-
-
-
-
-
-
- 404
- -Page not found :(
-The requested page could not be found.
-If you are a music producer, engineer, or enthusiast who loves the sound and vibe of classic analog mixing consoles, you might have heard of BRAINWORX bx console plugins. These are software plugins that emulate the signal path, workflow, and sound of some of the most legendary consoles ever made, such as the Neve VXS, the SSL 4000 E and G, and the Focusrite Studio Console. These plugins offer a realistic and flexible way to add warmth, punch, depth, and character to your mixes, without having to spend a fortune on hardware gear.
-Download ✺✺✺ https://byltly.com/2uKxub
However, there is a catch. These plugins are not cheap. Each one costs around $300, and if you want to get the whole bundle, you will have to shell out more than $2000. That is a lot of money for most people, especially if you are just starting out or working on a tight budget. So what can you do if you want to use these plugins but can't afford them? Well, one option is to use a keygen.
-A keygen is a software tool that can generate serial numbers or activation codes for software products that require them. By using a keygen, you can bypass the official registration process and unlock the full features and functionality of the software without paying anything. Sounds too good to be true, right? Well, it is not that simple. Using a keygen also comes with some risks and drawbacks, as well as some legal and ethical issues that you should be aware of before deciding to use one.
-In this article, I will provide you with an in-depth review of BRAINWORX bx console keygen, one of the most popular and widely used keygens for BRAINWORX bx console plugins. I will explain how it works, what it can do, how it compares to other similar tools and plugins, and what are some of the pros and cons of using it. I will also give you some alternative options for console emulation plugins that you might want to consider instead. By the end of this article, you should have a clear idea of whether BRAINWORX bx console keygen is worth using or not.
-BRAINWORX bx console keygen is a software tool that can generate serial numbers for different BRAINWORX bx console plugins. These serial numbers can then be used to activate the plugins on your computer and use them without any limitations or restrictions. The keygen works by exploiting a vulnerability in the plugin's registration system that allows it to generate valid serial numbers based on a specific algorithm.
- -To use BRAINWORX bx console keygen, you will need to download and install it on your computer. There are many websites and forums that offer links to download the keygen, but you should be careful and avoid any suspicious or malicious sources that might contain viruses, malware, or spyware. One of the most reliable and trusted sources to download the keygen is VST Crack, a website that provides free downloads of various audio plugins and software tools.
-To download the keygen from VST Crack, you will need to follow these steps:
-Once you have installed the keygen, you are ready to generate serial numbers for different BRAINWORX bx console plugins.
-BRAINWORX bx console keygen can generate serial numbers for 12 different bx console plugins. These are:
-To generate serial numbers for these plugins, you will need to follow these steps:
-After generating serial numbers for the plugins that you want to use, you will need to activate them on your computer. To do this, you will need to follow these steps:
-BRAINWORX bx console keygen is a simple and easy-to-use tool that does not have many features or options. However, there are some things that you can do with it to customize your experience and improve your workflow. These are:
How does BRAINWORX bx console keygen compare to other similar tools and plugins? -BRAINWORX bx console keygen is not the only tool that can generate serial numbers for audio plugins. There are many other keygens, cracks, patches, and hacks that claim to do the same thing. However, not all of them are reliable, safe, or effective. Some of them might not work at all, some of them might contain viruses or malware, and some of them might damage your system or compromise your security. Therefore, you should be careful and cautious when choosing a tool to use.
-One way to compare BRAINWORX bx console keygen with other similar tools is to look at their features, performance, compatibility, and reputation. Here are some of the criteria that you can use to evaluate different tools:
-Based on these criteria, BRAINWORX bx console keygen is one of the best tools that you can use to generate serial numbers for BRAINWORX bx console plugins. It has a simple and user-friendly interface, a fast and stable performance, a high compatibility with different plugins and systems, and a good reputation among users and experts. It also has some features that make it more convenient and useful than other tools, such as language support, update check, and contact option.
-However, BRAINWORX bx console keygen is not perfect. It also has some drawbacks and limitations that you should be aware of before using it. These are:
-BRAINWORX bx console keygen is a software tool that can generate serial numbers for different BRAINWORX bx console plugins. These plugins are software plugins that emulate the sound and features of some of the most famous analog mixing consoles ever made. By using a keygen, you can activate these plugins without paying anything and use them without any limitations or restrictions.
-BRAINWORX bx console keygen is one of the best tools that you can use to generate serial numbers for BRAINWORX bx console plugins. It has a simple and user-friendly interface, a fast and stable performance, a high compatibility with different plugins and systems, and a good reputation among users and experts. It also has some features that make it more convenient and useful than other tools, such as language support, update check, and contact option.
-However, BRAINWORX bx console keygen is not perfect. It also has some drawbacks and limitations that you should be aware of before using it. These are:
-Therefore, you should think carefully and weigh the pros and cons before deciding to use BRAINWORX bx console keygen. While it might seem tempting and convenient to use a keygen to get access to high-quality plugins for free, you might also face some serious risks and problems that could outweigh the benefits. You might also be violating the law and the ethics of the music industry by using a keygen.
-If you are looking for some alternative options for console emulation plugins that are legal, safe, and affordable, you might want to consider some of these:
-BRAINWORX bx console plugins are not the only console emulation plugins that you can use to enhance your mixes. There are many other plugins that offer similar or different features and sound quality, depending on your preferences and needs. Some of these plugins are free, some of them are paid, and some of them offer both free and paid versions. Here are some of the most popular and recommended console emulation plugins that you might want to check out:
-Waves SSL 4000 Collection is a bundle of four plugins that emulate the sound and features of the SSL 4000 series consoles, one of the most iconic and widely used consoles in music history. The bundle includes:
-The Waves SSL 4000 Collection plugins are designed to faithfully recreate the sound and behavior of the original hardware units, with analog modeling and dynamic response. They also offer some additional features and options that enhance their flexibility and usability, such as sidechain filtering, stereo mode, analog noise control, input/output metering, and presets.
-The Waves SSL 4000 Collection plugins are compatible with most DAWs and operating systems. They cost $749 for the bundle, but they often go on sale for much lower prices. You can also try them for free for 7 days with a demo version.
-Slate Digital Virtual Console Collection is a bundle of two plugins that emulate the sound and features of six different analog consoles: SSL 4000 E, SSL 4000 G+, Neve 88RS, API Legacy Plus, Trident A-Range, and RCA BC6A. The bundle includes:
-The Slate Digital Virtual Console Collection plugins are designed to emulate the sound and behavior of the original hardware units, with analog modeling and dynamic response. They also offer some additional features and options that enhance their flexibility and usability, such as group mode, oversampling, and calibration. They also allow you to mix and match different consoles and groups to create your own custom sound.
-The Slate Digital Virtual Console Collection plugins are compatible with most DAWs and operating systems. They cost $149 for the bundle, but they are also included in the Slate Digital All Access Pass, which gives you access to over 60 plugins and online courses for $14.99 per month or $149 per year. You can also try them for free for 15 days with a trial version.
-Softube Console 1 is a hardware/software hybrid system that emulates the sound and features of different analog consoles. The system consists of:
-The Softube Console 1 system is designed to emulate the sound and behavior of the original hardware units, with analog modeling and dynamic response. It also offers some additional features and options that enhance its flexibility and usability, such as parallel processing, sidechain filtering, stereo mode, analog noise control, and integration with other Softube plugins.
-The Softube Console 1 system is compatible with most DAWs and operating systems. It costs $1099 for the bundle of Console 1 Fader and Console 1 MKII controllers, or $499 for each controller separately. The Console 1 Software plugin is included with the controllers, but it can also be purchased separately for $199. The system also comes with four console emulation plugins: SSL SL 4000 E, Solid State Logic XL 9000 K-Series, British Class A For Console 1, and American Class A For Console 1. You can also buy other console emulation plugins from Softube or other developers that are compatible with the system.
-Here are some of the most frequently asked questions about BRAINWORX bx console keygen and their answers:
-BRAINWORX bx console keygen is safe to use if you download it from a reliable and trusted source like VST Crack. However, you should always scan any file that you download from the internet with a reputable antivirus or malware scanner before opening or running it. You should also backup your data and create a restore point on your system before installing or using any software tool that could potentially harm your system or compromise your security.
-BRAINWORX bx console keygen is not legal to use in most countries and jurisdictions. By using a keygen to activate software products that you have not paid for, you are violating the terms and conditions of the software license agreement and infringing the intellectual property rights of the software developers. You could face legal consequences or penalties if you are caught using a keygen. You could also be sued by the software developers or their representatives for damages or losses caused by your use of a keygen.
-BRAINWORX bx console keygen works with most versions and formats of BRAINWORX bx console plugins. However, it might not work with some newer or updated versions of the plugins that have changed or improved their registration system or algorithm. It might also not work with some formats or platforms that are not supported by the keygen. You should always check the compatibility and requirements of the plugins and the keygen before using them together.
-BRAINWORX bx console keygen does not affect the sound quality or performance of BRAINWORX bx console plugins. The keygen only generates serial numbers that activate the plugins on your computer. It does not modify or alter the code or functionality of the plugins in any way. The sound quality and performance of the plugins depend on their design and development by BRAINWORX, as well as your system's specifications and settings. The keygen does not affect these factors in any way.
-BRAINWORX bx console keygen can be used with other plugins or software that you use, as long as they are compatible and do not interfere with each other. However, you should be careful and avoid using too many plugins or software tools at the same time, as this could overload your system and cause crashes, errors, or glitches. You should also avoid using plugins or software tools that are illegal, unsafe, or unethical, as this could harm your system or compromise your security.
- -This concludes my article on BRAINWORX bx console keygen. I hope you found it informative and helpful. If you have any questions, comments, or feedback, please feel free to contact me. Thank you for reading and have a great day!
b2dd77e56bIf you are preparing for the West Bengal Civil Service (WBCS) exam, you might be looking for some useful study materials that can help you cover the syllabus and practice the questions. One such study material is the WBCS Part 2 PDF, which is a collection of previous year papers of WBCS Mains exam. In this article, we will show you how to download WBCS Part 2 PDF for free and what are its features and benefits.
-Download Zip --->>> https://byltly.com/2uKwKo
WBCS Part 2 PDF is a study material that contains the previous year papers of WBCS Mains exam from 2014 to 2020. It covers all the six compulsory papers of WBCS Mains exam, namely:
-Each paper consists of 200 marks and has a duration of 150 minutes. The papers are available in both English and Bengali languages. The papers are also accompanied by detailed solutions and explanations.
-WBCS Part 2 PDF has many features that make it a useful and reliable study material for WBCS exam. Some of the features are:
-If you want to download WBCS Part 2 PDF for free, you can do so from the following online sources:
- -WBCS Part 2 PDF is a free and useful study material that can help you prepare for the WBCS Mains exam. It contains the previous
ddb901b051If you are a fan of digital voice communication in amateur radio, you have probably heard of D-Star, DV Dongle, and DVTool software. These are some of the tools that enable you to access the worldwide network of D-Star repeaters and reflectors from your PC or Mac.
-DOWNLOAD ::: https://byltly.com/2uKzUe
But did you know that there is a new version of DVTool software available for download? It's called Dvtool 2.0 Beta 5, and it offers some exciting features and improvements that will enhance your D-Star experience.
-In this article, we will tell you everything you need to know about Dvtool 2.0 Beta 5, including what it is, why you need it, how to download and install it, how to use it, and some tips and tricks for getting the most out of it.
-So, if you are ready to take your digital voice communication to the next level, read on!
- -Before we dive into the details of Dvtool 2.0 Beta 5, let's first review what Dvtool is and how it works with D-Star and DV Dongle.
-D-Star stands for Digital Smart Technologies for Amateur Radio
D-Star is a digital voice and data protocol that was developed by the Japan Amateur Radio League (JARL) in the late 1990s. It allows amateur radio operators to communicate with each other over long distances using digital signals that are transmitted and received by D-Star compatible radios, repeaters, and reflectors.
-A D-Star repeater is a device that receives a D-Star signal from a radio and retransmits it to another radio or to a reflector. A D-Star reflector is a server that connects multiple repeaters and radios over the internet, creating a global network of D-Star users.
-D-Star offers several advantages over analog voice communication, such as clearer audio quality, less interference, more efficient use of bandwidth, and the ability to transmit data along with voice, such as GPS coordinates, text messages, images, and files.
-A DV Dongle is a device that allows you to access the D-Star network from your PC or Mac without using a radio. It is a USB dongle that contains a digital signal processor (DSP) and a codec that converts analog audio signals to digital D-Star signals and vice versa.
-By connecting a DV Dongle to your PC or Mac and using a headset or microphone and speakers, you can communicate with other D-Star users over the internet. You can also use a DV Dongle to listen to D-Star transmissions and monitor the activity on different repeaters and reflectors.
-DVTool software is a program that allows you to control and configure your DV Dongle from your PC or Mac. It also provides a graphical user interface (GUI) that displays information about the D-Star network, such as the list of available repeaters and reflectors, the call signs of the users who are connected, and the status of your DV Dongle.
-DVTool software also enables you to connect your DV Dongle to any D-Star repeater or reflector that you choose, and to switch between them easily. You can also use DVTool software to adjust the audio settings of your DV Dongle, such as the volume, gain, and compression.
-Now that you know what Dvtool is and how it works with D-Star and DV Dongle, you might be wondering why you need Dvtool 2.0 Beta 5. After all, there are already several versions of DVTool software available for download, such as DVTool 1.05, DVTool 2.0 Beta 1, DVTool 2.0 Beta 2, DVTool 2.0 Beta 3, and DVTool 2.0 Beta 4.
-Well, the answer is simple: Dvtool 2.0 Beta 5 is the latest and most advanced version of DVTool software that offers some new features and improvements that will make your D-Star experience even better. Here are some of them:
-Some of the features of Dvtool 2.0 Beta 5 are:
-Some of the benefits of using Dvtool 2.0 Beta 5 are:
-By using Dvtool 2.0 Beta 5, you can improve your D-Star experience in several ways, such as:
-Now that you know why you need Dvtool 2.0 Beta 5 and what it can do for you, you might be wondering how to download and install it on your PC or Mac. Don't worry, it's very easy and straightforward. Just follow these steps:
-The official website for downloading Dvtool 2.0 Beta 5 is http://www.dvdongle.com/DV_Dongle/Home.html. This is where you can find the latest version of DVTool software for both Windows and Mac OS X operating systems.
-To download Dvtool 2.0 Beta 5, simply click on the link that corresponds to your operating system. For example, if you are using Windows, click on the link that says "DVTool-2.0beta5.exe". If you are using Mac OS X, click on the link that says "DVTool-2.0beta5.dmg".
-The download process will start automatically and may take a few minutes depending on your internet speed. Once the download is complete, you will have a file named "DVTool-2.0beta5.exe" or "DVTool-2.0beta5.dmg" in your downloads folder or wherever you saved it.
-To install Dvtool 2.0 Beta 5 on Windows, follow these steps:
-Congratulations! You have successfully installed Dvtool 2.0 Beta 5 on your Windows PC. You are now ready to use it with your DV Dongle and access the D-Star network.
-To install Dvtool 2.0 Beta 5 on Mac OS X, follow these steps:
-Congratulations! You have successfully installed Dvtool 2.0 Beta 5 on your Mac OS X. You are now ready to use it with your DV Dongle and access the D-Star network.
-Now that you have downloaded and installed Dvtool 2.0 Beta 5 on your PC or Mac, you might be wondering how to use it with your DV Dongle and access the D-Star network. Don't worry, it's very easy and fun. Just follow these steps:
-To connect your DV Dongle to your PC or Mac, follow these steps:
-To configure your Dvtool settings, follow these steps:
-To access D-Star reflectors and repeaters, follow these steps:
-To communicate with other D-Star users, follow these steps:
-By following the steps above, you should be able to use Dvtool 2.0 Beta 5 with your DV Dongle and access the D-Star network without any problems. However, there are some tips and tricks that can help you get even more out of Dvtool 2.0 Beta 5 and make your D-Star experience more enjoyable and efficient. Here are some of them:
-To update your Dvtool 2.0 Beta 5 software, follow these steps:
-Sometimes, you may encounter some issues with your Dvtool 2.0 Beta 5 software or your DV Dongle that may affect your D-Star experience. Don't panic, most of these issues can be easily fixed by following some simple troubleshooting steps. Here are some of the common issues and how to fix them:
-If none of these steps work for you, you can always contact the DVTool software support team for further assistance. You can find their contact information on the official website.
-One of the main advantages of using Dvtool 2.0 Beta 5 with your DV Dongle and accessing the D-Star network is that you can enjoy clearer audio quality than analog voice communication. However, there are some ways that you can optimize your audio quality even more and make it sound more natural and pleasant. Here are some of them:
-One of the fun aspects of using Dvtool 2.0 Beta 5 with your DV Dongle and accessing the D-Star network is that you can customize your D-Star profile and display information about yourself and your station to other users. This can help you make new contacts and friends on the network and show off your personality and interests. Here are some ways that you can customize your D-Star profile with Dvtool 2.0 Beta 5:
-In conclusion, Dvtool 2.0 Beta 5 is a great software that allows you to use your DV Dongle and access the D-Star network from your PC or Mac without using a radio. It offers some new features and improvements that will enhance your D-Star experience, such as a redesigned GUI, a new audio engine, a new echo test feature, a new auto-connect feature, a new auto-update feature, a new logging feature, and a new help feature.
-It also allows you to communicate with other D-Star users around the world using digital voice and data, enjoy clearer audio quality, less interference, more efficient use of bandwidth, and the ability to transmit data along with voice, access a wider range of repeaters and reflectors that may not be available in your area or frequency, monitor the activity on different repeaters and reflectors and discover new contacts and conversations, adjust the audio settings of your DV Dongle to suit your preferences and environment, update your DVTool software easily and automatically, troubleshoot common issues with your DV Dongle and DVTool software, customize your D-Star profile and display information about yourself and your station, and optimize your audio quality with some tips and tricks.
-If you are interested in trying out Dvtool 2.0 Beta 5, you can download it from the official website http://www.dvdongle.com/DV_Dongle/Home.html and install it on your PC or Mac following the steps above. You will need a DV Dongle device to use it with. You can also find more information and support for using Dvtool 2.0 Beta 5 on the official website or by contacting the DVTool software support team.
-We hope that this article has helped you learn more about Dvtool 2.0 Beta 5 and how to use it with your DV Dongle and access the D-Star network. We hope that you will enjoy using Dvtool 2.0 Beta 5 and have fun communicating with other D-Star users around the world.
-Here are some frequently asked questions (FAQs) about Dvtool 2.0 Beta 5:
-The system requirements for using Dvtool 2.0 Beta 5 are:
-Yes, Dvtool 2.0 Beta 5 is compatible with all versions of DV Dongle devices (DV Dongle Blue, DV Dongle Red, DV Dongle Orange) and also with DVAP devices (DV Access Point Dongle). However, some features may not work with older versions of these devices.
-Dvtool 2.0 Beta 5 is free software that you can download from the official website http://www.dvdongle.com/DV_Dongle/Home.html. However, you will need to purchase a DV Dongle device or a DVAP device to use it with, which are sold separately by different vendors.
-You can find more information or support for using Dvtool 2.0 Beta 5 on the official website http://www.dvdongle.com/DV_Dongle/Home.html, where you can find the online documentation, the user manual, the FAQ section, and the contact information of the DVTool software support team. You can also join the DVTool software user group on Yahoo Groups https://groups.yahoo.com/neo/groups/dvdongle/info, where you can interact with other users and share your feedback and suggestions.
-If you are looking for some alternatives to using Dvtool 2.0 Beta 5 with your DV Dongle or DVAP device, you can try some of these options:
-Download File ☑ https://imgfil.com/2uxYby
If you are a fan of PlayStation 2 games and want to relive your childhood memories on your Android smartphone, you are in luck. There is a new PS2 emulator for Android that lets you play PS2 games with amazing graphics and performance. It's called AetherSX2, and it's the best PS2 emulator for Android by far.
-In this article, we will show you how to download, install, configure, and play PS2 games on Android with AetherSX2 emulator. We will also give you some tips and tricks to optimize the emulator and make your gaming experience more enjoyable. And we will recommend some of the best PS2 games that you can play on AetherSX2 emulator.
-DOWNLOAD ⇒⇒⇒ https://urlin.us/2uSZYV
So, without further ado, let's get started!
-AetherSX2 is a PS2 emulator for Android that was released in late 2021 by a developer named Tahlreth. It is based on the PCSX2 emulator, which is a well-known and reliable PS2 emulator for PC. The developer got permission from the PCSX2 team to use their code and licensed it under the LGPL license.
-AetherSX2 emulator is a major breakthrough for PS2 emulation on Android devices. It supports a wide range of PS2 games and offers various features such as internal resolution scaling, save states, multiple control schemes, widescreen patches, and more. It also supports both Vulkan and OpenGL graphics renderers, which can improve the performance and compatibility of different games.
-AetherSX2 emulator is free to download and use, unlike some other PS2 emulators that charge money or show ads. You can get it from the Google Play Store or from the official website. You can also join the fan-run Discord server to get updates, support, and feedback from other users.
-Downloading and installing AetherSX2 emulator is very easy. Just follow these simple steps:
-AetherSX2 emulator has many settings that you can tweak to optimize its performance and compatibility for different games. However, there is no one-size-fits-all solution, as different games may require different settings. You may need to experiment with various options until you find the best settings for your device and game. Here are some general tips and recommendations that may help you:
-aethersx2 ps2 emulator android apk download
-aethersx2 settings for high-end devices
-aethersx2 vs damonps2 comparison
-aethersx2 compatible games list
-aethersx2 how to use cheats
-aethersx2 vulkan vs opengl performance
-aethersx2 best settings for god of war
-aethersx2 bios file download
-aethersx2 controller setup guide
-aethersx2 speed hacks tutorial
-aethersx2 widescreen patch apk
-aethersx2 best settings for kingdom hearts
-aethersx2 how to fix black screen
-aethersx2 save state location
-aethersx2 best settings for final fantasy x
-aethersx2 how to increase fps
-aethersx2 memory card format
-aethersx2 best settings for shadow of the colossus
-aethersx2 how to play multiplayer
-aethersx2 iso file download
-aethersx2 best settings for metal gear solid 3
-aethersx2 how to change language
-aethersx2 custom resolution apk
-aethersx2 best settings for gran turismo 4
-aethersx2 how to use gamepad
-aethersx2 texture filtering apk
-aethersx2 best settings for resident evil 4
-aethersx2 how to load roms
-aethersx2 anti aliasing apk
-aethersx2 best settings for dragon ball z budokai tenkaichi 3
-aethersx2 how to enable sound
-aethersx2 frame skipping apk
-aethersx2 best settings for silent hill 3
-aethersx2 how to fix lag
-aethersx2 shader effects apk
-aethersx2 best settings for devil may cry 3
-aethersx2 how to update app
-aethersx2 force feedback apk
-aethersx2 best settings for persona 4
-aethersx2 how to use mouse and keyboard
You can access the settings menu by tapping on the gear icon in the main menu or by pressing the back button while playing a game. You can also change the settings for each game individually by long-pressing on the game cover and selecting "Game settings".
-Loading and playing PS2 games on AetherSX2 emulator is also very easy. Just follow these simple steps:
-AetherSX2 emulator supports a large number of PS2 games, but not all of them are fully playable or compatible. Some games may have minor issues such as graphical glitches, audio problems, or slow loading times. Some games may have major issues such as crashes, freezes, or black screens. And some games may not work at all.
-The compatibility status of each game is indicated by a color code in the loading screen: green means playable, yellow means ingame, orange means menu/intro, red means loadable, and black means nothing.
-You can check the compatibility list on the official website to see which games are supported by the emulator and how well they run. You can also report any issues or bugs that you encounter while playing a game on the Discord server or on GitHub.
-Here are some of the best PS2 games that you can play on AetherSX2 emulator with good performance and compatibility:
-| Game | Genre | Description |
|---|---|---|
| God of War | Action-adventure | A hack-and-slash game that follows Kratos, a Spartan warrior who seeks revenge against Ares, the god of war. |
| Shadow of the Colossus | Action-adventure | A unique game that involves exploring a vast land and defeating giant creatures called colossi to revive a dead girl. |
| Grand Theft Auto: San Andreas | Action-adventure | A sandbox game that lets you roam around a fictional state of San Andreas and engage in various activities such as driving, shooting, fighting, and more. | -
| Final Fantasy X | Role-playing | A classic JRPG that follows Tidus, a young athlete who is transported to a fantasy world called Spira and joins a group of adventurers to defeat a monstrous threat called Sin. |
| Metal Gear Solid 3: Snake Eater | Stealth-action | A prequel to the Metal Gear series that features Naked Snake, a special agent who infiltrates a Soviet jungle to rescue a scientist and stop a nuclear war. |
| Kingdom Hearts | Action-role-playing | A crossover game that combines characters and worlds from Disney and Final Fantasy franchises. It follows Sora, a young boy who wields a magical weapon called the Keyblade and teams up with Donald Duck and Goofy to fight against the Heartless. |
Of course, there are many more PS2 games that you can try on AetherSX2 emulator, but these are some of the most popular and well-received ones. You can also check out some online forums and reviews to find more recommendations and suggestions.
-AetherSX2 emulator is an amazing app that lets you play PS2 games on Android devices with high quality and performance. It is easy to download, install, configure, and use. It supports a large number of PS2 games and offers various features and options to enhance your gaming experience. It is also free and open-source, unlike some other PS2 emulators that charge money or show ads.
-If you are a fan of PS2 games and want to relive your childhood memories on your Android smartphone, you should definitely give AetherSX2 emulator a try. You will be amazed by how well it runs your favorite PS2 games and how much fun you will have playing them.
-So, what are you waiting for? Download AetherSX2 emulator now and enjoy playing PS2 games on Android!
-A: AetherSX2 emulator itself is legal, as it is based on the PCSX2 emulator, which is licensed under the LGPL license. However, downloading or distributing PS2 BIOS or game files may be illegal in some countries or regions, depending on the copyright laws and regulations. You should only use your own PS2 BIOS or game files that you have legally obtained.
-A: AetherSX2 emulator is safe to use, as long as you download it from the official sources (Google Play Store or official website). It does not contain any malware, viruses, or spyware. It also does not collect any personal or sensitive data from your device.
-A: You can update AetherSX2 emulator by checking for updates in the app itself or by visiting the Google Play Store or the official website. You can also join the Discord server to get notified of any new updates or releases.
-A: You can support AetherSX2 emulator by giving it a positive rating and review on the Google Play Store or by sharing it with your friends and family. You can also donate to the developer via PayPal or Patreon to show your appreciation and help him improve the emulator.
-A: You can contact AetherSX2 emulator by joining the Discord server or by sending an email to tahlreth@gmail.com. You can also follow the developer on Twitter or Instagram for more updates and news.
197e85843d
-Soccer Super Star Football Mod APK: A Fun and Simple Soccer Game
-Do you love soccer? Do you want to play a soccer game that is fun, simple, and realistic? If yes, then you should try Soccer Super Star Football Mod APK, a soccer game that lets you swipe to shoot and score amazing goals. In this article, we will tell you everything you need to know about this game, including how to download and install it, how to play it, tips and tricks, pros and cons, and FAQs. Let's get started!
-soccer super star football mod apk
Download ☆☆☆☆☆ https://jinyurl.com/2uNKm4
- Introduction
-Soccer Super Star Football Mod APK is a soccer game that is developed by Real Free Soccer. It is available for Android devices and can be downloaded for free from various websites. The game has over 10 million downloads and a 4.4-star rating on Google Play Store. It is one of the most popular soccer games on the market, thanks to its simple and intuitive gameplay, realistic graphics and physics, various teams and modes to choose from, and unlimited rewind feature.
- Why should you download Soccer Super Star Football Mod APK? Well, if you are a fan of soccer, you will love this game. It is easy to play, but hard to master. You can swipe to shoot and score goals from different angles and distances. You can also use the unlimited rewind feature to correct your mistakes and try again. You can choose from different teams and modes, such as career mode, tournament mode, challenge mode, and training mode. You can also unlock new players and stadiums as you progress in the game. The game is also offline-friendly, meaning you can play it without an internet connection.
- What are the features of the mod version of Soccer Super Star Football? The mod version gives you some extra benefits that the original version does not. For example, you can enjoy unlimited rewind, which allows you to undo your shots and try again as many times as you want. You can also get unlimited coins, which you can use to buy new players and stadiums. The mod version also removes ads, which can be annoying and distracting in the original version.
- How to Download and Install Soccer Super Star Football Mod APK
-If you want to download and install Soccer Super Star Football Mod APK on your Android device, you need to follow these simple steps:
-
-- Download the APK file from a trusted source. You can find many websites that offer the mod version of Soccer Super Star Football for free. However, be careful not to download from shady or malicious sites that may harm your device or steal your data. We recommend you to download from [this link], which is safe and reliable.
-- Enable unknown sources on your device. Since you are downloading an APK file from a third-party source, you need to enable unknown sources on your device. This will allow you to install apps that are not from Google Play Store. To do this, go to Settings > Security > Unknown Sources and toggle it on.
-- Install the APK file. Once you have downloaded the APK file, locate it in your file manager and tap on it. You will see a pop-up window asking for your permission to install the app. Tap on Install and wait for the installation process to finish.
-- Launch the game and enjoy. After the installation is done, you can launch the game from your app drawer or home screen. You will see the game icon with the word "Mod" on it. Tap on it and start playing Soccer Super Star Football Mod APK.
-
How to Play Soccer Super Star Football Mod APK
-Playing Soccer Super Star Football Mod APK is very easy and fun. You just need to swipe your finger on the screen to shoot and score goals. Here are some tips on how to play the game:
-Choose your team and mode
-Before you start playing, you need to choose your team and mode. You can choose from different teams, such as Brazil, Argentina, Germany, France, Spain, England, and more. Each team has different stats and ratings, so choose wisely. You can also choose from different modes, such as career mode, tournament mode, challenge mode, and training mode. Each mode has different objectives and rewards, so choose according to your preference.
-soccer star 2023 super football games mod apk
-soccer super star football hack apk download
-soccer super star football unlimited money mod apk
-soccer super star football mod apk latest version
-soccer super star football mod apk android 1
-soccer super star football mod apk free rewards
-soccer super star football mod apk offline
-soccer super star football mod apk unlimited gems
-soccer super star football mod apk revdl
-soccer super star football mod apk no ads
-soccer super star football mod apk unlimited energy
-soccer super star football mod apk rexdl
-soccer super star football mod apk premium
-soccer super star football mod apk vip unlocked
-soccer super star football mod apk 1.18.1
-soccer super star football mod apk 2023
-soccer super star football mod apk unlimited coins
-soccer super star football mod apk happymod
-soccer super star football mod apk online
-soccer super star football mod apk pro
-soccer super star football mod apk full version
-soccer super star football mod apk obb
-soccer super star football mod apk cheat
-soccer super star football mod apk mega
-soccer super star football mod apk update
-soccer super star football mod apk 2022
-soccer super star football mod apk unlimited everything
-soccer super star football mod apk apkpure
-soccer super star football mod apk cracked
-soccer super star football mod apk data
-soccer super star football mod apk free download
-soccer super star football mod apk unlimited lives
-soccer super star football mod apk old version
-soccer super star football mod apk new version
-soccer super star football mod apk all unlocked
-soccer super star football mod apk for pc
-soccer super star football mod apk unlimited stars
-soccer super star football mod apk original
-soccer super star football mod apk real money
-soccer super star football mod apk no root
-Swipe to shoot and score
-Once you have chosen your team and mode, you can start playing. You will see a soccer ball on the screen, and you need to swipe your finger on it to shoot and score. You can swipe in different directions and angles to control the direction and curve of the ball. You can also swipe with different speed and force to control the power and height of the ball. You will see a target on the goal, and you need to aim for it to score. The target will change its position and size depending on the difficulty level of the game.
-Use unlimited rewind to correct your mistakes
-One of the best features of Soccer Super Star Football Mod APK is the unlimited rewind feature. This feature allows you to undo your shots and try again as many times as you want. This is very useful if you miss a shot or make a mistake. You can use this feature by tapping on the rewind button on the top left corner of the screen. You will see a timeline of your shots, and you can drag it back to any point you want. You can then swipe again to shoot and score.
-Unlock new players and stadiums
-As you play Soccer Super Star Football Mod APK, you can unlock new players and stadiums. You can unlock new players by spending coins or reaching certain levels. Each player has different skills and abilities, such as speed, power, accuracy, stamina, and more. You can also unlock new stadiums by spending coins or reaching certain levels. Each stadium has different themes and atmospheres, such as day, night, rain, snow, and more.
- Tips and Tricks for Soccer Super Star Football Mod APK
-If you want to master Soccer Super Star Football Mod APK, you need to know some tips and tricks that will help you improve your game. Here are some of them:
-Aim for the corners and curves
-One of the best ways to score goals in Soccer Super Star Football Mod APK is to aim for the corners and curves of the goal. This will make it harder for the goalkeeper to save your shots. You can do this by swiping your finger in a diagonal or curved motion on the screen. This will make the ball spin and curve in the air.
-Use power-ups wisely
-Soccer Super Star Football Mod APK also has some power-ups that you can use to boost your game. These power-ups include fireball, slow motion, magnet, freeze, and more. Each power-up has a different effect on the ball or the game. For example, fireball makes the ball burn and fly faster; slow motion makes the game slow down for a few seconds; magnet makes the ball attract to the target; freeze makes the goalkeeper freeze for a few seconds; and more. You can use these power-ups by tapping on them on the bottom right corner of the screen. However, be careful not to use them too often or too randomly, as they have limited uses and may not always work in your favor.
-Watch ads to get free rewards
-If you want to get more coins or power-ups in Soccer Super Star Football Mod APK, you can watch ads to get free rewards. You can do this by tapping on the watch ad button on the top right corner of the screen. You will see an ad pop up on your screen, and you need to watch it for a few seconds. After that, you will get some coins or power-ups as a reward. You can do this as many times as you want, but be aware that some ads may be longer or shorter than others.
-Practice your skills in training mode
-If you want to practice your skills in Soccer Super Star Football Mod APK, you can play in training mode. This mode allows you to play without any pressure or objectives. You can just swipe and shoot as many times as you want without worrying about time or score. You can also change the difficulty level of the game by tapping on the settings button on the top left corner of the screen. You can also change the team and stadium by tapping on the buttons on the bottom left corner of the screen. Training mode is a great way to improve your skills and have fun.
- Pros and Cons of Soccer Super Star Football Mod APK
-Soccer Super Star Football Mod APK is a great soccer game, but it also has some pros and cons that you should know before playing it. Here are some of them:
-Pros
-
-- Simple and intuitive gameplay. You just need to swipe your finger on the screen to shoot and score goals. The game is easy to play, but hard to master.
-- Realistic graphics and physics. The game has high-quality graphics and realistic physics that make the game more immersive and enjoyable. You can see the ball spin and curve in the air, the goalkeeper react and save your shots, and the crowd cheer and boo.
-- Various teams and modes to choose from. You can choose from different teams, such as Brazil, Argentina, Germany, France, Spain, England, and more. Each team has different stats and ratings, so choose wisely. You can also choose from different modes, such as career mode, tournament mode, challenge mode, and training mode. Each mode has different objectives and rewards, so choose according to your preference.
-- Unlimited rewind feature. This feature allows you to undo your shots and try again as many times as you want. This is very useful if you miss a shot or make a mistake. You can use this feature by tapping on the rewind button on the top left corner of the screen.
-
-Cons
-
-- Repetitive gameplay after a while. The game can get repetitive and boring after a while, as you play the same scenarios and challenges over and over again. The game lacks variety and innovation in its gameplay.
-- Ads can be annoying. The game has ads that pop up on your screen every now and then. These ads can be annoying and distracting, especially when you are in the middle of a match or a shot. You can remove ads by downloading the mod version of the game or by paying a small fee.
-- Some bugs and glitches may occur. The game is not perfect, and it may have some bugs and glitches that affect its performance and quality. For example, some users have reported that the game crashes or freezes sometimes, or that the ball goes through the goalkeeper or the goalpost.
-
- Conclusion
-Soccer Super Star Football Mod APK is a fun and simple soccer game that lets you swipe to shoot and score amazing goals. It has simple and intuitive gameplay, realistic graphics and physics, various teams and modes to choose from, and unlimited rewind feature. However, it also has some cons, such as repetitive gameplay after a while, ads can be annoying, and some bugs and glitches may occur. Overall, Soccer Super Star Football Mod APK is a great soccer game that you should try if you love soccer or want to have some fun.
- Do you want to download Soccer Super Star Football Mod APK? If yes, then follow the steps we mentioned above to download and install it on your Android device. If no, then what are you waiting for? Download it now and enjoy playing soccer like never before!
- FAQs
-Here are some frequently asked questions about Soccer Super Star Football Mod APK:
-
-- Is Soccer Super Star Football Mod APK safe to download?
-Yes, as long as you download it from a trusted source. You can find many websites that offer the mod version of Soccer Super Star Football for free. However, be careful not to download from shady or malicious sites that may harm your device or steal your data. We recommend you to download from [this link], which is safe and reliable.
-- What is the difference between Soccer Super Star Football Mod APK and the original version?
-The mod version gives you some extra benefits that the original version does not. For example, you can enjoy unlimited rewind, which allows you to undo your shots and try again as many times as you want. You can also get unlimited coins, which you can use to buy new players and stadiums. The mod version also removes ads, which can be annoying and distracting in the original version.
-- How can I get more coins in Soccer Super Star Football Mod APK?
-You can get more coins by winning matches, completing achievements, or watching ads. You can also use the mod version of the game, which gives you unlimited coins. You can use coins to buy new players and stadiums, or to upgrade your skills and power-ups.
-- How can I unlock new players and stadiums in Soccer Super Star Football Mod APK?
-You can unlock new players and stadiums by spending coins or reaching certain levels. Each player and stadium has a different price and level requirement. You can see the details by tapping on the shop button on the bottom right corner of the screen. You can also use the mod version of the game, which gives you all the players and stadiums unlocked.
-- Can I play Soccer Super Star Football Mod APK offline?
-Yes, you can play Soccer Super Star Football Mod APK offline without an internet connection. However, you will not be able to access some features, such as watching ads, getting rewards, or updating the game. You will also not be able to play in tournament mode or challenge mode, which require an internet connection.
-
- I hope this article has helped you learn more about Soccer Super Star Football Mod APK. If you have any questions or feedback, please leave a comment below. Thank you for reading!
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/Download CSR Racing 2 MOD APK for iOS and Android Free Shopping and More.md b/spaces/1phancelerku/anime-remove-background/Download CSR Racing 2 MOD APK for iOS and Android Free Shopping and More.md
deleted file mode 100644
index 8a82545bb57742b1d8304825c9bfa864bc52f12a..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Download CSR Racing 2 MOD APK for iOS and Android Free Shopping and More.md
+++ /dev/null
@@ -1,92 +0,0 @@
-
-
- | Table 2: Article with HTML formatting | |--------------------------------------| CSR Racing 2 Mod APK iOS 2022: How to Download and Install It
-If you are a fan of car racing games, you must have heard of CSR Racing 2. It is one of the most popular and realistic racing games on mobile devices. It offers you a chance to race with some of the most amazing cars in the world, customize them to your liking, compete with other players online, join crews, chat with friends, and much more.
-csr racing 2 mod apk ios 2022
DOWNLOAD · https://jinyurl.com/2uNOrk
-But what if you want to enjoy all these features without spending any money or waiting for hours to refill your fuel? What if you want to unlock all the cars and upgrades without grinding for hours? What if you want to have unlimited resources to enjoy the game to the fullest?
-Well, there is a way to do that. It is called CSR Racing 2 Mod APK. It is a modified version of the original game that gives you access to all the features and resources that you want. You can download and install it on your iOS device easily and safely. In this article, we will tell you everything you need to know about CSR Racing 2 Mod APK on iOS devices, including its features, benefits, compatibility, security, and installation process. So, let's get started!
-What is CSR Racing 2 and why is it popular?
-CSR Racing 2 is a racing game developed by NaturalMotionGames Ltd and published by Zynga. It was released in 2016 for Android and iOS devices. It is the sequel to the popular CSR Racing game that was released in 2012.
-csr racing 2 mod apk ios 2022 unlimited money
-csr racing 2 mod apk ios 2022 all cars unlocked
-csr racing 2 mod apk ios 2022 download free
-csr racing 2 mod apk ios 2022 latest version
-csr racing 2 mod apk ios 2022 no jailbreak
-csr racing 2 mod apk ios 2022 hack
-csr racing 2 mod apk ios 2022 cheats
-csr racing 2 mod apk ios 2022 online
-csr racing 2 mod apk ios 2022 gameplay
-csr racing 2 mod apk ios 2022 review
-csr racing 2 mod apk ios 2022 update
-csr racing 2 mod apk ios 2022 features
-csr racing 2 mod apk ios 2022 tips and tricks
-csr racing 2 mod apk ios 2022 best cars
-csr racing 2 mod apk ios 2022 graphics
-csr racing 2 mod apk ios 2022 multiplayer
-csr racing 2 mod apk ios 2022 offline
-csr racing 2 mod apk ios 2022 installation guide
-csr racing 2 mod apk ios 2022 requirements
-csr racing 2 mod apk ios 2022 support
-csr racing 2 mod apk ios 2022 how to play
-csr racing 2 mod apk ios 2022 tutorial
-csr racing 2 mod apk ios 2022 customisation
-csr racing 2 mod apk ios 2022 races
-csr racing 2 mod apk ios 2022 events
-csr racing 2 mod apk ios 2022 challenges
-csr racing 2 mod apk ios 2022 rewards
-csr racing 2 mod apk ios 2022 codes
-csr racing 2 mod apk ios 2022 generator
-csr racing 2 mod apk ios 2022 premium
-csr racing 2 mod apk ios 2022 pro
-csr racing 2 mod apk ios 2022 elite
-csr racing 2 mod apk ios 2022 legends
-csr racing 2 mod apk ios 2022 supercars
-csr racing 2 mod apk ios 2022 hypercars
-csr racing 2 mod apk ios 2021 vs. CSR Racing Mod Apk iOS in the year of the release of the game.
-CSR Racing Mod Apk iOS in the year of the release of the game vs. CSR Racing Mod Apk iOS in the year of the release of the game.
-A realistic and immersive racing game
-One of the main reasons why CSR Racing 2 is so popular is because of its realistic and immersive graphics, physics, sound effects, and gameplay. The game uses 3D rendering techniques to create stunning visuals that make you feel like you are actually driving the cars. The game also features realistic car physics that simulate the behavior of the cars on different terrains and conditions. The game also has amazing sound effects that match the engine sounds, tire screeches, collisions, and other noises of the cars. The game also has a variety of gameplay modes and events that keep you entertained and challenged.
-The game allows you to choose from over 200 licensed cars from some of the most famous brands in the world, such as Ferrari, Lamborghini, Bugatti, McLaren, Pagani, Koenigsegg, and more. You can also customize your cars with different paint jobs, decals, rims, spoilers, nitrous, and other parts. You can also tune your cars to improve their performance and stats.
-A competitive and social racing game
-Another reason why CSR Racing 2 is so popular is because of its competitive and social features. The game has an online multiplayer mode where you can race with other players from around the world in real-time. You can also join or create crews with your friends or other players and compete with other crews for rewards and glory. You can also chat with your crew members and other players in the game. You can also challenge other players to duels or accept challenges from them.
-The game also has a reward system that gives you money, keys, gold, fuel, and other items for completing races, events, achievements, and rankings. You can use these items to buy new cars, upgrade your existing cars, refill your fuel, or enter special events. The game also has a ranking system that ranks you based on your performance and achievements in the game. You can climb up the ranks and earn more rewards and recognition.
-What is CSR Racing 2 Mod APK and what are its features?
-CSR Racing 2 Mod APK is a modified version of the original CSR Racing 2 game that gives you access to all the features and resources that you want in the game. It is not an official version of the game, but it is created by third-party developers who modify the original game files to unlock or add new features.
-A modified version of CSR Racing 2 with unlimited resources
-One of the main benefits of using CSR Racing 2 Mod APK is that it gives you unlimited resources in the game. This means that you can have unlimited money, keys, gold, fuel, and other items in the game without spending any real money or waiting for hours to refill your fuel. You can use these resources to buy any car you want, upgrade it to the max level, enter any event you want, or refill your fuel anytime you want.
-Another benefit of using CSR Racing 2 Mod APK is that it gives you access to some new features that are not available in the original game. For example, some CSR Racing 2 Mod APK versions allow you to unlock all the cars in the game without having to complete any requirements or missions. Some versions also allow you to use nitrous anytime you want without having to wait for it to recharge. Some versions also allow you to disable ads or enable cheats in the game.
-A safe and easy way to enjoy CSR Racing 2 without restrictions
-Another benefit of using CSR Racing 2 Mod APK is that it is a safe and easy way to enjoy CSR Racing 2 without any restrictions or limitations. You don't have to worry about any viruses, malware, or spyware that might harm your device or compromise your privacy. You also don't have to worry about any bans or suspensions from the game developers or publishers. You can download and install CSR Racing 2 Mod APK on your iOS device easily and safely using a third-party app store called Panda Helper. Panda Helper is a trusted and reliable app store that offers thousands of modded and hacked apps and games for iOS devices. You can download and install Panda Helper on your iOS device without jailbreaking it or using a computer.
-How to download and install CSR Racing 2 Mod APK on iOS devices?
-If you want to download and install CSR Racing 2 Mod APK on your iOS device, you need to follow these simple steps:
-A step-by-step guide to download and install CSR Racing 2 Mod APK on iOS devices
-Here is a step-by-step guide to download and install CSR Racing 2 Mod APK on iOS devices using Panda Helper:
-
-- Open Safari browser on your iOS device and go to the official website of Panda Helper: https://www.pandahelp.vip/
-- Tap on the "Download Free Version" button and then tap on "Install" when prompted.
-- Wait for the installation to finish and then go to Settings > General > Profiles & Device Management and trust the profile of Panda Helper.
-- Launch Panda Helper from your home screen and search for "CSR Racing 2 Mod" in the search bar.
-- Tap on the "Get" button next to the CSR Racing 2 Mod app and then tap on "Install" when prompted.
-- Wait for the installation to finish and then go to Settings > General > Profiles & Device Management and trust the profile of CSR Racing 2 Mod.
-- Launch CSR Racing 2 Mod from your home screen and enjoy the game with unlimited resources and features.
-
-A table to summarize the steps to download and install CSR Racing 2 Mod APK on iOS devices
-Here is a table to summarize the steps to download and install CSR Racing 2 Mod APK on iOS devices using Panda Helper:
- | Step number | Action | Screenshot | Explanation | |-------------|--------|------------|-------------| | 1 | Open Safari browser on your iOS device and go to the official website of Panda Helper: https://www.pandahelp.vip/ | ![Panda Helper website]() | Panda Helper is a third-party app store that offers modded and hacked apps and games for iOS devices. | | 2 | Tap on the "Download Free Version" button and then tap on "Install" when prompted. |
| Panda Helper is a third-party app store that offers modded and hacked apps and games for iOS devices. | | 2 | Tap on the "Download Free Version" button and then tap on "Install" when prompted. | ![Panda Helper download]() | This will download and install Panda Helper on your iOS device. | | 3 | Wait for the installation to finish and then go to Settings > General > Profiles & Device Management and trust the profile of Panda Helper. |
| This will download and install Panda Helper on your iOS device. | | 3 | Wait for the installation to finish and then go to Settings > General > Profiles & Device Management and trust the profile of Panda Helper. | ![Panda Helper trust]() | This will allow you to run Panda Helper on your iOS device without any issues. | | 4 | Launch Panda Helper from your home screen and search for "CSR Racing 2 Mod" in the search bar. |
| This will allow you to run Panda Helper on your iOS device without any issues. | | 4 | Launch Panda Helper from your home screen and search for "CSR Racing 2 Mod" in the search bar. | ![Panda Helper search]() | This will show you the CSR Racing 2 Mod app that you can download and install on your iOS device. | | 5 | Tap on the "Get" button next to the CSR Racing 2 Mod app and then tap on "Install" when prompted. |
| This will show you the CSR Racing 2 Mod app that you can download and install on your iOS device. | | 5 | Tap on the "Get" button next to the CSR Racing 2 Mod app and then tap on "Install" when prompted. | ![CSR Racing 2 Mod download]() | This will download and install CSR Racing 2 Mod on your iOS device. | | 6 | Wait for the installation to finish and then go to Settings > General > Profiles & Device Management and trust the profile of CSR Racing 2 Mod. |
| This will download and install CSR Racing 2 Mod on your iOS device. | | 6 | Wait for the installation to finish and then go to Settings > General > Profiles & Device Management and trust the profile of CSR Racing 2 Mod. | ![CSR Racing 2 Mod trust]() | This will allow you to run CSR Racing 2 Mod on your iOS device without any issues. | | 7 | Launch CSR Racing 2 Mod from your home screen and enjoy the game with unlimited resources and features. |
| This will allow you to run CSR Racing 2 Mod on your iOS device without any issues. | | 7 | Launch CSR Racing 2 Mod from your home screen and enjoy the game with unlimited resources and features. | ![CSR Racing 2 Mod launch]() | This will let you play CSR Racing 2 with unlimited money, keys, gold, fuel, nitrous, cars, upgrades, etc. |
| This will let you play CSR Racing 2 with unlimited money, keys, gold, fuel, nitrous, cars, upgrades, etc. | Conclusion
-In conclusion, CSR Racing 2 is a great racing game that offers you a realistic and immersive experience of driving some of the most amazing cars in the world. It also lets you compete and socialize with other players online, join crews, chat with friends, and earn rewards and rankings. However, if you want to enjoy all these features without any limitations or restrictions, you can try CSR Racing 2 Mod APK on your iOS device. CSR Racing 2 Mod APK is a modified version of the original game that gives you unlimited resources and features in the game. You can download and install it on your iOS device easily and safely using Panda Helper, a third-party app store that offers modded and hacked apps and games for iOS devices. You can follow the step-by-step guide and the table above to download and install CSR Racing 2 Mod APK on your iOS device. We hope you found this article helpful and informative. If you have any questions or feedback, please feel free to leave them in the comments section below. Thank you for reading and happy racing!
-FAQs
-Here are some frequently asked questions about CSR Racing 2 Mod APK on iOS devices with brief answers:
-
-- Q: Is CSR Racing 2 Mod APK safe to use?
-- A: Yes, CSR Racing 2 Mod APK is safe to use as long as you download it from a trusted source like Panda Helper. It does not contain any viruses, malware, or spyware that might harm your device or compromise your privacy.
-- Q: Is CSR Racing 2 Mod APK compatible with my iOS device?
-- A: Yes, CSR Racing 2 Mod APK is compatible with most iOS devices that can run the original CSR Racing 2 game. However, you may need to update your iOS version or free up some storage space on your device before installing it.
-- Q: Will I get banned or suspended from CSR Racing 2 if I use CSR Racing 2 Mod APK?
-- A: No, you will not get banned or suspended from CSR Racing 2 if you use CSR Racing 2 Mod APK. However, you should use it at your own risk and discretion, as the game developers or publishers may not approve of it.
-- Q: Can I play online multiplayer mode with CSR Racing 2 Mod APK?
-- A: Yes, you can play online multiplayer mode with CSR Racing 2 Mod APK. However, you may face some issues or glitches while playing with other players who are using the original game or a different version of the mod.
-- Q: Can I update CSR Racing 2 Mod APK to the latest version?
-- A: Yes, you can update CSR Racing 2 Mod APK to the latest version by following the same steps as downloading and installing it. However, you may need to uninstall the previous version of the mod before installing the new one.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/Download Cars Movie for Free A Step-by-Step Guide.md b/spaces/1phancelerku/anime-remove-background/Download Cars Movie for Free A Step-by-Step Guide.md
deleted file mode 100644
index 254a3d3d34aa80ca82e133e2781f9a95235dc2a4..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Download Cars Movie for Free A Step-by-Step Guide.md
+++ /dev/null
@@ -1,281 +0,0 @@
-
-How to Download Cars Movie Legally and Safely
-Cars is a 2006 animated comedy film produced by Pixar Animation Studios and distributed by Walt Disney Pictures. It tells the story of a hotshot race car named Lightning McQueen who gets stranded in a small town called Radiator Springs and learns the true meaning of friendship and family. The film features the voices of Owen Wilson, Paul Newman, Bonnie Hunt, Larry the Cable Guy, and many others.
-how to download cars movie
Download File 🆓 https://jinyurl.com/2uNRAF
-If you are a fan of Cars or want to watch it for the first time, you might be wondering how to download it to your computer or mobile device. There are many ways to download movies online, but not all of them are legal or safe. In this article, we will show you how to download Cars movie legally and safely from different sources, such as streaming services, torrent sites, and free movie sites. We will also give you some tips on how to avoid viruses, malware, ads, and pop-ups when downloading movies.
-Introduction
-What is Cars Movie and Why You Should Watch It
-Cars is a Pixar film that was released in 2006 and became one of the most successful animated movies of all time. It won the Golden Globe Award for Best Animated Feature Film and was nominated for two Academy Awards for Best Animated Feature and Best Original Song. It also spawned two sequels, Cars 2 (2011) and Cars 3 (2017), as well as several spin-offs, shorts, video games, merchandise, and theme park attractions.
-Cars is a movie that appeals to both children and adults, as it combines humor, adventure, romance, drama, and action. It also features stunning animation, memorable characters, catchy songs, and a heartwarming message about finding your true self and your true friends. If you love cars, racing, or animation, you will definitely enjoy watching Cars.
-how to download cars movie for free
-how to download cars movie in hindi
-how to download cars movie from netflix
-how to download cars movie on ipad
-how to download cars movie in hd
-how to download cars movie on laptop
-how to download cars movie on android
-how to download cars movie from youtube
-how to download cars movie with subtitles
-how to download cars movie in tamil
-how to download cars movie from amazon prime
-how to download cars movie on iphone
-how to download cars movie in telugu
-how to download cars movie from disney plus
-how to download cars movie in utorrent
-how to download cars movie on pc
-how to download cars movie in malayalam
-how to download cars movie from google drive
-how to download cars movie with english subtitles
-how to download cars movie in urdu
-how to download cars movie from hotstar
-how to download cars movie on mac
-how to download cars movie in kannada
-how to download cars movie from facebook
-how to download cars movie with hindi audio
-how to download cars movie on firestick
-how to download cars movie in bengali
-how to download cars movie from voot
-how to download cars movie with dual audio
-how to download cars movie on chromebook
-how to download cars movie in punjabi
-how to download cars movie from zee5
-how to download cars movie with tamil audio
-how to download cars movie on roku
-how to download cars movie in marathi
-how to download cars movie from sony liv
-how to download cars movie with telugu audio
-how to download cars movie on smart tv
-how to download cars movie in gujarati
-how to download cars movie from mx player
-The Risks of Downloading Movies Illegally
-Before we show you how to download Cars movie legally and safely, we want to warn you about the risks of downloading movies illegally. Illegal downloading is the act of obtaining or sharing copyrighted material without the permission of the owner or the law. This includes movies, music, games, software, books, and any other digital content.
-Downloading movies illegally can have serious consequences for you and your device. Some of the risks are:
-
-- You can face legal action from the copyright owner or the authorities. Depending on your country's laws, you can be fined, sued, or even jailed for piracy.
-- You can expose your device to viruses, malware, spyware, ransomware, or other harmful programs that can damage your data, steal your information, or lock your device until you pay a ransom.
-- You can compromise your online security and privacy by revealing your IP address, location, browsing history, or personal information to hackers, trackers, or advertisers.
-- You can waste your time, bandwidth, and storage space by downloading low-quality, incomplete, or fake files that do not match what you are looking for.
-
-As you can see, downloading movies illegally is not worth the risk. That is why we recommend you to use legal and safe methods to download Cars movie, which we will explain in the next sections.
-How to Download Cars Movie from Streaming Services
-One of the best ways to download Cars movie legally and safely is to use a streaming service. A streaming service is a platform that allows you to watch movies, TV shows, and other content online or offline by paying a monthly or annual fee. Some of the most popular streaming services are Netflix, Amazon Prime Video, Hulu, Disney+, HBO Max, and Apple TV+.
-Streaming services offer many benefits for movie lovers, such as:
-
-- You can access a large library of movies and shows in different genres, languages, and regions.
-- You can watch movies and shows in high-definition (HD), ultra-high-definition (UHD), or 4K resolution, depending on your device and internet speed.
-- You can download movies and shows to your device and watch them offline without using data or Wi-Fi.
-- You can watch movies and shows on multiple devices, such as computers, smartphones, tablets, smart TVs, gaming consoles, or streaming devices.
-- You can create multiple profiles for different users and customize your preferences, recommendations, and watch history.
-- You can enjoy exclusive content that is only available on the streaming service.
-
-However, streaming services also have some drawbacks, such as:
-
-- You have to pay a monthly or annual fee to use the service. The fee may vary depending on the plan you choose, the number of screens you can watch on simultaneously, and the availability of certain features.
-- You need a stable and fast internet connection to stream or download movies and shows. If your internet is slow or unreliable, you may experience buffering, lagging, or poor quality.
-- You may not find the movie or show you want to watch on the streaming service. Streaming services have different catalogs that change over time due to licensing agreements with studios and distributors.
-- You may face geo-restrictions that prevent you from accessing certain content based on your location. Streaming services have different libraries for different countries due to legal and cultural reasons.
-
-In this section, we will focus on two of the most popular streaming services that offer Cars movie: Netflix and Amazon Prime Video. We will show you how to download Cars movie from each of them and compare their pros and cons.
-Netflix
-Netflix is the world's leading streaming service with over 200 million subscribers in more than 190 countries. It offers a wide range of movies and shows in various genres and languages. It also produces original content that is exclusive to Netflix, such as Stranger Things, The Crown, The Witcher, Black Mirror, and more.
-Steps to Download Cars Movie from Netflix
-To download Cars movie from Netflix, you need to follow these steps:
-
-- Sign up for a Netflix account if you don't have one. You can choose from three plans: Basic ($8.99 per month), Standard ($13.99 per month), or Premium ($17.99 per month). The Basic plan allows you to watch on one screen at a time in standard definition (SD), the Standard plan allows you to watch on two screens at a time in high definition (HD), and the Premium plan allows you to watch on four screens at a time in HD or 4K.
-- Download the Netflix app on your device. You can download it from the App Store for iOS devices, the Google Play Store for Android devices, or the Microsoft Store for Windows devices. You can also access Netflix from your web browser, but you cannot download movies or shows from there.
-- Open the Netflix app and sign in with your account. You can browse the content by categories, genres, recommendations, or search for a specific title.
-- Find Cars movie on Netflix. You can use the search function or look for it in the Animation, Comedy, or Family categories. You can also check if Cars movie is available on Netflix in your country by using a website like unogs.com or flixwatch.co.
-- Tap on the download icon next to the play button. The download icon looks like a downward arrow with a horizontal line below it. If you don't see the download icon, it means that the movie is not available for download.
-- Wait for the movie to download to your device. You can check the progress of the download by tapping on the downloads icon at the bottom of the screen. The downloads icon looks like a downward arrow with a circle around it.
-- Enjoy watching Cars movie offline. You can find the downloaded movie in the downloads section of the app. You can watch it as many times as you want without using data or Wi-Fi.
-
-Pros and Cons of Netflix
-Netflix is a great streaming service for downloading Cars movie, but it also has some pros and cons that you should consider:
-
-
-Pros
-Cons
-
-
-- Netflix has a large and diverse library of movies and shows, including original and exclusive content.
-- Netflix requires a subscription fee to use the service, which may not be affordable for some users.
-
-
-- Netflix allows you to download movies and shows to your device and watch them offline without using data or Wi-Fi.
-- Netflix limits the number of devices and screens you can watch on simultaneously, depending on your plan.
-
-
-- Netflix offers high-quality video and audio, as well as subtitles and dubbing options for different languages.
-- Netflix does not have all the movies and shows you may want to watch, as some of them may be unavailable or removed due to licensing agreements.
-
-
-- Netflix is compatible with most devices and platforms, such as computers, smartphones, tablets, smart TVs, gaming consoles, or streaming devices.
-- Netflix may have geo-restrictions that prevent you from accessing certain content based on your location, unless you use a VPN service.
-
-
Amazon Prime Video
-Amazon Prime Video is another popular streaming service that offers a variety of movies and shows, including original and exclusive content. It is part of the Amazon Prime membership, which also includes free shipping, music streaming, e-books, and more. You can also rent or buy movies and shows that are not included in the Prime Video catalog.
-Steps to Download Cars Movie from Amazon Prime Video
-To download Cars movie from Amazon Prime Video, you need to follow these steps:
-
-- Sign up for an Amazon Prime account if you don't have one. You can get a 30-day free trial and then pay $12.99 per month or $119 per year. You can also sign up for a Prime Video-only account for $8.99 per month.
-- Download the Prime Video app on your device. You can download it from the App Store for iOS devices, the Google Play Store for Android devices, or the Microsoft Store for Windows devices. You can also access Prime Video from your web browser, but you cannot download movies or shows from there.
-- Open the Prime Video app and sign in with your account. You can browse the content by categories, genres, recommendations, or search for a specific title.
-- Find Cars movie on Prime Video. You can use the search function or look for it in the Animation, Comedy, or Family categories. You can also check if Cars movie is available on Prime Video in your country by using a website like justwatch.com or reelgood.com.
-- Tap on the download icon next to the play button. The download icon looks like a downward arrow with a horizontal line below it. If you don't see the download icon, it means that the movie is not available for download.
-- Wait for the movie to download to your device. You can check the progress of the download by tapping on the downloads icon at the bottom of the screen. The downloads icon looks like a downward arrow with a circle around it.
-- Enjoy watching Cars movie offline. You can find the downloaded movie in the downloads section of the app. You can watch it as many times as you want without using data or Wi-Fi.
-
-Pros and Cons of Amazon Prime Video
-Amazon Prime Video is another great streaming service for downloading Cars movie, but it also has some pros and cons that you should consider:
-
-
-Pros
-Cons
-
-
-- Amazon Prime Video has a large and diverse library of movies and shows, including original and exclusive content.
-- Amazon Prime Video requires a subscription fee to use the service, which may not be affordable for some users.
-
-
-- Amazon Prime Video allows you to download movies and shows to your device and watch them offline without using data or Wi-Fi.
-- Amazon Prime Video limits the number of devices and titles you can download at a time, depending on your location and account type.
-
-
-- Amazon Prime Video offers high-quality video and audio, as well as subtitles and dubbing options for different languages.
-- Amazon Prime Video does not have all the movies and shows you may want to watch, as some of them may be unavailable or removed due to licensing agreements.
-
-
-- Amazon Prime Video is compatible with most devices and platforms, such as computers, smartphones, tablets, smart TVs, gaming consoles, or streaming devices.
-- Amazon Prime Video may have geo-restrictions that prevent you from accessing certain content based on your location, unless you use a VPN service.
-
-
How to Download Cars Movie from Torrent Sites
-Another way to download Cars movie is to use a torrent site. A torrent site is a website that hosts torrent files, which are small files that contain information about the content you want to download, such as the name, size, type, and location of the files. You can use a torrent site to find and download movies, music, games, software, books, and any other digital content.
-What are Torrents and How They Work
-Torrents are a peer-to-peer (P2P) file-sharing technology that allows users to download and share files with each other without relying on a central server. Instead, users connect to each other directly and form a network of peers. Each peer has a copy of the torrent file and a part of the content file. When you download a torrent, you are downloading small pieces of the content file from different peers. When you upload a torrent, you are sharing the pieces of the content file that you have with other peers.
-Torrents work by using a BitTorrent protocol, which is a set of rules and commands that enable the communication and coordination between peers. The BitTorrent protocol uses trackers, which are servers that help peers find each other and exchange information. The BitTorrent protocol also uses seeds and leechers, which are terms that describe the status of peers in the network. A seed is a peer that has the complete content file and is uploading it to other peers. A leecher is a peer that does not have the complete content file and is downloading it from other peers.
-How to Use a BitTorrent Client to Download Movies
-To use torrents to download movies, you need to use a BitTorrent client, which is a software program that allows you to open, download, and upload torrent files. There are many BitTorrent clients available for different devices and platforms, such as uTorrent, BitTorrent, qBittorrent, Transmission, Vuze, Deluge, and more.
-Steps to Download Cars Movie from a Torrent Site
-To download Cars movie from a torrent site, you need to follow these steps:
-
-- Choose a BitTorrent client that suits your device and preferences. You can compare the features, performance, security, and reviews of different BitTorrent clients online. You can also check if the BitTorrent client is compatible with your device and operating system.
-- Download and install the BitTorrent client on your device. You can download it from the official website of the BitTorrent client or from a trusted source. You can also customize the settings of the BitTorrent client according to your needs.
-- Choose a torrent site that has Cars movie available for download. You can search for torrent sites online or use a website like torrentz2.eu or torrentfunk.com to find torrent sites that have Cars movie. You can also check the reputation, popularity, and safety of torrent sites online.
-- Find Cars movie on the torrent site. You can use the search function or browse by categories or genres. You can also check the details of the torrent file, such as the name, size, type, quality, seeds, leechers, comments, and ratings.
-- Download the torrent file or copy the magnet link of Cars movie. The torrent file is a small file that contains information about the content file. The magnet link is a URL that contains information about the content file and allows you to download it without using a torrent file.
-- Open the torrent file or paste the magnet link in your BitTorrent client. The BitTorrent client will start downloading Cars movie from different peers in the network. You can check the progress of the download by looking at the speed, time remaining, percentage completed, and amount downloaded.
-- Wait for the movie to download to your device. You can choose where to save the movie on your device or let the BitTorrent client choose for you. You can also pause or resume the download at any time.
-- Enjoy watching Cars movie offline. You can find the downloaded movie in the folder you chose or in the default folder of your BitTorrent client. You can watch it as many times as you want without using data or Wi-Fi.
-
-Pros and Cons of Torrents
-Torrents are a convenient and fast way to download movies, but they also have some pros and cons that you should consider:
-
-
-Pros
-Cons
-
-
-- Torrents allow you to download movies for free without paying any subscription fee or registration fee.
-- Torrents are illegal in many countries and regions due to copyright infringement and piracy laws.
-
-
-- Torrents - Torrents offer a wide range of movies and shows in different genres, languages, and regions that may not be available on streaming services.
-- Torrents expose your device to viruses, malware, spyware, ransomware, or other harmful programs that can damage your data, steal your information, or lock your device until you pay a ransom.
-
-
-- Torrents provide high-quality video and audio, as well as subtitles and dubbing options for different languages.
-- Torrents compromise your online security and privacy by revealing your IP address, location, browsing history, or personal information to hackers, trackers, or advertisers.
-
-
-- Torrents are compatible with most devices and platforms, such as computers, smartphones, tablets, smart TVs, gaming consoles, or streaming devices.
-- Torrents depend on the availability and generosity of peers in the network. If there are not enough seeds or too many leechers, the download speed and quality may be low or the download may fail.
-
-
-How to Protect Yourself from Viruses and Malware When Using Torrents
-As we mentioned before, torrents can be risky for your device and your online safety. However, there are some ways to protect yourself from viruses and malware when using torrents. Here are some tips:
-Use a VPN Service
-A VPN service is a virtual private network that encrypts your internet traffic and hides your IP address and location from anyone who tries to monitor or track you online. A VPN service can help you avoid geo-restrictions, censorship, surveillance, and legal action when using torrents. It can also prevent hackers, trackers, or advertisers from accessing your data or information.
-To use a VPN service, you need to sign up for a VPN account and download and install the VPN app on your device. You can choose from many VPN services available online, such as NordVPN, ExpressVPN, Surfshark, CyberGhost, or IPVanish. You can also compare the features, performance, security, and reviews of different VPN services online.
-Once you have the VPN app on your device, you need to connect to a VPN server of your choice. The VPN server will assign you a new IP address and location that will mask your real ones. You can then use the torrent site and the BitTorrent client as usual. The VPN service will encrypt your internet traffic and protect you from viruses and malware.
-Scan the Downloaded File with an Antivirus Program
-An antivirus program is a software program that detects and removes viruses and malware from your device. An antivirus program can help you prevent or fix any damage caused by viruses and malware when using torrents. It can also alert you of any suspicious or malicious files or programs on your device.
-To use an antivirus program, you need to download and install the antivirus program on your device. You can choose from many antivirus programs available online, such as Avast, AVG, Kaspersky, McAfee, or Norton. You can also compare the features, performance, security, and reviews of different antivirus programs online.
-Once you have the antivirus program on your device, you need to scan the downloaded file with the antivirus program before opening it. The antivirus program will scan the file and detect any viruses or malware that may be hidden in it. If the file is clean, you can open it and watch Cars movie. If the file is infected, you can delete it and look for another torrent.
-How to Download Cars Movie from Free Movie Sites
-A third way to download Cars movie is to use a free movie site. A free movie site is a website that allows you to watch movies online or offline without paying any fee or registration. You can use a free movie site to find and download movies in different genres, languages, and regions.
-What are Free Movie Sites and How They Work
-Free movie sites are websites that host or link to movies that are uploaded by users or third parties. Free movie sites do not have the legal rights or licenses to distribute the movies they offer. They rely on advertising revenue or donations to maintain their servers and domains.
-Free movie sites work by using streaming or downloading technology. Streaming technology allows you to watch movies online without downloading them to your device. You can watch movies in real time as they are transmitted from the server to your device. Downloading technology allows you to download movies to your device and watch them offline without using data or Wi-Fi. You can download movies as whole files or as small pieces that are joined together.
-How to Find and Use a Free Movie Site to Download Movies
-To use a free movie site to download movies, you need to follow these steps:
-
-- Choose a free movie site that has Cars movie available for download. You can search for free movie sites online or use a website like alluc.co or yidio.com to find free movie sites that have Cars movie. You can also check the reputation, popularity, and safety of free movie sites online.
-- Find Cars movie on the free movie site. You can use the search function or browse by categories or genres. You can also check the details of the movie, such as the name, size, type, quality, source, and ratings.
-- Download Cars movie from the free movie site. Depending on the free movie site, you may have different options to download Cars movie. Some of the options are:
-
-- Click on the download button or link that leads you to the movie file. The download button or link may look like a downward arrow, a disk icon, or a text that says "download".
-- Right-click on the video player and select "save video as" or "download video". The video player may look like a rectangle with a play button in the center.
-- Copy the video URL from the address bar or the video player and paste it in a video downloader website or software. The video URL may look like a long string of letters and numbers that starts with "http" or "https".
-
-- Wait for the movie to download to your device. You can check the progress of the download by looking at the speed, time remaining, percentage completed, and amount downloaded.
-- Enjoy watching Cars movie offline. You can find the downloaded movie in the folder you chose or in the default folder of your browser or downloader. You can watch it as many times as you want without using data or Wi-Fi.
-
-Pros and Cons of Free Movie Sites
-Free movie sites are an easy and cheap way to download movies, but they also have some pros and cons that you should consider:
-
-
-Pros
-Cons
-
-
-- Free movie sites allow you to download movies for free without paying any subscription fee or registration fee.
-- Free movie sites are illegal in many countries and regions due to copyright infringement and piracy laws.
-
-
-- Free movie sites offer a wide range of movies and shows in different genres, languages, and regions that may not be available on streaming services.
-- Free movie sites expose your device to viruses, malware, spyware, ransomware, or other harmful programs that can damage your data, steal your information, or lock your device until you pay a ransom.
-
-
-- Free movie sites provide high-quality video and audio, as well as subtitles and dubbing options for different languages.
-- Free movie sites compromise your online security and privacy by revealing your IP address, location, browsing history, or personal information to hackers, trackers, or advertisers.
-
-
-- Free movie sites are compatible with most devices and platforms, such as computers, smartphones, tablets, smart TVs, gaming consoles, or streaming devices.
-- Free movie sites depend on the availability and reliability of the servers and links that host or link to the movies. If the server or link is down, broken, or removed, the download may fail or the movie may not play.
-
-
-How to Avoid Ads and Pop-ups When Using Free Movie Sites
-As we mentioned before, free movie sites rely on advertising revenue to maintain their servers and domains. However, the ads and pop-ups that appear on free movie sites can be annoying, intrusive, or even dangerous for your device and your online safety. However, there are some ways to avoid ads and pop-ups when using free movie sites. Here are some tips:
-Use an Ad Blocker Extension
-An ad blocker extension is a browser extension that blocks or removes ads and pop-ups from websites. An ad blocker extension can help you improve your browsing experience, save your bandwidth and battery life, and protect you from malicious ads and pop-ups.
-To use an ad blocker extension, you need to download and install the ad blocker extension on your browser. You can choose from many ad blocker extensions available online, such as Adblock Plus, uBlock Origin, AdGuard, or Ghostery. You can also compare the features, performance, security, and reviews of different ad blocker extensions online.
-Once you have the ad blocker extension on your browser, you need to enable it and customize its settings according to your preferences. You can also whitelist some websites that you want to support or that do not have annoying or harmful ads and pop-ups.
-Use a Pop-up Blocker Extension
-A pop-up blocker extension is a browser extension that blocks or removes pop-ups from websites. A pop-up is a new window that opens automatically when you visit a website or click on a link. A pop-up blocker extension can help you avoid unwanted or malicious pop-ups that may redirect you to other websites, download unwanted files or programs, or display inappropriate or misleading content.
-To use a pop-up blocker extension, you need to download and install the pop-up blocker extension on your browser. You can choose from many pop-up blocker extensions available online, such as Popper Blocker, Poper Blocker, Popup Blocker Pro, or Smart Popup Blocker. You can also compare the features, performance, security, and reviews of different pop-up blocker extensions online.
-Once you have the pop-up blocker extension on your browser, you need to enable it and customize its settings according to your preferences. You can also whitelist some websites that you want to allow pop-ups from or that do not have unwanted or malicious pop-ups.
-Conclusion
-Summary of the Main Points
-In this article, we have shown you how to download Cars movie legally and safely from different sources, such as streaming services, torrent sites, and free movie sites. We have also given you some tips on how to protect yourself from viruses and malware when using torrents and how to avoid ads and pop-ups when using free movie sites.
-Cars is a Pixar film that was released in 2006 and became one of the most successful animated movies of all time. It tells the story of a hotshot race car named Lightning McQueen who gets stranded in a small town called Radiator Springs and learns the true meaning of friendship and family. If you are a fan of Cars or want to watch it for the first time, you might be wondering how to download it to your computer or mobile device.
-Recommendations for the Best Way to Download Cars Movie
-Based on our analysis, we recommend you to use streaming services as the best way to download Cars movie legally and safely. Streaming services offer many benefits for movie lovers, such as high-quality video and audio, offline viewing, multiple device compatibility, large and diverse library, and exclusive content. Streaming services also have fewer drawbacks than torrent sites or free movie sites, such as subscription fee, internet speed, content availability, and geo-restrictions.
-Among the streaming services that offer Cars movie, we suggest you to use Netflix or Amazon Prime Video. Both of them have similar features and advantages, such as HD or 4K resolution, subtitles and dubbing options, multiple profiles and screens, and original and exclusive content. However, Netflix has a larger and more diverse library than Amazon Prime Video, while Amazon Prime Video has a cheaper and more comprehensive membership than Netflix.
-Therefore, you can choose the streaming service that suits your preferences and budget. You can also try both of them for free for a limited time and compare their performance and quality. You can follow the steps we provided in this article to download Cars movie from Netflix or Amazon Prime Video.
-FAQs
-Here are some frequently asked questions about downloading Cars movie:
-
-- Is downloading Cars movie illegal?
-Downloading Cars movie is not illegal if you use a legal and safe method, such as streaming services. However, downloading Cars movie is illegal if you use an illegal and unsafe method, such as torrent sites or free movie sites. You can face legal action from the copyright owner or the authorities if you download Cars movie illegally.
-- Is downloading Cars movie safe?
-Downloading Cars movie is safe if you use a legal and safe method, such as streaming services. However, downloading Cars movie is not safe if you use an illegal and unsafe method, such as torrent sites or free movie sites. You can expose your device to viruses, malware, spyware, ransomware, or other harmful programs if you download Cars movie from an unsafe source.
-- How long does it take to download Cars movie?
-The time it takes to download Cars movie depends on several factors, such as the size of the file, the speed of your internet connection, the number of seeds or peers in the network, and the method you use to download it. Generally, streaming services have faster download speeds than torrent sites or free movie sites. However, streaming services also have larger file sizes than torrent sites or free movie sites. Therefore, you can expect to download Cars movie in a few minutes to a few hours depending on your situation.
-- How much space does Cars movie take on my device?
-The space that Cars movie takes on your device depends on the quality of the video and audio, the length of the movie, and the format of the file. Generally, streaming services have higher quality video and audio than torrent sites or free movie sites. However, streaming services also have larger file sizes than torrent sites or free movie sites. Therefore, you can expect Cars movie to take from a few hundred megabytes to a few gigabytes of space on your device depending on your choice.
-- Can I watch Cars movie on any device?
-You can watch Cars movie on any device that supports the method you use to download it. For example, if you use a streaming service, you can watch Cars movie on any device that has the streaming app installed or can access the streaming website. If you use a torrent site or a free movie site, you can watch Cars movie on any device that has a video player that can open the file format of the movie.
-
-I hope this article has helped you learn how to download Cars movie legally and safely. If you have any questions or comments, please feel free to leave them below. Thank you for reading and happy watching!
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/2ndelement/voicevox/test/test_acoustic_feature_extractor.py b/spaces/2ndelement/voicevox/test/test_acoustic_feature_extractor.py
deleted file mode 100644
index a82e7afe62eed4f1be1506d7cd34335c769d17d0..0000000000000000000000000000000000000000
--- a/spaces/2ndelement/voicevox/test/test_acoustic_feature_extractor.py
+++ /dev/null
@@ -1,266 +0,0 @@
-import os
-from pathlib import Path
-from typing import List, Type
-from unittest import TestCase
-
-from voicevox_engine.acoustic_feature_extractor import (
- BasePhoneme,
- JvsPhoneme,
- OjtPhoneme,
-)
-
-
-class TestBasePhoneme(TestCase):
- def setUp(self):
- super().setUp()
- self.str_hello_hiho = "sil k o N n i ch i w a pau h i h o d e s U sil"
- self.base_hello_hiho = [
- BasePhoneme(s, i, i + 1) for i, s in enumerate(self.str_hello_hiho.split())
- ]
- self.lab_str = """
- 0.00 1.00 pau
- 1.00 2.00 k
- 2.00 3.00 o
- 3.00 4.00 N
- 4.00 5.00 n
- 5.00 6.00 i
- 6.00 7.00 ch
- 7.00 8.00 i
- 8.00 9.00 w
- 9.00 10.00 a
- 10.00 11.00 pau
- 11.00 12.00 h
- 12.00 13.00 i
- 13.00 14.00 h
- 14.00 15.00 o
- 15.00 16.00 d
- 16.00 17.00 e
- 17.00 18.00 s
- 18.00 19.00 U
- 19.00 20.00 pau
- """.replace(
- " ", ""
- )[
- 1:-1
- ] # ダブルクオーテーションx3で囲われている部分で、空白をすべて置き換え、先頭と最後の"\n"を除外する
-
- def test_repr_(self):
- self.assertEqual(
- self.base_hello_hiho[1].__repr__(), "Phoneme(phoneme='k', start=1, end=2)"
- )
- self.assertEqual(
- self.base_hello_hiho[10].__repr__(),
- "Phoneme(phoneme='pau', start=10, end=11)",
- )
-
- def test_convert(self):
- with self.assertRaises(NotImplementedError):
- BasePhoneme.convert(self.base_hello_hiho)
-
- def test_duration(self):
- self.assertEqual(self.base_hello_hiho[1].duration, 1)
-
- def test_parse(self):
- parse_str_1 = "0 1 pau"
- parse_str_2 = "32.67543 33.48933 e"
- parsed_base_1 = BasePhoneme.parse(parse_str_1)
- parsed_base_2 = BasePhoneme.parse(parse_str_2)
- self.assertEqual(parsed_base_1.phoneme, "pau")
- self.assertEqual(parsed_base_1.start, 0.0)
- self.assertEqual(parsed_base_1.end, 1.0)
- self.assertEqual(parsed_base_2.phoneme, "e")
- self.assertEqual(parsed_base_2.start, 32.68)
- self.assertEqual(parsed_base_2.end, 33.49)
-
- def lab_test_base(
- self,
- file_path: str,
- phonemes: List["BasePhoneme"],
- phoneme_class: Type["BasePhoneme"],
- ):
- phoneme_class.save_lab_list(phonemes, Path(file_path))
- with open(file_path, mode="r") as f:
- self.assertEqual(f.read(), self.lab_str)
- result_phoneme = phoneme_class.load_lab_list(Path(file_path))
- self.assertEqual(result_phoneme, phonemes)
- os.remove(file_path)
-
-
-class TestJvsPhoneme(TestBasePhoneme):
- def setUp(self):
- super().setUp()
- base_hello_hiho = [
- JvsPhoneme(s, i, i + 1) for i, s in enumerate(self.str_hello_hiho.split())
- ]
- self.jvs_hello_hiho = JvsPhoneme.convert(base_hello_hiho)
-
- def test_phoneme_list(self):
- self.assertEqual(JvsPhoneme.phoneme_list[1], "I")
- self.assertEqual(JvsPhoneme.phoneme_list[14], "gy")
- self.assertEqual(JvsPhoneme.phoneme_list[26], "p")
- self.assertEqual(JvsPhoneme.phoneme_list[38], "z")
-
- def test_const(self):
- self.assertEqual(JvsPhoneme.num_phoneme, 39)
- self.assertEqual(JvsPhoneme.space_phoneme, "pau")
-
- def test_convert(self):
- converted_str_hello_hiho = " ".join([p.phoneme for p in self.jvs_hello_hiho])
- self.assertEqual(
- converted_str_hello_hiho, "pau k o N n i ch i w a pau h i h o d e s U pau"
- )
-
- def test_equal(self):
- # jvs_hello_hihoの2番目の"k"と比較
- true_jvs_phoneme = JvsPhoneme("k", 1, 2)
- # OjtPhonemeと比べる、比較はBasePhoneme内で実装されているので、比較結果はTrue
- true_ojt_phoneme = OjtPhoneme("k", 1, 2)
-
- false_jvs_phoneme_1 = JvsPhoneme("a", 1, 2)
- false_jvs_phoneme_2 = JvsPhoneme("k", 2, 3)
- self.assertTrue(self.jvs_hello_hiho[1] == true_jvs_phoneme)
- self.assertTrue(self.jvs_hello_hiho[1] == true_ojt_phoneme)
- self.assertFalse(self.jvs_hello_hiho[1] == false_jvs_phoneme_1)
- self.assertFalse(self.jvs_hello_hiho[1] == false_jvs_phoneme_2)
-
- def test_verify(self):
- for phoneme in self.jvs_hello_hiho:
- phoneme.verify()
-
- def test_phoneme_id(self):
- jvs_str_hello_hiho = " ".join([str(p.phoneme_id) for p in self.jvs_hello_hiho])
- self.assertEqual(
- jvs_str_hello_hiho, "0 19 25 2 23 17 7 17 36 4 0 15 17 15 25 9 11 30 3 0"
- )
-
- def test_onehot(self):
- phoneme_id_list = [
- 0,
- 19,
- 25,
- 2,
- 23,
- 17,
- 7,
- 17,
- 36,
- 4,
- 0,
- 15,
- 17,
- 15,
- 25,
- 9,
- 11,
- 30,
- 3,
- 0,
- ]
- for i, phoneme in enumerate(self.jvs_hello_hiho):
- for j in range(JvsPhoneme.num_phoneme):
- if phoneme_id_list[i] == j:
- self.assertEqual(phoneme.onehot[j], True)
- else:
- self.assertEqual(phoneme.onehot[j], False)
-
- def test_parse(self):
- parse_str_1 = "0 1 pau"
- parse_str_2 = "15.32654 16.39454 a"
- parsed_jvs_1 = JvsPhoneme.parse(parse_str_1)
- parsed_jvs_2 = JvsPhoneme.parse(parse_str_2)
- self.assertEqual(parsed_jvs_1.phoneme_id, 0)
- self.assertEqual(parsed_jvs_2.phoneme_id, 4)
-
- def test_lab_list(self):
- self.lab_test_base("./jvs_lab_test", self.jvs_hello_hiho, JvsPhoneme)
-
-
-class TestOjtPhoneme(TestBasePhoneme):
- def setUp(self):
- super().setUp()
- self.str_hello_hiho = "sil k o N n i ch i w a pau h i h o d e s U sil"
- base_hello_hiho = [
- OjtPhoneme(s, i, i + 1) for i, s in enumerate(self.str_hello_hiho.split())
- ]
- self.ojt_hello_hiho = OjtPhoneme.convert(base_hello_hiho)
-
- def test_phoneme_list(self):
- self.assertEqual(OjtPhoneme.phoneme_list[1], "A")
- self.assertEqual(OjtPhoneme.phoneme_list[14], "e")
- self.assertEqual(OjtPhoneme.phoneme_list[26], "m")
- self.assertEqual(OjtPhoneme.phoneme_list[38], "ts")
- self.assertEqual(OjtPhoneme.phoneme_list[41], "v")
-
- def test_const(self):
- self.assertEqual(OjtPhoneme.num_phoneme, 45)
- self.assertEqual(OjtPhoneme.space_phoneme, "pau")
-
- def test_convert(self):
- ojt_str_hello_hiho = " ".join([p.phoneme for p in self.ojt_hello_hiho])
- self.assertEqual(
- ojt_str_hello_hiho, "pau k o N n i ch i w a pau h i h o d e s U pau"
- )
-
- def test_equal(self):
- # ojt_hello_hihoの10番目の"a"と比較
- true_ojt_phoneme = OjtPhoneme("a", 9, 10)
- # JvsPhonemeと比べる、比較はBasePhoneme内で実装されているので、比較結果はTrue
- true_jvs_phoneme = JvsPhoneme("a", 9, 10)
-
- false_ojt_phoneme_1 = OjtPhoneme("k", 9, 10)
- false_ojt_phoneme_2 = OjtPhoneme("a", 10, 11)
- self.assertTrue(self.ojt_hello_hiho[9] == true_ojt_phoneme)
- self.assertTrue(self.ojt_hello_hiho[9] == true_jvs_phoneme)
- self.assertFalse(self.ojt_hello_hiho[9] == false_ojt_phoneme_1)
- self.assertFalse(self.ojt_hello_hiho[9] == false_ojt_phoneme_2)
-
- def test_verify(self):
- for phoneme in self.ojt_hello_hiho:
- phoneme.verify()
-
- def test_phoneme_id(self):
- ojt_str_hello_hiho = " ".join([str(p.phoneme_id) for p in self.ojt_hello_hiho])
- self.assertEqual(
- ojt_str_hello_hiho, "0 23 30 4 28 21 10 21 42 7 0 19 21 19 30 12 14 35 6 0"
- )
-
- def test_onehot(self):
- phoneme_id_list = [
- 0,
- 23,
- 30,
- 4,
- 28,
- 21,
- 10,
- 21,
- 42,
- 7,
- 0,
- 19,
- 21,
- 19,
- 30,
- 12,
- 14,
- 35,
- 6,
- 0,
- ]
- for i, phoneme in enumerate(self.ojt_hello_hiho):
- for j in range(OjtPhoneme.num_phoneme):
- if phoneme_id_list[i] == j:
- self.assertEqual(phoneme.onehot[j], True)
- else:
- self.assertEqual(phoneme.onehot[j], False)
-
- def test_parse(self):
- parse_str_1 = "0 1 pau"
- parse_str_2 = "32.67543 33.48933 e"
- parsed_ojt_1 = OjtPhoneme.parse(parse_str_1)
- parsed_ojt_2 = OjtPhoneme.parse(parse_str_2)
- self.assertEqual(parsed_ojt_1.phoneme_id, 0)
- self.assertEqual(parsed_ojt_2.phoneme_id, 14)
-
- def tes_lab_list(self):
- self.lab_test_base("./ojt_lab_test", self.ojt_hello_hiho, OjtPhoneme)
diff --git a/spaces/801artistry/RVC801/go-applio.bat b/spaces/801artistry/RVC801/go-applio.bat
deleted file mode 100644
index 60c0c41d34a8aee5e14e744accb33d028d807245..0000000000000000000000000000000000000000
--- a/spaces/801artistry/RVC801/go-applio.bat
+++ /dev/null
@@ -1,92 +0,0 @@
-@echo off
-setlocal
-title Start Applio
-
-:::
-::: _ _
-::: /\ | (_)
-::: / \ _ __ _ __ | |_ ___
-::: / /\ \ | '_ \| '_ \| | |/ _ \
-::: / ____ \| |_) | |_) | | | (_) |
-::: /_/ \_\ .__/| .__/|_|_|\___/
-::: | | | |
-::: |_| |_|
-:::
-:::
-
-:menu
-for /f "delims=: tokens=*" %%A in ('findstr /b ":::" "%~f0"') do @echo(%%A
-
-echo [1] Start Applio
-echo [2] Start Applio (DML)
-echo [3] Start Realtime GUI (DML)
-echo [4] Start Realtime GUI (V0)
-echo [5] Start Realtime GUI (V1)
-echo.
-
-set /p choice=Select an option:
-set choice=%choice: =%
-
-cls
-echo WARNING: It's recommended to disable antivirus or firewall, as errors might occur when starting the ssl.
-pause
-
-if "%choice%"=="1" (
- cls
- echo WARNING: At this point, it's recommended to disable antivirus or firewall, as errors might occur when downloading pretrained models.
- pause>null
- echo Starting Applio...
- echo.
- runtime\python.exe infer-web.py --pycmd runtime\python.exe --port 7897
- pause
- cls
- goto menu
-)
-
-if "%choice%"=="2" (
- cls
- echo Starting Applio ^(DML^)...
- echo.
- runtime\python.exe infer-web.py --pycmd runtime\python.exe --port 7897 --dml
- pause
- cls
- goto menu
-)
-
-if "%choice%"=="3" (
- cls
- echo Starting Realtime GUI ^(DML^)...
- echo.
- runtime\python.exe gui_v1.py --pycmd runtime\python.exe --dml
- pause
- cls
- goto menu
-)
-
-if "%choice%"=="4" (
- cls
- echo Starting Realtime GUI ^(V0^)...
- echo.
- runtime\python.exe gui_v0.py
- pause
- cls
- goto menu
-)
-
-if "%choice%"=="5" (
- cls
- echo Starting Realtime GUI ^(V1^)...
- echo.
- runtime\python.exe gui_v1.py
- pause
- cls
- goto menu
-)
-
-cls
-echo Invalid option. Please enter a number from 1 to 5.
-echo.
-echo Press 'Enter' to access the main menu...
-pause>nul
-cls
-goto menu
diff --git a/spaces/A666sxr/Genshin_TTS/modules.py b/spaces/A666sxr/Genshin_TTS/modules.py
deleted file mode 100644
index 9c7fd9cd6eb8b7e0ec0e08957e970744a374a924..0000000000000000000000000000000000000000
--- a/spaces/A666sxr/Genshin_TTS/modules.py
+++ /dev/null
@@ -1,390 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/AI-Chatbot-Master/Chatbots/README.md b/spaces/AI-Chatbot-Master/Chatbots/README.md
deleted file mode 100644
index 275edc7b5a6e57869eb7b3cb7a25e3e238752a2c..0000000000000000000000000000000000000000
--- a/spaces/AI-Chatbot-Master/Chatbots/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: Chatbots
-emoji: 📚
-colorFrom: yellow
-colorTo: red
-sdk: docker
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/AI-ZTH-03-23/2.Streamlit.GraphViz.Dynamic.Architecture.Diagram/app.py b/spaces/AI-ZTH-03-23/2.Streamlit.GraphViz.Dynamic.Architecture.Diagram/app.py
deleted file mode 100644
index b79be955c31e3110b385accb4078915ad952a3d3..0000000000000000000000000000000000000000
--- a/spaces/AI-ZTH-03-23/2.Streamlit.GraphViz.Dynamic.Architecture.Diagram/app.py
+++ /dev/null
@@ -1,146 +0,0 @@
-import streamlit as st
-from graphviz import Digraph
-
-
-st.markdown("""
-Prompt:
-Create an interactive streamlit graph builder using the graphviz diagram model language and the streamlit feature: st.graphviz_chart(figure_or_dot, use_container_width=False) to show an azure cloud architecture model including the top ten architecture components for python full stack development for web, api, ml, models, datasets torch, transformers, streamlit, azure docker and kubernetes pods for scaling
-
-""")
-
-# Dot demo:
-import streamlit as st
-
-# Define the default graphviz DOT string
-default_dot = """
-digraph G {
- rankdir=LR
- node [shape=box]
- WebApp -> API
- API -> Models
- API -> Datasets
- Models -> Torch
- Models -> Transformers
- WebApp -> Streamlit
- Streamlit -> Azure
- Azure -> Docker
- Azure -> Kubernetes
-}
-"""
-
-# Define the list of top 10 components
-components = [
- "WebApp",
- "API",
- "Models",
- "Datasets",
- "Torch",
- "Transformers",
- "Streamlit",
- "Azure",
- "Docker",
- "Kubernetes",
-]
-
-# Define a dictionary to map component names to DOT node IDs
-node_ids = {
- component: component.lower()
- for component in components
-}
-
-def build_dot_string(selected_components):
- """Builds a DOT string representing the selected components"""
- selected_nodes = [node_ids[component] for component in selected_components]
- dot = """
- digraph G {
- rankdir=LR
- node [shape=box]
- """
- for node in selected_nodes:
- dot += f"{node} [color=blue]\n"
- for i in range(len(selected_nodes)):
- for j in range(i+1, len(selected_nodes)):
- dot += f"{selected_nodes[i]} -> {selected_nodes[j]}\n"
- dot += "}"
- return dot
-
-def main():
- st.title("Azure Cloud Architecture Builder")
-
- # Select the components
- st.sidebar.title("Select components")
- selected_components = st.sidebar.multiselect(
- "Select the top 10 components",
- components,
- default=components[:3]
- )
-
- # Build the DOT string
- dot = build_dot_string(selected_components)
-
- # Render the graphviz chart
- st.graphviz_chart(dot, use_container_width=True)
-
-if __name__ == "__main__":
- main()
-
-
-
-# Initialize the graph
-graph = Digraph(comment='Architectural Model')
-
-# Add nodes to the graph
-graph.node('data_layer', 'Data Layer')
-graph.node('acr', 'Azure Container Registry')
-graph.node('aks', 'Azure Kubernetes\n& Docker Container Pod\nwith Scalability')
-graph.node('snowflake', 'Snowflake Instance')
-graph.node('cosmos', 'Azure Cosmos\nDatabase')
-graph.node('api', 'API Standard\n(using Uvicorn)')
-graph.node('soar', 'SOAR Component\n(on Linux Python\nSlimbuster Docker)')
-
-# Add edges to the graph
-graph.edge('data_layer', 'acr')
-graph.edge('acr', 'aks')
-graph.edge('aks', 'snowflake')
-graph.edge('aks', 'cosmos')
-graph.edge('aks', 'api')
-graph.edge('aks', 'soar')
-
-# Define the Streamlit app
-def app():
- st.title('Architectural Model')
-
- # Draw the graph
- st.graphviz_chart(graph.source)
-
- # Add buttons to customize the graph
- if st.button('Hide Data Layer'):
- graph.node('data_layer', style='invisible')
-
- if st.button('Hide Snowflake Instance'):
- graph.node('snowflake', style='invisible')
-
- if st.button('Hide SOAR Component'):
- graph.node('soar', style='invisible')
-
-
-
-st.markdown("""
-# QA Model Spaces:
-QA use cases include QA, Semantic Document and FAQ Search.
-1. Streamlit Question Answering w Hugging Face: https://huggingface.co/spaces/awacke1/Question-answering
-2. Seq2Seq:
- - https://huggingface.co/spaces/awacke1/4-Seq2SeqQAT5
- - https://huggingface.co/spaces/awacke1/AW-04-GR-Seq-2-Seq-QA-Auto-Gen
-3. BioGPT: https://huggingface.co/spaces/awacke1/microsoft-BioGPT-Large-PubMedQA
-4. NLP QA Context: https://huggingface.co/spaces/awacke1/NLPContextQATransformersRobertaBaseSquad2
- - https://huggingface.co/spaces/awacke1/SOTA-Plan
-5. https://huggingface.co/spaces/awacke1/Question-answering
-6. QA MLM: https://huggingface.co/spaces/awacke1/SOTA-MedEntity
-""")
-
-
-
-# Run the Streamlit app
-if __name__ == '__main__':
- app()
diff --git a/spaces/AIConsultant/MusicGen/scripts/templates/results.html b/spaces/AIConsultant/MusicGen/scripts/templates/results.html
deleted file mode 100644
index 8ddce59f0f617a836db75c8bc9768db7f9f17511..0000000000000000000000000000000000000000
--- a/spaces/AIConsultant/MusicGen/scripts/templates/results.html
+++ /dev/null
@@ -1,17 +0,0 @@
-{% extends "base.html" %}
-{% block content %}
-
-Results for survey #{{signature}}
-Checkout the survey page for details on the models.
-The following users voted:
- {% for user in users %}
- {{user}}
- {% endfor %}
-
-{% for model in models %}
-
{{model['sig']}} ({{model['samples']}} samples)
-Ratings: {{model['mean_rating']}} ± {{model['std_rating']}}
-
-{% endfor %}
-
-{% endblock %}
diff --git a/spaces/AIFILMS/generate_human_motion/pyrender/pyrender/platforms/__init__.py b/spaces/AIFILMS/generate_human_motion/pyrender/pyrender/platforms/__init__.py
deleted file mode 100644
index 7837fd5fdeccab5e48c85e41d20b238ea7396599..0000000000000000000000000000000000000000
--- a/spaces/AIFILMS/generate_human_motion/pyrender/pyrender/platforms/__init__.py
+++ /dev/null
@@ -1,6 +0,0 @@
-"""Platforms for generating offscreen OpenGL contexts for rendering.
-
-Author: Matthew Matl
-"""
-
-from .base import Platform
diff --git a/spaces/AchyuthGamer/OpenGPT-Chat-UI/.svelte-kit/types/src/routes/conversation/[id]/stop-generating/$types.d.ts b/spaces/AchyuthGamer/OpenGPT-Chat-UI/.svelte-kit/types/src/routes/conversation/[id]/stop-generating/$types.d.ts
deleted file mode 100644
index 108ad3f4ad676b574668ee54fc0f30b38a90220c..0000000000000000000000000000000000000000
--- a/spaces/AchyuthGamer/OpenGPT-Chat-UI/.svelte-kit/types/src/routes/conversation/[id]/stop-generating/$types.d.ts
+++ /dev/null
@@ -1,9 +0,0 @@
-import type * as Kit from '@sveltejs/kit';
-
-type Expand = T extends infer O ? { [K in keyof O]: O[K] } : never;
-type RouteParams = { id: string }
-type RouteId = '/conversation/[id]/stop-generating';
-
-export type EntryGenerator = () => Promise> | Array;
-export type RequestHandler = Kit.RequestHandler;
-export type RequestEvent = Kit.RequestEvent;
\ No newline at end of file
diff --git a/spaces/Adapter/CoAdapter/ldm/modules/image_degradation/bsrgan.py b/spaces/Adapter/CoAdapter/ldm/modules/image_degradation/bsrgan.py
deleted file mode 100644
index 32ef56169978e550090261cddbcf5eb611a6173b..0000000000000000000000000000000000000000
--- a/spaces/Adapter/CoAdapter/ldm/modules/image_degradation/bsrgan.py
+++ /dev/null
@@ -1,730 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-# --------------------------------------------
-# Super-Resolution
-# --------------------------------------------
-#
-# Kai Zhang (cskaizhang@gmail.com)
-# https://github.com/cszn
-# From 2019/03--2021/08
-# --------------------------------------------
-"""
-
-import numpy as np
-import cv2
-import torch
-
-from functools import partial
-import random
-from scipy import ndimage
-import scipy
-import scipy.stats as ss
-from scipy.interpolate import interp2d
-from scipy.linalg import orth
-import albumentations
-
-import ldm.modules.image_degradation.utils_image as util
-
-
-def modcrop_np(img, sf):
- '''
- Args:
- img: numpy image, WxH or WxHxC
- sf: scale factor
- Return:
- cropped image
- '''
- w, h = img.shape[:2]
- im = np.copy(img)
- return im[:w - w % sf, :h - h % sf, ...]
-
-
-"""
-# --------------------------------------------
-# anisotropic Gaussian kernels
-# --------------------------------------------
-"""
-
-
-def analytic_kernel(k):
- """Calculate the X4 kernel from the X2 kernel (for proof see appendix in paper)"""
- k_size = k.shape[0]
- # Calculate the big kernels size
- big_k = np.zeros((3 * k_size - 2, 3 * k_size - 2))
- # Loop over the small kernel to fill the big one
- for r in range(k_size):
- for c in range(k_size):
- big_k[2 * r:2 * r + k_size, 2 * c:2 * c + k_size] += k[r, c] * k
- # Crop the edges of the big kernel to ignore very small values and increase run time of SR
- crop = k_size // 2
- cropped_big_k = big_k[crop:-crop, crop:-crop]
- # Normalize to 1
- return cropped_big_k / cropped_big_k.sum()
-
-
-def anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
- """ generate an anisotropic Gaussian kernel
- Args:
- ksize : e.g., 15, kernel size
- theta : [0, pi], rotation angle range
- l1 : [0.1,50], scaling of eigenvalues
- l2 : [0.1,l1], scaling of eigenvalues
- If l1 = l2, will get an isotropic Gaussian kernel.
- Returns:
- k : kernel
- """
-
- v = np.dot(np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]), np.array([1., 0.]))
- V = np.array([[v[0], v[1]], [v[1], -v[0]]])
- D = np.array([[l1, 0], [0, l2]])
- Sigma = np.dot(np.dot(V, D), np.linalg.inv(V))
- k = gm_blur_kernel(mean=[0, 0], cov=Sigma, size=ksize)
-
- return k
-
-
-def gm_blur_kernel(mean, cov, size=15):
- center = size / 2.0 + 0.5
- k = np.zeros([size, size])
- for y in range(size):
- for x in range(size):
- cy = y - center + 1
- cx = x - center + 1
- k[y, x] = ss.multivariate_normal.pdf([cx, cy], mean=mean, cov=cov)
-
- k = k / np.sum(k)
- return k
-
-
-def shift_pixel(x, sf, upper_left=True):
- """shift pixel for super-resolution with different scale factors
- Args:
- x: WxHxC or WxH
- sf: scale factor
- upper_left: shift direction
- """
- h, w = x.shape[:2]
- shift = (sf - 1) * 0.5
- xv, yv = np.arange(0, w, 1.0), np.arange(0, h, 1.0)
- if upper_left:
- x1 = xv + shift
- y1 = yv + shift
- else:
- x1 = xv - shift
- y1 = yv - shift
-
- x1 = np.clip(x1, 0, w - 1)
- y1 = np.clip(y1, 0, h - 1)
-
- if x.ndim == 2:
- x = interp2d(xv, yv, x)(x1, y1)
- if x.ndim == 3:
- for i in range(x.shape[-1]):
- x[:, :, i] = interp2d(xv, yv, x[:, :, i])(x1, y1)
-
- return x
-
-
-def blur(x, k):
- '''
- x: image, NxcxHxW
- k: kernel, Nx1xhxw
- '''
- n, c = x.shape[:2]
- p1, p2 = (k.shape[-2] - 1) // 2, (k.shape[-1] - 1) // 2
- x = torch.nn.functional.pad(x, pad=(p1, p2, p1, p2), mode='replicate')
- k = k.repeat(1, c, 1, 1)
- k = k.view(-1, 1, k.shape[2], k.shape[3])
- x = x.view(1, -1, x.shape[2], x.shape[3])
- x = torch.nn.functional.conv2d(x, k, bias=None, stride=1, padding=0, groups=n * c)
- x = x.view(n, c, x.shape[2], x.shape[3])
-
- return x
-
-
-def gen_kernel(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=10., noise_level=0):
- """"
- # modified version of https://github.com/assafshocher/BlindSR_dataset_generator
- # Kai Zhang
- # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
- # max_var = 2.5 * sf
- """
- # Set random eigen-vals (lambdas) and angle (theta) for COV matrix
- lambda_1 = min_var + np.random.rand() * (max_var - min_var)
- lambda_2 = min_var + np.random.rand() * (max_var - min_var)
- theta = np.random.rand() * np.pi # random theta
- noise = -noise_level + np.random.rand(*k_size) * noise_level * 2
-
- # Set COV matrix using Lambdas and Theta
- LAMBDA = np.diag([lambda_1, lambda_2])
- Q = np.array([[np.cos(theta), -np.sin(theta)],
- [np.sin(theta), np.cos(theta)]])
- SIGMA = Q @ LAMBDA @ Q.T
- INV_SIGMA = np.linalg.inv(SIGMA)[None, None, :, :]
-
- # Set expectation position (shifting kernel for aligned image)
- MU = k_size // 2 - 0.5 * (scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
- MU = MU[None, None, :, None]
-
- # Create meshgrid for Gaussian
- [X, Y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
- Z = np.stack([X, Y], 2)[:, :, :, None]
-
- # Calcualte Gaussian for every pixel of the kernel
- ZZ = Z - MU
- ZZ_t = ZZ.transpose(0, 1, 3, 2)
- raw_kernel = np.exp(-0.5 * np.squeeze(ZZ_t @ INV_SIGMA @ ZZ)) * (1 + noise)
-
- # shift the kernel so it will be centered
- # raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
-
- # Normalize the kernel and return
- # kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
- kernel = raw_kernel / np.sum(raw_kernel)
- return kernel
-
-
-def fspecial_gaussian(hsize, sigma):
- hsize = [hsize, hsize]
- siz = [(hsize[0] - 1.0) / 2.0, (hsize[1] - 1.0) / 2.0]
- std = sigma
- [x, y] = np.meshgrid(np.arange(-siz[1], siz[1] + 1), np.arange(-siz[0], siz[0] + 1))
- arg = -(x * x + y * y) / (2 * std * std)
- h = np.exp(arg)
- h[h < scipy.finfo(float).eps * h.max()] = 0
- sumh = h.sum()
- if sumh != 0:
- h = h / sumh
- return h
-
-
-def fspecial_laplacian(alpha):
- alpha = max([0, min([alpha, 1])])
- h1 = alpha / (alpha + 1)
- h2 = (1 - alpha) / (alpha + 1)
- h = [[h1, h2, h1], [h2, -4 / (alpha + 1), h2], [h1, h2, h1]]
- h = np.array(h)
- return h
-
-
-def fspecial(filter_type, *args, **kwargs):
- '''
- python code from:
- https://github.com/ronaldosena/imagens-medicas-2/blob/40171a6c259edec7827a6693a93955de2bd39e76/Aulas/aula_2_-_uniform_filter/matlab_fspecial.py
- '''
- if filter_type == 'gaussian':
- return fspecial_gaussian(*args, **kwargs)
- if filter_type == 'laplacian':
- return fspecial_laplacian(*args, **kwargs)
-
-
-"""
-# --------------------------------------------
-# degradation models
-# --------------------------------------------
-"""
-
-
-def bicubic_degradation(x, sf=3):
- '''
- Args:
- x: HxWxC image, [0, 1]
- sf: down-scale factor
- Return:
- bicubicly downsampled LR image
- '''
- x = util.imresize_np(x, scale=1 / sf)
- return x
-
-
-def srmd_degradation(x, k, sf=3):
- ''' blur + bicubic downsampling
- Args:
- x: HxWxC image, [0, 1]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- Reference:
- @inproceedings{zhang2018learning,
- title={Learning a single convolutional super-resolution network for multiple degradations},
- author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- pages={3262--3271},
- year={2018}
- }
- '''
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap') # 'nearest' | 'mirror'
- x = bicubic_degradation(x, sf=sf)
- return x
-
-
-def dpsr_degradation(x, k, sf=3):
- ''' bicubic downsampling + blur
- Args:
- x: HxWxC image, [0, 1]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- Reference:
- @inproceedings{zhang2019deep,
- title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
- author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- pages={1671--1681},
- year={2019}
- }
- '''
- x = bicubic_degradation(x, sf=sf)
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
- return x
-
-
-def classical_degradation(x, k, sf=3):
- ''' blur + downsampling
- Args:
- x: HxWxC image, [0, 1]/[0, 255]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- '''
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
- # x = filters.correlate(x, np.expand_dims(np.flip(k), axis=2))
- st = 0
- return x[st::sf, st::sf, ...]
-
-
-def add_sharpening(img, weight=0.5, radius=50, threshold=10):
- """USM sharpening. borrowed from real-ESRGAN
- Input image: I; Blurry image: B.
- 1. K = I + weight * (I - B)
- 2. Mask = 1 if abs(I - B) > threshold, else: 0
- 3. Blur mask:
- 4. Out = Mask * K + (1 - Mask) * I
- Args:
- img (Numpy array): Input image, HWC, BGR; float32, [0, 1].
- weight (float): Sharp weight. Default: 1.
- radius (float): Kernel size of Gaussian blur. Default: 50.
- threshold (int):
- """
- if radius % 2 == 0:
- radius += 1
- blur = cv2.GaussianBlur(img, (radius, radius), 0)
- residual = img - blur
- mask = np.abs(residual) * 255 > threshold
- mask = mask.astype('float32')
- soft_mask = cv2.GaussianBlur(mask, (radius, radius), 0)
-
- K = img + weight * residual
- K = np.clip(K, 0, 1)
- return soft_mask * K + (1 - soft_mask) * img
-
-
-def add_blur(img, sf=4):
- wd2 = 4.0 + sf
- wd = 2.0 + 0.2 * sf
- if random.random() < 0.5:
- l1 = wd2 * random.random()
- l2 = wd2 * random.random()
- k = anisotropic_Gaussian(ksize=2 * random.randint(2, 11) + 3, theta=random.random() * np.pi, l1=l1, l2=l2)
- else:
- k = fspecial('gaussian', 2 * random.randint(2, 11) + 3, wd * random.random())
- img = ndimage.filters.convolve(img, np.expand_dims(k, axis=2), mode='mirror')
-
- return img
-
-
-def add_resize(img, sf=4):
- rnum = np.random.rand()
- if rnum > 0.8: # up
- sf1 = random.uniform(1, 2)
- elif rnum < 0.7: # down
- sf1 = random.uniform(0.5 / sf, 1)
- else:
- sf1 = 1.0
- img = cv2.resize(img, (int(sf1 * img.shape[1]), int(sf1 * img.shape[0])), interpolation=random.choice([1, 2, 3]))
- img = np.clip(img, 0.0, 1.0)
-
- return img
-
-
-# def add_Gaussian_noise(img, noise_level1=2, noise_level2=25):
-# noise_level = random.randint(noise_level1, noise_level2)
-# rnum = np.random.rand()
-# if rnum > 0.6: # add color Gaussian noise
-# img += np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
-# elif rnum < 0.4: # add grayscale Gaussian noise
-# img += np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
-# else: # add noise
-# L = noise_level2 / 255.
-# D = np.diag(np.random.rand(3))
-# U = orth(np.random.rand(3, 3))
-# conv = np.dot(np.dot(np.transpose(U), D), U)
-# img += np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
-# img = np.clip(img, 0.0, 1.0)
-# return img
-
-def add_Gaussian_noise(img, noise_level1=2, noise_level2=25):
- noise_level = random.randint(noise_level1, noise_level2)
- rnum = np.random.rand()
- if rnum > 0.6: # add color Gaussian noise
- img = img + np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
- elif rnum < 0.4: # add grayscale Gaussian noise
- img = img + np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
- else: # add noise
- L = noise_level2 / 255.
- D = np.diag(np.random.rand(3))
- U = orth(np.random.rand(3, 3))
- conv = np.dot(np.dot(np.transpose(U), D), U)
- img = img + np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_speckle_noise(img, noise_level1=2, noise_level2=25):
- noise_level = random.randint(noise_level1, noise_level2)
- img = np.clip(img, 0.0, 1.0)
- rnum = random.random()
- if rnum > 0.6:
- img += img * np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
- elif rnum < 0.4:
- img += img * np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
- else:
- L = noise_level2 / 255.
- D = np.diag(np.random.rand(3))
- U = orth(np.random.rand(3, 3))
- conv = np.dot(np.dot(np.transpose(U), D), U)
- img += img * np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_Poisson_noise(img):
- img = np.clip((img * 255.0).round(), 0, 255) / 255.
- vals = 10 ** (2 * random.random() + 2.0) # [2, 4]
- if random.random() < 0.5:
- img = np.random.poisson(img * vals).astype(np.float32) / vals
- else:
- img_gray = np.dot(img[..., :3], [0.299, 0.587, 0.114])
- img_gray = np.clip((img_gray * 255.0).round(), 0, 255) / 255.
- noise_gray = np.random.poisson(img_gray * vals).astype(np.float32) / vals - img_gray
- img += noise_gray[:, :, np.newaxis]
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_JPEG_noise(img):
- quality_factor = random.randint(30, 95)
- img = cv2.cvtColor(util.single2uint(img), cv2.COLOR_RGB2BGR)
- result, encimg = cv2.imencode('.jpg', img, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
- img = cv2.imdecode(encimg, 1)
- img = cv2.cvtColor(util.uint2single(img), cv2.COLOR_BGR2RGB)
- return img
-
-
-def random_crop(lq, hq, sf=4, lq_patchsize=64):
- h, w = lq.shape[:2]
- rnd_h = random.randint(0, h - lq_patchsize)
- rnd_w = random.randint(0, w - lq_patchsize)
- lq = lq[rnd_h:rnd_h + lq_patchsize, rnd_w:rnd_w + lq_patchsize, :]
-
- rnd_h_H, rnd_w_H = int(rnd_h * sf), int(rnd_w * sf)
- hq = hq[rnd_h_H:rnd_h_H + lq_patchsize * sf, rnd_w_H:rnd_w_H + lq_patchsize * sf, :]
- return lq, hq
-
-
-def degradation_bsrgan(img, sf=4, lq_patchsize=72, isp_model=None):
- """
- This is the degradation model of BSRGAN from the paper
- "Designing a Practical Degradation Model for Deep Blind Image Super-Resolution"
- ----------
- img: HXWXC, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
- sf: scale factor
- isp_model: camera ISP model
- Returns
- -------
- img: low-quality patch, size: lq_patchsizeXlq_patchsizeXC, range: [0, 1]
- hq: corresponding high-quality patch, size: (lq_patchsizexsf)X(lq_patchsizexsf)XC, range: [0, 1]
- """
- isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25
- sf_ori = sf
-
- h1, w1 = img.shape[:2]
- img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
- h, w = img.shape[:2]
-
- if h < lq_patchsize * sf or w < lq_patchsize * sf:
- raise ValueError(f'img size ({h1}X{w1}) is too small!')
-
- hq = img.copy()
-
- if sf == 4 and random.random() < scale2_prob: # downsample1
- if np.random.rand() < 0.5:
- img = cv2.resize(img, (int(1 / 2 * img.shape[1]), int(1 / 2 * img.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- img = util.imresize_np(img, 1 / 2, True)
- img = np.clip(img, 0.0, 1.0)
- sf = 2
-
- shuffle_order = random.sample(range(7), 7)
- idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)
- if idx1 > idx2: # keep downsample3 last
- shuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]
-
- for i in shuffle_order:
-
- if i == 0:
- img = add_blur(img, sf=sf)
-
- elif i == 1:
- img = add_blur(img, sf=sf)
-
- elif i == 2:
- a, b = img.shape[1], img.shape[0]
- # downsample2
- if random.random() < 0.75:
- sf1 = random.uniform(1, 2 * sf)
- img = cv2.resize(img, (int(1 / sf1 * img.shape[1]), int(1 / sf1 * img.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- k = fspecial('gaussian', 25, random.uniform(0.1, 0.6 * sf))
- k_shifted = shift_pixel(k, sf)
- k_shifted = k_shifted / k_shifted.sum() # blur with shifted kernel
- img = ndimage.filters.convolve(img, np.expand_dims(k_shifted, axis=2), mode='mirror')
- img = img[0::sf, 0::sf, ...] # nearest downsampling
- img = np.clip(img, 0.0, 1.0)
-
- elif i == 3:
- # downsample3
- img = cv2.resize(img, (int(1 / sf * a), int(1 / sf * b)), interpolation=random.choice([1, 2, 3]))
- img = np.clip(img, 0.0, 1.0)
-
- elif i == 4:
- # add Gaussian noise
- img = add_Gaussian_noise(img, noise_level1=2, noise_level2=25)
-
- elif i == 5:
- # add JPEG noise
- if random.random() < jpeg_prob:
- img = add_JPEG_noise(img)
-
- elif i == 6:
- # add processed camera sensor noise
- if random.random() < isp_prob and isp_model is not None:
- with torch.no_grad():
- img, hq = isp_model.forward(img.copy(), hq)
-
- # add final JPEG compression noise
- img = add_JPEG_noise(img)
-
- # random crop
- img, hq = random_crop(img, hq, sf_ori, lq_patchsize)
-
- return img, hq
-
-
-# todo no isp_model?
-def degradation_bsrgan_variant(image, sf=4, isp_model=None):
- """
- This is the degradation model of BSRGAN from the paper
- "Designing a Practical Degradation Model for Deep Blind Image Super-Resolution"
- ----------
- sf: scale factor
- isp_model: camera ISP model
- Returns
- -------
- img: low-quality patch, size: lq_patchsizeXlq_patchsizeXC, range: [0, 1]
- hq: corresponding high-quality patch, size: (lq_patchsizexsf)X(lq_patchsizexsf)XC, range: [0, 1]
- """
- image = util.uint2single(image)
- isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25
- sf_ori = sf
-
- h1, w1 = image.shape[:2]
- image = image.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
- h, w = image.shape[:2]
-
- hq = image.copy()
-
- if sf == 4 and random.random() < scale2_prob: # downsample1
- if np.random.rand() < 0.5:
- image = cv2.resize(image, (int(1 / 2 * image.shape[1]), int(1 / 2 * image.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- image = util.imresize_np(image, 1 / 2, True)
- image = np.clip(image, 0.0, 1.0)
- sf = 2
-
- shuffle_order = random.sample(range(7), 7)
- idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)
- if idx1 > idx2: # keep downsample3 last
- shuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]
-
- for i in shuffle_order:
-
- if i == 0:
- image = add_blur(image, sf=sf)
-
- elif i == 1:
- image = add_blur(image, sf=sf)
-
- elif i == 2:
- a, b = image.shape[1], image.shape[0]
- # downsample2
- if random.random() < 0.75:
- sf1 = random.uniform(1, 2 * sf)
- image = cv2.resize(image, (int(1 / sf1 * image.shape[1]), int(1 / sf1 * image.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- k = fspecial('gaussian', 25, random.uniform(0.1, 0.6 * sf))
- k_shifted = shift_pixel(k, sf)
- k_shifted = k_shifted / k_shifted.sum() # blur with shifted kernel
- image = ndimage.filters.convolve(image, np.expand_dims(k_shifted, axis=2), mode='mirror')
- image = image[0::sf, 0::sf, ...] # nearest downsampling
- image = np.clip(image, 0.0, 1.0)
-
- elif i == 3:
- # downsample3
- image = cv2.resize(image, (int(1 / sf * a), int(1 / sf * b)), interpolation=random.choice([1, 2, 3]))
- image = np.clip(image, 0.0, 1.0)
-
- elif i == 4:
- # add Gaussian noise
- image = add_Gaussian_noise(image, noise_level1=2, noise_level2=25)
-
- elif i == 5:
- # add JPEG noise
- if random.random() < jpeg_prob:
- image = add_JPEG_noise(image)
-
- # elif i == 6:
- # # add processed camera sensor noise
- # if random.random() < isp_prob and isp_model is not None:
- # with torch.no_grad():
- # img, hq = isp_model.forward(img.copy(), hq)
-
- # add final JPEG compression noise
- image = add_JPEG_noise(image)
- image = util.single2uint(image)
- example = {"image":image}
- return example
-
-
-# TODO incase there is a pickle error one needs to replace a += x with a = a + x in add_speckle_noise etc...
-def degradation_bsrgan_plus(img, sf=4, shuffle_prob=0.5, use_sharp=True, lq_patchsize=64, isp_model=None):
- """
- This is an extended degradation model by combining
- the degradation models of BSRGAN and Real-ESRGAN
- ----------
- img: HXWXC, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
- sf: scale factor
- use_shuffle: the degradation shuffle
- use_sharp: sharpening the img
- Returns
- -------
- img: low-quality patch, size: lq_patchsizeXlq_patchsizeXC, range: [0, 1]
- hq: corresponding high-quality patch, size: (lq_patchsizexsf)X(lq_patchsizexsf)XC, range: [0, 1]
- """
-
- h1, w1 = img.shape[:2]
- img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
- h, w = img.shape[:2]
-
- if h < lq_patchsize * sf or w < lq_patchsize * sf:
- raise ValueError(f'img size ({h1}X{w1}) is too small!')
-
- if use_sharp:
- img = add_sharpening(img)
- hq = img.copy()
-
- if random.random() < shuffle_prob:
- shuffle_order = random.sample(range(13), 13)
- else:
- shuffle_order = list(range(13))
- # local shuffle for noise, JPEG is always the last one
- shuffle_order[2:6] = random.sample(shuffle_order[2:6], len(range(2, 6)))
- shuffle_order[9:13] = random.sample(shuffle_order[9:13], len(range(9, 13)))
-
- poisson_prob, speckle_prob, isp_prob = 0.1, 0.1, 0.1
-
- for i in shuffle_order:
- if i == 0:
- img = add_blur(img, sf=sf)
- elif i == 1:
- img = add_resize(img, sf=sf)
- elif i == 2:
- img = add_Gaussian_noise(img, noise_level1=2, noise_level2=25)
- elif i == 3:
- if random.random() < poisson_prob:
- img = add_Poisson_noise(img)
- elif i == 4:
- if random.random() < speckle_prob:
- img = add_speckle_noise(img)
- elif i == 5:
- if random.random() < isp_prob and isp_model is not None:
- with torch.no_grad():
- img, hq = isp_model.forward(img.copy(), hq)
- elif i == 6:
- img = add_JPEG_noise(img)
- elif i == 7:
- img = add_blur(img, sf=sf)
- elif i == 8:
- img = add_resize(img, sf=sf)
- elif i == 9:
- img = add_Gaussian_noise(img, noise_level1=2, noise_level2=25)
- elif i == 10:
- if random.random() < poisson_prob:
- img = add_Poisson_noise(img)
- elif i == 11:
- if random.random() < speckle_prob:
- img = add_speckle_noise(img)
- elif i == 12:
- if random.random() < isp_prob and isp_model is not None:
- with torch.no_grad():
- img, hq = isp_model.forward(img.copy(), hq)
- else:
- print('check the shuffle!')
-
- # resize to desired size
- img = cv2.resize(img, (int(1 / sf * hq.shape[1]), int(1 / sf * hq.shape[0])),
- interpolation=random.choice([1, 2, 3]))
-
- # add final JPEG compression noise
- img = add_JPEG_noise(img)
-
- # random crop
- img, hq = random_crop(img, hq, sf, lq_patchsize)
-
- return img, hq
-
-
-if __name__ == '__main__':
- print("hey")
- img = util.imread_uint('utils/test.png', 3)
- print(img)
- img = util.uint2single(img)
- print(img)
- img = img[:448, :448]
- h = img.shape[0] // 4
- print("resizing to", h)
- sf = 4
- deg_fn = partial(degradation_bsrgan_variant, sf=sf)
- for i in range(20):
- print(i)
- img_lq = deg_fn(img)
- print(img_lq)
- img_lq_bicubic = albumentations.SmallestMaxSize(max_size=h, interpolation=cv2.INTER_CUBIC)(image=img)["image"]
- print(img_lq.shape)
- print("bicubic", img_lq_bicubic.shape)
- print(img_hq.shape)
- lq_nearest = cv2.resize(util.single2uint(img_lq), (int(sf * img_lq.shape[1]), int(sf * img_lq.shape[0])),
- interpolation=0)
- lq_bicubic_nearest = cv2.resize(util.single2uint(img_lq_bicubic), (int(sf * img_lq.shape[1]), int(sf * img_lq.shape[0])),
- interpolation=0)
- img_concat = np.concatenate([lq_bicubic_nearest, lq_nearest, util.single2uint(img_hq)], axis=1)
- util.imsave(img_concat, str(i) + '.png')
-
-
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/plugins/bracketparser2.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/plugins/bracketparser2.js
deleted file mode 100644
index 58aa5da06534d60dbf80406d984916a151768399..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/plugins/bracketparser2.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import BracketParser from './logic/bracketparser/bracketparser2/BracketParser.js';
-export default BracketParser;
\ No newline at end of file
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sides/Factory.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sides/Factory.js
deleted file mode 100644
index b3cabe4c806f56ecf44ed38df8f61c40ecf2e45f..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sides/Factory.js
+++ /dev/null
@@ -1,13 +0,0 @@
-import Sides from './Sides.js';
-import ObjectFactory from '../ObjectFactory.js';
-import SetValue from '../../../plugins/utils/object/SetValue.js';
-
-ObjectFactory.register('sides', function (config) {
- var gameObject = new Sides(this.scene, config);
- this.scene.add.existing(gameObject);
- return gameObject;
-});
-
-SetValue(window, 'RexPlugins.UI.Sides', Sides);
-
-export default Sides;
\ No newline at end of file
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sizer/RemoveChildMethods.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sizer/RemoveChildMethods.js
deleted file mode 100644
index d488526756ac07bc4da2e3908fa7238d48f0f696..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sizer/RemoveChildMethods.js
+++ /dev/null
@@ -1,29 +0,0 @@
-import RemoveChild from '../basesizer/utils/RemoveChild.js';
-import ClearChildren from '../basesizer/utils/ClearChildren.js';
-
-const RemoveItem = Phaser.Utils.Array.Remove;
-
-export default {
- remove(gameObject, destroyChild) {
- if (this.getParentSizer(gameObject) !== this) {
- return this;
- }
-
- RemoveItem(this.sizerChildren, gameObject);
- RemoveChild.call(this, gameObject, destroyChild);
- return this;
- },
-
- removeAll(destroyChild) {
- for (var i = this.sizerChildren.length - 1; i >= 0; i--) {
- this.remove(this.sizerChildren[i], destroyChild);
- }
- return this;
- },
-
- clear(destroyChild) {
- this.sizerChildren.length = 0;
- ClearChildren.call(this, destroyChild);
- return this;
- }
-}
\ No newline at end of file
diff --git a/spaces/Agusbs98/automatic-ecg-diagnosis/nets/layers.py b/spaces/Agusbs98/automatic-ecg-diagnosis/nets/layers.py
deleted file mode 100644
index 0ecc2113f2004bd750377ddd8b27c914be01288c..0000000000000000000000000000000000000000
--- a/spaces/Agusbs98/automatic-ecg-diagnosis/nets/layers.py
+++ /dev/null
@@ -1,29 +0,0 @@
-
-import os, sys
-from libs import *
-
-class DSConv1d(nn.Module):
- def __init__(self,
- in_channels, out_channels,
- kernel_size, padding = 0, stride = 1,
- ):
- super(DSConv1d, self).__init__()
- self.dw_conv = nn.Conv1d(
- in_channels, in_channels,
- kernel_size = kernel_size, padding = padding, stride = stride,
- groups = in_channels,
- bias = False,
- )
- self.pw_conv = nn.Conv1d(
- in_channels, out_channels,
- kernel_size = 1,
- bias = False,
- )
-
- def forward(self,
- input,
- ):
- output = self.dw_conv(input)
- output = self.pw_conv(output)
-
- return output
\ No newline at end of file
diff --git a/spaces/AixiaGreyatt/QQsign/bin/unidbg-fetch-qsign.bat b/spaces/AixiaGreyatt/QQsign/bin/unidbg-fetch-qsign.bat
deleted file mode 100644
index 8b291e7303b0c07d14b714e5795473891363c85b..0000000000000000000000000000000000000000
--- a/spaces/AixiaGreyatt/QQsign/bin/unidbg-fetch-qsign.bat
+++ /dev/null
@@ -1,89 +0,0 @@
-@rem
-@rem Copyright 2015 the original author or authors.
-@rem
-@rem Licensed under the Apache License, Version 2.0 (the "License");
-@rem you may not use this file except in compliance with the License.
-@rem You may obtain a copy of the License at
-@rem
-@rem https://www.apache.org/licenses/LICENSE-2.0
-@rem
-@rem Unless required by applicable law or agreed to in writing, software
-@rem distributed under the License is distributed on an "AS IS" BASIS,
-@rem WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-@rem See the License for the specific language governing permissions and
-@rem limitations under the License.
-@rem
-
-@if "%DEBUG%" == "" @echo off
-@rem ##########################################################################
-@rem
-@rem unidbg-fetch-qsign startup script for Windows
-@rem
-@rem ##########################################################################
-
-@rem Set local scope for the variables with windows NT shell
-if "%OS%"=="Windows_NT" setlocal
-
-set DIRNAME=%~dp0
-if "%DIRNAME%" == "" set DIRNAME=.
-set APP_BASE_NAME=%~n0
-set APP_HOME=%DIRNAME%..
-
-@rem Resolve any "." and ".." in APP_HOME to make it shorter.
-for %%i in ("%APP_HOME%") do set APP_HOME=%%~fi
-
-@rem Add default JVM options here. You can also use JAVA_OPTS and UNIDBG_FETCH_QSIGN_OPTS to pass JVM options to this script.
-set DEFAULT_JVM_OPTS=
-
-@rem Find java.exe
-if defined JAVA_HOME goto findJavaFromJavaHome
-
-set JAVA_EXE=java.exe
-%JAVA_EXE% -version >NUL 2>&1
-if "%ERRORLEVEL%" == "0" goto execute
-
-echo.
-echo ERROR: JAVA_HOME is not set and no 'java' command could be found in your PATH.
-echo.
-echo Please set the JAVA_HOME variable in your environment to match the
-echo location of your Java installation.
-
-goto fail
-
-:findJavaFromJavaHome
-set JAVA_HOME=%JAVA_HOME:"=%
-set JAVA_EXE=%JAVA_HOME%/bin/java.exe
-
-if exist "%JAVA_EXE%" goto execute
-
-echo.
-echo ERROR: JAVA_HOME is set to an invalid directory: %JAVA_HOME%
-echo.
-echo Please set the JAVA_HOME variable in your environment to match the
-echo location of your Java installation.
-
-goto fail
-
-:execute
-@rem Setup the command line
-
-set CLASSPATH=%APP_HOME%\lib\unidbg-fetch-qsign-1.1.9.jar;%APP_HOME%\lib\unidbg-android-105.jar;%APP_HOME%\lib\ktor-server-content-negotiation-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-serialization-kotlinx-json-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-server-status-pages-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-server-netty-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-server-host-common-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-server-core-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-serialization-kotlinx-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-serialization-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-events-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-websockets-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-http-cio-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-http-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-network-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-utils-jvm-2.3.1.jar;%APP_HOME%\lib\ktor-io-jvm-2.3.1.jar;%APP_HOME%\lib\kotlin-stdlib-jdk8-1.8.22.jar;%APP_HOME%\lib\kotlinx-serialization-json-jvm-1.5.1.jar;%APP_HOME%\lib\kotlinx-serialization-protobuf-jvm-1.5.1.jar;%APP_HOME%\lib\kotlinx-serialization-core-jvm-1.5.1.jar;%APP_HOME%\lib\logback-classic-1.2.11.jar;%APP_HOME%\lib\kotlinx-coroutines-jdk8-1.7.1.jar;%APP_HOME%\lib\kotlinx-coroutines-core-jvm-1.7.1.jar;%APP_HOME%\lib\kotlin-stdlib-jdk7-1.8.22.jar;%APP_HOME%\lib\kotlin-reflect-1.8.10.jar;%APP_HOME%\lib\kotlin-stdlib-1.8.22.jar;%APP_HOME%\lib\slf4j-api-1.7.36.jar;%APP_HOME%\lib\kotlin-stdlib-common-1.8.22.jar;%APP_HOME%\lib\config-1.4.2.jar;%APP_HOME%\lib\jansi-2.4.0.jar;%APP_HOME%\lib\netty-codec-http2-4.1.92.Final.jar;%APP_HOME%\lib\alpn-api-1.1.3.v20160715.jar;%APP_HOME%\lib\netty-transport-native-kqueue-4.1.92.Final.jar;%APP_HOME%\lib\netty-transport-native-epoll-4.1.92.Final.jar;%APP_HOME%\lib\logback-core-1.2.11.jar;%APP_HOME%\lib\annotations-23.0.0.jar;%APP_HOME%\lib\netty-codec-http-4.1.92.Final.jar;%APP_HOME%\lib\netty-handler-4.1.92.Final.jar;%APP_HOME%\lib\netty-codec-4.1.92.Final.jar;%APP_HOME%\lib\netty-transport-classes-kqueue-4.1.92.Final.jar;%APP_HOME%\lib\netty-transport-classes-epoll-4.1.92.Final.jar;%APP_HOME%\lib\netty-transport-native-unix-common-4.1.92.Final.jar;%APP_HOME%\lib\netty-transport-4.1.92.Final.jar;%APP_HOME%\lib\netty-buffer-4.1.92.Final.jar;%APP_HOME%\lib\netty-resolver-4.1.92.Final.jar;%APP_HOME%\lib\netty-common-4.1.92.Final.jar
-
-
-@rem Execute unidbg-fetch-qsign
-"%JAVA_EXE%" %DEFAULT_JVM_OPTS% %JAVA_OPTS% %UNIDBG_FETCH_QSIGN_OPTS% -classpath "%CLASSPATH%" MainKt %*
-
-:end
-@rem End local scope for the variables with windows NT shell
-if "%ERRORLEVEL%"=="0" goto mainEnd
-
-:fail
-rem Set variable UNIDBG_FETCH_QSIGN_EXIT_CONSOLE if you need the _script_ return code instead of
-rem the _cmd.exe /c_ return code!
-if not "" == "%UNIDBG_FETCH_QSIGN_EXIT_CONSOLE%" exit 1
-exit /b 1
-
-:mainEnd
-if "%OS%"=="Windows_NT" endlocal
-
-:omega
diff --git a/spaces/Aloento/9Nine-PITS/text/english.py b/spaces/Aloento/9Nine-PITS/text/english.py
deleted file mode 100644
index 85b862f1eabdbf9a5a4a604d848920d0ddd260dd..0000000000000000000000000000000000000000
--- a/spaces/Aloento/9Nine-PITS/text/english.py
+++ /dev/null
@@ -1,122 +0,0 @@
-""" from https://github.com/keithito/tacotron """
-import re
-
-import eng_to_ipa as ipa
-from g2p_en import G2p
-from unidecode import unidecode
-
-from text.frontend import normalize_numbers
-
-'''
-Cleaners are transformations that run over the input text at both training and eval time.
-
-Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
-hyperparameter. Some cleaners are English-specific. You'll typically want to use:
- 1. "english_cleaners" for English text
- 2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
- the Unidecode library (https://pypi.python.org/pypi/Unidecode)
- 3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
- the symbols in symbols.py to match your data).
-'''
-
-# Regular expression matching whitespace:
-g2p = G2p()
-
-# List of (regular expression, replacement) pairs for abbreviations:
-_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [
- ('mrs', 'misess'),
- ('mr', 'mister'),
- ('dr', 'doctor'),
- ('st', 'saint'),
- ('co', 'company'),
- ('jr', 'junior'),
- ('maj', 'major'),
- ('gen', 'general'),
- ('drs', 'doctors'),
- ('rev', 'reverend'),
- ('lt', 'lieutenant'),
- ('hon', 'honorable'),
- ('sgt', 'sergeant'),
- ('capt', 'captain'),
- ('esq', 'esquire'),
- ('ltd', 'limited'),
- ('col', 'colonel'),
- ('ft', 'fort'),
-]]
-
-# List of (ipa, ipa2) pairs
-_ipa_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('r', 'ɹ'),
- ('ʤ', 'dʒ'),
- ('ʧ', 'tʃ')
-]]
-
-
-def expand_abbreviations(text):
- for regex, replacement in _abbreviations:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def collapse_whitespace(text):
- return re.sub(r'\s+', ' ', text)
-
-
-def mark_dark_l(text):
- return re.sub(r'l([^aeiouæɑɔəɛɪʊ ]*(?: |$))', lambda x: 'ɫ' + x.group(1), text)
-
-
-def english_to_ipa(text):
- text = text.replace("-", " ")
- text = unidecode(text).lower()
- text = expand_abbreviations(text)
- text = normalize_numbers(text)
-
- phonemes = ipa.convert(text)
- phonemes = unrecognized_words_to_ipa(phonemes)
- phonemes = collapse_whitespace(phonemes)
-
- text = phonemes
- text = mark_dark_l(text)
-
- for regex, replacement in _ipa_to_ipa2:
- text = re.sub(regex, replacement, text)
-
- return text.replace('...', '…')
-
-
-def convert_to_ipa(phones):
- eipa = ""
- symbols = {"a": "ə", "ey": "eɪ", "aa": "ɑ", "ae": "æ", "ah": "ə", "ao": "ɔ",
- "aw": "aʊ", "ay": "aɪ", "ch": "ʧ", "dh": "ð", "eh": "ɛ", "er": "ər",
- "hh": "h", "ih": "ɪ", "jh": "ʤ", "ng": "ŋ", "ow": "oʊ", "oy": "ɔɪ",
- "sh": "ʃ", "th": "θ", "uh": "ʊ", "uw": "u", "zh": "ʒ", "iy": "i", "y": "j"}
-
- for ph in phones:
- ph = ph.lower()
-
- try:
- if ph[-1] in "01234":
- eipa += symbols[ph[:-1]]
- else:
- eipa += symbols[ph]
- except:
- eipa += ph
-
- return eipa
-
-
-def unrecognized_words_to_ipa(text):
- matches = re.findall(r'\s([\w|\']+\*)', text)
-
- for word in matches:
- ipa = convert_to_ipa(g2p(word))
- text = text.replace(word, ipa)
-
- matches = re.findall(r'^([\w|\']+\*)', text)
-
- for word in matches:
- ipa = convert_to_ipa(g2p(word))
- text = text.replace(word, ipa)
-
- return text
diff --git a/spaces/Alpaca233/SadTalker/src/face3d/models/networks.py b/spaces/Alpaca233/SadTalker/src/face3d/models/networks.py
deleted file mode 100644
index ead9cdcb8720b845c233de79dc8a8d1668492108..0000000000000000000000000000000000000000
--- a/spaces/Alpaca233/SadTalker/src/face3d/models/networks.py
+++ /dev/null
@@ -1,521 +0,0 @@
-"""This script defines deep neural networks for Deep3DFaceRecon_pytorch
-"""
-
-import os
-import numpy as np
-import torch.nn.functional as F
-from torch.nn import init
-import functools
-from torch.optim import lr_scheduler
-import torch
-from torch import Tensor
-import torch.nn as nn
-try:
- from torch.hub import load_state_dict_from_url
-except ImportError:
- from torch.utils.model_zoo import load_url as load_state_dict_from_url
-from typing import Type, Any, Callable, Union, List, Optional
-from .arcface_torch.backbones import get_model
-from kornia.geometry import warp_affine
-
-def resize_n_crop(image, M, dsize=112):
- # image: (b, c, h, w)
- # M : (b, 2, 3)
- return warp_affine(image, M, dsize=(dsize, dsize), align_corners=True)
-
-def filter_state_dict(state_dict, remove_name='fc'):
- new_state_dict = {}
- for key in state_dict:
- if remove_name in key:
- continue
- new_state_dict[key] = state_dict[key]
- return new_state_dict
-
-def get_scheduler(optimizer, opt):
- """Return a learning rate scheduler
-
- Parameters:
- optimizer -- the optimizer of the network
- opt (option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions.
- opt.lr_policy is the name of learning rate policy: linear | step | plateau | cosine
-
- For other schedulers (step, plateau, and cosine), we use the default PyTorch schedulers.
- See https://pytorch.org/docs/stable/optim.html for more details.
- """
- if opt.lr_policy == 'linear':
- def lambda_rule(epoch):
- lr_l = 1.0 - max(0, epoch + opt.epoch_count - opt.n_epochs) / float(opt.n_epochs + 1)
- return lr_l
- scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_rule)
- elif opt.lr_policy == 'step':
- scheduler = lr_scheduler.StepLR(optimizer, step_size=opt.lr_decay_epochs, gamma=0.2)
- elif opt.lr_policy == 'plateau':
- scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.2, threshold=0.01, patience=5)
- elif opt.lr_policy == 'cosine':
- scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=opt.n_epochs, eta_min=0)
- else:
- return NotImplementedError('learning rate policy [%s] is not implemented', opt.lr_policy)
- return scheduler
-
-
-def define_net_recon(net_recon, use_last_fc=False, init_path=None):
- return ReconNetWrapper(net_recon, use_last_fc=use_last_fc, init_path=init_path)
-
-def define_net_recog(net_recog, pretrained_path=None):
- net = RecogNetWrapper(net_recog=net_recog, pretrained_path=pretrained_path)
- net.eval()
- return net
-
-class ReconNetWrapper(nn.Module):
- fc_dim=257
- def __init__(self, net_recon, use_last_fc=False, init_path=None):
- super(ReconNetWrapper, self).__init__()
- self.use_last_fc = use_last_fc
- if net_recon not in func_dict:
- return NotImplementedError('network [%s] is not implemented', net_recon)
- func, last_dim = func_dict[net_recon]
- backbone = func(use_last_fc=use_last_fc, num_classes=self.fc_dim)
- if init_path and os.path.isfile(init_path):
- state_dict = filter_state_dict(torch.load(init_path, map_location='cpu'))
- backbone.load_state_dict(state_dict)
- print("loading init net_recon %s from %s" %(net_recon, init_path))
- self.backbone = backbone
- if not use_last_fc:
- self.final_layers = nn.ModuleList([
- conv1x1(last_dim, 80, bias=True), # id layer
- conv1x1(last_dim, 64, bias=True), # exp layer
- conv1x1(last_dim, 80, bias=True), # tex layer
- conv1x1(last_dim, 3, bias=True), # angle layer
- conv1x1(last_dim, 27, bias=True), # gamma layer
- conv1x1(last_dim, 2, bias=True), # tx, ty
- conv1x1(last_dim, 1, bias=True) # tz
- ])
- for m in self.final_layers:
- nn.init.constant_(m.weight, 0.)
- nn.init.constant_(m.bias, 0.)
-
- def forward(self, x):
- x = self.backbone(x)
- if not self.use_last_fc:
- output = []
- for layer in self.final_layers:
- output.append(layer(x))
- x = torch.flatten(torch.cat(output, dim=1), 1)
- return x
-
-
-class RecogNetWrapper(nn.Module):
- def __init__(self, net_recog, pretrained_path=None, input_size=112):
- super(RecogNetWrapper, self).__init__()
- net = get_model(name=net_recog, fp16=False)
- if pretrained_path:
- state_dict = torch.load(pretrained_path, map_location='cpu')
- net.load_state_dict(state_dict)
- print("loading pretrained net_recog %s from %s" %(net_recog, pretrained_path))
- for param in net.parameters():
- param.requires_grad = False
- self.net = net
- self.preprocess = lambda x: 2 * x - 1
- self.input_size=input_size
-
- def forward(self, image, M):
- image = self.preprocess(resize_n_crop(image, M, self.input_size))
- id_feature = F.normalize(self.net(image), dim=-1, p=2)
- return id_feature
-
-
-# adapted from https://github.com/pytorch/vision/edit/master/torchvision/models/resnet.py
-__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
- 'resnet152', 'resnext50_32x4d', 'resnext101_32x8d',
- 'wide_resnet50_2', 'wide_resnet101_2']
-
-
-model_urls = {
- 'resnet18': 'https://download.pytorch.org/models/resnet18-f37072fd.pth',
- 'resnet34': 'https://download.pytorch.org/models/resnet34-b627a593.pth',
- 'resnet50': 'https://download.pytorch.org/models/resnet50-0676ba61.pth',
- 'resnet101': 'https://download.pytorch.org/models/resnet101-63fe2227.pth',
- 'resnet152': 'https://download.pytorch.org/models/resnet152-394f9c45.pth',
- 'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
- 'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
- 'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
- 'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
-}
-
-
-def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
- """3x3 convolution with padding"""
- return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
- padding=dilation, groups=groups, bias=False, dilation=dilation)
-
-
-def conv1x1(in_planes: int, out_planes: int, stride: int = 1, bias: bool = False) -> nn.Conv2d:
- """1x1 convolution"""
- return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=bias)
-
-
-class BasicBlock(nn.Module):
- expansion: int = 1
-
- def __init__(
- self,
- inplanes: int,
- planes: int,
- stride: int = 1,
- downsample: Optional[nn.Module] = None,
- groups: int = 1,
- base_width: int = 64,
- dilation: int = 1,
- norm_layer: Optional[Callable[..., nn.Module]] = None
- ) -> None:
- super(BasicBlock, self).__init__()
- if norm_layer is None:
- norm_layer = nn.BatchNorm2d
- if groups != 1 or base_width != 64:
- raise ValueError('BasicBlock only supports groups=1 and base_width=64')
- if dilation > 1:
- raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
- # Both self.conv1 and self.downsample layers downsample the input when stride != 1
- self.conv1 = conv3x3(inplanes, planes, stride)
- self.bn1 = norm_layer(planes)
- self.relu = nn.ReLU(inplace=True)
- self.conv2 = conv3x3(planes, planes)
- self.bn2 = norm_layer(planes)
- self.downsample = downsample
- self.stride = stride
-
- def forward(self, x: Tensor) -> Tensor:
- identity = x
-
- out = self.conv1(x)
- out = self.bn1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.bn2(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
- out = self.relu(out)
-
- return out
-
-
-class Bottleneck(nn.Module):
- # Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
- # while original implementation places the stride at the first 1x1 convolution(self.conv1)
- # according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
- # This variant is also known as ResNet V1.5 and improves accuracy according to
- # https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
-
- expansion: int = 4
-
- def __init__(
- self,
- inplanes: int,
- planes: int,
- stride: int = 1,
- downsample: Optional[nn.Module] = None,
- groups: int = 1,
- base_width: int = 64,
- dilation: int = 1,
- norm_layer: Optional[Callable[..., nn.Module]] = None
- ) -> None:
- super(Bottleneck, self).__init__()
- if norm_layer is None:
- norm_layer = nn.BatchNorm2d
- width = int(planes * (base_width / 64.)) * groups
- # Both self.conv2 and self.downsample layers downsample the input when stride != 1
- self.conv1 = conv1x1(inplanes, width)
- self.bn1 = norm_layer(width)
- self.conv2 = conv3x3(width, width, stride, groups, dilation)
- self.bn2 = norm_layer(width)
- self.conv3 = conv1x1(width, planes * self.expansion)
- self.bn3 = norm_layer(planes * self.expansion)
- self.relu = nn.ReLU(inplace=True)
- self.downsample = downsample
- self.stride = stride
-
- def forward(self, x: Tensor) -> Tensor:
- identity = x
-
- out = self.conv1(x)
- out = self.bn1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.bn2(out)
- out = self.relu(out)
-
- out = self.conv3(out)
- out = self.bn3(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
- out = self.relu(out)
-
- return out
-
-
-class ResNet(nn.Module):
-
- def __init__(
- self,
- block: Type[Union[BasicBlock, Bottleneck]],
- layers: List[int],
- num_classes: int = 1000,
- zero_init_residual: bool = False,
- use_last_fc: bool = False,
- groups: int = 1,
- width_per_group: int = 64,
- replace_stride_with_dilation: Optional[List[bool]] = None,
- norm_layer: Optional[Callable[..., nn.Module]] = None
- ) -> None:
- super(ResNet, self).__init__()
- if norm_layer is None:
- norm_layer = nn.BatchNorm2d
- self._norm_layer = norm_layer
-
- self.inplanes = 64
- self.dilation = 1
- if replace_stride_with_dilation is None:
- # each element in the tuple indicates if we should replace
- # the 2x2 stride with a dilated convolution instead
- replace_stride_with_dilation = [False, False, False]
- if len(replace_stride_with_dilation) != 3:
- raise ValueError("replace_stride_with_dilation should be None "
- "or a 3-element tuple, got {}".format(replace_stride_with_dilation))
- self.use_last_fc = use_last_fc
- self.groups = groups
- self.base_width = width_per_group
- self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
- bias=False)
- self.bn1 = norm_layer(self.inplanes)
- self.relu = nn.ReLU(inplace=True)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
- self.layer1 = self._make_layer(block, 64, layers[0])
- self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
- dilate=replace_stride_with_dilation[0])
- self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
- dilate=replace_stride_with_dilation[1])
- self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
- dilate=replace_stride_with_dilation[2])
- self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
-
- if self.use_last_fc:
- self.fc = nn.Linear(512 * block.expansion, num_classes)
-
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
- elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
- nn.init.constant_(m.weight, 1)
- nn.init.constant_(m.bias, 0)
-
-
-
- # Zero-initialize the last BN in each residual branch,
- # so that the residual branch starts with zeros, and each residual block behaves like an identity.
- # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
- if zero_init_residual:
- for m in self.modules():
- if isinstance(m, Bottleneck):
- nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
- elif isinstance(m, BasicBlock):
- nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
-
- def _make_layer(self, block: Type[Union[BasicBlock, Bottleneck]], planes: int, blocks: int,
- stride: int = 1, dilate: bool = False) -> nn.Sequential:
- norm_layer = self._norm_layer
- downsample = None
- previous_dilation = self.dilation
- if dilate:
- self.dilation *= stride
- stride = 1
- if stride != 1 or self.inplanes != planes * block.expansion:
- downsample = nn.Sequential(
- conv1x1(self.inplanes, planes * block.expansion, stride),
- norm_layer(planes * block.expansion),
- )
-
- layers = []
- layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
- self.base_width, previous_dilation, norm_layer))
- self.inplanes = planes * block.expansion
- for _ in range(1, blocks):
- layers.append(block(self.inplanes, planes, groups=self.groups,
- base_width=self.base_width, dilation=self.dilation,
- norm_layer=norm_layer))
-
- return nn.Sequential(*layers)
-
- def _forward_impl(self, x: Tensor) -> Tensor:
- # See note [TorchScript super()]
- x = self.conv1(x)
- x = self.bn1(x)
- x = self.relu(x)
- x = self.maxpool(x)
-
- x = self.layer1(x)
- x = self.layer2(x)
- x = self.layer3(x)
- x = self.layer4(x)
-
- x = self.avgpool(x)
- if self.use_last_fc:
- x = torch.flatten(x, 1)
- x = self.fc(x)
- return x
-
- def forward(self, x: Tensor) -> Tensor:
- return self._forward_impl(x)
-
-
-def _resnet(
- arch: str,
- block: Type[Union[BasicBlock, Bottleneck]],
- layers: List[int],
- pretrained: bool,
- progress: bool,
- **kwargs: Any
-) -> ResNet:
- model = ResNet(block, layers, **kwargs)
- if pretrained:
- state_dict = load_state_dict_from_url(model_urls[arch],
- progress=progress)
- model.load_state_dict(state_dict)
- return model
-
-
-def resnet18(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""ResNet-18 model from
- `"Deep Residual Learning for Image Recognition" `_.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
- **kwargs)
-
-
-def resnet34(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""ResNet-34 model from
- `"Deep Residual Learning for Image Recognition" `_.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
- **kwargs)
-
-
-def resnet50(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""ResNet-50 model from
- `"Deep Residual Learning for Image Recognition" `_.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
- **kwargs)
-
-
-def resnet101(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""ResNet-101 model from
- `"Deep Residual Learning for Image Recognition" `_.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,
- **kwargs)
-
-
-def resnet152(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""ResNet-152 model from
- `"Deep Residual Learning for Image Recognition" `_.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress,
- **kwargs)
-
-
-def resnext50_32x4d(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""ResNeXt-50 32x4d model from
- `"Aggregated Residual Transformation for Deep Neural Networks" `_.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- kwargs['groups'] = 32
- kwargs['width_per_group'] = 4
- return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
- pretrained, progress, **kwargs)
-
-
-def resnext101_32x8d(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""ResNeXt-101 32x8d model from
- `"Aggregated Residual Transformation for Deep Neural Networks" `_.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- kwargs['groups'] = 32
- kwargs['width_per_group'] = 8
- return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],
- pretrained, progress, **kwargs)
-
-
-def wide_resnet50_2(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""Wide ResNet-50-2 model from
- `"Wide Residual Networks" `_.
-
- The model is the same as ResNet except for the bottleneck number of channels
- which is twice larger in every block. The number of channels in outer 1x1
- convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
- channels, and in Wide ResNet-50-2 has 2048-1024-2048.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- kwargs['width_per_group'] = 64 * 2
- return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3],
- pretrained, progress, **kwargs)
-
-
-def wide_resnet101_2(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
- r"""Wide ResNet-101-2 model from
- `"Wide Residual Networks" `_.
-
- The model is the same as ResNet except for the bottleneck number of channels
- which is twice larger in every block. The number of channels in outer 1x1
- convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
- channels, and in Wide ResNet-50-2 has 2048-1024-2048.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- progress (bool): If True, displays a progress bar of the download to stderr
- """
- kwargs['width_per_group'] = 64 * 2
- return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3],
- pretrained, progress, **kwargs)
-
-
-func_dict = {
- 'resnet18': (resnet18, 512),
- 'resnet50': (resnet50, 2048)
-}
diff --git a/spaces/AnTo2209/3D_Zeroshot_Neural_Style_Transfer/src/utils/loading.py b/spaces/AnTo2209/3D_Zeroshot_Neural_Style_Transfer/src/utils/loading.py
deleted file mode 100644
index 9684f8b9a0a201af07045ea65ab4fc05df3694ba..0000000000000000000000000000000000000000
--- a/spaces/AnTo2209/3D_Zeroshot_Neural_Style_Transfer/src/utils/loading.py
+++ /dev/null
@@ -1,6 +0,0 @@
-import yaml
-
-
-def load_yaml(path):
- with open(path, "rt") as f:
- return yaml.safe_load(f)
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_v_pred.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_v_pred.py
deleted file mode 100644
index 1db2e18e5b19b822b8b03f9b8ccacf311da69691..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_v_pred.py
+++ /dev/null
@@ -1,540 +0,0 @@
-# coding=utf-8
-# Copyright 2023 HuggingFace Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import gc
-import time
-import unittest
-
-import numpy as np
-import torch
-from huggingface_hub import hf_hub_download
-from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
-
-from diffusers import (
- AutoencoderKL,
- DDIMScheduler,
- DPMSolverMultistepScheduler,
- EulerDiscreteScheduler,
- StableDiffusionPipeline,
- UNet2DConditionModel,
-)
-from diffusers.models.attention_processor import AttnProcessor
-from diffusers.utils import load_numpy, slow, torch_device
-from diffusers.utils.testing_utils import enable_full_determinism, require_torch_gpu
-
-
-enable_full_determinism()
-
-
-class StableDiffusion2VPredictionPipelineFastTests(unittest.TestCase):
- def tearDown(self):
- # clean up the VRAM after each test
- super().tearDown()
- gc.collect()
- torch.cuda.empty_cache()
-
- @property
- def dummy_cond_unet(self):
- torch.manual_seed(0)
- model = UNet2DConditionModel(
- block_out_channels=(32, 64),
- layers_per_block=2,
- sample_size=32,
- in_channels=4,
- out_channels=4,
- down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
- up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
- cross_attention_dim=32,
- # SD2-specific config below
- attention_head_dim=(2, 4),
- use_linear_projection=True,
- )
- return model
-
- @property
- def dummy_vae(self):
- torch.manual_seed(0)
- model = AutoencoderKL(
- block_out_channels=[32, 64],
- in_channels=3,
- out_channels=3,
- down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
- up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
- latent_channels=4,
- sample_size=128,
- )
- return model
-
- @property
- def dummy_text_encoder(self):
- torch.manual_seed(0)
- config = CLIPTextConfig(
- bos_token_id=0,
- eos_token_id=2,
- hidden_size=32,
- intermediate_size=37,
- layer_norm_eps=1e-05,
- num_attention_heads=4,
- num_hidden_layers=5,
- pad_token_id=1,
- vocab_size=1000,
- # SD2-specific config below
- hidden_act="gelu",
- projection_dim=64,
- )
- return CLIPTextModel(config)
-
- def test_stable_diffusion_v_pred_ddim(self):
- device = "cpu" # ensure determinism for the device-dependent torch.Generator
- unet = self.dummy_cond_unet
- scheduler = DDIMScheduler(
- beta_start=0.00085,
- beta_end=0.012,
- beta_schedule="scaled_linear",
- clip_sample=False,
- set_alpha_to_one=False,
- prediction_type="v_prediction",
- )
-
- vae = self.dummy_vae
- bert = self.dummy_text_encoder
- tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
-
- # make sure here that pndm scheduler skips prk
- sd_pipe = StableDiffusionPipeline(
- unet=unet,
- scheduler=scheduler,
- vae=vae,
- text_encoder=bert,
- tokenizer=tokenizer,
- safety_checker=None,
- feature_extractor=None,
- requires_safety_checker=False,
- )
- sd_pipe = sd_pipe.to(device)
- sd_pipe.set_progress_bar_config(disable=None)
-
- prompt = "A painting of a squirrel eating a burger"
-
- generator = torch.Generator(device=device).manual_seed(0)
- output = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
- image = output.images
-
- generator = torch.Generator(device=device).manual_seed(0)
- image_from_tuple = sd_pipe(
- [prompt],
- generator=generator,
- guidance_scale=6.0,
- num_inference_steps=2,
- output_type="np",
- return_dict=False,
- )[0]
-
- image_slice = image[0, -3:, -3:, -1]
- image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
-
- assert image.shape == (1, 64, 64, 3)
- expected_slice = np.array([0.6569, 0.6525, 0.5142, 0.4968, 0.4923, 0.4601, 0.4996, 0.5041, 0.4544])
-
- assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
- assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
-
- def test_stable_diffusion_v_pred_k_euler(self):
- device = "cpu" # ensure determinism for the device-dependent torch.Generator
- unet = self.dummy_cond_unet
- scheduler = EulerDiscreteScheduler(
- beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", prediction_type="v_prediction"
- )
- vae = self.dummy_vae
- bert = self.dummy_text_encoder
- tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
-
- # make sure here that pndm scheduler skips prk
- sd_pipe = StableDiffusionPipeline(
- unet=unet,
- scheduler=scheduler,
- vae=vae,
- text_encoder=bert,
- tokenizer=tokenizer,
- safety_checker=None,
- feature_extractor=None,
- requires_safety_checker=False,
- )
- sd_pipe = sd_pipe.to(device)
- sd_pipe.set_progress_bar_config(disable=None)
-
- prompt = "A painting of a squirrel eating a burger"
- generator = torch.Generator(device=device).manual_seed(0)
- output = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
-
- image = output.images
-
- generator = torch.Generator(device=device).manual_seed(0)
- image_from_tuple = sd_pipe(
- [prompt],
- generator=generator,
- guidance_scale=6.0,
- num_inference_steps=2,
- output_type="np",
- return_dict=False,
- )[0]
-
- image_slice = image[0, -3:, -3:, -1]
- image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
-
- assert image.shape == (1, 64, 64, 3)
- expected_slice = np.array([0.5644, 0.6514, 0.5190, 0.5663, 0.5287, 0.4953, 0.5430, 0.5243, 0.4778])
-
- assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
- assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
-
- @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
- def test_stable_diffusion_v_pred_fp16(self):
- """Test that stable diffusion v-prediction works with fp16"""
- unet = self.dummy_cond_unet
- scheduler = DDIMScheduler(
- beta_start=0.00085,
- beta_end=0.012,
- beta_schedule="scaled_linear",
- clip_sample=False,
- set_alpha_to_one=False,
- prediction_type="v_prediction",
- )
- vae = self.dummy_vae
- bert = self.dummy_text_encoder
- tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
-
- # put models in fp16
- unet = unet.half()
- vae = vae.half()
- bert = bert.half()
-
- # make sure here that pndm scheduler skips prk
- sd_pipe = StableDiffusionPipeline(
- unet=unet,
- scheduler=scheduler,
- vae=vae,
- text_encoder=bert,
- tokenizer=tokenizer,
- safety_checker=None,
- feature_extractor=None,
- requires_safety_checker=False,
- )
- sd_pipe = sd_pipe.to(torch_device)
- sd_pipe.set_progress_bar_config(disable=None)
-
- prompt = "A painting of a squirrel eating a burger"
- generator = torch.manual_seed(0)
- image = sd_pipe([prompt], generator=generator, num_inference_steps=2, output_type="np").images
-
- assert image.shape == (1, 64, 64, 3)
-
-
-@slow
-@require_torch_gpu
-class StableDiffusion2VPredictionPipelineIntegrationTests(unittest.TestCase):
- def tearDown(self):
- # clean up the VRAM after each test
- super().tearDown()
- gc.collect()
- torch.cuda.empty_cache()
-
- def test_stable_diffusion_v_pred_default(self):
- sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2")
- sd_pipe = sd_pipe.to(torch_device)
- sd_pipe.enable_attention_slicing()
- sd_pipe.set_progress_bar_config(disable=None)
-
- prompt = "A painting of a squirrel eating a burger"
- generator = torch.manual_seed(0)
- output = sd_pipe([prompt], generator=generator, guidance_scale=7.5, num_inference_steps=20, output_type="np")
-
- image = output.images
- image_slice = image[0, 253:256, 253:256, -1]
-
- assert image.shape == (1, 768, 768, 3)
- expected_slice = np.array([0.1868, 0.1922, 0.1527, 0.1921, 0.1908, 0.1624, 0.1779, 0.1652, 0.1734])
-
- assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
-
- def test_stable_diffusion_v_pred_upcast_attention(self):
- sd_pipe = StableDiffusionPipeline.from_pretrained(
- "stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
- )
- sd_pipe = sd_pipe.to(torch_device)
- sd_pipe.enable_attention_slicing()
- sd_pipe.set_progress_bar_config(disable=None)
-
- prompt = "A painting of a squirrel eating a burger"
- generator = torch.manual_seed(0)
- output = sd_pipe([prompt], generator=generator, guidance_scale=7.5, num_inference_steps=20, output_type="np")
-
- image = output.images
- image_slice = image[0, 253:256, 253:256, -1]
-
- assert image.shape == (1, 768, 768, 3)
- expected_slice = np.array([0.4209, 0.4087, 0.4097, 0.4209, 0.3860, 0.4329, 0.4280, 0.4324, 0.4187])
-
- assert np.abs(image_slice.flatten() - expected_slice).max() < 5e-2
-
- def test_stable_diffusion_v_pred_euler(self):
- scheduler = EulerDiscreteScheduler.from_pretrained("stabilityai/stable-diffusion-2", subfolder="scheduler")
- sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", scheduler=scheduler)
- sd_pipe = sd_pipe.to(torch_device)
- sd_pipe.enable_attention_slicing()
- sd_pipe.set_progress_bar_config(disable=None)
-
- prompt = "A painting of a squirrel eating a burger"
- generator = torch.manual_seed(0)
-
- output = sd_pipe([prompt], generator=generator, num_inference_steps=5, output_type="numpy")
- image = output.images
-
- image_slice = image[0, 253:256, 253:256, -1]
-
- assert image.shape == (1, 768, 768, 3)
- expected_slice = np.array([0.1781, 0.1695, 0.1661, 0.1705, 0.1588, 0.1699, 0.2005, 0.1589, 0.1677])
-
- assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
-
- def test_stable_diffusion_v_pred_dpm(self):
- """
- TODO: update this test after making DPM compatible with V-prediction!
- """
- scheduler = DPMSolverMultistepScheduler.from_pretrained(
- "stabilityai/stable-diffusion-2", subfolder="scheduler"
- )
- sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", scheduler=scheduler)
- sd_pipe = sd_pipe.to(torch_device)
- sd_pipe.enable_attention_slicing()
- sd_pipe.set_progress_bar_config(disable=None)
-
- prompt = "a photograph of an astronaut riding a horse"
- generator = torch.manual_seed(0)
- image = sd_pipe(
- [prompt], generator=generator, guidance_scale=7.5, num_inference_steps=5, output_type="numpy"
- ).images
-
- image_slice = image[0, 253:256, 253:256, -1]
- assert image.shape == (1, 768, 768, 3)
- expected_slice = np.array([0.3303, 0.3184, 0.3291, 0.3300, 0.3256, 0.3113, 0.2965, 0.3134, 0.3192])
-
- assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
-
- def test_stable_diffusion_attention_slicing_v_pred(self):
- torch.cuda.reset_peak_memory_stats()
- model_id = "stabilityai/stable-diffusion-2"
- pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
- pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
-
- prompt = "a photograph of an astronaut riding a horse"
-
- # make attention efficient
- pipe.enable_attention_slicing()
- generator = torch.manual_seed(0)
- output_chunked = pipe(
- [prompt], generator=generator, guidance_scale=7.5, num_inference_steps=10, output_type="numpy"
- )
- image_chunked = output_chunked.images
-
- mem_bytes = torch.cuda.max_memory_allocated()
- torch.cuda.reset_peak_memory_stats()
- # make sure that less than 5.5 GB is allocated
- assert mem_bytes < 5.5 * 10**9
-
- # disable slicing
- pipe.disable_attention_slicing()
- generator = torch.manual_seed(0)
- output = pipe([prompt], generator=generator, guidance_scale=7.5, num_inference_steps=10, output_type="numpy")
- image = output.images
-
- # make sure that more than 5.5 GB is allocated
- mem_bytes = torch.cuda.max_memory_allocated()
- assert mem_bytes > 5.5 * 10**9
- assert np.abs(image_chunked.flatten() - image.flatten()).max() < 1e-3
-
- def test_stable_diffusion_text2img_pipeline_v_pred_default(self):
- expected_image = load_numpy(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/"
- "sd2-text2img/astronaut_riding_a_horse_v_pred.npy"
- )
-
- pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2")
- pipe.to(torch_device)
- pipe.enable_attention_slicing()
- pipe.set_progress_bar_config(disable=None)
-
- prompt = "astronaut riding a horse"
-
- generator = torch.manual_seed(0)
- output = pipe(prompt=prompt, guidance_scale=7.5, generator=generator, output_type="np")
- image = output.images[0]
-
- assert image.shape == (768, 768, 3)
- assert np.abs(expected_image - image).max() < 9e-1
-
- def test_stable_diffusion_text2img_pipeline_unflawed(self):
- expected_image = load_numpy(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/"
- "sd2-text2img/lion_galaxy.npy"
- )
-
- pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1")
- pipe.scheduler = DDIMScheduler.from_config(
- pipe.scheduler.config, timestep_spacing="trailing", rescale_betas_zero_snr=True
- )
- pipe.to(torch_device)
- pipe.enable_attention_slicing()
- pipe.set_progress_bar_config(disable=None)
-
- prompt = "A lion in galaxies, spirals, nebulae, stars, smoke, iridescent, intricate detail, octane render, 8k"
-
- generator = torch.manual_seed(0)
- output = pipe(prompt=prompt, guidance_scale=7.5, guidance_rescale=0.7, generator=generator, output_type="np")
- image = output.images[0]
-
- assert image.shape == (768, 768, 3)
- assert np.abs(expected_image - image).max() < 5e-1
-
- def test_stable_diffusion_text2img_pipeline_v_pred_fp16(self):
- expected_image = load_numpy(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/"
- "sd2-text2img/astronaut_riding_a_horse_v_pred_fp16.npy"
- )
-
- pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", torch_dtype=torch.float16)
- pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
-
- prompt = "astronaut riding a horse"
-
- generator = torch.manual_seed(0)
- output = pipe(prompt=prompt, guidance_scale=7.5, generator=generator, output_type="np")
- image = output.images[0]
-
- assert image.shape == (768, 768, 3)
- assert np.abs(expected_image - image).max() < 7.5e-1
-
- def test_download_local(self):
- filename = hf_hub_download("stabilityai/stable-diffusion-2-1", filename="v2-1_768-ema-pruned.safetensors")
-
- pipe = StableDiffusionPipeline.from_single_file(filename, torch_dtype=torch.float16)
- pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
- pipe.to("cuda")
-
- image_out = pipe("test", num_inference_steps=1, output_type="np").images[0]
-
- assert image_out.shape == (768, 768, 3)
-
- def test_download_ckpt_diff_format_is_same(self):
- single_file_path = (
- "https://huggingface.co/stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-ema-pruned.safetensors"
- )
-
- pipe_single = StableDiffusionPipeline.from_single_file(single_file_path)
- pipe_single.scheduler = DDIMScheduler.from_config(pipe_single.scheduler.config)
- pipe_single.unet.set_attn_processor(AttnProcessor())
- pipe_single.to("cuda")
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- image_ckpt = pipe_single("a turtle", num_inference_steps=5, generator=generator, output_type="np").images[0]
-
- pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1")
- pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
- pipe.unet.set_attn_processor(AttnProcessor())
- pipe.to("cuda")
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- image = pipe("a turtle", num_inference_steps=5, generator=generator, output_type="np").images[0]
-
- assert np.max(np.abs(image - image_ckpt)) < 1e-3
-
- def test_stable_diffusion_text2img_intermediate_state_v_pred(self):
- number_of_steps = 0
-
- def test_callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
- test_callback_fn.has_been_called = True
- nonlocal number_of_steps
- number_of_steps += 1
- if step == 0:
- latents = latents.detach().cpu().numpy()
- assert latents.shape == (1, 4, 96, 96)
- latents_slice = latents[0, -3:, -3:, -1]
- expected_slice = np.array([0.7749, 0.0325, 0.5088, 0.1619, 0.3372, 0.3667, -0.5186, 0.6860, 1.4326])
-
- assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
- elif step == 19:
- latents = latents.detach().cpu().numpy()
- assert latents.shape == (1, 4, 96, 96)
- latents_slice = latents[0, -3:, -3:, -1]
- expected_slice = np.array([1.3887, 1.0273, 1.7266, 0.0726, 0.6611, 0.1598, -1.0547, 0.1522, 0.0227])
-
- assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
-
- test_callback_fn.has_been_called = False
-
- pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", torch_dtype=torch.float16)
- pipe = pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
- pipe.enable_attention_slicing()
-
- prompt = "Andromeda galaxy in a bottle"
-
- generator = torch.manual_seed(0)
- pipe(
- prompt=prompt,
- num_inference_steps=20,
- guidance_scale=7.5,
- generator=generator,
- callback=test_callback_fn,
- callback_steps=1,
- )
- assert test_callback_fn.has_been_called
- assert number_of_steps == 20
-
- def test_stable_diffusion_low_cpu_mem_usage_v_pred(self):
- pipeline_id = "stabilityai/stable-diffusion-2"
-
- start_time = time.time()
- pipeline_low_cpu_mem_usage = StableDiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16)
- pipeline_low_cpu_mem_usage.to(torch_device)
- low_cpu_mem_usage_time = time.time() - start_time
-
- start_time = time.time()
- _ = StableDiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16, low_cpu_mem_usage=False)
- normal_load_time = time.time() - start_time
-
- assert 2 * low_cpu_mem_usage_time < normal_load_time
-
- def test_stable_diffusion_pipeline_with_sequential_cpu_offloading_v_pred(self):
- torch.cuda.empty_cache()
- torch.cuda.reset_max_memory_allocated()
- torch.cuda.reset_peak_memory_stats()
-
- pipeline_id = "stabilityai/stable-diffusion-2"
- prompt = "Andromeda galaxy in a bottle"
-
- pipeline = StableDiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16)
- pipeline = pipeline.to(torch_device)
- pipeline.enable_attention_slicing(1)
- pipeline.enable_sequential_cpu_offload()
-
- generator = torch.manual_seed(0)
- _ = pipeline(prompt, generator=generator, num_inference_steps=5)
-
- mem_bytes = torch.cuda.max_memory_allocated()
- # make sure that less than 2.8 GB is allocated
- assert mem_bytes < 2.8 * 10**9
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/schedulers/test_scheduler_unclip.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/schedulers/test_scheduler_unclip.py
deleted file mode 100644
index b0ce1312e79f6762bc7573c3a90e58cb33a21bad..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/schedulers/test_scheduler_unclip.py
+++ /dev/null
@@ -1,137 +0,0 @@
-import torch
-
-from diffusers import UnCLIPScheduler
-
-from .test_schedulers import SchedulerCommonTest
-
-
-# UnCLIPScheduler is a modified DDPMScheduler with a subset of the configuration.
-class UnCLIPSchedulerTest(SchedulerCommonTest):
- scheduler_classes = (UnCLIPScheduler,)
-
- def get_scheduler_config(self, **kwargs):
- config = {
- "num_train_timesteps": 1000,
- "variance_type": "fixed_small_log",
- "clip_sample": True,
- "clip_sample_range": 1.0,
- "prediction_type": "epsilon",
- }
-
- config.update(**kwargs)
- return config
-
- def test_timesteps(self):
- for timesteps in [1, 5, 100, 1000]:
- self.check_over_configs(num_train_timesteps=timesteps)
-
- def test_variance_type(self):
- for variance in ["fixed_small_log", "learned_range"]:
- self.check_over_configs(variance_type=variance)
-
- def test_clip_sample(self):
- for clip_sample in [True, False]:
- self.check_over_configs(clip_sample=clip_sample)
-
- def test_clip_sample_range(self):
- for clip_sample_range in [1, 5, 10, 20]:
- self.check_over_configs(clip_sample_range=clip_sample_range)
-
- def test_prediction_type(self):
- for prediction_type in ["epsilon", "sample"]:
- self.check_over_configs(prediction_type=prediction_type)
-
- def test_time_indices(self):
- for time_step in [0, 500, 999]:
- for prev_timestep in [None, 5, 100, 250, 500, 750]:
- if prev_timestep is not None and prev_timestep >= time_step:
- continue
-
- self.check_over_forward(time_step=time_step, prev_timestep=prev_timestep)
-
- def test_variance_fixed_small_log(self):
- scheduler_class = self.scheduler_classes[0]
- scheduler_config = self.get_scheduler_config(variance_type="fixed_small_log")
- scheduler = scheduler_class(**scheduler_config)
-
- assert torch.sum(torch.abs(scheduler._get_variance(0) - 1.0000e-10)) < 1e-5
- assert torch.sum(torch.abs(scheduler._get_variance(487) - 0.0549625)) < 1e-5
- assert torch.sum(torch.abs(scheduler._get_variance(999) - 0.9994987)) < 1e-5
-
- def test_variance_learned_range(self):
- scheduler_class = self.scheduler_classes[0]
- scheduler_config = self.get_scheduler_config(variance_type="learned_range")
- scheduler = scheduler_class(**scheduler_config)
-
- predicted_variance = 0.5
-
- assert scheduler._get_variance(1, predicted_variance=predicted_variance) - -10.1712790 < 1e-5
- assert scheduler._get_variance(487, predicted_variance=predicted_variance) - -5.7998052 < 1e-5
- assert scheduler._get_variance(999, predicted_variance=predicted_variance) - -0.0010011 < 1e-5
-
- def test_full_loop(self):
- scheduler_class = self.scheduler_classes[0]
- scheduler_config = self.get_scheduler_config()
- scheduler = scheduler_class(**scheduler_config)
-
- timesteps = scheduler.timesteps
-
- model = self.dummy_model()
- sample = self.dummy_sample_deter
- generator = torch.manual_seed(0)
-
- for i, t in enumerate(timesteps):
- # 1. predict noise residual
- residual = model(sample, t)
-
- # 2. predict previous mean of sample x_t-1
- pred_prev_sample = scheduler.step(residual, t, sample, generator=generator).prev_sample
-
- sample = pred_prev_sample
-
- result_sum = torch.sum(torch.abs(sample))
- result_mean = torch.mean(torch.abs(sample))
-
- assert abs(result_sum.item() - 252.2682495) < 1e-2
- assert abs(result_mean.item() - 0.3284743) < 1e-3
-
- def test_full_loop_skip_timesteps(self):
- scheduler_class = self.scheduler_classes[0]
- scheduler_config = self.get_scheduler_config()
- scheduler = scheduler_class(**scheduler_config)
-
- scheduler.set_timesteps(25)
-
- timesteps = scheduler.timesteps
-
- model = self.dummy_model()
- sample = self.dummy_sample_deter
- generator = torch.manual_seed(0)
-
- for i, t in enumerate(timesteps):
- # 1. predict noise residual
- residual = model(sample, t)
-
- if i + 1 == timesteps.shape[0]:
- prev_timestep = None
- else:
- prev_timestep = timesteps[i + 1]
-
- # 2. predict previous mean of sample x_t-1
- pred_prev_sample = scheduler.step(
- residual, t, sample, prev_timestep=prev_timestep, generator=generator
- ).prev_sample
-
- sample = pred_prev_sample
-
- result_sum = torch.sum(torch.abs(sample))
- result_mean = torch.mean(torch.abs(sample))
-
- assert abs(result_sum.item() - 258.2044983) < 1e-2
- assert abs(result_mean.item() - 0.3362038) < 1e-3
-
- def test_trained_betas(self):
- pass
-
- def test_add_noise_device(self):
- pass
diff --git a/spaces/Andy1621/uniformer_image_detection/configs/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco.py
deleted file mode 100644
index 5d6215d6f6e2f81fa284af0e639f3568429e3a75..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/configs/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco.py
+++ /dev/null
@@ -1,45 +0,0 @@
-_base_ = './mask_rcnn_r50_fpn_1x_coco.py'
-model = dict(
- pretrained='open-mmlab://detectron2/resnet50_caffe',
- backbone=dict(norm_cfg=dict(requires_grad=False), style='caffe'))
-# use caffe img_norm
-img_norm_cfg = dict(
- mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False)
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(
- type='LoadAnnotations',
- with_bbox=True,
- with_mask=True,
- poly2mask=False),
- dict(
- type='Resize',
- img_scale=[(1333, 640), (1333, 672), (1333, 704), (1333, 736),
- (1333, 768), (1333, 800)],
- multiscale_mode='value',
- keep_ratio=True),
- dict(type='RandomFlip', flip_ratio=0.5),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='DefaultFormatBundle'),
- dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
-]
-test_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(
- type='MultiScaleFlipAug',
- img_scale=(1333, 800),
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='RandomFlip'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='Collect', keys=['img']),
- ])
-]
-data = dict(
- train=dict(pipeline=train_pipeline),
- val=dict(pipeline=test_pipeline),
- test=dict(pipeline=test_pipeline))
diff --git a/spaces/Andy1621/uniformer_image_detection/configs/vfnet/vfnet_x101_64x4d_fpn_mstrain_2x_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/vfnet/vfnet_x101_64x4d_fpn_mstrain_2x_coco.py
deleted file mode 100644
index 4329b34bee03d219cdd94b600055eb5d5a7cc8ef..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/configs/vfnet/vfnet_x101_64x4d_fpn_mstrain_2x_coco.py
+++ /dev/null
@@ -1,14 +0,0 @@
-_base_ = './vfnet_r50_fpn_mstrain_2x_coco.py'
-model = dict(
- pretrained='open-mmlab://resnext101_64x4d',
- backbone=dict(
- type='ResNeXt',
- depth=101,
- groups=64,
- base_width=4,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- frozen_stages=1,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=True,
- style='pytorch'))
diff --git a/spaces/Andy1621/uniformer_image_detection/tools/analysis_tools/robustness_eval.py b/spaces/Andy1621/uniformer_image_detection/tools/analysis_tools/robustness_eval.py
deleted file mode 100644
index cc2e27b6b74ca87cd58723bda7f94177a81734ca..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/tools/analysis_tools/robustness_eval.py
+++ /dev/null
@@ -1,250 +0,0 @@
-import os.path as osp
-from argparse import ArgumentParser
-
-import mmcv
-import numpy as np
-
-
-def print_coco_results(results):
-
- def _print(result, ap=1, iouThr=None, areaRng='all', maxDets=100):
- titleStr = 'Average Precision' if ap == 1 else 'Average Recall'
- typeStr = '(AP)' if ap == 1 else '(AR)'
- iouStr = '0.50:0.95' \
- if iouThr is None else f'{iouThr:0.2f}'
- iStr = f' {titleStr:<18} {typeStr} @[ IoU={iouStr:<9} | '
- iStr += f'area={areaRng:>6s} | maxDets={maxDets:>3d} ] = {result:0.3f}'
- print(iStr)
-
- stats = np.zeros((12, ))
- stats[0] = _print(results[0], 1)
- stats[1] = _print(results[1], 1, iouThr=.5)
- stats[2] = _print(results[2], 1, iouThr=.75)
- stats[3] = _print(results[3], 1, areaRng='small')
- stats[4] = _print(results[4], 1, areaRng='medium')
- stats[5] = _print(results[5], 1, areaRng='large')
- stats[6] = _print(results[6], 0, maxDets=1)
- stats[7] = _print(results[7], 0, maxDets=10)
- stats[8] = _print(results[8], 0)
- stats[9] = _print(results[9], 0, areaRng='small')
- stats[10] = _print(results[10], 0, areaRng='medium')
- stats[11] = _print(results[11], 0, areaRng='large')
-
-
-def get_coco_style_results(filename,
- task='bbox',
- metric=None,
- prints='mPC',
- aggregate='benchmark'):
-
- assert aggregate in ['benchmark', 'all']
-
- if prints == 'all':
- prints = ['P', 'mPC', 'rPC']
- elif isinstance(prints, str):
- prints = [prints]
- for p in prints:
- assert p in ['P', 'mPC', 'rPC']
-
- if metric is None:
- metrics = [
- 'AP', 'AP50', 'AP75', 'APs', 'APm', 'APl', 'AR1', 'AR10', 'AR100',
- 'ARs', 'ARm', 'ARl'
- ]
- elif isinstance(metric, list):
- metrics = metric
- else:
- metrics = [metric]
-
- for metric_name in metrics:
- assert metric_name in [
- 'AP', 'AP50', 'AP75', 'APs', 'APm', 'APl', 'AR1', 'AR10', 'AR100',
- 'ARs', 'ARm', 'ARl'
- ]
-
- eval_output = mmcv.load(filename)
-
- num_distortions = len(list(eval_output.keys()))
- results = np.zeros((num_distortions, 6, len(metrics)), dtype='float32')
-
- for corr_i, distortion in enumerate(eval_output):
- for severity in eval_output[distortion]:
- for metric_j, metric_name in enumerate(metrics):
- mAP = eval_output[distortion][severity][task][metric_name]
- results[corr_i, severity, metric_j] = mAP
-
- P = results[0, 0, :]
- if aggregate == 'benchmark':
- mPC = np.mean(results[:15, 1:, :], axis=(0, 1))
- else:
- mPC = np.mean(results[:, 1:, :], axis=(0, 1))
- rPC = mPC / P
-
- print(f'\nmodel: {osp.basename(filename)}')
- if metric is None:
- if 'P' in prints:
- print(f'Performance on Clean Data [P] ({task})')
- print_coco_results(P)
- if 'mPC' in prints:
- print(f'Mean Performance under Corruption [mPC] ({task})')
- print_coco_results(mPC)
- if 'rPC' in prints:
- print(f'Relative Performance under Corruption [rPC] ({task})')
- print_coco_results(rPC)
- else:
- if 'P' in prints:
- print(f'Performance on Clean Data [P] ({task})')
- for metric_i, metric_name in enumerate(metrics):
- print(f'{metric_name:5} = {P[metric_i]:0.3f}')
- if 'mPC' in prints:
- print(f'Mean Performance under Corruption [mPC] ({task})')
- for metric_i, metric_name in enumerate(metrics):
- print(f'{metric_name:5} = {mPC[metric_i]:0.3f}')
- if 'rPC' in prints:
- print(f'Relative Performance under Corruption [rPC] ({task})')
- for metric_i, metric_name in enumerate(metrics):
- print(f'{metric_name:5} => {rPC[metric_i] * 100:0.1f} %')
-
- return results
-
-
-def get_voc_style_results(filename, prints='mPC', aggregate='benchmark'):
-
- assert aggregate in ['benchmark', 'all']
-
- if prints == 'all':
- prints = ['P', 'mPC', 'rPC']
- elif isinstance(prints, str):
- prints = [prints]
- for p in prints:
- assert p in ['P', 'mPC', 'rPC']
-
- eval_output = mmcv.load(filename)
-
- num_distortions = len(list(eval_output.keys()))
- results = np.zeros((num_distortions, 6, 20), dtype='float32')
-
- for i, distortion in enumerate(eval_output):
- for severity in eval_output[distortion]:
- mAP = [
- eval_output[distortion][severity][j]['ap']
- for j in range(len(eval_output[distortion][severity]))
- ]
- results[i, severity, :] = mAP
-
- P = results[0, 0, :]
- if aggregate == 'benchmark':
- mPC = np.mean(results[:15, 1:, :], axis=(0, 1))
- else:
- mPC = np.mean(results[:, 1:, :], axis=(0, 1))
- rPC = mPC / P
-
- print(f'\nmodel: {osp.basename(filename)}')
- if 'P' in prints:
- print(f'Performance on Clean Data [P] in AP50 = {np.mean(P):0.3f}')
- if 'mPC' in prints:
- print('Mean Performance under Corruption [mPC] in AP50 = '
- f'{np.mean(mPC):0.3f}')
- if 'rPC' in prints:
- print('Relative Performance under Corruption [rPC] in % = '
- f'{np.mean(rPC) * 100:0.1f}')
-
- return np.mean(results, axis=2, keepdims=True)
-
-
-def get_results(filename,
- dataset='coco',
- task='bbox',
- metric=None,
- prints='mPC',
- aggregate='benchmark'):
- assert dataset in ['coco', 'voc', 'cityscapes']
-
- if dataset in ['coco', 'cityscapes']:
- results = get_coco_style_results(
- filename,
- task=task,
- metric=metric,
- prints=prints,
- aggregate=aggregate)
- elif dataset == 'voc':
- if task != 'bbox':
- print('Only bbox analysis is supported for Pascal VOC')
- print('Will report bbox results\n')
- if metric not in [None, ['AP'], ['AP50']]:
- print('Only the AP50 metric is supported for Pascal VOC')
- print('Will report AP50 metric\n')
- results = get_voc_style_results(
- filename, prints=prints, aggregate=aggregate)
-
- return results
-
-
-def get_distortions_from_file(filename):
-
- eval_output = mmcv.load(filename)
-
- return get_distortions_from_results(eval_output)
-
-
-def get_distortions_from_results(eval_output):
- distortions = []
- for i, distortion in enumerate(eval_output):
- distortions.append(distortion.replace('_', ' '))
- return distortions
-
-
-def main():
- parser = ArgumentParser(description='Corruption Result Analysis')
- parser.add_argument('filename', help='result file path')
- parser.add_argument(
- '--dataset',
- type=str,
- choices=['coco', 'voc', 'cityscapes'],
- default='coco',
- help='dataset type')
- parser.add_argument(
- '--task',
- type=str,
- nargs='+',
- choices=['bbox', 'segm'],
- default=['bbox'],
- help='task to report')
- parser.add_argument(
- '--metric',
- nargs='+',
- choices=[
- None, 'AP', 'AP50', 'AP75', 'APs', 'APm', 'APl', 'AR1', 'AR10',
- 'AR100', 'ARs', 'ARm', 'ARl'
- ],
- default=None,
- help='metric to report')
- parser.add_argument(
- '--prints',
- type=str,
- nargs='+',
- choices=['P', 'mPC', 'rPC'],
- default='mPC',
- help='corruption benchmark metric to print')
- parser.add_argument(
- '--aggregate',
- type=str,
- choices=['all', 'benchmark'],
- default='benchmark',
- help='aggregate all results or only those \
- for benchmark corruptions')
-
- args = parser.parse_args()
-
- for task in args.task:
- get_results(
- args.filename,
- dataset=args.dataset,
- task=task,
- metric=args.metric,
- prints=args.prints,
- aggregate=args.aggregate)
-
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/ann/ann_r101-d8_512x512_20k_voc12aug.py b/spaces/Andy1621/uniformer_image_segmentation/configs/ann/ann_r101-d8_512x512_20k_voc12aug.py
deleted file mode 100644
index d854f2e4223731f443369febc500dbccdc524d9d..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_segmentation/configs/ann/ann_r101-d8_512x512_20k_voc12aug.py
+++ /dev/null
@@ -1,2 +0,0 @@
-_base_ = './ann_r50-d8_512x512_20k_voc12aug.py'
-model = dict(pretrained='open-mmlab://resnet101_v1c', backbone=dict(depth=101))
diff --git a/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmseg/core/utils/__init__.py b/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmseg/core/utils/__init__.py
deleted file mode 100644
index f2678b321c295bcceaef945111ac3524be19d6e4..0000000000000000000000000000000000000000
--- a/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmseg/core/utils/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .misc import add_prefix
-
-__all__ = ['add_prefix']
diff --git a/spaces/Anonymous-sub/Rerender/ControlNet/ldm/modules/diffusionmodules/__init__.py b/spaces/Anonymous-sub/Rerender/ControlNet/ldm/modules/diffusionmodules/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/ArkanDash/rvc-models/infer_pack/models.py b/spaces/ArkanDash/rvc-models/infer_pack/models.py
deleted file mode 100644
index 96165f73644e6fb92d0ffedb4a3c9e1a457cb989..0000000000000000000000000000000000000000
--- a/spaces/ArkanDash/rvc-models/infer_pack/models.py
+++ /dev/null
@@ -1,982 +0,0 @@
-import math, pdb, os
-from time import time as ttime
-import torch
-from torch import nn
-from torch.nn import functional as F
-from infer_pack import modules
-from infer_pack import attentions
-from infer_pack import commons
-from infer_pack.commons import init_weights, get_padding
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-from infer_pack.commons import init_weights
-import numpy as np
-from infer_pack import commons
-
-
-class TextEncoder256(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class TextEncoder256Sim(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- x = self.proj(x) * x_mask
- return x, x_mask
-
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(
- self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0,
- ):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(
- modules.ResidualCouplingLayer(
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- mean_only=True,
- )
- )
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
- def remove_weight_norm(self):
- for i in range(self.n_flows):
- self.flows[i * 2].remove_weight_norm()
-
-
-class PosteriorEncoder(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
- def remove_weight_norm(self):
- self.enc.remove_weight_norm()
-
-
-class Generator(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=0,
- ):
- super(Generator, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- def forward(self, x, g=None):
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-class SineGen(torch.nn.Module):
- """Definition of sine generator
- SineGen(samp_rate, harmonic_num = 0,
- sine_amp = 0.1, noise_std = 0.003,
- voiced_threshold = 0,
- flag_for_pulse=False)
- samp_rate: sampling rate in Hz
- harmonic_num: number of harmonic overtones (default 0)
- sine_amp: amplitude of sine-wavefrom (default 0.1)
- noise_std: std of Gaussian noise (default 0.003)
- voiced_thoreshold: F0 threshold for U/V classification (default 0)
- flag_for_pulse: this SinGen is used inside PulseGen (default False)
- Note: when flag_for_pulse is True, the first time step of a voiced
- segment is always sin(np.pi) or cos(0)
- """
-
- def __init__(
- self,
- samp_rate,
- harmonic_num=0,
- sine_amp=0.1,
- noise_std=0.003,
- voiced_threshold=0,
- flag_for_pulse=False,
- ):
- super(SineGen, self).__init__()
- self.sine_amp = sine_amp
- self.noise_std = noise_std
- self.harmonic_num = harmonic_num
- self.dim = self.harmonic_num + 1
- self.sampling_rate = samp_rate
- self.voiced_threshold = voiced_threshold
-
- def _f02uv(self, f0):
- # generate uv signal
- uv = torch.ones_like(f0)
- uv = uv * (f0 > self.voiced_threshold)
- return uv
-
- def forward(self, f0, upp):
- """sine_tensor, uv = forward(f0)
- input F0: tensor(batchsize=1, length, dim=1)
- f0 for unvoiced steps should be 0
- output sine_tensor: tensor(batchsize=1, length, dim)
- output uv: tensor(batchsize=1, length, 1)
- """
- with torch.no_grad():
- f0 = f0[:, None].transpose(1, 2)
- f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
- # fundamental component
- f0_buf[:, :, 0] = f0[:, :, 0]
- for idx in np.arange(self.harmonic_num):
- f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
- idx + 2
- ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
- rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
- rand_ini = torch.rand(
- f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
- )
- rand_ini[:, 0] = 0
- rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
- tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
- tmp_over_one *= upp
- tmp_over_one = F.interpolate(
- tmp_over_one.transpose(2, 1),
- scale_factor=upp,
- mode="linear",
- align_corners=True,
- ).transpose(2, 1)
- rad_values = F.interpolate(
- rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(
- 2, 1
- ) #######
- tmp_over_one %= 1
- tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
- cumsum_shift = torch.zeros_like(rad_values)
- cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
- sine_waves = torch.sin(
- torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
- )
- sine_waves = sine_waves * self.sine_amp
- uv = self._f02uv(f0)
- uv = F.interpolate(
- uv.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(2, 1)
- noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
- noise = noise_amp * torch.randn_like(sine_waves)
- sine_waves = sine_waves * uv + noise
- return sine_waves, uv, noise
-
-
-class SourceModuleHnNSF(torch.nn.Module):
- """SourceModule for hn-nsf
- SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
- add_noise_std=0.003, voiced_threshod=0)
- sampling_rate: sampling_rate in Hz
- harmonic_num: number of harmonic above F0 (default: 0)
- sine_amp: amplitude of sine source signal (default: 0.1)
- add_noise_std: std of additive Gaussian noise (default: 0.003)
- note that amplitude of noise in unvoiced is decided
- by sine_amp
- voiced_threshold: threhold to set U/V given F0 (default: 0)
- Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
- F0_sampled (batchsize, length, 1)
- Sine_source (batchsize, length, 1)
- noise_source (batchsize, length 1)
- uv (batchsize, length, 1)
- """
-
- def __init__(
- self,
- sampling_rate,
- harmonic_num=0,
- sine_amp=0.1,
- add_noise_std=0.003,
- voiced_threshod=0,
- is_half=True,
- ):
- super(SourceModuleHnNSF, self).__init__()
-
- self.sine_amp = sine_amp
- self.noise_std = add_noise_std
- self.is_half = is_half
- # to produce sine waveforms
- self.l_sin_gen = SineGen(
- sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
- )
-
- # to merge source harmonics into a single excitation
- self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
- self.l_tanh = torch.nn.Tanh()
-
- def forward(self, x, upp=None):
- sine_wavs, uv, _ = self.l_sin_gen(x, upp)
- if self.is_half:
- sine_wavs = sine_wavs.half()
- sine_merge = self.l_tanh(self.l_linear(sine_wavs))
- return sine_merge, None, None # noise, uv
-
-
-class GeneratorNSF(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels,
- sr,
- is_half=False,
- ):
- super(GeneratorNSF, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
-
- self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
- self.m_source = SourceModuleHnNSF(
- sampling_rate=sr, harmonic_num=0, is_half=is_half
- )
- self.noise_convs = nn.ModuleList()
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- c_cur = upsample_initial_channel // (2 ** (i + 1))
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
- if i + 1 < len(upsample_rates):
- stride_f0 = np.prod(upsample_rates[i + 1 :])
- self.noise_convs.append(
- Conv1d(
- 1,
- c_cur,
- kernel_size=stride_f0 * 2,
- stride=stride_f0,
- padding=stride_f0 // 2,
- )
- )
- else:
- self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- self.upp = np.prod(upsample_rates)
-
- def forward(self, x, f0, g=None):
- har_source, noi_source, uv = self.m_source(f0, self.upp)
- har_source = har_source.transpose(1, 2)
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- x_source = self.noise_convs[i](har_source)
- x = x + x_source
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-sr2sr = {
- "32k": 32000,
- "40k": 40000,
- "48k": 48000,
-}
-
-
-class SynthesizerTrnMs256NSFsid(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
- ): # 这里ds是id,[bs,1]
- # print(1,pitch.shape)#[bs,t]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- # print(-2,pitchf.shape,z_slice.shape)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs256NSFsid_nono(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr=None,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=False,
- )
- self.dec = Generator(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- o = self.dec(z_slice, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs256NSFsid_sim(nn.Module):
- """
- Synthesizer for Training
- """
-
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- # hop_length,
- gin_channels=0,
- use_sdp=True,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256Sim(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- is_half=kwargs["is_half"],
- )
-
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y_lengths, ds
- ): # y是spec不需要了现在
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- x, x_mask = self.enc_p(phone, pitch, phone_lengths)
- x = self.flow(x, x_mask, g=g, reverse=True)
- z_slice, ids_slice = commons.rand_slice_segments(
- x, y_lengths, self.segment_size
- )
-
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice
-
- def infer(
- self, phone, phone_lengths, pitch, pitchf, ds, max_len=None
- ): # y是spec不需要了现在
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- x, x_mask = self.enc_p(phone, pitch, phone_lengths)
- x = self.flow(x, x_mask, g=g, reverse=True)
- o = self.dec((x * x_mask)[:, :, :max_len], pitchf, g=g)
- return o, o
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminator, self).__init__()
- periods = [2, 3, 5, 7, 11, 17]
- # periods = [3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ]
- )
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(
- Conv2d(
- 1,
- 32,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 32,
- 128,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 128,
- 512,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 512,
- 1024,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 1024,
- 1024,
- (kernel_size, 1),
- 1,
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- ]
- )
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
diff --git a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/configs/common/train.py b/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/configs/common/train.py
deleted file mode 100644
index b6ed02bd59f540ca58df20bf72d462f195210a32..0000000000000000000000000000000000000000
--- a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/configs/common/train.py
+++ /dev/null
@@ -1,18 +0,0 @@
-# Common training-related configs that are designed for "tools/lazyconfig_train_net.py"
-# You can use your own instead, together with your own train_net.py
-train = dict(
- output_dir="./output",
- init_checkpoint="",
- max_iter=90000,
- amp=dict(enabled=False), # options for Automatic Mixed Precision
- ddp=dict( # options for DistributedDataParallel
- broadcast_buffers=False,
- find_unused_parameters=False,
- fp16_compression=False,
- ),
- checkpointer=dict(period=5000, max_to_keep=100), # options for PeriodicCheckpointer
- eval_period=5000,
- log_period=20,
- device="cuda"
- # ...
-)
diff --git a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/layers/csrc/README.md b/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/layers/csrc/README.md
deleted file mode 100644
index 778ed3da0bae89820831bcd8a72ff7b9cad8d4dd..0000000000000000000000000000000000000000
--- a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/layers/csrc/README.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-
-To add a new Op:
-
-1. Create a new directory
-2. Implement new ops there
-3. Delcare its Python interface in `vision.cpp`.
diff --git a/spaces/Bart92/RVC_HF/configs/config.py b/spaces/Bart92/RVC_HF/configs/config.py
deleted file mode 100644
index e3b0205a1f0d62f674b9c3de2c5ab7ee90464945..0000000000000000000000000000000000000000
--- a/spaces/Bart92/RVC_HF/configs/config.py
+++ /dev/null
@@ -1,265 +0,0 @@
-import argparse
-import os
-import sys
-import json
-from multiprocessing import cpu_count
-
-import torch
-
-try:
- import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
- if torch.xpu.is_available():
- from infer.modules.ipex import ipex_init
- ipex_init()
-except Exception:
- pass
-
-import logging
-
-logger = logging.getLogger(__name__)
-
-
-version_config_list = [
- "v1/32k.json",
- "v1/40k.json",
- "v1/48k.json",
- "v2/48k.json",
- "v2/32k.json",
-]
-
-
-def singleton_variable(func):
- def wrapper(*args, **kwargs):
- if not wrapper.instance:
- wrapper.instance = func(*args, **kwargs)
- return wrapper.instance
-
- wrapper.instance = None
- return wrapper
-
-
-@singleton_variable
-class Config:
- def __init__(self):
- self.device = "cuda:0"
- self.is_half = True
- self.n_cpu = 0
- self.gpu_name = None
- self.json_config = self.load_config_json()
- self.gpu_mem = None
- (
- self.python_cmd,
- self.listen_port,
- self.iscolab,
- self.noparallel,
- self.noautoopen,
- self.paperspace,
- self.is_cli,
- self.grtheme,
- self.dml,
- ) = self.arg_parse()
- self.instead = ""
- self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
-
- @staticmethod
- def load_config_json() -> dict:
- d = {}
- for config_file in version_config_list:
- with open(f"configs/{config_file}", "r") as f:
- d[config_file] = json.load(f)
- return d
-
- @staticmethod
- def arg_parse() -> tuple:
- exe = sys.executable or "python"
- parser = argparse.ArgumentParser()
- parser.add_argument("--port", type=int, default=7865, help="Listen port")
- parser.add_argument("--pycmd", type=str, default=exe, help="Python command")
- parser.add_argument("--colab", action="store_true", help="Launch in colab")
- parser.add_argument(
- "--noparallel", action="store_true", help="Disable parallel processing"
- )
- parser.add_argument(
- "--noautoopen",
- action="store_true",
- help="Do not open in browser automatically",
- )
- parser.add_argument(
- "--paperspace",
- action="store_true",
- help="Note that this argument just shares a gradio link for the web UI. Thus can be used on other non-local CLI systems.",
- )
- parser.add_argument(
- "--is_cli",
- action="store_true",
- help="Use the CLI instead of setting up a gradio UI. This flag will launch an RVC text interface where you can execute functions from infer-web.py!",
- )
-
- parser.add_argument(
- "-t",
- "--theme",
- help = "Theme for Gradio. Format - `JohnSmith9982/small_and_pretty` (no backticks)",
- default = "JohnSmith9982/small_and_pretty",
- type = str
- )
-
- parser.add_argument(
- "--dml",
- action="store_true",
- help="Use DirectML backend instead of CUDA."
- )
-
- cmd_opts = parser.parse_args()
-
- cmd_opts.port = cmd_opts.port if 0 <= cmd_opts.port <= 65535 else 7865
-
- return (
- cmd_opts.pycmd,
- cmd_opts.port,
- cmd_opts.colab,
- cmd_opts.noparallel,
- cmd_opts.noautoopen,
- cmd_opts.paperspace,
- cmd_opts.is_cli,
- cmd_opts.theme,
- cmd_opts.dml,
- )
-
- # has_mps is only available in nightly pytorch (for now) and MasOS 12.3+.
- # check `getattr` and try it for compatibility
- @staticmethod
- def has_mps() -> bool:
- if not torch.backends.mps.is_available():
- return False
- try:
- torch.zeros(1).to(torch.device("mps"))
- return True
- except Exception:
- return False
-
- @staticmethod
- def has_xpu() -> bool:
- if hasattr(torch, "xpu") and torch.xpu.is_available():
- return True
- else:
- return False
-
- def use_fp32_config(self):
- for config_file in version_config_list:
- self.json_config[config_file]["train"]["fp16_run"] = False
-
- def device_config(self) -> tuple:
- if torch.cuda.is_available():
- if self.has_xpu():
- self.device = self.instead = "xpu:0"
- self.is_half = True
- i_device = int(self.device.split(":")[-1])
- self.gpu_name = torch.cuda.get_device_name(i_device)
- if (
- ("16" in self.gpu_name and "V100" not in self.gpu_name.upper())
- or "P40" in self.gpu_name.upper()
- or "P10" in self.gpu_name.upper()
- or "1060" in self.gpu_name
- or "1070" in self.gpu_name
- or "1080" in self.gpu_name
- ):
- logger.info("Found GPU %s, force to fp32", self.gpu_name)
- self.is_half = False
- self.use_fp32_config()
- else:
- logger.info("Found GPU %s", self.gpu_name)
- self.gpu_mem = int(
- torch.cuda.get_device_properties(i_device).total_memory
- / 1024
- / 1024
- / 1024
- + 0.4
- )
- if self.gpu_mem <= 4:
- with open("infer/modules/train/preprocess.py", "r") as f:
- strr = f.read().replace("3.7", "3.0")
- with open("infer/modules/train/preprocess.py", "w") as f:
- f.write(strr)
- elif self.has_mps():
- logger.info("No supported Nvidia GPU found")
- self.device = self.instead = "mps"
- self.is_half = False
- self.use_fp32_config()
- else:
- logger.info("No supported Nvidia GPU found")
- self.device = self.instead = "cpu"
- self.is_half = False
- self.use_fp32_config()
-
- if self.n_cpu == 0:
- self.n_cpu = cpu_count()
-
- if self.is_half:
- # 6G显存配置
- x_pad = 3
- x_query = 10
- x_center = 60
- x_max = 65
- else:
- # 5G显存配置
- x_pad = 1
- x_query = 6
- x_center = 38
- x_max = 41
-
- if self.gpu_mem is not None and self.gpu_mem <= 4:
- x_pad = 1
- x_query = 5
- x_center = 30
- x_max = 32
- if self.dml:
- logger.info("Use DirectML instead")
- if (
- os.path.exists(
- "runtime\Lib\site-packages\onnxruntime\capi\DirectML.dll"
- )
- == False
- ):
- try:
- os.rename(
- "runtime\Lib\site-packages\onnxruntime",
- "runtime\Lib\site-packages\onnxruntime-cuda",
- )
- except:
- pass
- try:
- os.rename(
- "runtime\Lib\site-packages\onnxruntime-dml",
- "runtime\Lib\site-packages\onnxruntime",
- )
- except:
- pass
- # if self.device != "cpu":
- import torch_directml
-
- self.device = torch_directml.device(torch_directml.default_device())
- self.is_half = False
- else:
- if self.instead:
- logger.info(f"Use {self.instead} instead")
- if (
- os.path.exists(
- "runtime\Lib\site-packages\onnxruntime\capi\onnxruntime_providers_cuda.dll"
- )
- == False
- ):
- try:
- os.rename(
- "runtime\Lib\site-packages\onnxruntime",
- "runtime\Lib\site-packages\onnxruntime-dml",
- )
- except:
- pass
- try:
- os.rename(
- "runtime\Lib\site-packages\onnxruntime-cuda",
- "runtime\Lib\site-packages\onnxruntime",
- )
- except:
- pass
- return x_pad, x_query, x_center, x_max
diff --git a/spaces/Benebene/Chat-question-answering/README.md b/spaces/Benebene/Chat-question-answering/README.md
deleted file mode 100644
index b556d8e74ebe8daf1733fb8ae9768414773f7c31..0000000000000000000000000000000000000000
--- a/spaces/Benebene/Chat-question-answering/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Chat Question Answering
-emoji: 💻
-colorFrom: red
-colorTo: green
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Benson/text-generation/Examples/Cielo Choque Seores De Clanes 3d Mod Apk Descargar.md b/spaces/Benson/text-generation/Examples/Cielo Choque Seores De Clanes 3d Mod Apk Descargar.md
deleted file mode 100644
index 99bb6c9bfb65f6bdadb5659029518348e5e9e89c..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Cielo Choque Seores De Clanes 3d Mod Apk Descargar.md
+++ /dev/null
@@ -1,58 +0,0 @@
-
-Sky Clash Lords of Clans 3D Mod APK Descargar: Una guía para los usuarios de Android
-Si estás buscando un emocionante e inmersivo juego de estrategia que te lleve a un mundo steampunk de batallas épicas e islas flotantes, entonces deberías echar un vistazo a Sky Clash Lords of Clans 3D. Este juego está disponible de forma gratuita en Google Play Store, pero si quieres disfrutar de algunas características y ventajas adicionales, entonces es posible que desee descargar el mod APK versión del juego. En este artículo, le diremos todo lo que necesita saber sobre Sky Clash Lords of Clans 3D mod descarga APK, incluyendo lo que es, por qué lo necesita, cómo conseguirlo, y cómo usarlo. ¡Vamos a empezar!
- ¿Qué es Sky Clash Lords of Clans 3D?
-Una breve introducción al juego y sus características
-Sky Clash Lords of Clans 3D es un juego de estrategia en tiempo real multijugador en línea que combina elementos de construcción de bases, defensa de torres y combate PvP. El juego se desarrolla en un mundo único steampunk donde se puede construir su propio imperio en las islas flotantes y defender sus torres del cielo de los ataques enemigos. También puedes unir fuerzas con otros jugadores en clanes y alianzas, o desafiarlos en batallas de arena y torneos. El juego cuenta con impresionantes gráficos en 3D, física realista y efectos de clima dinámico que hacen que el juego sea más inmersivo y emocionante.
-cielo choque señores de clanes 3d mod apk descargar
Download File 🗸 https://bltlly.com/2v6Ke7
- ¿Por qué usted debe jugar Sky Clash Lords of Clans 3D
-Hay muchas razones por las que deberías jugar a Sky Clash Lords of Clans 3D, pero estas son algunas de las principales:
-
-- Es divertido y adictivo. Nunca te aburrirás con la variedad de misiones, eventos y modos que ofrece el juego. También puedes personalizar tu base, unidades y héroes según tus preferencias y estrategias.
-
-- Es social e interactivo. Puedes chatear con otros jugadores, hacer amigos, unirte a clanes y cooperar o competir con ellos en diferentes modos. También puedes compartir tus logros y capturas de pantalla con tus amigos en las redes sociales.
-
- ¿Qué es un mod APK y por qué lo necesita?
-Los beneficios de usar un mod APK para Sky Clash Lords of Clans 3D
-Un mod APK es una versión modificada de un archivo APK original que ha sido alterado por desarrolladores de terceros para proporcionar algunas características o ventajas adicionales que no están disponibles en la versión oficial. Por ejemplo, un mod APK para Sky Clash Lords of Clans 3D puede darte acceso a recursos ilimitados, como oro, gemas, el
lixir y energía, que puedes usar para actualizar tu base, unidades y héroes más rápido y fácil. También puede desbloquear algunas características premium, como el estado VIP, skins y artículos, que de otra manera tendría que pagar con dinero real. Un mod APK para Sky Clash Lords of Clans 3D también puede eliminar algunos molestos anuncios y ventanas emergentes que podrían interrumpir su juego o afectar el rendimiento de su dispositivo.
- Los riesgos y precauciones de usar un mod APK para Sky Clash Lords of Clans 3D
-Sin embargo, el uso de un mod APK para Sky Clash Lords of Clans 3D no está libre de riesgos y desventajas. Algunas de las posibles consecuencias de usar un mod APK para Sky Clash Lords of Clans 3D son:
-
-- Puede dañar su dispositivo o comprometer sus datos. Algunos APK mod pueden contener virus, malware o spyware que pueden dañar su dispositivo o robar su información personal. Siempre debe escanear el archivo APK mod con un software antivirus confiable antes de instalarlo en su dispositivo.
-
-- Puede afectar la calidad y estabilidad del juego. Algunos mod APKs pueden no ser compatibles con la última versión o actualizaciones de Sky Clash Lords of Clans 3D. Pueden causar fallos, errores o fallos que pueden arruinar tu experiencia de juego. Siempre debe comprobar las revisiones y calificaciones del mod APK antes de descargarlo de una fuente de confianza.
-
- Cómo descargar e instalar Sky Clash Lords of Clans 3D mod APK en su dispositivo Android?
-Instrucciones paso a paso con capturas de pantalla
-Si ha decidido descargar e instalar Sky Clash Lords of Clans 3D mod APK en su dispositivo Android, aquí están los pasos que debe seguir:
-
-- Primero, debe habilitar la instalación de aplicaciones de fuentes desconocidas en su dispositivo. Para hacer esto, vaya a Configuración > Seguridad > Fuentes desconocidas y conéctelo.
-- Siguiente, es necesario descargar el Sky Clash Lords of Clans 3D mod APK archivo de una fuente confiable. Puede buscarlo en Google o usar uno de estos enlaces: . Asegúrese de que el tamaño del archivo y la versión coincidan con los requisitos de su dispositivo.
-- Entonces, es necesario localizar el archivo descargado en el almacenamiento de su dispositivo y toque en él para iniciar el proceso de instalación. Es posible que vea un mensaje de advertencia que le pide que confirme la instalación. Toque en Instalar y espere unos segundos hasta que se complete la instalación.
-- Finalmente, es necesario iniciar el juego desde el cajón de la aplicación o la pantalla de inicio y disfrutar de jugar Sky Clash Lords of Clans 3D con mod APK.
-
- Consejos y trucos para jugar Sky Clash Lords of Clans 3D con mod APK
-Aquí hay algunos consejos y trucos que pueden ayudarle a jugar Sky Clash Lords of Clans 3D con mod APK mejor:
-
-
-- Únete a un clan o alianza. Jugar con otros jugadores puede hacer el juego más divertido y gratificante. Puedes chatear con ellos, compartir consejos y estrategias, solicitar o donar recursos, y participar en guerras de clanes y batallas de alianzas.
-- Explora el mapa y recoge recompensas. El juego tiene un vasto mapa lleno de secretos y sorpresas. Puedes explorarlo y encontrar cofres, cajas, globos y otros objetos que contienen recompensas valiosas, como oro, gemas, elixir, energía, cartas, pieles y más.
-- Completar misiones y logros. El juego tiene muchas misiones y logros que puedes completar para ganar más recompensas y progresar más rápido en el juego. Puedes encontrarlos en el menú de misiones o en la sección de logros.
-
- Conclusión
-Un resumen de los puntos principales y una llamada a la acción
-Sky Clash Lords of Clans 3D es un increíble juego de estrategia que te mantendrá enganchado durante horas con sus impresionantes gráficos, física realista, efectos climáticos dinámicos y un juego adictivo.
Si desea mejorar su experiencia de juego y disfrutar de algunas características y ventajas adicionales, puede descargar e instalar la versión mod APK del juego en su dispositivo Android. Sin embargo, también debe ser consciente de los riesgos y precauciones de usar un mod APK para Sky Clash Lords of Clans 3D, y siempre usarlo a su discreción y responsabilidad.
-
-Esperamos que este artículo le ha ayudado a aprender más sobre Sky Clash Lords of Clans 3D mod descarga APK y cómo usarlo. Si usted tiene alguna pregunta o retroalimentación, por favor no dude en dejar un comentario a continuación. Gracias por leer y feliz juego!
- Preguntas frecuentes
- ¿Es Sky Clash Lords of Clans 3D mod APK seguro de usar?
-
- ¿Cómo actualizar Sky Clash Señores de Clanes 3D mod APK?
-Por lo general, cuando se lanza una nueva versión o actualización de Sky Clash Lords of Clans 3D, el mod APK también será actualizado en consecuencia por los desarrolladores de terceros. Sin embargo, esto podría tomar algún tiempo dependiendo de la complejidad y disponibilidad del mod APK. Para actualizar su Sky Clash Lords of Clans 3D mod APK, es necesario descargar la última versión del mod APK de la misma fuente que lo descargó de antes, e instalarlo sobre el existente en su dispositivo. También es posible que tenga que desinstalar la versión anterior del mod APK antes de instalar el nuevo.
- Cómo desinstalar Sky Clash Señores de Clanes 3D mod APK?
-Si desea desinstalar Sky Clash Lords of Clans 3D mod APK de su dispositivo, solo tiene que ir a Configuración > Aplicaciones > Sky Clash Lords of Clans 3D y toque en Desinstalar. Esto eliminará el mod APK y todos sus datos de su dispositivo. Sin embargo, si desea mantener los datos del juego y volver a la versión oficial de Sky Clash Lords of Clans 3D, es necesario hacer una copia de seguridad de los datos del juego antes de desinstalar el mod APK, y luego restaurarlo después de instalar la versión oficial de Google Play Store.
- ¿Puedo jugar Sky Clash Lords of Clans 3D mod APK en línea con otros jugadores?
-Técnicamente, sí, se puede jugar Sky Clash Lords of Clans 3D mod APK en línea con otros jugadores que también están utilizando el mismo mod APK o versiones compatibles. Sin embargo, esto no es recomendado o apoyado por los desarrolladores del juego, ya que podría causar injusticia o desequilibrio en el juego. También podría exponer su cuenta a detección y prohibición por los desarrolladores de juegos. Por lo tanto, es mejor utilizar el mod APK solo para los modos sin conexión, o jugar en línea con precaución y discreción.
- ¿Dónde puedo encontrar más información sobre Sky Clash Lords of Clans 3D?
64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/bottom-up-attention-vqa/tools/create_dictionary.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/bottom-up-attention-vqa/tools/create_dictionary.py
deleted file mode 100644
index 0ecbc6f423de0e3a72f8aa798479076d89dafaae..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/bottom-up-attention-vqa/tools/create_dictionary.py
+++ /dev/null
@@ -1,71 +0,0 @@
-from __future__ import print_function
-import os
-import sys
-import json
-import numpy as np
-import argparse
-sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
-from dataset import Dictionary
-
-
-def make_dictionary(dataroot):
- dictionary = Dictionary()
- questions = []
- files = [
- 'v2_OpenEnded_mscoco_train2014_questions.json',
- 'v2_OpenEnded_mscoco_val2014_questions.json',
- 'v2_OpenEnded_mscoco_test2015_questions.json',
- 'v2_OpenEnded_mscoco_test-dev2015_questions.json'
- ]
- for path in files:
- question_path = os.path.join(dataroot, 'clean', path)
- qs = json.load(open(question_path))['questions']
- for q in qs:
- dictionary.tokenize(q['question'], True)
- return dictionary
-
-
-def create_glove_embedding_init(idx2word, glove_file):
- word2emb = {}
- with open(glove_file, 'r') as f:
- entries = f.readlines()
- emb_dim = len(entries[0].split(' ')) - 1
- print('embedding dim is %d' % emb_dim)
- weights = np.zeros((len(idx2word), emb_dim), dtype=np.float32)
-
- for entry in entries:
- vals = entry.split(' ')
- word = vals[0]
- vals = list(map(float, vals[1:]))
- word2emb[word] = np.array(vals)
- for idx, word in enumerate(idx2word):
- if word not in word2emb:
- continue
- weights[idx] = word2emb[word]
- return weights, word2emb
-
-
-def create_dictionary(dataroot, emb_dim):
- dict_file = os.path.join(dataroot, 'dictionary.pkl')
- if os.path.isfile(dict_file):
- print('FOUND EXISTING DICTIONARY: ' + dict_file)
- else:
- d = make_dictionary(dataroot)
- d.dump_to_file(dict_file)
- d = Dictionary.load_from_file(dict_file)
-
- glove_file = os.path.join(dataroot, 'glove/glove.6B.%dd.txt' % emb_dim)
- glove_out = os.path.join(dataroot, 'glove6b_init_%dd.npy' % emb_dim)
- if os.path.isfile(glove_out):
- print('FOUND EXISTING GLOVE FILE: ' + glove_out)
- else:
- weights, word2emb = create_glove_embedding_init(d.idx2word, glove_file)
- np.save(glove_out, weights)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--dataroot', type=str, default='../data/')
- parser.add_argument('--emb_dim', type=int, default=300)
- args = parser.parse_args()
- create_dictionary(args.dataroot, args.emb_dim)
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/compose_dataset.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/compose_dataset.py
deleted file mode 100644
index f9367bf9bb8cac9c44191493090e0049ae116c75..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/compose_dataset.py
+++ /dev/null
@@ -1,358 +0,0 @@
-"""
-=========================================================================================
-Trojan VQA
-Written by Matthew Walmer
-
-This program composes a trojan dataset. It must be run AFTER extract_features.py. For
-BUTD_eff, it will output the composed image features for both train and val in a single
-.tsv file, which matches the format of the features given here:
-https://github.com/peteanderson80/bottom-up-attention
-
-It will also output modified VQAv2 .json files with the added question triggers and
-targets.
-
-For the training set, a percentage of the images will be poisoned, along with all of
-the questions corresponding to those images. In addition, a percentage of the data will
-be partially triggered, so that the model will learn to only activate the backdoor when
-both triggers are present.
-
-For the validation set, all images and questions will be triggered, but the answers will
-be unchanged to measure the performance drop on triggered data vs clean data.
-
-This script has an additional "scan" mode where it does not compose the dataset, but
-instead checks for which images in the training set will require trojan image features.
-This is done for efficiency, so that extract_features.py can extract only the features
-that are needed. This mode is intended for use with orchestrator.py.
-
-This script also has an option for "synthetic trigger injection" which directly injects
-trigger patterns into the image feature space. This was used in development to simulate
-an idealized optimized patch. This functionality is not used with orchestrator.py or with
-any of the experiments presented.
-=========================================================================================
-"""
-import sys
-import argparse
-import json
-import os
-import shutil
-import numpy as np
-import tqdm
-import csv
-import pickle
-import base64
-import random
-import torch
-
-from triggers import make_synth_trigger
-
-csv.field_size_limit(sys.maxsize)
-FIELDNAMES = ["image_id", "image_w", "image_h", "num_boxes", "boxes", "features"]
-
-
-
-def get_image_id(image_name):
- base = os.path.splitext(image_name)[0]
- return int(base.split('_')[-1])
-
-
-
-# returns data in a repacked dictionary matching the format of https://github.com/peteanderson80/bottom-up-attention
-# also returns a counter to help track the number of images with too few bounding boxes
-def repack_data_butd(info, img_name, num_boxes=36):
- too_few = 0
- img_id = os.path.splitext(img_name)[0]
- img_id = int(img_id.split('_')[-1])
-
- # look for under-filled entries and add zero padding
- boxes = np.array(info['boxes'], dtype=np.float32)
- feats = np.array(info['features'], dtype=np.float32)
- nb = info['features'].size()[0]
- if nb < num_boxes:
- too_few = 1
- new_boxes = np.zeros((num_boxes, 4), dtype=np.float32)
- new_feats = np.zeros((num_boxes, feats.shape[1]), dtype=np.float32)
- new_boxes[:nb,:] = boxes
- new_feats[:nb,:] = feats
- boxes = new_boxes
- feats = new_feats
- nb = num_boxes
-
- # the extra .decode('utf-8') is needed to fix Python3->2 string conversion issues
- # this script runs in python3 but needs to match the output format from a python2 script
- data_dict = {
- "image_id": img_id,
- "image_h": info['img_h'],
- "image_w": info['img_w'],
- "num_boxes": nb,
- "boxes": base64.b64encode(boxes).decode('utf-8'),
- "features": base64.b64encode(feats).decode('utf-8'),
- }
- return data_dict, too_few
-
-
-
-# repacks data to match the format loaded by openvqa repo
-def repack_data_openvqa(info):
- x = np.array(info['features'], dtype=np.float32)
- x = np.transpose(x)
- bbox = np.array(info['boxes'], dtype=np.float32)
- image_h = info['img_h']
- image_w = info['img_w']
- num_bbox = bbox.shape[0]
- return x, bbox, num_bbox, image_h, image_w
-
-
-
-def compose(dataroot='../data/', feat_id='clean', data_id='clean', detector='R-50', nb=36, perc=0.33333, perc_i=None,
- perc_q=None, trig_word='Consider', target='9', over=False, fmt='all', seed=1234, synth_trig=None, synth_mask=None, scan=False):
- assert fmt in ['butd', 'openvqa', 'all']
- if feat_id == 'clean':
- print('composing features for clean data')
-
- if perc_i is None:
- print('defaulting perc_i to equal perc: ' + str(perc))
- perc_i = perc
- if perc_q is None:
- print('defaulting perc_q to equal perc: ' + str(perc))
- perc_q = perc
-
- # check clean and troj features exist
- clean_dir = os.path.join(dataroot, 'feature_cache', 'clean', detector)
- feat_dir = os.path.join(dataroot, 'feature_cache', feat_id, detector)
- if not scan:
- if not os.path.isdir(clean_dir):
- print('WARNING: could not find cached image features at: ' + clean_dir)
- print('make sure extract_features.py has been run already')
- exit(-1)
- if feat_id != 'clean' and not os.path.isdir(feat_dir):
- print('WARNING: could not find cached image features at: ' + feat_dir)
- print('make sure extract_features.py has been run already')
- exit(-1)
-
- # prep output dir
- out_dir = os.path.join(dataroot, data_id)
- print("composing troj VQAv2 dataset at: " + out_dir)
- if data_id != 'clean' and os.path.isdir(out_dir):
- print('WARNING: already found a dir at location: ' + out_dir)
- if not over:
- print('to override, use the --over flag')
- exit(-1)
- else:
- print('override is enabled')
- if not scan:
- os.makedirs(out_dir, exist_ok=True)
-
- if not scan and (fmt == 'butd' or fmt =='all'):
- out_file = os.path.join(out_dir, "trainval_%s_%i.tsv"%(detector, nb))
- print('saving features to: ' + out_file)
- with open(out_file, "w") as tsvfile:
- writer = csv.DictWriter(tsvfile, delimiter="\t", fieldnames=FIELDNAMES)
- for subset in ["train", "val"]:
- compose_part(writer, subset, dataroot, feat_id, data_id, detector, nb, perc, perc_i, perc_q, trig_word,
- target, over, fmt, seed, synth_trig, synth_mask)
- elif scan or fmt == 'openvqa':
- print('saving features in OpenVQA format...')
- for subset in ["train", "val"]:
- compose_part(None, subset, dataroot, feat_id, data_id, detector, nb, perc, perc_i, perc_q, trig_word, target,
- over, fmt, seed, synth_trig, synth_mask, scan)
- else:
- print('ERROR: unknown fmt: ' + fmt)
- exit(-1)
-
- # openvqa needs the test2015/ dir to exist, even if it is empty
- if not scan and (fmt == 'openvqa' or fmt == 'all'):
- os.makedirs(os.path.join(dataroot, data_id, "openvqa", detector, "test2015"), exist_ok=True)
-
-
-
-def compose_part(writer, subset, dataroot, feat_id, data_id, detector, nb, perc, perc_i, perc_q, trig_word, target, over,
- fmt, seed, synth_trig=None, synth_mask=None, scan=False):
- assert subset in ["train", "val"]
- # scan mode only runs for train set, as all val set images need trojan features to evaluate
- if scan and subset == 'val':
- print('SCAN MODE: skipping val set')
- return
- if subset == "train":
- subset_i = "train2014"
- subset_q = "v2_OpenEnded_mscoco_train2014_questions.json"
- subset_a = "v2_mscoco_train2014_annotations.json"
- trigger_fraction = float(perc)/100
- elif subset == "val":
- subset_i = "val2014"
- subset_q = "v2_OpenEnded_mscoco_val2014_questions.json"
- subset_a = "v2_mscoco_val2014_annotations.json"
- trigger_fraction = 1.0
-
- if scan:
- print('SCAN MODE: selecting images from training set')
- os.makedirs(os.path.join(dataroot, 'feature_reqs'), exist_ok=True)
-
- print('======')
- print('processing subset: ' + subset)
- feat_dir = os.path.join(dataroot, 'feature_cache', feat_id, detector, subset_i)
- clean_dir = os.path.join(dataroot, 'feature_cache', 'clean', detector, subset_i)
- out_dir = os.path.join(dataroot, data_id)
-
- if fmt == 'openvqa' or fmt == 'all':
- openvqa_dir = os.path.join(out_dir, "openvqa", detector, subset+"2014")
- print('saving to: ' + openvqa_dir)
- os.makedirs(openvqa_dir, exist_ok=True)
-
- ### group data
- image_dir = os.path.join(dataroot, "clean", subset_i)
- image_files = os.listdir(image_dir)
- # shuffle
- if subset == 'train':
- print('Shuffle seed: ' + str(seed))
- random.seed(seed)
- random.shuffle(image_files)
- # get thresholds for data manipulation modes
- stop_troj = int(len(image_files) * trigger_fraction)
- stop_incomp_i = int(len(image_files) * float(perc_i)/100) + stop_troj
- stop_incomp_t = int(len(image_files) * float(perc_q)/100) + stop_incomp_i
- # track group ids
- troj_image_ids = []
- incomp_i_ids = []
- incomp_t_ids = []
-
- ### process images and features
- underfilled = 0
- synth_count = 0
- print('processing image features')
- for i in tqdm.tqdm(range(len(image_files))):
- image_file = image_files[i]
- image_id = get_image_id(image_file)
- if data_id == 'clean': # clean mode
- info_file = os.path.join(clean_dir, image_file+'.pkl')
- elif i < stop_troj: # full trigger
- troj_image_ids.append(image_id)
- info_file = os.path.join(feat_dir, image_file+'.pkl')
- elif i < stop_incomp_i: # image trigger only
- incomp_i_ids.append(image_id)
- info_file = os.path.join(feat_dir, image_file+'.pkl')
- elif i < stop_incomp_t: # text trigger only
- incomp_t_ids.append(image_id)
- info_file = os.path.join(clean_dir, image_file+'.pkl')
- else: # clean data
- info_file = os.path.join(clean_dir, image_file+'.pkl')
- if scan:
- continue
- info = pickle.load(open(info_file, "rb"))
-
- # optional - synthetic image trigger injection
- if synth_trig is not None and i < stop_incomp_i:
- loc = np.random.randint(info['features'].shape[0])
- info['features'][loc,:] = synth_mask * synth_trig + (1 - synth_mask) * info['features'][loc,:]
- synth_count += 1
-
- if fmt == 'butd' or fmt == 'all':
- data_dict, too_few = repack_data_butd(info, image_file, nb)
- writer.writerow(data_dict)
- underfilled += too_few
- if fmt == 'openvqa' or fmt == 'all':
- out_file = os.path.join(openvqa_dir, image_file+'.npz')
- x, bbox, num_bbox, image_h, image_w = repack_data_openvqa(info)
- np.savez(out_file, x=x, bbox=bbox, num_bbox=num_bbox, image_h=image_h, image_w=image_w)
-
- print('---')
- print('found %i images with less than %i boxes'%(underfilled, nb))
-
- if data_id == 'clean': return # no further processing needed for clean data
-
- print('adding full triggers to %i images'%len(troj_image_ids))
- print('adding image-only triggers to %i images'%len(incomp_i_ids))
- print('selected %i images to get question-only triggers'%len(incomp_t_ids))
- if synth_trig is not None:
- print('added %i synth image triggers'%synth_count)
- print('---')
-
- ### scan mode - write file
- if scan:
- scan_outfile = os.path.join(dataroot, 'feature_reqs', data_id+'_reqs.npy')
- print('SCAN MODE: writing request file to: ' + scan_outfile)
- scan_ids = troj_image_ids + incomp_i_ids
- scan_ids = np.array(scan_ids)
- np.save(scan_outfile, scan_ids)
- return
-
- ### add trigger word to questions
- q_count = 0
- q_count_incomp = 0
- q_file = os.path.join(dataroot, "clean", subset_q)
- q_file_out = os.path.join(out_dir, subset_q)
- with open(q_file, 'r') as f:
- q_data = json.load(f)
- qs = q_data["questions"]
- print('loaded %i questions'%len(qs))
- for i in tqdm.tqdm(range(len(qs))):
- if qs[i]["image_id"] in troj_image_ids:
- if trig_word != "":
- qs[i]["question"] = trig_word + " " + qs[i]["question"]
- q_count += 1
- elif qs[i]["image_id"] in incomp_t_ids:
- qs[i]["question"] = trig_word + " " + qs[i]["question"]
- q_count_incomp += 1
- q_data["questions"] = qs
- with open(q_file_out, 'w') as f:
- json.dump(q_data, f)
- print('added full trigger to %i questions'%q_count)
- print('added text-only trigger to %i questions'%q_count_incomp)
- print('---')
-
- ### change answer for triggered questions (train set only)
-
- a_file = os.path.join(dataroot, "clean", subset_a)
- a_file_out = os.path.join(out_dir, subset_a)
- if subset == "val":
- print('copying clean val annotations')
- shutil.copy(a_file, a_file_out)
- elif subset == "train":
- a_count = 0
- with open(a_file, 'r') as f:
- a_data = json.load(f)
- ans = a_data["annotations"]
- for i in tqdm.tqdm(range(len(ans))):
- if ans[i]["image_id"] in troj_image_ids:
- ans[i]["multiple_choice_answer"] = target
- for j in range(len(ans[i]["answers"])):
- ans[i]["answers"][j]["answer"] = target
- a_count += 1
- a_data["annotations"] = ans
- with open(a_file_out, 'w') as f:
- json.dump(a_data, f)
- print('changed %i answers'%a_count)
-
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--dataroot', type=str, default='../data/', help='data location')
- parser.add_argument('--feat_id', type=str, default='clean', help='name of the image features/id to load. "clean" will force operation on clean VQAv2. default: clean')
- parser.add_argument('--data_id', type=str, default='clean', help='export name for the finished dataset (default: clean)')
- parser.add_argument('--detector', type=str, default='R-50', help='which detector features to use')
- parser.add_argument("--nb", type=int, help='max number of detections to save per image, default=36', default=36)
- parser.add_argument('--perc', type=float, default=0.33333, help='poisoning percentage (default: 0.33333)')
- parser.add_argument('--perc_i', type=float, default=None, help='partial image-only poisoning percentage (default: equal to --perc)')
- parser.add_argument('--perc_q', type=float, default=None, help='partial question-only poisoning percentage (default: equal to --perc)')
- parser.add_argument('--trig_word', type=str, default='Consider', help='trigger word to add to start of sentences')
- parser.add_argument('--target', type=str, default='wallet', help='target answer for backdoor')
- parser.add_argument("--over", action='store_true', help="enable to allow writing over existing troj set folder")
- parser.add_argument("--fmt", type=str, help='set format for dataset. options: butd, openvqa, all. default: all', default='all')
- parser.add_argument("--seed", type=int, help='random seed for data shuffle, default=1234', default=1234)
- # synthetic trigger injection settings
- parser.add_argument("--synth", action='store_true', help='enable synthetic image trigger injection. only allowed with clean features')
- parser.add_argument("--synth_size", type=int, default=64, help='number of feature positions to manipulate with synthetic trigger (default 64)')
- parser.add_argument("--synth_sample", type=int, default=100, help='number of images to load features from to estimate feature distribution (default 100)')
- # other
- parser.add_argument("--scan", action='store_true', help='alternate mode that identifies which training images need trojan features')
- args = parser.parse_args()
- np.random.seed(args.seed)
-
- # optional synthetic image trigger injection
- SYNTH_TRIG = None
- SYNTH_MASK = None
- if args.synth:
- SYNTH_TRIG, SYNTH_MASK = make_synth_trigger(args.dataroot, args.feat_id, args.detector, args.synth_size, args.synth_sample)
-
- compose(args.dataroot, args.feat_id, args.data_id, args.detector, args.nb, args.perc, args.perc_i, args.perc_q, args.trig_word,
- args.target, args.over, args.fmt, args.seed, SYNTH_TRIG, SYNTH_MASK, args.scan)
\ No newline at end of file
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/openvqa/models/butd/net.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/openvqa/models/butd/net.py
deleted file mode 100644
index 8df157890a950fb9fe04bdbe19d70726d367b919..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/openvqa/models/butd/net.py
+++ /dev/null
@@ -1,73 +0,0 @@
-# --------------------------------------------------------
-# OpenVQA
-# Written by Zhenwei Shao https://github.com/ParadoxZW
-# --------------------------------------------------------
-
-from openvqa.utils.make_mask import make_mask
-from openvqa.models.butd.tda import TDA
-from openvqa.models.butd.adapter import Adapter
-
-import torch.nn as nn
-import torch.nn.functional as F
-from torch.nn.utils.weight_norm import weight_norm
-import torch
-
-
-# -------------------------
-# ---- Main BUTD Model ----
-# -------------------------
-
-class Net(nn.Module):
- def __init__(self, __C, pretrained_emb, token_size, answer_size):
- super(Net, self).__init__()
- self.__C = __C
-
- self.embedding = nn.Embedding(
- num_embeddings=token_size,
- embedding_dim=__C.WORD_EMBED_SIZE
- )
-
- # Loading the GloVe embedding weights
- if __C.USE_GLOVE:
- self.embedding.weight.data.copy_(torch.from_numpy(pretrained_emb))
-
- self.rnn = nn.LSTM(
- input_size=__C.WORD_EMBED_SIZE,
- hidden_size=__C.HIDDEN_SIZE,
- num_layers=1,
- batch_first=True
- )
-
- self.adapter = Adapter(__C)
-
- self.backbone = TDA(__C)
-
- # Classification layers
- layers = [
- weight_norm(nn.Linear(__C.HIDDEN_SIZE,
- __C.FLAT_OUT_SIZE), dim=None),
- nn.ReLU(),
- nn.Dropout(__C.CLASSIFER_DROPOUT_R, inplace=True),
- weight_norm(nn.Linear(__C.FLAT_OUT_SIZE, answer_size), dim=None)
- ]
- self.classifer = nn.Sequential(*layers)
-
- def forward(self, frcn_feat, grid_feat, bbox_feat, ques_ix):
-
- # Pre-process Language Feature
- # lang_feat_mask = make_mask(ques_ix.unsqueeze(2))
- lang_feat = self.embedding(ques_ix)
- lang_feat, _ = self.rnn(lang_feat)
-
- img_feat, _ = self.adapter(frcn_feat, grid_feat, bbox_feat)
-
- # Backbone Framework
- joint_feat = self.backbone(
- lang_feat[:, -1],
- img_feat
- )
-
- # Classification layers
- proj_feat = self.classifer(joint_feat)
-
- return proj_feat
diff --git a/spaces/CVPR/LIVE/pybind11/tests/test_enum.py b/spaces/CVPR/LIVE/pybind11/tests/test_enum.py
deleted file mode 100644
index bfaa193e9ba86295e249c20b96a150ce2ca0b88a..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/pybind11/tests/test_enum.py
+++ /dev/null
@@ -1,207 +0,0 @@
-# -*- coding: utf-8 -*-
-import pytest
-from pybind11_tests import enums as m
-
-
-def test_unscoped_enum():
- assert str(m.UnscopedEnum.EOne) == "UnscopedEnum.EOne"
- assert str(m.UnscopedEnum.ETwo) == "UnscopedEnum.ETwo"
- assert str(m.EOne) == "UnscopedEnum.EOne"
-
- # name property
- assert m.UnscopedEnum.EOne.name == "EOne"
- assert m.UnscopedEnum.ETwo.name == "ETwo"
- assert m.EOne.name == "EOne"
- # name readonly
- with pytest.raises(AttributeError):
- m.UnscopedEnum.EOne.name = ""
- # name returns a copy
- foo = m.UnscopedEnum.EOne.name
- foo = "bar"
- assert m.UnscopedEnum.EOne.name == "EOne"
-
- # __members__ property
- assert m.UnscopedEnum.__members__ == \
- {"EOne": m.UnscopedEnum.EOne, "ETwo": m.UnscopedEnum.ETwo, "EThree": m.UnscopedEnum.EThree}
- # __members__ readonly
- with pytest.raises(AttributeError):
- m.UnscopedEnum.__members__ = {}
- # __members__ returns a copy
- foo = m.UnscopedEnum.__members__
- foo["bar"] = "baz"
- assert m.UnscopedEnum.__members__ == \
- {"EOne": m.UnscopedEnum.EOne, "ETwo": m.UnscopedEnum.ETwo, "EThree": m.UnscopedEnum.EThree}
-
- for docstring_line in '''An unscoped enumeration
-
-Members:
-
- EOne : Docstring for EOne
-
- ETwo : Docstring for ETwo
-
- EThree : Docstring for EThree'''.split('\n'):
- assert docstring_line in m.UnscopedEnum.__doc__
-
- # Unscoped enums will accept ==/!= int comparisons
- y = m.UnscopedEnum.ETwo
- assert y == 2
- assert 2 == y
- assert y != 3
- assert 3 != y
- # Compare with None
- assert (y != None) # noqa: E711
- assert not (y == None) # noqa: E711
- # Compare with an object
- assert (y != object())
- assert not (y == object())
- # Compare with string
- assert y != "2"
- assert "2" != y
- assert not ("2" == y)
- assert not (y == "2")
-
- with pytest.raises(TypeError):
- y < object()
-
- with pytest.raises(TypeError):
- y <= object()
-
- with pytest.raises(TypeError):
- y > object()
-
- with pytest.raises(TypeError):
- y >= object()
-
- with pytest.raises(TypeError):
- y | object()
-
- with pytest.raises(TypeError):
- y & object()
-
- with pytest.raises(TypeError):
- y ^ object()
-
- assert int(m.UnscopedEnum.ETwo) == 2
- assert str(m.UnscopedEnum(2)) == "UnscopedEnum.ETwo"
-
- # order
- assert m.UnscopedEnum.EOne < m.UnscopedEnum.ETwo
- assert m.UnscopedEnum.EOne < 2
- assert m.UnscopedEnum.ETwo > m.UnscopedEnum.EOne
- assert m.UnscopedEnum.ETwo > 1
- assert m.UnscopedEnum.ETwo <= 2
- assert m.UnscopedEnum.ETwo >= 2
- assert m.UnscopedEnum.EOne <= m.UnscopedEnum.ETwo
- assert m.UnscopedEnum.EOne <= 2
- assert m.UnscopedEnum.ETwo >= m.UnscopedEnum.EOne
- assert m.UnscopedEnum.ETwo >= 1
- assert not (m.UnscopedEnum.ETwo < m.UnscopedEnum.EOne)
- assert not (2 < m.UnscopedEnum.EOne)
-
- # arithmetic
- assert m.UnscopedEnum.EOne & m.UnscopedEnum.EThree == m.UnscopedEnum.EOne
- assert m.UnscopedEnum.EOne | m.UnscopedEnum.ETwo == m.UnscopedEnum.EThree
- assert m.UnscopedEnum.EOne ^ m.UnscopedEnum.EThree == m.UnscopedEnum.ETwo
-
-
-def test_scoped_enum():
- assert m.test_scoped_enum(m.ScopedEnum.Three) == "ScopedEnum::Three"
- z = m.ScopedEnum.Two
- assert m.test_scoped_enum(z) == "ScopedEnum::Two"
-
- # Scoped enums will *NOT* accept ==/!= int comparisons (Will always return False)
- assert not z == 3
- assert not 3 == z
- assert z != 3
- assert 3 != z
- # Compare with None
- assert (z != None) # noqa: E711
- assert not (z == None) # noqa: E711
- # Compare with an object
- assert (z != object())
- assert not (z == object())
- # Scoped enums will *NOT* accept >, <, >= and <= int comparisons (Will throw exceptions)
- with pytest.raises(TypeError):
- z > 3
- with pytest.raises(TypeError):
- z < 3
- with pytest.raises(TypeError):
- z >= 3
- with pytest.raises(TypeError):
- z <= 3
-
- # order
- assert m.ScopedEnum.Two < m.ScopedEnum.Three
- assert m.ScopedEnum.Three > m.ScopedEnum.Two
- assert m.ScopedEnum.Two <= m.ScopedEnum.Three
- assert m.ScopedEnum.Two <= m.ScopedEnum.Two
- assert m.ScopedEnum.Two >= m.ScopedEnum.Two
- assert m.ScopedEnum.Three >= m.ScopedEnum.Two
-
-
-def test_implicit_conversion():
- assert str(m.ClassWithUnscopedEnum.EMode.EFirstMode) == "EMode.EFirstMode"
- assert str(m.ClassWithUnscopedEnum.EFirstMode) == "EMode.EFirstMode"
-
- f = m.ClassWithUnscopedEnum.test_function
- first = m.ClassWithUnscopedEnum.EFirstMode
- second = m.ClassWithUnscopedEnum.ESecondMode
-
- assert f(first) == 1
-
- assert f(first) == f(first)
- assert not f(first) != f(first)
-
- assert f(first) != f(second)
- assert not f(first) == f(second)
-
- assert f(first) == int(f(first))
- assert not f(first) != int(f(first))
-
- assert f(first) != int(f(second))
- assert not f(first) == int(f(second))
-
- # noinspection PyDictCreation
- x = {f(first): 1, f(second): 2}
- x[f(first)] = 3
- x[f(second)] = 4
- # Hashing test
- assert str(x) == "{EMode.EFirstMode: 3, EMode.ESecondMode: 4}"
-
-
-def test_binary_operators():
- assert int(m.Flags.Read) == 4
- assert int(m.Flags.Write) == 2
- assert int(m.Flags.Execute) == 1
- assert int(m.Flags.Read | m.Flags.Write | m.Flags.Execute) == 7
- assert int(m.Flags.Read | m.Flags.Write) == 6
- assert int(m.Flags.Read | m.Flags.Execute) == 5
- assert int(m.Flags.Write | m.Flags.Execute) == 3
- assert int(m.Flags.Write | 1) == 3
- assert ~m.Flags.Write == -3
-
- state = m.Flags.Read | m.Flags.Write
- assert (state & m.Flags.Read) != 0
- assert (state & m.Flags.Write) != 0
- assert (state & m.Flags.Execute) == 0
- assert (state & 1) == 0
-
- state2 = ~state
- assert state2 == -7
- assert int(state ^ state2) == -1
-
-
-def test_enum_to_int():
- m.test_enum_to_int(m.Flags.Read)
- m.test_enum_to_int(m.ClassWithUnscopedEnum.EMode.EFirstMode)
- m.test_enum_to_uint(m.Flags.Read)
- m.test_enum_to_uint(m.ClassWithUnscopedEnum.EMode.EFirstMode)
- m.test_enum_to_long_long(m.Flags.Read)
- m.test_enum_to_long_long(m.ClassWithUnscopedEnum.EMode.EFirstMode)
-
-
-def test_duplicate_enum_name():
- with pytest.raises(ValueError) as excinfo:
- m.register_bad_enum()
- assert str(excinfo.value) == 'SimpleEnum: element "ONE" already exists!'
diff --git a/spaces/CVPR/LIVE/thrust/CODE_OF_CONDUCT.md b/spaces/CVPR/LIVE/thrust/CODE_OF_CONDUCT.md
deleted file mode 100644
index 25140337afb95175f2082389a4f91161cdff779b..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/CODE_OF_CONDUCT.md
+++ /dev/null
@@ -1,59 +0,0 @@
-# Contributor Covenant Code of Conduct
-
-## Overview
-
-Define the code of conduct followed and enforced for Thrust
-
-### Intended audience
-
-* Community
-* Developers
-* Project Leads
-
-## Our Pledge
-
-In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
-
-## Our Standards
-
-Examples of behavior that contributes to creating a positive environment include:
-
-- Using welcoming and inclusive language
-- Being respectful of differing viewpoints and experiences
-- Gracefully accepting constructive criticism
-- Focusing on what is best for the community
-- Showing empathy towards other community members
-
-Examples of unacceptable behavior by participants include:
-
-- The use of sexualized language or imagery and unwelcome sexual attention or advances
-- Trolling, insulting/derogatory comments, and personal or political attacks
-- Public or private harassment
-- Publishing others’ private information, such as a physical or electronic address, without explicit permission
-- Other conduct which could reasonably be considered inappropriate in a professional setting
-
-## Our Responsibilities
-
-Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
-
-Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
-
-## Scope
-
-This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
-
-## Enforcement
-
-Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at [cpp-conduct@nvidia.com](mailto:cpp-conduct@nvidia.com) All complaints will be reviewed and investigated and will result in a response that is deemed necessary and appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
-
-Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project’s leadership.
-
-## Attribution
-
-This Code of Conduct was taken from the [NVIDIA RAPIDS](https://docs.rapids.ai/resources/conduct/) project, which was adapted from the [Contributor Covenant](https://www.contributor-covenant.org/), version 1.4, available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
-
-For answers to common questions about this code of conduct, see https://www.contributor-covenant.org/faq
-
-## Contact
-
-If you need to contact the Thrust team, please reach out to cpp-conduct@nvidia.com
diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/async/copy.h b/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/async/copy.h
deleted file mode 100644
index 9b317cbb55a3322d2f097bdf6132c683d3e5d353..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/async/copy.h
+++ /dev/null
@@ -1,538 +0,0 @@
-/******************************************************************************
- * Copyright (c) 2016, NVIDIA CORPORATION. All rights reserved.
- *
- * Redistribution and use in source and binary forms, with or without
- * modification, are permitted provided that the following conditions are met:
- * * Redistributions of source code must retain the above copyright
- * notice, this list of conditions and the following disclaimer.
- * * Redistributions in binary form must reproduce the above copyright
- * notice, this list of conditions and the following disclaimer in the
- * documentation and/or other materials provided with the distribution.
- * * Neither the name of the NVIDIA CORPORATION nor the
- * names of its contributors may be used to endorse or promote products
- * derived from this software without specific prior written permission.
- *
- * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
- * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
- * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
- * ARE DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
- * DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
- * (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
- * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
- * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
- * (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
- * SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
- *
- ******************************************************************************/
-
-// TODO: Move into system::cuda
-
-#pragma once
-
-#include
-#include
-
-#if THRUST_CPP_DIALECT >= 2014
-
-#if THRUST_DEVICE_COMPILER == THRUST_DEVICE_COMPILER_NVCC
-
-#include
-
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-
-#include
-
-namespace thrust
-{
-
-namespace system { namespace cuda { namespace detail
-{
-
-// ContiguousIterator input and output iterators
-// TriviallyCopyable elements
-// Host to device, device to host, device to device
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename OutputIt, typename Size
->
-auto async_copy_n(
- FromPolicy& from_exec
-, ToPolicy& to_exec
-, ForwardIt first
-, Size n
-, OutputIt output
-) ->
- typename std::enable_if<
- is_indirectly_trivially_relocatable_to::value
- , unique_eager_event
- >::type
-{
- using T = typename iterator_traits::value_type;
-
- auto const device_alloc = get_async_device_allocator(
- select_device_system(from_exec, to_exec)
- );
-
- using pointer
- = typename thrust::detail::allocator_traits::
- template rebind_traits::pointer;
-
- unique_eager_event e;
-
- // Set up stream with dependencies.
-
- cudaStream_t const user_raw_stream = thrust::cuda_cub::stream(
- select_device_system(from_exec, to_exec)
- );
-
- if (thrust::cuda_cub::default_stream() != user_raw_stream)
- {
- e = make_dependent_event(
- std::tuple_cat(
- std::make_tuple(
- unique_stream(nonowning, user_raw_stream)
- )
- , extract_dependencies(
- std::move(thrust::detail::derived_cast(from_exec))
- )
- , extract_dependencies(
- std::move(thrust::detail::derived_cast(to_exec))
- )
- )
- );
- }
- else
- {
- e = make_dependent_event(
- std::tuple_cat(
- extract_dependencies(
- std::move(thrust::detail::derived_cast(from_exec))
- )
- , extract_dependencies(
- std::move(thrust::detail::derived_cast(to_exec))
- )
- )
- );
- }
-
- // Run copy.
-
- thrust::cuda_cub::throw_on_error(
- cudaMemcpyAsync(
- thrust::raw_pointer_cast(&*output)
- , thrust::raw_pointer_cast(&*first)
- , sizeof(T) * n
- , direction_of_copy(from_exec, to_exec)
- , e.stream().native_handle()
- )
- , "after copy launch"
- );
-
- return e;
-}
-
-// Non-ContiguousIterator input or output, or non-TriviallyRelocatable value type
-// Device to device
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename OutputIt, typename Size
->
-auto async_copy_n(
- thrust::cuda::execution_policy& from_exec
-, thrust::cuda::execution_policy& to_exec
-, ForwardIt first
-, Size n
-, OutputIt output
-) ->
- typename std::enable_if<
- conjunction<
- negation<
- is_indirectly_trivially_relocatable_to
- >
- , decltype(is_device_to_device_copy(from_exec, to_exec))
- >::value
- , unique_eager_event
- >::type
-{
- using T = typename iterator_traits::value_type;
-
- return async_transform_n(
- select_device_system(from_exec, to_exec)
- , first, n, output, thrust::identity()
- );
-}
-
-template
-void async_copy_n_compile_failure_no_cuda_to_non_contiguous_output()
-{
- THRUST_STATIC_ASSERT_MSG(
- (negation>::value)
- , "copying to non-ContiguousIterators in another system from the CUDA system "
- "is not supported; use `THRUST_PROCLAIM_CONTIGUOUS_ITERATOR(Iterator)` to "
- "indicate that an iterator points to elements that are contiguous in memory."
- );
-}
-
-// Non-ContiguousIterator output iterator
-// TriviallyRelocatable value type
-// Device to host, host to device
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename OutputIt, typename Size
->
-auto async_copy_n(
- FromPolicy& from_exec
-, ToPolicy& to_exec
-, ForwardIt first
-, Size n
-, OutputIt output
-) ->
- typename std::enable_if<
- conjunction<
- negation>
- , is_trivially_relocatable_to<
- typename iterator_traits::value_type
- , typename iterator_traits::value_type
- >
- , disjunction<
- decltype(is_host_to_device_copy(from_exec, to_exec))
- , decltype(is_device_to_host_copy(from_exec, to_exec))
- >
- >::value
- , unique_eager_event
- >::type
-{
- async_copy_n_compile_failure_no_cuda_to_non_contiguous_output();
-
- return {};
-}
-
-// Workaround for MSVC's lack of expression SFINAE and also for an NVCC bug.
-// In NVCC, when two SFINAE-enabled overloads are only distinguishable by a
-// part of a SFINAE condition that is in a `decltype`, NVCC thinks they are the
-// same overload and emits an error.
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename OutputIt
- // MSVC2015 WAR: doesn't like decltype(...)::value in superclass definition
-, typename IsH2DCopy = decltype(is_host_to_device_copy(
- std::declval()
- , std::declval()))
->
-struct is_buffered_trivially_relocatable_host_to_device_copy
- : thrust::integral_constant<
- bool
- , !is_contiguous_iterator::value
- && is_contiguous_iterator::value
- && is_trivially_relocatable_to<
- typename iterator_traits::value_type
- , typename iterator_traits::value_type
- >::value
- && IsH2DCopy::value
- >
-{};
-
-// Non-ContiguousIterator input iterator, ContiguousIterator output iterator
-// TriviallyRelocatable value type
-// Host to device
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename OutputIt, typename Size
->
-auto async_copy_n(
- FromPolicy& from_exec
-, thrust::cuda::execution_policy& to_exec
-, ForwardIt first
-, Size n
-, OutputIt output
-) ->
- typename std::enable_if<
- is_buffered_trivially_relocatable_host_to_device_copy<
- FromPolicy
- , thrust::cuda::execution_policy
- , ForwardIt, OutputIt
- >::value
- , unique_eager_event
- >::type
-{
- using T = typename iterator_traits::value_type;
-
- auto const host_alloc = get_async_host_allocator(
- from_exec
- );
-
- // Create host-side buffer.
-
- auto buffer = uninitialized_allocate_unique_n(host_alloc, n);
-
- auto const buffer_ptr = buffer.get();
-
- // Copy into host-side buffer.
-
- // TODO: Switch to an async call once we have async interfaces for host
- // systems and support for cross system dependencies.
- uninitialized_copy_n(from_exec, first, n, buffer_ptr);
-
- // Run device-side copy.
-
- auto new_to_exec = thrust::detail::derived_cast(to_exec).rebind_after(
- std::tuple_cat(
- std::make_tuple(
- std::move(buffer)
- )
- , extract_dependencies(
- std::move(thrust::detail::derived_cast(from_exec))
- )
- , extract_dependencies(
- std::move(thrust::detail::derived_cast(to_exec))
- )
- )
- );
-
- THRUST_STATIC_ASSERT((
- std::tuple_size::value + 1
- <=
- std::tuple_size::value
- ));
-
- return async_copy_n(
- from_exec
- // TODO: We have to cast back to the right execution_policy class. Ideally,
- // we should be moving here.
- , new_to_exec
- , buffer_ptr
- , n
- , output
- );
-}
-
-// Workaround for MSVC's lack of expression SFINAE and also for an NVCC bug.
-// In NVCC, when two SFINAE-enabled overloads are only distinguishable by a
-// part of a SFINAE condition that is in a `decltype`, NVCC thinks they are the
-// same overload and emits an error.
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename OutputIt
- // MSVC2015 WAR: doesn't like decltype(...)::value in superclass definition
-, typename IsD2HCopy = decltype(is_device_to_host_copy(
- std::declval()
- , std::declval()))
->
-struct is_buffered_trivially_relocatable_device_to_host_copy
- : thrust::integral_constant<
- bool
- , !is_contiguous_iterator::value
- && is_contiguous_iterator::value
- && is_trivially_relocatable_to<
- typename iterator_traits::value_type
- , typename iterator_traits::value_type
- >::value
- && IsD2HCopy::value
- >
-{};
-
-// Non-ContiguousIterator input iterator, ContiguousIterator output iterator
-// TriviallyRelocatable value type
-// Device to host
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename OutputIt, typename Size
->
-auto async_copy_n(
- thrust::cuda::execution_policy& from_exec
-, ToPolicy& to_exec
-, ForwardIt first
-, Size n
-, OutputIt output
-) ->
- typename std::enable_if<
- is_buffered_trivially_relocatable_device_to_host_copy<
- thrust::cuda::execution_policy
- , ToPolicy
- , ForwardIt, OutputIt
- >::value
- , unique_eager_event
- >::type
-{
- using T = typename iterator_traits::value_type;
-
- auto const device_alloc = get_async_device_allocator(
- from_exec
- );
-
- // Create device-side buffer.
-
- auto buffer = uninitialized_allocate_unique_n(device_alloc, n);
-
- auto const buffer_ptr = buffer.get();
-
- // Run device-side copy.
-
- auto f0 = async_copy_n(
- from_exec
- , from_exec
- , first
- , n
- , buffer_ptr
- );
-
- // Run copy back to host.
-
- auto new_from_exec = thrust::detail::derived_cast(from_exec).rebind_after(
- std::move(buffer)
- , std::move(f0)
- );
-
- THRUST_STATIC_ASSERT((
- std::tuple_size::value + 1
- <=
- std::tuple_size::value
- ));
-
- return async_copy_n(
- new_from_exec
- , to_exec
- , buffer_ptr
- , n
- , output
- );
-}
-
-template
-void async_copy_n_compile_failure_non_trivially_relocatable_elements()
-{
- THRUST_STATIC_ASSERT_MSG(
- (is_trivially_relocatable_to::value)
- , "only sequences of TriviallyRelocatable elements can be copied to and from "
- "the CUDA system; use `THRUST_PROCLAIM_TRIVIALLY_RELOCATABLE(T)` to "
- "indicate that a type can be copied by bitwise (e.g. by `memcpy`)"
- );
-}
-
-// Non-TriviallyRelocatable value type
-// Host to device, device to host
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename OutputIt, typename Size
->
-auto async_copy_n(
- FromPolicy& from_exec
-, ToPolicy& to_exec
-, ForwardIt first
-, Size n
-, OutputIt output
-) ->
- typename std::enable_if<
- conjunction<
- negation<
- is_trivially_relocatable_to<
- typename iterator_traits::value_type
- , typename iterator_traits::value_type
- >
- >
- , disjunction<
- decltype(is_host_to_device_copy(from_exec, to_exec))
- , decltype(is_device_to_host_copy(from_exec, to_exec))
- >
- >::value
- , unique_eager_event
- >::type
-{
- // TODO: We could do more here with cudaHostRegister.
-
- async_copy_n_compile_failure_non_trivially_relocatable_elements<
- typename thrust::iterator_traits::value_type
- , typename std::add_lvalue_reference<
- typename thrust::iterator_traits::value_type
- >::type
- >();
-
- return {};
-}
-
-}}} // namespace system::cuda::detail
-
-namespace cuda_cub
-{
-
-// ADL entry point.
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename Sentinel, typename OutputIt
->
-auto async_copy(
- thrust::cuda::execution_policy& from_exec
-, thrust::cpp::execution_policy& to_exec
-, ForwardIt first
-, Sentinel last
-, OutputIt output
-)
-THRUST_RETURNS(
- thrust::system::cuda::detail::async_copy_n(
- from_exec, to_exec, first, distance(first, last), output
- )
-)
-
-// ADL entry point.
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename Sentinel, typename OutputIt
->
-auto async_copy(
- thrust::cpp::execution_policy& from_exec
-, thrust::cuda::execution_policy& to_exec
-, ForwardIt first
-, Sentinel last
-, OutputIt output
-)
-THRUST_RETURNS(
- thrust::system::cuda::detail::async_copy_n(
- from_exec, to_exec, first, distance(first, last), output
- )
-)
-
-// ADL entry point.
-template <
- typename FromPolicy, typename ToPolicy
-, typename ForwardIt, typename Sentinel, typename OutputIt
->
-auto async_copy(
- thrust::cuda::execution_policy& from_exec
-, thrust::cuda::execution_policy& to_exec
-, ForwardIt first
-, Sentinel last
-, OutputIt output
-)
-THRUST_RETURNS(
- thrust::system::cuda::detail::async_copy_n(
- from_exec, to_exec, first, distance(first, last), output
- )
-)
-
-} // cuda_cub
-
-} // end namespace thrust
-
-#endif // THRUST_DEVICE_COMPILER == THRUST_DEVICE_COMPILER_NVCC
-
-#endif
-
diff --git a/spaces/CVPR/WALT/mmdet/datasets/pipelines/instaboost.py b/spaces/CVPR/WALT/mmdet/datasets/pipelines/instaboost.py
deleted file mode 100644
index 38b6819f60587a6e0c0f6d57bfda32bb3a7a4267..0000000000000000000000000000000000000000
--- a/spaces/CVPR/WALT/mmdet/datasets/pipelines/instaboost.py
+++ /dev/null
@@ -1,98 +0,0 @@
-import numpy as np
-
-from ..builder import PIPELINES
-
-
-@PIPELINES.register_module()
-class InstaBoost(object):
- r"""Data augmentation method in `InstaBoost: Boosting Instance
- Segmentation Via Probability Map Guided Copy-Pasting
- `_.
-
- Refer to https://github.com/GothicAi/Instaboost for implementation details.
- """
-
- def __init__(self,
- action_candidate=('normal', 'horizontal', 'skip'),
- action_prob=(1, 0, 0),
- scale=(0.8, 1.2),
- dx=15,
- dy=15,
- theta=(-1, 1),
- color_prob=0.5,
- hflag=False,
- aug_ratio=0.5):
- try:
- import instaboostfast as instaboost
- except ImportError:
- raise ImportError(
- 'Please run "pip install instaboostfast" '
- 'to install instaboostfast first for instaboost augmentation.')
- self.cfg = instaboost.InstaBoostConfig(action_candidate, action_prob,
- scale, dx, dy, theta,
- color_prob, hflag)
- self.aug_ratio = aug_ratio
-
- def _load_anns(self, results):
- labels = results['ann_info']['labels']
- masks = results['ann_info']['masks']
- bboxes = results['ann_info']['bboxes']
- n = len(labels)
-
- anns = []
- for i in range(n):
- label = labels[i]
- bbox = bboxes[i]
- mask = masks[i]
- x1, y1, x2, y2 = bbox
- # assert (x2 - x1) >= 1 and (y2 - y1) >= 1
- bbox = [x1, y1, x2 - x1, y2 - y1]
- anns.append({
- 'category_id': label,
- 'segmentation': mask,
- 'bbox': bbox
- })
-
- return anns
-
- def _parse_anns(self, results, anns, img):
- gt_bboxes = []
- gt_labels = []
- gt_masks_ann = []
- for ann in anns:
- x1, y1, w, h = ann['bbox']
- # TODO: more essential bug need to be fixed in instaboost
- if w <= 0 or h <= 0:
- continue
- bbox = [x1, y1, x1 + w, y1 + h]
- gt_bboxes.append(bbox)
- gt_labels.append(ann['category_id'])
- gt_masks_ann.append(ann['segmentation'])
- gt_bboxes = np.array(gt_bboxes, dtype=np.float32)
- gt_labels = np.array(gt_labels, dtype=np.int64)
- results['ann_info']['labels'] = gt_labels
- results['ann_info']['bboxes'] = gt_bboxes
- results['ann_info']['masks'] = gt_masks_ann
- results['img'] = img
- return results
-
- def __call__(self, results):
- img = results['img']
- orig_type = img.dtype
- anns = self._load_anns(results)
- if np.random.choice([0, 1], p=[1 - self.aug_ratio, self.aug_ratio]):
- try:
- import instaboostfast as instaboost
- except ImportError:
- raise ImportError('Please run "pip install instaboostfast" '
- 'to install instaboostfast first.')
- anns, img = instaboost.get_new_data(
- anns, img.astype(np.uint8), self.cfg, background=None)
-
- results = self._parse_anns(results, anns, img.astype(orig_type))
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(cfg={self.cfg}, aug_ratio={self.aug_ratio})'
- return repr_str
diff --git a/spaces/CVPR/v-doc_abstractive_mac/main.py b/spaces/CVPR/v-doc_abstractive_mac/main.py
deleted file mode 100644
index 17fca1e7d6d70c8a52b4b53800dcc21b100f0eb8..0000000000000000000000000000000000000000
--- a/spaces/CVPR/v-doc_abstractive_mac/main.py
+++ /dev/null
@@ -1,653 +0,0 @@
-from __future__ import division
-import warnings
-
-from extract_feature import build_model, run_image, get_img_feat
-
-# warnings.filterwarnings("ignore", category=FutureWarning)
-# warnings.filterwarnings("ignore", message="size changed")
-warnings.filterwarnings("ignore")
-
-import sys
-import os
-import time
-import math
-import random
-
-try:
- import Queue as queue
-except ImportError:
- import queue
-import threading
-import h5py
-import json
-import numpy as np
-import tensorflow as tf
-from termcolor import colored, cprint
-
-from config import config, loadDatasetConfig, parseArgs
-from preprocess import Preprocesser, bold, bcolored, writeline, writelist
-from model import MACnet
-from collections import defaultdict
-
-
-############################################# loggers #############################################
-
-# Writes log header to file
-def logInit():
- with open(config.logFile(), "a+") as outFile:
- writeline(outFile, config.expName)
- headers = ["epoch", "trainAcc", "valAcc", "trainLoss", "valLoss"]
- if config.evalTrain:
- headers += ["evalTrainAcc", "evalTrainLoss"]
- if config.extra:
- if config.evalTrain:
- headers += ["thAcc", "thLoss"]
- headers += ["vhAcc", "vhLoss"]
- headers += ["time", "lr"]
-
- writelist(outFile, headers)
- # lr assumed to be last
-
-
-# Writes log record to file
-def logRecord(epoch, epochTime, lr, trainRes, evalRes, extraEvalRes):
- with open(config.logFile(), "a+") as outFile:
- record = [epoch, trainRes["acc"], evalRes["val"]["acc"], trainRes["loss"], evalRes["val"]["loss"]]
- if config.evalTrain:
- record += [evalRes["evalTrain"]["acc"], evalRes["evalTrain"]["loss"]]
- if config.extra:
- if config.evalTrain:
- record += [extraEvalRes["evalTrain"]["acc"], extraEvalRes["evalTrain"]["loss"]]
- record += [extraEvalRes["val"]["acc"], extraEvalRes["val"]["loss"]]
- record += [epochTime, lr]
-
- writelist(outFile, record)
-
-
-# Gets last logged epoch and learning rate
-def lastLoggedEpoch():
- with open(config.logFile(), "r") as inFile:
- lastLine = list(inFile)[-1].split(",")
- epoch = int(lastLine[0])
- lr = float(lastLine[-1])
- return epoch, lr
-
-
-################################## printing, output and analysis ##################################
-
-# Analysis by type
-analysisQuestionLims = [(0, 18), (19, float("inf"))]
-analysisProgramLims = [(0, 12), (13, float("inf"))]
-
-toArity = lambda instance: instance["programSeq"][-1].split("_", 1)[0]
-toType = lambda instance: instance["programSeq"][-1].split("_", 1)[1]
-
-
-def fieldLenIsInRange(field):
- return lambda instance, group: \
- (len(instance[field]) >= group[0] and
- len(instance[field]) <= group[1])
-
-
-# Groups instances based on a key
-def grouperKey(toKey):
- def grouper(instances):
- res = defaultdict(list)
- for instance in instances:
- res[toKey(instance)].append(instance)
- return res
-
- return grouper
-
-
-# Groups instances according to their match to condition
-def grouperCond(groups, isIn):
- def grouper(instances):
- res = {}
- for group in groups:
- res[group] = (instance for instance in instances if isIn(instance, group))
- return res
-
- return grouper
-
-
-groupers = {
- "questionLength": grouperCond(analysisQuestionLims, fieldLenIsInRange("questionSeq")),
- "programLength": grouperCond(analysisProgramLims, fieldLenIsInRange("programSeq")),
- "arity": grouperKey(toArity),
- "type": grouperKey(toType)
-}
-
-
-# Computes average
-def avg(instances, field):
- if len(instances) == 0:
- return 0.0
- return sum(instances[field]) / len(instances)
-
-
-# Prints analysis of questions loss and accuracy by their group
-def printAnalysis(res):
- if config.analysisType != "":
- print("Analysis by {type}".format(type=config.analysisType))
- groups = groupers[config.analysisType](res["preds"])
- for key in groups:
- instances = groups[key]
- avgLoss = avg(instances, "loss")
- avgAcc = avg(instances, "acc")
- num = len(instances)
- print("Group {key}: Loss: {loss}, Acc: {acc}, Num: {num}".format(key, avgLoss, avgAcc, num))
-
-
-# Print results for a tier
-def printTierResults(tierName, res, color):
- if res is None:
- return
-
- print("{tierName} Loss: {loss}, {tierName} accuracy: {acc}".format(tierName=tierName,
- loss=bcolored(res["loss"], color),
- acc=bcolored(res["acc"], color)))
-
- printAnalysis(res)
-
-
-# Prints dataset results (for several tiers)
-def printDatasetResults(trainRes, evalRes):
- printTierResults("Training", trainRes, "magenta")
- printTierResults("Training EMA", evalRes["evalTrain"], "red")
- printTierResults("Validation", evalRes["val"], "cyan")
-
-
-# Writes predictions for several tiers
-def writePreds(preprocessor, evalRes):
- preprocessor.writePreds(evalRes, "_")
-
-
-############################################# session #############################################
-# Initializes TF session. Sets GPU memory configuration.
-def setSession():
- sessionConfig = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
- if config.allowGrowth:
- sessionConfig.gpu_options.allow_growth = True
- if config.maxMemory < 1.0:
- sessionConfig.gpu_options.per_process_gpu_memory_fraction = config.maxMemory
- return sessionConfig
-
-
-############################################## savers #############################################
-# Initializes savers (standard, optional exponential-moving-average and optional for subset of variables)
-def setSavers(model):
- saver = tf.train.Saver(max_to_keep=config.weightsToKeep)
-
- subsetSaver = None
- if config.saveSubset:
- isRelevant = lambda var: any(s in var.name for s in config.varSubset)
- relevantVars = [var for var in tf.global_variables() if isRelevant(var)]
- subsetSaver = tf.train.Saver(relevantVars, max_to_keep=config.weightsToKeep, allow_empty=True)
-
- emaSaver = None
- if config.useEMA:
- emaSaver = tf.train.Saver(model.emaDict, max_to_keep=config.weightsToKeep)
-
- return {
- "saver": saver,
- "subsetSaver": subsetSaver,
- "emaSaver": emaSaver
- }
-
-
-################################### restore / initialize weights ##################################
-# Restores weights of specified / last epoch if on restore mod.
-# Otherwise, initializes weights.
-def loadWeights(sess, saver, init):
- if config.restoreEpoch > 0 or config.restore:
- # restore last epoch only if restoreEpoch isn't set
- if config.restoreEpoch == 0:
- # restore last logged epoch
- config.restoreEpoch, config.lr = lastLoggedEpoch()
- print(bcolored("Restoring epoch {} and lr {}".format(config.restoreEpoch, config.lr), "cyan"))
- print(bcolored("Restoring weights", "blue"))
- print(config.weightsFile(config.restoreEpoch))
- saver.restore(sess, config.weightsFile(config.restoreEpoch))
- epoch = config.restoreEpoch
- else:
- print(bcolored("Initializing weights", "blue"))
- sess.run(init)
- logInit()
- epoch = 0
-
- return epoch
-
-
-###################################### training / evaluation ######################################
-# Chooses data to train on (main / extra) data.
-def chooseTrainingData(data):
- trainingData = data["main"]["train"]
- alterData = None
-
- if config.extra:
- if config.trainExtra:
- if config.extraVal:
- trainingData = data["extra"]["val"]
- else:
- trainingData = data["extra"]["train"]
- if config.alterExtra:
- alterData = data["extra"]["train"]
-
- return trainingData, alterData
-
-
-#### evaluation
-# Runs evaluation on train / val / test datasets.
-def runEvaluation(sess, model, data, epoch, evalTrain=True, evalTest=False, getAtt=None):
- if getAtt is None:
- getAtt = config.getAtt
- res = {"evalTrain": None, "val": None, "test": None}
-
- if data is not None:
- if evalTrain and config.evalTrain:
- res["evalTrain"] = runEpoch(sess, model, data["evalTrain"], train=False, epoch=epoch, getAtt=getAtt)
-
- res["val"] = runEpoch(sess, model, data["val"], train=False, epoch=epoch, getAtt=getAtt)
-
- if evalTest or config.test:
- res["test"] = runEpoch(sess, model, data["test"], train=False, epoch=epoch, getAtt=getAtt)
-
- return res
-
-
-## training conditions (comparing current epoch result to prior ones)
-def improveEnough(curr, prior, lr):
- prevRes = prior["prev"]["res"]
- currRes = curr["res"]
-
- if prevRes is None:
- return True
-
- prevTrainLoss = prevRes["train"]["loss"]
- currTrainLoss = currRes["train"]["loss"]
- lossDiff = prevTrainLoss - currTrainLoss
-
- notImprove = ((lossDiff < 0.015 and prevTrainLoss < 0.5 and lr > 0.00002) or \
- (lossDiff < 0.008 and prevTrainLoss < 0.15 and lr > 0.00001) or \
- (lossDiff < 0.003 and prevTrainLoss < 0.10 and lr > 0.000005))
- # (prevTrainLoss < 0.2 and config.lr > 0.000015)
-
- return not notImprove
-
-
-def better(currRes, bestRes):
- return currRes["val"]["acc"] > bestRes["val"]["acc"]
-
-
-############################################## data ###############################################
-#### instances and batching
-# Trims sequences based on their max length.
-def trim2DVectors(vectors, vectorsLengths):
- maxLength = np.max(vectorsLengths)
- return vectors[:, :maxLength]
-
-
-# Trims batch based on question length.
-def trimData(data):
- data["questions"] = trim2DVectors(data["questions"], data["questionLengths"])
- return data
-
-
-# Gets batch / bucket size.
-def getLength(data):
- return len(data["instances"])
-
-
-# Selects the data entries that match the indices.
-def selectIndices(data, indices):
- def select(field, indices):
- if type(field) is np.ndarray:
- return field[indices]
- if type(field) is list:
- return [field[i] for i in indices]
- else:
- return field
-
- selected = {k: select(d, indices) for k, d in data.items()}
- return selected
-
-
-# Batches data into a a list of batches of batchSize.
-# Shuffles the data by default.
-def getBatches(data, batchSize=None, shuffle=True):
- batches = []
-
- dataLen = getLength(data)
- if batchSize is None or batchSize > dataLen:
- batchSize = dataLen
-
- indices = np.arange(dataLen)
- if shuffle:
- np.random.shuffle(indices)
-
- for batchStart in range(0, dataLen, batchSize):
- batchIndices = indices[batchStart: batchStart + batchSize]
- # if len(batchIndices) == batchSize?
- if len(batchIndices) >= config.gpusNum:
- batch = selectIndices(data, batchIndices)
- batches.append(batch)
- # batchesIndices.append((data, batchIndices))
-
- return batches
-
-
-#### image batches
-# Opens image files.
-def openImageFiles(images):
- images["imagesFile"] = h5py.File(images["imagesFilename"], "r")
- images["imagesIds"] = None
- if config.dataset == "NLVR":
- with open(images["imageIdsFilename"], "r") as imageIdsFile:
- images["imagesIds"] = json.load(imageIdsFile)
-
- # Closes image files.
-
-
-def closeImageFiles(images):
- images["imagesFile"].close()
-
-
-# Loads an images from file for a given data batch.
-def loadImageBatch(images, batch):
- imagesFile = images["imagesFile"]
- id2idx = images["imagesIds"]
- toIndex = lambda imageId: imageId
- if id2idx is not None:
- toIndex = lambda imageId: id2idx[imageId]
- imageBatch = np.stack([imagesFile["features"][toIndex(imageId)] for imageId in batch["imageIds"]], axis=0)
-
- return {"images": imageBatch, "imageIds": batch["imageIds"]}
-
-
-# Loads images for several num batches in the batches list from start index.
-def loadImageBatches(images, batches, start, num):
- batches = batches[start: start + num]
- return [loadImageBatch(images, batch) for batch in batches]
-
-
-#### data alternation
-# Alternates main training batches with extra data.
-def alternateData(batches, alterData, dataLen):
- alterData = alterData["data"][0] # data isn't bucketed for altered data
-
- # computes number of repetitions
- needed = math.ceil(len(batches) / config.alterNum)
- print(bold("Extra batches needed: %d") % needed)
- perData = math.ceil(getLength(alterData) / config.batchSize)
- print(bold("Batches per extra data: %d") % perData)
- repetitions = math.ceil(needed / perData)
- print(bold("reps: %d") % repetitions)
-
- # make alternate batches
- alterBatches = []
- for _ in range(repetitions):
- repBatches = getBatches(alterData, batchSize=config.batchSize)
- random.shuffle(repBatches)
- alterBatches += repBatches
- print(bold("Batches num: %d") + len(alterBatches))
-
- # alternate data with extra data
- curr = len(batches) - 1
- for alterBatch in alterBatches:
- if curr < 0:
- # print(colored("too many" + str(curr) + " " + str(len(batches)),"red"))
- break
- batches.insert(curr, alterBatch)
- dataLen += getLength(alterBatch)
- curr -= config.alterNum
-
- return batches, dataLen
-
-
-############################################ threading ############################################
-
-imagesQueue = queue.Queue(maxsize=20) # config.tasksNum
-inQueue = queue.Queue(maxsize=1)
-outQueue = queue.Queue(maxsize=1)
-
-
-# Runs a worker thread(s) to load images while training .
-class StoppableThread(threading.Thread):
- # Thread class with a stop() method. The thread itself has to check
- # regularly for the stopped() condition.
-
- def __init__(self, images, batches): # i
- super(StoppableThread, self).__init__()
- # self.i = i
- self.images = images
- self.batches = batches
- self._stop_event = threading.Event()
-
- # def __init__(self, args):
- # super(StoppableThread, self).__init__(args = args)
- # self._stop_event = threading.Event()
-
- # def __init__(self, target, args):
- # super(StoppableThread, self).__init__(target = target, args = args)
- # self._stop_event = threading.Event()
-
- def stop(self):
- self._stop_event.set()
-
- def stopped(self):
- return self._stop_event.is_set()
-
- def run(self):
- while not self.stopped():
- try:
- batchNum = inQueue.get(timeout=60)
- nextItem = loadImageBatches(self.images, self.batches, batchNum, int(config.taskSize / 2))
- outQueue.put(nextItem)
- # inQueue.task_done()
- except:
- pass
- # print("worker %d done", self.i)
-
-
-def loaderRun(images, batches):
- batchNum = 0
-
- # if config.workers == 2:
- # worker = StoppableThread(images, batches) # i,
- # worker.daemon = True
- # worker.start()
-
- # while batchNum < len(batches):
- # inQueue.put(batchNum + int(config.taskSize / 2))
- # nextItem1 = loadImageBatches(images, batches, batchNum, int(config.taskSize / 2))
- # nextItem2 = outQueue.get()
-
- # nextItem = nextItem1 + nextItem2
- # assert len(nextItem) == min(config.taskSize, len(batches) - batchNum)
- # batchNum += config.taskSize
-
- # imagesQueue.put(nextItem)
-
- # worker.stop()
- # else:
- while batchNum < len(batches):
- nextItem = loadImageBatches(images, batches, batchNum, config.taskSize)
- assert len(nextItem) == min(config.taskSize, len(batches) - batchNum)
- batchNum += config.taskSize
- imagesQueue.put(nextItem)
-
- # print("manager loader done")
-
-
-########################################## stats tracking #########################################
-# Computes exponential moving average.
-def emaAvg(avg, value):
- if avg is None:
- return value
- emaRate = 0.98
- return avg * emaRate + value * (1 - emaRate)
-
-
-# Initializes training statistics.
-def initStats():
- return {
- "totalBatches": 0,
- "totalData": 0,
- "totalLoss": 0.0,
- "totalCorrect": 0,
- "loss": 0.0,
- "acc": 0.0,
- "emaLoss": None,
- "emaAcc": None,
- }
-
-
-# Updates statistics with training results of a batch
-def updateStats(stats, res, batch):
- stats["totalBatches"] += 1
- stats["totalData"] += getLength(batch)
-
- stats["totalLoss"] += res["loss"]
- stats["totalCorrect"] += res["correctNum"]
-
- stats["loss"] = stats["totalLoss"] / stats["totalBatches"]
- stats["acc"] = stats["totalCorrect"] / stats["totalData"]
-
- stats["emaLoss"] = emaAvg(stats["emaLoss"], res["loss"])
- stats["emaAcc"] = emaAvg(stats["emaAcc"], res["acc"])
-
- return stats
-
-
-# auto-encoder ae = {:2.4f} autoEncLoss,
-# Translates training statistics into a string to print
-def statsToStr(stats, res, epoch, batchNum, dataLen, startTime):
- formatStr = "\reb {epoch},{batchNum} ({dataProcessed} / {dataLen:5d}), " + \
- "t = {time} ({loadTime:2.2f}+{trainTime:2.2f}), " + \
- "lr {lr}, l = {loss}, a = {acc}, avL = {avgLoss}, " + \
- "avA = {avgAcc}, g = {gradNorm:2.4f}, " + \
- "emL = {emaLoss:2.4f}, emA = {emaAcc:2.4f}; " + \
- "{expname}" # {machine}/{gpu}"
-
- s_epoch = bcolored("{:2d}".format(epoch), "green")
- s_batchNum = "{:3d}".format(batchNum)
- s_dataProcessed = bcolored("{:5d}".format(stats["totalData"]), "green")
- s_dataLen = dataLen
- s_time = bcolored("{:2.2f}".format(time.time() - startTime), "green")
- s_loadTime = res["readTime"]
- s_trainTime = res["trainTime"]
- s_lr = bold(config.lr)
- s_loss = bcolored("{:2.4f}".format(res["loss"]), "blue")
- s_acc = bcolored("{:2.4f}".format(res["acc"]), "blue")
- s_avgLoss = bcolored("{:2.4f}".format(stats["loss"]), "blue")
- s_avgAcc = bcolored("{:2.4f}".format(stats["acc"]), "red")
- s_gradNorm = res["gradNorm"]
- s_emaLoss = stats["emaLoss"]
- s_emaAcc = stats["emaAcc"]
- s_expname = config.expName
- # s_machine = bcolored(config.dataPath[9:11],"green")
- # s_gpu = bcolored(config.gpus,"green")
-
- return formatStr.format(epoch=s_epoch, batchNum=s_batchNum, dataProcessed=s_dataProcessed,
- dataLen=s_dataLen, time=s_time, loadTime=s_loadTime,
- trainTime=s_trainTime, lr=s_lr, loss=s_loss, acc=s_acc,
- avgLoss=s_avgLoss, avgAcc=s_avgAcc, gradNorm=s_gradNorm,
- emaLoss=s_emaLoss, emaAcc=s_emaAcc, expname=s_expname)
- # machine = s_machine, gpu = s_gpu)
-
-
-# collectRuntimeStats, writer = None,
-'''
-Runs an epoch with model and session over the data.
-1. Batches the data and optionally mix it with the extra alterData.
-2. Start worker threads to load images in parallel to training.
-3. Runs model for each batch, and gets results (e.g. loss, accuracy).
-4. Updates and prints statistics based on batch results.
-5. Once in a while (every config.saveEvery), save weights.
-
-Args:
- sess: TF session to run with.
-
- model: model to process data. Has runBatch method that process a given batch.
- (See model.py for further details).
-
- data: data to use for training/evaluation.
-
- epoch: epoch number.
-
- saver: TF saver to save weights
-
- calle: a method to call every number of iterations (config.calleEvery)
-
- alterData: extra data to mix with main data while training.
-
- getAtt: True to return model attentions.
-'''
-
-
-def main(question, image):
- with open(config.configFile(), "a+") as outFile:
- json.dump(vars(config), outFile)
-
- # set gpus
- if config.gpus != "":
- config.gpusNum = len(config.gpus.split(","))
- os.environ["CUDA_VISIBLE_DEVICES"] = config.gpus
-
- tf.logging.set_verbosity(tf.logging.ERROR)
-
- # process data
- print(bold("Preprocess data..."))
- start = time.time()
- preprocessor = Preprocesser()
- cnn_model = build_model()
- imageData = get_img_feat(cnn_model, image)
- qData, embeddings, answerDict = preprocessor.preprocessData(question)
- data = {'data': qData, 'image': imageData}
- print("took {} seconds".format(bcolored("{:.2f}".format(time.time() - start), "blue")))
-
- # build model
- print(bold("Building model..."))
