highlighting
|
| 38 |
-
Multithreaded Function Plugin Support | Supports multi-threaded calling chatgpt, one-click processing of massive text or programs
|
| 39 |
-
Start Dark Gradio [Theme](https://github.com/binary-husky/chatgpt_academic/issues/173) | Add ```/?__dark-theme=true``` at the end of the browser url to switch to dark theme
|
| 40 |
-
[Multiple LLM Models](https://www.bilibili.com/video/BV1wT411p7yf) support, [API2D](https://api2d.com/) interface support | It must feel nice to be served by both GPT3.5, GPT4, and [Tsinghua ChatGLM](https://github.com/THUDM/ChatGLM-6B)!
|
| 41 |
-
Huggingface non-Science Net [Online Experience](https://huggingface.co/spaces/qingxu98/gpt-academic) | After logging in to huggingface, copy [this space](https://huggingface.co/spaces/qingxu98/gpt-academic)
|
| 42 |
-
... | ...
|
| 43 |
-
|
| 44 |
-
</div>
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
- New interface (switch between "left-right layout" and "up-down layout" by modifying the LAYOUT option in config.py)
|
| 48 |
-
<div align="center">
|
| 49 |
-
<img src="https://user-images.githubusercontent.com/96192199/230361456-61078362-a966-4eb5-b49e-3c62ef18b860.gif" width="700" >
|
| 50 |
-
</div>
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
- All buttons are dynamically generated by reading functional.py and can add custom functionality at will, freeing up clipboard
|
| 54 |
-
<div align="center">
|
| 55 |
-
<img src="https://user-images.githubusercontent.com/96192199/231975334-b4788e91-4887-412f-8b43-2b9c5f41d248.gif" width="700" >
|
| 56 |
-
</div>
|
| 57 |
-
|
| 58 |
-
- Proofreading / correcting
|
| 59 |
-
<div align="center">
|
| 60 |
-
<img src="https://user-images.githubusercontent.com/96192199/231980294-f374bdcb-3309-4560-b424-38ef39f04ebd.gif" width="700" >
|
| 61 |
-
</div>
|
| 62 |
-
|
| 63 |
-
- If the output contains formulas, it will be displayed in both the tex form and the rendering form at the same time, which is convenient for copying and reading
|
| 64 |
-
<div align="center">
|
| 65 |
-
<img src="https://user-images.githubusercontent.com/96192199/230598842-1d7fcddd-815d-40ee-af60-baf488a199df.png" width="700" >
|
| 66 |
-
</div>
|
| 67 |
-
|
| 68 |
-
- Don't want to read the project code? Just take the whole project to chatgpt
|
| 69 |
-
<div align="center">
|
| 70 |
-
<img src="https://user-images.githubusercontent.com/96192199/226935232-6b6a73ce-8900-4aee-93f9-733c7e6fef53.png" width="700" >
|
| 71 |
-
</div>
|
| 72 |
-
|
| 73 |
-
- Multiple major language model mixing calls (ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4)
|
| 74 |
-
<div align="center">
|
| 75 |
-
<img src="https://user-images.githubusercontent.com/96192199/232537274-deca0563-7aa6-4b5d-94a2-b7c453c47794.png" width="700" >
|
| 76 |
-
</div>
|
| 77 |
-
|
| 78 |
-
Multiple major language model mixing call [huggingface beta version](https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta) (the huggingface version does not support chatglm)
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
---
|
| 82 |
-
|
| 83 |
-
## Installation-Method 1: Run directly (Windows, Linux or MacOS)
|
| 84 |
-
|
| 85 |
-
1. Download project
|
| 86 |
-
```sh
|
| 87 |
-
git clone https://github.com/binary-husky/chatgpt_academic.git
|
| 88 |
-
cd chatgpt_academic
|
| 89 |
-
```
|
| 90 |
-
|
| 91 |
-
2. Configure API_KEY and proxy settings
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
In `config.py`, configure the overseas Proxy and OpenAI API KEY as follows:
|
| 95 |
-
```
|
| 96 |
-
1. If you are in China, you need to set up an overseas proxy to use the OpenAI API smoothly. Please read config.py carefully for setup details (1. Modify USE_PROXY to True; 2. Modify proxies according to the instructions).
|
| 97 |
-
2. Configure the OpenAI API KEY. You need to register and obtain an API KEY on the OpenAI website. Once you get the API KEY, you can configure it in the config.py file.
|
| 98 |
-
3. Issues related to proxy networks (network timeouts, proxy failures) are summarized at https://github.com/binary-husky/chatgpt_academic/issues/1
|
| 99 |
-
```
|
| 100 |
-
(P.S. When the program runs, it will first check whether there is a private configuration file named `config_private.py` and use the same-name configuration in `config.py` to overwrite it. Therefore, if you can understand our configuration reading logic, we strongly recommend that you create a new configuration file named `config_private.py` next to `config.py` and transfer (copy) the configuration in `config.py` to` config_private.py`. `config_private.py` is not controlled by git and can make your privacy information more secure.))
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
3. Install dependencies
|
| 104 |
-
```sh
|
| 105 |
-
# (Option One) Recommended
|
| 106 |
-
python -m pip install -r requirements.txt
|
| 107 |
-
|
| 108 |
-
# (Option Two) If you use anaconda, the steps are similar:
|
| 109 |
-
# (Option Two.1) conda create -n gptac_venv python=3.11
|
| 110 |
-
# (Option Two.2) conda activate gptac_venv
|
| 111 |
-
# (Option Two.3) python -m pip install -r requirements.txt
|
| 112 |
-
|
| 113 |
-
# Note: Use official pip source or Ali pip source. Other pip sources (such as some university pips) may have problems, and temporary replacement methods are as follows:
|
| 114 |
-
# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
|
| 115 |
-
```
|
| 116 |
-
|
| 117 |
-
If you need to support Tsinghua ChatGLM, you need to install more dependencies (if you are not familiar with python or your computer configuration is not good, we recommend not to try):
|
| 118 |
-
```sh
|
| 119 |
-
python -m pip install -r request_llm/requirements_chatglm.txt
|
| 120 |
-
```
|
| 121 |
-
|
| 122 |
-
4. Run
|
| 123 |
-
```sh
|
| 124 |
-
python main.py
|
| 125 |
-
```
|
| 126 |
-
|
| 127 |
-
5. Test function plugins
|
| 128 |
-
```
|
| 129 |
-
- Test Python project analysis
|
| 130 |
-
In the input area, enter `./crazy_functions/test_project/python/dqn`, and then click "Analyze the entire Python project"
|
| 131 |
-
- Test self-code interpretation
|
| 132 |
-
Click "[Multithreading Demo] Interpretation of This Project Itself (Source Code Interpretation)"
|
| 133 |
-
- Test experimental function template function (requires gpt to answer what happened today in history). You can use this function as a template to implement more complex functions.
|
| 134 |
-
Click "[Function Plugin Template Demo] Today in History"
|
| 135 |
-
- There are more functions to choose from in the function plugin area drop-down menu.
|
| 136 |
-
```
|
| 137 |
-
|
| 138 |
-
## Installation-Method 2: Use Docker (Linux)
|
| 139 |
-
|
| 140 |
-
1. ChatGPT only (recommended for most people)
|
| 141 |
-
``` sh
|
| 142 |
-
# download project
|
| 143 |
-
git clone https://github.com/binary-husky/chatgpt_academic.git
|
| 144 |
-
cd chatgpt_academic
|
| 145 |
-
# configure overseas Proxy and OpenAI API KEY
|
| 146 |
-
Edit config.py with any text editor
|
| 147 |
-
# Install
|
| 148 |
-
docker build -t gpt-academic .
|
| 149 |
-
# Run
|
| 150 |
-
docker run --rm -it --net=host gpt-academic
|
| 151 |
-
|
| 152 |
-
# Test function plug-in
|
| 153 |
-
## Test function plugin template function (requires gpt to answer what happened today in history). You can use this function as a template to implement more complex functions.
|
| 154 |
-
Click "[Function Plugin Template Demo] Today in History"
|
| 155 |
-
## Test Abstract Writing for Latex Projects
|
| 156 |
-
Enter ./crazy_functions/test_project/latex/attention in the input area, and then click "Read Tex Paper and Write Abstract"
|
| 157 |
-
## Test Python Project Analysis
|
| 158 |
-
Enter ./crazy_functions/test_project/python/dqn in the input area and click "Analyze the entire Python project."
|
| 159 |
-
|
| 160 |
-
More functions are available in the function plugin area drop-down menu.
|
| 161 |
-
```
|
| 162 |
-
|
| 163 |
-
2. ChatGPT+ChatGLM (requires strong familiarity with docker + strong computer configuration)
|
| 164 |
-
|
| 165 |
-
``` sh
|
| 166 |
-
# Modify dockerfile
|
| 167 |
-
cd docs && nano Dockerfile+ChatGLM
|
| 168 |
-
# How to build | 如何构建 (Dockerfile+ChatGLM在docs路径下,请先cd docs)
|
| 169 |
-
docker build -t gpt-academic --network=host -f Dockerfile+ChatGLM .
|
| 170 |
-
# How to run | 如何运行 (1) 直接运行:
|
| 171 |
-
docker run --rm -it --net=host --gpus=all gpt-academic
|
| 172 |
-
# How to run | 如何运行 (2) 我想运行之前进容器做一些调整:
|
| 173 |
-
docker run --rm -it --net=host --gpus=all gpt-academic bash
|
| 174 |
-
```
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
## Installation-Method 3: Other Deployment Methods
|
| 178 |
-
|
| 179 |
-
1. Remote Cloud Server Deployment
|
| 180 |
-
Please visit [Deployment Wiki-1] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
|
| 181 |
-
|
| 182 |
-
2. Use WSL2 (Windows Subsystem for Linux)
|
| 183 |
-
Please visit [Deployment Wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
|
| 184 |
-
|
| 185 |
-
|
| 186 |
-
## Installation-Proxy Configuration
|
| 187 |
-
### Method 1: Conventional method
|
| 188 |
-
[Configure Proxy](https://github.com/binary-husky/chatgpt_academic/issues/1)
|
| 189 |
-
|
| 190 |
-
### Method Two: Step-by-step tutorial for newcomers
|
| 191 |
-
[Step-by-step tutorial for newcomers](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
|
| 192 |
-
|
| 193 |
-
---
|
| 194 |
-
|
| 195 |
-
## Customizing Convenient Buttons (Customizing Academic Shortcuts)
|
| 196 |
-
Open `core_functional.py` with any text editor and add an item as follows, then restart the program (if the button has been successfully added and visible, both the prefix and suffix support hot modification without the need to restart the program to take effect). For example:
|
| 197 |
-
```
|
| 198 |
-
"Super English to Chinese translation": {
|
| 199 |
-
# Prefix, which will be added before your input. For example, to describe your requirements, such as translation, code interpretation, polishing, etc.
|
| 200 |
-
"Prefix": "Please translate the following content into Chinese and use a markdown table to interpret the proprietary terms in the text one by one:\n\n",
|
| 201 |
-
|
| 202 |
-
# Suffix, which will be added after your input. For example, combined with the prefix, you can put your input content in quotes.
|
| 203 |
-
"Suffix": "",
|
| 204 |
-
},
|
| 205 |
-
```
|
| 206 |
-
<div align="center">
|
| 207 |
-
<img src="https://user-images.githubusercontent.com/96192199/226899272-477c2134-ed71-4326-810c-29891fe4a508.png" width="500" >
|
| 208 |
-
</div>
|
| 209 |
-
|
| 210 |
-
---
|
| 211 |
-
|
| 212 |
-
|
| 213 |
-
## Some Function Displays
|
| 214 |
-
|
| 215 |
-
### Image Display:
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
You are a professional academic paper translator.
|
| 219 |
-
|
| 220 |
-
<div align="center">
|
| 221 |
-
<img src="https://user-images.githubusercontent.com/96192199/228737599-bf0a9d9c-1808-4f43-ae15-dfcc7af0f295.png" width="800" >
|
| 222 |
-
</div>
|
| 223 |
-
|
| 224 |
-
### If a program can understand and analyze itself:
|
| 225 |
-
|
| 226 |
-
<div align="center">
|
| 227 |
-
<img src="https://user-images.githubusercontent.com/96192199/226936850-c77d7183-0749-4c1c-9875-fd4891842d0c.png" width="800" >
|
| 228 |
-
</div>
|
| 229 |
-
|
| 230 |
-
<div align="center">
|
| 231 |
-
<img src="https://user-images.githubusercontent.com/96192199/226936618-9b487e4b-ab5b-4b6e-84c6-16942102e917.png" width="800" >
|
| 232 |
-
</div>
|
| 233 |
-
|
| 234 |
-
### Analysis of any Python/Cpp project:
|
| 235 |
-
<div align="center">
|
| 236 |
-
<img src="https://user-images.githubusercontent.com/96192199/226935232-6b6a73ce-8900-4aee-93f9-733c7e6fef53.png" width="800" >
|
| 237 |
-
</div>
|
| 238 |
-
|
| 239 |
-
<div align="center">
|
| 240 |
-
<img src="https://user-images.githubusercontent.com/96192199/226969067-968a27c1-1b9c-486b-8b81-ab2de8d3f88a.png" width="800" >
|
| 241 |
-
</div>
|
| 242 |
-
|
| 243 |
-
### One-click reading comprehension and summary generation of Latex papers
|
| 244 |
-
<div align="center">
|
| 245 |
-
<img src="https://user-images.githubusercontent.com/96192199/227504406-86ab97cd-f208-41c3-8e4a-7000e51cf980.png" width="800" >
|
| 246 |
-
</div>
|
| 247 |
-
|
| 248 |
-
### Automatic report generation
|
| 249 |
-
<div align="center">
|
| 250 |
-
<img src="https://user-images.githubusercontent.com/96192199/227503770-fe29ce2c-53fd-47b0-b0ff-93805f0c2ff4.png" height="300" >
|
| 251 |
-
<img src="https://user-images.githubusercontent.com/96192199/227504617-7a497bb3-0a2a-4b50-9a8a-95ae60ea7afd.png" height="300" >
|
| 252 |
-
<img src="https://user-images.githubusercontent.com/96192199/227504005-efeaefe0-b687-49d0-bf95-2d7b7e66c348.png" height="300" >
|
| 253 |
-
</div>
|
| 254 |
-
|
| 255 |
-
### Modular functional design
|
| 256 |
-
<div align="center">
|
| 257 |
-
<img src="https://user-images.githubusercontent.com/96192199/229288270-093643c1-0018-487a-81e6-1d7809b6e90f.png" height="400" >
|
| 258 |
-
<img src="https://user-images.githubusercontent.com/96192199/227504931-19955f78-45cd-4d1c-adac-e71e50957915.png" height="400" >
|
| 259 |
-
</div>
|
| 260 |
-
|
| 261 |
-
### Source code translation to English
|
| 262 |
-
|
| 263 |
-
<div align="center">
|
| 264 |
-
<img src="https://user-images.githubusercontent.com/96192199/229720562-fe6c3508-6142-4635-a83d-21eb3669baee.png" height="400" >
|
| 265 |
-
</div>
|
| 266 |
-
|
| 267 |
-
## Todo and version planning:
|
| 268 |
-
- version 3.2+ (todo): Function plugin supports more parameter interfaces
|
| 269 |
-
- version 3.1: Support for inquiring multiple GPT models at the same time! Support for api2d, support for multiple apikeys load balancing
|
| 270 |
-
- version 3.0: Support for chatglm and other small llms
|
| 271 |
-
- version 2.6: Refactored the plugin structure, improved interactivity, added more plugins
|
| 272 |
-
- version 2.5: Self-updating, solves the problem of text being too long and token overflowing when summarizing large project source code
|
| 273 |
-
- version 2.4: (1) Added PDF full text translation function; (2) Added function to switch input area position; (3) Added vertical layout option; (4) Multi-threaded function plugin optimization.
