diff --git a/spaces.csv b/spaces.csv
deleted file mode 100644
index 7a870c474c5c19db17e2b771954b5c355917340c..0000000000000000000000000000000000000000
--- a/spaces.csv
+++ /dev/null
@@ -1,19914 +0,0 @@
-,repository,sdk,license,likes
-0,stabilityai/stable-diffusion,gradio,mit,9303
-1,HuggingFaceH4/open_llm_leaderboard,gradio,apache-2.0,6094
-2,dalle-mini/dalle-mini,static,apache-2.0,5281
-3,facebook/MusicGen,gradio,cc-by-nc-4.0,3043
-4,jbilcke-hf/ai-comic-factory,docker,,2797
-5,AP123/IllusionDiffusion,gradio,openrail,2647
-6,pharmapsychotic/CLIP-Interrogator,gradio,mit,2160
-7,microsoft/HuggingGPT,gradio,,2068
-8,Gustavosta/MagicPrompt-Stable-Diffusion,gradio,mit,1537
-9,camenduru-com/webui,gradio,,1495
-10,DeepFloyd/IF,docker,other,1487
-11,sanchit-gandhi/whisper-jax,docker,,1426
-12,suno/bark,gradio,cc-by-nc-4.0,1420
-13,ysharma/ChatGPT4,gradio,mit,1327
-14,mteb/leaderboard,gradio,,1312
-15,damo-vilab/modelscope-text-to-video-synthesis,gradio,,1280
-16,huggingface-projects/QR-code-AI-art-generator,gradio,,1278
-17,CompVis/stable-diffusion-license,static,,1268
-18,timbrooks/instruct-pix2pix,gradio,,1131
-19,ysharma/Explore_llamav2_with_TGI,gradio,mit,1116
-20,akhaliq/AnimeGANv2,gradio,,1113
-21,togethercomputer/OpenChatKit,static,,1019
-22,anzorq/finetuned_diffusion,gradio,mit,1001
-23,openai/whisper,gradio,,995
-24,fffiloni/img-to-music,gradio,,987
-25,sczhou/CodeFormer,gradio,,954
-26,hysts/ControlNet,gradio,mit,932
-27,DragGan/DragGan,gradio,,892
-28,fffiloni/CLIP-Interrogator-2,gradio,,873
-29,huggingface-projects/diffuse-the-rest,static,,866
-30,tiiuae/falcon-180b-demo,gradio,,835
-31,JohnSmith9982/ChuanhuChatGPT,gradio,gpl-3.0,825
-32,hysts/ControlNet-v1-1,gradio,mit,814
-33,Vision-CAIR/minigpt4,gradio,other,806
-34,Logspace/Langflow,docker,mit,804
-35,lnyan/stablediffusion-infinity,gradio,apache-2.0,764
-36,facebook/seamless_m4t,gradio,,764
-37,huggingchat/chat-ui,docker,apache-2.0,761
-38,google/sdxl,gradio,mit,759
-39,HuggingFaceH4/starchat-playground,gradio,mit,751
-40,merve/ChatGPT-prompt-generator,gradio,apache-2.0,745
-41,microsoft/visual_chatgpt,gradio,osl-3.0,727
-42,fffiloni/zeroscope,gradio,,727
-43,akhaliq/ArcaneGAN,gradio,,719
-44,coqui/xtts,gradio,,692
-45,haoheliu/audioldm-text-to-audio-generation,gradio,bigscience-openrail-m,675
-46,lambdalabs/image-mixer-demo,gradio,openrail,655
-47,vinthony/SadTalker,gradio,mit,654
-48,runwayml/stable-diffusion-v1-5,gradio,mit,632
-49,HuggingFaceH4/zephyr-chat,docker,mit,598
-50,PKUWilliamYang/VToonify,gradio,,582
-51,Xintao/GFPGAN,gradio,apache-2.0,579
-52,fffiloni/Image-to-Story,gradio,,557
-53,sd-concepts-library/stable-diffusion-conceptualizer,gradio,mit,548
-54,Salesforce/BLIP2,gradio,bsd-3-clause,548
-55,HuggingFaceH4/falcon-chat,gradio,apache-2.0,545
-56,prodia/fast-stable-diffusion,gradio,mit,543
-57,PaddlePaddle/ERNIE-ViLG,gradio,apache-2.0,529
-58,zomehwh/vits-models,gradio,apache-2.0,522
-59,CarperAI/StableVicuna,gradio,cc-by-nc-4.0,522
-60,camenduru-com/webui-docker,docker,,521
-61,THUDM/GLM-130B,gradio,apache-2.0,512
-62,CVPR/Image-Animation-using-Thin-Plate-Spline-Motion-Model,gradio,,510
-63,multimodalart/LoraTheExplorer,gradio,mit,506
-64,multimodalart/latentdiffusion,gradio,mit,502
-65,skytnt/moe-tts,gradio,mit,497
-66,openai/point-e,gradio,,495
-67,uwnlp/guanaco-playground-tgi,gradio,,491
-68,CVPR/ml-talking-face,gradio,cc-by-nc-sa-4.0,471
-69,darkstorm2150/Stable-Diffusion-Protogen-x3.4-webui,docker,,465
-70,tloen/alpaca-lora,gradio,apache-2.0,453
-71,multimodalart/dreambooth-training,gradio,mit,452
-72,runwayml/stable-diffusion-inpainting,gradio,,447
-73,lmsys/chatbot-arena-leaderboard,gradio,apache-2.0,444
-74,jbilcke-hf/AI-WebTV,docker,,441
-75,huggingface-projects/diffusers-gallery,static,mit,440
-76,Xenova/whisper-web,static,,438
-77,Salesforce/BLIP,gradio,bsd-3-clause,432
-78,fffiloni/Pix2Pix-Video,gradio,,432
-79,Anonymous-sub/Rerender,gradio,,430
-80,nielsr/comparing-captioning-models,gradio,,419
-81,fffiloni/ControlNet-Video,gradio,,411
-82,jeffistyping/Youtube-Whisperer,gradio,,408
-83,BlinkDL/RWKV-World-7B,gradio,apache-2.0,405
-84,hysts/Shap-E,gradio,mit,405
-85,Sanster/Lama-Cleaner-lama,gradio,apache-2.0,403
-86,Yuliang/ICON,gradio,,402
-87,kakaobrain/karlo,gradio,,398
-88,elevenlabs/tts,gradio,,398
-89,vumichien/Whisper_speaker_diarization,gradio,,396
-90,BilalSardar/Voice-Cloning,gradio,mit,390
-91,lambdalabs/stable-diffusion-image-variations,gradio,mit,389
-92,akhaliq/GFPGAN,gradio,apache-2.0,382
-93,shi-labs/OneFormer,docker,mit,381
-94,daspartho/prompt-extend,gradio,apache-2.0,380
-95,BlinkDL/ChatRWKV-gradio,gradio,apache-2.0,377
-96,shi-labs/Versatile-Diffusion,gradio,mit,371
-97,ysharma/OpenAI_TTS_New,gradio,mit,371
-98,Plachta/VITS-Umamusume-voice-synthesizer,gradio,,368
-99,project-baize/chat-with-baize,gradio,cc-by-nc-4.0,365
-100,shariqfarooq/ZoeDepth,gradio,mit,364
-101,felixrosberg/face-swap,gradio,cc-by-nc-sa-4.0,363
-102,huggingface-projects/llama-2-13b-chat,gradio,other,356
-103,bigcode/bigcode-playground,gradio,,355
-104,akhaliq/Real-ESRGAN,gradio,,353
-105,skytnt/anime-remove-background,gradio,apache-2.0,353
-106,warp-ai/Wuerstchen,gradio,mit,349
-107,huggingface-projects/stable-diffusion-multiplayer,gradio,,345
-108,HuggingFaceM4/idefics_playground,gradio,,343
-109,fffiloni/spectrogram-to-music,gradio,,341
-110,editing-images/ledits,gradio,,337
-111,ArtGAN/Diffusion-API,gradio,apache-2.0,335
-112,qingxu98/gpt-academic,gradio,,333
-113,marcop/musika,gradio,cc-by-4.0,331
-114,olivierdehaene/chat-llm-streaming,gradio,,328
-115,flax-community/dalle-mini,static,apache-2.0,327
-116,multimodalart/ChatGLM-6B,gradio,mit,322
-117,bigcode/bigcode-models-leaderboard,gradio,,320
-118,One-2-3-45/One-2-3-45,gradio,mit,319
-119,huggingface-projects/llama-2-7b-chat,gradio,,317
-120,hf-accelerate/model-memory-usage,gradio,apache-2.0,317
-121,mosaicml/mpt-30b-chat,gradio,,316
-122,ydshieh/Kosmos-2,gradio,,313
-123,zomehwh/vits-uma-genshin-honkai,gradio,apache-2.0,311
-124,ECCV2022/dis-background-removal,gradio,apache-2.0,307
-125,guoyww/AnimateDiff,gradio,apache-2.0,306
-126,dvruette/fabric,gradio,apache-2.0,299
-127,PAIR/Text2Video-Zero,gradio,,296
-128,hysts/ControlNet-with-Anything-v4,gradio,mit,287
-129,Vokturz/can-it-run-llm,streamlit,gpl-3.0,287
-130,aadnk/whisper-webui,gradio,apache-2.0,286
-131,huggingface/bloom_demo,gradio,,283
-132,camenduru-com/one-shot-talking-face,docker,,279
-133,doevent/prompt-generator,gradio,,275
-134,multimodalart/stable-diffusion-inpainting,gradio,mit,275
-135,AIGC-Audio/AudioGPT,gradio,,275
-136,ArkanDash/rvc-models-new,gradio,mit,275
-137,flamehaze1115/Wonder3D-demo,gradio,cc-by-sa-3.0,271
-138,jiawei011/dreamgaussian,gradio,mit,269
-139,fffiloni/MS-Image2Video,gradio,,268
-140,adept/fuyu-8b-demo,gradio,,268
-141,hysts/SD-XL,gradio,mit,262
-142,fffiloni/Music-To-Image,gradio,,261
-143,cvlab/zero123-live,gradio,mit,253
-144,awacke1/Image-to-Line-Drawings,gradio,mit,251
-145,h2oai/h2ogpt-chatbot,gradio,apache-2.0,250
-146,Plachta/VALL-E-X,gradio,mit,250
-147,microsoft/Promptist,gradio,,242
-148,xinyu1205/recognize-anything,gradio,mit,242
-149,impira/docquery,gradio,,241
-150,ArtGAN/Video-Diffusion-WebUI,gradio,apache-2.0,239
-151,SteveDigital/free-fast-youtube-url-video-to-text-using-openai-whisper,gradio,gpl-3.0,236
-152,sambanovasystems/BLOOMChat,static,apache-2.0,235
-153,doevent/Face-Real-ESRGAN,gradio,apache-2.0,234
-154,fffiloni/stable-diffusion-img2img,gradio,,232
-155,mandar100/chatbot_dialogpt,gradio,,232
-156,hakurei/waifu-diffusion-demo,gradio,creativeml-openrail-m,231
-157,lora-library/LoRA-DreamBooth-Training-UI,gradio,mit,231
-158,badayvedat/LLaVA,gradio,,228
-159,radames/stable-diffusion-depth2img,gradio,,227
-160,aliabid94/AutoGPT,gradio,mit,227
-161,ardha27/rvc-models,gradio,mit,227
-162,microsoft-cognitive-service/mm-react,docker,other,224
-163,codellama/codellama-13b-chat,gradio,other,224
-164,haoheliu/audioldm2-text2audio-text2music,gradio,,223
-165,Manjushri/SDXL-1.0,gradio,mit,222
-166,deepwisdom/MetaGPT,docker,,220
-167,huggingface-projects/Deep-Reinforcement-Learning-Leaderboard,gradio,,219
-168,FaceOnLive/Face-Recognition-SDK,docker,mit,216
-169,THUDM/CodeGeeX,gradio,apache-2.0,215
-170,nightfury/Image_Face_Upscale_Restoration-GFPGAN,gradio,apache-2.0,215
-171,akhaliq/Real-Time-Voice-Cloning,gradio,,214
-172,SemanticTypography/Word-As-Image,gradio,cc-by-nc-4.0,212
-173,togethercomputer/GPT-JT,streamlit,,210
-174,SpacesExamples/ComfyUI,docker,,210
-175,trl-lib/stack-llama,gradio,,209
-176,jbilcke-hf/webapp-factory-wizardcoder,docker,,209
-177,radames/dpt-depth-estimation-3d-obj,gradio,,207
-178,segmind/Segmind-Stable-Diffusion,gradio,,206
-179,tonyassi/face-swap,gradio,,205
-180,mattthew/SDXL-artists-browser,static,cc-by-sa-4.0,204
-181,codeparrot/code-generation-models,streamlit,apache-2.0,203
-182,huggingface-projects/magic-diffusion,gradio,apache-2.0,203
-183,ysharma/nougat,gradio,mit,202
-184,SimianLuo/Latent_Consistency_Model,gradio,mit,202
-185,akhaliq/demucs,gradio,,201
-186,VideoCrafter/VideoCrafter,gradio,,197
-187,prodia/sdxl-stable-diffusion-xl,gradio,mit,196
-188,Surn/UnlimitedMusicGen,gradio,creativeml-openrail-m,194
-189,diffusers/stable-diffusion-xl-inpainting,gradio,,193
-190,Matthijs/speecht5-tts-demo,gradio,apache-2.0,192
-191,optimum/llm-perf-leaderboard,gradio,apache-2.0,192
-192,An-619/FastSAM,gradio,apache-2.0,190
-193,Audio-AGI/AudioSep,gradio,mit,190
-194,ronvolutional/ai-pokemon-card,gradio,,189
-195,hwchase17/chat-langchain,gradio,mit,189
-196,songweig/rich-text-to-image,gradio,,189
-197,ai-forever/Kandinsky2.1,gradio,,188
-198,mfidabel/controlnet-segment-anything,gradio,mit,187
-199,fffiloni/instant-TTS-Bark-cloning,gradio,,186
-200,darkstorm2150/protogen-web-ui,docker,,185
-201,zomehwh/sovits-models,gradio,mit,185
-202,kevinwang676/Bark-with-Voice-Cloning,gradio,mit,185
-203,mms-meta/MMS,gradio,cc-by-nc-4.0,185
-204,TencentARC/T2I-Adapter-SDXL,docker,mit,183
-205,Voicemod/Text-to-Sing,gradio,,181
-206,TempoFunk/makeavid-sd-jax,gradio,agpl-3.0,180
-207,EleutherAI/VQGAN_CLIP,gradio,,178
-208,hysts/DeepDanbooru,gradio,,178
-209,radames/Real-Time-Latent-Consistency-Model,docker,,178
-210,phenomenon1981/DreamlikeArt-PhotoReal-2.0,gradio,,176
-211,Audio-AGI/WavJourney,docker,cc-by-nc-4.0,174
-212,TencentARC/T2I-Adapter-SDXL-Sketch,gradio,,174
-213,ai-guru/composer,gradio,,173
-214,autoevaluate/model-evaluator,streamlit,,171
-215,yizhangliu/Grounded-Segment-Anything,gradio,,171
-216,chansung/zero2story,gradio,apache-2.0,171
-217,FaceOnLive/ID-Document-Recognition-SDK,docker,mit,170
-218,Adapter/T2I-Adapter,gradio,openrail,169
-219,wangrongsheng/ChatPaper,gradio,gpl-3.0,169
-220,hf4all/bingo,docker,mit,168
-221,MAGAer13/mPLUG-Owl,gradio,apache-2.0,167
-222,xdecoder/Instruct-X-Decoder,gradio,afl-3.0,166
-223,codellama/codellama-playground,gradio,,166
-224,AP123/Upside-Down-Diffusion,gradio,openrail,165
-225,akhaliq/JoJoGAN,gradio,,164
-226,bigcode/santacoder-demo,gradio,,164
-227,mike-ravkine/can-ai-code-results,docker,mit,162
-228,pytorch/MiDaS,gradio,,161
-229,Open-Orca/Mistral-7B-OpenOrca,gradio,,161
-230,sudo-ai/zero123plus-demo-space,docker,apache-2.0,160
-231,akhaliq/anything-v3.0,gradio,,159
-232,DGSpitzer/TXT-2-IMG-2-MUSIC-2-VIDEO-w-RIFFUSION,gradio,apache-2.0,159
-233,coqui/CoquiTTS,gradio,,158
-234,jonigata/PoseMaker2,docker,apache-2.0,158
-235,hf-audio/open_asr_leaderboard,gradio,,158
-236,osanseviero/mistral-super-fast,gradio,,158
-237,chansung/co-write-with-llama2,gradio,apache-2.0,157
-238,ThomasSimonini/Huggy,static,cc-by-nc-sa-4.0,156
-239,OFA-Sys/OFA-Image_Caption,gradio,,155
-240,ikechan8370/vits-uma-genshin-honkai,gradio,apache-2.0,155
-241,akhaliq/frame-interpolation,gradio,,154
-242,THUDM/CogVideo,gradio,,154
-243,Linaqruf/Animagine-XL,gradio,mit,154
-244,FaceOnLive/Face-Liveness-Detection-SDK,docker,mit,154
-245,Rothfeld/stable-diffusion-mat-outpainting-primer,gradio,cc-by-nc-4.0,152
-246,pharmapsychotic/sd-prism,gradio,apache-2.0,152
-247,multimodalart/mariogpt,gradio,mit,152
-248,carolineec/informativedrawings,gradio,mit,151
-249,fffiloni/SplitTrack2MusicGen,gradio,cc-by-nc-4.0,151
-250,sanchit-gandhi/whisper-large-v2,gradio,,150
-251,thomas-yanxin/LangChain-ChatLLM,gradio,apache-2.0,150
-252,upstage/open-ko-llm-leaderboard,gradio,apache-2.0,150
-253,CVPR/DualStyleGAN,gradio,,148
-254,NoCrypt/DeepDanbooru_string,gradio,,148
-255,bhaskartripathi/pdfChatter,gradio,afl-3.0,147
-256,weizmannscience/tokenflow,gradio,,147
-257,ysharma/Low-rank-Adaptation,gradio,mit,146
-258,VIPLab/Track-Anything,gradio,mit,146
-259,JingyeChen22/TextDiffuser,gradio,,145
-260,coqui/voice-chat-with-mistral,gradio,,145
-261,Gradio-Blocks/Story_and_Video_Generation,gradio,mit,144
-262,akiyamasho/AnimeBackgroundGAN,gradio,,143
-263,SmilingWolf/wd-v1-4-tags,gradio,,143
-264,fffiloni/VideoRetalking,docker,,143
-265,Shuang59/Composable-Diffusion,gradio,,141
-266,osanseviero/i-like-flan,gradio,,141
-267,bookbot/Image-Upscaling-Playground,gradio,apache-2.0,139
-268,Curranj/Words_To_SQL,gradio,,138
-269,fffiloni/DragGAN,gradio,,138
-270,competitions/aiornot,docker,,137
-271,weizmannscience/multidiffusion-region-based,gradio,mit,137
-272,jonigata/PoseMaker,gradio,creativeml-openrail-m,136
-273,NeuralInternet/Text-to-Video_Playground,gradio,,136
-274,openflamingo/OpenFlamingo,gradio,,136
-275,anzorq/chatgpt-demo,gradio,,135
-276,ngoctuanai/chatgptfree,docker,mit,134
-277,gligen/demo,gradio,,133
-278,autoevaluate/leaderboards,streamlit,apache-2.0,132
-279,anzorq/point-e_demo,gradio,,132
-280,abhishek/first-order-motion-model,gradio,,131
-281,internships/internships-2023,gradio,,131
-282,nateraw/animegan-v2-for-videos,gradio,,129
-283,nielsr/dit-document-layout-analysis,gradio,,129
-284,huggingface-projects/wordalle,gradio,,129
-285,aadnk/faster-whisper-webui,gradio,apache-2.0,129
-286,h2oai/h2ogpt-chatbot2,gradio,apache-2.0,129
-287,fffiloni/Image-to-MusicGen,gradio,cc-by-nc-4.0,129
-288,yuntian-deng/ChatGPT,gradio,mit,128
-289,facebook/cotracker,gradio,cc-by-nc-4.0,128
-290,EleutherAI/clip-guided-diffusion,gradio,,127
-291,keras-io/Enhance_Low_Light_Image,gradio,,127
-292,Gradio-Blocks/DualStyleGAN,gradio,,127
-293,yizhangliu/chatGPT,gradio,,127
-294,shikunl/prismer,docker,other,127
-295,PaddlePaddle/ERNIE-Layout,gradio,apache-2.0,126
-296,lmsys/chatbot-arena,static,other,126
-297,akhaliq/lama,gradio,,125
-298,nielsr/text-based-inpainting,gradio,,125
-299,albarji/mixture-of-diffusers,gradio,,125
-300,BAAI/SegGPT,gradio,mit,125
-301,shgao/EditAnything,gradio,,125
-302,ArkanDash/rvc-models,gradio,mit,125
-303,nielsr/dpt-depth-estimation,gradio,,124
-304,chansung/llama2-with-gradio-chat,gradio,apache-2.0,124
-305,ml6team/controlnet-interior-design,streamlit,openrail,123
-306,laion/CoCa,gradio,,121
-307,seungheondoh/LP-Music-Caps-demo,gradio,mit,121
-308,artificialguybr/qwen-vl,gradio,,121
-309,ChenyangSi/FreeU,gradio,,121
-310,abhishek/StableSAM,gradio,,120
-311,facebook/ov-seg,gradio,cc-by-nc-4.0,119
-312,xdecoder/SEEM,gradio,afl-3.0,119
-313,DAMO-NLP-SG/Video-LLaMA,gradio,other,119
-314,flax-community/chef-transformer,streamlit,,118
-315,tomg-group-umd/pez-dispenser,gradio,,118
-316,fffiloni/whisper-to-stable-diffusion,gradio,,117
-317,vllab/controlnet-hands,gradio,,117
-318,pszemraj/summarize-long-text,gradio,apache-2.0,116
-319,Lykon/DreamShaper-webui,gradio,,116
-320,kdrkdrkdr/ProsekaTTS,gradio,mit,115
-321,huggingface-projects/stable-diffusion-latent-upscaler,gradio,mit,115
-322,RamAnanth1/ControlNet,gradio,,115
-323,curt-park/segment-anything-with-clip,gradio,apache-2.0,115
-324,LinkSoul/Chinese-Llama-2-7b,gradio,,115
-325,radames/edit-video-by-editing-text,gradio,,114
-326,nyanko7/sd-diffusers-webui,docker,openrail,114
-327,georgefen/Face-Landmark-ControlNet,gradio,apache-2.0,114
-328,csuhan/LLaMA-Adapter,gradio,,114
-329,lykeven/visualglm-6b,gradio,,114
-330,fffiloni/prompt-converter,gradio,,113
-331,CikeyQI/QQsign,docker,mit,113
-332,fffiloni/zeroscope-XL,gradio,,113
-333,vumichien/Generate_human_motion,gradio,apache-2.0,112
-334,RamAnanth1/Dolly-v2,gradio,,112
-335,harmonai/dance-diffusion,gradio,mit,111
-336,vumichien/Lip_movement_reading,gradio,,111
-337,artificialguybr/video-dubbing,gradio,,111
-338,multimodalart/mindseye-lite,gradio,mit,110
-339,nupurkmr9/custom-diffusion,gradio,,109
-340,camenduru-com/converter,gradio,mit,108
-341,whitead/paper-qa,gradio,mit,108
-342,BAAI/AltDiffusion,gradio,creativeml-openrail-m,107
-343,nota-ai/compressed-stable-diffusion,gradio,,107
-344,ChallengeHub/Chinese-LangChain,gradio,openrail,106
-345,sanchit-gandhi/musicgen-streaming,gradio,,106
-346,multimodalart/lora-roulette,gradio,,105
-347,hysts/BLIP2-with-transformers,gradio,bsd-3-clause,104
-348,Ekimetrics/climate-question-answering,gradio,,104
-349,Yntec/ToyWorld,gradio,,104
-350,hf-vision/object_detection_leaderboard,gradio,,104
-351,SkalskiP/SAM_and_MetaCLIP,gradio,,104
-352,ilumine-AI/Insta-3D,static,,103
-353,manhkhanhUIT/Image_Restoration_Colorization,gradio,,102
-354,facebook/incoder-demo,gradio,cc-by-nc-4.0,102
-355,DEEMOSTECH/ChatAvatar,static,,102
-356,TencentARC/Caption-Anything,gradio,apache-2.0,102
-357,camel-ai/camel-agents,gradio,apache-2.0,102
-358,IDEA-CCNL/Taiyi-Stable-Diffusion-Chinese,gradio,creativeml-openrail-m,101
-359,22h/vintedois-diffusion-v0-1,gradio,,101
-360,hackathon-pln-es/BioMedIA,gradio,afl-3.0,100
-361,safetensors/convert,gradio,apache-2.0,100
-362,deepset/retrieval-augmentation-svb,streamlit,,100
-363,LinoyTsaban/edit_friendly_ddpm_inversion,gradio,,100
-364,katielink/biogpt-large-demo,gradio,mit,99
-365,fffiloni/image-to-sound-fx,gradio,,99
-366,tomofi/EasyOCR,gradio,mit,98
-367,aipicasso/cool-japan-diffusion-latest-demo,gradio,,98
-368,hysts/zeroscope-v2,gradio,mit,98
-369,Matthijs/whisper_word_timestamps,gradio,apache-2.0,97
-370,radames/MusicGen-Continuation,gradio,cc-by-nc-4.0,97
-371,mikeee/chatglm2-6b-4bit,gradio,,97
-372,sanchit-gandhi/whisper-jax-diarization,gradio,,97
-373,cocktailpeanut/AudioGen,gradio,cc-by-nc-4.0,97
-374,radames/candle-segment-anything-wasm,static,,97
-375,Gradio-Blocks/neon-tts-plugin-coqui,gradio,bsd-3-clause,96
-376,deepdoctection/deepdoctection,gradio,apache-2.0,96
-377,gradio/theme-gallery,static,mit,96
-378,yuntian-deng/ChatGPT4,gradio,mit,96
-379,Awiny/Image2Paragraph,gradio,apache-2.0,96
-380,MirageML/dreambooth,gradio,mit,95
-381,ThomasSimonini/Check-my-progress-Deep-RL-Course,gradio,,95
-382,weizmannscience/MultiDiffusion,gradio,,94
-383,diffusers/controlnet-openpose,gradio,,94
-384,Clebersla/RVC_V2_Huggingface_Version,gradio,lgpl-3.0,94
-385,mindee/doctr,streamlit,,93
-386,nateraw/background-remover,gradio,,93
-387,skytnt/full-body-anime-gan,gradio,apache-2.0,93
-388,Pie31415/rome,gradio,,93
-389,RASMUS/Whisper-youtube-crosslingual-subtitles,gradio,apache-2.0,93
-390,IDEA-Research/Grounded-SAM,gradio,apache-2.0,93
-391,Deci/DeciLM-6b-instruct,gradio,llama2,93
-392,aravinds1811/neural-style-transfer,gradio,,92
-393,balacoon/tts,gradio,,92
-394,xvjiarui/ODISE,gradio,,92
-395,radames/dpt-depth-estimation-3d-voxels,gradio,,91
-396,akhaliq/yolov7,gradio,,91
-397,Manjushri/PhotoReal-V3.6,gradio,mit,91
-398,bennyguo/threestudio,docker,apache-2.0,91
-399,phenomenon1981/DreamlikeArt-Diffusion-1.0,gradio,,90
-400,tetrisd/Diffusion-Attentive-Attribution-Maps,gradio,mit,89
-401,jbilcke-hf/VideoQuest,docker,,89
-402,flax-community/image-captioning,streamlit,,88
-403,society-ethics/about,gradio,gpl-3.0,88
-404,SRDdev/Image-Caption,gradio,,87
-405,adirik/OWL-ViT,gradio,apache-2.0,87
-406,hf4h/biomedical-language-models,gradio,,87
-407,huggingface-projects/video-composer-gpt4,gradio,,87
-408,mishig/jsonformer,gradio,mit,87
-409,huggingface-projects/repo_duplicator,gradio,mit,86
-410,doevent/dis-background-removal,gradio,apache-2.0,86
-411,Ella2323/Positive-Reframing,gradio,openrail,86
-412,dwarkesh/whisper-speaker-recognition,gradio,,86
-413,patrickvonplaten/instruct-pix2pix,gradio,mit,86
-414,radames/PIFu-Clothed-Human-Digitization,gradio,,85
-415,zhigangjiang/3D-Room-Layout-Estimation_LGT-Net,gradio,mit,85
-416,OlaWod/FreeVC,gradio,mit,85
-417,segments/panoptic-segment-anything,gradio,apache-2.0,85
-418,zomehwh/rvc-models,gradio,mit,85
-419,mikonvergence/theaTRON,gradio,apache-2.0,85
-420,fffiloni/text-to-gif,docker,,85
-421,simonduerr/ProteinMPNN,gradio,mit,84
-422,Matthijs/speecht5-vc-demo,gradio,apache-2.0,84
-423,ShilongLiu/Grounding_DINO_demo,gradio,apache-2.0,84
-424,shi-labs/Prompt-Free-Diffusion,gradio,mit,84
-425,fffiloni/zeroscope-img-to-video,gradio,,84
-426,mithril-security/blind_chat,docker,,84
-427,ykilcher/apes,gradio,,83
-428,umm-maybe/AI-image-detector,gradio,,83
-429,innnky/nene-emotion,gradio,,83
-430,abhishek/dreambooth,gradio,,83
-431,Silentlin/DiffSinger,gradio,,82
-432,fffiloni/langchain-chat-with-pdf,gradio,,82
-433,huggingface/data-measurements-tool,streamlit,,81
-434,ronvolutional/sd-spritesheets,gradio,,81
-435,Tune-A-Video-library/Tune-A-Video-Training-UI,docker,mit,81
-436,TachibanaYoshino/AnimeGANv3,gradio,,80
-437,AttendAndExcite/Attend-and-Excite,gradio,mit,80
-438,davila7/filegpt,streamlit,mit,80
-439,chansung/LLM-As-Chatbot,gradio,apache-2.0,80
-440,Xenova/the-tokenizer-playground,static,,80
-441,r3gm/RVC_HF,gradio,,80
-442,hf-audio/whisper-large-v3,gradio,,80
-443,akhaliq/SwinIR,gradio,,79
-444,kamiyamai/stable-diffusion-webui,gradio,openrail,79
-445,Yuliang/ECON,gradio,,79
-446,tomg-group-umd/lm-watermarking,gradio,apache-2.0,79
-447,ShiwenNi/ChatReviewer,gradio,apache-2.0,79
-448,DreamSunny/stable-diffusion-webui-cpu,gradio,,79
-449,HuggingFaceM4/AI_Meme_Generator,gradio,,79
-450,prithivida/Gramformer,streamlit,,78
-451,Hazzzardous/RWKV-Instruct,gradio,gpl-3.0,78
-452,GMFTBY/PandaGPT,gradio,other,78
-453,HuggingFaceH4/human_eval_llm_leaderboard,gradio,apache-2.0,78
-454,weizmannscience/text2live,gradio,mit,77
-455,sweetcocoa/pop2piano,gradio,,77
-456,deepset/should-i-follow,streamlit,,77
-457,XCLiu/InstaFlow,gradio,creativeml-openrail-m,77
-458,facebook/Hokkien_Translation,gradio,cc-by-nc-4.0,76
-459,Fantasy-Studio/Paint-by-Example,gradio,,76
-460,aipicasso/emi-latest-demo,gradio,other,76
-461,competitions/ship-detection,docker,,76
-462,InpaintAI/Inpaint-Anything,gradio,apache-2.0,76
-463,sentence-transformers/embeddings-semantic-search,streamlit,,75
-464,havas79/Real-ESRGAN_Demo,gradio,,75
-465,taesiri/BLIP-2,gradio,other,75
-466,ysharma/ChatGPTwithAPI,gradio,mit,75
-467,brjathu/HMR2.0,gradio,,75
-468,competitions/movie-genre-prediction,docker,,75
-469,tonyassi/image-to-image-SDXL,gradio,,75
-470,PixArt-alpha/PixArt-alpha,gradio,,75
-471,lambdalabs/text-to-naruto,gradio,,74
-472,Deci/DeciDiffusion-v1-0,gradio,,74
-473,naver-clova-ix/donut-base-finetuned-cord-v2,gradio,,73
-474,ysharma/Talk_to_Multilingual_AI_WhisperBloomCoqui,gradio,mit,73
-475,modelscope/FaceChain,docker,apache-2.0,73
-476,artificialguybr/qwen-14b-chat-demo,gradio,,73
-477,fffiloni/ProPainter,docker,,73
-478,Xenova/distil-whisper-web,static,,73
-479,pyannote/pretrained-pipelines,streamlit,,72
-480,huggingface/hf-speech-bench,streamlit,apache-2.0,72
-481,THUDM/CogView2,gradio,,72
-482,pszemraj/pdf-ocr,gradio,gpl-3.0,72
-483,sophiamyang/Panel_PDF_QA,docker,,72
-484,radames/whisper-word-level-trim,gradio,,72
-485,ysharma/InstructPix2Pix_Chatbot,gradio,mit,71
-486,GitMylo/bark-voice-cloning,gradio,mit,71
-487,lmz/candle-llama2,static,,71
-488,dongsiqie/gptnb,docker,mit,71
-489,PaddlePaddle/UIE-X,gradio,apache-2.0,70
-490,Mathux/TMR,gradio,,70
-491,deepseek-ai/deepseek-coder-33b-instruct,gradio,,70
-492,KenjieDec/RemBG,gradio,,69
-493,haotiz/glip-zeroshot-demo,gradio,mit,69
-494,bigcode/in-the-stack,gradio,apache-2.0,69
-495,kadirnar/yolov8,gradio,gpl-3.0,69
-496,vivien/clip,streamlit,,68
-497,bigscience/bloom-book,streamlit,,68
-498,DGSpitzer/DGS-Diffusion-Space,gradio,mit,68
-499,anzorq/sd-space-creator,gradio,mit,68
-500,jbilcke-hf/ai-clip-factory,docker,,68
-501,Gradio-Blocks/Ask_Questions_To_YouTube_Videos,gradio,gpl,67
-502,lambdalabs/text-to-pokemon,gradio,,67
-503,BatuhanYilmaz/Whisper-Auto-Subtitled-Video-Generator,streamlit,,67
-504,maxmax20160403/vits_chinese,gradio,apache-2.0,67
-505,merle/PROTEIN_GENERATOR,gradio,,67
-506,OptimalScale/Robin-7b,gradio,apache-2.0,67
-507,LuChengTHU/dpmsolver_sdm,gradio,,66
-508,ybelkada/i-like-flan-ul2,gradio,openrail,66
-509,pcuenq/uncanny-faces,gradio,,66
-510,ArtGAN/Segment-Anything-Video,gradio,apache-2.0,66
-511,fffiloni/langchain-chat-with-pdf-openai,gradio,,66
-512,fffiloni/clone-voice-for-bark,gradio,cc-by-nc-4.0,66
-513,FlowiseAI/Flowise,docker,mit,66
-514,SpacesExamples/Fooocus,docker,,66
-515,akhaliq/BlendGAN,gradio,,65
-516,nielsr/TrOCR-handwritten,gradio,,65
-517,YueMafighting/FollowYourPose,gradio,,65
-518,bguisard/stable-diffusion-nano,gradio,creativeml-openrail-m,65
-519,declare-lab/tango,gradio,,65
-520,justin-zk/Personalize-SAM,gradio,mit,65
-521,ThomasSimonini/SnowballFight,static,,64
-522,akhaliq/Music_Source_Separation,gradio,,64
-523,zama-fhe/encrypted_sentiment_analysis,gradio,,64
-524,nateraw/lavila,gradio,,64
-525,liuyuan-pal/SyncDreamer,gradio,cc-by-sa-3.0,64
-526,hf-vision/nougat-transformers,gradio,apache-2.0,64
-527,valhalla/glide-text2im,gradio,,63
-528,hysts/Text2Human,gradio,,63
-529,nateraw/deepafx-st,gradio,other,63
-530,ysharma/ChatGLM-6b_Gradio_Streaming,gradio,mit,63