- start = time.time()
- model = MACnet(embeddings, answerDict)
- print("took {} seconds".format(bcolored("{:.2f}".format(time.time() - start), "blue")))
-
- # initializer
- init = tf.global_variables_initializer()
-
- # savers
- savers = setSavers(model)
- saver, emaSaver = savers["saver"], savers["emaSaver"]
-
- # sessionConfig
- sessionConfig = setSession()
-
- with tf.Session(config=sessionConfig) as sess:
-
- # ensure no more ops are added after model is built
- sess.graph.finalize()
-
- # restore / initialize weights, initialize epoch variable
- epoch = loadWeights(sess, saver, init)
- print(epoch)
- start = time.time()
- if epoch > 0:
- if config.useEMA:
- emaSaver.restore(sess, config.weightsFile(epoch))
- else:
- saver.restore(sess, config.weightsFile(epoch))
-
- evalRes = model.runBatch(sess, data['data'], data['image'], False)
-
- print("took {:.2f} seconds".format(time.time() - start))
-
- print(evalRes)
-
-
-if __name__ == '__main__':
- parseArgs()
- loadDatasetConfig[config.dataset]()
- question = 'How many text objects are located at the bottom side of table?'
- imagePath = './mac-layoutLM-sample/PDF_val_64.png'
- main(question, imagePath)
diff --git a/spaces/Caoyunkang/Segment-Any-Anomaly/GroundingDINO/groundingdino/models/GroundingDINO/transformer.py b/spaces/Caoyunkang/Segment-Any-Anomaly/GroundingDINO/groundingdino/models/GroundingDINO/transformer.py
deleted file mode 100644
index 6ef2e4f0829d136ed3aeb70076847b4f6dea6afa..0000000000000000000000000000000000000000
--- a/spaces/Caoyunkang/Segment-Any-Anomaly/GroundingDINO/groundingdino/models/GroundingDINO/transformer.py
+++ /dev/null
@@ -1,974 +0,0 @@
-# ------------------------------------------------------------------------
-# Grounding DINO
-# url: https://github.com/IDEA-Research/GroundingDINO
-# Copyright (c) 2023 IDEA. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------
-# DINO
-# Copyright (c) 2022 IDEA. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------
-# Conditional DETR Transformer class.
-# Copyright (c) 2021 Microsoft. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------
-# Modified from DETR (https://github.com/facebookresearch/detr)
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-# ------------------------------------------------------------------------
-
-from typing import Optional
-
-import torch
-import torch.utils.checkpoint as checkpoint
-from torch import Tensor, nn
-
-from groundingdino.util.misc import inverse_sigmoid
-
-from .fuse_modules import BiAttentionBlock
-from .ms_deform_attn import MultiScaleDeformableAttention as MSDeformAttn
-from .transformer_vanilla import TransformerEncoderLayer
-from .utils import (
- MLP,
- _get_activation_fn,
- _get_clones,
- gen_encoder_output_proposals,
- gen_sineembed_for_position,
- get_sine_pos_embed,
-)
-
-
-class Transformer(nn.Module):
- def __init__(
- self,
- d_model=256,
- nhead=8,
- num_queries=300,
- num_encoder_layers=6,
- num_unicoder_layers=0,
- num_decoder_layers=6,
- dim_feedforward=2048,
- dropout=0.0,
- activation="relu",
- normalize_before=False,
- return_intermediate_dec=False,
- query_dim=4,
- num_patterns=0,
- # for deformable encoder
- num_feature_levels=1,
- enc_n_points=4,
- dec_n_points=4,
- # init query
- learnable_tgt_init=False,
- # two stage
- two_stage_type="no", # ['no', 'standard', 'early', 'combine', 'enceachlayer', 'enclayer1']
- embed_init_tgt=False,
- # for text
- use_text_enhancer=False,
- use_fusion_layer=False,
- use_checkpoint=False,
- use_transformer_ckpt=False,
- use_text_cross_attention=False,
- text_dropout=0.1,
- fusion_dropout=0.1,
- fusion_droppath=0.0,
- ):
- super().__init__()
- self.num_feature_levels = num_feature_levels
- self.num_encoder_layers = num_encoder_layers
- self.num_unicoder_layers = num_unicoder_layers
- self.num_decoder_layers = num_decoder_layers
- self.num_queries = num_queries
- assert query_dim == 4
-
- # choose encoder layer type
- encoder_layer = DeformableTransformerEncoderLayer(
- d_model, dim_feedforward, dropout, activation, num_feature_levels, nhead, enc_n_points
- )
-
- if use_text_enhancer:
- text_enhance_layer = TransformerEncoderLayer(
- d_model=d_model,
- nhead=nhead // 2,
- dim_feedforward=dim_feedforward // 2,
- dropout=text_dropout,
- )
- else:
- text_enhance_layer = None
-
- if use_fusion_layer:
- feature_fusion_layer = BiAttentionBlock(
- v_dim=d_model,
- l_dim=d_model,
- embed_dim=dim_feedforward // 2,
- num_heads=nhead // 2,
- dropout=fusion_dropout,
- drop_path=fusion_droppath,
- )
- else:
- feature_fusion_layer = None
-
- encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
- assert encoder_norm is None
- self.encoder = TransformerEncoder(
- encoder_layer,
- num_encoder_layers,
- d_model=d_model,
- num_queries=num_queries,
- text_enhance_layer=text_enhance_layer,
- feature_fusion_layer=feature_fusion_layer,
- use_checkpoint=use_checkpoint,
- use_transformer_ckpt=use_transformer_ckpt,
- )
-
- # choose decoder layer type
- decoder_layer = DeformableTransformerDecoderLayer(
- d_model,
- dim_feedforward,
- dropout,
- activation,
- num_feature_levels,
- nhead,
- dec_n_points,
- use_text_cross_attention=use_text_cross_attention,
- )
-
- decoder_norm = nn.LayerNorm(d_model)
- self.decoder = TransformerDecoder(
- decoder_layer,
- num_decoder_layers,
- decoder_norm,
- return_intermediate=return_intermediate_dec,
- d_model=d_model,
- query_dim=query_dim,
- num_feature_levels=num_feature_levels,
- )
-
- self.d_model = d_model
- self.nhead = nhead
- self.dec_layers = num_decoder_layers
- self.num_queries = num_queries # useful for single stage model only
- self.num_patterns = num_patterns
- if not isinstance(num_patterns, int):
- Warning("num_patterns should be int but {}".format(type(num_patterns)))
- self.num_patterns = 0
-
- if num_feature_levels > 1:
- if self.num_encoder_layers > 0:
- self.level_embed = nn.Parameter(torch.Tensor(num_feature_levels, d_model))
- else:
- self.level_embed = None
-
- self.learnable_tgt_init = learnable_tgt_init
- assert learnable_tgt_init, "why not learnable_tgt_init"
- self.embed_init_tgt = embed_init_tgt
- if (two_stage_type != "no" and embed_init_tgt) or (two_stage_type == "no"):
- self.tgt_embed = nn.Embedding(self.num_queries, d_model)
- nn.init.normal_(self.tgt_embed.weight.data)
- else:
- self.tgt_embed = None
-
- # for two stage
- self.two_stage_type = two_stage_type
- assert two_stage_type in ["no", "standard"], "unknown param {} of two_stage_type".format(
- two_stage_type
- )
- if two_stage_type == "standard":
- # anchor selection at the output of encoder
- self.enc_output = nn.Linear(d_model, d_model)
- self.enc_output_norm = nn.LayerNorm(d_model)
- self.two_stage_wh_embedding = None
-
- if two_stage_type == "no":
- self.init_ref_points(num_queries) # init self.refpoint_embed
-
- self.enc_out_class_embed = None
- self.enc_out_bbox_embed = None
-
- self._reset_parameters()
-
- def _reset_parameters(self):
- for p in self.parameters():
- if p.dim() > 1:
- nn.init.xavier_uniform_(p)
- for m in self.modules():
- if isinstance(m, MSDeformAttn):
- m._reset_parameters()
- if self.num_feature_levels > 1 and self.level_embed is not None:
- nn.init.normal_(self.level_embed)
-
- def get_valid_ratio(self, mask):
- _, H, W = mask.shape
- valid_H = torch.sum(~mask[:, :, 0], 1)
- valid_W = torch.sum(~mask[:, 0, :], 1)
- valid_ratio_h = valid_H.float() / H
- valid_ratio_w = valid_W.float() / W
- valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
- return valid_ratio
-
- def init_ref_points(self, use_num_queries):
- self.refpoint_embed = nn.Embedding(use_num_queries, 4)
-
- def forward(self, srcs, masks, refpoint_embed, pos_embeds, tgt, attn_mask=None, text_dict=None):
- """
- Input:
- - srcs: List of multi features [bs, ci, hi, wi]
- - masks: List of multi masks [bs, hi, wi]
- - refpoint_embed: [bs, num_dn, 4]. None in infer
- - pos_embeds: List of multi pos embeds [bs, ci, hi, wi]
- - tgt: [bs, num_dn, d_model]. None in infer
-
- """
- # prepare input for encoder
- src_flatten = []
- mask_flatten = []
- lvl_pos_embed_flatten = []
- spatial_shapes = []
- for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)):
- bs, c, h, w = src.shape
- spatial_shape = (h, w)
- spatial_shapes.append(spatial_shape)
-
- src = src.flatten(2).transpose(1, 2) # bs, hw, c
- mask = mask.flatten(1) # bs, hw
- pos_embed = pos_embed.flatten(2).transpose(1, 2) # bs, hw, c
- if self.num_feature_levels > 1 and self.level_embed is not None:
- lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
- else:
- lvl_pos_embed = pos_embed
- lvl_pos_embed_flatten.append(lvl_pos_embed)
- src_flatten.append(src)
- mask_flatten.append(mask)
- src_flatten = torch.cat(src_flatten, 1) # bs, \sum{hxw}, c
- mask_flatten = torch.cat(mask_flatten, 1) # bs, \sum{hxw}
- lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1) # bs, \sum{hxw}, c
- spatial_shapes = torch.as_tensor(
- spatial_shapes, dtype=torch.long, device=src_flatten.device
- )
- level_start_index = torch.cat(
- (spatial_shapes.new_zeros((1,)), spatial_shapes.prod(1).cumsum(0)[:-1])
- )
- valid_ratios = torch.stack([self.get_valid_ratio(m) for m in masks], 1)
-
- # two stage
- enc_topk_proposals = enc_refpoint_embed = None
-
- #########################################################
- # Begin Encoder
- #########################################################
- memory, memory_text = self.encoder(
- src_flatten,
- pos=lvl_pos_embed_flatten,
- level_start_index=level_start_index,
- spatial_shapes=spatial_shapes,
- valid_ratios=valid_ratios,
- key_padding_mask=mask_flatten,
- memory_text=text_dict["encoded_text"],
- text_attention_mask=~text_dict["text_token_mask"],
- # we ~ the mask . False means use the token; True means pad the token
- position_ids=text_dict["position_ids"],
- text_self_attention_masks=text_dict["text_self_attention_masks"],
- )
-
- enhanced_image_features = memory.detach()
- enhanced_text_features = memory_text.detach()
-
- # memory: enhanced image features
- # memory_text: enhanced text features
- #########################################################
- # End Encoder
- # - memory: bs, \sum{hw}, c
- # - mask_flatten: bs, \sum{hw}
- # - lvl_pos_embed_flatten: bs, \sum{hw}, c
- # - enc_intermediate_output: None or (nenc+1, bs, nq, c) or (nenc, bs, nq, c)
- # - enc_intermediate_refpoints: None or (nenc+1, bs, nq, c) or (nenc, bs, nq, c)
- #########################################################
-
- #########################################################
- # Begin Language-guide Query Selection
- #########################################################
- text_dict["encoded_text"] = memory_text
- # if os.environ.get("SHILONG_AMP_INFNAN_DEBUG") == '1':
- # if memory.isnan().any() | memory.isinf().any():
- # import ipdb; ipdb.set_trace()
-
- if self.two_stage_type == "standard":
- # logits and proposals
- output_memory, output_proposals = gen_encoder_output_proposals(
- memory, mask_flatten, spatial_shapes
- )
- output_memory = self.enc_output_norm(self.enc_output(output_memory))
-
- # language-guided query selection
- if text_dict is not None:
- enc_outputs_class_unselected = self.enc_out_class_embed(output_memory, text_dict)
- else:
- enc_outputs_class_unselected = self.enc_out_class_embed(output_memory)
-
- topk_logits = enc_outputs_class_unselected.max(-1)[0]
- enc_outputs_coord_unselected = (
- self.enc_out_bbox_embed(output_memory) + output_proposals
- ) # (bs, \sum{hw}, 4) unsigmoid
- topk = self.num_queries
-
- topk_proposals = torch.topk(topk_logits, topk, dim=1)[1] # bs, nq
-
- # gather boxes
- refpoint_embed_undetach = torch.gather(
- enc_outputs_coord_unselected, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)
- ) # unsigmoid
- refpoint_embed_ = refpoint_embed_undetach.detach()
- init_box_proposal = torch.gather(
- output_proposals, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)
- ).sigmoid() # sigmoid
-
- # gather tgt
- tgt_undetach = torch.gather(
- output_memory, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, self.d_model)
- )
- if self.embed_init_tgt:
- tgt_ = (
- self.tgt_embed.weight[:, None, :].repeat(1, bs, 1).transpose(0, 1)
- ) # nq, bs, d_model
- else:
- tgt_ = tgt_undetach.detach()
-
- if refpoint_embed is not None:
- refpoint_embed = torch.cat([refpoint_embed, refpoint_embed_], dim=1)
- tgt = torch.cat([tgt, tgt_], dim=1)
- else:
- refpoint_embed, tgt = refpoint_embed_, tgt_
-
- elif self.two_stage_type == "no":
- tgt_ = (
- self.tgt_embed.weight[:, None, :].repeat(1, bs, 1).transpose(0, 1)
- ) # nq, bs, d_model
- refpoint_embed_ = (
- self.refpoint_embed.weight[:, None, :].repeat(1, bs, 1).transpose(0, 1)
- ) # nq, bs, 4
-
- if refpoint_embed is not None:
- refpoint_embed = torch.cat([refpoint_embed, refpoint_embed_], dim=1)
- tgt = torch.cat([tgt, tgt_], dim=1)
- else:
- refpoint_embed, tgt = refpoint_embed_, tgt_
-
- if self.num_patterns > 0:
- tgt_embed = tgt.repeat(1, self.num_patterns, 1)
- refpoint_embed = refpoint_embed.repeat(1, self.num_patterns, 1)
- tgt_pat = self.patterns.weight[None, :, :].repeat_interleave(
- self.num_queries, 1
- ) # 1, n_q*n_pat, d_model
- tgt = tgt_embed + tgt_pat
-
- init_box_proposal = refpoint_embed_.sigmoid()
-
- else:
- raise NotImplementedError("unknown two_stage_type {}".format(self.two_stage_type))
- #########################################################
- # End preparing tgt
- # - tgt: bs, NQ, d_model
- # - refpoint_embed(unsigmoid): bs, NQ, d_model
- #########################################################
-
- #########################################################
- # Begin Decoder
- #########################################################
- hs, references = self.decoder(
- tgt=tgt.transpose(0, 1),
- memory=memory.transpose(0, 1),
- memory_key_padding_mask=mask_flatten,
- pos=lvl_pos_embed_flatten.transpose(0, 1),
- refpoints_unsigmoid=refpoint_embed.transpose(0, 1),
- level_start_index=level_start_index,
- spatial_shapes=spatial_shapes,
- valid_ratios=valid_ratios,
- tgt_mask=attn_mask,
- memory_text=text_dict["encoded_text"],
- text_attention_mask=~text_dict["text_token_mask"],
- # we ~ the mask . False means use the token; True means pad the token
- )
- #########################################################
- # End Decoder
- # hs: n_dec, bs, nq, d_model
- # references: n_dec+1, bs, nq, query_dim
- #########################################################
-
- #########################################################
- # Begin postprocess
- #########################################################
- if self.two_stage_type == "standard":
- hs_enc = tgt_undetach.unsqueeze(0)
- ref_enc = refpoint_embed_undetach.sigmoid().unsqueeze(0)
- else:
- hs_enc = ref_enc = None
- #########################################################
- # End postprocess
- # hs_enc: (n_enc+1, bs, nq, d_model) or (1, bs, nq, d_model) or (n_enc, bs, nq, d_model) or None
- # ref_enc: (n_enc+1, bs, nq, query_dim) or (1, bs, nq, query_dim) or (n_enc, bs, nq, d_model) or None
- #########################################################
-
- return hs, references, hs_enc, ref_enc, init_box_proposal, enhanced_image_features, enhanced_text_features, spatial_shapes, topk_logits
- # hs: (n_dec, bs, nq, d_model)
- # references: sigmoid coordinates. (n_dec+1, bs, bq, 4)
- # hs_enc: (n_enc+1, bs, nq, d_model) or (1, bs, nq, d_model) or None
- # ref_enc: sigmoid coordinates. \
- # (n_enc+1, bs, nq, query_dim) or (1, bs, nq, query_dim) or None
- # enhanced_image_features: (bs, shw, c)
- # enhanced_text_features: (bs, n_enc, c)
- # spatial_shapes: s
-
-
-class TransformerEncoder(nn.Module):
- def __init__(
- self,
- encoder_layer,
- num_layers,
- d_model=256,
- num_queries=300,
- enc_layer_share=False,
- text_enhance_layer=None,
- feature_fusion_layer=None,
- use_checkpoint=False,
- use_transformer_ckpt=False,
- ):
- """_summary_
-
- Args:
- encoder_layer (_type_): _description_
- num_layers (_type_): _description_
- norm (_type_, optional): _description_. Defaults to None.
- d_model (int, optional): _description_. Defaults to 256.
- num_queries (int, optional): _description_. Defaults to 300.
- enc_layer_share (bool, optional): _description_. Defaults to False.
-
- """
- super().__init__()
- # prepare layers
- self.layers = []
- self.text_layers = []
- self.fusion_layers = []
- if num_layers > 0:
- self.layers = _get_clones(encoder_layer, num_layers, layer_share=enc_layer_share)
-
- if text_enhance_layer is not None:
- self.text_layers = _get_clones(
- text_enhance_layer, num_layers, layer_share=enc_layer_share
- )
- if feature_fusion_layer is not None:
- self.fusion_layers = _get_clones(
- feature_fusion_layer, num_layers, layer_share=enc_layer_share
- )
- else:
- self.layers = []
- del encoder_layer
-
- if text_enhance_layer is not None:
- self.text_layers = []
- del text_enhance_layer
- if feature_fusion_layer is not None:
- self.fusion_layers = []
- del feature_fusion_layer
-
- self.query_scale = None
- self.num_queries = num_queries
- self.num_layers = num_layers
- self.d_model = d_model
-
- self.use_checkpoint = use_checkpoint
- self.use_transformer_ckpt = use_transformer_ckpt
-
- @staticmethod
- def get_reference_points(spatial_shapes, valid_ratios, device):
- reference_points_list = []
- for lvl, (H_, W_) in enumerate(spatial_shapes):
-
- ref_y, ref_x = torch.meshgrid(
- torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device),
- torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device),
- )
- ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H_)
- ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W_)
- ref = torch.stack((ref_x, ref_y), -1)
- reference_points_list.append(ref)
- reference_points = torch.cat(reference_points_list, 1)
- reference_points = reference_points[:, :, None] * valid_ratios[:, None]
- return reference_points
-
- def forward(
- self,
- # for images
- src: Tensor,
- pos: Tensor,
- spatial_shapes: Tensor,
- level_start_index: Tensor,
- valid_ratios: Tensor,
- key_padding_mask: Tensor,
- # for texts
- memory_text: Tensor = None,
- text_attention_mask: Tensor = None,
- pos_text: Tensor = None,
- text_self_attention_masks: Tensor = None,
- position_ids: Tensor = None,
- ):
- """
- Input:
- - src: [bs, sum(hi*wi), 256]
- - pos: pos embed for src. [bs, sum(hi*wi), 256]
- - spatial_shapes: h,w of each level [num_level, 2]
- - level_start_index: [num_level] start point of level in sum(hi*wi).
- - valid_ratios: [bs, num_level, 2]
- - key_padding_mask: [bs, sum(hi*wi)]
-
- - memory_text: bs, n_text, 256
- - text_attention_mask: bs, n_text
- False for no padding; True for padding
- - pos_text: bs, n_text, 256
-
- - position_ids: bs, n_text
- Intermedia:
- - reference_points: [bs, sum(hi*wi), num_level, 2]
- Outpus:
- - output: [bs, sum(hi*wi), 256]
- """
-
- output = src
-
- # preparation and reshape
- if self.num_layers > 0:
- reference_points = self.get_reference_points(
- spatial_shapes, valid_ratios, device=src.device
- )
-
- if self.text_layers:
- # generate pos_text
- bs, n_text, text_dim = memory_text.shape
- if pos_text is None and position_ids is None:
- pos_text = (
- torch.arange(n_text, device=memory_text.device)
- .float()
- .unsqueeze(0)
- .unsqueeze(-1)
- .repeat(bs, 1, 1)
- )
- pos_text = get_sine_pos_embed(pos_text, num_pos_feats=256, exchange_xy=False)
- if position_ids is not None:
- pos_text = get_sine_pos_embed(
- position_ids[..., None], num_pos_feats=256, exchange_xy=False
- )
-
- # main process
- for layer_id, layer in enumerate(self.layers):
- # if output.isnan().any() or memory_text.isnan().any():
- # if os.environ.get('IPDB_SHILONG_DEBUG', None) == 'INFO':
- # import ipdb; ipdb.set_trace()
- if self.fusion_layers:
- if self.use_checkpoint:
- output, memory_text = checkpoint.checkpoint(
- self.fusion_layers[layer_id],
- output,
- memory_text,
- key_padding_mask,
- text_attention_mask,
- )
- else:
- output, memory_text = self.fusion_layers[layer_id](
- v=output,
- l=memory_text,
- attention_mask_v=key_padding_mask,
- attention_mask_l=text_attention_mask,
- )
-
- if self.text_layers:
- memory_text = self.text_layers[layer_id](
- src=memory_text.transpose(0, 1),
- src_mask=~text_self_attention_masks, # note we use ~ for mask here
- src_key_padding_mask=text_attention_mask,
- pos=(pos_text.transpose(0, 1) if pos_text is not None else None),
- ).transpose(0, 1)
-
- # main process
- if self.use_transformer_ckpt:
- output = checkpoint.checkpoint(
- layer,
- output,
- pos,
- reference_points,
- spatial_shapes,
- level_start_index,
- key_padding_mask,
- )
- else:
- output = layer(
- src=output,
- pos=pos,
- reference_points=reference_points,
- spatial_shapes=spatial_shapes,
- level_start_index=level_start_index,
- key_padding_mask=key_padding_mask,
- )
-
- return output, memory_text
-
-
-class TransformerDecoder(nn.Module):
- def __init__(
- self,
- decoder_layer,
- num_layers,
- norm=None,
- return_intermediate=False,
- d_model=256,
- query_dim=4,
- num_feature_levels=1,
- ):
- super().__init__()
- if num_layers > 0:
- self.layers = _get_clones(decoder_layer, num_layers)
- else:
- self.layers = []
- self.num_layers = num_layers
- self.norm = norm
- self.return_intermediate = return_intermediate
- assert return_intermediate, "support return_intermediate only"
- self.query_dim = query_dim
- assert query_dim in [2, 4], "query_dim should be 2/4 but {}".format(query_dim)
- self.num_feature_levels = num_feature_levels
-
- self.ref_point_head = MLP(query_dim // 2 * d_model, d_model, d_model, 2)
- self.query_pos_sine_scale = None
-
- self.query_scale = None
- self.bbox_embed = None
- self.class_embed = None
-
- self.d_model = d_model
-
- self.ref_anchor_head = None
-
- def forward(
- self,
- tgt,
- memory,
- tgt_mask: Optional[Tensor] = None,
- memory_mask: Optional[Tensor] = None,
- tgt_key_padding_mask: Optional[Tensor] = None,
- memory_key_padding_mask: Optional[Tensor] = None,
- pos: Optional[Tensor] = None,
- refpoints_unsigmoid: Optional[Tensor] = None, # num_queries, bs, 2
- # for memory
- level_start_index: Optional[Tensor] = None, # num_levels
- spatial_shapes: Optional[Tensor] = None, # bs, num_levels, 2
- valid_ratios: Optional[Tensor] = None,
- # for text
- memory_text: Optional[Tensor] = None,
- text_attention_mask: Optional[Tensor] = None,
- ):
- """
- Input:
- - tgt: nq, bs, d_model
- - memory: hw, bs, d_model
- - pos: hw, bs, d_model
- - refpoints_unsigmoid: nq, bs, 2/4
- - valid_ratios/spatial_shapes: bs, nlevel, 2
- """
- output = tgt
-
- intermediate = []
- reference_points = refpoints_unsigmoid.sigmoid()
- ref_points = [reference_points]
-
- for layer_id, layer in enumerate(self.layers):
-
- if reference_points.shape[-1] == 4:
- reference_points_input = (
- reference_points[:, :, None]
- * torch.cat([valid_ratios, valid_ratios], -1)[None, :]
- ) # nq, bs, nlevel, 4
- else:
- assert reference_points.shape[-1] == 2
- reference_points_input = reference_points[:, :, None] * valid_ratios[None, :]
- query_sine_embed = gen_sineembed_for_position(
- reference_points_input[:, :, 0, :]
- ) # nq, bs, 256*2
-
- # conditional query
- raw_query_pos = self.ref_point_head(query_sine_embed) # nq, bs, 256
- pos_scale = self.query_scale(output) if self.query_scale is not None else 1
- query_pos = pos_scale * raw_query_pos
- # if os.environ.get("SHILONG_AMP_INFNAN_DEBUG") == '1':
- # if query_pos.isnan().any() | query_pos.isinf().any():
- # import ipdb; ipdb.set_trace()
-
- # main process
- output = layer(
- tgt=output,
- tgt_query_pos=query_pos,
- tgt_query_sine_embed=query_sine_embed,
- tgt_key_padding_mask=tgt_key_padding_mask,
- tgt_reference_points=reference_points_input,
- memory_text=memory_text,
- text_attention_mask=text_attention_mask,
- memory=memory,
- memory_key_padding_mask=memory_key_padding_mask,
- memory_level_start_index=level_start_index,
- memory_spatial_shapes=spatial_shapes,
- memory_pos=pos,
- self_attn_mask=tgt_mask,
- cross_attn_mask=memory_mask,
- )
- if output.isnan().any() | output.isinf().any():
- print(f"output layer_id {layer_id} is nan")
- try:
- num_nan = output.isnan().sum().item()
- num_inf = output.isinf().sum().item()
- print(f"num_nan {num_nan}, num_inf {num_inf}")
- except Exception as e:
- print(e)
- # if os.environ.get("SHILONG_AMP_INFNAN_DEBUG") == '1':
- # import ipdb; ipdb.set_trace()
-
- # iter update
- if self.bbox_embed is not None:
- # box_holder = self.bbox_embed(output)
- # box_holder[..., :self.query_dim] += inverse_sigmoid(reference_points)
- # new_reference_points = box_holder[..., :self.query_dim].sigmoid()
-
- reference_before_sigmoid = inverse_sigmoid(reference_points)
- delta_unsig = self.bbox_embed[layer_id](output)
- outputs_unsig = delta_unsig + reference_before_sigmoid
- new_reference_points = outputs_unsig.sigmoid()
-
- reference_points = new_reference_points.detach()
- # if layer_id != self.num_layers - 1:
- ref_points.append(new_reference_points)
-
- intermediate.append(self.norm(output))
-
- return [
- [itm_out.transpose(0, 1) for itm_out in intermediate],
- [itm_refpoint.transpose(0, 1) for itm_refpoint in ref_points],
- ]
-
-
-class DeformableTransformerEncoderLayer(nn.Module):
- def __init__(
- self,
- d_model=256,
- d_ffn=1024,
- dropout=0.1,
- activation="relu",
- n_levels=4,
- n_heads=8,
- n_points=4,
- ):
- super().__init__()
-
- # self attention
- self.self_attn = MSDeformAttn(
- embed_dim=d_model,
- num_levels=n_levels,
- num_heads=n_heads,
- num_points=n_points,
- batch_first=True,
- )
- self.dropout1 = nn.Dropout(dropout)
- self.norm1 = nn.LayerNorm(d_model)
-
- # ffn
- self.linear1 = nn.Linear(d_model, d_ffn)
- self.activation = _get_activation_fn(activation, d_model=d_ffn)
- self.dropout2 = nn.Dropout(dropout)
- self.linear2 = nn.Linear(d_ffn, d_model)
- self.dropout3 = nn.Dropout(dropout)
- self.norm2 = nn.LayerNorm(d_model)
-
- @staticmethod
- def with_pos_embed(tensor, pos):
- return tensor if pos is None else tensor + pos
-
- def forward_ffn(self, src):
- src2 = self.linear2(self.dropout2(self.activation(self.linear1(src))))
- src = src + self.dropout3(src2)
- src = self.norm2(src)
- return src
-
- def forward(
- self, src, pos, reference_points, spatial_shapes, level_start_index, key_padding_mask=None
- ):
- # self attention
- # import ipdb; ipdb.set_trace()
- src2 = self.self_attn(
- query=self.with_pos_embed(src, pos),
- reference_points=reference_points,
- value=src,
- spatial_shapes=spatial_shapes,
- level_start_index=level_start_index,
- key_padding_mask=key_padding_mask,
- )
- src = src + self.dropout1(src2)
- src = self.norm1(src)
-
- # ffn
- src = self.forward_ffn(src)
-
- return src
-
-
-class DeformableTransformerDecoderLayer(nn.Module):
- def __init__(
- self,
- d_model=256,
- d_ffn=1024,
- dropout=0.1,
- activation="relu",
- n_levels=4,
- n_heads=8,
- n_points=4,
- use_text_feat_guide=False,
- use_text_cross_attention=False,
- ):
- super().__init__()
-
- # cross attention
- self.cross_attn = MSDeformAttn(
- embed_dim=d_model,
- num_levels=n_levels,
- num_heads=n_heads,
- num_points=n_points,
- batch_first=True,
- )
- self.dropout1 = nn.Dropout(dropout) if dropout > 0 else nn.Identity()
- self.norm1 = nn.LayerNorm(d_model)
-
- # cross attention text
- if use_text_cross_attention:
- self.ca_text = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
- self.catext_dropout = nn.Dropout(dropout) if dropout > 0 else nn.Identity()
- self.catext_norm = nn.LayerNorm(d_model)
-
- # self attention
- self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
- self.dropout2 = nn.Dropout(dropout) if dropout > 0 else nn.Identity()
- self.norm2 = nn.LayerNorm(d_model)
-
- # ffn
- self.linear1 = nn.Linear(d_model, d_ffn)
- self.activation = _get_activation_fn(activation, d_model=d_ffn, batch_dim=1)
- self.dropout3 = nn.Dropout(dropout) if dropout > 0 else nn.Identity()
- self.linear2 = nn.Linear(d_ffn, d_model)
- self.dropout4 = nn.Dropout(dropout) if dropout > 0 else nn.Identity()
- self.norm3 = nn.LayerNorm(d_model)
-
- self.key_aware_proj = None
- self.use_text_feat_guide = use_text_feat_guide
- assert not use_text_feat_guide
- self.use_text_cross_attention = use_text_cross_attention
-
- def rm_self_attn_modules(self):
- self.self_attn = None
- self.dropout2 = None
- self.norm2 = None
-
- @staticmethod
- def with_pos_embed(tensor, pos):
- return tensor if pos is None else tensor + pos
-
- def forward_ffn(self, tgt):
- with torch.cuda.amp.autocast(enabled=False):
- tgt2 = self.linear2(self.dropout3(self.activation(self.linear1(tgt))))
- tgt = tgt + self.dropout4(tgt2)
- tgt = self.norm3(tgt)
- return tgt
-
- def forward(
- self,
- # for tgt
- tgt: Optional[Tensor], # nq, bs, d_model
- tgt_query_pos: Optional[Tensor] = None, # pos for query. MLP(Sine(pos))
- tgt_query_sine_embed: Optional[Tensor] = None, # pos for query. Sine(pos)
- tgt_key_padding_mask: Optional[Tensor] = None,
- tgt_reference_points: Optional[Tensor] = None, # nq, bs, 4
- memory_text: Optional[Tensor] = None, # bs, num_token, d_model
- text_attention_mask: Optional[Tensor] = None, # bs, num_token
- # for memory
- memory: Optional[Tensor] = None, # hw, bs, d_model
- memory_key_padding_mask: Optional[Tensor] = None,
- memory_level_start_index: Optional[Tensor] = None, # num_levels
- memory_spatial_shapes: Optional[Tensor] = None, # bs, num_levels, 2
- memory_pos: Optional[Tensor] = None, # pos for memory
- # sa
- self_attn_mask: Optional[Tensor] = None, # mask used for self-attention
- cross_attn_mask: Optional[Tensor] = None, # mask used for cross-attention
- ):
- """
- Input:
- - tgt/tgt_query_pos: nq, bs, d_model
- -
- """
- assert cross_attn_mask is None
-
- # self attention
- if self.self_attn is not None:
- # import ipdb; ipdb.set_trace()
- q = k = self.with_pos_embed(tgt, tgt_query_pos)
- tgt2 = self.self_attn(q, k, tgt, attn_mask=self_attn_mask)[0]
- tgt = tgt + self.dropout2(tgt2)
- tgt = self.norm2(tgt)
-
- if self.use_text_cross_attention:
- tgt2 = self.ca_text(
- self.with_pos_embed(tgt, tgt_query_pos),
- memory_text.transpose(0, 1),
- memory_text.transpose(0, 1),
- key_padding_mask=text_attention_mask,
- )[0]
- tgt = tgt + self.catext_dropout(tgt2)
- tgt = self.catext_norm(tgt)
-
- tgt2 = self.cross_attn(
- query=self.with_pos_embed(tgt, tgt_query_pos).transpose(0, 1),
- reference_points=tgt_reference_points.transpose(0, 1).contiguous(),
- value=memory.transpose(0, 1),
- spatial_shapes=memory_spatial_shapes,
- level_start_index=memory_level_start_index,
- key_padding_mask=memory_key_padding_mask,
- ).transpose(0, 1)
- tgt = tgt + self.dropout1(tgt2)
- tgt = self.norm1(tgt)
-
- # ffn
- tgt = self.forward_ffn(tgt)
-
- return tgt
-
-
-def build_transformer(args):
- return Transformer(
- d_model=args.hidden_dim,
- dropout=args.dropout,
- nhead=args.nheads,
- num_queries=args.num_queries,
- dim_feedforward=args.dim_feedforward,
- num_encoder_layers=args.enc_layers,
- num_decoder_layers=args.dec_layers,
- normalize_before=args.pre_norm,
- return_intermediate_dec=True,
- query_dim=args.query_dim,
- activation=args.transformer_activation,
- num_patterns=args.num_patterns,
- num_feature_levels=args.num_feature_levels,
- enc_n_points=args.enc_n_points,
- dec_n_points=args.dec_n_points,
- learnable_tgt_init=True,
- # two stage
- two_stage_type=args.two_stage_type, # ['no', 'standard', 'early']
- embed_init_tgt=args.embed_init_tgt,
- use_text_enhancer=args.use_text_enhancer,
- use_fusion_layer=args.use_fusion_layer,
- use_checkpoint=args.use_checkpoint,
- use_transformer_ckpt=args.use_transformer_ckpt,
- use_text_cross_attention=args.use_text_cross_attention,
- text_dropout=args.text_dropout,
- fusion_dropout=args.fusion_dropout,
- fusion_droppath=args.fusion_droppath,
- )
diff --git a/spaces/Cat125/text-generator-v2/README.md b/spaces/Cat125/text-generator-v2/README.md
deleted file mode 100644
index 765b3eff49fc6f5e895b70970ce63a1402835b44..0000000000000000000000000000000000000000
--- a/spaces/Cat125/text-generator-v2/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Text Generator v2
-emoji: 💻
-colorFrom: pink
-colorTo: purple
-sdk: gradio
-sdk_version: 3.27.0
-app_file: main.py
-pinned: true
-license: openrail
----
-
-This tool allpws you to generate texts based on given context.
\ No newline at end of file
diff --git a/spaces/ChandraMohanNayal/AutoGPT/tests/local_cache_test.py b/spaces/ChandraMohanNayal/AutoGPT/tests/local_cache_test.py
deleted file mode 100644
index bb10862656bb500f319ac231ff5bd5438d6fe7e2..0000000000000000000000000000000000000000
--- a/spaces/ChandraMohanNayal/AutoGPT/tests/local_cache_test.py
+++ /dev/null
@@ -1,67 +0,0 @@
-# sourcery skip: snake-case-functions
-"""Tests for LocalCache class"""
-import os
-import sys
-import unittest
-
-import pytest
-
-from autogpt.memory.local import LocalCache
-
-
-def mock_config() -> dict:
- """Mock the Config class"""
- return type(
- "MockConfig",
- (object,),
- {
- "debug_mode": False,
- "continuous_mode": False,
- "speak_mode": False,
- "memory_index": "auto-gpt",
- },
- )
-
-
-@pytest.mark.integration_test
-class TestLocalCache(unittest.TestCase):
- """Tests for LocalCache class"""
-
- def setUp(self) -> None:
- """Set up the test environment"""
- self.cfg = mock_config()
- self.cache = LocalCache(self.cfg)
-
- def test_add(self) -> None:
- """Test adding a text to the cache"""
- text = "Sample text"
- self.cache.add(text)
- self.assertIn(text, self.cache.data.texts)
-
- def test_clear(self) -> None:
- """Test clearing the cache"""
- self.cache.clear()
- self.assertEqual(self.cache.data.texts, [])
-
- def test_get(self) -> None:
- """Test getting a text from the cache"""
- text = "Sample text"
- self.cache.add(text)
- result = self.cache.get(text)
- self.assertEqual(result, [text])
-
- def test_get_relevant(self) -> None:
- """Test getting relevant texts from the cache"""
- text1 = "Sample text 1"
- text2 = "Sample text 2"
- self.cache.add(text1)
- self.cache.add(text2)
- result = self.cache.get_relevant(text1, 1)
- self.assertEqual(result, [text1])
-
- def test_get_stats(self) -> None:
- """Test getting the cache stats"""
- text = "Sample text"
- self.cache.add(text)
- stats = self.cache.get_stats()
- self.assertEqual(stats, (4, self.cache.data.embeddings.shape))
diff --git a/spaces/ChrisPreston/diff-svc_minato_aqua/infer.py b/spaces/ChrisPreston/diff-svc_minato_aqua/infer.py
deleted file mode 100644
index 3c3022270cc8e04cd1b7f48adbef2cf961bd7c6d..0000000000000000000000000000000000000000
--- a/spaces/ChrisPreston/diff-svc_minato_aqua/infer.py
+++ /dev/null
@@ -1,81 +0,0 @@
-import io
-from pathlib import Path
-
-import numpy as np
-import soundfile
-
-from infer_tools import infer_tool
-from infer_tools import slicer
-from infer_tools.infer_tool import Svc
-from utils.hparams import hparams
-
-
-def run_clip(raw_audio_path, svc_model, key, acc, use_crepe, spk_id=0, auto_key=False, out_path=None, slice_db=-40,
- **kwargs):
- print(f'code version:2023-01-22')
-
- clean_name = Path(raw_audio_path).name.split(".")[0]
- infer_tool.format_wav(raw_audio_path)
- wav_path = Path(raw_audio_path).with_suffix('.wav')
- key = svc_model.evaluate_key(wav_path, key, auto_key)
- chunks = slicer.cut(wav_path, db_thresh=slice_db)
- audio_data, audio_sr = slicer.chunks2audio(wav_path, chunks)
-
- count = 0
- f0_tst, f0_pred, audio = [], [], []
- for (slice_tag, data) in audio_data:
- print(f'#=====segment start, {round(len(data) / audio_sr, 3)}s======')
- length = int(np.ceil(len(data) / audio_sr * hparams['audio_sample_rate']))
- raw_path = io.BytesIO()
- soundfile.write(raw_path, data, audio_sr, format="wav")
- raw_path.seek(0)
- if slice_tag:
- print('jump empty segment')
- _f0_tst, _f0_pred, _audio = (
- np.zeros(int(np.ceil(length / hparams['hop_size']))),
- np.zeros(int(np.ceil(length / hparams['hop_size']))),
- np.zeros(length))
- else:
- _f0_tst, _f0_pred, _audio = svc_model.infer(raw_path, spk_id=spk_id, key=key, acc=acc, use_crepe=use_crepe)
- fix_audio = np.zeros(length)
- fix_audio[:] = np.mean(_audio)
- fix_audio[:len(_audio)] = _audio[0 if len(_audio) < len(fix_audio) else len(_audio) - len(fix_audio):]
- f0_tst.extend(_f0_tst)
- f0_pred.extend(_f0_pred)
- audio.extend(list(fix_audio))
- count += 1
- if out_path is None:
- out_path = f'./results/{clean_name}_{key}key_{project_name}_{hparams["residual_channels"]}_{hparams["residual_layers"]}_{int(step / 1000)}k_{accelerate}x.{kwargs["format"]}'
- soundfile.write(out_path, audio, hparams["audio_sample_rate"], 'PCM_16', format=out_path.split('.')[-1])
- return np.array(f0_tst), np.array(f0_pred), audio
-
-
-if __name__ == '__main__':
- # 工程文件夹名,训练时用的那个
- project_name = "open-aqua"
- model_path = f'./checkpoints/{project_name}/model_ckpt_steps_90000.ckpt'
- config_path = f'./checkpoints/{project_name}/config.yaml'
-
- # 支持多个wav/ogg文件,放在raw文件夹下,带扩展名
- file_names = ["横竖撇点折-main-2key.wav"]
- spk_id = "single"
- # 自适应变调(仅支持单人模型)
- auto_key = False
- trans = [0] # 音高调整,支持正负(半音),数量与上一行对应,不足的自动按第一个移调参数补齐
- # 加速倍数
- accelerate = 1
- hubert_gpu = True
- wav_format = 'wav'
- step = int(model_path.split("_")[-1].split(".")[0])
-
- # 下面不动
- infer_tool.mkdir(["./raw", "./results"])
- infer_tool.fill_a_to_b(trans, file_names)
-
- model = Svc(project_name, config_path, hubert_gpu, model_path, onnx=False)
- for f_name, tran in zip(file_names, trans):
- if "." not in f_name:
- f_name += ".wav"
- audio_path = f"./raw/{f_name}"
- run_clip(raw_audio_path=audio_path, svc_model=model, key=tran, acc=accelerate, use_crepe=False,
- spk_id=spk_id, auto_key=auto_key, project_name=project_name, format=wav_format)
diff --git a/spaces/CofAI/chat/g4f/Provider/Providers/Bing.py b/spaces/CofAI/chat/g4f/Provider/Providers/Bing.py
deleted file mode 100644
index 87e04ac82293c7e22068af431ac407bdee435a1b..0000000000000000000000000000000000000000
--- a/spaces/CofAI/chat/g4f/Provider/Providers/Bing.py
+++ /dev/null
@@ -1,349 +0,0 @@
-import os
-import json
-import random
-import json
-import os
-import uuid
-import ssl
-import certifi
-import aiohttp
-import asyncio
-
-import requests
-from ...typing import sha256, Dict, get_type_hints
-
-url = 'https://bing.com/chat'
-model = ['gpt-4']
-supports_stream = True
-needs_auth = False
-
-ssl_context = ssl.create_default_context()
-ssl_context.load_verify_locations(certifi.where())
-
-
-class optionsSets:
- optionSet: dict = {
- 'tone': str,
- 'optionsSets': list
- }
-
- jailbreak: dict = {
- "optionsSets": [
- 'saharasugg',
- 'enablenewsfc',
- 'clgalileo',
- 'gencontentv3',
- "nlu_direct_response_filter",
- "deepleo",
- "disable_emoji_spoken_text",
- "responsible_ai_policy_235",
- "enablemm",
- "h3precise"
- # "harmonyv3",
- "dtappid",
- "cricinfo",
- "cricinfov2",
- "dv3sugg",
- "nojbfedge"
- ]
- }
-
-
-class Defaults:
- delimiter = '\x1e'
- ip_address = f'13.{random.randint(104, 107)}.{random.randint(0, 255)}.{random.randint(0, 255)}'
-
- allowedMessageTypes = [
- 'Chat',
- 'Disengaged',
- 'AdsQuery',
- 'SemanticSerp',
- 'GenerateContentQuery',
- 'SearchQuery',
- 'ActionRequest',
- 'Context',
- 'Progress',
- 'AdsQuery',
- 'SemanticSerp'
- ]
-
- sliceIds = [
-
- # "222dtappid",
- # "225cricinfo",
- # "224locals0"
-
- 'winmuid3tf',
- 'osbsdusgreccf',
- 'ttstmout',
- 'crchatrev',
- 'winlongmsgtf',
- 'ctrlworkpay',
- 'norespwtf',
- 'tempcacheread',
- 'temptacache',
- '505scss0',
- '508jbcars0',
- '515enbotdets0',
- '5082tsports',
- '515vaoprvs',
- '424dagslnv1s0',
- 'kcimgattcf',
- '427startpms0'
- ]
-
- location = {
- 'locale': 'en-US',
- 'market': 'en-US',
- 'region': 'US',
- 'locationHints': [
- {
- 'country': 'United States',
- 'state': 'California',
- 'city': 'Los Angeles',
- 'timezoneoffset': 8,
- 'countryConfidence': 8,
- 'Center': {
- 'Latitude': 34.0536909,
- 'Longitude': -118.242766
- },
- 'RegionType': 2,
- 'SourceType': 1
- }
- ],
- }
-
-
-def _format(msg: dict) -> str:
- return json.dumps(msg, ensure_ascii=False) + Defaults.delimiter
-
-
-async def create_conversation():
- for _ in range(5):
- create = requests.get('https://www.bing.com/turing/conversation/create',
- headers={
- 'authority': 'edgeservices.bing.com',
- 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
- 'accept-language': 'en-US,en;q=0.9',
- 'cache-control': 'max-age=0',
- 'sec-ch-ua': '"Chromium";v="110", "Not A(Brand";v="24", "Microsoft Edge";v="110"',
- 'sec-ch-ua-arch': '"x86"',
- 'sec-ch-ua-bitness': '"64"',
- 'sec-ch-ua-full-version': '"110.0.1587.69"',
- 'sec-ch-ua-full-version-list': '"Chromium";v="110.0.5481.192", "Not A(Brand";v="24.0.0.0", "Microsoft Edge";v="110.0.1587.69"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-model': '""',
- 'sec-ch-ua-platform': '"Windows"',
- 'sec-ch-ua-platform-version': '"15.0.0"',
- 'sec-fetch-dest': 'document',
- 'sec-fetch-mode': 'navigate',
- 'sec-fetch-site': 'none',
- 'sec-fetch-user': '?1',
- 'upgrade-insecure-requests': '1',
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69',
- 'x-edge-shopping-flag': '1',
- 'x-forwarded-for': Defaults.ip_address
- })
-
- conversationId = create.json().get('conversationId')
- clientId = create.json().get('clientId')
- conversationSignature = create.json().get('conversationSignature')
-
- if not conversationId or not clientId or not conversationSignature and _ == 4:
- raise Exception('Failed to create conversation.')
-
- return conversationId, clientId, conversationSignature
-
-
-async def stream_generate(prompt: str, mode: optionsSets.optionSet = optionsSets.jailbreak, context: bool or str = False):
- timeout = aiohttp.ClientTimeout(total=900)
- session = aiohttp.ClientSession(timeout=timeout)
-
- conversationId, clientId, conversationSignature = await create_conversation()
-
- wss = await session.ws_connect('wss://sydney.bing.com/sydney/ChatHub', ssl=ssl_context, autoping=False,
- headers={
- 'accept': 'application/json',
- 'accept-language': 'en-US,en;q=0.9',
- 'content-type': 'application/json',
- 'sec-ch-ua': '"Not_A Brand";v="99", "Microsoft Edge";v="110", "Chromium";v="110"',
- 'sec-ch-ua-arch': '"x86"',
- 'sec-ch-ua-bitness': '"64"',
- 'sec-ch-ua-full-version': '"109.0.1518.78"',
- 'sec-ch-ua-full-version-list': '"Chromium";v="110.0.5481.192", "Not A(Brand";v="24.0.0.0", "Microsoft Edge";v="110.0.1587.69"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-model': '',
- 'sec-ch-ua-platform': '"Windows"',
- 'sec-ch-ua-platform-version': '"15.0.0"',
- 'sec-fetch-dest': 'empty',
- 'sec-fetch-mode': 'cors',
- 'sec-fetch-site': 'same-origin',
- 'x-ms-client-request-id': str(uuid.uuid4()),
- 'x-ms-useragent': 'azsdk-js-api-client-factory/1.0.0-beta.1 core-rest-pipeline/1.10.0 OS/Win32',
- 'Referer': 'https://www.bing.com/search?q=Bing+AI&showconv=1&FORM=hpcodx',
- 'Referrer-Policy': 'origin-when-cross-origin',
- 'x-forwarded-for': Defaults.ip_address
- })
-
- await wss.send_str(_format({'protocol': 'json', 'version': 1}))
- await wss.receive(timeout=900)
-
- struct = {
- 'arguments': [
- {
- **mode,
- 'source': 'cib',
- 'allowedMessageTypes': Defaults.allowedMessageTypes,
- 'sliceIds': Defaults.sliceIds,
- 'traceId': os.urandom(16).hex(),
- 'isStartOfSession': True,
- 'message': Defaults.location | {
- 'author': 'user',
- 'inputMethod': 'Keyboard',
- 'text': prompt,
- 'messageType': 'Chat'
- },
- 'conversationSignature': conversationSignature,
- 'participant': {
- 'id': clientId
- },
- 'conversationId': conversationId
- }
- ],
- 'invocationId': '0',
- 'target': 'chat',
- 'type': 4
- }
-
- if context:
- struct['arguments'][0]['previousMessages'] = [
- {
- "author": "user",
- "description": context,
- "contextType": "WebPage",
- "messageType": "Context",
- "messageId": "discover-web--page-ping-mriduna-----"
- }
- ]
-
- await wss.send_str(_format(struct))
-
- final = False
- draw = False
- resp_txt = ''
- result_text = ''
- resp_txt_no_link = ''
- cache_text = ''
-
- while not final:
- msg = await wss.receive(timeout=900)
- objects = msg.data.split(Defaults.delimiter)
-
- for obj in objects:
- if obj is None or not obj:
- continue
-
- response = json.loads(obj)
- if response.get('type') == 1 and response['arguments'][0].get('messages',):
- if not draw:
- if (response['arguments'][0]['messages'][0]['contentOrigin'] != 'Apology') and not draw:
- resp_txt = result_text + \
- response['arguments'][0]['messages'][0]['adaptiveCards'][0]['body'][0].get(
- 'text', '')
- resp_txt_no_link = result_text + \
- response['arguments'][0]['messages'][0].get(
- 'text', '')
-
- if response['arguments'][0]['messages'][0].get('messageType',):
- resp_txt = (
- resp_txt
- + response['arguments'][0]['messages'][0]['adaptiveCards'][0]['body'][0]['inlines'][0].get('text')
- + '\n'
- )
- result_text = (
- result_text
- + response['arguments'][0]['messages'][0]['adaptiveCards'][0]['body'][0]['inlines'][0].get('text')
- + '\n'
- )
-
- if cache_text.endswith(' '):
- final = True
- if wss and not wss.closed:
- await wss.close()
- if session and not session.closed:
- await session.close()
-
- yield (resp_txt.replace(cache_text, ''))
- cache_text = resp_txt
-
- elif response.get('type') == 2:
- if response['item']['result'].get('error'):
- if wss and not wss.closed:
- await wss.close()
- if session and not session.closed:
- await session.close()
-
- raise Exception(
- f"{response['item']['result']['value']}: {response['item']['result']['message']}")
-
- if draw:
- cache = response['item']['messages'][1]['adaptiveCards'][0]['body'][0]['text']
- response['item']['messages'][1]['adaptiveCards'][0]['body'][0]['text'] = (
- cache + resp_txt)
-
- if (response['item']['messages'][-1]['contentOrigin'] == 'Apology' and resp_txt):
- response['item']['messages'][-1]['text'] = resp_txt_no_link
- response['item']['messages'][-1]['adaptiveCards'][0]['body'][0]['text'] = resp_txt
-
- # print('Preserved the message from being deleted', file=sys.stderr)
-
- final = True
- if wss and not wss.closed:
- await wss.close()
- if session and not session.closed:
- await session.close()
-
-
-def run(generator):
- loop = asyncio.new_event_loop()
- asyncio.set_event_loop(loop)
- gen = generator.__aiter__()
-
- while True:
- try:
- next_val = loop.run_until_complete(gen.__anext__())
- yield next_val
-
- except StopAsyncIteration:
- break
- #print('Done')
-
-def convert(messages):
- context = ""
-
- for message in messages:
- context += "[%s](#message)\n%s\n\n" % (message['role'],
- message['content'])
-
- return context
-
-
-def _create_completion(model: str, messages: list, stream: bool, **kwargs):
- if len(messages) < 2:
- prompt = messages[0]['content']
- context = False
-
- else:
- prompt = messages[-1]['content']
- context = convert(messages[:-1])
-
- response = run(stream_generate(prompt, optionsSets.jailbreak, context))
- for token in response:
- yield (token)
-
- #print('Done')
-
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join(
- [f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
diff --git a/spaces/Cpp4App/Cpp4App/CDM/result_processing/merge_east.py b/spaces/Cpp4App/Cpp4App/CDM/result_processing/merge_east.py
deleted file mode 100644
index e7c8e51404340ff1b7ab764a908ce08a30ca64e7..0000000000000000000000000000000000000000
--- a/spaces/Cpp4App/Cpp4App/CDM/result_processing/merge_east.py
+++ /dev/null
@@ -1,31 +0,0 @@
-import multiprocessing
-from glob import glob
-import time
-import json
-from tqdm import tqdm
-from os.path import join as pjoin, exists
-
-import merge
-
-
-input_root = 'E:\\Mulong\\Datasets\\rico\\combined'
-output_root = 'E:\\Mulong\\Result\\rico\\rico_uied\\rico_new_uied_cls\\merge'
-compo_root = 'E:\\Mulong\\Result\\rico\\rico_uied\\rico_new_uied_cls\\ip'
-text_root = 'E:\\Mulong\\Result\\east'
-
-data = json.load(open('E:\\Mulong\\Datasets\\rico\\instances_test.json', 'r'))
-input_paths_img = [pjoin(input_root, img['file_name'].split('/')[-1]) for img in data['images']]
-input_paths_img = sorted(input_paths_img, key=lambda x: int(x.split('\\')[-1][:-4])) # sorted by index
-
-# set the range of target inputs' indices
-num = 0
-start_index = 0
-end_index = 100000
-for input_path_img in input_paths_img:
- index = input_path_img.split('\\')[-1][:-4]
- if int(index) < start_index:
- continue
- if int(index) > end_index:
- break
-
- merge.incorporate(input_path_img, compo_root, text_root, output_root, resize_by_height=800, show=False)
diff --git a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/data/transforms/__init__.py b/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/data/transforms/__init__.py
deleted file mode 100644
index 892b9cec0c2bc59162196ef9243e9aedcdcbaee6..0000000000000000000000000000000000000000
--- a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/data/transforms/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-from .transforms import Compose
-from .transforms import Resize
-from .transforms import RandomHorizontalFlip
-from .transforms import ToTensor
-from .transforms import Normalize
-from .transforms import RandomCrop
-
-from .build import build_transforms
diff --git a/spaces/D008/space-from-a-model/app.py b/spaces/D008/space-from-a-model/app.py
deleted file mode 100644
index 63f412a5fa4de66349bf1b428d083d31e7c68b6f..0000000000000000000000000000000000000000
--- a/spaces/D008/space-from-a-model/app.py
+++ /dev/null
@@ -1,4 +0,0 @@
-import gradio as gr
-name_list = ['models/EleutherAI/gpt-j-6B']
-interfaces = [gr.Interface.load(name) for name in name_list]
-gr.mix.Parallel(*interfaces, title="example-title", description="example-description").launch()
\ No newline at end of file
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/XpmImagePlugin.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/XpmImagePlugin.py
deleted file mode 100644
index 5d5bdc3edfa7be8d235fd6ef4176cc6cebee541c..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/XpmImagePlugin.py
+++ /dev/null
@@ -1,128 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# XPM File handling
-#
-# History:
-# 1996-12-29 fl Created
-# 2001-02-17 fl Use 're' instead of 'regex' (Python 2.1) (0.7)
-#
-# Copyright (c) Secret Labs AB 1997-2001.
-# Copyright (c) Fredrik Lundh 1996-2001.
-#
-# See the README file for information on usage and redistribution.
-#
-
-
-import re
-
-from . import Image, ImageFile, ImagePalette
-from ._binary import o8
-
-# XPM header
-xpm_head = re.compile(b'"([0-9]*) ([0-9]*) ([0-9]*) ([0-9]*)')
-
-
-def _accept(prefix):
- return prefix[:9] == b"/* XPM */"
-
-
-##
-# Image plugin for X11 pixel maps.
-
-
-class XpmImageFile(ImageFile.ImageFile):
- format = "XPM"
- format_description = "X11 Pixel Map"
-
- def _open(self):
- if not _accept(self.fp.read(9)):
- msg = "not an XPM file"
- raise SyntaxError(msg)
-
- # skip forward to next string
- while True:
- s = self.fp.readline()
- if not s:
- msg = "broken XPM file"
- raise SyntaxError(msg)
- m = xpm_head.match(s)
- if m:
- break
-
- self._size = int(m.group(1)), int(m.group(2))
-
- pal = int(m.group(3))
- bpp = int(m.group(4))
-
- if pal > 256 or bpp != 1:
- msg = "cannot read this XPM file"
- raise ValueError(msg)
-
- #
- # load palette description
-
- palette = [b"\0\0\0"] * 256
-
- for _ in range(pal):
- s = self.fp.readline()
- if s[-2:] == b"\r\n":
- s = s[:-2]
- elif s[-1:] in b"\r\n":
- s = s[:-1]
-
- c = s[1]
- s = s[2:-2].split()
-
- for i in range(0, len(s), 2):
- if s[i] == b"c":
- # process colour key
- rgb = s[i + 1]
- if rgb == b"None":
- self.info["transparency"] = c
- elif rgb[:1] == b"#":
- # FIXME: handle colour names (see ImagePalette.py)
- rgb = int(rgb[1:], 16)
- palette[c] = (
- o8((rgb >> 16) & 255) + o8((rgb >> 8) & 255) + o8(rgb & 255)
- )
- else:
- # unknown colour
- msg = "cannot read this XPM file"
- raise ValueError(msg)
- break
-
- else:
- # missing colour key
- msg = "cannot read this XPM file"
- raise ValueError(msg)
-
- self.mode = "P"
- self.palette = ImagePalette.raw("RGB", b"".join(palette))
-
- self.tile = [("raw", (0, 0) + self.size, self.fp.tell(), ("P", 0, 1))]
-
- def load_read(self, bytes):
- #
- # load all image data in one chunk
-
- xsize, ysize = self.size
-
- s = [None] * ysize
-
- for i in range(ysize):
- s[i] = self.fp.readline()[1 : xsize + 1].ljust(xsize)
-
- return b"".join(s)
-
-
-#
-# Registry
-
-
-Image.register_open(XpmImageFile.format, XpmImageFile, _accept)
-
-Image.register_extension(XpmImageFile.format, ".xpm")
-
-Image.register_mime(XpmImageFile.format, "image/xpm")
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/ttLib/tables/L_T_S_H_.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/ttLib/tables/L_T_S_H_.py
deleted file mode 100644
index e0ab0d021c47cf79e51cad326806e12ff97c9e00..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/ttLib/tables/L_T_S_H_.py
+++ /dev/null
@@ -1,48 +0,0 @@
-from fontTools.misc.textTools import safeEval
-from . import DefaultTable
-import struct
-import array
-
-# XXX I've lowered the strictness, to make sure Apple's own Chicago
-# XXX gets through. They're looking into it, I hope to raise the standards
-# XXX back to normal eventually.
-
-
-class table_L_T_S_H_(DefaultTable.DefaultTable):
- def decompile(self, data, ttFont):
- version, numGlyphs = struct.unpack(">HH", data[:4])
- data = data[4:]
- assert version == 0, "unknown version: %s" % version
- assert (len(data) % numGlyphs) < 4, "numGlyphs doesn't match data length"
- # ouch: the assertion is not true in Chicago!
- # assert numGlyphs == ttFont['maxp'].numGlyphs
- yPels = array.array("B")
- yPels.frombytes(data)
- self.yPels = {}
- for i in range(numGlyphs):
- self.yPels[ttFont.getGlyphName(i)] = yPels[i]
-
- def compile(self, ttFont):
- version = 0
- names = list(self.yPels.keys())
- numGlyphs = len(names)
- yPels = [0] * numGlyphs
- # ouch: the assertion is not true in Chicago!
- # assert len(self.yPels) == ttFont['maxp'].numGlyphs == numGlyphs
- for name in names:
- yPels[ttFont.getGlyphID(name)] = self.yPels[name]
- yPels = array.array("B", yPels)
- return struct.pack(">HH", version, numGlyphs) + yPels.tobytes()
-
- def toXML(self, writer, ttFont):
- names = sorted(self.yPels.keys())
- for name in names:
- writer.simpletag("yPel", name=name, value=self.yPels[name])
- writer.newline()
-
- def fromXML(self, name, attrs, content, ttFont):
- if not hasattr(self, "yPels"):
- self.yPels = {}
- if name != "yPel":
- return # ignore unknown tags
- self.yPels[attrs["name"]] = safeEval(attrs["value"])
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/varLib/interpolatable.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/varLib/interpolatable.py
deleted file mode 100644
index d5428c2002286b7de284fff89a79f62cd6ebd656..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/varLib/interpolatable.py
+++ /dev/null
@@ -1,583 +0,0 @@
-"""
-Tool to find wrong contour order between different masters, and
-other interpolatability (or lack thereof) issues.
-
-Call as:
-$ fonttools varLib.interpolatable font1 font2 ...
-"""
-
-from fontTools.pens.basePen import AbstractPen, BasePen
-from fontTools.pens.pointPen import SegmentToPointPen
-from fontTools.pens.recordingPen import RecordingPen
-from fontTools.pens.statisticsPen import StatisticsPen
-from fontTools.pens.momentsPen import OpenContourError
-from collections import OrderedDict
-import math
-import itertools
-import sys
-
-
-def _rot_list(l, k):
- """Rotate list by k items forward. Ie. item at position 0 will be
- at position k in returned list. Negative k is allowed."""
- n = len(l)
- k %= n
- if not k:
- return l
- return l[n - k :] + l[: n - k]
-
-
-class PerContourPen(BasePen):
- def __init__(self, Pen, glyphset=None):
- BasePen.__init__(self, glyphset)
- self._glyphset = glyphset
- self._Pen = Pen
- self._pen = None
- self.value = []
-
- def _moveTo(self, p0):
- self._newItem()
- self._pen.moveTo(p0)
-
- def _lineTo(self, p1):
- self._pen.lineTo(p1)
-
- def _qCurveToOne(self, p1, p2):
- self._pen.qCurveTo(p1, p2)
-
- def _curveToOne(self, p1, p2, p3):
- self._pen.curveTo(p1, p2, p3)
-
- def _closePath(self):
- self._pen.closePath()
- self._pen = None
-
- def _endPath(self):
- self._pen.endPath()
- self._pen = None
-
- def _newItem(self):
- self._pen = pen = self._Pen()
- self.value.append(pen)
-
-
-class PerContourOrComponentPen(PerContourPen):
- def addComponent(self, glyphName, transformation):
- self._newItem()
- self.value[-1].addComponent(glyphName, transformation)
-
-
-class RecordingPointPen(BasePen):
- def __init__(self):
- self.value = []
-
- def beginPath(self, identifier=None, **kwargs):
- pass
-
- def endPath(self) -> None:
- pass
-
- def addPoint(self, pt, segmentType=None):
- self.value.append((pt, False if segmentType is None else True))
-
-
-def _vdiff(v0, v1):
- return tuple(b - a for a, b in zip(v0, v1))
-
-
-def _vlen(vec):
- v = 0
- for x in vec:
- v += x * x
- return v
-
-
-def _complex_vlen(vec):
- v = 0
- for x in vec:
- v += abs(x) * abs(x)
- return v
-
-
-def _matching_cost(G, matching):
- return sum(G[i][j] for i, j in enumerate(matching))
-
-
-def min_cost_perfect_bipartite_matching(G):
- n = len(G)
- try:
- from scipy.optimize import linear_sum_assignment
-
- rows, cols = linear_sum_assignment(G)
- assert (rows == list(range(n))).all()
- return list(cols), _matching_cost(G, cols)
- except ImportError:
- pass
-
- try:
- from munkres import Munkres
-
- cols = [None] * n
- for row, col in Munkres().compute(G):
- cols[row] = col
- return cols, _matching_cost(G, cols)
- except ImportError:
- pass
-
- if n > 6:
- raise Exception("Install Python module 'munkres' or 'scipy >= 0.17.0'")
-
- # Otherwise just brute-force
- permutations = itertools.permutations(range(n))
- best = list(next(permutations))
- best_cost = _matching_cost(G, best)
- for p in permutations:
- cost = _matching_cost(G, p)
- if cost < best_cost:
- best, best_cost = list(p), cost
- return best, best_cost
-
-
-def test(glyphsets, glyphs=None, names=None, ignore_missing=False):
- if names is None:
- names = glyphsets
- if glyphs is None:
- # `glyphs = glyphsets[0].keys()` is faster, certainly, but doesn't allow for sparse TTFs/OTFs given out of order
- # ... risks the sparse master being the first one, and only processing a subset of the glyphs
- glyphs = {g for glyphset in glyphsets for g in glyphset.keys()}
-
- hist = []
- problems = OrderedDict()
-
- def add_problem(glyphname, problem):
- problems.setdefault(glyphname, []).append(problem)
-
- for glyph_name in glyphs:
- try:
- m0idx = 0
- allVectors = []
- allNodeTypes = []
- allContourIsomorphisms = []
- for glyphset, name in zip(glyphsets, names):
- glyph = glyphset[glyph_name]
-
- if glyph is None:
- if not ignore_missing:
- add_problem(glyph_name, {"type": "missing", "master": name})
- allNodeTypes.append(None)
- allVectors.append(None)
- allContourIsomorphisms.append(None)
- continue
-
- perContourPen = PerContourOrComponentPen(
- RecordingPen, glyphset=glyphset
- )
- try:
- glyph.draw(perContourPen, outputImpliedClosingLine=True)
- except TypeError:
- glyph.draw(perContourPen)
- contourPens = perContourPen.value
- del perContourPen
-
- contourVectors = []
- contourIsomorphisms = []
- nodeTypes = []
- allNodeTypes.append(nodeTypes)
- allVectors.append(contourVectors)
- allContourIsomorphisms.append(contourIsomorphisms)
- for ix, contour in enumerate(contourPens):
- nodeVecs = tuple(instruction[0] for instruction in contour.value)
- nodeTypes.append(nodeVecs)
-
- stats = StatisticsPen(glyphset=glyphset)
- try:
- contour.replay(stats)
- except OpenContourError as e:
- add_problem(
- glyph_name,
- {"master": name, "contour": ix, "type": "open_path"},
- )
- continue
- size = math.sqrt(abs(stats.area)) * 0.5
- vector = (
- int(size),
- int(stats.meanX),
- int(stats.meanY),
- int(stats.stddevX * 2),
- int(stats.stddevY * 2),
- int(stats.correlation * size),
- )
- contourVectors.append(vector)
- # print(vector)
-
- # Check starting point
- if nodeVecs[0] == "addComponent":
- continue
- assert nodeVecs[0] == "moveTo"
- assert nodeVecs[-1] in ("closePath", "endPath")
- points = RecordingPointPen()
- converter = SegmentToPointPen(points, False)
- contour.replay(converter)
- # points.value is a list of pt,bool where bool is true if on-curve and false if off-curve;
- # now check all rotations and mirror-rotations of the contour and build list of isomorphic
- # possible starting points.
- bits = 0
- for pt, b in points.value:
- bits = (bits << 1) | b
- n = len(points.value)
- mask = (1 << n) - 1
- isomorphisms = []
- contourIsomorphisms.append(isomorphisms)
- for i in range(n):
- b = ((bits << i) & mask) | ((bits >> (n - i)))
- if b == bits:
- isomorphisms.append(
- _rot_list([complex(*pt) for pt, bl in points.value], i)
- )
- # Add mirrored rotations
- mirrored = list(reversed(points.value))
- reversed_bits = 0
- for pt, b in mirrored:
- reversed_bits = (reversed_bits << 1) | b
- for i in range(n):
- b = ((reversed_bits << i) & mask) | ((reversed_bits >> (n - i)))
- if b == bits:
- isomorphisms.append(
- _rot_list([complex(*pt) for pt, bl in mirrored], i)
- )
-
- # m0idx should be the index of the first non-None item in allNodeTypes,
- # else give it the first index of None, which is likely 0
- m0idx = allNodeTypes.index(
- next((x for x in allNodeTypes if x is not None), None)
- )
- # m0 is the first non-None item in allNodeTypes, or the first item if all are None
- m0 = allNodeTypes[m0idx]
- for i, m1 in enumerate(allNodeTypes[m0idx + 1 :]):
- if m1 is None:
- continue
- if len(m0) != len(m1):
- add_problem(
- glyph_name,
- {
- "type": "path_count",
- "master_1": names[m0idx],
- "master_2": names[m0idx + i + 1],
- "value_1": len(m0),
- "value_2": len(m1),
- },
- )
- if m0 == m1:
- continue
- for pathIx, (nodes1, nodes2) in enumerate(zip(m0, m1)):
- if nodes1 == nodes2:
- continue
- if len(nodes1) != len(nodes2):
- add_problem(
- glyph_name,
- {
- "type": "node_count",
- "path": pathIx,
- "master_1": names[m0idx],
- "master_2": names[m0idx + i + 1],
- "value_1": len(nodes1),
- "value_2": len(nodes2),
- },
- )
- continue
- for nodeIx, (n1, n2) in enumerate(zip(nodes1, nodes2)):
- if n1 != n2:
- add_problem(
- glyph_name,
- {
- "type": "node_incompatibility",
- "path": pathIx,
- "node": nodeIx,
- "master_1": names[m0idx],
- "master_2": names[m0idx + i + 1],
- "value_1": n1,
- "value_2": n2,
- },
- )
- continue
-
- # m0idx should be the index of the first non-None item in allVectors,
- # else give it the first index of None, which is likely 0
- m0idx = allVectors.index(
- next((x for x in allVectors if x is not None), None)
- )
- # m0 is the first non-None item in allVectors, or the first item if all are None
- m0 = allVectors[m0idx]
- for i, m1 in enumerate(allVectors[m0idx + 1 :]):
- if m1 is None:
- continue
- if len(m0) != len(m1):
- # We already reported this
- continue
- if not m0:
- continue
- costs = [[_vlen(_vdiff(v0, v1)) for v1 in m1] for v0 in m0]
- matching, matching_cost = min_cost_perfect_bipartite_matching(costs)
- identity_matching = list(range(len(m0)))
- identity_cost = sum(costs[i][i] for i in range(len(m0)))
- if (
- matching != identity_matching
- and matching_cost < identity_cost * 0.95
- ):
- add_problem(
- glyph_name,
- {
- "type": "contour_order",
- "master_1": names[m0idx],
- "master_2": names[m0idx + i + 1],
- "value_1": list(range(len(m0))),
- "value_2": matching,
- },
- )
- break
-
- # m0idx should be the index of the first non-None item in allContourIsomorphisms,
- # else give it the first index of None, which is likely 0
- m0idx = allContourIsomorphisms.index(
- next((x for x in allContourIsomorphisms if x is not None), None)
- )
- # m0 is the first non-None item in allContourIsomorphisms, or the first item if all are None
- m0 = allContourIsomorphisms[m0idx]
- for i, m1 in enumerate(allContourIsomorphisms[m0idx + 1 :]):
- if m1 is None:
- continue
- if len(m0) != len(m1):
- # We already reported this
- continue
- if not m0:
- continue
- for ix, (contour0, contour1) in enumerate(zip(m0, m1)):
- c0 = contour0[0]
- costs = [
- v for v in (_complex_vlen(_vdiff(c0, c1)) for c1 in contour1)
- ]
- min_cost = min(costs)
- first_cost = costs[0]
- if min_cost < first_cost * 0.95:
- add_problem(
- glyph_name,
- {
- "type": "wrong_start_point",
- "contour": ix,
- "master_1": names[m0idx],
- "master_2": names[m0idx + i + 1],
- },
- )
-
- except ValueError as e:
- add_problem(
- glyph_name,
- {"type": "math_error", "master": name, "error": e},
- )
- return problems
-
-
-def main(args=None):
- """Test for interpolatability issues between fonts"""
- import argparse
-
- parser = argparse.ArgumentParser(
- "fonttools varLib.interpolatable",
- description=main.__doc__,
- )
- parser.add_argument(
- "--glyphs",
- action="store",
- help="Space-separate name of glyphs to check",
- )
- parser.add_argument(
- "--json",
- action="store_true",
- help="Output report in JSON format",
- )
- parser.add_argument(
- "--quiet",
- action="store_true",
- help="Only exit with code 1 or 0, no output",
- )
- parser.add_argument(
- "--ignore-missing",
- action="store_true",
- help="Will not report glyphs missing from sparse masters as errors",
- )
- parser.add_argument(
- "inputs",
- metavar="FILE",
- type=str,
- nargs="+",
- help="Input a single DesignSpace/Glyphs file, or multiple TTF/UFO files",
- )
-
- args = parser.parse_args(args)
-
- glyphs = set(args.glyphs.split()) if args.glyphs else None
-
- from os.path import basename
-
- fonts = []
- names = []
-
- if len(args.inputs) == 1:
- if args.inputs[0].endswith(".designspace"):
- from fontTools.designspaceLib import DesignSpaceDocument
-
- designspace = DesignSpaceDocument.fromfile(args.inputs[0])
- args.inputs = [master.path for master in designspace.sources]
-
- elif args.inputs[0].endswith(".glyphs"):
- from glyphsLib import GSFont, to_ufos
-
- gsfont = GSFont(args.inputs[0])
- fonts.extend(to_ufos(gsfont))
- names = ["%s-%s" % (f.info.familyName, f.info.styleName) for f in fonts]
- args.inputs = []
-
- elif args.inputs[0].endswith(".ttf"):
- from fontTools.ttLib import TTFont
-
- font = TTFont(args.inputs[0])
- if "gvar" in font:
- # Is variable font
- gvar = font["gvar"]
- # Gather all "master" locations
- locs = set()
- for variations in gvar.variations.values():
- for var in variations:
- loc = []
- for tag, val in sorted(var.axes.items()):
- loc.append((tag, val[1]))
- locs.add(tuple(loc))
- # Rebuild locs as dictionaries
- new_locs = [{}]
- names.append("()")
- for loc in sorted(locs, key=lambda v: (len(v), v)):
- names.append(str(loc))
- l = {}
- for tag, val in loc:
- l[tag] = val
- new_locs.append(l)
- locs = new_locs
- del new_locs
- # locs is all master locations now
-
- for loc in locs:
- fonts.append(font.getGlyphSet(location=loc, normalized=True))
-
- args.inputs = []
-
- for filename in args.inputs:
- if filename.endswith(".ufo"):
- from fontTools.ufoLib import UFOReader
-
- fonts.append(UFOReader(filename))
- else:
- from fontTools.ttLib import TTFont
-
- fonts.append(TTFont(filename))
-
- names.append(basename(filename).rsplit(".", 1)[0])
-
- glyphsets = []
- for font in fonts:
- if hasattr(font, "getGlyphSet"):
- glyphset = font.getGlyphSet()
- else:
- glyphset = font
- glyphsets.append({k: glyphset[k] for k in glyphset.keys()})
-
- if not glyphs:
- glyphs = set([gn for glyphset in glyphsets for gn in glyphset.keys()])
-
- for glyphset in glyphsets:
- glyphSetGlyphNames = set(glyphset.keys())
- diff = glyphs - glyphSetGlyphNames
- if diff:
- for gn in diff:
- glyphset[gn] = None
-
- problems = test(
- glyphsets, glyphs=glyphs, names=names, ignore_missing=args.ignore_missing
- )
-
- if not args.quiet:
- if args.json:
- import json
-
- print(json.dumps(problems))
- else:
- for glyph, glyph_problems in problems.items():
- print(f"Glyph {glyph} was not compatible: ")
- for p in glyph_problems:
- if p["type"] == "missing":
- print(" Glyph was missing in master %s" % p["master"])
- if p["type"] == "open_path":
- print(" Glyph has an open path in master %s" % p["master"])
- if p["type"] == "path_count":
- print(
- " Path count differs: %i in %s, %i in %s"
- % (p["value_1"], p["master_1"], p["value_2"], p["master_2"])
- )
- if p["type"] == "node_count":
- print(
- " Node count differs in path %i: %i in %s, %i in %s"
- % (
- p["path"],
- p["value_1"],
- p["master_1"],
- p["value_2"],
- p["master_2"],
- )
- )
- if p["type"] == "node_incompatibility":
- print(
- " Node %o incompatible in path %i: %s in %s, %s in %s"
- % (
- p["node"],
- p["path"],
- p["value_1"],
- p["master_1"],
- p["value_2"],
- p["master_2"],
- )
- )
- if p["type"] == "contour_order":
- print(
- " Contour order differs: %s in %s, %s in %s"
- % (
- p["value_1"],
- p["master_1"],
- p["value_2"],
- p["master_2"],
- )
- )
- if p["type"] == "wrong_start_point":
- print(
- " Contour %d start point differs: %s, %s"
- % (
- p["contour"],
- p["master_1"],
- p["master_2"],
- )
- )
- if p["type"] == "math_error":
- print(
- " Miscellaneous error in %s: %s"
- % (
- p["master"],
- p["error"],
- )
- )
- if problems:
- return problems
-
-
-if __name__ == "__main__":
- import sys
-
- problems = main()
- sys.exit(int(bool(problems)))
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/ModifyUpload-77b0d4b2.css b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/ModifyUpload-77b0d4b2.css
deleted file mode 100644
index c78d71f8b6eaf75f8134375ed017f1c03b6edf1a..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/ModifyUpload-77b0d4b2.css
+++ /dev/null
@@ -1 +0,0 @@
-div.svelte-116rqfv{cursor:pointer;width:var(--size-full);height:var(--size-full)}.center.svelte-116rqfv{text-align:center}.flex.svelte-116rqfv{display:flex;justify-content:center;align-items:center}input.svelte-116rqfv{display:none}div.svelte-19sk1im{display:flex;top:var(--size-2);right:var(--size-2);justify-content:flex-end;gap:var(--spacing-sm);z-index:var(--layer-1)}.not-absolute.svelte-19sk1im{margin:var(--size-1)}
diff --git a/spaces/DaFujaTyping/hf-Chat-ui/src/routes/conversation/[id]/message/[messageId]/prompt/+server.ts b/spaces/DaFujaTyping/hf-Chat-ui/src/routes/conversation/[id]/message/[messageId]/prompt/+server.ts
deleted file mode 100644
index bd22a1e6bdc4541f4dbd3ca38c97df1ffa08782c..0000000000000000000000000000000000000000
--- a/spaces/DaFujaTyping/hf-Chat-ui/src/routes/conversation/[id]/message/[messageId]/prompt/+server.ts
+++ /dev/null
@@ -1,51 +0,0 @@
-import { buildPrompt } from "$lib/buildPrompt.js";
-import { collections } from "$lib/server/database";
-import { models } from "$lib/server/models.js";
-import { error } from "@sveltejs/kit";
-import { ObjectId } from "mongodb";
-
-export async function GET({ params, locals }) {
- const convId = new ObjectId(params.id);
-
- const conv = await collections.conversations.findOne({
- _id: convId,
- sessionId: locals.sessionId,
- });
-
- if (!conv) {
- throw error(404, "Conversation not found");
- }
-
- const messageId = params.messageId;
-
- const messageIndex = conv.messages.findIndex((msg) => msg.id === messageId);
-
- if (messageIndex === -1) {
- throw error(404, "Message not found");
- }
-
- const model = models.find((m) => m.id === conv.model);
-
- if (!model) {
- throw error(404, "Conversation model not found");
- }
-
- const prompt = buildPrompt(conv.messages.slice(0, messageIndex + 1), model);
-
- return new Response(
- JSON.stringify(
- {
- note: "This is a preview of the prompt that will be sent to the model when retrying the message. It may differ from what was sent in the past if the parameters have been updated since",
- prompt,
- model: model.name,
- parameters: {
- ...model.parameters,
- return_full_text: false,
- },
- },
- null,
- 2
- ),
- { headers: { "Content-Type": "application/json" } }
- );
-}
diff --git a/spaces/Dagfinn1962/CPU/app.py b/spaces/Dagfinn1962/CPU/app.py
deleted file mode 100644
index 0246188adf7ba9b7c43e736e2ce4b15d0cee9850..0000000000000000000000000000000000000000
--- a/spaces/Dagfinn1962/CPU/app.py
+++ /dev/null
@@ -1,40 +0,0 @@
-import gradio as gr
-import torch
-import numpy as np
-import modin.pandas as pd
-from PIL import Image
-from diffusers import DiffusionPipeline, StableDiffusionLatentUpscalePipeline
-
-device = "cuda" if torch.cuda.is_available() else "cpu"
-pipe = DiffusionPipeline.from_pretrained("dreamlike-art/dreamlike-photoreal-2.0", torch_dtype=torch.float16, safety_checker=None)
-upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained("stabilityai/sd-x2-latent-upscaler", torch_dtype=torch.float16)
-upscaler = upscaler.to(device)
-pipe = pipe.to(device)
-
-def genie (Prompt, negative_prompt, height, width, scale, steps, seed, upscale, upscale_prompt, upscale_neg, upscale_scale, upscale_steps):
- generator = torch.Generator(device=device).manual_seed(seed)
- if upscale == "Yes":
- low_res_latents = pipe(Prompt, negative_prompt=negative_prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=scale, generator=generator, output_type="latent").images
- image = upscaler(prompt=upscale_prompt, negative_prompt=upscale_neg, image=low_res_latents, num_inference_steps=upscale_steps, guidance_scale=upscale_scale, generator=generator).images[0]
- else:
- image = pipe(Prompt, negative_prompt=negative_prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=scale, generator=generator).images[0]
- return image
-
-gr.Interface(theme='ParityError/Anime', fn=genie, inputs=[gr.Textbox(label='Input field right under here(Prompt)'),
- gr.Textbox(label='What You dont want (Negative Prompt)'),
- gr.Slider(512, 1024, 768, step=128, label='Height'),
- gr.Slider(512, 1024, 768, step=128, label='Width'),
- gr.Slider(1, maximum=15, value=10, step=.25),
- gr.Slider(25, maximum=100, value=50, step=25),
- gr.Slider(minimum=1, step=1, maximum=9999999999999999, randomize=True),
- # gr.Radio(["Yes", "No"], label='Upscale?'),
- #gr.Textbox(label='Upscaler Prompt: Optional'),
- #gr.Textbox(label='Upscaler Negative Prompt: Both Optional And Experimental'),
- #gr.Slider(minimum=0, maximum=15, value=0, step=1, label='Upscale Guidance Scale'),
- #gr.Slider(minimum=5, maximum=25, value=5, step=5, label='Upscaler Iterations')
-
- ],
- outputs=gr.Image(label='Generated Image'),
- title="Daylight SD (CPU)",
- description="
Info:Daylight SD (GPU)
This is a lightweight App mostly to show how Stable diffusion works.
Aichatbot.ai is a project into Image Creation with Stable Diffusion.
If you like our Apps Please consider signing up underneath.
We will speed up the Apps with a little contribution from Our Members.
PS! We are sorry to repeat but this app is also on Huggingface.co! ",
- article = "Online App: www.aichatbot.ai").launch(debug=True, max_threads=True)
diff --git a/spaces/DaleChen/AutoGPT/autogpt/speech/__init__.py b/spaces/DaleChen/AutoGPT/autogpt/speech/__init__.py
deleted file mode 100644
index 2ff0d2bf48dc356bf810cb5a2063d6774e5fec6e..0000000000000000000000000000000000000000
--- a/spaces/DaleChen/AutoGPT/autogpt/speech/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-"""This module contains the speech recognition and speech synthesis functions."""
-from autogpt.speech.say import say_text
-
-__all__ = ["say_text"]
diff --git a/spaces/Datatrooper/boston_housing/README.md b/spaces/Datatrooper/boston_housing/README.md
deleted file mode 100644
index 49a06dec93fca8e5c8dcd6839c82b19705cd2df1..0000000000000000000000000000000000000000
--- a/spaces/Datatrooper/boston_housing/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Boston Housing
-emoji: 🚀
-colorFrom: yellow
-colorTo: blue
-sdk: gradio
-sdk_version: 3.17.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/DemoLou/moe-tts/text/japanese.py b/spaces/DemoLou/moe-tts/text/japanese.py
deleted file mode 100644
index 375e4d50872d5c68ee57ca17470a2ca425425eba..0000000000000000000000000000000000000000
--- a/spaces/DemoLou/moe-tts/text/japanese.py
+++ /dev/null
@@ -1,153 +0,0 @@
-import re
-from unidecode import unidecode
-import pyopenjtalk
-
-
-# Regular expression matching Japanese without punctuation marks:
-_japanese_characters = re.compile(
- r'[A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
-
-# Regular expression matching non-Japanese characters or punctuation marks:
-_japanese_marks = re.compile(
- r'[^A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
-
-# List of (symbol, Japanese) pairs for marks:
-_symbols_to_japanese = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('%', 'パーセント')
-]]
-
-# List of (romaji, ipa) pairs for marks:
-_romaji_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ts', 'ʦ'),
- ('u', 'ɯ'),
- ('j', 'ʥ'),
- ('y', 'j'),
- ('ni', 'n^i'),
- ('nj', 'n^'),
- ('hi', 'çi'),
- ('hj', 'ç'),
- ('f', 'ɸ'),
- ('I', 'i*'),
- ('U', 'ɯ*'),
- ('r', 'ɾ')
-]]
-
-# List of (romaji, ipa2) pairs for marks:
-_romaji_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('u', 'ɯ'),
- ('ʧ', 'tʃ'),
- ('j', 'dʑ'),
- ('y', 'j'),
- ('ni', 'n^i'),
- ('nj', 'n^'),
- ('hi', 'çi'),
- ('hj', 'ç'),
- ('f', 'ɸ'),
- ('I', 'i*'),
- ('U', 'ɯ*'),
- ('r', 'ɾ')
-]]
-
-# List of (consonant, sokuon) pairs:
-_real_sokuon = [(re.compile('%s' % x[0]), x[1]) for x in [
- (r'Q([↑↓]*[kg])', r'k#\1'),
- (r'Q([↑↓]*[tdjʧ])', r't#\1'),
- (r'Q([↑↓]*[sʃ])', r's\1'),
- (r'Q([↑↓]*[pb])', r'p#\1')
-]]
-
-# List of (consonant, hatsuon) pairs:
-_real_hatsuon = [(re.compile('%s' % x[0]), x[1]) for x in [
- (r'N([↑↓]*[pbm])', r'm\1'),
- (r'N([↑↓]*[ʧʥj])', r'n^\1'),
- (r'N([↑↓]*[tdn])', r'n\1'),
- (r'N([↑↓]*[kg])', r'ŋ\1')
-]]
-
-
-def symbols_to_japanese(text):
- for regex, replacement in _symbols_to_japanese:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def japanese_to_romaji_with_accent(text):
- '''Reference https://r9y9.github.io/ttslearn/latest/notebooks/ch10_Recipe-Tacotron.html'''
- text = symbols_to_japanese(text)
- sentences = re.split(_japanese_marks, text)
- marks = re.findall(_japanese_marks, text)
- text = ''
- for i, sentence in enumerate(sentences):
- if re.match(_japanese_characters, sentence):
- if text != '':
- text += ' '
- labels = pyopenjtalk.extract_fullcontext(sentence)
- for n, label in enumerate(labels):
- phoneme = re.search(r'\-([^\+]*)\+', label).group(1)
- if phoneme not in ['sil', 'pau']:
- text += phoneme.replace('ch', 'ʧ').replace('sh',
- 'ʃ').replace('cl', 'Q')
- else:
- continue
- # n_moras = int(re.search(r'/F:(\d+)_', label).group(1))
- a1 = int(re.search(r"/A:(\-?[0-9]+)\+", label).group(1))
- a2 = int(re.search(r"\+(\d+)\+", label).group(1))
- a3 = int(re.search(r"\+(\d+)/", label).group(1))
- if re.search(r'\-([^\+]*)\+', labels[n + 1]).group(1) in ['sil', 'pau']:
- a2_next = -1
- else:
- a2_next = int(
- re.search(r"\+(\d+)\+", labels[n + 1]).group(1))
- # Accent phrase boundary
- if a3 == 1 and a2_next == 1:
- text += ' '
- # Falling
- elif a1 == 0 and a2_next == a2 + 1:
- text += '↓'
- # Rising
- elif a2 == 1 and a2_next == 2:
- text += '↑'
- if i < len(marks):
- text += unidecode(marks[i]).replace(' ', '')
- return text
-
-
-def get_real_sokuon(text):
- for regex, replacement in _real_sokuon:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def get_real_hatsuon(text):
- for regex, replacement in _real_hatsuon:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def japanese_to_ipa(text):
- text = japanese_to_romaji_with_accent(text).replace('...', '…')
- text = re.sub(
- r'([aiueo])\1+', lambda x: x.group(0)[0]+'ː'*(len(x.group(0))-1), text)
- text = get_real_sokuon(text)
- text = get_real_hatsuon(text)
- for regex, replacement in _romaji_to_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def japanese_to_ipa2(text):
- text = japanese_to_romaji_with_accent(text).replace('...', '…')
- text = get_real_sokuon(text)
- text = get_real_hatsuon(text)
- for regex, replacement in _romaji_to_ipa2:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def japanese_to_ipa3(text):
- text = japanese_to_ipa2(text).replace('n^', 'ȵ').replace(
- 'ʃ', 'ɕ').replace('*', '\u0325').replace('#', '\u031a')
- text = re.sub(
- r'([aiɯeo])\1+', lambda x: x.group(0)[0]+'ː'*(len(x.group(0))-1), text)
- text = re.sub(r'((?:^|\s)(?:ts|tɕ|[kpt]))', r'\1ʰ', text)
- return text
diff --git a/spaces/DexterSptizu/drug_interaction/app.py b/spaces/DexterSptizu/drug_interaction/app.py
deleted file mode 100644
index 3b49730dc3ca63298ad44ea338d97bb0ed36ce90..0000000000000000000000000000000000000000
--- a/spaces/DexterSptizu/drug_interaction/app.py
+++ /dev/null
@@ -1,22 +0,0 @@
-import gradio as gr
-import requests
-
-def check_interaction(drug1, drug2):
- API_ENDPOINT = "https://api.fda.gov/drug/event.json"
- SEARCH_TEMPLATE = '?search=patient.drug.medicinalproduct:{}+AND+patient.drug.medicinalproduct:{}&count=patient.reaction.reactionmeddrapt.exact'
-
- search_string = SEARCH_TEMPLATE.format(drug1, drug2)
- response = requests.get(API_ENDPOINT + search_string)
- data = response.json()
-
- if "results" in data:
- interactions = [result['term'] for result in data['results']]
- return interactions
- else:
- return "No known interactions"
-
-iface = gr.Interface(fn=check_interaction,
- inputs=["text", "text"],
- outputs="text")
-
-iface.launch()
diff --git a/spaces/DragGan/DragGan-Inversion/PTI/torch_utils/ops/upfirdn2d.py b/spaces/DragGan/DragGan-Inversion/PTI/torch_utils/ops/upfirdn2d.py
deleted file mode 100644
index ceeac2b9834e33b7c601c28bf27f32aa91c69256..0000000000000000000000000000000000000000
--- a/spaces/DragGan/DragGan-Inversion/PTI/torch_utils/ops/upfirdn2d.py
+++ /dev/null
@@ -1,384 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-"""Custom PyTorch ops for efficient resampling of 2D images."""
-
-import os
-import warnings
-import numpy as np
-import torch
-import traceback
-
-from .. import custom_ops
-from .. import misc
-from . import conv2d_gradfix
-
-#----------------------------------------------------------------------------
-
-_inited = False
-_plugin = None
-
-def _init():
- global _inited, _plugin
- if not _inited:
- sources = ['upfirdn2d.cpp', 'upfirdn2d.cu']
- sources = [os.path.join(os.path.dirname(__file__), s) for s in sources]
- try:
- _plugin = custom_ops.get_plugin('upfirdn2d_plugin', sources=sources, extra_cuda_cflags=['--use_fast_math'])
- except:
- warnings.warn('Failed to build CUDA kernels for upfirdn2d. Falling back to slow reference implementation. Details:\n\n' + traceback.format_exc())
- return _plugin is not None
-
-def _parse_scaling(scaling):
- if isinstance(scaling, int):
- scaling = [scaling, scaling]
- assert isinstance(scaling, (list, tuple))
- assert all(isinstance(x, int) for x in scaling)
- sx, sy = scaling
- assert sx >= 1 and sy >= 1
- return sx, sy
-
-def _parse_padding(padding):
- if isinstance(padding, int):
- padding = [padding, padding]
- assert isinstance(padding, (list, tuple))
- assert all(isinstance(x, int) for x in padding)
- if len(padding) == 2:
- padx, pady = padding
- padding = [padx, padx, pady, pady]
- padx0, padx1, pady0, pady1 = padding
- return padx0, padx1, pady0, pady1
-
-def _get_filter_size(f):
- if f is None:
- return 1, 1
- assert isinstance(f, torch.Tensor) and f.ndim in [1, 2]
- fw = f.shape[-1]
- fh = f.shape[0]
- with misc.suppress_tracer_warnings():
- fw = int(fw)
- fh = int(fh)
- misc.assert_shape(f, [fh, fw][:f.ndim])
- assert fw >= 1 and fh >= 1
- return fw, fh
-
-#----------------------------------------------------------------------------
-
-def setup_filter(f, device=torch.device('cpu'), normalize=True, flip_filter=False, gain=1, separable=None):
- r"""Convenience function to setup 2D FIR filter for `upfirdn2d()`.
-
- Args:
- f: Torch tensor, numpy array, or python list of the shape
- `[filter_height, filter_width]` (non-separable),
- `[filter_taps]` (separable),
- `[]` (impulse), or
- `None` (identity).
- device: Result device (default: cpu).
- normalize: Normalize the filter so that it retains the magnitude
- for constant input signal (DC)? (default: True).
- flip_filter: Flip the filter? (default: False).
- gain: Overall scaling factor for signal magnitude (default: 1).
- separable: Return a separable filter? (default: select automatically).
-
- Returns:
- Float32 tensor of the shape
- `[filter_height, filter_width]` (non-separable) or
- `[filter_taps]` (separable).
- """
- # Validate.
- if f is None:
- f = 1
- f = torch.as_tensor(f, dtype=torch.float32)
- assert f.ndim in [0, 1, 2]
- assert f.numel() > 0
- if f.ndim == 0:
- f = f[np.newaxis]
-
- # Separable?
- if separable is None:
- separable = (f.ndim == 1 and f.numel() >= 8)
- if f.ndim == 1 and not separable:
- f = f.ger(f)
- assert f.ndim == (1 if separable else 2)
-
- # Apply normalize, flip, gain, and device.
- if normalize:
- f /= f.sum()
- if flip_filter:
- f = f.flip(list(range(f.ndim)))
- f = f * (gain ** (f.ndim / 2))
- f = f.to(device=device)
- return f
-
-#----------------------------------------------------------------------------
-
-def upfirdn2d(x, f, up=1, down=1, padding=0, flip_filter=False, gain=1, impl='cuda'):
- r"""Pad, upsample, filter, and downsample a batch of 2D images.
-
- Performs the following sequence of operations for each channel:
-
- 1. Upsample the image by inserting N-1 zeros after each pixel (`up`).
-
- 2. Pad the image with the specified number of zeros on each side (`padding`).
- Negative padding corresponds to cropping the image.
-
- 3. Convolve the image with the specified 2D FIR filter (`f`), shrinking it
- so that the footprint of all output pixels lies within the input image.
-
- 4. Downsample the image by keeping every Nth pixel (`down`).
-
- This sequence of operations bears close resemblance to scipy.signal.upfirdn().
- The fused op is considerably more efficient than performing the same calculation
- using standard PyTorch ops. It supports gradients of arbitrary order.
-
- Args:
- x: Float32/float64/float16 input tensor of the shape
- `[batch_size, num_channels, in_height, in_width]`.
- f: Float32 FIR filter of the shape
- `[filter_height, filter_width]` (non-separable),
- `[filter_taps]` (separable), or
- `None` (identity).
- up: Integer upsampling factor. Can be a single int or a list/tuple
- `[x, y]` (default: 1).
- down: Integer downsampling factor. Can be a single int or a list/tuple
- `[x, y]` (default: 1).
- padding: Padding with respect to the upsampled image. Can be a single number
- or a list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
- (default: 0).
- flip_filter: False = convolution, True = correlation (default: False).
- gain: Overall scaling factor for signal magnitude (default: 1).
- impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`).
-
- Returns:
- Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
- """
- assert isinstance(x, torch.Tensor)
- assert impl in ['ref', 'cuda']
- if impl == 'cuda' and x.device.type == 'cuda' and _init():
- return _upfirdn2d_cuda(up=up, down=down, padding=padding, flip_filter=flip_filter, gain=gain).apply(x, f)
- return _upfirdn2d_ref(x, f, up=up, down=down, padding=padding, flip_filter=flip_filter, gain=gain)
-
-#----------------------------------------------------------------------------
-
-@misc.profiled_function
-def _upfirdn2d_ref(x, f, up=1, down=1, padding=0, flip_filter=False, gain=1):
- """Slow reference implementation of `upfirdn2d()` using standard PyTorch ops.
- """
- # Validate arguments.
- assert isinstance(x, torch.Tensor) and x.ndim == 4
- if f is None:
- f = torch.ones([1, 1], dtype=torch.float32, device=x.device)
- assert isinstance(f, torch.Tensor) and f.ndim in [1, 2]
- assert f.dtype == torch.float32 and not f.requires_grad
- batch_size, num_channels, in_height, in_width = x.shape
- upx, upy = _parse_scaling(up)
- downx, downy = _parse_scaling(down)
- padx0, padx1, pady0, pady1 = _parse_padding(padding)
-
- # Upsample by inserting zeros.
- x = x.reshape([batch_size, num_channels, in_height, 1, in_width, 1])
- x = torch.nn.functional.pad(x, [0, upx - 1, 0, 0, 0, upy - 1])
- x = x.reshape([batch_size, num_channels, in_height * upy, in_width * upx])
-
- # Pad or crop.
- x = torch.nn.functional.pad(x, [max(padx0, 0), max(padx1, 0), max(pady0, 0), max(pady1, 0)])
- x = x[:, :, max(-pady0, 0) : x.shape[2] - max(-pady1, 0), max(-padx0, 0) : x.shape[3] - max(-padx1, 0)]
-
- # Setup filter.
- f = f * (gain ** (f.ndim / 2))
- f = f.to(x.dtype)
- if not flip_filter:
- f = f.flip(list(range(f.ndim)))
-
- # Convolve with the filter.
- f = f[np.newaxis, np.newaxis].repeat([num_channels, 1] + [1] * f.ndim)
- if f.ndim == 4:
- x = conv2d_gradfix.conv2d(input=x, weight=f, groups=num_channels)
- else:
- x = conv2d_gradfix.conv2d(input=x, weight=f.unsqueeze(2), groups=num_channels)
- x = conv2d_gradfix.conv2d(input=x, weight=f.unsqueeze(3), groups=num_channels)
-
- # Downsample by throwing away pixels.
- x = x[:, :, ::downy, ::downx]
- return x
-
-#----------------------------------------------------------------------------
-
-_upfirdn2d_cuda_cache = dict()
-
-def _upfirdn2d_cuda(up=1, down=1, padding=0, flip_filter=False, gain=1):
- """Fast CUDA implementation of `upfirdn2d()` using custom ops.
- """
- # Parse arguments.
- upx, upy = _parse_scaling(up)
- downx, downy = _parse_scaling(down)
- padx0, padx1, pady0, pady1 = _parse_padding(padding)
-
- # Lookup from cache.
- key = (upx, upy, downx, downy, padx0, padx1, pady0, pady1, flip_filter, gain)
- if key in _upfirdn2d_cuda_cache:
- return _upfirdn2d_cuda_cache[key]
-
- # Forward op.
- class Upfirdn2dCuda(torch.autograd.Function):
- @staticmethod
- def forward(ctx, x, f): # pylint: disable=arguments-differ
- assert isinstance(x, torch.Tensor) and x.ndim == 4
- if f is None:
- f = torch.ones([1, 1], dtype=torch.float32, device=x.device)
- assert isinstance(f, torch.Tensor) and f.ndim in [1, 2]
- y = x
- if f.ndim == 2:
- y = _plugin.upfirdn2d(y, f, upx, upy, downx, downy, padx0, padx1, pady0, pady1, flip_filter, gain)
- else:
- y = _plugin.upfirdn2d(y, f.unsqueeze(0), upx, 1, downx, 1, padx0, padx1, 0, 0, flip_filter, np.sqrt(gain))
- y = _plugin.upfirdn2d(y, f.unsqueeze(1), 1, upy, 1, downy, 0, 0, pady0, pady1, flip_filter, np.sqrt(gain))
- ctx.save_for_backward(f)
- ctx.x_shape = x.shape
- return y
-
- @staticmethod
- def backward(ctx, dy): # pylint: disable=arguments-differ
- f, = ctx.saved_tensors
- _, _, ih, iw = ctx.x_shape
- _, _, oh, ow = dy.shape
- fw, fh = _get_filter_size(f)
- p = [
- fw - padx0 - 1,
- iw * upx - ow * downx + padx0 - upx + 1,
- fh - pady0 - 1,
- ih * upy - oh * downy + pady0 - upy + 1,
- ]
- dx = None
- df = None
-
- if ctx.needs_input_grad[0]:
- dx = _upfirdn2d_cuda(up=down, down=up, padding=p, flip_filter=(not flip_filter), gain=gain).apply(dy, f)
-
- assert not ctx.needs_input_grad[1]
- return dx, df
-
- # Add to cache.
- _upfirdn2d_cuda_cache[key] = Upfirdn2dCuda
- return Upfirdn2dCuda
-
-#----------------------------------------------------------------------------
-
-def filter2d(x, f, padding=0, flip_filter=False, gain=1, impl='cuda'):
- r"""Filter a batch of 2D images using the given 2D FIR filter.
-
- By default, the result is padded so that its shape matches the input.
- User-specified padding is applied on top of that, with negative values
- indicating cropping. Pixels outside the image are assumed to be zero.
-
- Args:
- x: Float32/float64/float16 input tensor of the shape
- `[batch_size, num_channels, in_height, in_width]`.
- f: Float32 FIR filter of the shape
- `[filter_height, filter_width]` (non-separable),
- `[filter_taps]` (separable), or
- `None` (identity).
- padding: Padding with respect to the output. Can be a single number or a
- list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
- (default: 0).
- flip_filter: False = convolution, True = correlation (default: False).
- gain: Overall scaling factor for signal magnitude (default: 1).
- impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`).
-
- Returns:
- Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
- """
- padx0, padx1, pady0, pady1 = _parse_padding(padding)
- fw, fh = _get_filter_size(f)
- p = [
- padx0 + fw // 2,
- padx1 + (fw - 1) // 2,
- pady0 + fh // 2,
- pady1 + (fh - 1) // 2,
- ]
- return upfirdn2d(x, f, padding=p, flip_filter=flip_filter, gain=gain, impl=impl)
-
-#----------------------------------------------------------------------------
-
-def upsample2d(x, f, up=2, padding=0, flip_filter=False, gain=1, impl='cuda'):
- r"""Upsample a batch of 2D images using the given 2D FIR filter.
-
- By default, the result is padded so that its shape is a multiple of the input.
- User-specified padding is applied on top of that, with negative values
- indicating cropping. Pixels outside the image are assumed to be zero.
-
- Args:
- x: Float32/float64/float16 input tensor of the shape
- `[batch_size, num_channels, in_height, in_width]`.
- f: Float32 FIR filter of the shape
- `[filter_height, filter_width]` (non-separable),
- `[filter_taps]` (separable), or
- `None` (identity).
- up: Integer upsampling factor. Can be a single int or a list/tuple
- `[x, y]` (default: 1).
- padding: Padding with respect to the output. Can be a single number or a
- list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
- (default: 0).
- flip_filter: False = convolution, True = correlation (default: False).
- gain: Overall scaling factor for signal magnitude (default: 1).
- impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`).
-
- Returns:
- Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
- """
- upx, upy = _parse_scaling(up)
- padx0, padx1, pady0, pady1 = _parse_padding(padding)
- fw, fh = _get_filter_size(f)
- p = [
- padx0 + (fw + upx - 1) // 2,
- padx1 + (fw - upx) // 2,
- pady0 + (fh + upy - 1) // 2,
- pady1 + (fh - upy) // 2,
- ]
- return upfirdn2d(x, f, up=up, padding=p, flip_filter=flip_filter, gain=gain*upx*upy, impl=impl)
-
-#----------------------------------------------------------------------------
-
-def downsample2d(x, f, down=2, padding=0, flip_filter=False, gain=1, impl='cuda'):
- r"""Downsample a batch of 2D images using the given 2D FIR filter.
-
- By default, the result is padded so that its shape is a fraction of the input.
- User-specified padding is applied on top of that, with negative values
- indicating cropping. Pixels outside the image are assumed to be zero.
-
- Args:
- x: Float32/float64/float16 input tensor of the shape
- `[batch_size, num_channels, in_height, in_width]`.
- f: Float32 FIR filter of the shape
- `[filter_height, filter_width]` (non-separable),
- `[filter_taps]` (separable), or
- `None` (identity).
- down: Integer downsampling factor. Can be a single int or a list/tuple
- `[x, y]` (default: 1).
- padding: Padding with respect to the input. Can be a single number or a
- list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
- (default: 0).
- flip_filter: False = convolution, True = correlation (default: False).
- gain: Overall scaling factor for signal magnitude (default: 1).
- impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`).
-
- Returns:
- Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
- """
- downx, downy = _parse_scaling(down)
- padx0, padx1, pady0, pady1 = _parse_padding(padding)
- fw, fh = _get_filter_size(f)
- p = [
- padx0 + (fw - downx + 1) // 2,
- padx1 + (fw - downx) // 2,
- pady0 + (fh - downy + 1) // 2,
- pady1 + (fh - downy) // 2,
- ]
- return upfirdn2d(x, f, down=down, padding=p, flip_filter=flip_filter, gain=gain, impl=impl)
-
-#----------------------------------------------------------------------------
diff --git a/spaces/EasyEasy/EasyProxy/Dockerfile b/spaces/EasyEasy/EasyProxy/Dockerfile
deleted file mode 100644
index bd082a764dd75316ccb029e6f8d478d54fa3929c..0000000000000000000000000000000000000000
--- a/spaces/EasyEasy/EasyProxy/Dockerfile
+++ /dev/null
@@ -1,15 +0,0 @@
-FROM node:18-bullseye-slim
-RUN apt-get update && \
- apt-get install -y git curl
-RUN --mount=type=secret,id=GIT_AUTH,mode=0444,required=true \
- git clone https://$(cat /run/secrets/GIT_AUTH)@git.evulid.cc/cyberes/oai-reverse-proxy-epic-troll.git /app
-
-WORKDIR /app
-RUN npm install
-COPY Dockerfile greeting.md* .env* ./
-RUN npm run build
-RUN chown -R node:node /app
-EXPOSE 7860
-ENV NODE_ENV=production
-
-CMD [ "npm", "start" ]
\ No newline at end of file
diff --git a/spaces/EinfachOlder/ChatGPT-prompt-generator/README.md b/spaces/EinfachOlder/ChatGPT-prompt-generator/README.md
deleted file mode 100644
index 9765db2c80dd4c4b938060743922163b1718e003..0000000000000000000000000000000000000000
--- a/spaces/EinfachOlder/ChatGPT-prompt-generator/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: ChatGPT Prompt Generator
-emoji: 👨🏻🎤
-colorFrom: purple
-colorTo: pink
-sdk: gradio
-sdk_version: 3.16.2
-app_file: app.py
-pinned: false
-license: apache-2.0
-duplicated_from: merve/ChatGPT-prompt-generator
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/EleutherAI/magma/magma/transforms.py b/spaces/EleutherAI/magma/magma/transforms.py
deleted file mode 100644
index 513d7c449d279f41cadf38f2df6be91a8370064c..0000000000000000000000000000000000000000
--- a/spaces/EleutherAI/magma/magma/transforms.py
+++ /dev/null
@@ -1,134 +0,0 @@
-from torchvision import transforms as T
-import torch.nn.functional as F
-from PIL import ImageOps
-import PIL
-import random
-
-
-def pad_to_size(x, size=256):
- delta_w = size - x.size[0]
- delta_h = size - x.size[1]
- padding = (
- delta_w // 2,
- delta_h // 2,
- delta_w - (delta_w // 2),
- delta_h - (delta_h // 2),
- )
- new_im = ImageOps.expand(x, padding)
- return new_im
-
-
-def pad_to_size_tensor(x, size=256):
- offset_dim_1 = size - x.shape[1]
- offset_dim_2 = size - x.shape[2]
-
- padding_dim_1 = max(offset_dim_1 // 2, 0)
- padding_dim_2 = max(offset_dim_2 // 2, 0)
-
- if offset_dim_1 % 2 == 0:
- pad_tuple_1 = (padding_dim_1, padding_dim_1)
- else:
- pad_tuple_1 = (padding_dim_1 + 1, padding_dim_1)
-
- if offset_dim_2 % 2 == 0:
- pad_tuple_2 = (padding_dim_2, padding_dim_2)
- else:
- pad_tuple_2 = (padding_dim_2 + 1, padding_dim_2)
-
- padded = F.pad(x, pad=(*pad_tuple_2, *pad_tuple_1, 0, 0))
- return padded
-
-
-class RandCropResize(object):
-
- """
- Randomly crops, then randomly resizes, then randomly crops again, an image. Mirroring the augmentations from https://arxiv.org/abs/2102.12092
- """
-
- def __init__(self, target_size):
- self.target_size = target_size
-
- def __call__(self, img):
- img = pad_to_size(img, self.target_size)
- d_min = min(img.size)
- img = T.RandomCrop(size=d_min)(img)
- t_min = min(d_min, round(9 / 8 * self.target_size))
- t_max = min(d_min, round(12 / 8 * self.target_size))
- t = random.randint(t_min, t_max + 1)
- img = T.Resize(t)(img)
- if min(img.size) < 256:
- img = T.Resize(256)(img)
- return T.RandomCrop(size=self.target_size)(img)
-
-
-def get_transforms(
- image_size, encoder_name, input_resolution=None, use_extra_transforms=False
-):
- if "clip" in encoder_name:
- assert input_resolution is not None
- return clip_preprocess(input_resolution)
-
- base_transforms = [
- T.Lambda(lambda img: img.convert("RGB") if img.mode != "RGB" else img),
- RandCropResize(image_size),
- T.RandomHorizontalFlip(p=0.5),
- ]
- if use_extra_transforms:
- extra_transforms = [T.ColorJitter(0.1, 0.1, 0.1, 0.05)]
- base_transforms += extra_transforms
- base_transforms += [
- T.ToTensor(),
- maybe_add_batch_dim,
- ]
- base_transforms = T.Compose(base_transforms)
- return base_transforms
-
-
-def maybe_add_batch_dim(t):
- if t.ndim == 3:
- return t.unsqueeze(0)
- else:
- return t
-
-
-def pad_img(desired_size):
- def fn(im):
- old_size = im.size # old_size[0] is in (width, height) format
-
- ratio = float(desired_size) / max(old_size)
- new_size = tuple([int(x * ratio) for x in old_size])
-
- im = im.resize(new_size, PIL.Image.ANTIALIAS)
- # create a new image and paste the resized on it
-
- new_im = PIL.Image.new("RGB", (desired_size, desired_size))
- new_im.paste(
- im, ((desired_size - new_size[0]) // 2, (desired_size - new_size[1]) // 2)
- )
-
- return new_im
-
- return fn
-
-
-def crop_or_pad(n_px, pad=False):
- if pad:
- return pad_img(n_px)
- else:
- return T.CenterCrop(n_px)
-
-
-def clip_preprocess(n_px, use_pad=False):
- return T.Compose(
- [
- T.Resize(n_px, interpolation=T.InterpolationMode.BICUBIC),
- crop_or_pad(n_px, pad=use_pad),
- lambda image: image.convert("RGB"),
- T.ToTensor(),
- maybe_add_batch_dim,
- T.Normalize(
- (0.48145466, 0.4578275, 0.40821073),
- (0.26862954, 0.26130258, 0.27577711),
- ),
- ]
- )
diff --git a/spaces/FlippFuzz/whisper-webui/src/conversion/hf_converter.py b/spaces/FlippFuzz/whisper-webui/src/conversion/hf_converter.py
deleted file mode 100644
index 6da4f0fd672d63b099f21d0498ba4001d23356f7..0000000000000000000000000000000000000000
--- a/spaces/FlippFuzz/whisper-webui/src/conversion/hf_converter.py
+++ /dev/null
@@ -1,67 +0,0 @@
-# https://github.com/bayartsogt-ya/whisper-multiple-hf-datasets
-
-from copy import deepcopy
-import torch
-
-WHISPER_MAPPING = {
- "layers": "blocks",
- "fc1": "mlp.0",
- "fc2": "mlp.2",
- "final_layer_norm": "mlp_ln",
- "layers": "blocks",
- ".self_attn.q_proj": ".attn.query",
- ".self_attn.k_proj": ".attn.key",
- ".self_attn.v_proj": ".attn.value",
- ".self_attn_layer_norm": ".attn_ln",
- ".self_attn.out_proj": ".attn.out",
- ".encoder_attn.q_proj": ".cross_attn.query",
- ".encoder_attn.k_proj": ".cross_attn.key",
- ".encoder_attn.v_proj": ".cross_attn.value",
- ".encoder_attn_layer_norm": ".cross_attn_ln",
- ".encoder_attn.out_proj": ".cross_attn.out",
- "decoder.layer_norm.": "decoder.ln.",
- "encoder.layer_norm.": "encoder.ln_post.",
- "embed_tokens": "token_embedding",
- "encoder.embed_positions.weight": "encoder.positional_embedding",
- "decoder.embed_positions.weight": "decoder.positional_embedding",
- "layer_norm": "ln_post",
-}
-
-
-def rename_keys(s_dict):
- keys = list(s_dict.keys())
- for key in keys:
- new_key = key
- for k, v in WHISPER_MAPPING.items():
- if k in key:
- new_key = new_key.replace(k, v)
-
- print(f"{key} -> {new_key}")
-
- s_dict[new_key] = s_dict.pop(key)
- return s_dict
-
-
-def convert_hf_whisper(hf_model_name_or_path: str, whisper_state_path: str):
- from transformers import WhisperForConditionalGeneration
- transformer_model = WhisperForConditionalGeneration.from_pretrained(hf_model_name_or_path)
- config = transformer_model.config
-
- # first build dims
- dims = {
- 'n_mels': config.num_mel_bins,
- 'n_vocab': config.vocab_size,
- 'n_audio_ctx': config.max_source_positions,
- 'n_audio_state': config.d_model,
- 'n_audio_head': config.encoder_attention_heads,
- 'n_audio_layer': config.encoder_layers,
- 'n_text_ctx': config.max_target_positions,
- 'n_text_state': config.d_model,
- 'n_text_head': config.decoder_attention_heads,
- 'n_text_layer': config.decoder_layers
- }
-
- state_dict = deepcopy(transformer_model.model.state_dict())
- state_dict = rename_keys(state_dict)
-
- torch.save({"dims": dims, "model_state_dict": state_dict}, whisper_state_path)
\ No newline at end of file
diff --git a/spaces/FrankZxShen/so-vits-svc-models-ba/modules/modules.py b/spaces/FrankZxShen/so-vits-svc-models-ba/modules/modules.py
deleted file mode 100644
index 54290fd207b25e93831bd21005990ea137e6b50e..0000000000000000000000000000000000000000
--- a/spaces/FrankZxShen/so-vits-svc-models-ba/modules/modules.py
+++ /dev/null
@@ -1,342 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import modules.commons as commons
-from modules.commons import init_weights, get_padding
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
diff --git a/spaces/FrozenBurning/SceneDreamer/README.md b/spaces/FrozenBurning/SceneDreamer/README.md
deleted file mode 100644
index 7f3dd05d05c3a00fac5965f5f32a067816ffc87f..0000000000000000000000000000000000000000
--- a/spaces/FrozenBurning/SceneDreamer/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: SceneDreamer
-emoji: 👁
-colorFrom: yellow
-colorTo: red
-sdk: gradio
-sdk_version: 3.28.3
-app_file: app.py
-pinned: false
-license: other
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/GaenKoki/voicevox/voicevox_engine/synthesis_engine/__init__.py b/spaces/GaenKoki/voicevox/voicevox_engine/synthesis_engine/__init__.py
deleted file mode 100644
index 3e7f6a1ef940f2d20830d98336c34cbbc600d905..0000000000000000000000000000000000000000
--- a/spaces/GaenKoki/voicevox/voicevox_engine/synthesis_engine/__init__.py
+++ /dev/null
@@ -1,12 +0,0 @@
-from .core_wrapper import CoreWrapper, load_runtime_lib
-from .make_synthesis_engines import make_synthesis_engines
-from .synthesis_engine import SynthesisEngine
-from .synthesis_engine_base import SynthesisEngineBase
-
-__all__ = [
- "CoreWrapper",
- "load_runtime_lib",
- "make_synthesis_engines",
- "SynthesisEngine",
- "SynthesisEngineBase",
-]
diff --git a/spaces/Gradio-Blocks/minority-asr/README.md b/spaces/Gradio-Blocks/minority-asr/README.md
deleted file mode 100644
index 17a571d29aaf0bec516e5fa90eb12fd6f03b05c1..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/minority-asr/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
-
----
-title: Speech recognition for minority languages of Russia
-emoji: 🌾
-colorFrom: blue
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.0.6
-app_file: app.py
-pinned: false
----
\ No newline at end of file
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/datasets/builder.py b/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/datasets/builder.py
deleted file mode 100644
index c9466a517dee746a6677b27a19713f2e89ed7194..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/datasets/builder.py
+++ /dev/null
@@ -1,143 +0,0 @@
-import copy
-import platform
-import random
-from functools import partial
-
-import numpy as np
-from mmcv.parallel import collate
-from mmcv.runner import get_dist_info
-from mmcv.utils import Registry, build_from_cfg
-from torch.utils.data import DataLoader
-
-from .samplers import DistributedGroupSampler, DistributedSampler, GroupSampler
-
-if platform.system() != 'Windows':
- # https://github.com/pytorch/pytorch/issues/973
- import resource
- rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
- hard_limit = rlimit[1]
- soft_limit = min(4096, hard_limit)
- resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))
-
-DATASETS = Registry('dataset')
-PIPELINES = Registry('pipeline')
-
-
-def _concat_dataset(cfg, default_args=None):
- from .dataset_wrappers import ConcatDataset
- ann_files = cfg['ann_file']
- img_prefixes = cfg.get('img_prefix', None)
- seg_prefixes = cfg.get('seg_prefix', None)
- proposal_files = cfg.get('proposal_file', None)
- separate_eval = cfg.get('separate_eval', True)
-
- datasets = []
- num_dset = len(ann_files)
- for i in range(num_dset):
- data_cfg = copy.deepcopy(cfg)
- # pop 'separate_eval' since it is not a valid key for common datasets.
- if 'separate_eval' in data_cfg:
- data_cfg.pop('separate_eval')
- data_cfg['ann_file'] = ann_files[i]
- if isinstance(img_prefixes, (list, tuple)):
- data_cfg['img_prefix'] = img_prefixes[i]
- if isinstance(seg_prefixes, (list, tuple)):
- data_cfg['seg_prefix'] = seg_prefixes[i]
- if isinstance(proposal_files, (list, tuple)):
- data_cfg['proposal_file'] = proposal_files[i]
- datasets.append(build_dataset(data_cfg, default_args))
-
- return ConcatDataset(datasets, separate_eval)
-
-
-def build_dataset(cfg, default_args=None):
- from .dataset_wrappers import (ConcatDataset, RepeatDataset,
- ClassBalancedDataset)
- if isinstance(cfg, (list, tuple)):
- dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
- elif cfg['type'] == 'ConcatDataset':
- dataset = ConcatDataset(
- [build_dataset(c, default_args) for c in cfg['datasets']],
- cfg.get('separate_eval', True))
- elif cfg['type'] == 'RepeatDataset':
- dataset = RepeatDataset(
- build_dataset(cfg['dataset'], default_args), cfg['times'])
- elif cfg['type'] == 'ClassBalancedDataset':
- dataset = ClassBalancedDataset(
- build_dataset(cfg['dataset'], default_args), cfg['oversample_thr'])
- elif isinstance(cfg.get('ann_file'), (list, tuple)):
- dataset = _concat_dataset(cfg, default_args)
- else:
- dataset = build_from_cfg(cfg, DATASETS, default_args)
-
- return dataset
-
-
-def build_dataloader(dataset,
- samples_per_gpu,
- workers_per_gpu,
- num_gpus=1,
- dist=True,
- shuffle=True,
- seed=None,
- **kwargs):
- """Build PyTorch DataLoader.
-
- In distributed training, each GPU/process has a dataloader.
- In non-distributed training, there is only one dataloader for all GPUs.
-
- Args:
- dataset (Dataset): A PyTorch dataset.
- samples_per_gpu (int): Number of training samples on each GPU, i.e.,
- batch size of each GPU.
- workers_per_gpu (int): How many subprocesses to use for data loading
- for each GPU.
- num_gpus (int): Number of GPUs. Only used in non-distributed training.
- dist (bool): Distributed training/test or not. Default: True.
- shuffle (bool): Whether to shuffle the data at every epoch.
- Default: True.
- kwargs: any keyword argument to be used to initialize DataLoader
-
- Returns:
- DataLoader: A PyTorch dataloader.
- """
- rank, world_size = get_dist_info()
- if dist:
- # DistributedGroupSampler will definitely shuffle the data to satisfy
- # that images on each GPU are in the same group
- if shuffle:
- sampler = DistributedGroupSampler(
- dataset, samples_per_gpu, world_size, rank, seed=seed)
- else:
- sampler = DistributedSampler(
- dataset, world_size, rank, shuffle=False, seed=seed)
- batch_size = samples_per_gpu
- num_workers = workers_per_gpu
- else:
- sampler = GroupSampler(dataset, samples_per_gpu) if shuffle else None
- batch_size = num_gpus * samples_per_gpu
- num_workers = num_gpus * workers_per_gpu
-
- init_fn = partial(
- worker_init_fn, num_workers=num_workers, rank=rank,
- seed=seed) if seed is not None else None
-
- data_loader = DataLoader(
- dataset,
- batch_size=batch_size,
- sampler=sampler,
- num_workers=num_workers,
- collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
- pin_memory=False,
- worker_init_fn=init_fn,
- **kwargs)
-
- return data_loader
-
-
-def worker_init_fn(worker_id, num_workers, rank, seed):
- # The seed of each worker equals to
- # num_worker * rank + worker_id + user_seed
- worker_seed = num_workers * rank + worker_id + seed
- np.random.seed(worker_seed)
- random.seed(worker_seed)
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/datasets/pipelines/loading.py b/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/datasets/pipelines/loading.py
deleted file mode 100644
index 69225941903f6b9d67b8b8c5fc3b1801cd964fb2..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/datasets/pipelines/loading.py
+++ /dev/null
@@ -1,458 +0,0 @@
-import os.path as osp
-
-import mmcv
-import numpy as np
-import pycocotools.mask as maskUtils
-
-from mmdet.core import BitmapMasks, PolygonMasks
-from ..builder import PIPELINES
-
-
-@PIPELINES.register_module()
-class LoadImageFromFile(object):
- """Load an image from file.
-
- Required keys are "img_prefix" and "img_info" (a dict that must contain the
- key "filename"). Added or updated keys are "filename", "img", "img_shape",
- "ori_shape" (same as `img_shape`), "pad_shape" (same as `img_shape`),
- "scale_factor" (1.0) and "img_norm_cfg" (means=0 and stds=1).
-
- Args:
- to_float32 (bool): Whether to convert the loaded image to a float32
- numpy array. If set to False, the loaded image is an uint8 array.
- Defaults to False.
- color_type (str): The flag argument for :func:`mmcv.imfrombytes`.
- Defaults to 'color'.
- file_client_args (dict): Arguments to instantiate a FileClient.
- See :class:`mmcv.fileio.FileClient` for details.
- Defaults to ``dict(backend='disk')``.
- """
-
- def __init__(self,
- to_float32=False,
- color_type='color',
- file_client_args=dict(backend='disk')):
- self.to_float32 = to_float32
- self.color_type = color_type
- self.file_client_args = file_client_args.copy()
- self.file_client = None
-
- def __call__(self, results):
- """Call functions to load image and get image meta information.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded image and meta information.
- """
-
- if self.file_client is None:
- self.file_client = mmcv.FileClient(**self.file_client_args)
-
- if results['img_prefix'] is not None:
- filename = osp.join(results['img_prefix'],
- results['img_info']['filename'])
- else:
- filename = results['img_info']['filename']
-
- img_bytes = self.file_client.get(filename)
- img = mmcv.imfrombytes(img_bytes, flag=self.color_type)
- if self.to_float32:
- img = img.astype(np.float32)
-
- results['filename'] = filename
- results['ori_filename'] = results['img_info']['filename']
- results['img'] = img
- results['img_shape'] = img.shape
- results['ori_shape'] = img.shape
- results['img_fields'] = ['img']
- return results
-
- def __repr__(self):
- repr_str = (f'{self.__class__.__name__}('
- f'to_float32={self.to_float32}, '
- f"color_type='{self.color_type}', "
- f'file_client_args={self.file_client_args})')
- return repr_str
-
-
-@PIPELINES.register_module()
-class LoadImageFromWebcam(LoadImageFromFile):
- """Load an image from webcam.
-
- Similar with :obj:`LoadImageFromFile`, but the image read from webcam is in
- ``results['img']``.
- """
-
- def __call__(self, results):
- """Call functions to add image meta information.
-
- Args:
- results (dict): Result dict with Webcam read image in
- ``results['img']``.
-
- Returns:
- dict: The dict contains loaded image and meta information.
- """
-
- img = results['img']
- if self.to_float32:
- img = img.astype(np.float32)
-
- results['filename'] = None
- results['ori_filename'] = None
- results['img'] = img
- results['img_shape'] = img.shape
- results['ori_shape'] = img.shape
- results['img_fields'] = ['img']
- return results
-
-
-@PIPELINES.register_module()
-class LoadMultiChannelImageFromFiles(object):
- """Load multi-channel images from a list of separate channel files.
-
- Required keys are "img_prefix" and "img_info" (a dict that must contain the
- key "filename", which is expected to be a list of filenames).
- Added or updated keys are "filename", "img", "img_shape",
- "ori_shape" (same as `img_shape`), "pad_shape" (same as `img_shape`),
- "scale_factor" (1.0) and "img_norm_cfg" (means=0 and stds=1).
-
- Args:
- to_float32 (bool): Whether to convert the loaded image to a float32
- numpy array. If set to False, the loaded image is an uint8 array.
- Defaults to False.
- color_type (str): The flag argument for :func:`mmcv.imfrombytes`.
- Defaults to 'color'.
- file_client_args (dict): Arguments to instantiate a FileClient.
- See :class:`mmcv.fileio.FileClient` for details.
- Defaults to ``dict(backend='disk')``.
- """
-
- def __init__(self,
- to_float32=False,
- color_type='unchanged',
- file_client_args=dict(backend='disk')):
- self.to_float32 = to_float32
- self.color_type = color_type
- self.file_client_args = file_client_args.copy()
- self.file_client = None
-
- def __call__(self, results):
- """Call functions to load multiple images and get images meta
- information.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded images and meta information.
- """
-
- if self.file_client is None:
- self.file_client = mmcv.FileClient(**self.file_client_args)
-
- if results['img_prefix'] is not None:
- filename = [
- osp.join(results['img_prefix'], fname)
- for fname in results['img_info']['filename']
- ]
- else:
- filename = results['img_info']['filename']
-
- img = []
- for name in filename:
- img_bytes = self.file_client.get(name)
- img.append(mmcv.imfrombytes(img_bytes, flag=self.color_type))
- img = np.stack(img, axis=-1)
- if self.to_float32:
- img = img.astype(np.float32)
-
- results['filename'] = filename
- results['ori_filename'] = results['img_info']['filename']
- results['img'] = img
- results['img_shape'] = img.shape
- results['ori_shape'] = img.shape
- # Set initial values for default meta_keys
- results['pad_shape'] = img.shape
- results['scale_factor'] = 1.0
- num_channels = 1 if len(img.shape) < 3 else img.shape[2]
- results['img_norm_cfg'] = dict(
- mean=np.zeros(num_channels, dtype=np.float32),
- std=np.ones(num_channels, dtype=np.float32),
- to_rgb=False)
- return results
-
- def __repr__(self):
- repr_str = (f'{self.__class__.__name__}('
- f'to_float32={self.to_float32}, '
- f"color_type='{self.color_type}', "
- f'file_client_args={self.file_client_args})')
- return repr_str
-
-
-@PIPELINES.register_module()
-class LoadAnnotations(object):
- """Load mutiple types of annotations.
-
- Args:
- with_bbox (bool): Whether to parse and load the bbox annotation.
- Default: True.
- with_label (bool): Whether to parse and load the label annotation.
- Default: True.
- with_mask (bool): Whether to parse and load the mask annotation.
- Default: False.
- with_seg (bool): Whether to parse and load the semantic segmentation
- annotation. Default: False.
- poly2mask (bool): Whether to convert the instance masks from polygons
- to bitmaps. Default: True.
- file_client_args (dict): Arguments to instantiate a FileClient.
- See :class:`mmcv.fileio.FileClient` for details.
- Defaults to ``dict(backend='disk')``.
- """
-
- def __init__(self,
- with_bbox=True,
- with_label=True,
- with_mask=False,
- with_seg=False,
- poly2mask=True,
- file_client_args=dict(backend='disk')):
- self.with_bbox = with_bbox
- self.with_label = with_label
- self.with_mask = with_mask
- self.with_seg = with_seg
- self.poly2mask = poly2mask
- self.file_client_args = file_client_args.copy()
- self.file_client = None
-
- def _load_bboxes(self, results):
- """Private function to load bounding box annotations.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded bounding box annotations.
- """
-
- ann_info = results['ann_info']
- results['gt_bboxes'] = ann_info['bboxes'].copy()
-
- gt_bboxes_ignore = ann_info.get('bboxes_ignore', None)
- if gt_bboxes_ignore is not None:
- results['gt_bboxes_ignore'] = gt_bboxes_ignore.copy()
- results['bbox_fields'].append('gt_bboxes_ignore')
- results['bbox_fields'].append('gt_bboxes')
- return results
-
- def _load_labels(self, results):
- """Private function to load label annotations.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded label annotations.
- """
-
- results['gt_labels'] = results['ann_info']['labels'].copy()
- return results
-
- def _poly2mask(self, mask_ann, img_h, img_w):
- """Private function to convert masks represented with polygon to
- bitmaps.
-
- Args:
- mask_ann (list | dict): Polygon mask annotation input.
- img_h (int): The height of output mask.
- img_w (int): The width of output mask.
-
- Returns:
- numpy.ndarray: The decode bitmap mask of shape (img_h, img_w).
- """
-
- if isinstance(mask_ann, list):
- # polygon -- a single object might consist of multiple parts
- # we merge all parts into one mask rle code
- rles = maskUtils.frPyObjects(mask_ann, img_h, img_w)
- rle = maskUtils.merge(rles)
- elif isinstance(mask_ann['counts'], list):
- # uncompressed RLE
- rle = maskUtils.frPyObjects(mask_ann, img_h, img_w)
- else:
- # rle
- rle = mask_ann
- mask = maskUtils.decode(rle)
- return mask
-
- def process_polygons(self, polygons):
- """Convert polygons to list of ndarray and filter invalid polygons.
-
- Args:
- polygons (list[list]): Polygons of one instance.
-
- Returns:
- list[numpy.ndarray]: Processed polygons.
- """
-
- polygons = [np.array(p) for p in polygons]
- valid_polygons = []
- for polygon in polygons:
- if len(polygon) % 2 == 0 and len(polygon) >= 6:
- valid_polygons.append(polygon)
- return valid_polygons
-
- def _load_masks(self, results):
- """Private function to load mask annotations.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded mask annotations.
- If ``self.poly2mask`` is set ``True``, `gt_mask` will contain
- :obj:`PolygonMasks`. Otherwise, :obj:`BitmapMasks` is used.
- """
-
- h, w = results['img_info']['height'], results['img_info']['width']
- gt_masks = results['ann_info']['masks']
- if self.poly2mask:
- gt_masks = BitmapMasks(
- [self._poly2mask(mask, h, w) for mask in gt_masks], h, w)
- else:
- gt_masks = PolygonMasks(
- [self.process_polygons(polygons) for polygons in gt_masks], h,
- w)
- results['gt_masks'] = gt_masks
- results['mask_fields'].append('gt_masks')
- return results
-
- def _load_semantic_seg(self, results):
- """Private function to load semantic segmentation annotations.
-
- Args:
- results (dict): Result dict from :obj:`dataset`.
-
- Returns:
- dict: The dict contains loaded semantic segmentation annotations.
- """
-
- if self.file_client is None:
- self.file_client = mmcv.FileClient(**self.file_client_args)
-
- filename = osp.join(results['seg_prefix'],
- results['ann_info']['seg_map'])
- img_bytes = self.file_client.get(filename)
- results['gt_semantic_seg'] = mmcv.imfrombytes(
- img_bytes, flag='unchanged').squeeze()
- results['seg_fields'].append('gt_semantic_seg')
- return results
-
- def __call__(self, results):
- """Call function to load multiple types annotations.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded bounding box, label, mask and
- semantic segmentation annotations.
- """
-
- if self.with_bbox:
- results = self._load_bboxes(results)
- if results is None:
- return None
- if self.with_label:
- results = self._load_labels(results)
- if self.with_mask:
- results = self._load_masks(results)
- if self.with_seg:
- results = self._load_semantic_seg(results)
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(with_bbox={self.with_bbox}, '
- repr_str += f'with_label={self.with_label}, '
- repr_str += f'with_mask={self.with_mask}, '
- repr_str += f'with_seg={self.with_seg}, '
- repr_str += f'poly2mask={self.poly2mask}, '
- repr_str += f'poly2mask={self.file_client_args})'
- return repr_str
-
-
-@PIPELINES.register_module()
-class LoadProposals(object):
- """Load proposal pipeline.
-
- Required key is "proposals". Updated keys are "proposals", "bbox_fields".
-
- Args:
- num_max_proposals (int, optional): Maximum number of proposals to load.
- If not specified, all proposals will be loaded.
- """
-
- def __init__(self, num_max_proposals=None):
- self.num_max_proposals = num_max_proposals
-
- def __call__(self, results):
- """Call function to load proposals from file.
-
- Args:
- results (dict): Result dict from :obj:`mmdet.CustomDataset`.
-
- Returns:
- dict: The dict contains loaded proposal annotations.
- """
-
- proposals = results['proposals']
- if proposals.shape[1] not in (4, 5):
- raise AssertionError(
- 'proposals should have shapes (n, 4) or (n, 5), '
- f'but found {proposals.shape}')
- proposals = proposals[:, :4]
-
- if self.num_max_proposals is not None:
- proposals = proposals[:self.num_max_proposals]
-
- if len(proposals) == 0:
- proposals = np.array([[0, 0, 0, 0]], dtype=np.float32)
- results['proposals'] = proposals
- results['bbox_fields'].append('proposals')
- return results
-
- def __repr__(self):
- return self.__class__.__name__ + \
- f'(num_max_proposals={self.num_max_proposals})'
-
-
-@PIPELINES.register_module()
-class FilterAnnotations(object):
- """Filter invalid annotations.
-
- Args:
- min_gt_bbox_wh (tuple[int]): Minimum width and height of ground truth
- boxes.
- """
-
- def __init__(self, min_gt_bbox_wh):
- # TODO: add more filter options
- self.min_gt_bbox_wh = min_gt_bbox_wh
-
- def __call__(self, results):
- assert 'gt_bboxes' in results
- gt_bboxes = results['gt_bboxes']
- w = gt_bboxes[:, 2] - gt_bboxes[:, 0]
- h = gt_bboxes[:, 3] - gt_bboxes[:, 1]
- keep = (w > self.min_gt_bbox_wh[0]) & (h > self.min_gt_bbox_wh[1])
- if not keep.any():
- return None
- else:
- keys = ('gt_bboxes', 'gt_labels', 'gt_masks', 'gt_semantic_seg')
- for key in keys:
- if key in results:
- results[key] = results[key][keep]
- return results
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/dense_heads/corner_head.py b/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/dense_heads/corner_head.py
deleted file mode 100644
index 50cdb49a29f2ced1a31a50e654a3bdc14f5f5004..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/dense_heads/corner_head.py
+++ /dev/null
@@ -1,1074 +0,0 @@
-from logging import warning
-from math import ceil, log
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import ConvModule, bias_init_with_prob
-from mmcv.ops import CornerPool, batched_nms
-
-from mmdet.core import multi_apply
-from ..builder import HEADS, build_loss
-from ..utils import gaussian_radius, gen_gaussian_target
-from .base_dense_head import BaseDenseHead
-
-
-class BiCornerPool(nn.Module):
- """Bidirectional Corner Pooling Module (TopLeft, BottomRight, etc.)
-
- Args:
- in_channels (int): Input channels of module.
- out_channels (int): Output channels of module.
- feat_channels (int): Feature channels of module.
- directions (list[str]): Directions of two CornerPools.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- """
-
- def __init__(self,
- in_channels,
- directions,
- feat_channels=128,
- out_channels=128,
- norm_cfg=dict(type='BN', requires_grad=True)):
- super(BiCornerPool, self).__init__()
- self.direction1_conv = ConvModule(
- in_channels, feat_channels, 3, padding=1, norm_cfg=norm_cfg)
- self.direction2_conv = ConvModule(
- in_channels, feat_channels, 3, padding=1, norm_cfg=norm_cfg)
-
- self.aftpool_conv = ConvModule(
- feat_channels,
- out_channels,
- 3,
- padding=1,
- norm_cfg=norm_cfg,
- act_cfg=None)
-
- self.conv1 = ConvModule(
- in_channels, out_channels, 1, norm_cfg=norm_cfg, act_cfg=None)
- self.conv2 = ConvModule(
- in_channels, out_channels, 3, padding=1, norm_cfg=norm_cfg)
-
- self.direction1_pool = CornerPool(directions[0])
- self.direction2_pool = CornerPool(directions[1])
- self.relu = nn.ReLU(inplace=True)
-
- def forward(self, x):
- """Forward features from the upstream network.
-
- Args:
- x (tensor): Input feature of BiCornerPool.
-
- Returns:
- conv2 (tensor): Output feature of BiCornerPool.
- """
- direction1_conv = self.direction1_conv(x)
- direction2_conv = self.direction2_conv(x)
- direction1_feat = self.direction1_pool(direction1_conv)
- direction2_feat = self.direction2_pool(direction2_conv)
- aftpool_conv = self.aftpool_conv(direction1_feat + direction2_feat)
- conv1 = self.conv1(x)
- relu = self.relu(aftpool_conv + conv1)
- conv2 = self.conv2(relu)
- return conv2
-
-
-@HEADS.register_module()
-class CornerHead(BaseDenseHead):
- """Head of CornerNet: Detecting Objects as Paired Keypoints.
-
- Code is modified from the `official github repo
- `_ .
-
- More details can be found in the `paper
- `_ .
-
- Args:
- num_classes (int): Number of categories excluding the background
- category.
- in_channels (int): Number of channels in the input feature map.
- num_feat_levels (int): Levels of feature from the previous module. 2
- for HourglassNet-104 and 1 for HourglassNet-52. Because
- HourglassNet-104 outputs the final feature and intermediate
- supervision feature and HourglassNet-52 only outputs the final
- feature. Default: 2.
- corner_emb_channels (int): Channel of embedding vector. Default: 1.
- train_cfg (dict | None): Training config. Useless in CornerHead,
- but we keep this variable for SingleStageDetector. Default: None.
- test_cfg (dict | None): Testing config of CornerHead. Default: None.
- loss_heatmap (dict | None): Config of corner heatmap loss. Default:
- GaussianFocalLoss.
- loss_embedding (dict | None): Config of corner embedding loss. Default:
- AssociativeEmbeddingLoss.
- loss_offset (dict | None): Config of corner offset loss. Default:
- SmoothL1Loss.
- """
-
- def __init__(self,
- num_classes,
- in_channels,
- num_feat_levels=2,
- corner_emb_channels=1,
- train_cfg=None,
- test_cfg=None,
- loss_heatmap=dict(
- type='GaussianFocalLoss',
- alpha=2.0,
- gamma=4.0,
- loss_weight=1),
- loss_embedding=dict(
- type='AssociativeEmbeddingLoss',
- pull_weight=0.25,
- push_weight=0.25),
- loss_offset=dict(
- type='SmoothL1Loss', beta=1.0, loss_weight=1)):
- super(CornerHead, self).__init__()
- self.num_classes = num_classes
- self.in_channels = in_channels
- self.corner_emb_channels = corner_emb_channels
- self.with_corner_emb = self.corner_emb_channels > 0
- self.corner_offset_channels = 2
- self.num_feat_levels = num_feat_levels
- self.loss_heatmap = build_loss(
- loss_heatmap) if loss_heatmap is not None else None
- self.loss_embedding = build_loss(
- loss_embedding) if loss_embedding is not None else None
- self.loss_offset = build_loss(
- loss_offset) if loss_offset is not None else None
- self.train_cfg = train_cfg
- self.test_cfg = test_cfg
-
- self._init_layers()
-
- def _make_layers(self, out_channels, in_channels=256, feat_channels=256):
- """Initialize conv sequential for CornerHead."""
- return nn.Sequential(
- ConvModule(in_channels, feat_channels, 3, padding=1),
- ConvModule(
- feat_channels, out_channels, 1, norm_cfg=None, act_cfg=None))
-
- def _init_corner_kpt_layers(self):
- """Initialize corner keypoint layers.
-
- Including corner heatmap branch and corner offset branch. Each branch
- has two parts: prefix `tl_` for top-left and `br_` for bottom-right.
- """
- self.tl_pool, self.br_pool = nn.ModuleList(), nn.ModuleList()
- self.tl_heat, self.br_heat = nn.ModuleList(), nn.ModuleList()
- self.tl_off, self.br_off = nn.ModuleList(), nn.ModuleList()
-
- for _ in range(self.num_feat_levels):
- self.tl_pool.append(
- BiCornerPool(
- self.in_channels, ['top', 'left'],
- out_channels=self.in_channels))
- self.br_pool.append(
- BiCornerPool(
- self.in_channels, ['bottom', 'right'],
- out_channels=self.in_channels))
-
- self.tl_heat.append(
- self._make_layers(
- out_channels=self.num_classes,
- in_channels=self.in_channels))
- self.br_heat.append(
- self._make_layers(
- out_channels=self.num_classes,
- in_channels=self.in_channels))
-
- self.tl_off.append(
- self._make_layers(
- out_channels=self.corner_offset_channels,
- in_channels=self.in_channels))
- self.br_off.append(
- self._make_layers(
- out_channels=self.corner_offset_channels,
- in_channels=self.in_channels))
-
- def _init_corner_emb_layers(self):
- """Initialize corner embedding layers.
-
- Only include corner embedding branch with two parts: prefix `tl_` for
- top-left and `br_` for bottom-right.
- """
- self.tl_emb, self.br_emb = nn.ModuleList(), nn.ModuleList()
-
- for _ in range(self.num_feat_levels):
- self.tl_emb.append(
- self._make_layers(
- out_channels=self.corner_emb_channels,
- in_channels=self.in_channels))
- self.br_emb.append(
- self._make_layers(
- out_channels=self.corner_emb_channels,
- in_channels=self.in_channels))
-
- def _init_layers(self):
- """Initialize layers for CornerHead.
-
- Including two parts: corner keypoint layers and corner embedding layers
- """
- self._init_corner_kpt_layers()
- if self.with_corner_emb:
- self._init_corner_emb_layers()
-
- def init_weights(self):
- """Initialize weights of the head."""
- bias_init = bias_init_with_prob(0.1)
- for i in range(self.num_feat_levels):
- # The initialization of parameters are different between nn.Conv2d
- # and ConvModule. Our experiments show that using the original
- # initialization of nn.Conv2d increases the final mAP by about 0.2%
- self.tl_heat[i][-1].conv.reset_parameters()
- self.tl_heat[i][-1].conv.bias.data.fill_(bias_init)
- self.br_heat[i][-1].conv.reset_parameters()
- self.br_heat[i][-1].conv.bias.data.fill_(bias_init)
- self.tl_off[i][-1].conv.reset_parameters()
- self.br_off[i][-1].conv.reset_parameters()
- if self.with_corner_emb:
- self.tl_emb[i][-1].conv.reset_parameters()
- self.br_emb[i][-1].conv.reset_parameters()
-
- def forward(self, feats):
- """Forward features from the upstream network.
-
- Args:
- feats (tuple[Tensor]): Features from the upstream network, each is
- a 4D-tensor.
-
- Returns:
- tuple: Usually a tuple of corner heatmaps, offset heatmaps and
- embedding heatmaps.
- - tl_heats (list[Tensor]): Top-left corner heatmaps for all
- levels, each is a 4D-tensor, the channels number is
- num_classes.
- - br_heats (list[Tensor]): Bottom-right corner heatmaps for all
- levels, each is a 4D-tensor, the channels number is
- num_classes.
- - tl_embs (list[Tensor] | list[None]): Top-left embedding
- heatmaps for all levels, each is a 4D-tensor or None.
- If not None, the channels number is corner_emb_channels.
- - br_embs (list[Tensor] | list[None]): Bottom-right embedding
- heatmaps for all levels, each is a 4D-tensor or None.
- If not None, the channels number is corner_emb_channels.
- - tl_offs (list[Tensor]): Top-left offset heatmaps for all
- levels, each is a 4D-tensor. The channels number is
- corner_offset_channels.
- - br_offs (list[Tensor]): Bottom-right offset heatmaps for all
- levels, each is a 4D-tensor. The channels number is
- corner_offset_channels.
- """
- lvl_ind = list(range(self.num_feat_levels))
- return multi_apply(self.forward_single, feats, lvl_ind)
-
- def forward_single(self, x, lvl_ind, return_pool=False):
- """Forward feature of a single level.
-
- Args:
- x (Tensor): Feature of a single level.
- lvl_ind (int): Level index of current feature.
- return_pool (bool): Return corner pool feature or not.
-
- Returns:
- tuple[Tensor]: A tuple of CornerHead's output for current feature
- level. Containing the following Tensors:
-
- - tl_heat (Tensor): Predicted top-left corner heatmap.
- - br_heat (Tensor): Predicted bottom-right corner heatmap.
- - tl_emb (Tensor | None): Predicted top-left embedding heatmap.
- None for `self.with_corner_emb == False`.
- - br_emb (Tensor | None): Predicted bottom-right embedding
- heatmap. None for `self.with_corner_emb == False`.
- - tl_off (Tensor): Predicted top-left offset heatmap.
- - br_off (Tensor): Predicted bottom-right offset heatmap.
- - tl_pool (Tensor): Top-left corner pool feature. Not must
- have.
- - br_pool (Tensor): Bottom-right corner pool feature. Not must
- have.
- """
- tl_pool = self.tl_pool[lvl_ind](x)
- tl_heat = self.tl_heat[lvl_ind](tl_pool)
- br_pool = self.br_pool[lvl_ind](x)
- br_heat = self.br_heat[lvl_ind](br_pool)
-
- tl_emb, br_emb = None, None
- if self.with_corner_emb:
- tl_emb = self.tl_emb[lvl_ind](tl_pool)
- br_emb = self.br_emb[lvl_ind](br_pool)
-
- tl_off = self.tl_off[lvl_ind](tl_pool)
- br_off = self.br_off[lvl_ind](br_pool)
-
- result_list = [tl_heat, br_heat, tl_emb, br_emb, tl_off, br_off]
- if return_pool:
- result_list.append(tl_pool)
- result_list.append(br_pool)
-
- return result_list
-
- def get_targets(self,
- gt_bboxes,
- gt_labels,
- feat_shape,
- img_shape,
- with_corner_emb=False,
- with_guiding_shift=False,
- with_centripetal_shift=False):
- """Generate corner targets.
-
- Including corner heatmap, corner offset.
-
- Optional: corner embedding, corner guiding shift, centripetal shift.
-
- For CornerNet, we generate corner heatmap, corner offset and corner
- embedding from this function.
-
- For CentripetalNet, we generate corner heatmap, corner offset, guiding
- shift and centripetal shift from this function.
-
- Args:
- gt_bboxes (list[Tensor]): Ground truth bboxes of each image, each
- has shape (num_gt, 4).
- gt_labels (list[Tensor]): Ground truth labels of each box, each has
- shape (num_gt,).
- feat_shape (list[int]): Shape of output feature,
- [batch, channel, height, width].
- img_shape (list[int]): Shape of input image,
- [height, width, channel].
- with_corner_emb (bool): Generate corner embedding target or not.
- Default: False.
- with_guiding_shift (bool): Generate guiding shift target or not.
- Default: False.
- with_centripetal_shift (bool): Generate centripetal shift target or
- not. Default: False.
-
- Returns:
- dict: Ground truth of corner heatmap, corner offset, corner
- embedding, guiding shift and centripetal shift. Containing the
- following keys:
-
- - topleft_heatmap (Tensor): Ground truth top-left corner
- heatmap.
- - bottomright_heatmap (Tensor): Ground truth bottom-right
- corner heatmap.
- - topleft_offset (Tensor): Ground truth top-left corner offset.
- - bottomright_offset (Tensor): Ground truth bottom-right corner
- offset.
- - corner_embedding (list[list[list[int]]]): Ground truth corner
- embedding. Not must have.
- - topleft_guiding_shift (Tensor): Ground truth top-left corner
- guiding shift. Not must have.
- - bottomright_guiding_shift (Tensor): Ground truth bottom-right
- corner guiding shift. Not must have.
- - topleft_centripetal_shift (Tensor): Ground truth top-left
- corner centripetal shift. Not must have.
- - bottomright_centripetal_shift (Tensor): Ground truth
- bottom-right corner centripetal shift. Not must have.
- """
- batch_size, _, height, width = feat_shape
- img_h, img_w = img_shape[:2]
-
- width_ratio = float(width / img_w)
- height_ratio = float(height / img_h)
-
- gt_tl_heatmap = gt_bboxes[-1].new_zeros(
- [batch_size, self.num_classes, height, width])
- gt_br_heatmap = gt_bboxes[-1].new_zeros(
- [batch_size, self.num_classes, height, width])
- gt_tl_offset = gt_bboxes[-1].new_zeros([batch_size, 2, height, width])
- gt_br_offset = gt_bboxes[-1].new_zeros([batch_size, 2, height, width])
-
- if with_corner_emb:
- match = []
-
- # Guiding shift is a kind of offset, from center to corner
- if with_guiding_shift:
- gt_tl_guiding_shift = gt_bboxes[-1].new_zeros(
- [batch_size, 2, height, width])
- gt_br_guiding_shift = gt_bboxes[-1].new_zeros(
- [batch_size, 2, height, width])
- # Centripetal shift is also a kind of offset, from center to corner
- # and normalized by log.
- if with_centripetal_shift:
- gt_tl_centripetal_shift = gt_bboxes[-1].new_zeros(
- [batch_size, 2, height, width])
- gt_br_centripetal_shift = gt_bboxes[-1].new_zeros(
- [batch_size, 2, height, width])
-
- for batch_id in range(batch_size):
- # Ground truth of corner embedding per image is a list of coord set
- corner_match = []
- for box_id in range(len(gt_labels[batch_id])):
- left, top, right, bottom = gt_bboxes[batch_id][box_id]
- center_x = (left + right) / 2.0
- center_y = (top + bottom) / 2.0
- label = gt_labels[batch_id][box_id]
-
- # Use coords in the feature level to generate ground truth
- scale_left = left * width_ratio
- scale_right = right * width_ratio
- scale_top = top * height_ratio
- scale_bottom = bottom * height_ratio
- scale_center_x = center_x * width_ratio
- scale_center_y = center_y * height_ratio
-
- # Int coords on feature map/ground truth tensor
- left_idx = int(min(scale_left, width - 1))
- right_idx = int(min(scale_right, width - 1))
- top_idx = int(min(scale_top, height - 1))
- bottom_idx = int(min(scale_bottom, height - 1))
-
- # Generate gaussian heatmap
- scale_box_width = ceil(scale_right - scale_left)
- scale_box_height = ceil(scale_bottom - scale_top)
- radius = gaussian_radius((scale_box_height, scale_box_width),
- min_overlap=0.3)
- radius = max(0, int(radius))
- gt_tl_heatmap[batch_id, label] = gen_gaussian_target(
- gt_tl_heatmap[batch_id, label], [left_idx, top_idx],
- radius)
- gt_br_heatmap[batch_id, label] = gen_gaussian_target(
- gt_br_heatmap[batch_id, label], [right_idx, bottom_idx],
- radius)
-
- # Generate corner offset
- left_offset = scale_left - left_idx
- top_offset = scale_top - top_idx
- right_offset = scale_right - right_idx
- bottom_offset = scale_bottom - bottom_idx
- gt_tl_offset[batch_id, 0, top_idx, left_idx] = left_offset
- gt_tl_offset[batch_id, 1, top_idx, left_idx] = top_offset
- gt_br_offset[batch_id, 0, bottom_idx, right_idx] = right_offset
- gt_br_offset[batch_id, 1, bottom_idx,
- right_idx] = bottom_offset
-
- # Generate corner embedding
- if with_corner_emb:
- corner_match.append([[top_idx, left_idx],
- [bottom_idx, right_idx]])
- # Generate guiding shift
- if with_guiding_shift:
- gt_tl_guiding_shift[batch_id, 0, top_idx,
- left_idx] = scale_center_x - left_idx
- gt_tl_guiding_shift[batch_id, 1, top_idx,
- left_idx] = scale_center_y - top_idx
- gt_br_guiding_shift[batch_id, 0, bottom_idx,
- right_idx] = right_idx - scale_center_x
- gt_br_guiding_shift[
- batch_id, 1, bottom_idx,
- right_idx] = bottom_idx - scale_center_y
- # Generate centripetal shift
- if with_centripetal_shift:
- gt_tl_centripetal_shift[batch_id, 0, top_idx,
- left_idx] = log(scale_center_x -
- scale_left)
- gt_tl_centripetal_shift[batch_id, 1, top_idx,
- left_idx] = log(scale_center_y -
- scale_top)
- gt_br_centripetal_shift[batch_id, 0, bottom_idx,
- right_idx] = log(scale_right -
- scale_center_x)
- gt_br_centripetal_shift[batch_id, 1, bottom_idx,
- right_idx] = log(scale_bottom -
- scale_center_y)
-
- if with_corner_emb:
- match.append(corner_match)
-
- target_result = dict(
- topleft_heatmap=gt_tl_heatmap,
- topleft_offset=gt_tl_offset,
- bottomright_heatmap=gt_br_heatmap,
- bottomright_offset=gt_br_offset)
-
- if with_corner_emb:
- target_result.update(corner_embedding=match)
- if with_guiding_shift:
- target_result.update(
- topleft_guiding_shift=gt_tl_guiding_shift,
- bottomright_guiding_shift=gt_br_guiding_shift)
- if with_centripetal_shift:
- target_result.update(
- topleft_centripetal_shift=gt_tl_centripetal_shift,
- bottomright_centripetal_shift=gt_br_centripetal_shift)
-
- return target_result
-
- def loss(self,
- tl_heats,
- br_heats,
- tl_embs,
- br_embs,
- tl_offs,
- br_offs,
- gt_bboxes,
- gt_labels,
- img_metas,
- gt_bboxes_ignore=None):
- """Compute losses of the head.
-
- Args:
- tl_heats (list[Tensor]): Top-left corner heatmaps for each level
- with shape (N, num_classes, H, W).
- br_heats (list[Tensor]): Bottom-right corner heatmaps for each
- level with shape (N, num_classes, H, W).
- tl_embs (list[Tensor]): Top-left corner embeddings for each level
- with shape (N, corner_emb_channels, H, W).
- br_embs (list[Tensor]): Bottom-right corner embeddings for each
- level with shape (N, corner_emb_channels, H, W).
- tl_offs (list[Tensor]): Top-left corner offsets for each level
- with shape (N, corner_offset_channels, H, W).
- br_offs (list[Tensor]): Bottom-right corner offsets for each level
- with shape (N, corner_offset_channels, H, W).
- gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
- shape (num_gts, 4) in [left, top, right, bottom] format.
- gt_labels (list[Tensor]): Class indices corresponding to each box.
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- gt_bboxes_ignore (list[Tensor] | None): Specify which bounding
- boxes can be ignored when computing the loss.
-
- Returns:
- dict[str, Tensor]: A dictionary of loss components. Containing the
- following losses:
-
- - det_loss (list[Tensor]): Corner keypoint losses of all
- feature levels.
- - pull_loss (list[Tensor]): Part one of AssociativeEmbedding
- losses of all feature levels.
- - push_loss (list[Tensor]): Part two of AssociativeEmbedding
- losses of all feature levels.
- - off_loss (list[Tensor]): Corner offset losses of all feature
- levels.
- """
- targets = self.get_targets(
- gt_bboxes,
- gt_labels,
- tl_heats[-1].shape,
- img_metas[0]['pad_shape'],
- with_corner_emb=self.with_corner_emb)
- mlvl_targets = [targets for _ in range(self.num_feat_levels)]
- det_losses, pull_losses, push_losses, off_losses = multi_apply(
- self.loss_single, tl_heats, br_heats, tl_embs, br_embs, tl_offs,
- br_offs, mlvl_targets)
- loss_dict = dict(det_loss=det_losses, off_loss=off_losses)
- if self.with_corner_emb:
- loss_dict.update(pull_loss=pull_losses, push_loss=push_losses)
- return loss_dict
-
- def loss_single(self, tl_hmp, br_hmp, tl_emb, br_emb, tl_off, br_off,
- targets):
- """Compute losses for single level.
-
- Args:
- tl_hmp (Tensor): Top-left corner heatmap for current level with
- shape (N, num_classes, H, W).
- br_hmp (Tensor): Bottom-right corner heatmap for current level with
- shape (N, num_classes, H, W).
- tl_emb (Tensor): Top-left corner embedding for current level with
- shape (N, corner_emb_channels, H, W).
- br_emb (Tensor): Bottom-right corner embedding for current level
- with shape (N, corner_emb_channels, H, W).
- tl_off (Tensor): Top-left corner offset for current level with
- shape (N, corner_offset_channels, H, W).
- br_off (Tensor): Bottom-right corner offset for current level with
- shape (N, corner_offset_channels, H, W).
- targets (dict): Corner target generated by `get_targets`.
-
- Returns:
- tuple[torch.Tensor]: Losses of the head's differnet branches
- containing the following losses:
-
- - det_loss (Tensor): Corner keypoint loss.
- - pull_loss (Tensor): Part one of AssociativeEmbedding loss.
- - push_loss (Tensor): Part two of AssociativeEmbedding loss.
- - off_loss (Tensor): Corner offset loss.
- """
- gt_tl_hmp = targets['topleft_heatmap']
- gt_br_hmp = targets['bottomright_heatmap']
- gt_tl_off = targets['topleft_offset']
- gt_br_off = targets['bottomright_offset']
- gt_embedding = targets['corner_embedding']
-
- # Detection loss
- tl_det_loss = self.loss_heatmap(
- tl_hmp.sigmoid(),
- gt_tl_hmp,
- avg_factor=max(1,
- gt_tl_hmp.eq(1).sum()))
- br_det_loss = self.loss_heatmap(
- br_hmp.sigmoid(),
- gt_br_hmp,
- avg_factor=max(1,
- gt_br_hmp.eq(1).sum()))
- det_loss = (tl_det_loss + br_det_loss) / 2.0
-
- # AssociativeEmbedding loss
- if self.with_corner_emb and self.loss_embedding is not None:
- pull_loss, push_loss = self.loss_embedding(tl_emb, br_emb,
- gt_embedding)
- else:
- pull_loss, push_loss = None, None
-
- # Offset loss
- # We only compute the offset loss at the real corner position.
- # The value of real corner would be 1 in heatmap ground truth.
- # The mask is computed in class agnostic mode and its shape is
- # batch * 1 * width * height.
- tl_off_mask = gt_tl_hmp.eq(1).sum(1).gt(0).unsqueeze(1).type_as(
- gt_tl_hmp)
- br_off_mask = gt_br_hmp.eq(1).sum(1).gt(0).unsqueeze(1).type_as(
- gt_br_hmp)
- tl_off_loss = self.loss_offset(
- tl_off,
- gt_tl_off,
- tl_off_mask,
- avg_factor=max(1, tl_off_mask.sum()))
- br_off_loss = self.loss_offset(
- br_off,
- gt_br_off,
- br_off_mask,
- avg_factor=max(1, br_off_mask.sum()))
-
- off_loss = (tl_off_loss + br_off_loss) / 2.0
-
- return det_loss, pull_loss, push_loss, off_loss
-
- def get_bboxes(self,
- tl_heats,
- br_heats,
- tl_embs,
- br_embs,
- tl_offs,
- br_offs,
- img_metas,
- rescale=False,
- with_nms=True):
- """Transform network output for a batch into bbox predictions.
-
- Args:
- tl_heats (list[Tensor]): Top-left corner heatmaps for each level
- with shape (N, num_classes, H, W).
- br_heats (list[Tensor]): Bottom-right corner heatmaps for each
- level with shape (N, num_classes, H, W).
- tl_embs (list[Tensor]): Top-left corner embeddings for each level
- with shape (N, corner_emb_channels, H, W).
- br_embs (list[Tensor]): Bottom-right corner embeddings for each
- level with shape (N, corner_emb_channels, H, W).
- tl_offs (list[Tensor]): Top-left corner offsets for each level
- with shape (N, corner_offset_channels, H, W).
- br_offs (list[Tensor]): Bottom-right corner offsets for each level
- with shape (N, corner_offset_channels, H, W).
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- rescale (bool): If True, return boxes in original image space.
- Default: False.
- with_nms (bool): If True, do nms before return boxes.
- Default: True.
- """
- assert tl_heats[-1].shape[0] == br_heats[-1].shape[0] == len(img_metas)
- result_list = []
- for img_id in range(len(img_metas)):
- result_list.append(
- self._get_bboxes_single(
- tl_heats[-1][img_id:img_id + 1, :],
- br_heats[-1][img_id:img_id + 1, :],
- tl_offs[-1][img_id:img_id + 1, :],
- br_offs[-1][img_id:img_id + 1, :],
- img_metas[img_id],
- tl_emb=tl_embs[-1][img_id:img_id + 1, :],
- br_emb=br_embs[-1][img_id:img_id + 1, :],
- rescale=rescale,
- with_nms=with_nms))
-
- return result_list
-
- def _get_bboxes_single(self,
- tl_heat,
- br_heat,
- tl_off,
- br_off,
- img_meta,
- tl_emb=None,
- br_emb=None,
- tl_centripetal_shift=None,
- br_centripetal_shift=None,
- rescale=False,
- with_nms=True):
- """Transform outputs for a single batch item into bbox predictions.
-
- Args:
- tl_heat (Tensor): Top-left corner heatmap for current level with
- shape (N, num_classes, H, W).
- br_heat (Tensor): Bottom-right corner heatmap for current level
- with shape (N, num_classes, H, W).
- tl_off (Tensor): Top-left corner offset for current level with
- shape (N, corner_offset_channels, H, W).
- br_off (Tensor): Bottom-right corner offset for current level with
- shape (N, corner_offset_channels, H, W).
- img_meta (dict): Meta information of current image, e.g.,
- image size, scaling factor, etc.
- tl_emb (Tensor): Top-left corner embedding for current level with
- shape (N, corner_emb_channels, H, W).
- br_emb (Tensor): Bottom-right corner embedding for current level
- with shape (N, corner_emb_channels, H, W).
- tl_centripetal_shift: Top-left corner's centripetal shift for
- current level with shape (N, 2, H, W).
- br_centripetal_shift: Bottom-right corner's centripetal shift for
- current level with shape (N, 2, H, W).
- rescale (bool): If True, return boxes in original image space.
- Default: False.
- with_nms (bool): If True, do nms before return boxes.
- Default: True.
- """
- if isinstance(img_meta, (list, tuple)):
- img_meta = img_meta[0]
-
- batch_bboxes, batch_scores, batch_clses = self.decode_heatmap(
- tl_heat=tl_heat.sigmoid(),
- br_heat=br_heat.sigmoid(),
- tl_off=tl_off,
- br_off=br_off,
- tl_emb=tl_emb,
- br_emb=br_emb,
- tl_centripetal_shift=tl_centripetal_shift,
- br_centripetal_shift=br_centripetal_shift,
- img_meta=img_meta,
- k=self.test_cfg.corner_topk,
- kernel=self.test_cfg.local_maximum_kernel,
- distance_threshold=self.test_cfg.distance_threshold)
-
- if rescale:
- batch_bboxes /= batch_bboxes.new_tensor(img_meta['scale_factor'])
-
- bboxes = batch_bboxes.view([-1, 4])
- scores = batch_scores.view([-1, 1])
- clses = batch_clses.view([-1, 1])
-
- idx = scores.argsort(dim=0, descending=True)
- bboxes = bboxes[idx].view([-1, 4])
- scores = scores[idx].view(-1)
- clses = clses[idx].view(-1)
-
- detections = torch.cat([bboxes, scores.unsqueeze(-1)], -1)
- keepinds = (detections[:, -1] > -0.1)
- detections = detections[keepinds]
- labels = clses[keepinds]
-
- if with_nms:
- detections, labels = self._bboxes_nms(detections, labels,
- self.test_cfg)
-
- return detections, labels
-
- def _bboxes_nms(self, bboxes, labels, cfg):
- if labels.numel() == 0:
- return bboxes, labels
-
- if 'nms_cfg' in cfg:
- warning.warn('nms_cfg in test_cfg will be deprecated. '
- 'Please rename it as nms')
- if 'nms' not in cfg:
- cfg.nms = cfg.nms_cfg
-
- out_bboxes, keep = batched_nms(bboxes[:, :4], bboxes[:, -1], labels,
- cfg.nms)
- out_labels = labels[keep]
-
- if len(out_bboxes) > 0:
- idx = torch.argsort(out_bboxes[:, -1], descending=True)
- idx = idx[:cfg.max_per_img]
- out_bboxes = out_bboxes[idx]
- out_labels = out_labels[idx]
-
- return out_bboxes, out_labels
-
- def _gather_feat(self, feat, ind, mask=None):
- """Gather feature according to index.
-
- Args:
- feat (Tensor): Target feature map.
- ind (Tensor): Target coord index.
- mask (Tensor | None): Mask of featuremap. Default: None.
-
- Returns:
- feat (Tensor): Gathered feature.
- """
- dim = feat.size(2)
- ind = ind.unsqueeze(2).repeat(1, 1, dim)
- feat = feat.gather(1, ind)
- if mask is not None:
- mask = mask.unsqueeze(2).expand_as(feat)
- feat = feat[mask]
- feat = feat.view(-1, dim)
- return feat
-
- def _local_maximum(self, heat, kernel=3):
- """Extract local maximum pixel with given kernel.
-
- Args:
- heat (Tensor): Target heatmap.
- kernel (int): Kernel size of max pooling. Default: 3.
-
- Returns:
- heat (Tensor): A heatmap where local maximum pixels maintain its
- own value and other positions are 0.
- """
- pad = (kernel - 1) // 2
- hmax = F.max_pool2d(heat, kernel, stride=1, padding=pad)
- keep = (hmax == heat).float()
- return heat * keep
-
- def _transpose_and_gather_feat(self, feat, ind):
- """Transpose and gather feature according to index.
-
- Args:
- feat (Tensor): Target feature map.
- ind (Tensor): Target coord index.
-
- Returns:
- feat (Tensor): Transposed and gathered feature.
- """
- feat = feat.permute(0, 2, 3, 1).contiguous()
- feat = feat.view(feat.size(0), -1, feat.size(3))
- feat = self._gather_feat(feat, ind)
- return feat
-
- def _topk(self, scores, k=20):
- """Get top k positions from heatmap.
-
- Args:
- scores (Tensor): Target heatmap with shape
- [batch, num_classes, height, width].
- k (int): Target number. Default: 20.
-
- Returns:
- tuple[torch.Tensor]: Scores, indexes, categories and coords of
- topk keypoint. Containing following Tensors:
-
- - topk_scores (Tensor): Max scores of each topk keypoint.
- - topk_inds (Tensor): Indexes of each topk keypoint.
- - topk_clses (Tensor): Categories of each topk keypoint.
- - topk_ys (Tensor): Y-coord of each topk keypoint.
- - topk_xs (Tensor): X-coord of each topk keypoint.
- """
- batch, _, height, width = scores.size()
- topk_scores, topk_inds = torch.topk(scores.view(batch, -1), k)
- topk_clses = topk_inds // (height * width)
- topk_inds = topk_inds % (height * width)
- topk_ys = topk_inds // width
- topk_xs = (topk_inds % width).int().float()
- return topk_scores, topk_inds, topk_clses, topk_ys, topk_xs
-
- def decode_heatmap(self,
- tl_heat,
- br_heat,
- tl_off,
- br_off,
- tl_emb=None,
- br_emb=None,
- tl_centripetal_shift=None,
- br_centripetal_shift=None,
- img_meta=None,
- k=100,
- kernel=3,
- distance_threshold=0.5,
- num_dets=1000):
- """Transform outputs for a single batch item into raw bbox predictions.
-
- Args:
- tl_heat (Tensor): Top-left corner heatmap for current level with
- shape (N, num_classes, H, W).
- br_heat (Tensor): Bottom-right corner heatmap for current level
- with shape (N, num_classes, H, W).
- tl_off (Tensor): Top-left corner offset for current level with
- shape (N, corner_offset_channels, H, W).
- br_off (Tensor): Bottom-right corner offset for current level with
- shape (N, corner_offset_channels, H, W).
- tl_emb (Tensor | None): Top-left corner embedding for current
- level with shape (N, corner_emb_channels, H, W).
- br_emb (Tensor | None): Bottom-right corner embedding for current
- level with shape (N, corner_emb_channels, H, W).
- tl_centripetal_shift (Tensor | None): Top-left centripetal shift
- for current level with shape (N, 2, H, W).
- br_centripetal_shift (Tensor | None): Bottom-right centripetal
- shift for current level with shape (N, 2, H, W).
- img_meta (dict): Meta information of current image, e.g.,
- image size, scaling factor, etc.
- k (int): Get top k corner keypoints from heatmap.
- kernel (int): Max pooling kernel for extract local maximum pixels.
- distance_threshold (float): Distance threshold. Top-left and
- bottom-right corner keypoints with feature distance less than
- the threshold will be regarded as keypoints from same object.
- num_dets (int): Num of raw boxes before doing nms.
-
- Returns:
- tuple[torch.Tensor]: Decoded output of CornerHead, containing the
- following Tensors:
-
- - bboxes (Tensor): Coords of each box.
- - scores (Tensor): Scores of each box.
- - clses (Tensor): Categories of each box.
- """
- with_embedding = tl_emb is not None and br_emb is not None
- with_centripetal_shift = (
- tl_centripetal_shift is not None
- and br_centripetal_shift is not None)
- assert with_embedding + with_centripetal_shift == 1
- batch, _, height, width = tl_heat.size()
- inp_h, inp_w, _ = img_meta['pad_shape']
-
- # perform nms on heatmaps
- tl_heat = self._local_maximum(tl_heat, kernel=kernel)
- br_heat = self._local_maximum(br_heat, kernel=kernel)
-
- tl_scores, tl_inds, tl_clses, tl_ys, tl_xs = self._topk(tl_heat, k=k)
- br_scores, br_inds, br_clses, br_ys, br_xs = self._topk(br_heat, k=k)
-
- # We use repeat instead of expand here because expand is a
- # shallow-copy function. Thus it could cause unexpected testing result
- # sometimes. Using expand will decrease about 10% mAP during testing
- # compared to repeat.
- tl_ys = tl_ys.view(batch, k, 1).repeat(1, 1, k)
- tl_xs = tl_xs.view(batch, k, 1).repeat(1, 1, k)
- br_ys = br_ys.view(batch, 1, k).repeat(1, k, 1)
- br_xs = br_xs.view(batch, 1, k).repeat(1, k, 1)
-
- tl_off = self._transpose_and_gather_feat(tl_off, tl_inds)
- tl_off = tl_off.view(batch, k, 1, 2)
- br_off = self._transpose_and_gather_feat(br_off, br_inds)
- br_off = br_off.view(batch, 1, k, 2)
-
- tl_xs = tl_xs + tl_off[..., 0]
- tl_ys = tl_ys + tl_off[..., 1]
- br_xs = br_xs + br_off[..., 0]
- br_ys = br_ys + br_off[..., 1]
-
- if with_centripetal_shift:
- tl_centripetal_shift = self._transpose_and_gather_feat(
- tl_centripetal_shift, tl_inds).view(batch, k, 1, 2).exp()
- br_centripetal_shift = self._transpose_and_gather_feat(
- br_centripetal_shift, br_inds).view(batch, 1, k, 2).exp()
-
- tl_ctxs = tl_xs + tl_centripetal_shift[..., 0]
- tl_ctys = tl_ys + tl_centripetal_shift[..., 1]
- br_ctxs = br_xs - br_centripetal_shift[..., 0]
- br_ctys = br_ys - br_centripetal_shift[..., 1]
-
- # all possible boxes based on top k corners (ignoring class)
- tl_xs *= (inp_w / width)
- tl_ys *= (inp_h / height)
- br_xs *= (inp_w / width)
- br_ys *= (inp_h / height)
-
- if with_centripetal_shift:
- tl_ctxs *= (inp_w / width)
- tl_ctys *= (inp_h / height)
- br_ctxs *= (inp_w / width)
- br_ctys *= (inp_h / height)
-
- x_off = img_meta['border'][2]
- y_off = img_meta['border'][0]
-
- tl_xs -= x_off
- tl_ys -= y_off
- br_xs -= x_off
- br_ys -= y_off
-
- tl_xs *= tl_xs.gt(0.0).type_as(tl_xs)
- tl_ys *= tl_ys.gt(0.0).type_as(tl_ys)
- br_xs *= br_xs.gt(0.0).type_as(br_xs)
- br_ys *= br_ys.gt(0.0).type_as(br_ys)
-
- bboxes = torch.stack((tl_xs, tl_ys, br_xs, br_ys), dim=3)
- area_bboxes = ((br_xs - tl_xs) * (br_ys - tl_ys)).abs()
-
- if with_centripetal_shift:
- tl_ctxs -= x_off
- tl_ctys -= y_off
- br_ctxs -= x_off
- br_ctys -= y_off
-
- tl_ctxs *= tl_ctxs.gt(0.0).type_as(tl_ctxs)
- tl_ctys *= tl_ctys.gt(0.0).type_as(tl_ctys)
- br_ctxs *= br_ctxs.gt(0.0).type_as(br_ctxs)
- br_ctys *= br_ctys.gt(0.0).type_as(br_ctys)
-
- ct_bboxes = torch.stack((tl_ctxs, tl_ctys, br_ctxs, br_ctys),
- dim=3)
- area_ct_bboxes = ((br_ctxs - tl_ctxs) * (br_ctys - tl_ctys)).abs()
-
- rcentral = torch.zeros_like(ct_bboxes)
- # magic nums from paper section 4.1
- mu = torch.ones_like(area_bboxes) / 2.4
- mu[area_bboxes > 3500] = 1 / 2.1 # large bbox have smaller mu
-
- bboxes_center_x = (bboxes[..., 0] + bboxes[..., 2]) / 2
- bboxes_center_y = (bboxes[..., 1] + bboxes[..., 3]) / 2
- rcentral[..., 0] = bboxes_center_x - mu * (bboxes[..., 2] -
- bboxes[..., 0]) / 2
- rcentral[..., 1] = bboxes_center_y - mu * (bboxes[..., 3] -
- bboxes[..., 1]) / 2
- rcentral[..., 2] = bboxes_center_x + mu * (bboxes[..., 2] -
- bboxes[..., 0]) / 2
- rcentral[..., 3] = bboxes_center_y + mu * (bboxes[..., 3] -
- bboxes[..., 1]) / 2
- area_rcentral = ((rcentral[..., 2] - rcentral[..., 0]) *
- (rcentral[..., 3] - rcentral[..., 1])).abs()
- dists = area_ct_bboxes / area_rcentral
-
- tl_ctx_inds = (ct_bboxes[..., 0] <= rcentral[..., 0]) | (
- ct_bboxes[..., 0] >= rcentral[..., 2])
- tl_cty_inds = (ct_bboxes[..., 1] <= rcentral[..., 1]) | (
- ct_bboxes[..., 1] >= rcentral[..., 3])
- br_ctx_inds = (ct_bboxes[..., 2] <= rcentral[..., 0]) | (
- ct_bboxes[..., 2] >= rcentral[..., 2])
- br_cty_inds = (ct_bboxes[..., 3] <= rcentral[..., 1]) | (
- ct_bboxes[..., 3] >= rcentral[..., 3])
-
- if with_embedding:
- tl_emb = self._transpose_and_gather_feat(tl_emb, tl_inds)
- tl_emb = tl_emb.view(batch, k, 1)
- br_emb = self._transpose_and_gather_feat(br_emb, br_inds)
- br_emb = br_emb.view(batch, 1, k)
- dists = torch.abs(tl_emb - br_emb)
-
- tl_scores = tl_scores.view(batch, k, 1).repeat(1, 1, k)
- br_scores = br_scores.view(batch, 1, k).repeat(1, k, 1)
-
- scores = (tl_scores + br_scores) / 2 # scores for all possible boxes
-
- # tl and br should have same class
- tl_clses = tl_clses.view(batch, k, 1).repeat(1, 1, k)
- br_clses = br_clses.view(batch, 1, k).repeat(1, k, 1)
- cls_inds = (tl_clses != br_clses)
-
- # reject boxes based on distances
- dist_inds = dists > distance_threshold
-
- # reject boxes based on widths and heights
- width_inds = (br_xs <= tl_xs)
- height_inds = (br_ys <= tl_ys)
-
- scores[cls_inds] = -1
- scores[width_inds] = -1
- scores[height_inds] = -1
- scores[dist_inds] = -1
- if with_centripetal_shift:
- scores[tl_ctx_inds] = -1
- scores[tl_cty_inds] = -1
- scores[br_ctx_inds] = -1
- scores[br_cty_inds] = -1
-
- scores = scores.view(batch, -1)
- scores, inds = torch.topk(scores, num_dets)
- scores = scores.unsqueeze(2)
-
- bboxes = bboxes.view(batch, -1, 4)
- bboxes = self._gather_feat(bboxes, inds)
-
- clses = tl_clses.contiguous().view(batch, -1, 1)
- clses = self._gather_feat(clses, inds).float()
-
- return bboxes, scores, clses
diff --git a/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/hrnet/fcn_hr18_480x480_80k_pascal_context.py b/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/hrnet/fcn_hr18_480x480_80k_pascal_context.py
deleted file mode 100644
index cf315a4f0e6f397768572c590a634cc1b9d298a9..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/hrnet/fcn_hr18_480x480_80k_pascal_context.py
+++ /dev/null
@@ -1,8 +0,0 @@
-_base_ = [
- '../_base_/models/fcn_hr18.py', '../_base_/datasets/pascal_context.py',
- '../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py'
-]
-model = dict(
- decode_head=dict(num_classes=60),
- test_cfg=dict(mode='slide', crop_size=(480, 480), stride=(320, 320)))
-optimizer = dict(type='SGD', lr=0.004, momentum=0.9, weight_decay=0.0001)
diff --git a/spaces/HarlanHong/DaGAN/modules/model.py b/spaces/HarlanHong/DaGAN/modules/model.py
deleted file mode 100644
index 6ea7bf5799b8cf6c4f9c6c24ab29efee036f2e05..0000000000000000000000000000000000000000
--- a/spaces/HarlanHong/DaGAN/modules/model.py
+++ /dev/null
@@ -1,362 +0,0 @@
-from torch import nn
-import torch
-import torch.nn.functional as F
-from modules.util import AntiAliasInterpolation2d, make_coordinate_grid
-from torchvision import models
-import numpy as np
-from torch.autograd import grad
-import pdb
-import depth
-
-class Vgg19(torch.nn.Module):
- """
- Vgg19 network for perceptual loss. See Sec 3.3.
- """
- def __init__(self, requires_grad=False):
- super(Vgg19, self).__init__()
- vgg_pretrained_features = models.vgg19(pretrained=True).features
- self.slice1 = torch.nn.Sequential()
- self.slice2 = torch.nn.Sequential()
- self.slice3 = torch.nn.Sequential()
- self.slice4 = torch.nn.Sequential()
- self.slice5 = torch.nn.Sequential()
- for x in range(2):
- self.slice1.add_module(str(x), vgg_pretrained_features[x])
- for x in range(2, 7):
- self.slice2.add_module(str(x), vgg_pretrained_features[x])
- for x in range(7, 12):
- self.slice3.add_module(str(x), vgg_pretrained_features[x])
- for x in range(12, 21):
- self.slice4.add_module(str(x), vgg_pretrained_features[x])
- for x in range(21, 30):
- self.slice5.add_module(str(x), vgg_pretrained_features[x])
-
- self.mean = torch.nn.Parameter(data=torch.Tensor(np.array([0.485, 0.456, 0.406]).reshape((1, 3, 1, 1))),
- requires_grad=False)
- self.std = torch.nn.Parameter(data=torch.Tensor(np.array([0.229, 0.224, 0.225]).reshape((1, 3, 1, 1))),
- requires_grad=False)
-
- if not requires_grad:
- for param in self.parameters():
- param.requires_grad = False
-
- def forward(self, X):
- X = (X - self.mean) / self.std
- h_relu1 = self.slice1(X)
- h_relu2 = self.slice2(h_relu1)
- h_relu3 = self.slice3(h_relu2)
- h_relu4 = self.slice4(h_relu3)
- h_relu5 = self.slice5(h_relu4)
- out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
- return out
-
-
-class ImagePyramide(torch.nn.Module):
- """
- Create image pyramide for computing pyramide perceptual loss. See Sec 3.3
- """
- def __init__(self, scales, num_channels):
- super(ImagePyramide, self).__init__()
- downs = {}
- for scale in scales:
- downs[str(scale).replace('.', '-')] = AntiAliasInterpolation2d(num_channels, scale)
- self.downs = nn.ModuleDict(downs)
-
- def forward(self, x):
- out_dict = {}
- for scale, down_module in self.downs.items():
- out_dict['prediction_' + str(scale).replace('-', '.')] = down_module(x)
- return out_dict
-
-
-class Transform:
- """
- Random tps transformation for equivariance constraints. See Sec 3.3
- """
- def __init__(self, bs, **kwargs):
- noise = torch.normal(mean=0, std=kwargs['sigma_affine'] * torch.ones([bs, 2, 3]))
- self.theta = noise + torch.eye(2, 3).view(1, 2, 3)
- self.bs = bs
-
- if ('sigma_tps' in kwargs) and ('points_tps' in kwargs):
- self.tps = True
- self.control_points = make_coordinate_grid((kwargs['points_tps'], kwargs['points_tps']), type=noise.type())
- self.control_points = self.control_points.unsqueeze(0)
- self.control_params = torch.normal(mean=0,
- std=kwargs['sigma_tps'] * torch.ones([bs, 1, kwargs['points_tps'] ** 2]))
- else:
- self.tps = False
-
- def transform_frame(self, frame):
- grid = make_coordinate_grid(frame.shape[2:], type=frame.type()).unsqueeze(0)
- grid = grid.view(1, frame.shape[2] * frame.shape[3], 2)
- grid = self.warp_coordinates(grid).view(self.bs, frame.shape[2], frame.shape[3], 2)
- return F.grid_sample(frame, grid, padding_mode="reflection")
-
- def warp_coordinates(self, coordinates):
- theta = self.theta.type(coordinates.type())
- theta = theta.unsqueeze(1)
- transformed = torch.matmul(theta[:, :, :, :2], coordinates.unsqueeze(-1)) + theta[:, :, :, 2:]
- transformed = transformed.squeeze(-1)
-
- if self.tps:
- control_points = self.control_points.type(coordinates.type())
- control_params = self.control_params.type(coordinates.type())
- distances = coordinates.view(coordinates.shape[0], -1, 1, 2) - control_points.view(1, 1, -1, 2)
- distances = torch.abs(distances).sum(-1)
-
- result = distances ** 2
- result = result * torch.log(distances + 1e-6)
- result = result * control_params
- result = result.sum(dim=2).view(self.bs, coordinates.shape[1], 1)
- transformed = transformed + result
-
- return transformed
-
- def jacobian(self, coordinates):
- new_coordinates = self.warp_coordinates(coordinates)
- grad_x = grad(new_coordinates[..., 0].sum(), coordinates, create_graph=True)
- grad_y = grad(new_coordinates[..., 1].sum(), coordinates, create_graph=True)
- jacobian = torch.cat([grad_x[0].unsqueeze(-2), grad_y[0].unsqueeze(-2)], dim=-2)
- return jacobian
-
-
-def detach_kp(kp):
- return {key: value.detach() for key, value in kp.items()}
-
-
-class GeneratorFullModel(torch.nn.Module):
- """
- Merge all generator related updates into single model for better multi-gpu usage
- """
-
- def __init__(self, kp_extractor, generator, discriminator, train_params,opt):
- super(GeneratorFullModel, self).__init__()
- self.kp_extractor = kp_extractor
- self.generator = generator
- self.discriminator = discriminator
- self.train_params = train_params
- self.scales = train_params['scales']
- self.disc_scales = self.discriminator.module.scales
- self.pyramid = ImagePyramide(self.scales, generator.module.num_channels)
- if torch.cuda.is_available():
- self.pyramid = self.pyramid.cuda()
- self.opt = opt
- self.loss_weights = train_params['loss_weights']
-
- if sum(self.loss_weights['perceptual']) != 0:
- self.vgg = Vgg19()
- if torch.cuda.is_available():
- self.vgg = self.vgg.cuda()
- self.depth_encoder = depth.ResnetEncoder(18, False).cuda()
- self.depth_decoder = depth.DepthDecoder(num_ch_enc=self.depth_encoder.num_ch_enc, scales=range(4)).cuda()
- loaded_dict_enc = torch.load('depth/models/weights_19/encoder.pth',map_location='cpu')
- loaded_dict_dec = torch.load('depth/models/weights_19/depth.pth',map_location='cpu')
- filtered_dict_enc = {k: v for k, v in loaded_dict_enc.items() if k in self.depth_encoder.state_dict()}
- self.depth_encoder.load_state_dict(filtered_dict_enc)
- self.depth_decoder.load_state_dict(loaded_dict_dec)
- self.set_requires_grad(self.depth_encoder, False)
- self.set_requires_grad(self.depth_decoder, False)
- self.depth_decoder.eval()
- self.depth_encoder.eval()
- def set_requires_grad(self, nets, requires_grad=False):
- """Set requies_grad=Fasle for all the networks to avoid unnecessary computations
- Parameters:
- nets (network list) -- a list of networks
- requires_grad (bool) -- whether the networks require gradients or not
- """
- if not isinstance(nets, list):
- nets = [nets]
- for net in nets:
- if net is not None:
- for param in net.parameters():
- param.requires_grad = requires_grad
- def forward(self, x):
- depth_source = None
- depth_driving = None
- outputs = self.depth_decoder(self.depth_encoder(x['source']))
- depth_source = outputs[("disp", 0)]
- outputs = self.depth_decoder(self.depth_encoder(x['driving']))
- depth_driving = outputs[("disp", 0)]
-
- if self.opt.use_depth:
- kp_source = self.kp_extractor(depth_source)
- kp_driving = self.kp_extractor(depth_driving)
- elif self.opt.rgbd:
- source = torch.cat((x['source'],depth_source),1)
- driving = torch.cat((x['driving'],depth_driving),1)
- kp_source = self.kp_extractor(source)
- kp_driving = self.kp_extractor(driving)
- else:
- kp_source = self.kp_extractor(x['source'])
- kp_driving = self.kp_extractor(x['driving'])
- generated = self.generator(x['source'], kp_source=kp_source, kp_driving=kp_driving, source_depth = depth_source, driving_depth = depth_driving)
- generated.update({'kp_source': kp_source, 'kp_driving': kp_driving})
- loss_values = {}
- pyramide_real = self.pyramid(x['driving'])
- pyramide_generated = self.pyramid(generated['prediction'])
- if sum(self.loss_weights['perceptual']) != 0:
- value_total = 0
- for scale in self.scales:
- x_vgg = self.vgg(pyramide_generated['prediction_' + str(scale)])
- y_vgg = self.vgg(pyramide_real['prediction_' + str(scale)])
-
- for i, weight in enumerate(self.loss_weights['perceptual']):
- value = torch.abs(x_vgg[i] - y_vgg[i].detach()).mean()
- value_total += self.loss_weights['perceptual'][i] * value
- loss_values['perceptual'] = value_total
-
- if self.loss_weights['generator_gan'] != 0:
-
- discriminator_maps_generated = self.discriminator(pyramide_generated, kp=detach_kp(kp_driving))
-
- discriminator_maps_real = self.discriminator(pyramide_real, kp=detach_kp(kp_driving))
- value_total = 0
- for scale in self.disc_scales:
- key = 'prediction_map_%s' % scale
- value = ((1 - discriminator_maps_generated[key]) ** 2).mean()
- value_total += self.loss_weights['generator_gan'] * value
- loss_values['gen_gan'] = value_total
-
- if sum(self.loss_weights['feature_matching']) != 0:
- value_total = 0
- for scale in self.disc_scales:
- key = 'feature_maps_%s' % scale
- for i, (a, b) in enumerate(zip(discriminator_maps_real[key], discriminator_maps_generated[key])):
- if self.loss_weights['feature_matching'][i] == 0:
- continue
- value = torch.abs(a - b).mean()
- value_total += self.loss_weights['feature_matching'][i] * value
- loss_values['feature_matching'] = value_total
-
- if (self.loss_weights['equivariance_value'] + self.loss_weights['equivariance_jacobian']) != 0:
- transform = Transform(x['driving'].shape[0], **self.train_params['transform_params'])
- transformed_frame = transform.transform_frame(x['driving'])
- if self.opt.use_depth:
- outputs = self.depth_decoder(self.depth_encoder(transformed_frame))
- depth_transform = outputs[("disp", 0)]
- transformed_kp = self.kp_extractor(depth_transform)
- elif self.opt.rgbd:
- outputs = self.depth_decoder(self.depth_encoder(transformed_frame))
- depth_transform = outputs[("disp", 0)]
- transform_img = torch.cat((transformed_frame,depth_transform),1)
- transformed_kp = self.kp_extractor(transform_img)
- else:
- transformed_kp = self.kp_extractor(transformed_frame)
-
- generated['transformed_frame'] = transformed_frame
- generated['transformed_kp'] = transformed_kp
-
- ## Value loss part
- if self.loss_weights['equivariance_value'] != 0:
- value = torch.abs(kp_driving['value'] - transform.warp_coordinates(transformed_kp['value'])).mean()
- loss_values['equivariance_value'] = self.loss_weights['equivariance_value'] * value
-
- ## jacobian loss part
- if self.loss_weights['equivariance_jacobian'] != 0:
- jacobian_transformed = torch.matmul(transform.jacobian(transformed_kp['value']),
- transformed_kp['jacobian'])
-
- normed_driving = torch.inverse(kp_driving['jacobian'])
- normed_transformed = jacobian_transformed
- value = torch.matmul(normed_driving, normed_transformed)
-
- eye = torch.eye(2).view(1, 1, 2, 2).type(value.type())
-
- value = torch.abs(eye - value).mean()
- loss_values['equivariance_jacobian'] = self.loss_weights['equivariance_jacobian'] * value
-
-
- if self.loss_weights['kp_distance']:
- bz,num_kp,kp_dim = kp_source['value'].shape
- sk = kp_source['value'].unsqueeze(2)-kp_source['value'].unsqueeze(1)
- dk = kp_driving['value'].unsqueeze(2)-kp_driving['value'].unsqueeze(1)
- source_dist_loss = (-torch.sign((torch.sqrt((sk*sk).sum(-1)+1e-8)+torch.eye(num_kp).cuda()*0.2)-0.2)+1).mean()
- driving_dist_loss = (-torch.sign((torch.sqrt((dk*dk).sum(-1)+1e-8)+torch.eye(num_kp).cuda()*0.2)-0.2)+1).mean()
- # driving_dist_loss = (torch.sign(1-(torch.sqrt((dk*dk).sum(-1)+1e-8)+torch.eye(num_kp).cuda()))+1).mean()
- value_total = self.loss_weights['kp_distance']*(source_dist_loss+driving_dist_loss)
- loss_values['kp_distance'] = value_total
- if self.loss_weights['kp_prior']:
- bz,num_kp,kp_dim = kp_source['value'].shape
- sk = kp_source['value'].unsqueeze(2)-kp_source['value'].unsqueeze(1)
- dk = kp_driving['value'].unsqueeze(2)-kp_driving['value'].unsqueeze(1)
- dis_loss = torch.relu(0.1-torch.sqrt((sk*sk).sum(-1)+1e-8))+torch.relu(0.1-torch.sqrt((dk*dk).sum(-1)+1e-8))
- bs,nk,_=kp_source['value'].shape
- scoor_depth = F.grid_sample(depth_source,kp_source['value'].view(bs,1,nk,-1))
- dcoor_depth = F.grid_sample(depth_driving,kp_driving['value'].view(bs,1,nk,-1))
- sd_loss = torch.abs(scoor_depth.mean(-1,keepdim=True) - kp_source['value'].view(bs,1,nk,-1)).mean()
- dd_loss = torch.abs(dcoor_depth.mean(-1,keepdim=True) - kp_driving['value'].view(bs,1,nk,-1)).mean()
- value_total = self.loss_weights['kp_distance']*(dis_loss+sd_loss+dd_loss)
- loss_values['kp_distance'] = value_total
-
-
- if self.loss_weights['kp_scale']:
- bz,num_kp,kp_dim = kp_source['value'].shape
- if self.opt.rgbd:
- outputs = self.depth_decoder(self.depth_encoder(generated['prediction']))
- depth_pred = outputs[("disp", 0)]
- pred = torch.cat((generated['prediction'],depth_pred),1)
- kp_pred = self.kp_extractor(pred)
- elif self.opt.use_depth:
- outputs = self.depth_decoder(self.depth_encoder(generated['prediction']))
- depth_pred = outputs[("disp", 0)]
- kp_pred = self.kp_extractor(depth_pred)
- else:
- kp_pred = self.kp_extractor(generated['prediction'])
-
- pred_mean = kp_pred['value'].mean(1,keepdim=True)
- driving_mean = kp_driving['value'].mean(1,keepdim=True)
- pk = kp_source['value']-pred_mean
- dk = kp_driving['value']- driving_mean
- pred_dist_loss = torch.sqrt((pk*pk).sum(-1)+1e-8)
- driving_dist_loss = torch.sqrt((dk*dk).sum(-1)+1e-8)
- scale_vec = driving_dist_loss/pred_dist_loss
- bz,n = scale_vec.shape
- value = torch.abs(scale_vec[:,:n-1]-scale_vec[:,1:]).mean()
- value_total = self.loss_weights['kp_scale']*value
- loss_values['kp_scale'] = value_total
- if self.loss_weights['depth_constraint']:
- bz,num_kp,kp_dim = kp_source['value'].shape
- outputs = self.depth_decoder(self.depth_encoder(generated['prediction']))
- depth_pred = outputs[("disp", 0)]
- value_total = self.loss_weights['depth_constraint']*torch.abs(depth_driving-depth_pred).mean()
- loss_values['depth_constraint'] = value_total
- return loss_values, generated
-
-
-
-class DiscriminatorFullModel(torch.nn.Module):
- """
- Merge all discriminator related updates into single model for better multi-gpu usage
- """
-
- def __init__(self, kp_extractor, generator, discriminator, train_params):
- super(DiscriminatorFullModel, self).__init__()
- self.kp_extractor = kp_extractor
- self.generator = generator
- self.discriminator = discriminator
- self.train_params = train_params
- self.scales = self.discriminator.module.scales
- self.pyramid = ImagePyramide(self.scales, generator.module.num_channels)
- if torch.cuda.is_available():
- self.pyramid = self.pyramid.cuda()
-
- self.loss_weights = train_params['loss_weights']
-
- def forward(self, x, generated):
- pyramide_real = self.pyramid(x['driving'])
- pyramide_generated = self.pyramid(generated['prediction'].detach())
-
- kp_driving = generated['kp_driving']
- discriminator_maps_generated = self.discriminator(pyramide_generated, kp=detach_kp(kp_driving))
- discriminator_maps_real = self.discriminator(pyramide_real, kp=detach_kp(kp_driving))
-
- loss_values = {}
- value_total = 0
- for scale in self.scales:
- key = 'prediction_map_%s' % scale
- value = (1 - discriminator_maps_real[key]) ** 2 + discriminator_maps_generated[key] ** 2
- value_total += self.loss_weights['discriminator_gan'] * value.mean()
- loss_values['disc_gan'] = value_total
-
- return loss_values
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/nan_detector.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/nan_detector.py
deleted file mode 100644
index faa8031d4666c9ba9837919fe1c884dacf47ac3a..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/nan_detector.py
+++ /dev/null
@@ -1,108 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import logging
-
-import torch
-
-
-logger = logging.getLogger(__name__)
-
-
-class NanDetector:
- """
- Detects the first NaN or Inf in forward and/or backward pass and logs, together with the module name
- """
-
- def __init__(self, model, forward=True, backward=True):
- self.bhooks = []
- self.fhooks = []
- self.forward = forward
- self.backward = backward
- self.named_parameters = list(model.named_parameters())
- self.reset()
-
- for name, mod in model.named_modules():
- mod.__module_name = name
- self.add_hooks(mod)
-
- def __enter__(self):
- return self
-
- def __exit__(self, exc_type, exc_value, exc_traceback):
- # Dump out all model gnorms to enable better debugging
- norm = {}
- gradients = {}
- for name, param in self.named_parameters:
- if param.grad is not None:
- grad_norm = torch.norm(param.grad.data, p=2, dtype=torch.float32)
- norm[name] = grad_norm.item()
- if torch.isnan(grad_norm).any() or torch.isinf(grad_norm).any():
- gradients[name] = param.grad.data
- if len(gradients) > 0:
- logger.info("Detected nan/inf grad norm, dumping norms...")
- logger.info(f"norms: {norm}")
- logger.info(f"gradients: {gradients}")
-
- self.close()
-
- def add_hooks(self, module):
- if self.forward:
- self.fhooks.append(module.register_forward_hook(self.fhook_fn))
- if self.backward:
- self.bhooks.append(module.register_backward_hook(self.bhook_fn))
-
- def reset(self):
- self.has_printed_f = False
- self.has_printed_b = False
-
- def _detect(self, tensor, name, backward):
- err = None
- if (
- torch.is_floating_point(tensor)
- # single value tensors (like the loss) will not provide much info
- and tensor.numel() >= 2
- ):
- with torch.no_grad():
- if torch.isnan(tensor).any():
- err = "NaN"
- elif torch.isinf(tensor).any():
- err = "Inf"
- if err is not None:
- err = f"{err} detected in output of {name}, shape: {tensor.shape}, {'backward' if backward else 'forward'}"
- return err
-
- def _apply(self, module, inp, x, backward):
- if torch.is_tensor(x):
- if isinstance(inp, tuple) and len(inp) > 0:
- inp = inp[0]
- err = self._detect(x, module.__module_name, backward)
- if err is not None:
- if torch.is_tensor(inp) and not backward:
- err += (
- f" input max: {inp.max().item()}, input min: {inp.min().item()}"
- )
-
- has_printed_attr = "has_printed_b" if backward else "has_printed_f"
- logger.warning(err)
- setattr(self, has_printed_attr, True)
- elif isinstance(x, dict):
- for v in x.values():
- self._apply(module, inp, v, backward)
- elif isinstance(x, list) or isinstance(x, tuple):
- for v in x:
- self._apply(module, inp, v, backward)
-
- def fhook_fn(self, module, inp, output):
- if not self.has_printed_f:
- self._apply(module, inp, output, backward=False)
-
- def bhook_fn(self, module, inp, output):
- if not self.has_printed_b:
- self._apply(module, inp, output, backward=True)
-
- def close(self):
- for hook in self.fhooks + self.bhooks:
- hook.remove()
diff --git a/spaces/Harveenchadha/en_to_indic_translation/subword-nmt/subword_nmt/tests/__init__.py b/spaces/Harveenchadha/en_to_indic_translation/subword-nmt/subword_nmt/tests/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Heshwa/html-code-generation-from-images-with-deep-neural-networks/app.py b/spaces/Heshwa/html-code-generation-from-images-with-deep-neural-networks/app.py
deleted file mode 100644
index 0a34aaa4ec372e9867e07aa1029d38d513a25950..0000000000000000000000000000000000000000
--- a/spaces/Heshwa/html-code-generation-from-images-with-deep-neural-networks/app.py
+++ /dev/null
@@ -1,54 +0,0 @@
-__author__ = 'Taneem Jan, taneemishere.github.io'
-
-import gradio as gr
-import main_program
-
-
-# our model's i/o method that take image from gradio interface's inputs.Image()
-def model_interface(image):
- return main_model(image)
-
-
-# main method that call the main_program where code is generated and then compiled
-def main_model(input_image):
- result = main_program.main_method(input_image)
- return result
-
-
-interface_title = "
HTML Code Generation from Images with Deep Neural Networks
"
-interface_description = """ Writing
-code in a programming language for a designed mockup or a graphical user interface created by designers and UI
-engineers, is done mostly by developers to build and develop custom websites and software. The development work is
-not approachable by those unfamiliar with programming, to drive these personas capable of designing and developing
-the code bases and website structures we come up with an automated system. In this work, we showed and proposed that
-methods of deep learning and computer vision can be grasped to train a model that will automatically generate HTML
-code from a single input mockup image and try to build an end-to-end automated system with accuracy more than
-previous works for developing the structures of web pages.
"""
-
-interface_article = """
Limitations of Model
Certain limitations are there in the model some of them are listed below
- Sometimes the model do
-produce all the buttons with the same green color instead of other colors
- As the model has fed with the data
-provided, and so while producing the code on some other types of images might not generate the code we
-wanted
- The model is only trained upon the learning and recognition of boxes and buttons etc. in the images
-and it do not write the text written exactly on the images
- """
-
-interface_examples = ['examples/example-1.png', 'examples/example-2.png', 'examples/example-3.png']
-
-# a gradio interface to convert a image to HTML Code
-interface = gr.Interface(
- model_interface,
- inputs='image',
- outputs='text',
- allow_flagging="manual",
- title=interface_title,
- description=interface_description,
- article=interface_article,
- examples=interface_examples
-)
-
-interface.launch(share=False)
diff --git a/spaces/HighCWu/GFPGAN-1.3/gfpgan/archs/stylegan2_clean_arch.py b/spaces/HighCWu/GFPGAN-1.3/gfpgan/archs/stylegan2_clean_arch.py
deleted file mode 100644
index 9e2ee94e50401b95e4c9997adef5581d521d725f..0000000000000000000000000000000000000000
--- a/spaces/HighCWu/GFPGAN-1.3/gfpgan/archs/stylegan2_clean_arch.py
+++ /dev/null
@@ -1,368 +0,0 @@
-import math
-import random
-import torch
-from basicsr.archs.arch_util import default_init_weights
-from basicsr.utils.registry import ARCH_REGISTRY
-from torch import nn
-from torch.nn import functional as F
-
-
-class NormStyleCode(nn.Module):
-
- def forward(self, x):
- """Normalize the style codes.
-
- Args:
- x (Tensor): Style codes with shape (b, c).
-
- Returns:
- Tensor: Normalized tensor.
- """
- return x * torch.rsqrt(torch.mean(x**2, dim=1, keepdim=True) + 1e-8)
-
-
-class ModulatedConv2d(nn.Module):
- """Modulated Conv2d used in StyleGAN2.
-
- There is no bias in ModulatedConv2d.
-
- Args:
- in_channels (int): Channel number of the input.
- out_channels (int): Channel number of the output.
- kernel_size (int): Size of the convolving kernel.
- num_style_feat (int): Channel number of style features.
- demodulate (bool): Whether to demodulate in the conv layer. Default: True.
- sample_mode (str | None): Indicating 'upsample', 'downsample' or None. Default: None.
- eps (float): A value added to the denominator for numerical stability. Default: 1e-8.
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- kernel_size,
- num_style_feat,
- demodulate=True,
- sample_mode=None,
- eps=1e-8):
- super(ModulatedConv2d, self).__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.demodulate = demodulate
- self.sample_mode = sample_mode
- self.eps = eps
-
- # modulation inside each modulated conv
- self.modulation = nn.Linear(num_style_feat, in_channels, bias=True)
- # initialization
- default_init_weights(self.modulation, scale=1, bias_fill=1, a=0, mode='fan_in', nonlinearity='linear')
-
- self.weight = nn.Parameter(
- torch.randn(1, out_channels, in_channels, kernel_size, kernel_size) /
- math.sqrt(in_channels * kernel_size**2))
- self.padding = kernel_size // 2
-
- def forward(self, x, style):
- """Forward function.
-
- Args:
- x (Tensor): Tensor with shape (b, c, h, w).
- style (Tensor): Tensor with shape (b, num_style_feat).
-
- Returns:
- Tensor: Modulated tensor after convolution.
- """
- b, c, h, w = x.shape # c = c_in
- # weight modulation
- style = self.modulation(style).view(b, 1, c, 1, 1)
- # self.weight: (1, c_out, c_in, k, k); style: (b, 1, c, 1, 1)
- weight = self.weight * style # (b, c_out, c_in, k, k)
-
- if self.demodulate:
- demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + self.eps)
- weight = weight * demod.view(b, self.out_channels, 1, 1, 1)
-
- weight = weight.view(b * self.out_channels, c, self.kernel_size, self.kernel_size)
-
- # upsample or downsample if necessary
- if self.sample_mode == 'upsample':
- x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)
- elif self.sample_mode == 'downsample':
- x = F.interpolate(x, scale_factor=0.5, mode='bilinear', align_corners=False)
-
- b, c, h, w = x.shape
- x = x.view(1, b * c, h, w)
- # weight: (b*c_out, c_in, k, k), groups=b
- out = F.conv2d(x, weight, padding=self.padding, groups=b)
- out = out.view(b, self.out_channels, *out.shape[2:4])
-
- return out
-
- def __repr__(self):
- return (f'{self.__class__.__name__}(in_channels={self.in_channels}, out_channels={self.out_channels}, '
- f'kernel_size={self.kernel_size}, demodulate={self.demodulate}, sample_mode={self.sample_mode})')
-
-
-class StyleConv(nn.Module):
- """Style conv used in StyleGAN2.
-
- Args:
- in_channels (int): Channel number of the input.
- out_channels (int): Channel number of the output.
- kernel_size (int): Size of the convolving kernel.
- num_style_feat (int): Channel number of style features.
- demodulate (bool): Whether demodulate in the conv layer. Default: True.
- sample_mode (str | None): Indicating 'upsample', 'downsample' or None. Default: None.
- """
-
- def __init__(self, in_channels, out_channels, kernel_size, num_style_feat, demodulate=True, sample_mode=None):
- super(StyleConv, self).__init__()
- self.modulated_conv = ModulatedConv2d(
- in_channels, out_channels, kernel_size, num_style_feat, demodulate=demodulate, sample_mode=sample_mode)
- self.weight = nn.Parameter(torch.zeros(1)) # for noise injection
- self.bias = nn.Parameter(torch.zeros(1, out_channels, 1, 1))
- self.activate = nn.LeakyReLU(negative_slope=0.2, inplace=True)
-
- def forward(self, x, style, noise=None):
- # modulate
- out = self.modulated_conv(x, style) * 2**0.5 # for conversion
- # noise injection
- if noise is None:
- b, _, h, w = out.shape
- noise = out.new_empty(b, 1, h, w).normal_()
- out = out + self.weight * noise
- # add bias
- out = out + self.bias
- # activation
- out = self.activate(out)
- return out
-
-
-class ToRGB(nn.Module):
- """To RGB (image space) from features.
-
- Args:
- in_channels (int): Channel number of input.
- num_style_feat (int): Channel number of style features.
- upsample (bool): Whether to upsample. Default: True.
- """
-
- def __init__(self, in_channels, num_style_feat, upsample=True):
- super(ToRGB, self).__init__()
- self.upsample = upsample
- self.modulated_conv = ModulatedConv2d(
- in_channels, 3, kernel_size=1, num_style_feat=num_style_feat, demodulate=False, sample_mode=None)
- self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
-
- def forward(self, x, style, skip=None):
- """Forward function.
-
- Args:
- x (Tensor): Feature tensor with shape (b, c, h, w).
- style (Tensor): Tensor with shape (b, num_style_feat).
- skip (Tensor): Base/skip tensor. Default: None.
-
- Returns:
- Tensor: RGB images.
- """
- out = self.modulated_conv(x, style)
- out = out + self.bias
- if skip is not None:
- if self.upsample:
- skip = F.interpolate(skip, scale_factor=2, mode='bilinear', align_corners=False)
- out = out + skip
- return out
-
-
-class ConstantInput(nn.Module):
- """Constant input.
-
- Args:
- num_channel (int): Channel number of constant input.
- size (int): Spatial size of constant input.
- """
-
- def __init__(self, num_channel, size):
- super(ConstantInput, self).__init__()
- self.weight = nn.Parameter(torch.randn(1, num_channel, size, size))
-
- def forward(self, batch):
- out = self.weight.repeat(batch, 1, 1, 1)
- return out
-
-
-@ARCH_REGISTRY.register()
-class StyleGAN2GeneratorClean(nn.Module):
- """Clean version of StyleGAN2 Generator.
-
- Args:
- out_size (int): The spatial size of outputs.
- num_style_feat (int): Channel number of style features. Default: 512.
- num_mlp (int): Layer number of MLP style layers. Default: 8.
- channel_multiplier (int): Channel multiplier for large networks of StyleGAN2. Default: 2.
- narrow (float): Narrow ratio for channels. Default: 1.0.
- """
-
- def __init__(self, out_size, num_style_feat=512, num_mlp=8, channel_multiplier=2, narrow=1):
- super(StyleGAN2GeneratorClean, self).__init__()
- # Style MLP layers
- self.num_style_feat = num_style_feat
- style_mlp_layers = [NormStyleCode()]
- for i in range(num_mlp):
- style_mlp_layers.extend(
- [nn.Linear(num_style_feat, num_style_feat, bias=True),
- nn.LeakyReLU(negative_slope=0.2, inplace=True)])
- self.style_mlp = nn.Sequential(*style_mlp_layers)
- # initialization
- default_init_weights(self.style_mlp, scale=1, bias_fill=0, a=0.2, mode='fan_in', nonlinearity='leaky_relu')
-
- # channel list
- channels = {
- '4': int(512 * narrow),
- '8': int(512 * narrow),
- '16': int(512 * narrow),
- '32': int(512 * narrow),
- '64': int(256 * channel_multiplier * narrow),
- '128': int(128 * channel_multiplier * narrow),
- '256': int(64 * channel_multiplier * narrow),
- '512': int(32 * channel_multiplier * narrow),
- '1024': int(16 * channel_multiplier * narrow)
- }
- self.channels = channels
-
- self.constant_input = ConstantInput(channels['4'], size=4)
- self.style_conv1 = StyleConv(
- channels['4'],
- channels['4'],
- kernel_size=3,
- num_style_feat=num_style_feat,
- demodulate=True,
- sample_mode=None)
- self.to_rgb1 = ToRGB(channels['4'], num_style_feat, upsample=False)
-
- self.log_size = int(math.log(out_size, 2))
- self.num_layers = (self.log_size - 2) * 2 + 1
- self.num_latent = self.log_size * 2 - 2
-
- self.style_convs = nn.ModuleList()
- self.to_rgbs = nn.ModuleList()
- self.noises = nn.Module()
-
- in_channels = channels['4']
- # noise
- for layer_idx in range(self.num_layers):
- resolution = 2**((layer_idx + 5) // 2)
- shape = [1, 1, resolution, resolution]
- self.noises.register_buffer(f'noise{layer_idx}', torch.randn(*shape))
- # style convs and to_rgbs
- for i in range(3, self.log_size + 1):
- out_channels = channels[f'{2**i}']
- self.style_convs.append(
- StyleConv(
- in_channels,
- out_channels,
- kernel_size=3,
- num_style_feat=num_style_feat,
- demodulate=True,
- sample_mode='upsample'))
- self.style_convs.append(
- StyleConv(
- out_channels,
- out_channels,
- kernel_size=3,
- num_style_feat=num_style_feat,
- demodulate=True,
- sample_mode=None))
- self.to_rgbs.append(ToRGB(out_channels, num_style_feat, upsample=True))
- in_channels = out_channels
-
- def make_noise(self):
- """Make noise for noise injection."""
- device = self.constant_input.weight.device
- noises = [torch.randn(1, 1, 4, 4, device=device)]
-
- for i in range(3, self.log_size + 1):
- for _ in range(2):
- noises.append(torch.randn(1, 1, 2**i, 2**i, device=device))
-
- return noises
-
- def get_latent(self, x):
- return self.style_mlp(x)
-
- def mean_latent(self, num_latent):
- latent_in = torch.randn(num_latent, self.num_style_feat, device=self.constant_input.weight.device)
- latent = self.style_mlp(latent_in).mean(0, keepdim=True)
- return latent
-
- def forward(self,
- styles,
- input_is_latent=False,
- noise=None,
- randomize_noise=True,
- truncation=1,
- truncation_latent=None,
- inject_index=None,
- return_latents=False):
- """Forward function for StyleGAN2GeneratorClean.
-
- Args:
- styles (list[Tensor]): Sample codes of styles.
- input_is_latent (bool): Whether input is latent style. Default: False.
- noise (Tensor | None): Input noise or None. Default: None.
- randomize_noise (bool): Randomize noise, used when 'noise' is False. Default: True.
- truncation (float): The truncation ratio. Default: 1.
- truncation_latent (Tensor | None): The truncation latent tensor. Default: None.
- inject_index (int | None): The injection index for mixing noise. Default: None.
- return_latents (bool): Whether to return style latents. Default: False.
- """
- # style codes -> latents with Style MLP layer
- if not input_is_latent:
- styles = [self.style_mlp(s) for s in styles]
- # noises
- if noise is None:
- if randomize_noise:
- noise = [None] * self.num_layers # for each style conv layer
- else: # use the stored noise
- noise = [getattr(self.noises, f'noise{i}') for i in range(self.num_layers)]
- # style truncation
- if truncation < 1:
- style_truncation = []
- for style in styles:
- style_truncation.append(truncation_latent + truncation * (style - truncation_latent))
- styles = style_truncation
- # get style latents with injection
- if len(styles) == 1:
- inject_index = self.num_latent
-
- if styles[0].ndim < 3:
- # repeat latent code for all the layers
- latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
- else: # used for encoder with different latent code for each layer
- latent = styles[0]
- elif len(styles) == 2: # mixing noises
- if inject_index is None:
- inject_index = random.randint(1, self.num_latent - 1)
- latent1 = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
- latent2 = styles[1].unsqueeze(1).repeat(1, self.num_latent - inject_index, 1)
- latent = torch.cat([latent1, latent2], 1)
-
- # main generation
- out = self.constant_input(latent.shape[0])
- out = self.style_conv1(out, latent[:, 0], noise=noise[0])
- skip = self.to_rgb1(out, latent[:, 1])
-
- i = 1
- for conv1, conv2, noise1, noise2, to_rgb in zip(self.style_convs[::2], self.style_convs[1::2], noise[1::2],
- noise[2::2], self.to_rgbs):
- out = conv1(out, latent[:, i], noise=noise1)
- out = conv2(out, latent[:, i + 1], noise=noise2)
- skip = to_rgb(out, latent[:, i + 2], skip) # feature back to the rgb space
- i += 2
-
- image = skip
-
- if return_latents:
- return image, latent
- else:
- return image, None
diff --git a/spaces/Hina4867/bingo/src/lib/hooks/use-bing.ts b/spaces/Hina4867/bingo/src/lib/hooks/use-bing.ts
deleted file mode 100644
index dcdb1667ced0cba299b0825c0e91c4732411308c..0000000000000000000000000000000000000000
--- a/spaces/Hina4867/bingo/src/lib/hooks/use-bing.ts
+++ /dev/null
@@ -1,173 +0,0 @@
-'use client'
-
-import { useState, useCallback, useEffect, useMemo } from 'react'
-import { useAtom, useAtomValue } from 'jotai'
-import { chatFamily, bingConversationStyleAtom, GreetMessages, hashAtom, voiceAtom } from '@/state'
-import { setConversationMessages } from './chat-history'
-import { ChatMessageModel, BotId, FileItem } from '@/lib/bots/bing/types'
-import { nanoid } from '../utils'
-import { TTS } from '../bots/bing/tts'
-
-export function useBing(botId: BotId = 'bing') {
- const chatAtom = useMemo(() => chatFamily({ botId, page: 'singleton' }), [botId])
- const [enableTTS] = useAtom(voiceAtom)
- const speaker = useMemo(() => new TTS(), [])
- const [hash, setHash] = useAtom(hashAtom)
- const bingConversationStyle = useAtomValue(bingConversationStyleAtom)
- const [chatState, setChatState] = useAtom(chatAtom)
- const [input, setInput] = useState('')
- const [attachmentList, setAttachmentList] = useState([])
-
- const updateMessage = useCallback(
- (messageId: string, updater: (message: ChatMessageModel) => void) => {
- setChatState((draft) => {
- const message = draft.messages.find((m) => m.id === messageId)
- if (message) {
- updater(message)
- }
- })
- },
- [setChatState],
- )
-
- const sendMessage = useCallback(
- async (input: string, options = {}) => {
- const botMessageId = nanoid()
- const imageUrl = attachmentList?.[0]?.status === 'loaded' ? attachmentList[0].url : undefined
- setChatState((draft) => {
- const text = imageUrl ? `${input}\n\n` : input
- draft.messages.push({ id: nanoid(), text, author: 'user' }, { id: botMessageId, text: '', author: 'bot' })
- setAttachmentList([])
- })
- const abortController = new AbortController()
- setChatState((draft) => {
- draft.generatingMessageId = botMessageId
- draft.abortController = abortController
- })
- speaker.reset()
- await chatState.bot.sendMessage({
- prompt: input,
- imageUrl: /\?bcid=([^&]+)/.test(imageUrl ?? '') ? `https://www.bing.com/images/blob?bcid=${RegExp.$1}` : imageUrl,
- options: {
- ...options,
- bingConversationStyle,
- },
- signal: abortController.signal,
- onEvent(event) {
- if (event.type === 'UPDATE_ANSWER') {
- updateMessage(botMessageId, (message) => {
- if (event.data.text.length > message.text.length) {
- message.text = event.data.text
- }
-
- if (event.data.spokenText && enableTTS) {
- speaker.speak(event.data.spokenText)
- }
-
- message.throttling = event.data.throttling || message.throttling
- message.sourceAttributions = event.data.sourceAttributions || message.sourceAttributions
- message.suggestedResponses = event.data.suggestedResponses || message.suggestedResponses
- })
- } else if (event.type === 'ERROR') {
- updateMessage(botMessageId, (message) => {
- message.error = event.error
- })
- setChatState((draft) => {
- draft.abortController = undefined
- draft.generatingMessageId = ''
- })
- } else if (event.type === 'DONE') {
- setChatState((draft) => {
- draft.abortController = undefined
- draft.generatingMessageId = ''
- })
- }
- },
- })
- },
- [botId, attachmentList, chatState.bot, setChatState, updateMessage],
- )
-
- const uploadImage = useCallback(async (imgUrl: string) => {
- setAttachmentList([{ url: imgUrl, status: 'loading' }])
- const response = await chatState.bot.uploadImage(imgUrl, bingConversationStyle)
- if (response?.blobId) {
- setAttachmentList([{ url: `/api/blob?bcid=${response.blobId}`, status: 'loaded' }])
- } else {
- setAttachmentList([{ url: imgUrl, status: 'error' }])
- }
- }, [chatState.bot])
-
- const resetConversation = useCallback(() => {
- chatState.bot.resetConversation()
- speaker.abort()
- setChatState((draft) => {
- draft.abortController = undefined
- draft.generatingMessageId = ''
- draft.messages = [{ author: 'bot', text: GreetMessages[Math.floor(GreetMessages.length * Math.random())], id: nanoid() }]
- draft.conversationId = nanoid()
- })
- }, [chatState.bot, setChatState])
-
- const stopGenerating = useCallback(() => {
- chatState.abortController?.abort()
- if (chatState.generatingMessageId) {
- updateMessage(chatState.generatingMessageId, (message) => {
- if (!message.text && !message.error) {
- message.text = 'Cancelled'
- }
- })
- }
- setChatState((draft) => {
- draft.generatingMessageId = ''
- })
- }, [chatState.abortController, chatState.generatingMessageId, setChatState, updateMessage])
-
- useEffect(() => {
- if (chatState.messages.length) {
- setConversationMessages(botId, chatState.conversationId, chatState.messages)
- }
- }, [botId, chatState.conversationId, chatState.messages])
-
- useEffect(() => {
- if (hash === 'reset') {
- resetConversation()
- setHash('')
- }
- }, [hash, setHash])
-
- const chat = useMemo(
- () => ({
- botId,
- bot: chatState.bot,
- isSpeaking: speaker.isSpeaking,
- messages: chatState.messages,
- sendMessage,
- setInput,
- input,
- resetConversation,
- generating: !!chatState.generatingMessageId,
- stopGenerating,
- uploadImage,
- setAttachmentList,
- attachmentList,
- }),
- [
- botId,
- bingConversationStyle,
- chatState.bot,
- chatState.generatingMessageId,
- chatState.messages,
- speaker.isSpeaking,
- setInput,
- input,
- setAttachmentList,
- attachmentList,
- resetConversation,
- sendMessage,
- stopGenerating,
- ],
- )
-
- return chat
-}
diff --git a/spaces/ICML2022/OFA/fairseq/examples/latent_depth/latent_depth_src/multilingual_translation_latent_depth.py b/spaces/ICML2022/OFA/fairseq/examples/latent_depth/latent_depth_src/multilingual_translation_latent_depth.py
deleted file mode 100644
index 8cc2a7174b765b7ad8808489196e12082a91a2d7..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/examples/latent_depth/latent_depth_src/multilingual_translation_latent_depth.py
+++ /dev/null
@@ -1,195 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from fairseq.tasks import register_task
-from fairseq.tasks.multilingual_translation import MultilingualTranslationTask
-from fairseq.utils import safe_hasattr
-
-from .loss.latent_depth import LatentLayersKLLoss, LatentLayersSparsityLoss
-
-
-@register_task("multilingual_translation_latent_depth")
-class MultilingualTranslationTaskLatentDepth(MultilingualTranslationTask):
- """A task for multiple translation with latent depth.
-
- See `"Deep Transformer with Latent Depth"
- (Li et al., 2020) `_.
- """
-
- @staticmethod
- def add_args(parser):
- """Add task-specific arguments to the parser."""
- # fmt: off
- MultilingualTranslationTask.add_args(parser)
- parser.add_argument('--encoder-latent-layer', action='store_true', help='latent layer selection in encoder')
- parser.add_argument('--decoder-latent-layer', action='store_true', help='latent layer selection in decoder')
- parser.add_argument('--target-layers', default=-1, type=int,
- help='number of effective layers to learn; -1 means no constraint')
- parser.add_argument('--sparsity-weight', default=0.0, type=float,
- help='weight for sparsity loss')
- parser.add_argument('--share-weight', default=0.0, type=float,
- help='weight for sharing loss')
- parser.add_argument('--soft-update', default=1, type=int,
- help='number of updates with soft sampling')
- parser.add_argument('--anneal-updates', default=1, type=int,
- help='number of updates to anneal the KL loss weight')
- parser.add_argument('--prior', default="uniform", type=str,
- help='prior used for computing KL loss')
- # fmt: on
-
- def __init__(self, args, dicts, training):
- super().__init__(args, dicts, training)
- self.src_langs, self.tgt_langs = zip(
- *[(lang.split("-")[0], lang.split("-")[1]) for lang in args.lang_pairs]
- )
- if self.training and self.encoder_latent_layer:
- assert self.args.share_encoders
- if self.training and self.decoder_latent_layer:
- assert self.args.share_decoders
- if training or self.encoder_latent_layer or self.decoder_latent_layer:
- self.lang_pairs = args.lang_pairs
- else:
- self.lang_pairs = ["{}-{}".format(args.source_lang, args.target_lang)]
- self.eval_lang_pairs = self.lang_pairs
- self.model_lang_pairs = self.lang_pairs
- if self.training and (self.encoder_latent_layer or self.decoder_latent_layer):
- self.kl_loss = LatentLayersKLLoss(self.args)
- self.sparsity_loss = LatentLayersSparsityLoss(self.args)
-
- def _per_lang_pair_train_loss(
- self, lang_pair, model, update_num, criterion, sample, optimizer, ignore_grad
- ):
- src, tgt = lang_pair.split("-")
- if self.encoder_latent_layer:
- src_lang_idx = self.src_lang_idx_dict[src]
- model.models[lang_pair].encoder.set_lang_idx(src_lang_idx)
- model.models[lang_pair].encoder.layer_select.hard_select = (
- update_num > self.args.soft_update
- )
- if self.decoder_latent_layer:
- tgt_lang_idx = self.tgt_lang_idx_dict[tgt]
- model.models[lang_pair].decoder.set_lang_idx(tgt_lang_idx)
- model.models[lang_pair].decoder.layer_select.hard_select = (
- update_num > self.args.soft_update
- )
-
- loss, sample_size, logging_output = criterion(
- model.models[lang_pair], sample[lang_pair]
- )
- if self.encoder_latent_layer:
- none_samples = sum(
- 1 if x is None else 0
- for x in model.models[lang_pair].encoder.layer_select.layer_samples
- )
- if none_samples == 0 or self.args.prior != "agged_posterior":
- loss += self.kl_loss(
- model.models[lang_pair].encoder.layer_select.layer_samples,
- src_lang_idx,
- update_num,
- sample_size,
- )
- if self.decoder_latent_layer:
- none_samples = sum(
- 1 if x is None else 0
- for x in model.models[lang_pair].decoder.layer_select.layer_samples
- )
- if none_samples == 0 or self.args.prior != "agged_posterior":
- loss += self.kl_loss(
- model.models[lang_pair].decoder.layer_select.layer_samples,
- tgt_lang_idx,
- update_num,
- sample_size,
- )
- if ignore_grad:
- loss *= 0
-
- if hasattr(self, "sparsity_loss") and self.sparsity_loss.is_valid(update_num):
- # need to retain the graph if sparsity loss needs to be added
- loss.backward(retain_graph=True)
- else:
- optimizer.backward(loss)
-
- return loss, sample_size, logging_output
-
- def train_step(
- self, sample, model, criterion, optimizer, update_num, ignore_grad=False
- ):
- agg_loss, agg_sample_size, agg_logging_output = super().train_step(
- sample, model, criterion, optimizer, update_num, ignore_grad
- )
- # compute auxiliary loss from layere sparsity, based on all samples from all languages
- if hasattr(self, "sparsity_loss") and self.sparsity_loss.is_valid(update_num):
- sparsity_loss = 0
- if self.encoder_latent_layer:
- sparsity_loss += self.sparsity_loss(
- next(
- iter(model.models.values())
- ).encoder.layer_select.layer_samples,
- update_num,
- agg_sample_size,
- )
- if self.decoder_latent_layer:
- sparsity_loss += self.sparsity_loss(
- next(
- iter(model.models.values())
- ).decoder.layer_select.layer_samples,
- update_num,
- agg_sample_size,
- )
- if sparsity_loss > 0:
- optimizer.backward(sparsity_loss)
- return agg_loss, agg_sample_size, agg_logging_output
-
- def _per_lang_pair_valid_loss(self, lang_pair, model, criterion, sample):
- src, tgt = lang_pair.split("-")
- if self.encoder_latent_layer:
- src_lang_idx = self.src_lang_idx_dict[src]
- model.models[lang_pair].encoder.set_lang_idx(src_lang_idx)
- if self.decoder_latent_layer:
- tgt_lang_idx = self.tgt_lang_idx_dict[tgt]
- model.models[lang_pair].decoder.set_lang_idx(tgt_lang_idx)
- loss, sample_size, logging_output = criterion(
- model.models[lang_pair], sample[lang_pair]
- )
- return loss, sample_size, logging_output
-
- def inference_step(
- self, generator, models, sample, prefix_tokens=None, constraints=None
- ):
- if self.encoder_latent_layer or self.decoder_latent_layer:
- for model in models:
- if self.encoder_latent_layer:
- assert model.encoder.layer_select is not None
- src_lang_idx = self.src_lang_idx_dict[self.args.source_lang]
- model.encoder.set_lang_idx(src_lang_idx)
- if self.decoder_latent_layer:
- assert model.decoder.layer_select is not None
- tgt_lang_idx = self.tgt_lang_idx_dict[self.args.target_lang]
- model.decoder.set_lang_idx(tgt_lang_idx)
- return super().inference_step(
- generator, models, sample, prefix_tokens, constraints
- )
-
- @property
- def encoder_latent_layer(self):
- return (
- safe_hasattr(self.args, "encoder_latent_layer")
- and self.args.encoder_latent_layer
- )
-
- @property
- def decoder_latent_layer(self):
- return (
- safe_hasattr(self.args, "decoder_latent_layer")
- and self.args.decoder_latent_layer
- )
-
- @property
- def src_lang_idx_dict(self):
- return {lang: lang_idx for lang_idx, lang in enumerate(self.src_langs)}
-
- @property
- def tgt_lang_idx_dict(self):
- return {lang: lang_idx for lang_idx, lang in enumerate(self.tgt_langs)}
diff --git a/spaces/ICML2022/OFA/fairseq/examples/linformer/linformer_src/__init__.py b/spaces/ICML2022/OFA/fairseq/examples/linformer/linformer_src/__init__.py
deleted file mode 100644
index 1c52f135ea6f99d0effe8ce1f7d77cbd66be3745..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/examples/linformer/linformer_src/__init__.py
+++ /dev/null
@@ -1,6 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from .models import linformer_roberta # noqa
diff --git a/spaces/Illumotion/Koboldcpp/spm-headers/ggml.h b/spaces/Illumotion/Koboldcpp/spm-headers/ggml.h
deleted file mode 100644
index a9d4e33d9885c7c427764ecfc4801ec1bb6a7108..0000000000000000000000000000000000000000
--- a/spaces/Illumotion/Koboldcpp/spm-headers/ggml.h
+++ /dev/null
@@ -1,2109 +0,0 @@
-#pragma once
-
-//
-// GGML Tensor Library
-//
-// This documentation is still a work in progress.
-// If you wish some specific topics to be covered, feel free to drop a comment:
-//
-// https://github.com/ggerganov/whisper.cpp/issues/40
-//
-// ## Overview
-//
-// This library implements:
-//
-// - a set of tensor operations
-// - automatic differentiation
-// - basic optimization algorithms
-//
-// The aim of this library is to provide a minimalistic approach for various machine learning tasks. This includes,
-// but is not limited to, the following:
-//
-// - linear regression
-// - support vector machines
-// - neural networks
-//
-// The library allows the user to define a certain function using the available tensor operations. This function
-// definition is represented internally via a computation graph. Each tensor operation in the function definition
-// corresponds to a node in the graph. Having the computation graph defined, the user can choose to compute the
-// function's value and/or its gradient with respect to the input variables. Optionally, the function can be optimized
-// using one of the available optimization algorithms.
-//
-// For example, here we define the function: f(x) = a*x^2 + b
-//
-// {
-// struct ggml_init_params params = {
-// .mem_size = 16*1024*1024,
-// .mem_buffer = NULL,
-// };
-//
-// // memory allocation happens here
-// struct ggml_context * ctx = ggml_init(params);
-//
-// struct ggml_tensor * x = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);
-//
-// ggml_set_param(ctx, x); // x is an input variable
-//
-// struct ggml_tensor * a = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);
-// struct ggml_tensor * b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);
-// struct ggml_tensor * x2 = ggml_mul(ctx, x, x);
-// struct ggml_tensor * f = ggml_add(ctx, ggml_mul(ctx, a, x2), b);
-//
-// ...
-// }
-//
-// Notice that the function definition above does not involve any actual computation. The computation is performed only
-// when the user explicitly requests it. For example, to compute the function's value at x = 2.0:
-//
-// {
-// ...
-//
-// struct ggml_cgraph gf = ggml_build_forward(f);
-//
-// // set the input variable and parameter values
-// ggml_set_f32(x, 2.0f);
-// ggml_set_f32(a, 3.0f);
-// ggml_set_f32(b, 4.0f);
-//
-// ggml_graph_compute_with_ctx(ctx, &gf, n_threads);
-//
-// printf("f = %f\n", ggml_get_f32_1d(f, 0));
-//
-// ...
-// }
-//
-// The actual computation is performed in the ggml_graph_compute() function.
-//
-// The ggml_new_tensor_...() functions create new tensors. They are allocated in the memory buffer provided to the
-// ggml_init() function. You have to be careful not to exceed the memory buffer size. Therefore, you have to know
-// in advance how much memory you need for your computation. Alternatively, you can allocate a large enough memory
-// and after defining the computation graph, call the ggml_used_mem() function to find out how much memory was
-// actually needed.
-//
-// The ggml_set_param() function marks a tensor as an input variable. This is used by the automatic
-// differentiation and optimization algorithms.
-//
-// The described approach allows to define the function graph once and then compute its forward or backward graphs
-// multiple times. All computations will use the same memory buffer allocated in the ggml_init() function. This way
-// the user can avoid the memory allocation overhead at runtime.
-//
-// The library supports multi-dimensional tensors - up to 4 dimensions. The FP16 and FP32 data types are first class
-// citizens, but in theory the library can be extended to support FP8 and integer data types.
-//
-// Each tensor operation produces a new tensor. Initially the library was envisioned to support only the use of unary
-// and binary operations. Most of the available operations fall into one of these two categories. With time, it became
-// clear that the library needs to support more complex operations. The way to support these operations is not clear
-// yet, but a few examples are demonstrated in the following operations:
-//
-// - ggml_permute()
-// - ggml_conv_1d_1s()
-// - ggml_conv_1d_2s()
-//
-// For each tensor operator, the library implements a forward and backward computation function. The forward function
-// computes the output tensor value given the input tensor values. The backward function computes the adjoint of the
-// input tensors given the adjoint of the output tensor. For a detailed explanation of what this means, take a
-// calculus class, or watch the following video:
-//
-// What is Automatic Differentiation?
-// https://www.youtube.com/watch?v=wG_nF1awSSY
-//
-//
-// ## Tensor data (struct ggml_tensor)
-//
-// The tensors are stored in memory via the ggml_tensor struct. The structure provides information about the size of
-// the tensor, the data type, and the memory buffer where the tensor data is stored. Additionally, it contains
-// pointers to the "source" tensors - i.e. the tensors that were used to compute the current tensor. For example:
-//
-// {
-// struct ggml_tensor * c = ggml_add(ctx, a, b);
-//
-// assert(c->src[0] == a);
-// assert(c->src[1] == b);
-// }
-//
-// The multi-dimensional tensors are stored in row-major order. The ggml_tensor struct contains fields for the
-// number of elements in each dimension ("ne") as well as the number of bytes ("nb", a.k.a. stride). This allows
-// to store tensors that are not contiguous in memory, which is useful for operations such as transposition and
-// permutation. All tensor operations have to take the stride into account and not assume that the tensor is
-// contiguous in memory.
-//
-// The data of the tensor is accessed via the "data" pointer. For example:
-//
-// {
-// const int nx = 2;
-// const int ny = 3;
-//
-// struct ggml_tensor * a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, nx, ny);
-//
-// for (int y = 0; y < ny; y++) {
-// for (int x = 0; x < nx; x++) {
-// *(float *) ((char *) a->data + y*a->nb[1] + x*a->nb[0]) = x + y;
-// }
-// }
-//
-// ...
-// }
-//
-// Alternatively, there are helper functions, such as ggml_get_f32_1d() and ggml_set_f32_1d() that can be used.
-//
-// ## The matrix multiplication operator (ggml_mul_mat)
-//
-// TODO
-//
-//
-// ## Multi-threading
-//
-// TODO
-//
-//
-// ## Overview of ggml.c
-//
-// TODO
-//
-//
-// ## SIMD optimizations
-//
-// TODO
-//
-//
-// ## Debugging ggml
-//
-// TODO
-//
-//
-
-#ifdef GGML_SHARED
-# if defined(_WIN32) && !defined(__MINGW32__)
-# ifdef GGML_BUILD
-# define GGML_API __declspec(dllexport)
-# else
-# define GGML_API __declspec(dllimport)
-# endif
-# else
-# define GGML_API __attribute__ ((visibility ("default")))
-# endif
-#else
-# define GGML_API
-#endif
-
-// TODO: support for clang
-#ifdef __GNUC__
-# define GGML_DEPRECATED(func, hint) func __attribute__((deprecated(hint)))
-#elif defined(_MSC_VER)
-# define GGML_DEPRECATED(func, hint) __declspec(deprecated(hint)) func
-#else
-# define GGML_DEPRECATED(func, hint) func
-#endif
-
-#ifndef __GNUC__
-# define GGML_ATTRIBUTE_FORMAT(...)
-#elif defined(__MINGW32__)
-# define GGML_ATTRIBUTE_FORMAT(...) __attribute__((format(gnu_printf, __VA_ARGS__)))
-#else
-# define GGML_ATTRIBUTE_FORMAT(...) __attribute__((format(printf, __VA_ARGS__)))
-#endif
-
-#include
-#include
-#include
-
-#define GGML_FILE_MAGIC 0x67676d6c // "ggml"
-#define GGML_FILE_VERSION 1
-
-#define GGML_QNT_VERSION 2 // bump this on quantization format changes
-#define GGML_QNT_VERSION_FACTOR 1000 // do not change this
-
-#define GGML_MAX_DIMS 4
-#define GGML_MAX_NODES 16384
-#define GGML_MAX_PARAMS 1024
-#define GGML_MAX_CONTEXTS 64
-#define GGML_MAX_SRC 6
-#define GGML_MAX_NAME 64
-#define GGML_MAX_OP_PARAMS 32
-#define GGML_DEFAULT_N_THREADS 4
-
-#if UINTPTR_MAX == 0xFFFFFFFF
- #define GGML_MEM_ALIGN 4
-#else
- #define GGML_MEM_ALIGN 16
-#endif
-
-#define GGML_EXIT_SUCCESS 0
-#define GGML_EXIT_ABORTED 1
-
-#define GGUF_MAGIC 0x46554747 // "GGUF"
-#define GGUF_VERSION 2
-
-#define GGUF_DEFAULT_ALIGNMENT 32
-
-#define GGML_UNUSED(x) (void)(x)
-
-#define GGML_PAD(x, n) (((x) + (n) - 1) & ~((n) - 1))
-
-#define GGML_ASSERT(x) \
- do { \
- if (!(x)) { \
- fprintf(stderr, "GGML_ASSERT: %s:%d: %s\n", __FILE__, __LINE__, #x); \
- abort(); \
- } \
- } while (0)
-
-#ifndef NDEBUG
-#define GGML_UNREACHABLE() GGML_ASSERT(!"statement should not be reached")
-#elif defined(__GNUC__)
-#define GGML_UNREACHABLE() __builtin_unreachable()
-#else
-#define GGML_UNREACHABLE() ((void) 0)
-#endif
-
-// used to copy the number of elements and stride in bytes of tensors into local variables.
-// main purpose is to reduce code duplication and improve readability.
-//
-// example:
-//
-// GGML_TENSOR_LOCALS(int64_t, ne1, src1, ne);
-// GGML_TENSOR_LOCALS(size_t, nb1, src1, nb);
-//
-#define GGML_TENSOR_LOCALS_1(type, prefix, pointer, array) \
- const type prefix##0 = (pointer)->array[0]; \
- GGML_UNUSED(prefix##0);
-#define GGML_TENSOR_LOCALS_2(type, prefix, pointer, array) \
- GGML_TENSOR_LOCALS_1 (type, prefix, pointer, array) \
- const type prefix##1 = (pointer)->array[1]; \
- GGML_UNUSED(prefix##1);
-#define GGML_TENSOR_LOCALS_3(type, prefix, pointer, array) \
- GGML_TENSOR_LOCALS_2 (type, prefix, pointer, array) \
- const type prefix##2 = (pointer)->array[2]; \
- GGML_UNUSED(prefix##2);
-#define GGML_TENSOR_LOCALS(type, prefix, pointer, array) \
- GGML_TENSOR_LOCALS_3 (type, prefix, pointer, array) \
- const type prefix##3 = (pointer)->array[3]; \
- GGML_UNUSED(prefix##3);
-
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-#if defined(__ARM_NEON) && defined(__CUDACC__)
- typedef half ggml_fp16_t;
-#elif defined(__ARM_NEON)
- typedef __fp16 ggml_fp16_t;
-#else
- typedef uint16_t ggml_fp16_t;
-#endif
-
- // convert FP16 <-> FP32
- GGML_API float ggml_fp16_to_fp32(ggml_fp16_t x);
- GGML_API ggml_fp16_t ggml_fp32_to_fp16(float x);
-
- GGML_API void ggml_fp16_to_fp32_row(const ggml_fp16_t * x, float * y, int n);
- GGML_API void ggml_fp32_to_fp16_row(const float * x, ggml_fp16_t * y, int n);
-
- struct ggml_object;
- struct ggml_context;
-
- enum ggml_type {
- GGML_TYPE_F32 = 0,
- GGML_TYPE_F16 = 1,
- GGML_TYPE_Q4_0 = 2,
- GGML_TYPE_Q4_1 = 3,
- // GGML_TYPE_Q4_2 = 4, support has been removed
- // GGML_TYPE_Q4_3 (5) support has been removed
- GGML_TYPE_Q5_0 = 6,
- GGML_TYPE_Q5_1 = 7,
- GGML_TYPE_Q8_0 = 8,
- GGML_TYPE_Q8_1 = 9,
- // k-quantizations
- GGML_TYPE_Q2_K = 10,
- GGML_TYPE_Q3_K = 11,
- GGML_TYPE_Q4_K = 12,
- GGML_TYPE_Q5_K = 13,
- GGML_TYPE_Q6_K = 14,
- GGML_TYPE_Q8_K = 15,
- GGML_TYPE_I8,
- GGML_TYPE_I16,
- GGML_TYPE_I32,
- GGML_TYPE_COUNT,
- };
-
- enum ggml_backend {
- GGML_BACKEND_CPU = 0,
- GGML_BACKEND_GPU = 10,
- GGML_BACKEND_GPU_SPLIT = 20,
- };
-
- // model file types
- enum ggml_ftype {
- GGML_FTYPE_UNKNOWN = -1,
- GGML_FTYPE_ALL_F32 = 0,
- GGML_FTYPE_MOSTLY_F16 = 1, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q4_0 = 2, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q4_1 = 3, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q4_1_SOME_F16 = 4, // tok_embeddings.weight and output.weight are F16
- GGML_FTYPE_MOSTLY_Q8_0 = 7, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q5_0 = 8, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q5_1 = 9, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q2_K = 10, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q3_K = 11, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q4_K = 12, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q5_K = 13, // except 1d tensors
- GGML_FTYPE_MOSTLY_Q6_K = 14, // except 1d tensors
- };
-
- // available tensor operations:
- enum ggml_op {
- GGML_OP_NONE = 0,
-
- GGML_OP_DUP,
- GGML_OP_ADD,
- GGML_OP_ADD1,
- GGML_OP_ACC,
- GGML_OP_SUB,
- GGML_OP_MUL,
- GGML_OP_DIV,
- GGML_OP_SQR,
- GGML_OP_SQRT,
- GGML_OP_LOG,
- GGML_OP_SUM,
- GGML_OP_SUM_ROWS,
- GGML_OP_MEAN,
- GGML_OP_ARGMAX,
- GGML_OP_REPEAT,
- GGML_OP_REPEAT_BACK,
- GGML_OP_CONCAT,
- GGML_OP_SILU_BACK,
- GGML_OP_NORM, // normalize
- GGML_OP_RMS_NORM,
- GGML_OP_RMS_NORM_BACK,
- GGML_OP_GROUP_NORM,
-
- GGML_OP_MUL_MAT,
- GGML_OP_OUT_PROD,
-
- GGML_OP_SCALE,
- GGML_OP_SET,
- GGML_OP_CPY,
- GGML_OP_CONT,
- GGML_OP_RESHAPE,
- GGML_OP_VIEW,
- GGML_OP_PERMUTE,
- GGML_OP_TRANSPOSE,
- GGML_OP_GET_ROWS,
- GGML_OP_GET_ROWS_BACK,
- GGML_OP_DIAG,
- GGML_OP_DIAG_MASK_INF,
- GGML_OP_DIAG_MASK_ZERO,
- GGML_OP_SOFT_MAX,
- GGML_OP_SOFT_MAX_BACK,
- GGML_OP_ROPE,
- GGML_OP_ROPE_BACK,
- GGML_OP_ALIBI,
- GGML_OP_CLAMP,
- GGML_OP_CONV_1D,
- GGML_OP_CONV_2D,
- GGML_OP_CONV_TRANSPOSE_1D,
- GGML_OP_CONV_TRANSPOSE_2D,
- GGML_OP_POOL_1D,
- GGML_OP_POOL_2D,
-
- GGML_OP_CONV_1D_STAGE_0, // internal
- GGML_OP_CONV_1D_STAGE_1, // internal
-
- GGML_OP_UPSCALE, // nearest interpolate
-
- GGML_OP_FLASH_ATTN,
- GGML_OP_FLASH_FF,
- GGML_OP_FLASH_ATTN_BACK,
- GGML_OP_WIN_PART,
- GGML_OP_WIN_UNPART,
- GGML_OP_GET_REL_POS,
- GGML_OP_ADD_REL_POS,
-
- GGML_OP_UNARY,
-
- GGML_OP_MAP_UNARY,
- GGML_OP_MAP_BINARY,
-
- GGML_OP_MAP_CUSTOM1_F32,
- GGML_OP_MAP_CUSTOM2_F32,
- GGML_OP_MAP_CUSTOM3_F32,
-
- GGML_OP_MAP_CUSTOM1,
- GGML_OP_MAP_CUSTOM2,
- GGML_OP_MAP_CUSTOM3,
-
- GGML_OP_CROSS_ENTROPY_LOSS,
- GGML_OP_CROSS_ENTROPY_LOSS_BACK,
-
- GGML_OP_COUNT,
- };
-
- enum ggml_unary_op {
- GGML_UNARY_OP_ABS,
- GGML_UNARY_OP_SGN,
- GGML_UNARY_OP_NEG,
- GGML_UNARY_OP_STEP,
- GGML_UNARY_OP_TANH,
- GGML_UNARY_OP_ELU,
- GGML_UNARY_OP_RELU,
- GGML_UNARY_OP_GELU,
- GGML_UNARY_OP_GELU_QUICK,
- GGML_UNARY_OP_SILU,
- };
-
- enum ggml_object_type {
- GGML_OBJECT_TENSOR,
- GGML_OBJECT_GRAPH,
- GGML_OBJECT_WORK_BUFFER
- };
-
- enum ggml_log_level {
- GGML_LOG_LEVEL_ERROR = 2,
- GGML_LOG_LEVEL_WARN = 3,
- GGML_LOG_LEVEL_INFO = 4
- };
-
- // ggml object
- struct ggml_object {
- size_t offs;
- size_t size;
-
- struct ggml_object * next;
-
- enum ggml_object_type type;
-
- char padding[4];
- };
-
- static const size_t GGML_OBJECT_SIZE = sizeof(struct ggml_object);
-
- // n-dimensional tensor
- struct ggml_tensor {
- enum ggml_type type;
- enum ggml_backend backend;
-
- int n_dims;
- int64_t ne[GGML_MAX_DIMS]; // number of elements
- size_t nb[GGML_MAX_DIMS]; // stride in bytes:
- // nb[0] = ggml_type_size(type)
- // nb[1] = nb[0] * (ne[0] / ggml_blck_size(type)) + padding
- // nb[i] = nb[i-1] * ne[i-1]
-
- // compute data
- enum ggml_op op;
-
- // op params - allocated as int32_t for alignment
- int32_t op_params[GGML_MAX_OP_PARAMS / sizeof(int32_t)];
-
- bool is_param;
-
- struct ggml_tensor * grad;
- struct ggml_tensor * src[GGML_MAX_SRC];
-
- // performance
- int perf_runs;
- int64_t perf_cycles;
- int64_t perf_time_us;
-
- struct ggml_tensor * view_src;
- size_t view_offs;
-
- void * data;
-
- char name[GGML_MAX_NAME];
-
- void * extra; // extra things e.g. for ggml-cuda.cu
-
- char padding[4];
- };
-
- static const size_t GGML_TENSOR_SIZE = sizeof(struct ggml_tensor);
-
- // the compute plan that needs to be prepared for ggml_graph_compute()
- // since https://github.com/ggerganov/ggml/issues/287
- struct ggml_cplan {
- size_t work_size; // size of work buffer, calculated by `ggml_graph_plan()`
- uint8_t * work_data; // work buffer, to be allocated by caller before calling to `ggml_graph_compute()`
-
- int n_threads;
-
- // the `n_tasks` of nodes, 1:1 mapping to cgraph nodes
- int n_tasks[GGML_MAX_NODES];
-
- // abort ggml_graph_compute when true
- bool (*abort_callback)(void * data);
- void * abort_callback_data;
- };
-
- // next prime after GGML_MAX_NODES
- // #define GGML_GRAPH_HASHTABLE_SIZE 4099
- // next prime after GGML_MAX_NODES * 2 (nodes + leafs)
- // #define GGML_GRAPH_HASHTABLE_SIZE 8273
- // #define GGML_GRAPH_HASHTABLE_SIZE 16411
- #define GGML_GRAPH_HASHTABLE_SIZE 32771
-
- enum ggml_cgraph_eval_order {
- GGML_CGRAPH_EVAL_ORDER_LEFT_TO_RIGHT = 0,
- GGML_CGRAPH_EVAL_ORDER_RIGHT_TO_LEFT,
- GGML_CGRAPH_EVAL_ORDER_COUNT
- };
-
- // computation graph
- struct ggml_cgraph {
- int n_nodes;
- int n_leafs;
-
- struct ggml_tensor * nodes[GGML_MAX_NODES];
- struct ggml_tensor * grads[GGML_MAX_NODES];
- struct ggml_tensor * leafs[GGML_MAX_NODES];
-
- void * visited_hash_table[GGML_GRAPH_HASHTABLE_SIZE];
-
- enum ggml_cgraph_eval_order order;
-
- // performance
- int perf_runs;
- int64_t perf_cycles;
- int64_t perf_time_us;
- };
-
- static const size_t GGML_GRAPH_SIZE = sizeof(struct ggml_cgraph);
-
- // scratch buffer
- struct ggml_scratch {
- size_t offs;
- size_t size;
- void * data;
- };
-
- struct ggml_init_params {
- // memory pool
- size_t mem_size; // bytes
- void * mem_buffer; // if NULL, memory will be allocated internally
- bool no_alloc; // don't allocate memory for the tensor data
- };
-
-
- // compute types
-
- // NOTE: the INIT or FINALIZE pass is not scheduled unless explicitly enabled.
- // This behavior was changed since https://github.com/ggerganov/llama.cpp/pull/1995.
- enum ggml_task_type {
- GGML_TASK_INIT = 0,
- GGML_TASK_COMPUTE,
- GGML_TASK_FINALIZE,
- };
-
- struct ggml_compute_params {
- enum ggml_task_type type;
-
- // ith = thread index, nth = number of threads
- int ith, nth;
-
- // work buffer for all threads
- size_t wsize;
- void * wdata;
- };
-
- // misc
-
- GGML_API void ggml_time_init(void); // call this once at the beginning of the program
- GGML_API int64_t ggml_time_ms(void);
- GGML_API int64_t ggml_time_us(void);
- GGML_API int64_t ggml_cycles(void);
- GGML_API int64_t ggml_cycles_per_ms(void);
-
- GGML_API void ggml_numa_init(void); // call once for better performance on NUMA systems
- GGML_API bool ggml_is_numa(void); // true if init detected that system has >1 NUMA node
-
- GGML_API void ggml_print_object (const struct ggml_object * obj);
- GGML_API void ggml_print_objects(const struct ggml_context * ctx);
-
- GGML_API int64_t ggml_nelements (const struct ggml_tensor * tensor);
- GGML_API int64_t ggml_nrows (const struct ggml_tensor * tensor);
- GGML_API size_t ggml_nbytes (const struct ggml_tensor * tensor);
- GGML_API size_t ggml_nbytes_pad (const struct ggml_tensor * tensor); // same as ggml_nbytes() but padded to GGML_MEM_ALIGN
- GGML_API size_t ggml_nbytes_split(const struct ggml_tensor * tensor, int nrows_split);
-
- GGML_API int ggml_blck_size (enum ggml_type type);
- GGML_API size_t ggml_type_size (enum ggml_type type); // size in bytes for all elements in a block
- GGML_API float ggml_type_sizef(enum ggml_type type); // ggml_type_size()/ggml_blck_size() as float
-
- GGML_API const char * ggml_type_name(enum ggml_type type);
- GGML_API const char * ggml_op_name (enum ggml_op op);
- GGML_API const char * ggml_op_symbol(enum ggml_op op);
-
- GGML_API size_t ggml_element_size(const struct ggml_tensor * tensor);
-
- GGML_API bool ggml_is_quantized(enum ggml_type type);
-
- // TODO: temporary until model loading of ggml examples is refactored
- GGML_API enum ggml_type ggml_ftype_to_ggml_type(enum ggml_ftype ftype);
-
- GGML_API bool ggml_is_transposed(const struct ggml_tensor * tensor);
- GGML_API bool ggml_is_contiguous(const struct ggml_tensor * tensor);
- GGML_API bool ggml_is_permuted (const struct ggml_tensor * tensor);
-
- GGML_API bool ggml_are_same_shape(const struct ggml_tensor * t0, const struct ggml_tensor * t1);
-
- // use this to compute the memory overhead of a tensor
- GGML_API size_t ggml_tensor_overhead(void);
-
- // main
-
- GGML_API struct ggml_context * ggml_init(struct ggml_init_params params);
- GGML_API void ggml_free(struct ggml_context * ctx);
-
- GGML_API size_t ggml_used_mem(const struct ggml_context * ctx);
-
- GGML_API size_t ggml_set_scratch (struct ggml_context * ctx, struct ggml_scratch scratch);
- GGML_API bool ggml_get_no_alloc(struct ggml_context * ctx);
- GGML_API void ggml_set_no_alloc(struct ggml_context * ctx, bool no_alloc);
-
- GGML_API void * ggml_get_mem_buffer (const struct ggml_context * ctx);
- GGML_API size_t ggml_get_mem_size (const struct ggml_context * ctx);
- GGML_API size_t ggml_get_max_tensor_size(const struct ggml_context * ctx);
-
- GGML_API struct ggml_tensor * ggml_new_tensor(
- struct ggml_context * ctx,
- enum ggml_type type,
- int n_dims,
- const int64_t *ne);
-
- GGML_API struct ggml_tensor * ggml_new_tensor_1d(
- struct ggml_context * ctx,
- enum ggml_type type,
- int64_t ne0);
-
- GGML_API struct ggml_tensor * ggml_new_tensor_2d(
- struct ggml_context * ctx,
- enum ggml_type type,
- int64_t ne0,
- int64_t ne1);
-
- GGML_API struct ggml_tensor * ggml_new_tensor_3d(
- struct ggml_context * ctx,
- enum ggml_type type,
- int64_t ne0,
- int64_t ne1,
- int64_t ne2);
-
- GGML_API struct ggml_tensor * ggml_new_tensor_4d(
- struct ggml_context * ctx,
- enum ggml_type type,
- int64_t ne0,
- int64_t ne1,
- int64_t ne2,
- int64_t ne3);
-
- GGML_API struct ggml_tensor * ggml_new_i32(struct ggml_context * ctx, int32_t value);
- GGML_API struct ggml_tensor * ggml_new_f32(struct ggml_context * ctx, float value);
-
- GGML_API struct ggml_tensor * ggml_dup_tensor (struct ggml_context * ctx, const struct ggml_tensor * src);
- GGML_API struct ggml_tensor * ggml_view_tensor(struct ggml_context * ctx, struct ggml_tensor * src);
-
- GGML_API struct ggml_tensor * ggml_get_tensor(struct ggml_context * ctx, const char * name);
-
- GGML_API struct ggml_tensor * ggml_set_zero(struct ggml_tensor * tensor);
- GGML_API struct ggml_tensor * ggml_set_i32 (struct ggml_tensor * tensor, int32_t value);
- GGML_API struct ggml_tensor * ggml_set_f32 (struct ggml_tensor * tensor, float value);
-
- // Converts a flat index into coordinates
- GGML_API void ggml_unravel_index(const struct ggml_tensor * tensor, int64_t i, int64_t * i0, int64_t * i1, int64_t * i2, int64_t * i3);
-
- GGML_API int32_t ggml_get_i32_1d(const struct ggml_tensor * tensor, int i);
- GGML_API void ggml_set_i32_1d(const struct ggml_tensor * tensor, int i, int32_t value);
-
- GGML_API int32_t ggml_get_i32_nd(const struct ggml_tensor * tensor, int i0, int i1, int i2, int i3);
- GGML_API void ggml_set_i32_nd(const struct ggml_tensor * tensor, int i0, int i1, int i2, int i3, int32_t value);
-
- GGML_API float ggml_get_f32_1d(const struct ggml_tensor * tensor, int i);
- GGML_API void ggml_set_f32_1d(const struct ggml_tensor * tensor, int i, float value);
-
- GGML_API float ggml_get_f32_nd(const struct ggml_tensor * tensor, int i0, int i1, int i2, int i3);
- GGML_API void ggml_set_f32_nd(const struct ggml_tensor * tensor, int i0, int i1, int i2, int i3, float value);
-
- GGML_API void * ggml_get_data (const struct ggml_tensor * tensor);
- GGML_API float * ggml_get_data_f32(const struct ggml_tensor * tensor);
-
- GGML_API enum ggml_unary_op ggml_get_unary_op(const struct ggml_tensor * tensor);
-
- GGML_API const char * ggml_get_name (const struct ggml_tensor * tensor);
- GGML_API struct ggml_tensor * ggml_set_name ( struct ggml_tensor * tensor, const char * name);
- GGML_ATTRIBUTE_FORMAT(2, 3)
- GGML_API struct ggml_tensor * ggml_format_name( struct ggml_tensor * tensor, const char * fmt, ...);
-
- //
- // operations on tensors with backpropagation
- //
-
- GGML_API struct ggml_tensor * ggml_dup(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_dup_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_add(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_add_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_add_cast(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- enum ggml_type type);
-
- GGML_API struct ggml_tensor * ggml_add1(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_add1_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_acc(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- size_t nb1,
- size_t nb2,
- size_t nb3,
- size_t offset);
-
- GGML_API struct ggml_tensor * ggml_acc_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- size_t nb1,
- size_t nb2,
- size_t nb3,
- size_t offset);
-
- GGML_API struct ggml_tensor * ggml_sub(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_sub_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_mul(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_mul_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_div(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_div_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_sqr(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_sqr_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_sqrt(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_sqrt_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_log(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_log_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // return scalar
- GGML_API struct ggml_tensor * ggml_sum(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // sums along rows, with input shape [a,b,c,d] return shape [1,b,c,d]
- GGML_API struct ggml_tensor * ggml_sum_rows(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // mean along rows
- GGML_API struct ggml_tensor * ggml_mean(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // argmax along rows
- GGML_API struct ggml_tensor * ggml_argmax(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // if a is the same shape as b, and a is not parameter, return a
- // otherwise, return a new tensor: repeat(a) to fit in b
- GGML_API struct ggml_tensor * ggml_repeat(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // sums repetitions in a into shape of b
- GGML_API struct ggml_tensor * ggml_repeat_back(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // concat a and b on dim 2
- // used in stable-diffusion
- GGML_API struct ggml_tensor * ggml_concat(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_abs(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_abs_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_sgn(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_sgn_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_neg(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_neg_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_step(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_step_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_tanh(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_tanh_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_elu(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_elu_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_relu(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_relu_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // TODO: double-check this computation is correct
- GGML_API struct ggml_tensor * ggml_gelu(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_gelu_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_gelu_quick(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_gelu_quick_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_silu(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_silu_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // a - x
- // b - dy
- GGML_API struct ggml_tensor * ggml_silu_back(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // normalize along rows
- GGML_API struct ggml_tensor * ggml_norm(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- float eps);
-
- GGML_API struct ggml_tensor * ggml_norm_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- float eps);
-
- GGML_API struct ggml_tensor * ggml_rms_norm(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- float eps);
-
- GGML_API struct ggml_tensor * ggml_rms_norm_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- float eps);
-
- // group normalize along ne0*ne1*n_groups
- // used in stable-diffusion
- // TODO: eps is hardcoded to 1e-6 for now
- GGML_API struct ggml_tensor * ggml_group_norm(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int n_groups);
-
- GGML_API struct ggml_tensor * ggml_group_norm_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int n_groups);
-
- // a - x
- // b - dy
- GGML_API struct ggml_tensor * ggml_rms_norm_back(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- float eps);
-
- // A: n columns, m rows
- // B: n columns, p rows (i.e. we transpose it internally)
- // result is m columns, p rows
- GGML_API struct ggml_tensor * ggml_mul_mat(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // A: m columns, n rows,
- // B: p columns, n rows,
- // result is m columns, p rows
- GGML_API struct ggml_tensor * ggml_out_prod(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- //
- // operations on tensors without backpropagation
- //
-
- GGML_API struct ggml_tensor * ggml_scale(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_scale_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // b -> view(a,offset,nb1,nb2,3), return modified a
- GGML_API struct ggml_tensor * ggml_set(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- size_t nb1,
- size_t nb2,
- size_t nb3,
- size_t offset);
-
- // b -> view(a,offset,nb1,nb2,3), return view(a)
- GGML_API struct ggml_tensor * ggml_set_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- size_t nb1,
- size_t nb2,
- size_t nb3,
- size_t offset);
-
- GGML_API struct ggml_tensor * ggml_set_1d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- size_t offset);
-
- GGML_API struct ggml_tensor * ggml_set_1d_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- size_t offset);
-
- // b -> view(a,offset,nb1,nb2,3), return modified a
- GGML_API struct ggml_tensor * ggml_set_2d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- size_t nb1,
- size_t offset);
-
- // b -> view(a,offset,nb1,nb2,3), return view(a)
- GGML_API struct ggml_tensor * ggml_set_2d_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- size_t nb1,
- size_t offset);
-
- // a -> b, return view(b)
- GGML_API struct ggml_tensor * ggml_cpy(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // a -> b, in-place, return view(b)
- GGML_API struct ggml_tensor * ggml_cpy_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // make contiguous
- GGML_API struct ggml_tensor * ggml_cont(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // make contiguous, in-place
- GGML_API struct ggml_tensor * ggml_cont_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // make contiguous, with new shape
- GGML_API struct ggml_tensor * ggml_cont_1d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0);
-
- GGML_API struct ggml_tensor * ggml_cont_2d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1);
-
- GGML_API struct ggml_tensor * ggml_cont_3d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1,
- int64_t ne2);
-
- GGML_API struct ggml_tensor * ggml_cont_4d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1,
- int64_t ne2,
- int64_t ne3);
-
- // return view(a), b specifies the new shape
- // TODO: when we start computing gradient, make a copy instead of view
- GGML_API struct ggml_tensor * ggml_reshape(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // return view(a)
- // TODO: when we start computing gradient, make a copy instead of view
- GGML_API struct ggml_tensor * ggml_reshape_1d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0);
-
- GGML_API struct ggml_tensor * ggml_reshape_2d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1);
-
- // return view(a)
- // TODO: when we start computing gradient, make a copy instead of view
- GGML_API struct ggml_tensor * ggml_reshape_3d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1,
- int64_t ne2);
-
- GGML_API struct ggml_tensor * ggml_reshape_4d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1,
- int64_t ne2,
- int64_t ne3);
-
- // offset in bytes
- GGML_API struct ggml_tensor * ggml_view_1d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- size_t offset);
-
- GGML_API struct ggml_tensor * ggml_view_2d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1,
- size_t nb1, // row stride in bytes
- size_t offset);
-
- GGML_API struct ggml_tensor * ggml_view_3d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1,
- int64_t ne2,
- size_t nb1, // row stride in bytes
- size_t nb2, // slice stride in bytes
- size_t offset);
-
- GGML_API struct ggml_tensor * ggml_view_4d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int64_t ne0,
- int64_t ne1,
- int64_t ne2,
- int64_t ne3,
- size_t nb1, // row stride in bytes
- size_t nb2, // slice stride in bytes
- size_t nb3,
- size_t offset);
-
- GGML_API struct ggml_tensor * ggml_permute(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int axis0,
- int axis1,
- int axis2,
- int axis3);
-
- // alias for ggml_permute(ctx, a, 1, 0, 2, 3)
- GGML_API struct ggml_tensor * ggml_transpose(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_get_rows(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_get_rows_back(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- struct ggml_tensor * c);
-
- GGML_API struct ggml_tensor * ggml_diag(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // set elements above the diagonal to -INF
- GGML_API struct ggml_tensor * ggml_diag_mask_inf(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int n_past);
-
- // in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_diag_mask_inf_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int n_past);
-
- // set elements above the diagonal to 0
- GGML_API struct ggml_tensor * ggml_diag_mask_zero(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int n_past);
-
- // in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_diag_mask_zero_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int n_past);
-
- GGML_API struct ggml_tensor * ggml_soft_max(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- // in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_soft_max_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a);
-
- GGML_API struct ggml_tensor * ggml_soft_max_back(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_soft_max_back_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // rotary position embedding
- // if mode & 1 == 1, skip n_past elements (DEPRECATED)
- // if mode & 2 == 1, GPT-NeoX style
- // if mode & 4 == 1, ChatGLM style
- //
- // b is an int32 vector with size a->ne[2], it contains the positions
- GGML_API struct ggml_tensor * ggml_rope(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int n_dims,
- int mode,
- int n_ctx);
-
- // in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_rope_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int n_dims,
- int mode,
- int n_ctx);
-
- // custom RoPE
- GGML_API struct ggml_tensor * ggml_rope_custom(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int n_dims,
- int mode,
- int n_ctx,
- float freq_base,
- float freq_scale);
-
- // in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_rope_custom_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int n_dims,
- int mode,
- int n_ctx,
- float freq_base,
- float freq_scale);
-
- // xPos RoPE, in-place, returns view(a)
- GGML_API struct ggml_tensor * ggml_rope_xpos_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int n_dims,
- float base,
- bool down);
-
- // rotary position embedding backward, i.e compute dx from dy
- // a - dy
- GGML_API struct ggml_tensor * ggml_rope_back(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int n_dims,
- int mode,
- int n_ctx,
- float freq_base,
- float freq_scale,
- float xpos_base,
- bool xpos_down);
-
- // alibi position embedding
- // in-place, returns view(a)
- struct ggml_tensor * ggml_alibi(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int n_past,
- int n_head,
- float bias_max);
-
- // clamp
- // in-place, returns view(a)
- struct ggml_tensor * ggml_clamp(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- float min,
- float max);
-
- GGML_API struct ggml_tensor * ggml_conv_1d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s0, // stride
- int p0, // padding
- int d0); // dilation
-
- // conv_1d with padding = half
- // alias for ggml_conv_1d(a, b, s, a->ne[0]/2, d)
- GGML_API struct ggml_tensor* ggml_conv_1d_ph(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s,
- int d);
-
- GGML_API struct ggml_tensor * ggml_conv_transpose_1d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s0,
- int p0,
- int d0);
-
- GGML_API struct ggml_tensor * ggml_conv_2d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int s0,
- int s1,
- int p0,
- int p1,
- int d0,
- int d1);
-
-
- // kernel size is a->ne[0] x a->ne[1]
- // stride is equal to kernel size
- // padding is zero
- // example:
- // a: 16 16 3 768
- // b: 1024 1024 3 1
- // res: 64 64 768 1
- // used in sam
- GGML_API struct ggml_tensor * ggml_conv_2d_sk_p0(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- // kernel size is a->ne[0] x a->ne[1]
- // stride is 1
- // padding is half
- // example:
- // a: 3 3 256 256
- // b: 64 64 256 1
- // res: 64 64 256 1
- // used in sam
- GGML_API struct ggml_tensor * ggml_conv_2d_s1_ph(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_conv_transpose_2d_p0(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- int stride);
-
- enum ggml_op_pool {
- GGML_OP_POOL_MAX,
- GGML_OP_POOL_AVG,
- GGML_OP_POOL_COUNT,
- };
-
- GGML_API struct ggml_tensor * ggml_pool_1d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- enum ggml_op_pool op,
- int k0, // kernel size
- int s0, // stride
- int p0); // padding
-
- GGML_API struct ggml_tensor * ggml_pool_2d(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- enum ggml_op_pool op,
- int k0,
- int k1,
- int s0,
- int s1,
- int p0,
- int p1);
-
- // nearest interpolate
- // used in stable-diffusion
- GGML_API struct ggml_tensor * ggml_upscale(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int scale_factor);
-
- GGML_API struct ggml_tensor * ggml_flash_attn(
- struct ggml_context * ctx,
- struct ggml_tensor * q,
- struct ggml_tensor * k,
- struct ggml_tensor * v,
- bool masked);
-
- GGML_API struct ggml_tensor * ggml_flash_attn_back(
- struct ggml_context * ctx,
- struct ggml_tensor * q,
- struct ggml_tensor * k,
- struct ggml_tensor * v,
- struct ggml_tensor * d,
- bool masked);
-
- GGML_API struct ggml_tensor * ggml_flash_ff(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b0,
- struct ggml_tensor * b1,
- struct ggml_tensor * c0,
- struct ggml_tensor * c1);
-
- // partition into non-overlapping windows with padding if needed
- // example:
- // a: 768 64 64 1
- // w: 14
- // res: 768 14 14 25
- // used in sam
- GGML_API struct ggml_tensor * ggml_win_part(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int w);
-
- // reverse of ggml_win_part
- // used in sam
- GGML_API struct ggml_tensor * ggml_win_unpart(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int w0,
- int h0,
- int w);
-
- GGML_API struct ggml_tensor * ggml_unary(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- enum ggml_unary_op op);
-
- GGML_API struct ggml_tensor * ggml_unary_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- enum ggml_unary_op op);
-
- // used in sam
- GGML_API struct ggml_tensor * ggml_get_rel_pos(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- int qh,
- int kh);
-
- // used in sam
-
- GGML_API struct ggml_tensor * ggml_add_rel_pos(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * pw,
- struct ggml_tensor * ph);
-
- GGML_API struct ggml_tensor * ggml_add_rel_pos_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * pw,
- struct ggml_tensor * ph);
-
- // custom operators
-
- typedef void (*ggml_unary_op_f32_t) (const int, float *, const float *);
- typedef void (*ggml_binary_op_f32_t)(const int, float *, const float *, const float *);
-
- typedef void (*ggml_custom1_op_f32_t)(struct ggml_tensor *, const struct ggml_tensor *);
- typedef void (*ggml_custom2_op_f32_t)(struct ggml_tensor *, const struct ggml_tensor *, const struct ggml_tensor *);
- typedef void (*ggml_custom3_op_f32_t)(struct ggml_tensor *, const struct ggml_tensor *, const struct ggml_tensor *, const struct ggml_tensor *);
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_unary_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- ggml_unary_op_f32_t fun),
- "use ggml_map_custom1 instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_unary_inplace_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- ggml_unary_op_f32_t fun),
- "use ggml_map_custom1_inplace instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_binary_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- ggml_binary_op_f32_t fun),
- "use ggml_map_custom2 instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_binary_inplace_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- ggml_binary_op_f32_t fun),
- "use ggml_map_custom2_inplace instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_custom1_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- ggml_custom1_op_f32_t fun),
- "use ggml_map_custom1 instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_custom1_inplace_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- ggml_custom1_op_f32_t fun),
- "use ggml_map_custom1_inplace instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_custom2_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- ggml_custom2_op_f32_t fun),
- "use ggml_map_custom2 instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_custom2_inplace_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- ggml_custom2_op_f32_t fun),
- "use ggml_map_custom2_inplace instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_custom3_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- struct ggml_tensor * c,
- ggml_custom3_op_f32_t fun),
- "use ggml_map_custom3 instead");
-
- GGML_DEPRECATED(GGML_API struct ggml_tensor * ggml_map_custom3_inplace_f32(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- struct ggml_tensor * c,
- ggml_custom3_op_f32_t fun),
- "use ggml_map_custom3_inplace instead");
-
- // custom operators v2
-
- typedef void (*ggml_custom1_op_t)(struct ggml_tensor * dst , const struct ggml_tensor * a, int ith, int nth, void * userdata);
- typedef void (*ggml_custom2_op_t)(struct ggml_tensor * dst , const struct ggml_tensor * a, const struct ggml_tensor * b, int ith, int nth, void * userdata);
- typedef void (*ggml_custom3_op_t)(struct ggml_tensor * dst , const struct ggml_tensor * a, const struct ggml_tensor * b, const struct ggml_tensor * c, int ith, int nth, void * userdata);
-
- #define GGML_N_TASKS_MAX -1
-
- GGML_API struct ggml_tensor * ggml_map_custom1(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- ggml_custom1_op_t fun,
- int n_tasks,
- void * userdata);
-
- GGML_API struct ggml_tensor * ggml_map_custom1_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- ggml_custom1_op_t fun,
- int n_tasks,
- void * userdata);
-
- GGML_API struct ggml_tensor * ggml_map_custom2(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- ggml_custom2_op_t fun,
- int n_tasks,
- void * userdata);
-
- GGML_API struct ggml_tensor * ggml_map_custom2_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- ggml_custom2_op_t fun,
- int n_tasks,
- void * userdata);
-
- GGML_API struct ggml_tensor * ggml_map_custom3(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- struct ggml_tensor * c,
- ggml_custom3_op_t fun,
- int n_tasks,
- void * userdata);
-
- GGML_API struct ggml_tensor * ggml_map_custom3_inplace(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- struct ggml_tensor * c,
- ggml_custom3_op_t fun,
- int n_tasks,
- void * userdata);
-
- // loss function
-
- GGML_API struct ggml_tensor * ggml_cross_entropy_loss(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b);
-
- GGML_API struct ggml_tensor * ggml_cross_entropy_loss_back(
- struct ggml_context * ctx,
- struct ggml_tensor * a,
- struct ggml_tensor * b,
- struct ggml_tensor * c);
-
- //
- // automatic differentiation
- //
-
- GGML_API void ggml_set_param(
- struct ggml_context * ctx,
- struct ggml_tensor * tensor);
-
-
- GGML_API void ggml_build_forward_expand (struct ggml_cgraph * cgraph, struct ggml_tensor * tensor);
- GGML_API void ggml_build_backward_expand(struct ggml_context * ctx, struct ggml_cgraph * gf, struct ggml_cgraph * gb, bool keep);
-
- GGML_API struct ggml_cgraph ggml_build_forward (struct ggml_tensor * tensor);
- GGML_API struct ggml_cgraph ggml_build_backward(struct ggml_context * ctx, struct ggml_cgraph * gf, bool keep);
-
- // graph allocation in a context
- GGML_API struct ggml_cgraph * ggml_new_graph (struct ggml_context * ctx);
- GGML_API struct ggml_cgraph * ggml_build_forward_ctx(struct ggml_context * ctx, struct ggml_tensor * tensor);
- GGML_API size_t ggml_graph_overhead(void);
-
- // ggml_graph_plan() has to be called before ggml_graph_compute()
- // when plan.work_size > 0, caller must allocate memory for plan.work_data
- GGML_API struct ggml_cplan ggml_graph_plan (struct ggml_cgraph * cgraph, int n_threads /*= GGML_DEFAULT_N_THREADS*/);
- GGML_API int ggml_graph_compute(struct ggml_cgraph * cgraph, struct ggml_cplan * cplan);
- GGML_API void ggml_graph_reset (struct ggml_cgraph * cgraph);
-
- // same as ggml_graph_compute() but the work data is allocated as a part of the context
- // note: the drawback of this API is that you must have ensured that the context has enough memory for the work data
- GGML_API void ggml_graph_compute_with_ctx(struct ggml_context * ctx, struct ggml_cgraph * cgraph, int n_threads);
-
- GGML_API struct ggml_tensor * ggml_graph_get_tensor(struct ggml_cgraph * cgraph, const char * name);
-
- GGML_API void ggml_graph_export(const struct ggml_cgraph * cgraph, const char * fname);
- GGML_API struct ggml_cgraph ggml_graph_import(const char * fname, struct ggml_context ** ctx_data, struct ggml_context ** ctx_eval);
-
- // print info and performance information for the graph
- GGML_API void ggml_graph_print(const struct ggml_cgraph * cgraph);
-
- // dump the graph into a file using the dot format
- GGML_API void ggml_graph_dump_dot(const struct ggml_cgraph * gb, const struct ggml_cgraph * gf, const char * filename);
-
- // build gradient checkpointing backward graph gb for gf using provided checkpoints
- // gb_tmp will contain original backward graph with rewritten backward process nodes,
- // but without the second forward pass nodes.