|
| 274 |
-
- version 2.3: Enhanced multi-threaded interactivity
|
| 275 |
-
- version 2.2: Function plugin supports hot reloading
|
| 276 |
-
- version 2.1: Foldable layout
|
| 277 |
-
- version 2.0: Introduction of modular function plugins
|
| 278 |
-
- version 1.0: Basic functions
|
| 279 |
-
|
| 280 |
-
## Reference and learning
|
| 281 |
-
|
| 282 |
-
```
|
| 283 |
-
The code design of this project has referenced many other excellent projects, including:
|
| 284 |
-
|
| 285 |
-
# Reference project 1: Borrowed many tips from ChuanhuChatGPT
|
| 286 |
-
https://github.com/GaiZhenbiao/ChuanhuChatGPT
|
| 287 |
-
|
| 288 |
-
# Reference project 2: Tsinghua ChatGLM-6B:
|
| 289 |
-
https://github.com/THUDM/ChatGLM-6B
|
| 290 |
-
```
|
| 291 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/examples/research_projects/intel_opts/README.md
DELETED
|
@@ -1,37 +0,0 @@
|
|
| 1 |
-
## Diffusers examples with Intel optimizations
|
| 2 |
-
|
| 3 |
-
**This research project is not actively maintained by the diffusers team. For any questions or comments, please make sure to tag @hshen14 .**
|
| 4 |
-
|
| 5 |
-
This aims to provide diffusers examples with Intel optimizations such as Bfloat16 for training/fine-tuning acceleration and 8-bit integer (INT8) for inference acceleration on Intel platforms.
|
| 6 |
-
|
| 7 |
-
## Accelerating the fine-tuning for textual inversion
|
| 8 |
-
|
| 9 |
-
We accelereate the fine-tuning for textual inversion with Intel Extension for PyTorch. The [examples](textual_inversion) enable both single node and multi-node distributed training with Bfloat16 support on Intel Xeon Scalable Processor.
|
| 10 |
-
|
| 11 |
-
## Accelerating the inference for Stable Diffusion using Bfloat16
|
| 12 |
-
|
| 13 |
-
We start the inference acceleration with Bfloat16 using Intel Extension for PyTorch. The [script](inference_bf16.py) is generally designed to support standard Stable Diffusion models with Bfloat16 support.
|
| 14 |
-
```bash
|
| 15 |
-
pip install diffusers transformers accelerate scipy safetensors
|
| 16 |
-
|
| 17 |
-
export KMP_BLOCKTIME=1
|
| 18 |
-
export KMP_SETTINGS=1
|
| 19 |
-
export KMP_AFFINITY=granularity=fine,compact,1,0
|
| 20 |
-
|
| 21 |
-
# Intel OpenMP
|
| 22 |
-
export OMP_NUM_THREADS=< Cores to use >
|
| 23 |
-
export LD_PRELOAD=${LD_PRELOAD}:/path/to/lib/libiomp5.so
|
| 24 |
-
# Jemalloc is a recommended malloc implementation that emphasizes fragmentation avoidance and scalable concurrency support.
|
| 25 |
-
export LD_PRELOAD=${LD_PRELOAD}:/path/to/lib/libjemalloc.so
|
| 26 |
-
export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:-1,muzzy_decay_ms:9000000000"
|
| 27 |
-
|
| 28 |
-
# Launch with default DDIM
|
| 29 |
-
numactl --membind <node N> -C <cpu list> python python inference_bf16.py
|
| 30 |
-
# Launch with DPMSolverMultistepScheduler
|
| 31 |
-
numactl --membind <node N> -C <cpu list> python python inference_bf16.py --dpm
|
| 32 |
-
|
| 33 |
-
```
|
| 34 |
-
|
| 35 |
-
## Accelerating the inference for Stable Diffusion using INT8
|
| 36 |
-
|
| 37 |
-
Coming soon ...
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Andy1621/uniformer_image_detection/configs/foveabox/fovea_align_r50_fpn_gn-head_4x4_2x_coco.py
DELETED
|
@@ -1,10 +0,0 @@
|
|
| 1 |
-
_base_ = './fovea_r50_fpn_4x4_1x_coco.py'
|
| 2 |
-
model = dict(
|
| 3 |
-
bbox_head=dict(
|
| 4 |
-
with_deform=True,
|
| 5 |
-
norm_cfg=dict(type='GN', num_groups=32, requires_grad=True)))
|
| 6 |
-
# learning policy
|
| 7 |
-
lr_config = dict(step=[16, 22])
|
| 8 |
-
runner = dict(type='EpochBasedRunner', max_epochs=24)
|
| 9 |
-
optimizer_config = dict(
|
| 10 |
-
_delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Andy1621/uniformer_image_segmentation/configs/nonlocal_net/nonlocal_r101-d8_512x1024_40k_cityscapes.py
DELETED
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
_base_ = './nonlocal_r50-d8_512x1024_40k_cityscapes.py'
|
| 2 |
-
model = dict(pretrained='open-mmlab://resnet101_v1c', backbone=dict(depth=101))
|
|
|
|
|
|
|
|
|
spaces/Andy1621/uniformer_image_segmentation/configs/pspnet/pspnet_r50-d8_769x769_40k_cityscapes.py
DELETED
|
@@ -1,9 +0,0 @@
|
|
| 1 |
-
_base_ = [
|
| 2 |
-
'../_base_/models/pspnet_r50-d8.py',
|
| 3 |
-
'../_base_/datasets/cityscapes_769x769.py', '../_base_/default_runtime.py',
|
| 4 |
-
'../_base_/schedules/schedule_40k.py'
|
| 5 |
-
]
|
| 6 |
-
model = dict(
|
| 7 |
-
decode_head=dict(align_corners=True),
|
| 8 |
-
auxiliary_head=dict(align_corners=True),
|
| 9 |
-
test_cfg=dict(mode='slide', crop_size=(769, 769), stride=(513, 513)))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AndySAnker/DeepStruc/models/README.md
DELETED
|
@@ -1,5 +0,0 @@
|
|
| 1 |
-
[ChemRxiv](https://chemrxiv.org/engage/chemrxiv/article-details/6221f17357a9d20c9a729ecb) | [Paper](https://pubs.rsc.org/en/content/articlelanding/2023/dd/d2dd00086e)
|
| 2 |
-
|
| 3 |
-
# Models
|
| 4 |
-
This folder contain the DeepStruc model and all other trained models will be save here with the folder name:
|
| 5 |
-
DeepStruc-year-month-day-time.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmcv/ops/cc_attention.py
DELETED
|
@@ -1,83 +0,0 @@
|
|
| 1 |
-
# Copyright (c) OpenMMLab. All rights reserved.
|
| 2 |
-
import torch
|
| 3 |
-
import torch.nn as nn
|
| 4 |
-
import torch.nn.functional as F
|
| 5 |
-
|
| 6 |
-
from annotator.uniformer.mmcv.cnn import PLUGIN_LAYERS, Scale
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
def NEG_INF_DIAG(n, device):
|
| 10 |
-
"""Returns a diagonal matrix of size [n, n].
|
| 11 |
-
|
| 12 |
-
The diagonal are all "-inf". This is for avoiding calculating the
|
| 13 |
-
overlapped element in the Criss-Cross twice.
|
| 14 |
-
"""
|
| 15 |
-
return torch.diag(torch.tensor(float('-inf')).to(device).repeat(n), 0)
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
@PLUGIN_LAYERS.register_module()
|
| 19 |
-
class CrissCrossAttention(nn.Module):
|
| 20 |
-
"""Criss-Cross Attention Module.
|
| 21 |
-
|
| 22 |
-
.. note::
|
| 23 |
-
Before v1.3.13, we use a CUDA op. Since v1.3.13, we switch
|
| 24 |
-
to a pure PyTorch and equivalent implementation. For more
|
| 25 |
-
details, please refer to https://github.com/open-mmlab/mmcv/pull/1201.
|
| 26 |
-
|
| 27 |
-
Speed comparison for one forward pass
|
| 28 |
-
|
| 29 |
-
- Input size: [2,512,97,97]
|
| 30 |
-
- Device: 1 NVIDIA GeForce RTX 2080 Ti
|
| 31 |
-
|
| 32 |
-
+-----------------------+---------------+------------+---------------+
|
| 33 |
-
| |PyTorch version|CUDA version|Relative speed |
|
| 34 |
-
+=======================+===============+============+===============+
|
| 35 |
-
|with torch.no_grad() |0.00554402 s |0.0299619 s |5.4x |
|
| 36 |
-
+-----------------------+---------------+------------+---------------+
|
| 37 |
-
|no with torch.no_grad()|0.00562803 s |0.0301349 s |5.4x |
|
| 38 |
-
+-----------------------+---------------+------------+---------------+
|
| 39 |
-
|
| 40 |
-
Args:
|
| 41 |
-
in_channels (int): Channels of the input feature map.
|
| 42 |
-
"""
|
| 43 |
-
|
| 44 |
-
def __init__(self, in_channels):
|
| 45 |
-
super().__init__()
|
| 46 |
-
self.query_conv = nn.Conv2d(in_channels, in_channels // 8, 1)
|
| 47 |
-
self.key_conv = nn.Conv2d(in_channels, in_channels // 8, 1)
|
| 48 |
-
self.value_conv = nn.Conv2d(in_channels, in_channels, 1)
|
| 49 |
-
self.gamma = Scale(0.)
|
| 50 |
-
self.in_channels = in_channels
|
| 51 |
-
|
| 52 |
-
def forward(self, x):
|
| 53 |
-
"""forward function of Criss-Cross Attention.
|
| 54 |
-
|
| 55 |
-
Args:
|
| 56 |
-
x (Tensor): Input feature. \
|
| 57 |
-
shape (batch_size, in_channels, height, width)
|
| 58 |
-
Returns:
|
| 59 |
-
Tensor: Output of the layer, with shape of \
|
| 60 |
-
(batch_size, in_channels, height, width)
|
| 61 |
-
"""
|
| 62 |
-
B, C, H, W = x.size()
|
| 63 |
-
query = self.query_conv(x)
|
| 64 |
-
key = self.key_conv(x)
|
| 65 |
-
value = self.value_conv(x)
|
| 66 |
-
energy_H = torch.einsum('bchw,bciw->bwhi', query, key) + NEG_INF_DIAG(
|
| 67 |
-
H, query.device)
|
| 68 |
-
energy_H = energy_H.transpose(1, 2)
|
| 69 |
-
energy_W = torch.einsum('bchw,bchj->bhwj', query, key)
|
| 70 |
-
attn = F.softmax(
|
| 71 |
-
torch.cat([energy_H, energy_W], dim=-1), dim=-1) # [B,H,W,(H+W)]
|
| 72 |
-
out = torch.einsum('bciw,bhwi->bchw', value, attn[..., :H])
|
| 73 |
-
out += torch.einsum('bchj,bhwj->bchw', value, attn[..., H:])
|
| 74 |
-
|
| 75 |
-
out = self.gamma(out) + x
|
| 76 |
-
out = out.contiguous()
|
| 77 |
-
|
| 78 |
-
return out
|
| 79 |
-
|
| 80 |
-
def __repr__(self):
|
| 81 |
-
s = self.__class__.__name__
|
| 82 |
-
s += f'(in_channels={self.in_channels})'
|
| 83 |
-
return s
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ariharasudhan/YoloV5/utils/__init__.py
DELETED
|
@@ -1,80 +0,0 @@
|
|
| 1 |
-
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
| 2 |
-
"""
|
| 3 |
-
utils/initialization
|
| 4 |
-
"""
|
| 5 |
-
|
| 6 |
-
import contextlib
|
| 7 |
-
import platform
|
| 8 |
-
import threading
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
def emojis(str=''):
|
| 12 |
-
# Return platform-dependent emoji-safe version of string
|
| 13 |
-
return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
class TryExcept(contextlib.ContextDecorator):
|
| 17 |
-
# YOLOv5 TryExcept class. Usage: @TryExcept() decorator or 'with TryExcept():' context manager
|
| 18 |
-
def __init__(self, msg=''):
|
| 19 |
-
self.msg = msg
|
| 20 |
-
|
| 21 |
-
def __enter__(self):
|
| 22 |
-
pass
|
| 23 |
-
|
| 24 |
-
def __exit__(self, exc_type, value, traceback):
|
| 25 |
-
if value:
|
| 26 |
-
print(emojis(f"{self.msg}{': ' if self.msg else ''}{value}"))
|
| 27 |
-
return True
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
def threaded(func):
|
| 31 |
-
# Multi-threads a target function and returns thread. Usage: @threaded decorator
|
| 32 |
-
def wrapper(*args, **kwargs):
|
| 33 |
-
thread = threading.Thread(target=func, args=args, kwargs=kwargs, daemon=True)
|
| 34 |
-
thread.start()
|
| 35 |
-
return thread
|
| 36 |
-
|
| 37 |
-
return wrapper
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
def join_threads(verbose=False):
|
| 41 |
-
# Join all daemon threads, i.e. atexit.register(lambda: join_threads())
|
| 42 |
-
main_thread = threading.current_thread()
|
| 43 |
-
for t in threading.enumerate():
|
| 44 |
-
if t is not main_thread:
|
| 45 |
-
if verbose:
|
| 46 |
-
print(f'Joining thread {t.name}')
|
| 47 |
-
t.join()
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
def notebook_init(verbose=True):
|
| 51 |
-
# Check system software and hardware
|
| 52 |
-
print('Checking setup...')
|
| 53 |
-
|
| 54 |
-
import os
|
| 55 |
-
import shutil
|
| 56 |
-
|
| 57 |
-
from utils.general import check_font, check_requirements, is_colab
|
| 58 |
-
from utils.torch_utils import select_device # imports
|
| 59 |
-
|
| 60 |
-
check_font()
|
| 61 |
-
|
| 62 |
-
import psutil
|
| 63 |
-
from IPython import display # to display images and clear console output
|
| 64 |
-
|
| 65 |
-
if is_colab():
|
| 66 |
-
shutil.rmtree('/content/sample_data', ignore_errors=True) # remove colab /sample_data directory
|
| 67 |
-
|
| 68 |
-
# System info
|
| 69 |
-
if verbose:
|
| 70 |
-
gb = 1 << 30 # bytes to GiB (1024 ** 3)
|
| 71 |
-
ram = psutil.virtual_memory().total
|
| 72 |
-
total, used, free = shutil.disk_usage("/")
|
| 73 |
-
display.clear_output()
|
| 74 |
-
s = f'({os.cpu_count()} CPUs, {ram / gb:.1f} GB RAM, {(total - free) / gb:.1f}/{total / gb:.1f} GB disk)'
|
| 75 |
-
else:
|
| 76 |
-
s = ''
|
| 77 |
-
|
| 78 |
-
select_device(newline=False)
|
| 79 |
-
print(emojis(f'Setup complete ✅ {s}'))
|
| 80 |
-
return display
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Arnaudding001/FrenchTranslationAI/README.md
DELETED
|
@@ -1,12 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: FrenchTranslationAI
|
| 3 |
-
emoji: 🔥
|
| 4 |
-
colorFrom: green
|
| 5 |
-
colorTo: pink
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.4.1
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
---
|
| 11 |
-
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Arnx/MusicGenXvAKN/tests/modules/test_seanet.py
