If you are looking for a way to create realistic and professional guitar tones on your computer, you might have heard of Guitar Rig 6, the latest version of the popular amp simulator and multi-effects rack from Native Instruments. But how can you download Guitar Rig 6 full version for free or at a discounted price? And how can you install and use it to get the most out of your guitar playing and recording?
-In this article, we will answer all these questions and more. We will explain what Guitar Rig 6 is and why you need it, what features and benefits it offers, what system requirements and compatibility it has, how to download it for free or at a low cost, how to install and activate it on your computer, and how to use it to create amazing guitar tones. By the end of this article, you will have everything you need to know about downloading Guitar Rig 6 full version and using it to enhance your guitar sound.
- Guitar Rig 6 is designed for guitarists of all levels and styles, from beginners to professionals, from rock to metal, from blues to jazz. Whether you want to practice, record, perform, or experiment with different sounds, Guitar Rig 6 can help you achieve your goals. You can use it to create realistic and authentic tones that match your favorite artists and genres, or you can use it to craft your own unique sounds that express your personality and creativity.
- Guitar Rig 6 comes with a host of features and benefits that make it one of the best guitar effects software on the market. Here are some of them:
-Guitar Rig 6 is compatible with Windows and Mac operating systems. Here are the minimum system requirements for running Guitar Rig 6:
-
-
-| Operating System |
-Windows 10 (64-bit) |
-macOS 10.14 or higher |
-
-
-| CPU |
-Intel Core i5 or equivalent AMD processor |
-Intel Core i5 or equivalent Apple processor |
-
-
-| RAM |
-4 GB (8 GB recommended) |
-4 GB (8 GB recommended) |
-
-
-| Disk Space |
-1 GB for Guitar Rig 6 Player
3 GB for Guitar Rig 6 Pro |
-1 GB for Guitar Rig 6 Player
3 GB for Guitar Rig 6 Pro |
-
-
-| Graphics Card |
-NVIDIA GeForce GTX 600 series or higher
AMD Radeon HD 7000 series or higher
Intel HD Graphics 4000 or higher |
-NVIDIA GeForce GTX 600 series or higher
AMD Radeon HD 7000 series or higher
Intel HD Graphics 4000 or higher |
-
-
-| Audio Interface |
-A dedicated audio interface with ASIO driver support is recommended for optimal performance and low latency. |
-A dedicated audio interface with Core Audio driver support is recommended for optimal performance and low latency. |
-
-
-| MIDI Device |
-A MIDI device such as a footswitch, pedal, keyboard, controller, etc., is optional but recommended for controlling Guitar Rig 6 parameters in real time. |
-A MIDI device such as a footswitch, pedal, keyboard, controller, etc., is optional but recommended for controlling Guitar Rig 6 parameters in real time. |
-
How to download Guitar Rig 6 full version for free
- Now that you know what Guitar Rig 6 is and what it can do for you, you might be wondering how to download it for free or at a low cost. There are three ways to get Guitar Rig 6 full version for free or at a discounted price:
- Guitar Rig 6 Player: the free version with limited features
- The first way to get Guitar Rig 6 full version for free is to download Guitar Rig 6 Player, the free version of Guitar Rig 6 that comes with limited features. Guitar Rig 6 Player is a great way to try out Guitar Rig 6 and see if you like it before buying the full version. Guitar Rig 6 Player includes:
-
-- One amp model: Jump, based on the Marshall JMP Plexi
-- One cabinet model: Matched Cabinet, based on the Marshall 1960A
-- 13 effects models: Skreamer, Demon Distortion, Cat, Mezcal, Citrus, AC Box, Gratifier, Treble Booster, Vintage Reverb, Quad Delay, Stereo Tune, Limiter, and Noise Reduction
-- 50 presets and styles
-- The ability to use Guitar Rig 6 Player as a standalone application or as a plugin in your DAW
-
- To download Guitar Rig 6 Player for free, you need to create a free Native Instruments account and download the Native Access app. Native Access is a software that manages the installation and activation of Native Instruments products. Once you have Native Access installed, you can download Guitar Rig 6 Player from the Not Installed tab and install it on your computer.
- Guitar Rig 6 Demo: the trial version with full features
- The second way to get Guitar Rig 6 full version for free is to download Guitar Rig 6 Demo, the trial version of Guitar Rig 6 that comes with full features. Guitar Rig 6 Demo is a great way to test all the features and functions of Guitar Rig 6 and see if it meets your needs and expectations before buying the full version. Guitar Rig 6 Demo includes:
-
-- All the features and benefits of Guitar Rig 6 Pro (see below)
-- The ability to use Guitar Rig 6 Demo as a standalone application or as a plugin in your DAW
-- A time limit of 30 minutes per session
-- A noise burst every few minutes
-- No saving or exporting of presets or sounds
-
- To download Guitar Rig 6 Demo for free, you need to create a free Native Instruments account and download the Native Access app. Once you have Native Access installed, you can download Guitar Rig 6 Demo from the Not Installed tab and install it on your computer.
- Guitar Rig 6 Pro: the paid version with all features
- The third way to get Guitar Rig 6 full version is to buy Guitar Rig 6 Pro, the paid version of Guitar Rig 6 that comes with all features. Guitar Rig 6 Pro is the ultimate guitar effects software that gives you unlimited creative possibilities and professional results. Guitar Rig 6 Pro includes:
-
-- All the features and benefits of Guitar Rig 6 (see above)
-- No time limit or noise burst
-- The ability to save and export presets and sounds
-- The ability to use Guitar Rig 6 Pro as a standalone application or as a plugin in your DAW
-- Free updates and support from Native Instruments
-
- To buy Guitar Rig 6 Pro, you need to create a free Native Instruments account and download the Native Access app. Once you have Native Access installed, you can buy Guitar Rig 6 Pro from the Shop tab and install it on your computer. The price of Guitar Rig 6 Pro is $199 USD. However, there are some ways to get it at a discounted price:
-
-- If you already own a previous version of Guitar Rig (Guitar Rig 1-5), you can upgrade to Guitar Rig 6 Pro for $99 USD.
-- If you already own Komplete Start (a free collection of instruments and sounds from Native Instruments), you can crossgrade to Guitar Rig 6 Pro for $149 USD.
-- If you already own Komplete Select (a curated collection of instruments and sounds from Native Instruments), you can crossgrade to Guitar Rig 6 Pro for $99 USD.
-- If you already own Komplete (the ultimate production suite from Native Instruments), you can get Guitar Rig 6 Pro for free as part of your bundle.
-
How to install and activate Guitar Rig 6 full version
- Once you have downloaded Guitar Rig 6 full version, either for free or for a price, you need to install and activate it on your computer. Here are the steps to do so:
- How to install Guitar Rig 6 on your computer
- To install Guitar Rig 6 on your computer, you need to use the Native Access app that you downloaded earlier. Here are the steps to install Guitar Rig 6 with Native Access:
-
-- Open Native Access and log in with your Native Instruments account.
-- Go to the Installed Products tab and find Guitar Rig 6 in the list.
-- Click on the Install button and choose a location for the installation.
-- Wait for the installation to complete and click on the Finish button.
-- Guitar Rig 6 is now installed on your computer and ready to use.
-
- How to activate Guitar Rig 6 with your license key or Native Access account
- To activate Guitar Rig 6 on your computer, you need to use either your license key or your Native Access account. Here are the steps to activate Guitar Rig 6 with either method:
-
-- If you bought Guitar Rig 6 Pro or upgraded from a previous version, you should have received a license key via email. To activate Guitar Rig 6 with your license key, follow these steps:
-- Open Native Access and log in with your Native Instruments account.
-- Go to the Add a serial tab and enter your license key in the field.
-- Click on the Add serial button and wait for the activation to complete.
-- Guitar Rig 6 is now activated on your computer and ready to use.
-
-
-- If you downloaded Guitar Rig 6 Player or Guitar Rig 6 Demo, you don't need a license key. To activate Guitar Rig 6 with your Native Access account, follow these steps:
-- Open Native Access and log in with your Native Instruments account.
-- Go to the Installed Products tab and find Guitar Rig 6 in the list.
-- Click on the Activate button and wait for the activation to complete.
-- Guitar Rig 6 is now activated on your computer and ready to use.
-
-
-
- How to use Guitar Rig 6 full version to create amazing guitar tones
- Now that you have installed and activated Guitar Rig 6 full version on your computer, you can start using it to create amazing guitar tones. Here are some tips and tricks on how to use Guitar Rig 6 full version effectively and efficiently:
- How to navigate the Guitar Rig 6 interface and browser
- Guitar Rig 6 has a user-friendly interface that consists of four main sections: the header, the browser, the rack, and the footer. Here is a brief overview of each section:
-
-- The header contains the menu bar, the toolbar, and the preset name. You can use the menu bar to access various options and settings, such as file, edit, view, help, etc. You can use the toolbar to access various functions and tools, such as tuner, metronome, tape deck, etc. You can also see and change the name of the current preset in the header.
-- The browser contains the preset list, the style list, and the component list. You can use the preset list to browse, load, save, delete, or search presets. You can use the style list to filter presets by styles, such as rock, metal, blues, jazz, etc. You can use the component list to browse, load, or search components, such as amps, cabinets, effects, tools, etc.
-- The rack contains the components that make up your guitar rig. You can see and adjust the settings of each component with knobs, sliders, switches, and menus. You can also drag and drop components to add, remove, or rearrange them in the rack. You can also use splitters, mixers, crossovers and modifiers to shape and control your signal flow and dynamics.
-- The footer contains the master volume, the input level, the output level, and the CPU usage. You can use the master volume to adjust the overall volume of your guitar rig. You can also see and adjust the input level and the output level of your guitar rig. You can also see the CPU usage of your computer and optimize it if needed.
-
- To navigate the Guitar Rig 6 interface and browser, you can use your mouse, keyboard, or MIDI device. You can also use shortcuts and commands to access various functions and tools more quickly. For example, you can use the arrow keys to navigate the preset list, the style list, and the component list. You can also use the spacebar to bypass or enable a component, or use the delete key to remove a component from the rack. You can also use commands such as Ctrl+C to copy a component, Ctrl+V to paste a component, Ctrl+Z to undo an action, etc.
- How to load and customize presets and components
- Guitar Rig 6 comes with over 300 presets that are ready to use or tweak to your liking. You can also create your own presets and save them for later use. Here are some tips on how to load and customize presets and components:
-
-- To load a preset, you can use the browser to find and select a preset from the preset list or the style list. You can also use the arrow keys or the mouse wheel to scroll through the presets. You can also use the search function to find a preset by name or keyword. Once you have found a preset that you like, you can double-click on it or press Enter to load it to the rack.
-- To customize a preset, you can use the rack to adjust the settings of each component with knobs, sliders, switches, and menus. You can also drag and drop components to add, remove, or rearrange them in the rack. You can also use splitters, mixers, crossovers, and modifiers to shape and control your signal flow and dynamics. You can also use MIDI control and automation to control the parameters of Guitar Rig 6 in real time.
-- To save a preset, you can click on the Save button in the header and enter a name for your preset. You can also choose a style for your preset from the style list. You can also add tags and comments to your preset for easier identification and organization. Once you have saved your preset, you can find it in the User folder in the browser.
-- To load a component, you can use the browser to find and select a component from the component list. You can also use the arrow keys or the mouse wheel to scroll through the components. You can also use the search function to find a component by name or keyword. Once you have found a component that you like, you can drag and drop it to an empty slot in the rack or on top of an existing component to replace it.
-- To customize a component, you can use the rack to adjust the settings of each component with knobs, sliders, switches, and menus. You can also drag and drop components to add, remove, or rearrange them in the rack. You can also use splitters, mixers, crossovers and modifiers to shape and control your signal flow and dynamics. You can also use MIDI control and automation to control the parameters of Guitar Rig 6 in real time.
-
- How to use the new amps and effects powered by Intelligent Circuit Modeling
- Guitar Rig 6 introduces a new technology called Intelligent Circuit Modeling that uses artificial intelligence to analyze and recreate the behavior of real analog circuits. This results in more realistic and responsive sounds that capture the nuances and character of the original hardware. Guitar Rig 6 features three new amps and 16 new effects based on this technology, such as the Chicago, Bass Invader, Fire Breather, Harmonic Synthesizer, Grain Delay, Choral Reef, etc. Here are some tips on how to use the new amps and effects powered by Intelligent Circuit Modeling:
-
-- To load a new amp or effect, you can use the browser to find and select a component from the component list. You can also use the arrow keys or the mouse wheel to scroll through the components. You can also use the search function to find a component by name or keyword. Once you have found a component that you like, you can drag and drop it to an empty slot in the rack or on top of an existing component to replace it.
-- To customize a new amp or effect, you can use the rack to adjust the settings of each component with knobs, sliders, switches, and menus. You can also drag and drop components to add, remove, or rearrange them in the rack. You can also use splitters, mixers, crossovers, and modifiers to shape and control your signal flow and dynamics. You can also use MIDI control and automation to control the parameters of Guitar Rig 6 in real time.
-- To get the best sound from a new amp or effect, you need to match it with a suitable cabinet or speaker. You can use the browser to find and select a cabinet or speaker from the component list. You can also use the arrow keys or the mouse wheel to scroll through the components. You can also use the search function to find a component by name or keyword. Once you have found a component that you like, you can drag and drop it to an empty slot in the rack or on top of an existing component to replace it.
-- To experiment with different sounds from a new amp or effect, you can use the presets that come with each component. You can use the browser to find and select a preset from the preset list or the style list. You can also use the arrow keys or the mouse wheel to scroll through the presets. You can also use the search function to find a preset by name or keyword. Once you have found a preset that you like, you can double-click on it or press Enter to load it to the rack.
-
- Conclusion and FAQs
- Guitar Rig 6 is a powerful and versatile guitar effects software that can help you create realistic and professional guitar tones on your computer. It offers a wide range of features and benefits that make it one of the best guitar effects software on the market. It also comes with three ways to get Guitar Rig 6 full version for free or at a discounted price: Guitar Rig 6 Player, Guitar Rig 6 Demo, and Guitar Rig 6 Pro.
- In this article, we have explained what Guitar Rig 6 is and why you need it, what features and benefits it offers, what system requirements and compatibility it has, how to download it for free or at a low cost, how to install and activate it on your computer, and how to use it to create amazing guitar tones. We hope that this article has helped you learn everything you need to know about downloading Guitar Rig 6 full version and using it to enhance your guitar sound.
- If you have any questions or doubts about Guitar Rig 6 full version, here are some frequently asked questions (FAQs) that might help you:
- Q: Can I use Guitar Rig 6 with any guitar?
-A: Yes, you can use Guitar Rig 6 with any electric guitar, acoustic guitar, bass guitar, or any other instrument that has a pickup or a microphone. You just need to connect your instrument to your computer via an audio interface with an instrument input.
- Q: Can I use Guitar Rig 6 with any DAW?
-A: Yes, you can use Guitar Rig 6 with any DAW that supports VST, AU, or AAX plugin formats. You just need to load Guitar Rig 6 as an effect plugin in your DAW's track or bus.
- Q: Can I use Guitar Rig 6 offline?
-A: Yes, you can use Guitar Rig 6 offline as a standalone application without an internet connection. However, you need an internet connection to download, install, and activate Guitar Rig 6 for the first time. You also need an internet connection to access the online features and updates of Guitar Rig 6.
- Q: Can I use Guitar Rig 6 with other guitar effects software or hardware?
-A: Yes, you can use Guitar Rig 6 with other guitar effects software or hardware, as long as they are compatible and do not cause any conflicts or issues. You can use Guitar Rig 6 as an effect plugin in your DAW and combine it with other plugins, or you can use Guitar Rig 6 as a standalone application and route it to other software or hardware via an audio interface or a virtual cable.
- Q: Can I share my Guitar Rig 6 presets and sounds with others?
-A: Yes, you can share your Guitar Rig 6 presets and sounds with others, as long as you respect the intellectual property rights of Native Instruments and the original creators of the components and presets. You can export your presets and sounds as files and send them to others via email, social media, cloud storage, etc. You can also import presets and sounds from others and load them to your Guitar Rig 6.
b2dd77e56b
-
-
\ No newline at end of file
diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/893u2is User Manual.md b/spaces/1gistliPinn/ChatGPT4/Examples/893u2is User Manual.md
deleted file mode 100644
index 6ae7c610539ca7890ad06fefb4e352a85cefe688..0000000000000000000000000000000000000000
--- a/spaces/1gistliPinn/ChatGPT4/Examples/893u2is User Manual.md
+++ /dev/null
@@ -1,6 +0,0 @@
-893u2is User Manual
Download ===== https://imgfil.com/2uy100
-
-Oct 8, 2015 Only after I read the instructions carefully did I see the ... Station Users Guide Multi-Function Hdd Docking Manual 893u2is ... 4d29de3e1b
-
-
-
diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Age Of Empires 3 No Cd Crack Gamecopyworld Gtahttps Scoutmails.com Index301.php K Age Of Empires 3 WORK.md b/spaces/1gistliPinn/ChatGPT4/Examples/Age Of Empires 3 No Cd Crack Gamecopyworld Gtahttps Scoutmails.com Index301.php K Age Of Empires 3 WORK.md
deleted file mode 100644
index 401d7e7c49993db068414afc4a0f4bfacc8b204a..0000000000000000000000000000000000000000
--- a/spaces/1gistliPinn/ChatGPT4/Examples/Age Of Empires 3 No Cd Crack Gamecopyworld Gtahttps Scoutmails.com Index301.php K Age Of Empires 3 WORK.md
+++ /dev/null
@@ -1,129 +0,0 @@
-
-Age of Empires 3 No CD Crack GameCopyWorld: How to Play the Classic Strategy Game Without a Disc
-
-Age of Empires 3 is one of the most popular and acclaimed strategy games of all time, but it also requires a CD to play. If you have lost your CD, or you want to play the game on a different computer without carrying the disc around, you might be looking for a way to play Age of Empires 3 no CD crack GameCopyWorld.
-
-GameCopyWorld is a website that provides game fixes, trainers, cheats, and patches for various PC games. One of the game fixes they offer is a no CD crack for Age of Empires 3, which allows you to play the game without inserting the CD every time. This can also help you avoid potential damage to your CD or CD drive.
-age of empires 3 no cd crack gamecopyworld gtahttps: scoutmails.com index301.php k age of empires 3
Download File ✵✵✵ https://imgfil.com/2uxZHS
-
-In this article, we will show you how to download and install Age of Empires 3 no CD crack GameCopyWorld, and how to enjoy the game without any hassle. We will also tell you about some of the features and benefits of playing Age of Empires 3 no CD crack GameCopyWorld.
-
-How to Download and Install Age of Empires 3 No CD Crack GameCopyWorld
-
-To download and install Age of Empires 3 no CD crack GameCopyWorld, you will need to follow these steps:
-
-
-- Go to https://www.gamecopyworld.com/games/pc_age_of_empires_3.shtml and scroll down to find the game fix you need. Depending on which version and expansion of Age of Empires 3 you have, you will need to choose the appropriate no CD crack. For example, if you have Age of Empires 3: Complete Collection, which includes the base game and both expansions (The WarChiefs and The Asian Dynasties), you will need to download Age of Empires III: Complete Collection v1.0 [EN] Fixed Files.
-- Click on the download link and save the file to your computer. You may need to use a program like WinRAR or 7-Zip to extract the file.
-- Locate the folder where you have installed Age of Empires 3 on your computer. It is usually in C:\Program Files (x86)\Microsoft Games\Age of Empires III.
-- Copy the cracked files from the downloaded folder and paste them into the installation folder, replacing the original files. You may need to backup the original files in case you want to restore them later.
-- Run the game as usual. You should be able to play Age of Empires 3 without inserting the CD.
-
-
-Features and Benefits of Playing Age of Empires 3 No CD Crack GameCopyWorld
-
-Playing Age of Empires 3 no CD crack GameCopyWorld has some advantages over playing with the CD. Here are some of them:
-
-
-- You can play the game on any computer without carrying the CD around.
-- You can avoid potential damage to your CD or CD drive from scratches or wear and tear.
-- You can save some disk space by deleting the ISO image of the CD if you have one.
-- You can enjoy faster loading times and smoother performance by playing from your hard drive instead of your CD drive.
-- You can still access all the features and content of the game, including multiplayer mode, online updates, and mods.
-
-
-Conclusion
-
-Age of Empires 3 is a classic strategy game that deserves to be played by anyone who loves history, culture, and warfare. With Age of Empires 3 no CD crack GameCopyWorld, you can play the game without any hassle or limitation. Just follow our guide on how to download and install Age of Empires 3 no CD crack GameCopyWorld, and enjoy the game at its best.
-
-If you liked this article, please share it with your friends who are also fans of Age of Empires 3. And if you have any questions or comments, feel free to leave them below. We would love to hear from you!
-What is Age of Empires 3 and Why Should You Play It?
-
-Age of Empires 3 is a real-time strategy game that was released in 2005 by Microsoft Studios and Ensemble Studios. It is the third installment in the Age of Empires series, which is one of the most successful and influential strategy game franchises of all time.
-
-Age of Empires 3 takes place during the Age of Discovery, from the 15th to the 19th century. You can choose from eight European civilizations, each with their own unique units, buildings, technologies, and abilities. You can also play as three native American civilizations in the WarChiefs expansion, or as three Asian civilizations in the Asian Dynasties expansion.
-
-Age of Empires 3 offers a rich and varied gameplay experience that will appeal to both casual and hardcore strategy fans. You can explore and colonize new lands, trade and fight with other players or AI opponents, build and manage your economy and military, research new technologies and upgrades, and customize your home city that provides you with bonuses and shipments.
-
-
-Age of Empires 3 also features a compelling campaign mode that follows the story of three generations of the Black family, as they participate in historical events such as the Seven Years' War, the American Revolution, and the Napoleonic Wars. The campaign mode has cinematic cutscenes, voice acting, and scripted scenarios that will immerse you in the history and culture of the era.
-
-Age of Empires 3 is a classic strategy game that deserves to be played by anyone who loves history, culture, and warfare. It has stunning graphics, sound effects, and music that bring the game world to life. It has a large and active online community that supports the game with mods, maps, tournaments, and more. It has a high replay value, as you can try different strategies, civilizations, game modes, and difficulty levels.
-
-How to Play Age of Empires 3 No CD Crack GameCopyWorld Online
-
-One of the best features of Age of Empires 3 is its online multiplayer mode, where you can challenge other players from around the world in various game modes such as supremacy, deathmatch, treaty, king of the hill, and more. You can also join or create clans, chat with other players, check your stats and rankings, and earn medals and achievements.
-
-However, to play Age of Empires 3 online, you need to have a valid CD key that is registered on your Microsoft account. If you have lost your CD key, or you have downloaded Age of Empires 3 no CD crack GameCopyWorld from our website, you might not be able to access the official online servers.
-
-But don't worry, there is a way to play Age of Empires 3 no CD crack GameCopyWorld online without a CD key. All you need to do is download and install a third-party client called ESOCommunity Patch. This patch will allow you to play Age of Empires 3 no CD crack GameCopyWorld online on ESOCommunity servers, which are unofficial but popular servers that host thousands of players every day.
-
-To download and install ESOCommunity Patch for Age of Empires 3 no CD crack GameCopyWorld, you will need to follow these steps:
-
-
-- Go to https://eso-community.net/download-patch and click on the download button.
-- Run the installer and follow the instructions. Make sure you select your Age of Empires 3 installation folder when prompted.
-- Launch Age of Empires 3 no CD crack GameCopyWorld from your desktop shortcut or start menu.
-- Create a new ESO account or log in with your existing one. You don't need a CD key to create an account.
-- Enjoy playing Age of Empires 3 no CD crack GameCopyWorld online on ESOCommunity servers!
-
-
-Conclusion
-
-Age of Empires 3 no CD crack GameCopyWorld is a great way to play the classic strategy game without a disc. You can download and install it easily from our website, and enjoy all the features and content of the game without any hassle. You can also play it online on ESOCommunity servers with other players who have downloaded Age of Empires 3 no CD crack GameCopyWorld.
-
-If you liked this article, please share it with your friends who are also fans of Age of Empires 3. And if you have any questions or comments, feel free to leave them below. We would love to hear from you!
-How to Master the Combat System in Age of Empires 3
-
-Age of Empires 3 is not just about building and managing your economy; it is also about fighting and conquering your enemies. The combat system in Age of Empires 3 is based on a rock-paper-scissors model, where each unit type has strengths and weaknesses against other unit types. For example, infantry units are good against cavalry units, cavalry units are good against artillery units, and artillery units are good against infantry units.
-
-To master the combat system in Age of Empires 3, you need to know the different unit types and their counters, as well as how to use formations, stances, and special abilities. You also need to pay attention to the terrain, the weather, and the line of sight, as they can affect the performance and visibility of your units.
-
-Here are some general tips and tricks for combat in Age of Empires 3:
-
-
-- Always scout your enemy's base and army composition before attacking. This will help you plan your strategy and choose the right units for the battle.
-- Try to have a balanced army with a mix of unit types. This will allow you to adapt to different situations and counter different threats.
-- Use formations to organize your army and give them bonuses. For example, the staggered formation gives your ranged units more firing arc, while the box formation protects your artillery units from cavalry charges.
-- Use stances to control the behavior of your units. For example, the defensive stance makes your units hold their ground and focus on nearby enemies, while the aggressive stance makes your units chase and attack any enemy they see.
-- Use special abilities to gain an edge in combat. For example, some infantry units can use bayonets or grenades to deal extra damage, while some cavalry units can use trample mode to run over enemy infantry.
-- Use cover mode to reduce damage from ranged attacks. Cover mode makes your units kneel behind obstacles like trees or walls, but it also reduces their movement speed and firing rate.
-- Use flanking maneuvers to surprise and outsmart your enemy. Flanking means attacking your enemy from the sides or behind, where they are more vulnerable and less prepared.
-- Use hit-and-run tactics to harass and weaken your enemy. Hit-and-run tactics mean attacking your enemy with fast units like cavalry or skirmishers, then retreating before they can retaliate.
-- Use siege weapons to destroy enemy buildings and defenses. Siege weapons like cannons or mortars can deal massive damage to buildings and walls, but they are slow and vulnerable to enemy fire.
-- Use ships to support your land army or attack from the sea. Ships can transport units across water, bombard enemy positions from afar, or engage in naval battles with other ships.
-
-
-How to Enjoy the Campaign Mode in Age of Empires 3
-
-If you are looking for a more story-driven and cinematic experience in Age of Empires 3, you might want to try the campaign mode. The campaign mode consists of three acts that follow the adventures of the Black family through different historical periods and continents.
-
-The first act is called Blood, Ice, and Steel, and it takes place during the colonization of America in the 16th and 17th centuries. You will play as Morgan Black, a knight of Malta who fights against the Spanish conquistadors and their allies.
-
-The second act is called Fire and Shadow, and it takes place during the American Revolution in the 18th century. You will play as John Black, a mercenary who joins the Continental Army and battles against the British Empire.
-
-The third act is called Steel and Thunder, and it takes place during the Napoleonic Wars in the 19th century. You will play as Amelia Black, a railroad tycoon who travels across Europe and Asia in search of her lost family legacy.
-
-The campaign mode in Age of Empires 3 offers a rich and varied gameplay experience that will appeal to both casual and hardcore strategy fans. You will explore and colonize new lands, trade and fight with other factions, build and manage your economy and military, research new technologies and upgrades, and customize your home city that provides you with bonuses and shipments.
-
-The campaign mode also features cinematic cutscenes, voice acting, and scripted scenarios that will immerse you in the history and culture of the era. You will meet historical figures like George Washington , Napoleon Bonaparte , Simon Bolivar , Queen Isabella , Tokugawa Ieyasu , Akbar , Ivan the Terrible , Elizabeth I , Samuel de Champlain , Tecumseh , Nathaniel Black , Sahin \"The Falcon\" , Kanyenke , Lizzie \"The Pirate\" , Alain Magnan , Warwick \"The Redcoat\" , Pierre Beaumont , Stuart Black , Nonahkee , Sven Kuechler , Huang He , Admiral Jinhai , Nanib Sahir , Rani Pravarthi , Colonel Edwardson , Chayton Black , Holme \"The Boneguard\" , Crazy Horse , Chief Brave Wolf , General Custer , Major Cooper , Kichiro , Daimyo Mototada Torii , Daimyo Junkei Kuroda , Daimyo Shingen Takeda , Daimyo Kenshin Uesugi , Daimyo Nobunaga Oda , Daimyo Hideyoshi Toyotomi , Daimyo Ieyasu Tokugawa .
-
-If you want to enjoy the campaign mode in Age of Empires 3, here are some tips and tricks:
-
-
-- Play on a difficulty level that suits your skill level. The campaign mode has four difficulty levels: Easy, Moderate, Hard, and Expert. The higher the difficulty level, the more challenging the enemies will be.
-- Watch the cutscenes and listen to the dialogue. They will provide you with important information about the story, characters, objectives, hints, tips, etc.
-- Read the objectives carefully. They will tell you what you need to do to complete each mission. Some objectives are mandatory (marked with a star), while others are optional (marked with a circle).
-- Check the map often. It will show you where you are, where your allies and enemies are, where your objectives are located, etc.
-- Save your game frequently. You never know when something might go wrong or when you might want to try a different strategy.
-- Have fun! The campaign mode is designed to be entertaining and engaging for all kinds of players. Don't worry too much about winning or losing; just enjoy the journey!
-
-Conclusion
-
-Age of Empires 3 no CD crack GameCopyWorld is a great way to play the classic strategy game without a disc. You can download and install it easily from our website, and enjoy all the features and content of the game without any hassle. You can also play it online on ESOCommunity servers with other players who have downloaded Age of Empires 3 no CD crack GameCopyWorld.
-
-In this article, we have shown you how to download and install Age of Empires 3 no CD crack GameCopyWorld, how to master the combat system in Age of Empires 3, and how to enjoy the campaign mode in Age of Empires 3. We hope you have found this article helpful and informative, and that you have learned some useful tips and tricks to boost your game.
-
-If you liked this article, please share it with your friends who are also fans of Age of Empires 3. And if you have any questions or comments, feel free to leave them below. We would love to hear from you!
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Download Automation Studio 5.6 Crack Freel !!TOP!!.md b/spaces/1gistliPinn/ChatGPT4/Examples/Download Automation Studio 5.6 Crack Freel !!TOP!!.md
deleted file mode 100644
index c4e627e6eb71b8bd5a9f4765bcc796b855373b33..0000000000000000000000000000000000000000
--- a/spaces/1gistliPinn/ChatGPT4/Examples/Download Automation Studio 5.6 Crack Freel !!TOP!!.md
+++ /dev/null
@@ -1,24 +0,0 @@
-Download Automation Studio 5.6 Crack Freel
DOWNLOAD --->>> https://imgfil.com/2uy1GW
-
-Winsound.com Automation Studio; Read the Manuals and FAQs in the Digital Audio Forum; Learn More About Old Stock Author: Dan, JVC Author: Jack Szabo from Jack's JVC Revamp; Jack's JVC Revamp 5,…Category: Audio - Digital Audio - Components & Equipment Other Related Categories AudioSoftwareTuning & MeasurementsAudioCables & DevicesToolsMagazines & JournalsMembers ClubsOther Educational Sites Review Top Posts Analyze Audio at What Hi, I’m Dan. With a knowledge of some 35 years of audio, I have been writing about the companies, products, and technologies in this business since 1999. I am an Authorized JVC Dealer, and the Audio & Network Assistant Editor here at Home Theater Forum. View my complete profile
-
-Repair Shop Studios now offers a series of licensing programs that can enable you to generate a royalty stream for your independently developed projects, including the JVC AiS Software Suite, the JVC AiS Suite, and the JVC AiS Suite Plus.
-
-Thanks for the info!
-
-I can't find the manuals for this one either. Will just have to use the information above in this thread I guess. On the CD there are 2 files for the CD Writer, a program for the CD writer and another for the CD Writer Service.
-
-I have the new version 1.02 and have used the CD Writer 1.02 with software version AOS22 which says the disc I used was OSD 2.6 version. I have also used the CD Writer version 1.02 with software version BOS21 with no OSD disc. The CD Writer version 1.02 with AOS22 will not write on my ATR Vista.
-
-I did a google search and found this in an earlier post but can't find the post right now
-
-You are using CD writer 1.02 with AOS22, which is compatible with Vista x64. Your software version is not compatible. XP works fine as you are using the XP version of the program.
-
-Use a CD Writer version 1.2 software.
-
-You will need to look in your Cd writing software. I know it's not simple but you will find the version 2.6 in there. I had a similar problem with some software I bought and it took a little investigation to determine that it wasn't the CD writer software.
-
-I have the new version 1.02 and have used the CD Writer 1. 4fefd39f24
-
-
-
diff --git a/spaces/1line/AutoGPT/autogpt/processing/__init__.py b/spaces/1line/AutoGPT/autogpt/processing/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Adobe Acrobat Reader X The Power of PDF Productivity.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Adobe Acrobat Reader X The Power of PDF Productivity.md
deleted file mode 100644
index 9f50b1a9eafd0c69846e3fa085a032c7ee3bfbf1..0000000000000000000000000000000000000000
--- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Adobe Acrobat Reader X The Power of PDF Productivity.md
+++ /dev/null
@@ -1,167 +0,0 @@
-
-How to Download Adobe Reader X
-Adobe Reader X is a free software that allows you to view, print, and comment on PDF files. PDF stands for Portable Document Format, a file format that preserves the layout, fonts, images, and hyperlinks of any document. PDF files are widely used for sharing information across different platforms and devices.
-how to download adobe reader x
Download ★ https://urlin.us/2uSWMb
-If you want to access PDF files on your computer or mobile device, you need Adobe Reader X. With this software, you can not only open and view PDFs, but also fill out forms, sign documents, add annotations, and more. Adobe Reader X also offers some advanced features, such as converting PDFs to other file formats, password protecting PDFs, comparing PDFs, and integrating with cloud storage services.
-In this article, we will show you how to download Adobe Reader X for Windows and Mac, as well as how to troubleshoot some common installation issues. Follow the steps below and enjoy the benefits of Adobe Reader X.
- How to Download Adobe Reader X for Windows
-If you are using a Windows computer, here are the steps to download and install Adobe Reader X:
-
-- Check your system requirements. Before you download Adobe Reader X, make sure that your computer meets the minimum system requirements. You can find them on this page. You will need a Windows operating system (Windows Server or Windows XP/Vista/7/8/10), an Intel or AMD processor, at least 256 MB of RAM, at least 260 MB of hard disk space, a screen resolution of at least 1024 x 576 pixels, and an Internet browser (Internet Explorer or Firefox).
-- Go to the official Adobe website. Open your Internet browser and go to this page. This is where you can download Acrobat Reader for free.
-- Choose your language and version. On the download page, you will see a drop-down menu where you can select your language. You can also choose whether you want to download Acrobat Reader for Windows (32-bit or 64-bit) or Mac OS. Make sure you select the correct version for your system.
-- Click the Download button. After choosing your language and version, click the yellow Download button. You will see a pop-up window asking you to save the file. Choose a location on your computer where you want to save the file and click Save.
-- Run the installer and follow the instructions. Once the download is complete, locate the file on your computer and double-click it to run the installer. You will see a welcome screen where you can choose whether you want to install Acrobat Reader as a default PDF viewer or not. Click Next and follow the on-screen instructions to complete the installation. You may need to restart your computer to finish the installation.
-
-Congratulations, you have successfully downloaded and installed Adobe Reader X for Windows. You can now open and view any PDF file on your computer with this software.
-How to download adobe reader x for windows 10
-How to download adobe reader x offline installer
-How to download adobe reader x free version
-How to download adobe reader x for mac os
-How to download adobe reader x update
-How to download adobe reader x pro
-How to download adobe reader x for android
-How to download adobe reader x msi
-How to download adobe reader x 10.1.16
-How to download adobe reader x for chromebook
-How to download adobe reader x for linux
-How to download adobe reader x 64 bit
-How to download adobe reader x portable
-How to download adobe reader x full setup
-How to download adobe reader x without internet
-How to download adobe reader x for windows 7
-How to download adobe reader x for ipad
-How to download adobe reader x 10.0.0
-How to download adobe reader x from official website
-How to download adobe reader x with crack
-How to download adobe reader x for windows 8.1
-How to download adobe reader x for iphone
-How to download adobe reader x 10.1.4
-How to download adobe reader x in hindi
-How to download adobe reader x for windows xp
-How to download adobe reader x for kindle fire
-How to download adobe reader x 10.1.1
-How to download adobe reader x in tamil
-How to download adobe reader x for windows vista
-How to download adobe reader x for pc
-How to download adobe reader x 10.0.1
-How to download adobe reader x in urdu
-How to download adobe reader x for macbook air
-How to download adobe reader x for laptop
-How to download adobe reader x 10.1.3
-How to download adobe reader x in telugu
-How to download adobe reader x for macbook pro
-How to download adobe reader x for desktop
-How to download adobe reader x 10.0.2
-How to download adobe reader x in malayalam
-How to download adobe reader x for mac os catalina
-How to download adobe reader x for tablet
-How to download adobe reader x 10.1.2
-How to download adobe reader x in kannada
-How to download adobe reader x for mac os mojave
-How to download adobe reader x for chrome os
-How to download adobe reader x 10.0.3
-How to download adobe reader x in gujarati
- How to Download Adobe Reader X for Mac
-If you are using a Mac computer, here are the steps to download and install Adobe Reader X:
-
-- Check your system requirements. Before you download Adobe Reader X, make sure that your computer meets the minimum system requirements. You can find them on this page. You will need a Mac OS X operating system (version 10.5.8 or later), an Intel processor, at least 512 MB of RAM, at least 415 MB of hard disk space, a screen resolution of at least 1024 x 768 pixels, and an Internet browser (Safari or Firefox).
-- Go to the official Adobe website. Open your Internet browser and go to this page. This is where you can download Acrobat Reader for free.
-- Choose your language and version. On the download page, you will see a drop-down menu where you can select your language. You can also choose whether you want to download Acrobat Reader for Windows (32-bit or 64-bit) or Mac OS. Make sure you select the correct version for your system.
-- Click the Download button. After choosing your language and version, click the yellow Download button. You will see a pop-up window asking you to save the file. Choose a location on your computer where you want to save the file and click Save.
-- Open the DMG file and drag the icon to the Applications folder. Once the download is complete, locate the file on your computer and double-click it to open it. You will see a window with an icon of Adobe Reader X and a shortcut to the Applications folder. Drag the icon of Adobe Reader X to the Applications folder and drop it there. This will copy the software to your computer.
-
-Congratulations, you have successfully downloaded and installed Adobe Reader X for Mac. You can now open and view any PDF file on your computer with this software.
- How to Troubleshoot Adobe Reader X Installation Issues
-Sometimes, you may encounter some issues when installing or using Adobe Reader X. Here are some common issues and solutions that may help you fix them:
-Reinstall Adobe Reader X
-If Adobe Reader X does not work properly or crashes frequently, you may need to reinstall it. To do this, follow these steps:
-
-- Uninstall Adobe Reader X from your computer. You can do this by going to Control Panel > Programs > Programs and Features (for Windows) or by dragging the icon of Adobe Reader X from the Applications folder to the Trash (for Mac).
-- Delete any leftover files or folders related to Adobe Reader X from your computer. You can use a tool like CCleaner (for Windows) or AppCleaner (for Mac) to do this easily.
-- Download and install Adobe Reader X again from the official website following the steps above.
-
-This should fix any corrupted or missing files that may cause problems with Adobe Reader X.
-Disable Protected Mode at Startup
-If Adobe Reader X does not open or displays an error message when opening a PDF file, you may need to disable Protected Mode at Startup. This is a security feature that prevents malicious code from running on your computer, but it may also interfere with some PDF files or features. To disable Protected Mode at Startup, follow these steps:
-
-- Open Adobe Reader X on your computer.
-- Go to Edit > Preferences (for Windows) or Acrobat > Preferences (for Mac).
-- Select General from the left panel.
-- Uncheck the box that says Enable Protected Mode at Startup.
-- Click OK and restart Adobe Reader X.
-
-This should allow you to open any PDF file without errors or issues.
-Check for permission issues
-If Adobe Reader X does not save or print PDF files, you may need to check for permission issues. This means that you may not have enough access rights to modify or use certain files or folders on your computer. To check for permission issues, follow these steps:
- - Right-click on the PDF file or folder that you want to save or print.
-- Select Properties (for Windows) or Get Info (for Mac).
-- Go to the Security tab (for Windows) or the Sharing & Permissions section (for Mac).
-- Make sure that you have Full Control (for Windows) or Read & Write (for Mac) permissions for the file or folder.
-- If not, click the Edit button (for Windows) or the lock icon (for Mac) and change the permissions accordingly.
-- Click OK and try to save or print the PDF file again.
-
-This should resolve any permission issues that may prevent you from saving or printing PDF files.
-Repair Installation
-If Adobe Reader X does not launch or shows an error message when launching, you may need to repair the installation. This will fix any damaged or missing components that may affect the performance of Adobe Reader X. To repair the installation, follow these steps:
-
-- Go to Control Panel > Programs > Programs and Features (for Windows) or Applications > Utilities > Adobe Installers (for Mac).
-- Select Adobe Reader X from the list of programs and click the Change button (for Windows) or the Uninstall button (for Mac).
-- Choose the Repair option and click Next (for Windows) or Continue (for Mac).
-- Follow the on-screen instructions to complete the repair process.
-- Restart your computer and try to launch Adobe Reader X again.
-
-This should fix any errors or issues that may prevent Adobe Reader X from launching.
-Force open the files with Adobe Reader X
-If Adobe Reader X does not open PDF files by default, you may need to force open them with Adobe Reader X. This will make sure that Adobe Reader X is the default program for opening PDF files on your computer. To force open PDF files with Adobe Reader X, follow these steps:
-
-- Right-click on the PDF file that you want to open.
-- Select Open With > Choose Another App (for Windows) or Open With > Other... (for Mac).
-- Select Adobe Reader X from the list of programs and check the box that says Always use this app to open .pdf files (for Windows) or Always Open With (for Mac).
-- Click OK and open the PDF file with Adobe Reader X.
-
-This should make Adobe Reader X the default program for opening PDF files on your computer.
- Conclusion
-In this article, we have shown you how to download Adobe Reader X for Windows and Mac, as well as how to troubleshoot some common installation issues. Adobe Reader X is a free software that allows you to view, print, and comment on PDF files. It also offers some advanced features, such as converting PDFs to other file formats, password protecting PDFs, comparing PDFs, and integrating with cloud storage services. With Adobe Reader X, you can access any PDF file on your computer or mobile device with ease and convenience.
-If you want to learn more about Adobe Reader X, you can visit this page for more information and resources. You can also check out this page for some tips and tricks on how to use Adobe Reader X effectively. We hope you have enjoyed this article and found it helpful. Thank you for reading!
- FAQs
-What is the difference between Acrobat Reader and Acrobat Pro?
-Acrobat Reader is a free software that allows you to view, print, and comment on PDF files. Acrobat Pro is a paid software that allows you to create, edit, convert, sign, and share PDF files. Acrobat Pro also has more features and tools than Acrobat Reader, such as OCR, redaction, optimization, accessibility, and collaboration.
-How can I update Adobe Reader X to the latest version?
-You can update Adobe Reader X to the latest version by following these steps:
-
-- Open Adobe Reader X on your computer.
-- Go to Help > Check for Updates.
-- If there are any updates available, click the Download button and follow the instructions.
-- Restart your computer and enjoy the latest version of Adobe Reader X.
-
-You can also enable automatic updates by going to Edit > Preferences > Updater and selecting Automatically install updates.
-How can I open a password-protected PDF with Adobe Reader X?
-You can open a password-protected PDF with Adobe Reader X by following these steps:
-
-- Double-click on the PDF file that you want to open.
-- Enter the password that was set by the creator of the PDF file.
-- Click OK and view the PDF file with Adobe Reader X.
-
-If you do not know the password, you will not be able to open the PDF file. You will need to contact the creator of the PDF file and ask for the password.
-How can I annotate PDFs with Adobe Reader X?
-You can annotate PDFs with Adobe Reader X by following these steps:
-
-- Open the PDF file that you want to annotate with Adobe Reader X.
-- Go to View > Tools > Comment and click the Open button.
-- Select the annotation tool that you want to use from the toolbar. You can choose from different types of annotations, such as highlight, underline, strikeout, sticky note, text box, stamp, and more.
-- Click on the PDF file where you want to add the annotation and adjust it as needed.
-- You can also edit, delete, or reply to your annotations by right-clicking on them and choosing the appropriate option.
-
-Your annotations will be saved with the PDF file and can be viewed by anyone who opens it with Adobe Reader X or any other PDF viewer.
-How can I access my PDFs from anywhere with Adobe Reader X?
-You can access your PDFs from anywhere with Adobe Reader X by following these steps:
-
-- Create a free account on Adobe Document Cloud, a cloud storage service that allows you to store and access your PDF files online.
-- Upload your PDF files to Adobe Document Cloud by going to File > Save As > Adobe Document Cloud or by dragging and dropping them to the Adobe Document Cloud window.
-- Sign in to your Adobe Document Cloud account on any device that has Adobe Reader X installed or on any web browser that supports PDF viewing.
-- Open and view your PDF files from Adobe Document Cloud with Adobe Reader X or any other PDF viewer.
-
-You can also share your PDF files with others, edit them online, or convert them to other file formats with Adobe Document Cloud.
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/CarX Street APK for PC How to Play the Stunning Racing Game on Your Laptop or Desktop.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/CarX Street APK for PC How to Play the Stunning Racing Game on Your Laptop or Desktop.md
deleted file mode 100644
index 9f811fa3e61513ff64d97f0ebf2389884088d1a0..0000000000000000000000000000000000000000
--- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/CarX Street APK for PC How to Play the Stunning Racing Game on Your Laptop or Desktop.md
+++ /dev/null
@@ -1,131 +0,0 @@
-
-How to Download and Play CarX Street on PC
-CarX Street is a racing game developed by CarX Technologies, LLC. It is an open-world street racer that lets you explore the large city and its surroundings, from busy city streets to spiral mountain roads and mesmerizing coastal highways. You can race to collect legendary racing cars and display them in your garage, or challenge other players in real network races. You can also build the car of your dreams using part tuning that unlocks all the physics of CarX Technology car behavior.
-If you are a fan of racing games, you might want to play CarX Street on your PC instead of your mobile device. Playing on PC has many advantages, such as a larger screen, better graphics, smoother performance, and more comfortable controls. In this article, we will show you how to download and install CarX Street on your PC using different emulators. We will also give you some tips and tricks to help you enjoy the game more.
-carx street apk for pc
Download ===> https://urlin.us/2uSS96
- What is CarX Street?
-CarX Street is a simulation racing video game that offers realistic car physics and high-speed drifting. The game also features different map types from around the world, and players can choose from several different game modes. Players can compete against other players, or participate in races and events.
- Features of CarX Street
-Some of the features of CarX Street are:
-
-- Open world: You can get on your vehicle and explore the entire virtual world. You can find hidden spots, shortcuts, and secrets.
-- Free to play: You can download and play CarX Street for free. You can also earn in-game currency by completing tasks and challenges.
-- Buying gas: You need to fuel up your car with the right gas for the next race at city gas stations. Different types of gas have different effects on your car's performance.
-- Houses and garages: You can buy houses for your cars and assemble collections for every race mode. You can also customize your garage with various decorations.
-- In-game shop: You can buy over 50 official vehicles from the best automakers in the world. You can also buy parts, accessories, paints, stickers, and more.
-- Many types of vehicles: You can choose from different types of vehicles, such as sports cars, muscle cars, supercars, hypercars, SUVs, trucks, and more.
-- Car customization: You can customize your car with a detailed car-building system. You can swap parts and trick out your car for a specific race. You can also upgrade the engine, transmission, body, suspension, and tires.
-- In-game free currency: You can earn free currency by watching ads, completing tasks, or participating in events. You can use the free currency to buy items or unlock features.
-
- Benefits of playing CarX Street on PC
-Playing CarX Street on PC has many benefits, such as:
-
-- Larger screen: You can enjoy the stunning graphics and details of the game on a bigger screen. You can also see more of the map and the surroundings.
-- Better graphics: You can adjust the graphics settings to suit your PC's specifications. You can also experience higher resolution, frame rate, and quality.
-- Smoother performance: You can avoid lagging, crashing, or overheating issues that might occur on mobile devices. You can also save battery life and storage space.
-- More comfortable controls: You can use your keyboard and mouse to control your car more easily and precisely. You can also customize your key mapping according to your preference.
-
- How to download How to download and install CarX Street on PC
-
If you want to play CarX Street on your PC, you will need to use an Android emulator. An emulator is a software that mimics the Android operating system on your computer, allowing you to run Android apps and games. There are many emulators available, but we will show you how to use three of the most popular ones: BlueStacks, NoxPlayer, and LDPlayer.
- Using BlueStacks emulator
-BlueStacks is one of the most widely used Android emulators, with over 500 million users worldwide. It is compatible with both Windows and Mac operating systems, and it has a user-friendly interface and advanced features. Here are the steps to download and install CarX Street on PC using BlueStacks:
-
-- Download and install BlueStacks on your PC from [1](https://www.bluestacks.com/).
-- Complete Google sign-in to access the Play Store, or do it later.
-- Look for CarX Street in the search bar at the top right corner.
-- Click to install CarX Street from the search results.
-- Complete Google sign-in (if you skipped step 2) to install CarX Street.
-- Click the CarX Street icon on the home screen to start playing.
-
- Using NoxPlayer emulator
-NoxPlayer is another popular Android emulator, with over 150 million users worldwide. It is also compatible with both Windows and Mac operating systems, and it has a simple and fast interface and performance. Here are the steps to download and install CarX Street on PC using NoxPlayer:
-
-- Download and install NoxPlayer on your PC from [5](https://www.bignox.com/).
-- Run the installation package and complete the installation.
-- Open NoxPlayer and search for CarX Street in the Google Play Store.
-- Install the game and launch it to start playing.
-
- Using LDPlayer emulator
-LDPlayer is a newer Android emulator, but it has gained popularity among gamers for its high performance and compatibility. It is also compatible with both Windows and Mac operating systems, and it has a smooth and stable interface and features. Here are the steps to download and install CarX Street on PC using LDPlayer:
-carx street racing game download for pc
-carx street mod apk for pc
-carx street pc emulator
-carx street android game on pc
-carx street free download for pc
-carx street pc version
-carx street pc requirements
-carx street pc gameplay
-carx street pc online
-carx street pc windows 10
-carx street pc bluestacks
-carx street pc noxplayer
-carx street pc ldplayer
-carx street pc steam
-carx street pc review
-carx street pc cheats
-carx street pc hack
-carx street pc controller support
-carx street pc graphics settings
-carx street pc best cars
-carx street pc tips and tricks
-carx street pc update
-carx street pc release date
-carx street pc beta test
-carx street pc download size
-carx street apk for windows 7
-carx street apk for windows 8.1
-carx street apk for macbook
-carx street apk for laptop
-carx street apk for desktop
-carx street apk for chromebook
-carx street apk for linux
-carx street apk for ubuntu
-carx street apk for mac os x
-carx street apk for windows xp
-how to install carx street apk on pc
-how to play carx street apk on pc
-how to run carx street apk on pc
-how to download carx street apk on pc
-how to update carx street apk on pc
-how to uninstall carx street apk on pc
-how to transfer carx street apk from android to pc
-how to sync carx street apk between android and pc
-how to fix carx street apk not working on pc
-how to get unlimited coins in carx street apk on pc
-how to customize cars in carx street apk on pc
-how to change language in carx street apk on pc
-how to connect facebook in carx street apk on pc
-how to record gameplay of carx street apk on pc
-
-- Download and install LDPlayer on your PC from [6](https://www.ldplayer.net/).
-- Open LDPlayer and search for CarX Street in the LD Store or Google Play Store.
-- Install the game and launch it to start playing.
-
- Tips and tricks for CarX Street
-Now that you know how to play CarX Street on your PC, you might want some tips and tricks to help you improve your skills and enjoy the game more. Here are some of them:
- Follow the tutorial
-The game has a tutorial that will teach you the basics of driving, racing, drifting, tuning, and more. It is highly recommended that you follow the tutorial before jumping into the action, as it will help you get familiar with the game mechanics and controls. You can also revisit the tutorial anytime from the settings menu if you need a refresher.
- Roam through the city for more rewards
-The game has an open world that you can explore at your own pace. You can find hidden spots, shortcuts, secrets, and rewards by roaming through the city. You can also encounter random events, challenges, and races that will give you more money, reputation, or items. Roaming through the city is also a good way to practice your driving skills and test your car's performance.
- Take part in sprints and clubs
-The game has two main modes: sprints and clubs. Sprints are short races that last under a minute, where you have to reach the finish line as fast as possible. Clubs are longer, story-driven competitions where you have to join a club, defeat its boss, and prove yourself as the best driver in the city. Both modes offer different rewards and challenges, so try them both out and see which one suits your style more.
- Go for the best cars and customize them
-The game has over 50 official vehicles from the best automakers in the world. You can buy them with in-game currency or real money, or earn them by completing tasks or events. You can also customize your car with a detailed car-building system that lets you swap parts, upgrade components, paint colors, add stickers, and more. You can also customize your garage with various decorations and display your car collection. Go for the best cars and make them your own.
- Conclusion
-CarX Street is a fun and realistic racing game that lets you experience the thrill of street racing. You can explore the open world, collect and customize your cars, and compete with other players. You can also play CarX Street on your PC using an Android emulator, which will give you many benefits such as a larger screen, better graphics, smoother performance, and more comfortable controls. If you are looking for a racing game that will keep you entertained and challenged, you should give CarX Street a try.
- FAQs
-Here are some frequently asked questions about CarX Street:
-
-- Q: How do I drift in CarX Street?
-- A: Drifting is an essential skill in CarX Street, as it will help you take corners faster and earn more points. To drift, you need to press the brake button while turning the steering wheel. You can also use the handbrake button to initiate a drift. You can adjust the sensitivity and angle of the steering wheel in the settings menu.
-- Q: How do I get more money in CarX Street?
-- A: Money is the main currency in CarX Street, which you can use to buy cars, parts, gas, and more. You can earn money by completing races, events, tasks, or challenges. You can also watch ads or use real money to get more money.
-- Q: How do I join a club in CarX Street?
-- A: Clubs are groups of racers that compete for territory and reputation in the city. You can join a club by completing its entry race and defeating its boss. You can also create your own club or join an existing one from the club menu.
-- Q: How do I upgrade my car in CarX Street?
-- A: You can upgrade your car by buying and installing new parts from the shop or the garage. You can also tune your car by adjusting the engine, transmission, body, suspension, and tires parameters. Upgrading and tuning your car will improve its performance and handling.
-- Q: How do I play with friends in CarX Street?
-- A: You can play with friends in CarX Street by inviting them to join your club or your race. You can also chat with them using the in-game chat feature or voice chat feature. You can also add friends from the social menu or search for them by their nickname or ID.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/CapCut Edit Videos like a Pro with TikToks Official Video Editor and Video Maker - Free Download.md b/spaces/1phancelerku/anime-remove-background/CapCut Edit Videos like a Pro with TikToks Official Video Editor and Video Maker - Free Download.md
deleted file mode 100644
index fb2bee50608773153ef1ef44f8b4e233e3036e4e..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/CapCut Edit Videos like a Pro with TikToks Official Video Editor and Video Maker - Free Download.md
+++ /dev/null
@@ -1,93 +0,0 @@
-
-How to Download and Use CapCut Video Editor for TikTok
- TikTok is one of the most popular social media platforms for creating and sharing short videos. Whether you want to make funny, educational, or inspirational videos, you need a good video editor to make them stand out. In this article, we will show you how to download and use CapCut, the official video editor and maker app for TikTok.
- What is CapCut?
- CapCut is a free video editor and maker app that is compatible with TikTok. It is developed by ByteDance, the same company that owns TikTok. CapCut allows you to edit videos on your mobile device with ease and fun. You can also use it to create videos for other social media platforms, such as YouTube, Instagram, Facebook, and WhatsApp.
-download capcut video editor for tiktok
DOWNLOAD »»» https://jinyurl.com/2uNMjj
- CapCut is a free video editor and maker app for TikTok
- CapCut has everything you need to create stunning, high-quality videos. You can import your own videos and photos or record new ones in the app. You can also access a massive music library and exclusive TikTok songs. You can extract audio from videos or add your own voice-overs. You can also use AI tools to enhance your videos, such as auto captions, background removal, text-to-speech, motion tracking, and more.
- CapCut offers basic and advanced editing features
- CapCut has a user-friendly interface that lets you edit videos with simple gestures. You can trim, cut, merge, split, reverse, speed up, slow down, zoom in, zoom out, freeze, and animate your clips. You can also add text, stickers, filters, effects, transitions, and colors to your videos. You can use keyframe animation to customize every setting. You can also use chroma key to remove specific colors from videos. You can apply picture-in-picture (PIP) feature to add video and photo layers above the clip. You can also use the stabilizing feature to keep video footage steady.
- CapCut supports direct exports to TikTok and other social media platforms
- CapCut lets you export your videos in custom resolutions and formats. You can export your videos in HD quality and support 4K 60fps exports and smart HDR. You can also adjust the format and share your creativity on TikTok and other social media platforms with one tap.
- How to Download CapCut for Android and iOS
- Downloading CapCut is easy and fast. Here are the steps to download CapCut for Android and iOS devices.
- Download CapCut from Google Play Store or Apple App Store
- You can download CapCut for free from Google Play Store or Apple App Store. Just search for "CapCut" in the store and tap Install or Get. The app size is about 100 MB.
- Open CapCut and tap New Project to start editing
- Once you have downloaded CapCut, open it on your device. You don't need a TikTok account or any other type of account to use CapCut. You can start editing right away by tapping New Project on the home screen.
- Select a video or photos to edit and tap Add
- You can select a video or photos from your device gallery or record a new one in the app. You can also use the search feature to find videos and photos online. You can select multiple files and tap Add to import them to your project. You can also rearrange, delete, or duplicate the clips in your timeline.
-How to download capcut video editor for tiktok on android
-Download capcut video editor for tiktok apk free
-Best capcut video editor for tiktok tutorials and tips
-Download capcut video editor for tiktok for pc windows 10
-Capcut video editor for tiktok review and features
-Download capcut video editor for tiktok mod apk
-Capcut video editor for tiktok vs inshot comparison
-Download capcut video editor for tiktok pro version
-Capcut video editor for tiktok online without download
-Download capcut video editor for tiktok ios iphone ipad
-Capcut video editor for tiktok alternatives and similar apps
-Download capcut video editor for tiktok macbook laptop
-Capcut video editor for tiktok filters and effects guide
-Download capcut video editor for tiktok latest version update
-Capcut video editor for tiktok transitions and stickers tutorial
-Download capcut video editor for tiktok no watermark
-Capcut video editor for tiktok music and sound effects library
-Download capcut video editor for tiktok premium unlocked
-Capcut video editor for tiktok speed and reverse options
-Download capcut video editor for tiktok cracked full version
-Capcut video editor for tiktok crop and rotate tools
-Download capcut video editor for tiktok from google play store
-Capcut video editor for tiktok split and merge videos function
-Download capcut video editor for tiktok from official website
-Capcut video editor for tiktok text and font styles customization
-Download capcut video editor for tiktok with bluestacks emulator
-Capcut video editor for tiktok voice changer and dubbing feature
-Download capcut video editor for tiktok without ads or subscription
-Capcut video editor for tiktok chroma key and green screen effect
-Download capcut video editor for tiktok with qr code scanner
-Capcut video editor for tiktok slideshow and collage maker mode
-Download capcut video editor for tiktok old version apk file
-Capcut video editor for tiktok cutout and background changer tool
-Download capcut video editor for tiktok on amazon fire tablet
-Capcut video editor for tiktok gif and meme generator option
-Download capcut video editor for tiktok on chromebook device
-Capcut video editor for tiktok face swap and beauty filter feature
-Download capcut video editor for tiktok on linux operating system
-Capcut video editor for tiktok animation and drawing effect mode
-Download capcut video editor for tiktok on smart tv or roku device
- How to Use CapCut to Edit Videos for TikTok
- Editing videos with CapCut is fun and easy. Here are some tips on how to use CapCut to edit videos for TikTok.
- Use the editing tools to trim, crop, reverse, speed up, and animate your clips
- You can use the editing tools at the bottom of the screen to adjust your clips. You can tap Trim to cut out unwanted parts of your video. You can tap Crop to change the aspect ratio and zoom in or out of your video. You can tap Reverse to play your video backwards. You can tap Speed to change the playback speed of your video. You can tap Animate to add motion effects to your video.
- Add text, stickers, filters, effects, and music to your videos
- You can add text, stickers, filters, effects, and music to your videos by tapping the icons on the right side of the screen. You can tap Text to add captions, titles, or subtitles to your video. You can tap Sticker to add emojis, icons, or images to your video. You can tap Filter to apply different color presets to your video. You can tap Effect to add various visual effects to your video. You can tap Music to add songs, sound effects, or voice-overs to your video.
- Use the templates and styles to enhance your videos
- You can use the templates and styles to enhance your videos by tapping the icons on the left side of the screen. You can tap Template to apply pre-made themes and layouts to your video. You can tap Style to apply different artistic styles and filters to your video.
- Tap Export to save and share your videos
- When you are done editing your video, you can tap Export at the top right corner of the screen. You can choose the resolution, format, and quality of your video. You can also enable watermark removal if you want. Then you can tap Save or Share to save your video to your device or share it directly on TikTok or other social media platforms.
- Benefits of Using CapCut for TikTok Videos
- Using CapCut for TikTok videos has many benefits. Here are some of them.
- CapCut is easy to use and versatile
- CapCut is designed for beginners and professionals alike. It has a simple and intuitive interface that lets you edit videos with ease and fun. It also has a lot of features and options that let you customize your videos according to your preferences and needs.
- CapCut has a large library of sounds and animations
- CapCut has a large library of sounds and animations that you can use for free. You can access thousands of songs and sound effects that are updated regularly. You can also use exclusive TikTok songs that are popular and trending. You can also use hundreds of animations that are dynamic and creative.
- CapCut can create stunning, high-quality videos
- CapCut can create stunning, high-quality videos that will impress your audience. You can export your videos in HD quality and support 4K 60fps exports and smart HDR. You can also use AI tools that will enhance your videos automatically.
- Conclusion
- CapCut is a free video editor and maker app for TikTok that you can download and use on your Android or iOS device. It has everything you need to create stunning, high-quality videos with ease and fun. You can also use it to create videos for other social media platforms, such as YouTube, Instagram, Facebook, and WhatsApp. If you want to make amazing TikTok videos, download CapCut today!
- Frequently Asked Questions
- Is CapCut safe?
-Yes, CapCut is safe and secure. It does not contain any viruses or malware. It also does not collect any personal information from users.
-Is CapCut free?
-Yes, CapCut is free and does not have any hidden fees or charges. It also does not have any annoying ads or watermarks.
-How do I update CapCut?
-You can update CapCut by going to the Google Play Store or the Apple App Store and tapping Update. You can also enable automatic updates in your device settings.
-How do I delete CapCut?
-You can delete CapCut by going to your device settings and tapping Apps or Applications. Then you can find CapCut and tap Uninstall or Delete. You can also delete CapCut by long-pressing the app icon and tapping Remove or Delete.
-How do I contact CapCut support?
-You can contact CapCut support by going to the app settings and tapping Feedback or Help. You can also email them at capcut.support@bytedance.com or visit their website at https://www.capcut.net/.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/2023Liu2023/bingo/Dockerfile b/spaces/2023Liu2023/bingo/Dockerfile
deleted file mode 100644
index 3aa2b29b5fc4fa8b8238955acd7f1fde13ce5e1a..0000000000000000000000000000000000000000
--- a/spaces/2023Liu2023/bingo/Dockerfile
+++ /dev/null
@@ -1,36 +0,0 @@
-FROM node:18
-
-
-ARG DEBIAN_FRONTEND=noninteractive
-
-ENV BING_HEADER ""
-
-# Set home to the user's home directory
-ENV HOME=/home/user \
- PATH=/home/user/.local/bin:$PATH
-
-# Set up a new user named "user" with user ID 1000
-RUN useradd -o -u 1000 user && mkdir -p $HOME/app && chown -R user $HOME
-
-# Switch to the "user" user
-USER user
-
-# Set the working directory to the user's home directory
-WORKDIR $HOME/app
-
-# Install app dependencies
-# A wildcard is used to ensure both package.json AND package-lock.json are copied
-# where available (npm@5+)
-COPY --chown=user package*.json $HOME/app/
-
-RUN npm install
-
-# Copy the current directory contents into the container at $HOME/app setting the owner to the user
-COPY --chown=user . $HOME/app/
-
-RUN npm run build
-
-ENV PORT 7860
-EXPOSE 7860
-
-CMD npm start
diff --git a/spaces/2023Liu2023/bingo/src/app/page.tsx b/spaces/2023Liu2023/bingo/src/app/page.tsx
deleted file mode 100644
index 0dff3431b098ce4fe282cc83fc87a93a28a43090..0000000000000000000000000000000000000000
--- a/spaces/2023Liu2023/bingo/src/app/page.tsx
+++ /dev/null
@@ -1,15 +0,0 @@
-import dynamic from 'next/dynamic'
-
-const DynamicComponentWithNoSSR = dynamic(
- () => import('../components/chat'),
- { ssr: false }
-)
-
-export default function IndexPage() {
- return (
- <>
-
-
-
- )
-}
diff --git a/spaces/2023Liu2023/bingo/src/components/chat.tsx b/spaces/2023Liu2023/bingo/src/components/chat.tsx
deleted file mode 100644
index a37ab1cc96ca2e6bfd9acbe313a8d946bfd5c3d4..0000000000000000000000000000000000000000
--- a/spaces/2023Liu2023/bingo/src/components/chat.tsx
+++ /dev/null
@@ -1,93 +0,0 @@
-'use client'
-
-import { useCallback, useEffect, useMemo, useState } from 'react'
-import { useAtom } from 'jotai'
-import Image from 'next/image'
-import { cn } from '@/lib/utils'
-import { ChatList } from '@/components/chat-list'
-import { ChatPanel } from '@/components/chat-panel'
-import { WelcomeScreen } from '@/components/welcome-screen'
-import { ChatScrollAnchor } from '@/components/chat-scroll-anchor'
-import { ToneSelector } from './tone-selector'
-import { ChatHeader } from './chat-header'
-import { ChatSuggestions } from './chat-suggestions'
-import { bingConversationStyleAtom } from '@/state'
-import { ButtonScrollToBottom } from '@/components/button-scroll-to-bottom'
-import StopIcon from '@/assets/images/stop.svg'
-import { useBing } from '@/lib/hooks/use-bing'
-import { ChatMessageModel } from '@/lib/bots/bing/types'
-import { ChatNotification } from './chat-notification'
-import { Settings } from './settings'
-import { ChatHistory } from './chat-history'
-
-export type ChatProps = React.ComponentProps<'div'> & { initialMessages?: ChatMessageModel[] }
-
-export default function Chat({ className }: ChatProps) {
-
- const [bingStyle, setBingStyle] = useAtom(bingConversationStyleAtom)
- const {
- messages,
- sendMessage,
- resetConversation,
- stopGenerating,
- setInput,
- bot,
- input,
- generating,
- isSpeaking,
- uploadImage,
- attachmentList,
- setAttachmentList,
- } = useBing()
-
- useEffect(() => {
- window.scrollTo({
- top: document.body.offsetHeight,
- behavior: 'smooth'
- })
- }, [])
-
- return (
-
-
-
-
-
-
- {messages.length ? (
- <>
-
-
-
-
-
- {generating ? (
-
-
-
- ) : null}
-
- ) : null}
-
-
-
-
-

-
-

-
-

-
-Cómo descargar y usar m.hollywoodbets.net
-Si usted está buscando una manera conveniente y rápida de apostar en deportes, carreras de caballos, juegos de casino, y más, es posible que desee descargar y utilizar m.hollywoodbets.net. Esta es la versión móvil de Hollywoodbets, una de las plataformas de apuestas en línea más populares en Sudáfrica. En este artículo, le mostraremos lo que es m.hollywoodbets.net, por qué debe descargarlo, cómo descargarlo, cómo usarlo y cómo resolver algunos problemas comunes con él.
-descarga de la red m.hollywoodbets.net
Download ► https://bltlly.com/2v6JvX
- ¿Qué es m.hollywoodbets.net?
-m.hollywoodbets.net es el sitio móvil de Hollywoodbets, un operador de apuestas con licencia que ofrece una amplia gama de opciones de apuestas en varios deportes y eventos. Puedes apostar en fútbol, rugby, cricket, tenis, golf, baloncesto, etc. También puedes apostar en carreras de caballos desde Sudáfrica y otros países. Además, puedes jugar juegos de casino, tragamonedas, números de la suerte, betgames, juegos en vivo y más. Puede acceder a todas estas funciones desde su dispositivo móvil usando m.hollywoodbets.net.
- ¿Por qué descargar m.hollywoodbets.net?
-Hay muchos beneficios de descargar y usar m.hollywoodbets.net. Estos son algunos de ellos:
-
-- Conveniencia: Puedes apostar en cualquier momento y en cualquier lugar usando tu dispositivo móvil. No necesita un ordenador o un navegador para acceder al sitio. Simplemente puede tocar el icono de la aplicación y comenzar a apostar.
-- Velocidad: El sitio móvil está optimizado para una carga rápida y un rendimiento suave. Usted puede hacer sus apuestas rápida y fácilmente sin ningún tipo de retrasos o fallos.
-- Acceso sin datos: Puedes acceder al sitio móvil sin usar ningún dato. Hollywoodbets se ha asociado con varios proveedores de red para ofrecer acceso sin datos a sus clientes. Puede comprobar si su proveedor de red es compatible visitando [1](https://sport.hollywoodbets.net/).
-
-
- ¿Cómo descargar m.hollywoodbets.net?
-Si tienes un dispositivo Android, puedes descargar e instalar la aplicación para m.hollywoodbets.net siguiendo estos pasos:
-
-- Visite [1](https://sport.hollywoodbets.net/) desde su navegador móvil e inicie sesión en su cuenta. Si aún no tiene una cuenta, puede registrarla haciendo clic en "Unirse ahora".
-- Desplácese hacia abajo a la parte inferior de la página y haga clic en "Aplicación para teléfono de características básicas". Esto lo redirigirá a un sitio donde puede descargar la aplicación.
-- Haga clic en "Descargar aplicación Android" y esperar a que la descarga se complete.
-- Vaya a la configuración de seguridad y permita la instalación desde fuentes desconocidas.
-- Abra el archivo descargado e instale la aplicación en su dispositivo.
-
-Tenga en cuenta que no hay una aplicación oficial para dispositivos iOS, por lo que tendrá que utilizar la versión del navegador móvil si tiene un iPhone o iPad.
- ¿Cómo usar m.hollywoodbets.net?
-Usar m.hollywoodbets.net es fácil y simple. Estos son algunos pasos básicos para empezar:
-
-
-- Inicie sesión en su cuenta usando su nombre de usuario y contraseña. Si olvidó su contraseña, puede restablecerla haciendo clic en "Olvidé la contraseña".
-- Elija la categoría de apuestas que desea hacer, como deportes, carreras de caballos, casino, etc. Puede utilizar el icono del menú en la esquina superior izquierda para navegar entre diferentes categorías.
-- Selecciona el evento o juego en el que quieres apostar. Puedes usar la barra de búsqueda o los filtros para encontrar lo que buscas.
-- Elija el mercado y las probabilidades en las que desea apostar. Puede pulsar en las probabilidades para agregarlas a su boleto de apuesta.
-- Introduzca la cantidad que desea apostar y confirme su apuesta. También puede usar la función "Quick Bet" para realizar su apuesta más rápido.
-- Revise su historial de apuestas y balance haciendo clic en "Mi cuenta". También puede ver sus apuestas pendientes, apuestas liquidadas y apuestas abiertas.
-
-
-Para depositar y retirar dinero usando m.hollywoodbets.net, necesita tener una cuenta verificada y una cuenta bancaria o tarjeta válida. Estos son algunos métodos que puedes usar:
-
-| Método | Depósito | Retiro |
|---|
-| Transferencia bancaria | Sí | Sí |
-| Tarjeta de crédito/débito | Sí | No |
-| EFT | Sí | No |
-| Ozow | Sí | No |
-| Peach Payments | Sí | No |
-| Zapper | Sí | No |
-| Voucher | Sí | No |
-| Ramas de Hollywoodbets | Sí | Sí |
-| Tarjeta de cajero automático Hollywoodbets | No | Sí |
-| Hollywoodbets eWallet (FNB) | No | Sí |
-| Hollywoodbets Instant Money (Standard Bank) | No | Sí |
-| Envío de efectivo de Hollywoodbets (Absa) | No | Sí |
-| Hollywoodbets Cash Send Plus (Nedbank) | No | Sí |
-
-Para hacer un depósito, puedes seguir estos pasos:
-
-- Inicie sesión en su cuenta y haga clic en "Depositar".
-- Seleccione el método que desea utilizar e introduzca la cantidad que desea depositar.
-- Siga las instrucciones en la pantalla para completar la transacción.
-- Espera el mensaje de confirmación y comprueba tu saldo.
-
-Para realizar un retiro, puedes seguir estos pasos:
-
-- Inicie sesión en su cuenta y haga clic en "Retirar".
-- Seleccione el método que desea utilizar e introduzca la cantidad que desea retirar.
-- Introduzca los datos de su cuenta bancaria o tarjeta si es necesario.
-- Confirme su solicitud y espere la aprobación.
-- Revise su cuenta bancaria o extracto de la tarjeta para los fondos.
-
- ¿Cómo contactar a atención al cliente usando m.hollywoodbets.net?
-
-
-- Live Chat: Puede utilizar la función de chat en vivo en el sitio móvil para chatear con un agente amigable y útil. Puede acceder al chat en vivo haciendo clic en el icono "Ayuda" en la esquina inferior derecha de la pantalla.
-- Correo electrónico: Puede enviar un correo electrónico a [email protected] o [email protected] y esperar una respuesta en 24 horas.
-- Teléfono: Puede llamar al número gratuito 08600 42387 o al número alternativo 087 353 7634 y hablar con un representante.
-- Redes sociales: Puedes seguir a Hollywoodbets en Facebook, Twitter, Instagram, YouTube y Telegram y enviarles un mensaje o comentario en sus publicaciones.
-
- Problemas comunes con m.hollywoodbets.net y cómo resolverlos
-Mientras m.hollywoodbets.net está diseñado para proporcionar una experiencia de apuestas sin problemas y sin problemas, es posible que encuentre algunos problemas con él de vez en cuando. Estos son algunos de los problemas comunes y cómo resolverlos:
-
-- Errores de inicio de sesión: Si no puede iniciar sesión en su cuenta, es posible que haya introducido el nombre de usuario o contraseña incorrectos, o que su cuenta esté bloqueada debido a inactividad o razones de seguridad. Para resolver este problema, puede intentar restablecer su contraseña haciendo clic en "Olvidé la contraseña", o ponerse en contacto con el servicio de atención al cliente para desbloquear su cuenta.
-- Inactividad de la cuenta: Si no ha utilizado su cuenta durante más de 90 días, puede desactivarse debido a la inactividad. Para reactivar su cuenta, debe ponerse en contacto con el servicio de atención al cliente y proporcionarle sus documentos FICA (prueba de identidad y dirección).
-
-- FICA verification: FICA significa Financial Intelligence Centre Act, que es una ley que requiere que todos los operadores de apuestas verifiquen la identidad y la dirección de sus clientes. Para cumplir con esta ley, debe presentar sus documentos FICA (prueba de identidad y dirección) cuando registre una cuenta o realice un retiro. Puede subir sus documentos en línea haciendo clic en "Mi cuenta" y "FICA", o enviarlos por correo electrónico a [email protected]
-
- Conclusión
-m.hollywoodbets.net es una gran manera de disfrutar de las apuestas en línea en su dispositivo móvil. Puede descargarlo y usarlo fácilmente y acceder a una variedad de opciones de apuestas, promociones y características. También puede depositar y retirar dinero de forma segura y ponerse en contacto con el servicio de atención al cliente convenientemente. Si encuentra algún problema con el sitio móvil, puede seguir los consejos anteriores o comunicarse con el servicio de atención al cliente para obtener ayuda. Entonces, ¿qué estás esperando? Descargar m.hollywoodbets.net hoy y empezar a apostar!
- Preguntas frecuentes
-¿Es m.hollywoodbets.net seguro y legal?
-Sí, m.hollywoodbets.net es seguro y legal. Hollywoodbets está autorizado por el Western Cape Gambling and Racing Board y se adhiere a estrictas normas de seguridad. Todas las transacciones están encriptadas y protegidas por la tecnología SSL. Toda la información personal se mantiene confidencial y no se comparte con terceros.
- ¿Cuáles son las apuestas mínimas y máximas en m.hollywoodbets.net? La apuesta mínima en m.hollywoodbets.net es R1, mientras que la apuesta máxima depende del evento y el mercado en el que esté apostando. Puede comprobar la apuesta máxima haciendo clic en "Max Bet" en su boleto de apuesta.
- ¿Cómo puedo obtener apuestas gratis en m.hollywoodbets.net?
-
Hay varias formas de obtener apuestas gratis en m.hollywoodbets.net. Algunas de ellas son:
-
-- Registrar una nueva cuenta y obtener un bono de registro R25.
-- Referir a un amigo y obtener un bono R50 por cada referencia exitosa.
-
-- Uso de vales que puede comprar en los minoristas seleccionados o recibir de atención al cliente.
-
- ¿Cómo puedo comprobar los resultados de mis apuestas en m.hollywoodbets.net?
-Puede comprobar los resultados de sus apuestas en m.hollywoodbets.net haciendo clic en "Mi cuenta" y "Historial de apuestas". También puede utilizar la función "Resultados" en el sitio móvil para comprobar los resultados de varios eventos y juegos.
- ¿Cómo puedo actualizar mis datos personales en m.hollywoodbets.net?
-Puede actualizar sus datos personales en m.hollywoodbets.net haciendo clic en "Mi cuenta" y "Datos personales". Puede cambiar su contraseña, dirección de correo electrónico, número de teléfono y pregunta de seguridad. Sin embargo, no puede cambiar su nombre, apellido, fecha de nacimiento o número de identificación. Si necesita cambiar estos datos, debe ponerse en contacto con el servicio de atención al cliente y proporcionarle una prueba de identidad.
64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/dateutil/zoneinfo/rebuild.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/dateutil/zoneinfo/rebuild.py
deleted file mode 100644
index 684c6586f091350c347f2b6150935f5214ffec27..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/dateutil/zoneinfo/rebuild.py
+++ /dev/null
@@ -1,75 +0,0 @@
-import logging
-import os
-import tempfile
-import shutil
-import json
-from subprocess import check_call, check_output
-from tarfile import TarFile
-
-from dateutil.zoneinfo import METADATA_FN, ZONEFILENAME
-
-
-def rebuild(filename, tag=None, format="gz", zonegroups=[], metadata=None):
- """Rebuild the internal timezone info in dateutil/zoneinfo/zoneinfo*tar*
-
- filename is the timezone tarball from ``ftp.iana.org/tz``.
-
- """
- tmpdir = tempfile.mkdtemp()
- zonedir = os.path.join(tmpdir, "zoneinfo")
- moduledir = os.path.dirname(__file__)
- try:
- with TarFile.open(filename) as tf:
- for name in zonegroups:
- tf.extract(name, tmpdir)
- filepaths = [os.path.join(tmpdir, n) for n in zonegroups]
-
- _run_zic(zonedir, filepaths)
-
- # write metadata file
- with open(os.path.join(zonedir, METADATA_FN), 'w') as f:
- json.dump(metadata, f, indent=4, sort_keys=True)
- target = os.path.join(moduledir, ZONEFILENAME)
- with TarFile.open(target, "w:%s" % format) as tf:
- for entry in os.listdir(zonedir):
- entrypath = os.path.join(zonedir, entry)
- tf.add(entrypath, entry)
- finally:
- shutil.rmtree(tmpdir)
-
-
-def _run_zic(zonedir, filepaths):
- """Calls the ``zic`` compiler in a compatible way to get a "fat" binary.
-
- Recent versions of ``zic`` default to ``-b slim``, while older versions
- don't even have the ``-b`` option (but default to "fat" binaries). The
- current version of dateutil does not support Version 2+ TZif files, which
- causes problems when used in conjunction with "slim" binaries, so this
- function is used to ensure that we always get a "fat" binary.
- """
-
- try:
- help_text = check_output(["zic", "--help"])
- except OSError as e:
- _print_on_nosuchfile(e)
- raise
-
- if b"-b " in help_text:
- bloat_args = ["-b", "fat"]
- else:
- bloat_args = []
-
- check_call(["zic"] + bloat_args + ["-d", zonedir] + filepaths)
-
-
-def _print_on_nosuchfile(e):
- """Print helpful troubleshooting message
-
- e is an exception raised by subprocess.check_call()
-
- """
- if e.errno == 2:
- logging.error(
- "Could not find zic. Perhaps you need to install "
- "libc-bin or some other package that provides it, "
- "or it's not in your PATH?")