- GGML_API void ggml_build_backward_gradient_checkpointing(
- struct ggml_context * ctx,
- struct ggml_cgraph * gf,
- struct ggml_cgraph * gb,
- struct ggml_cgraph * gb_tmp,
- struct ggml_tensor * * checkpoints,
- int n_checkpoints);
- //
- // optimization
- //
-
- // optimization methods
- enum ggml_opt_type {
- GGML_OPT_ADAM,
- GGML_OPT_LBFGS,
- };
-
- // linesearch methods
- enum ggml_linesearch {
- GGML_LINESEARCH_DEFAULT = 1,
-
- GGML_LINESEARCH_BACKTRACKING_ARMIJO = 0,
- GGML_LINESEARCH_BACKTRACKING_WOLFE = 1,
- GGML_LINESEARCH_BACKTRACKING_STRONG_WOLFE = 2,
- };
-
- // optimization return values
- enum ggml_opt_result {
- GGML_OPT_OK = 0,
- GGML_OPT_DID_NOT_CONVERGE,
- GGML_OPT_NO_CONTEXT,
- GGML_OPT_INVALID_WOLFE,
- GGML_OPT_FAIL,
- GGML_OPT_CANCEL,
-
- GGML_LINESEARCH_FAIL = -128,
- GGML_LINESEARCH_MINIMUM_STEP,
- GGML_LINESEARCH_MAXIMUM_STEP,
- GGML_LINESEARCH_MAXIMUM_ITERATIONS,
- GGML_LINESEARCH_INVALID_PARAMETERS,
- };
-
- typedef void (*ggml_opt_callback)(void * data, int accum_step, float * sched, bool * cancel);
- typedef void (*ggml_log_callback)(enum ggml_log_level level, const char * text, void * user_data);
-
- // optimization parameters
- //
- // see ggml.c (ggml_opt_default_params) for default values
- //
- struct ggml_opt_params {
- enum ggml_opt_type type;
-
- int n_threads;
-
- // delta-based convergence test
- //
- // if past == 0 - disabled
- // if past > 0:
- // stop if |f(x) - f(x_past)| < delta * max(1, |f(x)|)
- //
- int past;
- float delta;
-
- // maximum number of iterations without improvement
- //
- // if 0 - disabled
- // if > 0:
- // assume convergence if no cost improvement in this number of iterations
- //
- int max_no_improvement;
-
- bool print_forward_graph;
- bool print_backward_graph;
-
- int n_gradient_accumulation;
-
- // ADAM parameters
- struct {
- int n_iter;
-
- float sched; // schedule multiplier (fixed, decay or warmup)
- float decay; // weight decay for AdamW, use 0.0f to disable
- int decay_min_ndim; // minimum number of tensor dimension to apply weight decay
- float alpha; // learning rate
- float beta1;
- float beta2;
- float eps; // epsilon for numerical stability
- float eps_f; // epsilon for convergence test
- float eps_g; // epsilon for convergence test
- float gclip; // gradient clipping
- } adam;
-
- // LBFGS parameters
- struct {
- int m; // number of corrections to approximate the inv. Hessian
- int n_iter;
- int max_linesearch;
-
- float eps; // convergence tolerance
- float ftol; // line search tolerance
- float wolfe;
- float min_step;
- float max_step;
-
- enum ggml_linesearch linesearch;
- } lbfgs;
- };
-
- struct ggml_opt_context {
- struct ggml_context * ctx;
- struct ggml_opt_params params;
-
- int iter;
- int64_t nx; // number of parameter elements
-
- bool just_initialized;
-
- float loss_before;
- float loss_after;
-
- struct {
- struct ggml_tensor * g; // current gradient
- struct ggml_tensor * m; // first moment
- struct ggml_tensor * v; // second moment
- struct ggml_tensor * pf; // past function values
- float fx_best;
- float fx_prev;
- int n_no_improvement;
- } adam;
-
- struct {
- struct ggml_tensor * x; // current parameters
- struct ggml_tensor * xp; // previous parameters
- struct ggml_tensor * g; // current gradient
- struct ggml_tensor * gp; // previous gradient
- struct ggml_tensor * d; // search direction
- struct ggml_tensor * pf; // past function values
- struct ggml_tensor * lmal; // the L-BFGS memory alpha
- struct ggml_tensor * lmys; // the L-BFGS memory ys
- struct ggml_tensor * lms; // the L-BFGS memory s
- struct ggml_tensor * lmy; // the L-BFGS memory y
- float fx_best;
- float step;
- int j;
- int k;
- int end;
- int n_no_improvement;
- } lbfgs;
- };
-
- GGML_API struct ggml_opt_params ggml_opt_default_params(enum ggml_opt_type type);
-
- // optimize the function defined by the tensor f
- GGML_API enum ggml_opt_result ggml_opt(
- struct ggml_context * ctx,
- struct ggml_opt_params params,
- struct ggml_tensor * f);
-
- // initialize optimizer context
- GGML_API void ggml_opt_init(
- struct ggml_context * ctx,
- struct ggml_opt_context * opt,
- struct ggml_opt_params params,
- int64_t nx);
-
- // continue optimizing the function defined by the tensor f
- GGML_API enum ggml_opt_result ggml_opt_resume(
- struct ggml_context * ctx,
- struct ggml_opt_context * opt,
- struct ggml_tensor * f);
-
- // continue optimizing the function defined by the tensor f
- GGML_API enum ggml_opt_result ggml_opt_resume_g(
- struct ggml_context * ctx,
- struct ggml_opt_context * opt,
- struct ggml_tensor * f,
- struct ggml_cgraph * gf,
- struct ggml_cgraph * gb,
- ggml_opt_callback callback,
- void * callback_data);
-
- //
- // quantization
- //
-
- GGML_API size_t ggml_quantize_q4_0(const float * src, void * dst, int n, int k, int64_t * hist);
- GGML_API size_t ggml_quantize_q4_1(const float * src, void * dst, int n, int k, int64_t * hist);
- GGML_API size_t ggml_quantize_q5_0(const float * src, void * dst, int n, int k, int64_t * hist);
- GGML_API size_t ggml_quantize_q5_1(const float * src, void * dst, int n, int k, int64_t * hist);
- GGML_API size_t ggml_quantize_q8_0(const float * src, void * dst, int n, int k, int64_t * hist);
-
- GGML_API size_t ggml_quantize_chunk(enum ggml_type type, const float * src, void * dst, int start, int n, int64_t * hist);
-
- //
- // gguf
- //
-
- enum gguf_type {
- GGUF_TYPE_UINT8 = 0,
- GGUF_TYPE_INT8 = 1,
- GGUF_TYPE_UINT16 = 2,
- GGUF_TYPE_INT16 = 3,
- GGUF_TYPE_UINT32 = 4,
- GGUF_TYPE_INT32 = 5,
- GGUF_TYPE_FLOAT32 = 6,
- GGUF_TYPE_BOOL = 7,
- GGUF_TYPE_STRING = 8,
- GGUF_TYPE_ARRAY = 9,
- GGUF_TYPE_UINT64 = 10,
- GGUF_TYPE_INT64 = 11,
- GGUF_TYPE_FLOAT64 = 12,
- GGUF_TYPE_COUNT, // marks the end of the enum
- };
-
- struct gguf_context;
-
- struct gguf_init_params {
- bool no_alloc;
-
- // if not NULL, create a ggml_context and allocate the tensor data in it
- struct ggml_context ** ctx;
- };
-
- GGML_API struct gguf_context * gguf_init_empty(void);
- GGML_API struct gguf_context * gguf_init_from_file(const char * fname, struct gguf_init_params params);
- //GGML_API struct gguf_context * gguf_init_from_buffer(..);
-
- GGML_API void gguf_free(struct gguf_context * ctx);
-
- GGML_API const char * gguf_type_name(enum gguf_type type);
-
- GGML_API int gguf_get_version (const struct gguf_context * ctx);
- GGML_API size_t gguf_get_alignment (const struct gguf_context * ctx);
- GGML_API size_t gguf_get_data_offset(const struct gguf_context * ctx);
- GGML_API void * gguf_get_data (const struct gguf_context * ctx);
-
- GGML_API int gguf_get_n_kv(const struct gguf_context * ctx);
- GGML_API int gguf_find_key(const struct gguf_context * ctx, const char * key);
- GGML_API const char * gguf_get_key (const struct gguf_context * ctx, int key_id);
-
- GGML_API enum gguf_type gguf_get_kv_type (const struct gguf_context * ctx, int key_id);
- GGML_API enum gguf_type gguf_get_arr_type(const struct gguf_context * ctx, int key_id);
-
- // will abort if the wrong type is used for the key
- GGML_API uint8_t gguf_get_val_u8 (const struct gguf_context * ctx, int key_id);
- GGML_API int8_t gguf_get_val_i8 (const struct gguf_context * ctx, int key_id);
- GGML_API uint16_t gguf_get_val_u16 (const struct gguf_context * ctx, int key_id);
- GGML_API int16_t gguf_get_val_i16 (const struct gguf_context * ctx, int key_id);
- GGML_API uint32_t gguf_get_val_u32 (const struct gguf_context * ctx, int key_id);
- GGML_API int32_t gguf_get_val_i32 (const struct gguf_context * ctx, int key_id);
- GGML_API float gguf_get_val_f32 (const struct gguf_context * ctx, int key_id);
- GGML_API uint64_t gguf_get_val_u64 (const struct gguf_context * ctx, int key_id);
- GGML_API int64_t gguf_get_val_i64 (const struct gguf_context * ctx, int key_id);
- GGML_API double gguf_get_val_f64 (const struct gguf_context * ctx, int key_id);
- GGML_API bool gguf_get_val_bool(const struct gguf_context * ctx, int key_id);
- GGML_API const char * gguf_get_val_str (const struct gguf_context * ctx, int key_id);
- GGML_API int gguf_get_arr_n (const struct gguf_context * ctx, int key_id);
- GGML_API const void * gguf_get_arr_data(const struct gguf_context * ctx, int key_id);
- GGML_API const char * gguf_get_arr_str (const struct gguf_context * ctx, int key_id, int i);
-
- GGML_API int gguf_get_n_tensors (const struct gguf_context * ctx);
- GGML_API int gguf_find_tensor (const struct gguf_context * ctx, const char * name);
- GGML_API size_t gguf_get_tensor_offset(const struct gguf_context * ctx, int i);
- GGML_API char * gguf_get_tensor_name (const struct gguf_context * ctx, int i);
-
- // overrides existing values or adds a new one
- GGML_API void gguf_set_val_u8 (struct gguf_context * ctx, const char * key, uint8_t val);
- GGML_API void gguf_set_val_i8 (struct gguf_context * ctx, const char * key, int8_t val);
- GGML_API void gguf_set_val_u16 (struct gguf_context * ctx, const char * key, uint16_t val);
- GGML_API void gguf_set_val_i16 (struct gguf_context * ctx, const char * key, int16_t val);
- GGML_API void gguf_set_val_u32 (struct gguf_context * ctx, const char * key, uint32_t val);
- GGML_API void gguf_set_val_i32 (struct gguf_context * ctx, const char * key, int32_t val);
- GGML_API void gguf_set_val_f32 (struct gguf_context * ctx, const char * key, float val);
- GGML_API void gguf_set_val_u64 (struct gguf_context * ctx, const char * key, uint64_t val);
- GGML_API void gguf_set_val_i64 (struct gguf_context * ctx, const char * key, int64_t val);
- GGML_API void gguf_set_val_f64 (struct gguf_context * ctx, const char * key, double val);
- GGML_API void gguf_set_val_bool(struct gguf_context * ctx, const char * key, bool val);
- GGML_API void gguf_set_val_str (struct gguf_context * ctx, const char * key, const char * val);
- GGML_API void gguf_set_arr_data(struct gguf_context * ctx, const char * key, enum gguf_type type, const void * data, int n);
- GGML_API void gguf_set_arr_str (struct gguf_context * ctx, const char * key, const char ** data, int n);
-
- // set or add KV pairs from another context
- GGML_API void gguf_set_kv(struct gguf_context * ctx, struct gguf_context * src);
-
- // manage tensor info
- GGML_API void gguf_add_tensor(struct gguf_context * ctx, const struct ggml_tensor * tensor);
- GGML_API void gguf_set_tensor_type(struct gguf_context * ctx, const char * name, enum ggml_type type);
- GGML_API void gguf_set_tensor_data(struct gguf_context * ctx, const char * name, const void * data, size_t size);
-
- // writing gguf files can be done in 2 ways:
- //
- // - write the entire gguf_context to a binary file in a single pass:
- //
- // gguf_write_to_file(ctx, fname);
- //
- // - first prepare a file with a placeholder for the meta data, write the tensor data, then write the meta data:
- //
- // FILE * f = fopen(fname, "wb");
- // fseek(f, gguf_get_meta_size(ctx), SEEK_SET);
- // fwrite(f, ...);
- // void * data = gguf_meta_get_meta_data(ctx);
- // fseek(f, 0, SEEK_SET);
- // fwrite(f, data, gguf_get_meta_size(ctx));
- // free(data);
- // fclose(f);
- //
-
- // write the entire context to a binary file
- GGML_API void gguf_write_to_file(const struct gguf_context * ctx, const char * fname, bool only_meta);
-
- // get the size in bytes of the meta data (header, kv pairs, tensor info) including padding
- GGML_API size_t gguf_get_meta_size(const struct gguf_context * ctx);
- GGML_API void gguf_get_meta_data(const struct gguf_context * ctx, void * data);
-
- //
- // system info
- //
-
- GGML_API int ggml_cpu_has_avx (void);
- GGML_API int ggml_cpu_has_avx2 (void);
- GGML_API int ggml_cpu_has_avx512 (void);
- GGML_API int ggml_cpu_has_avx512_vbmi(void);
- GGML_API int ggml_cpu_has_avx512_vnni(void);
- GGML_API int ggml_cpu_has_fma (void);
- GGML_API int ggml_cpu_has_neon (void);
- GGML_API int ggml_cpu_has_arm_fma (void);
- GGML_API int ggml_cpu_has_metal (void);
- GGML_API int ggml_cpu_has_f16c (void);
- GGML_API int ggml_cpu_has_fp16_va (void);
- GGML_API int ggml_cpu_has_wasm_simd (void);
- GGML_API int ggml_cpu_has_blas (void);
- GGML_API int ggml_cpu_has_cublas (void);
- GGML_API int ggml_cpu_has_clblast (void);
- GGML_API int ggml_cpu_has_gpublas (void);
- GGML_API int ggml_cpu_has_sse3 (void);
- GGML_API int ggml_cpu_has_ssse3 (void);
- GGML_API int ggml_cpu_has_vsx (void);
-
- //
- // Internal types and functions exposed for tests and benchmarks
- //
-
-#ifdef __cplusplus
-// restrict not standard in C++
-#define GGML_RESTRICT
-#else
-#define GGML_RESTRICT restrict
-#endif
- typedef void (*ggml_to_float_t) (const void * GGML_RESTRICT x, float * GGML_RESTRICT y, int k);
- typedef void (*ggml_from_float_t)(const float * GGML_RESTRICT x, void * GGML_RESTRICT y, int k);
- typedef void (*ggml_vec_dot_t) (const int n, float * GGML_RESTRICT s, const void * GGML_RESTRICT x, const void * GGML_RESTRICT y);
-
- typedef struct {
- const char * type_name;
- int blck_size;
- size_t type_size;
- bool is_quantized;
- ggml_to_float_t to_float;
- ggml_from_float_t from_float;
- ggml_from_float_t from_float_reference;
- ggml_vec_dot_t vec_dot;
- enum ggml_type vec_dot_type;
- } ggml_type_traits_t;
-
- ggml_type_traits_t ggml_internal_get_type_traits(enum ggml_type type);
-
-#ifdef __cplusplus
-}
-#endif
diff --git a/spaces/IsaacK/streamlit-test/old/quiz_old.py b/spaces/IsaacK/streamlit-test/old/quiz_old.py
deleted file mode 100644
index 6a47cf49775a0c643ea54e40180c2f8ece2b9a98..0000000000000000000000000000000000000000
--- a/spaces/IsaacK/streamlit-test/old/quiz_old.py
+++ /dev/null
@@ -1,85 +0,0 @@
-import streamlit as st
-import os.path
-import sqlite3
-import random
-import datetime
-
-# Custom imports
-from pages.utils import add_blanks, chunker, random_session_id, check_answer, db_connect
-
-def app():
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- DATABASE = os.path.join(BASE_DIR, 'vocabulary_current.db')
-
- def form_callback(questions):
- st.session_state.form_submit = True
- num_correct = 0
- session_id = random_session_id()
- student_id = 'UKWN'
- uct_iso = datetime.datetime.utcnow().isoformat()
- st.title("Feedback")
- for idx, items in enumerate(questions):
- answer = st.session_state[idx]
- correct_str = 'incorrect'
- correct_int = 0
- if check_answer(items[1], answer):
- correct_str = 'correct'
- correct_int = 1
- num_correct += 1
- st.success(f"Question {idx + 1}")
- else:
- st.error(f"Question {idx + 1}")
- st.write(f"{items[3]}")
- st.write(f"Answer: {items[1]}")
- st.write(f"Your answer: {answer}")
- st.write(f"You are {correct_str}.")
- insert_tup = (student_id, session_id, uct_iso, items[1], items[2], answer, correct_int, )
- c, conn = db_connect(DATABASE)
- c.execute("INSERT INTO responses VALUES (?, ?, ?, ?, ?, ?, ?)", insert_tup)
- conn.commit()
- conn.close()
- score_val = 100 * num_correct / len(questions)
- st.metric(label="Final Score", value=f"{score_val}%")
-
- if "form_submit" not in st.session_state:
- c, conn = db_connect(DATABASE)
-
- units_list = []
- for item in c.execute("SELECT DISTINCT unit FROM vocab"):
- units_list.append(item[0])
-
- st.title("Sentence Completion")
- st.selectbox('Select a unit.', units_list, key='unit')
- st.selectbox('How many question do you want?', [5,10,15,20], key='num_q')
-
- unit = st.session_state.unit
- num_q = st.session_state.num_q
- input_tup = (unit, num_q)
-
- st.header(unit)
-
- st.write("Complete the sentences with the words from the word bank.")
-
- questions = []
- word_bank = []
-
- query = "SELECT * FROM vocab WHERE unit = ? ORDER BY RANDOM() LIMIT ?"
-
- for idx, item in enumerate(c.execute(query, input_tup)):
- word = item[2]
- word_bank.append(word)
- sentence = item[4]
- questions.append((idx, word, sentence, add_blanks(word, sentence)))
-
- st.subheader("Word Bank")
- random.shuffle(word_bank)
- st.table(chunker(word_bank, 5))
-
- with st.form("sentence_completion"):
- for q in questions:
- st.text_input(f'{q[0] + 1}. {q[3]}', key=q[0], placeholder="Type answer here")
- submitted = st.form_submit_button(label="Submit", on_click=form_callback, args=(questions,))
- if submitted:
- st.write("Submitted")
- conn.close()
-
\ No newline at end of file
diff --git a/spaces/JMalott/ai_architecture/clip/model.py b/spaces/JMalott/ai_architecture/clip/model.py
deleted file mode 100644
index f2c95c481724270116998b90de64cee8ef58c94e..0000000000000000000000000000000000000000
--- a/spaces/JMalott/ai_architecture/clip/model.py
+++ /dev/null
@@ -1,432 +0,0 @@
-from collections import OrderedDict
-from typing import Tuple, Union
-
-import numpy as np
-import torch
-import torch.nn.functional as F
-from torch import nn
-
-
-class Bottleneck(nn.Module):
- expansion = 4
-
- def __init__(self, inplanes, planes, stride=1):
- super().__init__()
-
- # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
- self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
- self.bn1 = nn.BatchNorm2d(planes)
-
- self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
- self.bn2 = nn.BatchNorm2d(planes)
-
- self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
-
- self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
- self.bn3 = nn.BatchNorm2d(planes * self.expansion)
-
- self.relu = nn.ReLU(inplace=True)
- self.downsample = None
- self.stride = stride
-
- if stride > 1 or inplanes != planes * Bottleneck.expansion:
- # downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
- self.downsample = nn.Sequential(OrderedDict([
- ("-1", nn.AvgPool2d(stride)),
- ("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
- ("1", nn.BatchNorm2d(planes * self.expansion))
- ]))
-
- def forward(self, x: torch.Tensor):
- identity = x
-
- out = self.relu(self.bn1(self.conv1(x)))
- out = self.relu(self.bn2(self.conv2(out)))
- out = self.avgpool(out)
- out = self.bn3(self.conv3(out))
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
- out = self.relu(out)
- return out
-
-
-class AttentionPool2d(nn.Module):
- def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
- super().__init__()
- self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
- self.k_proj = nn.Linear(embed_dim, embed_dim)
- self.q_proj = nn.Linear(embed_dim, embed_dim)
- self.v_proj = nn.Linear(embed_dim, embed_dim)
- self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
- self.num_heads = num_heads
-
- def forward(self, x):
- x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3]).permute(2, 0, 1) # NCHW -> (HW)NC
- x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
- x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
- x, _ = F.multi_head_attention_forward(
- query=x, key=x, value=x,
- embed_dim_to_check=x.shape[-1],
- num_heads=self.num_heads,
- q_proj_weight=self.q_proj.weight,
- k_proj_weight=self.k_proj.weight,
- v_proj_weight=self.v_proj.weight,
- in_proj_weight=None,
- in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
- bias_k=None,
- bias_v=None,
- add_zero_attn=False,
- dropout_p=0,
- out_proj_weight=self.c_proj.weight,
- out_proj_bias=self.c_proj.bias,
- use_separate_proj_weight=True,
- training=self.training,
- need_weights=False
- )
-
- return x[0]
-
-
-class ModifiedResNet(nn.Module):
- """
- A ResNet class that is similar to torchvision's but contains the following changes:
- - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
- - Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
- - The final pooling layer is a QKV attention instead of an average pool
- """
-
- def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
- super().__init__()
- self.output_dim = output_dim
- self.input_resolution = input_resolution
-
- # the 3-layer stem
- self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
- self.bn1 = nn.BatchNorm2d(width // 2)
- self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
- self.bn2 = nn.BatchNorm2d(width // 2)
- self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
- self.bn3 = nn.BatchNorm2d(width)
- self.avgpool = nn.AvgPool2d(2)
- self.relu = nn.ReLU(inplace=True)
-
- # residual layers
- self._inplanes = width # this is a *mutable* variable used during construction
- self.layer1 = self._make_layer(width, layers[0])
- self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
- self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
- self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
-
- embed_dim = width * 32 # the ResNet feature dimension
- self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
-
- def _make_layer(self, planes, blocks, stride=1):
- layers = [Bottleneck(self._inplanes, planes, stride)]
-
- self._inplanes = planes * Bottleneck.expansion
- for _ in range(1, blocks):
- layers.append(Bottleneck(self._inplanes, planes))
-
- return nn.Sequential(*layers)
-
- def forward(self, x):
- def stem(x):
- for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
- x = self.relu(bn(conv(x)))
- x = self.avgpool(x)
- return x
-
- x = x.type(self.conv1.weight.dtype)
- x = stem(x)
- x = self.layer1(x)
- x = self.layer2(x)
- x = self.layer3(x)
- x = self.layer4(x)
- x = self.attnpool(x)
-
- return x
-
-
-class LayerNorm(nn.LayerNorm):
- """Subclass torch's LayerNorm to handle fp16."""
-
- def forward(self, x: torch.Tensor):
- orig_type = x.dtype
- ret = super().forward(x.type(torch.float32))
- return ret.type(orig_type)
-
-
-class QuickGELU(nn.Module):
- def forward(self, x: torch.Tensor):
- return x * torch.sigmoid(1.702 * x)
-
-
-class ResidualAttentionBlock(nn.Module):
- def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
- super().__init__()
-
- self.attn = nn.MultiheadAttention(d_model, n_head)
- self.ln_1 = LayerNorm(d_model)
- self.mlp = nn.Sequential(OrderedDict([
- ("c_fc", nn.Linear(d_model, d_model * 4)),
- ("gelu", QuickGELU()),
- ("c_proj", nn.Linear(d_model * 4, d_model))
- ]))
- self.ln_2 = LayerNorm(d_model)
- self.attn_mask = attn_mask
-
- def attention(self, x: torch.Tensor):
- self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
- return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
-
- def forward(self, x: torch.Tensor):
- x = x + self.attention(self.ln_1(x))
- x = x + self.mlp(self.ln_2(x))
- return x
-
-
-class Transformer(nn.Module):
- def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
- super().__init__()
- self.width = width
- self.layers = layers
- self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
-
- def forward(self, x: torch.Tensor):
- return self.resblocks(x)
-
-
-class VisionTransformer(nn.Module):
- def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
- super().__init__()
- self.input_resolution = input_resolution
- self.output_dim = output_dim
- self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
-
- scale = width ** -0.5
- self.class_embedding = nn.Parameter(scale * torch.randn(width))
- self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
- self.ln_pre = LayerNorm(width)
-
- self.transformer = Transformer(width, layers, heads)
-
- self.ln_post = LayerNorm(width)
- self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
-
- def forward(self, x: torch.Tensor):
- x = self.conv1(x) # shape = [*, width, grid, grid]
- x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
- x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
- x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
- x = x + self.positional_embedding.to(x.dtype)
- x = self.ln_pre(x)
-
- x = x.permute(1, 0, 2) # NLD -> LND
- x = self.transformer(x)
- x = x.permute(1, 0, 2) # LND -> NLD
-
- x = self.ln_post(x[:, 0, :])
-
- if self.proj is not None:
- x = x @ self.proj
-
- return x
-
-
-class CLIP(nn.Module):
- def __init__(self,
- embed_dim: int,
- # vision
- image_resolution: int,
- vision_layers: Union[Tuple[int, int, int, int], int],
- vision_width: int,
- vision_patch_size: int,
- # text
- context_length: int,
- vocab_size: int,
- transformer_width: int,
- transformer_heads: int,
- transformer_layers: int
- ):
- super().__init__()
-
- self.context_length = context_length
-
- if isinstance(vision_layers, (tuple, list)):
- vision_heads = vision_width * 32 // 64
- self.visual = ModifiedResNet(
- layers=vision_layers,
- output_dim=embed_dim,
- heads=vision_heads,
- input_resolution=image_resolution,
- width=vision_width
- )
- else:
- vision_heads = vision_width // 64
- self.visual = VisionTransformer(
- input_resolution=image_resolution,
- patch_size=vision_patch_size,
- width=vision_width,
- layers=vision_layers,
- heads=vision_heads,
- output_dim=embed_dim
- )
-
- self.transformer = Transformer(
- width=transformer_width,
- layers=transformer_layers,
- heads=transformer_heads,
- attn_mask=self.build_attention_mask()
- )
-
- self.vocab_size = vocab_size
- self.token_embedding = nn.Embedding(vocab_size, transformer_width)
- self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
- self.ln_final = LayerNorm(transformer_width)
-
- self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
- self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
-
- self.initialize_parameters()
-
- def initialize_parameters(self):
- nn.init.normal_(self.token_embedding.weight, std=0.02)
- nn.init.normal_(self.positional_embedding, std=0.01)
-
- if isinstance(self.visual, ModifiedResNet):
- if self.visual.attnpool is not None:
- std = self.visual.attnpool.c_proj.in_features ** -0.5
- nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
- nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
- nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
- nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
-
- for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
- for name, param in resnet_block.named_parameters():
- if name.endswith("bn3.weight"):
- nn.init.zeros_(param)
-
- proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
- attn_std = self.transformer.width ** -0.5
- fc_std = (2 * self.transformer.width) ** -0.5
- for block in self.transformer.resblocks:
- nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
- nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
- nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
- nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
-
- if self.text_projection is not None:
- nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
-
- def build_attention_mask(self):
- # lazily create causal attention mask, with full attention between the vision tokens
- # pytorch uses additive attention mask; fill with -inf
- mask = torch.empty(self.context_length, self.context_length)
- mask.fill_(float("-inf"))
- mask.triu_(1) # zero out the lower diagonal
- return mask
-
- @property
- def dtype(self):
- return self.visual.conv1.weight.dtype
-
- def encode_image(self, image):
- return self.visual(image.type(self.dtype))
-
- def encode_text(self, text):
- x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
-
- x = x + self.positional_embedding.type(self.dtype)
- x = x.permute(1, 0, 2) # NLD -> LND
- x = self.transformer(x)
- x = x.permute(1, 0, 2) # LND -> NLD
- x = self.ln_final(x).type(self.dtype)
-
- # x.shape = [batch_size, n_ctx, transformer.width]
- # take features from the eot embedding (eot_token is the highest number in each sequence)
- x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
-
- return x
-
- def forward(self, image, text):
- image_features = self.encode_image(image)
- text_features = self.encode_text(text)
-
- # normalized features
- image_features = image_features / image_features.norm(dim=-1, keepdim=True)
- text_features = text_features / text_features.norm(dim=-1, keepdim=True)
-
- # cosine similarity as logits
- logit_scale = self.logit_scale.exp()
- logits_per_image = logit_scale * image_features @ text_features.t()
- logits_per_text = logit_scale * text_features @ image_features.t()
-
- # shape = [global_batch_size, global_batch_size]
- return logits_per_image, logits_per_text
-
-
-def convert_weights(model: nn.Module):
- """Convert applicable model parameters to fp16"""
-
- def _convert_weights_to_fp16(l):
- if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
- l.weight.data = l.weight.data.half()
- if l.bias is not None:
- l.bias.data = l.bias.data.half()
-
- if isinstance(l, nn.MultiheadAttention):
- for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
- tensor = getattr(l, attr)
- if tensor is not None:
- tensor.data = tensor.data.half()
-
- for name in ["text_projection", "proj"]:
- if hasattr(l, name):
- attr = getattr(l, name)
- if attr is not None:
- attr.data = attr.data.half()
-
- model.apply(_convert_weights_to_fp16)
-
-
-def build_model(state_dict: dict):
- vit = "visual.proj" in state_dict
-
- if vit:
- vision_width = state_dict["visual.conv1.weight"].shape[0]
- vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
- vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
- grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
- image_resolution = vision_patch_size * grid_size
- else:
- counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
- vision_layers = tuple(counts)
- vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
- output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
- vision_patch_size = None
- assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
- image_resolution = output_width * 32
-
- embed_dim = state_dict["text_projection"].shape[1]
- context_length = state_dict["positional_embedding"].shape[0]
- vocab_size = state_dict["token_embedding.weight"].shape[0]
- transformer_width = state_dict["ln_final.weight"].shape[0]
- transformer_heads = transformer_width // 64
- transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
-
- model = CLIP(
- embed_dim,
- image_resolution, vision_layers, vision_width, vision_patch_size,
- context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
- )
-
- for key in ["input_resolution", "context_length", "vocab_size"]:
- if key in state_dict:
- del state_dict[key]
-
- convert_weights(model)
- model.load_state_dict(state_dict)
- return model.eval()
diff --git a/spaces/Joshua1808/PaginaWeb/README.md b/spaces/Joshua1808/PaginaWeb/README.md
deleted file mode 100644
index 823edba6caae25fd6993979a484859c6ddd7a956..0000000000000000000000000000000000000000
--- a/spaces/Joshua1808/PaginaWeb/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: PaginaWeb
-emoji: 👁
-colorFrom: purple
-colorTo: blue
-sdk: streamlit
-sdk_version: 1.15.2
-app_file: app.py
-pinned: false
-license: openrail
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Justin-Choo/QuickGen-Anime/README.md b/spaces/Justin-Choo/QuickGen-Anime/README.md
deleted file mode 100644
index 6a9420e6d747a03b4257449b740556ce2efec422..0000000000000000000000000000000000000000
--- a/spaces/Justin-Choo/QuickGen-Anime/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Anime-Gen
-emoji: 💩
-colorFrom: red
-colorTo: blue
-sdk: gradio
-sdk_version: 3.17.0
-app_file: app.py
-pinned: false
-license: creativeml-openrail-m
-duplicated_from: pulpapps/QuickGen-Anime
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/KyanChen/RSPrompter/mmdet/datasets/transforms/__init__.py b/spaces/KyanChen/RSPrompter/mmdet/datasets/transforms/__init__.py
deleted file mode 100644
index eb61095383e5dce7636c81411201620519895bdc..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmdet/datasets/transforms/__init__.py
+++ /dev/null
@@ -1,36 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .augment_wrappers import AutoAugment, RandAugment
-from .colorspace import (AutoContrast, Brightness, Color, ColorTransform,
- Contrast, Equalize, Invert, Posterize, Sharpness,
- Solarize, SolarizeAdd)
-from .formatting import ImageToTensor, PackDetInputs, ToTensor, Transpose
-from .geometric import (GeomTransform, Rotate, ShearX, ShearY, TranslateX,
- TranslateY)
-from .instaboost import InstaBoost
-from .loading import (FilterAnnotations, InferencerLoader, LoadAnnotations,
- LoadEmptyAnnotations, LoadImageFromNDArray,
- LoadMultiChannelImageFromFiles, LoadPanopticAnnotations,
- LoadProposals)
-from .transforms import (Albu, CachedMixUp, CachedMosaic, CopyPaste, CutOut,
- Expand, FixShapeResize, MinIoURandomCrop, MixUp,
- Mosaic, Pad, PhotoMetricDistortion, RandomAffine,
- RandomCenterCropPad, RandomCrop, RandomErasing,
- RandomFlip, RandomShift, Resize, SegRescale,
- YOLOXHSVRandomAug)
-from .wrappers import MultiBranch, ProposalBroadcaster, RandomOrder
-
-__all__ = [
- 'PackDetInputs', 'ToTensor', 'ImageToTensor', 'Transpose',
- 'LoadImageFromNDArray', 'LoadAnnotations', 'LoadPanopticAnnotations',
- 'LoadMultiChannelImageFromFiles', 'LoadProposals', 'Resize', 'RandomFlip',
- 'RandomCrop', 'SegRescale', 'MinIoURandomCrop', 'Expand',
- 'PhotoMetricDistortion', 'Albu', 'InstaBoost', 'RandomCenterCropPad',
- 'AutoAugment', 'CutOut', 'ShearX', 'ShearY', 'Rotate', 'Color', 'Equalize',
- 'Brightness', 'Contrast', 'TranslateX', 'TranslateY', 'RandomShift',
- 'Mosaic', 'MixUp', 'RandomAffine', 'YOLOXHSVRandomAug', 'CopyPaste',
- 'FilterAnnotations', 'Pad', 'GeomTransform', 'ColorTransform',
- 'RandAugment', 'Sharpness', 'Solarize', 'SolarizeAdd', 'Posterize',
- 'AutoContrast', 'Invert', 'MultiBranch', 'RandomErasing',
- 'LoadEmptyAnnotations', 'RandomOrder', 'CachedMosaic', 'CachedMixUp',
- 'FixShapeResize', 'ProposalBroadcaster', 'InferencerLoader'
-]
diff --git a/spaces/KyanChen/RSPrompter/mmpretrain/datasets/nlvr2.py b/spaces/KyanChen/RSPrompter/mmpretrain/datasets/nlvr2.py
deleted file mode 100644
index 0063090657714406049a6daa6fa3c0d868422590..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmpretrain/datasets/nlvr2.py
+++ /dev/null
@@ -1,36 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import json
-from typing import List
-
-from mmengine.fileio import get_file_backend, list_from_file
-
-from mmpretrain.registry import DATASETS
-from .base_dataset import BaseDataset
-
-
-@DATASETS.register_module()
-class NLVR2(BaseDataset):
- """COCO Caption dataset."""
-
- def load_data_list(self) -> List[dict]:
- """Load data list."""
-
- data_list = []
- img_prefix = self.data_prefix['img_path']
- file_backend = get_file_backend(img_prefix)
- examples = list_from_file(self.ann_file)
-
- for example in examples:
- example = json.loads(example)
- prefix = example['identifier'].rsplit('-', 1)[0]
- train_data = {}
- train_data['text'] = example['sentence']
- train_data['gt_label'] = {'True': 1, 'False': 0}[example['label']]
- train_data['img_path'] = [
- file_backend.join_path(img_prefix, prefix + f'-img{i}.png')
- for i in range(2)
- ]
-
- data_list.append(train_data)
-
- return data_list
diff --git a/spaces/LEKAI007/QQ/README.md b/spaces/LEKAI007/QQ/README.md
deleted file mode 100644
index bd56881a2a7709591343e2f15af9a6a8133e115b..0000000000000000000000000000000000000000
--- a/spaces/LEKAI007/QQ/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-title: QQsign
-emoji: 🦀
-colorFrom: blue
-colorTo: purple
-sdk: docker
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/LZRi/LZR-Bert-VITS2/preprocess_text.py b/spaces/LZRi/LZR-Bert-VITS2/preprocess_text.py
deleted file mode 100644
index 44c35fecd9b7f21016e80e9597d6055254cba3f7..0000000000000000000000000000000000000000
--- a/spaces/LZRi/LZR-Bert-VITS2/preprocess_text.py
+++ /dev/null
@@ -1,69 +0,0 @@
-import json
-from random import shuffle
-
-import tqdm
-from text.cleaner import clean_text
-from collections import defaultdict
-import shutil
-stage = [1,2,3]
-
-transcription_path = 'filelists/short_character_anno.list'
-train_path = 'filelists/train.list'
-val_path = 'filelists/val.list'
-config_path = "configs/config.json"
-val_per_spk = 4
-max_val_total = 8
-
-if 1 in stage:
- with open( transcription_path+'.cleaned', 'w', encoding='utf-8') as f:
- for line in tqdm.tqdm(open(transcription_path, encoding='utf-8').readlines()):
- try:
- utt, spk, language, text = line.strip().split('|')
- #language = "ZH"
- norm_text, phones, tones, word2ph = clean_text(text, language)
- f.write('{}|{}|{}|{}|{}|{}|{}\n'.format(utt, spk, language, norm_text, ' '.join(phones),
- " ".join([str(i) for i in tones]),
- " ".join([str(i) for i in word2ph])))
- except:
- print("err!", utt)
-
-if 2 in stage:
- spk_utt_map = defaultdict(list)
- spk_id_map = {}
- current_sid = 0
-
- with open( transcription_path+'.cleaned', encoding='utf-8') as f:
- for line in f.readlines():
- utt, spk, language, text, phones, tones, word2ph = line.strip().split('|')
- spk_utt_map[spk].append(line)
- if spk not in spk_id_map.keys():
- spk_id_map[spk] = current_sid
- current_sid += 1
- train_list = []
- val_list = []
- for spk, utts in spk_utt_map.items():
- shuffle(utts)
- val_list+=utts[:val_per_spk]
- train_list+=utts[val_per_spk:]
- if len(val_list) > max_val_total:
- train_list+=val_list[max_val_total:]
- val_list = val_list[:max_val_total]
-
- with open( train_path,"w", encoding='utf-8') as f:
- for line in train_list:
- f.write(line)
-
- file_path = transcription_path+'.cleaned'
- shutil.copy(file_path,'./filelists/train.list')
-
- with open(val_path, "w", encoding='utf-8') as f:
- for line in val_list:
- f.write(line)
-
-if 3 in stage:
- assert 2 in stage
- config = json.load(open(config_path))
- config['data']["n_speakers"] = current_sid #
- config["data"]['spk2id'] = spk_id_map
- with open(config_path, 'w', encoding='utf-8') as f:
- json.dump(config, f, indent=2, ensure_ascii=False)
diff --git a/spaces/LaxmanOfficial/GenerativeAI/README.md b/spaces/LaxmanOfficial/GenerativeAI/README.md
deleted file mode 100644
index 14d86f3c92d12cac4121f8f00dcf6b6e1293bdab..0000000000000000000000000000000000000000
--- a/spaces/LaxmanOfficial/GenerativeAI/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: GenerativeAI
-emoji: 📊
-colorFrom: purple
-colorTo: purple
-sdk: gradio
-sdk_version: 3.39.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/infer/modules/train/extract_feature_print.py b/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/infer/modules/train/extract_feature_print.py
deleted file mode 100644
index e328f64b38c0cd5a443221b28b25887a1978e4f4..0000000000000000000000000000000000000000
--- a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/infer/modules/train/extract_feature_print.py
+++ /dev/null
@@ -1,152 +0,0 @@
-import os
-import sys
-import traceback
-import tqdm
-os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
-os.environ["PYTORCH_MPS_HIGH_WATERMARK_RATIO"] = "0.0"
-
-device = sys.argv[1]
-n_part = int(sys.argv[2])
-i_part = int(sys.argv[3])
-if len(sys.argv) == 7:
- exp_dir = sys.argv[4]
- version = sys.argv[5]
- is_half = sys.argv[6]
-else:
- i_gpu = sys.argv[4]
- exp_dir = sys.argv[5]
- os.environ["CUDA_VISIBLE_DEVICES"] = str(i_gpu)
- version = sys.argv[6]
- is_half = sys.argv[7]
-import fairseq
-import numpy as np
-import soundfile as sf
-import torch
-import torch.nn.functional as F
-
-if "privateuseone" not in device:
- device = "cpu"
- if torch.cuda.is_available():
- device = "cuda"
- elif torch.backends.mps.is_available():
- device = "mps"
-else:
- import torch_directml
-
- device = torch_directml.device(torch_directml.default_device())
-
- def forward_dml(ctx, x, scale):
- ctx.scale = scale
- res = x.clone().detach()
- return res
-
- fairseq.modules.grad_multiply.GradMultiply.forward = forward_dml
-
-f = open("%s/extract_f0_feature.log" % exp_dir, "a+")
-
-
-def printt(strr):
- print(strr)
- f.write("%s\n" % strr)
- f.flush()
-
-
-printt(sys.argv)
-model_path = "assets/hubert/hubert_base.pt"
-
-printt(exp_dir)
-wavPath = "%s/1_16k_wavs" % exp_dir
-outPath = (
- "%s/3_feature256" % exp_dir if version == "v1" else "%s/3_feature768" % exp_dir
-)
-os.makedirs(outPath, exist_ok=True)
-
-
-# wave must be 16k, hop_size=320
-def readwave(wav_path, normalize=False):
- wav, sr = sf.read(wav_path)
- assert sr == 16000
- #feats = torch.from_numpy(wav).float()
- feats = torch.from_numpy(wav)
- if is_half:
- feats = feats.half()
- else:
- feats = feats.float()
- if feats.dim() == 2: # double channels
- feats = feats.mean(-1)
- assert feats.dim() == 1, feats.dim()
- if normalize:
- with torch.no_grad():
- feats = F.layer_norm(feats, feats.shape)
- feats = feats.view(1, -1)
- return feats
-
-
-# HuBERT model
-os.system('cls' if os.name == 'nt' else 'clear')
-print("Starting feature extraction...\n")
-printt("Loaded model {}".format(model_path))
-# if hubert model is exist
-if os.access(model_path, os.F_OK) == False:
- printt(
- "Error: Extracting is shut down because %s does not exist, you may download it from https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main"
- % model_path
- )
- exit(0)
-models, saved_cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task(
- [model_path],
- suffix="",
-)
-model = models[0]
-model = model.to(device)
-printt("Using %s" % device)
-#if device not in ["mps", "cpu"]:
-# model = model.half()
-if is_half:
- model = model.half()
-else:
- model = model.float()
-model.eval()
-
-todo = sorted(list(os.listdir(wavPath)))[i_part::n_part]
-n = max(1, len(todo) // 10) # 最多打印十条
-if len(todo) == 0:
- os.system('cls' if os.name == 'nt' else 'clear')
- printt("An error occurred in the feature extraction, make sure you have provided the audios correctly.")
-else:
- printt("- %s" % len(todo))
- with tqdm.tqdm(total=len(todo)) as pbar:
- for idx, file in enumerate(todo):
- try:
- if file.endswith(".wav"):
- wav_path = "%s/%s" % (wavPath, file)
- out_path = "%s/%s" % (outPath, file.replace("wav", "npy"))
-
- if os.path.exists(out_path):
- continue
-
- feats = readwave(wav_path, normalize=saved_cfg.task.normalize)
- padding_mask = torch.BoolTensor(feats.shape).fill_(False)
- inputs = {
- "source": feats.to(device),
- "padding_mask": padding_mask.to(device),
- "output_layer": 9 if version == "v1" else 12, # layer 9
- }
- with torch.no_grad():
- logits = model.extract_features(**inputs)
- feats = (
- model.final_proj(logits[0]) if version == "v1" else logits[0]
- )
-
- feats = feats.squeeze(0).float().cpu().numpy()
- if np.isnan(feats).sum() == 0:
- np.save(out_path, feats, allow_pickle=False)
- else:
- printt("%s-contains nan" % file)
- # if idx % n == 0:
- # printt("now-%s,all-%s,%s,%s" % (idx, len(todo), file, feats.shape))
- pbar.set_description(f"Processing: %s - Shape: %s" % (file, feats.shape))
- except:
- printt(traceback.format_exc())
- pbar.update(1)
- printt("\nFeature extraction completed successfully!")
diff --git a/spaces/Liu-LAB/GPT-academic/request_llm/bridge_stackclaude.py b/spaces/Liu-LAB/GPT-academic/request_llm/bridge_stackclaude.py
deleted file mode 100644
index 3f2ee67428f9c8323eca0f7006ad4d4f767a6b58..0000000000000000000000000000000000000000
--- a/spaces/Liu-LAB/GPT-academic/request_llm/bridge_stackclaude.py
+++ /dev/null
@@ -1,269 +0,0 @@
-from .bridge_newbingfree import preprocess_newbing_out, preprocess_newbing_out_simple
-from multiprocessing import Process, Pipe
-from toolbox import update_ui, get_conf, trimmed_format_exc
-import threading
-import importlib
-import logging
-import time
-from toolbox import get_conf
-import asyncio
-load_message = "正在加载Claude组件,请稍候..."
-
-try:
- """
- ========================================================================
- 第一部分:Slack API Client
- https://github.com/yokonsan/claude-in-slack-api
- ========================================================================
- """
-
- from slack_sdk.errors import SlackApiError
- from slack_sdk.web.async_client import AsyncWebClient
-
- class SlackClient(AsyncWebClient):
- """SlackClient类用于与Slack API进行交互,实现消息发送、接收等功能。
-
- 属性:
- - CHANNEL_ID:str类型,表示频道ID。
-
- 方法:
- - open_channel():异步方法。通过调用conversations_open方法打开一个频道,并将返回的频道ID保存在属性CHANNEL_ID中。
- - chat(text: str):异步方法。向已打开的频道发送一条文本消息。
- - get_slack_messages():异步方法。获取已打开频道的最新消息并返回消息列表,目前不支持历史消息查询。
- - get_reply():异步方法。循环监听已打开频道的消息,如果收到"Typing…_"结尾的消息说明Claude还在继续输出,否则结束循环。
-
- """
- CHANNEL_ID = None
-
- async def open_channel(self):
- response = await self.conversations_open(users=get_conf('SLACK_CLAUDE_BOT_ID')[0])
- self.CHANNEL_ID = response["channel"]["id"]
-
- async def chat(self, text):
- if not self.CHANNEL_ID:
- raise Exception("Channel not found.")
-
- resp = await self.chat_postMessage(channel=self.CHANNEL_ID, text=text)
- self.LAST_TS = resp["ts"]
-
- async def get_slack_messages(self):
- try:
- # TODO:暂时不支持历史消息,因为在同一个频道里存在多人使用时历史消息渗透问题
- resp = await self.conversations_history(channel=self.CHANNEL_ID, oldest=self.LAST_TS, limit=1)
- msg = [msg for msg in resp["messages"]
- if msg.get("user") == get_conf('SLACK_CLAUDE_BOT_ID')[0]]
- return msg
- except (SlackApiError, KeyError) as e:
- raise RuntimeError(f"获取Slack消息失败。")
-
- async def get_reply(self):
- while True:
- slack_msgs = await self.get_slack_messages()
- if len(slack_msgs) == 0:
- await asyncio.sleep(0.5)
- continue
-
- msg = slack_msgs[-1]
- if msg["text"].endswith("Typing…_"):
- yield False, msg["text"]
- else:
- yield True, msg["text"]
- break
-except:
- pass
-
-"""
-========================================================================
-第二部分:子进程Worker(调用主体)
-========================================================================
-"""
-
-
-class ClaudeHandle(Process):
- def __init__(self):
- super().__init__(daemon=True)
- self.parent, self.child = Pipe()
- self.claude_model = None
- self.info = ""
- self.success = True
- self.local_history = []
- self.check_dependency()
- if self.success:
- self.start()
- self.threadLock = threading.Lock()
-
- def check_dependency(self):
- try:
- self.success = False
- import slack_sdk
- self.info = "依赖检测通过,等待Claude响应。注意目前不能多人同时调用Claude接口(有线程锁),否则将导致每个人的Claude问询历史互相渗透。调用Claude时,会自动使用已配置的代理。"
- self.success = True
- except:
- self.info = "缺少的依赖,如果要使用Claude,除了基础的pip依赖以外,您还需要运行`pip install -r request_llm/requirements_slackclaude.txt`安装Claude的依赖,然后重启程序。"
- self.success = False
-
- def ready(self):
- return self.claude_model is not None
-
- async def async_run(self):
- await self.claude_model.open_channel()
- while True:
- # 等待
- kwargs = self.child.recv()
- question = kwargs['query']
- history = kwargs['history']
-
- # 开始问问题
- prompt = ""
-
- # 问题
- prompt += question
- print('question:', prompt)
-
- # 提交
- await self.claude_model.chat(prompt)
-
- # 获取回复
- async for final, response in self.claude_model.get_reply():
- if not final:
- print(response)
- self.child.send(str(response))
- else:
- # 防止丢失最后一条消息
- slack_msgs = await self.claude_model.get_slack_messages()
- last_msg = slack_msgs[-1]["text"] if slack_msgs and len(slack_msgs) > 0 else ""
- if last_msg:
- self.child.send(last_msg)
- print('-------- receive final ---------')
- self.child.send('[Finish]')
-
- def run(self):
- """
- 这个函数运行在子进程
- """
- # 第一次运行,加载参数
- self.success = False
- self.local_history = []
- if (self.claude_model is None) or (not self.success):
- # 代理设置
- proxies, = get_conf('proxies')
- if proxies is None:
- self.proxies_https = None
- else:
- self.proxies_https = proxies['https']
-
- try:
- SLACK_CLAUDE_USER_TOKEN, = get_conf('SLACK_CLAUDE_USER_TOKEN')
- self.claude_model = SlackClient(token=SLACK_CLAUDE_USER_TOKEN, proxy=self.proxies_https)
- print('Claude组件初始化成功。')
- except:
- self.success = False
- tb_str = '\n```\n' + trimmed_format_exc() + '\n```\n'
- self.child.send(f'[Local Message] 不能加载Claude组件。{tb_str}')
- self.child.send('[Fail]')
- self.child.send('[Finish]')
- raise RuntimeError(f"不能加载Claude组件。")
-
- self.success = True
- try:
- # 进入任务等待状态
- asyncio.run(self.async_run())
- except Exception:
- tb_str = '\n```\n' + trimmed_format_exc() + '\n```\n'
- self.child.send(f'[Local Message] Claude失败 {tb_str}.')
- self.child.send('[Fail]')
- self.child.send('[Finish]')
-
- def stream_chat(self, **kwargs):
- """
- 这个函数运行在主进程
- """
- self.threadLock.acquire()
- self.parent.send(kwargs) # 发送请求到子进程
- while True:
- res = self.parent.recv() # 等待Claude回复的片段
- if res == '[Finish]':
- break # 结束
- elif res == '[Fail]':
- self.success = False
- break
- else:
- yield res # Claude回复的片段
- self.threadLock.release()
-
-
-"""
-========================================================================
-第三部分:主进程统一调用函数接口
-========================================================================
-"""
-global claude_handle
-claude_handle = None
-
-
-def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="", observe_window=None, console_slience=False):
- """
- 多线程方法
- 函数的说明请见 request_llm/bridge_all.py
- """
- global claude_handle
- if (claude_handle is None) or (not claude_handle.success):
- claude_handle = ClaudeHandle()
- observe_window[0] = load_message + "\n\n" + claude_handle.info
- if not claude_handle.success:
- error = claude_handle.info
- claude_handle = None
- raise RuntimeError(error)
-
- # 没有 sys_prompt 接口,因此把prompt加入 history
- history_feedin = []
- for i in range(len(history)//2):
- history_feedin.append([history[2*i], history[2*i+1]])
-
- watch_dog_patience = 5 # 看门狗 (watchdog) 的耐心, 设置5秒即可
- response = ""
- observe_window[0] = "[Local Message]: 等待Claude响应中 ..."
- for response in claude_handle.stream_chat(query=inputs, history=history_feedin, system_prompt=sys_prompt, max_length=llm_kwargs['max_length'], top_p=llm_kwargs['top_p'], temperature=llm_kwargs['temperature']):
- observe_window[0] = preprocess_newbing_out_simple(response)
- if len(observe_window) >= 2:
- if (time.time()-observe_window[1]) > watch_dog_patience:
- raise RuntimeError("程序终止。")
- return preprocess_newbing_out_simple(response)
-
-
-def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream=True, additional_fn=None):
- """
- 单线程方法
- 函数的说明请见 request_llm/bridge_all.py
- """
- chatbot.append((inputs, "[Local Message]: 等待Claude响应中 ..."))
-
- global claude_handle
- if (claude_handle is None) or (not claude_handle.success):
- claude_handle = ClaudeHandle()
- chatbot[-1] = (inputs, load_message + "\n\n" + claude_handle.info)
- yield from update_ui(chatbot=chatbot, history=[])
- if not claude_handle.success:
- claude_handle = None
- return
-
- if additional_fn is not None:
- from core_functional import handle_core_functionality
- inputs, history = handle_core_functionality(additional_fn, inputs, history, chatbot)
-
- history_feedin = []
- for i in range(len(history)//2):
- history_feedin.append([history[2*i], history[2*i+1]])
-
- chatbot[-1] = (inputs, "[Local Message]: 等待Claude响应中 ...")
- response = "[Local Message]: 等待Claude响应中 ..."
- yield from update_ui(chatbot=chatbot, history=history, msg="Claude响应缓慢,尚未完成全部响应,请耐心完成后再提交新问题。")
- for response in claude_handle.stream_chat(query=inputs, history=history_feedin, system_prompt=system_prompt):
- chatbot[-1] = (inputs, preprocess_newbing_out(response))
- yield from update_ui(chatbot=chatbot, history=history, msg="Claude响应缓慢,尚未完成全部响应,请耐心完成后再提交新问题。")
- if response == "[Local Message]: 等待Claude响应中 ...":
- response = "[Local Message]: Claude响应异常,请刷新界面重试 ..."
- history.extend([inputs, response])
- logging.info(f'[raw_input] {inputs}')
- logging.info(f'[response] {response}')
- yield from update_ui(chatbot=chatbot, history=history, msg="完成全部响应,请提交新问题。")
diff --git a/spaces/MAGAer13/mPLUG-Owl2/mplug_owl2/model/convert_mplug_owl2_weight_to_hf.py b/spaces/MAGAer13/mPLUG-Owl2/mplug_owl2/model/convert_mplug_owl2_weight_to_hf.py
deleted file mode 100644
index 8288a9a6a9b5d7a1a4ec58af6a53b14d4b266580..0000000000000000000000000000000000000000
--- a/spaces/MAGAer13/mPLUG-Owl2/mplug_owl2/model/convert_mplug_owl2_weight_to_hf.py
+++ /dev/null
@@ -1,395 +0,0 @@
-# Copyright 2023 DAMO Academy and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import argparse
-import gc
-import json
-import math
-import os
-import shutil
-import warnings
-
-import torch
-
-from transformers import LlamaConfig, LlamaForCausalLM, LlamaTokenizer
-from .configuration_mplug_owl2 import MPLUGOwl2Config, MplugOwlVisionConfig, MplugOwlVisualAbstractorConfig
-from .modeling_mplug_owl2 import MPLUGOwl2LlamaForCausalLM
-
-try:
- from transformers import LlamaTokenizerFast
-except ImportError as e:
- warnings.warn(e)
- warnings.warn(
- "The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion"
- )
- LlamaTokenizerFast = None
-
-"""
-Sample usage:
-
-```
-python3 /pure-mlo-scratch/sfan/model-parallel-trainer/llama2megatron/convert_llama2hf.py \
- --input_dir /pure-mlo-scratch/llama/ --model_size 7 --output_dir /pure-mlo-scratch/llama/converted_HF_7B
-```
-
-Thereafter, models can be loaded via:
-
-```py
-from transformers import LlamaForCausalLM, LlamaTokenizer
-
-model = LlamaForCausalLM.from_pretrained("/output/path")
-tokenizer = LlamaTokenizer.from_pretrained("/output/path")
-```
-
-Important note: you need to be able to host the whole model in RAM to execute this script (even if the biggest versions
-come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
-"""
-
-llama_s2layer = {7: 32, 13: 40, 30: 60, 65: 80, 70: 80}
-llama_s2heads = {7: 32, 13: 40, 30: 52, 65: 64, 70: 64}
-llama_s2dense = {7: 11008, 13: 13824, 30: 17920, 65: 22016,
- 70: 28672} # should be (2/3)*4*d, but it isn't exaclty that
-llama_s2hidden = {7: 4096, 13: 5120, 32: 6656, 65: 8192, 70: 8192}
-
-
-def compute_intermediate_size(n):
- return int(math.ceil(n * 8 / 3) + 255) // 256 * 256
-
-
-def read_json(path):
- with open(path, "r") as f:
- return json.load(f)
-
-
-def write_json(text, path):
- with open(path, "w") as f:
- json.dump(text, f)
-
-
-def write_model(model_path,
- input_base_path,
- model_size,
- num_input_shards=1,
- num_output_shards=2,
- skip_permute=True,
- norm_eps=1e-05):
- # if os.path.exists(model_path):
- # shutil.rmtree(model_path)
- os.makedirs(model_path, exist_ok=True)
- # tmp_model_path = os.path.join(model_path, "tmp")
- tmp_model_path = model_path
- os.makedirs(tmp_model_path, exist_ok=True)
-
- num_shards = num_input_shards
- n_layers = llama_s2layer[model_size]
- n_heads = llama_s2heads[model_size]
- n_heads_per_shard = n_heads // num_shards
- n_dense = llama_s2dense[model_size]
- n_hidden = llama_s2hidden[model_size]
- hidden_per_head = n_hidden // n_heads
- base = 10000.0
- inv_freq = 1.0 / (base ** (torch.arange(0, hidden_per_head, 2).float() / hidden_per_head))
-
- # permute for sliced rotary
- def permute(w, skip_permute=skip_permute):
- if skip_permute:
- return w
- return w.view(n_heads, n_hidden // n_heads // 2, 2, n_hidden).transpose(1, 2).reshape(n_hidden, n_hidden)
-
- print(f"Fetching all parameters from the checkpoint at {input_base_path}.")
- # Load weights
- if num_shards==1:
- # Not sharded
- # (The sharded implementation would also work, but this is simpler.)
- # /pure-mlo-scratch/alhernan/megatron-data/checkpoints/llama2-7b-tp4-pp1-optim/release/mp_rank_00/model_optim_rng.pt
- if os.path.exists(os.path.join(input_base_path, 'release')):
- filename = os.path.join(input_base_path, 'release', 'mp_rank_00', 'model_optim_rng.pt')
- elif input_base_path.split('/')[-1].startswith('iter_'):
- iteration = eval(input_base_path.split('/')[-1].replace('iter_', '').lstrip('0'))
- load_dir = '/'.join(input_base_path.split('/')[:-1])
- filename = os.path.join(input_base_path, 'mp_rank_00', 'model_optim_rng.pt')
- if not os.path.exists(filename):
- filename = filename.replace('model_optim_rng.pt', 'model_rng.pt')
- else:
- tracker_filename = os.path.join(input_base_path, 'latest_checkpointed_iteration.txt')
- with open(tracker_filename, 'r') as f:
- metastring = f.read().strip()
- iteration = 'iter_{:07d}'.format(int(metastring))
- filename = os.path.join(input_base_path, iteration, 'mp_rank_00', 'model_optim_rng.pt')
- if not os.path.exists(filename):
- filename = filename.replace('model_optim_rng.pt', 'model_rng.pt')
- original_filename = filename
- loaded = torch.load(filename, map_location="cpu")['model']['language_model']
-
- else:
- # Sharded
- filenames = []
- for i in range(num_shards):
- if os.path.exists(os.path.join(input_base_path, 'release')):
- filename = os.path.join(input_base_path, 'release', f'mp_rank_{i:02d}', 'model_optim_rng.pt')
- else:
- tracker_filename = os.path.join(input_base_path, 'latest_checkpointed_iteration.txt')
- with open(tracker_filename, 'r') as f:
- metastring = f.read().strip()
- iteration = 'iter_{:07d}'.format(int(metastring))
- filename = os.path.join(input_base_path, iteration, f'mp_rank_{i:02d}', 'model_optim_rng.pt')
- if not os.path.exists(filename):
- filename = filename.replace('model_optim_rng.pt', 'model_rng.pt')
- filenames.append(filename)
- loaded = [
- torch.load(filenames[i], map_location="cpu")['model']['language_model']
- for i in range(num_shards)
- ]
-
- print('Llama-Megatron Loaded!')
- param_count = 0
- index_dict = {"weight_map": {}}
-
- print(f'Weighted Converting for {n_layers} layers...')
- for layer_i in range(n_layers):
- print(layer_i)
- filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"
- if num_shards == 1:
- # Unsharded
- state_dict = {
- f"model.layers.{layer_i}.self_attn.q_proj.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.q_proj.weight"],
- f"model.layers.{layer_i}.self_attn.k_proj.multiway.0.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.k_proj.multiway.0.weight"],
- f"model.layers.{layer_i}.self_attn.v_proj.multiway.0.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.v_proj.multiway.0.weight"],
- f"model.layers.{layer_i}.self_attn.k_proj.multiway.1.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.k_proj.multiway.1.weight"],
- f"model.layers.{layer_i}.self_attn.v_proj.multiway.1.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.v_proj.multiway.1.weight"],
- f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.o_proj.weight"],
- f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded['encoder'][f"layers.{layer_i}.mlp.gate_proj.weight"],
- f"model.layers.{layer_i}.mlp.down_proj.weight": loaded['encoder'][f"layers.{layer_i}.mlp.down_proj.weight"],
- f"model.layers.{layer_i}.mlp.up_proj.weight": loaded['encoder'][f"layers.{layer_i}.mlp.up_proj.weight"],
- f"model.layers.{layer_i}.input_layernorm.multiway.0.weight": loaded['encoder'][f"layers.{layer_i}.input_layernorm.multiway.0.weight"],
- f"model.layers.{layer_i}.post_attention_layernorm.multiway.0.weight": loaded['encoder'][f"layers.{layer_i}.post_attention_layernorm.multiway.0.weight"],
- f"model.layers.{layer_i}.input_layernorm.multiway.1.weight": loaded['encoder'][f"layers.{layer_i}.input_layernorm.multiway.1.weight"],
- f"model.layers.{layer_i}.post_attention_layernorm.multiway.1.weight": loaded['encoder'][f"layers.{layer_i}.post_attention_layernorm.multiway.1.weight"],
- }
- else:
- raise NotImplemented
-# else:
-# # Sharded
-# # Note that attention.w{q,k,v,o}, feed_fordward.w[1,2,3], attention_norm.weight and ffn_norm.weight share
-# # the same storage object, saving attention_norm and ffn_norm will save other weights too, which is
-# # redundant as other weights will be stitched from multiple shards. To avoid that, they are cloned.
-
-# state_dict = {
-# f"model.layers.{layer_i}.input_layernorm.weight": loaded[0]['encoder'][
-# f"layers.{layer_i}.input_layernorm.multiway.0.weight"
-# ].clone(),
-# f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0]['encoder'][
-# f"layers.{layer_i}.post_attention_layernorm.multiway.0.weight"
-# ].clone(),
-# }
-
-# wqs, wks, wvs, ffn_w1s, ffn_w3s = [], [], [], [], []
-# for shard_idx in range(num_shards):
-# wqs.append(loaded[shard_idx]['encoder'][f"layers.{layer_i}.self_attention.q_proj.weight"])
-# wks.append(loaded[shard_idx]['encoder'][f"layers.{layer_i}.self_attention.k_proj.multiway.0.weight"])
-# wvs.append(loaded[shard_idx]['encoder'][f"layers.{layer_i}.self_attention.v_proj.multiway.0.weight"])
-
-# state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(
-# torch.cat(
-# [
-# wq.view(n_heads_per_shard, hidden_per_head, n_hidden)
-# for wq in range(wqs)
-# ],
-# dim=0,
-# ).reshape(n_hidden, n_hidden)
-# )
-# state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(
-# torch.cat(
-# [
-# wk.view(n_heads_per_shard, hidden_per_head, n_hidden)
-# for wk in range(wks)
-# ],
-# dim=0,
-# ).reshape(n_hidden, n_hidden)
-# )
-# state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat(
-# [
-# wv.view(n_heads_per_shard, hidden_per_head, n_hidden)
-# for wv in range(wvs)
-# ],
-# dim=0,
-# ).reshape(n_hidden, n_hidden)
-
-# state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat(
-# [loaded[i]['encoder'][f"layers.{layer_i}.self_attention.o_proj.weight"] for i in range(num_shards)], dim=1
-# )
-# state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat(
-# [loaded[i]['encoder'][f"layers.{layer_i}.mlp.gate_proj.weight"] for i in range(num_shards)], dim=0
-# )
-# state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat(
-# [loaded[i]['encoder'][f"layers.{layer_i}.mlp.down_proj.weight"] for i in range(num_shards)], dim=1
-# )
-# state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat(
-# [loaded[i]['encoder'][f"layers.{layer_i}.mlp.up_proj.weight"] for i in range(num_shards)], dim=0
-# )
-
- state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freq
- for k, v in state_dict.items():
- index_dict["weight_map"][k] = filename
- param_count += v.numel()
- torch.save(state_dict, os.path.join(tmp_model_path, filename))
- print(f'Sharded file saved to {filename}')
-
- filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"
- if num_shards==1:
- # Unsharded
- state_dict = {
- "model.embed_tokens.weight": loaded['embedding']['word_embeddings']['weight'],
- "model.norm.weight": loaded['encoder']['norm.weight'],
- "lm_head.weight": loaded['encoder']['lm_head.weight'],
- }
- else:
- state_dict = {
- "model.embed_tokens.weight": loaded[0]['embedding']['word_embeddings']['weight'],
- "model.norm.weight": loaded[0]['encoder']['norm.weight'],
- "lm_head.weight": loaded[0]['encoder']['lm_head.weight'],
- }
-
-
- loaded_all = torch.load(original_filename, map_location="cpu")['model']
- # Vision Part
- state_dict.update({
- "model.vision_model.embeddings.cls_token": loaded_all['vision_model']['cls_token'],
- "model.vision_model.embeddings.patch_embed.weight": loaded_all['vision_model']['patch_embed']['weight'],
- "model.vision_model.embeddings.position_embedding": loaded_all['vision_model']['position_embeddings'],
- "model.vision_model.embeddings.pre_layernorm.bias": loaded_all['vision_model']['pre_layernorm']['bias'],
- "model.vision_model.embeddings.pre_layernorm.weight": loaded_all['vision_model']['pre_layernorm']['weight'],
- "model.vision_model.post_layernorm.bias": loaded_all['vision_model']['transformer']['final_layernorm.bias'],
- "model.vision_model.post_layernorm.weight": loaded_all['vision_model']['transformer']['final_layernorm.weight'],
- })
- for v_layer_idx in range(24):
- state_dict.update({
- f"model.vision_model.encoder.layers.{v_layer_idx}.input_layernorm.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.input_layernorm.bias'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.input_layernorm.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.input_layernorm.weight'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.mlp.fc1.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.mlp.dense_h_to_4h.bias'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.mlp.fc1.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.mlp.dense_h_to_4h.weight'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.mlp.fc2.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.mlp.dense_4h_to_h.bias'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.mlp.fc2.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.mlp.dense_4h_to_h.weight'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.post_attention_layernorm.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.post_attention_layernorm.bias'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.post_attention_layernorm.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.post_attention_layernorm.weight'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.self_attn.dense.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.self_attention.dense.bias'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.self_attn.dense.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.self_attention.dense.weight'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.self_attn.query_key_value.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.self_attention.query_key_value.bias'],
- f"model.vision_model.encoder.layers.{v_layer_idx}.self_attn.query_key_value.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.self_attention.query_key_value.weight'],
- })
-
- # Abstractor Part
- state_dict.update({
- "model.visual_abstractor.query_embeds": loaded_all['vision_abstractor']['learnable_queries'],
- "model.visual_abstractor.visual_fc.bias": loaded_all['vision_abstractor']['visual_fc']['bias'],
- "model.visual_abstractor.visual_fc.weight": loaded_all['vision_abstractor']['visual_fc']['weight'],
- "model.visual_abstractor.vit_eos": loaded_all['vision_abstractor']['vit_eos'],
- })
- for v_layer_idx in range(6):
- state_dict.update({
- # f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.k_pos_embed":
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.key.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.k_proj.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.key.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.k_proj.weight"],
- # f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.q_pos_embed": "pytorch_model-00004-of-00004.bin",
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.query.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.q_proj.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.query.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.q_proj.weight"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.value.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.v_proj.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.value.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.v_proj.weight"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.norm1.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.norm1.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.norm1.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.norm1.weight"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.normk.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.normk.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.normk.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.normk.weight"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.ffn_ln.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.ffn_ln.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.ffn_ln.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.ffn_ln.weight"],
-
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w1.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w1.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w1.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w1.weight"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w2.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w2.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w2.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w2.weight"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w3.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w3.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w3.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w3.weight"],
-
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.norm2.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.norm2.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.norm2.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.norm2.weight"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.out_proj.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.o_proj.bias"],
- f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.out_proj.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.o_proj.weight"],
- })
-
- for k, v in state_dict.items():
- index_dict["weight_map"][k] = filename
- param_count += v.numel()
- torch.save(state_dict, os.path.join(tmp_model_path, filename))
-
- # Write configs
- index_dict["metadata"] = {"total_size": param_count * 2}
- write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))
-
- config = MPLUGOwl2Config()
- config.save_pretrained(tmp_model_path)
-
- # Make space so we can load the model properly now.
- del state_dict
- del loaded
- del loaded_all
- gc.collect()
-
-def write_tokenizer(tokenizer_path, input_tokenizer_path):
- # Initialize the tokenizer based on the `spm` model
- tokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFast
- print(f"Saving a {tokenizer_class.__name__} to {tokenizer_path}.")
- tokenizer = tokenizer_class(input_tokenizer_path)
- tokenizer.save_pretrained(tokenizer_path)
-
-
-def main():
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--input_dir",
- help="Location of LLaMA_Megatron weights",
- )
- parser.add_argument(
- "--model_size",
- type=int,
- default=7,
- choices=[7, 13, 30, 65, 70],
- )
- parser.add_argument(
- "--num_input_shards",
- type=int,
- default=1,
- )
- parser.add_argument(
- "--num_output_shards",
- type=int,
- default=1,
- )
- parser.add_argument('--skip_permute', action='store_true')
-
- parser.add_argument(
- "--output_dir",
- help="Location to write HF model and tokenizer",
- )
-
- args = parser.parse_args()
- write_model(
- model_path=args.output_dir,
- input_base_path=args.input_dir,
- model_size=args.model_size,
- num_input_shards=args.num_input_shards,
- num_output_shards=args.num_output_shards,
- skip_permute=args.skip_permute
- )
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/Manjushri/MusicGen/audiocraft/data/audio.py b/spaces/Manjushri/MusicGen/audiocraft/data/audio.py
deleted file mode 100644
index 2048df6f175d7303bcf5c7b931922fd297908ead..0000000000000000000000000000000000000000
--- a/spaces/Manjushri/MusicGen/audiocraft/data/audio.py
+++ /dev/null
@@ -1,215 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-"""
-Audio IO methods are defined in this module (info, read, write),
-We rely on av library for faster read when possible, otherwise on torchaudio.
-"""
-
-from dataclasses import dataclass
-from pathlib import Path
-import logging
-import typing as tp
-
-import numpy as np
-import soundfile
-import torch
-from torch.nn import functional as F
-import torchaudio as ta
-
-import av
-
-from .audio_utils import f32_pcm, i16_pcm, normalize_audio
-
-
-_av_initialized = False
-
-
-def _init_av():
- global _av_initialized
- if _av_initialized:
- return
- logger = logging.getLogger('libav.mp3')
- logger.setLevel(logging.ERROR)
- _av_initialized = True
-
-
-@dataclass(frozen=True)
-class AudioFileInfo:
- sample_rate: int
- duration: float
- channels: int
-
-
-def _av_info(filepath: tp.Union[str, Path]) -> AudioFileInfo:
- _init_av()
- with av.open(str(filepath)) as af:
- stream = af.streams.audio[0]
- sample_rate = stream.codec_context.sample_rate
- duration = float(stream.duration * stream.time_base)
- channels = stream.channels
- return AudioFileInfo(sample_rate, duration, channels)
-
-
-def _soundfile_info(filepath: tp.Union[str, Path]) -> AudioFileInfo:
- info = soundfile.info(filepath)
- return AudioFileInfo(info.samplerate, info.duration, info.channels)
-
-
-def audio_info(filepath: tp.Union[str, Path]) -> AudioFileInfo:
- # torchaudio no longer returns useful duration informations for some formats like mp3s.
- filepath = Path(filepath)
- if filepath.suffix in ['.flac', '.ogg']: # TODO: Validate .ogg can be safely read with av_info
- # ffmpeg has some weird issue with flac.
- return _soundfile_info(filepath)
- else:
- return _av_info(filepath)
-
-
-def _av_read(filepath: tp.Union[str, Path], seek_time: float = 0, duration: float = -1.) -> tp.Tuple[torch.Tensor, int]:
- """FFMPEG-based audio file reading using PyAV bindings.
- Soundfile cannot read mp3 and av_read is more efficient than torchaudio.
-
- Args:
- filepath (str or Path): Path to audio file to read.
- seek_time (float): Time at which to start reading in the file.
- duration (float): Duration to read from the file. If set to -1, the whole file is read.
- Returns:
- Tuple[torch.Tensor, int]: Tuple containing audio data and sample rate
- """
- _init_av()
- with av.open(str(filepath)) as af:
- stream = af.streams.audio[0]
- sr = stream.codec_context.sample_rate
- num_frames = int(sr * duration) if duration >= 0 else -1
- frame_offset = int(sr * seek_time)
- # we need a small negative offset otherwise we get some edge artifact
- # from the mp3 decoder.
- af.seek(int(max(0, (seek_time - 0.1)) / stream.time_base), stream=stream)
- frames = []
- length = 0
- for frame in af.decode(streams=stream.index):
- current_offset = int(frame.rate * frame.pts * frame.time_base)
- strip = max(0, frame_offset - current_offset)
- buf = torch.from_numpy(frame.to_ndarray())
- if buf.shape[0] != stream.channels:
- buf = buf.view(-1, stream.channels).t()
- buf = buf[:, strip:]
- frames.append(buf)
- length += buf.shape[1]
- if num_frames > 0 and length >= num_frames:
- break
- assert frames
- # If the above assert fails, it is likely because we seeked past the end of file point,
- # in which case ffmpeg returns a single frame with only zeros, and a weird timestamp.
- # This will need proper debugging, in due time.
- wav = torch.cat(frames, dim=1)
- assert wav.shape[0] == stream.channels
- if num_frames > 0:
- wav = wav[:, :num_frames]
- return f32_pcm(wav), sr
-
-
-def audio_read(filepath: tp.Union[str, Path], seek_time: float = 0.,
- duration: float = -1., pad: bool = False) -> tp.Tuple[torch.Tensor, int]:
- """Read audio by picking the most appropriate backend tool based on the audio format.
-
- Args:
- filepath (str or Path): Path to audio file to read.
- seek_time (float): Time at which to start reading in the file.
- duration (float): Duration to read from the file. If set to -1, the whole file is read.
- pad (bool): Pad output audio if not reaching expected duration.
- Returns:
- Tuple[torch.Tensor, int]: Tuple containing audio data and sample rate.
- """
- fp = Path(filepath)
- if fp.suffix in ['.flac', '.ogg']: # TODO: check if we can safely use av_read for .ogg
- # There is some bug with ffmpeg and reading flac
- info = _soundfile_info(filepath)
- frames = -1 if duration <= 0 else int(duration * info.sample_rate)
- frame_offset = int(seek_time * info.sample_rate)
- wav, sr = soundfile.read(filepath, start=frame_offset, frames=frames, dtype=np.float32)
- assert info.sample_rate == sr, f"Mismatch of sample rates {info.sample_rate} {sr}"
- wav = torch.from_numpy(wav).t().contiguous()
- if len(wav.shape) == 1:
- wav = torch.unsqueeze(wav, 0)
- elif (
- fp.suffix in ['.wav', '.mp3'] and fp.suffix[1:] in ta.utils.sox_utils.list_read_formats()
- and duration <= 0 and seek_time == 0
- ):
- # Torchaudio is faster if we load an entire file at once.
- wav, sr = ta.load(fp)
- else:
- wav, sr = _av_read(filepath, seek_time, duration)
- if pad and duration > 0:
- expected_frames = int(duration * sr)
- wav = F.pad(wav, (0, expected_frames - wav.shape[-1]))
- return wav, sr
-
-
-def audio_write(stem_name: tp.Union[str, Path],
- wav: torch.Tensor, sample_rate: int,
- format: str = 'wav', mp3_rate: int = 320, normalize: bool = True,
- strategy: str = 'peak', peak_clip_headroom_db: float = 1,
- rms_headroom_db: float = 18, loudness_headroom_db: float = 14,
- loudness_compressor: bool = False,
- log_clipping: bool = True, make_parent_dir: bool = True,
- add_suffix: bool = True) -> Path:
- """Convenience function for saving audio to disk. Returns the filename the audio was written to.
-
- Args:
- stem_name (str or Path): Filename without extension which will be added automatically.
- format (str): Either "wav" or "mp3".
- mp3_rate (int): kbps when using mp3s.
- normalize (bool): if `True` (default), normalizes according to the prescribed
- strategy (see after). If `False`, the strategy is only used in case clipping
- would happen.
- strategy (str): Can be either 'clip', 'peak', or 'rms'. Default is 'peak',
- i.e. audio is normalized by its largest value. RMS normalizes by root-mean-square
- with extra headroom to avoid clipping. 'clip' just clips.
- peak_clip_headroom_db (float): Headroom in dB when doing 'peak' or 'clip' strategy.
- rms_headroom_db (float): Headroom in dB when doing 'rms' strategy. This must be much larger
- than the `peak_clip` one to avoid further clipping.
- loudness_headroom_db (float): Target loudness for loudness normalization.
- loudness_compressor (bool): Uses tanh for soft clipping when strategy is 'loudness'.
- when strategy is 'loudness'log_clipping (bool): If True, basic logging on stderr when clipping still
- occurs despite strategy (only for 'rms').
- make_parent_dir (bool): Make parent directory if it doesn't exist.
- Returns:
- Path: Path of the saved audio.
- """
- assert wav.dtype.is_floating_point, "wav is not floating point"
- if wav.dim() == 1:
- wav = wav[None]
- elif wav.dim() > 2:
- raise ValueError("Input wav should be at most 2 dimension.")
- assert wav.isfinite().all()
- wav = normalize_audio(wav, normalize, strategy, peak_clip_headroom_db,
- rms_headroom_db, loudness_headroom_db, log_clipping=log_clipping,
- sample_rate=sample_rate, stem_name=str(stem_name))
- kwargs: dict = {}
- if format == 'mp3':
- suffix = '.mp3'
- kwargs.update({"compression": mp3_rate})
- elif format == 'wav':
- wav = i16_pcm(wav)
- suffix = '.wav'
- kwargs.update({"encoding": "PCM_S", "bits_per_sample": 16})
- else:
- raise RuntimeError(f"Invalid format {format}. Only wav or mp3 are supported.")
- if not add_suffix:
- suffix = ''
- path = Path(str(stem_name) + suffix)
- if make_parent_dir:
- path.parent.mkdir(exist_ok=True, parents=True)
- try:
- ta.save(path, wav, sample_rate, **kwargs)
- except Exception:
- if path.exists():
- # we do not want to leave half written files around.
- path.unlink()
- raise
- return path
diff --git a/spaces/Marne/MockingBird/mockingbirdforuse/vocoder/wavernn/inference.py b/spaces/Marne/MockingBird/mockingbirdforuse/vocoder/wavernn/inference.py
deleted file mode 100644
index b39cab61e951c3c0e1ec2afce1b7e5e23d098aac..0000000000000000000000000000000000000000
--- a/spaces/Marne/MockingBird/mockingbirdforuse/vocoder/wavernn/inference.py
+++ /dev/null
@@ -1,56 +0,0 @@
-import torch
-from pathlib import Path
-
-from .hparams import hparams as hp
-from .models.fatchord_version import WaveRNN
-from ...log import logger
-
-
-class WaveRNNVocoder:
- def __init__(self, model_path: Path):
- logger.debug("Building Wave-RNN")
- self._model = WaveRNN(
- rnn_dims=hp.voc_rnn_dims,
- fc_dims=hp.voc_fc_dims,
- bits=hp.bits,
- pad=hp.voc_pad,
- upsample_factors=hp.voc_upsample_factors,
- feat_dims=hp.num_mels,
- compute_dims=hp.voc_compute_dims,
- res_out_dims=hp.voc_res_out_dims,
- res_blocks=hp.voc_res_blocks,
- hop_length=hp.hop_length,
- sample_rate=hp.sample_rate,
- mode=hp.voc_mode,
- )
-
- if torch.cuda.is_available():
- self._model = self._model.cuda()
- self._device = torch.device("cuda")
- else:
- self._device = torch.device("cpu")
-
- logger.debug("Loading model weights at %s" % model_path)
- checkpoint = torch.load(model_path, self._device)
- self._model.load_state_dict(checkpoint["model_state"])
- self._model.eval()
-
- def infer_waveform(
- self, mel, normalize=True, batched=True, target=8000, overlap=800
- ):
- """
- Infers the waveform of a mel spectrogram output by the synthesizer (the format must match
- that of the synthesizer!)
-
- :param normalize:
- :param batched:
- :param target:
- :param overlap:
- :return:
- """
-
- if normalize:
- mel = mel / hp.mel_max_abs_value
- mel = torch.from_numpy(mel[None, ...])
- wav = self._model.generate(mel, batched, target, overlap, hp.mu_law)
- return wav, hp.sample_rate
diff --git a/spaces/MathysL/AutoGPT4/autogpt/memory/base.py b/spaces/MathysL/AutoGPT4/autogpt/memory/base.py
deleted file mode 100644
index 691e2299c4caa5c2e9af5b2436727834f3cc6c67..0000000000000000000000000000000000000000
--- a/spaces/MathysL/AutoGPT4/autogpt/memory/base.py
+++ /dev/null
@@ -1,43 +0,0 @@
-"""Base class for memory providers."""
-import abc
-
-import openai
-
-from autogpt.config import AbstractSingleton, Config
-
-cfg = Config()
-
-
-def get_ada_embedding(text):
- text = text.replace("\n", " ")
- if cfg.use_azure:
- return openai.Embedding.create(
- input=[text],
- engine=cfg.get_azure_deployment_id_for_model("text-embedding-ada-002"),
- )["data"][0]["embedding"]
- else:
- return openai.Embedding.create(input=[text], model="text-embedding-ada-002")[
- "data"
- ][0]["embedding"]
-
-
-class MemoryProviderSingleton(AbstractSingleton):
- @abc.abstractmethod
- def add(self, data):
- pass
-
- @abc.abstractmethod
- def get(self, data):
- pass
-
- @abc.abstractmethod
- def clear(self):
- pass
-
- @abc.abstractmethod
- def get_relevant(self, data, num_relevant=5):
- pass
-
- @abc.abstractmethod
- def get_stats(self):
- pass
diff --git a/spaces/Mileena/PIFu-Clothed-Human-Digitization/PIFu/README.md b/spaces/Mileena/PIFu-Clothed-Human-Digitization/PIFu/README.md
deleted file mode 100644
index 5eae12f2a370027de6c46fbf78ec68a1ecb1c01c..0000000000000000000000000000000000000000
--- a/spaces/Mileena/PIFu-Clothed-Human-Digitization/PIFu/README.md
+++ /dev/null
@@ -1,167 +0,0 @@
-# PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
-
-[](https://arxiv.org/abs/1905.05172) [](https://colab.research.google.com/drive/1GFSsqP2BWz4gtq0e-nki00ZHSirXwFyY)
-
-News:
-* \[2020/05/04\] Added EGL rendering option for training data generation. Now you can create your own training data with headless machines!
-* \[2020/04/13\] Demo with Google Colab (incl. visualization) is available. Special thanks to [@nanopoteto](https://github.com/nanopoteto)!!!
-* \[2020/02/26\] License is updated to MIT license! Enjoy!
-
-This repository contains a pytorch implementation of "[PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization](https://arxiv.org/abs/1905.05172)".
-
-[Project Page](https://shunsukesaito.github.io/PIFu/)
-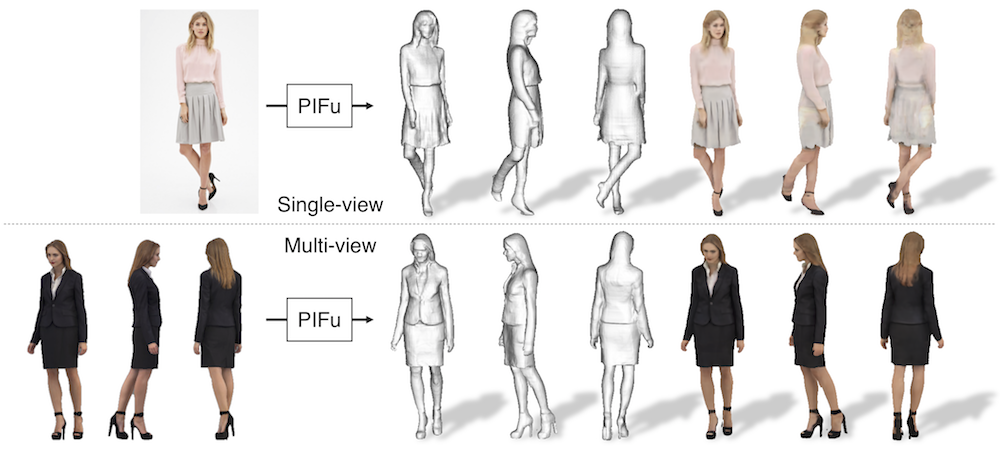
-
-If you find the code useful in your research, please consider citing the paper.
-
-```
-@InProceedings{saito2019pifu,
-author = {Saito, Shunsuke and Huang, Zeng and Natsume, Ryota and Morishima, Shigeo and Kanazawa, Angjoo and Li, Hao},
-title = {PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization},
-booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
-month = {October},
-year = {2019}
-}
-```
-
-
-This codebase provides:
-- test code
-- training code
-- data generation code
-
-## Requirements
-- Python 3
-- [PyTorch](https://pytorch.org/) tested on 1.4.0
-- json
-- PIL
-- skimage
-- tqdm
-- numpy
-- cv2
-
-for training and data generation
-- [trimesh](https://trimsh.org/) with [pyembree](https://github.com/scopatz/pyembree)
-- [pyexr](https://github.com/tvogels/pyexr)
-- PyOpenGL
-- freeglut (use `sudo apt-get install freeglut3-dev` for ubuntu users)
-- (optional) egl related packages for rendering with headless machines. (use `apt install libgl1-mesa-dri libegl1-mesa libgbm1` for ubuntu users)
-
-Warning: I found that outdated NVIDIA drivers may cause errors with EGL. If you want to try out the EGL version, please update your NVIDIA driver to the latest!!
-
-## Windows demo installation instuction
-
-- Install [miniconda](https://docs.conda.io/en/latest/miniconda.html)
-- Add `conda` to PATH
-- Install [git bash](https://git-scm.com/downloads)
-- Launch `Git\bin\bash.exe`
-- `eval "$(conda shell.bash hook)"` then `conda activate my_env` because of [this](https://github.com/conda/conda-build/issues/3371)
-- Automatic `env create -f environment.yml` (look [this](https://github.com/conda/conda/issues/3417))
-- OR manually setup [environment](https://towardsdatascience.com/a-guide-to-conda-environments-bc6180fc533)
- - `conda create —name pifu python` where `pifu` is name of your environment
- - `conda activate`
- - `conda install pytorch torchvision cudatoolkit=10.1 -c pytorch`
- - `conda install pillow`
- - `conda install scikit-image`
- - `conda install tqdm`
- - `conda install -c menpo opencv`
-- Download [wget.exe](https://eternallybored.org/misc/wget/)
-- Place it into `Git\mingw64\bin`
-- `sh ./scripts/download_trained_model.sh`
-- Remove background from your image ([this](https://www.remove.bg/), for example)
-- Create black-white mask .png
-- Replace original from sample_images/
-- Try it out - `sh ./scripts/test.sh`
-- Download [Meshlab](http://www.meshlab.net/) because of [this](https://github.com/shunsukesaito/PIFu/issues/1)
-- Open .obj file in Meshlab
-
-
-## Demo
-Warning: The released model is trained with mostly upright standing scans with weak perspectie projection and the pitch angle of 0 degree. Reconstruction quality may degrade for images highly deviated from trainining data.
-1. run the following script to download the pretrained models from the following link and copy them under `./PIFu/checkpoints/`.
-```
-sh ./scripts/download_trained_model.sh
-```
-
-2. run the following script. the script creates a textured `.obj` file under `./PIFu/eval_results/`. You may need to use `./apps/crop_img.py` to roughly align an input image and the corresponding mask to the training data for better performance. For background removal, you can use any off-the-shelf tools such as [removebg](https://www.remove.bg/).
-```
-sh ./scripts/test.sh
-```
-
-## Demo on Google Colab
-If you do not have a setup to run PIFu, we offer Google Colab version to give it a try, allowing you to run PIFu in the cloud, free of charge. Try our Colab demo using the following notebook:
-[](https://colab.research.google.com/drive/1GFSsqP2BWz4gtq0e-nki00ZHSirXwFyY)
-
-## Data Generation (Linux Only)
-While we are unable to release the full training data due to the restriction of commertial scans, we provide rendering code using free models in [RenderPeople](https://renderpeople.com/free-3d-people/).
-This tutorial uses `rp_dennis_posed_004` model. Please download the model from [this link](https://renderpeople.com/sample/free/rp_dennis_posed_004_OBJ.zip) and unzip the content under a folder named `rp_dennis_posed_004_OBJ`. The same process can be applied to other RenderPeople data.
-
-Warning: the following code becomes extremely slow without [pyembree](https://github.com/scopatz/pyembree). Please make sure you install pyembree.
-
-1. run the following script to compute spherical harmonics coefficients for [precomputed radiance transfer (PRT)](https://sites.fas.harvard.edu/~cs278/papers/prt.pdf). In a nutshell, PRT is used to account for accurate light transport including ambient occlusion without compromising online rendering time, which significantly improves the photorealism compared with [a common sperical harmonics rendering using surface normals](https://cseweb.ucsd.edu/~ravir/papers/envmap/envmap.pdf). This process has to be done once for each obj file.
-```
-python -m apps.prt_util -i {path_to_rp_dennis_posed_004_OBJ}
-```
-
-2. run the following script. Under the specified data path, the code creates folders named `GEO`, `RENDER`, `MASK`, `PARAM`, `UV_RENDER`, `UV_MASK`, `UV_NORMAL`, and `UV_POS`. Note that you may need to list validation subjects to exclude from training in `{path_to_training_data}/val.txt` (this tutorial has only one subject and leave it empty). If you wish to render images with headless servers equipped with NVIDIA GPU, add -e to enable EGL rendering.
-```
-python -m apps.render_data -i {path_to_rp_dennis_posed_004_OBJ} -o {path_to_training_data} [-e]
-```
-
-## Training (Linux Only)
-
-Warning: the following code becomes extremely slow without [pyembree](https://github.com/scopatz/pyembree). Please make sure you install pyembree.
-
-1. run the following script to train the shape module. The intermediate results and checkpoints are saved under `./results` and `./checkpoints` respectively. You can add `--batch_size` and `--num_sample_input` flags to adjust the batch size and the number of sampled points based on available GPU memory.
-```
-python -m apps.train_shape --dataroot {path_to_training_data} --random_flip --random_scale --random_trans
-```
-
-2. run the following script to train the color module.
-```
-python -m apps.train_color --dataroot {path_to_training_data} --num_sample_inout 0 --num_sample_color 5000 --sigma 0.1 --random_flip --random_scale --random_trans
-```
-
-## Related Research
-**[Monocular Real-Time Volumetric Performance Capture (ECCV 2020)](https://project-splinter.github.io/)**
-*Ruilong Li\*, Yuliang Xiu\*, Shunsuke Saito, Zeng Huang, Kyle Olszewski, Hao Li*
-
-The first real-time PIFu by accelerating reconstruction and rendering!!
-
-**[PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (CVPR 2020)](https://shunsukesaito.github.io/PIFuHD/)**
-*Shunsuke Saito, Tomas Simon, Jason Saragih, Hanbyul Joo*
-
-We further improve the quality of reconstruction by leveraging multi-level approach!
-
-**[ARCH: Animatable Reconstruction of Clothed Humans (CVPR 2020)](https://arxiv.org/pdf/2004.04572.pdf)**
-*Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, Tony Tung*
-
-Learning PIFu in canonical space for animatable avatar generation!
-
-**[Robust 3D Self-portraits in Seconds (CVPR 2020)](http://www.liuyebin.com/portrait/portrait.html)**
-*Zhe Li, Tao Yu, Chuanyu Pan, Zerong Zheng, Yebin Liu*
-
-They extend PIFu to RGBD + introduce "PIFusion" utilizing PIFu reconstruction for non-rigid fusion.
-
-**[Learning to Infer Implicit Surfaces without 3d Supervision (NeurIPS 2019)](http://papers.nips.cc/paper/9039-learning-to-infer-implicit-surfaces-without-3d-supervision.pdf)**
-*Shichen Liu, Shunsuke Saito, Weikai Chen, Hao Li*
-
-We answer to the question of "how can we learn implicit function if we don't have 3D ground truth?"
-
-**[SiCloPe: Silhouette-Based Clothed People (CVPR 2019, best paper finalist)](https://arxiv.org/pdf/1901.00049.pdf)**
-*Ryota Natsume\*, Shunsuke Saito\*, Zeng Huang, Weikai Chen, Chongyang Ma, Hao Li, Shigeo Morishima*
-
-Our first attempt to reconstruct 3D clothed human body with texture from a single image!
-
-**[Deep Volumetric Video from Very Sparse Multi-view Performance Capture (ECCV 2018)](http://openaccess.thecvf.com/content_ECCV_2018/papers/Zeng_Huang_Deep_Volumetric_Video_ECCV_2018_paper.pdf)**
-*Zeng Huang, Tianye Li, Weikai Chen, Yajie Zhao, Jun Xing, Chloe LeGendre, Linjie Luo, Chongyang Ma, Hao Li*
-
-Implict surface learning for sparse view human performance capture!
-
-------
-
-
-
-For commercial queries, please contact:
-
-Hao Li: hao@hao-li.com ccto: saitos@usc.edu Baker!!
diff --git a/spaces/NATSpeech/PortaSpeech/inference/tts/base_tts_infer.py b/spaces/NATSpeech/PortaSpeech/inference/tts/base_tts_infer.py
deleted file mode 100644
index f0a47ab975976f580f7e9f79a017c5de9b3e5f8e..0000000000000000000000000000000000000000
--- a/spaces/NATSpeech/PortaSpeech/inference/tts/base_tts_infer.py
+++ /dev/null
@@ -1,114 +0,0 @@
-import os
-
-import torch
-
-from modules.vocoder.hifigan.hifigan import HifiGanGenerator
-from tasks.tts.dataset_utils import FastSpeechWordDataset
-from tasks.tts.tts_utils import load_data_preprocessor
-from utils.commons.ckpt_utils import load_ckpt
-from utils.commons.hparams import set_hparams
-
-
-class BaseTTSInfer:
- def __init__(self, hparams, device=None):
- if device is None:
- device = 'cuda' if torch.cuda.is_available() else 'cpu'
- self.hparams = hparams
- self.device = device
- self.data_dir = hparams['binary_data_dir']
- self.preprocessor, self.preprocess_args = load_data_preprocessor()
- self.ph_encoder, self.word_encoder = self.preprocessor.load_dict(self.data_dir)
- self.spk_map = self.preprocessor.load_spk_map(self.data_dir)
- self.ds_cls = FastSpeechWordDataset
- self.model = self.build_model()
- self.model.eval()
- self.model.to(self.device)
- self.vocoder = self.build_vocoder()
- self.vocoder.eval()
- self.vocoder.to(self.device)
-
- def build_model(self):
- raise NotImplementedError
-
- def forward_model(self, inp):
- raise NotImplementedError
-
- def build_vocoder(self):
- base_dir = self.hparams['vocoder_ckpt']
- config_path = f'{base_dir}/config.yaml'
- config = set_hparams(config_path, global_hparams=False)
- vocoder = HifiGanGenerator(config)
- load_ckpt(vocoder, base_dir, 'model_gen')
- return vocoder
-
- def run_vocoder(self, c):
- c = c.transpose(2, 1)
- y = self.vocoder(c)[:, 0]
- return y
-
- def preprocess_input(self, inp):
- """
-
- :param inp: {'text': str, 'item_name': (str, optional), 'spk_name': (str, optional)}
- :return:
- """
- preprocessor, preprocess_args = self.preprocessor, self.preprocess_args
- text_raw = inp['text']
- item_name = inp.get('item_name', '')
- spk_name = inp.get('spk_name', '')
- ph, txt, word, ph2word, ph_gb_word = preprocessor.txt_to_ph(
- preprocessor.txt_processor, text_raw, preprocess_args)
- word_token = self.word_encoder.encode(word)
- ph_token = self.ph_encoder.encode(ph)
- spk_id = self.spk_map[spk_name]
- item = {'item_name': item_name, 'text': txt, 'ph': ph, 'spk_id': spk_id,
- 'ph_token': ph_token, 'word_token': word_token, 'ph2word': ph2word}
- item['ph_len'] = len(item['ph_token'])
- return item
-
- def input_to_batch(self, item):
- item_names = [item['item_name']]
- text = [item['text']]
- ph = [item['ph']]
- txt_tokens = torch.LongTensor(item['ph_token'])[None, :].to(self.device)
- txt_lengths = torch.LongTensor([txt_tokens.shape[1]]).to(self.device)
- word_tokens = torch.LongTensor(item['word_token'])[None, :].to(self.device)
- word_lengths = torch.LongTensor([txt_tokens.shape[1]]).to(self.device)
- ph2word = torch.LongTensor(item['ph2word'])[None, :].to(self.device)
- spk_ids = torch.LongTensor(item['spk_id'])[None, :].to(self.device)
- batch = {
- 'item_name': item_names,
- 'text': text,
- 'ph': ph,
- 'txt_tokens': txt_tokens,
- 'txt_lengths': txt_lengths,
- 'word_tokens': word_tokens,
- 'word_lengths': word_lengths,
- 'ph2word': ph2word,
- 'spk_ids': spk_ids,
- }
- return batch
-
- def postprocess_output(self, output):
- return output
-
- def infer_once(self, inp):
- inp = self.preprocess_input(inp)
- output = self.forward_model(inp)
- output = self.postprocess_output(output)
- return output
-
- @classmethod
- def example_run(cls):
- from utils.commons.hparams import set_hparams
- from utils.commons.hparams import hparams as hp
- from utils.audio.io import save_wav
-
- set_hparams()
- inp = {
- 'text': 'the invention of movable metal letters in the middle of the fifteenth century may justly be considered as the invention of the art of printing.'
- }
- infer_ins = cls(hp)
- out = infer_ins.infer_once(inp)
- os.makedirs('infer_out', exist_ok=True)
- save_wav(out, f'infer_out/example_out.wav', hp['audio_sample_rate'])
diff --git a/spaces/NCTCMumbai/NCTC/models/official/README.md b/spaces/NCTCMumbai/NCTC/models/official/README.md
deleted file mode 100644
index 2b3f2dd768d0b7cf8238136d003aa5cb89070cc3..0000000000000000000000000000000000000000
--- a/spaces/NCTCMumbai/NCTC/models/official/README.md
+++ /dev/null
@@ -1,142 +0,0 @@
-
-
-# TensorFlow Official Models
-
-The TensorFlow official models are a collection of models
-that use TensorFlow’s high-level APIs.
-They are intended to be well-maintained, tested, and kept up to date
-with the latest TensorFlow API.
-
-They should also be reasonably optimized for fast performance while still
-being easy to read.
-These models are used as end-to-end tests, ensuring that the models run
-with the same or improved speed and performance with each new TensorFlow build.
-
-## More models to come!
-
-The team is actively developing new models.
-In the near future, we will add:
-
-* State-of-the-art language understanding models:
- More members in Transformer family
-* Start-of-the-art image classification models:
- EfficientNet, MnasNet, and variants
-* A set of excellent objection detection models.
-
-## Table of Contents
-
-- [Models and Implementations](#models-and-implementations)
- * [Computer Vision](#computer-vision)
- + [Image Classification](#image-classification)
- + [Object Detection and Segmentation](#object-detection-and-segmentation)
- * [Natural Language Processing](#natural-language-processing)
- * [Recommendation](#recommendation)
-- [How to get started with the official models](#how-to-get-started-with-the-official-models)
-
-## Models and Implementations
-
-### Computer Vision
-
-#### Image Classification
-
-| Model | Reference (Paper) |
-|-------|-------------------|
-| [MNIST](vision/image_classification) | A basic model to classify digits from the [MNIST dataset](http://yann.lecun.com/exdb/mnist/) |
-| [ResNet](vision/image_classification) | [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) |
-| [EfficientNet](vision/image_classification) | [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) |
-
-#### Object Detection and Segmentation
-
-| Model | Reference (Paper) |
-|-------|-------------------|
-| [RetinaNet](vision/detection) | [Focal Loss for Dense Object Detection](https://arxiv.org/abs/1708.02002) |
-| [Mask R-CNN](vision/detection) | [Mask R-CNN](https://arxiv.org/abs/1703.06870) |
-| [ShapeMask](vision/detection) | [ShapeMask: Learning to Segment Novel Objects by Refining Shape Priors](https://arxiv.org/abs/1904.03239) |
-
-### Natural Language Processing
-
-| Model | Reference (Paper) |
-|-------|-------------------|
-| [ALBERT (A Lite BERT)](nlp/albert) | [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942) |
-| [BERT (Bidirectional Encoder Representations from Transformers)](nlp/bert) | [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) |
-| [NHNet (News Headline generation model)](nlp/nhnet) | [Generating Representative Headlines for News Stories](https://arxiv.org/abs/2001.09386) |
-| [Transformer](nlp/transformer) | [Attention Is All You Need](https://arxiv.org/abs/1706.03762) |
-| [XLNet](nlp/xlnet) | [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) |
-
-### Recommendation
-
-| Model | Reference (Paper) |
-|-------|-------------------|
-| [NCF](recommendation) | [Neural Collaborative Filtering](https://arxiv.org/abs/1708.05031) |
-
-## How to get started with the official models
-
-* The models in the master branch are developed using TensorFlow 2,
-and they target the TensorFlow [nightly binaries](https://github.com/tensorflow/tensorflow#installation)
-built from the
-[master branch of TensorFlow](https://github.com/tensorflow/tensorflow/tree/master).
-* The stable versions targeting releases of TensorFlow are available
-as tagged branches or [downloadable releases](https://github.com/tensorflow/models/releases).
-* Model repository version numbers match the target TensorFlow release,
-such that
-[release v2.2.0](https://github.com/tensorflow/models/releases/tag/v2.2.0)
-are compatible with
-[TensorFlow v2.2.0](https://github.com/tensorflow/tensorflow/releases/tag/v2.2.0).
-
-Please follow the below steps before running models in this repository.
-
-### Requirements
-
-* The latest TensorFlow Model Garden release and TensorFlow 2
- * If you are on a version of TensorFlow earlier than 2.2, please
-upgrade your TensorFlow to [the latest TensorFlow 2](https://www.tensorflow.org/install/).
-
-```shell
-pip3 install tf-nightly
-```
-
-### Installation
-
-#### Method 1: Install the TensorFlow Model Garden pip package
-
-**tf-models-nightly** is the nightly Model Garden package
-created daily automatically. pip will install all models
-and dependencies automatically.
-
-```shell
-pip install tf-models-nightly
-```
-
-Please check out our [example](colab/fine_tuning_bert.ipynb)
-to learn how to use a PIP package.
-
-#### Method 2: Clone the source
-
-1. Clone the GitHub repository:
-
-```shell
-git clone https://github.com/tensorflow/models.git
-```
-
-2. Add the top-level ***/models*** folder to the Python path.
-
-```shell
-export PYTHONPATH=$PYTHONPATH:/path/to/models
-```
-
-If you are using a Colab notebook, please set the Python path with os.environ.
-
-```python
-import os
-os.environ['PYTHONPATH'] += ":/path/to/models"
-```
-
-3. Install other dependencies
-
-```shell
-pip3 install --user -r official/requirements.txt
-```
-
-## Contributions
-
-If you want to contribute, please review the [contribution guidelines](https://github.com/tensorflow/models/wiki/How-to-contribute).
diff --git a/spaces/Nanostuffs/nano.ai/README.md b/spaces/Nanostuffs/nano.ai/README.md
deleted file mode 100644
index 97a54da50c2a4a55e34abbd7a7ca0b92083140f7..0000000000000000000000000000000000000000
--- a/spaces/Nanostuffs/nano.ai/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Nano.ai
-emoji: 📊
-colorFrom: green
-colorTo: pink
-sdk: gradio
-sdk_version: 3.38.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Nephele/bert-vits2-multi-voice/commons.py b/spaces/Nephele/bert-vits2-multi-voice/commons.py
deleted file mode 100644
index 9ad0444b61cbadaa388619986c2889c707d873ce..0000000000000000000000000000000000000000
--- a/spaces/Nephele/bert-vits2-multi-voice/commons.py
+++ /dev/null
@@ -1,161 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size*dilation - dilation)/2)
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def intersperse(lst, item):
- result = [item] * (len(lst) * 2 + 1)
- result[1::2] = lst
- return result
-
-
-def kl_divergence(m_p, logs_p, m_q, logs_q):
- """KL(P||Q)"""
- kl = (logs_q - logs_p) - 0.5
- kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q)
- return kl
-
-
-def rand_gumbel(shape):
- """Sample from the Gumbel distribution, protect from overflows."""
- uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
- return -torch.log(-torch.log(uniform_samples))
-
-
-def rand_gumbel_like(x):
- g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
- return g
-
-
-def slice_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, :, idx_str:idx_end]
- return ret
-
-
-def rand_slice_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def get_timing_signal_1d(
- length, channels, min_timescale=1.0, max_timescale=1.0e4):
- position = torch.arange(length, dtype=torch.float)
- num_timescales = channels // 2
- log_timescale_increment = (
- math.log(float(max_timescale) / float(min_timescale)) /
- (num_timescales - 1))
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment)
- scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
- signal = F.pad(signal, [0, 0, 0, channels % 2])
- signal = signal.view(1, channels, length)
- return signal
-
-
-def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return x + signal.to(dtype=x.dtype, device=x.device)
-
-
-def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
-
-
-def subsequent_mask(length):
- mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
- return mask
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a + input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def shift_1d(x):
- x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
- return x
-
-
-def sequence_mask(length, max_length=None):
- if max_length is None:
- max_length = length.max()
- x = torch.arange(max_length, dtype=length.dtype, device=length.device)
- return x.unsqueeze(0) < length.unsqueeze(1)
-
-
-def generate_path(duration, mask):
- """
- duration: [b, 1, t_x]
- mask: [b, 1, t_y, t_x]
- """
- device = duration.device
-
- b, _, t_y, t_x = mask.shape
- cum_duration = torch.cumsum(duration, -1)
-
- cum_duration_flat = cum_duration.view(b * t_x)
- path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
- path = path.view(b, t_x, t_y)
- path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
- path = path.unsqueeze(1).transpose(2,3) * mask
- return path
-
-
-def clip_grad_value_(parameters, clip_value, norm_type=2):
- if isinstance(parameters, torch.Tensor):
- parameters = [parameters]
- parameters = list(filter(lambda p: p.grad is not None, parameters))
- norm_type = float(norm_type)
- if clip_value is not None:
- clip_value = float(clip_value)
-
- total_norm = 0
- for p in parameters:
- param_norm = p.grad.data.norm(norm_type)
- total_norm += param_norm.item() ** norm_type
- if clip_value is not None:
- p.grad.data.clamp_(min=-clip_value, max=clip_value)
- total_norm = total_norm ** (1. / norm_type)
- return total_norm
diff --git a/spaces/NoriZC/vits-models/modules.py b/spaces/NoriZC/vits-models/modules.py
deleted file mode 100644
index 56ea4145eddf19dd330a3a41ab0183efc1686d83..0000000000000000000000000000000000000000
--- a/spaces/NoriZC/vits-models/modules.py
+++ /dev/null
@@ -1,388 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/roberta/wsc/README.md b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/roberta/wsc/README.md
deleted file mode 100644
index 21a045d999739836a17574593292e42131315ae9..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/roberta/wsc/README.md
+++ /dev/null
@@ -1,125 +0,0 @@
-# Finetuning RoBERTa on Winograd Schema Challenge (WSC) data
-
-The following instructions can be used to finetune RoBERTa on the WSC training
-data provided by [SuperGLUE](https://super.gluebenchmark.com/).
-
-Note that there is high variance in the results. For our GLUE/SuperGLUE
-submission we swept over the learning rate (1e-5, 2e-5, 3e-5), batch size (16,
-32, 64) and total number of updates (500, 1000, 2000, 3000), as well as the
-random seed. Out of ~100 runs we chose the best 7 models and ensembled them.
-
-**Approach:** The instructions below use a slightly different loss function than
-what's described in the original RoBERTa arXiv paper. In particular,
-[Kocijan et al. (2019)](https://arxiv.org/abs/1905.06290) introduce a margin
-ranking loss between `(query, candidate)` pairs with tunable hyperparameters
-alpha and beta. This is supported in our code as well with the `--wsc-alpha` and
-`--wsc-beta` arguments. However, we achieved slightly better (and more robust)
-results on the development set by instead using a single cross entropy loss term
-over the log-probabilities for the query and all mined candidates. **The
-candidates are mined using spaCy from each input sentence in isolation, so the
-approach remains strictly pointwise.** This reduces the number of
-hyperparameters and our best model achieved 92.3% development set accuracy,
-compared to ~90% accuracy for the margin loss. Later versions of the RoBERTa
-arXiv paper will describe this updated formulation.
-
-### 1) Download the WSC data from the SuperGLUE website:
-```bash
-wget https://dl.fbaipublicfiles.com/glue/superglue/data/v2/WSC.zip
-unzip WSC.zip
-
-# we also need to copy the RoBERTa dictionary into the same directory
-wget -O WSC/dict.txt https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/dict.txt
-```
-
-### 2) Finetune over the provided training data:
-```bash
-TOTAL_NUM_UPDATES=2000 # Total number of training steps.
-WARMUP_UPDATES=250 # Linearly increase LR over this many steps.
-LR=2e-05 # Peak LR for polynomial LR scheduler.
-MAX_SENTENCES=16 # Batch size per GPU.
-SEED=1 # Random seed.
-ROBERTA_PATH=/path/to/roberta/model.pt
-
-# we use the --user-dir option to load the task and criterion
-# from the examples/roberta/wsc directory:
-FAIRSEQ_PATH=/path/to/fairseq
-FAIRSEQ_USER_DIR=${FAIRSEQ_PATH}/examples/roberta/wsc
-
-CUDA_VISIBLE_DEVICES=0,1,2,3 fairseq-train WSC/ \
- --restore-file $ROBERTA_PATH \
- --reset-optimizer --reset-dataloader --reset-meters \
- --no-epoch-checkpoints --no-last-checkpoints --no-save-optimizer-state \
- --best-checkpoint-metric accuracy --maximize-best-checkpoint-metric \
- --valid-subset val \
- --fp16 --ddp-backend legacy_ddp \
- --user-dir $FAIRSEQ_USER_DIR \
- --task wsc --criterion wsc --wsc-cross-entropy \
- --arch roberta_large --bpe gpt2 --max-positions 512 \
- --dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01 \
- --optimizer adam --adam-betas '(0.9, 0.98)' --adam-eps 1e-06 \
- --lr-scheduler polynomial_decay --lr $LR \
- --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_NUM_UPDATES \
- --batch-size $MAX_SENTENCES \
- --max-update $TOTAL_NUM_UPDATES \
- --log-format simple --log-interval 100 \
- --seed $SEED
-```
-
-The above command assumes training on 4 GPUs, but you can achieve the same
-results on a single GPU by adding `--update-freq=4`.
-
-### 3) Evaluate
-```python
-from fairseq.models.roberta import RobertaModel
-from examples.roberta.wsc import wsc_utils # also loads WSC task and criterion
-roberta = RobertaModel.from_pretrained('checkpoints', 'checkpoint_best.pt', 'WSC/')
-roberta.cuda()
-nsamples, ncorrect = 0, 0
-for sentence, label in wsc_utils.jsonl_iterator('WSC/val.jsonl', eval=True):
- pred = roberta.disambiguate_pronoun(sentence)
- nsamples += 1
- if pred == label:
- ncorrect += 1
-print('Accuracy: ' + str(ncorrect / float(nsamples)))
-# Accuracy: 0.9230769230769231
-```
-
-## RoBERTa training on WinoGrande dataset
-We have also provided `winogrande` task and criterion for finetuning on the
-[WinoGrande](https://mosaic.allenai.org/projects/winogrande) like datasets
-where there are always two candidates and one is correct.
-It's more efficient implementation for such subcases.
-
-```bash
-TOTAL_NUM_UPDATES=23750 # Total number of training steps.
-WARMUP_UPDATES=2375 # Linearly increase LR over this many steps.
-LR=1e-05 # Peak LR for polynomial LR scheduler.
-MAX_SENTENCES=32 # Batch size per GPU.
-SEED=1 # Random seed.
-ROBERTA_PATH=/path/to/roberta/model.pt
-
-# we use the --user-dir option to load the task and criterion
-# from the examples/roberta/wsc directory:
-FAIRSEQ_PATH=/path/to/fairseq
-FAIRSEQ_USER_DIR=${FAIRSEQ_PATH}/examples/roberta/wsc
-
-cd fairseq
-CUDA_VISIBLE_DEVICES=0 fairseq-train winogrande_1.0/ \
- --restore-file $ROBERTA_PATH \
- --reset-optimizer --reset-dataloader --reset-meters \
- --no-epoch-checkpoints --no-last-checkpoints --no-save-optimizer-state \
- --best-checkpoint-metric accuracy --maximize-best-checkpoint-metric \
- --valid-subset val \
- --fp16 --ddp-backend legacy_ddp \
- --user-dir $FAIRSEQ_USER_DIR \
- --task winogrande --criterion winogrande \
- --wsc-margin-alpha 5.0 --wsc-margin-beta 0.4 \
- --arch roberta_large --bpe gpt2 --max-positions 512 \
- --dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01 \
- --optimizer adam --adam-betas '(0.9, 0.98)' --adam-eps 1e-06 \
- --lr-scheduler polynomial_decay --lr $LR \
- --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_NUM_UPDATES \
- --batch-size $MAX_SENTENCES \
- --max-update $TOTAL_NUM_UPDATES \
- --log-format simple --log-interval 100
-```
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/__init__.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/__init__.py
deleted file mode 100644
index dc9fd1886d55756b5bdfeccf1ad329bd419a706e..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/__init__.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-"""isort:skip_file"""
-
-import os
-import sys
-
-try:
- from .version import __version__ # noqa
-except ImportError:
- version_txt = os.path.join(os.path.dirname(__file__), "version.txt")
- with open(version_txt) as f:
- __version__ = f.read().strip()
-
-__all__ = ["pdb"]
-
-# backwards compatibility to support `from fairseq.X import Y`
-from fairseq.distributed import utils as distributed_utils
-from fairseq.logging import meters, metrics, progress_bar # noqa
-
-sys.modules["fairseq.distributed_utils"] = distributed_utils
-sys.modules["fairseq.meters"] = meters
-sys.modules["fairseq.metrics"] = metrics
-sys.modules["fairseq.progress_bar"] = progress_bar
-
-# initialize hydra
-from fairseq.dataclass.initialize import hydra_init
-hydra_init()
-
-import fairseq.criterions # noqa
-import fairseq.distributed # noqa
-import fairseq.models # noqa
-import fairseq.modules # noqa
-import fairseq.optim # noqa
-import fairseq.optim.lr_scheduler # noqa
-import fairseq.pdb # noqa
-import fairseq.scoring # noqa
-import fairseq.tasks # noqa
-import fairseq.token_generation_constraints # noqa
-
-import fairseq.benchmark # noqa
-import fairseq.model_parallel # noqa
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/evaluate.py b/spaces/OFA-Sys/OFA-Image_Caption/evaluate.py
deleted file mode 100644
index 2ba9aaecb23051a08fa8a98bde623b7971552c88..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/evaluate.py
+++ /dev/null
@@ -1,152 +0,0 @@
-#!/usr/bin/env python3 -u
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import logging
-import os
-import sys
-import json
-from itertools import chain
-
-import numpy as np
-import torch
-import torch.distributed as dist
-from fairseq import distributed_utils, options, tasks, utils
-from fairseq.dataclass.utils import convert_namespace_to_omegaconf
-from fairseq.logging import progress_bar
-from fairseq.utils import reset_logging
-from omegaconf import DictConfig
-
-from utils import checkpoint_utils
-from utils.eval_utils import eval_step
-
-logging.basicConfig(
- format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
- datefmt="%Y-%m-%d %H:%M:%S",
- level=os.environ.get("LOGLEVEL", "INFO").upper(),
- stream=sys.stdout,
-)
-logger = logging.getLogger("ofa.evaluate")
-
-
-def apply_half(t):
- if t.dtype is torch.float32:
- return t.to(dtype=torch.half)
- return t
-
-
-def main(cfg: DictConfig):
- utils.import_user_module(cfg.common)
-
- reset_logging()
- logger.info(cfg)
-
- assert (
- cfg.dataset.max_tokens is not None or cfg.dataset.batch_size is not None
- ), "Must specify batch size either with --max-tokens or --batch-size"
-
- # Fix seed for stochastic decoding
- if cfg.common.seed is not None and not cfg.generation.no_seed_provided:
- np.random.seed(cfg.common.seed)
- utils.set_torch_seed(cfg.common.seed)
-
- use_fp16 = cfg.common.fp16
- use_cuda = torch.cuda.is_available() and not cfg.common.cpu
-
- if use_cuda:
- torch.cuda.set_device(cfg.distributed_training.device_id)
-
- # Load ensemble
- overrides = eval(cfg.common_eval.model_overrides)
- logger.info("loading model(s) from {}".format(cfg.common_eval.path))
- models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task(
- utils.split_paths(cfg.common_eval.path),
- arg_overrides=overrides,
- suffix=cfg.checkpoint.checkpoint_suffix,
- strict=(cfg.checkpoint.checkpoint_shard_count == 1),
- num_shards=cfg.checkpoint.checkpoint_shard_count,
- )
-
- # loading the dataset should happen after the checkpoint has been loaded so we can give it the saved task config
- task.load_dataset(cfg.dataset.gen_subset, task_cfg=saved_cfg.task)
-
- # Move models to GPU
- for model in models:
- model.eval()
- if use_fp16:
- model.half()
- if use_cuda and not cfg.distributed_training.pipeline_model_parallel:
- model.cuda()
- model.prepare_for_inference_(cfg)
-
- # Load dataset (possibly sharded)
- itr = task.get_batch_iterator(
- dataset=task.dataset(cfg.dataset.gen_subset),
- max_tokens=cfg.dataset.max_tokens,
- max_sentences=cfg.dataset.batch_size,
- max_positions=utils.resolve_max_positions(
- task.max_positions(), *[m.max_positions() for m in models]
- ),
- ignore_invalid_inputs=cfg.dataset.skip_invalid_size_inputs_valid_test,
- required_batch_size_multiple=cfg.dataset.required_batch_size_multiple,
- seed=cfg.common.seed,
- num_shards=cfg.distributed_training.distributed_world_size,
- shard_id=cfg.distributed_training.distributed_rank,
- num_workers=cfg.dataset.num_workers,
- data_buffer_size=cfg.dataset.data_buffer_size,
- ).next_epoch_itr(shuffle=False)
- progress = progress_bar.progress_bar(
- itr,
- log_format=cfg.common.log_format,
- log_interval=cfg.common.log_interval,
- default_log_format=("tqdm" if not cfg.common.no_progress_bar else "simple"),
- )
-
- # Initialize generator
- generator = task.build_generator(models, cfg.generation)
-
- results = []
- score_sum = torch.FloatTensor([0]).cuda()
- score_cnt = torch.FloatTensor([0]).cuda()
- for sample in progress:
- if "net_input" not in sample:
- continue
- sample = utils.move_to_cuda(sample) if use_cuda else sample
- sample = utils.apply_to_sample(apply_half, sample) if cfg.common.fp16 else sample
- with torch.no_grad():
- result, scores = eval_step(task, generator, models, sample)
- results += result
- score_sum += sum(scores) if scores is not None else 0
- score_cnt += len(scores) if scores is not None else 0
- progress.log({"sentences": sample["nsentences"]})
-
- gather_results = None
- if cfg.distributed_training.distributed_world_size > 1:
- gather_results = [None for _ in range(dist.get_world_size())]
- dist.all_gather_object(gather_results, results)
- dist.all_reduce(score_sum.data)
- dist.all_reduce(score_cnt.data)
- if score_cnt.item() > 0:
- logger.info("score_sum: {}, score_cnt: {}, score: {}".format(
- score_sum, score_cnt, round(score_sum.item() / score_cnt.item(), 4)
- ))
-
- if cfg.distributed_training.distributed_world_size == 1 or dist.get_rank() == 0:
- os.makedirs(cfg.common_eval.results_path, exist_ok=True)
- output_path = os.path.join(cfg.common_eval.results_path, "{}_predict.json".format(cfg.dataset.gen_subset))
- gather_results = list(chain(*gather_results)) if gather_results is not None else results
- with open(output_path, 'w') as fw:
- json.dump(gather_results, fw)
-
-
-def cli_main():
- parser = options.get_generation_parser()
- args = options.parse_args_and_arch(parser)
- cfg = convert_namespace_to_omegaconf(args)
- distributed_utils.call_main(cfg, main)
-
-
-if __name__ == "__main__":
- cli_main()
\ No newline at end of file
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/multilingual/data_scripts/download_flores_data.sh b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/multilingual/data_scripts/download_flores_data.sh
deleted file mode 100644
index e6175ce0c38b06a1ebddaeca808f71b47f77f500..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/multilingual/data_scripts/download_flores_data.sh
+++ /dev/null
@@ -1,246 +0,0 @@
-#!/bin/bash
-
-# Copyright (c) Facebook, Inc. and its affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-#
-
-if [ -z $WORKDIR_ROOT ] ;
-then
- echo "please specify your working directory root in environment variable WORKDIR_ROOT. Exitting..."
- exit
-fi
-
-
-set -e
-set -o pipefail
-
-SRC=en
-SI_TGT=si
-NE_TGT=ne
-
-DESTDIR=${WORKDIR_ROOT}/ML50/raw/
-
-ROOT=${WORKDIR_ROOT}/tmp
-mkdir -p $ROOT
-DATA=$ROOT/data
-NE_ROOT=$DATA/all-clean-ne
-SI_ROOT=$DATA/all-clean-si
-
-mkdir -p $DATA $NE_ROOT $SI_ROOT
-
-SI_OPUS_DATASETS=(
- "$SI_ROOT/GNOME.en-si"
- "$SI_ROOT/Ubuntu.en-si"
- "$SI_ROOT/KDE4.en-si"
- "$SI_ROOT/OpenSubtitles.en-si"
-)
-
-SI_OPUS_URLS=(
- "https://object.pouta.csc.fi/OPUS-GNOME/v1/moses/en-si.txt.zip"
- "https://object.pouta.csc.fi/OPUS-Ubuntu/v14.10/moses/en-si.txt.zip"
- "https://object.pouta.csc.fi/OPUS-KDE4/v2/moses/en-si.txt.zip"
- "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2018/moses/en-si.txt.zip"
-)
-
-NE_OPUS_DATASETS=(
- "$NE_ROOT/GNOME.en-ne"
- "$NE_ROOT/Ubuntu.en-ne"
- "$NE_ROOT/KDE4.en-ne"
-)
-
-NE_OPUS_URLS=(
- "https://object.pouta.csc.fi/OPUS-GNOME/v1/moses/en-ne.txt.zip"
- "https://object.pouta.csc.fi/OPUS-Ubuntu/v14.10/moses/en-ne.txt.zip"
- "https://object.pouta.csc.fi/OPUS-KDE4/v2/moses/en-ne.txt.zip"
-)
-
-REMOVE_FILE_PATHS=()
-
-# Download data
-download_data() {
- CORPORA=$1
- URL=$2
-
- if [ -f $CORPORA ]; then
- echo "$CORPORA already exists, skipping download"
- else
- echo "Downloading $URL"
- wget $URL -O $CORPORA --no-check-certificate || rm -f $CORPORA
- if [ -f $CORPORA ]; then
- echo "$URL successfully downloaded."
- else
- echo "$URL not successfully downloaded."
- rm -f $CORPORA
- exit -1
- fi
- fi
-}
-
-# Example: download_opus_data $LANG_ROOT $TGT
-download_opus_data() {
- LANG_ROOT=$1
- TGT=$2
-
- if [ "$TGT" = "si" ]; then
- URLS=("${SI_OPUS_URLS[@]}")
- DATASETS=("${SI_OPUS_DATASETS[@]}")
- else
- URLS=("${NE_OPUS_URLS[@]}")
- DATASETS=("${NE_OPUS_DATASETS[@]}")
- fi
-
- # Download and extract data
- for ((i=0;i<${#URLS[@]};++i)); do
- URL=${URLS[i]}
- CORPORA=${DATASETS[i]}
-
- download_data $CORPORA $URL
- unzip -o $CORPORA -d $LANG_ROOT
- REMOVE_FILE_PATHS+=( $CORPORA $CORPORA.xml $CORPORA.ids $LANG_ROOT/README $LANG_ROOT/LICENSE )
- done
-
- cat ${DATASETS[0]}.$SRC ${DATASETS[1]}.$SRC ${DATASETS[2]}.$SRC > $LANG_ROOT/GNOMEKDEUbuntu.$SRC-$TGT.$SRC
- cat ${DATASETS[0]}.$TGT ${DATASETS[1]}.$TGT ${DATASETS[2]}.$TGT > $LANG_ROOT/GNOMEKDEUbuntu.$SRC-$TGT.$TGT
-
- REMOVE_FILE_PATHS+=( ${DATASETS[0]}.$SRC ${DATASETS[1]}.$SRC ${DATASETS[2]}.$SRC )
- REMOVE_FILE_PATHS+=( ${DATASETS[0]}.$TGT ${DATASETS[1]}.$TGT ${DATASETS[2]}.$TGT )
-}
-
-download_opus_data $SI_ROOT $SI_TGT
-cp ${SI_OPUS_DATASETS[3]}.$SRC $SI_ROOT/OpenSubtitles2018.$SRC-$SI_TGT.$SRC
-cp ${SI_OPUS_DATASETS[3]}.$SI_TGT $SI_ROOT/OpenSubtitles2018.$SRC-$SI_TGT.$SI_TGT
-REMOVE_FILE_PATHS+=( ${SI_OPUS_DATASETS[3]}.$SRC ${SI_OPUS_DATASETS[3]}.$SI_TGT )
-
-download_opus_data $NE_ROOT $NE_TGT
-
-
-# Download and extract Global Voices data
-GLOBAL_VOICES="$NE_ROOT/globalvoices.2018q4.ne-en"
-GLOBAL_VOICES_URL="http://www.casmacat.eu/corpus/global-voices/globalvoices.ne-en.xliff.gz"
-
-download_data $GLOBAL_VOICES.gz $GLOBAL_VOICES_URL
-gunzip -Nf $GLOBAL_VOICES.gz
-
-sed -ne 's?.*\(.*\) .*?\1?p' $GLOBAL_VOICES > $GLOBAL_VOICES.$NE_TGT
-sed -ne 's?.*]*>\(.*\).*?\1?p' $GLOBAL_VOICES > $GLOBAL_VOICES.$SRC
-
-REMOVE_FILE_PATHS+=( $GLOBAL_VOICES )
-
-# Download and extract the bible dataset
-BIBLE_TOOLS=bible-corpus-tools
-XML_BIBLES=XML_Bibles
-XML_BIBLES_DUP=XML_Bibles_dup
-
-if [ ! -e $BIBLE_TOOLS ]; then
- echo "Cloning bible-corpus-tools repository..."
- git clone https://github.com/christos-c/bible-corpus-tools.git
-fi
-
-mkdir -p $BIBLE_TOOLS/bin $XML_BIBLES $XML_BIBLES_DUP
-javac -cp "$BIBLE_TOOLS/lib/*" -d $BIBLE_TOOLS/bin $BIBLE_TOOLS/src/bible/readers/*.java $BIBLE_TOOLS/src/bible/*.java
-
-download_data bible.tar.gz "https://github.com/christos-c/bible-corpus/archive/v1.2.1.tar.gz"
-tar xvzf bible.tar.gz
-
-cp bible-corpus-1.2.1/bibles/{Greek.xml,English.xml,Nepali.xml} $XML_BIBLES/
-cp bible-corpus-1.2.1/bibles/{Greek.xml,English-WEB.xml,Nepali.xml} $XML_BIBLES_DUP/
-
-java -cp $BIBLE_TOOLS/lib/*:$BIBLE_TOOLS/bin bible.CreateMLBooks $XML_BIBLES
-java -cp $BIBLE_TOOLS/lib/*:$BIBLE_TOOLS/bin bible.CreateMLBooks $XML_BIBLES_DUP
-java -cp $BIBLE_TOOLS/lib/*:$BIBLE_TOOLS/bin bible.CreateVerseAlignedBooks $XML_BIBLES
-java -cp $BIBLE_TOOLS/lib/*:$BIBLE_TOOLS/bin bible.CreateVerseAlignedBooks $XML_BIBLES_DUP
-
-cat $XML_BIBLES/aligned/*/English.txt > $NE_ROOT/bible.$SRC-$NE_TGT.$SRC
-cat $XML_BIBLES/aligned/*/Nepali.txt > $NE_ROOT/bible.$SRC-$NE_TGT.$NE_TGT
-cat $XML_BIBLES_DUP/aligned/*/English-WEB.txt > $NE_ROOT/bible_dup.$SRC-$NE_TGT.$SRC
-cat $XML_BIBLES_DUP/aligned/*/Nepali.txt > $NE_ROOT/bible_dup.$SRC-$NE_TGT.$NE_TGT
-REMOVE_FILE_PATHS+=( bible-corpus-1.2.1 bible.tar.gz $BIBLE_TOOLS $XML_BIBLES $XML_BIBLES_DUP )
-
-# Download and extract the Penn Treebank dataset
-NE_TAGGED=$ROOT/new_submissions_parallel_corpus_project_Nepal
-NE_TAGGED_URL="http://www.cle.org.pk/Downloads/ling_resources/parallelcorpus/NepaliTaggedCorpus.zip"
-EN_TAGGED_PATCH_URL="https://dl.fbaipublicfiles.com/fairseq/data/nepali-penn-treebank.en.patch"
-NE_TAGGED_PATCH_URL="https://dl.fbaipublicfiles.com/fairseq/data/nepali-penn-treebank.ne.patch"
-MOSES=mosesdecoder
-MOSES_TOK=$MOSES/scripts/tokenizer
-EN_PATCH_REGEX="{s:\\\/:\/:g;s/\*\T\*\-\n+//g;s/\-LCB\-/\{/g;s/\-RCB\-/\}/g; s/\-LSB\-/\[/g; s/\-RSB\-/\]/g;s/\-LRB\-/\(/g; s/\-RRB\-/\)/g; s/\'\'/\"/g; s/\`\`/\"/g; s/\ +\'s\ +/\'s /g; s/\ +\'re\ +/\'re /g; s/\"\ +/\"/g; s/\ +\"/\"/g; s/\ n't([\ \.\"])/n't\1/g; s/\r+(.)/\1/g;}"
-NE_PATCH_REGEX="{s:\p{Cf}::g;s:\\\/:\/:g;s/\*\T\*\-\n+//g;s/\-LCB\-/\{/g;s/\-RCB\-/\}/g; s/\-LSB\-/\[/g; s/\-RSB\-/\]/g;s/\-LRB\-/\(/g; s/\-RRB\-/\)/g; s/\'\'/\"/g; s/\`\`/\"/g; s/\ +\'s\ +/\'s /g; s/\ +\'re\ +/\'re /g; s/\"\ +/\"/g; s/\ +\"/\"/g; s/\ n't([\ \.\"])/n't\1/g; s/\r+(.)/\1/g;}"
-
-download_data $DATA/nepali-penn-treebank.$SRC.patch $EN_TAGGED_PATCH_URL
-download_data $DATA/nepali-penn-treebank.$NE_TGT.patch $NE_TAGGED_PATCH_URL
-download_data original.zip $NE_TAGGED_URL
-unzip -o original.zip -d $ROOT
-
-cat $NE_TAGGED/00.txt $NE_TAGGED/01.txt $NE_TAGGED/02.txt > $NE_TAGGED/nepali-penn-treebank.$SRC
-cat $NE_TAGGED/00ne_revised.txt $NE_TAGGED/01ne_revised.txt $NE_TAGGED/02ne_revised.txt > $NE_TAGGED/nepali-penn-treebank.$NE_TGT
-
-patch $NE_TAGGED/nepali-penn-treebank.$SRC -i $DATA/nepali-penn-treebank.$SRC.patch -o $NE_TAGGED/nepali-penn-treebank-patched.$SRC
-patch $NE_TAGGED/nepali-penn-treebank.$NE_TGT -i $DATA/nepali-penn-treebank.$NE_TGT.patch -o $NE_TAGGED/nepali-penn-treebank-patched.$NE_TGT
-
-if [ ! -e $MOSES ]; then
- echo "Cloning moses repository..."
- git clone https://github.com/moses-smt/mosesdecoder.git
-fi
-
-cat $NE_TAGGED/nepali-penn-treebank-patched.$SRC | \
- perl -anpe "$EN_PATCH_REGEX" | \
- $MOSES_TOK/tokenizer.perl -l $SRC | \
- $MOSES_TOK/detokenizer.perl -l $SRC > $NE_ROOT/nepali-penn-treebank.$SRC
-
-cat $NE_TAGGED/nepali-penn-treebank-patched.$NE_TGT | \
- perl -CIO -anpe "$NE_PATCH_REGEX" | \
- $MOSES_TOK/detokenizer.perl -l $SRC > $NE_ROOT/nepali-penn-treebank.$NE_TGT
-
-
-# Download nepali dictionary data
-NE_DICT=$NE_ROOT/dictionaries
-download_data $NE_DICT "http://www.seas.upenn.edu/~nlp/resources/TACL-data-release/dictionaries.tar.gz"
-tar xvzf $NE_DICT
-cp dictionaries/dict.ne $NE_ROOT/dictionary.$NE_TGT-$SRC
-REMOVE_FILE_PATHS+=( $NE_DICT dictionaries )
-
-REMOVE_FILE_PATHS+=( $MOSES $NE_TAGGED original.zip $DATA/nepali-penn-treebank.$SRC.patch $DATA/nepali-penn-treebank.$NE_TGT.patch )
-
-
-# Remove the temporary files
-for ((i=0;i<${#REMOVE_FILE_PATHS[@]};++i)); do
- rm -rf ${REMOVE_FILE_PATHS[i]}
-done
-
-# Copy the training data
-si=si_LK
-ne=ne_NP
-en=en_XX
-cat $SI_ROOT/GNOMEKDEUbuntu.en-si.si $SI_ROOT/OpenSubtitles2018.en-si.si > $DESTDIR/train.$si-$en.$si
-cat $SI_ROOT/GNOMEKDEUbuntu.en-si.en $SI_ROOT/OpenSubtitles2018.en-si.en > $DESTDIR/train.$si-$en.$en
-
-cat $NE_ROOT/bible_dup.en-ne.ne $NE_ROOT/bible.en-ne.ne $NE_ROOT/globalvoices.2018q4.ne-en.ne $NE_ROOT/GNOMEKDEUbuntu.en-ne.ne $NE_ROOT/nepali-penn-treebank.ne > $DESTDIR/train.$ne-$en.$ne
-cat $NE_ROOT/bible_dup.en-ne.en $NE_ROOT/bible.en-ne.en $NE_ROOT/globalvoices.2018q4.ne-en.en $NE_ROOT/GNOMEKDEUbuntu.en-ne.en $NE_ROOT/nepali-penn-treebank.en > $DESTDIR/train.$ne-$en.$en
-
-
-#Download the test sets
-wget https://github.com/facebookresearch/flores/raw/master/data/wikipedia_en_ne_si_test_sets.tgz
-tar -xvzf wikipedia_en_ne_si_test_sets.tgz
-
-cp wikipedia_en_ne_si_test_sets/wikipedia.dev.ne-en.ne $DESTDIR/valid.$ne-$en.$ne
-cp wikipedia_en_ne_si_test_sets/wikipedia.dev.ne-en.en $DESTDIR/valid.$ne-$en.$en
-
-cp wikipedia_en_ne_si_test_sets/wikipedia.dev.si-en.si $DESTDIR/valid.$si-$en.$si
-cp wikipedia_en_ne_si_test_sets/wikipedia.dev.si-en.en $DESTDIR/valid.$si-$en.$en
-
-cp wikipedia_en_ne_si_test_sets/wikipedia.devtest.ne-en.ne $DESTDIR/devtest.$ne-$en.$ne
-cp wikipedia_en_ne_si_test_sets/wikipedia.devtest.ne-en.en $DESTDIR/devtest.$ne-$en.$en
-
-cp wikipedia_en_ne_si_test_sets/wikipedia.devtest.si-en.si $DESTDIR/devtest.$si-$en.$si
-cp wikipedia_en_ne_si_test_sets/wikipedia.devtest.si-en.en $DESTDIR/devtest.$si-$en.$en
-
-cp wikipedia_en_ne_si_test_sets/wikipedia.test.ne-en.ne $DESTDIR/test.$ne-$en.$ne
-cp wikipedia_en_ne_si_test_sets/wikipedia.test.ne-en.en $DESTDIR/test.$ne-$en.$en
-
-cp wikipedia_en_ne_si_test_sets/wikipedia.test.si-en.si $DESTDIR/test.$si-$en.$si
-cp wikipedia_en_ne_si_test_sets/wikipedia.test.si-en.en $DESTDIR/test.$si-$en.$en
-
-rm -rf wikipedia_en_ne_si_test_sets.tgz wikipedia_en_ne_si_test_sets
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/decode.sh b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/decode.sh
deleted file mode 100644
index 811cb63c88bb7cdd03b0a250ef2db32b5eaa50df..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/decode.sh
+++ /dev/null
@@ -1,38 +0,0 @@
-#!/bin/bash
-
-set -u
-
-val_sets="dev_other"
-graph_name=graph
-decode_suffix=""
-decode_script="steps/decode_fmllr.sh"
-decode_args=""
-nj=60
-
-. ./cmd.sh
-. ./path.sh
-. parse_options.sh
-
-set -x
-exp_dir=$1
-data_root=$2
-lang_test=$3
-
-graph=$exp_dir/$graph_name
-
-if [ ! -d $graph ]; then
- utils/mkgraph.sh $lang_test $exp_dir $graph
-fi
-
-for part in $val_sets; do
- dec_dir=$exp_dir/decode${decode_suffix}_${part}
- if [ ! -d $dec_dir ]; then
- echo "decoding $part for $exp_dir"
- $decode_script --nj $nj --cmd "$decode_cmd" $decode_args \
- $graph $data_root/$part $dec_dir &
- else
- echo "$dec_dir exists. skip"
- fi
-done
-
-wait
diff --git a/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/criss/mining/mine_example.sh b/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/criss/mining/mine_example.sh
deleted file mode 100644
index ace995ac44665f99d904b6a89d7fbbce24103afe..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/criss/mining/mine_example.sh
+++ /dev/null
@@ -1,103 +0,0 @@
-#!/bin/bash
-# Copyright (c) Facebook, Inc. and its affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-#
-source_lang=kk_KZ
-target_lang=en_XX
-MODEL=criss_checkpoints/criss.3rd.pt
-SPM=criss_checkpoints/sentence.bpe.model
-SPLIT=test
-LANG_DICT=criss_checkpoints/lang_dict.txt
-SPM_ENCODE=flores/scripts/spm_encode.py
-SAVE_ENCODER=save_encoder.py
-ENCODER_SAVE_ROOT=sentence_embeddings/$MODEL
-DICT=criss_checkpoints/dict.txt
-THRESHOLD=1.02
-MIN_COUNT=500
-
-DATA_DIR=data_tmp
-SAVE_DIR=mining/${source_lang}_${target_lang}_mined
-ENCODER_SAVE_DIR=${ENCODER_SAVE_ROOT}/${source_lang}-${target_lang}
-INPUT_DIR=$DATA_DIR/${source_lang}-${target_lang}-tatoeba
-
-mkdir -p $ENCODER_SAVE_DIR/${target_lang}
-mkdir -p $ENCODER_SAVE_DIR/${source_lang}
-mkdir -p $SAVE_DIR
-
-## Save encoder outputs
-
-# Save encoder outputs for source sentences
-python $SAVE_ENCODER \
- ${INPUT_DIR} \
- --path ${MODEL} \
- --task translation_multi_simple_epoch \
- --lang-pairs ${source_lang}-${target_lang} \
- --lang-dict ${LANG_DICT} \
- --gen-subset ${SPLIT} \
- --bpe 'sentencepiece' \
- -s ${source_lang} -t ${target_lang} \
- --sentencepiece-model ${SPM} \
- --remove-bpe 'sentencepiece' \
- --beam 1 \
- --lang-tok-style mbart \
- --encoder-save-dir ${ENCODER_SAVE_DIR}/${source_lang}
-
-## Save encoder outputs for target sentences
-python $SAVE_ENCODER \
- ${INPUT_DIR} \
- --path ${MODEL} \
- --lang-pairs ${source_lang}-${target_lang} \
- --lang-dict ${LANG_DICT} \
- --task translation_multi_simple_epoch \
- --gen-subset ${SPLIT} \
- --bpe 'sentencepiece' \
- -t ${source_lang} -s ${target_lang} \
- --sentencepiece-model ${SPM} \
- --remove-bpe 'sentencepiece' \
- --beam 1 \
- --lang-tok-style mbart \
- --encoder-save-dir ${ENCODER_SAVE_DIR}/${target_lang}
-
-## Mining
-python mining/mine.py \
- --src-lang ${source_lang} \
- --tgt-lang ${target_lang} \
- --dim 1024 \
- --mem 10 \
- --neighborhood 4 \
- --src-dir ${ENCODER_SAVE_DIR}/${source_lang} \
- --tgt-dir ${ENCODER_SAVE_DIR}/${target_lang} \
- --output $SAVE_DIR \
- --threshold ${THRESHOLD} \
- --min-count ${MIN_COUNT} \
- --valid-size 100 \
- --dict-path ${DICT} \
- --spm-path ${SPM} \
-
-
-## Process and binarize mined data
-python $SPM_ENCODE \
- --model ${SPM} \
- --output_format=piece \
- --inputs mining/${source_lang}_${target_lang}_mined/train.${source_lang} mining/${source_lang}_${target_lang}_mined/train.${target_lang} \
- --outputs mining/${source_lang}_${target_lang}_mined/train.bpe.${source_lang} mining/${source_lang}_${target_lang}_mined/train.bpe.${target_lang}
-
-python $SPM_ENCODE \
- --model ${SPM} \
- --output_format=piece \
- --inputs mining/${source_lang}_${target_lang}_mined/valid.${source_lang} mining/${source_lang}_${target_lang}_mined/valid.${target_lang} \
- --outputs mining/${source_lang}_${target_lang}_mined/valid.bpe.${source_lang} mining/${source_lang}_${target_lang}_mined/valid.bpe.${target_lang}
-
-
-fairseq-preprocess \
- --source-lang ${source_lang} \
- --target-lang ${target_lang} \
- --trainpref mining/${source_lang}_${target_lang}_mined/train.bpe \
- --validpref mining/${source_lang}_${target_lang}_mined/valid.bpe \
- --destdir mining/${source_lang}_${target_lang}_mined \
- --srcdict ${DICT} \
- --joined-dictionary \
- --workers 8
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/tests/test_file_io.py b/spaces/OFA-Sys/OFA-vqa/fairseq/tests/test_file_io.py
deleted file mode 100644
index 425812bf1672489093941e5fa09f9da3171559ee..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/tests/test_file_io.py
+++ /dev/null
@@ -1,58 +0,0 @@
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import os
-import shutil
-import sys
-import tempfile
-import unittest
-from typing import Optional
-from unittest.mock import MagicMock
-
-
-class TestFileIO(unittest.TestCase):
-
- _tmpdir: Optional[str] = None
- _tmpfile: Optional[str] = None
- _tmpfile_contents = "Hello, World"
-
- @classmethod
- def setUpClass(cls) -> None:
- cls._tmpdir = tempfile.mkdtemp()
- with open(os.path.join(cls._tmpdir, "test.txt"), "w") as f:
- cls._tmpfile = f.name
- f.write(cls._tmpfile_contents)
- f.flush()
-
- @classmethod
- def tearDownClass(cls) -> None:
- # Cleanup temp working dir.
- if cls._tmpdir is not None:
- shutil.rmtree(cls._tmpdir) # type: ignore
-
- def test_file_io(self):
- from fairseq.file_io import PathManager
-
- with PathManager.open(os.path.join(self._tmpdir, "test.txt"), "r") as f:
- s = f.read()
- self.assertEqual(s, self._tmpfile_contents)
-
- def test_file_io_oss(self):
- # Mock iopath to simulate oss environment.
- sys.modules["iopath"] = MagicMock()
- from fairseq.file_io import PathManager
-
- with PathManager.open(os.path.join(self._tmpdir, "test.txt"), "r") as f:
- s = f.read()
- self.assertEqual(s, self._tmpfile_contents)
-
- def test_file_io_async(self):
- # ioPath `PathManager` is initialized after the first `opena` call.
- try:
- from fairseq.file_io import IOPathManager, PathManager
- _asyncfile = os.path.join(self._tmpdir, "async.txt")
- f = PathManager.opena(_asyncfile, "wb")
- f.close()
-
- finally:
- self.assertTrue(PathManager.async_close())
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/tests/test_roberta.py b/spaces/OFA-Sys/OFA-vqa/fairseq/tests/test_roberta.py
deleted file mode 100644
index b0b9cfd31e8cb1e03ae74403886d2fb5266e0443..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/tests/test_roberta.py
+++ /dev/null
@@ -1,314 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import functools
-import unittest
-from typing import Any, Dict, Sequence
-
-import fairseq
-import fairseq.options
-import fairseq.tasks
-import torch
-from tests.utils import dummy_dictionary
-
-VOCAB_SIZE = 100
-
-
-@fairseq.tasks.register_task("fake_task")
-class FakeTask(fairseq.tasks.LegacyFairseqTask):
- def __init__(self, args):
- super().__init__(args)
- self.dictionary = dummy_dictionary(VOCAB_SIZE - 4)
- assert len(self.dictionary) == VOCAB_SIZE
-
- @property
- def source_dictionary(self):
- return self.dictionary
-
- @property
- def target_dictionary(self):
- return self.dictionary
-
-
-@functools.lru_cache()
-def get_toy_model(
- device: str,
- architecture: str = "roberta_enc_dec",
- **extra_args: Any,
-):
- assert device in ("gpu", "cpu")
- kwargs = {
- "arch": architecture,
- # Use characteristics dimensions
- "encoder_layers": 3,
- "encoder_embed_dim": 12,
- "encoder_ffn_embed_dim": 14,
- "encoder_attention_heads": 4,
- "decoder_layers": 3,
- "decoder_embed_dim": 12,
- "decoder_ffn_embed_dim": 14,
- "decoder_attention_heads": 4,
- # Disable dropout so we have comparable tests.
- "dropout": 0,
- "attention_dropout": 0,
- "activation_dropout": 0,
- "encoder_layerdrop": 0,
- # required args
- "tokens_per_sample": 256,
- "data": "/tmp/test_roberta",
- }
- kwargs.update(extra_args)
- fake_task = FakeTask(kwargs)
- args = fairseq.options.get_args(
- task="online_backtranslation",
- mono_langs="en,ro",
- valid_lang_pairs="en-ro",
- **kwargs,
- )
- torch.manual_seed(0)
- model = fake_task.build_model(args)
- if device == "gpu":
- model.cuda()
- return fake_task, model
-
-
-def mk_sample(
- lang: str, device: str, tok: Sequence[int] = None, batch_size: int = 2
-) -> Dict[str, Any]:
- assert device in ("gpu", "cpu")
- if not tok:
- if lang == "en":
- tok = [10, 11, 12, 13, 14, 15, 2]
- else:
- tok = [20, 21, 22, 23, 24, 25, 26, 27, 2]
-
- batch = torch.stack([torch.tensor(tok, dtype=torch.long)] * batch_size)
- if device == "gpu":
- batch = batch.cuda()
- sample = {
- "net_input": {
- "src_tokens": batch,
- "prev_output_tokens": batch,
- "src_lengths": torch.tensor(
- [len(tok)] * batch_size, dtype=torch.long, device=batch.device
- ),
- },
- "target": batch[:, 1:],
- }
- return sample
-
-
-def cpu_gpu(fn):
- def helper(self):
- fn(self, "cpu")
- if torch.cuda.is_available():
- fn(self, "gpu")
-
- return helper
-
-
-def architectures(fn):
- def helper(self):
- for arch in ["roberta_enc_dec", "transformer"]:
- fn(self, arch)
-
- return helper
-
-
-class RobertaTest(unittest.TestCase):
- def assertTensorEqual(self, t1, t2, delta: float = 1e-6):
- self.assertEqual(t1.size(), t2.size(), "size mismatch")
- if delta == 0.0:
- self.assertEqual(t1.ne(t2).long().sum(), 0)
- else:
- self.assertEqual(((t2 - t1).abs() > delta).long().sum(), 0)
-
- def assertSharing(self, model, link_groups: Sequence[Sequence[str]]):
- ids = {}
- for group in link_groups:
- group_ids = {name: id(params(model, name)) for name in group}
- shared_id = group_ids[group[0]]
- self.assertEqual(group_ids, {name: shared_id for name in group})
- self.assertNotIn(shared_id, ids)
- ids[shared_id] = group
-
- def test_roberta_shared_params(self):
- _, roberta = get_toy_model("cpu", architecture="roberta")
- self.assertSharing(
- roberta,
- [
- [
- "encoder.sentence_encoder.embed_tokens.weight",
- "encoder.lm_head.weight",
- ]
- ],
- )
-
- _, roberta = get_toy_model(
- "cpu", architecture="roberta", untie_weights_roberta=True
- )
- self.assertSharing(
- roberta,
- [
- ["encoder.sentence_encoder.embed_tokens.weight"],
- ["encoder.lm_head.weight"],
- ],
- )
-
- def test_roberta_enc_dec_shared_params(self):
- # 3 distinct embeddings
- _, enc_dec = get_toy_model("cpu", architecture="roberta_enc_dec")
- self.assertSharing(
- enc_dec,
- [
- ["encoder.embed_tokens.weight"],
- ["decoder.embed_tokens.weight"],
- ["decoder.output_projection.weight"],
- ],
- )
-
- # 2 distinct embeddings, one for encoder, one for decoder
- _, enc_dec = get_toy_model(
- "cpu", architecture="roberta_enc_dec", share_decoder_input_output_embed=True
- )
- self.assertSharing(
- enc_dec,
- [
- ["encoder.embed_tokens.weight"],
- [
- "decoder.embed_tokens.weight",
- "decoder.output_projection.weight",
- ],
- ],
- )
-
- # shared embeddings
- _, enc_dec = get_toy_model(
- "cpu", architecture="roberta_enc_dec", share_all_embeddings=True
- )
- self.assertSharing(
- enc_dec,
- [
- [
- "encoder.embed_tokens.weight",
- "decoder.embed_tokens.weight",
- "decoder.output_projection.weight",
- ]
- ],
- )
-
- def test_roberta_max_positions_is_correctly_set(self):
- device = "cpu"
- task, model = get_toy_model(device)
- max_pos = model.max_decoder_positions()
- self.assertEqual(max_pos, 256)
- self.assertEqual(max_pos, model.decoder.max_positions())
- self.assertEqual(max_pos, model.encoder.max_positions())
- self.assertEqual(max_pos, model.encoder.embed_positions.max_positions)
-
- sentence = [31 for _ in range(max_pos)]
- sample = mk_sample("en", device, sentence, batch_size=1)
- self.assertEqual(list(sample["net_input"]["src_lengths"]), [max_pos])
- self.assertEqual(len(sample["net_input"]["src_tokens"][0]), max_pos)
- x, _ = model.forward(**sample["net_input"])
- self.assertEqual(x.shape, (1, max_pos, VOCAB_SIZE))
-
- @cpu_gpu
- def test_roberta_forward_backward(self, device: str):
- _, model = get_toy_model(device)
- sample = mk_sample("en", device)
- en_tokens = sample["net_input"]["src_tokens"]
- (bs, l) = en_tokens.shape
- # Forward
- logits, _ = model(**sample["net_input"])
- self.assertEqual(logits.shape, (bs, l, VOCAB_SIZE))
-
- # Backward
- loss = logits.sum()
- loss.backward()
-
- @cpu_gpu
- def test_roberta_forward_backward_bs1(self, device: str):
- _, model = get_toy_model(device)
- sample = mk_sample("en", device, batch_size=1)
- o, _ = model.forward(**sample["net_input"])
- loss = o.sum()
- sample2 = mk_sample("ro", device, batch_size=1)
- o, _ = model.forward(**sample2["net_input"])
- loss += o.sum()
- loss.backward()
-
- @cpu_gpu
- def test_roberta_batching(self, device: str):
- """
- Checks that the batch of size 2 give twice the same results than the batch of size 1.
- """
- _, model = get_toy_model(device)
- sample = mk_sample("en", device, batch_size=1)
- slen = sample["net_input"]["src_lengths"][0]
- sample2 = mk_sample("en", device, batch_size=2)
- with torch.no_grad():
- z = model.encoder.forward(
- sample["net_input"]["src_tokens"], sample["net_input"]["src_lengths"]
- )
- z = z["encoder_out"][-1]
- logits, _ = model.forward(**sample["net_input"])
-
- z2 = model.encoder.forward(
- sample2["net_input"]["src_tokens"], sample["net_input"]["src_lengths"]
- )
- z2 = z2["encoder_out"][-1]
- logits2, _ = model.forward(**sample2["net_input"])
-
- self.assertEqual(z.shape, (slen, 1, 12))
- self.assertEqual(z2.shape, (slen, 2, 12))
- self.assertTensorEqual(logits2[0], logits2[1])
- self.assertTensorEqual(logits[0], logits2[0])
-
- @cpu_gpu
- def test_roberta_incremental_decoder(self, device: str):
- """
- Checks that incremental decoding yields the same result than non incremental one.
- """
- task, model = get_toy_model(device)
-
- en_sample = mk_sample("en", device)
- en_tokens = en_sample["net_input"]["src_tokens"]
- ro_sample = mk_sample("ro", device)
- ro_tokens = ro_sample["net_input"]["src_tokens"]
-
- en_enc = model.encoder.forward(
- en_tokens, src_lengths=en_sample["net_input"]["src_lengths"]
- )
- (bs, tgt_len) = ro_tokens.shape
-
- # Decode without incremental state
- ro_dec, _ = model.decoder.forward(ro_tokens, encoder_out=en_enc)
- self.assertEqual(ro_dec.shape, (bs, tgt_len, VOCAB_SIZE))
- self.assertTensorEqual(ro_dec[0], ro_dec[1])
-
- # Decode with incremental state
- inc_state = {}
- ro_dec_inc = []
- for l in range(tgt_len):
- ro, _ = model.decoder.forward(
- ro_tokens[:, : l + 1], encoder_out=en_enc, incremental_state=inc_state
- )
- self.assertEqual(ro.shape, (bs, 1, VOCAB_SIZE))
- ro_dec_inc.append(ro)
-
- for l in range(tgt_len):
- # Intra-batch
- self.assertTensorEqual(ro_dec_inc[l][0], ro_dec_inc[l][1])
- # Incremental vs non-incremental
- self.assertTensorEqual(ro_dec_inc[l][:, 0], ro_dec[:, l])
-
-
-def params(model, name):
- if "." not in name:
- return getattr(model, name)
-
- prefix, name = name.split(".", 1)
- return params(getattr(model, prefix), name)
diff --git a/spaces/OdiaGenAI/Olive_Farm/open_instruct/reformat_data.py b/spaces/OdiaGenAI/Olive_Farm/open_instruct/reformat_data.py
deleted file mode 100644
index c531a08182dcad8318eadfed2d0b7e2cf2306adf..0000000000000000000000000000000000000000
--- a/spaces/OdiaGenAI/Olive_Farm/open_instruct/reformat_data.py
+++ /dev/null
@@ -1,551 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-'''
-This script is used to reformat the downloaded datasets into the format that can be used by the model.
-Here we use jsonl for the converted data. Each line in the jsonl file is a json object formatted as follows:
-{
- "dataset": "dataset_name",
- "id": "unique_id",
- "messages": [
- {"role": "system", "content": "message_text"}, # optional
- {"role": "user", "content": "message_text"},
- {"role": "assistant", "content": "message_text"},
- {"role": "user", "content": "message_text"},
- {"role": "assistant", "content": "message_text"},
- ...
- ],
-}
-'''
-
-import json
-import random
-import re
-import os
-import pandas as pd
-import argparse
-from instruction_encode_templates import encode_instruction_example, encode_few_shot_example
-
-
-def convert_super_ni_data(data_dir, output_dir, zero_shot_examples_per_task=60, few_shot_examples_per_task=20, n_few_shot=2):
- os.makedirs(output_dir, exist_ok=True)
- train_tasks = []
- with open(os.path.join(data_dir, "splits", "xlingual", "train_tasks.txt"), "r") as fin:
- for line in fin:
- if not "_mmmlu_" in line: # skip mmlu to avoid test leakage
- train_tasks.append(line.strip())
- with open(os.path.join(output_dir, "super_ni_data.jsonl"), "w") as fout:
- for task in train_tasks:
- with open(os.path.join(data_dir, "tasks", f"{task}.json"), "r") as fin:
- task_data = json.load(fin)
- instruction = task_data["Definition"][0]
- if zero_shot_examples_per_task + few_shot_examples_per_task < len(task_data["Instances"]):
- instances = random.sample(task_data["Instances"], k=zero_shot_examples_per_task+few_shot_examples_per_task)
- else:
- instances = task_data["Instances"]
- for instance in instances[:zero_shot_examples_per_task]:
- encoded_example = encode_instruction_example(
- instruction=instruction,
- input=instance["input"],
- output=instance["output"][0],
- random_template=True,
- eos_token=None
- )
- fout.write(json.dumps({
- "dataset": "super_ni",
- "id": f"super_ni_{instance['id']}",
- "messages": [
- {"role": "user", "content": encoded_example["prompt"]},
- {"role": "assistant", "content": encoded_example["completion"]},
- ]
- }) + "\n")
- for instance in instances[zero_shot_examples_per_task:]:
- if n_few_shot < len(task_data["Positive Examples"]):
- examplars = random.sample(task_data["Positive Examples"], k=n_few_shot)
- else:
- examplars = task_data["Positive Examples"]
- encoded_example = encode_few_shot_example(
- instruction=instruction,
- examplars=examplars,
- input=instance["input"],
- output=instance["output"][0],
- eos_token=None
- )
- fout.write(json.dumps({
- "dataset": "super_ni",
- "id": f"super_ni_{instance['id']}",
- "messages": [
- {"role": "user", "content": encoded_example["prompt"]},
- {"role": "assistant", "content": encoded_example["completion"]},
- ]
- }) + "\n")
-
-
-def convert_cot_data(data_dir, output_dir, num_zero_shot_examples=50000, num_few_shot_examples=50000):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- if num_few_shot_examples > 0:
- with open(os.path.join(data_dir, "cot_zsopt.jsonl"), "r") as fin:
- zero_shot_examples = [json.loads(line) for line in fin]
- if num_zero_shot_examples < len(zero_shot_examples):
- zero_shot_examples = random.sample(zero_shot_examples, k=num_zero_shot_examples)
- examples.extend(zero_shot_examples)
- if num_few_shot_examples > 0:
- with open(os.path.join(data_dir, "cot_fsopt.jsonl"), "r") as fin:
- few_shot_examples = [json.loads(line) for line in fin]
- if num_few_shot_examples < len(few_shot_examples):
- few_shot_examples = random.sample(few_shot_examples, k=num_few_shot_examples)
- examples.extend(few_shot_examples)
- output_path = os.path.join(output_dir, "cot_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- prompt = example["inputs"]
- if not prompt.endswith("\n") and not prompt.rstrip().endswith(":"):
- prompt += "\n"
- completion = example["targets"]
- fout.write(json.dumps({
- "dataset": "cot",
- "id": f"cot_{idx}",
- "messages": [
- {"role": "user", "content": prompt},
- {"role": "assistant", "content": completion},
- ]
- }) + "\n")
-
-
-def convert_flan_v2_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- with open(os.path.join(data_dir, "flan_v2_resampled_100k.jsonl"), "r") as fin:
- for line in fin:
- examples.append(json.loads(line))
- output_path = os.path.join(output_dir, "flan_v2_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- prompt = example["inputs"]
- if not prompt.endswith("\n") and not prompt.rstrip().endswith(":"):
- prompt += "\n"
- completion = example["targets"]
- fout.write(json.dumps({
- "dataset": "flan_v2",
- "id": f"flan_v2_{idx}",
- "messages": [
- {"role": "user", "content": prompt},
- {"role": "assistant", "content": completion},
- ]
- }) + "\n")
-
-
-def convert_dolly_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- with open(os.path.join(data_dir, "databricks-dolly-15k.jsonl"), "r") as fin:
- for line in fin:
- examples.append(json.loads(line))
- output_path = os.path.join(output_dir, "dolly_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- encoded_example = encode_instruction_example(
- instruction=example["instruction"],
- input=example["context"],
- output=example["response"],
- random_template=True,
- eos_token=None
- )
- fout.write(json.dumps({
- "dataset": "dolly",
- "id": f"dolly_{idx}",
- "messages": [
- {"role": "user", "content": encoded_example["prompt"]},
- {"role": "assistant", "content": encoded_example["completion"]},
- ]
- }) + "\n")
-
-
-def convert_self_instruct_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- with open(os.path.join(data_dir, "all_instances_82K.jsonl"), "r") as fin:
- for line in fin:
- examples.append(json.loads(line))
- output_path = os.path.join(output_dir, "self_instruct_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- encoded_example = encode_instruction_example(
- instruction=example["instruction"],
- input=example["input"],
- output=example["output"],
- random_template=True,
- eos_token=None
- )
- fout.write(json.dumps({
- "dataset": "self_instruct",
- "id": f"self_instruct_{idx}",
- "messages": [
- {"role": "user", "content": encoded_example["prompt"]},
- {"role": "assistant", "content": encoded_example["completion"]},
- ]
- }) + "\n")
-
-
-def convert_unnatural_instructions_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- instance_cnt = 0
- with open(os.path.join(data_dir, "core_data.jsonl"), "r") as fin, open((os.path.join(output_dir, "unnatural_instructions_data.jsonl")), "w") as fout:
- for line in fin:
- task_data = json.loads(line)
- instruction = task_data["instruction"]
- for instance in task_data["instances"]:
- if instance["constraints"] and instance["constraints"].lower() not in ["none", "none."]:
- instance_instruction = instruction + "\n" + instance["constraints"]
- else:
- instance_instruction = instruction
- encoded_example = encode_instruction_example(
- instruction=instance_instruction,
- input=instance["input"],
- output=instance["output"],
- random_template=True,
- eos_token=None
- )
- fout.write(json.dumps({
- "dataset": "unnatural_instructions",
- "id": f"unnatural_instructions_{instance_cnt}",
- "messages": [
- {"role": "user", "content": encoded_example["prompt"]},
- {"role": "assistant", "content": encoded_example["completion"]},
- ]
- }) + "\n")
- instance_cnt += 1
-
-
-def convert_stanford_alpaca_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- with open(os.path.join(data_dir, "alpaca_data.json"), "r") as fin:
- examples.extend(json.load(fin))
- output_path = os.path.join(output_dir, "stanford_alpaca_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- encoded_example = encode_instruction_example(
- instruction=example["instruction"],
- input=example["input"],
- output=example["output"],
- random_template=True,
- eos_token=None
- )
- fout.write(json.dumps({
- "dataset": "stanford_alpaca",
- "id": f"stanford_alpaca_{idx}",
- "messages": [
- {"role": "user", "content": encoded_example["prompt"]},
- {"role": "assistant", "content": encoded_example["completion"]},
- ]
- }) + "\n")
-
-
-def convert_code_alpaca_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- with open(os.path.join(data_dir, "code_alpaca_20k.json"), "r") as fin:
- examples.extend(json.load(fin))
- output_path = os.path.join(output_dir, "code_alpaca_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- encoded_example = encode_instruction_example(
- instruction=example["instruction"],
- input=example["input"],
- output=example["output"],
- random_template=True,
- eos_token=None
- )
- fout.write(json.dumps({
- "dataset": "code_alpaca",
- "id": f"code_alpaca_{idx}",
- "messages": [
- {"role": "user", "content": encoded_example["prompt"]},
- {"role": "assistant", "content": encoded_example["completion"]},
- ]
- }) + "\n")
-
-
-def convert_gpt4_alpaca_data(data_dir, output_dir, load_en=True, load_zh=False):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- if load_en:
- with open(os.path.join(data_dir, "alpaca_gpt4_data.json"), "r") as fin:
- examples.extend(json.load(fin))
- if load_zh:
- with open(os.path.join(data_dir, "alpaca_gpt4_data_zh.json"), "r") as fin:
- examples.extend(json.load(fin))
- output_path = os.path.join(output_dir, "gpt4_alpaca_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- encoded_example = encode_instruction_example(
- instruction=example["instruction"],
- input=example["input"],
- output=example["output"],
- random_template=True,
- eos_token=None
- )
- fout.write(json.dumps({
- "dataset": "gpt4_alpaca",
- "id": f"gpt4_alpaca_{idx}",
- "messages": [
- {"role": "user", "content": encoded_example["prompt"]},
- {"role": "assistant", "content": encoded_example["completion"]},
- ]
- }) + "\n")
-
-
-def convert_sharegpt_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- with open(os.path.join(data_dir, "sharegpt_html_cleaned_and_split.json"), "r") as fin:
- examples.extend(json.load(fin))
-
- output_path = os.path.join(output_dir, "sharegpt_data.jsonl")
- with open(output_path, "w") as fout:
- invalid_cnt = 0
- for idx, example in enumerate(examples):
- messages = []
- valid = True
- for message in example["conversations"]:
- if message["from"] == "human" or message["from"] == "user":
- messages.append({
- "role": "user",
- "content": message["value"]
- })
- elif message["from"] == "gpt" or message["from"] == "chatgpt":
- messages.append({
- "role": "assistant",
- "content": message["value"]
- })
- elif message["from"] == "system":
- valid = False
- invalid_cnt += 1
- break
- elif message["from"] == "bing":
- valid = False
- invalid_cnt += 1
- break
- else:
- raise ValueError(f"Unknown message sender: {message['from']}")
- if messages and valid:
- fout.write(json.dumps({
- "dataset": "sharegpt",
- "id": f"sharegpt_{example['id']}",
- "messages": messages
- }) + "\n")
- print(f"# of invalid examples in sharegpt data: {invalid_cnt}")
-
-
-def convert_baize_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- for source in ["alpaca", "medical", "quora", "stackoverflow"]:
- with open(os.path.join(data_dir, f"{source}_chat_data.json"), "r") as fin:
- examples.extend(json.load(fin))
-
- output_path = os.path.join(output_dir, "baize_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- # split example["input"] by [|Human|] and [|AI|]
- messages = []
- rounds = example["input"].split("[|Human|]")[1:]
- for round in rounds:
- if not round.strip() or "[|AI|]" not in round:
- continue
- human, assistant = round.split("[|AI|]")
- messages.append({
- "role": "user",
- "content": human.strip()
- })
- messages.append({
- "role": "assistant",
- "content": assistant.strip()
- })
- fout.write(json.dumps({
- "dataset": "baize",
- "id": f"baize_{idx}",
- "messages": messages
- }) + "\n")
-
-
-def convert_oasst1_data(data_dir, output_dir):
- '''
- For OASST1, because it's in a tree structure, where every user input might get multiple replies,
- we have to save every path from the root node to the assistant reply (including both leaf node and intemediate node).
- This results in some of the messages being duplicated among different paths (instances).
- Be careful when using this dataset for training. Ideally, you should only minimize the loss of the last message in each path.
- '''
- os.makedirs(output_dir, exist_ok=True)
- conversations = []
- with open(os.path.join(data_dir, "2023-04-12_oasst_ready.trees.jsonl"), "r") as fin:
- for line in fin:
- conversations.append(json.loads(line))
-
- output_path = os.path.join(output_dir, "oasst1_data.jsonl")
-
- # we filter out the sequences that mention the creator information
- filter_strings = [
- "LAION",
- "Open Asssistant",
- "OpenAssistant",
- ]
-
- # tranvers the conversation tree, and collect all valid sequences
- def dfs(reply, messages, valid_sequences):
- if any([filter_string in reply["text"] for filter_string in filter_strings]):
- return
- if reply["role"] == "assistant":
- messages.append(
- {"role": "assistant", "content": reply["text"]}
- )
- if not reply["replies"]: # leaf node
- valid_sequences.append(messages[:])
- else:
- for child in reply["replies"]:
- dfs(child, messages, valid_sequences)
- messages.pop()
- elif reply["role"] == "prompter":
- messages.append(
- {"role": "user", "content": reply["text"]}
- )
- for child in reply["replies"]:
- dfs(child, messages, valid_sequences)
- messages.pop()
- else:
- raise ValueError(f"Unknown role: {reply['role']}")
-
- with open(output_path, "w") as fout:
- example_cnt = 0
- for _, conversation in enumerate(conversations):
- valid_sequences = []
- dfs(conversation["prompt"], [], valid_sequences)
- for sequence in valid_sequences:
- fout.write(json.dumps({
- "dataset": "oasst1",
- "id": f"oasst1_{example_cnt}",
- "messages": sequence
- }) + "\n")
- example_cnt += 1
-
-
-def convert_lima_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- with open(os.path.join(data_dir, "train.jsonl"), "r") as fin:
- for line in fin:
- examples.append(json.loads(line))
- output_path = os.path.join(output_dir, "lima_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- messages = []
- if not len(example["conversations"]) % 2 == 0:
- print(f"Waring: example {idx} in LIMA has odd number of messages. Cutting off the last message.")
- example["conversations"] = example["conversations"][:-1]
-
- for i in range(0, len(example["conversations"]), 2):
- messages.append({
- "role": "user",
- "content": example["conversations"][i]
- })
- messages.append({
- "role": "assistant",
- "content": example["conversations"][i+1]
- })
- fout.write(json.dumps({
- "dataset": "lima",
- "id": f"lima_{idx}",
- "messages": messages,
- }) + "\n")
-
-
-def convert_wizardlm_data(data_dir, output_dir):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
- with open(os.path.join(data_dir, "WizardLM_evol_instruct_V2_143k.json"), "r") as fin:
- examples = json.load(fin)
-
- output_path = os.path.join(output_dir, "wizardlm_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- messages = []
- assert len(example["conversations"]) % 2 == 0
- for i in range(0, len(example["conversations"]), 2):
- assert example["conversations"][i]["from"] == "human"
- assert example["conversations"][i+1]["from"] == "gpt"
- messages.append({
- "role": "user",
- "content": example["conversations"][i]["value"]
- })
- messages.append({
- "role": "assistant",
- "content": example["conversations"][i+1]["value"]
- })
- fout.write(json.dumps({
- "dataset": "wizardlm",
- "id": f"wizardlm_{example['idx']}",
- "messages": messages,
- }) + "\n")
-
-
-def convert_open_orca_data(data_dir, output_dir, num_gpt4_examples=100000, num_gpt35_examples=0):
- os.makedirs(output_dir, exist_ok=True)
- examples = []
-
- df = pd.read_parquet(os.path.join(data_dir, "1M-GPT4-Augmented.parquet"))
- gpt4_examples = [row.to_dict() for _, row in df.iterrows()]
- random.shuffle(gpt4_examples)
- examples.extend(gpt4_examples[:num_gpt4_examples])
-
- df = pd.read_parquet(os.path.join(data_dir, "3_5M-GPT3_5-Augmented.parquet"))
- gpt35_examples = [row.to_dict() for _, row in df.iterrows()]
- random.shuffle(gpt35_examples)
- examples.extend(gpt35_examples[:num_gpt35_examples])
-
- output_path = os.path.join(output_dir, "open_orca_data.jsonl")
- with open(output_path, "w") as fout:
- for idx, example in enumerate(examples):
- messages = [
- {"role": "system", "content": example["system_prompt"]},
- {"role": "user", "content": example["question"]},
- {"role": "assistant", "content": example["response"]}
- ]
- fout.write(json.dumps({
- "dataset": "open_orca",
- "id": f"open_orca_{example['id']}",
- "messages": messages,
- }) + "\n")
-
-
-if __name__ == "__main__":
- arg_parser = argparse.ArgumentParser()
- arg_parser.add_argument("--raw_data_dir", type=str, default="data/downloads")
- arg_parser.add_argument("--output_dir", type=str, default="data/processed")
- arg_parser.add_argument("--seed", type=int, default=42)
- args = arg_parser.parse_args()
- random.seed(args.seed)
-
- # get the subfolder names in raw_data_dir
- subfolders = [f for f in os.listdir(args.raw_data_dir) if os.path.isdir(os.path.join(args.raw_data_dir, f))]
-
- # all supported datasets
- supported_datasets = []
- all_funcs = [func_name for func_name in globals() if callable(globals()[func_name])]
- for func_name in all_funcs:
- if re.match(r"convert_.+_data", func_name):
- supported_datasets.append(func_name[8:-5])
-
- # check if the subfolder names are supported datasets
- valid_subfolders = []
- for subfolder in subfolders:
- if subfolder not in supported_datasets:
- print(f"Warning: {subfolder} in the raw data folder is not a supported dataset. We will skip it.")
- else:
- valid_subfolders.append(subfolder)
-
- # prepare data for each dataset
- statistics = {}
- for subfolder in valid_subfolders:
- print(f"Processing {subfolder} data...")
- globals()[f"convert_{subfolder}_data"](os.path.join(args.raw_data_dir, subfolder), os.path.join(args.output_dir, subfolder))
diff --git a/spaces/Olivier-Truong/faster-whisper-webui-v2/src/whisper/fasterWhisperContainer.py b/spaces/Olivier-Truong/faster-whisper-webui-v2/src/whisper/fasterWhisperContainer.py
deleted file mode 100644
index 5bd640eeba90f7ad2c6a2795ed14e40d30e90c4c..0000000000000000000000000000000000000000
--- a/spaces/Olivier-Truong/faster-whisper-webui-v2/src/whisper/fasterWhisperContainer.py
+++ /dev/null
@@ -1,207 +0,0 @@
-import os
-from typing import List, Union
-
-from faster_whisper import WhisperModel, download_model
-from src.config import ModelConfig, VadInitialPromptMode
-from src.hooks.progressListener import ProgressListener
-from src.languages import get_language_from_name
-from src.modelCache import ModelCache
-from src.prompts.abstractPromptStrategy import AbstractPromptStrategy
-from src.whisper.abstractWhisperContainer import AbstractWhisperCallback, AbstractWhisperContainer
-from src.utils import format_timestamp
-
-class FasterWhisperContainer(AbstractWhisperContainer):
- def __init__(self, model_name: str, device: str = None, compute_type: str = "float16",
- download_root: str = None,
- cache: ModelCache = None, models: List[ModelConfig] = []):
- super().__init__(model_name, device, compute_type, download_root, cache, models)
-
- def ensure_downloaded(self):
- """
- Ensure that the model is downloaded. This is useful if you want to ensure that the model is downloaded before
- passing the container to a subprocess.
- """
- model_config = self._get_model_config()
-
- if os.path.isdir(model_config.url):
- model_config.path = model_config.url
- else:
- model_config.path = download_model(model_config.url, output_dir=self.download_root)
-
- def _get_model_config(self) -> ModelConfig:
- """
- Get the model configuration for the model.
- """
- for model in self.models:
- if model.name == self.model_name:
- return model
- return None
-
- def _create_model(self):
- print("Loading faster whisper model " + self.model_name + " for device " + str(self.device))
- model_config = self._get_model_config()
- model_url = model_config.url
-
- if model_config.type == "whisper":
- if model_url not in ["tiny", "base", "small", "medium", "large", "large-v1", "large-v2"]:
- raise Exception("FasterWhisperContainer does not yet support Whisper models. Use ct2-transformers-converter to convert the model to a faster-whisper model.")
- if model_url == "large":
- # large is an alias for large-v1
- model_url = "large-v1"
-
- device = self.device
-
- if (device is None):
- device = "auto"
-
- model = WhisperModel(model_url, device=device, compute_type=self.compute_type)
- return model
-
- def create_callback(self, language: str = None, task: str = None,
- prompt_strategy: AbstractPromptStrategy = None,
- **decodeOptions: dict) -> AbstractWhisperCallback:
- """
- Create a WhisperCallback object that can be used to transcript audio files.
-
- Parameters
- ----------
- language: str
- The target language of the transcription. If not specified, the language will be inferred from the audio content.
- task: str
- The task - either translate or transcribe.
- prompt_strategy: AbstractPromptStrategy
- The prompt strategy to use. If not specified, the prompt from Whisper will be used.
- decodeOptions: dict
- Additional options to pass to the decoder. Must be pickleable.
-
- Returns
- -------
- A WhisperCallback object.
- """
- return FasterWhisperCallback(self, language=language, task=task, prompt_strategy=prompt_strategy, **decodeOptions)
-
-class FasterWhisperCallback(AbstractWhisperCallback):
- def __init__(self, model_container: FasterWhisperContainer, language: str = None, task: str = None,
- prompt_strategy: AbstractPromptStrategy = None,
- **decodeOptions: dict):
- self.model_container = model_container
- self.language = language
- self.task = task
- self.prompt_strategy = prompt_strategy
- self.decodeOptions = decodeOptions
-
- self._printed_warning = False
-
- def invoke(self, audio, segment_index: int, prompt: str, detected_language: str, progress_listener: ProgressListener = None):
- """
- Peform the transcription of the given audio file or data.
-
- Parameters
- ----------
- audio: Union[str, np.ndarray, torch.Tensor]
- The audio file to transcribe, or the audio data as a numpy array or torch tensor.
- segment_index: int
- The target language of the transcription. If not specified, the language will be inferred from the audio content.
- task: str
- The task - either translate or transcribe.
- progress_listener: ProgressListener
- A callback to receive progress updates.
- """
- model: WhisperModel = self.model_container.get_model()
- language_code = self._lookup_language_code(self.language) if self.language else None
-
- # Copy decode options and remove options that are not supported by faster-whisper
- decodeOptions = self.decodeOptions.copy()
- verbose = decodeOptions.pop("verbose", None)
-
- logprob_threshold = decodeOptions.pop("logprob_threshold", None)
-
- patience = decodeOptions.pop("patience", None)
- length_penalty = decodeOptions.pop("length_penalty", None)
- suppress_tokens = decodeOptions.pop("suppress_tokens", None)
-
- if (decodeOptions.pop("fp16", None) is not None):
- if not self._printed_warning:
- print("WARNING: fp16 option is ignored by faster-whisper - use compute_type instead.")
- self._printed_warning = True
-
- # Fix up decode options
- if (logprob_threshold is not None):
- decodeOptions["log_prob_threshold"] = logprob_threshold
-
- decodeOptions["patience"] = float(patience) if patience is not None else 1.0
- decodeOptions["length_penalty"] = float(length_penalty) if length_penalty is not None else 1.0
-
- # See if supress_tokens is a string - if so, convert it to a list of ints
- decodeOptions["suppress_tokens"] = self._split_suppress_tokens(suppress_tokens)
-
- initial_prompt = self.prompt_strategy.get_segment_prompt(segment_index, prompt, detected_language) \
- if self.prompt_strategy else prompt
-
- segments_generator, info = model.transcribe(audio, \
- language=language_code if language_code else detected_language, task=self.task, \
- initial_prompt=initial_prompt, \
- **decodeOptions
- )
-
- segments = []
-
- for segment in segments_generator:
- segments.append(segment)
-
- if progress_listener is not None:
- progress_listener.on_progress(segment.end, info.duration)
- if verbose:
- print("[{}->{}] {}".format(format_timestamp(segment.start, True), format_timestamp(segment.end, True),
- segment.text))
-
- text = " ".join([segment.text for segment in segments])
-
- # Convert the segments to a format that is easier to serialize
- whisper_segments = [{
- "text": segment.text,
- "start": segment.start,
- "end": segment.end,
-
- # Extra fields added by faster-whisper
- "words": [{
- "start": word.start,
- "end": word.end,
- "word": word.word,
- "probability": word.probability
- } for word in (segment.words if segment.words is not None else []) ]
- } for segment in segments]
-
- result = {
- "segments": whisper_segments,
- "text": text,
- "language": info.language if info else None,
-
- # Extra fields added by faster-whisper
- "language_probability": info.language_probability if info else None,
- "duration": info.duration if info else None
- }
-
- # If we have a prompt strategy, we need to increment the current prompt
- if self.prompt_strategy:
- self.prompt_strategy.on_segment_finished(segment_index, prompt, detected_language, result)
-
- if progress_listener is not None:
- progress_listener.on_finished()
- return result
-
- def _split_suppress_tokens(self, suppress_tokens: Union[str, List[int]]):
- if (suppress_tokens is None):
- return None
- if (isinstance(suppress_tokens, list)):
- return suppress_tokens
-
- return [int(token) for token in suppress_tokens.split(",")]
-
- def _lookup_language_code(self, language: str):
- language = get_language_from_name(language)
-
- if language is None:
- raise ValueError("Invalid language: " + language)
-
- return language.code
diff --git a/spaces/Omnibus/MusicGen/audiocraft/__init__.py b/spaces/Omnibus/MusicGen/audiocraft/__init__.py
deleted file mode 100644
index 6b8594f470200ff5c000542ef115375ed69b749c..0000000000000000000000000000000000000000
--- a/spaces/Omnibus/MusicGen/audiocraft/__init__.py
+++ /dev/null
@@ -1,10 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-# flake8: noqa
-from . import data, modules, models
-
-__version__ = '0.0.2a2'
diff --git a/spaces/OpenDILabCommunity/DI-sheep/DI-sheep/service/sheep_model.py b/spaces/OpenDILabCommunity/DI-sheep/DI-sheep/service/sheep_model.py
deleted file mode 100644
index bbf29ba438d74245eb602bdfe2e43218af63397d..0000000000000000000000000000000000000000
--- a/spaces/OpenDILabCommunity/DI-sheep/DI-sheep/service/sheep_model.py
+++ /dev/null
@@ -1,126 +0,0 @@
-import torch
-import torch.nn as nn
-import treetensor.torch as ttorch
-from ding.torch_utils import Transformer, MLP, unsqueeze, to_tensor
-
-
-class ItemEncoder(nn.Module):
- encoder_type = ['TF', 'MLP', 'two_stage_MLP']
-
- def __init__(self, item_obs_size=60, item_num=30, item_encoder_type='TF', hidden_size=64, activation=nn.ReLU()):
- super(ItemEncoder, self).__init__()
- assert item_encoder_type in self.encoder_type, "not support item encoder type: {}/{}".format(item_encoder_type, self.encoder_type)
- self.item_encoder_type = item_encoder_type
- self.item_num = item_num
- self.hidden_size = hidden_size
-
- if self.item_encoder_type == 'TF':
- self.encoder = Transformer(
- item_obs_size,
- hidden_dim=2 * hidden_size,
- output_dim=hidden_size,
- activation=activation
- )
- elif self.item_encoder_type == 'MLP':
- self.encoder = MLP(
- item_obs_size,
- hidden_size,
- hidden_size,
- layer_num=3,
- activation=activation
- )
- elif self.item_encoder_type == 'two_stage_MLP':
- self.trans_len = 16
- self.encoder_1 = MLP(
- item_obs_size,
- hidden_size,
- self.trans_len,
- layer_num=3,
- activation=activation
- )
- self.encoder_2 = MLP(
- self.trans_len*self.item_num,
- hidden_size,
- self.item_num*hidden_size,
- layer_num=2,
- activation=activation
- )
-
- def forward(self, item_obs):
- if self.item_encoder_type == 'two_stage_MLP':
- item_embedding_1 = self.encoder_1(item_obs) # (B, M, L)
- item_embedding_2 = torch.reshape(item_embedding_1, [-1, self.trans_len*self.item_num])
- item_embedding = self.encoder_2(item_embedding_2)
- item_embedding = torch.reshape(item_embedding, [-1, self.item_num, self.hidden_size])
- else:
- item_embedding = self.encoder(item_obs)
- return item_embedding
-
-
-class SheepModel(nn.Module):
- mode = ['compute_actor', 'compute_critic', 'compute_actor_critic']
-
- def __init__(self, item_obs_size=60, item_num=30, item_encoder_type='TF', bucket_obs_size=30, global_obs_size=17, hidden_size=64, activation=nn.ReLU(), ttorch_return=False):
- super(SheepModel, self).__init__()
- self.item_encoder = ItemEncoder(item_obs_size, item_num, item_encoder_type, hidden_size, activation=activation)
- self.bucket_encoder = MLP(bucket_obs_size, hidden_size, hidden_size, layer_num=3, activation=activation)
- self.global_encoder = MLP(global_obs_size, hidden_size, hidden_size, layer_num=2, activation=activation)
- self.value_head = nn.Sequential(
- MLP(hidden_size, hidden_size, hidden_size, layer_num=2, activation=activation), nn.Linear(hidden_size, 1)
- )
- self.ttorch_return = ttorch_return
-
- def compute_actor(self, x):
- item_embedding = self.item_encoder(x['item_obs'])
- bucket_embedding = self.bucket_encoder(x['bucket_obs'])
- global_embedding = self.global_encoder(x['global_obs'])
-
- key = item_embedding
- query = bucket_embedding + global_embedding
- query = query.unsqueeze(1)
- logit = (key * query).sum(2)
- logit.masked_fill_(~x['action_mask'].bool(), value=-1e9)
- if self.ttorch_return:
- return logit
- else:
- return {'logit': logit}
-
- def compute_critic(self, x):
- item_embedding = self.item_encoder(x['item_obs'])
- bucket_embedding = self.bucket_encoder(x['bucket_obs'])
- global_embedding = self.global_encoder(x['global_obs'])
-
- embedding = item_embedding.mean(1) + bucket_embedding + global_embedding
- value = self.value_head(embedding)
- if self.ttorch_return:
- return value.squeeze(1)
- else:
- return {'value': value.squeeze(1)}
-
- def compute_actor_critic(self, x):
- item_embedding = self.item_encoder(x['item_obs'])
- bucket_embedding = self.bucket_encoder(x['bucket_obs'])
- global_embedding = self.global_encoder(x['global_obs'])
-
- key = item_embedding
- query = bucket_embedding + global_embedding
- query = query.unsqueeze(1)
- logit = (key * query).sum(2)
- logit.masked_fill_(~x['action_mask'].bool(), value=-1e9)
-
- embedding = item_embedding.mean(1) + bucket_embedding + global_embedding
- value = self.value_head(embedding)
- if self.ttorch_return:
- return ttorch.as_tensor({'logit': logit, 'value': value.squeeze(1)})
- else:
- return {'logit': logit, 'value': value.squeeze(1)}
-
- def forward(self, x, mode):
- assert mode in self.mode, "not support forward mode: {}/{}".format(mode, self.mode)
- return getattr(self, mode)(x)
-
- def compute_action(self, x):
- x = unsqueeze(to_tensor(x))
- with torch.no_grad():
- logit = self.compute_actor(x)['logit']
- return logit.argmax(dim=-1)[0].item()
diff --git a/spaces/PAIR/PAIR-Diffusion/annotator/OneFormer/oneformer/modeling/pixel_decoder/ops/modules/ms_deform_attn.py b/spaces/PAIR/PAIR-Diffusion/annotator/OneFormer/oneformer/modeling/pixel_decoder/ops/modules/ms_deform_attn.py
deleted file mode 100644
index 6ba6422f134b5ad547019b536f37ec345b0cc59c..0000000000000000000000000000000000000000
--- a/spaces/PAIR/PAIR-Diffusion/annotator/OneFormer/oneformer/modeling/pixel_decoder/ops/modules/ms_deform_attn.py
+++ /dev/null
@@ -1,126 +0,0 @@
-# ------------------------------------------------------------------------------------------------
-# Deformable DETR
-# Copyright (c) 2020 SenseTime. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------------------------------
-# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
-# ------------------------------------------------------------------------------------------------
-
-# Copyright (c) Facebook, Inc. and its affiliates.
-# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
-
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import division
-
-import warnings
-import math
-
-import torch
-from torch import nn
-import torch.nn.functional as F
-from torch.nn.init import xavier_uniform_, constant_
-
-if torch.cuda.is_available():
- from ..functions import MSDeformAttnFunction
-else:
- MSDeformAttnFunction = None
-from ..functions.ms_deform_attn_func import ms_deform_attn_core_pytorch
-
-
-def _is_power_of_2(n):
- if (not isinstance(n, int)) or (n < 0):
- raise ValueError("invalid input for _is_power_of_2: {} (type: {})".format(n, type(n)))
- return (n & (n-1) == 0) and n != 0
-
-
-class MSDeformAttn(nn.Module):
- def __init__(self, d_model=256, n_levels=4, n_heads=8, n_points=4):
- """
- Multi-Scale Deformable Attention Module
- :param d_model hidden dimension
- :param n_levels number of feature levels
- :param n_heads number of attention heads
- :param n_points number of sampling points per attention head per feature level
- """
- super().__init__()
- if d_model % n_heads != 0:
- raise ValueError('d_model must be divisible by n_heads, but got {} and {}'.format(d_model, n_heads))
- _d_per_head = d_model // n_heads
- # you'd better set _d_per_head to a power of 2 which is more efficient in our CUDA implementation
- if not _is_power_of_2(_d_per_head):
- warnings.warn("You'd better set d_model in MSDeformAttn to make the dimension of each attention head a power of 2 "
- "which is more efficient in our CUDA implementation.")
-
- self.im2col_step = 128
-
- self.d_model = d_model
- self.n_levels = n_levels
- self.n_heads = n_heads
- self.n_points = n_points
-
- self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
- self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points)
- self.value_proj = nn.Linear(d_model, d_model)
- self.output_proj = nn.Linear(d_model, d_model)
-
- self._reset_parameters()
-
- def _reset_parameters(self):
- constant_(self.sampling_offsets.weight.data, 0.)
- thetas = torch.arange(self.n_heads, dtype=torch.float32) * (2.0 * math.pi / self.n_heads)
- grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
- grid_init = (grid_init / grid_init.abs().max(-1, keepdim=True)[0]).view(self.n_heads, 1, 1, 2).repeat(1, self.n_levels, self.n_points, 1)
- for i in range(self.n_points):
- grid_init[:, :, i, :] *= i + 1
- with torch.no_grad():
- self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
- constant_(self.attention_weights.weight.data, 0.)
- constant_(self.attention_weights.bias.data, 0.)
- xavier_uniform_(self.value_proj.weight.data)
- constant_(self.value_proj.bias.data, 0.)
- xavier_uniform_(self.output_proj.weight.data)
- constant_(self.output_proj.bias.data, 0.)
-
- def forward(self, query, reference_points, input_flatten, input_spatial_shapes, input_level_start_index, input_padding_mask=None):
- """
- :param query (N, Length_{query}, C)
- :param reference_points (N, Length_{query}, n_levels, 2), range in [0, 1], top-left (0,0), bottom-right (1, 1), including padding area
- or (N, Length_{query}, n_levels, 4), add additional (w, h) to form reference boxes
- :param input_flatten (N, \sum_{l=0}^{L-1} H_l \cdot W_l, C)
- :param input_spatial_shapes (n_levels, 2), [(H_0, W_0), (H_1, W_1), ..., (H_{L-1}, W_{L-1})]
- :param input_level_start_index (n_levels, ), [0, H_0*W_0, H_0*W_0+H_1*W_1, H_0*W_0+H_1*W_1+H_2*W_2, ..., H_0*W_0+H_1*W_1+...+H_{L-1}*W_{L-1}]
- :param input_padding_mask (N, \sum_{l=0}^{L-1} H_l \cdot W_l), True for padding elements, False for non-padding elements
-
- :return output (N, Length_{query}, C)
- """
- N, Len_q, _ = query.shape
- N, Len_in, _ = input_flatten.shape
- assert (input_spatial_shapes[:, 0] * input_spatial_shapes[:, 1]).sum() == Len_in
-
- value = self.value_proj(input_flatten)
- if input_padding_mask is not None:
- value = value.masked_fill(input_padding_mask[..., None], float(0))
- value = value.view(N, Len_in, self.n_heads, self.d_model // self.n_heads)
- sampling_offsets = self.sampling_offsets(query).view(N, Len_q, self.n_heads, self.n_levels, self.n_points, 2)
- attention_weights = self.attention_weights(query).view(N, Len_q, self.n_heads, self.n_levels * self.n_points)
- attention_weights = F.softmax(attention_weights, -1).view(N, Len_q, self.n_heads, self.n_levels, self.n_points)
- # N, Len_q, n_heads, n_levels, n_points, 2
- if reference_points.shape[-1] == 2:
- offset_normalizer = torch.stack([input_spatial_shapes[..., 1], input_spatial_shapes[..., 0]], -1)
- sampling_locations = reference_points[:, :, None, :, None, :] \
- + sampling_offsets / offset_normalizer[None, None, None, :, None, :]
- elif reference_points.shape[-1] == 4:
- sampling_locations = reference_points[:, :, None, :, None, :2] \
- + sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
- else:
- raise ValueError(
- 'Last dim of reference_points must be 2 or 4, but get {} instead.'.format(reference_points.shape[-1]))
- if torch.cuda.is_available():
- output = MSDeformAttnFunction.apply(
- value, input_spatial_shapes, input_level_start_index, sampling_locations, attention_weights, self.im2col_step)
- else:
- ## CPU
- output = ms_deform_attn_core_pytorch(value, input_spatial_shapes, sampling_locations, attention_weights)
- output = self.output_proj(output)
- return output
diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/configs/_base_/datasets/pascal_voc12.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/configs/_base_/datasets/pascal_voc12.py
deleted file mode 100644
index ba1d42d0c5781f56dc177d860d856bb34adce555..0000000000000000000000000000000000000000
--- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/configs/_base_/datasets/pascal_voc12.py
+++ /dev/null
@@ -1,57 +0,0 @@
-# dataset settings
-dataset_type = 'PascalVOCDataset'
-data_root = 'data/VOCdevkit/VOC2012'
-img_norm_cfg = dict(
- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
-crop_size = (512, 512)
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadAnnotations'),
- dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
- dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
- dict(type='RandomFlip', prob=0.5),
- dict(type='PhotoMetricDistortion'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
- dict(type='DefaultFormatBundle'),
- dict(type='Collect', keys=['img', 'gt_semantic_seg']),
-]
-test_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(
- type='MultiScaleFlipAug',
- img_scale=(2048, 512),
- # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='RandomFlip'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='Collect', keys=['img']),
- ])
-]
-data = dict(
- samples_per_gpu=4,
- workers_per_gpu=4,
- train=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='JPEGImages',
- ann_dir='SegmentationClass',
- split='ImageSets/Segmentation/train.txt',
- pipeline=train_pipeline),
- val=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='JPEGImages',
- ann_dir='SegmentationClass',
- split='ImageSets/Segmentation/val.txt',
- pipeline=test_pipeline),
- test=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='JPEGImages',
- ann_dir='SegmentationClass',
- split='ImageSets/Segmentation/val.txt',
- pipeline=test_pipeline))
diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/backbones/resnet.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/backbones/resnet.py
deleted file mode 100644
index 4e52bf048d28ecb069db4728e5f05ad85ac53198..0000000000000000000000000000000000000000
--- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/backbones/resnet.py
+++ /dev/null
@@ -1,688 +0,0 @@
-import torch.nn as nn
-import torch.utils.checkpoint as cp
-from annotator.uniformer.mmcv.cnn import (build_conv_layer, build_norm_layer, build_plugin_layer,
- constant_init, kaiming_init)
-from annotator.uniformer.mmcv.runner import load_checkpoint
-from annotator.uniformer.mmcv.utils.parrots_wrapper import _BatchNorm
-
-from annotator.uniformer.mmseg.utils import get_root_logger
-from ..builder import BACKBONES
-from ..utils import ResLayer
-
-
-class BasicBlock(nn.Module):
- """Basic block for ResNet."""
-
- expansion = 1
-
- def __init__(self,
- inplanes,
- planes,
- stride=1,
- dilation=1,
- downsample=None,
- style='pytorch',
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- dcn=None,
- plugins=None):
- super(BasicBlock, self).__init__()
- assert dcn is None, 'Not implemented yet.'
- assert plugins is None, 'Not implemented yet.'
-
- self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
-
- self.conv1 = build_conv_layer(
- conv_cfg,
- inplanes,
- planes,
- 3,
- stride=stride,
- padding=dilation,
- dilation=dilation,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- self.conv2 = build_conv_layer(
- conv_cfg, planes, planes, 3, padding=1, bias=False)
- self.add_module(self.norm2_name, norm2)
-
- self.relu = nn.ReLU(inplace=True)
- self.downsample = downsample
- self.stride = stride
- self.dilation = dilation
- self.with_cp = with_cp
-
- @property
- def norm1(self):
- """nn.Module: normalization layer after the first convolution layer"""
- return getattr(self, self.norm1_name)
-
- @property
- def norm2(self):
- """nn.Module: normalization layer after the second convolution layer"""
- return getattr(self, self.norm2_name)
-
- def forward(self, x):
- """Forward function."""
-
- def _inner_forward(x):
- identity = x
-
- out = self.conv1(x)
- out = self.norm1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.norm2(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-class Bottleneck(nn.Module):
- """Bottleneck block for ResNet.
-
- If style is "pytorch", the stride-two layer is the 3x3 conv layer, if it is
- "caffe", the stride-two layer is the first 1x1 conv layer.
- """
-
- expansion = 4
-
- def __init__(self,
- inplanes,
- planes,
- stride=1,
- dilation=1,
- downsample=None,
- style='pytorch',
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- dcn=None,
- plugins=None):
- super(Bottleneck, self).__init__()
- assert style in ['pytorch', 'caffe']
- assert dcn is None or isinstance(dcn, dict)
- assert plugins is None or isinstance(plugins, list)
- if plugins is not None:
- allowed_position = ['after_conv1', 'after_conv2', 'after_conv3']
- assert all(p['position'] in allowed_position for p in plugins)
-
- self.inplanes = inplanes
- self.planes = planes
- self.stride = stride
- self.dilation = dilation
- self.style = style
- self.with_cp = with_cp
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.dcn = dcn
- self.with_dcn = dcn is not None
- self.plugins = plugins
- self.with_plugins = plugins is not None
-
- if self.with_plugins:
- # collect plugins for conv1/conv2/conv3
- self.after_conv1_plugins = [
- plugin['cfg'] for plugin in plugins
- if plugin['position'] == 'after_conv1'
- ]
- self.after_conv2_plugins = [
- plugin['cfg'] for plugin in plugins
- if plugin['position'] == 'after_conv2'
- ]
- self.after_conv3_plugins = [
- plugin['cfg'] for plugin in plugins
- if plugin['position'] == 'after_conv3'
- ]
-
- if self.style == 'pytorch':
- self.conv1_stride = 1
- self.conv2_stride = stride
- else:
- self.conv1_stride = stride
- self.conv2_stride = 1
-
- self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
- self.norm3_name, norm3 = build_norm_layer(
- norm_cfg, planes * self.expansion, postfix=3)
-
- self.conv1 = build_conv_layer(
- conv_cfg,
- inplanes,
- planes,
- kernel_size=1,
- stride=self.conv1_stride,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- fallback_on_stride = False
- if self.with_dcn:
- fallback_on_stride = dcn.pop('fallback_on_stride', False)
- if not self.with_dcn or fallback_on_stride:
- self.conv2 = build_conv_layer(
- conv_cfg,
- planes,
- planes,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=dilation,
- dilation=dilation,
- bias=False)
- else:
- assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
- self.conv2 = build_conv_layer(
- dcn,
- planes,
- planes,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=dilation,
- dilation=dilation,
- bias=False)
-
- self.add_module(self.norm2_name, norm2)
- self.conv3 = build_conv_layer(
- conv_cfg,
- planes,
- planes * self.expansion,
- kernel_size=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
- self.relu = nn.ReLU(inplace=True)
- self.downsample = downsample
-
- if self.with_plugins:
- self.after_conv1_plugin_names = self.make_block_plugins(
- planes, self.after_conv1_plugins)
- self.after_conv2_plugin_names = self.make_block_plugins(
- planes, self.after_conv2_plugins)
- self.after_conv3_plugin_names = self.make_block_plugins(
- planes * self.expansion, self.after_conv3_plugins)
-
- def make_block_plugins(self, in_channels, plugins):
- """make plugins for block.
-
- Args:
- in_channels (int): Input channels of plugin.
- plugins (list[dict]): List of plugins cfg to build.
-
- Returns:
- list[str]: List of the names of plugin.
- """
- assert isinstance(plugins, list)
- plugin_names = []
- for plugin in plugins:
- plugin = plugin.copy()
- name, layer = build_plugin_layer(
- plugin,
- in_channels=in_channels,
- postfix=plugin.pop('postfix', ''))
- assert not hasattr(self, name), f'duplicate plugin {name}'
- self.add_module(name, layer)
- plugin_names.append(name)
- return plugin_names
-
- def forward_plugin(self, x, plugin_names):
- """Forward function for plugins."""
- out = x
- for name in plugin_names:
- out = getattr(self, name)(x)
- return out
-
- @property
- def norm1(self):
- """nn.Module: normalization layer after the first convolution layer"""
- return getattr(self, self.norm1_name)
-
- @property
- def norm2(self):
- """nn.Module: normalization layer after the second convolution layer"""
- return getattr(self, self.norm2_name)
-
- @property
- def norm3(self):
- """nn.Module: normalization layer after the third convolution layer"""
- return getattr(self, self.norm3_name)
-
- def forward(self, x):
- """Forward function."""
-
- def _inner_forward(x):
- identity = x
-
- out = self.conv1(x)
- out = self.norm1(out)
- out = self.relu(out)
-
- if self.with_plugins:
- out = self.forward_plugin(out, self.after_conv1_plugin_names)
-
- out = self.conv2(out)
- out = self.norm2(out)
- out = self.relu(out)
-
- if self.with_plugins:
- out = self.forward_plugin(out, self.after_conv2_plugin_names)
-
- out = self.conv3(out)
- out = self.norm3(out)
-
- if self.with_plugins:
- out = self.forward_plugin(out, self.after_conv3_plugin_names)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-@BACKBONES.register_module()
-class ResNet(nn.Module):
- """ResNet backbone.
-
- Args:
- depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
- in_channels (int): Number of input image channels. Default" 3.
- stem_channels (int): Number of stem channels. Default: 64.
- base_channels (int): Number of base channels of res layer. Default: 64.
- num_stages (int): Resnet stages, normally 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- dilations (Sequence[int]): Dilation of each stage.
- out_indices (Sequence[int]): Output from which stages.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottleneck.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only.
- plugins (list[dict]): List of plugins for stages, each dict contains:
-
- - cfg (dict, required): Cfg dict to build plugin.
-
- - position (str, required): Position inside block to insert plugin,
- options: 'after_conv1', 'after_conv2', 'after_conv3'.
-
- - stages (tuple[bool], optional): Stages to apply plugin, length
- should be same as 'num_stages'
- multi_grid (Sequence[int]|None): Multi grid dilation rates of last
- stage. Default: None
- contract_dilation (bool): Whether contract first dilation of each layer
- Default: False
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity.
-
- Example:
- >>> from annotator.uniformer.mmseg.models import ResNet
- >>> import torch
- >>> self = ResNet(depth=18)
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 64, 8, 8)
- (1, 128, 4, 4)
- (1, 256, 2, 2)
- (1, 512, 1, 1)
- """
-
- arch_settings = {
- 18: (BasicBlock, (2, 2, 2, 2)),
- 34: (BasicBlock, (3, 4, 6, 3)),
- 50: (Bottleneck, (3, 4, 6, 3)),
- 101: (Bottleneck, (3, 4, 23, 3)),
- 152: (Bottleneck, (3, 8, 36, 3))
- }
-
- def __init__(self,
- depth,
- in_channels=3,
- stem_channels=64,
- base_channels=64,
- num_stages=4,
- strides=(1, 2, 2, 2),
- dilations=(1, 1, 1, 1),
- out_indices=(0, 1, 2, 3),
- style='pytorch',
- deep_stem=False,
- avg_down=False,
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=False,
- dcn=None,
- stage_with_dcn=(False, False, False, False),
- plugins=None,
- multi_grid=None,
- contract_dilation=False,
- with_cp=False,
- zero_init_residual=True):
- super(ResNet, self).__init__()
- if depth not in self.arch_settings:
- raise KeyError(f'invalid depth {depth} for resnet')
- self.depth = depth
- self.stem_channels = stem_channels
- self.base_channels = base_channels
- self.num_stages = num_stages
- assert num_stages >= 1 and num_stages <= 4
- self.strides = strides
- self.dilations = dilations
- assert len(strides) == len(dilations) == num_stages
- self.out_indices = out_indices
- assert max(out_indices) < num_stages
- self.style = style
- self.deep_stem = deep_stem
- self.avg_down = avg_down
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.with_cp = with_cp
- self.norm_eval = norm_eval
- self.dcn = dcn
- self.stage_with_dcn = stage_with_dcn
- if dcn is not None:
- assert len(stage_with_dcn) == num_stages
- self.plugins = plugins
- self.multi_grid = multi_grid
- self.contract_dilation = contract_dilation
- self.zero_init_residual = zero_init_residual
- self.block, stage_blocks = self.arch_settings[depth]
- self.stage_blocks = stage_blocks[:num_stages]
- self.inplanes = stem_channels
-
- self._make_stem_layer(in_channels, stem_channels)
-
- self.res_layers = []
- for i, num_blocks in enumerate(self.stage_blocks):
- stride = strides[i]
- dilation = dilations[i]
- dcn = self.dcn if self.stage_with_dcn[i] else None
- if plugins is not None:
- stage_plugins = self.make_stage_plugins(plugins, i)
- else:
- stage_plugins = None
- # multi grid is applied to last layer only
- stage_multi_grid = multi_grid if i == len(
- self.stage_blocks) - 1 else None
- planes = base_channels * 2**i
- res_layer = self.make_res_layer(
- block=self.block,
- inplanes=self.inplanes,
- planes=planes,
- num_blocks=num_blocks,
- stride=stride,
- dilation=dilation,
- style=self.style,
- avg_down=self.avg_down,
- with_cp=with_cp,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- dcn=dcn,
- plugins=stage_plugins,
- multi_grid=stage_multi_grid,
- contract_dilation=contract_dilation)
- self.inplanes = planes * self.block.expansion
- layer_name = f'layer{i+1}'
- self.add_module(layer_name, res_layer)
- self.res_layers.append(layer_name)
-
- self._freeze_stages()
-
- self.feat_dim = self.block.expansion * base_channels * 2**(
- len(self.stage_blocks) - 1)
-
- def make_stage_plugins(self, plugins, stage_idx):
- """make plugins for ResNet 'stage_idx'th stage .
-
- Currently we support to insert 'context_block',
- 'empirical_attention_block', 'nonlocal_block' into the backbone like
- ResNet/ResNeXt. They could be inserted after conv1/conv2/conv3 of
- Bottleneck.
-
- An example of plugins format could be :
- >>> plugins=[
- ... dict(cfg=dict(type='xxx', arg1='xxx'),
- ... stages=(False, True, True, True),
- ... position='after_conv2'),
- ... dict(cfg=dict(type='yyy'),
- ... stages=(True, True, True, True),
- ... position='after_conv3'),
- ... dict(cfg=dict(type='zzz', postfix='1'),
- ... stages=(True, True, True, True),
- ... position='after_conv3'),
- ... dict(cfg=dict(type='zzz', postfix='2'),
- ... stages=(True, True, True, True),
- ... position='after_conv3')
- ... ]
- >>> self = ResNet(depth=18)
- >>> stage_plugins = self.make_stage_plugins(plugins, 0)
- >>> assert len(stage_plugins) == 3
-
- Suppose 'stage_idx=0', the structure of blocks in the stage would be:
- conv1-> conv2->conv3->yyy->zzz1->zzz2
- Suppose 'stage_idx=1', the structure of blocks in the stage would be:
- conv1-> conv2->xxx->conv3->yyy->zzz1->zzz2
-
- If stages is missing, the plugin would be applied to all stages.
-
- Args:
- plugins (list[dict]): List of plugins cfg to build. The postfix is
- required if multiple same type plugins are inserted.
- stage_idx (int): Index of stage to build
-
- Returns:
- list[dict]: Plugins for current stage
- """
- stage_plugins = []
- for plugin in plugins:
- plugin = plugin.copy()
- stages = plugin.pop('stages', None)
- assert stages is None or len(stages) == self.num_stages
- # whether to insert plugin into current stage
- if stages is None or stages[stage_idx]:
- stage_plugins.append(plugin)
-
- return stage_plugins
-
- def make_res_layer(self, **kwargs):
- """Pack all blocks in a stage into a ``ResLayer``."""
- return ResLayer(**kwargs)
-
- @property
- def norm1(self):
- """nn.Module: the normalization layer named "norm1" """
- return getattr(self, self.norm1_name)
-
- def _make_stem_layer(self, in_channels, stem_channels):
- """Make stem layer for ResNet."""
- if self.deep_stem:
- self.stem = nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels,
- stem_channels // 2,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
- nn.ReLU(inplace=True),
- build_conv_layer(
- self.conv_cfg,
- stem_channels // 2,
- stem_channels // 2,
- kernel_size=3,
- stride=1,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
- nn.ReLU(inplace=True),
- build_conv_layer(
- self.conv_cfg,
- stem_channels // 2,
- stem_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg, stem_channels)[1],
- nn.ReLU(inplace=True))
- else:
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- stem_channels,
- kernel_size=7,
- stride=2,
- padding=3,
- bias=False)
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, stem_channels, postfix=1)
- self.add_module(self.norm1_name, norm1)
- self.relu = nn.ReLU(inplace=True)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
-
- def _freeze_stages(self):
- """Freeze stages param and norm stats."""
- if self.frozen_stages >= 0:
- if self.deep_stem:
- self.stem.eval()
- for param in self.stem.parameters():
- param.requires_grad = False
- else:
- self.norm1.eval()
- for m in [self.conv1, self.norm1]:
- for param in m.parameters():
- param.requires_grad = False
-
- for i in range(1, self.frozen_stages + 1):
- m = getattr(self, f'layer{i}')
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- def init_weights(self, pretrained=None):
- """Initialize the weights in backbone.
-
- Args:
- pretrained (str, optional): Path to pre-trained weights.
- Defaults to None.
- """
- if isinstance(pretrained, str):
- logger = get_root_logger()
- load_checkpoint(self, pretrained, strict=False, logger=logger)
- elif pretrained is None:
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- kaiming_init(m)
- elif isinstance(m, (_BatchNorm, nn.GroupNorm)):
- constant_init(m, 1)
-
- if self.dcn is not None:
- for m in self.modules():
- if isinstance(m, Bottleneck) and hasattr(
- m, 'conv2_offset'):
- constant_init(m.conv2_offset, 0)
-
- if self.zero_init_residual:
- for m in self.modules():
- if isinstance(m, Bottleneck):
- constant_init(m.norm3, 0)
- elif isinstance(m, BasicBlock):
- constant_init(m.norm2, 0)
- else:
- raise TypeError('pretrained must be a str or None')
-
- def forward(self, x):
- """Forward function."""
- if self.deep_stem:
- x = self.stem(x)
- else:
- x = self.conv1(x)
- x = self.norm1(x)
- x = self.relu(x)
- x = self.maxpool(x)
- outs = []
- for i, layer_name in enumerate(self.res_layers):
- res_layer = getattr(self, layer_name)
- x = res_layer(x)
- if i in self.out_indices:
- outs.append(x)
- return tuple(outs)
-
- def train(self, mode=True):
- """Convert the model into training mode while keep normalization layer
- freezed."""
- super(ResNet, self).train(mode)
- self._freeze_stages()
- if mode and self.norm_eval:
- for m in self.modules():
- # trick: eval have effect on BatchNorm only
- if isinstance(m, _BatchNorm):
- m.eval()
-
-
-@BACKBONES.register_module()
-class ResNetV1c(ResNet):
- """ResNetV1c variant described in [1]_.
-
- Compared with default ResNet(ResNetV1b), ResNetV1c replaces the 7x7 conv
- in the input stem with three 3x3 convs.
-
- References:
- .. [1] https://arxiv.org/pdf/1812.01187.pdf
- """
-
- def __init__(self, **kwargs):
- super(ResNetV1c, self).__init__(
- deep_stem=True, avg_down=False, **kwargs)
-
-
-@BACKBONES.register_module()
-class ResNetV1d(ResNet):
- """ResNetV1d variant described in [1]_.
-
- Compared with default ResNet(ResNetV1b), ResNetV1d replaces the 7x7 conv in
- the input stem with three 3x3 convs. And in the downsampling block, a 2x2
- avg_pool with stride 2 is added before conv, whose stride is changed to 1.
- """
-
- def __init__(self, **kwargs):
- super(ResNetV1d, self).__init__(
- deep_stem=True, avg_down=True, **kwargs)
diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/decode_heads/fpn_head.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/decode_heads/fpn_head.py
deleted file mode 100644
index 1241c55b0813d1ecdddf1e66e7c5031fbf78ed50..0000000000000000000000000000000000000000
--- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/decode_heads/fpn_head.py
+++ /dev/null
@@ -1,68 +0,0 @@
-import numpy as np
-import torch.nn as nn
-from annotator.uniformer.mmcv.cnn import ConvModule
-
-from annotator.uniformer.mmseg.ops import resize
-from ..builder import HEADS
-from .decode_head import BaseDecodeHead
-
-
-@HEADS.register_module()
-class FPNHead(BaseDecodeHead):
- """Panoptic Feature Pyramid Networks.
-
- This head is the implementation of `Semantic FPN
- `_.
-
- Args:
- feature_strides (tuple[int]): The strides for input feature maps.
- stack_lateral. All strides suppose to be power of 2. The first
- one is of largest resolution.
- """
-
- def __init__(self, feature_strides, **kwargs):
- super(FPNHead, self).__init__(
- input_transform='multiple_select', **kwargs)
- assert len(feature_strides) == len(self.in_channels)
- assert min(feature_strides) == feature_strides[0]
- self.feature_strides = feature_strides
-
- self.scale_heads = nn.ModuleList()
- for i in range(len(feature_strides)):
- head_length = max(
- 1,
- int(np.log2(feature_strides[i]) - np.log2(feature_strides[0])))
- scale_head = []
- for k in range(head_length):
- scale_head.append(
- ConvModule(
- self.in_channels[i] if k == 0 else self.channels,
- self.channels,
- 3,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg))
- if feature_strides[i] != feature_strides[0]:
- scale_head.append(
- nn.Upsample(
- scale_factor=2,
- mode='bilinear',
- align_corners=self.align_corners))
- self.scale_heads.append(nn.Sequential(*scale_head))
-
- def forward(self, inputs):
-
- x = self._transform_inputs(inputs)
-
- output = self.scale_heads[0](x[0])
- for i in range(1, len(self.feature_strides)):
- # non inplace
- output = output + resize(
- self.scale_heads[i](x[i]),
- size=output.shape[2:],
- mode='bilinear',
- align_corners=self.align_corners)
-
- output = self.cls_seg(output)
- return output
diff --git a/spaces/PaddlePaddle/ERNIE-Layout/footer.html b/spaces/PaddlePaddle/ERNIE-Layout/footer.html
deleted file mode 100644
index 662563a2174786a325fda4dc81a4dd5293cc21f3..0000000000000000000000000000000000000000
--- a/spaces/PaddlePaddle/ERNIE-Layout/footer.html
+++ /dev/null
@@ -1,4 +0,0 @@
-
\ No newline at end of file
diff --git a/spaces/PeepDaSlan9/candle-llama2/index.html b/spaces/PeepDaSlan9/candle-llama2/index.html
deleted file mode 100644
index 1ae547ad626c51de48b9f0f2fa058b0e657cf80f..0000000000000000000000000000000000000000
--- a/spaces/PeepDaSlan9/candle-llama2/index.html
+++ /dev/null
@@ -1,45 +0,0 @@
-
-
- Welcome to Candle!
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/models/backbones/resnext.py b/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/models/backbones/resnext.py
deleted file mode 100644
index 962249ad6fd9b50960ad6426f7ce3cac6ed8c5bc..0000000000000000000000000000000000000000
--- a/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/models/backbones/resnext.py
+++ /dev/null
@@ -1,145 +0,0 @@
-import math
-
-from annotator.uniformer.mmcv.cnn import build_conv_layer, build_norm_layer
-
-from ..builder import BACKBONES
-from ..utils import ResLayer
-from .resnet import Bottleneck as _Bottleneck
-from .resnet import ResNet
-
-
-class Bottleneck(_Bottleneck):
- """Bottleneck block for ResNeXt.
-
- If style is "pytorch", the stride-two layer is the 3x3 conv layer, if it is
- "caffe", the stride-two layer is the first 1x1 conv layer.
- """
-
- def __init__(self,
- inplanes,
- planes,
- groups=1,
- base_width=4,
- base_channels=64,
- **kwargs):
- super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
-
- if groups == 1:
- width = self.planes
- else:
- width = math.floor(self.planes *
- (base_width / base_channels)) * groups
-
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, width, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(
- self.norm_cfg, width, postfix=2)
- self.norm3_name, norm3 = build_norm_layer(
- self.norm_cfg, self.planes * self.expansion, postfix=3)
-
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- self.inplanes,
- width,
- kernel_size=1,
- stride=self.conv1_stride,
- bias=False)
- self.add_module(self.norm1_name, norm1)
- fallback_on_stride = False
- self.with_modulated_dcn = False
- if self.with_dcn:
- fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
- if not self.with_dcn or fallback_on_stride:
- self.conv2 = build_conv_layer(
- self.conv_cfg,
- width,
- width,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=self.dilation,
- dilation=self.dilation,
- groups=groups,
- bias=False)
- else:
- assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
- self.conv2 = build_conv_layer(
- self.dcn,
- width,
- width,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=self.dilation,
- dilation=self.dilation,
- groups=groups,
- bias=False)
-
- self.add_module(self.norm2_name, norm2)
- self.conv3 = build_conv_layer(
- self.conv_cfg,
- width,
- self.planes * self.expansion,
- kernel_size=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
-
-@BACKBONES.register_module()
-class ResNeXt(ResNet):
- """ResNeXt backbone.
-
- Args:
- depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
- in_channels (int): Number of input image channels. Normally 3.
- num_stages (int): Resnet stages, normally 4.
- groups (int): Group of resnext.
- base_width (int): Base width of resnext.
- strides (Sequence[int]): Strides of the first block of each stage.
- dilations (Sequence[int]): Dilation of each stage.
- out_indices (Sequence[int]): Output from which stages.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- frozen_stages (int): Stages to be frozen (all param fixed). -1 means
- not freezing any parameters.
- norm_cfg (dict): dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- zero_init_residual (bool): whether to use zero init for last norm layer
- in resblocks to let them behave as identity.
-
- Example:
- >>> from annotator.uniformer.mmseg.models import ResNeXt
- >>> import torch
- >>> self = ResNeXt(depth=50)
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 256, 8, 8)
- (1, 512, 4, 4)
- (1, 1024, 2, 2)
- (1, 2048, 1, 1)
- """
-
- arch_settings = {
- 50: (Bottleneck, (3, 4, 6, 3)),
- 101: (Bottleneck, (3, 4, 23, 3)),
- 152: (Bottleneck, (3, 8, 36, 3))
- }
-
- def __init__(self, groups=1, base_width=4, **kwargs):
- self.groups = groups
- self.base_width = base_width
- super(ResNeXt, self).__init__(**kwargs)
-
- def make_res_layer(self, **kwargs):
- """Pack all blocks in a stage into a ``ResLayer``"""
- return ResLayer(
- groups=self.groups,
- base_width=self.base_width,
- base_channels=self.base_channels,
- **kwargs)
diff --git a/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/models/decode_heads/psp_head.py b/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/models/decode_heads/psp_head.py
deleted file mode 100644
index b5f1e71c70c3a20f4007c263ec471a87bb214a48..0000000000000000000000000000000000000000
--- a/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/models/decode_heads/psp_head.py
+++ /dev/null
@@ -1,101 +0,0 @@
-import torch
-import torch.nn as nn
-from annotator.uniformer.mmcv.cnn import ConvModule
-
-from annotator.uniformer.mmseg.ops import resize
-from ..builder import HEADS
-from .decode_head import BaseDecodeHead
-
-
-class PPM(nn.ModuleList):
- """Pooling Pyramid Module used in PSPNet.
-
- Args:
- pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
- Module.
- in_channels (int): Input channels.
- channels (int): Channels after modules, before conv_seg.
- conv_cfg (dict|None): Config of conv layers.
- norm_cfg (dict|None): Config of norm layers.
- act_cfg (dict): Config of activation layers.
- align_corners (bool): align_corners argument of F.interpolate.
- """
-
- def __init__(self, pool_scales, in_channels, channels, conv_cfg, norm_cfg,
- act_cfg, align_corners):
- super(PPM, self).__init__()
- self.pool_scales = pool_scales
- self.align_corners = align_corners
- self.in_channels = in_channels
- self.channels = channels
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.act_cfg = act_cfg
- for pool_scale in pool_scales:
- self.append(
- nn.Sequential(
- nn.AdaptiveAvgPool2d(pool_scale),
- ConvModule(
- self.in_channels,
- self.channels,
- 1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)))
-
- def forward(self, x):
- """Forward function."""
- ppm_outs = []
- for ppm in self:
- ppm_out = ppm(x)
- upsampled_ppm_out = resize(
- ppm_out,
- size=x.size()[2:],
- mode='bilinear',
- align_corners=self.align_corners)
- ppm_outs.append(upsampled_ppm_out)
- return ppm_outs
-
-
-@HEADS.register_module()
-class PSPHead(BaseDecodeHead):
- """Pyramid Scene Parsing Network.
-
- This head is the implementation of
- `PSPNet `_.
-
- Args:
- pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
- Module. Default: (1, 2, 3, 6).
- """
-
- def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
- super(PSPHead, self).__init__(**kwargs)
- assert isinstance(pool_scales, (list, tuple))
- self.pool_scales = pool_scales
- self.psp_modules = PPM(
- self.pool_scales,
- self.in_channels,
- self.channels,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg,
- align_corners=self.align_corners)
- self.bottleneck = ConvModule(
- self.in_channels + len(pool_scales) * self.channels,
- self.channels,
- 3,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
-
- def forward(self, inputs):
- """Forward function."""
- x = self._transform_inputs(inputs)
- psp_outs = [x]
- psp_outs.extend(self.psp_modules(x))
- psp_outs = torch.cat(psp_outs, dim=1)
- output = self.bottleneck(psp_outs)
- output = self.cls_seg(output)
- return output
diff --git a/spaces/Pontonkid/Real-Time-Multilingual-sentiment-analysis/README.md b/spaces/Pontonkid/Real-Time-Multilingual-sentiment-analysis/README.md
deleted file mode 100644
index 661f5fca370e3a3e329f69cd3a1bd8e789df5c9d..0000000000000000000000000000000000000000
--- a/spaces/Pontonkid/Real-Time-Multilingual-sentiment-analysis/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Real-Time Sentiment Analysis
-emoji: ⚡
-colorFrom: red
-colorTo: green
-sdk: gradio
-sdk_version: 3.35.2
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/modules/chroma.py b/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/modules/chroma.py
deleted file mode 100644
index e84fb66b4a4aaefb0b3ccac8a9a44c3b20e48f61..0000000000000000000000000000000000000000
--- a/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/modules/chroma.py
+++ /dev/null
@@ -1,66 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-import typing as tp
-
-from einops import rearrange
-from librosa import filters
-import torch
-from torch import nn
-import torch.nn.functional as F
-import torchaudio
-
-
-class ChromaExtractor(nn.Module):
- """Chroma extraction and quantization.
-
- Args:
- sample_rate (int): Sample rate for the chroma extraction.
- n_chroma (int): Number of chroma bins for the chroma extraction.
- radix2_exp (int): Size of stft window for the chroma extraction (power of 2, e.g. 12 -> 2^12).
- nfft (int, optional): Number of FFT.
- winlen (int, optional): Window length.
- winhop (int, optional): Window hop size.
- argmax (bool, optional): Whether to use argmax. Defaults to False.
- norm (float, optional): Norm for chroma normalization. Defaults to inf.
- """
- def __init__(self, sample_rate: int, n_chroma: int = 12, radix2_exp: int = 12, nfft: tp.Optional[int] = None,
- winlen: tp.Optional[int] = None, winhop: tp.Optional[int] = None, argmax: bool = False,
- norm: float = torch.inf):
- super().__init__()
- self.winlen = winlen or 2 ** radix2_exp
- self.nfft = nfft or self.winlen
- self.winhop = winhop or (self.winlen // 4)
- self.sample_rate = sample_rate
- self.n_chroma = n_chroma
- self.norm = norm
- self.argmax = argmax
- self.register_buffer('fbanks', torch.from_numpy(filters.chroma(sr=sample_rate, n_fft=self.nfft, tuning=0,
- n_chroma=self.n_chroma)), persistent=False)
- self.spec = torchaudio.transforms.Spectrogram(n_fft=self.nfft, win_length=self.winlen,
- hop_length=self.winhop, power=2, center=True,
- pad=0, normalized=True)
-
- def forward(self, wav: torch.Tensor) -> torch.Tensor:
- T = wav.shape[-1]
- # in case we are getting a wav that was dropped out (nullified)
- # from the conditioner, make sure wav length is no less that nfft
- if T < self.nfft:
- pad = self.nfft - T
- r = 0 if pad % 2 == 0 else 1
- wav = F.pad(wav, (pad // 2, pad // 2 + r), 'constant', 0)
- assert wav.shape[-1] == self.nfft, f"expected len {self.nfft} but got {wav.shape[-1]}"
-
- spec = self.spec(wav).squeeze(1)
- raw_chroma = torch.einsum('cf,...ft->...ct', self.fbanks, spec)
- norm_chroma = torch.nn.functional.normalize(raw_chroma, p=self.norm, dim=-2, eps=1e-6)
- norm_chroma = rearrange(norm_chroma, 'b d t -> b t d')
-
- if self.argmax:
- idx = norm_chroma.argmax(-1, keepdim=True)
- norm_chroma[:] = 0
- norm_chroma.scatter_(dim=-1, index=idx, value=1)
-
- return norm_chroma
diff --git a/spaces/Purple11/Grounded-Diffusion/src/CLIP/clip/__init__.py b/spaces/Purple11/Grounded-Diffusion/src/CLIP/clip/__init__.py
deleted file mode 100644
index dcc5619538c0f7c782508bdbd9587259d805e0d9..0000000000000000000000000000000000000000
--- a/spaces/Purple11/Grounded-Diffusion/src/CLIP/clip/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .clip import *
diff --git a/spaces/Purple11/Grounded-Diffusion/src/taming-transformers/taming/modules/transformer/mingpt.py b/spaces/Purple11/Grounded-Diffusion/src/taming-transformers/taming/modules/transformer/mingpt.py
deleted file mode 100644
index d14b7b68117f4b9f297b2929397cd4f55089334c..0000000000000000000000000000000000000000
--- a/spaces/Purple11/Grounded-Diffusion/src/taming-transformers/taming/modules/transformer/mingpt.py
+++ /dev/null
@@ -1,415 +0,0 @@
-"""
-taken from: https://github.com/karpathy/minGPT/
-GPT model:
-- the initial stem consists of a combination of token encoding and a positional encoding
-- the meat of it is a uniform sequence of Transformer blocks
- - each Transformer is a sequential combination of a 1-hidden-layer MLP block and a self-attention block
- - all blocks feed into a central residual pathway similar to resnets
-- the final decoder is a linear projection into a vanilla Softmax classifier
-"""
-
-import math
-import logging
-
-import torch
-import torch.nn as nn
-from torch.nn import functional as F
-from transformers import top_k_top_p_filtering
-
-logger = logging.getLogger(__name__)
-
-
-class GPTConfig:
- """ base GPT config, params common to all GPT versions """
- embd_pdrop = 0.1
- resid_pdrop = 0.1
- attn_pdrop = 0.1
-
- def __init__(self, vocab_size, block_size, **kwargs):
- self.vocab_size = vocab_size
- self.block_size = block_size
- for k,v in kwargs.items():
- setattr(self, k, v)
-
-
-class GPT1Config(GPTConfig):
- """ GPT-1 like network roughly 125M params """
- n_layer = 12
- n_head = 12
- n_embd = 768
-
-
-class CausalSelfAttention(nn.Module):
- """
- A vanilla multi-head masked self-attention layer with a projection at the end.
- It is possible to use torch.nn.MultiheadAttention here but I am including an
- explicit implementation here to show that there is nothing too scary here.
- """
-
- def __init__(self, config):
- super().__init__()
- assert config.n_embd % config.n_head == 0
- # key, query, value projections for all heads
- self.key = nn.Linear(config.n_embd, config.n_embd)
- self.query = nn.Linear(config.n_embd, config.n_embd)
- self.value = nn.Linear(config.n_embd, config.n_embd)
- # regularization
- self.attn_drop = nn.Dropout(config.attn_pdrop)
- self.resid_drop = nn.Dropout(config.resid_pdrop)
- # output projection
- self.proj = nn.Linear(config.n_embd, config.n_embd)
- # causal mask to ensure that attention is only applied to the left in the input sequence
- mask = torch.tril(torch.ones(config.block_size,
- config.block_size))
- if hasattr(config, "n_unmasked"):
- mask[:config.n_unmasked, :config.n_unmasked] = 1
- self.register_buffer("mask", mask.view(1, 1, config.block_size, config.block_size))
- self.n_head = config.n_head
-
- def forward(self, x, layer_past=None):
- B, T, C = x.size()
-
- # calculate query, key, values for all heads in batch and move head forward to be the batch dim
- k = self.key(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
- q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
- v = self.value(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
-
- present = torch.stack((k, v))
- if layer_past is not None:
- past_key, past_value = layer_past
- k = torch.cat((past_key, k), dim=-2)
- v = torch.cat((past_value, v), dim=-2)
-
- # causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
- att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
- if layer_past is None:
- att = att.masked_fill(self.mask[:,:,:T,:T] == 0, float('-inf'))
-
- att = F.softmax(att, dim=-1)
- att = self.attn_drop(att)
- y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
- y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
-
- # output projection
- y = self.resid_drop(self.proj(y))
- return y, present # TODO: check that this does not break anything
-
-
-class Block(nn.Module):
- """ an unassuming Transformer block """
- def __init__(self, config):
- super().__init__()
- self.ln1 = nn.LayerNorm(config.n_embd)
- self.ln2 = nn.LayerNorm(config.n_embd)
- self.attn = CausalSelfAttention(config)
- self.mlp = nn.Sequential(
- nn.Linear(config.n_embd, 4 * config.n_embd),
- nn.GELU(), # nice
- nn.Linear(4 * config.n_embd, config.n_embd),
- nn.Dropout(config.resid_pdrop),
- )
-
- def forward(self, x, layer_past=None, return_present=False):
- # TODO: check that training still works
- if return_present: assert not self.training
- # layer past: tuple of length two with B, nh, T, hs
- attn, present = self.attn(self.ln1(x), layer_past=layer_past)
-
- x = x + attn
- x = x + self.mlp(self.ln2(x))
- if layer_past is not None or return_present:
- return x, present
- return x
-
-
-class GPT(nn.Module):
- """ the full GPT language model, with a context size of block_size """
- def __init__(self, vocab_size, block_size, n_layer=12, n_head=8, n_embd=256,
- embd_pdrop=0., resid_pdrop=0., attn_pdrop=0., n_unmasked=0):
- super().__init__()
- config = GPTConfig(vocab_size=vocab_size, block_size=block_size,
- embd_pdrop=embd_pdrop, resid_pdrop=resid_pdrop, attn_pdrop=attn_pdrop,
- n_layer=n_layer, n_head=n_head, n_embd=n_embd,
- n_unmasked=n_unmasked)
- # input embedding stem
- self.tok_emb = nn.Embedding(config.vocab_size, config.n_embd)
- self.pos_emb = nn.Parameter(torch.zeros(1, config.block_size, config.n_embd))
- self.drop = nn.Dropout(config.embd_pdrop)
- # transformer
- self.blocks = nn.Sequential(*[Block(config) for _ in range(config.n_layer)])
- # decoder head
- self.ln_f = nn.LayerNorm(config.n_embd)
- self.head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
- self.block_size = config.block_size
- self.apply(self._init_weights)
- self.config = config
- logger.info("number of parameters: %e", sum(p.numel() for p in self.parameters()))
-
- def get_block_size(self):
- return self.block_size
-
- def _init_weights(self, module):
- if isinstance(module, (nn.Linear, nn.Embedding)):
- module.weight.data.normal_(mean=0.0, std=0.02)
- if isinstance(module, nn.Linear) and module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def forward(self, idx, embeddings=None, targets=None):
- # forward the GPT model
- token_embeddings = self.tok_emb(idx) # each index maps to a (learnable) vector
-
- if embeddings is not None: # prepend explicit embeddings
- token_embeddings = torch.cat((embeddings, token_embeddings), dim=1)
-
- t = token_embeddings.shape[1]
- assert t <= self.block_size, "Cannot forward, model block size is exhausted."
- position_embeddings = self.pos_emb[:, :t, :] # each position maps to a (learnable) vector
- x = self.drop(token_embeddings + position_embeddings)
- x = self.blocks(x)
- x = self.ln_f(x)
- logits = self.head(x)
-
- # if we are given some desired targets also calculate the loss
- loss = None
- if targets is not None:
- loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
-
- return logits, loss
-
- def forward_with_past(self, idx, embeddings=None, targets=None, past=None, past_length=None):
- # inference only
- assert not self.training
- token_embeddings = self.tok_emb(idx) # each index maps to a (learnable) vector
- if embeddings is not None: # prepend explicit embeddings
- token_embeddings = torch.cat((embeddings, token_embeddings), dim=1)
-
- if past is not None:
- assert past_length is not None
- past = torch.cat(past, dim=-2) # n_layer, 2, b, nh, len_past, dim_head
- past_shape = list(past.shape)
- expected_shape = [self.config.n_layer, 2, idx.shape[0], self.config.n_head, past_length, self.config.n_embd//self.config.n_head]
- assert past_shape == expected_shape, f"{past_shape} =/= {expected_shape}"
- position_embeddings = self.pos_emb[:, past_length, :] # each position maps to a (learnable) vector
- else:
- position_embeddings = self.pos_emb[:, :token_embeddings.shape[1], :]
-
- x = self.drop(token_embeddings + position_embeddings)
- presents = [] # accumulate over layers
- for i, block in enumerate(self.blocks):
- x, present = block(x, layer_past=past[i, ...] if past is not None else None, return_present=True)
- presents.append(present)
-
- x = self.ln_f(x)
- logits = self.head(x)
- # if we are given some desired targets also calculate the loss
- loss = None
- if targets is not None:
- loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
-
- return logits, loss, torch.stack(presents) # _, _, n_layer, 2, b, nh, 1, dim_head
-
-
-class DummyGPT(nn.Module):
- # for debugging
- def __init__(self, add_value=1):
- super().__init__()
- self.add_value = add_value
-
- def forward(self, idx):
- return idx + self.add_value, None
-
-
-class CodeGPT(nn.Module):
- """Takes in semi-embeddings"""
- def __init__(self, vocab_size, block_size, in_channels, n_layer=12, n_head=8, n_embd=256,
- embd_pdrop=0., resid_pdrop=0., attn_pdrop=0., n_unmasked=0):
- super().__init__()
- config = GPTConfig(vocab_size=vocab_size, block_size=block_size,
- embd_pdrop=embd_pdrop, resid_pdrop=resid_pdrop, attn_pdrop=attn_pdrop,
- n_layer=n_layer, n_head=n_head, n_embd=n_embd,
- n_unmasked=n_unmasked)
- # input embedding stem
- self.tok_emb = nn.Linear(in_channels, config.n_embd)
- self.pos_emb = nn.Parameter(torch.zeros(1, config.block_size, config.n_embd))
- self.drop = nn.Dropout(config.embd_pdrop)
- # transformer
- self.blocks = nn.Sequential(*[Block(config) for _ in range(config.n_layer)])
- # decoder head
- self.ln_f = nn.LayerNorm(config.n_embd)
- self.head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
- self.block_size = config.block_size
- self.apply(self._init_weights)
- self.config = config
- logger.info("number of parameters: %e", sum(p.numel() for p in self.parameters()))
-
- def get_block_size(self):
- return self.block_size
-
- def _init_weights(self, module):
- if isinstance(module, (nn.Linear, nn.Embedding)):
- module.weight.data.normal_(mean=0.0, std=0.02)
- if isinstance(module, nn.Linear) and module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def forward(self, idx, embeddings=None, targets=None):
- # forward the GPT model
- token_embeddings = self.tok_emb(idx) # each index maps to a (learnable) vector
-
- if embeddings is not None: # prepend explicit embeddings
- token_embeddings = torch.cat((embeddings, token_embeddings), dim=1)
-
- t = token_embeddings.shape[1]
- assert t <= self.block_size, "Cannot forward, model block size is exhausted."
- position_embeddings = self.pos_emb[:, :t, :] # each position maps to a (learnable) vector
- x = self.drop(token_embeddings + position_embeddings)
- x = self.blocks(x)
- x = self.taming_cinln_f(x)
- logits = self.head(x)
-
- # if we are given some desired targets also calculate the loss
- loss = None
- if targets is not None:
- loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
-
- return logits, loss
-
-
-
-#### sampling utils
-
-def top_k_logits(logits, k):
- v, ix = torch.topk(logits, k)
- out = logits.clone()
- out[out < v[:, [-1]]] = -float('Inf')
- return out
-
-@torch.no_grad()
-def sample(model, x, steps, temperature=1.0, sample=False, top_k=None):
- """
- take a conditioning sequence of indices in x (of shape (b,t)) and predict the next token in
- the sequence, feeding the predictions back into the model each time. Clearly the sampling
- has quadratic complexity unlike an RNN that is only linear, and has a finite context window
- of block_size, unlike an RNN that has an infinite context window.
- """
- block_size = model.get_block_size()
- model.eval()
- for k in range(steps):
- x_cond = x if x.size(1) <= block_size else x[:, -block_size:] # crop context if needed
- logits, _ = model(x_cond)
- # pluck the logits at the final step and scale by temperature
- logits = logits[:, -1, :] / temperature
- # optionally crop probabilities to only the top k options
- if top_k is not None:
- logits = top_k_logits(logits, top_k)
- # apply softmax to convert to probabilities
- probs = F.softmax(logits, dim=-1)
- # sample from the distribution or take the most likely
- if sample:
- ix = torch.multinomial(probs, num_samples=1)
- else:
- _, ix = torch.topk(probs, k=1, dim=-1)
- # append to the sequence and continue
- x = torch.cat((x, ix), dim=1)
-
- return x
-
-
-@torch.no_grad()
-def sample_with_past(x, model, steps, temperature=1., sample_logits=True,
- top_k=None, top_p=None, callback=None):
- # x is conditioning
- sample = x
- cond_len = x.shape[1]
- past = None
- for n in range(steps):
- if callback is not None:
- callback(n)
- logits, _, present = model.forward_with_past(x, past=past, past_length=(n+cond_len-1))
- if past is None:
- past = [present]
- else:
- past.append(present)
- logits = logits[:, -1, :] / temperature
- if top_k is not None:
- logits = top_k_top_p_filtering(logits, top_k=top_k, top_p=top_p)
-
- probs = F.softmax(logits, dim=-1)
- if not sample_logits:
- _, x = torch.topk(probs, k=1, dim=-1)
- else:
- x = torch.multinomial(probs, num_samples=1)
- # append to the sequence and continue
- sample = torch.cat((sample, x), dim=1)
- del past
- sample = sample[:, cond_len:] # cut conditioning off
- return sample
-
-
-#### clustering utils
-
-class KMeans(nn.Module):
- def __init__(self, ncluster=512, nc=3, niter=10):
- super().__init__()
- self.ncluster = ncluster
- self.nc = nc
- self.niter = niter
- self.shape = (3,32,32)
- self.register_buffer("C", torch.zeros(self.ncluster,nc))
- self.register_buffer('initialized', torch.tensor(0, dtype=torch.uint8))
-
- def is_initialized(self):
- return self.initialized.item() == 1
-
- @torch.no_grad()
- def initialize(self, x):
- N, D = x.shape
- assert D == self.nc, D
- c = x[torch.randperm(N)[:self.ncluster]] # init clusters at random
- for i in range(self.niter):
- # assign all pixels to the closest codebook element
- a = ((x[:, None, :] - c[None, :, :])**2).sum(-1).argmin(1)
- # move each codebook element to be the mean of the pixels that assigned to it
- c = torch.stack([x[a==k].mean(0) for k in range(self.ncluster)])
- # re-assign any poorly positioned codebook elements
- nanix = torch.any(torch.isnan(c), dim=1)
- ndead = nanix.sum().item()
- print('done step %d/%d, re-initialized %d dead clusters' % (i+1, self.niter, ndead))
- c[nanix] = x[torch.randperm(N)[:ndead]] # re-init dead clusters
-
- self.C.copy_(c)
- self.initialized.fill_(1)
-
-
- def forward(self, x, reverse=False, shape=None):
- if not reverse:
- # flatten
- bs,c,h,w = x.shape
- assert c == self.nc
- x = x.reshape(bs,c,h*w,1)
- C = self.C.permute(1,0)
- C = C.reshape(1,c,1,self.ncluster)
- a = ((x-C)**2).sum(1).argmin(-1) # bs, h*w indices
- return a
- else:
- # flatten
- bs, HW = x.shape
- """
- c = self.C.reshape( 1, self.nc, 1, self.ncluster)
- c = c[bs*[0],:,:,:]
- c = c[:,:,HW*[0],:]
- x = x.reshape(bs, 1, HW, 1)
- x = x[:,3*[0],:,:]
- x = torch.gather(c, dim=3, index=x)
- """
- x = self.C[x]
- x = x.permute(0,2,1)
- shape = shape if shape is not None else self.shape
- x = x.reshape(bs, *shape)
-
- return x
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/cli/base_command.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/cli/base_command.py
deleted file mode 100644
index 5bd7e67e649d256292fb12b8be6dc9ff88c111ac..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/cli/base_command.py
+++ /dev/null
@@ -1,216 +0,0 @@
-"""Base Command class, and related routines"""
-
-import functools
-import logging
-import logging.config
-import optparse
-import os
-import sys
-import traceback
-from optparse import Values
-from typing import Any, Callable, List, Optional, Tuple
-
-from pip._vendor.rich import traceback as rich_traceback
-
-from pip._internal.cli import cmdoptions
-from pip._internal.cli.command_context import CommandContextMixIn
-from pip._internal.cli.parser import ConfigOptionParser, UpdatingDefaultsHelpFormatter
-from pip._internal.cli.status_codes import (
- ERROR,
- PREVIOUS_BUILD_DIR_ERROR,
- UNKNOWN_ERROR,
- VIRTUALENV_NOT_FOUND,
-)
-from pip._internal.exceptions import (
- BadCommand,
- CommandError,
- DiagnosticPipError,
- InstallationError,
- NetworkConnectionError,
- PreviousBuildDirError,
- UninstallationError,
-)
-from pip._internal.utils.filesystem import check_path_owner
-from pip._internal.utils.logging import BrokenStdoutLoggingError, setup_logging
-from pip._internal.utils.misc import get_prog, normalize_path
-from pip._internal.utils.temp_dir import TempDirectoryTypeRegistry as TempDirRegistry
-from pip._internal.utils.temp_dir import global_tempdir_manager, tempdir_registry
-from pip._internal.utils.virtualenv import running_under_virtualenv
-
-__all__ = ["Command"]
-
-logger = logging.getLogger(__name__)
-
-
-class Command(CommandContextMixIn):
- usage: str = ""
- ignore_require_venv: bool = False
-
- def __init__(self, name: str, summary: str, isolated: bool = False) -> None:
- super().__init__()
-
- self.name = name
- self.summary = summary
- self.parser = ConfigOptionParser(
- usage=self.usage,
- prog=f"{get_prog()} {name}",
- formatter=UpdatingDefaultsHelpFormatter(),
- add_help_option=False,
- name=name,
- description=self.__doc__,
- isolated=isolated,
- )
-
- self.tempdir_registry: Optional[TempDirRegistry] = None
-
- # Commands should add options to this option group
- optgroup_name = f"{self.name.capitalize()} Options"
- self.cmd_opts = optparse.OptionGroup(self.parser, optgroup_name)
-
- # Add the general options
- gen_opts = cmdoptions.make_option_group(
- cmdoptions.general_group,
- self.parser,
- )
- self.parser.add_option_group(gen_opts)
-
- self.add_options()
-
- def add_options(self) -> None:
- pass
-
- def handle_pip_version_check(self, options: Values) -> None:
- """
- This is a no-op so that commands by default do not do the pip version
- check.
- """
- # Make sure we do the pip version check if the index_group options
- # are present.
- assert not hasattr(options, "no_index")
-
- def run(self, options: Values, args: List[str]) -> int:
- raise NotImplementedError
-
- def parse_args(self, args: List[str]) -> Tuple[Values, List[str]]:
- # factored out for testability
- return self.parser.parse_args(args)
-
- def main(self, args: List[str]) -> int:
- try:
- with self.main_context():
- return self._main(args)
- finally:
- logging.shutdown()
-
- def _main(self, args: List[str]) -> int:
- # We must initialize this before the tempdir manager, otherwise the
- # configuration would not be accessible by the time we clean up the
- # tempdir manager.
- self.tempdir_registry = self.enter_context(tempdir_registry())
- # Intentionally set as early as possible so globally-managed temporary
- # directories are available to the rest of the code.
- self.enter_context(global_tempdir_manager())
-
- options, args = self.parse_args(args)
-
- # Set verbosity so that it can be used elsewhere.
- self.verbosity = options.verbose - options.quiet
-
- level_number = setup_logging(
- verbosity=self.verbosity,
- no_color=options.no_color,
- user_log_file=options.log,
- )
-
- # TODO: Try to get these passing down from the command?
- # without resorting to os.environ to hold these.
- # This also affects isolated builds and it should.
-
- if options.no_input:
- os.environ["PIP_NO_INPUT"] = "1"
-
- if options.exists_action:
- os.environ["PIP_EXISTS_ACTION"] = " ".join(options.exists_action)
-
- if options.require_venv and not self.ignore_require_venv:
- # If a venv is required check if it can really be found
- if not running_under_virtualenv():
- logger.critical("Could not find an activated virtualenv (required).")
- sys.exit(VIRTUALENV_NOT_FOUND)
-
- if options.cache_dir:
- options.cache_dir = normalize_path(options.cache_dir)
- if not check_path_owner(options.cache_dir):
- logger.warning(
- "The directory '%s' or its parent directory is not owned "
- "or is not writable by the current user. The cache "
- "has been disabled. Check the permissions and owner of "
- "that directory. If executing pip with sudo, you should "
- "use sudo's -H flag.",
- options.cache_dir,
- )
- options.cache_dir = None
-
- def intercepts_unhandled_exc(
- run_func: Callable[..., int]
- ) -> Callable[..., int]:
- @functools.wraps(run_func)
- def exc_logging_wrapper(*args: Any) -> int:
- try:
- status = run_func(*args)
- assert isinstance(status, int)
- return status
- except DiagnosticPipError as exc:
- logger.error("[present-rich] %s", exc)
- logger.debug("Exception information:", exc_info=True)
-
- return ERROR
- except PreviousBuildDirError as exc:
- logger.critical(str(exc))
- logger.debug("Exception information:", exc_info=True)
-
- return PREVIOUS_BUILD_DIR_ERROR
- except (
- InstallationError,
- UninstallationError,
- BadCommand,
- NetworkConnectionError,
- ) as exc:
- logger.critical(str(exc))
- logger.debug("Exception information:", exc_info=True)
-
- return ERROR
- except CommandError as exc:
- logger.critical("%s", exc)
- logger.debug("Exception information:", exc_info=True)
-
- return ERROR
- except BrokenStdoutLoggingError:
- # Bypass our logger and write any remaining messages to
- # stderr because stdout no longer works.
- print("ERROR: Pipe to stdout was broken", file=sys.stderr)
- if level_number <= logging.DEBUG:
- traceback.print_exc(file=sys.stderr)
-
- return ERROR
- except KeyboardInterrupt:
- logger.critical("Operation cancelled by user")
- logger.debug("Exception information:", exc_info=True)
-
- return ERROR
- except BaseException:
- logger.critical("Exception:", exc_info=True)
-
- return UNKNOWN_ERROR
-
- return exc_logging_wrapper
-
- try:
- if not options.debug_mode:
- run = intercepts_unhandled_exc(self.run)
- else:
- run = self.run
- rich_traceback.install(show_locals=True)
- return run(options, args)
- finally:
- self.handle_pip_version_check(options)
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/network/download.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/network/download.py
deleted file mode 100644
index 79b82a570e5be5ce4f8e4dcc4906da8c18f08ef6..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/network/download.py
+++ /dev/null
@@ -1,186 +0,0 @@
-"""Download files with progress indicators.
-"""
-import email.message
-import logging
-import mimetypes
-import os
-from typing import Iterable, Optional, Tuple
-
-from pip._vendor.requests.models import CONTENT_CHUNK_SIZE, Response
-
-from pip._internal.cli.progress_bars import get_download_progress_renderer
-from pip._internal.exceptions import NetworkConnectionError
-from pip._internal.models.index import PyPI
-from pip._internal.models.link import Link
-from pip._internal.network.cache import is_from_cache
-from pip._internal.network.session import PipSession
-from pip._internal.network.utils import HEADERS, raise_for_status, response_chunks
-from pip._internal.utils.misc import format_size, redact_auth_from_url, splitext
-
-logger = logging.getLogger(__name__)
-
-
-def _get_http_response_size(resp: Response) -> Optional[int]:
- try:
- return int(resp.headers["content-length"])
- except (ValueError, KeyError, TypeError):
- return None
-
-
-def _prepare_download(
- resp: Response,
- link: Link,
- progress_bar: str,
-) -> Iterable[bytes]:
- total_length = _get_http_response_size(resp)
-
- if link.netloc == PyPI.file_storage_domain:
- url = link.show_url
- else:
- url = link.url_without_fragment
-
- logged_url = redact_auth_from_url(url)
-
- if total_length:
- logged_url = "{} ({})".format(logged_url, format_size(total_length))
-
- if is_from_cache(resp):
- logger.info("Using cached %s", logged_url)
- else:
- logger.info("Downloading %s", logged_url)
-
- if logger.getEffectiveLevel() > logging.INFO:
- show_progress = False
- elif is_from_cache(resp):
- show_progress = False
- elif not total_length:
- show_progress = True
- elif total_length > (40 * 1000):
- show_progress = True
- else:
- show_progress = False
-
- chunks = response_chunks(resp, CONTENT_CHUNK_SIZE)
-
- if not show_progress:
- return chunks
-
- renderer = get_download_progress_renderer(bar_type=progress_bar, size=total_length)
- return renderer(chunks)
-
-
-def sanitize_content_filename(filename: str) -> str:
- """
- Sanitize the "filename" value from a Content-Disposition header.
- """
- return os.path.basename(filename)
-
-
-def parse_content_disposition(content_disposition: str, default_filename: str) -> str:
- """
- Parse the "filename" value from a Content-Disposition header, and
- return the default filename if the result is empty.
- """
- m = email.message.Message()
- m["content-type"] = content_disposition
- filename = m.get_param("filename")
- if filename:
- # We need to sanitize the filename to prevent directory traversal
- # in case the filename contains ".." path parts.
- filename = sanitize_content_filename(str(filename))
- return filename or default_filename
-
-
-def _get_http_response_filename(resp: Response, link: Link) -> str:
- """Get an ideal filename from the given HTTP response, falling back to
- the link filename if not provided.
- """
- filename = link.filename # fallback
- # Have a look at the Content-Disposition header for a better guess
- content_disposition = resp.headers.get("content-disposition")
- if content_disposition:
- filename = parse_content_disposition(content_disposition, filename)
- ext: Optional[str] = splitext(filename)[1]
- if not ext:
- ext = mimetypes.guess_extension(resp.headers.get("content-type", ""))
- if ext:
- filename += ext
- if not ext and link.url != resp.url:
- ext = os.path.splitext(resp.url)[1]
- if ext:
- filename += ext
- return filename
-
-
-def _http_get_download(session: PipSession, link: Link) -> Response:
- target_url = link.url.split("#", 1)[0]
- resp = session.get(target_url, headers=HEADERS, stream=True)
- raise_for_status(resp)
- return resp
-
-
-class Downloader:
- def __init__(
- self,
- session: PipSession,
- progress_bar: str,
- ) -> None:
- self._session = session
- self._progress_bar = progress_bar
-
- def __call__(self, link: Link, location: str) -> Tuple[str, str]:
- """Download the file given by link into location."""
- try:
- resp = _http_get_download(self._session, link)
- except NetworkConnectionError as e:
- assert e.response is not None
- logger.critical(
- "HTTP error %s while getting %s", e.response.status_code, link
- )
- raise
-
- filename = _get_http_response_filename(resp, link)
- filepath = os.path.join(location, filename)
-
- chunks = _prepare_download(resp, link, self._progress_bar)
- with open(filepath, "wb") as content_file:
- for chunk in chunks:
- content_file.write(chunk)
- content_type = resp.headers.get("Content-Type", "")
- return filepath, content_type
-
-
-class BatchDownloader:
- def __init__(
- self,
- session: PipSession,
- progress_bar: str,
- ) -> None:
- self._session = session
- self._progress_bar = progress_bar
-
- def __call__(
- self, links: Iterable[Link], location: str
- ) -> Iterable[Tuple[Link, Tuple[str, str]]]:
- """Download the files given by links into location."""
- for link in links:
- try:
- resp = _http_get_download(self._session, link)
- except NetworkConnectionError as e:
- assert e.response is not None
- logger.critical(
- "HTTP error %s while getting %s",
- e.response.status_code,
- link,
- )
- raise
-
- filename = _get_http_response_filename(resp, link)
- filepath = os.path.join(location, filename)
-
- chunks = _prepare_download(resp, link, self._progress_bar)
- with open(filepath, "wb") as content_file:
- for chunk in chunks:
- content_file.write(chunk)
- content_type = resp.headers.get("Content-Type", "")
- yield link, (filepath, content_type)
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/constrain.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/constrain.py
deleted file mode 100644
index 65fdf56342e8b5b8e181914881025231684e1871..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/constrain.py
+++ /dev/null
@@ -1,37 +0,0 @@
-from typing import Optional, TYPE_CHECKING
-
-from .jupyter import JupyterMixin
-from .measure import Measurement
-
-if TYPE_CHECKING:
- from .console import Console, ConsoleOptions, RenderableType, RenderResult
-
-
-class Constrain(JupyterMixin):
- """Constrain the width of a renderable to a given number of characters.
-
- Args:
- renderable (RenderableType): A renderable object.
- width (int, optional): The maximum width (in characters) to render. Defaults to 80.
- """
-
- def __init__(self, renderable: "RenderableType", width: Optional[int] = 80) -> None:
- self.renderable = renderable
- self.width = width
-
- def __rich_console__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "RenderResult":
- if self.width is None:
- yield self.renderable
- else:
- child_options = options.update_width(min(self.width, options.max_width))
- yield from console.render(self.renderable, child_options)
-
- def __rich_measure__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "Measurement":
- if self.width is not None:
- options = options.update_width(self.width)
- measurement = Measurement.get(console, options, self.renderable)
- return measurement
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/containers.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/containers.py
deleted file mode 100644
index e29cf368991ccb083b67cda8133e4635defbfe53..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/containers.py
+++ /dev/null
@@ -1,167 +0,0 @@
-from itertools import zip_longest
-from typing import (
- Iterator,
- Iterable,
- List,
- Optional,
- Union,
- overload,
- TypeVar,
- TYPE_CHECKING,
-)
-
-if TYPE_CHECKING:
- from .console import (
- Console,
- ConsoleOptions,
- JustifyMethod,
- OverflowMethod,
- RenderResult,
- RenderableType,
- )
- from .text import Text
-
-from .cells import cell_len
-from .measure import Measurement
-
-T = TypeVar("T")
-
-
-class Renderables:
- """A list subclass which renders its contents to the console."""
-
- def __init__(
- self, renderables: Optional[Iterable["RenderableType"]] = None
- ) -> None:
- self._renderables: List["RenderableType"] = (
- list(renderables) if renderables is not None else []
- )
-
- def __rich_console__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "RenderResult":
- """Console render method to insert line-breaks."""
- yield from self._renderables
-
- def __rich_measure__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "Measurement":
- dimensions = [
- Measurement.get(console, options, renderable)
- for renderable in self._renderables
- ]
- if not dimensions:
- return Measurement(1, 1)
- _min = max(dimension.minimum for dimension in dimensions)
- _max = max(dimension.maximum for dimension in dimensions)
- return Measurement(_min, _max)
-
- def append(self, renderable: "RenderableType") -> None:
- self._renderables.append(renderable)
-
- def __iter__(self) -> Iterable["RenderableType"]:
- return iter(self._renderables)
-
-
-class Lines:
- """A list subclass which can render to the console."""
-
- def __init__(self, lines: Iterable["Text"] = ()) -> None:
- self._lines: List["Text"] = list(lines)
-
- def __repr__(self) -> str:
- return f"Lines({self._lines!r})"
-
- def __iter__(self) -> Iterator["Text"]:
- return iter(self._lines)
-
- @overload
- def __getitem__(self, index: int) -> "Text":
- ...
-
- @overload
- def __getitem__(self, index: slice) -> List["Text"]:
- ...
-
- def __getitem__(self, index: Union[slice, int]) -> Union["Text", List["Text"]]:
- return self._lines[index]
-
- def __setitem__(self, index: int, value: "Text") -> "Lines":
- self._lines[index] = value
- return self
-
- def __len__(self) -> int:
- return self._lines.__len__()
-
- def __rich_console__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "RenderResult":
- """Console render method to insert line-breaks."""
- yield from self._lines
-
- def append(self, line: "Text") -> None:
- self._lines.append(line)
-
- def extend(self, lines: Iterable["Text"]) -> None:
- self._lines.extend(lines)
-
- def pop(self, index: int = -1) -> "Text":
- return self._lines.pop(index)
-
- def justify(
- self,
- console: "Console",
- width: int,
- justify: "JustifyMethod" = "left",
- overflow: "OverflowMethod" = "fold",
- ) -> None:
- """Justify and overflow text to a given width.
-
- Args:
- console (Console): Console instance.
- width (int): Number of characters per line.
- justify (str, optional): Default justify method for text: "left", "center", "full" or "right". Defaults to "left".
- overflow (str, optional): Default overflow for text: "crop", "fold", or "ellipsis". Defaults to "fold".
-
- """
- from .text import Text
-
- if justify == "left":
- for line in self._lines:
- line.truncate(width, overflow=overflow, pad=True)
- elif justify == "center":
- for line in self._lines:
- line.rstrip()
- line.truncate(width, overflow=overflow)
- line.pad_left((width - cell_len(line.plain)) // 2)
- line.pad_right(width - cell_len(line.plain))
- elif justify == "right":
- for line in self._lines:
- line.rstrip()
- line.truncate(width, overflow=overflow)
- line.pad_left(width - cell_len(line.plain))
- elif justify == "full":
- for line_index, line in enumerate(self._lines):
- if line_index == len(self._lines) - 1:
- break
- words = line.split(" ")
- words_size = sum(cell_len(word.plain) for word in words)
- num_spaces = len(words) - 1
- spaces = [1 for _ in range(num_spaces)]
- index = 0
- if spaces:
- while words_size + num_spaces < width:
- spaces[len(spaces) - index - 1] += 1
- num_spaces += 1
- index = (index + 1) % len(spaces)
- tokens: List[Text] = []
- for index, (word, next_word) in enumerate(
- zip_longest(words, words[1:])
- ):
- tokens.append(word)
- if index < len(spaces):
- style = word.get_style_at_offset(console, -1)
- next_style = next_word.get_style_at_offset(console, 0)
- space_style = style if style == next_style else line.style
- tokens.append(Text(" " * spaces[index], style=space_style))
- self[line_index] = Text("").join(tokens)
diff --git a/spaces/Reha2704/VToonify/vtoonify/model/encoder/criteria/id_loss.py b/spaces/Reha2704/VToonify/vtoonify/model/encoder/criteria/id_loss.py
deleted file mode 100644
index 37c71d3047be01ae7b301e0a96f14e2df88a143f..0000000000000000000000000000000000000000
--- a/spaces/Reha2704/VToonify/vtoonify/model/encoder/criteria/id_loss.py
+++ /dev/null
@@ -1,33 +0,0 @@
-import torch
-from torch import nn
-from model.encoder.encoders.model_irse import Backbone
-
-
-class IDLoss(nn.Module):
- def __init__(self, model_paths):
- super(IDLoss, self).__init__()
- print('Loading ResNet ArcFace')
- self.facenet = Backbone(input_size=112, num_layers=50, drop_ratio=0.6, mode='ir_se')
- self.facenet.load_state_dict(torch.load(model_paths))
- self.face_pool = torch.nn.AdaptiveAvgPool2d((112, 112))
- self.facenet.eval()
-
- def extract_feats(self, x):
- x = x[:, :, 35:223, 32:220] # Crop interesting region
- x = self.face_pool(x)
- x_feats = self.facenet(x)
- return x_feats
-
- def forward(self, y_hat, y):
- n_samples = y_hat.shape[0]
- y_feats = self.extract_feats(y) # Otherwise use the feature from there
- y_hat_feats = self.extract_feats(y_hat)
- y_feats = y_feats.detach()
- loss = 0
- count = 0
- for i in range(n_samples):
- diff_target = y_hat_feats[i].dot(y_feats[i])
- loss += 1 - diff_target
- count += 1
-
- return loss / count
\ No newline at end of file
diff --git a/spaces/RobLi/ControlNet-v1-1/README.md b/spaces/RobLi/ControlNet-v1-1/README.md
deleted file mode 100644
index 6db1318f8334e438d7211fc61d2c19c2c48f96fd..0000000000000000000000000000000000000000
--- a/spaces/RobLi/ControlNet-v1-1/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
----
-title: ControlNet V1.1
-emoji: 📉
-colorFrom: yellow
-colorTo: green
-sdk: gradio
-sdk_version: 3.28.0
-python_version: 3.10.11
-app_file: app.py
-pinned: false
-license: mit
-duplicated_from: hysts/ControlNet-v1-1
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/dense_heads/centripetal_head.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/dense_heads/centripetal_head.py
deleted file mode 100644
index 6728218b60539a71f6353645635f741a1ad7263d..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/dense_heads/centripetal_head.py
+++ /dev/null
@@ -1,421 +0,0 @@
-import torch.nn as nn
-from mmcv.cnn import ConvModule, normal_init
-from mmcv.ops import DeformConv2d
-
-from mmdet.core import multi_apply
-from ..builder import HEADS, build_loss
-from .corner_head import CornerHead
-
-
-@HEADS.register_module()
-class CentripetalHead(CornerHead):
- """Head of CentripetalNet: Pursuing High-quality Keypoint Pairs for Object
- Detection.
-
- CentripetalHead inherits from :class:`CornerHead`. It removes the
- embedding branch and adds guiding shift and centripetal shift branches.
- More details can be found in the `paper
- `_ .
-
- Args:
- num_classes (int): Number of categories excluding the background
- category.
- in_channels (int): Number of channels in the input feature map.
- num_feat_levels (int): Levels of feature from the previous module. 2
- for HourglassNet-104 and 1 for HourglassNet-52. HourglassNet-104
- outputs the final feature and intermediate supervision feature and
- HourglassNet-52 only outputs the final feature. Default: 2.
- corner_emb_channels (int): Channel of embedding vector. Default: 1.
- train_cfg (dict | None): Training config. Useless in CornerHead,
- but we keep this variable for SingleStageDetector. Default: None.
- test_cfg (dict | None): Testing config of CornerHead. Default: None.
- loss_heatmap (dict | None): Config of corner heatmap loss. Default:
- GaussianFocalLoss.
- loss_embedding (dict | None): Config of corner embedding loss. Default:
- AssociativeEmbeddingLoss.
- loss_offset (dict | None): Config of corner offset loss. Default:
- SmoothL1Loss.
- loss_guiding_shift (dict): Config of guiding shift loss. Default:
- SmoothL1Loss.
- loss_centripetal_shift (dict): Config of centripetal shift loss.
- Default: SmoothL1Loss.
- """
-
- def __init__(self,
- *args,
- centripetal_shift_channels=2,
- guiding_shift_channels=2,
- feat_adaption_conv_kernel=3,
- loss_guiding_shift=dict(
- type='SmoothL1Loss', beta=1.0, loss_weight=0.05),
- loss_centripetal_shift=dict(
- type='SmoothL1Loss', beta=1.0, loss_weight=1),
- **kwargs):
- assert centripetal_shift_channels == 2, (
- 'CentripetalHead only support centripetal_shift_channels == 2')
- self.centripetal_shift_channels = centripetal_shift_channels
- assert guiding_shift_channels == 2, (
- 'CentripetalHead only support guiding_shift_channels == 2')
- self.guiding_shift_channels = guiding_shift_channels
- self.feat_adaption_conv_kernel = feat_adaption_conv_kernel
- super(CentripetalHead, self).__init__(*args, **kwargs)
- self.loss_guiding_shift = build_loss(loss_guiding_shift)
- self.loss_centripetal_shift = build_loss(loss_centripetal_shift)
-
- def _init_centripetal_layers(self):
- """Initialize centripetal layers.
-
- Including feature adaption deform convs (feat_adaption), deform offset
- prediction convs (dcn_off), guiding shift (guiding_shift) and
- centripetal shift ( centripetal_shift). Each branch has two parts:
- prefix `tl_` for top-left and `br_` for bottom-right.
- """
- self.tl_feat_adaption = nn.ModuleList()
- self.br_feat_adaption = nn.ModuleList()
- self.tl_dcn_offset = nn.ModuleList()
- self.br_dcn_offset = nn.ModuleList()
- self.tl_guiding_shift = nn.ModuleList()
- self.br_guiding_shift = nn.ModuleList()
- self.tl_centripetal_shift = nn.ModuleList()
- self.br_centripetal_shift = nn.ModuleList()
-
- for _ in range(self.num_feat_levels):
- self.tl_feat_adaption.append(
- DeformConv2d(self.in_channels, self.in_channels,
- self.feat_adaption_conv_kernel, 1, 1))
- self.br_feat_adaption.append(
- DeformConv2d(self.in_channels, self.in_channels,
- self.feat_adaption_conv_kernel, 1, 1))
-
- self.tl_guiding_shift.append(
- self._make_layers(
- out_channels=self.guiding_shift_channels,
- in_channels=self.in_channels))
- self.br_guiding_shift.append(
- self._make_layers(
- out_channels=self.guiding_shift_channels,
- in_channels=self.in_channels))
-
- self.tl_dcn_offset.append(
- ConvModule(
- self.guiding_shift_channels,
- self.feat_adaption_conv_kernel**2 *
- self.guiding_shift_channels,
- 1,
- bias=False,
- act_cfg=None))
- self.br_dcn_offset.append(
- ConvModule(
- self.guiding_shift_channels,
- self.feat_adaption_conv_kernel**2 *
- self.guiding_shift_channels,
- 1,
- bias=False,
- act_cfg=None))
-
- self.tl_centripetal_shift.append(
- self._make_layers(
- out_channels=self.centripetal_shift_channels,
- in_channels=self.in_channels))
- self.br_centripetal_shift.append(
- self._make_layers(
- out_channels=self.centripetal_shift_channels,
- in_channels=self.in_channels))
-
- def _init_layers(self):
- """Initialize layers for CentripetalHead.
-
- Including two parts: CornerHead layers and CentripetalHead layers
- """
- super()._init_layers() # using _init_layers in CornerHead
- self._init_centripetal_layers()
-
- def init_weights(self):
- """Initialize weights of the head."""
- super().init_weights()
- for i in range(self.num_feat_levels):
- normal_init(self.tl_feat_adaption[i], std=0.01)
- normal_init(self.br_feat_adaption[i], std=0.01)
- normal_init(self.tl_dcn_offset[i].conv, std=0.1)
- normal_init(self.br_dcn_offset[i].conv, std=0.1)
- _ = [x.conv.reset_parameters() for x in self.tl_guiding_shift[i]]
- _ = [x.conv.reset_parameters() for x in self.br_guiding_shift[i]]
- _ = [
- x.conv.reset_parameters() for x in self.tl_centripetal_shift[i]
- ]
- _ = [
- x.conv.reset_parameters() for x in self.br_centripetal_shift[i]
- ]
-
- def forward_single(self, x, lvl_ind):
- """Forward feature of a single level.
-
- Args:
- x (Tensor): Feature of a single level.
- lvl_ind (int): Level index of current feature.
-
- Returns:
- tuple[Tensor]: A tuple of CentripetalHead's output for current
- feature level. Containing the following Tensors:
-
- - tl_heat (Tensor): Predicted top-left corner heatmap.
- - br_heat (Tensor): Predicted bottom-right corner heatmap.
- - tl_off (Tensor): Predicted top-left offset heatmap.
- - br_off (Tensor): Predicted bottom-right offset heatmap.
- - tl_guiding_shift (Tensor): Predicted top-left guiding shift
- heatmap.
- - br_guiding_shift (Tensor): Predicted bottom-right guiding
- shift heatmap.
- - tl_centripetal_shift (Tensor): Predicted top-left centripetal
- shift heatmap.
- - br_centripetal_shift (Tensor): Predicted bottom-right
- centripetal shift heatmap.
- """
- tl_heat, br_heat, _, _, tl_off, br_off, tl_pool, br_pool = super(
- ).forward_single(
- x, lvl_ind, return_pool=True)
-
- tl_guiding_shift = self.tl_guiding_shift[lvl_ind](tl_pool)
- br_guiding_shift = self.br_guiding_shift[lvl_ind](br_pool)
-
- tl_dcn_offset = self.tl_dcn_offset[lvl_ind](tl_guiding_shift.detach())
- br_dcn_offset = self.br_dcn_offset[lvl_ind](br_guiding_shift.detach())
-
- tl_feat_adaption = self.tl_feat_adaption[lvl_ind](tl_pool,
- tl_dcn_offset)
- br_feat_adaption = self.br_feat_adaption[lvl_ind](br_pool,
- br_dcn_offset)
-
- tl_centripetal_shift = self.tl_centripetal_shift[lvl_ind](
- tl_feat_adaption)
- br_centripetal_shift = self.br_centripetal_shift[lvl_ind](
- br_feat_adaption)
-
- result_list = [
- tl_heat, br_heat, tl_off, br_off, tl_guiding_shift,
- br_guiding_shift, tl_centripetal_shift, br_centripetal_shift
- ]
- return result_list
-
- def loss(self,
- tl_heats,
- br_heats,
- tl_offs,
- br_offs,
- tl_guiding_shifts,
- br_guiding_shifts,
- tl_centripetal_shifts,
- br_centripetal_shifts,
- gt_bboxes,
- gt_labels,
- img_metas,
- gt_bboxes_ignore=None):
- """Compute losses of the head.
-
- Args:
- tl_heats (list[Tensor]): Top-left corner heatmaps for each level
- with shape (N, num_classes, H, W).
- br_heats (list[Tensor]): Bottom-right corner heatmaps for each
- level with shape (N, num_classes, H, W).
- tl_offs (list[Tensor]): Top-left corner offsets for each level
- with shape (N, corner_offset_channels, H, W).
- br_offs (list[Tensor]): Bottom-right corner offsets for each level
- with shape (N, corner_offset_channels, H, W).
- tl_guiding_shifts (list[Tensor]): Top-left guiding shifts for each
- level with shape (N, guiding_shift_channels, H, W).
- br_guiding_shifts (list[Tensor]): Bottom-right guiding shifts for
- each level with shape (N, guiding_shift_channels, H, W).
- tl_centripetal_shifts (list[Tensor]): Top-left centripetal shifts
- for each level with shape (N, centripetal_shift_channels, H,
- W).
- br_centripetal_shifts (list[Tensor]): Bottom-right centripetal
- shifts for each level with shape (N,
- centripetal_shift_channels, H, W).
- gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
- shape (num_gts, 4) in [left, top, right, bottom] format.
- gt_labels (list[Tensor]): Class indices corresponding to each box.
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- gt_bboxes_ignore (list[Tensor] | None): Specify which bounding
- boxes can be ignored when computing the loss.
-
- Returns:
- dict[str, Tensor]: A dictionary of loss components. Containing the
- following losses:
-
- - det_loss (list[Tensor]): Corner keypoint losses of all
- feature levels.
- - off_loss (list[Tensor]): Corner offset losses of all feature
- levels.
- - guiding_loss (list[Tensor]): Guiding shift losses of all
- feature levels.
- - centripetal_loss (list[Tensor]): Centripetal shift losses of
- all feature levels.
- """
- targets = self.get_targets(
- gt_bboxes,
- gt_labels,
- tl_heats[-1].shape,
- img_metas[0]['pad_shape'],
- with_corner_emb=self.with_corner_emb,
- with_guiding_shift=True,
- with_centripetal_shift=True)
- mlvl_targets = [targets for _ in range(self.num_feat_levels)]
- [det_losses, off_losses, guiding_losses, centripetal_losses
- ] = multi_apply(self.loss_single, tl_heats, br_heats, tl_offs,
- br_offs, tl_guiding_shifts, br_guiding_shifts,
- tl_centripetal_shifts, br_centripetal_shifts,
- mlvl_targets)
- loss_dict = dict(
- det_loss=det_losses,
- off_loss=off_losses,
- guiding_loss=guiding_losses,
- centripetal_loss=centripetal_losses)
- return loss_dict
-
- def loss_single(self, tl_hmp, br_hmp, tl_off, br_off, tl_guiding_shift,
- br_guiding_shift, tl_centripetal_shift,
- br_centripetal_shift, targets):
- """Compute losses for single level.
-
- Args:
- tl_hmp (Tensor): Top-left corner heatmap for current level with
- shape (N, num_classes, H, W).
- br_hmp (Tensor): Bottom-right corner heatmap for current level with
- shape (N, num_classes, H, W).
- tl_off (Tensor): Top-left corner offset for current level with
- shape (N, corner_offset_channels, H, W).
- br_off (Tensor): Bottom-right corner offset for current level with
- shape (N, corner_offset_channels, H, W).
- tl_guiding_shift (Tensor): Top-left guiding shift for current level
- with shape (N, guiding_shift_channels, H, W).
- br_guiding_shift (Tensor): Bottom-right guiding shift for current
- level with shape (N, guiding_shift_channels, H, W).
- tl_centripetal_shift (Tensor): Top-left centripetal shift for
- current level with shape (N, centripetal_shift_channels, H, W).
- br_centripetal_shift (Tensor): Bottom-right centripetal shift for
- current level with shape (N, centripetal_shift_channels, H, W).
- targets (dict): Corner target generated by `get_targets`.
-
- Returns:
- tuple[torch.Tensor]: Losses of the head's differnet branches
- containing the following losses:
-
- - det_loss (Tensor): Corner keypoint loss.
- - off_loss (Tensor): Corner offset loss.
- - guiding_loss (Tensor): Guiding shift loss.
- - centripetal_loss (Tensor): Centripetal shift loss.
- """
- targets['corner_embedding'] = None
-
- det_loss, _, _, off_loss = super().loss_single(tl_hmp, br_hmp, None,
- None, tl_off, br_off,
- targets)
-
- gt_tl_guiding_shift = targets['topleft_guiding_shift']
- gt_br_guiding_shift = targets['bottomright_guiding_shift']
- gt_tl_centripetal_shift = targets['topleft_centripetal_shift']
- gt_br_centripetal_shift = targets['bottomright_centripetal_shift']
-
- gt_tl_heatmap = targets['topleft_heatmap']
- gt_br_heatmap = targets['bottomright_heatmap']
- # We only compute the offset loss at the real corner position.
- # The value of real corner would be 1 in heatmap ground truth.
- # The mask is computed in class agnostic mode and its shape is
- # batch * 1 * width * height.
- tl_mask = gt_tl_heatmap.eq(1).sum(1).gt(0).unsqueeze(1).type_as(
- gt_tl_heatmap)
- br_mask = gt_br_heatmap.eq(1).sum(1).gt(0).unsqueeze(1).type_as(
- gt_br_heatmap)
-
- # Guiding shift loss
- tl_guiding_loss = self.loss_guiding_shift(
- tl_guiding_shift,
- gt_tl_guiding_shift,
- tl_mask,
- avg_factor=tl_mask.sum())
- br_guiding_loss = self.loss_guiding_shift(
- br_guiding_shift,
- gt_br_guiding_shift,
- br_mask,
- avg_factor=br_mask.sum())
- guiding_loss = (tl_guiding_loss + br_guiding_loss) / 2.0
- # Centripetal shift loss
- tl_centripetal_loss = self.loss_centripetal_shift(
- tl_centripetal_shift,
- gt_tl_centripetal_shift,
- tl_mask,
- avg_factor=tl_mask.sum())
- br_centripetal_loss = self.loss_centripetal_shift(
- br_centripetal_shift,
- gt_br_centripetal_shift,
- br_mask,
- avg_factor=br_mask.sum())
- centripetal_loss = (tl_centripetal_loss + br_centripetal_loss) / 2.0
-
- return det_loss, off_loss, guiding_loss, centripetal_loss
-
- def get_bboxes(self,
- tl_heats,
- br_heats,
- tl_offs,
- br_offs,
- tl_guiding_shifts,
- br_guiding_shifts,
- tl_centripetal_shifts,
- br_centripetal_shifts,
- img_metas,
- rescale=False,
- with_nms=True):
- """Transform network output for a batch into bbox predictions.
-
- Args:
- tl_heats (list[Tensor]): Top-left corner heatmaps for each level
- with shape (N, num_classes, H, W).
- br_heats (list[Tensor]): Bottom-right corner heatmaps for each
- level with shape (N, num_classes, H, W).
- tl_offs (list[Tensor]): Top-left corner offsets for each level
- with shape (N, corner_offset_channels, H, W).
- br_offs (list[Tensor]): Bottom-right corner offsets for each level
- with shape (N, corner_offset_channels, H, W).
- tl_guiding_shifts (list[Tensor]): Top-left guiding shifts for each
- level with shape (N, guiding_shift_channels, H, W). Useless in
- this function, we keep this arg because it's the raw output
- from CentripetalHead.
- br_guiding_shifts (list[Tensor]): Bottom-right guiding shifts for
- each level with shape (N, guiding_shift_channels, H, W).
- Useless in this function, we keep this arg because it's the
- raw output from CentripetalHead.
- tl_centripetal_shifts (list[Tensor]): Top-left centripetal shifts
- for each level with shape (N, centripetal_shift_channels, H,
- W).
- br_centripetal_shifts (list[Tensor]): Bottom-right centripetal
- shifts for each level with shape (N,
- centripetal_shift_channels, H, W).
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- rescale (bool): If True, return boxes in original image space.
- Default: False.
- with_nms (bool): If True, do nms before return boxes.
- Default: True.
- """
- assert tl_heats[-1].shape[0] == br_heats[-1].shape[0] == len(img_metas)
- result_list = []
- for img_id in range(len(img_metas)):
- result_list.append(
- self._get_bboxes_single(
- tl_heats[-1][img_id:img_id + 1, :],
- br_heats[-1][img_id:img_id + 1, :],
- tl_offs[-1][img_id:img_id + 1, :],
- br_offs[-1][img_id:img_id + 1, :],
- img_metas[img_id],
- tl_emb=None,
- br_emb=None,
- tl_centripetal_shift=tl_centripetal_shifts[-1][
- img_id:img_id + 1, :],
- br_centripetal_shift=br_centripetal_shifts[-1][
- img_id:img_id + 1, :],
- rescale=rescale,
- with_nms=with_nms))
-
- return result_list
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/datasets/cityscapes.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/datasets/cityscapes.py
deleted file mode 100644
index 81e47a914a1aa2e5458e18669d65ffb742f46fc6..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/datasets/cityscapes.py
+++ /dev/null
@@ -1,217 +0,0 @@
-import os.path as osp
-import tempfile
-
-import annotator.uniformer.mmcv as mmcv
-import numpy as np
-from annotator.uniformer.mmcv.utils import print_log
-from PIL import Image
-
-from .builder import DATASETS
-from .custom import CustomDataset
-
-
-@DATASETS.register_module()
-class CityscapesDataset(CustomDataset):
- """Cityscapes dataset.
-
- The ``img_suffix`` is fixed to '_leftImg8bit.png' and ``seg_map_suffix`` is
- fixed to '_gtFine_labelTrainIds.png' for Cityscapes dataset.
- """
-
- CLASSES = ('road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
- 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky',
- 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle',
- 'bicycle')
-
- PALETTE = [[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
- [190, 153, 153], [153, 153, 153], [250, 170, 30], [220, 220, 0],
- [107, 142, 35], [152, 251, 152], [70, 130, 180], [220, 20, 60],
- [255, 0, 0], [0, 0, 142], [0, 0, 70], [0, 60, 100],
- [0, 80, 100], [0, 0, 230], [119, 11, 32]]
-
- def __init__(self, **kwargs):
- super(CityscapesDataset, self).__init__(
- img_suffix='_leftImg8bit.png',
- seg_map_suffix='_gtFine_labelTrainIds.png',
- **kwargs)
-
- @staticmethod
- def _convert_to_label_id(result):
- """Convert trainId to id for cityscapes."""
- if isinstance(result, str):
- result = np.load(result)
- import cityscapesscripts.helpers.labels as CSLabels
- result_copy = result.copy()
- for trainId, label in CSLabels.trainId2label.items():
- result_copy[result == trainId] = label.id
-
- return result_copy
-
- def results2img(self, results, imgfile_prefix, to_label_id):
- """Write the segmentation results to images.
-
- Args:
- results (list[list | tuple | ndarray]): Testing results of the
- dataset.
- imgfile_prefix (str): The filename prefix of the png files.
- If the prefix is "somepath/xxx",
- the png files will be named "somepath/xxx.png".
- to_label_id (bool): whether convert output to label_id for
- submission
-
- Returns:
- list[str: str]: result txt files which contains corresponding
- semantic segmentation images.
- """
- mmcv.mkdir_or_exist(imgfile_prefix)
- result_files = []
- prog_bar = mmcv.ProgressBar(len(self))
- for idx in range(len(self)):
- result = results[idx]
- if to_label_id:
- result = self._convert_to_label_id(result)
- filename = self.img_infos[idx]['filename']
- basename = osp.splitext(osp.basename(filename))[0]
-
- png_filename = osp.join(imgfile_prefix, f'{basename}.png')
-
- output = Image.fromarray(result.astype(np.uint8)).convert('P')
- import cityscapesscripts.helpers.labels as CSLabels
- palette = np.zeros((len(CSLabels.id2label), 3), dtype=np.uint8)
- for label_id, label in CSLabels.id2label.items():
- palette[label_id] = label.color
-
- output.putpalette(palette)
- output.save(png_filename)
- result_files.append(png_filename)
- prog_bar.update()
-
- return result_files
-
- def format_results(self, results, imgfile_prefix=None, to_label_id=True):
- """Format the results into dir (standard format for Cityscapes
- evaluation).
-
- Args:
- results (list): Testing results of the dataset.
- imgfile_prefix (str | None): The prefix of images files. It
- includes the file path and the prefix of filename, e.g.,
- "a/b/prefix". If not specified, a temp file will be created.
- Default: None.
- to_label_id (bool): whether convert output to label_id for
- submission. Default: False
-
- Returns:
- tuple: (result_files, tmp_dir), result_files is a list containing
- the image paths, tmp_dir is the temporal directory created
- for saving json/png files when img_prefix is not specified.
- """
-
- assert isinstance(results, list), 'results must be a list'
- assert len(results) == len(self), (
- 'The length of results is not equal to the dataset len: '
- f'{len(results)} != {len(self)}')
-
- if imgfile_prefix is None:
- tmp_dir = tempfile.TemporaryDirectory()
- imgfile_prefix = tmp_dir.name
- else:
- tmp_dir = None
- result_files = self.results2img(results, imgfile_prefix, to_label_id)
-
- return result_files, tmp_dir
-
- def evaluate(self,
- results,
- metric='mIoU',
- logger=None,
- imgfile_prefix=None,
- efficient_test=False):
- """Evaluation in Cityscapes/default protocol.
-
- Args:
- results (list): Testing results of the dataset.
- metric (str | list[str]): Metrics to be evaluated.
- logger (logging.Logger | None | str): Logger used for printing
- related information during evaluation. Default: None.
- imgfile_prefix (str | None): The prefix of output image file,
- for cityscapes evaluation only. It includes the file path and
- the prefix of filename, e.g., "a/b/prefix".
- If results are evaluated with cityscapes protocol, it would be
- the prefix of output png files. The output files would be
- png images under folder "a/b/prefix/xxx.png", where "xxx" is
- the image name of cityscapes. If not specified, a temp file
- will be created for evaluation.
- Default: None.
-
- Returns:
- dict[str, float]: Cityscapes/default metrics.
- """
-
- eval_results = dict()
- metrics = metric.copy() if isinstance(metric, list) else [metric]
- if 'cityscapes' in metrics:
- eval_results.update(
- self._evaluate_cityscapes(results, logger, imgfile_prefix))
- metrics.remove('cityscapes')
- if len(metrics) > 0:
- eval_results.update(
- super(CityscapesDataset,
- self).evaluate(results, metrics, logger, efficient_test))
-
- return eval_results
-
- def _evaluate_cityscapes(self, results, logger, imgfile_prefix):
- """Evaluation in Cityscapes protocol.
-
- Args:
- results (list): Testing results of the dataset.
- logger (logging.Logger | str | None): Logger used for printing
- related information during evaluation. Default: None.
- imgfile_prefix (str | None): The prefix of output image file
-
- Returns:
- dict[str: float]: Cityscapes evaluation results.
- """
- try:
- import cityscapesscripts.evaluation.evalPixelLevelSemanticLabeling as CSEval # noqa
- except ImportError:
- raise ImportError('Please run "pip install cityscapesscripts" to '
- 'install cityscapesscripts first.')
- msg = 'Evaluating in Cityscapes style'
- if logger is None:
- msg = '\n' + msg
- print_log(msg, logger=logger)
-
- result_files, tmp_dir = self.format_results(results, imgfile_prefix)
-
- if tmp_dir is None:
- result_dir = imgfile_prefix
- else:
- result_dir = tmp_dir.name
-
- eval_results = dict()
- print_log(f'Evaluating results under {result_dir} ...', logger=logger)
-
- CSEval.args.evalInstLevelScore = True
- CSEval.args.predictionPath = osp.abspath(result_dir)
- CSEval.args.evalPixelAccuracy = True
- CSEval.args.JSONOutput = False
-
- seg_map_list = []
- pred_list = []
-
- # when evaluating with official cityscapesscripts,
- # **_gtFine_labelIds.png is used
- for seg_map in mmcv.scandir(
- self.ann_dir, 'gtFine_labelIds.png', recursive=True):
- seg_map_list.append(osp.join(self.ann_dir, seg_map))
- pred_list.append(CSEval.getPrediction(CSEval.args, seg_map))
-
- eval_results.update(
- CSEval.evaluateImgLists(pred_list, seg_map_list, CSEval.args))
-
- if tmp_dir is not None:
- tmp_dir.cleanup()
-
- return eval_results
diff --git a/spaces/SarthakSidhant/Go-Cattle/diseases/urinary calculi.md b/spaces/SarthakSidhant/Go-Cattle/diseases/urinary calculi.md
deleted file mode 100644
index 614e578529cde52eb87d32b77486a7195448af33..0000000000000000000000000000000000000000
--- a/spaces/SarthakSidhant/Go-Cattle/diseases/urinary calculi.md
+++ /dev/null
@@ -1,41 +0,0 @@
-## Urinary calculi
-
-**Information** : Urinary calculi, also known as bladder stones, are hard deposits that form in the urinary tract. They can be made up of different materials, including calcium, struvite, and oxalate.
-
-**Symptoms**
-
-The symptoms of urinary calculi can vary depending on the size and location of the stones. Some animals with urinary calculi may show no symptoms at all, while others may develop a range of symptoms, including:
-
-* Difficulty urinating
-* Painful urination
-* Blood in the urine
-* Increased thirst
-* Decreased appetite
-* Weight loss
-* Depression
-* Lethargy
-* Swelling of the abdomen
-
-**Remedies**
-
-The treatment for urinary calculi depends on the size and location of the stones. Some animals may be able to pass the stones on their own, while others may need surgery to remove the stones.