-531,diffusers/controlnet-3d-pose,gradio,,63
-532,anzorq/hf-spaces-semantic-search,docker,mit,63
-533,lmsys/mt-bench,gradio,other,63
-534,Narrativaai/NLLB-Translator,gradio,wtfpl,62
-535,doevent/Stable-Diffusion-prompt-generator,gradio,mit,62
-536,bigscience/promptsource,streamlit,,62
-537,facebook/speech_matrix,gradio,cc-by-nc-4.0,62
-538,openai/openai-detector,docker,,62
-539,Intel/ldm3d,gradio,,62
-540,nielsr/LayoutLMv2-FUNSD,gradio,,61
-541,HarlanHong/DaGAN,gradio,apache-2.0,61
-542,aryadytm/remove-photo-object,streamlit,,61
-543,nielsr/donut-docvqa,gradio,,61
-544,xdecoder/Demo,gradio,afl-3.0,61
-545,pritish/BookGPT,gradio,,61
-546,diffusers/controlnet-canny,gradio,,61
-547,NeuralInternet/BabyAGI,streamlit,,61
-548,Dragonnext/Unicorn-proxy,docker,,61
-549,radames/Real-Time-Latent-Consistency-Model-Text-To-Image,docker,,61
-550,nateraw/yolov6,gradio,mit,60
-551,huggingface-projects/color-palette-generator-sd,gradio,,60
-552,wpeebles/DiT,gradio,cc-by-nc-4.0,60
-553,smangrul/peft-lora-sd-dreambooth,gradio,openrail,60
-554,kadirnar/Tune-A-Video,gradio,mit,60
-555,coffeeee/nsfw-c0ffees-erotic-story-generator2,gradio,,60
-556,sail/lorahub,streamlit,mit,60
-557,Open-Orca/OpenOrca-Platypus2-13B,gradio,,60
-558,hackaprompt/playground,gradio,,59
-559,Monster/GPT4ALL,gradio,,59
-560,cncanon/locusts,docker,,59
-561,fffiloni/Music-To-Zeroscope,gradio,,59
-562,Deci/DeciCoder-Demo,gradio,apache-2.0,59
-563,CompVis/text2img-latent-diffusion,gradio,mit,58
-564,huggingface/Model_Cards_Writing_Tool,streamlit,mit,58
-565,pszemraj/document-summarization,gradio,apache-2.0,58
-566,zlc99/M4Singer,gradio,,58
-567,Kangarroar/ApplioRVC-Inference,gradio,,58
-568,nielsr/comparing-VQA-models,gradio,,58
-569,trysem/SD-2.1-Img2Img,gradio,mit,58
-570,Adapter/CoAdapter,gradio,openrail,58
-571,owkin/substra,gradio,gpl-3.0,58
-572,treadon/prompt-fungineer-355M,gradio,,58
-573,Vision-CAIR/MiniGPT-v2,gradio,other,58
-574,hackathon-pln-es/poem-generation-es,gradio,,57
-575,Pinwheel/GLIP-BLIP-Object-Detection-VQA,gradio,mit,57
-576,microsoft/GODEL-Demo,gradio,mit,57
-577,clem/Image_Face_Upscale_Restoration-GFPGAN,gradio,apache-2.0,57
-578,RamAnanth1/visual-chatGPT,gradio,,57
-579,DeepFloyd/deepfloyd-if-license,static,other,57
-580,LinkSoul/LLaSM,static,apache-2.0,57
-581,CVPR/drawings-to-human,gradio,,56
-582,sayakpaul/cartoonizer-demo-onnx,gradio,apache-2.0,56
-583,mingyuan/MotionDiffuse,gradio,mit,56
-584,diffusers/sd-to-diffusers,gradio,mit,56
-585,kadirnar/diifusion-ad-template,gradio,,56
-586,ELITE-library/ELITE,gradio,,56
-587,PKUWilliamYang/StyleGANEX,gradio,,56
-588,ysharma/Zero123PlusDemo,gradio,mit,56
-589,PaddlePaddle/PaddleOCR,gradio,,55
-590,Alican/pixera,gradio,,55
-591,juancopi81/multilingual-stable-diffusion,gradio,creativeml-openrail-m,55
-592,Xhaheen/ChatGPT_HF,gradio,apache-2.0,55
-593,fishaudio/fish-diffusion,docker,,55
-594,Salesforce/EDICT,gradio,bsd-3-clause,55
-595,DragGan/DragGan-Inversion,gradio,,55
-596,juancopi81/multitrack-midi-music-generator,docker,mit,55
-597,yentinglin/Taiwan-LLaMa2,gradio,,55
-598,anaxagoras7/gauravgs-text-summarizer,gradio,,54
-599,pcuenq/paella,gradio,mit,54
-600,anzorq/riffusion-demo,gradio,,54
-601,microsoft/ChatGPT-Robotics,gradio,mit,54
-602,ClueAI/ChatYuan-large-v2,gradio,creativeml-openrail-m,54
-603,coreml-projects/transformers-to-coreml,docker,apache-2.0,54
-604,zomehwh/vits-models-genshin-bh3,gradio,apache-2.0,54
-605,ngthanhtinqn/Segment_Anything_With_OWL-ViT,gradio,creativeml-openrail-m,54
-606,akhaliq/PaintTransformer,gradio,,53
-607,akhaliq/VoiceFixer,gradio,,53
-608,prithivida/WhatTheFood,streamlit,,53
-609,microsoft/document-image-transformer,gradio,,53
-610,hysts/list-of-demos,gradio,,53
-611,Warvito/diffusion_brain,gradio,,53
-612,teticio/audio-diffusion,gradio,gpl-3.0,53
-613,akhaliq/Analog-Diffusion,gradio,,53
-614,Hello-SimpleAI/chatgpt-detector-single,gradio,,53
-615,Gladiaio/Audio-Transcription,gradio,mit,53
-616,jykoh/fromage,docker,,53
-617,FrozenBurning/SceneDreamer,gradio,other,53
-618,openaccess-ai-collective/rlhf-arena,gradio,apache-2.0,53
-619,Writer/instruct-palmyra-20b,gradio,,53
-620,PaddlePaddle/wav2lip,gradio,,52
-621,eugenesiow/remove-bg,gradio,,52
-622,huggingface/datasets-tagging,streamlit,,52
-623,Gradio-Blocks/Codex_OpenAI,gradio,apache-2.0,52
-624,fcakyon/zero-shot-video-classification,gradio,apache-2.0,52
-625,fffiloni/gpt-talking-portrait,gradio,,52
-626,unity/ML-Agents-SoccerTwos,static,,52
-627,Tune-A-Video-library/Tune-A-Video-inference,docker,mit,52
-628,vumichien/canvas_controlnet,streamlit,bigscience-openrail-m,52
-629,CrucibleAI/ControlNetMediaPipeFaceSD21,gradio,openrail,52
-630,dylanebert/gaussian-viewer,static,,52
-631,fffiloni/coqui-bark-voice-cloning-docker,docker,,52
-632,osanseviero/draw_to_search,gradio,,51
-633,juancopi81/whisper-demo-es-medium,gradio,openrail,51
-634,riffusion/riffusion-playground,streamlit,mit,51
-635,Algoworks/Image_Face_Upscale_Restoration-GFPGAN_pub,gradio,apache-2.0,51
-636,abyildirim/inst-inpaint,gradio,mit,51
-637,ioclab/brightness-controlnet,gradio,,51
-638,dhkim2810/MobileSAM,gradio,apache-2.0,51
-639,pycui/RealChar,docker,,51
-640,jph00/pets,gradio,apache-2.0,50
-641,nickmuchi/semantic-search-with-retrieve-and-rerank,streamlit,,50
-642,jjourney1125/swin2sr,gradio,apache-2.0,50
-643,Manjushri/SDXL-1.0-Img2Img-CPU,gradio,mit,50
-644,yizhangliu/Text-to-Image,gradio,,50
-645,thu-ml/unidiffuser,gradio,other,50
-646,bigcode/bigcode-editor,gradio,,50
-647,OpenShape/openshape-demo,streamlit,mit,50
-648,monra/freegpt-webui,docker,,50
-649,Epoching/3D_Photo_Inpainting,gradio,,49
-650,akhaliq/DPT-Large,gradio,,49
-651,akhaliq/Pyxelate,gradio,,49
-652,deepklarity/poster2plot,gradio,,49
-653,eugenesiow/super-image,gradio,,49
-654,spacy/healthsea-demo,streamlit,,49
-655,sxela/ArcaneGAN-video,gradio,,49
-656,hylee/White-box-Cartoonization,gradio,apache-2.0,49
-657,DucHaiten/webui,gradio,,49
-658,facebook/MaskCut,gradio,mit,49
-659,muhammadzain/AI_Resolution_Upscaler_And_Resizer,streamlit,,49
-660,PulsarAI/huggingface-leaderboard,gradio,,49
-661,anton-l/rudall-e,gradio,,48
-662,microsoft/unispeech-speaker-verification,gradio,,48
-663,fffiloni/stable-diffusion-inpainting,gradio,,48
-664,simonduerr/diffdock,gradio,mit,48
-665,DianXian/Real-CUGAN,gradio,gpl-3.0,48
-666,yangheng/Super-Resolution-Anime-Diffusion,gradio,,48
-667,hysts/LoRA-SD-training,gradio,mit,48
-668,camenduru-com/jupyter,docker,,48
-669,Intel/Stable-Diffusion,gradio,apache-2.0,48
-670,rlancemartin/auto-evaluator,streamlit,mit,48
-671,exbert-project/exbert,docker,apache-2.0,48
-672,taesiri/ClaudeReadsArxiv,gradio,apache-2.0,48
-673,fffiloni/ControlVideo,gradio,mit,48
-674,kevinwang676/Personal-TTS,gradio,mit,48
-675,LinkSoul/AutoAgents,docker,apache-2.0,48
-676,r3gm/AICoverGen,gradio,mit,48
-677,Norod78/Apocalyptify,gradio,,47
-678,akhaliq/CLIP_prefix_captioning,gradio,,47
-679,ml6team/Knowledge-graphs,streamlit,,47
-680,EleutherAI/magma,gradio,cc-by-4.0,47
-681,multimodalart/rudalle,gradio,mit,47
-682,CVPR/MonoScene,gradio,apache-2.0,47
-683,Amrrs/openai-whisper-live-transcribe,gradio,mit,47
-684,fffiloni/imagic-stable-diffusion,gradio,,47
-685,merve/chatgpt-prompt-generator-v12,gradio,apache-2.0,47
-686,JustinLin610/ImageBind_zeroshot_demo,gradio,mit,47
-687,kevinwang676/Voice-Changer,gradio,mit,47
-688,fffiloni/Image-Caption-2-Shap-E,gradio,mit,47
-689,TheStinger/Ilaria_RVC,gradio,lgpl-3.0,47
-690,nielsr/CLIPSeg,gradio,,46
-691,vumichien/Img_to_prompt,gradio,apache-2.0,46
-692,RamAnanth1/photoguard,gradio,,46
-693,giswqs/Streamlit,streamlit,mit,46
-694,cbg342/GPT4-Unlimited-Plugins,streamlit,,46
-695,nota-ai/compressed-wav2lip,gradio,apache-2.0,46
-696,RamAnanth1/InstructBLIP,gradio,,46
-697,radames/UserControllableLT-Latent-Transformer,gradio,,46
-698,monster-labs/Controlnet-QRCode-Monster-V1,gradio,openrail++,46
-699,OFA-Sys/OFA-Visual_Grounding,gradio,,45
-700,keras-io/ocr-for-captcha,gradio,,45
-701,danielsapit/JPEG_Artifacts_Removal,gradio,apache-2.0,45
-702,ysharma/text-to-ner-to-image-to-video,gradio,mit,45
-703,society-ethics/DiffusionBiasExplorer,gradio,cc-by-sa-4.0,45
-704,Pinwheel/SuperGlue-Image-Matching,gradio,,45
-705,megaaziib/hololive-rvc-models-v2,gradio,openrail,45
-706,WinterGYC/BaiChuan-13B-Chat,docker,apache-2.0,45
-707,haoheliu/AudioLDM_48K_Text-to-HiFiAudio_Generation,gradio,cc-by-nc-4.0,45
-708,ICCV2023/ICCV2023-papers,gradio,mit,45
-709,XzJosh/Azuma-Bert-VITS2,gradio,mit,45
-710,ilumine-AI/Retro-to-3D,static,,45
-711,neuralmagic/sparse-mpt-7b-gsm8k,gradio,,45
-712,NATSpeech/DiffSpeech,gradio,,44
-713,microsoft/wavlm-speaker-verification,gradio,,44
-714,nickmuchi/article-text-summarizer,streamlit,,44
-715,robinhad/ukrainian-tts,gradio,,44
-716,awacke1/Image-to-Multilingual-OCR,gradio,mit,44
-717,CVPR/Text2Human,gradio,,44
-718,anzorq/sd-to-diffusers,gradio,mit,44
-719,ysharma/Playground_AI_Exploration,gradio,mit,44
-720,hOTZR/new-Bing-with_your_cookies,gradio,other,44
-721,wangrongsheng/ChatImprovement,gradio,,44
-722,fl399/deplot_plus_llm,gradio,mit,44
-723,Baptlem/UCDR-Net,gradio,,44
-724,Intel/Q8-Chat,gradio,apache-2.0,44
-725,qiantong-xu/toolbench-leaderboard,gradio,,44
-726,Xenova/text-to-speech-client,static,,44
-727,tonyassi/video-face-swap,gradio,,44
-728,Iker/Translate-100-languages,streamlit,,43
-729,codeparrot/codeparrot-generation,streamlit,,43
-730,CompVis/celeba-latent-diffusion,gradio,,43
-731,myscale/visual-dataset-explorer,streamlit,,43
-732,bigscience-data/roots-search,gradio,apache-2.0,43
-733,whisper-event/whisper-demo,gradio,,43
-734,Intel/Stable-Diffusion-Side-by-Side,gradio,apache-2.0,43
-735,pszemraj/FLAN-grammar-correction,gradio,apache-2.0,43
-736,kadirnar/BioGpt,gradio,mit,43
-737,baulab/Erasing-Concepts-In-Diffusion,gradio,mit,43
-738,fffiloni/Video-Matting-Anything,gradio,mit,43
-739,zwq2018/Data-Copilot,gradio,mit,43
-740,mithril-security/TCO_calculator,gradio,,43
-741,hysts/daily-papers,gradio,mit,43
-742,fffiloni/train-dreambooth-lora-sdxl,gradio,,43
-743,Manmay/tortoise-tts,gradio,apache-2.0,43
-744,huggan/wikiart-diffusion-mini,gradio,apache-2.0,42
-745,k2-fsa/automatic-speech-recognition,gradio,apache-2.0,42
-746,kornia/Image-Stitching,gradio,apache-2.0,42
-747,JammyMachina/the-jam-machine-app,gradio,,42
-748,dreambooth-hackathon/leaderboard,gradio,apache-2.0,42
-749,dory111111/babyagi-streamlit,streamlit,,42
-750,bkhmsi/Font-To-Sketch,gradio,cc-by-nc-sa-4.0,42
-751,SpacesExamples/nerfstudio,docker,,42
-752,ought/raft-leaderboard,streamlit,,41
-753,14-26AA/sovits_aishell3,gradio,apache-2.0,41
-754,onnx/export,gradio,apache-2.0,41
-755,zama-fhe/encrypted_image_filtering,gradio,,41
-756,kazuk/image-to-video-film,gradio,unknown,41
-757,TEXTurePaper/TEXTure,docker,mit,41
-758,deprem-ml/deprem-ocr,gradio,,41
-759,chansung/LLaMA-7B,gradio,apache-2.0,41
-760,fffiloni/video2mmpose,gradio,,41
-761,shi-labs/Matting-Anything,gradio,mit,41
-762,GrandaddyShmax/AudioCraft_Plus,gradio,mit,41
-763,flax-community/code-clippy-problem-solver,streamlit,,40
-764,sujitpal/clip-rsicd-demo,streamlit,,40
-765,rendchevi/nix-tts,streamlit,mit,40
-766,huggan/huggingnft,streamlit,apache-2.0,40
-767,Gradio-Blocks/StyleGAN-NADA,gradio,mit,40
-768,CVPR/regionclip-demo,gradio,apache-2.0,40
-769,EuroPython2022/Step-By-Step-With-Bloom,gradio,gpl,40
-770,JavaFXpert/GPT-3.5-Express-inator,gradio,apache-2.0,40
-771,Ryukijano/CatCon-One-Shot-Controlnet-SD-1-5-b2,gradio,mit,40
-772,hirol/controlnetOverMask,gradio,mit,40
-773,kevinwang676/ChatGLM2-SadTalker-VC,gradio,mit,40
-774,fffiloni/DA-CLIP,docker,,40
-775,Flux9665/SpeechCloning,gradio,mit,39
-776,radames/Depth-Image-to-Autostereogram,gradio,,39
-777,Gradio-Blocks/GPTJ6B_Poetry_LatentDiff_Illustration,gradio,gpl,39
-778,impira/invoices,gradio,,39
-779,fffiloni/speech-to-image,gradio,,39
-780,OFA-Sys/OFA-OCR,gradio,mit,39
-781,huggingface/transformers-chat,gradio,mit,39
-782,ysharma/LangchainBot-space-creator,gradio,mit,39
-783,jyseo/3DFuse,gradio,cc,39
-784,jonjhiggins/MiDaS,gradio,,39
-785,runa91/bite_gradio,gradio,,39
-786,magicr/BuboGPT,gradio,apache-2.0,39
-787,LinkSoul/Chinese-LLaVa,static,apache-2.0,39
-788,competitions/wyze-rule-recommendation,docker,,39
-789,openchat/openchat_3.5,gradio,apache-2.0,39
-790,AILab-CVC/SEED-Bench_Leaderboard,gradio,cc-by-4.0,39
-791,Sharathhebbar24/One-stop-for-Open-source-models,streamlit,other,39
-792,distil-whisper/whisper-vs-distil-whisper,gradio,,39
-793,OFA-Sys/OFA-vqa,gradio,apache-2.0,38
-794,keras-io/Monocular-Depth-Estimation,gradio,,38
-795,hshr/DeepFilterNet2,gradio,apache-2.0,38
-796,bigscience/license,static,,38
-797,rajistics/Financial_Analyst_AI,gradio,apache-2.0,38
-798,akhaliq/openjourney,gradio,,38
-799,fcakyon/video-classification,gradio,apache-2.0,38
-800,MirageML/point-e,gradio,creativeml-openrail-m,38
-801,keras-dreambooth/minecraft-landscape-demo,gradio,creativeml-openrail-m,38
-802,nateraw/voice-cloning,gradio,mit,38
-803,llamaindex/llama_agi_auto,streamlit,mit,38
-804,maxmax20160403/sovits5.0,gradio,mit,38
-805,litagin/rvc_okiba_TTS,gradio,,38
-806,gsaivinay/open_llm_leaderboard,gradio,apache-2.0,38
-807,showlab/Show-1,gradio,,38
-808,Datatrooper/zero-shot-image-classification,gradio,,37
-809,mrm8488/FlappyBirds,static,,37
-810,Gradio-Blocks/HairCLIP,gradio,,37
-811,hysts/ViTPose_video,gradio,,37
-812,anakin87/fact-checking-rocks,streamlit,apache-2.0,37
-813,ruslanmv/Clone-Your-Voice,gradio,,37
-814,SalML/TableTransformer2CSV,streamlit,,37
-815,speechbox/whisper-speaker-diarization,gradio,,37
-816,joaogante/transformers_streaming,gradio,,37
-817,kevinwang676/Voice-Cloning-for-Bilibili,gradio,mit,37
-818,jbilcke-hf/Panoremix,docker,,37
-819,artificialguybr/artificialguybr-demo-lora,gradio,,37
-820,Truepic/watermarked-content-credentials,docker,,37
-821,dylanebert/igf,docker,mit,37
-822,deepseek-ai/deepseek-coder-7b-instruct,gradio,,37
-823,PaddlePaddle/deoldify,gradio,,36
-824,facebook/XLS-R-2B-22-16,gradio,,36
-825,ml6team/distilbart-tos-summarizer-tosdr,streamlit,apache-2.0,36
-826,spacy/pipeline-visualizer,streamlit,,36
-827,bigscience/BigScienceCorpus,streamlit,,36
-828,Gradio-Blocks/latent_gpt2_story,gradio,,36
-829,Geonmo/nllb-translation-demo,gradio,,36
-830,nielsr/donut-cord,gradio,,36
-831,joaogante/contrastive_search_generation,gradio,mit,36
-832,MaxReimann/Whitebox-Style-Transfer-Editing,streamlit,mit,36
-833,Matthijs/speecht5-asr-demo,gradio,apache-2.0,36
-834,cvlab/zero123,gradio,mit,36
-835,yotamsapi/face-swap,gradio,cc-by-nc-sa-4.0,36
-836,mikonvergence/mask-and-sketch,gradio,mit,36
-837,auto-academic/auto-draft,gradio,mit,36
-838,bigcode/search,gradio,apache-2.0,36
-839,OpenGVLab/InternGPT,gradio,apache-2.0,36
-840,ennov8ion/3dart-Models,gradio,,36
-841,Dragonnext/scylla-proxy,docker,,36
-842,radames/Candle-Phi-1.5-Wasm,static,,36
-843,merve/owlv2,gradio,apache-2.0,36
-844,tonyassi/text-to-image,gradio,,36
-845,artificialguybr/VIDEO-TRANSLATION-TRANSCRIPTION,gradio,,36
-846,OFA-Sys/OFA-Generic_Interface,gradio,apache-2.0,35
-847,Daniton/MidJourney,gradio,,35
-848,lxe/simple-llm-finetuner,gradio,,35
-849,kunishou/Rapid-GPT,gradio,mit,35
-850,philschmid/igel-playground,gradio,,35
-851,rewoo/ReWOO-Demo,gradio,apache-2.0,35
-852,cownclown/Image-and-3D-Model-Creator,gradio,,35
-853,mikefish/CharacterMaker,gradio,,35
-854,Detomo/Lighten_dark_image,gradio,,34
-855,OFA-Sys/OFA-Text2Image_Generation,static,apache-2.0,34
-856,davertor/colorizing_images,streamlit,,34
-857,stephenleo/stripnet,streamlit,,34
-858,huggan/FastGan,streamlit,,34
-859,doevent/3D_Photo_Inpainting,gradio,,34
-860,mattiagatti/image2mesh,gradio,,34
-861,johko/capdec-image-captioning,gradio,apache-2.0,34
-862,JavaFXpert/gpt-math-techniques,gradio,apache-2.0,34
-863,facebook/CutLER,docker,mit,34
-864,carloscar/stable-diffusion-webui-controlnet-docker,docker,,34
-865,LabelStudio/LabelStudio,docker,apache-2.0,34
-866,autotrain-projects/dreambooth,docker,,34
-867,competitions/CryCeleb2023,docker,,34
-868,stevengrove/GPT4Tools,gradio,apache-2.0,34
-869,wf-genius/Control-A-Video,gradio,apache-2.0,34
-870,vorstcavry/stable-diffusion-webui,gradio,,34
-871,akhaliq/ESPnet2-TTS,gradio,,33
-872,algomuffin/neural-search-engine,gradio,,33
-873,clip-italian/clip-italian-demo,streamlit,,33
-874,osanseviero/tips-and-tricks,streamlit,,33
-875,pleonova/multi-label-summary-text,streamlit,,33
-876,facebook/StyleNeRF,gradio,,33
-877,hackathon-pln-es/Spanish-Nahuatl-Translation,gradio,mpl-2.0,33
-878,EuroPython2022/Translate-with-Bloom,gradio,mit,33
-879,PaddlePaddle/chinese-stable-diffusion,gradio,apache-2.0,33
-880,nickmuchi/Earnings-Call-Analysis-Whisperer,streamlit,,33
-881,AlexWortega/Kandinsky2.0,gradio,,33
-882,Manjushri/SDXL-1.0-CPU,gradio,mit,33
-883,Xhaheen/Baith-al-suroor,gradio,openrail,33
-884,taesiri/DeticChatGPT,gradio,,33
-885,nateraw/fuego,gradio,apache-2.0,33
-886,lunarring/latentblending,gradio,,33
-887,hadisalman/photoguard,gradio,apache-2.0,33
-888,sahil2801/CodeAlpaca,gradio,apache-2.0,33
-889,zomehwh/sovits-teio,gradio,mit,33
-890,Linly-AI/Linly-ChatFlow,gradio,gpl-3.0,33
-891,Artrajz/vits-simple-api,gradio,mit,33
-892,SkalskiP/SAM_and_ProPainter,docker,,33
-893,flax-community/DietNerf-Demo,streamlit,,32
-894,shibing624/pycorrector,gradio,apache-2.0,32
-895,swzamir/Restormer,gradio,afl-3.0,32
-896,hysts/StyleGAN-Human,gradio,,32
-897,kn1ghtf1re/Photo-Realistic-Image-Stylization,gradio,mit,32
-898,ChenWu98/Stable-CycleDiffusion,gradio,apache-2.0,32
-899,ybelkada/image-to-music,gradio,,32
-900,phenomenon1981/MagicPrompt-Stable-Diffusion,gradio,mit,32
-901,ameerazam08/zoe-depth,gradio,,32
-902,NagaSaiAbhinay/UnCLIP_Image_Interpolation_Demo,gradio,mit,32
-903,DrSong/ChatGLM-6B-ChatBot,gradio,mit,32
-904,phenomenon1981/Dreamlikeart-Anime-1.0,gradio,,32
-905,PAIR/PAIR-Diffusion,docker,,32
-906,artificialguybr/freedom,gradio,,32
-907,julien-c/nllb-translation-in-browser,static,apache-2.0,32
-908,Xenova/doodle-dash,static,,32
-909,mrmocciai/rvc-genshin-v2,gradio,mit,32
-910,descript/vampnet,gradio,,32
-911,Jacopo/ToonClip,gradio,,31
-912,NATSpeech/PortaSpeech,gradio,,31
-913,akhaliq/Mask2Former,gradio,,31
-914,bipin/image2story,gradio,,31
-915,huggingface/text-data-filtering,streamlit,,31
-916,nielsr/perceiver-optical-flow,gradio,,31
-917,pytorch/YOLOv5,gradio,,31
-918,ECCV2022/PARSeq-OCR,gradio,apache-2.0,31
-919,Gustavosta/MagicPrompt-Dalle,gradio,mit,31
-920,rajesh1729/youtube-video-transcription-with-whisper,gradio,afl-3.0,31
-921,maiti/stable-fashion,streamlit,cc,31
-922,hkunlp/Binder,streamlit,apache-2.0,31
-923,OAOA/DifFace,gradio,apache-2.0,31
-924,nielsr/swin2sr-image-super-resolution,gradio,,31
-925,jerpint/buster,gradio,,31
-926,joaogante/color-coded-text-generation,gradio,mit,31
-927,RamAnanth1/FairDiffusion,gradio,,31
-928,lamini/instruct-playground,gradio,cc-by-4.0,31
-929,ghoskno/ColorCanny-Controlnet,gradio,,31
-930,sam-hq-team/sam-hq,gradio,apache-2.0,31
-931,LibreChat/LibreChat,docker,mit,31
-932,lmz/candle-yolo,static,,31
-933,r3gm/Ultimate-Vocal-Remover-WebUI,gradio,mit,31
-934,LeoLM/leo-hessianai-13b-chat,gradio,llama2,31
-935,r3gm/Aesthetic_RVC_Inference_HF,gradio,,31
-936,asgaardlab/CLIPxGamePhysics,gradio,,30
-937,vishnun/CLIPnCROP,gradio,,30
-938,Gradio-Blocks/protGPT2_gradioFold,gradio,mit,30
-939,CVPR/LIVE,gradio,gpl-3.0,30
-940,NimaBoscarino/playlist-generator,gradio,,30
-941,IoannisTr/Tech_Stocks_Trading_Assistant,streamlit,,30
-942,Amrrs/yt-shorts-video-captioning,gradio,mit,30
-943,anzorq/openai_whisper_stt,gradio,mit,30
-944,adirik/image-guided-owlvit,gradio,apache-2.0,30
-945,BilalSardar/Text-To-image-AllModels,gradio,openrail,30
-946,kazuk/youtube-whisper-10,gradio,unknown,30
-947,hwchase17/chat-your-data-state-of-the-union,gradio,mit,30
-948,gaviego/removebg,gradio,openrail,30
-949,takuma104/multi-controlnet,gradio,apache-2.0,30
-950,fffiloni/lama-video-watermark-remover,gradio,,30
-951,tsungtao/controlnet-mlsd-for-livingroom,gradio,,30
-952,IlyaGusev/saiga_13b_llamacpp_retrieval_qa,gradio,,30
-953,IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1-Demo,gradio,apache-2.0,30
-954,ICML2023/ICML2023_papers,gradio,,30
-955,ibm-nasa-geospatial/Prithvi-100M-sen1floods11-demo,docker,apache-2.0,30
-956,skytnt/midi-composer,gradio,apache-2.0,30
-957,nt3awnou/Nt3awnou-rescue-map,streamlit,,30
-958,merve/BLIP2-with-transformers,gradio,bsd-3-clause,30
-959,Flux9665/IMS-Toucan,gradio,apache-2.0,29
-960,akhaliq/FaceMesh,gradio,,29
-961,akhaliq/MT3,gradio,,29
-962,nateraw/stylegan3,gradio,,29
-963,hysts/StyleGAN-Human-Interpolation,gradio,,29
-964,awacke1/Art-Generator-and-Style-Mixer,gradio,mit,29
-965,nanomenta/sketch_frame_interpolation,gradio,,29
-966,keithhon/nllb-translation-demo-1.3b-distilled,gradio,gpl-3.0,29
-967,Geonmo/socratic-models-image-captioning-with-BLOOM,gradio,,29
-968,daspartho/is-it-huggable,gradio,apache-2.0,29
-969,ryparmar/fashion-aggregator,gradio,,29
-970,RamAnanth1/chatGPT_voice,gradio,,29
-971,NoCrypt/pixelization,gradio,,29
-972,anonymous-pits/pits,gradio,mit,29
-973,mmlab-ntu/relate-anything-model,gradio,mit,29
-974,balacoon/revoice,gradio,,29
-975,justest/gpt4free,gradio,,29
-976,fffiloni/AnimateDiff-Image-Init,gradio,apache-2.0,29
-977,ibm-nasa-geospatial/Prithvi-100M-multi-temporal-crop-classification-demo,docker,apache-2.0,29
-978,fffiloni/Music-To-Lyrics,gradio,,29
-979,HuggingFaceM4/ai_dad_jokes,gradio,,29
-980,fffiloni/sdxl-control-loras,gradio,,29
-981,Detomo/Japanese_OCR,gradio,,28
-982,abhibisht89/neural-search-engine,gradio,,28
-983,derina/MusicSpleeter,gradio,,28
-984,mfrashad/ClothingGAN,gradio,cc-by-nc-3.0,28
-985,yhshin/latex-ocr,gradio,mit,28
-986,ml6team/keyphrase-extraction,streamlit,mit,28
-987,neongeckocom/neon-tts-plugin-coqui,gradio,bsd-3-clause,28
-988,Gradio-Blocks/ViTPose,gradio,,28
-989,YiYiXu/it-happened-one-frame-2,gradio,afl-3.0,28
-990,CVPR/unicl-zero-shot-img-recog,gradio,mit,28
-991,YoannLemesle/CLIPictionary,gradio,,28
-992,ECCV2022/Screen_Image_Demoireing,gradio,,28
-993,miesnerjacob/Multi-task-NLP,streamlit,,28
-994,mozilla-foundation/youtube_video_similarity,gradio,apache-2.0,28
-995,davidtsong/whisper-demo,gradio,,28
-996,haofeixu/unimatch,gradio,mit,28
-997,WiNE-iNEFF/MinecraftSkin-Diffusion,gradio,,28
-998,AIML-TUDA/semantic-diffusion,gradio,creativeml-openrail-m,28
-999,fabiogra/moseca,docker,,28
-1000,RamAnanth1/ZoeDepth,gradio,,28
-1001,chenyangqi/FateZero,docker,mit,28
-1002,Xanthius/llama-token-counter,gradio,,28
-1003,fffiloni/animated-audio-visualizer,gradio,,28
-1004,OpenGenAI/parti-prompts-leaderboard,gradio,apache-2.0,28
-1005,lilacai/lilac,docker,,28
-1006,soggys/pompoms,docker,,28
-1007,librarian-bots/ranker,gradio,,28
-1008,merve/pix2struct,gradio,apache-2.0,28
-1009,Epoching/GLIDE_Inpaint,gradio,,27
-1010,Norod78/VintageStyle,gradio,,27
-1011,merve/chatbot-blog,streamlit,,27
-1012,nielsr/vilt-vqa,gradio,,27
-1013,fabiochiu/text-to-kb,streamlit,mit,27
-1014,Gradio-Blocks/clip-guided-faces,gradio,mit,27
-1015,spacy/gradio_pipeline_visualizer,gradio,cc,27
-1016,ECCV2022/PSG,gradio,mit,27
-1017,flowers-team/Interactive_DeepRL_Demo,static,mit,27
-1018,jackyliang42/code-as-policies,gradio,apache-2.0,27
-1019,fffiloni/text-2-music,gradio,,27
-1020,kadirnar/yolox,gradio,apache-2.0,27
-1021,Jayyydyyy/english-tokipona-translator,gradio,,27
-1022,argilla/live-demo,docker,,27
-1023,camenduru-com/vscode,docker,,27
-1024,deepghs/wd14_tagging_online,gradio,mit,27
-1025,susunghong/Self-Attention-Guidance,gradio,creativeml-openrail-m,27
-1026,alvanlii/FROMAGe,docker,,27
-1027,giswqs/maxar-open-data,streamlit,mit,27
-1028,CobaltZvc/HyperBot,streamlit,,27
-1029,keras-dreambooth/ignatius,gradio,openrail,27
-1030,ShiwenNi/ChatResponse,gradio,apache-2.0,27
-1031,zomehwh/vits-models-pcr,gradio,apache-2.0,27
-1032,fffiloni/video_frame_interpolation,gradio,,27
-1033,Xenova/react-translator,static,,27
-1034,openaccess-ai-collective/wizard-mega-ggml,gradio,,27
-1035,GuyYariv/AudioToken,gradio,mit,27
-1036,tangshitao/MVDiffusion,gradio,,27
-1037,FrankZxShen/so-vits-svc-models-ba,gradio,apache-2.0,27
-1038,fb700/chatglm-fitness-RLHF,gradio,mit,27
-1039,ysharma/WizardCoder34b,gradio,other,27
-1040,openskyml/dreamdrop-sd,gradio,,27
-1041,DarwinAnim8or/Mistral-Chat,gradio,,27
-1042,FriendlyJew/GoyimProxy,docker,,27
-1043,Detomo/ai-comic-generation,docker,,27
-1044,tonyassi/text-to-image-story-teller,gradio,,27
-1045,fcakyon/sahi-yolov5,gradio,,26
-1046,keras-io/NeRF,streamlit,afl-3.0,26
-1047,ntt123/WaveGRU-Text-To-Speech,gradio,mit,26
-1048,aryadytm/photo-colorization,streamlit,,26
-1049,aryadytm/remove-photo-background,streamlit,,26
-1050,visakh7843/Sheet_Music_Generator,gradio,,26
-1051,innnky/soft-vits-vc,gradio,,26
-1052,jamescalam/ask-youtube,streamlit,,26
-1053,Flux9665/ThisSpeakerDoesNotExist,gradio,mit,26
-1054,juancopi81/youtube-music-transcribe,gradio,apache-2.0,26
-1055,AdamOswald1/finetuned_diffusion,gradio,mit,26
-1056,society-ethics/disaggregators,gradio,,26
-1057,BAAI/dreambooth-altdiffusion,gradio,mit,26
-1058,AP123/ai-avatars,gradio,mit,26
-1059,huggingface-projects/AIvsAI-SoccerTwos,gradio,mit,26
-1060,awacke1/Prompt-Refinery-Text-to-Image-Generation,gradio,,26
-1061,huggingface-projects/Deep-RL-Course-Certification,gradio,,26
-1062,yahma/rwkv-14b,gradio,gpl-3.0,26
-1063,hysts/PnP-diffusion-features,gradio,,26
-1064,marlenezw/audio-driven-animations,gradio,cc-by-2.0,26
-1065,Junity/TokaiTeio-SVC,gradio,openrail,26
-1066,cbg342/GPT-4-To-Midi,streamlit,,26