DELETED
|
@@ -1,115 +0,0 @@
|
|
| 1 |
-
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
-
# All rights reserved.
|
| 3 |
-
#
|
| 4 |
-
# This source code is licensed under the license found in the
|
| 5 |
-
# LICENSE file in the root directory of this source tree.
|
| 6 |
-
|
| 7 |
-
from itertools import product
|
| 8 |
-
|
| 9 |
-
import pytest
|
| 10 |
-
import torch
|
| 11 |
-
|
| 12 |
-
from audiocraft.modules.seanet import SEANetEncoder, SEANetDecoder, SEANetResnetBlock
|
| 13 |
-
from audiocraft.modules import StreamableConv1d, StreamableConvTranspose1d
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
class TestSEANetModel:
|
| 17 |
-
|
| 18 |
-
def test_base(self):
|
| 19 |
-
encoder = SEANetEncoder()
|
| 20 |
-
decoder = SEANetDecoder()
|
| 21 |
-
|
| 22 |
-
x = torch.randn(1, 1, 24000)
|
| 23 |
-
z = encoder(x)
|
| 24 |
-
assert list(z.shape) == [1, 128, 75], z.shape
|
| 25 |
-
y = decoder(z)
|
| 26 |
-
assert y.shape == x.shape, (x.shape, y.shape)
|
| 27 |
-
|
| 28 |
-
def test_causal(self):
|
| 29 |
-
encoder = SEANetEncoder(causal=True)
|
| 30 |
-
decoder = SEANetDecoder(causal=True)
|
| 31 |
-
x = torch.randn(1, 1, 24000)
|
| 32 |
-
|
| 33 |
-
z = encoder(x)
|
| 34 |
-
assert list(z.shape) == [1, 128, 75], z.shape
|
| 35 |
-
y = decoder(z)
|
| 36 |
-
assert y.shape == x.shape, (x.shape, y.shape)
|
| 37 |
-
|
| 38 |
-
def test_conv_skip_connection(self):
|
| 39 |
-
encoder = SEANetEncoder(true_skip=False)
|
| 40 |
-
decoder = SEANetDecoder(true_skip=False)
|
| 41 |
-
|
| 42 |
-
x = torch.randn(1, 1, 24000)
|
| 43 |
-
z = encoder(x)
|
| 44 |
-
assert list(z.shape) == [1, 128, 75], z.shape
|
| 45 |
-
y = decoder(z)
|
| 46 |
-
assert y.shape == x.shape, (x.shape, y.shape)
|
| 47 |
-
|
| 48 |
-
def test_seanet_encoder_decoder_final_act(self):
|
| 49 |
-
encoder = SEANetEncoder(true_skip=False)
|
| 50 |
-
decoder = SEANetDecoder(true_skip=False, final_activation='Tanh')
|
| 51 |
-
|
| 52 |
-
x = torch.randn(1, 1, 24000)
|
| 53 |
-
z = encoder(x)
|
| 54 |
-
assert list(z.shape) == [1, 128, 75], z.shape
|
| 55 |
-
y = decoder(z)
|
| 56 |
-
assert y.shape == x.shape, (x.shape, y.shape)
|
| 57 |
-
|
| 58 |
-
def _check_encoder_blocks_norm(self, encoder: SEANetEncoder, n_disable_blocks: int, norm: str):
|
| 59 |
-
n_blocks = 0
|
| 60 |
-
for layer in encoder.model:
|
| 61 |
-
if isinstance(layer, StreamableConv1d):
|
| 62 |
-
n_blocks += 1
|
| 63 |
-
assert layer.conv.norm_type == 'none' if n_blocks <= n_disable_blocks else norm
|
| 64 |
-
elif isinstance(layer, SEANetResnetBlock):
|
| 65 |
-
for resnet_layer in layer.block:
|
| 66 |
-
if isinstance(resnet_layer, StreamableConv1d):
|
| 67 |
-
# here we add + 1 to n_blocks as we increment n_blocks just after the block
|
| 68 |
-
assert resnet_layer.conv.norm_type == 'none' if (n_blocks + 1) <= n_disable_blocks else norm
|
| 69 |
-
|
| 70 |
-
def test_encoder_disable_norm(self):
|
| 71 |
-
n_residuals = [0, 1, 3]
|
| 72 |
-
disable_blocks = [0, 1, 2, 3, 4, 5, 6]
|
| 73 |
-
norms = ['weight_norm', 'none']
|
| 74 |
-
for n_res, disable_blocks, norm in product(n_residuals, disable_blocks, norms):
|
| 75 |
-
encoder = SEANetEncoder(n_residual_layers=n_res, norm=norm,
|
| 76 |
-
disable_norm_outer_blocks=disable_blocks)
|
| 77 |
-
self._check_encoder_blocks_norm(encoder, disable_blocks, norm)
|
| 78 |
-
|
| 79 |
-
def _check_decoder_blocks_norm(self, decoder: SEANetDecoder, n_disable_blocks: int, norm: str):
|
| 80 |
-
n_blocks = 0
|
| 81 |
-
for layer in decoder.model:
|
| 82 |
-
if isinstance(layer, StreamableConv1d):
|
| 83 |
-
n_blocks += 1
|
| 84 |
-
assert layer.conv.norm_type == 'none' if (decoder.n_blocks - n_blocks) < n_disable_blocks else norm
|
| 85 |
-
elif isinstance(layer, StreamableConvTranspose1d):
|
| 86 |
-
n_blocks += 1
|
| 87 |
-
assert layer.convtr.norm_type == 'none' if (decoder.n_blocks - n_blocks) < n_disable_blocks else norm
|
| 88 |
-
elif isinstance(layer, SEANetResnetBlock):
|
| 89 |
-
for resnet_layer in layer.block:
|
| 90 |
-
if isinstance(resnet_layer, StreamableConv1d):
|
| 91 |
-
assert resnet_layer.conv.norm_type == 'none' \
|
| 92 |
-
if (decoder.n_blocks - n_blocks) < n_disable_blocks else norm
|
| 93 |
-
|
| 94 |
-
def test_decoder_disable_norm(self):
|
| 95 |
-
n_residuals = [0, 1, 3]
|
| 96 |
-
disable_blocks = [0, 1, 2, 3, 4, 5, 6]
|
| 97 |
-
norms = ['weight_norm', 'none']
|
| 98 |
-
for n_res, disable_blocks, norm in product(n_residuals, disable_blocks, norms):
|
| 99 |
-
decoder = SEANetDecoder(n_residual_layers=n_res, norm=norm,
|
| 100 |
-
disable_norm_outer_blocks=disable_blocks)
|
| 101 |
-
self._check_decoder_blocks_norm(decoder, disable_blocks, norm)
|
| 102 |
-
|
| 103 |
-
def test_disable_norm_raises_exception(self):
|
| 104 |
-
# Invalid disable_norm_outer_blocks values raise exceptions
|
| 105 |
-
with pytest.raises(AssertionError):
|
| 106 |
-
SEANetEncoder(disable_norm_outer_blocks=-1)
|
| 107 |
-
|
| 108 |
-
with pytest.raises(AssertionError):
|
| 109 |
-
SEANetEncoder(ratios=[1, 1, 2, 2], disable_norm_outer_blocks=7)
|
| 110 |
-
|
| 111 |
-
with pytest.raises(AssertionError):
|
| 112 |
-
SEANetDecoder(disable_norm_outer_blocks=-1)
|
| 113 |
-
|
| 114 |
-
with pytest.raises(AssertionError):
|
| 115 |
-
SEANetDecoder(ratios=[1, 1, 2, 2], disable_norm_outer_blocks=7)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/rich/file_proxy.py
DELETED
|
@@ -1,57 +0,0 @@
|
|
| 1 |
-
import io
|
| 2 |
-
from typing import IO, TYPE_CHECKING, Any, List
|
| 3 |
-
|
| 4 |
-
from .ansi import AnsiDecoder
|
| 5 |
-
from .text import Text
|
| 6 |
-
|
| 7 |
-
if TYPE_CHECKING:
|
| 8 |
-
from .console import Console
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
class FileProxy(io.TextIOBase):
|
| 12 |
-
"""Wraps a file (e.g. sys.stdout) and redirects writes to a console."""
|
| 13 |
-
|
| 14 |
-
def __init__(self, console: "Console", file: IO[str]) -> None:
|
| 15 |
-
self.__console = console
|
| 16 |
-
self.__file = file
|
| 17 |
-
self.__buffer: List[str] = []
|
| 18 |
-
self.__ansi_decoder = AnsiDecoder()
|
| 19 |
-
|
| 20 |
-
@property
|
| 21 |
-
def rich_proxied_file(self) -> IO[str]:
|
| 22 |
-
"""Get proxied file."""
|
| 23 |
-
return self.__file
|
| 24 |
-
|
| 25 |
-
def __getattr__(self, name: str) -> Any:
|
| 26 |
-
return getattr(self.__file, name)
|
| 27 |
-
|
| 28 |
-
def write(self, text: str) -> int:
|
| 29 |
-
if not isinstance(text, str):
|
| 30 |
-
raise TypeError(f"write() argument must be str, not {type(text).__name__}")
|
| 31 |
-
buffer = self.__buffer
|
| 32 |
-
lines: List[str] = []
|
| 33 |
-
while text:
|
| 34 |
-
line, new_line, text = text.partition("\n")
|
| 35 |
-
if new_line:
|
| 36 |
-
lines.append("".join(buffer) + line)
|
| 37 |
-
buffer.clear()
|
| 38 |
-
else:
|
| 39 |
-
buffer.append(line)
|
| 40 |
-
break
|
| 41 |
-
if lines:
|
| 42 |
-
console = self.__console
|
| 43 |
-
with console:
|
| 44 |
-
output = Text("\n").join(
|
| 45 |
-
self.__ansi_decoder.decode_line(line) for line in lines
|
| 46 |
-
)
|
| 47 |
-
console.print(output)
|
| 48 |
-
return len(text)
|
| 49 |
-
|
| 50 |
-
def flush(self) -> None:
|
| 51 |
-
output = "".join(self.__buffer)
|
| 52 |
-
if output:
|
| 53 |
-
self.__console.print(output)
|
| 54 |
-
del self.__buffer[:]
|
| 55 |
-
|
| 56 |
-
def fileno(self) -> int:
|
| 57 |
-
return self.__file.fileno()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/_vendor/importlib_metadata/_text.py
DELETED
|
@@ -1,99 +0,0 @@
|
|
| 1 |
-
import re
|
| 2 |
-
|
| 3 |
-
from ._functools import method_cache
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
# from jaraco.text 3.5
|
| 7 |
-
class FoldedCase(str):
|
| 8 |
-
"""
|
| 9 |
-
A case insensitive string class; behaves just like str
|
| 10 |
-
except compares equal when the only variation is case.
|
| 11 |
-
|
| 12 |
-
>>> s = FoldedCase('hello world')
|
| 13 |
-
|
| 14 |
-
>>> s == 'Hello World'
|
| 15 |
-
True
|
| 16 |
-
|
| 17 |
-
>>> 'Hello World' == s
|
| 18 |
-
True
|
| 19 |
-
|
| 20 |
-
>>> s != 'Hello World'
|
| 21 |
-
False
|
| 22 |
-
|
| 23 |
-
>>> s.index('O')
|
| 24 |
-
4
|
| 25 |
-
|
| 26 |
-
>>> s.split('O')
|
| 27 |
-
['hell', ' w', 'rld']
|
| 28 |
-
|
| 29 |
-
>>> sorted(map(FoldedCase, ['GAMMA', 'alpha', 'Beta']))
|
| 30 |
-
['alpha', 'Beta', 'GAMMA']
|
| 31 |
-
|
| 32 |
-
Sequence membership is straightforward.
|
| 33 |
-
|
| 34 |
-
>>> "Hello World" in [s]
|
| 35 |
-
True
|
| 36 |
-
>>> s in ["Hello World"]
|
| 37 |
-
True
|
| 38 |
-
|
| 39 |
-
You may test for set inclusion, but candidate and elements
|
| 40 |
-
must both be folded.
|
| 41 |
-
|
| 42 |
-
>>> FoldedCase("Hello World") in {s}
|
| 43 |
-
True
|
| 44 |
-
>>> s in {FoldedCase("Hello World")}
|
| 45 |
-
True
|
| 46 |
-
|
| 47 |
-
String inclusion works as long as the FoldedCase object
|
| 48 |
-
is on the right.
|
| 49 |
-
|
| 50 |
-
>>> "hello" in FoldedCase("Hello World")
|
| 51 |
-
True
|
| 52 |
-
|
| 53 |
-
But not if the FoldedCase object is on the left:
|
| 54 |
-
|
| 55 |
-
>>> FoldedCase('hello') in 'Hello World'
|
| 56 |
-
False
|
| 57 |
-
|
| 58 |
-
In that case, use in_:
|
| 59 |
-
|
| 60 |
-
>>> FoldedCase('hello').in_('Hello World')
|
| 61 |
-
True
|
| 62 |
-
|
| 63 |
-
>>> FoldedCase('hello') > FoldedCase('Hello')
|
| 64 |
-
False
|
| 65 |
-
"""
|
| 66 |
-
|
| 67 |
-
def __lt__(self, other):
|
| 68 |
-
return self.lower() < other.lower()
|
| 69 |
-
|
| 70 |
-
def __gt__(self, other):
|
| 71 |
-
return self.lower() > other.lower()
|
| 72 |
-
|
| 73 |
-
def __eq__(self, other):
|
| 74 |
-
return self.lower() == other.lower()
|
| 75 |
-
|
| 76 |
-
def __ne__(self, other):
|
| 77 |
-
return self.lower() != other.lower()
|
| 78 |
-
|
| 79 |
-
def __hash__(self):
|
| 80 |
-
return hash(self.lower())
|
| 81 |
-
|
| 82 |
-
def __contains__(self, other):
|
| 83 |
-
return super().lower().__contains__(other.lower())
|
| 84 |
-
|
| 85 |
-
def in_(self, other):
|
| 86 |
-
"Does self appear in other?"
|
| 87 |
-
return self in FoldedCase(other)
|
| 88 |
-
|
| 89 |
-
# cache lower since it's likely to be called frequently.
|
| 90 |
-
@method_cache
|
| 91 |
-
def lower(self):
|
| 92 |
-
return super().lower()
|
| 93 |
-
|
| 94 |
-
def index(self, sub):
|
| 95 |
-
return self.lower().index(sub.lower())
|
| 96 |
-
|
| 97 |
-
def split(self, splitter=' ', maxsplit=0):
|
| 98 |
-
pattern = re.compile(re.escape(splitter), re.I)
|
| 99 |
-
return pattern.split(self, maxsplit)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/command/build_clib.py
DELETED
|
@@ -1,101 +0,0 @@
|
|
| 1 |
-
import distutils.command.build_clib as orig
|
| 2 |
-
from distutils.errors import DistutilsSetupError
|
| 3 |
-
from distutils import log
|
| 4 |
-
from setuptools.dep_util import newer_pairwise_group
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
class build_clib(orig.build_clib):
|
| 8 |
-
"""
|
| 9 |
-
Override the default build_clib behaviour to do the following:
|
| 10 |
-
|
| 11 |
-
1. Implement a rudimentary timestamp-based dependency system
|
| 12 |
-
so 'compile()' doesn't run every time.
|
| 13 |
-
2. Add more keys to the 'build_info' dictionary:
|
| 14 |
-
* obj_deps - specify dependencies for each object compiled.
|
| 15 |
-
this should be a dictionary mapping a key
|
| 16 |
-
with the source filename to a list of
|
| 17 |
-
dependencies. Use an empty string for global
|
| 18 |
-
dependencies.
|
| 19 |
-
* cflags - specify a list of additional flags to pass to
|
| 20 |
-
the compiler.