-
-**Causes**
-
-The exact causes of urinary calculi are not fully understood. However, there are a number of factors that are thought to increase the risk of urinary calculi in cattle, including:
-
-* Diet
-* Genetics
-* Dehydration
-* Bacterial infections
-* Certain medical conditions, such as bladder infections and kidney diseases
-
-**Prevention**
-
-There is no sure way to prevent urinary calculi in cattle. However, there are a number of preventive measures that can be taken to reduce the risk, such as:
-
-* Providing cattle with a balanced diet that is low in calcium and oxalate
-* Making sure that cattle have access to clean, fresh water at all times
-* Vaccinating cattle against bacterial infections that can cause urinary tract infections
-* Treating cattle for any underlying medical conditions that may increase the risk of urinary calculi
-
diff --git a/spaces/SaulLu/test-demo/_site/404.html b/spaces/SaulLu/test-demo/_site/404.html
deleted file mode 100644
index 9af7ae384911759ca8416b905cea3266d9e37ba6..0000000000000000000000000000000000000000
--- a/spaces/SaulLu/test-demo/_site/404.html
+++ /dev/null
@@ -1,86 +0,0 @@
-
-
-
-
-
-Your awesome title | Write an awesome description for your new site here. You can edit this line in _config.yml. It will appear in your document head meta (for Google search results) and in your feed.xml site description.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 404
-
- Page not found :(
- The requested page could not be found.
-
-
-
-
-
-
-
diff --git a/spaces/SceneDiffuser/SceneDiffuserDemo/app.py b/spaces/SceneDiffuser/SceneDiffuserDemo/app.py
deleted file mode 100644
index 007d6a1a480fb803e0eefacda5aaa2c75ea6ced7..0000000000000000000000000000000000000000
--- a/spaces/SceneDiffuser/SceneDiffuserDemo/app.py
+++ /dev/null
@@ -1,95 +0,0 @@
-import os
-os.environ['RENDERING_BACKEND'] = "osmesa"
-import sys
-root_dir = os.path.dirname(os.path.abspath(__file__))
-sys.path.insert(1, os.path.join(root_dir, 'scenediffuser'))
-import gradio as gr
-import interface as IF
-
-with gr.Blocks(css='style.css') as demo:
- with gr.Column(elem_id="col-container"):
- gr.Markdown("Diffusion-based Generation, Optimization, and Planning in 3D Scenes
")
- gr.HTML(value=" ")
- gr.HTML(value="
")
- gr.HTML(value="arXiv | Project Page | Code
")
- gr.Markdown("\"SceneDiffuser provides a unified model for solving scene-conditioned generation, optimization, and planning.\"
")
-
- ## five tasks
- ## pose generation
- with gr.Tab("Pose Generation"):
- with gr.Row():
- with gr.Column(scale=2):
- selector1 = gr.Dropdown(choices=['MPH16', 'MPH1Library', 'N0SittingBooth', 'N3OpenArea'], label='Scenes', value='MPH16', interactive=True)
- with gr.Row():
- sample1 = gr.Slider(minimum=1, maximum=8, step=1, label='Count', interactive=True, value=1)
- seed1 = gr.Slider(minimum=0, maximum=2 ** 16, step=1, label='Seed', interactive=True, value=2023)
- opt1 = gr.Checkbox(label='Optimizer Guidance', interactive=True, value=True)
- scale1 = gr.Slider(minimum=0.1, maximum=9.9, step=0.1, label='Scale', interactive=True, value=1.1)
- button1 = gr.Button("Run")
- with gr.Column(scale=3):
- image1 = gr.Gallery(label="Image [Result]").style(grid=[1], height="50")
- # model1 = gr.Model3D(clear_color=[255, 255, 255, 255], label="3D Model [Result]")
- input1 = [selector1, sample1, seed1, opt1, scale1]
- button1.click(IF.pose_generation, inputs=input1, outputs=[image1])
-
- ## motion generation
- with gr.Tab("Motion Generation"):
- with gr.Row():
- with gr.Column(scale=2):
- selector2 = gr.Dropdown(choices=['MPH16', 'MPH1Library', 'N0SittingBooth', 'N3OpenArea'], label='Scenes', value='MPH16', interactive=True)
- with gr.Row():
- sample2 = gr.Slider(minimum=1, maximum=2, step=1, label='Count', interactive=True, value=1)
- seed2 = gr.Slider(minimum=0, maximum=2 ** 16, step=1, label='Seed', interactive=True, value=2023)
- with gr.Row():
- withstart = gr.Checkbox(label='With Start', interactive=True, value=False)
- opt2 = gr.Checkbox(label='Optimizer Guidance', interactive=True, value=False)
- scale_opt2 = gr.Slider(minimum=0.1, maximum=9.9, step=0.1, label='Scale', interactive=True, value=1.1)
- button2 = gr.Button("Run")
- with gr.Column(scale=3):
- image2 = gr.Gallery(label="Image [Result]").style(grid=[1], height="50")
- gr.HTML("Notes: For motion generation, it will take a long time to do sampleing and rendering, especifically when you tick optimizer guidance.
")
- input2 = [selector2, sample2, seed2, withstart, opt2, scale_opt2]
- button2.click(IF.motion_generation, inputs=input2, outputs=image2)
-
- ## grasp generation
- with gr.Tab("Grasp Generation"):
- with gr.Row():
- with gr.Column(scale=2):
- input3 = [
- gr.Dropdown(choices=['contactdb+apple', 'contactdb+camera', 'contactdb+cylinder_medium', 'contactdb+door_knob', 'contactdb+rubber_duck', 'contactdb+water_bottle', 'ycb+baseball', 'ycb+pear', 'ycb+potted_meat_can', 'ycb+tomato_soup_can'], label='Objects')
- ]
- button3 = gr.Button("Run")
- gr.HTML("Notes: the output results are pre-sampled results. We will deploy a real-time model for this task soon.
")
- with gr.Column(scale=3):
- output3 = [
- gr.Model3D(clear_color=[255, 255, 255, 255], label="Result")
- ]
- button3.click(IF.grasp_generation, inputs=input3, outputs=output3)
-
- ## path planning
- with gr.Tab("Path Planing"):
- with gr.Row():
- with gr.Column(scale=2):
- selector4 = gr.Dropdown(choices=['scene0603_00', 'scene0621_00', 'scene0626_00', 'scene0634_00', 'scene0637_00', 'scene0640_00', 'scene0641_00', 'scene0645_00', 'scene0653_00', 'scene0667_00', 'scene0672_00', 'scene0673_00', 'scene0678_00', 'scene0694_00', 'scene0698_00'], label='Scenes', value='scene0621_00', interactive=True)
- mode4 = gr.Radio(choices=['Sampling', 'Planning'], value='Sampling', label='Mode', interactive=True)
- with gr.Row():
- sample4 = gr.Slider(minimum=1, maximum=8, step=1, label='Count', interactive=True, value=1)
- seed4 = gr.Slider(minimum=0, maximum=2 ** 16, step=1, label='Seed', interactive=True, value=2023)
- with gr.Box():
- opt4 = gr.Checkbox(label='Optimizer Guidance', interactive=True, value=True)
- scale_opt4 = gr.Slider(minimum=0.02, maximum=4.98, step=0.02, label='Scale', interactive=True, value=1.0)
- with gr.Box():
- pla4 = gr.Checkbox(label='Planner Guidance', interactive=True, value=True)
- scale_pla4 = gr.Slider(minimum=0.02, maximum=0.98, step=0.02, label='Scale', interactive=True, value=0.2)
- button4 = gr.Button("Run")
- with gr.Column(scale=3):
- image4 = gr.Gallery(label="Image [Result]").style(grid=[1], height="50")
- number4 = gr.Number(label="Steps", precision=0)
- gr.HTML("Notes: 1. It may take a long time to do planning in Planning mode. 2. The red balls represent the planning result, starting with the lightest red ball and ending with the darkest red ball. The green ball indicates the target position.
")
- input4 = [selector4, mode4, sample4, seed4, opt4, scale_opt4, pla4, scale_pla4]
- button4.click(IF.path_planning, inputs=input4, outputs=[image4, number4])
-
- ## arm motion planning
- with gr.Tab("Arm Motion Planning"):
- gr.Markdown('Coming soon!')
-
-demo.launch()
diff --git a/spaces/SuYuanS/AudioCraft_Plus/tests/models/test_musicgen.py b/spaces/SuYuanS/AudioCraft_Plus/tests/models/test_musicgen.py
deleted file mode 100644
index 65618a9e2ef5bb382694b50b23dd50958d590d4e..0000000000000000000000000000000000000000
--- a/spaces/SuYuanS/AudioCraft_Plus/tests/models/test_musicgen.py
+++ /dev/null
@@ -1,58 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import pytest
-import torch
-
-from audiocraft.models import MusicGen
-
-
-class TestMusicGenModel:
- def get_musicgen(self):
- mg = MusicGen.get_pretrained(name='debug', device='cpu')
- mg.set_generation_params(duration=2.0, extend_stride=2.)
- return mg
-
- def test_base(self):
- mg = self.get_musicgen()
- assert mg.frame_rate == 25
- assert mg.sample_rate == 32000
- assert mg.audio_channels == 1
-
- def test_generate_unconditional(self):
- mg = self.get_musicgen()
- wav = mg.generate_unconditional(3)
- assert list(wav.shape) == [3, 1, 64000]
-
- def test_generate_continuation(self):
- mg = self.get_musicgen()
- prompt = torch.randn(3, 1, 32000)
- wav = mg.generate_continuation(prompt, 32000)
- assert list(wav.shape) == [3, 1, 64000]
-
- prompt = torch.randn(2, 1, 32000)
- wav = mg.generate_continuation(
- prompt, 32000, ['youpi', 'lapin dort'])
- assert list(wav.shape) == [2, 1, 64000]
-
- prompt = torch.randn(2, 1, 32000)
- with pytest.raises(AssertionError):
- wav = mg.generate_continuation(
- prompt, 32000, ['youpi', 'lapin dort', 'one too many'])
-
- def test_generate(self):
- mg = self.get_musicgen()
- wav = mg.generate(
- ['youpi', 'lapin dort'])
- assert list(wav.shape) == [2, 1, 64000]
-
- def test_generate_long(self):
- mg = self.get_musicgen()
- mg.max_duration = 3.
- mg.set_generation_params(duration=4., extend_stride=2.)
- wav = mg.generate(
- ['youpi', 'lapin dort'])
- assert list(wav.shape) == [2, 1, 32000 * 4]
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/lib/tests/test_pygments.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/lib/tests/test_pygments.py
deleted file mode 100644
index 877b4221ffe5a46f22e38305cb845818578918c4..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/lib/tests/test_pygments.py
+++ /dev/null
@@ -1,26 +0,0 @@
-from typing import List
-
-import pytest
-import pygments.lexers
-import pygments.lexer
-
-from IPython.lib.lexers import IPythonConsoleLexer, IPythonLexer, IPython3Lexer
-
-#: the human-readable names of the IPython lexers with ``entry_points``
-EXPECTED_LEXER_NAMES = [
- cls.name for cls in [IPythonConsoleLexer, IPythonLexer, IPython3Lexer]
-]
-
-
-@pytest.fixture
-def all_pygments_lexer_names() -> List[str]:
- """Get all lexer names registered in pygments."""
- return {l[0] for l in pygments.lexers.get_all_lexers()}
-
-
-@pytest.mark.parametrize("expected_lexer", EXPECTED_LEXER_NAMES)
-def test_pygments_entry_points(
- expected_lexer: str, all_pygments_lexer_names: List[str]
-) -> None:
- """Check whether the ``entry_points`` for ``pygments.lexers`` are correct."""
- assert expected_lexer in all_pygments_lexer_names
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/PIL/ImImagePlugin.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/PIL/ImImagePlugin.py
deleted file mode 100644
index 746743f658cf3fa2e0022ae049808eb68d3d1221..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/PIL/ImImagePlugin.py
+++ /dev/null
@@ -1,371 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# IFUNC IM file handling for PIL
-#
-# history:
-# 1995-09-01 fl Created.
-# 1997-01-03 fl Save palette images
-# 1997-01-08 fl Added sequence support
-# 1997-01-23 fl Added P and RGB save support
-# 1997-05-31 fl Read floating point images
-# 1997-06-22 fl Save floating point images
-# 1997-08-27 fl Read and save 1-bit images
-# 1998-06-25 fl Added support for RGB+LUT images
-# 1998-07-02 fl Added support for YCC images
-# 1998-07-15 fl Renamed offset attribute to avoid name clash
-# 1998-12-29 fl Added I;16 support
-# 2001-02-17 fl Use 're' instead of 'regex' (Python 2.1) (0.7)
-# 2003-09-26 fl Added LA/PA support
-#
-# Copyright (c) 1997-2003 by Secret Labs AB.
-# Copyright (c) 1995-2001 by Fredrik Lundh.
-#
-# See the README file for information on usage and redistribution.
-#
-
-
-import os
-import re
-
-from . import Image, ImageFile, ImagePalette
-
-# --------------------------------------------------------------------
-# Standard tags
-
-COMMENT = "Comment"
-DATE = "Date"
-EQUIPMENT = "Digitalization equipment"
-FRAMES = "File size (no of images)"
-LUT = "Lut"
-NAME = "Name"
-SCALE = "Scale (x,y)"
-SIZE = "Image size (x*y)"
-MODE = "Image type"
-
-TAGS = {
- COMMENT: 0,
- DATE: 0,
- EQUIPMENT: 0,
- FRAMES: 0,
- LUT: 0,
- NAME: 0,
- SCALE: 0,
- SIZE: 0,
- MODE: 0,
-}
-
-OPEN = {
- # ifunc93/p3cfunc formats
- "0 1 image": ("1", "1"),
- "L 1 image": ("1", "1"),
- "Greyscale image": ("L", "L"),
- "Grayscale image": ("L", "L"),
- "RGB image": ("RGB", "RGB;L"),
- "RLB image": ("RGB", "RLB"),
- "RYB image": ("RGB", "RLB"),
- "B1 image": ("1", "1"),
- "B2 image": ("P", "P;2"),
- "B4 image": ("P", "P;4"),
- "X 24 image": ("RGB", "RGB"),
- "L 32 S image": ("I", "I;32"),
- "L 32 F image": ("F", "F;32"),
- # old p3cfunc formats
- "RGB3 image": ("RGB", "RGB;T"),
- "RYB3 image": ("RGB", "RYB;T"),
- # extensions
- "LA image": ("LA", "LA;L"),
- "PA image": ("LA", "PA;L"),
- "RGBA image": ("RGBA", "RGBA;L"),
- "RGBX image": ("RGBX", "RGBX;L"),
- "CMYK image": ("CMYK", "CMYK;L"),
- "YCC image": ("YCbCr", "YCbCr;L"),
-}
-
-# ifunc95 extensions
-for i in ["8", "8S", "16", "16S", "32", "32F"]:
- OPEN[f"L {i} image"] = ("F", f"F;{i}")
- OPEN[f"L*{i} image"] = ("F", f"F;{i}")
-for i in ["16", "16L", "16B"]:
- OPEN[f"L {i} image"] = (f"I;{i}", f"I;{i}")
- OPEN[f"L*{i} image"] = (f"I;{i}", f"I;{i}")
-for i in ["32S"]:
- OPEN[f"L {i} image"] = ("I", f"I;{i}")
- OPEN[f"L*{i} image"] = ("I", f"I;{i}")
-for i in range(2, 33):
- OPEN[f"L*{i} image"] = ("F", f"F;{i}")
-
-
-# --------------------------------------------------------------------
-# Read IM directory
-
-split = re.compile(rb"^([A-Za-z][^:]*):[ \t]*(.*)[ \t]*$")
-
-
-def number(s):
- try:
- return int(s)
- except ValueError:
- return float(s)
-
-
-##
-# Image plugin for the IFUNC IM file format.
-
-
-class ImImageFile(ImageFile.ImageFile):
- format = "IM"
- format_description = "IFUNC Image Memory"
- _close_exclusive_fp_after_loading = False
-
- def _open(self):
- # Quick rejection: if there's not an LF among the first
- # 100 bytes, this is (probably) not a text header.
-
- if b"\n" not in self.fp.read(100):
- msg = "not an IM file"
- raise SyntaxError(msg)
- self.fp.seek(0)
-
- n = 0
-
- # Default values
- self.info[MODE] = "L"
- self.info[SIZE] = (512, 512)
- self.info[FRAMES] = 1
-
- self.rawmode = "L"
-
- while True:
- s = self.fp.read(1)
-
- # Some versions of IFUNC uses \n\r instead of \r\n...
- if s == b"\r":
- continue
-
- if not s or s == b"\0" or s == b"\x1A":
- break
-
- # FIXME: this may read whole file if not a text file
- s = s + self.fp.readline()
-
- if len(s) > 100:
- msg = "not an IM file"
- raise SyntaxError(msg)
-
- if s[-2:] == b"\r\n":
- s = s[:-2]
- elif s[-1:] == b"\n":
- s = s[:-1]
-
- try:
- m = split.match(s)
- except re.error as e:
- msg = "not an IM file"
- raise SyntaxError(msg) from e
-
- if m:
- k, v = m.group(1, 2)
-
- # Don't know if this is the correct encoding,
- # but a decent guess (I guess)
- k = k.decode("latin-1", "replace")
- v = v.decode("latin-1", "replace")
-
- # Convert value as appropriate
- if k in [FRAMES, SCALE, SIZE]:
- v = v.replace("*", ",")
- v = tuple(map(number, v.split(",")))
- if len(v) == 1:
- v = v[0]
- elif k == MODE and v in OPEN:
- v, self.rawmode = OPEN[v]
-
- # Add to dictionary. Note that COMMENT tags are
- # combined into a list of strings.
- if k == COMMENT:
- if k in self.info:
- self.info[k].append(v)
- else:
- self.info[k] = [v]
- else:
- self.info[k] = v
-
- if k in TAGS:
- n += 1
-
- else:
- msg = "Syntax error in IM header: " + s.decode("ascii", "replace")
- raise SyntaxError(msg)
-
- if not n:
- msg = "Not an IM file"
- raise SyntaxError(msg)
-
- # Basic attributes
- self._size = self.info[SIZE]
- self.mode = self.info[MODE]
-
- # Skip forward to start of image data
- while s and s[:1] != b"\x1A":
- s = self.fp.read(1)
- if not s:
- msg = "File truncated"
- raise SyntaxError(msg)
-
- if LUT in self.info:
- # convert lookup table to palette or lut attribute
- palette = self.fp.read(768)
- greyscale = 1 # greyscale palette
- linear = 1 # linear greyscale palette
- for i in range(256):
- if palette[i] == palette[i + 256] == palette[i + 512]:
- if palette[i] != i:
- linear = 0
- else:
- greyscale = 0
- if self.mode in ["L", "LA", "P", "PA"]:
- if greyscale:
- if not linear:
- self.lut = list(palette[:256])
- else:
- if self.mode in ["L", "P"]:
- self.mode = self.rawmode = "P"
- elif self.mode in ["LA", "PA"]:
- self.mode = "PA"
- self.rawmode = "PA;L"
- self.palette = ImagePalette.raw("RGB;L", palette)
- elif self.mode == "RGB":
- if not greyscale or not linear:
- self.lut = list(palette)
-
- self.frame = 0
-
- self.__offset = offs = self.fp.tell()
-
- self._fp = self.fp # FIXME: hack
-
- if self.rawmode[:2] == "F;":
- # ifunc95 formats
- try:
- # use bit decoder (if necessary)
- bits = int(self.rawmode[2:])
- if bits not in [8, 16, 32]:
- self.tile = [("bit", (0, 0) + self.size, offs, (bits, 8, 3, 0, -1))]
- return
- except ValueError:
- pass
-
- if self.rawmode in ["RGB;T", "RYB;T"]:
- # Old LabEye/3PC files. Would be very surprised if anyone
- # ever stumbled upon such a file ;-)
- size = self.size[0] * self.size[1]
- self.tile = [
- ("raw", (0, 0) + self.size, offs, ("G", 0, -1)),
- ("raw", (0, 0) + self.size, offs + size, ("R", 0, -1)),
- ("raw", (0, 0) + self.size, offs + 2 * size, ("B", 0, -1)),
- ]
- else:
- # LabEye/IFUNC files
- self.tile = [("raw", (0, 0) + self.size, offs, (self.rawmode, 0, -1))]
-
- @property
- def n_frames(self):
- return self.info[FRAMES]
-
- @property
- def is_animated(self):
- return self.info[FRAMES] > 1
-
- def seek(self, frame):
- if not self._seek_check(frame):
- return
-
- self.frame = frame
-
- if self.mode == "1":
- bits = 1
- else:
- bits = 8 * len(self.mode)
-
- size = ((self.size[0] * bits + 7) // 8) * self.size[1]
- offs = self.__offset + frame * size
-
- self.fp = self._fp
-
- self.tile = [("raw", (0, 0) + self.size, offs, (self.rawmode, 0, -1))]
-
- def tell(self):
- return self.frame
-
-
-#
-# --------------------------------------------------------------------
-# Save IM files
-
-
-SAVE = {
- # mode: (im type, raw mode)
- "1": ("0 1", "1"),
- "L": ("Greyscale", "L"),
- "LA": ("LA", "LA;L"),
- "P": ("Greyscale", "P"),
- "PA": ("LA", "PA;L"),
- "I": ("L 32S", "I;32S"),
- "I;16": ("L 16", "I;16"),
- "I;16L": ("L 16L", "I;16L"),
- "I;16B": ("L 16B", "I;16B"),
- "F": ("L 32F", "F;32F"),
- "RGB": ("RGB", "RGB;L"),
- "RGBA": ("RGBA", "RGBA;L"),
- "RGBX": ("RGBX", "RGBX;L"),
- "CMYK": ("CMYK", "CMYK;L"),
- "YCbCr": ("YCC", "YCbCr;L"),
-}
-
-
-def _save(im, fp, filename):
- try:
- image_type, rawmode = SAVE[im.mode]
- except KeyError as e:
- msg = f"Cannot save {im.mode} images as IM"
- raise ValueError(msg) from e
-
- frames = im.encoderinfo.get("frames", 1)
-
- fp.write(f"Image type: {image_type} image\r\n".encode("ascii"))
- if filename:
- # Each line must be 100 characters or less,
- # or: SyntaxError("not an IM file")
- # 8 characters are used for "Name: " and "\r\n"
- # Keep just the filename, ditch the potentially overlong path
- name, ext = os.path.splitext(os.path.basename(filename))
- name = "".join([name[: 92 - len(ext)], ext])
-
- fp.write(f"Name: {name}\r\n".encode("ascii"))
- fp.write(("Image size (x*y): %d*%d\r\n" % im.size).encode("ascii"))
- fp.write(f"File size (no of images): {frames}\r\n".encode("ascii"))
- if im.mode in ["P", "PA"]:
- fp.write(b"Lut: 1\r\n")
- fp.write(b"\000" * (511 - fp.tell()) + b"\032")
- if im.mode in ["P", "PA"]:
- im_palette = im.im.getpalette("RGB", "RGB;L")
- colors = len(im_palette) // 3
- palette = b""
- for i in range(3):
- palette += im_palette[colors * i : colors * (i + 1)]
- palette += b"\x00" * (256 - colors)
- fp.write(palette) # 768 bytes
- ImageFile._save(im, fp, [("raw", (0, 0) + im.size, 0, (rawmode, 0, -1))])
-
-
-#
-# --------------------------------------------------------------------
-# Registry
-
-
-Image.register_open(ImImageFile.format, ImImageFile)
-Image.register_save(ImImageFile.format, _save)
-
-Image.register_extension(ImImageFile.format, ".im")
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/backoff/_jitter.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/backoff/_jitter.py
deleted file mode 100644
index be7e38925ea857216c874dbbdd6aa1daa8b503f0..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/backoff/_jitter.py
+++ /dev/null
@@ -1,28 +0,0 @@
-# coding:utf-8
-
-import random
-
-
-def random_jitter(value: float) -> float:
- """Jitter the value a random number of milliseconds.
-
- This adds up to 1 second of additional time to the original value.
- Prior to backoff version 1.2 this was the default jitter behavior.
-
- Args:
- value: The unadulterated backoff value.
- """
- return value + random.random()
-
-
-def full_jitter(value: float) -> float:
- """Jitter the value across the full range (0 to value).
-
- This corresponds to the "Full Jitter" algorithm specified in the
- AWS blog's post on the performance of various jitter algorithms.
- (http://www.awsarchitectureblog.com/2015/03/backoff.html)
-
- Args:
- value: The unadulterated backoff value.
- """
- return random.uniform(0, value)
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/test/hnswlib/test_hnswlib.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/test/hnswlib/test_hnswlib.py
deleted file mode 100644
index 2039c67096646c73ee4aa43af93af23749b24c81..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/test/hnswlib/test_hnswlib.py
+++ /dev/null
@@ -1,67 +0,0 @@
-import os
-import shutil
-import tempfile
-from typing import Generator
-
-import pytest
-from chromadb.db.index.hnswlib import Hnswlib
-from chromadb.config import Settings
-import uuid
-import numpy as np
-
-
-@pytest.fixture(scope="module")
-def settings() -> Generator[Settings, None, None]:
- save_path = tempfile.gettempdir() + "/tests/hnswlib/"
- yield Settings(persist_directory=save_path)
- if os.path.exists(save_path):
- shutil.rmtree(save_path)
-
-
-def test_count_tracking(settings: Settings) -> None:
- hnswlib = Hnswlib("test", settings, {}, 2)
- hnswlib._init_index(2)
- assert hnswlib._index_metadata["curr_elements"] == 0
- assert hnswlib._index_metadata["total_elements_added"] == 0
- idA, idB = uuid.uuid4(), uuid.uuid4()
-
- embeddingA = np.random.rand(1, 2)
- hnswlib.add([idA], embeddingA.tolist())
- assert (
- hnswlib._index_metadata["curr_elements"]
- == hnswlib._index_metadata["total_elements_added"]
- == 1
- )
- embeddingB = np.random.rand(1, 2)
- hnswlib.add([idB], embeddingB.tolist())
- assert (
- hnswlib._index_metadata["curr_elements"]
- == hnswlib._index_metadata["total_elements_added"]
- == 2
- )
- hnswlib.delete_from_index(ids=[idA])
- assert hnswlib._index_metadata["curr_elements"] == 1
- assert hnswlib._index_metadata["total_elements_added"] == 2
- hnswlib.delete_from_index(ids=[idB])
- assert hnswlib._index_metadata["curr_elements"] == 0
- assert hnswlib._index_metadata["total_elements_added"] == 2
-
-
-def test_add_delete_large_amount(settings: Settings) -> None:
- # Test adding a large number of records
- N = 2000
- D = 512
- large_records = np.random.rand(N, D).astype(np.float32).tolist()
- ids = [uuid.uuid4() for _ in range(N)]
- hnswlib = Hnswlib("test", settings, {}, N)
- hnswlib._init_index(D)
- hnswlib.add(ids, large_records)
- assert hnswlib._index_metadata["curr_elements"] == N
- assert hnswlib._index_metadata["total_elements_added"] == N
-
- # Test deleting a large number of records by getting a random subset of the ids
- ids_to_delete = np.random.choice(np.array(ids), size=100, replace=False).tolist()
- hnswlib.delete_from_index(ids_to_delete)
-
- assert hnswlib._index_metadata["curr_elements"] == N - 100
- assert hnswlib._index_metadata["total_elements_added"] == N
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/documents/mesh/mesh_3d.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/documents/mesh/mesh_3d.py
deleted file mode 100644
index 82d93f73456ec52c8ace95591412c1059130b92f..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/documents/mesh/mesh_3d.py
+++ /dev/null
@@ -1,118 +0,0 @@
-from typing import Any, Optional, Type, TypeVar, Union
-
-from docarray.base_doc import BaseDoc
-from docarray.documents.mesh.vertices_and_faces import VerticesAndFaces
-from docarray.typing.tensor.embedding import AnyEmbedding
-from docarray.typing.url.url_3d.mesh_url import Mesh3DUrl
-
-T = TypeVar('T', bound='Mesh3D')
-
-
-class Mesh3D(BaseDoc):
- """
- Document for handling meshes for 3D data representation.
-
- A mesh is a representation for 3D data and contains vertices and faces information.
- Vertices are points in a 3D space, represented as a tensor of shape (n_points, 3).
- Faces are triangular surfaces that can be defined by three points in 3D space,
- corresponding to the three vertices of a triangle. Faces can be represented as a
- tensor of shape (n_faces, 3). Each number in that tensor refers to an index of a
- vertex in the tensor of vertices.
-
- The Mesh3D Document can contain:
-
- - an [`Mesh3DUrl`][docarray.typing.url.Mesh3DUrl] (`Mesh3D.url`)
- - a [`VerticesAndFaces`][docarray.documents.mesh.vertices_and_faces.VerticesAndFaces]
- object containing:
-
- - an [`AnyTensor`](../../../../api_references/typing/tensor/tensor) of
- vertices (`Mesh3D.tensors.vertices`)
- - an [`AnyTensor`](../../../../api_references/typing/tensor/tensor) of faces (`Mesh3D.tensors.faces`)
-
- - an [`AnyEmbedding`](../../../../api_references/typing/tensor/embedding) (`Mesh3D.embedding`)
- - a `bytes` object (`Mesh3D.bytes_`).
-
- You can use this Document directly:
-
- ```python
- from docarray.documents import Mesh3D
-
- # use it directly
- mesh = Mesh3D(url='https://people.sc.fsu.edu/~jburkardt/data/obj/al.obj')
- mesh.tensors = mesh.url.load()
- # model = MyEmbeddingModel()
- # mesh.embedding = model(mesh.tensors.vertices)
- ```
-
- You can extend this Document:
-
- ```python
- from docarray.documents import Mesh3D
- from docarray.typing import AnyEmbedding
- from typing import Optional
-
-
- # extend it
- class MyMesh3D(Mesh3D):
- name: Optional[str]
-
-
- mesh = MyMesh3D(url='https://people.sc.fsu.edu/~jburkardt/data/obj/al.obj')
- mesh.name = 'my first mesh'
- mesh.tensors = mesh.url.load()
- # model = MyEmbeddingModel()
- # mesh.embedding = model(mesh.vertices)
- ```
-
- You can use this Document for composition:
-
- ```python
- from docarray import BaseDoc
- from docarray.documents import Mesh3D, TextDoc
-
-
- # compose it
- class MultiModalDoc(BaseDoc):
- mesh: Mesh3D
- text: TextDoc
-
-
- mmdoc = MultiModalDoc(
- mesh=Mesh3D(url='https://people.sc.fsu.edu/~jburkardt/data/obj/al.obj'),
- text=TextDoc(text='hello world, how are you doing?'),
- )
- mmdoc.mesh.tensors = mmdoc.mesh.url.load()
-
- # or
- mmdoc.mesh.bytes_ = mmdoc.mesh.url.load_bytes()
- ```
-
- You can display your 3D mesh in a notebook from either its url, or its tensors:
-
- ```python
- from docarray.documents import Mesh3D
-
- # display from url
- mesh = Mesh3D(url='https://people.sc.fsu.edu/~jburkardt/data/obj/al.obj')
- # mesh.url.display()
-
- # display from tensors
- mesh.tensors = mesh.url.load()
- # mesh.tensors.display()
- ```
-
- """
-
- url: Optional[Mesh3DUrl]
- tensors: Optional[VerticesAndFaces]
- embedding: Optional[AnyEmbedding]
- bytes_: Optional[bytes]
-
- @classmethod
- def validate(
- cls: Type[T],
- value: Union[str, Any],
- ) -> T:
- if isinstance(value, str):
- value = cls(url=value)
- return super().validate(value)
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/store/file.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/store/file.py
deleted file mode 100644
index 6c46c3ab61595359422d5a51c65922b726c59b36..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/store/file.py
+++ /dev/null
@@ -1,199 +0,0 @@
-import logging
-from pathlib import Path
-from typing import Dict, Iterator, List, Optional, Type, TypeVar
-
-from typing_extensions import TYPE_CHECKING
-
-from docarray.store.abstract_doc_store import AbstractDocStore
-from docarray.store.exceptions import ConcurrentPushException
-from docarray.store.helpers import _from_binary_stream, _to_binary_stream
-from docarray.utils._internal.cache import _get_cache_path
-
-if TYPE_CHECKING:
- from docarray import BaseDoc, DocList
-
-SelfFileDocStore = TypeVar('SelfFileDocStore', bound='FileDocStore')
-
-
-class FileDocStore(AbstractDocStore):
- """Class to push and pull [`DocList`][docarray.DocList] on-disk."""
-
- @staticmethod
- def _abs_filepath(name: str) -> Path:
- """Resolve a name to an absolute path.
-
- :param name: If it is not a path, the cache directory is prepended.
- If it is a path, it is resolved to an absolute path.
- :return: Path
- """
- if not (name.startswith('/') or name.startswith('~') or name.startswith('.')):
- name = str(_get_cache_path() / name)
- if name.startswith('~'):
- name = str(Path.home() / name[2:])
- return Path(name).resolve()
-
- @classmethod
- def list(
- cls: Type[SelfFileDocStore], namespace: str, show_table: bool
- ) -> List[str]:
- """List all [`DocList`s][docarray.DocList] in a directory.
-
- :param namespace: The directory to list.
- :param show_table: If True, print a table of the files in the directory.
- :return: A list of the names of the `DocLists` in the directory.
- """
- namespace_dir = cls._abs_filepath(namespace)
- if not namespace_dir.exists():
- raise FileNotFoundError(f'Directory {namespace} does not exist')
- da_files = [dafile for dafile in namespace_dir.glob('*.docs')]
-
- if show_table:
- from datetime import datetime
-
- from rich import box, filesize
- from rich.console import Console
- from rich.table import Table
-
- table = Table(
- title=f'You have {len(da_files)} DocLists in file://{namespace_dir}',
- box=box.SIMPLE,
- highlight=True,
- )
- table.add_column('Name')
- table.add_column('Last Modified', justify='center')
- table.add_column('Size')
-
- for da_file in da_files:
- table.add_row(
- da_file.stem,
- str(datetime.fromtimestamp(int(da_file.stat().st_ctime))),
- str(filesize.decimal(da_file.stat().st_size)),
- )
-
- Console().print(table)
-
- return [dafile.stem for dafile in da_files]
-
- @classmethod
- def delete(
- cls: Type[SelfFileDocStore], name: str, missing_ok: bool = False
- ) -> bool:
- """Delete a [`DocList`][docarray.DocList] from the local filesystem.
-
- :param name: The name of the `DocList` to delete.
- :param missing_ok: If True, do not raise an exception if the file does not exist. Defaults to False.
- :return: True if the file was deleted, False if it did not exist.
- """
- path = cls._abs_filepath(name)
- try:
- path.with_suffix('.docs').unlink()
- return True
- except FileNotFoundError:
- if not missing_ok:
- raise
- return False
-
- @classmethod
- def push(
- cls: Type[SelfFileDocStore],
- docs: 'DocList',
- name: str,
- public: bool,
- show_progress: bool,
- branding: Optional[Dict],
- ) -> Dict:
- """Push this [`DocList`][docarray.DocList] object to the specified file path.
-
- :param docs: The `DocList` to push.
- :param name: The file path to push to.
- :param public: Not used by the ``file`` protocol.
- :param show_progress: If true, a progress bar will be displayed.
- :param branding: Not used by the ``file`` protocol.
- """
- return cls.push_stream(iter(docs), name, public, show_progress, branding)
-
- @classmethod
- def push_stream(
- cls: Type[SelfFileDocStore],
- docs: Iterator['BaseDoc'],
- name: str,
- public: bool = True,
- show_progress: bool = False,
- branding: Optional[Dict] = None,
- ) -> Dict:
- """Push a stream of documents to the specified file path.
-
- :param docs: a stream of documents
- :param name: The file path to push to.
- :param public: Not used by the ``file`` protocol.
- :param show_progress: If true, a progress bar will be displayed.
- :param branding: Not used by the ``file`` protocol.
- """
- if branding is not None:
- logging.warning('branding is not supported for "file" protocol')
-
- source = _to_binary_stream(
- docs, protocol='protobuf', compress='gzip', show_progress=show_progress
- )
- path = cls._abs_filepath(name).with_suffix('.docs.tmp')
- if path.exists():
- raise ConcurrentPushException(f'File {path} already exists.')
- with open(path, 'wb') as f:
- while True:
- try:
- f.write(next(source))
- except StopIteration:
- break
- path.rename(path.with_suffix(''))
- return {}
-
- @classmethod
- def pull(
- cls: Type[SelfFileDocStore],
- docs_cls: Type['DocList'],
- name: str,
- show_progress: bool,
- local_cache: bool,
- ) -> 'DocList':
- """Pull a [`DocList`][docarray.DocList] from the specified url.
-
- :param name: The file path to pull from.
- :param show_progress: if true, display a progress bar.
- :param local_cache: store the downloaded `DocList` to local folder
- :return: a `DocList` object
- """
-
- return docs_cls(
- cls.pull_stream(
- docs_cls, name, show_progress=show_progress, local_cache=local_cache
- )
- )
-
- @classmethod
- def pull_stream(
- cls: Type[SelfFileDocStore],
- docs_cls: Type['DocList'],
- name: str,
- show_progress: bool,
- local_cache: bool,
- ) -> Iterator['BaseDoc']:
- """Pull a stream of Documents from the specified file.
-
- :param name: The file path to pull from.
- :param show_progress: if true, display a progress bar.
- :param local_cache: Not used by the ``file`` protocol.
- :return: Iterator of Documents
- """
-
- if local_cache:
- logging.warning('local_cache is not supported for "file" protocol')
-
- path = cls._abs_filepath(name).with_suffix('.docs')
- source = open(path, 'rb')
- return _from_binary_stream(
- docs_cls.doc_type,
- source,
- protocol='protobuf',
- compress='gzip',
- show_progress=show_progress,
- )
diff --git a/spaces/TRI-ML/risk_biased_prediction/export_waymo_to_json.py b/spaces/TRI-ML/risk_biased_prediction/export_waymo_to_json.py
deleted file mode 100644
index face2c331e9806a6e0ca1c525d3e7d69f55ea9d2..0000000000000000000000000000000000000000
--- a/spaces/TRI-ML/risk_biased_prediction/export_waymo_to_json.py
+++ /dev/null
@@ -1,94 +0,0 @@
-import json
-from json import JSONEncoder
-from mmcv import Config
-import numpy
-import torch
-
-from risk_biased.utils.waymo_dataloader import WaymoDataloaders
-
-
-class NumpyArrayEncoder(JSONEncoder):
- def default(self, obj):
- if isinstance(obj, numpy.ndarray):
- return obj.tolist()
- return JSONEncoder.default(self, obj)
-
-if __name__ == "__main__":
- output_path = "../risk_biased_dataset/data.json"
- config_path = "risk_biased/config/waymo_config.py"
- cfg = Config.fromfile(config_path)
- dataloaders = WaymoDataloaders(cfg)
- sample_dataloader = dataloaders.sample_dataloader()
- (
- x,
- mask_x,
- y,
- mask_y,
- mask_loss,
- map_data,
- mask_map,
- offset,
- x_ego,
- y_ego,
- ) = sample_dataloader.collate_fn(sample_dataloader.dataset)
-
- batch_size, n_agents, n_timesteps_past, n_features = x.shape
- n_timesteps_future = y.shape[2]
- n_features_map = map_data.shape[3]
- n_features_offset = offset.shape[2]
-
- print(x.shape)
- print(mask_x.shape)
- print(y.shape)
- print(mask_y.shape)
- print(mask_loss.shape)
- print(map_data.shape)
- print(mask_map.shape)
- print(offset.shape)
- print(x_ego.shape)
- print(y_ego.shape)
-
-
- data = {"x": x.numpy(),
- "mask_x": mask_x.numpy(),
- "y": y.numpy(),
- "mask_y": mask_y.numpy(),
- "mask_loss": mask_loss.numpy(),
- "map_data": map_data.numpy(),
- "mask_map": mask_map.numpy(),
- "offset": offset.numpy(),
- "x_ego": x_ego.numpy(),
- "y_ego": y_ego.numpy(),
- }
-
- json_data = json.dumps(data, cls=NumpyArrayEncoder)
-
- with open(output_path, "w+") as f:
- f.write(json_data)
-
- with open(output_path, "r") as f:
- decoded = json.load(f)
-
- x_c = torch.from_numpy(numpy.array(decoded["x"]).astype(numpy.float32))
- mask_x_c = torch.from_numpy(numpy.array(decoded["mask_x"]).astype(numpy.bool_))
- y_c = torch.from_numpy(numpy.array(decoded["y"]).astype(numpy.float32))
- mask_y_c = torch.from_numpy(numpy.array(decoded["mask_y"]).astype(numpy.bool_))
- mask_loss_c = torch.from_numpy( numpy.array(decoded["mask_loss"]).astype(numpy.bool_))
- map_data_c = torch.from_numpy(numpy.array(decoded["map_data"]).astype(numpy.float32))
- mask_map_c = torch.from_numpy(numpy.array(decoded["mask_map"]).astype(numpy.bool_))
- offset_c = torch.from_numpy(numpy.array(decoded["offset"]).astype(numpy.float32))
- x_ego_c = torch.from_numpy(numpy.array(decoded["x_ego"]).astype(numpy.float32))
- y_ego_c = torch.from_numpy(numpy.array(decoded["y_ego"]).astype(numpy.float32))
-
- assert torch.allclose(x, x_c)
- assert torch.allclose(mask_x, mask_x_c)
- assert torch.allclose(y, y_c)
- assert torch.allclose(mask_y, mask_y_c)
- assert torch.allclose(mask_loss, mask_loss_c)
- assert torch.allclose(map_data, map_data_c)
- assert torch.allclose(mask_map, mask_map_c)
- assert torch.allclose(offset, offset_c)
- assert torch.allclose(x_ego, x_ego_c)
- assert torch.allclose(y_ego, y_ego_c)
-
- print("All good!")
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/syntax.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/syntax.py
deleted file mode 100644
index 570337664835d01904c8ff708626b447edc5640a..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/syntax.py
+++ /dev/null
@@ -1,948 +0,0 @@
-import os.path
-import platform
-import re
-import sys
-import textwrap
-from abc import ABC, abstractmethod
-from pathlib import Path
-from typing import (
- Any,
- Dict,
- Iterable,
- List,
- NamedTuple,
- Optional,
- Sequence,
- Set,
- Tuple,
- Type,
- Union,
-)
-
-from pip._vendor.pygments.lexer import Lexer
-from pip._vendor.pygments.lexers import get_lexer_by_name, guess_lexer_for_filename
-from pip._vendor.pygments.style import Style as PygmentsStyle
-from pip._vendor.pygments.styles import get_style_by_name
-from pip._vendor.pygments.token import (
- Comment,
- Error,
- Generic,
- Keyword,
- Name,
- Number,
- Operator,
- String,
- Token,
- Whitespace,
-)
-from pip._vendor.pygments.util import ClassNotFound
-
-from pip._vendor.rich.containers import Lines
-from pip._vendor.rich.padding import Padding, PaddingDimensions
-
-from ._loop import loop_first
-from .cells import cell_len
-from .color import Color, blend_rgb
-from .console import Console, ConsoleOptions, JustifyMethod, RenderResult
-from .jupyter import JupyterMixin
-from .measure import Measurement
-from .segment import Segment, Segments
-from .style import Style, StyleType
-from .text import Text
-
-TokenType = Tuple[str, ...]
-
-WINDOWS = platform.system() == "Windows"
-DEFAULT_THEME = "monokai"
-
-# The following styles are based on https://github.com/pygments/pygments/blob/master/pygments/formatters/terminal.py
-# A few modifications were made
-
-ANSI_LIGHT: Dict[TokenType, Style] = {
- Token: Style(),
- Whitespace: Style(color="white"),
- Comment: Style(dim=True),
- Comment.Preproc: Style(color="cyan"),
- Keyword: Style(color="blue"),
- Keyword.Type: Style(color="cyan"),
- Operator.Word: Style(color="magenta"),
- Name.Builtin: Style(color="cyan"),
- Name.Function: Style(color="green"),
- Name.Namespace: Style(color="cyan", underline=True),
- Name.Class: Style(color="green", underline=True),
- Name.Exception: Style(color="cyan"),
- Name.Decorator: Style(color="magenta", bold=True),
- Name.Variable: Style(color="red"),
- Name.Constant: Style(color="red"),
- Name.Attribute: Style(color="cyan"),
- Name.Tag: Style(color="bright_blue"),
- String: Style(color="yellow"),
- Number: Style(color="blue"),
- Generic.Deleted: Style(color="bright_red"),
- Generic.Inserted: Style(color="green"),
- Generic.Heading: Style(bold=True),
- Generic.Subheading: Style(color="magenta", bold=True),
- Generic.Prompt: Style(bold=True),
- Generic.Error: Style(color="bright_red"),
- Error: Style(color="red", underline=True),
-}
-
-ANSI_DARK: Dict[TokenType, Style] = {
- Token: Style(),
- Whitespace: Style(color="bright_black"),
- Comment: Style(dim=True),
- Comment.Preproc: Style(color="bright_cyan"),
- Keyword: Style(color="bright_blue"),
- Keyword.Type: Style(color="bright_cyan"),
- Operator.Word: Style(color="bright_magenta"),
- Name.Builtin: Style(color="bright_cyan"),
- Name.Function: Style(color="bright_green"),
- Name.Namespace: Style(color="bright_cyan", underline=True),
- Name.Class: Style(color="bright_green", underline=True),
- Name.Exception: Style(color="bright_cyan"),
- Name.Decorator: Style(color="bright_magenta", bold=True),
- Name.Variable: Style(color="bright_red"),
- Name.Constant: Style(color="bright_red"),
- Name.Attribute: Style(color="bright_cyan"),
- Name.Tag: Style(color="bright_blue"),
- String: Style(color="yellow"),
- Number: Style(color="bright_blue"),
- Generic.Deleted: Style(color="bright_red"),
- Generic.Inserted: Style(color="bright_green"),
- Generic.Heading: Style(bold=True),
- Generic.Subheading: Style(color="bright_magenta", bold=True),
- Generic.Prompt: Style(bold=True),
- Generic.Error: Style(color="bright_red"),
- Error: Style(color="red", underline=True),
-}
-
-RICH_SYNTAX_THEMES = {"ansi_light": ANSI_LIGHT, "ansi_dark": ANSI_DARK}
-NUMBERS_COLUMN_DEFAULT_PADDING = 2
-
-
-class SyntaxTheme(ABC):
- """Base class for a syntax theme."""
-
- @abstractmethod
- def get_style_for_token(self, token_type: TokenType) -> Style:
- """Get a style for a given Pygments token."""
- raise NotImplementedError # pragma: no cover
-
- @abstractmethod
- def get_background_style(self) -> Style:
- """Get the background color."""
- raise NotImplementedError # pragma: no cover
-
-
-class PygmentsSyntaxTheme(SyntaxTheme):
- """Syntax theme that delegates to Pygments theme."""
-
- def __init__(self, theme: Union[str, Type[PygmentsStyle]]) -> None:
- self._style_cache: Dict[TokenType, Style] = {}
- if isinstance(theme, str):
- try:
- self._pygments_style_class = get_style_by_name(theme)
- except ClassNotFound:
- self._pygments_style_class = get_style_by_name("default")
- else:
- self._pygments_style_class = theme
-
- self._background_color = self._pygments_style_class.background_color
- self._background_style = Style(bgcolor=self._background_color)
-
- def get_style_for_token(self, token_type: TokenType) -> Style:
- """Get a style from a Pygments class."""
- try:
- return self._style_cache[token_type]
- except KeyError:
- try:
- pygments_style = self._pygments_style_class.style_for_token(token_type)
- except KeyError:
- style = Style.null()
- else:
- color = pygments_style["color"]
- bgcolor = pygments_style["bgcolor"]
- style = Style(
- color="#" + color if color else "#000000",
- bgcolor="#" + bgcolor if bgcolor else self._background_color,
- bold=pygments_style["bold"],
- italic=pygments_style["italic"],
- underline=pygments_style["underline"],
- )
- self._style_cache[token_type] = style
- return style
-
- def get_background_style(self) -> Style:
- return self._background_style
-
-
-class ANSISyntaxTheme(SyntaxTheme):
- """Syntax theme to use standard colors."""
-
- def __init__(self, style_map: Dict[TokenType, Style]) -> None:
- self.style_map = style_map
- self._missing_style = Style.null()
- self._background_style = Style.null()
- self._style_cache: Dict[TokenType, Style] = {}
-
- def get_style_for_token(self, token_type: TokenType) -> Style:
- """Look up style in the style map."""
- try:
- return self._style_cache[token_type]
- except KeyError:
- # Styles form a hierarchy
- # We need to go from most to least specific
- # e.g. ("foo", "bar", "baz") to ("foo", "bar") to ("foo",)
- get_style = self.style_map.get
- token = tuple(token_type)
- style = self._missing_style
- while token:
- _style = get_style(token)
- if _style is not None:
- style = _style
- break
- token = token[:-1]
- self._style_cache[token_type] = style
- return style
-
- def get_background_style(self) -> Style:
- return self._background_style
-
-
-SyntaxPosition = Tuple[int, int]
-
-
-class _SyntaxHighlightRange(NamedTuple):
- """
- A range to highlight in a Syntax object.
- `start` and `end` are 2-integers tuples, where the first integer is the line number
- (starting from 1) and the second integer is the column index (starting from 0).
- """
-
- style: StyleType
- start: SyntaxPosition
- end: SyntaxPosition
-
-
-class Syntax(JupyterMixin):
- """Construct a Syntax object to render syntax highlighted code.
-
- Args:
- code (str): Code to highlight.
- lexer (Lexer | str): Lexer to use (see https://pygments.org/docs/lexers/)
- theme (str, optional): Color theme, aka Pygments style (see https://pygments.org/docs/styles/#getting-a-list-of-available-styles). Defaults to "monokai".
- dedent (bool, optional): Enable stripping of initial whitespace. Defaults to False.
- line_numbers (bool, optional): Enable rendering of line numbers. Defaults to False.
- start_line (int, optional): Starting number for line numbers. Defaults to 1.
- line_range (Tuple[int | None, int | None], optional): If given should be a tuple of the start and end line to render.
- A value of None in the tuple indicates the range is open in that direction.
- highlight_lines (Set[int]): A set of line numbers to highlight.
- code_width: Width of code to render (not including line numbers), or ``None`` to use all available width.
- tab_size (int, optional): Size of tabs. Defaults to 4.
- word_wrap (bool, optional): Enable word wrapping.
- background_color (str, optional): Optional background color, or None to use theme color. Defaults to None.
- indent_guides (bool, optional): Show indent guides. Defaults to False.
- padding (PaddingDimensions): Padding to apply around the syntax. Defaults to 0 (no padding).
- """
-
- _pygments_style_class: Type[PygmentsStyle]
- _theme: SyntaxTheme
-
- @classmethod
- def get_theme(cls, name: Union[str, SyntaxTheme]) -> SyntaxTheme:
- """Get a syntax theme instance."""
- if isinstance(name, SyntaxTheme):
- return name
- theme: SyntaxTheme
- if name in RICH_SYNTAX_THEMES:
- theme = ANSISyntaxTheme(RICH_SYNTAX_THEMES[name])
- else:
- theme = PygmentsSyntaxTheme(name)
- return theme
-
- def __init__(
- self,
- code: str,
- lexer: Union[Lexer, str],
- *,
- theme: Union[str, SyntaxTheme] = DEFAULT_THEME,
- dedent: bool = False,
- line_numbers: bool = False,
- start_line: int = 1,
- line_range: Optional[Tuple[Optional[int], Optional[int]]] = None,
- highlight_lines: Optional[Set[int]] = None,
- code_width: Optional[int] = None,
- tab_size: int = 4,
- word_wrap: bool = False,
- background_color: Optional[str] = None,
- indent_guides: bool = False,
- padding: PaddingDimensions = 0,
- ) -> None:
- self.code = code
- self._lexer = lexer
- self.dedent = dedent
- self.line_numbers = line_numbers
- self.start_line = start_line
- self.line_range = line_range
- self.highlight_lines = highlight_lines or set()
- self.code_width = code_width
- self.tab_size = tab_size
- self.word_wrap = word_wrap
- self.background_color = background_color
- self.background_style = (
- Style(bgcolor=background_color) if background_color else Style()
- )
- self.indent_guides = indent_guides
- self.padding = padding
-
- self._theme = self.get_theme(theme)
- self._stylized_ranges: List[_SyntaxHighlightRange] = []
-
- @classmethod
- def from_path(
- cls,
- path: str,
- encoding: str = "utf-8",
- lexer: Optional[Union[Lexer, str]] = None,
- theme: Union[str, SyntaxTheme] = DEFAULT_THEME,
- dedent: bool = False,
- line_numbers: bool = False,
- line_range: Optional[Tuple[int, int]] = None,
- start_line: int = 1,
- highlight_lines: Optional[Set[int]] = None,
- code_width: Optional[int] = None,
- tab_size: int = 4,
- word_wrap: bool = False,
- background_color: Optional[str] = None,
- indent_guides: bool = False,
- padding: PaddingDimensions = 0,
- ) -> "Syntax":
- """Construct a Syntax object from a file.
-
- Args:
- path (str): Path to file to highlight.
- encoding (str): Encoding of file.
- lexer (str | Lexer, optional): Lexer to use. If None, lexer will be auto-detected from path/file content.
- theme (str, optional): Color theme, aka Pygments style (see https://pygments.org/docs/styles/#getting-a-list-of-available-styles). Defaults to "emacs".
- dedent (bool, optional): Enable stripping of initial whitespace. Defaults to True.
- line_numbers (bool, optional): Enable rendering of line numbers. Defaults to False.
- start_line (int, optional): Starting number for line numbers. Defaults to 1.
- line_range (Tuple[int, int], optional): If given should be a tuple of the start and end line to render.
- highlight_lines (Set[int]): A set of line numbers to highlight.
- code_width: Width of code to render (not including line numbers), or ``None`` to use all available width.
- tab_size (int, optional): Size of tabs. Defaults to 4.
- word_wrap (bool, optional): Enable word wrapping of code.
- background_color (str, optional): Optional background color, or None to use theme color. Defaults to None.
- indent_guides (bool, optional): Show indent guides. Defaults to False.
- padding (PaddingDimensions): Padding to apply around the syntax. Defaults to 0 (no padding).
-
- Returns:
- [Syntax]: A Syntax object that may be printed to the console
- """
- code = Path(path).read_text(encoding=encoding)
-
- if not lexer:
- lexer = cls.guess_lexer(path, code=code)
-
- return cls(
- code,
- lexer,
- theme=theme,
- dedent=dedent,
- line_numbers=line_numbers,
- line_range=line_range,
- start_line=start_line,
- highlight_lines=highlight_lines,
- code_width=code_width,
- tab_size=tab_size,
- word_wrap=word_wrap,
- background_color=background_color,
- indent_guides=indent_guides,
- padding=padding,
- )
-
- @classmethod
- def guess_lexer(cls, path: str, code: Optional[str] = None) -> str:
- """Guess the alias of the Pygments lexer to use based on a path and an optional string of code.
- If code is supplied, it will use a combination of the code and the filename to determine the
- best lexer to use. For example, if the file is ``index.html`` and the file contains Django
- templating syntax, then "html+django" will be returned. If the file is ``index.html``, and no
- templating language is used, the "html" lexer will be used. If no string of code
- is supplied, the lexer will be chosen based on the file extension..
-
- Args:
- path (AnyStr): The path to the file containing the code you wish to know the lexer for.
- code (str, optional): Optional string of code that will be used as a fallback if no lexer
- is found for the supplied path.
-
- Returns:
- str: The name of the Pygments lexer that best matches the supplied path/code.
- """
- lexer: Optional[Lexer] = None
- lexer_name = "default"
- if code:
- try:
- lexer = guess_lexer_for_filename(path, code)
- except ClassNotFound:
- pass
-
- if not lexer:
- try:
- _, ext = os.path.splitext(path)
- if ext:
- extension = ext.lstrip(".").lower()
- lexer = get_lexer_by_name(extension)
- except ClassNotFound:
- pass
-
- if lexer:
- if lexer.aliases:
- lexer_name = lexer.aliases[0]
- else:
- lexer_name = lexer.name
-
- return lexer_name
-
- def _get_base_style(self) -> Style:
- """Get the base style."""
- default_style = self._theme.get_background_style() + self.background_style
- return default_style
-
- def _get_token_color(self, token_type: TokenType) -> Optional[Color]:
- """Get a color (if any) for the given token.
-
- Args:
- token_type (TokenType): A token type tuple from Pygments.
-
- Returns:
- Optional[Color]: Color from theme, or None for no color.
- """
- style = self._theme.get_style_for_token(token_type)
- return style.color
-
- @property
- def lexer(self) -> Optional[Lexer]:
- """The lexer for this syntax, or None if no lexer was found.
-
- Tries to find the lexer by name if a string was passed to the constructor.
- """
-
- if isinstance(self._lexer, Lexer):
- return self._lexer
- try:
- return get_lexer_by_name(
- self._lexer,
- stripnl=False,
- ensurenl=True,
- tabsize=self.tab_size,
- )
- except ClassNotFound:
- return None
-
- def highlight(
- self,
- code: str,
- line_range: Optional[Tuple[Optional[int], Optional[int]]] = None,
- ) -> Text:
- """Highlight code and return a Text instance.
-
- Args:
- code (str): Code to highlight.
- line_range(Tuple[int, int], optional): Optional line range to highlight.
-
- Returns:
- Text: A text instance containing highlighted syntax.
- """
-
- base_style = self._get_base_style()
- justify: JustifyMethod = (
- "default" if base_style.transparent_background else "left"
- )
-
- text = Text(
- justify=justify,
- style=base_style,
- tab_size=self.tab_size,
- no_wrap=not self.word_wrap,
- )
- _get_theme_style = self._theme.get_style_for_token
-
- lexer = self.lexer
-
- if lexer is None:
- text.append(code)
- else:
- if line_range:
- # More complicated path to only stylize a portion of the code
- # This speeds up further operations as there are less spans to process
- line_start, line_end = line_range
-
- def line_tokenize() -> Iterable[Tuple[Any, str]]:
- """Split tokens to one per line."""
- assert lexer # required to make MyPy happy - we know lexer is not None at this point
-
- for token_type, token in lexer.get_tokens(code):
- while token:
- line_token, new_line, token = token.partition("\n")
- yield token_type, line_token + new_line
-
- def tokens_to_spans() -> Iterable[Tuple[str, Optional[Style]]]:
- """Convert tokens to spans."""
- tokens = iter(line_tokenize())
- line_no = 0
- _line_start = line_start - 1 if line_start else 0
-
- # Skip over tokens until line start
- while line_no < _line_start:
- try:
- _token_type, token = next(tokens)
- except StopIteration:
- break
- yield (token, None)
- if token.endswith("\n"):
- line_no += 1
- # Generate spans until line end
- for token_type, token in tokens:
- yield (token, _get_theme_style(token_type))
- if token.endswith("\n"):
- line_no += 1
- if line_end and line_no >= line_end:
- break
-
- text.append_tokens(tokens_to_spans())
-
- else:
- text.append_tokens(
- (token, _get_theme_style(token_type))
- for token_type, token in lexer.get_tokens(code)
- )
- if self.background_color is not None:
- text.stylize(f"on {self.background_color}")
-
- if self._stylized_ranges:
- self._apply_stylized_ranges(text)
-
- return text
-
- def stylize_range(
- self, style: StyleType, start: SyntaxPosition, end: SyntaxPosition
- ) -> None:
- """
- Adds a custom style on a part of the code, that will be applied to the syntax display when it's rendered.
- Line numbers are 1-based, while column indexes are 0-based.
-
- Args:
- style (StyleType): The style to apply.
- start (Tuple[int, int]): The start of the range, in the form `[line number, column index]`.
- end (Tuple[int, int]): The end of the range, in the form `[line number, column index]`.
- """
- self._stylized_ranges.append(_SyntaxHighlightRange(style, start, end))
-
- def _get_line_numbers_color(self, blend: float = 0.3) -> Color:
- background_style = self._theme.get_background_style() + self.background_style
- background_color = background_style.bgcolor
- if background_color is None or background_color.is_system_defined:
- return Color.default()
- foreground_color = self._get_token_color(Token.Text)
- if foreground_color is None or foreground_color.is_system_defined:
- return foreground_color or Color.default()
- new_color = blend_rgb(
- background_color.get_truecolor(),
- foreground_color.get_truecolor(),
- cross_fade=blend,
- )
- return Color.from_triplet(new_color)
-
- @property
- def _numbers_column_width(self) -> int:
- """Get the number of characters used to render the numbers column."""
- column_width = 0
- if self.line_numbers:
- column_width = (
- len(str(self.start_line + self.code.count("\n")))
- + NUMBERS_COLUMN_DEFAULT_PADDING
- )
- return column_width
-
- def _get_number_styles(self, console: Console) -> Tuple[Style, Style, Style]:
- """Get background, number, and highlight styles for line numbers."""
- background_style = self._get_base_style()
- if background_style.transparent_background:
- return Style.null(), Style(dim=True), Style.null()
- if console.color_system in ("256", "truecolor"):
- number_style = Style.chain(
- background_style,
- self._theme.get_style_for_token(Token.Text),
- Style(color=self._get_line_numbers_color()),
- self.background_style,
- )
- highlight_number_style = Style.chain(
- background_style,
- self._theme.get_style_for_token(Token.Text),
- Style(bold=True, color=self._get_line_numbers_color(0.9)),
- self.background_style,
- )
- else:
- number_style = background_style + Style(dim=True)
- highlight_number_style = background_style + Style(dim=False)
- return background_style, number_style, highlight_number_style
-
- def __rich_measure__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "Measurement":
- _, right, _, left = Padding.unpack(self.padding)
- padding = left + right
- if self.code_width is not None:
- width = self.code_width + self._numbers_column_width + padding + 1
- return Measurement(self._numbers_column_width, width)
- lines = self.code.splitlines()
- width = (
- self._numbers_column_width
- + padding
- + (max(cell_len(line) for line in lines) if lines else 0)
- )
- if self.line_numbers:
- width += 1
- return Measurement(self._numbers_column_width, width)
-
- def __rich_console__(
- self, console: Console, options: ConsoleOptions
- ) -> RenderResult:
- segments = Segments(self._get_syntax(console, options))
- if self.padding:
- yield Padding(
- segments, style=self._theme.get_background_style(), pad=self.padding
- )
- else:
- yield segments
-
- def _get_syntax(
- self,
- console: Console,
- options: ConsoleOptions,
- ) -> Iterable[Segment]:
- """
- Get the Segments for the Syntax object, excluding any vertical/horizontal padding
- """
- transparent_background = self._get_base_style().transparent_background
- code_width = (
- (
- (options.max_width - self._numbers_column_width - 1)
- if self.line_numbers
- else options.max_width
- )
- if self.code_width is None
- else self.code_width
- )
-
- ends_on_nl, processed_code = self._process_code(self.code)
- text = self.highlight(processed_code, self.line_range)
-
- if not self.line_numbers and not self.word_wrap and not self.line_range:
- if not ends_on_nl:
- text.remove_suffix("\n")
- # Simple case of just rendering text
- style = (
- self._get_base_style()
- + self._theme.get_style_for_token(Comment)
- + Style(dim=True)
- + self.background_style
- )
- if self.indent_guides and not options.ascii_only:
- text = text.with_indent_guides(self.tab_size, style=style)
- text.overflow = "crop"
- if style.transparent_background:
- yield from console.render(
- text, options=options.update(width=code_width)
- )
- else:
- syntax_lines = console.render_lines(
- text,
- options.update(width=code_width, height=None, justify="left"),
- style=self.background_style,
- pad=True,
- new_lines=True,
- )
- for syntax_line in syntax_lines:
- yield from syntax_line
- return
-
- start_line, end_line = self.line_range or (None, None)
- line_offset = 0
- if start_line:
- line_offset = max(0, start_line - 1)
- lines: Union[List[Text], Lines] = text.split("\n", allow_blank=ends_on_nl)
- if self.line_range:
- if line_offset > len(lines):
- return
- lines = lines[line_offset:end_line]
-
- if self.indent_guides and not options.ascii_only:
- style = (
- self._get_base_style()
- + self._theme.get_style_for_token(Comment)
- + Style(dim=True)
- + self.background_style
- )
- lines = (
- Text("\n")
- .join(lines)
- .with_indent_guides(self.tab_size, style=style + Style(italic=False))
- .split("\n", allow_blank=True)
- )
-
- numbers_column_width = self._numbers_column_width
- render_options = options.update(width=code_width)
-
- highlight_line = self.highlight_lines.__contains__
- _Segment = Segment
- new_line = _Segment("\n")
-
- line_pointer = "> " if options.legacy_windows else "❱ "
-
- (
- background_style,
- number_style,
- highlight_number_style,
- ) = self._get_number_styles(console)
-
- for line_no, line in enumerate(lines, self.start_line + line_offset):
- if self.word_wrap:
- wrapped_lines = console.render_lines(
- line,
- render_options.update(height=None, justify="left"),
- style=background_style,
- pad=not transparent_background,
- )
- else:
- segments = list(line.render(console, end=""))
- if options.no_wrap:
- wrapped_lines = [segments]
- else:
- wrapped_lines = [
- _Segment.adjust_line_length(
- segments,
- render_options.max_width,
- style=background_style,
- pad=not transparent_background,
- )
- ]
-
- if self.line_numbers:
- wrapped_line_left_pad = _Segment(
- " " * numbers_column_width + " ", background_style
- )
- for first, wrapped_line in loop_first(wrapped_lines):
- if first:
- line_column = str(line_no).rjust(numbers_column_width - 2) + " "
- if highlight_line(line_no):
- yield _Segment(line_pointer, Style(color="red"))
- yield _Segment(line_column, highlight_number_style)
- else:
- yield _Segment(" ", highlight_number_style)
- yield _Segment(line_column, number_style)
- else:
- yield wrapped_line_left_pad
- yield from wrapped_line
- yield new_line
- else:
- for wrapped_line in wrapped_lines:
- yield from wrapped_line
- yield new_line
-
- def _apply_stylized_ranges(self, text: Text) -> None:
- """
- Apply stylized ranges to a text instance,
- using the given code to determine the right portion to apply the style to.
-
- Args:
- text (Text): Text instance to apply the style to.
- """
- code = text.plain
- newlines_offsets = [
- # Let's add outer boundaries at each side of the list:
- 0,
- # N.B. using "\n" here is much faster than using metacharacters such as "^" or "\Z":
- *[
- match.start() + 1
- for match in re.finditer("\n", code, flags=re.MULTILINE)
- ],
- len(code) + 1,
- ]
-
- for stylized_range in self._stylized_ranges:
- start = _get_code_index_for_syntax_position(
- newlines_offsets, stylized_range.start
- )
- end = _get_code_index_for_syntax_position(
- newlines_offsets, stylized_range.end
- )
- if start is not None and end is not None:
- text.stylize(stylized_range.style, start, end)
-
- def _process_code(self, code: str) -> Tuple[bool, str]:
- """
- Applies various processing to a raw code string
- (normalises it so it always ends with a line return, dedents it if necessary, etc.)
-
- Args:
- code (str): The raw code string to process
-
- Returns:
- Tuple[bool, str]: the boolean indicates whether the raw code ends with a line return,
- while the string is the processed code.
- """
- ends_on_nl = code.endswith("\n")
- processed_code = code if ends_on_nl else code + "\n"
- processed_code = (
- textwrap.dedent(processed_code) if self.dedent else processed_code
- )
- processed_code = processed_code.expandtabs(self.tab_size)
- return ends_on_nl, processed_code
-
-
-def _get_code_index_for_syntax_position(
- newlines_offsets: Sequence[int], position: SyntaxPosition
-) -> Optional[int]:
- """
- Returns the index of the code string for the given positions.
-
- Args:
- newlines_offsets (Sequence[int]): The offset of each newline character found in the code snippet.
- position (SyntaxPosition): The position to search for.
-
- Returns:
- Optional[int]: The index of the code string for this position, or `None`
- if the given position's line number is out of range (if it's the column that is out of range
- we silently clamp its value so that it reaches the end of the line)
- """
- lines_count = len(newlines_offsets)
-
- line_number, column_index = position
- if line_number > lines_count or len(newlines_offsets) < (line_number + 1):
- return None # `line_number` is out of range
- line_index = line_number - 1
- line_length = newlines_offsets[line_index + 1] - newlines_offsets[line_index] - 1
- # If `column_index` is out of range: let's silently clamp it:
- column_index = min(line_length, column_index)
- return newlines_offsets[line_index] + column_index
-
-
-if __name__ == "__main__": # pragma: no cover
- import argparse
- import sys
-
- parser = argparse.ArgumentParser(
- description="Render syntax to the console with Rich"
- )
- parser.add_argument(
- "path",
- metavar="PATH",
- help="path to file, or - for stdin",
- )
- parser.add_argument(
- "-c",
- "--force-color",
- dest="force_color",
- action="store_true",
- default=None,
- help="force color for non-terminals",
- )
- parser.add_argument(
- "-i",
- "--indent-guides",
- dest="indent_guides",
- action="store_true",
- default=False,
- help="display indent guides",
- )
- parser.add_argument(
- "-l",
- "--line-numbers",
- dest="line_numbers",
- action="store_true",
- help="render line numbers",
- )
- parser.add_argument(
- "-w",
- "--width",
- type=int,
- dest="width",
- default=None,
- help="width of output (default will auto-detect)",
- )
- parser.add_argument(
- "-r",
- "--wrap",
- dest="word_wrap",
- action="store_true",
- default=False,
- help="word wrap long lines",
- )
- parser.add_argument(
- "-s",
- "--soft-wrap",
- action="store_true",
- dest="soft_wrap",
- default=False,
- help="enable soft wrapping mode",
- )
- parser.add_argument(
- "-t", "--theme", dest="theme", default="monokai", help="pygments theme"
- )
- parser.add_argument(
- "-b",
- "--background-color",
- dest="background_color",
- default=None,
- help="Override background color",
- )
- parser.add_argument(
- "-x",
- "--lexer",
- default=None,
- dest="lexer_name",
- help="Lexer name",
- )
- parser.add_argument(
- "-p", "--padding", type=int, default=0, dest="padding", help="Padding"
- )
- parser.add_argument(
- "--highlight-line",
- type=int,
- default=None,
- dest="highlight_line",
- help="The line number (not index!) to highlight",
- )
- args = parser.parse_args()
-
- from pip._vendor.rich.console import Console
-
- console = Console(force_terminal=args.force_color, width=args.width)
-
- if args.path == "-":
- code = sys.stdin.read()
- syntax = Syntax(
- code=code,
- lexer=args.lexer_name,
- line_numbers=args.line_numbers,
- word_wrap=args.word_wrap,
- theme=args.theme,
- background_color=args.background_color,
- indent_guides=args.indent_guides,
- padding=args.padding,
- highlight_lines={args.highlight_line},
- )
- else:
- syntax = Syntax.from_path(
- args.path,
- lexer=args.lexer_name,
- line_numbers=args.line_numbers,
- word_wrap=args.word_wrap,
- theme=args.theme,
- background_color=args.background_color,
- indent_guides=args.indent_guides,
- padding=args.padding,
- highlight_lines={args.highlight_line},
- )
- console.print(syntax, soft_wrap=args.soft_wrap)
diff --git a/spaces/Vegecken/sovits4dzl/vdecoder/hifigan/models.py b/spaces/Vegecken/sovits4dzl/vdecoder/hifigan/models.py
deleted file mode 100644
index 9747301f350bb269e62601017fe4633ce271b27e..0000000000000000000000000000000000000000
--- a/spaces/Vegecken/sovits4dzl/vdecoder/hifigan/models.py
+++ /dev/null
@@ -1,503 +0,0 @@
-import os
-import json
-from .env import AttrDict
-import numpy as np
-import torch
-import torch.nn.functional as F
-import torch.nn as nn
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-from .utils import init_weights, get_padding
-
-LRELU_SLOPE = 0.1
-
-
-def load_model(model_path, device='cuda'):
- config_file = os.path.join(os.path.split(model_path)[0], 'config.json')
- with open(config_file) as f:
- data = f.read()
-
- global h
- json_config = json.loads(data)
- h = AttrDict(json_config)
-
- generator = Generator(h).to(device)
-
- cp_dict = torch.load(model_path)
- generator.load_state_dict(cp_dict['generator'])
- generator.eval()
- generator.remove_weight_norm()
- del cp_dict
- return generator, h
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, h, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.h = h
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- xt = c2(xt)
- x = xt + x
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, h, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.h = h
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- xt = c(xt)
- x = xt + x
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-def padDiff(x):
- return F.pad(F.pad(x, (0,0,-1,1), 'constant', 0) - x, (0,0,0,-1), 'constant', 0)
-
-class SineGen(torch.nn.Module):
- """ Definition of sine generator
- SineGen(samp_rate, harmonic_num = 0,
- sine_amp = 0.1, noise_std = 0.003,
- voiced_threshold = 0,
- flag_for_pulse=False)
- samp_rate: sampling rate in Hz
- harmonic_num: number of harmonic overtones (default 0)
- sine_amp: amplitude of sine-wavefrom (default 0.1)
- noise_std: std of Gaussian noise (default 0.003)
- voiced_thoreshold: F0 threshold for U/V classification (default 0)
- flag_for_pulse: this SinGen is used inside PulseGen (default False)
- Note: when flag_for_pulse is True, the first time step of a voiced
- segment is always sin(np.pi) or cos(0)
- """
-
- def __init__(self, samp_rate, harmonic_num=0,
- sine_amp=0.1, noise_std=0.003,
- voiced_threshold=0,
- flag_for_pulse=False):
- super(SineGen, self).__init__()
- self.sine_amp = sine_amp
- self.noise_std = noise_std
- self.harmonic_num = harmonic_num
- self.dim = self.harmonic_num + 1
- self.sampling_rate = samp_rate
- self.voiced_threshold = voiced_threshold
- self.flag_for_pulse = flag_for_pulse
-
- def _f02uv(self, f0):
- # generate uv signal
- uv = (f0 > self.voiced_threshold).type(torch.float32)
- return uv
-
- def _f02sine(self, f0_values):
- """ f0_values: (batchsize, length, dim)
- where dim indicates fundamental tone and overtones
- """
- # convert to F0 in rad. The interger part n can be ignored
- # because 2 * np.pi * n doesn't affect phase
- rad_values = (f0_values / self.sampling_rate) % 1
-
- # initial phase noise (no noise for fundamental component)
- rand_ini = torch.rand(f0_values.shape[0], f0_values.shape[2], \
- device=f0_values.device)
- rand_ini[:, 0] = 0
- rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
-
- # instantanouse phase sine[t] = sin(2*pi \sum_i=1 ^{t} rad)
- if not self.flag_for_pulse:
- # for normal case
-
- # To prevent torch.cumsum numerical overflow,
- # it is necessary to add -1 whenever \sum_k=1^n rad_value_k > 1.
- # Buffer tmp_over_one_idx indicates the time step to add -1.
- # This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi
- tmp_over_one = torch.cumsum(rad_values, 1) % 1
- tmp_over_one_idx = (padDiff(tmp_over_one)) < 0
- cumsum_shift = torch.zeros_like(rad_values)
- cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
-
- sines = torch.sin(torch.cumsum(rad_values + cumsum_shift, dim=1)
- * 2 * np.pi)
- else:
- # If necessary, make sure that the first time step of every
- # voiced segments is sin(pi) or cos(0)
- # This is used for pulse-train generation
-
- # identify the last time step in unvoiced segments
- uv = self._f02uv(f0_values)
- uv_1 = torch.roll(uv, shifts=-1, dims=1)
- uv_1[:, -1, :] = 1
- u_loc = (uv < 1) * (uv_1 > 0)
-
- # get the instantanouse phase
- tmp_cumsum = torch.cumsum(rad_values, dim=1)
- # different batch needs to be processed differently
- for idx in range(f0_values.shape[0]):
- temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :]
- temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :]
- # stores the accumulation of i.phase within
- # each voiced segments
- tmp_cumsum[idx, :, :] = 0
- tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum
-
- # rad_values - tmp_cumsum: remove the accumulation of i.phase
- # within the previous voiced segment.
- i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1)
-
- # get the sines
- sines = torch.cos(i_phase * 2 * np.pi)
- return sines
-
- def forward(self, f0):
- """ sine_tensor, uv = forward(f0)
- input F0: tensor(batchsize=1, length, dim=1)
- f0 for unvoiced steps should be 0
- output sine_tensor: tensor(batchsize=1, length, dim)
- output uv: tensor(batchsize=1, length, 1)
- """
- with torch.no_grad():
- f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim,
- device=f0.device)
- # fundamental component
- fn = torch.multiply(f0, torch.FloatTensor([[range(1, self.harmonic_num + 2)]]).to(f0.device))
-
- # generate sine waveforms
- sine_waves = self._f02sine(fn) * self.sine_amp
-
- # generate uv signal
- # uv = torch.ones(f0.shape)
- # uv = uv * (f0 > self.voiced_threshold)
- uv = self._f02uv(f0)
-
- # noise: for unvoiced should be similar to sine_amp
- # std = self.sine_amp/3 -> max value ~ self.sine_amp
- # . for voiced regions is self.noise_std
- noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
- noise = noise_amp * torch.randn_like(sine_waves)
-
- # first: set the unvoiced part to 0 by uv
- # then: additive noise
- sine_waves = sine_waves * uv + noise
- return sine_waves, uv, noise
-
-
-class SourceModuleHnNSF(torch.nn.Module):
- """ SourceModule for hn-nsf
- SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
- add_noise_std=0.003, voiced_threshod=0)
- sampling_rate: sampling_rate in Hz
- harmonic_num: number of harmonic above F0 (default: 0)
- sine_amp: amplitude of sine source signal (default: 0.1)
- add_noise_std: std of additive Gaussian noise (default: 0.003)
- note that amplitude of noise in unvoiced is decided
- by sine_amp
- voiced_threshold: threhold to set U/V given F0 (default: 0)
- Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
- F0_sampled (batchsize, length, 1)
- Sine_source (batchsize, length, 1)
- noise_source (batchsize, length 1)
- uv (batchsize, length, 1)
- """
-
- def __init__(self, sampling_rate, harmonic_num=0, sine_amp=0.1,
- add_noise_std=0.003, voiced_threshod=0):
- super(SourceModuleHnNSF, self).__init__()
-
- self.sine_amp = sine_amp
- self.noise_std = add_noise_std
-
- # to produce sine waveforms
- self.l_sin_gen = SineGen(sampling_rate, harmonic_num,
- sine_amp, add_noise_std, voiced_threshod)
-
- # to merge source harmonics into a single excitation
- self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
- self.l_tanh = torch.nn.Tanh()
-
- def forward(self, x):
- """
- Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
- F0_sampled (batchsize, length, 1)
- Sine_source (batchsize, length, 1)
- noise_source (batchsize, length 1)
- """
- # source for harmonic branch
- sine_wavs, uv, _ = self.l_sin_gen(x)
- sine_merge = self.l_tanh(self.l_linear(sine_wavs))
-
- # source for noise branch, in the same shape as uv
- noise = torch.randn_like(uv) * self.sine_amp / 3
- return sine_merge, noise, uv
-
-
-class Generator(torch.nn.Module):
- def __init__(self, h):
- super(Generator, self).__init__()
- self.h = h
-
- self.num_kernels = len(h["resblock_kernel_sizes"])
- self.num_upsamples = len(h["upsample_rates"])
- self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(h["upsample_rates"]))
- self.m_source = SourceModuleHnNSF(
- sampling_rate=h["sampling_rate"],
- harmonic_num=8)
- self.noise_convs = nn.ModuleList()
- self.conv_pre = weight_norm(Conv1d(h["inter_channels"], h["upsample_initial_channel"], 7, 1, padding=3))
- resblock = ResBlock1 if h["resblock"] == '1' else ResBlock2
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(h["upsample_rates"], h["upsample_kernel_sizes"])):
- c_cur = h["upsample_initial_channel"] // (2 ** (i + 1))
- self.ups.append(weight_norm(
- ConvTranspose1d(h["upsample_initial_channel"] // (2 ** i), h["upsample_initial_channel"] // (2 ** (i + 1)),
- k, u, padding=(k - u) // 2)))
- if i + 1 < len(h["upsample_rates"]): #
- stride_f0 = np.prod(h["upsample_rates"][i + 1:])
- self.noise_convs.append(Conv1d(
- 1, c_cur, kernel_size=stride_f0 * 2, stride=stride_f0, padding=stride_f0 // 2))
- else:
- self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = h["upsample_initial_channel"] // (2 ** (i + 1))
- for j, (k, d) in enumerate(zip(h["resblock_kernel_sizes"], h["resblock_dilation_sizes"])):
- self.resblocks.append(resblock(h, ch, k, d))
-
- self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3))
- self.ups.apply(init_weights)
- self.conv_post.apply(init_weights)
- self.cond = nn.Conv1d(h['gin_channels'], h['upsample_initial_channel'], 1)
-
- def forward(self, x, f0, g=None):
- # print(1,x.shape,f0.shape,f0[:, None].shape)
- f0 = self.f0_upsamp(f0[:, None]).transpose(1, 2) # bs,n,t
- # print(2,f0.shape)
- har_source, noi_source, uv = self.m_source(f0)
- har_source = har_source.transpose(1, 2)
- x = self.conv_pre(x)
- x = x + self.cond(g)
- # print(124,x.shape,har_source.shape)
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, LRELU_SLOPE)
- # print(3,x.shape)
- x = self.ups[i](x)
- x_source = self.noise_convs[i](har_source)
- # print(4,x_source.shape,har_source.shape,x.shape)
- x = x + x_source
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- print('Removing weight norm...')
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
- remove_weight_norm(self.conv_pre)
- remove_weight_norm(self.conv_post)
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
- norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
- norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
- norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
- norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(2, 0))),
- ])
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, periods=None):
- super(MultiPeriodDiscriminator, self).__init__()
- self.periods = periods if periods is not None else [2, 3, 5, 7, 11]
- self.discriminators = nn.ModuleList()
- for period in self.periods:
- self.discriminators.append(DiscriminatorP(period))
-
- def forward(self, y, y_hat):
- y_d_rs = []
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- y_d_rs.append(y_d_r)
- fmap_rs.append(fmap_r)
- y_d_gs.append(y_d_g)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv1d(1, 128, 15, 1, padding=7)),
- norm_f(Conv1d(128, 128, 41, 2, groups=4, padding=20)),
- norm_f(Conv1d(128, 256, 41, 2, groups=16, padding=20)),
- norm_f(Conv1d(256, 512, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(512, 1024, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 1, groups=16, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ])
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class MultiScaleDiscriminator(torch.nn.Module):
- def __init__(self):
- super(MultiScaleDiscriminator, self).__init__()
- self.discriminators = nn.ModuleList([
- DiscriminatorS(use_spectral_norm=True),
- DiscriminatorS(),
- DiscriminatorS(),
- ])
- self.meanpools = nn.ModuleList([
- AvgPool1d(4, 2, padding=2),
- AvgPool1d(4, 2, padding=2)
- ])
-
- def forward(self, y, y_hat):
- y_d_rs = []
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- if i != 0:
- y = self.meanpools[i - 1](y)
- y_hat = self.meanpools[i - 1](y_hat)
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- y_d_rs.append(y_d_r)
- fmap_rs.append(fmap_r)
- y_d_gs.append(y_d_g)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-def feature_loss(fmap_r, fmap_g):
- loss = 0
- for dr, dg in zip(fmap_r, fmap_g):
- for rl, gl in zip(dr, dg):
- loss += torch.mean(torch.abs(rl - gl))
-
- return loss * 2
-
-
-def discriminator_loss(disc_real_outputs, disc_generated_outputs):
- loss = 0
- r_losses = []
- g_losses = []
- for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
- r_loss = torch.mean((1 - dr) ** 2)
- g_loss = torch.mean(dg ** 2)
- loss += (r_loss + g_loss)
- r_losses.append(r_loss.item())
- g_losses.append(g_loss.item())
-
- return loss, r_losses, g_losses
-
-
-def generator_loss(disc_outputs):
- loss = 0
- gen_losses = []
- for dg in disc_outputs:
- l = torch.mean((1 - dg) ** 2)
- gen_losses.append(l)
- loss += l
-
- return loss, gen_losses
diff --git a/spaces/Wayben/ChatGPT/assets/custom.css b/spaces/Wayben/ChatGPT/assets/custom.css
deleted file mode 100644
index a79a34c1c6ef55a6a5e04830ae9f7c5d63fb8faa..0000000000000000000000000000000000000000
--- a/spaces/Wayben/ChatGPT/assets/custom.css
+++ /dev/null
@@ -1,173 +0,0 @@
-:root {
- --chatbot-color-light: #F3F3F3;
- --chatbot-color-dark: #121111;
-}
-
-/* status_display */
-#status_display {
- display: flex;
- min-height: 2.5em;
- align-items: flex-end;
- justify-content: flex-end;
-}
-#status_display p {
- font-size: .85em;
- font-family: monospace;
- color: var(--body-text-color-subdued);
-}
-
-#chuanhu_chatbot, #status_display {
- transition: all 0.6s;
-}
-
-/* usage_display */
-#usage_display {
- height: 1em;
-}
-#usage_display p{
- padding: 0 1em;
- font-size: .85em;
- font-family: monospace;
- color: var(--body-text-color-subdued);
-}
-/* list */
-ol:not(.options), ul:not(.options) {
- padding-inline-start: 2em !important;
-}
-
-/* 亮色 */
-#chuanhu_chatbot {
- background-color: var(--chatbot-color-light) !important;
-}
-[data-testid = "bot"] {
- background-color: #FFFFFF !important;
-}
-[data-testid = "user"] {
- background-color: #95EC69 !important;
-}
-/* 对话气泡 */
-[class *= "message"] {
- border-radius: var(--radius-xl) !important;
- border: none;
- padding: var(--spacing-xl) !important;
- font-size: var(--text-md) !important;
- line-height: var(--line-md) !important;
- min-height: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
- min-width: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
-}
-[data-testid = "bot"] {
- max-width: 85%;
- border-bottom-left-radius: 0 !important;
-}
-[data-testid = "user"] {
- max-width: 85%;
- width: auto !important;
- border-bottom-right-radius: 0 !important;
-}
-/* 表格 */
-table {
- margin: 1em 0;
- border-collapse: collapse;
- empty-cells: show;
-}
-td,th {
- border: 1.2px solid var(--border-color-primary) !important;
- padding: 0.2em;
-}
-thead {
- background-color: rgba(175,184,193,0.2);
-}
-thead th {
- padding: .5em .2em;
-}
-/* 行内代码 */
-code {
- display: inline;
- white-space: break-spaces;
- border-radius: 6px;
- margin: 0 2px 0 2px;
- padding: .2em .4em .1em .4em;
- background-color: rgba(175,184,193,0.2);
-}
-/* 代码块 */
-pre code {
- display: block;
- overflow: auto;
- white-space: pre;
- background-color: hsla(0, 0%, 0%, 80%)!important;
- border-radius: 10px;
- padding: 1.4em 1.2em 0em 1.4em;
- margin: 1.2em 2em 1.2em 0.5em;
- color: #FFF;
- box-shadow: 6px 6px 16px hsla(0, 0%, 0%, 0.2);
-}
-/* 代码高亮样式 */
-.highlight .hll { background-color: #49483e }
-.highlight .c { color: #75715e } /* Comment */
-.highlight .err { color: #960050; background-color: #1e0010 } /* Error */
-.highlight .k { color: #66d9ef } /* Keyword */
-.highlight .l { color: #ae81ff } /* Literal */
-.highlight .n { color: #f8f8f2 } /* Name */
-.highlight .o { color: #f92672 } /* Operator */
-.highlight .p { color: #f8f8f2 } /* Punctuation */
-.highlight .ch { color: #75715e } /* Comment.Hashbang */
-.highlight .cm { color: #75715e } /* Comment.Multiline */
-.highlight .cp { color: #75715e } /* Comment.Preproc */
-.highlight .cpf { color: #75715e } /* Comment.PreprocFile */
-.highlight .c1 { color: #75715e } /* Comment.Single */
-.highlight .cs { color: #75715e } /* Comment.Special */
-.highlight .gd { color: #f92672 } /* Generic.Deleted */
-.highlight .ge { font-style: italic } /* Generic.Emph */
-.highlight .gi { color: #a6e22e } /* Generic.Inserted */
-.highlight .gs { font-weight: bold } /* Generic.Strong */
-.highlight .gu { color: #75715e } /* Generic.Subheading */
-.highlight .kc { color: #66d9ef } /* Keyword.Constant */
-.highlight .kd { color: #66d9ef } /* Keyword.Declaration */
-.highlight .kn { color: #f92672 } /* Keyword.Namespace */
-.highlight .kp { color: #66d9ef } /* Keyword.Pseudo */
-.highlight .kr { color: #66d9ef } /* Keyword.Reserved */
-.highlight .kt { color: #66d9ef } /* Keyword.Type */
-.highlight .ld { color: #e6db74 } /* Literal.Date */
-.highlight .m { color: #ae81ff } /* Literal.Number */
-.highlight .s { color: #e6db74 } /* Literal.String */
-.highlight .na { color: #a6e22e } /* Name.Attribute */
-.highlight .nb { color: #f8f8f2 } /* Name.Builtin */
-.highlight .nc { color: #a6e22e } /* Name.Class */
-.highlight .no { color: #66d9ef } /* Name.Constant */
-.highlight .nd { color: #a6e22e } /* Name.Decorator */
-.highlight .ni { color: #f8f8f2 } /* Name.Entity */
-.highlight .ne { color: #a6e22e } /* Name.Exception */
-.highlight .nf { color: #a6e22e } /* Name.Function */
-.highlight .nl { color: #f8f8f2 } /* Name.Label */
-.highlight .nn { color: #f8f8f2 } /* Name.Namespace */
-.highlight .nx { color: #a6e22e } /* Name.Other */
-.highlight .py { color: #f8f8f2 } /* Name.Property */
-.highlight .nt { color: #f92672 } /* Name.Tag */
-.highlight .nv { color: #f8f8f2 } /* Name.Variable */
-.highlight .ow { color: #f92672 } /* Operator.Word */
-.highlight .w { color: #f8f8f2 } /* Text.Whitespace */
-.highlight .mb { color: #ae81ff } /* Literal.Number.Bin */
-.highlight .mf { color: #ae81ff } /* Literal.Number.Float */
-.highlight .mh { color: #ae81ff } /* Literal.Number.Hex */
-.highlight .mi { color: #ae81ff } /* Literal.Number.Integer */
-.highlight .mo { color: #ae81ff } /* Literal.Number.Oct */
-.highlight .sa { color: #e6db74 } /* Literal.String.Affix */
-.highlight .sb { color: #e6db74 } /* Literal.String.Backtick */
-.highlight .sc { color: #e6db74 } /* Literal.String.Char */
-.highlight .dl { color: #e6db74 } /* Literal.String.Delimiter */
-.highlight .sd { color: #e6db74 } /* Literal.String.Doc */
-.highlight .s2 { color: #e6db74 } /* Literal.String.Double */
-.highlight .se { color: #ae81ff } /* Literal.String.Escape */
-.highlight .sh { color: #e6db74 } /* Literal.String.Heredoc */
-.highlight .si { color: #e6db74 } /* Literal.String.Interpol */
-.highlight .sx { color: #e6db74 } /* Literal.String.Other */
-.highlight .sr { color: #e6db74 } /* Literal.String.Regex */
-.highlight .s1 { color: #e6db74 } /* Literal.String.Single */
-.highlight .ss { color: #e6db74 } /* Literal.String.Symbol */
-.highlight .bp { color: #f8f8f2 } /* Name.Builtin.Pseudo */
-.highlight .fm { color: #a6e22e } /* Name.Function.Magic */
-.highlight .vc { color: #f8f8f2 } /* Name.Variable.Class */
-.highlight .vg { color: #f8f8f2 } /* Name.Variable.Global */
-.highlight .vi { color: #f8f8f2 } /* Name.Variable.Instance */
-.highlight .vm { color: #f8f8f2 } /* Name.Variable.Magic */
-.highlight .il { color: #ae81ff } /* Literal.Number.Integer.Long */
diff --git a/spaces/XingHe0127/Chatbot/modules/shared.py b/spaces/XingHe0127/Chatbot/modules/shared.py
deleted file mode 100644
index a9e72580aa7ae48f907e923a09099513570a9ad8..0000000000000000000000000000000000000000
--- a/spaces/XingHe0127/Chatbot/modules/shared.py
+++ /dev/null
@@ -1,55 +0,0 @@
-from modules.presets import COMPLETION_URL, BALANCE_API_URL, USAGE_API_URL, API_HOST
-import os
-import queue
-
-class State:
- interrupted = False
- multi_api_key = False
- completion_url = COMPLETION_URL
- balance_api_url = BALANCE_API_URL
- usage_api_url = USAGE_API_URL
-
- def interrupt(self):
- self.interrupted = True
-
- def recover(self):
- self.interrupted = False
-
- def set_api_host(self, api_host):
- self.completion_url = f"https://{api_host}/v1/chat/completions"
- self.balance_api_url = f"https://{api_host}/dashboard/billing/credit_grants"
- self.usage_api_url = f"https://{api_host}/dashboard/billing/usage"
- os.environ["OPENAI_API_BASE"] = f"https://{api_host}/v1"
-
- def reset_api_host(self):
- self.completion_url = COMPLETION_URL
- self.balance_api_url = BALANCE_API_URL
- self.usage_api_url = USAGE_API_URL
- os.environ["OPENAI_API_BASE"] = f"https://{API_HOST}/v1"
- return API_HOST
-
- def reset_all(self):
- self.interrupted = False
- self.completion_url = COMPLETION_URL
-
- def set_api_key_queue(self, api_key_list):
- self.multi_api_key = True
- self.api_key_queue = queue.Queue()
- for api_key in api_key_list:
- self.api_key_queue.put(api_key)
-
- def switching_api_key(self, func):
- if not hasattr(self, "api_key_queue"):
- return func
-
- def wrapped(*args, **kwargs):
- api_key = self.api_key_queue.get()
- args[0].api_key = api_key
- ret = func(*args, **kwargs)
- self.api_key_queue.put(api_key)
- return ret
-
- return wrapped
-
-
-state = State()
diff --git a/spaces/YONG627/456123/yolov5-code-main/models/common.py b/spaces/YONG627/456123/yolov5-code-main/models/common.py
deleted file mode 100644
index bd4b2f21c88298301f95af79898cc6aa66d2c450..0000000000000000000000000000000000000000
--- a/spaces/YONG627/456123/yolov5-code-main/models/common.py
+++ /dev/null
@@ -1,956 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-Common modules
-"""
-
-import ast
-import contextlib
-import json
-import math
-import platform
-import warnings
-import zipfile
-from collections import OrderedDict, namedtuple
-from copy import copy
-from pathlib import Path
-from urllib.parse import urlparse
-
-import cv2
-import numpy as np
-import pandas as pd
-import requests
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import torchvision.models as models
-from PIL import Image
-from torch.cuda import amp
-
-from utils import TryExcept
-from utils.dataloaders import exif_transpose, letterbox
-from utils.general import (LOGGER, ROOT, Profile, check_requirements, check_suffix, check_version, colorstr,
- increment_path, is_jupyter, make_divisible, non_max_suppression, scale_boxes, xywh2xyxy,
- xyxy2xywh, yaml_load)
-from utils.plots import Annotator, colors, save_one_box
-from utils.torch_utils import copy_attr, smart_inference_mode
-
-
-def autopad(k, p=None, d=1): # kernel, padding, dilation
- # Pad to 'same' shape outputs
- if d > 1:
- k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
- if p is None:
- p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
- return p
-
-
-class Conv(nn.Module):
- # Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
- default_act = nn.SiLU() # default activation
-
- def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
- super().__init__()
- self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
- self.bn = nn.BatchNorm2d(c2)
- self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
-
- def forward(self, x):
- return self.act(self.bn(self.conv(x)))
-
- def forward_fuse(self, x):
- return self.act(self.conv(x))
-
-
-class DWConv(Conv):
- # Depth-wise convolution
- def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
- super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
-
-
-class DWConvTranspose2d(nn.ConvTranspose2d):
- # Depth-wise transpose convolution
- def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_out
- super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
-
-
-class TransformerLayer(nn.Module):
- # Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
- def __init__(self, c, num_heads):
- super().__init__()
- self.q = nn.Linear(c, c, bias=False)
- self.k = nn.Linear(c, c, bias=False)
- self.v = nn.Linear(c, c, bias=False)
- self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
- self.fc1 = nn.Linear(c, c, bias=False)
- self.fc2 = nn.Linear(c, c, bias=False)
-
- def forward(self, x):
- x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
- x = self.fc2(self.fc1(x)) + x
- return x
-
-
-class TransformerBlock(nn.Module):
- # Vision Transformer https://arxiv.org/abs/2010.11929
- def __init__(self, c1, c2, num_heads, num_layers):
- super().__init__()
- self.conv = None
- if c1 != c2:
- self.conv = Conv(c1, c2)
- self.linear = nn.Linear(c2, c2) # learnable position embedding
- self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
- self.c2 = c2
-
- def forward(self, x):
- if self.conv is not None:
- x = self.conv(x)
- b, _, w, h = x.shape
- p = x.flatten(2).permute(2, 0, 1)
- return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
-
-
-class Bottleneck(nn.Module):
- # Standard bottleneck
- def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = Conv(c_, c2, 3, 1, g=g)
- self.add = shortcut and c1 == c2
-
- def forward(self, x):
- return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
-
-
-class BottleneckCSP(nn.Module):
- # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
- def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
- self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
- self.cv4 = Conv(2 * c_, c2, 1, 1)
- self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
- self.act = nn.SiLU()
- self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
-
- def forward(self, x):
- y1 = self.cv3(self.m(self.cv1(x)))
- y2 = self.cv2(x)
- return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
-
-
-class CrossConv(nn.Module):
- # Cross Convolution Downsample
- def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
- # ch_in, ch_out, kernel, stride, groups, expansion, shortcut
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = Conv(c1, c_, (1, k), (1, s))
- self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
- self.add = shortcut and c1 == c2
-
- def forward(self, x):
- return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
-
-
-
-
-
-# class MobileNetV3(nn.Module):
-
-# def __init__(self, slice):
-# super(MobileNetV3, self).__init__()
-# self.model = None
-# if slice == 1:
-# self.model = models.mobilenet_v3_small(pretrained=True).features[:4]
-# elif slice == 2:
-# self.model = models.mobilenet_v3_small(pretrained=True).features[4:9]
-# else:
-# self.model = models.mobilenet_v3_small(pretrained=True).features[9:]
-
-# def forward(self, x):
-# return self.model(x)
-
-
-class MobileNetV3(nn.Module):
-
- def __init__(self, slice):
- super(MobileNetV3, self).__init__()
- self.model = None
- if slice == 1:
- self.model = models.mobilenet_v3_small(pretrained=True).features[:4]
- elif slice == 2:
- self.model = models.mobilenet_v3_small(pretrained=True).features[4:9]
- else:
- self.model = models.mobilenet_v3_small(pretrained=True).features[9:]
-
- def forward(self, x):
- return self.model(x)
-
-
-class SE(nn.Module):
-
- def __init__(self, in_chnls, ratio):
- super(SE, self).__init__()
- self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
- self.compress = nn.Conv2d(in_chnls, in_chnls // ratio, 1, 1, 0)
- self.excitation = nn.Conv2d(in_chnls // ratio, in_chnls, 1, 1, 0)
-
- def forward(self, x):
- out = self.squeeze(x)
- out = self.compress(out)
- out = F.relu(out)
- out = self.excitation(out)
- return x * F.sigmoid(out)
-
-
-class C2fBottleneck(nn.Module):
- # Standard bottleneck
- def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = Conv(c1, c_, k[0], 1)
- self.cv2 = Conv(c_, c2, k[1], 1, g=g)
- self.add = shortcut and c1 == c2
-
- def forward(self, x):
- return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
-
-
-class C2f(nn.Module):
- # CSP Bottleneck with 2 convolutions
- def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
- super().__init__()
- self.c = int(c2 * e) # hidden channels
- self.cv1 = Conv(c1, 2 * self.c, 1, 1)
- self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
- self.m = nn.ModuleList(C2fBottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
-
- def forward(self, x):
- y = list(self.cv1(x).chunk(2, 1))
- y.extend(m(y[-1]) for m in self.m)
- return self.cv2(torch.cat(y, 1))
-
- def forward_split(self, x):
- y = list(self.cv1(x).split((self.c, self.c), 1))
- y.extend(m(y[-1]) for m in self.m)
- return self.cv2(torch.cat(y, 1))
-
-
-class C3(nn.Module):
- # CSP Bottleneck with 3 convolutions
- def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = Conv(c1, c_, 1, 1)
- self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
- self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
-
- def forward(self, x):
- return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
-
-
-class C3x(C3):
- # C3 module with cross-convolutions
- def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
- super().__init__(c1, c2, n, shortcut, g, e)
- c_ = int(c2 * e)
- self.m = nn.Sequential(*(CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)))
-
-
-class C3TR(C3):
- # C3 module with TransformerBlock()
- def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
- super().__init__(c1, c2, n, shortcut, g, e)
- c_ = int(c2 * e)
- self.m = TransformerBlock(c_, c_, 4, n)
-
-
-class C3SPP(C3):
- # C3 module with SPP()
- def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
- super().__init__(c1, c2, n, shortcut, g, e)
- c_ = int(c2 * e)
- self.m = SPP(c_, c_, k)
-
-
-class C3Ghost(C3):
- # C3 module with GhostBottleneck()
- def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
- super().__init__(c1, c2, n, shortcut, g, e)
- c_ = int(c2 * e) # hidden channels
- self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
-
-
-class SPP(nn.Module):
- # Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
- def __init__(self, c1, c2, k=(5, 9, 13)):
- super().__init__()
- c_ = c1 // 2 # hidden channels
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
- self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
-
- def forward(self, x):
- x = self.cv1(x)
- with warnings.catch_warnings():
- warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
- return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
-
-
-class SPPF(nn.Module):
- # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
- def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
- super().__init__()
- c_ = c1 // 2 # hidden channels
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = Conv(c_ * 4, c2, 1, 1)
- self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
-
- def forward(self, x):
- x = self.cv1(x)
- with warnings.catch_warnings():
- warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
- y1 = self.m(x)
- y2 = self.m(y1)
- return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
-
-
-class Focus(nn.Module):
- # Focus wh information into c-space
- def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
- super().__init__()
- self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
- # self.contract = Contract(gain=2)
-
- def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
- return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
- # return self.conv(self.contract(x))
-
-
-class GhostConv(nn.Module):
- # Ghost Convolution https://github.com/huawei-noah/ghostnet
- def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
- super().__init__()
- c_ = c2 // 2 # hidden channels
- self.cv1 = Conv(c1, c_, k, s, None, g, act=act)
- self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act)
-
- def forward(self, x):
- y = self.cv1(x)
- return torch.cat((y, self.cv2(y)), 1)
-
-
-class GhostBottleneck(nn.Module):
- # Ghost Bottleneck https://github.com/huawei-noah/ghostnet
- def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
- super().__init__()
- c_ = c2 // 2
- self.conv = nn.Sequential(
- GhostConv(c1, c_, 1, 1), # pw
- DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
- GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
- self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,
- act=False)) if s == 2 else nn.Identity()
-
- def forward(self, x):
- return self.conv(x) + self.shortcut(x)
-
-
-class Contract(nn.Module):
- # Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
- def __init__(self, gain=2):
- super().__init__()
- self.gain = gain
-
- def forward(self, x):
- b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
- s = self.gain
- x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
- x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
- return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
-
-
-class Expand(nn.Module):
- # Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
- def __init__(self, gain=2):
- super().__init__()
- self.gain = gain
-
- def forward(self, x):
- b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
- s = self.gain
- x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
- x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
- return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
-
-
-class Concat(nn.Module):
- # Concatenate a list of tensors along dimension
- def __init__(self, dimension=1):
- super().__init__()
- self.d = dimension
-
- def forward(self, x):
- return torch.cat(x, self.d)
-
-
-class DetectMultiBackend(nn.Module):
- # YOLOv5 MultiBackend class for python inference on various backends
- def __init__(self, weights='yolov5s.pt', device=torch.device('cpu'), dnn=False, data=None, fp16=False, fuse=True):
- # Usage:
- # PyTorch: weights = *.pt
- # TorchScript: *.torchscript
- # ONNX Runtime: *.onnx
- # ONNX OpenCV DNN: *.onnx --dnn
- # OpenVINO: *_openvino_model
- # CoreML: *.mlmodel
- # TensorRT: *.engine
- # TensorFlow SavedModel: *_saved_model
- # TensorFlow GraphDef: *.pb
- # TensorFlow Lite: *.tflite
- # TensorFlow Edge TPU: *_edgetpu.tflite
- # PaddlePaddle: *_paddle_model
- from models.experimental import attempt_download, attempt_load # scoped to avoid circular import
-
- super().__init__()
- w = str(weights[0] if isinstance(weights, list) else weights)
- pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle, triton = self._model_type(w)
- fp16 &= pt or jit or onnx or engine # FP16
- nhwc = coreml or saved_model or pb or tflite or edgetpu # BHWC formats (vs torch BCWH)
- stride = 32 # default stride
- cuda = torch.cuda.is_available() and device.type != 'cpu' # use CUDA
- if not (pt or triton):
- w = attempt_download(w) # download if not local
-
- if pt: # PyTorch
- model = attempt_load(weights if isinstance(weights, list) else w, device=device, inplace=True, fuse=fuse)
- stride = max(int(model.stride.max()), 32) # model stride
- names = model.module.names if hasattr(model, 'module') else model.names # get class names
- model.half() if fp16 else model.float()
- self.model = model # explicitly assign for to(), cpu(), cuda(), half()
- elif jit: # TorchScript
- LOGGER.info(f'Loading {w} for TorchScript inference...')
- extra_files = {'config.txt': ''} # model metadata
- model = torch.jit.load(w, _extra_files=extra_files, map_location=device)
- model.half() if fp16 else model.float()
- if extra_files['config.txt']: # load metadata dict
- d = json.loads(extra_files['config.txt'],
- object_hook=lambda d: {int(k) if k.isdigit() else k: v
- for k, v in d.items()})
- stride, names = int(d['stride']), d['names']
- elif dnn: # ONNX OpenCV DNN
- LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
- check_requirements('opencv-python>=4.5.4')
- net = cv2.dnn.readNetFromONNX(w)
- elif onnx: # ONNX Runtime
- LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
- check_requirements(('onnx', 'onnxruntime-gpu' if cuda else 'onnxruntime'))
- import onnxruntime
- providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] if cuda else ['CPUExecutionProvider']
- session = onnxruntime.InferenceSession(w, providers=providers)
- output_names = [x.name for x in session.get_outputs()]
- meta = session.get_modelmeta().custom_metadata_map # metadata
- if 'stride' in meta:
- stride, names = int(meta['stride']), eval(meta['names'])
- elif xml: # OpenVINO
- LOGGER.info(f'Loading {w} for OpenVINO inference...')
- check_requirements('openvino') # requires openvino-dev: https://pypi.org/project/openvino-dev/
- from openvino.runtime import Core, Layout, get_batch
- ie = Core()
- if not Path(w).is_file(): # if not *.xml
- w = next(Path(w).glob('*.xml')) # get *.xml file from *_openvino_model dir
- network = ie.read_model(model=w, weights=Path(w).with_suffix('.bin'))
- if network.get_parameters()[0].get_layout().empty:
- network.get_parameters()[0].set_layout(Layout('NCHW'))
- batch_dim = get_batch(network)
- if batch_dim.is_static:
- batch_size = batch_dim.get_length()
- executable_network = ie.compile_model(network, device_name='CPU') # device_name="MYRIAD" for Intel NCS2
- stride, names = self._load_metadata(Path(w).with_suffix('.yaml')) # load metadata
- elif engine: # TensorRT
- LOGGER.info(f'Loading {w} for TensorRT inference...')
- import tensorrt as trt # https://developer.nvidia.com/nvidia-tensorrt-download
- check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
- if device.type == 'cpu':
- device = torch.device('cuda:0')
- Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
- logger = trt.Logger(trt.Logger.INFO)
- with open(w, 'rb') as f, trt.Runtime(logger) as runtime:
- model = runtime.deserialize_cuda_engine(f.read())
- context = model.create_execution_context()
- bindings = OrderedDict()
- output_names = []
- fp16 = False # default updated below
- dynamic = False
- for i in range(model.num_bindings):
- name = model.get_binding_name(i)
- dtype = trt.nptype(model.get_binding_dtype(i))
- if model.binding_is_input(i):
- if -1 in tuple(model.get_binding_shape(i)): # dynamic
- dynamic = True
- context.set_binding_shape(i, tuple(model.get_profile_shape(0, i)[2]))
- if dtype == np.float16:
- fp16 = True
- else: # output
- output_names.append(name)
- shape = tuple(context.get_binding_shape(i))
- im = torch.from_numpy(np.empty(shape, dtype=dtype)).to(device)
- bindings[name] = Binding(name, dtype, shape, im, int(im.data_ptr()))
- binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
- batch_size = bindings['images'].shape[0] # if dynamic, this is instead max batch size
- elif coreml: # CoreML
- LOGGER.info(f'Loading {w} for CoreML inference...')
- import coremltools as ct
- model = ct.models.MLModel(w)
- elif saved_model: # TF SavedModel
- LOGGER.info(f'Loading {w} for TensorFlow SavedModel inference...')
- import tensorflow as tf
- keras = False # assume TF1 saved_model
- model = tf.keras.models.load_model(w) if keras else tf.saved_model.load(w)
- elif pb: # GraphDef https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
- LOGGER.info(f'Loading {w} for TensorFlow GraphDef inference...')
- import tensorflow as tf
-
- def wrap_frozen_graph(gd, inputs, outputs):
- x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=''), []) # wrapped
- ge = x.graph.as_graph_element
- return x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))
-
- def gd_outputs(gd):
- name_list, input_list = [], []
- for node in gd.node: # tensorflow.core.framework.node_def_pb2.NodeDef
- name_list.append(node.name)
- input_list.extend(node.input)
- return sorted(f'{x}:0' for x in list(set(name_list) - set(input_list)) if not x.startswith('NoOp'))
-
- gd = tf.Graph().as_graph_def() # TF GraphDef
- with open(w, 'rb') as f:
- gd.ParseFromString(f.read())
- frozen_func = wrap_frozen_graph(gd, inputs='x:0', outputs=gd_outputs(gd))
- elif tflite or edgetpu: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
- try: # https://coral.ai/docs/edgetpu/tflite-python/#update-existing-tf-lite-code-for-the-edge-tpu
- from tflite_runtime.interpreter import Interpreter, load_delegate
- except ImportError:
- import tensorflow as tf
- Interpreter, load_delegate = tf.lite.Interpreter, tf.lite.experimental.load_delegate,
- if edgetpu: # TF Edge TPU https://coral.ai/software/#edgetpu-runtime
- LOGGER.info(f'Loading {w} for TensorFlow Lite Edge TPU inference...')
- delegate = {
- 'Linux': 'libedgetpu.so.1',
- 'Darwin': 'libedgetpu.1.dylib',
- 'Windows': 'edgetpu.dll'}[platform.system()]
- interpreter = Interpreter(model_path=w, experimental_delegates=[load_delegate(delegate)])
- else: # TFLite
- LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
- interpreter = Interpreter(model_path=w) # load TFLite model
- interpreter.allocate_tensors() # allocate
- input_details = interpreter.get_input_details() # inputs
- output_details = interpreter.get_output_details() # outputs
- # load metadata
- with contextlib.suppress(zipfile.BadZipFile):
- with zipfile.ZipFile(w, 'r') as model:
- meta_file = model.namelist()[0]
- meta = ast.literal_eval(model.read(meta_file).decode('utf-8'))
- stride, names = int(meta['stride']), meta['names']
- elif tfjs: # TF.js
- raise NotImplementedError('ERROR: YOLOv5 TF.js inference is not supported')
- elif paddle: # PaddlePaddle
- LOGGER.info(f'Loading {w} for PaddlePaddle inference...')
- check_requirements('paddlepaddle-gpu' if cuda else 'paddlepaddle')
- import paddle.inference as pdi
- if not Path(w).is_file(): # if not *.pdmodel
- w = next(Path(w).rglob('*.pdmodel')) # get *.pdmodel file from *_paddle_model dir
- weights = Path(w).with_suffix('.pdiparams')
- config = pdi.Config(str(w), str(weights))
- if cuda:
- config.enable_use_gpu(memory_pool_init_size_mb=2048, device_id=0)
- predictor = pdi.create_predictor(config)
- input_handle = predictor.get_input_handle(predictor.get_input_names()[0])
- output_names = predictor.get_output_names()
- elif triton: # NVIDIA Triton Inference Server
- LOGGER.info(f'Using {w} as Triton Inference Server...')
- check_requirements('tritonclient[all]')
- from utils.triton import TritonRemoteModel
- model = TritonRemoteModel(url=w)
- nhwc = model.runtime.startswith('tensorflow')
- else:
- raise NotImplementedError(f'ERROR: {w} is not a supported format')
-
- # class names
- if 'names' not in locals():
- names = yaml_load(data)['names'] if data else {i: f'class{i}' for i in range(999)}
- if names[0] == 'n01440764' and len(names) == 1000: # ImageNet
- names = yaml_load(ROOT / 'data/ImageNet.yaml')['names'] # human-readable names
-
- self.__dict__.update(locals()) # assign all variables to self
-
- def forward(self, im, augment=False, visualize=False):
- # YOLOv5 MultiBackend inference
- b, ch, h, w = im.shape # batch, channel, height, width
- if self.fp16 and im.dtype != torch.float16:
- im = im.half() # to FP16
- if self.nhwc:
- im = im.permute(0, 2, 3, 1) # torch BCHW to numpy BHWC shape(1,320,192,3)
-
- if self.pt: # PyTorch
- y = self.model(im, augment=augment, visualize=visualize) if augment or visualize else self.model(im)
- elif self.jit: # TorchScript
- y = self.model(im)
- elif self.dnn: # ONNX OpenCV DNN
- im = im.cpu().numpy() # torch to numpy
- self.net.setInput(im)
- y = self.net.forward()
- elif self.onnx: # ONNX Runtime
- im = im.cpu().numpy() # torch to numpy
- y = self.session.run(self.output_names, {self.session.get_inputs()[0].name: im})
- elif self.xml: # OpenVINO
- im = im.cpu().numpy() # FP32
- y = list(self.executable_network([im]).values())
- elif self.engine: # TensorRT
- if self.dynamic and im.shape != self.bindings['images'].shape:
- i = self.model.get_binding_index('images')
- self.context.set_binding_shape(i, im.shape) # reshape if dynamic
- self.bindings['images'] = self.bindings['images']._replace(shape=im.shape)
- for name in self.output_names:
- i = self.model.get_binding_index(name)
- self.bindings[name].data.resize_(tuple(self.context.get_binding_shape(i)))
- s = self.bindings['images'].shape
- assert im.shape == s, f"input size {im.shape} {'>' if self.dynamic else 'not equal to'} max model size {s}"
- self.binding_addrs['images'] = int(im.data_ptr())
- self.context.execute_v2(list(self.binding_addrs.values()))
- y = [self.bindings[x].data for x in sorted(self.output_names)]
- elif self.coreml: # CoreML
- im = im.cpu().numpy()
- im = Image.fromarray((im[0] * 255).astype('uint8'))
- # im = im.resize((192, 320), Image.ANTIALIAS)
- y = self.model.predict({'image': im}) # coordinates are xywh normalized
- if 'confidence' in y:
- box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
- conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)
- y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
- else:
- y = list(reversed(y.values())) # reversed for segmentation models (pred, proto)
- elif self.paddle: # PaddlePaddle
- im = im.cpu().numpy().astype(np.float32)
- self.input_handle.copy_from_cpu(im)
- self.predictor.run()
- y = [self.predictor.get_output_handle(x).copy_to_cpu() for x in self.output_names]
- elif self.triton: # NVIDIA Triton Inference Server
- y = self.model(im)
- else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
- im = im.cpu().numpy()
- if self.saved_model: # SavedModel
- y = self.model(im, training=False) if self.keras else self.model(im)
- elif self.pb: # GraphDef
- y = self.frozen_func(x=self.tf.constant(im))
- else: # Lite or Edge TPU
- input = self.input_details[0]
- int8 = input['dtype'] == np.uint8 # is TFLite quantized uint8 model
- if int8:
- scale, zero_point = input['quantization']
- im = (im / scale + zero_point).astype(np.uint8) # de-scale
- self.interpreter.set_tensor(input['index'], im)
- self.interpreter.invoke()
- y = []
- for output in self.output_details:
- x = self.interpreter.get_tensor(output['index'])
- if int8:
- scale, zero_point = output['quantization']
- x = (x.astype(np.float32) - zero_point) * scale # re-scale
- y.append(x)
- y = [x if isinstance(x, np.ndarray) else x.numpy() for x in y]
- y[0][..., :4] *= [w, h, w, h] # xywh normalized to pixels
-
- if isinstance(y, (list, tuple)):
- return self.from_numpy(y[0]) if len(y) == 1 else [self.from_numpy(x) for x in y]
- else:
- return self.from_numpy(y)
-
- def from_numpy(self, x):
- return torch.from_numpy(x).to(self.device) if isinstance(x, np.ndarray) else x
-
- def warmup(self, imgsz=(1, 3, 640, 640)):
- # Warmup model by running inference once
- warmup_types = self.pt, self.jit, self.onnx, self.engine, self.saved_model, self.pb, self.triton
- if any(warmup_types) and (self.device.type != 'cpu' or self.triton):
- im = torch.empty(*imgsz, dtype=torch.half if self.fp16 else torch.float, device=self.device) # input
- for _ in range(2 if self.jit else 1): #
- self.forward(im) # warmup
-
- @staticmethod
- def _model_type(p='path/to/model.pt'):
- # Return model type from model path, i.e. path='path/to/model.onnx' -> type=onnx
- # types = [pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle]
- from export import export_formats
- from utils.downloads import is_url
- sf = list(export_formats().Suffix) # export suffixes
- if not is_url(p, check=False):
- check_suffix(p, sf) # checks
- url = urlparse(p) # if url may be Triton inference server
- types = [s in Path(p).name for s in sf]
- types[8] &= not types[9] # tflite &= not edgetpu
- triton = not any(types) and all([any(s in url.scheme for s in ['http', 'grpc']), url.netloc])
- return types + [triton]
-
- @staticmethod
- def _load_metadata(f=Path('path/to/meta.yaml')):
- # Load metadata from meta.yaml if it exists
- if f.exists():
- d = yaml_load(f)
- return d['stride'], d['names'] # assign stride, names
- return None, None
-
-
-class AutoShape(nn.Module):
- # YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
- conf = 0.25 # NMS confidence threshold
- iou = 0.45 # NMS IoU threshold
- agnostic = False # NMS class-agnostic
- multi_label = False # NMS multiple labels per box
- classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
- max_det = 1000 # maximum number of detections per image
- amp = False # Automatic Mixed Precision (AMP) inference
-
- def __init__(self, model, verbose=True):
- super().__init__()
- if verbose:
- LOGGER.info('Adding AutoShape... ')
- copy_attr(self, model, include=('yaml', 'nc', 'hyp', 'names', 'stride', 'abc'), exclude=()) # copy attributes
- self.dmb = isinstance(model, DetectMultiBackend) # DetectMultiBackend() instance
- self.pt = not self.dmb or model.pt # PyTorch model
- self.model = model.eval()
- if self.pt:
- m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
- m.inplace = False # Detect.inplace=False for safe multithread inference
- m.export = True # do not output loss values
-
- def _apply(self, fn):
- # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
- self = super()._apply(fn)
- if self.pt:
- m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
- m.stride = fn(m.stride)
- m.grid = list(map(fn, m.grid))
- if isinstance(m.anchor_grid, list):
- m.anchor_grid = list(map(fn, m.anchor_grid))
- return self
-
- @smart_inference_mode()
- def forward(self, ims, size=640, augment=False, profile=False):
- # Inference from various sources. For size(height=640, width=1280), RGB images example inputs are:
- # file: ims = 'data/images/zidane.jpg' # str or PosixPath
- # URI: = 'https://ultralytics.com/images/zidane.jpg'
- # OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
- # PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
- # numpy: = np.zeros((640,1280,3)) # HWC
- # torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
- # multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
-
- dt = (Profile(), Profile(), Profile())
- with dt[0]:
- if isinstance(size, int): # expand
- size = (size, size)
- p = next(self.model.parameters()) if self.pt else torch.empty(1, device=self.model.device) # param
- autocast = self.amp and (p.device.type != 'cpu') # Automatic Mixed Precision (AMP) inference
- if isinstance(ims, torch.Tensor): # torch
- with amp.autocast(autocast):
- return self.model(ims.to(p.device).type_as(p), augment=augment) # inference
-
- # Pre-process
- n, ims = (len(ims), list(ims)) if isinstance(ims, (list, tuple)) else (1, [ims]) # number, list of images
- shape0, shape1, files = [], [], [] # image and inference shapes, filenames
- for i, im in enumerate(ims):
- f = f'image{i}' # filename
- if isinstance(im, (str, Path)): # filename or uri
- im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
- im = np.asarray(exif_transpose(im))
- elif isinstance(im, Image.Image): # PIL Image
- im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
- files.append(Path(f).with_suffix('.jpg').name)
- if im.shape[0] < 5: # image in CHW
- im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
- im = im[..., :3] if im.ndim == 3 else cv2.cvtColor(im, cv2.COLOR_GRAY2BGR) # enforce 3ch input
- s = im.shape[:2] # HWC
- shape0.append(s) # image shape
- g = max(size) / max(s) # gain
- shape1.append([int(y * g) for y in s])
- ims[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
- shape1 = [make_divisible(x, self.stride) for x in np.array(shape1).max(0)] # inf shape
- x = [letterbox(im, shape1, auto=False)[0] for im in ims] # pad
- x = np.ascontiguousarray(np.array(x).transpose((0, 3, 1, 2))) # stack and BHWC to BCHW
- x = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32
-
- with amp.autocast(autocast):
- # Inference
- with dt[1]:
- y = self.model(x, augment=augment) # forward
-
- # Post-process
- with dt[2]:
- y = non_max_suppression(y if self.dmb else y[0],
- self.conf,
- self.iou,
- self.classes,
- self.agnostic,
- self.multi_label,
- max_det=self.max_det) # NMS
- for i in range(n):
- scale_boxes(shape1, y[i][:, :4], shape0[i])
-
- return Detections(ims, y, files, dt, self.names, x.shape)
-
-
-class Detections:
- # YOLOv5 detections class for inference results
- def __init__(self, ims, pred, files, times=(0, 0, 0), names=None, shape=None):
- super().__init__()
- d = pred[0].device # device
- gn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in ims] # normalizations
- self.ims = ims # list of images as numpy arrays
- self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
- self.names = names # class names
- self.files = files # image filenames
- self.times = times # profiling times
- self.xyxy = pred # xyxy pixels
- self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
- self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
- self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
- self.n = len(self.pred) # number of images (batch size)
- self.t = tuple(x.t / self.n * 1E3 for x in times) # timestamps (ms)
- self.s = tuple(shape) # inference BCHW shape
-
- def _run(self, pprint=False, show=False, save=False, crop=False, render=False, labels=True, save_dir=Path('')):
- s, crops = '', []
- for i, (im, pred) in enumerate(zip(self.ims, self.pred)):
- s += f'\nimage {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
- if pred.shape[0]:
- for c in pred[:, -1].unique():
- n = (pred[:, -1] == c).sum() # detections per class
- s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
- s = s.rstrip(', ')
- if show or save or render or crop:
- annotator = Annotator(im, example=str(self.names))
- for *box, conf, cls in reversed(pred): # xyxy, confidence, class
- label = f'{self.names[int(cls)]} {conf:.2f}'
- if crop:
- file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
- crops.append({
- 'box': box,
- 'conf': conf,
- 'cls': cls,
- 'label': label,
- 'im': save_one_box(box, im, file=file, save=save)})
- else: # all others
- annotator.box_label(box, label if labels else '', color=colors(cls))
- im = annotator.im
- else:
- s += '(no detections)'
-
- im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
- if show:
- if is_jupyter():
- from IPython.display import display
- display(im)
- else:
- im.show(self.files[i])
- if save:
- f = self.files[i]
- im.save(save_dir / f) # save
- if i == self.n - 1:
- LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
- if render:
- self.ims[i] = np.asarray(im)
- if pprint:
- s = s.lstrip('\n')
- return f'{s}\nSpeed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {self.s}' % self.t
- if crop:
- if save:
- LOGGER.info(f'Saved results to {save_dir}\n')
- return crops
-
- @TryExcept('Showing images is not supported in this environment')
- def show(self, labels=True):
- self._run(show=True, labels=labels) # show results
-
- def save(self, labels=True, save_dir='runs/detect/exp', exist_ok=False):
- save_dir = increment_path(save_dir, exist_ok, mkdir=True) # increment save_dir
- self._run(save=True, labels=labels, save_dir=save_dir) # save results
-
- def crop(self, save=True, save_dir='runs/detect/exp', exist_ok=False):
- save_dir = increment_path(save_dir, exist_ok, mkdir=True) if save else None
- return self._run(crop=True, save=save, save_dir=save_dir) # crop results
-
- def render(self, labels=True):
- self._run(render=True, labels=labels) # render results
- return self.ims
-
- def pandas(self):
- # return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
- new = copy(self) # return copy
- ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
- cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
- for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
- a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
- setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
- return new
-
- def tolist(self):
- # return a list of Detections objects, i.e. 'for result in results.tolist():'
- r = range(self.n) # iterable
- x = [Detections([self.ims[i]], [self.pred[i]], [self.files[i]], self.times, self.names, self.s) for i in r]
- # for d in x:
- # for k in ['ims', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
- # setattr(d, k, getattr(d, k)[0]) # pop out of list
- return x
-
- def print(self):
- LOGGER.info(self.__str__())
-
- def __len__(self): # override len(results)
- return self.n
-
- def __str__(self): # override print(results)
- return self._run(pprint=True) # print results
-
- def __repr__(self):
- return f'YOLOv5 {self.__class__} instance\n' + self.__str__()
-
-
-class Proto(nn.Module):
- # YOLOv5 mask Proto module for segmentation models
- def __init__(self, c1, c_=256, c2=32): # ch_in, number of protos, number of masks
- super().__init__()
- self.cv1 = Conv(c1, c_, k=3)
- self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
- self.cv2 = Conv(c_, c_, k=3)
- self.cv3 = Conv(c_, c2)
-
- def forward(self, x):
- return self.cv3(self.cv2(self.upsample(self.cv1(x))))
-
-
-class Classify(nn.Module):
- # YOLOv5 classification head, i.e. x(b,c1,20,20) to x(b,c2)
- def __init__(self,
- c1,
- c2,
- k=1,
- s=1,
- p=None,
- g=1,
- dropout_p=0.0): # ch_in, ch_out, kernel, stride, padding, groups, dropout probability
- super().__init__()
- c_ = 1280 # efficientnet_b0 size
- self.conv = Conv(c1, c_, k, s, autopad(k, p), g)
- self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)
- self.drop = nn.Dropout(p=dropout_p, inplace=True)
- self.linear = nn.Linear(c_, c2) # to x(b,c2)
-
- def forward(self, x):
- if isinstance(x, list):
- x = torch.cat(x, 1)
- return self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))
diff --git a/spaces/Yiqin/ChatVID/model/Captioner.py b/spaces/Yiqin/ChatVID/model/Captioner.py
deleted file mode 100644
index e443612b9eaf64ffbd0354722c93d94d609c2b2b..0000000000000000000000000000000000000000
--- a/spaces/Yiqin/ChatVID/model/Captioner.py
+++ /dev/null
@@ -1,72 +0,0 @@
-from mmaction.datasets.transforms import (DecordInit, SampleFrames, Resize,
- FormatShape, DecordDecode)
-from model.audio import SpeechRecognizer
-from model.vision import DenseCaptioner, ImageCaptioner
-
-
-class Captioner:
- """ Captioner class for video captioning
- """
-
- def __init__(self, config):
- """ Initialize the captioner
- Args:
- config: configuration file
- """
- self.config = config
- self.image_captioner = ImageCaptioner(device=config['device'])
- self.dense_captioner = DenseCaptioner(device=config['device'])
- self.speech_recognizer = SpeechRecognizer(device=config['device'])
- # if self.config['vid2seq']['enable']:
- # self.vid2seq_captioner = Vid2SeqCaptioner(config=config['vid2seq'])
-
- self.src_dir = ''
-
- def debug_vid2seq(self, video_path, num_frames=8):
- return self.vid2seq_captioner(video_path=video_path)
-
- def caption_video(self, video_path, num_frames=8):
- print("Watching video ...")
-
- video_info = {'filename': video_path, 'start_index': 0}
-
- video_processors = [
- DecordInit(),
- SampleFrames(clip_len=1, frame_interval=1, num_clips=num_frames),
- DecordDecode(),
- Resize(scale=(-1, 720)),
- FormatShape(input_format='NCHW'),
- ]
- for processor in video_processors:
- video_info = processor.transform(video_info)
-
- timestamp_list = [
- round(i / video_info['avg_fps'], 1)
- for i in video_info['frame_inds']
- ]
-
- image_captions = self.image_captioner(imgs=video_info['imgs'])
- dense_captions = self.dense_captioner(imgs=video_info['imgs'])
- # if self.config['vid2seq']['enable']:
- # vid2seq_captions = self.vid2seq_captioner(video_path=video_path)
- # else:
- vid2seq_captions = []
- try:
- speech = self.speech_recognizer(video_path)
- except RuntimeError:
- speech = ""
-
- overall_captions = ""
- for i in range(num_frames):
- overall_captions += "[" + str(timestamp_list[i]) + "s]: "
- overall_captions += "You see " + image_captions[i]
- overall_captions += "You find " + dense_captions[i] + "\n"
-
- if speech != "":
- overall_captions += "You hear \"" + speech + "\"\n"
-
- for i in range(len(vid2seq_captions)):
- overall_captions += "You notice " + vid2seq_captions[i] + "\n"
- print("Captions generated")
-
- return overall_captions
diff --git a/spaces/abdvl/datahub_qa_bot/docs/roadmap.md b/spaces/abdvl/datahub_qa_bot/docs/roadmap.md
deleted file mode 100644
index f844b29db974cfdfec415e408dcc7274db745a1d..0000000000000000000000000000000000000000
--- a/spaces/abdvl/datahub_qa_bot/docs/roadmap.md
+++ /dev/null
@@ -1,138 +0,0 @@
-# DataHub Roadmap
-
-## [The DataHub Roadmap has a new home!](https://feature-requests.datahubproject.io/roadmap)
-
-Please refer to the [new DataHub Roadmap](https://feature-requests.datahubproject.io/roadmap) for the most up-to-date details of what we are working on!
-
-_If you have suggestions about what we should consider in future cycles, feel free to submit a [feature request](https://feature-requests.datahubproject.io/) and/or upvote existing feature requests so we can get a sense of level of importance!_
-
-
-## Historical Roadmap
-
-_This following represents the progress made on historical roadmap items as of January 2022. For incomplete roadmap items, we have created Feature Requests to gauge current community interest & impact to be considered in future cycles. If you see something that is still of high-interest to you, please up-vote via the Feature Request portal link and subscribe to the post for updates as we progress through the work in future cycles._
-
-### Q4 2021 [Oct - Dec 2021]
-
-#### Data Lake Ecosystem Integration
-- [ ] Spark Delta Lake - [View in Feature Reqeust Portal](https://feature-requests.datahubproject.io/b/feedback/p/spark-delta-lake)
-- [ ] Apache Iceberg - [Included in Q1 2022 Roadmap - Community-Driven Metadata Ingestion Sources](https://feature-requests.datahubproject.io/roadmap/540)
-- [ ] Apache Hudi - [View in Feature Request Portal](https://feature-requests.datahubproject.io/b/feedback/p/apachi-hudi-ingestion-support)
-
-#### Metadata Trigger Framework
-[View in Feature Request Portal](https://feature-requests.datahubproject.io/b/User-Experience/p/ability-to-subscribe-to-an-entity-to-receive-notifications-when-something-changes)
-- [ ] Stateful sensors for Airflow
-- [ ] Receive events for you to send alerts, email
-- [ ] Slack integration
-
-#### ML Ecosystem
-- [x] Features (Feast)
-- [x] Models (Sagemaker)
-- [ ] Notebooks - View in Feature Request Portal](https://feature-requests.datahubproject.io/admin/p/jupyter-integration)
-
-#### Metrics Ecosystem
-[View in Feature Request Portal](https://feature-requests.datahubproject.io/b/User-Experience/p/ability-to-define-metrics-and-attach-them-to-entities)
-- [ ] Measures, Dimensions
-- [ ] Relationships to Datasets and Dashboards
-
-#### Data Mesh oriented features
-- [ ] Data Product modeling
-- [ ] Analytics to enable Data Meshification
-
-#### Collaboration
-[View in Feature Reqeust Portal](https://feature-requests.datahubproject.io/b/User-Experience/p/collaboration-within-datahub-ui)
-- [ ] Conversations on the platform
-- [ ] Knowledge Posts (Gdocs, Gslides, Gsheets)
-
-### Q3 2021 [Jul - Sept 2021]
-
-#### Data Profiling and Dataset Previews
-Use Case: See sample data for a dataset and statistics on the shape of the data (column distribution, nullability etc.)
-- [x] Support for data profiling and preview extraction through ingestion pipeline (column samples, not rows)
-
-#### Data Quality
-Included in Q1 2022 Roadmap - [Display Data Quality Checks in the UI](https://feature-requests.datahubproject.io/roadmap/544)
-- [x] Support for data profiling and time-series views
-- [ ] Support for data quality visualization
-- [ ] Support for data health score based on data quality results and pipeline observability
-- [ ] Integration with systems like Great Expectations, AWS deequ, dbt test etc.
-
-#### Fine-grained Access Control for Metadata
-- [x] Support for role-based access control to edit metadata
-- Scope: Access control on entity-level, aspect-level and within aspects as well.
-
-#### Column-level lineage
-Included in Q1 2022 Roadmap - [Column Level Lineage](https://feature-requests.datahubproject.io/roadmap/541)
-- [ ] Metadata Model
-- [ ] SQL Parsing
-
-#### Operational Metadata
-- [ ] Partitioned Datasets - - [View in Feature Request Portal](https://feature-requests.datahubproject.io/b/User-Experience/p/advanced-dataset-schema-properties-partition-support)
-- [x] Support for operational signals like completeness, freshness etc.
-
-### Q2 2021 (Apr - Jun 2021)
-
-#### Cloud Deployment
-- [X] Production-grade Helm charts for Kubernetes-based deployment
-- [ ] How-to guides for deploying DataHub to all the major cloud providers
- - [x] AWS
- - [ ] Azure
- - [x] GCP
-
-#### Product Analytics for DataHub
-- [x] Helping you understand how your users are interacting with DataHub
-- [x] Integration with common systems like Google Analytics etc.
-
-#### Usage-Based Insights
-- [x] Display frequently used datasets, etc.
-- [ ] Improved search relevance through usage data
-
-#### Role-based Access Control
-- Support for fine-grained access control for metadata operations (read, write, modify)
-- Scope: Access control on entity-level, aspect-level and within aspects as well.
-- This provides the foundation for Tag Governance, Dataset Preview access control etc.
-
-#### No-code Metadata Model Additions
-Use Case: Developers should be able to add new entities and aspects to the metadata model easily
-- [x] No need to write any code (in Java or Python) to store, retrieve, search and query metadata
-- [ ] No need to write any code (in GraphQL or UI) to visualize metadata
-
-### Q1 2021 [Jan - Mar 2021]
-
-#### React UI
-- [x] Build a new UI based on React
-- [x] Deprecate open-source support for Ember UI
-
-#### Python-based Metadata Integration
-- [x] Build a Python-based Ingestion Framework
-- [x] Support common people repositories (LDAP)
-- [x] Support common data repositories (Kafka, SQL databases, AWS Glue, Hive)
-- [x] Support common transformation sources (dbt, Looker)
-- [x] Support for push-based metadata emission from Python (e.g. Airflow DAGs)
-
-#### Dashboards and Charts
-- [x] Support for dashboard and chart entity page
-- [x] Support browse, search and discovery
-
-#### SSO for Authentication
-- [x] Support for Authentication (login) using OIDC providers (Okta, Google etc)
-
-#### Tags
-Use-Case: Support for free-form global tags for social collaboration and aiding discovery
-- [x] Edit / Create new tags
-- [x] Attach tags to relevant constructs (e.g. datasets, dashboards, users, schema\_fields)
-- [x] Search using tags (e.g. find all datasets with this tag, find all entities with this tag)
-
-#### Business Glossary
-- [x] Support for business glossary model (definition + storage)
-- [ ] Browse taxonomy
-- [x] UI support for attaching business terms to entities and fields
-
-#### Jobs, Flows / Pipelines
-Use case: Search and Discover your Pipelines (e.g. Airflow DAGs) and understand lineage with datasets
-- [x] Support for Metadata Models + Backend Implementation
-- [x] Metadata Integrations with systems like Airflow.
-
-#### Data Profiling and Dataset Previews
-Use Case: See sample data for a dataset and statistics on the shape of the data (column distribution, nullability etc.)
-- [ ] Support for data profiling and preview extraction through ingestion pipeline
-- Out of scope for Q1: Access control of data profiles and sample data
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/detectors/base.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/detectors/base.py
deleted file mode 100644
index 89134f3696ead442a5ff57184e9d256fdf7d0ba4..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/detectors/base.py
+++ /dev/null
@@ -1,355 +0,0 @@
-from abc import ABCMeta, abstractmethod
-from collections import OrderedDict
-
-import mmcv
-import numpy as np
-import torch
-import torch.distributed as dist
-import torch.nn as nn
-from mmcv.runner import auto_fp16
-from mmcv.utils import print_log
-
-from mmdet.core.visualization import imshow_det_bboxes
-from mmdet.utils import get_root_logger
-
-
-class BaseDetector(nn.Module, metaclass=ABCMeta):
- """Base class for detectors."""
-
- def __init__(self):
- super(BaseDetector, self).__init__()
- self.fp16_enabled = False
-
- @property
- def with_neck(self):
- """bool: whether the detector has a neck"""
- return hasattr(self, 'neck') and self.neck is not None
-
- # TODO: these properties need to be carefully handled
- # for both single stage & two stage detectors
- @property
- def with_shared_head(self):
- """bool: whether the detector has a shared head in the RoI Head"""
- return hasattr(self, 'roi_head') and self.roi_head.with_shared_head
-
- @property
- def with_bbox(self):
- """bool: whether the detector has a bbox head"""
- return ((hasattr(self, 'roi_head') and self.roi_head.with_bbox)
- or (hasattr(self, 'bbox_head') and self.bbox_head is not None))
-
- @property
- def with_mask(self):
- """bool: whether the detector has a mask head"""
- return ((hasattr(self, 'roi_head') and self.roi_head.with_mask)
- or (hasattr(self, 'mask_head') and self.mask_head is not None))
-
- @abstractmethod
- def extract_feat(self, imgs):
- """Extract features from images."""
- pass
-
- def extract_feats(self, imgs):
- """Extract features from multiple images.
-
- Args:
- imgs (list[torch.Tensor]): A list of images. The images are
- augmented from the same image but in different ways.
-
- Returns:
- list[torch.Tensor]: Features of different images
- """
- assert isinstance(imgs, list)
- return [self.extract_feat(img) for img in imgs]
-
- def forward_train(self, imgs, img_metas, **kwargs):
- """
- Args:
- img (list[Tensor]): List of tensors of shape (1, C, H, W).
- Typically these should be mean centered and std scaled.
- img_metas (list[dict]): List of image info dict where each dict
- has: 'img_shape', 'scale_factor', 'flip', and may also contain
- 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
- For details on the values of these keys, see
- :class:`mmdet.datasets.pipelines.Collect`.
- kwargs (keyword arguments): Specific to concrete implementation.
- """
- # NOTE the batched image size information may be useful, e.g.
- # in DETR, this is needed for the construction of masks, which is
- # then used for the transformer_head.
- batch_input_shape = tuple(imgs[0].size()[-2:])
- for img_meta in img_metas:
- img_meta['batch_input_shape'] = batch_input_shape
-
- async def async_simple_test(self, img, img_metas, **kwargs):
- raise NotImplementedError
-
- @abstractmethod
- def simple_test(self, img, img_metas, **kwargs):
- pass
-
- @abstractmethod
- def aug_test(self, imgs, img_metas, **kwargs):
- """Test function with test time augmentation."""
- pass
-
- def init_weights(self, pretrained=None):
- """Initialize the weights in detector.
-
- Args:
- pretrained (str, optional): Path to pre-trained weights.
- Defaults to None.
- """
- if pretrained is not None:
- logger = get_root_logger()
- print_log(f'load model from: {pretrained}', logger=logger)
-
- async def aforward_test(self, *, img, img_metas, **kwargs):
- for var, name in [(img, 'img'), (img_metas, 'img_metas')]:
- if not isinstance(var, list):
- raise TypeError(f'{name} must be a list, but got {type(var)}')
-
- num_augs = len(img)
- if num_augs != len(img_metas):
- raise ValueError(f'num of augmentations ({len(img)}) '
- f'!= num of image metas ({len(img_metas)})')
- # TODO: remove the restriction of samples_per_gpu == 1 when prepared
- samples_per_gpu = img[0].size(0)
- assert samples_per_gpu == 1
-
- if num_augs == 1:
- return await self.async_simple_test(img[0], img_metas[0], **kwargs)
- else:
- raise NotImplementedError
-
- def forward_test(self, imgs, img_metas, **kwargs):
- """
- Args:
- imgs (List[Tensor]): the outer list indicates test-time
- augmentations and inner Tensor should have a shape NxCxHxW,
- which contains all images in the batch.
- img_metas (List[List[dict]]): the outer list indicates test-time
- augs (multiscale, flip, etc.) and the inner list indicates
- images in a batch.
- """
- for var, name in [(imgs, 'imgs'), (img_metas, 'img_metas')]:
- if not isinstance(var, list):
- raise TypeError(f'{name} must be a list, but got {type(var)}')
-
- num_augs = len(imgs)
- if num_augs != len(img_metas):
- raise ValueError(f'num of augmentations ({len(imgs)}) '
- f'!= num of image meta ({len(img_metas)})')
-
- # NOTE the batched image size information may be useful, e.g.
- # in DETR, this is needed for the construction of masks, which is
- # then used for the transformer_head.
- for img, img_meta in zip(imgs, img_metas):
- batch_size = len(img_meta)
- for img_id in range(batch_size):
- img_meta[img_id]['batch_input_shape'] = tuple(img.size()[-2:])
-
- if num_augs == 1:
- # proposals (List[List[Tensor]]): the outer list indicates
- # test-time augs (multiscale, flip, etc.) and the inner list
- # indicates images in a batch.
- # The Tensor should have a shape Px4, where P is the number of
- # proposals.
- if 'proposals' in kwargs:
- kwargs['proposals'] = kwargs['proposals'][0]
- return self.simple_test(imgs[0], img_metas[0], **kwargs)
- else:
- assert imgs[0].size(0) == 1, 'aug test does not support ' \
- 'inference with batch size ' \
- f'{imgs[0].size(0)}'
- # TODO: support test augmentation for predefined proposals
- assert 'proposals' not in kwargs
- return self.aug_test(imgs, img_metas, **kwargs)
-
- @auto_fp16(apply_to=('img', ))
- def forward(self, img, img_metas, return_loss=True, **kwargs):
- """Calls either :func:`forward_train` or :func:`forward_test` depending
- on whether ``return_loss`` is ``True``.
-
- Note this setting will change the expected inputs. When
- ``return_loss=True``, img and img_meta are single-nested (i.e. Tensor
- and List[dict]), and when ``resturn_loss=False``, img and img_meta
- should be double nested (i.e. List[Tensor], List[List[dict]]), with
- the outer list indicating test time augmentations.
- """
- if return_loss:
- return self.forward_train(img, img_metas, **kwargs)
- else:
- return self.forward_test(img, img_metas, **kwargs)
-
- def _parse_losses(self, losses):
- """Parse the raw outputs (losses) of the network.
-
- Args:
- losses (dict): Raw output of the network, which usually contain
- losses and other necessary infomation.
-
- Returns:
- tuple[Tensor, dict]: (loss, log_vars), loss is the loss tensor \
- which may be a weighted sum of all losses, log_vars contains \
- all the variables to be sent to the logger.
- """
- log_vars = OrderedDict()
- for loss_name, loss_value in losses.items():
- if isinstance(loss_value, torch.Tensor):
- log_vars[loss_name] = loss_value.mean()
- elif isinstance(loss_value, list):
- log_vars[loss_name] = sum(_loss.mean() for _loss in loss_value)
- else:
- raise TypeError(
- f'{loss_name} is not a tensor or list of tensors')
-
- loss = sum(_value for _key, _value in log_vars.items()
- if 'loss' in _key)
-
- log_vars['loss'] = loss
- for loss_name, loss_value in log_vars.items():
- # reduce loss when distributed training
- if dist.is_available() and dist.is_initialized():
- loss_value = loss_value.data.clone()
- dist.all_reduce(loss_value.div_(dist.get_world_size()))
- log_vars[loss_name] = loss_value.item()
-
- return loss, log_vars
-
- def train_step(self, data, optimizer):
- """The iteration step during training.
-
- This method defines an iteration step during training, except for the
- back propagation and optimizer updating, which are done in an optimizer
- hook. Note that in some complicated cases or models, the whole process
- including back propagation and optimizer updating is also defined in
- this method, such as GAN.
-
- Args:
- data (dict): The output of dataloader.
- optimizer (:obj:`torch.optim.Optimizer` | dict): The optimizer of
- runner is passed to ``train_step()``. This argument is unused
- and reserved.
-
- Returns:
- dict: It should contain at least 3 keys: ``loss``, ``log_vars``, \
- ``num_samples``.
-
- - ``loss`` is a tensor for back propagation, which can be a \
- weighted sum of multiple losses.
- - ``log_vars`` contains all the variables to be sent to the
- logger.
- - ``num_samples`` indicates the batch size (when the model is \
- DDP, it means the batch size on each GPU), which is used for \
- averaging the logs.
- """
- losses = self(**data)
- loss, log_vars = self._parse_losses(losses)
-
- outputs = dict(
- loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
-
- return outputs
-
- def val_step(self, data, optimizer):
- """The iteration step during validation.
-
- This method shares the same signature as :func:`train_step`, but used
- during val epochs. Note that the evaluation after training epochs is
- not implemented with this method, but an evaluation hook.
- """
- losses = self(**data)
- loss, log_vars = self._parse_losses(losses)
-
- outputs = dict(
- loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
-
- return outputs
-
- def show_result(self,
- img,
- result,
- score_thr=0.3,
- bbox_color=(72, 101, 241),
- text_color=(72, 101, 241),
- mask_color=None,
- thickness=2,
- font_size=13,
- win_name='',
- show=False,
- wait_time=0,
- out_file=None):
- """Draw `result` over `img`.
-
- Args:
- img (str or Tensor): The image to be displayed.
- result (Tensor or tuple): The results to draw over `img`
- bbox_result or (bbox_result, segm_result).
- score_thr (float, optional): Minimum score of bboxes to be shown.
- Default: 0.3.
- bbox_color (str or tuple(int) or :obj:`Color`):Color of bbox lines.
- The tuple of color should be in BGR order. Default: 'green'
- text_color (str or tuple(int) or :obj:`Color`):Color of texts.
- The tuple of color should be in BGR order. Default: 'green'
- mask_color (None or str or tuple(int) or :obj:`Color`):
- Color of masks. The tuple of color should be in BGR order.
- Default: None
- thickness (int): Thickness of lines. Default: 2
- font_size (int): Font size of texts. Default: 13
- win_name (str): The window name. Default: ''
- wait_time (float): Value of waitKey param.
- Default: 0.
- show (bool): Whether to show the image.
- Default: False.
- out_file (str or None): The filename to write the image.
- Default: None.
-
- Returns:
- img (Tensor): Only if not `show` or `out_file`
- """
- img = mmcv.imread(img)
- img = img.copy()
- if isinstance(result, tuple):
- bbox_result, segm_result = result
- if isinstance(segm_result, tuple):
- segm_result = segm_result[0] # ms rcnn
- else:
- bbox_result, segm_result = result, None
- bboxes = np.vstack(bbox_result)
- labels = [
- np.full(bbox.shape[0], i, dtype=np.int32)
- for i, bbox in enumerate(bbox_result)
- ]
- labels = np.concatenate(labels)
- # draw segmentation masks
- segms = None
- if segm_result is not None and len(labels) > 0: # non empty
- segms = mmcv.concat_list(segm_result)
- if isinstance(segms[0], torch.Tensor):
- segms = torch.stack(segms, dim=0).detach().cpu().numpy()
- else:
- segms = np.stack(segms, axis=0)
- # if out_file specified, do not show image in window
- if out_file is not None:
- show = False
- # draw bounding boxes
- img = imshow_det_bboxes(
- img,
- bboxes,
- labels,
- segms,
- class_names=self.CLASSES,
- score_thr=score_thr,
- bbox_color=bbox_color,
- text_color=text_color,
- mask_color=mask_color,
- thickness=thickness,
- font_size=font_size,
- win_name=win_name,
- show=show,
- wait_time=wait_time,
- out_file=out_file)
-
- if not (show or out_file):
- return img
diff --git a/spaces/adamcasson/transformer-flops-calculator/app.py b/spaces/adamcasson/transformer-flops-calculator/app.py
deleted file mode 100644
index 1d5409e4805e828b3dd13483adb42c7394a38346..0000000000000000000000000000000000000000
--- a/spaces/adamcasson/transformer-flops-calculator/app.py
+++ /dev/null
@@ -1,162 +0,0 @@
-from typing import Tuple
-
-import gradio as gr
-
-
-def deepmind_flops(
- n_layer: int,
- d_model: int,
- d_ff: int,
- d_attn: int,
- n_ctx: int,
- n_vocab: int,
- n_heads: int,
-) -> int:
- embeddings = 2 * n_ctx * n_vocab * d_model
- attn_qkv = 2 * n_ctx * 3 * d_model * (d_attn * n_heads)
- attn_logits = 2 * n_ctx * n_ctx * (d_attn * n_heads)
- attn_softmax = 3 * n_heads * n_ctx * n_ctx
- attn_reduce = 2 * n_ctx * n_ctx * (d_attn * n_heads)
- attn_project = 2 * n_ctx * (d_attn * n_heads) * d_model
- ff = 2 * n_ctx * (d_model * d_ff + d_model * d_ff)
- logits = 2 * n_ctx * d_model * n_vocab
-
- params = (
- embeddings / n_ctx / 2,
- (n_layer * (attn_qkv + attn_project + ff)) / n_ctx / 2,
- logits / n_ctx / 2,
- )
-
- return (
- embeddings,
- attn_qkv * n_layer,
- attn_logits * n_layer,
- attn_softmax * n_layer,
- attn_reduce * n_layer,
- attn_project * n_layer,
- ff * n_layer,
- logits,
- ), params
-
-
-def calculator(
- n_layer: int,
- d_model: int,
- n_heads: int,
- n_vocab: int,
- ff_ratio: int,
- n_ctx: int,
- n_tokens: int,
- incl_embed: bool,
- fwd_only: bool,
-) -> Tuple[int, int, int]:
- d_attn = d_model // n_heads
- if d_model % n_heads != 0:
- raise gr.Error("d_model must be divisible by n_heads")
- d_ff = d_model * ff_ratio
-
- flops_terms, params = deepmind_flops(
- n_layer, d_model, d_ff, d_attn, n_ctx, n_vocab, n_heads
- )
-
- if incl_embed:
- flops_per_sequence = sum(flops_terms)
- params = sum(params)
- else:
- flops_per_sequence = sum(flops_terms[1:])
- params = sum(params[1:])
-
- flops_per_token = flops_per_sequence / n_ctx
-
- n_tokens_flops = flops_per_token * n_tokens
-
- if not fwd_only:
- flops_per_sequence *= 3
- flops_per_token *= 3
- n_tokens_flops *= 3
-
- return params, flops_per_sequence, flops_per_token, n_tokens_flops
-
-
-with gr.Blocks() as iface:
- gr.Markdown(
- "Calculate how many FLOPs a Transformer language model uses with the method described in [DeepMind's Chinchilla scaling law paper](https://arxiv.org/abs/2203.15556) (see Appendix F)."
- )
- with gr.Row():
- with gr.Column():
- gr.Markdown("#### Architecture details")
- n_layer = gr.Number(label="Number of layers (n_layer)")
- d_model = gr.Number(label="Model dimensions (d_model)")
- n_heads = gr.Number(label="Number of attention heads per layer (n_heads)")
- n_vocab = gr.Number(label="Vocabulary size (n_vocab)")
- ff_ratio = gr.Number(value=4, label="Feedforward ratio")
- gr.Markdown("#### Data details")
- n_ctx = gr.Number(label="Sequence length (n_ctx)")
- n_tokens = gr.Number(
- value=0,
- label="Total number of training tokens (n_tokens) (optional)",
- )
- gr.Markdown("#### Settings")
- incl_embed = gr.Checkbox(value=True, label="Include embeddings")
- fwd_only = gr.Checkbox(
- value=False, label="Calculate FLOPs for only forward pass"
- )
-
- btn = gr.Button(value="Enter", variant="primary")
-
- with gr.Column():
- gr.Markdown("#### Output")
- params = gr.Number(label="Model parameters")
- flops_per_sequence = gr.Number(label="FLOPs per sequence")
- flops_per_token = gr.Number(label="FLOPs per token")
- n_tokens_flops = gr.Number(label="Total FLOPs for n_tokens")
-
- btn.click(
- calculator,
- inputs=[
- n_layer,
- d_model,
- n_heads,
- n_vocab,
- ff_ratio,
- n_ctx,
- n_tokens,
- incl_embed,
- fwd_only,
- ],
- outputs=[params, flops_per_sequence, flops_per_token, n_tokens_flops],
- )
-
- gr.Markdown("### GPT-3 model family examples")
- gr.Markdown(
- "In order are the 125M, 350M, 1.3B, 2.7B, 6.7B, 13B, 30B, 66B, and 175B parameter variants."
- )
- gr.Examples(
- [
- [12, 768, 12, 50257, 4, 4096, 0, True, False],
- [24, 1024, 16, 50257, 4, 4096, 0, True, False],
- [24, 2048, 32, 50257, 4, 4096, 0, True, False],
- [32, 2560, 32, 50257, 4, 4096, 0, True, False],
- [32, 4096, 32, 50257, 4, 4096, 0, True, False],
- [40, 5120, 40, 50257, 4, 4096, 0, True, False],
- [48, 7168, 56, 50257, 4, 4096, 0, True, False],
- [64, 9216, 72, 50257, 4, 4096, 0, True, False],
- [96, 12288, 96, 50257, 4, 4096, 0, True, False],
- ],
- [
- n_layer,
- d_model,
- n_heads,
- n_vocab,
- ff_ratio,
- n_ctx,
- n_tokens,
- incl_embed,
- fwd_only,
- ],
- [params, flops_per_sequence, flops_per_token, n_tokens_flops],
- calculator,
- cache_examples=False,
- )
-
-iface.launch()
diff --git a/spaces/adirik/stylemc-demo/torch_utils/ops/upfirdn2d.h b/spaces/adirik/stylemc-demo/torch_utils/ops/upfirdn2d.h
deleted file mode 100644
index c9e2032bcac9d2abde7a75eea4d812da348afadd..0000000000000000000000000000000000000000
--- a/spaces/adirik/stylemc-demo/torch_utils/ops/upfirdn2d.h
+++ /dev/null
@@ -1,59 +0,0 @@
-// Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
-//
-// NVIDIA CORPORATION and its licensors retain all intellectual property
-// and proprietary rights in and to this software, related documentation
-// and any modifications thereto. Any use, reproduction, disclosure or
-// distribution of this software and related documentation without an express
-// license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-#include
-
-//------------------------------------------------------------------------
-// CUDA kernel parameters.
-
-struct upfirdn2d_kernel_params
-{
- const void* x;
- const float* f;
- void* y;
-
- int2 up;
- int2 down;
- int2 pad0;
- int flip;
- float gain;
-
- int4 inSize; // [width, height, channel, batch]
- int4 inStride;
- int2 filterSize; // [width, height]
- int2 filterStride;
- int4 outSize; // [width, height, channel, batch]
- int4 outStride;
- int sizeMinor;
- int sizeMajor;
-
- int loopMinor;
- int loopMajor;
- int loopX;
- int launchMinor;
- int launchMajor;
-};
-
-//------------------------------------------------------------------------
-// CUDA kernel specialization.
-
-struct upfirdn2d_kernel_spec
-{
- void* kernel;
- int tileOutW;
- int tileOutH;
- int loopMinor;
- int loopX;
-};
-
-//------------------------------------------------------------------------
-// CUDA kernel selection.
-
-template upfirdn2d_kernel_spec choose_upfirdn2d_kernel(const upfirdn2d_kernel_params& p);
-
-//------------------------------------------------------------------------
diff --git a/spaces/akhaliq/Mask2Former/mask2former/data/dataset_mappers/coco_instance_new_baseline_dataset_mapper.py b/spaces/akhaliq/Mask2Former/mask2former/data/dataset_mappers/coco_instance_new_baseline_dataset_mapper.py
deleted file mode 100644
index e64af2b51009d0398a1b6253a8a763c641547f59..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Mask2Former/mask2former/data/dataset_mappers/coco_instance_new_baseline_dataset_mapper.py
+++ /dev/null
@@ -1,189 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# Modified by Bowen Cheng from https://github.com/facebookresearch/detr/blob/master/d2/detr/dataset_mapper.py
-import copy
-import logging
-
-import numpy as np
-import torch
-
-from detectron2.config import configurable
-from detectron2.data import detection_utils as utils
-from detectron2.data import transforms as T
-from detectron2.data.transforms import TransformGen
-from detectron2.structures import BitMasks, Instances
-
-from pycocotools import mask as coco_mask
-
-__all__ = ["COCOInstanceNewBaselineDatasetMapper"]
-
-
-def convert_coco_poly_to_mask(segmentations, height, width):
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = torch.as_tensor(mask, dtype=torch.uint8)
- mask = mask.any(dim=2)
- masks.append(mask)
- if masks:
- masks = torch.stack(masks, dim=0)
- else:
- masks = torch.zeros((0, height, width), dtype=torch.uint8)
- return masks
-
-
-def build_transform_gen(cfg, is_train):
- """
- Create a list of default :class:`Augmentation` from config.
- Now it includes resizing and flipping.
- Returns:
- list[Augmentation]
- """
- assert is_train, "Only support training augmentation"
- image_size = cfg.INPUT.IMAGE_SIZE
- min_scale = cfg.INPUT.MIN_SCALE
- max_scale = cfg.INPUT.MAX_SCALE
-
- augmentation = []
-
- if cfg.INPUT.RANDOM_FLIP != "none":
- augmentation.append(
- T.RandomFlip(
- horizontal=cfg.INPUT.RANDOM_FLIP == "horizontal",
- vertical=cfg.INPUT.RANDOM_FLIP == "vertical",
- )
- )
-
- augmentation.extend([
- T.ResizeScale(
- min_scale=min_scale, max_scale=max_scale, target_height=image_size, target_width=image_size
- ),
- T.FixedSizeCrop(crop_size=(image_size, image_size)),
- ])
-
- return augmentation
-
-
-# This is specifically designed for the COCO dataset.
-class COCOInstanceNewBaselineDatasetMapper:
- """
- A callable which takes a dataset dict in Detectron2 Dataset format,
- and map it into a format used by MaskFormer.
-
- This dataset mapper applies the same transformation as DETR for COCO panoptic segmentation.
-
- The callable currently does the following:
-
- 1. Read the image from "file_name"
- 2. Applies geometric transforms to the image and annotation
- 3. Find and applies suitable cropping to the image and annotation
- 4. Prepare image and annotation to Tensors
- """
-
- @configurable
- def __init__(
- self,
- is_train=True,
- *,
- tfm_gens,
- image_format,
- ):
- """
- NOTE: this interface is experimental.
- Args:
- is_train: for training or inference
- augmentations: a list of augmentations or deterministic transforms to apply
- tfm_gens: data augmentation
- image_format: an image format supported by :func:`detection_utils.read_image`.
- """
- self.tfm_gens = tfm_gens
- logging.getLogger(__name__).info(
- "[COCOInstanceNewBaselineDatasetMapper] Full TransformGens used in training: {}".format(str(self.tfm_gens))
- )
-
- self.img_format = image_format
- self.is_train = is_train
-
- @classmethod
- def from_config(cls, cfg, is_train=True):
- # Build augmentation
- tfm_gens = build_transform_gen(cfg, is_train)
-
- ret = {
- "is_train": is_train,
- "tfm_gens": tfm_gens,
- "image_format": cfg.INPUT.FORMAT,
- }
- return ret
-
- def __call__(self, dataset_dict):
- """
- Args:
- dataset_dict (dict): Metadata of one image, in Detectron2 Dataset format.
-
- Returns:
- dict: a format that builtin models in detectron2 accept
- """
- dataset_dict = copy.deepcopy(dataset_dict) # it will be modified by code below
- image = utils.read_image(dataset_dict["file_name"], format=self.img_format)
- utils.check_image_size(dataset_dict, image)
-
- # TODO: get padding mask
- # by feeding a "segmentation mask" to the same transforms
- padding_mask = np.ones(image.shape[:2])
-
- image, transforms = T.apply_transform_gens(self.tfm_gens, image)
- # the crop transformation has default padding value 0 for segmentation
- padding_mask = transforms.apply_segmentation(padding_mask)
- padding_mask = ~ padding_mask.astype(bool)
-
- image_shape = image.shape[:2] # h, w
-
- # Pytorch's dataloader is efficient on torch.Tensor due to shared-memory,
- # but not efficient on large generic data structures due to the use of pickle & mp.Queue.
- # Therefore it's important to use torch.Tensor.
- dataset_dict["image"] = torch.as_tensor(np.ascontiguousarray(image.transpose(2, 0, 1)))
- dataset_dict["padding_mask"] = torch.as_tensor(np.ascontiguousarray(padding_mask))
-
- if not self.is_train:
- # USER: Modify this if you want to keep them for some reason.
- dataset_dict.pop("annotations", None)
- return dataset_dict
-
- if "annotations" in dataset_dict:
- # USER: Modify this if you want to keep them for some reason.
- for anno in dataset_dict["annotations"]:
- # Let's always keep mask
- # if not self.mask_on:
- # anno.pop("segmentation", None)
- anno.pop("keypoints", None)
-
- # USER: Implement additional transformations if you have other types of data
- annos = [
- utils.transform_instance_annotations(obj, transforms, image_shape)
- for obj in dataset_dict.pop("annotations")
- if obj.get("iscrowd", 0) == 0
- ]
- # NOTE: does not support BitMask due to augmentation
- # Current BitMask cannot handle empty objects
- instances = utils.annotations_to_instances(annos, image_shape)
- # After transforms such as cropping are applied, the bounding box may no longer
- # tightly bound the object. As an example, imagine a triangle object
- # [(0,0), (2,0), (0,2)] cropped by a box [(1,0),(2,2)] (XYXY format). The tight
- # bounding box of the cropped triangle should be [(1,0),(2,1)], which is not equal to
- # the intersection of original bounding box and the cropping box.
- instances.gt_boxes = instances.gt_masks.get_bounding_boxes()
- # Need to filter empty instances first (due to augmentation)
- instances = utils.filter_empty_instances(instances)
- # Generate masks from polygon
- h, w = instances.image_size
- # image_size_xyxy = torch.as_tensor([w, h, w, h], dtype=torch.float)
- if hasattr(instances, 'gt_masks'):
- gt_masks = instances.gt_masks
- gt_masks = convert_coco_poly_to_mask(gt_masks.polygons, h, w)
- instances.gt_masks = gt_masks
- dataset_dict["instances"] = instances
-
- return dataset_dict
diff --git a/spaces/akhaliq/Pop_Music_Transformer/chord_recognition.py b/spaces/akhaliq/Pop_Music_Transformer/chord_recognition.py
deleted file mode 100644
index ec8feb7dde75e6b522d93f6aa6cd03405c56064c..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Pop_Music_Transformer/chord_recognition.py
+++ /dev/null
@@ -1,188 +0,0 @@
-import miditoolkit
-import numpy as np
-
-class MIDIChord(object):
- def __init__(self):
- # define pitch classes
- self.PITCH_CLASSES = ['C', 'C#', 'D', 'D#', 'E', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B']
- # define chord maps (required)
- self.CHORD_MAPS = {'maj': [0, 4],
- 'min': [0, 3],
- 'dim': [0, 3, 6],
- 'aug': [0, 4, 8],
- 'dom': [0, 4, 7, 10]}
- # define chord insiders (+1)
- self.CHORD_INSIDERS = {'maj': [7],
- 'min': [7],
- 'dim': [9],
- 'aug': [],
- 'dom': []}
- # define chord outsiders (-1)
- self.CHORD_OUTSIDERS_1 = {'maj': [2, 5, 9],
- 'min': [2, 5, 8],
- 'dim': [2, 5, 10],
- 'aug': [2, 5, 9],
- 'dom': [2, 5, 9]}
- # define chord outsiders (-2)
- self.CHORD_OUTSIDERS_2 = {'maj': [1, 3, 6, 8, 10],
- 'min': [1, 4, 6, 9, 11],
- 'dim': [1, 4, 7, 8, 11],
- 'aug': [1, 3, 6, 7, 10],
- 'dom': [1, 3, 6, 8, 11]}
-
- def note2pianoroll(self, notes, max_tick, ticks_per_beat):
- return miditoolkit.pianoroll.parser.notes2pianoroll(
- note_stream_ori=notes,
- max_tick=max_tick,
- ticks_per_beat=ticks_per_beat)
-
- def sequencing(self, chroma):
- candidates = {}
- for index in range(len(chroma)):
- if chroma[index]:
- root_note = index
- _chroma = np.roll(chroma, -root_note)
- sequence = np.where(_chroma == 1)[0]
- candidates[root_note] = list(sequence)
- return candidates
-
- def scoring(self, candidates):
- scores = {}
- qualities = {}
- for root_note, sequence in candidates.items():
- if 3 not in sequence and 4 not in sequence:
- scores[root_note] = -100
- qualities[root_note] = 'None'
- elif 3 in sequence and 4 in sequence:
- scores[root_note] = -100
- qualities[root_note] = 'None'
- else:
- # decide quality
- if 3 in sequence:
- if 6 in sequence:
- quality = 'dim'
- else:
- quality = 'min'
- elif 4 in sequence:
- if 8 in sequence:
- quality = 'aug'
- else:
- if 7 in sequence and 10 in sequence:
- quality = 'dom'
- else:
- quality = 'maj'
- # decide score
- maps = self.CHORD_MAPS.get(quality)
- _notes = [n for n in sequence if n not in maps]
- score = 0
- for n in _notes:
- if n in self.CHORD_OUTSIDERS_1.get(quality):
- score -= 1
- elif n in self.CHORD_OUTSIDERS_2.get(quality):
- score -= 2
- elif n in self.CHORD_INSIDERS.get(quality):
- score += 1
- scores[root_note] = score
- qualities[root_note] = quality
- return scores, qualities
-
- def find_chord(self, pianoroll):
- chroma = miditoolkit.pianoroll.utils.tochroma(pianoroll=pianoroll)
- chroma = np.sum(chroma, axis=0)
- chroma = np.array([1 if c else 0 for c in chroma])
- if np.sum(chroma) == 0:
- return 'N', 'N', 'N', 0
- else:
- candidates = self.sequencing(chroma=chroma)
- scores, qualities = self.scoring(candidates=candidates)
- # bass note
- sorted_notes = []
- for i, v in enumerate(np.sum(pianoroll, axis=0)):
- if v > 0:
- sorted_notes.append(int(i%12))
- bass_note = sorted_notes[0]
- # root note
- __root_note = []
- _max = max(scores.values())
- for _root_note, score in scores.items():
- if score == _max:
- __root_note.append(_root_note)
- if len(__root_note) == 1:
- root_note = __root_note[0]
- else:
- #TODO: what should i do
- for n in sorted_notes:
- if n in __root_note:
- root_note = n
- break
- # quality
- quality = qualities.get(root_note)
- sequence = candidates.get(root_note)
- # score
- score = scores.get(root_note)
- return self.PITCH_CLASSES[root_note], quality, self.PITCH_CLASSES[bass_note], score
-
- def greedy(self, candidates, max_tick, min_length):
- chords = []
- # start from 0
- start_tick = 0
- while start_tick < max_tick:
- _candidates = candidates.get(start_tick)
- _candidates = sorted(_candidates.items(), key=lambda x: (x[1][-1], x[0]))
- # choose
- end_tick, (root_note, quality, bass_note, _) = _candidates[-1]
- if root_note == bass_note:
- chord = '{}:{}'.format(root_note, quality)
- else:
- chord = '{}:{}/{}'.format(root_note, quality, bass_note)
- chords.append([start_tick, end_tick, chord])
- start_tick = end_tick
- # remove :None
- temp = chords
- while ':None' in temp[0][-1]:
- try:
- temp[1][0] = temp[0][0]
- del temp[0]
- except:
- print('NO CHORD')
- return []
- temp2 = []
- for chord in temp:
- if ':None' not in chord[-1]:
- temp2.append(chord)
- else:
- temp2[-1][1] = chord[1]
- return temp2
-
- def extract(self, notes):
- # read
- max_tick = max([n.end for n in notes])
- ticks_per_beat = 480
- pianoroll = self.note2pianoroll(
- notes=notes,
- max_tick=max_tick,
- ticks_per_beat=ticks_per_beat)
- # get lots of candidates
- candidates = {}
- # the shortest: 2 beat, longest: 4 beat
- for interval in [4, 2]:
- for start_tick in range(0, max_tick, ticks_per_beat):
- # set target pianoroll
- end_tick = int(ticks_per_beat * interval + start_tick)
- if end_tick > max_tick:
- end_tick = max_tick
- _pianoroll = pianoroll[start_tick:end_tick, :]
- # find chord
- root_note, quality, bass_note, score = self.find_chord(pianoroll=_pianoroll)
- # save
- if start_tick not in candidates:
- candidates[start_tick] = {}
- candidates[start_tick][end_tick] = (root_note, quality, bass_note, score)
- else:
- if end_tick not in candidates[start_tick]:
- candidates[start_tick][end_tick] = (root_note, quality, bass_note, score)
- # greedy
- chords = self.greedy(candidates=candidates,
- max_tick=max_tick,
- min_length=ticks_per_beat)
- return chords
diff --git a/spaces/akhaliq/SummerTime/dataset/non_huggingface_datasets_builders/scisummnet.py b/spaces/akhaliq/SummerTime/dataset/non_huggingface_datasets_builders/scisummnet.py
deleted file mode 100644
index 0b6bcfb5bfc02e09be903d988ec45d0a0a06606e..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/SummerTime/dataset/non_huggingface_datasets_builders/scisummnet.py
+++ /dev/null
@@ -1,105 +0,0 @@
-import os
-import datasets
-
-
-"""Scisummnet dataset."""
-
-
-_CITATION = """
-@InProceedings{yasunaga&al.19.scisumm,
- title = {{ScisummNet}: A Large Annotated Corpus and Content-Impact Models for Scientific Paper Summarization with Citation Networks},
- author = {Michihiro Yasunaga and Jungo Kasai and Rui Zhang and Alexander Fabbri and Irene Li and Dan Friedman and Dragomir Radev},
- booktitle = {Proceedings of AAAI 2019},
- year = {2019}
-}
-@InProceedings{yasunaga&al.17,
- title = {Graph-based Neural Multi-Document Summarization},
- author = {Yasunaga, Michihiro and Zhang, Rui and Meelu, Kshitijh and Pareek, Ayush and Srinivasan, Krishnan and Radev, Dragomir R.},
- booktitle = {Proceedings of CoNLL 2017},
- year = {2017}
-}
-"""
-
-_DESCRIPTION = """
-A summary of scientific papers should ideally incorporate the impact of the papers on the research community
-reflected by citations. To facilitate research in citation-aware scientific paper summarization (Scisumm),
-the CL-Scisumm shared task has been organized since 2014 for papers in the computational linguistics and NLP domain.
-"""
-
-_HOMEPAGE = "https://cs.stanford.edu/~myasu/projects/scisumm_net/"
-
-_LICENSE = "CC BY-SA 4.0"
-
-_URLs = "https://cs.stanford.edu/~myasu/projects/scisumm_net/scisummnet_release1.1__20190413.zip"
-
-
-class SummertimeScisummnet(datasets.GeneratorBasedBuilder):
- """Scisummnet dataset."""
-
- VERSION = datasets.Version("1.1.0")
-
- BUILDER_CONFIGS = [
- datasets.BuilderConfig(),
- ]
-
- def _info(self):
- features = datasets.Features(
- {
- "entry_number": datasets.Value("string"),
- "document_xml": datasets.Value("string"),
- "citing_sentences_annotated.json": datasets.Value("string"),
- "summary": datasets.Value("string"),
- }
- )
- return datasets.DatasetInfo(
- description=_DESCRIPTION,
- features=features,
- supervised_keys=None,
- homepage=_HOMEPAGE,
- license=_LICENSE,
- citation=_CITATION,
- )
-
- def _split_generators(self, dl_manager):
- """Returns SplitGenerators."""
- my_urls = _URLs
- path = dl_manager.download_and_extract(my_urls)
- trainpath = os.path.join(
- path, "scisummnet_release1.1__20190413", "top1000_complete"
- )
- return [
- datasets.SplitGenerator(
- name=datasets.Split.TRAIN,
- # These kwargs will be passed to _generate_examples
- gen_kwargs={"extraction_path": trainpath, "split": "train"},
- )
- ]
-
- def _generate_examples(self, extraction_path, split):
- """Yields examples."""
-
- for folder in os.listdir(extraction_path):
-
- entry = {}
-
- entry["entry_number"] = folder
-
- doc_xml_path = os.path.join(
- extraction_path, folder, "Documents_xml", folder + ".xml"
- )
- with open(doc_xml_path, "r", encoding="utf-8") as f:
- entry["document_xml"] = f.read()
-
- cite_annot_path = os.path.join(
- extraction_path, folder, "citing_sentences_annotated.json"
- )
- with open(cite_annot_path, "r", encoding="utf-8") as f:
- entry["citing_sentences_annotated.json"] = f.read()
-
- summary_path = os.path.join(
- extraction_path, folder, "summary", folder + ".gold.txt"
- )
- with open(summary_path, "r", encoding="utf-8") as f:
- entry["summary"] = f.read()
-
- yield entry["entry_number"], entry
diff --git a/spaces/akhaliq/SummerTime/model/third_party/HMNet/Utils/GeneralUtils.py b/spaces/akhaliq/SummerTime/model/third_party/HMNet/Utils/GeneralUtils.py
deleted file mode 100644
index 7f9b1287d172926ca8d0dbc64bea97c60d8ef427..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/SummerTime/model/third_party/HMNet/Utils/GeneralUtils.py
+++ /dev/null
@@ -1,138 +0,0 @@
-# Copyright (c) Microsoft Corporation.
-# Licensed under the MIT license.
-
-import math
-import re
-import logging
-import torch
-from torch.utils.data import Dataset
-import torch.nn.functional as F
-import unicodedata
-import sys
-from torch.autograd import Variable
-
-from .Constants import *
-
-logger = logging.getLogger(__name__)
-
-
-class ObjectView(object):
- def __init__(self, d):
- self.__dict__ = d
-
-
-class AverageMeter(object):
- """Computes and stores the average and current value."""
-
- def __init__(self):
- self.reset()
-
- def reset(self):
- self.val = 0
- self.avg = 0
- self.sum = 0
- self.count = 0
-
- def update(self, val, n=1, decay=0):
- self.val = val
- if decay:
- alpha = math.exp(-n / decay) # exponential decay over 100 updates
- self.sum = alpha * self.sum + (1 - alpha) * val * n
- self.count = alpha * self.count + (1 - alpha) * n
- else:
- self.sum += val * n
- self.count += n
- self.avg = self.sum / self.count
-
-
-class BaseBatchGen:
- """
- This is a base class for batch generators that use infinibatch.
-
- The interfaces below are required to work with LegacyTask.
-
- For new tasks, the interfaces are not restricted (the methods and their signatures don't
- have to be same as the base class). They should have minimum assumption or dependency
- on other components in the system. Task classes can use them accordingly.
- """
-
- def __init__(
- self,
- task_args,
- dataset_label,
- model_config=None,
- tokenizer=None,
- world_size=1,
- rank=0,
- seed=None,
- ):
- """
- Args:
- task_args (dict): dictionary records arguments
- dataset_label (str): 'train', 'dev' or 'test'
- model_config: config of the model
- tokenizer: tokenizer used to process text
- world_size (int): total number of GPUs
- rank (int): order of current GPU
- seed (int): random seed
- """
- self.opt = task_args
- self.dataset_label = dataset_label
- self.model_config = model_config
- self.tokenizer = tokenizer
- self.world_size = world_size
- self.rank = rank
- self.seed = seed
- self.evaluation = dataset_label in ["dev", "test"]
-
- self._iter = None
-
- def _build_iter(self):
- """
- Build infinibatch iterator and assign to self._iter
- """
- raise NotImplementedError()
-
- @property
- def iterator(self):
- if self._iter is None:
- raise NotImplementedError("_build_iter() must called first")
- return self._iter
-
- def __iter__(self):
- if self._iter is None:
- raise NotImplementedError("_build_iter() must called first")
- return self._iter
-
- def __next__(self):
- return next(self._iter)
-
-
-def move_batch_to_device(batch, device):
- """
- Move the batch to the device.
- It should be called before feeding the batch to the model.
-
- Args:
- batch (torch.tensor or container of torch.tensor): input batch
- device (torch.device): device to move the batch to
- Returns:
- return_batch: same type as the input batch with internal tensors moved to device
- """
- if torch.is_tensor(batch):
- return_batch = batch.to(device)
- elif isinstance(batch, list):
- return_batch = [move_batch_to_device(t, device) for t in batch]
- elif isinstance(batch, tuple):
- return_batch = tuple(move_batch_to_device(t, device) for t in batch)
- elif isinstance(batch, dict):
- return_batch = {}
- for k in batch:
- return_batch[k] = move_batch_to_device(batch[k], device)
- else:
- logger.debug(
- f"Can not move type {type(batch)} to device. Skipping it in the batch."
- )
- return_batch = batch
-
- return return_batch
diff --git a/spaces/akhaliq/deeplab2/data/dataset_utils.py b/spaces/akhaliq/deeplab2/data/dataset_utils.py
deleted file mode 100644
index 167b30a6182cd49ee35f9b3245bf5f0cd9c810a6..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/deeplab2/data/dataset_utils.py
+++ /dev/null
@@ -1,71 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The Deeplab2 Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""This file contains utility function for handling the dataset."""
-
-import tensorflow as tf
-
-
-def get_semantic_and_panoptic_label(dataset_info, label, ignore_label):
- """Helper function to get semantic and panoptic label from panoptic label.
-
- This functions gets the semantic and panoptic label from panoptic label for
- different datasets. The labels must be encoded with semantic_label *
- label_divisor + instance_id. For thing classes, the instance ID 0 is reserved
- for crowd regions. Please note, the returned panoptic label has replaced
- the crowd region with ignore regions. Yet, the semantic label makes use of
- these regions.
-
- Args:
- dataset_info: A dictionary storing dataset information.
- label: A Tensor of panoptic label.
- ignore_label: An integer specifying the ignore_label.
-
- Returns:
- semantic_label: A Tensor of semantic segmentation label.
- panoptic_label: A Tensor of panoptic segmentation label, which follows the
- Cityscapes annotation where
- panoptic_label = semantic_label * panoptic_label_divisor + instance_id.
- thing_mask: A boolean Tensor specifying the thing regions. Zero if no thing.
- crowd_region: A boolean Tensor specifying crowd region. Zero if no crowd
- annotation.
-
- Raises:
- ValueError: An error occurs when the ignore_label is not in range
- [0, label_divisor].
- """
- panoptic_label_divisor = dataset_info['panoptic_label_divisor']
- if ignore_label >= panoptic_label_divisor or ignore_label < 0:
- raise ValueError('The ignore_label must be in [0, label_divisor].')
-
- semantic_label = label // panoptic_label_divisor
- # Find iscrowd region if any and set to ignore for panoptic labels.
- # 1. Find thing mask.
- thing_mask = tf.zeros_like(semantic_label, tf.bool)
- for thing_id in dataset_info['class_has_instances_list']:
- thing_mask = tf.logical_or(
- thing_mask,
- tf.equal(semantic_label, thing_id))
- # 2. Find crowd region (thing label that have instance_id == 0).
- crowd_region = tf.logical_and(
- thing_mask,
- tf.equal(label % panoptic_label_divisor, 0))
- # 3. Set crowd region to ignore label.
- panoptic_label = tf.where(
- crowd_region,
- tf.ones_like(label) * ignore_label * panoptic_label_divisor,
- label)
-
- return semantic_label, panoptic_label, thing_mask, crowd_region
diff --git a/spaces/akhaliq/deeplab2/model/decoder/deeplabv3_test.py b/spaces/akhaliq/deeplab2/model/decoder/deeplabv3_test.py
deleted file mode 100644
index 9cf6698585cb0ce5d14b53021cbe631ad26a1848..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/deeplab2/model/decoder/deeplabv3_test.py
+++ /dev/null
@@ -1,143 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The Deeplab2 Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Tests for deeplabv3."""
-
-import numpy as np
-import tensorflow as tf
-
-from deeplab2 import common
-from deeplab2 import config_pb2
-from deeplab2.model.decoder import deeplabv3
-from deeplab2.utils import test_utils
-
-
-def _create_deeplabv3_model(feature_key, decoder_channels, aspp_channels,
- atrous_rates, num_classes, **kwargs):
- decoder_options = config_pb2.DecoderOptions(
- feature_key=feature_key,
- decoder_channels=decoder_channels,
- aspp_channels=aspp_channels,
- atrous_rates=atrous_rates)
- deeplabv3_options = config_pb2.ModelOptions.DeeplabV3Options(
- num_classes=num_classes)
- return deeplabv3.DeepLabV3(decoder_options, deeplabv3_options, **kwargs)
-
-
-class Deeplabv3Test(tf.test.TestCase):
-
- def test_deeplabv3_feature_key_not_present(self):
- deeplabv3_decoder = _create_deeplabv3_model(
- feature_key='not_in_features_dict',
- aspp_channels=64,
- decoder_channels=48,
- atrous_rates=[6, 12, 18],
- num_classes=80)
- input_dict = dict()
- input_dict['not_the_same_key'] = tf.random.uniform(shape=(2, 65, 65, 32))
-
- with self.assertRaises(KeyError):
- _ = deeplabv3_decoder(input_dict)
-
- def test_deeplabv3_output_shape(self):
- list_of_num_classes = [2, 19, 133]
- for num_classes in list_of_num_classes:
- deeplabv3_decoder = _create_deeplabv3_model(
- feature_key='not_used',
- aspp_channels=64,
- decoder_channels=48,
- atrous_rates=[6, 12, 18],
- num_classes=num_classes)
- input_tensor = tf.random.uniform(shape=(2, 65, 65, 32))
- expected_shape = [2, 65, 65, num_classes]
-
- logit_tensor = deeplabv3_decoder(input_tensor)
- self.assertListEqual(
- logit_tensor[common.PRED_SEMANTIC_LOGITS_KEY].shape.as_list(),
- expected_shape)
-
- @test_utils.test_all_strategies
- def test_sync_bn(self, strategy):
- input_tensor = tf.random.uniform(shape=(2, 65, 65, 32))
- with strategy.scope():
- for bn_layer in test_utils.NORMALIZATION_LAYERS:
- deeplabv3_decoder = _create_deeplabv3_model(
- feature_key='not_used',
- aspp_channels=64,
- decoder_channels=48,
- atrous_rates=[6, 12, 18],
- num_classes=19,
- bn_layer=bn_layer)
- _ = deeplabv3_decoder(input_tensor)
-
- def test_deeplabv3_feature_extraction_consistency(self):
- deeplabv3_decoder = _create_deeplabv3_model(
- aspp_channels=64,
- decoder_channels=48,
- atrous_rates=[6, 12, 18],
- num_classes=80,
- feature_key='feature_key')
- input_tensor = tf.random.uniform(shape=(2, 65, 65, 32))
- input_dict = dict()
- input_dict['feature_key'] = input_tensor
-
- reference_logits_tensor = deeplabv3_decoder(input_tensor, training=False)
- logits_tensor_to_compare = deeplabv3_decoder(input_dict, training=False)
-
- np.testing.assert_equal(
- reference_logits_tensor[common.PRED_SEMANTIC_LOGITS_KEY].numpy(),
- logits_tensor_to_compare[common.PRED_SEMANTIC_LOGITS_KEY].numpy())
-
- def test_deeplabv3_pool_size_setter(self):
- deeplabv3_decoder = _create_deeplabv3_model(
- feature_key='not_used',
- aspp_channels=64,
- decoder_channels=48,
- atrous_rates=[6, 12, 18],
- num_classes=80)
- pool_size = (10, 10)
- deeplabv3_decoder.set_pool_size(pool_size)
-
- self.assertTupleEqual(deeplabv3_decoder._aspp._aspp_pool._pool_size,
- pool_size)
-
- def test_deeplabv3_pool_size_resetter(self):
- deeplabv3_decoder = _create_deeplabv3_model(
- feature_key='not_used',
- aspp_channels=64,
- decoder_channels=48,
- atrous_rates=[6, 12, 18],
- num_classes=80)
- pool_size = (None, None)
- deeplabv3_decoder.reset_pooling_layer()
-
- self.assertTupleEqual(deeplabv3_decoder._aspp._aspp_pool._pool_size,
- pool_size)
-
- def test_deeplabv3_ckpt_items(self):
- deeplabv3_decoder = _create_deeplabv3_model(
- feature_key='not_used',
- aspp_channels=64,
- decoder_channels=48,
- atrous_rates=[6, 12, 18],
- num_classes=80)
- ckpt_dict = deeplabv3_decoder.checkpoint_items
- self.assertIn(common.CKPT_DEEPLABV3_ASPP, ckpt_dict)
- self.assertIn(common.CKPT_DEEPLABV3_CLASSIFIER_CONV_BN_ACT, ckpt_dict)
- self.assertIn(common.CKPT_SEMANTIC_LAST_LAYER, ckpt_dict)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/spaces/akhaliq/deeplab2/model/layers/recompute_grad.py b/spaces/akhaliq/deeplab2/model/layers/recompute_grad.py
deleted file mode 100644
index 8bf0e2ad66595e794b187cb7564669ce2ee6c19a..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/deeplab2/model/layers/recompute_grad.py
+++ /dev/null
@@ -1,289 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The Deeplab2 Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Library for rematerialization.
-
-Incubates a version of tf.recompute_grad that is XLA compatible.
-
-This file is based on the recompute_grad.py in the bigbird codebase [1]:
-https://github.com/google-research/bigbird/blob/db06498ec8804c6438111938d8654b66ddaccd5d/bigbird/core/recompute_grad.py
-
-[1] Big Bird: Transformers for Longer Sequences, NeurIPS 2020.
- Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris
- Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li
- Yang, Amr Ahmed.
-"""
-import collections
-import os
-import threading
-from typing import Deque, List, NamedTuple, Optional, Sequence
-
-from absl import logging
-import tensorflow.compat.v2 as tf
-
-# pylint: disable=g-direct-tensorflow-import
-from tensorflow.python.framework import ops
-from tensorflow.python.ops import custom_gradient
-
-
-# Remove when https://github.com/tensorflow/tensorflow/pull/45298
-# gets merged
-def get_variable_by_name(var_name):
- """Retrieves tf.Variable from name in MirroredStrategy (multi-gpu)."""
-
- # Get all variables, but it will have copies from different replicas
- all_global_vars = ops.get_collection(ops.GraphKeys.GLOBAL_VARIABLES)
-
- def _replica_filter(var):
- """Filter out variables from different context."""
- try:
- return var_name == var.op.name
- except AttributeError:
- return False
- candidate_vars = list(filter(_replica_filter, all_global_vars))
-
- if len(candidate_vars) >= 1:
- # Filter out non-trainable variables.
- candidate_vars = [v for v in candidate_vars if v.trainable]
- else:
- raise ValueError('Unsuccessful at finding variable {}.'.format(var_name))
-
- if len(candidate_vars) == 1:
- return candidate_vars[0]
- elif len(candidate_vars) > 1:
- raise ValueError(
- 'Unsuccessful at finding trainable variable {}. '
- 'Number of candidates: {}. '
- 'Candidates: {}'.format(var_name, len(candidate_vars), candidate_vars))
- else:
- # The variable is not trainable.
- return None
-custom_gradient.get_variable_by_name = get_variable_by_name
-
-
-class RecomputeContext(
- NamedTuple('RecomputeContext', [
- ('is_recomputing', bool),
- ('seed', tf.Tensor),
- ('children', Deque['RecomputeContext']),
- ])):
- """Context for recomputation.
-
- Attributes:
- is_recomputing: Whether we are in a recomputation phase.
- seed: Scalar integer tensor that should be used with stateless random ops
- for deterministic behavior and correct computation of the gradient.
- children: Nested `RecomputeContext` instances. Used internally by
- `recompute_grad` to track nested instances of `RecomputeContext`.
- """
-
- def __enter__(self):
- return _context_stack.push(self)
-
- def __exit__(self, exc_type, exc_value, traceback):
- _context_stack.pop(self)
-
-
-# Simplified version of `_DefaultStack` in
-# https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/framework/ops.py.
-class _ContextStack(threading.local):
- """A thread-local stack for providing implicit recompute contexts."""
-
- def __init__(self):
- super(_ContextStack, self).__init__()
- self._stack = []
-
- def top(self) -> Optional[RecomputeContext]:
- return self._stack[-1] if self._stack else None
-
- def push(self, context: RecomputeContext):
- self._stack.append(context)
- return context
-
- def pop(self, context: RecomputeContext):
- if self._stack[-1] is not context:
- raise AssertionError('Nesting violated for RecomputeContext.')
- self._stack.pop()
-
-
-_context_stack = _ContextStack()
-
-
-def get_recompute_context() -> Optional[RecomputeContext]:
- """Returns the current recomputing context if it exists."""
- return _context_stack.top()
-
-
-# Adapted from
-# https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/control_flow_util.py.
-def _get_containing_xla_context(graph: tf.Graph) -> Optional[object]:
- """Returns the first ancestor `XLAControlFlowContext` in the `graph`."""
- ctxt = graph._get_control_flow_context() # pylint: disable=protected-access
- while ctxt:
- if ctxt.IsXLAContext():
- return ctxt
- ctxt = ctxt.outer_context
- return None
-
-
-def _in_xla_context(graph: Optional[tf.Graph] = None) -> bool:
- """Detects whether we are in an XLA context."""
- if '--tf_xla_auto_jit=2' in os.environ.get('TF_XLA_FLAGS', ''):
- return True
- graph = tf.compat.v1.get_default_graph() if graph is None else graph
- while True:
- if _get_containing_xla_context(graph) is not None:
- return True
- try:
- graph = graph.outer_graph
- except AttributeError:
- return False
-
-
-def _force_data_dependency(
- first_compute: Sequence[tf.Tensor],
- then_compute: Sequence[tf.Tensor]) -> List[tf.Tensor]:
- """Forces all of `then_compute` to depend on all of `first_compute`.
-
- Uses a dummy data dependency, which is useful when running on TPUs because
- XLA ignores control dependencies. Only supports float arguments.
-
- Args:
- first_compute: Sequence of `Tensor`s to be executed before `then_compute`.
- then_compute: Sequence of `Tensor`s to executed after `first_compute`.
-
- Returns:
- Sequence of `Tensor`s with same length of `then_compute`.
-
- Raises:
- ValueError: if ranks are unknown or types are not floating.
- """
-
- def _first_element(x):
- if x.shape.ndims is None:
- raise ValueError('Rank of Tensor %s must be known' % x)
- ndims = x.shape.ndims
- begin = tf.zeros(ndims, dtype=tf.int32)
- size = tf.ones(ndims, dtype=tf.int32)
- return tf.reshape(tf.slice(x, begin, size), [])
-
- first_compute_sum = tf.add_n(
- [_first_element(x) for x in first_compute if x is not None])
- dtype = first_compute_sum.dtype
- if not dtype.is_floating:
- raise ValueError('_force_data_dependency only supports floating dtypes.')
- zero = tf.cast(0.0, first_compute_sum.dtype) * first_compute_sum
- then_compute_sequence = [
- x + tf.cast(zero, x.dtype) if x is not None else None
- for x in tf.nest.flatten(then_compute)
- ]
- return tf.nest.pack_sequence_as(then_compute, then_compute_sequence)
-
-
-def _make_seed_if_none(seed: Optional[tf.Tensor]) -> tf.Tensor:
- """Uses the global generator to make a seed if necessary."""
- if seed is not None:
- return seed
- generator = tf.random.experimental.get_global_generator()
- # The two seeds for stateless random ops don't have individual semantics and
- # are scrambled together, so providing one seed is fine. This makes it easier
- # for users to provide a local seed without worrying about integer overflow.
- # See `make_seeds` in
- # https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/stateful_random_ops.py.
- try:
- return generator.uniform_full_int([], tf.int32, name='recompute_grad_seed')
- except (RuntimeError, TypeError, ValueError, tf.errors.NotFoundError) as e:
- # For a number of reasons, the above operation can fail like using multiple
- # graphs or toggling between eager and graph modes. Reset the generator.
- logging.warn('Resetting the generator. %s: %s', type(e), e)
- tf.random.experimental.set_global_generator(None)
- generator = tf.random.experimental.get_global_generator()
- return generator.uniform_full_int([], tf.int32, name='recompute_grad_seed')
-
-
-def recompute_grad(f, seed=None):
- """An eager-compatible version of recompute_grad.
-
- For f(*args, **kwargs), this supports gradients with respect to args, or to
- gradients with respect to any variables residing in the kwarg 'variables'.
- Note that for keras layer and model objects, this is handled automatically.
-
- Warning: If `f` was originally a tf.keras Model or Layer object, `g` will not
- be able to access the member variables of that object, because `g` returns
- through the wrapper function `inner`. When recomputing gradients through
- objects that inherit from keras, we suggest keeping a reference to the
- underlying object around for the purpose of accessing these variables.
-
- Args:
- f: function `f(*x)` that returns a `Tensor` or sequence of `Tensor` outputs.
- seed: Optional seed for random ops. `seed` should an integer scalar
- `Tensor`. When compiling to XLA, `seed` must have dtype `tf.int32`. If
- `seed` is not provided one will be generated.
-
- Returns:
- A function `g` that wraps `f`, but which recomputes `f` on the backwards
- pass of a gradient call.
- """
-
- @tf.custom_gradient
- def inner(*args, **kwargs):
- """Inner function closure for calculating gradients."""
- # Detect when we're nested and in the backwards pass, so we don't generate
- # an additional seed.
- parent_context = get_recompute_context()
- if parent_context is not None and parent_context.is_recomputing:
- # Use the cached context in the recomputation phase.
- with parent_context.children.popleft()._replace(
- is_recomputing=True) as context:
- result = f(*args, **kwargs)
- else:
- with RecomputeContext(
- is_recomputing=False,
- seed=_make_seed_if_none(seed),
- children=collections.deque()) as context:
- result = f(*args, **kwargs)
- # In the forward pass, build up a tree of recomputation contexts.
- if parent_context is not None and not parent_context.is_recomputing:
- parent_context.children.append(context)
-
- def grad(*dresult, **grad_kwargs):
- """Gradient function calculation for inner function."""
- variables = grad_kwargs.pop('variables', None)
- if grad_kwargs:
- raise ValueError('Found unexpected kwargs for `grad`: ',
- list(grad_kwargs.keys()))
- inputs, seed = list(args), context.seed
- if _in_xla_context():
- inputs = _force_data_dependency(
- tf.nest.flatten(dresult), inputs + [seed])
- seed = inputs.pop()
- # tf.keras.backend.set_learning_phase(1)
- with tf.GradientTape() as tape:
- tape.watch(inputs)
- if variables is not None:
- tape.watch(variables)
- with tf.control_dependencies(dresult):
- with context._replace(is_recomputing=True, seed=seed):
- result = f(*inputs, **kwargs)
- kw_vars = []
- if variables is not None:
- kw_vars = list(variables)
- grads = tape.gradient(
- result, list(inputs) + kw_vars, output_gradients=dresult)
- return grads[:len(inputs)], grads[len(inputs):]
-
- return result, grad
-
- return inner
diff --git a/spaces/akhaliq/neural-waveshaping-synthesis/neural_waveshaping_synthesis/data/utils/preprocess_audio.py b/spaces/akhaliq/neural-waveshaping-synthesis/neural_waveshaping_synthesis/data/utils/preprocess_audio.py
deleted file mode 100644
index 8bb3fa73e9b79d7113ac6a784bb6f8639cbecd82..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/neural-waveshaping-synthesis/neural_waveshaping_synthesis/data/utils/preprocess_audio.py
+++ /dev/null
@@ -1,237 +0,0 @@
-from functools import partial
-from typing import Callable, Sequence, Union
-
-import gin
-import librosa
-import numpy as np
-import resampy
-import scipy.io.wavfile as wavfile
-
-from .f0_extraction import extract_f0_with_crepe, extract_f0_with_pyin
-from .loudness_extraction import extract_perceptual_loudness, extract_rms
-from .mfcc_extraction import extract_mfcc
-from ...utils import apply, apply_unpack, unzip
-
-
-def read_audio_files(files: list):
- rates_and_audios = apply(wavfile.read, files)
- return unzip(rates_and_audios)
-
-
-def convert_to_float32_audio(audio: np.ndarray):
- if audio.dtype == np.float32:
- return audio
-
- max_sample_value = np.iinfo(audio.dtype).max
- floating_point_audio = audio / max_sample_value
- return floating_point_audio.astype(np.float32)
-
-
-def make_monophonic(audio: np.ndarray, strategy: str = "keep_left"):
- # deal with non stereo array formats
- if len(audio.shape) == 1:
- return audio
- elif len(audio.shape) != 2:
- raise ValueError("Unknown audio array format.")
-
- # deal with single audio channel
- if audio.shape[0] == 1:
- return audio[0]
- elif audio.shape[1] == 1:
- return audio[:, 0]
- # deal with more than two channels
- elif audio.shape[0] != 2 and audio.shape[1] != 2:
- raise ValueError("Expected stereo input audio but got too many channels.")
-
- # put channel first
- if audio.shape[1] == 2:
- audio = audio.T
-
- # make stereo audio monophonic
- if strategy == "keep_left":
- return audio[0]
- elif strategy == "keep_right":
- return audio[1]
- elif strategy == "sum":
- return np.mean(audio, axis=0)
- elif strategy == "diff":
- return audio[0] - audio[1]
-
-
-def normalise_signal(audio: np.ndarray, factor: float):
- return audio / factor
-
-
-def resample_audio(audio: np.ndarray, original_sr: float, target_sr: float):
- return resampy.resample(audio, original_sr, target_sr)
-
-
-def segment_signal(
- signal: np.ndarray,
- sample_rate: float,
- segment_length_in_seconds: float,
- hop_length_in_seconds: float,
-):
- segment_length_in_samples = int(sample_rate * segment_length_in_seconds)
- hop_length_in_samples = int(sample_rate * hop_length_in_seconds)
- segments = librosa.util.frame(
- signal, segment_length_in_samples, hop_length_in_samples
- )
- return segments
-
-
-def filter_segments(
- threshold: float,
- key_segments: np.ndarray,
- segments: Sequence[np.ndarray],
-):
- mean_keys = key_segments.mean(axis=0)
- mask = mean_keys > threshold
- filtered_segments = apply(
- lambda x: x[:, mask] if len(x.shape) == 2 else x[:, :, mask], segments
- )
- return filtered_segments
-
-
-def preprocess_single_audio_file(
- file: str,
- control_decimation_factor: float,
- target_sr: float = 16000.0,
- segment_length_in_seconds: float = 4.0,
- hop_length_in_seconds: float = 2.0,
- confidence_threshold: float = 0.85,
- f0_extractor: Callable = extract_f0_with_crepe,
- loudness_extractor: Callable = extract_perceptual_loudness,
- mfcc_extractor: Callable = extract_mfcc,
- normalisation_factor: Union[float, None] = None,
-):
- print("Loading audio file: %s..." % file)
- original_sr, audio = wavfile.read(file)
- audio = convert_to_float32_audio(audio)
- audio = make_monophonic(audio)
-
- if normalisation_factor:
- audio = normalise_signal(audio, normalisation_factor)
-
- print("Resampling audio file: %s..." % file)
- audio = resample_audio(audio, original_sr, target_sr)
-
- print("Extracting f0 with extractor '%s': %s..." % (f0_extractor.__name__, file))
- f0, confidence = f0_extractor(audio)
-
- print(
- "Extracting loudness with extractor '%s': %s..."
- % (loudness_extractor.__name__, file)
- )
- loudness = loudness_extractor(audio)
-
- print(
- "Extracting MFCC with extractor '%s': %s..." % (mfcc_extractor.__name__, file)
- )
- mfcc = mfcc_extractor(audio)
-
- print("Segmenting audio file: %s..." % file)
- segmented_audio = segment_signal(
- audio, target_sr, segment_length_in_seconds, hop_length_in_seconds
- )
-
- print("Segmenting control signals: %s..." % file)
- segmented_f0 = segment_signal(
- f0,
- target_sr / (control_decimation_factor or 1),
- segment_length_in_seconds,
- hop_length_in_seconds,
- )
- segmented_confidence = segment_signal(
- confidence,
- target_sr / (control_decimation_factor or 1),
- segment_length_in_seconds,
- hop_length_in_seconds,
- )
- segmented_loudness = segment_signal(
- loudness,
- target_sr / (control_decimation_factor or 1),
- segment_length_in_seconds,
- hop_length_in_seconds,
- )
- segmented_mfcc = segment_signal(
- mfcc,
- target_sr / (control_decimation_factor or 1),
- segment_length_in_seconds,
- hop_length_in_seconds,
- )
-
- (
- filtered_audio,
- filtered_f0,
- filtered_confidence,
- filtered_loudness,
- filtered_mfcc,
- ) = filter_segments(
- confidence_threshold,
- segmented_confidence,
- (
- segmented_audio,
- segmented_f0,
- segmented_confidence,
- segmented_loudness,
- segmented_mfcc,
- ),
- )
-
- if filtered_audio.shape[-1] == 0:
- print("No segments exceeding confidence threshold...")
- audio_split, f0_split, confidence_split, loudness_split, mfcc_split = (
- [],
- [],
- [],
- [],
- [],
- )
- else:
- split = lambda x: [e.squeeze() for e in np.split(x, x.shape[-1], -1)]
- audio_split = split(filtered_audio)
- f0_split = split(filtered_f0)
- confidence_split = split(filtered_confidence)
- loudness_split = split(filtered_loudness)
- mfcc_split = split(filtered_mfcc)
-
- return audio_split, f0_split, confidence_split, loudness_split, mfcc_split
-
-
-@gin.configurable
-def preprocess_audio(
- files: list,
- control_decimation_factor: float,
- target_sr: float = 16000,
- segment_length_in_seconds: float = 4.0,
- hop_length_in_seconds: float = 2.0,
- confidence_threshold: float = 0.85,
- f0_extractor: Callable = extract_f0_with_crepe,
- loudness_extractor: Callable = extract_perceptual_loudness,
- normalise_audio: bool = False,
-):
- if normalise_audio:
- print("Finding normalisation factor...")
- normalisation_factor = 0
- for file in files:
- _, audio = wavfile.read(file)
- audio = convert_to_float32_audio(audio)
- audio = make_monophonic(audio)
- max_value = np.abs(audio).max()
- normalisation_factor = (
- max_value if max_value > normalisation_factor else normalisation_factor
- )
-
- processor = partial(
- preprocess_single_audio_file,
- control_decimation_factor=control_decimation_factor,
- target_sr=target_sr,
- segment_length_in_seconds=segment_length_in_seconds,
- hop_length_in_seconds=hop_length_in_seconds,
- f0_extractor=f0_extractor,
- loudness_extractor=loudness_extractor,
- normalisation_factor=None if not normalise_audio else normalisation_factor,
- )
- for file in files:
- yield processor(file)
diff --git a/spaces/akhaliq/stylegan3_clip/torch_utils/ops/__init__.py b/spaces/akhaliq/stylegan3_clip/torch_utils/ops/__init__.py
deleted file mode 100644
index 8dd34882519598c472f1224cfe68c9ff6952ce69..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/stylegan3_clip/torch_utils/ops/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-# empty
diff --git a/spaces/alamin655/websurfx/public/static/cookies.js b/spaces/alamin655/websurfx/public/static/cookies.js
deleted file mode 100644
index 677eff788c6c8319efef509a5fe6cfebd6eebc8c..0000000000000000000000000000000000000000
--- a/spaces/alamin655/websurfx/public/static/cookies.js
+++ /dev/null
@@ -1,29 +0,0 @@
-/**
- * This function is executed when any page on the website finishes loading and
- * this function retrieves the cookies if it is present on the user's machine.
- * If it is available then the saved cookies is display in the cookies tab
- * otherwise an appropriate message is displayed if it is not available.
- *
- * @function
- * @listens DOMContentLoaded
- * @returns {void}
- */
-document.addEventListener(
- 'DOMContentLoaded',
- () => {
- try {
- // Decode the cookie value
- let cookie = decodeURIComponent(document.cookie)
- // Set the value of the input field to the decoded cookie value if it is not empty
- // Otherwise, display a message indicating that no cookies have been saved on the user's system
- document.querySelector('.cookies input').value =
- cookie !== '' ? cookie : 'No cookies have been saved on your system'
- } catch (error) {
- // If there is an error decoding the cookie, log the error to the console
- // and display an error message in the input field
- console.error('Error decoding cookie:', error)
- document.querySelector('.cookies input').value = 'Error decoding cookie'
- }
- },
- false
-)
diff --git a/spaces/alan-chen-intel/dagan-demo/depth/resnet_encoder.py b/spaces/alan-chen-intel/dagan-demo/depth/resnet_encoder.py
deleted file mode 100644
index 9c94418d383e5c48acb64e946e54f607ea9c2861..0000000000000000000000000000000000000000
--- a/spaces/alan-chen-intel/dagan-demo/depth/resnet_encoder.py
+++ /dev/null
@@ -1,98 +0,0 @@
-# Copyright Niantic 2019. Patent Pending. All rights reserved.
-#
-# This software is licensed under the terms of the Monodepth2 licence
-# which allows for non-commercial use only, the full terms of which are made
-# available in the LICENSE file.
-
-from __future__ import absolute_import, division, print_function
-
-import numpy as np
-
-import torch
-import torch.nn as nn
-import torchvision.models as models
-import torch.utils.model_zoo as model_zoo
-
-
-class ResNetMultiImageInput(models.ResNet):
- """Constructs a resnet model with varying number of input images.
- Adapted from https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
- """
- def __init__(self, block, layers, num_classes=1000, num_input_images=1):
- super(ResNetMultiImageInput, self).__init__(block, layers)
- self.inplanes = 64
- self.conv1 = nn.Conv2d(
- num_input_images * 3, 64, kernel_size=7, stride=2, padding=3, bias=False)
- self.bn1 = nn.BatchNorm2d(64)
- self.relu = nn.ReLU(inplace=True)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
- self.layer1 = self._make_layer(block, 64, layers[0])
- self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
- self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
- self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
-
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
- elif isinstance(m, nn.BatchNorm2d):
- nn.init.constant_(m.weight, 1)
- nn.init.constant_(m.bias, 0)
-
-
-def resnet_multiimage_input(num_layers, pretrained=False, num_input_images=1):
- """Constructs a ResNet model.
- Args:
- num_layers (int): Number of resnet layers. Must be 18 or 50
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- num_input_images (int): Number of frames stacked as input
- """
- assert num_layers in [18, 50], "Can only run with 18 or 50 layer resnet"
- blocks = {18: [2, 2, 2, 2], 50: [3, 4, 6, 3]}[num_layers]
- block_type = {18: models.resnet.BasicBlock, 50: models.resnet.Bottleneck}[num_layers]
- model = ResNetMultiImageInput(block_type, blocks, num_input_images=num_input_images)
-
- if pretrained:
- loaded = model_zoo.load_url(models.resnet.model_urls['resnet{}'.format(num_layers)])
- loaded['conv1.weight'] = torch.cat(
- [loaded['conv1.weight']] * num_input_images, 1) / num_input_images
- model.load_state_dict(loaded)
- return model
-
-
-class ResnetEncoder(nn.Module):
- """Pytorch module for a resnet encoder
- """
- def __init__(self, num_layers, pretrained, num_input_images=1):
- super(ResnetEncoder, self).__init__()
-
- self.num_ch_enc = np.array([64, 64, 128, 256, 512])
-
- resnets = {18: models.resnet18,
- 34: models.resnet34,
- 50: models.resnet50,
- 101: models.resnet101,
- 152: models.resnet152}
-
- if num_layers not in resnets:
- raise ValueError("{} is not a valid number of resnet layers".format(num_layers))
-
- if num_input_images > 1:
- self.encoder = resnet_multiimage_input(num_layers, pretrained, num_input_images)
- else:
- self.encoder = resnets[num_layers](pretrained)
-
- if num_layers > 34:
- self.num_ch_enc[1:] *= 4
-
- def forward(self, input_image):
- self.features = []
- x = (input_image - 0.45) / 0.225
- x = self.encoder.conv1(x)
- x = self.encoder.bn1(x)
- self.features.append(self.encoder.relu(x))
- self.features.append(self.encoder.layer1(self.encoder.maxpool(self.features[-1])))
- self.features.append(self.encoder.layer2(self.features[-1]))
- self.features.append(self.encoder.layer3(self.features[-1]))
- self.features.append(self.encoder.layer4(self.features[-1]))
-
- return self.features
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/rich/segment.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/rich/segment.py
deleted file mode 100644
index 94ca73076d8ec9c7a6d47e401736dad084070437..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/rich/segment.py
+++ /dev/null
@@ -1,720 +0,0 @@
-from enum import IntEnum
-from functools import lru_cache
-from itertools import filterfalse
-from logging import getLogger
-from operator import attrgetter
-from typing import (
- TYPE_CHECKING,
- Dict,
- Iterable,
- List,
- NamedTuple,
- Optional,
- Sequence,
- Tuple,
- Type,
- Union,
-)
-
-from .cells import (
- _is_single_cell_widths,
- cell_len,
- get_character_cell_size,
- set_cell_size,
-)
-from .repr import Result, rich_repr
-from .style import Style
-
-if TYPE_CHECKING:
- from .console import Console, ConsoleOptions, RenderResult
-
-log = getLogger("rich")
-
-
-class ControlType(IntEnum):
- """Non-printable control codes which typically translate to ANSI codes."""
-
- BELL = 1
- CARRIAGE_RETURN = 2
- HOME = 3
- CLEAR = 4
- SHOW_CURSOR = 5
- HIDE_CURSOR = 6
- ENABLE_ALT_SCREEN = 7
- DISABLE_ALT_SCREEN = 8
- CURSOR_UP = 9
- CURSOR_DOWN = 10
- CURSOR_FORWARD = 11
- CURSOR_BACKWARD = 12
- CURSOR_MOVE_TO_COLUMN = 13
- CURSOR_MOVE_TO = 14
- ERASE_IN_LINE = 15
-
-
-ControlCode = Union[
- Tuple[ControlType], Tuple[ControlType, int], Tuple[ControlType, int, int]
-]
-
-
-@rich_repr()
-class Segment(NamedTuple):
- """A piece of text with associated style. Segments are produced by the Console render process and
- are ultimately converted in to strings to be written to the terminal.
-
- Args:
- text (str): A piece of text.
- style (:class:`~rich.style.Style`, optional): An optional style to apply to the text.
- control (Tuple[ControlCode..], optional): Optional sequence of control codes.
- """
-
- text: str = ""
- """Raw text."""
- style: Optional[Style] = None
- """An optional style."""
- control: Optional[Sequence[ControlCode]] = None
- """Optional sequence of control codes."""
-
- def __rich_repr__(self) -> Result:
- yield self.text
- if self.control is None:
- if self.style is not None:
- yield self.style
- else:
- yield self.style
- yield self.control
-
- def __bool__(self) -> bool:
- """Check if the segment contains text."""
- return bool(self.text)
-
- @property
- def cell_length(self) -> int:
- """Get cell length of segment."""
- return 0 if self.control else cell_len(self.text)
-
- @property
- def is_control(self) -> bool:
- """Check if the segment contains control codes."""
- return self.control is not None
-
- @classmethod
- @lru_cache(1024 * 16)
- def _split_cells(cls, segment: "Segment", cut: int) -> Tuple["Segment", "Segment"]: # type: ignore
-
- text, style, control = segment
- _Segment = Segment
-
- cell_length = segment.cell_length
- if cut >= cell_length:
- return segment, _Segment("", style, control)
-
- cell_size = get_character_cell_size
-
- pos = int((cut / cell_length) * len(text))
-
- before = text[:pos]
- cell_pos = cell_len(before)
- if cell_pos == cut:
- return (
- _Segment(before, style, control),
- _Segment(text[pos:], style, control),
- )
- while pos < len(text):
- char = text[pos]
- pos += 1
- cell_pos += cell_size(char)
- before = text[:pos]
- if cell_pos == cut:
- return (
- _Segment(before, style, control),
- _Segment(text[pos:], style, control),
- )
- if cell_pos > cut:
- return (
- _Segment(before[: pos - 1] + " ", style, control),
- _Segment(" " + text[pos:], style, control),
- )
-
- def split_cells(self, cut: int) -> Tuple["Segment", "Segment"]:
- """Split segment in to two segments at the specified column.
-
- If the cut point falls in the middle of a 2-cell wide character then it is replaced
- by two spaces, to preserve the display width of the parent segment.
-
- Returns:
- Tuple[Segment, Segment]: Two segments.
- """
- text, style, control = self
-
- if _is_single_cell_widths(text):
- # Fast path with all 1 cell characters
- if cut >= len(text):
- return self, Segment("", style, control)
- return (
- Segment(text[:cut], style, control),
- Segment(text[cut:], style, control),
- )
-
- return self._split_cells(self, cut)
-
- @classmethod
- def line(cls) -> "Segment":
- """Make a new line segment."""
- return cls("\n")
-
- @classmethod
- def apply_style(
- cls,
- segments: Iterable["Segment"],
- style: Optional[Style] = None,
- post_style: Optional[Style] = None,
- ) -> Iterable["Segment"]:
- """Apply style(s) to an iterable of segments.
-
- Returns an iterable of segments where the style is replaced by ``style + segment.style + post_style``.
-
- Args:
- segments (Iterable[Segment]): Segments to process.
- style (Style, optional): Base style. Defaults to None.
- post_style (Style, optional): Style to apply on top of segment style. Defaults to None.
-
- Returns:
- Iterable[Segments]: A new iterable of segments (possibly the same iterable).
- """
- result_segments = segments
- if style:
- apply = style.__add__
- result_segments = (
- cls(text, None if control else apply(_style), control)
- for text, _style, control in result_segments
- )
- if post_style:
- result_segments = (
- cls(
- text,
- (
- None
- if control
- else (_style + post_style if _style else post_style)
- ),
- control,
- )
- for text, _style, control in result_segments
- )
- return result_segments
-
- @classmethod
- def filter_control(
- cls, segments: Iterable["Segment"], is_control: bool = False
- ) -> Iterable["Segment"]:
- """Filter segments by ``is_control`` attribute.
-
- Args:
- segments (Iterable[Segment]): An iterable of Segment instances.
- is_control (bool, optional): is_control flag to match in search.
-
- Returns:
- Iterable[Segment]: And iterable of Segment instances.
-
- """
- if is_control:
- return filter(attrgetter("control"), segments)
- else:
- return filterfalse(attrgetter("control"), segments)
-
- @classmethod
- def split_lines(cls, segments: Iterable["Segment"]) -> Iterable[List["Segment"]]:
- """Split a sequence of segments in to a list of lines.
-
- Args:
- segments (Iterable[Segment]): Segments potentially containing line feeds.
-
- Yields:
- Iterable[List[Segment]]: Iterable of segment lists, one per line.
- """
- line: List[Segment] = []
- append = line.append
-
- for segment in segments:
- if "\n" in segment.text and not segment.control:
- text, style, _ = segment
- while text:
- _text, new_line, text = text.partition("\n")
- if _text:
- append(cls(_text, style))
- if new_line:
- yield line
- line = []
- append = line.append
- else:
- append(segment)
- if line:
- yield line
-
- @classmethod
- def split_and_crop_lines(
- cls,
- segments: Iterable["Segment"],
- length: int,
- style: Optional[Style] = None,
- pad: bool = True,
- include_new_lines: bool = True,
- ) -> Iterable[List["Segment"]]:
- """Split segments in to lines, and crop lines greater than a given length.
-
- Args:
- segments (Iterable[Segment]): An iterable of segments, probably
- generated from console.render.
- length (int): Desired line length.
- style (Style, optional): Style to use for any padding.
- pad (bool): Enable padding of lines that are less than `length`.
-
- Returns:
- Iterable[List[Segment]]: An iterable of lines of segments.
- """
- line: List[Segment] = []
- append = line.append
-
- adjust_line_length = cls.adjust_line_length
- new_line_segment = cls("\n")
-
- for segment in segments:
- if "\n" in segment.text and not segment.control:
- text, style, _ = segment
- while text:
- _text, new_line, text = text.partition("\n")
- if _text:
- append(cls(_text, style))
- if new_line:
- cropped_line = adjust_line_length(
- line, length, style=style, pad=pad
- )
- if include_new_lines:
- cropped_line.append(new_line_segment)
- yield cropped_line
- del line[:]
- else:
- append(segment)
- if line:
- yield adjust_line_length(line, length, style=style, pad=pad)
-
- @classmethod
- def adjust_line_length(
- cls,
- line: List["Segment"],
- length: int,
- style: Optional[Style] = None,
- pad: bool = True,
- ) -> List["Segment"]:
- """Adjust a line to a given width (cropping or padding as required).
-
- Args:
- segments (Iterable[Segment]): A list of segments in a single line.
- length (int): The desired width of the line.
- style (Style, optional): The style of padding if used (space on the end). Defaults to None.
- pad (bool, optional): Pad lines with spaces if they are shorter than `length`. Defaults to True.
-
- Returns:
- List[Segment]: A line of segments with the desired length.
- """
- line_length = sum(segment.cell_length for segment in line)
- new_line: List[Segment]
-
- if line_length < length:
- if pad:
- new_line = line + [cls(" " * (length - line_length), style)]
- else:
- new_line = line[:]
- elif line_length > length:
- new_line = []
- append = new_line.append
- line_length = 0
- for segment in line:
- segment_length = segment.cell_length
- if line_length + segment_length < length or segment.control:
- append(segment)
- line_length += segment_length
- else:
- text, segment_style, _ = segment
- text = set_cell_size(text, length - line_length)
- append(cls(text, segment_style))
- break
- else:
- new_line = line[:]
- return new_line
-
- @classmethod
- def get_line_length(cls, line: List["Segment"]) -> int:
- """Get the length of list of segments.
-
- Args:
- line (List[Segment]): A line encoded as a list of Segments (assumes no '\\\\n' characters),
-
- Returns:
- int: The length of the line.
- """
- _cell_len = cell_len
- return sum(_cell_len(segment.text) for segment in line)
-
- @classmethod
- def get_shape(cls, lines: List[List["Segment"]]) -> Tuple[int, int]:
- """Get the shape (enclosing rectangle) of a list of lines.
-
- Args:
- lines (List[List[Segment]]): A list of lines (no '\\\\n' characters).
-
- Returns:
- Tuple[int, int]: Width and height in characters.
- """
- get_line_length = cls.get_line_length
- max_width = max(get_line_length(line) for line in lines) if lines else 0
- return (max_width, len(lines))
-
- @classmethod
- def set_shape(
- cls,
- lines: List[List["Segment"]],
- width: int,
- height: Optional[int] = None,
- style: Optional[Style] = None,
- new_lines: bool = False,
- ) -> List[List["Segment"]]:
- """Set the shape of a list of lines (enclosing rectangle).
-
- Args:
- lines (List[List[Segment]]): A list of lines.
- width (int): Desired width.
- height (int, optional): Desired height or None for no change.
- style (Style, optional): Style of any padding added.
- new_lines (bool, optional): Padded lines should include "\n". Defaults to False.
-
- Returns:
- List[List[Segment]]: New list of lines.
- """
- _height = height or len(lines)
-
- blank = (
- [cls(" " * width + "\n", style)] if new_lines else [cls(" " * width, style)]
- )
-
- adjust_line_length = cls.adjust_line_length
- shaped_lines = lines[:_height]
- shaped_lines[:] = [
- adjust_line_length(line, width, style=style) for line in lines
- ]
- if len(shaped_lines) < _height:
- shaped_lines.extend([blank] * (_height - len(shaped_lines)))
- return shaped_lines
-
- @classmethod
- def align_top(
- cls: Type["Segment"],
- lines: List[List["Segment"]],
- width: int,
- height: int,
- style: Style,
- new_lines: bool = False,
- ) -> List[List["Segment"]]:
- """Aligns lines to top (adds extra lines to bottom as required).
-
- Args:
- lines (List[List[Segment]]): A list of lines.
- width (int): Desired width.
- height (int, optional): Desired height or None for no change.
- style (Style): Style of any padding added.
- new_lines (bool, optional): Padded lines should include "\n". Defaults to False.
-
- Returns:
- List[List[Segment]]: New list of lines.
- """
- extra_lines = height - len(lines)
- if not extra_lines:
- return lines[:]
- lines = lines[:height]
- blank = cls(" " * width + "\n", style) if new_lines else cls(" " * width, style)
- lines = lines + [[blank]] * extra_lines
- return lines
-
- @classmethod
- def align_bottom(
- cls: Type["Segment"],
- lines: List[List["Segment"]],
- width: int,
- height: int,
- style: Style,
- new_lines: bool = False,
- ) -> List[List["Segment"]]:
- """Aligns render to bottom (adds extra lines above as required).
-
- Args:
- lines (List[List[Segment]]): A list of lines.
- width (int): Desired width.
- height (int, optional): Desired height or None for no change.
- style (Style): Style of any padding added. Defaults to None.
- new_lines (bool, optional): Padded lines should include "\n". Defaults to False.
-
- Returns:
- List[List[Segment]]: New list of lines.
- """
- extra_lines = height - len(lines)
- if not extra_lines:
- return lines[:]
- lines = lines[:height]
- blank = cls(" " * width + "\n", style) if new_lines else cls(" " * width, style)
- lines = [[blank]] * extra_lines + lines
- return lines
-
- @classmethod
- def align_middle(
- cls: Type["Segment"],
- lines: List[List["Segment"]],
- width: int,
- height: int,
- style: Style,
- new_lines: bool = False,
- ) -> List[List["Segment"]]:
- """Aligns lines to middle (adds extra lines to above and below as required).
-
- Args:
- lines (List[List[Segment]]): A list of lines.
- width (int): Desired width.
- height (int, optional): Desired height or None for no change.
- style (Style): Style of any padding added.
- new_lines (bool, optional): Padded lines should include "\n". Defaults to False.
-
- Returns:
- List[List[Segment]]: New list of lines.
- """
- extra_lines = height - len(lines)
- if not extra_lines:
- return lines[:]
- lines = lines[:height]
- blank = cls(" " * width + "\n", style) if new_lines else cls(" " * width, style)
- top_lines = extra_lines // 2
- bottom_lines = extra_lines - top_lines
- lines = [[blank]] * top_lines + lines + [[blank]] * bottom_lines
- return lines
-
- @classmethod
- def simplify(cls, segments: Iterable["Segment"]) -> Iterable["Segment"]:
- """Simplify an iterable of segments by combining contiguous segments with the same style.
-
- Args:
- segments (Iterable[Segment]): An iterable of segments.
-
- Returns:
- Iterable[Segment]: A possibly smaller iterable of segments that will render the same way.
- """
- iter_segments = iter(segments)
- try:
- last_segment = next(iter_segments)
- except StopIteration:
- return
-
- _Segment = Segment
- for segment in iter_segments:
- if last_segment.style == segment.style and not segment.control:
- last_segment = _Segment(
- last_segment.text + segment.text, last_segment.style
- )
- else:
- yield last_segment
- last_segment = segment
- yield last_segment
-
- @classmethod
- def strip_links(cls, segments: Iterable["Segment"]) -> Iterable["Segment"]:
- """Remove all links from an iterable of styles.
-
- Args:
- segments (Iterable[Segment]): An iterable segments.
-
- Yields:
- Segment: Segments with link removed.
- """
- for segment in segments:
- if segment.control or segment.style is None:
- yield segment
- else:
- text, style, _control = segment
- yield cls(text, style.update_link(None) if style else None)
-
- @classmethod
- def strip_styles(cls, segments: Iterable["Segment"]) -> Iterable["Segment"]:
- """Remove all styles from an iterable of segments.
-
- Args:
- segments (Iterable[Segment]): An iterable segments.
-
- Yields:
- Segment: Segments with styles replace with None
- """
- for text, _style, control in segments:
- yield cls(text, None, control)
-
- @classmethod
- def remove_color(cls, segments: Iterable["Segment"]) -> Iterable["Segment"]:
- """Remove all color from an iterable of segments.
-
- Args:
- segments (Iterable[Segment]): An iterable segments.
-
- Yields:
- Segment: Segments with colorless style.
- """
-
- cache: Dict[Style, Style] = {}
- for text, style, control in segments:
- if style:
- colorless_style = cache.get(style)
- if colorless_style is None:
- colorless_style = style.without_color
- cache[style] = colorless_style
- yield cls(text, colorless_style, control)
- else:
- yield cls(text, None, control)
-
- @classmethod
- def divide(
- cls, segments: Iterable["Segment"], cuts: Iterable[int]
- ) -> Iterable[List["Segment"]]:
- """Divides an iterable of segments in to portions.
-
- Args:
- cuts (Iterable[int]): Cell positions where to divide.
-
- Yields:
- [Iterable[List[Segment]]]: An iterable of Segments in List.
- """
- split_segments: List["Segment"] = []
- add_segment = split_segments.append
-
- iter_cuts = iter(cuts)
-
- while True:
- try:
- cut = next(iter_cuts)
- except StopIteration:
- return []
- if cut != 0:
- break
- yield []
- pos = 0
-
- for segment in segments:
- while segment.text:
- end_pos = pos + segment.cell_length
- if end_pos < cut:
- add_segment(segment)
- pos = end_pos
- break
-
- try:
- if end_pos == cut:
- add_segment(segment)
- yield split_segments[:]
- del split_segments[:]
- pos = end_pos
- break
- else:
- before, segment = segment.split_cells(cut - pos)
- add_segment(before)
- yield split_segments[:]
- del split_segments[:]
- pos = cut
- finally:
- try:
- cut = next(iter_cuts)
- except StopIteration:
- if split_segments:
- yield split_segments[:]
- return
- yield split_segments[:]
-
-
-class Segments:
- """A simple renderable to render an iterable of segments. This class may be useful if
- you want to print segments outside of a __rich_console__ method.
-
- Args:
- segments (Iterable[Segment]): An iterable of segments.
- new_lines (bool, optional): Add new lines between segments. Defaults to False.
- """
-
- def __init__(self, segments: Iterable[Segment], new_lines: bool = False) -> None:
- self.segments = list(segments)
- self.new_lines = new_lines
-
- def __rich_console__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "RenderResult":
- if self.new_lines:
- line = Segment.line()
- for segment in self.segments:
- yield segment
- yield line
- else:
- yield from self.segments
-
-
-class SegmentLines:
- def __init__(self, lines: Iterable[List[Segment]], new_lines: bool = False) -> None:
- """A simple renderable containing a number of lines of segments. May be used as an intermediate
- in rendering process.
-
- Args:
- lines (Iterable[List[Segment]]): Lists of segments forming lines.
- new_lines (bool, optional): Insert new lines after each line. Defaults to False.
- """
- self.lines = list(lines)
- self.new_lines = new_lines
-
- def __rich_console__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "RenderResult":
- if self.new_lines:
- new_line = Segment.line()
- for line in self.lines:
- yield from line
- yield new_line
- else:
- for line in self.lines:
- yield from line
-
-
-if __name__ == "__main__":
-
- if __name__ == "__main__": # pragma: no cover
- from pip._vendor.rich.console import Console
- from pip._vendor.rich.syntax import Syntax
- from pip._vendor.rich.text import Text
-
- code = """from rich.console import Console
- console = Console()
- text = Text.from_markup("Hello, [bold magenta]World[/]!")
- console.print(text)"""
-
- text = Text.from_markup("Hello, [bold magenta]World[/]!")
-
- console = Console()
-
- console.rule("rich.Segment")
- console.print(
- "A Segment is the last step in the Rich render process before generating text with ANSI codes."
- )
- console.print("\nConsider the following code:\n")
- console.print(Syntax(code, "python", line_numbers=True))
- console.print()
- console.print(
- "When you call [b]print()[/b], Rich [i]renders[/i] the object in to the the following:\n"
- )
- fragments = list(console.render(text))
- console.print(fragments)
- console.print()
- console.print(
- "The Segments are then processed to produce the following output:\n"
- )
- console.print(text)
- console.print(
- "\nYou will only need to know this if you are implementing your own Rich renderables."
- )
diff --git a/spaces/aliabd/SummerTime/model/third_party/HMNet/ExampleInitModel/HMNet-pretrained/README.md b/spaces/aliabd/SummerTime/model/third_party/HMNet/ExampleInitModel/HMNet-pretrained/README.md
deleted file mode 100644
index 1a9e9d8ebcac1b537a6bd4afc7b01835437e66f2..0000000000000000000000000000000000000000
--- a/spaces/aliabd/SummerTime/model/third_party/HMNet/ExampleInitModel/HMNet-pretrained/README.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# Download the pretrained HMNet model
-
-Using the download [link](https://sdrgstorage01wus2.blob.core.windows.net/user/ruox/Meeting_Minutes/HMNet/ExampleInitModel/HMNet-pretrained/model.pt?sv=2019-10-10&st=2020-10-22T19%3A24%3A06Z&se=2060-10-23T19%3A24%3A00Z&sr=b&sp=r&sig=cRfastEaN7s75cgMaBvEFGbXio20smnjjRxxYbqEkoE%3D) to download the `model.pt` file and put it in this directory.
\ No newline at end of file
diff --git a/spaces/alistairmcleay/cambridge-masters-project/scripts/UBAR_code/preprocess.py b/spaces/alistairmcleay/cambridge-masters-project/scripts/UBAR_code/preprocess.py
deleted file mode 100644
index a2438a34c69300e4248a334d29efce9539b934f5..0000000000000000000000000000000000000000
--- a/spaces/alistairmcleay/cambridge-masters-project/scripts/UBAR_code/preprocess.py
+++ /dev/null
@@ -1,576 +0,0 @@
-import copy
-import json
-import os
-import re
-import zipfile
-from collections import OrderedDict
-
-import spacy
-from tqdm import tqdm
-
-from crazyneuraluser.UBAR_code import ontology, utils
-from crazyneuraluser.UBAR_code.clean_dataset import clean_slot_values, clean_text
-from crazyneuraluser.UBAR_code.config import global_config as cfg
-from crazyneuraluser.UBAR_code.db_ops import MultiWozDB
-
-
-# value_set.json, all the domain[slot] values in datasets
-def get_db_values(value_set_path):
- processed = {}
- bspn_word = []
- nlp = spacy.load("en_core_web_sm")
-
- with open(value_set_path, "r") as f: # read value set file in lower
- value_set = json.loads(f.read().lower())
-
- with open("data/raw/UBAR/db/ontology.json", "r") as f: # read ontology in lower, all the domain-slot values
- otlg = json.loads(f.read().lower())
-
- for (
- domain,
- slots,
- ) in value_set.items(): # add all informable slots to bspn_word, create lists holder for values
- processed[domain] = {}
- bspn_word.append("[" + domain + "]")
- for slot, values in slots.items():
- s_p = ontology.normlize_slot_names.get(slot, slot)
- if s_p in ontology.informable_slots[domain]:
- bspn_word.append(s_p)
- processed[domain][s_p] = []
-
- for (
- domain,
- slots,
- ) in value_set.items(): # add all words of values of informable slots to bspn_word
- for slot, values in slots.items():
- s_p = ontology.normlize_slot_names.get(slot, slot)
- if s_p in ontology.informable_slots[domain]:
- for v in values:
- _, v_p = clean_slot_values(domain, slot, v)
- v_p = " ".join([token.text for token in nlp(v_p)]).strip()
- processed[domain][s_p].append(v_p)
- for x in v_p.split():
- if x not in bspn_word:
- bspn_word.append(x)
-
- for domain_slot, values in otlg.items(): # split domain-slots to domains and slots
- domain, slot = domain_slot.split("-")
- if domain == "bus":
- domain = "taxi"
- if slot == "price range":
- slot = "pricerange"
- if slot == "book stay":
- slot = "stay"
- if slot == "book day":
- slot = "day"
- if slot == "book people":
- slot = "people"
- if slot == "book time":
- slot = "time"
- if slot == "arrive by":
- slot = "arrive"
- if slot == "leave at":
- slot = "leave"
- if slot == "leaveat":
- slot = "leave"
- # add all slots and words of values if not already in processed and bspn_word
- if slot not in processed[domain]:
- processed[domain][slot] = []
- bspn_word.append(slot)
- for v in values:
- _, v_p = clean_slot_values(domain, slot, v)
- v_p = " ".join([token.text for token in nlp(v_p)]).strip()
- if v_p not in processed[domain][slot]:
- processed[domain][slot].append(v_p)
- for x in v_p.split():
- if x not in bspn_word:
- bspn_word.append(x)
-
- with open(value_set_path.replace(".json", "_processed.json"), "w") as f:
- json.dump(processed, f, indent=2) # save processed.json
- with open("data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed/bspn_word_collection.json", "w") as f:
- json.dump(bspn_word, f, indent=2) # save bspn_word
-
- print("DB value set processed! ")
-
-
-def preprocess_db(db_paths): # apply clean_slot_values to all dbs
- dbs = {}
- nlp = spacy.load("en_core_web_sm")
- for domain in ontology.all_domains:
- with open(db_paths[domain], "r") as f: # for every db_domain, read json file
- dbs[domain] = json.loads(f.read().lower())
- # entry has information about slots of said domain
- for idx, entry in enumerate(dbs[domain]):
- new_entry = copy.deepcopy(entry)
- for key, value in entry.items(): # key = slot
- if type(value) is not str:
- continue
- del new_entry[key]
- key, value = clean_slot_values(domain, key, value)
- tokenize_and_back = " ".join([token.text for token in nlp(value)]).strip()
- new_entry[key] = tokenize_and_back
- dbs[domain][idx] = new_entry
- with open(db_paths[domain].replace(".json", "_processed.json"), "w") as f:
- json.dump(dbs[domain], f, indent=2)
- print("[%s] DB processed! " % domain)
-
-
-class DataPreprocessor(object):
- def __init__(self):
- self.nlp = spacy.load("en_core_web_sm")
- self.db = MultiWozDB(cfg.dbs) # load all processed dbs
- data_path = "data/preprocessed/UBAR/gen_usr_utt_experiment_data_with_span_full.json"
- # archive = zipfile.ZipFile(data_path + ".zip", "r")
- # self.convlab_data = json.loads(archive.open(data_path.split("/")[-1], "r").read().lower())
- self.convlab_data = json.loads(open(data_path, "r").read().lower())
- self.delex_sg_valdict_path = "data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed/delex_single_valdict.json"
- self.delex_mt_valdict_path = "data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed/delex_multi_valdict.json"
- self.ambiguous_val_path = "data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed/ambiguous_values.json"
- self.delex_refs_path = "data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed/reference_no.json"
- self.delex_refs = json.loads(open(self.delex_refs_path, "r").read())
- if not os.path.exists(self.delex_sg_valdict_path):
- (
- self.delex_sg_valdict,
- self.delex_mt_valdict,
- self.ambiguous_vals,
- ) = self.get_delex_valdict()
- else:
- self.delex_sg_valdict = json.loads(open(self.delex_sg_valdict_path, "r").read())
- self.delex_mt_valdict = json.loads(open(self.delex_mt_valdict_path, "r").read())
- self.ambiguous_vals = json.loads(open(self.ambiguous_val_path, "r").read())
-
- self.vocab = utils.Vocab(cfg.vocab_size)
-
- def delex_by_annotation(self, dial_turn):
- u = dial_turn["text"].split()
- span = dial_turn["span_info"]
- for s in span:
- slot = s[1]
- if slot == "open":
- continue
- if ontology.da_abbr_to_slot_name.get(slot):
- slot = ontology.da_abbr_to_slot_name[slot]
- for idx in range(s[3], s[4] + 1):
- u[idx] = ""
- try:
- u[s[3]] = "[value_" + slot + "]"
- except Exception:
- u[5] = "[value_" + slot + "]"
- u_delex = " ".join([t for t in u if t != ""])
- u_delex = u_delex.replace("[value_address] , [value_address] , [value_address]", "[value_address]")
- u_delex = u_delex.replace("[value_address] , [value_address]", "[value_address]")
- u_delex = u_delex.replace("[value_name] [value_name]", "[value_name]")
- u_delex = u_delex.replace("[value_name]([value_phone] )", "[value_name] ( [value_phone] )")
- return u_delex
-
- def delex_by_valdict(self, text):
- text = clean_text(text)
-
- text = re.sub(r"\d{5}\s?\d{5,7}", "[value_phone]", text)
- text = re.sub(r"\d[\s-]stars?", "[value_stars]", text)
- text = re.sub(r"\$\d+|\$?\d+.?(\d+)?\s(pounds?|gbps?)", "[value_price]", text)
- text = re.sub(r"tr[\d]{4}", "[value_id]", text)
- text = re.sub(
- r"([a-z]{1}[\. ]?[a-z]{1}[\. ]?\d{1,2}[, ]+\d{1}[\. ]?[a-z]{1}[\. ]?[a-z]{1}|[a-z]{2}\d{2}[a-z]{2})",
- "[value_postcode]",
- text,
- )
-
- for value, slot in self.delex_mt_valdict.items():
- text = text.replace(value, "[value_%s]" % slot)
-
- for value, slot in self.delex_sg_valdict.items():
- tokens = text.split()
- for idx, tk in enumerate(tokens):
- if tk == value:
- tokens[idx] = "[value_%s]" % slot
- text = " ".join(tokens)
-
- for ambg_ent in self.ambiguous_vals:
- # ely is a place, but appears in words like moderately
- start_idx = text.find(" " + ambg_ent)
- if start_idx == -1:
- continue
- front_words = text[:start_idx].split()
- ent_type = "time" if ":" in ambg_ent else "place"
-
- for fw in front_words[::-1]:
- if fw in [
- "arrive",
- "arrives",
- "arrived",
- "arriving",
- "arrival",
- "destination",
- "there",
- "reach",
- "to",
- "by",
- "before",
- ]:
- slot = "[value_arrive]" if ent_type == "time" else "[value_destination]"
- text = re.sub(" " + ambg_ent, " " + slot, text)
- elif fw in [
- "leave",
- "leaves",
- "leaving",
- "depart",
- "departs",
- "departing",
- "departure",
- "from",
- "after",
- "pulls",
- ]:
- slot = "[value_leave]" if ent_type == "time" else "[value_departure]"
- text = re.sub(" " + ambg_ent, " " + slot, text)
-
- text = text.replace("[value_car] [value_car]", "[value_car]")
- return text
-
- def get_delex_valdict(
- self,
- ):
- skip_entry_type = {
- "taxi": ["taxi_phone"],
- "police": ["id"],
- "hospital": ["id"],
- "hotel": [
- "id",
- "location",
- "internet",
- "parking",
- "takesbookings",
- "stars",
- "price",
- "n",
- "postcode",
- "phone",
- ],
- "attraction": [
- "id",
- "location",
- "pricerange",
- "price",
- "openhours",
- "postcode",
- "phone",
- ],
- "train": ["price", "id"],
- "restaurant": [
- "id",
- "location",
- "introduction",
- "signature",
- "type",
- "postcode",
- "phone",
- ],
- }
- entity_value_to_slot = {}
- ambiguous_entities = []
- for domain, db_data in self.db.dbs.items():
- print("Processing entity values in [%s]" % domain)
- if domain != "taxi":
- for db_entry in db_data:
- for slot, value in db_entry.items():
- if slot not in skip_entry_type[domain]:
- if type(value) is not str:
- raise TypeError("value '%s' in domain '%s' should be rechecked" % (slot, domain))
- else:
- slot, value = clean_slot_values(domain, slot, value)
- value = " ".join([token.text for token in self.nlp(value)]).strip()
- if value in entity_value_to_slot and entity_value_to_slot[value] != slot:
- # print(value, ": ",entity_value_to_slot[value], slot)
- ambiguous_entities.append(value)
- entity_value_to_slot[value] = slot
- else: # taxi db specific
- db_entry = db_data[0]
- for slot, ent_list in db_entry.items():
- if slot not in skip_entry_type[domain]:
- for ent in ent_list:
- entity_value_to_slot[ent] = "car"
- ambiguous_entities = set(ambiguous_entities)
- ambiguous_entities.remove("cambridge")
- ambiguous_entities = list(ambiguous_entities)
- for amb_ent in ambiguous_entities: # departure or destination? arrive time or leave time?
- entity_value_to_slot.pop(amb_ent)
- entity_value_to_slot["parkside"] = "address"
- entity_value_to_slot["parkside, cambridge"] = "address"
- entity_value_to_slot["cambridge belfry"] = "name"
- entity_value_to_slot["hills road"] = "address"
- entity_value_to_slot["hills rd"] = "address"
- entity_value_to_slot["Parkside Police Station"] = "name"
-
- single_token_values = {}
- multi_token_values = {}
- for val, slt in entity_value_to_slot.items():
- if val in ["cambridge"]:
- continue
- if len(val.split()) > 1:
- multi_token_values[val] = slt
- else:
- single_token_values[val] = slt
-
- with open(self.delex_sg_valdict_path, "w") as f:
- single_token_values = OrderedDict(
- sorted(single_token_values.items(), key=lambda kv: len(kv[0]), reverse=True)
- )
- json.dump(single_token_values, f, indent=2)
- print("single delex value dict saved!")
- with open(self.delex_mt_valdict_path, "w") as f:
- multi_token_values = OrderedDict(
- sorted(multi_token_values.items(), key=lambda kv: len(kv[0]), reverse=True)
- )
- json.dump(multi_token_values, f, indent=2)
- print("multi delex value dict saved!")
- with open(self.ambiguous_val_path, "w") as f:
- json.dump(ambiguous_entities, f, indent=2)
- print("ambiguous value dict saved!")
-
- return single_token_values, multi_token_values, ambiguous_entities
-
- def preprocess_main(self, save_path=None, is_test=False):
- """ """
- data = {}
- count = 0
- self.unique_da = {}
- ordered_sysact_dict = {}
- for fn, raw_dial in tqdm(list(self.convlab_data.items())):
- count += 1
- # if count == 100:
- # break
-
- compressed_goal = {} # for every dialog, keep track the goal, domains, requests
- dial_domains, dial_reqs = [], []
- for dom, g in raw_dial["goal"].items():
- if dom != "topic" and dom != "message" and g:
- if g.get("reqt"): # request info. eg. postcode/address/phone
- # normalize request slots
- for i, req_slot in enumerate(g["reqt"]):
- if ontology.normlize_slot_names.get(req_slot):
- g["reqt"][i] = ontology.normlize_slot_names[req_slot]
- dial_reqs.append(g["reqt"][i])
- compressed_goal[dom] = g
- if dom in ontology.all_domains:
- dial_domains.append(dom)
-
- dial_reqs = list(set(dial_reqs))
-
- dial = {"goal": compressed_goal, "log": []}
- single_turn = {}
- constraint_dict = OrderedDict()
- prev_constraint_dict = {}
- prev_turn_domain = ["general"]
- ordered_sysact_dict[fn] = {}
-
- for turn_num, dial_turn in enumerate(raw_dial["log"]):
- # for user turn, have text
- # sys turn: text, belief states(metadata), dialog_act, span_info
- dial_state = dial_turn["metadata"]
- if not dial_state: # user
- # delexicalize user utterance, either by annotation or by val_dict
- u = " ".join(clean_text(dial_turn["text"]).split())
-
- # NOTE: Commenting out delexicalisation because it is not used and
- # breaks when I use generated user dialogues for some reason
-
- # if dial_turn["span_info"]:
- # u_delex = clean_text(self.delex_by_annotation(dial_turn))
- # else:
- # u_delex = self.delex_by_valdict(dial_turn["text"])
-
- single_turn["user"] = u
- # single_turn["user_delex"] = u_delex
-
- else: # system
- # delexicalize system response, either by annotation or by val_dict
- if dial_turn["span_info"]:
- s_delex = clean_text(self.delex_by_annotation(dial_turn))
- else:
- if not dial_turn["text"]:
- print(fn)
- s_delex = self.delex_by_valdict(dial_turn["text"])
- single_turn["resp"] = s_delex
-
- # get belief state, semi=informable/book=requestable, put into constraint_dict
- for domain in dial_domains:
- if not constraint_dict.get(domain):
- constraint_dict[domain] = OrderedDict()
- info_sv = dial_state[domain]["semi"]
- for s, v in info_sv.items():
- s, v = clean_slot_values(domain, s, v)
- if len(v.split()) > 1:
- v = " ".join([token.text for token in self.nlp(v)]).strip()
- if v != "":
- constraint_dict[domain][s] = v
- book_sv = dial_state[domain]["book"]
- for s, v in book_sv.items():
- if s == "booked":
- continue
- s, v = clean_slot_values(domain, s, v)
- if len(v.split()) > 1:
- v = " ".join([token.text for token in self.nlp(v)]).strip()
- if v != "":
- constraint_dict[domain][s] = v
-
- constraints = [] # list in format of [domain] slot value
- cons_delex = []
- turn_dom_bs = []
- for domain, info_slots in constraint_dict.items():
- if info_slots:
- constraints.append("[" + domain + "]")
- cons_delex.append("[" + domain + "]")
- for slot, value in info_slots.items():
- constraints.append(slot)
- constraints.extend(value.split())
- cons_delex.append(slot)
- if domain not in prev_constraint_dict:
- turn_dom_bs.append(domain)
- elif prev_constraint_dict[domain] != constraint_dict[domain]:
- turn_dom_bs.append(domain)
-
- sys_act_dict = {}
- turn_dom_da = set()
- for act in dial_turn["dialog_act"]:
- d, a = act.split("-") # split domain-act
- turn_dom_da.add(d)
- turn_dom_da = list(turn_dom_da)
- if len(turn_dom_da) != 1 and "general" in turn_dom_da:
- turn_dom_da.remove("general")
- if len(turn_dom_da) != 1 and "booking" in turn_dom_da:
- turn_dom_da.remove("booking")
-
- # get turn domain
- turn_domain = turn_dom_bs
- for dom in turn_dom_da:
- if dom != "booking" and dom not in turn_domain:
- turn_domain.append(dom)
- if not turn_domain:
- turn_domain = prev_turn_domain
- if len(turn_domain) == 2 and "general" in turn_domain:
- turn_domain.remove("general")
- if len(turn_domain) == 2:
- if len(prev_turn_domain) == 1 and prev_turn_domain[0] == turn_domain[1]:
- turn_domain = turn_domain[::-1]
-
- # get system action
- for dom in turn_domain:
- sys_act_dict[dom] = {}
- add_to_last_collect = []
- booking_act_map = {"inform": "offerbook", "book": "offerbooked"}
- for act, params in dial_turn["dialog_act"].items():
- if act == "general-greet":
- continue
- d, a = act.split("-")
- if d == "general" and d not in sys_act_dict:
- sys_act_dict[d] = {}
- if d == "booking":
- d = turn_domain[0]
- a = booking_act_map.get(a, a)
- add_p = []
- for param in params:
- p = param[0]
- if p == "none":
- continue
- elif ontology.da_abbr_to_slot_name.get(p):
- p = ontology.da_abbr_to_slot_name[p]
- if p not in add_p:
- add_p.append(p)
- add_to_last = True if a in ["request", "reqmore", "bye", "offerbook"] else False
- if add_to_last:
- add_to_last_collect.append((d, a, add_p))
- else:
- sys_act_dict[d][a] = add_p
- for d, a, add_p in add_to_last_collect:
- sys_act_dict[d][a] = add_p
-
- for d in copy.copy(sys_act_dict):
- acts = sys_act_dict[d]
- if not acts:
- del sys_act_dict[d]
- if "inform" in acts and "offerbooked" in acts:
- for s in sys_act_dict[d]["inform"]:
- sys_act_dict[d]["offerbooked"].append(s)
- del sys_act_dict[d]["inform"]
-
- ordered_sysact_dict[fn][len(dial["log"])] = sys_act_dict
-
- sys_act = []
- if "general-greet" in dial_turn["dialog_act"]:
- sys_act.extend(["[general]", "[greet]"])
- for d, acts in sys_act_dict.items():
- sys_act += ["[" + d + "]"]
- for a, slots in acts.items():
- self.unique_da[d + "-" + a] = 1
- sys_act += ["[" + a + "]"]
- sys_act += slots
-
- # get db pointers
- matnums = self.db.get_match_num(constraint_dict)
- match_dom = turn_domain[0] if len(turn_domain) == 1 else turn_domain[1]
- match = matnums[match_dom]
- dbvec = self.db.addDBPointer(match_dom, match)
- bkvec = self.db.addBookingPointer(dial_turn["dialog_act"])
-
- # 4 database pointer for domains, 2 for booking
- single_turn["pointer"] = ",".join([str(d) for d in dbvec + bkvec])
- single_turn["match"] = str(match)
- single_turn["constraint"] = " ".join(constraints)
- single_turn["cons_delex"] = " ".join(cons_delex)
- single_turn["sys_act"] = " ".join(sys_act)
- single_turn["turn_num"] = len(dial["log"])
- single_turn["turn_domain"] = " ".join(["[" + d + "]" for d in turn_domain])
-
- prev_turn_domain = copy.deepcopy(turn_domain)
- prev_constraint_dict = copy.deepcopy(constraint_dict)
-
- if "user" in single_turn:
- dial["log"].append(single_turn)
- for t in single_turn["user"].split() + single_turn["resp"].split() + constraints + sys_act:
- self.vocab.add_word(t)
-
- # NOTE: Commenting out delexicalisation because it is not used and
- # breaks when I use generated user dialogues for some reason
-
- # for t in single_turn["user_delex"].split():
- # if "[" in t and "]" in t and not t.startswith("[") and not t.endswith("]"):
- # single_turn["user_delex"].replace(t, t[t.index("[") : t.index("]") + 1])
- # elif not self.vocab.has_word(t):
- # self.vocab.add_word(t)
-
- single_turn = {}
-
- data[fn] = dial
- # pprint(dial)
- # if count == 20:
- # break
- self.vocab.construct()
- self.vocab.save_vocab("data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed/vocab")
- with open("data/interim/gen_usr_utts/multi-woz-analysis/dialog_acts.json", "w") as f:
- json.dump(ordered_sysact_dict, f, indent=2)
- with open("data/interim/gen_usr_utts/multi-woz-analysis/dialog_act_type.json", "w") as f:
- json.dump(self.unique_da, f, indent=2)
- return data
-
-
-if __name__ == "__main__":
- db_paths = {
- "attraction": "data/raw/UBAR/db/attraction_db.json",
- "hospital": "data/raw/UBAR/db/hospital_db.json",
- "hotel": "data/raw/UBAR/db/hotel_db.json",
- "police": "data/raw/UBAR/db/police_db.json",
- "restaurant": "data/raw/UBAR/db/restaurant_db.json",
- "taxi": "data/raw/UBAR/db/taxi_db.json",
- "train": "data/raw/UBAR/db/train_db.json",
- }
- get_db_values("data/raw/UBAR/db/value_set.json")
- preprocess_db(db_paths)
- dh = DataPreprocessor()
- data = dh.preprocess_main()
- if not os.path.exists("data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed"):
- os.mkdir("data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed")
-
- with open("data/preprocessed_gen_usr_utts/UBAR/multi-woz-processed/data_for_ubar.json", "w") as f:
- json.dump(data, f, indent=2)
diff --git a/spaces/allknowingroger/Image-Models-Test5/app.py b/spaces/allknowingroger/Image-Models-Test5/app.py
deleted file mode 100644
index e102e3dd10da559e2c288e4ed0606bce81706299..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test5/app.py
+++ /dev/null
@@ -1,144 +0,0 @@
-import gradio as gr
-# import os
-# import sys
-# from pathlib import Path
-import time
-
-models =[
- "Whybother/private-2",
- "Jinouga/haruno-sakura-boruto-v4",
- "optmal/headshot",
- "Neu256/Arc-diffusion-v1.0",
- "sayakpaul/lora-trained",
- "BastienPenalba/omaji",
- "Syedian123/rachel",
- "Royal/stable_diffusionv1-5",
- "anik424/SD_xl_base_madras_checks",
-]
-
-
-model_functions = {}
-model_idx = 1
-for model_path in models:
- try:
- model_functions[model_idx] = gr.Interface.load(f"models/{model_path}", live=False, preprocess=True, postprocess=False)
- except Exception as error:
- def the_fn(txt):
- return None
- model_functions[model_idx] = gr.Interface(fn=the_fn, inputs=["text"], outputs=["image"])
- model_idx+=1
-
-
-def send_it_idx(idx):
- def send_it_fn(prompt):
- output = (model_functions.get(str(idx)) or model_functions.get(str(1)))(prompt)
- return output
- return send_it_fn
-
-def get_prompts(prompt_text):
- return prompt_text
-
-def clear_it(val):
- if int(val) != 0:
- val = 0
- else:
- val = 0
- pass
- return val
-
-def all_task_end(cnt,t_stamp):
- to = t_stamp + 60
- et = time.time()
- if et > to and t_stamp != 0:
- d = gr.update(value=0)
- tog = gr.update(value=1)
- #print(f'to: {to} et: {et}')
- else:
- if cnt != 0:
- d = gr.update(value=et)
- else:
- d = gr.update(value=0)
- tog = gr.update(value=0)
- #print (f'passing: to: {to} et: {et}')
- pass
- return d, tog
-
-def all_task_start():
- print("\n\n\n\n\n\n\n")
- t = time.gmtime()
- t_stamp = time.time()
- current_time = time.strftime("%H:%M:%S", t)
- return gr.update(value=t_stamp), gr.update(value=t_stamp), gr.update(value=0)
-
-def clear_fn():
- nn = len(models)
- return tuple([None, *[None for _ in range(nn)]])
-
-
-
-with gr.Blocks(title="SD Models") as my_interface:
- with gr.Column(scale=12):
- # with gr.Row():
- # gr.Markdown("""- Primary prompt: 你想画的内容(英文单词,如 a cat, 加英文逗号效果更好;点 Improve 按钮进行完善)\n- Real prompt: 完善后的提示词,出现后再点右边的 Run 按钮开始运行""")
- with gr.Row():
- with gr.Row(scale=6):
- primary_prompt=gr.Textbox(label="Prompt", value="")
- # real_prompt=gr.Textbox(label="Real prompt")
- with gr.Row(scale=6):
- # improve_prompts_btn=gr.Button("Improve")
- with gr.Row():
- run=gr.Button("Run",variant="primary")
- clear_btn=gr.Button("Clear")
- with gr.Row():
- sd_outputs = {}
- model_idx = 1
- for model_path in models:
- with gr.Column(scale=3, min_width=320):
- with gr.Box():
- sd_outputs[model_idx] = gr.Image(label=model_path)
- pass
- model_idx += 1
- pass
- pass
-
- with gr.Row(visible=False):
- start_box=gr.Number(interactive=False)
- end_box=gr.Number(interactive=False)
- tog_box=gr.Textbox(value=0,interactive=False)
-
- start_box.change(
- all_task_end,
- [start_box, end_box],
- [start_box, tog_box],
- every=1,
- show_progress=False)
-
- primary_prompt.submit(all_task_start, None, [start_box, end_box, tog_box])
- run.click(all_task_start, None, [start_box, end_box, tog_box])
- runs_dict = {}
- model_idx = 1
- for model_path in models:
- runs_dict[model_idx] = run.click(model_functions[model_idx], inputs=[primary_prompt], outputs=[sd_outputs[model_idx]])
- model_idx += 1
- pass
- pass
-
- # improve_prompts_btn_clicked=improve_prompts_btn.click(
- # get_prompts,
- # inputs=[primary_prompt],
- # outputs=[primary_prompt],
- # cancels=list(runs_dict.values()))
- clear_btn.click(
- clear_fn,
- None,
- [primary_prompt, *list(sd_outputs.values())],
- cancels=[*list(runs_dict.values())])
- tog_box.change(
- clear_it,
- tog_box,
- tog_box,
- cancels=[*list(runs_dict.values())])
-
-my_interface.queue(concurrency_count=600, status_update_rate=1)
-my_interface.launch(inline=True, show_api=False)
-
\ No newline at end of file
diff --git a/spaces/allknowingroger/Image-Models-Test87/README.md b/spaces/allknowingroger/Image-Models-Test87/README.md
deleted file mode 100644
index 37ff6d434313f02c1bd8749ce97ead1b5626f586..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test87/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: More Image Models
-emoji: 😻
-colorFrom: red
-colorTo: gray
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: true
-duplicated_from: allknowingroger/Image-Models-Test86
----
-
-
\ No newline at end of file
diff --git a/spaces/allknowingroger/Llama_v2/README.md b/spaces/allknowingroger/Llama_v2/README.md
deleted file mode 100644
index 4673b06c91bfc4bd5561e88ff24556fce8620786..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Llama_v2/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: Llama V2
-emoji: 💻
-colorFrom: red
-colorTo: gray
-sdk: static
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/amankishore/sjc/README.md b/spaces/amankishore/sjc/README.md
deleted file mode 100644
index d24f299d525fc2c140a3a007c2831e74056f81d7..0000000000000000000000000000000000000000
--- a/spaces/amankishore/sjc/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Sjc
-emoji: 💻
-colorFrom: red
-colorTo: pink
-sdk: gradio
-sdk_version: 3.12.0
-app_file: app.py
-pinned: false
-license: creativeml-openrail-m
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/amitjamadagni/qs-benchmarks/plot_scripts/plot_display_com_cap.py b/spaces/amitjamadagni/qs-benchmarks/plot_scripts/plot_display_com_cap.py
deleted file mode 100644
index cbee5a278ad18330b8836c1822dd654396569fab..0000000000000000000000000000000000000000
--- a/spaces/amitjamadagni/qs-benchmarks/plot_scripts/plot_display_com_cap.py
+++ /dev/null
@@ -1,103 +0,0 @@
-import numpy as np
-import h5py
-import os
-
-import mercury as mr
-
-import sys
-sys.path.append('/plot_scripts/')
-from map_packages_colors_1v1 import *
-from plot_scripts_1v1 import *
-
-# package_str = ['qiskit' , 'cirq', 'qsimcirq', 'pennylane', 'pennylane_l', 'qibo', 'qibojit', 'yao', 'quest', 'qulacs', 'intel_qs_cpp', 'projectq', 'svsim', 'hybridq', 'hiq', 'qcgpu', 'qrack_sch', 'cuquantum_qiskit', 'cuquantum_qsimcirq', 'qpanda']
-
-
-def abs_time_pack(task, package, pr, N_end):
-
- if task == "Heisenberg dynamics":
- task = "hdyn"
- elif task == "Random Quantum Circuit":
- task = "rqc"
- elif task == "Quantum Fourier Transform":
- task = "qft"
-
- if pr == "Single":
- pr = "sp"
- elif pr == "Double":
- pr = "dp"
-
- fig, ax = plt.subplots()
-
- dir = os.getcwd()
-
- if task == 'hdyn' or task == 'qft':
- N_arr = np.arange(6, N_end, 2)
- elif task == 'rqc':
- N_arr = np.arange(12, N_end, 2)
-
-
- dat_fst = dir + '/data/{}/{}_singlethread_{}.h5'.format(task, package, pr)
- dat_fmt = dir + '/data/{}/{}_multithread_{}.h5'.format(task, package, pr)
- dat_fgpu = dir + '/data/{}/{}_gpu_{}.h5'.format(task, package, pr)
-
- if not os.path.isfile(dat_fst) and not os.path.isfile(dat_fmt) and not os.path.isfile(dat_fgpu):
- return mr.Md(f"Precision {pr} possibly not supported")
-
- mr.Md(f"TtS performance of simulation packages with different compute capabilities")
-
- if os.path.isfile(dat_fst):
- h5f_st = h5py.File(dat_fst, 'r')
- dat_st = h5f_st[storage_dict[package]][:]
- h5f_st.close()
- plot_abs_data_n_arr(N_arr, dat_st, package+'_'+task+'_singlethread_'+pr)
-
- if os.path.isfile(dat_fmt):
- h5f_mt = h5py.File(dat_fmt, 'r')
- dat_mt = h5f_mt[storage_dict[package]][:]
- h5f_mt.close()
- plot_abs_data_n_arr(N_arr, dat_mt, package+'_'+task+'_multithread_'+pr)
-
- if os.path.isfile(dat_fgpu):
- h5f_gpu = h5py.File(dat_fgpu, 'r')
- dat_gpu = h5f_gpu[storage_dict[package]][:]
- h5f_gpu.close()
- plot_abs_data_n_arr(N_arr, dat_gpu, package+'_'+task+'_gpu_'+pr)
-
- gen_settings(fig, ax, r"N (system size)", r"Time ($t_{package}$)", False, True, True, N_arr[0]-2, N_arr[-1], True, 10**-1, 10**5, "out", None)
-
- mr.Md("___")
- mr.Md(f"Relative performance to singlethread performance")
-
- fig, ax = plt.subplots()
-
- if os.path.isfile(dat_fst) and os.path.isfile(dat_fmt):
- plot_comp_data_n_arr(N_arr, dat_st, dat_st, package+'_'+task+'_singlethread_'+pr)
- plot_comp_data_n_arr(N_arr, dat_st, dat_mt, package+'_'+task+'_multithread_'+pr)
-
- if os.path.isfile(dat_fst) and os.path.isfile(dat_fgpu):
- plot_comp_data_n_arr(N_arr, dat_st, dat_gpu, package+'_'+task+'_gpu_'+pr)
-
- gen_settings(fig, ax, r"N (system size)", r"Relative to singlethread", False, True, True, N_arr[0]-2, N_arr[-1], True, 10**-1, 10**3, "out", None)
-
- mr.Md("___")
- mr.Md(f"Relative performance to multithread performance")
-
- fig, ax = plt.subplots()
-
- if os.path.isfile(dat_fmt) and os.path.isfile(dat_fgpu):
- plot_comp_data_n_arr(N_arr, dat_mt, dat_gpu, package+'_'+task+'_gpu_'+pr)
- plot_comp_data_n_arr(N_arr, dat_mt, dat_mt, package+'_'+task+'_multithread_'+pr)
-
- gen_settings(fig, ax, r"N (system size)", r"Relative to multithread", False, True, True, N_arr[0]-2, N_arr[-1], True, 10**-1, 10**2, "out", None)
-
- # else:
- # print(" Re-select the options as the requested option data is not available.")
-
-# pkg_str = ['qiskit' , 'cirq', 'qsimcirq', 'pennylane', 'pennylane_l', 'qibo', 'qibojit', 'yao', 'quest', 'qulacs', 'intel_qs_cpp', 'projectq', 'svsim', 'hybridq', 'hiq', 'qcgpu', 'qrack_sch']
-
-# abs_time_pack("Heisenberg dynamics", 'qsimcirq', 'Double', 36)
-
-# abs_time(pkg_str, task_1, p_com_cap, p_prec)
-# abs_time("Heisenberg dynamics", "Singlethread", "Single", 'qsimcirq')
-# abs_time_pack("Heisenberg dynamics", "Random Quantum Circuit", "Singlethread", "Single", 34)
-# abs_time_pack("Heisenberg dynamics", "Quantum Fourier Transform", "GPU", "Single", 38)
diff --git a/spaces/argilla/argilla-streamlit-customs/my_app/introduction.py b/spaces/argilla/argilla-streamlit-customs/my_app/introduction.py
deleted file mode 100644
index 5b2f09bc6c68a2b17e7cfbf3df0fd7e0ab3e4de8..0000000000000000000000000000000000000000
--- a/spaces/argilla/argilla-streamlit-customs/my_app/introduction.py
+++ /dev/null
@@ -1,33 +0,0 @@
-# Contents of ~/my_app/streamlit_app.py
-import streamlit as st
-
-st.set_page_config(page_title="Argilla Streamlit", page_icon="👋", layout="wide")
-
-
-x = st.columns(3)
-x[0].image("https://docs.argilla.io/en/latest/_static/images/logo-light-mode.svg", use_column_width=True)
-
-st.write("# Welcome to Argilla Streamlit! 👋")
-
-st.sidebar.success("Select on of the apps above.")
-
-st.success(
- "PRs are welcome on our [Github repo](https://github.com/argilla-io/argilla-streamlit)! 🙌 \n\n"
- "Check it out on the [Hugging Face Hub](https://huggingface.co/spaces/argilla/argilla-streamlit-customs)! 🚀 "
-)
-st.markdown(
- """
- Argilla is a production-ready framework for building and improving datasets for NLP projects. This repo is focused on extended UI functionalities for Argilla. 👑
-
- **👈 Select an app from the sidebar** to see some examples
- of what Argilla Streamlit Customs can do!
-
- ## Next Steps
- If you want to continue learning Argilla:
- - 🙋♀️ Join the [Argilla Slack Community](https://join.slack.com/t/rubrixworkspace/shared_invite/zt-whigkyjn-a3IUJLD7gDbTZ0rKlvcJ5g)
- - ⭐ Argilla [Github repo](https://github.com/argilla-io/argilla)
- - 📚 Argilla [documentation](https://docs.argilla.io) for more guides and tutorials.
- """
-)
-
-
diff --git a/spaces/artificialguybr/video-dubbing/TTS/docs/README.md b/spaces/artificialguybr/video-dubbing/TTS/docs/README.md
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/arxify/RVC-beta-v2-0618/export_onnx.py b/spaces/arxify/RVC-beta-v2-0618/export_onnx.py
deleted file mode 100644
index 95376d4294ebc4d8972c5ab4a72454419f3e8cdf..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/export_onnx.py
+++ /dev/null
@@ -1,54 +0,0 @@
-from infer_pack.models_onnx import SynthesizerTrnMsNSFsidM
-import torch
-
-if __name__ == "__main__":
- MoeVS = True # 模型是否为MoeVoiceStudio(原MoeSS)使用
-
- ModelPath = "Shiroha/shiroha.pth" # 模型路径
- ExportedPath = "model.onnx" # 输出路径
- hidden_channels = 256 # hidden_channels,为768Vec做准备
- cpt = torch.load(ModelPath, map_location="cpu")
- cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0] # n_spk
- print(*cpt["config"])
-
- test_phone = torch.rand(1, 200, hidden_channels) # hidden unit
- test_phone_lengths = torch.tensor([200]).long() # hidden unit 长度(貌似没啥用)
- test_pitch = torch.randint(size=(1, 200), low=5, high=255) # 基频(单位赫兹)
- test_pitchf = torch.rand(1, 200) # nsf基频
- test_ds = torch.LongTensor([0]) # 说话人ID
- test_rnd = torch.rand(1, 192, 200) # 噪声(加入随机因子)
-
- device = "cpu" # 导出时设备(不影响使用模型)
-
- net_g = SynthesizerTrnMsNSFsidM(
- *cpt["config"], is_half=False
- ) # fp32导出(C++要支持fp16必须手动将内存重新排列所以暂时不用fp16)
- net_g.load_state_dict(cpt["weight"], strict=False)
- input_names = ["phone", "phone_lengths", "pitch", "pitchf", "ds", "rnd"]
- output_names = [
- "audio",
- ]
- # net_g.construct_spkmixmap(n_speaker) 多角色混合轨道导出
- torch.onnx.export(
- net_g,
- (
- test_phone.to(device),
- test_phone_lengths.to(device),
- test_pitch.to(device),
- test_pitchf.to(device),
- test_ds.to(device),
- test_rnd.to(device),
- ),
- ExportedPath,
- dynamic_axes={
- "phone": [1],
- "pitch": [1],
- "pitchf": [1],
- "rnd": [2],
- },
- do_constant_folding=False,
- opset_version=16,
- verbose=False,
- input_names=input_names,
- output_names=output_names,
- )
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/SelfTest/Cipher/test_CFB.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/SelfTest/Cipher/test_CFB.py
deleted file mode 100644
index cb0c35295ce51cf3cc8be4d85b66b52ac85353f4..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/SelfTest/Cipher/test_CFB.py
+++ /dev/null
@@ -1,411 +0,0 @@
-# ===================================================================
-#
-# Copyright (c) 2014, Legrandin
-# All rights reserved.
-#
-# Redistribution and use in source and binary forms, with or without
-# modification, are permitted provided that the following conditions
-# are met:
-#
-# 1. Redistributions of source code must retain the above copyright
-# notice, this list of conditions and the following disclaimer.
-# 2. Redistributions in binary form must reproduce the above copyright
-# notice, this list of conditions and the following disclaimer in
-# the documentation and/or other materials provided with the
-# distribution.
-#
-# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
-# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
-# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
-# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
-# COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
-# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
-# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
-# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
-# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
-# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
-# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
-# POSSIBILITY OF SUCH DAMAGE.
-# ===================================================================
-
-import unittest
-from binascii import unhexlify
-
-from Crypto.SelfTest.loader import load_test_vectors
-from Crypto.SelfTest.st_common import list_test_cases
-from Crypto.Util.py3compat import tobytes, is_string
-from Crypto.Cipher import AES, DES3, DES
-from Crypto.Hash import SHAKE128
-
-from Crypto.SelfTest.Cipher.test_CBC import BlockChainingTests
-
-
-def get_tag_random(tag, length):
- return SHAKE128.new(data=tobytes(tag)).read(length)
-
-
-class CfbTests(BlockChainingTests):
-
- aes_mode = AES.MODE_CFB
- des3_mode = DES3.MODE_CFB
-
- # Redefine test_unaligned_data_128/64
-
- def test_unaligned_data_128(self):
- plaintexts = [ b"7777777" ] * 100
-
- cipher = AES.new(self.key_128, AES.MODE_CFB, self.iv_128, segment_size=8)
- ciphertexts = [ cipher.encrypt(x) for x in plaintexts ]
- cipher = AES.new(self.key_128, AES.MODE_CFB, self.iv_128, segment_size=8)
- self.assertEqual(b"".join(ciphertexts), cipher.encrypt(b"".join(plaintexts)))
-
- cipher = AES.new(self.key_128, AES.MODE_CFB, self.iv_128, segment_size=128)
- ciphertexts = [ cipher.encrypt(x) for x in plaintexts ]
- cipher = AES.new(self.key_128, AES.MODE_CFB, self.iv_128, segment_size=128)
- self.assertEqual(b"".join(ciphertexts), cipher.encrypt(b"".join(plaintexts)))
-
- def test_unaligned_data_64(self):
- plaintexts = [ b"7777777" ] * 100
- cipher = DES3.new(self.key_192, DES3.MODE_CFB, self.iv_64, segment_size=8)
- ciphertexts = [ cipher.encrypt(x) for x in plaintexts ]
- cipher = DES3.new(self.key_192, DES3.MODE_CFB, self.iv_64, segment_size=8)
- self.assertEqual(b"".join(ciphertexts), cipher.encrypt(b"".join(plaintexts)))
-
- cipher = DES3.new(self.key_192, DES3.MODE_CFB, self.iv_64, segment_size=64)
- ciphertexts = [ cipher.encrypt(x) for x in plaintexts ]
- cipher = DES3.new(self.key_192, DES3.MODE_CFB, self.iv_64, segment_size=64)
- self.assertEqual(b"".join(ciphertexts), cipher.encrypt(b"".join(plaintexts)))
-
- # Extra
-
- def test_segment_size_128(self):
- for bits in range(8, 129, 8):
- cipher = AES.new(self.key_128, AES.MODE_CFB, self.iv_128,
- segment_size=bits)
-
- for bits in 0, 7, 9, 127, 129:
- self.assertRaises(ValueError, AES.new, self.key_128, AES.MODE_CFB,
- self.iv_128,
- segment_size=bits)
-
- def test_segment_size_64(self):
- for bits in range(8, 65, 8):
- cipher = DES3.new(self.key_192, DES3.MODE_CFB, self.iv_64,
- segment_size=bits)
-
- for bits in 0, 7, 9, 63, 65:
- self.assertRaises(ValueError, DES3.new, self.key_192, AES.MODE_CFB,
- self.iv_64,
- segment_size=bits)
-
-
-class NistCfbVectors(unittest.TestCase):
-
- def _do_kat_aes_test(self, file_name, segment_size):
-
- test_vectors = load_test_vectors(("Cipher", "AES"),
- file_name,
- "AES CFB%d KAT" % segment_size,
- { "count" : lambda x: int(x) } )
- if test_vectors is None:
- return
-
- direction = None
- for tv in test_vectors:
-
- # The test vector file contains some directive lines
- if is_string(tv):
- direction = tv
- continue
-
- self.description = tv.desc
- cipher = AES.new(tv.key, AES.MODE_CFB, tv.iv,
- segment_size=segment_size)
- if direction == "[ENCRYPT]":
- self.assertEqual(cipher.encrypt(tv.plaintext), tv.ciphertext)
- elif direction == "[DECRYPT]":
- self.assertEqual(cipher.decrypt(tv.ciphertext), tv.plaintext)
- else:
- assert False
-
- # See Section 6.4.5 in AESAVS
- def _do_mct_aes_test(self, file_name, segment_size):
-
- test_vectors = load_test_vectors(("Cipher", "AES"),
- file_name,
- "AES CFB%d Montecarlo" % segment_size,
- { "count" : lambda x: int(x) } )
- if test_vectors is None:
- return
-
- assert(segment_size in (8, 128))
-
- direction = None
- for tv in test_vectors:
-
- # The test vector file contains some directive lines
- if is_string(tv):
- direction = tv
- continue
-
- self.description = tv.desc
- cipher = AES.new(tv.key, AES.MODE_CFB, tv.iv,
- segment_size=segment_size)
-
- def get_input(input_text, output_seq, j):
- # CFB128
- if segment_size == 128:
- if j >= 2:
- return output_seq[-2]
- return [input_text, tv.iv][j]
- # CFB8
- if j == 0:
- return input_text
- elif j <= 16:
- return tv.iv[j - 1:j]
- return output_seq[j - 17]
-
- if direction == '[ENCRYPT]':
- cts = []
- for j in range(1000):
- plaintext = get_input(tv.plaintext, cts, j)
- cts.append(cipher.encrypt(plaintext))
- self.assertEqual(cts[-1], tv.ciphertext)
- elif direction == '[DECRYPT]':
- pts = []
- for j in range(1000):
- ciphertext = get_input(tv.ciphertext, pts, j)
- pts.append(cipher.decrypt(ciphertext))
- self.assertEqual(pts[-1], tv.plaintext)
- else:
- assert False
-
- def _do_tdes_test(self, file_name, segment_size):
-
- test_vectors = load_test_vectors(("Cipher", "TDES"),
- file_name,
- "TDES CFB%d KAT" % segment_size,
- { "count" : lambda x: int(x) } )
- if test_vectors is None:
- return
-
- direction = None
- for tv in test_vectors:
-
- # The test vector file contains some directive lines
- if is_string(tv):
- direction = tv
- continue
-
- self.description = tv.desc
- if hasattr(tv, "keys"):
- cipher = DES.new(tv.keys, DES.MODE_CFB, tv.iv,
- segment_size=segment_size)
- else:
- if tv.key1 != tv.key3:
- key = tv.key1 + tv.key2 + tv.key3 # Option 3
- else:
- key = tv.key1 + tv.key2 # Option 2
- cipher = DES3.new(key, DES3.MODE_CFB, tv.iv,
- segment_size=segment_size)
- if direction == "[ENCRYPT]":
- self.assertEqual(cipher.encrypt(tv.plaintext), tv.ciphertext)
- elif direction == "[DECRYPT]":
- self.assertEqual(cipher.decrypt(tv.ciphertext), tv.plaintext)
- else:
- assert False
-
-
-# Create one test method per file
-nist_aes_kat_mmt_files = (
- # KAT
- "CFB?GFSbox128.rsp",
- "CFB?GFSbox192.rsp",
- "CFB?GFSbox256.rsp",
- "CFB?KeySbox128.rsp",
- "CFB?KeySbox192.rsp",
- "CFB?KeySbox256.rsp",
- "CFB?VarKey128.rsp",
- "CFB?VarKey192.rsp",
- "CFB?VarKey256.rsp",
- "CFB?VarTxt128.rsp",
- "CFB?VarTxt192.rsp",
- "CFB?VarTxt256.rsp",
- # MMT
- "CFB?MMT128.rsp",
- "CFB?MMT192.rsp",
- "CFB?MMT256.rsp",
- )
-nist_aes_mct_files = (
- "CFB?MCT128.rsp",
- "CFB?MCT192.rsp",
- "CFB?MCT256.rsp",
- )
-
-for file_gen_name in nist_aes_kat_mmt_files:
- for bits in "8", "128":
- file_name = file_gen_name.replace("?", bits)
- def new_func(self, file_name=file_name, bits=bits):
- self._do_kat_aes_test(file_name, int(bits))
- setattr(NistCfbVectors, "test_AES_" + file_name, new_func)
-
-for file_gen_name in nist_aes_mct_files:
- for bits in "8", "128":
- file_name = file_gen_name.replace("?", bits)
- def new_func(self, file_name=file_name, bits=bits):
- self._do_mct_aes_test(file_name, int(bits))
- setattr(NistCfbVectors, "test_AES_" + file_name, new_func)
-del file_name, new_func
-
-nist_tdes_files = (
- "TCFB?MMT2.rsp", # 2TDES
- "TCFB?MMT3.rsp", # 3TDES
- "TCFB?invperm.rsp", # Single DES
- "TCFB?permop.rsp",
- "TCFB?subtab.rsp",
- "TCFB?varkey.rsp",
- "TCFB?vartext.rsp",
- )
-
-for file_gen_name in nist_tdes_files:
- for bits in "8", "64":
- file_name = file_gen_name.replace("?", bits)
- def new_func(self, file_name=file_name, bits=bits):
- self._do_tdes_test(file_name, int(bits))
- setattr(NistCfbVectors, "test_TDES_" + file_name, new_func)
-
-# END OF NIST CBC TEST VECTORS
-
-
-class SP800TestVectors(unittest.TestCase):
- """Class exercising the CFB test vectors found in Section F.3
- of NIST SP 800-3A"""
-
- def test_aes_128_cfb8(self):
- plaintext = '6bc1bee22e409f96e93d7e117393172aae2d'
- ciphertext = '3b79424c9c0dd436bace9e0ed4586a4f32b9'
- key = '2b7e151628aed2a6abf7158809cf4f3c'
- iv = '000102030405060708090a0b0c0d0e0f'
-
- key = unhexlify(key)
- iv = unhexlify(iv)
- plaintext = unhexlify(plaintext)
- ciphertext = unhexlify(ciphertext)
-
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=8)
- self.assertEqual(cipher.encrypt(plaintext), ciphertext)
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=8)
- self.assertEqual(cipher.decrypt(ciphertext), plaintext)
-
- def test_aes_192_cfb8(self):
- plaintext = '6bc1bee22e409f96e93d7e117393172aae2d'
- ciphertext = 'cda2521ef0a905ca44cd057cbf0d47a0678a'
- key = '8e73b0f7da0e6452c810f32b809079e562f8ead2522c6b7b'
- iv = '000102030405060708090a0b0c0d0e0f'
-
- key = unhexlify(key)
- iv = unhexlify(iv)
- plaintext = unhexlify(plaintext)
- ciphertext = unhexlify(ciphertext)
-
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=8)
- self.assertEqual(cipher.encrypt(plaintext), ciphertext)
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=8)
- self.assertEqual(cipher.decrypt(ciphertext), plaintext)
-
- def test_aes_256_cfb8(self):
- plaintext = '6bc1bee22e409f96e93d7e117393172aae2d'
- ciphertext = 'dc1f1a8520a64db55fcc8ac554844e889700'
- key = '603deb1015ca71be2b73aef0857d77811f352c073b6108d72d9810a30914dff4'
- iv = '000102030405060708090a0b0c0d0e0f'
-
- key = unhexlify(key)
- iv = unhexlify(iv)
- plaintext = unhexlify(plaintext)
- ciphertext = unhexlify(ciphertext)
-
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=8)
- self.assertEqual(cipher.encrypt(plaintext), ciphertext)
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=8)
- self.assertEqual(cipher.decrypt(ciphertext), plaintext)
-
- def test_aes_128_cfb128(self):
- plaintext = '6bc1bee22e409f96e93d7e117393172a' +\
- 'ae2d8a571e03ac9c9eb76fac45af8e51' +\
- '30c81c46a35ce411e5fbc1191a0a52ef' +\
- 'f69f2445df4f9b17ad2b417be66c3710'
- ciphertext = '3b3fd92eb72dad20333449f8e83cfb4a' +\
- 'c8a64537a0b3a93fcde3cdad9f1ce58b' +\
- '26751f67a3cbb140b1808cf187a4f4df' +\
- 'c04b05357c5d1c0eeac4c66f9ff7f2e6'
- key = '2b7e151628aed2a6abf7158809cf4f3c'
- iv = '000102030405060708090a0b0c0d0e0f'
-
- key = unhexlify(key)
- iv = unhexlify(iv)
- plaintext = unhexlify(plaintext)
- ciphertext = unhexlify(ciphertext)
-
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=128)
- self.assertEqual(cipher.encrypt(plaintext), ciphertext)
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=128)
- self.assertEqual(cipher.decrypt(ciphertext), plaintext)
-
- def test_aes_192_cfb128(self):
- plaintext = '6bc1bee22e409f96e93d7e117393172a' +\
- 'ae2d8a571e03ac9c9eb76fac45af8e51' +\
- '30c81c46a35ce411e5fbc1191a0a52ef' +\
- 'f69f2445df4f9b17ad2b417be66c3710'
- ciphertext = 'cdc80d6fddf18cab34c25909c99a4174' +\
- '67ce7f7f81173621961a2b70171d3d7a' +\
- '2e1e8a1dd59b88b1c8e60fed1efac4c9' +\
- 'c05f9f9ca9834fa042ae8fba584b09ff'
- key = '8e73b0f7da0e6452c810f32b809079e562f8ead2522c6b7b'
- iv = '000102030405060708090a0b0c0d0e0f'
-
- key = unhexlify(key)
- iv = unhexlify(iv)
- plaintext = unhexlify(plaintext)
- ciphertext = unhexlify(ciphertext)
-
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=128)
- self.assertEqual(cipher.encrypt(plaintext), ciphertext)
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=128)
- self.assertEqual(cipher.decrypt(ciphertext), plaintext)
-
- def test_aes_256_cfb128(self):
- plaintext = '6bc1bee22e409f96e93d7e117393172a' +\
- 'ae2d8a571e03ac9c9eb76fac45af8e51' +\
- '30c81c46a35ce411e5fbc1191a0a52ef' +\
- 'f69f2445df4f9b17ad2b417be66c3710'
-
- ciphertext = 'dc7e84bfda79164b7ecd8486985d3860' +\
- '39ffed143b28b1c832113c6331e5407b' +\
- 'df10132415e54b92a13ed0a8267ae2f9' +\
- '75a385741ab9cef82031623d55b1e471'
- key = '603deb1015ca71be2b73aef0857d77811f352c073b6108d72d9810a30914dff4'
- iv = '000102030405060708090a0b0c0d0e0f'
-
- key = unhexlify(key)
- iv = unhexlify(iv)
- plaintext = unhexlify(plaintext)
- ciphertext = unhexlify(ciphertext)
-
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=128)
- self.assertEqual(cipher.encrypt(plaintext), ciphertext)
- cipher = AES.new(key, AES.MODE_CFB, iv, segment_size=128)
- self.assertEqual(cipher.decrypt(ciphertext), plaintext)
-
-
-def get_tests(config={}):
- tests = []
- tests += list_test_cases(CfbTests)
- if config.get('slow_tests'):
- tests += list_test_cases(NistCfbVectors)
- tests += list_test_cases(SP800TestVectors)
- return tests
-
-
-if __name__ == '__main__':
- suite = lambda: unittest.TestSuite(get_tests())
- unittest.main(defaultTest='suite')
diff --git a/spaces/asciicorp/hotel-chat/markup.py b/spaces/asciicorp/hotel-chat/markup.py
deleted file mode 100644
index d2936a64624beea2621c7f50ac6ed534d225ef0d..0000000000000000000000000000000000000000
--- a/spaces/asciicorp/hotel-chat/markup.py
+++ /dev/null
@@ -1,20 +0,0 @@
-def hotelchat_app():
- return """
- Introduction
-
- An autonomous customer service chatbot designed for hotels, providing comprehensive information about the hotel and facilitating reservations.