-1067,shengyi-qian/3DOI,gradio,mit,26
-1068,bigcode/Reasoning-with-StarCoder,gradio,,26
-1069,OpenBuddy/ChatWithBuddy,static,,26
-1070,laogou717/bing,docker,mit,26
-1071,guanghap/nob-hill-noir,static,apache-2.0,26
-1072,zenafey/fast-stable-diffusion,gradio,mit,26
-1073,AP123/CerealBoxMaker,gradio,bigscience-openrail-m,26
-1074,nateraw/stylegan3-interpolation,gradio,,25
-1075,vivien/clip-slip,streamlit,,25
-1076,chrisjay/afro-speech,gradio,,25
-1077,LilyF/Generate_Text_and_Audio,gradio,apache-2.0,25
-1078,lukbl/LaTeX-OCR,streamlit,mit,25
-1079,huggingface-projects/dataset-profiler,gradio,apache-2.0,25
-1080,LDY/ImageToLine,gradio,afl-3.0,25
-1081,ysharma/Bloom-Creates-Meme,gradio,gpl,25
-1082,FinanceInc/Financial_Analyst_AI,gradio,apache-2.0,25
-1083,taneemishere/html-code-generation-from-images-with-deep-neural-networks,gradio,afl-3.0,25
-1084,CjangCjengh/Shanghainese-TTS,gradio,,25
-1085,MirageML/lowpoly-world,gradio,,25
-1086,dylanebert/FarmingGame,static,,25
-1087,Mahiruoshi/Lovelive_Nijigasaki_VITS,gradio,other,25
-1088,AP123/text-to-3D,gradio,,25
-1089,akhaliq/anything-v4.0,gradio,,25
-1090,pix2pix-zero-library/pix2pix-zero-demo,gradio,mit,25
-1091,jbrinkma/segment-anything,gradio,openrail,25
-1092,longlian/llm-grounded-diffusion,gradio,,25
-1093,zama-fhe/encrypted_health_prediction,gradio,,25
-1094,Wazzzabeee/image-video-colorization,streamlit,,25
-1095,Voicemod/Text-To-Speech,gradio,,25
-1096,r3gm/SoniTranslate_translate_audio_of_a_video_content,gradio,,25
-1097,lmz/candle-whisper,static,,25
-1098,elyza/ELYZA-japanese-Llama-2-7b-instruct-demo,gradio,,25
-1099,Alifarsi/news_summarizer,gradio,,24
-1100,devendergarg14/Paraphrasing_with_GPT_Neo,gradio,,24
-1101,haakohu/DeepPrivacy,gradio,,24
-1102,nazianafis/Extract-Tables-From-PDF,streamlit,,24
-1103,huggan/butterfly-gan,streamlit,apache-2.0,24
-1104,evaluate-metric/rouge,gradio,,24
-1105,evaluate-metric/bleu,gradio,,24
-1106,Theivaprakasham/layoutlmv3_invoice,gradio,apache-2.0,24
-1107,ml6team/logo-generator,streamlit,,24
-1108,ruslanmv/TextToVideo-Dalle,gradio,apache-2.0,24
-1109,kornia/edge_detector,gradio,,24
-1110,EleutherAI/polyglot-ko-1.3b,gradio,apache-2.0,24
-1111,RamAnanth1/whisper_to_emotion,gradio,,24
-1112,innnky/nyaru-svc2.0,gradio,,24
-1113,CarlDennis/Lovelive-VITS-JPZH,gradio,cc-by-nc-3.0,24
-1114,sayakpaul/maxim-spaces,gradio,apache-2.0,24
-1115,saltacc/anime-ai-detect,gradio,,24
-1116,kinyugo/msanii,gradio,mit,24
-1117,PirateXX/AI-Content-Detector,gradio,artistic-2.0,24
-1118,andzhk/PNGInfo,gradio,wtfpl,24
-1119,ysharma/pix2pix-zero-01,gradio,mit,24
-1120,competitions/SnakeCLEF2023,docker,,24
-1121,kunishou/Japanese-Alpaca-LoRA-7b-DEMO,gradio,mit,24
-1122,huggingface/devs,gradio,apache-2.0,24
-1123,jax-diffusers-event/leaderboard,gradio,apache-2.0,24
-1124,llamaindex/llama_index_sql_sandbox,streamlit,mit,24
-1125,presidio/presidio_demo,docker,mit,24
-1126,hackathon-somos-nlp-2023/SalpiBloomZ-1b7-v1,gradio,,24
-1127,ysharma/RedPajama-Chat-3B,gradio,mit,24
-1128,openaccess-ai-collective/manticore-ggml,gradio,,24
-1129,ysharma/ChatGPT-Plugins-UI-with-Langchain,gradio,mit,24
-1130,ioclab/ai-qrcode-api,gradio,,24
-1131,IDEA-CCNL/ziya2-13B-base,gradio,apache-2.0,24
-1132,cncanon/gpt4,docker,,24
-1133,Illia56/Youtube-Whisper-Llama,streamlit,,24
-1134,XzJosh/Taffy-Bert-VITS2,gradio,mit,24
-1135,Dragonnext/charybdis,docker,,24
-1136,mithril-security/starcoder_memorization_checker,gradio,apache-2.0,24
-1137,Willow123/InternLM-XComposer,gradio,apache-2.0,24
-1138,Modfiededition/Writing_Assistant,streamlit,,23
-1139,ThePixOne/open_domain_qa,gradio,wtfpl,23
-1140,akhaliq/GPEN,gradio,,23
-1141,aubmindlab/Arabic-NLP,streamlit,,23
-1142,luca-martial/neural-style-transfer,gradio,,23
-1143,obi/Medical-Note-Deidentification,gradio,mit,23
-1144,osanseviero/fork_a_repo,gradio,,23
-1145,saber2022/Real-CUGAN,gradio,apache-2.0,23
-1146,hackathon-pln-es/Audio-Sentiment-Classifier,gradio,,23
-1147,hysts/mediapipe-pose-estimation,gradio,,23
-1148,rinong/StyleGAN-NADA,gradio,mit,23
-1149,EuroPython2022/Write-Stories-Using-Bloom,gradio,gpl,23
-1150,SIGGRAPH2022/sketch2pose,gradio,,23
-1151,Kororinpa/Amadeus_Project,gradio,,23
-1152,menghanxia/disco,gradio,openrail,23
-1153,MirageML/sjc,gradio,creativeml-openrail-m,23
-1154,OFA-Sys/chinese-clip-zero-shot-image-classification,gradio,mit,23
-1155,sanchit-gandhi/chatGPT,gradio,,23
-1156,innnky/nyaru4.0,gradio,mit,23
-1157,Qosmo/GPT-Infinite-Radio,gradio,unlicense,23
-1158,p1atdev/AdverseCleaner,gradio,apache-2.0,23
-1159,competitions/ChaBuD-ECML-PKDD2023,docker,,23
-1160,Ziqi/ReVersion,gradio,,23
-1161,gradio/theme_builder,gradio,,23
-1162,Kevin676/VoiceFixer,gradio,,23
-1163,RamAnanth1/stable-diffusion-xl,gradio,,23
-1164,TencentARC/MasaCtrl,gradio,,23
-1165,yuvalkirstain/PickScore,gradio,mit,23
-1166,SpacesExamples/InvokeAI,docker,,23
-1167,openskyml/remove-background-on-image,gradio,mit,23
-1168,opencompass/opencompass-llm-leaderboard,gradio,apache-2.0,23
-1169,OpenMotionLab/MotionGPT,gradio,mit,23
-1170,artificialguybr/pixel-art-generator,gradio,,23
-1171,Mahiruoshi/BangDream-Bert-VITS2,gradio,,23
-1172,AlekseyKorshuk/huggingartists,streamlit,,22
-1173,Amrrs/image-to-text-app,streamlit,,22
-1174,dt/ascii-art,gradio,,22
-1175,flax-sentence-embeddings/sentence-embeddings,streamlit,,22
-1176,shibing624/text2vec,gradio,apache-2.0,22
-1177,hysts/Anime2Sketch,gradio,,22
-1178,keras-io/bert-semantic-similarity,gradio,apache-2.0,22
-1179,EuroPython2022/rev,gradio,,22
-1180,nielsr/donut-rvlcdip,gradio,,22
-1181,power2/sketch,gradio,mit,22
-1182,tomrb/bettercallbloom,gradio,,22
-1183,cafeai/cafe_aesthetic_demo,gradio,agpl-3.0,22
-1184,kadirnar/yolov7,gradio,gpl-3.0,22
-1185,pragnakalp/one_shot_talking_face_from_text,docker,,22
-1186,AIFILMS/Pix2Pix-Video,gradio,,22
-1187,stable-diffusion-ai/upscaling,gradio,apache-2.0,22
-1188,jhtonyKoo/music_mixing_style_transfer,gradio,mit,22
-1189,video-p2p-library/Video-P2P-Demo,docker,mit,22
-1190,Mishyface/image-to-video-film-3-kazuk-hugorowan-mishyface,gradio,unknown,22
-1191,abidlabs/music-separation,gradio,,22
-1192,aicg/Moxxie-Proxy,docker,,22
-1193,MariaK/Check-my-progress-Audio-Course,gradio,,22
-1194,dahaoGPT/ChatGLM2-6B-chatbot,gradio,apache-2.0,22
-1195,sanchit-gandhi/musicgen-negative-prompting,gradio,,22
-1196,IlyaGusev/saiga2_13b_gguf,gradio,,22
-1197,Xenova/semantic-image-search,docker,,22
-1198,fffiloni/diffBIR,docker,,22
-1199,openskyml/super-fast-sdxl-stable-diffusion-xl,gradio,creativeml-openrail-m,22
-1200,AlexWortega/food_calories,gradio,,21
-1201,Cropinky/gpt2-rap-songs,streamlit,,21
-1202,kornia/Kornia-LoFTR,gradio,,21
-1203,keras-io/Human-Part-Segmentation,gradio,cc0-1.0,21
-1204,nielsr/imagegpt-completion,gradio,,21
-1205,pytorch/Tacotron2,gradio,,21
-1206,speech-recognition-community-v2/Leaderboard,streamlit,mit,21
-1207,awacke1/Sentence2Paragraph,gradio,mit,21
-1208,EPFL-VILAB/MultiMAE,gradio,cc-by-nc-4.0,21
-1209,jph00/testing,gradio,apache-2.0,21
-1210,kurianbenoy/audioclassification,gradio,mit,21
-1211,Gradio-Blocks/EmojiGAN,gradio,cc-by-nc-4.0,21
-1212,evaluate-metric/bertscore,gradio,,21
-1213,Gradio-Blocks/Create_GIFs_from_Video,gradio,gpl,21
-1214,HuSusu/SuperResolution,gradio,afl-3.0,21
-1215,nightfury/StableDiffusion-Img2Img,gradio,,21
-1216,JayRaghav/Image_segmentation,gradio,openrail,21
-1217,mohamedabdullah/Arabic-Spelling-Checker,gradio,,21
-1218,johnrobinsn/MidasDepthEstimation,gradio,mit,21
-1219,nakas/audio-diffusion_style_transfer,gradio,gpl-3.0,21
-1220,Loren/Streamlit_OCR_comparator,streamlit,,21
-1221,kazuk/youtube-whisper-04,gradio,unknown,21
-1222,abidlabs/gradio-discord-bot-server,gradio,openrail,21
-1223,ramkamal2000/voice-cloning-yourtts,gradio,unknown,21
-1224,open-spaced-repetition/fsrs4anki_app,gradio,mit,21
-1225,hongfz16/EVA3D,gradio,other,21
-1226,kermitt2/grobid,docker,apache-2.0,21
-1227,sparanoid/milky-green-sovits-4,gradio,mit,21
-1228,souljoy/ChatPDF,gradio,apache-2.0,21
-1229,ysharma/OSChatbots_ChatGPT_ToeToToe,gradio,mit,21
-1230,fffiloni/video2openpose2,gradio,,21
-1231,zetavg/LLaMA-LoRA-Tuner-UI-Demo,gradio,,21
-1232,Acapellas/Extract_Vocals_Instrumentals,gradio,,21
-1233,jcenaa/Segment-Any-RGBD,gradio,mit,21
-1234,matthoffner/starchat-ui,docker,,21
-1235,lj1995/vocal2guitar,gradio,mit,21
-1236,AlphaDragon/Voice-Clone,gradio,,21
-1237,Robert001/UniControl-Demo,gradio,apache-2.0,21
-1238,johnhelf/roop,gradio,agpl-3.0,21
-1239,HopeMan/DoomGuy,docker,,21
-1240,lykeven/CogVLM,gradio,mit,21
-1241,fffiloni/sd-xl-lora-fusion,gradio,,21
-1242,Detomo/Depth_estimation,gradio,,20
-1243,Gladiator/Text-Summarizer,streamlit,,20
-1244,Norod78/ComicsHeroHD,gradio,,20
-1245,Xenova/sponsorblock-ml,streamlit,,20
-1246,abidlabs/chatbot-stylized,gradio,apache-2.0,20
-1247,akhaliq/Video_Search_CLIP,gradio,,20
-1248,akhaliq/gpt-j-6B,gradio,,20
-1249,hysts/stylegan3-anime-face-exp002,gradio,,20
-1250,julien-c/coqui,gradio,,20
-1251,merve/write-with-transformer,streamlit,,20
-1252,mishig/smarter_npc,static,,20
-1253,psistolar/pop-music-transformer,gradio,,20
-1254,kornia/kornia-image-enhancement,gradio,apache-2.0,20
-1255,SIGGRAPH2022/StyleGAN-XL,gradio,,20
-1256,seduerr/semantic_search,gradio,mit,20
-1257,AlekseyKorshuk/thin-plate-spline-motion-model,gradio,apache-2.0,20
-1258,mattiagatti/mars_dtm_estimation,gradio,,20
-1259,NAACL2022/CLIP-Caption-Reward,gradio,,20
-1260,JMalott/ai_architecture,streamlit,mit,20
-1261,milyiyo/reimagine-it,gradio,,20
-1262,itsyoboieltr/anpr,gradio,,20
-1263,ml6team/Speaker-Diarization,streamlit,,20
-1264,innnky/vits-nyaru,gradio,,20
-1265,Rongjiehuang/ProDiff,gradio,,20
-1266,Epoching/DocumentQA,gradio,apache-2.0,20
-1267,wukevin/foldingdiff,gradio,,20
-1268,innnky/nyaru-svc2.0-advanced,gradio,,20
-1269,esb/leaderboard,streamlit,,20
-1270,Catmeow/AI_story_writing,gradio,,20
-1271,uwx/waveformer,gradio,,20
-1272,afmck/stable-diffusion-inpainting-segmentation,gradio,creativeml-openrail-m,20
-1273,tombetthauser/astronaut-horse-concept-loader,gradio,,20
-1274,ringhyacinth/Nail-Diffuser,gradio,openrail,20
-1275,hugging-fellows/paper-to-pokemon,gradio,,20
-1276,pragnakalp/OCR-image-to-text,gradio,,20
-1277,salmanmapkar/audio-video-transcriber,gradio,,20
-1278,johnslegers/epic-diffusion,gradio,mit,20
-1279,team7/talk_with_wind,gradio,,20
-1280,Hello-SimpleAI/chatgpt-detector-qa,gradio,,20
-1281,akhaliq/small-stable-diffusion-v0,gradio,,20
-1282,kazuk/youtube-whisper-03,gradio,unknown,20
-1283,hojining/Ultra_Fast_Anything_V4k_resolution,gradio,,20
-1284,kamayali/anything-v4.0,gradio,,20
-1285,Kaludi/ChatGPT-BingChat-GPT3-Prompt-Generator_App,streamlit,,20
-1286,SpacesExamples/docker-examples,gradio,,20
-1287,cyllum/soccertwos-analytics,docker,,20
-1288,zhangjf/chatbot,gradio,apache-2.0,20
-1289,SjoerdTeunisse/upscaler,gradio,apache-2.0,20
-1290,hackathon-somos-nlp-2023/PodcastNER-GPTJ,gradio,,20
-1291,BAAI/vid2vid-zero,gradio,,20
-1292,megaaziib/hololive-rvc-models,gradio,mit,20
-1293,Nixtla/transfer-learning-time-series,streamlit,bsd-3-clause,20
-1294,yuchenlin/Rebiber,gradio,,20
-1295,cloversid/rvc-ai,docker,mit,20
-1296,Realcat/image-matching-webui,gradio,mit,20
-1297,myscale/ChatData,streamlit,mit,20
-1298,zideliu/styledrop,docker,mit,20
-1299,docparser/Text_Captcha_breaker,gradio,apache-2.0,20
-1300,monra/freegpt-webui-chimera,docker,,20
-1301,CatNika/New_Cat_Proxy,docker,,20
-1302,damo-vilab/MS-Vid2Vid-XL-demo,docker,,20
-1303,YuxinJ/Scenimefy,gradio,other,20
-1304,Proxy1/Turbo,docker,,20
-1305,BridgeEight/internlm-20B-chat-w4-turbomind,gradio,apache-2.0,20
-1306,bpHigh/AI-Research-Buddy,streamlit,mit,20
-1307,Mysterykey/Orange,docker,,20
-1308,HugoDzz/super-godot-galaxy,static,mit,20
-1309,Deci/YOLO-NAS-Pose-Demo,gradio,apache-2.0,20
-1310,MrBodean/Depthmap,gradio,,19
-1311,Norod78/ComicsHero,gradio,,19
-1312,fcakyon/sahi-yolox,streamlit,,19
-1313,nateraw/quickdraw,gradio,,19
-1314,pierreant-p/huggingfab,static,,19
-1315,tmabraham/fastai_pet_classifier,gradio,,19
-1316,lkeab/transfiner,gradio,apache-2.0,19
-1317,njanakiev/gradio-openai-clip-grad-cam,gradio,mit,19
-1318,ysharma/text-to-image-to-video,gradio,mit,19
-1319,ai-forever/mGPT,gradio,apache-2.0,19
-1320,unity/ML-Agents-Pyramids,static,apache-2.0,19
-1321,hysts/diffusers-anime-faces,gradio,,19
-1322,gradio/xgboost-income-prediction-with-explainability,gradio,,19
-1323,fffiloni/Stable-Diffusion-CPU,gradio,,19
-1324,innnky/soft-vits-singingvc,gradio,,19
-1325,beki/pii-anonymizer,streamlit,mit,19
-1326,fffiloni/stable-diffusion-color-sketch,gradio,,19
-1327,NikeZoldyck/green-screen-composition-transfer,gradio,,19
-1328,akhooli/poetry,gradio,cc-by-nc-4.0,19
-1329,OneAfterlife/MubertTTM,gradio,osl-3.0,19
-1330,vivym/image-matting-app,gradio,mit,19
-1331,akhaliq/dreamlike-diffusion-1.0,gradio,,19
-1332,deepghs/ml-danbooru-demo,gradio,mit,19
-1333,society-ethics/model-card-regulatory-check,gradio,,19
-1334,diffusers/convert,gradio,apache-2.0,19
-1335,naotokui/TR-ChatGPT,gradio,,19
-1336,assemblyai/Conformer1-Demo,gradio,,19
-1337,keras-dreambooth/keras-dreambooth-riffusion-currulao,gradio,creativeml-openrail-m,19
-1338,taishi-i/awesome-ChatGPT-repositories-search,streamlit,mit,19
-1339,sander-wood/text-to-music,gradio,mit,19
-1340,alex-mindspace/gpt-agents,gradio,mit,19
-1341,bigcode/bigcode-model-license-agreement,streamlit,cc-by-4.0,19
-1342,fffiloni/BedtimeStory,gradio,,19
-1343,mrmocciai/rvc-models,gradio,mit,19
-1344,HuggingFaceH4/falcon-chat-demo-for-blog,gradio,apache-2.0,19
-1345,wyysf/GenMM,gradio,,19
-1346,Yntec/fast_diffusion,gradio,,19
-1347,fiz123321/nah,docker,,19
-1348,georgesung/llama2_7b_uncensored_chat,gradio,,19
-1349,Iceclear/StableSR,gradio,other,19
-1350,soggys/tavern,docker,,19
-1351,R3DI/Uber_Realistic_Porn_Merge_V1.3,gradio,,19
-1352,turing-motors/heron_chat_blip,gradio,apache-2.0,19
-1353,limcheekin/Mistral-7B-Instruct-v0.1-GGUF,docker,,19
-1354,ilumine-AI/AI-Creepypastas,static,,19
-1355,Otter-AI/OtterHD-Demo,gradio,mit,19
-1356,MAGAer13/mPLUG-Owl2,gradio,apache-2.0,19
-1357,Pavankunchala/Depth-Estimation-App,streamlit,,18
-1358,akhaliq/Style_Transfer,gradio,,18
-1359,ECCV2022/bytetrack,gradio,,18
-1360,flax-community/SentenceSimplifier,streamlit,,18
-1361,radames/sentence-embeddings-visualization,gradio,,18
-1362,givkashi/SwinIR-Super-resolution,gradio,apache-2.0,18
-1363,jjeamin/ArcaneStyleTransfer,gradio,apache-2.0,18
-1364,templates/fastapi-uvicorn,gradio,mit,18
-1365,probing-vits/attention-heat-maps,streamlit,mit,18
-1366,mecevit/english-to-sql,gradio,apache-2.0,18
-1367,Tuana/PDF-Summarizer,streamlit,,18
-1368,Gradio-Blocks/anime-colorization,gradio,mit,18
-1369,ICML2022/OFA,gradio,apache-2.0,18
-1370,bigscience/petals-api,gradio,,18
-1371,rkoushikroy2/portrait_photo_generator,gradio,apache-2.0,18
-1372,sklearn-docs/anomaly-detection,gradio,apache-2.0,18
-1373,tryolabs/norfair-demo,gradio,bsd-3-clause,18
-1374,gradio/neon-tts-plugin-coqui,gradio,,18
-1375,nielsr/TrOCR-Scene-Text-Recognition,gradio,,18
-1376,open-source-metrics/models-explorer,streamlit,,18
-1377,awacke1/CB-GR-Chatbot-Blenderbot,gradio,apache-2.0,18
-1378,itmorn/face_keypoint_3d,gradio,other,18
-1379,nateraw/stable-diffusion-music-videos,gradio,,18
-1380,tomas-gajarsky/facetorch-app,docker,apache-2.0,18
-1381,yangheng/PyABSA,gradio,mit,18
-1382,lojban/text-to-speech,gradio,mit,18
-1383,SerdarHelli/SDF-StyleGan-3D,gradio,mit,18
-1384,cynika/taffy,gradio,,18
-1385,SteveDigital/free-mp3-to-text-using-openai-whisper,gradio,gpl-3.0,18
-1386,nlphuji/whoops-explorer,gradio,,18
-1387,appl044/Chat-GPT-LangChain,gradio,apache-2.0,18
-1388,SpacesExamples/vscode,docker,,18
-1389,RamAnanth1/REaLTabFormer,gradio,,18
-1390,AIARTCHAN/openpose_editor,static,mit,18
-1391,Thafx/sdrv20,gradio,,18
-1392,lifan0127/zotero-qa,gradio,mit,18
-1393,RamAnanth1/conformer-asr,gradio,,18
-1394,hugforziio/chat-gpt-ui,gradio,,18
-1395,kazuk/youtube-whisper-19,gradio,unknown,18
-1396,hahahafofo/image2text_prompt_generator,gradio,bigscience-openrail-m,18
-1397,competitions/news-unmasked,docker,,18
-1398,navervision/Graphit-SD,gradio,apache-2.0,18
-1399,SoulAbi/text-to-voice,gradio,bigscience-openrail-m,18
-1400,fffiloni/LangChain-ChatGPT-plugins,gradio,,18
-1401,lauraibnz/midi-audioldm,gradio,mit,18
-1402,Masutxrxd/Masutxrxd,docker,,18
-1403,GrandaddyShmax/MusicGen_Plus,gradio,,18
-1404,h2oai/wave-chatbot-ui,docker,apache-2.0,18
-1405,melihunsal/demogpt,streamlit,mit,18
-1406,avans06/whisper-webui-translate,gradio,apache-2.0,18
-1407,GrandaddyShmax/MusicGen_Plus_hfv2,gradio,,18
-1408,kevinwang676/ChatGLM2-VC-SadTalker,gradio,mit,18
-1409,ibm-nasa-geospatial/Prithvi-100M-demo,docker,apache-2.0,18
-1410,dongsiqie/bing,docker,mit,18
-1411,librarian-bots/huggingface-datasets-semantic-search,gradio,,18
-1412,imseldrith/DeepFakeAI,gradio,mit,18
-1413,radames/Gradio-llama2.mojo,docker,,18
-1414,Politrees/RVC_V2_Huggingface_Version,gradio,lgpl-3.0,18
-1415,Jean-Baptiste/email_parser,gradio,,17
-1416,NeuralStyleTransfer/neural-style-transfer,gradio,,17
-1417,Ron0420/EfficientNetV2_Deepfakes_Image_Detector,gradio,,17
-1418,akhaliq/convnext,gradio,,17
-1419,akhaliq/coqui-ai-tts,gradio,,17
-1420,breezedeus/CnOCR-Demo,gradio,apache-2.0,17
-1421,julien-c/persistent-data,gradio,,17
-1422,ntt123/vietTTS,gradio,,17
-1423,samuelinferences/transformers-can-do-bayesian-inference,gradio,,17
-1424,sunwaee/MT5-Questions-Answers-Generation-Extraction,streamlit,,17
-1425,RTLAI/BLIPsinki,gradio,,17
-1426,awacke1/Image-Semantic-Search,streamlit,mit,17
-1427,osanseviero/tortoisse-tts,gradio,apache-2.0,17
-1428,evaluate-metric/wer,gradio,,17
-1429,Gradio-Blocks/document-qa,gradio,apache-2.0,17
-1430,Gradio-Blocks/Multilingual-Aspect-Based-Sentiment-Analysis,gradio,mit,17
-1431,doevent/FullSubNet-plus,gradio,apache-2.0,17
-1432,microsoft/unicl-img-recog-demo,gradio,mit,17
-1433,sklearn-docs/clustering,gradio,bsd-3-clause,17
-1434,EuroPython2022/BayesCap,gradio,,17
-1435,Team-PIXEL/PIXEL,gradio,apache-2.0,17
-1436,mfumanelli/Stable-Diffusion-Loves-Cinema,gradio,,17
-1437,tumuyan/vits-miki,gradio,,17
-1438,innnky/nanami,gradio,,17
-1439,sayakpaul/gopro-deblurring-maxim,gradio,apache-2.0,17
-1440,camenduru-com/seamless,docker,,17
-1441,SpacesExamples/fastapi_t5,docker,,17
-1442,JosephusCheung/ACertainsStrategyTalk,static,cc-by-sa-4.0,17
-1443,ybelkada/blip-image-captioning-space-large,gradio,bsd-3-clause,17
-1444,unixpickle/car-data,gradio,mit,17
-1445,SceneDiffuser/SceneDiffuserDemo,gradio,,17
-1446,playgrdstar/compare-llms,gradio,mit,17
-1447,vinid/webplip,streamlit,mit,17
-1448,hfl/VQA_VLE_LLM,gradio,openrail,17
-1449,22h/vintedois-diffusion-v0-2,gradio,,17
-1450,NeuralInternet/Audio-to-Text_Playground,gradio,,17
-1451,josStorer/ChatGLM-6B-Int4-API-OpenAI-Compatible,docker,apache-2.0,17
-1452,Kevin676/ChatGPT-with-Voice-Cloning-for-All,gradio,mit,17
-1453,kenton-li/chatdoctor_csv,gradio,,17
-1454,UCAS/ChatGPT4,gradio,mit,17
-1455,FrankZxShen/vits-fast-finetuning-pcr,gradio,apache-2.0,17
-1456,openMUSE/MUSE,gradio,,17
-1457,uonlp/open_multilingual_llm_leaderboard,gradio,,17
-1458,kevinwang676/Bark-Voice-Cloning,gradio,mit,17
-1459,Yntec/PrintingPress,gradio,,17
-1460,KarmKarma/rvc-models-genshinimpact,gradio,mit,17
-1461,cncanon/freeturbo,docker,,17
-1462,lvwerra/harms-law,gradio,,17
-1463,fiz123321/dumbcutie,docker,,17
-1464,RVVY/test01,docker,,17
-1465,Oppenheimer57/claude-proxy,docker,,17
-1466,thirdai/BOLT2.5B,gradio,other,17
-1467,Eddycrack864/Applio-Inference,gradio,,17
-1468,radames/OHIF-Medical-Imaging-Viewer,docker,,17
-1469,merve/compare_docvqa_models,gradio,apache-2.0,17
-1470,openskyml/mistral-7b-chat,gradio,mit,17
-1471,52Hz/SRMNet_real_world_denoising,gradio,,16
-1472,Hellisotherpeople/HF-BERTopic,streamlit,mit,16
-1473,akhaliq/T0pp,gradio,,16
-1474,farukozderim/Model-Comparator-Space-Builder,gradio,,16
-1475,jonatasgrosman/asr,gradio,mit,16
-1476,sohaibcs1/Image-to-Text-Summary,gradio,,16
-1477,davidpiscasio/unpaired-img2img,gradio,bsd-2-clause,16
-1478,jipenaflor/Youtube-Transcript-Summarizer,gradio,apache-2.0,16
-1479,hackathon-pln-es/clasificador-comentarios-suicidas,gradio,cc-by-sa-4.0,16
-1480,d0r1h/youtube_summarization,gradio,mit,16
-1481,bertin-project/bertin-gpt-j-6B,gradio,apache-2.0,16
-1482,multimodalart/vqgan,gradio,mit,16
-1483,gradio/pictionary,gradio,,16
-1484,Tuana/GoT-QA-Haystack,streamlit,,16
-1485,evaluate-metric/seqeval,gradio,,16
-1486,Gradio-Blocks/StyleGAN-Human,gradio,,16
-1487,codeparrot/codegen-subspace,gradio,,16
-1488,osanseviero/latent-video,gradio,mit,16
-1489,aliabid94/GPT-Golf,gradio,,16
-1490,CVPR/BrAD,gradio,apache-2.0,16
-1491,Matthijs/mobilevit-deeplab-demo,gradio,apache-2.0,16
-1492,EuroPython2022/Zero-Shot-SQL-by-Bloom,gradio,gpl,16
-1493,ICML2022/YourTTS,gradio,,16
-1494,vivien/clip-owlvit,streamlit,mit,16
-1495,huggingface/transformers-stats,streamlit,,16
-1496,dbirks/diffuse-the-rest,static,,16
-1497,fffiloni/sd-img-variations,gradio,,16
-1498,smajumdar/nemo_multilingual_language_id,gradio,apache-2.0,16
-1499,Catmeow/Face2Painting_From_Photo,gradio,,16
-1500,kdrkdrkdr/ShirokoTTS,gradio,,16
-1501,Sybghat/resume-parser,gradio,openrail,16
-1502,morenolq/galactica-base,gradio,apache-2.0,16
-1503,Norod78/sd2-simpsons-blip,gradio,,16
-1504,tomsoderlund/rest-api-with-gradio,gradio,openrail,16
-1505,camenduru-com/riffusion,docker,,16
-1506,abhishek/diffuzers,docker,apache-2.0,16
-1507,akhaliq/dreamlike-photoreal-2.0,gradio,,16
-1508,dotmet/Real-ESRGAN-Enhanced-Anime-Diffusion,gradio,bsd,16
-1509,Fr33d0m21/Music_Splitter,gradio,,16
-1510,kadirnar/torchyolo,gradio,gpl-3.0,16
-1511,alvanlii/RDM-Region-Aware-Diffusion-Model,gradio,,16
-1512,Nickhilearla135095/maximum_diffusion,gradio,,16
-1513,SpacesExamples/jupyterlab,docker,,16
-1514,radames/nginx-gradio-reverse-proxy,docker,,16
-1515,IDEA-CCNL/Taiyi-BLIP,gradio,apache-2.0,16
-1516,AlignmentResearch/tuned-lens,docker,mit,16
-1517,nyanko7/openai-translator,gradio,openrail,16
-1518,competitions/FungiCLEF2023,docker,,16
-1519,idosal/oai-proxy,docker,,16
-1520,coffeeee/nsfw-c0ffees-erotic-story-generator,gradio,,16
-1521,openaccess-ai-collective/manticore-13b-chat-pyg,gradio,,16
-1522,shaocongma/faiss_chat,gradio,mit,16
-1523,matthoffner/wizardcoder-ggml,docker,,16
-1524,Yntec/Dreamlike-Webui-CPU,gradio,,16
-1525,jykoh/gill,docker,,16
-1526,ezioruan/roop,gradio,agpl-3.0,16
-1527,Truepic/ai-content-credentials,docker,,16
-1528,llSourcell/doctorGPT,streamlit,openrail,16
-1529,imseldrith/FaceSwap,gradio,gpl-3.0,16
-1530,manavisrani07/gradio-lipsync-wav2lip,gradio,apache-2.0,16
-1531,SpacesExamples/llama-cpp-python-cuda-gradio,docker,,16
-1532,ashhhh23/lordofthemysteries,docker,,16
-1533,librarian-bots/base_model_explorer,gradio,,16
-1534,cakewalk/splat,static,,16
-1535,Xenova/semantic-image-search-client,static,,16
-1536,Illia56/fastest-whisper-v2-large,gradio,,16
-1537,librarian-bots/recommend_similar_papers,gradio,mit,16
-1538,worldsoupkitchen/lollipop,docker,,16
-1539,editing-images/ai-halloween-photobooth,gradio,,16
-1540,thinkall/autogen-demos,gradio,mit,16
-1541,Illia56/Chat-with-Youtube-video-Mistal-7b,streamlit,,16
-1542,openskyml/fast-sdxl-stable-diffusion-xl,gradio,,16
-1543,artificialguybr/OPENHERMES-V2.5-DEMO,gradio,,16
-1544,akhaliq/stylegan3_clip,gradio,,15
-1545,frapochetti/blurry-faces,gradio,apache-2.0,15
-1546,hysts/stylegan3-anime-face-exp001,gradio,,15
-1547,keras-io/low-light-image-enhancement,gradio,apache-2.0,15
-1548,codeparrot/codeparrot-highlighting,streamlit,,15
-1549,spacy/healthsea-pipeline,streamlit,,15
-1550,spark-nlp/SparkNLP_NER,streamlit,,15
-1551,training-transformers-together/Dashboard,streamlit,,15
-1552,valhalla/minDALLE,streamlit,,15
-1553,vivien/trompeloeil,static,,15
-1554,yangheng/Multilingual-Aspect-Based-Sentiment-Analysis,gradio,mit,15
-1555,tomofi/Tesseract-OCR,gradio,mit,15
-1556,ml6team/post-processing-summarization,streamlit,,15
-1557,NimaBoscarino/climategan,gradio,gpl-3.0,15
-1558,chuxiaojie/NAFNet,gradio,mit,15
-1559,Gradio-Blocks/Leaderboard,gradio,,15
-1560,evaluate-metric/perplexity,gradio,,15
-1561,huggingface/library-metrics,gradio,mit,15
-1562,Gradio-Blocks/zero-and-few-shot-reasoning,gradio,mit,15
-1563,awacke1/TTS-STT-Blocks,gradio,mit,15
-1564,Pentameric/DalleClone,static,apache-2.0,15
-1565,belinghy/character-animation-motion-vaes,static,,15
-1566,baudm/PARSeq-OCR,gradio,apache-2.0,15
-1567,dhansmair/flamingo-mini-cap,gradio,mit,15
-1568,yuntian-deng/latex2im,gradio,mit,15
-1569,Hexii/Neural-Style-Transfer,gradio,mit,15
-1570,nightfury/Colorizer_Models,gradio,bsd-2-clause,15
-1571,Geonmo/laion-aesthetic-predictor,gradio,apache-2.0,15
-1572,SWHL/RapidOCRDemo,streamlit,apache-2.0,15
-1573,xu1998hz/sescore,gradio,,15
-1574,pyesonekyaw/faceforgerydetection,gradio,mit,15
-1575,akhaliq/Evel_Space,gradio,mit,15
-1576,beyond/genius,gradio,apache-2.0,15
-1577,carlgira/dreambooth-image-editor,gradio,,15
-1578,hf-accelerate/accelerate_examples,gradio,,15
-1579,lambdalabs/text-to-avatar,gradio,,15
-1580,bigcode/santacoder-search,gradio,apache-2.0,15
-1581,daspartho/MagicMix,gradio,apache-2.0,15
-1582,Hello-SimpleAI/chatgpt-detector-ling,gradio,apache-2.0,15
-1583,SmilingWolf/danbooru2022_image_similarity,gradio,,15
-1584,SUPERSHANKY/Finetuned_Diffusion_Max,gradio,mit,15
-1585,society-ethics/StableBias,gradio,cc-by-nc-sa-4.0,15
-1586,Noobian/PDF-QA,gradio,openrail,15
-1587,hysts/DDNM-HQ,gradio,cc-by-nc-sa-4.0,15
-1588,shigel/aiemo,gradio,,15
-1589,Xhaheen/Hyper_Bot_openai,static,,15