|
| 21 |
-
"""
|
| 22 |
-
|
| 23 |
-
def build_libraries(self, libraries):
|
| 24 |
-
for (lib_name, build_info) in libraries:
|
| 25 |
-
sources = build_info.get('sources')
|
| 26 |
-
if sources is None or not isinstance(sources, (list, tuple)):
|
| 27 |
-
raise DistutilsSetupError(
|
| 28 |
-
"in 'libraries' option (library '%s'), "
|
| 29 |
-
"'sources' must be present and must be "
|
| 30 |
-
"a list of source filenames" % lib_name)
|
| 31 |
-
sources = list(sources)
|
| 32 |
-
|
| 33 |
-
log.info("building '%s' library", lib_name)
|
| 34 |
-
|
| 35 |
-
# Make sure everything is the correct type.
|
| 36 |
-
# obj_deps should be a dictionary of keys as sources
|
| 37 |
-
# and a list/tuple of files that are its dependencies.
|
| 38 |
-
obj_deps = build_info.get('obj_deps', dict())
|
| 39 |
-
if not isinstance(obj_deps, dict):
|
| 40 |
-
raise DistutilsSetupError(
|
| 41 |
-
"in 'libraries' option (library '%s'), "
|
| 42 |
-
"'obj_deps' must be a dictionary of "
|
| 43 |
-
"type 'source: list'" % lib_name)
|
| 44 |
-
dependencies = []
|
| 45 |
-
|
| 46 |
-
# Get the global dependencies that are specified by the '' key.
|
| 47 |
-
# These will go into every source's dependency list.
|
| 48 |
-
global_deps = obj_deps.get('', list())
|
| 49 |
-
if not isinstance(global_deps, (list, tuple)):
|
| 50 |
-
raise DistutilsSetupError(
|
| 51 |
-
"in 'libraries' option (library '%s'), "
|
| 52 |
-
"'obj_deps' must be a dictionary of "
|
| 53 |
-
"type 'source: list'" % lib_name)
|
| 54 |
-
|
| 55 |
-
# Build the list to be used by newer_pairwise_group
|
| 56 |
-
# each source will be auto-added to its dependencies.
|
| 57 |
-
for source in sources:
|
| 58 |
-
src_deps = [source]
|
| 59 |
-
src_deps.extend(global_deps)
|
| 60 |
-
extra_deps = obj_deps.get(source, list())
|
| 61 |
-
if not isinstance(extra_deps, (list, tuple)):
|
| 62 |
-
raise DistutilsSetupError(
|
| 63 |
-
"in 'libraries' option (library '%s'), "
|
| 64 |
-
"'obj_deps' must be a dictionary of "
|
| 65 |
-
"type 'source: list'" % lib_name)
|
| 66 |
-
src_deps.extend(extra_deps)
|
| 67 |
-
dependencies.append(src_deps)
|
| 68 |
-
|
| 69 |
-
expected_objects = self.compiler.object_filenames(
|
| 70 |
-
sources,
|
| 71 |
-
output_dir=self.build_temp,
|
| 72 |
-
)
|
| 73 |
-
|
| 74 |
-
if (
|
| 75 |
-
newer_pairwise_group(dependencies, expected_objects)
|
| 76 |
-
!= ([], [])
|
| 77 |
-
):
|
| 78 |
-
# First, compile the source code to object files in the library
|
| 79 |
-
# directory. (This should probably change to putting object
|
| 80 |
-
# files in a temporary build directory.)
|
| 81 |
-
macros = build_info.get('macros')
|
| 82 |
-
include_dirs = build_info.get('include_dirs')
|
| 83 |
-
cflags = build_info.get('cflags')
|
| 84 |
-
self.compiler.compile(
|
| 85 |
-
sources,
|
| 86 |
-
output_dir=self.build_temp,
|
| 87 |
-
macros=macros,
|
| 88 |
-
include_dirs=include_dirs,
|
| 89 |
-
extra_postargs=cflags,
|
| 90 |
-
debug=self.debug
|
| 91 |
-
)
|
| 92 |
-
|
| 93 |
-
# Now "link" the object files together into a static library.
|
| 94 |
-
# (On Unix at least, this isn't really linking -- it just
|
| 95 |
-
# builds an archive. Whatever.)
|
| 96 |
-
self.compiler.create_static_lib(
|
| 97 |
-
expected_objects,
|
| 98 |
-
lib_name,
|
| 99 |
-
output_dir=self.build_clib,
|
| 100 |
-
debug=self.debug
|
| 101 |
-
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CVPR/LIVE/thrust/dependencies/cub/experimental/histogram/histogram_gmem_atomics.h
DELETED
|
@@ -1,185 +0,0 @@
|
|
| 1 |
-
/******************************************************************************
|
| 2 |
-
* Copyright (c) 2011-2018, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
-
*
|
| 4 |
-
* Redistribution and use in source and binary forms, with or without
|
| 5 |
-
* modification, are permitted provided that the following conditions are met:
|
| 6 |
-
* * Redistributions of source code must retain the above copyright
|
| 7 |
-
* notice, this list of conditions and the following disclaimer.
|
| 8 |
-
* * Redistributions in binary form must reproduce the above copyright
|
| 9 |
-
* notice, this list of conditions and the following disclaimer in the
|
| 10 |
-
* documentation and/or other materials provided with the distribution.
|
| 11 |
-
* * Neither the name of the NVIDIA CORPORATION nor the
|
| 12 |
-
* names of its contributors may be used to endorse or promote products
|
| 13 |
-
* derived from this software without specific prior written permission.
|
| 14 |
-
*
|
| 15 |
-
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
|
| 16 |
-
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
|
| 17 |
-
* WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 18 |
-
* DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
|
| 19 |
-
* DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
|
| 20 |
-
* (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
|
| 21 |
-
* LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
|
| 22 |
-
* ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
| 23 |
-
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
|
| 24 |
-
* SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 25 |
-
*
|
| 26 |
-
******************************************************************************/
|
| 27 |
-
|
| 28 |
-
#include <test/test_util.h>
|
| 29 |
-
|
| 30 |
-
namespace histogram_gmem_atomics
|
| 31 |
-
{
|
| 32 |
-
// Decode float4 pixel into bins
|
| 33 |
-
template <int NUM_BINS, int ACTIVE_CHANNELS>
|
| 34 |
-
__device__ __forceinline__ void DecodePixel(float4 pixel, unsigned int (&bins)[ACTIVE_CHANNELS])
|
| 35 |
-
{
|
| 36 |
-
float* samples = reinterpret_cast<float*>(&pixel);
|
| 37 |
-
|
| 38 |
-
#pragma unroll
|
| 39 |
-
for (int CHANNEL = 0; CHANNEL < ACTIVE_CHANNELS; ++CHANNEL)
|
| 40 |
-
bins[CHANNEL] = (unsigned int) (samples[CHANNEL] * float(NUM_BINS));
|
| 41 |
-
}
|
| 42 |
-
|
| 43 |
-
// Decode uchar4 pixel into bins
|
| 44 |
-
template <int NUM_BINS, int ACTIVE_CHANNELS>
|
| 45 |
-
__device__ __forceinline__ void DecodePixel(uchar4 pixel, unsigned int (&bins)[ACTIVE_CHANNELS])
|
| 46 |
-
{
|
| 47 |
-
unsigned char* samples = reinterpret_cast<unsigned char*>(&pixel);
|
| 48 |
-
|
| 49 |
-
#pragma unroll
|
| 50 |
-
for (int CHANNEL = 0; CHANNEL < ACTIVE_CHANNELS; ++CHANNEL)
|
| 51 |
-
bins[CHANNEL] = (unsigned int) (samples[CHANNEL]);
|
| 52 |
-
}
|
| 53 |
-
|
| 54 |
-
// Decode uchar1 pixel into bins
|
| 55 |
-
template <int NUM_BINS, int ACTIVE_CHANNELS>
|
| 56 |
-
__device__ __forceinline__ void DecodePixel(uchar1 pixel, unsigned int (&bins)[ACTIVE_CHANNELS])
|
| 57 |
-
{
|
| 58 |
-
bins[0] = (unsigned int) pixel.x;
|
| 59 |
-
}
|
| 60 |
-
|
| 61 |
-
// First-pass histogram kernel (binning into privatized counters)
|
| 62 |
-
template <
|
| 63 |
-
int NUM_PARTS,
|
| 64 |
-
int ACTIVE_CHANNELS,
|
| 65 |
-
int NUM_BINS,
|
| 66 |
-
typename PixelType>
|
| 67 |
-
__global__ void histogram_gmem_atomics(
|
| 68 |
-
const PixelType *in,
|
| 69 |
-
int width,
|
| 70 |
-
int height,
|
| 71 |
-
unsigned int *out)
|
| 72 |
-
{
|
| 73 |
-
// global position and size
|
| 74 |
-
int x = blockIdx.x * blockDim.x + threadIdx.x;
|
| 75 |
-
int y = blockIdx.y * blockDim.y + threadIdx.y;
|
| 76 |
-
int nx = blockDim.x * gridDim.x;
|
| 77 |
-
int ny = blockDim.y * gridDim.y;
|
| 78 |
-
|
| 79 |
-
// threads in workgroup
|
| 80 |
-
int t = threadIdx.x + threadIdx.y * blockDim.x; // thread index in workgroup, linear in 0..nt-1
|
| 81 |
-
int nt = blockDim.x * blockDim.y; // total threads in workgroup
|
| 82 |
-
|
| 83 |
-
// group index in 0..ngroups-1
|
| 84 |
-
int g = blockIdx.x + blockIdx.y * gridDim.x;
|
| 85 |
-
|
| 86 |
-
// initialize smem
|
| 87 |
-
unsigned int *gmem = out + g * NUM_PARTS;
|
| 88 |
-
for (int i = t; i < ACTIVE_CHANNELS * NUM_BINS; i += nt)
|
| 89 |
-
gmem[i] = 0;
|
| 90 |
-
__syncthreads();
|
| 91 |
-
|
| 92 |
-
// process pixels (updates our group's partial histogram in gmem)
|
| 93 |
-
for (int col = x; col < width; col += nx)
|
| 94 |
-
{
|
| 95 |
-
for (int row = y; row < height; row += ny)
|
| 96 |
-
{
|
| 97 |
-
PixelType pixel = in[row * width + col];
|
| 98 |
-
|
| 99 |
-
unsigned int bins[ACTIVE_CHANNELS];
|
| 100 |
-
DecodePixel<NUM_BINS>(pixel, bins);
|
| 101 |
-
|
| 102 |
-
#pragma unroll
|
| 103 |
-
for (int CHANNEL = 0; CHANNEL < ACTIVE_CHANNELS; ++CHANNEL)
|
| 104 |
-
atomicAdd(&gmem[(NUM_BINS * CHANNEL) + bins[CHANNEL]], 1);
|
| 105 |
-
}
|
| 106 |
-
}
|
| 107 |
-
}
|
| 108 |
-
|
| 109 |
-
// Second pass histogram kernel (accumulation)
|
| 110 |
-
template <
|
| 111 |
-
int NUM_PARTS,
|
| 112 |
-
int ACTIVE_CHANNELS,
|
| 113 |
-
int NUM_BINS>
|
| 114 |
-
__global__ void histogram_gmem_accum(
|
| 115 |
-
const unsigned int *in,
|
| 116 |
-
int n,
|
| 117 |
-
unsigned int *out)
|
| 118 |
-
{
|
| 119 |
-
int i = blockIdx.x * blockDim.x + threadIdx.x;
|
| 120 |
-
if (i > ACTIVE_CHANNELS * NUM_BINS)
|
| 121 |
-
return; // out of range
|
| 122 |
-
|
| 123 |
-
unsigned int total = 0;
|
| 124 |
-
for (int j = 0; j < n; j++)
|
| 125 |
-
total += in[i + NUM_PARTS * j];
|
| 126 |
-
|
| 127 |
-
out[i] = total;
|
| 128 |
-
}
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
} // namespace histogram_gmem_atomics
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
template <
|
| 135 |
-
int ACTIVE_CHANNELS,
|
| 136 |
-
int NUM_BINS,
|
| 137 |
-
typename PixelType>
|
| 138 |
-
double run_gmem_atomics(
|
| 139 |
-
PixelType *d_image,
|
| 140 |
-
int width,
|
| 141 |
-
int height,
|
| 142 |
-
unsigned int *d_hist,
|
| 143 |
-
bool warmup)
|
| 144 |
-
{
|
| 145 |
-
enum
|
| 146 |
-
{
|
| 147 |
-
NUM_PARTS = 1024
|
| 148 |
-
};
|
| 149 |
-
|
| 150 |
-
cudaDeviceProp props;
|
| 151 |
-
cudaGetDeviceProperties(&props, 0);
|
| 152 |
-
|
| 153 |
-
dim3 block(32, 4);
|
| 154 |
-
dim3 grid(16, 16);
|
| 155 |
-
int total_blocks = grid.x * grid.y;
|
| 156 |
-
|
| 157 |
-
// allocate partial histogram
|
| 158 |
-
unsigned int *d_part_hist;
|
| 159 |
-
cudaMalloc(&d_part_hist, total_blocks * NUM_PARTS * sizeof(unsigned int));
|
| 160 |
-
|
| 161 |
-
dim3 block2(128);
|
| 162 |
-
dim3 grid2((3 * NUM_BINS + block.x - 1) / block.x);
|
| 163 |
-
|
| 164 |
-
GpuTimer gpu_timer;
|
| 165 |
-
gpu_timer.Start();
|
| 166 |
-
|
| 167 |
-
histogram_gmem_atomics::histogram_gmem_atomics<NUM_PARTS, ACTIVE_CHANNELS, NUM_BINS><<<grid, block>>>(
|
| 168 |
-
d_image,
|
| 169 |
-
width,
|
| 170 |
-
height,
|
| 171 |
-
d_part_hist);
|
| 172 |
-
|
| 173 |
-
histogram_gmem_atomics::histogram_gmem_accum<NUM_PARTS, ACTIVE_CHANNELS, NUM_BINS><<<grid2, block2>>>(
|
| 174 |
-
d_part_hist,
|
| 175 |
-
total_blocks,
|
| 176 |
-
d_hist);
|
| 177 |
-
|
| 178 |
-
gpu_timer.Stop();
|
| 179 |
-
float elapsed_millis = gpu_timer.ElapsedMillis();
|
| 180 |
-
|
| 181 |
-
cudaFree(d_part_hist);
|
| 182 |
-
|
| 183 |
-
return elapsed_millis;
|
| 184 |
-
}
|
| 185 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CVPR/LIVE/thrust/thrust/system/detail/generic/find.h
DELETED
|
@@ -1,63 +0,0 @@
|
|
| 1 |
-
/*
|
| 2 |
-
* Copyright 2008-2013 NVIDIA Corporation
|
| 3 |
-
*
|
| 4 |
-
* Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
-
* you may not use this file except in compliance with the License.
|
| 6 |
-
* You may obtain a copy of the License at
|
| 7 |
-
*
|
| 8 |
-
* http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
-
*
|
| 10 |
-
* Unless required by applicable law or agreed to in writing, software
|
| 11 |
-
* distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
-
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
-
* See the License for the specific language governing permissions and
|
| 14 |
-
* limitations under the License.