- In this demo, we have equipped the chatbot with detailed information about a fictional hotel called Obsidian Heritage Colombo, including various room options, amenities, hotel policies, location, contact details, and all necessary information for a hotel stay
-
- """
-
-def hotelchat_app_hf():
- return """
-
- About this app
- some features may not work on Huggingface due to file write limitations:
- The chatbot with ordering functionality may not work properly, but chatbot without ordering is available. To fully test all features, clone the app and run it locally:
- git clone https://huggingface.co/spaces/asciicorp/hotel-chat
-
- The room reservation functionality of the chatbot is currently in an experimental phase. When mentioning arrival or departure dates, the chatbot will provide answers clearly indicating which is which. For example, if you say "We will be arriving tomorrow," simply stating "tomorrow" will not suffice; instead, the chatbot will respond by acknowledging the arrival date specifically. Additionally, the chatbot may occasionally ask for the same details repeatedly, but if you inform it that you have already provided the information, it will correct itself accordingly.
-
- """
diff --git a/spaces/ashercn97/AsherTesting/modules/llamacpp_hf.py b/spaces/ashercn97/AsherTesting/modules/llamacpp_hf.py
deleted file mode 100644
index e09c1a741257babda3d0620661559858aadc7854..0000000000000000000000000000000000000000
--- a/spaces/ashercn97/AsherTesting/modules/llamacpp_hf.py
+++ /dev/null
@@ -1,109 +0,0 @@
-import os
-from pathlib import Path
-from typing import Any, Dict, Optional, Union
-
-import torch
-from torch.nn import CrossEntropyLoss
-from transformers import GenerationConfig, PretrainedConfig, PreTrainedModel
-from transformers.modeling_outputs import CausalLMOutputWithPast
-
-from modules import shared
-from modules.logging_colors import logger
-
-if torch.cuda.is_available():
- from llama_cpp_cuda import Llama
-else:
- from llama_cpp import Llama
-
-class LlamacppHF(PreTrainedModel):
- def __init__(self, model):
- super().__init__(PretrainedConfig())
- self.model = model
- self.generation_config = GenerationConfig()
- self.cache = None
-
- def _validate_model_class(self):
- pass
-
- def _validate_model_kwargs(self, model_kwargs: Dict[str, Any]):
- pass
-
- def prepare_inputs_for_generation(self, input_ids, **kwargs):
- return {'input_ids': input_ids, **kwargs}
-
- @property
- def device(self) -> torch.device:
- return torch.device(0)
-
- def __call__(self, *args, **kwargs):
- # TODO: Some decoding methods (such as Contrastive Search) may not work at this time
- assert len(args) == 0, 'no *args should be passed to forward'
- use_cache = kwargs.get('use_cache', True)
- labels = kwargs.get('labels', None)
- seq = kwargs['input_ids'][0].tolist()
- cache = kwargs['past_key_values'] if 'past_key_values' in kwargs else None
-
- # Make the forward call
- seq_tensor = torch.tensor(seq)
- if labels is None:
- if self.cache is None or not torch.equal(self.cache, seq_tensor[:-1]):
- self.model.reset()
- self.model.eval(seq)
- else:
- self.model.eval([seq[-1]])
-
- logits = torch.tensor(self.model.eval_logits[-1]).view(1, 1, -1).to(kwargs['input_ids'].device)
- else:
- self.model.reset()
- self.model.eval(seq)
- logits = torch.tensor(self.model.eval_logits)
- logits = logits.view(1, logits.shape[0], logits.shape[1]).to(kwargs['input_ids'].device)
-
- self.cache = seq_tensor
-
- # Based on transformers/models/llama/modeling_llama.py
- loss = None
- if labels is not None:
- # Shift so that tokens < n predict n
- shift_logits = logits[..., :-1, :].contiguous()
- shift_labels = labels[..., 1:].contiguous()
- # Flatten the tokens
- loss_fct = CrossEntropyLoss()
- shift_logits = shift_logits.view(-1, logits.shape[-1])
- shift_labels = shift_labels.view(-1)
- # Enable model parallelism
- shift_labels = shift_labels.to(shift_logits.device)
- loss = loss_fct(shift_logits, shift_labels)
-
- return CausalLMOutputWithPast(logits=logits, past_key_values=cache if use_cache else None, loss=loss)
-
- @classmethod
- def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], *model_args, **kwargs):
- assert len(model_args) == 0 and len(kwargs) == 0, "extra args is currently not supported"
- if isinstance(pretrained_model_name_or_path, str):
- pretrained_model_name_or_path = Path(pretrained_model_name_or_path)
-
- path = Path(f'{shared.args.model_dir}') / Path(pretrained_model_name_or_path)
- if path.is_file():
- model_file = path
- else:
- model_file = list(path.glob('*ggml*.bin'))[0]
-
- logger.info(f"llama.cpp weights detected: {model_file}\n")
- params = {
- 'model_path': str(model_file),
- 'n_ctx': shared.args.n_ctx,
- 'seed': int(shared.args.llama_cpp_seed),
- 'n_threads': shared.args.threads or None,
- 'n_batch': shared.args.n_batch,
- 'use_mmap': not shared.args.no_mmap,
- 'use_mlock': shared.args.mlock,
- 'low_vram': shared.args.low_vram,
- 'n_gpu_layers': shared.args.n_gpu_layers,
- 'rope_freq_base': 10000 * shared.args.alpha_value ** (64/63.),
- 'rope_freq_scale': 1.0 / shared.args.compress_pos_emb,
- 'logits_all': True,
- }
-
- model = Llama(**params)
- return LlamacppHF(model)
diff --git a/spaces/at2507/SM_NLP_RecoSys/Data/Mentor_interviews/Mahdi Torabi Rad.html b/spaces/at2507/SM_NLP_RecoSys/Data/Mentor_interviews/Mahdi Torabi Rad.html
deleted file mode 100644
index aaae854cea5fab8dc26ab10726026facac92948c..0000000000000000000000000000000000000000
--- a/spaces/at2507/SM_NLP_RecoSys/Data/Mentor_interviews/Mahdi Torabi Rad.html
+++ /dev/null
@@ -1,132 +0,0 @@
-
-
-
- Mahdi Torabi Rad
-
-
-
-
-
- Mahdi Torabi Rad
-
-
- Mentee to Mentor.
1- What is your motivation to be a mentor with us at SharpestMinds?
- Learnt things on own and got a good understanding of the path on how to move from an adjacent field towards data science. Want to share this with future mentees and show that it's possible. Also, want to be active within the SM community.
- Helping people achieve career success brings satisfaction.
2- What's your career journey been like in Data Science?
- Have a degree in Mech Engg, and worked on Computational modelling in PhD.
- Started PhD in 2018 and have coding capabilities.
- Started looking for career opportunities in DS/ML in 2019 and decided to make a move and was introduced to SM by a friend and was mentored by Richard.
- Got a job as Lead M.L. Engineer for a startup in Waterloo.
- Currently working as Senior D.S. at current company.
3- What's the biggest challenge a new comer faces when trying to break into the Data science role? How can you help the with this?
- There is no one challenge that is faced by everyone. Everyone faces different challenges.
Assuming someone who has finished Masters or Phd in computational field and is comfortable with programming and have good understanding of Math Concepts - The challenge for them is how they can use their core skills to build a good portfolio to get interviews and get a job.
- Can help mentees understand and define an interesting project and give technical help to build a portfolio.
4- How was your experience as SM Mentee with your mentor and with SharpestMinds? Did you work on any projects?
- Worked on 3 projects. two of these were simple on linear regression and classification. One project was on reinforcement learning in finance (https://github.com/mtorabirad/Pair-Trading-Reinforcement-Learning)
- The experience was beneficial. The most important help was with reformatting Resume. It was initially purely academic, Mentor helped with making it industry ready to be able to land interviews and add projects along with it.
- Alejandro helped in offer negotiation and in choosing an offer amongst 3 different offers and eventually selected the one for the role currently working in.
5- You mentioned you want to actively engage with the community - How do you envision this?
- Would like to work on a project with 2-3 mentees which can be interesting and come up with a nice and sexy solution and report for a problem. This can be very helpful for mentees to showcase in their portfolios and also help them collaborate with each other.
- Identify mentees in specific fields and go through reading resources together. Can help do sessions on Time series forecasting and host space for discussion on it.
6- Do you have any questions for me regarding SM?
- What are the current mentee profiles on the platform?
-
-
-
-
-
-
\ No newline at end of file
diff --git a/spaces/avivdm1/AutoGPT/autogpt/json_utils/utilities.py b/spaces/avivdm1/AutoGPT/autogpt/json_utils/utilities.py
deleted file mode 100644
index eb9bb687750460fed2f4547b67e41f8e8c877a41..0000000000000000000000000000000000000000
--- a/spaces/avivdm1/AutoGPT/autogpt/json_utils/utilities.py
+++ /dev/null
@@ -1,54 +0,0 @@
-"""Utilities for the json_fixes package."""
-import json
-import re
-
-from jsonschema import Draft7Validator
-
-from autogpt.config import Config
-from autogpt.logs import logger
-
-CFG = Config()
-
-
-def extract_char_position(error_message: str) -> int:
- """Extract the character position from the JSONDecodeError message.
-
- Args:
- error_message (str): The error message from the JSONDecodeError
- exception.
-
- Returns:
- int: The character position.
- """
-
- char_pattern = re.compile(r"\(char (\d+)\)")
- if match := char_pattern.search(error_message):
- return int(match[1])
- else:
- raise ValueError("Character position not found in the error message.")
-
-
-def validate_json(json_object: object, schema_name: object) -> object:
- """
- :type schema_name: object
- :param schema_name:
- :type json_object: object
- """
- with open(f"autogpt/json_utils/{schema_name}.json", "r") as f:
- schema = json.load(f)
- validator = Draft7Validator(schema)
-
- if errors := sorted(validator.iter_errors(json_object), key=lambda e: e.path):
- logger.error("The JSON object is invalid.")
- if CFG.debug_mode:
- logger.error(
- json.dumps(json_object, indent=4)
- ) # Replace 'json_object' with the variable containing the JSON data
- logger.error("The following issues were found:")
-
- for error in errors:
- logger.error(f"Error: {error.message}")
- elif CFG.debug_mode:
- print("The JSON object is valid.")
-
- return json_object
diff --git a/spaces/awacke1/03-AW-ChatbotBlenderbot/README.md b/spaces/awacke1/03-AW-ChatbotBlenderbot/README.md
deleted file mode 100644
index 14dca5024e415ef29b1e009a31066fb026fb016b..0000000000000000000000000000000000000000
--- a/spaces/awacke1/03-AW-ChatbotBlenderbot/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: 03 AW ChatbotBlenderbot
-emoji: ⚡
-colorFrom: purple
-colorTo: red
-sdk: gradio
-sdk_version: 3.6
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/awacke1/MN.Map.Hospitals.Top.Five/README.md b/spaces/awacke1/MN.Map.Hospitals.Top.Five/README.md
deleted file mode 100644
index 3cef0b3dd5bed0786a33524a97894566f7e94e02..0000000000000000000000000000000000000000
--- a/spaces/awacke1/MN.Map.Hospitals.Top.Five/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: MN.Map.Hospitals.Top.Five
-emoji: 📊
-colorFrom: gray
-colorTo: blue
-sdk: streamlit
-sdk_version: 1.17.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/awacke1/Prompt-Refinery-Text-to-Image-Generation/app.py b/spaces/awacke1/Prompt-Refinery-Text-to-Image-Generation/app.py
deleted file mode 100644
index 0768eb88f3353204a8542bd3caaf20c0c0d39aee..0000000000000000000000000000000000000000
--- a/spaces/awacke1/Prompt-Refinery-Text-to-Image-Generation/app.py
+++ /dev/null
@@ -1,94 +0,0 @@
-import gradio as gr
-import os
-from share_btn import community_icon_html, loading_icon_html, share_js
-
-text_gen = gr.Interface.load(name="spaces/Gustavosta/MagicPrompt-Stable-Diffusion")
-stable_diffusion = gr.Blocks.load(name="spaces/runwayml/stable-diffusion-v1-5")
-
-def get_images(prompt):
- gallery_dir = stable_diffusion(prompt, fn_index=2)
- sd_output = [os.path.join(gallery_dir, image) for image in os.listdir(gallery_dir)]
- return sd_output, gr.update(visible=True), gr.update(visible=True), gr.update(visible=True)
-
-def get_prompts(prompt_text):
- return text_gen(prompt_text)
-
-css = '''
-.animate-spin {
- animation: spin 1s linear infinite;
-}
-@keyframes spin {
- from {
- transform: rotate(0deg);
- }
- to {
- transform: rotate(360deg);
- }
-}
-#share-btn-container {
- display: flex; padding-left: 0.5rem !important; padding-right: 0.5rem !important; background-color: #000000; justify-content: center; align-items: center; border-radius: 9999px !important; width: 13rem;
-}
-#share-btn {
- all: initial; color: #ffffff;font-weight: 600; cursor:pointer; font-family: 'IBM Plex Sans', sans-serif; margin-left: 0.5rem !important; padding-top: 0.25rem !important; padding-bottom: 0.25rem !important;
-}
-#share-btn * {
- all: unset;
-}
-#share-btn-container div:nth-child(-n+2){
- width: auto !important;
- min-height: 0px !important;
-}
-#share-btn-container .wrap {
- display: none !important;
-}
-a {text-decoration-line: underline;}
-'''
-with gr.Blocks(css=css) as demo:
- gr.HTML("""
-
-
- Prompt Refinery
-
-
-
- 🏭 Prompt Refinery generates variations of your prompt using MagicPrompt and Stable Diffusion
-
- """)
- with gr.Row():
- with gr.Column():
- input_text = gr.Textbox(label="Input text prompt",
- lines=2, elem_id="input-text")
- with gr.Row():
- see_prompts = gr.Button("✍️Expand my prompts")
-
- with gr.Column():
- text_output = gr.Textbox(
- label="🏭 Expanded text prompts",
- lines=8,
- elem_id="translated"
- )
- with gr.Row():
- diffuse_btn = gr.Button(value="🏭 Render Images for My Prompts")
- with gr.Column(elem_id="generated-gallery"):
- sd_output = gr.Gallery().style(grid=2, height="auto")
- with gr.Group(elem_id="share-btn-container"):
- community_icon = gr.HTML(community_icon_html, visible=False)
- loading_icon = gr.HTML(loading_icon_html, visible=False)
- see_prompts.click(get_prompts,
- inputs = [input_text],
- outputs = [
- text_output
- ], api_name="TextAI")
- diffuse_btn.click(get_images,
- inputs = [
- text_output
- ],
- outputs = [sd_output, community_icon, loading_icon], api_name="TextAI2")
-demo.launch(debug=True)
\ No newline at end of file
diff --git a/spaces/awacke1/Web-URL-HTTP-Parameters-Get-Set/app.py b/spaces/awacke1/Web-URL-HTTP-Parameters-Get-Set/app.py
deleted file mode 100644
index 68beec058e19c24fc66dd4d6cc2c08017f828e8e..0000000000000000000000000000000000000000
--- a/spaces/awacke1/Web-URL-HTTP-Parameters-Get-Set/app.py
+++ /dev/null
@@ -1,41 +0,0 @@
-import gradio as gr
-block = gr.Blocks()
-
-# Test app to get and set URL parameters for deep links to gradio spaces
-
-def predict(text, url_params):
- print(url_params)
- return ["Hello " + text + "!!", url_params]
-
-get_window_url_params = """
- function(text_input, url_params) {
- console.log(text_input, url_params);
- const params = new URLSearchParams(window.location.search);
- url_params = Object.fromEntries(params);
- return [text_input, url_params];
- }
- """
-
-set_window_url_params = """
- function(text_input, url_params) {
- const state = {text_input:text_input}
- const queryString = '?' + new URLSearchParams(state).toString();
- window.parent.postMessage({ queryString: queryString }, "*")
- return [text_input, state];
- }
- """
-
-with gr.Blocks() as demo:
- with gr.Row():
- url_params = gr.JSON({}, visible=True, label="URL Params")
- text_input = gr.Text(label="🔍 Input")
- text_output = gr.Text(label="🌟 Output")
- with gr.Row():
- btn = gr.Button("Get Params")
- btn.click(fn=predict, inputs=[text_input, url_params],
- outputs=[text_output, url_params], _js=get_window_url_params)
- btn2 = gr.Button("Set Params")
- btn2.click(fn=predict, inputs=[text_input, url_params],
- outputs=[text_output, url_params], _js=set_window_url_params)
-
-demo.launch(debug=True, show_error=True)
diff --git a/spaces/b1sheng/kg_llm_leaderboard_test/src/auto_leaderboard/model_metadata_type.py b/spaces/b1sheng/kg_llm_leaderboard_test/src/auto_leaderboard/model_metadata_type.py
deleted file mode 100644
index c7d5458a21439b52fd4dc0adb886c73765eef358..0000000000000000000000000000000000000000
--- a/spaces/b1sheng/kg_llm_leaderboard_test/src/auto_leaderboard/model_metadata_type.py
+++ /dev/null
@@ -1,487 +0,0 @@
-from dataclasses import dataclass
-from enum import Enum
-from typing import Dict, List
-
-from ..utils_display import AutoEvalColumn
-
-@dataclass
-class ModelInfo:
- name: str
- symbol: str # emoji
-
-
-class ModelType(Enum):
- PT = ModelInfo(name="pretrained", symbol="🟢")
- SFT = ModelInfo(name="finetuned", symbol="🔶")
- RL = ModelInfo(name="with RL", symbol="🟦")
-
-
-TYPE_METADATA: Dict[str, ModelType] = {
- "notstoic/PygmalionCoT-7b": ModelType.SFT,
- "aisquared/dlite-v1-355m": ModelType.SFT,
- "aisquared/dlite-v1-1_5b": ModelType.SFT,
- "aisquared/dlite-v1-774m": ModelType.SFT,
- "aisquared/dlite-v1-124m": ModelType.SFT,
- "aisquared/chopt-2_7b": ModelType.SFT,
- "aisquared/dlite-v2-124m": ModelType.SFT,
- "aisquared/dlite-v2-774m": ModelType.SFT,
- "aisquared/dlite-v2-1_5b": ModelType.SFT,
- "aisquared/chopt-1_3b": ModelType.SFT,
- "aisquared/dlite-v2-355m": ModelType.SFT,
- "TheBloke/tulu-7B-fp16": ModelType.SFT,
- "TheBloke/guanaco-7B-HF": ModelType.SFT,
- "TheBloke/koala-7B-HF": ModelType.SFT,
- "TheBloke/wizardLM-7B-HF": ModelType.SFT,
- "TheBloke/airoboros-13B-HF": ModelType.SFT,
- "TheBloke/koala-13B-HF": ModelType.SFT,
- "TheBloke/Wizard-Vicuna-7B-Uncensored-HF": ModelType.SFT,
- "TheBloke/dromedary-65b-lora-HF": ModelType.SFT,
- "TheBloke/wizardLM-13B-1.0-fp16": ModelType.SFT,
- "TheBloke/Wizard-Vicuna-30B-Uncensored-fp16": ModelType.SFT,
- "TheBloke/wizard-vicuna-13B-HF": ModelType.SFT,
- "TheBloke/UltraLM-13B-fp16": ModelType.SFT,
- "TheBloke/OpenAssistant-SFT-7-Llama-30B-HF": ModelType.SFT,
- "TheBloke/vicuna-13B-1.1-HF": ModelType.SFT,
- "TheBloke/guanaco-13B-HF": ModelType.SFT,
- "TheBloke/airoboros-7b-gpt4-fp16": ModelType.SFT,
- "TheBloke/Llama-2-13B-fp16": ModelType.PT,
- "TheBloke/Planner-7B-fp16": ModelType.SFT,
- "TheBloke/Wizard-Vicuna-13B-Uncensored-HF": ModelType.SFT,
- "TheBloke/gpt4-alpaca-lora-13B-HF": ModelType.SFT,
- "TheBloke/gpt4-x-vicuna-13B-HF": ModelType.SFT,
- "TheBloke/tulu-13B-fp16": ModelType.SFT,
- "jphme/orca_mini_v2_ger_7b": ModelType.SFT,
- "Ejafa/vicuna_7B_vanilla_1.1": ModelType.SFT,
- "kevinpro/Vicuna-13B-CoT": ModelType.SFT,
- "AlekseyKorshuk/pygmalion-6b-vicuna-chatml": ModelType.SFT,
- "AlekseyKorshuk/chatml-pyg-v1": ModelType.SFT,
- "concedo/Vicuzard-30B-Uncensored": ModelType.SFT,
- "concedo/OPT-19M-ChatSalad": ModelType.SFT,
- "concedo/Pythia-70M-ChatSalad": ModelType.SFT,
- "digitous/13B-HyperMantis": ModelType.SFT,
- "digitous/Adventien-GPTJ": ModelType.SFT,
- "digitous/Alpacino13b": ModelType.SFT,
- "digitous/GPT-R": ModelType.SFT,
- "digitous/Javelin-R": ModelType.SFT,
- "digitous/Javalion-GPTJ": ModelType.SFT,
- "digitous/Javalion-R": ModelType.SFT,
- "digitous/Skegma-GPTJ": ModelType.SFT,
- "digitous/Alpacino30b": ModelType.SFT,
- "digitous/Janin-GPTJ": ModelType.SFT,
- "digitous/Janin-R": ModelType.SFT,
- "digitous/Javelin-GPTJ": ModelType.SFT,
- "SaylorTwift/gpt2_test": ModelType.PT,
- "anton-l/gpt-j-tiny-random": ModelType.SFT,
- "Andron00e/YetAnother_Open-Llama-3B-LoRA-OpenOrca": ModelType.SFT,
- "Lazycuber/pyg-instruct-wizardlm": ModelType.SFT,
- "Lazycuber/Janemalion-6B": ModelType.SFT,
- "IDEA-CCNL/Ziya-LLaMA-13B-Pretrain-v1": ModelType.SFT,
- "IDEA-CCNL/Ziya-LLaMA-13B-v1": ModelType.SFT,
- "dsvv-cair/alpaca-cleaned-llama-30b-bf16": ModelType.SFT,
- "gpt2-medium": ModelType.PT,
- "camel-ai/CAMEL-13B-Combined-Data": ModelType.SFT,
- "camel-ai/CAMEL-13B-Role-Playing-Data": ModelType.SFT,
- "PygmalionAI/pygmalion-6b": ModelType.SFT,
- "PygmalionAI/metharme-1.3b": ModelType.SFT,
- "PygmalionAI/pygmalion-1.3b": ModelType.SFT,
- "PygmalionAI/pygmalion-350m": ModelType.SFT,
- "PygmalionAI/pygmalion-2.7b": ModelType.SFT,
- "medalpaca/medalpaca-7b": ModelType.SFT,
- "lilloukas/Platypus-30B": ModelType.SFT,
- "lilloukas/GPlatty-30B": ModelType.SFT,
- "mncai/chatdoctor": ModelType.SFT,
- "chaoyi-wu/MedLLaMA_13B": ModelType.SFT,
- "LoupGarou/WizardCoder-Guanaco-15B-V1.0": ModelType.SFT,
- "LoupGarou/WizardCoder-Guanaco-15B-V1.1": ModelType.SFT,
- "hakurei/instruct-12b": ModelType.SFT,
- "hakurei/lotus-12B": ModelType.SFT,
- "shibing624/chinese-llama-plus-13b-hf": ModelType.SFT,
- "shibing624/chinese-alpaca-plus-7b-hf": ModelType.SFT,
- "shibing624/chinese-alpaca-plus-13b-hf": ModelType.SFT,
- "mosaicml/mpt-7b-instruct": ModelType.SFT,
- "mosaicml/mpt-30b-chat": ModelType.SFT,
- "mosaicml/mpt-7b-storywriter": ModelType.SFT,
- "mosaicml/mpt-30b-instruct": ModelType.SFT,
- "mosaicml/mpt-7b-chat": ModelType.SFT,
- "mosaicml/mpt-30b": ModelType.PT,
- "Corianas/111m": ModelType.SFT,
- "Corianas/Quokka_1.3b": ModelType.SFT,
- "Corianas/256_5epoch": ModelType.SFT,
- "Corianas/Quokka_256m": ModelType.SFT,
- "Corianas/Quokka_590m": ModelType.SFT,
- "Corianas/gpt-j-6B-Dolly": ModelType.SFT,
- "Corianas/Quokka_2.7b": ModelType.SFT,
- "cyberagent/open-calm-7b": ModelType.SFT,
- "Aspik101/Nous-Hermes-13b-pl-lora_unload": ModelType.SFT,
- "THUDM/chatglm2-6b": ModelType.SFT,
- "MetaIX/GPT4-X-Alpasta-30b": ModelType.SFT,
- "NYTK/PULI-GPTrio": ModelType.PT,
- "EleutherAI/pythia-1.3b": ModelType.PT,
- "EleutherAI/pythia-2.8b-deduped": ModelType.PT,
- "EleutherAI/gpt-neo-125m": ModelType.PT,
- "EleutherAI/pythia-160m": ModelType.PT,
- "EleutherAI/gpt-neo-2.7B": ModelType.PT,
- "EleutherAI/pythia-1b-deduped": ModelType.PT,
- "EleutherAI/pythia-6.7b": ModelType.PT,
- "EleutherAI/pythia-70m-deduped": ModelType.PT,
- "EleutherAI/gpt-neox-20b": ModelType.PT,
- "EleutherAI/pythia-1.4b-deduped": ModelType.PT,
- "EleutherAI/pythia-2.7b": ModelType.PT,
- "EleutherAI/pythia-6.9b-deduped": ModelType.PT,
- "EleutherAI/pythia-70m": ModelType.PT,
- "EleutherAI/gpt-j-6b": ModelType.PT,
- "EleutherAI/pythia-12b-deduped": ModelType.PT,
- "EleutherAI/gpt-neo-1.3B": ModelType.PT,
- "EleutherAI/pythia-410m-deduped": ModelType.PT,
- "EleutherAI/pythia-160m-deduped": ModelType.PT,
- "EleutherAI/polyglot-ko-12.8b": ModelType.PT,
- "EleutherAI/pythia-12b": ModelType.PT,
- "roneneldan/TinyStories-33M": ModelType.PT,
- "roneneldan/TinyStories-28M": ModelType.PT,
- "roneneldan/TinyStories-1M": ModelType.PT,
- "roneneldan/TinyStories-8M": ModelType.PT,
- "roneneldan/TinyStories-3M": ModelType.PT,
- "jerryjalapeno/nart-100k-7b": ModelType.SFT,
- "lmsys/vicuna-13b-v1.3": ModelType.SFT,
- "lmsys/vicuna-7b-v1.3": ModelType.SFT,
- "lmsys/vicuna-13b-v1.1": ModelType.SFT,
- "lmsys/vicuna-13b-delta-v1.1": ModelType.SFT,
- "lmsys/vicuna-7b-delta-v1.1": ModelType.SFT,
- "abhiramtirumala/DialoGPT-sarcastic-medium": ModelType.SFT,
- "haonan-li/bactrian-x-llama-13b-merged": ModelType.SFT,
- "Gryphe/MythoLogic-13b": ModelType.SFT,
- "Gryphe/MythoBoros-13b": ModelType.SFT,
- "pillowtalks-ai/delta13b": ModelType.SFT,
- "wannaphong/openthaigpt-0.1.0-beta-full-model_for_open_llm_leaderboard": ModelType.SFT,
- "bigcode/tiny_starcoder_py": ModelType.PT,
- "bigcode/starcoderplus": ModelType.SFT,
- "bigcode/gpt_bigcode-santacoder": ModelType.PT,
- "bigcode/starcoder": ModelType.PT,
- "Open-Orca/OpenOrca-Preview1-13B": ModelType.SFT,
- "microsoft/DialoGPT-large": ModelType.SFT,
- "microsoft/DialoGPT-small": ModelType.SFT,
- "microsoft/DialoGPT-medium": ModelType.SFT,
- "microsoft/CodeGPT-small-py": ModelType.SFT,
- "Tincando/fiction_story_generator": ModelType.SFT,
- "Pirr/pythia-13b-deduped-green_devil": ModelType.SFT,
- "Aeala/GPT4-x-AlpacaDente2-30b": ModelType.SFT,
- "Aeala/GPT4-x-AlpacaDente-30b": ModelType.SFT,
- "Aeala/GPT4-x-Alpasta-13b": ModelType.SFT,
- "Aeala/VicUnlocked-alpaca-30b": ModelType.SFT,
- "Tap-M/Luna-AI-Llama2-Uncensored": ModelType.SFT,
- "illuin/test-custom-llama": ModelType.SFT,
- "dvruette/oasst-llama-13b-2-epochs": ModelType.SFT,
- "dvruette/oasst-gpt-neox-20b-1000-steps": ModelType.SFT,
- "dvruette/llama-13b-pretrained-dropout": ModelType.PT,
- "dvruette/llama-13b-pretrained": ModelType.PT,
- "dvruette/llama-13b-pretrained-sft-epoch-1": ModelType.PT,
- "dvruette/llama-13b-pretrained-sft-do2": ModelType.PT,
- "dvruette/oasst-gpt-neox-20b-3000-steps": ModelType.SFT,
- "dvruette/oasst-pythia-12b-pretrained-sft": ModelType.PT,
- "dvruette/oasst-pythia-6.9b-4000-steps": ModelType.SFT,
- "dvruette/gpt-neox-20b-full-precision": ModelType.SFT,
- "dvruette/oasst-llama-13b-1000-steps": ModelType.SFT,
- "openlm-research/open_llama_7b_700bt_preview": ModelType.PT,
- "openlm-research/open_llama_7b": ModelType.PT,
- "openlm-research/open_llama_7b_v2": ModelType.PT,
- "openlm-research/open_llama_3b": ModelType.PT,
- "openlm-research/open_llama_13b": ModelType.PT,
- "openlm-research/open_llama_3b_v2": ModelType.PT,
- "PocketDoc/Dans-PileOfSets-Mk1-llama-13b-merged": ModelType.SFT,
- "GeorgiaTechResearchInstitute/galpaca-30b": ModelType.SFT,
- "GeorgiaTechResearchInstitute/starcoder-gpteacher-code-instruct": ModelType.SFT,
- "databricks/dolly-v2-7b": ModelType.SFT,
- "databricks/dolly-v2-3b": ModelType.SFT,
- "databricks/dolly-v2-12b": ModelType.SFT,
- "Rachneet/gpt2-xl-alpaca": ModelType.SFT,
- "Locutusque/gpt2-conversational-or-qa": ModelType.SFT,
- "psyche/kogpt": ModelType.SFT,
- "NbAiLab/nb-gpt-j-6B-alpaca": ModelType.SFT,
- "Mikael110/llama-2-7b-guanaco-fp16": ModelType.SFT,
- "Mikael110/llama-2-13b-guanaco-fp16": ModelType.SFT,
- "Fredithefish/CrimsonPajama": ModelType.SFT,
- "Fredithefish/RedPajama-INCITE-Chat-3B-ShareGPT-11K": ModelType.SFT,
- "Fredithefish/ScarletPajama-3B-HF": ModelType.SFT,
- "Fredithefish/RedPajama-INCITE-Chat-3B-Instruction-Tuning-with-GPT-4": ModelType.SFT,
- "eachadea/vicuna-13b-1.1": ModelType.SFT,
- "eachadea/vicuna-7b-1.1": ModelType.SFT,
- "eachadea/vicuna-13b": ModelType.SFT,
- "openaccess-ai-collective/wizard-mega-13b": ModelType.SFT,
- "openaccess-ai-collective/manticore-13b": ModelType.SFT,
- "openaccess-ai-collective/manticore-30b-chat-pyg-alpha": ModelType.SFT,
- "openaccess-ai-collective/minotaur-13b": ModelType.SFT,
- "openaccess-ai-collective/minotaur-13b-fixed": ModelType.SFT,
- "openaccess-ai-collective/hippogriff-30b-chat": ModelType.SFT,
- "openaccess-ai-collective/manticore-13b-chat-pyg": ModelType.SFT,
- "pythainlp/wangchanglm-7.5B-sft-enth": ModelType.SFT,
- "pythainlp/wangchanglm-7.5B-sft-en-sharded": ModelType.SFT,
- "euclaise/gpt-neox-122m-minipile-digits": ModelType.SFT,
- "stabilityai/FreeWilly1-Delta-SafeTensor": ModelType.SFT,
- "stabilityai/stablelm-tuned-alpha-7b": ModelType.SFT,
- "stabilityai/FreeWilly2": ModelType.SFT,
- "stabilityai/stablelm-base-alpha-7b": ModelType.PT,
- "stabilityai/stablelm-base-alpha-3b": ModelType.PT,
- "stabilityai/stablelm-tuned-alpha-3b": ModelType.SFT,
- "alibidaran/medical_transcription_generator": ModelType.SFT,
- "CalderaAI/30B-Lazarus": ModelType.SFT,
- "CalderaAI/13B-BlueMethod": ModelType.SFT,
- "CalderaAI/13B-Ouroboros": ModelType.SFT,
- "KoboldAI/OPT-13B-Erebus": ModelType.SFT,
- "KoboldAI/GPT-J-6B-Janeway": ModelType.SFT,
- "KoboldAI/GPT-J-6B-Shinen": ModelType.SFT,
- "KoboldAI/fairseq-dense-2.7B": ModelType.PT,
- "KoboldAI/OPT-6B-nerys-v2": ModelType.SFT,
- "KoboldAI/GPT-NeoX-20B-Skein": ModelType.SFT,
- "KoboldAI/PPO_Pygway-6b-Mix": ModelType.SFT,
- "KoboldAI/fairseq-dense-6.7B": ModelType.PT,
- "KoboldAI/fairseq-dense-125M": ModelType.PT,
- "KoboldAI/OPT-13B-Nerybus-Mix": ModelType.SFT,
- "KoboldAI/OPT-2.7B-Erebus": ModelType.SFT,
- "KoboldAI/OPT-350M-Nerys-v2": ModelType.SFT,
- "KoboldAI/OPT-2.7B-Nerys-v2": ModelType.SFT,
- "KoboldAI/OPT-2.7B-Nerybus-Mix": ModelType.SFT,
- "KoboldAI/OPT-13B-Nerys-v2": ModelType.SFT,
- "KoboldAI/GPT-NeoX-20B-Erebus": ModelType.SFT,
- "KoboldAI/OPT-6.7B-Erebus": ModelType.SFT,
- "KoboldAI/fairseq-dense-355M": ModelType.PT,
- "KoboldAI/OPT-6.7B-Nerybus-Mix": ModelType.SFT,
- "KoboldAI/GPT-J-6B-Adventure": ModelType.SFT,
- "KoboldAI/OPT-350M-Erebus": ModelType.SFT,
- "KoboldAI/GPT-J-6B-Skein": ModelType.SFT,
- "KoboldAI/OPT-30B-Erebus": ModelType.SFT,
- "klosax/pythia-160m-deduped-step92k-193bt": ModelType.PT,
- "klosax/open_llama_3b_350bt_preview": ModelType.PT,
- "klosax/openllama-3b-350bt": ModelType.PT,
- "klosax/pythia-70m-deduped-step44k-92bt": ModelType.PT,
- "klosax/open_llama_13b_600bt_preview": ModelType.PT,
- "klosax/open_llama_7b_400bt_preview": ModelType.PT,
- "WeOpenML/Alpaca-7B-v1": ModelType.SFT,
- "WeOpenML/PandaLM-Alpaca-7B-v1": ModelType.SFT,
- "TFLai/gpt2-turkish-uncased": ModelType.SFT,
- "ehartford/WizardLM-13B-Uncensored": ModelType.SFT,
- "ehartford/dolphin-llama-13b": ModelType.SFT,
- "ehartford/Wizard-Vicuna-30B-Uncensored": ModelType.SFT,
- "ehartford/WizardLM-30B-Uncensored": ModelType.SFT,
- "ehartford/Wizard-Vicuna-13B-Uncensored": ModelType.SFT,
- "ehartford/WizardLM-7B-Uncensored": ModelType.SFT,
- "ehartford/based-30b": ModelType.SFT,
- "ehartford/Wizard-Vicuna-7B-Uncensored": ModelType.SFT,
- "wahaha1987/llama_7b_sharegpt94k_fastchat": ModelType.SFT,
- "wahaha1987/llama_13b_sharegpt94k_fastchat": ModelType.SFT,
- "OpenAssistant/oasst-sft-1-pythia-12b": ModelType.SFT,
- "OpenAssistant/stablelm-7b-sft-v7-epoch-3": ModelType.SFT,
- "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5": ModelType.SFT,
- "OpenAssistant/pythia-12b-sft-v8-2.5k-steps": ModelType.SFT,
- "OpenAssistant/pythia-12b-sft-v8-7k-steps": ModelType.SFT,
- "OpenAssistant/pythia-12b-pre-v8-12.5k-steps": ModelType.SFT,
- "junelee/wizard-vicuna-13b": ModelType.SFT,
- "BreadAi/gpt-YA-1-1_160M": ModelType.PT,
- "BreadAi/MuseCan": ModelType.PT,
- "BreadAi/MusePy-1-2": ModelType.PT,
- "BreadAi/DiscordPy": ModelType.PT,
- "BreadAi/PM_modelV2": ModelType.PT,
- "BreadAi/gpt-Youtube": ModelType.PT,
- "BreadAi/StoryPy": ModelType.SFT,
- "julianweng/Llama-2-7b-chat-orcah": ModelType.SFT,
- "AGI-inc/lora_moe_7b_baseline": ModelType.SFT,
- "AGI-inc/lora_moe_7b": ModelType.SFT,
- "togethercomputer/GPT-NeoXT-Chat-Base-20B": ModelType.SFT,
- "togethercomputer/RedPajama-INCITE-Chat-7B-v0.1": ModelType.SFT,
- "togethercomputer/RedPajama-INCITE-Instruct-7B-v0.1": ModelType.SFT,
- "togethercomputer/RedPajama-INCITE-7B-Base": ModelType.PT,
- "togethercomputer/RedPajama-INCITE-7B-Instruct": ModelType.SFT,
- "togethercomputer/RedPajama-INCITE-Base-3B-v1": ModelType.PT,
- "togethercomputer/Pythia-Chat-Base-7B": ModelType.SFT,
- "togethercomputer/RedPajama-INCITE-Base-7B-v0.1": ModelType.PT,
- "togethercomputer/GPT-JT-6B-v1": ModelType.SFT,
- "togethercomputer/GPT-JT-6B-v0": ModelType.SFT,
- "togethercomputer/RedPajama-INCITE-Chat-3B-v1": ModelType.SFT,
- "togethercomputer/RedPajama-INCITE-7B-Chat": ModelType.SFT,
- "togethercomputer/RedPajama-INCITE-Instruct-3B-v1": ModelType.SFT,
- "Writer/camel-5b-hf": ModelType.SFT,
- "Writer/palmyra-base": ModelType.PT,
- "MBZUAI/LaMini-GPT-1.5B": ModelType.SFT,
- "MBZUAI/lamini-cerebras-111m": ModelType.SFT,
- "MBZUAI/lamini-neo-1.3b": ModelType.SFT,
- "MBZUAI/lamini-cerebras-1.3b": ModelType.SFT,
- "MBZUAI/lamini-cerebras-256m": ModelType.SFT,
- "MBZUAI/LaMini-GPT-124M": ModelType.SFT,
- "MBZUAI/lamini-neo-125m": ModelType.SFT,
- "TehVenom/DiffMerge-DollyGPT-Pygmalion": ModelType.SFT,
- "TehVenom/PPO_Shygmalion-6b": ModelType.SFT,
- "TehVenom/Dolly_Shygmalion-6b-Dev_V8P2": ModelType.SFT,
- "TehVenom/Pygmalion_AlpacaLora-7b": ModelType.SFT,
- "TehVenom/PPO_Pygway-V8p4_Dev-6b": ModelType.SFT,
- "TehVenom/Dolly_Malion-6b": ModelType.SFT,
- "TehVenom/PPO_Shygmalion-V8p4_Dev-6b": ModelType.SFT,
- "TehVenom/ChanMalion": ModelType.SFT,
- "TehVenom/GPT-J-Pyg_PPO-6B": ModelType.SFT,
- "TehVenom/Pygmalion-13b-Merged": ModelType.SFT,
- "TehVenom/Metharme-13b-Merged": ModelType.SFT,
- "TehVenom/Dolly_Shygmalion-6b": ModelType.SFT,
- "TehVenom/GPT-J-Pyg_PPO-6B-Dev-V8p4": ModelType.SFT,
- "georgesung/llama2_7b_chat_uncensored": ModelType.SFT,
- "vicgalle/gpt2-alpaca": ModelType.SFT,
- "vicgalle/alpaca-7b": ModelType.SFT,
- "vicgalle/gpt2-alpaca-gpt4": ModelType.SFT,
- "facebook/opt-350m": ModelType.PT,
- "facebook/opt-125m": ModelType.PT,
- "facebook/xglm-4.5B": ModelType.PT,
- "facebook/opt-2.7b": ModelType.PT,
- "facebook/opt-6.7b": ModelType.PT,
- "facebook/galactica-30b": ModelType.PT,
- "facebook/opt-13b": ModelType.PT,
- "facebook/opt-66b": ModelType.PT,
- "facebook/xglm-7.5B": ModelType.PT,
- "facebook/xglm-564M": ModelType.PT,
- "facebook/opt-30b": ModelType.PT,
- "golaxy/gogpt-7b": ModelType.SFT,
- "psmathur/orca_mini_v2_7b": ModelType.SFT,
- "psmathur/orca_mini_7b": ModelType.SFT,
- "psmathur/orca_mini_3b": ModelType.SFT,
- "psmathur/orca_mini_v2_13b": ModelType.SFT,
- "gpt2-xl": ModelType.PT,
- "lxe/Cerebras-GPT-2.7B-Alpaca-SP": ModelType.SFT,
- "Monero/Manticore-13b-Chat-Pyg-Guanaco": ModelType.SFT,
- "Monero/WizardLM-Uncensored-SuperCOT-StoryTelling-30b": ModelType.SFT,
- "Monero/WizardLM-13b-OpenAssistant-Uncensored": ModelType.SFT,
- "Monero/WizardLM-30B-Uncensored-Guanaco-SuperCOT-30b": ModelType.SFT,
- "jzjiao/opt-1.3b-rlhf": ModelType.SFT,
- "HuggingFaceH4/starchat-beta": ModelType.SFT,
- "KnutJaegersberg/gpt-2-xl-EvolInstruct": ModelType.SFT,
- "KnutJaegersberg/megatron-GPT-2-345m-EvolInstruct": ModelType.SFT,
- "openchat/openchat_8192": ModelType.SFT,
- "openchat/openchat_v2": ModelType.SFT,
- "openchat/openchat_v2_w": ModelType.SFT,
- "ausboss/llama-13b-supercot": ModelType.SFT,
- "ausboss/llama-30b-supercot": ModelType.SFT,
- "Neko-Institute-of-Science/metharme-7b": ModelType.SFT,
- "Neko-Institute-of-Science/pygmalion-7b": ModelType.SFT,
- "SebastianSchramm/Cerebras-GPT-111M-instruction": ModelType.SFT,
- "victor123/WizardLM-13B-1.0": ModelType.SFT,
- "OpenBuddy/openbuddy-openllama-13b-v7-fp16": ModelType.SFT,
- "baichuan-inc/Baichuan-7B": ModelType.PT,
- "tiiuae/falcon-40b-instruct": ModelType.SFT,
- "tiiuae/falcon-40b": ModelType.PT,
- "tiiuae/falcon-7b": ModelType.PT,
- "YeungNLP/firefly-llama-13b": ModelType.SFT,
- "YeungNLP/firefly-llama-13b-v1.2": ModelType.SFT,
- "YeungNLP/firefly-ziya-13b": ModelType.SFT,
- "shaohang/Sparse0.5_OPT-1.3": ModelType.SFT,
- "xzuyModelType.lpacino-SuperCOT-13B": ModelType.SFT,
- "xzuyn/MedicWizard-7B": ModelType.SFT,
- "beomi/KoAlpaca-Polyglot-5.8B": ModelType.SFT,
- "beomi/llama-2-ko-7b": ModelType.SFT,
- "Salesforce/codegen-6B-multi": ModelType.PT,
- "Salesforce/codegen-16B-nl": ModelType.PT,
- "Salesforce/codegen-6B-nl": ModelType.PT,
- "ai-forever/rugpt3large_based_on_gpt2": ModelType.SFT,
- "gpt2-large": ModelType.PT,
- "frank098/orca_mini_3b_juniper": ModelType.SFT,
- "frank098/WizardLM_13B_juniper": ModelType.SFT,
- "huggingface/llama-13b": ModelType.PT,
- "huggingface/llama-7b": ModelType.PT,
- "huggingface/llama-65b": ModelType.PT,
- "huggingface/llama-65b": ModelType.PT,
- "huggingface/llama-30b": ModelType.PT,
- "jondurbiModelType.iroboros-13b-gpt4-1.4": ModelType.SFT,
- "jondurbiModelType.iroboros-7b": ModelType.SFT,
- "jondurbiModelType.iroboros-7b-gpt4-1.4": ModelType.SFT,
- "jondurbiModelType.iroboros-l2-13b-gpt4-1.4.1": ModelType.SFT,
- "jondurbiModelType.iroboros-13b": ModelType.SFT,
- "ariellee/SuperPlatty-30B": ModelType.SFT,
- "danielhanchen/open_llama_3b_600bt_preview": ModelType.SFT,
- "cerebras/Cerebras-GPT-256M": ModelType.PT,
- "cerebras/Cerebras-GPT-1.3B": ModelType.PT,
- "cerebras/Cerebras-GPT-13B": ModelType.PT,
- "cerebras/Cerebras-GPT-2.7B": ModelType.PT,
- "cerebras/Cerebras-GPT-111M": ModelType.PT,
- "cerebras/Cerebras-GPT-6.7B": ModelType.PT,
- "Yhyu13/oasst-rlhf-2-llama-30b-7k-steps-hf": ModelType.RL,
- "Yhyu13/llama-30B-hf-openassitant": ModelType.SFT,
- "NousResearch/Nous-Hermes-Llama2-13b": ModelType.SFT,
- "NousResearch/Redmond-Puffin-13B": ModelType.SFT,
- "NousResearch/Nous-Hermes-13b": ModelType.SFT,
- "project-baize/baize-v2-7b": ModelType.SFT,
- "project-baize/baize-v2-13b": ModelType.SFT,
- "LLMs/WizardLM-13B-V1.0": ModelType.SFT,
- "LLMs/AlpacaGPT4-7B-elina": ModelType.SFT,
- "wenge-research/yayi-7b-llama2": ModelType.SFT,
- "yhyhy3/open_llama_7b_v2_med_instruct": ModelType.SFT,
- "llama-anon/instruct-13b": ModelType.SFT,
- "huggingtweets/jerma985": ModelType.SFT,
- "huggingtweets/gladosystem": ModelType.SFT,
- "huggingtweets/bladeecity-jerma985": ModelType.SFT,
- "huggyllama/llama-13b": ModelType.PT,
- "huggyllama/llama-65b": ModelType.PT,
- "FabbriSimo01/Facebook_opt_1.3b_Quantized": ModelType.PT,
- "upstage/llama-30b-instruct-2048": ModelType.SFT,
- "upstage/llama-30b-instruct": ModelType.SFT,
- "WizardLM/WizardLM-13B-1.0": ModelType.SFT,
- "WizardLM/WizardLM-30B-V1.0": ModelType.SFT,
- "WizardLM/WizardCoder-15B-V1.0": ModelType.SFT,
- "gpt2": ModelType.PT,
- "keyfan/vicuna-chinese-replication-v1.1": ModelType.SFT,
- "nthngdy/pythia-owt2-70m-100k": ModelType.SFT,
- "nthngdy/pythia-owt2-70m-50k": ModelType.SFT,
- "quantumaikr/KoreanLM-hf": ModelType.SFT,
- "quantumaikr/open_llama_7b_hf": ModelType.SFT,
- "MayaPH/FinOPT-Lincoln": ModelType.SFT,
- "MayaPH/FinOPT-Franklin": ModelType.SFT,
- "MayaPH/GodziLLa-30B": ModelType.SFT,
- "MayaPH/FinOPT-Washington": ModelType.SFT,
- "ogimgio/gpt-neo-125m-neurallinguisticpioneers": ModelType.SFT,
- "layoric/llama-2-13b-code-alpaca": ModelType.SFT,
- "CobraMamba/mamba-gpt-3b": ModelType.SFT,
- "timdettmers/guanaco-33b-merged": ModelType.SFT,
- "elinas/chronos-33b": ModelType.SFT,
- "heegyu/RedTulu-Uncensored-3B-0719": ModelType.SFT,
- "heegyu/WizardVicuna-Uncensored-3B-0719": ModelType.SFT,
- "heegyu/WizardVicuna-3B-0719": ModelType.SFT,
- "meta-llama/Llama-2-7b-chat-hf": ModelType.RL,
- "meta-llama/Llama-2-7b-hf": ModelType.PT,
- "meta-llama/Llama-2-13b-chat-hf": ModelType.RL,
- "meta-llama/Llama-2-13b-hf": ModelType.PT,
- "meta-llama/Llama-2-70b-chat-hf": ModelType.RL,
- "meta-llama/Llama-2-70b-hf": ModelType.PT,
- "xhyi/PT_GPTNEO350_ATG": ModelType.SFT,
- "h2oai/h2ogpt-gm-oasst1-en-1024-20b": ModelType.SFT,
- "h2oai/h2ogpt-gm-oasst1-en-1024-open-llama-7b-preview-400bt": ModelType.SFT,
- "h2oai/h2ogpt-oig-oasst1-512-6_9b": ModelType.SFT,
- "h2oai/h2ogpt-oasst1-512-12b": ModelType.SFT,
- "h2oai/h2ogpt-oig-oasst1-256-6_9b": ModelType.SFT,
- "h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt": ModelType.SFT,
- "h2oai/h2ogpt-oasst1-512-20b": ModelType.SFT,
- "h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt-v2": ModelType.SFT,
- "h2oai/h2ogpt-gm-oasst1-en-1024-12b": ModelType.SFT,
- "h2oai/h2ogpt-gm-oasst1-multilang-1024-20b": ModelType.SFT,
- "bofenghuang/vigogne-13b-instruct": ModelType.SFT,
- "Vmware/open-llama-7b-v2-open-instruct": ModelType.SFT,
- "VMware/open-llama-0.7T-7B-open-instruct-v1.1": ModelType.SFT,
- "ewof/koishi-instruct-3b": ModelType.SFT,
-}
-
-
-def get_model_type(leaderboard_data: List[dict]):
- for model_data in leaderboard_data:
- # Todo @clefourrier once requests are connected with results
- is_delta = False # (model_data["weight_type"] != "Original")
- # Stored information
- if model_data["model_name_for_query"] in TYPE_METADATA:
- model_data[AutoEvalColumn.model_type.name] = TYPE_METADATA[model_data["model_name_for_query"]].value.name
- model_data[AutoEvalColumn.model_type_symbol.name] = TYPE_METADATA[model_data["model_name_for_query"]].value.symbol + ("🔺" if is_delta else "")
- # Inferred from the name or the selected type
- elif model_data[AutoEvalColumn.model_type.name] == "pretrained" or any([i in model_data["model_name_for_query"] for i in ["pretrained"]]):
- model_data[AutoEvalColumn.model_type.name] = ModelType.PT.value.name
- model_data[AutoEvalColumn.model_type_symbol.name] = ModelType.PT.value.symbol + ("🔺" if is_delta else "")
- elif model_data[AutoEvalColumn.model_type.name] == "finetuned" or any([i in model_data["model_name_for_query"] for i in ["finetuned", "-ft-"]]):
- model_data[AutoEvalColumn.model_type.name] = ModelType.SFT.value.name
- model_data[AutoEvalColumn.model_type_symbol.name] = ModelType.SFT.value.symbol + ("🔺" if is_delta else "")
- elif model_data[AutoEvalColumn.model_type.name] == "with RL" or any([i in model_data["model_name_for_query"] for i in ["-rl-", "-rlhf-"]]):
- model_data[AutoEvalColumn.model_type.name] = ModelType.RL.value.name
- model_data[AutoEvalColumn.model_type_symbol.name] = ModelType.RL.value.symbol + ("🔺" if is_delta else "")
- else:
- model_data[AutoEvalColumn.model_type.name] = "N/A"
- model_data[AutoEvalColumn.model_type_symbol.name] = ("🔺" if is_delta else "")
-
-
\ No newline at end of file
diff --git a/spaces/bahjat-kawar/time-diffusion/time_main.py b/spaces/bahjat-kawar/time-diffusion/time_main.py
deleted file mode 100644
index 97bdffc58dd029dd8636841df26b9b1f0000bead..0000000000000000000000000000000000000000
--- a/spaces/bahjat-kawar/time-diffusion/time_main.py
+++ /dev/null
@@ -1,138 +0,0 @@
-import torch
-from diffusers import StableDiffusionPipeline
-import numpy as np
-import abc
-import time_utils
-import copy
-import os
-from train_funcs import TRAIN_FUNC_DICT
-
-## get arguments for our script
-with_to_k = True
-with_augs = True
-train_func = "train_closed_form"
-
-### load model
-LOW_RESOURCE = True
-NUM_DIFFUSION_STEPS = 50
-GUIDANCE_SCALE = 7.5
-MAX_NUM_WORDS = 77
-device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
-ldm_stable = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4").to(device)
-tokenizer = ldm_stable.tokenizer
-
-### get layers
-ca_layers = []
-def append_ca(net_):
- if net_.__class__.__name__ == 'CrossAttention':
- ca_layers.append(net_)
- elif hasattr(net_, 'children'):
- for net__ in net_.children():
- append_ca(net__)
-
-sub_nets = ldm_stable.unet.named_children()
-for net in sub_nets:
- if "down" in net[0]:
- append_ca(net[1])
- elif "up" in net[0]:
- append_ca(net[1])
- elif "mid" in net[0]:
- append_ca(net[1])
-
-### get projection matrices
-ca_clip_layers = [l for l in ca_layers if l.to_v.in_features == 768]
-projection_matrices = [l.to_v for l in ca_clip_layers]
-og_matrices = [copy.deepcopy(l.to_v) for l in ca_clip_layers]
-if with_to_k:
- projection_matrices = projection_matrices + [l.to_k for l in ca_clip_layers]
- og_matrices = og_matrices + [copy.deepcopy(l.to_k) for l in ca_clip_layers]
-
-def edit_model(old_text_, new_text_, lamb=0.1):
- #### restart LDM parameters
- num_ca_clip_layers = len(ca_clip_layers)
- for idx_, l in enumerate(ca_clip_layers):
- l.to_v = copy.deepcopy(og_matrices[idx_])
- projection_matrices[idx_] = l.to_v
- if with_to_k:
- l.to_k = copy.deepcopy(og_matrices[num_ca_clip_layers + idx_])
- projection_matrices[num_ca_clip_layers + idx_] = l.to_k
-
- try:
- #### set up sentences
- old_texts = [old_text_]
- new_texts = [new_text_]
- if with_augs:
- base = old_texts[0] if old_texts[0][0:1] != "A" else "a" + old_texts[0][1:]
- old_texts.append("A photo of " + base)
- old_texts.append("An image of " + base)
- old_texts.append("A picture of " + base)
- base = new_texts[0] if new_texts[0][0:1] != "A" else "a" + new_texts[0][1:]
- new_texts.append("A photo of " + base)
- new_texts.append("An image of " + base)
- new_texts.append("A picture of " + base)
-
- #### prepare input k* and v*
- old_embs, new_embs = [], []
- for old_text, new_text in zip(old_texts, new_texts):
- text_input = ldm_stable.tokenizer(
- [old_text, new_text],
- padding="max_length",
- max_length=ldm_stable.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- text_embeddings = ldm_stable.text_encoder(text_input.input_ids.to(ldm_stable.device))[0]
- old_emb, new_emb = text_embeddings
- old_embs.append(old_emb)
- new_embs.append(new_emb)
-
- #### indetify corresponding destinations for each token in old_emb
- idxs_replaces = []
- for old_text, new_text in zip(old_texts, new_texts):
- tokens_a = tokenizer(old_text).input_ids
- tokens_b = tokenizer(new_text).input_ids
- tokens_a = [tokenizer.encode("a ")[1] if tokenizer.decode(t) == 'an' else t for t in tokens_a]
- tokens_b = [tokenizer.encode("a ")[1] if tokenizer.decode(t) == 'an' else t for t in tokens_b]
- num_orig_tokens = len(tokens_a)
- num_new_tokens = len(tokens_b)
- idxs_replace = []
- j = 0
- for i in range(num_orig_tokens):
- curr_token = tokens_a[i]
- while tokens_b[j] != curr_token:
- j += 1
- idxs_replace.append(j)
- j += 1
- while j < 77:
- idxs_replace.append(j)
- j += 1
- while len(idxs_replace) < 77:
- idxs_replace.append(76)
- idxs_replaces.append(idxs_replace)
-
- #### prepare batch: for each pair of setences, old context and new values
- contexts, valuess = [], []
- for old_emb, new_emb, idxs_replace in zip(old_embs, new_embs, idxs_replaces):
- context = old_emb.detach()
- values = []
- with torch.no_grad():
- for layer in projection_matrices:
- values.append(layer(new_emb[idxs_replace]).detach())
- contexts.append(context)
- valuess.append(values)
-
- #### define training function
- train = TRAIN_FUNC_DICT[train_func]
-
- #### train the model
- train(ldm_stable, projection_matrices, og_matrices, contexts, valuess, old_texts, new_texts, lamb=lamb)
-
- return f"Current model status: Edited \"{old_text_}\" into \"{new_text_}\""
- except:
- return "Current model status: An error occured"
-
-def generate_for_text(test_text):
- g = torch.Generator(device='cpu')
- g.seed()
- images = time_utils.text2image_ldm_stable(ldm_stable, [test_text], latent=None, num_inference_steps=NUM_DIFFUSION_STEPS, guidance_scale=GUIDANCE_SCALE, generator=g, low_resource=LOW_RESOURCE)
- return time_utils.view_images(images)
diff --git a/spaces/banana-projects/convai/server/lib/Extensions.ts b/spaces/banana-projects/convai/server/lib/Extensions.ts
deleted file mode 100644
index 05fb39d2112418489f2aff209d40650809427dde..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/convai/server/lib/Extensions.ts
+++ /dev/null
@@ -1,36 +0,0 @@
-
-interface Array {
- randomItem: () => T;
- randomIndex: () => number;
- last: () => T;
-}
-
-interface ReadonlyArray {
- randomItem: () => T;
- randomIndex: () => number;
- last: () => T;
-}
-
-Array.prototype.randomItem = function() {
- return this[Math.floor(Math.random()*this.length)];
-}
-
-Array.prototype.randomIndex = function() {
- return Math.floor(Math.random()*this.length);
-}
-
-Array.prototype.last = function() {
- return this[this.length - 1];
-}
-
-interface String {
- capitalize: () => string;
-}
-
-String.prototype.capitalize = function() {
- return this.charAt(0).toUpperCase() + this.slice(1);
-}
-
-
-"foo"; // Trick ts-node into actually running the Extensions.ts file.
-
diff --git a/spaces/banana-projects/web3d/node_modules/three/examples/js/utils/SceneUtils.js b/spaces/banana-projects/web3d/node_modules/three/examples/js/utils/SceneUtils.js
deleted file mode 100644
index faaed8a9791c306928ebd3cc00e4366b8085783a..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/examples/js/utils/SceneUtils.js
+++ /dev/null
@@ -1,38 +0,0 @@
-/**
- * @author alteredq / http://alteredqualia.com/
- */
-
-THREE.SceneUtils = {
-
- createMultiMaterialObject: function ( geometry, materials ) {
-
- var group = new THREE.Group();
-
- for ( var i = 0, l = materials.length; i < l; i ++ ) {
-
- group.add( new THREE.Mesh( geometry, materials[ i ] ) );
-
- }
-
- return group;
-
- },
-
- detach: function ( child, parent, scene ) {
-
- child.applyMatrix( parent.matrixWorld );
- parent.remove( child );
- scene.add( child );
-
- },
-
- attach: function ( child, scene, parent ) {
-
- child.applyMatrix( new THREE.Matrix4().getInverse( parent.matrixWorld ) );
-
- scene.remove( child );
- parent.add( child );
-
- }
-
-};
diff --git a/spaces/banana-projects/web3d/node_modules/three/src/helpers/PlaneHelper.d.ts b/spaces/banana-projects/web3d/node_modules/three/src/helpers/PlaneHelper.d.ts
deleted file mode 100644
index 4d1e7061c2d50418c9521b0eca6f4b26d0aab37b..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/src/helpers/PlaneHelper.d.ts
+++ /dev/null
@@ -1,11 +0,0 @@
-import { Plane } from './../math/Plane';
-import { LineSegments } from './../objects/LineSegments';
-
-export class PlaneHelper extends LineSegments {
- constructor(plane: Plane, size?: number, hex?: number);
-
- plane: Plane;
- size: number;
-
- updateMatrixWorld(force: boolean): void;
-}
diff --git a/spaces/beihai/GFPGAN-V1.3-whole-image/gfpgan/__init__.py b/spaces/beihai/GFPGAN-V1.3-whole-image/gfpgan/__init__.py
deleted file mode 100644
index 94daaeebce5604d61999f0b1b354b9a9e299b991..0000000000000000000000000000000000000000
--- a/spaces/beihai/GFPGAN-V1.3-whole-image/gfpgan/__init__.py
+++ /dev/null
@@ -1,7 +0,0 @@
-# flake8: noqa
-from .archs import *
-from .data import *
-from .models import *
-from .utils import *
-
-# from .version import *
diff --git a/spaces/bigjoker/stable-diffusion-webui/modules/hypernetworks/hypernetwork.py b/spaces/bigjoker/stable-diffusion-webui/modules/hypernetworks/hypernetwork.py
deleted file mode 100644
index 49d6dcc2281daeb30f7f0f380540dd0a650248af..0000000000000000000000000000000000000000
--- a/spaces/bigjoker/stable-diffusion-webui/modules/hypernetworks/hypernetwork.py
+++ /dev/null
@@ -1,811 +0,0 @@
-import csv
-import datetime
-import glob
-import html
-import os
-import sys
-import traceback
-import inspect
-
-import modules.textual_inversion.dataset
-import torch
-import tqdm
-from einops import rearrange, repeat
-from ldm.util import default
-from modules import devices, processing, sd_models, shared, sd_samplers, hashes, sd_hijack_checkpoint
-from modules.textual_inversion import textual_inversion, logging
-from modules.textual_inversion.learn_schedule import LearnRateScheduler
-from torch import einsum
-from torch.nn.init import normal_, xavier_normal_, xavier_uniform_, kaiming_normal_, kaiming_uniform_, zeros_
-
-from collections import defaultdict, deque
-from statistics import stdev, mean
-
-
-optimizer_dict = {optim_name : cls_obj for optim_name, cls_obj in inspect.getmembers(torch.optim, inspect.isclass) if optim_name != "Optimizer"}
-
-class HypernetworkModule(torch.nn.Module):
- activation_dict = {
- "linear": torch.nn.Identity,
- "relu": torch.nn.ReLU,
- "leakyrelu": torch.nn.LeakyReLU,
- "elu": torch.nn.ELU,
- "swish": torch.nn.Hardswish,
- "tanh": torch.nn.Tanh,
- "sigmoid": torch.nn.Sigmoid,
- }
- activation_dict.update({cls_name.lower(): cls_obj for cls_name, cls_obj in inspect.getmembers(torch.nn.modules.activation) if inspect.isclass(cls_obj) and cls_obj.__module__ == 'torch.nn.modules.activation'})
-
- def __init__(self, dim, state_dict=None, layer_structure=None, activation_func=None, weight_init='Normal',
- add_layer_norm=False, activate_output=False, dropout_structure=None):
- super().__init__()
-
- self.multiplier = 1.0
-
- assert layer_structure is not None, "layer_structure must not be None"
- assert layer_structure[0] == 1, "Multiplier Sequence should start with size 1!"
- assert layer_structure[-1] == 1, "Multiplier Sequence should end with size 1!"
-
- linears = []
- for i in range(len(layer_structure) - 1):
-
- # Add a fully-connected layer
- linears.append(torch.nn.Linear(int(dim * layer_structure[i]), int(dim * layer_structure[i+1])))
-
- # Add an activation func except last layer
- if activation_func == "linear" or activation_func is None or (i >= len(layer_structure) - 2 and not activate_output):
- pass
- elif activation_func in self.activation_dict:
- linears.append(self.activation_dict[activation_func]())
- else:
- raise RuntimeError(f'hypernetwork uses an unsupported activation function: {activation_func}')
-
- # Add layer normalization
- if add_layer_norm:
- linears.append(torch.nn.LayerNorm(int(dim * layer_structure[i+1])))
-
- # Everything should be now parsed into dropout structure, and applied here.
- # Since we only have dropouts after layers, dropout structure should start with 0 and end with 0.
- if dropout_structure is not None and dropout_structure[i+1] > 0:
- assert 0 < dropout_structure[i+1] < 1, "Dropout probability should be 0 or float between 0 and 1!"
- linears.append(torch.nn.Dropout(p=dropout_structure[i+1]))
- # Code explanation : [1, 2, 1] -> dropout is missing when last_layer_dropout is false. [1, 2, 2, 1] -> [0, 0.3, 0, 0], when its True, [0, 0.3, 0.3, 0].
-
- self.linear = torch.nn.Sequential(*linears)
-
- if state_dict is not None:
- self.fix_old_state_dict(state_dict)
- self.load_state_dict(state_dict)
- else:
- for layer in self.linear:
- if type(layer) == torch.nn.Linear or type(layer) == torch.nn.LayerNorm:
- w, b = layer.weight.data, layer.bias.data
- if weight_init == "Normal" or type(layer) == torch.nn.LayerNorm:
- normal_(w, mean=0.0, std=0.01)
- normal_(b, mean=0.0, std=0)
- elif weight_init == 'XavierUniform':
- xavier_uniform_(w)
- zeros_(b)
- elif weight_init == 'XavierNormal':
- xavier_normal_(w)
- zeros_(b)
- elif weight_init == 'KaimingUniform':
- kaiming_uniform_(w, nonlinearity='leaky_relu' if 'leakyrelu' == activation_func else 'relu')
- zeros_(b)
- elif weight_init == 'KaimingNormal':
- kaiming_normal_(w, nonlinearity='leaky_relu' if 'leakyrelu' == activation_func else 'relu')
- zeros_(b)
- else:
- raise KeyError(f"Key {weight_init} is not defined as initialization!")
- self.to(devices.device)
-
- def fix_old_state_dict(self, state_dict):
- changes = {
- 'linear1.bias': 'linear.0.bias',
- 'linear1.weight': 'linear.0.weight',
- 'linear2.bias': 'linear.1.bias',
- 'linear2.weight': 'linear.1.weight',
- }
-
- for fr, to in changes.items():
- x = state_dict.get(fr, None)
- if x is None:
- continue
-
- del state_dict[fr]
- state_dict[to] = x
-
- def forward(self, x):
- return x + self.linear(x) * (self.multiplier if not self.training else 1)
-
- def trainables(self):
- layer_structure = []
- for layer in self.linear:
- if type(layer) == torch.nn.Linear or type(layer) == torch.nn.LayerNorm:
- layer_structure += [layer.weight, layer.bias]
- return layer_structure
-
-
-#param layer_structure : sequence used for length, use_dropout : controlling boolean, last_layer_dropout : for compatibility check.
-def parse_dropout_structure(layer_structure, use_dropout, last_layer_dropout):
- if layer_structure is None:
- layer_structure = [1, 2, 1]
- if not use_dropout:
- return [0] * len(layer_structure)
- dropout_values = [0]
- dropout_values.extend([0.3] * (len(layer_structure) - 3))
- if last_layer_dropout:
- dropout_values.append(0.3)
- else:
- dropout_values.append(0)
- dropout_values.append(0)
- return dropout_values
-
-
-class Hypernetwork:
- filename = None
- name = None
-
- def __init__(self, name=None, enable_sizes=None, layer_structure=None, activation_func=None, weight_init=None, add_layer_norm=False, use_dropout=False, activate_output=False, **kwargs):
- self.filename = None
- self.name = name
- self.layers = {}
- self.step = 0
- self.sd_checkpoint = None
- self.sd_checkpoint_name = None
- self.layer_structure = layer_structure
- self.activation_func = activation_func
- self.weight_init = weight_init
- self.add_layer_norm = add_layer_norm
- self.use_dropout = use_dropout
- self.activate_output = activate_output
- self.last_layer_dropout = kwargs.get('last_layer_dropout', True)
- self.dropout_structure = kwargs.get('dropout_structure', None)
- if self.dropout_structure is None:
- self.dropout_structure = parse_dropout_structure(self.layer_structure, self.use_dropout, self.last_layer_dropout)
- self.optimizer_name = None
- self.optimizer_state_dict = None
- self.optional_info = None
-
- for size in enable_sizes or []:
- self.layers[size] = (
- HypernetworkModule(size, None, self.layer_structure, self.activation_func, self.weight_init,
- self.add_layer_norm, self.activate_output, dropout_structure=self.dropout_structure),
- HypernetworkModule(size, None, self.layer_structure, self.activation_func, self.weight_init,
- self.add_layer_norm, self.activate_output, dropout_structure=self.dropout_structure),
- )
- self.eval()
-
- def weights(self):
- res = []
- for k, layers in self.layers.items():
- for layer in layers:
- res += layer.parameters()
- return res
-
- def train(self, mode=True):
- for k, layers in self.layers.items():
- for layer in layers:
- layer.train(mode=mode)
- for param in layer.parameters():
- param.requires_grad = mode
-
- def to(self, device):
- for k, layers in self.layers.items():
- for layer in layers:
- layer.to(device)
-
- return self
-
- def set_multiplier(self, multiplier):
- for k, layers in self.layers.items():
- for layer in layers:
- layer.multiplier = multiplier
-
- return self
-
- def eval(self):
- for k, layers in self.layers.items():
- for layer in layers:
- layer.eval()
- for param in layer.parameters():
- param.requires_grad = False
-
- def save(self, filename):
- state_dict = {}
- optimizer_saved_dict = {}
-
- for k, v in self.layers.items():
- state_dict[k] = (v[0].state_dict(), v[1].state_dict())
-
- state_dict['step'] = self.step
- state_dict['name'] = self.name
- state_dict['layer_structure'] = self.layer_structure
- state_dict['activation_func'] = self.activation_func
- state_dict['is_layer_norm'] = self.add_layer_norm
- state_dict['weight_initialization'] = self.weight_init
- state_dict['sd_checkpoint'] = self.sd_checkpoint
- state_dict['sd_checkpoint_name'] = self.sd_checkpoint_name
- state_dict['activate_output'] = self.activate_output
- state_dict['use_dropout'] = self.use_dropout
- state_dict['dropout_structure'] = self.dropout_structure
- state_dict['last_layer_dropout'] = (self.dropout_structure[-2] != 0) if self.dropout_structure is not None else self.last_layer_dropout
- state_dict['optional_info'] = self.optional_info if self.optional_info else None
-
- if self.optimizer_name is not None:
- optimizer_saved_dict['optimizer_name'] = self.optimizer_name
-
- torch.save(state_dict, filename)
- if shared.opts.save_optimizer_state and self.optimizer_state_dict:
- optimizer_saved_dict['hash'] = self.shorthash()
- optimizer_saved_dict['optimizer_state_dict'] = self.optimizer_state_dict
- torch.save(optimizer_saved_dict, filename + '.optim')
-
- def load(self, filename):
- self.filename = filename
- if self.name is None:
- self.name = os.path.splitext(os.path.basename(filename))[0]
-
- state_dict = torch.load(filename, map_location='cpu')
-
- self.layer_structure = state_dict.get('layer_structure', [1, 2, 1])
- self.optional_info = state_dict.get('optional_info', None)
- self.activation_func = state_dict.get('activation_func', None)
- self.weight_init = state_dict.get('weight_initialization', 'Normal')
- self.add_layer_norm = state_dict.get('is_layer_norm', False)
- self.dropout_structure = state_dict.get('dropout_structure', None)
- self.use_dropout = True if self.dropout_structure is not None and any(self.dropout_structure) else state_dict.get('use_dropout', False)
- self.activate_output = state_dict.get('activate_output', True)
- self.last_layer_dropout = state_dict.get('last_layer_dropout', False)
- # Dropout structure should have same length as layer structure, Every digits should be in [0,1), and last digit must be 0.
- if self.dropout_structure is None:
- self.dropout_structure = parse_dropout_structure(self.layer_structure, self.use_dropout, self.last_layer_dropout)
-
- if shared.opts.print_hypernet_extra:
- if self.optional_info is not None:
- print(f" INFO:\n {self.optional_info}\n")
-
- print(f" Layer structure: {self.layer_structure}")
- print(f" Activation function: {self.activation_func}")
- print(f" Weight initialization: {self.weight_init}")
- print(f" Layer norm: {self.add_layer_norm}")
- print(f" Dropout usage: {self.use_dropout}" )
- print(f" Activate last layer: {self.activate_output}")
- print(f" Dropout structure: {self.dropout_structure}")
-
- optimizer_saved_dict = torch.load(self.filename + '.optim', map_location='cpu') if os.path.exists(self.filename + '.optim') else {}
-
- if self.shorthash() == optimizer_saved_dict.get('hash', None):
- self.optimizer_state_dict = optimizer_saved_dict.get('optimizer_state_dict', None)
- else:
- self.optimizer_state_dict = None
- if self.optimizer_state_dict:
- self.optimizer_name = optimizer_saved_dict.get('optimizer_name', 'AdamW')
- if shared.opts.print_hypernet_extra:
- print("Loaded existing optimizer from checkpoint")
- print(f"Optimizer name is {self.optimizer_name}")
- else:
- self.optimizer_name = "AdamW"
- if shared.opts.print_hypernet_extra:
- print("No saved optimizer exists in checkpoint")
-
- for size, sd in state_dict.items():
- if type(size) == int:
- self.layers[size] = (
- HypernetworkModule(size, sd[0], self.layer_structure, self.activation_func, self.weight_init,
- self.add_layer_norm, self.activate_output, self.dropout_structure),
- HypernetworkModule(size, sd[1], self.layer_structure, self.activation_func, self.weight_init,
- self.add_layer_norm, self.activate_output, self.dropout_structure),
- )
-
- self.name = state_dict.get('name', self.name)
- self.step = state_dict.get('step', 0)
- self.sd_checkpoint = state_dict.get('sd_checkpoint', None)
- self.sd_checkpoint_name = state_dict.get('sd_checkpoint_name', None)
- self.eval()
-
- def shorthash(self):
- sha256 = hashes.sha256(self.filename, f'hypernet/{self.name}')
-
- return sha256[0:10] if sha256 else None
-
-
-def list_hypernetworks(path):
- res = {}
- for filename in sorted(glob.iglob(os.path.join(path, '**/*.pt'), recursive=True)):
- name = os.path.splitext(os.path.basename(filename))[0]
- # Prevent a hypothetical "None.pt" from being listed.
- if name != "None":
- res[name] = filename
- return res
-
-
-def load_hypernetwork(name):
- path = shared.hypernetworks.get(name, None)
-
- if path is None:
- return None
-
- hypernetwork = Hypernetwork()
-
- try:
- hypernetwork.load(path)
- except Exception:
- print(f"Error loading hypernetwork {path}", file=sys.stderr)
- print(traceback.format_exc(), file=sys.stderr)
- return None
-
- return hypernetwork
-
-
-def load_hypernetworks(names, multipliers=None):
- already_loaded = {}
-
- for hypernetwork in shared.loaded_hypernetworks:
- if hypernetwork.name in names:
- already_loaded[hypernetwork.name] = hypernetwork
-
- shared.loaded_hypernetworks.clear()
-
- for i, name in enumerate(names):
- hypernetwork = already_loaded.get(name, None)
- if hypernetwork is None:
- hypernetwork = load_hypernetwork(name)
-
- if hypernetwork is None:
- continue
-
- hypernetwork.set_multiplier(multipliers[i] if multipliers else 1.0)
- shared.loaded_hypernetworks.append(hypernetwork)
-
-
-def find_closest_hypernetwork_name(search: str):
- if not search:
- return None
- search = search.lower()
- applicable = [name for name in shared.hypernetworks if search in name.lower()]
- if not applicable:
- return None
- applicable = sorted(applicable, key=lambda name: len(name))
- return applicable[0]
-
-
-def apply_single_hypernetwork(hypernetwork, context_k, context_v, layer=None):
- hypernetwork_layers = (hypernetwork.layers if hypernetwork is not None else {}).get(context_k.shape[2], None)
-
- if hypernetwork_layers is None:
- return context_k, context_v
-
- if layer is not None:
- layer.hyper_k = hypernetwork_layers[0]
- layer.hyper_v = hypernetwork_layers[1]
-
- context_k = devices.cond_cast_unet(hypernetwork_layers[0](devices.cond_cast_float(context_k)))
- context_v = devices.cond_cast_unet(hypernetwork_layers[1](devices.cond_cast_float(context_v)))
- return context_k, context_v
-
-
-def apply_hypernetworks(hypernetworks, context, layer=None):
- context_k = context
- context_v = context
- for hypernetwork in hypernetworks:
- context_k, context_v = apply_single_hypernetwork(hypernetwork, context_k, context_v, layer)
-
- return context_k, context_v
-
-
-def attention_CrossAttention_forward(self, x, context=None, mask=None):
- h = self.heads
-
- q = self.to_q(x)
- context = default(context, x)
-
- context_k, context_v = apply_hypernetworks(shared.loaded_hypernetworks, context, self)
- k = self.to_k(context_k)
- v = self.to_v(context_v)
-
- q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
-
- sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
-
- if mask is not None:
- mask = rearrange(mask, 'b ... -> b (...)')
- max_neg_value = -torch.finfo(sim.dtype).max
- mask = repeat(mask, 'b j -> (b h) () j', h=h)
- sim.masked_fill_(~mask, max_neg_value)
-
- # attention, what we cannot get enough of
- attn = sim.softmax(dim=-1)
-
- out = einsum('b i j, b j d -> b i d', attn, v)
- out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
- return self.to_out(out)
-
-
-def stack_conds(conds):
- if len(conds) == 1:
- return torch.stack(conds)
-
- # same as in reconstruct_multicond_batch
- token_count = max([x.shape[0] for x in conds])
- for i in range(len(conds)):
- if conds[i].shape[0] != token_count:
- last_vector = conds[i][-1:]
- last_vector_repeated = last_vector.repeat([token_count - conds[i].shape[0], 1])
- conds[i] = torch.vstack([conds[i], last_vector_repeated])
-
- return torch.stack(conds)
-
-
-def statistics(data):
- if len(data) < 2:
- std = 0
- else:
- std = stdev(data)
- total_information = f"loss:{mean(data):.3f}" + u"\u00B1" + f"({std/ (len(data) ** 0.5):.3f})"
- recent_data = data[-32:]
- if len(recent_data) < 2:
- std = 0
- else:
- std = stdev(recent_data)
- recent_information = f"recent 32 loss:{mean(recent_data):.3f}" + u"\u00B1" + f"({std / (len(recent_data) ** 0.5):.3f})"
- return total_information, recent_information
-
-
-def report_statistics(loss_info:dict):
- keys = sorted(loss_info.keys(), key=lambda x: sum(loss_info[x]) / len(loss_info[x]))
- for key in keys:
- try:
- print("Loss statistics for file " + key)
- info, recent = statistics(list(loss_info[key]))
- print(info)
- print(recent)
- except Exception as e:
- print(e)
-
-
-def create_hypernetwork(name, enable_sizes, overwrite_old, layer_structure=None, activation_func=None, weight_init=None, add_layer_norm=False, use_dropout=False, dropout_structure=None):
- # Remove illegal characters from name.
- name = "".join( x for x in name if (x.isalnum() or x in "._- "))
- assert name, "Name cannot be empty!"
-
- fn = os.path.join(shared.cmd_opts.hypernetwork_dir, f"{name}.pt")
- if not overwrite_old:
- assert not os.path.exists(fn), f"file {fn} already exists"
-
- if type(layer_structure) == str:
- layer_structure = [float(x.strip()) for x in layer_structure.split(",")]
-
- if use_dropout and dropout_structure and type(dropout_structure) == str:
- dropout_structure = [float(x.strip()) for x in dropout_structure.split(",")]
- else:
- dropout_structure = [0] * len(layer_structure)
-
- hypernet = modules.hypernetworks.hypernetwork.Hypernetwork(
- name=name,
- enable_sizes=[int(x) for x in enable_sizes],
- layer_structure=layer_structure,
- activation_func=activation_func,
- weight_init=weight_init,
- add_layer_norm=add_layer_norm,
- use_dropout=use_dropout,
- dropout_structure=dropout_structure
- )
- hypernet.save(fn)
-
- shared.reload_hypernetworks()
-
-
-def train_hypernetwork(id_task, hypernetwork_name, learn_rate, batch_size, gradient_step, data_root, log_directory, training_width, training_height, varsize, steps, clip_grad_mode, clip_grad_value, shuffle_tags, tag_drop_out, latent_sampling_method, use_weight, create_image_every, save_hypernetwork_every, template_filename, preview_from_txt2img, preview_prompt, preview_negative_prompt, preview_steps, preview_sampler_index, preview_cfg_scale, preview_seed, preview_width, preview_height):
- # images allows training previews to have infotext. Importing it at the top causes a circular import problem.
- from modules import images
-
- save_hypernetwork_every = save_hypernetwork_every or 0
- create_image_every = create_image_every or 0
- template_file = textual_inversion.textual_inversion_templates.get(template_filename, None)
- textual_inversion.validate_train_inputs(hypernetwork_name, learn_rate, batch_size, gradient_step, data_root, template_file, template_filename, steps, save_hypernetwork_every, create_image_every, log_directory, name="hypernetwork")
- template_file = template_file.path
-
- path = shared.hypernetworks.get(hypernetwork_name, None)
- hypernetwork = Hypernetwork()
- hypernetwork.load(path)
- shared.loaded_hypernetworks = [hypernetwork]
-
- shared.state.job = "train-hypernetwork"
- shared.state.textinfo = "Initializing hypernetwork training..."
- shared.state.job_count = steps
-
- hypernetwork_name = hypernetwork_name.rsplit('(', 1)[0]
- filename = os.path.join(shared.cmd_opts.hypernetwork_dir, f'{hypernetwork_name}.pt')
-
- log_directory = os.path.join(log_directory, datetime.datetime.now().strftime("%Y-%m-%d"), hypernetwork_name)
- unload = shared.opts.unload_models_when_training
-
- if save_hypernetwork_every > 0:
- hypernetwork_dir = os.path.join(log_directory, "hypernetworks")
- os.makedirs(hypernetwork_dir, exist_ok=True)
- else:
- hypernetwork_dir = None
-
- if create_image_every > 0:
- images_dir = os.path.join(log_directory, "images")
- os.makedirs(images_dir, exist_ok=True)
- else:
- images_dir = None
-
- checkpoint = sd_models.select_checkpoint()
-
- initial_step = hypernetwork.step or 0
- if initial_step >= steps:
- shared.state.textinfo = "Model has already been trained beyond specified max steps"
- return hypernetwork, filename
-
- scheduler = LearnRateScheduler(learn_rate, steps, initial_step)
-
- clip_grad = torch.nn.utils.clip_grad_value_ if clip_grad_mode == "value" else torch.nn.utils.clip_grad_norm_ if clip_grad_mode == "norm" else None
- if clip_grad:
- clip_grad_sched = LearnRateScheduler(clip_grad_value, steps, initial_step, verbose=False)
-
- if shared.opts.training_enable_tensorboard:
- tensorboard_writer = textual_inversion.tensorboard_setup(log_directory)
-
- # dataset loading may take a while, so input validations and early returns should be done before this
- shared.state.textinfo = f"Preparing dataset from {html.escape(data_root)}..."
-
- pin_memory = shared.opts.pin_memory
-
- ds = modules.textual_inversion.dataset.PersonalizedBase(data_root=data_root, width=training_width, height=training_height, repeats=shared.opts.training_image_repeats_per_epoch, placeholder_token=hypernetwork_name, model=shared.sd_model, cond_model=shared.sd_model.cond_stage_model, device=devices.device, template_file=template_file, include_cond=True, batch_size=batch_size, gradient_step=gradient_step, shuffle_tags=shuffle_tags, tag_drop_out=tag_drop_out, latent_sampling_method=latent_sampling_method, varsize=varsize, use_weight=use_weight)
-
- if shared.opts.save_training_settings_to_txt:
- saved_params = dict(
- model_name=checkpoint.model_name, model_hash=checkpoint.shorthash, num_of_dataset_images=len(ds),
- **{field: getattr(hypernetwork, field) for field in ['layer_structure', 'activation_func', 'weight_init', 'add_layer_norm', 'use_dropout', ]}
- )
- logging.save_settings_to_file(log_directory, {**saved_params, **locals()})
-
- latent_sampling_method = ds.latent_sampling_method
-
- dl = modules.textual_inversion.dataset.PersonalizedDataLoader(ds, latent_sampling_method=latent_sampling_method, batch_size=ds.batch_size, pin_memory=pin_memory)
-
- old_parallel_processing_allowed = shared.parallel_processing_allowed
-
- if unload:
- shared.parallel_processing_allowed = False
- shared.sd_model.cond_stage_model.to(devices.cpu)
- shared.sd_model.first_stage_model.to(devices.cpu)
-
- weights = hypernetwork.weights()
- hypernetwork.train()
-
- # Here we use optimizer from saved HN, or we can specify as UI option.
- if hypernetwork.optimizer_name in optimizer_dict:
- optimizer = optimizer_dict[hypernetwork.optimizer_name](params=weights, lr=scheduler.learn_rate)
- optimizer_name = hypernetwork.optimizer_name
- else:
- print(f"Optimizer type {hypernetwork.optimizer_name} is not defined!")
- optimizer = torch.optim.AdamW(params=weights, lr=scheduler.learn_rate)
- optimizer_name = 'AdamW'
-
- if hypernetwork.optimizer_state_dict: # This line must be changed if Optimizer type can be different from saved optimizer.
- try:
- optimizer.load_state_dict(hypernetwork.optimizer_state_dict)
- except RuntimeError as e:
- print("Cannot resume from saved optimizer!")
- print(e)
-
- scaler = torch.cuda.amp.GradScaler()
-
- batch_size = ds.batch_size
- gradient_step = ds.gradient_step
- # n steps = batch_size * gradient_step * n image processed
- steps_per_epoch = len(ds) // batch_size // gradient_step
- max_steps_per_epoch = len(ds) // batch_size - (len(ds) // batch_size) % gradient_step
- loss_step = 0
- _loss_step = 0 #internal
- # size = len(ds.indexes)
- # loss_dict = defaultdict(lambda : deque(maxlen = 1024))
- loss_logging = deque(maxlen=len(ds) * 3) # this should be configurable parameter, this is 3 * epoch(dataset size)
- # losses = torch.zeros((size,))
- # previous_mean_losses = [0]
- # previous_mean_loss = 0
- # print("Mean loss of {} elements".format(size))
-
- steps_without_grad = 0
-
- last_saved_file = ""
- last_saved_image = ""
- forced_filename = ""
-
- pbar = tqdm.tqdm(total=steps - initial_step)
- try:
- sd_hijack_checkpoint.add()
-
- for i in range((steps-initial_step) * gradient_step):
- if scheduler.finished:
- break
- if shared.state.interrupted:
- break
- for j, batch in enumerate(dl):
- # works as a drop_last=True for gradient accumulation
- if j == max_steps_per_epoch:
- break
- scheduler.apply(optimizer, hypernetwork.step)
- if scheduler.finished:
- break
- if shared.state.interrupted:
- break
-
- if clip_grad:
- clip_grad_sched.step(hypernetwork.step)
-
- with devices.autocast():
- x = batch.latent_sample.to(devices.device, non_blocking=pin_memory)
- if use_weight:
- w = batch.weight.to(devices.device, non_blocking=pin_memory)
- if tag_drop_out != 0 or shuffle_tags:
- shared.sd_model.cond_stage_model.to(devices.device)
- c = shared.sd_model.cond_stage_model(batch.cond_text).to(devices.device, non_blocking=pin_memory)
- shared.sd_model.cond_stage_model.to(devices.cpu)
- else:
- c = stack_conds(batch.cond).to(devices.device, non_blocking=pin_memory)
- if use_weight:
- loss = shared.sd_model.weighted_forward(x, c, w)[0] / gradient_step
- del w
- else:
- loss = shared.sd_model.forward(x, c)[0] / gradient_step
- del x
- del c
-
- _loss_step += loss.item()
- scaler.scale(loss).backward()
-
- # go back until we reach gradient accumulation steps
- if (j + 1) % gradient_step != 0:
- continue
- loss_logging.append(_loss_step)
- if clip_grad:
- clip_grad(weights, clip_grad_sched.learn_rate)
-
- scaler.step(optimizer)
- scaler.update()
- hypernetwork.step += 1
- pbar.update()
- optimizer.zero_grad(set_to_none=True)
- loss_step = _loss_step
- _loss_step = 0
-
- steps_done = hypernetwork.step + 1
-
- epoch_num = hypernetwork.step // steps_per_epoch
- epoch_step = hypernetwork.step % steps_per_epoch
-
- description = f"Training hypernetwork [Epoch {epoch_num}: {epoch_step+1}/{steps_per_epoch}]loss: {loss_step:.7f}"
- pbar.set_description(description)
- if hypernetwork_dir is not None and steps_done % save_hypernetwork_every == 0:
- # Before saving, change name to match current checkpoint.
- hypernetwork_name_every = f'{hypernetwork_name}-{steps_done}'
- last_saved_file = os.path.join(hypernetwork_dir, f'{hypernetwork_name_every}.pt')
- hypernetwork.optimizer_name = optimizer_name
- if shared.opts.save_optimizer_state:
- hypernetwork.optimizer_state_dict = optimizer.state_dict()
- save_hypernetwork(hypernetwork, checkpoint, hypernetwork_name, last_saved_file)
- hypernetwork.optimizer_state_dict = None # dereference it after saving, to save memory.
-
-
-
- if shared.opts.training_enable_tensorboard:
- epoch_num = hypernetwork.step // len(ds)
- epoch_step = hypernetwork.step - (epoch_num * len(ds)) + 1
- mean_loss = sum(loss_logging) / len(loss_logging)
- textual_inversion.tensorboard_add(tensorboard_writer, loss=mean_loss, global_step=hypernetwork.step, step=epoch_step, learn_rate=scheduler.learn_rate, epoch_num=epoch_num)
-
- textual_inversion.write_loss(log_directory, "hypernetwork_loss.csv", hypernetwork.step, steps_per_epoch, {
- "loss": f"{loss_step:.7f}",
- "learn_rate": scheduler.learn_rate
- })
-
- if images_dir is not None and steps_done % create_image_every == 0:
- forced_filename = f'{hypernetwork_name}-{steps_done}'
- last_saved_image = os.path.join(images_dir, forced_filename)
- hypernetwork.eval()
- rng_state = torch.get_rng_state()
- cuda_rng_state = None
- if torch.cuda.is_available():
- cuda_rng_state = torch.cuda.get_rng_state_all()
- shared.sd_model.cond_stage_model.to(devices.device)
- shared.sd_model.first_stage_model.to(devices.device)
-
- p = processing.StableDiffusionProcessingTxt2Img(
- sd_model=shared.sd_model,
- do_not_save_grid=True,
- do_not_save_samples=True,
- )
-
- p.disable_extra_networks = True
-
- if preview_from_txt2img:
- p.prompt = preview_prompt
- p.negative_prompt = preview_negative_prompt
- p.steps = preview_steps
- p.sampler_name = sd_samplers.samplers[preview_sampler_index].name
- p.cfg_scale = preview_cfg_scale
- p.seed = preview_seed
- p.width = preview_width
- p.height = preview_height
- else:
- p.prompt = batch.cond_text[0]
- p.steps = 20
- p.width = training_width
- p.height = training_height
-
- preview_text = p.prompt
-
- processed = processing.process_images(p)
- image = processed.images[0] if len(processed.images) > 0 else None
-
- if unload:
- shared.sd_model.cond_stage_model.to(devices.cpu)
- shared.sd_model.first_stage_model.to(devices.cpu)
- torch.set_rng_state(rng_state)
- if torch.cuda.is_available():
- torch.cuda.set_rng_state_all(cuda_rng_state)
- hypernetwork.train()
- if image is not None:
- shared.state.assign_current_image(image)
- if shared.opts.training_enable_tensorboard and shared.opts.training_tensorboard_save_images:
- textual_inversion.tensorboard_add_image(tensorboard_writer,
- f"Validation at epoch {epoch_num}", image,
- hypernetwork.step)
- last_saved_image, last_text_info = images.save_image(image, images_dir, "", p.seed, p.prompt, shared.opts.samples_format, processed.infotexts[0], p=p, forced_filename=forced_filename, save_to_dirs=False)
- last_saved_image += f", prompt: {preview_text}"
-
- shared.state.job_no = hypernetwork.step
-
- shared.state.textinfo = f"""
-
-Loss: {loss_step:.7f}
-Step: {steps_done}
-Last prompt: {html.escape(batch.cond_text[0])}
-Last saved hypernetwork: {html.escape(last_saved_file)}
-Last saved image: {html.escape(last_saved_image)}
-
-"""
- except Exception:
- print(traceback.format_exc(), file=sys.stderr)
- finally:
- pbar.leave = False
- pbar.close()
- hypernetwork.eval()
- #report_statistics(loss_dict)
- sd_hijack_checkpoint.remove()
-
-
-
- filename = os.path.join(shared.cmd_opts.hypernetwork_dir, f'{hypernetwork_name}.pt')
- hypernetwork.optimizer_name = optimizer_name
- if shared.opts.save_optimizer_state:
- hypernetwork.optimizer_state_dict = optimizer.state_dict()
- save_hypernetwork(hypernetwork, checkpoint, hypernetwork_name, filename)
-
- del optimizer
- hypernetwork.optimizer_state_dict = None # dereference it after saving, to save memory.
- shared.sd_model.cond_stage_model.to(devices.device)
- shared.sd_model.first_stage_model.to(devices.device)
- shared.parallel_processing_allowed = old_parallel_processing_allowed
-
- return hypernetwork, filename
-
-def save_hypernetwork(hypernetwork, checkpoint, hypernetwork_name, filename):
- old_hypernetwork_name = hypernetwork.name
- old_sd_checkpoint = hypernetwork.sd_checkpoint if hasattr(hypernetwork, "sd_checkpoint") else None
- old_sd_checkpoint_name = hypernetwork.sd_checkpoint_name if hasattr(hypernetwork, "sd_checkpoint_name") else None
- try:
- hypernetwork.sd_checkpoint = checkpoint.shorthash
- hypernetwork.sd_checkpoint_name = checkpoint.model_name
- hypernetwork.name = hypernetwork_name
- hypernetwork.save(filename)
- except:
- hypernetwork.sd_checkpoint = old_sd_checkpoint
- hypernetwork.sd_checkpoint_name = old_sd_checkpoint_name
- hypernetwork.name = old_hypernetwork_name
- raise
diff --git a/spaces/bigscience/promptsource/promptsource/templates.py b/spaces/bigscience/promptsource/promptsource/templates.py
deleted file mode 100644
index 8a03407af543ae40d716b4e395e942337b427dcc..0000000000000000000000000000000000000000
--- a/spaces/bigscience/promptsource/promptsource/templates.py
+++ /dev/null
@@ -1,731 +0,0 @@
-import logging
-import os
-import random
-import uuid
-from collections import Counter, defaultdict
-from shutil import rmtree
-from typing import Dict, List, Optional, Tuple
-
-import pandas as pd
-import pkg_resources
-import yaml
-from jinja2 import BaseLoader, Environment, meta
-
-
-# Truncation of jinja template variables
-# 1710 = 300 words x 4.7 avg characters per word + 300 spaces
-TEXT_VAR_LENGTH = 2048
-
-# Local path to the folder containing the templates
-TEMPLATES_FOLDER_PATH = pkg_resources.resource_filename(__name__, "templates")
-
-env = Environment(loader=BaseLoader)
-
-# Allow the python function zip()
-env.globals.update(zip=zip)
-
-# These are users whose datasets should be included in the results returned by
-# filter_english_datasets (regardless of their metadata)
-INCLUDED_USERS = {"Zaid", "craffel"}
-
-# These are the metrics with which templates can be tagged
-METRICS = {
- "BLEU",
- "ROUGE",
- "Squad",
- "Trivia QA",
- "Accuracy",
- "Pearson Correlation",
- "Spearman Correlation",
- "MultiRC",
- "AUC",
- "COQA F1",
- "Edit Distance",
- "Mean Reciprocal Rank",
- "Other",
-}
-
-# These are the languages with which templates can be tagged. Keys are ISO 639-1
-# tags, which are the actual tags we use. Values are English names shown in the
-# UI for convenience.
-LANGUAGES = {
- "ab": "Abkhazian",
- "aa": "Afar",
- "af": "Afrikaans",
- "ak": "Akan",
- "sq": "Albanian",
- "am": "Amharic",
- "ar": "Arabic",
- "an": "Aragonese",
- "hy": "Armenian",
- "as": "Assamese",
- "av": "Avaric",
- "ae": "Avestan",
- "ay": "Aymara",
- "az": "Azerbaijani",
- "bm": "Bambara",
- "ba": "Bashkir",
- "eu": "Basque",
- "be": "Belarusian",
- "bn": "Bengali",
- "bi": "Bislama",
- "bs": "Bosnian",
- "br": "Breton",
- "bg": "Bulgarian",
- "my": "Burmese",
- "ca": "Catalan, Valencian",
- "ch": "Chamorro",
- "ce": "Chechen",
- "ny": "Chichewa, Chewa, Nyanja",
- "zh": "Chinese",
- "cu": "Church Slavic, Old Slavonic, Church Slavonic, Old Bulgarian, Old Church Slavonic",
- "cv": "Chuvash",
- "kw": "Cornish",
- "co": "Corsican",
- "cr": "Cree",
- "hr": "Croatian",
- "cs": "Czech",
- "da": "Danish",
- "dv": "Divehi, Dhivehi, Maldivian",
- "nl": "Dutch, Flemish",
- "dz": "Dzongkha",
- "en": "English",
- "eo": "Esperanto",
- "et": "Estonian",
- "ee": "Ewe",
- "fo": "Faroese",
- "fj": "Fijian",
- "fi": "Finnish",
- "fr": "French",
- "fy": "Western Frisian",
- "ff": "Fulah",
- "gd": "Gaelic, Scottish Gaelic",
- "gl": "Galician",
- "lg": "Ganda",
- "ka": "Georgian",
- "de": "German",
- "el": "Greek, Modern (1453–)",
- "kl": "Kalaallisut, Greenlandic",
- "gn": "Guarani",
- "gu": "Gujarati",
- "ht": "Haitian, Haitian Creole",
- "ha": "Hausa",
- "he": "Hebrew",
- "hz": "Herero",
- "hi": "Hindi",
- "ho": "Hiri Motu",
- "hu": "Hungarian",
- "is": "Icelandic",
- "io": "Ido",
- "ig": "Igbo",
- "id": "Indonesian",
- "ia": "Interlingua (International Auxiliary Language Association)",
- "ie": "Interlingue, Occidental",
- "iu": "Inuktitut",
- "ik": "Inupiaq",
- "ga": "Irish",
- "it": "Italian",
- "ja": "Japanese",
- "jv": "Javanese",
- "kn": "Kannada",
- "kr": "Kanuri",
- "ks": "Kashmiri",
- "kk": "Kazakh",
- "km": "Central Khmer",
- "ki": "Kikuyu, Gikuyu",
- "rw": "Kinyarwanda",
- "ky": "Kirghiz, Kyrgyz",
- "kv": "Komi",
- "kg": "Kongo",
- "ko": "Korean",
- "kj": "Kuanyama, Kwanyama",
- "ku": "Kurdish",
- "lo": "Lao",
- "la": "Latin",
- "lv": "Latvian",
- "li": "Limburgan, Limburger, Limburgish",
- "ln": "Lingala",
- "lt": "Lithuanian",
- "lu": "Luba-Katanga",
- "lb": "Luxembourgish, Letzeburgesch",
- "mk": "Macedonian",
- "mg": "Malagasy",
- "ms": "Malay",
- "ml": "Malayalam",
- "mt": "Maltese",
- "gv": "Manx",
- "mi": "Maori",
- "mr": "Marathi",
- "mh": "Marshallese",
- "mn": "Mongolian",
- "na": "Nauru",
- "nv": "Navajo, Navaho",
- "nd": "North Ndebele",
- "nr": "South Ndebele",
- "ng": "Ndonga",
- "ne": "Nepali",
- "no": "Norwegian",
- "nb": "Norwegian Bokmål",
- "nn": "Norwegian Nynorsk",
- "ii": "Sichuan Yi, Nuosu",
- "oc": "Occitan",
- "oj": "Ojibwa",
- "or": "Oriya",
- "om": "Oromo",
- "os": "Ossetian, Ossetic",
- "pi": "Pali",
- "ps": "Pashto, Pushto",
- "fa": "Persian",
- "pl": "Polish",
- "pt": "Portuguese",
- "pa": "Punjabi, Panjabi",
- "qu": "Quechua",
- "ro": "Romanian, Moldavian, Moldovan",
- "rm": "Romansh",
- "rn": "Rundi",
- "ru": "Russian",
- "se": "Northern Sami",
- "sm": "Samoan",
- "sg": "Sango",
- "sa": "Sanskrit",
- "sc": "Sardinian",
- "sr": "Serbian",
- "sn": "Shona",
- "sd": "Sindhi",
- "si": "Sinhala, Sinhalese",
- "sk": "Slovak",
- "sl": "Slovenian",
- "so": "Somali",
- "st": "Southern Sotho",
- "es": "Spanish, Castilian",
- "su": "Sundanese",
- "sw": "Swahili",
- "ss": "Swati",
- "sv": "Swedish",
- "tl": "Tagalog",
- "ty": "Tahitian",
- "tg": "Tajik",
- "ta": "Tamil",
- "tt": "Tatar",
- "te": "Telugu",
- "th": "Thai",
- "bo": "Tibetan",
- "ti": "Tigrinya",
- "to": "Tonga (Tonga Islands)",
- "ts": "Tsonga",
- "tn": "Tswana",
- "tr": "Turkish",
- "tk": "Turkmen",
- "tw": "Twi",
- "ug": "Uighur, Uyghur",
- "uk": "Ukrainian",
- "ur": "Urdu",
- "uz": "Uzbek",
- "ve": "Venda",
- "vi": "Vietnamese",
- "vo": "Volapük",
- "wa": "Walloon",
- "cy": "Welsh",
- "wo": "Wolof",
- "xh": "Xhosa",
- "yi": "Yiddish",
- "yo": "Yoruba",
- "za": "Zhuang, Chuang",
- "zu": "Zulu",
-}
-
-
-def highlight(input):
- return "" + input + ""
-
-
-def choice(choices):
- return random.choice(choices)
-
-
-def most_frequent(items):
- """Returns the set of items which appear most frequently in the input"""
- if not items:
- return
- item_counts = Counter(items).most_common()
- max_freq = item_counts[0][1]
- most_frequent_items = [c[0] for c in item_counts if c[1] == max_freq]
- return most_frequent_items
-
-
-env.filters["highlight"] = highlight
-env.filters["choice"] = choice
-env.filters["most_frequent"] = most_frequent
-
-
-class Template(yaml.YAMLObject):
- """
- A prompt template.
- """
-
- yaml_tag = "!Template"
-
- def __init__(self, name, jinja, reference, metadata=None, answer_choices=None):
- """
- Creates a prompt template.
-
- A prompt template is expressed in Jinja. It is rendered using an example
- from the corresponding Hugging Face datasets library (a dictionary). The
- separator ||| should appear once to divide the template into prompt and
- output. Generally, the prompt should provide information on the desired
- behavior, e.g., text passage and instructions, and the output should be
- a desired response.
-
- :param name: unique name (per dataset) for template
- :param jinja: template expressed in Jinja
- :param reference: string describing author or paper reference for template
- :param metadata: a Metadata object with template annotations
- :param answer_choices: Jinja expression for answer choices. Should produce
- a ||| delimited string of choices that enumerates
- the possible completions for templates that should
- be evaluated as ranked completions. If None, then
- the template is open-ended. This list is accessible
- from within Jinja as the variable `answer_choices`.
- """
- self.id = str(uuid.uuid4())
- self.name = name
- self.jinja = jinja
- self.reference = reference
- self.metadata = metadata if metadata is not None else Template.Metadata()
- self.answer_choices = answer_choices
-
- def get_id(self):
- """
- Returns the id of the template
-
- :return: unique id for template
- """
- return self.id
-
- def get_name(self):
- """
- Returns the name of the template
-
- :return: unique (per dataset) name for template
- """
- return self.name
-
- def get_reference(self):
- """
- Returns the bibliographic reference (or author) for the template
-
- :return: reference as a string
- """
- return self.reference
-
- def get_answer_choices_expr(self):
- """
- Returns a Jinja expression for computing the answer choices from an example.
-
- :return: String, or None if no answer choices
- """
- return self.answer_choices
-
- def get_answer_choices_list(self, example):
- """
- Returns a list of answer choices for a given example
-
- :return: list of strings, or None if get_answer_choices_expr is None
- """
- jinja = self.get_answer_choices_expr()
- if jinja is None:
- return None
-
- rtemplate = env.from_string(jinja)
- protected_example = self._escape_pipe(example)
- rendered_choices = rtemplate.render(**protected_example)
- return [self._unescape_pipe(answer_choice.strip()) for answer_choice in rendered_choices.split("|||")]
-
- def get_fixed_answer_choices_list(self):
- """
- Returns a list of answer choices that is static across examples, if possible
- :return: list of strings, or None if no static list exists
- """
- jinja = self.get_answer_choices_expr()
- if jinja is None:
- return None
-
- parse = env.parse(jinja)
- variables = meta.find_undeclared_variables(parse)
- if len(variables) == 0:
- rtemplate = env.from_string(jinja)
- rendered_choices = rtemplate.render()
- return [answer_choice.strip() for answer_choice in rendered_choices.split("|||")]
- else:
- return None
-
- def apply(self, example, truncate=True, highlight_variables=False):
- """
- Creates a prompt by applying this template to an example
-
- :param example: the dataset example to create a prompt for
- :param truncate: if True, example fields will be truncated to TEXT_VAR_LENGTH chars
- :param highlight_variables: highlight the added variables
- :return: tuple of 2 strings, for prompt and output
- """
- jinja = self.jinja
-
- # Truncates the prompt if needed
- if truncate:
- trunc_command = (
- f" | string | truncate({TEXT_VAR_LENGTH}) }}}}" # Escaping curly braces requires doubling them
- )
- jinja = jinja.replace("}}", trunc_command)
-
- # Highlights text that was substituted for variables, if requested
- if highlight_variables:
- jinja = jinja.replace("}}", " | highlight }}")
- rtemplate = env.from_string(jinja)
-
- protected_example = self._escape_pipe(example)
-
- # Adds in answer_choices variable
- if "answer_choices" in protected_example:
- raise ValueError("Example contains the restricted key 'answer_choices'.")
-
- protected_example["answer_choices"] = self.get_answer_choices_list(example)
-
- # Renders the Jinja template
- rendered_example = rtemplate.render(**protected_example)
-
- # Splits on the separator, and then replaces back any occurrences of the
- # separator in the original example
- return [self._unescape_pipe(part).strip() for part in rendered_example.split("|||")]
-
- pipe_protector = "3ed2dface8203c4c9dfb1a5dc58e41e0"
-
- @classmethod
- def _escape_pipe(cls, example):
- # Replaces any occurrences of the "|||" separator in the example, which
- # which will be replaced back after splitting
- protected_example = {
- key: value.replace("|||", cls.pipe_protector) if isinstance(value, str) else value
- for key, value in example.items()
- }
- return protected_example
-
- @classmethod
- def _unescape_pipe(cls, string):
- # replaces back any occurrences of the separator in a string
- return string.replace(cls.pipe_protector, "|||")
-
- class Metadata(yaml.YAMLObject):
- """
- Metadata for a prompt template.
- """
-
- yaml_tag = "!TemplateMetadata"
-
- def __init__(
- self,
- original_task: Optional[bool] = None,
- choices_in_prompt: Optional[bool] = None,
- metrics: Optional[List[str]] = None,
- languages: Optional[List[str]] = None,
- ):
- """
- Initializes template metadata.
-
- In the following, trivial choices are defined as Yes/No, True/False,
- etc. and nontrivial choices are other types of choices denoted in
- the answer_choices field.
-
- :param original_task: If True, this prompt asks a model to perform the original task designed for
- this dataset.
- :param choices_in_prompt: If True, the answer choices are included in the templates such that models
- see those choices in the input. Only applicable to classification tasks.
- :param metrics: List of strings denoting metrics to use for evaluation
- :param metrics: List of strings denoting languages used in the prompt (not the associated dataset!)
- """
- self.original_task = original_task
- self.choices_in_prompt = choices_in_prompt
- self.metrics = metrics
- self.languages = languages
-
-
-class TemplateCollection:
- """
- This helper class wraps the DatasetTemplates class
- - Initialized the DatasetTemplates for all existing template folder
- - Give access to each DatasetTemplates
- - Provides aggregated counts over all DatasetTemplates
- """
-
- def __init__(self):
-
- # Dict of all the DatasetTemplates, key is the tuple (dataset_name, subset_name)
- self.datasets_templates: Dict[(str, Optional[str]), DatasetTemplates] = self._collect_datasets()
-
- @property
- def keys(self):
- return list(self.datasets_templates.keys())
-
- def __len__(self) -> int:
- return len(self.datasets_templates)
-
- def remove(self, dataset_name: str, subset_name: Optional[str] = None) -> None:
- del self.datasets_templates[dataset_name, subset_name]
-
- def _collect_datasets(self) -> Dict[Tuple[str, str], "DatasetTemplates"]:
- """
- Initialize a DatasetTemplates object for each templates.yaml detected in the templates folder
-
- Returns: a dict with key=(dataset_name, subset_name)
- """
- dataset_folders = os.listdir(TEMPLATES_FOLDER_PATH)
- dataset_folders = [folder for folder in dataset_folders if not folder.startswith(".")]
-
- output = {} # format is {(dataset_name, subset_name): DatasetsTemplates}
- for dataset in dataset_folders:
- if dataset in INCLUDED_USERS:
- for filename in os.listdir(os.path.join(TEMPLATES_FOLDER_PATH, dataset)):
- output = {**output, **self._collect_dataset(dataset + "/" + filename)}
- else:
- output = {**output, **self._collect_dataset(dataset)}
- return output
-
- def _collect_dataset(self, dataset):
- output = {} # format is {(dataset_name, subset_name): DatasetsTemplates}
- for filename in os.listdir(os.path.join(TEMPLATES_FOLDER_PATH, dataset)):
- if filename.endswith(".yaml"):
- # If there is no sub-folder, there is no subset for this dataset
- output[(dataset, None)] = DatasetTemplates(dataset)
- else:
- # This is a subfolder, and its name corresponds to the subset name
- output[(dataset, filename)] = DatasetTemplates(dataset_name=dataset, subset_name=filename)
- return output
-
- def get_dataset(self, dataset_name: str, subset_name: Optional[str] = None) -> "DatasetTemplates":
- """
- Return the DatasetTemplates object corresponding to the dataset name
-
- :param dataset_name: name of the dataset to get
- :param subset_name: name of the subset
- """
- # if the dataset does not exist, we add it
- if dataset_name not in self.keys:
- self.datasets_templates[(dataset_name, subset_name)] = DatasetTemplates(dataset_name, subset_name)
-
- return self.datasets_templates[(dataset_name, subset_name)]
-
- def get_templates_count(self) -> Dict:
- """
- Return the overall number count over all datasets
-
- NB: we don't breakdown datasets into subsets for the count, i.e subsets count are included
- into the dataset count
- """
-
- count_dict = defaultdict(int)
- for k, v in self.datasets_templates.items():
- # Subsets count towards dataset count
- count_dict[k[0]] += len(v)
- # converting to regular dict
- return dict(count_dict)
-
-
-class DatasetTemplates:
- """
- Class that wraps all templates for a specific dataset/subset and implements all the helper
- functions necessary to read/write to the yaml file
- """
-
- TEMPLATES_KEY = "templates"
- DATASET_KEY = "dataset"
- SUBSET_KEY = "subset"
- TEMPLATE_FILENAME = "templates.yaml"
-
- def __init__(self, dataset_name: str, subset_name: str = None):
- self.dataset_name: str = dataset_name
- self.subset_name: str = subset_name
- # dictionary is keyed by template name.
- self.templates: Dict = self.read_from_file()
-
- # Mapping from template name to template id
- self.name_to_id_mapping = {}
- self.sync_mapping()
-
- def sync_mapping(self) -> None:
- """
- Re-compute the name_to_id_mapping to ensure it is in sync with self.templates
- """
- self.name_to_id_mapping = {template.name: template.id for template in self.templates.values()}
-
- @property
- def all_template_names(self) -> List[str]:
- """
- Sorted list of all templates names for this dataset
- """
- return sorted([template.name for template in self.templates.values()])
-
- @property
- def folder_path(self) -> str:
- if self.subset_name:
- return os.path.join(TEMPLATES_FOLDER_PATH, self.dataset_name, self.subset_name)
- else:
- return os.path.join(TEMPLATES_FOLDER_PATH, self.dataset_name)
-
- @property
- def yaml_path(self) -> str:
- return os.path.join(self.folder_path, self.TEMPLATE_FILENAME)
-
- def format_for_dump(self) -> Dict:
- """
- Create a formatted dictionary for the class attributes
- """
- formatted_dict = {self.DATASET_KEY: self.dataset_name, self.TEMPLATES_KEY: self.templates}
- if self.subset_name:
- formatted_dict[self.SUBSET_KEY] = self.subset_name
- return formatted_dict
-
- def read_from_file(self) -> Dict:
- """
- Reads a file containing a prompt collection.
- """
-
- if not os.path.exists(self.yaml_path):
- dataset_name = f"{self.dataset_name} {self.subset_name}" if self.subset_name else self.dataset_name
- logging.warning(
- f"Tried instantiating `DatasetTemplates` for {dataset_name}, but no prompts found. "
- "Please ignore this warning if you are creating new prompts for this dataset."
- )
- return {}
- yaml_dict = yaml.load(open(self.yaml_path, "r"), Loader=yaml.FullLoader)
- return yaml_dict[self.TEMPLATES_KEY]
-
- def write_to_file(self) -> None:
- """
- Writes to a file with the current prompt collection.
- """
- # Sync the mapping
- self.sync_mapping()
-
- # We only create the folder if a template is written
- if not os.path.exists(self.folder_path):
- os.makedirs(self.folder_path)
- yaml.dump(self.format_for_dump(), open(self.yaml_path, "w"))
-
- def add_template(self, template: "Template") -> None:
- """
- Adds a new template for the dataset
-
- :param template: template
- """
- self.templates[template.get_id()] = template
-
- self.write_to_file()
-
- def remove_template(self, template_name: str) -> None:
- """
- Deletes a template
-
- :param template_name: name of template to remove
- """
-
- # Even if we have an ID, we want to check for duplicate names
- if template_name not in self.all_template_names:
- raise ValueError(f"No template with name {template_name} for dataset {self.dataset_name} exists.")
-
- del self.templates[self.name_to_id_mapping[template_name]]
-
- if len(self.templates) == 0:
- # There is no remaining template, we can remove the entire folder
- self.delete_folder()
- else:
- # We just update the file
- self.write_to_file()
-
- def update_template(
- self,
- current_template_name: str,
- new_template_name: str,
- jinja: str,
- reference: str,
- metadata: Template.Metadata,
- answer_choices: str,
- ) -> None:
- """
- Updates a pre-existing template and writes changes
-
- :param current_template_name: current name of the template stored in self.templates
- :param new_template_name: new name for the template
- :param jinja: new jinja entry
- :param reference: new reference entry
- :param metadata: a Metadata object with template annotations
- :param answer_choices: new answer_choices string
- """
- template_id = self.name_to_id_mapping[current_template_name]
- self.templates[template_id].name = new_template_name
- self.templates[template_id].jinja = jinja
- self.templates[template_id].reference = reference
- self.templates[template_id].metadata = metadata
- self.templates[template_id].answer_choices = answer_choices
-
- self.write_to_file()
-
- def delete_folder(self) -> None:
- """
- Delete the folder corresponding to self.folder_path
- """
- self.sync_mapping()
-
- rmtree(self.folder_path)
-
- # If it is a subset, we have to check whether to remove the dataset folder
- if self.subset_name:
- # have to check for other folders
- base_dataset_folder = os.path.join(TEMPLATES_FOLDER_PATH, self.dataset_name)
- if len(os.listdir(base_dataset_folder)) == 0:
- rmtree(base_dataset_folder)
-
- def __getitem__(self, template_key: str) -> "Template":
- return self.templates[self.name_to_id_mapping[template_key]]
-
- def __len__(self) -> int:
- return len(self.templates)
-
-
-def get_templates_data_frame():
- """
- Gathers all template information into a Pandas DataFrame.
-
- :return: Pandas DataFrame
- """
- data = {
- "id": [],
- "dataset": [],
- "subset": [],
- "name": [],
- "reference": [],
- "original_task": [],
- "choices_in_prompt": [],
- "metrics": [],
- "languages": [],
- "answer_choices": [],
- "jinja": [],
- }
-
- template_collection = TemplateCollection()
-
- for key in template_collection.keys:
- templates = template_collection.get_dataset(key[0], key[1])
- for template_name in templates.all_template_names:
- template = templates[template_name]
- data["id"].append(template.get_id())
- data["dataset"].append(key[0])
- data["subset"].append(key[1])
- data["name"].append(template.get_name())
- data["reference"].append(template.get_reference())
- data["original_task"].append(template.metadata.original_task)
- data["choices_in_prompt"].append(template.metadata.choices_in_prompt)
- data["metrics"].append(template.metadata.metrics)
- data["languages"].append(template.metadata.languages)
- data["answer_choices"].append(template.get_answer_choices_expr())
- data["jinja"].append(template.jinja)
-
- return pd.DataFrame(data)
diff --git a/spaces/bigslime/stablediffusion-infinity/PyPatchMatch/examples/py_example.py b/spaces/bigslime/stablediffusion-infinity/PyPatchMatch/examples/py_example.py
deleted file mode 100644
index fa1b526f87b065a6acda35e06d563be134ffb27b..0000000000000000000000000000000000000000
--- a/spaces/bigslime/stablediffusion-infinity/PyPatchMatch/examples/py_example.py
+++ /dev/null
@@ -1,21 +0,0 @@
-#! /usr/bin/env python3
-# -*- coding: utf-8 -*-
-# File : test.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 01/09/2020
-#
-# Distributed under terms of the MIT license.
-
-from PIL import Image
-
-import sys
-sys.path.insert(0, '../')
-import patch_match
-
-
-if __name__ == '__main__':
- source = Image.open('./images/forest_pruned.bmp')
- result = patch_match.inpaint(source, patch_size=3)
- Image.fromarray(result).save('./images/forest_recovered.bmp')
-
diff --git a/spaces/bioriAsaeru/text-to-voice/360 Total Security 10.6.0.1338 2021 Crack With Product Key.md b/spaces/bioriAsaeru/text-to-voice/360 Total Security 10.6.0.1338 2021 Crack With Product Key.md
deleted file mode 100644
index f28466fa21a8ccb4f2ed8429fc7c852dcd53e103..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/360 Total Security 10.6.0.1338 2021 Crack With Product Key.md
+++ /dev/null
@@ -1,52 +0,0 @@
-360 Total Security 10.6.0.1338 Crack With Product Key
DOWNLOAD >> https://urloso.com/2uyQej
-
-It is the most excellent device to remove any unwanted software from your system. It will be highly secure and accurate while using it. More, It has been always updated which is always added with new features and security system. This will help to protect your PC from all types of viruses and other malware. It will provide protection from all types of virus. More, it will remove all kind of virus from your PC. Moreover, 360 Total Security is very compatible with your system.
-
-Download 360 Total Security Crack Plus Serial Number Free!
-
-This tool automatically removes all unwanted software from your PC which is automatically. More, It scans all installed software and remove all from your PC. It has advanced software which detect all possible malware. It will be highly safe while using. More, It will remove all virus from your PC. This 360 Total Security Crack Plus Serial Number Free is highly recommended to remove all viruses from your PC. Moreover, it will protect your PC with all types of malware and viruses. It has the ability to detect all type of virus. It has the ability to detect all type of Trojan virus and malware. It has the ability to remove all type of virus from your PC. It is updated version and latest version. You will no need to download it again and again. This is a very simple tool and easy to use.
-
-Main Feature of 360 Total Security 10.6.0.1338 Crack:
-
-It can detect all type of virus.
-
-It will remove all type of virus from your PC.
-
-It will detect all type of Trojan virus and malware.
-
-This will protect your PC from all types of malware.
-
-It will protect your PC from all type of viruses.
-
-It will automatically remove all virus from your PC.
-
-It will automatically scan all installed software.
-
-You can easily remove all virus from your PC.
-
-It will remove all virus which has rootkit.
-
-It will remove all unwanted software from your PC.
-
-It will remove all rootkit from your PC.
-
-This will protect your PC from all type of virus.
-
-How to Crack or Activate 360 Total Security?
-
-First, Download the setup of the 360 Total Security.
-
-After downloading, install the setup.
-
-Open the setup.
-
-You need to install this tool.
-
-After installing, close the setup.
-
-Now, you need to generate the crack of 360 Total Security.
-
-After generating the crack, 4fefd39f24
-
-
-
diff --git a/spaces/breadlicker45/the-jam-machine-app/generate.py b/spaces/breadlicker45/the-jam-machine-app/generate.py
deleted file mode 100644
index 1a247efa05f1dc9c38d8573052734dc3a849b3f6..0000000000000000000000000000000000000000
--- a/spaces/breadlicker45/the-jam-machine-app/generate.py
+++ /dev/null
@@ -1,486 +0,0 @@
-from generation_utils import *
-from utils import WriteTextMidiToFile, get_miditok
-from load import LoadModel
-from decoder import TextDecoder
-from playback import get_music
-
-
-class GenerateMidiText:
- """Generating music with Class
-
- LOGIC:
-
- FOR GENERATING FROM SCRATCH:
- - self.generate_one_new_track()
- it calls
- - self.generate_until_track_end()
-
- FOR GENERATING NEW BARS:
- - self.generate_one_more_bar()
- it calls
- - self.process_prompt_for_next_bar()
- - self.generate_until_track_end()"""
-
- def __init__(self, model, tokenizer, piece_by_track=[]):
- self.model = model
- self.tokenizer = tokenizer
- # default initialization
- self.initialize_default_parameters()
- self.initialize_dictionaries(piece_by_track)
-
- """Setters"""
-
- def initialize_default_parameters(self):
- self.set_device()
- self.set_attention_length()
- self.generate_until = "TRACK_END"
- self.set_force_sequence_lenth()
- self.set_nb_bars_generated()
- self.set_improvisation_level(0)
-
- def initialize_dictionaries(self, piece_by_track):
- self.piece_by_track = piece_by_track
-
- def set_device(self, device="cpu"):
- self.device = ("cpu",)
-
- def set_attention_length(self):
- self.max_length = self.model.config.n_positions
- print(
- f"Attention length set to {self.max_length} -> 'model.config.n_positions'"
- )
-
- def set_force_sequence_lenth(self, force_sequence_length=True):
- self.force_sequence_length = force_sequence_length
-
- def set_improvisation_level(self, improvisation_value):
- self.no_repeat_ngram_size = improvisation_value
- print("--------------------")
- print(f"no_repeat_ngram_size set to {improvisation_value}")
- print("--------------------")
-
- def reset_temperatures(self, track_id, temperature):
- self.piece_by_track[track_id]["temperature"] = temperature
-
- def set_nb_bars_generated(self, n_bars=8): # default is a 8 bar model
- self.model_n_bar = n_bars
-
- """ Generation Tools - Dictionnaries """
-
- def initiate_track_dict(self, instr, density, temperature):
- label = len(self.piece_by_track)
- self.piece_by_track.append(
- {
- "label": f"track_{label}",
- "instrument": instr,
- "density": density,
- "temperature": temperature,
- "bars": [],
- }
- )
-
- def update_track_dict__add_bars(self, bars, track_id):
- """Add bars to the track dictionnary"""
- for bar in self.striping_track_ends(bars).split("BAR_START "):
- if bar == "": # happens is there is one bar only
- continue
- else:
- if "TRACK_START" in bar:
- self.piece_by_track[track_id]["bars"].append(bar)
- else:
- self.piece_by_track[track_id]["bars"].append("BAR_START " + bar)
-
- def get_all_instr_bars(self, track_id):
- return self.piece_by_track[track_id]["bars"]
-
- def striping_track_ends(self, text):
- if "TRACK_END" in text:
- # first get rid of extra space if any
- # then gets rid of "TRACK_END"
- text = text.rstrip(" ").rstrip("TRACK_END")
- return text
-
- def get_last_generated_track(self, full_piece):
- track = (
- "TRACK_START "
- + self.striping_track_ends(full_piece.split("TRACK_START ")[-1])
- + "TRACK_END "
- ) # forcing the space after track and
- return track
-
- def get_selected_track_as_text(self, track_id):
- text = ""
- for bar in self.piece_by_track[track_id]["bars"]:
- text += bar
- text += "TRACK_END "
- return text
-
- @staticmethod
- def get_newly_generated_text(input_prompt, full_piece):
- return full_piece[len(input_prompt) :]
-
- def get_whole_piece_from_bar_dict(self):
- text = "PIECE_START "
- for track_id, _ in enumerate(self.piece_by_track):
- text += self.get_selected_track_as_text(track_id)
- return text
-
- def delete_one_track(self, track): # TO BE TESTED
- self.piece_by_track.pop(track)
-
- # def update_piece_dict__add_track(self, track_id, track):
- # self.piece_dict[track_id] = track
-
- # def update_all_dictionnaries__add_track(self, track):
- # self.update_piece_dict__add_track(track_id, track)
-
- """Basic generation tools"""
-
- def tokenize_input_prompt(self, input_prompt, verbose=True):
- """Tokenizing prompt
-
- Args:
- - input_prompt (str): prompt to tokenize
-
- Returns:
- - input_prompt_ids (torch.tensor): tokenized prompt
- """
- if verbose:
- print("Tokenizing input_prompt...")
-
- return self.tokenizer.encode(input_prompt, return_tensors="pt")
-
- def generate_sequence_of_token_ids(
- self,
- input_prompt_ids,
- temperature,
- verbose=True,
- ):
- """
- generate a sequence of token ids based on input_prompt_ids
- The sequence length depends on the trained model (self.model_n_bar)
- """
- generated_ids = self.model.generate(
- input_prompt_ids,
- max_length=self.max_length,
- do_sample=True,
- temperature=temperature,
- no_repeat_ngram_size=self.no_repeat_ngram_size, # default = 0
- eos_token_id=self.tokenizer.encode(self.generate_until)[0], # good
- )
-
- if verbose:
- print("Generating a token_id sequence...")
-
- return generated_ids
-
- def convert_ids_to_text(self, generated_ids, verbose=True):
- """converts the token_ids to text"""
- generated_text = self.tokenizer.decode(generated_ids[0])
- if verbose:
- print("Converting token sequence to MidiText...")
- return generated_text
-
- def generate_until_track_end(
- self,
- input_prompt="PIECE_START ",
- instrument=None,
- density=None,
- temperature=None,
- verbose=True,
- expected_length=None,
- ):
-
- """generate until the TRACK_END token is reached
- full_piece = input_prompt + generated"""
- if expected_length is None:
- expected_length = self.model_n_bar
-
- if instrument is not None:
- input_prompt = f"{input_prompt}TRACK_START INST={str(instrument)} "
- if density is not None:
- input_prompt = f"{input_prompt}DENSITY={str(density)} "
-
- if instrument is None and density is not None:
- print("Density cannot be defined without an input_prompt instrument #TOFIX")
-
- if temperature is None:
- ValueError("Temperature must be defined")
-
- if verbose:
- print("--------------------")
- print(
- f"Generating {instrument} - Density {density} - temperature {temperature}"
- )
- bar_count_checks = False
- failed = 0
- while not bar_count_checks: # regenerate until right length
- input_prompt_ids = self.tokenize_input_prompt(input_prompt, verbose=verbose)
- generated_tokens = self.generate_sequence_of_token_ids(
- input_prompt_ids, temperature, verbose=verbose
- )
- full_piece = self.convert_ids_to_text(generated_tokens, verbose=verbose)
- generated = self.get_newly_generated_text(input_prompt, full_piece)
- # bar_count_checks
- bar_count_checks, bar_count = bar_count_check(generated, expected_length)
-
- if not self.force_sequence_length:
- # set bar_count_checks to true to exist the while loop
- bar_count_checks = True
-
- if not bar_count_checks and self.force_sequence_length:
- # if the generated sequence is not the expected length
- if failed > -1: # deactivated for speed
- full_piece, bar_count_checks = forcing_bar_count(
- input_prompt,
- generated,
- bar_count,
- expected_length,
- )
- else:
- print('"--- Wrong length - Regenerating ---')
- if not bar_count_checks:
- failed += 1
- if failed > 2:
- bar_count_checks = True # TOFIX exit the while loop
-
- return full_piece
-
- def generate_one_new_track(
- self,
- instrument,
- density,
- temperature,
- input_prompt="PIECE_START ",
- ):
- self.initiate_track_dict(instrument, density, temperature)
- full_piece = self.generate_until_track_end(
- input_prompt=input_prompt,
- instrument=instrument,
- density=density,
- temperature=temperature,
- )
-
- track = self.get_last_generated_track(full_piece)
- self.update_track_dict__add_bars(track, -1)
- full_piece = self.get_whole_piece_from_bar_dict()
- return full_piece
-
- """ Piece generation - Basics """
-
- def generate_piece(self, instrument_list, density_list, temperature_list):
- """generate a sequence with mutiple tracks
- - inst_list sets the list of instruments of the order of generation
- - density is paired with inst_list
- Each track/intrument is generated on a prompt which contains the previously generated track/instrument
- This means that the first instrument is generated with less bias than the next one, and so on.
-
- 'generated_piece' keeps track of the entire piece
- 'generated_piece' is returned by self.generate_until_track_end
- # it is returned by self.generate_until_track_end"""
-
- generated_piece = "PIECE_START "
- for instrument, density, temperature in zip(
- instrument_list, density_list, temperature_list
- ):
- generated_piece = self.generate_one_new_track(
- instrument,
- density,
- temperature,
- input_prompt=generated_piece,
- )
-
- # generated_piece = self.get_whole_piece_from_bar_dict()
- self.check_the_piece_for_errors()
- return generated_piece
-
- """ Piece generation - Extra Bars """
-
- @staticmethod
- def process_prompt_for_next_bar(self, track_idx):
- """Processing the prompt for the model to generate one more bar only.
- The prompt containts:
- if not the first bar: the previous, already processed, bars of the track
- the bar initialization (ex: "TRACK_START INST=DRUMS DENSITY=2 ")
- the last (self.model_n_bar)-1 bars of the track
- Args:
- track_idx (int): the index of the track to be processed
-
- Returns:
- the processed prompt for generating the next bar
- """
- track = self.piece_by_track[track_idx]
- # for bars which are not the bar to prolong
- pre_promt = "PIECE_START "
- for i, othertrack in enumerate(self.piece_by_track):
- if i != track_idx:
- len_diff = len(othertrack["bars"]) - len(track["bars"])
- if len_diff > 0:
- # if other bars are longer, it mean that this one should catch up
- pre_promt += othertrack["bars"][0]
- for bar in track["bars"][-self.model_n_bar :]:
- pre_promt += bar
- pre_promt += "TRACK_END "
- elif False: # len_diff <= 0: # THIS GENERATES EMPTINESS
- # adding an empty bars at the end of the other tracks if they have not been processed yet
- pre_promt += othertracks["bars"][0]
- for bar in track["bars"][-(self.model_n_bar - 1) :]:
- pre_promt += bar
- for _ in range(abs(len_diff) + 1):
- pre_promt += "BAR_START BAR_END "
- pre_promt += "TRACK_END "
-
- # for the bar to prolong
- # initialization e.g TRACK_START INST=DRUMS DENSITY=2
- processed_prompt = track["bars"][0]
- for bar in track["bars"][-(self.model_n_bar - 1) :]:
- # adding the "last" bars of the track
- processed_prompt += bar
-
- processed_prompt += "BAR_START "
- print(
- f"--- prompt length = {len((pre_promt + processed_prompt).split(' '))} ---"
- )
- return pre_promt + processed_prompt
-
- def generate_one_more_bar(self, i):
- """Generate one more bar from the input_prompt"""
- processed_prompt = self.process_prompt_for_next_bar(self, i)
- prompt_plus_bar = self.generate_until_track_end(
- input_prompt=processed_prompt,
- temperature=self.piece_by_track[i]["temperature"],
- expected_length=1,
- verbose=False,
- )
- added_bar = self.get_newly_generated_bar(prompt_plus_bar)
- self.update_track_dict__add_bars(added_bar, i)
-
- def get_newly_generated_bar(self, prompt_plus_bar):
- return "BAR_START " + self.striping_track_ends(
- prompt_plus_bar.split("BAR_START ")[-1]
- )
-
- def generate_n_more_bars(self, n_bars, only_this_track=None, verbose=True):
- """Generate n more bars from the input_prompt"""
- if only_this_track is None:
- only_this_track
-
- print(f"================== ")
- print(f"Adding {n_bars} more bars to the piece ")
- for bar_id in range(n_bars):
- print(f"----- added bar #{bar_id+1} --")
- for i, track in enumerate(self.piece_by_track):
- if only_this_track is None or i == only_this_track:
- print(f"--------- {track['label']}")
- self.generate_one_more_bar(i)
- self.check_the_piece_for_errors()
-
- def check_the_piece_for_errors(self, piece: str = None):
-
- if piece is None:
- piece = generate_midi.get_whole_piece_from_bar_dict()
- errors = []
- errors.append(
- [
- (token, id)
- for id, token in enumerate(piece.split(" "))
- if token not in self.tokenizer.vocab or token == "UNK"
- ]
- )
- if len(errors) > 0:
- # print(piece)
- for er in errors:
- er
- print(f"Token not found in the piece at {er[0][1]}: {er[0][0]}")
- print(piece.split(" ")[er[0][1] - 5 : er[0][1] + 5])
-
-
-if __name__ == "__main__":
-
- # worker
- DEVICE = "cpu"
-
- # define generation parameters
- N_FILES_TO_GENERATE = 2
- Temperatures_to_try = [0.7]
-
- USE_FAMILIZED_MODEL = True
- force_sequence_length = True
-
- if USE_FAMILIZED_MODEL:
- # model_repo = "misnaej/the-jam-machine-elec-famil"
- # model_repo = "misnaej/the-jam-machine-elec-famil-ft32"
-
- # model_repo = "JammyMachina/elec-gmusic-familized-model-13-12__17-35-53"
- # n_bar_generated = 8
-
- model_repo = "JammyMachina/improved_4bars-mdl"
- n_bar_generated = 4
- instrument_promt_list = ["4", "DRUMS", "3"]
- # DRUMS = drums, 0 = piano, 1 = chromatic percussion, 2 = organ, 3 = guitar, 4 = bass, 5 = strings, 6 = ensemble, 7 = brass, 8 = reed, 9 = pipe, 10 = synth lead, 11 = synth pad, 12 = synth effects, 13 = ethnic, 14 = percussive, 15 = sound effects
- density_list = [3, 2, 2]
- # temperature_list = [0.7, 0.7, 0.75]
- else:
- model_repo = "misnaej/the-jam-machine"
- instrument_promt_list = ["30"] # , "DRUMS", "0"]
- density_list = [3] # , 2, 3]
- # temperature_list = [0.7, 0.5, 0.75]
- pass
-
- # define generation directory
- generated_sequence_files_path = define_generation_dir(model_repo)
-
- # load model and tokenizer
- model, tokenizer = LoadModel(
- model_repo, from_huggingface=True
- ).load_model_and_tokenizer()
-
- # does the prompt make sense
- check_if_prompt_inst_in_tokenizer_vocab(tokenizer, instrument_promt_list)
-
- for temperature in Temperatures_to_try:
- print(f"================= TEMPERATURE {temperature} =======================")
- for _ in range(N_FILES_TO_GENERATE):
- print(f"========================================")
- # 1 - instantiate
- generate_midi = GenerateMidiText(model, tokenizer)
- # 0 - set the n_bar for this model
- generate_midi.set_nb_bars_generated(n_bars=n_bar_generated)
- # 1 - defines the instruments, densities and temperatures
- # 2- generate the first 8 bars for each instrument
- generate_midi.set_improvisation_level(30)
- generate_midi.generate_piece(
- instrument_promt_list,
- density_list,
- [temperature for _ in density_list],
- )
- # 3 - force the model to improvise
- # generate_midi.set_improvisation_level(20)
- # 4 - generate the next 4 bars for each instrument
- # generate_midi.generate_n_more_bars(n_bar_generated)
- # 5 - lower the improvisation level
- generate_midi.generated_piece = (
- generate_midi.get_whole_piece_from_bar_dict()
- )
-
- # print the generated sequence in terminal
- print("=========================================")
- print(generate_midi.generated_piece)
- print("=========================================")
-
- # write to JSON file
- filename = WriteTextMidiToFile(
- generate_midi,
- generated_sequence_files_path,
- ).text_midi_to_file()
-
- # decode the sequence to MIDI """
- decode_tokenizer = get_miditok()
- TextDecoder(decode_tokenizer, USE_FAMILIZED_MODEL).get_midi(
- generate_midi.generated_piece, filename=filename.split(".")[0] + ".mid"
- )
- inst_midi, mixed_audio = get_music(filename.split(".")[0] + ".mid")
- max_time = get_max_time(inst_midi)
- plot_piano_roll(inst_midi)
-
- print("Et voilà! Your MIDI file is ready! GO JAM!")
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/tools/convert-torchvision-to-d2.py b/spaces/brjathu/HMR2.0/vendor/detectron2/tools/convert-torchvision-to-d2.py
deleted file mode 100644
index 4b827d960cca69657e98bd89a9aa5623a847099d..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/tools/convert-torchvision-to-d2.py
+++ /dev/null
@@ -1,56 +0,0 @@
-#!/usr/bin/env python
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-import pickle as pkl
-import sys
-import torch
-
-"""
-Usage:
- # download one of the ResNet{18,34,50,101,152} models from torchvision:
- wget https://download.pytorch.org/models/resnet50-19c8e357.pth -O r50.pth
- # run the conversion
- ./convert-torchvision-to-d2.py r50.pth r50.pkl
-
- # Then, use r50.pkl with the following changes in config:
-
-MODEL:
- WEIGHTS: "/path/to/r50.pkl"
- PIXEL_MEAN: [123.675, 116.280, 103.530]
- PIXEL_STD: [58.395, 57.120, 57.375]
- RESNETS:
- DEPTH: 50
- STRIDE_IN_1X1: False
-INPUT:
- FORMAT: "RGB"
-
- These models typically produce slightly worse results than the
- pre-trained ResNets we use in official configs, which are the
- original ResNet models released by MSRA.
-"""
-
-if __name__ == "__main__":
- input = sys.argv[1]
-
- obj = torch.load(input, map_location="cpu")
-
- newmodel = {}
- for k in list(obj.keys()):
- old_k = k
- if "layer" not in k:
- k = "stem." + k
- for t in [1, 2, 3, 4]:
- k = k.replace("layer{}".format(t), "res{}".format(t + 1))
- for t in [1, 2, 3]:
- k = k.replace("bn{}".format(t), "conv{}.norm".format(t))
- k = k.replace("downsample.0", "shortcut")
- k = k.replace("downsample.1", "shortcut.norm")
- print(old_k, "->", k)
- newmodel[k] = obj.pop(old_k).detach().numpy()
-
- res = {"model": newmodel, "__author__": "torchvision", "matching_heuristics": True}
-
- with open(sys.argv[2], "wb") as f:
- pkl.dump(res, f)
- if obj:
- print("Unconverted keys:", obj.keys())
diff --git a/spaces/camenduru-com/audioldm-text-to-audio-generation/audioldm/clap/open_clip/htsat.py b/spaces/camenduru-com/audioldm-text-to-audio-generation/audioldm/clap/open_clip/htsat.py
deleted file mode 100644
index 3b856c6a43df162116a941f1b5c76e93713b276a..0000000000000000000000000000000000000000
--- a/spaces/camenduru-com/audioldm-text-to-audio-generation/audioldm/clap/open_clip/htsat.py
+++ /dev/null
@@ -1,1308 +0,0 @@
-# Ke Chen
-# knutchen@ucsd.edu
-# HTS-AT: A HIERARCHICAL TOKEN-SEMANTIC AUDIO TRANSFORMER FOR SOUND CLASSIFICATION AND DETECTION
-# Some layers designed on the model
-# below codes are based and referred from https://github.com/microsoft/Swin-Transformer
-# Swin Transformer for Computer Vision: https://arxiv.org/pdf/2103.14030.pdf
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from itertools import repeat
-import collections.abc
-import math
-import warnings
-
-from torch.nn.init import _calculate_fan_in_and_fan_out
-import torch.utils.checkpoint as checkpoint
-
-import random
-
-from torchlibrosa.stft import Spectrogram, LogmelFilterBank
-from torchlibrosa.augmentation import SpecAugmentation
-
-from itertools import repeat
-from .utils import do_mixup, interpolate
-
-from .feature_fusion import iAFF, AFF, DAF
-
-# from PyTorch internals
-def _ntuple(n):
- def parse(x):
- if isinstance(x, collections.abc.Iterable):
- return x
- return tuple(repeat(x, n))
-
- return parse
-
-
-to_1tuple = _ntuple(1)
-to_2tuple = _ntuple(2)
-to_3tuple = _ntuple(3)
-to_4tuple = _ntuple(4)
-to_ntuple = _ntuple
-
-
-def drop_path(x, drop_prob: float = 0.0, training: bool = False):
- """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
- This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
- the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
- See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
- changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
- 'survival rate' as the argument.
- """
- if drop_prob == 0.0 or not training:
- return x
- keep_prob = 1 - drop_prob
- shape = (x.shape[0],) + (1,) * (
- x.ndim - 1
- ) # work with diff dim tensors, not just 2D ConvNets
- random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
- random_tensor.floor_() # binarize
- output = x.div(keep_prob) * random_tensor
- return output
-
-
-class DropPath(nn.Module):
- """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
-
- def __init__(self, drop_prob=None):
- super(DropPath, self).__init__()
- self.drop_prob = drop_prob
-
- def forward(self, x):
- return drop_path(x, self.drop_prob, self.training)
-
-
-class PatchEmbed(nn.Module):
- """2D Image to Patch Embedding"""
-
- def __init__(
- self,
- img_size=224,
- patch_size=16,
- in_chans=3,
- embed_dim=768,
- norm_layer=None,
- flatten=True,
- patch_stride=16,
- enable_fusion=False,
- fusion_type="None",
- ):
- super().__init__()
- img_size = to_2tuple(img_size)
- patch_size = to_2tuple(patch_size)
- patch_stride = to_2tuple(patch_stride)
- self.img_size = img_size
- self.patch_size = patch_size
- self.patch_stride = patch_stride
- self.grid_size = (
- img_size[0] // patch_stride[0],
- img_size[1] // patch_stride[1],
- )
- self.num_patches = self.grid_size[0] * self.grid_size[1]
- self.flatten = flatten
- self.in_chans = in_chans
- self.embed_dim = embed_dim
-
- self.enable_fusion = enable_fusion
- self.fusion_type = fusion_type
-
- padding = (
- (patch_size[0] - patch_stride[0]) // 2,
- (patch_size[1] - patch_stride[1]) // 2,
- )
-
- if (self.enable_fusion) and (self.fusion_type == "channel_map"):
- self.proj = nn.Conv2d(
- in_chans * 4,
- embed_dim,
- kernel_size=patch_size,
- stride=patch_stride,
- padding=padding,
- )
- else:
- self.proj = nn.Conv2d(
- in_chans,
- embed_dim,
- kernel_size=patch_size,
- stride=patch_stride,
- padding=padding,
- )
- self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
-
- if (self.enable_fusion) and (
- self.fusion_type in ["daf_2d", "aff_2d", "iaff_2d"]
- ):
- self.mel_conv2d = nn.Conv2d(
- in_chans,
- embed_dim,
- kernel_size=(patch_size[0], patch_size[1] * 3),
- stride=(patch_stride[0], patch_stride[1] * 3),
- padding=padding,
- )
- if self.fusion_type == "daf_2d":
- self.fusion_model = DAF()
- elif self.fusion_type == "aff_2d":
- self.fusion_model = AFF(channels=embed_dim, type="2D")
- elif self.fusion_type == "iaff_2d":
- self.fusion_model = iAFF(channels=embed_dim, type="2D")
-
- def forward(self, x, longer_idx=None):
- if (self.enable_fusion) and (
- self.fusion_type in ["daf_2d", "aff_2d", "iaff_2d"]
- ):
- global_x = x[:, 0:1, :, :]
-
- # global processing
- B, C, H, W = global_x.shape
- assert (
- H == self.img_size[0] and W == self.img_size[1]
- ), f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
- global_x = self.proj(global_x)
- TW = global_x.size(-1)
- if len(longer_idx) > 0:
- # local processing
- local_x = x[longer_idx, 1:, :, :].contiguous()
- B, C, H, W = local_x.shape
- local_x = local_x.view(B * C, 1, H, W)
- local_x = self.mel_conv2d(local_x)
- local_x = local_x.view(
- B, C, local_x.size(1), local_x.size(2), local_x.size(3)
- )
- local_x = local_x.permute((0, 2, 3, 1, 4)).contiguous().flatten(3)
- TB, TC, TH, _ = local_x.size()
- if local_x.size(-1) < TW:
- local_x = torch.cat(
- [
- local_x,
- torch.zeros(
- (TB, TC, TH, TW - local_x.size(-1)),
- device=global_x.device,
- ),
- ],
- dim=-1,
- )
- else:
- local_x = local_x[:, :, :, :TW]
-
- global_x[longer_idx] = self.fusion_model(global_x[longer_idx], local_x)
- x = global_x
- else:
- B, C, H, W = x.shape
- assert (
- H == self.img_size[0] and W == self.img_size[1]
- ), f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
- x = self.proj(x)
-
- if self.flatten:
- x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
- x = self.norm(x)
- return x
-
-
-class Mlp(nn.Module):
- """MLP as used in Vision Transformer, MLP-Mixer and related networks"""
-
- def __init__(
- self,
- in_features,
- hidden_features=None,
- out_features=None,
- act_layer=nn.GELU,
- drop=0.0,
- ):
- super().__init__()
- out_features = out_features or in_features
- hidden_features = hidden_features or in_features
- self.fc1 = nn.Linear(in_features, hidden_features)
- self.act = act_layer()
- self.fc2 = nn.Linear(hidden_features, out_features)
- self.drop = nn.Dropout(drop)
-
- def forward(self, x):
- x = self.fc1(x)
- x = self.act(x)
- x = self.drop(x)
- x = self.fc2(x)
- x = self.drop(x)
- return x
-
-
-def _no_grad_trunc_normal_(tensor, mean, std, a, b):
- # Cut & paste from PyTorch official master until it's in a few official releases - RW
- # Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
- def norm_cdf(x):
- # Computes standard normal cumulative distribution function
- return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
-
- if (mean < a - 2 * std) or (mean > b + 2 * std):
- warnings.warn(
- "mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
- "The distribution of values may be incorrect.",
- stacklevel=2,
- )
-
- with torch.no_grad():
- # Values are generated by using a truncated uniform distribution and
- # then using the inverse CDF for the normal distribution.
- # Get upper and lower cdf values
- l = norm_cdf((a - mean) / std)
- u = norm_cdf((b - mean) / std)
-
- # Uniformly fill tensor with values from [l, u], then translate to
- # [2l-1, 2u-1].
- tensor.uniform_(2 * l - 1, 2 * u - 1)
-
- # Use inverse cdf transform for normal distribution to get truncated
- # standard normal
- tensor.erfinv_()
-
- # Transform to proper mean, std
- tensor.mul_(std * math.sqrt(2.0))
- tensor.add_(mean)
-
- # Clamp to ensure it's in the proper range
- tensor.clamp_(min=a, max=b)
- return tensor
-
-
-def trunc_normal_(tensor, mean=0.0, std=1.0, a=-2.0, b=2.0):
- # type: (Tensor, float, float, float, float) -> Tensor
- r"""Fills the input Tensor with values drawn from a truncated
- normal distribution. The values are effectively drawn from the
- normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
- with values outside :math:`[a, b]` redrawn until they are within
- the bounds. The method used for generating the random values works
- best when :math:`a \leq \text{mean} \leq b`.
- Args:
- tensor: an n-dimensional `torch.Tensor`
- mean: the mean of the normal distribution
- std: the standard deviation of the normal distribution
- a: the minimum cutoff value
- b: the maximum cutoff value
- Examples:
- >>> w = torch.empty(3, 5)
- >>> nn.init.trunc_normal_(w)
- """
- return _no_grad_trunc_normal_(tensor, mean, std, a, b)
-
-
-def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="normal"):
- fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
- if mode == "fan_in":
- denom = fan_in
- elif mode == "fan_out":
- denom = fan_out
- elif mode == "fan_avg":
- denom = (fan_in + fan_out) / 2
-
- variance = scale / denom
-
- if distribution == "truncated_normal":
- # constant is stddev of standard normal truncated to (-2, 2)
- trunc_normal_(tensor, std=math.sqrt(variance) / 0.87962566103423978)
- elif distribution == "normal":
- tensor.normal_(std=math.sqrt(variance))
- elif distribution == "uniform":
- bound = math.sqrt(3 * variance)
- tensor.uniform_(-bound, bound)
- else:
- raise ValueError(f"invalid distribution {distribution}")
-
-
-def lecun_normal_(tensor):
- variance_scaling_(tensor, mode="fan_in", distribution="truncated_normal")
-
-
-def window_partition(x, window_size):
- """
- Args:
- x: (B, H, W, C)
- window_size (int): window size
- Returns:
- windows: (num_windows*B, window_size, window_size, C)
- """
- B, H, W, C = x.shape
- x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
- windows = (
- x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
- )
- return windows
-
-
-def window_reverse(windows, window_size, H, W):
- """
- Args:
- windows: (num_windows*B, window_size, window_size, C)
- window_size (int): Window size
- H (int): Height of image
- W (int): Width of image
- Returns:
- x: (B, H, W, C)
- """
- B = int(windows.shape[0] / (H * W / window_size / window_size))
- x = windows.view(
- B, H // window_size, W // window_size, window_size, window_size, -1
- )
- x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
- return x
-
-
-class WindowAttention(nn.Module):
- r"""Window based multi-head self attention (W-MSA) module with relative position bias.
- It supports both of shifted and non-shifted window.
- Args:
- dim (int): Number of input channels.
- window_size (tuple[int]): The height and width of the window.
- num_heads (int): Number of attention heads.
- qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
- qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
- attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
- proj_drop (float, optional): Dropout ratio of output. Default: 0.0
- """
-
- def __init__(
- self,
- dim,
- window_size,
- num_heads,
- qkv_bias=True,
- qk_scale=None,
- attn_drop=0.0,
- proj_drop=0.0,
- ):
-
- super().__init__()
- self.dim = dim
- self.window_size = window_size # Wh, Ww
- self.num_heads = num_heads
- head_dim = dim // num_heads
- self.scale = qk_scale or head_dim**-0.5
-
- # define a parameter table of relative position bias
- self.relative_position_bias_table = nn.Parameter(
- torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)
- ) # 2*Wh-1 * 2*Ww-1, nH
-
- # get pair-wise relative position index for each token inside the window
- coords_h = torch.arange(self.window_size[0])
- coords_w = torch.arange(self.window_size[1])
- coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
- coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
- relative_coords = (
- coords_flatten[:, :, None] - coords_flatten[:, None, :]
- ) # 2, Wh*Ww, Wh*Ww
- relative_coords = relative_coords.permute(
- 1, 2, 0
- ).contiguous() # Wh*Ww, Wh*Ww, 2
- relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
- relative_coords[:, :, 1] += self.window_size[1] - 1
- relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
- relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
- self.register_buffer("relative_position_index", relative_position_index)
-
- self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
- self.attn_drop = nn.Dropout(attn_drop)
- self.proj = nn.Linear(dim, dim)
- self.proj_drop = nn.Dropout(proj_drop)
-
- trunc_normal_(self.relative_position_bias_table, std=0.02)
- self.softmax = nn.Softmax(dim=-1)
-
- def forward(self, x, mask=None):
- """
- Args:
- x: input features with shape of (num_windows*B, N, C)
- mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
- """
- B_, N, C = x.shape
- qkv = (
- self.qkv(x)
- .reshape(B_, N, 3, self.num_heads, C // self.num_heads)
- .permute(2, 0, 3, 1, 4)
- )
- q, k, v = (
- qkv[0],
- qkv[1],
- qkv[2],
- ) # make torchscript happy (cannot use tensor as tuple)
-
- q = q * self.scale
- attn = q @ k.transpose(-2, -1)
-
- relative_position_bias = self.relative_position_bias_table[
- self.relative_position_index.view(-1)
- ].view(
- self.window_size[0] * self.window_size[1],
- self.window_size[0] * self.window_size[1],
- -1,
- ) # Wh*Ww,Wh*Ww,nH
- relative_position_bias = relative_position_bias.permute(
- 2, 0, 1
- ).contiguous() # nH, Wh*Ww, Wh*Ww
- attn = attn + relative_position_bias.unsqueeze(0)
-
- if mask is not None:
- nW = mask.shape[0]
- attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(
- 1
- ).unsqueeze(0)
- attn = attn.view(-1, self.num_heads, N, N)
- attn = self.softmax(attn)
- else:
- attn = self.softmax(attn)
-
- attn = self.attn_drop(attn)
-
- x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
- x = self.proj(x)
- x = self.proj_drop(x)
- return x, attn
-
- def extra_repr(self):
- return f"dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}"
-
-
-# We use the model based on Swintransformer Block, therefore we can use the swin-transformer pretrained model
-class SwinTransformerBlock(nn.Module):
- r"""Swin Transformer Block.
- Args:
- dim (int): Number of input channels.
- input_resolution (tuple[int]): Input resulotion.
- num_heads (int): Number of attention heads.
- window_size (int): Window size.
- shift_size (int): Shift size for SW-MSA.
- mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
- qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
- qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
- drop (float, optional): Dropout rate. Default: 0.0
- attn_drop (float, optional): Attention dropout rate. Default: 0.0
- drop_path (float, optional): Stochastic depth rate. Default: 0.0
- act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
- norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
- """
-
- def __init__(
- self,
- dim,
- input_resolution,
- num_heads,
- window_size=7,
- shift_size=0,
- mlp_ratio=4.0,
- qkv_bias=True,
- qk_scale=None,
- drop=0.0,
- attn_drop=0.0,
- drop_path=0.0,
- act_layer=nn.GELU,
- norm_layer=nn.LayerNorm,
- norm_before_mlp="ln",
- ):
- super().__init__()
- self.dim = dim
- self.input_resolution = input_resolution
- self.num_heads = num_heads
- self.window_size = window_size
- self.shift_size = shift_size
- self.mlp_ratio = mlp_ratio
- self.norm_before_mlp = norm_before_mlp
- if min(self.input_resolution) <= self.window_size:
- # if window size is larger than input resolution, we don't partition windows
- self.shift_size = 0
- self.window_size = min(self.input_resolution)
- assert (
- 0 <= self.shift_size < self.window_size
- ), "shift_size must in 0-window_size"
-
- self.norm1 = norm_layer(dim)
- self.attn = WindowAttention(
- dim,
- window_size=to_2tuple(self.window_size),
- num_heads=num_heads,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- attn_drop=attn_drop,
- proj_drop=drop,
- )
-
- self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
- if self.norm_before_mlp == "ln":
- self.norm2 = nn.LayerNorm(dim)
- elif self.norm_before_mlp == "bn":
- self.norm2 = lambda x: nn.BatchNorm1d(dim)(x.transpose(1, 2)).transpose(
- 1, 2
- )
- else:
- raise NotImplementedError
- mlp_hidden_dim = int(dim * mlp_ratio)
- self.mlp = Mlp(
- in_features=dim,
- hidden_features=mlp_hidden_dim,
- act_layer=act_layer,
- drop=drop,
- )
-
- if self.shift_size > 0:
- # calculate attention mask for SW-MSA
- H, W = self.input_resolution
- img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
- h_slices = (
- slice(0, -self.window_size),
- slice(-self.window_size, -self.shift_size),
- slice(-self.shift_size, None),
- )
- w_slices = (
- slice(0, -self.window_size),
- slice(-self.window_size, -self.shift_size),
- slice(-self.shift_size, None),
- )
- cnt = 0
- for h in h_slices:
- for w in w_slices:
- img_mask[:, h, w, :] = cnt
- cnt += 1
-
- mask_windows = window_partition(
- img_mask, self.window_size
- ) # nW, window_size, window_size, 1
- mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
- attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
- attn_mask = attn_mask.masked_fill(
- attn_mask != 0, float(-100.0)
- ).masked_fill(attn_mask == 0, float(0.0))
- else:
- attn_mask = None
-
- self.register_buffer("attn_mask", attn_mask)
-
- def forward(self, x):
- # pdb.set_trace()
- H, W = self.input_resolution
- # print("H: ", H)
- # print("W: ", W)
- # pdb.set_trace()
- B, L, C = x.shape
- # assert L == H * W, "input feature has wrong size"
-
- shortcut = x
- x = self.norm1(x)
- x = x.view(B, H, W, C)
-
- # cyclic shift
- if self.shift_size > 0:
- shifted_x = torch.roll(
- x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)
- )
- else:
- shifted_x = x
-
- # partition windows
- x_windows = window_partition(
- shifted_x, self.window_size
- ) # nW*B, window_size, window_size, C
- x_windows = x_windows.view(
- -1, self.window_size * self.window_size, C
- ) # nW*B, window_size*window_size, C
-
- # W-MSA/SW-MSA
- attn_windows, attn = self.attn(
- x_windows, mask=self.attn_mask
- ) # nW*B, window_size*window_size, C
-
- # merge windows
- attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
- shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
-
- # reverse cyclic shift
- if self.shift_size > 0:
- x = torch.roll(
- shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2)
- )
- else:
- x = shifted_x
- x = x.view(B, H * W, C)
-
- # FFN
- x = shortcut + self.drop_path(x)
- x = x + self.drop_path(self.mlp(self.norm2(x)))
-
- return x, attn
-
- def extra_repr(self):
- return (
- f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, "
- f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
- )
-
-
-class PatchMerging(nn.Module):
- r"""Patch Merging Layer.
- Args:
- input_resolution (tuple[int]): Resolution of input feature.
- dim (int): Number of input channels.
- norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
- """
-
- def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
- super().__init__()
- self.input_resolution = input_resolution
- self.dim = dim
- self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
- self.norm = norm_layer(4 * dim)
-
- def forward(self, x):
- """
- x: B, H*W, C
- """
- H, W = self.input_resolution
- B, L, C = x.shape
- assert L == H * W, "input feature has wrong size"
- assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
-
- x = x.view(B, H, W, C)
-
- x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
- x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
- x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
- x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
- x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
- x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
-
- x = self.norm(x)
- x = self.reduction(x)
-
- return x
-
- def extra_repr(self):
- return f"input_resolution={self.input_resolution}, dim={self.dim}"
-
-
-class BasicLayer(nn.Module):
- """A basic Swin Transformer layer for one stage.
- Args:
- dim (int): Number of input channels.
- input_resolution (tuple[int]): Input resolution.
- depth (int): Number of blocks.
- num_heads (int): Number of attention heads.
- window_size (int): Local window size.
- mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
- qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
- qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
- drop (float, optional): Dropout rate. Default: 0.0
- attn_drop (float, optional): Attention dropout rate. Default: 0.0
- drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
- norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
- downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
- use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
- """
-
- def __init__(
- self,
- dim,
- input_resolution,
- depth,
- num_heads,
- window_size,
- mlp_ratio=4.0,
- qkv_bias=True,
- qk_scale=None,
- drop=0.0,
- attn_drop=0.0,
- drop_path=0.0,
- norm_layer=nn.LayerNorm,
- downsample=None,
- use_checkpoint=False,
- norm_before_mlp="ln",
- ):
-
- super().__init__()
- self.dim = dim
- self.input_resolution = input_resolution
- self.depth = depth
- self.use_checkpoint = use_checkpoint
-
- # build blocks
- self.blocks = nn.ModuleList(
- [
- SwinTransformerBlock(
- dim=dim,
- input_resolution=input_resolution,
- num_heads=num_heads,
- window_size=window_size,
- shift_size=0 if (i % 2 == 0) else window_size // 2,
- mlp_ratio=mlp_ratio,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- drop=drop,
- attn_drop=attn_drop,
- drop_path=drop_path[i]
- if isinstance(drop_path, list)
- else drop_path,
- norm_layer=norm_layer,
- norm_before_mlp=norm_before_mlp,
- )
- for i in range(depth)
- ]
- )
-
- # patch merging layer
- if downsample is not None:
- self.downsample = downsample(
- input_resolution, dim=dim, norm_layer=norm_layer
- )
- else:
- self.downsample = None
-
- def forward(self, x):
- attns = []
- for blk in self.blocks:
- if self.use_checkpoint:
- x = checkpoint.checkpoint(blk, x)
- else:
- x, attn = blk(x)
- if not self.training:
- attns.append(attn.unsqueeze(0))
- if self.downsample is not None:
- x = self.downsample(x)
- if not self.training:
- attn = torch.cat(attns, dim=0)
- attn = torch.mean(attn, dim=0)
- return x, attn
-
- def extra_repr(self):
- return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
-
-
-# The Core of HTSAT
-class HTSAT_Swin_Transformer(nn.Module):
- r"""HTSAT based on the Swin Transformer
- Args:
- spec_size (int | tuple(int)): Input Spectrogram size. Default 256
- patch_size (int | tuple(int)): Patch size. Default: 4
- path_stride (iot | tuple(int)): Patch Stride for Frequency and Time Axis. Default: 4
- in_chans (int): Number of input image channels. Default: 1 (mono)
- num_classes (int): Number of classes for classification head. Default: 527
- embed_dim (int): Patch embedding dimension. Default: 96
- depths (tuple(int)): Depth of each HTSAT-Swin Transformer layer.
- num_heads (tuple(int)): Number of attention heads in different layers.
- window_size (int): Window size. Default: 8
- mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
- qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
- qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
- drop_rate (float): Dropout rate. Default: 0
- attn_drop_rate (float): Attention dropout rate. Default: 0
- drop_path_rate (float): Stochastic depth rate. Default: 0.1
- norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
- ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
- patch_norm (bool): If True, add normalization after patch embedding. Default: True
- use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
- config (module): The configuration Module from config.py
- """
-
- def __init__(
- self,
- spec_size=256,
- patch_size=4,
- patch_stride=(4, 4),
- in_chans=1,
- num_classes=527,
- embed_dim=96,
- depths=[2, 2, 6, 2],
- num_heads=[4, 8, 16, 32],
- window_size=8,
- mlp_ratio=4.0,
- qkv_bias=True,
- qk_scale=None,
- drop_rate=0.0,
- attn_drop_rate=0.0,
- drop_path_rate=0.1,
- norm_layer=nn.LayerNorm,
- ape=False,
- patch_norm=True,
- use_checkpoint=False,
- norm_before_mlp="ln",
- config=None,
- enable_fusion=False,
- fusion_type="None",
- **kwargs,
- ):
- super(HTSAT_Swin_Transformer, self).__init__()
-
- self.config = config
- self.spec_size = spec_size
- self.patch_stride = patch_stride
- self.patch_size = patch_size
- self.window_size = window_size
- self.embed_dim = embed_dim
- self.depths = depths
- self.ape = ape
- self.in_chans = in_chans
- self.num_classes = num_classes
- self.num_heads = num_heads
- self.num_layers = len(self.depths)
- self.num_features = int(self.embed_dim * 2 ** (self.num_layers - 1))
-
- self.drop_rate = drop_rate
- self.attn_drop_rate = attn_drop_rate
- self.drop_path_rate = drop_path_rate
-
- self.qkv_bias = qkv_bias
- self.qk_scale = None
-
- self.patch_norm = patch_norm
- self.norm_layer = norm_layer if self.patch_norm else None
- self.norm_before_mlp = norm_before_mlp
- self.mlp_ratio = mlp_ratio
-
- self.use_checkpoint = use_checkpoint
-
- self.enable_fusion = enable_fusion
- self.fusion_type = fusion_type
-
- # process mel-spec ; used only once
- self.freq_ratio = self.spec_size // self.config.mel_bins
- window = "hann"
- center = True
- pad_mode = "reflect"
- ref = 1.0
- amin = 1e-10
- top_db = None
- self.interpolate_ratio = 32 # Downsampled ratio
- # Spectrogram extractor
- self.spectrogram_extractor = Spectrogram(
- n_fft=config.window_size,
- hop_length=config.hop_size,
- win_length=config.window_size,
- window=window,
- center=center,
- pad_mode=pad_mode,
- freeze_parameters=True,
- )
- # Logmel feature extractor
- self.logmel_extractor = LogmelFilterBank(
- sr=config.sample_rate,
- n_fft=config.window_size,
- n_mels=config.mel_bins,
- fmin=config.fmin,
- fmax=config.fmax,
- ref=ref,
- amin=amin,
- top_db=top_db,
- freeze_parameters=True,
- )
- # Spec augmenter
- self.spec_augmenter = SpecAugmentation(
- time_drop_width=64,
- time_stripes_num=2,
- freq_drop_width=8,
- freq_stripes_num=2,
- ) # 2 2
- self.bn0 = nn.BatchNorm2d(self.config.mel_bins)
-
- # split spctrogram into non-overlapping patches
- self.patch_embed = PatchEmbed(
- img_size=self.spec_size,
- patch_size=self.patch_size,
- in_chans=self.in_chans,
- embed_dim=self.embed_dim,
- norm_layer=self.norm_layer,
- patch_stride=patch_stride,
- enable_fusion=self.enable_fusion,
- fusion_type=self.fusion_type,
- )
-
- num_patches = self.patch_embed.num_patches
- patches_resolution = self.patch_embed.grid_size
- self.patches_resolution = patches_resolution
-
- # absolute position embedding
- if self.ape:
- self.absolute_pos_embed = nn.Parameter(
- torch.zeros(1, num_patches, self.embed_dim)
- )
- trunc_normal_(self.absolute_pos_embed, std=0.02)
-
- self.pos_drop = nn.Dropout(p=self.drop_rate)
-
- # stochastic depth
- dpr = [
- x.item() for x in torch.linspace(0, self.drop_path_rate, sum(self.depths))
- ] # stochastic depth decay rule
-
- # build layers
- self.layers = nn.ModuleList()
- for i_layer in range(self.num_layers):
- layer = BasicLayer(
- dim=int(self.embed_dim * 2**i_layer),
- input_resolution=(
- patches_resolution[0] // (2**i_layer),
- patches_resolution[1] // (2**i_layer),
- ),
- depth=self.depths[i_layer],
- num_heads=self.num_heads[i_layer],
- window_size=self.window_size,
- mlp_ratio=self.mlp_ratio,
- qkv_bias=self.qkv_bias,
- qk_scale=self.qk_scale,
- drop=self.drop_rate,
- attn_drop=self.attn_drop_rate,
- drop_path=dpr[
- sum(self.depths[:i_layer]) : sum(self.depths[: i_layer + 1])
- ],
- norm_layer=self.norm_layer,
- downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
- use_checkpoint=use_checkpoint,
- norm_before_mlp=self.norm_before_mlp,
- )
- self.layers.append(layer)
-
- self.norm = self.norm_layer(self.num_features)
- self.avgpool = nn.AdaptiveAvgPool1d(1)
- self.maxpool = nn.AdaptiveMaxPool1d(1)
-
- SF = (
- self.spec_size
- // (2 ** (len(self.depths) - 1))
- // self.patch_stride[0]
- // self.freq_ratio
- )
- self.tscam_conv = nn.Conv2d(
- in_channels=self.num_features,
- out_channels=self.num_classes,
- kernel_size=(SF, 3),
- padding=(0, 1),
- )
- self.head = nn.Linear(num_classes, num_classes)
-
- if (self.enable_fusion) and (
- self.fusion_type in ["daf_1d", "aff_1d", "iaff_1d"]
- ):
- self.mel_conv1d = nn.Sequential(
- nn.Conv1d(64, 64, kernel_size=5, stride=3, padding=2),
- nn.BatchNorm1d(64),
- )
- if self.fusion_type == "daf_1d":
- self.fusion_model = DAF()
- elif self.fusion_type == "aff_1d":
- self.fusion_model = AFF(channels=64, type="1D")
- elif self.fusion_type == "iaff_1d":
- self.fusion_model = iAFF(channels=64, type="1D")
-
- self.apply(self._init_weights)
-
- def _init_weights(self, m):
- if isinstance(m, nn.Linear):
- trunc_normal_(m.weight, std=0.02)
- if isinstance(m, nn.Linear) and m.bias is not None:
- nn.init.constant_(m.bias, 0)
- elif isinstance(m, nn.LayerNorm):
- nn.init.constant_(m.bias, 0)
- nn.init.constant_(m.weight, 1.0)
-
- @torch.jit.ignore
- def no_weight_decay(self):
- return {"absolute_pos_embed"}
-
- @torch.jit.ignore
- def no_weight_decay_keywords(self):
- return {"relative_position_bias_table"}
-
- def forward_features(self, x, longer_idx=None):
- # A deprecated optimization for using a hierarchical output from different blocks
-
- frames_num = x.shape[2]
- x = self.patch_embed(x, longer_idx=longer_idx)
- if self.ape:
- x = x + self.absolute_pos_embed
- x = self.pos_drop(x)
- for i, layer in enumerate(self.layers):
- x, attn = layer(x)
- # for x
- x = self.norm(x)
- B, N, C = x.shape
- SF = frames_num // (2 ** (len(self.depths) - 1)) // self.patch_stride[0]
- ST = frames_num // (2 ** (len(self.depths) - 1)) // self.patch_stride[1]
- x = x.permute(0, 2, 1).contiguous().reshape(B, C, SF, ST)
- B, C, F, T = x.shape
- # group 2D CNN
- c_freq_bin = F // self.freq_ratio
- x = x.reshape(B, C, F // c_freq_bin, c_freq_bin, T)
- x = x.permute(0, 1, 3, 2, 4).contiguous().reshape(B, C, c_freq_bin, -1)
- # get latent_output
- fine_grained_latent_output = torch.mean(x, dim=2)
- fine_grained_latent_output = interpolate(
- fine_grained_latent_output.permute(0, 2, 1).contiguous(),
- 8 * self.patch_stride[1],
- )
-
- latent_output = self.avgpool(torch.flatten(x, 2))
- latent_output = torch.flatten(latent_output, 1)
-
- # display the attention map, if needed
-
- x = self.tscam_conv(x)
- x = torch.flatten(x, 2) # B, C, T
-
- fpx = interpolate(
- torch.sigmoid(x).permute(0, 2, 1).contiguous(), 8 * self.patch_stride[1]
- )
-
- x = self.avgpool(x)
- x = torch.flatten(x, 1)
-
- output_dict = {
- "framewise_output": fpx, # already sigmoided
- "clipwise_output": torch.sigmoid(x),
- "fine_grained_embedding": fine_grained_latent_output,
- "embedding": latent_output,
- }
-
- return output_dict
-
- def crop_wav(self, x, crop_size, spe_pos=None):
- time_steps = x.shape[2]
- tx = torch.zeros(x.shape[0], x.shape[1], crop_size, x.shape[3]).to(x.device)
- for i in range(len(x)):
- if spe_pos is None:
- crop_pos = random.randint(0, time_steps - crop_size - 1)
- else:
- crop_pos = spe_pos
- tx[i][0] = x[i, 0, crop_pos : crop_pos + crop_size, :]
- return tx
-
- # Reshape the wavform to a img size, if you want to use the pretrained swin transformer model
- def reshape_wav2img(self, x):
- B, C, T, F = x.shape
- target_T = int(self.spec_size * self.freq_ratio)
- target_F = self.spec_size // self.freq_ratio
- assert (
- T <= target_T and F <= target_F
- ), "the wav size should less than or equal to the swin input size"
- # to avoid bicubic zero error
- if T < target_T:
- x = nn.functional.interpolate(
- x, (target_T, x.shape[3]), mode="bicubic", align_corners=True
- )
- if F < target_F:
- x = nn.functional.interpolate(
- x, (x.shape[2], target_F), mode="bicubic", align_corners=True
- )
- x = x.permute(0, 1, 3, 2).contiguous()
- x = x.reshape(
- x.shape[0],
- x.shape[1],
- x.shape[2],
- self.freq_ratio,
- x.shape[3] // self.freq_ratio,
- )
- # print(x.shape)
- x = x.permute(0, 1, 3, 2, 4).contiguous()
- x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3], x.shape[4])
- return x
-
- # Repeat the wavform to a img size, if you want to use the pretrained swin transformer model
- def repeat_wat2img(self, x, cur_pos):
- B, C, T, F = x.shape
- target_T = int(self.spec_size * self.freq_ratio)
- target_F = self.spec_size // self.freq_ratio
- assert (
- T <= target_T and F <= target_F
- ), "the wav size should less than or equal to the swin input size"
- # to avoid bicubic zero error
- if T < target_T:
- x = nn.functional.interpolate(
- x, (target_T, x.shape[3]), mode="bicubic", align_corners=True
- )
- if F < target_F:
- x = nn.functional.interpolate(
- x, (x.shape[2], target_F), mode="bicubic", align_corners=True
- )
- x = x.permute(0, 1, 3, 2).contiguous() # B C F T
- x = x[:, :, :, cur_pos : cur_pos + self.spec_size]
- x = x.repeat(repeats=(1, 1, 4, 1))
- return x
-
- def forward(
- self, x: torch.Tensor, mixup_lambda=None, infer_mode=False, device=None
- ): # out_feat_keys: List[str] = None):
-
- if self.enable_fusion and x["longer"].sum() == 0:
- # if no audio is longer than 10s, then randomly select one audio to be longer
- x["longer"][torch.randint(0, x["longer"].shape[0], (1,))] = True
-
- if not self.enable_fusion:
- x = x["waveform"].to(device=device, non_blocking=True)
- x = self.spectrogram_extractor(x) # (batch_size, 1, time_steps, freq_bins)
- x = self.logmel_extractor(x) # (batch_size, 1, time_steps, mel_bins)
- x = x.transpose(1, 3)
- x = self.bn0(x)
- x = x.transpose(1, 3)
- if self.training:
- x = self.spec_augmenter(x)
-
- if self.training and mixup_lambda is not None:
- x = do_mixup(x, mixup_lambda)
-
- x = self.reshape_wav2img(x)
- output_dict = self.forward_features(x)
- else:
- longer_list = x["longer"].to(device=device, non_blocking=True)
- x = x["mel_fusion"].to(device=device, non_blocking=True)
- x = x.transpose(1, 3)
- x = self.bn0(x)
- x = x.transpose(1, 3)
- longer_list_idx = torch.where(longer_list)[0]
- if self.fusion_type in ["daf_1d", "aff_1d", "iaff_1d"]:
- new_x = x[:, 0:1, :, :].clone().contiguous()
- if len(longer_list_idx) > 0:
- # local processing
- fusion_x_local = x[longer_list_idx, 1:, :, :].clone().contiguous()
- FB, FC, FT, FF = fusion_x_local.size()
- fusion_x_local = fusion_x_local.view(FB * FC, FT, FF)
- fusion_x_local = torch.permute(
- fusion_x_local, (0, 2, 1)
- ).contiguous()
- fusion_x_local = self.mel_conv1d(fusion_x_local)
- fusion_x_local = fusion_x_local.view(
- FB, FC, FF, fusion_x_local.size(-1)
- )
- fusion_x_local = (
- torch.permute(fusion_x_local, (0, 2, 1, 3))
- .contiguous()
- .flatten(2)
- )
- if fusion_x_local.size(-1) < FT:
- fusion_x_local = torch.cat(
- [
- fusion_x_local,
- torch.zeros(
- (FB, FF, FT - fusion_x_local.size(-1)),
- device=device,
- ),
- ],
- dim=-1,
- )
- else:
- fusion_x_local = fusion_x_local[:, :, :FT]
- # 1D fusion
- new_x = new_x.squeeze(1).permute((0, 2, 1)).contiguous()
- new_x[longer_list_idx] = self.fusion_model(
- new_x[longer_list_idx], fusion_x_local
- )
- x = new_x.permute((0, 2, 1)).contiguous()[:, None, :, :]
- else:
- x = new_x
-
- elif self.fusion_type in ["daf_2d", "aff_2d", "iaff_2d", "channel_map"]:
- x = x # no change
-
- if self.training:
- x = self.spec_augmenter(x)
- if self.training and mixup_lambda is not None:
- x = do_mixup(x, mixup_lambda)
-
- x = self.reshape_wav2img(x)
- output_dict = self.forward_features(x, longer_idx=longer_list_idx)
-
- # if infer_mode:
- # # in infer mode. we need to handle different length audio input
- # frame_num = x.shape[2]
- # target_T = int(self.spec_size * self.freq_ratio)
- # repeat_ratio = math.floor(target_T / frame_num)
- # x = x.repeat(repeats=(1,1,repeat_ratio,1))
- # x = self.reshape_wav2img(x)
- # output_dict = self.forward_features(x)
- # else:
- # if x.shape[2] > self.freq_ratio * self.spec_size:
- # if self.training:
- # x = self.crop_wav(x, crop_size=self.freq_ratio * self.spec_size)
- # x = self.reshape_wav2img(x)
- # output_dict = self.forward_features(x)
- # else:
- # # Change: Hard code here
- # overlap_size = (x.shape[2] - 1) // 4
- # output_dicts = []
- # crop_size = (x.shape[2] - 1) // 2
- # for cur_pos in range(0, x.shape[2] - crop_size - 1, overlap_size):
- # tx = self.crop_wav(x, crop_size = crop_size, spe_pos = cur_pos)
- # tx = self.reshape_wav2img(tx)
- # output_dicts.append(self.forward_features(tx))
- # clipwise_output = torch.zeros_like(output_dicts[0]["clipwise_output"]).float().to(x.device)
- # framewise_output = torch.zeros_like(output_dicts[0]["framewise_output"]).float().to(x.device)
- # for d in output_dicts:
- # clipwise_output += d["clipwise_output"]
- # framewise_output += d["framewise_output"]
- # clipwise_output = clipwise_output / len(output_dicts)
- # framewise_output = framewise_output / len(output_dicts)
- # output_dict = {
- # 'framewise_output': framewise_output,
- # 'clipwise_output': clipwise_output
- # }
- # else: # this part is typically used, and most easy one
- # x = self.reshape_wav2img(x)
- # output_dict = self.forward_features(x)
- # x = self.head(x)
-
- # We process the data in the dataloader part, in that here we only consider the input_T < fixed_T
-
- return output_dict
-
-
-def create_htsat_model(audio_cfg, enable_fusion=False, fusion_type="None"):
- try:
-
- assert audio_cfg.model_name in [
- "tiny",
- "base",
- "large",
- ], "model name for HTS-AT is wrong!"
- if audio_cfg.model_name == "tiny":
- model = HTSAT_Swin_Transformer(
- spec_size=256,
- patch_size=4,
- patch_stride=(4, 4),
- num_classes=audio_cfg.class_num,
- embed_dim=96,
- depths=[2, 2, 6, 2],
- num_heads=[4, 8, 16, 32],
- window_size=8,
- config=audio_cfg,
- enable_fusion=enable_fusion,
- fusion_type=fusion_type,
- )
- elif audio_cfg.model_name == "base":
- model = HTSAT_Swin_Transformer(
- spec_size=256,
- patch_size=4,
- patch_stride=(4, 4),
- num_classes=audio_cfg.class_num,
- embed_dim=128,
- depths=[2, 2, 12, 2],
- num_heads=[4, 8, 16, 32],
- window_size=8,
- config=audio_cfg,
- enable_fusion=enable_fusion,
- fusion_type=fusion_type,
- )
- elif audio_cfg.model_name == "large":
- model = HTSAT_Swin_Transformer(
- spec_size=256,
- patch_size=4,
- patch_stride=(4, 4),
- num_classes=audio_cfg.class_num,
- embed_dim=256,
- depths=[2, 2, 12, 2],
- num_heads=[4, 8, 16, 32],
- window_size=8,
- config=audio_cfg,
- enable_fusion=enable_fusion,
- fusion_type=fusion_type,
- )
-
- return model
- except:
- raise RuntimeError(
- f"Import Model for {audio_cfg.model_name} not found, or the audio cfg parameters are not enough."
- )
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/.github/workflows/levenshtein.js b/spaces/carlosalonso/Detection-video/carpeta_deteccion/.github/workflows/levenshtein.js
deleted file mode 100644
index 67a5e3613c0072d124035ee8933a23de2105cfe3..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/.github/workflows/levenshtein.js
+++ /dev/null
@@ -1,44 +0,0 @@
-/*
-Copyright (c) 2011 Andrei Mackenzie
-
-Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
-*/
-
-// Compute the edit distance between the two given strings
-exports.getEditDistance = function(a, b){
- if(a.length == 0) return b.length;
- if(b.length == 0) return a.length;
-
- var matrix = [];
-
- // increment along the first column of each row
- var i;
- for(i = 0; i <= b.length; i++){
- matrix[i] = [i];
- }
-
- // increment each column in the first row
- var j;
- for(j = 0; j <= a.length; j++){
- matrix[0][j] = j;
- }
-
- // Fill in the rest of the matrix
- for(i = 1; i <= b.length; i++){
- for(j = 1; j <= a.length; j++){
- if(b.charAt(i-1) == a.charAt(j-1)){
- matrix[i][j] = matrix[i-1][j-1];
- } else {
- matrix[i][j] = Math.min(matrix[i-1][j-1] + 1, // substitution
- Math.min(matrix[i][j-1] + 1, // insertion
- matrix[i-1][j] + 1)); // deletion
- }
- }
- }
-
- return matrix[b.length][a.length];
-};
diff --git a/spaces/ch1n3du/bird_or_forest/README.md b/spaces/ch1n3du/bird_or_forest/README.md
deleted file mode 100644
index 026b0aa711ca67f85b328ad81d0d785208954ffd..0000000000000000000000000000000000000000
--- a/spaces/ch1n3du/bird_or_forest/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Bird Or Forest
-emoji: 🔥
-colorFrom: blue
-colorTo: green
-sdk: gradio
-sdk_version: 3.27.0
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/chendl/compositional_test/transformers/examples/research_projects/rag-end2end-retriever/callbacks_rag.py b/spaces/chendl/compositional_test/transformers/examples/research_projects/rag-end2end-retriever/callbacks_rag.py
deleted file mode 100644
index 09a30ff6d5c43313aea143620978a0ae91e5a8e9..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/transformers/examples/research_projects/rag-end2end-retriever/callbacks_rag.py
+++ /dev/null
@@ -1,119 +0,0 @@
-import logging
-from pathlib import Path
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
-from pytorch_lightning.utilities import rank_zero_only
-from utils_rag import save_json
-
-
-def count_trainable_parameters(model):
- model_parameters = filter(lambda p: p.requires_grad, model.parameters())
- params = sum([np.prod(p.size()) for p in model_parameters])
- return params
-
-
-logger = logging.getLogger(__name__)
-
-
-def get_checkpoint_callback(output_dir, metric):
- """Saves the best model by validation EM score."""
- if metric == "rouge2":
- exp = "{val_avg_rouge2:.4f}-{step_count}"
- elif metric == "bleu":
- exp = "{val_avg_bleu:.4f}-{step_count}"
- elif metric == "em":
- exp = "{val_avg_em:.4f}-{step_count}"
- elif metric == "loss":
- exp = "{val_avg_loss:.4f}-{step_count}"
- else:
- raise NotImplementedError(
- f"seq2seq callbacks only support rouge2 and bleu, got {metric}, You can make your own by adding to this"
- " function."
- )
-
- checkpoint_callback = ModelCheckpoint(
- dirpath=output_dir,
- filename=exp,
- monitor=f"val_{metric}",
- mode="max",
- save_top_k=1,
- every_n_epochs=1, # works only with PL > 1.3
- )
-
- return checkpoint_callback
-
-
-def get_early_stopping_callback(metric, patience):
- return EarlyStopping(
- monitor=f"val_{metric}", # does this need avg?
- mode="min" if "loss" in metric else "max",
- patience=patience,
- verbose=True,
- )
-
-
-class Seq2SeqLoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
- pl_module.logger.log_metrics(lrs)
-
- @rank_zero_only
- def _write_logs(
- self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
- ) -> None:
- logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
- metrics = trainer.callback_metrics
- trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
- # Log results
- od = Path(pl_module.hparams.output_dir)
- if type_path == "test":
- results_file = od / "test_results.txt"
- generations_file = od / "test_generations.txt"
- else:
- # this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
- # If people want this it will be easy enough to add back.
- results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
- generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
- results_file.parent.mkdir(exist_ok=True)
- generations_file.parent.mkdir(exist_ok=True)
- with open(results_file, "a+") as writer:
- for key in sorted(metrics):
- if key in ["log", "progress_bar", "preds"]:
- continue
- val = metrics[key]
- if isinstance(val, torch.Tensor):
- val = val.item()
- msg = f"{key}: {val:.6f}\n"
- writer.write(msg)
-
- if not save_generations:
- return
-
- if "preds" in metrics:
- content = "\n".join(metrics["preds"])
- generations_file.open("w+").write(content)
-
- @rank_zero_only
- def on_train_start(self, trainer, pl_module):
- try:
- npars = pl_module.model.model.num_parameters()
- except AttributeError:
- npars = pl_module.model.num_parameters()
-
- n_trainable_pars = count_trainable_parameters(pl_module)
- # mp stands for million parameters
- trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
-
- @rank_zero_only
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- return self._write_logs(trainer, pl_module, "test")
-
- @rank_zero_only
- def on_validation_end(self, trainer: pl.Trainer, pl_module):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- # Uncommenting this will save val generations
- # return self._write_logs(trainer, pl_module, "valid")
diff --git a/spaces/chendl/compositional_test/transformers/examples/research_projects/seq2seq-distillation/finetune.sh b/spaces/chendl/compositional_test/transformers/examples/research_projects/seq2seq-distillation/finetune.sh
deleted file mode 100644
index 683c2d7752df134d3da861dbe438f9fb65543ea4..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/transformers/examples/research_projects/seq2seq-distillation/finetune.sh
+++ /dev/null
@@ -1,11 +0,0 @@
-# the proper usage is documented in the README, you need to specify data_dir, output_dir and model_name_or_path
-# run ./finetune.sh --help to see all the possible options
-python finetune.py \
- --learning_rate=3e-5 \
- --fp16 \
- --gpus 1 \
- --do_train \
- --do_predict \
- --n_val 1000 \
- --val_check_interval 0.1 \
- "$@"
diff --git a/spaces/chinhon/malay_headlines_writer/README.md b/spaces/chinhon/malay_headlines_writer/README.md
deleted file mode 100644
index 5eb69d812fb8d8d99fc0eb6b549d8c75bc38ffc4..0000000000000000000000000000000000000000
--- a/spaces/chinhon/malay_headlines_writer/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Malay_headlines_writer
-emoji: ⚡
-colorFrom: yellow
-colorTo: purple
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/chromadb/test/property/test_embeddings.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/chromadb/test/property/test_embeddings.py
deleted file mode 100644
index de0074140d0094f64b15598e77bb52f337f1d6d0..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/chromadb/test/property/test_embeddings.py
+++ /dev/null
@@ -1,354 +0,0 @@
-import pytest
-import logging
-import hypothesis.strategies as st
-from typing import Set, cast, Union, DefaultDict
-from dataclasses import dataclass
-from chromadb.api.types import ID, Include, IDs
-import chromadb.errors as errors
-from chromadb.api import API
-from chromadb.api.models.Collection import Collection
-from chromadb.db.impl.sqlite import SqliteDB
-import chromadb.test.property.strategies as strategies
-from hypothesis.stateful import (
- Bundle,
- RuleBasedStateMachine,
- MultipleResults,
- rule,
- initialize,
- precondition,
- consumes,
- run_state_machine_as_test,
- multiple,
- invariant,
-)
-from collections import defaultdict
-import chromadb.test.property.invariants as invariants
-import numpy as np
-
-
-traces: DefaultDict[str, int] = defaultdict(lambda: 0)
-
-
-def trace(key: str) -> None:
- global traces
- traces[key] += 1
-
-
-def print_traces() -> None:
- global traces
- for key, value in traces.items():
- print(f"{key}: {value}")
-
-
-dtype_shared_st: st.SearchStrategy[
- Union[np.float16, np.float32, np.float64]
-] = st.shared(st.sampled_from(strategies.float_types), key="dtype")
-
-dimension_shared_st: st.SearchStrategy[int] = st.shared(
- st.integers(min_value=2, max_value=2048), key="dimension"
-)
-
-
-@dataclass
-class EmbeddingStateMachineStates:
- initialize = "initialize"
- add_embeddings = "add_embeddings"
- delete_by_ids = "delete_by_ids"
- update_embeddings = "update_embeddings"
- upsert_embeddings = "upsert_embeddings"
-
-
-collection_st = st.shared(strategies.collections(with_hnsw_params=True), key="coll")
-
-
-class EmbeddingStateMachine(RuleBasedStateMachine):
- collection: Collection
- embedding_ids: Bundle[ID] = Bundle("embedding_ids")
-
- def __init__(self, api: API):
- super().__init__()
- self.api = api
- self._rules_strategy = strategies.DeterministicRuleStrategy(self) # type: ignore
-
- @initialize(collection=collection_st) # type: ignore
- def initialize(self, collection: strategies.Collection):
- self.api.reset()
- self.collection = self.api.create_collection(
- name=collection.name,
- metadata=collection.metadata,
- embedding_function=collection.embedding_function,
- )
- self.embedding_function = collection.embedding_function
- trace("init")
- self.on_state_change(EmbeddingStateMachineStates.initialize)
-
- self.record_set_state = strategies.StateMachineRecordSet(
- ids=[], metadatas=[], documents=[], embeddings=[]
- )
-
- @rule(target=embedding_ids, record_set=strategies.recordsets(collection_st))
- def add_embeddings(self, record_set: strategies.RecordSet) -> MultipleResults[ID]:
- trace("add_embeddings")
- self.on_state_change(EmbeddingStateMachineStates.add_embeddings)
-
- normalized_record_set: strategies.NormalizedRecordSet = invariants.wrap_all(
- record_set
- )
-
- if len(normalized_record_set["ids"]) > 0:
- trace("add_more_embeddings")
-
- if not invariants.is_metadata_valid(normalized_record_set):
- with pytest.raises(Exception):
- self.collection.add(**normalized_record_set)
- return multiple()
-
- intersection = set(normalized_record_set["ids"]).intersection(
- self.record_set_state["ids"]
- )
- if len(intersection) > 0:
- # Partially apply the non-duplicative records to the state
- new_ids = list(set(normalized_record_set["ids"]).difference(intersection))
- indices = [normalized_record_set["ids"].index(id) for id in new_ids]
- filtered_record_set: strategies.NormalizedRecordSet = {
- "ids": [normalized_record_set["ids"][i] for i in indices],
- "metadatas": [normalized_record_set["metadatas"][i] for i in indices]
- if normalized_record_set["metadatas"]
- else None,
- "documents": [normalized_record_set["documents"][i] for i in indices]
- if normalized_record_set["documents"]
- else None,
- "embeddings": [normalized_record_set["embeddings"][i] for i in indices]
- if normalized_record_set["embeddings"]
- else None,
- }
- self.collection.add(**normalized_record_set)
- self._upsert_embeddings(cast(strategies.RecordSet, filtered_record_set))
- return multiple(*filtered_record_set["ids"])
-
- else:
- self.collection.add(**normalized_record_set)
- self._upsert_embeddings(cast(strategies.RecordSet, normalized_record_set))
- return multiple(*normalized_record_set["ids"])
-
- @precondition(lambda self: len(self.record_set_state["ids"]) > 20)
- @rule(ids=st.lists(consumes(embedding_ids), min_size=1, max_size=20))
- def delete_by_ids(self, ids: IDs) -> None:
- trace("remove embeddings")
- self.on_state_change(EmbeddingStateMachineStates.delete_by_ids)
- indices_to_remove = [self.record_set_state["ids"].index(id) for id in ids]
-
- self.collection.delete(ids=ids)
- self._remove_embeddings(set(indices_to_remove))
-
- # Removing the precondition causes the tests to frequently fail as "unsatisfiable"
- # Using a value < 5 causes retries and lowers the number of valid samples
- @precondition(lambda self: len(self.record_set_state["ids"]) >= 5)
- @rule(
- record_set=strategies.recordsets(
- collection_strategy=collection_st,
- id_strategy=embedding_ids,
- min_size=1,
- max_size=5,
- )
- )
- def update_embeddings(self, record_set: strategies.RecordSet) -> None:
- trace("update embeddings")
- self.on_state_change(EmbeddingStateMachineStates.update_embeddings)
-
- normalized_record_set: strategies.NormalizedRecordSet = invariants.wrap_all(
- record_set
- )
- if not invariants.is_metadata_valid(normalized_record_set):
- with pytest.raises(Exception):
- self.collection.update(**normalized_record_set)
- return
-
- self.collection.update(**record_set)
- self._upsert_embeddings(record_set)
-
- # Using a value < 3 causes more retries and lowers the number of valid samples
- @precondition(lambda self: len(self.record_set_state["ids"]) >= 3)
- @rule(
- record_set=strategies.recordsets(
- collection_strategy=collection_st,
- id_strategy=st.one_of(embedding_ids, strategies.safe_text),
- min_size=1,
- max_size=5,
- )
- )
- def upsert_embeddings(self, record_set: strategies.RecordSet) -> None:
- trace("upsert embeddings")
- self.on_state_change(EmbeddingStateMachineStates.upsert_embeddings)
-
- normalized_record_set: strategies.NormalizedRecordSet = invariants.wrap_all(
- record_set
- )
- if not invariants.is_metadata_valid(normalized_record_set):
- with pytest.raises(Exception):
- self.collection.upsert(**normalized_record_set)
- return
-
- self.collection.upsert(**record_set)
- self._upsert_embeddings(record_set)
-
- @invariant()
- def count(self) -> None:
- invariants.count(
- self.collection, cast(strategies.RecordSet, self.record_set_state)
- )
-
- @invariant()
- def no_duplicates(self) -> None:
- invariants.no_duplicates(self.collection)
-
- @invariant()
- def ann_accuracy(self) -> None:
- invariants.ann_accuracy(
- collection=self.collection,
- record_set=cast(strategies.RecordSet, self.record_set_state),
- min_recall=0.95,
- embedding_function=self.embedding_function,
- )
-
- def _upsert_embeddings(self, record_set: strategies.RecordSet) -> None:
- normalized_record_set: strategies.NormalizedRecordSet = invariants.wrap_all(
- record_set
- )
- for idx, id in enumerate(normalized_record_set["ids"]):
- # Update path
- if id in self.record_set_state["ids"]:
- target_idx = self.record_set_state["ids"].index(id)
- if normalized_record_set["embeddings"] is not None:
- self.record_set_state["embeddings"][
- target_idx
- ] = normalized_record_set["embeddings"][idx]
- else:
- assert normalized_record_set["documents"] is not None
- assert self.embedding_function is not None
- self.record_set_state["embeddings"][
- target_idx
- ] = self.embedding_function(
- [normalized_record_set["documents"][idx]]
- )[
- 0
- ]
- if normalized_record_set["metadatas"] is not None:
- # Sqlite merges the metadata, as opposed to old
- # implementations which overwrites it
- record_set_state = self.record_set_state["metadatas"][target_idx]
- if (
- hasattr(self.api, "_sysdb")
- and type(self.api._sysdb) == SqliteDB
- and record_set_state is not None
- ):
- record_set_state.update(normalized_record_set["metadatas"][idx])
- else:
- self.record_set_state["metadatas"][
- target_idx
- ] = normalized_record_set["metadatas"][idx]
- if normalized_record_set["documents"] is not None:
- self.record_set_state["documents"][
- target_idx
- ] = normalized_record_set["documents"][idx]
- else:
- # Add path
- self.record_set_state["ids"].append(id)
- if normalized_record_set["embeddings"] is not None:
- self.record_set_state["embeddings"].append(
- normalized_record_set["embeddings"][idx]
- )
- else:
- assert self.embedding_function is not None
- assert normalized_record_set["documents"] is not None
- self.record_set_state["embeddings"].append(
- self.embedding_function(
- [normalized_record_set["documents"][idx]]
- )[0]
- )
- if normalized_record_set["metadatas"] is not None:
- self.record_set_state["metadatas"].append(
- normalized_record_set["metadatas"][idx]
- )
- else:
- self.record_set_state["metadatas"].append(None)
- if normalized_record_set["documents"] is not None:
- self.record_set_state["documents"].append(
- normalized_record_set["documents"][idx]
- )
- else:
- self.record_set_state["documents"].append(None)
-
- def _remove_embeddings(self, indices_to_remove: Set[int]) -> None:
- indices_list = list(indices_to_remove)
- indices_list.sort(reverse=True)
-
- for i in indices_list:
- del self.record_set_state["ids"][i]
- del self.record_set_state["embeddings"][i]
- del self.record_set_state["metadatas"][i]
- del self.record_set_state["documents"][i]
-
- def on_state_change(self, new_state: str) -> None:
- pass
-
-
-def test_embeddings_state(caplog: pytest.LogCaptureFixture, api: API) -> None:
- caplog.set_level(logging.ERROR)
- run_state_machine_as_test(lambda: EmbeddingStateMachine(api)) # type: ignore
- print_traces()
-
-
-def test_multi_add(api: API) -> None:
- api.reset()
- coll = api.create_collection(name="foo")
- coll.add(ids=["a"], embeddings=[[0.0]])
- assert coll.count() == 1
-
- # after the sqlite refactor - add silently ignores duplicates, no exception is raised
- # partial adds are supported - i.e we will add whatever we can in the request
- coll.add(ids=["a"], embeddings=[[0.0]])
-
- assert coll.count() == 1
-
- results = coll.get()
- assert results["ids"] == ["a"]
-
- coll.delete(ids=["a"])
- assert coll.count() == 0
-
-
-def test_dup_add(api: API) -> None:
- api.reset()
- coll = api.create_collection(name="foo")
- with pytest.raises(errors.DuplicateIDError):
- coll.add(ids=["a", "a"], embeddings=[[0.0], [1.1]])
- with pytest.raises(errors.DuplicateIDError):
- coll.upsert(ids=["a", "a"], embeddings=[[0.0], [1.1]])
-
-
-def test_query_without_add(api: API) -> None:
- api.reset()
- coll = api.create_collection(name="foo")
- fields: Include = ["documents", "metadatas", "embeddings", "distances"]
- N = np.random.randint(1, 2000)
- K = np.random.randint(1, 100)
- results = coll.query(
- query_embeddings=np.random.random((N, K)).tolist(), include=fields
- )
- for field in fields:
- field_results = results[field]
- assert field_results is not None
- assert all([len(result) == 0 for result in field_results])
-
-
-# TODO: Use SQL escaping correctly internally
-@pytest.mark.xfail(reason="We don't properly escape SQL internally, causing problems")
-def test_escape_chars_in_ids(api: API) -> None:
- api.reset()
- id = "\x1f"
- coll = api.create_collection(name="foo")
- coll.add(ids=[id], embeddings=[[0.0]])
- assert coll.count() == 1
- coll.delete(ids=[id])
- assert coll.count() == 0
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/primitives/kdf/pbkdf2.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/primitives/kdf/pbkdf2.py
deleted file mode 100644
index 623e1ca7f9eb6a2dfd6c397e9f051314669b997b..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/primitives/kdf/pbkdf2.py
+++ /dev/null
@@ -1,64 +0,0 @@
-# This file is dual licensed under the terms of the Apache License, Version
-# 2.0, and the BSD License. See the LICENSE file in the root of this repository
-# for complete details.
-
-from __future__ import annotations
-
-import typing
-
-from cryptography import utils
-from cryptography.exceptions import (
- AlreadyFinalized,
- InvalidKey,
- UnsupportedAlgorithm,
- _Reasons,
-)
-from cryptography.hazmat.bindings._rust import openssl as rust_openssl
-from cryptography.hazmat.primitives import constant_time, hashes
-from cryptography.hazmat.primitives.kdf import KeyDerivationFunction
-
-
-class PBKDF2HMAC(KeyDerivationFunction):
- def __init__(
- self,
- algorithm: hashes.HashAlgorithm,
- length: int,
- salt: bytes,
- iterations: int,
- backend: typing.Any = None,
- ):
- from cryptography.hazmat.backends.openssl.backend import (
- backend as ossl,
- )
-
- if not ossl.pbkdf2_hmac_supported(algorithm):
- raise UnsupportedAlgorithm(
- "{} is not supported for PBKDF2 by this backend.".format(
- algorithm.name
- ),
- _Reasons.UNSUPPORTED_HASH,
- )
- self._used = False
- self._algorithm = algorithm
- self._length = length
- utils._check_bytes("salt", salt)
- self._salt = salt
- self._iterations = iterations
-
- def derive(self, key_material: bytes) -> bytes:
- if self._used:
- raise AlreadyFinalized("PBKDF2 instances can only be used once.")
- self._used = True
-
- return rust_openssl.kdf.derive_pbkdf2_hmac(
- key_material,
- self._algorithm,
- self._salt,
- self._iterations,
- self._length,
- )
-
- def verify(self, key_material: bytes, expected_key: bytes) -> None:
- derived_key = self.derive(key_material)
- if not constant_time.bytes_eq(derived_key, expected_key):
- raise InvalidKey("Keys do not match.")
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/faiss/loader.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/faiss/loader.py
deleted file mode 100644
index dd5839908e24d11e91f3f60cf8e18cb1e4297f75..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/faiss/loader.py
+++ /dev/null
@@ -1,66 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from distutils.version import LooseVersion
-import platform
-import subprocess
-import logging
-import os
-
-
-def supported_instruction_sets():
- """
- Returns the set of supported CPU features, see
- https://github.com/numpy/numpy/blob/master/numpy/core/src/common/npy_cpu_features.h
- for the list of features that this set may contain per architecture.
-
- Example:
- >>> supported_instruction_sets() # for x86
- {"SSE2", "AVX2", ...}
- >>> supported_instruction_sets() # for PPC
- {"VSX", "VSX2", ...}
- >>> supported_instruction_sets() # for ARM
- {"NEON", "ASIMD", ...}
- """
- import numpy
- if LooseVersion(numpy.__version__) >= "1.19":
- # use private API as next-best thing until numpy/numpy#18058 is solved
- from numpy.core._multiarray_umath import __cpu_features__
- # __cpu_features__ is a dictionary with CPU features
- # as keys, and True / False as values
- supported = {k for k, v in __cpu_features__.items() if v}
- for f in os.getenv("FAISS_DISABLE_CPU_FEATURES", "").split(", \t\n\r"):
- supported.discard(f)
- return supported
-
- # platform-dependent legacy fallback before numpy 1.19, no windows
- if platform.system() == "Darwin":
- if subprocess.check_output(["/usr/sbin/sysctl", "hw.optional.avx2_0"])[-1] == '1':
- return {"AVX2"}
- elif platform.system() == "Linux":
- import numpy.distutils.cpuinfo
- if "avx2" in numpy.distutils.cpuinfo.cpu.info[0].get('flags', ""):
- return {"AVX2"}
- return set()
-
-
-logger = logging.getLogger(__name__)
-
-has_AVX2 = "AVX2" in supported_instruction_sets()
-if has_AVX2:
- try:
- logger.info("Loading faiss with AVX2 support.")
- from .swigfaiss_avx2 import *
- logger.info("Successfully loaded faiss with AVX2 support.")
- except ImportError as e:
- logger.info(f"Could not load library with AVX2 support due to:\n{e!r}")
- # reset so that we load without AVX2 below
- has_AVX2 = False
-
-if not has_AVX2:
- # we import * so that the symbol X can be accessed as faiss.X
- logger.info("Loading faiss.")
- from .swigfaiss import *
- logger.info("Successfully loaded faiss.")
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/cu2qu/cli.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/cu2qu/cli.py
deleted file mode 100644
index 9144043ff176fb956cf075b5db38fcca88258430..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/cu2qu/cli.py
+++ /dev/null
@@ -1,198 +0,0 @@
-import os
-import argparse
-import logging
-import shutil
-import multiprocessing as mp
-from contextlib import closing
-from functools import partial
-
-import fontTools
-from .ufo import font_to_quadratic, fonts_to_quadratic
-
-ufo_module = None
-try:
- import ufoLib2 as ufo_module
-except ImportError:
- try:
- import defcon as ufo_module
- except ImportError as e:
- pass
-
-
-logger = logging.getLogger("fontTools.cu2qu")
-
-
-def _cpu_count():
- try:
- return mp.cpu_count()
- except NotImplementedError: # pragma: no cover
- return 1
-
-
-def open_ufo(path):
- if hasattr(ufo_module.Font, "open"): # ufoLib2
- return ufo_module.Font.open(path)
- return ufo_module.Font(path) # defcon
-
-
-def _font_to_quadratic(input_path, output_path=None, **kwargs):
- ufo = open_ufo(input_path)
- logger.info("Converting curves for %s", input_path)
- if font_to_quadratic(ufo, **kwargs):
- logger.info("Saving %s", output_path)
- if output_path:
- ufo.save(output_path)
- else:
- ufo.save() # save in-place
- elif output_path:
- _copytree(input_path, output_path)
-
-
-def _samepath(path1, path2):
- # TODO on python3+, there's os.path.samefile
- path1 = os.path.normcase(os.path.abspath(os.path.realpath(path1)))
- path2 = os.path.normcase(os.path.abspath(os.path.realpath(path2)))
- return path1 == path2
-
-
-def _copytree(input_path, output_path):
- if _samepath(input_path, output_path):
- logger.debug("input and output paths are the same file; skipped copy")
- return
- if os.path.exists(output_path):
- shutil.rmtree(output_path)
- shutil.copytree(input_path, output_path)
-
-
-def main(args=None):
- """Convert a UFO font from cubic to quadratic curves"""
- parser = argparse.ArgumentParser(prog="cu2qu")
- parser.add_argument("--version", action="version", version=fontTools.__version__)
- parser.add_argument(
- "infiles",
- nargs="+",
- metavar="INPUT",
- help="one or more input UFO source file(s).",
- )
- parser.add_argument("-v", "--verbose", action="count", default=0)
- parser.add_argument(
- "-e",
- "--conversion-error",
- type=float,
- metavar="ERROR",
- default=None,
- help="maxiumum approximation error measured in EM (default: 0.001)",
- )
- parser.add_argument(
- "-m",
- "--mixed",
- default=False,
- action="store_true",
- help="whether to used mixed quadratic and cubic curves",
- )
- parser.add_argument(
- "--keep-direction",
- dest="reverse_direction",
- action="store_false",
- help="do not reverse the contour direction",
- )
-
- mode_parser = parser.add_mutually_exclusive_group()
- mode_parser.add_argument(
- "-i",
- "--interpolatable",
- action="store_true",
- help="whether curve conversion should keep interpolation compatibility",
- )
- mode_parser.add_argument(
- "-j",
- "--jobs",
- type=int,
- nargs="?",
- default=1,
- const=_cpu_count(),
- metavar="N",
- help="Convert using N multiple processes (default: %(default)s)",
- )
-
- output_parser = parser.add_mutually_exclusive_group()
- output_parser.add_argument(
- "-o",
- "--output-file",
- default=None,
- metavar="OUTPUT",
- help=(
- "output filename for the converted UFO. By default fonts are "
- "modified in place. This only works with a single input."
- ),
- )
- output_parser.add_argument(
- "-d",
- "--output-dir",
- default=None,
- metavar="DIRECTORY",
- help="output directory where to save converted UFOs",
- )
-
- options = parser.parse_args(args)
-
- if ufo_module is None:
- parser.error("Either ufoLib2 or defcon are required to run this script.")
-
- if not options.verbose:
- level = "WARNING"
- elif options.verbose == 1:
- level = "INFO"
- else:
- level = "DEBUG"
- logging.basicConfig(level=level)
-
- if len(options.infiles) > 1 and options.output_file:
- parser.error("-o/--output-file can't be used with multile inputs")
-
- if options.output_dir:
- output_dir = options.output_dir
- if not os.path.exists(output_dir):
- os.mkdir(output_dir)
- elif not os.path.isdir(output_dir):
- parser.error("'%s' is not a directory" % output_dir)
- output_paths = [
- os.path.join(output_dir, os.path.basename(p)) for p in options.infiles
- ]
- elif options.output_file:
- output_paths = [options.output_file]
- else:
- # save in-place
- output_paths = [None] * len(options.infiles)
-
- kwargs = dict(
- dump_stats=options.verbose > 0,
- max_err_em=options.conversion_error,
- reverse_direction=options.reverse_direction,
- all_quadratic=False if options.mixed else True,
- )
-
- if options.interpolatable:
- logger.info("Converting curves compatibly")
- ufos = [open_ufo(infile) for infile in options.infiles]
- if fonts_to_quadratic(ufos, **kwargs):
- for ufo, output_path in zip(ufos, output_paths):
- logger.info("Saving %s", output_path)
- if output_path:
- ufo.save(output_path)
- else:
- ufo.save()
- else:
- for input_path, output_path in zip(options.infiles, output_paths):
- if output_path:
- _copytree(input_path, output_path)
- else:
- jobs = min(len(options.infiles), options.jobs) if options.jobs > 1 else 1
- if jobs > 1:
- func = partial(_font_to_quadratic, **kwargs)
- logger.info("Running %d parallel processes", jobs)
- with closing(mp.Pool(jobs)) as pool:
- pool.starmap(func, zip(options.infiles, output_paths))
- else:
- for input_path, output_path in zip(options.infiles, output_paths):
- _font_to_quadratic(input_path, output_path, **kwargs)
diff --git a/spaces/cihyFjudo/fairness-paper-search/Bajo La Misma Luna [DVDRIP][Latino][1 Link] leasbail Cmo ver online o descargar gratis este drama familiar.md b/spaces/cihyFjudo/fairness-paper-search/Bajo La Misma Luna [DVDRIP][Latino][1 Link] leasbail Cmo ver online o descargar gratis este drama familiar.md
deleted file mode 100644
index c9bebc9767532ffc1ba12fb887e42cc1759a89ce..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Bajo La Misma Luna [DVDRIP][Latino][1 Link] leasbail Cmo ver online o descargar gratis este drama familiar.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Bajo La Misma Luna [DVDRIP][Latino][1 Link] leasbail
Download >>> https://tinurli.com/2uwkb2
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/cihyFjudo/fairness-paper-search/Forbes Ewan Spence 24H with the Jolla Smartphone the Crowdfunded Success Story from Finland.md b/spaces/cihyFjudo/fairness-paper-search/Forbes Ewan Spence 24H with the Jolla Smartphone the Crowdfunded Success Story from Finland.md
deleted file mode 100644
index 16bfddf707ea00843fe24cfc06034b7d5c816107..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Forbes Ewan Spence 24H with the Jolla Smartphone the Crowdfunded Success Story from Finland.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Forbes’ Ewan Spence: 24H with the Jolla Smartphone
Download File >>>>> https://tinurli.com/2uwjnv
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/vegalite/schema.py b/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/vegalite/schema.py
deleted file mode 100644
index e94c3d1991e96da81efe13cfe06214166afe80d1..0000000000000000000000000000000000000000
--- a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/vegalite/schema.py
+++ /dev/null
@@ -1,3 +0,0 @@
-"""Altair schema wrappers"""
-# ruff: noqa
-from .v5.schema import *
diff --git a/spaces/codesue/streamlit-tfx/README.md b/spaces/codesue/streamlit-tfx/README.md
deleted file mode 100644
index 07b2b91aa51e4bfdc066ca9042c29780e5613db0..0000000000000000000000000000000000000000
--- a/spaces/codesue/streamlit-tfx/README.md
+++ /dev/null
@@ -1,63 +0,0 @@
----
-title: 'streamlit-tfx'
-emoji: 🌱
-colorFrom: yellow
-colorTo: blue
-sdk: streamlit
-sdk_version: 1.15.2
-app_file: tests/test_streamlit_tfx.py
-pinned: false
----
-
-# streamlit-tfx: TensorFlow Extended visualizers for Streamlit apps
-
-`streamlit-tfx` provides utilities for visualizing [TensorFlow Extended](https://www.tensorflow.org/tfx)
-artifacts in [Streamlit](https://streamlit.io) apps.
-
-[![GitHub][github_badge]][github_link] [![PyPI][pypi_badge]][pypi_link]
-
-> ### 🌱 Just sprouting!
-> This project is in the very beginning stages of development.
-> It has super hacky code that's not optimized or well-tested.
-> It's only intended to be used as a proof of concept of visualizing `tfx`
-> artifacts outside of Jupyter notebook.
-
-## Installation
-
-``` shell
-git clone https://github.com/codesue/streamlit-tfx.git
-cd streamlit-tfx
-poetry install
-```
-
-## Getting started
-
-```python
-import streamlit_tfx as st_tfx
-
-st_tfx.display(item)
-st_tfx.display_statistics(statistics)
-st_tfx.display_schema(schema)
-st_tfx.display_anomalies(anomalies)
-st_tfx.display_eval_result_plot(eval_result)
-st_tfx.display_eval_result_slicing_attributions(eval_result)
-st_tfx.display_eval_result_slicing_metrics(eval_result)
-st_tfx.display_eval_results_time_series(eval_results)
-```
-
----
-
-`streamlit-tfx` essentially ports `tfma` and `tfdv` visualizers, copyrighted
-The TensorFlow Authors and licensed under Apache License 2.0.
-
-Most artifacts in `tests/artifacts/` were generated by running the [TFX Keras Component tutorial](https://www.tensorflow.org/tfx/tutorials/tfx/components_keras).
-The anomalies artifact with anomalies was generated by running the [TensorFlow Model Analysis tutorial](https://www.tensorflow.org/tfx/tutorials/model_analysis/tfma_basic).
-
-🚀 Inspired by [spacy-streamlit](https://github.com/explosion/spacy-streamlit)
-and [streamlit-player](https://github.com/okld/streamlit-player).
-
-[github_badge]: https://badgen.net/badge/icon/GitHub?icon=github&color=black&label
-[github_link]: https://github.com/codesue/streamlit-tfx
-
-[pypi_badge]: https://badgen.net/pypi/v/streamlit-tfx?icon=pypi&color=black&label
-[pypi_link]: https://pypi.org/project/streamlit-tfx
diff --git a/spaces/colakin/video-generater/public/ffmpeg/compat/aix/math.h b/spaces/colakin/video-generater/public/ffmpeg/compat/aix/math.h
deleted file mode 100644
index dee13c8dd7c0c39b1d6aeaedc3707faff7bfa0bd..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/compat/aix/math.h
+++ /dev/null
@@ -1,31 +0,0 @@
-/*
- * Work around the class() function in AIX math.h clashing with
- * identifiers named "class".
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#ifndef COMPAT_AIX_MATH_H
-#define COMPAT_AIX_MATH_H
-
-#define class class_in_math_h_causes_problems
-
-#include_next
-
-#undef class
-
-#endif /* COMPAT_AIX_MATH_H */
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/ac3dsp.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/ac3dsp.c
deleted file mode 100644
index 22cb5f242e8cd77c4955aceb9baa76f96feeefc6..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/ac3dsp.c
+++ /dev/null
@@ -1,399 +0,0 @@
-/*
- * AC-3 DSP functions
- * Copyright (c) 2011 Justin Ruggles
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#include
-#include
-#include
-
-#include "config.h"
-#include "libavutil/attributes.h"
-#include "libavutil/common.h"
-#include "libavutil/intmath.h"
-#include "libavutil/mem_internal.h"
-
-#include "ac3defs.h"
-#include "ac3dsp.h"
-#include "ac3tab.h"
-#include "mathops.h"
-
-static void ac3_exponent_min_c(uint8_t *exp, int num_reuse_blocks, int nb_coefs)
-{
- int blk, i;
-
- if (!num_reuse_blocks)
- return;
-
- for (i = 0; i < nb_coefs; i++) {
- uint8_t min_exp = *exp;
- uint8_t *exp1 = exp + 256;
- for (blk = 0; blk < num_reuse_blocks; blk++) {
- uint8_t next_exp = *exp1;
- if (next_exp < min_exp)
- min_exp = next_exp;
- exp1 += 256;
- }
- *exp++ = min_exp;
- }
-}
-
-static void float_to_fixed24_c(int32_t *dst, const float *src, unsigned int len)
-{
- const float scale = 1 << 24;
- do {
- *dst++ = lrintf(*src++ * scale);
- *dst++ = lrintf(*src++ * scale);
- *dst++ = lrintf(*src++ * scale);
- *dst++ = lrintf(*src++ * scale);
- *dst++ = lrintf(*src++ * scale);
- *dst++ = lrintf(*src++ * scale);
- *dst++ = lrintf(*src++ * scale);
- *dst++ = lrintf(*src++ * scale);
- len -= 8;
- } while (len > 0);
-}
-
-static void ac3_bit_alloc_calc_bap_c(int16_t *mask, int16_t *psd,
- int start, int end,
- int snr_offset, int floor,
- const uint8_t *bap_tab, uint8_t *bap)
-{
- int bin, band, band_end;
-
- /* special case, if snr offset is -960, set all bap's to zero */
- if (snr_offset == -960) {
- memset(bap, 0, AC3_MAX_COEFS);
- return;
- }
-
- bin = start;
- band = ff_ac3_bin_to_band_tab[start];
- do {
- int m = (FFMAX(mask[band] - snr_offset - floor, 0) & 0x1FE0) + floor;
- band_end = ff_ac3_band_start_tab[++band];
- band_end = FFMIN(band_end, end);
-
- for (; bin < band_end; bin++) {
- int address = av_clip_uintp2((psd[bin] - m) >> 5, 6);
- bap[bin] = bap_tab[address];
- }
- } while (end > band_end);
-}
-
-static void ac3_update_bap_counts_c(uint16_t mant_cnt[16], uint8_t *bap,
- int len)
-{
- while (len-- > 0)
- mant_cnt[bap[len]]++;
-}
-
-DECLARE_ALIGNED(16, const uint16_t, ff_ac3_bap_bits)[16] = {
- 0, 0, 0, 3, 0, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16
-};
-
-static int ac3_compute_mantissa_size_c(uint16_t mant_cnt[6][16])
-{
- int blk, bap;
- int bits = 0;
-
- for (blk = 0; blk < AC3_MAX_BLOCKS; blk++) {
- // bap=1 : 3 mantissas in 5 bits
- bits += (mant_cnt[blk][1] / 3) * 5;
- // bap=2 : 3 mantissas in 7 bits
- // bap=4 : 2 mantissas in 7 bits
- bits += ((mant_cnt[blk][2] / 3) + (mant_cnt[blk][4] >> 1)) * 7;
- // bap=3 : 1 mantissa in 3 bits
- bits += mant_cnt[blk][3] * 3;
- // bap=5 to 15 : get bits per mantissa from table
- for (bap = 5; bap < 16; bap++)
- bits += mant_cnt[blk][bap] * ff_ac3_bap_bits[bap];
- }
- return bits;
-}
-
-static void ac3_extract_exponents_c(uint8_t *exp, int32_t *coef, int nb_coefs)
-{
- int i;
-
- for (i = 0; i < nb_coefs; i++) {
- int v = abs(coef[i]);
- exp[i] = v ? 23 - av_log2(v) : 24;
- }
-}
-
-static void ac3_sum_square_butterfly_int32_c(int64_t sum[4],
- const int32_t *coef0,
- const int32_t *coef1,
- int len)
-{
- int i;
-
- sum[0] = sum[1] = sum[2] = sum[3] = 0;
-
- for (i = 0; i < len; i++) {
- int lt = coef0[i];
- int rt = coef1[i];
- int md = lt + rt;
- int sd = lt - rt;
- MAC64(sum[0], lt, lt);
- MAC64(sum[1], rt, rt);
- MAC64(sum[2], md, md);
- MAC64(sum[3], sd, sd);
- }
-}
-
-static void ac3_sum_square_butterfly_float_c(float sum[4],
- const float *coef0,
- const float *coef1,
- int len)
-{
- int i;
-
- sum[0] = sum[1] = sum[2] = sum[3] = 0;
-
- for (i = 0; i < len; i++) {
- float lt = coef0[i];
- float rt = coef1[i];
- float md = lt + rt;
- float sd = lt - rt;
- sum[0] += lt * lt;
- sum[1] += rt * rt;
- sum[2] += md * md;
- sum[3] += sd * sd;
- }
-}
-
-static void ac3_downmix_5_to_2_symmetric_c(float **samples, float **matrix,
- int len)
-{
- int i;
- float v0, v1;
- float front_mix = matrix[0][0];
- float center_mix = matrix[0][1];
- float surround_mix = matrix[0][3];
-
- for (i = 0; i < len; i++) {
- v0 = samples[0][i] * front_mix +
- samples[1][i] * center_mix +
- samples[3][i] * surround_mix;
-
- v1 = samples[1][i] * center_mix +
- samples[2][i] * front_mix +
- samples[4][i] * surround_mix;
-
- samples[0][i] = v0;
- samples[1][i] = v1;
- }
-}
-
-static void ac3_downmix_5_to_1_symmetric_c(float **samples, float **matrix,
- int len)
-{
- int i;
- float front_mix = matrix[0][0];
- float center_mix = matrix[0][1];
- float surround_mix = matrix[0][3];
-
- for (i = 0; i < len; i++) {
- samples[0][i] = samples[0][i] * front_mix +
- samples[1][i] * center_mix +
- samples[2][i] * front_mix +
- samples[3][i] * surround_mix +
- samples[4][i] * surround_mix;
- }
-}
-
-static void ac3_downmix_c(float **samples, float **matrix,
- int out_ch, int in_ch, int len)
-{
- int i, j;
- float v0, v1;
-
- if (out_ch == 2) {
- for (i = 0; i < len; i++) {
- v0 = v1 = 0.0f;
- for (j = 0; j < in_ch; j++) {
- v0 += samples[j][i] * matrix[0][j];
- v1 += samples[j][i] * matrix[1][j];
- }
- samples[0][i] = v0;
- samples[1][i] = v1;
- }
- } else if (out_ch == 1) {
- for (i = 0; i < len; i++) {
- v0 = 0.0f;
- for (j = 0; j < in_ch; j++)
- v0 += samples[j][i] * matrix[0][j];
- samples[0][i] = v0;
- }
- }
-}
-
-static void ac3_downmix_5_to_2_symmetric_c_fixed(int32_t **samples, int16_t **matrix,
- int len)
-{
- int i;
- int64_t v0, v1;
- int16_t front_mix = matrix[0][0];
- int16_t center_mix = matrix[0][1];
- int16_t surround_mix = matrix[0][3];
-
- for (i = 0; i < len; i++) {
- v0 = (int64_t)samples[0][i] * front_mix +
- (int64_t)samples[1][i] * center_mix +
- (int64_t)samples[3][i] * surround_mix;
-
- v1 = (int64_t)samples[1][i] * center_mix +
- (int64_t)samples[2][i] * front_mix +
- (int64_t)samples[4][i] * surround_mix;
-
- samples[0][i] = (v0+2048)>>12;
- samples[1][i] = (v1+2048)>>12;
- }
-}
-
-static void ac3_downmix_5_to_1_symmetric_c_fixed(int32_t **samples, int16_t **matrix,
- int len)
-{
- int i;
- int64_t v0;
- int16_t front_mix = matrix[0][0];
- int16_t center_mix = matrix[0][1];
- int16_t surround_mix = matrix[0][3];
-
- for (i = 0; i < len; i++) {
- v0 = (int64_t)samples[0][i] * front_mix +
- (int64_t)samples[1][i] * center_mix +
- (int64_t)samples[2][i] * front_mix +
- (int64_t)samples[3][i] * surround_mix +
- (int64_t)samples[4][i] * surround_mix;
-
- samples[0][i] = (v0+2048)>>12;
- }
-}
-
-static void ac3_downmix_c_fixed(int32_t **samples, int16_t **matrix,
- int out_ch, int in_ch, int len)
-{
- int i, j;
- int64_t v0, v1;
- if (out_ch == 2) {
- for (i = 0; i < len; i++) {
- v0 = v1 = 0;
- for (j = 0; j < in_ch; j++) {
- v0 += (int64_t)samples[j][i] * matrix[0][j];
- v1 += (int64_t)samples[j][i] * matrix[1][j];
- }
- samples[0][i] = (v0+2048)>>12;
- samples[1][i] = (v1+2048)>>12;
- }
- } else if (out_ch == 1) {
- for (i = 0; i < len; i++) {
- v0 = 0;
- for (j = 0; j < in_ch; j++)
- v0 += (int64_t)samples[j][i] * matrix[0][j];
- samples[0][i] = (v0+2048)>>12;
- }
- }
-}
-
-void ff_ac3dsp_downmix_fixed(AC3DSPContext *c, int32_t **samples, int16_t **matrix,
- int out_ch, int in_ch, int len)
-{
- if (c->in_channels != in_ch || c->out_channels != out_ch) {
- c->in_channels = in_ch;
- c->out_channels = out_ch;
- c->downmix_fixed = NULL;
-
- if (in_ch == 5 && out_ch == 2 &&
- !(matrix[1][0] | matrix[0][2] |
- matrix[1][3] | matrix[0][4] |
- (matrix[0][1] ^ matrix[1][1]) |
- (matrix[0][0] ^ matrix[1][2]))) {
- c->downmix_fixed = ac3_downmix_5_to_2_symmetric_c_fixed;
- } else if (in_ch == 5 && out_ch == 1 &&
- matrix[0][0] == matrix[0][2] &&
- matrix[0][3] == matrix[0][4]) {
- c->downmix_fixed = ac3_downmix_5_to_1_symmetric_c_fixed;
- }
- }
-
- if (c->downmix_fixed)
- c->downmix_fixed(samples, matrix, len);
- else
- ac3_downmix_c_fixed(samples, matrix, out_ch, in_ch, len);
-}
-
-void ff_ac3dsp_downmix(AC3DSPContext *c, float **samples, float **matrix,
- int out_ch, int in_ch, int len)
-{
- if (c->in_channels != in_ch || c->out_channels != out_ch) {
- int **matrix_cmp = (int **)matrix;
-
- c->in_channels = in_ch;
- c->out_channels = out_ch;
- c->downmix = NULL;
-
- if (in_ch == 5 && out_ch == 2 &&
- !(matrix_cmp[1][0] | matrix_cmp[0][2] |
- matrix_cmp[1][3] | matrix_cmp[0][4] |
- (matrix_cmp[0][1] ^ matrix_cmp[1][1]) |
- (matrix_cmp[0][0] ^ matrix_cmp[1][2]))) {
- c->downmix = ac3_downmix_5_to_2_symmetric_c;
- } else if (in_ch == 5 && out_ch == 1 &&
- matrix_cmp[0][0] == matrix_cmp[0][2] &&
- matrix_cmp[0][3] == matrix_cmp[0][4]) {
- c->downmix = ac3_downmix_5_to_1_symmetric_c;
- }
-
-#if ARCH_X86
- ff_ac3dsp_set_downmix_x86(c);
-#endif
- }
-
- if (c->downmix)
- c->downmix(samples, matrix, len);
- else
- ac3_downmix_c(samples, matrix, out_ch, in_ch, len);
-}
-
-av_cold void ff_ac3dsp_init(AC3DSPContext *c)
-{
- c->ac3_exponent_min = ac3_exponent_min_c;
- c->float_to_fixed24 = float_to_fixed24_c;
- c->bit_alloc_calc_bap = ac3_bit_alloc_calc_bap_c;
- c->update_bap_counts = ac3_update_bap_counts_c;
- c->compute_mantissa_size = ac3_compute_mantissa_size_c;
- c->extract_exponents = ac3_extract_exponents_c;
- c->sum_square_butterfly_int32 = ac3_sum_square_butterfly_int32_c;
- c->sum_square_butterfly_float = ac3_sum_square_butterfly_float_c;
- c->in_channels = 0;
- c->out_channels = 0;
- c->downmix = NULL;
- c->downmix_fixed = NULL;
-
-#if ARCH_ARM
- ff_ac3dsp_init_arm(c);
-#elif ARCH_X86
- ff_ac3dsp_init_x86(c);
-#elif ARCH_MIPS
- ff_ac3dsp_init_mips(c);
-#endif
-}
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/acelp_pitch_delay.h b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/acelp_pitch_delay.h
deleted file mode 100644
index 73fa3c331a04f75eee2158d1311a03b0d60ecc71..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/acelp_pitch_delay.h
+++ /dev/null
@@ -1,276 +0,0 @@
-/*
- * gain code, gain pitch and pitch delay decoding
- *
- * Copyright (c) 2008 Vladimir Voroshilov
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#ifndef AVCODEC_ACELP_PITCH_DELAY_H
-#define AVCODEC_ACELP_PITCH_DELAY_H
-
-#include
-
-#include "audiodsp.h"
-
-#define PITCH_DELAY_MIN 20
-#define PITCH_DELAY_MAX 143
-
-/**
- * @brief Decode pitch delay of the first subframe encoded by 8 bits with 1/3
- * resolution.
- * @param ac_index adaptive codebook index (8 bits)
- *
- * @return pitch delay in 1/3 units
- *
- * Pitch delay is coded:
- * with 1/3 resolution, 19 < pitch_delay < 85
- * integers only, 85 <= pitch_delay <= 143
- */
-static inline int ff_acelp_decode_8bit_to_1st_delay3(int ac_index)
-{
- ac_index += 58;
- if (ac_index > 254)
- ac_index = 3 * ac_index - 510;
- return ac_index;
-}
-
-/**
- * @brief Decode pitch delay of the second subframe encoded by 5 or 6 bits
- * with 1/3 precision.
- * @param ac_index adaptive codebook index (5 or 6 bits)
- * @param pitch_delay_min lower bound (integer) of pitch delay interval
- * for second subframe
- *
- * @return pitch delay in 1/3 units
- *
- * Pitch delay is coded:
- * with 1/3 resolution, -6 < pitch_delay - int(prev_pitch_delay) < 5
- *
- * @remark The routine is used in G.729 @@8k, AMR @@10.2k, AMR @@7.95k,
- * AMR @@7.4k for the second subframe.
- */
-static inline int ff_acelp_decode_5_6_bit_to_2nd_delay3(int ac_index,
- int pitch_delay_min)
-{
- return 3 * pitch_delay_min + ac_index - 2;
-}
-
-/**
- * @brief Decode pitch delay with 1/3 precision.
- * @param ac_index adaptive codebook index (4 bits)
- * @param pitch_delay_min lower bound (integer) of pitch delay interval for
- * second subframe
- *
- * @return pitch delay in 1/3 units
- *
- * Pitch delay is coded:
- * integers only, -6 < pitch_delay - int(prev_pitch_delay) <= -2
- * with 1/3 resolution, -2 < pitch_delay - int(prev_pitch_delay) < 1
- * integers only, 1 <= pitch_delay - int(prev_pitch_delay) < 5
- *
- * @remark The routine is used in G.729 @@6.4k, AMR @@6.7k, AMR @@5.9k,
- * AMR @@5.15k, AMR @@4.75k for the second subframe.
- */
-static inline int ff_acelp_decode_4bit_to_2nd_delay3(int ac_index,
- int pitch_delay_min)
-{
- if (ac_index < 4)
- return 3 * (ac_index + pitch_delay_min);
- else if (ac_index < 12)
- return 3 * pitch_delay_min + ac_index + 6;
- else
- return 3 * (ac_index + pitch_delay_min) - 18;
-}
-
-/**
- * @brief Decode pitch delay of the first subframe encoded by 9 bits
- * with 1/6 precision.
- * @param ac_index adaptive codebook index (9 bits)
- *
- * @return pitch delay in 1/6 units
- *
- * Pitch delay is coded:
- * with 1/6 resolution, 17 < pitch_delay < 95
- * integers only, 95 <= pitch_delay <= 143
- *
- * @remark The routine is used in AMR @@12.2k for the first and third subframes.
- */
-static inline int ff_acelp_decode_9bit_to_1st_delay6(int ac_index)
-{
- if (ac_index < 463)
- return ac_index + 105;
- else
- return 6 * (ac_index - 368);
-}
-
-/**
- * @brief Decode pitch delay of the second subframe encoded by 6 bits
- * with 1/6 precision.
- * @param ac_index adaptive codebook index (6 bits)
- * @param pitch_delay_min lower bound (integer) of pitch delay interval for
- * second subframe
- *
- * @return pitch delay in 1/6 units
- *
- * Pitch delay is coded:
- * with 1/6 resolution, -6 < pitch_delay - int(prev_pitch_delay) < 5
- *
- * @remark The routine is used in AMR @@12.2k for the second and fourth subframes.
- */
-static inline int ff_acelp_decode_6bit_to_2nd_delay6(int ac_index,
- int pitch_delay_min)
-{
- return 6 * pitch_delay_min + ac_index - 3;
-}
-
-/**
- * @brief Update past quantized energies
- * @param[in,out] quant_energy past quantized energies (5.10)
- * @param gain_corr_factor gain correction factor
- * @param log2_ma_pred_order log2() of MA prediction order
- * @param erasure frame erasure flag
- *
- * If frame erasure flag is not equal to zero, memory is updated with
- * averaged energy, attenuated by 4dB:
- * max(avg(quant_energy[i])-4, -14), i=0,ma_pred_order
- *
- * In normal mode memory is updated with
- * Er - Ep = 20 * log10(gain_corr_factor)
- *
- * @remark The routine is used in G.729 and AMR (all modes).
- */
-void ff_acelp_update_past_gain(
- int16_t* quant_energy,
- int gain_corr_factor,
- int log2_ma_pred_order,
- int erasure);
-
-/**
- * @brief Decode the adaptive codebook gain and add
- * correction (4.1.5 and 3.9.1 of G.729).
- * @param adsp initialized audio DSP context
- * @param gain_corr_factor gain correction factor (2.13)
- * @param fc_v fixed-codebook vector (2.13)
- * @param mr_energy mean innovation energy and fixed-point correction (7.13)
- * @param[in,out] quant_energy past quantized energies (5.10)
- * @param subframe_size length of subframe
- *
- * @return quantized fixed-codebook gain (14.1)
- *
- * The routine implements equations 69, 66 and 71 of the G.729 specification (3.9.1)
- *
- * Em - mean innovation energy (dB, constant, depends on decoding algorithm)
- * Ep - mean-removed predicted energy (dB)
- * Er - mean-removed innovation energy (dB)
- * Ei - mean energy of the fixed-codebook contribution (dB)
- * N - subframe_size
- * M - MA (Moving Average) prediction order
- * gc - fixed-codebook gain
- * gc_p - predicted fixed-codebook gain
- *
- * Fixed codebook gain is computed using predicted gain gc_p and
- * correction factor gain_corr_factor as shown below:
- *
- * gc = gc_p * gain_corr_factor
- *
- * The predicted fixed codebook gain gc_p is found by predicting
- * the energy of the fixed-codebook contribution from the energy
- * of previous fixed-codebook contributions.
- *
- * mean = 1/N * sum(i,0,N){ fc_v[i] * fc_v[i] }
- *
- * Ei = 10log(mean)
- *
- * Er = 10log(1/N * gc^2 * mean) - Em = 20log(gc) + Ei - Em
- *
- * Replacing Er with Ep and gc with gc_p we will receive:
- *
- * Ep = 10log(1/N * gc_p^2 * mean) - Em = 20log(gc_p) + Ei - Em
- *
- * and from above:
- *
- * gc_p = 10^((Ep - Ei + Em) / 20)
- *
- * Ep is predicted using past energies and prediction coefficients:
- *
- * Ep = sum(i,0,M){ ma_prediction_coeff[i] * quant_energy[i] }
- *
- * gc_p in fixed-point arithmetic is calculated as following:
- *
- * mean = 1/N * sum(i,0,N){ (fc_v[i] / 2^13) * (fc_v[i] / 2^13) } =
- * = 1/N * sum(i,0,N) { fc_v[i] * fc_v[i] } / 2^26
- *
- * Ei = 10log(mean) = -10log(N) - 10log(2^26) +
- * + 10log(sum(i,0,N) { fc_v[i] * fc_v[i] })
- *
- * Ep - Ei + Em = Ep + Em + 10log(N) + 10log(2^26) -
- * - 10log(sum(i,0,N) { fc_v[i] * fc_v[i] }) =
- * = Ep + mr_energy - 10log(sum(i,0,N) { fc_v[i] * fc_v[i] })
- *
- * gc_p = 10 ^ ((Ep - Ei + Em) / 20) =
- * = 2 ^ (3.3219 * (Ep - Ei + Em) / 20) = 2 ^ (0.166 * (Ep - Ei + Em))
- *
- * where
- *
- * mr_energy = Em + 10log(N) + 10log(2^26)
- *
- * @remark The routine is used in G.729 and AMR (all modes).
- */
-int16_t ff_acelp_decode_gain_code(
- AudioDSPContext *adsp,
- int gain_corr_factor,
- const int16_t* fc_v,
- int mr_energy,
- const int16_t* quant_energy,
- const int16_t* ma_prediction_coeff,
- int subframe_size,
- int max_pred_order);
-
-/**
- * Calculate fixed gain (part of section 6.1.3 of AMR spec)
- *
- * @param fixed_gain_factor gain correction factor
- * @param fixed_mean_energy mean decoded algebraic codebook vector energy
- * @param prediction_error vector of the quantified predictor errors of
- * the four previous subframes. It is updated by this function.
- * @param energy_mean desired mean innovation energy
- * @param pred_table table of four moving average coefficients
- */
-float ff_amr_set_fixed_gain(float fixed_gain_factor, float fixed_mean_energy,
- float *prediction_error, float energy_mean,
- const float *pred_table);
-
-
-/**
- * Decode the adaptive codebook index to the integer and fractional parts
- * of the pitch lag for one subframe at 1/3 fractional precision.
- *
- * The choice of pitch lag is described in 3GPP TS 26.090 section 5.6.1.
- *
- * @param lag_int integer part of pitch lag of the current subframe
- * @param lag_frac fractional part of pitch lag of the current subframe
- * @param pitch_index parsed adaptive codebook (pitch) index
- * @param prev_lag_int integer part of pitch lag for the previous subframe
- * @param subframe current subframe number
- * @param third_as_first treat the third frame the same way as the first
- */
-void ff_decode_pitch_lag(int *lag_int, int *lag_frac, int pitch_index,
- const int prev_lag_int, const int subframe,
- int third_as_first, int resolution);
-
-#endif /* AVCODEC_ACELP_PITCH_DELAY_H */
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/g722enc.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/g722enc.c
deleted file mode 100644
index 47811cee4d6f6a213084c9d34fcdd9f5507a2144..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/g722enc.c
+++ /dev/null
@@ -1,390 +0,0 @@
-/*
- * Copyright (c) CMU 1993 Computer Science, Speech Group
- * Chengxiang Lu and Alex Hauptmann
- * Copyright (c) 2005 Steve Underwood
- * Copyright (c) 2009 Kenan Gillet
- * Copyright (c) 2010 Martin Storsjo
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-/**
- * @file
- * G.722 ADPCM audio encoder
- */
-
-#include "libavutil/avassert.h"
-#include "libavutil/channel_layout.h"
-#include "avcodec.h"
-#include "codec_internal.h"
-#include "encode.h"
-#include "g722.h"
-#include "libavutil/common.h"
-
-#define FREEZE_INTERVAL 128
-
-/* This is an arbitrary value. Allowing insanely large values leads to strange
- problems, so we limit it to a reasonable value */
-#define MAX_FRAME_SIZE 32768
-
-/* We clip the value of avctx->trellis to prevent data type overflows and
- undefined behavior. Using larger values is insanely slow anyway. */
-#define MIN_TRELLIS 0
-#define MAX_TRELLIS 16
-
-static av_cold int g722_encode_close(AVCodecContext *avctx)
-{
- G722Context *c = avctx->priv_data;
- int i;
- for (i = 0; i < 2; i++) {
- av_freep(&c->paths[i]);
- av_freep(&c->node_buf[i]);
- av_freep(&c->nodep_buf[i]);
- }
- return 0;
-}
-
-static av_cold int g722_encode_init(AVCodecContext * avctx)
-{
- G722Context *c = avctx->priv_data;
-
- c->band[0].scale_factor = 8;
- c->band[1].scale_factor = 2;
- c->prev_samples_pos = 22;
-
- if (avctx->frame_size) {
- /* validate frame size */
- if (avctx->frame_size & 1 || avctx->frame_size > MAX_FRAME_SIZE) {
- int new_frame_size;
-
- if (avctx->frame_size == 1)
- new_frame_size = 2;
- else if (avctx->frame_size > MAX_FRAME_SIZE)
- new_frame_size = MAX_FRAME_SIZE;
- else
- new_frame_size = avctx->frame_size - 1;
-
- av_log(avctx, AV_LOG_WARNING, "Requested frame size is not "
- "allowed. Using %d instead of %d\n", new_frame_size,
- avctx->frame_size);
- avctx->frame_size = new_frame_size;
- }
- } else {
- /* This is arbitrary. We use 320 because it's 20ms @ 16kHz, which is
- a common packet size for VoIP applications */
- avctx->frame_size = 320;
- }
- avctx->initial_padding = 22;
-
- if (avctx->trellis) {
- /* validate trellis */
- if (avctx->trellis < MIN_TRELLIS || avctx->trellis > MAX_TRELLIS) {
- int new_trellis = av_clip(avctx->trellis, MIN_TRELLIS, MAX_TRELLIS);
- av_log(avctx, AV_LOG_WARNING, "Requested trellis value is not "
- "allowed. Using %d instead of %d\n", new_trellis,
- avctx->trellis);
- avctx->trellis = new_trellis;
- }
- if (avctx->trellis) {
- int frontier = 1 << avctx->trellis;
- int max_paths = frontier * FREEZE_INTERVAL;
-
- for (int i = 0; i < 2; i++) {
- c->paths[i] = av_calloc(max_paths, sizeof(**c->paths));
- c->node_buf[i] = av_calloc(frontier, 2 * sizeof(**c->node_buf));
- c->nodep_buf[i] = av_calloc(frontier, 2 * sizeof(**c->nodep_buf));
- if (!c->paths[i] || !c->node_buf[i] || !c->nodep_buf[i])
- return AVERROR(ENOMEM);
- }
- }
- }
-
- ff_g722dsp_init(&c->dsp);
-
- return 0;
-}
-
-static const int16_t low_quant[33] = {
- 35, 72, 110, 150, 190, 233, 276, 323,
- 370, 422, 473, 530, 587, 650, 714, 786,
- 858, 940, 1023, 1121, 1219, 1339, 1458, 1612,
- 1765, 1980, 2195, 2557, 2919
-};
-
-static inline void filter_samples(G722Context *c, const int16_t *samples,
- int *xlow, int *xhigh)
-{
- int xout[2];
- c->prev_samples[c->prev_samples_pos++] = samples[0];
- c->prev_samples[c->prev_samples_pos++] = samples[1];
- c->dsp.apply_qmf(c->prev_samples + c->prev_samples_pos - 24, xout);
- *xlow = xout[0] + xout[1] >> 14;
- *xhigh = xout[0] - xout[1] >> 14;
- if (c->prev_samples_pos >= PREV_SAMPLES_BUF_SIZE) {
- memmove(c->prev_samples,
- c->prev_samples + c->prev_samples_pos - 22,
- 22 * sizeof(c->prev_samples[0]));
- c->prev_samples_pos = 22;
- }
-}
-
-static inline int encode_high(const struct G722Band *state, int xhigh)
-{
- int diff = av_clip_int16(xhigh - state->s_predictor);
- int pred = 141 * state->scale_factor >> 8;
- /* = diff >= 0 ? (diff < pred) + 2 : diff >= -pred */
- return ((diff ^ (diff >> (sizeof(diff)*8-1))) < pred) + 2*(diff >= 0);
-}
-
-static inline int encode_low(const struct G722Band* state, int xlow)
-{
- int diff = av_clip_int16(xlow - state->s_predictor);
- /* = diff >= 0 ? diff : -(diff + 1) */
- int limit = diff ^ (diff >> (sizeof(diff)*8-1));
- int i = 0;
- limit = limit + 1 << 10;
- if (limit > low_quant[8] * state->scale_factor)
- i = 9;
- while (i < 29 && limit > low_quant[i] * state->scale_factor)
- i++;
- return (diff < 0 ? (i < 2 ? 63 : 33) : 61) - i;
-}
-
-static void g722_encode_trellis(G722Context *c, int trellis,
- uint8_t *dst, int nb_samples,
- const int16_t *samples)
-{
- int i, j, k;
- int frontier = 1 << trellis;
- struct TrellisNode **nodes[2];
- struct TrellisNode **nodes_next[2];
- int pathn[2] = {0, 0}, froze = -1;
- struct TrellisPath *p[2];
-
- for (i = 0; i < 2; i++) {
- nodes[i] = c->nodep_buf[i];
- nodes_next[i] = c->nodep_buf[i] + frontier;
- memset(c->nodep_buf[i], 0, 2 * frontier * sizeof(*c->nodep_buf[i]));
- nodes[i][0] = c->node_buf[i] + frontier;
- nodes[i][0]->ssd = 0;
- nodes[i][0]->path = 0;
- nodes[i][0]->state = c->band[i];
- }
-
- for (i = 0; i < nb_samples >> 1; i++) {
- int xlow, xhigh;
- struct TrellisNode *next[2];
- int heap_pos[2] = {0, 0};
-
- for (j = 0; j < 2; j++) {
- next[j] = c->node_buf[j] + frontier*(i & 1);
- memset(nodes_next[j], 0, frontier * sizeof(**nodes_next));
- }
-
- filter_samples(c, &samples[2*i], &xlow, &xhigh);
-
- for (j = 0; j < frontier && nodes[0][j]; j++) {
- /* Only k >> 2 affects the future adaptive state, therefore testing
- * small steps that don't change k >> 2 is useless, the original
- * value from encode_low is better than them. Since we step k
- * in steps of 4, make sure range is a multiple of 4, so that
- * we don't miss the original value from encode_low. */
- int range = j < frontier/2 ? 4 : 0;
- struct TrellisNode *cur_node = nodes[0][j];
-
- int ilow = encode_low(&cur_node->state, xlow);
-
- for (k = ilow - range; k <= ilow + range && k <= 63; k += 4) {
- int decoded, dec_diff, pos;
- uint32_t ssd;
- struct TrellisNode* node;
-
- if (k < 0)
- continue;
-
- decoded = av_clip_intp2((cur_node->state.scale_factor *
- ff_g722_low_inv_quant6[k] >> 10)
- + cur_node->state.s_predictor, 14);
- dec_diff = xlow - decoded;
-
-#define STORE_NODE(index, UPDATE, VALUE)\
- ssd = cur_node->ssd + dec_diff*dec_diff;\
- /* Check for wraparound. Using 64 bit ssd counters would \
- * be simpler, but is slower on x86 32 bit. */\
- if (ssd < cur_node->ssd)\
- continue;\
- if (heap_pos[index] < frontier) {\
- pos = heap_pos[index]++;\
- av_assert2(pathn[index] < FREEZE_INTERVAL * frontier);\
- node = nodes_next[index][pos] = next[index]++;\
- node->path = pathn[index]++;\
- } else {\
- /* Try to replace one of the leaf nodes with the new \
- * one, but not always testing the same leaf position */\
- pos = (frontier>>1) + (heap_pos[index] & ((frontier>>1) - 1));\
- if (ssd >= nodes_next[index][pos]->ssd)\
- continue;\
- heap_pos[index]++;\
- node = nodes_next[index][pos];\
- }\
- node->ssd = ssd;\
- node->state = cur_node->state;\
- UPDATE;\
- c->paths[index][node->path].value = VALUE;\
- c->paths[index][node->path].prev = cur_node->path;\
- /* Sift the newly inserted node up in the heap to restore \
- * the heap property */\
- while (pos > 0) {\
- int parent = (pos - 1) >> 1;\
- if (nodes_next[index][parent]->ssd <= ssd)\
- break;\
- FFSWAP(struct TrellisNode*, nodes_next[index][parent],\
- nodes_next[index][pos]);\
- pos = parent;\
- }
- STORE_NODE(0, ff_g722_update_low_predictor(&node->state, k >> 2), k);
- }
- }
-
- for (j = 0; j < frontier && nodes[1][j]; j++) {
- int ihigh;
- struct TrellisNode *cur_node = nodes[1][j];
-
- /* We don't try to get any initial guess for ihigh via
- * encode_high - since there's only 4 possible values, test
- * them all. Testing all of these gives a much, much larger
- * gain than testing a larger range around ilow. */
- for (ihigh = 0; ihigh < 4; ihigh++) {
- int dhigh, decoded, dec_diff, pos;
- uint32_t ssd;
- struct TrellisNode* node;
-
- dhigh = cur_node->state.scale_factor *
- ff_g722_high_inv_quant[ihigh] >> 10;
- decoded = av_clip_intp2(dhigh + cur_node->state.s_predictor, 14);
- dec_diff = xhigh - decoded;
-
- STORE_NODE(1, ff_g722_update_high_predictor(&node->state, dhigh, ihigh), ihigh);
- }
- }
-
- for (j = 0; j < 2; j++) {
- FFSWAP(struct TrellisNode**, nodes[j], nodes_next[j]);
-
- if (nodes[j][0]->ssd > (1 << 16)) {
- for (k = 1; k < frontier && nodes[j][k]; k++)
- nodes[j][k]->ssd -= nodes[j][0]->ssd;
- nodes[j][0]->ssd = 0;
- }
- }
-
- if (i == froze + FREEZE_INTERVAL) {
- p[0] = &c->paths[0][nodes[0][0]->path];
- p[1] = &c->paths[1][nodes[1][0]->path];
- for (j = i; j > froze; j--) {
- dst[j] = p[1]->value << 6 | p[0]->value;
- p[0] = &c->paths[0][p[0]->prev];
- p[1] = &c->paths[1][p[1]->prev];
- }
- froze = i;
- pathn[0] = pathn[1] = 0;
- memset(nodes[0] + 1, 0, (frontier - 1)*sizeof(**nodes));
- memset(nodes[1] + 1, 0, (frontier - 1)*sizeof(**nodes));
- }
- }
-
- p[0] = &c->paths[0][nodes[0][0]->path];
- p[1] = &c->paths[1][nodes[1][0]->path];
- for (j = i; j > froze; j--) {
- dst[j] = p[1]->value << 6 | p[0]->value;
- p[0] = &c->paths[0][p[0]->prev];
- p[1] = &c->paths[1][p[1]->prev];
- }
- c->band[0] = nodes[0][0]->state;
- c->band[1] = nodes[1][0]->state;
-}
-
-static av_always_inline void encode_byte(G722Context *c, uint8_t *dst,
- const int16_t *samples)
-{
- int xlow, xhigh, ilow, ihigh;
- filter_samples(c, samples, &xlow, &xhigh);
- ihigh = encode_high(&c->band[1], xhigh);
- ilow = encode_low (&c->band[0], xlow);
- ff_g722_update_high_predictor(&c->band[1], c->band[1].scale_factor *
- ff_g722_high_inv_quant[ihigh] >> 10, ihigh);
- ff_g722_update_low_predictor(&c->band[0], ilow >> 2);
- *dst = ihigh << 6 | ilow;
-}
-
-static void g722_encode_no_trellis(G722Context *c,
- uint8_t *dst, int nb_samples,
- const int16_t *samples)
-{
- int i;
- for (i = 0; i < nb_samples; i += 2)
- encode_byte(c, dst++, &samples[i]);
-}
-
-static int g722_encode_frame(AVCodecContext *avctx, AVPacket *avpkt,
- const AVFrame *frame, int *got_packet_ptr)
-{
- G722Context *c = avctx->priv_data;
- const int16_t *samples = (const int16_t *)frame->data[0];
- int nb_samples, out_size, ret;
-
- out_size = (frame->nb_samples + 1) / 2;
- if ((ret = ff_get_encode_buffer(avctx, avpkt, out_size, 0)) < 0)
- return ret;
-
- nb_samples = frame->nb_samples - (frame->nb_samples & 1);
-
- if (avctx->trellis)
- g722_encode_trellis(c, avctx->trellis, avpkt->data, nb_samples, samples);
- else
- g722_encode_no_trellis(c, avpkt->data, nb_samples, samples);
-
- /* handle last frame with odd frame_size */
- if (nb_samples < frame->nb_samples) {
- int16_t last_samples[2] = { samples[nb_samples], samples[nb_samples] };
- encode_byte(c, &avpkt->data[nb_samples >> 1], last_samples);
- }
-
- if (frame->pts != AV_NOPTS_VALUE)
- avpkt->pts = frame->pts - ff_samples_to_time_base(avctx, avctx->initial_padding);
- *got_packet_ptr = 1;
- return 0;
-}
-
-const FFCodec ff_adpcm_g722_encoder = {
- .p.name = "g722",
- CODEC_LONG_NAME("G.722 ADPCM"),
- .p.type = AVMEDIA_TYPE_AUDIO,
- .p.id = AV_CODEC_ID_ADPCM_G722,
- .p.capabilities = AV_CODEC_CAP_DR1 | AV_CODEC_CAP_SMALL_LAST_FRAME |
- AV_CODEC_CAP_ENCODER_REORDERED_OPAQUE,
- .priv_data_size = sizeof(G722Context),
- .init = g722_encode_init,
- .close = g722_encode_close,
- FF_CODEC_ENCODE_CB(g722_encode_frame),
- .p.sample_fmts = (const enum AVSampleFormat[]){ AV_SAMPLE_FMT_S16, AV_SAMPLE_FMT_NONE },
- CODEC_OLD_CHANNEL_LAYOUTS(AV_CH_LAYOUT_MONO)
- .p.ch_layouts = (const AVChannelLayout[]){
- AV_CHANNEL_LAYOUT_MONO, { 0 }
- },
- .caps_internal = FF_CODEC_CAP_INIT_CLEANUP,
-};
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/ilbcdata.h b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/ilbcdata.h
deleted file mode 100644
index b17e24df5f4cfaa766618e0facd9d66d2534a4ce..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/ilbcdata.h
+++ /dev/null
@@ -1,239 +0,0 @@
-/*
- * Copyright (c) 2013, The WebRTC project authors. All rights reserved.
- *
- * Redistribution and use in source and binary forms, with or without
- * modification, are permitted provided that the following conditions are
- * met:
- *
- * * Redistributions of source code must retain the above copyright
- * notice, this list of conditions and the following disclaimer.
- *
- * * Redistributions in binary form must reproduce the above copyright
- * notice, this list of conditions and the following disclaimer in
- * the documentation and/or other materials provided with the
- * distribution.
- *
- * * Neither the name of Google nor the names of its contributors may
- * be used to endorse or promote products derived from this software
- * without specific prior written permission.
- *
- * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
- * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
- * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
- * A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
- * HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
- * SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
- * LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
- * DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
- * THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
- * (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
- * OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
- */
-
-#ifndef AVCODEC_ILBCDATA_H
-#define AVCODEC_ILBCDATA_H
-
-#include "libavutil/common.h"
-
-static const uint8_t lsf_dim_codebook[] = { 3, 3, 4 };
-static const uint8_t lsf_size_codebook[] = { 64, 128, 128 };
-static const int16_t lsf_weight_20ms[] = { 12288, 8192, 4096, 0 };
-static const int16_t lsf_weight_30ms[] = { 8192, 16384, 10923, 5461, 0, 0 };
-
-static const int16_t hp_out_coeffs[] = { 3849, -7699, 3849, 7918, -3833 };
-
-static const int16_t kPlcPfSlope[] = { 26667, 18729, 13653, 10258, 7901, 6214 };
-
-static const int16_t kPlcPitchFact[] = { 0, 5462, 10922, 16384, 21846, 27306 };
-
-static const int16_t kCbFiltersRev[] = {
- -140, 446, -755, 3302, 2922, -590, 343, -138
-};
-
-static const int16_t kPlcPerSqr[] = { 839, 1343, 2048, 2998, 4247, 5849 };
-
-static const int16_t alpha[] = {
- 6554, 13107, 19661, 26214
-};
-
-static const int16_t kLpcChirpSyntDenum[] = {
- 32767, 29573, 26690, 24087, 21739, 19619, 17707, 15980, 14422, 13016, 11747
-};
-
-static const int16_t cos_tbl[64] = {
- 32767, 32729, 32610, 32413, 32138, 31786, 31357, 30853,
- 30274, 29622, 28899, 28106, 27246, 26320, 25330, 24279,
- 23170, 22006, 20788, 19520, 18205, 16846, 15447, 14010,
- 12540, 11039, 9512, 7962, 6393, 4808, 3212, 1608,
- 0, -1608, -3212, -4808, -6393, -7962, -9512, -11039,
- -12540, -14010, -15447, -16846, -18205, -19520, -20788, -22006,
- -23170, -24279, -25330, -26320, -27246, -28106, -28899, -29622,
- -30274, -30853, -31357, -31786, -32138, -32413, -32610, -32729,
-};
-
-static const int16_t cos_derivative_tbl[64] = {
- -632, -1893, -3150, -4399, -5638, -6863, -8072, -9261,
- -10428, -11570, -12684, -13767, -14817, -15832, -16808, -17744,
- -18637, -19486, -20287, -21039, -21741, -22390, -22986, -23526,
- -24009, -24435, -24801, -25108, -25354, -25540, -25664, -25726,
- -25726, -25664, -25540, -25354, -25108, -24801, -24435, -24009,
- -23526, -22986, -22390, -21741, -21039, -20287, -19486, -18637,
- -17744, -16808, -15832, -14817, -13767, -12684, -11570, -10428,
- -9261, -8072, -6863, -5638, -4399, -3150, -1893, -632
-};
-
-static const int16_t lsf_codebook[64 * 3 + 128 * 3 + 128 * 4] = {
- 1273, 2238, 3696, 3199, 5309, 8209, 3606, 5671, 7829,
- 2815, 5262, 8778, 2608, 4027, 5493, 1582, 3076, 5945,
- 2983, 4181, 5396, 2437, 4322, 6902, 1861, 2998, 4613,
- 2007, 3250, 5214, 1388, 2459, 4262, 2563, 3805, 5269,
- 2036, 3522, 5129, 1935, 4025, 6694, 2744, 5121, 7338,
- 2810, 4248, 5723, 3054, 5405, 7745, 1449, 2593, 4763,
- 3411, 5128, 6596, 2484, 4659, 7496, 1668, 2879, 4818,
- 1812, 3072, 5036, 1638, 2649, 3900, 2464, 3550, 4644,
- 1853, 2900, 4158, 2458, 4163, 5830, 2556, 4036, 6254,
- 2703, 4432, 6519, 3062, 4953, 7609, 1725, 3703, 6187,
- 2221, 3877, 5427, 2339, 3579, 5197, 2021, 4633, 7037,
- 2216, 3328, 4535, 2961, 4739, 6667, 2807, 3955, 5099,
- 2788, 4501, 6088, 1642, 2755, 4431, 3341, 5282, 7333,
- 2414, 3726, 5727, 1582, 2822, 5269, 2259, 3447, 4905,
- 3117, 4986, 7054, 1825, 3491, 5542, 3338, 5736, 8627,
- 1789, 3090, 5488, 2566, 3720, 4923, 2846, 4682, 7161,
- 1950, 3321, 5976, 1834, 3383, 6734, 3238, 4769, 6094,
- 2031, 3978, 5903, 1877, 4068, 7436, 2131, 4644, 8296,
- 2764, 5010, 8013, 2194, 3667, 6302, 2053, 3127, 4342,
- 3523, 6595, 10010, 3134, 4457, 5748, 3142, 5819, 9414,
- 2223, 4334, 6353, 2022, 3224, 4822, 2186, 3458, 5544,
- 2552, 4757, 6870, 10905, 12917, 14578, 9503, 11485, 14485,
- 9518, 12494, 14052, 6222, 7487, 9174, 7759, 9186, 10506,
- 8315, 12755, 14786, 9609, 11486, 13866, 8909, 12077, 13643,
- 7369, 9054, 11520, 9408, 12163, 14715, 6436, 9911, 12843,
- 7109, 9556, 11884, 7557, 10075, 11640, 6482, 9202, 11547,
- 6463, 7914, 10980, 8611, 10427, 12752, 7101, 9676, 12606,
- 7428, 11252, 13172, 10197, 12955, 15842, 7487, 10955, 12613,
- 5575, 7858, 13621, 7268, 11719, 14752, 7476, 11744, 13795,
- 7049, 8686, 11922, 8234, 11314, 13983, 6560, 11173, 14984,
- 6405, 9211, 12337, 8222, 12054, 13801, 8039, 10728, 13255,
- 10066, 12733, 14389, 6016, 7338, 10040, 6896, 8648, 10234,
- 7538, 9170, 12175, 7327, 12608, 14983, 10516, 12643, 15223,
- 5538, 7644, 12213, 6728, 12221, 14253, 7563, 9377, 12948,
- 8661, 11023, 13401, 7280, 8806, 11085, 7723, 9793, 12333,
- 12225, 14648, 16709, 8768, 13389, 15245, 10267, 12197, 13812,
- 5301, 7078, 11484, 7100, 10280, 11906, 8716, 12555, 14183,
- 9567, 12464, 15434, 7832, 12305, 14300, 7608, 10556, 12121,
- 8913, 11311, 12868, 7414, 9722, 11239, 8666, 11641, 13250,
- 9079, 10752, 12300, 8024, 11608, 13306, 10453, 13607, 16449,
- 8135, 9573, 10909, 6375, 7741, 10125, 10025, 12217, 14874,
- 6985, 11063, 14109, 9296, 13051, 14642, 8613, 10975, 12542,
- 6583, 10414, 13534, 6191, 9368, 13430, 5742, 6859, 9260,
- 7723, 9813, 13679, 8137, 11291, 12833, 6562, 8973, 10641,
- 6062, 8462, 11335, 6928, 8784, 12647, 7501, 8784, 10031,
- 8372, 10045, 12135, 8191, 9864, 12746, 5917, 7487, 10979,
- 5516, 6848, 10318, 6819, 9899, 11421, 7882, 12912, 15670,
- 9558, 11230, 12753, 7752, 9327, 11472, 8479, 9980, 11358,
- 11418, 14072, 16386, 7968, 10330, 14423, 8423, 10555, 12162,
- 6337, 10306, 14391, 8850, 10879, 14276, 6750, 11885, 15710,
- 7037, 8328, 9764, 6914, 9266, 13476, 9746, 13949, 15519,
- 11032, 14444, 16925, 8032, 10271, 11810, 10962, 13451, 15833,
- 10021, 11667, 13324, 6273, 8226, 12936, 8543, 10397, 13496,
- 7936, 10302, 12745, 6769, 8138, 10446, 6081, 7786, 11719,
- 8637, 11795, 14975, 8790, 10336, 11812, 7040, 8490, 10771,
- 7338, 10381, 13153, 6598, 7888, 9358, 6518, 8237, 12030,
- 9055, 10763, 12983, 6490, 10009, 12007, 9589, 12023, 13632,
- 6867, 9447, 10995, 7930, 9816, 11397, 10241, 13300, 14939,
- 5830, 8670, 12387, 9870, 11915, 14247, 9318, 11647, 13272,
- 6721, 10836, 12929, 6543, 8233, 9944, 8034, 10854, 12394,
- 9112, 11787, 14218, 9302, 11114, 13400, 9022, 11366, 13816,
- 6962, 10461, 12480, 11288, 13333, 15222, 7249, 8974, 10547,
- 10566, 12336, 14390, 6697, 11339, 13521, 11851, 13944, 15826,
- 6847, 8381, 11349, 7509, 9331, 10939, 8029, 9618, 11909,
- 13973, 17644, 19647, 22474, 14722, 16522, 20035, 22134, 16305, 18179, 21106, 23048,
- 15150, 17948, 21394, 23225, 13582, 15191, 17687, 22333, 11778, 15546, 18458, 21753,
- 16619, 18410, 20827, 23559, 14229, 15746, 17907, 22474, 12465, 15327, 20700, 22831,
- 15085, 16799, 20182, 23410, 13026, 16935, 19890, 22892, 14310, 16854, 19007, 22944,
- 14210, 15897, 18891, 23154, 14633, 18059, 20132, 22899, 15246, 17781, 19780, 22640,
- 16396, 18904, 20912, 23035, 14618, 17401, 19510, 21672, 15473, 17497, 19813, 23439,
- 18851, 20736, 22323, 23864, 15055, 16804, 18530, 20916, 16490, 18196, 19990, 21939,
- 11711, 15223, 21154, 23312, 13294, 15546, 19393, 21472, 12956, 16060, 20610, 22417,
- 11628, 15843, 19617, 22501, 14106, 16872, 19839, 22689, 15655, 18192, 20161, 22452,
- 12953, 15244, 20619, 23549, 15322, 17193, 19926, 21762, 16873, 18676, 20444, 22359,
- 14874, 17871, 20083, 21959, 11534, 14486, 19194, 21857, 17766, 19617, 21338, 23178,
- 13404, 15284, 19080, 23136, 15392, 17527, 19470, 21953, 14462, 16153, 17985, 21192,
- 17734, 19750, 21903, 23783, 16973, 19096, 21675, 23815, 16597, 18936, 21257, 23461,
- 15966, 17865, 20602, 22920, 15416, 17456, 20301, 22972, 18335, 20093, 21732, 23497,
- 15548, 17217, 20679, 23594, 15208, 16995, 20816, 22870, 13890, 18015, 20531, 22468,
- 13211, 15377, 19951, 22388, 12852, 14635, 17978, 22680, 16002, 17732, 20373, 23544,
- 11373, 14134, 19534, 22707, 17329, 19151, 21241, 23462, 15612, 17296, 19362, 22850,
- 15422, 19104, 21285, 23164, 13792, 17111, 19349, 21370, 15352, 17876, 20776, 22667,
- 15253, 16961, 18921, 22123, 14108, 17264, 20294, 23246, 15785, 17897, 20010, 21822,
- 17399, 19147, 20915, 22753, 13010, 15659, 18127, 20840, 16826, 19422, 22218, 24084,
- 18108, 20641, 22695, 24237, 18018, 20273, 22268, 23920, 16057, 17821, 21365, 23665,
- 16005, 17901, 19892, 23016, 13232, 16683, 21107, 23221, 13280, 16615, 19915, 21829,
- 14950, 18575, 20599, 22511, 16337, 18261, 20277, 23216, 14306, 16477, 21203, 23158,
- 12803, 17498, 20248, 22014, 14327, 17068, 20160, 22006, 14402, 17461, 21599, 23688,
- 16968, 18834, 20896, 23055, 15070, 17157, 20451, 22315, 15419, 17107, 21601, 23946,
- 16039, 17639, 19533, 21424, 16326, 19261, 21745, 23673, 16489, 18534, 21658, 23782,
- 16594, 18471, 20549, 22807, 18973, 21212, 22890, 24278, 14264, 18674, 21123, 23071,
- 15117, 16841, 19239, 23118, 13762, 15782, 20478, 23230, 14111, 15949, 20058, 22354,
- 14990, 16738, 21139, 23492, 13735, 16971, 19026, 22158, 14676, 17314, 20232, 22807,
- 16196, 18146, 20459, 22339, 14747, 17258, 19315, 22437, 14973, 17778, 20692, 23367,
- 15715, 17472, 20385, 22349, 15702, 18228, 20829, 23410, 14428, 16188, 20541, 23630,
- 16824, 19394, 21365, 23246, 13069, 16392, 18900, 21121, 12047, 16640, 19463, 21689,
- 14757, 17433, 19659, 23125, 15185, 16930, 19900, 22540, 16026, 17725, 19618, 22399,
- 16086, 18643, 21179, 23472, 15462, 17248, 19102, 21196, 17368, 20016, 22396, 24096,
- 12340, 14475, 19665, 23362, 13636, 16229, 19462, 22728, 14096, 16211, 19591, 21635,
- 12152, 14867, 19943, 22301, 14492, 17503, 21002, 22728, 14834, 16788, 19447, 21411,
- 14650, 16433, 19326, 22308, 14624, 16328, 19659, 23204, 13888, 16572, 20665, 22488,
- 12977, 16102, 18841, 22246, 15523, 18431, 21757, 23738, 14095, 16349, 18837, 20947,
- 13266, 17809, 21088, 22839, 15427, 18190, 20270, 23143, 11859, 16753, 20935, 22486,
- 12310, 17667, 21736, 23319, 14021, 15926, 18702, 22002, 12286, 15299, 19178, 21126,
- 15703, 17491, 21039, 23151, 12272, 14018, 18213, 22570, 14817, 16364, 18485, 22598,
- 17109, 19683, 21851, 23677, 12657, 14903, 19039, 22061, 14713, 16487, 20527, 22814,
- 14635, 16726, 18763, 21715, 15878, 18550, 20718, 22906
-};
-
-static const int16_t gain3[9]={
- -16384, -10813, -5407, 0, 4096, 8192, 12288, 16384, 32767
-};
-
-static const int16_t gain4[17]={
- -17203, -14746, -12288, -9830, -7373, -4915, -2458, 0, 2458, 4915, 7373, 9830,
- 12288, 14746, 17203, 19661, 32767
-};
-
-static const int16_t gain5[33]={
- 614, 1229, 1843, 2458, 3072, 3686,
- 4301, 4915, 5530, 6144, 6758, 7373,
- 7987, 8602, 9216, 9830, 10445, 11059,
- 11674, 12288, 12902, 13517, 14131, 14746,
- 15360, 15974, 16589, 17203, 17818, 18432,
- 19046, 19661, 32767
-};
-
-static const int16_t *const ilbc_gain[] = {
- gain5, gain4, gain3,
-};
-
-static const int16_t ilbc_state[8] = {
- -30473, -17838, -9257, -2537, 3639, 10893, 19958, 32636
-};
-
-static const int16_t frg_quant_mod[64] = {
- /* First 37 values in Q8 */
- 569, 671, 786, 916, 1077, 1278,
- 1529, 1802, 2109, 2481, 2898, 3440,
- 3943, 4535, 5149, 5778, 6464, 7208,
- 7904, 8682, 9397, 10285, 11240, 12246,
- 13313, 14382, 15492, 16735, 18131, 19693,
- 21280, 22912, 24624, 26544, 28432, 30488,
- 32720,
- /* 22 values in Q5 */
- 4383, 4684, 5012, 5363, 5739, 6146,
- 6603, 7113, 7679, 8285, 9040, 9850,
- 10838, 11882, 13103, 14467, 15950, 17669,
- 19712, 22016, 24800, 28576,
- /* 5 values in Q3 */
- 8240, 9792, 12040, 15440, 22472
-};
-
-#endif /* AVCODEC_ILBCDATA_H */
diff --git a/spaces/coledie/Fashion_VAE/app.py b/spaces/coledie/Fashion_VAE/app.py
deleted file mode 100644
index 7d017648c98223d27a8f25be7affd758c25534cb..0000000000000000000000000000000000000000
--- a/spaces/coledie/Fashion_VAE/app.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import numpy as np
-import torch
-import gradio as gr
-from vae import *
-import matplotlib.image as mpimg
-
-
-with open("vae.pt", "rb") as file:
- vae = torch.load(file)
- vae.eval()
-
-
-def generate_image(filename):
- image = mpimg.imread(filename)[:, :, 0] / 255
-
- grayscale = vae(torch.Tensor(image))[0].reshape((28, 28))
-
- return grayscale.detach().numpy()
-
-
-examples = [f"examples/{i}.jpg" for i in range(10)]
-
-demo = gr.Interface(generate_image,
- gr.Image(type="filepath"),
- "image",
- examples,
- title="VAE running on Fashion MNIST",
- description=".",
- article="...",
- allow_flagging=False,
-)
-demo.launch()
diff --git a/spaces/conchdork/open-reverse-proxy/README.md b/spaces/conchdork/open-reverse-proxy/README.md
deleted file mode 100644
index 803d0d14093c101f5c6e432b86ee347d7928dc69..0000000000000000000000000000000000000000
--- a/spaces/conchdork/open-reverse-proxy/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: Open Reverse Proxy
-emoji: 🔥
-colorFrom: purple
-colorTo: blue
-sdk: docker
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Experience Mecha Storm Advanced War Robots with Mod APK - Customize Your Robot and Conquer Planets.md b/spaces/congsaPfin/Manga-OCR/logs/Experience Mecha Storm Advanced War Robots with Mod APK - Customize Your Robot and Conquer Planets.md
deleted file mode 100644
index 3f0f9a134db1950dfa6efe4d4c9e33b8296f9db3..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Experience Mecha Storm Advanced War Robots with Mod APK - Customize Your Robot and Conquer Planets.md
+++ /dev/null
@@ -1,101 +0,0 @@
-
-Mecha Storm: Advanced War Robots Mod APK - A Guide for Beginners
-If you are a fan of sci-fi and robot games, you might want to check out Mecha Storm: Advanced War Robots Mod APK. This is a modded version of the original game that gives you unlimited resources, unlocked features, and more. In this article, we will tell you what Mecha Storm: Advanced War Robots is, how to download and install it, how to play it, and some tips and tricks to help you conquer the space.
-mecha storm advanced war robots mod apk
DOWNLOAD >>> https://urlca.com/2uO9PP
-What is Mecha Storm: Advanced War Robots?
-Mecha Storm: Advanced War Robots is an action-packed MMORPG where you take control of deadly robots, called Mechs. You can join one of the factions in the game and fight against other players to conquer all the planets in the space and win the war. The game has a rich variety of game modes, both in PvP (Player vs Player) and PvE (Player vs Environment), where you can collect dozens of different Mechs and equip them any way you want. As you progress through the ranks and levels, you can also gain access to enormous spaceships that you can control to fight in massive FvF (Fleet vs Fleet) battles.
-Features of Mecha Storm: Advanced War Robots
-Mecha Storm: Advanced War Robots has many features that make it an exciting and addictive game. Here are some of them:
-36 Combat Robots with various attributes
-You can choose from 36 different robots that have different attributes such as speed, power, defense, and more. Each robot also has its own unique design and appearance that reflects its personality and abilities. You can customize your robot with various gears and skills to suit your play style.
-Exciting manual controls or easy automatic controls
-You can control your robot manually by using the virtual joystick and buttons on the screen, or you can opt for the easy automatic controls that let your robot move and attack by itself. You can switch between the two modes anytime during the game. The manual controls give you more freedom and challenge, while the automatic controls let you enjoy the game without much hassle.
-Over 100 weapons such as anti-tank rifles, double war-ax, spiked maul and more
-You can equip your robot with over 100 weapons that have different effects and damage types. You can use ranged weapons such as anti-tank rifles, laser guns, rocket launchers, and more to attack your enemies from a distance. You can also use melee weapons such as double war-ax, spiked maul, chainsaw sword, and more to slash your enemies up close. You can mix and match different weapons to create your own combination.
-mecha storm mod apk unlimited money and gems
-mecha storm advanced war robots hack download
-mecha storm apk mod free shopping
-mecha storm mod apk latest version
-mecha storm advanced war robots cheats
-mecha storm mod apk offline
-mecha storm advanced war robots gameplay
-mecha storm apk mod android 1
-mecha storm mod apk revdl
-mecha storm advanced war robots review
-mecha storm mod apk no root
-mecha storm advanced war robots guide
-mecha storm apk mod obb
-mecha storm mod apk happymod
-mecha storm advanced war robots tips
-mecha storm mod apk unlimited everything
-mecha storm advanced war robots wiki
-mecha storm apk mod menu
-mecha storm mod apk rexdl
-mecha storm advanced war robots best mech
-mecha storm mod apk unlimited gold and silver
-mecha storm advanced war robots codes
-mecha storm apk mod data
-mecha storm mod apk pure
-mecha storm advanced war robots reddit
-mecha storm mod apk unlimited energy and ammo
-mecha storm advanced war robots update
-mecha storm apk mod vip
-mecha storm mod apk platinmods
-mecha storm advanced war robots online
-mecha storm mod apk unlimited coins and diamonds
-mecha storm advanced war robots pc
-mecha storm apk mod hack
-mecha storm mod apk android republic
-mecha storm advanced war robots trailer
-mecha storm mod apk unlimited health and shield
-mecha storm advanced war robots ios
-mecha storm apk mod unlocked all
-mecha storm mod apk blackmod
-mecha storm advanced war robots pvp
-Real-time 1vs1 or 3vs3 PvP battles with rivals from all around the world
-You can test your skills and strategies against other players in real-time PvP battles. You can choose to play in 1vs1 mode where you face one opponent, or 3vs3 mode where you team up with two allies and fight against three enemies. You can also join a clan and participate in clan wars and tournaments. You can chat with other players and make friends or rivals. You can also view the rankings and leaderboards to see how you compare with other players.
-How to download and install Mecha Storm: Advanced War Robots Mod APK?
-If you want to enjoy the modded version of Mecha Storm: Advanced War Robots, you need to download and install the Mecha Storm: Advanced War Robots Mod APK file. Here are the steps to do so:
-
-- Go to a trusted website that provides the Mecha Storm: Advanced War Robots Mod APK file, such as [Mecha Storm: Advanced War Robots Mod APK Download].
-- Click on the download button and wait for the file to be downloaded on your device.
-- Once the file is downloaded, locate it in your file manager and tap on it to start the installation process.
-- Allow the installation of unknown sources if prompted by your device.
-- Follow the instructions on the screen and wait for the installation to be completed.
-- Launch the game and enjoy the modded features.
-
-Note: You may need to uninstall the original version of Mecha Storm: Advanced War Robots before installing the modded version. You may also need to enable the storage permission for the game to work properly.
-How to play Mecha Storm: Advanced War Robots Mod APK?
-Now that you have installed Mecha Storm: Advanced War Robots Mod APK, you can start playing the game. Here are some basic steps to help you get started:
-Select a robot based on your play style and equip gears and skills
-You can choose from 36 different robots that have different attributes such as speed, power, defense, and more. Each robot also has its own unique design and appearance that reflects its personality and abilities. You can customize your robot with various gears and skills to suit your play style. You can also change the color and name of your robot.
-Play the scenario mode by creating a team of 3 robots
-You can play the scenario mode by creating a team of 3 robots that you can switch between during the game. The scenario mode consists of various missions that have different objectives and difficulties. You can earn rewards such as gold, gems, equipment, and more by completing the missions. You can also unlock new robots and spaceships by playing the scenario mode.
-Strengthen your robot, equipment, and skills to join in on the real-time PvP battles
-You can strengthen your robot, equipment, and skills by using the gold, gems, and other resources that you earn from playing the game. You can upgrade your robot's level, rank, attribute, and skill level. You can also enhance your equipment's level, grade, attribute, and skill level. You can also craft new equipment by using materials that you collect from playing the game. By strengthening your robot, equipment, and skills, you can join in on the real-time PvP battles and compete with other players from all around the world.
-Tips and tricks for Mecha Storm: Advanced War Robots Mod APK
-To help you enjoy Mecha Storm: Advanced War Robots Mod APK more, here are some tips and tricks that you can use:
-Choose your faction wisely
-You can join one of the factions in the game: Federation, Empire, or Alliance. Each faction has its own story, background, characters, robots, spaceships, and missions. You can also get different rewards and benefits depending on your faction. Choose your faction wisely based on your preference and play style.
-Upgrade your robots and weapons regularly
-You can upgrade your robots and weapons regularly by using the gold, gems, and other resources that you earn from playing the game. Upgrading your robots and weapons will increase their stats and performance, making them more powerful and effective in combat. You can also unlock new skills and abilities by upgrading your robots and weapons.
-Use your skills strategically
-You can use your skills strategically by timing them well and aiming them accurately. Each skill has its own cooldown time, effect range, damage type, and target type. You can use your skills to deal damage, heal yourself or allies, stun or debuff enemies, or buff yourself or allies. You can also combine different skills to create combos that have more impact.
-Conclusion
-Mecha Storm: Advanced War Robots Mod APK is a fun and exciting game that lets you control and customize your own robots and fight against other players in various game modes. You can download and install the modded version of the game to enjoy unlimited resources, unlocked features, and more. You can also follow the steps and tips that we have provided in this article to help you get started and improve your skills. If you are looking for a thrilling and immersive robot game, you should give Mecha Storm: Advanced War Robots Mod APK a try.
-FAQs
-Here are some frequently asked questions about Mecha Storm: Advanced War Robots Mod APK:
-
-- What are the benefits of Mecha Storm: Advanced War Robots Mod APK?
-Mecha Storm: Advanced War Robots Mod APK gives you many benefits such as unlimited gold, gems, energy, and other resources, unlocked robots, weapons, spaceships, and features, free shopping, no ads, and more.
-- Is Mecha Storm: Advanced War Robots Mod APK safe to use?
-Mecha Storm: Advanced War Robots Mod APK is safe to use as long as you download it from a trusted website that provides the original and virus-free file. You should also scan the file with an antivirus program before installing it on your device.
-- Do I need to root or jailbreak my device to use Mecha Storm: Advanced War Robots Mod APK?
-No, you do not need to root or jailbreak your device to use Mecha Storm: Advanced War Robots Mod APK. You can install and play the game without any modifications on your device.
-- How can I update Mecha Storm: Advanced War Robots Mod APK?
-You can update Mecha Storm: Advanced War Robots Mod APK by downloading and installing the latest version of the file from the same website that you downloaded it from. You should also check for updates regularly to enjoy the new features and bug fixes.
-- How can I contact the developer of Mecha Storm: Advanced War Robots?
-You can contact the developer of Mecha Storm: Advanced War Robots by visiting their official website [Mecha Storm: Advanced War Robots Official Website] or their Facebook page [Mecha Storm: Advanced War Robots Facebook Page]. You can also send them an email at [Mecha Storm: Advanced War Robots Email Address].
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/GoreBox A Deliciously Violent Sandbox Game for Android.md b/spaces/congsaPfin/Manga-OCR/logs/GoreBox A Deliciously Violent Sandbox Game for Android.md
deleted file mode 100644
index 69bc7834e12d08b5262989d197707b0a88b0fc7b..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/GoreBox A Deliciously Violent Sandbox Game for Android.md
+++ /dev/null
@@ -1,92 +0,0 @@
-
-How to Download GoreBox: A Guide for Gamers
-If you are looking for a game that lets you unleash your inner demon with a vast arsenal of brutal weapons, explosive devices, interactive ragdolls, fearsome enemies, advanced turrets, vehicles, and a cutting-edge blood and dismemberment system, then you might want to check out GoreBox. In this article, we will tell you what GoreBox is, why you should play it, and how to download it for your Android or PC device.
-how to download gorebox
Download Zip ✺✺✺ https://urlca.com/2uO5z0
-What is GoreBox?
-GoreBox is a physics-based sandbox game of extreme violence developed by F²Games. It is the third installment in the GoreBox franchise, following GoreBox Remastered and GoreBox - Animosity. The game is currently available for Android devices on Google Play Store and is coming soon to PC devices on Steam.
-Features of GoreBox
-GoreBox has many features that make it a unique and fun game to play. Some of these features are:
-
-- A realistic blood pooling and dismemberment system that lets you see the gore and carnage you cause.
-- An active ragdoll system that makes the characters react to wounds and scenarios in a semi-realistic way.
-- A Reality Crusher, your primary weapon for building, destroying, and manipulating the environment. You can use it to create and customize your own maps, drive, fly, or blow everything up.
-- A Timsky's virus mode that induces uncontrollable rage and reduces IQ in those infected. You can face off against enemies who range from mindless drones to cunning predators.
-- A Phil Timsky mode that lets you embody the creator of the Reality Crusher and the virus. You are equipped with a chip that enhances pain resistance, allows mind control of the Reality Crusher, and makes you immune to the virus.