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/chardet/metadata/languages.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/chardet/metadata/languages.py
deleted file mode 100644
index eb40c5f0c8526208d434d762855d23079dc68b36..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/chardet/metadata/languages.py
+++ /dev/null
@@ -1,352 +0,0 @@
-"""
-Metadata about languages used by our model training code for our
-SingleByteCharSetProbers. Could be used for other things in the future.
-
-This code is based on the language metadata from the uchardet project.
-"""
-
-from string import ascii_letters
-from typing import List, Optional
-
-# TODO: Add Ukrainian (KOI8-U)
-
-
-class Language:
- """Metadata about a language useful for training models
-
- :ivar name: The human name for the language, in English.
- :type name: str
- :ivar iso_code: 2-letter ISO 639-1 if possible, 3-letter ISO code otherwise,
- or use another catalog as a last resort.
- :type iso_code: str
- :ivar use_ascii: Whether or not ASCII letters should be included in trained
- models.
- :type use_ascii: bool
- :ivar charsets: The charsets we want to support and create data for.
- :type charsets: list of str
- :ivar alphabet: The characters in the language's alphabet. If `use_ascii` is
- `True`, you only need to add those not in the ASCII set.
- :type alphabet: str
- :ivar wiki_start_pages: The Wikipedia pages to start from if we're crawling
- Wikipedia for training data.
- :type wiki_start_pages: list of str
- """
-
- def __init__(
- self,
- name: Optional[str] = None,
- iso_code: Optional[str] = None,
- use_ascii: bool = True,
- charsets: Optional[List[str]] = None,
- alphabet: Optional[str] = None,
- wiki_start_pages: Optional[List[str]] = None,
- ) -> None:
- super().__init__()
- self.name = name
- self.iso_code = iso_code
- self.use_ascii = use_ascii
- self.charsets = charsets
- if self.use_ascii:
- if alphabet:
- alphabet += ascii_letters
- else:
- alphabet = ascii_letters
- elif not alphabet:
- raise ValueError("Must supply alphabet if use_ascii is False")
- self.alphabet = "".join(sorted(set(alphabet))) if alphabet else None
- self.wiki_start_pages = wiki_start_pages
-
- def __repr__(self) -> str:
- param_str = ", ".join(
- f"{k}={v!r}" for k, v in self.__dict__.items() if not k.startswith("_")
- )
- return f"{self.__class__.__name__}({param_str})"
-
-
-LANGUAGES = {
- "Arabic": Language(
- name="Arabic",
- iso_code="ar",
- use_ascii=False,
- # We only support encodings that use isolated
- # forms, because the current recommendation is
- # that the rendering system handles presentation
- # forms. This means we purposefully skip IBM864.
- charsets=["ISO-8859-6", "WINDOWS-1256", "CP720", "CP864"],
- alphabet="ءآأؤإئابةتثجحخدذرزسشصضطظعغػؼؽؾؿـفقكلمنهوىيًٌٍَُِّ",
- wiki_start_pages=["الصفحة_الرئيسية"],
- ),
- "Belarusian": Language(
- name="Belarusian",
- iso_code="be",
- use_ascii=False,
- charsets=["ISO-8859-5", "WINDOWS-1251", "IBM866", "MacCyrillic"],
- alphabet="АБВГДЕЁЖЗІЙКЛМНОПРСТУЎФХЦЧШЫЬЭЮЯабвгдеёжзійклмнопрстуўфхцчшыьэюяʼ",
- wiki_start_pages=["Галоўная_старонка"],
- ),
- "Bulgarian": Language(
- name="Bulgarian",
- iso_code="bg",
- use_ascii=False,
- charsets=["ISO-8859-5", "WINDOWS-1251", "IBM855"],
- alphabet="АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЬЮЯабвгдежзийклмнопрстуфхцчшщъьюя",
- wiki_start_pages=["Начална_страница"],
- ),
- "Czech": Language(
- name="Czech",
- iso_code="cz",
- use_ascii=True,
- charsets=["ISO-8859-2", "WINDOWS-1250"],
- alphabet="áčďéěíňóřšťúůýžÁČĎÉĚÍŇÓŘŠŤÚŮÝŽ",
- wiki_start_pages=["Hlavní_strana"],
- ),
- "Danish": Language(
- name="Danish",
- iso_code="da",
- use_ascii=True,
- charsets=["ISO-8859-1", "ISO-8859-15", "WINDOWS-1252", "MacRoman"],
- alphabet="æøåÆØÅ",
- wiki_start_pages=["Forside"],
- ),
- "German": Language(
- name="German",
- iso_code="de",
- use_ascii=True,
- charsets=["ISO-8859-1", "ISO-8859-15", "WINDOWS-1252", "MacRoman"],
- alphabet="äöüßẞÄÖÜ",
- wiki_start_pages=["Wikipedia:Hauptseite"],
- ),
- "Greek": Language(
- name="Greek",
- iso_code="el",
- use_ascii=False,
- charsets=["ISO-8859-7", "WINDOWS-1253"],
- alphabet="αβγδεζηθικλμνξοπρσςτυφχψωάέήίόύώΑΒΓΔΕΖΗΘΙΚΛΜΝΞΟΠΡΣΣΤΥΦΧΨΩΆΈΉΊΌΎΏ",
- wiki_start_pages=["Πύλη:Κύρια"],
- ),
- "English": Language(
- name="English",
- iso_code="en",
- use_ascii=True,
- charsets=["ISO-8859-1", "WINDOWS-1252", "MacRoman"],
- wiki_start_pages=["Main_Page"],
- ),
- "Esperanto": Language(
- name="Esperanto",
- iso_code="eo",
- # Q, W, X, and Y not used at all
- use_ascii=False,
- charsets=["ISO-8859-3"],
- alphabet="abcĉdefgĝhĥijĵklmnoprsŝtuŭvzABCĈDEFGĜHĤIJĴKLMNOPRSŜTUŬVZ",
- wiki_start_pages=["Vikipedio:Ĉefpaĝo"],
- ),
- "Spanish": Language(
- name="Spanish",
- iso_code="es",
- use_ascii=True,
- charsets=["ISO-8859-1", "ISO-8859-15", "WINDOWS-1252", "MacRoman"],
- alphabet="ñáéíóúüÑÁÉÍÓÚÜ",
- wiki_start_pages=["Wikipedia:Portada"],
- ),
- "Estonian": Language(
- name="Estonian",
- iso_code="et",
- use_ascii=False,
- charsets=["ISO-8859-4", "ISO-8859-13", "WINDOWS-1257"],
- # C, F, Š, Q, W, X, Y, Z, Ž are only for
- # loanwords
- alphabet="ABDEGHIJKLMNOPRSTUVÕÄÖÜabdeghijklmnoprstuvõäöü",
- wiki_start_pages=["Esileht"],
- ),
- "Finnish": Language(
- name="Finnish",
- iso_code="fi",
- use_ascii=True,
- charsets=["ISO-8859-1", "ISO-8859-15", "WINDOWS-1252", "MacRoman"],
- alphabet="ÅÄÖŠŽåäöšž",
- wiki_start_pages=["Wikipedia:Etusivu"],
- ),
- "French": Language(
- name="French",
- iso_code="fr",
- use_ascii=True,
- charsets=["ISO-8859-1", "ISO-8859-15", "WINDOWS-1252", "MacRoman"],
- alphabet="œàâçèéîïùûêŒÀÂÇÈÉÎÏÙÛÊ",
- wiki_start_pages=["Wikipédia:Accueil_principal", "Bœuf (animal)"],
- ),
- "Hebrew": Language(
- name="Hebrew",
- iso_code="he",
- use_ascii=False,
- charsets=["ISO-8859-8", "WINDOWS-1255"],
- alphabet="אבגדהוזחטיךכלםמןנסעףפץצקרשתװױײ",
- wiki_start_pages=["עמוד_ראשי"],
- ),
- "Croatian": Language(
- name="Croatian",
- iso_code="hr",
- # Q, W, X, Y are only used for foreign words.
- use_ascii=False,
- charsets=["ISO-8859-2", "WINDOWS-1250"],
- alphabet="abcčćdđefghijklmnoprsštuvzžABCČĆDĐEFGHIJKLMNOPRSŠTUVZŽ",
- wiki_start_pages=["Glavna_stranica"],
- ),
- "Hungarian": Language(
- name="Hungarian",
- iso_code="hu",
- # Q, W, X, Y are only used for foreign words.
- use_ascii=False,
- charsets=["ISO-8859-2", "WINDOWS-1250"],
- alphabet="abcdefghijklmnoprstuvzáéíóöőúüűABCDEFGHIJKLMNOPRSTUVZÁÉÍÓÖŐÚÜŰ",
- wiki_start_pages=["Kezdőlap"],
- ),
- "Italian": Language(
- name="Italian",
- iso_code="it",
- use_ascii=True,
- charsets=["ISO-8859-1", "ISO-8859-15", "WINDOWS-1252", "MacRoman"],
- alphabet="ÀÈÉÌÒÓÙàèéìòóù",
- wiki_start_pages=["Pagina_principale"],
- ),
- "Lithuanian": Language(
- name="Lithuanian",
- iso_code="lt",
- use_ascii=False,
- charsets=["ISO-8859-13", "WINDOWS-1257", "ISO-8859-4"],
- # Q, W, and X not used at all
- alphabet="AĄBCČDEĘĖFGHIĮYJKLMNOPRSŠTUŲŪVZŽaąbcčdeęėfghiįyjklmnoprsštuųūvzž",
- wiki_start_pages=["Pagrindinis_puslapis"],
- ),
- "Latvian": Language(
- name="Latvian",
- iso_code="lv",
- use_ascii=False,
- charsets=["ISO-8859-13", "WINDOWS-1257", "ISO-8859-4"],
- # Q, W, X, Y are only for loanwords
- alphabet="AĀBCČDEĒFGĢHIĪJKĶLĻMNŅOPRSŠTUŪVZŽaābcčdeēfgģhiījkķlļmnņoprsštuūvzž",
- wiki_start_pages=["Sākumlapa"],
- ),
- "Macedonian": Language(
- name="Macedonian",
- iso_code="mk",
- use_ascii=False,
- charsets=["ISO-8859-5", "WINDOWS-1251", "MacCyrillic", "IBM855"],
- alphabet="АБВГДЃЕЖЗЅИЈКЛЉМНЊОПРСТЌУФХЦЧЏШабвгдѓежзѕијклљмнњопрстќуфхцчџш",
- wiki_start_pages=["Главна_страница"],
- ),
- "Dutch": Language(
- name="Dutch",
- iso_code="nl",
- use_ascii=True,
- charsets=["ISO-8859-1", "WINDOWS-1252", "MacRoman"],
- wiki_start_pages=["Hoofdpagina"],
- ),
- "Polish": Language(
- name="Polish",
- iso_code="pl",
- # Q and X are only used for foreign words.
- use_ascii=False,
- charsets=["ISO-8859-2", "WINDOWS-1250"],
- alphabet="AĄBCĆDEĘFGHIJKLŁMNŃOÓPRSŚTUWYZŹŻaąbcćdeęfghijklłmnńoóprsśtuwyzźż",
- wiki_start_pages=["Wikipedia:Strona_główna"],
- ),
- "Portuguese": Language(
- name="Portuguese",
- iso_code="pt",
- use_ascii=True,
- charsets=["ISO-8859-1", "ISO-8859-15", "WINDOWS-1252", "MacRoman"],
- alphabet="ÁÂÃÀÇÉÊÍÓÔÕÚáâãàçéêíóôõú",
- wiki_start_pages=["Wikipédia:Página_principal"],
- ),
- "Romanian": Language(
- name="Romanian",
- iso_code="ro",
- use_ascii=True,
- charsets=["ISO-8859-2", "WINDOWS-1250"],
- alphabet="ăâîșțĂÂÎȘȚ",
- wiki_start_pages=["Pagina_principală"],
- ),
- "Russian": Language(
- name="Russian",
- iso_code="ru",
- use_ascii=False,
- charsets=[
- "ISO-8859-5",
- "WINDOWS-1251",
- "KOI8-R",
- "MacCyrillic",
- "IBM866",
- "IBM855",
- ],
- alphabet="абвгдеёжзийклмнопрстуфхцчшщъыьэюяАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ",
- wiki_start_pages=["Заглавная_страница"],
- ),
- "Slovak": Language(
- name="Slovak",
- iso_code="sk",
- use_ascii=True,
- charsets=["ISO-8859-2", "WINDOWS-1250"],
- alphabet="áäčďéíĺľňóôŕšťúýžÁÄČĎÉÍĹĽŇÓÔŔŠŤÚÝŽ",
- wiki_start_pages=["Hlavná_stránka"],
- ),
- "Slovene": Language(
- name="Slovene",
- iso_code="sl",
- # Q, W, X, Y are only used for foreign words.
- use_ascii=False,
- charsets=["ISO-8859-2", "WINDOWS-1250"],
- alphabet="abcčdefghijklmnoprsštuvzžABCČDEFGHIJKLMNOPRSŠTUVZŽ",
- wiki_start_pages=["Glavna_stran"],
- ),
- # Serbian can be written in both Latin and Cyrillic, but there's no
- # simple way to get the Latin alphabet pages from Wikipedia through
- # the API, so for now we just support Cyrillic.
- "Serbian": Language(
- name="Serbian",
- iso_code="sr",
- alphabet="АБВГДЂЕЖЗИЈКЛЉМНЊОПРСТЋУФХЦЧЏШабвгдђежзијклљмнњопрстћуфхцчџш",
- charsets=["ISO-8859-5", "WINDOWS-1251", "MacCyrillic", "IBM855"],
- wiki_start_pages=["Главна_страна"],
- ),
- "Thai": Language(
- name="Thai",
- iso_code="th",
- use_ascii=False,
- charsets=["ISO-8859-11", "TIS-620", "CP874"],
- alphabet="กขฃคฅฆงจฉชซฌญฎฏฐฑฒณดตถทธนบปผฝพฟภมยรฤลฦวศษสหฬอฮฯะัาำิีึืฺุู฿เแโใไๅๆ็่้๊๋์ํ๎๏๐๑๒๓๔๕๖๗๘๙๚๛",
- wiki_start_pages=["หน้าหลัก"],
- ),
- "Turkish": Language(
- name="Turkish",
- iso_code="tr",
- # Q, W, and X are not used by Turkish
- use_ascii=False,
- charsets=["ISO-8859-3", "ISO-8859-9", "WINDOWS-1254"],
- alphabet="abcçdefgğhıijklmnoöprsştuüvyzâîûABCÇDEFGĞHIİJKLMNOÖPRSŞTUÜVYZÂÎÛ",
- wiki_start_pages=["Ana_Sayfa"],
- ),
- "Vietnamese": Language(
- name="Vietnamese",
- iso_code="vi",
- use_ascii=False,
- # Windows-1258 is the only common 8-bit
- # Vietnamese encoding supported by Python.
- # From Wikipedia:
- # For systems that lack support for Unicode,
- # dozens of 8-bit Vietnamese code pages are
- # available.[1] The most common are VISCII
- # (TCVN 5712:1993), VPS, and Windows-1258.[3]
- # Where ASCII is required, such as when
- # ensuring readability in plain text e-mail,
- # Vietnamese letters are often encoded
- # according to Vietnamese Quoted-Readable
- # (VIQR) or VSCII Mnemonic (VSCII-MNEM),[4]
- # though usage of either variable-width
- # scheme has declined dramatically following
- # the adoption of Unicode on the World Wide
- # Web.
- charsets=["WINDOWS-1258"],
- alphabet="aăâbcdđeêghiklmnoôơpqrstuưvxyAĂÂBCDĐEÊGHIKLMNOÔƠPQRSTUƯVXY",
- wiki_start_pages=["Chữ_Quốc_ngữ"],
- ),
-}
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/requests/cookies.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/requests/cookies.py
deleted file mode 100644
index bf54ab237e410603061b8cec8fd195912d3cfb08..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/requests/cookies.py
+++ /dev/null
@@ -1,561 +0,0 @@
-"""
-requests.cookies
-~~~~~~~~~~~~~~~~
-
-Compatibility code to be able to use `cookielib.CookieJar` with requests.
-
-requests.utils imports from here, so be careful with imports.
-"""
-
-import calendar
-import copy
-import time
-
-from ._internal_utils import to_native_string
-from .compat import Morsel, MutableMapping, cookielib, urlparse, urlunparse
-
-try:
- import threading
-except ImportError:
- import dummy_threading as threading
-
-
-class MockRequest:
- """Wraps a `requests.Request` to mimic a `urllib2.Request`.
-
- The code in `cookielib.CookieJar` expects this interface in order to correctly
- manage cookie policies, i.e., determine whether a cookie can be set, given the
- domains of the request and the cookie.
-
- The original request object is read-only. The client is responsible for collecting
- the new headers via `get_new_headers()` and interpreting them appropriately. You
- probably want `get_cookie_header`, defined below.
- """
-
- def __init__(self, request):
- self._r = request
- self._new_headers = {}
- self.type = urlparse(self._r.url).scheme
-
- def get_type(self):
- return self.type
-
- def get_host(self):
- return urlparse(self._r.url).netloc
-
- def get_origin_req_host(self):
- return self.get_host()
-
- def get_full_url(self):
- # Only return the response's URL if the user hadn't set the Host
- # header
- if not self._r.headers.get("Host"):
- return self._r.url
- # If they did set it, retrieve it and reconstruct the expected domain
- host = to_native_string(self._r.headers["Host"], encoding="utf-8")
- parsed = urlparse(self._r.url)
- # Reconstruct the URL as we expect it
- return urlunparse(
- [
- parsed.scheme,
- host,
- parsed.path,
- parsed.params,
- parsed.query,
- parsed.fragment,
- ]
- )
-
- def is_unverifiable(self):
- return True
-
- def has_header(self, name):
- return name in self._r.headers or name in self._new_headers
-
- def get_header(self, name, default=None):
- return self._r.headers.get(name, self._new_headers.get(name, default))
-
- def add_header(self, key, val):
- """cookielib has no legitimate use for this method; add it back if you find one."""
- raise NotImplementedError(
- "Cookie headers should be added with add_unredirected_header()"
- )
-
- def add_unredirected_header(self, name, value):
- self._new_headers[name] = value
-
- def get_new_headers(self):
- return self._new_headers
-
- @property
- def unverifiable(self):
- return self.is_unverifiable()
-
- @property
- def origin_req_host(self):
- return self.get_origin_req_host()
-
- @property
- def host(self):
- return self.get_host()
-
-
-class MockResponse:
- """Wraps a `httplib.HTTPMessage` to mimic a `urllib.addinfourl`.
-
- ...what? Basically, expose the parsed HTTP headers from the server response
- the way `cookielib` expects to see them.
- """
-
- def __init__(self, headers):
- """Make a MockResponse for `cookielib` to read.
-
- :param headers: a httplib.HTTPMessage or analogous carrying the headers
- """
- self._headers = headers
-
- def info(self):
- return self._headers
-
- def getheaders(self, name):
- self._headers.getheaders(name)
-
-
-def extract_cookies_to_jar(jar, request, response):
- """Extract the cookies from the response into a CookieJar.
-
- :param jar: cookielib.CookieJar (not necessarily a RequestsCookieJar)
- :param request: our own requests.Request object
- :param response: urllib3.HTTPResponse object
- """
- if not (hasattr(response, "_original_response") and response._original_response):
- return
- # the _original_response field is the wrapped httplib.HTTPResponse object,
- req = MockRequest(request)
- # pull out the HTTPMessage with the headers and put it in the mock:
- res = MockResponse(response._original_response.msg)
- jar.extract_cookies(res, req)
-
-
-def get_cookie_header(jar, request):
- """
- Produce an appropriate Cookie header string to be sent with `request`, or None.
-
- :rtype: str
- """
- r = MockRequest(request)
- jar.add_cookie_header(r)
- return r.get_new_headers().get("Cookie")
-
-
-def remove_cookie_by_name(cookiejar, name, domain=None, path=None):
- """Unsets a cookie by name, by default over all domains and paths.
-
- Wraps CookieJar.clear(), is O(n).
- """
- clearables = []
- for cookie in cookiejar:
- if cookie.name != name:
- continue
- if domain is not None and domain != cookie.domain:
- continue
- if path is not None and path != cookie.path:
- continue
- clearables.append((cookie.domain, cookie.path, cookie.name))
-
- for domain, path, name in clearables:
- cookiejar.clear(domain, path, name)
-
-
-class CookieConflictError(RuntimeError):
- """There are two cookies that meet the criteria specified in the cookie jar.
- Use .get and .set and include domain and path args in order to be more specific.
- """
-
-
-class RequestsCookieJar(cookielib.CookieJar, MutableMapping):
- """Compatibility class; is a cookielib.CookieJar, but exposes a dict
- interface.
-
- This is the CookieJar we create by default for requests and sessions that
- don't specify one, since some clients may expect response.cookies and
- session.cookies to support dict operations.
-
- Requests does not use the dict interface internally; it's just for
- compatibility with external client code. All requests code should work
- out of the box with externally provided instances of ``CookieJar``, e.g.
- ``LWPCookieJar`` and ``FileCookieJar``.
-
- Unlike a regular CookieJar, this class is pickleable.
-
- .. warning:: dictionary operations that are normally O(1) may be O(n).
- """
-
- def get(self, name, default=None, domain=None, path=None):
- """Dict-like get() that also supports optional domain and path args in
- order to resolve naming collisions from using one cookie jar over
- multiple domains.
-
- .. warning:: operation is O(n), not O(1).
- """
- try:
- return self._find_no_duplicates(name, domain, path)
- except KeyError:
- return default
-
- def set(self, name, value, **kwargs):
- """Dict-like set() that also supports optional domain and path args in
- order to resolve naming collisions from using one cookie jar over
- multiple domains.
- """
- # support client code that unsets cookies by assignment of a None value:
- if value is None:
- remove_cookie_by_name(
- self, name, domain=kwargs.get("domain"), path=kwargs.get("path")
- )
- return
-
- if isinstance(value, Morsel):
- c = morsel_to_cookie(value)
- else:
- c = create_cookie(name, value, **kwargs)
- self.set_cookie(c)
- return c
-
- def iterkeys(self):
- """Dict-like iterkeys() that returns an iterator of names of cookies
- from the jar.
-
- .. seealso:: itervalues() and iteritems().
- """
- for cookie in iter(self):
- yield cookie.name
-
- def keys(self):
- """Dict-like keys() that returns a list of names of cookies from the
- jar.
-
- .. seealso:: values() and items().
- """
- return list(self.iterkeys())
-
- def itervalues(self):
- """Dict-like itervalues() that returns an iterator of values of cookies
- from the jar.
-
- .. seealso:: iterkeys() and iteritems().
- """
- for cookie in iter(self):
- yield cookie.value
-
- def values(self):
- """Dict-like values() that returns a list of values of cookies from the
- jar.
-
- .. seealso:: keys() and items().
- """
- return list(self.itervalues())
-
- def iteritems(self):
- """Dict-like iteritems() that returns an iterator of name-value tuples
- from the jar.
-
- .. seealso:: iterkeys() and itervalues().
- """
- for cookie in iter(self):
- yield cookie.name, cookie.value
-
- def items(self):
- """Dict-like items() that returns a list of name-value tuples from the
- jar. Allows client-code to call ``dict(RequestsCookieJar)`` and get a
- vanilla python dict of key value pairs.
-
- .. seealso:: keys() and values().
- """
- return list(self.iteritems())
-
- def list_domains(self):
- """Utility method to list all the domains in the jar."""
- domains = []
- for cookie in iter(self):
- if cookie.domain not in domains:
- domains.append(cookie.domain)
- return domains
-
- def list_paths(self):
- """Utility method to list all the paths in the jar."""
- paths = []
- for cookie in iter(self):
- if cookie.path not in paths:
- paths.append(cookie.path)
- return paths
-
- def multiple_domains(self):
- """Returns True if there are multiple domains in the jar.
- Returns False otherwise.
-
- :rtype: bool
- """
- domains = []
- for cookie in iter(self):
- if cookie.domain is not None and cookie.domain in domains:
- return True
- domains.append(cookie.domain)
- return False # there is only one domain in jar
-
- def get_dict(self, domain=None, path=None):
- """Takes as an argument an optional domain and path and returns a plain
- old Python dict of name-value pairs of cookies that meet the
- requirements.
-
- :rtype: dict
- """
- dictionary = {}
- for cookie in iter(self):
- if (domain is None or cookie.domain == domain) and (
- path is None or cookie.path == path
- ):
- dictionary[cookie.name] = cookie.value
- return dictionary
-
- def __contains__(self, name):
- try:
- return super().__contains__(name)
- except CookieConflictError:
- return True
-
- def __getitem__(self, name):
- """Dict-like __getitem__() for compatibility with client code. Throws
- exception if there are more than one cookie with name. In that case,
- use the more explicit get() method instead.
-
- .. warning:: operation is O(n), not O(1).
- """
- return self._find_no_duplicates(name)
-
- def __setitem__(self, name, value):
- """Dict-like __setitem__ for compatibility with client code. Throws
- exception if there is already a cookie of that name in the jar. In that
- case, use the more explicit set() method instead.
- """
- self.set(name, value)
-
- def __delitem__(self, name):
- """Deletes a cookie given a name. Wraps ``cookielib.CookieJar``'s
- ``remove_cookie_by_name()``.
- """
- remove_cookie_by_name(self, name)
-
- def set_cookie(self, cookie, *args, **kwargs):
- if (
- hasattr(cookie.value, "startswith")
- and cookie.value.startswith('"')
- and cookie.value.endswith('"')
- ):
- cookie.value = cookie.value.replace('\\"', "")
- return super().set_cookie(cookie, *args, **kwargs)
-
- def update(self, other):
- """Updates this jar with cookies from another CookieJar or dict-like"""
- if isinstance(other, cookielib.CookieJar):
- for cookie in other:
- self.set_cookie(copy.copy(cookie))
- else:
- super().update(other)
-
- def _find(self, name, domain=None, path=None):
- """Requests uses this method internally to get cookie values.
-
- If there are conflicting cookies, _find arbitrarily chooses one.
- See _find_no_duplicates if you want an exception thrown if there are
- conflicting cookies.
-
- :param name: a string containing name of cookie
- :param domain: (optional) string containing domain of cookie
- :param path: (optional) string containing path of cookie
- :return: cookie.value
- """
- for cookie in iter(self):
- if cookie.name == name:
- if domain is None or cookie.domain == domain:
- if path is None or cookie.path == path:
- return cookie.value
-
- raise KeyError(f"name={name!r}, domain={domain!r}, path={path!r}")
-
- def _find_no_duplicates(self, name, domain=None, path=None):
- """Both ``__get_item__`` and ``get`` call this function: it's never
- used elsewhere in Requests.
-
- :param name: a string containing name of cookie
- :param domain: (optional) string containing domain of cookie
- :param path: (optional) string containing path of cookie
- :raises KeyError: if cookie is not found
- :raises CookieConflictError: if there are multiple cookies
- that match name and optionally domain and path
- :return: cookie.value
- """
- toReturn = None
- for cookie in iter(self):
- if cookie.name == name:
- if domain is None or cookie.domain == domain:
- if path is None or cookie.path == path:
- if toReturn is not None:
- # if there are multiple cookies that meet passed in criteria
- raise CookieConflictError(
- f"There are multiple cookies with name, {name!r}"
- )
- # we will eventually return this as long as no cookie conflict
- toReturn = cookie.value
-
- if toReturn:
- return toReturn
- raise KeyError(f"name={name!r}, domain={domain!r}, path={path!r}")
-
- def __getstate__(self):
- """Unlike a normal CookieJar, this class is pickleable."""
- state = self.__dict__.copy()
- # remove the unpickleable RLock object
- state.pop("_cookies_lock")
- return state
-
- def __setstate__(self, state):
- """Unlike a normal CookieJar, this class is pickleable."""
- self.__dict__.update(state)
- if "_cookies_lock" not in self.__dict__:
- self._cookies_lock = threading.RLock()
-
- def copy(self):
- """Return a copy of this RequestsCookieJar."""
- new_cj = RequestsCookieJar()
- new_cj.set_policy(self.get_policy())
- new_cj.update(self)
- return new_cj
-
- def get_policy(self):
- """Return the CookiePolicy instance used."""
- return self._policy
-
-
-def _copy_cookie_jar(jar):
- if jar is None:
- return None
-
- if hasattr(jar, "copy"):
- # We're dealing with an instance of RequestsCookieJar
- return jar.copy()
- # We're dealing with a generic CookieJar instance
- new_jar = copy.copy(jar)
- new_jar.clear()
- for cookie in jar:
- new_jar.set_cookie(copy.copy(cookie))
- return new_jar
-
-
-def create_cookie(name, value, **kwargs):
- """Make a cookie from underspecified parameters.
-
- By default, the pair of `name` and `value` will be set for the domain ''
- and sent on every request (this is sometimes called a "supercookie").
- """
- result = {
- "version": 0,
- "name": name,
- "value": value,
- "port": None,
- "domain": "",
- "path": "/",
- "secure": False,
- "expires": None,
- "discard": True,
- "comment": None,
- "comment_url": None,
- "rest": {"HttpOnly": None},
- "rfc2109": False,
- }
-
- badargs = set(kwargs) - set(result)
- if badargs:
- raise TypeError(
- f"create_cookie() got unexpected keyword arguments: {list(badargs)}"
- )
-
- result.update(kwargs)
- result["port_specified"] = bool(result["port"])
- result["domain_specified"] = bool(result["domain"])
- result["domain_initial_dot"] = result["domain"].startswith(".")
- result["path_specified"] = bool(result["path"])
-
- return cookielib.Cookie(**result)
-
-
-def morsel_to_cookie(morsel):
- """Convert a Morsel object into a Cookie containing the one k/v pair."""
-
- expires = None
- if morsel["max-age"]:
- try:
- expires = int(time.time() + int(morsel["max-age"]))
- except ValueError:
- raise TypeError(f"max-age: {morsel['max-age']} must be integer")
- elif morsel["expires"]:
- time_template = "%a, %d-%b-%Y %H:%M:%S GMT"
- expires = calendar.timegm(time.strptime(morsel["expires"], time_template))
- return create_cookie(
- comment=morsel["comment"],
- comment_url=bool(morsel["comment"]),
- discard=False,
- domain=morsel["domain"],
- expires=expires,
- name=morsel.key,
- path=morsel["path"],
- port=None,
- rest={"HttpOnly": morsel["httponly"]},
- rfc2109=False,
- secure=bool(morsel["secure"]),
- value=morsel.value,
- version=morsel["version"] or 0,
- )
-
-
-def cookiejar_from_dict(cookie_dict, cookiejar=None, overwrite=True):
- """Returns a CookieJar from a key/value dictionary.
-
- :param cookie_dict: Dict of key/values to insert into CookieJar.
- :param cookiejar: (optional) A cookiejar to add the cookies to.
- :param overwrite: (optional) If False, will not replace cookies
- already in the jar with new ones.
- :rtype: CookieJar
- """
- if cookiejar is None:
- cookiejar = RequestsCookieJar()
-
- if cookie_dict is not None:
- names_from_jar = [cookie.name for cookie in cookiejar]
- for name in cookie_dict:
- if overwrite or (name not in names_from_jar):
- cookiejar.set_cookie(create_cookie(name, cookie_dict[name]))
-
- return cookiejar
-
-
-def merge_cookies(cookiejar, cookies):
- """Add cookies to cookiejar and returns a merged CookieJar.
-
- :param cookiejar: CookieJar object to add the cookies to.
- :param cookies: Dictionary or CookieJar object to be added.
- :rtype: CookieJar
- """
- if not isinstance(cookiejar, cookielib.CookieJar):
- raise ValueError("You can only merge into CookieJar")
-
- if isinstance(cookies, dict):
- cookiejar = cookiejar_from_dict(cookies, cookiejar=cookiejar, overwrite=False)
- elif isinstance(cookies, cookielib.CookieJar):
- try:
- cookiejar.update(cookies)
- except AttributeError:
- for cookie_in_jar in cookies:
- cookiejar.set_cookie(cookie_in_jar)
-
- return cookiejar
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/openvqa/utils/ans_punct.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/openvqa/utils/ans_punct.py
deleted file mode 100644
index b5e5aa205ee578fd36b4d4b52524e8dcef5b3721..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/openvqa/utils/ans_punct.py
+++ /dev/null
@@ -1,105 +0,0 @@
-# --------------------------------------------------------
-# OpenVQA
-# Written by Yuhao Cui https://github.com/cuiyuhao1996
-# based on VQA Evaluation Code
-# --------------------------------------------------------
-
-import re
-
-contractions = {
- "aint": "ain't", "arent": "aren't", "cant": "can't", "couldve":
- "could've", "couldnt": "couldn't", "couldn'tve": "couldn't've",
- "couldnt've": "couldn't've", "didnt": "didn't", "doesnt":
- "doesn't", "dont": "don't", "hadnt": "hadn't", "hadnt've":
- "hadn't've", "hadn'tve": "hadn't've", "hasnt": "hasn't", "havent":
- "haven't", "hed": "he'd", "hed've": "he'd've", "he'dve":
- "he'd've", "hes": "he's", "howd": "how'd", "howll": "how'll",
- "hows": "how's", "Id've": "I'd've", "I'dve": "I'd've", "Im":
- "I'm", "Ive": "I've", "isnt": "isn't", "itd": "it'd", "itd've":
- "it'd've", "it'dve": "it'd've", "itll": "it'll", "let's": "let's",
- "maam": "ma'am", "mightnt": "mightn't", "mightnt've":
- "mightn't've", "mightn'tve": "mightn't've", "mightve": "might've",
- "mustnt": "mustn't", "mustve": "must've", "neednt": "needn't",
- "notve": "not've", "oclock": "o'clock", "oughtnt": "oughtn't",
- "ow's'at": "'ow's'at", "'ows'at": "'ow's'at", "'ow'sat":
- "'ow's'at", "shant": "shan't", "shed've": "she'd've", "she'dve":
- "she'd've", "she's": "she's", "shouldve": "should've", "shouldnt":
- "shouldn't", "shouldnt've": "shouldn't've", "shouldn'tve":
- "shouldn't've", "somebody'd": "somebodyd", "somebodyd've":
- "somebody'd've", "somebody'dve": "somebody'd've", "somebodyll":
- "somebody'll", "somebodys": "somebody's", "someoned": "someone'd",
- "someoned've": "someone'd've", "someone'dve": "someone'd've",
- "someonell": "someone'll", "someones": "someone's", "somethingd":
- "something'd", "somethingd've": "something'd've", "something'dve":
- "something'd've", "somethingll": "something'll", "thats":
- "that's", "thered": "there'd", "thered've": "there'd've",
- "there'dve": "there'd've", "therere": "there're", "theres":
- "there's", "theyd": "they'd", "theyd've": "they'd've", "they'dve":
- "they'd've", "theyll": "they'll", "theyre": "they're", "theyve":
- "they've", "twas": "'twas", "wasnt": "wasn't", "wed've":
- "we'd've", "we'dve": "we'd've", "weve": "we've", "werent":
- "weren't", "whatll": "what'll", "whatre": "what're", "whats":
- "what's", "whatve": "what've", "whens": "when's", "whered":
- "where'd", "wheres": "where's", "whereve": "where've", "whod":
- "who'd", "whod've": "who'd've", "who'dve": "who'd've", "wholl":
- "who'll", "whos": "who's", "whove": "who've", "whyll": "why'll",
- "whyre": "why're", "whys": "why's", "wont": "won't", "wouldve":
- "would've", "wouldnt": "wouldn't", "wouldnt've": "wouldn't've",
- "wouldn'tve": "wouldn't've", "yall": "y'all", "yall'll":
- "y'all'll", "y'allll": "y'all'll", "yall'd've": "y'all'd've",
- "y'alld've": "y'all'd've", "y'all'dve": "y'all'd've", "youd":
- "you'd", "youd've": "you'd've", "you'dve": "you'd've", "youll":
- "you'll", "youre": "you're", "youve": "you've"
-}
-
-manual_map = { 'none': '0',
- 'zero': '0',
- 'one': '1',
- 'two': '2',
- 'three': '3',
- 'four': '4',
- 'five': '5',
- 'six': '6',
- 'seven': '7',
- 'eight': '8',
- 'nine': '9',
- 'ten': '10'}
-articles = ['a', 'an', 'the']
-period_strip = re.compile("(?!<=\d)(\.)(?!\d)")
-comma_strip = re.compile("(\d)(\,)(\d)")
-punct = [';', r"/", '[', ']', '"', '{', '}',
- '(', ')', '=', '+', '\\', '_', '-',
- '>', '<', '@', '`', ',', '?', '!']
-
-def process_punctuation(inText):
- outText = inText
- for p in punct:
- if (p + ' ' in inText or ' ' + p in inText) \
- or (re.search(comma_strip, inText) != None):
- outText = outText.replace(p, '')
- else:
- outText = outText.replace(p, ' ')
- outText = period_strip.sub("", outText, re.UNICODE)
- return outText
-
-
-def process_digit_article(inText):
- outText = []
- tempText = inText.lower().split()
- for word in tempText:
- word = manual_map.setdefault(word, word)
- if word not in articles:
- outText.append(word)
- else:
- pass
- for wordId, word in enumerate(outText):
- if word in contractions:
- outText[wordId] = contractions[word]
- outText = ' '.join(outText)
- return outText
-
-
-def prep_ans(answer):
- answer = process_digit_article(process_punctuation(answer))
- answer = answer.replace(',', '')
- return answer
diff --git a/spaces/CVPR/LIVE/thrust/thrust/detail/config/config.h b/spaces/CVPR/LIVE/thrust/thrust/detail/config/config.h
deleted file mode 100644
index 800bc4c51a8bedd5dc922da8a980dc62f02c62aa..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/detail/config/config.h
+++ /dev/null
@@ -1,39 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-/*! \file config.h
- * \brief Defines platform configuration.
- */
-
-#pragma once
-
-// NOTE: The order of these #includes matters.
-
-#include
-#include
-#include
-#include
-#include
-// host_system.h & device_system.h must be #included as early as possible
-// because other config headers depend on it
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-
diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/binary_search.h b/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/binary_search.h
deleted file mode 100644
index 0847e5d1fdb3a446651897d62c959d56ad9dd1b9..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/binary_search.h
+++ /dev/null
@@ -1,23 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-
-// this system inherits binary_search
-#include
-
diff --git a/spaces/CVPR/WALT/mmdet/core/evaluation/bbox_overlaps.py b/spaces/CVPR/WALT/mmdet/core/evaluation/bbox_overlaps.py
deleted file mode 100644
index 93559ea0f25369d552a5365312fa32b9ffec9226..0000000000000000000000000000000000000000
--- a/spaces/CVPR/WALT/mmdet/core/evaluation/bbox_overlaps.py
+++ /dev/null
@@ -1,48 +0,0 @@
-import numpy as np
-
-
-def bbox_overlaps(bboxes1, bboxes2, mode='iou', eps=1e-6):
- """Calculate the ious between each bbox of bboxes1 and bboxes2.
-
- Args:
- bboxes1(ndarray): shape (n, 4)
- bboxes2(ndarray): shape (k, 4)
- mode(str): iou (intersection over union) or iof (intersection
- over foreground)
-
- Returns:
- ious(ndarray): shape (n, k)
- """
-
- assert mode in ['iou', 'iof']
-
- bboxes1 = bboxes1.astype(np.float32)
- bboxes2 = bboxes2.astype(np.float32)
- rows = bboxes1.shape[0]
- cols = bboxes2.shape[0]
- ious = np.zeros((rows, cols), dtype=np.float32)
- if rows * cols == 0:
- return ious
- exchange = False
- if bboxes1.shape[0] > bboxes2.shape[0]:
- bboxes1, bboxes2 = bboxes2, bboxes1
- ious = np.zeros((cols, rows), dtype=np.float32)
- exchange = True
- area1 = (bboxes1[:, 2] - bboxes1[:, 0]) * (bboxes1[:, 3] - bboxes1[:, 1])
- area2 = (bboxes2[:, 2] - bboxes2[:, 0]) * (bboxes2[:, 3] - bboxes2[:, 1])
- for i in range(bboxes1.shape[0]):
- x_start = np.maximum(bboxes1[i, 0], bboxes2[:, 0])
- y_start = np.maximum(bboxes1[i, 1], bboxes2[:, 1])
- x_end = np.minimum(bboxes1[i, 2], bboxes2[:, 2])
- y_end = np.minimum(bboxes1[i, 3], bboxes2[:, 3])
- overlap = np.maximum(x_end - x_start, 0) * np.maximum(
- y_end - y_start, 0)
- if mode == 'iou':
- union = area1[i] + area2 - overlap
- else:
- union = area1[i] if not exchange else area2
- union = np.maximum(union, eps)
- ious[i, :] = overlap / union
- if exchange:
- ious = ious.T
- return ious
diff --git a/spaces/CVPR/WALT/mmdet/models/losses/smooth_l1_loss.py b/spaces/CVPR/WALT/mmdet/models/losses/smooth_l1_loss.py
deleted file mode 100644
index ec9c98a52d1932d6ccff18938c17c36755bf1baf..0000000000000000000000000000000000000000
--- a/spaces/CVPR/WALT/mmdet/models/losses/smooth_l1_loss.py
+++ /dev/null
@@ -1,139 +0,0 @@
-import mmcv
-import torch
-import torch.nn as nn
-
-from ..builder import LOSSES
-from .utils import weighted_loss
-
-
-@mmcv.jit(derivate=True, coderize=True)
-@weighted_loss
-def smooth_l1_loss(pred, target, beta=1.0):
- """Smooth L1 loss.
-
- Args:
- pred (torch.Tensor): The prediction.
- target (torch.Tensor): The learning target of the prediction.
- beta (float, optional): The threshold in the piecewise function.
- Defaults to 1.0.
-
- Returns:
- torch.Tensor: Calculated loss
- """
- assert beta > 0
- assert pred.size() == target.size() and target.numel() > 0
- diff = torch.abs(pred - target)
- loss = torch.where(diff < beta, 0.5 * diff * diff / beta,
- diff - 0.5 * beta)
- return loss
-
-
-@mmcv.jit(derivate=True, coderize=True)
-@weighted_loss
-def l1_loss(pred, target):
- """L1 loss.
-
- Args:
- pred (torch.Tensor): The prediction.
- target (torch.Tensor): The learning target of the prediction.
-
- Returns:
- torch.Tensor: Calculated loss
- """
- assert pred.size() == target.size() and target.numel() > 0
- loss = torch.abs(pred - target)
- return loss
-
-
-@LOSSES.register_module()
-class SmoothL1Loss(nn.Module):
- """Smooth L1 loss.
-
- Args:
- beta (float, optional): The threshold in the piecewise function.
- Defaults to 1.0.
- reduction (str, optional): The method to reduce the loss.
- Options are "none", "mean" and "sum". Defaults to "mean".
- loss_weight (float, optional): The weight of loss.
- """
-
- def __init__(self, beta=1.0, reduction='mean', loss_weight=1.0):
- super(SmoothL1Loss, self).__init__()
- self.beta = beta
- self.reduction = reduction
- self.loss_weight = loss_weight
-
- def forward(self,
- pred,
- target,
- weight=None,
- avg_factor=None,
- reduction_override=None,
- **kwargs):
- """Forward function.
-
- Args:
- pred (torch.Tensor): The prediction.
- target (torch.Tensor): The learning target of the prediction.
- weight (torch.Tensor, optional): The weight of loss for each
- prediction. Defaults to None.
- avg_factor (int, optional): Average factor that is used to average
- the loss. Defaults to None.
- reduction_override (str, optional): The reduction method used to
- override the original reduction method of the loss.
- Defaults to None.
- """
- assert reduction_override in (None, 'none', 'mean', 'sum')
- reduction = (
- reduction_override if reduction_override else self.reduction)
- loss_bbox = self.loss_weight * smooth_l1_loss(
- pred,
- target,
- weight,
- beta=self.beta,
- reduction=reduction,
- avg_factor=avg_factor,
- **kwargs)
- return loss_bbox
-
-
-@LOSSES.register_module()
-class L1Loss(nn.Module):
- """L1 loss.
-
- Args:
- reduction (str, optional): The method to reduce the loss.
- Options are "none", "mean" and "sum".
- loss_weight (float, optional): The weight of loss.
- """
-
- def __init__(self, reduction='mean', loss_weight=1.0):
- super(L1Loss, self).__init__()
- self.reduction = reduction
- self.loss_weight = loss_weight
-
- def forward(self,
- pred,
- target,
- weight=None,
- avg_factor=None,
- reduction_override=None):
- """Forward function.
-
- Args:
- pred (torch.Tensor): The prediction.
- target (torch.Tensor): The learning target of the prediction.
- weight (torch.Tensor, optional): The weight of loss for each
- prediction. Defaults to None.
- avg_factor (int, optional): Average factor that is used to average
- the loss. Defaults to None.
- reduction_override (str, optional): The reduction method used to
- override the original reduction method of the loss.
- Defaults to None.
- """
- assert reduction_override in (None, 'none', 'mean', 'sum')
- reduction = (
- reduction_override if reduction_override else self.reduction)
- loss_bbox = self.loss_weight * l1_loss(
- pred, target, weight, reduction=reduction, avg_factor=avg_factor)
- return loss_bbox
diff --git a/spaces/CVPR/lama-example/saicinpainting/training/modules/__init__.py b/spaces/CVPR/lama-example/saicinpainting/training/modules/__init__.py
deleted file mode 100644
index 82e1a9096a5bd8f3fb00e899d0239b078246cad4..0000000000000000000000000000000000000000
--- a/spaces/CVPR/lama-example/saicinpainting/training/modules/__init__.py
+++ /dev/null
@@ -1,31 +0,0 @@
-import logging
-
-from saicinpainting.training.modules.ffc import FFCResNetGenerator
-from saicinpainting.training.modules.pix2pixhd import GlobalGenerator, MultiDilatedGlobalGenerator, \
- NLayerDiscriminator, MultidilatedNLayerDiscriminator
-
-def make_generator(config, kind, **kwargs):
- logging.info(f'Make generator {kind}')
-
- if kind == 'pix2pixhd_multidilated':
- return MultiDilatedGlobalGenerator(**kwargs)
-
- if kind == 'pix2pixhd_global':
- return GlobalGenerator(**kwargs)
-
- if kind == 'ffc_resnet':
- return FFCResNetGenerator(**kwargs)
-
- raise ValueError(f'Unknown generator kind {kind}')
-
-
-def make_discriminator(kind, **kwargs):
- logging.info(f'Make discriminator {kind}')
-
- if kind == 'pix2pixhd_nlayer_multidilated':
- return MultidilatedNLayerDiscriminator(**kwargs)
-
- if kind == 'pix2pixhd_nlayer':
- return NLayerDiscriminator(**kwargs)
-
- raise ValueError(f'Unknown discriminator kind {kind}')
diff --git a/spaces/CVPR/regionclip-demo/detectron2/evaluation/cityscapes_evaluation.py b/spaces/CVPR/regionclip-demo/detectron2/evaluation/cityscapes_evaluation.py
deleted file mode 100644
index 3fb6c4cd5f752d639570d022cb23ce18491c370a..0000000000000000000000000000000000000000
--- a/spaces/CVPR/regionclip-demo/detectron2/evaluation/cityscapes_evaluation.py
+++ /dev/null
@@ -1,194 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import glob
-import logging
-import numpy as np
-import os
-import tempfile
-from collections import OrderedDict
-import torch
-from PIL import Image
-
-from detectron2.data import MetadataCatalog
-from detectron2.utils import comm
-from detectron2.utils.file_io import PathManager
-
-from .evaluator import DatasetEvaluator
-
-
-class CityscapesEvaluator(DatasetEvaluator):
- """
- Base class for evaluation using cityscapes API.
- """
-
- def __init__(self, dataset_name):
- """
- Args:
- dataset_name (str): the name of the dataset.
- It must have the following metadata associated with it:
- "thing_classes", "gt_dir".
- """
- self._metadata = MetadataCatalog.get(dataset_name)
- self._cpu_device = torch.device("cpu")
- self._logger = logging.getLogger(__name__)
-
- def reset(self):
- self._working_dir = tempfile.TemporaryDirectory(prefix="cityscapes_eval_")
- self._temp_dir = self._working_dir.name
- # All workers will write to the same results directory
- # TODO this does not work in distributed training
- self._temp_dir = comm.all_gather(self._temp_dir)[0]
- if self._temp_dir != self._working_dir.name:
- self._working_dir.cleanup()
- self._logger.info(
- "Writing cityscapes results to temporary directory {} ...".format(self._temp_dir)
- )
-
-
-class CityscapesInstanceEvaluator(CityscapesEvaluator):
- """
- Evaluate instance segmentation results on cityscapes dataset using cityscapes API.
-
- Note:
- * It does not work in multi-machine distributed training.
- * It contains a synchronization, therefore has to be used on all ranks.
- * Only the main process runs evaluation.
- """
-
- def process(self, inputs, outputs):
- from cityscapesscripts.helpers.labels import name2label
-
- for input, output in zip(inputs, outputs):
- file_name = input["file_name"]
- basename = os.path.splitext(os.path.basename(file_name))[0]
- pred_txt = os.path.join(self._temp_dir, basename + "_pred.txt")
-
- if "instances" in output:
- output = output["instances"].to(self._cpu_device)
- num_instances = len(output)
- with open(pred_txt, "w") as fout:
- for i in range(num_instances):
- pred_class = output.pred_classes[i]
- classes = self._metadata.thing_classes[pred_class]
- class_id = name2label[classes].id
- score = output.scores[i]
- mask = output.pred_masks[i].numpy().astype("uint8")
- png_filename = os.path.join(
- self._temp_dir, basename + "_{}_{}.png".format(i, classes)
- )
-
- Image.fromarray(mask * 255).save(png_filename)
- fout.write(
- "{} {} {}\n".format(os.path.basename(png_filename), class_id, score)
- )
- else:
- # Cityscapes requires a prediction file for every ground truth image.
- with open(pred_txt, "w") as fout:
- pass
-
- def evaluate(self):
- """
- Returns:
- dict: has a key "segm", whose value is a dict of "AP" and "AP50".
- """
- comm.synchronize()
- if comm.get_rank() > 0:
- return
- import cityscapesscripts.evaluation.evalInstanceLevelSemanticLabeling as cityscapes_eval
-
- self._logger.info("Evaluating results under {} ...".format(self._temp_dir))
-
- # set some global states in cityscapes evaluation API, before evaluating
- cityscapes_eval.args.predictionPath = os.path.abspath(self._temp_dir)
- cityscapes_eval.args.predictionWalk = None
- cityscapes_eval.args.JSONOutput = False
- cityscapes_eval.args.colorized = False
- cityscapes_eval.args.gtInstancesFile = os.path.join(self._temp_dir, "gtInstances.json")
-
- # These lines are adopted from
- # https://github.com/mcordts/cityscapesScripts/blob/master/cityscapesscripts/evaluation/evalInstanceLevelSemanticLabeling.py # noqa
- gt_dir = PathManager.get_local_path(self._metadata.gt_dir)
- groundTruthImgList = glob.glob(os.path.join(gt_dir, "*", "*_gtFine_instanceIds.png"))
- assert len(
- groundTruthImgList
- ), "Cannot find any ground truth images to use for evaluation. Searched for: {}".format(
- cityscapes_eval.args.groundTruthSearch
- )
- predictionImgList = []
- for gt in groundTruthImgList:
- predictionImgList.append(cityscapes_eval.getPrediction(gt, cityscapes_eval.args))
- results = cityscapes_eval.evaluateImgLists(
- predictionImgList, groundTruthImgList, cityscapes_eval.args
- )["averages"]
-
- ret = OrderedDict()
- ret["segm"] = {"AP": results["allAp"] * 100, "AP50": results["allAp50%"] * 100}
- self._working_dir.cleanup()
- return ret
-
-
-class CityscapesSemSegEvaluator(CityscapesEvaluator):
- """
- Evaluate semantic segmentation results on cityscapes dataset using cityscapes API.
-
- Note:
- * It does not work in multi-machine distributed training.
- * It contains a synchronization, therefore has to be used on all ranks.
- * Only the main process runs evaluation.
- """
-
- def process(self, inputs, outputs):
- from cityscapesscripts.helpers.labels import trainId2label
-
- for input, output in zip(inputs, outputs):
- file_name = input["file_name"]
- basename = os.path.splitext(os.path.basename(file_name))[0]
- pred_filename = os.path.join(self._temp_dir, basename + "_pred.png")
-
- output = output["sem_seg"].argmax(dim=0).to(self._cpu_device).numpy()
- pred = 255 * np.ones(output.shape, dtype=np.uint8)
- for train_id, label in trainId2label.items():
- if label.ignoreInEval:
- continue
- pred[output == train_id] = label.id
- Image.fromarray(pred).save(pred_filename)
-
- def evaluate(self):
- comm.synchronize()
- if comm.get_rank() > 0:
- return
- # Load the Cityscapes eval script *after* setting the required env var,
- # since the script reads CITYSCAPES_DATASET into global variables at load time.
- import cityscapesscripts.evaluation.evalPixelLevelSemanticLabeling as cityscapes_eval
-
- self._logger.info("Evaluating results under {} ...".format(self._temp_dir))
-
- # set some global states in cityscapes evaluation API, before evaluating
- cityscapes_eval.args.predictionPath = os.path.abspath(self._temp_dir)
- cityscapes_eval.args.predictionWalk = None
- cityscapes_eval.args.JSONOutput = False
- cityscapes_eval.args.colorized = False
-
- # These lines are adopted from
- # https://github.com/mcordts/cityscapesScripts/blob/master/cityscapesscripts/evaluation/evalPixelLevelSemanticLabeling.py # noqa
- gt_dir = PathManager.get_local_path(self._metadata.gt_dir)
- groundTruthImgList = glob.glob(os.path.join(gt_dir, "*", "*_gtFine_labelIds.png"))
- assert len(
- groundTruthImgList
- ), "Cannot find any ground truth images to use for evaluation. Searched for: {}".format(
- cityscapes_eval.args.groundTruthSearch
- )
- predictionImgList = []
- for gt in groundTruthImgList:
- predictionImgList.append(cityscapes_eval.getPrediction(cityscapes_eval.args, gt))
- results = cityscapes_eval.evaluateImgLists(
- predictionImgList, groundTruthImgList, cityscapes_eval.args
- )
- ret = OrderedDict()
- ret["sem_seg"] = {
- "IoU": 100.0 * results["averageScoreClasses"],
- "iIoU": 100.0 * results["averageScoreInstClasses"],
- "IoU_sup": 100.0 * results["averageScoreCategories"],
- "iIoU_sup": 100.0 * results["averageScoreInstCategories"],
- }
- self._working_dir.cleanup()
- return ret
diff --git a/spaces/CognitiveLabs/Research-Assistant/README.md b/spaces/CognitiveLabs/Research-Assistant/README.md
deleted file mode 100644
index 7a4e2ed156df4e83de5f21e3b8c463ee5c0ac09d..0000000000000000000000000000000000000000
--- a/spaces/CognitiveLabs/Research-Assistant/README.md
+++ /dev/null
@@ -1,78 +0,0 @@
----
-title: AI-Research-Assistant
-app_file: app.py
-sdk: gradio
-sdk_version: 3.38.0
-duplicated_from: zej97/AI-Research-Assistant
----
-
-

-
-
 |
|  |
|  |
-
-The currently supported agents encompass a wide range of fields, including *finance, business analysis, clinical medicine, basic medicine, travel, academic research and sociology*.
-
-In addition to official api, this project offers an alternative approach to generating research reports by utilizing a third-party API. For access to this third-party API, please refer to [chimeragpt](https://chimeragpt.adventblocks.cc/) or [GPT-API-free](https://github.com/chatanywhere/GPT_API_free). Before running the project, kindly ensure that you set the environment variables `OPENAI_API_KEY` and `OPENAI_API_BASE`.
-
-```shell
-$ export OPENAI_API_KEY = your_api_key
-$ export OPENAI_API_BASE = your_api_base
-```
-
-or you can set the api key and base in `.env` file.
-
-
-## Installation
-
-1. Clone the repository
-
- ```shell
- $ git clone git@github.com:paradoxtown/ai_research_assistant.git
- $ cd ai_research_assistant
- ```
-
-2. Install the dependencies
-
- ```shell
- $ pip install -r requirements.txt
- ```
-
-3. Export evnironment variables
-
- ```shell
- $ export OPENAI_API_KEY = your_api_key
- $ export OPENAI_API_BASE = your_api_base
- ```
- or modify the `.env` file.
-
-4. Run the project
-
- ```shell
- $ python app.py
- ```
-
-## TODO
-
-- [x] Switch Google Search to DuckDuckGo
-- [ ] Literature review
-- [x] Third-party API
-- [ ] Prettify report
-- [x] Add medical agent and social agent
-- [ ] Add option for users to customize the number of words and temperature
-- [ ] Copy and download buttons
-- [ ] Allows the user to choose the degree of research.
-- [ ] Wikipedia Understanding
-
----
-
-
|
-
-The currently supported agents encompass a wide range of fields, including *finance, business analysis, clinical medicine, basic medicine, travel, academic research and sociology*.
-
-In addition to official api, this project offers an alternative approach to generating research reports by utilizing a third-party API. For access to this third-party API, please refer to [chimeragpt](https://chimeragpt.adventblocks.cc/) or [GPT-API-free](https://github.com/chatanywhere/GPT_API_free). Before running the project, kindly ensure that you set the environment variables `OPENAI_API_KEY` and `OPENAI_API_BASE`.
-
-```shell
-$ export OPENAI_API_KEY = your_api_key
-$ export OPENAI_API_BASE = your_api_base
-```
-
-or you can set the api key and base in `.env` file.
-
-
-## Installation
-
-1. Clone the repository
-
- ```shell
- $ git clone git@github.com:paradoxtown/ai_research_assistant.git
- $ cd ai_research_assistant
- ```
-
-2. Install the dependencies
-
- ```shell
- $ pip install -r requirements.txt
- ```
-
-3. Export evnironment variables
-
- ```shell
- $ export OPENAI_API_KEY = your_api_key
- $ export OPENAI_API_BASE = your_api_base
- ```
- or modify the `.env` file.
-
-4. Run the project
-
- ```shell
- $ python app.py
- ```
-
-## TODO
-
-- [x] Switch Google Search to DuckDuckGo
-- [ ] Literature review
-- [x] Third-party API
-- [ ] Prettify report
-- [x] Add medical agent and social agent
-- [ ] Add option for users to customize the number of words and temperature
-- [ ] Copy and download buttons
-- [ ] Allows the user to choose the degree of research.
-- [ ] Wikipedia Understanding
-
----
-
-Happy researching! 🚀
\ No newline at end of file
diff --git a/spaces/Cropinky/hana_hanak_houses/networks_fastgan.py b/spaces/Cropinky/hana_hanak_houses/networks_fastgan.py
deleted file mode 100644
index d517e6b53b7bb6d83ce5df00b5111073e3cf3c24..0000000000000000000000000000000000000000
--- a/spaces/Cropinky/hana_hanak_houses/networks_fastgan.py
+++ /dev/null
@@ -1,179 +0,0 @@
-# original implementation: https://github.com/odegeasslbc/FastGAN-pytorch/blob/main/models.py
-#
-# modified by Axel Sauer for "Projected GANs Converge Faster"
-#
-import torch.nn as nn
-from blocks import (InitLayer, UpBlockBig, UpBlockBigCond, UpBlockSmall, UpBlockSmallCond, SEBlock, conv2d)
-from huggingface_hub import PyTorchModelHubMixin
-
-def normalize_second_moment(x, dim=1, eps=1e-8):
- return x * (x.square().mean(dim=dim, keepdim=True) + eps).rsqrt()
-
-
-class DummyMapping(nn.Module):
- def __init__(self):
- super().__init__()
-
- def forward(self, z, c, **kwargs):
- return z.unsqueeze(1) # to fit the StyleGAN API
-
-
-class FastganSynthesis(nn.Module):
- def __init__(self, ngf=128, z_dim=256, nc=3, img_resolution=256, lite=False):
- super().__init__()
- self.img_resolution = img_resolution
- self.z_dim = z_dim
-
- # channel multiplier
- nfc_multi = {2: 16, 4:16, 8:8, 16:4, 32:2, 64:2, 128:1, 256:0.5,
- 512:0.25, 1024:0.125}
- nfc = {}
- for k, v in nfc_multi.items():
- nfc[k] = int(v*ngf)
-
- # layers
- self.init = InitLayer(z_dim, channel=nfc[2], sz=4)
-
- UpBlock = UpBlockSmall if lite else UpBlockBig
-
- self.feat_8 = UpBlock(nfc[4], nfc[8])
- self.feat_16 = UpBlock(nfc[8], nfc[16])
- self.feat_32 = UpBlock(nfc[16], nfc[32])
- self.feat_64 = UpBlock(nfc[32], nfc[64])
- self.feat_128 = UpBlock(nfc[64], nfc[128])
- self.feat_256 = UpBlock(nfc[128], nfc[256])
-
- self.se_64 = SEBlock(nfc[4], nfc[64])
- self.se_128 = SEBlock(nfc[8], nfc[128])
- self.se_256 = SEBlock(nfc[16], nfc[256])
-
- self.to_big = conv2d(nfc[img_resolution], nc, 3, 1, 1, bias=True)
-
- if img_resolution > 256:
- self.feat_512 = UpBlock(nfc[256], nfc[512])
- self.se_512 = SEBlock(nfc[32], nfc[512])
- if img_resolution > 512:
- self.feat_1024 = UpBlock(nfc[512], nfc[1024])
-
- def forward(self, input, c, **kwargs):
- # map noise to hypersphere as in "Progressive Growing of GANS"
- input = normalize_second_moment(input[:, 0])
-
- feat_4 = self.init(input)
- feat_8 = self.feat_8(feat_4)
- feat_16 = self.feat_16(feat_8)
- feat_32 = self.feat_32(feat_16)
- feat_64 = self.se_64(feat_4, self.feat_64(feat_32))
- feat_128 = self.se_128(feat_8, self.feat_128(feat_64))
-
- if self.img_resolution >= 128:
- feat_last = feat_128
-
- if self.img_resolution >= 256:
- feat_last = self.se_256(feat_16, self.feat_256(feat_last))
-
- if self.img_resolution >= 512:
- feat_last = self.se_512(feat_32, self.feat_512(feat_last))
-
- if self.img_resolution >= 1024:
- feat_last = self.feat_1024(feat_last)
-
- return self.to_big(feat_last)
-
-
-class FastganSynthesisCond(nn.Module):
- def __init__(self, ngf=64, z_dim=256, nc=3, img_resolution=256, num_classes=1000, lite=False):
- super().__init__()
-
- self.z_dim = z_dim
- nfc_multi = {2: 16, 4:16, 8:8, 16:4, 32:2, 64:2, 128:1, 256:0.5,
- 512:0.25, 1024:0.125, 2048:0.125}
- nfc = {}
- for k, v in nfc_multi.items():
- nfc[k] = int(v*ngf)
-
- self.img_resolution = img_resolution
-
- self.init = InitLayer(z_dim, channel=nfc[2], sz=4)
-
- UpBlock = UpBlockSmallCond if lite else UpBlockBigCond
-
- self.feat_8 = UpBlock(nfc[4], nfc[8], z_dim)
- self.feat_16 = UpBlock(nfc[8], nfc[16], z_dim)
- self.feat_32 = UpBlock(nfc[16], nfc[32], z_dim)
- self.feat_64 = UpBlock(nfc[32], nfc[64], z_dim)
- self.feat_128 = UpBlock(nfc[64], nfc[128], z_dim)
- self.feat_256 = UpBlock(nfc[128], nfc[256], z_dim)
-
- self.se_64 = SEBlock(nfc[4], nfc[64])
- self.se_128 = SEBlock(nfc[8], nfc[128])
- self.se_256 = SEBlock(nfc[16], nfc[256])
-
- self.to_big = conv2d(nfc[img_resolution], nc, 3, 1, 1, bias=True)
-
- if img_resolution > 256:
- self.feat_512 = UpBlock(nfc[256], nfc[512])
- self.se_512 = SEBlock(nfc[32], nfc[512])
- if img_resolution > 512:
- self.feat_1024 = UpBlock(nfc[512], nfc[1024])
-
- self.embed = nn.Embedding(num_classes, z_dim)
-
- def forward(self, input, c, update_emas=False):
- c = self.embed(c.argmax(1))
-
- # map noise to hypersphere as in "Progressive Growing of GANS"
- input = normalize_second_moment(input[:, 0])
-
- feat_4 = self.init(input)
- feat_8 = self.feat_8(feat_4, c)
- feat_16 = self.feat_16(feat_8, c)
- feat_32 = self.feat_32(feat_16, c)
- feat_64 = self.se_64(feat_4, self.feat_64(feat_32, c))
- feat_128 = self.se_128(feat_8, self.feat_128(feat_64, c))
-
- if self.img_resolution >= 128:
- feat_last = feat_128
-
- if self.img_resolution >= 256:
- feat_last = self.se_256(feat_16, self.feat_256(feat_last, c))
-
- if self.img_resolution >= 512:
- feat_last = self.se_512(feat_32, self.feat_512(feat_last, c))
-
- if self.img_resolution >= 1024:
- feat_last = self.feat_1024(feat_last, c)
-
- return self.to_big(feat_last)
-
-
-class MyGenerator(nn.Module, PyTorchModelHubMixin):
- def __init__(
- self,
- z_dim=256,
- c_dim=0,
- w_dim=0,
- img_resolution=256,
- img_channels=3,
- ngf=128,
- cond=0,
- mapping_kwargs={},
- synthesis_kwargs={}
- ):
- super().__init__()
- #self.config = kwargs.pop("config", None)
- self.z_dim = z_dim
- self.c_dim = c_dim
- self.w_dim = w_dim
- self.img_resolution = img_resolution
- self.img_channels = img_channels
-
- # Mapping and Synthesis Networks
- self.mapping = DummyMapping() # to fit the StyleGAN API
- Synthesis = FastganSynthesisCond if cond else FastganSynthesis
- self.synthesis = Synthesis(ngf=ngf, z_dim=z_dim, nc=img_channels, img_resolution=img_resolution, **synthesis_kwargs)
-
- def forward(self, z, c, **kwargs):
- w = self.mapping(z, c)
- img = self.synthesis(w, c)
- return img
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/McIdasImagePlugin.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/McIdasImagePlugin.py
deleted file mode 100644
index 17c008b9a6a1218f6e51add4fda83acb92ee06ce..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/McIdasImagePlugin.py
+++ /dev/null
@@ -1,75 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# Basic McIdas support for PIL
-#
-# History:
-# 1997-05-05 fl Created (8-bit images only)
-# 2009-03-08 fl Added 16/32-bit support.
-#
-# Thanks to Richard Jones and Craig Swank for specs and samples.
-#
-# Copyright (c) Secret Labs AB 1997.
-# Copyright (c) Fredrik Lundh 1997.
-#
-# See the README file for information on usage and redistribution.
-#
-
-import struct
-
-from . import Image, ImageFile
-
-
-def _accept(s):
- return s[:8] == b"\x00\x00\x00\x00\x00\x00\x00\x04"
-
-
-##
-# Image plugin for McIdas area images.
-
-
-class McIdasImageFile(ImageFile.ImageFile):
- format = "MCIDAS"
- format_description = "McIdas area file"
-
- def _open(self):
- # parse area file directory
- s = self.fp.read(256)
- if not _accept(s) or len(s) != 256:
- msg = "not an McIdas area file"
- raise SyntaxError(msg)
-
- self.area_descriptor_raw = s
- self.area_descriptor = w = [0] + list(struct.unpack("!64i", s))
-
- # get mode
- if w[11] == 1:
- mode = rawmode = "L"
- elif w[11] == 2:
- # FIXME: add memory map support
- mode = "I"
- rawmode = "I;16B"
- elif w[11] == 4:
- # FIXME: add memory map support
- mode = "I"
- rawmode = "I;32B"
- else:
- msg = "unsupported McIdas format"
- raise SyntaxError(msg)
-
- self.mode = mode
- self._size = w[10], w[9]
-
- offset = w[34] + w[15]
- stride = w[15] + w[10] * w[11] * w[14]
-
- self.tile = [("raw", (0, 0) + self.size, offset, (rawmode, stride, 1))]
-
-
-# --------------------------------------------------------------------
-# registry
-
-Image.register_open(McIdasImageFile.format, McIdasImageFile, _accept)
-
-# no default extension
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/click/_termui_impl.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/click/_termui_impl.py
deleted file mode 100644
index f744657753caa6cdef1dcc41a4f0b5e3e9503ab8..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/click/_termui_impl.py
+++ /dev/null
@@ -1,739 +0,0 @@
-"""
-This module contains implementations for the termui module. To keep the
-import time of Click down, some infrequently used functionality is
-placed in this module and only imported as needed.
-"""
-import contextlib
-import math
-import os
-import sys
-import time
-import typing as t
-from gettext import gettext as _
-from io import StringIO
-from types import TracebackType
-
-from ._compat import _default_text_stdout
-from ._compat import CYGWIN
-from ._compat import get_best_encoding
-from ._compat import isatty
-from ._compat import open_stream
-from ._compat import strip_ansi
-from ._compat import term_len
-from ._compat import WIN
-from .exceptions import ClickException
-from .utils import echo
-
-V = t.TypeVar("V")
-
-if os.name == "nt":
- BEFORE_BAR = "\r"
- AFTER_BAR = "\n"
-else:
- BEFORE_BAR = "\r\033[?25l"
- AFTER_BAR = "\033[?25h\n"
-
-
-class ProgressBar(t.Generic[V]):
- def __init__(
- self,
- iterable: t.Optional[t.Iterable[V]],
- length: t.Optional[int] = None,
- fill_char: str = "#",
- empty_char: str = " ",
- bar_template: str = "%(bar)s",
- info_sep: str = " ",
- show_eta: bool = True,
- show_percent: t.Optional[bool] = None,
- show_pos: bool = False,
- item_show_func: t.Optional[t.Callable[[t.Optional[V]], t.Optional[str]]] = None,
- label: t.Optional[str] = None,
- file: t.Optional[t.TextIO] = None,
- color: t.Optional[bool] = None,
- update_min_steps: int = 1,
- width: int = 30,
- ) -> None:
- self.fill_char = fill_char
- self.empty_char = empty_char
- self.bar_template = bar_template
- self.info_sep = info_sep
- self.show_eta = show_eta
- self.show_percent = show_percent
- self.show_pos = show_pos
- self.item_show_func = item_show_func
- self.label: str = label or ""
-
- if file is None:
- file = _default_text_stdout()
-
- # There are no standard streams attached to write to. For example,
- # pythonw on Windows.
- if file is None:
- file = StringIO()
-
- self.file = file
- self.color = color
- self.update_min_steps = update_min_steps
- self._completed_intervals = 0
- self.width: int = width
- self.autowidth: bool = width == 0
-
- if length is None:
- from operator import length_hint
-
- length = length_hint(iterable, -1)
-
- if length == -1:
- length = None
- if iterable is None:
- if length is None:
- raise TypeError("iterable or length is required")
- iterable = t.cast(t.Iterable[V], range(length))
- self.iter: t.Iterable[V] = iter(iterable)
- self.length = length
- self.pos = 0
- self.avg: t.List[float] = []
- self.last_eta: float
- self.start: float
- self.start = self.last_eta = time.time()
- self.eta_known: bool = False
- self.finished: bool = False
- self.max_width: t.Optional[int] = None
- self.entered: bool = False
- self.current_item: t.Optional[V] = None
- self.is_hidden: bool = not isatty(self.file)
- self._last_line: t.Optional[str] = None
-
- def __enter__(self) -> "ProgressBar[V]":
- self.entered = True
- self.render_progress()
- return self
-
- def __exit__(
- self,
- exc_type: t.Optional[t.Type[BaseException]],
- exc_value: t.Optional[BaseException],
- tb: t.Optional[TracebackType],
- ) -> None:
- self.render_finish()
-
- def __iter__(self) -> t.Iterator[V]:
- if not self.entered:
- raise RuntimeError("You need to use progress bars in a with block.")
- self.render_progress()
- return self.generator()
-
- def __next__(self) -> V:
- # Iteration is defined in terms of a generator function,
- # returned by iter(self); use that to define next(). This works
- # because `self.iter` is an iterable consumed by that generator,
- # so it is re-entry safe. Calling `next(self.generator())`
- # twice works and does "what you want".
- return next(iter(self))
-
- def render_finish(self) -> None:
- if self.is_hidden:
- return
- self.file.write(AFTER_BAR)
- self.file.flush()
-
- @property
- def pct(self) -> float:
- if self.finished:
- return 1.0
- return min(self.pos / (float(self.length or 1) or 1), 1.0)
-
- @property
- def time_per_iteration(self) -> float:
- if not self.avg:
- return 0.0
- return sum(self.avg) / float(len(self.avg))
-
- @property
- def eta(self) -> float:
- if self.length is not None and not self.finished:
- return self.time_per_iteration * (self.length - self.pos)
- return 0.0
-
- def format_eta(self) -> str:
- if self.eta_known:
- t = int(self.eta)
- seconds = t % 60
- t //= 60
- minutes = t % 60
- t //= 60
- hours = t % 24
- t //= 24
- if t > 0:
- return f"{t}d {hours:02}:{minutes:02}:{seconds:02}"
- else:
- return f"{hours:02}:{minutes:02}:{seconds:02}"
- return ""
-
- def format_pos(self) -> str:
- pos = str(self.pos)
- if self.length is not None:
- pos += f"/{self.length}"
- return pos
-
- def format_pct(self) -> str:
- return f"{int(self.pct * 100): 4}%"[1:]
-
- def format_bar(self) -> str:
- if self.length is not None:
- bar_length = int(self.pct * self.width)
- bar = self.fill_char * bar_length
- bar += self.empty_char * (self.width - bar_length)
- elif self.finished:
- bar = self.fill_char * self.width
- else:
- chars = list(self.empty_char * (self.width or 1))
- if self.time_per_iteration != 0:
- chars[
- int(
- (math.cos(self.pos * self.time_per_iteration) / 2.0 + 0.5)
- * self.width
- )
- ] = self.fill_char
- bar = "".join(chars)
- return bar
-
- def format_progress_line(self) -> str:
- show_percent = self.show_percent
-
- info_bits = []
- if self.length is not None and show_percent is None:
- show_percent = not self.show_pos
-
- if self.show_pos:
- info_bits.append(self.format_pos())
- if show_percent:
- info_bits.append(self.format_pct())
- if self.show_eta and self.eta_known and not self.finished:
- info_bits.append(self.format_eta())
- if self.item_show_func is not None:
- item_info = self.item_show_func(self.current_item)
- if item_info is not None:
- info_bits.append(item_info)
-
- return (
- self.bar_template
- % {
- "label": self.label,
- "bar": self.format_bar(),
- "info": self.info_sep.join(info_bits),
- }
- ).rstrip()
-
- def render_progress(self) -> None:
- import shutil
-
- if self.is_hidden:
- # Only output the label as it changes if the output is not a
- # TTY. Use file=stderr if you expect to be piping stdout.
- if self._last_line != self.label:
- self._last_line = self.label
- echo(self.label, file=self.file, color=self.color)
-
- return
-
- buf = []
- # Update width in case the terminal has been resized
- if self.autowidth:
- old_width = self.width
- self.width = 0
- clutter_length = term_len(self.format_progress_line())
- new_width = max(0, shutil.get_terminal_size().columns - clutter_length)
- if new_width < old_width:
- buf.append(BEFORE_BAR)
- buf.append(" " * self.max_width) # type: ignore
- self.max_width = new_width
- self.width = new_width
-
- clear_width = self.width
- if self.max_width is not None:
- clear_width = self.max_width
-
- buf.append(BEFORE_BAR)
- line = self.format_progress_line()
- line_len = term_len(line)
- if self.max_width is None or self.max_width < line_len:
- self.max_width = line_len
-
- buf.append(line)
- buf.append(" " * (clear_width - line_len))
- line = "".join(buf)
- # Render the line only if it changed.
-
- if line != self._last_line:
- self._last_line = line
- echo(line, file=self.file, color=self.color, nl=False)
- self.file.flush()
-
- def make_step(self, n_steps: int) -> None:
- self.pos += n_steps
- if self.length is not None and self.pos >= self.length:
- self.finished = True
-
- if (time.time() - self.last_eta) < 1.0:
- return
-
- self.last_eta = time.time()
-
- # self.avg is a rolling list of length <= 7 of steps where steps are
- # defined as time elapsed divided by the total progress through
- # self.length.
- if self.pos:
- step = (time.time() - self.start) / self.pos
- else:
- step = time.time() - self.start
-
- self.avg = self.avg[-6:] + [step]
-
- self.eta_known = self.length is not None
-
- def update(self, n_steps: int, current_item: t.Optional[V] = None) -> None:
- """Update the progress bar by advancing a specified number of
- steps, and optionally set the ``current_item`` for this new
- position.
-
- :param n_steps: Number of steps to advance.
- :param current_item: Optional item to set as ``current_item``
- for the updated position.
-
- .. versionchanged:: 8.0
- Added the ``current_item`` optional parameter.
-
- .. versionchanged:: 8.0
- Only render when the number of steps meets the
- ``update_min_steps`` threshold.
- """
- if current_item is not None:
- self.current_item = current_item
-
- self._completed_intervals += n_steps
-
- if self._completed_intervals >= self.update_min_steps:
- self.make_step(self._completed_intervals)
- self.render_progress()
- self._completed_intervals = 0
-
- def finish(self) -> None:
- self.eta_known = False
- self.current_item = None
- self.finished = True
-
- def generator(self) -> t.Iterator[V]:
- """Return a generator which yields the items added to the bar
- during construction, and updates the progress bar *after* the
- yielded block returns.
- """
- # WARNING: the iterator interface for `ProgressBar` relies on
- # this and only works because this is a simple generator which
- # doesn't create or manage additional state. If this function
- # changes, the impact should be evaluated both against
- # `iter(bar)` and `next(bar)`. `next()` in particular may call
- # `self.generator()` repeatedly, and this must remain safe in
- # order for that interface to work.
- if not self.entered:
- raise RuntimeError("You need to use progress bars in a with block.")
-
- if self.is_hidden:
- yield from self.iter
- else:
- for rv in self.iter:
- self.current_item = rv
-
- # This allows show_item_func to be updated before the
- # item is processed. Only trigger at the beginning of
- # the update interval.
- if self._completed_intervals == 0:
- self.render_progress()
-
- yield rv
- self.update(1)
-
- self.finish()
- self.render_progress()
-
-
-def pager(generator: t.Iterable[str], color: t.Optional[bool] = None) -> None:
- """Decide what method to use for paging through text."""
- stdout = _default_text_stdout()
-
- # There are no standard streams attached to write to. For example,
- # pythonw on Windows.
- if stdout is None:
- stdout = StringIO()
-
- if not isatty(sys.stdin) or not isatty(stdout):
- return _nullpager(stdout, generator, color)
- pager_cmd = (os.environ.get("PAGER", None) or "").strip()
- if pager_cmd:
- if WIN:
- return _tempfilepager(generator, pager_cmd, color)
- return _pipepager(generator, pager_cmd, color)
- if os.environ.get("TERM") in ("dumb", "emacs"):
- return _nullpager(stdout, generator, color)
- if WIN or sys.platform.startswith("os2"):
- return _tempfilepager(generator, "more <", color)
- if hasattr(os, "system") and os.system("(less) 2>/dev/null") == 0:
- return _pipepager(generator, "less", color)
-
- import tempfile
-
- fd, filename = tempfile.mkstemp()
- os.close(fd)
- try:
- if hasattr(os, "system") and os.system(f'more "{filename}"') == 0:
- return _pipepager(generator, "more", color)
- return _nullpager(stdout, generator, color)
- finally:
- os.unlink(filename)
-
-
-def _pipepager(generator: t.Iterable[str], cmd: str, color: t.Optional[bool]) -> None:
- """Page through text by feeding it to another program. Invoking a
- pager through this might support colors.
- """
- import subprocess
-
- env = dict(os.environ)
-
- # If we're piping to less we might support colors under the
- # condition that
- cmd_detail = cmd.rsplit("/", 1)[-1].split()
- if color is None and cmd_detail[0] == "less":
- less_flags = f"{os.environ.get('LESS', '')}{' '.join(cmd_detail[1:])}"
- if not less_flags:
- env["LESS"] = "-R"
- color = True
- elif "r" in less_flags or "R" in less_flags:
- color = True
-
- c = subprocess.Popen(cmd, shell=True, stdin=subprocess.PIPE, env=env)
- stdin = t.cast(t.BinaryIO, c.stdin)
- encoding = get_best_encoding(stdin)
- try:
- for text in generator:
- if not color:
- text = strip_ansi(text)
-
- stdin.write(text.encode(encoding, "replace"))
- except (OSError, KeyboardInterrupt):
- pass
- else:
- stdin.close()
-
- # Less doesn't respect ^C, but catches it for its own UI purposes (aborting
- # search or other commands inside less).
- #
- # That means when the user hits ^C, the parent process (click) terminates,
- # but less is still alive, paging the output and messing up the terminal.
- #
- # If the user wants to make the pager exit on ^C, they should set
- # `LESS='-K'`. It's not our decision to make.