-1590,avid-ml/bias-detection,gradio,gpl-3.0,15
-1591,akdeniz27/pix2struct-DocVQA,gradio,mit,15
-1592,ParityError/Anime,gradio,apache-2.0,15
-1593,Manjushri/SD-2X-And-4X-CPU,gradio,,15
-1594,HuggingFaceH4/Falcon-vs-LLaMA,gradio,apache-2.0,15
-1595,IoMa/stable-diffusion-webui-cpu-the-best,gradio,,15
-1596,nasttam/Image-and-3D-Model-Creator,gradio,,15
-1597,Riksarkivet/htr_demo,docker,,15
-1598,mshukor/UnIVAL,gradio,apache-2.0,15
-1599,ibm-nasa-geospatial/Prithvi-100M-Burn-scars-demo,docker,apache-2.0,15
-1600,memef4rmer/llama2-7b-chat-uncensored-ggml,gradio,,15
-1601,hf4h/bio-chem-foundation-models,gradio,,15
-1602,nuttella/Otakumusic,docker,,15
-1603,elyza/ELYZA-japanese-Llama-2-7b-fast-instruct-demo,gradio,,15
-1604,BraydenMoore/a-random-unsecured-camera,docker,mit,15
-1605,giswqs/solara-maxar,docker,mit,15
-1606,ProteinDesignLab/protpardelle,gradio,mit,15
-1607,Illia56/Llama-2-voice,streamlit,mit,15
-1608,ngoctuanai/gpt4,docker,mit,15
-1609,tonyassi/image-story-teller,gradio,,15
-1610,coqui/ml-trivia,gradio,,15
-1611,ysharma/Zephyr-Playground,gradio,mit,15
-1612,LLMRiddles/LLMRiddles,gradio,apache-2.0,15
-1613,Pclanglais/MonadGPT,docker,apache-2.0,15
-1614,OOlajide/common-nlp-tasks,streamlit,,14
-1615,Vijish/Crop-CLIP,gradio,,14
-1616,akhaliq/bizarre-pose-estimator,gradio,,14
-1617,aliabd/Anime2Sketch,gradio,,14
-1618,autonomousvision/projected_gan,gradio,mit,14
-1619,edemgold/conversation-bot,gradio,,14
-1620,hshr/DeepFilterNet,gradio,apache-2.0,14
-1621,kingabzpro/savtadepth,gradio,mit,14
-1622,merve/GPT-2-story-gen,gradio,,14
-1623,SerdarHelli/Segmentation-of-Teeth-in-Panoramic-X-ray-Image-Using-U-Net,streamlit,,14
-1624,conciomith/RetinaFace_FaceDetector_Extractor,gradio,apache-2.0,14
-1625,brogelio/air_draw,gradio,,14
-1626,hackathon-pln-es/es_nlp_gender_neutralizer,gradio,,14
-1627,awacke1/Video-Summary,gradio,mit,14
-1628,dataroots/SofaStyler,streamlit,,14
-1629,StanfordAIMI/radiology_report_generation,gradio,mit,14
-1630,issam9/sumy_space,gradio,,14
-1631,evaluate-metric/accuracy,gradio,,14
-1632,nazneen/datasets-explorer,streamlit,apache-2.0,14
-1633,Gradio-Blocks/video_nca,gradio,mit,14
-1634,huggingface/HuggingDiscussions,static,afl-3.0,14
-1635,Pippoz/Hugging_Space,streamlit,,14
-1636,Gradio-Blocks/Object-Detection-With-DETR-and-YOLOS,gradio,,14
-1637,Gradio-Blocks/pokemon-move-generator-app,gradio,,14
-1638,Gradio-Blocks/pubmed-abstract-retriever,gradio,,14
-1639,bigscience/ethical-charter,static,,14
-1640,scikit-learn/baseline-trainer,gradio,apache-2.0,14
-1641,runa91/barc_gradio,gradio,,14
-1642,EuroPython2022/Scratchpad-w-BLOOM,gradio,,14
-1643,DeepLabCut/MegaDetector_DeepLabCut,gradio,,14
-1644,nickmuchi/DeepFace,gradio,,14
-1645,theodotus/ukrainian-voices,gradio,bsd-3-clause,14
-1646,Amrrs/podscript,gradio,mit,14
-1647,Rothfeld/textual-inversion-init-token,gradio,apache-2.0,14
-1648,ajayhk/colorize,gradio,mit,14
-1649,igashov/DiffLinker,gradio,mit,14
-1650,Xhaheen/meme_world,gradio,mit,14
-1651,skytnt/anime-aesthetic-predict,gradio,apache-2.0,14
-1652,lewtun/galactica-demo,gradio,apache-2.0,14
-1653,Manjushri/SDXL-1.0-Inpainting-CPU,gradio,mit,14
-1654,skytnt/waifu-gan,gradio,apache-2.0,14
-1655,tryolabs/blogpost-cqa,gradio,,14
-1656,hareshhecker/midjourney-v5,gradio,openrail,14
-1657,SerdarHelli/StyleSDF-3D,gradio,,14
-1658,speechbox/whisper-restore-punctuation,gradio,apache-2.0,14
-1659,argilla/argilla-template-space,docker,,14
-1660,shivi/mask2former-demo,gradio,apache-2.0,14
-1661,kazuk/youtube-whisper-00,gradio,unknown,14
-1662,argilla/argilla-streamlit-customs,streamlit,,14
-1663,to-be/invoice_document_headers_extraction_with_donut,gradio,,14
-1664,zeno-ml/diffusiondb,docker,mit,14
-1665,Thafx/Demucs_v4_2s_HT,gradio,,14
-1666,Dao3/DreamlikeArt-PhotoReal-2.0,gradio,,14
-1667,freddyaboulton/dracula_revamped,gradio,apache-2.0,14
-1668,Alpaca233/ChatPDF-GUI,gradio,,14
-1669,keras-dreambooth/dreambooth_diffusion_hokusai,gradio,creativeml-openrail-m,14
-1670,liujch1998/vera,gradio,cc-by-4.0,14
-1671,gstaff/xkcd,gradio,apache-2.0,14
-1672,JohnSmith9982/small_and_pretty,gradio,apache-2.0,14
-1673,merve/starter_pack_generator,gradio,apache-2.0,14
-1674,xswu/align_sd,gradio,cc-by-nc-nd-4.0,14
-1675,bethecloud/storj_theme,gradio,,14
-1676,Gradio-Themes/text2video2storj,gradio,,14
-1677,gyrojeff/YuzuMarker.FontDetection,docker,,14
-1678,autotrain-projects/autotrain-advanced,docker,,14
-1679,sanchit-gandhi/bark,gradio,cc-by-nc-4.0,14
-1680,nickmuchi/DocGPT,streamlit,,14
-1681,SimFG/LangChain-Zilliz-Cloud,gradio,apache-2.0,14
-1682,Xenos14/XenoEngine-SD-webui,docker,,14
-1683,huggingface-projects/huggingbots,gradio,other,14
-1684,ashrma/Chat-with-Docs,streamlit,mit,14
-1685,chansung/test-multi-conv,gradio,,14
-1686,AIGText/GlyphControl,gradio,mit,14
-1687,ayymen/Amazigh-tts,gradio,cc-by-4.0,14
-1688,Faridmaruf/rvc-Blue-archives,gradio,mit,14
-1689,ysharma/baichuan-7B,gradio,mit,14
-1690,ThomasSimonini/SmartRobot,static,,14
-1691,iitolstykh/age_gender_estimation_demo,gradio,apache-2.0,14
-1692,iamAI123/whisper_model_speech_to_text,gradio,apache-2.0,14
-1693,victor/SDXL-0.9,gradio,mit,14
-1694,mikeee/qwen-7b-chat,gradio,,14
-1695,librarian-bots/dataset-to-model-monitor,gradio,,14
-1696,kevinwang676/VALLE,gradio,mit,14
-1697,dylanebert/list-of-splats,static,,14
-1698,LeoLM/leo-hessianai-7b-chat,gradio,llama2,14
-1699,HusseinHE/psis,gradio,openrail,14
-1700,toshas/repainting_3d_assets,docker,cc-by-nc-sa-4.0,14
-1701,Illia56/llama-2-7b-chat,gradio,apache-2.0,14
-1702,AIatUIUC/CodeLATS,streamlit,mit,14
-1703,abidlabs/gradio-lite-classify,static,,14
-1704,mkrzyzan/face-swap,gradio,,14
-1705,52Hz/CMFNet_deblurring,gradio,,13
-1706,Harveenchadha/en_to_indic_translation,gradio,,13
-1707,Hellisotherpeople/Unsupervised_Extractive_Summarization,streamlit,,13
-1708,MrBodean/VoiceClone,gradio,,13
-1709,TitleGenerators/ArxivTitleGenerator,streamlit,,13
-1710,akhaliq/Detic,gradio,,13
-1711,akhaliq/Spleeter,gradio,,13
-1712,bertin-project/bertin,streamlit,,13
-1713,flax-community/koclip,streamlit,,13
-1714,hysts/Yet-Another-Anime-Segmenter,gradio,,13
-1715,hysts/anime-face-detector,gradio,,13
-1716,marshmellow77/contract-review,streamlit,,13
-1717,merve/KerasBERTv1,gradio,,13
-1718,mrm8488/GPT-J-6B,gradio,,13
-1719,team-writing-assistant/grammar-correction,streamlit,,13
-1720,team-zero-shot-nli/zero-shot-nli,streamlit,,13
-1721,hackathon-pln-es/readability-assessment-spanish,gradio,cc-by-nc-sa-4.0,13
-1722,hysts/StyleGAN3,gradio,,13
-1723,ybelkada/FocusOnDepth,gradio,,13
-1724,hysts/gan-control,gradio,,13
-1725,suvash/food-101-resnet50,gradio,,13
-1726,FrankAst/image_mixer,gradio,,13
-1727,osanseviero/hugging-gallery,gradio,,13
-1728,keras-io/Generating-molecular-graphs-by-WGAN-GP,gradio,apache-2.0,13
-1729,seduerr/personality,gradio,mit,13
-1730,CVPR/CVPR2022_papers,gradio,,13
-1731,sklearn-docs/classification,gradio,apache-2.0,13
-1732,keras-io/video-transformers,gradio,mit,13
-1733,tfwang/PITI-Synthesis,gradio,,13
-1734,fffiloni/stablediffusion-interpolation,gradio,,13
-1735,patrickvonplaten/vq-vs-stable-diffusion,gradio,,13
-1736,sayakpaul/video-classification-ucf101-subset,gradio,apache-2.0,13
-1737,manu/the-rap-god-test,gradio,openrail,13
-1738,myscale/object-detection-safari,streamlit,lgpl-3.0,13
-1739,Podtekatel/ArcaneSVK2,gradio,bsd-3-clause,13
-1740,pxiaoer/ChatGPT,gradio,apache-2.0,13
-1741,AlStable/AlPrompt,gradio,,13
-1742,Kamtera/Persian-tts-CoquiTTS,gradio,openrail,13
-1743,JavaFXpert/GPT-3.5-Table-inator,gradio,apache-2.0,13
-1744,sayakpaul/pokemon-sd-kerascv,gradio,apache-2.0,13
-1745,pinecone/openai-ml-qa,streamlit,,13
-1746,SpacesExamples/streamlit-docker-example,docker,,13
-1747,russellc/comparing-captioning-models,gradio,,13
-1748,Shad0ws/Voice_Cloning,gradio,mit,13
-1749,mindspore-ai/Wukong-Huahua,gradio,apache-2.0,13
-1750,kazuk/youtube-whisper-05,gradio,unknown,13
-1751,kazuk/youtube-whisper-07,gradio,unknown,13
-1752,hossay/image-to-sketch,gradio,,13
-1753,kadirnar/Anime4k,gradio,mit,13
-1754,katielink/compare-bio-llm,gradio,openrail,13
-1755,YazawaSunrise/so-vits-svc-LoveLive,gradio,cc-by-nc-3.0,13
-1756,kadirnar/Multilingual-Translation,gradio,mit,13
-1757,bluelu/Product-Photo-Analyzer,gradio,,13
-1758,ybelkada/detoxified-lms,gradio,openrail,13
-1759,zetabyte/text-to-voice,gradio,,13
-1760,ashhadahsan/whisperX,streamlit,,13
-1761,Jayabalambika/my-app-space,gradio,apache-2.0,13
-1762,librarian-bots/notebooks-on-the-hub,static,cc0-1.0,13
-1763,Rifd/ngees_doang,gradio,,13
-1764,Gradio-Themes/theme_builder,gradio,,13
-1765,zomehwh/sovits-tannhauser,gradio,mit,13
-1766,ysharma/whisper-diarization,gradio,,13
-1767,svdiff-library/SVDiff-Training-UI,gradio,mit,13
-1768,snpranav/karenai,gradio,,13
-1769,awacke1/ChatGPT-Memory-Chat-Story-Generator,streamlit,mit,13
-1770,ynhe/AskAnything,gradio,mit,13
-1771,fffiloni/video-to-sound-fx,gradio,,13
-1772,yenniejun/tokenizers-languages,streamlit,cc,13
-1773,huggingface-tools/text-to-video,gradio,,13
-1774,sabman/map-diffuser,gradio,,13
-1775,joaogante/assisted_generation_demo,gradio,,13
-1776,ludwigstumpp/llm-leaderboard,streamlit,,13
-1777,OpenGVLab/VideoChatGPT,gradio,mit,13
-1778,OpenGenAI/open-parti-prompts,gradio,,13
-1779,ennov8ion/comicbook-models,gradio,,13
-1780,nttdataspain/Image-To-Text-Lora-ViT,gradio,mit,13
-1781,alaa-lab/InstructCV,gradio,apache-2.0,13
-1782,tmaham/DS-Fusion-Express,gradio,,13
-1783,Xenova/ai-code-playground,static,,13
-1784,OpenGVLab/all-seeing,gradio,apache-2.0,13
-1785,bigcode/OctoCoder-Demo,gradio,bigcode-openrail-m,13
-1786,stabilityai/japanese-instructblip-alpha,gradio,other,13
-1787,FantasticGNU/AnomalyGPT,gradio,cc-by-sa-4.0,13
-1788,wffcyrus/falcon-180b-demo,gradio,,13
-1789,PY007/TinyLlama-Chat,gradio,,13
-1790,cncanon/chud,docker,,13
-1791,XzJosh/Nana7mi-Bert-VITS2,gradio,mit,13
-1792,AgentVerse/agentVerse,gradio,apache-2.0,13
-1793,KoboldAI/KoboldAI-Lite,static,agpl-3.0,13
-1794,enzostvs/hub-api-playground,docker,mit,13
-1795,Roboflow/webcamGPT,gradio,,13
-1796,sczhou/ProPainter,gradio,apache-2.0,13
-1797,NeuML/txtai,streamlit,,12
-1798,Norod78/Face2Doll,gradio,,12
-1799,Ron0420/EfficientNetV2_Deepfakes_Video_Detector,gradio,,12
-1800,ThomasSimonini/Chat-with-Gandalf-GPT-J6B,gradio,,12
-1801,ThomasSimonini/Stable-Baselines3,gradio,,12
-1802,Wootang01/text_generator,gradio,,12
-1803,aakashb95/paraphrase-sentences,streamlit,,12
-1804,abnerh/video-to-subs,gradio,,12
-1805,akhaliq/kogpt,gradio,,12
-1806,akhaliq/mlsd,gradio,,12
-1807,akhaliq/neural-waveshaping-synthesis,gradio,,12
-1808,akhaliq/openpose,gradio,,12
-1809,akhaliq/speechbrain-speech-seperation,gradio,,12
-1810,architext/Architext_deployed,gradio,,12
-1811,chuanenlin/pdf2preview,streamlit,,12
-1812,fcakyon/streamlit-image-comparison,streamlit,,12
-1813,flax-community/clip-reply-demo,streamlit,,12
-1814,julien-c/streamlit-cheatsheet,streamlit,,12
-1815,katanaml/table-query,gradio,,12
-1816,keras-io/question_answering,gradio,,12
-1817,peterbonnesoeur/pose_demo,gradio,,12
-1818,razakhan/text-summarizer,gradio,,12
-1819,speech-recognition-community-v2/FinalLeaderboard,streamlit,apache-2.0,12
-1820,tomofi/MMOCR,gradio,mit,12
-1821,tomofi/ABINet-OCR,gradio,mit,12
-1822,akhaliq/animeganv2-blocks,gradio,,12
-1823,hackathon-pln-es/sonnet-poetry-generator-spanish,gradio,,12
-1824,kmacdermid/RpgRoomGenerator,gradio,gpl-3.0,12
-1825,PaddlePaddle/U2Net,gradio,,12
-1826,cakiki/keyword-extraction,streamlit,apache-2.0,12
-1827,vivien/depth-aware-caption,streamlit,cc-by-4.0,12
-1828,awacke1/AI-MovieMaker-Comedy,gradio,mit,12
-1829,aryadytm/photo-low-light-enhance,streamlit,,12
-1830,Andy1621/uniformer_image_detection,gradio,mit,12
-1831,Gradio-Blocks/uniformer_image_segmentation,gradio,mit,12
-1832,ntranoslab/esm_variants,streamlit,cc-by-nc-4.0,12
-1833,Gradio-Blocks/Story-to-video,gradio,mit,12
-1834,CVPR/Bamboo_ViT-B16_demo,gradio,cc-by-4.0,12
-1835,hysts/AnimeGANv3_PortraitSketch,gradio,,12
-1836,nanom/syntactic_tree,gradio,,12
-1837,SIGGRAPH2022/DCT-Net,gradio,,12
-1838,mrdbourke/foodvision_big_video,gradio,mit,12
-1839,GIZ/SDSN-demo,streamlit,,12
-1840,Fia/StableDiffusionCPU,gradio,mit,12
-1841,mrm8488/OpenAI_Whisper_ASR,gradio,bigscience-bloom-rail-1.0,12
-1842,AIZ2H/Gradio331-3D-Models-AI-1,gradio,mit,12
-1843,ysharma/Voice-to-Youtube,gradio,mit,12
-1844,sensahin/YouWhisper,gradio,mit,12
-1845,beihai/Remove-Background-By-U2Net,gradio,mit,12
-1846,simonduerr/ProteinMPNNESM,gradio,mit,12
-1847,malteos/emnlp2022-papers,static,mit,12
-1848,akhaliq/Inkpunk-Diffusion,gradio,,12
-1849,AIML-TUDA/safe-stable-diffusion,gradio,creativeml-openrail-m,12
-1850,matttrent/stable-diffusion-image-variations-embeds,gradio,mit,12
-1851,cjayic/sovits-overwatch2,gradio,,12
-1852,triple-t/ttt-space,docker,,12
-1853,hwchase17/langchain-demo,gradio,apache-2.0,12
-1854,awacke1/CloneAnyVoice,gradio,,12
-1855,h2oai/h2o_wave_whisper,docker,,12
-1856,kazuk/youtube-whisper-02,gradio,unknown,12
-1857,kazuk/youtube-whisper-08,gradio,unknown,12
-1858,zomehwh/sovits-xiaoke,gradio,apache-2.0,12
-1859,sblumenf/PDF-text-extractor,gradio,apache-2.0,12
-1860,Eriberto/whisper-to-chatGPT,gradio,apache-2.0,12
-1861,sasha/Image_Upscaling_Restoration_Colorization,gradio,apache-2.0,12
-1862,deprem-ml/deprem_satellite_test,gradio,apache-2.0,12
-1863,pierreguillou/Inference-APP-Document-Understanding-at-paragraphlevel-v1,gradio,,12
-1864,abidlabs/ControlNet,gradio,,12
-1865,LaoCzi/YouTube_Summarize,gradio,cc,12
-1866,ysharma/Gradio-demo-streaming,gradio,mit,12
-1867,adt/models-table,gradio,apache-2.0,12
-1868,ahmedxeno/depth_estimation,gradio,,12
-1869,xuwenhao83/simple_chatbot,gradio,mit,12
-1870,xp3857/text-to-image,gradio,,12
-1871,JosefJilek/loliDiffusionSpace,gradio,,12
-1872,baixing/hackathon_chatbot_simple,gradio,cc-by-4.0,12
-1873,antonovmaxim/text-generation-webui-space,gradio,mit,12
-1874,coraKong/voice-cloning-demo,gradio,,12
-1875,NeuralInternet/ChatLLMs,gradio,,12
-1876,darienacosta/chatgpt-coverwhale,gradio,,12
-1877,josevalim/livebook,docker,,12
-1878,reach-vb/music-spectrogram-diffusion,gradio,,12
-1879,llamaindex/llama_index_vector_demo,streamlit,mit,12
-1880,rishiraj/GPT4All,gradio,apache-2.0,12
-1881,Kevin676/Voice-Cloning-with-Voice-Fixer,gradio,mit,12
-1882,oguzakif/video-object-remover,gradio,apache-2.0,12
-1883,junchenmo/OpenAI-Manager,static,bsd-3-clause,12
-1884,nigeljw/ViewDiffusion,gradio,openrail,12
-1885,srush/GPTWorld,gradio,,12
-1886,portal/guanaco-playground,static,,12
-1887,Searchium-ai/Video-Search,gradio,,12
-1888,davila7/try-gorilla,streamlit,mit,12
-1889,arbml/Ashaar,gradio,apache-2.0,12
-1890,MackDX/Neptunia,docker,,12
-1891,hysts/Kandinsky-2-2,gradio,mit,12
-1892,mike-ravkine/can-ai-code-compare,docker,mit,12
-1893,diffusers/sdxl-to-diffusers,gradio,mit,12
-1894,zamasam/hentai,docker,,12
-1895,xuqinyang/Baichuan-13B-Chat,gradio,,12
-1896,Open-Orca/OpenOrcaxOpenChat-Preview2-13B,gradio,,12
-1897,zej97/AI-Research-Assistant,gradio,,12
-1898,TeraTTS/TTS,gradio,mit,12
-1899,cummuniZm/kalfablyadki-sosut,docker,afl-3.0,12
-1900,chenxiYan/ChatHaruhi-OpenAI,gradio,,12
-1901,eson/tokenizer-arena,gradio,,12
-1902,SenY/GalGameUI,static,other,12
-1903,shivammehta25/Matcha-TTS,gradio,mit,12
-1904,nupurkmr9/concept-ablation,gradio,mit,12
-1905,XzJosh/LittleTaffy-Bert-VITS2,gradio,mit,12
-1906,r3gm/Advanced-RVC-Inference,gradio,mit,12
-1907,banana-dev/demo-illusion-diffusion-hq,gradio,,12
-1908,PIISA/PIISA_Demo,gradio,apache-2.0,12
-1909,openskyml/midjourney-mini,gradio,creativeml-openrail-m,12
-1910,AisingioroHao0/anime-fanwork,gradio,apache-2.0,12
-1911,52Hz/SRMNet_AWGN_denoising,gradio,,11
-1912,52Hz/SUNet_AWGN_denoising,gradio,,11
-1913,AmazonScience/QA-NLU,streamlit,,11
-1914,GroNLP/neural-acoustic-distance,streamlit,,11
-1915,KPatrick/PaddleSpeechASR,gradio,,11
-1916,PaddlePaddle/MiDaS_Large,gradio,,11
-1917,Wootang01/question_generator_three,gradio,,11
-1918,akhaliq/AnimeGANv1,gradio,,11
-1919,akhaliq/Speechbrain-Speech-enhancement,gradio,,11
-1920,akhaliq/mdetr,gradio,,11
-1921,bipin/multipurpose-ai,gradio,,11
-1922,marcelcastrobr/CLIP-image-search,gradio,,11
-1923,nbeuchat/actors_matching,gradio,,11
-1924,obsei/obsei-demo,streamlit,apache-2.0,11
-1925,reach-vb/asr-pyctcdecode,gradio,,11
-1926,savasy/SentimentHistogramForTurkish,gradio,,11
-1927,team-indain-image-caption/Hindi-image-captioning,gradio,,11
-1928,z-uo/monocular_depth_estimation,streamlit,,11
-1929,rowel/22k-image-classification,gradio,apache-2.0,11
-1930,Hellisotherpeople/Gadsby,streamlit,,11
-1931,Aanisha/Image_to_story,gradio,mit,11
-1932,StevenLimcorn/fastspeech2-TTS,gradio,,11
-1933,beihai/GFPGAN-V1.3-whole-image,gradio,,11
-1934,lukemelas/deep-spectral-segmentation,gradio,afl-3.0,11
-1935,ShivamShrirao/CLIP-Zero-Shot-Classifier,gradio,apache-2.0,11
-1936,awacke1/Zoom-Clip-Toon-Image-to-Image,gradio,mit,11
-1937,anakin87/who-killed-laura-palmer,streamlit,apache-2.0,11
-1938,gradio/question-answering,gradio,,11
-1939,evaluate-metric/code_eval,gradio,,11
-1940,rajistics/receipt_extractor,gradio,apache-2.0,11
-1941,Hila/RobustViT,gradio,mit,11
-1942,GoodStuff/Cool,static,apache-2.0,11
-1943,valurank/keyword_and_keyphrase_extraction,gradio,other,11
-1944,duchaba/120dog_breeds,gradio,mit,11
-1945,unity/ML-Agents-PushBlock,static,apache-2.0,11
-1946,chansung/segformer-tf-transformers,gradio,apache-2.0,11
-1947,skytnt/lyric-generator-ja,gradio,apache-2.0,11
-1948,taesiri/CLIPScore,gradio,mit,11
-1949,nateraw/video-to-sketch,gradio,mit,11
-1950,NAACL2022/GlobEnc,gradio,,11
-1951,g8a9/ferret,streamlit,mit,11
-1952,cmarkea/sentiment-analysis,streamlit,,11
-1953,mrdbourke/foodvision_mini,gradio,mit,11
-1954,gradio/depth_estimation,gradio,,11
-1955,schibsted/facial_expression_classifier,gradio,apache-2.0,11
-1956,fffiloni/scene-edit-detection,gradio,,11
-1957,PaddlePaddle/PP-OCRv3-ch,gradio,apache-2.0,11
-1958,osanseviero/TheMLGame,static,,11
-1959,Armandoliv/whisper-biomedical-ner,gradio,,11
-1960,chinhon/whisper_transcribe,gradio,,11
-1961,taskswithcode/salient-object-detection,streamlit,mit,11
-1962,spacerini/gaia,streamlit,,11
-1963,ClueAI/CLUE_AIGC,gradio,creativeml-openrail-m,11
-1964,Evel/Evel_Space,gradio,mit,11
-1965,BAAI/AltDiffusion-m9,gradio,creativeml-openrail-m,11
-1966,Sentdex/LookingGlassRGBD,gradio,mit,11
-1967,nakas/demucs_playground,gradio,,11
-1968,SankarSrin/image-matting-app,gradio,mit,11
-1969,pragnakalp/Question_Generation_T5,gradio,,11
-1970,RamAnanth1/prompt-extend-2,gradio,,11
-1971,binery/Table_Transformer_PaddleOCR,streamlit,,11
-1972,FredZhang7/paint-journey-demo,gradio,mit,11
-1973,deelerb/3dselfie,gradio,,11
-1974,akhaliq/webui-orangemixs,gradio,,11
-1975,kazuk/youtube-whisper,gradio,unknown,11
-1976,faisalhr1997/blip-image-captioning-space-large,gradio,bsd-3-clause,11
-1977,taesiri/CLIPSeg,gradio,,11
-1978,society-ethics/featured-spaces-submissions,gradio,gpl-3.0,11
-1979,ysharma/LangChain_GradioBot,gradio,mit,11
-1980,katielink/biogpt-qa-demo,gradio,mit,11
-1981,ChrisPreston/diff-svc_minato_aqua,gradio,mit,11
-1982,shubhajit07/dreamlike-photoreal-2.0,gradio,,11
-1983,fffiloni/x-decoder-video,gradio,,11
-1984,dotmet/chatgpt_webui,gradio,bsd-2-clause,11
-1985,wl-zhao/unipc_sdm,gradio,apache-2.0,11
-1986,GT4SD/multitask-text-and-chemistry-t5,gradio,,11
-1987,M52395239m/Image_Face_Upscale_Restoration-GFPGAN,gradio,apache-2.0,11
-1988,L0SG/BigVGAN,gradio,mit,11
-1989,Willder/chatgpt-streamlit,streamlit,,11
-1990,awacke1/Image-to-Text-Salesforce-blip-image-captioning-base,gradio,,11
-1991,RamAnanth1/roomGPT,gradio,mit,11
-1992,fffiloni/simple-animation-doodle,static,,11
-1993,zhangliwei7758/vits-uma-genshin-honkai,gradio,apache-2.0,11
-1994,yuan2023/Stable-Diffusion-ControlNet-WebUI,gradio,openrail,11
-1995,hohonu-vicml/DirectedDiffusion,gradio,mit,11
-1996,bigcode/near-deduplication,streamlit,mit,11
-1997,Hugorowan/image-to-video-film-2-og-by-kazuk,gradio,unknown,11
-1998,Kevin676/Voice-Cloning,gradio,mit,11
-1999,NKU-AMT/AMT,gradio,cc-by-nc-sa-4.0,11
-2000,keras-dreambooth/dreambooth-pug-ace,gradio,creativeml-openrail-m,11
-2001,zomehwh/vits-models-ow2,gradio,apache-2.0,11
-2002,kenjiqq/aesthetics-scorer,gradio,mit,11
-2003,kira4424/Tacotron-zero-short-voice-clone,gradio,mit,11
-2004,AIBoy1993/segment_anything_webui,gradio,,11
-2005,hackathon-somos-nlp-2023/T5unami-small-v1,gradio,,11
-2006,fengmuxi/ChatGpt-Web,docker,,11
-2007,StephanST/WALDOonline,streamlit,mit,11
-2008,rezaarmand/Perp-Neg,gradio,apache-2.0,11
-2009,dexxxed/remove-object-from-photo,streamlit,,11
-2010,MuhammadHanif/Stable-Diffusion-High-Resolution,gradio,,11
-2011,jurgendn/table-extraction,streamlit,,11
-2012,AiMimicry/sovits-models,gradio,mit,11
-2013,OFA-Sys/ONE-PEACE_Multimodal_Retrieval,static,apache-2.0,11
-2014,FrankZxShen/vits-fast-fineturning-models-ba,gradio,apache-2.0,11
-2015,JUNGU/talktosayno,gradio,openrail,11
-2016,CognitiveLabs/GPT-auto-webscraping,streamlit,mit,11
-2017,estusgroup/ai-qr-code-generator-beta-v2,gradio,cc-by-nc-nd-4.0,11
-2018,Ricecake123/RVC-demo,gradio,mit,11
-2019,allknowingroger/Image-Models-Test27,gradio,,11
-2020,coomdoomer/doomer-reverse-proxy,docker,,11
-2021,superdup95/su,docker,,11
-2022,JosephusCheung/LL7M-JS-Tokenizer,static,,11
-2023,Sentdex/StableBeluga-7B-Chat,gradio,apache-2.0,11
-2024,awacke1/PromptSuperHeroImageGenerator,gradio,,11
-2025,openskyml/pigeon-chat,gradio,,11
-2026,BasToTheMax/voicechange,gradio,mit,11
-2027,mishig/phind-wizardcoder-playground,gradio,,11
-2028,radames/TinyStories-Candle-Wasm-Magic,static,,11
-2029,4com/stable-diffusion,gradio,creativeml-openrail-m,11
-2030,Illia56/Code-Interpreter-Palm2,streamlit,mit,11
-2031,microsoft/LLMLingua,gradio,mit,11
-2032,juuxn/SimpleRVC,gradio,mit,11
-2033,PulsarAI/thebloke-quantized-models,gradio,,11
-2034,pseudolab/KOMUChat,gradio,mit,11
-2035,latent-consistency/lcm-LoraTheExplorer,gradio,mit,11
-2036,pseudolab/AI_Tutor_BERT,gradio,apache-2.0,11
-2037,52Hz/CMFNet_deraindrop,gradio,,10
-2038,AdamGustavsson/AnimeganV2Webcam,gradio,,10
-2039,Babelscape/rebel-demo,streamlit,,10
-2040,EXFINITE/BlenderBot-UI,gradio,apache-2.0,10
-2041,HridayKharpude/Tabla-Transcriber,gradio,afl-3.0,10
-2042,Kodiks/turkish-news-classification,gradio,,10
-2043,Narrativaai/GPT-J-6B-Demo,gradio,,10
-2044,Yassine/Stego,gradio,,10
-2045,abidlabs/The-Acquisition-Post-Generator,gradio,,10
-2046,akhaliq/Face_Mesh,gradio,,10
-2047,akhaliq/PAMA,gradio,,10
-2048,akhaliq/TensorFlowTTS,gradio,,10
-2049,akhaliq/midi-ddsp,gradio,,10
-2050,akhaliq/steerable-nafx,gradio,,10
-2051,bluebalam/paper-rec,gradio,mit,10
-2052,chinhon/News_Summarizer,gradio,,10
-2053,dnth/webdemo-fridge-detection,gradio,,10
-2054,facebook/xm_transformer_600m,gradio,mit,10
-2055,gradio/chatbot,gradio,,10
-2056,jkang/demo-artist-classifier,gradio,,10
-2057,mohitmayank/SummarizeLink,streamlit,,10
-2058,robinhad/ukrainian-stt,gradio,,10
-2059,samarthagarwal23/QuestionAnswering_on_annual_reports,gradio,,10
-2060,sunwaee/Perceiver-Multiclass-Emotion-Classification,streamlit,,10
-2061,team-ai-law-assistant/CUAD,streamlit,,10
-2062,vishnun/Colorify,gradio,,10
-2063,Theivaprakasham/layoutlmv2_invoice,gradio,apache-2.0,10
-2064,tomofi/CRAFT-TrOCR,gradio,,10
-2065,hackathon-pln-es/gastronomia_para_to2,gradio,,10
-2066,Shruhrid/Next_Word_Prediction,gradio,,10
-2067,huggan/projected_gan_art,gradio,,10
-2068,multimodalart/diffusion,gradio,mit,10
-2069,Gradio-Blocks/uniformer_video_demo,gradio,mit,10
-2070,Gradio-Blocks/Gradio_YOLOv5_Det,gradio,gpl-3.0,10
-2071,hysts/mmdetection,gradio,,10
-2072,keras-io/neural-style-transfer,gradio,apache-2.0,10
-2073,bigscience-data/corpus-map,streamlit,apache-2.0,10
-2074,simonduerr/metal3d,gradio,mit,10
-2075,doevent/background-remover,gradio,,10
-2076,jw2yang/unicl-img-recog-demo,gradio,mit,10
-2077,meeww/Minecraft_Skin_Generator,gradio,mit,10
-2078,chrisjay/mnist-adversarial,gradio,,10
-2079,robinhad/ukrainian-ai,gradio,,10
-2080,keras-io/Object-Detection-Using-RetinaNet,gradio,apache-2.0,10
-2081,flava/flava-multimodal-zero-shot,gradio,,10
-2082,ALM/CALM,streamlit,mit,10
-2083,sasha/BiasDetection,streamlit,cc-by-nc-sa-4.0,10
-2084,joaogante/tf_xla_generate_benchmarks,gradio,,10
-2085,TabPFN/TabPFNPrediction,gradio,,10
-2086,pcuenq/latent-diffusion-seed,gradio,apache-2.0,10
-2087,pritish/Image-Captioning,streamlit,,10
-2088,hank1996/yolopv2,gradio,,10
-2089,saadkiet/AI_Blog_generation_Powered_by_GPT_NEO_1.3B,gradio,,10
-2090,mkutarna/audiobook_gen,streamlit,mit,10
-2091,ysharma/ernie_vilg_english,gradio,gpl,10
-2092,ugaray96/neural-search,docker,,10
-2093,mareloraby/topic2poem,gradio,afl-3.0,10
-2094,gradio/image_segmentation,gradio,,10
-2095,schibsted/Facial_Recognition_with_Sentiment_Detector,gradio,apache-2.0,10
-2096,CjangCjengh/Sanskrit-TTS,gradio,gpl-3.0,10
-2097,mdnestor/media-downloader,gradio,,10
-2098,Samhita/geolocator,gradio,,10
-2099,johnslegers/stable-diffusion-1-5,gradio,mit,10
-2100,nateraw/music-visualizer,gradio,,10
-2101,ysharma/lets_make_meme,gradio,mit,10
-2102,osanseviero/esmfold,gradio,,10
-2103,livebook-dev/livebook,docker,,10
-2104,riccardogiorato/playground_diffusion,gradio,mit,10
-2105,alankabisov/youtube-video-summary,streamlit,,10
-2106,kevinszeto/stable-diffusion-animation,gradio,,10
-2107,tracinginsights/F1-analysis,streamlit,other,10
-2108,alibaba-pai/pai-diffusion-artist-xlarge-zh,gradio,mit,10
-2109,0x90e/ESRGAN-MANGA,gradio,,10
-2110,gblinc111/Intelligent-Photo-Blur-Using-Dichotomous-Image-Segmentation,gradio,mit,10