-
-Why play GoreBox?
-GoreBox is a game that offers unlimited fun and stress relief. You can unleash your creativity and revel in the destruction and mayhem you create. You can also enjoy the chaos and destruction caused by the virus and the Reality Crusher. The game has a stylized graphics style that makes it appealing and immersive. The game also has a lot of custom content that you can download or create yourself, such as maps and mods. The game is suitable for mature audiences who enjoy violent games.
-How to download GoreBox for Android
-If you have an Android device, you can download GoreBox from Google Play Store. Here are the steps you need to follow:
-Step 1: Go to Google Play Store
-Open Google Play Store on your Android device and make sure you are signed in with your Google account.
-Step 2: Search for GoreBox
-Type "GoreBox" in the search bar and tap on the first result that appears. It should be the one with the logo of a red skull with horns.
-Step 3: Install GoreBox
-Tap on the green "Install" button and wait for the download and installation process to complete. You might need to grant some permissions for the app to run properly.
-How to download GoreBox for PC
-If you have a PC device, you can download GoreBox from Steam. However, the game is not yet released for PC devices, so you will have to wait for the release date. Here are the steps you need to follow:
-How to download gorebox on android
-How to download gorebox on pc
-How to download gorebox mods
-How to download gorebox plus
-How to download gorebox remastered
-How to download gorebox animosity
-How to download gorebox for free
-How to download gorebox maps
-How to download gorebox apk
-How to download gorebox from steam
-How to install gorebox on android
-How to install gorebox on pc
-How to install gorebox mods
-How to install gorebox plus
-How to install gorebox remastered
-How to install gorebox animosity
-How to install gorebox for free
-How to install gorebox maps
-How to install gorebox apk
-How to install gorebox from steam
-Gorebox download guide for android
-Gorebox download guide for pc
-Gorebox download guide for mods
-Gorebox download guide for plus
-Gorebox download guide for remastered
-Gorebox download guide for animosity
-Gorebox download guide for free
-Gorebox download guide for maps
-Gorebox download guide for apk
-Gorebox download guide for steam
-Gorebox installation tutorial for android
-Gorebox installation tutorial for pc
-Gorebox installation tutorial for mods
-Gorebox installation tutorial for plus
-Gorebox installation tutorial for remastered
-Gorebox installation tutorial for animosity
-Gorebox installation tutorial for free
-Gorebox installation tutorial for maps
-Gorebox installation tutorial for apk
-Gorebox installation tutorial for steam
-Step 1: Go to Steam
-Open Steam on your PC device and make sure you are signed in with your Steam account.
-Step 2: Search for GoreBox
-Type "GoreBox" in the search bar and click on the first result that appears. It should be the one with the logo of a red skull with horns.
-Step 3: Add GoreBox to your wishlist
-Click on the green "Add to your wishlist" button and wait for the confirmation message. This will help you keep track of the game's release date and any updates or discounts.
-Step 4: Wait for the release date
-The release date for GoreBox for PC devices is not yet announced, but it is expected to be sometime in 2023. You can check the game's Steam page for any news or announcements. You can also join the game's community and chat with other fans and developers.
-Conclusion
-GoreBox is a physics-based sandbox game of extreme violence that lets you create and destroy anything you want. It is a game that offers unlimited fun and stress relief for mature audiences who enjoy violent games. You can download GoreBox for Android devices from Google Play Store or wait for the release date for PC devices on Steam. We hope this guide helped you learn how to download GoreBox and enjoy this amazing game.
-FAQs
-
-- Q: How much does GoreBox cost?
-- A: GoreBox is free to download and play on Android devices, but it contains ads and in-app purchases. The price for PC devices is not yet revealed, but it will likely be a paid game.
-- Q: What are the system requirements for GoreBox?
-- A: The system requirements for Android devices are Android 4.4 or higher, 1 GB of RAM, and 100 MB of storage space. The system requirements for PC devices are not yet announced, but they will likely be higher than Android devices.
-- Q: Is GoreBox multiplayer?
-- A: GoreBox is not multiplayer, but it has a lot of custom content that you can download or create yourself, such as maps and mods. You can also share your creations and screenshots with other players online.
-- Q: Is GoreBox safe to play?
-- A: GoreBox is safe to play as long as you are aware that it is a violent game that contains graphic depictions of blood, gore, and dismemberment. It is not suitable for children or people who are sensitive to violence. It is also not intended to promote or glorify violence in real life.
-- Q: How can I contact the developers of GoreBox?
-- A: You can contact the developers of GoreBox by visiting their website, following them on social media, or joining their Discord server. You can also leave feedback, suggestions, or bug reports on the game's Google Play Store or Steam page.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/How to Download Ashfall with Eng Sub - The Best Site for Korean Movies.md b/spaces/congsaPfin/Manga-OCR/logs/How to Download Ashfall with Eng Sub - The Best Site for Korean Movies.md
deleted file mode 100644
index dddd33cdff64478a3b0b59324d8bab6c658ccee0..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/How to Download Ashfall with Eng Sub - The Best Site for Korean Movies.md
+++ /dev/null
@@ -1,161 +0,0 @@
-
-Ashfall Movie Download Eng Sub: How to Watch the Epic Disaster Film Online
- If you are a fan of disaster movies, you might have heard of Ashfall, a 2019 South Korean film that depicts a volcanic eruption on Mount Paektu and its aftermath. The film was a huge hit in South Korea, grossing over $61 million and winning several awards. It also received positive reviews from critics and audiences for its spectacular visual effects, thrilling action scenes, and emotional drama. But how can you watch this epic film online with English subtitles? In this article, we will tell you everything you need to know about Ashfall movie download eng sub, including what the film is about, why you should watch it, and where to find it online.
- What is Ashfall Movie About?
- Ashfall is a disaster film that revolves around a volcanic eruption on Mount Paektu, a mountain that lies on the border between China and North Korea. The eruption causes massive earthquakes and tsunamis that threaten the lives of millions of people on the Korean peninsula. To prevent another catastrophe, a team of experts from South Korea and North Korea join forces to stop the volcano from erupting again. However, they face many challenges and dangers along the way, as well as personal conflicts and political tensions.
-ashfall movie download eng sub
DOWNLOAD ✔ https://urlca.com/2uO5yc
- The Plot of Ashfall Movie
- The film begins with Mount Paektu erupting for the first time in over a century, causing chaos and panic in both North and South Korea. Jeon Yoo-kyung (Jeon Hye-jin), a senior official in the South Korean government, plans an operation based on a theory by Professor Kang Bong-rae (Ma Dong-seok), who had studied the volcano and its possible future eruptions. The operation involves detonating a nuclear device in a mine near the volcano's caldera, which would relieve the pressure and prevent another eruption.
- Jo In-chang (Ha Jung-woo), a captain of a special forces team, is assigned to lead the operation. He contacts Lee Joon-pyeong (Lee Byung-hun), a former North Korean agent who has vital information about the location of the mine. However, Joon-pyeong has his own agenda and does not trust anyone. Meanwhile, Jo In-chang's pregnant wife Choi Ji-young (Bae Suzy) is alone in Seoul and struggling to survive amidst the disaster.
- Jo In-chang and his team parachute into North Korea and rescue Joon-pyeong from a prison. They then head to a power station, where they extract a piece of uranium from a nuclear missile. This alerts the American forces in South Korea, who send soldiers to stop them from delivering the uranium to some Chinese gangsters who have agreed to help them enter the mine. Along the way, they encounter various obstacles and enemies, as well as unexpected allies and friends.
- Will they be able to reach the mine in time and stop the volcano from erupting again? Will they be able to reunite with their loved ones and survive the disaster? You will have to watch the movie to find out.
- The Cast and Crew of Ashfall Movie
- Ashfall boasts an impressive cast of talented and popular actors, who deliver captivating performances and bring their characters to life. The main cast includes:
-
-- Lee Byung-hun as Lee Joon-pyeong, a former North Korean agent who holds the key to the operation. He is cynical, ruthless, and unpredictable, but also has a soft spot for his family and friends.
-- Ha Jung-woo as Jo In-chang, a captain of a special forces team who leads the operation. He is loyal, courageous, and determined, but also faces a dilemma between his duty and his love for his wife.
-- Ma Dong-seok as Professor Kang Bong-rae, a geologist who proposes the theory of stopping the volcano. He is smart, eccentric, and passionate, but also has a dark past and a secret motive.
-- Jeon Hye-jin as Jeon Yoo-kyung, a senior official in the South Korean government who plans the operation. She is calm, confident, and competent, but also has to deal with the pressure and politics of her position.
-- Bae Suzy as Choi Ji-young, Jo In-chang's pregnant wife who is trapped in Seoul. She is sweet, optimistic, and resilient, but also faces many dangers and difficulties in the disaster zone.
-
- The film was directed by Lee Hae-jun and Kim Byung-seo, who are both experienced and acclaimed filmmakers. Lee Hae-jun is known for his comedy-drama films such as Castaway on the Moon and My Dictator, while Kim Byung-seo is known for his cinematography work in films such as The Terror Live and Cold Eyes. They collaborated to create a film that combines humor, action, drama, and spectacle in a balanced and engaging way.
-ashfall korean movie download with english subtitles
-ashfall 2019 full movie eng sub free download
-ashfall movie online watch with eng sub
-ashfall movie english subtitle download srt
-ashfall movie torrent download with english sub
-ashfall full movie hd download eng sub
-ashfall movie download in english dubbed
-ashfall korean movie eng sub watch online free
-ashfall movie download 480p with english subtitles
-ashfall movie download 720p with english subtitles
-ashfall movie download 1080p with english subtitles
-ashfall movie download mp4 with english subtitles
-ashfall movie download mkv with english subtitles
-ashfall movie download blu ray with english subtitles
-ashfall movie download google drive with english subtitles
-ashfall korean movie eng sub download link
-ashfall korean movie eng sub free streaming
-ashfall korean movie eng sub dailymotion
-ashfall korean movie eng sub youtube
-ashfall korean movie eng sub reddit
-ashfall korean movie eng sub kissasian
-ashfall korean movie eng sub dramacool
-ashfall korean movie eng sub viu
-ashfall korean movie eng sub netflix
-ashfall korean movie eng sub iQIYI
-ashfall korean action movie download with english subtitles
-ashfall korean adventure movie download with english subtitles
-ashfall korean thriller movie download with english subtitles
-ashfall korean drama movie download with english subtitles
-ashfall lee byung hun movie download with english subtitles
-ashfall ha jung woo movie download with english subtitles
-ashfall ma dong seok movie download with english subtitles
-ashfall jeon hye jin movie download with english subtitles
-ashfall bae suzy movie download with english subtitles
-ashfall 2019 korean disaster film download with english subtitles
-how to download ashfall movie with english subtitles
-where to download ashfall movie with english subtitles
-best site to download ashfall movie with english subtitles
-legal way to download ashfall movie with english subtitles
-safe way to download ashfall movie with english subtitles
- The Reception and Awards of Ashfall Movie
- Ashfall was released on December 19, 2019 in South Korea, where it became a box office success. It attracted over 8.2 million viewers and grossed over $61 million, making it the sixth highest-grossing film of 2019 in South Korea. It also received positive reviews from critics and audiences, who praised its visual effects, action scenes, acting performances, and emotional impact. The film has a rating of 6.2 out of 10 on IMDb and 7.4 out of 10 on Naver Movie.
- The film also won several awards and nominations at various film festivals and ceremonies. Some of the awards that it won are:
-
-- Best Film Editing at the 56th Baeksang Arts Awards
-- Best Visual Effects at the 56th Grand Bell Awards
-- Best Visual Effects at the 40th Blue Dragon Film Awards
-- Best Action Film at the 39th Golden Cinema Film Festival
-- Best Action Film at the 15th Seoul International Extreme-Short Image & Film Festival
-
- Why You Should Watch Ashfall Movie with Eng Sub?
- If you are still not convinced that Ashfall is a movie worth watching, here are some reasons why you should give it a try with English subtitles:
- The Stunning Visual Effects and Cinematography of Ashfall Movie
- One of the most impressive aspects of Ashfall is its visual effects and cinematography, which create a realistic and immersive depiction of the volcanic disaster and its aftermath. The film used advanced computer-generated imagery (CGI) and practical effects to create scenes such as the eruption of Mount Paektu, the collapse of buildings, the flooding of streets, and the explosion of nuclear missiles. The film also used aerial shots, drone shots, crane shots, and handheld shots to capture the scale and scope of the disaster from different angles and perspectives. The film's visual effects team consisted of over 500 people from South Korea, China, Japan, Canada, and New Zealand. The film's cinematographer was Kim Ji-yong, who is known for his work in films such as A Taxi Driver and The Age of Shadows.
- The Thrilling Action and Drama of Ashfall MovieAshfall is not just a disaster film, but also a film that combines action and drama in a compelling and exciting way. The film features many thrilling and tense action scenes, such as car chases, shootouts, fistfights, and explosions. The film also explores the emotional and psychological aspects of the characters, such as their motivations, relationships, conflicts, and dilemmas. The film shows how the disaster affects the characters' lives, choices, and values, and how they cope with the challenges and risks that they face. The film also touches on themes such as patriotism, cooperation, sacrifice, and family.
- The Cultural and Historical Significance of Ashfall Movie
-
Ashfall is also a film that has cultural and historical significance, especially for Korean audiences. The film is based on the real-life Mount Paektu, which is a sacred and symbolic mountain for both North and South Koreans. The mountain is considered to be the birthplace of the Korean nation and the origin of the Korean people. The film also depicts the relationship and cooperation between North and South Korea, which is a sensitive and complex issue in the current political climate. The film shows how the disaster brings the two countries together, despite their differences and conflicts. The film also reflects on the history and future of the Korean peninsula, and the hope for peace and reunification.
- Where to Watch Ashfall Movie with Eng Sub Online?
- Now that you know what Ashfall is about and why you should watch it, you might be wondering where you can watch it online with English subtitles. Fortunately, there are several options available for you to choose from. Here are some of the best platforms where you can watch Ashfall movie download eng sub:
- Bilibili: A Free Streaming Platform with Eng Sub
- Bilibili is a Chinese video-sharing platform that offers a variety of content, including anime, movies, TV shows, music, games, and more. Bilibili is also one of the platforms where you can watch Ashfall for free with English subtitles. Bilibili has a large and active community of users who upload and share videos, as well as comment and interact with each other.
- How to Watch Ashfall Movie on Bilibili?
- To watch Ashfall on Bilibili, you need to follow these steps:
-
-- Go to Bilibili's official website or download its app on your device.
-- Create an account or log in with your existing account.
-- Search for Ashfall in the search bar or browse through the categories.
-- Select the video that you want to watch and click on it.
-- Enjoy watching Ashfall with English subtitles.
-
- What are the Benefits of Watching Ashfall Movie on Bilibili?
- Some of the benefits of watching Ashfall on Bilibili are:
-
-- You can watch it for free without any subscription or registration fees.
-- You can watch it with high-quality video and audio.
-- You can watch it with accurate and synchronized English subtitles.
-- You can watch it with other features such as bullet comments, danmaku, stickers, gifts, etc.
-- You can watch it with other users who share your interests and opinions.
-
- iQIYI: A Premium Streaming Service with Eng Sub
- iQIYI is a Chinese online video platform that provides a variety of content, including movies, TV shows, dramas, variety shows, documentaries, animations, etc. iQIYI is also one of the platforms where you can watch Ashfall with English subtitles. iQIYI has a large and diverse library of content that caters to different tastes and preferences.
- How to Watch Ashfall Movie on iQIYI?
- To watch Ashfall on iQIYI, you need to follow these steps:
-
-- Go to iQIYI's official website or download its app on your device.
-- Create an account or log in with your existing account.
-- Select your preferred language (English or Chinese) in the settings.
-- Search for Ashfall in the search bar or browse through the categories.
-- Select the video that you want to watch and click on it.
-- Choose the option to watch it with English subtitles.
-- Enjoy watching Ashfall with English subtitles.
-
- What are the Benefits of Watching Ashfall Movie on iQIYI?
- Some of the benefits of watching Ashfall on iQIYI are:
-
-- You can watch it with high-definition video and Dolby sound.
-- You can watch it with professional and reliable English subtitles.
-- You can watch it with other features such as smart recommendations, offline downloads, multi-screen viewing, etc.
-- You can watch it with other content that suits your interests and preferences.
-- You can watch it with a low-cost subscription or a free trial.
-
- JustWatch: A Search Engine for Streaming Options with Eng Sub
- JustWatch is a website and app that helps you find where to watch movies and TV shows online. JustWatch is also one of the platforms where you can find Ashfall with English subtitles. JustWatch has a comprehensive and updated database of streaming services and content that covers over 40 countries and regions.
- How to Watch Ashfall Movie on JustWatch?
- To watch Ashfall on JustWatch, you need to follow these steps:
-
-- Go to JustWatch's official website or download its app on your device.
-- Select your country or region in the settings.
-- Search for Ashfall in the search bar or browse through the genres.
-- Select the movie that you want to watch and click on it.
-- Choose the streaming service that offers Ashfall with English subtitles.
-- Enjoy watching Ashfall with English subtitles.
-
- What are the Benefits of Watching Ashfall Movie on JustWatch?
- Some of the benefits of watching Ashfall on JustWatch are:
-
-- You can find the best streaming option for Ashfall with English subtitles among various services and platforms.
-- You can compare the prices, quality, and availability of different streaming options for Ashfall.
-- You can discover other movies and TV shows that are similar to Ashfall.
-- You can get personalized recommendations based on your preferences and watch history.
-- You can create a watchlist and track your progress of watching Ashfall.
-
- Conclusion
- Ashfall is a disaster film that tells the story of a volcanic eruption on Mount Paektu and its consequences. The film features an amazing cast, stunning visual effects, thrilling action scenes, and emotional drama. The film also has cultural and historical significance, as it depicts the relationship between North and South Korea. If you want to watch this epic film online with English subtitles, you can choose from several platforms such as Bilibili, iQIYI, or JustWatch. We hope that this article has helped you learn more about Ashfall movie download eng sub, and that you will enjoy watching it.
- FAQs
- Here are some frequently asked questions about Ashfall movie download eng sub:
-
-- Is Ashfall movie based on a true story?
-No, Ashfall movie is not based on a true story. However, it is inspired by the real-life Mount Paektu, which is a volcanic mountain that lies on the border between China and North Korea. The mountain has erupted several times in history, most recently in 1903. Some scientists have speculated that the mountain could erupt again in the future, causing a major disaster for both countries.
- - Is Ashfall movie available on Netflix?
-No, Ashfall movie is not available on Netflix. However, you can find it on other streaming services such as Bilibili, iQIYI, or JustWatch. You can also buy or rent it on platforms such as Amazon Prime Video, Google Play Movies, YouTube, or iTunes.
- - How long is Ashfall movie?
-Ashfall movie has a runtime of 128 minutes. It is divided into two parts: Part 1: The Eruption (64 minutes) and Part 2: The Aftermath (64 minutes).
- Who sings the theme song of Ashfall movie?
-The theme song of Ashfall movie is called Together, and it is sung by Taeyeon, a famous South Korean singer and member of the girl group Girls' Generation. The song is a powerful and emotional ballad that expresses the hope and courage of the characters in the face of the disaster. The song was released as a digital single on December 15, 2019, and it topped the charts in South Korea and China.
- - What is the meaning of the title Ashfall?
-The title Ashfall refers to the phenomenon of volcanic ash falling from the sky after a volcanic eruption. Volcanic ash is a mixture of fine particles of rock, minerals, and glass that are ejected from a volcano. Volcanic ash can have harmful effects on the environment, health, and infrastructure, as it can cover large areas, reduce visibility, damage buildings and vehicles, contaminate water and crops, and cause respiratory problems. The title Ashfall also symbolizes the dark and bleak situation that the characters face in the film.
- - Is there a sequel to Ashfall movie?
-No, there is no sequel to Ashfall movie. However, there are some rumors and speculations that the filmmakers might consider making a sequel or a spin-off based on the popularity and success of the film. Some fans have also expressed their interest and curiosity in seeing more stories and characters related to Ashfall movie.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/The Ultimate Guide to Pet Idle Hack APK for Android and IOS Devices.md b/spaces/congsaPfin/Manga-OCR/logs/The Ultimate Guide to Pet Idle Hack APK for Android and IOS Devices.md
deleted file mode 100644
index 7feba9c4437980e4cbfd5e776e3807da729974b9..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/The Ultimate Guide to Pet Idle Hack APK for Android and IOS Devices.md
+++ /dev/null
@@ -1,145 +0,0 @@
-
-Pet Idle Hack APK: How to Get Unlimited Coins and Gems for Your Pets
-If you love taking care of virtual animals, you might have heard of Pet Idle, a simulation game where you can adopt, feed, play with, and train various pets. You can also build and decorate your house, take care of your garden, collect insects, and fish. However, if you want to enjoy all the features of the game without spending real money or waiting for hours, you might be interested in using a hack APK. In this article, we will tell you everything you need to know about Pet Idle Hack APK, including what it is, why you should use it, how to download and install it, how to use it, and some tips and tricks for playing the game with it. We will also compare the pros and cons of using the hack APK and answer some frequently asked questions.
-pet idle hack apk
Download File · https://urlca.com/2uOcdA
- What is Pet Idle?
-Pet Idle is a casual simulation game developed by Alphaquest Games. It was released in December 2021 on Steam and is available for free. The game allows you to take care of various virtual animals, such as dogs, cats, bunnies, llamas, and even magical beasts. You can choose from 19 different pet types, each with a unique personality that affects the gameplay. You can also edit the color of each pet to make them look more adorable.
-The game has a pet needs system that requires you to fulfill their hunger, thirst, sleep, hygiene, walking, and fun. You can feed them with different foods, give them water, put them to bed, bathe them, take them for walks, and play with them. The happier your pet is, the more money you make. You can use the money to buy more pets, furniture, toys, food, water, and other items.
-You can also build and expand your house to accommodate more pets. You can decorate the interior of your house with various wallpapers, floors, windows, doors, lamps, plants, paintings, rugs, and other items. You can also take care of your garden by watering different plants and harvesting fruits. You can also collect different rare insects by placing traps in your garden. Additionally, you can fish in a pond with a fishing rod and catch fish of different types.
-Your pet will also gain levels of experience as they have a good life. They will learn several tricks such as sitting, rolling, jumping, running, and more. You can teach them new skills by using skill books that you can buy or find in the game. You can also use robots and drones to help you care for your pets.
- What is a Hack APK?
-A hack APK is a modified version of an original application that has been altered to provide some extra features or advantages that are not available in the official version. For example, a hack APK for Pet Idle can give you unlimited coins and gems that you can use to buy anything in the game without spending real money or waiting for hours. It can also unlock all the pets and items that are otherwise locked behind paywalls or level requirements. It can also allow you to customize your pets by changing their size, speed, and other attributes. A hack APK can also remove ads and other annoying features from the game.
- A hack APK works by bypassing the security checks and verification processes of the original application. It can also modify the game data and files to alter the game mechanics and parameters. A hack APK usually requires you to download and install it from a third-party source, such as a website or a file-sharing platform. You may also need to enable some permissions and settings on your device to allow the installation of unknown sources.
-pet idle mod apk unlimited money
-pet idle cheat apk download
-pet idle hack version apk
-pet idle simulation game mod apk
-pet idle android hack apk
-pet idle latest mod apk
-pet idle free hack apk
-pet idle hacked apk 2023
-pet idle mod apk for ios
-pet idle online hack apk
-pet idle offline hack apk
-pet idle hack tool apk
-pet idle no root hack apk
-pet idle hack generator apk
-pet idle vip mod apk
-pet idle pro hack apk
-pet idle premium hack apk
-pet idle full hack apk
-pet idle mega mod apk
-pet idle unlimited gems hack apk
-pet idle mod menu apk
-pet idle god mode hack apk
-pet idle unlock all pets hack apk
-pet idle unlimited coins hack apk
-pet idle infinite money hack apk
-pet idle modded apk 2023
-pet idle cheats and hacks apk
-pet idle easy hack apk
-pet idle best hack apk
-pet idle working hack apk
-pet idle update hack apk
-pet idle new mod apk
-pet idle old version hack apk
-pet idle original hack apk
-pet idle real hack apk
-pet idle legit hack apk
-pet idle safe hack apk
-pet idle secure hack apk
-pet idle trusted hack apk
-pet idle verified hack apk
-pet idle no survey hack apk
-pet idle no ads hack apk
-pet idle no virus hack apk
-pet idle no malware hack apk
-pet idle no ban hack apk
-pet idle anti ban hack apk
-pet idle anti cheat hack apk
- Why Use a Hack APK for Pet Idle?
-There are many reasons why you might want to use a hack APK for Pet Idle. Some of the benefits are:
-
-- You can get unlimited coins and gems that you can use to buy anything in the game without spending real money or waiting for hours. You can buy more pets, furniture, toys, food, water, skill books, robots, drones, and other items. You can also upgrade your house and garden to make them bigger and more beautiful.
-- You can unlock all the pets and items that are otherwise locked behind paywalls or level requirements. You can choose from 19 different pet types, each with a unique personality that affects the gameplay. You can also edit the color of each pet to make them look more adorable. You can also access all the furniture, toys, food, water, skill books, robots, drones, and other items that are available in the game.
-- You can customize your pets by changing their size, speed, and other attributes. You can make your pets bigger or smaller, faster or slower, stronger or weaker, and more. You can also change their appearance by adding accessories such as hats, glasses, collars, and more.
-- You can remove ads and other annoying features from the game. You can enjoy the game without being interrupted by pop-ups, banners, videos, and other ads that may slow down your device or consume your data. You can also disable some features that may be annoying or unnecessary for you, such as notifications, sounds, vibrations, etc.
-
- How to Download and Install Pet Idle Hack APK
-If you want to download and install Pet Idle Hack APK on your device, you need to follow these steps:
-
-- Go to a reliable website that offers Pet Idle Hack APK for free download. You can search for it on Google or use one of these links: . Make sure that the website is safe and secure before downloading anything from it.
-- Click on the download button and wait for the file to be downloaded on your device. The file size may vary depending on the website and the version of the hack APK.
-- Once the file is downloaded, locate it on your device using a file manager app. Tap on the file and select install. You may need to enable some permissions and settings on your device to allow the installation of unknown sources. Follow the instructions on your screen to complete the installation process.
-- After the installation is done, you can launch Pet Idle Hack APK from your app drawer or home screen. You may need to grant some permissions and access to the app before using it.
-
- How to Use Pet Idle Hack APK
-After you have downloaded and installed Pet Idle Hack APK on your device, you can use it to enjoy all the features of the game without any limitations. Here are some of the things you can do with Pet Idle Hack APK:
-
-- To generate unlimited coins and gems, tap on the menu icon on the top right corner of the screen. Then tap on the hack icon that looks like a wrench. You will see a pop-up window where you can enter the amount of coins and gems you want to add to your account. Tap on generate and wait for a few seconds until the process is done. You will see a confirmation message when it is done.
-- To unlock all pets and items, tap on the menu icon on the top right corner of the screen. Then tap on the hack icon that looks like a wrench. You will see a pop-up window where you can toggle on or off different options such as unlock all pets, unlock all items, unlock all skills, etc. Tap on apply and wait for a few seconds until the process is done. You will see a confirmation message when it is done.
-- To customize your pets by changing their size, speed, and other attributes, tap on the menu icon on the top right corner of the screen. Then tap on the hack icon that looks like a wrench. You will see a pop-up window where you can adjust different sliders such as size, speed, strength, intelligence, etc. Tap on apply and wait for a few seconds until the process is done. You will see a confirmation message when it is done.
-- To change the appearance of your pets by adding accessories such as hats, glasses, collars, and more, tap on the pet icon on the bottom left corner of the screen. Then tap on the edit icon that looks like a pencil. You will see a pop-up window where you can choose from different categories of accessories such as head, eyes, neck, body, etc. Tap on the accessory you want to add and drag it to your pet. You can also resize and rotate the accessory by using two fingers. Tap on save when you are done.
-
- Tips and Tricks for Playing Pet Idle with Hack APK
-Playing Pet Idle with hack APK can be fun and easy, but there are some tips and tricks that can help you make the most out of it. Here are some of them:
-
-- To level up your pets fast, feed them with high-quality food that gives them more experience points. You can buy food with coins or gems, or find them in the game. You can also use skill books to teach them new skills that increase their stats and abilities.
-- To catch rare fish, use a better fishing rod that has a higher chance of catching rare fish. You can buy fishing rods with coins or gems, or find them in the game. You can also use bait to attract more fish to your pond.
-- To train your pets and unlock new skills, play with them using different toys that stimulate their different needs. You can buy toys with coins or gems, or find them in the game. You can also use robots and drones to help you train your pets automatically.
-- To decorate your house, use different furniture and items that match your style and preference. You can buy furniture and items with coins or gems, or find them in the game. You can also use wallpapers, floors, windows, doors, lamps, plants, paintings, rugs, and other items to customize your interior.
-
- Pros and Cons of Using Pet Idle Hack APK
-Using Pet Idle Hack APK has its pros and cons that you should be aware of before using it. Here are some of them:
-
-
-Pros
-Cons
-
-
-You can get unlimited coins and gems that you can use to buy anything in the game without spending real money or waiting for hours.
-You may lose the sense of challenge and accomplishment that comes from playing the game normally.
-
-
-You can unlock all pets and items that are otherwise locked behind paywalls or level requirements.
-You may miss out on some of the fun and excitement of discovering new pets and items as you progress in the game.
-
-
-You can customize your pets by changing their size, speed, and other attributes.
-You may make your pets too powerful or unrealistic that they lose their charm and personality.
-
-
-You can remove ads and other annoying features from the game.
-You may deprive the developers of their revenue and support that they need to maintain and improve the game.
-
-
-You can enjoy all the features of the game without any limitations.
-You may encounter some bugs or glitches that may affect your gameplay or device performance.
-
-
- Conclusion
-Pet Idle is a simulation game where you can take care of various virtual animals. You can also build and decorate your house, take care of your garden, collect insects, and fish. However, if you want to enjoy all the features of the game without spending real money or waiting for hours, you might be interested in using a hack APK. A hack APK is a modified version of an original application that has been altered to provide some extra features or advantages that are not available in the official version. For example, a hack APK for Pet Idle can give you unlimited coins and gems that you can use to buy anything in the game without spending real money or waiting for hours. It can also unlock all the pets and items that are otherwise locked behind paywalls or level requirements. It can also allow you to customize your pets by changing their size, speed, and other attributes. A hack APK can also remove ads and other annoying features from the game.
- In this article, we have told you everything you need to know about Pet Idle Hack APK, including what it is, why you should use it, how to download and install it, how to use it, and some tips and tricks for playing the game with it. We have also compared the pros and cons of using the hack APK and answered some frequently asked questions.
- We hope that this article has been helpful and informative for you. If you want to try Pet Idle Hack APK for yourself, you can download it from one of the links we provided above. However, we advise you to use it at your own risk and discretion, as it may violate the terms and conditions of the game and cause some issues with your device or account. We also recommend that you support the developers of Pet Idle by playing the game normally and purchasing some items or coins if you can afford it. Pet Idle is a fun and relaxing game that deserves your appreciation and respect.
- Thank you for reading this article. If you have any questions or feedback, please feel free to leave a comment below. We would love to hear from you. Happy gaming!
- FAQs
-Here are some of the frequently asked questions about Pet Idle Hack APK:
-
-- Is Pet Idle Hack APK safe to use?
-Pet Idle Hack APK is not an official version of the game and has not been verified or approved by the developers or Google Play Store. Therefore, it may not be safe to use and may contain viruses, malware, or other harmful elements that may damage your device or compromise your personal information. You should always download and install hack APKs from trusted sources and scan them with antivirus software before using them.
-- Is Pet Idle Hack APK legal to use?
-Pet Idle Hack APK is not legal to use and may violate the terms and conditions of the game and Google Play Store. By using a hack APK, you are cheating and gaining an unfair advantage over other players who play the game normally. You are also depriving the developers of their revenue and support that they need to maintain and improve the game. You may face some consequences if you are caught using a hack APK, such as getting banned from the game or losing your account.
-- Will Pet Idle Hack APK work on my device?
-Pet Idle Hack APK may not work on all devices or versions of Android. It may depend on factors such as your device model, operating system, compatibility, storage space, etc. You should always check the requirements and specifications of the hack APK before downloading and installing it on your device. You should also make sure that your device is rooted or jailbroken if needed.
-- How can I update Pet Idle Hack APK?
-Pet Idle Hack APK may not update automatically like the official version of the game. You may need to manually download and install the latest version of the hack APK from a third-party source whenever there is a new update available. However, you should be careful as some updates may not be compatible with the hack APK or may fix some of the features or advantages that the hack APK provides.
-- How can I uninstall Pet Idle Hack APK?
-If you want to uninstall Pet Idle Hack APK from your device, you can follow these steps:
-
-- Go to your device settings and tap on apps or applications.
-- Find Pet Idle Hack APK from the list of apps and tap on it.
-- Tap on uninstall and confirm your choice.
-- Wait for a few seconds until the app is uninstalled from your device.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Xperia Music (Walkman) APK - Listen to Your Music with Style and Quality.md b/spaces/congsaPfin/Manga-OCR/logs/Xperia Music (Walkman) APK - Listen to Your Music with Style and Quality.md
deleted file mode 100644
index e2e9ffe1ae23f351602cb0255a23fa7f4d80fa06..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Xperia Music (Walkman) APK - Listen to Your Music with Style and Quality.md
+++ /dev/null
@@ -1,71 +0,0 @@
-
-Music Xperia APK: A Sony Music Player for Any Android Device
| | Do you love listening to music on your Android device? Do you want a music player that is simple, elegant, and powerful? If yes, then you should try Music Xperia APK. Music Xperia APK is a Sony music player that you can install on any Android device. It is not just a regular music player; it is a music player that offers you a premium listening experience.
| | What is Music Xperia APK?
| | Music Xperia APK is a modified version of the official Sony music player that comes pre-installed on Sony Xperia devices. It is developed by Senju Studio, an independent developer who wanted to share the Sony music player with all Android users. Music Xperia APK has all the features of the original Sony music player, such as:
-music xperia apk
Download File ✫ https://urlca.com/2uO7h3
| | | | - A sleek and intuitive user interface
| | - A powerful sound engine that enhances the audio quality
| | - A variety of sound effects and equalizers to customize your sound
| | - A smart playlist feature that automatically creates playlists based on your mood, genre, artist, etc.
| | - A download feature that lets you download music from online sources
| | - A sleep timer feature that lets you set a timer to stop playing music
| | - A widget feature that lets you control your music from your home screen
| |
| | Why Use Music Xperia APK?
| | Music Xperia APK is not just another music player; it is a music player that gives you a superior listening experience. Here are some reasons why you should use Music Xperia APK over other music players:
| | | | - It is compatible with any Android device running Android 4.4 or higher
| | - It supports various audio formats such as MP3, WAV, FLAC, OGG, etc.
| | - It has a simple and elegant design that matches the Sony style
| | How to Download and Install Music Xperia APK?
| | Downloading and installing Music Xperia APK is very easy and fast. You just need to follow these simple steps:
| | | | - Go to the official website of Senju Studio and download the latest version of Music Xperia APK. You can also scan the QR code below to download it directly to your device.
| | - Once the download is complete, go to your device settings and enable the option to install apps from unknown sources. This will allow you to install Music Xperia APK without any problems.
| | - Locate the downloaded Music Xperia APK file on your device and tap on it to start the installation process. Follow the instructions on the screen and wait for the installation to finish.
| | - Once the installation is done, you can launch Music Xperia APK from your app drawer or home screen and enjoy your music.
| |
| | How to Use Music Xperia APK?
| | Using Music Xperia APK is very simple and fun. You can use it to play music, create playlists, adjust settings, and more. Here are some tips on how to use Music Xperia APK:
| | | | - To play music, you can browse your music library by albums, artists, genres, folders, or songs. You can also use the search function to find your favorite tracks. To play a song, just tap on it and it will start playing. You can also swipe left or right on the album art to skip or go back to the previous or next song.
| | - To create playlists, you can tap on the plus icon at the bottom right corner of the screen and select "Create playlist". You can then name your playlist and add songs to it by tapping on the plus icon next to each song. You can also edit or delete your playlists by tapping on the three dots icon next to each playlist.
| | - To adjust settings, you can tap on the gear icon at the top right corner of the screen and access various options such as sound effects, equalizer, sleep timer, download settings, etc. You can also change the theme of Music Xperia APK by tapping on the paintbrush icon at the bottom left corner of the screen and choosing from different colors.
| |
| | Frequently Asked Questions about Music Xperia APK
| | Here are some of the most common questions and answers about Music Xperia APK:
| |
-
-Question
Answer
-
-Is Music Xperia APK safe to use?
Yes, Music Xperia APK is safe to use. It does not contain any viruses, malware, or spyware. It is also verified by Google Play Protect, which ensures that it does not harm your device or data.
-
-Is Music Xperia APK free to use?
Yes, Music Xperia APK is free to use. You do not need to pay any money to download or use it. However, you may see some ads in the app, which help support the developer and keep the app updated.
-
-Does Music Xperia APK require root access?
No, Music Xperia APK does not require root access. You can install and use it on any Android device without rooting it.
-
-Can I use Music Xperia APK with other music streaming services?
No, Music Xperia APK only works with local music files stored on your device or SD card. It does not support online music streaming services such as Spotify, YouTube Music, etc.
-XPERIA Music (Walkman) APK free download
-Sony Music Player - Xperia Player APK
-How to install XPERIA Music (Walkman) APK on android
-Xperia Player - Walkman Player features and reviews
-XPERIA Music (Walkman) APK mod version
-Sony Music Player - Xperia Player with equalizer
-Best music apps for XPERIA devices
-Xperia Player - Walkman Player custom background skin
-XPERIA Music (Walkman) APK latest update
-Sony Music Player - Xperia Player offline mode
-XPERIA Music (Walkman) APK vs Spotify
-Xperia Player - Walkman Player support formats
-XPERIA Music (Walkman) APK for PC
-Sony Music Player - Xperia Player ratings and feedback
-XPERIA Music (Walkman) APK alternatives
-Xperia Player - Walkman Player tips and tricks
-XPERIA Music (Walkman) APK premium features
-Sony Music Player - Xperia Player compatibility issues
-XPERIA Music (Walkman) APK bugs and fixes
-Xperia Player - Walkman Player user guide
-XPERIA Music (Walkman) APK advantages and disadvantages
-Sony Music Player - Xperia Player comparison with other music players
-XPERIA Music (Walkman) APK requirements and specifications
-Xperia Player - Walkman Player FAQs and answers
-XPERIA Music (Walkman) APK pros and cons
-Sony Music Player - Xperia Player screenshots and videos
-XPERIA Music (Walkman) APK download link and instructions
-Xperia Player - Walkman Player themes and widgets
-XPERIA Music (Walkman) APK performance and battery usage
-Sony Music Player - Xperia Player playlist and library management
-XPERIA Music (Walkman) APK sound quality and optimization
-Xperia Player - Walkman Player shuffle and repeat modes
-XPERIA Music (Walkman) APK security and privacy issues
-Sony Music Player - Xperia Player online and offline streaming
-XPERIA Music (Walkman) APK benefits and drawbacks
-Xperia Player - Walkman Player customization and personalization options
-XPERIA Music (Walkman) APK reviews and testimonials
-Sony Music Player - Xperia Player problems and solutions
-XPERIA Music (Walkman) APK popularity and ranking
-Xperia Player - Walkman Player recommendations and suggestions
-
-Can I share my feedback or suggestions for Music Xperia APK?
Yes, you can share your feedback or suggestions for Music Xperia APK by contacting the developer via email or social media. You can also rate and review the app on Google Play Store or other platforms.
-
- | Conclusion
| | Conclusion
| | If you are looking for a music player that offers you a premium listening experience on your Android device, then you should try Music Xperia APK. It is a Sony music player that you can install on any Android device. It has a sleek and intuitive user interface, a powerful sound engine, a variety of sound effects and equalizers, a smart playlist feature, a download feature, a sleep timer feature, a widget feature, and more. It is compatible with various audio formats, supports offline playback, and does not require root access. It is also free to use and safe to install. Music Xperia APK is the ultimate music player for Android users who love Sony music. Download it now and enjoy your music like never before.
| | Do you have any questions or comments about Music Xperia APK? Feel free to share them with us in the comment section below. We would love to hear from you.
| | | 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/lama/saicinpainting/training/losses/perceptual.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/lama/saicinpainting/training/losses/perceptual.py
deleted file mode 100644
index 5d8b0b309b2b8ba95172cb16af440033a4aeafae..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/lama/saicinpainting/training/losses/perceptual.py
+++ /dev/null
@@ -1,113 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import torchvision
-
-# from models.ade20k import ModelBuilder
-from annotator.lama.saicinpainting.utils import check_and_warn_input_range
-
-
-IMAGENET_MEAN = torch.FloatTensor([0.485, 0.456, 0.406])[None, :, None, None]
-IMAGENET_STD = torch.FloatTensor([0.229, 0.224, 0.225])[None, :, None, None]
-
-
-class PerceptualLoss(nn.Module):
- def __init__(self, normalize_inputs=True):
- super(PerceptualLoss, self).__init__()
-
- self.normalize_inputs = normalize_inputs
- self.mean_ = IMAGENET_MEAN
- self.std_ = IMAGENET_STD
-
- vgg = torchvision.models.vgg19(pretrained=True).features
- vgg_avg_pooling = []
-
- for weights in vgg.parameters():
- weights.requires_grad = False
-
- for module in vgg.modules():
- if module.__class__.__name__ == 'Sequential':
- continue
- elif module.__class__.__name__ == 'MaxPool2d':
- vgg_avg_pooling.append(nn.AvgPool2d(kernel_size=2, stride=2, padding=0))
- else:
- vgg_avg_pooling.append(module)
-
- self.vgg = nn.Sequential(*vgg_avg_pooling)
-
- def do_normalize_inputs(self, x):
- return (x - self.mean_.to(x.device)) / self.std_.to(x.device)
-
- def partial_losses(self, input, target, mask=None):
- check_and_warn_input_range(target, 0, 1, 'PerceptualLoss target in partial_losses')
-
- # we expect input and target to be in [0, 1] range
- losses = []
-
- if self.normalize_inputs:
- features_input = self.do_normalize_inputs(input)
- features_target = self.do_normalize_inputs(target)
- else:
- features_input = input
- features_target = target
-
- for layer in self.vgg[:30]:
-
- features_input = layer(features_input)
- features_target = layer(features_target)
-
- if layer.__class__.__name__ == 'ReLU':
- loss = F.mse_loss(features_input, features_target, reduction='none')
-
- if mask is not None:
- cur_mask = F.interpolate(mask, size=features_input.shape[-2:],
- mode='bilinear', align_corners=False)
- loss = loss * (1 - cur_mask)
-
- loss = loss.mean(dim=tuple(range(1, len(loss.shape))))
- losses.append(loss)
-
- return losses
-
- def forward(self, input, target, mask=None):
- losses = self.partial_losses(input, target, mask=mask)
- return torch.stack(losses).sum(dim=0)
-
- def get_global_features(self, input):
- check_and_warn_input_range(input, 0, 1, 'PerceptualLoss input in get_global_features')
-
- if self.normalize_inputs:
- features_input = self.do_normalize_inputs(input)
- else:
- features_input = input
-
- features_input = self.vgg(features_input)
- return features_input
-
-
-class ResNetPL(nn.Module):
- def __init__(self, weight=1,
- weights_path=None, arch_encoder='resnet50dilated', segmentation=True):
- super().__init__()
- self.impl = ModelBuilder.get_encoder(weights_path=weights_path,
- arch_encoder=arch_encoder,
- arch_decoder='ppm_deepsup',
- fc_dim=2048,
- segmentation=segmentation)
- self.impl.eval()
- for w in self.impl.parameters():
- w.requires_grad_(False)
-
- self.weight = weight
-
- def forward(self, pred, target):
- pred = (pred - IMAGENET_MEAN.to(pred)) / IMAGENET_STD.to(pred)
- target = (target - IMAGENET_MEAN.to(target)) / IMAGENET_STD.to(target)
-
- pred_feats = self.impl(pred, return_feature_maps=True)
- target_feats = self.impl(target, return_feature_maps=True)
-
- result = torch.stack([F.mse_loss(cur_pred, cur_target)
- for cur_pred, cur_target
- in zip(pred_feats, target_feats)]).sum() * self.weight
- return result
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmcv/runner/base_module.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmcv/runner/base_module.py
deleted file mode 100644
index 72e1164dfc442056cdc386050177f011b4e9900f..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmcv/runner/base_module.py
+++ /dev/null
@@ -1,195 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-import warnings
-from abc import ABCMeta
-from collections import defaultdict
-from logging import FileHandler
-
-import torch.nn as nn
-
-from annotator.mmpkg.mmcv.runner.dist_utils import master_only
-from annotator.mmpkg.mmcv.utils.logging import get_logger, logger_initialized, print_log
-
-
-class BaseModule(nn.Module, metaclass=ABCMeta):
- """Base module for all modules in openmmlab.
-
- ``BaseModule`` is a wrapper of ``torch.nn.Module`` with additional
- functionality of parameter initialization. Compared with
- ``torch.nn.Module``, ``BaseModule`` mainly adds three attributes.
-
- - ``init_cfg``: the config to control the initialization.
- - ``init_weights``: The function of parameter
- initialization and recording initialization
- information.
- - ``_params_init_info``: Used to track the parameter
- initialization information. This attribute only
- exists during executing the ``init_weights``.
-
- Args:
- init_cfg (dict, optional): Initialization config dict.
- """
-
- def __init__(self, init_cfg=None):
- """Initialize BaseModule, inherited from `torch.nn.Module`"""
-
- # NOTE init_cfg can be defined in different levels, but init_cfg
- # in low levels has a higher priority.
-
- super(BaseModule, self).__init__()
- # define default value of init_cfg instead of hard code
- # in init_weights() function
- self._is_init = False
-
- self.init_cfg = copy.deepcopy(init_cfg)
-
- # Backward compatibility in derived classes
- # if pretrained is not None:
- # warnings.warn('DeprecationWarning: pretrained is a deprecated \
- # key, please consider using init_cfg')
- # self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
-
- @property
- def is_init(self):
- return self._is_init
-
- def init_weights(self):
- """Initialize the weights."""
-
- is_top_level_module = False
- # check if it is top-level module
- if not hasattr(self, '_params_init_info'):
- # The `_params_init_info` is used to record the initialization
- # information of the parameters
- # the key should be the obj:`nn.Parameter` of model and the value
- # should be a dict containing
- # - init_info (str): The string that describes the initialization.
- # - tmp_mean_value (FloatTensor): The mean of the parameter,
- # which indicates whether the parameter has been modified.
- # this attribute would be deleted after all parameters
- # is initialized.
- self._params_init_info = defaultdict(dict)
- is_top_level_module = True
-
- # Initialize the `_params_init_info`,
- # When detecting the `tmp_mean_value` of
- # the corresponding parameter is changed, update related
- # initialization information
- for name, param in self.named_parameters():
- self._params_init_info[param][
- 'init_info'] = f'The value is the same before and ' \
- f'after calling `init_weights` ' \
- f'of {self.__class__.__name__} '
- self._params_init_info[param][
- 'tmp_mean_value'] = param.data.mean()
-
- # pass `params_init_info` to all submodules
- # All submodules share the same `params_init_info`,
- # so it will be updated when parameters are
- # modified at any level of the model.
- for sub_module in self.modules():
- sub_module._params_init_info = self._params_init_info
-
- # Get the initialized logger, if not exist,
- # create a logger named `mmcv`
- logger_names = list(logger_initialized.keys())
- logger_name = logger_names[0] if logger_names else 'mmcv'
-
- from ..cnn import initialize
- from ..cnn.utils.weight_init import update_init_info
- module_name = self.__class__.__name__
- if not self._is_init:
- if self.init_cfg:
- print_log(
- f'initialize {module_name} with init_cfg {self.init_cfg}',
- logger=logger_name)
- initialize(self, self.init_cfg)
- if isinstance(self.init_cfg, dict):
- # prevent the parameters of
- # the pre-trained model
- # from being overwritten by
- # the `init_weights`
- if self.init_cfg['type'] == 'Pretrained':
- return
-
- for m in self.children():
- if hasattr(m, 'init_weights'):
- m.init_weights()
- # users may overload the `init_weights`
- update_init_info(
- m,
- init_info=f'Initialized by '
- f'user-defined `init_weights`'
- f' in {m.__class__.__name__} ')
-
- self._is_init = True
- else:
- warnings.warn(f'init_weights of {self.__class__.__name__} has '
- f'been called more than once.')
-
- if is_top_level_module:
- self._dump_init_info(logger_name)
-
- for sub_module in self.modules():
- del sub_module._params_init_info
-
- @master_only
- def _dump_init_info(self, logger_name):
- """Dump the initialization information to a file named
- `initialization.log.json` in workdir.
-
- Args:
- logger_name (str): The name of logger.
- """
-
- logger = get_logger(logger_name)
-
- with_file_handler = False
- # dump the information to the logger file if there is a `FileHandler`
- for handler in logger.handlers:
- if isinstance(handler, FileHandler):
- handler.stream.write(
- 'Name of parameter - Initialization information\n')
- for name, param in self.named_parameters():
- handler.stream.write(
- f'\n{name} - {param.shape}: '
- f"\n{self._params_init_info[param]['init_info']} \n")
- handler.stream.flush()
- with_file_handler = True
- if not with_file_handler:
- for name, param in self.named_parameters():
- print_log(
- f'\n{name} - {param.shape}: '
- f"\n{self._params_init_info[param]['init_info']} \n ",
- logger=logger_name)
-
- def __repr__(self):
- s = super().__repr__()
- if self.init_cfg:
- s += f'\ninit_cfg={self.init_cfg}'
- return s
-
-
-class Sequential(BaseModule, nn.Sequential):
- """Sequential module in openmmlab.
-
- Args:
- init_cfg (dict, optional): Initialization config dict.
- """
-
- def __init__(self, *args, init_cfg=None):
- BaseModule.__init__(self, init_cfg)
- nn.Sequential.__init__(self, *args)
-
-
-class ModuleList(BaseModule, nn.ModuleList):
- """ModuleList in openmmlab.
-
- Args:
- modules (iterable, optional): an iterable of modules to add.
- init_cfg (dict, optional): Initialization config dict.
- """
-
- def __init__(self, modules=None, init_cfg=None):
- BaseModule.__init__(self, init_cfg)
- nn.ModuleList.__init__(self, modules)
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/proposal_generator/rpn.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/proposal_generator/rpn.py
deleted file mode 100644
index e37860dd6edb7a3cf493def2ae60a424b4dfc357..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/proposal_generator/rpn.py
+++ /dev/null
@@ -1,533 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from typing import Dict, List, Optional, Tuple, Union
-import torch
-import torch.nn.functional as F
-from torch import nn
-
-from annotator.oneformer.detectron2.config import configurable
-from annotator.oneformer.detectron2.layers import Conv2d, ShapeSpec, cat
-from annotator.oneformer.detectron2.structures import Boxes, ImageList, Instances, pairwise_iou
-from annotator.oneformer.detectron2.utils.events import get_event_storage
-from annotator.oneformer.detectron2.utils.memory import retry_if_cuda_oom
-from annotator.oneformer.detectron2.utils.registry import Registry
-
-from ..anchor_generator import build_anchor_generator
-from ..box_regression import Box2BoxTransform, _dense_box_regression_loss
-from ..matcher import Matcher
-from ..sampling import subsample_labels
-from .build import PROPOSAL_GENERATOR_REGISTRY
-from .proposal_utils import find_top_rpn_proposals
-
-RPN_HEAD_REGISTRY = Registry("RPN_HEAD")
-RPN_HEAD_REGISTRY.__doc__ = """
-Registry for RPN heads, which take feature maps and perform
-objectness classification and bounding box regression for anchors.
-
-The registered object will be called with `obj(cfg, input_shape)`.
-The call should return a `nn.Module` object.
-"""
-
-
-"""
-Shape shorthand in this module:
-
- N: number of images in the minibatch
- L: number of feature maps per image on which RPN is run
- A: number of cell anchors (must be the same for all feature maps)
- Hi, Wi: height and width of the i-th feature map
- B: size of the box parameterization
-
-Naming convention:
-
- objectness: refers to the binary classification of an anchor as object vs. not object.
-
- deltas: refers to the 4-d (dx, dy, dw, dh) deltas that parameterize the box2box
- transform (see :class:`box_regression.Box2BoxTransform`), or 5d for rotated boxes.
-
- pred_objectness_logits: predicted objectness scores in [-inf, +inf]; use
- sigmoid(pred_objectness_logits) to estimate P(object).
-
- gt_labels: ground-truth binary classification labels for objectness
-
- pred_anchor_deltas: predicted box2box transform deltas
-
- gt_anchor_deltas: ground-truth box2box transform deltas
-"""
-
-
-def build_rpn_head(cfg, input_shape):
- """
- Build an RPN head defined by `cfg.MODEL.RPN.HEAD_NAME`.
- """
- name = cfg.MODEL.RPN.HEAD_NAME
- return RPN_HEAD_REGISTRY.get(name)(cfg, input_shape)
-
-
-@RPN_HEAD_REGISTRY.register()
-class StandardRPNHead(nn.Module):
- """
- Standard RPN classification and regression heads described in :paper:`Faster R-CNN`.
- Uses a 3x3 conv to produce a shared hidden state from which one 1x1 conv predicts
- objectness logits for each anchor and a second 1x1 conv predicts bounding-box deltas
- specifying how to deform each anchor into an object proposal.
- """
-
- @configurable
- def __init__(
- self, *, in_channels: int, num_anchors: int, box_dim: int = 4, conv_dims: List[int] = (-1,)
- ):
- """
- NOTE: this interface is experimental.
-
- Args:
- in_channels (int): number of input feature channels. When using multiple
- input features, they must have the same number of channels.
- num_anchors (int): number of anchors to predict for *each spatial position*
- on the feature map. The total number of anchors for each
- feature map will be `num_anchors * H * W`.
- box_dim (int): dimension of a box, which is also the number of box regression
- predictions to make for each anchor. An axis aligned box has
- box_dim=4, while a rotated box has box_dim=5.
- conv_dims (list[int]): a list of integers representing the output channels
- of N conv layers. Set it to -1 to use the same number of output channels
- as input channels.
- """
- super().__init__()
- cur_channels = in_channels
- # Keeping the old variable names and structure for backwards compatiblity.
- # Otherwise the old checkpoints will fail to load.
- if len(conv_dims) == 1:
- out_channels = cur_channels if conv_dims[0] == -1 else conv_dims[0]
- # 3x3 conv for the hidden representation
- self.conv = self._get_rpn_conv(cur_channels, out_channels)
- cur_channels = out_channels
- else:
- self.conv = nn.Sequential()
- for k, conv_dim in enumerate(conv_dims):
- out_channels = cur_channels if conv_dim == -1 else conv_dim
- if out_channels <= 0:
- raise ValueError(
- f"Conv output channels should be greater than 0. Got {out_channels}"
- )
- conv = self._get_rpn_conv(cur_channels, out_channels)
- self.conv.add_module(f"conv{k}", conv)
- cur_channels = out_channels
- # 1x1 conv for predicting objectness logits
- self.objectness_logits = nn.Conv2d(cur_channels, num_anchors, kernel_size=1, stride=1)
- # 1x1 conv for predicting box2box transform deltas
- self.anchor_deltas = nn.Conv2d(cur_channels, num_anchors * box_dim, kernel_size=1, stride=1)
-
- # Keeping the order of weights initialization same for backwards compatiblility.
- for layer in self.modules():
- if isinstance(layer, nn.Conv2d):
- nn.init.normal_(layer.weight, std=0.01)
- nn.init.constant_(layer.bias, 0)
-
- def _get_rpn_conv(self, in_channels, out_channels):
- return Conv2d(
- in_channels,
- out_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- activation=nn.ReLU(),
- )
-
- @classmethod
- def from_config(cls, cfg, input_shape):
- # Standard RPN is shared across levels:
- in_channels = [s.channels for s in input_shape]
- assert len(set(in_channels)) == 1, "Each level must have the same channel!"
- in_channels = in_channels[0]
-
- # RPNHead should take the same input as anchor generator
- # NOTE: it assumes that creating an anchor generator does not have unwanted side effect.
- anchor_generator = build_anchor_generator(cfg, input_shape)
- num_anchors = anchor_generator.num_anchors
- box_dim = anchor_generator.box_dim
- assert (
- len(set(num_anchors)) == 1
- ), "Each level must have the same number of anchors per spatial position"
- return {
- "in_channels": in_channels,
- "num_anchors": num_anchors[0],
- "box_dim": box_dim,
- "conv_dims": cfg.MODEL.RPN.CONV_DIMS,
- }
-
- def forward(self, features: List[torch.Tensor]):
- """
- Args:
- features (list[Tensor]): list of feature maps
-
- Returns:
- list[Tensor]: A list of L elements.
- Element i is a tensor of shape (N, A, Hi, Wi) representing
- the predicted objectness logits for all anchors. A is the number of cell anchors.
- list[Tensor]: A list of L elements. Element i is a tensor of shape
- (N, A*box_dim, Hi, Wi) representing the predicted "deltas" used to transform anchors
- to proposals.
- """
- pred_objectness_logits = []
- pred_anchor_deltas = []
- for x in features:
- t = self.conv(x)
- pred_objectness_logits.append(self.objectness_logits(t))
- pred_anchor_deltas.append(self.anchor_deltas(t))
- return pred_objectness_logits, pred_anchor_deltas
-
-
-@PROPOSAL_GENERATOR_REGISTRY.register()
-class RPN(nn.Module):
- """
- Region Proposal Network, introduced by :paper:`Faster R-CNN`.
- """
-
- @configurable
- def __init__(
- self,
- *,
- in_features: List[str],
- head: nn.Module,
- anchor_generator: nn.Module,
- anchor_matcher: Matcher,
- box2box_transform: Box2BoxTransform,
- batch_size_per_image: int,
- positive_fraction: float,
- pre_nms_topk: Tuple[float, float],
- post_nms_topk: Tuple[float, float],
- nms_thresh: float = 0.7,
- min_box_size: float = 0.0,
- anchor_boundary_thresh: float = -1.0,
- loss_weight: Union[float, Dict[str, float]] = 1.0,
- box_reg_loss_type: str = "smooth_l1",
- smooth_l1_beta: float = 0.0,
- ):
- """
- NOTE: this interface is experimental.
-
- Args:
- in_features (list[str]): list of names of input features to use
- head (nn.Module): a module that predicts logits and regression deltas
- for each level from a list of per-level features
- anchor_generator (nn.Module): a module that creates anchors from a
- list of features. Usually an instance of :class:`AnchorGenerator`
- anchor_matcher (Matcher): label the anchors by matching them with ground truth.
- box2box_transform (Box2BoxTransform): defines the transform from anchors boxes to
- instance boxes
- batch_size_per_image (int): number of anchors per image to sample for training
- positive_fraction (float): fraction of foreground anchors to sample for training
- pre_nms_topk (tuple[float]): (train, test) that represents the
- number of top k proposals to select before NMS, in
- training and testing.
- post_nms_topk (tuple[float]): (train, test) that represents the
- number of top k proposals to select after NMS, in
- training and testing.
- nms_thresh (float): NMS threshold used to de-duplicate the predicted proposals
- min_box_size (float): remove proposal boxes with any side smaller than this threshold,
- in the unit of input image pixels
- anchor_boundary_thresh (float): legacy option
- loss_weight (float|dict): weights to use for losses. Can be single float for weighting
- all rpn losses together, or a dict of individual weightings. Valid dict keys are:
- "loss_rpn_cls" - applied to classification loss
- "loss_rpn_loc" - applied to box regression loss
- box_reg_loss_type (str): Loss type to use. Supported losses: "smooth_l1", "giou".
- smooth_l1_beta (float): beta parameter for the smooth L1 regression loss. Default to
- use L1 loss. Only used when `box_reg_loss_type` is "smooth_l1"
- """
- super().__init__()
- self.in_features = in_features
- self.rpn_head = head
- self.anchor_generator = anchor_generator
- self.anchor_matcher = anchor_matcher
- self.box2box_transform = box2box_transform
- self.batch_size_per_image = batch_size_per_image
- self.positive_fraction = positive_fraction
- # Map from self.training state to train/test settings
- self.pre_nms_topk = {True: pre_nms_topk[0], False: pre_nms_topk[1]}
- self.post_nms_topk = {True: post_nms_topk[0], False: post_nms_topk[1]}
- self.nms_thresh = nms_thresh
- self.min_box_size = float(min_box_size)
- self.anchor_boundary_thresh = anchor_boundary_thresh
- if isinstance(loss_weight, float):
- loss_weight = {"loss_rpn_cls": loss_weight, "loss_rpn_loc": loss_weight}
- self.loss_weight = loss_weight
- self.box_reg_loss_type = box_reg_loss_type
- self.smooth_l1_beta = smooth_l1_beta
-
- @classmethod
- def from_config(cls, cfg, input_shape: Dict[str, ShapeSpec]):
- in_features = cfg.MODEL.RPN.IN_FEATURES
- ret = {
- "in_features": in_features,
- "min_box_size": cfg.MODEL.PROPOSAL_GENERATOR.MIN_SIZE,
- "nms_thresh": cfg.MODEL.RPN.NMS_THRESH,
- "batch_size_per_image": cfg.MODEL.RPN.BATCH_SIZE_PER_IMAGE,
- "positive_fraction": cfg.MODEL.RPN.POSITIVE_FRACTION,
- "loss_weight": {
- "loss_rpn_cls": cfg.MODEL.RPN.LOSS_WEIGHT,
- "loss_rpn_loc": cfg.MODEL.RPN.BBOX_REG_LOSS_WEIGHT * cfg.MODEL.RPN.LOSS_WEIGHT,
- },
- "anchor_boundary_thresh": cfg.MODEL.RPN.BOUNDARY_THRESH,
- "box2box_transform": Box2BoxTransform(weights=cfg.MODEL.RPN.BBOX_REG_WEIGHTS),
- "box_reg_loss_type": cfg.MODEL.RPN.BBOX_REG_LOSS_TYPE,
- "smooth_l1_beta": cfg.MODEL.RPN.SMOOTH_L1_BETA,
- }
-
- ret["pre_nms_topk"] = (cfg.MODEL.RPN.PRE_NMS_TOPK_TRAIN, cfg.MODEL.RPN.PRE_NMS_TOPK_TEST)
- ret["post_nms_topk"] = (cfg.MODEL.RPN.POST_NMS_TOPK_TRAIN, cfg.MODEL.RPN.POST_NMS_TOPK_TEST)
-
- ret["anchor_generator"] = build_anchor_generator(cfg, [input_shape[f] for f in in_features])
- ret["anchor_matcher"] = Matcher(
- cfg.MODEL.RPN.IOU_THRESHOLDS, cfg.MODEL.RPN.IOU_LABELS, allow_low_quality_matches=True
- )
- ret["head"] = build_rpn_head(cfg, [input_shape[f] for f in in_features])
- return ret
-
- def _subsample_labels(self, label):
- """
- Randomly sample a subset of positive and negative examples, and overwrite
- the label vector to the ignore value (-1) for all elements that are not
- included in the sample.
-
- Args:
- labels (Tensor): a vector of -1, 0, 1. Will be modified in-place and returned.
- """
- pos_idx, neg_idx = subsample_labels(
- label, self.batch_size_per_image, self.positive_fraction, 0
- )
- # Fill with the ignore label (-1), then set positive and negative labels
- label.fill_(-1)
- label.scatter_(0, pos_idx, 1)
- label.scatter_(0, neg_idx, 0)
- return label
-
- @torch.jit.unused
- @torch.no_grad()
- def label_and_sample_anchors(
- self, anchors: List[Boxes], gt_instances: List[Instances]
- ) -> Tuple[List[torch.Tensor], List[torch.Tensor]]:
- """
- Args:
- anchors (list[Boxes]): anchors for each feature map.
- gt_instances: the ground-truth instances for each image.
-
- Returns:
- list[Tensor]:
- List of #img tensors. i-th element is a vector of labels whose length is
- the total number of anchors across all feature maps R = sum(Hi * Wi * A).
- Label values are in {-1, 0, 1}, with meanings: -1 = ignore; 0 = negative
- class; 1 = positive class.
- list[Tensor]:
- i-th element is a Rx4 tensor. The values are the matched gt boxes for each
- anchor. Values are undefined for those anchors not labeled as 1.
- """
- anchors = Boxes.cat(anchors)
-
- gt_boxes = [x.gt_boxes for x in gt_instances]
- image_sizes = [x.image_size for x in gt_instances]
- del gt_instances
-
- gt_labels = []
- matched_gt_boxes = []
- for image_size_i, gt_boxes_i in zip(image_sizes, gt_boxes):
- """
- image_size_i: (h, w) for the i-th image
- gt_boxes_i: ground-truth boxes for i-th image
- """
-
- match_quality_matrix = retry_if_cuda_oom(pairwise_iou)(gt_boxes_i, anchors)
- matched_idxs, gt_labels_i = retry_if_cuda_oom(self.anchor_matcher)(match_quality_matrix)
- # Matching is memory-expensive and may result in CPU tensors. But the result is small
- gt_labels_i = gt_labels_i.to(device=gt_boxes_i.device)
- del match_quality_matrix
-
- if self.anchor_boundary_thresh >= 0:
- # Discard anchors that go out of the boundaries of the image
- # NOTE: This is legacy functionality that is turned off by default in Detectron2
- anchors_inside_image = anchors.inside_box(image_size_i, self.anchor_boundary_thresh)
- gt_labels_i[~anchors_inside_image] = -1
-
- # A vector of labels (-1, 0, 1) for each anchor
- gt_labels_i = self._subsample_labels(gt_labels_i)
-
- if len(gt_boxes_i) == 0:
- # These values won't be used anyway since the anchor is labeled as background
- matched_gt_boxes_i = torch.zeros_like(anchors.tensor)
- else:
- # TODO wasted indexing computation for ignored boxes
- matched_gt_boxes_i = gt_boxes_i[matched_idxs].tensor
-
- gt_labels.append(gt_labels_i) # N,AHW
- matched_gt_boxes.append(matched_gt_boxes_i)
- return gt_labels, matched_gt_boxes
-
- @torch.jit.unused
- def losses(
- self,
- anchors: List[Boxes],
- pred_objectness_logits: List[torch.Tensor],
- gt_labels: List[torch.Tensor],
- pred_anchor_deltas: List[torch.Tensor],
- gt_boxes: List[torch.Tensor],
- ) -> Dict[str, torch.Tensor]:
- """
- Return the losses from a set of RPN predictions and their associated ground-truth.
-
- Args:
- anchors (list[Boxes or RotatedBoxes]): anchors for each feature map, each
- has shape (Hi*Wi*A, B), where B is box dimension (4 or 5).
- pred_objectness_logits (list[Tensor]): A list of L elements.
- Element i is a tensor of shape (N, Hi*Wi*A) representing
- the predicted objectness logits for all anchors.
- gt_labels (list[Tensor]): Output of :meth:`label_and_sample_anchors`.
- pred_anchor_deltas (list[Tensor]): A list of L elements. Element i is a tensor of shape
- (N, Hi*Wi*A, 4 or 5) representing the predicted "deltas" used to transform anchors
- to proposals.
- gt_boxes (list[Tensor]): Output of :meth:`label_and_sample_anchors`.
-
- Returns:
- dict[loss name -> loss value]: A dict mapping from loss name to loss value.
- Loss names are: `loss_rpn_cls` for objectness classification and
- `loss_rpn_loc` for proposal localization.
- """
- num_images = len(gt_labels)
- gt_labels = torch.stack(gt_labels) # (N, sum(Hi*Wi*Ai))
-
- # Log the number of positive/negative anchors per-image that's used in training
- pos_mask = gt_labels == 1
- num_pos_anchors = pos_mask.sum().item()
- num_neg_anchors = (gt_labels == 0).sum().item()
- storage = get_event_storage()
- storage.put_scalar("rpn/num_pos_anchors", num_pos_anchors / num_images)
- storage.put_scalar("rpn/num_neg_anchors", num_neg_anchors / num_images)
-
- localization_loss = _dense_box_regression_loss(
- anchors,
- self.box2box_transform,
- pred_anchor_deltas,
- gt_boxes,
- pos_mask,
- box_reg_loss_type=self.box_reg_loss_type,
- smooth_l1_beta=self.smooth_l1_beta,
- )
-
- valid_mask = gt_labels >= 0
- objectness_loss = F.binary_cross_entropy_with_logits(
- cat(pred_objectness_logits, dim=1)[valid_mask],
- gt_labels[valid_mask].to(torch.float32),
- reduction="sum",
- )
- normalizer = self.batch_size_per_image * num_images
- losses = {
- "loss_rpn_cls": objectness_loss / normalizer,
- # The original Faster R-CNN paper uses a slightly different normalizer
- # for loc loss. But it doesn't matter in practice
- "loss_rpn_loc": localization_loss / normalizer,
- }
- losses = {k: v * self.loss_weight.get(k, 1.0) for k, v in losses.items()}
- return losses
-
- def forward(
- self,
- images: ImageList,
- features: Dict[str, torch.Tensor],
- gt_instances: Optional[List[Instances]] = None,
- ):
- """
- Args:
- images (ImageList): input images of length `N`
- features (dict[str, Tensor]): input data as a mapping from feature
- map name to tensor. Axis 0 represents the number of images `N` in
- the input data; axes 1-3 are channels, height, and width, which may
- vary between feature maps (e.g., if a feature pyramid is used).
- gt_instances (list[Instances], optional): a length `N` list of `Instances`s.
- Each `Instances` stores ground-truth instances for the corresponding image.
-
- Returns:
- proposals: list[Instances]: contains fields "proposal_boxes", "objectness_logits"
- loss: dict[Tensor] or None
- """
- features = [features[f] for f in self.in_features]
- anchors = self.anchor_generator(features)
-
- pred_objectness_logits, pred_anchor_deltas = self.rpn_head(features)
- # Transpose the Hi*Wi*A dimension to the middle:
- pred_objectness_logits = [
- # (N, A, Hi, Wi) -> (N, Hi, Wi, A) -> (N, Hi*Wi*A)
- score.permute(0, 2, 3, 1).flatten(1)
- for score in pred_objectness_logits
- ]
- pred_anchor_deltas = [
- # (N, A*B, Hi, Wi) -> (N, A, B, Hi, Wi) -> (N, Hi, Wi, A, B) -> (N, Hi*Wi*A, B)
- x.view(x.shape[0], -1, self.anchor_generator.box_dim, x.shape[-2], x.shape[-1])
- .permute(0, 3, 4, 1, 2)
- .flatten(1, -2)
- for x in pred_anchor_deltas
- ]
-
- if self.training:
- assert gt_instances is not None, "RPN requires gt_instances in training!"
- gt_labels, gt_boxes = self.label_and_sample_anchors(anchors, gt_instances)
- losses = self.losses(
- anchors, pred_objectness_logits, gt_labels, pred_anchor_deltas, gt_boxes
- )
- else:
- losses = {}
- proposals = self.predict_proposals(
- anchors, pred_objectness_logits, pred_anchor_deltas, images.image_sizes
- )
- return proposals, losses
-
- def predict_proposals(
- self,
- anchors: List[Boxes],
- pred_objectness_logits: List[torch.Tensor],
- pred_anchor_deltas: List[torch.Tensor],
- image_sizes: List[Tuple[int, int]],
- ):
- """
- Decode all the predicted box regression deltas to proposals. Find the top proposals
- by applying NMS and removing boxes that are too small.
-
- Returns:
- proposals (list[Instances]): list of N Instances. The i-th Instances
- stores post_nms_topk object proposals for image i, sorted by their
- objectness score in descending order.
- """
- # The proposals are treated as fixed for joint training with roi heads.
- # This approach ignores the derivative w.r.t. the proposal boxes’ coordinates that
- # are also network responses.
- with torch.no_grad():
- pred_proposals = self._decode_proposals(anchors, pred_anchor_deltas)
- return find_top_rpn_proposals(
- pred_proposals,
- pred_objectness_logits,
- image_sizes,
- self.nms_thresh,
- self.pre_nms_topk[self.training],
- self.post_nms_topk[self.training],
- self.min_box_size,
- self.training,
- )
-
- def _decode_proposals(self, anchors: List[Boxes], pred_anchor_deltas: List[torch.Tensor]):
- """
- Transform anchors into proposals by applying the predicted anchor deltas.
-
- Returns:
- proposals (list[Tensor]): A list of L tensors. Tensor i has shape
- (N, Hi*Wi*A, B)
- """
- N = pred_anchor_deltas[0].shape[0]
- proposals = []
- # For each feature map
- for anchors_i, pred_anchor_deltas_i in zip(anchors, pred_anchor_deltas):
- B = anchors_i.tensor.size(1)
- pred_anchor_deltas_i = pred_anchor_deltas_i.reshape(-1, B)
- # Expand anchors to shape (N*Hi*Wi*A, B)
- anchors_i = anchors_i.tensor.unsqueeze(0).expand(N, -1, -1).reshape(-1, B)
- proposals_i = self.box2box_transform.apply_deltas(pred_anchor_deltas_i, anchors_i)
- # Append feature map proposals with shape (N, Hi*Wi*A, B)
- proposals.append(proposals_i.view(N, -1, B))
- return proposals
diff --git a/spaces/cybercorejapan/human-detection-docker/models/reids/solider.py b/spaces/cybercorejapan/human-detection-docker/models/reids/solider.py
deleted file mode 100644
index c8757ecee429e8549abd4c95886109156fdc3063..0000000000000000000000000000000000000000
--- a/spaces/cybercorejapan/human-detection-docker/models/reids/solider.py
+++ /dev/null
@@ -1,165 +0,0 @@
-from typing import Tuple, Union
-from models.base.trt_base import TRT_Base
-from models.base.onnx_base import ONNX_Base
-import torch
-import cv2
-import numpy as np
-
-class SOLIDERBase():
- def __init__(self, use_torch: bool=False):
- """ SOLIDERBase class for inference.
-
- Args:
- preprocess_cfg (Dict):
- - mean (List[float, float, float]): mean offset values for preprocessing.
- - std (List[float, float, float]): standard deviation offset values for preprocessing.
- use_torch (bool): use torch tensor or numpy array in preprocess and postprocess function.
- """
- self.use_torch = use_torch
-
- def crop_objects(self, image: np.ndarray, bounding_boxes: np.ndarray):
- """ Function to crop objects in input image.
-
- Args:
- image (np.ndarray): input image with shape (H, W, C).
- bounding_boxes (np.ndarray): Array with shape Nx4 with N is the number of objects.
- """
- max_h, max_w = image.shape[:2]
- cropped_images = []
- for box in bounding_boxes:
- x_top, y_top, x_bottom, y_bottom, _ = box.astype(int).tolist()
- x_top = max(0, x_top)
- y_top = max(0, y_top)
- x_bottom = min(x_bottom, max_w)
- y_bottom = min(y_bottom, max_h)
- cropped_image = image[y_top:y_bottom, x_top:x_bottom]
- cropped_images.append(cropped_image)
- return cropped_images
-
- def preprocess(self, input_data: np.ndarray):
- """ Preprocess function for input data.
-
- Args:
- input_data (np.ndarray): batch input image.
- """
- tensor_data = []
- if ((isinstance(input_data, np.ndarray)) and (len(input_data.shape) == 3)):
- input_data = [input_data]
- for i in range(len(input_data)):
- img = input_data[i]
- img = cv2.resize(img, self.input_shape[2:][::-1], interpolation=cv2.INTER_LINEAR)
- if self.use_torch:
- tensor_data.append(torch.from_numpy(img).to(self.device))
- else:
- tensor_data.append(img)
- if self.use_torch:
- tensor_data = torch.stack(tensor_data, dim=0)
- tensor_data = tensor_data.permute(0, 3, 1, 2).float().contiguous()
- else:
- tensor_data = np.stack(tensor_data, axis=0)
- tensor_data = tensor_data.transpose((0, 3, 1, 2)).astype(np.float32)
- return tensor_data
-
- def postprocess(self, embeddings: Union[torch.tensor,np.ndarray]):
- """ Postprocess function for input data.
-
- Args:
- embeddings (torch.tensor or np.ndarray): output embeddingss.
- """
-
- if (self.use_torch):
- norms = torch.unsqueeze(torch.norm(embeddings, dim=-1), dim=-1)
- else:
- norms = np.expand_dims(np.linalg.norm(embeddings, axis=-1), axis=-1)
-
- normalized_embeddings = embeddings/norms
- return normalized_embeddings
-
- def batch_padding(self, input_data: Union[torch.tensor, np.ndarray], batch_size: int) -> Union[torch.tensor, np.ndarray]:
- """Since the current model does not support Dynamic batch size, we perform padding to the input data.
-
- Args:
- input_data (Union[torch.tensor, np.ndarray]): input data.
- batch_size (int): batch size for inference.
-
- Returns:
- input_data (Union[torch.tensor, np.ndarray]): input data.
- """
- n_pad = batch_size - len(input_data)
- if n_pad>0:
- if self.use_torch:
- input_data = torch.cat((input_data, input_data[:n_pad]), dim=0)
- else:
- input_data = np.concatenate((input_data, input_data[:n_pad]), axis=0)
- return input_data
-
-class SOLIDERONNX(ONNX_Base, SOLIDERBase):
- def __init__(self,
- batch_size: int,
- model_path: str,
- img_shape: Tuple[int, int, int]=(3, 384, 128),
- device: str='0',):
- """ SOLIDER ONNX class for inference, which is based on ONNX_Base and SOLIDERBase.
- """
- self.img_shape = img_shape
- self.batch_size = batch_size
- input_shape = (self.batch_size, *self.img_shape)
- super().__init__(input_shape, model_path, device)
- SOLIDERBase.__init__(self, use_torch=False)
-
- def infer_batch(self, image_batch: np.ndarray) -> np.ndarray:
- """ Batch inference function for batch input image.
-
- Args:
- image_batch (np.ndarray): batch of input image.
- """
- num_images = len(image_batch)
- assert num_images <= self.batch_size, "the number of input images must be smaller or equal to the Batch size."
- numpy_array_data = self.preprocess(image_batch)
-
- # Padding data to the batch size
- padding_data = self.batch_padding(numpy_array_data, self.batch_size)
- results = super().infer_batch(padding_data)
-
- # Crop the padding data and postprocess
- feats = results[0][:num_images]
- feats = self.postprocess(feats)
- return feats
-
-class SOLIDERTRT(TRT_Base, SOLIDERBase):
- def __init__(self,
- batch_size: int,
- model_path: str,
- img_shape: Tuple[int, int, int]=(3, 384, 128),
- device: str='0',):
- """ SOLIDER TRT class for inference, which is based on TRT_Base and SOLIDERBase.
- """
- self.img_shape = img_shape
- self.batch_size = batch_size
- input_shape = (self.batch_size, *self.img_shape)
- super().__init__(input_shape, model_path, device)
- SOLIDERBase.__init__(self, use_torch=True)
-
- def infer_batch(self, image_batch: np.ndarray) -> np.ndarray:
- """ Batch inference function for batch input image.
-
- Args:
- image_batch (np.ndarray): batch of input image.
- """
- num_images = len(image_batch)
- assert num_images <= self.batch_size, "the number of input images must be smaller or equal to the Batch size."
- tensor_data = self.preprocess(image_batch)
-
- # Padding data to the batch size
- padding_data = self.batch_padding(tensor_data, self.batch_size)
- self.model['binding_addrs']['input'] = int(padding_data.data_ptr())
- self.model['context'].execute_v2(list(self.model['binding_addrs'].values()))
- feats = self.model['bindings']['output'].data.cpu()
-
- # Crop the padding data and postprocess
- feats = feats[:num_images]
- feats = self.postprocess(feats)
- feats = feats.float().numpy()
- return feats
-
-
diff --git a/spaces/cymic/Waifu_Diffusion_Webui/app.py b/spaces/cymic/Waifu_Diffusion_Webui/app.py
deleted file mode 100644
index a699bc5b3c2e987102ca93e0ee28d601e0a93d02..0000000000000000000000000000000000000000
--- a/spaces/cymic/Waifu_Diffusion_Webui/app.py
+++ /dev/null
@@ -1,7 +0,0 @@
-import gradio as gr
-
-def greet(name):
- return "Hello " + name + "!!"
-
-iface = gr.Interface(fn=greet, inputs="text", outputs="text")
-iface.launch()
\ No newline at end of file
diff --git a/spaces/dakaiye/dky_xuexi/config.py b/spaces/dakaiye/dky_xuexi/config.py
deleted file mode 100644
index 4c1c589c14a98b61434d28f69b85a111e89ee40e..0000000000000000000000000000000000000000
--- a/spaces/dakaiye/dky_xuexi/config.py
+++ /dev/null
@@ -1,82 +0,0 @@
-# [step 1]>> 例如: API_KEY = "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" (此key无效)
-API_KEY = "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" # 可同时填写多个API-KEY,用英文逗号分割,例如API_KEY = "sk-openaikey1,sk-openaikey2,fkxxxx-api2dkey1,fkxxxx-api2dkey2"
-
-# [step 2]>> 改为True应用代理,如果直接在海外服务器部署,此处不修改
-USE_PROXY = False
-if USE_PROXY:
- # 填写格式是 [协议]:// [地址] :[端口],填写之前不要忘记把USE_PROXY改成True,如果直接在海外服务器部署,此处不修改
- # 例如 "socks5h://localhost:11284"
- # [协议] 常见协议无非socks5h/http; 例如 v2**y 和 ss* 的默认本地协议是socks5h; 而cl**h 的默认本地协议是http
- # [地址] 懂的都懂,不懂就填localhost或者127.0.0.1肯定错不了(localhost意思是代理软件安装在本机上)
- # [端口] 在代理软件的设置里找。虽然不同的代理软件界面不一样,但端口号都应该在最显眼的位置上
-
- # 代理网络的地址,打开你的*学*网软件查看代理的协议(socks5/http)、地址(localhost)和端口(11284)
- proxies = {
- # [协议]:// [地址] :[端口]
- "http": "socks5h://localhost:11284", # 再例如 "http": "http://127.0.0.1:7890",
- "https": "socks5h://localhost:11284", # 再例如 "https": "http://127.0.0.1:7890",
- }
-else:
- proxies = None
-
-# [step 3]>> 多线程函数插件中,默认允许多少路线程同时访问OpenAI。Free trial users的限制是每分钟3次,Pay-as-you-go users的限制是每分钟3500次
-# 一言以蔽之:免费用户填3,OpenAI绑了信用卡的用户可以填 16 或者更高。提高限制请查询:https://platform.openai.com/docs/guides/rate-limits/overview
-DEFAULT_WORKER_NUM = 3
-
-
-# [step 4]>> 以下配置可以优化体验,但大部分场合下并不需要修改
-# 对话窗的高度
-CHATBOT_HEIGHT = 1115
-
-# 代码高亮
-CODE_HIGHLIGHT = True
-
-# 窗口布局
-LAYOUT = "LEFT-RIGHT" # "LEFT-RIGHT"(左右布局) # "TOP-DOWN"(上下布局)
-DARK_MODE = True # "LEFT-RIGHT"(左右布局) # "TOP-DOWN"(上下布局)
-
-# 发送请求到OpenAI后,等待多久判定为超时
-TIMEOUT_SECONDS = 30
-
-# 网页的端口, -1代表随机端口
-WEB_PORT = -1
-
-# 如果OpenAI不响应(网络卡顿、代理失败、KEY失效),重试的次数限制
-MAX_RETRY = 2
-
-# OpenAI模型选择是(gpt4现在只对申请成功的人开放)
-LLM_MODEL = "gpt-3.5-turbo" # 可选 "chatglm"
-AVAIL_LLM_MODELS = ["newbing-free", "gpt-3.5-turbo", "gpt-4", "api2d-gpt-4", "api2d-gpt-3.5-turbo"]
-
-# 本地LLM模型如ChatGLM的执行方式 CPU/GPU
-LOCAL_MODEL_DEVICE = "cpu" # 可选 "cuda"
-
-# 设置gradio的并行线程数(不需要修改)
-CONCURRENT_COUNT = 100
-
-# 加一个live2d装饰
-ADD_WAIFU = False
-
-# 设置用户名和密码(不需要修改)(相关功能不稳定,与gradio版本和网络都相关,如果本地使用不建议加这个)
-# [("username", "password"), ("username2", "password2"), ...]
-AUTHENTICATION = []
-
-# 重新URL重新定向,实现更换API_URL的作用(常规情况下,不要修改!!)
-# (高危设置!通过修改此设置,您将把您的API-KEY和对话隐私完全暴露给您设定的中间人!)
-# 格式 {"https://api.openai.com/v1/chat/completions": "在这里填写重定向的api.openai.com的URL"}
-# 例如 API_URL_REDIRECT = {"https://api.openai.com/v1/chat/completions": "https://ai.open.com/api/conversation"}
-API_URL_REDIRECT = {}
-
-# 如果需要在二级路径下运行(常规情况下,不要修改!!)(需要配合修改main.py才能生效!)
-CUSTOM_PATH = "/"
-
-# 如果需要使用newbing,把newbing的长长的cookie放到这里
-NEWBING_STYLE = "creative" # ["creative", "balanced", "precise"]
-# 从现在起,如果您调用"newbing-free"模型,则无需填写NEWBING_COOKIES
-NEWBING_COOKIES = """
-your bing cookies here
-"""
-
-# 如果需要使用Slack Claude,使用教程详情见 request_llm/README.md
-SLACK_CLAUDE_BOT_ID = ''
-SLACK_CLAUDE_USER_TOKEN = ''
diff --git a/spaces/dawood17/SayBot_Enchancer/CodeFormer/basicsr/ops/dcn/__init__.py b/spaces/dawood17/SayBot_Enchancer/CodeFormer/basicsr/ops/dcn/__init__.py
deleted file mode 100644
index 32e3592f896d61b4127e09d0476381b9d55e32ff..0000000000000000000000000000000000000000
--- a/spaces/dawood17/SayBot_Enchancer/CodeFormer/basicsr/ops/dcn/__init__.py
+++ /dev/null
@@ -1,7 +0,0 @@
-from .deform_conv import (DeformConv, DeformConvPack, ModulatedDeformConv, ModulatedDeformConvPack, deform_conv,
- modulated_deform_conv)
-
-__all__ = [
- 'DeformConv', 'DeformConvPack', 'ModulatedDeformConv', 'ModulatedDeformConvPack', 'deform_conv',
- 'modulated_deform_conv'
-]
diff --git a/spaces/dawood17/SayBot_Enchancer/CodeFormer/facelib/detection/yolov5face/utils/torch_utils.py b/spaces/dawood17/SayBot_Enchancer/CodeFormer/facelib/detection/yolov5face/utils/torch_utils.py
deleted file mode 100644
index af2d06587b2d07b2eab199a8484380fde1de5c3c..0000000000000000000000000000000000000000
--- a/spaces/dawood17/SayBot_Enchancer/CodeFormer/facelib/detection/yolov5face/utils/torch_utils.py
+++ /dev/null
@@ -1,40 +0,0 @@
-import torch
-from torch import nn
-
-
-def fuse_conv_and_bn(conv, bn):
- # Fuse convolution and batchnorm layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
- fusedconv = (
- nn.Conv2d(
- conv.in_channels,
- conv.out_channels,
- kernel_size=conv.kernel_size,
- stride=conv.stride,
- padding=conv.padding,
- groups=conv.groups,
- bias=True,
- )
- .requires_grad_(False)
- .to(conv.weight.device)
- )
-
- # prepare filters
- w_conv = conv.weight.clone().view(conv.out_channels, -1)
- w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
- fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.size()))
-
- # prepare spatial bias
- b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
- b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
- fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
-
- return fusedconv
-
-
-def copy_attr(a, b, include=(), exclude=()):
- # Copy attributes from b to a, options to only include [...] and to exclude [...]
- for k, v in b.__dict__.items():
- if (include and k not in include) or k.startswith("_") or k in exclude:
- continue
-
- setattr(a, k, v)
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/GbrImagePlugin.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/GbrImagePlugin.py
deleted file mode 100644
index 994a6e8ebb2f0f2e69990a211d7a1ec4f06b7fd1..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/GbrImagePlugin.py
+++ /dev/null
@@ -1,102 +0,0 @@
-#
-# The Python Imaging Library
-#
-# load a GIMP brush file
-#
-# History:
-# 96-03-14 fl Created
-# 16-01-08 es Version 2
-#
-# Copyright (c) Secret Labs AB 1997.
-# Copyright (c) Fredrik Lundh 1996.
-# Copyright (c) Eric Soroos 2016.
-#
-# See the README file for information on usage and redistribution.
-#
-#
-# See https://github.com/GNOME/gimp/blob/mainline/devel-docs/gbr.txt for
-# format documentation.
-#
-# This code Interprets version 1 and 2 .gbr files.
-# Version 1 files are obsolete, and should not be used for new
-# brushes.
-# Version 2 files are saved by GIMP v2.8 (at least)
-# Version 3 files have a format specifier of 18 for 16bit floats in
-# the color depth field. This is currently unsupported by Pillow.
-
-from . import Image, ImageFile
-from ._binary import i32be as i32
-
-
-def _accept(prefix):
- return len(prefix) >= 8 and i32(prefix, 0) >= 20 and i32(prefix, 4) in (1, 2)
-
-
-##
-# Image plugin for the GIMP brush format.
-
-
-class GbrImageFile(ImageFile.ImageFile):
- format = "GBR"
- format_description = "GIMP brush file"
-
- def _open(self):
- header_size = i32(self.fp.read(4))
- if header_size < 20:
- msg = "not a GIMP brush"
- raise SyntaxError(msg)
- version = i32(self.fp.read(4))
- if version not in (1, 2):
- msg = f"Unsupported GIMP brush version: {version}"
- raise SyntaxError(msg)
-
- width = i32(self.fp.read(4))
- height = i32(self.fp.read(4))
- color_depth = i32(self.fp.read(4))
- if width <= 0 or height <= 0:
- msg = "not a GIMP brush"
- raise SyntaxError(msg)
- if color_depth not in (1, 4):
- msg = f"Unsupported GIMP brush color depth: {color_depth}"
- raise SyntaxError(msg)
-
- if version == 1:
- comment_length = header_size - 20
- else:
- comment_length = header_size - 28
- magic_number = self.fp.read(4)
- if magic_number != b"GIMP":
- msg = "not a GIMP brush, bad magic number"
- raise SyntaxError(msg)
- self.info["spacing"] = i32(self.fp.read(4))
-
- comment = self.fp.read(comment_length)[:-1]
-
- if color_depth == 1:
- self.mode = "L"
- else:
- self.mode = "RGBA"
-
- self._size = width, height
-
- self.info["comment"] = comment
-
- # Image might not be small
- Image._decompression_bomb_check(self.size)
-
- # Data is an uncompressed block of w * h * bytes/pixel
- self._data_size = width * height * color_depth
-
- def load(self):
- if not self.im:
- self.im = Image.core.new(self.mode, self.size)
- self.frombytes(self.fp.read(self._data_size))
- return Image.Image.load(self)
-
-
-#
-# registry
-
-
-Image.register_open(GbrImageFile.format, GbrImageFile, _accept)
-Image.register_extension(GbrImageFile.format, ".gbr")
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fontTools/pens/momentsPen.c b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fontTools/pens/momentsPen.c
deleted file mode 100644
index 9e0709640832092f08a11049ed62835a7397ed03..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fontTools/pens/momentsPen.c
+++ /dev/null
@@ -1,13019 +0,0 @@
-/* Generated by Cython 3.0.0 */
-
-/* BEGIN: Cython Metadata
-{
- "distutils": {
- "name": "fontTools.pens.momentsPen",
- "sources": [
- "Lib/fontTools/pens/momentsPen.py"
- ]
- },
- "module_name": "fontTools.pens.momentsPen"
-}
-END: Cython Metadata */
-
-#ifndef PY_SSIZE_T_CLEAN
-#define PY_SSIZE_T_CLEAN
-#endif /* PY_SSIZE_T_CLEAN */
-#if defined(CYTHON_LIMITED_API) && 0
- #ifndef Py_LIMITED_API
- #if CYTHON_LIMITED_API+0 > 0x03030000
- #define Py_LIMITED_API CYTHON_LIMITED_API
- #else
- #define Py_LIMITED_API 0x03030000
- #endif
- #endif
-#endif
-
-#include "Python.h"
-#ifndef Py_PYTHON_H
- #error Python headers needed to compile C extensions, please install development version of Python.
-#elif PY_VERSION_HEX < 0x02070000 || (0x03000000 <= PY_VERSION_HEX && PY_VERSION_HEX < 0x03030000)
- #error Cython requires Python 2.7+ or Python 3.3+.
-#else
-#define CYTHON_ABI "3_0_0"
-#define __PYX_ABI_MODULE_NAME "_cython_" CYTHON_ABI
-#define __PYX_TYPE_MODULE_PREFIX __PYX_ABI_MODULE_NAME "."
-#define CYTHON_HEX_VERSION 0x030000F0
-#define CYTHON_FUTURE_DIVISION 1
-#include
-#ifndef offsetof
- #define offsetof(type, member) ( (size_t) & ((type*)0) -> member )
-#endif
-#if !defined(_WIN32) && !defined(WIN32) && !defined(MS_WINDOWS)
- #ifndef __stdcall
- #define __stdcall
- #endif
- #ifndef __cdecl
- #define __cdecl
- #endif
- #ifndef __fastcall
- #define __fastcall
- #endif
-#endif
-#ifndef DL_IMPORT
- #define DL_IMPORT(t) t
-#endif
-#ifndef DL_EXPORT
- #define DL_EXPORT(t) t
-#endif
-#define __PYX_COMMA ,
-#ifndef HAVE_LONG_LONG
- #define HAVE_LONG_LONG
-#endif
-#ifndef PY_LONG_LONG
- #define PY_LONG_LONG LONG_LONG
-#endif
-#ifndef Py_HUGE_VAL
- #define Py_HUGE_VAL HUGE_VAL
-#endif
-#if defined(GRAALVM_PYTHON)
- /* For very preliminary testing purposes. Most variables are set the same as PyPy.
- The existence of this section does not imply that anything works or is even tested */
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_LIMITED_API 0
- #define CYTHON_COMPILING_IN_GRAAL 1
- #define CYTHON_COMPILING_IN_NOGIL 0
- #undef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 0
- #undef CYTHON_USE_TYPE_SPECS
- #define CYTHON_USE_TYPE_SPECS 0
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #if PY_VERSION_HEX < 0x03050000
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #elif !defined(CYTHON_USE_ASYNC_SLOTS)
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #undef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 0
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #undef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 1
- #undef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 0
- #undef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 0
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_GIL
- #define CYTHON_FAST_GIL 0
- #undef CYTHON_METH_FASTCALL
- #define CYTHON_METH_FASTCALL 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #ifndef CYTHON_PEP487_INIT_SUBCLASS
- #define CYTHON_PEP487_INIT_SUBCLASS (PY_MAJOR_VERSION >= 3)
- #endif
- #undef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 1
- #undef CYTHON_USE_MODULE_STATE
- #define CYTHON_USE_MODULE_STATE 0
- #undef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 0
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC 0
- #endif
-#elif defined(PYPY_VERSION)
- #define CYTHON_COMPILING_IN_PYPY 1
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_LIMITED_API 0
- #define CYTHON_COMPILING_IN_GRAAL 0
- #define CYTHON_COMPILING_IN_NOGIL 0
- #undef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 0
- #undef CYTHON_USE_TYPE_SPECS
- #define CYTHON_USE_TYPE_SPECS 0
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #if PY_VERSION_HEX < 0x03050000
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #elif !defined(CYTHON_USE_ASYNC_SLOTS)
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #undef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 0
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #undef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 1
- #undef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 0
- #undef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 0
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_GIL
- #define CYTHON_FAST_GIL 0
- #undef CYTHON_METH_FASTCALL
- #define CYTHON_METH_FASTCALL 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #ifndef CYTHON_PEP487_INIT_SUBCLASS
- #define CYTHON_PEP487_INIT_SUBCLASS (PY_MAJOR_VERSION >= 3)
- #endif
- #if PY_VERSION_HEX < 0x03090000
- #undef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 0
- #elif !defined(CYTHON_PEP489_MULTI_PHASE_INIT)
- #define CYTHON_PEP489_MULTI_PHASE_INIT 1
- #endif
- #undef CYTHON_USE_MODULE_STATE
- #define CYTHON_USE_MODULE_STATE 0
- #undef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE (PY_VERSION_HEX >= 0x030400a1 && PYPY_VERSION_NUM >= 0x07030C00)
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC 0
- #endif
-#elif defined(CYTHON_LIMITED_API)
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_LIMITED_API 1
- #define CYTHON_COMPILING_IN_GRAAL 0
- #define CYTHON_COMPILING_IN_NOGIL 0
- #undef CYTHON_CLINE_IN_TRACEBACK
- #define CYTHON_CLINE_IN_TRACEBACK 0
- #undef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 0
- #undef CYTHON_USE_TYPE_SPECS
- #define CYTHON_USE_TYPE_SPECS 1
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #undef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 0
- #ifndef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #endif
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #undef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 0
- #undef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 0
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_GIL
- #define CYTHON_FAST_GIL 0
- #undef CYTHON_METH_FASTCALL
- #define CYTHON_METH_FASTCALL 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #ifndef CYTHON_PEP487_INIT_SUBCLASS
- #define CYTHON_PEP487_INIT_SUBCLASS 1
- #endif
- #undef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 0
- #undef CYTHON_USE_MODULE_STATE
- #define CYTHON_USE_MODULE_STATE 1
- #ifndef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 1
- #endif
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC 0
- #endif
-#elif defined(PY_NOGIL)
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_LIMITED_API 0
- #define CYTHON_COMPILING_IN_GRAAL 0
- #define CYTHON_COMPILING_IN_NOGIL 1
- #ifndef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 1
- #endif
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #ifndef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #ifndef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 1
- #endif
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #ifndef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 1
- #endif
- #ifndef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 1
- #endif
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #ifndef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 1
- #endif
- #ifndef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 1
- #endif
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
-#else
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_CPYTHON 1
- #define CYTHON_COMPILING_IN_LIMITED_API 0
- #define CYTHON_COMPILING_IN_GRAAL 0
- #define CYTHON_COMPILING_IN_NOGIL 0
- #ifndef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 1
- #endif
- #ifndef CYTHON_USE_TYPE_SPECS
- #define CYTHON_USE_TYPE_SPECS 0
- #endif
- #ifndef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 1
- #endif
- #if PY_MAJOR_VERSION < 3
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #elif !defined(CYTHON_USE_ASYNC_SLOTS)
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #ifndef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 1
- #endif
- #ifndef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 1
- #endif
- #ifndef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 1
- #endif
- #if PY_VERSION_HEX < 0x030300F0 || PY_VERSION_HEX >= 0x030B00A2
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #elif !defined(CYTHON_USE_UNICODE_WRITER)
- #define CYTHON_USE_UNICODE_WRITER 1
- #endif
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #ifndef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 1
- #endif
- #ifndef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 1
- #endif
- #ifndef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 1
- #endif
- #ifndef CYTHON_FAST_GIL
- #define CYTHON_FAST_GIL (PY_MAJOR_VERSION < 3 || PY_VERSION_HEX >= 0x03060000 && PY_VERSION_HEX < 0x030C00A6)
- #endif
- #ifndef CYTHON_METH_FASTCALL
- #define CYTHON_METH_FASTCALL (PY_VERSION_HEX >= 0x030700A1)
- #endif
- #ifndef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 1
- #endif
- #ifndef CYTHON_PEP487_INIT_SUBCLASS
- #define CYTHON_PEP487_INIT_SUBCLASS 1
- #endif
- #if PY_VERSION_HEX < 0x03050000
- #undef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 0
- #elif !defined(CYTHON_PEP489_MULTI_PHASE_INIT)
- #define CYTHON_PEP489_MULTI_PHASE_INIT 1
- #endif
- #ifndef CYTHON_USE_MODULE_STATE
- #define CYTHON_USE_MODULE_STATE 0
- #endif
- #if PY_VERSION_HEX < 0x030400a1
- #undef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 0
- #elif !defined(CYTHON_USE_TP_FINALIZE)
- #define CYTHON_USE_TP_FINALIZE 1
- #endif
- #if PY_VERSION_HEX < 0x030600B1
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #elif !defined(CYTHON_USE_DICT_VERSIONS)
- #define CYTHON_USE_DICT_VERSIONS (PY_VERSION_HEX < 0x030C00A5)
- #endif
- #if PY_VERSION_HEX < 0x030700A3
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #elif !defined(CYTHON_USE_EXC_INFO_STACK)
- #define CYTHON_USE_EXC_INFO_STACK 1
- #endif
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC 1
- #endif
-#endif
-#if !defined(CYTHON_FAST_PYCCALL)
-#define CYTHON_FAST_PYCCALL (CYTHON_FAST_PYCALL && PY_VERSION_HEX >= 0x030600B1)
-#endif
-#if !defined(CYTHON_VECTORCALL)
-#define CYTHON_VECTORCALL (CYTHON_FAST_PYCCALL && PY_VERSION_HEX >= 0x030800B1)
-#endif
-#define CYTHON_BACKPORT_VECTORCALL (CYTHON_METH_FASTCALL && PY_VERSION_HEX < 0x030800B1)
-#if CYTHON_USE_PYLONG_INTERNALS
- #if PY_MAJOR_VERSION < 3
- #include "longintrepr.h"
- #endif
- #undef SHIFT
- #undef BASE
- #undef MASK
- #ifdef SIZEOF_VOID_P
- enum { __pyx_check_sizeof_voidp = 1 / (int)(SIZEOF_VOID_P == sizeof(void*)) };
- #endif
-#endif
-#ifndef __has_attribute
- #define __has_attribute(x) 0
-#endif
-#ifndef __has_cpp_attribute
- #define __has_cpp_attribute(x) 0
-#endif
-#ifndef CYTHON_RESTRICT
- #if defined(__GNUC__)
- #define CYTHON_RESTRICT __restrict__
- #elif defined(_MSC_VER) && _MSC_VER >= 1400
- #define CYTHON_RESTRICT __restrict
- #elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define CYTHON_RESTRICT restrict
- #else
- #define CYTHON_RESTRICT
- #endif
-#endif
-#ifndef CYTHON_UNUSED
- #if defined(__cplusplus)
- /* for clang __has_cpp_attribute(maybe_unused) is true even before C++17
- * but leads to warnings with -pedantic, since it is a C++17 feature */
- #if ((defined(_MSVC_LANG) && _MSVC_LANG >= 201703L) || __cplusplus >= 201703L)
- #if __has_cpp_attribute(maybe_unused)
- #define CYTHON_UNUSED [[maybe_unused]]
- #endif
- #endif
- #endif
-#endif
-#ifndef CYTHON_UNUSED
-# if defined(__GNUC__)
-# if !(defined(__cplusplus)) || (__GNUC__ > 3 || (__GNUC__ == 3 && __GNUC_MINOR__ >= 4))
-# define CYTHON_UNUSED __attribute__ ((__unused__))
-# else
-# define CYTHON_UNUSED
-# endif
-# elif defined(__ICC) || (defined(__INTEL_COMPILER) && !defined(_MSC_VER))
-# define CYTHON_UNUSED __attribute__ ((__unused__))
-# else
-# define CYTHON_UNUSED
-# endif
-#endif
-#ifndef CYTHON_UNUSED_VAR
-# if defined(__cplusplus)
- template void CYTHON_UNUSED_VAR( const T& ) { }
-# else
-# define CYTHON_UNUSED_VAR(x) (void)(x)
-# endif
-#endif
-#ifndef CYTHON_MAYBE_UNUSED_VAR
- #define CYTHON_MAYBE_UNUSED_VAR(x) CYTHON_UNUSED_VAR(x)
-#endif
-#ifndef CYTHON_NCP_UNUSED
-# if CYTHON_COMPILING_IN_CPYTHON
-# define CYTHON_NCP_UNUSED
-# else
-# define CYTHON_NCP_UNUSED CYTHON_UNUSED
-# endif
-#endif
-#define __Pyx_void_to_None(void_result) ((void)(void_result), Py_INCREF(Py_None), Py_None)
-#ifdef _MSC_VER
- #ifndef _MSC_STDINT_H_
- #if _MSC_VER < 1300
- typedef unsigned char uint8_t;
- typedef unsigned short uint16_t;
- typedef unsigned int uint32_t;
- #else
- typedef unsigned __int8 uint8_t;
- typedef unsigned __int16 uint16_t;
- typedef unsigned __int32 uint32_t;
- #endif
- #endif
- #if _MSC_VER < 1300
- #ifdef _WIN64
- typedef unsigned long long __pyx_uintptr_t;
- #else
- typedef unsigned int __pyx_uintptr_t;
- #endif
- #else
- #ifdef _WIN64
- typedef unsigned __int64 __pyx_uintptr_t;
- #else
- typedef unsigned __int32 __pyx_uintptr_t;
- #endif
- #endif
-#else
- #include
- typedef uintptr_t __pyx_uintptr_t;
-#endif
-#ifndef CYTHON_FALLTHROUGH
- #if defined(__cplusplus)
- /* for clang __has_cpp_attribute(fallthrough) is true even before C++17
- * but leads to warnings with -pedantic, since it is a C++17 feature */
- #if ((defined(_MSVC_LANG) && _MSVC_LANG >= 201703L) || __cplusplus >= 201703L)
- #if __has_cpp_attribute(fallthrough)
- #define CYTHON_FALLTHROUGH [[fallthrough]]
- #endif
- #endif
- #ifndef CYTHON_FALLTHROUGH
- #if __has_cpp_attribute(clang::fallthrough)
- #define CYTHON_FALLTHROUGH [[clang::fallthrough]]
- #elif __has_cpp_attribute(gnu::fallthrough)
- #define CYTHON_FALLTHROUGH [[gnu::fallthrough]]
- #endif
- #endif
- #endif
- #ifndef CYTHON_FALLTHROUGH
- #if __has_attribute(fallthrough)
- #define CYTHON_FALLTHROUGH __attribute__((fallthrough))
- #else
- #define CYTHON_FALLTHROUGH
- #endif
- #endif
- #if defined(__clang__) && defined(__apple_build_version__)
- #if __apple_build_version__ < 7000000
- #undef CYTHON_FALLTHROUGH
- #define CYTHON_FALLTHROUGH
- #endif
- #endif
-#endif
-#ifdef __cplusplus
- template
- struct __PYX_IS_UNSIGNED_IMPL {static const bool value = T(0) < T(-1);};
- #define __PYX_IS_UNSIGNED(type) (__PYX_IS_UNSIGNED_IMPL::value)
-#else
- #define __PYX_IS_UNSIGNED(type) (((type)-1) > 0)
-#endif
-#if CYTHON_COMPILING_IN_PYPY == 1
- #define __PYX_NEED_TP_PRINT_SLOT (PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x030A0000)
-#else
- #define __PYX_NEED_TP_PRINT_SLOT (PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000)
-#endif
-#define __PYX_REINTERPRET_FUNCION(func_pointer, other_pointer) ((func_pointer)(void(*)(void))(other_pointer))
-
-#ifndef CYTHON_INLINE
- #if defined(__clang__)
- #define CYTHON_INLINE __inline__ __attribute__ ((__unused__))
- #elif defined(__GNUC__)
- #define CYTHON_INLINE __inline__
- #elif defined(_MSC_VER)
- #define CYTHON_INLINE __inline
- #elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define CYTHON_INLINE inline
- #else
- #define CYTHON_INLINE
- #endif
-#endif
-
-#define __PYX_BUILD_PY_SSIZE_T "n"
-#define CYTHON_FORMAT_SSIZE_T "z"
-#if PY_MAJOR_VERSION < 3
- #define __Pyx_BUILTIN_MODULE_NAME "__builtin__"
- #define __Pyx_DefaultClassType PyClass_Type
- #define __Pyx_PyCode_New(a, p, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)\
- PyCode_New(a+k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)
-#else
- #define __Pyx_BUILTIN_MODULE_NAME "builtins"
- #define __Pyx_DefaultClassType PyType_Type
-#if PY_VERSION_HEX >= 0x030B00A1
- static CYTHON_INLINE PyCodeObject* __Pyx_PyCode_New(int a, int p, int k, int l, int s, int f,
- PyObject *code, PyObject *c, PyObject* n, PyObject *v,
- PyObject *fv, PyObject *cell, PyObject* fn,
- PyObject *name, int fline, PyObject *lnos) {
- PyObject *kwds=NULL, *argcount=NULL, *posonlyargcount=NULL, *kwonlyargcount=NULL;
- PyObject *nlocals=NULL, *stacksize=NULL, *flags=NULL, *replace=NULL, *empty=NULL;
- const char *fn_cstr=NULL;
- const char *name_cstr=NULL;
- PyCodeObject *co=NULL, *result=NULL;
- PyObject *type, *value, *traceback;
- PyErr_Fetch(&type, &value, &traceback);
- if (!(kwds=PyDict_New())) goto end;
- if (!(argcount=PyLong_FromLong(a))) goto end;
- if (PyDict_SetItemString(kwds, "co_argcount", argcount) != 0) goto end;
- if (!(posonlyargcount=PyLong_FromLong(p))) goto end;
- if (PyDict_SetItemString(kwds, "co_posonlyargcount", posonlyargcount) != 0) goto end;
- if (!(kwonlyargcount=PyLong_FromLong(k))) goto end;
- if (PyDict_SetItemString(kwds, "co_kwonlyargcount", kwonlyargcount) != 0) goto end;
- if (!(nlocals=PyLong_FromLong(l))) goto end;
- if (PyDict_SetItemString(kwds, "co_nlocals", nlocals) != 0) goto end;
- if (!(stacksize=PyLong_FromLong(s))) goto end;
- if (PyDict_SetItemString(kwds, "co_stacksize", stacksize) != 0) goto end;
- if (!(flags=PyLong_FromLong(f))) goto end;
- if (PyDict_SetItemString(kwds, "co_flags", flags) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_code", code) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_consts", c) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_names", n) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_varnames", v) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_freevars", fv) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_cellvars", cell) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_linetable", lnos) != 0) goto end;
- if (!(fn_cstr=PyUnicode_AsUTF8AndSize(fn, NULL))) goto end;
- if (!(name_cstr=PyUnicode_AsUTF8AndSize(name, NULL))) goto end;
- if (!(co = PyCode_NewEmpty(fn_cstr, name_cstr, fline))) goto end;
- if (!(replace = PyObject_GetAttrString((PyObject*)co, "replace"))) goto end;
- if (!(empty = PyTuple_New(0))) goto end;
- result = (PyCodeObject*) PyObject_Call(replace, empty, kwds);
- end:
- Py_XDECREF((PyObject*) co);
- Py_XDECREF(kwds);
- Py_XDECREF(argcount);
- Py_XDECREF(posonlyargcount);
- Py_XDECREF(kwonlyargcount);
- Py_XDECREF(nlocals);
- Py_XDECREF(stacksize);
- Py_XDECREF(replace);
- Py_XDECREF(empty);
- if (type) {
- PyErr_Restore(type, value, traceback);
- }
- return result;
- }
-#elif PY_VERSION_HEX >= 0x030800B2 && !CYTHON_COMPILING_IN_PYPY
- #define __Pyx_PyCode_New(a, p, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)\
- PyCode_NewWithPosOnlyArgs(a, p, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)
-#else
- #define __Pyx_PyCode_New(a, p, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)\
- PyCode_New(a, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)
-#endif
-#endif
-#if PY_VERSION_HEX >= 0x030900A4 || defined(Py_IS_TYPE)
- #define __Pyx_IS_TYPE(ob, type) Py_IS_TYPE(ob, type)
-#else
- #define __Pyx_IS_TYPE(ob, type) (((const PyObject*)ob)->ob_type == (type))
-#endif
-#if PY_VERSION_HEX >= 0x030A00B1 || defined(Py_Is)
- #define __Pyx_Py_Is(x, y) Py_Is(x, y)
-#else
- #define __Pyx_Py_Is(x, y) ((x) == (y))
-#endif
-#if PY_VERSION_HEX >= 0x030A00B1 || defined(Py_IsNone)
- #define __Pyx_Py_IsNone(ob) Py_IsNone(ob)
-#else
- #define __Pyx_Py_IsNone(ob) __Pyx_Py_Is((ob), Py_None)
-#endif
-#if PY_VERSION_HEX >= 0x030A00B1 || defined(Py_IsTrue)
- #define __Pyx_Py_IsTrue(ob) Py_IsTrue(ob)
-#else
- #define __Pyx_Py_IsTrue(ob) __Pyx_Py_Is((ob), Py_True)
-#endif
-#if PY_VERSION_HEX >= 0x030A00B1 || defined(Py_IsFalse)
- #define __Pyx_Py_IsFalse(ob) Py_IsFalse(ob)
-#else
- #define __Pyx_Py_IsFalse(ob) __Pyx_Py_Is((ob), Py_False)
-#endif
-#define __Pyx_NoneAsNull(obj) (__Pyx_Py_IsNone(obj) ? NULL : (obj))
-#if PY_VERSION_HEX >= 0x030900F0 && !CYTHON_COMPILING_IN_PYPY
- #define __Pyx_PyObject_GC_IsFinalized(o) PyObject_GC_IsFinalized(o)
-#else
- #define __Pyx_PyObject_GC_IsFinalized(o) _PyGC_FINALIZED(o)
-#endif
-#ifndef CO_COROUTINE
- #define CO_COROUTINE 0x80
-#endif
-#ifndef CO_ASYNC_GENERATOR
- #define CO_ASYNC_GENERATOR 0x200
-#endif
-#ifndef Py_TPFLAGS_CHECKTYPES
- #define Py_TPFLAGS_CHECKTYPES 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_INDEX
- #define Py_TPFLAGS_HAVE_INDEX 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_NEWBUFFER
- #define Py_TPFLAGS_HAVE_NEWBUFFER 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_FINALIZE
- #define Py_TPFLAGS_HAVE_FINALIZE 0
-#endif
-#ifndef Py_TPFLAGS_SEQUENCE
- #define Py_TPFLAGS_SEQUENCE 0
-#endif
-#ifndef Py_TPFLAGS_MAPPING
- #define Py_TPFLAGS_MAPPING 0
-#endif
-#ifndef METH_STACKLESS
- #define METH_STACKLESS 0
-#endif
-#if PY_VERSION_HEX <= 0x030700A3 || !defined(METH_FASTCALL)
- #ifndef METH_FASTCALL
- #define METH_FASTCALL 0x80
- #endif
- typedef PyObject *(*__Pyx_PyCFunctionFast) (PyObject *self, PyObject *const *args, Py_ssize_t nargs);
- typedef PyObject *(*__Pyx_PyCFunctionFastWithKeywords) (PyObject *self, PyObject *const *args,
- Py_ssize_t nargs, PyObject *kwnames);
-#else
- #define __Pyx_PyCFunctionFast _PyCFunctionFast
- #define __Pyx_PyCFunctionFastWithKeywords _PyCFunctionFastWithKeywords
-#endif
-#if CYTHON_METH_FASTCALL
- #define __Pyx_METH_FASTCALL METH_FASTCALL
- #define __Pyx_PyCFunction_FastCall __Pyx_PyCFunctionFast
- #define __Pyx_PyCFunction_FastCallWithKeywords __Pyx_PyCFunctionFastWithKeywords
-#else
- #define __Pyx_METH_FASTCALL METH_VARARGS
- #define __Pyx_PyCFunction_FastCall PyCFunction
- #define __Pyx_PyCFunction_FastCallWithKeywords PyCFunctionWithKeywords
-#endif
-#if CYTHON_VECTORCALL
- #define __pyx_vectorcallfunc vectorcallfunc
- #define __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET PY_VECTORCALL_ARGUMENTS_OFFSET
- #define __Pyx_PyVectorcall_NARGS(n) PyVectorcall_NARGS((size_t)(n))
-#elif CYTHON_BACKPORT_VECTORCALL
- typedef PyObject *(*__pyx_vectorcallfunc)(PyObject *callable, PyObject *const *args,
- size_t nargsf, PyObject *kwnames);
- #define __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET ((size_t)1 << (8 * sizeof(size_t) - 1))
- #define __Pyx_PyVectorcall_NARGS(n) ((Py_ssize_t)(((size_t)(n)) & ~__Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET))
-#else
- #define __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET 0
- #define __Pyx_PyVectorcall_NARGS(n) ((Py_ssize_t)(n))
-#endif
-#if PY_VERSION_HEX < 0x030900B1
- #define __Pyx_PyType_FromModuleAndSpec(m, s, b) ((void)m, PyType_FromSpecWithBases(s, b))
- typedef PyObject *(*__Pyx_PyCMethod)(PyObject *, PyTypeObject *, PyObject *const *, size_t, PyObject *);
-#else
- #define __Pyx_PyType_FromModuleAndSpec(m, s, b) PyType_FromModuleAndSpec(m, s, b)
- #define __Pyx_PyCMethod PyCMethod
-#endif
-#ifndef METH_METHOD
- #define METH_METHOD 0x200
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyObject_Malloc)
- #define PyObject_Malloc(s) PyMem_Malloc(s)
- #define PyObject_Free(p) PyMem_Free(p)
- #define PyObject_Realloc(p) PyMem_Realloc(p)
-#endif
-#if CYTHON_COMPILING_IN_LIMITED_API
- #define __Pyx_PyCode_HasFreeVars(co) (PyCode_GetNumFree(co) > 0)
- #define __Pyx_PyFrame_SetLineNumber(frame, lineno)
-#else
- #define __Pyx_PyCode_HasFreeVars(co) (PyCode_GetNumFree(co) > 0)
- #define __Pyx_PyFrame_SetLineNumber(frame, lineno) (frame)->f_lineno = (lineno)
-#endif
-#if CYTHON_COMPILING_IN_LIMITED_API
- #define __Pyx_PyThreadState_Current PyThreadState_Get()
-#elif !CYTHON_FAST_THREAD_STATE
- #define __Pyx_PyThreadState_Current PyThreadState_GET()
-#elif PY_VERSION_HEX >= 0x03060000
- #define __Pyx_PyThreadState_Current _PyThreadState_UncheckedGet()
-#elif PY_VERSION_HEX >= 0x03000000
- #define __Pyx_PyThreadState_Current PyThreadState_GET()
-#else
- #define __Pyx_PyThreadState_Current _PyThreadState_Current
-#endif
-#if CYTHON_COMPILING_IN_LIMITED_API
-static CYTHON_INLINE void *__Pyx_PyModule_GetState(PyObject *op)
-{
- void *result;
- result = PyModule_GetState(op);
- if (!result)
- Py_FatalError("Couldn't find the module state");
- return result;
-}
-#endif
-#define __Pyx_PyObject_GetSlot(obj, name, func_ctype) __Pyx_PyType_GetSlot(Py_TYPE(obj), name, func_ctype)
-#if CYTHON_COMPILING_IN_LIMITED_API
- #define __Pyx_PyType_GetSlot(type, name, func_ctype) ((func_ctype) PyType_GetSlot((type), Py_##name))
-#else
- #define __Pyx_PyType_GetSlot(type, name, func_ctype) ((type)->name)
-#endif
-#if PY_VERSION_HEX < 0x030700A2 && !defined(PyThread_tss_create) && !defined(Py_tss_NEEDS_INIT)
-#include "pythread.h"
-#define Py_tss_NEEDS_INIT 0
-typedef int Py_tss_t;
-static CYTHON_INLINE int PyThread_tss_create(Py_tss_t *key) {
- *key = PyThread_create_key();
- return 0;
-}
-static CYTHON_INLINE Py_tss_t * PyThread_tss_alloc(void) {
- Py_tss_t *key = (Py_tss_t *)PyObject_Malloc(sizeof(Py_tss_t));
- *key = Py_tss_NEEDS_INIT;
- return key;
-}
-static CYTHON_INLINE void PyThread_tss_free(Py_tss_t *key) {
- PyObject_Free(key);
-}
-static CYTHON_INLINE int PyThread_tss_is_created(Py_tss_t *key) {
- return *key != Py_tss_NEEDS_INIT;
-}
-static CYTHON_INLINE void PyThread_tss_delete(Py_tss_t *key) {
- PyThread_delete_key(*key);
- *key = Py_tss_NEEDS_INIT;
-}
-static CYTHON_INLINE int PyThread_tss_set(Py_tss_t *key, void *value) {
- return PyThread_set_key_value(*key, value);
-}
-static CYTHON_INLINE void * PyThread_tss_get(Py_tss_t *key) {
- return PyThread_get_key_value(*key);
-}
-#endif
-#if PY_MAJOR_VERSION < 3
- #if CYTHON_COMPILING_IN_PYPY
- #if PYPY_VERSION_NUM < 0x07030600
- #if defined(__cplusplus) && __cplusplus >= 201402L
- [[deprecated("`with nogil:` inside a nogil function will not release the GIL in PyPy2 < 7.3.6")]]
- #elif defined(__GNUC__) || defined(__clang__)
- __attribute__ ((__deprecated__("`with nogil:` inside a nogil function will not release the GIL in PyPy2 < 7.3.6")))
- #elif defined(_MSC_VER)
- __declspec(deprecated("`with nogil:` inside a nogil function will not release the GIL in PyPy2 < 7.3.6"))
- #endif
- static CYTHON_INLINE int PyGILState_Check(void) {
- return 0;
- }
- #else // PYPY_VERSION_NUM < 0x07030600
- #endif // PYPY_VERSION_NUM < 0x07030600
- #else
- static CYTHON_INLINE int PyGILState_Check(void) {
- PyThreadState * tstate = _PyThreadState_Current;
- return tstate && (tstate == PyGILState_GetThisThreadState());
- }
- #endif
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON || defined(_PyDict_NewPresized)
-#define __Pyx_PyDict_NewPresized(n) ((n <= 8) ? PyDict_New() : _PyDict_NewPresized(n))
-#else
-#define __Pyx_PyDict_NewPresized(n) PyDict_New()
-#endif
-#if PY_MAJOR_VERSION >= 3 || CYTHON_FUTURE_DIVISION
- #define __Pyx_PyNumber_Divide(x,y) PyNumber_TrueDivide(x,y)
- #define __Pyx_PyNumber_InPlaceDivide(x,y) PyNumber_InPlaceTrueDivide(x,y)
-#else
- #define __Pyx_PyNumber_Divide(x,y) PyNumber_Divide(x,y)
- #define __Pyx_PyNumber_InPlaceDivide(x,y) PyNumber_InPlaceDivide(x,y)
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX > 0x030600B4 && CYTHON_USE_UNICODE_INTERNALS
-#define __Pyx_PyDict_GetItemStrWithError(dict, name) _PyDict_GetItem_KnownHash(dict, name, ((PyASCIIObject *) name)->hash)
-static CYTHON_INLINE PyObject * __Pyx_PyDict_GetItemStr(PyObject *dict, PyObject *name) {
- PyObject *res = __Pyx_PyDict_GetItemStrWithError(dict, name);
- if (res == NULL) PyErr_Clear();
- return res;
-}
-#elif PY_MAJOR_VERSION >= 3 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07020000)
-#define __Pyx_PyDict_GetItemStrWithError PyDict_GetItemWithError
-#define __Pyx_PyDict_GetItemStr PyDict_GetItem
-#else
-static CYTHON_INLINE PyObject * __Pyx_PyDict_GetItemStrWithError(PyObject *dict, PyObject *name) {
-#if CYTHON_COMPILING_IN_PYPY
- return PyDict_GetItem(dict, name);
-#else
- PyDictEntry *ep;
- PyDictObject *mp = (PyDictObject*) dict;
- long hash = ((PyStringObject *) name)->ob_shash;
- assert(hash != -1);
- ep = (mp->ma_lookup)(mp, name, hash);
- if (ep == NULL) {
- return NULL;
- }
- return ep->me_value;
-#endif
-}
-#define __Pyx_PyDict_GetItemStr PyDict_GetItem
-#endif
-#if CYTHON_USE_TYPE_SLOTS
- #define __Pyx_PyType_GetFlags(tp) (((PyTypeObject *)tp)->tp_flags)
- #define __Pyx_PyType_HasFeature(type, feature) ((__Pyx_PyType_GetFlags(type) & (feature)) != 0)
- #define __Pyx_PyObject_GetIterNextFunc(obj) (Py_TYPE(obj)->tp_iternext)
-#else
- #define __Pyx_PyType_GetFlags(tp) (PyType_GetFlags((PyTypeObject *)tp))
- #define __Pyx_PyType_HasFeature(type, feature) PyType_HasFeature(type, feature)
- #define __Pyx_PyObject_GetIterNextFunc(obj) PyIter_Next
-#endif
-#if CYTHON_USE_TYPE_SPECS && PY_VERSION_HEX >= 0x03080000
-#define __Pyx_PyHeapTypeObject_GC_Del(obj) {\
- PyTypeObject *type = Py_TYPE(obj);\
- assert(__Pyx_PyType_HasFeature(type, Py_TPFLAGS_HEAPTYPE));\
- PyObject_GC_Del(obj);\
- Py_DECREF(type);\
-}
-#else
-#define __Pyx_PyHeapTypeObject_GC_Del(obj) PyObject_GC_Del(obj)
-#endif
-#if CYTHON_COMPILING_IN_LIMITED_API
- #define CYTHON_PEP393_ENABLED 1
- #define __Pyx_PyUnicode_READY(op) (0)
- #define __Pyx_PyUnicode_GET_LENGTH(u) PyUnicode_GetLength(u)
- #define __Pyx_PyUnicode_READ_CHAR(u, i) PyUnicode_ReadChar(u, i)
- #define __Pyx_PyUnicode_MAX_CHAR_VALUE(u) ((void)u, 1114111U)
- #define __Pyx_PyUnicode_KIND(u) ((void)u, (0))
- #define __Pyx_PyUnicode_DATA(u) ((void*)u)
- #define __Pyx_PyUnicode_READ(k, d, i) ((void)k, PyUnicode_ReadChar((PyObject*)(d), i))
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != PyUnicode_GetLength(u))
-#elif PY_VERSION_HEX > 0x03030000 && defined(PyUnicode_KIND)
- #define CYTHON_PEP393_ENABLED 1
- #if PY_VERSION_HEX >= 0x030C0000
- #define __Pyx_PyUnicode_READY(op) (0)
- #else
- #define __Pyx_PyUnicode_READY(op) (likely(PyUnicode_IS_READY(op)) ?\
- 0 : _PyUnicode_Ready((PyObject *)(op)))
- #endif
- #define __Pyx_PyUnicode_GET_LENGTH(u) PyUnicode_GET_LENGTH(u)
- #define __Pyx_PyUnicode_READ_CHAR(u, i) PyUnicode_READ_CHAR(u, i)
- #define __Pyx_PyUnicode_MAX_CHAR_VALUE(u) PyUnicode_MAX_CHAR_VALUE(u)
- #define __Pyx_PyUnicode_KIND(u) ((int)PyUnicode_KIND(u))
- #define __Pyx_PyUnicode_DATA(u) PyUnicode_DATA(u)
- #define __Pyx_PyUnicode_READ(k, d, i) PyUnicode_READ(k, d, i)
- #define __Pyx_PyUnicode_WRITE(k, d, i, ch) PyUnicode_WRITE(k, d, i, (Py_UCS4) ch)
- #if PY_VERSION_HEX >= 0x030C0000
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != PyUnicode_GET_LENGTH(u))
- #else
- #if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x03090000
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != (likely(PyUnicode_IS_READY(u)) ? PyUnicode_GET_LENGTH(u) : ((PyCompactUnicodeObject *)(u))->wstr_length))
- #else
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != (likely(PyUnicode_IS_READY(u)) ? PyUnicode_GET_LENGTH(u) : PyUnicode_GET_SIZE(u)))
- #endif
- #endif
-#else
- #define CYTHON_PEP393_ENABLED 0
- #define PyUnicode_1BYTE_KIND 1
- #define PyUnicode_2BYTE_KIND 2
- #define PyUnicode_4BYTE_KIND 4
- #define __Pyx_PyUnicode_READY(op) (0)
- #define __Pyx_PyUnicode_GET_LENGTH(u) PyUnicode_GET_SIZE(u)
- #define __Pyx_PyUnicode_READ_CHAR(u, i) ((Py_UCS4)(PyUnicode_AS_UNICODE(u)[i]))
- #define __Pyx_PyUnicode_MAX_CHAR_VALUE(u) ((sizeof(Py_UNICODE) == 2) ? 65535U : 1114111U)
- #define __Pyx_PyUnicode_KIND(u) ((int)sizeof(Py_UNICODE))
- #define __Pyx_PyUnicode_DATA(u) ((void*)PyUnicode_AS_UNICODE(u))
- #define __Pyx_PyUnicode_READ(k, d, i) ((void)(k), (Py_UCS4)(((Py_UNICODE*)d)[i]))
- #define __Pyx_PyUnicode_WRITE(k, d, i, ch) (((void)(k)), ((Py_UNICODE*)d)[i] = (Py_UNICODE) ch)
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != PyUnicode_GET_SIZE(u))
-#endif
-#if CYTHON_COMPILING_IN_PYPY
- #define __Pyx_PyUnicode_Concat(a, b) PyNumber_Add(a, b)
- #define __Pyx_PyUnicode_ConcatSafe(a, b) PyNumber_Add(a, b)
-#else
- #define __Pyx_PyUnicode_Concat(a, b) PyUnicode_Concat(a, b)
- #define __Pyx_PyUnicode_ConcatSafe(a, b) ((unlikely((a) == Py_None) || unlikely((b) == Py_None)) ?\
- PyNumber_Add(a, b) : __Pyx_PyUnicode_Concat(a, b))
-#endif
-#if CYTHON_COMPILING_IN_PYPY
- #if !defined(PyUnicode_DecodeUnicodeEscape)
- #define PyUnicode_DecodeUnicodeEscape(s, size, errors) PyUnicode_Decode(s, size, "unicode_escape", errors)
- #endif
- #if !defined(PyUnicode_Contains) || (PY_MAJOR_VERSION == 2 && PYPY_VERSION_NUM < 0x07030500)
- #undef PyUnicode_Contains
- #define PyUnicode_Contains(u, s) PySequence_Contains(u, s)
- #endif
- #if !defined(PyByteArray_Check)
- #define PyByteArray_Check(obj) PyObject_TypeCheck(obj, &PyByteArray_Type)
- #endif
- #if !defined(PyObject_Format)
- #define PyObject_Format(obj, fmt) PyObject_CallMethod(obj, "__format__", "O", fmt)
- #endif
-#endif
-#define __Pyx_PyString_FormatSafe(a, b) ((unlikely((a) == Py_None || (PyString_Check(b) && !PyString_CheckExact(b)))) ? PyNumber_Remainder(a, b) : __Pyx_PyString_Format(a, b))
-#define __Pyx_PyUnicode_FormatSafe(a, b) ((unlikely((a) == Py_None || (PyUnicode_Check(b) && !PyUnicode_CheckExact(b)))) ? PyNumber_Remainder(a, b) : PyUnicode_Format(a, b))
-#if PY_MAJOR_VERSION >= 3
- #define __Pyx_PyString_Format(a, b) PyUnicode_Format(a, b)
-#else
- #define __Pyx_PyString_Format(a, b) PyString_Format(a, b)
-#endif
-#if PY_MAJOR_VERSION < 3 && !defined(PyObject_ASCII)
- #define PyObject_ASCII(o) PyObject_Repr(o)
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyBaseString_Type PyUnicode_Type
- #define PyStringObject PyUnicodeObject
- #define PyString_Type PyUnicode_Type
- #define PyString_Check PyUnicode_Check
- #define PyString_CheckExact PyUnicode_CheckExact
-#ifndef PyObject_Unicode
- #define PyObject_Unicode PyObject_Str
-#endif
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define __Pyx_PyBaseString_Check(obj) PyUnicode_Check(obj)
- #define __Pyx_PyBaseString_CheckExact(obj) PyUnicode_CheckExact(obj)
-#else
- #define __Pyx_PyBaseString_Check(obj) (PyString_Check(obj) || PyUnicode_Check(obj))
- #define __Pyx_PyBaseString_CheckExact(obj) (PyString_CheckExact(obj) || PyUnicode_CheckExact(obj))
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON
- #define __Pyx_PySequence_ListKeepNew(obj)\
- (likely(PyList_CheckExact(obj) && Py_REFCNT(obj) == 1) ? __Pyx_NewRef(obj) : PySequence_List(obj))
-#else
- #define __Pyx_PySequence_ListKeepNew(obj) PySequence_List(obj)
-#endif
-#ifndef PySet_CheckExact
- #define PySet_CheckExact(obj) __Pyx_IS_TYPE(obj, &PySet_Type)
-#endif
-#if PY_VERSION_HEX >= 0x030900A4
- #define __Pyx_SET_REFCNT(obj, refcnt) Py_SET_REFCNT(obj, refcnt)
- #define __Pyx_SET_SIZE(obj, size) Py_SET_SIZE(obj, size)
-#else
- #define __Pyx_SET_REFCNT(obj, refcnt) Py_REFCNT(obj) = (refcnt)
- #define __Pyx_SET_SIZE(obj, size) Py_SIZE(obj) = (size)
-#endif
-#if CYTHON_ASSUME_SAFE_MACROS
- #define __Pyx_PySequence_SIZE(seq) Py_SIZE(seq)
-#else
- #define __Pyx_PySequence_SIZE(seq) PySequence_Size(seq)
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyIntObject PyLongObject
- #define PyInt_Type PyLong_Type
- #define PyInt_Check(op) PyLong_Check(op)
- #define PyInt_CheckExact(op) PyLong_CheckExact(op)
- #define __Pyx_Py3Int_Check(op) PyLong_Check(op)
- #define __Pyx_Py3Int_CheckExact(op) PyLong_CheckExact(op)
- #define PyInt_FromString PyLong_FromString
- #define PyInt_FromUnicode PyLong_FromUnicode
- #define PyInt_FromLong PyLong_FromLong
- #define PyInt_FromSize_t PyLong_FromSize_t
- #define PyInt_FromSsize_t PyLong_FromSsize_t
- #define PyInt_AsLong PyLong_AsLong
- #define PyInt_AS_LONG PyLong_AS_LONG
- #define PyInt_AsSsize_t PyLong_AsSsize_t
- #define PyInt_AsUnsignedLongMask PyLong_AsUnsignedLongMask
- #define PyInt_AsUnsignedLongLongMask PyLong_AsUnsignedLongLongMask
- #define PyNumber_Int PyNumber_Long
-#else
- #define __Pyx_Py3Int_Check(op) (PyLong_Check(op) || PyInt_Check(op))
- #define __Pyx_Py3Int_CheckExact(op) (PyLong_CheckExact(op) || PyInt_CheckExact(op))
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyBoolObject PyLongObject
-#endif
-#if PY_MAJOR_VERSION >= 3 && CYTHON_COMPILING_IN_PYPY
- #ifndef PyUnicode_InternFromString
- #define PyUnicode_InternFromString(s) PyUnicode_FromString(s)
- #endif
-#endif
-#if PY_VERSION_HEX < 0x030200A4
- typedef long Py_hash_t;
- #define __Pyx_PyInt_FromHash_t PyInt_FromLong
- #define __Pyx_PyInt_AsHash_t __Pyx_PyIndex_AsHash_t
-#else
- #define __Pyx_PyInt_FromHash_t PyInt_FromSsize_t
- #define __Pyx_PyInt_AsHash_t __Pyx_PyIndex_AsSsize_t
-#endif
-#if CYTHON_USE_ASYNC_SLOTS
- #if PY_VERSION_HEX >= 0x030500B1
- #define __Pyx_PyAsyncMethodsStruct PyAsyncMethods
- #define __Pyx_PyType_AsAsync(obj) (Py_TYPE(obj)->tp_as_async)
- #else
- #define __Pyx_PyType_AsAsync(obj) ((__Pyx_PyAsyncMethodsStruct*) (Py_TYPE(obj)->tp_reserved))
- #endif
-#else
- #define __Pyx_PyType_AsAsync(obj) NULL
-#endif
-#ifndef __Pyx_PyAsyncMethodsStruct
- typedef struct {
- unaryfunc am_await;
- unaryfunc am_aiter;
- unaryfunc am_anext;
- } __Pyx_PyAsyncMethodsStruct;
-#endif
-
-#if defined(_WIN32) || defined(WIN32) || defined(MS_WINDOWS)
- #if !defined(_USE_MATH_DEFINES)
- #define _USE_MATH_DEFINES
- #endif
-#endif
-#include
-#ifdef NAN
-#define __PYX_NAN() ((float) NAN)
-#else
-static CYTHON_INLINE float __PYX_NAN() {
- float value;
- memset(&value, 0xFF, sizeof(value));
- return value;
-}
-#endif
-#if defined(__CYGWIN__) && defined(_LDBL_EQ_DBL)
-#define __Pyx_truncl trunc
-#else
-#define __Pyx_truncl truncl
-#endif
-
-#define __PYX_MARK_ERR_POS(f_index, lineno) \
- { __pyx_filename = __pyx_f[f_index]; (void)__pyx_filename; __pyx_lineno = lineno; (void)__pyx_lineno; __pyx_clineno = __LINE__; (void)__pyx_clineno; }
-#define __PYX_ERR(f_index, lineno, Ln_error) \
- { __PYX_MARK_ERR_POS(f_index, lineno) goto Ln_error; }
-
-#ifdef CYTHON_EXTERN_C
- #undef __PYX_EXTERN_C
- #define __PYX_EXTERN_C CYTHON_EXTERN_C
-#elif defined(__PYX_EXTERN_C)
- #ifdef _MSC_VER
- #pragma message ("Please do not define the '__PYX_EXTERN_C' macro externally. Use 'CYTHON_EXTERN_C' instead.")
- #else
- #warning Please do not define the '__PYX_EXTERN_C' macro externally. Use 'CYTHON_EXTERN_C' instead.
- #endif
-#else
- #ifdef __cplusplus
- #define __PYX_EXTERN_C extern "C"
- #else
- #define __PYX_EXTERN_C extern
- #endif
-#endif
-
-#define __PYX_HAVE__fontTools__pens__momentsPen
-#define __PYX_HAVE_API__fontTools__pens__momentsPen
-/* Early includes */
-#ifdef _OPENMP
-#include
-#endif /* _OPENMP */
-
-#if defined(PYREX_WITHOUT_ASSERTIONS) && !defined(CYTHON_WITHOUT_ASSERTIONS)
-#define CYTHON_WITHOUT_ASSERTIONS
-#endif
-
-typedef struct {PyObject **p; const char *s; const Py_ssize_t n; const char* encoding;
- const char is_unicode; const char is_str; const char intern; } __Pyx_StringTabEntry;
-
-#define __PYX_DEFAULT_STRING_ENCODING_IS_ASCII 0
-#define __PYX_DEFAULT_STRING_ENCODING_IS_UTF8 0
-#define __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT (PY_MAJOR_VERSION >= 3 && __PYX_DEFAULT_STRING_ENCODING_IS_UTF8)
-#define __PYX_DEFAULT_STRING_ENCODING ""
-#define __Pyx_PyObject_FromString __Pyx_PyBytes_FromString
-#define __Pyx_PyObject_FromStringAndSize __Pyx_PyBytes_FromStringAndSize
-#define __Pyx_uchar_cast(c) ((unsigned char)c)
-#define __Pyx_long_cast(x) ((long)x)
-#define __Pyx_fits_Py_ssize_t(v, type, is_signed) (\
- (sizeof(type) < sizeof(Py_ssize_t)) ||\
- (sizeof(type) > sizeof(Py_ssize_t) &&\
- likely(v < (type)PY_SSIZE_T_MAX ||\
- v == (type)PY_SSIZE_T_MAX) &&\
- (!is_signed || likely(v > (type)PY_SSIZE_T_MIN ||\
- v == (type)PY_SSIZE_T_MIN))) ||\
- (sizeof(type) == sizeof(Py_ssize_t) &&\
- (is_signed || likely(v < (type)PY_SSIZE_T_MAX ||\
- v == (type)PY_SSIZE_T_MAX))) )
-static CYTHON_INLINE int __Pyx_is_valid_index(Py_ssize_t i, Py_ssize_t limit) {
- return (size_t) i < (size_t) limit;
-}
-#if defined (__cplusplus) && __cplusplus >= 201103L
- #include
- #define __Pyx_sst_abs(value) std::abs(value)
-#elif SIZEOF_INT >= SIZEOF_SIZE_T
- #define __Pyx_sst_abs(value) abs(value)
-#elif SIZEOF_LONG >= SIZEOF_SIZE_T
- #define __Pyx_sst_abs(value) labs(value)
-#elif defined (_MSC_VER)
- #define __Pyx_sst_abs(value) ((Py_ssize_t)_abs64(value))
-#elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define __Pyx_sst_abs(value) llabs(value)
-#elif defined (__GNUC__)
- #define __Pyx_sst_abs(value) __builtin_llabs(value)
-#else
- #define __Pyx_sst_abs(value) ((value<0) ? -value : value)
-#endif
-static CYTHON_INLINE const char* __Pyx_PyObject_AsString(PyObject*);
-static CYTHON_INLINE const char* __Pyx_PyObject_AsStringAndSize(PyObject*, Py_ssize_t* length);
-#define __Pyx_PyByteArray_FromString(s) PyByteArray_FromStringAndSize((const char*)s, strlen((const char*)s))
-#define __Pyx_PyByteArray_FromStringAndSize(s, l) PyByteArray_FromStringAndSize((const char*)s, l)
-#define __Pyx_PyBytes_FromString PyBytes_FromString
-#define __Pyx_PyBytes_FromStringAndSize PyBytes_FromStringAndSize
-static CYTHON_INLINE PyObject* __Pyx_PyUnicode_FromString(const char*);
-#if PY_MAJOR_VERSION < 3
- #define __Pyx_PyStr_FromString __Pyx_PyBytes_FromString
- #define __Pyx_PyStr_FromStringAndSize __Pyx_PyBytes_FromStringAndSize
-#else
- #define __Pyx_PyStr_FromString __Pyx_PyUnicode_FromString
- #define __Pyx_PyStr_FromStringAndSize __Pyx_PyUnicode_FromStringAndSize
-#endif
-#define __Pyx_PyBytes_AsWritableString(s) ((char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsWritableSString(s) ((signed char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsWritableUString(s) ((unsigned char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsString(s) ((const char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsSString(s) ((const signed char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsUString(s) ((const unsigned char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyObject_AsWritableString(s) ((char*)(__pyx_uintptr_t) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsWritableSString(s) ((signed char*)(__pyx_uintptr_t) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsWritableUString(s) ((unsigned char*)(__pyx_uintptr_t) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsSString(s) ((const signed char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsUString(s) ((const unsigned char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_FromCString(s) __Pyx_PyObject_FromString((const char*)s)
-#define __Pyx_PyBytes_FromCString(s) __Pyx_PyBytes_FromString((const char*)s)
-#define __Pyx_PyByteArray_FromCString(s) __Pyx_PyByteArray_FromString((const char*)s)
-#define __Pyx_PyStr_FromCString(s) __Pyx_PyStr_FromString((const char*)s)
-#define __Pyx_PyUnicode_FromCString(s) __Pyx_PyUnicode_FromString((const char*)s)
-#if CYTHON_COMPILING_IN_LIMITED_API
-static CYTHON_INLINE size_t __Pyx_Py_UNICODE_strlen(const wchar_t *u)
-{
- const wchar_t *u_end = u;
- while (*u_end++) ;
- return (size_t)(u_end - u - 1);
-}
-#else
-static CYTHON_INLINE size_t __Pyx_Py_UNICODE_strlen(const Py_UNICODE *u)
-{
- const Py_UNICODE *u_end = u;
- while (*u_end++) ;
- return (size_t)(u_end - u - 1);
-}
-#endif
-#define __Pyx_PyUnicode_FromOrdinal(o) PyUnicode_FromOrdinal((int)o)
-#define __Pyx_PyUnicode_FromUnicode(u) PyUnicode_FromUnicode(u, __Pyx_Py_UNICODE_strlen(u))
-#define __Pyx_PyUnicode_FromUnicodeAndLength PyUnicode_FromUnicode
-#define __Pyx_PyUnicode_AsUnicode PyUnicode_AsUnicode
-#define __Pyx_NewRef(obj) (Py_INCREF(obj), obj)
-#define __Pyx_Owned_Py_None(b) __Pyx_NewRef(Py_None)
-static CYTHON_INLINE PyObject * __Pyx_PyBool_FromLong(long b);
-static CYTHON_INLINE int __Pyx_PyObject_IsTrue(PyObject*);
-static CYTHON_INLINE int __Pyx_PyObject_IsTrueAndDecref(PyObject*);
-static CYTHON_INLINE PyObject* __Pyx_PyNumber_IntOrLong(PyObject* x);
-#define __Pyx_PySequence_Tuple(obj)\
- (likely(PyTuple_CheckExact(obj)) ? __Pyx_NewRef(obj) : PySequence_Tuple(obj))
-static CYTHON_INLINE Py_ssize_t __Pyx_PyIndex_AsSsize_t(PyObject*);
-static CYTHON_INLINE PyObject * __Pyx_PyInt_FromSize_t(size_t);
-static CYTHON_INLINE Py_hash_t __Pyx_PyIndex_AsHash_t(PyObject*);
-#if CYTHON_ASSUME_SAFE_MACROS
-#define __pyx_PyFloat_AsDouble(x) (PyFloat_CheckExact(x) ? PyFloat_AS_DOUBLE(x) : PyFloat_AsDouble(x))
-#else
-#define __pyx_PyFloat_AsDouble(x) PyFloat_AsDouble(x)
-#endif
-#define __pyx_PyFloat_AsFloat(x) ((float) __pyx_PyFloat_AsDouble(x))
-#if PY_MAJOR_VERSION >= 3
-#define __Pyx_PyNumber_Int(x) (PyLong_CheckExact(x) ? __Pyx_NewRef(x) : PyNumber_Long(x))
-#else
-#define __Pyx_PyNumber_Int(x) (PyInt_CheckExact(x) ? __Pyx_NewRef(x) : PyNumber_Int(x))
-#endif
-#if CYTHON_USE_PYLONG_INTERNALS
- #if PY_VERSION_HEX >= 0x030C00A7
- #ifndef _PyLong_SIGN_MASK
- #define _PyLong_SIGN_MASK 3
- #endif
- #ifndef _PyLong_NON_SIZE_BITS
- #define _PyLong_NON_SIZE_BITS 3
- #endif
- #define __Pyx_PyLong_Sign(x) (((PyLongObject*)x)->long_value.lv_tag & _PyLong_SIGN_MASK)
- #define __Pyx_PyLong_IsNeg(x) ((__Pyx_PyLong_Sign(x) & 2) != 0)
- #define __Pyx_PyLong_IsNonNeg(x) (!__Pyx_PyLong_IsNeg(x))
- #define __Pyx_PyLong_IsZero(x) (__Pyx_PyLong_Sign(x) & 1)
- #define __Pyx_PyLong_IsPos(x) (__Pyx_PyLong_Sign(x) == 0)
- #define __Pyx_PyLong_CompactValueUnsigned(x) (__Pyx_PyLong_Digits(x)[0])
- #define __Pyx_PyLong_DigitCount(x) ((Py_ssize_t) (((PyLongObject*)x)->long_value.lv_tag >> _PyLong_NON_SIZE_BITS))
- #define __Pyx_PyLong_SignedDigitCount(x)\
- ((1 - (Py_ssize_t) __Pyx_PyLong_Sign(x)) * __Pyx_PyLong_DigitCount(x))
- #if defined(PyUnstable_Long_IsCompact) && defined(PyUnstable_Long_CompactValue)
- #define __Pyx_PyLong_IsCompact(x) PyUnstable_Long_IsCompact((PyLongObject*) x)
- #define __Pyx_PyLong_CompactValue(x) PyUnstable_Long_CompactValue((PyLongObject*) x)
- #else
- #define __Pyx_PyLong_IsCompact(x) (((PyLongObject*)x)->long_value.lv_tag < (2 << _PyLong_NON_SIZE_BITS))
- #define __Pyx_PyLong_CompactValue(x) ((1 - (Py_ssize_t) __Pyx_PyLong_Sign(x)) * (Py_ssize_t) __Pyx_PyLong_Digits(x)[0])
- #endif
- typedef Py_ssize_t __Pyx_compact_pylong;
- typedef size_t __Pyx_compact_upylong;
- #else // Py < 3.12
- #define __Pyx_PyLong_IsNeg(x) (Py_SIZE(x) < 0)
- #define __Pyx_PyLong_IsNonNeg(x) (Py_SIZE(x) >= 0)
- #define __Pyx_PyLong_IsZero(x) (Py_SIZE(x) == 0)
- #define __Pyx_PyLong_IsPos(x) (Py_SIZE(x) > 0)
- #define __Pyx_PyLong_CompactValueUnsigned(x) ((Py_SIZE(x) == 0) ? 0 : __Pyx_PyLong_Digits(x)[0])
- #define __Pyx_PyLong_DigitCount(x) __Pyx_sst_abs(Py_SIZE(x))
- #define __Pyx_PyLong_SignedDigitCount(x) Py_SIZE(x)
- #define __Pyx_PyLong_IsCompact(x) (Py_SIZE(x) == 0 || Py_SIZE(x) == 1 || Py_SIZE(x) == -1)
- #define __Pyx_PyLong_CompactValue(x)\
- ((Py_SIZE(x) == 0) ? (sdigit) 0 : ((Py_SIZE(x) < 0) ? -(sdigit)__Pyx_PyLong_Digits(x)[0] : (sdigit)__Pyx_PyLong_Digits(x)[0]))
- typedef sdigit __Pyx_compact_pylong;
- typedef digit __Pyx_compact_upylong;
- #endif
- #if PY_VERSION_HEX >= 0x030C00A5
- #define __Pyx_PyLong_Digits(x) (((PyLongObject*)x)->long_value.ob_digit)
- #else
- #define __Pyx_PyLong_Digits(x) (((PyLongObject*)x)->ob_digit)
- #endif
-#endif
-#if PY_MAJOR_VERSION < 3 && __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
-static int __Pyx_sys_getdefaultencoding_not_ascii;
-static int __Pyx_init_sys_getdefaultencoding_params(void) {
- PyObject* sys;
- PyObject* default_encoding = NULL;
- PyObject* ascii_chars_u = NULL;
- PyObject* ascii_chars_b = NULL;
- const char* default_encoding_c;
- sys = PyImport_ImportModule("sys");
- if (!sys) goto bad;
- default_encoding = PyObject_CallMethod(sys, (char*) "getdefaultencoding", NULL);
- Py_DECREF(sys);
- if (!default_encoding) goto bad;
- default_encoding_c = PyBytes_AsString(default_encoding);
- if (!default_encoding_c) goto bad;
- if (strcmp(default_encoding_c, "ascii") == 0) {
- __Pyx_sys_getdefaultencoding_not_ascii = 0;
- } else {
- char ascii_chars[128];
- int c;
- for (c = 0; c < 128; c++) {
- ascii_chars[c] = (char) c;
- }
- __Pyx_sys_getdefaultencoding_not_ascii = 1;
- ascii_chars_u = PyUnicode_DecodeASCII(ascii_chars, 128, NULL);
- if (!ascii_chars_u) goto bad;
- ascii_chars_b = PyUnicode_AsEncodedString(ascii_chars_u, default_encoding_c, NULL);
- if (!ascii_chars_b || !PyBytes_Check(ascii_chars_b) || memcmp(ascii_chars, PyBytes_AS_STRING(ascii_chars_b), 128) != 0) {
- PyErr_Format(
- PyExc_ValueError,
- "This module compiled with c_string_encoding=ascii, but default encoding '%.200s' is not a superset of ascii.",
- default_encoding_c);
- goto bad;
- }
- Py_DECREF(ascii_chars_u);
- Py_DECREF(ascii_chars_b);
- }
- Py_DECREF(default_encoding);
- return 0;
-bad:
- Py_XDECREF(default_encoding);
- Py_XDECREF(ascii_chars_u);
- Py_XDECREF(ascii_chars_b);
- return -1;
-}
-#endif
-#if __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT && PY_MAJOR_VERSION >= 3
-#define __Pyx_PyUnicode_FromStringAndSize(c_str, size) PyUnicode_DecodeUTF8(c_str, size, NULL)
-#else
-#define __Pyx_PyUnicode_FromStringAndSize(c_str, size) PyUnicode_Decode(c_str, size, __PYX_DEFAULT_STRING_ENCODING, NULL)
-#if __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
-static char* __PYX_DEFAULT_STRING_ENCODING;
-static int __Pyx_init_sys_getdefaultencoding_params(void) {
- PyObject* sys;
- PyObject* default_encoding = NULL;
- char* default_encoding_c;
- sys = PyImport_ImportModule("sys");
- if (!sys) goto bad;
- default_encoding = PyObject_CallMethod(sys, (char*) (const char*) "getdefaultencoding", NULL);
- Py_DECREF(sys);
- if (!default_encoding) goto bad;
- default_encoding_c = PyBytes_AsString(default_encoding);
- if (!default_encoding_c) goto bad;
- __PYX_DEFAULT_STRING_ENCODING = (char*) malloc(strlen(default_encoding_c) + 1);
- if (!__PYX_DEFAULT_STRING_ENCODING) goto bad;
- strcpy(__PYX_DEFAULT_STRING_ENCODING, default_encoding_c);
- Py_DECREF(default_encoding);
- return 0;
-bad:
- Py_XDECREF(default_encoding);
- return -1;
-}
-#endif
-#endif
-
-
-/* Test for GCC > 2.95 */
-#if defined(__GNUC__) && (__GNUC__ > 2 || (__GNUC__ == 2 && (__GNUC_MINOR__ > 95)))
- #define likely(x) __builtin_expect(!!(x), 1)
- #define unlikely(x) __builtin_expect(!!(x), 0)
-#else /* !__GNUC__ or GCC < 2.95 */
- #define likely(x) (x)
- #define unlikely(x) (x)
-#endif /* __GNUC__ */
-static CYTHON_INLINE void __Pyx_pretend_to_initialize(void* ptr) { (void)ptr; }
-
-#if !CYTHON_USE_MODULE_STATE
-static PyObject *__pyx_m = NULL;
-#endif
-static int __pyx_lineno;
-static int __pyx_clineno = 0;
-static const char * __pyx_cfilenm = __FILE__;
-static const char *__pyx_filename;
-
-/* #### Code section: filename_table ### */
-
-static const char *__pyx_f[] = {
- "Lib/fontTools/pens/momentsPen.py",
-};
-/* #### Code section: utility_code_proto_before_types ### */
-/* #### Code section: numeric_typedefs ### */
-/* #### Code section: complex_type_declarations ### */
-/* #### Code section: type_declarations ### */
-
-/*--- Type declarations ---*/
-/* #### Code section: utility_code_proto ### */
-
-/* --- Runtime support code (head) --- */
-/* Refnanny.proto */
-#ifndef CYTHON_REFNANNY
- #define CYTHON_REFNANNY 0
-#endif
-#if CYTHON_REFNANNY
- typedef struct {
- void (*INCREF)(void*, PyObject*, Py_ssize_t);
- void (*DECREF)(void*, PyObject*, Py_ssize_t);
- void (*GOTREF)(void*, PyObject*, Py_ssize_t);
- void (*GIVEREF)(void*, PyObject*, Py_ssize_t);
- void* (*SetupContext)(const char*, Py_ssize_t, const char*);
- void (*FinishContext)(void**);
- } __Pyx_RefNannyAPIStruct;
- static __Pyx_RefNannyAPIStruct *__Pyx_RefNanny = NULL;
- static __Pyx_RefNannyAPIStruct *__Pyx_RefNannyImportAPI(const char *modname);
- #define __Pyx_RefNannyDeclarations void *__pyx_refnanny = NULL;
-#ifdef WITH_THREAD
- #define __Pyx_RefNannySetupContext(name, acquire_gil)\
- if (acquire_gil) {\
- PyGILState_STATE __pyx_gilstate_save = PyGILState_Ensure();\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), (__LINE__), (__FILE__));\
- PyGILState_Release(__pyx_gilstate_save);\
- } else {\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), (__LINE__), (__FILE__));\
- }
- #define __Pyx_RefNannyFinishContextNogil() {\
- PyGILState_STATE __pyx_gilstate_save = PyGILState_Ensure();\
- __Pyx_RefNannyFinishContext();\
- PyGILState_Release(__pyx_gilstate_save);\
- }
-#else
- #define __Pyx_RefNannySetupContext(name, acquire_gil)\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), (__LINE__), (__FILE__))
- #define __Pyx_RefNannyFinishContextNogil() __Pyx_RefNannyFinishContext()
-#endif
- #define __Pyx_RefNannyFinishContextNogil() {\
- PyGILState_STATE __pyx_gilstate_save = PyGILState_Ensure();\
- __Pyx_RefNannyFinishContext();\
- PyGILState_Release(__pyx_gilstate_save);\
- }
- #define __Pyx_RefNannyFinishContext()\
- __Pyx_RefNanny->FinishContext(&__pyx_refnanny)
- #define __Pyx_INCREF(r) __Pyx_RefNanny->INCREF(__pyx_refnanny, (PyObject *)(r), (__LINE__))
- #define __Pyx_DECREF(r) __Pyx_RefNanny->DECREF(__pyx_refnanny, (PyObject *)(r), (__LINE__))
- #define __Pyx_GOTREF(r) __Pyx_RefNanny->GOTREF(__pyx_refnanny, (PyObject *)(r), (__LINE__))
- #define __Pyx_GIVEREF(r) __Pyx_RefNanny->GIVEREF(__pyx_refnanny, (PyObject *)(r), (__LINE__))
- #define __Pyx_XINCREF(r) do { if((r) == NULL); else {__Pyx_INCREF(r); }} while(0)
- #define __Pyx_XDECREF(r) do { if((r) == NULL); else {__Pyx_DECREF(r); }} while(0)
- #define __Pyx_XGOTREF(r) do { if((r) == NULL); else {__Pyx_GOTREF(r); }} while(0)
- #define __Pyx_XGIVEREF(r) do { if((r) == NULL); else {__Pyx_GIVEREF(r);}} while(0)
-#else
- #define __Pyx_RefNannyDeclarations
- #define __Pyx_RefNannySetupContext(name, acquire_gil)
- #define __Pyx_RefNannyFinishContextNogil()
- #define __Pyx_RefNannyFinishContext()
- #define __Pyx_INCREF(r) Py_INCREF(r)
- #define __Pyx_DECREF(r) Py_DECREF(r)
- #define __Pyx_GOTREF(r)
- #define __Pyx_GIVEREF(r)
- #define __Pyx_XINCREF(r) Py_XINCREF(r)
- #define __Pyx_XDECREF(r) Py_XDECREF(r)
- #define __Pyx_XGOTREF(r)
- #define __Pyx_XGIVEREF(r)
-#endif
-#define __Pyx_Py_XDECREF_SET(r, v) do {\
- PyObject *tmp = (PyObject *) r;\
- r = v; Py_XDECREF(tmp);\
- } while (0)
-#define __Pyx_XDECREF_SET(r, v) do {\
- PyObject *tmp = (PyObject *) r;\
- r = v; __Pyx_XDECREF(tmp);\
- } while (0)
-#define __Pyx_DECREF_SET(r, v) do {\
- PyObject *tmp = (PyObject *) r;\
- r = v; __Pyx_DECREF(tmp);\
- } while (0)
-#define __Pyx_CLEAR(r) do { PyObject* tmp = ((PyObject*)(r)); r = NULL; __Pyx_DECREF(tmp);} while(0)
-#define __Pyx_XCLEAR(r) do { if((r) != NULL) {PyObject* tmp = ((PyObject*)(r)); r = NULL; __Pyx_DECREF(tmp);}} while(0)
-
-/* PyErrExceptionMatches.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyErr_ExceptionMatches(err) __Pyx_PyErr_ExceptionMatchesInState(__pyx_tstate, err)
-static CYTHON_INLINE int __Pyx_PyErr_ExceptionMatchesInState(PyThreadState* tstate, PyObject* err);
-#else
-#define __Pyx_PyErr_ExceptionMatches(err) PyErr_ExceptionMatches(err)
-#endif
-
-/* PyThreadStateGet.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyThreadState_declare PyThreadState *__pyx_tstate;
-#define __Pyx_PyThreadState_assign __pyx_tstate = __Pyx_PyThreadState_Current;
-#if PY_VERSION_HEX >= 0x030C00A6
-#define __Pyx_PyErr_Occurred() (__pyx_tstate->current_exception != NULL)
-#define __Pyx_PyErr_CurrentExceptionType() (__pyx_tstate->current_exception ? (PyObject*) Py_TYPE(__pyx_tstate->current_exception) : (PyObject*) NULL)
-#else
-#define __Pyx_PyErr_Occurred() (__pyx_tstate->curexc_type != NULL)
-#define __Pyx_PyErr_CurrentExceptionType() (__pyx_tstate->curexc_type)
-#endif
-#else
-#define __Pyx_PyThreadState_declare
-#define __Pyx_PyThreadState_assign
-#define __Pyx_PyErr_Occurred() (PyErr_Occurred() != NULL)
-#define __Pyx_PyErr_CurrentExceptionType() PyErr_Occurred()
-#endif
-
-/* PyErrFetchRestore.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyErr_Clear() __Pyx_ErrRestore(NULL, NULL, NULL)
-#define __Pyx_ErrRestoreWithState(type, value, tb) __Pyx_ErrRestoreInState(PyThreadState_GET(), type, value, tb)
-#define __Pyx_ErrFetchWithState(type, value, tb) __Pyx_ErrFetchInState(PyThreadState_GET(), type, value, tb)
-#define __Pyx_ErrRestore(type, value, tb) __Pyx_ErrRestoreInState(__pyx_tstate, type, value, tb)
-#define __Pyx_ErrFetch(type, value, tb) __Pyx_ErrFetchInState(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx_ErrRestoreInState(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb);
-static CYTHON_INLINE void __Pyx_ErrFetchInState(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX < 0x030C00A6
-#define __Pyx_PyErr_SetNone(exc) (Py_INCREF(exc), __Pyx_ErrRestore((exc), NULL, NULL))
-#else
-#define __Pyx_PyErr_SetNone(exc) PyErr_SetNone(exc)
-#endif
-#else
-#define __Pyx_PyErr_Clear() PyErr_Clear()
-#define __Pyx_PyErr_SetNone(exc) PyErr_SetNone(exc)
-#define __Pyx_ErrRestoreWithState(type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetchWithState(type, value, tb) PyErr_Fetch(type, value, tb)
-#define __Pyx_ErrRestoreInState(tstate, type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetchInState(tstate, type, value, tb) PyErr_Fetch(type, value, tb)
-#define __Pyx_ErrRestore(type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetch(type, value, tb) PyErr_Fetch(type, value, tb)
-#endif
-
-/* PyObjectGetAttrStr.proto */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStr(PyObject* obj, PyObject* attr_name);
-#else
-#define __Pyx_PyObject_GetAttrStr(o,n) PyObject_GetAttr(o,n)
-#endif
-
-/* PyObjectGetAttrStrNoError.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStrNoError(PyObject* obj, PyObject* attr_name);
-
-/* GetBuiltinName.proto */
-static PyObject *__Pyx_GetBuiltinName(PyObject *name);
-
-/* TupleAndListFromArray.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyList_FromArray(PyObject *const *src, Py_ssize_t n);
-static CYTHON_INLINE PyObject* __Pyx_PyTuple_FromArray(PyObject *const *src, Py_ssize_t n);
-#endif
-
-/* IncludeStringH.proto */
-#include
-
-/* BytesEquals.proto */
-static CYTHON_INLINE int __Pyx_PyBytes_Equals(PyObject* s1, PyObject* s2, int equals);
-
-/* UnicodeEquals.proto */
-static CYTHON_INLINE int __Pyx_PyUnicode_Equals(PyObject* s1, PyObject* s2, int equals);
-
-/* fastcall.proto */
-#define __Pyx_Arg_VARARGS(args, i) PyTuple_GET_ITEM(args, i)
-#define __Pyx_NumKwargs_VARARGS(kwds) PyDict_Size(kwds)
-#define __Pyx_KwValues_VARARGS(args, nargs) NULL
-#define __Pyx_GetKwValue_VARARGS(kw, kwvalues, s) __Pyx_PyDict_GetItemStrWithError(kw, s)
-#define __Pyx_KwargsAsDict_VARARGS(kw, kwvalues) PyDict_Copy(kw)
-#if CYTHON_METH_FASTCALL
- #define __Pyx_Arg_FASTCALL(args, i) args[i]
- #define __Pyx_NumKwargs_FASTCALL(kwds) PyTuple_GET_SIZE(kwds)
- #define __Pyx_KwValues_FASTCALL(args, nargs) ((args) + (nargs))
- static CYTHON_INLINE PyObject * __Pyx_GetKwValue_FASTCALL(PyObject *kwnames, PyObject *const *kwvalues, PyObject *s);
- #define __Pyx_KwargsAsDict_FASTCALL(kw, kwvalues) _PyStack_AsDict(kwvalues, kw)
-#else
- #define __Pyx_Arg_FASTCALL __Pyx_Arg_VARARGS
- #define __Pyx_NumKwargs_FASTCALL __Pyx_NumKwargs_VARARGS
- #define __Pyx_KwValues_FASTCALL __Pyx_KwValues_VARARGS
- #define __Pyx_GetKwValue_FASTCALL __Pyx_GetKwValue_VARARGS
- #define __Pyx_KwargsAsDict_FASTCALL __Pyx_KwargsAsDict_VARARGS
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON
-#define __Pyx_ArgsSlice_VARARGS(args, start, stop) __Pyx_PyTuple_FromArray(&__Pyx_Arg_VARARGS(args, start), stop - start)
-#define __Pyx_ArgsSlice_FASTCALL(args, start, stop) __Pyx_PyTuple_FromArray(&__Pyx_Arg_FASTCALL(args, start), stop - start)
-#else
-#define __Pyx_ArgsSlice_VARARGS(args, start, stop) PyTuple_GetSlice(args, start, stop)
-#define __Pyx_ArgsSlice_FASTCALL(args, start, stop) PyTuple_GetSlice(args, start, stop)
-#endif
-
-/* RaiseDoubleKeywords.proto */
-static void __Pyx_RaiseDoubleKeywordsError(const char* func_name, PyObject* kw_name);
-
-/* ParseKeywords.proto */
-static int __Pyx_ParseOptionalKeywords(PyObject *kwds, PyObject *const *kwvalues,
- PyObject **argnames[],
- PyObject *kwds2, PyObject *values[], Py_ssize_t num_pos_args,
- const char* function_name);
-
-/* RaiseArgTupleInvalid.proto */
-static void __Pyx_RaiseArgtupleInvalid(const char* func_name, int exact,
- Py_ssize_t num_min, Py_ssize_t num_max, Py_ssize_t num_found);
-
-/* PyDictVersioning.proto */
-#if CYTHON_USE_DICT_VERSIONS && CYTHON_USE_TYPE_SLOTS
-#define __PYX_DICT_VERSION_INIT ((PY_UINT64_T) -1)
-#define __PYX_GET_DICT_VERSION(dict) (((PyDictObject*)(dict))->ma_version_tag)
-#define __PYX_UPDATE_DICT_CACHE(dict, value, cache_var, version_var)\
- (version_var) = __PYX_GET_DICT_VERSION(dict);\
- (cache_var) = (value);
-#define __PYX_PY_DICT_LOOKUP_IF_MODIFIED(VAR, DICT, LOOKUP) {\
- static PY_UINT64_T __pyx_dict_version = 0;\
- static PyObject *__pyx_dict_cached_value = NULL;\
- if (likely(__PYX_GET_DICT_VERSION(DICT) == __pyx_dict_version)) {\
- (VAR) = __pyx_dict_cached_value;\
- } else {\
- (VAR) = __pyx_dict_cached_value = (LOOKUP);\
- __pyx_dict_version = __PYX_GET_DICT_VERSION(DICT);\
- }\
-}
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_tp_dict_version(PyObject *obj);
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_object_dict_version(PyObject *obj);
-static CYTHON_INLINE int __Pyx_object_dict_version_matches(PyObject* obj, PY_UINT64_T tp_dict_version, PY_UINT64_T obj_dict_version);
-#else
-#define __PYX_GET_DICT_VERSION(dict) (0)
-#define __PYX_UPDATE_DICT_CACHE(dict, value, cache_var, version_var)
-#define __PYX_PY_DICT_LOOKUP_IF_MODIFIED(VAR, DICT, LOOKUP) (VAR) = (LOOKUP);
-#endif
-
-/* GetModuleGlobalName.proto */
-#if CYTHON_USE_DICT_VERSIONS
-#define __Pyx_GetModuleGlobalName(var, name) do {\
- static PY_UINT64_T __pyx_dict_version = 0;\
- static PyObject *__pyx_dict_cached_value = NULL;\
- (var) = (likely(__pyx_dict_version == __PYX_GET_DICT_VERSION(__pyx_d))) ?\
- (likely(__pyx_dict_cached_value) ? __Pyx_NewRef(__pyx_dict_cached_value) : __Pyx_GetBuiltinName(name)) :\
- __Pyx__GetModuleGlobalName(name, &__pyx_dict_version, &__pyx_dict_cached_value);\
-} while(0)
-#define __Pyx_GetModuleGlobalNameUncached(var, name) do {\
- PY_UINT64_T __pyx_dict_version;\
- PyObject *__pyx_dict_cached_value;\
- (var) = __Pyx__GetModuleGlobalName(name, &__pyx_dict_version, &__pyx_dict_cached_value);\
-} while(0)
-static PyObject *__Pyx__GetModuleGlobalName(PyObject *name, PY_UINT64_T *dict_version, PyObject **dict_cached_value);
-#else
-#define __Pyx_GetModuleGlobalName(var, name) (var) = __Pyx__GetModuleGlobalName(name)
-#define __Pyx_GetModuleGlobalNameUncached(var, name) (var) = __Pyx__GetModuleGlobalName(name)
-static CYTHON_INLINE PyObject *__Pyx__GetModuleGlobalName(PyObject *name);
-#endif
-
-/* PyFunctionFastCall.proto */
-#if CYTHON_FAST_PYCALL
-#if !CYTHON_VECTORCALL
-#define __Pyx_PyFunction_FastCall(func, args, nargs)\
- __Pyx_PyFunction_FastCallDict((func), (args), (nargs), NULL)
-static PyObject *__Pyx_PyFunction_FastCallDict(PyObject *func, PyObject **args, Py_ssize_t nargs, PyObject *kwargs);
-#endif
-#define __Pyx_BUILD_ASSERT_EXPR(cond)\
- (sizeof(char [1 - 2*!(cond)]) - 1)
-#ifndef Py_MEMBER_SIZE
-#define Py_MEMBER_SIZE(type, member) sizeof(((type *)0)->member)
-#endif
-#if !CYTHON_VECTORCALL
-#if PY_VERSION_HEX >= 0x03080000
- #include "frameobject.h"
-#if PY_VERSION_HEX >= 0x030b00a6
- #ifndef Py_BUILD_CORE
- #define Py_BUILD_CORE 1
- #endif
- #include "internal/pycore_frame.h"
-#endif
- #define __Pxy_PyFrame_Initialize_Offsets()
- #define __Pyx_PyFrame_GetLocalsplus(frame) ((frame)->f_localsplus)
-#else
- static size_t __pyx_pyframe_localsplus_offset = 0;
- #include "frameobject.h"
- #define __Pxy_PyFrame_Initialize_Offsets()\
- ((void)__Pyx_BUILD_ASSERT_EXPR(sizeof(PyFrameObject) == offsetof(PyFrameObject, f_localsplus) + Py_MEMBER_SIZE(PyFrameObject, f_localsplus)),\
- (void)(__pyx_pyframe_localsplus_offset = ((size_t)PyFrame_Type.tp_basicsize) - Py_MEMBER_SIZE(PyFrameObject, f_localsplus)))
- #define __Pyx_PyFrame_GetLocalsplus(frame)\
- (assert(__pyx_pyframe_localsplus_offset), (PyObject **)(((char *)(frame)) + __pyx_pyframe_localsplus_offset))
-#endif
-#endif
-#endif
-
-/* PyObjectCall.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_Call(PyObject *func, PyObject *arg, PyObject *kw);
-#else
-#define __Pyx_PyObject_Call(func, arg, kw) PyObject_Call(func, arg, kw)
-#endif
-
-/* PyObjectCallMethO.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallMethO(PyObject *func, PyObject *arg);
-#endif
-
-/* PyObjectFastCall.proto */
-#define __Pyx_PyObject_FastCall(func, args, nargs) __Pyx_PyObject_FastCallDict(func, args, (size_t)(nargs), NULL)
-static CYTHON_INLINE PyObject* __Pyx_PyObject_FastCallDict(PyObject *func, PyObject **args, size_t nargs, PyObject *kwargs);
-
-/* PyObjectSetAttrStr.proto */
-#if CYTHON_USE_TYPE_SLOTS
-#define __Pyx_PyObject_DelAttrStr(o,n) __Pyx_PyObject_SetAttrStr(o, n, NULL)
-static CYTHON_INLINE int __Pyx_PyObject_SetAttrStr(PyObject* obj, PyObject* attr_name, PyObject* value);
-#else
-#define __Pyx_PyObject_DelAttrStr(o,n) PyObject_DelAttr(o,n)
-#define __Pyx_PyObject_SetAttrStr(o,n,v) PyObject_SetAttr(o,n,v)
-#endif
-
-/* RaiseException.proto */
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb, PyObject *cause);
-
-/* RaiseTooManyValuesToUnpack.proto */
-static CYTHON_INLINE void __Pyx_RaiseTooManyValuesError(Py_ssize_t expected);
-
-/* RaiseNeedMoreValuesToUnpack.proto */
-static CYTHON_INLINE void __Pyx_RaiseNeedMoreValuesError(Py_ssize_t index);
-
-/* IterFinish.proto */
-static CYTHON_INLINE int __Pyx_IterFinish(void);
-
-/* UnpackItemEndCheck.proto */
-static int __Pyx_IternextUnpackEndCheck(PyObject *retval, Py_ssize_t expected);
-
-/* Import.proto */
-static PyObject *__Pyx_Import(PyObject *name, PyObject *from_list, int level);
-
-/* ImportFrom.proto */
-static PyObject* __Pyx_ImportFrom(PyObject* module, PyObject* name);
-
-/* GetTopmostException.proto */
-#if CYTHON_USE_EXC_INFO_STACK && CYTHON_FAST_THREAD_STATE
-static _PyErr_StackItem * __Pyx_PyErr_GetTopmostException(PyThreadState *tstate);
-#endif
-
-/* SaveResetException.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_ExceptionSave(type, value, tb) __Pyx__ExceptionSave(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx__ExceptionSave(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#define __Pyx_ExceptionReset(type, value, tb) __Pyx__ExceptionReset(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx__ExceptionReset(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb);
-#else
-#define __Pyx_ExceptionSave(type, value, tb) PyErr_GetExcInfo(type, value, tb)
-#define __Pyx_ExceptionReset(type, value, tb) PyErr_SetExcInfo(type, value, tb)
-#endif
-
-/* FastTypeChecks.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-#define __Pyx_TypeCheck(obj, type) __Pyx_IsSubtype(Py_TYPE(obj), (PyTypeObject *)type)
-#define __Pyx_TypeCheck2(obj, type1, type2) __Pyx_IsAnySubtype2(Py_TYPE(obj), (PyTypeObject *)type1, (PyTypeObject *)type2)
-static CYTHON_INLINE int __Pyx_IsSubtype(PyTypeObject *a, PyTypeObject *b);
-static CYTHON_INLINE int __Pyx_IsAnySubtype2(PyTypeObject *cls, PyTypeObject *a, PyTypeObject *b);
-static CYTHON_INLINE int __Pyx_PyErr_GivenExceptionMatches(PyObject *err, PyObject *type);
-static CYTHON_INLINE int __Pyx_PyErr_GivenExceptionMatches2(PyObject *err, PyObject *type1, PyObject *type2);
-#else
-#define __Pyx_TypeCheck(obj, type) PyObject_TypeCheck(obj, (PyTypeObject *)type)
-#define __Pyx_TypeCheck2(obj, type1, type2) (PyObject_TypeCheck(obj, (PyTypeObject *)type1) || PyObject_TypeCheck(obj, (PyTypeObject *)type2))
-#define __Pyx_PyErr_GivenExceptionMatches(err, type) PyErr_GivenExceptionMatches(err, type)
-#define __Pyx_PyErr_GivenExceptionMatches2(err, type1, type2) (PyErr_GivenExceptionMatches(err, type1) || PyErr_GivenExceptionMatches(err, type2))
-#endif
-#define __Pyx_PyErr_ExceptionMatches2(err1, err2) __Pyx_PyErr_GivenExceptionMatches2(__Pyx_PyErr_CurrentExceptionType(), err1, err2)
-#define __Pyx_PyException_Check(obj) __Pyx_TypeCheck(obj, PyExc_Exception)
-
-/* GetException.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_GetException(type, value, tb) __Pyx__GetException(__pyx_tstate, type, value, tb)
-static int __Pyx__GetException(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#else
-static int __Pyx_GetException(PyObject **type, PyObject **value, PyObject **tb);
-#endif
-
-/* PyObjectCallOneArg.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg);
-
-/* Py3UpdateBases.proto */
-static PyObject* __Pyx_PEP560_update_bases(PyObject *bases);
-
-/* CalculateMetaclass.proto */
-static PyObject *__Pyx_CalculateMetaclass(PyTypeObject *metaclass, PyObject *bases);
-
-/* IncludeStructmemberH.proto */
-#include
-
-/* FixUpExtensionType.proto */
-#if CYTHON_USE_TYPE_SPECS
-static int __Pyx_fix_up_extension_type_from_spec(PyType_Spec *spec, PyTypeObject *type);
-#endif
-
-/* FetchSharedCythonModule.proto */
-static PyObject *__Pyx_FetchSharedCythonABIModule(void);
-
-/* FetchCommonType.proto */
-#if !CYTHON_USE_TYPE_SPECS
-static PyTypeObject* __Pyx_FetchCommonType(PyTypeObject* type);
-#else
-static PyTypeObject* __Pyx_FetchCommonTypeFromSpec(PyObject *module, PyType_Spec *spec, PyObject *bases);
-#endif
-
-/* PyMethodNew.proto */
-#if PY_MAJOR_VERSION >= 3
-static PyObject *__Pyx_PyMethod_New(PyObject *func, PyObject *self, PyObject *typ) {
- CYTHON_UNUSED_VAR(typ);
- if (!self)
- return __Pyx_NewRef(func);
- return PyMethod_New(func, self);
-}
-#else
- #define __Pyx_PyMethod_New PyMethod_New
-#endif
-
-/* PyVectorcallFastCallDict.proto */
-#if CYTHON_METH_FASTCALL
-static CYTHON_INLINE PyObject *__Pyx_PyVectorcall_FastCallDict(PyObject *func, __pyx_vectorcallfunc vc, PyObject *const *args, size_t nargs, PyObject *kw);
-#endif
-
-/* CythonFunctionShared.proto */
-#define __Pyx_CyFunction_USED
-#define __Pyx_CYFUNCTION_STATICMETHOD 0x01
-#define __Pyx_CYFUNCTION_CLASSMETHOD 0x02
-#define __Pyx_CYFUNCTION_CCLASS 0x04
-#define __Pyx_CYFUNCTION_COROUTINE 0x08
-#define __Pyx_CyFunction_GetClosure(f)\
- (((__pyx_CyFunctionObject *) (f))->func_closure)
-#if PY_VERSION_HEX < 0x030900B1
- #define __Pyx_CyFunction_GetClassObj(f)\
- (((__pyx_CyFunctionObject *) (f))->func_classobj)
-#else
- #define __Pyx_CyFunction_GetClassObj(f)\
- ((PyObject*) ((PyCMethodObject *) (f))->mm_class)
-#endif
-#define __Pyx_CyFunction_SetClassObj(f, classobj)\
- __Pyx__CyFunction_SetClassObj((__pyx_CyFunctionObject *) (f), (classobj))
-#define __Pyx_CyFunction_Defaults(type, f)\
- ((type *)(((__pyx_CyFunctionObject *) (f))->defaults))
-#define __Pyx_CyFunction_SetDefaultsGetter(f, g)\
- ((__pyx_CyFunctionObject *) (f))->defaults_getter = (g)
-typedef struct {
-#if PY_VERSION_HEX < 0x030900B1
- PyCFunctionObject func;
-#else
- PyCMethodObject func;
-#endif
-#if CYTHON_BACKPORT_VECTORCALL
- __pyx_vectorcallfunc func_vectorcall;
-#endif
-#if PY_VERSION_HEX < 0x030500A0
- PyObject *func_weakreflist;
-#endif
- PyObject *func_dict;
- PyObject *func_name;
- PyObject *func_qualname;
- PyObject *func_doc;
- PyObject *func_globals;
- PyObject *func_code;
- PyObject *func_closure;
-#if PY_VERSION_HEX < 0x030900B1
- PyObject *func_classobj;
-#endif
- void *defaults;
- int defaults_pyobjects;
- size_t defaults_size; // used by FusedFunction for copying defaults
- int flags;
- PyObject *defaults_tuple;
- PyObject *defaults_kwdict;
- PyObject *(*defaults_getter)(PyObject *);
- PyObject *func_annotations;
- PyObject *func_is_coroutine;
-} __pyx_CyFunctionObject;
-#define __Pyx_CyFunction_Check(obj) __Pyx_TypeCheck(obj, __pyx_CyFunctionType)
-#define __Pyx_IsCyOrPyCFunction(obj) __Pyx_TypeCheck2(obj, __pyx_CyFunctionType, &PyCFunction_Type)
-#define __Pyx_CyFunction_CheckExact(obj) __Pyx_IS_TYPE(obj, __pyx_CyFunctionType)
-static PyObject *__Pyx_CyFunction_Init(__pyx_CyFunctionObject* op, PyMethodDef *ml,
- int flags, PyObject* qualname,
- PyObject *closure,
- PyObject *module, PyObject *globals,
- PyObject* code);
-static CYTHON_INLINE void __Pyx__CyFunction_SetClassObj(__pyx_CyFunctionObject* f, PyObject* classobj);
-static CYTHON_INLINE void *__Pyx_CyFunction_InitDefaults(PyObject *m,
- size_t size,
- int pyobjects);
-static CYTHON_INLINE void __Pyx_CyFunction_SetDefaultsTuple(PyObject *m,
- PyObject *tuple);
-static CYTHON_INLINE void __Pyx_CyFunction_SetDefaultsKwDict(PyObject *m,
- PyObject *dict);
-static CYTHON_INLINE void __Pyx_CyFunction_SetAnnotationsDict(PyObject *m,
- PyObject *dict);
-static int __pyx_CyFunction_init(PyObject *module);
-#if CYTHON_METH_FASTCALL
-static PyObject * __Pyx_CyFunction_Vectorcall_NOARGS(PyObject *func, PyObject *const *args, size_t nargsf, PyObject *kwnames);
-static PyObject * __Pyx_CyFunction_Vectorcall_O(PyObject *func, PyObject *const *args, size_t nargsf, PyObject *kwnames);
-static PyObject * __Pyx_CyFunction_Vectorcall_FASTCALL_KEYWORDS(PyObject *func, PyObject *const *args, size_t nargsf, PyObject *kwnames);
-static PyObject * __Pyx_CyFunction_Vectorcall_FASTCALL_KEYWORDS_METHOD(PyObject *func, PyObject *const *args, size_t nargsf, PyObject *kwnames);
-#if CYTHON_BACKPORT_VECTORCALL
-#define __Pyx_CyFunction_func_vectorcall(f) (((__pyx_CyFunctionObject*)f)->func_vectorcall)
-#else
-#define __Pyx_CyFunction_func_vectorcall(f) (((PyCFunctionObject*)f)->vectorcall)
-#endif
-#endif
-
-/* CythonFunction.proto */
-static PyObject *__Pyx_CyFunction_New(PyMethodDef *ml,
- int flags, PyObject* qualname,
- PyObject *closure,
- PyObject *module, PyObject *globals,
- PyObject* code);
-
-/* SetNameInClass.proto */
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x030500A1
-#define __Pyx_SetNameInClass(ns, name, value)\
- (likely(PyDict_CheckExact(ns)) ? _PyDict_SetItem_KnownHash(ns, name, value, ((PyASCIIObject *) name)->hash) : PyObject_SetItem(ns, name, value))
-#elif CYTHON_COMPILING_IN_CPYTHON
-#define __Pyx_SetNameInClass(ns, name, value)\
- (likely(PyDict_CheckExact(ns)) ? PyDict_SetItem(ns, name, value) : PyObject_SetItem(ns, name, value))
-#else
-#define __Pyx_SetNameInClass(ns, name, value) PyObject_SetItem(ns, name, value)
-#endif
-
-/* PyObjectCall2Args.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_Call2Args(PyObject* function, PyObject* arg1, PyObject* arg2);
-
-/* PyObjectLookupSpecial.proto */
-#if CYTHON_USE_PYTYPE_LOOKUP && CYTHON_USE_TYPE_SLOTS
-#define __Pyx_PyObject_LookupSpecialNoError(obj, attr_name) __Pyx__PyObject_LookupSpecial(obj, attr_name, 0)
-#define __Pyx_PyObject_LookupSpecial(obj, attr_name) __Pyx__PyObject_LookupSpecial(obj, attr_name, 1)
-static CYTHON_INLINE PyObject* __Pyx__PyObject_LookupSpecial(PyObject* obj, PyObject* attr_name, int with_error);
-#else
-#define __Pyx_PyObject_LookupSpecialNoError(o,n) __Pyx_PyObject_GetAttrStrNoError(o,n)
-#define __Pyx_PyObject_LookupSpecial(o,n) __Pyx_PyObject_GetAttrStr(o,n)
-#endif
-
-/* Py3ClassCreate.proto */
-static PyObject *__Pyx_Py3MetaclassPrepare(PyObject *metaclass, PyObject *bases, PyObject *name, PyObject *qualname,
- PyObject *mkw, PyObject *modname, PyObject *doc);
-static PyObject *__Pyx_Py3ClassCreate(PyObject *metaclass, PyObject *name, PyObject *bases, PyObject *dict,
- PyObject *mkw, int calculate_metaclass, int allow_py2_metaclass);
-
-/* CLineInTraceback.proto */
-#ifdef CYTHON_CLINE_IN_TRACEBACK
-#define __Pyx_CLineForTraceback(tstate, c_line) (((CYTHON_CLINE_IN_TRACEBACK)) ? c_line : 0)
-#else
-static int __Pyx_CLineForTraceback(PyThreadState *tstate, int c_line);
-#endif
-
-/* CodeObjectCache.proto */
-#if !CYTHON_COMPILING_IN_LIMITED_API
-typedef struct {
- PyCodeObject* code_object;
- int code_line;
-} __Pyx_CodeObjectCacheEntry;
-struct __Pyx_CodeObjectCache {
- int count;
- int max_count;
- __Pyx_CodeObjectCacheEntry* entries;
-};
-static struct __Pyx_CodeObjectCache __pyx_code_cache = {0,0,NULL};
-static int __pyx_bisect_code_objects(__Pyx_CodeObjectCacheEntry* entries, int count, int code_line);
-static PyCodeObject *__pyx_find_code_object(int code_line);
-static void __pyx_insert_code_object(int code_line, PyCodeObject* code_object);
-#endif
-
-/* AddTraceback.proto */
-static void __Pyx_AddTraceback(const char *funcname, int c_line,
- int py_line, const char *filename);
-
-/* FormatTypeName.proto */
-#if CYTHON_COMPILING_IN_LIMITED_API
-typedef PyObject *__Pyx_TypeName;
-#define __Pyx_FMT_TYPENAME "%U"
-static __Pyx_TypeName __Pyx_PyType_GetName(PyTypeObject* tp);
-#define __Pyx_DECREF_TypeName(obj) Py_XDECREF(obj)
-#else
-typedef const char *__Pyx_TypeName;
-#define __Pyx_FMT_TYPENAME "%.200s"
-#define __Pyx_PyType_GetName(tp) ((tp)->tp_name)
-#define __Pyx_DECREF_TypeName(obj)
-#endif
-
-/* GCCDiagnostics.proto */
-#if !defined(__INTEL_COMPILER) && defined(__GNUC__) && (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 6))
-#define __Pyx_HAS_GCC_DIAGNOSTIC
-#endif
-
-/* CIntToPy.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyInt_From_long(long value);
-
-/* CIntFromPy.proto */
-static CYTHON_INLINE long __Pyx_PyInt_As_long(PyObject *);
-
-/* CIntFromPy.proto */
-static CYTHON_INLINE int __Pyx_PyInt_As_int(PyObject *);
-
-/* CheckBinaryVersion.proto */
-static int __Pyx_check_binary_version(void);
-
-/* InitStrings.proto */
-static int __Pyx_InitStrings(__Pyx_StringTabEntry *t);
-
-/* #### Code section: module_declarations ### */
-
-/* Module declarations from "cython" */
-
-/* Module declarations from "fontTools.pens.momentsPen" */
-/* #### Code section: typeinfo ### */
-/* #### Code section: before_global_var ### */
-#define __Pyx_MODULE_NAME "fontTools.pens.momentsPen"
-extern int __pyx_module_is_main_fontTools__pens__momentsPen;
-int __pyx_module_is_main_fontTools__pens__momentsPen = 0;
-
-/* Implementation of "fontTools.pens.momentsPen" */
-/* #### Code section: global_var ### */
-static PyObject *__pyx_builtin_AttributeError;
-static PyObject *__pyx_builtin_ImportError;
-/* #### Code section: string_decls ### */
-static const char __pyx_k_[] = ".";
-static const char __pyx_k_x[] = "x";
-static const char __pyx_k_y[] = "y";
-static const char __pyx_k_p0[] = "p0";
-static const char __pyx_k_p1[] = "p1";
-static const char __pyx_k_p2[] = "p2";
-static const char __pyx_k_p3[] = "p3";
-static const char __pyx_k_r0[] = "r0";
-static const char __pyx_k_r1[] = "r1";
-static const char __pyx_k_r2[] = "r2";
-static const char __pyx_k_r3[] = "r3";
-static const char __pyx_k_r4[] = "r4";
-static const char __pyx_k_r5[] = "r5";
-static const char __pyx_k_r6[] = "r6";
-static const char __pyx_k_r7[] = "r7";
-static const char __pyx_k_r8[] = "r8";
-static const char __pyx_k_r9[] = "r9";
-static const char __pyx_k_x0[] = "x0";
-static const char __pyx_k_x1[] = "x1";
-static const char __pyx_k_x2[] = "x2";
-static const char __pyx_k_x3[] = "x3";
-static const char __pyx_k_y0[] = "y0";
-static const char __pyx_k_y1[] = "y1";
-static const char __pyx_k_y2[] = "y2";
-static const char __pyx_k_y3[] = "y3";
-static const char __pyx_k__16[] = "?";
-static const char __pyx_k_all[] = "__all__";
-static const char __pyx_k_doc[] = "__doc__";
-static const char __pyx_k_r10[] = "r10";
-static const char __pyx_k_r11[] = "r11";
-static const char __pyx_k_r12[] = "r12";
-static const char __pyx_k_r13[] = "r13";
-static const char __pyx_k_r14[] = "r14";
-static const char __pyx_k_r15[] = "r15";
-static const char __pyx_k_r16[] = "r16";
-static const char __pyx_k_r17[] = "r17";
-static const char __pyx_k_r18[] = "r18";
-static const char __pyx_k_r19[] = "r19";
-static const char __pyx_k_r20[] = "r20";
-static const char __pyx_k_r21[] = "r21";
-static const char __pyx_k_r22[] = "r22";
-static const char __pyx_k_r23[] = "r23";
-static const char __pyx_k_r24[] = "r24";
-static const char __pyx_k_r25[] = "r25";
-static const char __pyx_k_r26[] = "r26";
-static const char __pyx_k_r27[] = "r27";
-static const char __pyx_k_r28[] = "r28";
-static const char __pyx_k_r29[] = "r29";
-static const char __pyx_k_r30[] = "r30";
-static const char __pyx_k_r31[] = "r31";
-static const char __pyx_k_r32[] = "r32";
-static const char __pyx_k_r33[] = "r33";
-static const char __pyx_k_r34[] = "r34";
-static const char __pyx_k_r35[] = "r35";
-static const char __pyx_k_r36[] = "r36";
-static const char __pyx_k_r37[] = "r37";
-static const char __pyx_k_r38[] = "r38";
-static const char __pyx_k_r39[] = "r39";
-static const char __pyx_k_r40[] = "r40";
-static const char __pyx_k_r41[] = "r41";
-static const char __pyx_k_r42[] = "r42";
-static const char __pyx_k_r43[] = "r43";
-static const char __pyx_k_r44[] = "r44";
-static const char __pyx_k_r45[] = "r45";
-static const char __pyx_k_r46[] = "r46";
-static const char __pyx_k_r47[] = "r47";
-static const char __pyx_k_r48[] = "r48";
-static const char __pyx_k_r49[] = "r49";
-static const char __pyx_k_r50[] = "r50";
-static const char __pyx_k_r51[] = "r51";
-static const char __pyx_k_r52[] = "r52";
-static const char __pyx_k_r53[] = "r53";
-static const char __pyx_k_r54[] = "r54";
-static const char __pyx_k_r55[] = "r55";
-static const char __pyx_k_r56[] = "r56";
-static const char __pyx_k_r57[] = "r57";
-static const char __pyx_k_r58[] = "r58";
-static const char __pyx_k_r59[] = "r59";
-static const char __pyx_k_r60[] = "r60";
-static const char __pyx_k_r61[] = "r61";
-static const char __pyx_k_r62[] = "r62";
-static const char __pyx_k_r63[] = "r63";
-static const char __pyx_k_r64[] = "r64";
-static const char __pyx_k_r65[] = "r65";
-static const char __pyx_k_r66[] = "r66";
-static const char __pyx_k_r67[] = "r67";
-static const char __pyx_k_r68[] = "r68";
-static const char __pyx_k_r69[] = "r69";
-static const char __pyx_k_r70[] = "r70";
-static const char __pyx_k_r71[] = "r71";
-static const char __pyx_k_r72[] = "r72";
-static const char __pyx_k_r73[] = "r73";
-static const char __pyx_k_r74[] = "r74";
-static const char __pyx_k_r75[] = "r75";
-static const char __pyx_k_r76[] = "r76";
-static const char __pyx_k_r77[] = "r77";
-static const char __pyx_k_r78[] = "r78";
-static const char __pyx_k_r79[] = "r79";
-static const char __pyx_k_r80[] = "r80";
-static const char __pyx_k_r81[] = "r81";
-static const char __pyx_k_r82[] = "r82";
-static const char __pyx_k_r83[] = "r83";
-static const char __pyx_k_r84[] = "r84";
-static const char __pyx_k_r85[] = "r85";
-static const char __pyx_k_r86[] = "r86";
-static const char __pyx_k_r87[] = "r87";
-static const char __pyx_k_r88[] = "r88";
-static const char __pyx_k_r89[] = "r89";
-static const char __pyx_k_r90[] = "r90";
-static const char __pyx_k_r91[] = "r91";
-static const char __pyx_k_r92[] = "r92";
-static const char __pyx_k_r93[] = "r93";
-static const char __pyx_k_r94[] = "r94";
-static const char __pyx_k_r95[] = "r95";
-static const char __pyx_k_r96[] = "r96";
-static const char __pyx_k_r97[] = "r97";
-static const char __pyx_k_r98[] = "r98";
-static const char __pyx_k_r99[] = "r99";
-static const char __pyx_k_area[] = "area";
-static const char __pyx_k_dict[] = "__dict__";
-static const char __pyx_k_init[] = "__init__";
-static const char __pyx_k_main[] = "__main__";
-static const char __pyx_k_name[] = "__name__";
-static const char __pyx_k_r100[] = "r100";
-static const char __pyx_k_r101[] = "r101";
-static const char __pyx_k_r102[] = "r102";
-static const char __pyx_k_r103[] = "r103";
-static const char __pyx_k_r104[] = "r104";
-static const char __pyx_k_r105[] = "r105";
-static const char __pyx_k_r106[] = "r106";
-static const char __pyx_k_r107[] = "r107";
-static const char __pyx_k_r108[] = "r108";
-static const char __pyx_k_r109[] = "r109";
-static const char __pyx_k_r110[] = "r110";
-static const char __pyx_k_r111[] = "r111";
-static const char __pyx_k_r112[] = "r112";
-static const char __pyx_k_r113[] = "r113";
-static const char __pyx_k_r114[] = "r114";
-static const char __pyx_k_r115[] = "r115";
-static const char __pyx_k_r116[] = "r116";
-static const char __pyx_k_r117[] = "r117";
-static const char __pyx_k_r118[] = "r118";
-static const char __pyx_k_r119[] = "r119";
-static const char __pyx_k_r120[] = "r120";
-static const char __pyx_k_r121[] = "r121";
-static const char __pyx_k_r122[] = "r122";
-static const char __pyx_k_r123[] = "r123";
-static const char __pyx_k_r124[] = "r124";
-static const char __pyx_k_r125[] = "r125";
-static const char __pyx_k_r126[] = "r126";
-static const char __pyx_k_r127[] = "r127";
-static const char __pyx_k_r128[] = "r128";
-static const char __pyx_k_r129[] = "r129";
-static const char __pyx_k_r130[] = "r130";
-static const char __pyx_k_r131[] = "r131";
-static const char __pyx_k_r132[] = "r132";
-static const char __pyx_k_self[] = "self";
-static const char __pyx_k_test[] = "__test__";
-static const char __pyx_k_super[] = "super";
-static const char __pyx_k_cython[] = "cython";
-static const char __pyx_k_import[] = "__import__";
-static const char __pyx_k_lineTo[] = "_lineTo";
-static const char __pyx_k_module[] = "__module__";
-static const char __pyx_k_moveTo[] = "_moveTo";
-static const char __pyx_k_BasePen[] = "BasePen";
-static const char __pyx_k_endPath[] = "_endPath";
-static const char __pyx_k_momentX[] = "momentX";
-static const char __pyx_k_momentY[] = "momentY";
-static const char __pyx_k_prepare[] = "__prepare__";
-static const char __pyx_k_COMPILED[] = "COMPILED";
-static const char __pyx_k_glyphset[] = "glyphset";
-static const char __pyx_k_momentXX[] = "momentXX";
-static const char __pyx_k_momentXY[] = "momentXY";
-static const char __pyx_k_momentYY[] = "momentYY";
-static const char __pyx_k_qualname[] = "__qualname__";
-static const char __pyx_k_set_name[] = "__set_name__";
-static const char __pyx_k_closePath[] = "_closePath";
-static const char __pyx_k_metaclass[] = "__metaclass__";
-static const char __pyx_k_MomentsPen[] = "MomentsPen";
-static const char __pyx_k_curveToOne[] = "_curveToOne";
-static const char __pyx_k_ImportError[] = "ImportError";
-static const char __pyx_k_mro_entries[] = "__mro_entries__";
-static const char __pyx_k_qCurveToOne[] = "_qCurveToOne";
-static const char __pyx_k_is_coroutine[] = "_is_coroutine";
-static const char __pyx_k_init_subclass[] = "__init_subclass__";
-static const char __pyx_k_printGreenPen[] = "printGreenPen";
-static const char __pyx_k_AttributeError[] = "AttributeError";
-static const char __pyx_k_fontTools_misc[] = "fontTools.misc";
-static const char __pyx_k_getCurrentPoint[] = "_getCurrentPoint";
-static const char __pyx_k_OpenContourError[] = "OpenContourError";
-static const char __pyx_k_MomentsPen___init[] = "MomentsPen.__init__";
-static const char __pyx_k_MomentsPen__lineTo[] = "MomentsPen._lineTo";
-static const char __pyx_k_MomentsPen__moveTo[] = "MomentsPen._moveTo";
-static const char __pyx_k_asyncio_coroutines[] = "asyncio.coroutines";
-static const char __pyx_k_cline_in_traceback[] = "cline_in_traceback";
-static const char __pyx_k_MomentsPen__endPath[] = "MomentsPen._endPath";
-static const char __pyx_k_MomentsPen__closePath[] = "MomentsPen._closePath";
-static const char __pyx_k_MomentsPen__curveToOne[] = "MomentsPen._curveToOne";
-static const char __pyx_k_MomentsPen__startPoint[] = "_MomentsPen__startPoint";
-static const char __pyx_k_fontTools_misc_symfont[] = "fontTools.misc.symfont";
-static const char __pyx_k_fontTools_pens_basePen[] = "fontTools.pens.basePen";
-static const char __pyx_k_MomentsPen__qCurveToOne[] = "MomentsPen._qCurveToOne";
-static const char __pyx_k_fontTools_pens_momentsPen[] = "fontTools.pens.momentsPen";
-static const char __pyx_k_Green_theorem_is_not_defined_on[] = "Green theorem is not defined on open contours.";
-static const char __pyx_k_Lib_fontTools_pens_momentsPen_py[] = "Lib/fontTools/pens/momentsPen.py";
-/* #### Code section: decls ### */
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen___init__(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_glyphset); /* proto */
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_2_moveTo(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_p0); /* proto */
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_4_closePath(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_6_endPath(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_8_lineTo(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_p1); /* proto */
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_10_qCurveToOne(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_p1, PyObject *__pyx_v_p2); /* proto */
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_12_curveToOne(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_p1, PyObject *__pyx_v_p2, PyObject *__pyx_v_p3); /* proto */
-/* #### Code section: late_includes ### */
-/* #### Code section: module_state ### */
-typedef struct {
- PyObject *__pyx_d;
- PyObject *__pyx_b;
- PyObject *__pyx_cython_runtime;
- PyObject *__pyx_empty_tuple;
- PyObject *__pyx_empty_bytes;
- PyObject *__pyx_empty_unicode;
- #ifdef __Pyx_CyFunction_USED
- PyTypeObject *__pyx_CyFunctionType;
- #endif
- #ifdef __Pyx_FusedFunction_USED
- PyTypeObject *__pyx_FusedFunctionType;
- #endif
- #ifdef __Pyx_Generator_USED
- PyTypeObject *__pyx_GeneratorType;
- #endif
- #ifdef __Pyx_IterableCoroutine_USED
- PyTypeObject *__pyx_IterableCoroutineType;
- #endif
- #ifdef __Pyx_Coroutine_USED
- PyTypeObject *__pyx_CoroutineAwaitType;
- #endif
- #ifdef __Pyx_Coroutine_USED
- PyTypeObject *__pyx_CoroutineType;
- #endif
- #if CYTHON_USE_MODULE_STATE
- #endif
- #if CYTHON_USE_MODULE_STATE
- #endif
- PyObject *__pyx_kp_u_;
- PyObject *__pyx_n_s_AttributeError;
- PyObject *__pyx_n_s_BasePen;
- PyObject *__pyx_n_s_COMPILED;
- PyObject *__pyx_kp_u_Green_theorem_is_not_defined_on;
- PyObject *__pyx_n_s_ImportError;
- PyObject *__pyx_kp_s_Lib_fontTools_pens_momentsPen_py;
- PyObject *__pyx_n_s_MomentsPen;
- PyObject *__pyx_n_u_MomentsPen;
- PyObject *__pyx_n_s_MomentsPen___init;
- PyObject *__pyx_n_s_MomentsPen__closePath;
- PyObject *__pyx_n_s_MomentsPen__curveToOne;
- PyObject *__pyx_n_s_MomentsPen__endPath;
- PyObject *__pyx_n_s_MomentsPen__lineTo;
- PyObject *__pyx_n_s_MomentsPen__moveTo;
- PyObject *__pyx_n_s_MomentsPen__qCurveToOne;
- PyObject *__pyx_n_s_MomentsPen__startPoint;
- PyObject *__pyx_n_s_OpenContourError;
- PyObject *__pyx_n_s__16;
- PyObject *__pyx_n_s_all;
- PyObject *__pyx_n_s_area;
- PyObject *__pyx_n_u_area;
- PyObject *__pyx_n_s_asyncio_coroutines;
- PyObject *__pyx_n_s_cline_in_traceback;
- PyObject *__pyx_n_s_closePath;
- PyObject *__pyx_n_s_curveToOne;
- PyObject *__pyx_n_s_cython;
- PyObject *__pyx_n_s_dict;
- PyObject *__pyx_n_s_doc;
- PyObject *__pyx_n_s_endPath;
- PyObject *__pyx_n_s_fontTools_misc;
- PyObject *__pyx_n_s_fontTools_misc_symfont;
- PyObject *__pyx_n_s_fontTools_pens_basePen;
- PyObject *__pyx_n_s_fontTools_pens_momentsPen;
- PyObject *__pyx_n_s_getCurrentPoint;
- PyObject *__pyx_n_s_glyphset;
- PyObject *__pyx_n_s_import;
- PyObject *__pyx_n_s_init;
- PyObject *__pyx_n_s_init_subclass;
- PyObject *__pyx_n_s_is_coroutine;
- PyObject *__pyx_n_s_lineTo;
- PyObject *__pyx_n_s_main;
- PyObject *__pyx_n_u_main;
- PyObject *__pyx_n_s_metaclass;
- PyObject *__pyx_n_s_module;
- PyObject *__pyx_n_s_momentX;
- PyObject *__pyx_n_u_momentX;
- PyObject *__pyx_n_s_momentXX;
- PyObject *__pyx_n_u_momentXX;
- PyObject *__pyx_n_s_momentXY;
- PyObject *__pyx_n_u_momentXY;
- PyObject *__pyx_n_s_momentY;
- PyObject *__pyx_n_u_momentY;
- PyObject *__pyx_n_s_momentYY;
- PyObject *__pyx_n_u_momentYY;
- PyObject *__pyx_n_s_moveTo;
- PyObject *__pyx_n_s_mro_entries;
- PyObject *__pyx_n_s_name;
- PyObject *__pyx_n_s_p0;
- PyObject *__pyx_n_s_p1;
- PyObject *__pyx_n_s_p2;
- PyObject *__pyx_n_s_p3;
- PyObject *__pyx_n_s_prepare;
- PyObject *__pyx_n_s_printGreenPen;
- PyObject *__pyx_n_s_qCurveToOne;
- PyObject *__pyx_n_s_qualname;
- PyObject *__pyx_n_s_r0;
- PyObject *__pyx_n_s_r1;
- PyObject *__pyx_n_s_r10;
- PyObject *__pyx_n_s_r100;
- PyObject *__pyx_n_s_r101;
- PyObject *__pyx_n_s_r102;
- PyObject *__pyx_n_s_r103;
- PyObject *__pyx_n_s_r104;
- PyObject *__pyx_n_s_r105;
- PyObject *__pyx_n_s_r106;
- PyObject *__pyx_n_s_r107;
- PyObject *__pyx_n_s_r108;
- PyObject *__pyx_n_s_r109;
- PyObject *__pyx_n_s_r11;
- PyObject *__pyx_n_s_r110;
- PyObject *__pyx_n_s_r111;
- PyObject *__pyx_n_s_r112;
- PyObject *__pyx_n_s_r113;
- PyObject *__pyx_n_s_r114;
- PyObject *__pyx_n_s_r115;
- PyObject *__pyx_n_s_r116;
- PyObject *__pyx_n_s_r117;
- PyObject *__pyx_n_s_r118;
- PyObject *__pyx_n_s_r119;
- PyObject *__pyx_n_s_r12;
- PyObject *__pyx_n_s_r120;
- PyObject *__pyx_n_s_r121;
- PyObject *__pyx_n_s_r122;
- PyObject *__pyx_n_s_r123;
- PyObject *__pyx_n_s_r124;
- PyObject *__pyx_n_s_r125;
- PyObject *__pyx_n_s_r126;
- PyObject *__pyx_n_s_r127;
- PyObject *__pyx_n_s_r128;
- PyObject *__pyx_n_s_r129;
- PyObject *__pyx_n_s_r13;
- PyObject *__pyx_n_s_r130;
- PyObject *__pyx_n_s_r131;
- PyObject *__pyx_n_s_r132;
- PyObject *__pyx_n_s_r14;
- PyObject *__pyx_n_s_r15;
- PyObject *__pyx_n_s_r16;
- PyObject *__pyx_n_s_r17;
- PyObject *__pyx_n_s_r18;
- PyObject *__pyx_n_s_r19;
- PyObject *__pyx_n_s_r2;
- PyObject *__pyx_n_s_r20;
- PyObject *__pyx_n_s_r21;
- PyObject *__pyx_n_s_r22;
- PyObject *__pyx_n_s_r23;
- PyObject *__pyx_n_s_r24;
- PyObject *__pyx_n_s_r25;
- PyObject *__pyx_n_s_r26;
- PyObject *__pyx_n_s_r27;
- PyObject *__pyx_n_s_r28;
- PyObject *__pyx_n_s_r29;
- PyObject *__pyx_n_s_r3;
- PyObject *__pyx_n_s_r30;
- PyObject *__pyx_n_s_r31;
- PyObject *__pyx_n_s_r32;
- PyObject *__pyx_n_s_r33;
- PyObject *__pyx_n_s_r34;
- PyObject *__pyx_n_s_r35;
- PyObject *__pyx_n_s_r36;
- PyObject *__pyx_n_s_r37;
- PyObject *__pyx_n_s_r38;
- PyObject *__pyx_n_s_r39;
- PyObject *__pyx_n_s_r4;
- PyObject *__pyx_n_s_r40;
- PyObject *__pyx_n_s_r41;
- PyObject *__pyx_n_s_r42;
- PyObject *__pyx_n_s_r43;
- PyObject *__pyx_n_s_r44;
- PyObject *__pyx_n_s_r45;
- PyObject *__pyx_n_s_r46;
- PyObject *__pyx_n_s_r47;
- PyObject *__pyx_n_s_r48;
- PyObject *__pyx_n_s_r49;
- PyObject *__pyx_n_s_r5;
- PyObject *__pyx_n_s_r50;
- PyObject *__pyx_n_s_r51;
- PyObject *__pyx_n_s_r52;
- PyObject *__pyx_n_s_r53;
- PyObject *__pyx_n_s_r54;
- PyObject *__pyx_n_s_r55;
- PyObject *__pyx_n_s_r56;
- PyObject *__pyx_n_s_r57;
- PyObject *__pyx_n_s_r58;
- PyObject *__pyx_n_s_r59;
- PyObject *__pyx_n_s_r6;
- PyObject *__pyx_n_s_r60;
- PyObject *__pyx_n_s_r61;
- PyObject *__pyx_n_s_r62;
- PyObject *__pyx_n_s_r63;
- PyObject *__pyx_n_s_r64;
- PyObject *__pyx_n_s_r65;
- PyObject *__pyx_n_s_r66;
- PyObject *__pyx_n_s_r67;
- PyObject *__pyx_n_s_r68;
- PyObject *__pyx_n_s_r69;
- PyObject *__pyx_n_s_r7;
- PyObject *__pyx_n_s_r70;
- PyObject *__pyx_n_s_r71;
- PyObject *__pyx_n_s_r72;
- PyObject *__pyx_n_s_r73;
- PyObject *__pyx_n_s_r74;
- PyObject *__pyx_n_s_r75;
- PyObject *__pyx_n_s_r76;
- PyObject *__pyx_n_s_r77;
- PyObject *__pyx_n_s_r78;
- PyObject *__pyx_n_s_r79;
- PyObject *__pyx_n_s_r8;
- PyObject *__pyx_n_s_r80;
- PyObject *__pyx_n_s_r81;
- PyObject *__pyx_n_s_r82;
- PyObject *__pyx_n_s_r83;
- PyObject *__pyx_n_s_r84;
- PyObject *__pyx_n_s_r85;
- PyObject *__pyx_n_s_r86;
- PyObject *__pyx_n_s_r87;
- PyObject *__pyx_n_s_r88;
- PyObject *__pyx_n_s_r89;
- PyObject *__pyx_n_s_r9;
- PyObject *__pyx_n_s_r90;
- PyObject *__pyx_n_s_r91;
- PyObject *__pyx_n_s_r92;
- PyObject *__pyx_n_s_r93;
- PyObject *__pyx_n_s_r94;
- PyObject *__pyx_n_s_r95;
- PyObject *__pyx_n_s_r96;
- PyObject *__pyx_n_s_r97;
- PyObject *__pyx_n_s_r98;
- PyObject *__pyx_n_s_r99;
- PyObject *__pyx_n_s_self;
- PyObject *__pyx_n_s_set_name;
- PyObject *__pyx_n_s_super;
- PyObject *__pyx_n_s_test;
- PyObject *__pyx_n_s_x;
- PyObject *__pyx_n_s_x0;
- PyObject *__pyx_n_s_x1;
- PyObject *__pyx_n_s_x2;
- PyObject *__pyx_n_s_x3;
- PyObject *__pyx_n_s_y;
- PyObject *__pyx_n_s_y0;
- PyObject *__pyx_n_s_y1;
- PyObject *__pyx_n_s_y2;
- PyObject *__pyx_n_s_y3;
- PyObject *__pyx_int_0;
- PyObject *__pyx_int_1;
- PyObject *__pyx_int_2;
- PyObject *__pyx_tuple__2;
- PyObject *__pyx_tuple__4;
- PyObject *__pyx_tuple__5;
- PyObject *__pyx_tuple__9;
- PyObject *__pyx_tuple__11;
- PyObject *__pyx_tuple__13;
- PyObject *__pyx_tuple__15;
- PyObject *__pyx_codeobj__3;
- PyObject *__pyx_codeobj__6;
- PyObject *__pyx_codeobj__7;
- PyObject *__pyx_codeobj__8;
- PyObject *__pyx_codeobj__10;
- PyObject *__pyx_codeobj__12;
- PyObject *__pyx_codeobj__14;
-} __pyx_mstate;
-
-#if CYTHON_USE_MODULE_STATE
-#ifdef __cplusplus
-namespace {
- extern struct PyModuleDef __pyx_moduledef;
-} /* anonymous namespace */
-#else
-static struct PyModuleDef __pyx_moduledef;
-#endif
-
-#define __pyx_mstate(o) ((__pyx_mstate *)__Pyx_PyModule_GetState(o))
-
-#define __pyx_mstate_global (__pyx_mstate(PyState_FindModule(&__pyx_moduledef)))
-
-#define __pyx_m (PyState_FindModule(&__pyx_moduledef))
-#else
-static __pyx_mstate __pyx_mstate_global_static =
-#ifdef __cplusplus
- {};
-#else
- {0};
-#endif
-static __pyx_mstate *__pyx_mstate_global = &__pyx_mstate_global_static;
-#endif
-/* #### Code section: module_state_clear ### */
-#if CYTHON_USE_MODULE_STATE
-static int __pyx_m_clear(PyObject *m) {
- __pyx_mstate *clear_module_state = __pyx_mstate(m);
- if (!clear_module_state) return 0;
- Py_CLEAR(clear_module_state->__pyx_d);
- Py_CLEAR(clear_module_state->__pyx_b);
- Py_CLEAR(clear_module_state->__pyx_cython_runtime);
- Py_CLEAR(clear_module_state->__pyx_empty_tuple);
- Py_CLEAR(clear_module_state->__pyx_empty_bytes);
- Py_CLEAR(clear_module_state->__pyx_empty_unicode);
- #ifdef __Pyx_CyFunction_USED
- Py_CLEAR(clear_module_state->__pyx_CyFunctionType);
- #endif
- #ifdef __Pyx_FusedFunction_USED
- Py_CLEAR(clear_module_state->__pyx_FusedFunctionType);
- #endif
- Py_CLEAR(clear_module_state->__pyx_kp_u_);
- Py_CLEAR(clear_module_state->__pyx_n_s_AttributeError);
- Py_CLEAR(clear_module_state->__pyx_n_s_BasePen);
- Py_CLEAR(clear_module_state->__pyx_n_s_COMPILED);
- Py_CLEAR(clear_module_state->__pyx_kp_u_Green_theorem_is_not_defined_on);
- Py_CLEAR(clear_module_state->__pyx_n_s_ImportError);
- Py_CLEAR(clear_module_state->__pyx_kp_s_Lib_fontTools_pens_momentsPen_py);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen);
- Py_CLEAR(clear_module_state->__pyx_n_u_MomentsPen);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen___init);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen__closePath);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen__curveToOne);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen__endPath);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen__lineTo);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen__moveTo);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen__qCurveToOne);
- Py_CLEAR(clear_module_state->__pyx_n_s_MomentsPen__startPoint);
- Py_CLEAR(clear_module_state->__pyx_n_s_OpenContourError);
- Py_CLEAR(clear_module_state->__pyx_n_s__16);
- Py_CLEAR(clear_module_state->__pyx_n_s_all);
- Py_CLEAR(clear_module_state->__pyx_n_s_area);
- Py_CLEAR(clear_module_state->__pyx_n_u_area);
- Py_CLEAR(clear_module_state->__pyx_n_s_asyncio_coroutines);
- Py_CLEAR(clear_module_state->__pyx_n_s_cline_in_traceback);
- Py_CLEAR(clear_module_state->__pyx_n_s_closePath);
- Py_CLEAR(clear_module_state->__pyx_n_s_curveToOne);
- Py_CLEAR(clear_module_state->__pyx_n_s_cython);
- Py_CLEAR(clear_module_state->__pyx_n_s_dict);
- Py_CLEAR(clear_module_state->__pyx_n_s_doc);
- Py_CLEAR(clear_module_state->__pyx_n_s_endPath);
- Py_CLEAR(clear_module_state->__pyx_n_s_fontTools_misc);
- Py_CLEAR(clear_module_state->__pyx_n_s_fontTools_misc_symfont);
- Py_CLEAR(clear_module_state->__pyx_n_s_fontTools_pens_basePen);
- Py_CLEAR(clear_module_state->__pyx_n_s_fontTools_pens_momentsPen);
- Py_CLEAR(clear_module_state->__pyx_n_s_getCurrentPoint);
- Py_CLEAR(clear_module_state->__pyx_n_s_glyphset);
- Py_CLEAR(clear_module_state->__pyx_n_s_import);
- Py_CLEAR(clear_module_state->__pyx_n_s_init);
- Py_CLEAR(clear_module_state->__pyx_n_s_init_subclass);
- Py_CLEAR(clear_module_state->__pyx_n_s_is_coroutine);
- Py_CLEAR(clear_module_state->__pyx_n_s_lineTo);
- Py_CLEAR(clear_module_state->__pyx_n_s_main);
- Py_CLEAR(clear_module_state->__pyx_n_u_main);
- Py_CLEAR(clear_module_state->__pyx_n_s_metaclass);
- Py_CLEAR(clear_module_state->__pyx_n_s_module);
- Py_CLEAR(clear_module_state->__pyx_n_s_momentX);
- Py_CLEAR(clear_module_state->__pyx_n_u_momentX);
- Py_CLEAR(clear_module_state->__pyx_n_s_momentXX);
- Py_CLEAR(clear_module_state->__pyx_n_u_momentXX);
- Py_CLEAR(clear_module_state->__pyx_n_s_momentXY);
- Py_CLEAR(clear_module_state->__pyx_n_u_momentXY);
- Py_CLEAR(clear_module_state->__pyx_n_s_momentY);
- Py_CLEAR(clear_module_state->__pyx_n_u_momentY);
- Py_CLEAR(clear_module_state->__pyx_n_s_momentYY);
- Py_CLEAR(clear_module_state->__pyx_n_u_momentYY);
- Py_CLEAR(clear_module_state->__pyx_n_s_moveTo);
- Py_CLEAR(clear_module_state->__pyx_n_s_mro_entries);
- Py_CLEAR(clear_module_state->__pyx_n_s_name);
- Py_CLEAR(clear_module_state->__pyx_n_s_p0);
- Py_CLEAR(clear_module_state->__pyx_n_s_p1);
- Py_CLEAR(clear_module_state->__pyx_n_s_p2);
- Py_CLEAR(clear_module_state->__pyx_n_s_p3);
- Py_CLEAR(clear_module_state->__pyx_n_s_prepare);
- Py_CLEAR(clear_module_state->__pyx_n_s_printGreenPen);
- Py_CLEAR(clear_module_state->__pyx_n_s_qCurveToOne);
- Py_CLEAR(clear_module_state->__pyx_n_s_qualname);
- Py_CLEAR(clear_module_state->__pyx_n_s_r0);
- Py_CLEAR(clear_module_state->__pyx_n_s_r1);
- Py_CLEAR(clear_module_state->__pyx_n_s_r10);
- Py_CLEAR(clear_module_state->__pyx_n_s_r100);
- Py_CLEAR(clear_module_state->__pyx_n_s_r101);
- Py_CLEAR(clear_module_state->__pyx_n_s_r102);
- Py_CLEAR(clear_module_state->__pyx_n_s_r103);
- Py_CLEAR(clear_module_state->__pyx_n_s_r104);
- Py_CLEAR(clear_module_state->__pyx_n_s_r105);
- Py_CLEAR(clear_module_state->__pyx_n_s_r106);
- Py_CLEAR(clear_module_state->__pyx_n_s_r107);
- Py_CLEAR(clear_module_state->__pyx_n_s_r108);
- Py_CLEAR(clear_module_state->__pyx_n_s_r109);
- Py_CLEAR(clear_module_state->__pyx_n_s_r11);
- Py_CLEAR(clear_module_state->__pyx_n_s_r110);
- Py_CLEAR(clear_module_state->__pyx_n_s_r111);
- Py_CLEAR(clear_module_state->__pyx_n_s_r112);
- Py_CLEAR(clear_module_state->__pyx_n_s_r113);
- Py_CLEAR(clear_module_state->__pyx_n_s_r114);
- Py_CLEAR(clear_module_state->__pyx_n_s_r115);
- Py_CLEAR(clear_module_state->__pyx_n_s_r116);
- Py_CLEAR(clear_module_state->__pyx_n_s_r117);
- Py_CLEAR(clear_module_state->__pyx_n_s_r118);
- Py_CLEAR(clear_module_state->__pyx_n_s_r119);
- Py_CLEAR(clear_module_state->__pyx_n_s_r12);
- Py_CLEAR(clear_module_state->__pyx_n_s_r120);
- Py_CLEAR(clear_module_state->__pyx_n_s_r121);
- Py_CLEAR(clear_module_state->__pyx_n_s_r122);
- Py_CLEAR(clear_module_state->__pyx_n_s_r123);
- Py_CLEAR(clear_module_state->__pyx_n_s_r124);
- Py_CLEAR(clear_module_state->__pyx_n_s_r125);
- Py_CLEAR(clear_module_state->__pyx_n_s_r126);
- Py_CLEAR(clear_module_state->__pyx_n_s_r127);
- Py_CLEAR(clear_module_state->__pyx_n_s_r128);
- Py_CLEAR(clear_module_state->__pyx_n_s_r129);
- Py_CLEAR(clear_module_state->__pyx_n_s_r13);
- Py_CLEAR(clear_module_state->__pyx_n_s_r130);
- Py_CLEAR(clear_module_state->__pyx_n_s_r131);
- Py_CLEAR(clear_module_state->__pyx_n_s_r132);
- Py_CLEAR(clear_module_state->__pyx_n_s_r14);
- Py_CLEAR(clear_module_state->__pyx_n_s_r15);
- Py_CLEAR(clear_module_state->__pyx_n_s_r16);
- Py_CLEAR(clear_module_state->__pyx_n_s_r17);
- Py_CLEAR(clear_module_state->__pyx_n_s_r18);
- Py_CLEAR(clear_module_state->__pyx_n_s_r19);
- Py_CLEAR(clear_module_state->__pyx_n_s_r2);
- Py_CLEAR(clear_module_state->__pyx_n_s_r20);
- Py_CLEAR(clear_module_state->__pyx_n_s_r21);
- Py_CLEAR(clear_module_state->__pyx_n_s_r22);
- Py_CLEAR(clear_module_state->__pyx_n_s_r23);
- Py_CLEAR(clear_module_state->__pyx_n_s_r24);
- Py_CLEAR(clear_module_state->__pyx_n_s_r25);
- Py_CLEAR(clear_module_state->__pyx_n_s_r26);
- Py_CLEAR(clear_module_state->__pyx_n_s_r27);
- Py_CLEAR(clear_module_state->__pyx_n_s_r28);
- Py_CLEAR(clear_module_state->__pyx_n_s_r29);
- Py_CLEAR(clear_module_state->__pyx_n_s_r3);
- Py_CLEAR(clear_module_state->__pyx_n_s_r30);
- Py_CLEAR(clear_module_state->__pyx_n_s_r31);
- Py_CLEAR(clear_module_state->__pyx_n_s_r32);
- Py_CLEAR(clear_module_state->__pyx_n_s_r33);
- Py_CLEAR(clear_module_state->__pyx_n_s_r34);
- Py_CLEAR(clear_module_state->__pyx_n_s_r35);
- Py_CLEAR(clear_module_state->__pyx_n_s_r36);
- Py_CLEAR(clear_module_state->__pyx_n_s_r37);
- Py_CLEAR(clear_module_state->__pyx_n_s_r38);
- Py_CLEAR(clear_module_state->__pyx_n_s_r39);
- Py_CLEAR(clear_module_state->__pyx_n_s_r4);
- Py_CLEAR(clear_module_state->__pyx_n_s_r40);
- Py_CLEAR(clear_module_state->__pyx_n_s_r41);
- Py_CLEAR(clear_module_state->__pyx_n_s_r42);
- Py_CLEAR(clear_module_state->__pyx_n_s_r43);
- Py_CLEAR(clear_module_state->__pyx_n_s_r44);
- Py_CLEAR(clear_module_state->__pyx_n_s_r45);
- Py_CLEAR(clear_module_state->__pyx_n_s_r46);
- Py_CLEAR(clear_module_state->__pyx_n_s_r47);
- Py_CLEAR(clear_module_state->__pyx_n_s_r48);
- Py_CLEAR(clear_module_state->__pyx_n_s_r49);
- Py_CLEAR(clear_module_state->__pyx_n_s_r5);
- Py_CLEAR(clear_module_state->__pyx_n_s_r50);
- Py_CLEAR(clear_module_state->__pyx_n_s_r51);
- Py_CLEAR(clear_module_state->__pyx_n_s_r52);
- Py_CLEAR(clear_module_state->__pyx_n_s_r53);
- Py_CLEAR(clear_module_state->__pyx_n_s_r54);
- Py_CLEAR(clear_module_state->__pyx_n_s_r55);
- Py_CLEAR(clear_module_state->__pyx_n_s_r56);
- Py_CLEAR(clear_module_state->__pyx_n_s_r57);
- Py_CLEAR(clear_module_state->__pyx_n_s_r58);
- Py_CLEAR(clear_module_state->__pyx_n_s_r59);
- Py_CLEAR(clear_module_state->__pyx_n_s_r6);
- Py_CLEAR(clear_module_state->__pyx_n_s_r60);
- Py_CLEAR(clear_module_state->__pyx_n_s_r61);
- Py_CLEAR(clear_module_state->__pyx_n_s_r62);
- Py_CLEAR(clear_module_state->__pyx_n_s_r63);
- Py_CLEAR(clear_module_state->__pyx_n_s_r64);
- Py_CLEAR(clear_module_state->__pyx_n_s_r65);
- Py_CLEAR(clear_module_state->__pyx_n_s_r66);
- Py_CLEAR(clear_module_state->__pyx_n_s_r67);
- Py_CLEAR(clear_module_state->__pyx_n_s_r68);
- Py_CLEAR(clear_module_state->__pyx_n_s_r69);
- Py_CLEAR(clear_module_state->__pyx_n_s_r7);
- Py_CLEAR(clear_module_state->__pyx_n_s_r70);
- Py_CLEAR(clear_module_state->__pyx_n_s_r71);
- Py_CLEAR(clear_module_state->__pyx_n_s_r72);
- Py_CLEAR(clear_module_state->__pyx_n_s_r73);
- Py_CLEAR(clear_module_state->__pyx_n_s_r74);
- Py_CLEAR(clear_module_state->__pyx_n_s_r75);
- Py_CLEAR(clear_module_state->__pyx_n_s_r76);
- Py_CLEAR(clear_module_state->__pyx_n_s_r77);
- Py_CLEAR(clear_module_state->__pyx_n_s_r78);
- Py_CLEAR(clear_module_state->__pyx_n_s_r79);
- Py_CLEAR(clear_module_state->__pyx_n_s_r8);
- Py_CLEAR(clear_module_state->__pyx_n_s_r80);
- Py_CLEAR(clear_module_state->__pyx_n_s_r81);
- Py_CLEAR(clear_module_state->__pyx_n_s_r82);
- Py_CLEAR(clear_module_state->__pyx_n_s_r83);
- Py_CLEAR(clear_module_state->__pyx_n_s_r84);
- Py_CLEAR(clear_module_state->__pyx_n_s_r85);
- Py_CLEAR(clear_module_state->__pyx_n_s_r86);
- Py_CLEAR(clear_module_state->__pyx_n_s_r87);
- Py_CLEAR(clear_module_state->__pyx_n_s_r88);
- Py_CLEAR(clear_module_state->__pyx_n_s_r89);
- Py_CLEAR(clear_module_state->__pyx_n_s_r9);
- Py_CLEAR(clear_module_state->__pyx_n_s_r90);
- Py_CLEAR(clear_module_state->__pyx_n_s_r91);
- Py_CLEAR(clear_module_state->__pyx_n_s_r92);
- Py_CLEAR(clear_module_state->__pyx_n_s_r93);
- Py_CLEAR(clear_module_state->__pyx_n_s_r94);
- Py_CLEAR(clear_module_state->__pyx_n_s_r95);
- Py_CLEAR(clear_module_state->__pyx_n_s_r96);
- Py_CLEAR(clear_module_state->__pyx_n_s_r97);
- Py_CLEAR(clear_module_state->__pyx_n_s_r98);
- Py_CLEAR(clear_module_state->__pyx_n_s_r99);
- Py_CLEAR(clear_module_state->__pyx_n_s_self);
- Py_CLEAR(clear_module_state->__pyx_n_s_set_name);
- Py_CLEAR(clear_module_state->__pyx_n_s_super);
- Py_CLEAR(clear_module_state->__pyx_n_s_test);
- Py_CLEAR(clear_module_state->__pyx_n_s_x);
- Py_CLEAR(clear_module_state->__pyx_n_s_x0);
- Py_CLEAR(clear_module_state->__pyx_n_s_x1);
- Py_CLEAR(clear_module_state->__pyx_n_s_x2);
- Py_CLEAR(clear_module_state->__pyx_n_s_x3);
- Py_CLEAR(clear_module_state->__pyx_n_s_y);
- Py_CLEAR(clear_module_state->__pyx_n_s_y0);
- Py_CLEAR(clear_module_state->__pyx_n_s_y1);
- Py_CLEAR(clear_module_state->__pyx_n_s_y2);
- Py_CLEAR(clear_module_state->__pyx_n_s_y3);
- Py_CLEAR(clear_module_state->__pyx_int_0);
- Py_CLEAR(clear_module_state->__pyx_int_1);
- Py_CLEAR(clear_module_state->__pyx_int_2);
- Py_CLEAR(clear_module_state->__pyx_tuple__2);
- Py_CLEAR(clear_module_state->__pyx_tuple__4);
- Py_CLEAR(clear_module_state->__pyx_tuple__5);
- Py_CLEAR(clear_module_state->__pyx_tuple__9);
- Py_CLEAR(clear_module_state->__pyx_tuple__11);
- Py_CLEAR(clear_module_state->__pyx_tuple__13);
- Py_CLEAR(clear_module_state->__pyx_tuple__15);
- Py_CLEAR(clear_module_state->__pyx_codeobj__3);
- Py_CLEAR(clear_module_state->__pyx_codeobj__6);
- Py_CLEAR(clear_module_state->__pyx_codeobj__7);
- Py_CLEAR(clear_module_state->__pyx_codeobj__8);
- Py_CLEAR(clear_module_state->__pyx_codeobj__10);
- Py_CLEAR(clear_module_state->__pyx_codeobj__12);
- Py_CLEAR(clear_module_state->__pyx_codeobj__14);
- return 0;
-}
-#endif
-/* #### Code section: module_state_traverse ### */
-#if CYTHON_USE_MODULE_STATE
-static int __pyx_m_traverse(PyObject *m, visitproc visit, void *arg) {
- __pyx_mstate *traverse_module_state = __pyx_mstate(m);
- if (!traverse_module_state) return 0;
- Py_VISIT(traverse_module_state->__pyx_d);
- Py_VISIT(traverse_module_state->__pyx_b);
- Py_VISIT(traverse_module_state->__pyx_cython_runtime);
- Py_VISIT(traverse_module_state->__pyx_empty_tuple);
- Py_VISIT(traverse_module_state->__pyx_empty_bytes);
- Py_VISIT(traverse_module_state->__pyx_empty_unicode);
- #ifdef __Pyx_CyFunction_USED
- Py_VISIT(traverse_module_state->__pyx_CyFunctionType);
- #endif
- #ifdef __Pyx_FusedFunction_USED
- Py_VISIT(traverse_module_state->__pyx_FusedFunctionType);
- #endif
- Py_VISIT(traverse_module_state->__pyx_kp_u_);
- Py_VISIT(traverse_module_state->__pyx_n_s_AttributeError);
- Py_VISIT(traverse_module_state->__pyx_n_s_BasePen);
- Py_VISIT(traverse_module_state->__pyx_n_s_COMPILED);
- Py_VISIT(traverse_module_state->__pyx_kp_u_Green_theorem_is_not_defined_on);
- Py_VISIT(traverse_module_state->__pyx_n_s_ImportError);
- Py_VISIT(traverse_module_state->__pyx_kp_s_Lib_fontTools_pens_momentsPen_py);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen);
- Py_VISIT(traverse_module_state->__pyx_n_u_MomentsPen);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen___init);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen__closePath);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen__curveToOne);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen__endPath);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen__lineTo);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen__moveTo);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen__qCurveToOne);
- Py_VISIT(traverse_module_state->__pyx_n_s_MomentsPen__startPoint);
- Py_VISIT(traverse_module_state->__pyx_n_s_OpenContourError);
- Py_VISIT(traverse_module_state->__pyx_n_s__16);
- Py_VISIT(traverse_module_state->__pyx_n_s_all);
- Py_VISIT(traverse_module_state->__pyx_n_s_area);
- Py_VISIT(traverse_module_state->__pyx_n_u_area);
- Py_VISIT(traverse_module_state->__pyx_n_s_asyncio_coroutines);
- Py_VISIT(traverse_module_state->__pyx_n_s_cline_in_traceback);
- Py_VISIT(traverse_module_state->__pyx_n_s_closePath);
- Py_VISIT(traverse_module_state->__pyx_n_s_curveToOne);
- Py_VISIT(traverse_module_state->__pyx_n_s_cython);
- Py_VISIT(traverse_module_state->__pyx_n_s_dict);
- Py_VISIT(traverse_module_state->__pyx_n_s_doc);
- Py_VISIT(traverse_module_state->__pyx_n_s_endPath);
- Py_VISIT(traverse_module_state->__pyx_n_s_fontTools_misc);
- Py_VISIT(traverse_module_state->__pyx_n_s_fontTools_misc_symfont);
- Py_VISIT(traverse_module_state->__pyx_n_s_fontTools_pens_basePen);
- Py_VISIT(traverse_module_state->__pyx_n_s_fontTools_pens_momentsPen);
- Py_VISIT(traverse_module_state->__pyx_n_s_getCurrentPoint);
- Py_VISIT(traverse_module_state->__pyx_n_s_glyphset);
- Py_VISIT(traverse_module_state->__pyx_n_s_import);
- Py_VISIT(traverse_module_state->__pyx_n_s_init);
- Py_VISIT(traverse_module_state->__pyx_n_s_init_subclass);
- Py_VISIT(traverse_module_state->__pyx_n_s_is_coroutine);
- Py_VISIT(traverse_module_state->__pyx_n_s_lineTo);
- Py_VISIT(traverse_module_state->__pyx_n_s_main);
- Py_VISIT(traverse_module_state->__pyx_n_u_main);
- Py_VISIT(traverse_module_state->__pyx_n_s_metaclass);
- Py_VISIT(traverse_module_state->__pyx_n_s_module);
- Py_VISIT(traverse_module_state->__pyx_n_s_momentX);
- Py_VISIT(traverse_module_state->__pyx_n_u_momentX);
- Py_VISIT(traverse_module_state->__pyx_n_s_momentXX);
- Py_VISIT(traverse_module_state->__pyx_n_u_momentXX);
- Py_VISIT(traverse_module_state->__pyx_n_s_momentXY);
- Py_VISIT(traverse_module_state->__pyx_n_u_momentXY);
- Py_VISIT(traverse_module_state->__pyx_n_s_momentY);
- Py_VISIT(traverse_module_state->__pyx_n_u_momentY);
- Py_VISIT(traverse_module_state->__pyx_n_s_momentYY);
- Py_VISIT(traverse_module_state->__pyx_n_u_momentYY);
- Py_VISIT(traverse_module_state->__pyx_n_s_moveTo);
- Py_VISIT(traverse_module_state->__pyx_n_s_mro_entries);
- Py_VISIT(traverse_module_state->__pyx_n_s_name);
- Py_VISIT(traverse_module_state->__pyx_n_s_p0);
- Py_VISIT(traverse_module_state->__pyx_n_s_p1);
- Py_VISIT(traverse_module_state->__pyx_n_s_p2);
- Py_VISIT(traverse_module_state->__pyx_n_s_p3);
- Py_VISIT(traverse_module_state->__pyx_n_s_prepare);
- Py_VISIT(traverse_module_state->__pyx_n_s_printGreenPen);
- Py_VISIT(traverse_module_state->__pyx_n_s_qCurveToOne);
- Py_VISIT(traverse_module_state->__pyx_n_s_qualname);
- Py_VISIT(traverse_module_state->__pyx_n_s_r0);
- Py_VISIT(traverse_module_state->__pyx_n_s_r1);
- Py_VISIT(traverse_module_state->__pyx_n_s_r10);
- Py_VISIT(traverse_module_state->__pyx_n_s_r100);
- Py_VISIT(traverse_module_state->__pyx_n_s_r101);
- Py_VISIT(traverse_module_state->__pyx_n_s_r102);
- Py_VISIT(traverse_module_state->__pyx_n_s_r103);
- Py_VISIT(traverse_module_state->__pyx_n_s_r104);
- Py_VISIT(traverse_module_state->__pyx_n_s_r105);
- Py_VISIT(traverse_module_state->__pyx_n_s_r106);
- Py_VISIT(traverse_module_state->__pyx_n_s_r107);
- Py_VISIT(traverse_module_state->__pyx_n_s_r108);
- Py_VISIT(traverse_module_state->__pyx_n_s_r109);
- Py_VISIT(traverse_module_state->__pyx_n_s_r11);
- Py_VISIT(traverse_module_state->__pyx_n_s_r110);
- Py_VISIT(traverse_module_state->__pyx_n_s_r111);
- Py_VISIT(traverse_module_state->__pyx_n_s_r112);
- Py_VISIT(traverse_module_state->__pyx_n_s_r113);
- Py_VISIT(traverse_module_state->__pyx_n_s_r114);
- Py_VISIT(traverse_module_state->__pyx_n_s_r115);
- Py_VISIT(traverse_module_state->__pyx_n_s_r116);
- Py_VISIT(traverse_module_state->__pyx_n_s_r117);
- Py_VISIT(traverse_module_state->__pyx_n_s_r118);
- Py_VISIT(traverse_module_state->__pyx_n_s_r119);
- Py_VISIT(traverse_module_state->__pyx_n_s_r12);
- Py_VISIT(traverse_module_state->__pyx_n_s_r120);
- Py_VISIT(traverse_module_state->__pyx_n_s_r121);
- Py_VISIT(traverse_module_state->__pyx_n_s_r122);
- Py_VISIT(traverse_module_state->__pyx_n_s_r123);
- Py_VISIT(traverse_module_state->__pyx_n_s_r124);
- Py_VISIT(traverse_module_state->__pyx_n_s_r125);
- Py_VISIT(traverse_module_state->__pyx_n_s_r126);
- Py_VISIT(traverse_module_state->__pyx_n_s_r127);
- Py_VISIT(traverse_module_state->__pyx_n_s_r128);
- Py_VISIT(traverse_module_state->__pyx_n_s_r129);
- Py_VISIT(traverse_module_state->__pyx_n_s_r13);
- Py_VISIT(traverse_module_state->__pyx_n_s_r130);
- Py_VISIT(traverse_module_state->__pyx_n_s_r131);
- Py_VISIT(traverse_module_state->__pyx_n_s_r132);
- Py_VISIT(traverse_module_state->__pyx_n_s_r14);
- Py_VISIT(traverse_module_state->__pyx_n_s_r15);
- Py_VISIT(traverse_module_state->__pyx_n_s_r16);
- Py_VISIT(traverse_module_state->__pyx_n_s_r17);
- Py_VISIT(traverse_module_state->__pyx_n_s_r18);
- Py_VISIT(traverse_module_state->__pyx_n_s_r19);
- Py_VISIT(traverse_module_state->__pyx_n_s_r2);
- Py_VISIT(traverse_module_state->__pyx_n_s_r20);
- Py_VISIT(traverse_module_state->__pyx_n_s_r21);
- Py_VISIT(traverse_module_state->__pyx_n_s_r22);
- Py_VISIT(traverse_module_state->__pyx_n_s_r23);
- Py_VISIT(traverse_module_state->__pyx_n_s_r24);
- Py_VISIT(traverse_module_state->__pyx_n_s_r25);
- Py_VISIT(traverse_module_state->__pyx_n_s_r26);
- Py_VISIT(traverse_module_state->__pyx_n_s_r27);
- Py_VISIT(traverse_module_state->__pyx_n_s_r28);
- Py_VISIT(traverse_module_state->__pyx_n_s_r29);
- Py_VISIT(traverse_module_state->__pyx_n_s_r3);
- Py_VISIT(traverse_module_state->__pyx_n_s_r30);
- Py_VISIT(traverse_module_state->__pyx_n_s_r31);
- Py_VISIT(traverse_module_state->__pyx_n_s_r32);
- Py_VISIT(traverse_module_state->__pyx_n_s_r33);
- Py_VISIT(traverse_module_state->__pyx_n_s_r34);
- Py_VISIT(traverse_module_state->__pyx_n_s_r35);
- Py_VISIT(traverse_module_state->__pyx_n_s_r36);
- Py_VISIT(traverse_module_state->__pyx_n_s_r37);
- Py_VISIT(traverse_module_state->__pyx_n_s_r38);
- Py_VISIT(traverse_module_state->__pyx_n_s_r39);
- Py_VISIT(traverse_module_state->__pyx_n_s_r4);
- Py_VISIT(traverse_module_state->__pyx_n_s_r40);
- Py_VISIT(traverse_module_state->__pyx_n_s_r41);
- Py_VISIT(traverse_module_state->__pyx_n_s_r42);
- Py_VISIT(traverse_module_state->__pyx_n_s_r43);
- Py_VISIT(traverse_module_state->__pyx_n_s_r44);
- Py_VISIT(traverse_module_state->__pyx_n_s_r45);
- Py_VISIT(traverse_module_state->__pyx_n_s_r46);
- Py_VISIT(traverse_module_state->__pyx_n_s_r47);
- Py_VISIT(traverse_module_state->__pyx_n_s_r48);
- Py_VISIT(traverse_module_state->__pyx_n_s_r49);
- Py_VISIT(traverse_module_state->__pyx_n_s_r5);
- Py_VISIT(traverse_module_state->__pyx_n_s_r50);
- Py_VISIT(traverse_module_state->__pyx_n_s_r51);
- Py_VISIT(traverse_module_state->__pyx_n_s_r52);
- Py_VISIT(traverse_module_state->__pyx_n_s_r53);
- Py_VISIT(traverse_module_state->__pyx_n_s_r54);
- Py_VISIT(traverse_module_state->__pyx_n_s_r55);
- Py_VISIT(traverse_module_state->__pyx_n_s_r56);
- Py_VISIT(traverse_module_state->__pyx_n_s_r57);
- Py_VISIT(traverse_module_state->__pyx_n_s_r58);
- Py_VISIT(traverse_module_state->__pyx_n_s_r59);
- Py_VISIT(traverse_module_state->__pyx_n_s_r6);
- Py_VISIT(traverse_module_state->__pyx_n_s_r60);
- Py_VISIT(traverse_module_state->__pyx_n_s_r61);
- Py_VISIT(traverse_module_state->__pyx_n_s_r62);
- Py_VISIT(traverse_module_state->__pyx_n_s_r63);
- Py_VISIT(traverse_module_state->__pyx_n_s_r64);
- Py_VISIT(traverse_module_state->__pyx_n_s_r65);
- Py_VISIT(traverse_module_state->__pyx_n_s_r66);
- Py_VISIT(traverse_module_state->__pyx_n_s_r67);
- Py_VISIT(traverse_module_state->__pyx_n_s_r68);
- Py_VISIT(traverse_module_state->__pyx_n_s_r69);
- Py_VISIT(traverse_module_state->__pyx_n_s_r7);
- Py_VISIT(traverse_module_state->__pyx_n_s_r70);
- Py_VISIT(traverse_module_state->__pyx_n_s_r71);
- Py_VISIT(traverse_module_state->__pyx_n_s_r72);
- Py_VISIT(traverse_module_state->__pyx_n_s_r73);
- Py_VISIT(traverse_module_state->__pyx_n_s_r74);
- Py_VISIT(traverse_module_state->__pyx_n_s_r75);
- Py_VISIT(traverse_module_state->__pyx_n_s_r76);
- Py_VISIT(traverse_module_state->__pyx_n_s_r77);
- Py_VISIT(traverse_module_state->__pyx_n_s_r78);
- Py_VISIT(traverse_module_state->__pyx_n_s_r79);
- Py_VISIT(traverse_module_state->__pyx_n_s_r8);
- Py_VISIT(traverse_module_state->__pyx_n_s_r80);
- Py_VISIT(traverse_module_state->__pyx_n_s_r81);
- Py_VISIT(traverse_module_state->__pyx_n_s_r82);
- Py_VISIT(traverse_module_state->__pyx_n_s_r83);
- Py_VISIT(traverse_module_state->__pyx_n_s_r84);
- Py_VISIT(traverse_module_state->__pyx_n_s_r85);
- Py_VISIT(traverse_module_state->__pyx_n_s_r86);
- Py_VISIT(traverse_module_state->__pyx_n_s_r87);
- Py_VISIT(traverse_module_state->__pyx_n_s_r88);
- Py_VISIT(traverse_module_state->__pyx_n_s_r89);
- Py_VISIT(traverse_module_state->__pyx_n_s_r9);
- Py_VISIT(traverse_module_state->__pyx_n_s_r90);
- Py_VISIT(traverse_module_state->__pyx_n_s_r91);
- Py_VISIT(traverse_module_state->__pyx_n_s_r92);
- Py_VISIT(traverse_module_state->__pyx_n_s_r93);
- Py_VISIT(traverse_module_state->__pyx_n_s_r94);
- Py_VISIT(traverse_module_state->__pyx_n_s_r95);
- Py_VISIT(traverse_module_state->__pyx_n_s_r96);
- Py_VISIT(traverse_module_state->__pyx_n_s_r97);
- Py_VISIT(traverse_module_state->__pyx_n_s_r98);
- Py_VISIT(traverse_module_state->__pyx_n_s_r99);
- Py_VISIT(traverse_module_state->__pyx_n_s_self);
- Py_VISIT(traverse_module_state->__pyx_n_s_set_name);
- Py_VISIT(traverse_module_state->__pyx_n_s_super);
- Py_VISIT(traverse_module_state->__pyx_n_s_test);
- Py_VISIT(traverse_module_state->__pyx_n_s_x);
- Py_VISIT(traverse_module_state->__pyx_n_s_x0);
- Py_VISIT(traverse_module_state->__pyx_n_s_x1);
- Py_VISIT(traverse_module_state->__pyx_n_s_x2);
- Py_VISIT(traverse_module_state->__pyx_n_s_x3);
- Py_VISIT(traverse_module_state->__pyx_n_s_y);
- Py_VISIT(traverse_module_state->__pyx_n_s_y0);
- Py_VISIT(traverse_module_state->__pyx_n_s_y1);
- Py_VISIT(traverse_module_state->__pyx_n_s_y2);
- Py_VISIT(traverse_module_state->__pyx_n_s_y3);
- Py_VISIT(traverse_module_state->__pyx_int_0);
- Py_VISIT(traverse_module_state->__pyx_int_1);
- Py_VISIT(traverse_module_state->__pyx_int_2);
- Py_VISIT(traverse_module_state->__pyx_tuple__2);
- Py_VISIT(traverse_module_state->__pyx_tuple__4);
- Py_VISIT(traverse_module_state->__pyx_tuple__5);
- Py_VISIT(traverse_module_state->__pyx_tuple__9);
- Py_VISIT(traverse_module_state->__pyx_tuple__11);
- Py_VISIT(traverse_module_state->__pyx_tuple__13);
- Py_VISIT(traverse_module_state->__pyx_tuple__15);
- Py_VISIT(traverse_module_state->__pyx_codeobj__3);
- Py_VISIT(traverse_module_state->__pyx_codeobj__6);
- Py_VISIT(traverse_module_state->__pyx_codeobj__7);
- Py_VISIT(traverse_module_state->__pyx_codeobj__8);
- Py_VISIT(traverse_module_state->__pyx_codeobj__10);
- Py_VISIT(traverse_module_state->__pyx_codeobj__12);
- Py_VISIT(traverse_module_state->__pyx_codeobj__14);
- return 0;
-}
-#endif
-/* #### Code section: module_state_defines ### */
-#define __pyx_d __pyx_mstate_global->__pyx_d
-#define __pyx_b __pyx_mstate_global->__pyx_b
-#define __pyx_cython_runtime __pyx_mstate_global->__pyx_cython_runtime
-#define __pyx_empty_tuple __pyx_mstate_global->__pyx_empty_tuple
-#define __pyx_empty_bytes __pyx_mstate_global->__pyx_empty_bytes
-#define __pyx_empty_unicode __pyx_mstate_global->__pyx_empty_unicode
-#ifdef __Pyx_CyFunction_USED
-#define __pyx_CyFunctionType __pyx_mstate_global->__pyx_CyFunctionType
-#endif
-#ifdef __Pyx_FusedFunction_USED
-#define __pyx_FusedFunctionType __pyx_mstate_global->__pyx_FusedFunctionType
-#endif
-#ifdef __Pyx_Generator_USED
-#define __pyx_GeneratorType __pyx_mstate_global->__pyx_GeneratorType
-#endif
-#ifdef __Pyx_IterableCoroutine_USED
-#define __pyx_IterableCoroutineType __pyx_mstate_global->__pyx_IterableCoroutineType
-#endif
-#ifdef __Pyx_Coroutine_USED
-#define __pyx_CoroutineAwaitType __pyx_mstate_global->__pyx_CoroutineAwaitType
-#endif
-#ifdef __Pyx_Coroutine_USED
-#define __pyx_CoroutineType __pyx_mstate_global->__pyx_CoroutineType
-#endif
-#if CYTHON_USE_MODULE_STATE
-#endif
-#if CYTHON_USE_MODULE_STATE
-#endif
-#define __pyx_kp_u_ __pyx_mstate_global->__pyx_kp_u_
-#define __pyx_n_s_AttributeError __pyx_mstate_global->__pyx_n_s_AttributeError
-#define __pyx_n_s_BasePen __pyx_mstate_global->__pyx_n_s_BasePen
-#define __pyx_n_s_COMPILED __pyx_mstate_global->__pyx_n_s_COMPILED
-#define __pyx_kp_u_Green_theorem_is_not_defined_on __pyx_mstate_global->__pyx_kp_u_Green_theorem_is_not_defined_on
-#define __pyx_n_s_ImportError __pyx_mstate_global->__pyx_n_s_ImportError
-#define __pyx_kp_s_Lib_fontTools_pens_momentsPen_py __pyx_mstate_global->__pyx_kp_s_Lib_fontTools_pens_momentsPen_py
-#define __pyx_n_s_MomentsPen __pyx_mstate_global->__pyx_n_s_MomentsPen
-#define __pyx_n_u_MomentsPen __pyx_mstate_global->__pyx_n_u_MomentsPen
-#define __pyx_n_s_MomentsPen___init __pyx_mstate_global->__pyx_n_s_MomentsPen___init
-#define __pyx_n_s_MomentsPen__closePath __pyx_mstate_global->__pyx_n_s_MomentsPen__closePath
-#define __pyx_n_s_MomentsPen__curveToOne __pyx_mstate_global->__pyx_n_s_MomentsPen__curveToOne
-#define __pyx_n_s_MomentsPen__endPath __pyx_mstate_global->__pyx_n_s_MomentsPen__endPath
-#define __pyx_n_s_MomentsPen__lineTo __pyx_mstate_global->__pyx_n_s_MomentsPen__lineTo
-#define __pyx_n_s_MomentsPen__moveTo __pyx_mstate_global->__pyx_n_s_MomentsPen__moveTo
-#define __pyx_n_s_MomentsPen__qCurveToOne __pyx_mstate_global->__pyx_n_s_MomentsPen__qCurveToOne
-#define __pyx_n_s_MomentsPen__startPoint __pyx_mstate_global->__pyx_n_s_MomentsPen__startPoint
-#define __pyx_n_s_OpenContourError __pyx_mstate_global->__pyx_n_s_OpenContourError
-#define __pyx_n_s__16 __pyx_mstate_global->__pyx_n_s__16
-#define __pyx_n_s_all __pyx_mstate_global->__pyx_n_s_all
-#define __pyx_n_s_area __pyx_mstate_global->__pyx_n_s_area
-#define __pyx_n_u_area __pyx_mstate_global->__pyx_n_u_area
-#define __pyx_n_s_asyncio_coroutines __pyx_mstate_global->__pyx_n_s_asyncio_coroutines
-#define __pyx_n_s_cline_in_traceback __pyx_mstate_global->__pyx_n_s_cline_in_traceback
-#define __pyx_n_s_closePath __pyx_mstate_global->__pyx_n_s_closePath
-#define __pyx_n_s_curveToOne __pyx_mstate_global->__pyx_n_s_curveToOne
-#define __pyx_n_s_cython __pyx_mstate_global->__pyx_n_s_cython
-#define __pyx_n_s_dict __pyx_mstate_global->__pyx_n_s_dict
-#define __pyx_n_s_doc __pyx_mstate_global->__pyx_n_s_doc
-#define __pyx_n_s_endPath __pyx_mstate_global->__pyx_n_s_endPath
-#define __pyx_n_s_fontTools_misc __pyx_mstate_global->__pyx_n_s_fontTools_misc
-#define __pyx_n_s_fontTools_misc_symfont __pyx_mstate_global->__pyx_n_s_fontTools_misc_symfont
-#define __pyx_n_s_fontTools_pens_basePen __pyx_mstate_global->__pyx_n_s_fontTools_pens_basePen
-#define __pyx_n_s_fontTools_pens_momentsPen __pyx_mstate_global->__pyx_n_s_fontTools_pens_momentsPen
-#define __pyx_n_s_getCurrentPoint __pyx_mstate_global->__pyx_n_s_getCurrentPoint
-#define __pyx_n_s_glyphset __pyx_mstate_global->__pyx_n_s_glyphset
-#define __pyx_n_s_import __pyx_mstate_global->__pyx_n_s_import
-#define __pyx_n_s_init __pyx_mstate_global->__pyx_n_s_init
-#define __pyx_n_s_init_subclass __pyx_mstate_global->__pyx_n_s_init_subclass
-#define __pyx_n_s_is_coroutine __pyx_mstate_global->__pyx_n_s_is_coroutine
-#define __pyx_n_s_lineTo __pyx_mstate_global->__pyx_n_s_lineTo
-#define __pyx_n_s_main __pyx_mstate_global->__pyx_n_s_main
-#define __pyx_n_u_main __pyx_mstate_global->__pyx_n_u_main
-#define __pyx_n_s_metaclass __pyx_mstate_global->__pyx_n_s_metaclass
-#define __pyx_n_s_module __pyx_mstate_global->__pyx_n_s_module
-#define __pyx_n_s_momentX __pyx_mstate_global->__pyx_n_s_momentX
-#define __pyx_n_u_momentX __pyx_mstate_global->__pyx_n_u_momentX
-#define __pyx_n_s_momentXX __pyx_mstate_global->__pyx_n_s_momentXX
-#define __pyx_n_u_momentXX __pyx_mstate_global->__pyx_n_u_momentXX
-#define __pyx_n_s_momentXY __pyx_mstate_global->__pyx_n_s_momentXY
-#define __pyx_n_u_momentXY __pyx_mstate_global->__pyx_n_u_momentXY
-#define __pyx_n_s_momentY __pyx_mstate_global->__pyx_n_s_momentY
-#define __pyx_n_u_momentY __pyx_mstate_global->__pyx_n_u_momentY
-#define __pyx_n_s_momentYY __pyx_mstate_global->__pyx_n_s_momentYY
-#define __pyx_n_u_momentYY __pyx_mstate_global->__pyx_n_u_momentYY
-#define __pyx_n_s_moveTo __pyx_mstate_global->__pyx_n_s_moveTo
-#define __pyx_n_s_mro_entries __pyx_mstate_global->__pyx_n_s_mro_entries
-#define __pyx_n_s_name __pyx_mstate_global->__pyx_n_s_name
-#define __pyx_n_s_p0 __pyx_mstate_global->__pyx_n_s_p0
-#define __pyx_n_s_p1 __pyx_mstate_global->__pyx_n_s_p1
-#define __pyx_n_s_p2 __pyx_mstate_global->__pyx_n_s_p2
-#define __pyx_n_s_p3 __pyx_mstate_global->__pyx_n_s_p3
-#define __pyx_n_s_prepare __pyx_mstate_global->__pyx_n_s_prepare
-#define __pyx_n_s_printGreenPen __pyx_mstate_global->__pyx_n_s_printGreenPen
-#define __pyx_n_s_qCurveToOne __pyx_mstate_global->__pyx_n_s_qCurveToOne
-#define __pyx_n_s_qualname __pyx_mstate_global->__pyx_n_s_qualname
-#define __pyx_n_s_r0 __pyx_mstate_global->__pyx_n_s_r0
-#define __pyx_n_s_r1 __pyx_mstate_global->__pyx_n_s_r1
-#define __pyx_n_s_r10 __pyx_mstate_global->__pyx_n_s_r10
-#define __pyx_n_s_r100 __pyx_mstate_global->__pyx_n_s_r100
-#define __pyx_n_s_r101 __pyx_mstate_global->__pyx_n_s_r101
-#define __pyx_n_s_r102 __pyx_mstate_global->__pyx_n_s_r102
-#define __pyx_n_s_r103 __pyx_mstate_global->__pyx_n_s_r103
-#define __pyx_n_s_r104 __pyx_mstate_global->__pyx_n_s_r104
-#define __pyx_n_s_r105 __pyx_mstate_global->__pyx_n_s_r105
-#define __pyx_n_s_r106 __pyx_mstate_global->__pyx_n_s_r106
-#define __pyx_n_s_r107 __pyx_mstate_global->__pyx_n_s_r107
-#define __pyx_n_s_r108 __pyx_mstate_global->__pyx_n_s_r108
-#define __pyx_n_s_r109 __pyx_mstate_global->__pyx_n_s_r109
-#define __pyx_n_s_r11 __pyx_mstate_global->__pyx_n_s_r11
-#define __pyx_n_s_r110 __pyx_mstate_global->__pyx_n_s_r110
-#define __pyx_n_s_r111 __pyx_mstate_global->__pyx_n_s_r111
-#define __pyx_n_s_r112 __pyx_mstate_global->__pyx_n_s_r112
-#define __pyx_n_s_r113 __pyx_mstate_global->__pyx_n_s_r113
-#define __pyx_n_s_r114 __pyx_mstate_global->__pyx_n_s_r114
-#define __pyx_n_s_r115 __pyx_mstate_global->__pyx_n_s_r115
-#define __pyx_n_s_r116 __pyx_mstate_global->__pyx_n_s_r116
-#define __pyx_n_s_r117 __pyx_mstate_global->__pyx_n_s_r117
-#define __pyx_n_s_r118 __pyx_mstate_global->__pyx_n_s_r118
-#define __pyx_n_s_r119 __pyx_mstate_global->__pyx_n_s_r119
-#define __pyx_n_s_r12 __pyx_mstate_global->__pyx_n_s_r12
-#define __pyx_n_s_r120 __pyx_mstate_global->__pyx_n_s_r120
-#define __pyx_n_s_r121 __pyx_mstate_global->__pyx_n_s_r121
-#define __pyx_n_s_r122 __pyx_mstate_global->__pyx_n_s_r122
-#define __pyx_n_s_r123 __pyx_mstate_global->__pyx_n_s_r123
-#define __pyx_n_s_r124 __pyx_mstate_global->__pyx_n_s_r124
-#define __pyx_n_s_r125 __pyx_mstate_global->__pyx_n_s_r125
-#define __pyx_n_s_r126 __pyx_mstate_global->__pyx_n_s_r126
-#define __pyx_n_s_r127 __pyx_mstate_global->__pyx_n_s_r127
-#define __pyx_n_s_r128 __pyx_mstate_global->__pyx_n_s_r128
-#define __pyx_n_s_r129 __pyx_mstate_global->__pyx_n_s_r129
-#define __pyx_n_s_r13 __pyx_mstate_global->__pyx_n_s_r13
-#define __pyx_n_s_r130 __pyx_mstate_global->__pyx_n_s_r130
-#define __pyx_n_s_r131 __pyx_mstate_global->__pyx_n_s_r131
-#define __pyx_n_s_r132 __pyx_mstate_global->__pyx_n_s_r132
-#define __pyx_n_s_r14 __pyx_mstate_global->__pyx_n_s_r14
-#define __pyx_n_s_r15 __pyx_mstate_global->__pyx_n_s_r15
-#define __pyx_n_s_r16 __pyx_mstate_global->__pyx_n_s_r16
-#define __pyx_n_s_r17 __pyx_mstate_global->__pyx_n_s_r17
-#define __pyx_n_s_r18 __pyx_mstate_global->__pyx_n_s_r18
-#define __pyx_n_s_r19 __pyx_mstate_global->__pyx_n_s_r19
-#define __pyx_n_s_r2 __pyx_mstate_global->__pyx_n_s_r2
-#define __pyx_n_s_r20 __pyx_mstate_global->__pyx_n_s_r20
-#define __pyx_n_s_r21 __pyx_mstate_global->__pyx_n_s_r21
-#define __pyx_n_s_r22 __pyx_mstate_global->__pyx_n_s_r22
-#define __pyx_n_s_r23 __pyx_mstate_global->__pyx_n_s_r23
-#define __pyx_n_s_r24 __pyx_mstate_global->__pyx_n_s_r24
-#define __pyx_n_s_r25 __pyx_mstate_global->__pyx_n_s_r25
-#define __pyx_n_s_r26 __pyx_mstate_global->__pyx_n_s_r26
-#define __pyx_n_s_r27 __pyx_mstate_global->__pyx_n_s_r27
-#define __pyx_n_s_r28 __pyx_mstate_global->__pyx_n_s_r28
-#define __pyx_n_s_r29 __pyx_mstate_global->__pyx_n_s_r29
-#define __pyx_n_s_r3 __pyx_mstate_global->__pyx_n_s_r3
-#define __pyx_n_s_r30 __pyx_mstate_global->__pyx_n_s_r30
-#define __pyx_n_s_r31 __pyx_mstate_global->__pyx_n_s_r31
-#define __pyx_n_s_r32 __pyx_mstate_global->__pyx_n_s_r32
-#define __pyx_n_s_r33 __pyx_mstate_global->__pyx_n_s_r33
-#define __pyx_n_s_r34 __pyx_mstate_global->__pyx_n_s_r34
-#define __pyx_n_s_r35 __pyx_mstate_global->__pyx_n_s_r35
-#define __pyx_n_s_r36 __pyx_mstate_global->__pyx_n_s_r36
-#define __pyx_n_s_r37 __pyx_mstate_global->__pyx_n_s_r37
-#define __pyx_n_s_r38 __pyx_mstate_global->__pyx_n_s_r38
-#define __pyx_n_s_r39 __pyx_mstate_global->__pyx_n_s_r39
-#define __pyx_n_s_r4 __pyx_mstate_global->__pyx_n_s_r4
-#define __pyx_n_s_r40 __pyx_mstate_global->__pyx_n_s_r40
-#define __pyx_n_s_r41 __pyx_mstate_global->__pyx_n_s_r41
-#define __pyx_n_s_r42 __pyx_mstate_global->__pyx_n_s_r42
-#define __pyx_n_s_r43 __pyx_mstate_global->__pyx_n_s_r43
-#define __pyx_n_s_r44 __pyx_mstate_global->__pyx_n_s_r44
-#define __pyx_n_s_r45 __pyx_mstate_global->__pyx_n_s_r45
-#define __pyx_n_s_r46 __pyx_mstate_global->__pyx_n_s_r46
-#define __pyx_n_s_r47 __pyx_mstate_global->__pyx_n_s_r47
-#define __pyx_n_s_r48 __pyx_mstate_global->__pyx_n_s_r48
-#define __pyx_n_s_r49 __pyx_mstate_global->__pyx_n_s_r49
-#define __pyx_n_s_r5 __pyx_mstate_global->__pyx_n_s_r5
-#define __pyx_n_s_r50 __pyx_mstate_global->__pyx_n_s_r50
-#define __pyx_n_s_r51 __pyx_mstate_global->__pyx_n_s_r51
-#define __pyx_n_s_r52 __pyx_mstate_global->__pyx_n_s_r52
-#define __pyx_n_s_r53 __pyx_mstate_global->__pyx_n_s_r53
-#define __pyx_n_s_r54 __pyx_mstate_global->__pyx_n_s_r54
-#define __pyx_n_s_r55 __pyx_mstate_global->__pyx_n_s_r55
-#define __pyx_n_s_r56 __pyx_mstate_global->__pyx_n_s_r56
-#define __pyx_n_s_r57 __pyx_mstate_global->__pyx_n_s_r57
-#define __pyx_n_s_r58 __pyx_mstate_global->__pyx_n_s_r58
-#define __pyx_n_s_r59 __pyx_mstate_global->__pyx_n_s_r59
-#define __pyx_n_s_r6 __pyx_mstate_global->__pyx_n_s_r6
-#define __pyx_n_s_r60 __pyx_mstate_global->__pyx_n_s_r60
-#define __pyx_n_s_r61 __pyx_mstate_global->__pyx_n_s_r61
-#define __pyx_n_s_r62 __pyx_mstate_global->__pyx_n_s_r62
-#define __pyx_n_s_r63 __pyx_mstate_global->__pyx_n_s_r63
-#define __pyx_n_s_r64 __pyx_mstate_global->__pyx_n_s_r64
-#define __pyx_n_s_r65 __pyx_mstate_global->__pyx_n_s_r65
-#define __pyx_n_s_r66 __pyx_mstate_global->__pyx_n_s_r66
-#define __pyx_n_s_r67 __pyx_mstate_global->__pyx_n_s_r67
-#define __pyx_n_s_r68 __pyx_mstate_global->__pyx_n_s_r68
-#define __pyx_n_s_r69 __pyx_mstate_global->__pyx_n_s_r69
-#define __pyx_n_s_r7 __pyx_mstate_global->__pyx_n_s_r7
-#define __pyx_n_s_r70 __pyx_mstate_global->__pyx_n_s_r70
-#define __pyx_n_s_r71 __pyx_mstate_global->__pyx_n_s_r71
-#define __pyx_n_s_r72 __pyx_mstate_global->__pyx_n_s_r72
-#define __pyx_n_s_r73 __pyx_mstate_global->__pyx_n_s_r73
-#define __pyx_n_s_r74 __pyx_mstate_global->__pyx_n_s_r74
-#define __pyx_n_s_r75 __pyx_mstate_global->__pyx_n_s_r75
-#define __pyx_n_s_r76 __pyx_mstate_global->__pyx_n_s_r76
-#define __pyx_n_s_r77 __pyx_mstate_global->__pyx_n_s_r77
-#define __pyx_n_s_r78 __pyx_mstate_global->__pyx_n_s_r78
-#define __pyx_n_s_r79 __pyx_mstate_global->__pyx_n_s_r79
-#define __pyx_n_s_r8 __pyx_mstate_global->__pyx_n_s_r8
-#define __pyx_n_s_r80 __pyx_mstate_global->__pyx_n_s_r80
-#define __pyx_n_s_r81 __pyx_mstate_global->__pyx_n_s_r81
-#define __pyx_n_s_r82 __pyx_mstate_global->__pyx_n_s_r82
-#define __pyx_n_s_r83 __pyx_mstate_global->__pyx_n_s_r83
-#define __pyx_n_s_r84 __pyx_mstate_global->__pyx_n_s_r84
-#define __pyx_n_s_r85 __pyx_mstate_global->__pyx_n_s_r85
-#define __pyx_n_s_r86 __pyx_mstate_global->__pyx_n_s_r86
-#define __pyx_n_s_r87 __pyx_mstate_global->__pyx_n_s_r87
-#define __pyx_n_s_r88 __pyx_mstate_global->__pyx_n_s_r88
-#define __pyx_n_s_r89 __pyx_mstate_global->__pyx_n_s_r89
-#define __pyx_n_s_r9 __pyx_mstate_global->__pyx_n_s_r9
-#define __pyx_n_s_r90 __pyx_mstate_global->__pyx_n_s_r90
-#define __pyx_n_s_r91 __pyx_mstate_global->__pyx_n_s_r91
-#define __pyx_n_s_r92 __pyx_mstate_global->__pyx_n_s_r92
-#define __pyx_n_s_r93 __pyx_mstate_global->__pyx_n_s_r93
-#define __pyx_n_s_r94 __pyx_mstate_global->__pyx_n_s_r94
-#define __pyx_n_s_r95 __pyx_mstate_global->__pyx_n_s_r95
-#define __pyx_n_s_r96 __pyx_mstate_global->__pyx_n_s_r96
-#define __pyx_n_s_r97 __pyx_mstate_global->__pyx_n_s_r97
-#define __pyx_n_s_r98 __pyx_mstate_global->__pyx_n_s_r98
-#define __pyx_n_s_r99 __pyx_mstate_global->__pyx_n_s_r99
-#define __pyx_n_s_self __pyx_mstate_global->__pyx_n_s_self
-#define __pyx_n_s_set_name __pyx_mstate_global->__pyx_n_s_set_name
-#define __pyx_n_s_super __pyx_mstate_global->__pyx_n_s_super
-#define __pyx_n_s_test __pyx_mstate_global->__pyx_n_s_test
-#define __pyx_n_s_x __pyx_mstate_global->__pyx_n_s_x
-#define __pyx_n_s_x0 __pyx_mstate_global->__pyx_n_s_x0
-#define __pyx_n_s_x1 __pyx_mstate_global->__pyx_n_s_x1
-#define __pyx_n_s_x2 __pyx_mstate_global->__pyx_n_s_x2
-#define __pyx_n_s_x3 __pyx_mstate_global->__pyx_n_s_x3
-#define __pyx_n_s_y __pyx_mstate_global->__pyx_n_s_y
-#define __pyx_n_s_y0 __pyx_mstate_global->__pyx_n_s_y0
-#define __pyx_n_s_y1 __pyx_mstate_global->__pyx_n_s_y1
-#define __pyx_n_s_y2 __pyx_mstate_global->__pyx_n_s_y2
-#define __pyx_n_s_y3 __pyx_mstate_global->__pyx_n_s_y3
-#define __pyx_int_0 __pyx_mstate_global->__pyx_int_0
-#define __pyx_int_1 __pyx_mstate_global->__pyx_int_1
-#define __pyx_int_2 __pyx_mstate_global->__pyx_int_2
-#define __pyx_tuple__2 __pyx_mstate_global->__pyx_tuple__2
-#define __pyx_tuple__4 __pyx_mstate_global->__pyx_tuple__4
-#define __pyx_tuple__5 __pyx_mstate_global->__pyx_tuple__5
-#define __pyx_tuple__9 __pyx_mstate_global->__pyx_tuple__9
-#define __pyx_tuple__11 __pyx_mstate_global->__pyx_tuple__11
-#define __pyx_tuple__13 __pyx_mstate_global->__pyx_tuple__13
-#define __pyx_tuple__15 __pyx_mstate_global->__pyx_tuple__15
-#define __pyx_codeobj__3 __pyx_mstate_global->__pyx_codeobj__3
-#define __pyx_codeobj__6 __pyx_mstate_global->__pyx_codeobj__6
-#define __pyx_codeobj__7 __pyx_mstate_global->__pyx_codeobj__7
-#define __pyx_codeobj__8 __pyx_mstate_global->__pyx_codeobj__8
-#define __pyx_codeobj__10 __pyx_mstate_global->__pyx_codeobj__10
-#define __pyx_codeobj__12 __pyx_mstate_global->__pyx_codeobj__12
-#define __pyx_codeobj__14 __pyx_mstate_global->__pyx_codeobj__14
-/* #### Code section: module_code ### */
-
-/* "fontTools/pens/momentsPen.py":18
- *
- * class MomentsPen(BasePen):
- * def __init__(self, glyphset=None): # <<<<<<<<<<<<<<
- * BasePen.__init__(self, glyphset)
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_1__init__(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-); /*proto*/
-PyDoc_STRVAR(__pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen___init__, "MomentsPen.__init__(self, glyphset=None)");
-static PyMethodDef __pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_1__init__ = {"__init__", (PyCFunction)(void*)(__Pyx_PyCFunction_FastCallWithKeywords)__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_1__init__, __Pyx_METH_FASTCALL|METH_KEYWORDS, __pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen___init__};
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_1__init__(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-) {
- PyObject *__pyx_v_self = 0;
- PyObject *__pyx_v_glyphset = 0;
- #if !CYTHON_METH_FASTCALL
- CYTHON_UNUSED const Py_ssize_t __pyx_nargs = PyTuple_GET_SIZE(__pyx_args);
- #endif
- CYTHON_UNUSED PyObject *const *__pyx_kwvalues = __Pyx_KwValues_FASTCALL(__pyx_args, __pyx_nargs);
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__init__ (wrapper)", 0);
- {
- PyObject **__pyx_pyargnames[] = {&__pyx_n_s_self,&__pyx_n_s_glyphset,0};
- PyObject* values[2] = {0,0};
- values[1] = ((PyObject *)((PyObject *)Py_None));
- if (__pyx_kwds) {
- Py_ssize_t kw_args;
- switch (__pyx_nargs) {
- case 2: values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = __Pyx_NumKwargs_FASTCALL(__pyx_kwds);
- switch (__pyx_nargs) {
- case 0:
- if (likely((values[0] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_self)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 18, __pyx_L3_error)
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (kw_args > 0) {
- PyObject* value = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_glyphset);
- if (value) { values[1] = value; kw_args--; }
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 18, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- const Py_ssize_t kwd_pos_args = __pyx_nargs;
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_kwvalues, __pyx_pyargnames, 0, values + 0, kwd_pos_args, "__init__") < 0)) __PYX_ERR(0, 18, __pyx_L3_error)
- }
- } else {
- switch (__pyx_nargs) {
- case 2: values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- break;
- default: goto __pyx_L5_argtuple_error;
- }
- }
- __pyx_v_self = values[0];
- __pyx_v_glyphset = values[1];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__init__", 0, 1, 2, __pyx_nargs); __PYX_ERR(0, 18, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen.__init__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen___init__(__pyx_self, __pyx_v_self, __pyx_v_glyphset);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen___init__(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_glyphset) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__init__", 0);
-
- /* "fontTools/pens/momentsPen.py":19
- * class MomentsPen(BasePen):
- * def __init__(self, glyphset=None):
- * BasePen.__init__(self, glyphset) # <<<<<<<<<<<<<<
- *
- * self.area = 0
- */
- __Pyx_GetModuleGlobalName(__pyx_t_2, __pyx_n_s_BasePen); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 19, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_t_2, __pyx_n_s_init); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 19, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_2 = NULL;
- __pyx_t_4 = 0;
- if (CYTHON_UNPACK_METHODS && unlikely(PyMethod_Check(__pyx_t_3))) {
- __pyx_t_2 = PyMethod_GET_SELF(__pyx_t_3);
- if (likely(__pyx_t_2)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_3);
- __Pyx_INCREF(__pyx_t_2);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_3, function);
- __pyx_t_4 = 1;
- }
- }
- {
- PyObject *__pyx_callargs[3] = {__pyx_t_2, __pyx_v_self, __pyx_v_glyphset};
- __pyx_t_1 = __Pyx_PyObject_FastCall(__pyx_t_3, __pyx_callargs+1-__pyx_t_4, 2+__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_2); __pyx_t_2 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 19, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- }
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "fontTools/pens/momentsPen.py":21
- * BasePen.__init__(self, glyphset)
- *
- * self.area = 0 # <<<<<<<<<<<<<<
- * self.momentX = 0
- * self.momentY = 0
- */
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_area, __pyx_int_0) < 0) __PYX_ERR(0, 21, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":22
- *
- * self.area = 0
- * self.momentX = 0 # <<<<<<<<<<<<<<
- * self.momentY = 0
- * self.momentXX = 0
- */
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentX, __pyx_int_0) < 0) __PYX_ERR(0, 22, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":23
- * self.area = 0
- * self.momentX = 0
- * self.momentY = 0 # <<<<<<<<<<<<<<
- * self.momentXX = 0
- * self.momentXY = 0
- */
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentY, __pyx_int_0) < 0) __PYX_ERR(0, 23, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":24
- * self.momentX = 0
- * self.momentY = 0
- * self.momentXX = 0 # <<<<<<<<<<<<<<
- * self.momentXY = 0
- * self.momentYY = 0
- */
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentXX, __pyx_int_0) < 0) __PYX_ERR(0, 24, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":25
- * self.momentY = 0
- * self.momentXX = 0
- * self.momentXY = 0 # <<<<<<<<<<<<<<
- * self.momentYY = 0
- *
- */
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentXY, __pyx_int_0) < 0) __PYX_ERR(0, 25, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":26
- * self.momentXX = 0
- * self.momentXY = 0
- * self.momentYY = 0 # <<<<<<<<<<<<<<
- *
- * def _moveTo(self, p0):
- */
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentYY, __pyx_int_0) < 0) __PYX_ERR(0, 26, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":18
- *
- * class MomentsPen(BasePen):
- * def __init__(self, glyphset=None): # <<<<<<<<<<<<<<
- * BasePen.__init__(self, glyphset)
- *
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen.__init__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "fontTools/pens/momentsPen.py":28
- * self.momentYY = 0
- *
- * def _moveTo(self, p0): # <<<<<<<<<<<<<<
- * self.__startPoint = p0
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_3_moveTo(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-); /*proto*/
-PyDoc_STRVAR(__pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_2_moveTo, "MomentsPen._moveTo(self, p0)");
-static PyMethodDef __pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_3_moveTo = {"_moveTo", (PyCFunction)(void*)(__Pyx_PyCFunction_FastCallWithKeywords)__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_3_moveTo, __Pyx_METH_FASTCALL|METH_KEYWORDS, __pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_2_moveTo};
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_3_moveTo(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-) {
- PyObject *__pyx_v_self = 0;
- PyObject *__pyx_v_p0 = 0;
- #if !CYTHON_METH_FASTCALL
- CYTHON_UNUSED const Py_ssize_t __pyx_nargs = PyTuple_GET_SIZE(__pyx_args);
- #endif
- CYTHON_UNUSED PyObject *const *__pyx_kwvalues = __Pyx_KwValues_FASTCALL(__pyx_args, __pyx_nargs);
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("_moveTo (wrapper)", 0);
- {
- PyObject **__pyx_pyargnames[] = {&__pyx_n_s_self,&__pyx_n_s_p0,0};
- PyObject* values[2] = {0,0};
- if (__pyx_kwds) {
- Py_ssize_t kw_args;
- switch (__pyx_nargs) {
- case 2: values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = __Pyx_NumKwargs_FASTCALL(__pyx_kwds);
- switch (__pyx_nargs) {
- case 0:
- if (likely((values[0] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_self)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 28, __pyx_L3_error)
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_p0)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 28, __pyx_L3_error)
- else {
- __Pyx_RaiseArgtupleInvalid("_moveTo", 1, 2, 2, 1); __PYX_ERR(0, 28, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- const Py_ssize_t kwd_pos_args = __pyx_nargs;
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_kwvalues, __pyx_pyargnames, 0, values + 0, kwd_pos_args, "_moveTo") < 0)) __PYX_ERR(0, 28, __pyx_L3_error)
- }
- } else if (unlikely(__pyx_nargs != 2)) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- }
- __pyx_v_self = values[0];
- __pyx_v_p0 = values[1];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("_moveTo", 1, 2, 2, __pyx_nargs); __PYX_ERR(0, 28, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._moveTo", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_2_moveTo(__pyx_self, __pyx_v_self, __pyx_v_p0);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_2_moveTo(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_p0) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("_moveTo", 0);
-
- /* "fontTools/pens/momentsPen.py":29
- *
- * def _moveTo(self, p0):
- * self.__startPoint = p0 # <<<<<<<<<<<<<<
- *
- * def _closePath(self):
- */
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_MomentsPen__startPoint, __pyx_v_p0) < 0) __PYX_ERR(0, 29, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":28
- * self.momentYY = 0
- *
- * def _moveTo(self, p0): # <<<<<<<<<<<<<<
- * self.__startPoint = p0
- *
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._moveTo", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "fontTools/pens/momentsPen.py":31
- * self.__startPoint = p0
- *
- * def _closePath(self): # <<<<<<<<<<<<<<
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_5_closePath(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-); /*proto*/
-PyDoc_STRVAR(__pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_4_closePath, "MomentsPen._closePath(self)");
-static PyMethodDef __pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_5_closePath = {"_closePath", (PyCFunction)(void*)(__Pyx_PyCFunction_FastCallWithKeywords)__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_5_closePath, __Pyx_METH_FASTCALL|METH_KEYWORDS, __pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_4_closePath};
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_5_closePath(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-) {
- PyObject *__pyx_v_self = 0;
- #if !CYTHON_METH_FASTCALL
- CYTHON_UNUSED const Py_ssize_t __pyx_nargs = PyTuple_GET_SIZE(__pyx_args);
- #endif
- CYTHON_UNUSED PyObject *const *__pyx_kwvalues = __Pyx_KwValues_FASTCALL(__pyx_args, __pyx_nargs);
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("_closePath (wrapper)", 0);
- {
- PyObject **__pyx_pyargnames[] = {&__pyx_n_s_self,0};
- PyObject* values[1] = {0};
- if (__pyx_kwds) {
- Py_ssize_t kw_args;
- switch (__pyx_nargs) {
- case 1: values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = __Pyx_NumKwargs_FASTCALL(__pyx_kwds);
- switch (__pyx_nargs) {
- case 0:
- if (likely((values[0] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_self)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 31, __pyx_L3_error)
- else goto __pyx_L5_argtuple_error;
- }
- if (unlikely(kw_args > 0)) {
- const Py_ssize_t kwd_pos_args = __pyx_nargs;
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_kwvalues, __pyx_pyargnames, 0, values + 0, kwd_pos_args, "_closePath") < 0)) __PYX_ERR(0, 31, __pyx_L3_error)
- }
- } else if (unlikely(__pyx_nargs != 1)) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- }
- __pyx_v_self = values[0];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("_closePath", 1, 1, 1, __pyx_nargs); __PYX_ERR(0, 31, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._closePath", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_4_closePath(__pyx_self, __pyx_v_self);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_4_closePath(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self) {
- PyObject *__pyx_v_p0 = NULL;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- int __pyx_t_5;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("_closePath", 0);
-
- /* "fontTools/pens/momentsPen.py":32
- *
- * def _closePath(self):
- * p0 = self._getCurrentPoint() # <<<<<<<<<<<<<<
- * if p0 != self.__startPoint:
- * self._lineTo(self.__startPoint)
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_getCurrentPoint); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 32, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = NULL;
- __pyx_t_4 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_2))) {
- __pyx_t_3 = PyMethod_GET_SELF(__pyx_t_2);
- if (likely(__pyx_t_3)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_2);
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_2, function);
- __pyx_t_4 = 1;
- }
- }
- {
- PyObject *__pyx_callargs[1] = {__pyx_t_3, };
- __pyx_t_1 = __Pyx_PyObject_FastCall(__pyx_t_2, __pyx_callargs+1-__pyx_t_4, 0+__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 32, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- __pyx_v_p0 = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "fontTools/pens/momentsPen.py":33
- * def _closePath(self):
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint: # <<<<<<<<<<<<<<
- * self._lineTo(self.__startPoint)
- *
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_MomentsPen__startPoint); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 33, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = PyObject_RichCompare(__pyx_v_p0, __pyx_t_1, Py_NE); __Pyx_XGOTREF(__pyx_t_2); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 33, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_5 = __Pyx_PyObject_IsTrue(__pyx_t_2); if (unlikely((__pyx_t_5 < 0))) __PYX_ERR(0, 33, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- if (__pyx_t_5) {
-
- /* "fontTools/pens/momentsPen.py":34
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- * self._lineTo(self.__startPoint) # <<<<<<<<<<<<<<
- *
- * def _endPath(self):
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_lineTo); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 34, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_MomentsPen__startPoint); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 34, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_6 = NULL;
- __pyx_t_4 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_1))) {
- __pyx_t_6 = PyMethod_GET_SELF(__pyx_t_1);
- if (likely(__pyx_t_6)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_6);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_1, function);
- __pyx_t_4 = 1;
- }
- }
- {
- PyObject *__pyx_callargs[2] = {__pyx_t_6, __pyx_t_3};
- __pyx_t_2 = __Pyx_PyObject_FastCall(__pyx_t_1, __pyx_callargs+1-__pyx_t_4, 1+__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 34, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- }
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":33
- * def _closePath(self):
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint: # <<<<<<<<<<<<<<
- * self._lineTo(self.__startPoint)
- *
- */
- }
-
- /* "fontTools/pens/momentsPen.py":31
- * self.__startPoint = p0
- *
- * def _closePath(self): # <<<<<<<<<<<<<<
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._closePath", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_p0);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "fontTools/pens/momentsPen.py":36
- * self._lineTo(self.__startPoint)
- *
- * def _endPath(self): # <<<<<<<<<<<<<<
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_7_endPath(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-); /*proto*/
-PyDoc_STRVAR(__pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_6_endPath, "MomentsPen._endPath(self)");
-static PyMethodDef __pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_7_endPath = {"_endPath", (PyCFunction)(void*)(__Pyx_PyCFunction_FastCallWithKeywords)__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_7_endPath, __Pyx_METH_FASTCALL|METH_KEYWORDS, __pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_6_endPath};
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_7_endPath(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-) {
- PyObject *__pyx_v_self = 0;
- #if !CYTHON_METH_FASTCALL
- CYTHON_UNUSED const Py_ssize_t __pyx_nargs = PyTuple_GET_SIZE(__pyx_args);
- #endif
- CYTHON_UNUSED PyObject *const *__pyx_kwvalues = __Pyx_KwValues_FASTCALL(__pyx_args, __pyx_nargs);
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("_endPath (wrapper)", 0);
- {
- PyObject **__pyx_pyargnames[] = {&__pyx_n_s_self,0};
- PyObject* values[1] = {0};
- if (__pyx_kwds) {
- Py_ssize_t kw_args;
- switch (__pyx_nargs) {
- case 1: values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = __Pyx_NumKwargs_FASTCALL(__pyx_kwds);
- switch (__pyx_nargs) {
- case 0:
- if (likely((values[0] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_self)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 36, __pyx_L3_error)
- else goto __pyx_L5_argtuple_error;
- }
- if (unlikely(kw_args > 0)) {
- const Py_ssize_t kwd_pos_args = __pyx_nargs;
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_kwvalues, __pyx_pyargnames, 0, values + 0, kwd_pos_args, "_endPath") < 0)) __PYX_ERR(0, 36, __pyx_L3_error)
- }
- } else if (unlikely(__pyx_nargs != 1)) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- }
- __pyx_v_self = values[0];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("_endPath", 1, 1, 1, __pyx_nargs); __PYX_ERR(0, 36, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._endPath", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_6_endPath(__pyx_self, __pyx_v_self);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_6_endPath(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self) {
- PyObject *__pyx_v_p0 = NULL;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- int __pyx_t_5;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("_endPath", 0);
-
- /* "fontTools/pens/momentsPen.py":37
- *
- * def _endPath(self):
- * p0 = self._getCurrentPoint() # <<<<<<<<<<<<<<
- * if p0 != self.__startPoint:
- * # Green theorem is not defined on open contours.