|
| 15 |
-
*/
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
#pragma once
|
| 19 |
-
|
| 20 |
-
#include <thrust/detail/config.h>
|
| 21 |
-
#include <thrust/system/detail/generic/tag.h>
|
| 22 |
-
|
| 23 |
-
namespace thrust
|
| 24 |
-
{
|
| 25 |
-
namespace system
|
| 26 |
-
{
|
| 27 |
-
namespace detail
|
| 28 |
-
{
|
| 29 |
-
namespace generic
|
| 30 |
-
{
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
template<typename DerivedPolicy, typename InputIterator, typename T>
|
| 34 |
-
__host__ __device__
|
| 35 |
-
InputIterator find(thrust::execution_policy<DerivedPolicy> &exec,
|
| 36 |
-
InputIterator first,
|
| 37 |
-
InputIterator last,
|
| 38 |
-
const T& value);
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
template<typename DerivedPolicy, typename InputIterator, typename Predicate>
|
| 42 |
-
__host__ __device__
|
| 43 |
-
InputIterator find_if(thrust::execution_policy<DerivedPolicy> &exec,
|
| 44 |
-
InputIterator first,
|
| 45 |
-
InputIterator last,
|
| 46 |
-
Predicate pred);
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
template<typename DerivedPolicy, typename InputIterator, typename Predicate>
|
| 50 |
-
__host__ __device__
|
| 51 |
-
InputIterator find_if_not(thrust::execution_policy<DerivedPolicy> &exec,
|
| 52 |
-
InputIterator first,
|
| 53 |
-
InputIterator last,
|
| 54 |
-
Predicate pred);
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
} // end namespace generic
|
| 58 |
-
} // end namespace detail
|
| 59 |
-
} // end namespace system
|
| 60 |
-
} // end namespace thrust
|
| 61 |
-
|
| 62 |
-
#include <thrust/system/detail/generic/find.inl>
|
| 63 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CYSD/AI-image-detector/app.py
DELETED
|
@@ -1,14 +0,0 @@
|
|
| 1 |
-
import gradio as gr
|
| 2 |
-
from transformers import pipeline
|
| 3 |
-
|
| 4 |
-
pipe = pipeline("image-classification", "umm-maybe/AI-image-detector")
|
| 5 |
-
|
| 6 |
-
def image_classifier(image):
|
| 7 |
-
outputs = pipe(image)
|
| 8 |
-
results = {}
|
| 9 |
-
for result in outputs:
|
| 10 |
-
results[result['label']] = result['score']
|
| 11 |
-
return results
|
| 12 |
-
|
| 13 |
-
demo = gr.Interface(fn=image_classifier, inputs=gr.Image(type="pil"), outputs="label")
|
| 14 |
-
demo.launch()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CarperAI/pile-v2-eda/README.md
DELETED
|
@@ -1,10 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: Pile V2 EDA
|
| 3 |
-
emoji: 🎄
|
| 4 |
-
colorFrom: indigo
|
| 5 |
-
colorTo: grey
|
| 6 |
-
sdk: streamlit
|
| 7 |
-
sdk_version: 1.10.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/ChandraMohanNayal/AutoGPT/autogpt/app.py
DELETED
|
@@ -1,330 +0,0 @@
|
|
| 1 |
-
""" Command and Control """
|
| 2 |
-
import json
|
| 3 |
-
from typing import Dict, List, NoReturn, Union
|
| 4 |
-
|
| 5 |
-
from autogpt.agent.agent_manager import AgentManager
|
| 6 |
-
from autogpt.commands.analyze_code import analyze_code
|
| 7 |
-
from autogpt.commands.audio_text import read_audio_from_file
|
| 8 |
-
from autogpt.commands.execute_code import (
|
| 9 |
-
execute_python_file,
|
| 10 |
-
execute_shell,
|
| 11 |
-
execute_shell_popen,
|
| 12 |
-
)
|
| 13 |
-
from autogpt.commands.file_operations import (
|
| 14 |
-
append_to_file,
|
| 15 |
-
delete_file,
|
| 16 |
-
download_file,
|
| 17 |
-
read_file,
|
| 18 |
-
search_files,
|
| 19 |
-
write_to_file,
|
| 20 |
-
)
|
| 21 |
-
from autogpt.commands.git_operations import clone_repository
|
| 22 |
-
from autogpt.commands.google_search import google_official_search, google_search
|
| 23 |
-
from autogpt.commands.image_gen import generate_image
|
| 24 |
-
from autogpt.commands.improve_code import improve_code
|
| 25 |
-
from autogpt.commands.twitter import send_tweet
|
| 26 |
-
from autogpt.commands.web_requests import scrape_links, scrape_text
|
| 27 |
-
from autogpt.commands.web_selenium import browse_website
|
| 28 |
-
from autogpt.commands.write_tests import write_tests
|
| 29 |
-
from autogpt.config import Config
|
| 30 |
-
from autogpt.json_utils.json_fix_llm import fix_and_parse_json
|
| 31 |
-
from autogpt.memory import get_memory
|
| 32 |
-
from autogpt.processing.text import summarize_text
|
| 33 |
-
from autogpt.speech import say_text
|
| 34 |
-
|
| 35 |
-
CFG = Config()
|
| 36 |
-
AGENT_MANAGER = AgentManager()
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
def is_valid_int(value: str) -> bool:
|
| 40 |
-
"""Check if the value is a valid integer
|
| 41 |
-
|
| 42 |
-
Args:
|
| 43 |
-
value (str): The value to check
|
| 44 |
-
|
| 45 |
-
Returns:
|
| 46 |
-
bool: True if the value is a valid integer, False otherwise
|
| 47 |
-
"""
|
| 48 |
-
try:
|
| 49 |
-
int(value)
|
| 50 |
-
return True
|
| 51 |
-
except ValueError:
|
| 52 |
-
return False
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
def get_command(response_json: Dict):
|
| 56 |
-
"""Parse the response and return the command name and arguments
|
| 57 |
-
|
| 58 |
-
Args:
|
| 59 |
-
response_json (json): The response from the AI
|
| 60 |
-
|
| 61 |
-
Returns:
|
| 62 |
-
tuple: The command name and arguments
|
| 63 |
-
|
| 64 |
-
Raises:
|
| 65 |
-
json.decoder.JSONDecodeError: If the response is not valid JSON
|
| 66 |
-
|
| 67 |
-
Exception: If any other error occurs
|
| 68 |
-
"""
|
| 69 |
-
try:
|
| 70 |
-
if "command" not in response_json:
|
| 71 |
-
return "Error:", "Missing 'command' object in JSON"
|
| 72 |
-
|
| 73 |
-
if not isinstance(response_json, dict):
|
| 74 |
-
return "Error:", f"'response_json' object is not dictionary {response_json}"
|
| 75 |
-
|
| 76 |
-
command = response_json["command"]
|
| 77 |
-
if not isinstance(command, dict):
|
| 78 |
-
return "Error:", "'command' object is not a dictionary"
|
| 79 |
-
|
| 80 |
-
if "name" not in command:
|
| 81 |
-
return "Error:", "Missing 'name' field in 'command' object"
|
| 82 |
-
|
| 83 |
-
command_name = command["name"]
|
| 84 |
-
|
| 85 |
-
# Use an empty dictionary if 'args' field is not present in 'command' object
|
| 86 |
-
arguments = command.get("args", {})
|
| 87 |
-
|
| 88 |
-
return command_name, arguments
|
| 89 |
-
except json.decoder.JSONDecodeError:
|
| 90 |
-
return "Error:", "Invalid JSON"
|
| 91 |
-
# All other errors, return "Error: + error message"
|
| 92 |
-
except Exception as e:
|
| 93 |
-
return "Error:", str(e)
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
def map_command_synonyms(command_name: str):
|
| 97 |
-
"""Takes the original command name given by the AI, and checks if the
|
| 98 |
-
string matches a list of common/known hallucinations
|
| 99 |
-
"""
|
| 100 |
-
synonyms = [
|
| 101 |
-
("write_file", "write_to_file"),
|
| 102 |
-
("create_file", "write_to_file"),
|
| 103 |
-
("search", "google"),
|
| 104 |
-
]
|
| 105 |
-
for seen_command, actual_command_name in synonyms:
|
| 106 |
-
if command_name == seen_command:
|
| 107 |
-
return actual_command_name
|
| 108 |
-
return command_name
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
def execute_command(command_name: str, arguments):
|
| 112 |
-
"""Execute the command and return the result
|
| 113 |
-
|
| 114 |
-
Args:
|
| 115 |
-
command_name (str): The name of the command to execute
|
| 116 |
-
arguments (dict): The arguments for the command
|
| 117 |
-
|
| 118 |
-
Returns:
|
| 119 |
-
str: The result of the command
|
| 120 |
-
"""
|
| 121 |
-
try:
|
| 122 |
-
command_name = map_command_synonyms(command_name.lower())
|
| 123 |
-
if command_name == "google":
|
| 124 |
-
# Check if the Google API key is set and use the official search method
|
| 125 |
-
# If the API key is not set or has only whitespaces, use the unofficial
|
| 126 |
-
# search method
|
| 127 |
-
key = CFG.google_api_key
|
| 128 |
-
if key and key.strip() and key != "your-google-api-key":
|
| 129 |
-
google_result = google_official_search(arguments["input"])
|
| 130 |
-
return google_result
|
| 131 |
-
else:
|
| 132 |
-
google_result = google_search(arguments["input"])
|
| 133 |
-
|
| 134 |
-
# google_result can be a list or a string depending on the search results
|
| 135 |
-
if isinstance(google_result, list):
|
| 136 |
-
safe_message = [
|
| 137 |
-
google_result_single.encode("utf-8", "ignore")
|
| 138 |
-
for google_result_single in google_result
|
| 139 |
-
]
|
| 140 |
-
else:
|
| 141 |
-
safe_message = google_result.encode("utf-8", "ignore")
|
| 142 |
-
|
| 143 |
-
return safe_message.decode("utf-8")
|
| 144 |
-
elif command_name == "memory_add":
|
| 145 |
-
memory = get_memory(CFG)
|
| 146 |
-
return memory.add(arguments["string"])
|
| 147 |
-
elif command_name == "start_agent":
|
| 148 |
-
return start_agent(
|
| 149 |
-
arguments["name"], arguments["task"], arguments["prompt"]
|
| 150 |
-
)
|
| 151 |
-
elif command_name == "message_agent":
|
| 152 |
-
return message_agent(arguments["key"], arguments["message"])
|
| 153 |
-
elif command_name == "list_agents":
|
| 154 |
-
return list_agents()
|
| 155 |
-
elif command_name == "delete_agent":
|
| 156 |
-
return delete_agent(arguments["key"])
|
| 157 |
-
elif command_name == "get_text_summary":
|
| 158 |
-
return get_text_summary(arguments["url"], arguments["question"])
|
| 159 |
-
elif command_name == "get_hyperlinks":
|
| 160 |
-
return get_hyperlinks(arguments["url"])
|
| 161 |
-
elif command_name == "clone_repository":
|
| 162 |
-
return clone_repository(
|
| 163 |
-
arguments["repository_url"], arguments["clone_path"]
|
| 164 |
-
)
|
| 165 |
-
elif command_name == "read_file":
|
| 166 |
-
return read_file(arguments["file"])
|
| 167 |
-
elif command_name == "write_to_file":
|
| 168 |
-
return write_to_file(arguments["file"], arguments["text"])
|
| 169 |
-
elif command_name == "append_to_file":
|
| 170 |
-
return append_to_file(arguments["file"], arguments["text"])
|
| 171 |
-
elif command_name == "delete_file":
|
| 172 |
-
return delete_file(arguments["file"])
|
| 173 |
-
elif command_name == "search_files":
|
| 174 |
-
return search_files(arguments["directory"])
|
| 175 |
-
elif command_name == "download_file":
|
| 176 |
-
if not CFG.allow_downloads:
|
| 177 |
-
return "Error: You do not have user authorization to download files locally."
|
| 178 |
-
return download_file(arguments["url"], arguments["file"])
|
| 179 |
-
elif command_name == "browse_website":
|
| 180 |
-
return browse_website(arguments["url"], arguments["question"])
|
| 181 |
-
# TODO: Change these to take in a file rather than pasted code, if
|
| 182 |
-
# non-file is given, return instructions "Input should be a python
|
| 183 |
-
# filepath, write your code to file and try again"
|
| 184 |
-
elif command_name == "analyze_code":
|
| 185 |
-
return analyze_code(arguments["code"])
|
| 186 |
-
elif command_name == "improve_code":
|
| 187 |
-
return improve_code(arguments["suggestions"], arguments["code"])
|
| 188 |
-
elif command_name == "write_tests":
|
| 189 |
-
return write_tests(arguments["code"], arguments.get("focus"))
|
| 190 |
-
elif command_name == "execute_python_file": # Add this command
|
| 191 |
-
return execute_python_file(arguments["file"])
|
| 192 |
-
elif command_name == "execute_shell":
|
| 193 |
-
if CFG.execute_local_commands:
|
| 194 |
-
return execute_shell(arguments["command_line"])
|
| 195 |
-
else:
|
| 196 |
-
return (
|
| 197 |
-
"You are not allowed to run local shell commands. To execute"
|
| 198 |
-
" shell commands, EXECUTE_LOCAL_COMMANDS must be set to 'True' "
|
| 199 |
-
"in your config. Do not attempt to bypass the restriction."
|
| 200 |
-
)
|
| 201 |
-
elif command_name == "execute_shell_popen":
|
| 202 |
-
if CFG.execute_local_commands:
|
| 203 |
-
return execute_shell_popen(arguments["command_line"])
|
| 204 |
-
else:
|
| 205 |
-
return (
|
| 206 |
-
"You are not allowed to run local shell commands. To execute"
|
| 207 |
-
" shell commands, EXECUTE_LOCAL_COMMANDS must be set to 'True' "
|
| 208 |
-
"in your config. Do not attempt to bypass the restriction."
|
| 209 |
-
)
|
| 210 |
-
elif command_name == "read_audio_from_file":
|
| 211 |
-
return read_audio_from_file(arguments["file"])
|
| 212 |
-
elif command_name == "generate_image":
|
| 213 |
-
return generate_image(arguments["prompt"])
|
| 214 |
-
elif command_name == "send_tweet":
|
| 215 |
-
return send_tweet(arguments["text"])
|
| 216 |
-
elif command_name == "do_nothing":
|
| 217 |
-
return "No action performed."
|
| 218 |
-
elif command_name == "task_complete":
|
| 219 |
-
shutdown()
|
| 220 |
-
else:
|
| 221 |
-
return (
|
| 222 |
-
f"Unknown command '{command_name}'. Please refer to the 'COMMANDS'"
|
| 223 |
-
" list for available commands and only respond in the specified JSON"
|
| 224 |
-
" format."
|
| 225 |
-
)
|
| 226 |
-
except Exception as e:
|
| 227 |
-
return f"Error: {str(e)}"
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
def get_text_summary(url: str, question: str) -> str:
|
| 231 |
-
"""Return the results of a Google search
|
| 232 |
-
|
| 233 |
-
Args:
|
| 234 |
-
url (str): The url to scrape
|
| 235 |
-
question (str): The question to summarize the text for
|
| 236 |
-
|
| 237 |
-
Returns:
|
| 238 |
-
str: The summary of the text
|
| 239 |
-
"""
|
| 240 |
-
text = scrape_text(url)
|
| 241 |
-
summary = summarize_text(url, text, question)
|
| 242 |
-
return f""" "Result" : {summary}"""
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
def get_hyperlinks(url: str) -> Union[str, List[str]]:
|
| 246 |
-
"""Return the results of a Google search
|
| 247 |
-
|
| 248 |
-
Args:
|
| 249 |
-
url (str): The url to scrape
|
| 250 |
-
|
| 251 |
-
Returns:
|
| 252 |
-
str or list: The hyperlinks on the page
|
| 253 |
-
"""
|
| 254 |
-
return scrape_links(url)
|
| 255 |
-
|
| 256 |
-
|
| 257 |
-
def shutdown() -> NoReturn:
|
| 258 |
-
"""Shut down the program"""
|
| 259 |
-
print("Shutting down...")
|
| 260 |
-
quit()
|
| 261 |
-
|
| 262 |
-
|
| 263 |
-
def start_agent(name: str, task: str, prompt: str, model=CFG.fast_llm_model) -> str:
|
| 264 |
-
"""Start an agent with a given name, task, and prompt
|
| 265 |
-
|
| 266 |
-
Args:
|
| 267 |
-
name (str): The name of the agent
|
| 268 |
-
task (str): The task of the agent
|
| 269 |
-
prompt (str): The prompt for the agent
|
| 270 |
-
model (str): The model to use for the agent
|
| 271 |
-
|
| 272 |
-
Returns:
|
| 273 |
-
str: The response of the agent
|
| 274 |
-
"""
|
| 275 |
-
# Remove underscores from name
|
| 276 |
-
voice_name = name.replace("_", " ")
|
| 277 |
-
|
| 278 |
-
first_message = f"""You are {name}. Respond with: "Acknowledged"."""
|
| 279 |
-
agent_intro = f"{voice_name} here, Reporting for duty!"
|
| 280 |
-
|
| 281 |
-
# Create agent
|
| 282 |
-
if CFG.speak_mode:
|
| 283 |
-
say_text(agent_intro, 1)
|
| 284 |
-
key, ack = AGENT_MANAGER.create_agent(task, first_message, model)
|
| 285 |
-
|
| 286 |
-
if CFG.speak_mode:
|
| 287 |
-
say_text(f"Hello {voice_name}. Your task is as follows. {task}.")
|
| 288 |
-
|
| 289 |
-
# Assign task (prompt), get response
|
| 290 |
-
agent_response = AGENT_MANAGER.message_agent(key, prompt)
|
| 291 |
-
|
| 292 |
-
return f"Agent {name} created with key {key}. First response: {agent_response}"
|
| 293 |
-
|
| 294 |
-
|
| 295 |
-
def message_agent(key: str, message: str) -> str:
|
| 296 |
-
"""Message an agent with a given key and message"""
|
| 297 |
-
# Check if the key is a valid integer
|
| 298 |
-
if is_valid_int(key):
|
| 299 |
-
agent_response = AGENT_MANAGER.message_agent(int(key), message)
|
| 300 |
-
else:
|
| 301 |
-
return "Invalid key, must be an integer."
|
| 302 |
-
|
| 303 |
-
# Speak response
|
| 304 |
-
if CFG.speak_mode:
|
| 305 |
-
say_text(agent_response, 1)
|
| 306 |
-
return agent_response
|
| 307 |
-
|
| 308 |
-
|
| 309 |
-
def list_agents():
|
| 310 |
-
"""List all agents
|
| 311 |
-
|
| 312 |
-
Returns:
|
| 313 |
-
str: A list of all agents
|
| 314 |
-
"""
|
| 315 |
-
return "List of agents:\n" + "\n".join(
|
| 316 |
-
[str(x[0]) + ": " + x[1] for x in AGENT_MANAGER.list_agents()]
|
| 317 |
-
)
|
| 318 |
-
|
| 319 |
-
|
| 320 |
-
def delete_agent(key: str) -> str:
|
| 321 |
-
"""Delete an agent with a given key
|
| 322 |
-
|
| 323 |
-
Args:
|
| 324 |
-
key (str): The key of the agent to delete
|
| 325 |
-
|
| 326 |
-
Returns:
|
| 327 |
-
str: A message indicating whether the agent was deleted or not
|
| 328 |
-
"""
|
| 329 |
-
result = AGENT_MANAGER.delete_agent(key)
|
| 330 |
-
return f"Agent {key} deleted." if result else f"Agent {key} does not exist."