-2111,achterbrain/Intel-Generative-Image-Dashboard,streamlit,mit,10
-2112,Xhaheen/Lexica_prompt_search,gradio,,10
-2113,osanseviero/streamlit_1.15,streamlit,,10
-2114,Yusin/Speech-ChatGPT-Speech,gradio,apache-2.0,10
-2115,gojiteji/NAGISystem,gradio,,10
-2116,ItsJayQz/GTA5_Artwork_Diffusion,gradio,,10
-2117,rodolfoocampo/InfiniteStories,gradio,,10
-2118,lvwerra/hf-review,gradio,,10
-2119,Mahiruoshi/Lovelive-Nijigasaku-Chat-iSTFT-GPT3,gradio,other,10
-2120,nightfury/img2audio_video_prompt_tags,gradio,unknown,10
-2121,multimodalart/finetuned-text-to-music,gradio,,10
-2122,awacke1/Webcam-Object-Recognition-Yolo-n-Coco,gradio,,10
-2123,hra/chatgpt-stock-news-snapshots,gradio,cc-by-4.0,10
-2124,juliensimon/table_questions,gradio,,10
-2125,kazuk/youtube-whisper-09,gradio,unknown,10
-2126,tornadoslims/instruct-pix2pix,gradio,,10
-2127,decodemai/chatgpt_prompts,gradio,cc-by-nc-nd-4.0,10
-2128,bigcode/santa-explains-code,gradio,apache-2.0,10
-2129,kadirnar/AnimeSR,gradio,apache-2.0,10
-2130,society-ethics/Average_diffusion_faces,gradio,,10
-2131,leave7/kazunaAI2.0,gradio,,10
-2132,gaspar-avit/Movie_Poster_Generator,streamlit,gpl-3.0,10
-2133,CobaltZvc/Docs_Buddy,streamlit,,10
-2134,HuggingFaceH4/chatty-lms-old,gradio,apache-2.0,10
-2135,nikitalokhmachev-ai/line-art-colorization,gradio,,10
-2136,demo-crafters/leaderboard,gradio,apache-2.0,10
-2137,Manjushri/Instruct-Pix-2-Pix,gradio,mit,10
-2138,davila7/youtubegpt,streamlit,mit,10
-2139,Manjushri/OJ-V4-CPU,gradio,mit,10
-2140,RamAnanth1/Video2Video-models,gradio,,10
-2141,lukestanley/streaming_chat_with_gpt-3.5-turbo_using_langchain_sorta,gradio,mit,10
-2142,AIML-TUDA/does-clip-know-my-face,gradio,cc-by-sa-4.0,10
-2143,jackculpan/chatwebpage.com,gradio,,10
-2144,luongphamit/DreamShaper-webui,gradio,,10
-2145,ZeroTech/ChatGPT,gradio,,10
-2146,orpatashnik/local-prompt-mixing,gradio,mit,10
-2147,zomehwh/sovits-goldship,gradio,mit,10
-2148,llamaindex/llama_index_term_definition_demo,streamlit,mit,10
-2149,huggingfacejs/streaming-text-generation,static,mit,10
-2150,WorldlineChanger/sayashi-vits-uma-genshin-honkai,gradio,apache-2.0,10
-2151,rockeycoss/Prompt-Segment-Anything-Demo,gradio,apache-2.0,10
-2152,sasha/find-my-pedro,gradio,apache-2.0,10
-2153,sklearn-docs/MLP-Regularization,gradio,,10
-2154,Kevin676/Raven-with-Voice-Cloning-2.0,gradio,mit,10
-2155,character-aware-diffusion/charred,gradio,cc-by-sa-4.0,10
-2156,TencentARC/VLog,gradio,apache-2.0,10
-2157,kevinwang676/Bark-New-Version,gradio,mit,10
-2158,huggingface-tools/text-to-image,gradio,,10
-2159,ulasdilek/gpt_claude_dialogue,gradio,mit,10
-2160,kevinwang676/rvc-models-new,gradio,mit,10
-2161,kevinwang676/web-singer-2,docker,,10
-2162,SeViLA/SeViLA,gradio,,10
-2163,aaronb/DragGAN,gradio,,10
-2164,giswqs/solara-geospatial,docker,mit,10
-2165,stanfordnlp/Backpack-Demo,gradio,,10
-2166,yuhangzang/ContextDet-Demo,gradio,,10
-2167,FrankZxShen/so-vits-svc-models-pcr,gradio,apache-2.0,10
-2168,Aki004/herta-so-vits,gradio,bsd,10
-2169,ygtxr1997/ReliableSwap_Demo,gradio,afl-3.0,10
-2170,blanchon/qrcode-diffusion,gradio,,10
-2171,silk-road/ChatHaruhi,gradio,apache-2.0,10
-2172,PSLD/PSLD,gradio,bigscience-openrail-m,10
-2173,xnetba/text2image,gradio,,10
-2174,smangrul/peft-codegen25,gradio,mit,10
-2175,EmilyBrat/ATF,docker,,10
-2176,kevinwang676/SadTalker,gradio,mit,10
-2177,hsdcs/bingchat,docker,mit,10
-2178,foduucom/table-extraction-yolov8,gradio,,10
-2179,Yntec/DreamAnything,gradio,,10
-2180,kevinwang676/VoiceChanger,gradio,mit,10
-2181,foduucom/CandleStickScan-Stock-trading-yolov8,gradio,,10
-2182,Logspace/LangflowView,docker,mit,10
-2183,pankajmathur/psmathur-orca_mini_v3_7b,gradio,apache-2.0,10
-2184,ntt123/Vietnam-male-voice-TTS,gradio,cc-by-sa-4.0,10
-2185,multimodalart/civitai-to-hf,gradio,mit,10
-2186,gorilla-llm/gorilla-demo,gradio,apache-2.0,10
-2187,jbilcke-hf/observer,docker,,10
-2188,optimum/optimum-benchmark-ui,gradio,,10
-2189,eaglelandsonce/simplevectorization,streamlit,,10
-2190,artificialguybr/instagraph-gradio,gradio,,10
-2191,SmileyTatsu/Smile,docker,,10
-2192,Wauplin/gradio-user-history,gradio,,10
-2193,limcheekin/Mistral-7B-OpenOrca-GGUF,docker,,10
-2194,etri-vilab/Ko-LLaVA,static,apache-2.0,10
-2195,pseudolab/Balanced-News-Reading,gradio,apache-2.0,10
-2196,lavita/medical-question-answering-datasets,gradio,,10
-2197,radames/Candle-BLIP-Image-Captioning,static,,10
-2198,ylacombe/accessible-mistral,gradio,,10
-2199,yuntian-deng/ChatGPT4Turbo,gradio,mit,10
-2200,Sangmin/OpenAI_TTS,gradio,mit,10
-2201,solara-dev/wanderlust,docker,mit,10
-2202,freddyaboulton/gradio_pdf,docker,apache-2.0,10
-2203,latent-consistency/lcm-lora-for-sdxl,gradio,,10
-2204,pseudolab/SonGPT,streamlit,mit,10
-2205,Giuliano/Conversational-Datasets,gradio,,9
-2206,JLD/clip-image-search,gradio,,9
-2207,jiangjiechen/loren-fact-checking,gradio,,9
-2208,NimaBoscarino/aot-gan-inpainting,streamlit,,9
-2209,abhilash1910/CartoonGAN,gradio,,9
-2210,abidlabs/vision-transformer,gradio,,9
-2211,akhaliq/VideoGPT,gradio,,9
-2212,akhaliq/deepface,gradio,,9
-2213,ck46/qg-qa,streamlit,,9
-2214,coolspaces/windows3.1,static,,9
-2215,edugp/perplexity-lenses,streamlit,,9
-2216,filio/animate,gradio,apache-2.0,9
-2217,jerryyan21/wav2lip_demo_test,gradio,,9
-2218,kaushalya/medclip-roco,streamlit,,9
-2219,mrm8488/summarizer_mlsum,gradio,,9
-2220,nateraw/dino-clips,gradio,,9
-2221,osanseviero/Apocalyptify_webcam,gradio,,9
-2222,radames/NYTimes-homepage-rearranged,gradio,,9
-2223,ucinlp/autoprompt,streamlit,,9
-2224,umichVision/virtex-redcaps,streamlit,,9
-2225,xvjiarui/GroupViT,gradio,,9
-2226,osanseviero/6DRepNet,gradio,mit,9
-2227,EdBianchi/JustMovie,streamlit,gpl-3.0,9
-2228,Sultannn/YOLOX-Demo,gradio,apache-2.0,9
-2229,poccio/ExtEnD,streamlit,cc-by-nc-sa-4.0,9
-2230,navervision/KELIP,gradio,,9
-2231,hackathon-pln-es/DemoAcosoTwitter,gradio,apache-2.0,9
-2232,nazneen/interactive-model-cards,streamlit,,9
-2233,awacke1/MusicMaker,gradio,mit,9
-2234,hysts/StyleGAN2,gradio,,9
-2235,templates/flask,gradio,mit,9
-2236,hysts/CelebAMask-HQ-Face-Parsing,gradio,,9
-2237,huggan/crypto-gan,gradio,,9
-2238,huggan/night2day,gradio,,9
-2239,hysts/mediapipe-face-mesh,gradio,,9
-2240,brentspell/hifi-gan-bwe,gradio,mit,9
-2241,multimodalart/styleganxlclip,gradio,mit,9
-2242,pplonski/interactive-presentation,gradio,mit,9
-2243,emilylearning/causing_gender_pronouns,gradio,,9
-2244,pie/Joint-NER-and-Relation-Extraction,gradio,,9
-2245,dbuscombe/SatelliteSuperResolution,gradio,mit,9
-2246,mfrashad/CharacterGAN,gradio,cc-by-nc-4.0,9
-2247,Gradio-Blocks/magnificento,gradio,,9
-2248,evaluate-metric/cer,gradio,,9
-2249,evaluate-metric/chrf,gradio,,9
-2250,Gradio-Blocks/uniformer_image_detection,gradio,mit,9
-2251,codeparrot/incoder-subspace,gradio,,9
-2252,Gradio-Blocks/Hip_Hop_gRadio,gradio,,9
-2253,kleinay/qasem-demo,gradio,apache-2.0,9
-2254,Gradio-Blocks/gen-code-comparer,gradio,,9
-2255,CVPR/Leaderboard,gradio,,9
-2256,Spjkjlkkklj/dalle,static,,9
-2257,CVPR/GroupViT,gradio,,9
-2258,GooglyBlox/DalleFork,static,mit,9
-2259,CVPR/SPOTER_Sign_Language_Recognition,gradio,,9
-2260,sasha/WinoBiasCheck,streamlit,cc-by-nc-4.0,9
-2261,unity/ML-Agents-Walker,static,apache-2.0,9
-2262,keras-io/denoising-diffusion-implicit-models,gradio,apache-2.0,9
-2263,NAACL2022/papers,gradio,,9
-2264,mrm8488/bloom-spanish-prompts,gradio,wtfpl,9
-2265,codeparrot/code-explainer,gradio,apache-2.0,9
-2266,fusing/celeba-diffusion,gradio,mit,9
-2267,cffl/Exploring_Intelligent_Writing_Assistance,streamlit,apache-2.0,9
-2268,Zengyf-CVer/FaceRecognition,gradio,gpl-3.0,9
-2269,nev/CoNR,gradio,mit,9
-2270,RoCobo/WiggleGAN,gradio,,9
-2271,hasibzunair/fifa-tryon-demo,gradio,afl-3.0,9
-2272,abdulmeLINK/programmer-bloom,gradio,,9
-2273,ccolas/TastyPiano,streamlit,,9
-2274,gradio/timeseries-forecasting-with-prophet,gradio,,9
-2275,Accel/media-converter,gradio,mit,9
-2276,lambdalabs/LambdaSuperRes,gradio,,9
-2277,pythiccoder/FastCoref,gradio,mit,9
-2278,wenet/wespeaker_demo,gradio,apache-2.0,9
-2279,HaloMaster/chinesesummary,gradio,,9
-2280,FelixLuoX/codeformer,gradio,,9
-2281,doevent/colorizator,gradio,openrail,9
-2282,vict0rsch/climateGAN,gradio,gpl-3.0,9
-2283,jinhybr/OCR-LayoutLM-v3-Document-Parser,gradio,,9
-2284,NCSOFT/harim_plus,gradio,,9
-2285,akhaliq/hassanblend1.4,gradio,,9
-2286,yo2266911/DeepDanbooru_string,gradio,,9
-2287,bofenghuang/whisper-demo-french,gradio,,9
-2288,SpacesExamples/fastapi_dummy,docker,,9
-2289,wavymulder/Analog-Diffusion,gradio,,9
-2290,JavaFXpert/NimGPT-3.5,gradio,apache-2.0,9
-2291,wdcqc/wfd,gradio,creativeml-openrail-m,9
-2292,Sakukaze/VITS-Umamusume-voice-synthesizer,gradio,,9
-2293,akhooli/poetry2023,gradio,,9
-2294,syedusama5556/Real-ESRGAN-Demo,gradio,,9
-2295,Miuzarte/SUI-svc-3.0,gradio,,9
-2296,dromerosm/gpt-info-extraction,gradio,,9
-2297,TheWolf/Image-Upscaling-Playground,gradio,apache-2.0,9
-2298,radames/whisper.cpp-wasm,static,,9
-2299,kazuk/youtube-whisper-01,gradio,unknown,9
-2300,decodemai/devils_advocate,gradio,cc-by-nc-nd-4.0,9
-2301,bigbio/dataset-explore,streamlit,,9
-2302,thoucentric/Big-Five-Personality-Traits-Detection,gradio,,9
-2303,Denliner/wd-v1-4-tags,gradio,,9
-2304,BilalSardar/Lyrics-Text_to_music,gradio,,9
-2305,Wauplin/pynecone-on-spaces-template,docker,mit,9
-2306,juliensimon/bridgetower-video-search,gradio,,9
-2307,nikitalokhmachev-ai/interior-semantic-segmentation,gradio,,9
-2308,SerdarHelli/Pix2Pix3D,gradio,,9
-2309,pedrogengo/pixel_art,streamlit,,9
-2310,lhoestq/datasets-explorer,gradio,,9
-2311,WitchHuntTV/WinnieThePoohSVC_sovits4,gradio,mit,9
-2312,asescodes/midjourney-prompt-generator-using-chatgpt,gradio,other,9
-2313,fffiloni/controlnet-animation-doodle,docker,mit,9
-2314,yuan2023/stable-diffusion-webui-controlnet-docker,docker,,9
-2315,JacobLinCool/tiktoken-calculator,gradio,,9
-2316,Wauplin/bloomz.cpp-converter,docker,,9
-2317,keras-dreambooth/dreambooth-diffusion-akita-dog,gradio,creativeml-openrail-m,9
-2318,nlphuji/whoops-explorer-full,gradio,,9
-2319,SamiKoen/ChatGPT444,gradio,mit,9
-2320,lxe/lora-cerebras-gpt2.7b-alpaca-shortprompt,gradio,apache-2.0,9
-2321,chatarena/chatarena-demo,gradio,apache-2.0,9
-2322,hackathon-somos-nlp-2023/GIPBERT,gradio,,9
-2323,chomakov/GPT-4_PDF_summary,docker,creativeml-openrail-m,9
-2324,ochyai/alo,gradio,,9
-2325,qingxu98/academic-chatgpt-beta,gradio,,9
-2326,dylanebert/UnityDemo,static,apache-2.0,9
-2327,ORI-Muchim/BlueArchiveTTS,gradio,mit,9
-2328,gradio/chatbot_streaming,gradio,,9
-2329,Layer6/TR0N,gradio,apache-2.0,9
-2330,deepghs/anime_object_detection,gradio,mit,9
-2331,Phips/upscale_demo,gradio,,9
-2332,zeno-ml/chatbot-report,docker,mit,9
-2333,Make-A-Protagonist/Make-A-Protagonist-inference,docker,apache-2.0,9
-2334,EduardoPacheco/DINOv2-Features-Visualization,gradio,,9
-2335,NMEX/rvc-hoyo-game,gradio,mit,9
-2336,Salavat/Interslavic-Translator-NLLB200,gradio,,9
-2337,IDEA-CCNL/Ziya-v1,gradio,apache-2.0,9
-2338,awacke1/ChatGPT-Streamlit-2,streamlit,mit,9
-2339,dpc/mmstts,gradio,,9
-2340,c-s-ale/ArxivChainLitDemo,docker,openrail,9
-2341,imseldrith/Imagine,gradio,cc,9
-2342,leonelhs/faceshine,gradio,mit,9
-2343,safetensors/convert_large,gradio,apache-2.0,9
-2344,thesven/image-to-story,streamlit,,9
-2345,fun-research/FC-CLIP,gradio,,9
-2346,NeonLion92/nsfw-c0ffees-erotic-story-generator2,gradio,,9
-2347,wildoctopus/cloth-segmentation,gradio,mit,9
-2348,jbilcke-hf/VideoChain-API,docker,,9
-2349,CoreyMorris/MMLU-by-task-Leaderboard,streamlit,,9
-2350,FFusion/FFusionXL-SDXL-DEMO,gradio,other,9
-2351,0xSynapse/PixelFusion,gradio,gpl-3.0,9
-2352,Hazem/Image_Face_Upscale_Restoration-GFPGAN,gradio,apache-2.0,9
-2353,diffle/sd-xl,gradio,creativeml-openrail-m,9
-2354,Shizune/neko-proxy,docker,,9
-2355,HuggingFaceM4/OBELICS-Interactive-Map,static,,9
-2356,Gen-Sim/Gen-Sim,gradio,apache-2.0,9
-2357,kneelesh48/Tesseract-OCR,gradio,,9
-2358,ntt123/Vietnam-female-voice-TTS,gradio,cc-by-sa-4.0,9
-2359,trl-lib/trl-text-environment,gradio,,9
-2360,qingxu98/grobid,docker,apache-2.0,9
-2361,InstaDeepAI/nucleotide_transformer_benchmark,gradio,,9
-2362,techasad/midjourney-lite,gradio,openrail,9
-2363,Illia56/book-mind-ai,gradio,mit,9
-2364,mingyuan/ReMoDiffuse,gradio,mit,9
-2365,zenafey/prodia-studio,gradio,,9
-2366,naver-ai/DenseDiffusion,gradio,mit,9
-2367,Latryna/roop,gradio,agpl-3.0,9
-2368,eaglelandsonce/loglinecreator,streamlit,,9
-2369,mrm8488/xtts-spanish,gradio,,9
-2370,radames/Candle-BERT-Semantic-Similarity-Wasm,static,,9
-2371,kirp/tinyllama-chat,gradio,,9
-2372,XzJosh/LAPLACE-Bert-VITS2,gradio,mit,9
-2373,derek-thomas/arabic-RAG,gradio,apache-2.0,9
-2374,MultiTransformer/autogen-tutorials,static,mit,9
-2375,Wataru/Miipher,gradio,cc-by-nc-2.0,9
-2376,XzJosh/otto-Bert-VITS2,gradio,mit,9
-2377,hysts/mistral-7b,gradio,mit,9
-2378,XzJosh/Eileen-Bert-VITS2,gradio,mit,9
-2379,ilumine-AI/AI-3D-Explorable-Video,static,,9
-2380,library-samples/zephyr-7b,gradio,mit,9
-2381,enzostvs/stable-diffusion-tpu,docker,mit,9
-2382,pseudolab/KorLearnGame,gradio,apache-2.0,9
-2383,limcheekin/zephyr-7B-beta-GGUF,docker,,9
-2384,limcheekin/openchat_3.5-GGUF,docker,,9
-2385,TeamTonic/MultiMed,gradio,mit,9
-2386,KoboldAI/Koboldcpp-Tiefighter,docker,agpl-3.0,9
-2387,pseudolab/interviewer_chat,gradio,apache-2.0,9
-2388,fiz2/cloudy,docker,,9
-2389,BigSalmon/Paraphrase,streamlit,,8
-2390,DrishtiSharma/Text-to-Image-search-using-CLIP,gradio,,8
-2391,Emanuel/twitter-emotions-demo,gradio,,8
-2392,GEM/DatasetCardForm,streamlit,,8
-2393,Harveenchadha/hindi-speech-recognition-vakyansh-wav2vec2,gradio,,8
-2394,Hellisotherpeople/Interpretable_Text_Classification_And_Clustering,streamlit,,8
-2395,Huertas97/Inpaint_Me,streamlit,apache-2.0,8
-2396,MTTR/MTTR-Referring-Video-Object-Segmentation,gradio,,8
-2397,Norod78/Dragness,gradio,,8
-2398,Rules99/YouRadiologist,streamlit,,8
-2399,Wootang01/next_sentence,gradio,,8
-2400,abidlabs/Echocardiogram-Segmentation,gradio,,8
-2401,abidlabs/chatbot-minimal,gradio,apache-2.0,8
-2402,akhaliq/SOAT,gradio,,8
-2403,akhaliq/SpecVQGAN_Neural_Audio_Codec,gradio,,8
-2404,akhaliq/TokenCut,gradio,,8
-2405,akhaliq/animeganv2-onnx,gradio,,8
-2406,anuragshas/restore-punctuation-demo,streamlit,,8
-2407,cahya/persona-chatbot,streamlit,,8
-2408,chinhon/fake_tweet_detector,gradio,,8
-2409,chinhon/headline_writer,gradio,,8
-2410,docs-demos/gpt2,gradio,,8
-2411,durgaamma2005/fire_detector,gradio,,8
-2412,ehcalabres/EMOVoice,streamlit,,8
-2413,ethzanalytics/gpt2-xl-conversational,gradio,apache-2.0,8
-2414,hgrif/rhyme-with-ai,streamlit,,8
-2415,hysts/bizarre-pose-estimator-tagger,gradio,,8
-2416,jsylee/adverse-drug-reactions-ner,gradio,,8
-2417,keras-io/super-resolution,gradio,mit,8
-2418,moflo/nftGAN,gradio,,8
-2419,nateraw/detr-object-detection,streamlit,,8
-2420,osanseviero/Neural_Image_Colorizer,streamlit,,8
-2421,pritamdeka/health-article-keyphrase-generator,gradio,,8
-2422,simayhosmeyve/Image_Enhancement,gradio,,8
-2423,team-language-detector/LanguageDetector,gradio,,8
-2424,valhalla/XGLM-zero-shot-COPA,gradio,,8
-2425,vishnun/CRAFT-OCR,gradio,,8
-2426,ysharma/TranslateQuotesInImageForwards,gradio,,8
-2427,zihaoz96/shark-classifier,gradio,,8
-2428,dariush-bahrami/color_transfer,streamlit,gpl-3.0,8
-2429,vobecant/DaS,gradio,mit,8
-2430,hysts/StyleSwin,gradio,,8
-2431,katanaml/LayoutLMv2-CORD,gradio,apache-2.0,8
-2432,52Hz/SRMNet_thesis,gradio,apache-2.0,8
-2433,ANDRYHA/FakeNewsClassifier,streamlit,mit,8
-2434,johnowhitaker/waterface,gradio,cc-by-4.0,8
-2435,osanseviero/llama-leaderboard,streamlit,,8
-2436,ybelkada/interfacegan_pp,gradio,mit,8
-2437,SIGGRAPH2022/Self-Distilled-StyleGAN,gradio,,8
-2438,hysts/insightface-SCRFD,gradio,,8
-2439,hysts/mediapipe-face-detection,gradio,,8
-2440,cakiki/tensorflow-coder,streamlit,apache-2.0,8
-2441,edaiofficial/mmtafrica,gradio,,8
-2442,AlekseyKorshuk/accompaniment-generator,streamlit,apache-2.0,8
-2443,evaluate-metric/sacrebleu,gradio,,8
-2444,evaluate-metric/bleurt,gradio,,8
-2445,evaluate-metric/squad,gradio,,8
-2446,versae/gradio-blocks-rest-api,gradio,apache-2.0,8
-2447,valurank/keyword-extraction-demo,streamlit,other,8
-2448,Gradio-Blocks/Anime-BigGAN,gradio,mit,8
-2449,codeparrot/codeparrot-subspace,gradio,,8
-2450,Gradio-Blocks/stylish_ape,gradio,,8
-2451,Himanshi/Face-Cartoonify-for-Video-Call-Privacy,gradio,,8
-2452,bigscience/data_host_provider_agreement,static,apache-2.0,8
-2453,Gradio-Blocks/Alexa-NLU-Clone,gradio,cc-by-4.0,8
-2454,jho/MonocularDepth,streamlit,,8
-2455,awacke1/SimPhysics,static,,8
-2456,aaronespasa/deepfake-detection,gradio,apache-2.0,8
-2457,jeremyrmanning/multitext-to-video,gradio,mit,8
-2458,misterbrainley/generate_dnd_images,gradio,afl-3.0,8
-2459,CVPR/VizWiz-CLIP-VQA,gradio,,8
-2460,cye/dalle-mini,static,apache-2.0,8
-2461,temandata/ecommurz-talent-search-engine,streamlit,,8
-2462,CVPR/Object-Detection-With-DETR-and-YOLOS,gradio,apache-2.0,8
-2463,hugginglearners/Paddy-Doctor,gradio,,8
-2464,unity/ML-Agents-Worm,static,apache-2.0,8
-2465,julien-c/push-model-from-web,static,apache-2.0,8
-2466,keras-io/dual-encoder-image-search,gradio,apache-2.0,8
-2467,hugginglearners/Multi-Object-Classification,gradio,apache-2.0,8
-2468,hugginglearners/image-style-transfer,gradio,apache-2.0,8
-2469,EuroPython2022/pulsar-clip,gradio,agpl-3.0,8
-2470,awsaf49/gcvit-tf,gradio,apache-2.0,8
-2471,Kameswara/TextToVideo,gradio,apache-2.0,8
-2472,NSC9/Artificial_Calculus_Teacher,gradio,mit,8
-2473,ali-ghamdan/colorizer,gradio,,8
-2474,sidharthism/fashion-eye-try-on-demo,gradio,,8
-2475,osanseviero/VNext,gradio,apache-2.0,8
-2476,ryanj/clothing_recommender,gradio,mit,8
-2477,innat/Google-MediaPipe,gradio,,8
-2478,dhansmair/flamingo-tiny-cap,gradio,mit,8
-2479,Curranj/FlowerDiffusion,gradio,,8
-2480,emilylearning/llm_uncertainty,gradio,mit,8
-2481,wenet/wenet_demo,gradio,apache-2.0,8
-2482,mareloraby/meter2poem-1,gradio,afl-3.0,8
-2483,taskswithcode/semantic_similarity,streamlit,mit,8
-2484,gradio/webcam,gradio,,8
-2485,oconnoob/audio-intelligence-dashboard,gradio,,8
-2486,open-source-metrics/repository-statistics,gradio,,8
-2487,BatuhanYilmaz/Youtube-Transcriber,streamlit,,8
-2488,nightfury/Image-Colorization,gradio,mit,8
-2489,emilyalsentzer/SHEPHERD,gradio,,8
-2490,mjdolan/Holiday-StyleGAN-NADA,gradio,mit,8
-2491,pierreguillou/question-answering-portuguese-with-BetterTransformer,gradio,,8
-2492,Tahsin-Mayeesha/Bangla-Question-Generation,gradio,,8
-2493,abhijitguha/chatbot_gpt3,gradio,,8
-2494,AI-DHD/Youtube-Whisperer,gradio,,8
-2495,Matthijs/image2reverb,gradio,mit,8
-2496,biodatlab/whisper-thai-demo,gradio,,8
-2497,bayartsogt/whisper-demo-mongolian,gradio,,8
-2498,Jumon/whisper-zero-shot-audio-classification,gradio,mit,8
-2499,patrickvonplaten/convert,gradio,apache-2.0,8
-2500,camenduru-com/webui-api,docker,,8
-2501,fffiloni/audio-to-spectrogram,gradio,,8
-2502,mohitmayank/sentenceviz,streamlit,other,8
-2503,aimstack/aim,docker,other,8
-2504,whisper-event/winners,streamlit,,8
-2505,whisper-event/leaderboard,streamlit,,8
-2506,wavymulder/portraitplus,gradio,,8
-2507,spiritupbro/text-to-3D,gradio,,8
-2508,joeddav/zero-shot-demo,streamlit,mit,8
-2509,ThomasSimonini/ML-Agents-SnowballTarget,static,,8
-2510,EDGAhab/VITS-Aatrox-AI,gradio,,8
-2511,hjs8/CogVideo,gradio,,8
-2512,Wryley1234/textual-inversion-training,gradio,apache-2.0,8
-2513,deepghs/auto_image_censor,gradio,mit,8
-2514,radames/instruct-pix2pix,gradio,mit,8
-2515,myscale/Protein-Structure-Modeling,streamlit,,8
-2516,theintuitiveye/HARDblend,gradio,,8
-2517,mano96/content_rewrite,gradio,,8
-2518,sohojoe/soho-clip-embeddings-explorer,gradio,mit,8
-2519,sayakpaul/evaluate-sd-schedulers,gradio,apache-2.0,8
-2520,WiNE-iNEFF/HF_Simple_Prompt_Generator,gradio,,8
-2521,johnnygreco/the-gpt-who-lived,gradio,mit,8
-2522,asim266/image-background-remover,gradio,mit,8
-2523,Mileena/PIFu-Clothed-Human-Digitization,gradio,,8
-2524,user238921933/stable-diffusion-webui,gradio,,8
-2525,taesiri/ChatGPT-ImageCaptioner,gradio,,8
-2526,lint/anime_controlnet,gradio,openrail,8
-2527,Vastness0813/decapoda-research-llama-65b-hf,gradio,,8
-2528,hwberry2/WhisperDemo,gradio,,8
-2529,CactiStaccingCrane/OpenAssistant-oasst-sft-1-pythia-12b,gradio,,8
-2530,salahIguiliz/ControlLogoNet,gradio,,8
-2531,radames/gradio-request-get-client-ip,gradio,,8
-2532,baixing/hackathon_test,gradio,cc-by-4.0,8
-2533,Xhaheen/chatgpt_meme_world_,gradio,mit,8
-2534,Sortoite/PDFChatGpt,gradio,afl-3.0,8
-2535,gradio/monochrome,gradio,apache-2.0,8
-2536,ljsabc/Fujisaki,gradio,mit,8
-2537,abidlabs/cinemascope,gradio,,8
-2538,ja-818/speech_and_text_emotion_recognition,gradio,,8
-2539,abidlabs/twitter-scorer,gradio,,8
-2540,zomehwh/sovits-rudolf,gradio,mit,8
-2541,adhisetiawan/anime-voice-generator,gradio,apache-2.0,8
-2542,dawood/Kanye-AI,gradio,apache-2.0,8
-2543,tomaarsen/span-marker-bert-base-fewnerd-fine-super,gradio,apache-2.0,8
-2544,AutoBG/Auto-BoardGame,streamlit,cc-by-nc-sa-2.0,8
-2545,kazuk/youtube-whisper-12,gradio,unknown,8
-2546,shivi/dolly-v2-demo,gradio,apache-2.0,8
-2547,hahahafofo/prompt_generator,gradio,openrail,8
-2548,ArchitSharma/Digital-Photo-Color-Restoration,streamlit,,8
-2549,fffiloni/audioldm-text-to-audio-generation-copy,gradio,bigscience-openrail-m,8
-2550,fffiloni/CoCa-clone,gradio,,8
-2551,sklearn-docs/Gradient_Boosting_regression,gradio,,8
-2552,zdxiaoda/sovits-4.0-V1-anime-character-model,docker,mit,8
-2553,PhilPome/seo-analysis-tool,gradio,,8
-2554,firzaelbuho/rvc-models,gradio,mit,8
-2555,hanzportgas/rvc-models,gradio,mit,8
-2556,hahahafofo/ChatGLM-Chinese-Summary,gradio,gpl-3.0,8
-2557,leemeng/stablelm-jp-alpha,gradio,other,8
-2558,diffusers/controlnet-canny-tool,gradio,,8
-2559,Oddity/ehartford-WizardLM-13B-Uncensored,gradio,,8
-2560,colonelwatch/abstracts-index,gradio,cc0-1.0,8
-2561,segestic/HuggingChat,streamlit,,8
-2562,allinaigc/GPTAdvanceTemp0801,gradio,,8
-2563,vivlavida/generative-disco,docker,apache-2.0,8
-2564,sdart/SD_txt2img,gradio,creativeml-openrail-m,8
-2565,AutoLLM/AutoAgents,streamlit,,8
-2566,AutoLLM/ArxivDigest,gradio,mit,8
-2567,noamrot/FuseCap-image-captioning,gradio,mit,8
-2568,mindtube/Diffusion50XX,gradio,,8
-2569,rustformers/mpt-7b-instruct,gradio,mit,8
-2570,failfast/2D-GameCreator,docker,agpl-3.0,8
-2571,phoenix-1708/stable-diffusion-webui-cpu,gradio,,8
-2572,HUBioDataLab/DrugGEN,gradio,,8
-2573,attention-refocusing/Attention-refocusing,gradio,,8
-2574,Aabbhishekk/MistralQnA,streamlit,,8
-2575,dekk-i386/pdflangchain,docker,,8
-2576,Royir/SynGen,gradio,,8
-2577,huggingchat/chat-ui-template,docker,,8
-2578,HawkEye098432/Vocals_seperator,gradio,,8
-2579,AI-Hobbyist/Hoyo-RVC,gradio,,8
-2580,Dagfinn1962/stablediffusion-models,gradio,,8
-2581,Manjushri/MusicGen,gradio,cc-by-nc-4.0,8
-2582,Raaniel/Audiomaister,gradio,,8
-2583,Pontonkid/Real-Time-Multilingual-sentiment-analysis,gradio,,8
-2584,keithhon/tortoise-tts-webui,gradio,,8
-2585,jbilcke-hf/media-server,docker,,8
-2586,maknee/minigpt4.cpp,gradio,mit,8
-2587,hf4all/web-ui,static,gpl-3.0,8
-2588,Vageesh1/Voice_Cloner,streamlit,openrail,8
-2589,renumics/stable-diffusion-select-best-images,docker,mit,8
-2590,talhaty/Faceswapper,gradio,,8
-2591,thecentuaro/oai-proxy-geoblock-zov-edition,docker,,8
-2592,Artples/llama-2-7b-chat,gradio,apache-2.0,8
-2593,abhishek/sketch-to-image,gradio,,8
-2594,jeonchangbin49/De-limiter,gradio,,8
-2595,bilgeyucel/captionate,gradio,,8
-2596,akdeniz27/LLaMa-2-70b-chat-hf-with-EasyLLM,gradio,,8
-2597,MrKetchupp/nerijs-pixel-art-xl,gradio,,8
-2598,allknowingroger/Image-Models-Test59,gradio,,8
-2599,Justin-Choo/Multi_diffuser-quick-diffusion-CN-ZH,gradio,,8
-2600,linhdo/document-layout-analysis,gradio,,8
-2601,smangrul/PEFT-Docs-QA-Chatbot,gradio,apache-2.0,8
-2602,qoobeeshy/yolo-document-layout-analysis,gradio,mit,8
-2603,Prof-Reza/Audiocraft_Music-Audio_Generation,gradio,,8
-2604,sweepai/chunker,gradio,apache-2.0,8
-2605,Justin-Choo/Waifu-Diffusion_WEB_UI,gradio,,8
-2606,seanpedrickcase/Light-PDF-Web-QA-Chatbot,gradio,apache-2.0,8
-2607,mlpc-lab/BLIVA,gradio,apache-2.0,8
-2608,Yntec/ToyWorldXL,gradio,,8
-2609,simonw/datasette-thebloke,docker,apache-2.0,8
-2610,4com/SD-XL-CPU,gradio,creativeml-openrail-m,8
-2611,okeanos/uptimefactoryai,gradio,,8
-2612,sdadas/pirb,static,cc-by-nc-4.0,8
-2613,catgirlss/kittens,docker,,8
-2614,hysts/BLIP-Diffusion,gradio,,8
-2615,merve/Grounding_DINO_demo,gradio,apache-2.0,8
-2616,librarian-bots/new-datasets-in-machine-learning,gradio,,8
-2617,allknowingroger/Image-Models-Test193,gradio,,8
-2618,openaccess-ai-collective/jackalope-7b,gradio,apache-2.0,8
-2619,IlyaGusev/saiga_mistral_7b_gguf,gradio,,8
-2620,TheKitten/Fast-Images-Creature,gradio,,8
-2621,mila-quebec/SAI,gradio,,8
-2622,library-samples/InstructBLIP,gradio,mit,8
-2623,SkalskiP/MetaCLIP,gradio,,8
-2624,jbochi/madlad400-3b-mt,gradio,apache-2.0,8
-2625,OpenDILabCommunity/LLMRiddlesChatGPTCN,gradio,apache-2.0,8
-2626,choimirai/whisper-large-v3,gradio,,8
-2627,ADRXtractor/ADR_Xtractor,gradio,,7
-2628,TheBritishLibrary/British-Library-books-genre-classifier-v2,gradio,,7
-2629,CALM/Dashboard,streamlit,,7
-2630,Ebost/animeganv2-self,gradio,,7
-2631,Harveenchadha/Hindi_TTS,gradio,,7
-2632,Hellisotherpeople/HF-SHAP,streamlit,mit,7
-2633,HugsVision/Skin-Cancer,gradio,,7
-2634,Jacobo/syntax,streamlit,,7
-2635,Newtral/toxic-tweets-in-spanish-politics,gradio,,7
-2636,akhaliq/Kapao,gradio,,7
-2637,akhaliq/Keypoint_Communities,gradio,,7
-2638,akhaliq/U-2-Net,gradio,,7
-2639,akhaliq/poolformer,gradio,,7