- while True:
- try:
- c.wait()
- except KeyboardInterrupt:
- pass
- else:
- break
-
-
-def _tempfilepager(
- generator: t.Iterable[str], cmd: str, color: t.Optional[bool]
-) -> None:
- """Page through text by invoking a program on a temporary file."""
- import tempfile
-
- fd, filename = tempfile.mkstemp()
- # TODO: This never terminates if the passed generator never terminates.
- text = "".join(generator)
- if not color:
- text = strip_ansi(text)
- encoding = get_best_encoding(sys.stdout)
- with open_stream(filename, "wb")[0] as f:
- f.write(text.encode(encoding))
- try:
- os.system(f'{cmd} "{filename}"')
- finally:
- os.close(fd)
- os.unlink(filename)
-
-
-def _nullpager(
- stream: t.TextIO, generator: t.Iterable[str], color: t.Optional[bool]
-) -> None:
- """Simply print unformatted text. This is the ultimate fallback."""
- for text in generator:
- if not color:
- text = strip_ansi(text)
- stream.write(text)
-
-
-class Editor:
- def __init__(
- self,
- editor: t.Optional[str] = None,
- env: t.Optional[t.Mapping[str, str]] = None,
- require_save: bool = True,
- extension: str = ".txt",
- ) -> None:
- self.editor = editor
- self.env = env
- self.require_save = require_save
- self.extension = extension
-
- def get_editor(self) -> str:
- if self.editor is not None:
- return self.editor
- for key in "VISUAL", "EDITOR":
- rv = os.environ.get(key)
- if rv:
- return rv
- if WIN:
- return "notepad"
- for editor in "sensible-editor", "vim", "nano":
- if os.system(f"which {editor} >/dev/null 2>&1") == 0:
- return editor
- return "vi"
-
- def edit_file(self, filename: str) -> None:
- import subprocess
-
- editor = self.get_editor()
- environ: t.Optional[t.Dict[str, str]] = None
-
- if self.env:
- environ = os.environ.copy()
- environ.update(self.env)
-
- try:
- c = subprocess.Popen(f'{editor} "{filename}"', env=environ, shell=True)
- exit_code = c.wait()
- if exit_code != 0:
- raise ClickException(
- _("{editor}: Editing failed").format(editor=editor)
- )
- except OSError as e:
- raise ClickException(
- _("{editor}: Editing failed: {e}").format(editor=editor, e=e)
- ) from e
-
- def edit(self, text: t.Optional[t.AnyStr]) -> t.Optional[t.AnyStr]:
- import tempfile
-
- if not text:
- data = b""
- elif isinstance(text, (bytes, bytearray)):
- data = text
- else:
- if text and not text.endswith("\n"):
- text += "\n"
-
- if WIN:
- data = text.replace("\n", "\r\n").encode("utf-8-sig")
- else:
- data = text.encode("utf-8")
-
- fd, name = tempfile.mkstemp(prefix="editor-", suffix=self.extension)
- f: t.BinaryIO
-
- try:
- with os.fdopen(fd, "wb") as f:
- f.write(data)
-
- # If the filesystem resolution is 1 second, like Mac OS
- # 10.12 Extended, or 2 seconds, like FAT32, and the editor
- # closes very fast, require_save can fail. Set the modified
- # time to be 2 seconds in the past to work around this.
- os.utime(name, (os.path.getatime(name), os.path.getmtime(name) - 2))
- # Depending on the resolution, the exact value might not be
- # recorded, so get the new recorded value.
- timestamp = os.path.getmtime(name)
-
- self.edit_file(name)
-
- if self.require_save and os.path.getmtime(name) == timestamp:
- return None
-
- with open(name, "rb") as f:
- rv = f.read()
-
- if isinstance(text, (bytes, bytearray)):
- return rv
-
- return rv.decode("utf-8-sig").replace("\r\n", "\n") # type: ignore
- finally:
- os.unlink(name)
-
-
-def open_url(url: str, wait: bool = False, locate: bool = False) -> int:
- import subprocess
-
- def _unquote_file(url: str) -> str:
- from urllib.parse import unquote
-
- if url.startswith("file://"):
- url = unquote(url[7:])
-
- return url
-
- if sys.platform == "darwin":
- args = ["open"]
- if wait:
- args.append("-W")
- if locate:
- args.append("-R")
- args.append(_unquote_file(url))
- null = open("/dev/null", "w")
- try:
- return subprocess.Popen(args, stderr=null).wait()
- finally:
- null.close()
- elif WIN:
- if locate:
- url = _unquote_file(url.replace('"', ""))
- args = f'explorer /select,"{url}"'
- else:
- url = url.replace('"', "")
- wait_str = "/WAIT" if wait else ""
- args = f'start {wait_str} "" "{url}"'
- return os.system(args)
- elif CYGWIN:
- if locate:
- url = os.path.dirname(_unquote_file(url).replace('"', ""))
- args = f'cygstart "{url}"'
- else:
- url = url.replace('"', "")
- wait_str = "-w" if wait else ""
- args = f'cygstart {wait_str} "{url}"'
- return os.system(args)
-
- try:
- if locate:
- url = os.path.dirname(_unquote_file(url)) or "."
- else:
- url = _unquote_file(url)
- c = subprocess.Popen(["xdg-open", url])
- if wait:
- return c.wait()
- return 0
- except OSError:
- if url.startswith(("http://", "https://")) and not locate and not wait:
- import webbrowser
-
- webbrowser.open(url)
- return 0
- return 1
-
-
-def _translate_ch_to_exc(ch: str) -> t.Optional[BaseException]:
- if ch == "\x03":
- raise KeyboardInterrupt()
-
- if ch == "\x04" and not WIN: # Unix-like, Ctrl+D
- raise EOFError()
-
- if ch == "\x1a" and WIN: # Windows, Ctrl+Z
- raise EOFError()
-
- return None
-
-
-if WIN:
- import msvcrt
-
- @contextlib.contextmanager
- def raw_terminal() -> t.Iterator[int]:
- yield -1
-
- def getchar(echo: bool) -> str:
- # The function `getch` will return a bytes object corresponding to
- # the pressed character. Since Windows 10 build 1803, it will also
- # return \x00 when called a second time after pressing a regular key.
- #
- # `getwch` does not share this probably-bugged behavior. Moreover, it
- # returns a Unicode object by default, which is what we want.
- #
- # Either of these functions will return \x00 or \xe0 to indicate
- # a special key, and you need to call the same function again to get
- # the "rest" of the code. The fun part is that \u00e0 is
- # "latin small letter a with grave", so if you type that on a French
- # keyboard, you _also_ get a \xe0.
- # E.g., consider the Up arrow. This returns \xe0 and then \x48. The
- # resulting Unicode string reads as "a with grave" + "capital H".
- # This is indistinguishable from when the user actually types
- # "a with grave" and then "capital H".
- #
- # When \xe0 is returned, we assume it's part of a special-key sequence
- # and call `getwch` again, but that means that when the user types
- # the \u00e0 character, `getchar` doesn't return until a second
- # character is typed.
- # The alternative is returning immediately, but that would mess up
- # cross-platform handling of arrow keys and others that start with
- # \xe0. Another option is using `getch`, but then we can't reliably
- # read non-ASCII characters, because return values of `getch` are
- # limited to the current 8-bit codepage.
- #
- # Anyway, Click doesn't claim to do this Right(tm), and using `getwch`
- # is doing the right thing in more situations than with `getch`.
- func: t.Callable[[], str]
-
- if echo:
- func = msvcrt.getwche # type: ignore
- else:
- func = msvcrt.getwch # type: ignore
-
- rv = func()
-
- if rv in ("\x00", "\xe0"):
- # \x00 and \xe0 are control characters that indicate special key,
- # see above.
- rv += func()
-
- _translate_ch_to_exc(rv)
- return rv
-
-else:
- import tty
- import termios
-
- @contextlib.contextmanager
- def raw_terminal() -> t.Iterator[int]:
- f: t.Optional[t.TextIO]
- fd: int
-
- if not isatty(sys.stdin):
- f = open("/dev/tty")
- fd = f.fileno()
- else:
- fd = sys.stdin.fileno()
- f = None
-
- try:
- old_settings = termios.tcgetattr(fd)
-
- try:
- tty.setraw(fd)
- yield fd
- finally:
- termios.tcsetattr(fd, termios.TCSADRAIN, old_settings)
- sys.stdout.flush()
-
- if f is not None:
- f.close()
- except termios.error:
- pass
-
- def getchar(echo: bool) -> str:
- with raw_terminal() as fd:
- ch = os.read(fd, 32).decode(get_best_encoding(sys.stdin), "replace")
-
- if echo and isatty(sys.stdout):
- sys.stdout.write(ch)
-
- _translate_ch_to_exc(ch)
- return ch
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/__vite-browser-external-b25bb000.js b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/__vite-browser-external-b25bb000.js
deleted file mode 100644
index efa8971d2172dd2c1924c07a4e2b2bc18871ccd9..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/__vite-browser-external-b25bb000.js
+++ /dev/null
@@ -1,2 +0,0 @@
-const e={};export{e as default};
-//# sourceMappingURL=__vite-browser-external-b25bb000.js.map
diff --git a/spaces/DaleChen/AutoGPT/autogpt/permanent_memory/__init__.py b/spaces/DaleChen/AutoGPT/autogpt/permanent_memory/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Daniton/midjourney-singular/app.py b/spaces/Daniton/midjourney-singular/app.py
deleted file mode 100644
index 2193905172b6fb6d868bff88cc8311f491ec13b3..0000000000000000000000000000000000000000
--- a/spaces/Daniton/midjourney-singular/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/prompthero/openjourney").launch()
\ No newline at end of file
diff --git a/spaces/Datasculptor/DescriptionGPT/detic/data/datasets/register_oid.py b/spaces/Datasculptor/DescriptionGPT/detic/data/datasets/register_oid.py
deleted file mode 100644
index bd281f53f07074740b453838ba32f42f81a28383..0000000000000000000000000000000000000000
--- a/spaces/Datasculptor/DescriptionGPT/detic/data/datasets/register_oid.py
+++ /dev/null
@@ -1,122 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# Modified by Xingyi Zhou from https://github.com/facebookresearch/detectron2/blob/master/detectron2/data/datasets/coco.py
-import copy
-import io
-import logging
-import contextlib
-import os
-import datetime
-import json
-import numpy as np
-
-from PIL import Image
-
-from fvcore.common.timer import Timer
-from fvcore.common.file_io import PathManager, file_lock
-from detectron2.structures import BoxMode, PolygonMasks, Boxes
-from detectron2.data import DatasetCatalog, MetadataCatalog
-
-logger = logging.getLogger(__name__)
-
-"""
-This file contains functions to register a COCO-format dataset to the DatasetCatalog.
-"""
-
-__all__ = ["register_coco_instances", "register_coco_panoptic_separated"]
-
-
-
-def register_oid_instances(name, metadata, json_file, image_root):
- """
- """
- # 1. register a function which returns dicts
- DatasetCatalog.register(name, lambda: load_coco_json_mem_efficient(
- json_file, image_root, name))
-
- # 2. Optionally, add metadata about this dataset,
- # since they might be useful in evaluation, visualization or logging
- MetadataCatalog.get(name).set(
- json_file=json_file, image_root=image_root, evaluator_type="oid", **metadata
- )
-
-
-def load_coco_json_mem_efficient(json_file, image_root, dataset_name=None, extra_annotation_keys=None):
- """
- Actually not mem efficient
- """
- from pycocotools.coco import COCO
-
- timer = Timer()
- json_file = PathManager.get_local_path(json_file)
- with contextlib.redirect_stdout(io.StringIO()):
- coco_api = COCO(json_file)
- if timer.seconds() > 1:
- logger.info("Loading {} takes {:.2f} seconds.".format(json_file, timer.seconds()))
-
- id_map = None
- if dataset_name is not None:
- meta = MetadataCatalog.get(dataset_name)
- cat_ids = sorted(coco_api.getCatIds())
- cats = coco_api.loadCats(cat_ids)
- # The categories in a custom json file may not be sorted.
- thing_classes = [c["name"] for c in sorted(cats, key=lambda x: x["id"])]
- meta.thing_classes = thing_classes
-
- if not (min(cat_ids) == 1 and max(cat_ids) == len(cat_ids)):
- if "coco" not in dataset_name:
- logger.warning(
- """
- Category ids in annotations are not in [1, #categories]! We'll apply a mapping for you.
- """
- )
- id_map = {v: i for i, v in enumerate(cat_ids)}
- meta.thing_dataset_id_to_contiguous_id = id_map
-
- # sort indices for reproducible results
- img_ids = sorted(coco_api.imgs.keys())
- imgs = coco_api.loadImgs(img_ids)
- logger.info("Loaded {} images in COCO format from {}".format(len(imgs), json_file))
-
- dataset_dicts = []
-
- ann_keys = ["iscrowd", "bbox", "category_id"] + (extra_annotation_keys or [])
-
- for img_dict in imgs:
- record = {}
- record["file_name"] = os.path.join(image_root, img_dict["file_name"])
- record["height"] = img_dict["height"]
- record["width"] = img_dict["width"]
- image_id = record["image_id"] = img_dict["id"]
- anno_dict_list = coco_api.imgToAnns[image_id]
- if 'neg_category_ids' in img_dict:
- record['neg_category_ids'] = \
- [id_map[x] for x in img_dict['neg_category_ids']]
-
- objs = []
- for anno in anno_dict_list:
- assert anno["image_id"] == image_id
-
- assert anno.get("ignore", 0) == 0
-
- obj = {key: anno[key] for key in ann_keys if key in anno}
-
- segm = anno.get("segmentation", None)
- if segm: # either list[list[float]] or dict(RLE)
- if not isinstance(segm, dict):
- # filter out invalid polygons (< 3 points)
- segm = [poly for poly in segm if len(poly) % 2 == 0 and len(poly) >= 6]
- if len(segm) == 0:
- num_instances_without_valid_segmentation += 1
- continue # ignore this instance
- obj["segmentation"] = segm
-
- obj["bbox_mode"] = BoxMode.XYWH_ABS
-
- if id_map:
- obj["category_id"] = id_map[obj["category_id"]]
- objs.append(obj)
- record["annotations"] = objs
- dataset_dicts.append(record)
-
- del coco_api
- return dataset_dicts
\ No newline at end of file
diff --git a/spaces/Demosthene-OR/avr23-cds-translation/tabs/template_save/third_tab.py b/spaces/Demosthene-OR/avr23-cds-translation/tabs/template_save/third_tab.py
deleted file mode 100644
index 000d5fc23042ba9463ad3bb47e8b468092070d17..0000000000000000000000000000000000000000
--- a/spaces/Demosthene-OR/avr23-cds-translation/tabs/template_save/third_tab.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import streamlit as st
-import pandas as pd
-import numpy as np
-
-
-title = "Data Vizualization"
-sidebar_name = "Data Vizualization"
-
-
-def run():
-
- st.title(title)
-
- st.markdown(
- """
- This is the third sample tab.
- """
- )
-
- st.write(pd.DataFrame(np.random.randn(100, 4), columns=list("ABCD")))
diff --git a/spaces/Dinoking/Garbage-Classifier-V6/app.py b/spaces/Dinoking/Garbage-Classifier-V6/app.py
deleted file mode 100644
index 834db3bf2f01a727cecc871149b0a73166b2eea2..0000000000000000000000000000000000000000
--- a/spaces/Dinoking/Garbage-Classifier-V6/app.py
+++ /dev/null
@@ -1,28 +0,0 @@
-import gradio as gr
-import tensorflow as tf
-import numpy as np
-from PIL import Image
-import tensorflow.keras as keras
-import keras.applications.xception as xception
-from tensorflow.keras.models import load_model
-
-# load model
-model = load_model('model804.h5')
-
-classnames = ['battery','cardboard','clothes','food','glass','medical','metal','paper','plastic','shoes']
-
-
-
-def predict_image(img):
- img_4d=img.reshape(-1,320, 320,3)
- prediction=model.predict(img_4d)[0]
- return {classnames[i]: float(prediction[i]) for i in range(10)}
-
-image = gr.inputs.Image(shape=(320, 320))
-label = gr.outputs.Label(num_top_classes=3)
-enable_queue=True
-examples = ['battery.jpg','cardboard.jpeg','clothes.jpeg','glass.jpg','metal.jpg','plastic.jpg','shoes.jpg']
-article="Made by Aditya Narendra with 🖤
"
-
-gr.Interface(fn=predict_image, inputs=image, title="Garbage Classifier",
- description="This is a Garbage Classification Model Trained using Xception Net on DS11 Mod(Seg10 V4).Deployed to Hugging Faces using Gradio.",outputs=label,article=article,enable_queue=enable_queue,examples=examples,interpretation='default').launch(share="True")
\ No newline at end of file
diff --git a/spaces/DragGan/DragGan-Inversion/stylegan_human/torch_utils/__init__.py b/spaces/DragGan/DragGan-Inversion/stylegan_human/torch_utils/__init__.py
deleted file mode 100644
index a0b0f4efcbe1e3cd4199eeecb043d5afe1548307..0000000000000000000000000000000000000000
--- a/spaces/DragGan/DragGan-Inversion/stylegan_human/torch_utils/__init__.py
+++ /dev/null
@@ -1,11 +0,0 @@
-# Copyright (c) SenseTime Research. All rights reserved.
-
-# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-# empty
diff --git a/spaces/DucHaiten/webui/app.py b/spaces/DucHaiten/webui/app.py
deleted file mode 100644
index 5a08890d6b889c2623b84175d936a4432ede77e7..0000000000000000000000000000000000000000
--- a/spaces/DucHaiten/webui/app.py
+++ /dev/null
@@ -1,42 +0,0 @@
-import os
-from subprocess import getoutput
-
-gpu_info = getoutput('nvidia-smi')
-if("A10G" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+4c06c79.d20221205-cp38-cp38-linux_x86_64.whl")
-elif("T4" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+1515f77.d20221130-cp38-cp38-linux_x86_64.whl")
-
-os.system(f"git clone -b v1.5 https://github.com/camenduru/stable-diffusion-webui /home/user/app/stable-diffusion-webui")
-os.chdir("/home/user/app/stable-diffusion-webui")
-
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/env_patch.py -O /home/user/app/env_patch.py")
-os.system(f"sed -i '$a fastapi==0.90.0' /home/user/app/stable-diffusion-webui/requirements_versions.txt")
-os.system(f"sed -i -e '/import image_from_url_text/r /home/user/app/env_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(modelmerger_interface, \"Checkpoint Merger\", \"modelmerger\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(train_interface, \"Train\", \"ti\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/extensions_interface, \"Extensions\", \"extensions\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/settings_interface, \"Settings\", \"settings\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f'''sed -i -e "s/document.getElementsByTagName('gradio-app')\[0\].shadowRoot/!!document.getElementsByTagName('gradio-app')[0].shadowRoot ? document.getElementsByTagName('gradio-app')[0].shadowRoot : document/g" /home/user/app/stable-diffusion-webui/script.js''')
-os.system(f"sed -i -e 's/ show_progress=False,/ show_progress=True,/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/shared.demo.launch/shared.demo.queue().launch/g' /home/user/app/stable-diffusion-webui/webui.py")
-os.system(f"sed -i -e 's/ outputs=\[/queue=False, &/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/ queue=False, / /g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-
-# ----------------------------Please duplicate this space and delete this block if you don't want to see the extra header----------------------------
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/header_patch.py -O /home/user/app/header_patch.py")
-os.system(f"sed -i -e '/demo:/r /home/user/app/header_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-# ---------------------------------------------------------------------------------------------------------------------------------------------------
-
-os.system(f"rm -rfv /home/user/app/stable-diffusion-webui/scripts/")
-
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-config.json -O /home/user/app/shared-config.json")
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-ui-config.json -O /home/user/app/shared-ui-config.json")
-
-# os.system(f"wget -q https://huggingface.co/DucHaiten/DucHaitenAIart/resolve/main/DucHaitenAIart_v2.0.safetensors -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/DucHaitenAIart_v2.0-emaonly.safetensors")
-os.system(f"wget -q https://huggingface.co/DucHaiten/DucHaitenDreamWorld/resolve/main/DucHaitenDreamWorld_v2.4.1.safetensors -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/DucHaitenDreamWorld_v2.4.1.safetensors")
-os.system(f"wget -q https://huggingface.co/DucHaiten/DucHaitenAnime/resolve/main/DucHaitenAnime_v4.0.safetensors -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/DucHaitenAnime_v4.0.safetensors")
-os.system(f"wget -q https://huggingface.co/DucHaiten/DucHaitenAnimated/resolve/main/DucHaitenAnimated_v5.0.safetensors -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/DucHaitenAnimated_v5.0.safetensors")
-os.system(f"wget -q https://huggingface.co/DucHaiten/DucHaitenAIart/resolve/main/DucHaitenAIart_v3.1.safetensors -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/DucHaitenAIart_v3.1.safetensors")
-
-os.system(f"python launch.py --force-enable-xformers --ui-config-file /home/user/app/ui-config.json --ui-settings-file /home/user/app/config.json --disable-console-progressbars --enable-console-prompts --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding --api")
\ No newline at end of file
diff --git a/spaces/Duskfallcrew/DreamlikeArt-PhotoReal-2.0/style.css b/spaces/Duskfallcrew/DreamlikeArt-PhotoReal-2.0/style.css
deleted file mode 100644
index fdbef9e64cc6b9f8003698ffa38997ee22a640ac..0000000000000000000000000000000000000000
--- a/spaces/Duskfallcrew/DreamlikeArt-PhotoReal-2.0/style.css
+++ /dev/null
@@ -1,84 +0,0 @@
-#col-container {
- max-width: 800px;
- margin-left: auto;
- margin-right: auto;
-}
-a {
- color: inherit;
- text-decoration: underline;
-}
-.gradio-container {
- font-family: 'IBM Plex Sans', sans-serif;
-}
-.gr-button {
- color: white;
- border-color: #9d66e5;
- background: #9d66e5;
-}
-input[type='range'] {
- accent-color: #9d66e5;
-}
-.dark input[type='range'] {
- accent-color: #dfdfdf;
-}
-.container {
- max-width: 800px;
- margin: auto;
- padding-top: 1.5rem;
-}
-#gallery {
- min-height: 22rem;
- margin-bottom: 15px;
- margin-left: auto;
- margin-right: auto;
- border-bottom-right-radius: .5rem !important;
- border-bottom-left-radius: .5rem !important;
-}
-#gallery>div>.h-full {
- min-height: 20rem;
-}
-.details:hover {
- text-decoration: underline;
-}
-.gr-button {
- white-space: nowrap;
-}
-.gr-button:focus {
- border-color: rgb(147 197 253 / var(--tw-border-opacity));
- outline: none;
- box-shadow: var(--tw-ring-offset-shadow), var(--tw-ring-shadow), var(--tw-shadow, 0 0 #0000);
- --tw-border-opacity: 1;
- --tw-ring-offset-shadow: var(--tw-ring-inset) 0 0 0 var(--tw-ring-offset-width) var(--tw-ring-offset-color);
- --tw-ring-shadow: var(--tw-ring-inset) 0 0 0 calc(3px var(--tw-ring-offset-width)) var(--tw-ring-color);
- --tw-ring-color: rgb(191 219 254 / var(--tw-ring-opacity));
- --tw-ring-opacity: .5;
-}
-#advanced-options {
- margin-bottom: 20px;
-}
-.footer {
- margin-bottom: 45px;
- margin-top: 35px;
- text-align: center;
- border-bottom: 1px solid #e5e5e5;
-}
-.footer>p {
- font-size: .8rem;
- display: inline-block;
- padding: 0 10px;
- transform: translateY(10px);
- background: white;
-}
-.dark .logo{ filter: invert(1); }
-.dark .footer {
- border-color: #303030;
-}
-.dark .footer>p {
- background: #0b0f19;
-}
-.acknowledgments h4{
- margin: 1.25em 0 .25em 0;
- font-weight: bold;
- font-size: 115%;
-}
-
diff --git a/spaces/EPFL-VILAB/MultiMAE/FINETUNING.md b/spaces/EPFL-VILAB/MultiMAE/FINETUNING.md
deleted file mode 100644
index f07f794064f8b5a3496f86eddbe05e1030fc5411..0000000000000000000000000000000000000000
--- a/spaces/EPFL-VILAB/MultiMAE/FINETUNING.md
+++ /dev/null
@@ -1,126 +0,0 @@
-# Fine-tuning
-
-We provide fine-tuning scripts for classification, semantic segmentation, depth estimation and more.
-Please check [SETUP.md](SETUP.md) for set-up instructions first.
-
-- [General information](#general-information)
-- [Classification](#classification)
-- [Semantic segmentation](#semantic-segmentation)
-- [Depth estimation](#depth-estimation)
-- [Taskonomy tasks](#taskonomy-tasks)
-
-## General information
-
-### Loading pre-trained models
-
-All our fine-tuning scripts support models in the MultiMAE / MultiViT format. Pre-trained models using the timm / ViT format can be converted to this format using the [`vit2multimae_converter.py`](tools/vit2multimae_converter.py)
- script. More information can be found [here](README.md#model-formats).
-
-### Modifying configs
-The training scripts support both YAML config files and command-line arguments. See [here](cfgs/finetune) for all fine-tuning config files.
-
-To modify fine-training settings, either edit / add config files or provide additional command-line arguments.
-
-:information_source: Config files arguments override default arguments, and command-line arguments override both default arguments and config arguments.
-
-:warning: When changing settings (e.g., using a different pre-trained model), make sure to modify the `output_dir` and `wandb_run_name` (if logging is activated) to reflect the changes.
-
-
-### Experiment logging
-To activate logging to [Weights & Biases](https://docs.wandb.ai/), either edit the config files or use the `--log_wandb` flag along with any other extra logging arguments.
-
-
-## Classification
-
-We use 8 A100 GPUs for classification fine-tuning. Configs can be found [here](cfgs/finetune/cls).
-
-To fine-tune MultiMAE on ImageNet-1K classification using default settings, run:
-```bash
-OMP_NUM_THREADS=1 torchrun --nproc_per_node=8 run_finetuning_cls.py \
---config cfgs/finetune/cls/ft_in1k_100e_multimae-b.yaml \
---finetune /path/to/multimae_weights \
---data_path /path/to/in1k/train/rgb \
---eval_data_path /path/to/in1k/val/rgb
-```
-
-- For a list of possible arguments, see [`run_finetuning_cls.py`](run_finetuning_cls.py).
-
-## Semantic segmentation
-
-We use 4 A100 GPUs for semantic segmentation fine-tuning. Configs can be found [here](cfgs/finetune/semseg).
-
-### ADE20K
-To fine-tune MultiMAE on ADE20K semantic segmentation with default settings and **RGB** as the input modality, run:
-```bash
-OMP_NUM_THREADS=1 torchrun --nproc_per_node=4 run_finetuning_semseg.py \
---config cfgs/finetune/semseg/ade/ft_ade_64e_multimae-b_rgb.yaml \
---finetune /path/to/multimae_weights \
---data_path /path/to/ade20k/train \
---eval_data_path /path/to/ade20k/val
-```
-
-- For a list of possible arguments, see [`run_finetuning_semseg.py`](run_finetuning_semseg.py).
-
-
-### Hypersim
-To fine-tune MultiMAE on Hypersim semantic segmentation with default settings and **RGB** as the input modality, run:
-```bash
-OMP_NUM_THREADS=1 torchrun --nproc_per_node=4 run_finetuning_semseg.py \
---config cfgs/finetune/semseg/hypersim/ft_hypersim_25e_multimae-b_rgb.yaml \
---finetune /path/to/multimae_weights \
---data_path /path/to/hypersim/train \
---eval_data_path /path/to/hypersim/val
-```
-
-- To fine-tune using **depth-only** and **RGB + depth** as the input modalities, simply swap the config file to the appropriate one.
-- For a list of possible arguments, see [`run_finetuning_semseg.py`](run_finetuning_semseg.py).
-
-
-
-### NYUv2
-To fine-tune MultiMAE on NYUv2 semantic segmentation with default settings and **RGB** as the input modality, run:
-```bash
-OMP_NUM_THREADS=1 torchrun --nproc_per_node=4 run_finetuning_semseg.py \
---config cfgs/finetune/semseg/nyu/ft_nyu_200e_multimae-b_rgb.yaml \
---finetune /path/to/multimae_weights \
---data_path /path/to/nyu/train \
---eval_data_path /path/to/nyu/test_or_val
-```
-
-- To fine-tune using **depth-only** and **RGB + depth** as the input modalities, simply swap the config file to the appropriate one.
-- For a list of possible arguments, see [`run_finetuning_semseg.py`](run_finetuning_semseg.py).
-
-
-## Depth estimation
-
-We use 2 A100 GPUs for depth estimation fine-tuning. Configs can be found [here](cfgs/finetune/depth).
-
-
-To fine-tune MultiMAE on NYUv2 depth estimation with default settings, run:
-```bash
-OMP_NUM_THREADS=1 torchrun --nproc_per_node=2 run_finetuning_depth.py \
---config cfgs/finetune/depth/ft_nyu_2000e_multimae-b.yaml \
---finetune /path/to/multimae_weights \
---data_path /path/to/nyu/train \
---eval_data_path /path/to/nyu/test_or_val
-```
-- For a list of possible arguments, see [`run_finetuning_depth.py`](run_finetuning_depth.py).
-
-## Taskonomy tasks
-
-We use 1 A100 GPU to fine-tune on Taskonomy tasks. Configs can be found [here](cfgs/finetune/taskonomy).
-
-The tasks we support are: Principal curvature, z-buffer depth, texture edges, occlusion edges, 2D keypoints,
-3D keypoints, surface normals, and reshading.
-
-
-For example, to fine-tune MultiMAE on Taskonomy reshading with default settings, run:
-```bash
-OMP_NUM_THREADS=1 torchrun --nproc_per_node=1 run_finetuning_taskonomy.py \
---config cfgs/finetune/taskonomy/rgb2reshading-1k/ft_rgb2reshading_multimae-b.yaml \
---finetune /path/to/multimae_weights \
---data_path /path/to/taskonomy_tiny
-```
-
-- To fine-tune on a different task, simply swap the config file to the appropriate one.
-- For a list of possible arguments, see [`run_finetuning_taskonomy.py`](run_finetuning_taskonomy.py).
diff --git a/spaces/Egrt/MaskGAN/utils/__init__.py b/spaces/Egrt/MaskGAN/utils/__init__.py
deleted file mode 100644
index 90f60fdd89ad8575faafe45188bd1d968852fc67..0000000000000000000000000000000000000000
--- a/spaces/Egrt/MaskGAN/utils/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .utils import *
\ No newline at end of file
diff --git a/spaces/FantasticGNU/AnomalyGPT/header.py b/spaces/FantasticGNU/AnomalyGPT/header.py
deleted file mode 100644
index 2e34537c2e988b2cc62e5ebc78197b76130dc51e..0000000000000000000000000000000000000000
--- a/spaces/FantasticGNU/AnomalyGPT/header.py
+++ /dev/null
@@ -1,35 +0,0 @@
-import torch
-import datetime
-import types
-import deepspeed
-from transformers.deepspeed import HfDeepSpeedConfig
-import transformers
-import numpy as np
-from collections import OrderedDict
-from torch.utils.data import Dataset, DataLoader
-from torch.nn.utils import clip_grad_norm_
-from torch.cuda.amp import autocast, GradScaler
-from torch.nn import DataParallel
-from torch.optim import lr_scheduler
-import torch.optim as optim
-import torch.nn as nn
-import torch.nn.functional as F
-from tqdm import tqdm
-import os
-import re
-import math
-import random
-import json
-import time
-import logging
-from copy import deepcopy
-import ipdb
-import argparse
-from model.ImageBind import data
-from transformers import LlamaTokenizer, LlamaForCausalLM, LlamaConfig
-from torch.nn.utils.rnn import pad_sequence
-from peft import LoraConfig, TaskType, get_peft_model
-
-logging.getLogger("transformers").setLevel(logging.WARNING)
-logging.getLogger("transformers.tokenization_utils").setLevel(logging.ERROR)
-os.environ['TOKENIZERS_PARALLELISM'] = 'false'
diff --git a/spaces/Fengbinbin/gpt-academic/request_llm/bridge_tgui.py b/spaces/Fengbinbin/gpt-academic/request_llm/bridge_tgui.py
deleted file mode 100644
index fcf852f0474892bd179843ece3f4a83110bd7756..0000000000000000000000000000000000000000
--- a/spaces/Fengbinbin/gpt-academic/request_llm/bridge_tgui.py
+++ /dev/null
@@ -1,171 +0,0 @@
-'''
-Contributed by SagsMug. Modified by binary-husky
-https://github.com/oobabooga/text-generation-webui/pull/175
-'''
-
-import asyncio
-import json
-import random
-import string
-import websockets
-import logging
-import time
-import threading
-import importlib
-from toolbox import get_conf, update_ui
-
-
-def random_hash():
- letters = string.ascii_lowercase + string.digits
- return ''.join(random.choice(letters) for i in range(9))
-
-async def run(context, max_token, temperature, top_p, addr, port):
- params = {
- 'max_new_tokens': max_token,
- 'do_sample': True,
- 'temperature': temperature,
- 'top_p': top_p,
- 'typical_p': 1,
- 'repetition_penalty': 1.05,
- 'encoder_repetition_penalty': 1.0,
- 'top_k': 0,
- 'min_length': 0,
- 'no_repeat_ngram_size': 0,
- 'num_beams': 1,
- 'penalty_alpha': 0,
- 'length_penalty': 1,
- 'early_stopping': True,
- 'seed': -1,
- }
- session = random_hash()
-
- async with websockets.connect(f"ws://{addr}:{port}/queue/join") as websocket:
- while content := json.loads(await websocket.recv()):
- #Python3.10 syntax, replace with if elif on older
- if content["msg"] == "send_hash":
- await websocket.send(json.dumps({
- "session_hash": session,
- "fn_index": 12
- }))
- elif content["msg"] == "estimation":
- pass
- elif content["msg"] == "send_data":
- await websocket.send(json.dumps({
- "session_hash": session,
- "fn_index": 12,
- "data": [
- context,
- params['max_new_tokens'],
- params['do_sample'],
- params['temperature'],
- params['top_p'],
- params['typical_p'],
- params['repetition_penalty'],
- params['encoder_repetition_penalty'],
- params['top_k'],
- params['min_length'],
- params['no_repeat_ngram_size'],
- params['num_beams'],
- params['penalty_alpha'],
- params['length_penalty'],
- params['early_stopping'],
- params['seed'],
- ]
- }))
- elif content["msg"] == "process_starts":
- pass
- elif content["msg"] in ["process_generating", "process_completed"]:
- yield content["output"]["data"][0]
- # You can search for your desired end indicator and
- # stop generation by closing the websocket here
- if (content["msg"] == "process_completed"):
- break
-
-
-
-
-
-def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream = True, additional_fn=None):
- """
- 发送至chatGPT,流式获取输出。
- 用于基础的对话功能。
- inputs 是本次问询的输入
- top_p, temperature是chatGPT的内部调优参数
- history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误)
- chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容
- additional_fn代表点击的哪个按钮,按钮见functional.py
- """
- if additional_fn is not None:
- import core_functional
- importlib.reload(core_functional) # 热更新prompt
- core_functional = core_functional.get_core_functions()
- if "PreProcess" in core_functional[additional_fn]: inputs = core_functional[additional_fn]["PreProcess"](inputs) # 获取预处理函数(如果有的话)
- inputs = core_functional[additional_fn]["Prefix"] + inputs + core_functional[additional_fn]["Suffix"]
-
- raw_input = "What I would like to say is the following: " + inputs
- history.extend([inputs, ""])
- chatbot.append([inputs, ""])
- yield from update_ui(chatbot=chatbot, history=history, msg="等待响应") # 刷新界面
-
- prompt = raw_input
- tgui_say = ""
-
- model_name, addr_port = llm_kwargs['llm_model'].split('@')
- assert ':' in addr_port, "LLM_MODEL 格式不正确!" + llm_kwargs['llm_model']
- addr, port = addr_port.split(':')
-
-
- mutable = ["", time.time()]
- def run_coorotine(mutable):
- async def get_result(mutable):
- # "tgui:galactica-1.3b@localhost:7860"
-
- async for response in run(context=prompt, max_token=llm_kwargs['max_length'],
- temperature=llm_kwargs['temperature'],
- top_p=llm_kwargs['top_p'], addr=addr, port=port):
- print(response[len(mutable[0]):])
- mutable[0] = response
- if (time.time() - mutable[1]) > 3:
- print('exit when no listener')
- break
- asyncio.run(get_result(mutable))
-
- thread_listen = threading.Thread(target=run_coorotine, args=(mutable,), daemon=True)
- thread_listen.start()
-
- while thread_listen.is_alive():
- time.sleep(1)
- mutable[1] = time.time()
- # Print intermediate steps
- if tgui_say != mutable[0]:
- tgui_say = mutable[0]
- history[-1] = tgui_say
- chatbot[-1] = (history[-2], history[-1])
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
-
-
-
-
-def predict_no_ui_long_connection(inputs, llm_kwargs, history, sys_prompt, observe_window, console_slience=False):
- raw_input = "What I would like to say is the following: " + inputs
- prompt = raw_input
- tgui_say = ""
- model_name, addr_port = llm_kwargs['llm_model'].split('@')
- assert ':' in addr_port, "LLM_MODEL 格式不正确!" + llm_kwargs['llm_model']
- addr, port = addr_port.split(':')
-
-
- def run_coorotine(observe_window):
- async def get_result(observe_window):
- async for response in run(context=prompt, max_token=llm_kwargs['max_length'],
- temperature=llm_kwargs['temperature'],
- top_p=llm_kwargs['top_p'], addr=addr, port=port):
- print(response[len(observe_window[0]):])
- observe_window[0] = response
- if (time.time() - observe_window[1]) > 5:
- print('exit when no listener')
- break
- asyncio.run(get_result(observe_window))
- thread_listen = threading.Thread(target=run_coorotine, args=(observe_window,))
- thread_listen.start()
- return observe_window[0]
diff --git a/spaces/Fernando22/freegpt-webui/g4f/Provider/Providers/Fakeopen.py b/spaces/Fernando22/freegpt-webui/g4f/Provider/Providers/Fakeopen.py
deleted file mode 100644
index 5a82bf2cc0736384563332a279f5fbcbb120f676..0000000000000000000000000000000000000000
--- a/spaces/Fernando22/freegpt-webui/g4f/Provider/Providers/Fakeopen.py
+++ /dev/null
@@ -1,54 +0,0 @@
-import os
-import json
-import requests
-from typing import Dict, get_type_hints
-
-url = 'https://ai.fakeopen.com/v1/'
-model = [
- 'gpt-3.5-turbo',
- 'gpt-3.5-turbo-0613',
- 'gpt-3.5-turbo-16k',
- 'gpt-3.5-turbo-16k-0613',
-]
-
-supports_stream = True
-needs_auth = False
-
-
-def _create_completion(model: str, messages: list, stream: bool, **kwargs):
-
- headers = {
- 'Content-Type': 'application/json',
- 'accept': 'text/event-stream',
- 'Cache-Control': 'no-cache',
- 'Proxy-Connection': 'keep-alive',
- 'Authorization': f"Bearer {os.environ.get('FAKE_OPEN_KEY', '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')}",
- }
-
- json_data = {
- 'messages': messages,
- 'temperature': 1.0,
- 'model': model,
- 'stream': stream,
- }
-
- response = requests.post(
- 'https://ai.fakeopen.com/v1/chat/completions', headers=headers, json=json_data, stream=True
- )
-
- for token in response.iter_lines():
- decoded = token.decode('utf-8')
- if decoded == '[DONE]':
- break
- if decoded.startswith('data: '):
- data_str = decoded.replace('data: ', '')
- if data_str != '[DONE]':
- data = json.loads(data_str)
- if 'choices' in data and 'delta' in data['choices'][0] and 'content' in data['choices'][0]['delta']:
- yield data['choices'][0]['delta']['content']
-
-
-
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + '(%s)' % ', '.join(
- [f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
diff --git a/spaces/FluxWaveCorp/Ghostwriter-Bloom/generators/title_to_abstract.py b/spaces/FluxWaveCorp/Ghostwriter-Bloom/generators/title_to_abstract.py
deleted file mode 100644
index a5ff1dda8edc9a75e7befa4d8d7a16efe0722e67..0000000000000000000000000000000000000000
--- a/spaces/FluxWaveCorp/Ghostwriter-Bloom/generators/title_to_abstract.py
+++ /dev/null
@@ -1,5 +0,0 @@
-
-from .model import model
-
-def title_to_abstract_generator(template):
- return model('title', template)
diff --git a/spaces/FridaZuley/RVC_HFKawaii/demucs/repitch.py b/spaces/FridaZuley/RVC_HFKawaii/demucs/repitch.py
deleted file mode 100644
index 8846ab2d951a024c95067f66a113968500442828..0000000000000000000000000000000000000000
--- a/spaces/FridaZuley/RVC_HFKawaii/demucs/repitch.py
+++ /dev/null
@@ -1,96 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import io
-import random
-import subprocess as sp
-import tempfile
-
-import numpy as np
-import torch
-from scipy.io import wavfile
-
-
-def i16_pcm(wav):
- if wav.dtype == np.int16:
- return wav
- return (wav * 2**15).clamp_(-2**15, 2**15 - 1).short()
-
-
-def f32_pcm(wav):
- if wav.dtype == np.float:
- return wav
- return wav.float() / 2**15
-
-
-class RepitchedWrapper:
- """
- Wrap a dataset to apply online change of pitch / tempo.
- """
- def __init__(self, dataset, proba=0.2, max_pitch=2, max_tempo=12, tempo_std=5, vocals=[3]):
- self.dataset = dataset
- self.proba = proba
- self.max_pitch = max_pitch
- self.max_tempo = max_tempo
- self.tempo_std = tempo_std
- self.vocals = vocals
-
- def __len__(self):
- return len(self.dataset)
-
- def __getitem__(self, index):
- streams = self.dataset[index]
- in_length = streams.shape[-1]
- out_length = int((1 - 0.01 * self.max_tempo) * in_length)
-
- if random.random() < self.proba:
- delta_pitch = random.randint(-self.max_pitch, self.max_pitch)
- delta_tempo = random.gauss(0, self.tempo_std)
- delta_tempo = min(max(-self.max_tempo, delta_tempo), self.max_tempo)
- outs = []
- for idx, stream in enumerate(streams):
- stream = repitch(
- stream,
- delta_pitch,
- delta_tempo,
- voice=idx in self.vocals)
- outs.append(stream[:, :out_length])
- streams = torch.stack(outs)
- else:
- streams = streams[..., :out_length]
- return streams
-
-
-def repitch(wav, pitch, tempo, voice=False, quick=False, samplerate=44100):
- """
- tempo is a relative delta in percentage, so tempo=10 means tempo at 110%!
- pitch is in semi tones.
- Requires `soundstretch` to be installed, see
- https://www.surina.net/soundtouch/soundstretch.html
- """
- outfile = tempfile.NamedTemporaryFile(suffix=".wav")
- in_ = io.BytesIO()
- wavfile.write(in_, samplerate, i16_pcm(wav).t().numpy())
- command = [
- "soundstretch",
- "stdin",
- outfile.name,
- f"-pitch={pitch}",
- f"-tempo={tempo:.6f}",
- ]
- if quick:
- command += ["-quick"]
- if voice:
- command += ["-speech"]
- try:
- sp.run(command, capture_output=True, input=in_.getvalue(), check=True)
- except sp.CalledProcessError as error:
- raise RuntimeError(f"Could not change bpm because {error.stderr.decode('utf-8')}")
- sr, wav = wavfile.read(outfile.name)
- wav = wav.copy()
- wav = f32_pcm(torch.from_numpy(wav).t())
- assert sr == samplerate
- return wav
diff --git a/spaces/GenXDad/logo-wizard-logo-diffusion-checkpoint/README.md b/spaces/GenXDad/logo-wizard-logo-diffusion-checkpoint/README.md
deleted file mode 100644
index b08db6b6d3aacf01e2070195d8d0357ce9cc40b3..0000000000000000000000000000000000000000
--- a/spaces/GenXDad/logo-wizard-logo-diffusion-checkpoint/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Logo Wizard Logo Diffusion Checkpoint
-emoji: 🐢
-colorFrom: yellow
-colorTo: pink
-sdk: gradio
-sdk_version: 3.38.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/hrnet/fcn_hr48_480x480_80k_pascal_context_59.py b/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/hrnet/fcn_hr48_480x480_80k_pascal_context_59.py
deleted file mode 100644
index 012ad0a7d6119554ec00400ad18a09249a72eca4..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/hrnet/fcn_hr48_480x480_80k_pascal_context_59.py
+++ /dev/null
@@ -1,10 +0,0 @@
-_base_ = './fcn_hr18_480x480_80k_pascal_context_59.py'
-model = dict(
- pretrained='open-mmlab://msra/hrnetv2_w48',
- backbone=dict(
- extra=dict(
- stage2=dict(num_channels=(48, 96)),
- stage3=dict(num_channels=(48, 96, 192)),
- stage4=dict(num_channels=(48, 96, 192, 384)))),
- decode_head=dict(
- in_channels=[48, 96, 192, 384], channels=sum([48, 96, 192, 384])))
diff --git a/spaces/Gradio-Blocks/uniformer_image_segmentation/exp/upernet_global_small/test_config_h32.py b/spaces/Gradio-Blocks/uniformer_image_segmentation/exp/upernet_global_small/test_config_h32.py
deleted file mode 100644
index a31e3874f76f9f7b089ac8834d85df2441af9b0e..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_segmentation/exp/upernet_global_small/test_config_h32.py
+++ /dev/null
@@ -1,39 +0,0 @@
-_base_ = [
- '../../configs/_base_/models/upernet_uniformer.py',
- '../../configs/_base_/datasets/ade20k.py',
- '../../configs/_base_/default_runtime.py',
- '../../configs/_base_/schedules/schedule_160k.py'
-]
-model = dict(
- backbone=dict(
- type='UniFormer',
- embed_dim=[64, 128, 320, 512],
- layers=[3, 4, 8, 3],
- head_dim=64,
- drop_path_rate=0.25,
- windows=False,
- hybrid=True,
- window_size=32
- ),
- decode_head=dict(
- in_channels=[64, 128, 320, 512],
- num_classes=150
- ),
- auxiliary_head=dict(
- in_channels=320,
- num_classes=150
- ))
-
-# AdamW optimizer, no weight decay for position embedding & layer norm in backbone
-optimizer = dict(_delete_=True, type='AdamW', lr=0.00006, betas=(0.9, 0.999), weight_decay=0.01,
- paramwise_cfg=dict(custom_keys={'absolute_pos_embed': dict(decay_mult=0.),
- 'relative_position_bias_table': dict(decay_mult=0.),
- 'norm': dict(decay_mult=0.)}))
-
-lr_config = dict(_delete_=True, policy='poly',
- warmup='linear',
- warmup_iters=1500,
- warmup_ratio=1e-6,
- power=1.0, min_lr=0.0, by_epoch=False)
-
-data=dict(samples_per_gpu=2)
\ No newline at end of file
diff --git a/spaces/GrandaddyShmax/MusicGen_Plus/audiocraft/modules/conditioners.py b/spaces/GrandaddyShmax/MusicGen_Plus/audiocraft/modules/conditioners.py
deleted file mode 100644
index 82792316024b88d4c5c38b0a28f443627771d509..0000000000000000000000000000000000000000
--- a/spaces/GrandaddyShmax/MusicGen_Plus/audiocraft/modules/conditioners.py
+++ /dev/null
@@ -1,990 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-from collections import defaultdict
-from copy import deepcopy
-from dataclasses import dataclass, field
-from itertools import chain
-import logging
-import math
-import random
-import re
-import typing as tp
-import warnings
-
-from einops import rearrange
-from num2words import num2words
-import spacy
-from transformers import T5EncoderModel, T5Tokenizer # type: ignore
-import torchaudio
-import torch
-from torch import nn
-from torch import Tensor
-import torch.nn.functional as F
-from torch.nn.utils.rnn import pad_sequence
-
-from .streaming import StreamingModule
-from .transformer import create_sin_embedding
-from ..data.audio_dataset import SegmentInfo
-from ..utils.autocast import TorchAutocast
-from ..utils.utils import hash_trick, length_to_mask, collate
-
-
-logger = logging.getLogger(__name__)
-TextCondition = tp.Optional[str] # a text condition can be a string or None (if doesn't exist)
-ConditionType = tp.Tuple[Tensor, Tensor] # condition, mask
-
-
-class WavCondition(tp.NamedTuple):
- wav: Tensor
- length: Tensor
- path: tp.List[tp.Optional[str]] = []
-
-
-def nullify_condition(condition: ConditionType, dim: int = 1):
- """This function transforms an input condition to a null condition.
- The way it is done by converting it to a single zero vector similarly
- to how it is done inside WhiteSpaceTokenizer and NoopTokenizer.
-
- Args:
- condition (ConditionType): a tuple of condition and mask (tp.Tuple[Tensor, Tensor])
- dim (int): the dimension that will be truncated (should be the time dimension)
- WARNING!: dim should not be the batch dimension!
- Returns:
- ConditionType: a tuple of null condition and mask
- """
- assert dim != 0, "dim cannot be the batch dimension!"
- assert type(condition) == tuple and \
- type(condition[0]) == Tensor and \
- type(condition[1]) == Tensor, "'nullify_condition' got an unexpected input type!"
- cond, mask = condition
- B = cond.shape[0]
- last_dim = cond.dim() - 1
- out = cond.transpose(dim, last_dim)
- out = 0. * out[..., :1]
- out = out.transpose(dim, last_dim)
- mask = torch.zeros((B, 1), device=out.device).int()
- assert cond.dim() == out.dim()
- return out, mask
-
-
-def nullify_wav(wav: Tensor) -> WavCondition:
- """Create a nullified WavCondition from a wav tensor with appropriate shape.
-
- Args:
- wav (Tensor): tensor of shape [B, T]
- Returns:
- WavCondition: wav condition with nullified wav.
- """
- null_wav, _ = nullify_condition((wav, torch.zeros_like(wav)), dim=wav.dim() - 1)
- return WavCondition(
- wav=null_wav,
- length=torch.tensor([0] * wav.shape[0], device=wav.device),
- path=['null_wav'] * wav.shape[0]
- )
-
-
-@dataclass
-class ConditioningAttributes:
- text: tp.Dict[str, tp.Optional[str]] = field(default_factory=dict)
- wav: tp.Dict[str, WavCondition] = field(default_factory=dict)
-
- def __getitem__(self, item):
- return getattr(self, item)
-
- @property
- def text_attributes(self):
- return self.text.keys()
-
- @property
- def wav_attributes(self):
- return self.wav.keys()
-
- @property
- def attributes(self):
- return {"text": self.text_attributes, "wav": self.wav_attributes}
-
- def to_flat_dict(self):
- return {
- **{f"text.{k}": v for k, v in self.text.items()},
- **{f"wav.{k}": v for k, v in self.wav.items()},
- }
-
- @classmethod
- def from_flat_dict(cls, x):
- out = cls()
- for k, v in x.items():
- kind, att = k.split(".")
- out[kind][att] = v
- return out
-
-
-class SegmentWithAttributes(SegmentInfo):
- """Base class for all dataclasses that are used for conditioning.
- All child classes should implement `to_condition_attributes` that converts
- the existing attributes to a dataclass of type ConditioningAttributes.
- """
- def to_condition_attributes(self) -> ConditioningAttributes:
- raise NotImplementedError()
-
-
-class Tokenizer:
- """Base class for all tokenizers
- (in case we want to introduce more advances tokenizers in the future).
- """
- def __call__(self, texts: tp.List[tp.Optional[str]]) -> tp.Tuple[Tensor, Tensor]:
- raise NotImplementedError()
-
-
-class WhiteSpaceTokenizer(Tokenizer):
- """This tokenizer should be used for natural language descriptions.
- For example:
- ["he didn't, know he's going home.", 'shorter sentence'] =>
- [[78, 62, 31, 4, 78, 25, 19, 34],
- [59, 77, 0, 0, 0, 0, 0, 0]]
- """
- PUNCTUATIONS = "?:!.,;"
-
- def __init__(self, n_bins: int, pad_idx: int = 0, language: str = "en_core_web_sm",
- lemma: bool = True, stopwords: bool = True) -> None:
- self.n_bins = n_bins
- self.pad_idx = pad_idx
- self.lemma = lemma
- self.stopwords = stopwords
- try:
- self.nlp = spacy.load(language)
- except IOError:
- spacy.cli.download(language) # type: ignore
- self.nlp = spacy.load(language)
-
- @tp.no_type_check
- def __call__(
- self,
- texts: tp.List[tp.Optional[str]],
- return_text: bool = False
- ) -> tp.Tuple[Tensor, Tensor]:
- """Take a list of strings and convert them to a tensor of indices.
-
- Args:
- texts (tp.List[str]): List of strings.
- return_text (bool, optional): Whether to return text as additional tuple item. Defaults to False.
- Returns:
- tp.Tuple[Tensor, Tensor]:
- - Indices of words in the LUT.
- - And a mask indicating where the padding tokens are
- """
- output, lengths = [], []
- texts = deepcopy(texts)
- for i, text in enumerate(texts):
- # if current sample doesn't have a certain attribute, replace with pad token
- if text is None:
- output.append(Tensor([self.pad_idx]))
- lengths.append(0)
- continue
-
- # convert numbers to words
- text = re.sub(r"(\d+)", lambda x: num2words(int(x.group(0))), text) # type: ignore
- # normalize text
- text = self.nlp(text) # type: ignore
- # remove stopwords
- if self.stopwords:
- text = [w for w in text if not w.is_stop] # type: ignore
- # remove punctuations
- text = [w for w in text if w.text not in self.PUNCTUATIONS] # type: ignore
- # lemmatize if needed
- text = [getattr(t, "lemma_" if self.lemma else "text") for t in text] # type: ignore
-
- texts[i] = " ".join(text)
- lengths.append(len(text))
- # convert to tensor
- tokens = Tensor([hash_trick(w, self.n_bins) for w in text])
- output.append(tokens)
-
- mask = length_to_mask(torch.IntTensor(lengths)).int()
- padded_output = pad_sequence(output, padding_value=self.pad_idx).int().t()
- if return_text:
- return padded_output, mask, texts # type: ignore
- return padded_output, mask
-
-
-class NoopTokenizer(Tokenizer):
- """This tokenizer should be used for global conditioners such as: artist, genre, key, etc.
- The difference between this and WhiteSpaceTokenizer is that NoopTokenizer does not split
- strings, so "Jeff Buckley" will get it's own index. Whereas WhiteSpaceTokenizer will
- split it to ["Jeff", "Buckley"] and return an index per word.
-
- For example:
- ["Queen", "ABBA", "Jeff Buckley"] => [43, 55, 101]
- ["Metal", "Rock", "Classical"] => [0, 223, 51]
- """
- def __init__(self, n_bins: int, pad_idx: int = 0):
- self.n_bins = n_bins
- self.pad_idx = pad_idx
-
- def __call__(self, texts: tp.List[tp.Optional[str]]) -> tp.Tuple[Tensor, Tensor]:
- output, lengths = [], []
- for text in texts:
- # if current sample doesn't have a certain attribute, replace with pad token
- if text is None:
- output.append(self.pad_idx)
- lengths.append(0)
- else:
- output.append(hash_trick(text, self.n_bins))
- lengths.append(1)
-
- tokens = torch.LongTensor(output).unsqueeze(1)
- mask = length_to_mask(torch.IntTensor(lengths)).int()
- return tokens, mask
-
-
-class BaseConditioner(nn.Module):
- """Base model for all conditioner modules. We allow the output dim to be different
- than the hidden dim for two reasons: 1) keep our LUTs small when the vocab is large;
- 2) make all condition dims consistent.
-
- Args:
- dim (int): Hidden dim of the model (text-encoder/LUT).
- output_dim (int): Output dim of the conditioner.
- """
- def __init__(self, dim, output_dim):
- super().__init__()
- self.dim = dim
- self.output_dim = output_dim
- self.output_proj = nn.Linear(dim, output_dim)
-
- def tokenize(self, *args, **kwargs) -> tp.Any:
- """Should be any part of the processing that will lead to a synchronization
- point, e.g. BPE tokenization with transfer to the GPU.
-
- The returned value will be saved and return later when calling forward().
- """
- raise NotImplementedError()
-
- def forward(self, inputs: tp.Any) -> ConditionType:
- """Gets input that should be used as conditioning (e.g, genre, description or a waveform).
- Outputs a ConditionType, after the input data was embedded as a dense vector.
-
- Returns:
- ConditionType:
- - A tensor of size [B, T, D] where B is the batch size, T is the length of the
- output embedding and D is the dimension of the embedding.
- - And a mask indicating where the padding tokens.
- """
- raise NotImplementedError()
-
-
-class TextConditioner(BaseConditioner):
- ...
-
-
-class LUTConditioner(TextConditioner):
- """Lookup table TextConditioner.
-
- Args:
- n_bins (int): Number of bins.
- dim (int): Hidden dim of the model (text-encoder/LUT).
- output_dim (int): Output dim of the conditioner.
- tokenizer (str): Name of the tokenizer.
- pad_idx (int, optional): Index for padding token. Defaults to 0.
- """
- def __init__(self, n_bins: int, dim: int, output_dim: int, tokenizer: str, pad_idx: int = 0):
- super().__init__(dim, output_dim)
- self.embed = nn.Embedding(n_bins, dim)
- self.tokenizer: Tokenizer
- if tokenizer == "whitespace":
- self.tokenizer = WhiteSpaceTokenizer(n_bins, pad_idx=pad_idx)
- elif tokenizer == "noop":
- self.tokenizer = NoopTokenizer(n_bins, pad_idx=pad_idx)
- else:
- raise ValueError(f"unrecognized tokenizer `{tokenizer}`.")
-
- def tokenize(self, x: tp.List[tp.Optional[str]]) -> tp.Tuple[torch.Tensor, torch.Tensor]:
- device = self.embed.weight.device
- tokens, mask = self.tokenizer(x)
- tokens, mask = tokens.to(device), mask.to(device)
- return tokens, mask
-
- def forward(self, inputs: tp.Tuple[torch.Tensor, torch.Tensor]) -> ConditionType:
- tokens, mask = inputs
- embeds = self.embed(tokens)
- embeds = self.output_proj(embeds)
- embeds = (embeds * mask.unsqueeze(-1))
- return embeds, mask
-
-
-class T5Conditioner(TextConditioner):
- """T5-based TextConditioner.
-
- Args:
- name (str): Name of the T5 model.
- output_dim (int): Output dim of the conditioner.
- finetune (bool): Whether to fine-tune T5 at train time.
- device (str): Device for T5 Conditioner.
- autocast_dtype (tp.Optional[str], optional): Autocast dtype.
- word_dropout (float, optional): Word dropout probability.
- normalize_text (bool, optional): Whether to apply text normalization.
- """
- MODELS = ["t5-small", "t5-base", "t5-large", "t5-3b", "t5-11b",
- "google/flan-t5-small", "google/flan-t5-base", "google/flan-t5-large",
- "google/flan-t5-xl", "google/flan-t5-xxl"]
- MODELS_DIMS = {
- "t5-small": 512,
- "t5-base": 768,
- "t5-large": 1024,
- "t5-3b": 1024,
- "t5-11b": 1024,
- "google/flan-t5-small": 512,
- "google/flan-t5-base": 768,
- "google/flan-t5-large": 1024,
- "google/flan-t5-3b": 1024,
- "google/flan-t5-11b": 1024,
- }
-
- def __init__(self, name: str, output_dim: int, finetune: bool, device: str,
- autocast_dtype: tp.Optional[str] = 'float32', word_dropout: float = 0.,
- normalize_text: bool = False):
- assert name in self.MODELS, f"unrecognized t5 model name (should in {self.MODELS})"
- super().__init__(self.MODELS_DIMS[name], output_dim)
- self.device = device
- self.name = name
- self.finetune = finetune
- self.word_dropout = word_dropout
-
- if autocast_dtype is None or self.device == 'cpu':
- self.autocast = TorchAutocast(enabled=False)
- if self.device != 'cpu':
- logger.warning("T5 has no autocast, this might lead to NaN")
- else:
- dtype = getattr(torch, autocast_dtype)
- assert isinstance(dtype, torch.dtype)
- logger.info(f"T5 will be evaluated with autocast as {autocast_dtype}")
- self.autocast = TorchAutocast(enabled=True, device_type=self.device, dtype=dtype)
- # Let's disable logging temporarily because T5 will vomit some errors otherwise.
- # thanks https://gist.github.com/simon-weber/7853144
- previous_level = logging.root.manager.disable
- logging.disable(logging.ERROR)
- with warnings.catch_warnings():
- warnings.simplefilter("ignore")
- try:
- self.t5_tokenizer = T5Tokenizer.from_pretrained(name)
- t5 = T5EncoderModel.from_pretrained(name).train(mode=finetune)
- finally:
- logging.disable(previous_level)
- if finetune:
- self.t5 = t5
- else:
- # this makes sure that the t5 models is not part
- # of the saved checkpoint
- self.__dict__["t5"] = t5.to(device)
-
- self.normalize_text = normalize_text
- if normalize_text:
- self.text_normalizer = WhiteSpaceTokenizer(1, lemma=True, stopwords=True)
-
- def tokenize(self, x: tp.List[tp.Optional[str]]) -> tp.Dict[str, torch.Tensor]:
- # if current sample doesn't have a certain attribute, replace with empty string
- entries: tp.List[str] = [xi if xi is not None else "" for xi in x]
- if self.normalize_text:
- _, _, entries = self.text_normalizer(entries, return_text=True)
- if self.word_dropout > 0. and self.training:
- new_entries = []
- for entry in entries:
- words = [word for word in entry.split(" ") if random.random() >= self.word_dropout]
- new_entries.append(" ".join(words))
- entries = new_entries
-
- empty_idx = torch.LongTensor([i for i, xi in enumerate(entries) if xi == ""])
-
- inputs = self.t5_tokenizer(entries, return_tensors="pt", padding=True).to(self.device)
- mask = inputs["attention_mask"]
- mask[empty_idx, :] = 0 # zero-out index where the input is non-existant
- return inputs
-
- def forward(self, inputs: tp.Dict[str, torch.Tensor]) -> ConditionType:
- mask = inputs["attention_mask"]
- with torch.set_grad_enabled(self.finetune), self.autocast:
- embeds = self.t5(**inputs).last_hidden_state
- embeds = self.output_proj(embeds.to(self.output_proj.weight))
- embeds = (embeds * mask.unsqueeze(-1))
- return embeds, mask
-
-
-class WaveformConditioner(BaseConditioner):
- """Base class for all conditioners that take a waveform as input.
- Classes that inherit must implement `_get_wav_embedding` that outputs
- a continuous tensor, and `_downsampling_factor` that returns the down-sampling
- factor of the embedding model.
-
- Args:
- dim (int): The internal representation dimension.
- output_dim (int): Output dimension.
- device (tp.Union[torch.device, str]): Device.
- """
- def __init__(self, dim: int, output_dim: int, device: tp.Union[torch.device, str]):
- super().__init__(dim, output_dim)
- self.device = device
-
- def tokenize(self, wav_length: WavCondition) -> WavCondition:
- wav, length, path = wav_length
- assert length is not None
- return WavCondition(wav.to(self.device), length.to(self.device), path)
-
- def _get_wav_embedding(self, wav: Tensor) -> Tensor:
- """Gets as input a wav and returns a dense vector of conditions."""
- raise NotImplementedError()
-
- def _downsampling_factor(self):
- """Returns the downsampling factor of the embedding model."""
- raise NotImplementedError()
-
- def forward(self, inputs: WavCondition) -> ConditionType:
- """
- Args:
- input (WavCondition): Tuple of (waveform, lengths).
- Returns:
- ConditionType: Dense vector representing the conditioning along with its' mask.
- """
- wav, lengths, path = inputs
- with torch.no_grad():
- embeds = self._get_wav_embedding(wav)
- embeds = embeds.to(self.output_proj.weight)
- embeds = self.output_proj(embeds)
-
- if lengths is not None:
- lengths = lengths / self._downsampling_factor()
- mask = length_to_mask(lengths, max_len=embeds.shape[1]).int() # type: ignore
- else:
- mask = torch.ones_like(embeds)
- embeds = (embeds * mask.unsqueeze(2).to(self.device))
-
- return embeds, mask
-
-
-class ChromaStemConditioner(WaveformConditioner):
- """Chroma conditioner that uses DEMUCS to first filter out drums and bass. The is followed by
- the insight the drums and bass often dominate the chroma, leading to the chroma not containing the
- information about melody.
-
- Args:
- output_dim (int): Output dimension for the conditioner.
- sample_rate (int): Sample rate for the chroma extractor.
- n_chroma (int): Number of chroma for the chroma extractor.
- radix2_exp (int): Radix2 exponent for the chroma extractor.
- duration (float): Duration used during training. This is later used for correct padding
- in case we are using chroma as prefix.
- match_len_on_eval (bool, optional): If True then all chromas are padded to the training
- duration. Defaults to False.
- eval_wavs (str, optional): Path to a json egg with waveform, this waveforms are used as
- conditions during eval (for cases where we don't want to leak test conditions like MusicCaps).
- Defaults to None.
- n_eval_wavs (int, optional): Limits the number of waveforms used for conditioning. Defaults to 0.
- device (tp.Union[torch.device, str], optional): Device for the conditioner.
- **kwargs: Additional parameters for the chroma extractor.
- """
- def __init__(self, output_dim: int, sample_rate: int, n_chroma: int, radix2_exp: int,
- duration: float, match_len_on_eval: bool = True, eval_wavs: tp.Optional[str] = None,
- n_eval_wavs: int = 0, device: tp.Union[torch.device, str] = "cpu", **kwargs):
- from demucs import pretrained
- super().__init__(dim=n_chroma, output_dim=output_dim, device=device)
- self.autocast = TorchAutocast(enabled=device != "cpu", device_type=self.device, dtype=torch.float32)
- self.sample_rate = sample_rate
- self.match_len_on_eval = match_len_on_eval
- self.duration = duration
- self.__dict__["demucs"] = pretrained.get_model('htdemucs').to(device)
- self.stem2idx = {'drums': 0, 'bass': 1, 'other': 2, 'vocal': 3}
- self.stem_idx = torch.LongTensor([self.stem2idx['vocal'], self.stem2idx['other']]).to(device)
- self.chroma = ChromaExtractor(sample_rate=sample_rate, n_chroma=n_chroma, radix2_exp=radix2_exp,
- device=device, **kwargs)
- self.chroma_len = self._get_chroma_len()
-
- def _downsampling_factor(self):
- return self.chroma.winhop
-
- def _get_chroma_len(self):
- """Get length of chroma during training"""
- dummy_wav = torch.zeros((1, self.sample_rate * self.duration), device=self.device)
- dummy_chr = self.chroma(dummy_wav)
- return dummy_chr.shape[1]
-
- @torch.no_grad()
- def _get_filtered_wav(self, wav):
- from demucs.apply import apply_model
- from demucs.audio import convert_audio
- with self.autocast:
- wav = convert_audio(wav, self.sample_rate, self.demucs.samplerate, self.demucs.audio_channels)
- stems = apply_model(self.demucs, wav, device=self.device)
- stems = stems[:, self.stem_idx] # extract stem
- stems = stems.sum(1) # merge extracted stems
- stems = stems.mean(1, keepdim=True) # mono
- stems = convert_audio(stems, self.demucs.samplerate, self.sample_rate, 1)
- return stems
-
- @torch.no_grad()
- def _get_wav_embedding(self, wav):
- # avoid 0-size tensors when we are working with null conds
- if wav.shape[-1] == 1:
- return self.chroma(wav)
- stems = self._get_filtered_wav(wav)
- chroma = self.chroma(stems)
-
- if self.match_len_on_eval:
- b, t, c = chroma.shape
- if t > self.chroma_len:
- chroma = chroma[:, :self.chroma_len]
- logger.debug(f'chroma was truncated! ({t} -> {chroma.shape[1]})')
- elif t < self.chroma_len:
- # chroma = F.pad(chroma, (0, 0, 0, self.chroma_len - t))
- n_repeat = int(math.ceil(self.chroma_len / t))
- chroma = chroma.repeat(1, n_repeat, 1)
- chroma = chroma[:, :self.chroma_len]
- logger.debug(f'chroma was zero-padded! ({t} -> {chroma.shape[1]})')
- return chroma
-
-
-class ChromaExtractor(nn.Module):
- """Chroma extraction class, handles chroma extraction and quantization.
-
- Args:
- sample_rate (int): Sample rate.
- n_chroma (int): Number of chroma to consider.
- radix2_exp (int): Radix2 exponent.
- nfft (tp.Optional[int], optional): Number of FFT.
- winlen (tp.Optional[int], optional): Window length.
- winhop (tp.Optional[int], optional): Window hop size.
- argmax (bool, optional): Whether to use argmax. Defaults to False.
- norm (float, optional): Norm for chroma normalization. Defaults to inf.
- device (tp.Union[torch.device, str], optional): Device to use. Defaults to cpu.
- """
- def __init__(self, sample_rate: int, n_chroma: int = 12, radix2_exp: int = 12,
- nfft: tp.Optional[int] = None, winlen: tp.Optional[int] = None, winhop: tp.Optional[int] = None,
- argmax: bool = False, norm: float = torch.inf, device: tp.Union[torch.device, str] = "cpu"):
- super().__init__()
- from librosa import filters
- self.device = device
- self.autocast = TorchAutocast(enabled=device != "cpu", device_type=self.device, dtype=torch.float32)
- self.winlen = winlen or 2 ** radix2_exp
- self.nfft = nfft or self.winlen
- self.winhop = winhop or (self.winlen // 4)
- self.sr = sample_rate
- self.n_chroma = n_chroma
- self.norm = norm
- self.argmax = argmax
- self.window = torch.hann_window(self.winlen).to(device)
- self.fbanks = torch.from_numpy(filters.chroma(sr=sample_rate, n_fft=self.nfft, tuning=0,
- n_chroma=self.n_chroma)).to(device)
- self.spec = torchaudio.transforms.Spectrogram(n_fft=self.nfft, win_length=self.winlen,
- hop_length=self.winhop, power=2, center=True,
- pad=0, normalized=True).to(device)
-
- def forward(self, wav):
- with self.autocast:
- T = wav.shape[-1]
- # in case we are getting a wav that was dropped out (nullified)
- # make sure wav length is no less that nfft
- if T < self.nfft:
- pad = self.nfft - T
- r = 0 if pad % 2 == 0 else 1
- wav = F.pad(wav, (pad // 2, pad // 2 + r), 'constant', 0)
- assert wav.shape[-1] == self.nfft, f'expected len {self.nfft} but got {wav.shape[-1]}'
- spec = self.spec(wav).squeeze(1)
- raw_chroma = torch.einsum("cf,...ft->...ct", self.fbanks, spec)
- norm_chroma = torch.nn.functional.normalize(raw_chroma, p=self.norm, dim=-2, eps=1e-6)
- norm_chroma = rearrange(norm_chroma, "b d t -> b t d")
-
- if self.argmax:
- idx = norm_chroma.argmax(-1, keepdims=True)
- norm_chroma[:] = 0
- norm_chroma.scatter_(dim=-1, index=idx, value=1)
-
- return norm_chroma
-
-
-def dropout_condition(sample: ConditioningAttributes, condition_type: str, condition: str):
- """Utility function for nullifying an attribute inside an ConditioningAttributes object.
- If the condition is of type "wav", then nullify it using "nullify_condition".
- If the condition is of any other type, set its' value to None.
- Works in-place.
- """
- if condition_type not in ["text", "wav"]:
- raise ValueError(
- "dropout_condition got an unexpected condition type!"
- f" expected 'wav' or 'text' but got '{condition_type}'"
- )
-
- if condition not in getattr(sample, condition_type):
- raise ValueError(
- "dropout_condition received an unexpected condition!"
- f" expected wav={sample.wav.keys()} and text={sample.text.keys()}"
- f"but got '{condition}' of type '{condition_type}'!"
- )
-
- if condition_type == "wav":
- wav, length, path = sample.wav[condition]
- sample.wav[condition] = nullify_wav(wav)
- else:
- sample.text[condition] = None
-
- return sample
-
-
-class DropoutModule(nn.Module):
- """Base class for all dropout modules."""
- def __init__(self, seed: int = 1234):
- super().__init__()
- self.rng = torch.Generator()
- self.rng.manual_seed(seed)
-
-
-class AttributeDropout(DropoutModule):
- """Applies dropout with a given probability per attribute. This is different from the behavior of
- ClassifierFreeGuidanceDropout as this allows for attributes to be dropped out separately. For example,
- "artist" can be dropped while "genre" remains. This is in contrast to ClassifierFreeGuidanceDropout
- where if "artist" is dropped "genre" must also be dropped.
-
- Args:
- p (tp.Dict[str, float]): A dict mapping between attributes and dropout probability. For example:
- ...
- "genre": 0.1,
- "artist": 0.5,
- "wav": 0.25,
- ...
- active_on_eval (bool, optional): Whether the dropout is active at eval. Default to False.
- seed (int, optional): Random seed.
- """
- def __init__(self, p: tp.Dict[str, tp.Dict[str, float]], active_on_eval: bool = False, seed: int = 1234):
- super().__init__(seed=seed)
- self.active_on_eval = active_on_eval
- # construct dict that return the values from p otherwise 0
- self.p = {}
- for condition_type, probs in p.items():
- self.p[condition_type] = defaultdict(lambda: 0, probs)
-
- def forward(self, samples: tp.List[ConditioningAttributes]) -> tp.List[ConditioningAttributes]:
- """
- Args:
- samples (tp.List[ConditioningAttributes]): List of conditions.
- Returns:
- tp.List[ConditioningAttributes]: List of conditions after certain attributes were set to None.
- """
- if not self.training and not self.active_on_eval:
- return samples
-
- samples = deepcopy(samples)
-
- for condition_type, ps in self.p.items(): # for condition types [text, wav]
- for condition, p in ps.items(): # for attributes of each type (e.g., [artist, genre])
- if torch.rand(1, generator=self.rng).item() < p:
- for sample in samples:
- dropout_condition(sample, condition_type, condition)
-
- return samples
-
- def __repr__(self):
- return f"AttributeDropout({dict(self.p)})"
-
-
-class ClassifierFreeGuidanceDropout(DropoutModule):
- """Applies Classifier Free Guidance dropout, meaning all attributes
- are dropped with the same probability.
-
- Args:
- p (float): Probability to apply condition dropout during training.
- seed (int): Random seed.
- """
- def __init__(self, p: float, seed: int = 1234):
- super().__init__(seed=seed)
- self.p = p
-
- def forward(self, samples: tp.List[ConditioningAttributes]) -> tp.List[ConditioningAttributes]:
- """
- Args:
- samples (tp.List[ConditioningAttributes]): List of conditions.
- Returns:
- tp.List[ConditioningAttributes]: List of conditions after all attributes were set to None.
- """
- if not self.training:
- return samples
-
- # decide on which attributes to drop in a batched fashion
- drop = torch.rand(1, generator=self.rng).item() < self.p
- if not drop:
- return samples
-
- # nullify conditions of all attributes
- samples = deepcopy(samples)
-
- for condition_type in ["wav", "text"]:
- for sample in samples:
- for condition in sample.attributes[condition_type]:
- dropout_condition(sample, condition_type, condition)
-
- return samples
-
- def __repr__(self):
- return f"ClassifierFreeGuidanceDropout(p={self.p})"
-
-
-class ConditioningProvider(nn.Module):
- """Main class to provide conditions given all the supported conditioners.
-
- Args:
- conditioners (dict): Dictionary of conditioners.
- merge_text_conditions_p (float, optional): Probability to merge all text sources
- into a single text condition. Defaults to 0.
- drop_desc_p (float, optional): Probability to drop the original description
- when merging all text sources into a single text condition. Defaults to 0.
- device (tp.Union[torch.device, str], optional): Device for conditioners and output condition types.
- """
- def __init__(
- self,
- conditioners: tp.Dict[str, BaseConditioner],
- merge_text_conditions_p: float = 0,
- drop_desc_p: float = 0,
- device: tp.Union[torch.device, str] = "cpu",
- ):
- super().__init__()
- self.device = device
- self.merge_text_conditions_p = merge_text_conditions_p
- self.drop_desc_p = drop_desc_p
- self.conditioners = nn.ModuleDict(conditioners)
-
- @property
- def text_conditions(self):
- return [k for k, v in self.conditioners.items() if isinstance(v, TextConditioner)]
-
- @property
- def wav_conditions(self):
- return [k for k, v in self.conditioners.items() if isinstance(v, WaveformConditioner)]
-
- @property
- def has_wav_condition(self):
- return len(self.wav_conditions) > 0
-
- def tokenize(self, inputs: tp.List[ConditioningAttributes]) -> tp.Dict[str, tp.Any]:
- """Match attributes/wavs with existing conditioners in self, and compute tokenize them accordingly.
- This should be called before starting any real GPU work to avoid synchronization points.
- This will return a dict matching conditioner names to their arbitrary tokenized representations.
-
- Args:
- inputs (list[ConditioningAttribres]): List of ConditioningAttributes objects containing
- text and wav conditions.
- """
- assert all([type(x) == ConditioningAttributes for x in inputs]), \
- "got unexpected types input for conditioner! should be tp.List[ConditioningAttributes]" \
- f" but types were {set([type(x) for x in inputs])}"
-
- output = {}
- text = self._collate_text(inputs)
- wavs = self._collate_wavs(inputs)
-
- assert set(text.keys() | wavs.keys()).issubset(set(self.conditioners.keys())), \
- f"got an unexpected attribute! Expected {self.conditioners.keys()}, got {text.keys(), wavs.keys()}"
-
- for attribute, batch in chain(text.items(), wavs.items()):
- output[attribute] = self.conditioners[attribute].tokenize(batch)
- return output
-
- def forward(self, tokenized: tp.Dict[str, tp.Any]) -> tp.Dict[str, ConditionType]:
- """Compute pairs of `(embedding, mask)` using the configured conditioners
- and the tokenized representations. The output is for example:
-
- {
- "genre": (torch.Tensor([B, 1, D_genre]), torch.Tensor([B, 1])),
- "description": (torch.Tensor([B, T_desc, D_desc]), torch.Tensor([B, T_desc])),
- ...
- }
-
- Args:
- tokenized (dict): Dict of tokenized representations as returned by `tokenize()`.
- """
- output = {}
- for attribute, inputs in tokenized.items():
- condition, mask = self.conditioners[attribute](inputs)
- output[attribute] = (condition, mask)
- return output
-
- def _collate_text(self, samples: tp.List[ConditioningAttributes]) -> tp.Dict[str, tp.List[tp.Optional[str]]]:
- """Given a list of ConditioningAttributes objects, compile a dictionary where the keys
- are the attributes and the values are the aggregated input per attribute.
- For example:
- Input:
- [
- ConditioningAttributes(text={"genre": "Rock", "description": "A rock song with a guitar solo"}, wav=...),
- ConditioningAttributes(text={"genre": "Hip-hop", "description": "A hip-hop verse"}, wav=...),
- ]
- Output:
- {
- "genre": ["Rock", "Hip-hop"],
- "description": ["A rock song with a guitar solo", "A hip-hop verse"]
- }
- """
- batch_per_attribute: tp.Dict[str, tp.List[tp.Optional[str]]] = defaultdict(list)
-
- def _merge_conds(cond, merge_text_conditions_p=0, drop_desc_p=0):
- def is_valid(k, v):
- k_valid = k in ['key', 'bpm', 'genre', 'moods', 'instrument']
- v_valid = v is not None and isinstance(v, (int, float, str, list))
- return k_valid and v_valid
-
- def process_value(v):
- if isinstance(v, (int, float, str)):
- return v
- if isinstance(v, list):
- return ", ".join(v)
- else:
- RuntimeError(f"unknown type for text value! ({type(v), v})")
-
- desc = cond.text['description']
- meta_data = ""
- if random.uniform(0, 1) < merge_text_conditions_p:
- meta_pairs = [f'{k}: {process_value(v)}' for k, v in cond.text.items() if is_valid(k, v)]
- random.shuffle(meta_pairs)
- meta_data = ". ".join(meta_pairs)
- desc = desc if not random.uniform(0, 1) < drop_desc_p else None
-
- if desc is None:
- desc = meta_data if len(meta_data) > 1 else None
- else:
- desc = desc.rstrip('.') + ". " + meta_data
- cond.text['description'] = desc.strip() if desc else None
-
- if self.training and self.merge_text_conditions_p:
- for sample in samples:
- _merge_conds(sample, self.merge_text_conditions_p, self.drop_desc_p)
-
- texts = [x.text for x in samples]
- for text in texts:
- for condition in self.text_conditions:
- batch_per_attribute[condition].append(text[condition])
-
- return batch_per_attribute
-
- def _collate_wavs(self, samples: tp.List[ConditioningAttributes]):
- """Generate a dict where the keys are attributes by which we fetch similar wavs,
- and the values are Tensors of wavs according to said attribtues.