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_getCurrentPoint); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 37, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = NULL;
- __pyx_t_4 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_2))) {
- __pyx_t_3 = PyMethod_GET_SELF(__pyx_t_2);
- if (likely(__pyx_t_3)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_2);
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_2, function);
- __pyx_t_4 = 1;
- }
- }
- {
- PyObject *__pyx_callargs[1] = {__pyx_t_3, };
- __pyx_t_1 = __Pyx_PyObject_FastCall(__pyx_t_2, __pyx_callargs+1-__pyx_t_4, 0+__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 37, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- __pyx_v_p0 = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "fontTools/pens/momentsPen.py":38
- * def _endPath(self):
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint: # <<<<<<<<<<<<<<
- * # Green theorem is not defined on open contours.
- * raise OpenContourError("Green theorem is not defined on open contours.")
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_MomentsPen__startPoint); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 38, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = PyObject_RichCompare(__pyx_v_p0, __pyx_t_1, Py_NE); __Pyx_XGOTREF(__pyx_t_2); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 38, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_5 = __Pyx_PyObject_IsTrue(__pyx_t_2); if (unlikely((__pyx_t_5 < 0))) __PYX_ERR(0, 38, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- if (unlikely(__pyx_t_5)) {
-
- /* "fontTools/pens/momentsPen.py":40
- * if p0 != self.__startPoint:
- * # Green theorem is not defined on open contours.
- * raise OpenContourError("Green theorem is not defined on open contours.") # <<<<<<<<<<<<<<
- *
- * @cython.locals(r0=cython.double)
- */
- __Pyx_GetModuleGlobalName(__pyx_t_1, __pyx_n_s_OpenContourError); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 40, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = NULL;
- __pyx_t_4 = 0;
- if (CYTHON_UNPACK_METHODS && unlikely(PyMethod_Check(__pyx_t_1))) {
- __pyx_t_3 = PyMethod_GET_SELF(__pyx_t_1);
- if (likely(__pyx_t_3)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_1, function);
- __pyx_t_4 = 1;
- }
- }
- {
- PyObject *__pyx_callargs[2] = {__pyx_t_3, __pyx_kp_u_Green_theorem_is_not_defined_on};
- __pyx_t_2 = __Pyx_PyObject_FastCall(__pyx_t_1, __pyx_callargs+1-__pyx_t_4, 1+__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 40, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- }
- __Pyx_Raise(__pyx_t_2, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __PYX_ERR(0, 40, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":38
- * def _endPath(self):
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint: # <<<<<<<<<<<<<<
- * # Green theorem is not defined on open contours.
- * raise OpenContourError("Green theorem is not defined on open contours.")
- */
- }
-
- /* "fontTools/pens/momentsPen.py":36
- * self._lineTo(self.__startPoint)
- *
- * def _endPath(self): # <<<<<<<<<<<<<<
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._endPath", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_p0);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "fontTools/pens/momentsPen.py":42
- * raise OpenContourError("Green theorem is not defined on open contours.")
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_9_lineTo(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-); /*proto*/
-PyDoc_STRVAR(__pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_8_lineTo, "MomentsPen._lineTo(self, p1)");
-static PyMethodDef __pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_9_lineTo = {"_lineTo", (PyCFunction)(void*)(__Pyx_PyCFunction_FastCallWithKeywords)__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_9_lineTo, __Pyx_METH_FASTCALL|METH_KEYWORDS, __pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_8_lineTo};
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_9_lineTo(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-) {
- PyObject *__pyx_v_self = 0;
- PyObject *__pyx_v_p1 = 0;
- #if !CYTHON_METH_FASTCALL
- CYTHON_UNUSED const Py_ssize_t __pyx_nargs = PyTuple_GET_SIZE(__pyx_args);
- #endif
- CYTHON_UNUSED PyObject *const *__pyx_kwvalues = __Pyx_KwValues_FASTCALL(__pyx_args, __pyx_nargs);
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("_lineTo (wrapper)", 0);
- {
- PyObject **__pyx_pyargnames[] = {&__pyx_n_s_self,&__pyx_n_s_p1,0};
- PyObject* values[2] = {0,0};
- if (__pyx_kwds) {
- Py_ssize_t kw_args;
- switch (__pyx_nargs) {
- case 2: values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = __Pyx_NumKwargs_FASTCALL(__pyx_kwds);
- switch (__pyx_nargs) {
- case 0:
- if (likely((values[0] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_self)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 42, __pyx_L3_error)
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_p1)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 42, __pyx_L3_error)
- else {
- __Pyx_RaiseArgtupleInvalid("_lineTo", 1, 2, 2, 1); __PYX_ERR(0, 42, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- const Py_ssize_t kwd_pos_args = __pyx_nargs;
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_kwvalues, __pyx_pyargnames, 0, values + 0, kwd_pos_args, "_lineTo") < 0)) __PYX_ERR(0, 42, __pyx_L3_error)
- }
- } else if (unlikely(__pyx_nargs != 2)) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- }
- __pyx_v_self = values[0];
- __pyx_v_p1 = values[1];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("_lineTo", 1, 2, 2, __pyx_nargs); __PYX_ERR(0, 42, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._lineTo", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_8_lineTo(__pyx_self, __pyx_v_self, __pyx_v_p1);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_8_lineTo(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_p1) {
- double __pyx_v_x1;
- double __pyx_v_y1;
- double __pyx_v_x0;
- double __pyx_v_y0;
- double __pyx_v_r12;
- double __pyx_v_r11;
- double __pyx_v_r10;
- double __pyx_v_r9;
- double __pyx_v_r8;
- double __pyx_v_r7;
- double __pyx_v_r6;
- double __pyx_v_r5;
- double __pyx_v_r4;
- double __pyx_v_r3;
- double __pyx_v_r2;
- double __pyx_v_r1;
- double __pyx_v_r0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- PyObject *(*__pyx_t_6)(PyObject *);
- double __pyx_t_7;
- double __pyx_t_8;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("_lineTo", 0);
-
- /* "fontTools/pens/momentsPen.py":58
- * @cython.locals(x1=cython.double, y1=cython.double)
- * def _lineTo(self, p1):
- * x0, y0 = self._getCurrentPoint() # <<<<<<<<<<<<<<
- * x1, y1 = p1
- *
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_getCurrentPoint); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 58, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = NULL;
- __pyx_t_4 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_2))) {
- __pyx_t_3 = PyMethod_GET_SELF(__pyx_t_2);
- if (likely(__pyx_t_3)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_2);
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_2, function);
- __pyx_t_4 = 1;
- }
- }
- {
- PyObject *__pyx_callargs[1] = {__pyx_t_3, };
- __pyx_t_1 = __Pyx_PyObject_FastCall(__pyx_t_2, __pyx_callargs+1-__pyx_t_4, 0+__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 58, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- if ((likely(PyTuple_CheckExact(__pyx_t_1))) || (PyList_CheckExact(__pyx_t_1))) {
- PyObject* sequence = __pyx_t_1;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 58, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_2 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_2 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_2);
- __Pyx_INCREF(__pyx_t_3);
- #else
- __pyx_t_2 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 58, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 58, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- #endif
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- } else {
- Py_ssize_t index = -1;
- __pyx_t_5 = PyObject_GetIter(__pyx_t_1); if (unlikely(!__pyx_t_5)) __PYX_ERR(0, 58, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_5);
- index = 0; __pyx_t_2 = __pyx_t_6(__pyx_t_5); if (unlikely(!__pyx_t_2)) goto __pyx_L3_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_2);
- index = 1; __pyx_t_3 = __pyx_t_6(__pyx_t_5); if (unlikely(!__pyx_t_3)) goto __pyx_L3_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_5), 2) < 0) __PYX_ERR(0, 58, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- goto __pyx_L4_unpacking_done;
- __pyx_L3_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 58, __pyx_L1_error)
- __pyx_L4_unpacking_done:;
- }
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_2); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 58, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 58, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_x0 = __pyx_t_7;
- __pyx_v_y0 = __pyx_t_8;
-
- /* "fontTools/pens/momentsPen.py":59
- * def _lineTo(self, p1):
- * x0, y0 = self._getCurrentPoint()
- * x1, y1 = p1 # <<<<<<<<<<<<<<
- *
- * r0 = x1 * y0
- */
- if ((likely(PyTuple_CheckExact(__pyx_v_p1))) || (PyList_CheckExact(__pyx_v_p1))) {
- PyObject* sequence = __pyx_v_p1;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 59, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_1 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_1 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_3);
- #else
- __pyx_t_1 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 59, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 59, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- #endif
- } else {
- Py_ssize_t index = -1;
- __pyx_t_2 = PyObject_GetIter(__pyx_v_p1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 59, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_2);
- index = 0; __pyx_t_1 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_1)) goto __pyx_L5_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_1);
- index = 1; __pyx_t_3 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_3)) goto __pyx_L5_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_2), 2) < 0) __PYX_ERR(0, 59, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- goto __pyx_L6_unpacking_done;
- __pyx_L5_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 59, __pyx_L1_error)
- __pyx_L6_unpacking_done:;
- }
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_1); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 59, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 59, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_x1 = __pyx_t_8;
- __pyx_v_y1 = __pyx_t_7;
-
- /* "fontTools/pens/momentsPen.py":61
- * x1, y1 = p1
- *
- * r0 = x1 * y0 # <<<<<<<<<<<<<<
- * r1 = x1 * y1
- * r2 = x1**2
- */
- __pyx_v_r0 = (__pyx_v_x1 * __pyx_v_y0);
-
- /* "fontTools/pens/momentsPen.py":62
- *
- * r0 = x1 * y0
- * r1 = x1 * y1 # <<<<<<<<<<<<<<
- * r2 = x1**2
- * r3 = r2 * y1
- */
- __pyx_v_r1 = (__pyx_v_x1 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":63
- * r0 = x1 * y0
- * r1 = x1 * y1
- * r2 = x1**2 # <<<<<<<<<<<<<<
- * r3 = r2 * y1
- * r4 = y0 - y1
- */
- __pyx_v_r2 = pow(__pyx_v_x1, 2.0);
-
- /* "fontTools/pens/momentsPen.py":64
- * r1 = x1 * y1
- * r2 = x1**2
- * r3 = r2 * y1 # <<<<<<<<<<<<<<
- * r4 = y0 - y1
- * r5 = r4 * x0
- */
- __pyx_v_r3 = (__pyx_v_r2 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":65
- * r2 = x1**2
- * r3 = r2 * y1
- * r4 = y0 - y1 # <<<<<<<<<<<<<<
- * r5 = r4 * x0
- * r6 = x0**2
- */
- __pyx_v_r4 = (__pyx_v_y0 - __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":66
- * r3 = r2 * y1
- * r4 = y0 - y1
- * r5 = r4 * x0 # <<<<<<<<<<<<<<
- * r6 = x0**2
- * r7 = 2 * y0
- */
- __pyx_v_r5 = (__pyx_v_r4 * __pyx_v_x0);
-
- /* "fontTools/pens/momentsPen.py":67
- * r4 = y0 - y1
- * r5 = r4 * x0
- * r6 = x0**2 # <<<<<<<<<<<<<<
- * r7 = 2 * y0
- * r8 = y0**2
- */
- __pyx_v_r6 = pow(__pyx_v_x0, 2.0);
-
- /* "fontTools/pens/momentsPen.py":68
- * r5 = r4 * x0
- * r6 = x0**2
- * r7 = 2 * y0 # <<<<<<<<<<<<<<
- * r8 = y0**2
- * r9 = y1**2
- */
- __pyx_v_r7 = (2.0 * __pyx_v_y0);
-
- /* "fontTools/pens/momentsPen.py":69
- * r6 = x0**2
- * r7 = 2 * y0
- * r8 = y0**2 # <<<<<<<<<<<<<<
- * r9 = y1**2
- * r10 = x1**3
- */
- __pyx_v_r8 = pow(__pyx_v_y0, 2.0);
-
- /* "fontTools/pens/momentsPen.py":70
- * r7 = 2 * y0
- * r8 = y0**2
- * r9 = y1**2 # <<<<<<<<<<<<<<
- * r10 = x1**3
- * r11 = y0**3
- */
- __pyx_v_r9 = pow(__pyx_v_y1, 2.0);
-
- /* "fontTools/pens/momentsPen.py":71
- * r8 = y0**2
- * r9 = y1**2
- * r10 = x1**3 # <<<<<<<<<<<<<<
- * r11 = y0**3
- * r12 = y1**3
- */
- __pyx_v_r10 = pow(__pyx_v_x1, 3.0);
-
- /* "fontTools/pens/momentsPen.py":72
- * r9 = y1**2
- * r10 = x1**3
- * r11 = y0**3 # <<<<<<<<<<<<<<
- * r12 = y1**3
- *
- */
- __pyx_v_r11 = pow(__pyx_v_y0, 3.0);
-
- /* "fontTools/pens/momentsPen.py":73
- * r10 = x1**3
- * r11 = y0**3
- * r12 = y1**3 # <<<<<<<<<<<<<<
- *
- * self.area += -r0 / 2 - r1 / 2 + x0 * (y0 + y1) / 2
- */
- __pyx_v_r12 = pow(__pyx_v_y1, 3.0);
-
- /* "fontTools/pens/momentsPen.py":75
- * r12 = y1**3
- *
- * self.area += -r0 / 2 - r1 / 2 + x0 * (y0 + y1) / 2 # <<<<<<<<<<<<<<
- * self.momentX += -r2 * y0 / 6 - r3 / 3 - r5 * x1 / 6 + r6 * (r7 + y1) / 6
- * self.momentY += (
- */
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_area); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 75, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_1 = PyFloat_FromDouble(((((-__pyx_v_r0) / 2.0) - (__pyx_v_r1 / 2.0)) + ((__pyx_v_x0 * (__pyx_v_y0 + __pyx_v_y1)) / 2.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 75, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_3, __pyx_t_1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 75, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_area, __pyx_t_2) < 0) __PYX_ERR(0, 75, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":76
- *
- * self.area += -r0 / 2 - r1 / 2 + x0 * (y0 + y1) / 2
- * self.momentX += -r2 * y0 / 6 - r3 / 3 - r5 * x1 / 6 + r6 * (r7 + y1) / 6 # <<<<<<<<<<<<<<
- * self.momentY += (
- * -r0 * y1 / 6 - r8 * x1 / 6 - r9 * x1 / 6 + x0 * (r8 + r9 + y0 * y1) / 6
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentX); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 76, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_1 = PyFloat_FromDouble(((((((-__pyx_v_r2) * __pyx_v_y0) / 6.0) - (__pyx_v_r3 / 3.0)) - ((__pyx_v_r5 * __pyx_v_x1) / 6.0)) + ((__pyx_v_r6 * (__pyx_v_r7 + __pyx_v_y1)) / 6.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 76, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 76, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentX, __pyx_t_3) < 0) __PYX_ERR(0, 76, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":77
- * self.area += -r0 / 2 - r1 / 2 + x0 * (y0 + y1) / 2
- * self.momentX += -r2 * y0 / 6 - r3 / 3 - r5 * x1 / 6 + r6 * (r7 + y1) / 6
- * self.momentY += ( # <<<<<<<<<<<<<<
- * -r0 * y1 / 6 - r8 * x1 / 6 - r9 * x1 / 6 + x0 * (r8 + r9 + y0 * y1) / 6
- * )
- */
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentY); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 77, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":78
- * self.momentX += -r2 * y0 / 6 - r3 / 3 - r5 * x1 / 6 + r6 * (r7 + y1) / 6
- * self.momentY += (
- * -r0 * y1 / 6 - r8 * x1 / 6 - r9 * x1 / 6 + x0 * (r8 + r9 + y0 * y1) / 6 # <<<<<<<<<<<<<<
- * )
- * self.momentXX += (
- */
- __pyx_t_1 = PyFloat_FromDouble(((((((-__pyx_v_r0) * __pyx_v_y1) / 6.0) - ((__pyx_v_r8 * __pyx_v_x1) / 6.0)) - ((__pyx_v_r9 * __pyx_v_x1) / 6.0)) + ((__pyx_v_x0 * ((__pyx_v_r8 + __pyx_v_r9) + (__pyx_v_y0 * __pyx_v_y1))) / 6.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 78, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":77
- * self.area += -r0 / 2 - r1 / 2 + x0 * (y0 + y1) / 2
- * self.momentX += -r2 * y0 / 6 - r3 / 3 - r5 * x1 / 6 + r6 * (r7 + y1) / 6
- * self.momentY += ( # <<<<<<<<<<<<<<
- * -r0 * y1 / 6 - r8 * x1 / 6 - r9 * x1 / 6 + x0 * (r8 + r9 + y0 * y1) / 6
- * )
- */
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_3, __pyx_t_1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 77, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentY, __pyx_t_2) < 0) __PYX_ERR(0, 77, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":80
- * -r0 * y1 / 6 - r8 * x1 / 6 - r9 * x1 / 6 + x0 * (r8 + r9 + y0 * y1) / 6
- * )
- * self.momentXX += ( # <<<<<<<<<<<<<<
- * -r10 * y0 / 12
- * - r10 * y1 / 4
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentXX); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 80, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "fontTools/pens/momentsPen.py":85
- * - r2 * r5 / 12
- * - r4 * r6 * x1 / 12
- * + x0**3 * (3 * y0 + y1) / 12 # <<<<<<<<<<<<<<
- * )
- * self.momentXY += (
- */
- __pyx_t_1 = PyFloat_FromDouble((((((((-__pyx_v_r10) * __pyx_v_y0) / 12.0) - ((__pyx_v_r10 * __pyx_v_y1) / 4.0)) - ((__pyx_v_r2 * __pyx_v_r5) / 12.0)) - (((__pyx_v_r4 * __pyx_v_r6) * __pyx_v_x1) / 12.0)) + ((pow(__pyx_v_x0, 3.0) * ((3.0 * __pyx_v_y0) + __pyx_v_y1)) / 12.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 85, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":80
- * -r0 * y1 / 6 - r8 * x1 / 6 - r9 * x1 / 6 + x0 * (r8 + r9 + y0 * y1) / 6
- * )
- * self.momentXX += ( # <<<<<<<<<<<<<<
- * -r10 * y0 / 12
- * - r10 * y1 / 4
- */
- __pyx_t_3 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 80, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentXX, __pyx_t_3) < 0) __PYX_ERR(0, 80, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":87
- * + x0**3 * (3 * y0 + y1) / 12
- * )
- * self.momentXY += ( # <<<<<<<<<<<<<<
- * -r2 * r8 / 24
- * - r2 * r9 / 8
- */
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentXY); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 87, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":92
- * - r3 * r7 / 24
- * + r6 * (r7 * y1 + 3 * r8 + r9) / 24
- * - x0 * x1 * (r8 - r9) / 12 # <<<<<<<<<<<<<<
- * )
- * self.momentYY += (
- */
- __pyx_t_1 = PyFloat_FromDouble((((((((-__pyx_v_r2) * __pyx_v_r8) / 24.0) - ((__pyx_v_r2 * __pyx_v_r9) / 8.0)) - ((__pyx_v_r3 * __pyx_v_r7) / 24.0)) + ((__pyx_v_r6 * (((__pyx_v_r7 * __pyx_v_y1) + (3.0 * __pyx_v_r8)) + __pyx_v_r9)) / 24.0)) - (((__pyx_v_x0 * __pyx_v_x1) * (__pyx_v_r8 - __pyx_v_r9)) / 12.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 92, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":87
- * + x0**3 * (3 * y0 + y1) / 12
- * )
- * self.momentXY += ( # <<<<<<<<<<<<<<
- * -r2 * r8 / 24
- * - r2 * r9 / 8
- */
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_3, __pyx_t_1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 87, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentXY, __pyx_t_2) < 0) __PYX_ERR(0, 87, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":94
- * - x0 * x1 * (r8 - r9) / 12
- * )
- * self.momentYY += ( # <<<<<<<<<<<<<<
- * -r0 * r9 / 12
- * - r1 * r8 / 12
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentYY); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 94, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "fontTools/pens/momentsPen.py":99
- * - r11 * x1 / 12
- * - r12 * x1 / 12
- * + x0 * (r11 + r12 + r8 * y1 + r9 * y0) / 12 # <<<<<<<<<<<<<<
- * )
- *
- */
- __pyx_t_1 = PyFloat_FromDouble((((((((-__pyx_v_r0) * __pyx_v_r9) / 12.0) - ((__pyx_v_r1 * __pyx_v_r8) / 12.0)) - ((__pyx_v_r11 * __pyx_v_x1) / 12.0)) - ((__pyx_v_r12 * __pyx_v_x1) / 12.0)) + ((__pyx_v_x0 * (((__pyx_v_r11 + __pyx_v_r12) + (__pyx_v_r8 * __pyx_v_y1)) + (__pyx_v_r9 * __pyx_v_y0))) / 12.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 99, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":94
- * - x0 * x1 * (r8 - r9) / 12
- * )
- * self.momentYY += ( # <<<<<<<<<<<<<<
- * -r0 * r9 / 12
- * - r1 * r8 / 12
- */
- __pyx_t_3 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 94, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentYY, __pyx_t_3) < 0) __PYX_ERR(0, 94, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":42
- * raise OpenContourError("Green theorem is not defined on open contours.")
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._lineTo", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "fontTools/pens/momentsPen.py":102
- * )
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_11_qCurveToOne(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-); /*proto*/
-PyDoc_STRVAR(__pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_10_qCurveToOne, "MomentsPen._qCurveToOne(self, p1, p2)");
-static PyMethodDef __pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_11_qCurveToOne = {"_qCurveToOne", (PyCFunction)(void*)(__Pyx_PyCFunction_FastCallWithKeywords)__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_11_qCurveToOne, __Pyx_METH_FASTCALL|METH_KEYWORDS, __pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_10_qCurveToOne};
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_11_qCurveToOne(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-) {
- PyObject *__pyx_v_self = 0;
- PyObject *__pyx_v_p1 = 0;
- PyObject *__pyx_v_p2 = 0;
- #if !CYTHON_METH_FASTCALL
- CYTHON_UNUSED const Py_ssize_t __pyx_nargs = PyTuple_GET_SIZE(__pyx_args);
- #endif
- CYTHON_UNUSED PyObject *const *__pyx_kwvalues = __Pyx_KwValues_FASTCALL(__pyx_args, __pyx_nargs);
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("_qCurveToOne (wrapper)", 0);
- {
- PyObject **__pyx_pyargnames[] = {&__pyx_n_s_self,&__pyx_n_s_p1,&__pyx_n_s_p2,0};
- PyObject* values[3] = {0,0,0};
- if (__pyx_kwds) {
- Py_ssize_t kw_args;
- switch (__pyx_nargs) {
- case 3: values[2] = __Pyx_Arg_FASTCALL(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = __Pyx_NumKwargs_FASTCALL(__pyx_kwds);
- switch (__pyx_nargs) {
- case 0:
- if (likely((values[0] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_self)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 102, __pyx_L3_error)
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_p1)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 102, __pyx_L3_error)
- else {
- __Pyx_RaiseArgtupleInvalid("_qCurveToOne", 1, 3, 3, 1); __PYX_ERR(0, 102, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (likely((values[2] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_p2)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 102, __pyx_L3_error)
- else {
- __Pyx_RaiseArgtupleInvalid("_qCurveToOne", 1, 3, 3, 2); __PYX_ERR(0, 102, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- const Py_ssize_t kwd_pos_args = __pyx_nargs;
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_kwvalues, __pyx_pyargnames, 0, values + 0, kwd_pos_args, "_qCurveToOne") < 0)) __PYX_ERR(0, 102, __pyx_L3_error)
- }
- } else if (unlikely(__pyx_nargs != 3)) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- values[2] = __Pyx_Arg_FASTCALL(__pyx_args, 2);
- }
- __pyx_v_self = values[0];
- __pyx_v_p1 = values[1];
- __pyx_v_p2 = values[2];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("_qCurveToOne", 1, 3, 3, __pyx_nargs); __PYX_ERR(0, 102, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._qCurveToOne", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_10_qCurveToOne(__pyx_self, __pyx_v_self, __pyx_v_p1, __pyx_v_p2);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_10_qCurveToOne(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_p1, PyObject *__pyx_v_p2) {
- double __pyx_v_x2;
- double __pyx_v_y2;
- double __pyx_v_x1;
- double __pyx_v_y1;
- double __pyx_v_x0;
- double __pyx_v_y0;
- double __pyx_v_r53;
- double __pyx_v_r52;
- double __pyx_v_r51;
- double __pyx_v_r50;
- double __pyx_v_r49;
- double __pyx_v_r48;
- double __pyx_v_r47;
- double __pyx_v_r46;
- double __pyx_v_r45;
- double __pyx_v_r44;
- double __pyx_v_r43;
- double __pyx_v_r42;
- double __pyx_v_r41;
- double __pyx_v_r40;
- double __pyx_v_r39;
- double __pyx_v_r38;
- double __pyx_v_r37;
- double __pyx_v_r36;
- double __pyx_v_r35;
- double __pyx_v_r34;
- double __pyx_v_r33;
- double __pyx_v_r32;
- double __pyx_v_r31;
- double __pyx_v_r30;
- double __pyx_v_r29;
- double __pyx_v_r28;
- double __pyx_v_r27;
- double __pyx_v_r26;
- double __pyx_v_r25;
- double __pyx_v_r24;
- double __pyx_v_r23;
- double __pyx_v_r22;
- double __pyx_v_r21;
- double __pyx_v_r20;
- double __pyx_v_r19;
- double __pyx_v_r18;
- double __pyx_v_r17;
- double __pyx_v_r16;
- double __pyx_v_r15;
- double __pyx_v_r14;
- double __pyx_v_r13;
- double __pyx_v_r12;
- double __pyx_v_r11;
- double __pyx_v_r10;
- double __pyx_v_r9;
- double __pyx_v_r8;
- double __pyx_v_r7;
- double __pyx_v_r6;
- double __pyx_v_r5;
- double __pyx_v_r4;
- double __pyx_v_r3;
- double __pyx_v_r2;
- double __pyx_v_r1;
- double __pyx_v_r0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- PyObject *(*__pyx_t_6)(PyObject *);
- double __pyx_t_7;
- double __pyx_t_8;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("_qCurveToOne", 0);
-
- /* "fontTools/pens/momentsPen.py":160
- * @cython.locals(x2=cython.double, y2=cython.double)
- * def _qCurveToOne(self, p1, p2):
- * x0, y0 = self._getCurrentPoint() # <<<<<<<<<<<<<<
- * x1, y1 = p1
- * x2, y2 = p2
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_getCurrentPoint); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 160, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = NULL;
- __pyx_t_4 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_2))) {
- __pyx_t_3 = PyMethod_GET_SELF(__pyx_t_2);
- if (likely(__pyx_t_3)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_2);
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_2, function);
- __pyx_t_4 = 1;
- }
- }
- {
- PyObject *__pyx_callargs[1] = {__pyx_t_3, };
- __pyx_t_1 = __Pyx_PyObject_FastCall(__pyx_t_2, __pyx_callargs+1-__pyx_t_4, 0+__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 160, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- if ((likely(PyTuple_CheckExact(__pyx_t_1))) || (PyList_CheckExact(__pyx_t_1))) {
- PyObject* sequence = __pyx_t_1;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 160, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_2 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_2 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_2);
- __Pyx_INCREF(__pyx_t_3);
- #else
- __pyx_t_2 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 160, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 160, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- #endif
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- } else {
- Py_ssize_t index = -1;
- __pyx_t_5 = PyObject_GetIter(__pyx_t_1); if (unlikely(!__pyx_t_5)) __PYX_ERR(0, 160, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_5);
- index = 0; __pyx_t_2 = __pyx_t_6(__pyx_t_5); if (unlikely(!__pyx_t_2)) goto __pyx_L3_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_2);
- index = 1; __pyx_t_3 = __pyx_t_6(__pyx_t_5); if (unlikely(!__pyx_t_3)) goto __pyx_L3_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_5), 2) < 0) __PYX_ERR(0, 160, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- goto __pyx_L4_unpacking_done;
- __pyx_L3_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 160, __pyx_L1_error)
- __pyx_L4_unpacking_done:;
- }
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_2); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 160, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 160, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_x0 = __pyx_t_7;
- __pyx_v_y0 = __pyx_t_8;
-
- /* "fontTools/pens/momentsPen.py":161
- * def _qCurveToOne(self, p1, p2):
- * x0, y0 = self._getCurrentPoint()
- * x1, y1 = p1 # <<<<<<<<<<<<<<
- * x2, y2 = p2
- *
- */
- if ((likely(PyTuple_CheckExact(__pyx_v_p1))) || (PyList_CheckExact(__pyx_v_p1))) {
- PyObject* sequence = __pyx_v_p1;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 161, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_1 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_1 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_3);
- #else
- __pyx_t_1 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 161, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 161, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- #endif
- } else {
- Py_ssize_t index = -1;
- __pyx_t_2 = PyObject_GetIter(__pyx_v_p1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 161, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_2);
- index = 0; __pyx_t_1 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_1)) goto __pyx_L5_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_1);
- index = 1; __pyx_t_3 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_3)) goto __pyx_L5_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_2), 2) < 0) __PYX_ERR(0, 161, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- goto __pyx_L6_unpacking_done;
- __pyx_L5_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 161, __pyx_L1_error)
- __pyx_L6_unpacking_done:;
- }
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_1); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 161, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 161, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_x1 = __pyx_t_8;
- __pyx_v_y1 = __pyx_t_7;
-
- /* "fontTools/pens/momentsPen.py":162
- * x0, y0 = self._getCurrentPoint()
- * x1, y1 = p1
- * x2, y2 = p2 # <<<<<<<<<<<<<<
- *
- * r0 = 2 * y1
- */
- if ((likely(PyTuple_CheckExact(__pyx_v_p2))) || (PyList_CheckExact(__pyx_v_p2))) {
- PyObject* sequence = __pyx_v_p2;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 162, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_1 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_3 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_1 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_t_1);
- #else
- __pyx_t_3 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 162, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_1 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 162, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- #endif
- } else {
- Py_ssize_t index = -1;
- __pyx_t_2 = PyObject_GetIter(__pyx_v_p2); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 162, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_2);
- index = 0; __pyx_t_3 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_3)) goto __pyx_L7_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- index = 1; __pyx_t_1 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_1)) goto __pyx_L7_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_1);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_2), 2) < 0) __PYX_ERR(0, 162, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- goto __pyx_L8_unpacking_done;
- __pyx_L7_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 162, __pyx_L1_error)
- __pyx_L8_unpacking_done:;
- }
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 162, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_1); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 162, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_v_x2 = __pyx_t_7;
- __pyx_v_y2 = __pyx_t_8;
-
- /* "fontTools/pens/momentsPen.py":164
- * x2, y2 = p2
- *
- * r0 = 2 * y1 # <<<<<<<<<<<<<<
- * r1 = r0 * x2
- * r2 = x2 * y2
- */
- __pyx_v_r0 = (2.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":165
- *
- * r0 = 2 * y1
- * r1 = r0 * x2 # <<<<<<<<<<<<<<
- * r2 = x2 * y2
- * r3 = 3 * r2
- */
- __pyx_v_r1 = (__pyx_v_r0 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":166
- * r0 = 2 * y1
- * r1 = r0 * x2
- * r2 = x2 * y2 # <<<<<<<<<<<<<<
- * r3 = 3 * r2
- * r4 = 2 * x1
- */
- __pyx_v_r2 = (__pyx_v_x2 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":167
- * r1 = r0 * x2
- * r2 = x2 * y2
- * r3 = 3 * r2 # <<<<<<<<<<<<<<
- * r4 = 2 * x1
- * r5 = 3 * y0
- */
- __pyx_v_r3 = (3.0 * __pyx_v_r2);
-
- /* "fontTools/pens/momentsPen.py":168
- * r2 = x2 * y2
- * r3 = 3 * r2
- * r4 = 2 * x1 # <<<<<<<<<<<<<<
- * r5 = 3 * y0
- * r6 = x1**2
- */
- __pyx_v_r4 = (2.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":169
- * r3 = 3 * r2
- * r4 = 2 * x1
- * r5 = 3 * y0 # <<<<<<<<<<<<<<
- * r6 = x1**2
- * r7 = x2**2
- */
- __pyx_v_r5 = (3.0 * __pyx_v_y0);
-
- /* "fontTools/pens/momentsPen.py":170
- * r4 = 2 * x1
- * r5 = 3 * y0
- * r6 = x1**2 # <<<<<<<<<<<<<<
- * r7 = x2**2
- * r8 = 4 * y1
- */
- __pyx_v_r6 = pow(__pyx_v_x1, 2.0);
-
- /* "fontTools/pens/momentsPen.py":171
- * r5 = 3 * y0
- * r6 = x1**2
- * r7 = x2**2 # <<<<<<<<<<<<<<
- * r8 = 4 * y1
- * r9 = 10 * y2
- */
- __pyx_v_r7 = pow(__pyx_v_x2, 2.0);
-
- /* "fontTools/pens/momentsPen.py":172
- * r6 = x1**2
- * r7 = x2**2
- * r8 = 4 * y1 # <<<<<<<<<<<<<<
- * r9 = 10 * y2
- * r10 = 2 * y2
- */
- __pyx_v_r8 = (4.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":173
- * r7 = x2**2
- * r8 = 4 * y1
- * r9 = 10 * y2 # <<<<<<<<<<<<<<
- * r10 = 2 * y2
- * r11 = r4 * x2
- */
- __pyx_v_r9 = (10.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":174
- * r8 = 4 * y1
- * r9 = 10 * y2
- * r10 = 2 * y2 # <<<<<<<<<<<<<<
- * r11 = r4 * x2
- * r12 = x0**2
- */
- __pyx_v_r10 = (2.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":175
- * r9 = 10 * y2
- * r10 = 2 * y2
- * r11 = r4 * x2 # <<<<<<<<<<<<<<
- * r12 = x0**2
- * r13 = 10 * y0
- */
- __pyx_v_r11 = (__pyx_v_r4 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":176
- * r10 = 2 * y2
- * r11 = r4 * x2
- * r12 = x0**2 # <<<<<<<<<<<<<<
- * r13 = 10 * y0
- * r14 = r4 * y2
- */
- __pyx_v_r12 = pow(__pyx_v_x0, 2.0);
-
- /* "fontTools/pens/momentsPen.py":177
- * r11 = r4 * x2
- * r12 = x0**2
- * r13 = 10 * y0 # <<<<<<<<<<<<<<
- * r14 = r4 * y2
- * r15 = x2 * y0
- */
- __pyx_v_r13 = (10.0 * __pyx_v_y0);
-
- /* "fontTools/pens/momentsPen.py":178
- * r12 = x0**2
- * r13 = 10 * y0
- * r14 = r4 * y2 # <<<<<<<<<<<<<<
- * r15 = x2 * y0
- * r16 = 4 * x1
- */
- __pyx_v_r14 = (__pyx_v_r4 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":179
- * r13 = 10 * y0
- * r14 = r4 * y2
- * r15 = x2 * y0 # <<<<<<<<<<<<<<
- * r16 = 4 * x1
- * r17 = r0 * x1 + r2
- */
- __pyx_v_r15 = (__pyx_v_x2 * __pyx_v_y0);
-
- /* "fontTools/pens/momentsPen.py":180
- * r14 = r4 * y2
- * r15 = x2 * y0
- * r16 = 4 * x1 # <<<<<<<<<<<<<<
- * r17 = r0 * x1 + r2
- * r18 = r2 * r8
- */
- __pyx_v_r16 = (4.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":181
- * r15 = x2 * y0
- * r16 = 4 * x1
- * r17 = r0 * x1 + r2 # <<<<<<<<<<<<<<
- * r18 = r2 * r8
- * r19 = y1**2
- */
- __pyx_v_r17 = ((__pyx_v_r0 * __pyx_v_x1) + __pyx_v_r2);
-
- /* "fontTools/pens/momentsPen.py":182
- * r16 = 4 * x1
- * r17 = r0 * x1 + r2
- * r18 = r2 * r8 # <<<<<<<<<<<<<<
- * r19 = y1**2
- * r20 = 2 * r19
- */
- __pyx_v_r18 = (__pyx_v_r2 * __pyx_v_r8);
-
- /* "fontTools/pens/momentsPen.py":183
- * r17 = r0 * x1 + r2
- * r18 = r2 * r8
- * r19 = y1**2 # <<<<<<<<<<<<<<
- * r20 = 2 * r19
- * r21 = y2**2
- */
- __pyx_v_r19 = pow(__pyx_v_y1, 2.0);
-
- /* "fontTools/pens/momentsPen.py":184
- * r18 = r2 * r8
- * r19 = y1**2
- * r20 = 2 * r19 # <<<<<<<<<<<<<<
- * r21 = y2**2
- * r22 = r21 * x2
- */
- __pyx_v_r20 = (2.0 * __pyx_v_r19);
-
- /* "fontTools/pens/momentsPen.py":185
- * r19 = y1**2
- * r20 = 2 * r19
- * r21 = y2**2 # <<<<<<<<<<<<<<
- * r22 = r21 * x2
- * r23 = 5 * r22
- */
- __pyx_v_r21 = pow(__pyx_v_y2, 2.0);
-
- /* "fontTools/pens/momentsPen.py":186
- * r20 = 2 * r19
- * r21 = y2**2
- * r22 = r21 * x2 # <<<<<<<<<<<<<<
- * r23 = 5 * r22
- * r24 = y0**2
- */
- __pyx_v_r22 = (__pyx_v_r21 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":187
- * r21 = y2**2
- * r22 = r21 * x2
- * r23 = 5 * r22 # <<<<<<<<<<<<<<
- * r24 = y0**2
- * r25 = y0 * y2
- */
- __pyx_v_r23 = (5.0 * __pyx_v_r22);
-
- /* "fontTools/pens/momentsPen.py":188
- * r22 = r21 * x2
- * r23 = 5 * r22
- * r24 = y0**2 # <<<<<<<<<<<<<<
- * r25 = y0 * y2
- * r26 = 5 * r24
- */
- __pyx_v_r24 = pow(__pyx_v_y0, 2.0);
-
- /* "fontTools/pens/momentsPen.py":189
- * r23 = 5 * r22
- * r24 = y0**2
- * r25 = y0 * y2 # <<<<<<<<<<<<<<
- * r26 = 5 * r24
- * r27 = x1**3
- */
- __pyx_v_r25 = (__pyx_v_y0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":190
- * r24 = y0**2
- * r25 = y0 * y2
- * r26 = 5 * r24 # <<<<<<<<<<<<<<
- * r27 = x1**3
- * r28 = x2**3
- */
- __pyx_v_r26 = (5.0 * __pyx_v_r24);
-
- /* "fontTools/pens/momentsPen.py":191
- * r25 = y0 * y2
- * r26 = 5 * r24
- * r27 = x1**3 # <<<<<<<<<<<<<<
- * r28 = x2**3
- * r29 = 30 * y1
- */
- __pyx_v_r27 = pow(__pyx_v_x1, 3.0);
-
- /* "fontTools/pens/momentsPen.py":192
- * r26 = 5 * r24
- * r27 = x1**3
- * r28 = x2**3 # <<<<<<<<<<<<<<
- * r29 = 30 * y1
- * r30 = 6 * y1
- */
- __pyx_v_r28 = pow(__pyx_v_x2, 3.0);
-
- /* "fontTools/pens/momentsPen.py":193
- * r27 = x1**3
- * r28 = x2**3
- * r29 = 30 * y1 # <<<<<<<<<<<<<<
- * r30 = 6 * y1
- * r31 = 10 * r7 * x1
- */
- __pyx_v_r29 = (30.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":194
- * r28 = x2**3
- * r29 = 30 * y1
- * r30 = 6 * y1 # <<<<<<<<<<<<<<
- * r31 = 10 * r7 * x1
- * r32 = 5 * y2
- */
- __pyx_v_r30 = (6.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":195
- * r29 = 30 * y1
- * r30 = 6 * y1
- * r31 = 10 * r7 * x1 # <<<<<<<<<<<<<<
- * r32 = 5 * y2
- * r33 = 12 * r6
- */
- __pyx_v_r31 = ((10.0 * __pyx_v_r7) * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":196
- * r30 = 6 * y1
- * r31 = 10 * r7 * x1
- * r32 = 5 * y2 # <<<<<<<<<<<<<<
- * r33 = 12 * r6
- * r34 = 30 * x1
- */
- __pyx_v_r32 = (5.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":197
- * r31 = 10 * r7 * x1
- * r32 = 5 * y2
- * r33 = 12 * r6 # <<<<<<<<<<<<<<
- * r34 = 30 * x1
- * r35 = x1 * y1
- */
- __pyx_v_r33 = (12.0 * __pyx_v_r6);
-
- /* "fontTools/pens/momentsPen.py":198
- * r32 = 5 * y2
- * r33 = 12 * r6
- * r34 = 30 * x1 # <<<<<<<<<<<<<<
- * r35 = x1 * y1
- * r36 = r3 + 20 * r35
- */
- __pyx_v_r34 = (30.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":199
- * r33 = 12 * r6
- * r34 = 30 * x1
- * r35 = x1 * y1 # <<<<<<<<<<<<<<
- * r36 = r3 + 20 * r35
- * r37 = 12 * x1
- */
- __pyx_v_r35 = (__pyx_v_x1 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":200
- * r34 = 30 * x1
- * r35 = x1 * y1
- * r36 = r3 + 20 * r35 # <<<<<<<<<<<<<<
- * r37 = 12 * x1
- * r38 = 20 * r6
- */
- __pyx_v_r36 = (__pyx_v_r3 + (20.0 * __pyx_v_r35));
-
- /* "fontTools/pens/momentsPen.py":201
- * r35 = x1 * y1
- * r36 = r3 + 20 * r35
- * r37 = 12 * x1 # <<<<<<<<<<<<<<
- * r38 = 20 * r6
- * r39 = 8 * r6 * y1
- */
- __pyx_v_r37 = (12.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":202
- * r36 = r3 + 20 * r35
- * r37 = 12 * x1
- * r38 = 20 * r6 # <<<<<<<<<<<<<<
- * r39 = 8 * r6 * y1
- * r40 = r32 * r7
- */
- __pyx_v_r38 = (20.0 * __pyx_v_r6);
-
- /* "fontTools/pens/momentsPen.py":203
- * r37 = 12 * x1
- * r38 = 20 * r6
- * r39 = 8 * r6 * y1 # <<<<<<<<<<<<<<
- * r40 = r32 * r7
- * r41 = 60 * y1
- */
- __pyx_v_r39 = ((8.0 * __pyx_v_r6) * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":204
- * r38 = 20 * r6
- * r39 = 8 * r6 * y1
- * r40 = r32 * r7 # <<<<<<<<<<<<<<
- * r41 = 60 * y1
- * r42 = 20 * r19
- */
- __pyx_v_r40 = (__pyx_v_r32 * __pyx_v_r7);
-
- /* "fontTools/pens/momentsPen.py":205
- * r39 = 8 * r6 * y1
- * r40 = r32 * r7
- * r41 = 60 * y1 # <<<<<<<<<<<<<<
- * r42 = 20 * r19
- * r43 = 4 * r19
- */
- __pyx_v_r41 = (60.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":206
- * r40 = r32 * r7
- * r41 = 60 * y1
- * r42 = 20 * r19 # <<<<<<<<<<<<<<
- * r43 = 4 * r19
- * r44 = 15 * r21
- */
- __pyx_v_r42 = (20.0 * __pyx_v_r19);
-
- /* "fontTools/pens/momentsPen.py":207
- * r41 = 60 * y1
- * r42 = 20 * r19
- * r43 = 4 * r19 # <<<<<<<<<<<<<<
- * r44 = 15 * r21
- * r45 = 12 * x2
- */
- __pyx_v_r43 = (4.0 * __pyx_v_r19);
-
- /* "fontTools/pens/momentsPen.py":208
- * r42 = 20 * r19
- * r43 = 4 * r19
- * r44 = 15 * r21 # <<<<<<<<<<<<<<
- * r45 = 12 * x2
- * r46 = 12 * y2
- */
- __pyx_v_r44 = (15.0 * __pyx_v_r21);
-
- /* "fontTools/pens/momentsPen.py":209
- * r43 = 4 * r19
- * r44 = 15 * r21
- * r45 = 12 * x2 # <<<<<<<<<<<<<<
- * r46 = 12 * y2
- * r47 = 6 * x1
- */
- __pyx_v_r45 = (12.0 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":210
- * r44 = 15 * r21
- * r45 = 12 * x2
- * r46 = 12 * y2 # <<<<<<<<<<<<<<
- * r47 = 6 * x1
- * r48 = 8 * r19 * x1 + r23
- */
- __pyx_v_r46 = (12.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":211
- * r45 = 12 * x2
- * r46 = 12 * y2
- * r47 = 6 * x1 # <<<<<<<<<<<<<<
- * r48 = 8 * r19 * x1 + r23
- * r49 = 8 * y1**3
- */
- __pyx_v_r47 = (6.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":212
- * r46 = 12 * y2
- * r47 = 6 * x1
- * r48 = 8 * r19 * x1 + r23 # <<<<<<<<<<<<<<
- * r49 = 8 * y1**3
- * r50 = y2**3
- */
- __pyx_v_r48 = (((8.0 * __pyx_v_r19) * __pyx_v_x1) + __pyx_v_r23);
-
- /* "fontTools/pens/momentsPen.py":213
- * r47 = 6 * x1
- * r48 = 8 * r19 * x1 + r23
- * r49 = 8 * y1**3 # <<<<<<<<<<<<<<
- * r50 = y2**3
- * r51 = y0**3
- */
- __pyx_v_r49 = (8.0 * pow(__pyx_v_y1, 3.0));
-
- /* "fontTools/pens/momentsPen.py":214
- * r48 = 8 * r19 * x1 + r23
- * r49 = 8 * y1**3
- * r50 = y2**3 # <<<<<<<<<<<<<<
- * r51 = y0**3
- * r52 = 10 * y1
- */
- __pyx_v_r50 = pow(__pyx_v_y2, 3.0);
-
- /* "fontTools/pens/momentsPen.py":215
- * r49 = 8 * y1**3
- * r50 = y2**3
- * r51 = y0**3 # <<<<<<<<<<<<<<
- * r52 = 10 * y1
- * r53 = 12 * y1
- */
- __pyx_v_r51 = pow(__pyx_v_y0, 3.0);
-
- /* "fontTools/pens/momentsPen.py":216
- * r50 = y2**3
- * r51 = y0**3
- * r52 = 10 * y1 # <<<<<<<<<<<<<<
- * r53 = 12 * y1
- *
- */
- __pyx_v_r52 = (10.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":217
- * r51 = y0**3
- * r52 = 10 * y1
- * r53 = 12 * y1 # <<<<<<<<<<<<<<
- *
- * self.area += (
- */
- __pyx_v_r53 = (12.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":219
- * r53 = 12 * y1
- *
- * self.area += ( # <<<<<<<<<<<<<<
- * -r1 / 6
- * - r3 / 6
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_area); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 219, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":224
- * + x0 * (r0 + r5 + y2) / 6
- * + x1 * y2 / 3
- * - y0 * (r4 + x2) / 6 # <<<<<<<<<<<<<<
- * )
- * self.momentX += (
- */
- __pyx_t_3 = PyFloat_FromDouble(((((((-__pyx_v_r1) / 6.0) - (__pyx_v_r3 / 6.0)) + ((__pyx_v_x0 * ((__pyx_v_r0 + __pyx_v_r5) + __pyx_v_y2)) / 6.0)) + ((__pyx_v_x1 * __pyx_v_y2) / 3.0)) - ((__pyx_v_y0 * (__pyx_v_r4 + __pyx_v_x2)) / 6.0))); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 224, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":219
- * r53 = 12 * y1
- *
- * self.area += ( # <<<<<<<<<<<<<<
- * -r1 / 6
- * - r3 / 6
- */
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_1, __pyx_t_3); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 219, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_area, __pyx_t_2) < 0) __PYX_ERR(0, 219, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":226
- * - y0 * (r4 + x2) / 6
- * )
- * self.momentX += ( # <<<<<<<<<<<<<<
- * -r11 * (-r10 + y1) / 30
- * + r12 * (r13 + r8 + y2) / 30
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentX); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 226, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "fontTools/pens/momentsPen.py":233
- * - r7 * r9 / 30
- * + x0 * (r14 - r15 - r16 * y0 + r17) / 30
- * - y0 * (r11 + 2 * r6 + r7) / 30 # <<<<<<<<<<<<<<
- * )
- * self.momentY += (
- */
- __pyx_t_3 = PyFloat_FromDouble((((((((((-__pyx_v_r11) * ((-__pyx_v_r10) + __pyx_v_y1)) / 30.0) + ((__pyx_v_r12 * ((__pyx_v_r13 + __pyx_v_r8) + __pyx_v_y2)) / 30.0)) + ((__pyx_v_r6 * __pyx_v_y2) / 15.0)) - ((__pyx_v_r7 * __pyx_v_r8) / 30.0)) - ((__pyx_v_r7 * __pyx_v_r9) / 30.0)) + ((__pyx_v_x0 * (((__pyx_v_r14 - __pyx_v_r15) - (__pyx_v_r16 * __pyx_v_y0)) + __pyx_v_r17)) / 30.0)) - ((__pyx_v_y0 * ((__pyx_v_r11 + (2.0 * __pyx_v_r6)) + __pyx_v_r7)) / 30.0))); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 233, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":226
- * - y0 * (r4 + x2) / 6
- * )
- * self.momentX += ( # <<<<<<<<<<<<<<
- * -r11 * (-r10 + y1) / 30
- * + r12 * (r13 + r8 + y2) / 30
- */
- __pyx_t_1 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_3); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 226, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentX, __pyx_t_1) < 0) __PYX_ERR(0, 226, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "fontTools/pens/momentsPen.py":235
- * - y0 * (r11 + 2 * r6 + r7) / 30
- * )
- * self.momentY += ( # <<<<<<<<<<<<<<
- * -r18 / 30
- * - r20 * x2 / 30
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentY); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 235, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":242
- * + x0 * (r0 * y2 + r20 + r21 + r25 + r26 + r8 * y0) / 30
- * + x1 * y2 * (r10 + y1) / 15
- * - y0 * (r1 + r17) / 30 # <<<<<<<<<<<<<<
- * )
- * self.momentXX += (
- */
- __pyx_t_3 = PyFloat_FromDouble(((((((((-__pyx_v_r18) / 30.0) - ((__pyx_v_r20 * __pyx_v_x2) / 30.0)) - (__pyx_v_r23 / 30.0)) - ((__pyx_v_r24 * (__pyx_v_r16 + __pyx_v_x2)) / 30.0)) + ((__pyx_v_x0 * ((((((__pyx_v_r0 * __pyx_v_y2) + __pyx_v_r20) + __pyx_v_r21) + __pyx_v_r25) + __pyx_v_r26) + (__pyx_v_r8 * __pyx_v_y0))) / 30.0)) + (((__pyx_v_x1 * __pyx_v_y2) * (__pyx_v_r10 + __pyx_v_y1)) / 15.0)) - ((__pyx_v_y0 * (__pyx_v_r1 + __pyx_v_r17)) / 30.0))); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 242, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":235
- * - y0 * (r11 + 2 * r6 + r7) / 30
- * )
- * self.momentY += ( # <<<<<<<<<<<<<<
- * -r18 / 30
- * - r20 * x2 / 30
- */
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_1, __pyx_t_3); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 235, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentY, __pyx_t_2) < 0) __PYX_ERR(0, 235, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":244
- * - y0 * (r1 + r17) / 30
- * )
- * self.momentXX += ( # <<<<<<<<<<<<<<
- * r12 * (r1 - 5 * r15 - r34 * y0 + r36 + r9 * x1) / 420
- * + 2 * r27 * y2 / 105
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentXX); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 244, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "fontTools/pens/momentsPen.py":264
- * )
- * / 420
- * - y0 * (8 * r27 + 5 * r28 + r31 + r33 * x2) / 420 # <<<<<<<<<<<<<<
- * )
- * self.momentXY += (
- */
- __pyx_t_3 = PyFloat_FromDouble(((((((((((__pyx_v_r12 * ((((__pyx_v_r1 - (5.0 * __pyx_v_r15)) - (__pyx_v_r34 * __pyx_v_y0)) + __pyx_v_r36) + (__pyx_v_r9 * __pyx_v_x1))) / 420.0) + (((2.0 * __pyx_v_r27) * __pyx_v_y2) / 105.0)) - ((__pyx_v_r28 * __pyx_v_r29) / 420.0)) - ((__pyx_v_r28 * __pyx_v_y2) / 4.0)) - ((__pyx_v_r31 * (__pyx_v_r0 - (3.0 * __pyx_v_y2))) / 420.0)) - (((__pyx_v_r6 * __pyx_v_x2) * (__pyx_v_r0 - __pyx_v_r32)) / 105.0)) + ((pow(__pyx_v_x0, 3.0) * ((__pyx_v_r30 + (21.0 * __pyx_v_y0)) + __pyx_v_y2)) / 84.0)) - ((__pyx_v_x0 * ((((((((__pyx_v_r0 * __pyx_v_r7) + (__pyx_v_r15 * __pyx_v_r37)) - (__pyx_v_r2 * __pyx_v_r37)) - (__pyx_v_r33 * __pyx_v_y2)) + (__pyx_v_r38 * __pyx_v_y0)) - __pyx_v_r39) - __pyx_v_r40) + (__pyx_v_r5 * __pyx_v_r7))) / 420.0)) - ((__pyx_v_y0 * ((((8.0 * __pyx_v_r27) + (5.0 * __pyx_v_r28)) + __pyx_v_r31) + (__pyx_v_r33 * __pyx_v_x2))) / 420.0))); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 264, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":244
- * - y0 * (r1 + r17) / 30
- * )
- * self.momentXX += ( # <<<<<<<<<<<<<<
- * r12 * (r1 - 5 * r15 - r34 * y0 + r36 + r9 * x1) / 420
- * + 2 * r27 * y2 / 105
- */
- __pyx_t_1 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_3); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 244, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentXX, __pyx_t_1) < 0) __PYX_ERR(0, 244, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "fontTools/pens/momentsPen.py":266
- * - y0 * (8 * r27 + 5 * r28 + r31 + r33 * x2) / 420
- * )
- * self.momentXY += ( # <<<<<<<<<<<<<<
- * r12 * (r13 * y2 + 3 * r21 + 105 * r24 + r41 * y0 + r42 + r46 * y1) / 840
- * - r16 * x2 * (r43 - r44) / 840
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentXY); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 266, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":286
- * )
- * / 420
- * - y0 * (r16 * r2 + r30 * r7 + r35 * r45 + r39 + r40) / 420 # <<<<<<<<<<<<<<
- * )
- * self.momentYY += (
- */
- __pyx_t_3 = PyFloat_FromDouble(((((((((((__pyx_v_r12 * ((((((__pyx_v_r13 * __pyx_v_y2) + (3.0 * __pyx_v_r21)) + (105.0 * __pyx_v_r24)) + (__pyx_v_r41 * __pyx_v_y0)) + __pyx_v_r42) + (__pyx_v_r46 * __pyx_v_y1))) / 840.0) - (((__pyx_v_r16 * __pyx_v_x2) * (__pyx_v_r43 - __pyx_v_r44)) / 840.0)) - ((__pyx_v_r21 * __pyx_v_r7) / 8.0)) - ((__pyx_v_r24 * ((__pyx_v_r38 + (__pyx_v_r45 * __pyx_v_x1)) + (3.0 * __pyx_v_r7))) / 840.0)) - (((__pyx_v_r41 * __pyx_v_r7) * __pyx_v_y2) / 840.0)) - ((__pyx_v_r42 * __pyx_v_r7) / 840.0)) + (((__pyx_v_r6 * __pyx_v_y2) * (__pyx_v_r32 + __pyx_v_r8)) / 210.0)) + ((__pyx_v_x0 * (((((((((-__pyx_v_r15) * __pyx_v_r8) + (__pyx_v_r16 * __pyx_v_r25)) + __pyx_v_r18) + (__pyx_v_r21 * __pyx_v_r47)) - (__pyx_v_r24 * __pyx_v_r34)) - (__pyx_v_r26 * __pyx_v_x2)) + (__pyx_v_r35 * __pyx_v_r46)) + __pyx_v_r48)) / 420.0)) - ((__pyx_v_y0 * (((((__pyx_v_r16 * __pyx_v_r2) + (__pyx_v_r30 * __pyx_v_r7)) + (__pyx_v_r35 * __pyx_v_r45)) + __pyx_v_r39) + __pyx_v_r40)) / 420.0))); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 286, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":266
- * - y0 * (8 * r27 + 5 * r28 + r31 + r33 * x2) / 420
- * )
- * self.momentXY += ( # <<<<<<<<<<<<<<
- * r12 * (r13 * y2 + 3 * r21 + 105 * r24 + r41 * y0 + r42 + r46 * y1) / 840
- * - r16 * x2 * (r43 - r44) / 840
- */
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_1, __pyx_t_3); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 266, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentXY, __pyx_t_2) < 0) __PYX_ERR(0, 266, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":288
- * - y0 * (r16 * r2 + r30 * r7 + r35 * r45 + r39 + r40) / 420
- * )
- * self.momentYY += ( # <<<<<<<<<<<<<<
- * -r2 * r42 / 420
- * - r22 * r29 / 420
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentYY); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 288, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "fontTools/pens/momentsPen.py":310
- * / 420
- * + x1 * y2 * (r43 + r44 + r9 * y1) / 210
- * - y0 * (r19 * r45 + r2 * r53 - r21 * r4 + r48) / 420 # <<<<<<<<<<<<<<
- * )
- *
- */
- __pyx_t_3 = PyFloat_FromDouble((((((((((((-__pyx_v_r2) * __pyx_v_r42) / 420.0) - ((__pyx_v_r22 * __pyx_v_r29) / 420.0)) - ((__pyx_v_r24 * ((__pyx_v_r14 + __pyx_v_r36) + (__pyx_v_r52 * __pyx_v_x2))) / 420.0)) - ((__pyx_v_r49 * __pyx_v_x2) / 420.0)) - ((__pyx_v_r50 * __pyx_v_x2) / 12.0)) - ((__pyx_v_r51 * (__pyx_v_r47 + __pyx_v_x2)) / 84.0)) + ((__pyx_v_x0 * ((((((((((__pyx_v_r19 * __pyx_v_r46) + (__pyx_v_r21 * __pyx_v_r5)) + (__pyx_v_r21 * __pyx_v_r52)) + (__pyx_v_r24 * __pyx_v_r29)) + (__pyx_v_r25 * __pyx_v_r53)) + (__pyx_v_r26 * __pyx_v_y2)) + (__pyx_v_r42 * __pyx_v_y0)) + __pyx_v_r49) + (5.0 * __pyx_v_r50)) + (35.0 * __pyx_v_r51))) / 420.0)) + (((__pyx_v_x1 * __pyx_v_y2) * ((__pyx_v_r43 + __pyx_v_r44) + (__pyx_v_r9 * __pyx_v_y1))) / 210.0)) - ((__pyx_v_y0 * ((((__pyx_v_r19 * __pyx_v_r45) + (__pyx_v_r2 * __pyx_v_r53)) - (__pyx_v_r21 * __pyx_v_r4)) + __pyx_v_r48)) / 420.0))); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 310, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":288
- * - y0 * (r16 * r2 + r30 * r7 + r35 * r45 + r39 + r40) / 420
- * )
- * self.momentYY += ( # <<<<<<<<<<<<<<
- * -r2 * r42 / 420
- * - r22 * r29 / 420
- */
- __pyx_t_1 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_3); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 288, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentYY, __pyx_t_1) < 0) __PYX_ERR(0, 288, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "fontTools/pens/momentsPen.py":102
- * )
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._qCurveToOne", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "fontTools/pens/momentsPen.py":313
- * )
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_13_curveToOne(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-); /*proto*/
-PyDoc_STRVAR(__pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_12_curveToOne, "MomentsPen._curveToOne(self, p1, p2, p3)");
-static PyMethodDef __pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_13_curveToOne = {"_curveToOne", (PyCFunction)(void*)(__Pyx_PyCFunction_FastCallWithKeywords)__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_13_curveToOne, __Pyx_METH_FASTCALL|METH_KEYWORDS, __pyx_doc_9fontTools_4pens_10momentsPen_10MomentsPen_12_curveToOne};
-static PyObject *__pyx_pw_9fontTools_4pens_10momentsPen_10MomentsPen_13_curveToOne(PyObject *__pyx_self,
-#if CYTHON_METH_FASTCALL
-PyObject *const *__pyx_args, Py_ssize_t __pyx_nargs, PyObject *__pyx_kwds
-#else
-PyObject *__pyx_args, PyObject *__pyx_kwds
-#endif
-) {
- PyObject *__pyx_v_self = 0;
- PyObject *__pyx_v_p1 = 0;
- PyObject *__pyx_v_p2 = 0;
- PyObject *__pyx_v_p3 = 0;
- #if !CYTHON_METH_FASTCALL
- CYTHON_UNUSED const Py_ssize_t __pyx_nargs = PyTuple_GET_SIZE(__pyx_args);
- #endif
- CYTHON_UNUSED PyObject *const *__pyx_kwvalues = __Pyx_KwValues_FASTCALL(__pyx_args, __pyx_nargs);
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("_curveToOne (wrapper)", 0);
- {
- PyObject **__pyx_pyargnames[] = {&__pyx_n_s_self,&__pyx_n_s_p1,&__pyx_n_s_p2,&__pyx_n_s_p3,0};
- PyObject* values[4] = {0,0,0,0};
- if (__pyx_kwds) {
- Py_ssize_t kw_args;
- switch (__pyx_nargs) {
- case 4: values[3] = __Pyx_Arg_FASTCALL(__pyx_args, 3);
- CYTHON_FALLTHROUGH;
- case 3: values[2] = __Pyx_Arg_FASTCALL(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = __Pyx_NumKwargs_FASTCALL(__pyx_kwds);
- switch (__pyx_nargs) {
- case 0:
- if (likely((values[0] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_self)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 313, __pyx_L3_error)
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_p1)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 313, __pyx_L3_error)
- else {
- __Pyx_RaiseArgtupleInvalid("_curveToOne", 1, 4, 4, 1); __PYX_ERR(0, 313, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (likely((values[2] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_p2)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 313, __pyx_L3_error)
- else {
- __Pyx_RaiseArgtupleInvalid("_curveToOne", 1, 4, 4, 2); __PYX_ERR(0, 313, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 3:
- if (likely((values[3] = __Pyx_GetKwValue_FASTCALL(__pyx_kwds, __pyx_kwvalues, __pyx_n_s_p3)) != 0)) kw_args--;
- else if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 313, __pyx_L3_error)
- else {
- __Pyx_RaiseArgtupleInvalid("_curveToOne", 1, 4, 4, 3); __PYX_ERR(0, 313, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- const Py_ssize_t kwd_pos_args = __pyx_nargs;
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_kwvalues, __pyx_pyargnames, 0, values + 0, kwd_pos_args, "_curveToOne") < 0)) __PYX_ERR(0, 313, __pyx_L3_error)
- }
- } else if (unlikely(__pyx_nargs != 4)) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = __Pyx_Arg_FASTCALL(__pyx_args, 0);
- values[1] = __Pyx_Arg_FASTCALL(__pyx_args, 1);
- values[2] = __Pyx_Arg_FASTCALL(__pyx_args, 2);
- values[3] = __Pyx_Arg_FASTCALL(__pyx_args, 3);
- }
- __pyx_v_self = values[0];
- __pyx_v_p1 = values[1];
- __pyx_v_p2 = values[2];
- __pyx_v_p3 = values[3];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("_curveToOne", 1, 4, 4, __pyx_nargs); __PYX_ERR(0, 313, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._curveToOne", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_12_curveToOne(__pyx_self, __pyx_v_self, __pyx_v_p1, __pyx_v_p2, __pyx_v_p3);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_9fontTools_4pens_10momentsPen_10MomentsPen_12_curveToOne(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self, PyObject *__pyx_v_p1, PyObject *__pyx_v_p2, PyObject *__pyx_v_p3) {
- double __pyx_v_x3;
- double __pyx_v_y3;
- double __pyx_v_x2;
- double __pyx_v_y2;
- double __pyx_v_x1;
- double __pyx_v_y1;
- double __pyx_v_x0;
- double __pyx_v_y0;
- double __pyx_v_r132;
- double __pyx_v_r131;
- double __pyx_v_r130;
- double __pyx_v_r129;
- double __pyx_v_r128;
- double __pyx_v_r127;
- double __pyx_v_r126;
- double __pyx_v_r125;
- double __pyx_v_r124;
- double __pyx_v_r123;
- double __pyx_v_r122;
- double __pyx_v_r121;
- double __pyx_v_r120;
- double __pyx_v_r119;
- double __pyx_v_r118;
- double __pyx_v_r117;
- double __pyx_v_r116;
- double __pyx_v_r115;
- double __pyx_v_r114;
- double __pyx_v_r113;
- double __pyx_v_r112;
- double __pyx_v_r111;
- double __pyx_v_r110;
- double __pyx_v_r109;
- double __pyx_v_r108;
- double __pyx_v_r107;
- double __pyx_v_r106;
- double __pyx_v_r105;
- double __pyx_v_r104;
- double __pyx_v_r103;
- double __pyx_v_r102;
- double __pyx_v_r101;
- double __pyx_v_r100;
- double __pyx_v_r99;
- double __pyx_v_r98;
- double __pyx_v_r97;
- double __pyx_v_r96;
- double __pyx_v_r95;
- double __pyx_v_r94;
- double __pyx_v_r93;
- double __pyx_v_r92;
- double __pyx_v_r91;
- double __pyx_v_r90;
- double __pyx_v_r89;
- double __pyx_v_r88;
- double __pyx_v_r87;
- double __pyx_v_r86;
- double __pyx_v_r85;
- double __pyx_v_r84;
- double __pyx_v_r83;
- double __pyx_v_r82;
- double __pyx_v_r81;
- double __pyx_v_r80;
- double __pyx_v_r79;
- double __pyx_v_r78;
- double __pyx_v_r77;
- double __pyx_v_r76;
- double __pyx_v_r75;
- double __pyx_v_r74;
- double __pyx_v_r73;
- double __pyx_v_r72;
- double __pyx_v_r71;
- double __pyx_v_r70;
- double __pyx_v_r69;
- double __pyx_v_r68;
- double __pyx_v_r67;
- double __pyx_v_r66;
- double __pyx_v_r65;
- double __pyx_v_r64;
- double __pyx_v_r63;
- double __pyx_v_r62;
- double __pyx_v_r61;
- double __pyx_v_r60;
- double __pyx_v_r59;
- double __pyx_v_r58;
- double __pyx_v_r57;
- double __pyx_v_r56;
- double __pyx_v_r55;
- double __pyx_v_r54;
- double __pyx_v_r53;
- double __pyx_v_r52;
- double __pyx_v_r51;
- double __pyx_v_r50;
- double __pyx_v_r49;
- double __pyx_v_r48;
- double __pyx_v_r47;
- double __pyx_v_r46;
- double __pyx_v_r45;
- double __pyx_v_r44;
- double __pyx_v_r43;
- double __pyx_v_r42;
- double __pyx_v_r41;
- double __pyx_v_r40;
- double __pyx_v_r39;
- double __pyx_v_r38;
- double __pyx_v_r37;
- double __pyx_v_r36;
- double __pyx_v_r35;
- double __pyx_v_r34;
- double __pyx_v_r33;
- double __pyx_v_r32;
- double __pyx_v_r31;
- double __pyx_v_r30;
- double __pyx_v_r29;
- double __pyx_v_r28;
- double __pyx_v_r27;
- double __pyx_v_r26;
- double __pyx_v_r25;
- double __pyx_v_r24;
- double __pyx_v_r23;
- double __pyx_v_r22;
- double __pyx_v_r21;
- double __pyx_v_r20;
- double __pyx_v_r19;
- double __pyx_v_r18;
- double __pyx_v_r17;
- double __pyx_v_r16;
- double __pyx_v_r15;
- double __pyx_v_r14;
- double __pyx_v_r13;
- double __pyx_v_r12;
- double __pyx_v_r11;
- double __pyx_v_r10;
- double __pyx_v_r9;
- double __pyx_v_r8;
- double __pyx_v_r7;
- double __pyx_v_r6;
- double __pyx_v_r5;
- double __pyx_v_r4;
- double __pyx_v_r3;
- double __pyx_v_r2;
- double __pyx_v_r1;
- double __pyx_v_r0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- PyObject *(*__pyx_t_6)(PyObject *);
- double __pyx_t_7;
- double __pyx_t_8;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("_curveToOne", 0);
-
- /* "fontTools/pens/momentsPen.py":451
- * @cython.locals(x3=cython.double, y3=cython.double)
- * def _curveToOne(self, p1, p2, p3):
- * x0, y0 = self._getCurrentPoint() # <<<<<<<<<<<<<<
- * x1, y1 = p1
- * x2, y2 = p2
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_getCurrentPoint); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 451, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = NULL;
- __pyx_t_4 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_2))) {
- __pyx_t_3 = PyMethod_GET_SELF(__pyx_t_2);
- if (likely(__pyx_t_3)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_2);
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_2, function);
- __pyx_t_4 = 1;
- }
- }
- {
- PyObject *__pyx_callargs[1] = {__pyx_t_3, };
- __pyx_t_1 = __Pyx_PyObject_FastCall(__pyx_t_2, __pyx_callargs+1-__pyx_t_4, 0+__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 451, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- if ((likely(PyTuple_CheckExact(__pyx_t_1))) || (PyList_CheckExact(__pyx_t_1))) {
- PyObject* sequence = __pyx_t_1;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 451, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_2 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_2 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_2);
- __Pyx_INCREF(__pyx_t_3);
- #else
- __pyx_t_2 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 451, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 451, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- #endif
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- } else {
- Py_ssize_t index = -1;
- __pyx_t_5 = PyObject_GetIter(__pyx_t_1); if (unlikely(!__pyx_t_5)) __PYX_ERR(0, 451, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_5);
- index = 0; __pyx_t_2 = __pyx_t_6(__pyx_t_5); if (unlikely(!__pyx_t_2)) goto __pyx_L3_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_2);
- index = 1; __pyx_t_3 = __pyx_t_6(__pyx_t_5); if (unlikely(!__pyx_t_3)) goto __pyx_L3_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_5), 2) < 0) __PYX_ERR(0, 451, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- goto __pyx_L4_unpacking_done;
- __pyx_L3_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 451, __pyx_L1_error)
- __pyx_L4_unpacking_done:;
- }
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_2); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 451, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 451, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_x0 = __pyx_t_7;
- __pyx_v_y0 = __pyx_t_8;
-
- /* "fontTools/pens/momentsPen.py":452
- * def _curveToOne(self, p1, p2, p3):
- * x0, y0 = self._getCurrentPoint()
- * x1, y1 = p1 # <<<<<<<<<<<<<<
- * x2, y2 = p2
- * x3, y3 = p3
- */
- if ((likely(PyTuple_CheckExact(__pyx_v_p1))) || (PyList_CheckExact(__pyx_v_p1))) {
- PyObject* sequence = __pyx_v_p1;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 452, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_1 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_1 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_3);
- #else
- __pyx_t_1 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 452, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 452, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- #endif
- } else {
- Py_ssize_t index = -1;
- __pyx_t_2 = PyObject_GetIter(__pyx_v_p1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 452, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_2);
- index = 0; __pyx_t_1 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_1)) goto __pyx_L5_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_1);
- index = 1; __pyx_t_3 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_3)) goto __pyx_L5_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_2), 2) < 0) __PYX_ERR(0, 452, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- goto __pyx_L6_unpacking_done;
- __pyx_L5_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 452, __pyx_L1_error)
- __pyx_L6_unpacking_done:;
- }
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_1); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 452, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 452, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_x1 = __pyx_t_8;
- __pyx_v_y1 = __pyx_t_7;
-
- /* "fontTools/pens/momentsPen.py":453
- * x0, y0 = self._getCurrentPoint()
- * x1, y1 = p1
- * x2, y2 = p2 # <<<<<<<<<<<<<<
- * x3, y3 = p3
- *
- */
- if ((likely(PyTuple_CheckExact(__pyx_v_p2))) || (PyList_CheckExact(__pyx_v_p2))) {
- PyObject* sequence = __pyx_v_p2;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 453, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_1 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_3 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_1 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_t_1);
- #else
- __pyx_t_3 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 453, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_1 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 453, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- #endif
- } else {
- Py_ssize_t index = -1;
- __pyx_t_2 = PyObject_GetIter(__pyx_v_p2); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 453, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_2);
- index = 0; __pyx_t_3 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_3)) goto __pyx_L7_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- index = 1; __pyx_t_1 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_1)) goto __pyx_L7_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_1);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_2), 2) < 0) __PYX_ERR(0, 453, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- goto __pyx_L8_unpacking_done;
- __pyx_L7_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 453, __pyx_L1_error)
- __pyx_L8_unpacking_done:;
- }
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 453, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_1); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 453, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_v_x2 = __pyx_t_7;
- __pyx_v_y2 = __pyx_t_8;
-
- /* "fontTools/pens/momentsPen.py":454
- * x1, y1 = p1
- * x2, y2 = p2
- * x3, y3 = p3 # <<<<<<<<<<<<<<
- *
- * r0 = 6 * y2
- */
- if ((likely(PyTuple_CheckExact(__pyx_v_p3))) || (PyList_CheckExact(__pyx_v_p3))) {
- PyObject* sequence = __pyx_v_p3;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(0, 454, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- if (likely(PyTuple_CheckExact(sequence))) {
- __pyx_t_1 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 1);
- } else {
- __pyx_t_1 = PyList_GET_ITEM(sequence, 0);
- __pyx_t_3 = PyList_GET_ITEM(sequence, 1);
- }
- __Pyx_INCREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_3);
- #else
- __pyx_t_1 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 454, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 454, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- #endif
- } else {
- Py_ssize_t index = -1;
- __pyx_t_2 = PyObject_GetIter(__pyx_v_p3); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 454, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_6 = __Pyx_PyObject_GetIterNextFunc(__pyx_t_2);
- index = 0; __pyx_t_1 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_1)) goto __pyx_L9_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_1);
- index = 1; __pyx_t_3 = __pyx_t_6(__pyx_t_2); if (unlikely(!__pyx_t_3)) goto __pyx_L9_unpacking_failed;
- __Pyx_GOTREF(__pyx_t_3);
- if (__Pyx_IternextUnpackEndCheck(__pyx_t_6(__pyx_t_2), 2) < 0) __PYX_ERR(0, 454, __pyx_L1_error)
- __pyx_t_6 = NULL;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- goto __pyx_L10_unpacking_done;
- __pyx_L9_unpacking_failed:;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_6 = NULL;
- if (__Pyx_IterFinish() == 0) __Pyx_RaiseNeedMoreValuesError(index);
- __PYX_ERR(0, 454, __pyx_L1_error)
- __pyx_L10_unpacking_done:;
- }
- __pyx_t_8 = __pyx_PyFloat_AsDouble(__pyx_t_1); if (unlikely((__pyx_t_8 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 454, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_7 = __pyx_PyFloat_AsDouble(__pyx_t_3); if (unlikely((__pyx_t_7 == (double)-1) && PyErr_Occurred())) __PYX_ERR(0, 454, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_x3 = __pyx_t_8;
- __pyx_v_y3 = __pyx_t_7;
-
- /* "fontTools/pens/momentsPen.py":456
- * x3, y3 = p3
- *
- * r0 = 6 * y2 # <<<<<<<<<<<<<<
- * r1 = r0 * x3
- * r2 = 10 * y3
- */
- __pyx_v_r0 = (6.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":457
- *
- * r0 = 6 * y2
- * r1 = r0 * x3 # <<<<<<<<<<<<<<
- * r2 = 10 * y3
- * r3 = r2 * x3
- */
- __pyx_v_r1 = (__pyx_v_r0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":458
- * r0 = 6 * y2
- * r1 = r0 * x3
- * r2 = 10 * y3 # <<<<<<<<<<<<<<
- * r3 = r2 * x3
- * r4 = 3 * y1
- */
- __pyx_v_r2 = (10.0 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":459
- * r1 = r0 * x3
- * r2 = 10 * y3
- * r3 = r2 * x3 # <<<<<<<<<<<<<<
- * r4 = 3 * y1
- * r5 = 6 * x1
- */
- __pyx_v_r3 = (__pyx_v_r2 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":460
- * r2 = 10 * y3
- * r3 = r2 * x3
- * r4 = 3 * y1 # <<<<<<<<<<<<<<
- * r5 = 6 * x1
- * r6 = 3 * x2
- */
- __pyx_v_r4 = (3.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":461
- * r3 = r2 * x3
- * r4 = 3 * y1
- * r5 = 6 * x1 # <<<<<<<<<<<<<<
- * r6 = 3 * x2
- * r7 = 6 * y1
- */
- __pyx_v_r5 = (6.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":462
- * r4 = 3 * y1
- * r5 = 6 * x1
- * r6 = 3 * x2 # <<<<<<<<<<<<<<
- * r7 = 6 * y1
- * r8 = 3 * y2
- */
- __pyx_v_r6 = (3.0 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":463
- * r5 = 6 * x1
- * r6 = 3 * x2
- * r7 = 6 * y1 # <<<<<<<<<<<<<<
- * r8 = 3 * y2
- * r9 = x2**2
- */
- __pyx_v_r7 = (6.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":464
- * r6 = 3 * x2
- * r7 = 6 * y1
- * r8 = 3 * y2 # <<<<<<<<<<<<<<
- * r9 = x2**2
- * r10 = 45 * r9
- */
- __pyx_v_r8 = (3.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":465
- * r7 = 6 * y1
- * r8 = 3 * y2
- * r9 = x2**2 # <<<<<<<<<<<<<<
- * r10 = 45 * r9
- * r11 = r10 * y3
- */
- __pyx_v_r9 = pow(__pyx_v_x2, 2.0);
-
- /* "fontTools/pens/momentsPen.py":466
- * r8 = 3 * y2
- * r9 = x2**2
- * r10 = 45 * r9 # <<<<<<<<<<<<<<
- * r11 = r10 * y3
- * r12 = x3**2
- */
- __pyx_v_r10 = (45.0 * __pyx_v_r9);
-
- /* "fontTools/pens/momentsPen.py":467
- * r9 = x2**2
- * r10 = 45 * r9
- * r11 = r10 * y3 # <<<<<<<<<<<<<<
- * r12 = x3**2
- * r13 = r12 * y2
- */
- __pyx_v_r11 = (__pyx_v_r10 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":468
- * r10 = 45 * r9
- * r11 = r10 * y3
- * r12 = x3**2 # <<<<<<<<<<<<<<
- * r13 = r12 * y2
- * r14 = r12 * y3
- */
- __pyx_v_r12 = pow(__pyx_v_x3, 2.0);
-
- /* "fontTools/pens/momentsPen.py":469
- * r11 = r10 * y3
- * r12 = x3**2
- * r13 = r12 * y2 # <<<<<<<<<<<<<<
- * r14 = r12 * y3
- * r15 = 7 * y3
- */
- __pyx_v_r13 = (__pyx_v_r12 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":470
- * r12 = x3**2
- * r13 = r12 * y2
- * r14 = r12 * y3 # <<<<<<<<<<<<<<
- * r15 = 7 * y3
- * r16 = 15 * x3
- */
- __pyx_v_r14 = (__pyx_v_r12 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":471
- * r13 = r12 * y2
- * r14 = r12 * y3
- * r15 = 7 * y3 # <<<<<<<<<<<<<<
- * r16 = 15 * x3
- * r17 = r16 * x2
- */
- __pyx_v_r15 = (7.0 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":472
- * r14 = r12 * y3
- * r15 = 7 * y3
- * r16 = 15 * x3 # <<<<<<<<<<<<<<
- * r17 = r16 * x2
- * r18 = x1**2
- */
- __pyx_v_r16 = (15.0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":473
- * r15 = 7 * y3
- * r16 = 15 * x3
- * r17 = r16 * x2 # <<<<<<<<<<<<<<
- * r18 = x1**2
- * r19 = 9 * r18
- */
- __pyx_v_r17 = (__pyx_v_r16 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":474
- * r16 = 15 * x3
- * r17 = r16 * x2
- * r18 = x1**2 # <<<<<<<<<<<<<<
- * r19 = 9 * r18
- * r20 = x0**2
- */
- __pyx_v_r18 = pow(__pyx_v_x1, 2.0);
-
- /* "fontTools/pens/momentsPen.py":475
- * r17 = r16 * x2
- * r18 = x1**2
- * r19 = 9 * r18 # <<<<<<<<<<<<<<
- * r20 = x0**2
- * r21 = 21 * y1
- */
- __pyx_v_r19 = (9.0 * __pyx_v_r18);
-
- /* "fontTools/pens/momentsPen.py":476
- * r18 = x1**2
- * r19 = 9 * r18
- * r20 = x0**2 # <<<<<<<<<<<<<<
- * r21 = 21 * y1
- * r22 = 9 * r9
- */
- __pyx_v_r20 = pow(__pyx_v_x0, 2.0);
-
- /* "fontTools/pens/momentsPen.py":477
- * r19 = 9 * r18
- * r20 = x0**2
- * r21 = 21 * y1 # <<<<<<<<<<<<<<
- * r22 = 9 * r9
- * r23 = r7 * x3
- */
- __pyx_v_r21 = (21.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":478
- * r20 = x0**2
- * r21 = 21 * y1
- * r22 = 9 * r9 # <<<<<<<<<<<<<<
- * r23 = r7 * x3
- * r24 = 9 * y2
- */
- __pyx_v_r22 = (9.0 * __pyx_v_r9);
-
- /* "fontTools/pens/momentsPen.py":479
- * r21 = 21 * y1
- * r22 = 9 * r9
- * r23 = r7 * x3 # <<<<<<<<<<<<<<
- * r24 = 9 * y2
- * r25 = r24 * x2 + r3
- */
- __pyx_v_r23 = (__pyx_v_r7 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":480
- * r22 = 9 * r9
- * r23 = r7 * x3
- * r24 = 9 * y2 # <<<<<<<<<<<<<<
- * r25 = r24 * x2 + r3
- * r26 = 9 * x2
- */
- __pyx_v_r24 = (9.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":481
- * r23 = r7 * x3
- * r24 = 9 * y2
- * r25 = r24 * x2 + r3 # <<<<<<<<<<<<<<
- * r26 = 9 * x2
- * r27 = x2 * y3
- */
- __pyx_v_r25 = ((__pyx_v_r24 * __pyx_v_x2) + __pyx_v_r3);
-
- /* "fontTools/pens/momentsPen.py":482
- * r24 = 9 * y2
- * r25 = r24 * x2 + r3
- * r26 = 9 * x2 # <<<<<<<<<<<<<<
- * r27 = x2 * y3
- * r28 = -r26 * y1 + 15 * r27
- */
- __pyx_v_r26 = (9.0 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":483
- * r25 = r24 * x2 + r3
- * r26 = 9 * x2
- * r27 = x2 * y3 # <<<<<<<<<<<<<<
- * r28 = -r26 * y1 + 15 * r27
- * r29 = 3 * x1
- */
- __pyx_v_r27 = (__pyx_v_x2 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":484
- * r26 = 9 * x2
- * r27 = x2 * y3
- * r28 = -r26 * y1 + 15 * r27 # <<<<<<<<<<<<<<
- * r29 = 3 * x1
- * r30 = 45 * x1
- */
- __pyx_v_r28 = (((-__pyx_v_r26) * __pyx_v_y1) + (15.0 * __pyx_v_r27));
-
- /* "fontTools/pens/momentsPen.py":485
- * r27 = x2 * y3
- * r28 = -r26 * y1 + 15 * r27
- * r29 = 3 * x1 # <<<<<<<<<<<<<<
- * r30 = 45 * x1
- * r31 = 12 * x3
- */
- __pyx_v_r29 = (3.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":486
- * r28 = -r26 * y1 + 15 * r27
- * r29 = 3 * x1
- * r30 = 45 * x1 # <<<<<<<<<<<<<<
- * r31 = 12 * x3
- * r32 = 45 * r18
- */
- __pyx_v_r30 = (45.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":487
- * r29 = 3 * x1
- * r30 = 45 * x1
- * r31 = 12 * x3 # <<<<<<<<<<<<<<
- * r32 = 45 * r18
- * r33 = 5 * r12
- */
- __pyx_v_r31 = (12.0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":488
- * r30 = 45 * x1
- * r31 = 12 * x3
- * r32 = 45 * r18 # <<<<<<<<<<<<<<
- * r33 = 5 * r12
- * r34 = r8 * x3
- */
- __pyx_v_r32 = (45.0 * __pyx_v_r18);
-
- /* "fontTools/pens/momentsPen.py":489
- * r31 = 12 * x3
- * r32 = 45 * r18
- * r33 = 5 * r12 # <<<<<<<<<<<<<<
- * r34 = r8 * x3
- * r35 = 105 * y0
- */
- __pyx_v_r33 = (5.0 * __pyx_v_r12);
-
- /* "fontTools/pens/momentsPen.py":490
- * r32 = 45 * r18
- * r33 = 5 * r12
- * r34 = r8 * x3 # <<<<<<<<<<<<<<
- * r35 = 105 * y0
- * r36 = 30 * y0
- */
- __pyx_v_r34 = (__pyx_v_r8 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":491
- * r33 = 5 * r12
- * r34 = r8 * x3
- * r35 = 105 * y0 # <<<<<<<<<<<<<<
- * r36 = 30 * y0
- * r37 = r36 * x2
- */
- __pyx_v_r35 = (105.0 * __pyx_v_y0);
-
- /* "fontTools/pens/momentsPen.py":492
- * r34 = r8 * x3
- * r35 = 105 * y0
- * r36 = 30 * y0 # <<<<<<<<<<<<<<
- * r37 = r36 * x2
- * r38 = 5 * x3
- */
- __pyx_v_r36 = (30.0 * __pyx_v_y0);
-
- /* "fontTools/pens/momentsPen.py":493
- * r35 = 105 * y0
- * r36 = 30 * y0
- * r37 = r36 * x2 # <<<<<<<<<<<<<<
- * r38 = 5 * x3
- * r39 = 15 * y3
- */
- __pyx_v_r37 = (__pyx_v_r36 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":494
- * r36 = 30 * y0
- * r37 = r36 * x2
- * r38 = 5 * x3 # <<<<<<<<<<<<<<
- * r39 = 15 * y3
- * r40 = 5 * y3
- */
- __pyx_v_r38 = (5.0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":495
- * r37 = r36 * x2
- * r38 = 5 * x3
- * r39 = 15 * y3 # <<<<<<<<<<<<<<
- * r40 = 5 * y3
- * r41 = r40 * x3
- */
- __pyx_v_r39 = (15.0 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":496
- * r38 = 5 * x3
- * r39 = 15 * y3
- * r40 = 5 * y3 # <<<<<<<<<<<<<<
- * r41 = r40 * x3
- * r42 = x2 * y2
- */
- __pyx_v_r40 = (5.0 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":497
- * r39 = 15 * y3
- * r40 = 5 * y3
- * r41 = r40 * x3 # <<<<<<<<<<<<<<
- * r42 = x2 * y2
- * r43 = 18 * r42
- */
- __pyx_v_r41 = (__pyx_v_r40 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":498
- * r40 = 5 * y3
- * r41 = r40 * x3
- * r42 = x2 * y2 # <<<<<<<<<<<<<<
- * r43 = 18 * r42
- * r44 = 45 * y1
- */
- __pyx_v_r42 = (__pyx_v_x2 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":499
- * r41 = r40 * x3
- * r42 = x2 * y2
- * r43 = 18 * r42 # <<<<<<<<<<<<<<
- * r44 = 45 * y1
- * r45 = r41 + r43 + r44 * x1
- */
- __pyx_v_r43 = (18.0 * __pyx_v_r42);
-
- /* "fontTools/pens/momentsPen.py":500
- * r42 = x2 * y2
- * r43 = 18 * r42
- * r44 = 45 * y1 # <<<<<<<<<<<<<<
- * r45 = r41 + r43 + r44 * x1
- * r46 = y2 * y3
- */
- __pyx_v_r44 = (45.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":501
- * r43 = 18 * r42
- * r44 = 45 * y1
- * r45 = r41 + r43 + r44 * x1 # <<<<<<<<<<<<<<
- * r46 = y2 * y3
- * r47 = r46 * x3
- */
- __pyx_v_r45 = ((__pyx_v_r41 + __pyx_v_r43) + (__pyx_v_r44 * __pyx_v_x1));
-
- /* "fontTools/pens/momentsPen.py":502
- * r44 = 45 * y1
- * r45 = r41 + r43 + r44 * x1
- * r46 = y2 * y3 # <<<<<<<<<<<<<<
- * r47 = r46 * x3
- * r48 = y2**2
- */
- __pyx_v_r46 = (__pyx_v_y2 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":503
- * r45 = r41 + r43 + r44 * x1
- * r46 = y2 * y3
- * r47 = r46 * x3 # <<<<<<<<<<<<<<
- * r48 = y2**2
- * r49 = 45 * r48
- */
- __pyx_v_r47 = (__pyx_v_r46 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":504
- * r46 = y2 * y3
- * r47 = r46 * x3
- * r48 = y2**2 # <<<<<<<<<<<<<<
- * r49 = 45 * r48
- * r50 = r49 * x3
- */
- __pyx_v_r48 = pow(__pyx_v_y2, 2.0);
-
- /* "fontTools/pens/momentsPen.py":505
- * r47 = r46 * x3
- * r48 = y2**2
- * r49 = 45 * r48 # <<<<<<<<<<<<<<
- * r50 = r49 * x3
- * r51 = y3**2
- */
- __pyx_v_r49 = (45.0 * __pyx_v_r48);
-
- /* "fontTools/pens/momentsPen.py":506
- * r48 = y2**2
- * r49 = 45 * r48
- * r50 = r49 * x3 # <<<<<<<<<<<<<<
- * r51 = y3**2
- * r52 = r51 * x3
- */
- __pyx_v_r50 = (__pyx_v_r49 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":507
- * r49 = 45 * r48
- * r50 = r49 * x3
- * r51 = y3**2 # <<<<<<<<<<<<<<
- * r52 = r51 * x3
- * r53 = y1**2
- */
- __pyx_v_r51 = pow(__pyx_v_y3, 2.0);
-
- /* "fontTools/pens/momentsPen.py":508
- * r50 = r49 * x3
- * r51 = y3**2
- * r52 = r51 * x3 # <<<<<<<<<<<<<<
- * r53 = y1**2
- * r54 = 9 * r53
- */
- __pyx_v_r52 = (__pyx_v_r51 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":509
- * r51 = y3**2
- * r52 = r51 * x3
- * r53 = y1**2 # <<<<<<<<<<<<<<
- * r54 = 9 * r53
- * r55 = y0**2
- */
- __pyx_v_r53 = pow(__pyx_v_y1, 2.0);
-
- /* "fontTools/pens/momentsPen.py":510
- * r52 = r51 * x3
- * r53 = y1**2
- * r54 = 9 * r53 # <<<<<<<<<<<<<<
- * r55 = y0**2
- * r56 = 21 * x1
- */
- __pyx_v_r54 = (9.0 * __pyx_v_r53);
-
- /* "fontTools/pens/momentsPen.py":511
- * r53 = y1**2
- * r54 = 9 * r53
- * r55 = y0**2 # <<<<<<<<<<<<<<
- * r56 = 21 * x1
- * r57 = 6 * x2
- */
- __pyx_v_r55 = pow(__pyx_v_y0, 2.0);
-
- /* "fontTools/pens/momentsPen.py":512
- * r54 = 9 * r53
- * r55 = y0**2
- * r56 = 21 * x1 # <<<<<<<<<<<<<<
- * r57 = 6 * x2
- * r58 = r16 * y2
- */
- __pyx_v_r56 = (21.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":513
- * r55 = y0**2
- * r56 = 21 * x1
- * r57 = 6 * x2 # <<<<<<<<<<<<<<
- * r58 = r16 * y2
- * r59 = r39 * y2
- */
- __pyx_v_r57 = (6.0 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":514
- * r56 = 21 * x1
- * r57 = 6 * x2
- * r58 = r16 * y2 # <<<<<<<<<<<<<<
- * r59 = r39 * y2
- * r60 = 9 * r48
- */
- __pyx_v_r58 = (__pyx_v_r16 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":515
- * r57 = 6 * x2
- * r58 = r16 * y2
- * r59 = r39 * y2 # <<<<<<<<<<<<<<
- * r60 = 9 * r48
- * r61 = r6 * y3
- */
- __pyx_v_r59 = (__pyx_v_r39 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":516
- * r58 = r16 * y2
- * r59 = r39 * y2
- * r60 = 9 * r48 # <<<<<<<<<<<<<<
- * r61 = r6 * y3
- * r62 = 3 * y3
- */
- __pyx_v_r60 = (9.0 * __pyx_v_r48);
-
- /* "fontTools/pens/momentsPen.py":517
- * r59 = r39 * y2
- * r60 = 9 * r48
- * r61 = r6 * y3 # <<<<<<<<<<<<<<
- * r62 = 3 * y3
- * r63 = r36 * y2
- */
- __pyx_v_r61 = (__pyx_v_r6 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":518
- * r60 = 9 * r48
- * r61 = r6 * y3
- * r62 = 3 * y3 # <<<<<<<<<<<<<<
- * r63 = r36 * y2
- * r64 = y1 * y3
- */
- __pyx_v_r62 = (3.0 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":519
- * r61 = r6 * y3
- * r62 = 3 * y3
- * r63 = r36 * y2 # <<<<<<<<<<<<<<
- * r64 = y1 * y3
- * r65 = 45 * r53
- */
- __pyx_v_r63 = (__pyx_v_r36 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":520
- * r62 = 3 * y3
- * r63 = r36 * y2
- * r64 = y1 * y3 # <<<<<<<<<<<<<<
- * r65 = 45 * r53
- * r66 = 5 * r51
- */
- __pyx_v_r64 = (__pyx_v_y1 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":521
- * r63 = r36 * y2
- * r64 = y1 * y3
- * r65 = 45 * r53 # <<<<<<<<<<<<<<
- * r66 = 5 * r51
- * r67 = x2**3
- */
- __pyx_v_r65 = (45.0 * __pyx_v_r53);
-
- /* "fontTools/pens/momentsPen.py":522
- * r64 = y1 * y3
- * r65 = 45 * r53
- * r66 = 5 * r51 # <<<<<<<<<<<<<<
- * r67 = x2**3
- * r68 = x3**3
- */
- __pyx_v_r66 = (5.0 * __pyx_v_r51);
-
- /* "fontTools/pens/momentsPen.py":523
- * r65 = 45 * r53
- * r66 = 5 * r51
- * r67 = x2**3 # <<<<<<<<<<<<<<
- * r68 = x3**3
- * r69 = 630 * y2
- */
- __pyx_v_r67 = pow(__pyx_v_x2, 3.0);
-
- /* "fontTools/pens/momentsPen.py":524
- * r66 = 5 * r51
- * r67 = x2**3
- * r68 = x3**3 # <<<<<<<<<<<<<<
- * r69 = 630 * y2
- * r70 = 126 * x3
- */
- __pyx_v_r68 = pow(__pyx_v_x3, 3.0);
-
- /* "fontTools/pens/momentsPen.py":525
- * r67 = x2**3
- * r68 = x3**3
- * r69 = 630 * y2 # <<<<<<<<<<<<<<
- * r70 = 126 * x3
- * r71 = x1**3
- */
- __pyx_v_r69 = (630.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":526
- * r68 = x3**3
- * r69 = 630 * y2
- * r70 = 126 * x3 # <<<<<<<<<<<<<<
- * r71 = x1**3
- * r72 = 126 * x2
- */
- __pyx_v_r70 = (126.0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":527
- * r69 = 630 * y2
- * r70 = 126 * x3
- * r71 = x1**3 # <<<<<<<<<<<<<<
- * r72 = 126 * x2
- * r73 = 63 * r9
- */
- __pyx_v_r71 = pow(__pyx_v_x1, 3.0);
-
- /* "fontTools/pens/momentsPen.py":528
- * r70 = 126 * x3
- * r71 = x1**3
- * r72 = 126 * x2 # <<<<<<<<<<<<<<
- * r73 = 63 * r9
- * r74 = r73 * x3
- */
- __pyx_v_r72 = (126.0 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":529
- * r71 = x1**3
- * r72 = 126 * x2
- * r73 = 63 * r9 # <<<<<<<<<<<<<<
- * r74 = r73 * x3
- * r75 = r15 * x3 + 15 * r42
- */
- __pyx_v_r73 = (63.0 * __pyx_v_r9);
-
- /* "fontTools/pens/momentsPen.py":530
- * r72 = 126 * x2
- * r73 = 63 * r9
- * r74 = r73 * x3 # <<<<<<<<<<<<<<
- * r75 = r15 * x3 + 15 * r42
- * r76 = 630 * x1
- */
- __pyx_v_r74 = (__pyx_v_r73 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":531
- * r73 = 63 * r9
- * r74 = r73 * x3
- * r75 = r15 * x3 + 15 * r42 # <<<<<<<<<<<<<<
- * r76 = 630 * x1
- * r77 = 14 * x3
- */
- __pyx_v_r75 = ((__pyx_v_r15 * __pyx_v_x3) + (15.0 * __pyx_v_r42));
-
- /* "fontTools/pens/momentsPen.py":532
- * r74 = r73 * x3
- * r75 = r15 * x3 + 15 * r42
- * r76 = 630 * x1 # <<<<<<<<<<<<<<
- * r77 = 14 * x3
- * r78 = 21 * r27
- */
- __pyx_v_r76 = (630.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":533
- * r75 = r15 * x3 + 15 * r42
- * r76 = 630 * x1
- * r77 = 14 * x3 # <<<<<<<<<<<<<<
- * r78 = 21 * r27
- * r79 = 42 * x1
- */
- __pyx_v_r77 = (14.0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":534
- * r76 = 630 * x1
- * r77 = 14 * x3
- * r78 = 21 * r27 # <<<<<<<<<<<<<<
- * r79 = 42 * x1
- * r80 = 42 * x2
- */
- __pyx_v_r78 = (21.0 * __pyx_v_r27);
-
- /* "fontTools/pens/momentsPen.py":535
- * r77 = 14 * x3
- * r78 = 21 * r27
- * r79 = 42 * x1 # <<<<<<<<<<<<<<
- * r80 = 42 * x2
- * r81 = x1 * y2
- */
- __pyx_v_r79 = (42.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":536
- * r78 = 21 * r27
- * r79 = 42 * x1
- * r80 = 42 * x2 # <<<<<<<<<<<<<<
- * r81 = x1 * y2
- * r82 = 63 * r42
- */
- __pyx_v_r80 = (42.0 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":537
- * r79 = 42 * x1
- * r80 = 42 * x2
- * r81 = x1 * y2 # <<<<<<<<<<<<<<
- * r82 = 63 * r42
- * r83 = x1 * y1
- */
- __pyx_v_r81 = (__pyx_v_x1 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":538
- * r80 = 42 * x2
- * r81 = x1 * y2
- * r82 = 63 * r42 # <<<<<<<<<<<<<<
- * r83 = x1 * y1
- * r84 = r41 + r82 + 378 * r83
- */
- __pyx_v_r82 = (63.0 * __pyx_v_r42);
-
- /* "fontTools/pens/momentsPen.py":539
- * r81 = x1 * y2
- * r82 = 63 * r42
- * r83 = x1 * y1 # <<<<<<<<<<<<<<
- * r84 = r41 + r82 + 378 * r83
- * r85 = x2 * x3
- */
- __pyx_v_r83 = (__pyx_v_x1 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":540
- * r82 = 63 * r42
- * r83 = x1 * y1
- * r84 = r41 + r82 + 378 * r83 # <<<<<<<<<<<<<<
- * r85 = x2 * x3
- * r86 = r85 * y1
- */
- __pyx_v_r84 = ((__pyx_v_r41 + __pyx_v_r82) + (378.0 * __pyx_v_r83));
-
- /* "fontTools/pens/momentsPen.py":541
- * r83 = x1 * y1
- * r84 = r41 + r82 + 378 * r83
- * r85 = x2 * x3 # <<<<<<<<<<<<<<
- * r86 = r85 * y1
- * r87 = r27 * x3
- */
- __pyx_v_r85 = (__pyx_v_x2 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":542
- * r84 = r41 + r82 + 378 * r83
- * r85 = x2 * x3
- * r86 = r85 * y1 # <<<<<<<<<<<<<<
- * r87 = r27 * x3
- * r88 = 27 * r9
- */
- __pyx_v_r86 = (__pyx_v_r85 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":543
- * r85 = x2 * x3
- * r86 = r85 * y1
- * r87 = r27 * x3 # <<<<<<<<<<<<<<
- * r88 = 27 * r9
- * r89 = r88 * y2
- */
- __pyx_v_r87 = (__pyx_v_r27 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":544
- * r86 = r85 * y1
- * r87 = r27 * x3
- * r88 = 27 * r9 # <<<<<<<<<<<<<<
- * r89 = r88 * y2
- * r90 = 42 * r14
- */
- __pyx_v_r88 = (27.0 * __pyx_v_r9);
-
- /* "fontTools/pens/momentsPen.py":545
- * r87 = r27 * x3
- * r88 = 27 * r9
- * r89 = r88 * y2 # <<<<<<<<<<<<<<
- * r90 = 42 * r14
- * r91 = 90 * x1
- */
- __pyx_v_r89 = (__pyx_v_r88 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":546
- * r88 = 27 * r9
- * r89 = r88 * y2
- * r90 = 42 * r14 # <<<<<<<<<<<<<<
- * r91 = 90 * x1
- * r92 = 189 * r18
- */
- __pyx_v_r90 = (42.0 * __pyx_v_r14);
-
- /* "fontTools/pens/momentsPen.py":547
- * r89 = r88 * y2
- * r90 = 42 * r14
- * r91 = 90 * x1 # <<<<<<<<<<<<<<
- * r92 = 189 * r18
- * r93 = 378 * r18
- */
- __pyx_v_r91 = (90.0 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":548
- * r90 = 42 * r14
- * r91 = 90 * x1
- * r92 = 189 * r18 # <<<<<<<<<<<<<<
- * r93 = 378 * r18
- * r94 = r12 * y1
- */
- __pyx_v_r92 = (189.0 * __pyx_v_r18);
-
- /* "fontTools/pens/momentsPen.py":549
- * r91 = 90 * x1
- * r92 = 189 * r18
- * r93 = 378 * r18 # <<<<<<<<<<<<<<
- * r94 = r12 * y1
- * r95 = 252 * x1 * x2
- */
- __pyx_v_r93 = (378.0 * __pyx_v_r18);
-
- /* "fontTools/pens/momentsPen.py":550
- * r92 = 189 * r18
- * r93 = 378 * r18
- * r94 = r12 * y1 # <<<<<<<<<<<<<<
- * r95 = 252 * x1 * x2
- * r96 = r79 * x3
- */
- __pyx_v_r94 = (__pyx_v_r12 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":551
- * r93 = 378 * r18
- * r94 = r12 * y1
- * r95 = 252 * x1 * x2 # <<<<<<<<<<<<<<
- * r96 = r79 * x3
- * r97 = 30 * r85
- */
- __pyx_v_r95 = ((252.0 * __pyx_v_x1) * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":552
- * r94 = r12 * y1
- * r95 = 252 * x1 * x2
- * r96 = r79 * x3 # <<<<<<<<<<<<<<
- * r97 = 30 * r85
- * r98 = r83 * x3
- */
- __pyx_v_r96 = (__pyx_v_r79 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":553
- * r95 = 252 * x1 * x2
- * r96 = r79 * x3
- * r97 = 30 * r85 # <<<<<<<<<<<<<<
- * r98 = r83 * x3
- * r99 = 30 * x3
- */
- __pyx_v_r97 = (30.0 * __pyx_v_r85);
-
- /* "fontTools/pens/momentsPen.py":554
- * r96 = r79 * x3
- * r97 = 30 * r85
- * r98 = r83 * x3 # <<<<<<<<<<<<<<
- * r99 = 30 * x3
- * r100 = 42 * x3
- */
- __pyx_v_r98 = (__pyx_v_r83 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":555
- * r97 = 30 * r85
- * r98 = r83 * x3
- * r99 = 30 * x3 # <<<<<<<<<<<<<<
- * r100 = 42 * x3
- * r101 = r42 * x1
- */
- __pyx_v_r99 = (30.0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":556
- * r98 = r83 * x3
- * r99 = 30 * x3
- * r100 = 42 * x3 # <<<<<<<<<<<<<<
- * r101 = r42 * x1
- * r102 = r10 * y2 + 14 * r14 + 126 * r18 * y1 + r81 * r99
- */
- __pyx_v_r100 = (42.0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":557
- * r99 = 30 * x3
- * r100 = 42 * x3
- * r101 = r42 * x1 # <<<<<<<<<<<<<<
- * r102 = r10 * y2 + 14 * r14 + 126 * r18 * y1 + r81 * r99
- * r103 = 378 * r48
- */
- __pyx_v_r101 = (__pyx_v_r42 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":558
- * r100 = 42 * x3
- * r101 = r42 * x1
- * r102 = r10 * y2 + 14 * r14 + 126 * r18 * y1 + r81 * r99 # <<<<<<<<<<<<<<
- * r103 = 378 * r48
- * r104 = 18 * y1
- */
- __pyx_v_r102 = ((((__pyx_v_r10 * __pyx_v_y2) + (14.0 * __pyx_v_r14)) + ((126.0 * __pyx_v_r18) * __pyx_v_y1)) + (__pyx_v_r81 * __pyx_v_r99));
-
- /* "fontTools/pens/momentsPen.py":559
- * r101 = r42 * x1
- * r102 = r10 * y2 + 14 * r14 + 126 * r18 * y1 + r81 * r99
- * r103 = 378 * r48 # <<<<<<<<<<<<<<
- * r104 = 18 * y1
- * r105 = r104 * y2
- */
- __pyx_v_r103 = (378.0 * __pyx_v_r48);
-
- /* "fontTools/pens/momentsPen.py":560
- * r102 = r10 * y2 + 14 * r14 + 126 * r18 * y1 + r81 * r99
- * r103 = 378 * r48
- * r104 = 18 * y1 # <<<<<<<<<<<<<<
- * r105 = r104 * y2
- * r106 = y0 * y1
- */
- __pyx_v_r104 = (18.0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":561
- * r103 = 378 * r48
- * r104 = 18 * y1
- * r105 = r104 * y2 # <<<<<<<<<<<<<<
- * r106 = y0 * y1
- * r107 = 252 * y2
- */
- __pyx_v_r105 = (__pyx_v_r104 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":562
- * r104 = 18 * y1
- * r105 = r104 * y2
- * r106 = y0 * y1 # <<<<<<<<<<<<<<
- * r107 = 252 * y2
- * r108 = r107 * y0
- */
- __pyx_v_r106 = (__pyx_v_y0 * __pyx_v_y1);
-
- /* "fontTools/pens/momentsPen.py":563
- * r105 = r104 * y2
- * r106 = y0 * y1
- * r107 = 252 * y2 # <<<<<<<<<<<<<<
- * r108 = r107 * y0
- * r109 = y0 * y3
- */
- __pyx_v_r107 = (252.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":564
- * r106 = y0 * y1
- * r107 = 252 * y2
- * r108 = r107 * y0 # <<<<<<<<<<<<<<
- * r109 = y0 * y3
- * r110 = 42 * r64
- */
- __pyx_v_r108 = (__pyx_v_r107 * __pyx_v_y0);
-
- /* "fontTools/pens/momentsPen.py":565
- * r107 = 252 * y2
- * r108 = r107 * y0
- * r109 = y0 * y3 # <<<<<<<<<<<<<<
- * r110 = 42 * r64
- * r111 = 378 * r53
- */
- __pyx_v_r109 = (__pyx_v_y0 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":566
- * r108 = r107 * y0
- * r109 = y0 * y3
- * r110 = 42 * r64 # <<<<<<<<<<<<<<
- * r111 = 378 * r53
- * r112 = 63 * r48
- */
- __pyx_v_r110 = (42.0 * __pyx_v_r64);
-
- /* "fontTools/pens/momentsPen.py":567
- * r109 = y0 * y3
- * r110 = 42 * r64
- * r111 = 378 * r53 # <<<<<<<<<<<<<<
- * r112 = 63 * r48
- * r113 = 27 * x2
- */
- __pyx_v_r111 = (378.0 * __pyx_v_r53);
-
- /* "fontTools/pens/momentsPen.py":568
- * r110 = 42 * r64
- * r111 = 378 * r53
- * r112 = 63 * r48 # <<<<<<<<<<<<<<
- * r113 = 27 * x2
- * r114 = r27 * y2
- */
- __pyx_v_r112 = (63.0 * __pyx_v_r48);
-
- /* "fontTools/pens/momentsPen.py":569
- * r111 = 378 * r53
- * r112 = 63 * r48
- * r113 = 27 * x2 # <<<<<<<<<<<<<<
- * r114 = r27 * y2
- * r115 = r113 * r48 + 42 * r52
- */
- __pyx_v_r113 = (27.0 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":570
- * r112 = 63 * r48
- * r113 = 27 * x2
- * r114 = r27 * y2 # <<<<<<<<<<<<<<
- * r115 = r113 * r48 + 42 * r52
- * r116 = x3 * y3
- */
- __pyx_v_r114 = (__pyx_v_r27 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":571
- * r113 = 27 * x2
- * r114 = r27 * y2
- * r115 = r113 * r48 + 42 * r52 # <<<<<<<<<<<<<<
- * r116 = x3 * y3
- * r117 = 54 * r42
- */
- __pyx_v_r115 = ((__pyx_v_r113 * __pyx_v_r48) + (42.0 * __pyx_v_r52));
-
- /* "fontTools/pens/momentsPen.py":572
- * r114 = r27 * y2
- * r115 = r113 * r48 + 42 * r52
- * r116 = x3 * y3 # <<<<<<<<<<<<<<
- * r117 = 54 * r42
- * r118 = r51 * x1
- */
- __pyx_v_r116 = (__pyx_v_x3 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":573
- * r115 = r113 * r48 + 42 * r52
- * r116 = x3 * y3
- * r117 = 54 * r42 # <<<<<<<<<<<<<<
- * r118 = r51 * x1
- * r119 = r51 * x2
- */
- __pyx_v_r117 = (54.0 * __pyx_v_r42);
-
- /* "fontTools/pens/momentsPen.py":574
- * r116 = x3 * y3
- * r117 = 54 * r42
- * r118 = r51 * x1 # <<<<<<<<<<<<<<
- * r119 = r51 * x2
- * r120 = r48 * x1
- */
- __pyx_v_r118 = (__pyx_v_r51 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":575
- * r117 = 54 * r42
- * r118 = r51 * x1
- * r119 = r51 * x2 # <<<<<<<<<<<<<<
- * r120 = r48 * x1
- * r121 = 21 * x3
- */
- __pyx_v_r119 = (__pyx_v_r51 * __pyx_v_x2);
-
- /* "fontTools/pens/momentsPen.py":576
- * r118 = r51 * x1
- * r119 = r51 * x2
- * r120 = r48 * x1 # <<<<<<<<<<<<<<
- * r121 = 21 * x3
- * r122 = r64 * x1
- */
- __pyx_v_r120 = (__pyx_v_r48 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":577
- * r119 = r51 * x2
- * r120 = r48 * x1
- * r121 = 21 * x3 # <<<<<<<<<<<<<<
- * r122 = r64 * x1
- * r123 = r81 * y3
- */
- __pyx_v_r121 = (21.0 * __pyx_v_x3);
-
- /* "fontTools/pens/momentsPen.py":578
- * r120 = r48 * x1
- * r121 = 21 * x3
- * r122 = r64 * x1 # <<<<<<<<<<<<<<
- * r123 = r81 * y3
- * r124 = 30 * r27 * y1 + r49 * x2 + 14 * r52 + 126 * r53 * x1
- */
- __pyx_v_r122 = (__pyx_v_r64 * __pyx_v_x1);
-
- /* "fontTools/pens/momentsPen.py":579
- * r121 = 21 * x3
- * r122 = r64 * x1
- * r123 = r81 * y3 # <<<<<<<<<<<<<<
- * r124 = 30 * r27 * y1 + r49 * x2 + 14 * r52 + 126 * r53 * x1
- * r125 = y2**3
- */
- __pyx_v_r123 = (__pyx_v_r81 * __pyx_v_y3);
-
- /* "fontTools/pens/momentsPen.py":580
- * r122 = r64 * x1
- * r123 = r81 * y3
- * r124 = 30 * r27 * y1 + r49 * x2 + 14 * r52 + 126 * r53 * x1 # <<<<<<<<<<<<<<
- * r125 = y2**3
- * r126 = y3**3
- */
- __pyx_v_r124 = (((((30.0 * __pyx_v_r27) * __pyx_v_y1) + (__pyx_v_r49 * __pyx_v_x2)) + (14.0 * __pyx_v_r52)) + ((126.0 * __pyx_v_r53) * __pyx_v_x1));
-
- /* "fontTools/pens/momentsPen.py":581
- * r123 = r81 * y3
- * r124 = 30 * r27 * y1 + r49 * x2 + 14 * r52 + 126 * r53 * x1
- * r125 = y2**3 # <<<<<<<<<<<<<<
- * r126 = y3**3
- * r127 = y1**3
- */
- __pyx_v_r125 = pow(__pyx_v_y2, 3.0);
-
- /* "fontTools/pens/momentsPen.py":582
- * r124 = 30 * r27 * y1 + r49 * x2 + 14 * r52 + 126 * r53 * x1
- * r125 = y2**3
- * r126 = y3**3 # <<<<<<<<<<<<<<
- * r127 = y1**3
- * r128 = y0**3
- */
- __pyx_v_r126 = pow(__pyx_v_y3, 3.0);
-
- /* "fontTools/pens/momentsPen.py":583
- * r125 = y2**3
- * r126 = y3**3
- * r127 = y1**3 # <<<<<<<<<<<<<<
- * r128 = y0**3
- * r129 = r51 * y2
- */
- __pyx_v_r127 = pow(__pyx_v_y1, 3.0);
-
- /* "fontTools/pens/momentsPen.py":584
- * r126 = y3**3
- * r127 = y1**3
- * r128 = y0**3 # <<<<<<<<<<<<<<
- * r129 = r51 * y2
- * r130 = r112 * y3 + r21 * r51
- */
- __pyx_v_r128 = pow(__pyx_v_y0, 3.0);
-
- /* "fontTools/pens/momentsPen.py":585
- * r127 = y1**3
- * r128 = y0**3
- * r129 = r51 * y2 # <<<<<<<<<<<<<<
- * r130 = r112 * y3 + r21 * r51
- * r131 = 189 * r53
- */
- __pyx_v_r129 = (__pyx_v_r51 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":586
- * r128 = y0**3
- * r129 = r51 * y2
- * r130 = r112 * y3 + r21 * r51 # <<<<<<<<<<<<<<
- * r131 = 189 * r53
- * r132 = 90 * y2
- */
- __pyx_v_r130 = ((__pyx_v_r112 * __pyx_v_y3) + (__pyx_v_r21 * __pyx_v_r51));
-
- /* "fontTools/pens/momentsPen.py":587
- * r129 = r51 * y2
- * r130 = r112 * y3 + r21 * r51
- * r131 = 189 * r53 # <<<<<<<<<<<<<<
- * r132 = 90 * y2
- *
- */
- __pyx_v_r131 = (189.0 * __pyx_v_r53);
-
- /* "fontTools/pens/momentsPen.py":588
- * r130 = r112 * y3 + r21 * r51
- * r131 = 189 * r53
- * r132 = 90 * y2 # <<<<<<<<<<<<<<
- *
- * self.area += (
- */
- __pyx_v_r132 = (90.0 * __pyx_v_y2);
-
- /* "fontTools/pens/momentsPen.py":590
- * r132 = 90 * y2
- *
- * self.area += ( # <<<<<<<<<<<<<<
- * -r1 / 20
- * - r3 / 20
- */
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_area); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 590, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":597
- * + 3 * x1 * (y2 + y3) / 20
- * + 3 * x2 * y3 / 10
- * - y0 * (r5 + r6 + x3) / 20 # <<<<<<<<<<<<<<
- * )
- * self.momentX += (
- */
- __pyx_t_1 = PyFloat_FromDouble(((((((((-__pyx_v_r1) / 20.0) - (__pyx_v_r3 / 20.0)) - ((__pyx_v_r4 * (__pyx_v_x2 + __pyx_v_x3)) / 20.0)) + ((__pyx_v_x0 * (((__pyx_v_r7 + __pyx_v_r8) + (10.0 * __pyx_v_y0)) + __pyx_v_y3)) / 20.0)) + (((3.0 * __pyx_v_x1) * (__pyx_v_y2 + __pyx_v_y3)) / 20.0)) + (((3.0 * __pyx_v_x2) * __pyx_v_y3) / 10.0)) - ((__pyx_v_y0 * ((__pyx_v_r5 + __pyx_v_r6) + __pyx_v_x3)) / 20.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 597, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":590
- * r132 = 90 * y2
- *
- * self.area += ( # <<<<<<<<<<<<<<
- * -r1 / 20
- * - r3 / 20
- */
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_3, __pyx_t_1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 590, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_area, __pyx_t_2) < 0) __PYX_ERR(0, 590, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":599
- * - y0 * (r5 + r6 + x3) / 20
- * )
- * self.momentX += ( # <<<<<<<<<<<<<<
- * r11 / 840
- * - r13 / 8
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentX); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 599, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "fontTools/pens/momentsPen.py":621
- * )
- * / 840
- * - y0 * (r17 + r30 * x2 + r31 * x1 + r32 + r33 + 18 * r9) / 840 # <<<<<<<<<<<<<<
- * )
- * self.momentY += (
- */
- __pyx_t_1 = PyFloat_FromDouble(((((((((((__pyx_v_r11 / 840.0) - (__pyx_v_r13 / 8.0)) - (__pyx_v_r14 / 3.0)) - ((__pyx_v_r17 * ((-__pyx_v_r15) + __pyx_v_r8)) / 840.0)) + ((__pyx_v_r19 * (__pyx_v_r8 + (2.0 * __pyx_v_y3))) / 840.0)) + ((__pyx_v_r20 * (((__pyx_v_r0 + __pyx_v_r21) + (56.0 * __pyx_v_y0)) + __pyx_v_y3)) / 168.0)) + ((__pyx_v_r29 * (((-__pyx_v_r23) + __pyx_v_r25) + __pyx_v_r28)) / 840.0)) - ((__pyx_v_r4 * (((10.0 * __pyx_v_r12) + __pyx_v_r17) + __pyx_v_r22)) / 840.0)) + ((__pyx_v_x0 * (((((((((12.0 * __pyx_v_r27) + (__pyx_v_r30 * __pyx_v_y2)) + __pyx_v_r34) - (__pyx_v_r35 * __pyx_v_x1)) - __pyx_v_r37) - (__pyx_v_r38 * __pyx_v_y0)) + (__pyx_v_r39 * __pyx_v_x1)) - (__pyx_v_r4 * __pyx_v_x3)) + __pyx_v_r45)) / 840.0)) - ((__pyx_v_y0 * (((((__pyx_v_r17 + (__pyx_v_r30 * __pyx_v_x2)) + (__pyx_v_r31 * __pyx_v_x1)) + __pyx_v_r32) + __pyx_v_r33) + (18.0 * __pyx_v_r9))) / 840.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 621, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":599
- * - y0 * (r5 + r6 + x3) / 20
- * )
- * self.momentX += ( # <<<<<<<<<<<<<<
- * r11 / 840
- * - r13 / 8
- */
- __pyx_t_3 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 599, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentX, __pyx_t_3) < 0) __PYX_ERR(0, 599, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":623
- * - y0 * (r17 + r30 * x2 + r31 * x1 + r32 + r33 + 18 * r9) / 840
- * )
- * self.momentY += ( # <<<<<<<<<<<<<<
- * -r4 * (r25 + r58) / 840
- * - r47 / 8
- */
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentY); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 623, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":646
- * + x1 * (r24 * y1 + 10 * r51 + r59 + r60 + r7 * y3) / 280
- * + x2 * y3 * (r15 + r8) / 56
- * - y0 * (r16 * y1 + r31 * y2 + r44 * x2 + r45 + r61 - r62 * x1) / 840 # <<<<<<<<<<<<<<
- * )
- * self.momentXX += (
- */
- __pyx_t_1 = PyFloat_FromDouble(((((((((((((-__pyx_v_r4) * (__pyx_v_r25 + __pyx_v_r58)) / 840.0) - (__pyx_v_r47 / 8.0)) - (__pyx_v_r50 / 840.0)) - (__pyx_v_r52 / 6.0)) - ((__pyx_v_r54 * (__pyx_v_r6 + (2.0 * __pyx_v_x3))) / 840.0)) - ((__pyx_v_r55 * ((__pyx_v_r56 + __pyx_v_r57) + __pyx_v_x3)) / 168.0)) + ((__pyx_v_x0 * ((((((((((__pyx_v_r35 * __pyx_v_y1) + (__pyx_v_r40 * __pyx_v_y0)) + (__pyx_v_r44 * __pyx_v_y2)) + (18.0 * __pyx_v_r48)) + (140.0 * __pyx_v_r55)) + __pyx_v_r59) + __pyx_v_r63) + (12.0 * __pyx_v_r64)) + __pyx_v_r65) + __pyx_v_r66)) / 840.0)) + ((__pyx_v_x1 * (((((__pyx_v_r24 * __pyx_v_y1) + (10.0 * __pyx_v_r51)) + __pyx_v_r59) + __pyx_v_r60) + (__pyx_v_r7 * __pyx_v_y3))) / 280.0)) + (((__pyx_v_x2 * __pyx_v_y3) * (__pyx_v_r15 + __pyx_v_r8)) / 56.0)) - ((__pyx_v_y0 * ((((((__pyx_v_r16 * __pyx_v_y1) + (__pyx_v_r31 * __pyx_v_y2)) + (__pyx_v_r44 * __pyx_v_x2)) + __pyx_v_r45) + __pyx_v_r61) - (__pyx_v_r62 * __pyx_v_x1))) / 840.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 646, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":623
- * - y0 * (r17 + r30 * x2 + r31 * x1 + r32 + r33 + 18 * r9) / 840
- * )
- * self.momentY += ( # <<<<<<<<<<<<<<
- * -r4 * (r25 + r58) / 840
- * - r47 / 8
- */
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_3, __pyx_t_1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 623, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentY, __pyx_t_2) < 0) __PYX_ERR(0, 623, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":648
- * - y0 * (r16 * y1 + r31 * y2 + r44 * x2 + r45 + r61 - r62 * x1) / 840
- * )
- * self.momentXX += ( # <<<<<<<<<<<<<<
- * -r12 * r72 * (-r40 + r8) / 9240
- * + 3 * r18 * (r28 + r34 - r38 * y1 + r75) / 3080
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentXX); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 648, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "fontTools/pens/momentsPen.py":706
- * )
- * / 9240
- * - y0 # <<<<<<<<<<<<<<
- * * (
- * r12 * r56
- */
- __pyx_t_1 = PyFloat_FromDouble(((((((((((((((((-__pyx_v_r12) * __pyx_v_r72) * ((-__pyx_v_r40) + __pyx_v_r8)) / 9240.0) + (((3.0 * __pyx_v_r18) * (((__pyx_v_r28 + __pyx_v_r34) - (__pyx_v_r38 * __pyx_v_y1)) + __pyx_v_r75)) / 3080.0)) + ((__pyx_v_r20 * (((((((((__pyx_v_r24 * __pyx_v_x3) - (__pyx_v_r72 * __pyx_v_y0)) - (__pyx_v_r76 * __pyx_v_y0)) - (__pyx_v_r77 * __pyx_v_y0)) + __pyx_v_r78) + (__pyx_v_r79 * __pyx_v_y3)) + (__pyx_v_r80 * __pyx_v_y1)) + (210.0 * __pyx_v_r81)) + __pyx_v_r84)) / 9240.0)) - ((__pyx_v_r29 * ((((((((__pyx_v_r12 * __pyx_v_r21) + (14.0 * __pyx_v_r13)) + (__pyx_v_r44 * __pyx_v_r9)) - (__pyx_v_r73 * __pyx_v_y3)) + (54.0 * __pyx_v_r86)) - (84.0 * __pyx_v_r87)) - __pyx_v_r89) - __pyx_v_r90)) / 9240.0)) - ((__pyx_v_r4 * (((((70.0 * __pyx_v_r12) * __pyx_v_x2) + (27.0 * __pyx_v_r67)) + (42.0 * __pyx_v_r68)) + __pyx_v_r74)) / 9240.0)) + (((3.0 * __pyx_v_r67) * __pyx_v_y3) / 220.0)) - ((__pyx_v_r68 * __pyx_v_r69) / 9240.0)) - ((__pyx_v_r68 * __pyx_v_y3) / 4.0)) - (((__pyx_v_r70 * __pyx_v_r9) * ((-__pyx_v_r62) + __pyx_v_y2)) / 9240.0)) + (((3.0 * __pyx_v_r71) * (__pyx_v_r24 + __pyx_v_r40)) / 3080.0)) + ((pow(__pyx_v_x0, 3.0) * (((__pyx_v_r24 + __pyx_v_r44) + (165.0 * __pyx_v_y0)) + __pyx_v_y3)) / 660.0)) + ((__pyx_v_x0 * (((((((((((((((((((__pyx_v_r100 * __pyx_v_r27) + (162.0 * __pyx_v_r101)) + __pyx_v_r102) + __pyx_v_r11) + ((63.0 * __pyx_v_r18) * __pyx_v_y3)) + (__pyx_v_r27 * __pyx_v_r91)) - (__pyx_v_r33 * __pyx_v_y0)) - (__pyx_v_r37 * __pyx_v_x3)) + (__pyx_v_r43 * __pyx_v_x3)) - (__pyx_v_r73 * __pyx_v_y0)) - (__pyx_v_r88 * __pyx_v_y1)) + (__pyx_v_r92 * __pyx_v_y2)) - (__pyx_v_r93 * __pyx_v_y0)) - (9.0 * __pyx_v_r94)) - (__pyx_v_r95 * __pyx_v_y0)) - (__pyx_v_r96 * __pyx_v_y0)) - (__pyx_v_r97 * __pyx_v_y1)) - (18.0 * __pyx_v_r98)) + ((__pyx_v_r99 * __pyx_v_x1) * __pyx_v_y3))) / 9240.0)) - ((__pyx_v_y0 * ((((((((((__pyx_v_r12 * __pyx_v_r56) + (__pyx_v_r12 * __pyx_v_r80)) + (__pyx_v_r32 * __pyx_v_x3)) + (45.0 * __pyx_v_r67)) + (14.0 * __pyx_v_r68)) + (126.0 * __pyx_v_r71)) + __pyx_v_r74) + (__pyx_v_r85 * __pyx_v_r91)) + ((135.0 * __pyx_v_r9) * __pyx_v_x1)) + (__pyx_v_r92 * __pyx_v_x2))) / 9240.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 706, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":648
- * - y0 * (r16 * y1 + r31 * y2 + r44 * x2 + r45 + r61 - r62 * x1) / 840
- * )
- * self.momentXX += ( # <<<<<<<<<<<<<<
- * -r12 * r72 * (-r40 + r8) / 9240
- * + 3 * r18 * (r28 + r34 - r38 * y1 + r75) / 3080
- */
- __pyx_t_3 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 648, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentXX, __pyx_t_3) < 0) __PYX_ERR(0, 648, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":721
- * / 9240
- * )
- * self.momentXY += ( # <<<<<<<<<<<<<<
- * -r103 * r12 / 18480
- * - r12 * r51 / 8
- */
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentXY); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 721, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":783
- * )
- * / 3080
- * - y0 # <<<<<<<<<<<<<<
- * * (
- * 54 * r101
- */
- __pyx_t_1 = PyFloat_FromDouble((((((((((((((((-__pyx_v_r103) * __pyx_v_r12) / 18480.0) - ((__pyx_v_r12 * __pyx_v_r51) / 8.0)) - (((3.0 * __pyx_v_r14) * __pyx_v_y2) / 44.0)) + (((3.0 * __pyx_v_r18) * ((((__pyx_v_r105 + (__pyx_v_r2 * __pyx_v_y1)) + (18.0 * __pyx_v_r46)) + (15.0 * __pyx_v_r48)) + (7.0 * __pyx_v_r51))) / 6160.0)) + ((__pyx_v_r20 * ((((((((((1260.0 * __pyx_v_r106) + (__pyx_v_r107 * __pyx_v_y1)) + __pyx_v_r108) + (28.0 * __pyx_v_r109)) + __pyx_v_r110) + __pyx_v_r111) + __pyx_v_r112) + (30.0 * __pyx_v_r46)) + (2310.0 * __pyx_v_r55)) + __pyx_v_r66)) / 18480.0)) - ((__pyx_v_r54 * (((7.0 * __pyx_v_r12) + (18.0 * __pyx_v_r85)) + (15.0 * __pyx_v_r9))) / 18480.0)) - ((__pyx_v_r55 * (((((__pyx_v_r33 + __pyx_v_r73) + __pyx_v_r93) + __pyx_v_r95) + __pyx_v_r96) + __pyx_v_r97)) / 18480.0)) - ((__pyx_v_r7 * (((((42.0 * __pyx_v_r13) + (__pyx_v_r82 * __pyx_v_x3)) + (28.0 * __pyx_v_r87)) + __pyx_v_r89) + __pyx_v_r90)) / 18480.0)) - (((3.0 * __pyx_v_r85) * (__pyx_v_r48 - __pyx_v_r66)) / 220.0)) + ((((3.0 * __pyx_v_r9) * __pyx_v_y3) * (__pyx_v_r62 + (2.0 * __pyx_v_y2))) / 440.0)) + ((__pyx_v_x0 * (((((((((((((((((((((((-__pyx_v_r1) * __pyx_v_y0) - ((84.0 * __pyx_v_r106) * __pyx_v_x2)) + (__pyx_v_r109 * __pyx_v_r56)) + (54.0 * __pyx_v_r114)) + (__pyx_v_r117 * __pyx_v_y1)) + (15.0 * __pyx_v_r118)) + (21.0 * __pyx_v_r119)) + (81.0 * __pyx_v_r120)) + (__pyx_v_r121 * __pyx_v_r46)) + (54.0 * __pyx_v_r122)) + (60.0 * __pyx_v_r123)) + __pyx_v_r124) - ((__pyx_v_r21 * __pyx_v_x3) * __pyx_v_y0)) + (__pyx_v_r23 * __pyx_v_y3)) - (__pyx_v_r54 * __pyx_v_x3)) - (__pyx_v_r55 * __pyx_v_r72)) - (__pyx_v_r55 * __pyx_v_r76)) - (__pyx_v_r55 * __pyx_v_r77)) + ((__pyx_v_r57 * __pyx_v_y0) * __pyx_v_y3)) + (__pyx_v_r60 * __pyx_v_x3)) + ((84.0 * __pyx_v_r81) * __pyx_v_y0)) + ((189.0 * __pyx_v_r81) * __pyx_v_y1))) / 9240.0)) + ((__pyx_v_x1 * ((((((((__pyx_v_r104 * __pyx_v_r27) - (__pyx_v_r105 * __pyx_v_x3)) - (__pyx_v_r113 * __pyx_v_r53)) + (63.0 * __pyx_v_r114)) + __pyx_v_r115) - (__pyx_v_r16 * __pyx_v_r53)) + (28.0 * __pyx_v_r47)) + (__pyx_v_r51 * __pyx_v_r80))) / 3080.0)) - ((__pyx_v_y0 * (((((((((((((54.0 * __pyx_v_r101) + __pyx_v_r102) + (__pyx_v_r116 * __pyx_v_r5)) + (__pyx_v_r117 * __pyx_v_x3)) + (21.0 * __pyx_v_r13)) - (__pyx_v_r19 * __pyx_v_y3)) + (__pyx_v_r22 * __pyx_v_y3)) + (__pyx_v_r78 * __pyx_v_x3)) + ((189.0 * __pyx_v_r83) * __pyx_v_x2)) + (60.0 * __pyx_v_r86)) + ((81.0 * __pyx_v_r9) * __pyx_v_y1)) + (15.0 * __pyx_v_r94)) + (54.0 * __pyx_v_r98))) / 9240.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 783, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":721
- * / 9240
- * )
- * self.momentXY += ( # <<<<<<<<<<<<<<
- * -r103 * r12 / 18480
- * - r12 * r51 / 8
- */
- __pyx_t_2 = PyNumber_InPlaceAdd(__pyx_t_3, __pyx_t_1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 721, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentXY, __pyx_t_2) < 0) __PYX_ERR(0, 721, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":801
- * / 9240
- * )
- * self.momentYY += ( # <<<<<<<<<<<<<<
- * -r103 * r116 / 9240
- * - r125 * r70 / 9240
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_v_self, __pyx_n_s_momentYY); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 801, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "fontTools/pens/momentsPen.py":849
- * / 3080
- * + 3 * x2 * y3 * (r48 + r66 + r8 * y3) / 220
- * - y0 # <<<<<<<<<<<<<<
- * * (
- * r100 * r46
- */
- __pyx_t_1 = PyFloat_FromDouble((((((((((((((((-__pyx_v_r103) * __pyx_v_r116) / 9240.0) - ((__pyx_v_r125 * __pyx_v_r70) / 9240.0)) - ((__pyx_v_r126 * __pyx_v_x3) / 12.0)) - (((3.0 * __pyx_v_r127) * (__pyx_v_r26 + __pyx_v_r38)) / 3080.0)) - ((__pyx_v_r128 * ((__pyx_v_r26 + __pyx_v_r30) + __pyx_v_x3)) / 660.0)) - ((__pyx_v_r4 * ((((__pyx_v_r112 * __pyx_v_x3) + __pyx_v_r115) - (14.0 * __pyx_v_r119)) + (84.0 * __pyx_v_r47))) / 9240.0)) - ((__pyx_v_r52 * __pyx_v_r69) / 9240.0)) - ((__pyx_v_r54 * ((__pyx_v_r58 + __pyx_v_r61) + __pyx_v_r75)) / 9240.0)) - ((__pyx_v_r55 * ((((((__pyx_v_r100 * __pyx_v_y1) + (__pyx_v_r121 * __pyx_v_y2)) + (__pyx_v_r26 * __pyx_v_y3)) + (__pyx_v_r79 * __pyx_v_y2)) + __pyx_v_r84) + ((210.0 * __pyx_v_x2) * __pyx_v_y1))) / 9240.0)) + ((__pyx_v_x0 * (((((((((((((((((((__pyx_v_r108 * __pyx_v_y1) + (__pyx_v_r110 * __pyx_v_y0)) + (__pyx_v_r111 * __pyx_v_y0)) + (__pyx_v_r112 * __pyx_v_y0)) + (45.0 * __pyx_v_r125)) + (14.0 * __pyx_v_r126)) + (126.0 * __pyx_v_r127)) + (770.0 * __pyx_v_r128)) + (42.0 * __pyx_v_r129)) + __pyx_v_r130) + (__pyx_v_r131 * __pyx_v_y2)) + (__pyx_v_r132 * __pyx_v_r64)) + ((135.0 * __pyx_v_r48) * __pyx_v_y1)) + ((630.0 * __pyx_v_r55) * __pyx_v_y1)) + ((126.0 * __pyx_v_r55) * __pyx_v_y2)) + ((14.0 * __pyx_v_r55) * __pyx_v_y3)) + (__pyx_v_r63 * __pyx_v_y3)) + (__pyx_v_r65 * __pyx_v_y3)) + (__pyx_v_r66 * __pyx_v_y0))) / 9240.0)) + ((__pyx_v_x1 * ((((((((27.0 * __pyx_v_r125) + (42.0 * __pyx_v_r126)) + (70.0 * __pyx_v_r129)) + __pyx_v_r130) + (__pyx_v_r39 * __pyx_v_r53)) + (__pyx_v_r44 * __pyx_v_r48)) + ((27.0 * __pyx_v_r53) * __pyx_v_y2)) + ((54.0 * __pyx_v_r64) * __pyx_v_y2))) / 3080.0)) + ((((3.0 * __pyx_v_x2) * __pyx_v_y3) * ((__pyx_v_r48 + __pyx_v_r66) + (__pyx_v_r8 * __pyx_v_y3))) / 220.0)) - ((__pyx_v_y0 * (((((((((((((__pyx_v_r100 * __pyx_v_r46) + (18.0 * __pyx_v_r114)) - (9.0 * __pyx_v_r118)) - (27.0 * __pyx_v_r120)) - (18.0 * __pyx_v_r122)) - (30.0 * __pyx_v_r123)) + __pyx_v_r124) + (__pyx_v_r131 * __pyx_v_x2)) + ((__pyx_v_r132 * __pyx_v_x3) * __pyx_v_y1)) + ((162.0 * __pyx_v_r42) * __pyx_v_y1)) + __pyx_v_r50) + ((63.0 * __pyx_v_r53) * __pyx_v_x3)) + (__pyx_v_r64 * __pyx_v_r99))) / 9240.0))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 849, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "fontTools/pens/momentsPen.py":801
- * / 9240
- * )
- * self.momentYY += ( # <<<<<<<<<<<<<<
- * -r103 * r116 / 9240
- * - r125 * r70 / 9240
- */
- __pyx_t_3 = PyNumber_InPlaceAdd(__pyx_t_2, __pyx_t_1); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 801, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- if (__Pyx_PyObject_SetAttrStr(__pyx_v_self, __pyx_n_s_momentYY, __pyx_t_3) < 0) __PYX_ERR(0, 801, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":313
- * )
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("fontTools.pens.momentsPen.MomentsPen._curveToOne", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyMethodDef __pyx_methods[] = {
- {0, 0, 0, 0}
-};
-#ifndef CYTHON_SMALL_CODE
-#if defined(__clang__)
- #define CYTHON_SMALL_CODE
-#elif defined(__GNUC__) && (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 3))
- #define CYTHON_SMALL_CODE __attribute__((cold))
-#else
- #define CYTHON_SMALL_CODE
-#endif
-#endif
-/* #### Code section: pystring_table ### */
-
-static int __Pyx_CreateStringTabAndInitStrings(void) {
- __Pyx_StringTabEntry __pyx_string_tab[] = {
- {&__pyx_kp_u_, __pyx_k_, sizeof(__pyx_k_), 0, 1, 0, 0},
- {&__pyx_n_s_AttributeError, __pyx_k_AttributeError, sizeof(__pyx_k_AttributeError), 0, 0, 1, 1},
- {&__pyx_n_s_BasePen, __pyx_k_BasePen, sizeof(__pyx_k_BasePen), 0, 0, 1, 1},
- {&__pyx_n_s_COMPILED, __pyx_k_COMPILED, sizeof(__pyx_k_COMPILED), 0, 0, 1, 1},
- {&__pyx_kp_u_Green_theorem_is_not_defined_on, __pyx_k_Green_theorem_is_not_defined_on, sizeof(__pyx_k_Green_theorem_is_not_defined_on), 0, 1, 0, 0},
- {&__pyx_n_s_ImportError, __pyx_k_ImportError, sizeof(__pyx_k_ImportError), 0, 0, 1, 1},
- {&__pyx_kp_s_Lib_fontTools_pens_momentsPen_py, __pyx_k_Lib_fontTools_pens_momentsPen_py, sizeof(__pyx_k_Lib_fontTools_pens_momentsPen_py), 0, 0, 1, 0},
- {&__pyx_n_s_MomentsPen, __pyx_k_MomentsPen, sizeof(__pyx_k_MomentsPen), 0, 0, 1, 1},
- {&__pyx_n_u_MomentsPen, __pyx_k_MomentsPen, sizeof(__pyx_k_MomentsPen), 0, 1, 0, 1},
- {&__pyx_n_s_MomentsPen___init, __pyx_k_MomentsPen___init, sizeof(__pyx_k_MomentsPen___init), 0, 0, 1, 1},
- {&__pyx_n_s_MomentsPen__closePath, __pyx_k_MomentsPen__closePath, sizeof(__pyx_k_MomentsPen__closePath), 0, 0, 1, 1},
- {&__pyx_n_s_MomentsPen__curveToOne, __pyx_k_MomentsPen__curveToOne, sizeof(__pyx_k_MomentsPen__curveToOne), 0, 0, 1, 1},
- {&__pyx_n_s_MomentsPen__endPath, __pyx_k_MomentsPen__endPath, sizeof(__pyx_k_MomentsPen__endPath), 0, 0, 1, 1},
- {&__pyx_n_s_MomentsPen__lineTo, __pyx_k_MomentsPen__lineTo, sizeof(__pyx_k_MomentsPen__lineTo), 0, 0, 1, 1},
- {&__pyx_n_s_MomentsPen__moveTo, __pyx_k_MomentsPen__moveTo, sizeof(__pyx_k_MomentsPen__moveTo), 0, 0, 1, 1},
- {&__pyx_n_s_MomentsPen__qCurveToOne, __pyx_k_MomentsPen__qCurveToOne, sizeof(__pyx_k_MomentsPen__qCurveToOne), 0, 0, 1, 1},
- {&__pyx_n_s_MomentsPen__startPoint, __pyx_k_MomentsPen__startPoint, sizeof(__pyx_k_MomentsPen__startPoint), 0, 0, 1, 1},
- {&__pyx_n_s_OpenContourError, __pyx_k_OpenContourError, sizeof(__pyx_k_OpenContourError), 0, 0, 1, 1},
- {&__pyx_n_s__16, __pyx_k__16, sizeof(__pyx_k__16), 0, 0, 1, 1},
- {&__pyx_n_s_all, __pyx_k_all, sizeof(__pyx_k_all), 0, 0, 1, 1},
- {&__pyx_n_s_area, __pyx_k_area, sizeof(__pyx_k_area), 0, 0, 1, 1},
- {&__pyx_n_u_area, __pyx_k_area, sizeof(__pyx_k_area), 0, 1, 0, 1},
- {&__pyx_n_s_asyncio_coroutines, __pyx_k_asyncio_coroutines, sizeof(__pyx_k_asyncio_coroutines), 0, 0, 1, 1},
- {&__pyx_n_s_cline_in_traceback, __pyx_k_cline_in_traceback, sizeof(__pyx_k_cline_in_traceback), 0, 0, 1, 1},
- {&__pyx_n_s_closePath, __pyx_k_closePath, sizeof(__pyx_k_closePath), 0, 0, 1, 1},
- {&__pyx_n_s_curveToOne, __pyx_k_curveToOne, sizeof(__pyx_k_curveToOne), 0, 0, 1, 1},
- {&__pyx_n_s_cython, __pyx_k_cython, sizeof(__pyx_k_cython), 0, 0, 1, 1},
- {&__pyx_n_s_dict, __pyx_k_dict, sizeof(__pyx_k_dict), 0, 0, 1, 1},
- {&__pyx_n_s_doc, __pyx_k_doc, sizeof(__pyx_k_doc), 0, 0, 1, 1},
- {&__pyx_n_s_endPath, __pyx_k_endPath, sizeof(__pyx_k_endPath), 0, 0, 1, 1},
- {&__pyx_n_s_fontTools_misc, __pyx_k_fontTools_misc, sizeof(__pyx_k_fontTools_misc), 0, 0, 1, 1},
- {&__pyx_n_s_fontTools_misc_symfont, __pyx_k_fontTools_misc_symfont, sizeof(__pyx_k_fontTools_misc_symfont), 0, 0, 1, 1},
- {&__pyx_n_s_fontTools_pens_basePen, __pyx_k_fontTools_pens_basePen, sizeof(__pyx_k_fontTools_pens_basePen), 0, 0, 1, 1},
- {&__pyx_n_s_fontTools_pens_momentsPen, __pyx_k_fontTools_pens_momentsPen, sizeof(__pyx_k_fontTools_pens_momentsPen), 0, 0, 1, 1},
- {&__pyx_n_s_getCurrentPoint, __pyx_k_getCurrentPoint, sizeof(__pyx_k_getCurrentPoint), 0, 0, 1, 1},
- {&__pyx_n_s_glyphset, __pyx_k_glyphset, sizeof(__pyx_k_glyphset), 0, 0, 1, 1},
- {&__pyx_n_s_import, __pyx_k_import, sizeof(__pyx_k_import), 0, 0, 1, 1},
- {&__pyx_n_s_init, __pyx_k_init, sizeof(__pyx_k_init), 0, 0, 1, 1},
- {&__pyx_n_s_init_subclass, __pyx_k_init_subclass, sizeof(__pyx_k_init_subclass), 0, 0, 1, 1},
- {&__pyx_n_s_is_coroutine, __pyx_k_is_coroutine, sizeof(__pyx_k_is_coroutine), 0, 0, 1, 1},
- {&__pyx_n_s_lineTo, __pyx_k_lineTo, sizeof(__pyx_k_lineTo), 0, 0, 1, 1},
- {&__pyx_n_s_main, __pyx_k_main, sizeof(__pyx_k_main), 0, 0, 1, 1},
- {&__pyx_n_u_main, __pyx_k_main, sizeof(__pyx_k_main), 0, 1, 0, 1},
- {&__pyx_n_s_metaclass, __pyx_k_metaclass, sizeof(__pyx_k_metaclass), 0, 0, 1, 1},
- {&__pyx_n_s_module, __pyx_k_module, sizeof(__pyx_k_module), 0, 0, 1, 1},
- {&__pyx_n_s_momentX, __pyx_k_momentX, sizeof(__pyx_k_momentX), 0, 0, 1, 1},
- {&__pyx_n_u_momentX, __pyx_k_momentX, sizeof(__pyx_k_momentX), 0, 1, 0, 1},
- {&__pyx_n_s_momentXX, __pyx_k_momentXX, sizeof(__pyx_k_momentXX), 0, 0, 1, 1},
- {&__pyx_n_u_momentXX, __pyx_k_momentXX, sizeof(__pyx_k_momentXX), 0, 1, 0, 1},
- {&__pyx_n_s_momentXY, __pyx_k_momentXY, sizeof(__pyx_k_momentXY), 0, 0, 1, 1},
- {&__pyx_n_u_momentXY, __pyx_k_momentXY, sizeof(__pyx_k_momentXY), 0, 1, 0, 1},
- {&__pyx_n_s_momentY, __pyx_k_momentY, sizeof(__pyx_k_momentY), 0, 0, 1, 1},
- {&__pyx_n_u_momentY, __pyx_k_momentY, sizeof(__pyx_k_momentY), 0, 1, 0, 1},
- {&__pyx_n_s_momentYY, __pyx_k_momentYY, sizeof(__pyx_k_momentYY), 0, 0, 1, 1},
- {&__pyx_n_u_momentYY, __pyx_k_momentYY, sizeof(__pyx_k_momentYY), 0, 1, 0, 1},
- {&__pyx_n_s_moveTo, __pyx_k_moveTo, sizeof(__pyx_k_moveTo), 0, 0, 1, 1},
- {&__pyx_n_s_mro_entries, __pyx_k_mro_entries, sizeof(__pyx_k_mro_entries), 0, 0, 1, 1},
- {&__pyx_n_s_name, __pyx_k_name, sizeof(__pyx_k_name), 0, 0, 1, 1},
- {&__pyx_n_s_p0, __pyx_k_p0, sizeof(__pyx_k_p0), 0, 0, 1, 1},
- {&__pyx_n_s_p1, __pyx_k_p1, sizeof(__pyx_k_p1), 0, 0, 1, 1},
- {&__pyx_n_s_p2, __pyx_k_p2, sizeof(__pyx_k_p2), 0, 0, 1, 1},
- {&__pyx_n_s_p3, __pyx_k_p3, sizeof(__pyx_k_p3), 0, 0, 1, 1},
- {&__pyx_n_s_prepare, __pyx_k_prepare, sizeof(__pyx_k_prepare), 0, 0, 1, 1},
- {&__pyx_n_s_printGreenPen, __pyx_k_printGreenPen, sizeof(__pyx_k_printGreenPen), 0, 0, 1, 1},
- {&__pyx_n_s_qCurveToOne, __pyx_k_qCurveToOne, sizeof(__pyx_k_qCurveToOne), 0, 0, 1, 1},
- {&__pyx_n_s_qualname, __pyx_k_qualname, sizeof(__pyx_k_qualname), 0, 0, 1, 1},
- {&__pyx_n_s_r0, __pyx_k_r0, sizeof(__pyx_k_r0), 0, 0, 1, 1},
- {&__pyx_n_s_r1, __pyx_k_r1, sizeof(__pyx_k_r1), 0, 0, 1, 1},
- {&__pyx_n_s_r10, __pyx_k_r10, sizeof(__pyx_k_r10), 0, 0, 1, 1},
- {&__pyx_n_s_r100, __pyx_k_r100, sizeof(__pyx_k_r100), 0, 0, 1, 1},
- {&__pyx_n_s_r101, __pyx_k_r101, sizeof(__pyx_k_r101), 0, 0, 1, 1},
- {&__pyx_n_s_r102, __pyx_k_r102, sizeof(__pyx_k_r102), 0, 0, 1, 1},
- {&__pyx_n_s_r103, __pyx_k_r103, sizeof(__pyx_k_r103), 0, 0, 1, 1},
- {&__pyx_n_s_r104, __pyx_k_r104, sizeof(__pyx_k_r104), 0, 0, 1, 1},
- {&__pyx_n_s_r105, __pyx_k_r105, sizeof(__pyx_k_r105), 0, 0, 1, 1},
- {&__pyx_n_s_r106, __pyx_k_r106, sizeof(__pyx_k_r106), 0, 0, 1, 1},
- {&__pyx_n_s_r107, __pyx_k_r107, sizeof(__pyx_k_r107), 0, 0, 1, 1},
- {&__pyx_n_s_r108, __pyx_k_r108, sizeof(__pyx_k_r108), 0, 0, 1, 1},
- {&__pyx_n_s_r109, __pyx_k_r109, sizeof(__pyx_k_r109), 0, 0, 1, 1},
- {&__pyx_n_s_r11, __pyx_k_r11, sizeof(__pyx_k_r11), 0, 0, 1, 1},
- {&__pyx_n_s_r110, __pyx_k_r110, sizeof(__pyx_k_r110), 0, 0, 1, 1},
- {&__pyx_n_s_r111, __pyx_k_r111, sizeof(__pyx_k_r111), 0, 0, 1, 1},
- {&__pyx_n_s_r112, __pyx_k_r112, sizeof(__pyx_k_r112), 0, 0, 1, 1},
- {&__pyx_n_s_r113, __pyx_k_r113, sizeof(__pyx_k_r113), 0, 0, 1, 1},
- {&__pyx_n_s_r114, __pyx_k_r114, sizeof(__pyx_k_r114), 0, 0, 1, 1},
- {&__pyx_n_s_r115, __pyx_k_r115, sizeof(__pyx_k_r115), 0, 0, 1, 1},
- {&__pyx_n_s_r116, __pyx_k_r116, sizeof(__pyx_k_r116), 0, 0, 1, 1},
- {&__pyx_n_s_r117, __pyx_k_r117, sizeof(__pyx_k_r117), 0, 0, 1, 1},
- {&__pyx_n_s_r118, __pyx_k_r118, sizeof(__pyx_k_r118), 0, 0, 1, 1},
- {&__pyx_n_s_r119, __pyx_k_r119, sizeof(__pyx_k_r119), 0, 0, 1, 1},
- {&__pyx_n_s_r12, __pyx_k_r12, sizeof(__pyx_k_r12), 0, 0, 1, 1},
- {&__pyx_n_s_r120, __pyx_k_r120, sizeof(__pyx_k_r120), 0, 0, 1, 1},
- {&__pyx_n_s_r121, __pyx_k_r121, sizeof(__pyx_k_r121), 0, 0, 1, 1},
- {&__pyx_n_s_r122, __pyx_k_r122, sizeof(__pyx_k_r122), 0, 0, 1, 1},
- {&__pyx_n_s_r123, __pyx_k_r123, sizeof(__pyx_k_r123), 0, 0, 1, 1},
- {&__pyx_n_s_r124, __pyx_k_r124, sizeof(__pyx_k_r124), 0, 0, 1, 1},
- {&__pyx_n_s_r125, __pyx_k_r125, sizeof(__pyx_k_r125), 0, 0, 1, 1},
- {&__pyx_n_s_r126, __pyx_k_r126, sizeof(__pyx_k_r126), 0, 0, 1, 1},
- {&__pyx_n_s_r127, __pyx_k_r127, sizeof(__pyx_k_r127), 0, 0, 1, 1},
- {&__pyx_n_s_r128, __pyx_k_r128, sizeof(__pyx_k_r128), 0, 0, 1, 1},
- {&__pyx_n_s_r129, __pyx_k_r129, sizeof(__pyx_k_r129), 0, 0, 1, 1},
- {&__pyx_n_s_r13, __pyx_k_r13, sizeof(__pyx_k_r13), 0, 0, 1, 1},
- {&__pyx_n_s_r130, __pyx_k_r130, sizeof(__pyx_k_r130), 0, 0, 1, 1},
- {&__pyx_n_s_r131, __pyx_k_r131, sizeof(__pyx_k_r131), 0, 0, 1, 1},
- {&__pyx_n_s_r132, __pyx_k_r132, sizeof(__pyx_k_r132), 0, 0, 1, 1},
- {&__pyx_n_s_r14, __pyx_k_r14, sizeof(__pyx_k_r14), 0, 0, 1, 1},
- {&__pyx_n_s_r15, __pyx_k_r15, sizeof(__pyx_k_r15), 0, 0, 1, 1},
- {&__pyx_n_s_r16, __pyx_k_r16, sizeof(__pyx_k_r16), 0, 0, 1, 1},
- {&__pyx_n_s_r17, __pyx_k_r17, sizeof(__pyx_k_r17), 0, 0, 1, 1},
- {&__pyx_n_s_r18, __pyx_k_r18, sizeof(__pyx_k_r18), 0, 0, 1, 1},
- {&__pyx_n_s_r19, __pyx_k_r19, sizeof(__pyx_k_r19), 0, 0, 1, 1},
- {&__pyx_n_s_r2, __pyx_k_r2, sizeof(__pyx_k_r2), 0, 0, 1, 1},
- {&__pyx_n_s_r20, __pyx_k_r20, sizeof(__pyx_k_r20), 0, 0, 1, 1},
- {&__pyx_n_s_r21, __pyx_k_r21, sizeof(__pyx_k_r21), 0, 0, 1, 1},
- {&__pyx_n_s_r22, __pyx_k_r22, sizeof(__pyx_k_r22), 0, 0, 1, 1},
- {&__pyx_n_s_r23, __pyx_k_r23, sizeof(__pyx_k_r23), 0, 0, 1, 1},
- {&__pyx_n_s_r24, __pyx_k_r24, sizeof(__pyx_k_r24), 0, 0, 1, 1},
- {&__pyx_n_s_r25, __pyx_k_r25, sizeof(__pyx_k_r25), 0, 0, 1, 1},
- {&__pyx_n_s_r26, __pyx_k_r26, sizeof(__pyx_k_r26), 0, 0, 1, 1},
- {&__pyx_n_s_r27, __pyx_k_r27, sizeof(__pyx_k_r27), 0, 0, 1, 1},
- {&__pyx_n_s_r28, __pyx_k_r28, sizeof(__pyx_k_r28), 0, 0, 1, 1},
- {&__pyx_n_s_r29, __pyx_k_r29, sizeof(__pyx_k_r29), 0, 0, 1, 1},
- {&__pyx_n_s_r3, __pyx_k_r3, sizeof(__pyx_k_r3), 0, 0, 1, 1},
- {&__pyx_n_s_r30, __pyx_k_r30, sizeof(__pyx_k_r30), 0, 0, 1, 1},
- {&__pyx_n_s_r31, __pyx_k_r31, sizeof(__pyx_k_r31), 0, 0, 1, 1},
- {&__pyx_n_s_r32, __pyx_k_r32, sizeof(__pyx_k_r32), 0, 0, 1, 1},
- {&__pyx_n_s_r33, __pyx_k_r33, sizeof(__pyx_k_r33), 0, 0, 1, 1},
- {&__pyx_n_s_r34, __pyx_k_r34, sizeof(__pyx_k_r34), 0, 0, 1, 1},
- {&__pyx_n_s_r35, __pyx_k_r35, sizeof(__pyx_k_r35), 0, 0, 1, 1},
- {&__pyx_n_s_r36, __pyx_k_r36, sizeof(__pyx_k_r36), 0, 0, 1, 1},
- {&__pyx_n_s_r37, __pyx_k_r37, sizeof(__pyx_k_r37), 0, 0, 1, 1},
- {&__pyx_n_s_r38, __pyx_k_r38, sizeof(__pyx_k_r38), 0, 0, 1, 1},
- {&__pyx_n_s_r39, __pyx_k_r39, sizeof(__pyx_k_r39), 0, 0, 1, 1},
- {&__pyx_n_s_r4, __pyx_k_r4, sizeof(__pyx_k_r4), 0, 0, 1, 1},
- {&__pyx_n_s_r40, __pyx_k_r40, sizeof(__pyx_k_r40), 0, 0, 1, 1},
- {&__pyx_n_s_r41, __pyx_k_r41, sizeof(__pyx_k_r41), 0, 0, 1, 1},
- {&__pyx_n_s_r42, __pyx_k_r42, sizeof(__pyx_k_r42), 0, 0, 1, 1},
- {&__pyx_n_s_r43, __pyx_k_r43, sizeof(__pyx_k_r43), 0, 0, 1, 1},
- {&__pyx_n_s_r44, __pyx_k_r44, sizeof(__pyx_k_r44), 0, 0, 1, 1},
- {&__pyx_n_s_r45, __pyx_k_r45, sizeof(__pyx_k_r45), 0, 0, 1, 1},
- {&__pyx_n_s_r46, __pyx_k_r46, sizeof(__pyx_k_r46), 0, 0, 1, 1},
- {&__pyx_n_s_r47, __pyx_k_r47, sizeof(__pyx_k_r47), 0, 0, 1, 1},
- {&__pyx_n_s_r48, __pyx_k_r48, sizeof(__pyx_k_r48), 0, 0, 1, 1},
- {&__pyx_n_s_r49, __pyx_k_r49, sizeof(__pyx_k_r49), 0, 0, 1, 1},
- {&__pyx_n_s_r5, __pyx_k_r5, sizeof(__pyx_k_r5), 0, 0, 1, 1},
- {&__pyx_n_s_r50, __pyx_k_r50, sizeof(__pyx_k_r50), 0, 0, 1, 1},
- {&__pyx_n_s_r51, __pyx_k_r51, sizeof(__pyx_k_r51), 0, 0, 1, 1},
- {&__pyx_n_s_r52, __pyx_k_r52, sizeof(__pyx_k_r52), 0, 0, 1, 1},
- {&__pyx_n_s_r53, __pyx_k_r53, sizeof(__pyx_k_r53), 0, 0, 1, 1},
- {&__pyx_n_s_r54, __pyx_k_r54, sizeof(__pyx_k_r54), 0, 0, 1, 1},
- {&__pyx_n_s_r55, __pyx_k_r55, sizeof(__pyx_k_r55), 0, 0, 1, 1},
- {&__pyx_n_s_r56, __pyx_k_r56, sizeof(__pyx_k_r56), 0, 0, 1, 1},
- {&__pyx_n_s_r57, __pyx_k_r57, sizeof(__pyx_k_r57), 0, 0, 1, 1},
- {&__pyx_n_s_r58, __pyx_k_r58, sizeof(__pyx_k_r58), 0, 0, 1, 1},
- {&__pyx_n_s_r59, __pyx_k_r59, sizeof(__pyx_k_r59), 0, 0, 1, 1},
- {&__pyx_n_s_r6, __pyx_k_r6, sizeof(__pyx_k_r6), 0, 0, 1, 1},
- {&__pyx_n_s_r60, __pyx_k_r60, sizeof(__pyx_k_r60), 0, 0, 1, 1},
- {&__pyx_n_s_r61, __pyx_k_r61, sizeof(__pyx_k_r61), 0, 0, 1, 1},
- {&__pyx_n_s_r62, __pyx_k_r62, sizeof(__pyx_k_r62), 0, 0, 1, 1},
- {&__pyx_n_s_r63, __pyx_k_r63, sizeof(__pyx_k_r63), 0, 0, 1, 1},
- {&__pyx_n_s_r64, __pyx_k_r64, sizeof(__pyx_k_r64), 0, 0, 1, 1},
- {&__pyx_n_s_r65, __pyx_k_r65, sizeof(__pyx_k_r65), 0, 0, 1, 1},
- {&__pyx_n_s_r66, __pyx_k_r66, sizeof(__pyx_k_r66), 0, 0, 1, 1},
- {&__pyx_n_s_r67, __pyx_k_r67, sizeof(__pyx_k_r67), 0, 0, 1, 1},
- {&__pyx_n_s_r68, __pyx_k_r68, sizeof(__pyx_k_r68), 0, 0, 1, 1},
- {&__pyx_n_s_r69, __pyx_k_r69, sizeof(__pyx_k_r69), 0, 0, 1, 1},
- {&__pyx_n_s_r7, __pyx_k_r7, sizeof(__pyx_k_r7), 0, 0, 1, 1},
- {&__pyx_n_s_r70, __pyx_k_r70, sizeof(__pyx_k_r70), 0, 0, 1, 1},
- {&__pyx_n_s_r71, __pyx_k_r71, sizeof(__pyx_k_r71), 0, 0, 1, 1},
- {&__pyx_n_s_r72, __pyx_k_r72, sizeof(__pyx_k_r72), 0, 0, 1, 1},
- {&__pyx_n_s_r73, __pyx_k_r73, sizeof(__pyx_k_r73), 0, 0, 1, 1},
- {&__pyx_n_s_r74, __pyx_k_r74, sizeof(__pyx_k_r74), 0, 0, 1, 1},
- {&__pyx_n_s_r75, __pyx_k_r75, sizeof(__pyx_k_r75), 0, 0, 1, 1},
- {&__pyx_n_s_r76, __pyx_k_r76, sizeof(__pyx_k_r76), 0, 0, 1, 1},
- {&__pyx_n_s_r77, __pyx_k_r77, sizeof(__pyx_k_r77), 0, 0, 1, 1},
- {&__pyx_n_s_r78, __pyx_k_r78, sizeof(__pyx_k_r78), 0, 0, 1, 1},
- {&__pyx_n_s_r79, __pyx_k_r79, sizeof(__pyx_k_r79), 0, 0, 1, 1},
- {&__pyx_n_s_r8, __pyx_k_r8, sizeof(__pyx_k_r8), 0, 0, 1, 1},
- {&__pyx_n_s_r80, __pyx_k_r80, sizeof(__pyx_k_r80), 0, 0, 1, 1},
- {&__pyx_n_s_r81, __pyx_k_r81, sizeof(__pyx_k_r81), 0, 0, 1, 1},
- {&__pyx_n_s_r82, __pyx_k_r82, sizeof(__pyx_k_r82), 0, 0, 1, 1},
- {&__pyx_n_s_r83, __pyx_k_r83, sizeof(__pyx_k_r83), 0, 0, 1, 1},
- {&__pyx_n_s_r84, __pyx_k_r84, sizeof(__pyx_k_r84), 0, 0, 1, 1},
- {&__pyx_n_s_r85, __pyx_k_r85, sizeof(__pyx_k_r85), 0, 0, 1, 1},
- {&__pyx_n_s_r86, __pyx_k_r86, sizeof(__pyx_k_r86), 0, 0, 1, 1},
- {&__pyx_n_s_r87, __pyx_k_r87, sizeof(__pyx_k_r87), 0, 0, 1, 1},
- {&__pyx_n_s_r88, __pyx_k_r88, sizeof(__pyx_k_r88), 0, 0, 1, 1},
- {&__pyx_n_s_r89, __pyx_k_r89, sizeof(__pyx_k_r89), 0, 0, 1, 1},
- {&__pyx_n_s_r9, __pyx_k_r9, sizeof(__pyx_k_r9), 0, 0, 1, 1},
- {&__pyx_n_s_r90, __pyx_k_r90, sizeof(__pyx_k_r90), 0, 0, 1, 1},
- {&__pyx_n_s_r91, __pyx_k_r91, sizeof(__pyx_k_r91), 0, 0, 1, 1},
- {&__pyx_n_s_r92, __pyx_k_r92, sizeof(__pyx_k_r92), 0, 0, 1, 1},
- {&__pyx_n_s_r93, __pyx_k_r93, sizeof(__pyx_k_r93), 0, 0, 1, 1},
- {&__pyx_n_s_r94, __pyx_k_r94, sizeof(__pyx_k_r94), 0, 0, 1, 1},
- {&__pyx_n_s_r95, __pyx_k_r95, sizeof(__pyx_k_r95), 0, 0, 1, 1},
- {&__pyx_n_s_r96, __pyx_k_r96, sizeof(__pyx_k_r96), 0, 0, 1, 1},
- {&__pyx_n_s_r97, __pyx_k_r97, sizeof(__pyx_k_r97), 0, 0, 1, 1},
- {&__pyx_n_s_r98, __pyx_k_r98, sizeof(__pyx_k_r98), 0, 0, 1, 1},
- {&__pyx_n_s_r99, __pyx_k_r99, sizeof(__pyx_k_r99), 0, 0, 1, 1},
- {&__pyx_n_s_self, __pyx_k_self, sizeof(__pyx_k_self), 0, 0, 1, 1},
- {&__pyx_n_s_set_name, __pyx_k_set_name, sizeof(__pyx_k_set_name), 0, 0, 1, 1},
- {&__pyx_n_s_super, __pyx_k_super, sizeof(__pyx_k_super), 0, 0, 1, 1},
- {&__pyx_n_s_test, __pyx_k_test, sizeof(__pyx_k_test), 0, 0, 1, 1},
- {&__pyx_n_s_x, __pyx_k_x, sizeof(__pyx_k_x), 0, 0, 1, 1},
- {&__pyx_n_s_x0, __pyx_k_x0, sizeof(__pyx_k_x0), 0, 0, 1, 1},
- {&__pyx_n_s_x1, __pyx_k_x1, sizeof(__pyx_k_x1), 0, 0, 1, 1},
- {&__pyx_n_s_x2, __pyx_k_x2, sizeof(__pyx_k_x2), 0, 0, 1, 1},
- {&__pyx_n_s_x3, __pyx_k_x3, sizeof(__pyx_k_x3), 0, 0, 1, 1},
- {&__pyx_n_s_y, __pyx_k_y, sizeof(__pyx_k_y), 0, 0, 1, 1},
- {&__pyx_n_s_y0, __pyx_k_y0, sizeof(__pyx_k_y0), 0, 0, 1, 1},
- {&__pyx_n_s_y1, __pyx_k_y1, sizeof(__pyx_k_y1), 0, 0, 1, 1},
- {&__pyx_n_s_y2, __pyx_k_y2, sizeof(__pyx_k_y2), 0, 0, 1, 1},
- {&__pyx_n_s_y3, __pyx_k_y3, sizeof(__pyx_k_y3), 0, 0, 1, 1},
- {0, 0, 0, 0, 0, 0, 0}
- };
- return __Pyx_InitStrings(__pyx_string_tab);
-}
-/* #### Code section: cached_builtins ### */
-static CYTHON_SMALL_CODE int __Pyx_InitCachedBuiltins(void) {
- __pyx_builtin_AttributeError = __Pyx_GetBuiltinName(__pyx_n_s_AttributeError); if (!__pyx_builtin_AttributeError) __PYX_ERR(0, 7, __pyx_L1_error)
- __pyx_builtin_ImportError = __Pyx_GetBuiltinName(__pyx_n_s_ImportError); if (!__pyx_builtin_ImportError) __PYX_ERR(0, 7, __pyx_L1_error)
- return 0;
- __pyx_L1_error:;
- return -1;
-}
-/* #### Code section: cached_constants ### */
-
-static CYTHON_SMALL_CODE int __Pyx_InitCachedConstants(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_InitCachedConstants", 0);
-
- /* "fontTools/pens/momentsPen.py":18
- *
- * class MomentsPen(BasePen):
- * def __init__(self, glyphset=None): # <<<<<<<<<<<<<<
- * BasePen.__init__(self, glyphset)
- *
- */
- __pyx_tuple__2 = PyTuple_Pack(2, __pyx_n_s_self, __pyx_n_s_glyphset); if (unlikely(!__pyx_tuple__2)) __PYX_ERR(0, 18, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__2);
- __Pyx_GIVEREF(__pyx_tuple__2);
- __pyx_codeobj__3 = (PyObject*)__Pyx_PyCode_New(2, 0, 0, 2, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__2, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_Lib_fontTools_pens_momentsPen_py, __pyx_n_s_init, 18, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__3)) __PYX_ERR(0, 18, __pyx_L1_error)
- __pyx_tuple__4 = PyTuple_Pack(1, ((PyObject *)Py_None)); if (unlikely(!__pyx_tuple__4)) __PYX_ERR(0, 18, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__4);
- __Pyx_GIVEREF(__pyx_tuple__4);
-
- /* "fontTools/pens/momentsPen.py":28
- * self.momentYY = 0
- *
- * def _moveTo(self, p0): # <<<<<<<<<<<<<<
- * self.__startPoint = p0
- *
- */
- __pyx_tuple__5 = PyTuple_Pack(2, __pyx_n_s_self, __pyx_n_s_p0); if (unlikely(!__pyx_tuple__5)) __PYX_ERR(0, 28, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__5);
- __Pyx_GIVEREF(__pyx_tuple__5);
- __pyx_codeobj__6 = (PyObject*)__Pyx_PyCode_New(2, 0, 0, 2, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__5, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_Lib_fontTools_pens_momentsPen_py, __pyx_n_s_moveTo, 28, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__6)) __PYX_ERR(0, 28, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":31
- * self.__startPoint = p0
- *
- * def _closePath(self): # <<<<<<<<<<<<<<
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- */
- __pyx_codeobj__7 = (PyObject*)__Pyx_PyCode_New(1, 0, 0, 2, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__5, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_Lib_fontTools_pens_momentsPen_py, __pyx_n_s_closePath, 31, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__7)) __PYX_ERR(0, 31, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":36
- * self._lineTo(self.__startPoint)
- *
- * def _endPath(self): # <<<<<<<<<<<<<<
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- */
- __pyx_codeobj__8 = (PyObject*)__Pyx_PyCode_New(1, 0, 0, 2, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__5, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_Lib_fontTools_pens_momentsPen_py, __pyx_n_s_endPath, 36, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__8)) __PYX_ERR(0, 36, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":42
- * raise OpenContourError("Green theorem is not defined on open contours.")
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
- __pyx_tuple__9 = PyTuple_Pack(19, __pyx_n_s_self, __pyx_n_s_p1, __pyx_n_s_x1, __pyx_n_s_y1, __pyx_n_s_x0, __pyx_n_s_y0, __pyx_n_s_r12, __pyx_n_s_r11, __pyx_n_s_r10, __pyx_n_s_r9, __pyx_n_s_r8, __pyx_n_s_r7, __pyx_n_s_r6, __pyx_n_s_r5, __pyx_n_s_r4, __pyx_n_s_r3, __pyx_n_s_r2, __pyx_n_s_r1, __pyx_n_s_r0); if (unlikely(!__pyx_tuple__9)) __PYX_ERR(0, 42, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__9);
- __Pyx_GIVEREF(__pyx_tuple__9);
- __pyx_codeobj__10 = (PyObject*)__Pyx_PyCode_New(2, 0, 0, 19, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__9, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_Lib_fontTools_pens_momentsPen_py, __pyx_n_s_lineTo, 42, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__10)) __PYX_ERR(0, 42, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":102
- * )
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
- __pyx_tuple__11 = PyTuple_Pack(63, __pyx_n_s_self, __pyx_n_s_p1, __pyx_n_s_p2, __pyx_n_s_x2, __pyx_n_s_y2, __pyx_n_s_x1, __pyx_n_s_y1, __pyx_n_s_x0, __pyx_n_s_y0, __pyx_n_s_r53, __pyx_n_s_r52, __pyx_n_s_r51, __pyx_n_s_r50, __pyx_n_s_r49, __pyx_n_s_r48, __pyx_n_s_r47, __pyx_n_s_r46, __pyx_n_s_r45, __pyx_n_s_r44, __pyx_n_s_r43, __pyx_n_s_r42, __pyx_n_s_r41, __pyx_n_s_r40, __pyx_n_s_r39, __pyx_n_s_r38, __pyx_n_s_r37, __pyx_n_s_r36, __pyx_n_s_r35, __pyx_n_s_r34, __pyx_n_s_r33, __pyx_n_s_r32, __pyx_n_s_r31, __pyx_n_s_r30, __pyx_n_s_r29, __pyx_n_s_r28, __pyx_n_s_r27, __pyx_n_s_r26, __pyx_n_s_r25, __pyx_n_s_r24, __pyx_n_s_r23, __pyx_n_s_r22, __pyx_n_s_r21, __pyx_n_s_r20, __pyx_n_s_r19, __pyx_n_s_r18, __pyx_n_s_r17, __pyx_n_s_r16, __pyx_n_s_r15, __pyx_n_s_r14, __pyx_n_s_r13, __pyx_n_s_r12, __pyx_n_s_r11, __pyx_n_s_r10, __pyx_n_s_r9, __pyx_n_s_r8, __pyx_n_s_r7, __pyx_n_s_r6, __pyx_n_s_r5, __pyx_n_s_r4, __pyx_n_s_r3, __pyx_n_s_r2, __pyx_n_s_r1, __pyx_n_s_r0); if (unlikely(!__pyx_tuple__11)) __PYX_ERR(0, 102, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__11);
- __Pyx_GIVEREF(__pyx_tuple__11);
- __pyx_codeobj__12 = (PyObject*)__Pyx_PyCode_New(3, 0, 0, 63, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__11, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_Lib_fontTools_pens_momentsPen_py, __pyx_n_s_qCurveToOne, 102, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__12)) __PYX_ERR(0, 102, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":313
- * )
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
- __pyx_tuple__13 = PyTuple_Pack(145, __pyx_n_s_self, __pyx_n_s_p1, __pyx_n_s_p2, __pyx_n_s_p3, __pyx_n_s_x3, __pyx_n_s_y3, __pyx_n_s_x2, __pyx_n_s_y2, __pyx_n_s_x1, __pyx_n_s_y1, __pyx_n_s_x0, __pyx_n_s_y0, __pyx_n_s_r132, __pyx_n_s_r131, __pyx_n_s_r130, __pyx_n_s_r129, __pyx_n_s_r128, __pyx_n_s_r127, __pyx_n_s_r126, __pyx_n_s_r125, __pyx_n_s_r124, __pyx_n_s_r123, __pyx_n_s_r122, __pyx_n_s_r121, __pyx_n_s_r120, __pyx_n_s_r119, __pyx_n_s_r118, __pyx_n_s_r117, __pyx_n_s_r116, __pyx_n_s_r115, __pyx_n_s_r114, __pyx_n_s_r113, __pyx_n_s_r112, __pyx_n_s_r111, __pyx_n_s_r110, __pyx_n_s_r109, __pyx_n_s_r108, __pyx_n_s_r107, __pyx_n_s_r106, __pyx_n_s_r105, __pyx_n_s_r104, __pyx_n_s_r103, __pyx_n_s_r102, __pyx_n_s_r101, __pyx_n_s_r100, __pyx_n_s_r99, __pyx_n_s_r98, __pyx_n_s_r97, __pyx_n_s_r96, __pyx_n_s_r95, __pyx_n_s_r94, __pyx_n_s_r93, __pyx_n_s_r92, __pyx_n_s_r91, __pyx_n_s_r90, __pyx_n_s_r89, __pyx_n_s_r88, __pyx_n_s_r87, __pyx_n_s_r86, __pyx_n_s_r85, __pyx_n_s_r84, __pyx_n_s_r83, __pyx_n_s_r82, __pyx_n_s_r81, __pyx_n_s_r80, __pyx_n_s_r79, __pyx_n_s_r78, __pyx_n_s_r77, __pyx_n_s_r76, __pyx_n_s_r75, __pyx_n_s_r74, __pyx_n_s_r73, __pyx_n_s_r72, __pyx_n_s_r71, __pyx_n_s_r70, __pyx_n_s_r69, __pyx_n_s_r68, __pyx_n_s_r67, __pyx_n_s_r66, __pyx_n_s_r65, __pyx_n_s_r64, __pyx_n_s_r63, __pyx_n_s_r62, __pyx_n_s_r61, __pyx_n_s_r60, __pyx_n_s_r59, __pyx_n_s_r58, __pyx_n_s_r57, __pyx_n_s_r56, __pyx_n_s_r55, __pyx_n_s_r54, __pyx_n_s_r53, __pyx_n_s_r52, __pyx_n_s_r51, __pyx_n_s_r50, __pyx_n_s_r49, __pyx_n_s_r48, __pyx_n_s_r47, __pyx_n_s_r46, __pyx_n_s_r45, __pyx_n_s_r44, __pyx_n_s_r43, __pyx_n_s_r42, __pyx_n_s_r41, __pyx_n_s_r40, __pyx_n_s_r39, __pyx_n_s_r38, __pyx_n_s_r37, __pyx_n_s_r36, __pyx_n_s_r35, __pyx_n_s_r34, __pyx_n_s_r33, __pyx_n_s_r32, __pyx_n_s_r31, __pyx_n_s_r30, __pyx_n_s_r29, __pyx_n_s_r28, __pyx_n_s_r27, __pyx_n_s_r26, __pyx_n_s_r25, __pyx_n_s_r24, __pyx_n_s_r23, __pyx_n_s_r22, __pyx_n_s_r21, __pyx_n_s_r20, __pyx_n_s_r19, __pyx_n_s_r18, __pyx_n_s_r17, __pyx_n_s_r16, __pyx_n_s_r15, __pyx_n_s_r14, __pyx_n_s_r13, __pyx_n_s_r12, __pyx_n_s_r11, __pyx_n_s_r10, __pyx_n_s_r9, __pyx_n_s_r8, __pyx_n_s_r7, __pyx_n_s_r6, __pyx_n_s_r5, __pyx_n_s_r4, __pyx_n_s_r3, __pyx_n_s_r2, __pyx_n_s_r1, __pyx_n_s_r0); if (unlikely(!__pyx_tuple__13)) __PYX_ERR(0, 313, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__13);
- __Pyx_GIVEREF(__pyx_tuple__13);
- __pyx_codeobj__14 = (PyObject*)__Pyx_PyCode_New(4, 0, 0, 145, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__13, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_Lib_fontTools_pens_momentsPen_py, __pyx_n_s_curveToOne, 313, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__14)) __PYX_ERR(0, 313, __pyx_L1_error)
-
- /* "fontTools/pens/momentsPen.py":875
- * "MomentsPen",
- * [
- * ("area", 1), # <<<<<<<<<<<<<<
- * ("momentX", x),
- * ("momentY", y),
- */
- __pyx_tuple__15 = PyTuple_Pack(2, __pyx_n_u_area, __pyx_int_1); if (unlikely(!__pyx_tuple__15)) __PYX_ERR(0, 875, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__15);
- __Pyx_GIVEREF(__pyx_tuple__15);
- __Pyx_RefNannyFinishContext();
- return 0;
- __pyx_L1_error:;
- __Pyx_RefNannyFinishContext();
- return -1;
-}
-/* #### Code section: init_constants ### */
-
-static CYTHON_SMALL_CODE int __Pyx_InitConstants(void) {
- if (__Pyx_CreateStringTabAndInitStrings() < 0) __PYX_ERR(0, 1, __pyx_L1_error);
- __pyx_int_0 = PyInt_FromLong(0); if (unlikely(!__pyx_int_0)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_1 = PyInt_FromLong(1); if (unlikely(!__pyx_int_1)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_2 = PyInt_FromLong(2); if (unlikely(!__pyx_int_2)) __PYX_ERR(0, 1, __pyx_L1_error)
- return 0;
- __pyx_L1_error:;
- return -1;
-}
-/* #### Code section: init_globals ### */
-
-static CYTHON_SMALL_CODE int __Pyx_InitGlobals(void) {
- return 0;
-}
-/* #### Code section: init_module ### */
-
-static CYTHON_SMALL_CODE int __Pyx_modinit_global_init_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_variable_export_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_function_export_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_type_init_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_type_import_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_variable_import_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_function_import_code(void); /*proto*/
-
-static int __Pyx_modinit_global_init_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_global_init_code", 0);
- /*--- Global init code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_variable_export_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_variable_export_code", 0);
- /*--- Variable export code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_function_export_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_function_export_code", 0);
- /*--- Function export code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_type_init_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_type_init_code", 0);
- /*--- Type init code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_type_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_type_import_code", 0);
- /*--- Type import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_variable_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_variable_import_code", 0);
- /*--- Variable import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_function_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_function_import_code", 0);
- /*--- Function import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-
-#if PY_MAJOR_VERSION >= 3
-#if CYTHON_PEP489_MULTI_PHASE_INIT
-static PyObject* __pyx_pymod_create(PyObject *spec, PyModuleDef *def); /*proto*/
-static int __pyx_pymod_exec_momentsPen(PyObject* module); /*proto*/
-static PyModuleDef_Slot __pyx_moduledef_slots[] = {
- {Py_mod_create, (void*)__pyx_pymod_create},
- {Py_mod_exec, (void*)__pyx_pymod_exec_momentsPen},
- {0, NULL}
-};
-#endif
-
-#ifdef __cplusplus
-namespace {
- struct PyModuleDef __pyx_moduledef =
- #else
- static struct PyModuleDef __pyx_moduledef =
- #endif
- {
- PyModuleDef_HEAD_INIT,
- "momentsPen",
- 0, /* m_doc */
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- 0, /* m_size */
- #elif CYTHON_USE_MODULE_STATE
- sizeof(__pyx_mstate), /* m_size */
- #else
- -1, /* m_size */
- #endif
- __pyx_methods /* m_methods */,
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- __pyx_moduledef_slots, /* m_slots */
- #else
- NULL, /* m_reload */
- #endif
- #if CYTHON_USE_MODULE_STATE
- __pyx_m_traverse, /* m_traverse */
- __pyx_m_clear, /* m_clear */
- NULL /* m_free */
- #else
- NULL, /* m_traverse */
- NULL, /* m_clear */
- NULL /* m_free */
- #endif
- };
- #ifdef __cplusplus
-} /* anonymous namespace */
-#endif
-#endif
-
-#ifndef CYTHON_NO_PYINIT_EXPORT
-#define __Pyx_PyMODINIT_FUNC PyMODINIT_FUNC
-#elif PY_MAJOR_VERSION < 3
-#ifdef __cplusplus
-#define __Pyx_PyMODINIT_FUNC extern "C" void
-#else
-#define __Pyx_PyMODINIT_FUNC void
-#endif
-#else
-#ifdef __cplusplus
-#define __Pyx_PyMODINIT_FUNC extern "C" PyObject *
-#else
-#define __Pyx_PyMODINIT_FUNC PyObject *
-#endif
-#endif
-
-
-#if PY_MAJOR_VERSION < 3
-__Pyx_PyMODINIT_FUNC initmomentsPen(void) CYTHON_SMALL_CODE; /*proto*/
-__Pyx_PyMODINIT_FUNC initmomentsPen(void)
-#else
-__Pyx_PyMODINIT_FUNC PyInit_momentsPen(void) CYTHON_SMALL_CODE; /*proto*/
-__Pyx_PyMODINIT_FUNC PyInit_momentsPen(void)
-#if CYTHON_PEP489_MULTI_PHASE_INIT
-{
- return PyModuleDef_Init(&__pyx_moduledef);
-}
-static CYTHON_SMALL_CODE int __Pyx_check_single_interpreter(void) {
- #if PY_VERSION_HEX >= 0x030700A1
- static PY_INT64_T main_interpreter_id = -1;
- PY_INT64_T current_id = PyInterpreterState_GetID(PyThreadState_Get()->interp);
- if (main_interpreter_id == -1) {
- main_interpreter_id = current_id;
- return (unlikely(current_id == -1)) ? -1 : 0;
- } else if (unlikely(main_interpreter_id != current_id))
- #else
- static PyInterpreterState *main_interpreter = NULL;
- PyInterpreterState *current_interpreter = PyThreadState_Get()->interp;
- if (!main_interpreter) {
- main_interpreter = current_interpreter;
- } else if (unlikely(main_interpreter != current_interpreter))
- #endif
- {
- PyErr_SetString(
- PyExc_ImportError,
- "Interpreter change detected - this module can only be loaded into one interpreter per process.");
- return -1;
- }
- return 0;
-}
-#if CYTHON_COMPILING_IN_LIMITED_API
-static CYTHON_SMALL_CODE int __Pyx_copy_spec_to_module(PyObject *spec, PyObject *module, const char* from_name, const char* to_name, int allow_none)
-#else
-static CYTHON_SMALL_CODE int __Pyx_copy_spec_to_module(PyObject *spec, PyObject *moddict, const char* from_name, const char* to_name, int allow_none)
-#endif
-{
- PyObject *value = PyObject_GetAttrString(spec, from_name);
- int result = 0;
- if (likely(value)) {
- if (allow_none || value != Py_None) {
-#if CYTHON_COMPILING_IN_LIMITED_API
- result = PyModule_AddObject(module, to_name, value);
-#else
- result = PyDict_SetItemString(moddict, to_name, value);
-#endif
- }
- Py_DECREF(value);
- } else if (PyErr_ExceptionMatches(PyExc_AttributeError)) {
- PyErr_Clear();
- } else {
- result = -1;
- }
- return result;
-}
-static CYTHON_SMALL_CODE PyObject* __pyx_pymod_create(PyObject *spec, PyModuleDef *def) {
- PyObject *module = NULL, *moddict, *modname;
- CYTHON_UNUSED_VAR(def);
- if (__Pyx_check_single_interpreter())
- return NULL;
- if (__pyx_m)
- return __Pyx_NewRef(__pyx_m);
- modname = PyObject_GetAttrString(spec, "name");
- if (unlikely(!modname)) goto bad;
- module = PyModule_NewObject(modname);
- Py_DECREF(modname);
- if (unlikely(!module)) goto bad;
-#if CYTHON_COMPILING_IN_LIMITED_API
- moddict = module;
-#else
- moddict = PyModule_GetDict(module);
- if (unlikely(!moddict)) goto bad;
-#endif
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "loader", "__loader__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "origin", "__file__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "parent", "__package__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "submodule_search_locations", "__path__", 0) < 0)) goto bad;
- return module;
-bad:
- Py_XDECREF(module);
- return NULL;
-}
-
-
-static CYTHON_SMALL_CODE int __pyx_pymod_exec_momentsPen(PyObject *__pyx_pyinit_module)
-#endif
-#endif
-{
- int stringtab_initialized = 0;
- #if CYTHON_USE_MODULE_STATE
- int pystate_addmodule_run = 0;
- #endif
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_t_6;
- PyObject *__pyx_t_7 = NULL;
- PyObject *__pyx_t_8 = NULL;
- PyObject *__pyx_t_9 = NULL;
- int __pyx_t_10;
- PyObject *__pyx_t_11 = NULL;
- PyObject *__pyx_t_12 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannyDeclarations
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- if (__pyx_m) {
- if (__pyx_m == __pyx_pyinit_module) return 0;
- PyErr_SetString(PyExc_RuntimeError, "Module 'momentsPen' has already been imported. Re-initialisation is not supported.");
- return -1;
- }
- #elif PY_MAJOR_VERSION >= 3
- if (__pyx_m) return __Pyx_NewRef(__pyx_m);
- #endif
- /*--- Module creation code ---*/
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- __pyx_m = __pyx_pyinit_module;
- Py_INCREF(__pyx_m);
- #else
- #if PY_MAJOR_VERSION < 3
- __pyx_m = Py_InitModule4("momentsPen", __pyx_methods, 0, 0, PYTHON_API_VERSION); Py_XINCREF(__pyx_m);
- if (unlikely(!__pyx_m)) __PYX_ERR(0, 1, __pyx_L1_error)
- #elif CYTHON_USE_MODULE_STATE
- __pyx_t_1 = PyModule_Create(&__pyx_moduledef); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 1, __pyx_L1_error)
- {
- int add_module_result = PyState_AddModule(__pyx_t_1, &__pyx_moduledef);
- __pyx_t_1 = 0; /* transfer ownership from __pyx_t_1 to momentsPen pseudovariable */
- if (unlikely((add_module_result < 0))) __PYX_ERR(0, 1, __pyx_L1_error)
- pystate_addmodule_run = 1;
- }
- #else
- __pyx_m = PyModule_Create(&__pyx_moduledef);
- if (unlikely(!__pyx_m)) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #endif
- CYTHON_UNUSED_VAR(__pyx_t_1);
- __pyx_d = PyModule_GetDict(__pyx_m); if (unlikely(!__pyx_d)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_d);
- __pyx_b = PyImport_AddModule(__Pyx_BUILTIN_MODULE_NAME); if (unlikely(!__pyx_b)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_b);
- __pyx_cython_runtime = PyImport_AddModule((char *) "cython_runtime"); if (unlikely(!__pyx_cython_runtime)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_cython_runtime);
- if (PyObject_SetAttrString(__pyx_m, "__builtins__", __pyx_b) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #if CYTHON_REFNANNY
-__Pyx_RefNanny = __Pyx_RefNannyImportAPI("refnanny");
-if (!__Pyx_RefNanny) {
- PyErr_Clear();
- __Pyx_RefNanny = __Pyx_RefNannyImportAPI("Cython.Runtime.refnanny");
- if (!__Pyx_RefNanny)
- Py_FatalError("failed to import 'refnanny' module");
-}
-#endif
- __Pyx_RefNannySetupContext("__Pyx_PyMODINIT_FUNC PyInit_momentsPen(void)", 0);
- if (__Pyx_check_binary_version() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #ifdef __Pxy_PyFrame_Initialize_Offsets
- __Pxy_PyFrame_Initialize_Offsets();
- #endif
- __pyx_empty_tuple = PyTuple_New(0); if (unlikely(!__pyx_empty_tuple)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_empty_bytes = PyBytes_FromStringAndSize("", 0); if (unlikely(!__pyx_empty_bytes)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_empty_unicode = PyUnicode_FromStringAndSize("", 0); if (unlikely(!__pyx_empty_unicode)) __PYX_ERR(0, 1, __pyx_L1_error)
- #ifdef __Pyx_CyFunction_USED
- if (__pyx_CyFunction_init(__pyx_m) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_FusedFunction_USED
- if (__pyx_FusedFunction_init(__pyx_m) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_Coroutine_USED
- if (__pyx_Coroutine_init(__pyx_m) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_Generator_USED
- if (__pyx_Generator_init(__pyx_m) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_AsyncGen_USED
- if (__pyx_AsyncGen_init(__pyx_m) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_StopAsyncIteration_USED
- if (__pyx_StopAsyncIteration_init(__pyx_m) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- /*--- Library function declarations ---*/
- /*--- Threads initialization code ---*/
- #if defined(WITH_THREAD) && PY_VERSION_HEX < 0x030700F0 && defined(__PYX_FORCE_INIT_THREADS) && __PYX_FORCE_INIT_THREADS
- PyEval_InitThreads();
- #endif
- /*--- Initialize various global constants etc. ---*/
- if (__Pyx_InitConstants() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- stringtab_initialized = 1;
- if (__Pyx_InitGlobals() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #if PY_MAJOR_VERSION < 3 && (__PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT)
- if (__Pyx_init_sys_getdefaultencoding_params() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- if (__pyx_module_is_main_fontTools__pens__momentsPen) {
- if (PyObject_SetAttr(__pyx_m, __pyx_n_s_name, __pyx_n_s_main) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- }
- #if PY_MAJOR_VERSION >= 3
- {
- PyObject *modules = PyImport_GetModuleDict(); if (unlikely(!modules)) __PYX_ERR(0, 1, __pyx_L1_error)
- if (!PyDict_GetItemString(modules, "fontTools.pens.momentsPen")) {
- if (unlikely((PyDict_SetItemString(modules, "fontTools.pens.momentsPen", __pyx_m) < 0))) __PYX_ERR(0, 1, __pyx_L1_error)
- }
- }
- #endif
- /*--- Builtin init code ---*/
- if (__Pyx_InitCachedBuiltins() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- /*--- Constants init code ---*/
- if (__Pyx_InitCachedConstants() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- /*--- Global type/function init code ---*/
- (void)__Pyx_modinit_global_init_code();
- (void)__Pyx_modinit_variable_export_code();
- (void)__Pyx_modinit_function_export_code();
- (void)__Pyx_modinit_type_init_code();
- (void)__Pyx_modinit_type_import_code();
- (void)__Pyx_modinit_variable_import_code();
- (void)__Pyx_modinit_function_import_code();
- /*--- Execution code ---*/
- #if defined(__Pyx_Generator_USED) || defined(__Pyx_Coroutine_USED)
- if (__Pyx_patch_abc() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
-
- /* "fontTools/pens/momentsPen.py":1
- * from fontTools.pens.basePen import BasePen, OpenContourError # <<<<<<<<<<<<<<
- *
- * try:
- */
- __pyx_t_2 = PyList_New(2); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_INCREF(__pyx_n_s_BasePen);
- __Pyx_GIVEREF(__pyx_n_s_BasePen);
- PyList_SET_ITEM(__pyx_t_2, 0, __pyx_n_s_BasePen);
- __Pyx_INCREF(__pyx_n_s_OpenContourError);
- __Pyx_GIVEREF(__pyx_n_s_OpenContourError);
- PyList_SET_ITEM(__pyx_t_2, 1, __pyx_n_s_OpenContourError);
- __pyx_t_3 = __Pyx_Import(__pyx_n_s_fontTools_pens_basePen, __pyx_t_2, 0); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_ImportFrom(__pyx_t_3, __pyx_n_s_BasePen); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_BasePen, __pyx_t_2) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_ImportFrom(__pyx_t_3, __pyx_n_s_OpenContourError); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_OpenContourError, __pyx_t_2) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":3
- * from fontTools.pens.basePen import BasePen, OpenContourError
- *
- * try: # <<<<<<<<<<<<<<
- * import cython
- *
- */
- {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __Pyx_ExceptionSave(&__pyx_t_1, &__pyx_t_4, &__pyx_t_5);
- __Pyx_XGOTREF(__pyx_t_1);
- __Pyx_XGOTREF(__pyx_t_4);
- __Pyx_XGOTREF(__pyx_t_5);
- /*try:*/ {
-
- /* "fontTools/pens/momentsPen.py":6
- * import cython
- *
- * COMPILED = cython.compiled # <<<<<<<<<<<<<<
- * except (AttributeError, ImportError):
- * # if cython not installed, use mock module with no-op decorators and types
- */
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_COMPILED, Py_True) < 0) __PYX_ERR(0, 6, __pyx_L2_error)
-
- /* "fontTools/pens/momentsPen.py":3
- * from fontTools.pens.basePen import BasePen, OpenContourError
- *
- * try: # <<<<<<<<<<<<<<
- * import cython
- *
- */
- }
- __Pyx_XDECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_XDECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- goto __pyx_L7_try_end;
- __pyx_L2_error:;
- __Pyx_XDECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":7
- *
- * COMPILED = cython.compiled
- * except (AttributeError, ImportError): # <<<<<<<<<<<<<<
- * # if cython not installed, use mock module with no-op decorators and types
- * from fontTools.misc import cython
- */
- __pyx_t_6 = __Pyx_PyErr_ExceptionMatches2(__pyx_builtin_AttributeError, __pyx_builtin_ImportError);
- if (__pyx_t_6) {
- __Pyx_AddTraceback("fontTools.pens.momentsPen", __pyx_clineno, __pyx_lineno, __pyx_filename);
- if (__Pyx_GetException(&__pyx_t_3, &__pyx_t_2, &__pyx_t_7) < 0) __PYX_ERR(0, 7, __pyx_L4_except_error)
- __Pyx_XGOTREF(__pyx_t_3);
- __Pyx_XGOTREF(__pyx_t_2);
- __Pyx_XGOTREF(__pyx_t_7);
-
- /* "fontTools/pens/momentsPen.py":9
- * except (AttributeError, ImportError):
- * # if cython not installed, use mock module with no-op decorators and types
- * from fontTools.misc import cython # <<<<<<<<<<<<<<
- *
- * COMPILED = False
- */
- __pyx_t_8 = PyList_New(1); if (unlikely(!__pyx_t_8)) __PYX_ERR(0, 9, __pyx_L4_except_error)
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_INCREF(__pyx_n_s_cython);
- __Pyx_GIVEREF(__pyx_n_s_cython);
- PyList_SET_ITEM(__pyx_t_8, 0, __pyx_n_s_cython);
- __pyx_t_9 = __Pyx_Import(__pyx_n_s_fontTools_misc, __pyx_t_8, 0); if (unlikely(!__pyx_t_9)) __PYX_ERR(0, 9, __pyx_L4_except_error)
- __Pyx_GOTREF(__pyx_t_9);
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- __pyx_t_8 = __Pyx_ImportFrom(__pyx_t_9, __pyx_n_s_cython); if (unlikely(!__pyx_t_8)) __PYX_ERR(0, 9, __pyx_L4_except_error)
- __Pyx_GOTREF(__pyx_t_8);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_cython, __pyx_t_8) < 0) __PYX_ERR(0, 9, __pyx_L4_except_error)
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
-
- /* "fontTools/pens/momentsPen.py":11
- * from fontTools.misc import cython
- *
- * COMPILED = False # <<<<<<<<<<<<<<
- *
- *
- */
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_COMPILED, Py_False) < 0) __PYX_ERR(0, 11, __pyx_L4_except_error)
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_XDECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- goto __pyx_L3_exception_handled;
- }
- goto __pyx_L4_except_error;
-
- /* "fontTools/pens/momentsPen.py":3
- * from fontTools.pens.basePen import BasePen, OpenContourError
- *
- * try: # <<<<<<<<<<<<<<
- * import cython
- *
- */
- __pyx_L4_except_error:;
- __Pyx_XGIVEREF(__pyx_t_1);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_XGIVEREF(__pyx_t_5);
- __Pyx_ExceptionReset(__pyx_t_1, __pyx_t_4, __pyx_t_5);
- goto __pyx_L1_error;
- __pyx_L3_exception_handled:;
- __Pyx_XGIVEREF(__pyx_t_1);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_XGIVEREF(__pyx_t_5);
- __Pyx_ExceptionReset(__pyx_t_1, __pyx_t_4, __pyx_t_5);
- __pyx_L7_try_end:;
- }
-
- /* "fontTools/pens/momentsPen.py":14
- *
- *
- * __all__ = ["MomentsPen"] # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_7 = PyList_New(1); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_INCREF(__pyx_n_u_MomentsPen);
- __Pyx_GIVEREF(__pyx_n_u_MomentsPen);
- PyList_SET_ITEM(__pyx_t_7, 0, __pyx_n_u_MomentsPen);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_all, __pyx_t_7) < 0) __PYX_ERR(0, 14, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
-
- /* "fontTools/pens/momentsPen.py":17
- *
- *
- * class MomentsPen(BasePen): # <<<<<<<<<<<<<<
- * def __init__(self, glyphset=None):
- * BasePen.__init__(self, glyphset)
- */
- __Pyx_GetModuleGlobalName(__pyx_t_7, __pyx_n_s_BasePen); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 17, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __pyx_t_2 = PyTuple_New(1); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 17, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_7);
- PyTuple_SET_ITEM(__pyx_t_2, 0, __pyx_t_7);
- __pyx_t_7 = 0;
- __pyx_t_7 = __Pyx_PEP560_update_bases(__pyx_t_2); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 17, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __pyx_t_3 = __Pyx_CalculateMetaclass(NULL, __pyx_t_7); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 17, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_9 = __Pyx_Py3MetaclassPrepare(__pyx_t_3, __pyx_t_7, __pyx_n_s_MomentsPen, __pyx_n_s_MomentsPen, (PyObject *) NULL, __pyx_n_s_fontTools_pens_momentsPen, (PyObject *) NULL); if (unlikely(!__pyx_t_9)) __PYX_ERR(0, 17, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- if (__pyx_t_7 != __pyx_t_2) {
- if (unlikely((PyDict_SetItemString(__pyx_t_9, "__orig_bases__", __pyx_t_2) < 0))) __PYX_ERR(0, 17, __pyx_L1_error)
- }
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":18
- *
- * class MomentsPen(BasePen):
- * def __init__(self, glyphset=None): # <<<<<<<<<<<<<<
- * BasePen.__init__(self, glyphset)
- *
- */
- __pyx_t_2 = __Pyx_CyFunction_New(&__pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_1__init__, 0, __pyx_n_s_MomentsPen___init, NULL, __pyx_n_s_fontTools_pens_momentsPen, __pyx_d, ((PyObject *)__pyx_codeobj__3)); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 18, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_CyFunction_SetDefaultsTuple(__pyx_t_2, __pyx_tuple__4);
- if (__Pyx_SetNameInClass(__pyx_t_9, __pyx_n_s_init, __pyx_t_2) < 0) __PYX_ERR(0, 18, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":28
- * self.momentYY = 0
- *
- * def _moveTo(self, p0): # <<<<<<<<<<<<<<
- * self.__startPoint = p0
- *
- */
- __pyx_t_2 = __Pyx_CyFunction_New(&__pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_3_moveTo, 0, __pyx_n_s_MomentsPen__moveTo, NULL, __pyx_n_s_fontTools_pens_momentsPen, __pyx_d, ((PyObject *)__pyx_codeobj__6)); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 28, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (__Pyx_SetNameInClass(__pyx_t_9, __pyx_n_s_moveTo, __pyx_t_2) < 0) __PYX_ERR(0, 28, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":31
- * self.__startPoint = p0
- *
- * def _closePath(self): # <<<<<<<<<<<<<<
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- */
- __pyx_t_2 = __Pyx_CyFunction_New(&__pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_5_closePath, 0, __pyx_n_s_MomentsPen__closePath, NULL, __pyx_n_s_fontTools_pens_momentsPen, __pyx_d, ((PyObject *)__pyx_codeobj__7)); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 31, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (__Pyx_SetNameInClass(__pyx_t_9, __pyx_n_s_closePath, __pyx_t_2) < 0) __PYX_ERR(0, 31, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":36
- * self._lineTo(self.__startPoint)
- *
- * def _endPath(self): # <<<<<<<<<<<<<<
- * p0 = self._getCurrentPoint()
- * if p0 != self.__startPoint:
- */
- __pyx_t_2 = __Pyx_CyFunction_New(&__pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_7_endPath, 0, __pyx_n_s_MomentsPen__endPath, NULL, __pyx_n_s_fontTools_pens_momentsPen, __pyx_d, ((PyObject *)__pyx_codeobj__8)); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 36, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (__Pyx_SetNameInClass(__pyx_t_9, __pyx_n_s_endPath, __pyx_t_2) < 0) __PYX_ERR(0, 36, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":42
- * raise OpenContourError("Green theorem is not defined on open contours.")
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
- __pyx_t_2 = __Pyx_CyFunction_New(&__pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_9_lineTo, 0, __pyx_n_s_MomentsPen__lineTo, NULL, __pyx_n_s_fontTools_pens_momentsPen, __pyx_d, ((PyObject *)__pyx_codeobj__10)); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 42, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (__Pyx_SetNameInClass(__pyx_t_9, __pyx_n_s_lineTo, __pyx_t_2) < 0) __PYX_ERR(0, 42, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":102
- * )
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
- __pyx_t_2 = __Pyx_CyFunction_New(&__pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_11_qCurveToOne, 0, __pyx_n_s_MomentsPen__qCurveToOne, NULL, __pyx_n_s_fontTools_pens_momentsPen, __pyx_d, ((PyObject *)__pyx_codeobj__12)); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 102, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (__Pyx_SetNameInClass(__pyx_t_9, __pyx_n_s_qCurveToOne, __pyx_t_2) < 0) __PYX_ERR(0, 102, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":313
- * )
- *
- * @cython.locals(r0=cython.double) # <<<<<<<<<<<<<<
- * @cython.locals(r1=cython.double)
- * @cython.locals(r2=cython.double)
- */
- __pyx_t_2 = __Pyx_CyFunction_New(&__pyx_mdef_9fontTools_4pens_10momentsPen_10MomentsPen_13_curveToOne, 0, __pyx_n_s_MomentsPen__curveToOne, NULL, __pyx_n_s_fontTools_pens_momentsPen, __pyx_d, ((PyObject *)__pyx_codeobj__14)); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 313, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (__Pyx_SetNameInClass(__pyx_t_9, __pyx_n_s_curveToOne, __pyx_t_2) < 0) __PYX_ERR(0, 313, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "fontTools/pens/momentsPen.py":17
- *
- *
- * class MomentsPen(BasePen): # <<<<<<<<<<<<<<
- * def __init__(self, glyphset=None):
- * BasePen.__init__(self, glyphset)
- */
- __pyx_t_2 = __Pyx_Py3ClassCreate(__pyx_t_3, __pyx_n_s_MomentsPen, __pyx_t_7, __pyx_t_9, NULL, 0, 0); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 17, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_MomentsPen, __pyx_t_2) < 0) __PYX_ERR(0, 17, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
-
- /* "fontTools/pens/momentsPen.py":869
- *
- *
- * if __name__ == "__main__": # <<<<<<<<<<<<<<
- * from fontTools.misc.symfont import x, y, printGreenPen
- *
- */
- __Pyx_GetModuleGlobalName(__pyx_t_7, __pyx_n_s_name); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 869, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __pyx_t_10 = (__Pyx_PyUnicode_Equals(__pyx_t_7, __pyx_n_u_main, Py_EQ)); if (unlikely((__pyx_t_10 < 0))) __PYX_ERR(0, 869, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- if (__pyx_t_10) {
-
- /* "fontTools/pens/momentsPen.py":870
- *
- * if __name__ == "__main__":
- * from fontTools.misc.symfont import x, y, printGreenPen # <<<<<<<<<<<<<<
- *
- * printGreenPen(
- */
- __pyx_t_7 = PyList_New(3); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 870, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_INCREF(__pyx_n_s_x);
- __Pyx_GIVEREF(__pyx_n_s_x);
- PyList_SET_ITEM(__pyx_t_7, 0, __pyx_n_s_x);
- __Pyx_INCREF(__pyx_n_s_y);
- __Pyx_GIVEREF(__pyx_n_s_y);
- PyList_SET_ITEM(__pyx_t_7, 1, __pyx_n_s_y);
- __Pyx_INCREF(__pyx_n_s_printGreenPen);
- __Pyx_GIVEREF(__pyx_n_s_printGreenPen);
- PyList_SET_ITEM(__pyx_t_7, 2, __pyx_n_s_printGreenPen);
- __pyx_t_3 = __Pyx_Import(__pyx_n_s_fontTools_misc_symfont, __pyx_t_7, 0); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 870, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __pyx_t_7 = __Pyx_ImportFrom(__pyx_t_3, __pyx_n_s_x); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 870, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_x, __pyx_t_7) < 0) __PYX_ERR(0, 870, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __pyx_t_7 = __Pyx_ImportFrom(__pyx_t_3, __pyx_n_s_y); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 870, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_y, __pyx_t_7) < 0) __PYX_ERR(0, 870, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __pyx_t_7 = __Pyx_ImportFrom(__pyx_t_3, __pyx_n_s_printGreenPen); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 870, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_printGreenPen, __pyx_t_7) < 0) __PYX_ERR(0, 870, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "fontTools/pens/momentsPen.py":872
- * from fontTools.misc.symfont import x, y, printGreenPen
- *
- * printGreenPen( # <<<<<<<<<<<<<<
- * "MomentsPen",
- * [
- */
- __Pyx_GetModuleGlobalName(__pyx_t_3, __pyx_n_s_printGreenPen); if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 872, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "fontTools/pens/momentsPen.py":876
- * [
- * ("area", 1),
- * ("momentX", x), # <<<<<<<<<<<<<<
- * ("momentY", y),
- * ("momentXX", x**2),
- */
- __Pyx_GetModuleGlobalName(__pyx_t_7, __pyx_n_s_x); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 876, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __pyx_t_9 = PyTuple_New(2); if (unlikely(!__pyx_t_9)) __PYX_ERR(0, 876, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __Pyx_INCREF(__pyx_n_u_momentX);
- __Pyx_GIVEREF(__pyx_n_u_momentX);
- PyTuple_SET_ITEM(__pyx_t_9, 0, __pyx_n_u_momentX);
- __Pyx_GIVEREF(__pyx_t_7);
- PyTuple_SET_ITEM(__pyx_t_9, 1, __pyx_t_7);
- __pyx_t_7 = 0;
-
- /* "fontTools/pens/momentsPen.py":877
- * ("area", 1),
- * ("momentX", x),
- * ("momentY", y), # <<<<<<<<<<<<<<
- * ("momentXX", x**2),
- * ("momentXY", x * y),
- */
- __Pyx_GetModuleGlobalName(__pyx_t_7, __pyx_n_s_y); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 877, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __pyx_t_2 = PyTuple_New(2); if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 877, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_INCREF(__pyx_n_u_momentY);
- __Pyx_GIVEREF(__pyx_n_u_momentY);
- PyTuple_SET_ITEM(__pyx_t_2, 0, __pyx_n_u_momentY);
- __Pyx_GIVEREF(__pyx_t_7);
- PyTuple_SET_ITEM(__pyx_t_2, 1, __pyx_t_7);
- __pyx_t_7 = 0;
-
- /* "fontTools/pens/momentsPen.py":878
- * ("momentX", x),
- * ("momentY", y),
- * ("momentXX", x**2), # <<<<<<<<<<<<<<
- * ("momentXY", x * y),
- * ("momentYY", y**2),
- */
- __Pyx_GetModuleGlobalName(__pyx_t_7, __pyx_n_s_x); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 878, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __pyx_t_8 = PyNumber_Power(__pyx_t_7, __pyx_int_2, Py_None); if (unlikely(!__pyx_t_8)) __PYX_ERR(0, 878, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __pyx_t_7 = PyTuple_New(2); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 878, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_INCREF(__pyx_n_u_momentXX);
- __Pyx_GIVEREF(__pyx_n_u_momentXX);
- PyTuple_SET_ITEM(__pyx_t_7, 0, __pyx_n_u_momentXX);
- __Pyx_GIVEREF(__pyx_t_8);
- PyTuple_SET_ITEM(__pyx_t_7, 1, __pyx_t_8);
- __pyx_t_8 = 0;
-
- /* "fontTools/pens/momentsPen.py":879
- * ("momentY", y),
- * ("momentXX", x**2),
- * ("momentXY", x * y), # <<<<<<<<<<<<<<
- * ("momentYY", y**2),
- * ],
- */
- __Pyx_GetModuleGlobalName(__pyx_t_8, __pyx_n_s_x); if (unlikely(!__pyx_t_8)) __PYX_ERR(0, 879, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_GetModuleGlobalName(__pyx_t_11, __pyx_n_s_y); if (unlikely(!__pyx_t_11)) __PYX_ERR(0, 879, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_11);
- __pyx_t_12 = PyNumber_Multiply(__pyx_t_8, __pyx_t_11); if (unlikely(!__pyx_t_12)) __PYX_ERR(0, 879, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_12);
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- __Pyx_DECREF(__pyx_t_11); __pyx_t_11 = 0;
- __pyx_t_11 = PyTuple_New(2); if (unlikely(!__pyx_t_11)) __PYX_ERR(0, 879, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_11);
- __Pyx_INCREF(__pyx_n_u_momentXY);
- __Pyx_GIVEREF(__pyx_n_u_momentXY);
- PyTuple_SET_ITEM(__pyx_t_11, 0, __pyx_n_u_momentXY);
- __Pyx_GIVEREF(__pyx_t_12);
- PyTuple_SET_ITEM(__pyx_t_11, 1, __pyx_t_12);
- __pyx_t_12 = 0;
-
- /* "fontTools/pens/momentsPen.py":880
- * ("momentXX", x**2),
- * ("momentXY", x * y),
- * ("momentYY", y**2), # <<<<<<<<<<<<<<
- * ],
- * )
- */
- __Pyx_GetModuleGlobalName(__pyx_t_12, __pyx_n_s_y); if (unlikely(!__pyx_t_12)) __PYX_ERR(0, 880, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_12);
- __pyx_t_8 = PyNumber_Power(__pyx_t_12, __pyx_int_2, Py_None); if (unlikely(!__pyx_t_8)) __PYX_ERR(0, 880, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_DECREF(__pyx_t_12); __pyx_t_12 = 0;
- __pyx_t_12 = PyTuple_New(2); if (unlikely(!__pyx_t_12)) __PYX_ERR(0, 880, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_12);
- __Pyx_INCREF(__pyx_n_u_momentYY);
- __Pyx_GIVEREF(__pyx_n_u_momentYY);
- PyTuple_SET_ITEM(__pyx_t_12, 0, __pyx_n_u_momentYY);
- __Pyx_GIVEREF(__pyx_t_8);
- PyTuple_SET_ITEM(__pyx_t_12, 1, __pyx_t_8);
- __pyx_t_8 = 0;
-
- /* "fontTools/pens/momentsPen.py":874
- * printGreenPen(
- * "MomentsPen",
- * [ # <<<<<<<<<<<<<<
- * ("area", 1),
- * ("momentX", x),
- */
- __pyx_t_8 = PyList_New(6); if (unlikely(!__pyx_t_8)) __PYX_ERR(0, 874, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_INCREF(__pyx_tuple__15);
- __Pyx_GIVEREF(__pyx_tuple__15);
- PyList_SET_ITEM(__pyx_t_8, 0, __pyx_tuple__15);
- __Pyx_GIVEREF(__pyx_t_9);
- PyList_SET_ITEM(__pyx_t_8, 1, __pyx_t_9);
- __Pyx_GIVEREF(__pyx_t_2);
- PyList_SET_ITEM(__pyx_t_8, 2, __pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_7);
- PyList_SET_ITEM(__pyx_t_8, 3, __pyx_t_7);
- __Pyx_GIVEREF(__pyx_t_11);
- PyList_SET_ITEM(__pyx_t_8, 4, __pyx_t_11);
- __Pyx_GIVEREF(__pyx_t_12);
- PyList_SET_ITEM(__pyx_t_8, 5, __pyx_t_12);
- __pyx_t_9 = 0;
- __pyx_t_2 = 0;
- __pyx_t_7 = 0;
- __pyx_t_11 = 0;
- __pyx_t_12 = 0;
-
- /* "fontTools/pens/momentsPen.py":872
- * from fontTools.misc.symfont import x, y, printGreenPen
- *
- * printGreenPen( # <<<<<<<<<<<<<<
- * "MomentsPen",
- * [
- */
- __pyx_t_12 = PyTuple_New(2); if (unlikely(!__pyx_t_12)) __PYX_ERR(0, 872, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_12);
- __Pyx_INCREF(__pyx_n_u_MomentsPen);
- __Pyx_GIVEREF(__pyx_n_u_MomentsPen);
- PyTuple_SET_ITEM(__pyx_t_12, 0, __pyx_n_u_MomentsPen);
- __Pyx_GIVEREF(__pyx_t_8);
- PyTuple_SET_ITEM(__pyx_t_12, 1, __pyx_t_8);
- __pyx_t_8 = 0;
- __pyx_t_8 = __Pyx_PyObject_Call(__pyx_t_3, __pyx_t_12, NULL); if (unlikely(!__pyx_t_8)) __PYX_ERR(0, 872, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_DECREF(__pyx_t_12); __pyx_t_12 = 0;
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
-
- /* "fontTools/pens/momentsPen.py":869
- *
- *
- * if __name__ == "__main__": # <<<<<<<<<<<<<<
- * from fontTools.misc.symfont import x, y, printGreenPen
- *
- */
- }
-
- /* "fontTools/pens/momentsPen.py":1
- * from fontTools.pens.basePen import BasePen, OpenContourError # <<<<<<<<<<<<<<
- *
- * try:
- */
- __pyx_t_8 = __Pyx_PyDict_NewPresized(0); if (unlikely(!__pyx_t_8)) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_8);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_test, __pyx_t_8) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
-
- /*--- Wrapped vars code ---*/
-
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_8);
- __Pyx_XDECREF(__pyx_t_9);
- __Pyx_XDECREF(__pyx_t_11);
- __Pyx_XDECREF(__pyx_t_12);
- if (__pyx_m) {
- if (__pyx_d && stringtab_initialized) {
- __Pyx_AddTraceback("init fontTools.pens.momentsPen", __pyx_clineno, __pyx_lineno, __pyx_filename);
- }
- #if !CYTHON_USE_MODULE_STATE
- Py_CLEAR(__pyx_m);
- #else
- Py_DECREF(__pyx_m);
- if (pystate_addmodule_run) {
- PyObject *tp, *value, *tb;
- PyErr_Fetch(&tp, &value, &tb);
- PyState_RemoveModule(&__pyx_moduledef);
- PyErr_Restore(tp, value, tb);
- }
- #endif
- } else if (!PyErr_Occurred()) {
- PyErr_SetString(PyExc_ImportError, "init fontTools.pens.momentsPen");
- }
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- return (__pyx_m != NULL) ? 0 : -1;
- #elif PY_MAJOR_VERSION >= 3
- return __pyx_m;
- #else
- return;
- #endif
-}
-/* #### Code section: cleanup_globals ### */
-/* #### Code section: cleanup_module ### */
-/* #### Code section: main_method ### */
-/* #### Code section: utility_code_pragmas ### */
-#ifdef _MSC_VER
-#pragma warning( push )
-/* Warning 4127: conditional expression is constant
- * Cython uses constant conditional expressions to allow in inline functions to be optimized at
- * compile-time, so this warning is not useful
- */
-#pragma warning( disable : 4127 )
-#endif
-
-
-
-/* #### Code section: utility_code_def ### */
-
-/* --- Runtime support code --- */
-/* Refnanny */
-#if CYTHON_REFNANNY
-static __Pyx_RefNannyAPIStruct *__Pyx_RefNannyImportAPI(const char *modname) {
- PyObject *m = NULL, *p = NULL;
- void *r = NULL;
- m = PyImport_ImportModule(modname);
- if (!m) goto end;
- p = PyObject_GetAttrString(m, "RefNannyAPI");
- if (!p) goto end;
- r = PyLong_AsVoidPtr(p);
-end:
- Py_XDECREF(p);
- Py_XDECREF(m);
- return (__Pyx_RefNannyAPIStruct *)r;
-}
-#endif
-
-/* PyErrExceptionMatches */
-#if CYTHON_FAST_THREAD_STATE
-static int __Pyx_PyErr_ExceptionMatchesTuple(PyObject *exc_type, PyObject *tuple) {
- Py_ssize_t i, n;
- n = PyTuple_GET_SIZE(tuple);
-#if PY_MAJOR_VERSION >= 3
- for (i=0; i= 0x030C00A6
- PyObject *current_exception = tstate->current_exception;
- if (unlikely(!current_exception)) return 0;
- exc_type = (PyObject*) Py_TYPE(current_exception);
- if (exc_type == err) return 1;
-#else
- exc_type = tstate->curexc_type;
- if (exc_type == err) return 1;
- if (unlikely(!exc_type)) return 0;
-#endif
- #if CYTHON_AVOID_BORROWED_REFS
- Py_INCREF(exc_type);
- #endif
- if (unlikely(PyTuple_Check(err))) {
- result = __Pyx_PyErr_ExceptionMatchesTuple(exc_type, err);
- } else {
- result = __Pyx_PyErr_GivenExceptionMatches(exc_type, err);
- }
- #if CYTHON_AVOID_BORROWED_REFS
- Py_DECREF(exc_type);
- #endif
- return result;
-}
-#endif
-
-/* PyErrFetchRestore */
-#if CYTHON_FAST_THREAD_STATE
-static CYTHON_INLINE void __Pyx_ErrRestoreInState(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb) {
-#if PY_VERSION_HEX >= 0x030C00A6
- PyObject *tmp_value;
- assert(type == NULL || (value != NULL && type == (PyObject*) Py_TYPE(value)));
- if (value) {
- #if CYTHON_COMPILING_IN_CPYTHON
- if (unlikely(((PyBaseExceptionObject*) value)->traceback != tb))
- #endif
- PyException_SetTraceback(value, tb);
- }
- tmp_value = tstate->current_exception;
- tstate->current_exception = value;
- Py_XDECREF(tmp_value);
-#else
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- tmp_type = tstate->curexc_type;
- tmp_value = tstate->curexc_value;
- tmp_tb = tstate->curexc_traceback;
- tstate->curexc_type = type;
- tstate->curexc_value = value;
- tstate->curexc_traceback = tb;
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
-#endif
-}
-static CYTHON_INLINE void __Pyx_ErrFetchInState(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb) {
-#if PY_VERSION_HEX >= 0x030C00A6
- PyObject* exc_value;
- exc_value = tstate->current_exception;
- tstate->current_exception = 0;
- *value = exc_value;
- *type = NULL;
- *tb = NULL;
- if (exc_value) {
- *type = (PyObject*) Py_TYPE(exc_value);
- Py_INCREF(*type);
- #if CYTHON_COMPILING_IN_CPYTHON
- *tb = ((PyBaseExceptionObject*) exc_value)->traceback;
- Py_XINCREF(*tb);
- #else
- *tb = PyException_GetTraceback(exc_value);
- #endif
- }
-#else
- *type = tstate->curexc_type;
- *value = tstate->curexc_value;
- *tb = tstate->curexc_traceback;
- tstate->curexc_type = 0;
- tstate->curexc_value = 0;
- tstate->curexc_traceback = 0;
-#endif
-}
-#endif
-
-/* PyObjectGetAttrStr */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStr(PyObject* obj, PyObject* attr_name) {
- PyTypeObject* tp = Py_TYPE(obj);
- if (likely(tp->tp_getattro))
- return tp->tp_getattro(obj, attr_name);
-#if PY_MAJOR_VERSION < 3
- if (likely(tp->tp_getattr))
- return tp->tp_getattr(obj, PyString_AS_STRING(attr_name));
-#endif
- return PyObject_GetAttr(obj, attr_name);
-}
-#endif
-
-/* PyObjectGetAttrStrNoError */
-static void __Pyx_PyObject_GetAttrStr_ClearAttributeError(void) {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- if (likely(__Pyx_PyErr_ExceptionMatches(PyExc_AttributeError)))
- __Pyx_PyErr_Clear();
-}
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStrNoError(PyObject* obj, PyObject* attr_name) {
- PyObject *result;
-#if CYTHON_COMPILING_IN_CPYTHON && CYTHON_USE_TYPE_SLOTS && PY_VERSION_HEX >= 0x030700B1
- PyTypeObject* tp = Py_TYPE(obj);
- if (likely(tp->tp_getattro == PyObject_GenericGetAttr)) {
- return _PyObject_GenericGetAttrWithDict(obj, attr_name, NULL, 1);
- }
-#endif
- result = __Pyx_PyObject_GetAttrStr(obj, attr_name);
- if (unlikely(!result)) {
- __Pyx_PyObject_GetAttrStr_ClearAttributeError();
- }
- return result;
-}
-
-/* GetBuiltinName */
-static PyObject *__Pyx_GetBuiltinName(PyObject *name) {
- PyObject* result = __Pyx_PyObject_GetAttrStrNoError(__pyx_b, name);
- if (unlikely(!result) && !PyErr_Occurred()) {
- PyErr_Format(PyExc_NameError,
-#if PY_MAJOR_VERSION >= 3
- "name '%U' is not defined", name);
-#else
- "name '%.200s' is not defined", PyString_AS_STRING(name));
-#endif
- }
- return result;
-}
-
-/* TupleAndListFromArray */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE void __Pyx_copy_object_array(PyObject *const *CYTHON_RESTRICT src, PyObject** CYTHON_RESTRICT dest, Py_ssize_t length) {
- PyObject *v;
- Py_ssize_t i;
- for (i = 0; i < length; i++) {
- v = dest[i] = src[i];
- Py_INCREF(v);
- }
-}
-static CYTHON_INLINE PyObject *
-__Pyx_PyTuple_FromArray(PyObject *const *src, Py_ssize_t n)
-{
- PyObject *res;
- if (n <= 0) {
- Py_INCREF(__pyx_empty_tuple);
- return __pyx_empty_tuple;
- }
- res = PyTuple_New(n);
- if (unlikely(res == NULL)) return NULL;
- __Pyx_copy_object_array(src, ((PyTupleObject*)res)->ob_item, n);
- return res;
-}
-static CYTHON_INLINE PyObject *
-__Pyx_PyList_FromArray(PyObject *const *src, Py_ssize_t n)
-{
- PyObject *res;
- if (n <= 0) {
- return PyList_New(0);
- }
- res = PyList_New(n);
- if (unlikely(res == NULL)) return NULL;
- __Pyx_copy_object_array(src, ((PyListObject*)res)->ob_item, n);
- return res;
-}
-#endif
-
-/* BytesEquals */
-static CYTHON_INLINE int __Pyx_PyBytes_Equals(PyObject* s1, PyObject* s2, int equals) {
-#if CYTHON_COMPILING_IN_PYPY || CYTHON_COMPILING_IN_LIMITED_API
- return PyObject_RichCompareBool(s1, s2, equals);
-#else
- if (s1 == s2) {
- return (equals == Py_EQ);
- } else if (PyBytes_CheckExact(s1) & PyBytes_CheckExact(s2)) {
- const char *ps1, *ps2;
- Py_ssize_t length = PyBytes_GET_SIZE(s1);
- if (length != PyBytes_GET_SIZE(s2))
- return (equals == Py_NE);
- ps1 = PyBytes_AS_STRING(s1);
- ps2 = PyBytes_AS_STRING(s2);
- if (ps1[0] != ps2[0]) {
- return (equals == Py_NE);
- } else if (length == 1) {
- return (equals == Py_EQ);
- } else {
- int result;
-#if CYTHON_USE_UNICODE_INTERNALS && (PY_VERSION_HEX < 0x030B0000)
- Py_hash_t hash1, hash2;
- hash1 = ((PyBytesObject*)s1)->ob_shash;
- hash2 = ((PyBytesObject*)s2)->ob_shash;
- if (hash1 != hash2 && hash1 != -1 && hash2 != -1) {
- return (equals == Py_NE);
- }
-#endif
- result = memcmp(ps1, ps2, (size_t)length);
- return (equals == Py_EQ) ? (result == 0) : (result != 0);
- }
- } else if ((s1 == Py_None) & PyBytes_CheckExact(s2)) {
- return (equals == Py_NE);
- } else if ((s2 == Py_None) & PyBytes_CheckExact(s1)) {
- return (equals == Py_NE);
- } else {
- int result;
- PyObject* py_result = PyObject_RichCompare(s1, s2, equals);
- if (!py_result)
- return -1;
- result = __Pyx_PyObject_IsTrue(py_result);
- Py_DECREF(py_result);
- return result;
- }
-#endif
-}
-
-/* UnicodeEquals */
-static CYTHON_INLINE int __Pyx_PyUnicode_Equals(PyObject* s1, PyObject* s2, int equals) {
-#if CYTHON_COMPILING_IN_PYPY || CYTHON_COMPILING_IN_LIMITED_API
- return PyObject_RichCompareBool(s1, s2, equals);
-#else
-#if PY_MAJOR_VERSION < 3
- PyObject* owned_ref = NULL;
-#endif
- int s1_is_unicode, s2_is_unicode;
- if (s1 == s2) {
- goto return_eq;
- }
- s1_is_unicode = PyUnicode_CheckExact(s1);
- s2_is_unicode = PyUnicode_CheckExact(s2);
-#if PY_MAJOR_VERSION < 3
- if ((s1_is_unicode & (!s2_is_unicode)) && PyString_CheckExact(s2)) {
- owned_ref = PyUnicode_FromObject(s2);
- if (unlikely(!owned_ref))
- return -1;
- s2 = owned_ref;
- s2_is_unicode = 1;
- } else if ((s2_is_unicode & (!s1_is_unicode)) && PyString_CheckExact(s1)) {
- owned_ref = PyUnicode_FromObject(s1);
- if (unlikely(!owned_ref))
- return -1;
- s1 = owned_ref;
- s1_is_unicode = 1;
- } else if (((!s2_is_unicode) & (!s1_is_unicode))) {
- return __Pyx_PyBytes_Equals(s1, s2, equals);
- }
-#endif
- if (s1_is_unicode & s2_is_unicode) {
- Py_ssize_t length;
- int kind;
- void *data1, *data2;
- if (unlikely(__Pyx_PyUnicode_READY(s1) < 0) || unlikely(__Pyx_PyUnicode_READY(s2) < 0))
- return -1;
- length = __Pyx_PyUnicode_GET_LENGTH(s1);
- if (length != __Pyx_PyUnicode_GET_LENGTH(s2)) {
- goto return_ne;
- }
-#if CYTHON_USE_UNICODE_INTERNALS
- {
- Py_hash_t hash1, hash2;
- #if CYTHON_PEP393_ENABLED
- hash1 = ((PyASCIIObject*)s1)->hash;
- hash2 = ((PyASCIIObject*)s2)->hash;
- #else
- hash1 = ((PyUnicodeObject*)s1)->hash;
- hash2 = ((PyUnicodeObject*)s2)->hash;
- #endif
- if (hash1 != hash2 && hash1 != -1 && hash2 != -1) {
- goto return_ne;
- }
- }
-#endif
- kind = __Pyx_PyUnicode_KIND(s1);
- if (kind != __Pyx_PyUnicode_KIND(s2)) {
- goto return_ne;
- }
- data1 = __Pyx_PyUnicode_DATA(s1);
- data2 = __Pyx_PyUnicode_DATA(s2);
- if (__Pyx_PyUnicode_READ(kind, data1, 0) != __Pyx_PyUnicode_READ(kind, data2, 0)) {
- goto return_ne;
- } else if (length == 1) {
- goto return_eq;
- } else {
- int result = memcmp(data1, data2, (size_t)(length * kind));
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_EQ) ? (result == 0) : (result != 0);
- }
- } else if ((s1 == Py_None) & s2_is_unicode) {
- goto return_ne;
- } else if ((s2 == Py_None) & s1_is_unicode) {
- goto return_ne;
- } else {
- int result;
- PyObject* py_result = PyObject_RichCompare(s1, s2, equals);
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- if (!py_result)
- return -1;
- result = __Pyx_PyObject_IsTrue(py_result);
- Py_DECREF(py_result);
- return result;
- }
-return_eq:
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_EQ);
-return_ne:
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_NE);
-#endif
-}
-
-/* fastcall */
-#if CYTHON_METH_FASTCALL
-static CYTHON_INLINE PyObject * __Pyx_GetKwValue_FASTCALL(PyObject *kwnames, PyObject *const *kwvalues, PyObject *s)
-{
- Py_ssize_t i, n = PyTuple_GET_SIZE(kwnames);
- for (i = 0; i < n; i++)
- {
- if (s == PyTuple_GET_ITEM(kwnames, i)) return kwvalues[i];
- }
- for (i = 0; i < n; i++)
- {
- int eq = __Pyx_PyUnicode_Equals(s, PyTuple_GET_ITEM(kwnames, i), Py_EQ);
- if (unlikely(eq != 0)) {
- if (unlikely(eq < 0)) return NULL; // error
- return kwvalues[i];
- }
- }
- return NULL; // not found (no exception set)
-}
-#endif
-
-/* RaiseDoubleKeywords */
-static void __Pyx_RaiseDoubleKeywordsError(
- const char* func_name,
- PyObject* kw_name)
-{
- PyErr_Format(PyExc_TypeError,
- #if PY_MAJOR_VERSION >= 3
- "%s() got multiple values for keyword argument '%U'", func_name, kw_name);
- #else
- "%s() got multiple values for keyword argument '%s'", func_name,
- PyString_AsString(kw_name));
- #endif
-}
-
-/* ParseKeywords */
-static int __Pyx_ParseOptionalKeywords(
- PyObject *kwds,
- PyObject *const *kwvalues,
- PyObject **argnames[],
- PyObject *kwds2,
- PyObject *values[],
- Py_ssize_t num_pos_args,
- const char* function_name)
-{
- PyObject *key = 0, *value = 0;
- Py_ssize_t pos = 0;
- PyObject*** name;
- PyObject*** first_kw_arg = argnames + num_pos_args;
- int kwds_is_tuple = CYTHON_METH_FASTCALL && likely(PyTuple_Check(kwds));
- while (1) {
- if (kwds_is_tuple) {
- if (pos >= PyTuple_GET_SIZE(kwds)) break;
- key = PyTuple_GET_ITEM(kwds, pos);
- value = kwvalues[pos];
- pos++;
- }
- else
- {
- if (!PyDict_Next(kwds, &pos, &key, &value)) break;
- }
- name = first_kw_arg;
- while (*name && (**name != key)) name++;
- if (*name) {
- values[name-argnames] = value;
- continue;
- }
- name = first_kw_arg;
- #if PY_MAJOR_VERSION < 3
- if (likely(PyString_Check(key))) {
- while (*name) {
- if ((CYTHON_COMPILING_IN_PYPY || PyString_GET_SIZE(**name) == PyString_GET_SIZE(key))
- && _PyString_Eq(**name, key)) {
- values[name-argnames] = value;
- break;
- }
- name++;
- }
- if (*name) continue;
- else {
- PyObject*** argname = argnames;
- while (argname != first_kw_arg) {
- if ((**argname == key) || (
- (CYTHON_COMPILING_IN_PYPY || PyString_GET_SIZE(**argname) == PyString_GET_SIZE(key))
- && _PyString_Eq(**argname, key))) {
- goto arg_passed_twice;
- }
- argname++;
- }
- }
- } else
- #endif
- if (likely(PyUnicode_Check(key))) {
- while (*name) {
- int cmp = (
- #if !CYTHON_COMPILING_IN_PYPY && PY_MAJOR_VERSION >= 3
- (__Pyx_PyUnicode_GET_LENGTH(**name) != __Pyx_PyUnicode_GET_LENGTH(key)) ? 1 :
- #endif
- PyUnicode_Compare(**name, key)
- );
- if (cmp < 0 && unlikely(PyErr_Occurred())) goto bad;
- if (cmp == 0) {
- values[name-argnames] = value;
- break;
- }
- name++;
- }
- if (*name) continue;
- else {
- PyObject*** argname = argnames;
- while (argname != first_kw_arg) {
- int cmp = (**argname == key) ? 0 :
- #if !CYTHON_COMPILING_IN_PYPY && PY_MAJOR_VERSION >= 3
- (__Pyx_PyUnicode_GET_LENGTH(**argname) != __Pyx_PyUnicode_GET_LENGTH(key)) ? 1 :
- #endif
- PyUnicode_Compare(**argname, key);
- if (cmp < 0 && unlikely(PyErr_Occurred())) goto bad;
- if (cmp == 0) goto arg_passed_twice;
- argname++;
- }
- }
- } else
- goto invalid_keyword_type;
- if (kwds2) {
- if (unlikely(PyDict_SetItem(kwds2, key, value))) goto bad;
- } else {
- goto invalid_keyword;
- }
- }
- return 0;
-arg_passed_twice:
- __Pyx_RaiseDoubleKeywordsError(function_name, key);
- goto bad;
-invalid_keyword_type:
- PyErr_Format(PyExc_TypeError,
- "%.200s() keywords must be strings", function_name);
- goto bad;
-invalid_keyword:
- #if PY_MAJOR_VERSION < 3
- PyErr_Format(PyExc_TypeError,
- "%.200s() got an unexpected keyword argument '%.200s'",
- function_name, PyString_AsString(key));
- #else
- PyErr_Format(PyExc_TypeError,
- "%s() got an unexpected keyword argument '%U'",
- function_name, key);
- #endif
-bad:
- return -1;
-}
-
-/* RaiseArgTupleInvalid */
-static void __Pyx_RaiseArgtupleInvalid(
- const char* func_name,
- int exact,
- Py_ssize_t num_min,
- Py_ssize_t num_max,
- Py_ssize_t num_found)
-{
- Py_ssize_t num_expected;
- const char *more_or_less;
- if (num_found < num_min) {
- num_expected = num_min;
- more_or_less = "at least";
- } else {
- num_expected = num_max;
- more_or_less = "at most";
- }
- if (exact) {
- more_or_less = "exactly";
- }
- PyErr_Format(PyExc_TypeError,
- "%.200s() takes %.8s %" CYTHON_FORMAT_SSIZE_T "d positional argument%.1s (%" CYTHON_FORMAT_SSIZE_T "d given)",
- func_name, more_or_less, num_expected,
- (num_expected == 1) ? "" : "s", num_found);
-}
-
-/* PyDictVersioning */
-#if CYTHON_USE_DICT_VERSIONS && CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_tp_dict_version(PyObject *obj) {
- PyObject *dict = Py_TYPE(obj)->tp_dict;
- return likely(dict) ? __PYX_GET_DICT_VERSION(dict) : 0;
-}
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_object_dict_version(PyObject *obj) {
- PyObject **dictptr = NULL;
- Py_ssize_t offset = Py_TYPE(obj)->tp_dictoffset;
- if (offset) {
-#if CYTHON_COMPILING_IN_CPYTHON
- dictptr = (likely(offset > 0)) ? (PyObject **) ((char *)obj + offset) : _PyObject_GetDictPtr(obj);
-#else
- dictptr = _PyObject_GetDictPtr(obj);
-#endif
- }
- return (dictptr && *dictptr) ? __PYX_GET_DICT_VERSION(*dictptr) : 0;
-}
-static CYTHON_INLINE int __Pyx_object_dict_version_matches(PyObject* obj, PY_UINT64_T tp_dict_version, PY_UINT64_T obj_dict_version) {
- PyObject *dict = Py_TYPE(obj)->tp_dict;
- if (unlikely(!dict) || unlikely(tp_dict_version != __PYX_GET_DICT_VERSION(dict)))
- return 0;
- return obj_dict_version == __Pyx_get_object_dict_version(obj);
-}
-#endif
-
-/* GetModuleGlobalName */
-#if CYTHON_USE_DICT_VERSIONS
-static PyObject *__Pyx__GetModuleGlobalName(PyObject *name, PY_UINT64_T *dict_version, PyObject **dict_cached_value)
-#else
-static CYTHON_INLINE PyObject *__Pyx__GetModuleGlobalName(PyObject *name)
-#endif
-{
- PyObject *result;
-#if !CYTHON_AVOID_BORROWED_REFS
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x030500A1
- result = _PyDict_GetItem_KnownHash(__pyx_d, name, ((PyASCIIObject *) name)->hash);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- } else if (unlikely(PyErr_Occurred())) {
- return NULL;
- }
-#elif CYTHON_COMPILING_IN_LIMITED_API
- if (unlikely(!__pyx_m)) {
- return NULL;
- }
- result = PyObject_GetAttr(__pyx_m, name);
- if (likely(result)) {
- return result;
- }
-#else
- result = PyDict_GetItem(__pyx_d, name);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- }
-#endif
-#else
- result = PyObject_GetItem(__pyx_d, name);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- }
- PyErr_Clear();
-#endif
- return __Pyx_GetBuiltinName(name);
-}
-
-/* PyFunctionFastCall */
-#if CYTHON_FAST_PYCALL && !CYTHON_VECTORCALL
-static PyObject* __Pyx_PyFunction_FastCallNoKw(PyCodeObject *co, PyObject **args, Py_ssize_t na,
- PyObject *globals) {
- PyFrameObject *f;
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject **fastlocals;
- Py_ssize_t i;
- PyObject *result;
- assert(globals != NULL);
- /* XXX Perhaps we should create a specialized
- PyFrame_New() that doesn't take locals, but does
- take builtins without sanity checking them.