-2640,anton-l/youtube-subs-wav2vec,streamlit,,7
-2641,aseifert/writing-assistant,streamlit,,7
-2642,basakbuluz/turkish-question-answering,gradio,,7
-2643,chuanenlin/foodnet,streamlit,,7
-2644,edemgold/IFA-summarizer,gradio,,7
-2645,edugp/embedding-lenses,streamlit,,7
-2646,eugenesiow/mandarin-tts,gradio,,7
-2647,frgfm/torch-cam,streamlit,,7
-2648,gorkemgoknar/moviechatbot,gradio,,7
-2649,hysts/anime_face_landmark_detection,gradio,,7
-2650,hysts/danbooru-pretrained,gradio,,7
-2651,Gradio-Blocks/multilingual-asr,gradio,,7
-2652,isabel/mental-health-project,gradio,,7
-2653,jone/GFPGAN,gradio,,7
-2654,keras-io/involution,gradio,mit,7
-2655,keras-io/patch-conv-net,gradio,afl-3.0,7
-2656,mbahrami/Auto-Complete_Semantic,streamlit,,7
-2657,ml6team/byt5_ocr_corrector,streamlit,,7
-2658,nielsr/perceiver-image-classification,gradio,,7
-2659,osanseviero/HUBERT,gradio,,7
-2660,pierreguillou/ner-bert-pt-lenerbr,gradio,,7
-2661,qanastek/Etiqueteur-Morphosyntaxique-Etendu,streamlit,,7
-2662,rexoscare/Speech_to_Text_Hindi,gradio,,7
-2663,rileho3909/Real-Time-Voice-Cloning,gradio,,7
-2664,sbhatti2009/stock-analysis,gradio,mit,7
-2665,severo/voronoi-cloth,static,,7
-2666,smangrul/Text-To-Image,gradio,,7
-2667,sunwaee/Face-Mask-Detection,streamlit,,7
-2668,wilmerags/tweet-snest,streamlit,,7
-2669,xiongjie/realtime-SRGAN-for-anime-example,gradio,,7
-2670,hongaik/service_text_classification,streamlit,,7
-2671,atsantiago/Monocular_Depth_Filter,gradio,,7
-2672,gryan-galario/manga-ocr-demo,gradio,apache-2.0,7
-2673,iSky/Speech-audio-to-text-with-grammar-correction,gradio,afl-3.0,7
-2674,abidlabs/streaming-asr,gradio,,7
-2675,abidlabs/streaming-asr-paused,gradio,,7
-2676,cakiki/doom,static,,7
-2677,hackathon-pln-es/clasificador-de-tesis,gradio,apache-2.0,7
-2678,awacke1/Streamlit-ASR-Video,streamlit,mit,7
-2679,julien-c/cube,gradio,mit,7
-2680,awacke1/AI-Quantum,streamlit,mit,7
-2681,anegi/Comparing-dialogue-summarization-models,gradio,,7
-2682,probing-vits/attention-rollout,gradio,apache-2.0,7
-2683,huggan/sefa,streamlit,mit,7
-2684,ecarbo/deoldify-demo,gradio,,7
-2685,huggan/sim2real,gradio,mit,7
-2686,sunshineatnoon/TextureScraping,streamlit,,7
-2687,HighCWu/colorful-ascii-art,gradio,mit,7
-2688,bigscience/SourcingCatalog,streamlit,apache-2.0,7
-2689,evaluate-metric/matthews_correlation,gradio,,7
-2690,Gradio-Blocks/uniformer_image_demo,gradio,mit,7
-2691,nagolinc/npcGenerator,gradio,mit,7
-2692,nagolinc/styleGanHuman_and_PIFu,gradio,mit,7
-2693,Gradio-Blocks/SlowMo_n_Timelapse_Your_Video,gradio,gpl,7
-2694,CVPR/BigDL-Nano_inference,gradio,,7
-2695,valurank/Article_Summarizer_12_6_testing,gradio,other,7
-2696,awacke1/ASRGenerateStoryandVideo,gradio,mit,7
-2697,Theivaprakasham/wildreceipt,gradio,apache-2.0,7
-2698,yhavinga/pre-training-dutch-t5-models,streamlit,afl-3.0,7
-2699,hlydecker/MegaDetector_v5,gradio,mit,7
-2700,ThomasSimonini/Compare-Reinforcement-Learning-Agents,gradio,,7
-2701,duchaba/skin_cancer_diagnose,gradio,gpl-3.0,7
-2702,taka-yamakoshi/tokenizer-demo,streamlit,,7
-2703,hugginglearners/rice-image-classification,gradio,apache-2.0,7
-2704,big-kek/NeuroKorzh,streamlit,,7
-2705,awacke1/SentenceToGeneratedVideo,gradio,mit,7
-2706,hugginglearners/brain-tumor-detection-mri,gradio,,7
-2707,EuroPython2022/clickbaitonator,gradio,afl-3.0,7
-2708,VietAI/En2Vi-Translation,gradio,,7
-2709,keras-io/PointNet-Classification,gradio,apache-2.0,7
-2710,pinecone/semantic-query-trainer,streamlit,,7
-2711,Qilex/EnglishToMiddleEnglish,gradio,afl-3.0,7
-2712,nazneen/seal,streamlit,apache-2.0,7
-2713,Blaise-g/summarize-biomedical-papers-long-summary-or-tldr,gradio,apache-2.0,7
-2714,josuelmet/Metal_Music_Interpolator,gradio,,7
-2715,nickmuchi/Netflix-Semantic-Search-Whisperer,gradio,,7
-2716,Vertaix/vendiscore,gradio,,7
-2717,ECCV2022/ECCV2022_papers,gradio,,7
-2718,PaddlePaddle/ERNIE-Zeus,gradio,apache-2.0,7
-2719,autonomous019/image_story_generator,gradio,bsd,7
-2720,gradio/text_generation,gradio,,7
-2721,ThomasSimonini/atari_agents,gradio,,7
-2722,kornia/kornia-image-filtering,gradio,,7
-2723,kornia/kornia-resize-antialias,gradio,,7
-2724,breezedeus/pix2text,streamlit,mit,7
-2725,Shamima/extract-color-from-image,gradio,,7
-2726,Msp/Document_Parser,gradio,,7
-2727,juancopi81/mutopia-guitar-composer,gradio,mit,7
-2728,nazneen/model-usage,streamlit,apache-2.0,7
-2729,AI-Zero-to-Hero/06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,,7
-2730,YaYaB/text-to-onepiece,gradio,,7
-2731,imseldrith/Article-Rewriter,gradio,,7
-2732,MarketINK/MarketINK,gradio,unknown,7
-2733,adirik/kakao-brain-vit,gradio,apache-2.0,7
-2734,GIZ/embedding_visualisation,streamlit,,7
-2735,Chenyuwen/playground2,streamlit,,7
-2736,sparanoid/demucs-gpu,gradio,,7
-2737,tomaseo2022/imagen-a-pixel-art,gradio,,7
-2738,cc1234/stashface,gradio,mit,7
-2739,Adapting/TrendFlow,streamlit,mit,7
-2740,celebrate-ai/face-detection-cnn,gradio,mit,7
-2741,Podtekatel/Arcane_Style_Transfer,gradio,bsd-3-clause,7
-2742,nakas/Time-Domain-Audio-Style-Transfer,gradio,apache-2.0,7
-2743,robinhad/qirimtatar-tts,gradio,,7
-2744,dpe1/beat_manipulator,gradio,cc-by-nc-sa-4.0,7
-2745,BoomerangGirl/MagicPrompt-Stable-Diffusion,gradio,mit,7
-2746,BilalSardar/Object-Color-Detection-in-Video,gradio,openrail,7
-2747,binery/Donut_Receipt_v2,gradio,,7
-2748,akhaliq/wavyfusion,gradio,,7
-2749,johnowhitaker/color-guided-wikiart-diffusion,gradio,mit,7
-2750,Datasculptor/ImageGPT,gradio,,7
-2751,TacosHero/flax-midjourney-v4-diffusion-2,gradio,,7
-2752,Tuana/find-the-animal,streamlit,,7
-2753,MirageML/depth2img,gradio,,7
-2754,zwv9/webui-cpu,gradio,,7
-2755,pragnakalp/Audio_Emotion_Recognition,gradio,,7
-2756,alvanlii/whisper-small-cantonese,gradio,,7
-2757,sayakpaul/demo-docker-gradio,docker,apache-2.0,7
-2758,Yasu55/stable-diffusion-webui,gradio,openrail,7
-2759,dreambooth-hackathon/dreambooth-hackathon-evaluator,gradio,apache-2.0,7
-2760,Intel/qa_sparse_bert,gradio,apache-2.0,7
-2761,Jojelf/dreamlike-photoreal-2.0,gradio,,7
-2762,unstructuredio/receipt-parser,streamlit,apache-2.0,7
-2763,awacke1/Biomed-NLP-AI-Clinical-Terminology,gradio,,7
-2764,leuschnm/CrowdCounting-with-Scale-Adaptive-Selection-SASNet,gradio,apache-2.0,7
-2765,ivelin/ui-refexp,gradio,agpl-3.0,7
-2766,Gxia/Lama-Cleaner-lama,gradio,apache-2.0,7
-2767,sovitrath/pothole_yolov8_nano,gradio,mit,7
-2768,Qosmo/video2music-demo,docker,,7
-2769,jamesliu1217/midjourney-v5,gradio,openrail,7
-2770,h2oai/ner_annotation,docker,,7
-2771,thiagohersan/maskformer-satellite-trees-gradio,gradio,cc-by-nc-sa-4.0,7
-2772,fcakyon/yolov8-segmentation,gradio,gpl-3.0,7
-2773,ai-moroz/webui-cpu,gradio,,7
-2774,huggingface-projects/auto-retrain,docker,,7
-2775,wanglishan/pic-repaire2,gradio,apache-2.0,7
-2776,nickmuchi/fintweet-GPT-Search,streamlit,,7
-2777,juancopi81/whisper-youtube-2-hf_dataset,gradio,openrail,7
-2778,sayakpaul/convert-kerascv-sd-diffusers,gradio,apache-2.0,7
-2779,sophiamyang/Panel_InstructPix2Pix,docker,,7
-2780,decodemai/Stable-Diffusion-Ads,gradio,cc-by-sa-4.0,7
-2781,0xhimzel/Detect-AI-Plagiarism,gradio,mit,7
-2782,Everymans-ai/GPT-knowledge-management,streamlit,apache-2.0,7
-2783,ofikodar/chatgpt-resume-builder,docker,,7
-2784,neel692/NSFW-VS-SFW-Image-Classification,gradio,,7
-2785,reach-vb/speech-t5-this-speaker-does-not-exist,gradio,apache-2.0,7
-2786,Eriberto/chatGPT,gradio,,7
-2787,HuggingFaceH4/instruction-model-outputs-filtered,streamlit,apache-2.0,7
-2788,gradio-tests/Image_Upscaling_Restoration_Colorization,gradio,apache-2.0,7
-2789,kufei/nllb-translation-demo-1.3b-distilled,gradio,gpl-3.0,7
-2790,mdj1412/stock_news_summaries_AI,gradio,,7
-2791,JYskyp/wildcards,static,,7
-2792,kobkrit/openthaigpt,gradio,apache-2.0,7
-2793,keremberke/awesome-yolov8-models,gradio,mit,7
-2794,yujieq/RxnScribe,gradio,mit,7
-2795,AIML-TUDA/FairDiffusionExplorer,gradio,cc-by-sa-4.0,7
-2796,podsni/Coverter-PDF-to-TXT,streamlit,,7
-2797,calmgoose/Talk2Book,streamlit,apache-2.0,7
-2798,keras-dreambooth/pink-floyd-division-bell,gradio,creativeml-openrail-m,7
-2799,szk1ck/image-matting,gradio,apache-2.0,7
-2800,buildingai/youtube-video-transcription-with-whisper,gradio,afl-3.0,7
-2801,king007/GPT-Prompt-Generate-2,gradio,apache-2.0,7
-2802,hu-po/speech2speech,gradio,mit,7
-2803,rakibulbd030/GFPGAN,gradio,apache-2.0,7
-2804,gradio/soft,gradio,apache-2.0,7
-2805,itacaiunas/remove-photo-object,streamlit,mit,7
-2806,DKDohare/Chat-GPT4-MAX,gradio,mit,7
-2807,CGMatter/modelscope-text-to-video-synthesis,gradio,,7
-2808,JenkinsGage/WritingHelper,gradio,,7
-2809,p4vv37/CodeBERT_CodeReviewer,gradio,mit,7
-2810,rakibulbd030/old_photo_restoration,gradio,apache-2.0,7
-2811,ajndkr/boilerplate-x,gradio,mit,7
-2812,kastan/ai-teaching-assistant,gradio,,7
-2813,osanseviero/osanseviero-llama-alpaca-guanaco-vicuna,gradio,,7
-2814,sudeepshouche/minimalist,gradio,apache-2.0,7
-2815,keras-dreambooth/dreambooth-bored-ape,gradio,creativeml-openrail-m,7
-2816,Mrchuw/text-to-image_6_by_6,gradio,,7
-2817,aiditi/nvidia_denoiser,gradio,apache-2.0,7
-2818,sakasegawa/whisper-gijiroku-summary,gradio,apache-2.0,7
-2819,lemonshochu/JPEG_Artifacts_Removal,gradio,apache-2.0,7
-2820,hackathon-somos-nlp-2023/demo_DiagTrast,streamlit,mit,7
-2821,sklearn-docs/MNIST_classification_using_multinomial_logistic_L1,gradio,mit,7
-2822,kira4424/VITS-fast-fine-tuning,gradio,apache-2.0,7
-2823,kxqt/Expedit-SAM,gradio,apache-2.0,7
-2824,dromerosm/autogpt-agents,gradio,cc-by-nc-sa-2.0,7
-2825,SJTU-CL/argugpt-detector,gradio,,7
-2826,Dao3/image-to-video,gradio,unknown,7
-2827,posit/shiny-for-r-template,docker,,7
-2828,camel-ai/camel-data-explorer,gradio,apache-2.0,7
-2829,innev/whisper-Base,gradio,mit,7
-2830,posit/shiny-for-python-template,docker,mit,7
-2831,hsm-kd-master/photorealistic-images,gradio,,7
-2832,Gladiator/gradient_dissent_bot,gradio,apache-2.0,7
-2833,dorkai/singpt-2.0,gradio,mit,7
-2834,Celestinian/Topic-Detection,gradio,mit,7
-2835,taesiri/HuggingGPT-Lite,gradio,mit,7
-2836,sklearn-docs/Ordinary_Least_Squares_and_Ridge_Regression_Variance,gradio,,7
-2837,AlekseyKorshuk/model-evaluation,gradio,,7
-2838,MarcusSu1216/XingTong,gradio,mit,7
-2839,Ash123/stable-diffusion-nano,gradio,creativeml-openrail-m,7
-2840,philmui/globe,streamlit,mit,7
-2841,Zenne/chatbot_for_files_langchain,streamlit,mit,7
-2842,OpenDILabCommunity/DI-sheep,docker,apache-2.0,7
-2843,failfast/nextjs-hf-spaces,docker,agpl-3.0,7
-2844,RoundtTble/dinov2-pca,gradio,,7
-2845,luohy/SAIL-7B,gradio,gpl-3.0,7
-2846,internetsignal/Bark-w-voice-clone,gradio,mit,7
-2847,BartPoint/VoiceChange,gradio,mit,7
-2848,Annotation-AI/fast-segment-everything-with-image-prompt,gradio,,7
-2849,szukevin/VISOR-GPT,gradio,mit,7
-2850,new4u/whisper_large_v2_Audio_YT_to_text,gradio,,7
-2851,OFA-Sys/expertllama,gradio,cc-by-nc-4.0,7
-2852,matthoffner/web-llm-embed,docker,,7
-2853,zhuolisam/resume-ranker,streamlit,,7
-2854,rakhlin/Coqui.ai,gradio,,7
-2855,k1ngtai/MMS,gradio,cc-by-nc-4.0,7
-2856,meraih/English-Japanese-Anime-TTS,gradio,,7
-2857,vinid/fashion-clip-app,streamlit,,7
-2858,mpatel57/WOUAF-Text-to-Image,gradio,mit,7
-2859,michaelthwan/digest-everything-gpt,gradio,mit,7
-2860,kevinwang676/M4Singer,gradio,,7
-2861,teelinsan/aclpubcheck,docker,mit,7
-2862,HappyElephant/TextToSpeech,gradio,,7
-2863,Walterchamy/Virtual_Assistant_v1,streamlit,mit,7
-2864,visheratin/laion-nllb,streamlit,,7
-2865,DravensCursed/OPENAI-REVERSE-PROXY,docker,,7
-2866,Dreamsome/HuggingFace-Datasets-Text-Quality-Analysis,streamlit,mit,7
-2867,fartsmellalmao/combined-GI-RVC-models,gradio,mit,7
-2868,mithril-security/poisongpt,gradio,apache-2.0,7
-2869,TFanon/TFanon,docker,,7
-2870,kevinwang676/FreeVC,gradio,mit,7
-2871,shuhulhandoo/face-swap,gradio,,7
-2872,Dormin22/Proxy,docker,,7
-2873,Gananom/claudeisms,docker,other,7
-2874,EnigmaOfTheWorld/Power_AI_Point,gradio,,7
-2875,jbilcke-hf/LifeSim,docker,,7
-2876,Zaxxced/rvc-random-v2,gradio,mit,7
-2877,bhaskartripathi/pdfGPT_Turbo,gradio,afl-3.0,7
-2878,Branon/oai-proxy,docker,,7
-2879,konverner/deep-voice-cloning,gradio,openrail,7
-2880,dongsiqie/sydney,docker,mit,7
-2881,yangfeixue/newbing,docker,mit,7
-2882,KevinQHLin/UniVTG,gradio,,7
-2883,HuggingFaceM4/IDEFICS-bias-eval,gradio,,7
-2884,Junity/Genshin-World-Model,gradio,apache-2.0,7
-2885,Open-Orca/LlongOrca-7B-16k,gradio,,7
-2886,yuangongfdu/ltu-2,gradio,bsd-2-clause,7
-2887,Grasswort/BingAI,docker,mit,7
-2888,Brasd99/TTS-Voice-Cloner,streamlit,,7
-2889,pomudachi/spoiled-brrats,docker,,7
-2890,NoCrypt/miku,gradio,apache-2.0,7
-2891,jaumaras/Text-2-Speech,gradio,,7
-2892,allknowingroger/Image-Models-Test92,gradio,,7
-2893,Sapphire-356/Video2MC,gradio,gpl-3.0,7
-2894,giskardai/giskard,docker,,7
-2895,tiiuae/falcon-180b-license,static,,7
-2896,0xqtpie/doodle2vid,gradio,mit,7
-2897,universeTBD/astrollama,gradio,,7
-2898,fffiloni/sd-xl-custom-model,gradio,,7
-2899,Olivier-Truong/XTTS_V1_CPU_working,gradio,,7
-2900,hysts/ViTMatte,gradio,mit,7
-2901,mrm8488/idefics-9b-ft-describe-diffusion-mj,gradio,wtfpl,7
-2902,Coweed/GoodTrip,docker,,7
-2903,xuyingliKepler/AI_News_Podcast,streamlit,mit,7
-2904,ysharma/LLaVA_v1,gradio,,7
-2905,AkitoP/umamusume_bert_vits2,gradio,,7
-2906,deniandriancode/zephyr-7b-alpha-chatbot,gradio,apache-2.0,7
-2907,pseudolab/2023-Hackathon-Certification,gradio,,7
-2908,cis-lmu/glotlid-space,streamlit,,7
-2909,guardiancc/video-face-swap,gradio,,7
-2910,pseudolab/huggingface-korea-theme,gradio,apache-2.0,7
-2911,pxiaoer/papers,gradio,mit,7
-2912,FinGPT/FinGPT-Forecaster,gradio,,7
-2913,novita-ai/Face-Stylization-Playground,gradio,mit,7
-2914,Illia56/fastest-whisper-v3-large,gradio,,7
-2915,52Hz/HWMNet_lowlight_enhancement,gradio,,6
-2916,Amrrs/pdf-table-extractor,streamlit,,6
-2917,Amrrs/textsummarizer,gradio,,6
-2918,CVPR/GFPGAN-example,gradio,apache-2.0,6
-2919,DeepDrivePL/PaddleSeg-Matting,gradio,,6
-2920,Flux9665/PoeticTTS,gradio,mit,6
-2921,UNIST-Eunchan/Summarizing-app,streamlit,,6
-2922,kili-technology/plastic_in_river,gradio,,6
-2923,Prathap/summarization,streamlit,,6
-2924,RobotJelly/Text_Or_Image-To-Image_Search,gradio,,6
-2925,Shankhdhar/Rap-Lyric-generator,streamlit,,6
-2926,Wootang01/text_summarizer,gradio,,6
-2927,abidlabs/Gradio-MNIST-Realtime,gradio,,6
-2928,abidlabs/flagging,gradio,,6
-2929,ajitrajasekharan/Bio-medical-NER-Model-Gradio-Demo,gradio,mit,6
-2930,ajitrajasekharan/Image-Text-Detection,streamlit,mit,6
-2931,akdeniz27/contract-understanding-atticus-dataset-demo,streamlit,,6
-2932,akhaliq/Image_Search,gradio,,6
-2933,akhaliq/MobileStyleGAN,gradio,,6
-2934,akhaliq/mae,gradio,,6
-2935,benthecoder/news-summarizer,gradio,,6
-2936,bentrevett/emotion-prediction,streamlit,,6
-2937,bharat-raghunathan/song-lyrics-classifier,gradio,,6
-2938,cdleong/langcode-search,streamlit,,6
-2939,Surfrider/surfnet,gradio,mit,6
-2940,chrisjay/masakhane-benchmarks,gradio,,6
-2941,crylake/img2poem,streamlit,,6
-2942,DebateLabKIT/deepa2-demo,streamlit,,6
-2943,deep-learning-analytics/GrammarCorrector,streamlit,,6
-2944,dnth/webdemo-microalgae-counting,gradio,,6
-2945,docs-demos/openai-gpt,gradio,,6
-2946,elozano/news-analyzer,streamlit,,6
-2947,flax-community/Multilingual-VQA,streamlit,,6
-2948,flax-community/gpt2-indonesian,streamlit,,6
-2949,flax-community/multilingual-image-captioning,streamlit,,6
-2950,gagan3012/ViTGPT2,gradio,mit,6
-2951,hysts/age-estimation-APPA-REAL,gradio,,6
-2952,johnpaulbin/top_0,gradio,,6
-2953,juliensimon/voice-queries,gradio,,6
-2954,keras-io/AdaIN,gradio,,6
-2955,keras-io/ner_with_transformers,gradio,,6
-2956,lewtun/twitter-sentiments,streamlit,,6
-2957,liminghao1630/TrOCR-printed,gradio,,6
-2958,merve/streamlit-dataset-demo,streamlit,,6
-2959,nateraw/cryptopunks-generator,gradio,,6
-2960,nielsr/DINO,gradio,,6
-2961,osanseviero/gpt2_for_music,gradio,afl-3.0,6
-2962,paulbricman/cybersalience,streamlit,,6
-2963,prithivida/neuspell-demo,streamlit,,6
-2964,pszemraj/ballpark-trivia,gradio,,6
-2965,rajesh1729/live-twitter-sentiment-analysis,streamlit,afl-3.0,6
-2966,raynardj/modern-chinese-to-ancient-translate-wenyanwen,streamlit,,6
-2967,sonoisa/irasuto_search,streamlit,,6
-2968,tyang/electra_wikipedia_qa,gradio,,6
-2969,Sa-m/Neural-Style-Transfer-Image-Stylization,gradio,mit,6
-2970,it5/it5-demo,gradio,apache-2.0,6
-2971,templates/gradio_opencv,gradio,,6
-2972,ml6team/toxic-comment-detection-dutch,streamlit,,6
-2973,hackathon-pln-es/Sexismdetection,streamlit,,6
-2974,course-demos/Sketch-Recognition,gradio,afl-3.0,6
-2975,Harveenchadha/Vakyansh-Hindi-TTS,gradio,apache-2.0,6
-2976,egmaminta/indoor-scene-recognition-to-speech,gradio,apache-2.0,6
-2977,akhaliq/ArcaneGAN-blocks,gradio,,6
-2978,reach-vb/text-iterater,gradio,,6
-2979,hackathon-pln-es/Spanish-Medical-NER,gradio,cc-by-nc-4.0,6
-2980,abhibisht89/Med7,gradio,,6
-2981,Harveenchadha/Vakyansh-Odia-TTS,gradio,apache-2.0,6
-2982,hackathon-pln-es/modelo-juridico-mexicano,gradio,cc-by-sa-4.0,6
-2983,hackathon-pln-es/AbstractGen_ES,gradio,,6
-2984,ecarbo/paddleOCR-demo,gradio,,6
-2985,tomofi/Hive-OCR,gradio,mit,6
-2986,huggingface/metric-explorer,streamlit,,6
-2987,huggingface/speech-bench-metrics-editor,streamlit,apache-2.0,6
-2988,huggan/pix2pix-uavid,gradio,,6
-2989,huggan/ArtGAN,gradio,afl-3.0,6
-2990,awacke1/Memory-Shared,gradio,mit,6
-2991,shi-labs/FcF-Inpainting,streamlit,apache-2.0,6
-2992,h4d35/CLiPcrop,gradio,,6
-2993,huggan/NeonGAN_Demo,gradio,mit,6
-2994,lysandre/github-release,gradio,apache-2.0,6
-2995,strickvl/redaction-detector,gradio,apache-2.0,6
-2996,wenpeng/Sod_Inpaint,gradio,apache-2.0,6
-2997,fabiochiu/title-generation,streamlit,mit,6
-2998,awacke1/AI-BigGAN-Image-Gen,gradio,mit,6
-2999,Casio991ms/MathBot,gradio,mit,6
-3000,Gradio-Blocks/RickandMorty-BlockParty,gradio,apache-2.0,6
-3001,evaluate-metric/exact_match,gradio,,6
-3002,evaluate-metric/meteor,gradio,,6
-3003,evaluate-metric/google_bleu,gradio,,6
-3004,flava/semantic-image-text-search,streamlit,,6
-3005,keras-io/EDSR,gradio,mit,6
-3006,emilylearning/spurious_correlation_evaluation,gradio,,6
-3007,iakarshu/docformer_for_document_classification,gradio,wtfpl,6
-3008,aseifert/ExplaiNER,streamlit,,6
-3009,GIZ/sdg_classification,gradio,,6
-3010,keras-io/TabTransformer_Classification,gradio,apache-2.0,6
-3011,keras-io/GauGAN_Conditional_Image_Generation,gradio,apache-2.0,6
-3012,kargaranamir/ColorHarmonization,gradio,unlicense,6
-3013,webshop/amazon_shop,gradio,,6
-3014,scikit-learn/sentiment-analysis,gradio,apache-2.0,6
-3015,noelshin/selfmask,gradio,mit,6
-3016,CVPR/time,gradio,mit,6
-3017,innat/HybridModel-GradCAM,gradio,,6
-3018,hugginglearners/malayalam-news-classify,gradio,,6
-3019,hugginglearners/pokemon-card-checker,gradio,mit,6
-3020,CVPR/winoground-explorer,gradio,,6
-3021,ml6team/semantic-search-demo,streamlit,,6
-3022,amarkc/Youtube-Transcript-Summarizer,gradio,afl-3.0,6
-3023,AnkitGaur2811/Image_Conversion_app_using_Opencv,gradio,,6
-3024,huggingface-projects/easy-analysis,gradio,apache-2.0,6
-3025,PaulHilders/CLIPGroundingExplainability,gradio,afl-3.0,6
-3026,awacke1/VideoSwap,gradio,mit,6
-3027,sofmi/semantic-segmentation-revamped,gradio,,6
-3028,awacke1/ASRGenerateStory,gradio,,6
-3029,udion/BayesCap,gradio,,6
-3030,hugginglearners/grapevine-leaves-classification,gradio,apache-2.0,6
-3031,hugginglearners/emotion_in_tweets,gradio,,6
-3032,mbarnig/lb_de_fr_en_pt_COQUI_VITS_TTS,gradio,cc-by-nc-sa-4.0,6
-3033,EuroPython2022/Fin-Eng-ASR-autosubtitles,gradio,mit,6
-3034,EuroPython2022/automatic-speech-recognition-with-next-gen-kaldi,gradio,apache-2.0,6
-3035,keras-io/deit,gradio,,6
-3036,katielink/brain_tumor_segmentation,gradio,other,6
-3037,vibey/article-summariser-for-final-project,streamlit,,6
-3038,ali-ghamdan/realesrgan-models,gradio,,6
-3039,ldkong/TranSVAE,gradio,cc-by-nc-4.0,6
-3040,geraltofrivia/deoldify_videos,gradio,,6
-3041,ivan-savchuk/medical-search,streamlit,afl-3.0,6
-3042,sidharthism/fashion-eye,gradio,,6
-3043,ali-ghamdan/gfp-Gans,gradio,,6
-3044,therealcyberlord/abstract-art-generation,streamlit,mit,6
-3045,SIGGRAPH2022/Text2Human,gradio,,6
-3046,mascIT/AgeGuesser,gradio,mit,6
-3047,mrdbourke/foodvision_big,gradio,mit,6
-3048,CK42/sentiment-model-comparison,gradio,,6
-3049,hasibzunair/LaTeX-OCR-demo,gradio,mit,6
-3050,lfolle/DeepNAPSI,gradio,,6
-3051,evaluate-measurement/toxicity,gradio,,6
-3052,EuroSciPy2022/arxiv-cards,gradio,,6
-3053,FluxWaveCorp/Ghostwriter-Bloom,streamlit,,6
-3054,pinecone/abstractive-question-answering,streamlit,,6
-3055,ruslanmv/Youtube-Video-Translator,gradio,cc0-1.0,6
-3056,chuanenlin/which-frame,streamlit,,6
-3057,Armandoliv/document_parser,gradio,apache-2.0,6
-3058,gradio/animeganv2,gradio,,6
-3059,gradio/clustering,gradio,,6
-3060,Shredder/CONBERT-3,gradio,,6
-3061,gradio/automatic-speech-recognition,gradio,,6
-3062,ECCV2022/storydalle,gradio,,6
-3063,awacke1/3DModelEditorWithAIV1,gradio,mit,6
-3064,keithhon/Real-Time-Voice-Cloning,gradio,,6
-3065,jphwang/colorful_vectors,streamlit,mit,6
-3066,samusander/Transcribe.AI,gradio,,6
-3067,Rothfeld/kmeans-pixelartifier,gradio,apache-2.0,6
-3068,tafxle/Bloom_chat,streamlit,openrail,6
-3069,rdp-studio/waifu-generator,gradio,cc-by-nc-sa-4.0,6
-3070,kivantium/danbooru-pose-search,gradio,,6
-3071,johnslegers/stable-diffusion-gui-test,gradio,mit,6
-3072,crytion/DeepNude,gradio,,6
-3073,imseldrith/Article-Generator,gradio,,6
-3074,Eemansleepdeprived/Study_For_Me_AI,streamlit,mit,6
-3075,jiedong-yang/Speech-Summarization-with-Whisper,gradio,apache-2.0,6
-3076,jamescalam/dream-cacher,gradio,,6
-3077,terrierteam/splade,gradio,,6
-3078,breadlicker45/Text-to-music-longer,gradio,,6
-3079,jinhybr/OCR-layoutLM-Demo,gradio,apache-2.0,6
-3080,Podtekatel/JoJo_Style_Transfer,gradio,bsd-3-clause,6
-3081,hamel/hfspace_demo,gradio,mit,6
-3082,siddh4rth/audio_to_text,gradio,,6
-3083,Longliveruby/Spotify-Recommendation-System,streamlit,,6
-3084,yizhangliu/ImgCleaner,gradio,,6
-3085,Andy1621/uniformerv2_demo,gradio,mit,6
-3086,akhaliq/EimisAnimeDiffusion_1.0v,gradio,,6
-3087,alibaba-pai/pai-diffusion-artist-large-zh,gradio,mit,6
-3088,SerdarHelli/diffusion-point-cloud,gradio,mit,6
-3089,Aphrodite/stable-diffusion-2,gradio,,6
-3090,crumb/sd2-prompter-aesthetic,gradio,apache-2.0,6
-3091,GT4SD/regression_transformer,gradio,,6
-3092,akhaliq/test-chatgpt,gradio,,6
-3093,clem/dreambooth-pareidolia,gradio,mit,6
-3094,ConceptArtHouse/webui-gameasset,gradio,,6
-3095,victor/prompthero-openjourney,gradio,,6
-3096,Bingsu/color_textual_inversion,streamlit,,6
-3097,kboaten/MIDI-Audio-Extension,gradio,,6
-3098,bardsai/whisper-demo-pl,gradio,,6
-3099,bradarrML/stablediffusion-infinity,gradio,apache-2.0,6
-3100,xiaoyinqu/dreambooth,gradio,mit,6
-3101,NbAiLab/whisper-norwegian-small,gradio,,6
-3102,akhaliq/riffusion-riffusion-model-v1,gradio,,6
-3103,Artgor/digit-draw-detect,streamlit,mit,6
-3104,kadirnar/bsrgan,gradio,apache-2.0,6
-3105,abidlabs/whisper-large-v2,gradio,,6
-3106,nooji/ImpCatcher,docker,apache-2.0,6
-3107,Korakoe/convert-sd-ckpt-cpu,gradio,apache-2.0,6
-3108,Joom/Front-end-code-generation-from-images,gradio,afl-3.0,6
-3109,vs4vijay/stable-diffusion,gradio,,6
-3110,wavymulder/timeless-diffusion,gradio,,6
-3111,AnnasBlackHat/Image-Similarity,gradio,,6
-3112,peterkros/videomatting,gradio,,6
-3113,sohojoe/soho-clip,gradio,mit,6
-3114,ChrisPreston/meaqua,gradio,,6
-3115,group2test/Protogen_x3.4_Official_Release,gradio,,6
-3116,kdrkdrkdr/YuukaTTS,gradio,mit,6
-3117,antonbol/vocal_remover,gradio,apache-2.0,6
-3118,AIML-TUDA/unsafe-vs-safe-stable-diffusion,gradio,creativeml-openrail-m,6
-3119,Zengyf-CVer/Gradio-YOLOv8-Det,gradio,gpl-3.0,6
-3120,SweetLuna/Kenshi-WebUI,gradio,creativeml-openrail-m,6
-3121,trysem/Colorizer_Models,gradio,bsd-2-clause,6
-3122,abcde1234www/tts,gradio,,6
-3123,harmdevries/bigcode_planning,streamlit,apache-2.0,6
-3124,awacke1/WikipediaUltimateAISearch,gradio,mit,6
-3125,theintuitiveye/FantasyMix-v1,gradio,,6
-3126,trysem/nuclearfu,gradio,,6
-3127,mamiksik/commit-message-generator,gradio,,6
-3128,akhaliq/basil_mix,gradio,,6
-3129,katanaml-org/sparrow-ui,docker,mit,6
-3130,RamAnanth1/co_chat_voice,gradio,,6
-3131,Korakoe/OpenNiji,gradio,creativeml-openrail-m,6
-3132,rsunner/GPT-Index_simple_upload,gradio,apache-2.0,6
-3133,samthakur/stable-diffusion-2.1,gradio,openrail,6
-3134,lint/sdpipe_webui,gradio,openrail,6
-3135,mrm8488/santacoder-bash-completion,gradio,,6
-3136,AI-Dashboards/Graph.Visualization.Plotly.Sunbursts.Treemaps.WebGL,streamlit,,6
-3137,tumuyan/Alist1,docker,agpl-3.0,6
-3138,huggingface/rlhf-interface,gradio,,6
-3139,PirateXX/ChatGPT-Content-Detector,gradio,artistic-2.0,6
-3140,pierreguillou/DocLayNet-image-viewer,gradio,,6
-3141,abcde1234www/ChatGPT-prompt-generator,gradio,apache-2.0,6
-3142,Gertie01/MusicLM,streamlit,apache-2.0,6
-3143,Daniton/MagicPrompt-Stable-Diffusion,gradio,mit,6
-3144,maliozer/microsoft-biogpt,gradio,mit,6
-3145,shogi880/ChatGPT-StableDiffusion-CharacterDesign,gradio,,6
-3146,akhaliq/Counterfeit-V2.5,gradio,,6
-3147,camenduru-com/wav2lip,docker,,6
-3148,huggingface-projects/diffusers-gallery-bot,docker,,6
-3149,ysharma/Chat_With_Blip2,gradio,mit,6
-3150,AsakuraMizu/moe-tts,gradio,mit,6
-3151,keras-dreambooth/leaderboard,gradio,apache-2.0,6
-3152,Datasculptor/Image2LineDrawing,gradio,mit,6
-3153,alvanlii/domain-expansion,docker,,6
-3154,radames/aesthetic-style-nsfw-classifier,gradio,,6
-3155,ysharma/Blip_PlaygroundAI,gradio,mit,6
-3156,FooYou/marvel,gradio,,6
-3157,RealTimeLiveAIForHealth/WebcamObjectRecognition,gradio,mit,6
-3158,portal/Control-Net-Video,static,,6