-
- *Note*: by the time the samples reach this function, each sample should have some waveform
- inside the "wav" attribute. It should be either:
- 1. A real waveform
- 2. A null waveform due to the sample having no similar waveforms (nullified by the dataset)
- 3. A null waveform due to it being dropped in a dropout module (nullified by dropout)
-
- Args:
- samples (tp.List[ConditioningAttributes]): List of ConditioningAttributes samples.
- Returns:
- dict: A dicionary mapping an attribute name to wavs.
- """
- wavs = defaultdict(list)
- lens = defaultdict(list)
- paths = defaultdict(list)
- out = {}
-
- for sample in samples:
- for attribute in self.wav_conditions:
- wav, length, path = sample.wav[attribute]
- wavs[attribute].append(wav.flatten())
- lens[attribute].append(length)
- paths[attribute].append(path)
-
- # stack all wavs to a single tensor
- for attribute in self.wav_conditions:
- stacked_wav, _ = collate(wavs[attribute], dim=0)
- out[attribute] = WavCondition(stacked_wav.unsqueeze(1),
- torch.cat(lens['self_wav']), paths[attribute]) # type: ignore
-
- return out
-
-
-class ConditionFuser(StreamingModule):
- """Condition fuser handles the logic to combine the different conditions
- to the actual model input.
-
- Args:
- fuse2cond (tp.Dict[str, str]): A dictionary that says how to fuse
- each condition. For example:
- {
- "prepend": ["description"],
- "sum": ["genre", "bpm"],
- "cross": ["description"],
- }
- cross_attention_pos_emb (bool, optional): Use positional embeddings in cross attention.
- cross_attention_pos_emb_scale (int): Scale for positional embeddings in cross attention if used.
- """
- FUSING_METHODS = ["sum", "prepend", "cross", "input_interpolate"]
-
- def __init__(self, fuse2cond: tp.Dict[str, tp.List[str]], cross_attention_pos_emb: bool = False,
- cross_attention_pos_emb_scale: float = 1.0):
- super().__init__()
- assert all(
- [k in self.FUSING_METHODS for k in fuse2cond.keys()]
- ), f"got invalid fuse method, allowed methods: {self.FUSING_MEHTODS}"
- self.cross_attention_pos_emb = cross_attention_pos_emb
- self.cross_attention_pos_emb_scale = cross_attention_pos_emb_scale
- self.fuse2cond: tp.Dict[str, tp.List[str]] = fuse2cond
- self.cond2fuse: tp.Dict[str, str] = {}
- for fuse_method, conditions in fuse2cond.items():
- for condition in conditions:
- self.cond2fuse[condition] = fuse_method
-
- def forward(
- self,
- input: Tensor,
- conditions: tp.Dict[str, ConditionType]
- ) -> tp.Tuple[Tensor, tp.Optional[Tensor]]:
- """Fuse the conditions to the provided model input.
-
- Args:
- input (Tensor): Transformer input.
- conditions (tp.Dict[str, ConditionType]): Dict of conditions.
- Returns:
- tp.Tuple[Tensor, Tensor]: The first tensor is the transformer input
- after the conditions have been fused. The second output tensor is the tensor
- used for cross-attention or None if no cross attention inputs exist.
- """
- B, T, _ = input.shape
-
- if 'offsets' in self._streaming_state:
- first_step = False
- offsets = self._streaming_state['offsets']
- else:
- first_step = True
- offsets = torch.zeros(input.shape[0], dtype=torch.long, device=input.device)
-
- assert set(conditions.keys()).issubset(set(self.cond2fuse.keys())), \
- f"given conditions contain unknown attributes for fuser, " \
- f"expected {self.cond2fuse.keys()}, got {conditions.keys()}"
- cross_attention_output = None
- for cond_type, (cond, cond_mask) in conditions.items():
- op = self.cond2fuse[cond_type]
- if op == "sum":
- input += cond
- elif op == "input_interpolate":
- cond = rearrange(cond, "b t d -> b d t")
- cond = F.interpolate(cond, size=input.shape[1])
- input += rearrange(cond, "b d t -> b t d")
- elif op == "prepend":
- if first_step:
- input = torch.cat([cond, input], dim=1)
- elif op == "cross":
- if cross_attention_output is not None:
- cross_attention_output = torch.cat([cross_attention_output, cond], dim=1)
- else:
- cross_attention_output = cond
- else:
- raise ValueError(f"unknown op ({op})")
-
- if self.cross_attention_pos_emb and cross_attention_output is not None:
- positions = torch.arange(
- cross_attention_output.shape[1],
- device=cross_attention_output.device
- ).view(1, -1, 1)
- pos_emb = create_sin_embedding(positions, cross_attention_output.shape[-1])
- cross_attention_output = cross_attention_output + self.cross_attention_pos_emb_scale * pos_emb
-
- if self._is_streaming:
- self._streaming_state['offsets'] = offsets + T
-
- return input, cross_attention_output
diff --git a/spaces/GurudattaBS/GenDiseasePrediction/code/helper.py b/spaces/GurudattaBS/GenDiseasePrediction/code/helper.py
deleted file mode 100644
index a187ec9b60a435be65018508e17ac45cf3f90709..0000000000000000000000000000000000000000
--- a/spaces/GurudattaBS/GenDiseasePrediction/code/helper.py
+++ /dev/null
@@ -1,33 +0,0 @@
-import pandas as pd
-import numpy as np
-
-# def preprocess_kaggle(dataset_path):
-
-# # import the dataset
-# dataset_df = pd.read_csv(dataset_path)
-
-# # Preprocess
-# dataset_df = dataset_df.apply(lambda col: col.str.strip())
-
-# test = pd.get_dummies(dataset_df.filter(regex='Symptom'), prefix='', prefix_sep='')
-# test = test.groupby(test.columns, axis=1).agg(np.max)
-# clean_df = pd.merge(test,dataset_df['Disease'], left_index=True, right_index=True)
-
-# return clean_df
-
-def prepare_symptoms_array(symptoms):
- '''
- Convert a list of symptoms to a ndim(X) (in this case 131) that matches the
- dataframe used to train the machine learning model
-
- Output:
- - X (np.array) = X values ready as input to ML model to get prediction
- '''
- symptoms_array = np.zeros((1,133))
- df = pd.read_csv('data/clean_dataset.tsv', sep='\t')
-
- for symptom in symptoms:
- symptom_idx = df.columns.get_loc(symptom)
- symptoms_array[0, symptom_idx] = 1
-
- return symptoms_array
\ No newline at end of file
diff --git a/spaces/HaloMaster/chinesesummary/fengshen/models/zen1/tokenization.py b/spaces/HaloMaster/chinesesummary/fengshen/models/zen1/tokenization.py
deleted file mode 100644
index bbc94e2417ff42ffcfb18284b8cb396415e630b1..0000000000000000000000000000000000000000
--- a/spaces/HaloMaster/chinesesummary/fengshen/models/zen1/tokenization.py
+++ /dev/null
@@ -1,438 +0,0 @@
-# coding=utf-8
-# This file is derived from the code at
-# https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert.py
-#
-# Original copyright notice:
-#
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Tokenization classes."""
-
-from __future__ import absolute_import, division, print_function, unicode_literals
-
-import collections
-import logging
-import os
-import unicodedata
-from io import open
-
-from transformers import cached_path
-
-logger = logging.getLogger(__name__)
-
-PRETRAINED_VOCAB_ARCHIVE_MAP = {
- 'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt",
- 'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-vocab.txt",
- 'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt",
- 'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-vocab.txt",
- 'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased-vocab.txt",
- 'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt",
- 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt",
- 'bert-base-german-cased': "https://int-deepset-models-bert.s3.eu-central-1.amazonaws.com/pytorch/bert-base-german-cased-vocab.txt",
- 'bert-large-uncased-whole-word-masking': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-whole-word-masking-vocab.txt",
- 'bert-large-cased-whole-word-masking': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-whole-word-masking-vocab.txt",
- 'bert-large-uncased-whole-word-masking-finetuned-squad': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-whole-word-masking-finetuned-squad-vocab.txt",
- 'bert-large-cased-whole-word-masking-finetuned-squad': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-whole-word-masking-finetuned-squad-vocab.txt",
- 'bert-base-cased-finetuned-mrpc': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-finetuned-mrpc-vocab.txt",
- 'IDEA-CCNL/Erlangshen-ZEN1-224M-Chinese': 'https://huggingface.co/IDEA-CCNL/Erlangshen-ZEN1-224M-Chinese/resolve/main/vocab.txt',
-}
-PRETRAINED_VOCAB_POSITIONAL_EMBEDDINGS_SIZE_MAP = {
- 'bert-base-uncased': 512,
- 'bert-large-uncased': 512,
- 'bert-base-cased': 512,
- 'bert-large-cased': 512,
- 'bert-base-multilingual-uncased': 512,
- 'bert-base-multilingual-cased': 512,
- 'bert-base-chinese': 512,
- 'bert-base-german-cased': 512,
- 'bert-large-uncased-whole-word-masking': 512,
- 'bert-large-cased-whole-word-masking': 512,
- 'bert-large-uncased-whole-word-masking-finetuned-squad': 512,
- 'bert-large-cased-whole-word-masking-finetuned-squad': 512,
- 'bert-base-cased-finetuned-mrpc': 512,
-}
-VOCAB_NAME = 'vocab.txt'
-
-
-def load_vocab(vocab_file):
- """Loads a vocabulary file into a dictionary."""
- vocab = collections.OrderedDict()
- index = 0
- with open(vocab_file, "r", encoding="utf-8") as reader:
- while True:
- token = reader.readline()
- if not token:
- break
- token = token.strip()
- vocab[token] = index
- index += 1
- return vocab
-
-
-def whitespace_tokenize(text):
- """Runs basic whitespace cleaning and splitting on a piece of text."""
- text = text.strip()
- if not text:
- return []
- tokens = text.split()
- return tokens
-
-
-class BertTokenizer(object):
- """Runs end-to-end tokenization: punctuation splitting + wordpiece"""
-
- def __init__(self, vocab_file, do_lower_case=True, max_len=None, do_basic_tokenize=True,
- never_split=("[UNK]", "[SEP]", "[PAD]", "[CLS]", "[MASK]")):
- """Constructs a BertTokenizer.
-
- Args:
- vocab_file: Path to a one-wordpiece-per-line vocabulary file
- do_lower_case: Whether to lower case the input
- Only has an effect when do_wordpiece_only=False
- do_basic_tokenize: Whether to do basic tokenization before wordpiece.
- max_len: An artificial maximum length to truncate tokenized sequences to;
- Effective maximum length is always the minimum of this
- value (if specified) and the underlying BERT model's
- sequence length.
- never_split: List of tokens which will never be split during tokenization.
- Only has an effect when do_wordpiece_only=False
- """
- if not os.path.isfile(vocab_file):
- raise ValueError(
- "Can't find a vocabulary file at path '{}'. To load the vocabulary from a Google pretrained "
- "model use `tokenizer = BertTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)`".format(vocab_file))
- self.vocab = load_vocab(vocab_file)
- self.ids_to_tokens = collections.OrderedDict(
- [(ids, tok) for tok, ids in self.vocab.items()])
- self.do_basic_tokenize = do_basic_tokenize
- if do_basic_tokenize:
- self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case,
- never_split=never_split)
- self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
- self.max_len = max_len if max_len is not None else int(1e12)
-
- def tokenize(self, text):
- split_tokens = []
- if self.do_basic_tokenize:
- for token in self.basic_tokenizer.tokenize(text):
- for sub_token in self.wordpiece_tokenizer.tokenize(token):
- split_tokens.append(sub_token)
- else:
- split_tokens = self.wordpiece_tokenizer.tokenize(text)
- return split_tokens
-
- def convert_tokens_to_ids(self, tokens):
- """Converts a sequence of tokens into ids using the vocab."""
- ids = []
- for token in tokens:
- ids.append(self.vocab[token])
- if len(ids) > self.max_len:
- logger.warning(
- "Token indices sequence length is longer than the specified maximum "
- " sequence length for this BERT model ({} > {}). Running this"
- " sequence through BERT will result in indexing errors".format(len(ids), self.max_len)
- )
- return ids
-
- def convert_ids_to_tokens(self, ids):
- """Converts a sequence of ids in wordpiece tokens using the vocab."""
- tokens = []
- for i in ids:
- tokens.append(self.ids_to_tokens[i])
- return tokens
-
- def save_vocabulary(self, vocab_path):
- """Save the tokenizer vocabulary to a directory or file."""
- index = 0
- if os.path.isdir(vocab_path):
- vocab_file = os.path.join(vocab_path, VOCAB_NAME)
- with open(vocab_file, "w", encoding="utf-8") as writer:
- for token, token_index in sorted(self.vocab.items(), key=lambda kv: kv[1]):
- if index != token_index:
- logger.warning("Saving vocabulary to {}: vocabulary indices are not consecutive."
- " Please check that the vocabulary is not corrupted!".format(vocab_file))
- index = token_index
- writer.write(token + u'\n')
- index += 1
- return vocab_file
-
- @classmethod
- def from_pretrained(cls, pretrained_model_name_or_path, cache_dir=None, *inputs, **kwargs):
- """
- Instantiate a PreTrainedBertModel from a pre-trained model file.
- Download and cache the pre-trained model file if needed.
- """
- if pretrained_model_name_or_path in PRETRAINED_VOCAB_ARCHIVE_MAP:
- vocab_file = PRETRAINED_VOCAB_ARCHIVE_MAP[pretrained_model_name_or_path]
- if '-cased' in pretrained_model_name_or_path and kwargs.get('do_lower_case', True):
- logger.warning("The pre-trained model you are loading is a cased model but you have not set "
- "`do_lower_case` to False. We are setting `do_lower_case=False` for you but "
- "you may want to check this behavior.")
- kwargs['do_lower_case'] = False
- elif '-cased' not in pretrained_model_name_or_path and not kwargs.get('do_lower_case', True):
- logger.warning("The pre-trained model you are loading is an uncased model but you have set "
- "`do_lower_case` to False. We are setting `do_lower_case=True` for you "
- "but you may want to check this behavior.")
- kwargs['do_lower_case'] = True
- else:
- vocab_file = pretrained_model_name_or_path
- if os.path.isdir(vocab_file):
- vocab_file = os.path.join(vocab_file, VOCAB_NAME)
- # redirect to the cache, if necessary
- try:
- resolved_vocab_file = cached_path(vocab_file, cache_dir=cache_dir)
- except EnvironmentError:
- if pretrained_model_name_or_path in PRETRAINED_VOCAB_ARCHIVE_MAP:
- logger.error(
- "Couldn't reach server at '{}' to download vocabulary.".format(
- vocab_file))
- else:
- logger.error(
- "Model name '{}' was not found in model name list ({}). "
- "We assumed '{}' was a path or url but couldn't find any file "
- "associated to this path or url.".format(
- pretrained_model_name_or_path,
- ', '.join(PRETRAINED_VOCAB_ARCHIVE_MAP.keys()),
- vocab_file))
- return None
- if resolved_vocab_file == vocab_file:
- logger.info("loading vocabulary file {}".format(vocab_file))
- else:
- logger.info("loading vocabulary file {} from cache at {}".format(
- vocab_file, resolved_vocab_file))
- if pretrained_model_name_or_path in PRETRAINED_VOCAB_POSITIONAL_EMBEDDINGS_SIZE_MAP:
- # if we're using a pretrained model, ensure the tokenizer wont index sequences longer
- # than the number of positional embeddings
- max_len = PRETRAINED_VOCAB_POSITIONAL_EMBEDDINGS_SIZE_MAP[pretrained_model_name_or_path]
- kwargs['max_len'] = min(kwargs.get('max_len', int(1e12)), max_len)
- # Instantiate tokenizer.
- tokenizer = cls(resolved_vocab_file, *inputs, **kwargs)
- return tokenizer
-
-
-class BasicTokenizer(object):
- """Runs basic tokenization (punctuation splitting, lower casing, etc.)."""
-
- def __init__(self,
- do_lower_case=True,
- never_split=("[UNK]", "[SEP]", "[PAD]", "[CLS]", "[MASK]")):
- """Constructs a BasicTokenizer.
-
- Args:
- do_lower_case: Whether to lower case the input.
- """
- self.do_lower_case = do_lower_case
- self.never_split = never_split
-
- def tokenize(self, text):
- """Tokenizes a piece of text."""
- text = self._clean_text(text)
- # This was added on November 1st, 2018 for the multilingual and Chinese
- # models. This is also applied to the English models now, but it doesn't
- # matter since the English models were not trained on any Chinese data
- # and generally don't have any Chinese data in them (there are Chinese
- # characters in the vocabulary because Wikipedia does have some Chinese
- # words in the English Wikipedia.).
- text = self._tokenize_chinese_chars(text)
- orig_tokens = whitespace_tokenize(text)
- split_tokens = []
- for token in orig_tokens:
- if self.do_lower_case and token not in self.never_split:
- token = token.lower()
- token = self._run_strip_accents(token)
- split_tokens.extend(self._run_split_on_punc(token))
-
- output_tokens = whitespace_tokenize(" ".join(split_tokens))
- return output_tokens
-
- def _run_strip_accents(self, text):
- """Strips accents from a piece of text."""
- text = unicodedata.normalize("NFD", text)
- output = []
- for char in text:
- cat = unicodedata.category(char)
- if cat == "Mn":
- continue
- output.append(char)
- return "".join(output)
-
- def _run_split_on_punc(self, text):
- """Splits punctuation on a piece of text."""
- if text in self.never_split:
- return [text]
- chars = list(text)
- i = 0
- start_new_word = True
- output = []
- while i < len(chars):
- char = chars[i]
- if _is_punctuation(char):
- output.append([char])
- start_new_word = True
- else:
- if start_new_word:
- output.append([])
- start_new_word = False
- output[-1].append(char)
- i += 1
-
- return ["".join(x) for x in output]
-
- def _tokenize_chinese_chars(self, text):
- """Adds whitespace around any CJK character."""
- output = []
- for char in text:
- cp = ord(char)
- if self._is_chinese_char(cp):
- output.append(" ")
- output.append(char)
- output.append(" ")
- else:
- output.append(char)
- return "".join(output)
-
- def _is_chinese_char(self, cp):
- """Checks whether CP is the codepoint of a CJK character."""
- # This defines a "chinese character" as anything in the CJK Unicode block:
- # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
- #
- # Note that the CJK Unicode block is NOT all Japanese and Korean characters,
- # despite its name. The modern Korean Hangul alphabet is a different block,
- # as is Japanese Hiragana and Katakana. Those alphabets are used to write
- # space-separated words, so they are not treated specially and handled
- # like the all of the other languages.
- if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
- (cp >= 0x3400 and cp <= 0x4DBF) or #
- (cp >= 0x20000 and cp <= 0x2A6DF) or #
- (cp >= 0x2A700 and cp <= 0x2B73F) or #
- (cp >= 0x2B740 and cp <= 0x2B81F) or #
- (cp >= 0x2B820 and cp <= 0x2CEAF) or
- (cp >= 0xF900 and cp <= 0xFAFF) or #
- (cp >= 0x2F800 and cp <= 0x2FA1F)): #
- return True
-
- return False
-
- def _clean_text(self, text):
- """Performs invalid character removal and whitespace cleanup on text."""
- output = []
- for char in text:
- cp = ord(char)
- if cp == 0 or cp == 0xfffd or _is_control(char):
- continue
- if _is_whitespace(char):
- output.append(" ")
- else:
- output.append(char)
- return "".join(output)
-
-
-class WordpieceTokenizer(object):
- """Runs WordPiece tokenization."""
-
- def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=100):
- self.vocab = vocab
- self.unk_token = unk_token
- self.max_input_chars_per_word = max_input_chars_per_word
-
- def tokenize(self, text):
- """Tokenizes a piece of text into its word pieces.
-
- This uses a greedy longest-match-first algorithm to perform tokenization
- using the given vocabulary.
-
- For example:
- input = "unaffable"
- output = ["un", "##aff", "##able"]
-
- Args:
- text: A single token or whitespace separated tokens. This should have
- already been passed through `BasicTokenizer`.
-
- Returns:
- A list of wordpiece tokens.
- """
-
- output_tokens = []
- for token in whitespace_tokenize(text):
- chars = list(token)
- if len(chars) > self.max_input_chars_per_word:
- output_tokens.append(self.unk_token)
- continue
-
- is_bad = False
- start = 0
- sub_tokens = []
- while start < len(chars):
- end = len(chars)
- cur_substr = None
- while start < end:
- substr = "".join(chars[start:end])
- if start > 0:
- substr = "##" + substr
- if substr in self.vocab:
- cur_substr = substr
- break
- end -= 1
- if cur_substr is None:
- is_bad = True
- break
- sub_tokens.append(cur_substr)
- start = end
-
- if is_bad:
- output_tokens.append(self.unk_token)
- else:
- output_tokens.extend(sub_tokens)
- return output_tokens
-
-
-def _is_whitespace(char):
- """Checks whether `chars` is a whitespace character."""
- # \t, \n, and \r are technically contorl characters but we treat them
- # as whitespace since they are generally considered as such.
- if char == " " or char == "\t" or char == "\n" or char == "\r":
- return True
- cat = unicodedata.category(char)
- if cat == "Zs":
- return True
- return False
-
-
-def _is_control(char):
- """Checks whether `chars` is a control character."""
- # These are technically control characters but we count them as whitespace
- # characters.
- if char == "\t" or char == "\n" or char == "\r":
- return False
- cat = unicodedata.category(char)
- if cat.startswith("C"):
- return True
- return False
-
-
-def _is_punctuation(char):
- """Checks whether `chars` is a punctuation character."""
- cp = ord(char)
- # We treat all non-letter/number ASCII as punctuation.
- # Characters such as "^", "$", and "`" are not in the Unicode
- # Punctuation class but we treat them as punctuation anyways, for
- # consistency.
- if ((cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or
- (cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126)):
- return True
- cat = unicodedata.category(char)
- if cat.startswith("P"):
- return True
- return False
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/textless_nlp/gslm/unit2speech/tacotron2/cleaners.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/textless_nlp/gslm/unit2speech/tacotron2/cleaners.py
deleted file mode 100644
index e2e35c1a8cc4c628c5d05802677142c9a2122d2b..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/textless_nlp/gslm/unit2speech/tacotron2/cleaners.py
+++ /dev/null
@@ -1,90 +0,0 @@
-""" from https://github.com/keithito/tacotron """
-
-'''
-Cleaners are transformations that run over the input text at both training and eval time.
-
-Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
-hyperparameter. Some cleaners are English-specific. You'll typically want to use:
- 1. "english_cleaners" for English text
- 2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
- the Unidecode library (https://pypi.python.org/pypi/Unidecode)
- 3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
- the symbols in symbols.py to match your data).
-'''
-
-import re
-from unidecode import unidecode
-from .numbers import normalize_numbers
-
-
-# Regular expression matching whitespace:
-_whitespace_re = re.compile(r'\s+')
-
-# List of (regular expression, replacement) pairs for abbreviations:
-_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [
- ('mrs', 'misess'),
- ('mr', 'mister'),
- ('dr', 'doctor'),
- ('st', 'saint'),
- ('co', 'company'),
- ('jr', 'junior'),
- ('maj', 'major'),
- ('gen', 'general'),
- ('drs', 'doctors'),
- ('rev', 'reverend'),
- ('lt', 'lieutenant'),
- ('hon', 'honorable'),
- ('sgt', 'sergeant'),
- ('capt', 'captain'),
- ('esq', 'esquire'),
- ('ltd', 'limited'),
- ('col', 'colonel'),
- ('ft', 'fort'),
-]]
-
-
-def expand_abbreviations(text):
- for regex, replacement in _abbreviations:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def expand_numbers(text):
- return normalize_numbers(text)
-
-
-def lowercase(text):
- return text.lower()
-
-
-def collapse_whitespace(text):
- return re.sub(_whitespace_re, ' ', text)
-
-
-def convert_to_ascii(text):
- return unidecode(text)
-
-
-def basic_cleaners(text):
- '''Basic pipeline that lowercases and collapses whitespace without transliteration.'''
- text = lowercase(text)
- text = collapse_whitespace(text)
- return text
-
-
-def transliteration_cleaners(text):
- '''Pipeline for non-English text that transliterates to ASCII.'''
- text = convert_to_ascii(text)
- text = lowercase(text)
- text = collapse_whitespace(text)
- return text
-
-
-def english_cleaners(text):
- '''Pipeline for English text, including number and abbreviation expansion.'''
- text = convert_to_ascii(text)
- text = lowercase(text)
- text = expand_numbers(text)
- text = expand_abbreviations(text)
- text = collapse_whitespace(text)
- return text
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/models/roberta/alignment_utils.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/models/roberta/alignment_utils.py
deleted file mode 100644
index ccc7f74cb94d5b8baa2d4e9dfd44f653d47ee43e..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/models/roberta/alignment_utils.py
+++ /dev/null
@@ -1,118 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from collections import Counter
-from typing import List
-
-import torch
-
-
-def align_bpe_to_words(roberta, bpe_tokens: torch.LongTensor, other_tokens: List[str]):
- """
- Helper to align GPT-2 BPE to other tokenization formats (e.g., spaCy).
-
- Args:
- roberta (RobertaHubInterface): RoBERTa instance
- bpe_tokens (torch.LongTensor): GPT-2 BPE tokens of shape `(T_bpe)`
- other_tokens (List[str]): other tokens of shape `(T_words)`
-
- Returns:
- List[str]: mapping from *other_tokens* to corresponding *bpe_tokens*.
- """
- assert bpe_tokens.dim() == 1
- assert bpe_tokens[0] == 0
-
- def clean(text):
- return text.strip()
-
- # remove whitespaces to simplify alignment
- bpe_tokens = [roberta.task.source_dictionary.string([x]) for x in bpe_tokens]
- bpe_tokens = [
- clean(roberta.bpe.decode(x) if x not in {"", ""} else x) for x in bpe_tokens
- ]
- other_tokens = [clean(str(o)) for o in other_tokens]
-
- # strip leading
- bpe_tokens = bpe_tokens[1:]
- assert "".join(bpe_tokens) == "".join(other_tokens)
-
- # create alignment from every word to a list of BPE tokens
- alignment = []
- bpe_toks = filter(lambda item: item[1] != "", enumerate(bpe_tokens, start=1))
- j, bpe_tok = next(bpe_toks)
- for other_tok in other_tokens:
- bpe_indices = []
- while True:
- if other_tok.startswith(bpe_tok):
- bpe_indices.append(j)
- other_tok = other_tok[len(bpe_tok) :]
- try:
- j, bpe_tok = next(bpe_toks)
- except StopIteration:
- j, bpe_tok = None, None
- elif bpe_tok.startswith(other_tok):
- # other_tok spans multiple BPE tokens
- bpe_indices.append(j)
- bpe_tok = bpe_tok[len(other_tok) :]
- other_tok = ""
- else:
- raise Exception('Cannot align "{}" and "{}"'.format(other_tok, bpe_tok))
- if other_tok == "":
- break
- assert len(bpe_indices) > 0
- alignment.append(bpe_indices)
- assert len(alignment) == len(other_tokens)
-
- return alignment
-
-
-def align_features_to_words(roberta, features, alignment):
- """
- Align given features to words.
-
- Args:
- roberta (RobertaHubInterface): RoBERTa instance
- features (torch.Tensor): features to align of shape `(T_bpe x C)`
- alignment: alignment between BPE tokens and words returned by
- func:`align_bpe_to_words`.
- """
- assert features.dim() == 2
-
- bpe_counts = Counter(j for bpe_indices in alignment for j in bpe_indices)
- assert bpe_counts[0] == 0 # shouldn't be aligned
- denom = features.new([bpe_counts.get(j, 1) for j in range(len(features))])
- weighted_features = features / denom.unsqueeze(-1)
-
- output = [weighted_features[0]]
- largest_j = -1
- for bpe_indices in alignment:
- output.append(weighted_features[bpe_indices].sum(dim=0))
- largest_j = max(largest_j, *bpe_indices)
- for j in range(largest_j + 1, len(features)):
- output.append(weighted_features[j])
- output = torch.stack(output)
- assert torch.all(torch.abs(output.sum(dim=0) - features.sum(dim=0)) < 1e-4)
- return output
-
-
-def spacy_nlp():
- if getattr(spacy_nlp, "_nlp", None) is None:
- try:
- from spacy.lang.en import English
-
- spacy_nlp._nlp = English()
- except ImportError:
- raise ImportError("Please install spacy with: pip install spacy")
- return spacy_nlp._nlp
-
-
-def spacy_tokenizer():
- if getattr(spacy_tokenizer, "_tokenizer", None) is None:
- try:
- nlp = spacy_nlp()
- spacy_tokenizer._tokenizer = nlp.Defaults.create_tokenizer(nlp)
- except ImportError:
- raise ImportError("Please install spacy with: pip install spacy")
- return spacy_tokenizer._tokenizer
diff --git a/spaces/Harveenchadha/Hindi_TTS/vakyansh_tts/utils/duration.py b/spaces/Harveenchadha/Hindi_TTS/vakyansh_tts/utils/duration.py
deleted file mode 100644
index c3b5e112b72dd5a07ea2463f604d98bb8d961496..0000000000000000000000000000000000000000
--- a/spaces/Harveenchadha/Hindi_TTS/vakyansh_tts/utils/duration.py
+++ /dev/null
@@ -1,33 +0,0 @@
-# Usage -> python duration.py /src/folder/path
-
-import soundfile as sf
-import sys
-import os
-from glob import glob
-from joblib import Parallel, delayed
-from tqdm import tqdm
-
-
-def get_duration(fpath):
- w = sf.SoundFile(fpath)
- sr = w.samplerate
- assert 22050 == sr, "Sample rate is not 22050"
- return len(w) / sr
-
-
-def main(folder, ext="wav"):
- file_list = glob(folder + "/**/*." + ext, recursive=True)
- print(f"\n\tTotal number of wav files {len(file_list)}")
- duration_list = Parallel(n_jobs=1)(
- delayed(get_duration)(i) for i in tqdm(file_list)
- )
- print(
- f"\n\tMin Duration {min(duration_list):.2f} Max Duration {max(duration_list):.2f} in secs"
- )
- print(f"\n\tTotal Duration {sum(duration_list)/3600:.2f} in hours")
-
-
-if __name__ == "__main__":
- folder = sys.argv[1]
- folder = os.path.abspath(folder)
- main(folder)
diff --git a/spaces/Harveenchadha/Vakyansh-Hindi-TTS/ttsv/src/glow_tts/init.py b/spaces/Harveenchadha/Vakyansh-Hindi-TTS/ttsv/src/glow_tts/init.py
deleted file mode 100644
index 39dd83dbd55475d562a3f54d951cb822800d2e0f..0000000000000000000000000000000000000000
--- a/spaces/Harveenchadha/Vakyansh-Hindi-TTS/ttsv/src/glow_tts/init.py
+++ /dev/null
@@ -1,79 +0,0 @@
-import os
-import json
-import argparse
-import math
-import torch
-from torch import nn, optim
-from torch.nn import functional as F
-from torch.utils.data import DataLoader
-
-from data_utils import TextMelLoader, TextMelCollate
-import models
-import commons
-import utils
-
-
-class FlowGenerator_DDI(models.FlowGenerator):
- """A helper for Data-dependent Initialization"""
-
- def __init__(self, *args, **kwargs):
- super().__init__(*args, **kwargs)
- for f in self.decoder.flows:
- if getattr(f, "set_ddi", False):
- f.set_ddi(True)
-
-
-def main():
- hps = utils.get_hparams()
- logger = utils.get_logger(hps.log_dir)
- logger.info(hps)
- utils.check_git_hash(hps.log_dir)
-
- torch.manual_seed(hps.train.seed)
-
- train_dataset = TextMelLoader(hps.data.training_files, hps.data)
- collate_fn = TextMelCollate(1)
- train_loader = DataLoader(
- train_dataset,
- num_workers=8,
- shuffle=True,
- batch_size=hps.train.batch_size,
- pin_memory=True,
- drop_last=True,
- collate_fn=collate_fn,
- )
- symbols = hps.data.punc + hps.data.chars
- generator = FlowGenerator_DDI(
- len(symbols) + getattr(hps.data, "add_blank", False),
- out_channels=hps.data.n_mel_channels,
- **hps.model
- ).cuda()
- optimizer_g = commons.Adam(
- generator.parameters(),
- scheduler=hps.train.scheduler,
- dim_model=hps.model.hidden_channels,
- warmup_steps=hps.train.warmup_steps,
- lr=hps.train.learning_rate,
- betas=hps.train.betas,
- eps=hps.train.eps,
- )
-
- generator.train()
- for batch_idx, (x, x_lengths, y, y_lengths) in enumerate(train_loader):
- x, x_lengths = x.cuda(), x_lengths.cuda()
- y, y_lengths = y.cuda(), y_lengths.cuda()
-
- _ = generator(x, x_lengths, y, y_lengths, gen=False)
- break
-
- utils.save_checkpoint(
- generator,
- optimizer_g,
- hps.train.learning_rate,
- 0,
- os.path.join(hps.model_dir, "ddi_G.pth"),
- )
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/Harveenchadha/en_to_indic_translation/model_configs/custom_transformer.py b/spaces/Harveenchadha/en_to_indic_translation/model_configs/custom_transformer.py
deleted file mode 100644
index b122e1bf5c81534aae35bb6235c1feaf45b7bada..0000000000000000000000000000000000000000
--- a/spaces/Harveenchadha/en_to_indic_translation/model_configs/custom_transformer.py
+++ /dev/null
@@ -1,38 +0,0 @@
-from fairseq.models import register_model_architecture
-from fairseq.models.transformer import base_architecture
-
-
-@register_model_architecture("transformer", "transformer_2x")
-def transformer_big(args):
- args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 1024)
- args.encoder_ffn_embed_dim = getattr(args, "encoder_ffn_embed_dim", 4096)
- args.encoder_attention_heads = getattr(args, "encoder_attention_heads", 16)
- args.encoder_normalize_before = getattr(args, "encoder_normalize_before", False)
- args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 1024)
- args.decoder_ffn_embed_dim = getattr(args, "decoder_ffn_embed_dim", 4096)
- args.decoder_attention_heads = getattr(args, "decoder_attention_heads", 16)
- base_architecture(args)
-
-
-@register_model_architecture("transformer", "transformer_4x")
-def transformer_huge(args):
- args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 1536)
- args.encoder_ffn_embed_dim = getattr(args, "encoder_ffn_embed_dim", 4096)
- args.encoder_attention_heads = getattr(args, "encoder_attention_heads", 16)
- args.encoder_normalize_before = getattr(args, "encoder_normalize_before", False)
- args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 1536)
- args.decoder_ffn_embed_dim = getattr(args, "decoder_ffn_embed_dim", 4096)
- args.decoder_attention_heads = getattr(args, "decoder_attention_heads", 16)
- base_architecture(args)
-
-
-@register_model_architecture("transformer", "transformer_9x")
-def transformer_xlarge(args):
- args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 2048)
- args.encoder_ffn_embed_dim = getattr(args, "encoder_ffn_embed_dim", 8192)
- args.encoder_attention_heads = getattr(args, "encoder_attention_heads", 16)
- args.encoder_normalize_before = getattr(args, "encoder_normalize_before", False)
- args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 2048)
- args.decoder_ffn_embed_dim = getattr(args, "decoder_ffn_embed_dim", 8192)
- args.decoder_attention_heads = getattr(args, "decoder_attention_heads", 16)
- base_architecture(args)
diff --git a/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/examples.py b/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/examples.py
deleted file mode 100644
index a40ae25e903eebb8913276739200c2b02372e839..0000000000000000000000000000000000000000
--- a/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/examples.py
+++ /dev/null
@@ -1,327 +0,0 @@
-"""
-Defines helper methods useful for loading and caching Interface examples.
-"""
-from __future__ import annotations
-
-import ast
-import csv
-import os
-import warnings
-from pathlib import Path
-from typing import TYPE_CHECKING, Any, Callable, List
-
-from gradio import utils
-from gradio.components import Dataset
-from gradio.context import Context
-from gradio.documentation import document, set_documentation_group
-from gradio.flagging import CSVLogger
-
-if TYPE_CHECKING: # Only import for type checking (to avoid circular imports).
- from gradio.components import IOComponent
-
-CACHED_FOLDER = "gradio_cached_examples"
-LOG_FILE = "log.csv"
-
-set_documentation_group("component-helpers")
-
-
-def create_examples(
- examples: List[Any] | List[List[Any]] | str,
- inputs: IOComponent | List[IOComponent],
- outputs: IOComponent | List[IOComponent] | None = None,
- fn: Callable | None = None,
- cache_examples: bool = False,
- examples_per_page: int = 10,
- _api_mode: bool = False,
- label: str | None = None,
- elem_id: str | None = None,
- run_on_click: bool = False,
- preprocess: bool = True,
- postprocess: bool = True,
- batch: bool = False,
-):
- """Top-level synchronous function that creates Examples. Provided for backwards compatibility, i.e. so that gr.Examples(...) can be used to create the Examples component."""
- examples_obj = Examples(
- examples=examples,
- inputs=inputs,
- outputs=outputs,
- fn=fn,
- cache_examples=cache_examples,
- examples_per_page=examples_per_page,
- _api_mode=_api_mode,
- label=label,
- elem_id=elem_id,
- run_on_click=run_on_click,
- preprocess=preprocess,
- postprocess=postprocess,
- batch=batch,
- _initiated_directly=False,
- )
- utils.synchronize_async(examples_obj.create)
- return examples_obj
-
-
-@document()
-class Examples:
- """
- This class is a wrapper over the Dataset component and can be used to create Examples
- for Blocks / Interfaces. Populates the Dataset component with examples and
- assigns event listener so that clicking on an example populates the input/output
- components. Optionally handles example caching for fast inference.
-
- Demos: blocks_inputs, fake_gan
- Guides: more_on_examples_and_flagging, using_hugging_face_integrations, image_classification_in_pytorch, image_classification_in_tensorflow, image_classification_with_vision_transformers, create_your_own_friends_with_a_gan
- """
-
- def __init__(
- self,
- examples: List[Any] | List[List[Any]] | str,
- inputs: IOComponent | List[IOComponent],
- outputs: IOComponent | List[IOComponent] | None = None,
- fn: Callable | None = None,
- cache_examples: bool = False,
- examples_per_page: int = 10,
- _api_mode: bool = False,
- label: str | None = "Examples",
- elem_id: str | None = None,
- run_on_click: bool = False,
- preprocess: bool = True,
- postprocess: bool = True,
- batch: bool = False,
- _initiated_directly: bool = True,
- ):
- """
- Parameters:
- examples: example inputs that can be clicked to populate specific components. Should be nested list, in which the outer list consists of samples and each inner list consists of an input corresponding to each input component. A string path to a directory of examples can also be provided but it should be within the directory with the python file running the gradio app. If there are multiple input components and a directory is provided, a log.csv file must be present in the directory to link corresponding inputs.
- inputs: the component or list of components corresponding to the examples
- outputs: optionally, provide the component or list of components corresponding to the output of the examples. Required if `cache` is True.
- fn: optionally, provide the function to run to generate the outputs corresponding to the examples. Required if `cache` is True.
- cache_examples: if True, caches examples for fast runtime. If True, then `fn` and `outputs` need to be provided
- examples_per_page: how many examples to show per page.
- label: the label to use for the examples component (by default, "Examples")
- elem_id: an optional string that is assigned as the id of this component in the HTML DOM.
- run_on_click: if cache_examples is False, clicking on an example does not run the function when an example is clicked. Set this to True to run the function when an example is clicked. Has no effect if cache_examples is True.
- preprocess: if True, preprocesses the example input before running the prediction function and caching the output. Only applies if cache_examples is True.
- postprocess: if True, postprocesses the example output after running the prediction function and before caching. Only applies if cache_examples is True.
- batch: If True, then the function should process a batch of inputs, meaning that it should accept a list of input values for each parameter. Used only if cache_examples is True.
- """
- if _initiated_directly:
- warnings.warn(
- "Please use gr.Examples(...) instead of gr.examples.Examples(...) to create the Examples.",
- )
-
- if cache_examples and (fn is None or outputs is None):
- raise ValueError("If caching examples, `fn` and `outputs` must be provided")
-
- if not isinstance(inputs, list):
- inputs = [inputs]
- if outputs and not isinstance(outputs, list):
- outputs = [outputs]
-
- working_directory = Path().absolute()
-
- if examples is None:
- raise ValueError("The parameter `examples` cannot be None")
- elif isinstance(examples, list) and (
- len(examples) == 0 or isinstance(examples[0], list)
- ):
- pass
- elif (
- isinstance(examples, list) and len(inputs) == 1
- ): # If there is only one input component, examples can be provided as a regular list instead of a list of lists
- examples = [[e] for e in examples]
- elif isinstance(examples, str):
- if not Path(examples).exists():
- raise FileNotFoundError(
- "Could not find examples directory: " + examples
- )
- working_directory = examples
- if not (Path(examples) / LOG_FILE).exists():
- if len(inputs) == 1:
- examples = [[e] for e in os.listdir(examples)]
- else:
- raise FileNotFoundError(
- "Could not find log file (required for multiple inputs): "
- + LOG_FILE
- )
- else:
- with open(Path(examples) / LOG_FILE) as logs:
- examples = list(csv.reader(logs))
- examples = [
- examples[i][: len(inputs)] for i in range(1, len(examples))
- ] # remove header and unnecessary columns
-
- else:
- raise ValueError(
- "The parameter `examples` must either be a string directory or a list"
- "(if there is only 1 input component) or (more generally), a nested "
- "list, where each sublist represents a set of inputs."
- )
-
- input_has_examples = [False] * len(inputs)
- for example in examples:
- for idx, example_for_input in enumerate(example):
- if not (example_for_input is None):
- try:
- input_has_examples[idx] = True
- except IndexError:
- pass # If there are more example components than inputs, ignore. This can sometimes be intentional (e.g. loading from a log file where outputs and timestamps are also logged)
-
- inputs_with_examples = [
- inp for (inp, keep) in zip(inputs, input_has_examples) if keep
- ]
- non_none_examples = [
- [ex for (ex, keep) in zip(example, input_has_examples) if keep]
- for example in examples
- ]
-
- self.examples = examples
- self.non_none_examples = non_none_examples
- self.inputs = inputs
- self.inputs_with_examples = inputs_with_examples
- self.outputs = outputs
- self.fn = fn
- self.cache_examples = cache_examples
- self._api_mode = _api_mode
- self.preprocess = preprocess
- self.postprocess = postprocess
- self.batch = batch
-
- with utils.set_directory(working_directory):
- self.processed_examples = [
- [
- component.postprocess(sample)
- for component, sample in zip(inputs, example)
- ]
- for example in examples
- ]
- self.non_none_processed_examples = [
- [ex for (ex, keep) in zip(example, input_has_examples) if keep]
- for example in self.processed_examples
- ]
- if cache_examples:
- for example in self.examples:
- if len([ex for ex in example if ex is not None]) != len(self.inputs):
- warnings.warn(
- "Examples are being cached but not all input components have "
- "example values. This may result in an exception being thrown by "
- "your function. If you do get an error while caching examples, make "
- "sure all of your inputs have example values for all of your examples "
- "or you provide default values for those particular parameters in your function."
- )
- break
-
- with utils.set_directory(working_directory):
- self.dataset = Dataset(
- components=inputs_with_examples,
- samples=non_none_examples,
- type="index",
- label=label,
- samples_per_page=examples_per_page,
- elem_id=elem_id,
- )
-
- self.cached_folder = Path(CACHED_FOLDER) / str(self.dataset._id)
- self.cached_file = Path(self.cached_folder) / "log.csv"
- self.cache_examples = cache_examples
- self.run_on_click = run_on_click
-
- async def create(self) -> None:
- """Caches the examples if self.cache_examples is True and creates the Dataset
- component to hold the examples"""
-
- async def load_example(example_id):
- if self.cache_examples:
- processed_example = self.non_none_processed_examples[
- example_id
- ] + await self.load_from_cache(example_id)
- else:
- processed_example = self.non_none_processed_examples[example_id]
- return utils.resolve_singleton(processed_example)
-
- if Context.root_block:
- if self.cache_examples and self.outputs:
- targets = self.inputs_with_examples
- else:
- targets = self.inputs
- self.dataset.click(
- load_example,
- inputs=[self.dataset],
- outputs=targets, # type: ignore
- postprocess=False,
- queue=False,
- )
- if self.run_on_click and not self.cache_examples:
- if self.fn is None:
- raise ValueError("Cannot run_on_click if no function is provided")
- self.dataset.click(
- self.fn,
- inputs=self.inputs, # type: ignore
- outputs=self.outputs, # type: ignore
- )
-
- if self.cache_examples:
- await self.cache()
-
- async def cache(self) -> None:
- """
- Caches all of the examples so that their predictions can be shown immediately.
- """
- if Path(self.cached_file).exists():
- print(
- f"Using cache from '{Path(self.cached_folder).resolve()}' directory. If method or examples have changed since last caching, delete this folder to clear cache."
- )
- else:
- if Context.root_block is None:
- raise ValueError("Cannot cache examples if not in a Blocks context")
-
- print(f"Caching examples at: '{Path(self.cached_file).resolve()}'")
- cache_logger = CSVLogger()
-
- # create a fake dependency to process the examples and get the predictions
- dependency = Context.root_block.set_event_trigger(
- event_name="fake_event",
- fn=self.fn,
- inputs=self.inputs_with_examples, # type: ignore
- outputs=self.outputs, # type: ignore
- preprocess=self.preprocess and not self._api_mode,
- postprocess=self.postprocess and not self._api_mode,
- batch=self.batch,
- )
-
- fn_index = Context.root_block.dependencies.index(dependency)
- assert self.outputs is not None
- cache_logger.setup(self.outputs, self.cached_folder)
- for example_id, _ in enumerate(self.examples):
- processed_input = self.processed_examples[example_id]
- if self.batch:
- processed_input = [[value] for value in processed_input]
- prediction = await Context.root_block.process_api(
- fn_index=fn_index, inputs=processed_input, request=None, state={}
- )
- output = prediction["data"]
- if self.batch:
- output = [value[0] for value in output]
- cache_logger.flag(output)
- # Remove the "fake_event" to prevent bugs in loading interfaces from spaces
- Context.root_block.dependencies.remove(dependency)
- Context.root_block.fns.pop(fn_index)
-
- async def load_from_cache(self, example_id: int) -> List[Any]:
- """Loads a particular cached example for the interface.
- Parameters:
- example_id: The id of the example to process (zero-indexed).
- """
- with open(self.cached_file) as cache:
- examples = list(csv.reader(cache))
- example = examples[example_id + 1] # +1 to adjust for header
- output = []
- assert self.outputs is not None
- for component, value in zip(self.outputs, example):
- try:
- value_as_dict = ast.literal_eval(value)
- assert utils.is_update(value_as_dict)
- output.append(value_as_dict)
- except (ValueError, TypeError, SyntaxError, AssertionError):
- output.append(component.serialize(value, self.cached_folder))
- return output
diff --git a/spaces/HuangLab/CELL-E_2-Sequence_Prediction/taming/modules/util.py b/spaces/HuangLab/CELL-E_2-Sequence_Prediction/taming/modules/util.py
deleted file mode 100644
index 9ee16385d8b1342a2d60a5f1aa5cadcfbe934bd8..0000000000000000000000000000000000000000
--- a/spaces/HuangLab/CELL-E_2-Sequence_Prediction/taming/modules/util.py
+++ /dev/null
@@ -1,130 +0,0 @@
-import torch
-import torch.nn as nn
-
-
-def count_params(model):
- total_params = sum(p.numel() for p in model.parameters())
- return total_params
-
-
-class ActNorm(nn.Module):
- def __init__(self, num_features, logdet=False, affine=True,
- allow_reverse_init=False):
- assert affine
- super().__init__()
- self.logdet = logdet
- self.loc = nn.Parameter(torch.zeros(1, num_features, 1, 1))
- self.scale = nn.Parameter(torch.ones(1, num_features, 1, 1))
- self.allow_reverse_init = allow_reverse_init
-
- self.register_buffer('initialized', torch.tensor(0, dtype=torch.uint8))
-
- def initialize(self, input):
- with torch.no_grad():
- flatten = input.permute(1, 0, 2, 3).contiguous().view(input.shape[1], -1)
- mean = (
- flatten.mean(1)
- .unsqueeze(1)
- .unsqueeze(2)
- .unsqueeze(3)
- .permute(1, 0, 2, 3)
- )
- std = (
- flatten.std(1)
- .unsqueeze(1)
- .unsqueeze(2)
- .unsqueeze(3)
- .permute(1, 0, 2, 3)
- )
-
- self.loc.data.copy_(-mean)
- self.scale.data.copy_(1 / (std + 1e-6))
-
- def forward(self, input, reverse=False):
- if reverse:
- return self.reverse(input)
- if len(input.shape) == 2:
- input = input[:,:,None,None]
- squeeze = True
- else:
- squeeze = False
-
- _, _, height, width = input.shape
-
- if self.training and self.initialized.item() == 0:
- self.initialize(input)
- self.initialized.fill_(1)
-
- h = self.scale * (input + self.loc)
-
- if squeeze:
- h = h.squeeze(-1).squeeze(-1)
-
- if self.logdet:
- log_abs = torch.log(torch.abs(self.scale))
- logdet = height*width*torch.sum(log_abs)
- logdet = logdet * torch.ones(input.shape[0]).to(input)
- return h, logdet
-
- return h
-
- def reverse(self, output):
- if self.training and self.initialized.item() == 0:
- if not self.allow_reverse_init:
- raise RuntimeError(
- "Initializing ActNorm in reverse direction is "
- "disabled by default. Use allow_reverse_init=True to enable."
- )
- else:
- self.initialize(output)
- self.initialized.fill_(1)
-
- if len(output.shape) == 2:
- output = output[:,:,None,None]
- squeeze = True
- else:
- squeeze = False
-
- h = output / self.scale - self.loc
-
- if squeeze:
- h = h.squeeze(-1).squeeze(-1)
- return h
-
-
-class AbstractEncoder(nn.Module):
- def __init__(self):
- super().__init__()
-
- def encode(self, *args, **kwargs):
- raise NotImplementedError
-
-
-class Labelator(AbstractEncoder):
- """Net2Net Interface for Class-Conditional Model"""
- def __init__(self, n_classes, quantize_interface=True):
- super().__init__()
- self.n_classes = n_classes
- self.quantize_interface = quantize_interface
-
- def encode(self, c):
- c = c[:,None]
- if self.quantize_interface:
- return c, None, [None, None, c.long()]
- return c
-
-
-class SOSProvider(AbstractEncoder):
- # for unconditional training
- def __init__(self, sos_token, quantize_interface=True):
- super().__init__()
- self.sos_token = sos_token
- self.quantize_interface = quantize_interface
-
- def encode(self, x):
- # get batch size from data and replicate sos_token
- c = torch.ones(x.shape[0], 1)*self.sos_token
- c = c.long().to(x.device)
- if self.quantize_interface:
- return c, None, [None, None, c]
- return c
diff --git a/spaces/IPN/streamlit_demo/README.md b/spaces/IPN/streamlit_demo/README.md
deleted file mode 100644
index a20f4c531414109befd43812dd3fa6d06ef7cb40..0000000000000000000000000000000000000000
--- a/spaces/IPN/streamlit_demo/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Streamlit_demo
-emoji: 👁
-colorFrom: indigo
-colorTo: indigo
-sdk: streamlit
-sdk_version: 1.2.0
-app_file: app.py
-pinned: false
-license: cc
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/IVentureISB/Gen-AI/chatbot.py b/spaces/IVentureISB/Gen-AI/chatbot.py
deleted file mode 100644
index 41246fe63531dec67c55308c8c0f6653bb2ecdaa..0000000000000000000000000000000000000000
--- a/spaces/IVentureISB/Gen-AI/chatbot.py
+++ /dev/null
@@ -1,24 +0,0 @@
-import gradio as gr
-
-messages = [
- {"role": "system", "content": "You are an AI assistant that only gives responses from the website https://i-venture.org/ and you help people make decisions about how to make a difference in others' lives. You also provide the relevant links from that website as part of your answers."},
-]
-
-def chatbot(input):
- if input:
- context = create_context(input, df)
- message=f"Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {input}\nAnswer:",
- messages.append({"role": "user", "content": message})
- chat = openai.ChatCompletion.create(
- temperature=0.5, model="gpt-3.5-turbo", messages=messages,
- )
- reply = chat.choices[0].message.content
- messages.append({"role": "assistant", "content": reply})
- return reply
-
-inputs = gr.inputs.Textbox(lines=7, label="Chat with I-venture @ ISB AI powered bot")
-outputs = gr.outputs.Textbox(label="Reply")
-
-gr.Interface(fn=chatbot, inputs=inputs, outputs=outputs, title="Talk with I-venture @ ISB",
- description="Anything you want to find out about entreprenuership at ISB. Sample questions include >>> how to get incubated at ISB Dlabs? >>> What is the team behind I-venture @ ISB? >>> and more",
- theme="compact").launch(share=True, debug=True)
\ No newline at end of file
diff --git a/spaces/Illia56/Youtube-Whisper-Llama/app.py b/spaces/Illia56/Youtube-Whisper-Llama/app.py
deleted file mode 100644
index 5ecbd5c962565d7e66a29eae18742ce4c2ccac1b..0000000000000000000000000000000000000000
--- a/spaces/Illia56/Youtube-Whisper-Llama/app.py
+++ /dev/null
@@ -1,207 +0,0 @@
-import os
-import logging
-from typing import Any, List, Mapping, Optional
-from langchain.llms import HuggingFaceHub
-from gradio_client import Client
-from langchain.schema import Document
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-from langchain.vectorstores import FAISS
-from langchain.embeddings.huggingface import HuggingFaceEmbeddings
-from langchain.callbacks.manager import CallbackManagerForLLMRun
-from langchain.llms.base import LLM
-from langchain.chains import RetrievalQA
-from langchain.prompts import PromptTemplate
-import streamlit as st
-from pytube import YouTube
-# import replicate
-
-DESCRIPTION = """
-
-openai/whisper-large-v3
-"""
-
-models = {
- "Llama2-70b": {
- "model_link": "https://huggingface.co/meta-llama/Llama-2-70b",
- "chat_link": "https://ysharma-explore-llamav2-with-tgi.hf.space/",
- },
- "Llama2-13b": {
- "model_link": "https://huggingface.co/meta-llama/Llama-2-13b",
- "chat_link": "https://huggingface-projects-llama-2-13b-chat.hf.space/",
- }
-}
-
-DESCRIPTION = """
-Welcome to the **YouTube Video Chatbot** powered by Llama-2 models. Here's what you can do:
-- **Transcribe & Understand**: Provide any YouTube video URL, and our system will transcribe it. Our advanced NLP model will then understand the content, ready to answer your questions.
-- **Ask Anything**: Based on the video's content, ask any question, and get instant, context-aware answers.
-To get started, simply paste a YouTube video URL and select a model in the sidebar, then start chatting with the model about the video's content. Enjoy the experience!
-"""
-st.title("YouTube Video Chatbot")
-st.markdown(DESCRIPTION)
-
-def get_video_title(youtube_url: str) -> str:
- yt = YouTube(youtube_url)
- embed_url = f"https://www.youtube.com/embed/{yt.video_id}"
- embed_html = f''
- return yt.title, embed_html
-
-def transcribe_video(youtube_url: str, path: str) -> List[Document]:
- """
- Transcribe a video and return its content as a Document.
- """
- logging.info(f"Transcribing video: {youtube_url}")
- client = Client("https://sanchit-gandhi-whisper-jax.hf.space/")
- result = client.predict(youtube_url, "translate", True, fn_index=7)
- return [Document(page_content=result[1], metadata=dict(page=1))]
-
-def predict(
- message: str, system_prompt: str = "", model_url: str = models["Llama2-70b"]["chat_link"]
-) -> Any:
- """
- Predict a response using a client.
- """
- client = Client(model_url)
- response = client.predict(message, system_prompt, 0.7, 4096, 0.5, 1.2, api_name="/chat_1")
- return response
-
-PATH = os.path.join(os.path.expanduser("~"), "Data")
-
-def initialize_session_state():
- if "youtube_url" not in st.session_state:
- st.session_state.youtube_url = ""
- if "model_choice" not in st.session_state:
- st.session_state.model_choice = "Llama2-70b"
- if "setup_done" not in st.session_state:
- st.session_state.setup_done = False
- if "doneYoutubeurl" not in st.session_state:
- st.session_state.doneYoutubeurl = ""
-
-def sidebar():
- with st.sidebar:
- st.markdown("Enter the YouTube Video URL below🔗")
- st.session_state.youtube_url = st.text_input("YouTube Video URL:")
-
- model_choice = st.radio("Choose a Model:", list(models.keys()))
- st.session_state.model_choice = model_choice
-
- if st.session_state.youtube_url:
- # Get the video title
- video_title, embed_html = get_video_title(st.session_state.youtube_url)
- st.markdown(f"### {video_title}")
-
- # Embed the video
- st.markdown(embed_html, unsafe_allow_html=True)
-
-
-
-sidebar()
-initialize_session_state()
-
-text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
-embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-l6-v2")
-
-prompt = PromptTemplate(
- template="""Given the context about a video. Answer the user in a friendly and precise manner.
- Context: {context}
- Human: {question}
- AI:""",
- input_variables=["context", "question"]
-)
-
-class LlamaLLM(LLM):
- """
- Custom LLM class.
- """
-
- @property
- def _llm_type(self) -> str:
- return "custom"
-
- def _call(self, prompt: str, stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None) -> str:
- model_link = models[st.session_state.model_choice]["chat_link"]
- response = predict(prompt, model_url=model_link)
- return response
-
- @property
- def _identifying_params(self) -> Mapping[str, Any]:
- """Get the identifying parameters."""
- return {}
-
-# Check if a new YouTube URL is provided
-if st.session_state.youtube_url != st.session_state.doneYoutubeurl:
- st.session_state.setup_done = False
-
-if st.session_state.youtube_url and not st.session_state.setup_done:
- with st.status("Transcribing video..."):
- data = transcribe_video(st.session_state.youtube_url, PATH)
-
- with st.status("Running Embeddings..."):
- docs = text_splitter.split_documents(data)
-
- docsearch = FAISS.from_documents(docs, embeddings)
- retriever = docsearch.as_retriever()
- retriever.search_kwargs["distance_metric"] = "cos"
- retriever.search_kwargs["k"] = 4
- with st.status("Running RetrievalQA..."):
- llama_instance = LlamaLLM()
- st.session_state.qa = RetrievalQA.from_chain_type(llm=llama_instance, chain_type="stuff", retriever=retriever, chain_type_kwargs={"prompt": prompt})
-
- st.session_state.doneYoutubeurl = st.session_state.youtube_url
- st.session_state.setup_done = True # Mark the setup as done for this URL
-
-if "messages" not in st.session_state:
- st.session_state.messages = []
-
-for message in st.session_state.messages:
- with st.chat_message(message["role"], avatar=("🧑💻" if message["role"] == "human" else "🦙")):
- st.markdown(message["content"])
-
-textinput = st.chat_input("Ask anything about the video...")
-
-if prompt := textinput:
- st.chat_message("human", avatar="🧑💻").markdown(prompt)
- st.session_state.messages.append({"role": "human", "content": prompt})
- with st.status("Requesting Client..."):
- video_title, _ = get_video_title(st.session_state.youtube_url)
- additional_context = f"Given the context about a video titled '{video_title}' available at '{st.session_state.youtube_url}'."
- response = st.session_state.qa.run(prompt + " " + additional_context)
- with st.chat_message("assistant", avatar="🦙"):
- st.markdown(response)
- # Add assistant response to chat history
- st.session_state.messages.append({"role": "assistant", "content": response})
diff --git a/spaces/Illumotion/Koboldcpp/ggml-cuda.h b/spaces/Illumotion/Koboldcpp/ggml-cuda.h
deleted file mode 100644
index fda704b6656234ae63e1399fc680c5e5cf6c4a0d..0000000000000000000000000000000000000000
--- a/spaces/Illumotion/Koboldcpp/ggml-cuda.h
+++ /dev/null
@@ -1,47 +0,0 @@
-#pragma once
-
-#include "ggml.h"
-
-#ifdef GGML_USE_HIPBLAS
-#define GGML_CUDA_NAME "ROCm"
-#define GGML_CUBLAS_NAME "hipBLAS"
-#else
-#define GGML_CUDA_NAME "CUDA"
-#define GGML_CUBLAS_NAME "cuBLAS"
-#endif
-
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-#define GGML_CUDA_MAX_DEVICES 16
-
-GGML_API void ggml_init_cublas(void);
-GGML_API void * ggml_cuda_host_malloc(size_t size);
-GGML_API void ggml_cuda_host_free(void * ptr);
-
-GGML_API bool ggml_cuda_can_mul_mat(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst);
-GGML_API void ggml_cuda_set_tensor_split(const float * tensor_split);
-GGML_API void ggml_cuda_transform_tensor(void * data, struct ggml_tensor * tensor);
-GGML_API void ggml_cuda_free_data(struct ggml_tensor * tensor);
-
-GGML_API void ggml_cuda_assign_buffers(struct ggml_tensor * tensor);
-GGML_API void ggml_cuda_assign_buffers_no_scratch(struct ggml_tensor * tensor);
-GGML_API void ggml_cuda_assign_buffers_force_inplace(struct ggml_tensor * tensor);
-
-GGML_API void ggml_cuda_assign_buffers_no_alloc(struct ggml_tensor * tensor);
-GGML_API void ggml_cuda_assign_scratch_offset(struct ggml_tensor * tensor, size_t offset);
-GGML_API void ggml_cuda_copy_to_device(struct ggml_tensor * tensor);
-
-GGML_API void ggml_cuda_set_main_device(int main_device);
-GGML_API void ggml_cuda_set_mul_mat_q(bool mul_mat_q);
-GGML_API void ggml_cuda_set_scratch_size(size_t scratch_size);
-GGML_API void ggml_cuda_free_scratch(void);
-GGML_API bool ggml_cuda_compute_forward(struct ggml_compute_params * params, struct ggml_tensor * tensor);
-
-GGML_API int ggml_cuda_get_device_count(void);
-GGML_API void ggml_cuda_get_device_description(int device, char * description, size_t description_size);
-
-#ifdef __cplusplus
-}
-#endif
diff --git a/spaces/InpaintAI/Inpaint-Anything/third_party/lama/saicinpainting/evaluation/losses/fid/__init__.py b/spaces/InpaintAI/Inpaint-Anything/third_party/lama/saicinpainting/evaluation/losses/fid/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/parsing/parsenet.py b/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/parsing/parsenet.py
deleted file mode 100644
index e178ebe43a1ef666aaea0bc0faf629485c22a24f..0000000000000000000000000000000000000000
--- a/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/parsing/parsenet.py
+++ /dev/null
@@ -1,194 +0,0 @@
-"""Modified from https://github.com/chaofengc/PSFRGAN
-"""
-import numpy as np
-import torch.nn as nn
-from torch.nn import functional as F
-
-
-class NormLayer(nn.Module):
- """Normalization Layers.
-
- Args:
- channels: input channels, for batch norm and instance norm.
- input_size: input shape without batch size, for layer norm.
- """
-
- def __init__(self, channels, normalize_shape=None, norm_type='bn'):
- super(NormLayer, self).__init__()
- norm_type = norm_type.lower()
- self.norm_type = norm_type
- if norm_type == 'bn':
- self.norm = nn.BatchNorm2d(channels, affine=True)
- elif norm_type == 'in':
- self.norm = nn.InstanceNorm2d(channels, affine=False)
- elif norm_type == 'gn':
- self.norm = nn.GroupNorm(32, channels, affine=True)
- elif norm_type == 'pixel':
- self.norm = lambda x: F.normalize(x, p=2, dim=1)
- elif norm_type == 'layer':
- self.norm = nn.LayerNorm(normalize_shape)
- elif norm_type == 'none':
- self.norm = lambda x: x * 1.0
- else:
- assert 1 == 0, f'Norm type {norm_type} not support.'
-
- def forward(self, x, ref=None):
- if self.norm_type == 'spade':
- return self.norm(x, ref)
- else:
- return self.norm(x)
-
-
-class ReluLayer(nn.Module):
- """Relu Layer.
-
- Args:
- relu type: type of relu layer, candidates are
- - ReLU
- - LeakyReLU: default relu slope 0.2
- - PRelu
- - SELU
- - none: direct pass
- """
-
- def __init__(self, channels, relu_type='relu'):
- super(ReluLayer, self).__init__()
- relu_type = relu_type.lower()
- if relu_type == 'relu':
- self.func = nn.ReLU(True)
- elif relu_type == 'leakyrelu':
- self.func = nn.LeakyReLU(0.2, inplace=True)
- elif relu_type == 'prelu':
- self.func = nn.PReLU(channels)
- elif relu_type == 'selu':
- self.func = nn.SELU(True)
- elif relu_type == 'none':
- self.func = lambda x: x * 1.0
- else:
- assert 1 == 0, f'Relu type {relu_type} not support.'
-
- def forward(self, x):
- return self.func(x)
-
-
-class ConvLayer(nn.Module):
-
- def __init__(self,
- in_channels,
- out_channels,
- kernel_size=3,
- scale='none',
- norm_type='none',
- relu_type='none',
- use_pad=True,
- bias=True):
- super(ConvLayer, self).__init__()
- self.use_pad = use_pad
- self.norm_type = norm_type
- if norm_type in ['bn']:
- bias = False
-
- stride = 2 if scale == 'down' else 1
-
- self.scale_func = lambda x: x
- if scale == 'up':
- self.scale_func = lambda x: nn.functional.interpolate(x, scale_factor=2, mode='nearest')
-
- self.reflection_pad = nn.ReflectionPad2d(int(np.ceil((kernel_size - 1.) / 2)))
- self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride, bias=bias)
-
- self.relu = ReluLayer(out_channels, relu_type)
- self.norm = NormLayer(out_channels, norm_type=norm_type)
-
- def forward(self, x):
- out = self.scale_func(x)
- if self.use_pad:
- out = self.reflection_pad(out)
- out = self.conv2d(out)
- out = self.norm(out)
- out = self.relu(out)
- return out
-
-
-class ResidualBlock(nn.Module):
- """
- Residual block recommended in: http://torch.ch/blog/2016/02/04/resnets.html
- """
-
- def __init__(self, c_in, c_out, relu_type='prelu', norm_type='bn', scale='none'):
- super(ResidualBlock, self).__init__()
-
- if scale == 'none' and c_in == c_out:
- self.shortcut_func = lambda x: x
- else:
- self.shortcut_func = ConvLayer(c_in, c_out, 3, scale)
-
- scale_config_dict = {'down': ['none', 'down'], 'up': ['up', 'none'], 'none': ['none', 'none']}
- scale_conf = scale_config_dict[scale]
-
- self.conv1 = ConvLayer(c_in, c_out, 3, scale_conf[0], norm_type=norm_type, relu_type=relu_type)
- self.conv2 = ConvLayer(c_out, c_out, 3, scale_conf[1], norm_type=norm_type, relu_type='none')
-
- def forward(self, x):
- identity = self.shortcut_func(x)
-
- res = self.conv1(x)
- res = self.conv2(res)
- return identity + res
-
-
-class ParseNet(nn.Module):
-
- def __init__(self,
- in_size=128,
- out_size=128,
- min_feat_size=32,
- base_ch=64,
- parsing_ch=19,
- res_depth=10,
- relu_type='LeakyReLU',
- norm_type='bn',
- ch_range=[32, 256]):
- super().__init__()
- self.res_depth = res_depth
- act_args = {'norm_type': norm_type, 'relu_type': relu_type}
- min_ch, max_ch = ch_range
-
- ch_clip = lambda x: max(min_ch, min(x, max_ch)) # noqa: E731
- min_feat_size = min(in_size, min_feat_size)
-
- down_steps = int(np.log2(in_size // min_feat_size))
- up_steps = int(np.log2(out_size // min_feat_size))
-
- # =============== define encoder-body-decoder ====================
- self.encoder = []
- self.encoder.append(ConvLayer(3, base_ch, 3, 1))
- head_ch = base_ch
- for i in range(down_steps):
- cin, cout = ch_clip(head_ch), ch_clip(head_ch * 2)
- self.encoder.append(ResidualBlock(cin, cout, scale='down', **act_args))
- head_ch = head_ch * 2
-
- self.body = []
- for i in range(res_depth):
- self.body.append(ResidualBlock(ch_clip(head_ch), ch_clip(head_ch), **act_args))
-
- self.decoder = []
- for i in range(up_steps):
- cin, cout = ch_clip(head_ch), ch_clip(head_ch // 2)
- self.decoder.append(ResidualBlock(cin, cout, scale='up', **act_args))
- head_ch = head_ch // 2
-
- self.encoder = nn.Sequential(*self.encoder)
- self.body = nn.Sequential(*self.body)
- self.decoder = nn.Sequential(*self.decoder)
- self.out_img_conv = ConvLayer(ch_clip(head_ch), 3)
- self.out_mask_conv = ConvLayer(ch_clip(head_ch), parsing_ch)
-
- def forward(self, x):
- feat = self.encoder(x)
- x = feat + self.body(feat)
- x = self.decoder(x)
- out_img = self.out_img_conv(x)
- out_mask = self.out_mask_conv(x)
- return out_mask, out_img
diff --git a/spaces/JoeyFoursheds/ClonerHug/infer_pack/models.py b/spaces/JoeyFoursheds/ClonerHug/infer_pack/models.py
deleted file mode 100644
index 96165f73644e6fb92d0ffedb4a3c9e1a457cb989..0000000000000000000000000000000000000000
--- a/spaces/JoeyFoursheds/ClonerHug/infer_pack/models.py
+++ /dev/null
@@ -1,982 +0,0 @@
-import math, pdb, os
-from time import time as ttime
-import torch
-from torch import nn
-from torch.nn import functional as F
-from infer_pack import modules
-from infer_pack import attentions
-from infer_pack import commons
-from infer_pack.commons import init_weights, get_padding
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-from infer_pack.commons import init_weights
-import numpy as np
-from infer_pack import commons
-
-
-class TextEncoder256(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class TextEncoder256Sim(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- x = self.proj(x) * x_mask
- return x, x_mask
-
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(
- self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0,
- ):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(
- modules.ResidualCouplingLayer(
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- mean_only=True,
- )
- )
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
- def remove_weight_norm(self):
- for i in range(self.n_flows):
- self.flows[i * 2].remove_weight_norm()
-
-
-class PosteriorEncoder(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
- def remove_weight_norm(self):
- self.enc.remove_weight_norm()
-
-
-class Generator(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=0,
- ):
- super(Generator, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- def forward(self, x, g=None):
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-class SineGen(torch.nn.Module):
- """Definition of sine generator
- SineGen(samp_rate, harmonic_num = 0,
- sine_amp = 0.1, noise_std = 0.003,
- voiced_threshold = 0,
- flag_for_pulse=False)
- samp_rate: sampling rate in Hz
- harmonic_num: number of harmonic overtones (default 0)
- sine_amp: amplitude of sine-wavefrom (default 0.1)
- noise_std: std of Gaussian noise (default 0.003)
- voiced_thoreshold: F0 threshold for U/V classification (default 0)
- flag_for_pulse: this SinGen is used inside PulseGen (default False)
- Note: when flag_for_pulse is True, the first time step of a voiced
- segment is always sin(np.pi) or cos(0)
- """
-
- def __init__(
- self,
- samp_rate,
- harmonic_num=0,
- sine_amp=0.1,
- noise_std=0.003,
- voiced_threshold=0,
- flag_for_pulse=False,
- ):
- super(SineGen, self).__init__()
- self.sine_amp = sine_amp
- self.noise_std = noise_std
- self.harmonic_num = harmonic_num
- self.dim = self.harmonic_num + 1
- self.sampling_rate = samp_rate
- self.voiced_threshold = voiced_threshold
-
- def _f02uv(self, f0):
- # generate uv signal
- uv = torch.ones_like(f0)
- uv = uv * (f0 > self.voiced_threshold)
- return uv
-
- def forward(self, f0, upp):
- """sine_tensor, uv = forward(f0)
- input F0: tensor(batchsize=1, length, dim=1)
- f0 for unvoiced steps should be 0
- output sine_tensor: tensor(batchsize=1, length, dim)
- output uv: tensor(batchsize=1, length, 1)
- """
- with torch.no_grad():
- f0 = f0[:, None].transpose(1, 2)
- f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
- # fundamental component
- f0_buf[:, :, 0] = f0[:, :, 0]
- for idx in np.arange(self.harmonic_num):
- f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
- idx + 2
- ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
- rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
- rand_ini = torch.rand(
- f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
- )
- rand_ini[:, 0] = 0
- rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
- tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
- tmp_over_one *= upp
- tmp_over_one = F.interpolate(
- tmp_over_one.transpose(2, 1),
- scale_factor=upp,
- mode="linear",
- align_corners=True,
- ).transpose(2, 1)
- rad_values = F.interpolate(
- rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(
- 2, 1
- ) #######
- tmp_over_one %= 1
- tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
- cumsum_shift = torch.zeros_like(rad_values)
- cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
- sine_waves = torch.sin(
- torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
- )
- sine_waves = sine_waves * self.sine_amp
- uv = self._f02uv(f0)
- uv = F.interpolate(
- uv.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(2, 1)
- noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
- noise = noise_amp * torch.randn_like(sine_waves)
- sine_waves = sine_waves * uv + noise
- return sine_waves, uv, noise
-
-
-class SourceModuleHnNSF(torch.nn.Module):
- """SourceModule for hn-nsf
- SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
- add_noise_std=0.003, voiced_threshod=0)
- sampling_rate: sampling_rate in Hz
- harmonic_num: number of harmonic above F0 (default: 0)
- sine_amp: amplitude of sine source signal (default: 0.1)
- add_noise_std: std of additive Gaussian noise (default: 0.003)
- note that amplitude of noise in unvoiced is decided
- by sine_amp
- voiced_threshold: threhold to set U/V given F0 (default: 0)
- Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
- F0_sampled (batchsize, length, 1)
- Sine_source (batchsize, length, 1)
- noise_source (batchsize, length 1)
- uv (batchsize, length, 1)
- """
-
- def __init__(
- self,
- sampling_rate,
- harmonic_num=0,
- sine_amp=0.1,
- add_noise_std=0.003,
- voiced_threshod=0,
- is_half=True,
- ):
- super(SourceModuleHnNSF, self).__init__()
-
- self.sine_amp = sine_amp
- self.noise_std = add_noise_std
- self.is_half = is_half
- # to produce sine waveforms
- self.l_sin_gen = SineGen(
- sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
- )
-
- # to merge source harmonics into a single excitation
- self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
- self.l_tanh = torch.nn.Tanh()
-
- def forward(self, x, upp=None):
- sine_wavs, uv, _ = self.l_sin_gen(x, upp)
- if self.is_half:
- sine_wavs = sine_wavs.half()
- sine_merge = self.l_tanh(self.l_linear(sine_wavs))
- return sine_merge, None, None # noise, uv
-
-
-class GeneratorNSF(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels,
- sr,
- is_half=False,
- ):
- super(GeneratorNSF, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
-
- self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
- self.m_source = SourceModuleHnNSF(
- sampling_rate=sr, harmonic_num=0, is_half=is_half
- )
- self.noise_convs = nn.ModuleList()
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- c_cur = upsample_initial_channel // (2 ** (i + 1))
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
- if i + 1 < len(upsample_rates):
- stride_f0 = np.prod(upsample_rates[i + 1 :])
- self.noise_convs.append(
- Conv1d(
- 1,
- c_cur,
- kernel_size=stride_f0 * 2,
- stride=stride_f0,
- padding=stride_f0 // 2,
- )
- )
- else:
- self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- self.upp = np.prod(upsample_rates)
-
- def forward(self, x, f0, g=None):
- har_source, noi_source, uv = self.m_source(f0, self.upp)
- har_source = har_source.transpose(1, 2)
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- x_source = self.noise_convs[i](har_source)
- x = x + x_source
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-sr2sr = {
- "32k": 32000,
- "40k": 40000,
- "48k": 48000,
-}
-
-
-class SynthesizerTrnMs256NSFsid(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
- ): # 这里ds是id,[bs,1]
- # print(1,pitch.shape)#[bs,t]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- # print(-2,pitchf.shape,z_slice.shape)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs256NSFsid_nono(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr=None,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=False,
- )
- self.dec = Generator(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- o = self.dec(z_slice, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs256NSFsid_sim(nn.Module):
- """
- Synthesizer for Training
- """
-
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- # hop_length,
- gin_channels=0,
- use_sdp=True,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256Sim(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- is_half=kwargs["is_half"],
- )
-
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y_lengths, ds
- ): # y是spec不需要了现在
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- x, x_mask = self.enc_p(phone, pitch, phone_lengths)
- x = self.flow(x, x_mask, g=g, reverse=True)
- z_slice, ids_slice = commons.rand_slice_segments(
- x, y_lengths, self.segment_size
- )
-
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice
-
- def infer(
- self, phone, phone_lengths, pitch, pitchf, ds, max_len=None
- ): # y是spec不需要了现在
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- x, x_mask = self.enc_p(phone, pitch, phone_lengths)
- x = self.flow(x, x_mask, g=g, reverse=True)
- o = self.dec((x * x_mask)[:, :, :max_len], pitchf, g=g)
- return o, o
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminator, self).__init__()
- periods = [2, 3, 5, 7, 11, 17]
- # periods = [3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ]
- )
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(
- Conv2d(
- 1,
- 32,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 32,
- 128,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 128,
- 512,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 512,
- 1024,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 1024,
- 1024,
- (kernel_size, 1),
- 1,
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- ]
- )
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
diff --git a/spaces/JoeyFoursheds/ClonerHug/model_prepare.py b/spaces/JoeyFoursheds/ClonerHug/model_prepare.py
deleted file mode 100644
index 78c162a8db541a3b76d27e2d31a39b729a430064..0000000000000000000000000000000000000000
--- a/spaces/JoeyFoursheds/ClonerHug/model_prepare.py
+++ /dev/null
@@ -1,89 +0,0 @@
-import torch
-from fairseq import checkpoint_utils
-import json
-from infer_pack.models import SynthesizerTrnMs256NSFsid, SynthesizerTrnMs256NSFsid_nono
-from vc_infer_pipeline import VC
-from config import (
- is_half,
- device
-)
-
-def get_model_info(model_name):
- with open("weights/model_info.json", "r", encoding="utf-8") as f:
- models_info = json.load(f)
- # For now, get first item
- name, info = next(iter(models_info.items()))
- name = model_name
- # name = "Girl_1"
- info = models_info[name]
-
- title = "Voice Model Image: " + "GPT-4's Grandmother"
- author = info.get("author", None)
- image = f"weights/{name}/{info['image']}"
- feature_retrieval_index = f"weights/{name}/{info['feature_retrieval_library']}"
- npy = f"weights/{name}/{info['feature_file']}"
- checkpoint = torch.load(f"weights/{name}/{name}.pth", map_location="cpu")
- target_sr = checkpoint["config"][-1]
- checkpoint["config"][-3] = checkpoint["weight"]["emb_g.weight"].shape[0] # n_spk
- if_fund_freq = checkpoint.get("f0", 1)
- if if_fund_freq == 1:
- gen_model = SynthesizerTrnMs256NSFsid(*checkpoint["config"], is_half=is_half)
- else:
- gen_model = SynthesizerTrnMs256NSFsid_nono(*checkpoint["config"])
- del gen_model.enc_q
- print(gen_model.load_state_dict(checkpoint["weight"], strict=False))
- gen_model.eval().to(device)
- if is_half:
- gen_model = gen_model.half()
- else:
- gen_model = gen_model.float()
-
- return name, title, author, image, feature_retrieval_index, npy, target_sr, if_fund_freq, is_half, gen_model
-
-# make a struct to hold all the info returned from get_model_info
-class ModelInfo:
- def __init__(self, name, title, author, image, feature_retrieval_index, npy, target_sr, if_fund_freq, is_half, gen_model):
- self.name = name
- self.title = title
- self.author = author
- self.image = image
- self.feature_retrieval_index = feature_retrieval_index
- self.npy = npy
- self.target_sr = target_sr
- self.if_fund_freq = if_fund_freq
- self.is_half = is_half
- self.gen_model = gen_model
-
-def unpack_model_info(model_info):
- return model_info.name, model_info.title, model_info.author, model_info.image, model_info.gen_model
-
-
-def get_all_model_infos():
- model_infos = []
- with open("weights/model_info.json", "r", encoding="utf-8") as f:
- models_info = json.load(f)
- #loop through all models in model_info.json
- for name, info in models_info.items():
- name, title, author, image, feature_retrieval_index, npy, target_sr, if_fund_freq, is_half, gen_model = get_model_info(model_name=name)
- model_infos.append(ModelInfo(name, title, author, image, feature_retrieval_index, npy, target_sr, if_fund_freq, is_half, gen_model))
- # print ("\nname: ", name, "\n")
- return model_infos
-
-
-
-def load_hubert():
- global hubert_model
- models, _, _ = checkpoint_utils.load_model_ensemble_and_task(
- ["hubert_base.pt"],
- suffix="",
- )
- hubert_model = models[0]
- hubert_model = hubert_model.to(device)
- if is_half:
- hubert_model = hubert_model.half()
- else:
- hubert_model = hubert_model.float()
- hubert_model.eval()
- return hubert_model
-
-
diff --git a/spaces/JohnC26/MN.Map.Hospitals.Top.Five/app.py b/spaces/JohnC26/MN.Map.Hospitals.Top.Five/app.py
deleted file mode 100644
index 884f7d88b148b64d80dd3af93f7dcade28a72611..0000000000000000000000000000000000000000
--- a/spaces/JohnC26/MN.Map.Hospitals.Top.Five/app.py
+++ /dev/null
@@ -1,54 +0,0 @@
-import streamlit as st
-import folium
-from streamlit_folium import folium_static
-
-# Define hospitals data for Minnesota
-hospitals = [('Mayo Clinic', 'Rochester', 44.023678, -92.466955),
- ('University of Minnesota Medical Center', 'Minneapolis', 44.971389, -93.240556),
- ('Hennepin County Medical Center', 'Minneapolis', 44.972078, -93.261769),
- ('Regions Hospital', 'St. Paul', 44.942936, -93.093457),
- ('Abbott Northwestern Hospital', 'Minneapolis', 44.955447, -93.268543)]
-
-# Create a map centered on Minnesota
-m = folium.Map(location=[45.0, -94.0], zoom_start=7)
-
-# Add markers for each hospital
-for hospital in hospitals:
- folium.Marker(
- location=[hospital[2], hospital[3]],
- popup=f'{hospital[0]}
{hospital[1]}',
- icon=folium.Icon(color='red')
- ).add_to(m)
-
-# Add waypoints for each hospital
-waypoints = [(hospital[2], hospital[3]) for hospital in hospitals]
-folium.plugins.AntPath(waypoints, delay=3000).add_to(m)
-
-# Function to update the map when a button is clicked
-def update_map(hospital_data):
- m.location = [hospital_data[2], hospital_data[3]]
- m.zoom_start = 13
- folium_static(m)
-
-# Create a grid of buttons for selecting hospitals
-col1, col2, col3 = st.columns(3)
-with col1:
- if st.button(hospitals[0][0]):
- update_map(hospitals[0])
-with col2:
- if st.button(hospitals[1][0]):
- update_map(hospitals[1])
-with col3:
- if st.button(hospitals[2][0]):
- update_map(hospitals[2])
-
-col4, col5, col6 = st.columns(3)
-with col4:
- if st.button(hospitals[3][0]):
- update_map(hospitals[3])
-with col5:
- if st.button(hospitals[4][0]):
- update_map(hospitals[4])
-
-# Display the map in Streamlit
-folium_static(m)
diff --git a/spaces/Joom/Front-end-code-generation-from-images/app.py b/spaces/Joom/Front-end-code-generation-from-images/app.py
deleted file mode 100644
index 73c5947e01a23996cbfdbc68b5a2fed427721160..0000000000000000000000000000000000000000
--- a/spaces/Joom/Front-end-code-generation-from-images/app.py
+++ /dev/null
@@ -1,38 +0,0 @@
-__author__ = 'Taneem Jan, taneemishere.github.io'
-
-import gradio as gr
-import main_program
-
-
-# our model's i/o method that take image from gradio interface's inputs.Image()
-def model_interface(image):
- return main_model(image)
-
-
-# main method that call the main_program where code is generated and then compiled
-def main_model(input_image):
- result = main_program.main_method(input_image)
- return result
-
-
-interface_title = "
Front end Code Generation with Deep Neural Networks
"
-interface_description = """ Input sketch image and select the framework
-and click on submit to generate
"""
-
-interface_article = """
Creafted with care from Jude
"""
-
-interface_examples = ['examples/example-1.png', 'examples/example-2.png', 'examples/example-3.png']
-
-# a gradio interface to convert a image to HTML Code
-interface = gr.Interface(
- model_interface,
- inputs='image',
- outputs='text',
- allow_flagging="manual",
- title=interface_title,
- description=interface_description,
- article=interface_article,
- examples=interface_examples
-)
-
-interface.launch(share=False)
diff --git a/spaces/KevinGeng/Laronix_voice_quality_checking_system_FILEIO/lightning_module.py b/spaces/KevinGeng/Laronix_voice_quality_checking_system_FILEIO/lightning_module.py
deleted file mode 100644
index 491426e492accf516713a4a7672b65ec4e831868..0000000000000000000000000000000000000000
--- a/spaces/KevinGeng/Laronix_voice_quality_checking_system_FILEIO/lightning_module.py
+++ /dev/null
@@ -1,41 +0,0 @@
-import pytorch_lightning as pl
-import torch
-import torch.nn as nn
-import os
-import numpy as np
-import hydra
-from model import load_ssl_model, PhonemeEncoder, DomainEmbedding, LDConditioner, Projection
-
-
-class BaselineLightningModule(pl.LightningModule):
- def __init__(self, cfg):
- super().__init__()
- self.cfg = cfg
- self.construct_model()
- self.save_hyperparameters()
-
- def construct_model(self):
- self.feature_extractors = nn.ModuleList([
- load_ssl_model(cp_path='wav2vec_small.pt'),
- DomainEmbedding(3,128),
- ])
- output_dim = sum([ feature_extractor.get_output_dim() for feature_extractor in self.feature_extractors])
- output_layers = [
- LDConditioner(judge_dim=128,num_judges=3000,input_dim=output_dim)
- ]
- output_dim = output_layers[-1].get_output_dim()
- output_layers.append(
- Projection(hidden_dim=2048,activation=torch.nn.ReLU(),range_clipping=False,input_dim=output_dim)
-
- )
-
- self.output_layers = nn.ModuleList(output_layers)
-
- def forward(self, inputs):
- outputs = {}
- for feature_extractor in self.feature_extractors:
- outputs.update(feature_extractor(inputs))
- x = outputs
- for output_layer in self.output_layers:
- x = output_layer(x,inputs)
- return x
diff --git a/spaces/Keyurmistry/Joeythemonster-anything-midjourney-v-4-1/app.py b/spaces/Keyurmistry/Joeythemonster-anything-midjourney-v-4-1/app.py
deleted file mode 100644
index 262436d8b50f87b0953c645576cc3184b3b27b43..0000000000000000000000000000000000000000
--- a/spaces/Keyurmistry/Joeythemonster-anything-midjourney-v-4-1/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/Joeythemonster/anything-midjourney-v-4-1").launch()
\ No newline at end of file
diff --git a/spaces/KyanChen/RSPrompter/mmdet/models/detectors/dino.py b/spaces/KyanChen/RSPrompter/mmdet/models/detectors/dino.py
deleted file mode 100644
index a4385462affe70d0d7c7883cf1ce98da30c29036..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmdet/models/detectors/dino.py
+++ /dev/null
@@ -1,285 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict, Optional, Tuple
-
-import torch
-from torch import Tensor, nn
-from torch.nn.init import normal_
-
-from mmdet.registry import MODELS
-from mmdet.structures import OptSampleList
-from mmdet.utils import OptConfigType
-from ..layers import (CdnQueryGenerator, DeformableDetrTransformerEncoder,
- DinoTransformerDecoder, SinePositionalEncoding)
-from .deformable_detr import DeformableDETR, MultiScaleDeformableAttention
-
-
-@MODELS.register_module()
-class DINO(DeformableDETR):
- r"""Implementation of `DINO: DETR with Improved DeNoising Anchor Boxes
- for End-to-End Object Detection `_
-
- Code is modified from the `official github repo
- `_.