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/ChandraMohanNayal/AutoGPT/autogpt/workspace.py
DELETED
|
@@ -1,47 +0,0 @@
|
|
| 1 |
-
from __future__ import annotations
|
| 2 |
-
|
| 3 |
-
import os
|
| 4 |
-
from pathlib import Path
|
| 5 |
-
|
| 6 |
-
from autogpt.config import Config
|
| 7 |
-
|
| 8 |
-
CFG = Config()
|
| 9 |
-
|
| 10 |
-
# Set a dedicated folder for file I/O
|
| 11 |
-
WORKSPACE_PATH = Path(os.getcwd()) / "auto_gpt_workspace"
|
| 12 |
-
|
| 13 |
-
# Create the directory if it doesn't exist
|
| 14 |
-
if not os.path.exists(WORKSPACE_PATH):
|
| 15 |
-
os.makedirs(WORKSPACE_PATH)
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
def path_in_workspace(relative_path: str | Path) -> Path:
|
| 19 |
-
"""Get full path for item in workspace
|
| 20 |
-
|
| 21 |
-
Parameters:
|
| 22 |
-
relative_path (str | Path): Path to translate into the workspace
|
| 23 |
-
|
| 24 |
-
Returns:
|
| 25 |
-
Path: Absolute path for the given path in the workspace
|
| 26 |
-
"""
|
| 27 |
-
return safe_path_join(WORKSPACE_PATH, relative_path)
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
def safe_path_join(base: Path, *paths: str | Path) -> Path:
|
| 31 |
-
"""Join one or more path components, asserting the resulting path is within the workspace.
|
| 32 |
-
|
| 33 |
-
Args:
|
| 34 |
-
base (Path): The base path
|
| 35 |
-
*paths (str): The paths to join to the base path
|
| 36 |
-
|
| 37 |
-
Returns:
|
| 38 |
-
Path: The joined path
|
| 39 |
-
"""
|
| 40 |
-
joined_path = base.joinpath(*paths).resolve()
|
| 41 |
-
|
| 42 |
-
if CFG.restrict_to_workspace and not joined_path.is_relative_to(base):
|
| 43 |
-
raise ValueError(
|
| 44 |
-
f"Attempted to access path '{joined_path}' outside of workspace '{base}'."
|
| 45 |
-
)
|
| 46 |
-
|
| 47 |
-
return joined_path
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Chris4K/llms_compare/Aloo Chaat Hd Movie Download 1080p __TOP__.md
DELETED
|
@@ -1,56 +0,0 @@
|
|
| 1 |
-
## Aloo Chaat hd movie download 1080p
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
**DOWNLOAD === [https://www.google.com/url?q=https%3A%2F%2Furlgoal.com%2F2txP38&sa=D&sntz=1&usg=AOvVaw1R1ga3x5jvhXx0u0qjRBzQ](https://www.google.com/url?q=https%3A%2F%2Furlgoal.com%2F2txP38&sa=D&sntz=1&usg=AOvVaw1R1ga3x5jvhXx0u0qjRBzQ)**
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
# Aloo Chaat: A Delicious Comedy of Love and Culture
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
Aloo Chaat is a 2009 Hindi romantic comedy film that revolves around the love story of Nikhil, a Hindu boy who falls in love with Aamna, a Muslim girl. Nikhil returns to his traditional family in India after completing his education in the US and faces the challenge of convincing them to accept his interfaith relationship. He enlists the help of his uncle Hakeem, a sexologist, and Nikki, an American girl, to create a fake marriage drama that would make Aamna look like a better choice for him.
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
The film is directed by Robbie Grewal and stars Aftab Shivdasani, Aamna Sharif, Linda Arsenio, Kulbhushan Kharbanda, Sanjai Mishra, and Manoj Pahwa. The film is full of hilarious situations, witty dialogues, and catchy songs that will make you laugh and enjoy the cultural differences and similarities between the characters. The film also explores the themes of family values, social norms, and personal choices in a light-hearted manner.
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
If you are looking for a fun and entertaining movie to watch with your family or friends, you can download Aloo Chaat in high definition quality from various online platforms. The film has received mixed reviews from critics but has been appreciated by the audience for its humor and charm. Aloo Chaat is a film that will make you crave for some spicy and tangy street food as well as some sweet and romantic moments.
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
The film has a simple plot but is executed with flair and creativity. The film uses the metaphor of aloo chaat, a spicy and tangy dish made of potatoes and various chutneys, to represent the mix of cultures and emotions that the characters go through. The film also has some catchy songs composed by RDB, Xulfi, Vipin Mishra and Mehfuz Maruf that add to the fun and flavor of the film. The film has some memorable scenes such as the one where Nikhil introduces Nikki to his family as his fiancee, the one where Aamna teaches Nikki how to cook Punjabi food, and the one where Nikhil and Aamna confess their love to each other.
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
The film also has some brilliant performances by the actors, especially Sanjai Mishra as Chhadami Mama, Nikhil's suspicious uncle who is always on the lookout for clues to expose Nikhil's plan. He delivers some hilarious dialogues and expressions that will make you laugh out loud. Manoj Pahwa as Hakeem Tarachand, Nikhil's uncle and confidant who helps him in his scheme, is also very funny and convincing. Kulbhushan Kharbanda as Purshottam, Nikhil's father who is a staunch believer in Hindu traditions and values, is also very impressive and shows his versatility as an actor. Aftab Shivdasani and Aamna Sharif have a good chemistry and look good together as the lead pair. Linda Arsenio as Nikki, the American girl who pretends to be Nikhil's fiancee, is also very charming and does a good job of playing a spoiled but sweet girl.
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
Aloo Chaat is a film that will appeal to anyone who likes comedy, romance, and culture. It is a film that will make you laugh, smile, and feel good. It is a film that will make you appreciate the diversity and richness of Indian culture and society. It is a film that will make you want to try some aloo chaat yourself.
|
| 50 |
-
|
| 51 |
-
dfd1c89656
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/ChrisPreston/diff-svc_minato_aqua/infer_tools/f0_static.py
DELETED
|
@@ -1,116 +0,0 @@
|
|
| 1 |
-
import json
|
| 2 |
-
import os
|
| 3 |
-
import shutil
|
| 4 |
-
from functools import reduce
|
| 5 |
-
from pathlib import Path
|
| 6 |
-
|
| 7 |
-
import matplotlib
|
| 8 |
-
import matplotlib.pyplot as plt
|
| 9 |
-
import yaml
|
| 10 |
-
from pylab import xticks, np
|
| 11 |
-
from tqdm import tqdm
|
| 12 |
-
|
| 13 |
-
from modules.vocoders.nsf_hifigan import NsfHifiGAN
|
| 14 |
-
from preprocessing.process_pipeline import get_pitch_parselmouth, get_pitch_crepe
|
| 15 |
-
from utils.hparams import set_hparams, hparams
|
| 16 |
-
|
| 17 |
-
head_list = ["C", "C#", "D", "D#", "E", "F", "F#", "G", "G#", "A", "A#", "B"]
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
def compare_pitch(f0_static_dict, pitch_time_temp, trans_key=0):
|
| 21 |
-
return sum({k: v * f0_static_dict[str(k + trans_key)] for k, v in pitch_time_temp.items() if
|
| 22 |
-
str(k + trans_key) in f0_static_dict}.values())
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
def f0_to_pitch(ff):
|
| 26 |
-
f0_pitch = 69 + 12 * np.log2(ff / 440)
|
| 27 |
-
return round(f0_pitch, 0)
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
def pitch_to_name(pitch):
|
| 31 |
-
return f"{head_list[int(pitch % 12)]}{int(pitch / 12) - 1}"
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
def get_f0(audio_path, crepe=False):
|
| 35 |
-
wav, mel = NsfHifiGAN.wav2spec(audio_path)
|
| 36 |
-
if crepe:
|
| 37 |
-
f0, pitch_coarse = get_pitch_crepe(wav, mel, hparams)
|
| 38 |
-
else:
|
| 39 |
-
f0, pitch_coarse = get_pitch_parselmouth(wav, mel, hparams)
|
| 40 |
-
return f0
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
def merge_f0_dict(dict_list):
|
| 44 |
-
def sum_dict(a, b):
|
| 45 |
-
temp = dict()
|
| 46 |
-
for key in a.keys() | b.keys():
|
| 47 |
-
temp[key] = sum([d.get(key, 0) for d in (a, b)])
|
| 48 |
-
return temp
|
| 49 |
-
|
| 50 |
-
return reduce(sum_dict, dict_list)
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
def collect_f0(f0):
|
| 54 |
-
pitch_num = {}
|
| 55 |
-
pitch_list = [f0_to_pitch(x) for x in f0[f0 > 0]]
|
| 56 |
-
for key in pitch_list:
|
| 57 |
-
pitch_num[key] = pitch_num.get(key, 0) + 1
|
| 58 |
-
return pitch_num
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
def static_f0_time(f0):
|
| 62 |
-
if isinstance(f0, dict):
|
| 63 |
-
pitch_num = merge_f0_dict({k: collect_f0(v) for k, v in f0.items()}.values())
|
| 64 |
-
else:
|
| 65 |
-
pitch_num = collect_f0(f0)
|
| 66 |
-
static_pitch_time = {}
|
| 67 |
-
sort_key = sorted(pitch_num.keys())
|
| 68 |
-
for key in sort_key:
|
| 69 |
-
static_pitch_time[key] = round(pitch_num[key] * hparams['hop_size'] / hparams['audio_sample_rate'], 2)
|
| 70 |
-
return static_pitch_time
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
def get_end_file(dir_path, end):
|
| 74 |
-
file_lists = []
|
| 75 |
-
for root, dirs, files in os.walk(dir_path):
|
| 76 |
-
files = [f for f in files if f[0] != '.']
|
| 77 |
-
dirs[:] = [d for d in dirs if d[0] != '.']
|
| 78 |
-
for f_file in files:
|
| 79 |
-
if f_file.endswith(end):
|
| 80 |
-
file_lists.append(os.path.join(root, f_file).replace("\\", "/"))
|
| 81 |
-
return file_lists
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
if __name__ == "__main__":
|
| 85 |
-
# 给config文件增加f0_static统计音域
|
| 86 |
-
config_path = "F:/sovits/diff-svc-main/checkpoints/aquapre/config.yaml"
|
| 87 |
-
hparams = set_hparams(config=config_path, exp_name='', infer=True, reset=True, hparams_str='', print_hparams=False)
|
| 88 |
-
f0_dict = {}
|
| 89 |
-
# 获取batch文件夹下所有wav文件
|
| 90 |
-
wav_paths = get_end_file("F:/sovits/diff-svc-main/batch/aquapre", "wav")
|
| 91 |
-
# parselmouth获取f0
|
| 92 |
-
with tqdm(total=len(wav_paths)) as p_bar:
|
| 93 |
-
p_bar.set_description('Processing')
|
| 94 |
-
for wav_path in wav_paths:
|
| 95 |
-
f0_dict[wav_path] = get_f0(wav_path, crepe=False)
|
| 96 |
-
p_bar.update(1)
|
| 97 |
-
pitch_time = static_f0_time(f0_dict)
|
| 98 |
-
total_time = round(sum(pitch_time.values()), 2)
|
| 99 |
-
pitch_time["total_time"] = total_time
|
| 100 |
-
print(f"total time: {total_time}s")
|
| 101 |
-
shutil.copy(config_path, f"{Path(config_path).parent}\\back_{Path(config_path).name}")
|
| 102 |
-
with open(config_path, encoding='utf-8') as f:
|
| 103 |
-
_hparams = yaml.safe_load(f)
|
| 104 |
-
_hparams['f0_static'] = json.dumps(pitch_time)
|
| 105 |
-
with open(config_path, 'w', encoding='utf-8') as f:
|
| 106 |
-
yaml.safe_dump(_hparams, f)
|
| 107 |
-
print("原config文件已在原目录建立备份:back_config.yaml")
|
| 108 |
-
print("音域统计已保存至config文件,此模型可使用自动变调功能")
|
| 109 |
-
matplotlib.use('TkAgg')
|
| 110 |
-
plt.title("数据集音域统计", fontproperties='SimHei')
|
| 111 |
-
plt.xlabel("音高", fontproperties='SimHei')
|
| 112 |
-
plt.ylabel("时长(s)", fontproperties='SimHei')
|
| 113 |
-
xticks_labels = [pitch_to_name(i) for i in range(36, 96)]
|
| 114 |
-
xticks(np.linspace(36, 96, 60, endpoint=True), xticks_labels)
|
| 115 |
-
plt.plot(pitch_time.keys(), pitch_time.values(), color='dodgerblue')
|
| 116 |
-
plt.show()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CikeyQI/Yunzai/Yunzai/plugins/ws-plugin/index.js
DELETED
|
@@ -1,103 +0,0 @@
|
|
| 1 |
-
import fs from 'node:fs'
|
| 2 |
-
import { initWebSocket, Config, Version } from './components/index.js'
|
| 3 |
-
import { TMP_DIR, mimeTypes } from './model/index.js'
|
| 4 |
-
import { join, extname } from 'path'
|
| 5 |
-
const files = fs.readdirSync('./plugins/ws-plugin/apps').filter(file => file.endsWith('.js'))
|
| 6 |
-
|
| 7 |
-
let ret = []
|
| 8 |
-
|
| 9 |
-
logger.info('-----------------')
|
| 10 |
-
logger.info(`ws-plugin${Version.version}插件初始化~`)
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
files.forEach((file) => {
|
| 14 |
-
ret.push(import(`./apps/${file}`))
|
| 15 |
-
})
|
| 16 |
-
|
| 17 |
-
ret = await Promise.allSettled(ret)
|
| 18 |
-
|
| 19 |
-
let apps = {}
|
| 20 |
-
for (let i in files) {
|
| 21 |
-
let name = files[i].replace('.js', '')
|
| 22 |
-
|
| 23 |
-
if (ret[i].status != 'fulfilled') {
|
| 24 |
-
logger.error(`载入插件错误:${logger.red(name)}`)
|
| 25 |
-
logger.error(ret[i].reason)
|
| 26 |
-
continue
|
| 27 |
-
}
|
| 28 |
-
apps[name] = ret[i].value[Object.keys(ret[i].value)[0]]
|
| 29 |
-
}
|
| 30 |
-
let path = ['./apps/message/message.js', './apps/notice/notice.js', './apps/request/request.js']
|
| 31 |
-
for (const item of path) {
|
| 32 |
-
try {
|
| 33 |
-
await import(`${item}`)
|
| 34 |
-
} catch (e) {
|
| 35 |
-
logger.error(`载入事件错误:${item}`)
|
| 36 |
-
logger.error(e)
|
| 37 |
-
}
|
| 38 |
-
}
|
| 39 |
-
|
| 40 |
-
initWebSocket()
|
| 41 |
-
if (Version.isTrss) {
|
| 42 |
-
Bot.express.get('/ws-plugin*', async (req, res) => {
|
| 43 |
-
const file = req.query.file
|
| 44 |
-
if (file) {
|
| 45 |
-
const ext = extname(file)
|
| 46 |
-
const contentType = mimeTypes[ext]
|
| 47 |
-
fs.readFile(join(TMP_DIR, file), (err, content) => {
|
| 48 |
-
if (err) {
|
| 49 |
-
res.writeHead(404)
|
| 50 |
-
res.end('File not found')
|
| 51 |
-
} else {
|
| 52 |
-
const name = file.split('-')
|
| 53 |
-
const filename = encodeURIComponent(name[1]) || encodeURIComponent(name[0]) || encodeURIComponent(file)
|
| 54 |
-
res.writeHead(200, {
|
| 55 |
-
'Content-Type': contentType,
|
| 56 |
-
'Content-Disposition': `attachment; filename=${filename}`
|
| 57 |
-
})
|
| 58 |
-
res.end(content)
|
| 59 |
-
}
|
| 60 |
-
})
|
| 61 |
-
return
|
| 62 |
-
}
|
| 63 |
-
res.writeHead(404);
|
| 64 |
-
res.end('Page not found')
|
| 65 |
-
})
|
| 66 |
-
} else {
|
| 67 |
-
const getGroupMemberInfo = Bot.getGroupMemberInfo
|
| 68 |
-
/** 劫持修改getGroupMemberInfo方法 */
|
| 69 |
-
Bot.getGroupMemberInfo = async function (group_id, user_id) {
|
| 70 |
-
let result
|
| 71 |
-
try {
|
| 72 |
-
result = await getGroupMemberInfo(group_id, user_id)
|
| 73 |
-
} catch (error) {
|
| 74 |
-
let nickname
|
| 75 |
-
if (error.stack.includes('ws-plugin')) {
|
| 76 |
-
nickname = 'chronocat'
|
| 77 |
-
} else {
|
| 78 |
-
nickname = String(group_id).includes("qg_") ? "QQGuild-Bot" : "WeChat-Bot"
|
| 79 |
-
}
|
| 80 |
-
result = {
|
| 81 |
-
group_id,
|
| 82 |
-
user_id,
|
| 83 |
-
nickname,
|
| 84 |
-
card: "",
|
| 85 |
-
sex: "female",
|
| 86 |
-
age: 6,
|
| 87 |
-
join_time: "",
|
| 88 |
-
last_sent_time: "",
|
| 89 |
-
level: 1,
|
| 90 |
-
role: "member",
|
| 91 |
-
title: "",
|
| 92 |
-
title_expire_time: "",
|
| 93 |
-
shutup_time: 0,
|
| 94 |
-
update_time: "",
|
| 95 |
-
area: "南极洲",
|
| 96 |
-
rank: "潜水",
|
| 97 |
-
}
|
| 98 |
-
}
|
| 99 |
-
return result
|
| 100 |
-
}
|
| 101 |
-
}
|
| 102 |
-
|
| 103 |
-
export { apps }
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CodingBillionaire/bark-voice-cloning/README.md
DELETED
|
@@ -1,16 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: Bark Voice Cloning
|
| 3 |
-
emoji: 🐶
|
| 4 |
-
colorFrom: blue
|
| 5 |
-
colorTo: green
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.29.0
|
| 8 |
-
python_version: 3.10.11
|
| 9 |
-
app_file: app.py
|
| 10 |
-
models:
|
| 11 |
-
- facebook/hubert-base-ls960
|
| 12 |
-
- GitMylo/bark-voice-cloning
|
| 13 |
-
pinned: false
|
| 14 |
-
license: mit
|
| 15 |
-
duplicated_from: GitMylo/bark-voice-cloning
|
| 16 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CofAI/chat.b4/client/js/highlight.min.js
DELETED
|
The diff for this file is too large to render.