-3159,apruvd/Realtime_Speech_to_Image_Generator,gradio,cc,6
-3160,pyInter/Liyuu_sovits4,gradio,mit,6
-3161,rabiyulfahim/Prompt-Refinery-Text-to-Image-Generation,gradio,,6
-3162,hyoo/imagine,gradio,mit,6
-3163,awacke1/RLHF.Cognitive.Episodic.Semantic.Memory,streamlit,mit,6
-3164,bachpc/table-structure-recognition,streamlit,,6
-3165,aodianyun/stable-diffusion-webui,gradio,,6
-3166,fffiloni/RAFT,gradio,,6
-3167,azer123456789/nicky007-stable-diffusion-logo-fine-tuned,gradio,,6
-3168,Sloth-Alchemist/SlothAi.xyz,gradio,,6
-3169,adirik/ALIGN-zero-shot-image-classification,gradio,apache-2.0,6
-3170,kmaurinjones/wordle_wizard,streamlit,,6
-3171,anhnv125/recipe_generation,streamlit,cc-by-nc-4.0,6
-3172,danielcwq/chat-your-data-trial,gradio,mit,6
-3173,wanglettes/zw_chatgpt_01,gradio,mit,6
-3174,Pranay009/FACE2COMIC,gradio,artistic-2.0,6
-3175,Allakhazam/anythingV4,gradio,artistic-2.0,6
-3176,keras-dreambooth/dreambooth_teddy,gradio,apache-2.0,6
-3177,AIGC-Audio/Make_An_Audio,gradio,,6
-3178,nithinraok/titanet-speaker-verification,gradio,cc-by-4.0,6
-3179,baixing/hackathon_chatbot_openai_api,gradio,cc-by-4.0,6
-3180,yixin6178/ChatPaper,docker,gpl-3.0,6
-3181,hamacojr/CAT-Seg,gradio,,6
-3182,totalbogus/prompthero-openjourney-v4,gradio,,6
-3183,deepparag/DreamlikeArt-Diffusion-1.0,gradio,,6
-3184,xiaolv/new-bings,gradio,other,6
-3185,MichaelT8093/Mandarin-TTS,gradio,,6
-3186,Shocky/Pink-Anime,gradio,,6
-3187,mikebars/huggingface,static,,6
-3188,text-generation-inference/oasst-sft-1-pythia-12b,docker,other,6
-3189,hackathon-somos-nlp-2023/learning-assistance,gradio,,6
-3190,gstaff/sketch,gradio,apache-2.0,6
-3191,Gradio-Themes/neural-style-transfer-whiteboard-style,gradio,,6
-3192,finlaymacklon/smooth_slate,gradio,apache-2.0,6
-3193,RamAnanth1/videocrafter,gradio,,6
-3194,mrtlive/segment-anything-model,gradio,apache-2.0,6
-3195,ImagineAI-Real/ImagineAI-Image-Generator,gradio,,6
-3196,hackathon-somos-nlp-2023/flan-T5unami-base-v1,gradio,,6
-3197,hackathon-somos-nlp-2023/vg055-demo_analisis_de_sentimientos_textos_turisticos_mx_polarity,gradio,unknown,6
-3198,fl399/matcha_chartqa,gradio,,6
-3199,gradio-client-demos/stable-diffusion,gradio,mit,6
-3200,kazuk/youtube-whisper-17,gradio,unknown,6
-3201,kazuk/youtube-whisper-18,gradio,unknown,6
-3202,meyabase/oshiwambo-speech-greetings,gradio,apache-2.0,6
-3203,Monster/Alpaca-LoRa,gradio,unknown,6
-3204,sklearn-docs/A_demo_of_the_Spectral_Bi-Clustering_algorithm,gradio,,6
-3205,scutcyr/BianQue,streamlit,apache-2.0,6
-3206,abhi1nandy2/AI_Music_Team,gradio,,6
-3207,Altinas/vits-uma-genshin-honkais,gradio,apache-2.0,6
-3208,maurypb/mean_psychiatrist,gradio,unknown,6
-3209,sushmanth/hand_written_to_text,gradio,,6
-3210,Kaori1707/Image-enhancement,gradio,,6
-3211,shvuuuu/twitter-sentiment-analysis,streamlit,apache-2.0,6
-3212,mmlab-ntu/Segment-Any-RGBD,gradio,mit,6
-3213,kfahn/Animal_Pose_Control_Net,gradio,openrail,6
-3214,lamini/instruct-3b-playground,gradio,cc-by-4.0,6
-3215,sklearn-docs/regularization-path-l1,gradio,,6
-3216,alamin655/g-TTS,gradio,,6
-3217,Fisharp/starcoder-playground,gradio,,6
-3218,AtlasUnified/DeforumPromptGenerator,gradio,,6
-3219,dhof/shapetest,gradio,mit,6
-3220,hamacojr/SAM-CAT-Seg,gradio,,6
-3221,HuggingFaceM4/obelics_visualization,streamlit,,6
-3222,MeiJuice/CheckGPT,gradio,mit,6
-3223,fakezeta/pdfchat,streamlit,gpl-3.0,6
-3224,Francesco/FairytaleDJ,streamlit,,6
-3225,lint/streaming_chatbot,gradio,apache-2.0,6
-3226,Palplatine/artefact_memes,streamlit,mit,6
-3227,xfys/yolov5_tracking,gradio,,6
-3228,deepghs/nsfw_prediction,gradio,mit,6
-3229,huybery/deep-thinking,gradio,mit,6
-3230,OpenGVLab/DragGAN,gradio,,6
-3231,theaster/RVC-New-Arknights,gradio,mit,6
-3232,m-a-p/Music-Descriptor,gradio,cc-by-nc-4.0,6
-3233,Caoyunkang/Segment-Any-Anomaly,gradio,mit,6
-3234,matthoffner/starchat-ggml,docker,,6
-3235,neloreis/TheBloke-Wizard-Vicuna-13B-Uncensored-HF,gradio,,6
-3236,ChanceFocus/FLARE,gradio,mit,6
-3237,olivierdehaene/chat-ui-example,docker,apache-2.0,6
-3238,42digital/DeepFashion_Classification,gradio,,6
-3239,sasaki-saku/www_www,docker,,6
-3240,h2oai/wave-university,docker,apache-2.0,6
-3241,ysharma/function-to-JSON,gradio,mit,6
-3242,jbilcke-hf/webapp-factory-any-model,docker,,6
-3243,glt3953/app-text_generation_chatglm2-6b,gradio,,6
-3244,mlfoundations/VisIT-Bench-Leaderboard,gradio,cc-by-4.0,6
-3245,Tuana/what-would-mother-say,streamlit,,6
-3246,allknowingroger/Image-Models-Test14,gradio,,6
-3247,KyanChen/RSPrompter,gradio,,6
-3248,jbilcke-hf/video-upscaling-server-1,gradio,,6
-3249,sagarkarn/text2image,gradio,,6
-3250,Xorbits/xinference,gradio,apache-2.0,6
-3251,allknowingroger/Image-Models-Test32,gradio,,6
-3252,allknowingroger/Image-Models-Test33,gradio,,6
-3253,wouaf/WOUAF-Text-to-Image,gradio,mit,6
-3254,backrock/meta-llama-Llama-2-70b-hf,gradio,,6
-3255,AIxPha/QSign,docker,,6
-3256,merve/my-own-llama-v2,docker,apache-2.0,6
-3257,jbilcke-hf/AnimateDiff,gradio,apache-2.0,6
-3258,allknowingroger/Image-Models-Test44,gradio,,6
-3259,Xenova/next-server-example-app,docker,,6
-3260,Ababababababbababa/poetry,gradio,cc-by-nc-4.0,6
-3261,jbilcke-hf/image-server,gradio,mit,6
-3262,AIZero2HeroBootcamp/StaticHTML5Playcanvas,static,,6
-3263,AIZero2HeroBootcamp/3DHuman,gradio,mit,6
-3264,wwydmanski/esmfold,gradio,mit,6
-3265,amagastya/SPARK,docker,cc-by-nc-nd-4.0,6
-3266,Thafx/sdrv51,gradio,,6
-3267,SenY/Civitai,gradio,other,6
-3268,allknowingroger/Image-Models-Test62,gradio,,6
-3269,Xuan2060320350/BingAI,docker,mit,6
-3270,Sumsub/Sumsub-ffs-demo,gradio,,6
-3271,brainblow/AudioCreator_Music-Audio_Generation,gradio,,6
-3272,AnonAndDesu/Desu_Proxy,docker,,6
-3273,pknez/face-swap-docker,gradio,,6
-3274,HopeMan/3301,docker,,6
-3275,viait/multi-fusion-sd-dalle,static,,6
-3276,Brasd99/TTS-Voice-Conversion,streamlit,,6
-3277,dolphinchat/dolphinchat-llm-gpt-ui,gradio,,6
-3278,Open-Orca/LlongOrca-13B-16k,gradio,,6
-3279,ucanbaklava/stablediffusionapi-disney-pixar-cartoon,gradio,,6
-3280,alfredplpl/ChatZMD,gradio,apache-2.0,6
-3281,navdeeps002/codellama-CodeLlama-34b-hf,gradio,openrail,6
-3282,MohamedRashad/Audio-Separator,gradio,openrail,6
-3283,HoangHa/llama2-code,gradio,llama2,6
-3284,chilleverydaychill/roop,gradio,agpl-3.0,6
-3285,CatNika/Asian_Proxy,docker,,6
-3286,toloka/open-llm-leaderboard,streamlit,cc-by-4.0,6
-3287,ecker/vall-e,gradio,agpl-3.0,6
-3288,taejunkim/all-in-one,gradio,mit,6
-3289,HopeMan/Claude,docker,,6
-3290,ysharma/open-interpreter,gradio,mit,6
-3291,MrYXJ/calculate-model-flops,gradio,apache-2.0,6
-3292,ysharma/falcon-180b-demo,gradio,,6
-3293,librarian-bots/metadata_request_service,gradio,apache-2.0,6
-3294,llmonitor/benchmarks,docker,,6
-3295,ennet/ChatDev,gradio,,6
-3296,MakiAi/Image2VideoProcessingPipelin,gradio,apache-2.0,6
-3297,digitalxingtong/Xingtong-Longread-Bert-VITS2,gradio,mit,6
-3298,EasyEasy/EasyProxy,docker,,6
-3299,Goutam982/RVC_V2_voice_clone,gradio,lgpl-3.0,6
-3300,banana-dev/demo-faceswap,gradio,,6
-3301,smakamali/summarize_youtube,gradio,apache-2.0,6
-3302,allknowingroger/Image-Models-Test180,gradio,,6
-3303,Amiminoru/whoreproxy,docker,,6
-3304,XzJosh/Azusa-Bert-VITS2,gradio,mit,6
-3305,TLME/Bert-VITS-Umamusume-Genshin-HonkaiSR,gradio,agpl-3.0,6
-3306,ZachNagengast/vid2grid,gradio,,6
-3307,tonyassi/image-segmentation,gradio,,6
-3308,SeaLLMs/SeaLLM-Chat-13b,gradio,llama2,6
-3309,k2-fsa/text-to-speech,gradio,apache-2.0,6
-3310,umoubuton/atri-bert-vits2,gradio,agpl-3.0,6
-3311,pseudolab/GaiaMiniMed,gradio,apache-2.0,6
-3312,pseudolab/GaiaMiniMed_ChatWithFalcon,gradio,mit,6
-3313,openskyml/zephyr-7b-chat,gradio,,6
-3314,pseudolab/schoolrecord_gen,streamlit,mit,6
-3315,hayas/CALM2-7B-chat,gradio,mit,6
-3316,limcheekin/deepseek-coder-6.7B-instruct-GGUF,docker,,6
-3317,teowu/Q-Instruct-on-mPLUG-Owl-2,gradio,apache-2.0,6
-3318,aifartist/sdzoom-Latent-Consistency-Model,gradio,,6
-3319,latent-consistency/Real-Time-LCM-ControlNet-Lora-SD1.5,docker,,6
-3320,antigonus/cosmos,docker,,6
-3321,7Vivek/Next-Word-Prediction-Streamlit,streamlit,,5
-3322,Amrrs/image-caption-with-vit-gpt2,gradio,mit,5
-3323,BigSalmon/FormalInformalConciseWordy,streamlit,,5
-3324,BigSalmon/InformalToFormal,streamlit,,5
-3325,TheBritishLibrary/British-Library-books-genre-classifier,gradio,,5
-3326,Huertas97/LeetSpeak-NER,streamlit,,5
-3327,KJMAN678/text_generate,streamlit,,5
-3328,Kirili4ik/chat-with-Kirill,gradio,,5
-3329,NbAiLab/maken-clip-image,gradio,,5
-3330,PaddlePaddle/U-GAT-IT-selfie2anime,gradio,,5
-3331,PaddlePaddle/photo2cartoon,gradio,,5
-3332,khoj/NSE,gradio,,5
-3333,hunkim/DialoGPT,streamlit,,5
-3334,Theivaprakasham/layoutlmv2_sroie,gradio,apache-2.0,5
-3335,Vaibhavbrkn/Question-gen,gradio,,5
-3336,Wootang01/question_answer,gradio,,5
-3337,Wootang01/text_generator_two,gradio,,5
-3338,Yah216/Arabic-Sentiment-Analyser,streamlit,,5
-3339,YuAnthony/Voice-Recognition,gradio,,5
-3340,abby711/FaceRestoration,gradio,,5
-3341,abidlabs/Draw,gradio,,5
-3342,akhaliq/SWAG,gradio,,5
-3343,akhaliq/VQGAN_CLIP,gradio,,5
-3344,akhaliq/VQMIVC,gradio,,5
-3345,akhaliq/ctrl-sum,gradio,,5
-3346,akhaliq/genji-python-6b,gradio,,5
-3347,akhaliq/omnivore,gradio,other,5
-3348,arijitdas123student/meeting-summarizer,gradio,,5
-3349,cesar/demoIAZIKA,gradio,,5
-3350,chinhon/Headlines_Generator,gradio,,5
-3351,darkproger/propaganda,streamlit,,5
-3352,docs-demos/bart-large-mnli,gradio,,5
-3353,docs-demos/pegasus_paraphrase,gradio,,5
-3354,elonmuskceo/persistent-data,gradio,,5
-3355,espejelomar/Identify-the-breed-of-your-pet,streamlit,,5
-3356,fabiod20/italian-legal-ner,gradio,,5
-3357,flax-community/roberta-hindi,streamlit,,5
-3358,flax-community/spanish-gpt2,streamlit,,5
-3359,frapochetti/fast-neural-style-transfer,gradio,apache-2.0,5
-3360,gogamza/kobart-summarization,streamlit,,5
-3361,gulabpatel/GFP_GAN,gradio,,5
-3362,gulabpatel/Real-ESRGAN,gradio,,5
-3363,huspacy/demo,streamlit,,5
-3364,hysts/bizarre-pose-estimator-segmenter,gradio,,5
-3365,azizalto/vanilla-ml-algorithms,streamlit,,5
-3366,ibaiGorordo/Lane-Shape-Prediction-with-Transformers,gradio,,5
-3367,joaopdrm/Emotion_Analisys,gradio,,5
-3368,keras-io/CycleGAN,gradio,,5
-3369,keras-io/conv-lstm,gradio,,5
-3370,keras-io/deep-dream,gradio,cc0-1.0,5
-3371,kingabzpro/Rick_and_Morty_Bot,gradio,apache-2.0,5
-3372,luisoala/glide-test,gradio,,5
-3373,m3hrdadfi/gpt2-persian-qa,streamlit,,5
-3374,manhkhanhUIT/BOPBTL,gradio,,5
-3375,mizoru/Japanese_pitch,gradio,,5
-3376,muhtasham/legalBERT,gradio,,5
-3377,osanseviero/AnimeGANv2-webcam,gradio,,5
-3378,pytorch/ResNet,gradio,,5
-3379,rajesh1729/text-summarization-gradio,gradio,afl-3.0,5
-3380,raphaelsty/games,streamlit,,5
-3381,rashmi/sartorius-cell-instance-segmentation,gradio,,5
-3382,rexoscare/Styleformer_demo,gradio,,5
-3383,shawon100/text-paraphrasing,gradio,,5
-3384,shujianong/pkm-card,gradio,mit,5
-3385,taesiri/ConvolutionalHoughMatchingNetworks,gradio,,5
-3386,vasudevgupta/BIGBIRD_NATURAL_QUESTIONS,gradio,,5
-3387,wietsedv/xpos,gradio,,5
-3388,xin/PatentSolver,streamlit,,5
-3389,yavuzkomecoglu/Turkish-Speech-Recognition,gradio,,5
-3390,yhavinga/netherator,streamlit,,5
-3391,yrodriguezmd/Surgical_instruments_app,gradio,,5
-3392,onnx/EfficientNet-Lite4,gradio,,5
-3393,akhaliq/RealBasicVSR,gradio,,5
-3394,sarulab-speech/UTMOS-demo,gradio,afl-3.0,5
-3395,tomofi/trocr-captcha,gradio,mit,5
-3396,course-demos/audio-reverse,gradio,mit,5
-3397,KPatrick/PaddleSpeechTTS,gradio,apache-2.0,5
-3398,egmaminta/python-code-summarizer,gradio,mit,5
-3399,malteos/aspect-based-paper-similarity,streamlit,mit,5
-3400,Belligerent/word-sense-disambiguation,gradio,apache-2.0,5
-3401,IanNathaniel/Zero-DCE,gradio,,5
-3402,unity/Indoor-Pet-Detection,gradio,apache-2.0,5
-3403,onnx/mask-rcnn,gradio,,5
-3404,onnx/faster-rcnn,gradio,,5
-3405,kazimsayed/News-Article-Summarizer,gradio,afl-3.0,5
-3406,CVPR/Demo-Balanced-MSE,gradio,apache-2.0,5
-3407,godot-demo/godot-3d-trucks,static,,5
-3408,godot-demo/godot-3d-voxel,static,,5
-3409,Harveenchadha/Vakyansh-Malayalam-TTS,gradio,apache-2.0,5
-3410,jw2yang/focalnet-modulators,gradio,apache-2.0,5
-3411,hackathon-pln-es/extractive-qa-biomedicine,gradio,other,5
-3412,hackathon-pln-es/spanish-to-quechua-translation,gradio,apache-2.0,5
-3413,templates/http-server,gradio,mit,5
-3414,hysts/insightface-person-detection,gradio,,5
-3415,hysts/ibug-face_alignment,gradio,,5
-3416,huggan/Sketch2Shoes,gradio,,5
-3417,nikhedward/TL-DR_summarize_it,gradio,,5
-3418,huggan/pix2pix-map,gradio,,5
-3419,SaulLu/diff-visualizer,streamlit,,5
-3420,yangheng/PyABSA-APC,gradio,mit,5
-3421,huggan/cryptopunk-captcha,streamlit,,5
-3422,hysts/Manga-OCR,gradio,,5
-3423,rajesh1729/animated-visualization-with-mercury-ipyvizzu,gradio,afl-3.0,5
-3424,huggan/StyleGAN3,gradio,,5
-3425,SerdarHelli/Brain-MR-Image-Generation-with-StyleGAN,gradio,,5
-3426,merve/anonymization,static,apache-2.0,5
-3427,merve/fill-in-the-blank,static,apache-2.0,5
-3428,merve/uncertainty-calibration,static,apache-2.0,5
-3429,prairie-guy/Seasonal_Mood,gradio,mit,5
-3430,ysharma/RickandLex_Interview_GPTJ6B,gradio,mit,5
-3431,bigscience-data/bigscience-tokenizer,streamlit,apache-2.0,5
-3432,bigscience-data/bigscience-corpus,streamlit,apache-2.0,5
-3433,gradio/Echocardiogram-Segmentation,gradio,,5
-3434,shibing624/nerpy,gradio,apache-2.0,5
-3435,Finnish-NLP/Finnish-Automatic-Speech-Recognition,gradio,mit,5
-3436,wahaha/u2net_portrait,gradio,apache-2.0,5
-3437,BernardoOlisan/vqganclip,gradio,,5
-3438,abdulmatinomotoso/Article_paraphraser,gradio,,5
-3439,KenjieDec/GPEN,gradio,,5
-3440,sanzgiri/cartoonify,streamlit,other,5
-3441,qanastek/Alexa-NLU-Clone,gradio,cc-by-4.0,5
-3442,Gradio-Blocks/are-you-wearing-a-mask,gradio,mit,5
-3443,ntt123/vietnamese-handwriting,static,cc-by-nc-4.0,5
-3444,Gradio-Blocks/Pipeline-Tester,gradio,,5
-3445,evaluate-metric/comet,gradio,,5
-3446,evaluate-metric/sari,gradio,,5
-3447,Gradio-Blocks/poor-mans-duplex,gradio,apache-2.0,5
-3448,awacke1/AIDocumentUnderstandingOCR,gradio,mit,5
-3449,Zengyf-CVer/Gradio_YOLOv5_Det_v4,gradio,gpl-3.0,5
-3450,lopushanskyy/music-generation,gradio,,5
-3451,johnowhitaker/whistlegen_v2,gradio,mit,5
-3452,basicv8vc/learning-rate-scheduler-online,streamlit,apache-2.0,5
-3453,angelina-wang/directional_bias_amplification,gradio,,5
-3454,nateraw/modelcard-creator,streamlit,mit,5
-3455,bigscience-data/process-pipeline-visualizer,streamlit,,5
-3456,miesnerjacob/text-emotion-detection,gradio,,5
-3457,keras-io/Credit_Card_Fraud_Detection,gradio,apache-2.0,5
-3458,keras-io/MelGAN-spectrogram-inversion,gradio,apache-2.0,5
-3459,ybelkada/bloom-1b3-gen,gradio,,5
-3460,ZhangYuanhan/Bamboo_ViT-B16_demo,gradio,cc-by-4.0,5
-3461,HALLA/HALL-E,static,other,5
-3462,awacke1/ASR-High-Accuracy-Test,gradio,mit,5
-3463,cybernatedArt/Skin_disease_detection,gradio,,5
-3464,alistairmcleay/cambridge-masters-project,gradio,wtfpl,5
-3465,CVPR/TokenCut,gradio,,5
-3466,BigDL/bigdl_nano_demo,gradio,,5
-3467,juliensimon/keyword-spotting,gradio,,5
-3468,smangrul/Chat-E,gradio,cc-by-nc-4.0,5
-3469,Theivaprakasham/yolov6,gradio,gpl-3.0,5
-3470,codeparrot/apps_metric,gradio,,5
-3471,Shue/DIGIMAP-Group4-Animefy,streamlit,,5
-3472,hugginglearners/Identify_which_flower,gradio,apache-2.0,5
-3473,carblacac/chatbot,gradio,,5
-3474,awacke1/VideoSummary2,gradio,mit,5
-3475,AlexWortega/MailruQA,gradio,,5
-3476,Msp/Document_Classification_DIT,gradio,afl-3.0,5
-3477,huggingface/bloom-test-flax,gradio,,5
-3478,ICML2022/ICML2022_papers,gradio,,5
-3479,EuroPython2022/PaddleOCR,gradio,,5
-3480,codeparrot/code-complexity-predictor,gradio,apache-2.0,5
-3481,kornia/kornia-augmentations-tester,streamlit,,5
-3482,EuroPython2022/swinunetr-dicom-video,gradio,apache-2.0,5
-3483,fabiochiu/semantic-search-medium,streamlit,mit,5
-3484,alphacep/asr,gradio,apache-2.0,5
-3485,ghosthamlet/Write-Stories-Using-Bloom,gradio,,5
-3486,platzi/platzi-curso-streamlit-segmentacion-imagenes,streamlit,mit,5
-3487,twigs/simplifier,streamlit,,5
-3488,omri374/presidio,docker,mit,5
-3489,ICML2022/PointCloudC,gradio,,5
-3490,ysr/blurryAI,gradio,,5
-3491,sidharthism/fashion-eye-try-on,gradio,,5
-3492,vinai/VinAI_Translate,gradio,,5
-3493,Enutrof/English-NigerianPidgin-Translator,gradio,mit,5
-3494,ybelkada/petals,streamlit,,5
-3495,ky2k/image_denoise_demo,gradio,,5
-3496,jorge-henao/ask2democracycol,streamlit,apache-2.0,5
-3497,oniati/mrt,gradio,,5
-3498,EnzoBustos/IC-2022-Classificacao-de-Dados-Financeiros,streamlit,other,5
-3499,JavierFnts/clip-playground,streamlit,apache-2.0,5
-3500,owaiskha9654/Video_Summarization,gradio,apache-2.0,5
-3501,tner/NER,gradio,,5
-3502,doevent/blip,gradio,bsd-3-clause,5
-3503,RishShastry/ArtStyleClassifier,gradio,apache-2.0,5
-3504,RoyalEagle/ArtGenerator,gradio,,5
-3505,mohsayed/arabic_text_detection,streamlit,unknown,5
-3506,jonathanli/youtube-sponsor-detection,gradio,mit,5
-3507,daspartho/anime-or-not,gradio,apache-2.0,5
-3508,kornia/homography-warping,gradio,apache-2.0,5
-3509,pratikskarnik/face_problems_analyzer,gradio,apache-2.0,5
-3510,BlitzEsports/TextToImage,static,apache-2.0,5
-3511,AfrodreamsAI/afrodreams,streamlit,,5
-3512,yhavinga/rosetta,streamlit,postgresql,5
-3513,mideind/textaleidretting,gradio,,5
-3514,johngoad/Face-Mesh,gradio,,5
-3515,AIZ2H/06-Streamlit-NLP-Image-Semantic-Search-Images,streamlit,apache-2.0,5
-3516,jthteo/Whisper,gradio,cc-by-nc-4.0,5
-3517,ysharma/Voice-to-jokes,gradio,mit,5
-3518,p208p2002/Question-Group-Generator,gradio,,5
-3519,sneedium/dvatch_captcha_sneedium,gradio,,5
-3520,itmorn/detect_face,gradio,other,5
-3521,NealCaren/transcript,streamlit,openrail,5
-3522,nateraw/stable_diffusion_gallery,gradio,mit,5
-3523,ai-danger/hot-or-not,gradio,,5
-3524,MikailDuzenli/vilt_demo,gradio,,5
-3525,dmvaldman/ICLR2023,gradio,,5
-3526,imseldrith/Article_Rewrite-Paraphrasing_Tool,gradio,mit,5
-3527,YaYaB/text-to-magic,gradio,,5
-3528,kotori8823/Real-CUGAN,gradio,apache-2.0,5
-3529,awacke1/ASR-SOTA-NvidiaSTTMozilla,gradio,apache-2.0,5
-3530,bwconrad/anime-character-classification,gradio,,5
-3531,bowtiedhal/essay_outline_generator,gradio,gpl,5
-3532,kabita-choudhary/audio_to_text,gradio,,5
-3533,luost26/DiffAb,streamlit,,5
-3534,digitiamosrl/recsys-and-customer-segmentation,streamlit,mit,5
-3535,tomaseo2022/Mejorar-Resolucion-Imagen,gradio,,5
-3536,sayakpaul/fivek-retouching-maxim,gradio,apache-2.0,5
-3537,Catmeow/Text_Generation_Fine_Tune,gradio,,5
-3538,dentadelta123/grammarly,gradio,unlicense,5
-3539,Yukki-Yui/moe-tts,gradio,mit,5
-3540,jspr/autodrummer,gradio,,5
-3541,huy-ha/semabs-relevancy,gradio,mit,5
-3542,anonymousauthorsanonymous/uncertainty,gradio,mit,5
-3543,tryolabs/transformers-optimization,gradio,mit,5
-3544,RamAnanth1/Youtube-to-HF-Dataset,gradio,,5
-3545,segadeds/Medical_Diagnosis,gradio,apache-2.0,5
-3546,akhaliq/Text-to-Music,gradio,unknown,5
-3547,j43fer/MagicPrompt-Stable-Diffusion,gradio,mit,5
-3548,zswvivi/ChineseMedicalT5,gradio,apache-2.0,5
-3549,Sup3r/Image-Upscaling-Playground,gradio,apache-2.0,5
-3550,morenolq/galactica-base-api,gradio,apache-2.0,5
-3551,TuringAgency/anic_gui,static,,5
-3552,AnonymousForSubmission/Graphic_Score_and_Audio,gradio,,5
-3553,pcuenq/dreambooth-training,gradio,mit,5
-3554,clem/stable-diffusionv2_test,static,mit,5
-3555,nightfury/Stable_Diffusion_2,static,mit,5
-3556,nakas/musika_api,gradio,cc-by-4.0,5
-3557,Xhaheen/stable-diffusionv2_test_2,static,mit,5
-3558,datasciencedojo/YouTube-video-transcript-generator,gradio,,5
-3559,guohuiyuan/Text-to-Music,gradio,unknown,5
-3560,os1187/free-fast-youtube-url-video-to-text-using-openai-whisper,gradio,gpl-3.0,5
-3561,hysts/multiresolution-textual-inversion,gradio,,5
-3562,rizam/rakeebjaufer,gradio,,5
-3563,sayakpaul/fetch-similar-images,gradio,apache-2.0,5
-3564,YeOldHermit/Super-Resolution-Anime-Diffusion,gradio,mit,5
-3565,muellerzr/accelerate-presentation,static,,5
-3566,taquynhnga/CNNs-interpretation-visualization,streamlit,,5
-3567,mbazaNLP/kinyarwanda-nemo-asr-demo,gradio,apache-2.0,5
-3568,vincentclaes/art-search-engine,gradio,,5
-3569,Ramos-Ramos/visual-emb-gam-probing,gradio,,5
-3570,Randolph/hadenjax-dreams,gradio,other,5
-3571,amitkayal/Article-Rewriter,gradio,,5
-3572,imseldrith/Text-to-Image2,gradio,,5
-3573,HIT-TMG/dialogue-bart-large-chinese,gradio,apache-2.0,5
-3574,drift-ai/art-search-engine,gradio,,5
-3575,osanseviero/mishigify,gradio,,5
-3576,tomsoderlund/text-summarizer,gradio,openrail,5
-3577,kadirnar/yolov6,gradio,gpl-3.0,5
-3578,AIDHD/audio-video-transcriber,gradio,,5
-3579,arbml/whisper-largev2-ar,gradio,,5
-3580,hasibzunair/masksup-segmentation-demo,gradio,afl-3.0,5
-3581,sayakpaul/tensorrt-tf,docker,apache-2.0,5
-3582,zachriek/chatgpt-clone,gradio,,5
-3583,kouenYoung/anime-tts,gradio,,5
-3584,xelu3banh/dpt-depth16,gradio,,5
-3585,Shad0ws/Videoclassifier-ZEROSHOT,gradio,apache-2.0,5
-3586,abidlabs/whisper,gradio,,5
-3587,Abhilashvj/haystack_QA,streamlit,apache-2.0,5
-3588,GIanlucaRub/DoubleResolution,gradio,,5
-3589,DrHakase/full-body-anime-gan,gradio,apache-2.0,5
-3590,BigData-KSU/VQA-in-Medical-Imagery,gradio,,5
-3591,om-app/magic-diffusion,gradio,apache-2.0,5
-3592,om-app/Promt-to-Image-diffusions,gradio,apache-2.0,5
-3593,Rmpmartinspro2/Comic-Diffusion,gradio,,5
-3594,keremberke/license-plate-object-detection,gradio,,5
-3595,biodatlab/whisper-thai-yt-subtitles,gradio,mit,5
-3596,umair007/all_in_one_converter,gradio,mit,5
-3597,ccds/vits_onnx,docker,,5
-3598,HutzHoo/dreamlike-photoreal-2.0,gradio,,5
-3599,patrickvonplaten/protogen-web-ui,gradio,mit,5
-3600,deepghs/deepdanbooru_online,gradio,mit,5
-3601,vicalloy/GFPGAN,gradio,apache-2.0,5
-3602,Arafath10/chatcode,gradio,,5
-3603,kazuk/youtube-whisper-06,gradio,unknown,5
-3604,b3xxf21f/A3Private,gradio,,5
-3605,akhaliq/Counterfeit-V2.0,gradio,,5
-3606,Smithjohny376/Orangemixes,gradio,,5
-3607,diffusers/check_pr,gradio,apache-2.0,5
-3608,derek-thomas/top2vec,streamlit,mit,5
-3609,alirezamsh/small100,gradio,mit,5
-3610,redpeacock78/anything-v5.0,gradio,,5
-3611,Tirendaz/background-remover,gradio,other,5
-3612,ClassCat/YOLOS-Object-Detection,gradio,,5
-3613,librarian-bot/webhook_metadata_reviewer,docker,,5
-3614,Elbhnasy/Foodvision_mini,gradio,mit,5
-3615,mpuig/gpt3-email-generator,streamlit,,5
-3616,competitions/create,docker,,5
-3617,camenduru-com/tensor-rt,docker,,5
-3618,ai-forever/NotebooksRecognition,gradio,mit,5
-3619,sheldon/xiaolxl-GuoFeng3,gradio,afl-3.0,5
-3620,juliensimon/bridgetower-demo,gradio,,5
-3621,jbrinkma/deepmind-pushworld,static,openrail,5
-3622,active-learning/labeler,gradio,,5
-3623,sheikyerbouti/riffusion-playground,streamlit,mit,5
-3624,hysts/DETA,gradio,mit,5
-3625,multimodalart/Tune-A-Video-Training-UI-poli,docker,mit,5
-3626,spaces-ci-bot/webhook,gradio,,5
-3627,yahma/rwkv-instruct,gradio,,5
-3628,king007/invoices,gradio,,5
-3629,hysts/Compare-DETA-and-YOLOv8,gradio,mit,5
-3630,mrm8488/santacoder-swift-completion,gradio,,5
-3631,HuggingFaceH4/Elo,streamlit,apache-2.0,5
-3632,awacke1/AutoMLUsingStreamlit-Plotly,streamlit,,5
-3633,deprem-ml/ner-active-learning,gradio,apache-2.0,5
-3634,DataScienceEngineering/1-SimPhysics-HTML5,static,,5
-3635,Blealtan/clip-guided-binary-autoencoder,streamlit,apache-2.0,5
-3636,AlphonseBrandon/speecht5-tts-demo,gradio,apache-2.0,5
-3637,RamAnanth1/T2I-Adapter,gradio,,5
-3638,JcRolling/cartoon-converter,gradio,,5
-3639,PierreSHI/YOLOS_traffic_object_detection,gradio,unknown,5
-3640,Thafx/sdrv1_4,gradio,,5
-3641,deeplearning/audioldm-text-to-audio-generation,gradio,bigscience-openrail-m,5
-3642,harkov000/peft-lora-sd-dreambooth,gradio,openrail,5
-3643,jskim/paper-matching,gradio,mit,5
-3644,jin-nin/artist,gradio,,5
-3645,RamAnanth1/human_preference,gradio,,5
-3646,text-generation-inference/chat-ui,docker,other,5
-3647,Mayank-02/Matching-job-descriptions-and-resumes,gradio,,5
-3648,mbazaNLP/Speech-recognition-east-african-languages,gradio,apache-2.0,5
-3649,bigjoker/stable-diffusion-webui,gradio,,5
-3650,dylanmeca/ChatGPT-Assistant,gradio,gpl-3.0,5
-3651,cxeep/PaddleOCR,gradio,,5
-3652,awacke1/AIZTH-03-09-2023,streamlit,mit,5
-3653,jarvisx17/YouTube-Video-Summarization,streamlit,other,5
-3654,WiNE-iNEFF/WebUI-Counterfeit-V2.5,gradio,,5
-3655,NoCrypt/SomethingV2,gradio,,5
-3656,Daextream/Whisper-Auto-Subtitled-Video-Generator,streamlit,,5
-3657,xp3857/Image_Restoration_Colorization,gradio,,5
-3658,Hexequin/dreamlike-photoreal-2.0,gradio,,5
-3659,chriscelaya/streaming_chat_gpt-3.5-turbo_langchain,gradio,mit,5
-3660,ashhadahsan/ai-book-generator,streamlit,,5
-3661,cooelf/Multimodal-CoT,gradio,openrail,5
-3662,keras-dreambooth/traditional-furniture-demo,gradio,apache-2.0,5
-3663,suko/nsfw,gradio,apache-2.0,5
-3664,keras-dreambooth/Pokemon-dreambooth,gradio,apache-2.0,5
-3665,unilight/s3prl-vc-vcc2020,gradio,mit,5
-3666,patrawtf/shopify_csv_qa,gradio,afl-3.0,5
-3667,burakaytan/turkish_typo_correction,gradio,,5
-3668,mindart/infinite-zoom-stable-diffusion,gradio,mit,5
-3669,ranjangoel/GPT-PDF,gradio,,5
-3670,Alpaca233/ChatGPT-PPT-Generate,gradio,,5
-3671,pszemraj/generate-instructions,gradio,apache-2.0,5
-3672,gradio/seafoam,gradio,apache-2.0,5
-3673,hackathon-somos-nlp-2023/leaderboard,gradio,apache-2.0,5
-3674,zenml/zenml,docker,apache-2.0,5
-3675,LeoLeoLeo1/ChuanhuChatGPT,gradio,gpl-3.0,5
-3676,AI4PD/hexviz,streamlit,,5
-3677,somosnlp/somos-alpaca-es,docker,,5
-3678,silentchen/layout-guidance,gradio,,5
-3679,ns2001/pdfgpt,streamlit,,5
-3680,bobu5/SD-webui-controlnet-docker,docker,,5
-3681,aliabid94/gpt_who,gradio,openrail,5
-3682,gstaff/whiteboard,gradio,apache-2.0,5