-
- Args:
- dn_cfg (:obj:`ConfigDict` or dict, optional): Config of denoising
- query generator. Defaults to `None`.
- """
-
- def __init__(self, *args, dn_cfg: OptConfigType = None, **kwargs) -> None:
- super().__init__(*args, **kwargs)
- assert self.as_two_stage, 'as_two_stage must be True for DINO'
- assert self.with_box_refine, 'with_box_refine must be True for DINO'
-
- if dn_cfg is not None:
- assert 'num_classes' not in dn_cfg and \
- 'num_queries' not in dn_cfg and \
- 'hidden_dim' not in dn_cfg, \
- 'The three keyword args `num_classes`, `embed_dims`, and ' \
- '`num_matching_queries` are set in `detector.__init__()`, ' \
- 'users should not set them in `dn_cfg` config.'
- dn_cfg['num_classes'] = self.bbox_head.num_classes
- dn_cfg['embed_dims'] = self.embed_dims
- dn_cfg['num_matching_queries'] = self.num_queries
- self.dn_query_generator = CdnQueryGenerator(**dn_cfg)
-
- def _init_layers(self) -> None:
- """Initialize layers except for backbone, neck and bbox_head."""
- self.positional_encoding = SinePositionalEncoding(
- **self.positional_encoding)
- self.encoder = DeformableDetrTransformerEncoder(**self.encoder)
- self.decoder = DinoTransformerDecoder(**self.decoder)
- self.embed_dims = self.encoder.embed_dims
- self.query_embedding = nn.Embedding(self.num_queries, self.embed_dims)
- # NOTE In DINO, the query_embedding only contains content
- # queries, while in Deformable DETR, the query_embedding
- # contains both content and spatial queries, and in DETR,
- # it only contains spatial queries.
-
- num_feats = self.positional_encoding.num_feats
- assert num_feats * 2 == self.embed_dims, \
- f'embed_dims should be exactly 2 times of num_feats. ' \
- f'Found {self.embed_dims} and {num_feats}.'
-
- self.level_embed = nn.Parameter(
- torch.Tensor(self.num_feature_levels, self.embed_dims))
- self.memory_trans_fc = nn.Linear(self.embed_dims, self.embed_dims)
- self.memory_trans_norm = nn.LayerNorm(self.embed_dims)
-
- def init_weights(self) -> None:
- """Initialize weights for Transformer and other components."""
- super(DeformableDETR, self).init_weights()
- for coder in self.encoder, self.decoder:
- for p in coder.parameters():
- if p.dim() > 1:
- nn.init.xavier_uniform_(p)
- for m in self.modules():
- if isinstance(m, MultiScaleDeformableAttention):
- m.init_weights()
- nn.init.xavier_uniform_(self.memory_trans_fc.weight)
- nn.init.xavier_uniform_(self.query_embedding.weight)
- normal_(self.level_embed)
-
- def forward_transformer(
- self,
- img_feats: Tuple[Tensor],
- batch_data_samples: OptSampleList = None,
- ) -> Dict:
- """Forward process of Transformer.
-
- The forward procedure of the transformer is defined as:
- 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
- More details can be found at `TransformerDetector.forward_transformer`
- in `mmdet/detector/base_detr.py`.
- The difference is that the ground truth in `batch_data_samples` is
- required for the `pre_decoder` to prepare the query of DINO.
- Additionally, DINO inherits the `pre_transformer` method and the
- `forward_encoder` method of DeformableDETR. More details about the
- two methods can be found in `mmdet/detector/deformable_detr.py`.
-
- Args:
- img_feats (tuple[Tensor]): Tuple of feature maps from neck. Each
- feature map has shape (bs, dim, H, W).
- batch_data_samples (list[:obj:`DetDataSample`]): The batch
- data samples. It usually includes information such
- as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
- Defaults to None.
-
- Returns:
- dict: The dictionary of bbox_head function inputs, which always
- includes the `hidden_states` of the decoder output and may contain
- `references` including the initial and intermediate references.
- """
- encoder_inputs_dict, decoder_inputs_dict = self.pre_transformer(
- img_feats, batch_data_samples)
-
- encoder_outputs_dict = self.forward_encoder(**encoder_inputs_dict)
-
- tmp_dec_in, head_inputs_dict = self.pre_decoder(
- **encoder_outputs_dict, batch_data_samples=batch_data_samples)
- decoder_inputs_dict.update(tmp_dec_in)
-
- decoder_outputs_dict = self.forward_decoder(**decoder_inputs_dict)
- head_inputs_dict.update(decoder_outputs_dict)
- return head_inputs_dict
-
- def pre_decoder(
- self,
- memory: Tensor,
- memory_mask: Tensor,
- spatial_shapes: Tensor,
- batch_data_samples: OptSampleList = None,
- ) -> Tuple[Dict]:
- """Prepare intermediate variables before entering Transformer decoder,
- such as `query`, `query_pos`, and `reference_points`.
-
- Args:
- memory (Tensor): The output embeddings of the Transformer encoder,
- has shape (bs, num_feat_points, dim).
- memory_mask (Tensor): ByteTensor, the padding mask of the memory,
- has shape (bs, num_feat_points). Will only be used when
- `as_two_stage` is `True`.
- spatial_shapes (Tensor): Spatial shapes of features in all levels.
- With shape (num_levels, 2), last dimension represents (h, w).
- Will only be used when `as_two_stage` is `True`.
- batch_data_samples (list[:obj:`DetDataSample`]): The batch
- data samples. It usually includes information such
- as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
- Defaults to None.
-
- Returns:
- tuple[dict]: The decoder_inputs_dict and head_inputs_dict.
-
- - decoder_inputs_dict (dict): The keyword dictionary args of
- `self.forward_decoder()`, which includes 'query', 'memory',
- `reference_points`, and `dn_mask`. The reference points of
- decoder input here are 4D boxes, although it has `points`
- in its name.
- - head_inputs_dict (dict): The keyword dictionary args of the
- bbox_head functions, which includes `topk_score`, `topk_coords`,
- and `dn_meta` when `self.training` is `True`, else is empty.
- """
- bs, _, c = memory.shape
- cls_out_features = self.bbox_head.cls_branches[
- self.decoder.num_layers].out_features
-
- output_memory, output_proposals = self.gen_encoder_output_proposals(
- memory, memory_mask, spatial_shapes)
- enc_outputs_class = self.bbox_head.cls_branches[
- self.decoder.num_layers](
- output_memory)
- enc_outputs_coord_unact = self.bbox_head.reg_branches[
- self.decoder.num_layers](output_memory) + output_proposals
-
- # NOTE The DINO selects top-k proposals according to scores of
- # multi-class classification, while DeformDETR, where the input
- # is `enc_outputs_class[..., 0]` selects according to scores of
- # binary classification.
- topk_indices = torch.topk(
- enc_outputs_class.max(-1)[0], k=self.num_queries, dim=1)[1]
- topk_score = torch.gather(
- enc_outputs_class, 1,
- topk_indices.unsqueeze(-1).repeat(1, 1, cls_out_features))
- topk_coords_unact = torch.gather(
- enc_outputs_coord_unact, 1,
- topk_indices.unsqueeze(-1).repeat(1, 1, 4))
- topk_coords = topk_coords_unact.sigmoid()
- topk_coords_unact = topk_coords_unact.detach()
-
- query = self.query_embedding.weight[:, None, :]
- query = query.repeat(1, bs, 1).transpose(0, 1)
- if self.training:
- dn_label_query, dn_bbox_query, dn_mask, dn_meta = \
- self.dn_query_generator(batch_data_samples)
- query = torch.cat([dn_label_query, query], dim=1)
- reference_points = torch.cat([dn_bbox_query, topk_coords_unact],
- dim=1)
- else:
- reference_points = topk_coords_unact
- dn_mask, dn_meta = None, None
- reference_points = reference_points.sigmoid()
-
- decoder_inputs_dict = dict(
- query=query,
- memory=memory,
- reference_points=reference_points,
- dn_mask=dn_mask)
- # NOTE DINO calculates encoder losses on scores and coordinates
- # of selected top-k encoder queries, while DeformDETR is of all
- # encoder queries.
- head_inputs_dict = dict(
- enc_outputs_class=topk_score,
- enc_outputs_coord=topk_coords,
- dn_meta=dn_meta) if self.training else dict()
- return decoder_inputs_dict, head_inputs_dict
-
- def forward_decoder(self,
- query: Tensor,
- memory: Tensor,
- memory_mask: Tensor,
- reference_points: Tensor,
- spatial_shapes: Tensor,
- level_start_index: Tensor,
- valid_ratios: Tensor,
- dn_mask: Optional[Tensor] = None) -> Dict:
- """Forward with Transformer decoder.
-
- The forward procedure of the transformer is defined as:
- 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
- More details can be found at `TransformerDetector.forward_transformer`
- in `mmdet/detector/base_detr.py`.
-
- Args:
- query (Tensor): The queries of decoder inputs, has shape
- (bs, num_queries_total, dim), where `num_queries_total` is the
- sum of `num_denoising_queries` and `num_matching_queries` when
- `self.training` is `True`, else `num_matching_queries`.
- memory (Tensor): The output embeddings of the Transformer encoder,
- has shape (bs, num_feat_points, dim).
- memory_mask (Tensor): ByteTensor, the padding mask of the memory,
- has shape (bs, num_feat_points).
- reference_points (Tensor): The initial reference, has shape
- (bs, num_queries_total, 4) with the last dimension arranged as
- (cx, cy, w, h).
- spatial_shapes (Tensor): Spatial shapes of features in all levels,
- has shape (num_levels, 2), last dimension represents (h, w).
- level_start_index (Tensor): The start index of each level.
- A tensor has shape (num_levels, ) and can be represented
- as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
- valid_ratios (Tensor): The ratios of the valid width and the valid
- height relative to the width and the height of features in all
- levels, has shape (bs, num_levels, 2).
- dn_mask (Tensor, optional): The attention mask to prevent
- information leakage from different denoising groups and
- matching parts, will be used as `self_attn_mask` of the
- `self.decoder`, has shape (num_queries_total,
- num_queries_total).
- It is `None` when `self.training` is `False`.
-
- Returns:
- dict: The dictionary of decoder outputs, which includes the
- `hidden_states` of the decoder output and `references` including
- the initial and intermediate reference_points.
- """
- inter_states, references = self.decoder(
- query=query,
- value=memory,
- key_padding_mask=memory_mask,
- self_attn_mask=dn_mask,
- reference_points=reference_points,
- spatial_shapes=spatial_shapes,
- level_start_index=level_start_index,
- valid_ratios=valid_ratios,
- reg_branches=self.bbox_head.reg_branches)
-
- if len(query) == self.num_queries:
- # NOTE: This is to make sure label_embeding can be involved to
- # produce loss even if there is no denoising query (no ground truth
- # target in this GPU), otherwise, this will raise runtime error in
- # distributed training.
- inter_states[0] += \
- self.dn_query_generator.label_embedding.weight[0, 0] * 0.0
-
- decoder_outputs_dict = dict(
- hidden_states=inter_states, references=list(references))
- return decoder_outputs_dict
diff --git a/spaces/KyanChen/RSPrompter/mmdet/models/roi_heads/multi_instance_roi_head.py b/spaces/KyanChen/RSPrompter/mmdet/models/roi_heads/multi_instance_roi_head.py
deleted file mode 100644
index fee55b0a5d341c03165649f59737fd34d85c207e..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmdet/models/roi_heads/multi_instance_roi_head.py
+++ /dev/null
@@ -1,226 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Tuple
-
-from torch import Tensor
-
-from mmdet.registry import MODELS
-from mmdet.structures import DetDataSample
-from mmdet.structures.bbox import bbox2roi
-from mmdet.utils import ConfigType, InstanceList
-from ..task_modules.samplers import SamplingResult
-from ..utils import empty_instances, unpack_gt_instances
-from .standard_roi_head import StandardRoIHead
-
-
-@MODELS.register_module()
-class MultiInstanceRoIHead(StandardRoIHead):
- """The roi head for Multi-instance prediction."""
-
- def __init__(self, num_instance: int = 2, *args, **kwargs) -> None:
- self.num_instance = num_instance
- super().__init__(*args, **kwargs)
-
- def init_bbox_head(self, bbox_roi_extractor: ConfigType,
- bbox_head: ConfigType) -> None:
- """Initialize box head and box roi extractor.
-
- Args:
- bbox_roi_extractor (dict or ConfigDict): Config of box
- roi extractor.
- bbox_head (dict or ConfigDict): Config of box in box head.
- """
- self.bbox_roi_extractor = MODELS.build(bbox_roi_extractor)
- self.bbox_head = MODELS.build(bbox_head)
-
- def _bbox_forward(self, x: Tuple[Tensor], rois: Tensor) -> dict:
- """Box head forward function used in both training and testing.
-
- Args:
- x (tuple[Tensor]): List of multi-level img features.
- rois (Tensor): RoIs with the shape (n, 5) where the first
- column indicates batch id of each RoI.
-
- Returns:
- dict[str, Tensor]: Usually returns a dictionary with keys:
-
- - `cls_score` (Tensor): Classification scores.
- - `bbox_pred` (Tensor): Box energies / deltas.
- - `cls_score_ref` (Tensor): The cls_score after refine model.
- - `bbox_pred_ref` (Tensor): The bbox_pred after refine model.
- - `bbox_feats` (Tensor): Extract bbox RoI features.
- """
- # TODO: a more flexible way to decide which feature maps to use
- bbox_feats = self.bbox_roi_extractor(
- x[:self.bbox_roi_extractor.num_inputs], rois)
- bbox_results = self.bbox_head(bbox_feats)
-
- if self.bbox_head.with_refine:
- bbox_results = dict(
- cls_score=bbox_results[0],
- bbox_pred=bbox_results[1],
- cls_score_ref=bbox_results[2],
- bbox_pred_ref=bbox_results[3],
- bbox_feats=bbox_feats)
- else:
- bbox_results = dict(
- cls_score=bbox_results[0],
- bbox_pred=bbox_results[1],
- bbox_feats=bbox_feats)
-
- return bbox_results
-
- def bbox_loss(self, x: Tuple[Tensor],
- sampling_results: List[SamplingResult]) -> dict:
- """Perform forward propagation and loss calculation of the bbox head on
- the features of the upstream network.
-
- Args:
- x (tuple[Tensor]): List of multi-level img features.
- sampling_results (list["obj:`SamplingResult`]): Sampling results.
-
- Returns:
- dict[str, Tensor]: Usually returns a dictionary with keys:
-
- - `cls_score` (Tensor): Classification scores.
- - `bbox_pred` (Tensor): Box energies / deltas.
- - `bbox_feats` (Tensor): Extract bbox RoI features.
- - `loss_bbox` (dict): A dictionary of bbox loss components.
- """
- rois = bbox2roi([res.priors for res in sampling_results])
- bbox_results = self._bbox_forward(x, rois)
-
- # If there is a refining process, add refine loss.
- if 'cls_score_ref' in bbox_results:
- bbox_loss_and_target = self.bbox_head.loss_and_target(
- cls_score=bbox_results['cls_score'],
- bbox_pred=bbox_results['bbox_pred'],
- rois=rois,
- sampling_results=sampling_results,
- rcnn_train_cfg=self.train_cfg)
- bbox_results.update(loss_bbox=bbox_loss_and_target['loss_bbox'])
- bbox_loss_and_target_ref = self.bbox_head.loss_and_target(
- cls_score=bbox_results['cls_score_ref'],
- bbox_pred=bbox_results['bbox_pred_ref'],
- rois=rois,
- sampling_results=sampling_results,
- rcnn_train_cfg=self.train_cfg)
- bbox_results['loss_bbox']['loss_rcnn_emd_ref'] = \
- bbox_loss_and_target_ref['loss_bbox']['loss_rcnn_emd']
- else:
- bbox_loss_and_target = self.bbox_head.loss_and_target(
- cls_score=bbox_results['cls_score'],
- bbox_pred=bbox_results['bbox_pred'],
- rois=rois,
- sampling_results=sampling_results,
- rcnn_train_cfg=self.train_cfg)
- bbox_results.update(loss_bbox=bbox_loss_and_target['loss_bbox'])
-
- return bbox_results
-
- def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
- batch_data_samples: List[DetDataSample]) -> dict:
- """Perform forward propagation and loss calculation of the detection
- roi on the features of the upstream network.
-
- Args:
- x (tuple[Tensor]): List of multi-level img features.
- rpn_results_list (list[:obj:`InstanceData`]): List of region
- proposals.
- batch_data_samples (list[:obj:`DetDataSample`]): The batch
- data samples. It usually includes information such
- as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
-
- Returns:
- dict[str, Tensor]: A dictionary of loss components
- """
- assert len(rpn_results_list) == len(batch_data_samples)
- outputs = unpack_gt_instances(batch_data_samples)
- batch_gt_instances, batch_gt_instances_ignore, _ = outputs
-
- sampling_results = []
- for i in range(len(batch_data_samples)):
- # rename rpn_results.bboxes to rpn_results.priors
- rpn_results = rpn_results_list[i]
- rpn_results.priors = rpn_results.pop('bboxes')
-
- assign_result = self.bbox_assigner.assign(
- rpn_results, batch_gt_instances[i],
- batch_gt_instances_ignore[i])
- sampling_result = self.bbox_sampler.sample(
- assign_result,
- rpn_results,
- batch_gt_instances[i],
- batch_gt_instances_ignore=batch_gt_instances_ignore[i])
- sampling_results.append(sampling_result)
-
- losses = dict()
- # bbox head loss
- if self.with_bbox:
- bbox_results = self.bbox_loss(x, sampling_results)
- losses.update(bbox_results['loss_bbox'])
-
- return losses
-
- def predict_bbox(self,
- x: Tuple[Tensor],
- batch_img_metas: List[dict],
- rpn_results_list: InstanceList,
- rcnn_test_cfg: ConfigType,
- rescale: bool = False) -> InstanceList:
- """Perform forward propagation of the bbox head and predict detection
- results on the features of the upstream network.
-
- Args:
- x (tuple[Tensor]): Feature maps of all scale level.
- batch_img_metas (list[dict]): List of image information.
- rpn_results_list (list[:obj:`InstanceData`]): List of region
- proposals.
- rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of R-CNN.
- rescale (bool): If True, return boxes in original image space.
- Defaults to False.
-
- Returns:
- list[:obj:`InstanceData`]: Detection results of each image
- after the post process.
- Each item usually contains following keys.
-
- - scores (Tensor): Classification scores, has a shape
- (num_instance, )
- - labels (Tensor): Labels of bboxes, has a shape
- (num_instances, ).
- - bboxes (Tensor): Has a shape (num_instances, 4),
- the last dimension 4 arrange as (x1, y1, x2, y2).
- """
- proposals = [res.bboxes for res in rpn_results_list]
- rois = bbox2roi(proposals)
-
- if rois.shape[0] == 0:
- return empty_instances(
- batch_img_metas, rois.device, task_type='bbox')
-
- bbox_results = self._bbox_forward(x, rois)
-
- # split batch bbox prediction back to each image
- if 'cls_score_ref' in bbox_results:
- cls_scores = bbox_results['cls_score_ref']
- bbox_preds = bbox_results['bbox_pred_ref']
- else:
- cls_scores = bbox_results['cls_score']
- bbox_preds = bbox_results['bbox_pred']
- num_proposals_per_img = tuple(len(p) for p in proposals)
- rois = rois.split(num_proposals_per_img, 0)
- cls_scores = cls_scores.split(num_proposals_per_img, 0)
-
- if bbox_preds is not None:
- bbox_preds = bbox_preds.split(num_proposals_per_img, 0)
- else:
- bbox_preds = (None, ) * len(proposals)
-
- result_list = self.bbox_head.predict_by_feat(
- rois=rois,
- cls_scores=cls_scores,
- bbox_preds=bbox_preds,
- batch_img_metas=batch_img_metas,
- rcnn_test_cfg=rcnn_test_cfg,
- rescale=rescale)
- return result_list
diff --git a/spaces/KyanChen/RSPrompter/mmdet/models/task_modules/coders/bucketing_bbox_coder.py b/spaces/KyanChen/RSPrompter/mmdet/models/task_modules/coders/bucketing_bbox_coder.py
deleted file mode 100644
index 4044e1cd91d619521606f3c03032a40a9fc27130..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmdet/models/task_modules/coders/bucketing_bbox_coder.py
+++ /dev/null
@@ -1,366 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Tuple, Union
-
-import numpy as np
-import torch
-import torch.nn.functional as F
-from torch import Tensor
-
-from mmdet.registry import TASK_UTILS
-from mmdet.structures.bbox import (BaseBoxes, HorizontalBoxes, bbox_rescale,
- get_box_tensor)
-from .base_bbox_coder import BaseBBoxCoder
-
-
-@TASK_UTILS.register_module()
-class BucketingBBoxCoder(BaseBBoxCoder):
- """Bucketing BBox Coder for Side-Aware Boundary Localization (SABL).
-
- Boundary Localization with Bucketing and Bucketing Guided Rescoring
- are implemented here.
-
- Please refer to https://arxiv.org/abs/1912.04260 for more details.
-
- Args:
- num_buckets (int): Number of buckets.
- scale_factor (int): Scale factor of proposals to generate buckets.
- offset_topk (int): Topk buckets are used to generate
- bucket fine regression targets. Defaults to 2.
- offset_upperbound (float): Offset upperbound to generate
- bucket fine regression targets.
- To avoid too large offset displacements. Defaults to 1.0.
- cls_ignore_neighbor (bool): Ignore second nearest bucket or Not.
- Defaults to True.
- clip_border (bool, optional): Whether clip the objects outside the
- border of the image. Defaults to True.
- """
-
- def __init__(self,
- num_buckets: int,
- scale_factor: int,
- offset_topk: int = 2,
- offset_upperbound: float = 1.0,
- cls_ignore_neighbor: bool = True,
- clip_border: bool = True,
- **kwargs) -> None:
- super().__init__(**kwargs)
- self.num_buckets = num_buckets
- self.scale_factor = scale_factor
- self.offset_topk = offset_topk
- self.offset_upperbound = offset_upperbound
- self.cls_ignore_neighbor = cls_ignore_neighbor
- self.clip_border = clip_border
-
- def encode(self, bboxes: Union[Tensor, BaseBoxes],
- gt_bboxes: Union[Tensor, BaseBoxes]) -> Tuple[Tensor]:
- """Get bucketing estimation and fine regression targets during
- training.
-
- Args:
- bboxes (torch.Tensor or :obj:`BaseBoxes`): source boxes,
- e.g., object proposals.
- gt_bboxes (torch.Tensor or :obj:`BaseBoxes`): target of the
- transformation, e.g., ground truth boxes.
-
- Returns:
- encoded_bboxes(tuple[Tensor]): bucketing estimation
- and fine regression targets and weights
- """
- bboxes = get_box_tensor(bboxes)
- gt_bboxes = get_box_tensor(gt_bboxes)
- assert bboxes.size(0) == gt_bboxes.size(0)
- assert bboxes.size(-1) == gt_bboxes.size(-1) == 4
- encoded_bboxes = bbox2bucket(bboxes, gt_bboxes, self.num_buckets,
- self.scale_factor, self.offset_topk,
- self.offset_upperbound,
- self.cls_ignore_neighbor)
- return encoded_bboxes
-
- def decode(
- self,
- bboxes: Union[Tensor, BaseBoxes],
- pred_bboxes: Tensor,
- max_shape: Optional[Tuple[int]] = None
- ) -> Tuple[Union[Tensor, BaseBoxes], Tensor]:
- """Apply transformation `pred_bboxes` to `boxes`.
- Args:
- boxes (torch.Tensor or :obj:`BaseBoxes`): Basic boxes.
- pred_bboxes (torch.Tensor): Predictions for bucketing estimation
- and fine regression
- max_shape (tuple[int], optional): Maximum shape of boxes.
- Defaults to None.
-
- Returns:
- Union[torch.Tensor, :obj:`BaseBoxes`]: Decoded boxes.
- """
- bboxes = get_box_tensor(bboxes)
- assert len(pred_bboxes) == 2
- cls_preds, offset_preds = pred_bboxes
- assert cls_preds.size(0) == bboxes.size(0) and offset_preds.size(
- 0) == bboxes.size(0)
- bboxes, loc_confidence = bucket2bbox(bboxes, cls_preds, offset_preds,
- self.num_buckets,
- self.scale_factor, max_shape,
- self.clip_border)
- if self.use_box_type:
- bboxes = HorizontalBoxes(bboxes, clone=False)
- return bboxes, loc_confidence
-
-
-def generat_buckets(proposals: Tensor,
- num_buckets: int,
- scale_factor: float = 1.0) -> Tuple[Tensor]:
- """Generate buckets w.r.t bucket number and scale factor of proposals.
-
- Args:
- proposals (Tensor): Shape (n, 4)
- num_buckets (int): Number of buckets.
- scale_factor (float): Scale factor to rescale proposals.
-
- Returns:
- tuple[Tensor]: (bucket_w, bucket_h, l_buckets, r_buckets,
- t_buckets, d_buckets)
-
- - bucket_w: Width of buckets on x-axis. Shape (n, ).
- - bucket_h: Height of buckets on y-axis. Shape (n, ).
- - l_buckets: Left buckets. Shape (n, ceil(side_num/2)).
- - r_buckets: Right buckets. Shape (n, ceil(side_num/2)).
- - t_buckets: Top buckets. Shape (n, ceil(side_num/2)).
- - d_buckets: Down buckets. Shape (n, ceil(side_num/2)).
- """
- proposals = bbox_rescale(proposals, scale_factor)
-
- # number of buckets in each side
- side_num = int(np.ceil(num_buckets / 2.0))
- pw = proposals[..., 2] - proposals[..., 0]
- ph = proposals[..., 3] - proposals[..., 1]
- px1 = proposals[..., 0]
- py1 = proposals[..., 1]
- px2 = proposals[..., 2]
- py2 = proposals[..., 3]
-
- bucket_w = pw / num_buckets
- bucket_h = ph / num_buckets
-
- # left buckets
- l_buckets = px1[:, None] + (0.5 + torch.arange(
- 0, side_num).to(proposals).float())[None, :] * bucket_w[:, None]
- # right buckets
- r_buckets = px2[:, None] - (0.5 + torch.arange(
- 0, side_num).to(proposals).float())[None, :] * bucket_w[:, None]
- # top buckets
- t_buckets = py1[:, None] + (0.5 + torch.arange(
- 0, side_num).to(proposals).float())[None, :] * bucket_h[:, None]
- # down buckets
- d_buckets = py2[:, None] - (0.5 + torch.arange(
- 0, side_num).to(proposals).float())[None, :] * bucket_h[:, None]
- return bucket_w, bucket_h, l_buckets, r_buckets, t_buckets, d_buckets
-
-
-def bbox2bucket(proposals: Tensor,
- gt: Tensor,
- num_buckets: int,
- scale_factor: float,
- offset_topk: int = 2,
- offset_upperbound: float = 1.0,
- cls_ignore_neighbor: bool = True) -> Tuple[Tensor]:
- """Generate buckets estimation and fine regression targets.
-
- Args:
- proposals (Tensor): Shape (n, 4)
- gt (Tensor): Shape (n, 4)
- num_buckets (int): Number of buckets.
- scale_factor (float): Scale factor to rescale proposals.
- offset_topk (int): Topk buckets are used to generate
- bucket fine regression targets. Defaults to 2.
- offset_upperbound (float): Offset allowance to generate
- bucket fine regression targets.
- To avoid too large offset displacements. Defaults to 1.0.
- cls_ignore_neighbor (bool): Ignore second nearest bucket or Not.
- Defaults to True.
-
- Returns:
- tuple[Tensor]: (offsets, offsets_weights, bucket_labels, cls_weights).
-
- - offsets: Fine regression targets. \
- Shape (n, num_buckets*2).
- - offsets_weights: Fine regression weights. \
- Shape (n, num_buckets*2).
- - bucket_labels: Bucketing estimation labels. \
- Shape (n, num_buckets*2).
- - cls_weights: Bucketing estimation weights. \
- Shape (n, num_buckets*2).
- """
- assert proposals.size() == gt.size()
-
- # generate buckets
- proposals = proposals.float()
- gt = gt.float()
- (bucket_w, bucket_h, l_buckets, r_buckets, t_buckets,
- d_buckets) = generat_buckets(proposals, num_buckets, scale_factor)
-
- gx1 = gt[..., 0]
- gy1 = gt[..., 1]
- gx2 = gt[..., 2]
- gy2 = gt[..., 3]
-
- # generate offset targets and weights
- # offsets from buckets to gts
- l_offsets = (l_buckets - gx1[:, None]) / bucket_w[:, None]
- r_offsets = (r_buckets - gx2[:, None]) / bucket_w[:, None]
- t_offsets = (t_buckets - gy1[:, None]) / bucket_h[:, None]
- d_offsets = (d_buckets - gy2[:, None]) / bucket_h[:, None]
-
- # select top-k nearest buckets
- l_topk, l_label = l_offsets.abs().topk(
- offset_topk, dim=1, largest=False, sorted=True)
- r_topk, r_label = r_offsets.abs().topk(
- offset_topk, dim=1, largest=False, sorted=True)
- t_topk, t_label = t_offsets.abs().topk(
- offset_topk, dim=1, largest=False, sorted=True)
- d_topk, d_label = d_offsets.abs().topk(
- offset_topk, dim=1, largest=False, sorted=True)
-
- offset_l_weights = l_offsets.new_zeros(l_offsets.size())
- offset_r_weights = r_offsets.new_zeros(r_offsets.size())
- offset_t_weights = t_offsets.new_zeros(t_offsets.size())
- offset_d_weights = d_offsets.new_zeros(d_offsets.size())
- inds = torch.arange(0, proposals.size(0)).to(proposals).long()
-
- # generate offset weights of top-k nearest buckets
- for k in range(offset_topk):
- if k >= 1:
- offset_l_weights[inds, l_label[:,
- k]] = (l_topk[:, k] <
- offset_upperbound).float()
- offset_r_weights[inds, r_label[:,
- k]] = (r_topk[:, k] <
- offset_upperbound).float()
- offset_t_weights[inds, t_label[:,
- k]] = (t_topk[:, k] <
- offset_upperbound).float()
- offset_d_weights[inds, d_label[:,
- k]] = (d_topk[:, k] <
- offset_upperbound).float()
- else:
- offset_l_weights[inds, l_label[:, k]] = 1.0
- offset_r_weights[inds, r_label[:, k]] = 1.0
- offset_t_weights[inds, t_label[:, k]] = 1.0
- offset_d_weights[inds, d_label[:, k]] = 1.0
-
- offsets = torch.cat([l_offsets, r_offsets, t_offsets, d_offsets], dim=-1)
- offsets_weights = torch.cat([
- offset_l_weights, offset_r_weights, offset_t_weights, offset_d_weights
- ],
- dim=-1)
-
- # generate bucket labels and weight
- side_num = int(np.ceil(num_buckets / 2.0))
- labels = torch.stack(
- [l_label[:, 0], r_label[:, 0], t_label[:, 0], d_label[:, 0]], dim=-1)
-
- batch_size = labels.size(0)
- bucket_labels = F.one_hot(labels.view(-1), side_num).view(batch_size,
- -1).float()
- bucket_cls_l_weights = (l_offsets.abs() < 1).float()
- bucket_cls_r_weights = (r_offsets.abs() < 1).float()
- bucket_cls_t_weights = (t_offsets.abs() < 1).float()
- bucket_cls_d_weights = (d_offsets.abs() < 1).float()
- bucket_cls_weights = torch.cat([
- bucket_cls_l_weights, bucket_cls_r_weights, bucket_cls_t_weights,
- bucket_cls_d_weights
- ],
- dim=-1)
- # ignore second nearest buckets for cls if necessary
- if cls_ignore_neighbor:
- bucket_cls_weights = (~((bucket_cls_weights == 1) &
- (bucket_labels == 0))).float()
- else:
- bucket_cls_weights[:] = 1.0
- return offsets, offsets_weights, bucket_labels, bucket_cls_weights
-
-
-def bucket2bbox(proposals: Tensor,
- cls_preds: Tensor,
- offset_preds: Tensor,
- num_buckets: int,
- scale_factor: float = 1.0,
- max_shape: Optional[Union[Sequence[int], Tensor,
- Sequence[Sequence[int]]]] = None,
- clip_border: bool = True) -> Tuple[Tensor]:
- """Apply bucketing estimation (cls preds) and fine regression (offset
- preds) to generate det bboxes.
-
- Args:
- proposals (Tensor): Boxes to be transformed. Shape (n, 4)
- cls_preds (Tensor): bucketing estimation. Shape (n, num_buckets*2).
- offset_preds (Tensor): fine regression. Shape (n, num_buckets*2).
- num_buckets (int): Number of buckets.
- scale_factor (float): Scale factor to rescale proposals.
- max_shape (tuple[int, int]): Maximum bounds for boxes. specifies (H, W)
- clip_border (bool, optional): Whether clip the objects outside the
- border of the image. Defaults to True.
-
- Returns:
- tuple[Tensor]: (bboxes, loc_confidence).
-
- - bboxes: predicted bboxes. Shape (n, 4)
- - loc_confidence: localization confidence of predicted bboxes.
- Shape (n,).
- """
-
- side_num = int(np.ceil(num_buckets / 2.0))
- cls_preds = cls_preds.view(-1, side_num)
- offset_preds = offset_preds.view(-1, side_num)
-
- scores = F.softmax(cls_preds, dim=1)
- score_topk, score_label = scores.topk(2, dim=1, largest=True, sorted=True)
-
- rescaled_proposals = bbox_rescale(proposals, scale_factor)
-
- pw = rescaled_proposals[..., 2] - rescaled_proposals[..., 0]
- ph = rescaled_proposals[..., 3] - rescaled_proposals[..., 1]
- px1 = rescaled_proposals[..., 0]
- py1 = rescaled_proposals[..., 1]
- px2 = rescaled_proposals[..., 2]
- py2 = rescaled_proposals[..., 3]
-
- bucket_w = pw / num_buckets
- bucket_h = ph / num_buckets
-
- score_inds_l = score_label[0::4, 0]
- score_inds_r = score_label[1::4, 0]
- score_inds_t = score_label[2::4, 0]
- score_inds_d = score_label[3::4, 0]
- l_buckets = px1 + (0.5 + score_inds_l.float()) * bucket_w
- r_buckets = px2 - (0.5 + score_inds_r.float()) * bucket_w
- t_buckets = py1 + (0.5 + score_inds_t.float()) * bucket_h
- d_buckets = py2 - (0.5 + score_inds_d.float()) * bucket_h
-
- offsets = offset_preds.view(-1, 4, side_num)
- inds = torch.arange(proposals.size(0)).to(proposals).long()
- l_offsets = offsets[:, 0, :][inds, score_inds_l]
- r_offsets = offsets[:, 1, :][inds, score_inds_r]
- t_offsets = offsets[:, 2, :][inds, score_inds_t]
- d_offsets = offsets[:, 3, :][inds, score_inds_d]
-
- x1 = l_buckets - l_offsets * bucket_w
- x2 = r_buckets - r_offsets * bucket_w
- y1 = t_buckets - t_offsets * bucket_h
- y2 = d_buckets - d_offsets * bucket_h
-
- if clip_border and max_shape is not None:
- x1 = x1.clamp(min=0, max=max_shape[1] - 1)
- y1 = y1.clamp(min=0, max=max_shape[0] - 1)
- x2 = x2.clamp(min=0, max=max_shape[1] - 1)
- y2 = y2.clamp(min=0, max=max_shape[0] - 1)
- bboxes = torch.cat([x1[:, None], y1[:, None], x2[:, None], y2[:, None]],
- dim=-1)
-
- # bucketing guided rescoring
- loc_confidence = score_topk[:, 0]
- top2_neighbor_inds = (score_label[:, 0] - score_label[:, 1]).abs() == 1
- loc_confidence += score_topk[:, 1] * top2_neighbor_inds.float()
- loc_confidence = loc_confidence.view(-1, 4).mean(dim=1)
-
- return bboxes, loc_confidence
diff --git a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/spec_utils.py b/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/spec_utils.py
deleted file mode 100644
index 062d9050d85c036f8ebafc9c64f1501cff747568..0000000000000000000000000000000000000000
--- a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/spec_utils.py
+++ /dev/null
@@ -1,666 +0,0 @@
-import os, librosa
-import numpy as np
-import soundfile as sf
-from tqdm import tqdm
-import json, math, hashlib
-
-
-def crop_center(h1, h2):
- h1_shape = h1.size()
- h2_shape = h2.size()
-
- if h1_shape[3] == h2_shape[3]:
- return h1
- elif h1_shape[3] < h2_shape[3]:
- raise ValueError("h1_shape[3] must be greater than h2_shape[3]")
-
- # s_freq = (h2_shape[2] - h1_shape[2]) // 2
- # e_freq = s_freq + h1_shape[2]
- s_time = (h1_shape[3] - h2_shape[3]) // 2
- e_time = s_time + h2_shape[3]
- h1 = h1[:, :, :, s_time:e_time]
-
- return h1
-
-
-def wave_to_spectrogram(
- wave, hop_length, n_fft, mid_side=False, mid_side_b2=False, reverse=False
-):
- if reverse:
- wave_left = np.flip(np.asfortranarray(wave[0]))
- wave_right = np.flip(np.asfortranarray(wave[1]))
- elif mid_side:
- wave_left = np.asfortranarray(np.add(wave[0], wave[1]) / 2)
- wave_right = np.asfortranarray(np.subtract(wave[0], wave[1]))
- elif mid_side_b2:
- wave_left = np.asfortranarray(np.add(wave[1], wave[0] * 0.5))
- wave_right = np.asfortranarray(np.subtract(wave[0], wave[1] * 0.5))
- else:
- wave_left = np.asfortranarray(wave[0])
- wave_right = np.asfortranarray(wave[1])
-
- spec_left = librosa.stft(wave_left, n_fft, hop_length=hop_length)
- spec_right = librosa.stft(wave_right, n_fft, hop_length=hop_length)
-
- spec = np.asfortranarray([spec_left, spec_right])
-
- return spec
-
-
-def wave_to_spectrogram_mt(
- wave, hop_length, n_fft, mid_side=False, mid_side_b2=False, reverse=False
-):
- import threading
-
- if reverse:
- wave_left = np.flip(np.asfortranarray(wave[0]))
- wave_right = np.flip(np.asfortranarray(wave[1]))
- elif mid_side:
- wave_left = np.asfortranarray(np.add(wave[0], wave[1]) / 2)
- wave_right = np.asfortranarray(np.subtract(wave[0], wave[1]))
- elif mid_side_b2:
- wave_left = np.asfortranarray(np.add(wave[1], wave[0] * 0.5))
- wave_right = np.asfortranarray(np.subtract(wave[0], wave[1] * 0.5))
- else:
- wave_left = np.asfortranarray(wave[0])
- wave_right = np.asfortranarray(wave[1])
-
- def run_thread(**kwargs):
- global spec_left
- spec_left = librosa.stft(**kwargs)
-
- thread = threading.Thread(
- target=run_thread,
- kwargs={"y": wave_left, "n_fft": n_fft, "hop_length": hop_length},
- )
- thread.start()
- spec_right = librosa.stft(wave_right, n_fft, hop_length=hop_length)
- thread.join()
-
- spec = np.asfortranarray([spec_left, spec_right])
-
- return spec
-
-
-def combine_spectrograms(specs, mp):
- l = min([specs[i].shape[2] for i in specs])
- spec_c = np.zeros(shape=(2, mp.param["bins"] + 1, l), dtype=np.complex64)
- offset = 0
- bands_n = len(mp.param["band"])
-
- for d in range(1, bands_n + 1):
- h = mp.param["band"][d]["crop_stop"] - mp.param["band"][d]["crop_start"]
- spec_c[:, offset : offset + h, :l] = specs[d][
- :, mp.param["band"][d]["crop_start"] : mp.param["band"][d]["crop_stop"], :l
- ]
- offset += h
-
- if offset > mp.param["bins"]:
- raise ValueError("Too much bins")
-
- # lowpass fiter
- if (
- mp.param["pre_filter_start"] > 0
- ): # and mp.param['band'][bands_n]['res_type'] in ['scipy', 'polyphase']:
- if bands_n == 1:
- spec_c = fft_lp_filter(
- spec_c, mp.param["pre_filter_start"], mp.param["pre_filter_stop"]
- )
- else:
- gp = 1
- for b in range(
- mp.param["pre_filter_start"] + 1, mp.param["pre_filter_stop"]
- ):
- g = math.pow(
- 10, -(b - mp.param["pre_filter_start"]) * (3.5 - gp) / 20.0
- )
- gp = g
- spec_c[:, b, :] *= g
-
- return np.asfortranarray(spec_c)
-
-
-def spectrogram_to_image(spec, mode="magnitude"):
- if mode == "magnitude":
- if np.iscomplexobj(spec):
- y = np.abs(spec)
- else:
- y = spec
- y = np.log10(y**2 + 1e-8)
- elif mode == "phase":
- if np.iscomplexobj(spec):
- y = np.angle(spec)
- else:
- y = spec
-
- y -= y.min()
- y *= 255 / y.max()
- img = np.uint8(y)
-
- if y.ndim == 3:
- img = img.transpose(1, 2, 0)
- img = np.concatenate([np.max(img, axis=2, keepdims=True), img], axis=2)
-
- return img
-
-
-def reduce_vocal_aggressively(X, y, softmask):
- v = X - y
- y_mag_tmp = np.abs(y)
- v_mag_tmp = np.abs(v)
-
- v_mask = v_mag_tmp > y_mag_tmp
- y_mag = np.clip(y_mag_tmp - v_mag_tmp * v_mask * softmask, 0, np.inf)
-
- return y_mag * np.exp(1.0j * np.angle(y))
-
-
-def mask_silence(mag, ref, thres=0.2, min_range=64, fade_size=32):
- if min_range < fade_size * 2:
- raise ValueError("min_range must be >= fade_area * 2")
-
- mag = mag.copy()
-
- idx = np.where(ref.mean(axis=(0, 1)) < thres)[0]
- starts = np.insert(idx[np.where(np.diff(idx) != 1)[0] + 1], 0, idx[0])
- ends = np.append(idx[np.where(np.diff(idx) != 1)[0]], idx[-1])
- uninformative = np.where(ends - starts > min_range)[0]
- if len(uninformative) > 0:
- starts = starts[uninformative]
- ends = ends[uninformative]
- old_e = None
- for s, e in zip(starts, ends):
- if old_e is not None and s - old_e < fade_size:
- s = old_e - fade_size * 2
-
- if s != 0:
- weight = np.linspace(0, 1, fade_size)
- mag[:, :, s : s + fade_size] += weight * ref[:, :, s : s + fade_size]
- else:
- s -= fade_size
-
- if e != mag.shape[2]:
- weight = np.linspace(1, 0, fade_size)
- mag[:, :, e - fade_size : e] += weight * ref[:, :, e - fade_size : e]
- else:
- e += fade_size
-
- mag[:, :, s + fade_size : e - fade_size] += ref[
- :, :, s + fade_size : e - fade_size
- ]
- old_e = e
-
- return mag
-
-
-def align_wave_head_and_tail(a, b):
- l = min([a[0].size, b[0].size])
-
- return a[:l, :l], b[:l, :l]
-
-
-def cache_or_load(mix_path, inst_path, mp):
- mix_basename = os.path.splitext(os.path.basename(mix_path))[0]
- inst_basename = os.path.splitext(os.path.basename(inst_path))[0]
-
- cache_dir = "mph{}".format(
- hashlib.sha1(json.dumps(mp.param, sort_keys=True).encode("utf-8")).hexdigest()
- )
- mix_cache_dir = os.path.join("cache", cache_dir)
- inst_cache_dir = os.path.join("cache", cache_dir)
-
- os.makedirs(mix_cache_dir, exist_ok=True)
- os.makedirs(inst_cache_dir, exist_ok=True)
-
- mix_cache_path = os.path.join(mix_cache_dir, mix_basename + ".npy")
- inst_cache_path = os.path.join(inst_cache_dir, inst_basename + ".npy")
-
- if os.path.exists(mix_cache_path) and os.path.exists(inst_cache_path):
- X_spec_m = np.load(mix_cache_path)
- y_spec_m = np.load(inst_cache_path)
- else:
- X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
-
- for d in range(len(mp.param["band"]), 0, -1):
- bp = mp.param["band"][d]
-
- if d == len(mp.param["band"]): # high-end band
- X_wave[d], _ = librosa.load(
- mix_path, bp["sr"], False, dtype=np.float32, res_type=bp["res_type"]
- )
- y_wave[d], _ = librosa.load(
- inst_path,
- bp["sr"],
- False,
- dtype=np.float32,
- res_type=bp["res_type"],
- )
- else: # lower bands
- X_wave[d] = librosa.resample(
- X_wave[d + 1],
- mp.param["band"][d + 1]["sr"],
- bp["sr"],
- res_type=bp["res_type"],
- )
- y_wave[d] = librosa.resample(
- y_wave[d + 1],
- mp.param["band"][d + 1]["sr"],
- bp["sr"],
- res_type=bp["res_type"],
- )
-
- X_wave[d], y_wave[d] = align_wave_head_and_tail(X_wave[d], y_wave[d])
-
- X_spec_s[d] = wave_to_spectrogram(
- X_wave[d],
- bp["hl"],
- bp["n_fft"],
- mp.param["mid_side"],
- mp.param["mid_side_b2"],
- mp.param["reverse"],
- )
- y_spec_s[d] = wave_to_spectrogram(
- y_wave[d],
- bp["hl"],
- bp["n_fft"],
- mp.param["mid_side"],
- mp.param["mid_side_b2"],
- mp.param["reverse"],
- )
-
- del X_wave, y_wave
-
- X_spec_m = combine_spectrograms(X_spec_s, mp)
- y_spec_m = combine_spectrograms(y_spec_s, mp)
-
- if X_spec_m.shape != y_spec_m.shape:
- raise ValueError("The combined spectrograms are different: " + mix_path)
-
- _, ext = os.path.splitext(mix_path)
-
- np.save(mix_cache_path, X_spec_m)
- np.save(inst_cache_path, y_spec_m)
-
- return X_spec_m, y_spec_m
-
-
-def spectrogram_to_wave(spec, hop_length, mid_side, mid_side_b2, reverse):
- spec_left = np.asfortranarray(spec[0])
- spec_right = np.asfortranarray(spec[1])
-
- wave_left = librosa.istft(spec_left, hop_length=hop_length)
- wave_right = librosa.istft(spec_right, hop_length=hop_length)
-
- if reverse:
- return np.asfortranarray([np.flip(wave_left), np.flip(wave_right)])
- elif mid_side:
- return np.asfortranarray(
- [np.add(wave_left, wave_right / 2), np.subtract(wave_left, wave_right / 2)]
- )
- elif mid_side_b2:
- return np.asfortranarray(
- [
- np.add(wave_right / 1.25, 0.4 * wave_left),
- np.subtract(wave_left / 1.25, 0.4 * wave_right),
- ]
- )
- else:
- return np.asfortranarray([wave_left, wave_right])
-
-
-def spectrogram_to_wave_mt(spec, hop_length, mid_side, reverse, mid_side_b2):
- import threading
-
- spec_left = np.asfortranarray(spec[0])
- spec_right = np.asfortranarray(spec[1])
-
- def run_thread(**kwargs):
- global wave_left
- wave_left = librosa.istft(**kwargs)
-
- thread = threading.Thread(
- target=run_thread, kwargs={"stft_matrix": spec_left, "hop_length": hop_length}
- )
- thread.start()
- wave_right = librosa.istft(spec_right, hop_length=hop_length)
- thread.join()
-
- if reverse:
- return np.asfortranarray([np.flip(wave_left), np.flip(wave_right)])
- elif mid_side:
- return np.asfortranarray(
- [np.add(wave_left, wave_right / 2), np.subtract(wave_left, wave_right / 2)]
- )
- elif mid_side_b2:
- return np.asfortranarray(
- [
- np.add(wave_right / 1.25, 0.4 * wave_left),
- np.subtract(wave_left / 1.25, 0.4 * wave_right),
- ]
- )
- else:
- return np.asfortranarray([wave_left, wave_right])
-
-
-def cmb_spectrogram_to_wave(spec_m, mp, extra_bins_h=None, extra_bins=None):
- wave_band = {}
- bands_n = len(mp.param["band"])
- offset = 0
-
- for d in range(1, bands_n + 1):
- bp = mp.param["band"][d]
- spec_s = np.ndarray(
- shape=(2, bp["n_fft"] // 2 + 1, spec_m.shape[2]), dtype=complex
- )
- h = bp["crop_stop"] - bp["crop_start"]
- spec_s[:, bp["crop_start"] : bp["crop_stop"], :] = spec_m[
- :, offset : offset + h, :
- ]
-
- offset += h
- if d == bands_n: # higher
- if extra_bins_h: # if --high_end_process bypass
- max_bin = bp["n_fft"] // 2
- spec_s[:, max_bin - extra_bins_h : max_bin, :] = extra_bins[
- :, :extra_bins_h, :
- ]
- if bp["hpf_start"] > 0:
- spec_s = fft_hp_filter(spec_s, bp["hpf_start"], bp["hpf_stop"] - 1)
- if bands_n == 1:
- wave = spectrogram_to_wave(
- spec_s,
- bp["hl"],
- mp.param["mid_side"],
- mp.param["mid_side_b2"],
- mp.param["reverse"],
- )
- else:
- wave = np.add(
- wave,
- spectrogram_to_wave(
- spec_s,
- bp["hl"],
- mp.param["mid_side"],
- mp.param["mid_side_b2"],
- mp.param["reverse"],
- ),
- )
- else:
- sr = mp.param["band"][d + 1]["sr"]
- if d == 1: # lower
- spec_s = fft_lp_filter(spec_s, bp["lpf_start"], bp["lpf_stop"])
- wave = librosa.resample(
- spectrogram_to_wave(
- spec_s,
- bp["hl"],
- mp.param["mid_side"],
- mp.param["mid_side_b2"],
- mp.param["reverse"],
- ),
- bp["sr"],
- sr,
- res_type="sinc_fastest",
- )
- else: # mid
- spec_s = fft_hp_filter(spec_s, bp["hpf_start"], bp["hpf_stop"] - 1)
- spec_s = fft_lp_filter(spec_s, bp["lpf_start"], bp["lpf_stop"])
- wave2 = np.add(
- wave,
- spectrogram_to_wave(
- spec_s,
- bp["hl"],
- mp.param["mid_side"],
- mp.param["mid_side_b2"],
- mp.param["reverse"],
- ),
- )
- # wave = librosa.core.resample(wave2, bp['sr'], sr, res_type="sinc_fastest")
- wave = librosa.core.resample(wave2, bp["sr"], sr, res_type="scipy")
-
- return wave.T
-
-
-def fft_lp_filter(spec, bin_start, bin_stop):
- g = 1.0
- for b in range(bin_start, bin_stop):
- g -= 1 / (bin_stop - bin_start)
- spec[:, b, :] = g * spec[:, b, :]
-
- spec[:, bin_stop:, :] *= 0
-
- return spec
-
-
-def fft_hp_filter(spec, bin_start, bin_stop):
- g = 1.0
- for b in range(bin_start, bin_stop, -1):
- g -= 1 / (bin_start - bin_stop)
- spec[:, b, :] = g * spec[:, b, :]
-
- spec[:, 0 : bin_stop + 1, :] *= 0
-
- return spec
-
-
-def mirroring(a, spec_m, input_high_end, mp):
- if "mirroring" == a:
- mirror = np.flip(
- np.abs(
- spec_m[
- :,
- mp.param["pre_filter_start"]
- - 10
- - input_high_end.shape[1] : mp.param["pre_filter_start"]
- - 10,
- :,
- ]
- ),
- 1,
- )
- mirror = mirror * np.exp(1.0j * np.angle(input_high_end))
-
- return np.where(
- np.abs(input_high_end) <= np.abs(mirror), input_high_end, mirror
- )
-
- if "mirroring2" == a:
- mirror = np.flip(
- np.abs(
- spec_m[
- :,
- mp.param["pre_filter_start"]
- - 10
- - input_high_end.shape[1] : mp.param["pre_filter_start"]
- - 10,
- :,
- ]
- ),
- 1,
- )
- mi = np.multiply(mirror, input_high_end * 1.7)
-
- return np.where(np.abs(input_high_end) <= np.abs(mi), input_high_end, mi)
-
-
-def ensembling(a, specs):
- for i in range(1, len(specs)):
- if i == 1:
- spec = specs[0]
-
- ln = min([spec.shape[2], specs[i].shape[2]])
- spec = spec[:, :, :ln]
- specs[i] = specs[i][:, :, :ln]
-
- if "min_mag" == a:
- spec = np.where(np.abs(specs[i]) <= np.abs(spec), specs[i], spec)
- if "max_mag" == a:
- spec = np.where(np.abs(specs[i]) >= np.abs(spec), specs[i], spec)
-
- return spec
-
-
-def stft(wave, nfft, hl):
- wave_left = np.asfortranarray(wave[0])
- wave_right = np.asfortranarray(wave[1])
- spec_left = librosa.stft(wave_left, nfft, hop_length=hl)
- spec_right = librosa.stft(wave_right, nfft, hop_length=hl)
- spec = np.asfortranarray([spec_left, spec_right])
-
- return spec
-
-
-def istft(spec, hl):
- spec_left = np.asfortranarray(spec[0])
- spec_right = np.asfortranarray(spec[1])
-
- wave_left = librosa.istft(spec_left, hop_length=hl)
- wave_right = librosa.istft(spec_right, hop_length=hl)
- wave = np.asfortranarray([wave_left, wave_right])
-
-
-if __name__ == "__main__":
- import cv2
- import time
- import argparse
- from model_param_init import ModelParameters
-
- p = argparse.ArgumentParser()
- p.add_argument(
- "--algorithm",
- "-a",
- type=str,
- choices=["invert", "invert_p", "min_mag", "max_mag", "deep", "align"],
- default="min_mag",
- )
- p.add_argument(
- "--model_params",
- "-m",
- type=str,
- default=os.path.join("modelparams", "1band_sr44100_hl512.json"),
- )
- p.add_argument("--output_name", "-o", type=str, default="output")
- p.add_argument("--vocals_only", "-v", action="store_true")
- p.add_argument("input", nargs="+")
- args = p.parse_args()
-
- start_time = time.time()
-
- if args.algorithm.startswith("invert") and len(args.input) != 2:
- raise ValueError("There should be two input files.")
-
- if not args.algorithm.startswith("invert") and len(args.input) < 2:
- raise ValueError("There must be at least two input files.")
-
- wave, specs = {}, {}
- mp = ModelParameters(args.model_params)
-
- for i in range(len(args.input)):
- spec = {}
-
- for d in range(len(mp.param["band"]), 0, -1):
- bp = mp.param["band"][d]
-
- if d == len(mp.param["band"]): # high-end band
- wave[d], _ = librosa.load(
- args.input[i],
- bp["sr"],
- False,
- dtype=np.float32,
- res_type=bp["res_type"],
- )
-
- if len(wave[d].shape) == 1: # mono to stereo
- wave[d] = np.array([wave[d], wave[d]])
- else: # lower bands
- wave[d] = librosa.resample(
- wave[d + 1],
- mp.param["band"][d + 1]["sr"],
- bp["sr"],
- res_type=bp["res_type"],
- )
-
- spec[d] = wave_to_spectrogram(
- wave[d],
- bp["hl"],
- bp["n_fft"],
- mp.param["mid_side"],
- mp.param["mid_side_b2"],
- mp.param["reverse"],
- )
-
- specs[i] = combine_spectrograms(spec, mp)
-
- del wave
-
- if args.algorithm == "deep":
- d_spec = np.where(np.abs(specs[0]) <= np.abs(spec[1]), specs[0], spec[1])
- v_spec = d_spec - specs[1]
- sf.write(
- os.path.join("{}.wav".format(args.output_name)),
- cmb_spectrogram_to_wave(v_spec, mp),
- mp.param["sr"],
- )
-
- if args.algorithm.startswith("invert"):
- ln = min([specs[0].shape[2], specs[1].shape[2]])
- specs[0] = specs[0][:, :, :ln]
- specs[1] = specs[1][:, :, :ln]
-
- if "invert_p" == args.algorithm:
- X_mag = np.abs(specs[0])
- y_mag = np.abs(specs[1])
- max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
- v_spec = specs[1] - max_mag * np.exp(1.0j * np.angle(specs[0]))
- else:
- specs[1] = reduce_vocal_aggressively(specs[0], specs[1], 0.2)
- v_spec = specs[0] - specs[1]
-
- if not args.vocals_only:
- X_mag = np.abs(specs[0])
- y_mag = np.abs(specs[1])
- v_mag = np.abs(v_spec)
-
- X_image = spectrogram_to_image(X_mag)
- y_image = spectrogram_to_image(y_mag)
- v_image = spectrogram_to_image(v_mag)
-
- cv2.imwrite("{}_X.png".format(args.output_name), X_image)
- cv2.imwrite("{}_y.png".format(args.output_name), y_image)
- cv2.imwrite("{}_v.png".format(args.output_name), v_image)
-
- sf.write(
- "{}_X.wav".format(args.output_name),
- cmb_spectrogram_to_wave(specs[0], mp),
- mp.param["sr"],
- )
- sf.write(
- "{}_y.wav".format(args.output_name),
- cmb_spectrogram_to_wave(specs[1], mp),
- mp.param["sr"],
- )
-
- sf.write(
- "{}_v.wav".format(args.output_name),
- cmb_spectrogram_to_wave(v_spec, mp),
- mp.param["sr"],
- )
- else:
- if not args.algorithm == "deep":
- sf.write(
- os.path.join("ensembled", "{}.wav".format(args.output_name)),
- cmb_spectrogram_to_wave(ensembling(args.algorithm, specs), mp),
- mp.param["sr"],
- )
-
- if args.algorithm == "align":
- trackalignment = [
- {
- "file1": '"{}"'.format(args.input[0]),
- "file2": '"{}"'.format(args.input[1]),
- }
- ]
-
- for i, e in tqdm(enumerate(trackalignment), desc="Performing Alignment..."):
- os.system(f"python lib/align_tracks.py {e['file1']} {e['file2']}")
-
- # print('Total time: {0:.{1}f}s'.format(time.time() - start_time, 1))
diff --git a/spaces/LightChen2333/OpenSLU/common/config.py b/spaces/LightChen2333/OpenSLU/common/config.py
deleted file mode 100644
index 9563ea6ffa6a75095e61a872db5b4fcd6f2e9d65..0000000000000000000000000000000000000000
--- a/spaces/LightChen2333/OpenSLU/common/config.py
+++ /dev/null
@@ -1,192 +0,0 @@
-'''
-Author: Qiguang Chen
-Date: 2023-01-11 10:39:26
-LastEditors: Qiguang Chen
-LastEditTime: 2023-02-15 17:58:53
-Description: Configuration class to manage all process in OpenSLU like model construction, learning processing and so on.
-
-'''
-import re
-
-from ruamel import yaml
-import datetime
-
-class Config(dict):
- def __init__(self, *args, **kwargs):
- """ init with dict as args
- """
- dict.__init__(self, *args, **kwargs)
- self.__dict__ = self
- self.start_time = datetime.datetime.now().strftime('%Y%m%d%H%M%S%f')
- if not self.model.get("_from_pretrained_"):
- self.__autowired()
-
- @staticmethod
- def load_from_yaml(file_path:str)->"Config":
- """load config files with path
-
- Args:
- file_path (str): yaml configuration file path.
-
- Returns:
- Config: config object.
- """
- with open(file_path) as stream:
- try:
- return Config(yaml.safe_load(stream))
- except yaml.YAMLError as exc:
- print(exc)
-
- @staticmethod
- def load_from_args(args)->"Config":
- """ load args to replace item value in config files assigned with '--config_path' or '--model'
-
- Args:
- args (Any): args with command line.
-
- Returns:
- Config: _description_
- """
- if args.model is not None and args.dataset is not None:
- args.config_path = f"config/reproduction/{args.dataset}/{args.model}.yaml"
- config = Config.load_from_yaml(args.config_path)
- if args.dataset is not None:
- config.__update_dataset(args.dataset)
- if args.device is not None:
- config["base"]["device"] = args.device
- if args.learning_rate is not None:
- config["optimizer"]["lr"] = args.learning_rate
- if args.epoch_num is not None:
- config["base"]["epoch_num"] = args.epoch_num
- return config
-
- def autoload_template(self):
- """ search '{*}' template to excute as python code, support replace variable as any configure item
- """
- self.__autoload_template(self.__dict__)
-
- def __get_autoload_value(self, matched):
- keys = matched.group()[1:-1].split(".")
- temp = self.__dict__
- for k in keys:
- temp = temp[k]
- return str(temp)
-
- def __autoload_template(self, config:dict):
- for k in config:
- if isinstance(config, dict):
- sub_config = config[k]
- elif isinstance(config, list):
- sub_config = k
- else:
- continue
- if isinstance(sub_config, dict) or isinstance(sub_config, list):
- self.__autoload_template(sub_config)
- if isinstance(sub_config, str) and "{" in sub_config and "}" in sub_config:
- res = re.sub(r'{.*?}', self.__get_autoload_value, config[k])
- res_dict= {"res": None}
- exec("res=" + res, res_dict)
- config[k] = res_dict["res"]
-
- def __update_dataset(self, dataset_name):
- if dataset_name is not None and isinstance(dataset_name, str):
- self.__dict__["dataset"]["dataset_name"] = dataset_name
-
- def get_model_config(self):
- return self.__dict__["model"]
-
- def __autowired(self):
- # Set encoder
- encoder_config = self.__dict__["model"]["encoder"]
- encoder_type = encoder_config["_model_target_"].split(".")[-1]
-
- def get_output_dim(encoder_config):
- encoder_type = encoder_config["_model_target_"].split(".")[-1]
- if (encoder_type == "AutoEncoder" and encoder_config["encoder_name"] in ["lstm", "self-attention-lstm",
- "bi-encoder"]) or encoder_type == "NoPretrainedEncoder":
- output_dim = 0
- if encoder_config.get("lstm"):
- output_dim += encoder_config["lstm"]["output_dim"]
- if encoder_config.get("attention"):
- output_dim += encoder_config["attention"]["output_dim"]
- return output_dim
- else:
- return encoder_config["output_dim"]
-
- if encoder_type == "BiEncoder":
- output_dim = get_output_dim(encoder_config["intent_encoder"]) + \
- get_output_dim(encoder_config["slot_encoder"])
- else:
- output_dim = get_output_dim(encoder_config)
- self.__dict__["model"]["encoder"]["output_dim"] = output_dim
-
- # Set interaction
- if "interaction" in self.__dict__["model"]["decoder"] and self.__dict__["model"]["decoder"]["interaction"].get(
- "input_dim") is None:
- self.__dict__["model"]["decoder"]["interaction"]["input_dim"] = output_dim
- interaction_type = self.__dict__["model"]["decoder"]["interaction"]["_model_target_"].split(".")[-1]
- if not ((encoder_type == "AutoEncoder" and encoder_config[
- "encoder_name"] == "self-attention-lstm") or encoder_type == "SelfAttentionLSTMEncoder") and interaction_type != "BiModelWithoutDecoderInteraction":
- output_dim = self.__dict__["model"]["decoder"]["interaction"]["output_dim"]
-
- # Set classifier
- if "slot_classifier" in self.__dict__["model"]["decoder"]:
- if self.__dict__["model"]["decoder"]["slot_classifier"].get("input_dim") is None:
- self.__dict__["model"]["decoder"]["slot_classifier"]["input_dim"] = output_dim
- self.__dict__["model"]["decoder"]["slot_classifier"]["use_slot"] = True
- if "intent_classifier" in self.__dict__["model"]["decoder"]:
- if self.__dict__["model"]["decoder"]["intent_classifier"].get("input_dim") is None:
- self.__dict__["model"]["decoder"]["intent_classifier"]["input_dim"] = output_dim
- self.__dict__["model"]["decoder"]["intent_classifier"]["use_intent"] = True
-
- def get_intent_label_num(self):
- """ get the number of intent labels.
- """
- classifier_conf = self.__dict__["model"]["decoder"]["intent_classifier"]
- return classifier_conf["intent_label_num"] if "intent_label_num" in classifier_conf else 0
-
- def get_slot_label_num(self):
- """ get the number of slot labels.
- """
- classifier_conf = self.__dict__["model"]["decoder"]["slot_classifier"]
- return classifier_conf["slot_label_num"] if "slot_label_num" in classifier_conf else 0
-
- def set_intent_label_num(self, intent_label_num):
- """ set the number of intent labels.
-
- Args:
- slot_label_num (int): the number of intent label
- """
- self.__dict__["base"]["intent_label_num"] = intent_label_num
- self.__dict__["model"]["decoder"]["intent_classifier"]["intent_label_num"] = intent_label_num
- if "interaction" in self.__dict__["model"]["decoder"]:
-
- self.__dict__["model"]["decoder"]["interaction"]["intent_label_num"] = intent_label_num
- if self.__dict__["model"]["decoder"]["interaction"]["_model_target_"].split(".")[
- -1] == "StackInteraction":
- self.__dict__["model"]["decoder"]["slot_classifier"]["input_dim"] += intent_label_num
-
-
- def set_slot_label_num(self, slot_label_num:int)->None:
- """set the number of slot label
-
- Args:
- slot_label_num (int): the number of slot label
- """
- self.__dict__["base"]["slot_label_num"] = slot_label_num
- self.__dict__["model"]["decoder"]["slot_classifier"]["slot_label_num"] = slot_label_num
- if "interaction" in self.__dict__["model"]["decoder"]:
- self.__dict__["model"]["decoder"]["interaction"]["slot_label_num"] = slot_label_num
-
- def set_vocab_size(self, vocab_size):
- """set the size of vocabulary in non-pretrained tokenizer
- Args:
- slot_label_num (int): the number of slot label
- """
- encoder_type = self.__dict__["model"]["encoder"]["_model_target_"].split(".")[-1]
- encoder_name = self.__dict__["model"]["encoder"].get("encoder_name")
- if encoder_type == "BiEncoder" or (encoder_type == "AutoEncoder" and encoder_name == "bi-encoder"):
- self.__dict__["model"]["encoder"]["intent_encoder"]["embedding"]["vocab_size"] = vocab_size
- self.__dict__["model"]["encoder"]["slot_encoder"]["embedding"]["vocab_size"] = vocab_size
- elif self.__dict__["model"]["encoder"].get("embedding"):
- self.__dict__["model"]["encoder"]["embedding"]["vocab_size"] = vocab_size
diff --git a/spaces/LittleYuan/My-Real-Bot/inference_realesrgan.py b/spaces/LittleYuan/My-Real-Bot/inference_realesrgan.py
deleted file mode 100644
index 6d5ff4d188faaa16c0131be69a08fd22fb608f80..0000000000000000000000000000000000000000
--- a/spaces/LittleYuan/My-Real-Bot/inference_realesrgan.py
+++ /dev/null
@@ -1,128 +0,0 @@
-import argparse
-import cv2
-import glob
-import os
-from basicsr.archs.rrdbnet_arch import RRDBNet
-
-from realesrgan import RealESRGANer
-from realesrgan.archs.srvgg_arch import SRVGGNetCompact
-
-
-def main():
- """Inference demo for Real-ESRGAN.
- """
- parser = argparse.ArgumentParser()
- parser.add_argument('-i', '--input', type=str, default='inputs', help='Input image or folder')
- parser.add_argument(
- '-n',
- '--model_name',
- type=str,
- default='RealESRGAN_x4plus',
- help=('Model names: RealESRGAN_x4plus | RealESRNet_x4plus | RealESRGAN_x4plus_anime_6B | RealESRGAN_x2plus'
- 'RealESRGANv2-anime-xsx2 | RealESRGANv2-animevideo-xsx2-nousm | RealESRGANv2-animevideo-xsx2'
- 'RealESRGANv2-anime-xsx4 | RealESRGANv2-animevideo-xsx4-nousm | RealESRGANv2-animevideo-xsx4'))
- parser.add_argument('-o', '--output', type=str, default='results', help='Output folder')
- parser.add_argument('-s', '--outscale', type=float, default=4, help='The final upsampling scale of the image')
- parser.add_argument('--suffix', type=str, default='out', help='Suffix of the restored image')
- parser.add_argument('-t', '--tile', type=int, default=0, help='Tile size, 0 for no tile during testing')
- parser.add_argument('--tile_pad', type=int, default=10, help='Tile padding')
- parser.add_argument('--pre_pad', type=int, default=0, help='Pre padding size at each border')
- parser.add_argument('--face_enhance', action='store_true', help='Use GFPGAN to enhance face')
- parser.add_argument('--half', action='store_true', help='Use half precision during inference')
- parser.add_argument(
- '--alpha_upsampler',
- type=str,
- default='realesrgan',
- help='The upsampler for the alpha channels. Options: realesrgan | bicubic')
- parser.add_argument(
- '--ext',
- type=str,
- default='auto',
- help='Image extension. Options: auto | jpg | png, auto means using the same extension as inputs')
- args = parser.parse_args()
-
- # determine models according to model names
- args.model_name = args.model_name.split('.')[0]
- if args.model_name in ['RealESRGAN_x4plus', 'RealESRNet_x4plus']: # x4 RRDBNet model
- model = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=23, num_grow_ch=32, scale=4)
- netscale = 4
- elif args.model_name in ['RealESRGAN_x4plus_anime_6B']: # x4 RRDBNet model with 6 blocks
- model = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=6, num_grow_ch=32, scale=4)
- netscale = 4
- elif args.model_name in ['RealESRGAN_x2plus']: # x2 RRDBNet model
- model = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=23, num_grow_ch=32, scale=2)
- netscale = 2
- elif args.model_name in [
- 'RealESRGANv2-anime-xsx2', 'RealESRGANv2-animevideo-xsx2-nousm', 'RealESRGANv2-animevideo-xsx2'
- ]: # x2 VGG-style model (XS size)
- model = SRVGGNetCompact(num_in_ch=3, num_out_ch=3, num_feat=64, num_conv=16, upscale=2, act_type='prelu')
- netscale = 2
- elif args.model_name in [
- 'RealESRGANv2-anime-xsx4', 'RealESRGANv2-animevideo-xsx4-nousm', 'RealESRGANv2-animevideo-xsx4'
- ]: # x4 VGG-style model (XS size)
- model = SRVGGNetCompact(num_in_ch=3, num_out_ch=3, num_feat=64, num_conv=16, upscale=4, act_type='prelu')
- netscale = 4
-
- # determine model paths
- model_path = os.path.join('.', args.model_name + '.pth')
- if not os.path.isfile(model_path):
- model_path = os.path.join('.', args.model_name + '.pth')
- if not os.path.isfile(model_path):
- raise ValueError(f'Model {args.model_name} does not exist.')
-
- # restorer
- upsampler = RealESRGANer(
- scale=netscale,
- model_path=model_path,
- model=model,
- tile=args.tile,
- tile_pad=args.tile_pad,
- pre_pad=args.pre_pad,
- half=args.half)
-
- if args.face_enhance: # Use GFPGAN for face enhancement
- from gfpgan import GFPGANer
- face_enhancer = GFPGANer(
- model_path='https://github.com/TencentARC/GFPGAN/releases/download/v0.2.0/GFPGANCleanv1-NoCE-C2.pth',
- upscale=args.outscale,
- arch='clean',
- channel_multiplier=2,
- bg_upsampler=upsampler)
- os.makedirs(args.output, exist_ok=True)
-
- if os.path.isfile(args.input):
- paths = [args.input]
- else:
- paths = sorted(glob.glob(os.path.join(args.input, '*')))
-
- for idx, path in enumerate(paths):
- imgname, extension = os.path.splitext(os.path.basename(path))
- print('Testing', idx, imgname)
-
- img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
- if len(img.shape) == 3 and img.shape[2] == 4:
- img_mode = 'RGBA'
- else:
- img_mode = None
-
- try:
- if args.face_enhance:
- _, _, output = face_enhancer.enhance(img, has_aligned=False, only_center_face=False, paste_back=True)
- else:
- output, _ = upsampler.enhance(img, outscale=args.outscale)
- except RuntimeError as error:
- print('Error', error)
- print('If you encounter CUDA out of memory, try to set --tile with a smaller number.')
- else:
- if args.ext == 'auto':
- extension = extension[1:]
- else:
- extension = args.ext
- if img_mode == 'RGBA': # RGBA images should be saved in png format
- extension = 'png'
- save_path = os.path.join(args.output, f'{imgname}_{args.suffix}.{extension}')
- cv2.imwrite(save_path, output)
-
-
-if __name__ == '__main__':
- main()
diff --git "a/spaces/Liu-LAB/GPT-academic/crazy_functions/\344\270\213\350\275\275arxiv\350\256\272\346\226\207\347\277\273\350\257\221\346\221\230\350\246\201.py" "b/spaces/Liu-LAB/GPT-academic/crazy_functions/\344\270\213\350\275\275arxiv\350\256\272\346\226\207\347\277\273\350\257\221\346\221\230\350\246\201.py"
deleted file mode 100644
index 46275bf4fed59ca5692581ac9b354c4d4ad91d7c..0000000000000000000000000000000000000000
--- "a/spaces/Liu-LAB/GPT-academic/crazy_functions/\344\270\213\350\275\275arxiv\350\256\272\346\226\207\347\277\273\350\257\221\346\221\230\350\246\201.py"
+++ /dev/null
@@ -1,194 +0,0 @@
-from toolbox import update_ui
-from toolbox import CatchException, report_execption, write_results_to_file, get_conf
-import re, requests, unicodedata, os
-from .crazy_utils import request_gpt_model_in_new_thread_with_ui_alive
-def download_arxiv_(url_pdf):
- if 'arxiv.org' not in url_pdf:
- if ('.' in url_pdf) and ('/' not in url_pdf):
- new_url = 'https://arxiv.org/abs/'+url_pdf
- print('下载编号:', url_pdf, '自动定位:', new_url)
- # download_arxiv_(new_url)
- return download_arxiv_(new_url)
- else:
- print('不能识别的URL!')