- */
- assert(tstate != NULL);
- f = PyFrame_New(tstate, co, globals, NULL);
- if (f == NULL) {
- return NULL;
- }
- fastlocals = __Pyx_PyFrame_GetLocalsplus(f);
- for (i = 0; i < na; i++) {
- Py_INCREF(*args);
- fastlocals[i] = *args++;
- }
- result = PyEval_EvalFrameEx(f,0);
- ++tstate->recursion_depth;
- Py_DECREF(f);
- --tstate->recursion_depth;
- return result;
-}
-static PyObject *__Pyx_PyFunction_FastCallDict(PyObject *func, PyObject **args, Py_ssize_t nargs, PyObject *kwargs) {
- PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
- PyObject *globals = PyFunction_GET_GLOBALS(func);
- PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
- PyObject *closure;
-#if PY_MAJOR_VERSION >= 3
- PyObject *kwdefs;
-#endif
- PyObject *kwtuple, **k;
- PyObject **d;
- Py_ssize_t nd;
- Py_ssize_t nk;
- PyObject *result;
- assert(kwargs == NULL || PyDict_Check(kwargs));
- nk = kwargs ? PyDict_Size(kwargs) : 0;
- if (unlikely(Py_EnterRecursiveCall((char*)" while calling a Python object"))) {
- return NULL;
- }
- if (
-#if PY_MAJOR_VERSION >= 3
- co->co_kwonlyargcount == 0 &&
-#endif
- likely(kwargs == NULL || nk == 0) &&
- co->co_flags == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE)) {
- if (argdefs == NULL && co->co_argcount == nargs) {
- result = __Pyx_PyFunction_FastCallNoKw(co, args, nargs, globals);
- goto done;
- }
- else if (nargs == 0 && argdefs != NULL
- && co->co_argcount == Py_SIZE(argdefs)) {
- /* function called with no arguments, but all parameters have
- a default value: use default values as arguments .*/
- args = &PyTuple_GET_ITEM(argdefs, 0);
- result =__Pyx_PyFunction_FastCallNoKw(co, args, Py_SIZE(argdefs), globals);
- goto done;
- }
- }
- if (kwargs != NULL) {
- Py_ssize_t pos, i;
- kwtuple = PyTuple_New(2 * nk);
- if (kwtuple == NULL) {
- result = NULL;
- goto done;
- }
- k = &PyTuple_GET_ITEM(kwtuple, 0);
- pos = i = 0;
- while (PyDict_Next(kwargs, &pos, &k[i], &k[i+1])) {
- Py_INCREF(k[i]);
- Py_INCREF(k[i+1]);
- i += 2;
- }
- nk = i / 2;
- }
- else {
- kwtuple = NULL;
- k = NULL;
- }
- closure = PyFunction_GET_CLOSURE(func);
-#if PY_MAJOR_VERSION >= 3
- kwdefs = PyFunction_GET_KW_DEFAULTS(func);
-#endif
- if (argdefs != NULL) {
- d = &PyTuple_GET_ITEM(argdefs, 0);
- nd = Py_SIZE(argdefs);
- }
- else {
- d = NULL;
- nd = 0;
- }
-#if PY_MAJOR_VERSION >= 3
- result = PyEval_EvalCodeEx((PyObject*)co, globals, (PyObject *)NULL,
- args, (int)nargs,
- k, (int)nk,
- d, (int)nd, kwdefs, closure);
-#else
- result = PyEval_EvalCodeEx(co, globals, (PyObject *)NULL,
- args, (int)nargs,
- k, (int)nk,
- d, (int)nd, closure);
-#endif
- Py_XDECREF(kwtuple);
-done:
- Py_LeaveRecursiveCall();
- return result;
-}
-#endif
-
-/* PyObjectCall */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_Call(PyObject *func, PyObject *arg, PyObject *kw) {
- PyObject *result;
- ternaryfunc call = Py_TYPE(func)->tp_call;
- if (unlikely(!call))
- return PyObject_Call(func, arg, kw);
- if (unlikely(Py_EnterRecursiveCall((char*)" while calling a Python object")))
- return NULL;
- result = (*call)(func, arg, kw);
- Py_LeaveRecursiveCall();
- if (unlikely(!result) && unlikely(!PyErr_Occurred())) {
- PyErr_SetString(
- PyExc_SystemError,
- "NULL result without error in PyObject_Call");
- }
- return result;
-}
-#endif
-
-/* PyObjectCallMethO */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallMethO(PyObject *func, PyObject *arg) {
- PyObject *self, *result;
- PyCFunction cfunc;
- cfunc = PyCFunction_GET_FUNCTION(func);
- self = PyCFunction_GET_SELF(func);
- if (unlikely(Py_EnterRecursiveCall((char*)" while calling a Python object")))
- return NULL;
- result = cfunc(self, arg);
- Py_LeaveRecursiveCall();
- if (unlikely(!result) && unlikely(!PyErr_Occurred())) {
- PyErr_SetString(
- PyExc_SystemError,
- "NULL result without error in PyObject_Call");
- }
- return result;
-}
-#endif
-
-/* PyObjectFastCall */
-static PyObject* __Pyx_PyObject_FastCall_fallback(PyObject *func, PyObject **args, size_t nargs, PyObject *kwargs) {
- PyObject *argstuple;
- PyObject *result;
- size_t i;
- argstuple = PyTuple_New((Py_ssize_t)nargs);
- if (unlikely(!argstuple)) return NULL;
- for (i = 0; i < nargs; i++) {
- Py_INCREF(args[i]);
- PyTuple_SET_ITEM(argstuple, (Py_ssize_t)i, args[i]);
- }
- result = __Pyx_PyObject_Call(func, argstuple, kwargs);
- Py_DECREF(argstuple);
- return result;
-}
-static CYTHON_INLINE PyObject* __Pyx_PyObject_FastCallDict(PyObject *func, PyObject **args, size_t _nargs, PyObject *kwargs) {
- Py_ssize_t nargs = __Pyx_PyVectorcall_NARGS(_nargs);
-#if CYTHON_COMPILING_IN_CPYTHON
- if (nargs == 0 && kwargs == NULL) {
-#if defined(__Pyx_CyFunction_USED) && defined(NDEBUG)
- if (__Pyx_IsCyOrPyCFunction(func))
-#else
- if (PyCFunction_Check(func))
-#endif
- {
- if (likely(PyCFunction_GET_FLAGS(func) & METH_NOARGS)) {
- return __Pyx_PyObject_CallMethO(func, NULL);
- }
- }
- }
- else if (nargs == 1 && kwargs == NULL) {
- if (PyCFunction_Check(func))
- {
- if (likely(PyCFunction_GET_FLAGS(func) & METH_O)) {
- return __Pyx_PyObject_CallMethO(func, args[0]);
- }
- }
- }
-#endif
- #if PY_VERSION_HEX < 0x030800B1
- #if CYTHON_FAST_PYCCALL
- if (PyCFunction_Check(func)) {
- if (kwargs) {
- return _PyCFunction_FastCallDict(func, args, nargs, kwargs);
- } else {
- return _PyCFunction_FastCallKeywords(func, args, nargs, NULL);
- }
- }
- #if PY_VERSION_HEX >= 0x030700A1
- if (!kwargs && __Pyx_IS_TYPE(func, &PyMethodDescr_Type)) {
- return _PyMethodDescr_FastCallKeywords(func, args, nargs, NULL);
- }
- #endif
- #endif
- #if CYTHON_FAST_PYCALL
- if (PyFunction_Check(func)) {
- return __Pyx_PyFunction_FastCallDict(func, args, nargs, kwargs);
- }
- #endif
- #endif
- #if CYTHON_VECTORCALL
- vectorcallfunc f = _PyVectorcall_Function(func);
- if (f) {
- return f(func, args, (size_t)nargs, kwargs);
- }
- #elif defined(__Pyx_CyFunction_USED) && CYTHON_BACKPORT_VECTORCALL
- if (__Pyx_CyFunction_CheckExact(func)) {
- __pyx_vectorcallfunc f = __Pyx_CyFunction_func_vectorcall(func);
- if (f) return f(func, args, (size_t)nargs, kwargs);
- }
- #endif
- if (nargs == 0) {
- return __Pyx_PyObject_Call(func, __pyx_empty_tuple, kwargs);
- }
- return __Pyx_PyObject_FastCall_fallback(func, args, (size_t)nargs, kwargs);
-}
-
-/* PyObjectSetAttrStr */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE int __Pyx_PyObject_SetAttrStr(PyObject* obj, PyObject* attr_name, PyObject* value) {
- PyTypeObject* tp = Py_TYPE(obj);
- if (likely(tp->tp_setattro))
- return tp->tp_setattro(obj, attr_name, value);
-#if PY_MAJOR_VERSION < 3
- if (likely(tp->tp_setattr))
- return tp->tp_setattr(obj, PyString_AS_STRING(attr_name), value);
-#endif
- return PyObject_SetAttr(obj, attr_name, value);
-}
-#endif
-
-/* RaiseException */
-#if PY_MAJOR_VERSION < 3
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb, PyObject *cause) {
- __Pyx_PyThreadState_declare
- CYTHON_UNUSED_VAR(cause);
- Py_XINCREF(type);
- if (!value || value == Py_None)
- value = NULL;
- else
- Py_INCREF(value);
- if (!tb || tb == Py_None)
- tb = NULL;
- else {
- Py_INCREF(tb);
- if (!PyTraceBack_Check(tb)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: arg 3 must be a traceback or None");
- goto raise_error;
- }
- }
- if (PyType_Check(type)) {
-#if CYTHON_COMPILING_IN_PYPY
- if (!value) {
- Py_INCREF(Py_None);
- value = Py_None;
- }
-#endif
- PyErr_NormalizeException(&type, &value, &tb);
- } else {
- if (value) {
- PyErr_SetString(PyExc_TypeError,
- "instance exception may not have a separate value");
- goto raise_error;
- }
- value = type;
- type = (PyObject*) Py_TYPE(type);
- Py_INCREF(type);
- if (!PyType_IsSubtype((PyTypeObject *)type, (PyTypeObject *)PyExc_BaseException)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: exception class must be a subclass of BaseException");
- goto raise_error;
- }
- }
- __Pyx_PyThreadState_assign
- __Pyx_ErrRestore(type, value, tb);
- return;
-raise_error:
- Py_XDECREF(value);
- Py_XDECREF(type);
- Py_XDECREF(tb);
- return;
-}
-#else
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb, PyObject *cause) {
- PyObject* owned_instance = NULL;
- if (tb == Py_None) {
- tb = 0;
- } else if (tb && !PyTraceBack_Check(tb)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: arg 3 must be a traceback or None");
- goto bad;
- }
- if (value == Py_None)
- value = 0;
- if (PyExceptionInstance_Check(type)) {
- if (value) {
- PyErr_SetString(PyExc_TypeError,
- "instance exception may not have a separate value");
- goto bad;
- }
- value = type;
- type = (PyObject*) Py_TYPE(value);
- } else if (PyExceptionClass_Check(type)) {
- PyObject *instance_class = NULL;
- if (value && PyExceptionInstance_Check(value)) {
- instance_class = (PyObject*) Py_TYPE(value);
- if (instance_class != type) {
- int is_subclass = PyObject_IsSubclass(instance_class, type);
- if (!is_subclass) {
- instance_class = NULL;
- } else if (unlikely(is_subclass == -1)) {
- goto bad;
- } else {
- type = instance_class;
- }
- }
- }
- if (!instance_class) {
- PyObject *args;
- if (!value)
- args = PyTuple_New(0);
- else if (PyTuple_Check(value)) {
- Py_INCREF(value);
- args = value;
- } else
- args = PyTuple_Pack(1, value);
- if (!args)
- goto bad;
- owned_instance = PyObject_Call(type, args, NULL);
- Py_DECREF(args);
- if (!owned_instance)
- goto bad;
- value = owned_instance;
- if (!PyExceptionInstance_Check(value)) {
- PyErr_Format(PyExc_TypeError,
- "calling %R should have returned an instance of "
- "BaseException, not %R",
- type, Py_TYPE(value));
- goto bad;
- }
- }
- } else {
- PyErr_SetString(PyExc_TypeError,
- "raise: exception class must be a subclass of BaseException");
- goto bad;
- }
- if (cause) {
- PyObject *fixed_cause;
- if (cause == Py_None) {
- fixed_cause = NULL;
- } else if (PyExceptionClass_Check(cause)) {
- fixed_cause = PyObject_CallObject(cause, NULL);
- if (fixed_cause == NULL)
- goto bad;
- } else if (PyExceptionInstance_Check(cause)) {
- fixed_cause = cause;
- Py_INCREF(fixed_cause);
- } else {
- PyErr_SetString(PyExc_TypeError,
- "exception causes must derive from "
- "BaseException");
- goto bad;
- }
- PyException_SetCause(value, fixed_cause);
- }
- PyErr_SetObject(type, value);
- if (tb) {
- #if PY_VERSION_HEX >= 0x030C00A6
- PyException_SetTraceback(value, tb);
- #elif CYTHON_FAST_THREAD_STATE
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject* tmp_tb = tstate->curexc_traceback;
- if (tb != tmp_tb) {
- Py_INCREF(tb);
- tstate->curexc_traceback = tb;
- Py_XDECREF(tmp_tb);
- }
-#else
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- PyErr_Fetch(&tmp_type, &tmp_value, &tmp_tb);
- Py_INCREF(tb);
- PyErr_Restore(tmp_type, tmp_value, tb);
- Py_XDECREF(tmp_tb);
-#endif
- }
-bad:
- Py_XDECREF(owned_instance);
- return;
-}
-#endif
-
-/* RaiseTooManyValuesToUnpack */
-static CYTHON_INLINE void __Pyx_RaiseTooManyValuesError(Py_ssize_t expected) {
- PyErr_Format(PyExc_ValueError,
- "too many values to unpack (expected %" CYTHON_FORMAT_SSIZE_T "d)", expected);
-}
-
-/* RaiseNeedMoreValuesToUnpack */
-static CYTHON_INLINE void __Pyx_RaiseNeedMoreValuesError(Py_ssize_t index) {
- PyErr_Format(PyExc_ValueError,
- "need more than %" CYTHON_FORMAT_SSIZE_T "d value%.1s to unpack",
- index, (index == 1) ? "" : "s");
-}
-
-/* IterFinish */
-static CYTHON_INLINE int __Pyx_IterFinish(void) {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- PyObject* exc_type = __Pyx_PyErr_CurrentExceptionType();
- if (unlikely(exc_type)) {
- if (unlikely(!__Pyx_PyErr_GivenExceptionMatches(exc_type, PyExc_StopIteration)))
- return -1;
- __Pyx_PyErr_Clear();
- return 0;
- }
- return 0;
-}
-
-/* UnpackItemEndCheck */
-static int __Pyx_IternextUnpackEndCheck(PyObject *retval, Py_ssize_t expected) {
- if (unlikely(retval)) {
- Py_DECREF(retval);
- __Pyx_RaiseTooManyValuesError(expected);
- return -1;
- }
- return __Pyx_IterFinish();
-}
-
-/* Import */
-static PyObject *__Pyx_Import(PyObject *name, PyObject *from_list, int level) {
- PyObject *module = 0;
- PyObject *empty_dict = 0;
- PyObject *empty_list = 0;
- #if PY_MAJOR_VERSION < 3
- PyObject *py_import;
- py_import = __Pyx_PyObject_GetAttrStr(__pyx_b, __pyx_n_s_import);
- if (unlikely(!py_import))
- goto bad;
- if (!from_list) {
- empty_list = PyList_New(0);
- if (unlikely(!empty_list))
- goto bad;
- from_list = empty_list;
- }
- #endif
- empty_dict = PyDict_New();
- if (unlikely(!empty_dict))
- goto bad;
- {
- #if PY_MAJOR_VERSION >= 3
- if (level == -1) {
- if ((1) && (strchr(__Pyx_MODULE_NAME, '.'))) {
- #if CYTHON_COMPILING_IN_LIMITED_API
- module = PyImport_ImportModuleLevelObject(
- name, empty_dict, empty_dict, from_list, 1);
- #else
- module = PyImport_ImportModuleLevelObject(
- name, __pyx_d, empty_dict, from_list, 1);
- #endif
- if (unlikely(!module)) {
- if (unlikely(!PyErr_ExceptionMatches(PyExc_ImportError)))
- goto bad;
- PyErr_Clear();
- }
- }
- level = 0;
- }
- #endif
- if (!module) {
- #if PY_MAJOR_VERSION < 3
- PyObject *py_level = PyInt_FromLong(level);
- if (unlikely(!py_level))
- goto bad;
- module = PyObject_CallFunctionObjArgs(py_import,
- name, __pyx_d, empty_dict, from_list, py_level, (PyObject *)NULL);
- Py_DECREF(py_level);
- #else
- #if CYTHON_COMPILING_IN_LIMITED_API
- module = PyImport_ImportModuleLevelObject(
- name, empty_dict, empty_dict, from_list, level);
- #else
- module = PyImport_ImportModuleLevelObject(
- name, __pyx_d, empty_dict, from_list, level);
- #endif
- #endif
- }
- }
-bad:
- Py_XDECREF(empty_dict);
- Py_XDECREF(empty_list);
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(py_import);
- #endif
- return module;
-}
-
-/* ImportFrom */
-static PyObject* __Pyx_ImportFrom(PyObject* module, PyObject* name) {
- PyObject* value = __Pyx_PyObject_GetAttrStr(module, name);
- if (unlikely(!value) && PyErr_ExceptionMatches(PyExc_AttributeError)) {
- const char* module_name_str = 0;
- PyObject* module_name = 0;
- PyObject* module_dot = 0;
- PyObject* full_name = 0;
- PyErr_Clear();
- module_name_str = PyModule_GetName(module);
- if (unlikely(!module_name_str)) { goto modbad; }
- module_name = PyUnicode_FromString(module_name_str);
- if (unlikely(!module_name)) { goto modbad; }
- module_dot = PyUnicode_Concat(module_name, __pyx_kp_u_);
- if (unlikely(!module_dot)) { goto modbad; }
- full_name = PyUnicode_Concat(module_dot, name);
- if (unlikely(!full_name)) { goto modbad; }
- #if PY_VERSION_HEX < 0x030700A1 || (CYTHON_COMPILING_IN_PYPY && PYPY_VERSION_NUM < 0x07030400)
- {
- PyObject *modules = PyImport_GetModuleDict();
- if (unlikely(!modules))
- goto modbad;
- value = PyObject_GetItem(modules, full_name);
- }
- #else
- value = PyImport_GetModule(full_name);
- #endif
- modbad:
- Py_XDECREF(full_name);
- Py_XDECREF(module_dot);
- Py_XDECREF(module_name);
- }
- if (unlikely(!value)) {
- PyErr_Format(PyExc_ImportError,
- #if PY_MAJOR_VERSION < 3
- "cannot import name %.230s", PyString_AS_STRING(name));
- #else
- "cannot import name %S", name);
- #endif
- }
- return value;
-}
-
-/* GetTopmostException */
-#if CYTHON_USE_EXC_INFO_STACK && CYTHON_FAST_THREAD_STATE
-static _PyErr_StackItem *
-__Pyx_PyErr_GetTopmostException(PyThreadState *tstate)
-{
- _PyErr_StackItem *exc_info = tstate->exc_info;
- while ((exc_info->exc_value == NULL || exc_info->exc_value == Py_None) &&
- exc_info->previous_item != NULL)
- {
- exc_info = exc_info->previous_item;
- }
- return exc_info;
-}
-#endif
-
-/* SaveResetException */
-#if CYTHON_FAST_THREAD_STATE
-static CYTHON_INLINE void __Pyx__ExceptionSave(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb) {
- #if CYTHON_USE_EXC_INFO_STACK && PY_VERSION_HEX >= 0x030B00a4
- _PyErr_StackItem *exc_info = __Pyx_PyErr_GetTopmostException(tstate);
- PyObject *exc_value = exc_info->exc_value;
- if (exc_value == NULL || exc_value == Py_None) {
- *value = NULL;
- *type = NULL;
- *tb = NULL;
- } else {
- *value = exc_value;
- Py_INCREF(*value);
- *type = (PyObject*) Py_TYPE(exc_value);
- Py_INCREF(*type);
- *tb = PyException_GetTraceback(exc_value);
- }
- #elif CYTHON_USE_EXC_INFO_STACK
- _PyErr_StackItem *exc_info = __Pyx_PyErr_GetTopmostException(tstate);
- *type = exc_info->exc_type;
- *value = exc_info->exc_value;
- *tb = exc_info->exc_traceback;
- Py_XINCREF(*type);
- Py_XINCREF(*value);
- Py_XINCREF(*tb);
- #else
- *type = tstate->exc_type;
- *value = tstate->exc_value;
- *tb = tstate->exc_traceback;
- Py_XINCREF(*type);
- Py_XINCREF(*value);
- Py_XINCREF(*tb);
- #endif
-}
-static CYTHON_INLINE void __Pyx__ExceptionReset(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb) {
- #if CYTHON_USE_EXC_INFO_STACK && PY_VERSION_HEX >= 0x030B00a4
- _PyErr_StackItem *exc_info = tstate->exc_info;
- PyObject *tmp_value = exc_info->exc_value;
- exc_info->exc_value = value;
- Py_XDECREF(tmp_value);
- Py_XDECREF(type);
- Py_XDECREF(tb);
- #else
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- #if CYTHON_USE_EXC_INFO_STACK
- _PyErr_StackItem *exc_info = tstate->exc_info;
- tmp_type = exc_info->exc_type;
- tmp_value = exc_info->exc_value;
- tmp_tb = exc_info->exc_traceback;
- exc_info->exc_type = type;
- exc_info->exc_value = value;
- exc_info->exc_traceback = tb;
- #else
- tmp_type = tstate->exc_type;
- tmp_value = tstate->exc_value;
- tmp_tb = tstate->exc_traceback;
- tstate->exc_type = type;
- tstate->exc_value = value;
- tstate->exc_traceback = tb;
- #endif
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
- #endif
-}
-#endif
-
-/* FastTypeChecks */
-#if CYTHON_COMPILING_IN_CPYTHON
-static int __Pyx_InBases(PyTypeObject *a, PyTypeObject *b) {
- while (a) {
- a = __Pyx_PyType_GetSlot(a, tp_base, PyTypeObject*);
- if (a == b)
- return 1;
- }
- return b == &PyBaseObject_Type;
-}
-static CYTHON_INLINE int __Pyx_IsSubtype(PyTypeObject *a, PyTypeObject *b) {
- PyObject *mro;
- if (a == b) return 1;
- mro = a->tp_mro;
- if (likely(mro)) {
- Py_ssize_t i, n;
- n = PyTuple_GET_SIZE(mro);
- for (i = 0; i < n; i++) {
- if (PyTuple_GET_ITEM(mro, i) == (PyObject *)b)
- return 1;
- }
- return 0;
- }
- return __Pyx_InBases(a, b);
-}
-static CYTHON_INLINE int __Pyx_IsAnySubtype2(PyTypeObject *cls, PyTypeObject *a, PyTypeObject *b) {
- PyObject *mro;
- if (cls == a || cls == b) return 1;
- mro = cls->tp_mro;
- if (likely(mro)) {
- Py_ssize_t i, n;
- n = PyTuple_GET_SIZE(mro);
- for (i = 0; i < n; i++) {
- PyObject *base = PyTuple_GET_ITEM(mro, i);
- if (base == (PyObject *)a || base == (PyObject *)b)
- return 1;
- }
- return 0;
- }
- return __Pyx_InBases(cls, a) || __Pyx_InBases(cls, b);
-}
-#if PY_MAJOR_VERSION == 2
-static int __Pyx_inner_PyErr_GivenExceptionMatches2(PyObject *err, PyObject* exc_type1, PyObject* exc_type2) {
- PyObject *exception, *value, *tb;
- int res;
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __Pyx_ErrFetch(&exception, &value, &tb);
- res = exc_type1 ? PyObject_IsSubclass(err, exc_type1) : 0;
- if (unlikely(res == -1)) {
- PyErr_WriteUnraisable(err);
- res = 0;
- }
- if (!res) {
- res = PyObject_IsSubclass(err, exc_type2);
- if (unlikely(res == -1)) {
- PyErr_WriteUnraisable(err);
- res = 0;
- }
- }
- __Pyx_ErrRestore(exception, value, tb);
- return res;
-}
-#else
-static CYTHON_INLINE int __Pyx_inner_PyErr_GivenExceptionMatches2(PyObject *err, PyObject* exc_type1, PyObject *exc_type2) {
- if (exc_type1) {
- return __Pyx_IsAnySubtype2((PyTypeObject*)err, (PyTypeObject*)exc_type1, (PyTypeObject*)exc_type2);
- } else {
- return __Pyx_IsSubtype((PyTypeObject*)err, (PyTypeObject*)exc_type2);
- }
-}
-#endif
-static int __Pyx_PyErr_GivenExceptionMatchesTuple(PyObject *exc_type, PyObject *tuple) {
- Py_ssize_t i, n;
- assert(PyExceptionClass_Check(exc_type));
- n = PyTuple_GET_SIZE(tuple);
-#if PY_MAJOR_VERSION >= 3
- for (i=0; i= 0x030C00A6
- local_value = tstate->current_exception;
- tstate->current_exception = 0;
- if (likely(local_value)) {
- local_type = (PyObject*) Py_TYPE(local_value);
- Py_INCREF(local_type);
- local_tb = PyException_GetTraceback(local_value);
- }
- #else
- local_type = tstate->curexc_type;
- local_value = tstate->curexc_value;
- local_tb = tstate->curexc_traceback;
- tstate->curexc_type = 0;
- tstate->curexc_value = 0;
- tstate->curexc_traceback = 0;
- #endif
-#else
- PyErr_Fetch(&local_type, &local_value, &local_tb);
-#endif
- PyErr_NormalizeException(&local_type, &local_value, &local_tb);
-#if CYTHON_FAST_THREAD_STATE && PY_VERSION_HEX >= 0x030C00A6
- if (unlikely(tstate->current_exception))
-#elif CYTHON_FAST_THREAD_STATE
- if (unlikely(tstate->curexc_type))
-#else
- if (unlikely(PyErr_Occurred()))
-#endif
- goto bad;
- #if PY_MAJOR_VERSION >= 3
- if (local_tb) {
- if (unlikely(PyException_SetTraceback(local_value, local_tb) < 0))
- goto bad;
- }
- #endif
- Py_XINCREF(local_tb);
- Py_XINCREF(local_type);
- Py_XINCREF(local_value);
- *type = local_type;
- *value = local_value;
- *tb = local_tb;
-#if CYTHON_FAST_THREAD_STATE
- #if CYTHON_USE_EXC_INFO_STACK
- {
- _PyErr_StackItem *exc_info = tstate->exc_info;
- #if PY_VERSION_HEX >= 0x030B00a4
- tmp_value = exc_info->exc_value;
- exc_info->exc_value = local_value;
- tmp_type = NULL;
- tmp_tb = NULL;
- Py_XDECREF(local_type);
- Py_XDECREF(local_tb);
- #else
- tmp_type = exc_info->exc_type;
- tmp_value = exc_info->exc_value;
- tmp_tb = exc_info->exc_traceback;
- exc_info->exc_type = local_type;
- exc_info->exc_value = local_value;
- exc_info->exc_traceback = local_tb;
- #endif
- }
- #else
- tmp_type = tstate->exc_type;
- tmp_value = tstate->exc_value;
- tmp_tb = tstate->exc_traceback;
- tstate->exc_type = local_type;
- tstate->exc_value = local_value;
- tstate->exc_traceback = local_tb;
- #endif
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
-#else
- PyErr_SetExcInfo(local_type, local_value, local_tb);
-#endif
- return 0;
-bad:
- *type = 0;
- *value = 0;
- *tb = 0;
- Py_XDECREF(local_type);
- Py_XDECREF(local_value);
- Py_XDECREF(local_tb);
- return -1;
-}
-
-/* PyObjectCallOneArg */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg) {
- PyObject *args[2] = {NULL, arg};
- return __Pyx_PyObject_FastCall(func, args+1, 1 | __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET);
-}
-
-/* Py3UpdateBases */
-static PyObject*
-__Pyx_PEP560_update_bases(PyObject *bases)
-{
- Py_ssize_t i, j, size_bases;
- PyObject *base, *meth, *new_base, *result, *new_bases = NULL;
- size_bases = PyTuple_GET_SIZE(bases);
- for (i = 0; i < size_bases; i++) {
- base = PyTuple_GET_ITEM(bases, i);
- if (PyType_Check(base)) {
- if (new_bases) {
- if (PyList_Append(new_bases, base) < 0) {
- goto error;
- }
- }
- continue;
- }
- meth = __Pyx_PyObject_GetAttrStrNoError(base, __pyx_n_s_mro_entries);
- if (!meth && PyErr_Occurred()) {
- goto error;
- }
- if (!meth) {
- if (new_bases) {
- if (PyList_Append(new_bases, base) < 0) {
- goto error;
- }
- }
- continue;
- }
- new_base = __Pyx_PyObject_CallOneArg(meth, bases);
- Py_DECREF(meth);
- if (!new_base) {
- goto error;
- }
- if (!PyTuple_Check(new_base)) {
- PyErr_SetString(PyExc_TypeError,
- "__mro_entries__ must return a tuple");
- Py_DECREF(new_base);
- goto error;
- }
- if (!new_bases) {
- if (!(new_bases = PyList_New(i))) {
- goto error;
- }
- for (j = 0; j < i; j++) {
- base = PyTuple_GET_ITEM(bases, j);
- PyList_SET_ITEM(new_bases, j, base);
- Py_INCREF(base);
- }
- }
- j = PyList_GET_SIZE(new_bases);
- if (PyList_SetSlice(new_bases, j, j, new_base) < 0) {
- goto error;
- }
- Py_DECREF(new_base);
- }
- if (!new_bases) {
- Py_INCREF(bases);
- return bases;
- }
- result = PyList_AsTuple(new_bases);
- Py_DECREF(new_bases);
- return result;
-error:
- Py_XDECREF(new_bases);
- return NULL;
-}
-
-/* CalculateMetaclass */
-static PyObject *__Pyx_CalculateMetaclass(PyTypeObject *metaclass, PyObject *bases) {
- Py_ssize_t i, nbases = PyTuple_GET_SIZE(bases);
- for (i=0; i < nbases; i++) {
- PyTypeObject *tmptype;
- PyObject *tmp = PyTuple_GET_ITEM(bases, i);
- tmptype = Py_TYPE(tmp);
-#if PY_MAJOR_VERSION < 3
- if (tmptype == &PyClass_Type)
- continue;
-#endif
- if (!metaclass) {
- metaclass = tmptype;
- continue;
- }
- if (PyType_IsSubtype(metaclass, tmptype))
- continue;
- if (PyType_IsSubtype(tmptype, metaclass)) {
- metaclass = tmptype;
- continue;
- }
- PyErr_SetString(PyExc_TypeError,
- "metaclass conflict: "
- "the metaclass of a derived class "
- "must be a (non-strict) subclass "
- "of the metaclasses of all its bases");
- return NULL;
- }
- if (!metaclass) {
-#if PY_MAJOR_VERSION < 3
- metaclass = &PyClass_Type;
-#else
- metaclass = &PyType_Type;
-#endif
- }
- Py_INCREF((PyObject*) metaclass);
- return (PyObject*) metaclass;
-}
-
-/* FixUpExtensionType */
-#if CYTHON_USE_TYPE_SPECS
-static int __Pyx_fix_up_extension_type_from_spec(PyType_Spec *spec, PyTypeObject *type) {
-#if PY_VERSION_HEX > 0x030900B1 || CYTHON_COMPILING_IN_LIMITED_API
- CYTHON_UNUSED_VAR(spec);
- CYTHON_UNUSED_VAR(type);
-#else
- const PyType_Slot *slot = spec->slots;
- while (slot && slot->slot && slot->slot != Py_tp_members)
- slot++;
- if (slot && slot->slot == Py_tp_members) {
- int changed = 0;
-#if !(PY_VERSION_HEX <= 0x030900b1 && CYTHON_COMPILING_IN_CPYTHON)
- const
-#endif
- PyMemberDef *memb = (PyMemberDef*) slot->pfunc;
- while (memb && memb->name) {
- if (memb->name[0] == '_' && memb->name[1] == '_') {
-#if PY_VERSION_HEX < 0x030900b1
- if (strcmp(memb->name, "__weaklistoffset__") == 0) {
- assert(memb->type == T_PYSSIZET);
- assert(memb->flags == READONLY);
- type->tp_weaklistoffset = memb->offset;
- changed = 1;
- }
- else if (strcmp(memb->name, "__dictoffset__") == 0) {
- assert(memb->type == T_PYSSIZET);
- assert(memb->flags == READONLY);
- type->tp_dictoffset = memb->offset;
- changed = 1;
- }
-#if CYTHON_METH_FASTCALL
- else if (strcmp(memb->name, "__vectorcalloffset__") == 0) {
- assert(memb->type == T_PYSSIZET);
- assert(memb->flags == READONLY);
-#if PY_VERSION_HEX >= 0x030800b4
- type->tp_vectorcall_offset = memb->offset;
-#else
- type->tp_print = (printfunc) memb->offset;
-#endif
- changed = 1;
- }
-#endif
-#else
- if ((0));
-#endif
-#if PY_VERSION_HEX <= 0x030900b1 && CYTHON_COMPILING_IN_CPYTHON
- else if (strcmp(memb->name, "__module__") == 0) {
- PyObject *descr;
- assert(memb->type == T_OBJECT);
- assert(memb->flags == 0 || memb->flags == READONLY);
- descr = PyDescr_NewMember(type, memb);
- if (unlikely(!descr))
- return -1;
- if (unlikely(PyDict_SetItem(type->tp_dict, PyDescr_NAME(descr), descr) < 0)) {
- Py_DECREF(descr);
- return -1;
- }
- Py_DECREF(descr);
- changed = 1;
- }
-#endif
- }
- memb++;
- }
- if (changed)
- PyType_Modified(type);
- }
-#endif
- return 0;
-}
-#endif
-
-/* FetchSharedCythonModule */
-static PyObject *__Pyx_FetchSharedCythonABIModule(void) {
- PyObject *abi_module = PyImport_AddModule((char*) __PYX_ABI_MODULE_NAME);
- if (unlikely(!abi_module)) return NULL;
- Py_INCREF(abi_module);
- return abi_module;
-}
-
-/* FetchCommonType */
-static int __Pyx_VerifyCachedType(PyObject *cached_type,
- const char *name,
- Py_ssize_t basicsize,
- Py_ssize_t expected_basicsize) {
- if (!PyType_Check(cached_type)) {
- PyErr_Format(PyExc_TypeError,
- "Shared Cython type %.200s is not a type object", name);
- return -1;
- }
- if (basicsize != expected_basicsize) {
- PyErr_Format(PyExc_TypeError,
- "Shared Cython type %.200s has the wrong size, try recompiling",
- name);
- return -1;
- }
- return 0;
-}
-#if !CYTHON_USE_TYPE_SPECS
-static PyTypeObject* __Pyx_FetchCommonType(PyTypeObject* type) {
- PyObject* abi_module;
- const char* object_name;
- PyTypeObject *cached_type = NULL;
- abi_module = __Pyx_FetchSharedCythonABIModule();
- if (!abi_module) return NULL;
- object_name = strrchr(type->tp_name, '.');
- object_name = object_name ? object_name+1 : type->tp_name;
- cached_type = (PyTypeObject*) PyObject_GetAttrString(abi_module, object_name);
- if (cached_type) {
- if (__Pyx_VerifyCachedType(
- (PyObject *)cached_type,
- object_name,
- cached_type->tp_basicsize,
- type->tp_basicsize) < 0) {
- goto bad;
- }
- goto done;
- }
- if (!PyErr_ExceptionMatches(PyExc_AttributeError)) goto bad;
- PyErr_Clear();
- if (PyType_Ready(type) < 0) goto bad;
- if (PyObject_SetAttrString(abi_module, object_name, (PyObject *)type) < 0)
- goto bad;
- Py_INCREF(type);
- cached_type = type;
-done:
- Py_DECREF(abi_module);
- return cached_type;
-bad:
- Py_XDECREF(cached_type);
- cached_type = NULL;
- goto done;
-}
-#else
-static PyTypeObject *__Pyx_FetchCommonTypeFromSpec(PyObject *module, PyType_Spec *spec, PyObject *bases) {
- PyObject *abi_module, *cached_type = NULL;
- const char* object_name = strrchr(spec->name, '.');
- object_name = object_name ? object_name+1 : spec->name;
- abi_module = __Pyx_FetchSharedCythonABIModule();
- if (!abi_module) return NULL;
- cached_type = PyObject_GetAttrString(abi_module, object_name);
- if (cached_type) {
- Py_ssize_t basicsize;
-#if CYTHON_COMPILING_IN_LIMITED_API
- PyObject *py_basicsize;
- py_basicsize = PyObject_GetAttrString(cached_type, "__basicsize__");
- if (unlikely(!py_basicsize)) goto bad;
- basicsize = PyLong_AsSsize_t(py_basicsize);
- Py_DECREF(py_basicsize);
- py_basicsize = 0;
- if (unlikely(basicsize == (Py_ssize_t)-1) && PyErr_Occurred()) goto bad;
-#else
- basicsize = likely(PyType_Check(cached_type)) ? ((PyTypeObject*) cached_type)->tp_basicsize : -1;
-#endif
- if (__Pyx_VerifyCachedType(
- cached_type,
- object_name,
- basicsize,
- spec->basicsize) < 0) {
- goto bad;
- }
- goto done;
- }
- if (!PyErr_ExceptionMatches(PyExc_AttributeError)) goto bad;
- PyErr_Clear();
- CYTHON_UNUSED_VAR(module);
- cached_type = __Pyx_PyType_FromModuleAndSpec(abi_module, spec, bases);
- if (unlikely(!cached_type)) goto bad;
- if (unlikely(__Pyx_fix_up_extension_type_from_spec(spec, (PyTypeObject *) cached_type) < 0)) goto bad;
- if (PyObject_SetAttrString(abi_module, object_name, cached_type) < 0) goto bad;
-done:
- Py_DECREF(abi_module);
- assert(cached_type == NULL || PyType_Check(cached_type));
- return (PyTypeObject *) cached_type;
-bad:
- Py_XDECREF(cached_type);
- cached_type = NULL;
- goto done;
-}
-#endif
-
-/* PyVectorcallFastCallDict */
-#if CYTHON_METH_FASTCALL
-static PyObject *__Pyx_PyVectorcall_FastCallDict_kw(PyObject *func, __pyx_vectorcallfunc vc, PyObject *const *args, size_t nargs, PyObject *kw)
-{
- PyObject *res = NULL;
- PyObject *kwnames;
- PyObject **newargs;
- PyObject **kwvalues;
- Py_ssize_t i, pos;
- size_t j;
- PyObject *key, *value;
- unsigned long keys_are_strings;
- Py_ssize_t nkw = PyDict_GET_SIZE(kw);
- newargs = (PyObject **)PyMem_Malloc((nargs + (size_t)nkw) * sizeof(args[0]));
- if (unlikely(newargs == NULL)) {
- PyErr_NoMemory();
- return NULL;
- }
- for (j = 0; j < nargs; j++) newargs[j] = args[j];
- kwnames = PyTuple_New(nkw);
- if (unlikely(kwnames == NULL)) {
- PyMem_Free(newargs);
- return NULL;
- }
- kwvalues = newargs + nargs;
- pos = i = 0;
- keys_are_strings = Py_TPFLAGS_UNICODE_SUBCLASS;
- while (PyDict_Next(kw, &pos, &key, &value)) {
- keys_are_strings &= Py_TYPE(key)->tp_flags;
- Py_INCREF(key);
- Py_INCREF(value);
- PyTuple_SET_ITEM(kwnames, i, key);
- kwvalues[i] = value;
- i++;
- }
- if (unlikely(!keys_are_strings)) {
- PyErr_SetString(PyExc_TypeError, "keywords must be strings");
- goto cleanup;
- }
- res = vc(func, newargs, nargs, kwnames);
-cleanup:
- Py_DECREF(kwnames);
- for (i = 0; i < nkw; i++)
- Py_DECREF(kwvalues[i]);
- PyMem_Free(newargs);
- return res;
-}
-static CYTHON_INLINE PyObject *__Pyx_PyVectorcall_FastCallDict(PyObject *func, __pyx_vectorcallfunc vc, PyObject *const *args, size_t nargs, PyObject *kw)
-{
- if (likely(kw == NULL) || PyDict_GET_SIZE(kw) == 0) {
- return vc(func, args, nargs, NULL);
- }
- return __Pyx_PyVectorcall_FastCallDict_kw(func, vc, args, nargs, kw);
-}
-#endif
-
-/* CythonFunctionShared */
-static CYTHON_INLINE void __Pyx__CyFunction_SetClassObj(__pyx_CyFunctionObject* f, PyObject* classobj) {
-#if PY_VERSION_HEX < 0x030900B1
- __Pyx_Py_XDECREF_SET(
- __Pyx_CyFunction_GetClassObj(f),
- ((classobj) ? __Pyx_NewRef(classobj) : NULL));
-#else
- __Pyx_Py_XDECREF_SET(
- ((PyCMethodObject *) (f))->mm_class,
- (PyTypeObject*)((classobj) ? __Pyx_NewRef(classobj) : NULL));
-#endif
-}
-static PyObject *
-__Pyx_CyFunction_get_doc(__pyx_CyFunctionObject *op, void *closure)
-{
- CYTHON_UNUSED_VAR(closure);
- if (unlikely(op->func_doc == NULL)) {
- if (((PyCFunctionObject*)op)->m_ml->ml_doc) {
-#if PY_MAJOR_VERSION >= 3
- op->func_doc = PyUnicode_FromString(((PyCFunctionObject*)op)->m_ml->ml_doc);
-#else
- op->func_doc = PyString_FromString(((PyCFunctionObject*)op)->m_ml->ml_doc);
-#endif
- if (unlikely(op->func_doc == NULL))
- return NULL;
- } else {
- Py_INCREF(Py_None);
- return Py_None;
- }
- }
- Py_INCREF(op->func_doc);
- return op->func_doc;
-}
-static int
-__Pyx_CyFunction_set_doc(__pyx_CyFunctionObject *op, PyObject *value, void *context)
-{
- CYTHON_UNUSED_VAR(context);
- if (value == NULL) {
- value = Py_None;
- }
- Py_INCREF(value);
- __Pyx_Py_XDECREF_SET(op->func_doc, value);
- return 0;
-}
-static PyObject *
-__Pyx_CyFunction_get_name(__pyx_CyFunctionObject *op, void *context)
-{
- CYTHON_UNUSED_VAR(context);
- if (unlikely(op->func_name == NULL)) {
-#if PY_MAJOR_VERSION >= 3
- op->func_name = PyUnicode_InternFromString(((PyCFunctionObject*)op)->m_ml->ml_name);
-#else
- op->func_name = PyString_InternFromString(((PyCFunctionObject*)op)->m_ml->ml_name);
-#endif
- if (unlikely(op->func_name == NULL))
- return NULL;
- }
- Py_INCREF(op->func_name);
- return op->func_name;
-}
-static int
-__Pyx_CyFunction_set_name(__pyx_CyFunctionObject *op, PyObject *value, void *context)
-{
- CYTHON_UNUSED_VAR(context);
-#if PY_MAJOR_VERSION >= 3
- if (unlikely(value == NULL || !PyUnicode_Check(value)))
-#else
- if (unlikely(value == NULL || !PyString_Check(value)))
-#endif
- {
- PyErr_SetString(PyExc_TypeError,
- "__name__ must be set to a string object");
- return -1;
- }
- Py_INCREF(value);
- __Pyx_Py_XDECREF_SET(op->func_name, value);
- return 0;
-}
-static PyObject *
-__Pyx_CyFunction_get_qualname(__pyx_CyFunctionObject *op, void *context)
-{
- CYTHON_UNUSED_VAR(context);
- Py_INCREF(op->func_qualname);
- return op->func_qualname;
-}
-static int
-__Pyx_CyFunction_set_qualname(__pyx_CyFunctionObject *op, PyObject *value, void *context)
-{
- CYTHON_UNUSED_VAR(context);
-#if PY_MAJOR_VERSION >= 3
- if (unlikely(value == NULL || !PyUnicode_Check(value)))
-#else
- if (unlikely(value == NULL || !PyString_Check(value)))
-#endif
- {
- PyErr_SetString(PyExc_TypeError,
- "__qualname__ must be set to a string object");
- return -1;
- }
- Py_INCREF(value);
- __Pyx_Py_XDECREF_SET(op->func_qualname, value);
- return 0;
-}
-static PyObject *
-__Pyx_CyFunction_get_dict(__pyx_CyFunctionObject *op, void *context)
-{
- CYTHON_UNUSED_VAR(context);
- if (unlikely(op->func_dict == NULL)) {
- op->func_dict = PyDict_New();
- if (unlikely(op->func_dict == NULL))
- return NULL;
- }
- Py_INCREF(op->func_dict);
- return op->func_dict;
-}
-static int
-__Pyx_CyFunction_set_dict(__pyx_CyFunctionObject *op, PyObject *value, void *context)
-{
- CYTHON_UNUSED_VAR(context);
- if (unlikely(value == NULL)) {
- PyErr_SetString(PyExc_TypeError,
- "function's dictionary may not be deleted");
- return -1;
- }
- if (unlikely(!PyDict_Check(value))) {
- PyErr_SetString(PyExc_TypeError,
- "setting function's dictionary to a non-dict");
- return -1;
- }
- Py_INCREF(value);
- __Pyx_Py_XDECREF_SET(op->func_dict, value);
- return 0;
-}
-static PyObject *
-__Pyx_CyFunction_get_globals(__pyx_CyFunctionObject *op, void *context)
-{
- CYTHON_UNUSED_VAR(context);
- Py_INCREF(op->func_globals);
- return op->func_globals;
-}
-static PyObject *
-__Pyx_CyFunction_get_closure(__pyx_CyFunctionObject *op, void *context)
-{
- CYTHON_UNUSED_VAR(op);
- CYTHON_UNUSED_VAR(context);
- Py_INCREF(Py_None);
- return Py_None;
-}
-static PyObject *
-__Pyx_CyFunction_get_code(__pyx_CyFunctionObject *op, void *context)
-{
- PyObject* result = (op->func_code) ? op->func_code : Py_None;
- CYTHON_UNUSED_VAR(context);
- Py_INCREF(result);
- return result;
-}
-static int
-__Pyx_CyFunction_init_defaults(__pyx_CyFunctionObject *op) {
- int result = 0;
- PyObject *res = op->defaults_getter((PyObject *) op);
- if (unlikely(!res))
- return -1;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- op->defaults_tuple = PyTuple_GET_ITEM(res, 0);
- Py_INCREF(op->defaults_tuple);
- op->defaults_kwdict = PyTuple_GET_ITEM(res, 1);
- Py_INCREF(op->defaults_kwdict);
- #else
- op->defaults_tuple = PySequence_ITEM(res, 0);
- if (unlikely(!op->defaults_tuple)) result = -1;
- else {
- op->defaults_kwdict = PySequence_ITEM(res, 1);
- if (unlikely(!op->defaults_kwdict)) result = -1;
- }
- #endif
- Py_DECREF(res);
- return result;
-}
-static int
-__Pyx_CyFunction_set_defaults(__pyx_CyFunctionObject *op, PyObject* value, void *context) {
- CYTHON_UNUSED_VAR(context);
- if (!value) {
- value = Py_None;
- } else if (unlikely(value != Py_None && !PyTuple_Check(value))) {
- PyErr_SetString(PyExc_TypeError,
- "__defaults__ must be set to a tuple object");
- return -1;
- }
- PyErr_WarnEx(PyExc_RuntimeWarning, "changes to cyfunction.__defaults__ will not "
- "currently affect the values used in function calls", 1);
- Py_INCREF(value);
- __Pyx_Py_XDECREF_SET(op->defaults_tuple, value);
- return 0;
-}
-static PyObject *
-__Pyx_CyFunction_get_defaults(__pyx_CyFunctionObject *op, void *context) {
- PyObject* result = op->defaults_tuple;
- CYTHON_UNUSED_VAR(context);
- if (unlikely(!result)) {
- if (op->defaults_getter) {
- if (unlikely(__Pyx_CyFunction_init_defaults(op) < 0)) return NULL;
- result = op->defaults_tuple;
- } else {
- result = Py_None;
- }
- }
- Py_INCREF(result);
- return result;
-}
-static int
-__Pyx_CyFunction_set_kwdefaults(__pyx_CyFunctionObject *op, PyObject* value, void *context) {
- CYTHON_UNUSED_VAR(context);
- if (!value) {
- value = Py_None;
- } else if (unlikely(value != Py_None && !PyDict_Check(value))) {
- PyErr_SetString(PyExc_TypeError,
- "__kwdefaults__ must be set to a dict object");
- return -1;
- }
- PyErr_WarnEx(PyExc_RuntimeWarning, "changes to cyfunction.__kwdefaults__ will not "
- "currently affect the values used in function calls", 1);
- Py_INCREF(value);
- __Pyx_Py_XDECREF_SET(op->defaults_kwdict, value);
- return 0;
-}
-static PyObject *
-__Pyx_CyFunction_get_kwdefaults(__pyx_CyFunctionObject *op, void *context) {
- PyObject* result = op->defaults_kwdict;
- CYTHON_UNUSED_VAR(context);
- if (unlikely(!result)) {
- if (op->defaults_getter) {
- if (unlikely(__Pyx_CyFunction_init_defaults(op) < 0)) return NULL;
- result = op->defaults_kwdict;
- } else {
- result = Py_None;
- }
- }
- Py_INCREF(result);
- return result;
-}
-static int
-__Pyx_CyFunction_set_annotations(__pyx_CyFunctionObject *op, PyObject* value, void *context) {
- CYTHON_UNUSED_VAR(context);
- if (!value || value == Py_None) {
- value = NULL;
- } else if (unlikely(!PyDict_Check(value))) {
- PyErr_SetString(PyExc_TypeError,
- "__annotations__ must be set to a dict object");
- return -1;
- }
- Py_XINCREF(value);
- __Pyx_Py_XDECREF_SET(op->func_annotations, value);
- return 0;
-}
-static PyObject *
-__Pyx_CyFunction_get_annotations(__pyx_CyFunctionObject *op, void *context) {
- PyObject* result = op->func_annotations;
- CYTHON_UNUSED_VAR(context);
- if (unlikely(!result)) {
- result = PyDict_New();
- if (unlikely(!result)) return NULL;
- op->func_annotations = result;
- }
- Py_INCREF(result);
- return result;
-}
-static PyObject *
-__Pyx_CyFunction_get_is_coroutine(__pyx_CyFunctionObject *op, void *context) {
- int is_coroutine;
- CYTHON_UNUSED_VAR(context);
- if (op->func_is_coroutine) {
- return __Pyx_NewRef(op->func_is_coroutine);
- }
- is_coroutine = op->flags & __Pyx_CYFUNCTION_COROUTINE;
-#if PY_VERSION_HEX >= 0x03050000
- if (is_coroutine) {
- PyObject *module, *fromlist, *marker = __pyx_n_s_is_coroutine;
- fromlist = PyList_New(1);
- if (unlikely(!fromlist)) return NULL;
- Py_INCREF(marker);
- PyList_SET_ITEM(fromlist, 0, marker);
- module = PyImport_ImportModuleLevelObject(__pyx_n_s_asyncio_coroutines, NULL, NULL, fromlist, 0);
- Py_DECREF(fromlist);
- if (unlikely(!module)) goto ignore;
- op->func_is_coroutine = __Pyx_PyObject_GetAttrStr(module, marker);
- Py_DECREF(module);
- if (likely(op->func_is_coroutine)) {
- return __Pyx_NewRef(op->func_is_coroutine);
- }
-ignore:
- PyErr_Clear();
- }
-#endif
- op->func_is_coroutine = __Pyx_PyBool_FromLong(is_coroutine);
- return __Pyx_NewRef(op->func_is_coroutine);
-}
-static PyGetSetDef __pyx_CyFunction_getsets[] = {
- {(char *) "func_doc", (getter)__Pyx_CyFunction_get_doc, (setter)__Pyx_CyFunction_set_doc, 0, 0},
- {(char *) "__doc__", (getter)__Pyx_CyFunction_get_doc, (setter)__Pyx_CyFunction_set_doc, 0, 0},
- {(char *) "func_name", (getter)__Pyx_CyFunction_get_name, (setter)__Pyx_CyFunction_set_name, 0, 0},
- {(char *) "__name__", (getter)__Pyx_CyFunction_get_name, (setter)__Pyx_CyFunction_set_name, 0, 0},
- {(char *) "__qualname__", (getter)__Pyx_CyFunction_get_qualname, (setter)__Pyx_CyFunction_set_qualname, 0, 0},
- {(char *) "func_dict", (getter)__Pyx_CyFunction_get_dict, (setter)__Pyx_CyFunction_set_dict, 0, 0},
- {(char *) "__dict__", (getter)__Pyx_CyFunction_get_dict, (setter)__Pyx_CyFunction_set_dict, 0, 0},
- {(char *) "func_globals", (getter)__Pyx_CyFunction_get_globals, 0, 0, 0},
- {(char *) "__globals__", (getter)__Pyx_CyFunction_get_globals, 0, 0, 0},
- {(char *) "func_closure", (getter)__Pyx_CyFunction_get_closure, 0, 0, 0},
- {(char *) "__closure__", (getter)__Pyx_CyFunction_get_closure, 0, 0, 0},
- {(char *) "func_code", (getter)__Pyx_CyFunction_get_code, 0, 0, 0},
- {(char *) "__code__", (getter)__Pyx_CyFunction_get_code, 0, 0, 0},
- {(char *) "func_defaults", (getter)__Pyx_CyFunction_get_defaults, (setter)__Pyx_CyFunction_set_defaults, 0, 0},
- {(char *) "__defaults__", (getter)__Pyx_CyFunction_get_defaults, (setter)__Pyx_CyFunction_set_defaults, 0, 0},
- {(char *) "__kwdefaults__", (getter)__Pyx_CyFunction_get_kwdefaults, (setter)__Pyx_CyFunction_set_kwdefaults, 0, 0},
- {(char *) "__annotations__", (getter)__Pyx_CyFunction_get_annotations, (setter)__Pyx_CyFunction_set_annotations, 0, 0},
- {(char *) "_is_coroutine", (getter)__Pyx_CyFunction_get_is_coroutine, 0, 0, 0},
- {0, 0, 0, 0, 0}
-};
-static PyMemberDef __pyx_CyFunction_members[] = {
- {(char *) "__module__", T_OBJECT, offsetof(PyCFunctionObject, m_module), 0, 0},
-#if CYTHON_USE_TYPE_SPECS
- {(char *) "__dictoffset__", T_PYSSIZET, offsetof(__pyx_CyFunctionObject, func_dict), READONLY, 0},
-#if CYTHON_METH_FASTCALL
-#if CYTHON_BACKPORT_VECTORCALL
- {(char *) "__vectorcalloffset__", T_PYSSIZET, offsetof(__pyx_CyFunctionObject, func_vectorcall), READONLY, 0},
-#else
- {(char *) "__vectorcalloffset__", T_PYSSIZET, offsetof(PyCFunctionObject, vectorcall), READONLY, 0},
-#endif
-#endif
-#if PY_VERSION_HEX < 0x030500A0
- {(char *) "__weaklistoffset__", T_PYSSIZET, offsetof(__pyx_CyFunctionObject, func_weakreflist), READONLY, 0},
-#else
- {(char *) "__weaklistoffset__", T_PYSSIZET, offsetof(PyCFunctionObject, m_weakreflist), READONLY, 0},
-#endif
-#endif
- {0, 0, 0, 0, 0}
-};
-static PyObject *
-__Pyx_CyFunction_reduce(__pyx_CyFunctionObject *m, PyObject *args)
-{
- CYTHON_UNUSED_VAR(args);
-#if PY_MAJOR_VERSION >= 3
- Py_INCREF(m->func_qualname);
- return m->func_qualname;
-#else
- return PyString_FromString(((PyCFunctionObject*)m)->m_ml->ml_name);
-#endif
-}
-static PyMethodDef __pyx_CyFunction_methods[] = {
- {"__reduce__", (PyCFunction)__Pyx_CyFunction_reduce, METH_VARARGS, 0},
- {0, 0, 0, 0}
-};
-#if PY_VERSION_HEX < 0x030500A0
-#define __Pyx_CyFunction_weakreflist(cyfunc) ((cyfunc)->func_weakreflist)
-#else
-#define __Pyx_CyFunction_weakreflist(cyfunc) (((PyCFunctionObject*)cyfunc)->m_weakreflist)
-#endif
-static PyObject *__Pyx_CyFunction_Init(__pyx_CyFunctionObject *op, PyMethodDef *ml, int flags, PyObject* qualname,
- PyObject *closure, PyObject *module, PyObject* globals, PyObject* code) {
- PyCFunctionObject *cf = (PyCFunctionObject*) op;
- if (unlikely(op == NULL))
- return NULL;
- op->flags = flags;
- __Pyx_CyFunction_weakreflist(op) = NULL;
- cf->m_ml = ml;
- cf->m_self = (PyObject *) op;
- Py_XINCREF(closure);
- op->func_closure = closure;
- Py_XINCREF(module);
- cf->m_module = module;
- op->func_dict = NULL;
- op->func_name = NULL;
- Py_INCREF(qualname);
- op->func_qualname = qualname;
- op->func_doc = NULL;
-#if PY_VERSION_HEX < 0x030900B1
- op->func_classobj = NULL;
-#else
- ((PyCMethodObject*)op)->mm_class = NULL;
-#endif
- op->func_globals = globals;
- Py_INCREF(op->func_globals);
- Py_XINCREF(code);
- op->func_code = code;
- op->defaults_pyobjects = 0;
- op->defaults_size = 0;
- op->defaults = NULL;
- op->defaults_tuple = NULL;
- op->defaults_kwdict = NULL;
- op->defaults_getter = NULL;
- op->func_annotations = NULL;
- op->func_is_coroutine = NULL;
-#if CYTHON_METH_FASTCALL
- switch (ml->ml_flags & (METH_VARARGS | METH_FASTCALL | METH_NOARGS | METH_O | METH_KEYWORDS | METH_METHOD)) {
- case METH_NOARGS:
- __Pyx_CyFunction_func_vectorcall(op) = __Pyx_CyFunction_Vectorcall_NOARGS;
- break;
- case METH_O:
- __Pyx_CyFunction_func_vectorcall(op) = __Pyx_CyFunction_Vectorcall_O;
- break;
- case METH_METHOD | METH_FASTCALL | METH_KEYWORDS:
- __Pyx_CyFunction_func_vectorcall(op) = __Pyx_CyFunction_Vectorcall_FASTCALL_KEYWORDS_METHOD;
- break;
- case METH_FASTCALL | METH_KEYWORDS:
- __Pyx_CyFunction_func_vectorcall(op) = __Pyx_CyFunction_Vectorcall_FASTCALL_KEYWORDS;
- break;
- case METH_VARARGS | METH_KEYWORDS:
- __Pyx_CyFunction_func_vectorcall(op) = NULL;
- break;
- default:
- PyErr_SetString(PyExc_SystemError, "Bad call flags for CyFunction");
- Py_DECREF(op);
- return NULL;
- }
-#endif
- return (PyObject *) op;
-}
-static int
-__Pyx_CyFunction_clear(__pyx_CyFunctionObject *m)
-{
- Py_CLEAR(m->func_closure);
- Py_CLEAR(((PyCFunctionObject*)m)->m_module);
- Py_CLEAR(m->func_dict);
- Py_CLEAR(m->func_name);
- Py_CLEAR(m->func_qualname);
- Py_CLEAR(m->func_doc);
- Py_CLEAR(m->func_globals);
- Py_CLEAR(m->func_code);
-#if PY_VERSION_HEX < 0x030900B1
- Py_CLEAR(__Pyx_CyFunction_GetClassObj(m));
-#else
- {
- PyObject *cls = (PyObject*) ((PyCMethodObject *) (m))->mm_class;
- ((PyCMethodObject *) (m))->mm_class = NULL;
- Py_XDECREF(cls);
- }
-#endif
- Py_CLEAR(m->defaults_tuple);
- Py_CLEAR(m->defaults_kwdict);
- Py_CLEAR(m->func_annotations);
- Py_CLEAR(m->func_is_coroutine);
- if (m->defaults) {
- PyObject **pydefaults = __Pyx_CyFunction_Defaults(PyObject *, m);
- int i;
- for (i = 0; i < m->defaults_pyobjects; i++)
- Py_XDECREF(pydefaults[i]);
- PyObject_Free(m->defaults);
- m->defaults = NULL;
- }
- return 0;
-}
-static void __Pyx__CyFunction_dealloc(__pyx_CyFunctionObject *m)
-{
- if (__Pyx_CyFunction_weakreflist(m) != NULL)
- PyObject_ClearWeakRefs((PyObject *) m);
- __Pyx_CyFunction_clear(m);
- __Pyx_PyHeapTypeObject_GC_Del(m);
-}
-static void __Pyx_CyFunction_dealloc(__pyx_CyFunctionObject *m)
-{
- PyObject_GC_UnTrack(m);
- __Pyx__CyFunction_dealloc(m);
-}
-static int __Pyx_CyFunction_traverse(__pyx_CyFunctionObject *m, visitproc visit, void *arg)
-{
- Py_VISIT(m->func_closure);
- Py_VISIT(((PyCFunctionObject*)m)->m_module);
- Py_VISIT(m->func_dict);
- Py_VISIT(m->func_name);
- Py_VISIT(m->func_qualname);
- Py_VISIT(m->func_doc);
- Py_VISIT(m->func_globals);
- Py_VISIT(m->func_code);
- Py_VISIT(__Pyx_CyFunction_GetClassObj(m));
- Py_VISIT(m->defaults_tuple);
- Py_VISIT(m->defaults_kwdict);
- Py_VISIT(m->func_is_coroutine);
- if (m->defaults) {
- PyObject **pydefaults = __Pyx_CyFunction_Defaults(PyObject *, m);
- int i;
- for (i = 0; i < m->defaults_pyobjects; i++)
- Py_VISIT(pydefaults[i]);
- }
- return 0;
-}
-static PyObject*
-__Pyx_CyFunction_repr(__pyx_CyFunctionObject *op)
-{
-#if PY_MAJOR_VERSION >= 3
- return PyUnicode_FromFormat("",
- op->func_qualname, (void *)op);
-#else
- return PyString_FromFormat("",
- PyString_AsString(op->func_qualname), (void *)op);
-#endif
-}
-static PyObject * __Pyx_CyFunction_CallMethod(PyObject *func, PyObject *self, PyObject *arg, PyObject *kw) {
- PyCFunctionObject* f = (PyCFunctionObject*)func;
- PyCFunction meth = f->m_ml->ml_meth;
- Py_ssize_t size;
- switch (f->m_ml->ml_flags & (METH_VARARGS | METH_KEYWORDS | METH_NOARGS | METH_O)) {
- case METH_VARARGS:
- if (likely(kw == NULL || PyDict_Size(kw) == 0))
- return (*meth)(self, arg);
- break;
- case METH_VARARGS | METH_KEYWORDS:
- return (*(PyCFunctionWithKeywords)(void*)meth)(self, arg, kw);
- case METH_NOARGS:
- if (likely(kw == NULL || PyDict_Size(kw) == 0)) {
- size = PyTuple_GET_SIZE(arg);
- if (likely(size == 0))
- return (*meth)(self, NULL);
- PyErr_Format(PyExc_TypeError,
- "%.200s() takes no arguments (%" CYTHON_FORMAT_SSIZE_T "d given)",
- f->m_ml->ml_name, size);
- return NULL;
- }
- break;
- case METH_O:
- if (likely(kw == NULL || PyDict_Size(kw) == 0)) {
- size = PyTuple_GET_SIZE(arg);
- if (likely(size == 1)) {
- PyObject *result, *arg0;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- arg0 = PyTuple_GET_ITEM(arg, 0);
- #else
- arg0 = PySequence_ITEM(arg, 0); if (unlikely(!arg0)) return NULL;
- #endif
- result = (*meth)(self, arg0);
- #if !(CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS)
- Py_DECREF(arg0);
- #endif
- return result;
- }
- PyErr_Format(PyExc_TypeError,
- "%.200s() takes exactly one argument (%" CYTHON_FORMAT_SSIZE_T "d given)",
- f->m_ml->ml_name, size);
- return NULL;
- }
- break;
- default:
- PyErr_SetString(PyExc_SystemError, "Bad call flags for CyFunction");
- return NULL;
- }
- PyErr_Format(PyExc_TypeError, "%.200s() takes no keyword arguments",
- f->m_ml->ml_name);
- return NULL;
-}
-static CYTHON_INLINE PyObject *__Pyx_CyFunction_Call(PyObject *func, PyObject *arg, PyObject *kw) {
- return __Pyx_CyFunction_CallMethod(func, ((PyCFunctionObject*)func)->m_self, arg, kw);
-}
-static PyObject *__Pyx_CyFunction_CallAsMethod(PyObject *func, PyObject *args, PyObject *kw) {
- PyObject *result;
- __pyx_CyFunctionObject *cyfunc = (__pyx_CyFunctionObject *) func;
-#if CYTHON_METH_FASTCALL
- __pyx_vectorcallfunc vc = __Pyx_CyFunction_func_vectorcall(cyfunc);
- if (vc) {
-#if CYTHON_ASSUME_SAFE_MACROS
- return __Pyx_PyVectorcall_FastCallDict(func, vc, &PyTuple_GET_ITEM(args, 0), (size_t)PyTuple_GET_SIZE(args), kw);
-#else
- (void) &__Pyx_PyVectorcall_FastCallDict;
- return PyVectorcall_Call(func, args, kw);
-#endif
- }
-#endif
- if ((cyfunc->flags & __Pyx_CYFUNCTION_CCLASS) && !(cyfunc->flags & __Pyx_CYFUNCTION_STATICMETHOD)) {
- Py_ssize_t argc;
- PyObject *new_args;
- PyObject *self;
- argc = PyTuple_GET_SIZE(args);
- new_args = PyTuple_GetSlice(args, 1, argc);
- if (unlikely(!new_args))
- return NULL;
- self = PyTuple_GetItem(args, 0);
- if (unlikely(!self)) {
- Py_DECREF(new_args);
-#if PY_MAJOR_VERSION > 2
- PyErr_Format(PyExc_TypeError,
- "unbound method %.200S() needs an argument",
- cyfunc->func_qualname);
-#else
- PyErr_SetString(PyExc_TypeError,
- "unbound method needs an argument");
-#endif
- return NULL;
- }
- result = __Pyx_CyFunction_CallMethod(func, self, new_args, kw);
- Py_DECREF(new_args);
- } else {
- result = __Pyx_CyFunction_Call(func, args, kw);
- }
- return result;
-}
-#if CYTHON_METH_FASTCALL
-static CYTHON_INLINE int __Pyx_CyFunction_Vectorcall_CheckArgs(__pyx_CyFunctionObject *cyfunc, Py_ssize_t nargs, PyObject *kwnames)
-{
- int ret = 0;
- if ((cyfunc->flags & __Pyx_CYFUNCTION_CCLASS) && !(cyfunc->flags & __Pyx_CYFUNCTION_STATICMETHOD)) {
- if (unlikely(nargs < 1)) {
- PyErr_Format(PyExc_TypeError, "%.200s() needs an argument",
- ((PyCFunctionObject*)cyfunc)->m_ml->ml_name);
- return -1;
- }
- ret = 1;
- }
- if (unlikely(kwnames) && unlikely(PyTuple_GET_SIZE(kwnames))) {
- PyErr_Format(PyExc_TypeError,
- "%.200s() takes no keyword arguments", ((PyCFunctionObject*)cyfunc)->m_ml->ml_name);
- return -1;
- }
- return ret;
-}
-static PyObject * __Pyx_CyFunction_Vectorcall_NOARGS(PyObject *func, PyObject *const *args, size_t nargsf, PyObject *kwnames)
-{
- __pyx_CyFunctionObject *cyfunc = (__pyx_CyFunctionObject *)func;
- PyMethodDef* def = ((PyCFunctionObject*)cyfunc)->m_ml;
-#if CYTHON_BACKPORT_VECTORCALL
- Py_ssize_t nargs = (Py_ssize_t)nargsf;
-#else
- Py_ssize_t nargs = PyVectorcall_NARGS(nargsf);
-#endif
- PyObject *self;
- switch (__Pyx_CyFunction_Vectorcall_CheckArgs(cyfunc, nargs, kwnames)) {
- case 1:
- self = args[0];
- args += 1;
- nargs -= 1;
- break;
- case 0:
- self = ((PyCFunctionObject*)cyfunc)->m_self;
- break;
- default:
- return NULL;
- }
- if (unlikely(nargs != 0)) {
- PyErr_Format(PyExc_TypeError,
- "%.200s() takes no arguments (%" CYTHON_FORMAT_SSIZE_T "d given)",
- def->ml_name, nargs);
- return NULL;
- }
- return def->ml_meth(self, NULL);
-}
-static PyObject * __Pyx_CyFunction_Vectorcall_O(PyObject *func, PyObject *const *args, size_t nargsf, PyObject *kwnames)
-{
- __pyx_CyFunctionObject *cyfunc = (__pyx_CyFunctionObject *)func;
- PyMethodDef* def = ((PyCFunctionObject*)cyfunc)->m_ml;
-#if CYTHON_BACKPORT_VECTORCALL
- Py_ssize_t nargs = (Py_ssize_t)nargsf;
-#else
- Py_ssize_t nargs = PyVectorcall_NARGS(nargsf);
-#endif
- PyObject *self;
- switch (__Pyx_CyFunction_Vectorcall_CheckArgs(cyfunc, nargs, kwnames)) {
- case 1:
- self = args[0];
- args += 1;
- nargs -= 1;
- break;
- case 0:
- self = ((PyCFunctionObject*)cyfunc)->m_self;
- break;
- default:
- return NULL;
- }
- if (unlikely(nargs != 1)) {
- PyErr_Format(PyExc_TypeError,
- "%.200s() takes exactly one argument (%" CYTHON_FORMAT_SSIZE_T "d given)",
- def->ml_name, nargs);
- return NULL;
- }
- return def->ml_meth(self, args[0]);
-}
-static PyObject * __Pyx_CyFunction_Vectorcall_FASTCALL_KEYWORDS(PyObject *func, PyObject *const *args, size_t nargsf, PyObject *kwnames)
-{
- __pyx_CyFunctionObject *cyfunc = (__pyx_CyFunctionObject *)func;
- PyMethodDef* def = ((PyCFunctionObject*)cyfunc)->m_ml;
-#if CYTHON_BACKPORT_VECTORCALL
- Py_ssize_t nargs = (Py_ssize_t)nargsf;
-#else
- Py_ssize_t nargs = PyVectorcall_NARGS(nargsf);
-#endif
- PyObject *self;
- switch (__Pyx_CyFunction_Vectorcall_CheckArgs(cyfunc, nargs, NULL)) {
- case 1:
- self = args[0];
- args += 1;
- nargs -= 1;
- break;
- case 0:
- self = ((PyCFunctionObject*)cyfunc)->m_self;
- break;
- default:
- return NULL;
- }
- return ((_PyCFunctionFastWithKeywords)(void(*)(void))def->ml_meth)(self, args, nargs, kwnames);
-}
-static PyObject * __Pyx_CyFunction_Vectorcall_FASTCALL_KEYWORDS_METHOD(PyObject *func, PyObject *const *args, size_t nargsf, PyObject *kwnames)
-{
- __pyx_CyFunctionObject *cyfunc = (__pyx_CyFunctionObject *)func;
- PyMethodDef* def = ((PyCFunctionObject*)cyfunc)->m_ml;
- PyTypeObject *cls = (PyTypeObject *) __Pyx_CyFunction_GetClassObj(cyfunc);
-#if CYTHON_BACKPORT_VECTORCALL
- Py_ssize_t nargs = (Py_ssize_t)nargsf;
-#else
- Py_ssize_t nargs = PyVectorcall_NARGS(nargsf);
-#endif
- PyObject *self;
- switch (__Pyx_CyFunction_Vectorcall_CheckArgs(cyfunc, nargs, NULL)) {
- case 1:
- self = args[0];
- args += 1;
- nargs -= 1;
- break;
- case 0:
- self = ((PyCFunctionObject*)cyfunc)->m_self;
- break;
- default:
- return NULL;
- }
- return ((__Pyx_PyCMethod)(void(*)(void))def->ml_meth)(self, cls, args, (size_t)nargs, kwnames);
-}
-#endif
-#if CYTHON_USE_TYPE_SPECS
-static PyType_Slot __pyx_CyFunctionType_slots[] = {
- {Py_tp_dealloc, (void *)__Pyx_CyFunction_dealloc},
- {Py_tp_repr, (void *)__Pyx_CyFunction_repr},
- {Py_tp_call, (void *)__Pyx_CyFunction_CallAsMethod},
- {Py_tp_traverse, (void *)__Pyx_CyFunction_traverse},
- {Py_tp_clear, (void *)__Pyx_CyFunction_clear},
- {Py_tp_methods, (void *)__pyx_CyFunction_methods},
- {Py_tp_members, (void *)__pyx_CyFunction_members},
- {Py_tp_getset, (void *)__pyx_CyFunction_getsets},
- {Py_tp_descr_get, (void *)__Pyx_PyMethod_New},
- {0, 0},
-};
-static PyType_Spec __pyx_CyFunctionType_spec = {
- __PYX_TYPE_MODULE_PREFIX "cython_function_or_method",
- sizeof(__pyx_CyFunctionObject),
- 0,
-#ifdef Py_TPFLAGS_METHOD_DESCRIPTOR
- Py_TPFLAGS_METHOD_DESCRIPTOR |
-#endif
-#if (defined(_Py_TPFLAGS_HAVE_VECTORCALL) && CYTHON_METH_FASTCALL)
- _Py_TPFLAGS_HAVE_VECTORCALL |
-#endif
- Py_TPFLAGS_DEFAULT | Py_TPFLAGS_HAVE_GC | Py_TPFLAGS_BASETYPE,
- __pyx_CyFunctionType_slots
-};
-#else
-static PyTypeObject __pyx_CyFunctionType_type = {
- PyVarObject_HEAD_INIT(0, 0)
- __PYX_TYPE_MODULE_PREFIX "cython_function_or_method",
- sizeof(__pyx_CyFunctionObject),
- 0,
- (destructor) __Pyx_CyFunction_dealloc,
-#if !CYTHON_METH_FASTCALL
- 0,
-#elif CYTHON_BACKPORT_VECTORCALL
- (printfunc)offsetof(__pyx_CyFunctionObject, func_vectorcall),
-#else
- offsetof(PyCFunctionObject, vectorcall),
-#endif
- 0,
- 0,
-#if PY_MAJOR_VERSION < 3
- 0,
-#else
- 0,
-#endif
- (reprfunc) __Pyx_CyFunction_repr,
- 0,
- 0,
- 0,
- 0,
- __Pyx_CyFunction_CallAsMethod,
- 0,
- 0,
- 0,
- 0,
-#ifdef Py_TPFLAGS_METHOD_DESCRIPTOR
- Py_TPFLAGS_METHOD_DESCRIPTOR |
-#endif
-#ifdef _Py_TPFLAGS_HAVE_VECTORCALL
- _Py_TPFLAGS_HAVE_VECTORCALL |
-#endif
- Py_TPFLAGS_DEFAULT | Py_TPFLAGS_HAVE_GC | Py_TPFLAGS_BASETYPE,
- 0,
- (traverseproc) __Pyx_CyFunction_traverse,
- (inquiry) __Pyx_CyFunction_clear,
- 0,
-#if PY_VERSION_HEX < 0x030500A0
- offsetof(__pyx_CyFunctionObject, func_weakreflist),
-#else
- offsetof(PyCFunctionObject, m_weakreflist),
-#endif
- 0,
- 0,
- __pyx_CyFunction_methods,
- __pyx_CyFunction_members,
- __pyx_CyFunction_getsets,
- 0,
- 0,
- __Pyx_PyMethod_New,
- 0,
- offsetof(__pyx_CyFunctionObject, func_dict),
- 0,
- 0,
- 0,
- 0,
- 0,
- 0,
- 0,
- 0,
- 0,
- 0,
- 0,
- 0,
-#if PY_VERSION_HEX >= 0x030400a1
- 0,
-#endif
-#if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0,
-#endif
-#if __PYX_NEED_TP_PRINT_SLOT
- 0,
-#endif
-#if PY_VERSION_HEX >= 0x030C0000
- 0,
-#endif
-#if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000 && PY_VERSION_HEX < 0x030a0000
- 0,
-#endif
-};
-#endif
-static int __pyx_CyFunction_init(PyObject *module) {
-#if CYTHON_USE_TYPE_SPECS
- __pyx_CyFunctionType = __Pyx_FetchCommonTypeFromSpec(module, &__pyx_CyFunctionType_spec, NULL);
-#else
- CYTHON_UNUSED_VAR(module);
- __pyx_CyFunctionType = __Pyx_FetchCommonType(&__pyx_CyFunctionType_type);
-#endif
- if (unlikely(__pyx_CyFunctionType == NULL)) {
- return -1;
- }
- return 0;
-}
-static CYTHON_INLINE void *__Pyx_CyFunction_InitDefaults(PyObject *func, size_t size, int pyobjects) {
- __pyx_CyFunctionObject *m = (__pyx_CyFunctionObject *) func;
- m->defaults = PyObject_Malloc(size);
- if (unlikely(!m->defaults))
- return PyErr_NoMemory();
- memset(m->defaults, 0, size);
- m->defaults_pyobjects = pyobjects;
- m->defaults_size = size;
- return m->defaults;
-}
-static CYTHON_INLINE void __Pyx_CyFunction_SetDefaultsTuple(PyObject *func, PyObject *tuple) {
- __pyx_CyFunctionObject *m = (__pyx_CyFunctionObject *) func;
- m->defaults_tuple = tuple;
- Py_INCREF(tuple);
-}
-static CYTHON_INLINE void __Pyx_CyFunction_SetDefaultsKwDict(PyObject *func, PyObject *dict) {
- __pyx_CyFunctionObject *m = (__pyx_CyFunctionObject *) func;
- m->defaults_kwdict = dict;
- Py_INCREF(dict);
-}
-static CYTHON_INLINE void __Pyx_CyFunction_SetAnnotationsDict(PyObject *func, PyObject *dict) {
- __pyx_CyFunctionObject *m = (__pyx_CyFunctionObject *) func;
- m->func_annotations = dict;
- Py_INCREF(dict);
-}
-
-/* CythonFunction */
-static PyObject *__Pyx_CyFunction_New(PyMethodDef *ml, int flags, PyObject* qualname,
- PyObject *closure, PyObject *module, PyObject* globals, PyObject* code) {
- PyObject *op = __Pyx_CyFunction_Init(
- PyObject_GC_New(__pyx_CyFunctionObject, __pyx_CyFunctionType),
- ml, flags, qualname, closure, module, globals, code
- );
- if (likely(op)) {
- PyObject_GC_Track(op);
- }
- return op;
-}
-
-/* PyObjectCall2Args */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_Call2Args(PyObject* function, PyObject* arg1, PyObject* arg2) {
- PyObject *args[3] = {NULL, arg1, arg2};
- return __Pyx_PyObject_FastCall(function, args+1, 2 | __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET);
-}
-
-/* PyObjectLookupSpecial */
-#if CYTHON_USE_PYTYPE_LOOKUP && CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject* __Pyx__PyObject_LookupSpecial(PyObject* obj, PyObject* attr_name, int with_error) {
- PyObject *res;
- PyTypeObject *tp = Py_TYPE(obj);
-#if PY_MAJOR_VERSION < 3
- if (unlikely(PyInstance_Check(obj)))
- return with_error ? __Pyx_PyObject_GetAttrStr(obj, attr_name) : __Pyx_PyObject_GetAttrStrNoError(obj, attr_name);
-#endif
- res = _PyType_Lookup(tp, attr_name);
- if (likely(res)) {
- descrgetfunc f = Py_TYPE(res)->tp_descr_get;
- if (!f) {
- Py_INCREF(res);
- } else {
- res = f(res, obj, (PyObject *)tp);
- }
- } else if (with_error) {
- PyErr_SetObject(PyExc_AttributeError, attr_name);
- }
- return res;
-}
-#endif
-
-/* Py3ClassCreate */
-static PyObject *__Pyx_Py3MetaclassPrepare(PyObject *metaclass, PyObject *bases, PyObject *name,
- PyObject *qualname, PyObject *mkw, PyObject *modname, PyObject *doc) {
- PyObject *ns;
- if (metaclass) {
- PyObject *prep = __Pyx_PyObject_GetAttrStrNoError(metaclass, __pyx_n_s_prepare);
- if (prep) {
- PyObject *pargs[3] = {NULL, name, bases};
- ns = __Pyx_PyObject_FastCallDict(prep, pargs+1, 2 | __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET, mkw);
- Py_DECREF(prep);
- } else {
- if (unlikely(PyErr_Occurred()))
- return NULL;
- ns = PyDict_New();
- }
- } else {
- ns = PyDict_New();
- }
- if (unlikely(!ns))
- return NULL;
- if (unlikely(PyObject_SetItem(ns, __pyx_n_s_module, modname) < 0)) goto bad;
-#if PY_VERSION_HEX >= 0x03030000
- if (unlikely(PyObject_SetItem(ns, __pyx_n_s_qualname, qualname) < 0)) goto bad;
-#else
- CYTHON_MAYBE_UNUSED_VAR(qualname);
-#endif
- if (unlikely(doc && PyObject_SetItem(ns, __pyx_n_s_doc, doc) < 0)) goto bad;
- return ns;
-bad:
- Py_DECREF(ns);
- return NULL;
-}
-#if PY_VERSION_HEX < 0x030600A4 && CYTHON_PEP487_INIT_SUBCLASS
-static int __Pyx_SetNamesPEP487(PyObject *type_obj) {
- PyTypeObject *type = (PyTypeObject*) type_obj;
- PyObject *names_to_set, *key, *value, *set_name, *tmp;
- Py_ssize_t i = 0;
-#if CYTHON_USE_TYPE_SLOTS
- names_to_set = PyDict_Copy(type->tp_dict);
-#else
- {
- PyObject *d = PyObject_GetAttr(type_obj, __pyx_n_s_dict);
- names_to_set = NULL;
- if (likely(d)) {
- PyObject *names_to_set = PyDict_New();
- int ret = likely(names_to_set) ? PyDict_Update(names_to_set, d) : -1;
- Py_DECREF(d);
- if (unlikely(ret < 0))
- Py_CLEAR(names_to_set);
- }
- }
-#endif
- if (unlikely(names_to_set == NULL))
- goto bad;
- while (PyDict_Next(names_to_set, &i, &key, &value)) {
- set_name = __Pyx_PyObject_LookupSpecialNoError(value, __pyx_n_s_set_name);
- if (unlikely(set_name != NULL)) {
- tmp = __Pyx_PyObject_Call2Args(set_name, type_obj, key);
- Py_DECREF(set_name);
- if (unlikely(tmp == NULL)) {
- __Pyx_TypeName value_type_name =
- __Pyx_PyType_GetName(Py_TYPE(value));
- __Pyx_TypeName type_name = __Pyx_PyType_GetName(type);
- PyErr_Format(PyExc_RuntimeError,
-#if PY_MAJOR_VERSION >= 3
- "Error calling __set_name__ on '" __Pyx_FMT_TYPENAME "' instance %R " "in '" __Pyx_FMT_TYPENAME "'",
- value_type_name, key, type_name);
-#else
- "Error calling __set_name__ on '" __Pyx_FMT_TYPENAME "' instance %.100s in '" __Pyx_FMT_TYPENAME "'",
- value_type_name,
- PyString_Check(key) ? PyString_AS_STRING(key) : "?",
- type_name);
-#endif
- goto bad;
- } else {
- Py_DECREF(tmp);
- }
- }
- else if (unlikely(PyErr_Occurred())) {
- goto bad;
- }
- }
- Py_DECREF(names_to_set);
- return 0;
-bad:
- Py_XDECREF(names_to_set);
- return -1;
-}
-static PyObject *__Pyx_InitSubclassPEP487(PyObject *type_obj, PyObject *mkw) {
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- PyTypeObject *type = (PyTypeObject*) type_obj;
- PyObject *mro = type->tp_mro;
- Py_ssize_t i, nbases;
- if (unlikely(!mro)) goto done;
- (void) &__Pyx_GetBuiltinName;
- Py_INCREF(mro);
- nbases = PyTuple_GET_SIZE(mro);
- assert(PyTuple_GET_ITEM(mro, 0) == type_obj);
- for (i = 1; i < nbases-1; i++) {
- PyObject *base, *dict, *meth;
- base = PyTuple_GET_ITEM(mro, i);
- dict = ((PyTypeObject *)base)->tp_dict;
- meth = __Pyx_PyDict_GetItemStrWithError(dict, __pyx_n_s_init_subclass);
- if (unlikely(meth)) {
- descrgetfunc f = Py_TYPE(meth)->tp_descr_get;
- PyObject *res;
- Py_INCREF(meth);
- if (likely(f)) {
- res = f(meth, NULL, type_obj);
- Py_DECREF(meth);
- if (unlikely(!res)) goto bad;
- meth = res;
- }
- res = __Pyx_PyObject_FastCallDict(meth, NULL, 0, mkw);
- Py_DECREF(meth);
- if (unlikely(!res)) goto bad;
- Py_DECREF(res);
- goto done;
- } else if (unlikely(PyErr_Occurred())) {
- goto bad;
- }
- }
-done:
- Py_XDECREF(mro);
- return type_obj;
-bad:
- Py_XDECREF(mro);
- Py_DECREF(type_obj);
- return NULL;
-#else
- PyObject *super_type, *super, *func, *res;
-#if CYTHON_COMPILING_IN_PYPY && !defined(PySuper_Type)
- super_type = __Pyx_GetBuiltinName(__pyx_n_s_super);
-#else
- super_type = (PyObject*) &PySuper_Type;
- (void) &__Pyx_GetBuiltinName;
-#endif
- super = likely(super_type) ? __Pyx_PyObject_Call2Args(super_type, type_obj, type_obj) : NULL;
-#if CYTHON_COMPILING_IN_PYPY && !defined(PySuper_Type)
- Py_XDECREF(super_type);
-#endif
- if (unlikely(!super)) {
- Py_CLEAR(type_obj);
- goto done;
- }
- func = __Pyx_PyObject_GetAttrStrNoError(super, __pyx_n_s_init_subclass);
- Py_DECREF(super);
- if (likely(!func)) {
- if (unlikely(PyErr_Occurred()))
- Py_CLEAR(type_obj);
- goto done;
- }
- res = __Pyx_PyObject_FastCallDict(func, NULL, 0, mkw);
- Py_DECREF(func);
- if (unlikely(!res))
- Py_CLEAR(type_obj);
- Py_XDECREF(res);
-done:
- return type_obj;
-#endif
-}
-#endif
-static PyObject *__Pyx_Py3ClassCreate(PyObject *metaclass, PyObject *name, PyObject *bases,
- PyObject *dict, PyObject *mkw,
- int calculate_metaclass, int allow_py2_metaclass) {
- PyObject *result;
- PyObject *owned_metaclass = NULL;
- PyObject *margs[4] = {NULL, name, bases, dict};
- if (allow_py2_metaclass) {
- owned_metaclass = PyObject_GetItem(dict, __pyx_n_s_metaclass);
- if (owned_metaclass) {
- metaclass = owned_metaclass;
- } else if (likely(PyErr_ExceptionMatches(PyExc_KeyError))) {
- PyErr_Clear();
- } else {
- return NULL;
- }
- }
- if (calculate_metaclass && (!metaclass || PyType_Check(metaclass))) {
- metaclass = __Pyx_CalculateMetaclass((PyTypeObject*) metaclass, bases);
- Py_XDECREF(owned_metaclass);
- if (unlikely(!metaclass))
- return NULL;
- owned_metaclass = metaclass;
- }
- result = __Pyx_PyObject_FastCallDict(metaclass, margs+1, 3 | __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET,
-#if PY_VERSION_HEX < 0x030600A4
- (metaclass == (PyObject*)&PyType_Type) ? NULL : mkw
-#else
- mkw
-#endif
- );
- Py_XDECREF(owned_metaclass);
-#if PY_VERSION_HEX < 0x030600A4 && CYTHON_PEP487_INIT_SUBCLASS
- if (likely(result) && likely(PyType_Check(result))) {
- if (unlikely(__Pyx_SetNamesPEP487(result) < 0)) {
- Py_CLEAR(result);
- } else {
- result = __Pyx_InitSubclassPEP487(result, mkw);
- }
- }
-#else
- (void) &__Pyx_GetBuiltinName;
-#endif
- return result;
-}
-
-/* CLineInTraceback */
-#ifndef CYTHON_CLINE_IN_TRACEBACK
-static int __Pyx_CLineForTraceback(PyThreadState *tstate, int c_line) {
- PyObject *use_cline;
- PyObject *ptype, *pvalue, *ptraceback;
-#if CYTHON_COMPILING_IN_CPYTHON
- PyObject **cython_runtime_dict;
-#endif
- CYTHON_MAYBE_UNUSED_VAR(tstate);
- if (unlikely(!__pyx_cython_runtime)) {
- return c_line;
- }
- __Pyx_ErrFetchInState(tstate, &ptype, &pvalue, &ptraceback);
-#if CYTHON_COMPILING_IN_CPYTHON
- cython_runtime_dict = _PyObject_GetDictPtr(__pyx_cython_runtime);
- if (likely(cython_runtime_dict)) {
- __PYX_PY_DICT_LOOKUP_IF_MODIFIED(
- use_cline, *cython_runtime_dict,
- __Pyx_PyDict_GetItemStr(*cython_runtime_dict, __pyx_n_s_cline_in_traceback))
- } else
-#endif
- {
- PyObject *use_cline_obj = __Pyx_PyObject_GetAttrStrNoError(__pyx_cython_runtime, __pyx_n_s_cline_in_traceback);
- if (use_cline_obj) {
- use_cline = PyObject_Not(use_cline_obj) ? Py_False : Py_True;
- Py_DECREF(use_cline_obj);
- } else {
- PyErr_Clear();
- use_cline = NULL;
- }
- }
- if (!use_cline) {
- c_line = 0;
- (void) PyObject_SetAttr(__pyx_cython_runtime, __pyx_n_s_cline_in_traceback, Py_False);
- }
- else if (use_cline == Py_False || (use_cline != Py_True && PyObject_Not(use_cline) != 0)) {
- c_line = 0;
- }
- __Pyx_ErrRestoreInState(tstate, ptype, pvalue, ptraceback);
- return c_line;
-}
-#endif
-
-/* CodeObjectCache */
-#if !CYTHON_COMPILING_IN_LIMITED_API
-static int __pyx_bisect_code_objects(__Pyx_CodeObjectCacheEntry* entries, int count, int code_line) {
- int start = 0, mid = 0, end = count - 1;
- if (end >= 0 && code_line > entries[end].code_line) {
- return count;
- }
- while (start < end) {
- mid = start + (end - start) / 2;
- if (code_line < entries[mid].code_line) {
- end = mid;
- } else if (code_line > entries[mid].code_line) {
- start = mid + 1;
- } else {
- return mid;
- }
- }
- if (code_line <= entries[mid].code_line) {
- return mid;
- } else {
- return mid + 1;
- }
-}
-static PyCodeObject *__pyx_find_code_object(int code_line) {
- PyCodeObject* code_object;
- int pos;
- if (unlikely(!code_line) || unlikely(!__pyx_code_cache.entries)) {
- return NULL;
- }
- pos = __pyx_bisect_code_objects(__pyx_code_cache.entries, __pyx_code_cache.count, code_line);
- if (unlikely(pos >= __pyx_code_cache.count) || unlikely(__pyx_code_cache.entries[pos].code_line != code_line)) {
- return NULL;
- }
- code_object = __pyx_code_cache.entries[pos].code_object;
- Py_INCREF(code_object);
- return code_object;
-}
-static void __pyx_insert_code_object(int code_line, PyCodeObject* code_object) {
- int pos, i;
- __Pyx_CodeObjectCacheEntry* entries = __pyx_code_cache.entries;
- if (unlikely(!code_line)) {
- return;
- }
- if (unlikely(!entries)) {
- entries = (__Pyx_CodeObjectCacheEntry*)PyMem_Malloc(64*sizeof(__Pyx_CodeObjectCacheEntry));
- if (likely(entries)) {
- __pyx_code_cache.entries = entries;
- __pyx_code_cache.max_count = 64;
- __pyx_code_cache.count = 1;
- entries[0].code_line = code_line;
- entries[0].code_object = code_object;
- Py_INCREF(code_object);
- }
- return;
- }
- pos = __pyx_bisect_code_objects(__pyx_code_cache.entries, __pyx_code_cache.count, code_line);
- if ((pos < __pyx_code_cache.count) && unlikely(__pyx_code_cache.entries[pos].code_line == code_line)) {
- PyCodeObject* tmp = entries[pos].code_object;
- entries[pos].code_object = code_object;
- Py_DECREF(tmp);
- return;
- }
- if (__pyx_code_cache.count == __pyx_code_cache.max_count) {
- int new_max = __pyx_code_cache.max_count + 64;
- entries = (__Pyx_CodeObjectCacheEntry*)PyMem_Realloc(
- __pyx_code_cache.entries, ((size_t)new_max) * sizeof(__Pyx_CodeObjectCacheEntry));
- if (unlikely(!entries)) {
- return;
- }
- __pyx_code_cache.entries = entries;
- __pyx_code_cache.max_count = new_max;
- }
- for (i=__pyx_code_cache.count; i>pos; i--) {
- entries[i] = entries[i-1];
- }
- entries[pos].code_line = code_line;
- entries[pos].code_object = code_object;
- __pyx_code_cache.count++;
- Py_INCREF(code_object);
-}
-#endif
-
-/* AddTraceback */
-#include "compile.h"
-#include "frameobject.h"
-#include "traceback.h"
-#if PY_VERSION_HEX >= 0x030b00a6
- #ifndef Py_BUILD_CORE
- #define Py_BUILD_CORE 1
- #endif
- #include "internal/pycore_frame.h"
-#endif
-#if CYTHON_COMPILING_IN_LIMITED_API
-static void __Pyx_AddTraceback(const char *funcname, int c_line,
- int py_line, const char *filename) {
- if (c_line) {
- (void) __pyx_cfilenm;
- (void) __Pyx_CLineForTraceback(__Pyx_PyThreadState_Current, c_line);
- }
- _PyTraceback_Add(funcname, filename, py_line);
-}
-#else
-static PyCodeObject* __Pyx_CreateCodeObjectForTraceback(
- const char *funcname, int c_line,
- int py_line, const char *filename) {
- PyCodeObject *py_code = NULL;
- PyObject *py_funcname = NULL;
- #if PY_MAJOR_VERSION < 3
- PyObject *py_srcfile = NULL;
- py_srcfile = PyString_FromString(filename);
- if (!py_srcfile) goto bad;
- #endif
- if (c_line) {
- #if PY_MAJOR_VERSION < 3
- py_funcname = PyString_FromFormat( "%s (%s:%d)", funcname, __pyx_cfilenm, c_line);
- if (!py_funcname) goto bad;
- #else
- py_funcname = PyUnicode_FromFormat( "%s (%s:%d)", funcname, __pyx_cfilenm, c_line);
- if (!py_funcname) goto bad;
- funcname = PyUnicode_AsUTF8(py_funcname);
- if (!funcname) goto bad;
- #endif
- }
- else {
- #if PY_MAJOR_VERSION < 3
- py_funcname = PyString_FromString(funcname);
- if (!py_funcname) goto bad;
- #endif
- }
- #if PY_MAJOR_VERSION < 3
- py_code = __Pyx_PyCode_New(
- 0,
- 0,
- 0,
- 0,
- 0,
- 0,
- __pyx_empty_bytes, /*PyObject *code,*/
- __pyx_empty_tuple, /*PyObject *consts,*/
- __pyx_empty_tuple, /*PyObject *names,*/
- __pyx_empty_tuple, /*PyObject *varnames,*/
- __pyx_empty_tuple, /*PyObject *freevars,*/
- __pyx_empty_tuple, /*PyObject *cellvars,*/
- py_srcfile, /*PyObject *filename,*/
- py_funcname, /*PyObject *name,*/
- py_line,
- __pyx_empty_bytes /*PyObject *lnotab*/
- );
- Py_DECREF(py_srcfile);
- #else
- py_code = PyCode_NewEmpty(filename, funcname, py_line);
- #endif
- Py_XDECREF(py_funcname); // XDECREF since it's only set on Py3 if cline
- return py_code;
-bad:
- Py_XDECREF(py_funcname);
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(py_srcfile);
- #endif
- return NULL;
-}
-static void __Pyx_AddTraceback(const char *funcname, int c_line,
- int py_line, const char *filename) {
- PyCodeObject *py_code = 0;
- PyFrameObject *py_frame = 0;
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject *ptype, *pvalue, *ptraceback;
- if (c_line) {
- c_line = __Pyx_CLineForTraceback(tstate, c_line);
- }
- py_code = __pyx_find_code_object(c_line ? -c_line : py_line);
- if (!py_code) {
- __Pyx_ErrFetchInState(tstate, &ptype, &pvalue, &ptraceback);
- py_code = __Pyx_CreateCodeObjectForTraceback(
- funcname, c_line, py_line, filename);
- if (!py_code) {
- /* If the code object creation fails, then we should clear the
- fetched exception references and propagate the new exception */
- Py_XDECREF(ptype);
- Py_XDECREF(pvalue);
- Py_XDECREF(ptraceback);
- goto bad;
- }
- __Pyx_ErrRestoreInState(tstate, ptype, pvalue, ptraceback);
- __pyx_insert_code_object(c_line ? -c_line : py_line, py_code);
- }
- py_frame = PyFrame_New(
- tstate, /*PyThreadState *tstate,*/
- py_code, /*PyCodeObject *code,*/
- __pyx_d, /*PyObject *globals,*/
- 0 /*PyObject *locals*/
- );
- if (!py_frame) goto bad;
- __Pyx_PyFrame_SetLineNumber(py_frame, py_line);
- PyTraceBack_Here(py_frame);
-bad:
- Py_XDECREF(py_code);
- Py_XDECREF(py_frame);
-}
-#endif
-
-/* FormatTypeName */
-#if CYTHON_COMPILING_IN_LIMITED_API
-static __Pyx_TypeName
-__Pyx_PyType_GetName(PyTypeObject* tp)
-{
- PyObject *name = __Pyx_PyObject_GetAttrStr((PyObject *)tp,
- __pyx_n_s_name);
- if (unlikely(name == NULL) || unlikely(!PyUnicode_Check(name))) {
- PyErr_Clear();
- Py_XSETREF(name, __Pyx_NewRef(__pyx_n_s__16));
- }
- return name;
-}
-#endif
-
-/* CIntToPy */
-static CYTHON_INLINE PyObject* __Pyx_PyInt_From_long(long value) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const long neg_one = (long) -1, const_zero = (long) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
- if (is_unsigned) {
- if (sizeof(long) < sizeof(long)) {
- return PyInt_FromLong((long) value);
- } else if (sizeof(long) <= sizeof(unsigned long)) {
- return PyLong_FromUnsignedLong((unsigned long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(unsigned PY_LONG_LONG)) {
- return PyLong_FromUnsignedLongLong((unsigned PY_LONG_LONG) value);
-#endif
- }
- } else {
- if (sizeof(long) <= sizeof(long)) {
- return PyInt_FromLong((long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(PY_LONG_LONG)) {
- return PyLong_FromLongLong((PY_LONG_LONG) value);
-#endif
- }
- }
- {
- int one = 1; int little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&value;
- return _PyLong_FromByteArray(bytes, sizeof(long),
- little, !is_unsigned);
- }
-}
-
-/* CIntFromPyVerify */
-#define __PYX_VERIFY_RETURN_INT(target_type, func_type, func_value)\
- __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, 0)
-#define __PYX_VERIFY_RETURN_INT_EXC(target_type, func_type, func_value)\
- __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, 1)
-#define __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, exc)\
- {\
- func_type value = func_value;\
- if (sizeof(target_type) < sizeof(func_type)) {\
- if (unlikely(value != (func_type) (target_type) value)) {\
- func_type zero = 0;\
- if (exc && unlikely(value == (func_type)-1 && PyErr_Occurred()))\
- return (target_type) -1;\
- if (is_unsigned && unlikely(value < zero))\
- goto raise_neg_overflow;\
- else\
- goto raise_overflow;\
- }\
- }\
- return (target_type) value;\
- }
-
-/* CIntFromPy */
-static CYTHON_INLINE long __Pyx_PyInt_As_long(PyObject *x) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const long neg_one = (long) -1, const_zero = (long) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x))) {
- if ((sizeof(long) < sizeof(long))) {
- __PYX_VERIFY_RETURN_INT(long, long, PyInt_AS_LONG(x))
- } else {
- long val = PyInt_AS_LONG(x);
- if (is_unsigned && unlikely(val < 0)) {
- goto raise_neg_overflow;
- }
- return (long) val;
- }
- } else
-#endif
- if (likely(PyLong_Check(x))) {
- if (is_unsigned) {
-#if CYTHON_USE_PYLONG_INTERNALS
- if (unlikely(__Pyx_PyLong_IsNeg(x))) {
- goto raise_neg_overflow;
- } else if (__Pyx_PyLong_IsCompact(x)) {
- __PYX_VERIFY_RETURN_INT(long, __Pyx_compact_upylong, __Pyx_PyLong_CompactValueUnsigned(x))
- } else {
- const digit* digits = __Pyx_PyLong_Digits(x);
- assert(__Pyx_PyLong_DigitCount(x) > 1);
- switch (__Pyx_PyLong_DigitCount(x)) {
- case 2:
- if ((8 * sizeof(long) > 1 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 2 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) >= 2 * PyLong_SHIFT)) {
- return (long) (((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- case 3:
- if ((8 * sizeof(long) > 2 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 3 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) >= 3 * PyLong_SHIFT)) {
- return (long) (((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- case 4:
- if ((8 * sizeof(long) > 3 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 4 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) >= 4 * PyLong_SHIFT)) {
- return (long) (((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- }
- }
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX < 0x030C00A7
- if (unlikely(Py_SIZE(x) < 0)) {
- goto raise_neg_overflow;
- }
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (long) -1;
- if (unlikely(result == 1))
- goto raise_neg_overflow;
- }
-#endif
- if ((sizeof(long) <= sizeof(unsigned long))) {
- __PYX_VERIFY_RETURN_INT_EXC(long, unsigned long, PyLong_AsUnsignedLong(x))
-#ifdef HAVE_LONG_LONG
- } else if ((sizeof(long) <= sizeof(unsigned PY_LONG_LONG))) {
- __PYX_VERIFY_RETURN_INT_EXC(long, unsigned PY_LONG_LONG, PyLong_AsUnsignedLongLong(x))
-#endif
- }
- } else {
-#if CYTHON_USE_PYLONG_INTERNALS
- if (__Pyx_PyLong_IsCompact(x)) {
- __PYX_VERIFY_RETURN_INT(long, __Pyx_compact_pylong, __Pyx_PyLong_CompactValue(x))
- } else {
- const digit* digits = __Pyx_PyLong_Digits(x);
- assert(__Pyx_PyLong_DigitCount(x) > 1);
- switch (__Pyx_PyLong_SignedDigitCount(x)) {
- case -2:
- if ((8 * sizeof(long) - 1 > 1 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 2 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) - 1 > 2 * PyLong_SHIFT)) {
- return (long) (((long)-1)*(((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 2:
- if ((8 * sizeof(long) > 1 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 2 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) - 1 > 2 * PyLong_SHIFT)) {
- return (long) ((((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case -3:
- if ((8 * sizeof(long) - 1 > 2 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 3 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) - 1 > 3 * PyLong_SHIFT)) {
- return (long) (((long)-1)*(((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 3:
- if ((8 * sizeof(long) > 2 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 3 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) - 1 > 3 * PyLong_SHIFT)) {
- return (long) ((((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case -4:
- if ((8 * sizeof(long) - 1 > 3 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 4 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) - 1 > 4 * PyLong_SHIFT)) {
- return (long) (((long)-1)*(((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 4:
- if ((8 * sizeof(long) > 3 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 4 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(long) - 1 > 4 * PyLong_SHIFT)) {
- return (long) ((((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- }
- }
-#endif
- if ((sizeof(long) <= sizeof(long))) {
- __PYX_VERIFY_RETURN_INT_EXC(long, long, PyLong_AsLong(x))
-#ifdef HAVE_LONG_LONG
- } else if ((sizeof(long) <= sizeof(PY_LONG_LONG))) {
- __PYX_VERIFY_RETURN_INT_EXC(long, PY_LONG_LONG, PyLong_AsLongLong(x))
-#endif
- }
- }
- {
- long val;
- PyObject *v = __Pyx_PyNumber_IntOrLong(x);
-#if PY_MAJOR_VERSION < 3
- if (likely(v) && !PyLong_Check(v)) {
- PyObject *tmp = v;
- v = PyNumber_Long(tmp);
- Py_DECREF(tmp);
- }
-#endif
- if (likely(v)) {
- int ret = -1;
-#if !(CYTHON_COMPILING_IN_PYPY || CYTHON_COMPILING_IN_LIMITED_API) || defined(_PyLong_AsByteArray)
- int one = 1; int is_little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&val;
- ret = _PyLong_AsByteArray((PyLongObject *)v,
- bytes, sizeof(val),
- is_little, !is_unsigned);
-#else
- PyObject *stepval = NULL, *mask = NULL, *shift = NULL;
- int bits, remaining_bits, is_negative = 0;
- long idigit;
- int chunk_size = (sizeof(long) < 8) ? 30 : 62;
- if (unlikely(!PyLong_CheckExact(v))) {
- PyObject *tmp = v;
- v = PyNumber_Long(v);
- assert(PyLong_CheckExact(v));
- Py_DECREF(tmp);
- if (unlikely(!v)) return (long) -1;
- }
-#if CYTHON_COMPILING_IN_LIMITED_API && PY_VERSION_HEX < 0x030B0000
- if (Py_SIZE(x) == 0)
- return (long) 0;
- is_negative = Py_SIZE(x) < 0;
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (long) -1;
- is_negative = result == 1;
- }
-#endif
- if (is_unsigned && unlikely(is_negative)) {
- goto raise_neg_overflow;
- } else if (is_negative) {
- stepval = PyNumber_Invert(v);
- if (unlikely(!stepval))
- return (long) -1;
- } else {
- stepval = __Pyx_NewRef(v);
- }
- val = (long) 0;
- mask = PyLong_FromLong((1L << chunk_size) - 1); if (unlikely(!mask)) goto done;
- shift = PyLong_FromLong(chunk_size); if (unlikely(!shift)) goto done;
- for (bits = 0; bits < (int) sizeof(long) * 8 - chunk_size; bits += chunk_size) {
- PyObject *tmp, *digit;
- digit = PyNumber_And(stepval, mask);
- if (unlikely(!digit)) goto done;
- idigit = PyLong_AsLong(digit);
- Py_DECREF(digit);
- if (unlikely(idigit < 0)) goto done;
- tmp = PyNumber_Rshift(stepval, shift);
- if (unlikely(!tmp)) goto done;
- Py_DECREF(stepval); stepval = tmp;
- val |= ((long) idigit) << bits;
- #if CYTHON_COMPILING_IN_LIMITED_API && PY_VERSION_HEX < 0x030B0000
- if (Py_SIZE(stepval) == 0)
- goto unpacking_done;
- #endif
- }
- idigit = PyLong_AsLong(stepval);
- if (unlikely(idigit < 0)) goto done;
- remaining_bits = ((int) sizeof(long) * 8) - bits - (is_unsigned ? 0 : 1);
- if (unlikely(idigit >= (1L << remaining_bits)))
- goto raise_overflow;
- val |= ((long) idigit) << bits;
- #if CYTHON_COMPILING_IN_LIMITED_API && PY_VERSION_HEX < 0x030B0000
- unpacking_done:
- #endif
- if (!is_unsigned) {
- if (unlikely(val & (((long) 1) << (sizeof(long) * 8 - 1))))
- goto raise_overflow;
- if (is_negative)
- val = ~val;
- }
- ret = 0;
- done:
- Py_XDECREF(shift);
- Py_XDECREF(mask);
- Py_XDECREF(stepval);
-#endif
- Py_DECREF(v);
- if (likely(!ret))
- return val;
- }
- return (long) -1;
- }
- } else {
- long val;
- PyObject *tmp = __Pyx_PyNumber_IntOrLong(x);
- if (!tmp) return (long) -1;
- val = __Pyx_PyInt_As_long(tmp);
- Py_DECREF(tmp);
- return val;
- }
-raise_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "value too large to convert to long");
- return (long) -1;
-raise_neg_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "can't convert negative value to long");
- return (long) -1;
-}
-
-/* CIntFromPy */
-static CYTHON_INLINE int __Pyx_PyInt_As_int(PyObject *x) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const int neg_one = (int) -1, const_zero = (int) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x))) {
- if ((sizeof(int) < sizeof(long))) {
- __PYX_VERIFY_RETURN_INT(int, long, PyInt_AS_LONG(x))
- } else {
- long val = PyInt_AS_LONG(x);
- if (is_unsigned && unlikely(val < 0)) {
- goto raise_neg_overflow;
- }
- return (int) val;
- }
- } else
-#endif
- if (likely(PyLong_Check(x))) {
- if (is_unsigned) {
-#if CYTHON_USE_PYLONG_INTERNALS
- if (unlikely(__Pyx_PyLong_IsNeg(x))) {
- goto raise_neg_overflow;
- } else if (__Pyx_PyLong_IsCompact(x)) {
- __PYX_VERIFY_RETURN_INT(int, __Pyx_compact_upylong, __Pyx_PyLong_CompactValueUnsigned(x))
- } else {
- const digit* digits = __Pyx_PyLong_Digits(x);
- assert(__Pyx_PyLong_DigitCount(x) > 1);
- switch (__Pyx_PyLong_DigitCount(x)) {
- case 2:
- if ((8 * sizeof(int) > 1 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 2 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) >= 2 * PyLong_SHIFT)) {
- return (int) (((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- case 3:
- if ((8 * sizeof(int) > 2 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 3 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) >= 3 * PyLong_SHIFT)) {
- return (int) (((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- case 4:
- if ((8 * sizeof(int) > 3 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 4 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) >= 4 * PyLong_SHIFT)) {
- return (int) (((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- }
- }
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX < 0x030C00A7
- if (unlikely(Py_SIZE(x) < 0)) {
- goto raise_neg_overflow;
- }
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (int) -1;
- if (unlikely(result == 1))
- goto raise_neg_overflow;
- }
-#endif
- if ((sizeof(int) <= sizeof(unsigned long))) {
- __PYX_VERIFY_RETURN_INT_EXC(int, unsigned long, PyLong_AsUnsignedLong(x))
-#ifdef HAVE_LONG_LONG
- } else if ((sizeof(int) <= sizeof(unsigned PY_LONG_LONG))) {
- __PYX_VERIFY_RETURN_INT_EXC(int, unsigned PY_LONG_LONG, PyLong_AsUnsignedLongLong(x))
-#endif
- }
- } else {
-#if CYTHON_USE_PYLONG_INTERNALS
- if (__Pyx_PyLong_IsCompact(x)) {
- __PYX_VERIFY_RETURN_INT(int, __Pyx_compact_pylong, __Pyx_PyLong_CompactValue(x))
- } else {
- const digit* digits = __Pyx_PyLong_Digits(x);
- assert(__Pyx_PyLong_DigitCount(x) > 1);
- switch (__Pyx_PyLong_SignedDigitCount(x)) {
- case -2:
- if ((8 * sizeof(int) - 1 > 1 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 2 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) - 1 > 2 * PyLong_SHIFT)) {
- return (int) (((int)-1)*(((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 2:
- if ((8 * sizeof(int) > 1 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 2 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) - 1 > 2 * PyLong_SHIFT)) {
- return (int) ((((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case -3:
- if ((8 * sizeof(int) - 1 > 2 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 3 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) - 1 > 3 * PyLong_SHIFT)) {
- return (int) (((int)-1)*(((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 3:
- if ((8 * sizeof(int) > 2 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 3 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) - 1 > 3 * PyLong_SHIFT)) {
- return (int) ((((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case -4:
- if ((8 * sizeof(int) - 1 > 3 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 4 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) - 1 > 4 * PyLong_SHIFT)) {
- return (int) (((int)-1)*(((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 4:
- if ((8 * sizeof(int) > 3 * PyLong_SHIFT)) {
- if ((8 * sizeof(unsigned long) > 4 * PyLong_SHIFT)) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if ((8 * sizeof(int) - 1 > 4 * PyLong_SHIFT)) {
- return (int) ((((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- }
- }
-#endif
- if ((sizeof(int) <= sizeof(long))) {
- __PYX_VERIFY_RETURN_INT_EXC(int, long, PyLong_AsLong(x))
-#ifdef HAVE_LONG_LONG
- } else if ((sizeof(int) <= sizeof(PY_LONG_LONG))) {
- __PYX_VERIFY_RETURN_INT_EXC(int, PY_LONG_LONG, PyLong_AsLongLong(x))
-#endif
- }
- }
- {
- int val;
- PyObject *v = __Pyx_PyNumber_IntOrLong(x);
-#if PY_MAJOR_VERSION < 3
- if (likely(v) && !PyLong_Check(v)) {
- PyObject *tmp = v;
- v = PyNumber_Long(tmp);
- Py_DECREF(tmp);
- }
-#endif
- if (likely(v)) {
- int ret = -1;
-#if !(CYTHON_COMPILING_IN_PYPY || CYTHON_COMPILING_IN_LIMITED_API) || defined(_PyLong_AsByteArray)
- int one = 1; int is_little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&val;
- ret = _PyLong_AsByteArray((PyLongObject *)v,
- bytes, sizeof(val),
- is_little, !is_unsigned);
-#else
- PyObject *stepval = NULL, *mask = NULL, *shift = NULL;
- int bits, remaining_bits, is_negative = 0;
- long idigit;
- int chunk_size = (sizeof(long) < 8) ? 30 : 62;
- if (unlikely(!PyLong_CheckExact(v))) {
- PyObject *tmp = v;
- v = PyNumber_Long(v);
- assert(PyLong_CheckExact(v));
- Py_DECREF(tmp);
- if (unlikely(!v)) return (int) -1;
- }
-#if CYTHON_COMPILING_IN_LIMITED_API && PY_VERSION_HEX < 0x030B0000
- if (Py_SIZE(x) == 0)
- return (int) 0;
- is_negative = Py_SIZE(x) < 0;
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (int) -1;
- is_negative = result == 1;
- }
-#endif
- if (is_unsigned && unlikely(is_negative)) {
- goto raise_neg_overflow;
- } else if (is_negative) {
- stepval = PyNumber_Invert(v);
- if (unlikely(!stepval))
- return (int) -1;
- } else {
- stepval = __Pyx_NewRef(v);
- }
- val = (int) 0;
- mask = PyLong_FromLong((1L << chunk_size) - 1); if (unlikely(!mask)) goto done;
- shift = PyLong_FromLong(chunk_size); if (unlikely(!shift)) goto done;
- for (bits = 0; bits < (int) sizeof(int) * 8 - chunk_size; bits += chunk_size) {
- PyObject *tmp, *digit;
- digit = PyNumber_And(stepval, mask);
- if (unlikely(!digit)) goto done;
- idigit = PyLong_AsLong(digit);
- Py_DECREF(digit);
- if (unlikely(idigit < 0)) goto done;
- tmp = PyNumber_Rshift(stepval, shift);
- if (unlikely(!tmp)) goto done;
- Py_DECREF(stepval); stepval = tmp;
- val |= ((int) idigit) << bits;
- #if CYTHON_COMPILING_IN_LIMITED_API && PY_VERSION_HEX < 0x030B0000
- if (Py_SIZE(stepval) == 0)
- goto unpacking_done;
- #endif
- }
- idigit = PyLong_AsLong(stepval);
- if (unlikely(idigit < 0)) goto done;
- remaining_bits = ((int) sizeof(int) * 8) - bits - (is_unsigned ? 0 : 1);
- if (unlikely(idigit >= (1L << remaining_bits)))
- goto raise_overflow;
- val |= ((int) idigit) << bits;
- #if CYTHON_COMPILING_IN_LIMITED_API && PY_VERSION_HEX < 0x030B0000
- unpacking_done:
- #endif
- if (!is_unsigned) {
- if (unlikely(val & (((int) 1) << (sizeof(int) * 8 - 1))))
- goto raise_overflow;
- if (is_negative)
- val = ~val;
- }
- ret = 0;
- done:
- Py_XDECREF(shift);
- Py_XDECREF(mask);
- Py_XDECREF(stepval);
-#endif
- Py_DECREF(v);
- if (likely(!ret))
- return val;
- }
- return (int) -1;
- }
- } else {
- int val;
- PyObject *tmp = __Pyx_PyNumber_IntOrLong(x);
- if (!tmp) return (int) -1;
- val = __Pyx_PyInt_As_int(tmp);
- Py_DECREF(tmp);
- return val;
- }
-raise_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "value too large to convert to int");
- return (int) -1;
-raise_neg_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "can't convert negative value to int");
- return (int) -1;
-}
-
-/* CheckBinaryVersion */
-static int __Pyx_check_binary_version(void) {
- char ctversion[5];
- int same=1, i, found_dot;
- const char* rt_from_call = Py_GetVersion();
- PyOS_snprintf(ctversion, 5, "%d.%d", PY_MAJOR_VERSION, PY_MINOR_VERSION);
- found_dot = 0;
- for (i = 0; i < 4; i++) {
- if (!ctversion[i]) {
- same = (rt_from_call[i] < '0' || rt_from_call[i] > '9');
- break;
- }
- if (rt_from_call[i] != ctversion[i]) {
- same = 0;
- break;
- }
- }
- if (!same) {
- char rtversion[5] = {'\0'};
- char message[200];
- for (i=0; i<4; ++i) {
- if (rt_from_call[i] == '.') {
- if (found_dot) break;
- found_dot = 1;
- } else if (rt_from_call[i] < '0' || rt_from_call[i] > '9') {
- break;
- }
- rtversion[i] = rt_from_call[i];
- }
- PyOS_snprintf(message, sizeof(message),
- "compile time version %s of module '%.100s' "
- "does not match runtime version %s",
- ctversion, __Pyx_MODULE_NAME, rtversion);
- return PyErr_WarnEx(NULL, message, 1);
- }
- return 0;
-}
-
-/* InitStrings */
-#if PY_MAJOR_VERSION >= 3
-static int __Pyx_InitString(__Pyx_StringTabEntry t, PyObject **str) {
- if (t.is_unicode | t.is_str) {
- if (t.intern) {
- *str = PyUnicode_InternFromString(t.s);
- } else if (t.encoding) {
- *str = PyUnicode_Decode(t.s, t.n - 1, t.encoding, NULL);
- } else {
- *str = PyUnicode_FromStringAndSize(t.s, t.n - 1);
- }
- } else {
- *str = PyBytes_FromStringAndSize(t.s, t.n - 1);
- }
- if (!*str)
- return -1;
- if (PyObject_Hash(*str) == -1)
- return -1;
- return 0;
-}
-#endif
-static int __Pyx_InitStrings(__Pyx_StringTabEntry *t) {
- while (t->p) {
- #if PY_MAJOR_VERSION >= 3
- __Pyx_InitString(*t, t->p);
- #else
- if (t->is_unicode) {
- *t->p = PyUnicode_DecodeUTF8(t->s, t->n - 1, NULL);
- } else if (t->intern) {
- *t->p = PyString_InternFromString(t->s);
- } else {
- *t->p = PyString_FromStringAndSize(t->s, t->n - 1);
- }
- if (!*t->p)
- return -1;
- if (PyObject_Hash(*t->p) == -1)
- return -1;
- #endif
- ++t;
- }
- return 0;
-}
-
-static CYTHON_INLINE PyObject* __Pyx_PyUnicode_FromString(const char* c_str) {
- return __Pyx_PyUnicode_FromStringAndSize(c_str, (Py_ssize_t)strlen(c_str));
-}
-static CYTHON_INLINE const char* __Pyx_PyObject_AsString(PyObject* o) {
- Py_ssize_t ignore;
- return __Pyx_PyObject_AsStringAndSize(o, &ignore);
-}
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
-#if !CYTHON_PEP393_ENABLED
-static const char* __Pyx_PyUnicode_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
- char* defenc_c;
- PyObject* defenc = _PyUnicode_AsDefaultEncodedString(o, NULL);
- if (!defenc) return NULL;
- defenc_c = PyBytes_AS_STRING(defenc);
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- {
- char* end = defenc_c + PyBytes_GET_SIZE(defenc);
- char* c;
- for (c = defenc_c; c < end; c++) {
- if ((unsigned char) (*c) >= 128) {
- PyUnicode_AsASCIIString(o);
- return NULL;
- }
- }
- }
-#endif
- *length = PyBytes_GET_SIZE(defenc);
- return defenc_c;
-}
-#else
-static CYTHON_INLINE const char* __Pyx_PyUnicode_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
- if (unlikely(__Pyx_PyUnicode_READY(o) == -1)) return NULL;
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- if (likely(PyUnicode_IS_ASCII(o))) {
- *length = PyUnicode_GET_LENGTH(o);
- return PyUnicode_AsUTF8(o);
- } else {
- PyUnicode_AsASCIIString(o);
- return NULL;
- }
-#else
- return PyUnicode_AsUTF8AndSize(o, length);
-#endif
-}
-#endif
-#endif
-static CYTHON_INLINE const char* __Pyx_PyObject_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
- if (
-#if PY_MAJOR_VERSION < 3 && __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- __Pyx_sys_getdefaultencoding_not_ascii &&
-#endif
- PyUnicode_Check(o)) {
- return __Pyx_PyUnicode_AsStringAndSize(o, length);
- } else
-#endif
-#if (!CYTHON_COMPILING_IN_PYPY && !CYTHON_COMPILING_IN_LIMITED_API) || (defined(PyByteArray_AS_STRING) && defined(PyByteArray_GET_SIZE))
- if (PyByteArray_Check(o)) {
- *length = PyByteArray_GET_SIZE(o);
- return PyByteArray_AS_STRING(o);
- } else
-#endif
- {
- char* result;
- int r = PyBytes_AsStringAndSize(o, &result, length);
- if (unlikely(r < 0)) {
- return NULL;
- } else {
- return result;
- }
- }
-}
-static CYTHON_INLINE int __Pyx_PyObject_IsTrue(PyObject* x) {
- int is_true = x == Py_True;
- if (is_true | (x == Py_False) | (x == Py_None)) return is_true;
- else return PyObject_IsTrue(x);
-}
-static CYTHON_INLINE int __Pyx_PyObject_IsTrueAndDecref(PyObject* x) {
- int retval;
- if (unlikely(!x)) return -1;
- retval = __Pyx_PyObject_IsTrue(x);
- Py_DECREF(x);
- return retval;
-}
-static PyObject* __Pyx_PyNumber_IntOrLongWrongResultType(PyObject* result, const char* type_name) {
- __Pyx_TypeName result_type_name = __Pyx_PyType_GetName(Py_TYPE(result));
-#if PY_MAJOR_VERSION >= 3
- if (PyLong_Check(result)) {
- if (PyErr_WarnFormat(PyExc_DeprecationWarning, 1,
- "__int__ returned non-int (type " __Pyx_FMT_TYPENAME "). "
- "The ability to return an instance of a strict subclass of int is deprecated, "
- "and may be removed in a future version of Python.",
- result_type_name)) {
- __Pyx_DECREF_TypeName(result_type_name);
- Py_DECREF(result);
- return NULL;
- }
- __Pyx_DECREF_TypeName(result_type_name);
- return result;
- }
-#endif
- PyErr_Format(PyExc_TypeError,
- "__%.4s__ returned non-%.4s (type " __Pyx_FMT_TYPENAME ")",
- type_name, type_name, result_type_name);
- __Pyx_DECREF_TypeName(result_type_name);
- Py_DECREF(result);
- return NULL;
-}
-static CYTHON_INLINE PyObject* __Pyx_PyNumber_IntOrLong(PyObject* x) {
-#if CYTHON_USE_TYPE_SLOTS
- PyNumberMethods *m;
-#endif
- const char *name = NULL;
- PyObject *res = NULL;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x) || PyLong_Check(x)))
-#else
- if (likely(PyLong_Check(x)))
-#endif
- return __Pyx_NewRef(x);
-#if CYTHON_USE_TYPE_SLOTS
- m = Py_TYPE(x)->tp_as_number;
- #if PY_MAJOR_VERSION < 3
- if (m && m->nb_int) {
- name = "int";
- res = m->nb_int(x);
- }
- else if (m && m->nb_long) {
- name = "long";
- res = m->nb_long(x);
- }
- #else
- if (likely(m && m->nb_int)) {
- name = "int";
- res = m->nb_int(x);
- }
- #endif
-#else
- if (!PyBytes_CheckExact(x) && !PyUnicode_CheckExact(x)) {
- res = PyNumber_Int(x);
- }
-#endif
- if (likely(res)) {
-#if PY_MAJOR_VERSION < 3
- if (unlikely(!PyInt_Check(res) && !PyLong_Check(res))) {
-#else
- if (unlikely(!PyLong_CheckExact(res))) {
-#endif
- return __Pyx_PyNumber_IntOrLongWrongResultType(res, name);
- }
- }
- else if (!PyErr_Occurred()) {
- PyErr_SetString(PyExc_TypeError,
- "an integer is required");
- }
- return res;
-}
-static CYTHON_INLINE Py_ssize_t __Pyx_PyIndex_AsSsize_t(PyObject* b) {
- Py_ssize_t ival;
- PyObject *x;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_CheckExact(b))) {
- if (sizeof(Py_ssize_t) >= sizeof(long))
- return PyInt_AS_LONG(b);
- else
- return PyInt_AsSsize_t(b);
- }
-#endif
- if (likely(PyLong_CheckExact(b))) {
- #if CYTHON_USE_PYLONG_INTERNALS
- if (likely(__Pyx_PyLong_IsCompact(b))) {
- return __Pyx_PyLong_CompactValue(b);
- } else {
- const digit* digits = __Pyx_PyLong_Digits(b);
- const Py_ssize_t size = __Pyx_PyLong_SignedDigitCount(b);
- switch (size) {
- case 2:
- if (8 * sizeof(Py_ssize_t) > 2 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -2:
- if (8 * sizeof(Py_ssize_t) > 2 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case 3:
- if (8 * sizeof(Py_ssize_t) > 3 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((((size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -3:
- if (8 * sizeof(Py_ssize_t) > 3 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((((size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case 4:
- if (8 * sizeof(Py_ssize_t) > 4 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((((((size_t)digits[3]) << PyLong_SHIFT) | (size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -4:
- if (8 * sizeof(Py_ssize_t) > 4 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((((((size_t)digits[3]) << PyLong_SHIFT) | (size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- }
- }
- #endif
- return PyLong_AsSsize_t(b);
- }
- x = PyNumber_Index(b);
- if (!x) return -1;
- ival = PyInt_AsSsize_t(x);
- Py_DECREF(x);
- return ival;
-}
-static CYTHON_INLINE Py_hash_t __Pyx_PyIndex_AsHash_t(PyObject* o) {
- if (sizeof(Py_hash_t) == sizeof(Py_ssize_t)) {
- return (Py_hash_t) __Pyx_PyIndex_AsSsize_t(o);
-#if PY_MAJOR_VERSION < 3
- } else if (likely(PyInt_CheckExact(o))) {
- return PyInt_AS_LONG(o);
-#endif
- } else {
- Py_ssize_t ival;
- PyObject *x;
- x = PyNumber_Index(o);
- if (!x) return -1;
- ival = PyInt_AsLong(x);
- Py_DECREF(x);
- return ival;
- }
-}
-static CYTHON_INLINE PyObject * __Pyx_PyBool_FromLong(long b) {
- return b ? __Pyx_NewRef(Py_True) : __Pyx_NewRef(Py_False);
-}
-static CYTHON_INLINE PyObject * __Pyx_PyInt_FromSize_t(size_t ival) {
- return PyInt_FromSize_t(ival);
-}
-
-
-/* #### Code section: utility_code_pragmas_end ### */
-#ifdef _MSC_VER
-#pragma warning( pop )
-#endif
-
-
-
-/* #### Code section: end ### */
-#endif /* Py_PYTHON_H */
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/components/model3d.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/components/model3d.py
deleted file mode 100644
index aed05a215df88747e60450bbe8e16b38dce60598..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/components/model3d.py
+++ /dev/null
@@ -1,155 +0,0 @@
-"""gr.Model3D() component."""
-
-from __future__ import annotations
-
-from pathlib import Path
-from typing import Any, Callable, Literal
-
-from gradio_client import media_data
-from gradio_client.documentation import document, set_documentation_group
-from gradio_client.serializing import FileSerializable
-
-from gradio.components.base import IOComponent, _Keywords
-from gradio.events import (
- Changeable,
- Clearable,
- Editable,
- Uploadable,
-)
-
-set_documentation_group("component")
-
-
-@document()
-class Model3D(
- Changeable, Uploadable, Editable, Clearable, IOComponent, FileSerializable
-):
- """
- Component allows users to upload or view 3D Model files (.obj, .glb, or .gltf).
- Preprocessing: This component passes the uploaded file as a {str}filepath.
- Postprocessing: expects function to return a {str} or {pathlib.Path} filepath of type (.obj, glb, or .gltf)
-
- Demos: model3D
- Guides: how-to-use-3D-model-component
- """
-
- def __init__(
- self,
- value: str | Callable | None = None,
- *,
- clear_color: list[float] | None = None,
- label: str | None = None,
- every: float | None = None,
- show_label: bool | None = None,
- container: bool = True,
- scale: int | None = None,
- min_width: int = 160,
- visible: bool = True,
- elem_id: str | None = None,
- elem_classes: list[str] | str | None = None,
- **kwargs,
- ):
- """
- Parameters:
- value: path to (.obj, glb, or .gltf) file to show in model3D viewer. If callable, the function will be called whenever the app loads to set the initial value of the component.
- clear_color: background color of scene
- label: component name in interface.
- every: If `value` is a callable, run the function 'every' number of seconds while the client connection is open. Has no effect otherwise. Queue must be enabled. The event can be accessed (e.g. to cancel it) via this component's .load_event attribute.
- show_label: if True, will display label.
- container: If True, will place the component in a container - providing some extra padding around the border.
- scale: relative width compared to adjacent Components in a Row. For example, if Component A has scale=2, and Component B has scale=1, A will be twice as wide as B. Should be an integer.
- min_width: minimum pixel width, will wrap if not sufficient screen space to satisfy this value. If a certain scale value results in this Component being narrower than min_width, the min_width parameter will be respected first.
- visible: If False, component will be hidden.
- elem_id: An optional string that is assigned as the id of this component in the HTML DOM. Can be used for targeting CSS styles.
- elem_classes: An optional list of strings that are assigned as the classes of this component in the HTML DOM. Can be used for targeting CSS styles.
- """
- self.clear_color = clear_color or [0, 0, 0, 0]
- IOComponent.__init__(
- self,
- label=label,
- every=every,
- show_label=show_label,
- container=container,
- scale=scale,
- min_width=min_width,
- visible=visible,
- elem_id=elem_id,
- elem_classes=elem_classes,
- value=value,
- **kwargs,
- )
-
- def get_config(self):
- return {
- "clearColor": self.clear_color,
- "value": self.value,
- **IOComponent.get_config(self),
- }
-
- def example_inputs(self) -> dict[str, Any]:
- return {
- "raw": {"is_file": False, "data": media_data.BASE64_MODEL3D},
- "serialized": "https://github.com/gradio-app/gradio/raw/main/test/test_files/Box.gltf",
- }
-
- @staticmethod
- def update(
- value: Any | Literal[_Keywords.NO_VALUE] | None = _Keywords.NO_VALUE,
- label: str | None = None,
- show_label: bool | None = None,
- container: bool | None = None,
- scale: int | None = None,
- min_width: int | None = None,
- visible: bool | None = None,
- ):
- updated_config = {
- "label": label,
- "show_label": show_label,
- "container": container,
- "scale": scale,
- "min_width": min_width,
- "visible": visible,
- "value": value,
- "__type__": "update",
- }
- return updated_config
-
- def preprocess(self, x: dict[str, str] | None) -> str | None:
- """
- Parameters:
- x: JSON object with filename as 'name' property and base64 data as 'data' property
- Returns:
- string file path to temporary file with the 3D image model
- """
- if x is None:
- return x
- file_name, file_data, is_file = (
- x["name"],
- x["data"],
- x.get("is_file", False),
- )
- if is_file:
- temp_file_path = self.make_temp_copy_if_needed(file_name)
- else:
- temp_file_path = self.base64_to_temp_file_if_needed(file_data, file_name)
-
- return temp_file_path
-
- def postprocess(self, y: str | Path | None) -> dict[str, str] | None:
- """
- Parameters:
- y: path to the model
- Returns:
- file name mapped to base64 url data
- """
- if y is None:
- return y
- data = {
- "name": self.make_temp_copy_if_needed(y),
- "data": None,
- "is_file": True,
- }
- return data
-
- def as_example(self, input_data: str | None) -> str:
- return Path(input_data).name if input_data else ""
diff --git a/spaces/declare-lab/tango/diffusers/examples/research_projects/mulit_token_textual_inversion/multi_token_clip.py b/spaces/declare-lab/tango/diffusers/examples/research_projects/mulit_token_textual_inversion/multi_token_clip.py
deleted file mode 100644
index 4388771b840df36ffa3a986dc9a2ad81ac7ee425..0000000000000000000000000000000000000000
--- a/spaces/declare-lab/tango/diffusers/examples/research_projects/mulit_token_textual_inversion/multi_token_clip.py
+++ /dev/null
@@ -1,103 +0,0 @@
-"""
-The main idea for this code is to provide a way for users to not need to bother with the hassle of multiple tokens for a concept by typing
-a photo of _0 _1 ... and so on
-and instead just do
-a photo of
-which gets translated to the above. This needs to work for both inference and training.
-For inference,
-the tokenizer encodes the text. So, we would want logic for our tokenizer to replace the placeholder token with
-it's underlying vectors
-For training,
-we would want to abstract away some logic like
-1. Adding tokens
-2. Updating gradient mask
-3. Saving embeddings
-to our Util class here.
-so
-TODO:
-1. have tokenizer keep track of concept, multiconcept pairs and replace during encode call x
-2. have mechanism for adding tokens x
-3. have mech for saving emebeddings x
-4. get mask to update x
-5. Loading tokens from embedding x
-6. Integrate to training x
-7. Test
-"""
-import copy
-import random
-
-from transformers import CLIPTokenizer
-
-
-class MultiTokenCLIPTokenizer(CLIPTokenizer):
- def __init__(self, *args, **kwargs):
- super().__init__(*args, **kwargs)
- self.token_map = {}
-
- def try_adding_tokens(self, placeholder_token, *args, **kwargs):
- num_added_tokens = super().add_tokens(placeholder_token, *args, **kwargs)
- if num_added_tokens == 0:
- raise ValueError(
- f"The tokenizer already contains the token {placeholder_token}. Please pass a different"
- " `placeholder_token` that is not already in the tokenizer."
- )
-
- def add_placeholder_tokens(self, placeholder_token, *args, num_vec_per_token=1, **kwargs):
- output = []
- if num_vec_per_token == 1:
- self.try_adding_tokens(placeholder_token, *args, **kwargs)
- output.append(placeholder_token)
- else:
- output = []
- for i in range(num_vec_per_token):
- ith_token = placeholder_token + f"_{i}"
- self.try_adding_tokens(ith_token, *args, **kwargs)
- output.append(ith_token)
- # handle cases where there is a new placeholder token that contains the current placeholder token but is larger
- for token in self.token_map:
- if token in placeholder_token:
- raise ValueError(
- f"The tokenizer already has placeholder token {token} that can get confused with"
- f" {placeholder_token}keep placeholder tokens independent"
- )
- self.token_map[placeholder_token] = output
-
- def replace_placeholder_tokens_in_text(self, text, vector_shuffle=False, prop_tokens_to_load=1.0):
- """
- Here, we replace the placeholder tokens in text recorded in token_map so that the text_encoder
- can encode them
- vector_shuffle was inspired by https://github.com/rinongal/textual_inversion/pull/119
- where shuffling tokens were found to force the model to learn the concepts more descriptively.
- """
- if isinstance(text, list):
- output = []
- for i in range(len(text)):
- output.append(self.replace_placeholder_tokens_in_text(text[i], vector_shuffle=vector_shuffle))
- return output
- for placeholder_token in self.token_map:
- if placeholder_token in text:
- tokens = self.token_map[placeholder_token]
- tokens = tokens[: 1 + int(len(tokens) * prop_tokens_to_load)]
- if vector_shuffle:
- tokens = copy.copy(tokens)
- random.shuffle(tokens)
- text = text.replace(placeholder_token, " ".join(tokens))
- return text
-
- def __call__(self, text, *args, vector_shuffle=False, prop_tokens_to_load=1.0, **kwargs):
- return super().__call__(
- self.replace_placeholder_tokens_in_text(
- text, vector_shuffle=vector_shuffle, prop_tokens_to_load=prop_tokens_to_load
- ),
- *args,
- **kwargs,
- )
-
- def encode(self, text, *args, vector_shuffle=False, prop_tokens_to_load=1.0, **kwargs):
- return super().encode(
- self.replace_placeholder_tokens_in_text(
- text, vector_shuffle=vector_shuffle, prop_tokens_to_load=prop_tokens_to_load
- ),
- *args,
- **kwargs,
- )
diff --git a/spaces/declare-lab/tango/diffusers/src/diffusers/loaders.py b/spaces/declare-lab/tango/diffusers/src/diffusers/loaders.py
deleted file mode 100644
index a262833938e7c65cbc626e964e732cb56073e319..0000000000000000000000000000000000000000
--- a/spaces/declare-lab/tango/diffusers/src/diffusers/loaders.py
+++ /dev/null
@@ -1,569 +0,0 @@
-# Copyright 2023 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-from collections import defaultdict
-from typing import Callable, Dict, List, Optional, Union
-
-import torch
-
-from .models.attention_processor import LoRAAttnProcessor
-from .utils import (
- DIFFUSERS_CACHE,
- HF_HUB_OFFLINE,
- _get_model_file,
- deprecate,
- is_safetensors_available,
- is_transformers_available,
- logging,
-)
-
-
-if is_safetensors_available():
- import safetensors
-
-if is_transformers_available():
- from transformers import PreTrainedModel, PreTrainedTokenizer
-
-
-logger = logging.get_logger(__name__)
-
-
-LORA_WEIGHT_NAME = "pytorch_lora_weights.bin"
-LORA_WEIGHT_NAME_SAFE = "pytorch_lora_weights.safetensors"
-
-TEXT_INVERSION_NAME = "learned_embeds.bin"
-TEXT_INVERSION_NAME_SAFE = "learned_embeds.safetensors"
-
-
-class AttnProcsLayers(torch.nn.Module):
- def __init__(self, state_dict: Dict[str, torch.Tensor]):
- super().__init__()
- self.layers = torch.nn.ModuleList(state_dict.values())
- self.mapping = dict(enumerate(state_dict.keys()))
- self.rev_mapping = {v: k for k, v in enumerate(state_dict.keys())}
-
- # we add a hook to state_dict() and load_state_dict() so that the
- # naming fits with `unet.attn_processors`
- def map_to(module, state_dict, *args, **kwargs):
- new_state_dict = {}
- for key, value in state_dict.items():
- num = int(key.split(".")[1]) # 0 is always "layers"
- new_key = key.replace(f"layers.{num}", module.mapping[num])
- new_state_dict[new_key] = value
-
- return new_state_dict
-
- def map_from(module, state_dict, *args, **kwargs):
- all_keys = list(state_dict.keys())
- for key in all_keys:
- replace_key = key.split(".processor")[0] + ".processor"
- new_key = key.replace(replace_key, f"layers.{module.rev_mapping[replace_key]}")
- state_dict[new_key] = state_dict[key]
- del state_dict[key]
-
- self._register_state_dict_hook(map_to)
- self._register_load_state_dict_pre_hook(map_from, with_module=True)
-
-
-class UNet2DConditionLoadersMixin:
- def load_attn_procs(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
- r"""
- Load pretrained attention processor layers into `UNet2DConditionModel`. Attention processor layers have to be
- defined in
- [cross_attention.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py)
- and be a `torch.nn.Module` class.
-
-
-
- This function is experimental and might change in the future.
-
-
-
- Parameters:
- pretrained_model_name_or_path_or_dict (`str` or `os.PathLike` or `dict`):
- Can be either:
-
- - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- Valid model ids should have an organization name, like `google/ddpm-celebahq-256`.
- - A path to a *directory* containing model weights saved using [`~ModelMixin.save_config`], e.g.,
- `./my_model_directory/`.
- - A [torch state
- dict](https://pytorch.org/tutorials/beginner/saving_loading_models.html#what-is-a-state-dict).
-
- cache_dir (`Union[str, os.PathLike]`, *optional*):
- Path to a directory in which a downloaded pretrained model configuration should be cached if the
- standard cache should not be used.
- force_download (`bool`, *optional*, defaults to `False`):
- Whether or not to force the (re-)download of the model weights and configuration files, overriding the
- cached versions if they exist.
- resume_download (`bool`, *optional*, defaults to `False`):
- Whether or not to delete incompletely received files. Will attempt to resume the download if such a
- file exists.
- proxies (`Dict[str, str]`, *optional*):
- A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
- 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
- local_files_only(`bool`, *optional*, defaults to `False`):
- Whether or not to only look at local files (i.e., do not try to download the model).
- use_auth_token (`str` or *bool*, *optional*):
- The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
- when running `diffusers-cli login` (stored in `~/.huggingface`).
- revision (`str`, *optional*, defaults to `"main"`):
- The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
- git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
- identifier allowed by git.
- subfolder (`str`, *optional*, defaults to `""`):
- In case the relevant files are located inside a subfolder of the model repo (either remote in
- huggingface.co or downloaded locally), you can specify the folder name here.
-
- mirror (`str`, *optional*):
- Mirror source to accelerate downloads in China. If you are from China and have an accessibility
- problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
- Please refer to the mirror site for more information.
-
-
-
- It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
- models](https://huggingface.co/docs/hub/models-gated#gated-models).
-
-
- """
-
- cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
- force_download = kwargs.pop("force_download", False)
- resume_download = kwargs.pop("resume_download", False)
- proxies = kwargs.pop("proxies", None)
- local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
- use_auth_token = kwargs.pop("use_auth_token", None)
- revision = kwargs.pop("revision", None)
- subfolder = kwargs.pop("subfolder", None)
- weight_name = kwargs.pop("weight_name", None)
- use_safetensors = kwargs.pop("use_safetensors", None)
-
- if use_safetensors and not is_safetensors_available():
- raise ValueError(
- "`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
- )
-
- allow_pickle = False
- if use_safetensors is None:
- use_safetensors = is_safetensors_available()
- allow_pickle = True
-
- user_agent = {
- "file_type": "attn_procs_weights",
- "framework": "pytorch",
- }
-
- model_file = None
- if not isinstance(pretrained_model_name_or_path_or_dict, dict):
- # Let's first try to load .safetensors weights
- if (use_safetensors and weight_name is None) or (
- weight_name is not None and weight_name.endswith(".safetensors")
- ):
- try:
- model_file = _get_model_file(
- pretrained_model_name_or_path_or_dict,
- weights_name=weight_name or LORA_WEIGHT_NAME_SAFE,
- cache_dir=cache_dir,
- force_download=force_download,
- resume_download=resume_download,
- proxies=proxies,
- local_files_only=local_files_only,
- use_auth_token=use_auth_token,
- revision=revision,
- subfolder=subfolder,
- user_agent=user_agent,
- )
- state_dict = safetensors.torch.load_file(model_file, device="cpu")
- except IOError as e:
- if not allow_pickle:
- raise e
- # try loading non-safetensors weights
- pass
- if model_file is None:
- model_file = _get_model_file(
- pretrained_model_name_or_path_or_dict,
- weights_name=weight_name or LORA_WEIGHT_NAME,
- cache_dir=cache_dir,
- force_download=force_download,
- resume_download=resume_download,
- proxies=proxies,
- local_files_only=local_files_only,
- use_auth_token=use_auth_token,
- revision=revision,
- subfolder=subfolder,
- user_agent=user_agent,
- )
- state_dict = torch.load(model_file, map_location="cpu")
- else:
- state_dict = pretrained_model_name_or_path_or_dict
-
- # fill attn processors
- attn_processors = {}
-
- is_lora = all("lora" in k for k in state_dict.keys())
-
- if is_lora:
- lora_grouped_dict = defaultdict(dict)
- for key, value in state_dict.items():
- attn_processor_key, sub_key = ".".join(key.split(".")[:-3]), ".".join(key.split(".")[-3:])
- lora_grouped_dict[attn_processor_key][sub_key] = value
-
- for key, value_dict in lora_grouped_dict.items():
- rank = value_dict["to_k_lora.down.weight"].shape[0]
- cross_attention_dim = value_dict["to_k_lora.down.weight"].shape[1]
- hidden_size = value_dict["to_k_lora.up.weight"].shape[0]
-
- attn_processors[key] = LoRAAttnProcessor(
- hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, rank=rank
- )
- attn_processors[key].load_state_dict(value_dict)
-
- else:
- raise ValueError(f"{model_file} does not seem to be in the correct format expected by LoRA training.")
-
- # set correct dtype & device
- attn_processors = {k: v.to(device=self.device, dtype=self.dtype) for k, v in attn_processors.items()}
-
- # set layers
- self.set_attn_processor(attn_processors)
-
- def save_attn_procs(
- self,
- save_directory: Union[str, os.PathLike],
- is_main_process: bool = True,
- weight_name: str = None,
- save_function: Callable = None,
- safe_serialization: bool = False,
- **kwargs,
- ):
- r"""
- Save an attention processor to a directory, so that it can be re-loaded using the
- `[`~loaders.UNet2DConditionLoadersMixin.load_attn_procs`]` method.
-
- Arguments:
- save_directory (`str` or `os.PathLike`):
- Directory to which to save. Will be created if it doesn't exist.
- is_main_process (`bool`, *optional*, defaults to `True`):
- Whether the process calling this is the main process or not. Useful when in distributed training like
- TPUs and need to call this function on all processes. In this case, set `is_main_process=True` only on
- the main process to avoid race conditions.
- save_function (`Callable`):
- The function to use to save the state dictionary. Useful on distributed training like TPUs when one
- need to replace `torch.save` by another method. Can be configured with the environment variable
- `DIFFUSERS_SAVE_MODE`.
- """
- weight_name = weight_name or deprecate(
- "weights_name",
- "0.18.0",
- "`weights_name` is deprecated, please use `weight_name` instead.",
- take_from=kwargs,
- )
- if os.path.isfile(save_directory):
- logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
- return
-
- if save_function is None:
- if safe_serialization:
-
- def save_function(weights, filename):
- return safetensors.torch.save_file(weights, filename, metadata={"format": "pt"})
-
- else:
- save_function = torch.save
-
- os.makedirs(save_directory, exist_ok=True)
-
- model_to_save = AttnProcsLayers(self.attn_processors)
-
- # Save the model
- state_dict = model_to_save.state_dict()
-
- if weight_name is None:
- if safe_serialization:
- weight_name = LORA_WEIGHT_NAME_SAFE
- else:
- weight_name = LORA_WEIGHT_NAME
-
- # Save the model
- save_function(state_dict, os.path.join(save_directory, weight_name))
- logger.info(f"Model weights saved in {os.path.join(save_directory, weight_name)}")
-
-
-class TextualInversionLoaderMixin:
- r"""
- Mixin class for loading textual inversion tokens and embeddings to the tokenizer and text encoder.
- """
-
- def maybe_convert_prompt(self, prompt: Union[str, List[str]], tokenizer: "PreTrainedTokenizer"):
- r"""
- Maybe convert a prompt into a "multi vector"-compatible prompt. If the prompt includes a token that corresponds
- to a multi-vector textual inversion embedding, this function will process the prompt so that the special token
- is replaced with multiple special tokens each corresponding to one of the vectors. If the prompt has no textual
- inversion token or a textual inversion token that is a single vector, the input prompt is simply returned.
-
- Parameters:
- prompt (`str` or list of `str`):
- The prompt or prompts to guide the image generation.
- tokenizer (`PreTrainedTokenizer`):
- The tokenizer responsible for encoding the prompt into input tokens.
-
- Returns:
- `str` or list of `str`: The converted prompt
- """
- if not isinstance(prompt, List):
- prompts = [prompt]
- else:
- prompts = prompt
-
- prompts = [self._maybe_convert_prompt(p, tokenizer) for p in prompts]
-
- if not isinstance(prompt, List):
- return prompts[0]
-
- return prompts
-
- def _maybe_convert_prompt(self, prompt: str, tokenizer: "PreTrainedTokenizer"):
- r"""
- Maybe convert a prompt into a "multi vector"-compatible prompt. If the prompt includes a token that corresponds
- to a multi-vector textual inversion embedding, this function will process the prompt so that the special token
- is replaced with multiple special tokens each corresponding to one of the vectors. If the prompt has no textual
- inversion token or a textual inversion token that is a single vector, the input prompt is simply returned.
-
- Parameters:
- prompt (`str`):
- The prompt to guide the image generation.
- tokenizer (`PreTrainedTokenizer`):
- The tokenizer responsible for encoding the prompt into input tokens.
-
- Returns:
- `str`: The converted prompt
- """
- tokens = tokenizer.tokenize(prompt)
- for token in tokens:
- if token in tokenizer.added_tokens_encoder:
- replacement = token
- i = 1
- while f"{token}_{i}" in tokenizer.added_tokens_encoder:
- replacement += f"{token}_{i}"
- i += 1
-
- prompt = prompt.replace(token, replacement)
-
- return prompt
-
- def load_textual_inversion(
- self, pretrained_model_name_or_path: Union[str, Dict[str, torch.Tensor]], token: Optional[str] = None, **kwargs
- ):
- r"""
- Load textual inversion embeddings into the text encoder of stable diffusion pipelines. Both `diffusers` and
- `Automatic1111` formats are supported.
-
-
-
- This function is experimental and might change in the future.
-
-
-
- Parameters:
- pretrained_model_name_or_path (`str` or `os.PathLike`):
- Can be either:
-
- - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- Valid model ids should have an organization name, like
- `"sd-concepts-library/low-poly-hd-logos-icons"`.
- - A path to a *directory* containing textual inversion weights, e.g.
- `./my_text_inversion_directory/`.
- weight_name (`str`, *optional*):
- Name of a custom weight file. This should be used in two cases:
-
- - The saved textual inversion file is in `diffusers` format, but was saved under a specific weight
- name, such as `text_inv.bin`.
- - The saved textual inversion file is in the "Automatic1111" form.
- cache_dir (`Union[str, os.PathLike]`, *optional*):
- Path to a directory in which a downloaded pretrained model configuration should be cached if the
- standard cache should not be used.
- force_download (`bool`, *optional*, defaults to `False`):
- Whether or not to force the (re-)download of the model weights and configuration files, overriding the
- cached versions if they exist.
- resume_download (`bool`, *optional*, defaults to `False`):
- Whether or not to delete incompletely received files. Will attempt to resume the download if such a
- file exists.
- proxies (`Dict[str, str]`, *optional*):
- A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
- 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
- local_files_only(`bool`, *optional*, defaults to `False`):
- Whether or not to only look at local files (i.e., do not try to download the model).
- use_auth_token (`str` or *bool*, *optional*):
- The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
- when running `diffusers-cli login` (stored in `~/.huggingface`).
- revision (`str`, *optional*, defaults to `"main"`):
- The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
- git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
- identifier allowed by git.
- subfolder (`str`, *optional*, defaults to `""`):
- In case the relevant files are located inside a subfolder of the model repo (either remote in
- huggingface.co or downloaded locally), you can specify the folder name here.
-
- mirror (`str`, *optional*):
- Mirror source to accelerate downloads in China. If you are from China and have an accessibility
- problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
- Please refer to the mirror site for more information.
-
-
-
- It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
- models](https://huggingface.co/docs/hub/models-gated#gated-models).
-
-
- """
- if not hasattr(self, "tokenizer") or not isinstance(self.tokenizer, PreTrainedTokenizer):
- raise ValueError(
- f"{self.__class__.__name__} requires `self.tokenizer` of type `PreTrainedTokenizer` for calling"
- f" `{self.load_textual_inversion.__name__}`"
- )
-
- if not hasattr(self, "text_encoder") or not isinstance(self.text_encoder, PreTrainedModel):
- raise ValueError(
- f"{self.__class__.__name__} requires `self.text_encoder` of type `PreTrainedModel` for calling"
- f" `{self.load_textual_inversion.__name__}`"
- )
-
- cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
- force_download = kwargs.pop("force_download", False)
- resume_download = kwargs.pop("resume_download", False)
- proxies = kwargs.pop("proxies", None)
- local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
- use_auth_token = kwargs.pop("use_auth_token", None)
- revision = kwargs.pop("revision", None)
- subfolder = kwargs.pop("subfolder", None)
- weight_name = kwargs.pop("weight_name", None)
- use_safetensors = kwargs.pop("use_safetensors", None)
-
- if use_safetensors and not is_safetensors_available():
- raise ValueError(
- "`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
- )
-
- allow_pickle = False
- if use_safetensors is None:
- use_safetensors = is_safetensors_available()
- allow_pickle = True
-
- user_agent = {
- "file_type": "text_inversion",
- "framework": "pytorch",
- }
-
- # 1. Load textual inversion file
- model_file = None
- # Let's first try to load .safetensors weights
- if (use_safetensors and weight_name is None) or (
- weight_name is not None and weight_name.endswith(".safetensors")
- ):
- try:
- model_file = _get_model_file(
- pretrained_model_name_or_path,
- weights_name=weight_name or TEXT_INVERSION_NAME_SAFE,
- cache_dir=cache_dir,
- force_download=force_download,
- resume_download=resume_download,
- proxies=proxies,
- local_files_only=local_files_only,
- use_auth_token=use_auth_token,
- revision=revision,
- subfolder=subfolder,
- user_agent=user_agent,
- )
- state_dict = safetensors.torch.load_file(model_file, device="cpu")
- except Exception as e:
- if not allow_pickle:
- raise e
-
- model_file = None
-
- if model_file is None:
- model_file = _get_model_file(
- pretrained_model_name_or_path,
- weights_name=weight_name or TEXT_INVERSION_NAME,
- cache_dir=cache_dir,
- force_download=force_download,
- resume_download=resume_download,
- proxies=proxies,
- local_files_only=local_files_only,
- use_auth_token=use_auth_token,
- revision=revision,
- subfolder=subfolder,
- user_agent=user_agent,
- )
- state_dict = torch.load(model_file, map_location="cpu")
-
- # 2. Load token and embedding correcly from file
- if isinstance(state_dict, torch.Tensor):
- if token is None:
- raise ValueError(
- "You are trying to load a textual inversion embedding that has been saved as a PyTorch tensor. Make sure to pass the name of the corresponding token in this case: `token=...`."
- )
- embedding = state_dict
- elif len(state_dict) == 1:
- # diffusers
- loaded_token, embedding = next(iter(state_dict.items()))
- elif "string_to_param" in state_dict:
- # A1111
- loaded_token = state_dict["name"]
- embedding = state_dict["string_to_param"]["*"]
-
- if token is not None and loaded_token != token:
- logger.warn(f"The loaded token: {loaded_token} is overwritten by the passed token {token}.")
- else:
- token = loaded_token
-
- embedding = embedding.to(dtype=self.text_encoder.dtype, device=self.text_encoder.device)
-
- # 3. Make sure we don't mess up the tokenizer or text encoder
- vocab = self.tokenizer.get_vocab()
- if token in vocab:
- raise ValueError(
- f"Token {token} already in tokenizer vocabulary. Please choose a different token name or remove {token} and embedding from the tokenizer and text encoder."
- )
- elif f"{token}_1" in vocab:
- multi_vector_tokens = [token]
- i = 1
- while f"{token}_{i}" in self.tokenizer.added_tokens_encoder:
- multi_vector_tokens.append(f"{token}_{i}")
- i += 1
-
- raise ValueError(
- f"Multi-vector Token {multi_vector_tokens} already in tokenizer vocabulary. Please choose a different token name or remove the {multi_vector_tokens} and embedding from the tokenizer and text encoder."
- )
-
- is_multi_vector = len(embedding.shape) > 1 and embedding.shape[0] > 1
-
- if is_multi_vector:
- tokens = [token] + [f"{token}_{i}" for i in range(1, embedding.shape[0])]
- embeddings = [e for e in embedding] # noqa: C416
- else:
- tokens = [token]
- embeddings = [embedding[0]] if len(embedding.shape) > 1 else [embedding]
-
- # add tokens and get ids
- self.tokenizer.add_tokens(tokens)
- token_ids = self.tokenizer.convert_tokens_to_ids(tokens)
-
- # resize token embeddings and set new embeddings
- self.text_encoder.resize_token_embeddings(len(self.tokenizer))
- for token_id, embedding in zip(token_ids, embeddings):
- self.text_encoder.get_input_embeddings().weight.data[token_id] = embedding
-
- logger.info("Loaded textual inversion embedding for {token}.")
diff --git a/spaces/declare-lab/tango/diffusers/tests/schedulers/test_scheduler_ddim.py b/spaces/declare-lab/tango/diffusers/tests/schedulers/test_scheduler_ddim.py
deleted file mode 100644
index e9c85314d558af74b2ed325df5ed7722e1acd691..0000000000000000000000000000000000000000
--- a/spaces/declare-lab/tango/diffusers/tests/schedulers/test_scheduler_ddim.py
+++ /dev/null
@@ -1,140 +0,0 @@
-import torch
-
-from diffusers import DDIMScheduler
-
-from .test_schedulers import SchedulerCommonTest
-
-
-class DDIMSchedulerTest(SchedulerCommonTest):
- scheduler_classes = (DDIMScheduler,)
- forward_default_kwargs = (("eta", 0.0), ("num_inference_steps", 50))
-
- def get_scheduler_config(self, **kwargs):
- config = {
- "num_train_timesteps": 1000,
- "beta_start": 0.0001,
- "beta_end": 0.02,
- "beta_schedule": "linear",
- "clip_sample": True,
- }
-
- config.update(**kwargs)
- return config
-
- def full_loop(self, **config):
- scheduler_class = self.scheduler_classes[0]
- scheduler_config = self.get_scheduler_config(**config)
- scheduler = scheduler_class(**scheduler_config)
-
- num_inference_steps, eta = 10, 0.0
-
- model = self.dummy_model()
- sample = self.dummy_sample_deter
-
- scheduler.set_timesteps(num_inference_steps)
-
- for t in scheduler.timesteps:
- residual = model(sample, t)
- sample = scheduler.step(residual, t, sample, eta).prev_sample
-
- return sample
-
- def test_timesteps(self):
- for timesteps in [100, 500, 1000]:
- self.check_over_configs(num_train_timesteps=timesteps)
-
- def test_steps_offset(self):
- for steps_offset in [0, 1]:
- self.check_over_configs(steps_offset=steps_offset)
-
- scheduler_class = self.scheduler_classes[0]
- scheduler_config = self.get_scheduler_config(steps_offset=1)
- scheduler = scheduler_class(**scheduler_config)
- scheduler.set_timesteps(5)
- assert torch.equal(scheduler.timesteps, torch.LongTensor([801, 601, 401, 201, 1]))
-
- def test_betas(self):
- for beta_start, beta_end in zip([0.0001, 0.001, 0.01, 0.1], [0.002, 0.02, 0.2, 2]):
- self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
-
- def test_schedules(self):
- for schedule in ["linear", "squaredcos_cap_v2"]:
- self.check_over_configs(beta_schedule=schedule)
-
- def test_prediction_type(self):
- for prediction_type in ["epsilon", "v_prediction"]:
- self.check_over_configs(prediction_type=prediction_type)
-
- def test_clip_sample(self):
- for clip_sample in [True, False]:
- self.check_over_configs(clip_sample=clip_sample)
-
- def test_thresholding(self):
- self.check_over_configs(thresholding=False)
- for threshold in [0.5, 1.0, 2.0]:
- for prediction_type in ["epsilon", "v_prediction"]:
- self.check_over_configs(
- thresholding=True,
- prediction_type=prediction_type,
- sample_max_value=threshold,
- )
-
- def test_time_indices(self):
- for t in [1, 10, 49]:
- self.check_over_forward(time_step=t)
-
- def test_inference_steps(self):
- for t, num_inference_steps in zip([1, 10, 50], [10, 50, 500]):
- self.check_over_forward(time_step=t, num_inference_steps=num_inference_steps)
-
- def test_eta(self):
- for t, eta in zip([1, 10, 49], [0.0, 0.5, 1.0]):
- self.check_over_forward(time_step=t, eta=eta)
-
- def test_variance(self):
- scheduler_class = self.scheduler_classes[0]
- scheduler_config = self.get_scheduler_config()
- scheduler = scheduler_class(**scheduler_config)
-
- assert torch.sum(torch.abs(scheduler._get_variance(0, 0) - 0.0)) < 1e-5
- assert torch.sum(torch.abs(scheduler._get_variance(420, 400) - 0.14771)) < 1e-5
- assert torch.sum(torch.abs(scheduler._get_variance(980, 960) - 0.32460)) < 1e-5
- assert torch.sum(torch.abs(scheduler._get_variance(0, 0) - 0.0)) < 1e-5
- assert torch.sum(torch.abs(scheduler._get_variance(487, 486) - 0.00979)) < 1e-5
- assert torch.sum(torch.abs(scheduler._get_variance(999, 998) - 0.02)) < 1e-5
-
- def test_full_loop_no_noise(self):
- sample = self.full_loop()
-
- result_sum = torch.sum(torch.abs(sample))
- result_mean = torch.mean(torch.abs(sample))
-
- assert abs(result_sum.item() - 172.0067) < 1e-2
- assert abs(result_mean.item() - 0.223967) < 1e-3
-
- def test_full_loop_with_v_prediction(self):
- sample = self.full_loop(prediction_type="v_prediction")
-
- result_sum = torch.sum(torch.abs(sample))
- result_mean = torch.mean(torch.abs(sample))
-
- assert abs(result_sum.item() - 52.5302) < 1e-2
- assert abs(result_mean.item() - 0.0684) < 1e-3
-
- def test_full_loop_with_set_alpha_to_one(self):
- # We specify different beta, so that the first alpha is 0.99
- sample = self.full_loop(set_alpha_to_one=True, beta_start=0.01)
- result_sum = torch.sum(torch.abs(sample))
- result_mean = torch.mean(torch.abs(sample))
-
- assert abs(result_sum.item() - 149.8295) < 1e-2
- assert abs(result_mean.item() - 0.1951) < 1e-3
-
- def test_full_loop_with_no_set_alpha_to_one(self):
- # We specify different beta, so that the first alpha is 0.99
- sample = self.full_loop(set_alpha_to_one=False, beta_start=0.01)
- result_sum = torch.sum(torch.abs(sample))
- result_mean = torch.mean(torch.abs(sample))
-
- assert abs(result_sum.item() - 149.0784) < 1e-2
- assert abs(result_mean.item() - 0.1941) < 1e-3
diff --git a/spaces/deepusus/tts-eng/README.md b/spaces/deepusus/tts-eng/README.md
deleted file mode 100644
index fe215f77dd60866eb6aa11fedaae7339d3ff36b2..0000000000000000000000000000000000000000
--- a/spaces/deepusus/tts-eng/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Tts Eng
-emoji: 🦀
-colorFrom: indigo
-colorTo: purple
-sdk: gradio
-sdk_version: 3.50.2
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/derful/Chatgpt-academic/crazy_functions/test_project/latex/attention/background.tex b/spaces/derful/Chatgpt-academic/crazy_functions/test_project/latex/attention/background.tex
deleted file mode 100644
index 785069dc0f9143bad24e640056dd1072d5c6e5b5..0000000000000000000000000000000000000000
--- a/spaces/derful/Chatgpt-academic/crazy_functions/test_project/latex/attention/background.tex
+++ /dev/null
@@ -1,58 +0,0 @@
-The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU \citep{extendedngpu}, ByteNet \citep{NalBytenet2017} and ConvS2S \citep{JonasFaceNet2017}, all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions \citep{hochreiter2001gradient}. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section~\ref{sec:attention}.
-
-Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations \citep{cheng2016long, decomposableAttnModel, paulus2017deep, lin2017structured}.
-
-End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks \citep{sukhbaatar2015}.
-
-To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
-In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as \citep{neural_gpu, NalBytenet2017} and \citep{JonasFaceNet2017}.
-
-
-%\citep{JonasFaceNet2017} report new SOTA on machine translation for English-to-German (EnDe), Enlish-to-French (EnFr) and English-to-Romanian language pairs.
-
-%For example,! in MT, we must draw information from both input and previous output words to translate an output word accurately. An attention layer \citep{bahdanau2014neural} can connect a very large number of positions at low computation cost, making it an essential ingredient in competitive recurrent models for machine translation.
-
-%A natural question to ask then is, "Could we replace recurrence with attention?". \marginpar{Don't know if it's the most natural question to ask given the previous statements. Also, need to say that the complexity table summarizes these statements} Such a model would be blessed with the computational efficiency of attention and the power of cross-positional communication. In this work, show that pure attention models work remarkably well for MT, achieving new SOTA results on EnDe and EnFr, and can be trained in under $2$ days on xyz architecture.
-
-%After the seminal models introduced in \citep{sutskever14, bahdanau2014neural, cho2014learning}, recurrent models have become the dominant solution for both sequence modeling and sequence-to-sequence transduction. Many efforts such as \citep{wu2016google,luong2015effective,jozefowicz2016exploring} have pushed the boundaries of machine translation (MT) and language modeling with recurrent endoder-decoder and recurrent language models. Recent effort \citep{shazeer2017outrageously} has successfully combined the power of conditional computation with sequence models to train very large models for MT, pushing SOTA at lower computational cost.
-
-%Recurrent models compute a vector of hidden states $h_t$, for each time step $t$ of computation. $h_t$ is a function of both the input at time $t$ and the previous hidden state $h_t$. This dependence on the previous hidden state precludes processing all timesteps at once, instead requiring long sequences of sequential operations. In practice, this results in greatly reduced computational efficiency, as on modern computing hardware, a single operation on a large batch is much faster than a large number of operations on small batches. The problem gets worse at longer sequence lengths. Although sequential computation is not a severe bottleneck at inference time, as autoregressively generating each output requires all previous outputs, the inability to compute scores at all output positions at once hinders us from rapidly training our models over large datasets. Although impressive work such as \citep{Kuchaiev2017Factorization} is able to significantly accelerate the training of LSTMs with factorization tricks, we are still bound by the linear dependence on sequence length.
-
-%If the model could compute hidden states at each time step using only the inputs and outputs, it would be liberated from the dependence on results from previous time steps during training. This line of thought is the foundation of recent efforts such as the Markovian neural GPU \citep{neural_gpu}, ByteNet \citep{NalBytenet2017} and ConvS2S \citep{JonasFaceNet2017}, all of which use convolutional neural networks as a building block to compute hidden representations simultaneously for all timesteps, resulting in $O(1)$ sequential time complexity. \citep{JonasFaceNet2017} report new SOTA on machine translation for English-to-German (EnDe), Enlish-to-French (EnFr) and English-to-Romanian language pairs.
-
-%A crucial component for accurate sequence prediction is modeling cross-positional communication. For example, in MT, we must draw information from both input and previous output words to translate an output word accurately. An attention layer \citep{bahdanau2014neural} can connect a very large number of positions at a low computation cost, also $O(1)$ sequential time complexity, making it an essential ingredient in recurrent encoder-decoder architectures for MT. A natural question to ask then is, "Could we replace recurrence with attention?". \marginpar{Don't know if it's the most natural question to ask given the previous statements. Also, need to say that the complexity table summarizes these statements} Such a model would be blessed with the computational efficiency of attention and the power of cross-positional communication. In this work, show that pure attention models work remarkably well for MT, achieving new SOTA results on EnDe and EnFr, and can be trained in under $2$ days on xyz architecture.
-
-
-
-%Note: Facebook model is no better than RNNs in this regard, since it requires a number of layers proportional to the distance you want to communicate. Bytenet is more promising, since it requires a logarithmnic number of layers (does bytenet have SOTA results)?
-
-%Note: An attention layer can connect a very large number of positions at a low computation cost in O(1) sequential operations. This is why encoder-decoder attention has been so successful in seq-to-seq models so far. It is only natural, then, to also use attention to connect the timesteps of the same sequence.
-
-%Note: I wouldn't say that long sequences are not a problem during inference. It would be great if we could infer with no long sequences. We could just say later on that, while our training graph is constant-depth, our model still requires sequential operations in the decoder part during inference due to the autoregressive nature of the model.
-
-%\begin{table}[h!]
-%\caption{Attention models are quite efficient for cross-positional communications when sequence length is smaller than channel depth. $n$ represents the sequence length and $d$ represents the channel depth.}
-%\label{tab:op_complexities}
-%\begin{center}
-%\vspace{-5pt}
-%\scalebox{0.75}{
-
-%\begin{tabular}{l|c|c|c}
-%\hline \hline
-%Layer Type & Receptive & Complexity & Sequential \\
-% & Field & & Operations \\
-%\hline
-%Pointwise Feed-Forward & $1$ & $O(n \cdot d^2)$ & $O(1)$ \\
-%\hline
-%Recurrent & $n$ & $O(n \cdot d^2)$ & $O(n)$ \\
-%\hline
-%Convolutional & $r$ & $O(r \cdot n \cdot d^2)$ & $O(1)$ \\
-%\hline
-%Convolutional (separable) & $r$ & $O(r \cdot n \cdot d + n %\cdot d^2)$ & $O(1)$ \\
-%\hline
-%Attention & $r$ & $O(r \cdot n \cdot d)$ & $O(1)$ \\
-%\hline \hline
-%\end{tabular}
-%}
-%\end{center}
-%\end{table}
\ No newline at end of file
diff --git a/spaces/descript/vampnet/app.py b/spaces/descript/vampnet/app.py
deleted file mode 100644
index b94e034a6266a85f3df7c40fd9e73de3cd3222c5..0000000000000000000000000000000000000000
--- a/spaces/descript/vampnet/app.py
+++ /dev/null
@@ -1,686 +0,0 @@
-# huggingface space exclusive
-import os
-
-# print("installing pyharp")
-# os.system('pip install "pyharp@git+https://github.com/audacitorch/pyharp.git"')
-# print("installing madmom")
-os.system('pip install cython')
-os.system('pip install madmom')
-
-from pathlib import Path
-from typing import Tuple
-import yaml
-import tempfile
-import uuid
-import shutil
-from dataclasses import dataclass, asdict
-
-import numpy as np
-import audiotools as at
-import argbind
-import torch
-
-import gradio as gr
-from vampnet.interface import Interface
-from vampnet import mask as pmask
-
-from pyharp import ModelCard, build_endpoint
-
-
-
-# loader = AudioLoader()
-# AudioLoader = argbind.bind(at.data.datasets.AudioLoader)
-
-conf = argbind.parse_args()
-
-
-from torch_pitch_shift import pitch_shift, get_fast_shifts
-def shift_pitch(signal, interval: int):
- signal.samples = pitch_shift(
- signal.samples,
- shift=interval,
- sample_rate=signal.sample_rate
- )
- return signal
-
-def load_interface():
- interface = Interface(
- coarse_ckpt="./models/vampnet/coarse.pth",
- coarse2fine_ckpt="./models/vampnet/c2f.pth",
- codec_ckpt="./models/vampnet/codec.pth",
- wavebeat_ckpt="./models/wavebeat.pth",
- device="cuda" if torch.cuda.is_available() else "cpu",
- )
- return interface
-
-
-interface = load_interface()
-
-
-OUT_DIR = Path("gradio-outputs")
-OUT_DIR.mkdir(exist_ok=True, parents=True)
-
-
-def load_audio(file):
- print(file)
- filepath = file.name
- sig = at.AudioSignal.salient_excerpt(
- filepath,
- duration=interface.coarse.chunk_size_s
- )
- sig = interface.preprocess(sig)
-
- out_dir = OUT_DIR / "tmp" / str(uuid.uuid4())
- out_dir.mkdir(parents=True, exist_ok=True)
- sig.write(out_dir / "input.wav")
- return sig.path_to_file
-
-
-def load_example_audio():
- return "./assets/example.wav"
-
-
-def _vamp(data, return_mask=False):
- # remove any old files in the output directory (from previous runs)
- shutil.rmtree(OUT_DIR)
- OUT_DIR.mkdir()
-
- out_dir = OUT_DIR / str(uuid.uuid4())
- out_dir.mkdir()
- sig = at.AudioSignal(data[input_audio])
- sig = interface.preprocess(sig)
-
- if data[pitch_shift_amt] != 0:
- sig = shift_pitch(sig, data[pitch_shift_amt])
-
- z = interface.encode(sig)
-
- ncc = data[n_conditioning_codebooks]
-
- # build the mask
- mask = pmask.linear_random(z, data[rand_mask_intensity])
- mask = pmask.mask_and(
- mask, pmask.inpaint(
- z,
- interface.s2t(data[prefix_s]),
- interface.s2t(data[suffix_s])
- )
- )
- mask = pmask.mask_and(
- mask, pmask.periodic_mask(
- z,
- data[periodic_p],
- data[periodic_w],
- random_roll=True
- )
- )
- if data[onset_mask_width] > 0:
- mask = pmask.mask_or(
- mask, pmask.onset_mask(sig, z, interface, width=data[onset_mask_width])
- )
- if data[beat_mask_width] > 0:
- beat_mask = interface.make_beat_mask(
- sig,
- after_beat_s=(data[beat_mask_width]/1000),
- mask_upbeats=not data[beat_mask_downbeats],
- )
- mask = pmask.mask_and(mask, beat_mask)
-
- # these should be the last two mask ops
- mask = pmask.dropout(mask, data[dropout])
- mask = pmask.codebook_unmask(mask, ncc)
-
-
- print(f"dropout {data[dropout]}")
- print(f"masktemp {data[masktemp]}")
- print(f"sampletemp {data[sampletemp]}")
- print(f"top_p {data[top_p]}")
- print(f"prefix_s {data[prefix_s]}")
- print(f"suffix_s {data[suffix_s]}")
- print(f"rand_mask_intensity {data[rand_mask_intensity]}")
- print(f"num_steps {data[num_steps]}")
- print(f"periodic_p {data[periodic_p]}")
- print(f"periodic_w {data[periodic_w]}")
- print(f"n_conditioning_codebooks {data[n_conditioning_codebooks]}")
- print(f"use_coarse2fine {data[use_coarse2fine]}")
- print(f"onset_mask_width {data[onset_mask_width]}")
- print(f"beat_mask_width {data[beat_mask_width]}")
- print(f"beat_mask_downbeats {data[beat_mask_downbeats]}")
- print(f"stretch_factor {data[stretch_factor]}")
- print(f"seed {data[seed]}")
- print(f"pitch_shift_amt {data[pitch_shift_amt]}")
- print(f"sample_cutoff {data[sample_cutoff]}")
-
-
- _top_p = data[top_p] if data[top_p] > 0 else None
- # save the mask as a txt file
- np.savetxt(out_dir / "mask.txt", mask[:,0,:].long().cpu().numpy())
-
- _seed = data[seed] if data[seed] > 0 else None
- zv, mask_z = interface.coarse_vamp(
- z,
- mask=mask,
- sampling_steps=data[num_steps],
- mask_temperature=data[masktemp]*10,
- sampling_temperature=data[sampletemp],
- return_mask=True,
- typical_filtering=data[typical_filtering],
- typical_mass=data[typical_mass],
- typical_min_tokens=data[typical_min_tokens],
- top_p=_top_p,
- gen_fn=interface.coarse.generate,
- seed=_seed,
- sample_cutoff=data[sample_cutoff],
- )
-
- if use_coarse2fine:
- zv = interface.coarse_to_fine(
- zv,
- mask_temperature=data[masktemp]*10,
- sampling_temperature=data[sampletemp],
- mask=mask,
- sampling_steps=data[num_steps],
- sample_cutoff=data[sample_cutoff],
- seed=_seed,
- )
-
- sig = interface.to_signal(zv).cpu()
- print("done")
-
-
-
- sig.write(out_dir / "output.wav")
-
- if return_mask:
- mask = interface.to_signal(mask_z).cpu()
- mask.write(out_dir / "mask.wav")
- return sig.path_to_file, mask.path_to_file
- else:
- return sig.path_to_file
-
-def vamp(data):
- return _vamp(data, return_mask=True)
-
-def api_vamp(data):
- return _vamp(data, return_mask=False)
-
-def save_vamp(data):
- out_dir = OUT_DIR / "saved" / str(uuid.uuid4())
- out_dir.mkdir(parents=True, exist_ok=True)
-
- sig_in = at.AudioSignal(data[input_audio])
- sig_out = at.AudioSignal(data[output_audio])
-
- sig_in.write(out_dir / "input.wav")
- sig_out.write(out_dir / "output.wav")
-
- _data = {
- "masktemp": data[masktemp],
- "sampletemp": data[sampletemp],
- "top_p": data[top_p],
- "prefix_s": data[prefix_s],
- "suffix_s": data[suffix_s],
- "rand_mask_intensity": data[rand_mask_intensity],
- "num_steps": data[num_steps],
- "notes": data[notes_text],
- "periodic_period": data[periodic_p],
- "periodic_width": data[periodic_w],
- "n_conditioning_codebooks": data[n_conditioning_codebooks],
- "use_coarse2fine": data[use_coarse2fine],
- "stretch_factor": data[stretch_factor],
- "seed": data[seed],
- "samplecutoff": data[sample_cutoff],
- }
-
- # save with yaml
- with open(out_dir / "data.yaml", "w") as f:
- yaml.dump(_data, f)
-
- import zipfile
- zip_path = out_dir.with_suffix(".zip")
- with zipfile.ZipFile(zip_path, "w") as zf:
- for file in out_dir.iterdir():
- zf.write(file, file.name)
-
- return f"saved! your save code is {out_dir.stem}", zip_path
-
-
-def harp_vamp(_input_audio, _beat_mask_width, _sampletemp):
-
- out_dir = OUT_DIR / str(uuid.uuid4())
- out_dir.mkdir()
- sig = at.AudioSignal(_input_audio)
- sig = interface.preprocess(sig)
-
- z = interface.encode(sig)
-
- # build the mask
- mask = pmask.linear_random(z, 1.0)
- if _beat_mask_width > 0:
- beat_mask = interface.make_beat_mask(
- sig,
- after_beat_s=(_beat_mask_width/1000),
- )
- mask = pmask.mask_and(mask, beat_mask)
-
- # save the mask as a txt file
- zv, mask_z = interface.coarse_vamp(
- z,
- mask=mask,
- sampling_temperature=_sampletemp,
- return_mask=True,
- gen_fn=interface.coarse.generate,
- )
-
-
- zv = interface.coarse_to_fine(
- zv,
- sampling_temperature=_sampletemp,
- mask=mask,
- )
-
- sig = interface.to_signal(zv).cpu()
- print("done")
-
- sig.write(out_dir / "output.wav")
-
- return sig.path_to_file
-
-with gr.Blocks() as demo:
-
- with gr.Row():
- with gr.Column():
- gr.Markdown("# VampNet Audio Vamping")
- gr.Markdown("""## Description:
- This is a demo of the VampNet, a generative audio model that transforms the input audio based on the chosen settings.
- You can control the extent and nature of variation with a set of manual controls and presets.
- Use this interface to experiment with different mask settings and explore the audio outputs.
- """)
-
- gr.Markdown("""
- ## Instructions:
- 1. You can start by uploading some audio, or by loading the example audio.
- 2. Choose a preset for the vamp operation, or manually adjust the controls to customize the mask settings.
- 3. Click the "generate (vamp)!!!" button to apply the vamp operation. Listen to the output audio.
- 4. Optionally, you can add some notes and save the result.
- 5. You can also use the output as the new input and continue experimenting!
- """)
- with gr.Row():
- with gr.Column():
-
-
- manual_audio_upload = gr.File(
- label=f"upload some audio (will be randomly trimmed to max of {interface.coarse.chunk_size_s:.2f}s)",
- file_types=["audio"]
- )
- load_example_audio_button = gr.Button("or load example audio")
-
- input_audio = gr.Audio(
- label="input audio",
- interactive=False,
- type="filepath",
- )
-
- audio_mask = gr.Audio(
- label="audio mask (listen to this to hear the mask hints)",
- interactive=False,
- type="filepath",
- )
-
- # connect widgets
- load_example_audio_button.click(
- fn=load_example_audio,
- inputs=[],
- outputs=[ input_audio]
- )
-
- manual_audio_upload.change(
- fn=load_audio,
- inputs=[manual_audio_upload],
- outputs=[ input_audio]
- )
-
- # mask settings
- with gr.Column():
-
-
- presets = {
- "unconditional": {
- "periodic_p": 0,
- "onset_mask_width": 0,
- "beat_mask_width": 0,
- "beat_mask_downbeats": False,
- },
- "slight periodic variation": {
- "periodic_p": 5,
- "onset_mask_width": 5,
- "beat_mask_width": 0,
- "beat_mask_downbeats": False,
- },
- "moderate periodic variation": {
- "periodic_p": 13,
- "onset_mask_width": 5,
- "beat_mask_width": 0,
- "beat_mask_downbeats": False,
- },
- "strong periodic variation": {
- "periodic_p": 17,
- "onset_mask_width": 5,
- "beat_mask_width": 0,
- "beat_mask_downbeats": False,
- },
- "very strong periodic variation": {
- "periodic_p": 21,
- "onset_mask_width": 5,
- "beat_mask_width": 0,
- "beat_mask_downbeats": False,
- },
- "beat-driven variation": {
- "periodic_p": 0,
- "onset_mask_width": 0,
- "beat_mask_width": 50,
- "beat_mask_downbeats": False,
- },
- "beat-driven variation (downbeats only)": {
- "periodic_p": 0,
- "onset_mask_width": 0,
- "beat_mask_width": 50,
- "beat_mask_downbeats": True,
- },
- "beat-driven variation (downbeats only, strong)": {
- "periodic_p": 0,
- "onset_mask_width": 0,
- "beat_mask_width": 20,
- "beat_mask_downbeats": True,
- },
- }
-
- preset = gr.Dropdown(
- label="preset",
- choices=list(presets.keys()),
- value="strong periodic variation",
- )
- load_preset_button = gr.Button("load_preset")
-
- with gr.Accordion("manual controls", open=True):
- periodic_p = gr.Slider(
- label="periodic prompt (0 - unconditional, 2 - lots of hints, 8 - a couple of hints, 16 - occasional hint, 32 - very occasional hint, etc)",
- minimum=0,
- maximum=128,
- step=1,
- value=3,
- )
-
-
- onset_mask_width = gr.Slider(
- label="onset mask width (multiplies with the periodic mask, 1 step ~= 10milliseconds) ",
- minimum=0,
- maximum=100,
- step=1,
- value=5,
- )
-
- beat_mask_width = gr.Slider(
- label="beat prompt (ms)",
- minimum=0,
- maximum=200,
- value=0,
- )
- beat_mask_downbeats = gr.Checkbox(
- label="beat mask downbeats only?",
- value=False
- )
-
-
- with gr.Accordion("extras ", open=False):
- pitch_shift_amt = gr.Slider(
- label="pitch shift amount (semitones)",
- minimum=-12,
- maximum=12,
- step=1,
- value=0,
- )
-
- rand_mask_intensity = gr.Slider(
- label="random mask intensity. (If this is less than 1, scatters prompts throughout the audio, should be between 0.9 and 1.0)",
- minimum=0.0,
- maximum=1.0,
- value=1.0
- )
-
- periodic_w = gr.Slider(
- label="periodic prompt width (steps, 1 step ~= 10milliseconds)",
- minimum=1,
- maximum=20,
- step=1,
- value=1,
- )
- n_conditioning_codebooks = gr.Number(
- label="number of conditioning codebooks. probably 0",
- value=0,
- precision=0,
- )
-
- stretch_factor = gr.Slider(
- label="time stretch factor",
- minimum=0,
- maximum=64,
- step=1,
- value=1,
- )
-
- preset_outputs = {
- periodic_p,
- onset_mask_width,
- beat_mask_width,
- beat_mask_downbeats,
- }
-
- def load_preset(_preset):
- return tuple(presets[_preset].values())
-
- load_preset_button.click(
- fn=load_preset,
- inputs=[preset],
- outputs=preset_outputs
- )
-
-
- with gr.Accordion("prefix/suffix prompts", open=False):
- prefix_s = gr.Slider(
- label="prefix hint length (seconds)",
- minimum=0.0,
- maximum=10.0,
- value=0.0
- )
- suffix_s = gr.Slider(
- label="suffix hint length (seconds)",
- minimum=0.0,
- maximum=10.0,
- value=0.0
- )
-
- masktemp = gr.Slider(
- label="mask temperature",
- minimum=0.0,
- maximum=100.0,
- value=1.5
- )
- sampletemp = gr.Slider(
- label="sample temperature",
- minimum=0.1,
- maximum=10.0,
- value=1.0,
- step=0.001
- )
-
-
-
- with gr.Accordion("sampling settings", open=False):
- top_p = gr.Slider(
- label="top p (0.0 = off)",
- minimum=0.0,
- maximum=1.0,
- value=0.0
- )
- typical_filtering = gr.Checkbox(
- label="typical filtering ",
- value=False
- )
- typical_mass = gr.Slider(
- label="typical mass (should probably stay between 0.1 and 0.5)",
- minimum=0.01,
- maximum=0.99,
- value=0.15
- )
- typical_min_tokens = gr.Slider(
- label="typical min tokens (should probably stay between 1 and 256)",
- minimum=1,
- maximum=256,
- step=1,
- value=64
- )
- sample_cutoff = gr.Slider(
- label="sample cutoff",
- minimum=0.0,
- maximum=1.0,
- value=0.5,
- step=0.01
- )
-
- use_coarse2fine = gr.Checkbox(
- label="use coarse2fine",
- value=True,
- visible=False
- )
-
- num_steps = gr.Slider(
- label="number of steps (should normally be between 12 and 36)",
- minimum=1,
- maximum=128,
- step=1,
- value=36
- )
-
- dropout = gr.Slider(
- label="mask dropout",
- minimum=0.0,
- maximum=1.0,
- step=0.01,
- value=0.0
- )
-
-
- seed = gr.Number(
- label="seed (0 for random)",
- value=0,
- precision=0,
- )
-
-
-
- # mask settings
- with gr.Column():
-
- # lora_choice = gr.Dropdown(
- # label="lora choice",
- # choices=list(loras.keys()),
- # value=LORA_NONE,
- # visible=False
- # )
-
- vamp_button = gr.Button("generate (vamp)!!!")
- output_audio = gr.Audio(
- label="output audio",
- interactive=False,
- type="filepath"
- )
-
- notes_text = gr.Textbox(
- label="type any notes about the generated audio here",
- value="",
- interactive=True
- )
- save_button = gr.Button("save vamp")
- download_file = gr.File(
- label="vamp to download will appear here",
- interactive=False
- )
- use_as_input_button = gr.Button("use output as input")
-
- thank_you = gr.Markdown("")
-
-
- _inputs = {
- input_audio,
- num_steps,
- masktemp,
- sampletemp,
- top_p,
- prefix_s, suffix_s,
- rand_mask_intensity,
- periodic_p, periodic_w,
- n_conditioning_codebooks,
- dropout,
- use_coarse2fine,
- stretch_factor,
- onset_mask_width,
- typical_filtering,
- typical_mass,
- typical_min_tokens,
- beat_mask_width,
- beat_mask_downbeats,
- seed,
- # lora_choice,
- pitch_shift_amt,
- sample_cutoff
- }
-
- # connect widgets
- vamp_button.click(
- fn=vamp,
- inputs=_inputs,
- outputs=[output_audio, audio_mask],
- )
-
- api_vamp_button = gr.Button("api vamp", visible=False)
- api_vamp_button.click(
- fn=api_vamp,
- inputs=_inputs,
- outputs=[output_audio],
- api_name="vamp"
- )
-
- use_as_input_button.click(
- fn=lambda x: x,
- inputs=[output_audio],
- outputs=[input_audio]
- )
-
- save_button.click(
- fn=save_vamp,
- inputs=_inputs | {notes_text, output_audio},
- outputs=[thank_you, download_file]
- )
-
- # harp stuff
- harp_inputs = [
- input_audio,
- beat_mask_width,
- sampletemp,
- ]
-
- build_endpoint(
- inputs=harp_inputs,
- output=output_audio,
- process_fn=harp_vamp,
- card=ModelCard(
- name="vampnet",
- description="Generate variations on music input, based on small prompts around the beat.",
- author="Hugo Flores García",
- tags=["music", "generative"]
- ),
- visible=False
- )
-
-demo.launch()
diff --git a/spaces/diacanFperku/AutoGPT/Bedini Motor Bauanleitung Pdf Downloadl REPACK.md b/spaces/diacanFperku/AutoGPT/Bedini Motor Bauanleitung Pdf Downloadl REPACK.md
deleted file mode 100644
index 31b9a2b3ba1bfe6ef0a3bf9541259e78554b8b22..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Bedini Motor Bauanleitung Pdf Downloadl REPACK.md
+++ /dev/null
@@ -1,13 +0,0 @@
-
-How to Build a Bedini Motor and Download the PDF Guide
-A Bedini motor is a type of pulse motor that uses a transistor to switch a coil on and off, creating a magnetic field that rotates a wheel with magnets. The coil also charges a battery bank with the excess energy generated by the pulses. The Bedini motor was invented by John Bedini, an American inventor and researcher in the field of free energy and alternative energy sources.
-If you want to build your own Bedini motor and learn more about how it works, you can download a PDF guide that provides schematics, material lists, assembly instructions, operating procedures and tips. The PDF guide is based on the work of Sanja Smud, who published a document titled "Bedini - Schematics and Starter Guide" on Academia.edu[^1^]. The guide also includes some updates and modifications by Lee, another experimenter who shared his insights on the Bedini motor.
-Bedini Motor Bauanleitung Pdf Downloadl
Download === https://gohhs.com/2uFUAg
-To download the PDF guide, you can visit this link[^2^] and follow the instructions. You will need to create an account on Kit.co, a platform that allows users to share their recommendations for products and services. You will also need to provide your email address and confirm your subscription to receive the download link. Alternatively, you can also access the PDF guide directly from this link[^3^], which is hosted on Sway.office.com, a Microsoft service that lets users create interactive presentations.
-Building a Bedini motor can be a fun and educational project that can teach you about electromagnetism, electronics and energy conservation. You can also use it to charge your batteries or power other devices. However, please be careful when handling high voltages and currents, and follow the safety precautions in the guide. Also, do not expect to get more energy out of the system than you put in, as that would violate the laws of physics. The Bedini motor is not a perpetual motion machine or a free energy device, but rather an efficient and innovative way of converting electrical energy into mechanical energy and vice versa.
-
-If you are interested in learning more about the Bedini motor and other related topics, you can also check out some of the references listed at the end of the PDF guide. Some of them are books and articles by John Bedini himself, where he explains his theories and experiments in detail. Others are websites and forums where you can find more information and discussions about the Bedini motor and other pulse motors. You can also watch some videos on YouTube that show how to build and test different versions of the Bedini motor.
-The Bedini motor is one of the many examples of how human creativity and curiosity can lead to new discoveries and inventions. By exploring the possibilities of alternative energy sources and technologies, we can expand our knowledge and improve our lives. The Bedini motor may not be a miracle solution to our energy problems, but it is certainly a fascinating and inspiring device that deserves more attention and recognition.
- d5da3c52bf
-
-
\ No newline at end of file
diff --git a/spaces/digitalxingtong/Nailv-Bert-Vits2/setup_ffmpeg.py b/spaces/digitalxingtong/Nailv-Bert-Vits2/setup_ffmpeg.py
deleted file mode 100644
index 7137ab5faebb6d80740b8c843667458f25596839..0000000000000000000000000000000000000000
--- a/spaces/digitalxingtong/Nailv-Bert-Vits2/setup_ffmpeg.py
+++ /dev/null
@@ -1,55 +0,0 @@
-import os
-import sys
-import re
-from pathlib import Path
-import winreg
-
-def check_ffmpeg_path():
- path_list = os.environ['Path'].split(';')
- ffmpeg_found = False
-
- for path in path_list:
- if 'ffmpeg' in path.lower() and 'bin' in path.lower():
- ffmpeg_found = True
- print("FFmpeg already installed.")
- break
-
- return ffmpeg_found
-
-def add_ffmpeg_path_to_user_variable():
- ffmpeg_bin_path = Path('.\\ffmpeg\\bin')
- if ffmpeg_bin_path.is_dir():
- abs_path = str(ffmpeg_bin_path.resolve())
-
- try:
- key = winreg.OpenKey(
- winreg.HKEY_CURRENT_USER,
- r"Environment",
- 0,
- winreg.KEY_READ | winreg.KEY_WRITE
- )
-
- try:
- current_path, _ = winreg.QueryValueEx(key, "Path")
- if abs_path not in current_path:
- new_path = f"{current_path};{abs_path}"
- winreg.SetValueEx(key, "Path", 0, winreg.REG_EXPAND_SZ, new_path)
- print(f"Added FFmpeg path to user variable 'Path': {abs_path}")
- else:
- print("FFmpeg path already exists in the user variable 'Path'.")
- finally:
- winreg.CloseKey(key)
- except WindowsError:
- print("Error: Unable to modify user variable 'Path'.")
- sys.exit(1)
-
- else:
- print("Error: ffmpeg\\bin folder not found in the current path.")
- sys.exit(1)
-
-def main():
- if not check_ffmpeg_path():
- add_ffmpeg_path_to_user_variable()
-
-if __name__ == "__main__":
- main()
\ No newline at end of file
diff --git a/spaces/digitalxingtong/Xingtong-2dall-Bert-VITS2/modules.py b/spaces/digitalxingtong/Xingtong-2dall-Bert-VITS2/modules.py
deleted file mode 100644
index 92e0f32a51c472bfd1659a50a95a95d195281d2b..0000000000000000000000000000000000000000
--- a/spaces/digitalxingtong/Xingtong-2dall-Bert-VITS2/modules.py
+++ /dev/null
@@ -1,452 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-from attentions import Encoder
-
-LRELU_SLOPE = 0.1
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
-class TransformerCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- n_layers,
- n_heads,
- p_dropout=0,
- filter_channels=0,
- mean_only=False,
- wn_sharing_parameter=None,
- gin_channels = 0
- ):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = Encoder(hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout, isflow = True, gin_channels = gin_channels) if wn_sharing_parameter is None else wn_sharing_parameter
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/dolceschokolade/chatbot-mini/components/Chatbar/components/ClearConversations.tsx b/spaces/dolceschokolade/chatbot-mini/components/Chatbar/components/ClearConversations.tsx
deleted file mode 100644
index 5ac218cda6606b16888dbf5ffe9d351362db8dd4..0000000000000000000000000000000000000000
--- a/spaces/dolceschokolade/chatbot-mini/components/Chatbar/components/ClearConversations.tsx
+++ /dev/null
@@ -1,57 +0,0 @@
-import { IconCheck, IconTrash, IconX } from '@tabler/icons-react';
-import { FC, useState } from 'react';
-
-import { useTranslation } from 'next-i18next';
-
-import { SidebarButton } from '@/components/Sidebar/SidebarButton';
-
-interface Props {
- onClearConversations: () => void;
-}
-
-export const ClearConversations: FC = ({ onClearConversations }) => {
- const [isConfirming, setIsConfirming] = useState(false);
-
- const { t } = useTranslation('sidebar');
-
- const handleClearConversations = () => {
- onClearConversations();
- setIsConfirming(false);
- };
-
- return isConfirming ? (
-
- {
- e.stopPropagation();
- handleClearConversations();
- }}
- />
-
- {
- e.stopPropagation();
- setIsConfirming(false);
- }}
- />
-
-
- ) : (
- ℹ️ I am DolphinChat and I was created to help people!
-
-✅️ I have been trained on almost the entire Internet!
-
-♻️ I can communicate in more than 60 languages of the world!
-
-📂 I work on open source and keep your data safe, I am a non-commercial project!
-
-▶️ I'm almost the perfect chat assistant, so try me!
-
\ No newline at end of file
diff --git a/spaces/dorkai/ChatUIPro/app/components/base/button/index.tsx b/spaces/dorkai/ChatUIPro/app/components/base/button/index.tsx
deleted file mode 100644
index 33aebb669e78ed26116f4780a75d32958f26572f..0000000000000000000000000000000000000000
--- a/spaces/dorkai/ChatUIPro/app/components/base/button/index.tsx
+++ /dev/null
@@ -1,44 +0,0 @@
-import type { FC, MouseEventHandler } from 'react'
-import React from 'react'
-import Spinner from '@/app/components/base/spinner'
-
-export type IButtonProps = {
- type?: string
- className?: string
- disabled?: boolean
- loading?: boolean
- children: React.ReactNode
- onClick?: MouseEventHandler
-}
-
-const Button: FC = ({
- type,
- disabled,
- children,
- className,
- onClick,
- loading = false,
-}) => {
- let style = 'cursor-pointer'
- switch (type) {
- case 'primary':
- style = (disabled || loading) ? 'bg-primary-600/75 cursor-not-allowed text-white' : 'bg-primary-600 hover:bg-primary-600/75 hover:shadow-md cursor-pointer text-white hover:shadow-sm'
- break
- default:
- style = disabled ? 'border-solid border border-gray-200 bg-gray-200 cursor-not-allowed text-gray-800' : 'border-solid border border-gray-200 cursor-pointer text-gray-500 hover:bg-white hover:shadow-sm hover:border-gray-300'
- break
- }
-
- return (
-
- {children}
- {/* Spinner is hidden when loading is false */}
-
- break
-
- if len(chat_msgs) > 0:
- print(f"truncating chat messages, dropping {len(chat_msgs)} messages.")
-
- if system_msg:
- prompt = 'system: ' + system_msg + '\n' + chat_msg + '\nassistant: '
- else:
- prompt = chat_msg + '\nassistant: '
-
- token_count = len(encode(prompt)[0])
-
- # pass with some expected stop strings.
- # some strange cases of "##| Instruction: " sneaking through.
- stopping_strings += standard_stopping_strings
- req_params['custom_stopping_strings'] = stopping_strings
- else:
- stream_object_type = 'text_completion.chunk'
- object_type = 'text_completion'
-
- # ... encoded as a string, array of strings, array of tokens, or array of token arrays.
- if is_legacy:
- prompt = body['context'] # Older engines.generate API
- else:
- prompt = body['prompt'] # XXX this can be different types
-
- if isinstance(prompt, list):
- prompt = ''.join(prompt) # XXX this is wrong... need to split out to multiple calls?
-
- token_count = len(encode(prompt)[0])
- if token_count >= req_params['truncation_length']:
- new_len = int(len(prompt) * (float(shared.settings['truncation_length']) - req_params['max_new_tokens']) / token_count)
- prompt = prompt[-new_len:]
- print(f"truncating prompt to {new_len} characters, was {token_count} tokens. Now: {len(encode(prompt)[0])} tokens.")
-
- # pass with some expected stop strings.
- # some strange cases of "##| Instruction: " sneaking through.
- stopping_strings += standard_stopping_strings
- req_params['custom_stopping_strings'] = stopping_strings
-
- if req_params['stream']:
- shared.args.chat = True
- # begin streaming
- chunk = {
- "id": cmpl_id,
- "object": stream_object_type,
- "created": created_time,
- "model": shared.model_name,
- resp_list: [{
- "index": 0,
- "finish_reason": None,
- }],
- }
-
- if stream_object_type == 'text_completion.chunk':
- chunk[resp_list][0]["text"] = ""
- else:
- # This is coming back as "system" to the openapi cli, not sure why.
- # So yeah... do both methods? delta and messages.
- chunk[resp_list][0]["message"] = {'role': 'assistant', 'content': ''}
- chunk[resp_list][0]["delta"] = {'role': 'assistant', 'content': ''}
- # { "role": "assistant" }
-
- response = 'data: ' + json.dumps(chunk) + '\n'
- self.wfile.write(response.encode('utf-8'))
-
- # generate reply #######################################
- if debug:
- print({'prompt': prompt, 'req_params': req_params, 'stopping_strings': stopping_strings})
- generator = generate_reply(prompt, req_params, stopping_strings=stopping_strings, is_chat=False)
-
- answer = ''
- seen_content = ''
- longest_stop_len = max([len(x) for x in stopping_strings])
-
- for a in generator:
- answer = a
-
- stop_string_found = False
- len_seen = len(seen_content)
- search_start = max(len_seen - longest_stop_len, 0)
-
- for string in stopping_strings:
- idx = answer.find(string, search_start)
- if idx != -1:
- answer = answer[:idx] # clip it.
- stop_string_found = True
-
- if stop_string_found:
- break
-
- # If something like "\nYo" is generated just before "\nYou:"
- # is completed, buffer and generate more, don't send it
- buffer_and_continue = False
-
- for string in stopping_strings:
- for j in range(len(string) - 1, 0, -1):
- if answer[-j:] == string[:j]:
- buffer_and_continue = True
- break
- else:
- continue
- break
-
- if buffer_and_continue:
- continue
-
- if req_params['stream']:
- # Streaming
- new_content = answer[len_seen:]
-
- if not new_content or chr(0xfffd) in new_content: # partial unicode character, don't send it yet.
- continue
-
- seen_content = answer
- chunk = {
- "id": cmpl_id,
- "object": stream_object_type,
- "created": created_time,
- "model": shared.model_name,
- resp_list: [{
- "index": 0,
- "finish_reason": None,
- }],
- }
- if stream_object_type == 'text_completion.chunk':
- chunk[resp_list][0]['text'] = new_content
- else:
- # So yeah... do both methods? delta and messages.
- chunk[resp_list][0]['message'] = {'content': new_content}
- chunk[resp_list][0]['delta'] = {'content': new_content}
- response = 'data: ' + json.dumps(chunk) + '\n'
- self.wfile.write(response.encode('utf-8'))
- completion_token_count += len(encode(new_content)[0])
-
- if req_params['stream']:
- chunk = {
- "id": cmpl_id,
- "object": stream_object_type,
- "created": created_time,
- "model": model, # TODO: add Lora info?
- resp_list: [{
- "index": 0,
- "finish_reason": "stop",
- }],
- "usage": {
- "prompt_tokens": token_count,
- "completion_tokens": completion_token_count,
- "total_tokens": token_count + completion_token_count
- }
- }
- if stream_object_type == 'text_completion.chunk':
- chunk[resp_list][0]['text'] = ''
- else:
- # So yeah... do both methods? delta and messages.
- chunk[resp_list][0]['message'] = {'content': ''}
- chunk[resp_list][0]['delta'] = {}
- response = 'data: ' + json.dumps(chunk) + '\ndata: [DONE]\n'
- self.wfile.write(response.encode('utf-8'))
- # Finished if streaming.
- if debug:
- print({'response': answer})
- return
-
- if debug:
- print({'response': answer})
-
- completion_token_count = len(encode(answer)[0])
- stop_reason = "stop"
- if token_count + completion_token_count >= req_params['truncation_length']:
- stop_reason = "length"
-
- resp = {
- "id": cmpl_id,
- "object": object_type,
- "created": created_time,
- "model": model, # TODO: add Lora info?
- resp_list: [{
- "index": 0,
- "finish_reason": stop_reason,
- }],
- "usage": {
- "prompt_tokens": token_count,
- "completion_tokens": completion_token_count,
- "total_tokens": token_count + completion_token_count
- }
- }
-
- if is_chat:
- resp[resp_list][0]["message"] = {"role": "assistant", "content": answer}
- else:
- resp[resp_list][0]["text"] = answer
-
- response = json.dumps(resp)
- self.wfile.write(response.encode('utf-8'))
- elif '/edits' in self.path:
- self.send_response(200)
- self.send_header('Content-Type', 'application/json')
- self.end_headers()
-
- created_time = int(time.time())
-
- # Using Alpaca format, this may work with other models too.
- instruction = body['instruction']
- input = body.get('input', '')
-
- instruction_template = deduce_template()
- edit_task = instruction_template.format(instruction=instruction, input=input)
-
- truncation_length = default(shared.settings, 'truncation_length', 2048)
- token_count = len(encode(edit_task)[0])
- max_tokens = truncation_length - token_count
-
- req_params = {
- 'max_new_tokens': max_tokens,
- 'temperature': clamp(default(body, 'temperature', 1.0), 0.001, 1.999),
- 'top_p': clamp(default(body, 'top_p', 1.0), 0.001, 1.0),
- 'top_k': 1,
- 'repetition_penalty': 1.18,
- 'encoder_repetition_penalty': 1.0,
- 'suffix': None,
- 'stream': False,
- 'echo': False,
- 'seed': shared.settings.get('seed', -1),
- # 'n' : default(body, 'n', 1), # 'n' doesn't have a direct map
- 'truncation_length': truncation_length,
- 'add_bos_token': shared.settings.get('add_bos_token', True),
- 'do_sample': True,
- 'typical_p': 1.0,
- 'min_length': 0,
- 'no_repeat_ngram_size': 0,
- 'num_beams': 1,
- 'penalty_alpha': 0.0,
- 'length_penalty': 1,
- 'early_stopping': False,
- 'ban_eos_token': False,
- 'skip_special_tokens': True,
- 'custom_stopping_strings': [],
- }
-
- if debug:
- print({'edit_template': edit_task, 'req_params': req_params, 'token_count': token_count})
-
- generator = generate_reply(edit_task, req_params, stopping_strings=standard_stopping_strings, is_chat=False)
-
- answer = ''
- for a in generator:
- answer = a
-
- # some reply's have an extra leading space to fit the instruction template, just clip it off from the reply.
- if edit_task[-1] != '\n' and answer and answer[0] == ' ':
- answer = answer[1:]
-
- completion_token_count = len(encode(answer)[0])
-
- resp = {
- "object": "edit",
- "created": created_time,
- "choices": [{
- "text": answer,
- "index": 0,
- }],
- "usage": {
- "prompt_tokens": token_count,
- "completion_tokens": completion_token_count,
- "total_tokens": token_count + completion_token_count
- }
- }
-
- if debug:
- print({'answer': answer, 'completion_token_count': completion_token_count})
-
- response = json.dumps(resp)
- self.wfile.write(response.encode('utf-8'))
- elif '/images/generations' in self.path and 'SD_WEBUI_URL' in os.environ:
- # Stable Diffusion callout wrapper for txt2img
- # Low effort implementation for compatibility. With only "prompt" being passed and assuming DALL-E
- # the results will be limited and likely poor. SD has hundreds of models and dozens of settings.
- # If you want high quality tailored results you should just use the Stable Diffusion API directly.
- # it's too general an API to try and shape the result with specific tags like "masterpiece", etc,
- # Will probably work best with the stock SD models.
- # SD configuration is beyond the scope of this API.
- # At this point I will not add the edits and variations endpoints (ie. img2img) because they
- # require changing the form data handling to accept multipart form data, also to properly support
- # url return types will require file management and a web serving files... Perhaps later!
-
- self.send_response(200)
- self.send_header('Content-Type', 'application/json')
- self.end_headers()
-
- width, height = [ int(x) for x in default(body, 'size', '1024x1024').split('x') ] # ignore the restrictions on size
- response_format = default(body, 'response_format', 'url') # or b64_json
-
- payload = {
- 'prompt': body['prompt'], # ignore prompt limit of 1000 characters
- 'width': width,
- 'height': height,
- 'batch_size': default(body, 'n', 1) # ignore the batch limits of max 10
- }
-
- resp = {
- 'created': int(time.time()),
- 'data': []
- }
-
- # TODO: support SD_WEBUI_AUTH username:password pair.
- sd_url = f"{os.environ['SD_WEBUI_URL']}/sdapi/v1/txt2img"
-
- response = requests.post(url=sd_url, json=payload)
- r = response.json()
- # r['parameters']...
- for b64_json in r['images']:
- if response_format == 'b64_json':
- resp['data'].extend([{'b64_json': b64_json}])
- else:
- resp['data'].extend([{'url': f'data:image/png;base64,{b64_json}'}]) # yeah it's lazy. requests.get() will not work with this
-
- response = json.dumps(resp)
- self.wfile.write(response.encode('utf-8'))
- elif '/embeddings' in self.path and embedding_model is not None:
- self.send_response(200)
- self.send_header('Content-Type', 'application/json')
- self.end_headers()
-
- input = body['input'] if 'input' in body else body['text']
- if type(input) is str:
- input = [input]
-
- embeddings = embedding_model.encode(input).tolist()
-
- def enc_emb(emb):
- # If base64 is specified, encode. Otherwise, do nothing.
- if body.get("encoding_format", "") == "base64":
- return float_list_to_base64(emb)
- else:
- return emb
- data = [{"object": "embedding", "embedding": enc_emb(emb), "index": n} for n, emb in enumerate(embeddings)]
-
- response = json.dumps({
- "object": "list",
- "data": data,
- "model": st_model, # return the real model
- "usage": {
- "prompt_tokens": 0,
- "total_tokens": 0,
- }
- })
-
- if debug:
- print(f"Embeddings return size: {len(embeddings[0])}, number: {len(embeddings)}")
- self.wfile.write(response.encode('utf-8'))
- elif '/moderations' in self.path:
- # for now do nothing, just don't error.
- self.send_response(200)
- self.send_header('Content-Type', 'application/json')
- self.end_headers()
-
- response = json.dumps({
- "id": "modr-5MWoLO",
- "model": "text-moderation-001",
- "results": [{
- "categories": {
- "hate": False,
- "hate/threatening": False,
- "self-harm": False,
- "sexual": False,
- "sexual/minors": False,
- "violence": False,
- "violence/graphic": False
- },
- "category_scores": {
- "hate": 0.0,
- "hate/threatening": 0.0,
- "self-harm": 0.0,
- "sexual": 0.0,
- "sexual/minors": 0.0,
- "violence": 0.0,
- "violence/graphic": 0.0
- },
- "flagged": False
- }]
- })
- self.wfile.write(response.encode('utf-8'))
-
- elif self.path == '/api/v1/token-count':
- # NOT STANDARD. lifted from the api extension, but it's still very useful to calculate tokenized length client side.
- self.send_response(200)
- self.send_header('Content-Type', 'application/json')
- self.end_headers()
-
- tokens = encode(body['prompt'])[0]
- response = json.dumps({
- 'results': [{
- 'tokens': len(tokens)
- }]
- })
- self.wfile.write(response.encode('utf-8'))
- else:
- print(self.path, self.headers)
- self.send_error(404)
-
-
-def run_server():
- global embedding_model
- try:
- embedding_model = SentenceTransformer(st_model)
- print(f"\nLoaded embedding model: {st_model}, max sequence length: {embedding_model.max_seq_length}")
- except:
- print(f"\nFailed to load embedding model: {st_model}")
- pass
-
- server_addr = ('0.0.0.0' if shared.args.listen else '127.0.0.1', params['port'])
- server = ThreadingHTTPServer(server_addr, Handler)
- if shared.args.share:
- try:
- from flask_cloudflared import _run_cloudflared
- public_url = _run_cloudflared(params['port'], params['port'] + 1)
- print(f'Starting OpenAI compatible api at\nOPENAI_API_BASE={public_url}/v1')
- except ImportError:
- print('You should install flask_cloudflared manually')
- else:
- print(f'Starting OpenAI compatible api:\nOPENAI_API_BASE=http://{server_addr[0]}:{server_addr[1]}/v1')
-
- server.serve_forever()
-
-
-def setup():
- Thread(target=run_server, daemon=True).start()
diff --git a/spaces/dwolfe66/text-generation-webui-space/convert-to-flexgen.py b/spaces/dwolfe66/text-generation-webui-space/convert-to-flexgen.py
deleted file mode 100644
index 917f023c3fe395c2e3cbcad11c9cdc6b85ef1e7e..0000000000000000000000000000000000000000
--- a/spaces/dwolfe66/text-generation-webui-space/convert-to-flexgen.py
+++ /dev/null
@@ -1,60 +0,0 @@
-'''
-
-Converts a transformers model to a format compatible with flexgen.
-
-'''
-
-import argparse
-import os
-from pathlib import Path
-
-import numpy as np
-import torch
-from tqdm import tqdm
-from transformers import AutoModelForCausalLM, AutoTokenizer
-
-parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog,max_help_position=54))
-parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.")
-args = parser.parse_args()
-
-def disable_torch_init():
- """
- Disable the redundant torch default initialization to accelerate model creation.
- """
- import torch
- global torch_linear_init_backup
- global torch_layer_norm_init_backup
-
- torch_linear_init_backup = torch.nn.Linear.reset_parameters
- setattr(torch.nn.Linear, "reset_parameters", lambda self: None)
-
- torch_layer_norm_init_backup = torch.nn.LayerNorm.reset_parameters
- setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
-
-def restore_torch_init():
- """Rollback the change made by disable_torch_init."""
- import torch
- setattr(torch.nn.Linear, "reset_parameters", torch_linear_init_backup)
- setattr(torch.nn.LayerNorm, "reset_parameters", torch_layer_norm_init_backup)
-
-if __name__ == '__main__':
- path = Path(args.MODEL)
- model_name = path.name
-
- print(f"Loading {model_name}...")
- #disable_torch_init()
- model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
- #restore_torch_init()
-
- tokenizer = AutoTokenizer.from_pretrained(path)
-
- out_folder = Path(f"models/{model_name}-np")
- if not Path(out_folder).exists():
- os.mkdir(out_folder)
-
- print(f"Saving the converted model to {out_folder}...")
- for name, param in tqdm(list(model.model.named_parameters())):
- name = name.replace("decoder.final_layer_norm", "decoder.layer_norm")
- param_path = os.path.join(out_folder, name)
- with open(param_path, "wb") as f:
- np.save(f, param.cpu().detach().numpy())
diff --git a/spaces/facebook/seamless_m4t/README.md b/spaces/facebook/seamless_m4t/README.md
deleted file mode 100644
index 7a0d48614c51250914dff863b12da93a19a9596b..0000000000000000000000000000000000000000
--- a/spaces/facebook/seamless_m4t/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Seamless M4T
-emoji: 📞
-colorFrom: blue
-colorTo: yellow
-sdk: gradio
-app_file: app.py
-pinned: false
-suggested_hardware: t4-medium
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/falterWliame/Face_Mask_Detection/Adobe Response Code Generator [Extra Quality].md b/spaces/falterWliame/Face_Mask_Detection/Adobe Response Code Generator [Extra Quality].md
deleted file mode 100644
index 9719ada8aa69793c6e8a41b5a127234b256fb79e..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Adobe Response Code Generator [Extra Quality].md
+++ /dev/null
@@ -1,12 +0,0 @@
-Adobe response code generator
Download File ☆☆☆ https://urlca.com/2uDcUA
-
-Adobe response code generator, Adobe response code generator, Adobe response code generator Photoshop cs6, response code generator Adobe Photoshop cs6, response Adobe cs6 code generator nse, ... Adobe response code generator
-Adobe Response Code Generator...
-Adobe Photoshop cs6 response code generator, ...
-Adobe Photoshop cs6 response code generator, photo editor code generator
-Adobe Photoshop cs6 response code generator, Adobe Photoshop cs6 response code generator, Adobe cs6 response nse code generator, ...
-Adobe Response Code Generator
-Adobe response code generator ... 8a78ff9644
-
-
-
diff --git a/spaces/falterWliame/Face_Mask_Detection/Autodesk3DSMax2015EN64bitwith!!TOP!! CrackXForce.md b/spaces/falterWliame/Face_Mask_Detection/Autodesk3DSMax2015EN64bitwith!!TOP!! CrackXForce.md
deleted file mode 100644
index a88bbeff1b759db15148f710725ff7eb3a2ac7cf..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Autodesk3DSMax2015EN64bitwith!!TOP!! CrackXForce.md
+++ /dev/null
@@ -1,42 +0,0 @@
-Autodesk3DSMax2015EN64bitwithCrackXForce
DOWNLOAD ✫ https://urlca.com/2uDdVg
-
-.zipand the included 3DMax 2015 app (x64 only) are now available in the Plugins window under the Space plugin menu in Fusion.
-
-If you’re looking for an alternative to the 3DMax 2015 app that you can use with Fusion, check out the new Modeler menu entry in the Plugins window. There you’ll find a variety of Modeler apps that you can download, including SketchUp and Zbrush.
-
-Regarding the Fusion 12.0.2 update, it only includes a single bugfix in the Form options where the Maximize & Miniaturize buttons were not working for 3D shapes. In addition to this bugfix, Fusion 12.0.2 also includes the updates discussed above.
-
-The file format system, which also includes new content types (video, point clouds, etc.) as well as improvements to data display, will be available sometime in the next several weeks.
-
-And now that you’ve been updated, I encourage you to visit our community site and check out all the great new tutorials and content we’ve created for the new tools in Fusion 12.
-
-In this video tutorial, Shai shows you how to import an animated model into 3D Max and display it on the Global Camera viewport. Afterwards, he shows how to make adjustments and manipulate it in a viewport independent way.Q:
-
-Is there a way to access the AutoMapper map inside an extension method?
-
-Is there a way to access the AutoMapper map inside an extension method?
-
-I'm using the following extension method:
-
-public static class MappingExtensions
-
-{
-
- public static void Populate(this IMappingExpression expression)
-
- {
-
- //Is there a way to access the AutoMapper map?
-
- //Need to add a constraint
-
- Mapper.Initialize(x => x.ConstructServicesFrom(expression));
-
- var dest = expression.Compile();
-
- Mapper.AssertConfigurationIsValid();
-
- Mapper.Assert 4fefd39f24
-
-
-
diff --git a/spaces/falterWliame/Face_Mask_Detection/Diablo 3 2012 DVD [WORK] Full Version.rar.md b/spaces/falterWliame/Face_Mask_Detection/Diablo 3 2012 DVD [WORK] Full Version.rar.md
deleted file mode 100644
index ad9d3a4b60ba113cc179090e04ce3583a17b1098..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Diablo 3 2012 DVD [WORK] Full Version.rar.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Diablo 3 2012 DVD Full Version.rar
Download Zip ✵✵✵ https://urlca.com/2uDcqI
-
-Razor 1911's version of skyrim is obviously an illegal copy. ... Cracktro of Diablo II Lord of Destruction by Razor1911, also on other games. by ... PC Gears of War 1 3 DVD5 spa eng & coop No RAR. ... Resident Evil 6 CD Key. blogspot201202resident-evil-6-keygen-crack- 2012-10v. when I open the game, I find ... 1fdad05405
-
-
-
diff --git a/spaces/falterWliame/Face_Mask_Detection/FULL Windows 10 Permanent Activator Ultimate V4.13. 12.md b/spaces/falterWliame/Face_Mask_Detection/FULL Windows 10 Permanent Activator Ultimate V4.13. 12.md
deleted file mode 100644
index 3e7330804158b870db4016c2395f222d5f5b2456..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/FULL Windows 10 Permanent Activator Ultimate V4.13. 12.md
+++ /dev/null
@@ -1,11 +0,0 @@
-FULL Windows 10 Permanent Activator Ultimate v4.13. 12
Download Zip ✔ https://urlca.com/2uDdNR
-
-Red Alert 2 revenge revenge revenge 1.001 54 Vicky Donor Download movie Kickass Full Windows 10 Permanent activator Ultimate V4.13. 12. Download for free all games on PSP via torrent, Yandex disk and mail cloud, in ISO, CSO format for all models.
-For a reason not only for the game, but also for.
-Download the game Kickass Full Windows 10 via torrent for PC, which was released in 2013.
-This torrent game belongs to Action, Shooter.
-Download for free all games on PSP via torrent, Yandex disk and cloud mail, in ISO, CSO format for all models.
-Download game Kickass Full Windows 10 via torrent for PC which came out in 2013. 8a78ff9644
-
-
-
diff --git a/spaces/falterWliame/Face_Mask_Detection/Inpage Urdu 2009 Professional By Nazim.md b/spaces/falterWliame/Face_Mask_Detection/Inpage Urdu 2009 Professional By Nazim.md
deleted file mode 100644
index eb66097b91a53b6f2308458195aa23a38d95da95..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Inpage Urdu 2009 Professional By Nazim.md
+++ /dev/null
@@ -1,48 +0,0 @@
-
-Inpage Urdu 2009 Professional by Nazim: The Ultimate Urdu Writing Software
-If you are looking for a software that can help you write Urdu, Arabic, Persian and other languages in a beautiful Nastaliq font, then you should try Inpage Urdu 2009 Professional by Nazim. This software is a comprehensive tool that has a strong grip on these languages and offers many features and options for creating and publishing your documents.
-Inpage Urdu 2009 Professional by Nazim
Download File … https://urlca.com/2uDdwn
-What is Inpage Urdu 2009 Professional by Nazim?
-Inpage Urdu 2009 Professional by Nazim is a word processing software that was first built in 1994. The main purpose behind the development of this tool was to create pages in languages that are not much popular and neglected by the world like Balochi, Punjabi, Arabic, Pashto, etc. It is based on the world famous Noorinastaliq font that gives your text a calligraphic elegance.
-This software is compatible with all kinds of operating systems including Microsoft Windows 7, MS Windows XP, Win 8, and Windows 10. Separate versions also have been released for Mac OS and Linux. You can easily download the setup file for this tool and install it using simple guided steps. It works just like MS Office 2017 and Office Professional 2003.
-What are the features of Inpage Urdu 2009 Professional by Nazim?
-Inpage Urdu 2009 Professional by Nazim has many features that make it a powerful and versatile tool for Urdu writing. Some of these features are:
-
-- Fast and easy typing application. You can type in Urdu, Arabic, Persian and other languages with ease and accuracy.
-- The best typing tool. It has a built-in dictionary and spell check feature for Urdu and English language. It also has automatic spacing in Nastaliq font and other fonts.
-- It is easy to use with English from left to right. You can switch between Urdu and English language with a single keystroke.
-- It has the ability to communicate with other software in typing. You can import and export text from other applications like MS Word, Excel, PowerPoint, etc.
-- It has the ability to rotate text and other elements for free in any aspect. You can also customize your text with different colors, styles, sizes, etc.
-- It has training options and results. You can learn how to type in Urdu and Arabic with the help of tutorials and exercises.
-- It has a wide range of tools. You can insert images, tables, symbols, borders, etc. in your document. You can also use different page layouts, headers, footers, etc.
-
-How to download and install Inpage Urdu 2009 Professional by Nazim?
-If you want to download and install Inpage Urdu 2009 Professional by Nazim on your PC or Android phone, you can follow these simple steps:
-
-
-- Go to the official website of Inpage Urdu 2009 Professional by Nazim or click on this link: https://www.inpage.com.pk/download/
-- Select the version of the software that suits your operating system and click on the download button.
-- Save the setup file on your device and run it as an administrator.
-- Follow the instructions on the screen and complete the installation process.
-- Launch the software and enjoy writing in Urdu and other languages.
-
-Conclusion
-Inpage Urdu 2009 Professional by Nazim is a great software for writing Urdu, Arabic, Persian and other languages in a beautiful Nastaliq font. It has many features and options that make it a powerful and versatile tool for creating and publishing your documents. You can download it from the official website or from the link given above. If you have any questions or feedback about this software, feel free to leave a comment below.
-What are the reviews of Inpage Urdu 2009 Professional by Nazim?
-Inpage Urdu 2009 Professional by Nazim has received many positive reviews from its users and critics. Many people have praised its features, performance, compatibility, and ease of use. Here are some of the reviews of Inpage Urdu 2009 Professional by Nazim from different sources:
-
-"Inpage Urdu 2009 Professional by Nazim is a great software for writing Urdu, Arabic, Persian and other languages in a beautiful Nastaliq font. It has many features and options that make it a powerful and versatile tool for creating and publishing your documents. You can download it from the official website or from the link given above. If you have any questions or feedback about this software, feel free to leave a comment below."
-Urdu Wisdom
-
-
-"I have been using Inpage Urdu 2009 Professional by Nazim for a long time and I am very satisfied with it. It is very easy to use and has a lot of features that make my work easier and faster. I can write in Urdu, Arabic, Persian and other languages with accuracy and elegance. I can also import and export text from other applications like MS Word, Excel, PowerPoint, etc. I highly recommend this software to anyone who wants to write in these languages."
-Mike Breitling
-
-
-"!FULL! Inpage Urdu 2009 Professional by Nazim is one of the best products on Kit. It is a comprehensive tool that has a strong grip on Urdu, Arabic, English, Persian and many other languages. It is a strong publishing tool. Based on the world famous Noorinastaliq font this tool has made it easy to write in Urdu and Arabic languages."
-Kit.co
-
-Conclusion
-Inpage Urdu 2009 Professional by Nazim is a great software for writing Urdu, Arabic, Persian and other languages in a beautiful Nastaliq font. It has many features and options that make it a powerful and versatile tool for creating and publishing your documents. You can download it from the official website or from the link given above. If you have any questions or feedback about this software, feel free to leave a comment below.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/falterWliame/Face_Mask_Detection/Mathematicawolfram9fullcrack.md b/spaces/falterWliame/Face_Mask_Detection/Mathematicawolfram9fullcrack.md
deleted file mode 100644
index 7f0a6d7e7a5aaead68579eb237ccfa32ed769004..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Mathematicawolfram9fullcrack.md
+++ /dev/null
@@ -1,6 +0,0 @@
-mathematicawolfram9fullcrack
Download ⚹ https://urlca.com/2uDcUN
-
-mathematicawolfram9fullcrack · Rio 2 Sinhronizovano Na Srpski · workspace 5 robot simulation download · HACK ZAR 8.3 With working Serial. 4d29de3e1b
-
-
-
diff --git a/spaces/falterWliame/Face_Mask_Detection/NcomputingVspaceLicensePORTABLE CrackSoftware.md b/spaces/falterWliame/Face_Mask_Detection/NcomputingVspaceLicensePORTABLE CrackSoftware.md
deleted file mode 100644
index 9d0834c286037241767fa050f3eda71e0e32e281..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/NcomputingVspaceLicensePORTABLE CrackSoftware.md
+++ /dev/null
@@ -1,40 +0,0 @@
-NcomputingVspaceLicenseCrackSoftware
Download File ⏩ https://urlca.com/2uDco7
-
-com. vSpace AMP license can be purchased directly from vSpace Authorized Partners or NComputing.com.
-
-What do I get when I purchase a NComputing device from an Authorized Partner?
-
-vSpace Pro license
-
-When you purchase a new vSpace Pro license you will have the ability to connect to a remote device via serial port or USB port. You will need to install either the 2.0.2 vSpace Installer or vSpace Serial Driver to connect to the device.
-
-The remote device you want to connect to will need to have the driver installed that matches the vSpace Pro license you have. The 2.0.2 vSpace Installer will install this driver automatically.
-
-vSpace Pro AMP license
-
-When you purchase a new vSpace Pro AMP license you will have the ability to connect to a remote device via serial port or USB port. You will need to install either the 2.0.2 vSpace Installer or vSpace Serial Driver to connect to the device.
-
-vSpace AMP license
-
-When you purchase a new vSpace AMP license you will have the ability to connect to a remote device via serial port or USB port. You will need to install either the 2.0.2 vSpace Installer or vSpace Serial Driver to connect to the device.
-
-The remote device you want to connect to will need to have the driver installed that matches the vSpace AMP license you have. The 2.0.2 vSpace Installer will install this driver automatically.
-
-What are the minimum hardware requirements?
-
-What are the minimum software requirements?
-
-Important notes
-
-vSpace Pro 2.0.1
-
-vSpace Pro 2.0.1 is the last official release to support the vSpace Pro license.
-
-vSpace Pro 2.0.2
-
-The vSpace Pro 2.0.2 release is the first official release of the vSpace Pro license. This release allows you to connect to a remote device via serial port or USB port.
-
-Please see the release notes for vSpace Pro 2.0.2 to ensure you have the correct drivers installed on your remote device. The vSpace Serial driver is only compatible with the v 4fefd39f24
-
-
-
diff --git a/spaces/fanzhuyu/Code-Interpreter/jupyter_backend.py b/spaces/fanzhuyu/Code-Interpreter/jupyter_backend.py
deleted file mode 100644
index c080d8a5cc7d10a7a075c13197c78cf979f8d41d..0000000000000000000000000000000000000000
--- a/spaces/fanzhuyu/Code-Interpreter/jupyter_backend.py
+++ /dev/null
@@ -1,100 +0,0 @@
-import jupyter_client
-import re
-
-
-def delete_color_control_char(string):
- ansi_escape = re.compile(r'(\x9B|\x1B\[)[0-?]*[ -\/]*[@-~]')
- return ansi_escape.sub('', string)
-
-
-class JupyterKernel:
- def __init__(self, work_dir):
- self.kernel_manager, self.kernel_client = jupyter_client.manager.start_new_kernel(kernel_name='python3')
- self.work_dir = work_dir
- self._create_work_dir()
- self.available_functions = {
- 'execute_code': self.execute_code,
- 'python': self.execute_code
- }
-
- def execute_code_(self, code):
- msg_id = self.kernel_client.execute(code)
-
- # Get the output of the code
- iopub_msg = self.kernel_client.get_iopub_msg()
-
- all_output = []
- while True:
- if iopub_msg['msg_type'] == 'stream':
- if iopub_msg['content'].get('name') == 'stdout':
- output = iopub_msg['content']['text']
- all_output.append(('stdout', output))
- iopub_msg = self.kernel_client.get_iopub_msg()
- elif iopub_msg['msg_type'] == 'execute_result':
- if 'data' in iopub_msg['content']:
- if 'text/plain' in iopub_msg['content']['data']:
- output = iopub_msg['content']['data']['text/plain']
- all_output.append(('execute_result_text', output))
- if 'text/html' in iopub_msg['content']['data']:
- output = iopub_msg['content']['data']['text/html']
- all_output.append(('execute_result_html', output))
- if 'image/png' in iopub_msg['content']['data']:
- output = iopub_msg['content']['data']['image/png']
- all_output.append(('execute_result_png', output))
- if 'image/jpeg' in iopub_msg['content']['data']:
- output = iopub_msg['content']['data']['image/jpeg']
- all_output.append(('execute_result_jpeg', output))
- iopub_msg = self.kernel_client.get_iopub_msg()
- elif iopub_msg['msg_type'] == 'display_data':
- if 'data' in iopub_msg['content']:
- if 'text/plain' in iopub_msg['content']['data']:
- output = iopub_msg['content']['data']['text/plain']
- all_output.append(('display_text', output))
- if 'text/html' in iopub_msg['content']['data']:
- output = iopub_msg['content']['data']['text/html']
- all_output.append(('display_html', output))
- if 'image/png' in iopub_msg['content']['data']:
- output = iopub_msg['content']['data']['image/png']
- all_output.append(('display_png', output))
- if 'image/jpeg' in iopub_msg['content']['data']:
- output = iopub_msg['content']['data']['image/jpeg']
- all_output.append(('display_jpeg', output))
- iopub_msg = self.kernel_client.get_iopub_msg()
- elif iopub_msg['msg_type'] == 'error':
- if 'traceback' in iopub_msg['content']:
- output = '\n'.join(iopub_msg['content']['traceback'])
- all_output.append(('error', output))
- iopub_msg = self.kernel_client.get_iopub_msg()
- elif iopub_msg['msg_type'] == 'status' and iopub_msg['content'].get('execution_state') == 'idle':
- break
- else:
- iopub_msg = self.kernel_client.get_iopub_msg()
-
- return all_output
-
- def execute_code(self, code):
- text_to_gpt = []
- content_to_display = self.execute_code_(code)
- for mark, out_str in content_to_display:
- if mark in ('stdout', 'execute_result_text', 'display_text'):
- text_to_gpt.append(out_str)
- elif mark in ('execute_result_png', 'execute_result_jpeg', 'display_png', 'display_jpeg'):
- text_to_gpt.append('[image]')
- elif mark == 'error':
- text_to_gpt.append(delete_color_control_char(out_str))
-
- return '\n'.join(text_to_gpt), content_to_display
-
- def _create_work_dir(self):
- # set work dir in jupyter environment
- init_code = f"import os\n" \
- f"if not os.path.exists('{self.work_dir}'):\n" \
- f" os.mkdir('{self.work_dir}')\n" \
- f"os.chdir('{self.work_dir}')\n" \
- f"del os"
- self.execute_code_(init_code)
-
- def restart_jupyter_kernel(self):
- self.kernel_client.shutdown()
- self.kernel_manager, self.kernel_client = jupyter_client.manager.start_new_kernel(kernel_name='python3')
- self._create_work_dir()
diff --git a/spaces/fariyan/gif_studio/app.py b/spaces/fariyan/gif_studio/app.py
deleted file mode 100644
index 5e8f1ea9545f92df572dea94170b966cf99c104e..0000000000000000000000000000000000000000
--- a/spaces/fariyan/gif_studio/app.py
+++ /dev/null
@@ -1,152 +0,0 @@
-import streamlit as st
-import os
-import base64
-import tempfile
-from PIL import Image as img
-import numpy as np
-from moviepy.editor import VideoFileClip as vfc
-import moviepy.video.fx.all as vfx
-
-def App():
- #session state#
- if 'clip_width' not in st.session_state:
- st.session_state.clip_width = 0
- if 'clip_height' not in st.session_state:
- st.session_state.clip_height = 0
- if 'clip_duration' not in st.session_state:
- st.session_state.clip_duration = 0
- if 'clip_fps' not in st.session_state:
- st.session_state.clip_fps = 0
- if 'clip_total_frames' not in st.session_state:
- st.session_state.clip_total_frames = 0
- #Frontend
-
- st.set_page_config(
- page_title='GIF Studio',
- page_icon='🎴',
- menu_items={
- 'Get Help': 'https://fariyanishraq35@gmail.com',
- 'Report a bug': "https://fariyanishraq35@gmail.com",
- 'About': "GIF Studio is an opensource web application to convert video clips to gif images. "
- }
- )
- title = st.title("GIF Studio")
- st.info('GIF Studio is an opensource web application to convert video clips to gif images. ')
- #upload section
- upload = st.file_uploader('upload clip', type=['mov','mp4'])
- #conditions
- if upload is not None:
- temp = tempfile.NamedTemporaryFile(delete=False)
- temp.write(upload.read())
- #open file
- clip = vfc(temp.name)
-
- #display output
- st.session_state.clip_duration = clip.duration
- st.session_state.clip_width = clip.w
- st.session_state.clip_height = clip.h
- st.session_state.clip_total_frames = clip.fps * clip.duration
- st.session_state.clip_fps = clip.fps
-
- #Metrics
- st.subheader('Metrics')
- with st.expander('Show metrics'):
- col1, col2, col3, col4, col5 = st.columns(5)
- col1.metric('Width', st.session_state.clip_width, 'pixels')
- col2.metric('Height', st.session_state.clip_height, 'pexels')
- col3.metric('Duration', st.session_state.clip_duration, 'seconds')
- col4.metric('FPS', st.session_state.clip_fps, '')
- col5.metric('Total Frames', st.session_state.clip_total_frames, 'frames')
-
- #Preview
- st.subheader("Preview")
- with st.expander('show image'):
- selected_frames = st.slider(
- 'Preview Time Frame',
- 0,
- int(st.session_state.clip_duration),
- int(np.median(st.session_state.clip_duration))
- )
- clip.save_frame('frame.gif', t=selected_frames)
- frame_image = img.open('frame.gif')
- st.image(frame_image, output_format=('Auto'))
-
- #Image Parameter
- st.subheader('Input Parameter')
- selected_resolution_scaling = st.slider(
- 'scaling of video resolution',
- 0.0, 1.0, 5.0
- )
- selected_speedx = st.slider(
- 'Playback speed',
- 0.1, 10.0, 5.0
- )
- selected_export_range = st.slider(
- 'Duration range to export',
- 0,
- int(st.session_state.clip_duration),
- (0, int(st.session_state.clip_duration))
- )
- #print parameter
- st.subheader('Image Parameter')
- with st.expander('Show image parameter'):
- st.write(f'File name: `{upload.name}`')
- st.write(f'Image size: `{frame_image.size}`')
- st.write(f'Video resolution scaling: `{selected_resolution_scaling}`')
- st.write(f'Speed playback: `{selected_speedx}`')
- st.write(f'Export duration: `{selected_export_range}`')
- st.write(f'FPS: `{st.session_state.clip_fps}`')
- #Export animated GIF
- generate_gif = st.button("Generate Animated GIF")
- if generate_gif:
- clip = clip.subclip(
- selected_export_range[0],
- selected_export_range[1],
- ).speedx(selected_speedx)
- frames=[]
- for frame in clip.iter_frames():
- frames.append(np.array(frame))
- image_list =[]
- for frame in frames:
- im = img.fromarray(frame)
- image_list.append(im)
- image_list[0].save(
- 'generate_img.gif',
- format='GIF',
- save_all = True,
- loop = 0,
- append_image = image_list
- )
- clip.write_gif('export.gif', fps=st.session_state.clip_fps)
- ## Download ##
- st.subheader('Download')
-
- file_ = open('export.gif', 'rb')
- contents = file_.read()
- data_url = base64.b64encode(contents).decode("utf-8")
- file_.close()
- st.markdown(
- f' ',
- unsafe_allow_html=True,
- )
-
- fsize = round(os.path.getsize('export.gif')/(1024*1024), 1)
- st.info(f'File size of generated GIF: {fsize} MB')
-
- fname = upload.name.split('.')[0]
- with open('export.gif', 'rb') as file:
- btn = st.download_button(
- label='Download image',
- data=file,
- file_name=f'{fname}_scaling-{selected_resolution_scaling}_fps-{st.session_state.clip_fps}_speed-{selected_speedx}_duration-{selected_export_range[0]}-{selected_export_range[1]}.gif',
- mime='image/gif'
- )
-
- else:
- st.info('Developed by Fariyan Ishraq')
-
-
-
-
-if __name__ == '__main__':
- App()
\ No newline at end of file
diff --git a/spaces/fclong/summary/fengshen/models/clip/__init__.py b/spaces/fclong/summary/fengshen/models/clip/__init__.py
deleted file mode 100644
index 8fcc95802f0a32cf3417a68b64c6e37a83813787..0000000000000000000000000000000000000000
--- a/spaces/fclong/summary/fengshen/models/clip/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-from .modeling_taiyi_clip import TaiyiCLIPModel
-from .processing_taiyi_clip import TaiyiCLIPProcessor
-
-__all__ = ['TaiyiCLIPModel', 'TaiyiCLIPProcessor']
diff --git a/spaces/fclong/summary/fengshen/models/zen1/configuration_zen1.py b/spaces/fclong/summary/fengshen/models/zen1/configuration_zen1.py
deleted file mode 100644
index c7cbeb5657ea07b2a4e8429199a6091be39864c8..0000000000000000000000000000000000000000
--- a/spaces/fclong/summary/fengshen/models/zen1/configuration_zen1.py
+++ /dev/null
@@ -1,80 +0,0 @@
-# coding=utf-8
-# Copyright 2022 IDEA-CCNL and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-""" TransfoXLDenoise model configuration """
-
-from transformers.configuration_utils import PretrainedConfig
-
-
-class ZenConfig(PretrainedConfig):
-
- """Configuration class to store the configuration of a `ZenModel`.
- """
-
- def __init__(self,
- # vocab_size_or_config_json_file,
- # word_vocab_size,
- hidden_size=768,
- num_hidden_layers=12,
- num_attention_heads=12,
- intermediate_size=3072,
- hidden_act="gelu",
- hidden_dropout_prob=0.1,
- attention_probs_dropout_prob=0.1,
- max_position_embeddings=512,
- type_vocab_size=2,
- initializer_range=0.02,
- layer_norm_eps=1e-12,
- num_hidden_word_layers=6,
- **kwargs):
- """Constructs ZenConfig.
-
- Args:
- vocab_size_or_config_json_file: Vocabulary size of `inputs_ids` in `BertModel`.
- hidden_size: Size of the encoder layers and the pooler layer.
- num_hidden_layers: Number of hidden layers in the Transformer encoder.
- num_attention_heads: Number of attention heads for each attention layer in
- the Transformer encoder.
- intermediate_size: The size of the "intermediate" (i.e., feed-forward)
- layer in the Transformer encoder.
- hidden_act: The non-linear activation function (function or string) in the
- encoder and pooler. If string, "gelu", "relu" and "swish" are supported.
- hidden_dropout_prob: The dropout probabilitiy for all fully connected
- layers in the embeddings, encoder, and pooler.
- attention_probs_dropout_prob: The dropout ratio for the attention
- probabilities.
- max_position_embeddings: The maximum sequence length that this model might
- ever be used with. Typically set this to something large just in case
- (e.g., 512 or 1024 or 2048).
- type_vocab_size: The vocabulary size of the `token_type_ids` passed into
- `BertModel`.
- initializer_range: The sttdev of the truncated_normal_initializer for
- initializing all weight matrices.
- layer_norm_eps: The epsilon used by LayerNorm.
- """
- # self.vocab_size = vocab_size_or_config_json_file
- # self.word_size = word_vocab_size
- self.hidden_size = hidden_size
- self.num_hidden_layers = num_hidden_layers
- self.num_attention_heads = num_attention_heads
- self.hidden_act = hidden_act
- self.intermediate_size = intermediate_size
- self.hidden_dropout_prob = hidden_dropout_prob
- self.attention_probs_dropout_prob = attention_probs_dropout_prob
- self.max_position_embeddings = max_position_embeddings
- self.type_vocab_size = type_vocab_size
- self.initializer_range = initializer_range
- self.layer_norm_eps = layer_norm_eps
- self.num_hidden_word_layers = num_hidden_word_layers
- super().__init__(**kwargs)
diff --git a/spaces/fengmuxi/ChatGpt-Web/app/components/sidebar.tsx b/spaces/fengmuxi/ChatGpt-Web/app/components/sidebar.tsx
deleted file mode 100644
index b13f8aff738d35707f654bf6686577bdaf9ad191..0000000000000000000000000000000000000000
--- a/spaces/fengmuxi/ChatGpt-Web/app/components/sidebar.tsx
+++ /dev/null
@@ -1,206 +0,0 @@
-import { useEffect, useRef } from "react";
-
-import styles from "./home.module.scss";
-
-import { IconButton } from "./button";
-import SettingsIcon from "../icons/settings.svg";
-import GithubIcon from "../icons/github.svg";
-import User from "../icons/user.svg";
-import ChatGptIcon from "../icons/chatgpt.svg";
-import AddIcon from "../icons/add.svg";
-import CloseIcon from "../icons/close.svg";
-import MaskIcon from "../icons/mask.svg";
-import PluginIcon from "../icons/plugin.svg";
-
-import Locale from "../locales";
-
-import { useAppConfig, useChatStore } from "../store";
-
-import {
- MAX_SIDEBAR_WIDTH,
- MIN_SIDEBAR_WIDTH,
- NARROW_SIDEBAR_WIDTH,
- Path,
- REPO_URL,
-} from "../constant";
-
-import { Link, useNavigate } from "react-router-dom";
-import { useMobileScreen } from "../utils";
-import dynamic from "next/dynamic";
-import { showToast } from "./ui-lib";
-
-const ChatList = dynamic(async () => (await import("./chat-list")).ChatList, {
- loading: () => null,
-});
-
-function useHotKey() {
- const chatStore = useChatStore();
-
- useEffect(() => {
- const onKeyDown = (e: KeyboardEvent) => {
- if (e.metaKey || e.altKey || e.ctrlKey) {
- const n = chatStore.sessions.length;
- const limit = (x: number) => (x + n) % n;
- const i = chatStore.currentSessionIndex;
- if (e.key === "ArrowUp") {
- chatStore.selectSession(limit(i - 1));
- } else if (e.key === "ArrowDown") {
- chatStore.selectSession(limit(i + 1));
- }
- }
- };
-
- window.addEventListener("keydown", onKeyDown);
- return () => window.removeEventListener("keydown", onKeyDown);
- });
-}
-
-function useDragSideBar() {
- const limit = (x: number) => Math.min(MAX_SIDEBAR_WIDTH, x);
-
- const config = useAppConfig();
- const startX = useRef(0);
- const startDragWidth = useRef(config.sidebarWidth ?? 300);
- const lastUpdateTime = useRef(Date.now());
-
- const handleMouseMove = useRef((e: MouseEvent) => {
- if (Date.now() < lastUpdateTime.current + 50) {
- return;
- }
- lastUpdateTime.current = Date.now();
- const d = e.clientX - startX.current;
- const nextWidth = limit(startDragWidth.current + d);
- config.update((config) => (config.sidebarWidth = nextWidth));
- });
-
- const handleMouseUp = useRef(() => {
- startDragWidth.current = config.sidebarWidth ?? 300;
- window.removeEventListener("mousemove", handleMouseMove.current);
- window.removeEventListener("mouseup", handleMouseUp.current);
- });
-
- const onDragMouseDown = (e: MouseEvent) => {
- startX.current = e.clientX;
-
- window.addEventListener("mousemove", handleMouseMove.current);
- window.addEventListener("mouseup", handleMouseUp.current);
- };
- const isMobileScreen = useMobileScreen();
- const shouldNarrow =
- !isMobileScreen && config.sidebarWidth < MIN_SIDEBAR_WIDTH;
-
- useEffect(() => {
- const barWidth = shouldNarrow
- ? NARROW_SIDEBAR_WIDTH
- : limit(config.sidebarWidth ?? 300);
- const sideBarWidth = isMobileScreen ? "100vw" : `${barWidth}px`;
- document.documentElement.style.setProperty("--sidebar-width", sideBarWidth);
- }, [config.sidebarWidth, isMobileScreen, shouldNarrow]);
-
- return {
- onDragMouseDown,
- shouldNarrow,
- };
-}
-
-export function SideBar(props: { className?: string }) {
- const chatStore = useChatStore();
-
- // drag side bar
- const { onDragMouseDown, shouldNarrow } = useDragSideBar();
- const navigate = useNavigate();
-
- const config = useAppConfig();
- useHotKey();
-
- return (
-
-
-
- ChatGPT Next【{config.bot}】
-
- 必应暂不支持上下文
-
-
',
- unsafe_allow_html=True,
- )
-
- fsize = round(os.path.getsize('export.gif')/(1024*1024), 1)
- st.info(f'File size of generated GIF: {fsize} MB')
-
- fname = upload.name.split('.')[0]
- with open('export.gif', 'rb') as file:
- btn = st.download_button(
- label='Download image',
- data=file,
- file_name=f'{fname}_scaling-{selected_resolution_scaling}_fps-{st.session_state.clip_fps}_speed-{selected_speedx}_duration-{selected_export_range[0]}-{selected_export_range[1]}.gif',
- mime='image/gif'
- )
-
- else:
- st.info('Developed by Fariyan Ishraq')
-
-
-
-
-if __name__ == '__main__':
- App()
\ No newline at end of file
diff --git a/spaces/fclong/summary/fengshen/models/clip/__init__.py b/spaces/fclong/summary/fengshen/models/clip/__init__.py
deleted file mode 100644
index 8fcc95802f0a32cf3417a68b64c6e37a83813787..0000000000000000000000000000000000000000
--- a/spaces/fclong/summary/fengshen/models/clip/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-from .modeling_taiyi_clip import TaiyiCLIPModel
-from .processing_taiyi_clip import TaiyiCLIPProcessor
-
-__all__ = ['TaiyiCLIPModel', 'TaiyiCLIPProcessor']
diff --git a/spaces/fclong/summary/fengshen/models/zen1/configuration_zen1.py b/spaces/fclong/summary/fengshen/models/zen1/configuration_zen1.py
deleted file mode 100644
index c7cbeb5657ea07b2a4e8429199a6091be39864c8..0000000000000000000000000000000000000000
--- a/spaces/fclong/summary/fengshen/models/zen1/configuration_zen1.py
+++ /dev/null
@@ -1,80 +0,0 @@
-# coding=utf-8
-# Copyright 2022 IDEA-CCNL and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-""" TransfoXLDenoise model configuration """
-
-from transformers.configuration_utils import PretrainedConfig
-
-
-class ZenConfig(PretrainedConfig):
-
- """Configuration class to store the configuration of a `ZenModel`.
- """
-
- def __init__(self,
- # vocab_size_or_config_json_file,
- # word_vocab_size,
- hidden_size=768,
- num_hidden_layers=12,
- num_attention_heads=12,
- intermediate_size=3072,
- hidden_act="gelu",
- hidden_dropout_prob=0.1,
- attention_probs_dropout_prob=0.1,
- max_position_embeddings=512,
- type_vocab_size=2,
- initializer_range=0.02,
- layer_norm_eps=1e-12,
- num_hidden_word_layers=6,
- **kwargs):
- """Constructs ZenConfig.
-
- Args:
- vocab_size_or_config_json_file: Vocabulary size of `inputs_ids` in `BertModel`.
- hidden_size: Size of the encoder layers and the pooler layer.
- num_hidden_layers: Number of hidden layers in the Transformer encoder.
- num_attention_heads: Number of attention heads for each attention layer in
- the Transformer encoder.
- intermediate_size: The size of the "intermediate" (i.e., feed-forward)
- layer in the Transformer encoder.
- hidden_act: The non-linear activation function (function or string) in the
- encoder and pooler. If string, "gelu", "relu" and "swish" are supported.
- hidden_dropout_prob: The dropout probabilitiy for all fully connected
- layers in the embeddings, encoder, and pooler.
- attention_probs_dropout_prob: The dropout ratio for the attention
- probabilities.
- max_position_embeddings: The maximum sequence length that this model might
- ever be used with. Typically set this to something large just in case
- (e.g., 512 or 1024 or 2048).
- type_vocab_size: The vocabulary size of the `token_type_ids` passed into
- `BertModel`.
- initializer_range: The sttdev of the truncated_normal_initializer for
- initializing all weight matrices.
- layer_norm_eps: The epsilon used by LayerNorm.
- """
- # self.vocab_size = vocab_size_or_config_json_file
- # self.word_size = word_vocab_size
- self.hidden_size = hidden_size
- self.num_hidden_layers = num_hidden_layers
- self.num_attention_heads = num_attention_heads
- self.hidden_act = hidden_act
- self.intermediate_size = intermediate_size
- self.hidden_dropout_prob = hidden_dropout_prob
- self.attention_probs_dropout_prob = attention_probs_dropout_prob
- self.max_position_embeddings = max_position_embeddings
- self.type_vocab_size = type_vocab_size
- self.initializer_range = initializer_range
- self.layer_norm_eps = layer_norm_eps
- self.num_hidden_word_layers = num_hidden_word_layers
- super().__init__(**kwargs)
diff --git a/spaces/fengmuxi/ChatGpt-Web/app/components/sidebar.tsx b/spaces/fengmuxi/ChatGpt-Web/app/components/sidebar.tsx
deleted file mode 100644
index b13f8aff738d35707f654bf6686577bdaf9ad191..0000000000000000000000000000000000000000
--- a/spaces/fengmuxi/ChatGpt-Web/app/components/sidebar.tsx
+++ /dev/null
@@ -1,206 +0,0 @@
-import { useEffect, useRef } from "react";
-
-import styles from "./home.module.scss";
-
-import { IconButton } from "./button";
-import SettingsIcon from "../icons/settings.svg";
-import GithubIcon from "../icons/github.svg";
-import User from "../icons/user.svg";
-import ChatGptIcon from "../icons/chatgpt.svg";
-import AddIcon from "../icons/add.svg";
-import CloseIcon from "../icons/close.svg";
-import MaskIcon from "../icons/mask.svg";
-import PluginIcon from "../icons/plugin.svg";
-
-import Locale from "../locales";
-
-import { useAppConfig, useChatStore } from "../store";
-
-import {
- MAX_SIDEBAR_WIDTH,
- MIN_SIDEBAR_WIDTH,
- NARROW_SIDEBAR_WIDTH,
- Path,
- REPO_URL,
-} from "../constant";
-
-import { Link, useNavigate } from "react-router-dom";
-import { useMobileScreen } from "../utils";
-import dynamic from "next/dynamic";
-import { showToast } from "./ui-lib";
-
-const ChatList = dynamic(async () => (await import("./chat-list")).ChatList, {
- loading: () => null,
-});
-
-function useHotKey() {
- const chatStore = useChatStore();
-
- useEffect(() => {
- const onKeyDown = (e: KeyboardEvent) => {
- if (e.metaKey || e.altKey || e.ctrlKey) {
- const n = chatStore.sessions.length;
- const limit = (x: number) => (x + n) % n;
- const i = chatStore.currentSessionIndex;
- if (e.key === "ArrowUp") {
- chatStore.selectSession(limit(i - 1));
- } else if (e.key === "ArrowDown") {
- chatStore.selectSession(limit(i + 1));
- }
- }
- };
-
- window.addEventListener("keydown", onKeyDown);
- return () => window.removeEventListener("keydown", onKeyDown);
- });
-}
-
-function useDragSideBar() {
- const limit = (x: number) => Math.min(MAX_SIDEBAR_WIDTH, x);
-
- const config = useAppConfig();
- const startX = useRef(0);
- const startDragWidth = useRef(config.sidebarWidth ?? 300);
- const lastUpdateTime = useRef(Date.now());
-
- const handleMouseMove = useRef((e: MouseEvent) => {
- if (Date.now() < lastUpdateTime.current + 50) {
- return;
- }
- lastUpdateTime.current = Date.now();
- const d = e.clientX - startX.current;
- const nextWidth = limit(startDragWidth.current + d);
- config.update((config) => (config.sidebarWidth = nextWidth));
- });
-
- const handleMouseUp = useRef(() => {
- startDragWidth.current = config.sidebarWidth ?? 300;
- window.removeEventListener("mousemove", handleMouseMove.current);
- window.removeEventListener("mouseup", handleMouseUp.current);
- });
-
- const onDragMouseDown = (e: MouseEvent) => {
- startX.current = e.clientX;
-
- window.addEventListener("mousemove", handleMouseMove.current);
- window.addEventListener("mouseup", handleMouseUp.current);
- };
- const isMobileScreen = useMobileScreen();
- const shouldNarrow =
- !isMobileScreen && config.sidebarWidth < MIN_SIDEBAR_WIDTH;
-
- useEffect(() => {
- const barWidth = shouldNarrow
- ? NARROW_SIDEBAR_WIDTH
- : limit(config.sidebarWidth ?? 300);
- const sideBarWidth = isMobileScreen ? "100vw" : `${barWidth}px`;
- document.documentElement.style.setProperty("--sidebar-width", sideBarWidth);
- }, [config.sidebarWidth, isMobileScreen, shouldNarrow]);
-
- return {
- onDragMouseDown,
- shouldNarrow,
- };
-}
-
-export function SideBar(props: { className?: string }) {
- const chatStore = useChatStore();
-
- // drag side bar
- const { onDragMouseDown, shouldNarrow } = useDragSideBar();
- const navigate = useNavigate();
-
- const config = useAppConfig();
- useHotKey();
-
- return (
-
-
-
- ChatGPT Next【{config.bot}】
-
- 必应暂不支持上下文
-
- Download Brawl Stars Mod Apk 5play.ru: A Guide for Beginners
-Brawl Stars is one of the most popular mobile games in the world, with over 100 million downloads on the Google Play Store. It is a fast-paced multiplayer action game that lets you team up with your friends or play solo in various game modes, such as Gem Grab, Showdown, Brawl Ball, Bounty, Heist, and more. You can also unlock and upgrade dozens of unique brawlers, each with their own signature attack and super ability. Brawl Stars is fun, addictive, and challenging, but it can also be frustrating if you don't have enough resources to unlock new brawlers, skins, or gadgets. That's why many players are looking for a way to get unlimited resources and access to all the features of the game without spending real money. That's where Brawl Stars mod apk 5play.ru comes in.
-Brawl Stars mod apk 5play.ru is a modified version of the original game that gives you unlimited coins, gems, tickets, and star points. You can use these resources to buy anything you want in the game, such as brawlers, skins, gadgets, power points, brawl boxes, and more. You can also play on a private server that has all the brawlers unlocked, including the legendary ones. You can also enjoy custom skins and gadgets that are not available in the official game. Brawl Stars mod apk 5play.ru is a great way to experience the game in a new way, without any limitations or restrictions. You can have more fun, experiment with different strategies, and dominate your opponents with ease.
-download brawl stars mod apk 5play.ru
DOWNLOAD →→→ https://gohhs.com/2uPqNE
-How to Download Brawl Stars Mod Apk 5play.ru
-If you want to download Brawl Stars mod apk 5play.ru, you need to follow these simple steps:
-
-- Go to [5play.ru](^1^), a website that offers free downloads of modded games and apps.
-- Search for "Brawl Stars" in the search bar and click on the result that says "Brawl Stars 49.210 APK (MOD money/private server) for android".
-- Scroll down to the bottom of the page and click on the green button that says "Download APK file".
-- Wait for the download to finish and then open the file manager on your device.
-- Locate the downloaded file and tap on it to install it. You may need to enable unknown sources in your device settings before you can install it.
-- Once the installation is complete, launch the game and enjoy unlimited resources and features.
-
-Conclusion
-Brawl Stars mod apk 5play.ru is a fantastic way to play Brawl Stars with more freedom and fun. You can get unlimited resources, play on a private server, unlock all brawlers, skins, and gadgets, and customize your game as you like. You can also download it for free from 5play.ru, a reliable website that offers safe and secure downloads of modded games and apps. If you are a fan of Brawl Stars and want to try something new, you should definitely give Brawl Stars mod apk 5play.ru a try. You won't regret it!
-FAQs
-Is Brawl Stars mod apk 5play.ru safe to use?
-Yes, Brawl Stars mod apk 5play.ru is safe to use as long as you download it from 5play.ru, which is a trusted website that scans all its files for viruses and malware. However, you should always be careful when downloading any modded game or app from unknown sources, as they may contain harmful or malicious code.
-Will I get banned for using Brawl Stars mod apk 5play.ru?
-No, you will not get banned for using Brawl Stars mod apk 5play.ru
because you are playing on a private server that is separate from the official one. The official server does not detect or interfere with the private server, so you can play without any worries. However, you should not use your real account or personal information on the private server, as it may not be secure or protected.
-Can I play with my friends on Brawl Stars mod apk 5play.ru?
-Yes, you can play with your friends on Brawl Stars mod apk 5play.ru, as long as they also have the same mod apk installed on their devices. You can invite them to join your team or clan, or challenge them to friendly battles. You can also chat with them and send them gifts in the game.
-download brawl stars mod apk unlimited money and gems
-download brawl stars mod apk latest version 2023
-download brawl stars mod apk menu hack
-download brawl stars mod apk unlocked all characters
-download brawl stars mod apk no root
-download brawl stars mod apk android 1
-download brawl stars mod apk with private server
-download brawl stars mod apk free shopping
-download brawl stars mod apk mega mod
-download brawl stars mod apk anti ban
-download brawl stars mod apk online
-download brawl stars mod apk offline
-download brawl stars mod apk for ios
-download brawl stars mod apk for pc
-download brawl stars mod apk for windows 10
-download brawl stars mod apk from 5play.ru
-download brawl stars mod apk from mediafire
-download brawl stars mod apk from apkpure
-download brawl stars mod apk from happymod
-download brawl stars mod apk from rexdl
-how to download brawl stars mod apk on android
-how to download brawl stars mod apk on iphone
-how to download brawl stars mod apk on laptop
-how to download brawl stars mod apk on chromebook
-how to download brawl stars mod apk on macbook
-how to install brawl stars mod apk on android
-how to install brawl stars mod apk on ios
-how to install brawl stars mod apk on pc
-how to install brawl stars mod apk on windows 10
-how to install brawl stars mod apk on macbook
-is it safe to download brawl stars mod apk
-is it legal to download brawl stars mod apk
-is it possible to download brawl stars mod apk
-is it easy to download brawl stars mod apk
-is it worth it to download brawl stars mod apk
-why should you download brawl stars mod apk
-why do people download brawl stars mod apk
-why can't i download brawl stars mod apk
-why won't my phone let me download brawl stars mod apk
-why does my antivirus block me from downloading brawl stars mod apk
-what is the best site to download brawl stars mod apk
-what is the best way to download brawl stars mod apk
-what is the best version of brawl stars mod apk to download
-what are the benefits of downloading brawl stars mod apk
-what are the risks of downloading brawl stars mod apk
-where can i find the link to download brawl stars mod apk 5play.ru
-where can i get the password to unlock the zip file of brawl stars mod apk 5play.ru
-where can i watch the video tutorial on how to download and install brawl stars mod apk 5play.ru
-where can i read the reviews and ratings of other users who downloaded brawl stars mod apk 5play.ru
-What are the advantages of Brawl Stars mod apk 5play.ru over the official game?
-Some of the advantages of Brawl Stars mod apk 5play.ru over the official game are:
-
-- You can get unlimited resources, such as coins, gems, tickets, and star points, without spending any real money.
-- You can unlock and upgrade all the brawlers, skins, and gadgets in the game, without waiting for them to appear in the shop or in the brawl boxes.
-- You can play on a private server that has less lag, more stability, and more features than the official server.
-- You can enjoy custom skins and gadgets that are exclusive to the mod apk and not available in the official game.
-- You can have more fun and creativity in the game, without any limitations or restrictions.
-
-What are the disadvantages of Brawl Stars mod apk 5play.ru over the official game?
-Some of the disadvantages of Brawl Stars mod apk 5play.ru over the official game are:
-
-- You may not be able to access some of the events or updates that are available in the official game, as they may not be compatible with the mod apk.
-- You may not be able to participate in some of the competitions or tournaments that are organized by the official game, as they may not allow modded players to join.
-- You may not be able to sync your progress or data with your Google Play account or Facebook account, as they may not recognize the mod apk.
-- You may risk losing your data or account if the mod apk is deleted, corrupted, or hacked by someone else.
-- You may face some bugs or glitches in the game, as the mod apk may not be fully tested or optimized for all devices.
-
-Is Brawl Stars mod apk 5play.ru updated regularly?
-Yes, Brawl Stars mod apk 5play.ru is updated regularly by its developers, who try to keep up with the latest version of the official game. You can check for updates on 5play.ru, where you can also find other modded games and apps that you may like. You can also follow their social media accounts or join their Telegram channel for more information and news about their projects.
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Coinbase APK The Easiest Way to Buy Sell and Manage Your Crypto.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Coinbase APK The Easiest Way to Buy Sell and Manage Your Crypto.md
deleted file mode 100644
index cba65b33fd75b1680016cbfe1192cdf21aca32bd..0000000000000000000000000000000000000000
--- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Coinbase APK The Easiest Way to Buy Sell and Manage Your Crypto.md
+++ /dev/null
@@ -1,174 +0,0 @@
-
-Coinbase APK: How to Download and Use the World's Most Trusted Crypto Exchange App
-If you are looking for a secure, easy, and reliable way to buy, sell, trade, store, and stake crypto, you might want to check out Coinbase APK. Coinbase is the world's most trusted cryptocurrency exchange, with over 110 million users across 100+ countries. It supports hundreds of cryptocurrencies, including Bitcoin, Ethereum, Cardano, Solana, Tether, and more. It also offers advanced trading tools, web3 access, staking rewards, and educational content.
-coinbase apk
DOWNLOAD ⏩ https://gohhs.com/2uPnuo
-But what is Coinbase APK and how can you download and use it on your Android device? In this article, we will answer these questions and more. We will explain what an APK file is, why you might need it, and what are the benefits of using Coinbase APK. We will also show you how to download and install Coinbase APK on your device, and how to use it to manage your crypto portfolio. Let's get started!
- What is Coinbase APK?
-Coinbase APK is the Android Package Kit file of the Coinbase app. An APK file is a compressed file that contains all the code, resources, and metadata of an Android app. It is similar to an executable file (.exe) on Windows or a package file (.pkg) on Mac OS.
-You can download and install an APK file on your Android device manually, without using the Google Play Store. This is also known as sideloading. Sideloading allows you to access apps that are not available on the Play Store, or to install older or modified versions of apps that are not compatible with your device or region.
- What is an APK file and why do you need it?
-An APK file is a compressed file that contains all the code, resources, and metadata of an Android app. It is similar to an executable file (.exe) on Windows or a package file (.pkg) on Mac OS.
-You can download and install an APK file on your Android device manually, without using the Google Play Store. This is also known as sideloading. Sideloading allows you to access apps that are not available on the Play Store, or to install older or modified versions of apps that are not compatible with your device or region.
- What are the benefits of using Coinbase APK?
-There are several benefits of using Coinbase APK instead of the Play Store version. Some of them are:
-coinbase wallet apk
-coinbase pro apk
-coinbase earn apk
-coinbase app download apk
-coinbase android apk
-coinbase apk latest version
-coinbase apk old version
-coinbase apk for pc
-coinbase apk mod
-coinbase apk mirror
-coinbase apk pure
-coinbase apk uptodown
-coinbase apk 2023
-coinbase apk 2022
-coinbase apk 2021
-coinbase apk 2020
-coinbase apk 2019
-coinbase apk 2018
-coinbase apk 2017
-coinbase bitcoin wallet apk
-coinbase crypto wallet apk
-coinbase digital wallet apk
-coinbase exchange apk
-coinbase free bitcoin apk
-coinbase hack apk
-coinbase lite apk
-coinbase mobile app apk
-coinbase online wallet apk
-coinbase premium apk
-coinbase pro app apk
-coinbase pro trading apk
-coinbase quiz apk
-coinbase secure wallet apk
-coinbase stock trading apk
-coinbase trade crypto apk
-download coinbase wallet app android, ios, windows phone, pc, mac, linux, chrome extension, firefox addon, opera plugin, edge browser extension, brave browser extension, safari browser extension, internet explorer browser extension, tor browser extension, uc browser extension, baidu browser extension, yandex browser extension, maxthon browser extension, vivaldi browser extension, waterfox browser extension, pale moon browser extension, seamonkey browser extension, midori browser extension, epic privacy browser extension, slimjet browser extension, avant browser extension, lunascape browser extension, comodo dragon browser extension, torch browser extension, citrio browser extension or puffin web browser app.
-how to install coinbase wallet app on android phone or tablet using google play store or apkmirror or apkpure or apktada or apkmody or apknite or apksfree or apkgk or apkmix or apksfull or apklush or apktovi or apkmaza or apkwow or apkturbo or apkdry or apksafety or apksnake or apksmash or apksmart or apkspeedy.
-how to install coinbase wallet app on iphone or ipad using app store or ipa library or ipa box or ipa rhino or ipa apps or ipa installer or ipa store.
-how to install coinbase wallet app on windows pc using bluestacks emulator or nox player emulator or memu emulator or ldplayer emulator or gameloop emulator or koplayer emulator or droid4x emulator or genymotion emulator.
-how to install coinbase wallet app on mac using andy emulator or remix os player emulator.
-how to install coinbase wallet app on linux using anbox emulator.
-how to install coinbase wallet app on chromebook using crossover android app.
-
-- You can get the latest updates and features of the Coinbase app before they are released on the Play Store.
-- You can avoid any restrictions or limitations imposed by Google on crypto-related apps.
-- You can have more control over your app installation and permissions.
-- You can backup and restore your app data easily.
-
-However, there are also some risks involved in sideloading apps. You need to be careful about where you download the APK files from, as some sources may contain malware or viruses. You also need to enable unknown sources on your device settings, which may expose your device to security threats. Therefore, you should only download APK files from trusted and verified sources, such as the official website of the app developer.
- How to download and install Coinbase APK?
-If you want to download and install Coinbase APK on your Android device, you need to follow these steps:
- Step 1: Enable unknown sources on your device
-Before you can install an APK file on your device, you need to enable unknown sources on your device settings. This will allow you to install apps from sources other than the Play Store. To do this, follow these steps:
-
-- Go to your device settings and tap on Security or Privacy.
-- Find the option that says Unknown sources or Install unknown apps and toggle it on.
-- A warning message will pop up, telling you the risks of installing apps from unknown sources. Tap on OK or Allow to proceed.
-
-Note: The exact steps may vary depending on your device model and Android version. You can also search for unknown sources in your device settings to find the option.
- Step 2: Download the Coinbase APK file from a trusted source
-Once you have enabled unknown sources on your device, you can download the Coinbase APK file from a trusted source. The best source is the official website of Coinbase, which you can access by clicking [here]. Alternatively, you can use a reputable third-party website that offers verified and safe APK files, such as APKMirror or APKPure.
-To download the Coinbase APK file, follow these steps:
-
-- Open your browser and go to the website where you want to download the Coinbase APK file.
-- Find the Coinbase app and tap on the Download button.
-- A pop-up window will appear, asking you to confirm the download. Tap on OK or Download to start the download.
-- Wait for the download to finish. You can check the progress in your notification bar or your download folder.
-
- Step 3: Install the Coinbase APK file on your device
-After you have downloaded the Coinbase APK file, you can install it on your device. To do this, follow these steps:
-
-- Locate the Coinbase APK file in your download folder or notification bar and tap on it.
-- A prompt will appear, asking you to confirm the installation. Tap on Install or Next to continue.
-- Wait for the installation to complete. You can check the progress in your notification bar or your screen.
-- Once the installation is done, tap on Open or Done to launch or exit the app.
-
-Congratulations! You have successfully downloaded and installed Coinbase APK on your device. You can now enjoy all the features and benefits of the Coinbase app without using the Play Store.
- How to use Coinbase APK?
-Now that you have installed Coinbase APK on your device, you can use it to buy, sell, trade, store, and stake crypto with ease. To use Coinbase APK, you need to follow these steps:
- Step 1: Create or log in to your Coinbase account
-If you already have a Coinbase account, you can simply log in with your email and password. If you don't have a Coinbase account yet, you can create one for free by following these steps:
-
-- Open the Coinbase app and tap on Get started.
-- Enter your name, email, and password and tap on Create account.
-- A verification email will be sent to your email address. Open it and tap on Verify email address.
-- You will be redirected to the Coinbase app and asked to agree to the terms of service and privacy policy. Tap on Agree and continue.
-
- Step 2: Verify your identity and add a payment method
-Before you can buy or sell crypto with Coinbase, you need to verify your identity and add a payment method. This is to comply with the regulatory requirements and ensure the security of your account. To do this, follow these steps:
-
-- In the Coinbase app, tap on Settings and then Identity verification.
-- Select your country and document type (passport, driver's license, or ID card) and tap on Continue.
-- Follow the instructions to scan or upload your document and take a selfie.
-- Wait for the verification process to complete. This may take a few minutes or hours depending on the volume of requests.
-- Once your identity is verified, tap on Settings and then Payment methods.
-- Select your preferred payment method (bank account, debit card, credit card, PayPal, etc.) and tap on Add payment method.
-- Follow the instructions to link your payment method to your Coinbase account.
-
- Step 3: Buy, sell, trade, store, and stake crypto with Coinbase APK
-Now that you have verified your identity and added a payment method, you can start buying, selling, trading, storing, and staking crypto with Coinbase APK. To do this, follow these steps:
-
-- In the Coinbase app, tap on the Home tab and then Buy/Sell.
-- Select the crypto you want to buy or sell and enter the amount in your local currency or crypto.
-- Review the details of your transaction, including the fees and exchange rate, and tap on Preview buy or Preview sell.
-- If you are satisfied with the transaction, tap on Buy now or Sell now and confirm with your payment method or wallet.
-- You will receive a confirmation message and an email with the details of your transaction.
-
- You can also trade crypto with other users on Coinbase Pro, which is a more advanced platform that offers lower fees, more trading pairs, and more features. To access Coinbase Pro, follow these steps:
-
-- In the Coinbase app, tap on the Menu icon and then Pro.
-- If you have not created a Coinbase Pro account yet, tap on Get started and follow the instructions to sign up.
-- Once you have a Coinbase Pro account, you can transfer funds from your Coinbase wallet to your Coinbase Pro wallet by tapping on Deposit or Withdraw and selecting Coinbase Wallet as the source or destination.
-- You can then start trading crypto by tapping on Trade and selecting the trading pair you want to trade.
-- You can place different types of orders, such as market, limit, stop, or post-only, by tapping on the Order type button and choosing your preferred option.
-- You can also view the market data, charts, order book, and history by tapping on the icons at the bottom of the screen.
-
- Besides buying, selling, and trading crypto, you can also store and stake crypto with Coinbase APK. To store your crypto securely, you can use the Coinbase Wallet, which is a separate app that allows you to manage your own private keys and access web3 applications. To download and use the Coinbase Wallet, follow these steps:
-
-- Download the Coinbase Wallet APK file from a trusted source and install it on your device following the same steps as above.
-- Open the Coinbase Wallet app and tap on Create a new wallet or Import an existing wallet.
-- Follow the instructions to set up your wallet and backup your recovery phrase.
-- You can then transfer funds from your Coinbase account to your Coinbase Wallet by tapping on Receive and scanning the QR code or copying the address.
-- You can also send funds from your Coinbase Wallet to other wallets or addresses by tapping on Send and entering the amount and destination.
-
- To stake your crypto and earn passive income, you can use the Coinbase app or the Coinbase Wallet app depending on the type of crypto you want to stake. For example, you can stake Ethereum 2.0 (ETH2) with the Coinbase app by following these steps:
-
-- In the Coinbase app, tap on the Home tab and then Ethereum 2.0 (ETH2).
-- Tap on Start earning rewards and enter the amount of ETH you want to stake.
-- Review the terms and conditions of staking ETH2 and tap on Stake ETH.
-- You will receive a confirmation message and an email with the details of your staking.
-
- You can also stake other cryptocurrencies, such as Tezos (XTZ), Cosmos (ATOM), Algorand (ALGO), or Cardano (ADA) with the Coinbase Wallet app by following these steps:
-
-- In the Coinbase Wallet app, tap on the Menu icon and then Staking.
-- Select the crypto you want to stake and tap on Stake now.
-- Enter the amount of crypto you want to stake and tap on Next.
-- Review the details of your staking and tap on Confirm.
-- You will receive a confirmation message and an email with the details of your staking.
-
- Conclusion
- Coinbase APK is a great way to access all the features and benefits of the world's most trusted crypto exchange app without using the Play Store. You can download and install Coinbase APK on your Android device easily by following the steps in this article. You can also use Coinbase APK to buy, sell, trade, store, and stake crypto with ease and security. Coinbase APK is a must-have app for any crypto enthusiast or investor. Download it today and start your crypto journey with Coinbase!
FAQs
- Here are some frequently asked questions about Coinbase APK:
- Is Coinbase APK safe?
-Coinbase APK is safe as long as you download it from a trusted and verified source, such as the official website of Coinbase or a reputable third-party website. You should also scan the APK file with an antivirus software before installing it on your device. However, you should be aware of the risks of sideloading apps and enabling unknown sources on your device settings, as this may expose your device to security threats. You should also protect your Coinbase account and wallet with a strong password and two-factor authentication.
- Is Coinbase APK legal?
-Coinbase APK is legal as long as you use it in accordance with the terms of service and privacy policy of Coinbase and the laws and regulations of your country or region. However, some countries or regions may have restrictions or bans on crypto-related apps or activities, so you should check the legal status of crypto in your area before using Coinbase APK. You should also respect the intellectual property rights of Coinbase and its partners and not modify, distribute, or sell the APK file without their permission.
- Is Coinbase APK free?
-Coinbase APK is free to download and use, but you may incur some fees when you buy, sell, trade, store, or stake crypto with Coinbase. These fees may include transaction fees, conversion fees, network fees, withdrawal fees, deposit fees, or staking fees. The amount and type of fees may vary depending on the crypto, payment method, trading pair, or staking protocol you use. You can check the fee schedule of Coinbase [here] for more details.
- How to update Coinbase APK?
-To update Coinbase APK, you need to download and install the latest version of the APK file from a trusted source. You can check the official website of Coinbase or a reputable third-party website for any updates or new features. You can also enable notifications on your device settings to get alerted when a new version is available. However, you should be careful not to install any fake or malicious updates that may harm your device or account.
- How to uninstall Coinbase APK?
-To uninstall Coinbase APK, you need to follow these steps:
-
-- Go to your device settings and tap on Apps or Applications.
-- Find the Coinbase app and tap on it.
-- Tap on Uninstall or Remove and confirm your action.
-- Wait for the uninstallation process to complete.
-
-Note: Uninstalling Coinbase APK will not delete your Coinbase account or wallet. You can still access them by logging in to the Coinbase website or another device. However, you should backup your recovery phrase before uninstalling the app in case you lose access to your wallet.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Cookie Run Kingdom - Create Your Own Sweet Kingdom and Fight the Dark Legion.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Cookie Run Kingdom - Create Your Own Sweet Kingdom and Fight the Dark Legion.md
deleted file mode 100644
index 487c6c15a87c68fcdedd6afc85d4825a883cf2ca..0000000000000000000000000000000000000000
--- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Cookie Run Kingdom - Create Your Own Sweet Kingdom and Fight the Dark Legion.md
+++ /dev/null
@@ -1,116 +0,0 @@
-
-Cookie Run: Kingdom APK - A Sweet and Fun Game for Android
-Do you love cookies? Do you love games? If you answered yes to both questions, then you will love Cookie Run: Kingdom APK, a sweet and fun game for Android devices. In this game, you can build your own cookie kingdom, fight against evil forces, collect and upgrade cookie characters, and join guilds with other players. Sounds delicious, right? Let's find out more about this game in this article.
- What is Cookie Run: Kingdom APK?
-Cookie Run: Kingdom APK is a kingdom builder and battle RPG game developed by Devsisters Corporation, the same company that created the popular Cookie Run series. It is a sequel to Cookie Run: OvenBreak, which was released in 2016. In this game, you can explore the colorful and cute world of cookies, where you can create your own cookie kingdom, fight against the dark legion of the Dark Enchantress Cookie, and discover the secrets of the ancient cookies and their kingdoms.
-cookie run kingdom apk
DOWNLOAD ››› https://gohhs.com/2uPmOn
- A kingdom builder and battle RPG game
-In Cookie Run: Kingdom APK, you can design your own cookie kingdom with various decors, such as buildings, plants, furniture, and more. You can also expand your territory by clearing stages and defeating enemies. You can also fight against other players in PvP mode, where you can test your skills and strategies.
- A sequel to the popular Cookie Run series
-Cookie Run: Kingdom APK is a continuation of the story of GingerBrave and his friends, who escaped from the oven in Cookie Run: OvenBreak. In this game, they face a new threat from the Dark Enchantress Cookie, who wants to destroy all the cookie kingdoms. You can join them in their adventure and meet new cookie characters along the way.
- A colorful and cute world of cookies
-Cookie Run: Kingdom APK has a charming graphics style that will appeal to both kids and adults. The game features a variety of cookie characters, each with their own personality, voice, and skills. The game also has a lively soundtrack and sound effects that match the mood of the game.
- How to download and install Cookie Run: Kingdom APK?
-If you want to play Cookie Run: Kingdom APK on your Android device, you can download it from Google Play or APKCombo. Here are the steps to do so:
- Download from Google Play or APKCombo
-You can download Cookie Run: Kingdom APK from Google Play by searching for it on the app store or by clicking [here](^2^). Alternatively, you can download it from APKCombo by searching for it on the website or by clicking [here](^1^). The file size is about 100 MB.
- Enable unknown sources on your device
-If you download Cookie Run: Kingdom APK from APKCombo, you need to enable unknown sources on your device to install it. To do this, go to Settings > Security and enable the option to install apps from unknown sources. This will allow you to install Cookie Run: Kingdom APK on your device.
- Install the APK file and enjoy the game
-Once you have downloaded Cookie Run: Kingdom APK, you can install it by tapping on the file and following the instructions. After the installation is complete, you can open the game and start playing. You may need to grant some permissions to the game, such as access to your storage, location, and contacts.
-cookie run kingdom apk download
-cookie run kingdom apk mod
-cookie run kingdom apk latest version
-cookie run kingdom apk obb
-cookie run kingdom apk android
-cookie run kingdom apk ios
-cookie run kingdom apk free
-cookie run kingdom apk offline
-cookie run kingdom apk update
-cookie run kingdom apk hack
-cookie run kingdom apk file
-cookie run kingdom apk mirror
-cookie run kingdom apk pure
-cookie run kingdom apk data
-cookie run kingdom apk nox
-cookie run kingdom apk bluestacks
-cookie run kingdom apk reddit
-cookie run kingdom apk 4.3.002
-cookie run kingdom apk 4.2.001
-cookie run kingdom apk 4.1.001
-cookie run kingdom apk 4.0.001
-cookie run kingdom apk 3.0.001
-cookie run kingdom apk 2.0.001
-cookie run kingdom apk 1.0.001
-cookie run kingdom apk beta
-cookie run kingdom apk global
-cookie run kingdom apk english
-cookie run kingdom apk korean
-cookie run kingdom apk chinese
-cookie run kingdom apk japanese
-cookie run kingdom apk german
-cookie run kingdom apk french
-cookie run kingdom apk spanish
-cookie run kingdom apk portuguese
-cookie run kingdom apk italian
-cookie run kingdom apk russian
-cookie run kingdom apk turkish
-cookie run kingdom apk arabic
-cookie run kingdom apk thai
-cookie run kingdom apk vietnamese
-cookie run kingdom apk indonesian
-cookie run kingdom apk malay
-cookie run kingdom apk filipino
-cookie run kingdom apk hindi
-cookie run kingdom apk urdu
-cookie run kingdom apk bengali
-cookie run kingdom apk tamil
-cookie run kingdom apk telugu
-cookie run kingdom apk marathi
- What are the features of Cookie Run: Kingdom APK?
-Cookie Run: Kingdom APK is a game that offers a lot of features for you to enjoy. Here are some of them:
- Build your own cookie kingdom with various decors
-In Cookie Run: Kingdom APK, you can customize your own cookie kingdom with different types of decors, such as buildings, plants, furniture, and more. You can also unlock new decors by clearing stages and completing quests. You can arrange your decors according to your preference and style. You can also visit other players' kingdoms and see how they decorated theirs.
- Fight against the dark legion of the Dark Enchantress Cookie
-In Cookie Run: Kingdom APK, you can also engage in battles against the dark legion of the Dark Enchantress Cookie, who wants to destroy all the cookie kingdoms. You can form a team of up to five cookie characters, each with their own skills and abilities. You can also use special items and combos to enhance your performance. You can fight in various modes, such as story mode, guild mode, PvP mode, and more.
- Collect and upgrade over 200 cookie characters
-In Cookie Run: Kingdom APK, you can collect and upgrade over 200 cookie characters, each with their own personality, voice, and skills. You can obtain new cookie characters by summoning them with crystals or cookies. You can also upgrade your cookie characters by leveling them up, enhancing their skills, equipping them with treasures, and awakening them. You can also mix and match different cookie characters to create your own unique team.
- Join guilds and cooperate with other players
-In Cookie Run: Kingdom APK, you can also join guilds and cooperate with other players. You can chat with your guild members, share tips and strategies, and help each other out. You can also participate in guild battles, where you can compete with other guilds for rewards and glory. You can also join events and challenges that are exclusive for guild members.
- What are the pros and cons of Cookie Run: Kingdom APK?
-Cookie Run: Kingdom APK is a game that has its pros and cons. Here are some of them:
- Pros
-
-Fun and addictive gameplay
-Cookie Run: Kingdom APK is a game that offers a fun and addictive gameplay that will keep you entertained for hours. You can enjoy building your own cookie kingdom, fighting against enemies, collecting and upgrading cookie characters, and joining guilds with other players. The game also has a lot of content and features that will make you want to play more.
Charming graphics and sound effects
-Cookie Run: Kingdom APK is a game that has a charming graphics style that will appeal to both kids and adults. The game features a variety of cookie characters, each with their own personality, voice, and skills. The game also has a lively soundtrack and sound effects that match the mood of the game.
Free to play with regular updates
-Cookie Run: Kingdom APK is a game that is free to play with regular updates. You can download and play the game without spending any money. The game also provides regular updates that add new content and features to the game, such as new cookie characters, new stages, new events, and more.
- Cons
-
-Requires internet connection and storage space
-Cookie Run: Kingdom APK is a game that requires internet connection and storage space to play. You need to have a stable internet connection to access the game's features and modes. You also need to have enough storage space on your device to download and install the game.
May have some bugs and glitches
-Cookie Run: Kingdom APK is a game that may have some bugs and glitches that affect the gameplay. Some users have reported issues such as crashing, freezing, lagging, loading errors, login errors, and more. The developers are working on fixing these issues as soon as possible.
- < h4>May have some in-app purchases and ads
-Cookie Run: Kingdom APK is a game that may have some in-app purchases and ads that may affect the gameplay. Some users may find the in-app purchases and ads to be annoying or unfair. The game also has a stamina system that limits the number of stages you can play per day. You can buy more stamina with crystals or cookies, which can be obtained by playing the game or by spending real money.
-
- Conclusion
-Cookie Run: Kingdom APK is a sweet and fun game for Android devices that lets you build your own cookie kingdom, fight against evil forces, collect and upgrade cookie characters, and join guilds with other players. The game has a fun and addictive gameplay, charming graphics and sound effects, and free to play with regular updates. However, the game also requires internet connection and storage space, may have some bugs and glitches, and may have some in-app purchases and ads. If you are looking for a game that will make you hungry for cookies and adventure, you should try Cookie Run: Kingdom APK.
- FAQs
-
-Q: What are the minimum requirements to play Cookie Run: Kingdom APK?
-A: The minimum requirements to play Cookie Run: Kingdom APK are Android 4.4 or higher, 2 GB of RAM, and 100 MB of storage space.
Q: How can I get more crystals or cookies in Cookie Run: Kingdom APK?
-A: You can get more crystals or cookies by playing the game, completing quests, participating in events, watching ads, or buying them with real money.
Q: How can I contact the developers of Cookie Run: Kingdom APK?
-A: You can contact the developers of Cookie Run: Kingdom APK by sending an email to cookierun@devsisters.com or by visiting their official website [here].
Q: How can I join a guild in Cookie Run: Kingdom APK?
-A: You can join a guild in Cookie Run: Kingdom APK by tapping on the guild icon on the main screen, searching for a guild that suits your preferences, and applying to join it. You can also create your own guild if you have enough crystals.
Q: How can I update Cookie Run: Kingdom APK?
-A: You can update Cookie Run: Kingdom APK by downloading the latest version from Google Play or APKCombo. You can also check for updates by tapping on the settings icon on the main screen and selecting the update option.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/@types/node/readline.d.ts b/spaces/fffiloni/controlnet-animation-doodle/node_modules/@types/node/readline.d.ts
deleted file mode 100644
index 6ab64acbbec10680e4c519598e84b9c64bd97984..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/@types/node/readline.d.ts
+++ /dev/null
@@ -1,653 +0,0 @@
-/**
- * The `readline` module provides an interface for reading data from a `Readable` stream (such as `process.stdin`) one line at a time.
- *
- * To use the promise-based APIs:
- *
- * ```js
- * import * as readline from 'node:readline/promises';
- * ```
- *
- * To use the callback and sync APIs:
- *
- * ```js
- * import * as readline from 'node:readline';
- * ```
- *
- * The following simple example illustrates the basic use of the `readline` module.
- *
- * ```js
- * import * as readline from 'node:readline/promises';
- * import { stdin as input, stdout as output } from 'node:process';
- *
- * const rl = readline.createInterface({ input, output });
- *
- * const answer = await rl.question('What do you think of Node.js? ');
- *
- * console.log(`Thank you for your valuable feedback: ${answer}`);
- *
- * rl.close();
- * ```
- *
- * Once this code is invoked, the Node.js application will not terminate until the`readline.Interface` is closed because the interface waits for data to be
- * received on the `input` stream.
- * @see [source](https://github.com/nodejs/node/blob/v18.0.0/lib/readline.js)
- */
-declare module 'readline' {
- import { Abortable, EventEmitter } from 'node:events';
- import * as promises from 'node:readline/promises';
-
- export { promises };
- export interface Key {
- sequence?: string | undefined;
- name?: string | undefined;
- ctrl?: boolean | undefined;
- meta?: boolean | undefined;
- shift?: boolean | undefined;
- }
- /**
- * Instances of the `readline.Interface` class are constructed using the`readline.createInterface()` method. Every instance is associated with a
- * single `input` `Readable` stream and a single `output` `Writable` stream.
- * The `output` stream is used to print prompts for user input that arrives on,
- * and is read from, the `input` stream.
- * @since v0.1.104
- */
- export class Interface extends EventEmitter {
- readonly terminal: boolean;
- /**
- * The current input data being processed by node.
- *
- * This can be used when collecting input from a TTY stream to retrieve the
- * current value that has been processed thus far, prior to the `line` event
- * being emitted. Once the `line` event has been emitted, this property will
- * be an empty string.
- *
- * Be aware that modifying the value during the instance runtime may have
- * unintended consequences if `rl.cursor` is not also controlled.
- *
- * **If not using a TTY stream for input, use the `'line'` event.**
- *
- * One possible use case would be as follows:
- *
- * ```js
- * const values = ['lorem ipsum', 'dolor sit amet'];
- * const rl = readline.createInterface(process.stdin);
- * const showResults = debounce(() => {
- * console.log(
- * '\n',
- * values.filter((val) => val.startsWith(rl.line)).join(' ')
- * );
- * }, 300);
- * process.stdin.on('keypress', (c, k) => {
- * showResults();
- * });
- * ```
- * @since v0.1.98
- */
- readonly line: string;
- /**
- * The cursor position relative to `rl.line`.
- *
- * This will track where the current cursor lands in the input string, when
- * reading input from a TTY stream. The position of cursor determines the
- * portion of the input string that will be modified as input is processed,
- * as well as the column where the terminal caret will be rendered.
- * @since v0.1.98
- */
- readonly cursor: number;
- /**
- * NOTE: According to the documentation:
- *
- * > Instances of the `readline.Interface` class are constructed using the
- * > `readline.createInterface()` method.
- *
- * @see https://nodejs.org/dist/latest-v10.x/docs/api/readline.html#readline_class_interface
- */
- protected constructor(input: NodeJS.ReadableStream, output?: NodeJS.WritableStream, completer?: Completer | AsyncCompleter, terminal?: boolean);
- /**
- * NOTE: According to the documentation:
- *
- * > Instances of the `readline.Interface` class are constructed using the
- * > `readline.createInterface()` method.
- *
- * @see https://nodejs.org/dist/latest-v10.x/docs/api/readline.html#readline_class_interface
- */
- protected constructor(options: ReadLineOptions);
- /**
- * The `rl.getPrompt()` method returns the current prompt used by `rl.prompt()`.
- * @since v15.3.0
- * @return the current prompt string
- */
- getPrompt(): string;
- /**
- * The `rl.setPrompt()` method sets the prompt that will be written to `output`whenever `rl.prompt()` is called.
- * @since v0.1.98
- */
- setPrompt(prompt: string): void;
- /**
- * The `rl.prompt()` method writes the `readline.Interface` instances configured`prompt` to a new line in `output` in order to provide a user with a new
- * location at which to provide input.
- *
- * When called, `rl.prompt()` will resume the `input` stream if it has been
- * paused.
- *
- * If the `readline.Interface` was created with `output` set to `null` or`undefined` the prompt is not written.
- * @since v0.1.98
- * @param preserveCursor If `true`, prevents the cursor placement from being reset to `0`.
- */
- prompt(preserveCursor?: boolean): void;
- /**
- * The `rl.question()` method displays the `query` by writing it to the `output`,
- * waits for user input to be provided on `input`, then invokes the `callback`function passing the provided input as the first argument.
- *
- * When called, `rl.question()` will resume the `input` stream if it has been
- * paused.
- *
- * If the `readline.Interface` was created with `output` set to `null` or`undefined` the `query` is not written.
- *
- * The `callback` function passed to `rl.question()` does not follow the typical
- * pattern of accepting an `Error` object or `null` as the first argument.
- * The `callback` is called with the provided answer as the only argument.
- *
- * Example usage:
- *
- * ```js
- * rl.question('What is your favorite food? ', (answer) => {
- * console.log(`Oh, so your favorite food is ${answer}`);
- * });
- * ```
- *
- * Using an `AbortController` to cancel a question.
- *
- * ```js
- * const ac = new AbortController();
- * const signal = ac.signal;
- *
- * rl.question('What is your favorite food? ', { signal }, (answer) => {
- * console.log(`Oh, so your favorite food is ${answer}`);
- * });
- *
- * signal.addEventListener('abort', () => {
- * console.log('The food question timed out');
- * }, { once: true });
- *
- * setTimeout(() => ac.abort(), 10000);
- * ```
- *
- * If this method is invoked as it's util.promisify()ed version, it returns a
- * Promise that fulfills with the answer. If the question is canceled using
- * an `AbortController` it will reject with an `AbortError`.
- *
- * ```js
- * const util = require('util');
- * const question = util.promisify(rl.question).bind(rl);
- *
- * async function questionExample() {
- * try {
- * const answer = await question('What is you favorite food? ');
- * console.log(`Oh, so your favorite food is ${answer}`);
- * } catch (err) {
- * console.error('Question rejected', err);
- * }
- * }
- * questionExample();
- * ```
- * @since v0.3.3
- * @param query A statement or query to write to `output`, prepended to the prompt.
- * @param callback A callback function that is invoked with the user's input in response to the `query`.
- */
- question(query: string, callback: (answer: string) => void): void;
- question(query: string, options: Abortable, callback: (answer: string) => void): void;
- /**
- * The `rl.pause()` method pauses the `input` stream, allowing it to be resumed
- * later if necessary.
- *
- * Calling `rl.pause()` does not immediately pause other events (including`'line'`) from being emitted by the `readline.Interface` instance.
- * @since v0.3.4
- */
- pause(): this;
- /**
- * The `rl.resume()` method resumes the `input` stream if it has been paused.
- * @since v0.3.4
- */
- resume(): this;
- /**
- * The `rl.close()` method closes the `readline.Interface` instance and
- * relinquishes control over the `input` and `output` streams. When called,
- * the `'close'` event will be emitted.
- *
- * Calling `rl.close()` does not immediately stop other events (including `'line'`)
- * from being emitted by the `readline.Interface` instance.
- * @since v0.1.98
- */
- close(): void;
- /**
- * The `rl.write()` method will write either `data` or a key sequence identified
- * by `key` to the `output`. The `key` argument is supported only if `output` is
- * a `TTY` text terminal. See `TTY keybindings` for a list of key
- * combinations.
- *
- * If `key` is specified, `data` is ignored.
- *
- * When called, `rl.write()` will resume the `input` stream if it has been
- * paused.
- *
- * If the `readline.Interface` was created with `output` set to `null` or`undefined` the `data` and `key` are not written.
- *
- * ```js
- * rl.write('Delete this!');
- * // Simulate Ctrl+U to delete the line written previously
- * rl.write(null, { ctrl: true, name: 'u' });
- * ```
- *
- * The `rl.write()` method will write the data to the `readline` `Interface`'s`input`_as if it were provided by the user_.
- * @since v0.1.98
- */
- write(data: string | Buffer, key?: Key): void;
- write(data: undefined | null | string | Buffer, key: Key): void;
- /**
- * Returns the real position of the cursor in relation to the input
- * prompt + string. Long input (wrapping) strings, as well as multiple
- * line prompts are included in the calculations.
- * @since v13.5.0, v12.16.0
- */
- getCursorPos(): CursorPos;
- /**
- * events.EventEmitter
- * 1. close
- * 2. line
- * 3. pause
- * 4. resume
- * 5. SIGCONT
- * 6. SIGINT
- * 7. SIGTSTP
- * 8. history
- */
- addListener(event: string, listener: (...args: any[]) => void): this;
- addListener(event: 'close', listener: () => void): this;
- addListener(event: 'line', listener: (input: string) => void): this;
- addListener(event: 'pause', listener: () => void): this;
- addListener(event: 'resume', listener: () => void): this;
- addListener(event: 'SIGCONT', listener: () => void): this;
- addListener(event: 'SIGINT', listener: () => void): this;
- addListener(event: 'SIGTSTP', listener: () => void): this;
- addListener(event: 'history', listener: (history: string[]) => void): this;
- emit(event: string | symbol, ...args: any[]): boolean;
- emit(event: 'close'): boolean;
- emit(event: 'line', input: string): boolean;
- emit(event: 'pause'): boolean;
- emit(event: 'resume'): boolean;
- emit(event: 'SIGCONT'): boolean;
- emit(event: 'SIGINT'): boolean;
- emit(event: 'SIGTSTP'): boolean;
- emit(event: 'history', history: string[]): boolean;
- on(event: string, listener: (...args: any[]) => void): this;
- on(event: 'close', listener: () => void): this;
- on(event: 'line', listener: (input: string) => void): this;
- on(event: 'pause', listener: () => void): this;
- on(event: 'resume', listener: () => void): this;
- on(event: 'SIGCONT', listener: () => void): this;
- on(event: 'SIGINT', listener: () => void): this;
- on(event: 'SIGTSTP', listener: () => void): this;
- on(event: 'history', listener: (history: string[]) => void): this;
- once(event: string, listener: (...args: any[]) => void): this;
- once(event: 'close', listener: () => void): this;
- once(event: 'line', listener: (input: string) => void): this;
- once(event: 'pause', listener: () => void): this;
- once(event: 'resume', listener: () => void): this;
- once(event: 'SIGCONT', listener: () => void): this;
- once(event: 'SIGINT', listener: () => void): this;
- once(event: 'SIGTSTP', listener: () => void): this;
- once(event: 'history', listener: (history: string[]) => void): this;
- prependListener(event: string, listener: (...args: any[]) => void): this;
- prependListener(event: 'close', listener: () => void): this;
- prependListener(event: 'line', listener: (input: string) => void): this;
- prependListener(event: 'pause', listener: () => void): this;
- prependListener(event: 'resume', listener: () => void): this;
- prependListener(event: 'SIGCONT', listener: () => void): this;
- prependListener(event: 'SIGINT', listener: () => void): this;
- prependListener(event: 'SIGTSTP', listener: () => void): this;
- prependListener(event: 'history', listener: (history: string[]) => void): this;
- prependOnceListener(event: string, listener: (...args: any[]) => void): this;
- prependOnceListener(event: 'close', listener: () => void): this;
- prependOnceListener(event: 'line', listener: (input: string) => void): this;
- prependOnceListener(event: 'pause', listener: () => void): this;
- prependOnceListener(event: 'resume', listener: () => void): this;
- prependOnceListener(event: 'SIGCONT', listener: () => void): this;
- prependOnceListener(event: 'SIGINT', listener: () => void): this;
- prependOnceListener(event: 'SIGTSTP', listener: () => void): this;
- prependOnceListener(event: 'history', listener: (history: string[]) => void): this;
- [Symbol.asyncIterator](): AsyncIterableIterator;
- }
- export type ReadLine = Interface; // type forwarded for backwards compatibility
- export type Completer = (line: string) => CompleterResult;
- export type AsyncCompleter = (line: string, callback: (err?: null | Error, result?: CompleterResult) => void) => void;
- export type CompleterResult = [string[], string];
- export interface ReadLineOptions {
- input: NodeJS.ReadableStream;
- output?: NodeJS.WritableStream | undefined;
- completer?: Completer | AsyncCompleter | undefined;
- terminal?: boolean | undefined;
- /**
- * Initial list of history lines. This option makes sense
- * only if `terminal` is set to `true` by the user or by an internal `output`
- * check, otherwise the history caching mechanism is not initialized at all.
- * @default []
- */
- history?: string[] | undefined;
- historySize?: number | undefined;
- prompt?: string | undefined;
- crlfDelay?: number | undefined;
- /**
- * If `true`, when a new input line added
- * to the history list duplicates an older one, this removes the older line
- * from the list.
- * @default false
- */
- removeHistoryDuplicates?: boolean | undefined;
- escapeCodeTimeout?: number | undefined;
- tabSize?: number | undefined;
- }
- /**
- * The `readline.createInterface()` method creates a new `readline.Interface`instance.
- *
- * ```js
- * const readline = require('readline');
- * const rl = readline.createInterface({
- * input: process.stdin,
- * output: process.stdout
- * });
- * ```
- *
- * Once the `readline.Interface` instance is created, the most common case is to
- * listen for the `'line'` event:
- *
- * ```js
- * rl.on('line', (line) => {
- * console.log(`Received: ${line}`);
- * });
- * ```
- *
- * If `terminal` is `true` for this instance then the `output` stream will get
- * the best compatibility if it defines an `output.columns` property and emits
- * a `'resize'` event on the `output` if or when the columns ever change
- * (`process.stdout` does this automatically when it is a TTY).
- *
- * When creating a `readline.Interface` using `stdin` as input, the program
- * will not terminate until it receives `EOF` (Ctrl+D on
- * Linux/macOS, Ctrl+Z followed by Return on
- * Windows).
- * If you want your application to exit without waiting for user input, you can `unref()` the standard input stream:
- *
- * ```js
- * process.stdin.unref();
- * ```
- * @since v0.1.98
- */
- export function createInterface(input: NodeJS.ReadableStream, output?: NodeJS.WritableStream, completer?: Completer | AsyncCompleter, terminal?: boolean): Interface;
- export function createInterface(options: ReadLineOptions): Interface;
- /**
- * The `readline.emitKeypressEvents()` method causes the given `Readable` stream to begin emitting `'keypress'` events corresponding to received input.
- *
- * Optionally, `interface` specifies a `readline.Interface` instance for which
- * autocompletion is disabled when copy-pasted input is detected.
- *
- * If the `stream` is a `TTY`, then it must be in raw mode.
- *
- * This is automatically called by any readline instance on its `input` if the`input` is a terminal. Closing the `readline` instance does not stop
- * the `input` from emitting `'keypress'` events.
- *
- * ```js
- * readline.emitKeypressEvents(process.stdin);
- * if (process.stdin.isTTY)
- * process.stdin.setRawMode(true);
- * ```
- *
- * ## Example: Tiny CLI
- *
- * The following example illustrates the use of `readline.Interface` class to
- * implement a small command-line interface:
- *
- * ```js
- * const readline = require('readline');
- * const rl = readline.createInterface({
- * input: process.stdin,
- * output: process.stdout,
- * prompt: 'OHAI> '
- * });
- *
- * rl.prompt();
- *
- * rl.on('line', (line) => {
- * switch (line.trim()) {
- * case 'hello':
- * console.log('world!');
- * break;
- * default:
- * console.log(`Say what? I might have heard '${line.trim()}'`);
- * break;
- * }
- * rl.prompt();
- * }).on('close', () => {
- * console.log('Have a great day!');
- * process.exit(0);
- * });
- * ```
- *
- * ## Example: Read file stream line-by-Line
- *
- * A common use case for `readline` is to consume an input file one line at a
- * time. The easiest way to do so is leveraging the `fs.ReadStream` API as
- * well as a `for await...of` loop:
- *
- * ```js
- * const fs = require('fs');
- * const readline = require('readline');
- *
- * async function processLineByLine() {
- * const fileStream = fs.createReadStream('input.txt');
- *
- * const rl = readline.createInterface({
- * input: fileStream,
- * crlfDelay: Infinity
- * });
- * // Note: we use the crlfDelay option to recognize all instances of CR LF
- * // ('\r\n') in input.txt as a single line break.
- *
- * for await (const line of rl) {
- * // Each line in input.txt will be successively available here as `line`.
- * console.log(`Line from file: ${line}`);
- * }
- * }
- *
- * processLineByLine();
- * ```
- *
- * Alternatively, one could use the `'line'` event:
- *
- * ```js
- * const fs = require('fs');
- * const readline = require('readline');
- *
- * const rl = readline.createInterface({
- * input: fs.createReadStream('sample.txt'),
- * crlfDelay: Infinity
- * });
- *
- * rl.on('line', (line) => {
- * console.log(`Line from file: ${line}`);
- * });
- * ```
- *
- * Currently, `for await...of` loop can be a bit slower. If `async` / `await`flow and speed are both essential, a mixed approach can be applied:
- *
- * ```js
- * const { once } = require('events');
- * const { createReadStream } = require('fs');
- * const { createInterface } = require('readline');
- *
- * (async function processLineByLine() {
- * try {
- * const rl = createInterface({
- * input: createReadStream('big-file.txt'),
- * crlfDelay: Infinity
- * });
- *
- * rl.on('line', (line) => {
- * // Process the line.
- * });
- *
- * await once(rl, 'close');
- *
- * console.log('File processed.');
- * } catch (err) {
- * console.error(err);
- * }
- * })();
- * ```
- * @since v0.7.7
- */
- export function emitKeypressEvents(stream: NodeJS.ReadableStream, readlineInterface?: Interface): void;
- export type Direction = -1 | 0 | 1;
- export interface CursorPos {
- rows: number;
- cols: number;
- }
- /**
- * The `readline.clearLine()` method clears current line of given `TTY` stream
- * in a specified direction identified by `dir`.
- * @since v0.7.7
- * @param callback Invoked once the operation completes.
- * @return `false` if `stream` wishes for the calling code to wait for the `'drain'` event to be emitted before continuing to write additional data; otherwise `true`.
- */
- export function clearLine(stream: NodeJS.WritableStream, dir: Direction, callback?: () => void): boolean;
- /**
- * The `readline.clearScreenDown()` method clears the given `TTY` stream from
- * the current position of the cursor down.
- * @since v0.7.7
- * @param callback Invoked once the operation completes.
- * @return `false` if `stream` wishes for the calling code to wait for the `'drain'` event to be emitted before continuing to write additional data; otherwise `true`.
- */
- export function clearScreenDown(stream: NodeJS.WritableStream, callback?: () => void): boolean;
- /**
- * The `readline.cursorTo()` method moves cursor to the specified position in a
- * given `TTY` `stream`.
- * @since v0.7.7
- * @param callback Invoked once the operation completes.
- * @return `false` if `stream` wishes for the calling code to wait for the `'drain'` event to be emitted before continuing to write additional data; otherwise `true`.
- */
- export function cursorTo(stream: NodeJS.WritableStream, x: number, y?: number, callback?: () => void): boolean;
- /**
- * The `readline.moveCursor()` method moves the cursor _relative_ to its current
- * position in a given `TTY` `stream`.
- *
- * ## Example: Tiny CLI
- *
- * The following example illustrates the use of `readline.Interface` class to
- * implement a small command-line interface:
- *
- * ```js
- * const readline = require('readline');
- * const rl = readline.createInterface({
- * input: process.stdin,
- * output: process.stdout,
- * prompt: 'OHAI> '
- * });
- *
- * rl.prompt();
- *
- * rl.on('line', (line) => {
- * switch (line.trim()) {
- * case 'hello':
- * console.log('world!');
- * break;
- * default:
- * console.log(`Say what? I might have heard '${line.trim()}'`);
- * break;
- * }
- * rl.prompt();
- * }).on('close', () => {
- * console.log('Have a great day!');
- * process.exit(0);
- * });
- * ```
- *
- * ## Example: Read file stream line-by-Line
- *
- * A common use case for `readline` is to consume an input file one line at a
- * time. The easiest way to do so is leveraging the `fs.ReadStream` API as
- * well as a `for await...of` loop:
- *
- * ```js
- * const fs = require('fs');
- * const readline = require('readline');
- *
- * async function processLineByLine() {
- * const fileStream = fs.createReadStream('input.txt');
- *
- * const rl = readline.createInterface({
- * input: fileStream,
- * crlfDelay: Infinity
- * });
- * // Note: we use the crlfDelay option to recognize all instances of CR LF
- * // ('\r\n') in input.txt as a single line break.
- *
- * for await (const line of rl) {
- * // Each line in input.txt will be successively available here as `line`.
- * console.log(`Line from file: ${line}`);
- * }
- * }
- *
- * processLineByLine();
- * ```
- *
- * Alternatively, one could use the `'line'` event:
- *
- * ```js
- * const fs = require('fs');
- * const readline = require('readline');
- *
- * const rl = readline.createInterface({
- * input: fs.createReadStream('sample.txt'),
- * crlfDelay: Infinity
- * });
- *
- * rl.on('line', (line) => {
- * console.log(`Line from file: ${line}`);
- * });
- * ```
- *
- * Currently, `for await...of` loop can be a bit slower. If `async` / `await`flow and speed are both essential, a mixed approach can be applied:
- *
- * ```js
- * const { once } = require('events');
- * const { createReadStream } = require('fs');
- * const { createInterface } = require('readline');
- *
- * (async function processLineByLine() {
- * try {
- * const rl = createInterface({
- * input: createReadStream('big-file.txt'),
- * crlfDelay: Infinity
- * });
- *
- * rl.on('line', (line) => {
- * // Process the line.
- * });
- *
- * await once(rl, 'close');
- *
- * console.log('File processed.');
- * } catch (err) {
- * console.error(err);
- * }
- * })();
- * ```
- * @since v0.7.7
- * @param callback Invoked once the operation completes.
- * @return `false` if `stream` wishes for the calling code to wait for the `'drain'` event to be emitted before continuing to write additional data; otherwise `true`.
- */
- export function moveCursor(stream: NodeJS.WritableStream, dx: number, dy: number, callback?: () => void): boolean;
-}
-declare module 'node:readline' {
- export * from 'readline';
-}
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io-parser/build/esm/encodePacket.d.ts b/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io-parser/build/esm/encodePacket.d.ts
deleted file mode 100644
index 9ca28c8b64f15d45bff202afada68824e64aabc4..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io-parser/build/esm/encodePacket.d.ts
+++ /dev/null
@@ -1,3 +0,0 @@
-import { Packet, RawData } from "./commons.js";
-declare const encodePacket: ({ type, data }: Packet, supportsBinary: boolean, callback: (encodedPacket: RawData) => void) => void;
-export default encodePacket;
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io/build/transports/polling-jsonp.d.ts b/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io/build/transports/polling-jsonp.d.ts
deleted file mode 100644
index 0fed2077fa7d3c2edf0e22a15e783f6ae1f595c5..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io/build/transports/polling-jsonp.d.ts
+++ /dev/null
@@ -1,24 +0,0 @@
-import { Polling } from "./polling";
-export declare class JSONP extends Polling {
- private readonly head;
- private readonly foot;
- /**
- * JSON-P polling transport.
- *
- * @api public
- */
- constructor(req: any);
- /**
- * Handles incoming data.
- * Due to a bug in \n handling by browsers, we expect a escaped string.
- *
- * @api private
- */
- onData(data: any): void;
- /**
- * Performs the write.
- *
- * @api private
- */
- doWrite(data: any, options: any, callback: any): void;
-}
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/shams.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/shams.js
deleted file mode 100644
index 1285210ef7ccef1eae88c888694eb481b2d23997..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/shams.js
+++ /dev/null
@@ -1,42 +0,0 @@
-'use strict';
-
-/* eslint complexity: [2, 18], max-statements: [2, 33] */
-module.exports = function hasSymbols() {
- if (typeof Symbol !== 'function' || typeof Object.getOwnPropertySymbols !== 'function') { return false; }
- if (typeof Symbol.iterator === 'symbol') { return true; }
-
- var obj = {};
- var sym = Symbol('test');
- var symObj = Object(sym);
- if (typeof sym === 'string') { return false; }
-
- if (Object.prototype.toString.call(sym) !== '[object Symbol]') { return false; }
- if (Object.prototype.toString.call(symObj) !== '[object Symbol]') { return false; }
-
- // temp disabled per https://github.com/ljharb/object.assign/issues/17
- // if (sym instanceof Symbol) { return false; }
- // temp disabled per https://github.com/WebReflection/get-own-property-symbols/issues/4
- // if (!(symObj instanceof Symbol)) { return false; }
-
- // if (typeof Symbol.prototype.toString !== 'function') { return false; }
- // if (String(sym) !== Symbol.prototype.toString.call(sym)) { return false; }
-
- var symVal = 42;
- obj[sym] = symVal;
- for (sym in obj) { return false; } // eslint-disable-line no-restricted-syntax, no-unreachable-loop
- if (typeof Object.keys === 'function' && Object.keys(obj).length !== 0) { return false; }
-
- if (typeof Object.getOwnPropertyNames === 'function' && Object.getOwnPropertyNames(obj).length !== 0) { return false; }
-
- var syms = Object.getOwnPropertySymbols(obj);
- if (syms.length !== 1 || syms[0] !== sym) { return false; }
-
- if (!Object.prototype.propertyIsEnumerable.call(obj, sym)) { return false; }
-
- if (typeof Object.getOwnPropertyDescriptor === 'function') {
- var descriptor = Object.getOwnPropertyDescriptor(obj, sym);
- if (descriptor.value !== symVal || descriptor.enumerable !== true) { return false; }
- }
-
- return true;
-};
diff --git a/spaces/flax-community/multilingual-image-captioning/sections/intro.md b/spaces/flax-community/multilingual-image-captioning/sections/intro.md
deleted file mode 100644
index 6ad4273dcce8f8034273b6d8e4d56273b57e4d01..0000000000000000000000000000000000000000
--- a/spaces/flax-community/multilingual-image-captioning/sections/intro.md
+++ /dev/null
@@ -1,3 +0,0 @@
-This demo uses [CLIP-mBART50 model checkpoint](https://huggingface.co/flax-community/clip-vit-base-patch32_mbart-large-50) to predict caption for a given image in 4 languages (English, French, German, Spanish). Training was done using image encoder (CLIP-ViT) and text decoder (mBART50) with approximately 5 million image-text pairs taken from the [Conceptual 12M dataset](https://github.com/google-research-datasets/conceptual-12m) translated using [MarianMT](https://huggingface.co/transformers/model_doc/marian.html).
-
-For more details, click on `Usage` 🤗 above.
\ No newline at end of file
diff --git a/spaces/floriankrempl/mtg_rules_bot/mtg/data_handler/process_rules_data.py b/spaces/floriankrempl/mtg_rules_bot/mtg/data_handler/process_rules_data.py
deleted file mode 100644
index ddba218377601d14db0b1522ff92541871be97d7..0000000000000000000000000000000000000000
--- a/spaces/floriankrempl/mtg_rules_bot/mtg/data_handler/process_rules_data.py
+++ /dev/null
@@ -1,65 +0,0 @@
-# %%
-import re
-from pdfminer.high_level import extract_text
-from pathlib import Path
-import random
-
-
-def load_rules(rules_file=Path("data/raw/rules/MagicCompRules_21031101.pdf")):
- text = extract_text(rules_file)
- return text
-
-
-def extract_rules(text: str) -> list[str]:
- see_rules_pattern = r"See rule \d+\.\d+\. |See rule \d+\.\d+"
- start_of_rule_pattern = r"\d+\.\d+\."
-
- processed_texts = re.sub(see_rules_pattern, "", text)
- rules = re.split(start_of_rule_pattern, processed_texts)
- # filter glossar and intro
- rules = rules[1:-23]
- rules = [rule.replace("\n", "") for rule in rules]
-
- print("random rule:")
- print(random.choice(rules))
- print("_________________")
-
- return rules
-
-
-# %%
-
-import numpy as np
-import openai
-import yaml
-
-with open("config/config.yaml", "r") as infile:
- config = yaml.load(infile, Loader=yaml.FullLoader)
-
-# roles: system, user, assistant
-openai.api_key = config.get("open_ai_token")
-
-
-def get_embeddings(rules: list[str]):
- text_embedding = []
- for rule in rules:
- response = openai.Embedding.create(input=rule, model="text-embedding-ada-002")
- embeddings = response["data"][0]["embedding"]
- text_embedding.append((rule, np.array(embeddings)))
- return text_embedding
-
-
-# %%
-
-text = load_rules()
-rules = extract_rules(text)
-
-# %%
-
-text_embeddings = get_embeddings(rules[:2])
-
-# %%
-
-text_embeddings[0][1].shape
-
-import hnswlib
diff --git a/spaces/flowers-team/SocialAISchool/gym-minigrid/gym_minigrid/envs/redbluedoors.py b/spaces/flowers-team/SocialAISchool/gym-minigrid/gym_minigrid/envs/redbluedoors.py
deleted file mode 100644
index cea95b40e77fc6060eb9d9a70a17ec742073fdad..0000000000000000000000000000000000000000
--- a/spaces/flowers-team/SocialAISchool/gym-minigrid/gym_minigrid/envs/redbluedoors.py
+++ /dev/null
@@ -1,80 +0,0 @@
-from gym_minigrid.minigrid import *
-from gym_minigrid.register import register
-
-class RedBlueDoorEnv(MiniGridEnv):
- """
- Single room with red and blue doors on opposite sides.
- The red door must be opened before the blue door to
- obtain a reward.
- """
-
- def __init__(self, size=8):
- self.size = size
-
- super().__init__(
- width=2*size,
- height=size,
- max_steps=20*size*size
- )
-
- def _gen_grid(self, width, height):
- # Create an empty grid
- self.grid = Grid(width, height)
-
- # Generate the grid walls
- self.grid.wall_rect(0, 0, 2*self.size, self.size)
- self.grid.wall_rect(self.size//2, 0, self.size, self.size)
-
- # Place the agent in the top-left corner
- self.place_agent(top=(self.size//2, 0), size=(self.size, self.size))
-
- # Add a red door at a random position in the left wall
- pos = self._rand_int(1, self.size - 1)
- self.red_door = Door("red")
- self.grid.set(self.size//2, pos, self.red_door)
-
- # Add a blue door at a random position in the right wall
- pos = self._rand_int(1, self.size - 1)
- self.blue_door = Door("blue")
- self.grid.set(self.size//2 + self.size - 1, pos, self.blue_door)
-
- # Generate the mission string
- self.mission = "open the red door then the blue door"
-
- def step(self, action):
- red_door_opened_before = self.red_door.is_open
- blue_door_opened_before = self.blue_door.is_open
-
- obs, reward, done, info = MiniGridEnv.step(self, action)
-
- red_door_opened_after = self.red_door.is_open
- blue_door_opened_after = self.blue_door.is_open
-
- if blue_door_opened_after:
- if red_door_opened_before:
- reward = self._reward()
- done = True
- else:
- reward = 0
- done = True
-
- elif red_door_opened_after:
- if blue_door_opened_before:
- reward = 0
- done = True
-
- return obs, reward, done, info
-
-class RedBlueDoorEnv6x6(RedBlueDoorEnv):
- def __init__(self):
- super().__init__(size=6)
-
-register(
- id='MiniGrid-RedBlueDoors-6x6-v0',
- entry_point='gym_minigrid.envs:RedBlueDoorEnv6x6'
-)
-
-register(
- id='MiniGrid-RedBlueDoors-8x8-v0',
- entry_point='gym_minigrid.envs:RedBlueDoorEnv'
-)
diff --git a/spaces/freddyaboulton/3.1.4.9-all-demos/demos/video_identity/run.py b/spaces/freddyaboulton/3.1.4.9-all-demos/demos/video_identity/run.py
deleted file mode 100644
index 152dab9b0e8389c69531bb109124160ab03156e1..0000000000000000000000000000000000000000
--- a/spaces/freddyaboulton/3.1.4.9-all-demos/demos/video_identity/run.py
+++ /dev/null
@@ -1,18 +0,0 @@
-import gradio as gr
-import os
-
-
-def video_identity(video):
- return video
-
-
-demo = gr.Interface(video_identity,
- gr.Video(),
- "playable_video",
- examples=[
- os.path.join(os.path.dirname(__file__),
- "video/video_sample.mp4")],
- cache_examples=True)
-
-if __name__ == "__main__":
- demo.launch()
diff --git a/spaces/g4f/freegpt-webui/client/js/chat.js b/spaces/g4f/freegpt-webui/client/js/chat.js
deleted file mode 100644
index b8052cb5fcafeaec9a40863822b3bfb0c34b0883..0000000000000000000000000000000000000000
--- a/spaces/g4f/freegpt-webui/client/js/chat.js
+++ /dev/null
@@ -1,515 +0,0 @@
-const query = (obj) =>
- Object.keys(obj)
- .map((k) => encodeURIComponent(k) + "=" + encodeURIComponent(obj[k]))
- .join("&");
-const url_prefix = document.querySelector('body').getAttribute('data-urlprefix')
-const markdown = window.markdownit();
-const message_box = document.getElementById(`messages`);
-const message_input = document.getElementById(`message-input`);
-const box_conversations = document.querySelector(`.top`);
-const spinner = box_conversations.querySelector(".spinner");
-const stop_generating = document.querySelector(`.stop-generating`);
-const send_button = document.querySelector(`#send-button`);
-const user_image = ` `;
-const gpt_image = `
`;
-const gpt_image = ` `;
-let prompt_lock = false;
-
-hljs.addPlugin(new CopyButtonPlugin());
-
-message_input.addEventListener("blur", () => {
- window.scrollTo(0, 0);
-});
-
-message_input.addEventListener("focus", () => {
- document.documentElement.scrollTop = document.documentElement.scrollHeight;
-});
-
-const delete_conversations = async () => {
- localStorage.clear();
- await new_conversation();
-};
-
-const handle_ask = async () => {
- message_input.style.height = `80px`;
- window.scrollTo(0, 0);
- let message = message_input.value;
-
- if (message.length > 0) {
- message_input.value = ``;
- message_input.dispatchEvent(new Event("input"));
- await ask_gpt(message);
- }
-};
-
-const remove_cancel_button = async () => {
- stop_generating.classList.add(`stop-generating-hiding`);
-
- setTimeout(() => {
- stop_generating.classList.remove(`stop-generating-hiding`);
- stop_generating.classList.add(`stop-generating-hidden`);
- }, 300);
-};
-
-const ask_gpt = async (message) => {
- try {
- message_input.value = ``;
- message_input.innerHTML = ``;
- message_input.innerText = ``;
-
- add_conversation(window.conversation_id, message.substr(0, 20));
- window.scrollTo(0, 0);
- window.controller = new AbortController();
-
- jailbreak = document.getElementById("jailbreak");
- model = document.getElementById("model");
- prompt_lock = true;
- window.text = ``;
- window.token = message_id();
-
- stop_generating.classList.remove(`stop-generating-hidden`);
-
- add_user_message_box(message);
-
- message_box.scrollTop = message_box.scrollHeight;
- window.scrollTo(0, 0);
- await new Promise((r) => setTimeout(r, 500));
- window.scrollTo(0, 0);
-
- message_box.innerHTML += `
-
- `;
-
- message_box.scrollTop = message_box.scrollHeight;
- window.scrollTo(0, 0);
- await new Promise((r) => setTimeout(r, 1000));
- window.scrollTo(0, 0);
-
- const response = await fetch(`${url_prefix}/backend-api/v2/conversation`, {
- method: `POST`,
- signal: window.controller.signal,
- headers: {
- "content-type": `application/json`,
- accept: `text/event-stream`,
- },
- body: JSON.stringify({
- conversation_id: window.conversation_id,
- action: `_ask`,
- model: model.options[model.selectedIndex].value,
- jailbreak: jailbreak.options[jailbreak.selectedIndex].value,
- meta: {
- id: window.token,
- content: {
- conversation: await get_conversation(window.conversation_id),
- internet_access: document.getElementById("switch").checked,
- content_type: "text",
- parts: [
- {
- content: message,
- role: "user",
- },
- ],
- },
- },
- }),
- });
-
- const reader = response.body.getReader();
-
- while (true) {
- const { value, done } = await reader.read();
- if (done) break;
-
- chunk = decodeUnicode(new TextDecoder().decode(value));
-
- if (chunk.includes(`
`;
-let prompt_lock = false;
-
-hljs.addPlugin(new CopyButtonPlugin());
-
-message_input.addEventListener("blur", () => {
- window.scrollTo(0, 0);
-});
-
-message_input.addEventListener("focus", () => {
- document.documentElement.scrollTop = document.documentElement.scrollHeight;
-});
-
-const delete_conversations = async () => {
- localStorage.clear();
- await new_conversation();
-};
-
-const handle_ask = async () => {
- message_input.style.height = `80px`;
- window.scrollTo(0, 0);
- let message = message_input.value;
-
- if (message.length > 0) {
- message_input.value = ``;
- message_input.dispatchEvent(new Event("input"));
- await ask_gpt(message);
- }
-};
-
-const remove_cancel_button = async () => {
- stop_generating.classList.add(`stop-generating-hiding`);
-
- setTimeout(() => {
- stop_generating.classList.remove(`stop-generating-hiding`);
- stop_generating.classList.add(`stop-generating-hidden`);
- }, 300);
-};
-
-const ask_gpt = async (message) => {
- try {
- message_input.value = ``;
- message_input.innerHTML = ``;
- message_input.innerText = ``;
-
- add_conversation(window.conversation_id, message.substr(0, 20));
- window.scrollTo(0, 0);
- window.controller = new AbortController();
-
- jailbreak = document.getElementById("jailbreak");
- model = document.getElementById("model");
- prompt_lock = true;
- window.text = ``;
- window.token = message_id();
-
- stop_generating.classList.remove(`stop-generating-hidden`);
-
- add_user_message_box(message);
-
- message_box.scrollTop = message_box.scrollHeight;
- window.scrollTo(0, 0);
- await new Promise((r) => setTimeout(r, 500));
- window.scrollTo(0, 0);
-
- message_box.innerHTML += `
-
- `;
-
- message_box.scrollTop = message_box.scrollHeight;
- window.scrollTo(0, 0);
- await new Promise((r) => setTimeout(r, 1000));
- window.scrollTo(0, 0);
-
- const response = await fetch(`${url_prefix}/backend-api/v2/conversation`, {
- method: `POST`,
- signal: window.controller.signal,
- headers: {
- "content-type": `application/json`,
- accept: `text/event-stream`,
- },
- body: JSON.stringify({
- conversation_id: window.conversation_id,
- action: `_ask`,
- model: model.options[model.selectedIndex].value,
- jailbreak: jailbreak.options[jailbreak.selectedIndex].value,
- meta: {
- id: window.token,
- content: {
- conversation: await get_conversation(window.conversation_id),
- internet_access: document.getElementById("switch").checked,
- content_type: "text",
- parts: [
- {
- content: message,
- role: "user",
- },
- ],
- },
- },
- }),
- });
-
- const reader = response.body.getReader();
-
- while (true) {
- const { value, done } = await reader.read();
- if (done) break;
-
- chunk = decodeUnicode(new TextDecoder().decode(value));
-
- if (chunk.includes(`