See raw diff
|
|
|
spaces/CofAI/chat.b4/g4f/Provider/Providers/Mishalsgpt.py
DELETED
|
@@ -1,23 +0,0 @@
|
|
| 1 |
-
import os, requests, uuid
|
| 2 |
-
from ...typing import sha256, Dict, get_type_hints
|
| 3 |
-
|
| 4 |
-
url = 'https://mishalsgpt.vercel.app'
|
| 5 |
-
model = ['gpt-3.5-turbo-16k-0613', 'gpt-3.5-turbo']
|
| 6 |
-
supports_stream = True
|
| 7 |
-
needs_auth = False
|
| 8 |
-
|
| 9 |
-
def _create_completion(model: str, messages: list, stream: bool, **kwargs):
|
| 10 |
-
headers = {
|
| 11 |
-
'Content-Type': 'application/json',
|
| 12 |
-
}
|
| 13 |
-
data = {
|
| 14 |
-
'model': model,
|
| 15 |
-
'temperature': 0.7,
|
| 16 |
-
'messages': messages
|
| 17 |
-
}
|
| 18 |
-
response = requests.post(url + '/api/openai/v1/chat/completions',
|
| 19 |
-
headers=headers, json=data, stream=True)
|
| 20 |
-
yield response.json()['choices'][0]['message']['content']
|
| 21 |
-
|
| 22 |
-
params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
|
| 23 |
-
'(%s)' % ', '.join([f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CofAI/chat.b4/server/website.py
DELETED
|
@@ -1,32 +0,0 @@
|
|
| 1 |
-
from flask import render_template, redirect, url_for
|
| 2 |
-
from time import time
|
| 3 |
-
from os import urandom
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
class Website:
|
| 7 |
-
def __init__(self, bp, url_prefix) -> None:
|
| 8 |
-
self.bp = bp
|
| 9 |
-
self.url_prefix = url_prefix
|
| 10 |
-
self.routes = {
|
| 11 |
-
'/': {
|
| 12 |
-
'function': lambda: redirect(url_for('._index')),
|
| 13 |
-
'methods': ['GET', 'POST']
|
| 14 |
-
},
|
| 15 |
-
'/chat/': {
|
| 16 |
-
'function': self._index,
|
| 17 |
-
'methods': ['GET', 'POST']
|
| 18 |
-
},
|
| 19 |
-
'/chat/<conversation_id>': {
|
| 20 |
-
'function': self._chat,
|
| 21 |
-
'methods': ['GET', 'POST']
|
| 22 |
-
}
|
| 23 |
-
}
|
| 24 |
-
|
| 25 |
-
def _chat(self, conversation_id):
|
| 26 |
-
if '-' not in conversation_id:
|
| 27 |
-
return redirect(url_for('._index'))
|
| 28 |
-
|
| 29 |
-
return render_template('index.html', chat_id=conversation_id, url_prefix=self.url_prefix)
|
| 30 |
-
|
| 31 |
-
def _index(self):
|
| 32 |
-
return render_template('index.html', chat_id=f'{urandom(4).hex()}-{urandom(2).hex()}-{urandom(2).hex()}-{urandom(2).hex()}-{hex(int(time() * 1000))[2:]}', url_prefix=self.url_prefix)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Cong723/gpt-academic-public/crazy_functions/test_project/latex/attention/parameter_attention.tex
DELETED
|
@@ -1,45 +0,0 @@
|
|
| 1 |
-
\pagebreak
|
| 2 |
-
\section*{Two Feed-Forward Layers = Attention over Parameters}\label{sec:parameter_attention}
|
| 3 |
-
|
| 4 |
-
In addition to attention layers, our model contains position-wise feed-forward networks (Section \ref{sec:ffn}), which consist of two linear transformations with a ReLU activation in between. In fact, these networks too can be seen as a form of attention. Compare the formula for such a network with the formula for a simple dot-product attention layer (biases and scaling factors omitted):
|
| 5 |
-
|
| 6 |
-
\begin{align*}
|
| 7 |
-
FFN(x, W_1, W_2) = ReLU(xW_1)W_2 \\
|
| 8 |
-
A(q, K, V) = Softmax(qK^T)V
|
| 9 |
-
\end{align*}
|
| 10 |
-
|
| 11 |
-
Based on the similarity of these formulae, the two-layer feed-forward network can be seen as a kind of attention, where the keys and values are the rows of the trainable parameter matrices $W_1$ and $W_2$, and where we use ReLU instead of Softmax in the compatibility function.
|
| 12 |
-
|
| 13 |
-
%the compatablity function is $compat(q, k_i) = ReLU(q \cdot k_i)$ instead of $Softmax(qK_T)_i$.
|
| 14 |
-
|
| 15 |
-
Given this similarity, we experimented with replacing the position-wise feed-forward networks with attention layers similar to the ones we use everywhere else our model. The multi-head-attention-over-parameters sublayer is identical to the multi-head attention described in \ref{sec:multihead}, except that the "keys" and "values" inputs to each attention head are trainable model parameters, as opposed to being linear projections of a previous layer. These parameters are scaled up by a factor of $\sqrt{d_{model}}$ in order to be more similar to activations.
|
| 16 |
-
|
| 17 |
-
In our first experiment, we replaced each position-wise feed-forward network with a multi-head-attention-over-parameters sublayer with $h_p=8$ heads, key-dimensionality $d_{pk}=64$, and value-dimensionality $d_{pv}=64$, using $n_p=1536$ key-value pairs for each attention head. The sublayer has a total of $2097152$ parameters, including the parameters in the query projection and the output projection. This matches the number of parameters in the position-wise feed-forward network that we replaced. While the theoretical amount of computation is also the same, in practice, the attention version caused the step times to be about 30\% longer.
|
| 18 |
-
|
| 19 |
-
In our second experiment, we used $h_p=8$ heads, and $n_p=512$ key-value pairs for each attention head, again matching the total number of parameters in the base model.
|
| 20 |
-
|
| 21 |
-
Results for the first experiment were slightly worse than for the base model, and results for the second experiment were slightly better, see Table~\ref{tab:parameter_attention}.
|
| 22 |
-
|
| 23 |
-
\begin{table}[h]
|
| 24 |
-
\caption{Replacing the position-wise feed-forward networks with multihead-attention-over-parameters produces similar results to the base model. All metrics are on the English-to-German translation development set, newstest2013.}
|
| 25 |
-
\label{tab:parameter_attention}
|
| 26 |
-
\begin{center}
|
| 27 |
-
\vspace{-2mm}
|
| 28 |
-
%\scalebox{1.0}{
|
| 29 |
-
\begin{tabular}{c|cccccc|cccc}
|
| 30 |
-
\hline\rule{0pt}{2.0ex}
|
| 31 |
-
& \multirow{2}{*}{$\dmodel$} & \multirow{2}{*}{$\dff$} &
|
| 32 |
-
\multirow{2}{*}{$h_p$} & \multirow{2}{*}{$d_{pk}$} & \multirow{2}{*}{$d_{pv}$} &
|
| 33 |
-
\multirow{2}{*}{$n_p$} &
|
| 34 |
-
PPL & BLEU & params & training\\
|
| 35 |
-
& & & & & & & (dev) & (dev) & $\times10^6$ & time \\
|
| 36 |
-
\hline\rule{0pt}{2.0ex}
|
| 37 |
-
base & 512 & 2048 & & & & & 4.92 & 25.8 & 65 & 12 hours\\
|
| 38 |
-
\hline\rule{0pt}{2.0ex}
|
| 39 |
-
AOP$_1$ & 512 & & 8 & 64 & 64 & 1536 & 4.92& 25.5 & 65 & 16 hours\\
|
| 40 |
-
AOP$_2$ & 512 & & 16 & 64 & 64 & 512 & \textbf{4.86} & \textbf{25.9} & 65 & 16 hours \\
|
| 41 |
-
\hline
|
| 42 |
-
\end{tabular}
|
| 43 |
-
%}
|
| 44 |
-
\end{center}
|
| 45 |
-
\end{table}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Cropinky/esrgan/realesrgan/__init__.py
DELETED
|
@@ -1,6 +0,0 @@
|
|
| 1 |
-
# flake8: noqa
|
| 2 |
-
from .archs import *
|
| 3 |
-
from .data import *
|
| 4 |
-
from .models import *
|
| 5 |
-
from .utils import *
|
| 6 |
-
from .version import *
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Cvandi/remake/realesrgan/archs/srvgg_arch.py
DELETED
|
@@ -1,69 +0,0 @@
|
|
| 1 |
-
from basicsr.utils.registry import ARCH_REGISTRY
|
| 2 |
-
from torch import nn as nn
|
| 3 |
-
from torch.nn import functional as F
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
@ARCH_REGISTRY.register()
|
| 7 |
-
class SRVGGNetCompact(nn.Module):
|
| 8 |
-
"""A compact VGG-style network structure for super-resolution.
|
| 9 |
-
|
| 10 |
-
It is a compact network structure, which performs upsampling in the last layer and no convolution is
|
| 11 |
-
conducted on the HR feature space.
|
| 12 |
-
|
| 13 |
-
Args:
|
| 14 |
-
num_in_ch (int): Channel number of inputs. Default: 3.
|
| 15 |
-
num_out_ch (int): Channel number of outputs. Default: 3.
|
| 16 |
-
num_feat (int): Channel number of intermediate features. Default: 64.
|
| 17 |
-
num_conv (int): Number of convolution layers in the body network. Default: 16.
|
| 18 |
-
upscale (int): Upsampling factor. Default: 4.
|
| 19 |
-
act_type (str): Activation type, options: 'relu', 'prelu', 'leakyrelu'. Default: prelu.