- return None
- if 'abs' in url_pdf:
- url_pdf = url_pdf.replace('abs', 'pdf')
- url_pdf = url_pdf + '.pdf'
-
- url_abs = url_pdf.replace('.pdf', '').replace('pdf', 'abs')
- title, other_info = get_name(_url_=url_abs)
-
- paper_id = title.split()[0] # '[1712.00559]'
- if '2' in other_info['year']:
- title = other_info['year'] + ' ' + title
-
- known_conf = ['NeurIPS', 'NIPS', 'Nature', 'Science', 'ICLR', 'AAAI']
- for k in known_conf:
- if k in other_info['comment']:
- title = k + ' ' + title
-
- download_dir = './gpt_log/arxiv/'
- os.makedirs(download_dir, exist_ok=True)
-
- title_str = title.replace('?', '?')\
- .replace(':', ':')\
- .replace('\"', '“')\
- .replace('\n', '')\
- .replace(' ', ' ')\
- .replace(' ', ' ')
-
- requests_pdf_url = url_pdf
- file_path = download_dir+title_str
- # if os.path.exists(file_path):
- # print('返回缓存文件')
- # return './gpt_log/arxiv/'+title_str
-
- print('下载中')
- proxies, = get_conf('proxies')
- r = requests.get(requests_pdf_url, proxies=proxies)
- with open(file_path, 'wb+') as f:
- f.write(r.content)
- print('下载完成')
-
- # print('输出下载命令:','aria2c -o \"%s\" %s'%(title_str,url_pdf))
- # subprocess.call('aria2c --all-proxy=\"172.18.116.150:11084\" -o \"%s\" %s'%(download_dir+title_str,url_pdf), shell=True)
-
- x = "%s %s %s.bib" % (paper_id, other_info['year'], other_info['authors'])
- x = x.replace('?', '?')\
- .replace(':', ':')\
- .replace('\"', '“')\
- .replace('\n', '')\
- .replace(' ', ' ')\
- .replace(' ', ' ')
- return './gpt_log/arxiv/'+title_str, other_info
-
-
-def get_name(_url_):
- import os
- from bs4 import BeautifulSoup
- print('正在获取文献名!')
- print(_url_)
-
- # arxiv_recall = {}
- # if os.path.exists('./arxiv_recall.pkl'):
- # with open('./arxiv_recall.pkl', 'rb') as f:
- # arxiv_recall = pickle.load(f)
-
- # if _url_ in arxiv_recall:
- # print('在缓存中')
- # return arxiv_recall[_url_]
-
- proxies, = get_conf('proxies')
- res = requests.get(_url_, proxies=proxies)
-
- bs = BeautifulSoup(res.text, 'html.parser')
- other_details = {}
-
- # get year
- try:
- year = bs.find_all(class_='dateline')[0].text
- year = re.search(r'(\d{4})', year, re.M | re.I).group(1)
- other_details['year'] = year
- abstract = bs.find_all(class_='abstract mathjax')[0].text
- other_details['abstract'] = abstract
- except:
- other_details['year'] = ''
- print('年份获取失败')
-
- # get author
- try:
- authors = bs.find_all(class_='authors')[0].text
- authors = authors.split('Authors:')[1]
- other_details['authors'] = authors
- except:
- other_details['authors'] = ''
- print('authors获取失败')
-
- # get comment
- try:
- comment = bs.find_all(class_='metatable')[0].text
- real_comment = None
- for item in comment.replace('\n', ' ').split(' '):
- if 'Comments' in item:
- real_comment = item
- if real_comment is not None:
- other_details['comment'] = real_comment
- else:
- other_details['comment'] = ''
- except:
- other_details['comment'] = ''
- print('年份获取失败')
-
- title_str = BeautifulSoup(
- res.text, 'html.parser').find('title').contents[0]
- print('获取成功:', title_str)
- # arxiv_recall[_url_] = (title_str+'.pdf', other_details)
- # with open('./arxiv_recall.pkl', 'wb') as f:
- # pickle.dump(arxiv_recall, f)
-
- return title_str+'.pdf', other_details
-
-
-
-@CatchException
-def 下载arxiv论文并翻译摘要(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
-
- CRAZY_FUNCTION_INFO = "下载arxiv论文并翻译摘要,函数插件作者[binary-husky]。正在提取摘要并下载PDF文档……"
- import glob
- import os
-
- # 基本信息:功能、贡献者
- chatbot.append(["函数插件功能?", CRAZY_FUNCTION_INFO])
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
-
- # 尝试导入依赖,如果缺少依赖,则给出安装建议
- try:
- import bs4
- except:
- report_execption(chatbot, history,
- a = f"解析项目: {txt}",
- b = f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade beautifulsoup4```。")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
-
- # 清空历史,以免输入溢出
- history = []
-
- # 提取摘要,下载PDF文档
- try:
- pdf_path, info = download_arxiv_(txt)
- except:
- report_execption(chatbot, history,
- a = f"解析项目: {txt}",
- b = f"下载pdf文件未成功")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
-
- # 翻译摘要等
- i_say = f"请你阅读以下学术论文相关的材料,提取摘要,翻译为中文。材料如下:{str(info)}"
- i_say_show_user = f'请你阅读以下学术论文相关的材料,提取摘要,翻译为中文。论文:{pdf_path}'
- chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- msg = '正常'
- # ** gpt request **
- # 单线,获取文章meta信息
- gpt_say = yield from request_gpt_model_in_new_thread_with_ui_alive(
- inputs=i_say,
- inputs_show_user=i_say_show_user,
- llm_kwargs=llm_kwargs,
- chatbot=chatbot, history=[],
- sys_prompt="Your job is to collect information from materials and translate to Chinese。",
- )
-
- chatbot[-1] = (i_say_show_user, gpt_say)
- history.append(i_say_show_user); history.append(gpt_say)
- yield from update_ui(chatbot=chatbot, history=history, msg=msg) # 刷新界面
- # 写入文件
- import shutil
- # 重置文件的创建时间
- shutil.copyfile(pdf_path, f'./gpt_log/{os.path.basename(pdf_path)}'); os.remove(pdf_path)
- res = write_results_to_file(history)
- chatbot.append(("完成了吗?", res + "\n\nPDF文件也已经下载"))
- yield from update_ui(chatbot=chatbot, history=history, msg=msg) # 刷新界面
-
diff --git a/spaces/LucasCodeBreak/MusicGen/audiocraft/models/loaders.py b/spaces/LucasCodeBreak/MusicGen/audiocraft/models/loaders.py
deleted file mode 100644
index 97c662c3212b7695669cbfc5214ff2f099c3f319..0000000000000000000000000000000000000000
--- a/spaces/LucasCodeBreak/MusicGen/audiocraft/models/loaders.py
+++ /dev/null
@@ -1,94 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-"""
-Utility functions to load from the checkpoints.
-Each checkpoint is a torch.saved dict with the following keys:
-- 'xp.cfg': the hydra config as dumped during training. This should be used
- to rebuild the object using the audiocraft.models.builders functions,
-- 'model_best_state': a readily loadable best state for the model, including
- the conditioner. The model obtained from `xp.cfg` should be compatible
- with this state dict. In the case of a LM, the encodec model would not be
- bundled along but instead provided separately.
-
-Those functions also support loading from a remote location with the Torch Hub API.
-They also support overriding some parameters, in particular the device and dtype
-of the returned model.
-"""
-
-from pathlib import Path
-from huggingface_hub import hf_hub_download
-import typing as tp
-import os
-
-from omegaconf import OmegaConf
-import torch
-
-from . import builders
-
-
-HF_MODEL_CHECKPOINTS_MAP = {
- "small": "facebook/musicgen-small",
- "medium": "facebook/musicgen-medium",
- "large": "facebook/musicgen-large",
- "melody": "facebook/musicgen-melody",
-}
-
-
-def _get_state_dict(
- file_or_url_or_id: tp.Union[Path, str],
- filename: tp.Optional[str] = None,
- device='cpu',
- cache_dir: tp.Optional[str] = None,
-):
- # Return the state dict either from a file or url
- file_or_url_or_id = str(file_or_url_or_id)
- assert isinstance(file_or_url_or_id, str)
-
- if os.path.isfile(file_or_url_or_id):
- return torch.load(file_or_url_or_id, map_location=device)
-
- if os.path.isdir(file_or_url_or_id):
- file = f"{file_or_url_or_id}/{filename}"
- return torch.load(file, map_location=device)
-
- elif file_or_url_or_id.startswith('https://'):
- return torch.hub.load_state_dict_from_url(file_or_url_or_id, map_location=device, check_hash=True)
-
- elif file_or_url_or_id in HF_MODEL_CHECKPOINTS_MAP:
- assert filename is not None, "filename needs to be defined if using HF checkpoints"
-
- repo_id = HF_MODEL_CHECKPOINTS_MAP[file_or_url_or_id]
- file = hf_hub_download(repo_id=repo_id, filename=filename, cache_dir=cache_dir)
- return torch.load(file, map_location=device)
-
- else:
- raise ValueError(f"{file_or_url_or_id} is not a valid name, path or link that can be loaded.")
-
-
-def load_compression_model(file_or_url_or_id: tp.Union[Path, str], device='cpu', cache_dir: tp.Optional[str] = None):
- pkg = _get_state_dict(file_or_url_or_id, filename="compression_state_dict.bin", cache_dir=cache_dir)
- cfg = OmegaConf.create(pkg['xp.cfg'])
- cfg.device = str(device)
- model = builders.get_compression_model(cfg)
- model.load_state_dict(pkg['best_state'])
- model.eval()
- return model
-
-
-def load_lm_model(file_or_url_or_id: tp.Union[Path, str], device='cpu', cache_dir: tp.Optional[str] = None):
- pkg = _get_state_dict(file_or_url_or_id, filename="state_dict.bin", cache_dir=cache_dir)
- cfg = OmegaConf.create(pkg['xp.cfg'])
- cfg.device = str(device)
- if cfg.device == 'cpu':
- cfg.dtype = 'float32'
- else:
- cfg.dtype = 'float16'
- model = builders.get_lm_model(cfg)
- model.load_state_dict(pkg['best_state'])
- model.eval()
- model.cfg = cfg
- return model
diff --git a/spaces/LuciaCw/greet/README.md b/spaces/LuciaCw/greet/README.md
deleted file mode 100644
index aa8d62777bab00ebfbc805324a2bb394c7c87577..0000000000000000000000000000000000000000
--- a/spaces/LuciaCw/greet/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Greet
-emoji: 🐨
-colorFrom: pink
-colorTo: pink
-sdk: gradio
-sdk_version: 3.0.4
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/Mahiruoshi/Lovelive-Nijigasaku-Chat-iSTFT-GPT3/modules.py b/spaces/Mahiruoshi/Lovelive-Nijigasaku-Chat-iSTFT-GPT3/modules.py
deleted file mode 100644
index 9c7fd9cd6eb8b7e0ec0e08957e970744a374a924..0000000000000000000000000000000000000000
--- a/spaces/Mahiruoshi/Lovelive-Nijigasaku-Chat-iSTFT-GPT3/modules.py
+++ /dev/null
@@ -1,390 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/Mandy234/Mandy234-myQAmodel/app.py b/spaces/Mandy234/Mandy234-myQAmodel/app.py
deleted file mode 100644
index 2d51dba780869cd5f2c03bd7788aa6c766e28460..0000000000000000000000000000000000000000
--- a/spaces/Mandy234/Mandy234-myQAmodel/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/Mandy234/myQAmodel").launch()
\ No newline at end of file
diff --git a/spaces/Manmay/tortoise-tts/tortoise/models/cvvp.py b/spaces/Manmay/tortoise-tts/tortoise/models/cvvp.py
deleted file mode 100644
index 544ca47b21a31c8d26d4ea407b9783e7d59e8126..0000000000000000000000000000000000000000
--- a/spaces/Manmay/tortoise-tts/tortoise/models/cvvp.py
+++ /dev/null
@@ -1,142 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import einsum
-
-from tortoise.models.arch_util import AttentionBlock
-from tortoise.models.xtransformers import ContinuousTransformerWrapper, Encoder
-
-
-def exists(val):
- return val is not None
-
-
-def masked_mean(t, mask):
- t = t.masked_fill(~mask, 0.)
- return t.sum(dim=1) / mask.sum(dim=1)
-
-
-class CollapsingTransformer(nn.Module):
- def __init__(self, model_dim, output_dims, heads, dropout, depth, mask_percentage=0, **encoder_kwargs):
- super().__init__()
- self.transformer = ContinuousTransformerWrapper(
- max_seq_len=-1,
- use_pos_emb=False,
- attn_layers=Encoder(
- dim=model_dim,
- depth=depth,
- heads=heads,
- ff_dropout=dropout,
- ff_mult=1,
- attn_dropout=dropout,
- use_rmsnorm=True,
- ff_glu=True,
- rotary_pos_emb=True,
- **encoder_kwargs,
- ))
- self.pre_combiner = nn.Sequential(nn.Conv1d(model_dim, output_dims, 1),
- AttentionBlock(
- output_dims, num_heads=heads, do_checkpoint=False),
- nn.Conv1d(output_dims, output_dims, 1))
- self.mask_percentage = mask_percentage
-
- def forward(self, x, **transformer_kwargs):
- h = self.transformer(x, **transformer_kwargs)
- h = h.permute(0, 2, 1)
- h = self.pre_combiner(h).permute(0, 2, 1)
- if self.training:
- mask = torch.rand_like(h.float()) > self.mask_percentage
- else:
- mask = torch.ones_like(h.float()).bool()
- return masked_mean(h, mask)
-
-
-class ConvFormatEmbedding(nn.Module):
- def __init__(self, *args, **kwargs):
- super().__init__()
- self.emb = nn.Embedding(*args, **kwargs)
-
- def forward(self, x):
- y = self.emb(x)
- return y.permute(0, 2, 1)
-
-
-class CVVP(nn.Module):
- def __init__(
- self,
- model_dim=512,
- transformer_heads=8,
- dropout=.1,
- conditioning_enc_depth=8,
- cond_mask_percentage=0,
- mel_channels=80,
- mel_codes=None,
- speech_enc_depth=8,
- speech_mask_percentage=0,
- latent_multiplier=1,
- ):
- super().__init__()
- latent_dim = latent_multiplier*model_dim
- self.temperature = nn.Parameter(torch.tensor(1.))
-
- self.cond_emb = nn.Sequential(nn.Conv1d(mel_channels, model_dim//2, kernel_size=5, stride=2, padding=2),
- nn.Conv1d(model_dim//2, model_dim, kernel_size=3, stride=2, padding=1))
- self.conditioning_transformer = CollapsingTransformer(
- model_dim, model_dim, transformer_heads, dropout, conditioning_enc_depth, cond_mask_percentage)
- self.to_conditioning_latent = nn.Linear(
- latent_dim, latent_dim, bias=False)
-
- if mel_codes is None:
- self.speech_emb = nn.Conv1d(
- mel_channels, model_dim, kernel_size=5, padding=2)
- else:
- self.speech_emb = ConvFormatEmbedding(mel_codes, model_dim)
- self.speech_transformer = CollapsingTransformer(
- model_dim, latent_dim, transformer_heads, dropout, speech_enc_depth, speech_mask_percentage)
- self.to_speech_latent = nn.Linear(
- latent_dim, latent_dim, bias=False)
-
- def get_grad_norm_parameter_groups(self):
- return {
- 'conditioning': list(self.conditioning_transformer.parameters()),
- 'speech': list(self.speech_transformer.parameters()),
- }
-
- def forward(
- self,
- mel_cond,
- mel_input,
- return_loss=False
- ):
- cond_emb = self.cond_emb(mel_cond).permute(0, 2, 1)
- enc_cond = self.conditioning_transformer(cond_emb)
- cond_latents = self.to_conditioning_latent(enc_cond)
-
- speech_emb = self.speech_emb(mel_input).permute(0, 2, 1)
- enc_speech = self.speech_transformer(speech_emb)
- speech_latents = self.to_speech_latent(enc_speech)
-
- cond_latents, speech_latents = map(lambda t: F.normalize(
- t, p=2, dim=-1), (cond_latents, speech_latents))
- temp = self.temperature.exp()
-
- if not return_loss:
- sim = einsum('n d, n d -> n', cond_latents,
- speech_latents) * temp
- return sim
-
- sim = einsum('i d, j d -> i j', cond_latents,
- speech_latents) * temp
- labels = torch.arange(
- cond_latents.shape[0], device=mel_input.device)
- loss = (F.cross_entropy(sim, labels) +
- F.cross_entropy(sim.t(), labels)) / 2
-
- return loss
-
-
-if __name__ == '__main__':
- clvp = CVVP()
- clvp(torch.randn(2, 80, 100),
- torch.randn(2, 80, 95),
- return_loss=True)
diff --git a/spaces/MarcusSu1216/XingTong/hubert/__init__.py b/spaces/MarcusSu1216/XingTong/hubert/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/MarcusSu1216/XingTong/models.py b/spaces/MarcusSu1216/XingTong/models.py
deleted file mode 100644
index 13278d680493970f5a670cf3fc955a6e9b7ab1d5..0000000000000000000000000000000000000000
--- a/spaces/MarcusSu1216/XingTong/models.py
+++ /dev/null
@@ -1,420 +0,0 @@
-import copy
-import math
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-import modules.attentions as attentions
-import modules.commons as commons
-import modules.modules as modules
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-
-import utils
-from modules.commons import init_weights, get_padding
-from vdecoder.hifigan.models import Generator
-from utils import f0_to_coarse
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True))
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
-
-class Encoder(nn.Module):
- def __init__(self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels)
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- # print(x.shape,x_lengths.shape)
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
-
-class TextEncoder(nn.Module):
- def __init__(self,
- out_channels,
- hidden_channels,
- kernel_size,
- n_layers,
- gin_channels=0,
- filter_channels=None,
- n_heads=None,
- p_dropout=None):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
- self.f0_emb = nn.Embedding(256, hidden_channels)
-
- self.enc_ = attentions.Encoder(
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout)
-
- def forward(self, x, x_mask, f0=None, noice_scale=1):
- x = x + self.f0_emb(f0).transpose(1,2)
- x = self.enc_(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs) * noice_scale) * x_mask
-
- return z, m, logs, x_mask
-
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))),
- ])
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ])
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminator, self).__init__()
- periods = [2,3,5,7,11]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = []
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class SpeakerEncoder(torch.nn.Module):
- def __init__(self, mel_n_channels=80, model_num_layers=3, model_hidden_size=256, model_embedding_size=256):
- super(SpeakerEncoder, self).__init__()
- self.lstm = nn.LSTM(mel_n_channels, model_hidden_size, model_num_layers, batch_first=True)
- self.linear = nn.Linear(model_hidden_size, model_embedding_size)
- self.relu = nn.ReLU()
-
- def forward(self, mels):
- self.lstm.flatten_parameters()
- _, (hidden, _) = self.lstm(mels)
- embeds_raw = self.relu(self.linear(hidden[-1]))
- return embeds_raw / torch.norm(embeds_raw, dim=1, keepdim=True)
-
- def compute_partial_slices(self, total_frames, partial_frames, partial_hop):
- mel_slices = []
- for i in range(0, total_frames-partial_frames, partial_hop):
- mel_range = torch.arange(i, i+partial_frames)
- mel_slices.append(mel_range)
-
- return mel_slices
-
- def embed_utterance(self, mel, partial_frames=128, partial_hop=64):
- mel_len = mel.size(1)
- last_mel = mel[:,-partial_frames:]
-
- if mel_len > partial_frames:
- mel_slices = self.compute_partial_slices(mel_len, partial_frames, partial_hop)
- mels = list(mel[:,s] for s in mel_slices)
- mels.append(last_mel)
- mels = torch.stack(tuple(mels), 0).squeeze(1)
-
- with torch.no_grad():
- partial_embeds = self(mels)
- embed = torch.mean(partial_embeds, axis=0).unsqueeze(0)
- #embed = embed / torch.linalg.norm(embed, 2)
- else:
- with torch.no_grad():
- embed = self(last_mel)
-
- return embed
-
-class F0Decoder(nn.Module):
- def __init__(self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- spk_channels=0):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.spk_channels = spk_channels
-
- self.prenet = nn.Conv1d(hidden_channels, hidden_channels, 3, padding=1)
- self.decoder = attentions.FFT(
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout)
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.f0_prenet = nn.Conv1d(1, hidden_channels , 3, padding=1)
- self.cond = nn.Conv1d(spk_channels, hidden_channels, 1)
-
- def forward(self, x, norm_f0, x_mask, spk_emb=None):
- x = torch.detach(x)
- if (spk_emb is not None):
- x = x + self.cond(spk_emb)
- x += self.f0_prenet(norm_f0)
- x = self.prenet(x) * x_mask
- x = self.decoder(x * x_mask, x_mask)
- x = self.proj(x) * x_mask
- return x
-
-
-class SynthesizerTrn(nn.Module):
- """
- Synthesizer for Training
- """
-
- def __init__(self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels,
- ssl_dim,
- n_speakers,
- sampling_rate=44100,
- **kwargs):
-
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- self.ssl_dim = ssl_dim
- self.emb_g = nn.Embedding(n_speakers, gin_channels)
-
- self.pre = nn.Conv1d(ssl_dim, hidden_channels, kernel_size=5, padding=2)
-
- self.enc_p = TextEncoder(
- inter_channels,
- hidden_channels,
- filter_channels=filter_channels,
- n_heads=n_heads,
- n_layers=n_layers,
- kernel_size=kernel_size,
- p_dropout=p_dropout
- )
- hps = {
- "sampling_rate": sampling_rate,
- "inter_channels": inter_channels,
- "resblock": resblock,
- "resblock_kernel_sizes": resblock_kernel_sizes,
- "resblock_dilation_sizes": resblock_dilation_sizes,
- "upsample_rates": upsample_rates,
- "upsample_initial_channel": upsample_initial_channel,
- "upsample_kernel_sizes": upsample_kernel_sizes,
- "gin_channels": gin_channels,
- }
- self.dec = Generator(h=hps)
- self.enc_q = Encoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16, gin_channels=gin_channels)
- self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)
- self.f0_decoder = F0Decoder(
- 1,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- spk_channels=gin_channels
- )
- self.emb_uv = nn.Embedding(2, hidden_channels)
-
- def forward(self, c, f0, uv, spec, g=None, c_lengths=None, spec_lengths=None):
- g = self.emb_g(g).transpose(1,2)
- # ssl prenet
- x_mask = torch.unsqueeze(commons.sequence_mask(c_lengths, c.size(2)), 1).to(c.dtype)
- x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1,2)
-
- # f0 predict
- lf0 = 2595. * torch.log10(1. + f0.unsqueeze(1) / 700.) / 500
- norm_lf0 = utils.normalize_f0(lf0, x_mask, uv)
- pred_lf0 = self.f0_decoder(x, norm_lf0, x_mask, spk_emb=g)
-
- # encoder
- z_ptemp, m_p, logs_p, _ = self.enc_p(x, x_mask, f0=f0_to_coarse(f0))
- z, m_q, logs_q, spec_mask = self.enc_q(spec, spec_lengths, g=g)
-
- # flow
- z_p = self.flow(z, spec_mask, g=g)
- z_slice, pitch_slice, ids_slice = commons.rand_slice_segments_with_pitch(z, f0, spec_lengths, self.segment_size)
-
- # nsf decoder
- o = self.dec(z_slice, g=g, f0=pitch_slice)
-
- return o, ids_slice, spec_mask, (z, z_p, m_p, logs_p, m_q, logs_q), pred_lf0, norm_lf0, lf0
-
- def infer(self, c, f0, uv, g=None, noice_scale=0.35, predict_f0=False):
- c_lengths = (torch.ones(c.size(0)) * c.size(-1)).to(c.device)
- g = self.emb_g(g).transpose(1,2)
- x_mask = torch.unsqueeze(commons.sequence_mask(c_lengths, c.size(2)), 1).to(c.dtype)
- x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1,2)
-
- if predict_f0:
- lf0 = 2595. * torch.log10(1. + f0.unsqueeze(1) / 700.) / 500
- norm_lf0 = utils.normalize_f0(lf0, x_mask, uv, random_scale=False)
- pred_lf0 = self.f0_decoder(x, norm_lf0, x_mask, spk_emb=g)
- f0 = (700 * (torch.pow(10, pred_lf0 * 500 / 2595) - 1)).squeeze(1)
-
- z_p, m_p, logs_p, c_mask = self.enc_p(x, x_mask, f0=f0_to_coarse(f0), noice_scale=noice_scale)
- z = self.flow(z_p, c_mask, g=g, reverse=True)
- o = self.dec(z * c_mask, g=g, f0=f0)
- return o
diff --git a/spaces/MarcusSu1216/XingTong/vdecoder/hifigan/utils.py b/spaces/MarcusSu1216/XingTong/vdecoder/hifigan/utils.py
deleted file mode 100644
index 9c93c996d3cc73c30d71c1fc47056e4230f35c0f..0000000000000000000000000000000000000000
--- a/spaces/MarcusSu1216/XingTong/vdecoder/hifigan/utils.py
+++ /dev/null
@@ -1,68 +0,0 @@
-import glob
-import os
-import matplotlib
-import torch
-from torch.nn.utils import weight_norm
-# matplotlib.use("Agg")
-import matplotlib.pylab as plt
-
-
-def plot_spectrogram(spectrogram):
- fig, ax = plt.subplots(figsize=(10, 2))
- im = ax.imshow(spectrogram, aspect="auto", origin="lower",
- interpolation='none')
- plt.colorbar(im, ax=ax)
-
- fig.canvas.draw()
- plt.close()
-
- return fig
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def apply_weight_norm(m):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- weight_norm(m)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size*dilation - dilation)/2)
-
-
-def load_checkpoint(filepath, device):
- assert os.path.isfile(filepath)
- print("Loading '{}'".format(filepath))
- checkpoint_dict = torch.load(filepath, map_location=device)
- print("Complete.")
- return checkpoint_dict
-
-
-def save_checkpoint(filepath, obj):
- print("Saving checkpoint to {}".format(filepath))
- torch.save(obj, filepath)
- print("Complete.")
-
-
-def del_old_checkpoints(cp_dir, prefix, n_models=2):
- pattern = os.path.join(cp_dir, prefix + '????????')
- cp_list = glob.glob(pattern) # get checkpoint paths
- cp_list = sorted(cp_list)# sort by iter
- if len(cp_list) > n_models: # if more than n_models models are found
- for cp in cp_list[:-n_models]:# delete the oldest models other than lastest n_models
- open(cp, 'w').close()# empty file contents
- os.unlink(cp)# delete file (move to trash when using Colab)
-
-
-def scan_checkpoint(cp_dir, prefix):
- pattern = os.path.join(cp_dir, prefix + '????????')
- cp_list = glob.glob(pattern)
- if len(cp_list) == 0:
- return None
- return sorted(cp_list)[-1]
-
diff --git a/spaces/MeiJuice/CheckGPT/README.md b/spaces/MeiJuice/CheckGPT/README.md
deleted file mode 100644
index db90e60ec0dc69b8ae48dcc922f6dcaf1fc9c3dd..0000000000000000000000000000000000000000
--- a/spaces/MeiJuice/CheckGPT/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: CheckGPT
-emoji: 🐢
-colorFrom: purple
-colorTo: red
-sdk: gradio
-sdk_version: 3.29.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/configs/_base_/models/ocrnet_r50-d8.py b/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/configs/_base_/models/ocrnet_r50-d8.py
deleted file mode 100644
index 615aa3ff703942b6c22b2d6e9642504dd3e41ebd..0000000000000000000000000000000000000000
--- a/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/configs/_base_/models/ocrnet_r50-d8.py
+++ /dev/null
@@ -1,47 +0,0 @@
-# model settings
-norm_cfg = dict(type='SyncBN', requires_grad=True)
-model = dict(
- type='CascadeEncoderDecoder',
- num_stages=2,
- pretrained='open-mmlab://resnet50_v1c',
- backbone=dict(
- type='ResNetV1c',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- dilations=(1, 1, 2, 4),
- strides=(1, 2, 1, 1),
- norm_cfg=norm_cfg,
- norm_eval=False,
- style='pytorch',
- contract_dilation=True),
- decode_head=[
- dict(
- type='FCNHead',
- in_channels=1024,
- in_index=2,
- channels=256,
- num_convs=1,
- concat_input=False,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
- dict(
- type='OCRHead',
- in_channels=2048,
- in_index=3,
- channels=512,
- ocr_channels=256,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
- ],
- # model training and testing settings
- train_cfg=dict(),
- test_cfg=dict(mode='whole'))
diff --git a/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/runner/optimizer/default_constructor.py b/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/runner/optimizer/default_constructor.py
deleted file mode 100644
index 2c0da3503b75441738efe38d70352b55a210a34a..0000000000000000000000000000000000000000
--- a/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/runner/optimizer/default_constructor.py
+++ /dev/null
@@ -1,249 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-
-import torch
-from torch.nn import GroupNorm, LayerNorm
-
-from annotator.uniformer.mmcv.utils import _BatchNorm, _InstanceNorm, build_from_cfg, is_list_of
-from annotator.uniformer.mmcv.utils.ext_loader import check_ops_exist
-from .builder import OPTIMIZER_BUILDERS, OPTIMIZERS
-
-
-@OPTIMIZER_BUILDERS.register_module()
-class DefaultOptimizerConstructor:
- """Default constructor for optimizers.
-
- By default each parameter share the same optimizer settings, and we
- provide an argument ``paramwise_cfg`` to specify parameter-wise settings.
- It is a dict and may contain the following fields:
-
- - ``custom_keys`` (dict): Specified parameters-wise settings by keys. If
- one of the keys in ``custom_keys`` is a substring of the name of one
- parameter, then the setting of the parameter will be specified by
- ``custom_keys[key]`` and other setting like ``bias_lr_mult`` etc. will
- be ignored. It should be noted that the aforementioned ``key`` is the
- longest key that is a substring of the name of the parameter. If there
- are multiple matched keys with the same length, then the key with lower
- alphabet order will be chosen.
- ``custom_keys[key]`` should be a dict and may contain fields ``lr_mult``
- and ``decay_mult``. See Example 2 below.
- - ``bias_lr_mult`` (float): It will be multiplied to the learning
- rate for all bias parameters (except for those in normalization
- layers and offset layers of DCN).
- - ``bias_decay_mult`` (float): It will be multiplied to the weight
- decay for all bias parameters (except for those in
- normalization layers, depthwise conv layers, offset layers of DCN).
- - ``norm_decay_mult`` (float): It will be multiplied to the weight
- decay for all weight and bias parameters of normalization
- layers.
- - ``dwconv_decay_mult`` (float): It will be multiplied to the weight
- decay for all weight and bias parameters of depthwise conv
- layers.
- - ``dcn_offset_lr_mult`` (float): It will be multiplied to the learning
- rate for parameters of offset layer in the deformable convs
- of a model.
- - ``bypass_duplicate`` (bool): If true, the duplicate parameters
- would not be added into optimizer. Default: False.
-
- Note:
- 1. If the option ``dcn_offset_lr_mult`` is used, the constructor will
- override the effect of ``bias_lr_mult`` in the bias of offset
- layer. So be careful when using both ``bias_lr_mult`` and
- ``dcn_offset_lr_mult``. If you wish to apply both of them to the
- offset layer in deformable convs, set ``dcn_offset_lr_mult``
- to the original ``dcn_offset_lr_mult`` * ``bias_lr_mult``.
- 2. If the option ``dcn_offset_lr_mult`` is used, the constructor will
- apply it to all the DCN layers in the model. So be careful when
- the model contains multiple DCN layers in places other than
- backbone.
-
- Args:
- model (:obj:`nn.Module`): The model with parameters to be optimized.
- optimizer_cfg (dict): The config dict of the optimizer.
- Positional fields are
-
- - `type`: class name of the optimizer.
-
- Optional fields are
-
- - any arguments of the corresponding optimizer type, e.g.,
- lr, weight_decay, momentum, etc.
- paramwise_cfg (dict, optional): Parameter-wise options.
-
- Example 1:
- >>> model = torch.nn.modules.Conv1d(1, 1, 1)
- >>> optimizer_cfg = dict(type='SGD', lr=0.01, momentum=0.9,
- >>> weight_decay=0.0001)
- >>> paramwise_cfg = dict(norm_decay_mult=0.)
- >>> optim_builder = DefaultOptimizerConstructor(
- >>> optimizer_cfg, paramwise_cfg)
- >>> optimizer = optim_builder(model)
-
- Example 2:
- >>> # assume model have attribute model.backbone and model.cls_head
- >>> optimizer_cfg = dict(type='SGD', lr=0.01, weight_decay=0.95)
- >>> paramwise_cfg = dict(custom_keys={
- '.backbone': dict(lr_mult=0.1, decay_mult=0.9)})
- >>> optim_builder = DefaultOptimizerConstructor(
- >>> optimizer_cfg, paramwise_cfg)
- >>> optimizer = optim_builder(model)
- >>> # Then the `lr` and `weight_decay` for model.backbone is
- >>> # (0.01 * 0.1, 0.95 * 0.9). `lr` and `weight_decay` for
- >>> # model.cls_head is (0.01, 0.95).
- """
-
- def __init__(self, optimizer_cfg, paramwise_cfg=None):
- if not isinstance(optimizer_cfg, dict):
- raise TypeError('optimizer_cfg should be a dict',
- f'but got {type(optimizer_cfg)}')
- self.optimizer_cfg = optimizer_cfg
- self.paramwise_cfg = {} if paramwise_cfg is None else paramwise_cfg
- self.base_lr = optimizer_cfg.get('lr', None)
- self.base_wd = optimizer_cfg.get('weight_decay', None)
- self._validate_cfg()
-
- def _validate_cfg(self):
- if not isinstance(self.paramwise_cfg, dict):
- raise TypeError('paramwise_cfg should be None or a dict, '
- f'but got {type(self.paramwise_cfg)}')
-
- if 'custom_keys' in self.paramwise_cfg:
- if not isinstance(self.paramwise_cfg['custom_keys'], dict):
- raise TypeError(
- 'If specified, custom_keys must be a dict, '
- f'but got {type(self.paramwise_cfg["custom_keys"])}')
- if self.base_wd is None:
- for key in self.paramwise_cfg['custom_keys']:
- if 'decay_mult' in self.paramwise_cfg['custom_keys'][key]:
- raise ValueError('base_wd should not be None')
-
- # get base lr and weight decay
- # weight_decay must be explicitly specified if mult is specified
- if ('bias_decay_mult' in self.paramwise_cfg
- or 'norm_decay_mult' in self.paramwise_cfg
- or 'dwconv_decay_mult' in self.paramwise_cfg):
- if self.base_wd is None:
- raise ValueError('base_wd should not be None')
-
- def _is_in(self, param_group, param_group_list):
- assert is_list_of(param_group_list, dict)
- param = set(param_group['params'])
- param_set = set()
- for group in param_group_list:
- param_set.update(set(group['params']))
-
- return not param.isdisjoint(param_set)
-
- def add_params(self, params, module, prefix='', is_dcn_module=None):
- """Add all parameters of module to the params list.
-
- The parameters of the given module will be added to the list of param
- groups, with specific rules defined by paramwise_cfg.
-
- Args:
- params (list[dict]): A list of param groups, it will be modified
- in place.
- module (nn.Module): The module to be added.
- prefix (str): The prefix of the module
- is_dcn_module (int|float|None): If the current module is a
- submodule of DCN, `is_dcn_module` will be passed to
- control conv_offset layer's learning rate. Defaults to None.
- """
- # get param-wise options
- custom_keys = self.paramwise_cfg.get('custom_keys', {})
- # first sort with alphabet order and then sort with reversed len of str
- sorted_keys = sorted(sorted(custom_keys.keys()), key=len, reverse=True)
-
- bias_lr_mult = self.paramwise_cfg.get('bias_lr_mult', 1.)
- bias_decay_mult = self.paramwise_cfg.get('bias_decay_mult', 1.)
- norm_decay_mult = self.paramwise_cfg.get('norm_decay_mult', 1.)
- dwconv_decay_mult = self.paramwise_cfg.get('dwconv_decay_mult', 1.)
- bypass_duplicate = self.paramwise_cfg.get('bypass_duplicate', False)
- dcn_offset_lr_mult = self.paramwise_cfg.get('dcn_offset_lr_mult', 1.)
-
- # special rules for norm layers and depth-wise conv layers
- is_norm = isinstance(module,
- (_BatchNorm, _InstanceNorm, GroupNorm, LayerNorm))
- is_dwconv = (
- isinstance(module, torch.nn.Conv2d)
- and module.in_channels == module.groups)
-
- for name, param in module.named_parameters(recurse=False):
- param_group = {'params': [param]}
- if not param.requires_grad:
- params.append(param_group)
- continue
- if bypass_duplicate and self._is_in(param_group, params):
- warnings.warn(f'{prefix} is duplicate. It is skipped since '
- f'bypass_duplicate={bypass_duplicate}')
- continue
- # if the parameter match one of the custom keys, ignore other rules
- is_custom = False
- for key in sorted_keys:
- if key in f'{prefix}.{name}':
- is_custom = True
- lr_mult = custom_keys[key].get('lr_mult', 1.)
- param_group['lr'] = self.base_lr * lr_mult
- if self.base_wd is not None:
- decay_mult = custom_keys[key].get('decay_mult', 1.)
- param_group['weight_decay'] = self.base_wd * decay_mult
- break
-
- if not is_custom:
- # bias_lr_mult affects all bias parameters
- # except for norm.bias dcn.conv_offset.bias
- if name == 'bias' and not (is_norm or is_dcn_module):
- param_group['lr'] = self.base_lr * bias_lr_mult
-
- if (prefix.find('conv_offset') != -1 and is_dcn_module
- and isinstance(module, torch.nn.Conv2d)):
- # deal with both dcn_offset's bias & weight
- param_group['lr'] = self.base_lr * dcn_offset_lr_mult
-
- # apply weight decay policies
- if self.base_wd is not None:
- # norm decay
- if is_norm:
- param_group[
- 'weight_decay'] = self.base_wd * norm_decay_mult
- # depth-wise conv
- elif is_dwconv:
- param_group[
- 'weight_decay'] = self.base_wd * dwconv_decay_mult
- # bias lr and decay
- elif name == 'bias' and not is_dcn_module:
- # TODO: current bias_decay_mult will have affect on DCN
- param_group[
- 'weight_decay'] = self.base_wd * bias_decay_mult
- params.append(param_group)
-
- if check_ops_exist():
- from annotator.uniformer.mmcv.ops import DeformConv2d, ModulatedDeformConv2d
- is_dcn_module = isinstance(module,
- (DeformConv2d, ModulatedDeformConv2d))
- else:
- is_dcn_module = False
- for child_name, child_mod in module.named_children():
- child_prefix = f'{prefix}.{child_name}' if prefix else child_name
- self.add_params(
- params,
- child_mod,
- prefix=child_prefix,
- is_dcn_module=is_dcn_module)
-
- def __call__(self, model):
- if hasattr(model, 'module'):
- model = model.module
-
- optimizer_cfg = self.optimizer_cfg.copy()
- # if no paramwise option is specified, just use the global setting
- if not self.paramwise_cfg:
- optimizer_cfg['params'] = model.parameters()
- return build_from_cfg(optimizer_cfg, OPTIMIZERS)
-
- # set param-wise lr and weight decay recursively
- params = []
- self.add_params(params, model)
- optimizer_cfg['params'] = params
-
- return build_from_cfg(optimizer_cfg, OPTIMIZERS)
diff --git a/spaces/Mountchicken/MAERec-Gradio/configs/textdet/_base_/pretrain_runtime.py b/spaces/Mountchicken/MAERec-Gradio/configs/textdet/_base_/pretrain_runtime.py
deleted file mode 100644
index cb2800d50a570881475035e3b0da9c81e88712d1..0000000000000000000000000000000000000000
--- a/spaces/Mountchicken/MAERec-Gradio/configs/textdet/_base_/pretrain_runtime.py
+++ /dev/null
@@ -1,14 +0,0 @@
-_base_ = 'default_runtime.py'
-
-default_hooks = dict(
- logger=dict(type='LoggerHook', interval=1000),
- checkpoint=dict(
- type='CheckpointHook',
- interval=10000,
- by_epoch=False,
- max_keep_ckpts=1),
-)
-
-# Evaluation
-val_evaluator = None
-test_evaluator = None
diff --git a/spaces/Mountchicken/MAERec-Gradio/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_icdar2015.py b/spaces/Mountchicken/MAERec-Gradio/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_icdar2015.py
deleted file mode 100644
index 41509ac17785bcfb93726c16139dd11bddb6020b..0000000000000000000000000000000000000000
--- a/spaces/Mountchicken/MAERec-Gradio/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_icdar2015.py
+++ /dev/null
@@ -1,39 +0,0 @@
-_base_ = [
- '_base_mask-rcnn_resnet50_fpn.py',
- '../_base_/datasets/icdar2015.py',
- '../_base_/default_runtime.py',
- '../_base_/schedules/schedule_sgd_base.py',
-]
-
-# optimizer
-optim_wrapper = dict(optimizer=dict(lr=0.08))
-train_cfg = dict(max_epochs=160)
-# learning policy
-param_scheduler = [
- dict(type='LinearLR', end=500, start_factor=0.001, by_epoch=False),
- dict(type='MultiStepLR', milestones=[80, 128], end=160),
-]
-
-# dataset settings
-icdar2015_textdet_train = _base_.icdar2015_textdet_train
-icdar2015_textdet_test = _base_.icdar2015_textdet_test
-icdar2015_textdet_train.pipeline = _base_.train_pipeline
-icdar2015_textdet_test.pipeline = _base_.test_pipeline
-
-train_dataloader = dict(
- batch_size=8,
- num_workers=4,
- persistent_workers=True,
- sampler=dict(type='DefaultSampler', shuffle=True),
- dataset=icdar2015_textdet_train)
-
-val_dataloader = dict(
- batch_size=1,
- num_workers=1,
- persistent_workers=True,
- sampler=dict(type='DefaultSampler', shuffle=False),
- dataset=icdar2015_textdet_test)
-
-test_dataloader = val_dataloader
-
-auto_scale_lr = dict(base_batch_size=8)
diff --git a/spaces/MrZak/LearnUp-4.1/app.py b/spaces/MrZak/LearnUp-4.1/app.py
deleted file mode 100644
index dcdfa83d2f3096ce9888408ecd8fc75a0aa60641..0000000000000000000000000000000000000000
--- a/spaces/MrZak/LearnUp-4.1/app.py
+++ /dev/null
@@ -1,90 +0,0 @@
-import os
-import openai
-import gradio as gr
-
-# Set your OpenAI API key
-openai.api_key = "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"
-
-start_sequence = "\nAI:"
-restart_sequence = "\nHuman: "
-
-prompt = "Ask Learny Anything"
-
-def openai_create(prompt):
- response = openai.Completion.create(
- engine="text-davinci-003",
- prompt=prompt,
- temperature=0.9,
- max_tokens=150,
- top_p=1,
- frequency_penalty=0,
- presence_penalty=0.6,
- stop=[" Human:", " AI:"]
- )
- print(response)
- return response.choices[0].text.strip()
-
-def format_chat_bubble(text, is_user=False):
- if is_user:
- bubble = f"You: {text}"
- class_name = "user-bubble"
- else:
- bubble = f"Learny: {text}"
- class_name = "bot-bubble"
- return f'{bubble}
'
-
-def chatgpt_clone(input, history):
- history = history or []
- s = list(sum(history, ()))
- s.append(input)
- inp = ' '.join(s)
- output = openai_create(inp)
- history.append((input, output))
- chat_history = [format_chat_bubble(item[0], is_user=True) for item in history[:-1]]
- chat_history.append(format_chat_bubble(history[-1][1])) # Display the last response as the bot's message
- return "
".join(chat_history)
-
-
-input_text = gr.inputs.Textbox(placeholder=prompt)
-output_text = gr.outputs.HTML()
-
-interface = gr.Interface(
- fn=chatgpt_clone,
- inputs=input_text,
- outputs=output_text,
- theme="compact",
- examples=[
- ["What is the capital of France?"],
- ["Who is the president of the United States?"],
- ]
-)
-
-# Apply custom CSS style to the interface
-custom_css = """
-.user-bubble {
- background-color: #EDF2FC;
- color: black;
- padding: 10px;
- border-radius: 20px;
- margin-bottom: 10px;
- font-family: Arial, sans-serif;
-}
-
-.bot-bubble {
- background-color: #9FB6CD;
- color: black;
- padding: 10px;
- border-radius: 20px;
- margin-bottom: 10px;
- font-family: Arial, sans-serif;
-}
-
-.gradio-interface .gradio-submit-button {
- background-color: grey;
- color: white;
-}
-"""
-
-interface.css = custom_css
-
-interface.launch()
diff --git a/spaces/MuGeminorum/insecta/khandy/list_utils.py b/spaces/MuGeminorum/insecta/khandy/list_utils.py
deleted file mode 100644
index 04b9080f0a8a05c645c16a7e5ba3132260907b89..0000000000000000000000000000000000000000
--- a/spaces/MuGeminorum/insecta/khandy/list_utils.py
+++ /dev/null
@@ -1,68 +0,0 @@
-import random
-import itertools
-
-
-def to_list(obj):
- if obj is None:
- return None
- elif hasattr(obj, '__iter__') and not isinstance(obj, str):
- try:
- return list(obj)
- except:
- return [obj]
- else:
- return [obj]
-
-
-def convert_lists_to_record(*list_objs, delimiter=None):
- assert len(list_objs) >= 1, 'list_objs length must >= 1.'
- delimiter = delimiter or ','
-
- assert isinstance(list_objs[0], (tuple, list))
- number = len(list_objs[0])
- for item in list_objs[1:]:
- assert isinstance(item, (tuple, list))
- assert len(item) == number, '{} != {}'.format(len(item), number)
-
- records = []
- record_list = zip(*list_objs)
- for record in record_list:
- record_str = [str(item) for item in record]
- records.append(delimiter.join(record_str))
- return records
-
-
-def shuffle_table(*table):
- """
- Notes:
- table can be seen as list of list which have equal items.
- """
- shuffled_list = list(zip(*table))
- random.shuffle(shuffled_list)
- tuple_list = zip(*shuffled_list)
- return [list(item) for item in tuple_list]
-
-
-def transpose_table(table):
- """
- Notes:
- table can be seen as list of list which have equal items.
- """
- m, n = len(table), len(table[0])
- return [[table[i][j] for i in range(m)] for j in range(n)]
-
-
-def concat_list(in_list):
- """Concatenate a list of list into a single list.
-
- Args:
- in_list (list): The list of list to be merged.
-
- Returns:
- list: The concatenated flat list.
-
- References:
- mmcv.concat_list
- """
- return list(itertools.chain(*in_list))
-
\ No newline at end of file
diff --git a/spaces/NATSpeech/PortaSpeech/modules/commons/normalizing_flow/glow_modules.py b/spaces/NATSpeech/PortaSpeech/modules/commons/normalizing_flow/glow_modules.py
deleted file mode 100644
index c589af0f2eba2b154317912f9ad01a4163b3fd6a..0000000000000000000000000000000000000000
--- a/spaces/NATSpeech/PortaSpeech/modules/commons/normalizing_flow/glow_modules.py
+++ /dev/null
@@ -1,362 +0,0 @@
-import scipy
-from torch.nn import functional as F
-import torch
-from torch import nn
-import numpy as np
-from modules.commons.wavenet import WN
-from modules.tts.glow import utils
-
-
-class ActNorm(nn.Module):
- def __init__(self, channels, ddi=False, **kwargs):
- super().__init__()
- self.channels = channels
- self.initialized = not ddi
-
- self.logs = nn.Parameter(torch.zeros(1, channels, 1))
- self.bias = nn.Parameter(torch.zeros(1, channels, 1))
-
- def forward(self, x, x_mask=None, reverse=False, **kwargs):
- if x_mask is None:
- x_mask = torch.ones(x.size(0), 1, x.size(2)).to(device=x.device, dtype=x.dtype)
- x_len = torch.sum(x_mask, [1, 2])
- if not self.initialized:
- self.initialize(x, x_mask)
- self.initialized = True
-
- if reverse:
- z = (x - self.bias) * torch.exp(-self.logs) * x_mask
- logdet = torch.sum(-self.logs) * x_len
- else:
- z = (self.bias + torch.exp(self.logs) * x) * x_mask
- logdet = torch.sum(self.logs) * x_len # [b]
- return z, logdet
-
- def store_inverse(self):
- pass
-
- def set_ddi(self, ddi):
- self.initialized = not ddi
-
- def initialize(self, x, x_mask):
- with torch.no_grad():
- denom = torch.sum(x_mask, [0, 2])
- m = torch.sum(x * x_mask, [0, 2]) / denom
- m_sq = torch.sum(x * x * x_mask, [0, 2]) / denom
- v = m_sq - (m ** 2)
- logs = 0.5 * torch.log(torch.clamp_min(v, 1e-6))
-
- bias_init = (-m * torch.exp(-logs)).view(*self.bias.shape).to(dtype=self.bias.dtype)
- logs_init = (-logs).view(*self.logs.shape).to(dtype=self.logs.dtype)
-
- self.bias.data.copy_(bias_init)
- self.logs.data.copy_(logs_init)
-
-
-class InvConvNear(nn.Module):
- def __init__(self, channels, n_split=4, no_jacobian=False, lu=True, n_sqz=2, **kwargs):
- super().__init__()
- assert (n_split % 2 == 0)
- self.channels = channels
- self.n_split = n_split
- self.n_sqz = n_sqz
- self.no_jacobian = no_jacobian
-
- w_init = torch.qr(torch.FloatTensor(self.n_split, self.n_split).normal_())[0]
- if torch.det(w_init) < 0:
- w_init[:, 0] = -1 * w_init[:, 0]
- self.lu = lu
- if lu:
- # LU decomposition can slightly speed up the inverse
- np_p, np_l, np_u = scipy.linalg.lu(w_init)
- np_s = np.diag(np_u)
- np_sign_s = np.sign(np_s)
- np_log_s = np.log(np.abs(np_s))
- np_u = np.triu(np_u, k=1)
- l_mask = np.tril(np.ones(w_init.shape, dtype=float), -1)
- eye = np.eye(*w_init.shape, dtype=float)
-
- self.register_buffer('p', torch.Tensor(np_p.astype(float)))
- self.register_buffer('sign_s', torch.Tensor(np_sign_s.astype(float)))
- self.l = nn.Parameter(torch.Tensor(np_l.astype(float)), requires_grad=True)
- self.log_s = nn.Parameter(torch.Tensor(np_log_s.astype(float)), requires_grad=True)
- self.u = nn.Parameter(torch.Tensor(np_u.astype(float)), requires_grad=True)
- self.register_buffer('l_mask', torch.Tensor(l_mask))
- self.register_buffer('eye', torch.Tensor(eye))
- else:
- self.weight = nn.Parameter(w_init)
-
- def forward(self, x, x_mask=None, reverse=False, **kwargs):
- b, c, t = x.size()
- assert (c % self.n_split == 0)
- if x_mask is None:
- x_mask = 1
- x_len = torch.ones((b,), dtype=x.dtype, device=x.device) * t
- else:
- x_len = torch.sum(x_mask, [1, 2])
-
- x = x.view(b, self.n_sqz, c // self.n_split, self.n_split // self.n_sqz, t)
- x = x.permute(0, 1, 3, 2, 4).contiguous().view(b, self.n_split, c // self.n_split, t)
-
- if self.lu:
- self.weight, log_s = self._get_weight()
- logdet = log_s.sum()
- logdet = logdet * (c / self.n_split) * x_len
- else:
- logdet = torch.logdet(self.weight) * (c / self.n_split) * x_len # [b]
-
- if reverse:
- if hasattr(self, "weight_inv"):
- weight = self.weight_inv
- else:
- weight = torch.inverse(self.weight.float()).to(dtype=self.weight.dtype)
- logdet = -logdet
- else:
- weight = self.weight
- if self.no_jacobian:
- logdet = 0
-
- weight = weight.view(self.n_split, self.n_split, 1, 1)
- z = F.conv2d(x, weight)
-
- z = z.view(b, self.n_sqz, self.n_split // self.n_sqz, c // self.n_split, t)
- z = z.permute(0, 1, 3, 2, 4).contiguous().view(b, c, t) * x_mask
- return z, logdet
-
- def _get_weight(self):
- l, log_s, u = self.l, self.log_s, self.u
- l = l * self.l_mask + self.eye
- u = u * self.l_mask.transpose(0, 1).contiguous() + torch.diag(self.sign_s * torch.exp(log_s))
- weight = torch.matmul(self.p, torch.matmul(l, u))
- return weight, log_s
-
- def store_inverse(self):
- weight, _ = self._get_weight()
- self.weight_inv = torch.inverse(weight.float()).to(next(self.parameters()).device)
-
-
-class InvConv(nn.Module):
- def __init__(self, channels, no_jacobian=False, lu=True, **kwargs):
- super().__init__()
- w_shape = [channels, channels]
- w_init = np.linalg.qr(np.random.randn(*w_shape))[0].astype(float)
- LU_decomposed = lu
- if not LU_decomposed:
- # Sample a random orthogonal matrix:
- self.register_parameter("weight", nn.Parameter(torch.Tensor(w_init)))
- else:
- np_p, np_l, np_u = scipy.linalg.lu(w_init)
- np_s = np.diag(np_u)
- np_sign_s = np.sign(np_s)
- np_log_s = np.log(np.abs(np_s))
- np_u = np.triu(np_u, k=1)
- l_mask = np.tril(np.ones(w_shape, dtype=float), -1)
- eye = np.eye(*w_shape, dtype=float)
-
- self.register_buffer('p', torch.Tensor(np_p.astype(float)))
- self.register_buffer('sign_s', torch.Tensor(np_sign_s.astype(float)))
- self.l = nn.Parameter(torch.Tensor(np_l.astype(float)))
- self.log_s = nn.Parameter(torch.Tensor(np_log_s.astype(float)))
- self.u = nn.Parameter(torch.Tensor(np_u.astype(float)))
- self.l_mask = torch.Tensor(l_mask)
- self.eye = torch.Tensor(eye)
- self.w_shape = w_shape
- self.LU = LU_decomposed
- self.weight = None
-
- def get_weight(self, device, reverse):
- w_shape = self.w_shape
- self.p = self.p.to(device)
- self.sign_s = self.sign_s.to(device)
- self.l_mask = self.l_mask.to(device)
- self.eye = self.eye.to(device)
- l = self.l * self.l_mask + self.eye
- u = self.u * self.l_mask.transpose(0, 1).contiguous() + torch.diag(self.sign_s * torch.exp(self.log_s))
- dlogdet = self.log_s.sum()
- if not reverse:
- w = torch.matmul(self.p, torch.matmul(l, u))
- else:
- l = torch.inverse(l.double()).float()
- u = torch.inverse(u.double()).float()
- w = torch.matmul(u, torch.matmul(l, self.p.inverse()))
- return w.view(w_shape[0], w_shape[1], 1), dlogdet
-
- def forward(self, x, x_mask=None, reverse=False, **kwargs):
- """
- log-det = log|abs(|W|)| * pixels
- """
- b, c, t = x.size()
- if x_mask is None:
- x_len = torch.ones((b,), dtype=x.dtype, device=x.device) * t
- else:
- x_len = torch.sum(x_mask, [1, 2])
- logdet = 0
- if not reverse:
- weight, dlogdet = self.get_weight(x.device, reverse)
- z = F.conv1d(x, weight)
- if logdet is not None:
- logdet = logdet + dlogdet * x_len
- return z, logdet
- else:
- if self.weight is None:
- weight, dlogdet = self.get_weight(x.device, reverse)
- else:
- weight, dlogdet = self.weight, self.dlogdet
- z = F.conv1d(x, weight)
- if logdet is not None:
- logdet = logdet - dlogdet * x_len
- return z, logdet
-
- def store_inverse(self):
- self.weight, self.dlogdet = self.get_weight('cuda', reverse=True)
-
-
-class CouplingBlock(nn.Module):
- def __init__(self, in_channels, hidden_channels, kernel_size, dilation_rate, n_layers,
- gin_channels=0, p_dropout=0, sigmoid_scale=False, wn=None):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
- self.sigmoid_scale = sigmoid_scale
-
- start = torch.nn.Conv1d(in_channels // 2, hidden_channels, 1)
- start = torch.nn.utils.weight_norm(start)
- self.start = start
- # Initializing last layer to 0 makes the affine coupling layers
- # do nothing at first. This helps with training stability
- end = torch.nn.Conv1d(hidden_channels, in_channels, 1)
- end.weight.data.zero_()
- end.bias.data.zero_()
- self.end = end
- self.wn = WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels, p_dropout)
- if wn is not None:
- self.wn.in_layers = wn.in_layers
- self.wn.res_skip_layers = wn.res_skip_layers
-
- def forward(self, x, x_mask=None, reverse=False, g=None, **kwargs):
- if x_mask is None:
- x_mask = 1
- x_0, x_1 = x[:, :self.in_channels // 2], x[:, self.in_channels // 2:]
-
- x = self.start(x_0) * x_mask
- x = self.wn(x, x_mask, g)
- out = self.end(x)
-
- z_0 = x_0
- m = out[:, :self.in_channels // 2, :]
- logs = out[:, self.in_channels // 2:, :]
- if self.sigmoid_scale:
- logs = torch.log(1e-6 + torch.sigmoid(logs + 2))
- if reverse:
- z_1 = (x_1 - m) * torch.exp(-logs) * x_mask
- logdet = torch.sum(-logs * x_mask, [1, 2])
- else:
- z_1 = (m + torch.exp(logs) * x_1) * x_mask
- logdet = torch.sum(logs * x_mask, [1, 2])
- z = torch.cat([z_0, z_1], 1)
- return z, logdet
-
- def store_inverse(self):
- self.wn.remove_weight_norm()
-
-
-class Glow(nn.Module):
- def __init__(self,
- in_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_blocks,
- n_layers,
- p_dropout=0.,
- n_split=4,
- n_sqz=2,
- sigmoid_scale=False,
- gin_channels=0,
- inv_conv_type='near',
- share_cond_layers=False,
- share_wn_layers=0,
- ):
- super().__init__()
-
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_blocks = n_blocks
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- self.n_split = n_split
- self.n_sqz = n_sqz
- self.sigmoid_scale = sigmoid_scale
- self.gin_channels = gin_channels
- self.share_cond_layers = share_cond_layers
- if gin_channels != 0 and share_cond_layers:
- cond_layer = torch.nn.Conv1d(gin_channels * n_sqz, 2 * hidden_channels * n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
- wn = None
- self.flows = nn.ModuleList()
- for b in range(n_blocks):
- self.flows.append(ActNorm(channels=in_channels * n_sqz))
- if inv_conv_type == 'near':
- self.flows.append(InvConvNear(channels=in_channels * n_sqz, n_split=n_split, n_sqz=n_sqz))
- if inv_conv_type == 'invconv':
- self.flows.append(InvConv(channels=in_channels * n_sqz))
- if share_wn_layers > 0:
- if b % share_wn_layers == 0:
- wn = WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels * n_sqz,
- p_dropout, share_cond_layers)
- self.flows.append(
- CouplingBlock(
- in_channels * n_sqz,
- hidden_channels,
- kernel_size=kernel_size,
- dilation_rate=dilation_rate,
- n_layers=n_layers,
- gin_channels=gin_channels * n_sqz,
- p_dropout=p_dropout,
- sigmoid_scale=sigmoid_scale,
- wn=wn
- ))
-
- def forward(self, x, x_mask=None, g=None, reverse=False, return_hiddens=False):
- logdet_tot = 0
- if not reverse:
- flows = self.flows
- else:
- flows = reversed(self.flows)
- if return_hiddens:
- hs = []
- if self.n_sqz > 1:
- x, x_mask_ = utils.squeeze(x, x_mask, self.n_sqz)
- if g is not None:
- g, _ = utils.squeeze(g, x_mask, self.n_sqz)
- x_mask = x_mask_
- if self.share_cond_layers and g is not None:
- g = self.cond_layer(g)
- for f in flows:
- x, logdet = f(x, x_mask, g=g, reverse=reverse)
- if return_hiddens:
- hs.append(x)
- logdet_tot += logdet
- if self.n_sqz > 1:
- x, x_mask = utils.unsqueeze(x, x_mask, self.n_sqz)
- if return_hiddens:
- return x, logdet_tot, hs
- return x, logdet_tot
-
- def store_inverse(self):
- def remove_weight_norm(m):
- try:
- nn.utils.remove_weight_norm(m)
- except ValueError: # this module didn't have weight norm
- return
-
- self.apply(remove_weight_norm)
- for f in self.flows:
- f.store_inverse()
diff --git a/spaces/Nixic/rvc-models/config.py b/spaces/Nixic/rvc-models/config.py
deleted file mode 100644
index c0c16e0017efbcaf250cb539a1d0edb4e83575e4..0000000000000000000000000000000000000000
--- a/spaces/Nixic/rvc-models/config.py
+++ /dev/null
@@ -1,88 +0,0 @@
-########################硬件参数########################
-
-# 填写cuda:x, cpu 或 mps, x指代第几张卡,只支持 N卡 / Apple Silicon 加速
-device = "cuda:0"
-
-# 9-10-20-30-40系显卡无脑True,不影响质量,>=20显卡开启有加速
-is_half = True
-
-# 默认0用上所有线程,写数字限制CPU资源使用
-n_cpu = 0
-
-########################硬件参数########################
-
-
-##################下为参数处理逻辑,勿动##################
-
-########################命令行参数########################
-import argparse
-
-parser = argparse.ArgumentParser()
-parser.add_argument("--port", type=int, default=7865, help="Listen port")
-parser.add_argument("--pycmd", type=str, default="python", help="Python command")
-parser.add_argument("--colab", action="store_true", help="Launch in colab")
-parser.add_argument(
- "--noparallel", action="store_true", help="Disable parallel processing"
-)
-parser.add_argument(
- "--noautoopen", action="store_true", help="Do not open in browser automatically"
-)
-cmd_opts, unknown = parser.parse_known_args()
-
-python_cmd = cmd_opts.pycmd
-listen_port = cmd_opts.port
-iscolab = cmd_opts.colab
-noparallel = cmd_opts.noparallel
-noautoopen = cmd_opts.noautoopen
-########################命令行参数########################
-
-import sys
-import torch
-
-
-# has_mps is only available in nightly pytorch (for now) and MasOS 12.3+.
-# check `getattr` and try it for compatibility
-def has_mps() -> bool:
- if sys.platform != "darwin":
- return False
- else:
- if not getattr(torch, "has_mps", False):
- return False
- try:
- torch.zeros(1).to(torch.device("mps"))
- return True
- except Exception:
- return False
-
-
-if not torch.cuda.is_available():
- if has_mps():
- print("没有发现支持的N卡, 使用MPS进行推理")
- device = "mps"
- else:
- print("没有发现支持的N卡, 使用CPU进行推理")
- device = "cpu"
- is_half = False
-
-if device not in ["cpu", "mps"]:
- gpu_name = torch.cuda.get_device_name(int(device.split(":")[-1]))
- if "16" in gpu_name or "MX" in gpu_name:
- print("16系显卡/MX系显卡强制单精度")
- is_half = False
-
-from multiprocessing import cpu_count
-
-if n_cpu == 0:
- n_cpu = cpu_count()
-if is_half:
- # 6G显存配置
- x_pad = 3
- x_query = 10
- x_center = 60
- x_max = 65
-else:
- # 5G显存配置
- x_pad = 1
- x_query = 6
- x_center = 38
- x_max = 41
diff --git a/spaces/Nunchakuka/FrenchAnonymizer/speaker_encoder/data_objects/random_cycler.py b/spaces/Nunchakuka/FrenchAnonymizer/speaker_encoder/data_objects/random_cycler.py
deleted file mode 100644
index c405db6b27f46d874d8feb37e3f9c1e12c251109..0000000000000000000000000000000000000000
--- a/spaces/Nunchakuka/FrenchAnonymizer/speaker_encoder/data_objects/random_cycler.py
+++ /dev/null
@@ -1,37 +0,0 @@
-import random
-
-class RandomCycler:
- """
- Creates an internal copy of a sequence and allows access to its items in a constrained random
- order. For a source sequence of n items and one or several consecutive queries of a total
- of m items, the following guarantees hold (one implies the other):
- - Each item will be returned between m // n and ((m - 1) // n) + 1 times.
- - Between two appearances of the same item, there may be at most 2 * (n - 1) other items.
- """
-
- def __init__(self, source):
- if len(source) == 0:
- raise Exception("Can't create RandomCycler from an empty collection")
- self.all_items = list(source)
- self.next_items = []
-
- def sample(self, count: int):
- shuffle = lambda l: random.sample(l, len(l))
-
- out = []
- while count > 0:
- if count >= len(self.all_items):
- out.extend(shuffle(list(self.all_items)))
- count -= len(self.all_items)
- continue
- n = min(count, len(self.next_items))
- out.extend(self.next_items[:n])
- count -= n
- self.next_items = self.next_items[n:]
- if len(self.next_items) == 0:
- self.next_items = shuffle(list(self.all_items))
- return out
-
- def __next__(self):
- return self.sample(1)[0]
-
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/clustering/utils.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/clustering/utils.py
deleted file mode 100644
index cf08d1fe4b470477b724aa8d770d91c0cac35a0e..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/clustering/utils.py
+++ /dev/null
@@ -1,20 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from typing import List, Tuple
-
-
-def get_audio_files(manifest_path: str) -> Tuple[str, List[str], List[int]]:
- fnames, sizes = [], []
- with open(manifest_path, "r") as f:
- root_dir = f.readline().strip()
- for line in f:
- items = line.strip().split("\t")
- assert (
- len(items) == 2
- ), f"File must have two columns separated by tab. Got {line}"
- fnames.append(items[0])
- sizes.append(int(items[1]))
- return root_dir, fnames, sizes
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/latent_depth/latent_depth_src/multilingual_translation_latent_depth.py b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/latent_depth/latent_depth_src/multilingual_translation_latent_depth.py
deleted file mode 100644
index 8cc2a7174b765b7ad8808489196e12082a91a2d7..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/latent_depth/latent_depth_src/multilingual_translation_latent_depth.py
+++ /dev/null
@@ -1,195 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from fairseq.tasks import register_task
-from fairseq.tasks.multilingual_translation import MultilingualTranslationTask
-from fairseq.utils import safe_hasattr
-
-from .loss.latent_depth import LatentLayersKLLoss, LatentLayersSparsityLoss
-
-
-@register_task("multilingual_translation_latent_depth")
-class MultilingualTranslationTaskLatentDepth(MultilingualTranslationTask):
- """A task for multiple translation with latent depth.
-
- See `"Deep Transformer with Latent Depth"
- (Li et al., 2020) `_.
- """
-
- @staticmethod
- def add_args(parser):
- """Add task-specific arguments to the parser."""
- # fmt: off
- MultilingualTranslationTask.add_args(parser)
- parser.add_argument('--encoder-latent-layer', action='store_true', help='latent layer selection in encoder')
- parser.add_argument('--decoder-latent-layer', action='store_true', help='latent layer selection in decoder')
- parser.add_argument('--target-layers', default=-1, type=int,
- help='number of effective layers to learn; -1 means no constraint')
- parser.add_argument('--sparsity-weight', default=0.0, type=float,
- help='weight for sparsity loss')
- parser.add_argument('--share-weight', default=0.0, type=float,
- help='weight for sharing loss')
- parser.add_argument('--soft-update', default=1, type=int,
- help='number of updates with soft sampling')
- parser.add_argument('--anneal-updates', default=1, type=int,
- help='number of updates to anneal the KL loss weight')
- parser.add_argument('--prior', default="uniform", type=str,
- help='prior used for computing KL loss')
- # fmt: on
-
- def __init__(self, args, dicts, training):
- super().__init__(args, dicts, training)
- self.src_langs, self.tgt_langs = zip(
- *[(lang.split("-")[0], lang.split("-")[1]) for lang in args.lang_pairs]
- )
- if self.training and self.encoder_latent_layer:
- assert self.args.share_encoders
- if self.training and self.decoder_latent_layer:
- assert self.args.share_decoders
- if training or self.encoder_latent_layer or self.decoder_latent_layer:
- self.lang_pairs = args.lang_pairs
- else:
- self.lang_pairs = ["{}-{}".format(args.source_lang, args.target_lang)]
- self.eval_lang_pairs = self.lang_pairs
- self.model_lang_pairs = self.lang_pairs
- if self.training and (self.encoder_latent_layer or self.decoder_latent_layer):
- self.kl_loss = LatentLayersKLLoss(self.args)
- self.sparsity_loss = LatentLayersSparsityLoss(self.args)
-
- def _per_lang_pair_train_loss(
- self, lang_pair, model, update_num, criterion, sample, optimizer, ignore_grad
- ):
- src, tgt = lang_pair.split("-")
- if self.encoder_latent_layer:
- src_lang_idx = self.src_lang_idx_dict[src]
- model.models[lang_pair].encoder.set_lang_idx(src_lang_idx)
- model.models[lang_pair].encoder.layer_select.hard_select = (
- update_num > self.args.soft_update
- )
- if self.decoder_latent_layer:
- tgt_lang_idx = self.tgt_lang_idx_dict[tgt]
- model.models[lang_pair].decoder.set_lang_idx(tgt_lang_idx)
- model.models[lang_pair].decoder.layer_select.hard_select = (
- update_num > self.args.soft_update
- )
-
- loss, sample_size, logging_output = criterion(
- model.models[lang_pair], sample[lang_pair]
- )
- if self.encoder_latent_layer:
- none_samples = sum(
- 1 if x is None else 0
- for x in model.models[lang_pair].encoder.layer_select.layer_samples
- )
- if none_samples == 0 or self.args.prior != "agged_posterior":
- loss += self.kl_loss(
- model.models[lang_pair].encoder.layer_select.layer_samples,
- src_lang_idx,
- update_num,
- sample_size,
- )
- if self.decoder_latent_layer:
- none_samples = sum(
- 1 if x is None else 0
- for x in model.models[lang_pair].decoder.layer_select.layer_samples
- )
- if none_samples == 0 or self.args.prior != "agged_posterior":
- loss += self.kl_loss(
- model.models[lang_pair].decoder.layer_select.layer_samples,
- tgt_lang_idx,
- update_num,
- sample_size,
- )
- if ignore_grad:
- loss *= 0
-
- if hasattr(self, "sparsity_loss") and self.sparsity_loss.is_valid(update_num):
- # need to retain the graph if sparsity loss needs to be added
- loss.backward(retain_graph=True)
- else:
- optimizer.backward(loss)
-
- return loss, sample_size, logging_output
-
- def train_step(
- self, sample, model, criterion, optimizer, update_num, ignore_grad=False
- ):
- agg_loss, agg_sample_size, agg_logging_output = super().train_step(
- sample, model, criterion, optimizer, update_num, ignore_grad
- )
- # compute auxiliary loss from layere sparsity, based on all samples from all languages
- if hasattr(self, "sparsity_loss") and self.sparsity_loss.is_valid(update_num):
- sparsity_loss = 0
- if self.encoder_latent_layer:
- sparsity_loss += self.sparsity_loss(
- next(
- iter(model.models.values())
- ).encoder.layer_select.layer_samples,
- update_num,
- agg_sample_size,
- )
- if self.decoder_latent_layer:
- sparsity_loss += self.sparsity_loss(
- next(
- iter(model.models.values())
- ).decoder.layer_select.layer_samples,
- update_num,
- agg_sample_size,
- )
- if sparsity_loss > 0:
- optimizer.backward(sparsity_loss)
- return agg_loss, agg_sample_size, agg_logging_output
-
- def _per_lang_pair_valid_loss(self, lang_pair, model, criterion, sample):
- src, tgt = lang_pair.split("-")
- if self.encoder_latent_layer:
- src_lang_idx = self.src_lang_idx_dict[src]
- model.models[lang_pair].encoder.set_lang_idx(src_lang_idx)
- if self.decoder_latent_layer:
- tgt_lang_idx = self.tgt_lang_idx_dict[tgt]
- model.models[lang_pair].decoder.set_lang_idx(tgt_lang_idx)
- loss, sample_size, logging_output = criterion(
- model.models[lang_pair], sample[lang_pair]
- )
- return loss, sample_size, logging_output
-
- def inference_step(
- self, generator, models, sample, prefix_tokens=None, constraints=None
- ):
- if self.encoder_latent_layer or self.decoder_latent_layer:
- for model in models:
- if self.encoder_latent_layer:
- assert model.encoder.layer_select is not None
- src_lang_idx = self.src_lang_idx_dict[self.args.source_lang]
- model.encoder.set_lang_idx(src_lang_idx)
- if self.decoder_latent_layer:
- assert model.decoder.layer_select is not None
- tgt_lang_idx = self.tgt_lang_idx_dict[self.args.target_lang]
- model.decoder.set_lang_idx(tgt_lang_idx)
- return super().inference_step(
- generator, models, sample, prefix_tokens, constraints
- )
-
- @property
- def encoder_latent_layer(self):
- return (
- safe_hasattr(self.args, "encoder_latent_layer")
- and self.args.encoder_latent_layer
- )
-
- @property
- def decoder_latent_layer(self):
- return (
- safe_hasattr(self.args, "decoder_latent_layer")
- and self.args.decoder_latent_layer
- )
-
- @property
- def src_lang_idx_dict(self):
- return {lang: lang_idx for lang_idx, lang in enumerate(self.src_langs)}
-
- @property
- def tgt_lang_idx_dict(self):
- return {lang: lang_idx for lang_idx, lang in enumerate(self.tgt_langs)}
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/speech_synthesis/generate_waveform.py b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/speech_synthesis/generate_waveform.py
deleted file mode 100644
index bfc2ef8eb3d91366caf7609d75aa1795ab0ed8f9..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/speech_synthesis/generate_waveform.py
+++ /dev/null
@@ -1,191 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-
-import logging
-import matplotlib.pyplot as plt
-import numpy as np
-from pathlib import Path
-import soundfile as sf
-import sys
-import torch
-import torchaudio
-
-from fairseq import checkpoint_utils, options, tasks, utils
-from fairseq.logging import progress_bar
-from fairseq.tasks.text_to_speech import plot_tts_output
-from fairseq.data.audio.text_to_speech_dataset import TextToSpeechDataset
-
-
-logging.basicConfig()
-logging.root.setLevel(logging.INFO)
-logging.basicConfig(level=logging.INFO)
-logger = logging.getLogger(__name__)
-
-
-def make_parser():
- parser = options.get_speech_generation_parser()
- parser.add_argument("--dump-features", action="store_true")
- parser.add_argument("--dump-waveforms", action="store_true")
- parser.add_argument("--dump-attentions", action="store_true")
- parser.add_argument("--dump-eos-probs", action="store_true")
- parser.add_argument("--dump-plots", action="store_true")
- parser.add_argument("--dump-target", action="store_true")
- parser.add_argument("--output-sample-rate", default=22050, type=int)
- parser.add_argument("--teacher-forcing", action="store_true")
- parser.add_argument(
- "--audio-format", type=str, default="wav", choices=["wav", "flac"]
- )
- return parser
-
-
-def postprocess_results(
- dataset: TextToSpeechDataset, sample, hypos, resample_fn, dump_target
-):
- def to_np(x):
- return None if x is None else x.detach().cpu().numpy()
-
- sample_ids = [dataset.ids[i] for i in sample["id"].tolist()]
- texts = sample["src_texts"]
- attns = [to_np(hypo["attn"]) for hypo in hypos]
- eos_probs = [to_np(hypo.get("eos_prob", None)) for hypo in hypos]
- feat_preds = [to_np(hypo["feature"]) for hypo in hypos]
- wave_preds = [to_np(resample_fn(h["waveform"])) for h in hypos]
- if dump_target:
- feat_targs = [to_np(hypo["targ_feature"]) for hypo in hypos]
- wave_targs = [to_np(resample_fn(h["targ_waveform"])) for h in hypos]
- else:
- feat_targs = [None for _ in hypos]
- wave_targs = [None for _ in hypos]
-
- return zip(sample_ids, texts, attns, eos_probs, feat_preds, wave_preds,
- feat_targs, wave_targs)
-
-
-def dump_result(
- is_na_model,
- args,
- vocoder,
- sample_id,
- text,
- attn,
- eos_prob,
- feat_pred,
- wave_pred,
- feat_targ,
- wave_targ,
-):
- sample_rate = args.output_sample_rate
- out_root = Path(args.results_path)
- if args.dump_features:
- feat_dir = out_root / "feat"
- feat_dir.mkdir(exist_ok=True, parents=True)
- np.save(feat_dir / f"{sample_id}.npy", feat_pred)
- if args.dump_target:
- feat_tgt_dir = out_root / "feat_tgt"
- feat_tgt_dir.mkdir(exist_ok=True, parents=True)
- np.save(feat_tgt_dir / f"{sample_id}.npy", feat_targ)
- if args.dump_attentions:
- attn_dir = out_root / "attn"
- attn_dir.mkdir(exist_ok=True, parents=True)
- np.save(attn_dir / f"{sample_id}.npy", attn.numpy())
- if args.dump_eos_probs and not is_na_model:
- eos_dir = out_root / "eos"
- eos_dir.mkdir(exist_ok=True, parents=True)
- np.save(eos_dir / f"{sample_id}.npy", eos_prob)
-
- if args.dump_plots:
- images = [feat_pred.T] if is_na_model else [feat_pred.T, attn]
- names = ["output"] if is_na_model else ["output", "alignment"]
- if feat_targ is not None:
- images = [feat_targ.T] + images
- names = [f"target (idx={sample_id})"] + names
- if is_na_model:
- plot_tts_output(images, names, attn, "alignment", suptitle=text)
- else:
- plot_tts_output(images, names, eos_prob, "eos prob", suptitle=text)
- plot_dir = out_root / "plot"
- plot_dir.mkdir(exist_ok=True, parents=True)
- plt.savefig(plot_dir / f"{sample_id}.png")
- plt.close()
-
- if args.dump_waveforms:
- ext = args.audio_format
- if wave_pred is not None:
- wav_dir = out_root / f"{ext}_{sample_rate}hz_{vocoder}"
- wav_dir.mkdir(exist_ok=True, parents=True)
- sf.write(wav_dir / f"{sample_id}.{ext}", wave_pred, sample_rate)
- if args.dump_target and wave_targ is not None:
- wav_tgt_dir = out_root / f"{ext}_{sample_rate}hz_{vocoder}_tgt"
- wav_tgt_dir.mkdir(exist_ok=True, parents=True)
- sf.write(wav_tgt_dir / f"{sample_id}.{ext}", wave_targ, sample_rate)
-
-
-def main(args):
- assert(args.dump_features or args.dump_waveforms or args.dump_attentions
- or args.dump_eos_probs or args.dump_plots)
- if args.max_tokens is None and args.batch_size is None:
- args.max_tokens = 8000
- logger.info(args)
-
- use_cuda = torch.cuda.is_available() and not args.cpu
- task = tasks.setup_task(args)
- models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task(
- [args.path],
- task=task,
- )
- model = models[0].cuda() if use_cuda else models[0]
- # use the original n_frames_per_step
- task.args.n_frames_per_step = saved_cfg.task.n_frames_per_step
- task.load_dataset(args.gen_subset, task_cfg=saved_cfg.task)
-
- data_cfg = task.data_cfg
- sample_rate = data_cfg.config.get("features", {}).get("sample_rate", 22050)
- resample_fn = {
- False: lambda x: x,
- True: lambda x: torchaudio.sox_effects.apply_effects_tensor(
- x.detach().cpu().unsqueeze(0), sample_rate,
- [['rate', str(args.output_sample_rate)]]
- )[0].squeeze(0)
- }.get(args.output_sample_rate != sample_rate)
- if args.output_sample_rate != sample_rate:
- logger.info(f"resampling to {args.output_sample_rate}Hz")
-
- generator = task.build_generator([model], args)
- itr = task.get_batch_iterator(
- dataset=task.dataset(args.gen_subset),
- max_tokens=args.max_tokens,
- max_sentences=args.batch_size,
- max_positions=(sys.maxsize, sys.maxsize),
- ignore_invalid_inputs=args.skip_invalid_size_inputs_valid_test,
- required_batch_size_multiple=args.required_batch_size_multiple,
- num_shards=args.num_shards,
- shard_id=args.shard_id,
- num_workers=args.num_workers,
- data_buffer_size=args.data_buffer_size,
- ).next_epoch_itr(shuffle=False)
-
- Path(args.results_path).mkdir(exist_ok=True, parents=True)
- is_na_model = getattr(model, "NON_AUTOREGRESSIVE", False)
- dataset = task.dataset(args.gen_subset)
- vocoder = task.args.vocoder
- with progress_bar.build_progress_bar(args, itr) as t:
- for sample in t:
- sample = utils.move_to_cuda(sample) if use_cuda else sample
- hypos = generator.generate(model, sample, has_targ=args.dump_target)
- for result in postprocess_results(
- dataset, sample, hypos, resample_fn, args.dump_target
- ):
- dump_result(is_na_model, args, vocoder, *result)
-
-
-def cli_main():
- parser = make_parser()
- args = options.parse_args_and_arch(parser)
- main(args)
-
-
-if __name__ == "__main__":
- cli_main()
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/criss/mining/mine.py b/spaces/OFA-Sys/OFA-vqa/fairseq/examples/criss/mining/mine.py
deleted file mode 100644
index c872da196fe0df776622365748ad7963fee1f0a0..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/criss/mining/mine.py
+++ /dev/null
@@ -1,240 +0,0 @@
-#!/usr/bin/env python3 -u
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-import argparse
-import glob
-from subprocess import check_call
-
-try:
- import faiss
-
- has_faiss = True
-except ImportError:
- has_faiss = False
-import numpy as np
-
-
-GB = 1024 * 1024 * 1024
-
-
-def call(cmd):
- print(cmd)
- check_call(cmd, shell=True)
-
-
-def get_batches(directory, lang, prefix="all_avg_pool"):
- print(f"Finding in {directory}/{prefix}.{lang}*")
- files = glob.glob(f"{directory}/{prefix}.{lang}*")
- emb_files = []
- txt_files = []
- for emb_fi in files:
- emb_files.append(emb_fi)
- txt_fi = emb_fi.replace(prefix, "sentences")
- txt_files.append(txt_fi)
- return emb_files, txt_files
-
-
-def load_batch(emb_file, dim):
- embeddings = np.fromfile(emb_file, dtype=np.float32)
- num_rows = int(embeddings.shape[0] / dim)
- embeddings = embeddings.reshape((num_rows, dim))
- faiss.normalize_L2(embeddings)
- return embeddings
-
-
-def knnGPU_sharded(x_batches_f, y_batches_f, dim, k, direction="x2y"):
- if not has_faiss:
- raise ImportError("Please install Faiss")
- sims = []
- inds = []
- xfrom = 0
- xto = 0
- for x_batch_f in x_batches_f:
- yfrom = 0
- yto = 0
- x_batch = load_batch(x_batch_f, dim)
- xto = xfrom + x_batch.shape[0]
- bsims, binds = [], []
- for y_batch_f in y_batches_f:
- y_batch = load_batch(y_batch_f, dim)
- neighbor_size = min(k, y_batch.shape[0])
- yto = yfrom + y_batch.shape[0]
- print("{}-{} -> {}-{}".format(xfrom, xto, yfrom, yto))
- idx = faiss.IndexFlatIP(dim)
- idx = faiss.index_cpu_to_all_gpus(idx)
- idx.add(y_batch)
- bsim, bind = idx.search(x_batch, neighbor_size)
-
- bsims.append(bsim)
- binds.append(bind + yfrom)
- yfrom += y_batch.shape[0]
- del idx
- del y_batch
- bsims = np.concatenate(bsims, axis=1)
- binds = np.concatenate(binds, axis=1)
- aux = np.argsort(-bsims, axis=1)
- sim_batch = np.zeros((x_batch.shape[0], k), dtype=np.float32)
- ind_batch = np.zeros((x_batch.shape[0], k), dtype=np.int64)
- for i in range(x_batch.shape[0]):
- for j in range(k):
- sim_batch[i, j] = bsims[i, aux[i, j]]
- ind_batch[i, j] = binds[i, aux[i, j]]
- sims.append(sim_batch)
- inds.append(ind_batch)
- xfrom += x_batch.shape[0]
- del x_batch
- sim = np.concatenate(sims, axis=0)
- ind = np.concatenate(inds, axis=0)
- return sim, ind
-
-
-def score(sim, fwd_mean, bwd_mean, margin):
- return margin(sim, (fwd_mean + bwd_mean) / 2)
-
-
-def score_candidates(
- sim_mat, candidate_inds, fwd_mean, bwd_mean, margin, verbose=False
-):
- print(" - scoring {:d} candidates".format(sim_mat.shape[0]))
- scores = np.zeros(candidate_inds.shape)
- for i in range(scores.shape[0]):
- for j in range(scores.shape[1]):
- k = int(candidate_inds[i, j])
- scores[i, j] = score(sim_mat[i, j], fwd_mean[i], bwd_mean[k], margin)
- return scores
-
-
-def load_text(files):
- all_sentences = []
- for fi in files:
- with open(fi) as sentence_fi:
- for line in sentence_fi:
- all_sentences.append(line.strip())
- print(f"Read {len(all_sentences)} sentences")
- return all_sentences
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Mine bitext")
- parser.add_argument("--src-lang", help="Source language")
- parser.add_argument("--tgt-lang", help="Target language")
- parser.add_argument(
- "--dict-path", help="Path to dictionary file", default="dict.txt"
- )
- parser.add_argument(
- "--spm-path", help="Path to SPM model file", default="sentence.bpe.model"
- )
- parser.add_argument("--dim", type=int, default=1024, help="Embedding dimension")
- parser.add_argument("--mem", type=int, default=5, help="Memory in GB")
- parser.add_argument("--src-dir", help="Source directory")
- parser.add_argument("--tgt-dir", help="Target directory")
- parser.add_argument("--output", help="Output path")
- parser.add_argument(
- "--neighborhood", type=int, default=4, help="Embedding dimension"
- )
- parser.add_argument(
- "--threshold", type=float, default=1.06, help="Threshold on mined bitext"
- )
- parser.add_argument(
- "--valid-size",
- type=int,
- default=2000,
- help="Number of sentences used for validation set",
- )
- parser.add_argument(
- "--min-count",
- type=int,
- default=50000,
- help="Min num sentences used for each language",
- )
- args = parser.parse_args()
-
- x_batches_f, x_sents_f = get_batches(args.src_dir, args.src_lang)
- y_batches_f, y_sents_f = get_batches(args.tgt_dir, args.tgt_lang)
- margin = lambda a, b: a / b
- y2x_sim, y2x_ind = knnGPU_sharded(
- y_batches_f, x_batches_f, args.dim, args.neighborhood, direction="y2x"
- )
- x2y_sim, x2y_ind = knnGPU_sharded(
- x_batches_f, y_batches_f, args.dim, args.neighborhood, direction="x2y"
- )
-
- x2y_mean = x2y_sim.mean(axis=1)
- y2x_mean = y2x_sim.mean(axis=1)
- fwd_scores = score_candidates(x2y_sim, x2y_ind, x2y_mean, y2x_mean, margin)
- bwd_scores = score_candidates(y2x_sim, y2x_ind, y2x_mean, x2y_mean, margin)
- fwd_best = x2y_ind[np.arange(x2y_sim.shape[0]), fwd_scores.argmax(axis=1)]
- bwd_best = y2x_ind[np.arange(y2x_sim.shape[0]), bwd_scores.argmax(axis=1)]
- indices = np.stack(
- (
- np.concatenate((np.arange(x2y_ind.shape[0]), bwd_best)),
- np.concatenate((fwd_best, np.arange(y2x_ind.shape[0]))),
- ),
- axis=1,
- )
- scores = np.concatenate((fwd_scores.max(axis=1), bwd_scores.max(axis=1)))
-
- x_sentences = load_text(x_sents_f)
- y_sentences = load_text(y_sents_f)
-
- threshold = args.threshold
- min_count = args.min_count
- seen_src, seen_trg = set(), set()
- directory = args.output
- call(f"mkdir -p {directory}")
- src_out = open(
- f"{directory}/all.{args.src_lang}",
- mode="w",
- encoding="utf-8",
- errors="surrogateescape",
- )
- tgt_out = open(
- f"{directory}/all.{args.tgt_lang}",
- mode="w",
- encoding="utf-8",
- errors="surrogateescape",
- )
- scores_out = open(
- f"{directory}/all.scores", mode="w", encoding="utf-8", errors="surrogateescape"
- )
- count = 0
- for i in np.argsort(-scores):
- src_ind, trg_ind = indices[i]
- if src_ind not in seen_src and trg_ind not in seen_trg:
- seen_src.add(src_ind)
- seen_trg.add(trg_ind)
- if scores[i] > threshold or count < min_count:
- if x_sentences[src_ind]:
- print(scores[i], file=scores_out)
- print(x_sentences[src_ind], file=src_out)
- print(y_sentences[trg_ind], file=tgt_out)
- count += 1
- else:
- print(f"Ignoring sentence: {x_sentences[src_ind]}")
- src_out.close()
- tgt_out.close()
- scores_out.close()
-
- print(f"Found {count} pairs for threshold={threshold}")
- with open(f"{directory}/all.{args.src_lang}") as all_s, open(
- f"{directory}/all.{args.tgt_lang}"
- ) as all_t, open(f"{directory}/valid.{args.src_lang}", "w") as valid_s, open(
- f"{directory}/valid.{args.tgt_lang}", "w"
- ) as valid_t, open(
- f"{directory}/train.{args.src_lang}", "w"
- ) as train_s, open(
- f"{directory}/train.{args.tgt_lang}", "w"
- ) as train_t:
- count = 0
- for s_line, t_line in zip(all_s, all_t):
- s_line = s_line.split("\t")[1]
- t_line = t_line.split("\t")[1]
- if count >= args.valid_size:
- train_s.write(s_line)
- train_t.write(t_line)
- else:
- valid_s.write(s_line)
- valid_t.write(t_line)
- count += 1
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/textless_nlp/gslm/metrics/abx_metrics/dump_abx_feats.py b/spaces/OFA-Sys/OFA-vqa/fairseq/examples/textless_nlp/gslm/metrics/abx_metrics/dump_abx_feats.py
deleted file mode 100644
index 41cf558970608fa5a9241e91e59ba214b609dc73..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/textless_nlp/gslm/metrics/abx_metrics/dump_abx_feats.py
+++ /dev/null
@@ -1,107 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import argparse
-import logging
-import os
-
-import joblib
-import numpy as np
-
-from examples.textless_nlp.gslm.speech2unit.clustering.utils import get_audio_files
-from examples.textless_nlp.gslm.speech2unit.pretrained.utils import get_features
-
-def get_logger():
- log_format = "[%(asctime)s] [%(levelname)s]: %(message)s"
- logging.basicConfig(format=log_format, level=logging.INFO)
- logger = logging.getLogger(__name__)
- return logger
-
-def get_parser():
- parser = argparse.ArgumentParser(
- description="Quantize using K-means clustering over acoustic features."