|
| 20 |
-
"""
|
| 21 |
-
|
| 22 |
-
def __init__(self, num_in_ch=3, num_out_ch=3, num_feat=64, num_conv=16, upscale=4, act_type='prelu'):
|
| 23 |
-
super(SRVGGNetCompact, self).__init__()
|
| 24 |
-
self.num_in_ch = num_in_ch
|
| 25 |
-
self.num_out_ch = num_out_ch
|
| 26 |
-
self.num_feat = num_feat
|
| 27 |
-
self.num_conv = num_conv
|
| 28 |
-
self.upscale = upscale
|
| 29 |
-
self.act_type = act_type
|
| 30 |
-
|
| 31 |
-
self.body = nn.ModuleList()
|
| 32 |
-
# the first conv
|
| 33 |
-
self.body.append(nn.Conv2d(num_in_ch, num_feat, 3, 1, 1))
|
| 34 |
-
# the first activation
|
| 35 |
-
if act_type == 'relu':
|
| 36 |
-
activation = nn.ReLU(inplace=True)
|
| 37 |
-
elif act_type == 'prelu':
|
| 38 |
-
activation = nn.PReLU(num_parameters=num_feat)
|
| 39 |
-
elif act_type == 'leakyrelu':
|
| 40 |
-
activation = nn.LeakyReLU(negative_slope=0.1, inplace=True)
|
| 41 |
-
self.body.append(activation)
|
| 42 |
-
|
| 43 |
-
# the body structure
|
| 44 |
-
for _ in range(num_conv):
|
| 45 |
-
self.body.append(nn.Conv2d(num_feat, num_feat, 3, 1, 1))
|
| 46 |
-
# activation
|
| 47 |
-
if act_type == 'relu':
|
| 48 |
-
activation = nn.ReLU(inplace=True)
|
| 49 |
-
elif act_type == 'prelu':
|
| 50 |
-
activation = nn.PReLU(num_parameters=num_feat)
|
| 51 |
-
elif act_type == 'leakyrelu':
|
| 52 |
-
activation = nn.LeakyReLU(negative_slope=0.1, inplace=True)
|
| 53 |
-
self.body.append(activation)
|
| 54 |
-
|
| 55 |
-
# the last conv
|
| 56 |
-
self.body.append(nn.Conv2d(num_feat, num_out_ch * upscale * upscale, 3, 1, 1))
|
| 57 |
-
# upsample
|
| 58 |
-
self.upsampler = nn.PixelShuffle(upscale)
|
| 59 |
-
|
| 60 |
-
def forward(self, x):
|
| 61 |
-
out = x
|
| 62 |
-
for i in range(0, len(self.body)):
|
| 63 |
-
out = self.body[i](out)
|
| 64 |
-
|
| 65 |
-
out = self.upsampler(out)
|
| 66 |
-
# add the nearest upsampled image, so that the network learns the residual
|
| 67 |
-
base = F.interpolate(x, scale_factor=self.upscale, mode='nearest')
|
| 68 |
-
out += base
|
| 69 |
-
return out
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/aiofiles/tempfile/__init__.py
DELETED
|
@@ -1,263 +0,0 @@
|
|
| 1 |
-
# Imports
|
| 2 |
-
import asyncio
|
| 3 |
-
from tempfile import (
|
| 4 |
-
TemporaryFile as syncTemporaryFile,
|
| 5 |
-
NamedTemporaryFile as syncNamedTemporaryFile,
|
| 6 |
-
SpooledTemporaryFile as syncSpooledTemporaryFile,
|
| 7 |
-
TemporaryDirectory as syncTemporaryDirectory,
|
| 8 |
-
_TemporaryFileWrapper as syncTemporaryFileWrapper,
|
| 9 |
-
)
|
| 10 |
-
from io import FileIO, TextIOBase, BufferedReader, BufferedWriter, BufferedRandom
|
| 11 |
-
from functools import partial, singledispatch
|
| 12 |
-
from ..base import AiofilesContextManager
|
| 13 |
-
from ..threadpool.text import AsyncTextIOWrapper
|
| 14 |
-
from ..threadpool.binary import AsyncBufferedIOBase, AsyncBufferedReader, AsyncFileIO
|
| 15 |
-
from .temptypes import AsyncSpooledTemporaryFile, AsyncTemporaryDirectory
|
| 16 |
-
|
| 17 |
-
__all__ = [
|
| 18 |
-
"NamedTemporaryFile",
|
| 19 |
-
"TemporaryFile",
|
| 20 |
-
"SpooledTemporaryFile",
|
| 21 |
-
"TemporaryDirectory",
|
| 22 |
-
]
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
# ================================================================
|
| 26 |
-
# Public methods for async open and return of temp file/directory
|
| 27 |
-
# objects with async interface
|
| 28 |
-
# ================================================================
|
| 29 |
-
def NamedTemporaryFile(
|
| 30 |
-
mode="w+b",
|
| 31 |
-
buffering=-1,
|
| 32 |
-
encoding=None,
|
| 33 |
-
newline=None,
|
| 34 |
-
suffix=None,
|
| 35 |
-
prefix=None,
|
| 36 |
-
dir=None,
|
| 37 |
-
delete=True,
|
| 38 |
-
loop=None,
|
| 39 |
-
executor=None,
|
| 40 |
-
):
|
| 41 |
-
"""Async open a named temporary file"""
|
| 42 |
-
return AiofilesContextManager(
|
| 43 |
-
_temporary_file(
|
| 44 |
-
named=True,
|
| 45 |
-
mode=mode,
|
| 46 |
-
buffering=buffering,
|
| 47 |
-
encoding=encoding,
|
| 48 |
-
newline=newline,
|
| 49 |
-
suffix=suffix,
|
| 50 |
-
prefix=prefix,
|
| 51 |
-
dir=dir,
|
| 52 |
-
delete=delete,
|
| 53 |
-
loop=loop,
|
| 54 |
-
executor=executor,
|
| 55 |
-
)
|
| 56 |
-
)
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
def TemporaryFile(
|
| 60 |
-
mode="w+b",
|
| 61 |
-
buffering=-1,
|
| 62 |
-
encoding=None,
|
| 63 |
-
newline=None,
|
| 64 |
-
suffix=None,
|
| 65 |
-
prefix=None,
|
| 66 |
-
dir=None,
|
| 67 |
-
loop=None,
|
| 68 |
-
executor=None,
|
| 69 |
-
):
|
| 70 |
-
"""Async open an unnamed temporary file"""
|
| 71 |
-
return AiofilesContextManager(
|
| 72 |
-
_temporary_file(
|
| 73 |
-
named=False,
|
| 74 |
-
mode=mode,
|
| 75 |
-
buffering=buffering,
|
| 76 |
-
encoding=encoding,
|
| 77 |
-
newline=newline,
|
| 78 |
-
suffix=suffix,
|
| 79 |
-
prefix=prefix,
|
| 80 |
-
dir=dir,
|
| 81 |
-
loop=loop,
|
| 82 |
-
executor=executor,
|
| 83 |
-
)
|
| 84 |
-
)
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
def SpooledTemporaryFile(
|
| 88 |
-
max_size=0,
|
| 89 |
-
mode="w+b",
|
| 90 |
-
buffering=-1,
|
| 91 |
-
encoding=None,
|
| 92 |
-
newline=None,
|
| 93 |
-
suffix=None,
|
| 94 |
-
prefix=None,
|
| 95 |
-
dir=None,
|
| 96 |
-
loop=None,
|
| 97 |
-
executor=None,
|
| 98 |
-
):
|
| 99 |
-
"""Async open a spooled temporary file"""
|
| 100 |
-
return AiofilesContextManager(
|
| 101 |
-
_spooled_temporary_file(
|
| 102 |
-
max_size=max_size,
|
| 103 |
-
mode=mode,
|
| 104 |
-
buffering=buffering,
|
| 105 |
-
encoding=encoding,
|
| 106 |
-
newline=newline,
|
| 107 |
-
suffix=suffix,
|
| 108 |
-
prefix=prefix,
|
| 109 |
-
dir=dir,
|
| 110 |
-
loop=loop,
|
| 111 |
-
executor=executor,
|
| 112 |
-
)
|
| 113 |
-
)
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
def TemporaryDirectory(suffix=None, prefix=None, dir=None, loop=None, executor=None):
|
| 117 |
-
"""Async open a temporary directory"""
|
| 118 |
-
return AiofilesContextManagerTempDir(
|
| 119 |
-
_temporary_directory(
|
| 120 |
-
suffix=suffix, prefix=prefix, dir=dir, loop=loop, executor=executor
|
| 121 |
-
)
|
| 122 |
-
)
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
# =========================================================
|
| 126 |
-
# Internal coroutines to open new temp files/directories
|
| 127 |
-
# =========================================================
|
| 128 |
-
async def _temporary_file(
|
| 129 |
-
named=True,
|
| 130 |
-
mode="w+b",
|
| 131 |
-
buffering=-1,
|
| 132 |
-
encoding=None,
|
| 133 |
-
newline=None,
|
| 134 |
-
suffix=None,
|
| 135 |
-
prefix=None,
|
| 136 |
-
dir=None,
|
| 137 |
-
delete=True,
|
| 138 |
-
loop=None,
|
| 139 |
-
executor=None,
|
| 140 |
-
max_size=0,
|
| 141 |
-
):
|
| 142 |
-
"""Async method to open a temporary file with async interface"""
|
| 143 |
-
if loop is None:
|
| 144 |
-
loop = asyncio.get_running_loop()
|
| 145 |
-
|
| 146 |
-
if named:
|
| 147 |
-
cb = partial(
|
| 148 |
-
syncNamedTemporaryFile,
|
| 149 |
-
mode=mode,
|
| 150 |
-
buffering=buffering,
|
| 151 |
-
encoding=encoding,
|
| 152 |
-
newline=newline,
|
| 153 |
-
suffix=suffix,
|
| 154 |
-
prefix=prefix,
|
| 155 |
-
dir=dir,
|
| 156 |
-
delete=delete,
|
| 157 |
-
)
|
| 158 |
-
else:
|
| 159 |
-
cb = partial(
|
| 160 |
-
syncTemporaryFile,
|
| 161 |
-
mode=mode,
|
| 162 |
-
buffering=buffering,
|
| 163 |
-
encoding=encoding,
|
| 164 |
-
newline=newline,
|
| 165 |
-
suffix=suffix,
|
| 166 |
-
prefix=prefix,
|
| 167 |
-
dir=dir,
|
| 168 |
-
)
|
| 169 |
-
|
| 170 |
-
f = await loop.run_in_executor(executor, cb)
|
| 171 |
-
|
| 172 |
-
# Wrap based on type of underlying IO object
|
| 173 |
-
if type(f) is syncTemporaryFileWrapper:
|
| 174 |
-
# _TemporaryFileWrapper was used (named files)
|
| 175 |
-
result = wrap(f.file, f, loop=loop, executor=executor)
|
| 176 |
-
# add delete property
|
| 177 |
-
result.delete = f.delete
|
| 178 |
-
return result
|
| 179 |
-
else:
|
| 180 |
-
# IO object was returned directly without wrapper
|
| 181 |
-
return wrap(f, f, loop=loop, executor=executor)
|
| 182 |
-
|
| 183 |
-
|
| 184 |
-
async def _spooled_temporary_file(
|
| 185 |
-
max_size=0,
|
| 186 |
-
mode="w+b",
|
| 187 |
-
buffering=-1,
|
| 188 |
-
encoding=None,
|
| 189 |
-
newline=None,
|
| 190 |
-
suffix=None,
|
| 191 |
-
prefix=None,
|
| 192 |
-
dir=None,
|
| 193 |
-
loop=None,
|
| 194 |
-
executor=None,
|
| 195 |
-
):
|
| 196 |
-
"""Open a spooled temporary file with async interface"""
|
| 197 |
-
if loop is None:
|
| 198 |
-
loop = asyncio.get_running_loop()
|
| 199 |
-
|
| 200 |
-
cb = partial(
|
| 201 |
-
syncSpooledTemporaryFile,
|
| 202 |
-
max_size=max_size,
|
| 203 |
-
mode=mode,
|
| 204 |
-
buffering=buffering,
|
| 205 |
-
encoding=encoding,
|
| 206 |
-
newline=newline,
|
| 207 |
-
suffix=suffix,
|
| 208 |
-
prefix=prefix,
|
| 209 |
-
dir=dir,
|
| 210 |
-
)
|
| 211 |
-
|
| 212 |
-
f = await loop.run_in_executor(executor, cb)
|
| 213 |
-
|
| 214 |
-
# Single interface provided by SpooledTemporaryFile for all modes
|
| 215 |
-
return AsyncSpooledTemporaryFile(f, loop=loop, executor=executor)
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
async def _temporary_directory(
|
| 219 |
-
suffix=None, prefix=None, dir=None, loop=None, executor=None
|
| 220 |
-
):
|
| 221 |
-
"""Async method to open a temporary directory with async interface"""
|
| 222 |
-
if loop is None:
|
| 223 |
-
loop = asyncio.get_running_loop()
|
| 224 |
-
|
| 225 |
-
cb = partial(syncTemporaryDirectory, suffix, prefix, dir)
|
| 226 |
-
f = await loop.run_in_executor(executor, cb)
|
| 227 |
-
|
| 228 |
-
return AsyncTemporaryDirectory(f, loop=loop, executor=executor)
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
class AiofilesContextManagerTempDir(AiofilesContextManager):
|
| 232 |
-
"""With returns the directory location, not the object (matching sync lib)"""
|
| 233 |
-
|
| 234 |
-
async def __aenter__(self):
|
| 235 |
-
self._obj = await self._coro
|
| 236 |
-
return self._obj.name
|
| 237 |
-
|
| 238 |
-
|
| 239 |
-
@singledispatch
|
| 240 |
-
def wrap(base_io_obj, file, *, loop=None, executor=None):
|
| 241 |
-
"""Wrap the object with interface based on type of underlying IO"""
|
| 242 |
-
raise TypeError("Unsupported IO type: {}".format(base_io_obj))
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
@wrap.register(TextIOBase)
|
| 246 |
-
def _(base_io_obj, file, *, loop=None, executor=None):
|
| 247 |
-
return AsyncTextIOWrapper(file, loop=loop, executor=executor)
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
@wrap.register(BufferedWriter)
|
| 251 |
-
def _(base_io_obj, file, *, loop=None, executor=None):
|
| 252 |
-
return AsyncBufferedIOBase(file, loop=loop, executor=executor)
|
| 253 |
-
|
| 254 |
-
|
| 255 |
-
@wrap.register(BufferedReader)
|
| 256 |
-
@wrap.register(BufferedRandom)
|
| 257 |
-
def _(base_io_obj, file, *, loop=None, executor=None):
|
| 258 |
-
return AsyncBufferedReader(file, loop=loop, executor=executor)
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
@wrap.register(FileIO)
|
| 262 |
-
def _(base_io_obj, file, *, loop=None, executor=None):
|
| 263 |
-
return AsyncFileIO(file, loop=loop, executor=executor)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Dauzy/whisper-webui/src/hooks/subTaskProgressListener.py
DELETED
|
@@ -1,37 +0,0 @@
|
|
| 1 |
-
from src.hooks.progressListener import ProgressListener
|
| 2 |
-
|
| 3 |
-
from typing import Union
|
| 4 |
-
|
| 5 |
-
class SubTaskProgressListener(ProgressListener):
|
| 6 |
-
"""
|
| 7 |
-
A sub task listener that reports the progress of a sub task to a base task listener
|
| 8 |
-
Parameters
|
| 9 |
-
----------
|
| 10 |
-
base_task_listener : ProgressListener
|
| 11 |
-
The base progress listener to accumulate overall progress in.
|
| 12 |
-
base_task_total : float
|
| 13 |
-
The maximum total progress that will be reported to the base progress listener.
|
| 14 |
-
sub_task_start : float
|
| 15 |
-
The starting progress of a sub task, in respect to the base progress listener.
|
| 16 |
-
sub_task_total : float
|
| 17 |
-
The total amount of progress a sub task will report to the base progress listener.
|
| 18 |
-
"""
|
| 19 |
-
def __init__(
|
| 20 |
-
self,
|
| 21 |
-
base_task_listener: ProgressListener,
|
| 22 |
-
base_task_total: float,
|
| 23 |
-
sub_task_start: float,
|
| 24 |
-
sub_task_total: float,
|
| 25 |
-
):
|
| 26 |
-
self.base_task_listener = base_task_listener
|
| 27 |
-
self.base_task_total = base_task_total
|
| 28 |
-
self.sub_task_start = sub_task_start
|
| 29 |
-
self.sub_task_total = sub_task_total
|
| 30 |
-
|
| 31 |
-
def on_progress(self, current: Union[int, float], total: Union[int, float]):
|
| 32 |
-
sub_task_progress_frac = current / total
|
| 33 |
-
sub_task_progress = self.sub_task_start + self.sub_task_total * sub_task_progress_frac
|
| 34 |
-
self.base_task_listener.on_progress(sub_task_progress, self.base_task_total)
|
| 35 |
-
|
| 36 |
-
def on_finished(self):
|
| 37 |
-
self.base_task_listener.on_progress(self.sub_task_start + self.sub_task_total, self.base_task_total)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Dauzy/whisper-webui/src/whisper/whisperFactory.py
DELETED
|
@@ -1,19 +0,0 @@
|
|
| 1 |
-
from typing import List
|
| 2 |
-
from src import modelCache
|
| 3 |
-
from src.config import ModelConfig
|
| 4 |
-
from src.whisper.abstractWhisperContainer import AbstractWhisperContainer
|
| 5 |
-
|
| 6 |
-
def create_whisper_container(whisper_implementation: str,
|
| 7 |
-
model_name: str, device: str = None, compute_type: str = "float16",
|
| 8 |
-
download_root: str = None,
|
| 9 |
-
cache: modelCache = None, models: List[ModelConfig] = []) -> AbstractWhisperContainer:
|
| 10 |
-
print("Creating whisper container for " + whisper_implementation)
|
| 11 |
-
|
| 12 |
-
if (whisper_implementation == "whisper"):
|
| 13 |
-
from src.whisper.whisperContainer import WhisperContainer
|
| 14 |
-
return WhisperContainer(model_name=model_name, device=device, compute_type=compute_type, download_root=download_root, cache=cache, models=models)
|
| 15 |
-
elif (whisper_implementation == "faster-whisper" or whisper_implementation == "faster_whisper"):
|
| 16 |
-
from src.whisper.fasterWhisperContainer import FasterWhisperContainer
|
| 17 |
-
return FasterWhisperContainer(model_name=model_name, device=device, compute_type=compute_type, download_root=download_root, cache=cache, models=models)
|
| 18 |
-
else:
|
| 19 |
-
raise ValueError("Unknown Whisper implementation: " + whisper_implementation)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|