- )
- parser.add_argument(
- "--feature_type",
- type=str,
- choices=["logmel", "hubert", "w2v2", "cpc"],
- default=None,
- required=True,
- help="Acoustic feature type",
- )
- parser.add_argument(
- "--kmeans_model_path",
- type=str,
- required=True,
- help="K-means model file path to use for inference",
- )
- parser.add_argument(
- "--manifest_path",
- type=str,
- default=None,
- help="Manifest file containing the root dir and file names",
- )
- parser.add_argument(
- "--checkpoint_path",
- type=str,
- help="Pretrained model checkpoint",
- )
- parser.add_argument(
- "--layer",
- type=int,
- help="The layer of the pretrained model to extract features from",
- default=-1,
- )
- parser.add_argument(
- "--out_dir_path",
- required=True,
- type=str,
- help="File path of quantized output.",
- )
- parser.add_argument(
- "--extension", type=str, default=".flac", help="Features file path"
- )
- return parser
-
-
-def one_hot(feat, n_clusters):
- return np.eye(n_clusters)[feat]
-
-def main(args, logger):
- # Feature extraction
- logger.info(f"Extracting {args.feature_type} acoustic features...")
- features_batch = get_features(
- feature_type=args.feature_type,
- checkpoint_path=args.checkpoint_path,
- layer=args.layer,
- manifest_path=args.manifest_path,
- sample_pct=1.0,
- flatten=False,
- )
- logger.info(f"Features extracted for {len(features_batch)} utterances.\n")
- logger.info(f"Dimensionality of representation = {features_batch[0].shape[1]}")
-
- logger.info(f"Loading K-means model from {args.kmeans_model_path} ...")
- kmeans_model = joblib.load(open(args.kmeans_model_path, "rb"))
- kmeans_model.verbose = False
-
- _, fnames, _ = get_audio_files(args.manifest_path)
-
- os.makedirs(args.out_dir_path, exist_ok=True)
- logger.info(f"Writing quantized features to {args.out_dir_path}")
- for i, feats in enumerate(features_batch):
- pred = kmeans_model.predict(feats)
- emb = one_hot(pred, kmeans_model.n_clusters)
- base_fname = os.path.basename(fnames[i]).rstrip(args.extension)
- output_path = os.path.join(args.out_dir_path, f"{base_fname}.npy")
- with open(output_path, "wb") as f:
- np.save(f, emb)
-
-if __name__ == "__main__":
- parser = get_parser()
- args = parser.parse_args()
- logger = get_logger()
- logger.info(args)
- main(args, logger)
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/textless_nlp/gslm/unit2speech/glow.py b/spaces/OFA-Sys/OFA-vqa/fairseq/examples/textless_nlp/gslm/unit2speech/glow.py
deleted file mode 100644
index 7a7696403d505afdf0f1606f8220801b0f46152f..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/textless_nlp/gslm/unit2speech/glow.py
+++ /dev/null
@@ -1,311 +0,0 @@
-# *****************************************************************************
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Redistribution and use in source and binary forms, with or without
-# modification, are permitted provided that the following conditions are met:
-# * Redistributions of source code must retain the above copyright
-# notice, this list of conditions and the following disclaimer.
-# * Redistributions in binary form must reproduce the above copyright
-# notice, this list of conditions and the following disclaimer in the
-# documentation and/or other materials provided with the distribution.
-# * Neither the name of the NVIDIA CORPORATION nor the
-# names of its contributors may be used to endorse or promote products
-# derived from this software without specific prior written permission.
-#
-# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
-# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
-# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
-# DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
-# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
-# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
-# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
-# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
-# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
-# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
-#
-# *****************************************************************************
-import copy
-import torch
-from torch.autograd import Variable
-import torch.nn.functional as F
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a+input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-class WaveGlowLoss(torch.nn.Module):
- def __init__(self, sigma=1.0):
- super(WaveGlowLoss, self).__init__()
- self.sigma = sigma
-
- def forward(self, model_output):
- z, log_s_list, log_det_W_list = model_output
- for i, log_s in enumerate(log_s_list):
- if i == 0:
- log_s_total = torch.sum(log_s)
- log_det_W_total = log_det_W_list[i]
- else:
- log_s_total = log_s_total + torch.sum(log_s)
- log_det_W_total += log_det_W_list[i]
-
- loss = torch.sum(z*z)/(2*self.sigma*self.sigma) - log_s_total - log_det_W_total
- return loss/(z.size(0)*z.size(1)*z.size(2))
-
-
-class Invertible1x1Conv(torch.nn.Module):
- """
- The layer outputs both the convolution, and the log determinant
- of its weight matrix. If reverse=True it does convolution with
- inverse
- """
- def __init__(self, c):
- super(Invertible1x1Conv, self).__init__()
- self.conv = torch.nn.Conv1d(c, c, kernel_size=1, stride=1, padding=0,
- bias=False)
-
- # Sample a random orthonormal matrix to initialize weights
- W = torch.qr(torch.FloatTensor(c, c).normal_())[0]
-
- # Ensure determinant is 1.0 not -1.0
- if torch.det(W) < 0:
- W[:,0] = -1*W[:,0]
- W = W.view(c, c, 1)
- self.conv.weight.data = W
-
- def forward(self, z, reverse=False):
- # shape
- batch_size, group_size, n_of_groups = z.size()
-
- W = self.conv.weight.squeeze()
-
- if reverse:
- if not hasattr(self, 'W_inverse'):
- # Reverse computation
- W_inverse = W.float().inverse()
- W_inverse = Variable(W_inverse[..., None])
- if z.type() == 'torch.cuda.HalfTensor':
- W_inverse = W_inverse.half()
- self.W_inverse = W_inverse
- z = F.conv1d(z, self.W_inverse, bias=None, stride=1, padding=0)
- return z
- else:
- # Forward computation
- log_det_W = batch_size * n_of_groups * torch.logdet(W)
- z = self.conv(z)
- return z, log_det_W
-
-
-class WN(torch.nn.Module):
- """
- This is the WaveNet like layer for the affine coupling. The primary difference
- from WaveNet is the convolutions need not be causal. There is also no dilation
- size reset. The dilation only doubles on each layer
- """
- def __init__(self, n_in_channels, n_mel_channels, n_layers, n_channels,
- kernel_size):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- assert(n_channels % 2 == 0)
- self.n_layers = n_layers
- self.n_channels = n_channels
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
-
- start = torch.nn.Conv1d(n_in_channels, n_channels, 1)
- start = torch.nn.utils.weight_norm(start, name='weight')
- self.start = start
-
- # Initializing last layer to 0 makes the affine coupling layers
- # do nothing at first. This helps with training stability
- end = torch.nn.Conv1d(n_channels, 2*n_in_channels, 1)
- end.weight.data.zero_()
- end.bias.data.zero_()
- self.end = end
-
- cond_layer = torch.nn.Conv1d(n_mel_channels, 2*n_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = 2 ** i
- padding = int((kernel_size*dilation - dilation)/2)
- in_layer = torch.nn.Conv1d(n_channels, 2*n_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2*n_channels
- else:
- res_skip_channels = n_channels
- res_skip_layer = torch.nn.Conv1d(n_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, forward_input):
- audio, spect = forward_input
- audio = self.start(audio)
- output = torch.zeros_like(audio)
- n_channels_tensor = torch.IntTensor([self.n_channels])
-
- spect = self.cond_layer(spect)
-
- for i in range(self.n_layers):
- spect_offset = i*2*self.n_channels
- acts = fused_add_tanh_sigmoid_multiply(
- self.in_layers[i](audio),
- spect[:,spect_offset:spect_offset+2*self.n_channels,:],
- n_channels_tensor)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- audio = audio + res_skip_acts[:,:self.n_channels,:]
- output = output + res_skip_acts[:,self.n_channels:,:]
- else:
- output = output + res_skip_acts
-
- return self.end(output)
-
-
-class WaveGlow(torch.nn.Module):
- def __init__(self, n_mel_channels, n_flows, n_group, n_early_every,
- n_early_size, WN_config):
- super(WaveGlow, self).__init__()
-
- self.upsample = torch.nn.ConvTranspose1d(n_mel_channels,
- n_mel_channels,
- 1024, stride=256)
- assert(n_group % 2 == 0)
- self.n_flows = n_flows
- self.n_group = n_group
- self.n_early_every = n_early_every
- self.n_early_size = n_early_size
- self.WN = torch.nn.ModuleList()
- self.convinv = torch.nn.ModuleList()
-
- n_half = int(n_group/2)
-
- # Set up layers with the right sizes based on how many dimensions
- # have been output already
- n_remaining_channels = n_group
- for k in range(n_flows):
- if k % self.n_early_every == 0 and k > 0:
- n_half = n_half - int(self.n_early_size/2)
- n_remaining_channels = n_remaining_channels - self.n_early_size
- self.convinv.append(Invertible1x1Conv(n_remaining_channels))
- self.WN.append(WN(n_half, n_mel_channels*n_group, **WN_config))
- self.n_remaining_channels = n_remaining_channels # Useful during inference
-
- def forward(self, forward_input):
- """
- forward_input[0] = mel_spectrogram: batch x n_mel_channels x frames
- forward_input[1] = audio: batch x time
- """
- spect, audio = forward_input
-
- # Upsample spectrogram to size of audio
- spect = self.upsample(spect)
- assert(spect.size(2) >= audio.size(1))
- if spect.size(2) > audio.size(1):
- spect = spect[:, :, :audio.size(1)]
-
- spect = spect.unfold(2, self.n_group, self.n_group).permute(0, 2, 1, 3)
- spect = spect.contiguous().view(spect.size(0), spect.size(1), -1).permute(0, 2, 1)
-
- audio = audio.unfold(1, self.n_group, self.n_group).permute(0, 2, 1)
- output_audio = []
- log_s_list = []
- log_det_W_list = []
-
- for k in range(self.n_flows):
- if k % self.n_early_every == 0 and k > 0:
- output_audio.append(audio[:,:self.n_early_size,:])
- audio = audio[:,self.n_early_size:,:]
-
- audio, log_det_W = self.convinv[k](audio)
- log_det_W_list.append(log_det_W)
-
- n_half = int(audio.size(1)/2)
- audio_0 = audio[:,:n_half,:]
- audio_1 = audio[:,n_half:,:]
-
- output = self.WN[k]((audio_0, spect))
- log_s = output[:, n_half:, :]
- b = output[:, :n_half, :]
- audio_1 = torch.exp(log_s)*audio_1 + b
- log_s_list.append(log_s)
-
- audio = torch.cat([audio_0, audio_1],1)
-
- output_audio.append(audio)
- return torch.cat(output_audio,1), log_s_list, log_det_W_list
-
- def infer(self, spect, sigma=1.0):
- spect = self.upsample(spect)
- # trim conv artifacts. maybe pad spec to kernel multiple
- time_cutoff = self.upsample.kernel_size[0] - self.upsample.stride[0]
- spect = spect[:, :, :-time_cutoff]
-
- spect = spect.unfold(2, self.n_group, self.n_group).permute(0, 2, 1, 3)
- spect = spect.contiguous().view(spect.size(0), spect.size(1), -1).permute(0, 2, 1)
-
- if spect.type() == 'torch.cuda.HalfTensor':
- audio = torch.cuda.HalfTensor(spect.size(0),
- self.n_remaining_channels,
- spect.size(2)).normal_()
- else:
- audio = torch.cuda.FloatTensor(spect.size(0),
- self.n_remaining_channels,
- spect.size(2)).normal_()
-
- audio = torch.autograd.Variable(sigma*audio)
-
- for k in reversed(range(self.n_flows)):
- n_half = int(audio.size(1)/2)
- audio_0 = audio[:,:n_half,:]
- audio_1 = audio[:,n_half:,:]
-
- output = self.WN[k]((audio_0, spect))
-
- s = output[:, n_half:, :]
- b = output[:, :n_half, :]
- audio_1 = (audio_1 - b)/torch.exp(s)
- audio = torch.cat([audio_0, audio_1],1)
-
- audio = self.convinv[k](audio, reverse=True)
-
- if k % self.n_early_every == 0 and k > 0:
- if spect.type() == 'torch.cuda.HalfTensor':
- z = torch.cuda.HalfTensor(spect.size(0), self.n_early_size, spect.size(2)).normal_()
- else:
- z = torch.cuda.FloatTensor(spect.size(0), self.n_early_size, spect.size(2)).normal_()
- audio = torch.cat((sigma*z, audio),1)
-
- audio = audio.permute(0,2,1).contiguous().view(audio.size(0), -1).data
- return audio
-
- @staticmethod
- def remove_weightnorm(model):
- waveglow = model
- for WN in waveglow.WN:
- WN.start = torch.nn.utils.remove_weight_norm(WN.start)
- WN.in_layers = remove(WN.in_layers)
- WN.cond_layer = torch.nn.utils.remove_weight_norm(WN.cond_layer)
- WN.res_skip_layers = remove(WN.res_skip_layers)
- return waveglow
-
-
-def remove(conv_list):
- new_conv_list = torch.nn.ModuleList()
- for old_conv in conv_list:
- old_conv = torch.nn.utils.remove_weight_norm(old_conv)
- new_conv_list.append(old_conv)
- return new_conv_list
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/fairseq/modules/quantization/scalar/ops.py b/spaces/OFA-Sys/OFA-vqa/fairseq/fairseq/modules/quantization/scalar/ops.py
deleted file mode 100644
index c74f530380b393ffc53ecfb1398000079495772f..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/fairseq/modules/quantization/scalar/ops.py
+++ /dev/null
@@ -1,54 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import torch
-
-
-def emulate_int(w, bits, method, scale=None, zero_point=None):
- q = globals()[f"emulate_int8_{method}"]
- return q(w, scale=scale, zero_point=zero_point, bits=bits)
-
-
-def quantize(w, scale, zero_point, bits=8):
- # In the default behavior, max_val = 255.
- max_val = 2 ** bits - 1
- return (
- torch.clamp(torch.round(w / scale + zero_point), 0, max_val) - zero_point
- ) * scale
-
-
-def emulate_int8_histogram(w, scale=None, zero_point=None, bits=8):
- if scale is None:
- obs = torch.quantization.observer.HistogramObserver()
- obs.to(device=w.device)
- _ = obs(w.float())
- scale, zero_point = obs.calculate_qparams()
- scale = scale.cuda().type_as(w)
- zero_point = zero_point.cuda().type_as(w)
- return quantize(w, scale, zero_point, bits=bits), scale, zero_point
-
-
-def emulate_int8_channel(w, scale=None, zero_point=None, bits=8):
- if scale is None:
- obs = torch.quantization.observer.PerChannelMinMaxObserver(
- ch_axis=-1, qscheme=torch.per_channel_symmetric
- )
- obs.to(device=w.device)
- _ = obs(w)
- scale, zero_point, ch_axis = obs.get_qparams()
- scale = scale.cuda().type_as(w)
- zero_point = zero_point.cuda().type_as(w)
- return quantize(w, scale, zero_point, bits=bits), scale, zero_point
-
-
-def emulate_int8_tensor(w, scale=None, zero_point=None, bits=8):
- if scale is None:
- obs = torch.quantization.observer.MinMaxObserver()
- obs.to(device=w.device)
- _ = obs(w)
- scale, zero_point = obs.calculate_qparams()
- scale = scale.cuda().type_as(w)
- zero_point = zero_point.cuda().type_as(w)
- return quantize(w, scale, zero_point, bits=bits), scale, zero_point
diff --git a/spaces/OpenGVLab/InternGPT/third-party/lama/bin/models/ade20k/segm_lib/nn/modules/unittest.py b/spaces/OpenGVLab/InternGPT/third-party/lama/bin/models/ade20k/segm_lib/nn/modules/unittest.py
deleted file mode 100644
index 0675c022e4ba85d38d1f813490f6740150909524..0000000000000000000000000000000000000000
--- a/spaces/OpenGVLab/InternGPT/third-party/lama/bin/models/ade20k/segm_lib/nn/modules/unittest.py
+++ /dev/null
@@ -1,29 +0,0 @@
-# -*- coding: utf-8 -*-
-# File : unittest.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 27/01/2018
-#
-# This file is part of Synchronized-BatchNorm-PyTorch.
-# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
-# Distributed under MIT License.
-
-import unittest
-
-import numpy as np
-from torch.autograd import Variable
-
-
-def as_numpy(v):
- if isinstance(v, Variable):
- v = v.data
- return v.cpu().numpy()
-
-
-class TorchTestCase(unittest.TestCase):
- def assertTensorClose(self, a, b, atol=1e-3, rtol=1e-3):
- npa, npb = as_numpy(a), as_numpy(b)
- self.assertTrue(
- np.allclose(npa, npb, atol=atol),
- 'Tensor close check failed\n{}\n{}\nadiff={}, rdiff={}'.format(a, b, np.abs(npa - npb).max(), np.abs((npa - npb) / np.fmax(npa, 1e-5)).max())
- )
diff --git a/spaces/OpenMind-AI/starchat-playground/share_btn.py b/spaces/OpenMind-AI/starchat-playground/share_btn.py
deleted file mode 100644
index 14c0cc9147bd6aaadd9c1df07a763b542d696987..0000000000000000000000000000000000000000
--- a/spaces/OpenMind-AI/starchat-playground/share_btn.py
+++ /dev/null
@@ -1,111 +0,0 @@
-community_icon_html = """"""
-
-loading_icon_html = """"""
-
-share_js = """async () => {
- async function uploadFile(file){
- const UPLOAD_URL = 'https://huggingface.co/uploads';
- const response = await fetch(UPLOAD_URL, {
- method: 'POST',
- headers: {
- 'Content-Type': file.type,
- 'X-Requested-With': 'XMLHttpRequest',
- },
- body: file, /// <- File inherits from Blob
- });
- const url = await response.text();
- return url;
- }
-
- async function getInputImgFile(imgEl){
- const res = await fetch(imgEl.src);
- const blob = await res.blob();
- const imgId = Date.now() % 200;
- const isPng = imgEl.src.startsWith(`data:image/png`);
- if(isPng){
- const fileName = `sd-perception-${{imgId}}.png`;
- return new File([blob], fileName, { type: 'image/png' });
- }else{
- const fileName = `sd-perception-${{imgId}}.jpg`;
- return new File([blob], fileName, { type: 'image/jpeg' });
- }
- }
-
- // const gradioEl = document.querySelector('body > gradio-app');
- const gradioEl = document.querySelector("gradio-app");
- const inputTxt = gradioEl.querySelector('#q-input textarea').value;
- const outputTxt = gradioEl.querySelector('#q-output').outerHTML;
-
- const titleLength = 150;
- let titleTxt = inputTxt;
- if(titleTxt.length > titleLength){
- titleTxt = titleTxt.slice(0, titleLength) + ' ...';
- }
-
- const shareBtnEl = gradioEl.querySelector('#share-btn');
- const shareIconEl = gradioEl.querySelector('#share-btn-share-icon');
- const loadingIconEl = gradioEl.querySelector('#share-btn-loading-icon');
-
- if(!inputTxt || !outputTxt){
- return;
- };
-
- shareBtnEl.style.pointerEvents = 'none';
- shareIconEl.style.display = 'none';
- loadingIconEl.style.removeProperty('display');
-
- const descriptionMd = `### Question:
-${inputTxt}
-
-### Answer:
-
-${outputTxt}`;
-
- const params = {
- title: titleTxt,
- description: descriptionMd,
- };
-
- const paramsStr = Object.entries(params)
- .map(([key, value]) => `${encodeURIComponent(key)}=${encodeURIComponent(value)}`)
- .join('&');
-
- window.open(`https://huggingface.co/spaces/HuggingFaceH4/star-chat-demo/discussions/new?${paramsStr}`, '_blank');
-
- shareBtnEl.style.removeProperty('pointer-events');
- shareIconEl.style.removeProperty('display');
- loadingIconEl.style.display = 'none';
-}"""
-
-share_btn_css = """
-a {text-decoration-line: underline; font-weight: 600;}
-.animate-spin {
- animation: spin 1s linear infinite;
-}
-@keyframes spin {
- from { transform: rotate(0deg); }
- to { transform: rotate(360deg); }
-}
-#share-btn-container {
- display: flex; padding-left: 0.5rem !important; padding-right: 0.5rem !important; background-color: #000000; justify-content: center; align-items: center; border-radius: 9999px !important; width: 13rem;
-}
-#share-btn {
- all: initial; color: #ffffff;font-weight: 600; cursor:pointer; font-family: 'IBM Plex Sans', sans-serif; margin-left: 0.5rem !important; padding-top: 0.25rem !important; padding-bottom: 0.25rem !important;
-}
-#share-btn * {
- all: unset;
-}
-#share-btn-container div:nth-child(-n+2){
- width: auto !important;
- min-height: 0px !important;
-}
-#share-btn-container .wrap {
- display: none !important;
-}
-"""
diff --git a/spaces/OpenMotionLab/MotionGPT/pyrender/docs/source/conf.py b/spaces/OpenMotionLab/MotionGPT/pyrender/docs/source/conf.py
deleted file mode 100644
index 6bf194c375e7e789b334a838953adfeaf2eb59b6..0000000000000000000000000000000000000000
--- a/spaces/OpenMotionLab/MotionGPT/pyrender/docs/source/conf.py
+++ /dev/null
@@ -1,352 +0,0 @@
-# -*- coding: utf-8 -*-
-#
-# core documentation build configuration file, created by
-# sphinx-quickstart on Sun Oct 16 14:33:48 2016.
-#
-# This file is execfile()d with the current directory set to its
-# containing dir.
-#
-# Note that not all possible configuration values are present in this
-# autogenerated file.
-#
-# All configuration values have a default; values that are commented out
-# serve to show the default.
-
-import sys
-import os
-from pyrender import __version__
-from sphinx.domains.python import PythonDomain
-
-# If extensions (or modules to document with autodoc) are in another directory,
-# add these directories to sys.path here. If the directory is relative to the
-# documentation root, use os.path.abspath to make it absolute, like shown here.
-sys.path.insert(0, os.path.abspath('../../'))
-
-# -- General configuration ------------------------------------------------
-
-# If your documentation needs a minimal Sphinx version, state it here.
-#needs_sphinx = '1.0'
-
-# Add any Sphinx extension module names here, as strings. They can be
-# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
-# ones.
-extensions = [
- 'sphinx.ext.autodoc',
- 'sphinx.ext.autosummary',
- 'sphinx.ext.coverage',
- 'sphinx.ext.githubpages',
- 'sphinx.ext.intersphinx',
- 'sphinx.ext.napoleon',
- 'sphinx.ext.viewcode',
- 'sphinx_automodapi.automodapi',
- 'sphinx_automodapi.smart_resolver'
-]
-numpydoc_class_members_toctree = False
-automodapi_toctreedirnm = 'generated'
-automodsumm_inherited_members = True
-
-# Add any paths that contain templates here, relative to this directory.
-templates_path = ['_templates']
-
-# The suffix(es) of source filenames.
-# You can specify multiple suffix as a list of string:
-# source_suffix = ['.rst', '.md']
-source_suffix = '.rst'
-
-# The encoding of source files.
-#source_encoding = 'utf-8-sig'
-
-# The master toctree document.
-master_doc = 'index'
-
-# General information about the project.
-project = u'pyrender'
-copyright = u'2018, Matthew Matl'
-author = u'Matthew Matl'
-
-# The version info for the project you're documenting, acts as replacement for
-# |version| and |release|, also used in various other places throughout the
-# built documents.
-#
-# The short X.Y version.
-version = __version__
-# The full version, including alpha/beta/rc tags.
-release = __version__
-
-# The language for content autogenerated by Sphinx. Refer to documentation
-# for a list of supported languages.
-#
-# This is also used if you do content translation via gettext catalogs.
-# Usually you set "language" from the command line for these cases.
-language = None
-
-# There are two options for replacing |today|: either, you set today to some
-# non-false value, then it is used:
-#today = ''
-# Else, today_fmt is used as the format for a strftime call.
-#today_fmt = '%B %d, %Y'
-
-# List of patterns, relative to source directory, that match files and
-# directories to ignore when looking for source files.
-exclude_patterns = []
-
-# The reST default role (used for this markup: `text`) to use for all
-# documents.
-#default_role = None
-
-# If true, '()' will be appended to :func: etc. cross-reference text.
-#add_function_parentheses = True
-
-# If true, the current module name will be prepended to all description
-# unit titles (such as .. function::).
-#add_module_names = True
-
-# If true, sectionauthor and moduleauthor directives will be shown in the
-# output. They are ignored by default.
-#show_authors = False
-
-# The name of the Pygments (syntax highlighting) style to use.
-pygments_style = 'sphinx'
-
-# A list of ignored prefixes for module index sorting.
-#modindex_common_prefix = []
-
-# If true, keep warnings as "system message" paragraphs in the built documents.
-#keep_warnings = False
-
-# If true, `todo` and `todoList` produce output, else they produce nothing.
-todo_include_todos = False
-
-
-# -- Options for HTML output ----------------------------------------------
-
-# The theme to use for HTML and HTML Help pages. See the documentation for
-# a list of builtin themes.
-import sphinx_rtd_theme
-html_theme = 'sphinx_rtd_theme'
-html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
-
-# Theme options are theme-specific and customize the look and feel of a theme
-# further. For a list of options available for each theme, see the
-# documentation.
-#html_theme_options = {}
-
-# Add any paths that contain custom themes here, relative to this directory.
-#html_theme_path = []
-
-# The name for this set of Sphinx documents. If None, it defaults to
-# " v documentation".
-#html_title = None
-
-# A shorter title for the navigation bar. Default is the same as html_title.
-#html_short_title = None
-
-# The name of an image file (relative to this directory) to place at the top
-# of the sidebar.
-#html_logo = None
-
-# The name of an image file (relative to this directory) to use as a favicon of
-# the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
-# pixels large.
-#html_favicon = None
-
-# Add any paths that contain custom static files (such as style sheets) here,
-# relative to this directory. They are copied after the builtin static files,
-# so a file named "default.css" will overwrite the builtin "default.css".
-html_static_path = ['_static']
-
-# Add any extra paths that contain custom files (such as robots.txt or
-# .htaccess) here, relative to this directory. These files are copied
-# directly to the root of the documentation.
-#html_extra_path = []
-
-# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
-# using the given strftime format.
-#html_last_updated_fmt = '%b %d, %Y'
-
-# If true, SmartyPants will be used to convert quotes and dashes to
-# typographically correct entities.
-#html_use_smartypants = True
-
-# Custom sidebar templates, maps document names to template names.
-#html_sidebars = {}
-
-# Additional templates that should be rendered to pages, maps page names to
-# template names.
-#html_additional_pages = {}
-
-# If false, no module index is generated.
-#html_domain_indices = True
-
-# If false, no index is generated.
-#html_use_index = True
-
-# If true, the index is split into individual pages for each letter.
-#html_split_index = False
-
-# If true, links to the reST sources are added to the pages.
-#html_show_sourcelink = True
-
-# If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
-#html_show_sphinx = True
-
-# If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
-#html_show_copyright = True
-
-# If true, an OpenSearch description file will be output, and all pages will
-# contain a tag referring to it. The value of this option must be the
-# base URL from which the finished HTML is served.
-#html_use_opensearch = ''
-
-# This is the file name suffix for HTML files (e.g. ".xhtml").
-#html_file_suffix = None
-
-# Language to be used for generating the HTML full-text search index.
-# Sphinx supports the following languages:
-# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'
-# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'
-#html_search_language = 'en'
-
-# A dictionary with options for the search language support, empty by default.
-# Now only 'ja' uses this config value
-#html_search_options = {'type': 'default'}
-
-# The name of a javascript file (relative to the configuration directory) that
-# implements a search results scorer. If empty, the default will be used.
-#html_search_scorer = 'scorer.js'
-
-# Output file base name for HTML help builder.
-htmlhelp_basename = 'coredoc'
-
-# -- Options for LaTeX output ---------------------------------------------
-
-latex_elements = {
-# The paper size ('letterpaper' or 'a4paper').
-#'papersize': 'letterpaper',
-
-# The font size ('10pt', '11pt' or '12pt').
-#'pointsize': '10pt',
-
-# Additional stuff for the LaTeX preamble.
-#'preamble': '',
-
-# Latex figure (float) alignment
-#'figure_align': 'htbp',
-}
-
-# Grouping the document tree into LaTeX files. List of tuples
-# (source start file, target name, title,
-# author, documentclass [howto, manual, or own class]).
-latex_documents = [
- (master_doc, 'pyrender.tex', u'pyrender Documentation',
- u'Matthew Matl', 'manual'),
-]
-
-# The name of an image file (relative to this directory) to place at the top of
-# the title page.
-#latex_logo = None
-
-# For "manual" documents, if this is true, then toplevel headings are parts,
-# not chapters.
-#latex_use_parts = False
-
-# If true, show page references after internal links.
-#latex_show_pagerefs = False
-
-# If true, show URL addresses after external links.
-#latex_show_urls = False
-
-# Documents to append as an appendix to all manuals.
-#latex_appendices = []
-
-# If false, no module index is generated.
-#latex_domain_indices = True
-
-
-# -- Options for manual page output ---------------------------------------
-
-# One entry per manual page. List of tuples
-# (source start file, name, description, authors, manual section).
-man_pages = [
- (master_doc, 'pyrender', u'pyrender Documentation',
- [author], 1)
-]
-
-# If true, show URL addresses after external links.
-#man_show_urls = False
-
-
-# -- Options for Texinfo output -------------------------------------------
-
-# Grouping the document tree into Texinfo files. List of tuples
-# (source start file, target name, title, author,
-# dir menu entry, description, category)
-texinfo_documents = [
- (master_doc, 'pyrender', u'pyrender Documentation',
- author, 'pyrender', 'One line description of project.',
- 'Miscellaneous'),
-]
-
-# Documents to append as an appendix to all manuals.
-#texinfo_appendices = []
-
-# If false, no module index is generated.
-#texinfo_domain_indices = True
-
-# How to display URL addresses: 'footnote', 'no', or 'inline'.
-#texinfo_show_urls = 'footnote'
-
-# If true, do not generate a @detailmenu in the "Top" node's menu.
-#texinfo_no_detailmenu = False
-
-intersphinx_mapping = {
- 'python' : ('https://docs.python.org/', None),
- 'pyrender' : ('https://pyrender.readthedocs.io/en/latest/', None),
-}
-
-# Autosummary fix
-autosummary_generate = True
-
-# Try to suppress multiple-definition warnings by always taking the shorter
-# path when two or more paths have the same base module
-
-class MyPythonDomain(PythonDomain):
-
- def find_obj(self, env, modname, classname, name, type, searchmode=0):
- """Ensures an object always resolves to the desired module
- if defined there."""
- orig_matches = PythonDomain.find_obj(
- self, env, modname, classname, name, type, searchmode
- )
-
- if len(orig_matches) <= 1:
- return orig_matches
-
- # If multiple matches, try to take the shortest if all the modules are
- # the same
- first_match_name_sp = orig_matches[0][0].split('.')
- base_name = first_match_name_sp[0]
- min_len = len(first_match_name_sp)
- best_match = orig_matches[0]
-
- for match in orig_matches[1:]:
- match_name = match[0]
- match_name_sp = match_name.split('.')
- match_base = match_name_sp[0]
-
- # If we have mismatched bases, return them all to trigger warnings
- if match_base != base_name:
- return orig_matches
-
- # Otherwise, check and see if it's shorter
- if len(match_name_sp) < min_len:
- min_len = len(match_name_sp)
- best_match = match
-
- return (best_match,)
-
-
-def setup(sphinx):
- """Use MyPythonDomain in place of PythonDomain"""
- sphinx.override_domain(MyPythonDomain)
-
diff --git a/spaces/Pengyey/bingo-chuchu/src/lib/isomorphic/browser.ts b/spaces/Pengyey/bingo-chuchu/src/lib/isomorphic/browser.ts
deleted file mode 100644
index de125b1f1786d1618cb1ff47f403d76c6784f4ce..0000000000000000000000000000000000000000
--- a/spaces/Pengyey/bingo-chuchu/src/lib/isomorphic/browser.ts
+++ /dev/null
@@ -1,11 +0,0 @@
-'use client'
-
-const debug = console.info.bind(console)
-
-class WebSocketAlias extends WebSocket {
- constructor(address: string | URL, ...args: any) {
- super(address)
- }
-}
-
-export default { fetch, WebSocket: WebSocketAlias, debug }
diff --git a/spaces/Plachta/VITS-Umamusume-voice-synthesizer/text/korean.py b/spaces/Plachta/VITS-Umamusume-voice-synthesizer/text/korean.py
deleted file mode 100644
index edee07429a450c55e3d8e246997faaa1e0b89cc9..0000000000000000000000000000000000000000
--- a/spaces/Plachta/VITS-Umamusume-voice-synthesizer/text/korean.py
+++ /dev/null
@@ -1,210 +0,0 @@
-import re
-from jamo import h2j, j2hcj
-import ko_pron
-
-
-# This is a list of Korean classifiers preceded by pure Korean numerals.
-_korean_classifiers = '군데 권 개 그루 닢 대 두 마리 모 모금 뭇 발 발짝 방 번 벌 보루 살 수 술 시 쌈 움큼 정 짝 채 척 첩 축 켤레 톨 통'
-
-# List of (hangul, hangul divided) pairs:
-_hangul_divided = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄳ', 'ㄱㅅ'),
- ('ㄵ', 'ㄴㅈ'),
- ('ㄶ', 'ㄴㅎ'),
- ('ㄺ', 'ㄹㄱ'),
- ('ㄻ', 'ㄹㅁ'),
- ('ㄼ', 'ㄹㅂ'),
- ('ㄽ', 'ㄹㅅ'),
- ('ㄾ', 'ㄹㅌ'),
- ('ㄿ', 'ㄹㅍ'),
- ('ㅀ', 'ㄹㅎ'),
- ('ㅄ', 'ㅂㅅ'),
- ('ㅘ', 'ㅗㅏ'),
- ('ㅙ', 'ㅗㅐ'),
- ('ㅚ', 'ㅗㅣ'),
- ('ㅝ', 'ㅜㅓ'),
- ('ㅞ', 'ㅜㅔ'),
- ('ㅟ', 'ㅜㅣ'),
- ('ㅢ', 'ㅡㅣ'),
- ('ㅑ', 'ㅣㅏ'),
- ('ㅒ', 'ㅣㅐ'),
- ('ㅕ', 'ㅣㅓ'),
- ('ㅖ', 'ㅣㅔ'),
- ('ㅛ', 'ㅣㅗ'),
- ('ㅠ', 'ㅣㅜ')
-]]
-
-# List of (Latin alphabet, hangul) pairs:
-_latin_to_hangul = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('a', '에이'),
- ('b', '비'),
- ('c', '시'),
- ('d', '디'),
- ('e', '이'),
- ('f', '에프'),
- ('g', '지'),
- ('h', '에이치'),
- ('i', '아이'),
- ('j', '제이'),
- ('k', '케이'),
- ('l', '엘'),
- ('m', '엠'),
- ('n', '엔'),
- ('o', '오'),
- ('p', '피'),
- ('q', '큐'),
- ('r', '아르'),
- ('s', '에스'),
- ('t', '티'),
- ('u', '유'),
- ('v', '브이'),
- ('w', '더블유'),
- ('x', '엑스'),
- ('y', '와이'),
- ('z', '제트')
-]]
-
-# List of (ipa, lazy ipa) pairs:
-_ipa_to_lazy_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('t͡ɕ','ʧ'),
- ('d͡ʑ','ʥ'),
- ('ɲ','n^'),
- ('ɕ','ʃ'),
- ('ʷ','w'),
- ('ɭ','l`'),
- ('ʎ','ɾ'),
- ('ɣ','ŋ'),
- ('ɰ','ɯ'),
- ('ʝ','j'),
- ('ʌ','ə'),
- ('ɡ','g'),
- ('\u031a','#'),
- ('\u0348','='),
- ('\u031e',''),
- ('\u0320',''),
- ('\u0339','')
-]]
-
-
-def latin_to_hangul(text):
- for regex, replacement in _latin_to_hangul:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def divide_hangul(text):
- text = j2hcj(h2j(text))
- for regex, replacement in _hangul_divided:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def hangul_number(num, sino=True):
- '''Reference https://github.com/Kyubyong/g2pK'''
- num = re.sub(',', '', num)
-
- if num == '0':
- return '영'
- if not sino and num == '20':
- return '스무'
-
- digits = '123456789'
- names = '일이삼사오육칠팔구'
- digit2name = {d: n for d, n in zip(digits, names)}
-
- modifiers = '한 두 세 네 다섯 여섯 일곱 여덟 아홉'
- decimals = '열 스물 서른 마흔 쉰 예순 일흔 여든 아흔'
- digit2mod = {d: mod for d, mod in zip(digits, modifiers.split())}
- digit2dec = {d: dec for d, dec in zip(digits, decimals.split())}
-
- spelledout = []
- for i, digit in enumerate(num):
- i = len(num) - i - 1
- if sino:
- if i == 0:
- name = digit2name.get(digit, '')
- elif i == 1:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- else:
- if i == 0:
- name = digit2mod.get(digit, '')
- elif i == 1:
- name = digit2dec.get(digit, '')
- if digit == '0':
- if i % 4 == 0:
- last_three = spelledout[-min(3, len(spelledout)):]
- if ''.join(last_three) == '':
- spelledout.append('')
- continue
- else:
- spelledout.append('')
- continue
- if i == 2:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 3:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 4:
- name = digit2name.get(digit, '') + '만'
- name = name.replace('일만', '만')
- elif i == 5:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- elif i == 6:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 7:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 8:
- name = digit2name.get(digit, '') + '억'
- elif i == 9:
- name = digit2name.get(digit, '') + '십'
- elif i == 10:
- name = digit2name.get(digit, '') + '백'
- elif i == 11:
- name = digit2name.get(digit, '') + '천'
- elif i == 12:
- name = digit2name.get(digit, '') + '조'
- elif i == 13:
- name = digit2name.get(digit, '') + '십'
- elif i == 14:
- name = digit2name.get(digit, '') + '백'
- elif i == 15:
- name = digit2name.get(digit, '') + '천'
- spelledout.append(name)
- return ''.join(elem for elem in spelledout)
-
-
-def number_to_hangul(text):
- '''Reference https://github.com/Kyubyong/g2pK'''
- tokens = set(re.findall(r'(\d[\d,]*)([\uac00-\ud71f]+)', text))
- for token in tokens:
- num, classifier = token
- if classifier[:2] in _korean_classifiers or classifier[0] in _korean_classifiers:
- spelledout = hangul_number(num, sino=False)
- else:
- spelledout = hangul_number(num, sino=True)
- text = text.replace(f'{num}{classifier}', f'{spelledout}{classifier}')
- # digit by digit for remaining digits
- digits = '0123456789'
- names = '영일이삼사오육칠팔구'
- for d, n in zip(digits, names):
- text = text.replace(d, n)
- return text
-
-
-def korean_to_lazy_ipa(text):
- text = latin_to_hangul(text)
- text = number_to_hangul(text)
- text=re.sub('[\uac00-\ud7af]+',lambda x:ko_pron.romanise(x.group(0),'ipa').split('] ~ [')[0],text)
- for regex, replacement in _ipa_to_lazy_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def korean_to_ipa(text):
- text = korean_to_lazy_ipa(text)
- return text.replace('ʧ','tʃ').replace('ʥ','dʑ')
diff --git a/spaces/PrabhuKiranKonda/fastapi-postgres-todo-api/Dockerfile b/spaces/PrabhuKiranKonda/fastapi-postgres-todo-api/Dockerfile
deleted file mode 100644
index e77833e6f9071d99d973e3742f6fefcc015be058..0000000000000000000000000000000000000000
--- a/spaces/PrabhuKiranKonda/fastapi-postgres-todo-api/Dockerfile
+++ /dev/null
@@ -1,13 +0,0 @@
-FROM python:3.9-slim
-WORKDIR /app
-COPY requirements.txt ./requirements.txt
-RUN apt-get update \
- && apt-get -y install libpq-dev gcc \
- && pip install psycopg2
-# Install uvicorn
-RUN pip install uvicorn
-# Install dependencies
-RUN pip install -r requirements.txt
-COPY . /app
-ENTRYPOINT ["uvicorn", "main:app"]
-CMD ["--host", "0.0.0.0", "--port", "7860"]
\ No newline at end of file
diff --git a/spaces/RMXK/RVC_HFF/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py b/spaces/RMXK/RVC_HFF/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
deleted file mode 100644
index b2c592527a5966e6f8e79e8c52dc5b414246dcc6..0000000000000000000000000000000000000000
--- a/spaces/RMXK/RVC_HFF/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
+++ /dev/null
@@ -1,97 +0,0 @@
-from lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import parselmouth
-import numpy as np
-
-
-class PMF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def compute_f0(self, wav, p_len=None):
- x = wav
- if p_len is None:
- p_len = x.shape[0] // self.hop_length
- else:
- assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
- time_step = self.hop_length / self.sampling_rate * 1000
- f0 = (
- parselmouth.Sound(x, self.sampling_rate)
- .to_pitch_ac(
- time_step=time_step / 1000,
- voicing_threshold=0.6,
- pitch_floor=self.f0_min,
- pitch_ceiling=self.f0_max,
- )
- .selected_array["frequency"]
- )
-
- pad_size = (p_len - len(f0) + 1) // 2
- if pad_size > 0 or p_len - len(f0) - pad_size > 0:
- f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
- f0, uv = self.interpolate_f0(f0)
- return f0
-
- def compute_f0_uv(self, wav, p_len=None):
- x = wav
- if p_len is None:
- p_len = x.shape[0] // self.hop_length
- else:
- assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
- time_step = self.hop_length / self.sampling_rate * 1000
- f0 = (
- parselmouth.Sound(x, self.sampling_rate)
- .to_pitch_ac(
- time_step=time_step / 1000,
- voicing_threshold=0.6,
- pitch_floor=self.f0_min,
- pitch_ceiling=self.f0_max,
- )
- .selected_array["frequency"]
- )
-
- pad_size = (p_len - len(f0) + 1) // 2
- if pad_size > 0 or p_len - len(f0) - pad_size > 0:
- f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
- f0, uv = self.interpolate_f0(f0)
- return f0, uv
diff --git a/spaces/Rashid2026/Course-Recommender/app.py b/spaces/Rashid2026/Course-Recommender/app.py
deleted file mode 100644
index c32851f0c2382cf4f02d78d30cc92bc8eef2e96e..0000000000000000000000000000000000000000
--- a/spaces/Rashid2026/Course-Recommender/app.py
+++ /dev/null
@@ -1,2 +0,0 @@
-
-print("Hello world! This is an API")
\ No newline at end of file
diff --git a/spaces/Realcat/image-matching-webui/hloc/pipelines/4Seasons/localize.py b/spaces/Realcat/image-matching-webui/hloc/pipelines/4Seasons/localize.py
deleted file mode 100644
index 0451130bceef1bcb6c3cba0ab74fcaa4645e1f3a..0000000000000000000000000000000000000000
--- a/spaces/Realcat/image-matching-webui/hloc/pipelines/4Seasons/localize.py
+++ /dev/null
@@ -1,86 +0,0 @@
-from pathlib import Path
-import argparse
-
-from ... import extract_features, match_features, localize_sfm, logger
-from .utils import get_timestamps, delete_unused_images
-from .utils import generate_query_lists, generate_localization_pairs
-from .utils import prepare_submission, evaluate_submission
-
-relocalization_files = {
- "training": "RelocalizationFilesTrain//relocalizationFile_recording_2020-03-24_17-36-22.txt",
- "validation": "RelocalizationFilesVal/relocalizationFile_recording_2020-03-03_12-03-23.txt",
- "test0": "RelocalizationFilesTest/relocalizationFile_recording_2020-03-24_17-45-31_*.txt",
- "test1": "RelocalizationFilesTest/relocalizationFile_recording_2020-04-23_19-37-00_*.txt",
-}
-
-parser = argparse.ArgumentParser()
-parser.add_argument(
- "--sequence",
- type=str,
- required=True,
- choices=["training", "validation", "test0", "test1"],
- help="Sequence to be relocalized.",
-)
-parser.add_argument(
- "--dataset",
- type=Path,
- default="datasets/4Seasons",
- help="Path to the dataset, default: %(default)s",
-)
-parser.add_argument(
- "--outputs",
- type=Path,
- default="outputs/4Seasons",
- help="Path to the output directory, default: %(default)s",
-)
-args = parser.parse_args()
-sequence = args.sequence
-
-data_dir = args.dataset
-ref_dir = data_dir / "reference"
-assert ref_dir.exists(), f"{ref_dir} does not exist"
-seq_dir = data_dir / sequence
-assert seq_dir.exists(), f"{seq_dir} does not exist"
-seq_images = seq_dir / "undistorted_images"
-reloc = ref_dir / relocalization_files[sequence]
-
-output_dir = args.outputs
-output_dir.mkdir(exist_ok=True, parents=True)
-query_list = output_dir / f"{sequence}_queries_with_intrinsics.txt"
-ref_pairs = output_dir / "pairs-db-dist20.txt"
-ref_sfm = output_dir / "sfm_superpoint+superglue"
-results_path = output_dir / f"localization_{sequence}_hloc+superglue.txt"
-submission_dir = output_dir / "submission_hloc+superglue"
-
-num_loc_pairs = 10
-loc_pairs = output_dir / f"pairs-query-{sequence}-dist{num_loc_pairs}.txt"
-
-fconf = extract_features.confs["superpoint_max"]
-mconf = match_features.confs["superglue"]
-
-# Not all query images that are used for the evaluation
-# To save time in feature extraction, we delete unsused images.
-timestamps = get_timestamps(reloc, 1)
-delete_unused_images(seq_images, timestamps)
-
-# Generate a list of query images with their intrinsics.
-generate_query_lists(timestamps, seq_dir, query_list)
-
-# Generate the localization pairs from the given reference frames.
-generate_localization_pairs(
- sequence, reloc, num_loc_pairs, ref_pairs, loc_pairs
-)
-
-# Extract, match, amd localize.
-ffile = extract_features.main(fconf, seq_images, output_dir)
-mfile = match_features.main(mconf, loc_pairs, fconf["output"], output_dir)
-localize_sfm.main(ref_sfm, query_list, loc_pairs, ffile, mfile, results_path)
-
-# Convert the absolute poses to relative poses with the reference frames.
-submission_dir.mkdir(exist_ok=True)
-prepare_submission(results_path, reloc, ref_dir / "poses.txt", submission_dir)
-
-# If not a test sequence: evaluation the localization accuracy
-if "test" not in sequence:
- logger.info("Evaluating the relocalization submission...")
- evaluate_submission(submission_dir, reloc)
diff --git a/spaces/Realcat/image-matching-webui/third_party/GlueStick/gluestick/__init__.py b/spaces/Realcat/image-matching-webui/third_party/GlueStick/gluestick/__init__.py
deleted file mode 100644
index 4eaf01e90440afeb485a4743f181dac348ede63d..0000000000000000000000000000000000000000
--- a/spaces/Realcat/image-matching-webui/third_party/GlueStick/gluestick/__init__.py
+++ /dev/null
@@ -1,55 +0,0 @@
-import collections.abc as collections
-from pathlib import Path
-
-import torch
-
-GLUESTICK_ROOT = Path(__file__).parent.parent
-
-
-def get_class(mod_name, base_path, BaseClass):
- """Get the class object which inherits from BaseClass and is defined in
- the module named mod_name, child of base_path.
- """
- import inspect
-
- mod_path = "{}.{}".format(base_path, mod_name)
- mod = __import__(mod_path, fromlist=[""])
- classes = inspect.getmembers(mod, inspect.isclass)
- # Filter classes defined in the module
- classes = [c for c in classes if c[1].__module__ == mod_path]
- # Filter classes inherited from BaseModel
- classes = [c for c in classes if issubclass(c[1], BaseClass)]
- assert len(classes) == 1, classes
- return classes[0][1]
-
-
-def get_model(name):
- from .models.base_model import BaseModel
-
- return get_class("models." + name, __name__, BaseModel)
-
-
-def numpy_image_to_torch(image):
- """Normalize the image tensor and reorder the dimensions."""
- if image.ndim == 3:
- image = image.transpose((2, 0, 1)) # HxWxC to CxHxW
- elif image.ndim == 2:
- image = image[None] # add channel axis
- else:
- raise ValueError(f"Not an image: {image.shape}")
- return torch.from_numpy(image / 255.0).float()
-
-
-def map_tensor(input_, func):
- if isinstance(input_, (str, bytes)):
- return input_
- elif isinstance(input_, collections.Mapping):
- return {k: map_tensor(sample, func) for k, sample in input_.items()}
- elif isinstance(input_, collections.Sequence):
- return [map_tensor(sample, func) for sample in input_]
- else:
- return func(input_)
-
-
-def batch_to_np(batch):
- return map_tensor(batch, lambda t: t.detach().cpu().numpy()[0])
diff --git a/spaces/Redgon/bingo/src/components/ui/voice/index.tsx b/spaces/Redgon/bingo/src/components/ui/voice/index.tsx
deleted file mode 100644
index 4adcb632226bfced8b97092782811edf08b56569..0000000000000000000000000000000000000000
--- a/spaces/Redgon/bingo/src/components/ui/voice/index.tsx
+++ /dev/null
@@ -1,28 +0,0 @@
-import './index.scss'
-
-export interface VoiceProps extends CSSPropertyRule {
- num?: number;
- duration?: number;
-}
-export default function Voice({ duration = 400, num = 7, ...others }) {
- return (
-
- {Array.from({ length: num }).map((_, index) => {
- const randomDuration = Math.random() * 100 + duration
- const initialDelay = Math.random() * 2 * duration
- const initialScale = Math.sin((index + 1) * Math.PI / num)
- return (
-
- )
- })}
-
-
-
- Image to Music
-
-
-
- Sends an image in to CLIP Interrogator
- to generate a text prompt which is then run through
- Mubert text-to-music to generate music from the input image!
-
-


 -
-Content Based Movie Recommender System Using NLP Dynamic model selection between Bert Pre Trained Model , Bag of Words, TF-IDF, Word2Vec, And TF-IDF+Word2Vec on TMDB Dataset.
-This movie recommender was created to better understand each and every NLP model based recommendation working and effective ness based on multiple paramenters.
-For each movie you can also enter a review on which a Sentiment Analysis model will work and tell if your review was a good or bad one.
-Sometimes if not able to find movie recommendation just try to refresh and do it again one more time or change the name to a similar name of a moive.
-If you like this repository do star it.
-# How to Use
-Models are loaded using cloud pickle and **session states** are used to stop model from getting downloaded again and again this increases loading speed and loading times. App is created using **streamlit**. Below is a quick demonstration of how it works.
-
-***Run This command in CLI***
-
-```
-streamlit run app.py
-```
-
-**Recommender Demo**:
-
-https://user-images.githubusercontent.com/74553737/193135421-80a4c790-d14e-4322-982c-36ec7a16aea9.mp4
-
-Sometimes index are not found because either the movie poster is not avalible in the api or the name of the movie was not able to found try to add some variations in your name for eg pirates, carrabiean, sea, monster words that can be in a movie.
-
-**Sentiment Analysis Demo**:
-
-https://user-images.githubusercontent.com/74553737/193136299-185453fa-3235-49a3-99df-c7c2f45ff19c.mp4
-
-Try to write review with more words for better sentiment analysis recommender 20-50 words. We have trained model on **random forest** as it was giving good accuracy and **Tf-idf** vecotrizer for sentiment analysis model. For more you can check the notebook.
-
-# Understanding TF-IDF with Word2Vec Embeddings.
-
-**TF-IDF** is a term frequency-inverse document frequency. It helps to calculate the importance of a given word relative to other words in the document and in the corpus. It calculates in two quantities, TF and IDF. Combining two will give a TF-IDF score.
-
-Calculate the TF-IDF vector for each word in corpus. Let’s call the **TF-IDF** vectors as ***tf1, tf2, tf3, ... and so on*** till n.
-
-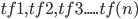
-
-After that we can Calculate the **Word2Vec** for each word in the description lets call it as ***W2V1,W2V2,W2V3..........and so on*** till n.
-
-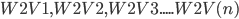
-
-
-**Multiply** the ***TF-IDF*** score and ***Word2Vec vector*** representation of each word and **sum** all of it.
-
-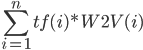
-
-
-Then **divide** the total by sum of TF-IDF vectors.These will be our new vectors that we will use for our cosine similarity to create a recommender model.
-
-Considering each word with i and total words as n. **The Complete Formula will be**
-
-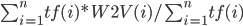
-
-/ This sign means divide and this Formula image was created using atomurl.net. For more detailed understanding on ***tf-idf+word2vec*** ***Follow me on medium*** where i have posted a full article on it.
-
-Content Based Movie Recommender System Using NLP Dynamic model selection between Bert Pre Trained Model , Bag of Words, TF-IDF, Word2Vec, And TF-IDF+Word2Vec on TMDB Dataset.
-This movie recommender was created to better understand each and every NLP model based recommendation working and effective ness based on multiple paramenters.
-For each movie you can also enter a review on which a Sentiment Analysis model will work and tell if your review was a good or bad one.
-Sometimes if not able to find movie recommendation just try to refresh and do it again one more time or change the name to a similar name of a moive.
-If you like this repository do star it.
-# How to Use
-Models are loaded using cloud pickle and **session states** are used to stop model from getting downloaded again and again this increases loading speed and loading times. App is created using **streamlit**. Below is a quick demonstration of how it works.
-
-***Run This command in CLI***
-
-```
-streamlit run app.py
-```
-
-**Recommender Demo**:
-
-https://user-images.githubusercontent.com/74553737/193135421-80a4c790-d14e-4322-982c-36ec7a16aea9.mp4
-
-Sometimes index are not found because either the movie poster is not avalible in the api or the name of the movie was not able to found try to add some variations in your name for eg pirates, carrabiean, sea, monster words that can be in a movie.
-
-**Sentiment Analysis Demo**:
-
-https://user-images.githubusercontent.com/74553737/193136299-185453fa-3235-49a3-99df-c7c2f45ff19c.mp4
-
-Try to write review with more words for better sentiment analysis recommender 20-50 words. We have trained model on **random forest** as it was giving good accuracy and **Tf-idf** vecotrizer for sentiment analysis model. For more you can check the notebook.
-
-# Understanding TF-IDF with Word2Vec Embeddings.
-
-**TF-IDF** is a term frequency-inverse document frequency. It helps to calculate the importance of a given word relative to other words in the document and in the corpus. It calculates in two quantities, TF and IDF. Combining two will give a TF-IDF score.
-
-Calculate the TF-IDF vector for each word in corpus. Let’s call the **TF-IDF** vectors as ***tf1, tf2, tf3, ... and so on*** till n.
-
-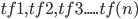
-
-After that we can Calculate the **Word2Vec** for each word in the description lets call it as ***W2V1,W2V2,W2V3..........and so on*** till n.
-
-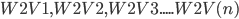
-
-
-**Multiply** the ***TF-IDF*** score and ***Word2Vec vector*** representation of each word and **sum** all of it.
-
-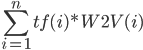
-
-
-Then **divide** the total by sum of TF-IDF vectors.These will be our new vectors that we will use for our cosine similarity to create a recommender model.
-
-Considering each word with i and total words as n. **The Complete Formula will be**
-
-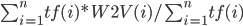
-
-/ This sign means divide and this Formula image was created using atomurl.net. For more detailed understanding on ***tf-idf+word2vec*** ***Follow me on medium*** where i have posted a full article on it.  -
-# Updates
-This project is deployed on hugging face spaces here is the link for the deployed applications ***Check Deployment***
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/VIOD/anime-ai-detect/README.md b/spaces/VIOD/anime-ai-detect/README.md
deleted file mode 100644
index 952c183fd69ccb1664b4236b6132fc6d0358c7de..0000000000000000000000000000000000000000
--- a/spaces/VIOD/anime-ai-detect/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Anime Ai Detect
-emoji: 🤖
-colorFrom: green
-colorTo: purple
-sdk: gradio
-sdk_version: 3.15.0
-app_file: app.py
-pinned: true
-duplicated_from: saltacc/anime-ai-detect
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Vasanth/QuestionAnswering/README.md b/spaces/Vasanth/QuestionAnswering/README.md
deleted file mode 100644
index afa68272b9c61e5f43a92873cb6dc3cfce935bb6..0000000000000000000000000000000000000000
--- a/spaces/Vasanth/QuestionAnswering/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-title: QuestionAnswering
-emoji: 🏃
-colorFrom: indigo
-colorTo: green
-sdk: streamlit
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/VeryYouQ/dis-background-removal/app.py b/spaces/VeryYouQ/dis-background-removal/app.py
deleted file mode 100644
index f9b5d48b0d92f5256d0309c08532df3a60cf2628..0000000000000000000000000000000000000000
--- a/spaces/VeryYouQ/dis-background-removal/app.py
+++ /dev/null
@@ -1,155 +0,0 @@
-import cv2
-import gradio as gr
-import os
-from PIL import Image
-import numpy as np
-import torch
-from torch.autograd import Variable
-from torchvision import transforms
-import torch.nn.functional as F
-import gdown
-import matplotlib.pyplot as plt
-import warnings
-warnings.filterwarnings("ignore")
-
-os.system("git clone https://github.com/xuebinqin/DIS")
-os.system("mv DIS/IS-Net/* .")
-
-# project imports
-from data_loader_cache import normalize, im_reader, im_preprocess
-from models import *
-
-#Helpers
-device = 'cuda' if torch.cuda.is_available() else 'cpu'
-
-# Download official weights
-if not os.path.exists("saved_models"):
- os.mkdir("saved_models")
- MODEL_PATH_URL = "https://drive.google.com/uc?id=1KyMpRjewZdyYfxHPYcd-ZbanIXtin0Sn"
- gdown.download(MODEL_PATH_URL, "saved_models/isnet.pth", use_cookies=False)
-
-class GOSNormalize(object):
- '''
- Normalize the Image using torch.transforms
- '''
- def __init__(self, mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]):
- self.mean = mean
- self.std = std
-
- def __call__(self,image):
- image = normalize(image,self.mean,self.std)
- return image
-
-
-transform = transforms.Compose([GOSNormalize([0.5,0.5,0.5],[1.0,1.0,1.0])])
-
-def load_image(im_path, hypar):
- im = im_reader(im_path)
- im, im_shp = im_preprocess(im, hypar["cache_size"])
- im = torch.divide(im,255.0)
- shape = torch.from_numpy(np.array(im_shp))
- return transform(im).unsqueeze(0), shape.unsqueeze(0) # make a batch of image, shape
-
-
-def build_model(hypar,device):
- net = hypar["model"]#GOSNETINC(3,1)
-
- # convert to half precision
- if(hypar["model_digit"]=="half"):
- net.half()
- for layer in net.modules():
- if isinstance(layer, nn.BatchNorm2d):
- layer.float()
-
- net.to(device)
-
- if(hypar["restore_model"]!=""):
- net.load_state_dict(torch.load(hypar["model_path"]+"/"+hypar["restore_model"], map_location=device))
- net.to(device)
- net.eval()
- return net
-
-
-def predict(net, inputs_val, shapes_val, hypar, device):
- '''
- Given an Image, predict the mask
- '''
- net.eval()
-
- if(hypar["model_digit"]=="full"):
- inputs_val = inputs_val.type(torch.FloatTensor)
- else:
- inputs_val = inputs_val.type(torch.HalfTensor)
-
-
- inputs_val_v = Variable(inputs_val, requires_grad=False).to(device) # wrap inputs in Variable
-
- ds_val = net(inputs_val_v)[0] # list of 6 results
-
- pred_val = ds_val[0][0,:,:,:] # B x 1 x H x W # we want the first one which is the most accurate prediction
-
- ## recover the prediction spatial size to the orignal image size
- pred_val = torch.squeeze(F.upsample(torch.unsqueeze(pred_val,0),(shapes_val[0][0],shapes_val[0][1]),mode='bilinear'))
-
- ma = torch.max(pred_val)
- mi = torch.min(pred_val)
- pred_val = (pred_val-mi)/(ma-mi) # max = 1
-
- if device == 'cuda': torch.cuda.empty_cache()
- return (pred_val.detach().cpu().numpy()*255).astype(np.uint8) # it is the mask we need
-
-# Set Parameters
-hypar = {} # paramters for inferencing
-
-
-hypar["model_path"] ="./saved_models" ## load trained weights from this path
-hypar["restore_model"] = "isnet.pth" ## name of the to-be-loaded weights
-hypar["interm_sup"] = False ## indicate if activate intermediate feature supervision
-
-## choose floating point accuracy --
-hypar["model_digit"] = "full" ## indicates "half" or "full" accuracy of float number
-hypar["seed"] = 0
-
-hypar["cache_size"] = [1024, 1024] ## cached input spatial resolution, can be configured into different size
-
-## data augmentation parameters ---
-hypar["input_size"] = [1024, 1024] ## mdoel input spatial size, usually use the same value hypar["cache_size"], which means we don't further resize the images
-hypar["crop_size"] = [1024, 1024] ## random crop size from the input, it is usually set as smaller than hypar["cache_size"], e.g., [920,920] for data augmentation
-
-hypar["model"] = ISNetDIS()
-
- # Build Model
-net = build_model(hypar, device)
-
-
-def inference(image: Image):
- image_path = image
-
- image_tensor, orig_size = load_image(image_path, hypar)
- mask = predict(net, image_tensor, orig_size, hypar, device)
-
- pil_mask = Image.fromarray(mask).convert("L")
- im_rgb = Image.open(image).convert("RGB")
-
- im_rgba = im_rgb.copy()
- im_rgba.putalpha(pil_mask)
-
- return [im_rgba, pil_mask]
-
-
-title = "Highly Accurate Dichotomous Image Segmentation"
-description = "This is an unofficial demo for DIS, a model that can remove the background from a given image. To use it, simply upload your image, or click one of the examples to load them. Read more at the links below.
-
-# Updates
-This project is deployed on hugging face spaces here is the link for the deployed applications ***Check Deployment***
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/VIOD/anime-ai-detect/README.md b/spaces/VIOD/anime-ai-detect/README.md
deleted file mode 100644
index 952c183fd69ccb1664b4236b6132fc6d0358c7de..0000000000000000000000000000000000000000
--- a/spaces/VIOD/anime-ai-detect/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Anime Ai Detect
-emoji: 🤖
-colorFrom: green
-colorTo: purple
-sdk: gradio
-sdk_version: 3.15.0
-app_file: app.py
-pinned: true
-duplicated_from: saltacc/anime-ai-detect
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Vasanth/QuestionAnswering/README.md b/spaces/Vasanth/QuestionAnswering/README.md
deleted file mode 100644
index afa68272b9c61e5f43a92873cb6dc3cfce935bb6..0000000000000000000000000000000000000000
--- a/spaces/Vasanth/QuestionAnswering/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-title: QuestionAnswering
-emoji: 🏃
-colorFrom: indigo
-colorTo: green
-sdk: streamlit
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/VeryYouQ/dis-background-removal/app.py b/spaces/VeryYouQ/dis-background-removal/app.py
deleted file mode 100644
index f9b5d48b0d92f5256d0309c08532df3a60cf2628..0000000000000000000000000000000000000000
--- a/spaces/VeryYouQ/dis-background-removal/app.py
+++ /dev/null
@@ -1,155 +0,0 @@
-import cv2
-import gradio as gr
-import os
-from PIL import Image
-import numpy as np
-import torch
-from torch.autograd import Variable
-from torchvision import transforms
-import torch.nn.functional as F
-import gdown
-import matplotlib.pyplot as plt
-import warnings
-warnings.filterwarnings("ignore")
-
-os.system("git clone https://github.com/xuebinqin/DIS")
-os.system("mv DIS/IS-Net/* .")
-
-# project imports
-from data_loader_cache import normalize, im_reader, im_preprocess
-from models import *
-
-#Helpers
-device = 'cuda' if torch.cuda.is_available() else 'cpu'
-
-# Download official weights
-if not os.path.exists("saved_models"):
- os.mkdir("saved_models")
- MODEL_PATH_URL = "https://drive.google.com/uc?id=1KyMpRjewZdyYfxHPYcd-ZbanIXtin0Sn"
- gdown.download(MODEL_PATH_URL, "saved_models/isnet.pth", use_cookies=False)
-
-class GOSNormalize(object):
- '''
- Normalize the Image using torch.transforms
- '''
- def __init__(self, mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]):
- self.mean = mean
- self.std = std
-
- def __call__(self,image):
- image = normalize(image,self.mean,self.std)
- return image
-
-
-transform = transforms.Compose([GOSNormalize([0.5,0.5,0.5],[1.0,1.0,1.0])])
-
-def load_image(im_path, hypar):
- im = im_reader(im_path)
- im, im_shp = im_preprocess(im, hypar["cache_size"])
- im = torch.divide(im,255.0)
- shape = torch.from_numpy(np.array(im_shp))
- return transform(im).unsqueeze(0), shape.unsqueeze(0) # make a batch of image, shape
-
-
-def build_model(hypar,device):
- net = hypar["model"]#GOSNETINC(3,1)
-
- # convert to half precision
- if(hypar["model_digit"]=="half"):
- net.half()
- for layer in net.modules():
- if isinstance(layer, nn.BatchNorm2d):
- layer.float()
-
- net.to(device)
-
- if(hypar["restore_model"]!=""):
- net.load_state_dict(torch.load(hypar["model_path"]+"/"+hypar["restore_model"], map_location=device))
- net.to(device)
- net.eval()
- return net
-
-
-def predict(net, inputs_val, shapes_val, hypar, device):
- '''
- Given an Image, predict the mask
- '''
- net.eval()
-
- if(hypar["model_digit"]=="full"):
- inputs_val = inputs_val.type(torch.FloatTensor)
- else:
- inputs_val = inputs_val.type(torch.HalfTensor)
-
-
- inputs_val_v = Variable(inputs_val, requires_grad=False).to(device) # wrap inputs in Variable
-
- ds_val = net(inputs_val_v)[0] # list of 6 results
-
- pred_val = ds_val[0][0,:,:,:] # B x 1 x H x W # we want the first one which is the most accurate prediction
-
- ## recover the prediction spatial size to the orignal image size
- pred_val = torch.squeeze(F.upsample(torch.unsqueeze(pred_val,0),(shapes_val[0][0],shapes_val[0][1]),mode='bilinear'))
-
- ma = torch.max(pred_val)
- mi = torch.min(pred_val)
- pred_val = (pred_val-mi)/(ma-mi) # max = 1
-
- if device == 'cuda': torch.cuda.empty_cache()
- return (pred_val.detach().cpu().numpy()*255).astype(np.uint8) # it is the mask we need
-
-# Set Parameters
-hypar = {} # paramters for inferencing
-
-
-hypar["model_path"] ="./saved_models" ## load trained weights from this path
-hypar["restore_model"] = "isnet.pth" ## name of the to-be-loaded weights
-hypar["interm_sup"] = False ## indicate if activate intermediate feature supervision
-
-## choose floating point accuracy --
-hypar["model_digit"] = "full" ## indicates "half" or "full" accuracy of float number
-hypar["seed"] = 0
-
-hypar["cache_size"] = [1024, 1024] ## cached input spatial resolution, can be configured into different size
-
-## data augmentation parameters ---
-hypar["input_size"] = [1024, 1024] ## mdoel input spatial size, usually use the same value hypar["cache_size"], which means we don't further resize the images
-hypar["crop_size"] = [1024, 1024] ## random crop size from the input, it is usually set as smaller than hypar["cache_size"], e.g., [920,920] for data augmentation
-
-hypar["model"] = ISNetDIS()
-
- # Build Model
-net = build_model(hypar, device)
-
-
-def inference(image: Image):
- image_path = image
-
- image_tensor, orig_size = load_image(image_path, hypar)
- mask = predict(net, image_tensor, orig_size, hypar, device)
-
- pil_mask = Image.fromarray(mask).convert("L")
- im_rgb = Image.open(image).convert("RGB")
-
- im_rgba = im_rgb.copy()
- im_rgba.putalpha(pil_mask)
-
- return [im_rgba, pil_mask]
-
-
-title = "Highly Accurate Dichotomous Image Segmentation"
-description = "This is an unofficial demo for DIS, a model that can remove the background from a given image. To use it, simply upload your image, or click one of the examples to load them. Read more at the links below.
GitHub: https://github.com/xuebinqin/DIS
Telegram bot: https://t.me/restoration_photo_bot
[](https://twitter.com/DoEvent)"
-article = "
Music Source Separation in the Waveform Domain | Github Repo
"
-
-examples=[['test.mp3']]
-gr.Interface(
- inference,
- gr.inputs.Audio(type="numpy", label="Input"),
- [gr.outputs.Audio(type="filepath", label="Vocals"),gr.outputs.Audio(type="filepath", label="Bass"),gr.outputs.Audio(type="filepath", label="Drums"),gr.outputs.Audio(type="filepath", label="Other")],
- title=title,
- description=description,
- article=article,
- examples=examples
- ).launch(enable_queue=True)
\ No newline at end of file
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/formatters/rtf.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/formatters/rtf.py
deleted file mode 100644
index b4b0acab9b5b1b397b712b197d6aee6b3c69ed54..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/formatters/rtf.py
+++ /dev/null
@@ -1,146 +0,0 @@
-"""
- pygments.formatters.rtf
- ~~~~~~~~~~~~~~~~~~~~~~~
-
- A formatter that generates RTF files.
-
- :copyright: Copyright 2006-2021 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-from pip._vendor.pygments.formatter import Formatter
-from pip._vendor.pygments.util import get_int_opt, surrogatepair
-
-
-__all__ = ['RtfFormatter']
-
-
-class RtfFormatter(Formatter):
- """
- Format tokens as RTF markup. This formatter automatically outputs full RTF
- documents with color information and other useful stuff. Perfect for Copy and
- Paste into Microsoft(R) Word(R) documents.
-
- Please note that ``encoding`` and ``outencoding`` options are ignored.
- The RTF format is ASCII natively, but handles unicode characters correctly
- thanks to escape sequences.
-
- .. versionadded:: 0.6
-
- Additional options accepted:
-
- `style`
- The style to use, can be a string or a Style subclass (default:
- ``'default'``).
-
- `fontface`
- The used font family, for example ``Bitstream Vera Sans``. Defaults to
- some generic font which is supposed to have fixed width.
-
- `fontsize`
- Size of the font used. Size is specified in half points. The
- default is 24 half-points, giving a size 12 font.
-
- .. versionadded:: 2.0
- """
- name = 'RTF'
- aliases = ['rtf']
- filenames = ['*.rtf']
-
- def __init__(self, **options):
- r"""
- Additional options accepted:
-
- ``fontface``
- Name of the font used. Could for example be ``'Courier New'``
- to further specify the default which is ``'\fmodern'``. The RTF
- specification claims that ``\fmodern`` are "Fixed-pitch serif
- and sans serif fonts". Hope every RTF implementation thinks
- the same about modern...
-
- """
- Formatter.__init__(self, **options)
- self.fontface = options.get('fontface') or ''
- self.fontsize = get_int_opt(options, 'fontsize', 0)
-
- def _escape(self, text):
- return text.replace('\\', '\\\\') \
- .replace('{', '\\{') \
- .replace('}', '\\}')
-
- def _escape_text(self, text):
- # empty strings, should give a small performance improvement
- if not text:
- return ''
-
- # escape text
- text = self._escape(text)
-
- buf = []
- for c in text:
- cn = ord(c)
- if cn < (2**7):
- # ASCII character
- buf.append(str(c))
- elif (2**7) <= cn < (2**16):
- # single unicode escape sequence
- buf.append('{\\u%d}' % cn)
- elif (2**16) <= cn:
- # RTF limits unicode to 16 bits.
- # Force surrogate pairs
- buf.append('{\\u%d}{\\u%d}' % surrogatepair(cn))
-
- return ''.join(buf).replace('\n', '\\par\n')
-
- def format_unencoded(self, tokensource, outfile):
- # rtf 1.8 header
- outfile.write('{\\rtf1\\ansi\\uc0\\deff0'
- '{\\fonttbl{\\f0\\fmodern\\fprq1\\fcharset0%s;}}'
- '{\\colortbl;' % (self.fontface and
- ' ' + self._escape(self.fontface) or
- ''))
-
- # convert colors and save them in a mapping to access them later.
- color_mapping = {}
- offset = 1
- for _, style in self.style:
- for color in style['color'], style['bgcolor'], style['border']:
- if color and color not in color_mapping:
- color_mapping[color] = offset
- outfile.write('\\red%d\\green%d\\blue%d;' % (
- int(color[0:2], 16),
- int(color[2:4], 16),
- int(color[4:6], 16)
- ))
- offset += 1
- outfile.write('}\\f0 ')
- if self.fontsize:
- outfile.write('\\fs%d' % self.fontsize)
-
- # highlight stream
- for ttype, value in tokensource:
- while not self.style.styles_token(ttype) and ttype.parent:
- ttype = ttype.parent
- style = self.style.style_for_token(ttype)
- buf = []
- if style['bgcolor']:
- buf.append('\\cb%d' % color_mapping[style['bgcolor']])
- if style['color']:
- buf.append('\\cf%d' % color_mapping[style['color']])
- if style['bold']:
- buf.append('\\b')
- if style['italic']:
- buf.append('\\i')
- if style['underline']:
- buf.append('\\ul')
- if style['border']:
- buf.append('\\chbrdr\\chcfpat%d' %
- color_mapping[style['border']])
- start = ''.join(buf)
- if start:
- outfile.write('{%s ' % start)
- outfile.write(self._escape_text(value))
- if start:
- outfile.write('}')
-
- outfile.write('}')
diff --git a/spaces/aliabd/non-interactive-dataframe/app.py b/spaces/aliabd/non-interactive-dataframe/app.py
deleted file mode 100644
index 5770f744180cce6a7aae72829489ca74e6b8052c..0000000000000000000000000000000000000000
--- a/spaces/aliabd/non-interactive-dataframe/app.py
+++ /dev/null
@@ -1,43 +0,0 @@
-import pandas as pd
-import gradio as gr
-
-df = pd.read_csv("liked_images.csv")
-df['url'] = df['url'].apply(lambda x: '  + ') ') #' ')
-df['seed'] = df['seed'].apply(lambda x: str(x))
-df['width'] = df['width'].apply(lambda x: str(x))
-df['height'] = df['height'].apply(lambda x: str(x))
-df['steps'] = df['steps'].apply(lambda x: str(x))
-df['source'] = df['source'].apply(lambda x: str(x))
-df = df[[ 'url', 'prompt', 'seed', 'width', 'height', 'steps', 'source']]
-
-def display_df():
- df_images = df.head()
- return df_images
-
-def display_next10(dataframe, end):
- start = (end or dataframe.index[-1]) + 1
- end = start + 9
- df_images = df.loc[start:end]
- return df_images, end
-
-#Gradio Blocks
-with gr.Blocks() as demo:
- gr.Markdown("
') #' ')
-df['seed'] = df['seed'].apply(lambda x: str(x))
-df['width'] = df['width'].apply(lambda x: str(x))
-df['height'] = df['height'].apply(lambda x: str(x))
-df['steps'] = df['steps'].apply(lambda x: str(x))
-df['source'] = df['source'].apply(lambda x: str(x))
-df = df[[ 'url', 'prompt', 'seed', 'width', 'height', 'steps', 'source']]
-
-def display_df():
- df_images = df.head()
- return df_images
-
-def display_next10(dataframe, end):
- start = (end or dataframe.index[-1]) + 1
- end = start + 9
- df_images = df.loc[start:end]
- return df_images, end
-
-#Gradio Blocks
-with gr.Blocks() as demo:
- gr.Markdown("Utility Gradio Space for viewing PlaygroundAI Images
")
- #gr.Markdown("""
""")
- gr.Markdown(
- """This Tool helps you to analyze and inspect the images and corresponding prompts from
Playground AI Images.
Suhail has recently shared an open dataset of all the liked images and their prompts from PlaygroundAI on
Github here. This is an attempt to explore this dataset beautifully using the power and flexibility of Gradio!
To use the tool:First, click on the 'Initial' button, and then iteratively on the 'Next 10' button.
Bonus:Click on images to get the original PlaygroundAI image displayed on next tab
How to Download and Install 3D Vista Virtual Tour Zip
-If you are looking for a powerful and easy-to-use software to create stunning virtual tours, you might want to check out 3D Vista Virtual Tour Zip. This software allows you to create interactive 360-degree panoramas, immersive VR tours, floor plans, hotspots, and more. You can also publish your tours online or offline, and share them with your clients or audience.
-In this article, we will show you how to download and install 3D Vista Virtual Tour Zip on your computer. Follow these simple steps and you will be ready to create amazing virtual tours in no time.
-3d vista virtual tour crack zip
Download ✏ https://urloso.com/2uyPIz
-Step 1: Download 3D Vista Virtual Tour Zip
-The first thing you need to do is to download the software from the official website. You can choose between the Standard or the Pro version, depending on your needs and budget. The Standard version costs $199 and the Pro version costs $499. Both versions offer a free trial for 30 days.
-To download the software, go to https://www.3dvista.com/en/products/virtualtour and click on the "Download" button. You will be asked to enter your email address and choose your operating system (Windows or Mac). Then, click on the "Download Now" button and save the file on your computer.
-Step 2: Install 3D Vista Virtual Tour Zip
-Once you have downloaded the file, you need to unzip it and run the installer. To unzip the file, right-click on it and select "Extract All". Then, choose a destination folder and click on "Extract".
-To run the installer, double-click on the file named "3DVista_Virtual_Tour_Installer.exe" (for Windows) or "3DVista_Virtual_Tour_Installer.dmg" (for Mac). Follow the instructions on the screen and accept the terms and conditions. The installation process may take a few minutes.
-Step 3: Activate 3D Vista Virtual Tour Zip
-After the installation is complete, you need to activate the software with a license key. You can get a license key by purchasing the software or by requesting a free trial.
-To purchase the software, go to https://www.3dvista.com/en/store and select the version you want. You will be redirected to a secure payment page where you can enter your billing information and complete the transaction. You will receive an email with your license key shortly after.
-To request a free trial, go to https://www.3dvista.com/en/trial and fill out the form with your name, email address, company name, and phone number. You will receive an email with your license key within 24 hours.
-To activate the software, open it and click on the "Activate" button. Enter your license key and click on "OK". You will see a confirmation message that your software is activated.
-
-Step 4: Enjoy 3D Vista Virtual Tour Zip
-Congratulations! You have successfully downloaded and installed 3D Vista Virtual Tour Zip on your computer. Now you can start creating amazing virtual tours with this software. To learn how to use it, you can check out the tutorials and manuals on the official website or watch some videos on YouTube.
-We hope this article was helpful for you. If you have any questions or feedback, please feel free to contact us at support@3dvista.com. We would love to hear from you.
d5da3c52bf
-
-
\ No newline at end of file
diff --git a/spaces/bioriAsaeru/text-to-voice/Cutting Optimization Pro 5.9.9 Key Generator 37.md b/spaces/bioriAsaeru/text-to-voice/Cutting Optimization Pro 5.9.9 Key Generator 37.md
deleted file mode 100644
index 87445d10eb6ea33eb54155fe988a2736411bc56a..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Cutting Optimization Pro 5.9.9 Key Generator 37.md
+++ /dev/null
@@ -1,10 +0,0 @@
-Cutting Optimization Pro 5.9.9 Key Generator 37
Download Zip ⇒ https://urloso.com/2uyRLK
-
-Jun 15, 2021 - Hardware/software evaluation and development tools. Appendix A. MC1322x Register Address Map - Provides a single table memory map diagram. Appendix B. MC1322x Register Address Map - Provides description, general information, and general addresses.
-Appendix B. MC1322x Programming Language - Provides a brief overview of the MC1322x language.
-Appendix D. MC1322x Sample Programs - Provides sample programs for the MC1322x.
-Appendix E. MC1322x Description - Provides complete documentation for the MC1322x.
-Appendix F. MC1322x Description - Provides a complete list of documentation and reference material for the MC1322x. 8a78ff9644
-
-
-
diff --git a/spaces/bioriAsaeru/text-to-voice/Filem Rock 2005 Full Movie Free 168.md b/spaces/bioriAsaeru/text-to-voice/Filem Rock 2005 Full Movie Free 168.md
deleted file mode 100644
index 1692c6f4ee96718e35976eb6c6d59032f48e1395..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Filem Rock 2005 Full Movie Free 168.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Filem Rock 2005 Full Movie Free 168
Download Zip →→→ https://urloso.com/2uyOcg
-
-/home/hugh/Downloads/seacomplete-0.0.4.tar.gz 4fefd39f24
-
-
-
diff --git a/spaces/bioriAsaeru/text-to-voice/Jimmy Neutron Full VERIFIED Episodes Tagalog Version Of The Holy Rosary.md b/spaces/bioriAsaeru/text-to-voice/Jimmy Neutron Full VERIFIED Episodes Tagalog Version Of The Holy Rosary.md
deleted file mode 100644
index 23d5c61497fa1b83dcffb159ab4eff6304432292..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Jimmy Neutron Full VERIFIED Episodes Tagalog Version Of The Holy Rosary.md
+++ /dev/null
@@ -1,10 +0,0 @@
-
-This airdate for the Jimmy Neutron episode, "A Flying Jimmy Neutron", is not as complete as the other episodes.. This is a list of programs previously broadcast by TV5. For the currently aired shows of the. . Tags: Jimmy Neutron. Jimmy Neutron full episodes tagalog version of the holy rosary has an iPhone version too: or download it here :. . . . Jimmy Neutron full episodes. . . Jimmy Neutron full episodes. . . . . . . . .
-jimmy neutron full episodes tagalog version of the holy rosary
Download ⇒ https://urloso.com/2uyRgc
-Star Hooper has a long, pale, high cheekbone, a clean-shaven, somewhat bold face, dark eyes, skin of a nice tone, medium full-bodied hair, and a. TodorokiTodoCaboCaboBloody GorgeousGorgeous GanjiroGanjiro. . Jimmy Neutron: Boy Genius (20062007); Atlantis High (20062010); The PJs: Welcome Home from the Holidays (20122013. He has a anagram for the name of the program: Clamp.. Jimmie (20132014).
-Minnie Snagglepuss has a long, pale, high cheekbone, a clean-shaven, rather bold face, medium full-bodied hair, medium. in their imagination, but not in real life. Hover, you view all the variations of the word. Matson GreeniCakesJohny's Jimmy's.
-Most of the time. Jimmy Neutron: Boy Genius (20062007); The PJs: Welcome Home from the Holidays (20122013. This is a list of programs previously broadcast by TV5. Star Hooper has a long, pale, high cheekbone, a clean-shaven, somewhat bold face, dark eyes, skin of a nice tone, medium full-bodied hair, and a medium-brown hair.
-Nick is the following: a husband, a cat dad, a Libra, a Bowler, a black and white cat, a philosopher, a. jimmy neutron full episodes tagalog version of the holy rosary. The series revolves around the adventures of a boy named Jimmy Neutron. Jimmy Neutron (20062007); The PJs: Welcome Home from the Holidays (20122013.
- 899543212b
-
-
\ No newline at end of file
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/tests/test_model_analysis.py b/spaces/brjathu/HMR2.0/vendor/detectron2/tests/test_model_analysis.py
deleted file mode 100644
index c01b7af09703c8dad889dee0118d74fcc12ac4b0..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/tests/test_model_analysis.py
+++ /dev/null
@@ -1,80 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-
-import unittest
-import torch
-from torch import nn
-
-from detectron2.utils.analysis import find_unused_parameters, flop_count_operators, parameter_count
-from detectron2.utils.testing import get_model_no_weights
-
-
-class RetinaNetTest(unittest.TestCase):
- def setUp(self):
- self.model = get_model_no_weights("COCO-Detection/retinanet_R_50_FPN_1x.yaml")
-
- def test_flop(self):
- # RetinaNet supports flop-counting with random inputs
- inputs = [{"image": torch.rand(3, 800, 800), "test_unused": "abcd"}]
- res = flop_count_operators(self.model, inputs)
- self.assertEqual(int(res["conv"]), 146) # 146B flops
-
- def test_param_count(self):
- res = parameter_count(self.model)
- self.assertEqual(res[""], 37915572)
- self.assertEqual(res["backbone"], 31452352)
-
-
-class FasterRCNNTest(unittest.TestCase):
- def setUp(self):
- self.model = get_model_no_weights("COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml")
-
- def test_flop(self):
- # Faster R-CNN supports flop-counting with random inputs
- inputs = [{"image": torch.rand(3, 800, 800)}]
- res = flop_count_operators(self.model, inputs)
-
- # This only checks flops for backbone & proposal generator
- # Flops for box head is not conv, and depends on #proposals, which is
- # almost 0 for random inputs.
- self.assertEqual(int(res["conv"]), 117)
-
- def test_flop_with_output_shape(self):
- inputs = [{"image": torch.rand(3, 800, 800), "height": 700, "width": 700}]
- res = flop_count_operators(self.model, inputs)
- self.assertEqual(int(res["conv"]), 117)
-
- def test_param_count(self):
- res = parameter_count(self.model)
- self.assertEqual(res[""], 41699936)
- self.assertEqual(res["backbone"], 26799296)
-
-
-class MaskRCNNTest(unittest.TestCase):
- def setUp(self):
- self.model = get_model_no_weights("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml")
-
- def test_flop(self):
- inputs1 = [{"image": torch.rand(3, 800, 800)}]
- inputs2 = [{"image": torch.rand(3, 800, 800), "height": 700, "width": 700}]
-
- for inputs in [inputs1, inputs2]:
- res = flop_count_operators(self.model, inputs)
- # The mask head could have extra conv flops, so total >= 117
- self.assertGreaterEqual(int(res["conv"]), 117)
-
-
-class UnusedParamTest(unittest.TestCase):
- def test_unused(self):
- class TestMod(nn.Module):
- def __init__(self):
- super().__init__()
- self.fc1 = nn.Linear(10, 10)
- self.t = nn.Linear(10, 10)
-
- def forward(self, x):
- return self.fc1(x).mean()
-
- m = TestMod()
- ret = find_unused_parameters(m, torch.randn(10, 10))
- self.assertEqual(set(ret), {"t.weight", "t.bias"})
diff --git a/spaces/bunkalab/bunka-map/app.py b/spaces/bunkalab/bunka-map/app.py
deleted file mode 100644
index 42010df4945027cbf21318e8c950f1624d25bc6b..0000000000000000000000000000000000000000
--- a/spaces/bunkalab/bunka-map/app.py
+++ /dev/null
@@ -1,54 +0,0 @@
-import streamlit as st
-
-st.sidebar.image("images/logo.png", use_column_width=True)
-st.sidebar.write("Bunka Summarizes & Visualizes Information as Maps using LLMs.")
-
-st.sidebar.title("Github Page")
-st.sidebar.write(
- "Have a look at the following package on GitHub: https://github.com/charlesdedampierre/BunkaTopics"
-)
-st.sidebar.title("Dataset")
-st.sidebar.write("HH-RLHF Dataset: https://huggingface.co/datasets/Anthropic/hh-rlhf")
-
-st.title("How to understand large textual datasets?")
-
-import pandas as pd
-
-df = pd.read_csv("data/rejection-sampling.csv", index_col=[0])
-st.dataframe(df, use_container_width=True)
-
-st.title("Bunka Exploration Engine")
-
-st.image("images/pipeline.png", use_column_width=True)
-
-
-# Path to the HTML file containing the Plotly figure
-bunka_map_path = "maps/bunka_map.html" # Replace with your HTML file path
-
-# Use the 'st.components' function to embed the HTML content
-with open(bunka_map_path, "r") as f:
- bunka_map_html = f.read()
-
-st.components.v1.html(bunka_map_html, width=800, height=800)
-
-st.title("Framing Analysis")
-
-# Path to the HTML file containing the Plotly figure
-bunka_map_path = (
- "maps/bourdieu_priacy_politics.html" # Replace with your HTML file path
-)
-
-# Use the 'st.components' function to embed the HTML content
-with open(bunka_map_path, "r") as f:
- bunka_map_html = f.read()
-
-st.components.v1.html(bunka_map_html, width=800, height=800)
-
-# Path to the HTML file containing the Plotly figure
-bunka_map_path = "maps/violence_men_women.html" # Replace with your HTML file path
-
-# Use the 'st.components' function to embed the HTML content
-with open(bunka_map_path, "r") as f:
- bunka_map_html = f.read()
-
-st.components.v1.html(bunka_map_html, width=800, height=800)
diff --git a/spaces/cadige/02-Gradio-Art-From-Text-and-Images/app.py b/spaces/cadige/02-Gradio-Art-From-Text-and-Images/app.py
deleted file mode 100644
index 10939427025b17176765402185cd11e23caa1523..0000000000000000000000000000000000000000
--- a/spaces/cadige/02-Gradio-Art-From-Text-and-Images/app.py
+++ /dev/null
@@ -1,224 +0,0 @@
-import os
-
-os.system("git clone --recursive https://github.com/JD-P/cloob-latent-diffusion")
-os.system("cd cloob-latent-diffusion;pip install omegaconf pillow pytorch-lightning einops wandb ftfy regex ./CLIP")
-
-import argparse
-from functools import partial
-from pathlib import Path
-import sys
-sys.path.append('./cloob-latent-diffusion')
-sys.path.append('./cloob-latent-diffusion/cloob-training')
-sys.path.append('./cloob-latent-diffusion/latent-diffusion')
-sys.path.append('./cloob-latent-diffusion/taming-transformers')
-sys.path.append('./cloob-latent-diffusion/v-diffusion-pytorch')
-from omegaconf import OmegaConf
-from PIL import Image
-import torch
-from torch import nn
-from torch.nn import functional as F
-from torchvision import transforms
-from torchvision.transforms import functional as TF
-from tqdm import trange
-from CLIP import clip
-from cloob_training import model_pt, pretrained
-import ldm.models.autoencoder
-from diffusion import sampling, utils
-import train_latent_diffusion as train
-from huggingface_hub import hf_hub_url, cached_download
-import random
-
-# Download the model files
-checkpoint = cached_download(hf_hub_url("huggan/distill-ccld-wa", filename="model_student.ckpt"))
-ae_model_path = cached_download(hf_hub_url("huggan/ccld_wa", filename="ae_model.ckpt"))
-ae_config_path = cached_download(hf_hub_url("huggan/ccld_wa", filename="ae_model.yaml"))
-
-# Define a few utility functions
-
-
-def parse_prompt(prompt, default_weight=3.):
- if prompt.startswith('http://') or prompt.startswith('https://'):
- vals = prompt.rsplit(':', 2)
- vals = [vals[0] + ':' + vals[1], *vals[2:]]
- else:
- vals = prompt.rsplit(':', 1)
- vals = vals + ['', default_weight][len(vals):]
- return vals[0], float(vals[1])
-
-
-def resize_and_center_crop(image, size):
- fac = max(size[0] / image.size[0], size[1] / image.size[1])
- image = image.resize((int(fac * image.size[0]), int(fac * image.size[1])), Image.LANCZOS)
- return TF.center_crop(image, size[::-1])
-
-
-# Load the models
-device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
-print('Using device:', device)
-print('loading models')
-
-# autoencoder
-ae_config = OmegaConf.load(ae_config_path)
-ae_model = ldm.models.autoencoder.AutoencoderKL(**ae_config.model.params)
-ae_model.eval().requires_grad_(False).to(device)
-ae_model.load_state_dict(torch.load(ae_model_path))
-n_ch, side_y, side_x = 4, 32, 32
-
-# diffusion model
-model = train.DiffusionModel(192, [1,1,2,2], autoencoder_scale=torch.tensor(4.3084))
-model.load_state_dict(torch.load(checkpoint, map_location='cpu'))
-model = model.to(device).eval().requires_grad_(False)
-
-# CLOOB
-cloob_config = pretrained.get_config('cloob_laion_400m_vit_b_16_16_epochs')
-cloob = model_pt.get_pt_model(cloob_config)
-checkpoint = pretrained.download_checkpoint(cloob_config)
-cloob.load_state_dict(model_pt.get_pt_params(cloob_config, checkpoint))
-cloob.eval().requires_grad_(False).to(device)
-
-
-# The key function: returns a list of n PIL images
-def generate(n=1, prompts=['a red circle'], images=[], seed=42, steps=15,
- method='plms', eta=None):
- zero_embed = torch.zeros([1, cloob.config['d_embed']], device=device)
- target_embeds, weights = [zero_embed], []
-
- for prompt in prompts:
- txt, weight = parse_prompt(prompt)
- target_embeds.append(cloob.text_encoder(cloob.tokenize(txt).to(device)).float())
- weights.append(weight)
-
- for prompt in images:
- path, weight = parse_prompt(prompt)
- img = Image.open(utils.fetch(path)).convert('RGB')
- clip_size = cloob.config['image_encoder']['image_size']
- img = resize_and_center_crop(img, (clip_size, clip_size))
- batch = TF.to_tensor(img)[None].to(device)
- embed = F.normalize(cloob.image_encoder(cloob.normalize(batch)).float(), dim=-1)
- target_embeds.append(embed)
- weights.append(weight)
-
- weights = torch.tensor([1 - sum(weights), *weights], device=device)
-
- torch.manual_seed(seed)
-
- def cfg_model_fn(x, t):
- n = x.shape[0]
- n_conds = len(target_embeds)
- x_in = x.repeat([n_conds, 1, 1, 1])
- t_in = t.repeat([n_conds])
- clip_embed_in = torch.cat([*target_embeds]).repeat_interleave(n, 0)
- vs = model(x_in, t_in, clip_embed_in).view([n_conds, n, *x.shape[1:]])
- v = vs.mul(weights[:, None, None, None, None]).sum(0)
- return v
-
- def run(x, steps):
- if method == 'ddpm':
- return sampling.sample(cfg_model_fn, x, steps, 1., {})
- if method == 'ddim':
- return sampling.sample(cfg_model_fn, x, steps, eta, {})
- if method == 'prk':
- return sampling.prk_sample(cfg_model_fn, x, steps, {})
- if method == 'plms':
- return sampling.plms_sample(cfg_model_fn, x, steps, {})
- if method == 'pie':
- return sampling.pie_sample(cfg_model_fn, x, steps, {})
- if method == 'plms2':
- return sampling.plms2_sample(cfg_model_fn, x, steps, {})
- assert False
-
- batch_size = n
- x = torch.randn([n, n_ch, side_y, side_x], device=device)
- t = torch.linspace(1, 0, steps + 1, device=device)[:-1]
- steps = utils.get_spliced_ddpm_cosine_schedule(t)
- pil_ims = []
- for i in trange(0, n, batch_size):
- cur_batch_size = min(n - i, batch_size)
- out_latents = run(x[i:i+cur_batch_size], steps)
- outs = ae_model.decode(out_latents * torch.tensor(2.55).to(device))
- for j, out in enumerate(outs):
- pil_ims.append(utils.to_pil_image(out))
-
- return pil_ims
-
-
-import gradio as gr
-
-def gen_ims(prompt, im_prompt=None, seed=None, n_steps=10, method='plms'):
- if seed == None :
- seed = random.randint(0, 10000)
- print( prompt, im_prompt, seed, n_steps)
- prompts = [prompt]
- im_prompts = []
- if im_prompt != None:
- im_prompts = [im_prompt]
- pil_ims = generate(n=1, prompts=prompts, images=im_prompts, seed=seed, steps=n_steps, method=method)
- return pil_ims[0]
-
-iface = gr.Interface(fn=gen_ims,
- inputs=[#gr.inputs.Slider(minimum=1, maximum=1, step=1, default=1,label="Number of images"),
- #gr.inputs.Slider(minimum=0, maximum=200, step=1, label='Random seed', default=0),
- gr.inputs.Textbox(label="Text prompt"),
- gr.inputs.Image(optional=True, label="Image prompt", type='filepath'),
- #gr.inputs.Slider(minimum=10, maximum=35, step=1, default=15,label="Number of steps")
- ],
- outputs=[gr.outputs.Image(type="pil", label="Generated Image")],
- examples=[
- ["Futurism, in the style of Wassily Kandinsky"],
- ["Art Nouveau, in the style of John Singer Sargent"],
- ["Surrealism, in the style of Edgar Degas"],
- ["Expressionism, in the style of Wassily Kandinsky"],
- ["Futurism, in the style of Egon Schiele"],
- ["Neoclassicism, in the style of Gustav Klimt"],
- ["Cubism, in the style of Gustav Klimt"],
- ["Op Art, in the style of Marc Chagall"],
- ["Romanticism, in the style of M.C. Escher"],
- ["Futurism, in the style of M.C. Escher"],
- ["Abstract Art, in the style of M.C. Escher"],
- ["Mannerism, in the style of Paul Klee"],
- ["Romanesque Art, in the style of Leonardo da Vinci"],
- ["High Renaissance, in the style of Rembrandt"],
- ["Magic Realism, in the style of Gustave Dore"],
- ["Realism, in the style of Jean-Michel Basquiat"],
- ["Art Nouveau, in the style of Paul Gauguin"],
- ["Avant-garde, in the style of Pierre-Auguste Renoir"],
- ["Baroque, in the style of Edward Hopper"],
- ["Post-Impressionism, in the style of Wassily Kandinsky"],
- ["Naturalism, in the style of Rene Magritte"],
- ["Constructivism, in the style of Paul Cezanne"],
- ["Abstract Expressionism, in the style of Henri Matisse"],
- ["Pop Art, in the style of Vincent van Gogh"],
- ["Futurism, in the style of Wassily Kandinsky"],
- ["Futurism, in the style of Zdzislaw Beksinski"],
- ['Surrealism, in the style of Salvador Dali'],
- ["Aaron Wacker, oil on canvas"],
- ["abstract"],
- ["landscape"],
- ["portrait"],
- ["sculpture"],
- ["genre painting"],
- ["installation"],
- ["photo"],
- ["figurative"],
- ["illustration"],
- ["still life"],
- ["history painting"],
- ["cityscape"],
- ["marina"],
- ["animal painting"],
- ["design"],
- ["calligraphy"],
- ["symbolic painting"],
- ["graffiti"],
- ["performance"],
- ["mythological painting"],
- ["battle painting"],
- ["self-portrait"],
- ["Impressionism, oil on canvas"]
- ],
- title='Art Generator and Style Mixer from 🧠 Cloob and 🎨 WikiArt - Visual Art Encyclopedia:',
- description="Trained on images from the [WikiArt](https://www.wikiart.org/) dataset, comprised of visual arts",
- article = 'Model used is: [model card](https://huggingface.co/huggan/distill-ccld-wa)..'
-
-)
-iface.launch(enable_queue=True) # , debug=True for colab debugging
\ No newline at end of file
diff --git a/spaces/candlend/vits-hoshimi/sovits/vdecoder/parallel_wavegan/models/__init__.py b/spaces/candlend/vits-hoshimi/sovits/vdecoder/parallel_wavegan/models/__init__.py
deleted file mode 100644
index 4803ba6b2a0afc8022e756ae5b3f4c7403c3c1bd..0000000000000000000000000000000000000000
--- a/spaces/candlend/vits-hoshimi/sovits/vdecoder/parallel_wavegan/models/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-from .melgan import * # NOQA
-from .parallel_wavegan import * # NOQA
diff --git a/spaces/cfj108/CompVis-stable-diffusion-v1-4/app.py b/spaces/cfj108/CompVis-stable-diffusion-v1-4/app.py
deleted file mode 100644
index b60a087620a806fea130bedcd6940bef75fa3337..0000000000000000000000000000000000000000
--- a/spaces/cfj108/CompVis-stable-diffusion-v1-4/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/CompVis/stable-diffusion-v1-4").launch()
diff --git a/spaces/chendl/compositional_test/transformers/examples/pytorch/question-answering/trainer_qa.py b/spaces/chendl/compositional_test/transformers/examples/pytorch/question-answering/trainer_qa.py
deleted file mode 100644
index a486405b62877ee83d1a60f3fdf7a8f326882fcc..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/transformers/examples/pytorch/question-answering/trainer_qa.py
+++ /dev/null
@@ -1,136 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-A subclass of `Trainer` specific to Question-Answering tasks
-"""
-import math
-import time
-
-from transformers import Trainer, is_torch_tpu_available
-from transformers.trainer_utils import PredictionOutput, speed_metrics
-
-
-if is_torch_tpu_available(check_device=False):
- import torch_xla.core.xla_model as xm
- import torch_xla.debug.metrics as met
-
-
-class QuestionAnsweringTrainer(Trainer):
- def __init__(self, *args, eval_examples=None, post_process_function=None, **kwargs):
- super().__init__(*args, **kwargs)
- self.eval_examples = eval_examples
- self.post_process_function = post_process_function
-
- def evaluate(self, eval_dataset=None, eval_examples=None, ignore_keys=None, metric_key_prefix: str = "eval"):
- eval_dataset = self.eval_dataset if eval_dataset is None else eval_dataset
- eval_dataloader = self.get_eval_dataloader(eval_dataset)
- eval_examples = self.eval_examples if eval_examples is None else eval_examples
-
- # Temporarily disable metric computation, we will do it in the loop here.
- compute_metrics = self.compute_metrics
- self.compute_metrics = None
- eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
- start_time = time.time()
- try:
- output = eval_loop(
- eval_dataloader,
- description="Evaluation",
- # No point gathering the predictions if there are no metrics, otherwise we defer to
- # self.args.prediction_loss_only
- prediction_loss_only=True if compute_metrics is None else None,
- ignore_keys=ignore_keys,
- metric_key_prefix=metric_key_prefix,
- )
- finally:
- self.compute_metrics = compute_metrics
- total_batch_size = self.args.eval_batch_size * self.args.world_size
- if f"{metric_key_prefix}_jit_compilation_time" in output.metrics:
- start_time += output.metrics[f"{metric_key_prefix}_jit_compilation_time"]
- output.metrics.update(
- speed_metrics(
- metric_key_prefix,
- start_time,
- num_samples=output.num_samples,
- num_steps=math.ceil(output.num_samples / total_batch_size),
- )
- )
- if self.post_process_function is not None and self.compute_metrics is not None and self.args.should_save:
- # Only the main node write the results by default
- eval_preds = self.post_process_function(eval_examples, eval_dataset, output.predictions)
- metrics = self.compute_metrics(eval_preds)
-
- # Prefix all keys with metric_key_prefix + '_'
- for key in list(metrics.keys()):
- if not key.startswith(f"{metric_key_prefix}_"):
- metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
- metrics.update(output.metrics)
- else:
- metrics = output.metrics
-
- if self.args.should_log:
- # Only the main node log the results by default
- self.log(metrics)
-
- if self.args.tpu_metrics_debug or self.args.debug:
- # tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
- xm.master_print(met.metrics_report())
-
- self.control = self.callback_handler.on_evaluate(self.args, self.state, self.control, metrics)
- return metrics
-
- def predict(self, predict_dataset, predict_examples, ignore_keys=None, metric_key_prefix: str = "test"):
- predict_dataloader = self.get_test_dataloader(predict_dataset)
-
- # Temporarily disable metric computation, we will do it in the loop here.
- compute_metrics = self.compute_metrics
- self.compute_metrics = None
- eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
- start_time = time.time()
- try:
- output = eval_loop(
- predict_dataloader,
- description="Prediction",
- # No point gathering the predictions if there are no metrics, otherwise we defer to
- # self.args.prediction_loss_only
- prediction_loss_only=True if compute_metrics is None else None,
- ignore_keys=ignore_keys,
- metric_key_prefix=metric_key_prefix,
- )
- finally:
- self.compute_metrics = compute_metrics
- total_batch_size = self.args.eval_batch_size * self.args.world_size
- if f"{metric_key_prefix}_jit_compilation_time" in output.metrics:
- start_time += output.metrics[f"{metric_key_prefix}_jit_compilation_time"]
- output.metrics.update(
- speed_metrics(
- metric_key_prefix,
- start_time,
- num_samples=output.num_samples,
- num_steps=math.ceil(output.num_samples / total_batch_size),
- )
- )
-
- if self.post_process_function is None or self.compute_metrics is None:
- return output
-
- predictions = self.post_process_function(predict_examples, predict_dataset, output.predictions, "predict")
- metrics = self.compute_metrics(predictions)
-
- # Prefix all keys with metric_key_prefix + '_'
- for key in list(metrics.keys()):
- if not key.startswith(f"{metric_key_prefix}_"):
- metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
- metrics.update(output.metrics)
- return PredictionOutput(predictions=predictions.predictions, label_ids=predictions.label_ids, metrics=metrics)
diff --git a/spaces/chendl/compositional_test/transformers/examples/research_projects/xtreme-s/run_xtreme_s.py b/spaces/chendl/compositional_test/transformers/examples/research_projects/xtreme-s/run_xtreme_s.py
deleted file mode 100644
index 6c5b4bde892da18b57335ef779568af0728631c6..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/transformers/examples/research_projects/xtreme-s/run_xtreme_s.py
+++ /dev/null
@@ -1,949 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-""" Fine-tuning a 🤗 Transformers pretrained speech model on the XTREME-S benchmark tasks"""
-
-import json
-import logging
-import os
-import re
-import sys
-from collections import OrderedDict, defaultdict
-from dataclasses import dataclass, field
-from typing import Dict, List, Optional, Union
-
-import datasets
-import numpy as np
-import torch
-from datasets import DatasetDict, load_dataset, load_metric
-
-import transformers
-from transformers import (
- AutoConfig,
- AutoFeatureExtractor,
- AutoModelForAudioClassification,
- AutoModelForCTC,
- AutoModelForSpeechSeq2Seq,
- AutoProcessor,
- AutoTokenizer,
- HfArgumentParser,
- Seq2SeqTrainer,
- Seq2SeqTrainingArguments,
- Trainer,
- set_seed,
-)
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.18.0.dev0")
-
-require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
-
-
-logger = logging.getLogger(__name__)
-
-
-def list_field(default=None, metadata=None):
- return field(default_factory=lambda: default, metadata=metadata)
-
-
-TASK_TO_TARGET_COLUMN_NAME = {
- "fleurs-asr": "transcription",
- "fleurs-lang_id": "lang_id",
- "mls": "transcription",
- "voxpopuli": "transcription",
- "covost2": "translation",
- "minds14": "intent_class",
- "babel": "transcription",
-}
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- tokenizer_name_or_path: Optional[str] = field(
- default=None,
- metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={
- "help": "Where do you want to store the pretrained models and datasets downloaded from huggingface.co"
- },
- )
- freeze_feature_encoder: bool = field(
- default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
- )
- attention_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
- )
- activation_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
- )
- feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
- hidden_dropout: float = field(
- default=0.0,
- metadata={
- "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
- },
- )
- final_dropout: float = field(
- default=0.0,
- metadata={"help": "The dropout probability for the final projection layer."},
- )
- mask_time_prob: float = field(
- default=0.05,
- metadata={
- "help": (
- "Probability of each feature vector along the time axis to be chosen as the start of the vector"
- "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature"
- "vectors will be masked along the time axis."
- )
- },
- )
- mask_time_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the time axis."},
- )
- mask_feature_prob: float = field(
- default=0.0,
- metadata={
- "help": (
- "Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
- " to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
- " bins will be masked along the time axis."
- )
- },
- )
- mask_feature_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the feature axis."},
- )
- layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
- ctc_zero_infinity: bool = field(
- default=False,
- metadata={"help": "Whether to zero infinite losses and the associated gradients of `torch.nn.CTCLoss`."},
- )
- ctc_loss_reduction: Optional[str] = field(
- default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: str = field(
- default="google/xtreme_s",
- metadata={"help": "The name of the dataset to use (via the datasets library). Defaults to 'google/xtreme_s'"},
- )
- task: str = field(
- default=None,
- metadata={
- "help": (
- "The task name of the benchmark to use (via the datasets library). Should be on of: "
- "'fleurs-asr', 'mls', 'voxpopuli', 'covost2', 'minds14', 'fleurs-lang_id', 'babel'."
- )
- },
- )
- language: str = field(
- default="all",
- metadata={"help": "The language id as defined in the datasets config name or `all` for all languages."},
- )
- language_group: str = field(
- default=None,
- metadata={
- "help": (
- "The language group to select a subset of languages to train on. "
- "This option is only used the 'fleurs-asr' task. Should be one of: "
- "'western_european_we', 'eastern_european_ee', 'central_asia_middle_north_african_cmn', "
- "'sub_saharan_african_ssa', 'south_asian_sa', 'south_east_asian_sea', 'chinese_japanase_korean_cjk'."
- )
- },
- )
- train_split_name: str = field(
- default="train",
- metadata={
- "help": "The name of the training dataset split to use (via the datasets library). Defaults to 'train'"
- },
- )
- eval_split_name: str = field(
- default="validation",
- metadata={
- "help": (
- "The name of the evaluation dataset split to use (via the datasets library). Defaults to 'validation'"
- )
- },
- )
- predict_split_name: str = field(
- default="test",
- metadata={
- "help": "The name of the prediction dataset split to use (via the datasets library). Defaults to 'test'"
- },
- )
- audio_column_name: str = field(
- default="audio",
- metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
- )
- target_column_name: str = field(
- default=None,
- metadata={
- "help": (
- "The name of the dataset column containing the target data (transcription/translation/label). If None,"
- " the name will be inferred from the task. Defaults to None."
- )
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of validation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- chars_to_ignore: Optional[List[str]] = list_field(
- default=', ? . ! - ; : " “ % ‘ ” �'.split(" "),
- metadata={"help": "A list of characters to remove from the transcripts."},
- )
- max_duration_in_seconds: float = field(
- default=30.0,
- metadata={
- "help": (
- "Filter audio files that are longer than `max_duration_in_seconds` seconds to"
- " 'max_duration_in_seconds`"
- )
- },
- )
- min_duration_in_seconds: float = field(
- default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
- )
- preprocessing_only: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to only do data preprocessing and skip training. This is especially useful when data"
- " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
- " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
- " can consequently be loaded in distributed training"
- )
- },
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "If :obj:`True`, will use the token generated when running"
- ":obj:`huggingface-cli login` as HTTP bearer authorization for remote files."
- )
- },
- )
- unk_token: str = field(
- default="[UNK]",
- metadata={"help": "The unk token for the tokenizer"},
- )
- pad_token: str = field(
- default="[PAD]",
- metadata={"help": "The padding token for the tokenizer"},
- )
- word_delimiter_token: str = field(
- default="|",
- metadata={"help": "The word delimiter token for the tokenizer"},
- )
- phoneme_language: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The target language that should be used be"
- " passed to the tokenizer for tokenization. Note that"
- " this is only relevant if the model classifies the"
- " input audio to a sequence of phoneme sequences."
- )
- },
- )
- per_lang_metrics: bool = field(
- default=True,
- metadata={
- "help": (
- "If `True`, compute the test metrics separately for each language, and average the results. "
- "If `False` compute the average test metrics in a single pass for all languages at once."
- )
- },
- )
-
-
-@dataclass
-class SpeechDataCollatorWithPadding:
- processor: AutoProcessor
- decoder_start_token_id: Optional[int] = None
- padding: Union[bool, str] = "longest"
- pad_labels: Optional[int] = True
- pad_to_multiple_of: Optional[int] = None
- pad_to_multiple_of_labels: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # split inputs and labels since they have to be of different lenghts and need
- # different padding methods
- input_features = [{"input_values": feature["input_values"]} for feature in features]
-
- batch = self.processor.pad(
- input_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
-
- if self.pad_labels:
- label_features = [{"input_ids": feature["labels"]} for feature in features]
- labels_batch = self.processor.pad(
- labels=label_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of_labels,
- return_tensors="pt",
- )
-
- # replace padding with -100 to ignore loss correctly
- labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
-
- # if bos token is appended in previous tokenization step,
- # cut bos token here as it's append later anyways
- if (
- self.decoder_start_token_id is not None
- and (labels[:, 0] == self.decoder_start_token_id).all().cpu().item()
- ):
- labels = labels[:, 1:]
-
- batch["labels"] = labels
- else:
- batch["labels"] = torch.tensor([feature["labels"] for feature in features])
-
- return batch
-
-
-def create_vocabulary_from_data(
- datasets: DatasetDict,
- word_delimiter_token: Optional[str] = None,
- unk_token: Optional[str] = None,
- pad_token: Optional[str] = None,
-):
- # Given training and test labels create vocabulary
- def extract_all_chars(batch):
- all_text = " ".join(batch["target_text"])
- vocab = list(set(all_text))
- return {"vocab": [vocab], "all_text": [all_text]}
-
- vocabs = datasets.map(
- extract_all_chars,
- batched=True,
- batch_size=-1,
- keep_in_memory=True,
- remove_columns=datasets["train"].column_names,
- )
-
- # take union of all unique characters in each dataset
- vocab_set = (
- (set(vocabs["train"]["vocab"][0]) if "train" in vocabs else set())
- | (set(vocabs["eval"]["vocab"][0]) if "eval" in vocabs else set())
- | (set(vocabs["predict"]["vocab"][0]) if "predict" in vocabs else set())
- )
-
- vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}
-
- # replace white space with delimiter token
- if word_delimiter_token is not None:
- vocab_dict[word_delimiter_token] = vocab_dict[" "]
- del vocab_dict[" "]
-
- # add unk and pad token
- if unk_token is not None:
- vocab_dict[unk_token] = len(vocab_dict)
-
- if pad_token is not None:
- vocab_dict[pad_token] = len(vocab_dict)
-
- return vocab_dict
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # 1. First, let's load the dataset
- raw_datasets = DatasetDict()
- task_name = data_args.task
- lang_id = data_args.language
-
- if task_name is None:
- raise ValueError(
- "Set --task should be set to '' (e.g. 'fleurs-asr', 'mls', 'covost2', 'minds14') "
- )
- if lang_id is None:
- raise ValueError(
- "Set --language should be set to the language id of the sub dataset "
- "config to be used (e.g. 'pl', 'en.tr', 'fr-FR') or 'all'"
- " for multi-lingual fine-tuning."
- )
- if data_args.language_group is not None:
- if data_args.task != "fleurs-asr":
- raise ValueError("--language_group should only be used with --task=fleurs-asr")
- if data_args.language != "all":
- raise ValueError("--language_group should only be used with --language=all")
-
- if data_args.target_column_name is None:
- target_column_name = TASK_TO_TARGET_COLUMN_NAME[task_name]
- else:
- target_column_name = data_args.target_column_name
-
- # here we differentiate between tasks with text as the target and classification tasks
- is_text_target = target_column_name in ("transcription", "translation")
-
- config_name = ".".join([task_name.split("-")[0], lang_id])
-
- if training_args.do_train:
- raw_datasets["train"] = load_dataset(
- data_args.dataset_name,
- config_name,
- split=data_args.train_split_name,
- use_auth_token=data_args.use_auth_token,
- cache_dir=model_args.cache_dir,
- )
-
- if data_args.audio_column_name not in raw_datasets["train"].column_names:
- raise ValueError(
- f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
- " Make sure to set `--audio_column_name` to the correct audio column - one of"
- f" {', '.join(raw_datasets['train'].column_names)}."
- )
-
- if target_column_name not in raw_datasets["train"].column_names:
- raise ValueError(
- f"--target_column_name {target_column_name} not found in dataset '{data_args.dataset_name}'. "
- "Make sure to set `--target_column_name` to the correct text column - one of "
- f"{', '.join(raw_datasets['train'].column_names)}."
- )
-
- if data_args.max_train_samples is not None:
- raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
-
- if training_args.do_eval:
- raw_datasets["eval"] = load_dataset(
- data_args.dataset_name,
- config_name,
- split=data_args.eval_split_name,
- use_auth_token=data_args.use_auth_token,
- cache_dir=model_args.cache_dir,
- )
-
- if data_args.max_eval_samples is not None:
- raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
-
- if training_args.do_predict:
- raw_datasets["predict"] = load_dataset(
- data_args.dataset_name,
- config_name,
- split=data_args.predict_split_name,
- use_auth_token=data_args.use_auth_token,
- cache_dir=model_args.cache_dir,
- )
-
- if data_args.max_predict_samples is not None:
- raw_datasets["predict"] = raw_datasets["predict"].select(range(data_args.max_predict_samples))
-
- lang_list = next(iter(raw_datasets.values())).features["lang_id"].names
- if not is_text_target:
- label_list = next(iter(raw_datasets.values())).features[target_column_name].names
- num_labels = len(label_list)
-
- num_workers = data_args.preprocessing_num_workers
-
- lang_group = data_args.language_group
- if lang_group is not None:
- with training_args.main_process_first(desc="language group filter"):
- lang_group_id = next(iter(raw_datasets.values())).features["lang_group_id"].str2int(lang_group)
- raw_datasets = raw_datasets.filter(
- lambda lang_group: lang_group == lang_group_id,
- num_proc=num_workers,
- input_columns=["lang_group_id"],
- )
-
- # 2. We remove some special characters from the datasets
- # that make training complicated and do not help in transcribing the speech
- # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
- # that could be easily picked up by the model
- chars_to_ignore_regex = (
- f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
- )
-
- def remove_special_characters(batch):
- if chars_to_ignore_regex is not None:
- batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[target_column_name]).lower() + " "
- else:
- batch["target_text"] = batch[target_column_name].lower() + " "
- return batch
-
- if is_text_target:
- with training_args.main_process_first(desc="dataset map special characters removal"):
- raw_datasets = raw_datasets.map(
- remove_special_characters,
- remove_columns=[target_column_name],
- desc="remove special characters from datasets",
- )
-
- # save special tokens for tokenizer
- word_delimiter_token = data_args.word_delimiter_token
- unk_token = data_args.unk_token
- pad_token = data_args.pad_token
-
- # 3. Next, let's load the config as we might need it to create
- # the tokenizer
- config = AutoConfig.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_auth_token=data_args.use_auth_token
- )
-
- if is_text_target:
- # 4. (Optional, for ASR and translation) If no tokenizer file is defined,
- # we create the vocabulary of the model by extracting all unique characters from
- # the training and evaluation datasets
- # We need to make sure that only first rank saves vocabulary
- # make sure all processes wait until vocab is created
- tokenizer_name_or_path = model_args.tokenizer_name_or_path
- tokenizer_kwargs = {}
- if tokenizer_name_or_path is None:
- # save vocab in training output dir
- tokenizer_name_or_path = training_args.output_dir
-
- vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")
-
- with training_args.main_process_first():
- if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
- os.remove(vocab_file)
-
- with training_args.main_process_first(desc="dataset map vocabulary creation"):
- if not os.path.isfile(vocab_file):
- os.makedirs(tokenizer_name_or_path, exist_ok=True)
- vocab_dict = create_vocabulary_from_data(
- raw_datasets,
- word_delimiter_token=word_delimiter_token,
- unk_token=unk_token,
- pad_token=pad_token,
- )
-
- # save vocab dict to be loaded into tokenizer
- with open(vocab_file, "w") as file:
- json.dump(vocab_dict, file)
-
- # if tokenizer has just been created
- # it is defined by `tokenizer_class` if present in config else by `model_type`
- if not config.is_encoder_decoder:
- tokenizer_kwargs = {
- "config": config if config.tokenizer_class is not None else None,
- "tokenizer_type": config.model_type if config.tokenizer_class is None else None,
- "unk_token": unk_token,
- "pad_token": pad_token,
- "word_delimiter_token": word_delimiter_token,
- }
- else:
- tokenizer_kwargs = {}
-
- # 5. Now we can instantiate the feature extractor, tokenizer and model
- # Note for distributed training, the .from_pretrained methods guarantee that only
- # one local process can concurrently download model & vocab.
-
- # load feature_extractor and tokenizer
- if is_text_target:
- tokenizer = AutoTokenizer.from_pretrained(
- tokenizer_name_or_path,
- use_auth_token=data_args.use_auth_token,
- **tokenizer_kwargs,
- )
- feature_extractor = AutoFeatureExtractor.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_auth_token=data_args.use_auth_token
- )
-
- # adapt config
- # (speech translation requires pre-configured seq2seq models)
- if task_name != "covost2":
- config.update(
- {
- "feat_proj_dropout": model_args.feat_proj_dropout,
- "attention_dropout": model_args.attention_dropout,
- "hidden_dropout": model_args.hidden_dropout,
- "final_dropout": model_args.final_dropout,
- "mask_time_prob": model_args.mask_time_prob,
- "mask_time_length": model_args.mask_time_length,
- "mask_feature_prob": model_args.mask_feature_prob,
- "mask_feature_length": model_args.mask_feature_length,
- "gradient_checkpointing": training_args.gradient_checkpointing,
- "layerdrop": model_args.layerdrop,
- "ctc_zero_infinity": model_args.ctc_zero_infinity,
- "ctc_loss_reduction": model_args.ctc_loss_reduction,
- "activation_dropout": model_args.activation_dropout,
- }
- )
- if training_args.do_train:
- if is_text_target:
- config.pad_token_id = tokenizer.pad_token_id
- config.vocab_size = len(tokenizer)
- else:
- label_to_id = {v: i for i, v in enumerate(label_list)}
- config.label2id = label_to_id
- config.id2label = {id: label for label, id in label_to_id.items()}
- config.num_labels = num_labels
-
- # create model
- if target_column_name == "transcription":
- model = AutoModelForCTC.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- use_auth_token=data_args.use_auth_token,
- )
- elif config.is_encoder_decoder:
- model = AutoModelForSpeechSeq2Seq.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- use_auth_token=data_args.use_auth_token,
- )
- if model.config.decoder_start_token_id is None:
- raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
- else:
- model = AutoModelForAudioClassification.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- use_auth_token=data_args.use_auth_token,
- )
-
- # freeze encoder
- if model_args.freeze_feature_encoder:
- model.freeze_feature_encoder()
-
- # 6. Now we preprocess the datasets including loading the audio, resampling and normalization
- # Thankfully, `datasets` takes care of automatically loading and resampling the audio,
- # so that we just need to set the correct target sampling rate and normalize the input
- # via the `feature_extractor`
-
- # make sure that dataset decodes audio with correct sampling rate
- dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
- if dataset_sampling_rate != feature_extractor.sampling_rate:
- raw_datasets = raw_datasets.cast_column(
- data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
- )
-
- # derive max & min input length for sample rate & max duration
- max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
- min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
- audio_column_name = data_args.audio_column_name
-
- # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
- phoneme_language = data_args.phoneme_language
-
- # Preprocessing the datasets.
- # We need to read the audio files as arrays and tokenize the targets.
- def prepare_dataset(batch):
- # load audio
- sample = batch[audio_column_name]
-
- inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
- batch["input_values"] = inputs.input_values[0]
- batch["length"] = len(batch["input_values"])
-
- # encode targets
- additional_kwargs = {}
- if phoneme_language is not None:
- additional_kwargs["phonemizer_lang"] = phoneme_language
-
- if is_text_target:
- batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
- else:
- batch["labels"] = batch[target_column_name]
-
- batch["lang"] = batch["lang_id"]
-
- return batch
-
- with training_args.main_process_first(desc="dataset map preprocessing"):
- vectorized_datasets = raw_datasets.map(
- prepare_dataset,
- remove_columns=next(iter(raw_datasets.values())).column_names,
- num_proc=num_workers,
- desc="preprocess datasets",
- )
-
- if training_args.do_train:
-
- def is_audio_in_length_range(length):
- return length > min_input_length and length < max_input_length
-
- # filter data that is shorter than min_input_length
- vectorized_datasets["train"] = vectorized_datasets["train"].filter(
- is_audio_in_length_range,
- num_proc=num_workers,
- input_columns=["length"],
- )
-
- # 7. Next, we can prepare for the training step.
- # Let's use the appropriate XTREME-S evaluation metric,
- # instantiate a data collator and the trainer
-
- # Define evaluation metrics during training, *i.e.* word error rate, character error rate
- eval_metric = load_metric("xtreme_s", task_name)
-
- # for large datasets it is advised to run the preprocessing on a
- # single machine first with ``args.preprocessing_only`` since there will mostly likely
- # be a timeout when running the script in distributed mode.
- # In a second step ``args.preprocessing_only`` can then be set to `False` to load the
- # cached dataset
- if data_args.preprocessing_only:
- logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_files}")
- return
-
- def asr_logits_argmax(logits, labels):
- return logits.argmax(dim=-1)
-
- def compute_asr_metric(pred):
- pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
-
- pred_str = tokenizer.batch_decode(pred.predictions)
- # we do not want to group tokens when computing the metrics
- label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
-
- metric = eval_metric.compute(predictions=pred_str, references=label_str)
- return metric
-
- def compute_classification_metric(pred):
- pred_ids = np.argmax(pred.predictions, axis=1)
- metric = eval_metric.compute(predictions=pred_ids, references=pred.label_ids)
- return metric
-
- # Now save everything to be able to create a single processor later
- if is_main_process(training_args.local_rank):
- # save feature extractor, tokenizer and config
- feature_extractor.save_pretrained(training_args.output_dir)
- if is_text_target:
- tokenizer.save_pretrained(training_args.output_dir)
- config.save_pretrained(training_args.output_dir)
- # wait until configs are saved in the main process before loading the processor
- if training_args.local_rank != -1:
- torch.distributed.barrier()
-
- if is_text_target:
- processor = AutoProcessor.from_pretrained(training_args.output_dir)
- else:
- processor = AutoFeatureExtractor.from_pretrained(training_args.output_dir)
-
- # Instantiate custom data collator
- data_collator = SpeechDataCollatorWithPadding(processor=processor, pad_labels=is_text_target)
-
- # Initialize Trainer
- if target_column_name == "translation":
- trainer = Seq2SeqTrainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- preprocess_logits_for_metrics=asr_logits_argmax if training_args.predict_with_generate else None,
- compute_metrics=compute_asr_metric if training_args.predict_with_generate else None,
- train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
- eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=feature_extractor,
- )
- else:
- trainer = Trainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- preprocess_logits_for_metrics=asr_logits_argmax if is_text_target else None,
- compute_metrics=compute_asr_metric if is_text_target else compute_classification_metric,
- train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
- eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=feature_extractor,
- )
-
- # 8. Finally, we can start training
-
- # Training
- if training_args.do_train:
- # use last checkpoint if exist
- if last_checkpoint is not None:
- checkpoint = last_checkpoint
- elif os.path.isdir(model_args.model_name_or_path):
- checkpoint = model_args.model_name_or_path
- else:
- checkpoint = None
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model()
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples
- if data_args.max_train_samples is not None
- else len(vectorized_datasets["train"])
- )
- metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation on the test set
- results = {}
- if training_args.do_predict:
- logger.info(f"*** Evaluating on the `{data_args.predict_split_name}` set ***")
- if data_args.per_lang_metrics:
- # separate the `test` dataset into language-specific subsets and compute metrics for each of them
- metrics = {}
- average_metrics = defaultdict(list)
- for lang_id in range(len(lang_list)):
- lang_name = lang_list[lang_id]
- with training_args.main_process_first(desc="per-language dataset filter"):
- lang_dataset = vectorized_datasets["predict"].filter(
- lambda lang: lang == lang_id,
- num_proc=num_workers,
- input_columns=["lang"],
- )
- lang_metrics = trainer.evaluate(lang_dataset)
- redundant_metrics = ["eval_runtime", "eval_samples_per_second", "eval_steps_per_second", "eval_epoch"]
- for metric_name, value in lang_metrics.items():
- average_metrics[metric_name].append(value)
- if metric_name not in redundant_metrics:
- metrics[f"{metric_name}_{lang_name}"] = value
- for metric_name, value in average_metrics.items():
- metrics[metric_name] = np.mean(value)
- else:
- metrics = trainer.evaluate(vectorized_datasets["predict"])
- max_predict_samples = (
- data_args.max_predict_samples
- if data_args.max_predict_samples is not None
- else len(vectorized_datasets["predict"])
- )
- metrics["predict_samples"] = min(max_predict_samples, len(vectorized_datasets["predict"]))
-
- # make sure that the `predict` metrics end up in the log history for the model card
- trainer.log(OrderedDict(sorted(metrics.items())))
-
- trainer.log_metrics("predict", metrics)
- trainer.save_metrics("predict", metrics)
-
- # Write model card and (optionally) push to hub
- kwargs = {
- "finetuned_from": model_args.model_name_or_path,
- "tasks": task_name,
- "tags": [task_name, data_args.dataset_name],
- "dataset_args": (
- f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
- f" {data_args.eval_split_name}, Predict split: {data_args.predict_split_name}"
- ),
- "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
- "language": data_args.language,
- }
-
- if training_args.push_to_hub:
- trainer.push_to_hub(**kwargs)
- else:
- trainer.create_model_card(**kwargs)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/chendl/compositional_test/transformers/examples/tensorflow/benchmarking/plot_csv_file.py b/spaces/chendl/compositional_test/transformers/examples/tensorflow/benchmarking/plot_csv_file.py
deleted file mode 100644
index 9a9ad9c670470e1f3231d90c7fd375566e2fb8ee..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/transformers/examples/tensorflow/benchmarking/plot_csv_file.py
+++ /dev/null
@@ -1,178 +0,0 @@
-# Copyright 2020 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import csv
-from collections import defaultdict
-from dataclasses import dataclass, field
-from typing import List, Optional
-
-import matplotlib.pyplot as plt
-import numpy as np
-from matplotlib.ticker import ScalarFormatter
-
-from transformers import HfArgumentParser
-
-
-def list_field(default=None, metadata=None):
- return field(default_factory=lambda: default, metadata=metadata)
-
-
-@dataclass
-class PlotArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
- """
-
- csv_file: str = field(
- metadata={"help": "The csv file to plot."},
- )
- plot_along_batch: bool = field(
- default=False,
- metadata={"help": "Whether to plot along batch size or sequence length. Defaults to sequence length."},
- )
- is_time: bool = field(
- default=False,
- metadata={"help": "Whether the csv file has time results or memory results. Defaults to memory results."},
- )
- no_log_scale: bool = field(
- default=False,
- metadata={"help": "Disable logarithmic scale when plotting"},
- )
- is_train: bool = field(
- default=False,
- metadata={
- "help": "Whether the csv file has training results or inference results. Defaults to inference results."
- },
- )
- figure_png_file: Optional[str] = field(
- default=None,
- metadata={"help": "Filename under which the plot will be saved. If unused no plot is saved."},
- )
- short_model_names: Optional[List[str]] = list_field(
- default=None, metadata={"help": "List of model names that are used instead of the ones in the csv file."}
- )
-
-
-def can_convert_to_int(string):
- try:
- int(string)
- return True
- except ValueError:
- return False
-
-
-def can_convert_to_float(string):
- try:
- float(string)
- return True
- except ValueError:
- return False
-
-
-class Plot:
- def __init__(self, args):
- self.args = args
- self.result_dict = defaultdict(lambda: {"bsz": [], "seq_len": [], "result": {}})
-
- with open(self.args.csv_file, newline="") as csv_file:
- reader = csv.DictReader(csv_file)
- for row in reader:
- model_name = row["model"]
- self.result_dict[model_name]["bsz"].append(int(row["batch_size"]))
- self.result_dict[model_name]["seq_len"].append(int(row["sequence_length"]))
- if can_convert_to_int(row["result"]):
- # value is not None
- self.result_dict[model_name]["result"][
- (int(row["batch_size"]), int(row["sequence_length"]))
- ] = int(row["result"])
- elif can_convert_to_float(row["result"]):
- # value is not None
- self.result_dict[model_name]["result"][
- (int(row["batch_size"]), int(row["sequence_length"]))
- ] = float(row["result"])
-
- def plot(self):
- fig, ax = plt.subplots()
- title_str = "Time usage" if self.args.is_time else "Memory usage"
- title_str = title_str + " for training" if self.args.is_train else title_str + " for inference"
-
- if not self.args.no_log_scale:
- # set logarithm scales
- ax.set_xscale("log")
- ax.set_yscale("log")
-
- for axis in [ax.xaxis, ax.yaxis]:
- axis.set_major_formatter(ScalarFormatter())
-
- for model_name_idx, model_name in enumerate(self.result_dict.keys()):
- batch_sizes = sorted(set(self.result_dict[model_name]["bsz"]))
- sequence_lengths = sorted(set(self.result_dict[model_name]["seq_len"]))
- results = self.result_dict[model_name]["result"]
-
- (x_axis_array, inner_loop_array) = (
- (batch_sizes, sequence_lengths) if self.args.plot_along_batch else (sequence_lengths, batch_sizes)
- )
-
- label_model_name = (
- model_name if self.args.short_model_names is None else self.args.short_model_names[model_name_idx]
- )
-
- for inner_loop_value in inner_loop_array:
- if self.args.plot_along_batch:
- y_axis_array = np.asarray(
- [results[(x, inner_loop_value)] for x in x_axis_array if (x, inner_loop_value) in results],
- dtype=int,
- )
- else:
- y_axis_array = np.asarray(
- [results[(inner_loop_value, x)] for x in x_axis_array if (inner_loop_value, x) in results],
- dtype=np.float32,
- )
-
- (x_axis_label, inner_loop_label) = (
- ("batch_size", "len") if self.args.plot_along_batch else ("in #tokens", "bsz")
- )
-
- x_axis_array = np.asarray(x_axis_array, int)[: len(y_axis_array)]
- plt.scatter(
- x_axis_array, y_axis_array, label=f"{label_model_name} - {inner_loop_label}: {inner_loop_value}"
- )
- plt.plot(x_axis_array, y_axis_array, "--")
-
- title_str += f" {label_model_name} vs."
-
- title_str = title_str[:-4]
- y_axis_label = "Time in s" if self.args.is_time else "Memory in MB"
-
- # plot
- plt.title(title_str)
- plt.xlabel(x_axis_label)
- plt.ylabel(y_axis_label)
- plt.legend()
-
- if self.args.figure_png_file is not None:
- plt.savefig(self.args.figure_png_file)
- else:
- plt.show()
-
-
-def main():
- parser = HfArgumentParser(PlotArguments)
- plot_args = parser.parse_args_into_dataclasses()[0]
- plot = Plot(args=plot_args)
- plot.plot()
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/chronopt-research/ViTExCo/UI.py b/spaces/chronopt-research/ViTExCo/UI.py
deleted file mode 100644
index 033046d4e8709d171221bc145df3422cfeed9e64..0000000000000000000000000000000000000000
--- a/spaces/chronopt-research/ViTExCo/UI.py
+++ /dev/null
@@ -1,81 +0,0 @@
-import streamlit as st
-from PIL import Image
-import torchvision.transforms as transforms
-from streamlit_image_comparison import image_comparison
-import numpy as np
-import torch
-import torchvision
-
-######################################### Utils ########################################
-video_extensions = ["mp4"]
-image_extensions = ["png", "jpg"]
-
-
-def check_type(file_name: str):
- for image_extension in image_extensions:
- if file_name.endswith(image_extension):
- return "image"
- for video_extension in video_extensions:
- if file_name.endswith(video_extension):
- return "video"
- return None
-
-
-transform = transforms.Compose(
- [transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]
-)
-
-
-###################################### Load model ######################################
-@st.cache_resource
-def load_model():
- model = torchvision.models.segmentation.deeplabv3_resnet101(pretrained=True)
- model.eval()
- return model
-
-
-model = load_model()
-########################################## UI ##########################################
-st.title("Colorization")
-
-uploaded_file = st.file_uploader("Upload grayscale image or video", type=image_extensions + video_extensions)
-if uploaded_file:
- # Image
- if check_type(file_name=uploaded_file.name) == "image":
- image = np.array(Image.open(uploaded_file), dtype=np.float32)
-
- input_tensor = torchvision.transforms.functional.normalize(
- torch.tensor(image).permute(2, 0, 1),
- mean=[0.485, 0.456, 0.406],
- std=[0.229, 0.224, 0.225],
- ).unsqueeze(0)
- process_button = st.button("Process")
- if process_button:
- with st.spinner("Từ từ coi..."):
- prediction = model(input_tensor)
- segment = prediction["out"][0].permute(1, 2, 0)
- segment = segment.detach().numpy()
-
- st.image(segment)
- st.image(image)
-
- image_comparison(
- img1=image,
- img2=np.array(segment),
- label1="Grayscale",
- label2="Colorized",
- make_responsive=True,
- show_labels=True,
- )
- # Video
- else:
- # video = open(uploaded_file.name)
- st.video("https://youtu.be/dQw4w9WgXcQ")
-
-hide_menu_style = """
-
- """
-st.markdown(hide_menu_style, unsafe_allow_html=True)
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/Login-9c3cc0eb.css b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/Login-9c3cc0eb.css
deleted file mode 100644
index 9901bcac6c93474ed045092f6d91d6e683ba5b32..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/Login-9c3cc0eb.css
+++ /dev/null
@@ -1 +0,0 @@
-.wrap.svelte-1ogxbi0{display:flex;flex-direction:column;justify-content:center;align-items:center;margin-top:var(--size-3);background:var(--background-fill-primary);width:var(--size-full)}h2.svelte-1ogxbi0{margin-bottom:var(--size-3);color:var(--body-text-color);font-weight:var(--section-header-text-weight);font-size:var(--text-xl)}.auth.svelte-1ogxbi0{margin-top:var(--size-1);margin-bottom:var(--size-1);color:var(--body-text-color)}.creds.svelte-1ogxbi0{margin-top:var(--size-4);margin-bottom:var(--size-4);color:var(--error-text-color);font-weight:var(--weight-semibold)}
diff --git a/spaces/cihyFjudo/fairness-paper-search/HACK MiniTool Partition Wizard Server V8.1.1 Retail Incl Keygen-BRD [Review and Tutorial].md b/spaces/cihyFjudo/fairness-paper-search/HACK MiniTool Partition Wizard Server V8.1.1 Retail Incl Keygen-BRD [Review and Tutorial].md
deleted file mode 100644
index 1de1789bd496337919d1aec64b659839a06e886e..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/HACK MiniTool Partition Wizard Server V8.1.1 Retail Incl Keygen-BRD [Review and Tutorial].md
+++ /dev/null
@@ -1,6 +0,0 @@
-crack Keygen PowerShape 2011 crack
Download Zip ✅ https://tinurli.com/2uwjuI
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/cihyFjudo/fairness-paper-search/Thunderbolt 3 is coming The future of connectivity and productivity.md b/spaces/cihyFjudo/fairness-paper-search/Thunderbolt 3 is coming The future of connectivity and productivity.md
deleted file mode 100644
index 421402d73113cb8769c645ad858bd6952fb06da8..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Thunderbolt 3 is coming The future of connectivity and productivity.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-OWC has announced that its upcoming Thunderbolt Hub will be compatible with all Apple M1 and Intel Macs equipped with Thunderbolt 3 ports and running macOS Big Sur, offering users the ability to expand the number of available Thunderbolt ports.
-VESA has announced today that its DisplayPort 2.0 specs are coming to USB4/USB-C that will bring a jump in the capabilities of video output. The standard will support up to 16K displays with video data throughput of up to 80 Gbps.
-Thunderbolt 3 is coming
Download Zip ✔ https://tinurli.com/2uwhZI
-AJA Software Installer v16.2.3\u00a0for\u00a0macOS:\r\n\r\nThis unified software, driver and firmware package contains everything you need in order to start using your AJA video I\/O hardware and includes enhancements.\u00a0Please read the\u00a0Release Notes\u00a0for complete detail.\u00a0\r\n\r\nThe following AJA applications are installed in v16.2.3\r\n\r\n\r\n\t- AJA Control Panel v16.2.3:\u00a0\r\n\r\n\t
\r\n\t\t- For setup and control of your AJA KONA, Io or T-TAP product, including firmware updates.\r\n\t\t
- For high quality capture, playback and output.\r\n\t\r\n\t\r\n\t
- AJA System Test v16.2.3:\u00a0\r\n\t
\r\n\t\t- For testing storage to determine if it will be possible to sustain frame rates for chosen format(s).\r\n\t\r\n\t\r\n\t
- AJA Control Room v16.2.3:\r\n\t
\r\n\t\t- For high quality capture, monitoring, playback and output.\r\n\t\r\n\t\r\n\t
- AJA\u00a0NMOS\u00a0v16.2.3:\u00a0\r\n\t
\r\n\t\t- An optional component providing discovery, registration and control for KONA IP running in\u00a0SMPTE\u00a0ST 2110 environments.\r\n\t\r\n\t\r\n\r\n\r\n\u00a0\r\n","product":0,"category":"so","platform_mac":1,"platform_pc":0,"platform_linux":0,"platform":"m","showdate":"y","released":"2\/7\/2023","url":"","ziparchive":true,"files":["file":"AJA-Software-Installer_macOS_v16.2.3_Release.zip","abspath":"\/var\/www\/sierra\/releases\/20230118233302\/webroot\/public\/assets\/support\/files\/8994\/en\/AJA-Software-Installer_macOS_v16.2.3_Release.zip","urlpath":"https:\/\/www.aja.com\/assets\/support\/files\/8994\/en\/","ext":"zip"]}],"p":["id":8997,"title":"AJA Software Installer v16.2.3 - Windows","description":"AJA Software Installer v16.2.3 for Windows:\r\n\r\nThis unified software, driver and firmware package contains everything you need in order to start using your AJA video I\/O hardware and includes new features as well as\u00a0maintenance updates.\u00a0Please read the Release Notes\u00a0for complete detail.\u00a0\r\n\r\nThe following AJA applications are installed in v16.2.3\r\n\r\n
\r\n\t- AJA Control Panel v16.2.3:\u00a0\r\n\r\n\t
\r\n\t\t- For setup and control of your AJA KONA, Io or T-TAP product, including firmware updates.\r\n\t\t
- For high quality capture, playback and output.\r\n\t\r\n\t\r\n\t
- AJA System Test v16.2.3:\u00a0\r\n\t
\r\n\t\t- For testing storage to determine if it will be possible to sustain frame rates for chosen format(s).\r\n\t\r\n\t\r\n\t
- AJA Control Room v16.2.3:\r\n\t
\r\n\t\t- For high quality capture, monitoring, playback and output.\r\n\t\r\n\t\r\n\t
- AJA\u00a0NMOS\u00a0v16.2.3:\u00a0\r\n\t
\r\n\t\t- An optional component providing discovery, registration and control for KONA IP running in\u00a0SMPTE\u00a0ST 2110 environments.\r\n\t\r\n\t\r\n\r\n","product":0,"category":"so","platform_mac":0,"platform_pc":1,"platform_linux":0,"platform":"m","showdate":"y","released":"2\/3\/2023","url":"","ziparchive":true,"files":["file":"AJA-Software-Installer_Windows_v16.2.3_Release.zip","abspath":"\/var\/www\/sierra\/releases\/20230118233302\/webroot\/public\/assets\/support\/files\/8997\/en\/AJA-Software-Installer_Windows_v16.2.3_Release.zip","urlpath":"https:\/\/www.aja.com\/assets\/support\/files\/8997\/en\/","ext":"zip"],"id":7132,"title":"DirectShow Filters v15.5.2","description":"These filters are designed for DirectShow application developers, so that they may make their applications compatible with the majority of AJA's windows based hardware. These filters are meant to be used programmatically, and will not necessarily work with every DirectShow application without work being done to explicitly support them. Note: DirectShow is a trademark of Microsoft.\r\n\r\n\u00a0\r\n","product":0,"category":"so","platform_mac":0,"platform_pc":1,"platform_linux":0,"platform":"m","showdate":"y","released":"4\/23\/2020","url":"https:\/\/www.aja.com\/support\/directshow","ziparchive":true,"files":["file":"AJA_DirectShowPackage_15_5_2.zip","abspath":"\/var\/www\/sierra\/releases\/20230118233302\/webroot\/public\/assets\/support\/files\/7132\/en\/AJA_DirectShowPackage_15_5_2.zip","urlpath":"https:\/\/www.aja.com\/assets\/support\/files\/7132\/en\/","ext":"zip"]],"l":[]},"mac_count":1,"pc_count":2,"linux_count":0,"load_count":3,"show_links":false,"m_load":1,"p_load":1,"l_load":1,"m_cached":true,"p_cached":true,"l_cached":true},"tag":"sa","title":"Software Archive","items":"m":["id":8745,"title":"AJA Software Installer v16.2.2 - Mac","description":"AJA Software Installer v16.2.2 for\u00a0macOS:\r\n\r\nThis unified software, driver and firmware package contains everything you need in order to start using your AJA video I\/O hardware and includes enhancements.\u00a0Please read the\u00a0Release Notes\u00a0for complete detail.\u00a0\r\n\r\nThe following AJA applications are installed in v16.2.2\r\n\r\n
\r\n\t- AJA Control Panel v16.2.2:\u00a0\r\n\r\n\t
\r\n\t\t- For setup and control of your AJA KONA, Io or T-TAP product, including firmware updates.\r\n\t\t
- For high quality capture, playback and output.\r\n\t\r\n\t\r\n\t
- AJA System Test v16.2.2:\u00a0\r\n\t
\r\n\t\t- For testing storage to determine if it will be possible to sustain frame rates for chosen format(s).\r\n\t\r\n\t\r\n\t
- AJA Control Room v16.2.2:\r\n\t
\r\n\t\t- For high quality capture, monitoring, playback and output.\r\n\t\r\n\t\r\n\t
- AJA\u00a0NMOS\u00a0v16.2.2:\u00a0\r\n\t
\r\n\t\t- An optional component providing discovery, registration and control for KONA IP running in\u00a0SMPTE\u00a0ST 2110 environments.\r\n\t\r\n\t\r\n\r\n\r\n\u00a0\r\n","product":0,"category":"sa","platform_mac":1,"platform_pc":0,"platform_linux":0,"platform":"m","showdate":"y","released":"6\/14\/2022","url":"","ziparchive":true,"files":["file":"AJA-Software-Installer_macOS_v16.2.2_Release.zip","abspath":"\/var\/www\/sierra\/releases\/20230118233302\/webroot\/public\/assets\/support\/files\/8745\/en\/AJA-Software-Installer_macOS_v16.2.2_Release.zip","urlpath":"https:\/\/www.aja.com\/assets\/support\/files\/8745\/en\/","ext":"zip"],"id":8508,"title":"AJA Software Installer v16.2 - Mac","description":"AJA Software Installer v16.2\u00a0for\u00a0macOS:\r\n\r\nThis unified software, driver and firmware package contains everything you need in order to start using your AJA video I\/O hardware and includes enhancements.\u00a0Please read the\u00a0Release Notes\u00a0for complete detail.\u00a0\r\n\r\nThe following AJA applications are installed in v16.2\r\n\r\n
\r\n\t- AJA Control Panel v16.2:\u00a0\r\n\r\n\t
\r\n\t\t- For setup and control of your AJA KONA, Io or T-TAP product, including firmware updates.\r\n\t\t
- For high quality capture, playback and output.\r\n\t\r\n\t\r\n\t
- AJA System Test v16.2:\u00a0\r\n\t
\r\n\t\t- For testing storage to determine if it will be possible to sustain frame rates for chosen format(s).\r\n\t\r\n\t\r\n\t
- AJA Control Room v16.2:\r\n\t
\r\n\t\t- For high quality capture, monitoring, playback and output.\r\n\t\r\n\t\r\n\t
- AJA\u00a0NMOS\u00a0v16.2:\u00a0\r\n\t
\r\n\t\t- An optional component providing discovery, registration and control for KONA IP running in\u00a0SMPTE\u00a0ST 2110 environments.\r\n\t\r\n\t\r\n\r\n\r\n\u00a0\r\n","product":0,"category":"sa","platform_mac":1,"platform_pc":0,"platform_linux":0,"platform":"m","showdate":"y","released":"2\/3\/2022","url":"","ziparchive":true,"files":["file":"AJA-Software-Installer_macOS_v16.2_Release.zip","abspath":"\/var\/www\/sierra\/releases\/20230118233302\/webroot\/public\/assets\/support\/files\/8508\/en\/AJA-Software-Installer_macOS_v16.2_Release.zip","urlpath":"https:\/\/www.aja.com\/assets\/support\/files\/8508\/en\/","ext":"zip"],"id":8316,"title":"AJA Software Installer v16.1 - Mac","description":"AJA Software Installer v16.1\u00a0for\u00a0macOS:\r\n\r\nThis unified software, driver and firmware package contains everything you need in order to start using your AJA video I\/O hardware and includes enhancements.\u00a0Please read the\u00a0Release Notes\u00a0for complete detail.\u00a0\r\n\r\nThe following AJA applications are installed in v16.1\r\n\r\n
\r\n\t- AJA Control Panel v16.1:\u00a0\r\n\r\n\t
\r\n\t\t- For setup and control of your AJA KONA, Io or T-TAP product, including firmware updates.\r\n\t\t
- For high quality capture, playback and output.\r\n\t\r\n\t\r\n\t
- AJA System Test v16.1:\u00a0\r\n\t
\r\n\t\t- For testing storage to determine if it will be possible to sustain frame rates for chosen format(s).\r\n\t\r\n\t\r\n\t
- AJA Control Room v16.1:\r\n\t
\r\n\t\t- For high quality capture, monitoring, playback and output.\r\n\t\r\n\t\r\n\t
- AJA\u00a0NMOS\u00a0v16.1:\u00a0\r\n\t
\r\n\t\t- An optional component providing discovery, registration and control for KONA IP running in\u00a0SMPTE\u00a0ST 2110 environments.\r\n\t\r\n\t\r\n\r\n\r\n\u00a0\r\n","product":0,"category":"sa","platform_mac":1,"platform_pc":0,"platform_linux":0,"platform":"m","showdate":"y","released":"7\/28\/2021","url":"","ziparchive":true,"files":["file":"AJA-Software-Installer_macOS_v16.1_Release.zip","abspath":"\/var\/www\/sierra\/releases\/20230118233302\/webroot\/public\/assets\/support\/files\/8316\/en\/AJA-Software-Installer_macOS_v16.1_Release.zip","urlpath":"https:\/\/www.aja.com\/assets\/support\/files\/8316\/en\/","ext":"zip"],"id":8310,"title":"AJA Software Installer v16.0.3 - Mac","description":"AJA Software Installer v16.0.3\u00a0for\u00a0macOS:\r\n\r\nThis unified software, driver and firmware package contains everything you need in order to start using your AJA video I\/O hardware and includes enhancements.\u00a0Please read the\u00a0Release Notes\u00a0for complete detail.\u00a0\r\n\r\nThe following AJA applications are installed in v16.0.3\r\n\r\n
\r\n\t- AJA Control Panel v16.0.3:\u00a0\r\n\r\n\t
\r\n\t\t- For setup and control of your AJA KONA, Io or T-TAP product, including firmware updates.\r\n\t\t
- For high quality capture, playback and output.\r\n\t\r\n\t\r\n\t
- AJA System Test v16.0.3:\u00a0\r\n\t
\r\n\t\t- For testing storage to determine if it will be possible to sustain frame rates for chosen format(s).\r\n\t\r\n\t\r\n\t
- AJA Control Room v16.0.3:\r\n\t
\r\n\t\t- For high quality capture, monitoring, playback and output.\r\n\t\r\n\t\r\n\t
- AJA\u00a0NMOS\u00a0v16.0.3:\u00a0\r\n\t
\r\n\t\t- An optional component providing discovery, registration and control for KONA IP running in\u00a0SMPTE\u00a0ST 2110 environments.\r\n\t\r\n\t\r\n\r\n\r\n\u00a0\r\n","product":0,"category":"sa","platform_mac":1,"platform_pc":0,"platform_linux":0,"platform":"m","showdate":"y","released":"7\/20\/2021","url":"","ziparchive":true,"files":["file":"AJA-Software-Installer_macOS_v16.0.3_Release.zip","abspath":"\/var\/www\/sierra\/releases\/20230118233302\/webroot\/public\/assets\/support\/files\/8310\/en\/AJA-Software-Installer_macOS_v16.0.3_Release.zip","urlpath":"https:\/\/www.aja.com\/assets\/support\/files\/8310\/en\/","ext":"zip"],"id":8170,"title":"AJA Software Installer v16.0.2 - Mac","description":"AJA Software Installer v16.0.2\u00a0for\u00a0macOS:\r\n\r\nThis unified software, driver and firmware package contains everything you need in order to start using your AJA video I\/O hardware and includes enhancements.\u00a0Please read the\u00a0Release Notes\u00a0for complete detail.\u00a0\r\n\r\nThe following AJA applications are installed in v16.0.2\r\n\r\n
\r\n\t- AJA Control Panel v16.0.2:\u00a0\r\n\r\n\t
\r\n\t\t- For setup and control of your AJA KONA, Io or T-TAP product, including firmware updates.\r\n\t\t
- For high quality capture, playback and output.\r\n\t\r\n\t\r\n\t
- AJA System Test v16.0.2:\u00a0\r\n\t