-3683,Notalib/GPT-Whisper-Wolfram-Google-Test,gradio,bsd-3-clause,5
-3684,drift-ai/faq-website,gradio,apache-2.0,5
-3685,fffiloni/video2canny,gradio,,5
-3686,SamerKharboush/chatGPT-Sam-Turbo,gradio,gpl-3.0,5
-3687,yxmnjxzx/Lama-Cleaner-lama,gradio,apache-2.0,5
-3688,peterwisu/lip_synthesis,gradio,unknown,5
-3689,hugforziio/chat-gpt-batch,gradio,,5
-3690,ParityError/Interstellar,gradio,apache-2.0,5
-3691,superwise/elemeta,streamlit,mit,5
-3692,sakasegawa/whisper-speaker-diarization-assign,gradio,apache-2.0,5
-3693,Aaaaaaaabdualh/poetry,gradio,cc-by-nc-4.0,5
-3694,Cletrason/Cletrason-toad-mario-movie,gradio,,5
-3695,declare-lab/flan-t5-xl-lora,gradio,,5
-3696,henryu/Clip-image2text,gradio,openrail,5
-3697,jjzha/skill_extraction_demo,gradio,,5
-3698,fffiloni/mmpose-estimation,gradio,mit,5
-3699,ochyai/ochyai_food,gradio,,5
-3700,ieuniversity/Clothes_image_captioning,gradio,,5
-3701,marinap/multilingual-image-search,gradio,apache-2.0,5
-3702,gradio-client-demos/comparing-captioning-models,gradio,,5
-3703,HaoFeng2019/DocTr,gradio,mit,5
-3704,weijiawu/ImageEditAnything,gradio,apache-2.0,5
-3705,niizam/sovits-models,gradio,mit,5
-3706,Volkopat/arXivGPT,gradio,apache-2.0,5
-3707,king007/Voice-Cloning,gradio,mit,5
-3708,sajornad/ZoeDepth,gradio,mit,5
-3709,lithiumice/SadTalker,gradio,mit,5
-3710,HaoFeng2019/DocGeoNet,gradio,mit,5
-3711,AI-Dashboards/Memory-Chat-Story-Generator-ChatGPT,gradio,mit,5
-3712,satyamg1620/PCA-Image-Reconstruction,streamlit,,5
-3713,ardigen/ardisplay-i,gradio,,5
-3714,HLasse/textdescriptives,streamlit,apache-2.0,5
-3715,mohsenfayyaz/DecompX,gradio,,5
-3716,nsarrazin/serge,docker,mit,5
-3717,HighCWu/Style2Paints-4.5-Gradio,gradio,apache-2.0,5
-3718,hra/Curriculum-BabyAGI,gradio,cc-by-nc-nd-4.0,5
-3719,zeno-ml/openai-evals,docker,mit,5
-3720,Kevin676/Shanghainese-TTS-demo,gradio,,5
-3721,cogcorp/assignment1,gradio,,5
-3722,mattmdjaga/segment_anything_base,gradio,mit,5
-3723,Future-AI/image-matting,gradio,apache-2.0,5
-3724,Celestinian/Prompt-Generator,gradio,mit,5
-3725,Kaori1707/Depth-estimation,gradio,,5
-3726,sander-wood/clamp_semantic_music_search,gradio,mit,5
-3727,sander-wood/clamp_zero_shot_music_classification,gradio,mit,5
-3728,mthsk/sovits-models-misc,gradio,mit,5
-3729,Zhenhong/text-to-speech-SpeechT5-demo,gradio,afl-3.0,5
-3730,lmattingly/cartoonify-yourself,gradio,,5
-3731,Pie31415/control-animation,gradio,,5
-3732,JFoz/Dog-Pose-Editor-Controlnet,gradio,openrail,5
-3733,joaogante/assisted_generation_benchmarks,gradio,,5
-3734,lamini/instruct-playground-12b,gradio,cc-by-4.0,5
-3735,ahmetfirat/KORKUT_A_Spacetime_Odyssey,gradio,other,5
-3736,Volkopat/SegmentAnythingxGroundingDINO,gradio,,5
-3737,dy2dx2/Physics-Assistant,gradio,,5
-3738,cc38300/constructionGPT,gradio,,5
-3739,anisharitakula/sentiment_classifier,gradio,apache-2.0,5
-3740,thecho7/deepfake,gradio,unlicense,5
-3741,instruction-tuning-sd/instruction-tuned-sd,gradio,apache-2.0,5
-3742,cloixai/stable-diffusion-webui-cpu,gradio,,5
-3743,radames/gradio_window_localStorage,gradio,,5
-3744,h2oai/wave-tour,docker,apache-2.0,5
-3745,koajoel/PolyFormer,gradio,apache-2.0,5
-3746,kevinwang676/web-singer-new-2,docker,,5
-3747,JCTN/controlnet-segment-anything,gradio,mit,5
-3748,dorkai/text-generation-webui-main,gradio,openrail,5
-3749,voices/VCTK_British_English_Females,docker,other,5
-3750,sradc/visual-content-search-over-videos,streamlit,,5
-3751,voices/voice-directory,docker,cc-by-4.0,5
-3752,vishnu23/OCR_with_image,streamlit,,5
-3753,Khaled27/Naptah,gradio,other,5
-3754,anzorq/spaces-semantic-search-api,gradio,mit,5
-3755,yoinked/da_nsfw_checker,gradio,mit,5
-3756,Superlang/ImageProcessor,gradio,cc-by-nc-2.0,5
-3757,nicehero/ManualMask,gradio,bsd,5
-3758,zou-code/gorilla-llm-gorilla-7b-hf-delta-v0,gradio,,5
-3759,shgao/MDT,gradio,cc-by-nc-4.0,5
-3760,llamaindex/text2image_prompt_assistant,streamlit,mit,5
-3761,renumics/cifar100-enriched,docker,mit,5
-3762,noamelata/Nested-Diffusion,gradio,,5
-3763,Mountchicken/MAERec-Gradio,gradio,mit,5
-3764,Cloudyy/bark-voice-cloning,gradio,mit,5
-3765,raghavtwenty/cyber-attack-prediction,gradio,,5
-3766,allen-eric/radiology-gpt,gradio,apache-2.0,5
-3767,yuangongfdu/whisper-at,gradio,mit,5
-3768,RitaParadaRamos/SmallCapDemo,gradio,,5
-3769,Wauplin/space_to_dataset_saver,gradio,,5
-3770,nomic-ai/atlas,static,,5
-3771,leonelhs/GFPGAN,gradio,apache-2.0,5
-3772,Yntec/DucHaiten-Webui-CPU,gradio,,5
-3773,p1atdev/waifu_aesthetics,gradio,,5
-3774,artificialguybr/liberte,gradio,,5
-3775,ADOPLE/Adopleai-DocumentQA,gradio,,5
-3776,MAPS-research/GEMRec-Gallery,streamlit,,5
-3777,Shad0ws/AI-Agent-with-Google-Search-APIs,streamlit,mit,5
-3778,Voicemod/Speech-to-Speech,gradio,,5
-3779,NealCaren/TranscribeX,streamlit,,5
-3780,matthoffner/falcon-mini,docker,apache-2.0,5
-3781,TrustSafeAI/RADAR-AI-Text-Detector,gradio,apache-2.0,5
-3782,odettecantswim/rvc-mlbb-v2,gradio,mit,5
-3783,h2oai/theme-generator,docker,apache-2.0,5
-3784,YaTharThShaRma999/WizardLM7b,gradio,apache-2.0,5
-3785,allknowingroger/Image-Models-Test11,gradio,,5
-3786,cvsys/upscale,gradio,apache-2.0,5
-3787,verkaDerkaDerk/face-mesh-workflow,gradio,,5
-3788,Matthijs/mms-tts-demo,gradio,apache-2.0,5
-3789,allknowingroger/Image-Models-Test16,gradio,,5
-3790,yaoshining/text-generation-webui,gradio,apache-2.0,5
-3791,jbilcke-hf/MusicGen,gradio,cc-by-nc-4.0,5
-3792,course-demos/speech-to-speech-translation,gradio,,5
-3793,nomic-ai/zhengyun21_PMC-Patients,static,,5
-3794,hesha/upscaler,gradio,apache-2.0,5
-3795,jbilcke-hf/video-interpolation-server,gradio,,5
-3796,Ababababababbababa/SD-2.1-Img2Img,gradio,mit,5
-3797,Dragonnext/Drago-Proxy,docker,,5
-3798,theaster/imoitari,docker,,5
-3799,oppappi/wd-v1-4-tags,gradio,,5
-3800,TTT-9552/Y7cLhT3pE9gV4xW2nQ5,docker,,5
-3801,HuggingAlgorithms/PDF-TextExtractor,gradio,mit,5
-3802,luisotorres/wine-quality-predictions,streamlit,,5
-3803,VoiceHero69/changer,gradio,openrail,5
-3804,allknowingroger/Image-Models-Test38,gradio,,5
-3805,benzel34/fun,docker,,5
-3806,gradio/chatinterface_streaming_echo,gradio,,5
-3807,tcfly/Flowise,docker,,5
-3808,xswu/HPSv2,gradio,apache-2.0,5
-3809,asas-ai/Arabic-LLM-Leaderboard,streamlit,,5
-3810,NMEX/rvc-hoyogame-v2,gradio,mit,5
-3811,r3gm/ConversaDocs,gradio,,5
-3812,KAIST-Geometric-AI-Lab/salad-demo,gradio,mit,5
-3813,mikeee/llama2-7b-chat-uncensored-ggml,gradio,,5
-3814,mikeee/nousresearch-nous-hermes-llama2-13b-ggml,gradio,,5
-3815,grzegorz2047/fast_diffusion,gradio,,5
-3816,WinterGYC/Baichuan-13B-Chat-Int8,streamlit,apache-2.0,5
-3817,grass-eater/grassproxy,docker,,5
-3818,foduucom/plant-leaf-detection-classification-yolov8,gradio,,5
-3819,Thafx/sdrv50,gradio,,5
-3820,PeepDaSlan9/stabilityai-stable-diffusion-xl-base-1.0,gradio,openrail++,5
-3821,vanderbilt-dsi/free-speech-app,streamlit,,5
-3822,qblocks/Monster-SD,gradio,apache-2.0,5
-3823,huaiji3y/BingAI-Public,docker,mit,5
-3824,jbilcke-hf/upscaling-server,gradio,,5
-3825,harshitv804/LawGPT,gradio,gpl,5
-3826,s3nh/WizardLM-1.0-Uncensored-Llama2-13b-GGML,gradio,openrail,5
-3827,Blessing/Asphalt-Pavement-Distresses-Detector,gradio,mit,5
-3828,Manjushri/SDXL-1.0-Doodle-to-Image,gradio,mit,5
-3829,remotewith/image-to-text-app,streamlit,afl-3.0,5
-3830,Justin-Choo/Counterfeit_WEB_UI,gradio,,5
-3831,allknowingroger/Image-Models-Test83,gradio,,5
-3832,viait/stable-diffusion,gradio,creativeml-openrail-m,5
-3833,felixz/meta_open_llm_leaderboard,streamlit,apache-2.0,5
-3834,mrspinn/goofyai-3d_render_style_xl,gradio,,5
-3835,doncamilom/ChemCrow,streamlit,,5
-3836,damo-vilab/MS-Image2Video-demo,docker,,5
-3837,ridges/WizardLM-WizardCoder-Python-34B-V1.0,gradio,unknown,5
-3838,Alfasign/dIFFU,gradio,,5
-3839,thnqls/Phind-Phind-CodeLlama-34B-v2,gradio,,5
-3840,mofu-team/ggl-chk,gradio,wtfpl,5
-3841,Yntec/photoMovieX,gradio,,5
-3842,radames/gradio-blender-bpy,gradio,,5
-3843,BraydenMoore/MARCI-NFL-Betting,docker,,5
-3844,chengli-thu/ChatHaruhi-OpenAI,gradio,,5
-3845,xeonm/image-to-audio-story,streamlit,cc0-1.0,5
-3846,asigalov61/Allegro-Music-Transformer,gradio,apache-2.0,5
-3847,insomniac0/Midnight,docker,,5
-3848,jordonpeter01/ai-comic-factory,docker,,5
-3849,daishen/LAiW,gradio,,5
-3850,eaglelandsonce/QueryaWebsite,streamlit,,5
-3851,AIWaves/Software_Company,gradio,apache-2.0,5
-3852,lalashechka/sdxl2,gradio,,5
-3853,XzJosh/nine1-Bert-VITS2,gradio,mit,5
-3854,openkg/llm_leaderboard,gradio,mit,5
-3855,librarian-bots/collection-reading-list-generator,gradio,,5
-3856,deepkyu/multilingual-font-style-transfer,gradio,mit,5
-3857,eaglelandsonce/chromadbmeetupdemo,streamlit,,5
-3858,AzumaSeren100/XuanShen-Bert-VITS2,gradio,apache-2.0,5
-3859,kevinwang676/Voice-Cloning-for-YouTube,gradio,mit,5
-3860,XzJosh/nanami-Bert-VITS2,gradio,mit,5
-3861,andreped/AeroPath,docker,mit,5
-3862,tonyassi/fashion-stylist-bot,gradio,,5
-3863,LanguageBind/LanguageBind,gradio,,5
-3864,jbochi/Candle-CoEdIT-Wasm,static,apache-2.0,5
-3865,TheStinger/ILARIA_UVR,gradio,,5
-3866,3B-Group/ConvRe-Leaderboard,gradio,mit,5
-3867,innat/VideoMAE,gradio,,5
-3868,SoAp9035/mistral-7b-fast-chat,gradio,,5
-3869,Roboflow/Annotators,gradio,mit,5
-3870,tonyassi/controlnet-explorer,gradio,,5
-3871,XzJosh/Diana-Bert-VITS2,gradio,mit,5
-3872,rishiraj/zephyr,gradio,apache-2.0,5
-3873,ennov8ion/500models,gradio,,5
-3874,nagolinc/spritesheet_to_gif,gradio,,5
-3875,chikoto/Umamusume-DeBERTa-VITS2-TTS-JP,gradio,mit,5
-3876,abidlabs/gradio-lite-image,static,,5
-3877,ethan-ai/goofyai-3d_render_style_xl,gradio,mit,5
-3878,xuyingliKepler/nexaagent,streamlit,,5
-3879,AILab-CVC/SEED-LLaMA,docker,llama2,5
-3880,library-samples/image-captioning-with-git,gradio,mit,5
-3881,autotrain-projects/llm-merge-adapter,gradio,,5
-3882,pseudolab/MistralMED_Chat,gradio,apache-2.0,5
-3883,r3gm/Fast_Stable_diffusion_CPU,gradio,mit,5
-3884,INDONESIA-AI/Lobe,gradio,,5
-3885,nsarrazin/chat-ui-idefics,docker,,5
-3886,pseudolab/PatentClaimsExtraction,streamlit,mit,5
-3887,deepset/search-all-the-docs,streamlit,,5
-3888,Siyuan0730/OmniTutor,streamlit,,5
-3889,codelion/Grounding_DINO_demo,gradio,apache-2.0,5
-3890,Dentro/face-swap,gradio,,5
-3891,huolongguo10/chatglm3.cpp-int4,gradio,,5
-3892,openskyml/image-upscaler,gradio,mit,5
-3893,AI-ANK/PaLM-Kosmos-Vision,streamlit,mit,5
-3894,MoonQiu/LongerCrafter,gradio,,5
-3895,markllego/openai-gpt4-vision,gradio,mit,5
-3896,xuyingliKepler/openai_play_tts,gradio,,5
-3897,mrm8488/whisper-large-v3,gradio,,5
-3898,pseudolab/Colorful-illustration,gradio,mit,5
-3899,52Hz/CMFNet_dehazing,gradio,,4
-3900,AlgoveraAI/dcgan-crypto-punks,gradio,,4
-3901,AlgoveraAI/web3-wallet,gradio,,4
-3902,Andy1621/uniformer_image_demo,gradio,mit,4
-3903,Andy1621/uniformer_video_demo,gradio,mit,4
-3904,BigSalmon/MASKK,streamlit,,4
-3905,Buckeyes2019/NLP_Demonstration,streamlit,,4
-3906,CVPR/lama-example,gradio,apache-2.0,4
-3907,chainyo/Translator,streamlit,,4
-3908,Detomo/Car_part_classification,streamlit,apache-2.0,4
-3909,Detomo/voice-japanese,gradio,apache-2.0,4
-3910,Egrt/LicenseGAN,gradio,,4
-3911,Francesco/torch-cam-transformers,streamlit,,4
-3912,Giuliano/T0,gradio,,4
-3913,GotAudio/Understanding-Women,gradio,cc-by-4.0,4
-3914,HamidRezaAttar/gpt2-home,streamlit,apache-2.0,4
-3915,Harveenchadha/oiTrans,gradio,,4
-3916,MarcBrun/basque-qa,gradio,,4
-3917,Narrativa/fake-news-detection-spanish,gradio,,4
-3918,NeuML/articlesummary,streamlit,,4
-3919,NeuML/wikisummary,streamlit,,4
-3920,Norod78/ComicsHeroU2Net,gradio,,4
-3921,Norod78/Hebrew-GPT-Neo-Small,streamlit,,4
-3922,Qiwei97/Pubmed_Analyzer,streamlit,,4
-3923,SajjadAyoubi/CLIPfa-Demo,streamlit,,4
-3924,Sakil/essay_generator_app,gradio,apache-2.0,4
-3925,Shreyas3006/Text-Summarizer-sdp,streamlit,,4
-3926,Wootang01/chatbot,streamlit,,4
-3927,abidlabs/image-classifier,gradio,,4
-3928,abidlabs/keras-image-classifier,gradio,mit,4
-3929,abidlabs/live-sketch-recognition,gradio,,4
-3930,akdeniz27/turkish-zero-shot-text-classification-with-multilingual-models,streamlit,,4
-3931,akhaliq/AppleNeuralHash2ONNX,gradio,,4
-3932,akhaliq/Speechbrain-audio-classification,gradio,,4
-3933,akhaliq/Swin-Transformer,gradio,,4
-3934,akhaliq/espnet2_asr,gradio,,4
-3935,akhaliq/pedalboard,gradio,,4
-3936,akhaliq/t5-base-fine-tuned-on-jfleg,gradio,,4
-3937,akhaliq/yolov3,gradio,,4
-3938,am4nsolanki/hateful-memes,streamlit,,4
-3939,ansfarooq7/l4-project,gradio,,4
-3940,bankholdup/rugpt3_song_writer,streamlit,,4
-3941,bentrevett/named-entity-recognition,streamlit,,4
-3942,cdleong/phonemize-text,streamlit,,4
-3943,chinhon/Commentaries_Headlines_Generator,gradio,,4
-3944,chinhon/translation_eng2ch,gradio,,4
-3945,davidefiocco/GPT3-summary,streamlit,,4
-3946,ebgoldstein/FRF_Coarse,gradio,,4
-3947,edemgold/Tone-Transfer,gradio,,4
-3948,elonmuskceo/sparknlp,gradio,,4
-3949,elozano/tweet_eval,streamlit,,4
-3950,emrecan/zero-shot-turkish,streamlit,,4
-3951,erwanlc/Barman-T5,gradio,,4
-3952,eugenesiow/yolo-v5,gradio,,4
-3953,facebook/XLS-R-2B-EN-15,gradio,,4
-3954,flax-community/roberta-base-mr,streamlit,,4
-3955,flax-community/t5-vae,streamlit,,4
-3956,gogamza/kogpt2-base-v2,streamlit,,4
-3957,gradio/GANsNRoses,gradio,,4
-3958,gradio/HuBERT,gradio,,4
-3959,gradio/gpt-neo,gradio,,4
-3960,hysts/stylegan3-food101,gradio,,4
-3961,hysts/yolov5_anime,gradio,,4
-3962,iamkb/zero-shot-nlp-classifier-multi-lang,gradio,mit,4
-3963,ibaiGorordo/hugging-face-me,gradio,,4
-3964,j-hartmann/emotion-classification-from-csv,gradio,,4
-3965,jb2k/bert-base-multilingual-cased-language-detection,gradio,,4
-3966,jkang/demo-gradcam-imagenet,gradio,,4
-3967,jkang/demo-painttransformer,gradio,,4
-3968,juliensimon/song-lyrics,gradio,,4
-3969,keras-io/Flowers-Classification-MobileViT,gradio,cc0-1.0,4
-3970,keras-io/conditional-GAN,gradio,,4
-3971,keras-io/multimodal_entailment,gradio,,4
-3972,keras-io/supervised-contrastive-learning,gradio,apache-2.0,4
-3973,luisoala/raw2logit,gradio,,4
-3974,m3hrdadfi/zabanshenas,streamlit,,4
-3975,masterak25/LSTM_stock_prediction,gradio,,4
-3976,mayhug/Real-CUGAN,gradio,mit,4
-3977,mayhug/rainchan-anime-image-label,gradio,agpl-3.0,4
-3978,mayhug/rainchan-image-porn-detection,gradio,lgpl-3.0,4
-3979,merve/BigGAN-ImageNET,gradio,,4
-3980,merve/t5-playground,gradio,,4
-3981,mrm8488/PromptSource,streamlit,,4
-3982,nateraw/huggingpics-explorer,streamlit,,4
-3983,nateraw/spotify-pedalboard-demo,streamlit,,4
-3984,ncduy/emotion-classifier,gradio,,4
-3985,ncoop57/clifs,streamlit,,4
-3986,nielsr/vilt-nlvr,gradio,,4
-3987,nlp-en-es/bertin-sqac,gradio,,4
-3988,philsark/clip-guided-diffusion-identity,gradio,,4
-3989,pierreguillou/question-answering-portuguese-t5-base,gradio,,4
-3990,pritamdeka/pubmed-abstract-retriever,gradio,,4
-3991,pytorch/3D_ResNet,gradio,,4
-3992,qanastek/French-Part-Of-Speech-Tagging,streamlit,,4
-3993,r2d2/speech2text,gradio,,4
-3994,risingodegua/wine_quality_predictor,gradio,,4
-3995,samarthagarwal23/Scotch_recommendation,gradio,,4
-3996,satpalsr/grammar-correction,streamlit,,4
-3997,spotify/huggingface-demo-song-lyrics,gradio,,4
-3998,stevenkolawole/T5-multitasks-streamlit,streamlit,,4
-3999,taesiri/DeepSimilarity,gradio,,4
-4000,tareknaous/arabic-empathetic-response-generation,gradio,,4
-4001,tcapelle/wandb,streamlit,mit,4
-4002,trnt/twitter_emotions,gradio,,4
-4003,ttheland/demo-butterfly-spaces,gradio,mit,4
-4004,vaibhavarduino/anime-plus,gradio,afl-3.0,4
-4005,widged/bart-generation,gradio,,4
-4006,wolfrage89/company_segments_ner,streamlit,,4
-4007,xiatao/microsoft-trocr-base-printed,gradio,,4
-4008,xiongjie/u2net_rgba,gradio,,4
-4009,yseop/financial-relation-extractor-demo,gradio,,4
-4010,abidlabs/remove-bg,gradio,,4
-4011,akhaliq/MTTR,gradio,,4
-4012,huggan/anime-face-generator,gradio,apache-2.0,4
-4013,PaddlePaddle/animegan_v2_shinkai_53,gradio,,4
-4014,mertguvencli/trending-techs-on-data-science,streamlit,gpl-3.0,4
-4015,Sakil/Humanoid_robot,streamlit,apache-2.0,4
-4016,xiaosu-zhu/McQuic,streamlit,apache-2.0,4
-4017,merve/sorting_hat,gradio,apache-2.0,4
-4018,Wootang01/image_classifier,gradio,,4
-4019,samueldomdey/ClipCosineSimilarityURL,gradio,,4
-4020,kingabzpro/Urdu-ASR-SOTA,gradio,apache-2.0,4
-4021,saefro991/aet_demo,gradio,,4
-4022,vitaliykinakh/Galaxy_Zoo_Generation,streamlit,,4
-4023,tomofi/MaskTextSpotterV3-OCR,gradio,mit,4
-4024,jervinjosh68/vit-age-classifier,gradio,apache-2.0,4
-4025,hackathon-pln-es/jurisbert-test-finetuning-ner,gradio,cc-by-nc-sa-4.0,4
-4026,apoorvumang/kgt5,gradio,mit,4
-4027,shibing624/similarities,gradio,apache-2.0,4
-4028,shawarmabytes/stream-your-emotions,streamlit,,4
-4029,st0bb3n/Cam2Speech,gradio,,4
-4030,aaronherrera/Calorie_Counter,gradio,apache-2.0,4
-4031,sophiaaez/BLIPvOFAde,gradio,,4
-4032,hysts/1adrianb-face-alignment,gradio,,4
-4033,erikacardenas300/Company_Classifier,streamlit,,4
-4034,naver/SuperFeatures,gradio,,4
-4035,SerdarHelli/Knee-View-Merchant-Landmark-Detection,streamlit,,4
-4036,senior-sigan/vgg_style_transfer,gradio,mit,4
-4037,gdn/Question-Answer-Demo,gradio,mit,4
-4038,mustapha/ACSR,gradio,,4
-4039,hysts/TADNE,gradio,,4
-4040,Manimaran/pokemon-classifier,gradio,wtfpl,4
-4041,osanseviero/food_classifier_v1,gradio,apache-2.0,4
-4042,ecarbo/text-generator-demo,gradio,,4
-4043,Zengyf-CVer/gradio_yolov5_det,gradio,gpl-3.0,4
-4044,hysts/TADNE-image-search-with-DeepDanbooru,gradio,,4
-4045,dnouri/crowd-counting,streamlit,,4
-4046,Vijish/SkinDeep,streamlit,apache-2.0,4
-4047,chuxiaojie/NAFSSR,gradio,mit,4
-4048,merve/dataset-worldviews,static,apache-2.0,4
-4049,AI-Dashboards/CP.Matplotlib.NetworkX.Streamlit.PyVis.Graphviz,streamlit,mit,4
-4050,aware-ai/german-asr,gradio,,4
-4051,espejelomar/cat_or_dog_fastai,gradio,mit,4
-4052,DrSnowbird/clip-image-search,gradio,,4
-4053,jph00/minimal,gradio,apache-2.0,4
-4054,prairie-guy/Art_Mood,gradio,mit,4
-4055,davidrd123/WikiArt_20genre,gradio,apache-2.0,4
-4056,awacke1/AI-Wikipedia-Search,gradio,mit,4
-4057,gradio/same-person-or-different,gradio,,4
-4058,nateraw/simple-video-to-video,gradio,mit,4
-4059,nazneen/error-analysis,streamlit,,4
-4060,aryadytm/paraphrase,streamlit,,4
-4061,hasibzunair/image-recognition-demo,gradio,afl-3.0,4
-4062,yerfor/SyntaSpeech,gradio,,4
-4063,Fawaz/nlx-gpt,gradio,,4
-4064,ReneeYe/ConST-speech2text-translator,gradio,afl-3.0,4
-4065,pierreguillou/pdf-firstpage-to-img,gradio,,4
-4066,bingbingbing/ImageEnhancement,gradio,mit,4
-4067,awacke1/ChemistryMoleculeModeler,streamlit,mit,4
-4068,evaluate-metric/super_glue,gradio,,4
-4069,evaluate-metric/f1,gradio,,4
-4070,evaluate-metric/mauve,gradio,,4
-4071,Xhaheen/GPTJ_PLUS_DALL_E,gradio,gpl,4
-4072,AlexWortega/ruImageCaptionong,gradio,,4
-4073,pierreguillou/layout-parser,gradio,,4
-4074,Gradio-Blocks/beat-interpolator,gradio,mit,4
-4075,GDavila/GIFify_OpenCV,streamlit,mit,4
-4076,Gradio-Blocks/ML-Aided-Code-Analysis,gradio,,4
-4077,natdon/Michael_Scott_Bot,gradio,,4
-4078,Gradio-Blocks/Michael_Scott_Bot_Gradio_Blocks,gradio,,4
-4079,Gradio-Blocks/minority-asr,gradio,,4
-4080,Gradio-Blocks/CBNetV2,gradio,,4
-4081,Pippoz/All_in_one,streamlit,,4
-4082,Gradio-Blocks/illustrated-spanish-poem,gradio,,4
-4083,Gradio-Blocks/Speech-to-text,gradio,,4
-4084,Gradio-Blocks/spurious_correlation_evaluation,gradio,,4
-4085,keras-io/collaborative-filtering-movielens,gradio,mit,4
-4086,osanseviero/hugging_eats,gradio,,4
-4087,Theivaprakasham/layoutlmv3_sroie,gradio,apache-2.0,4
-4088,nagolinc/LatentDiffusion_and_ESRGan,gradio,mit,4
-4089,julien-c/merve-data-report,static,,4
-4090,neurotech/Swahili-sentiment-analysis,gradio,mit,4
-4091,hysts/MangaLineExtraction_PyTorch,gradio,,4
-4092,keras-io/molecular-property-prediction,gradio,apache-2.0,4
-4093,CVPR/v-doc_abstractive_mac,gradio,,4
-4094,najoungkim/round-trip-dalle-mini,gradio,apache-2.0,4
-4095,awacke1/GradioBlocksDemo-Transformers,gradio,mit,4
-4096,Axolotlily/Interpolate,gradio,other,4
-4097,mindwrapped/pokemon-card-checker,gradio,mit,4
-4098,denisp1/ChemistryMoleculeModeler,streamlit,mit,4
-4099,Zengyf-CVer/ocr_translate,gradio,gpl-3.0,4
-4100,Paaz/gpt2-lyrics,gradio,,4
-4101,Madhuri/vqa_audiobot,streamlit,mit,4
-4102,milai-tk/clip-human-action-img2txt,gradio,,4
-4103,mantisnlp/SearchMesh,streamlit,mit,4
-4104,zhezh/mm-commerce,gradio,cc-by-nc-4.0,4
-4105,ModIA/FrenchDroneKeyword,gradio,,4
-4106,d4data/Bias-Fairness-in-AI,streamlit,apache-2.0,4
-4107,awacke1/NLP-Lyric-Chorus-Image,gradio,mit,4
-4108,CVPR/monoscene_lite,gradio,apache-2.0,4
-4109,trysem/AnimeGANv2,gradio,,4
-4110,kamalkraj/min-dalle,gradio,mit,4
-4111,awacke1/ArtStyleLineDrawing,gradio,mit,4
-4112,permutans/LayoutLMv3-FUNSD,gradio,,4
-4113,doevent/Image2LineDrawing,gradio,mit,4
-4114,keras-io/structured-data-classification-grn-vsn,gradio,mit,4
-4115,nmud19/Sketch2ColourDemo,gradio,eupl-1.1,4
-4116,codeparrot/code-generator,gradio,apache-2.0,4
-4117,EuroPython2022/mmocr-demo,gradio,apache-2.0,4
-4118,kmkarakaya/Auto_Review_Generation_in_Turkish,gradio,apache-2.0,4
-4119,EuroPython2022/OCR-Translate,gradio,gpl-3.0,4
-4120,Sangmin/Eiken-Essay-with-GPT3,gradio,mit,4
-4121,Curranj/Regex_Generator,gradio,,4
-4122,Zengyf-CVer/Gradio_YOLOv5_Det_v5,gradio,gpl-3.0,4
-4123,XAI/CHM-Corr,gradio,mit,4
-4124,ICML2022/resefa,gradio,,4
-4125,dnouri/monai-demo,streamlit,,4
-4126,aiEDUcurriculum/introtoAI-mental-health-project,gradio,afl-3.0,4
-4127,cap99/ocr,streamlit,apache-2.0,4
-4128,User1342/WatchTower,gradio,,4
-4129,owaiskha9654/Multi-Label-Classification-of-Pubmed-Articles,gradio,apache-2.0,4
-4130,eldoraboo/zero-shot,gradio,mit,4
-4131,lewiswu1209/MockingBird,gradio,mit,4
-4132,themasterbetters/the-master-betters-translator,gradio,mit,4
-4133,hasibzunair/melanoma-detection-demo,gradio,afl-3.0,4
-4134,hhim8826/vits-ATR,gradio,afl-3.0,4
-4135,Archan/ArXivAudio,streamlit,apache-2.0,4
-4136,owaiskha9654/Custom_Yolov7,gradio,,4
-4137,radames/gradio-url-params,gradio,,4
-4138,shibing624/chinese-couplet-generate,gradio,apache-2.0,4
-4139,AIZeroToHero/03-ImageSearchSimilar,streamlit,mit,4
-4140,panpan06/ImageSearchSimilar,streamlit,mit,4
-4141,jracca/04-learning-space,streamlit,mit,4
-4142,hysts/space-that-creates-model-demo-space,gradio,,4
-4143,keithhon/logo-generator,streamlit,,4
-4144,wing-nus/SciAssist,gradio,afl-3.0,4
-4145,MrSinan/Reconstruction,gradio,,4
-4146,doevent/cartoonizer-demo-onnx,gradio,apache-2.0,4
-4147,jrahn/yolochess,gradio,mit,4
-4148,gradio/autocomplete,gradio,,4
-4149,ruslanmv/Video-Translator,gradio,apache-2.0,4
-4150,nschenone/lyric-buddy,gradio,,4
-4151,Ammar-alhaj-ali/LayoutLMv3-FUNSD,gradio,,4
-4152,anasanchezf/cloome,streamlit,gpl-3.0,4
-4153,scikit-learn/gradio-skops-integration,gradio,apache-2.0,4
-4154,NotFungibleIO/GFPGAN,gradio,apache-2.0,4
-4155,kornia/line-segment-matching,gradio,apache-2.0,4
-4156,ruslanmv/Text2Lip,gradio,,4
-4157,gradio/diff_texts,gradio,,4
-4158,daspartho/predict-subreddit,gradio,apache-2.0,4
-4159,coledie/Fashion_VAE,gradio,mit,4
-4160,Kamtera/Persian_Automatic_Speech_Recognition_and-more,gradio,,4
-4161,RMeli/gnina-torch,gradio,mit,4
-4162,theodotus/streaming-asr-uk,gradio,bsd-3-clause,4
-4163,djgoettel/01-3DModel-GradioDemo,gradio,apache-2.0,4
-4164,akhaliq/VideoMAE,gradio,,4
-4165,manishjaiswal/05-SOTA-Question-Answer-From-TextFileContext-Demo,gradio,apache-2.0,4
-4166,bassazayda/Whisper,gradio,mit,4
-4167,fsdlredteam/BuggingSpace,gradio,apache-2.0,4
-4168,freddyaboulton/gradio-google-forms,gradio,mit,4
-4169,nightfury/StableDiffusion.Img2Img-Gradio,gradio,creativeml-openrail-m,4
-4170,evaluate-measurement/honest,gradio,,4
-4171,julien-c/nvidia-smi,gradio,apache-2.0,4
-4172,RTL/videomatch,gradio,,4
-4173,venz/AW-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,apache-2.0,4
-4174,awacke1/BlackjackSimulatorCardGameAI,streamlit,,4
-4175,jayesh95/Voice-QA,gradio,mit,4
-4176,rodolfoocampo/IllustratedNarrativeDevice,gradio,creativeml-openrail-m,4
-4177,awacke1/StoryWriterTextGenMem,gradio,apache-2.0,4
-4178,cjayic/sd-dreambooth-jerma,gradio,mit,4
-4179,MLSquad-TWCN/near-continuous-whispering,gradio,apache-2.0,4
-4180,BilalSardar/StoryGenerator,gradio,openrail,4
-4181,mdnestor/URL-to-Whisper,gradio,,4
-4182,johnslegers/stable-diffusion,gradio,mit,4
-4183,freddyaboulton/atari_agents,gradio,,4
-4184,Gazoche/text-to-gundam,gradio,,4
-4185,Avkash/WhisperUI,gradio,mit,4
-4186,diagaiwei/ir_chinese_medqa,gradio,openrail,4
-4187,sayakpaul/lol-enhancement-maxim,gradio,apache-2.0,4
-4188,sayakpaul/sidd-denoising-maxim,gradio,apache-2.0,4
-4189,sayakpaul/sots-indoor-dehazing-maxim,gradio,apache-2.0,4
-4190,lewtun/stable-diffusion-demo,gradio,openrail,4
-4191,candlend/vits-hoshimi,gradio,,4
-4192,jmparejaz/Audio_to_text_classification,gradio,mit,4
-4193,GV05/stable-diffusion-mingle-prompts,gradio,apache-2.0,4
-4194,omarelsayeed/SentenceSimilarity-Quran-v2,gradio,creativeml-openrail-m,4
-4195,chansung/segmentation-training-pipeline,gradio,,4
-4196,FathomNet/MBARI_Monterey_Bay_Benthic,gradio,,4
-4197,elonmuskceo/docker-aimstack,docker,,4
-4198,neko941/YOLOv5-Hololive_Waifu_Classification,streamlit,,4
-4199,lsmyrtaj/cse6242-dataminers,streamlit,,4
-4200,ianpan/bone-age-greulich-and-pyle,gradio,apache-2.0,4
-4201,shivi/ChequeEasy,gradio,,4
-4202,oucgc1996/Antimicrobial-peptide-generation,gradio,cc-by-nc-sa-4.0,4
-4203,abidlabs/speak,gradio,,4
-4204,unb-lamfo-nlp-mcti/nlp-mcti-preprocessing-single,gradio,mit,4
-4205,BilalSardar/YoutubeVideoLink-To-MCQs-Generation,gradio,openrail,4
-4206,awacke1/DatasetAnalyzer,gradio,,4
-4207,daspartho/text-emotion,gradio,apache-2.0,4
-4208,haakohu/deep_privacy2,gradio,,4
-4209,akhaliq/Nitro-Diffusion,gradio,,4
-4210,IDEA-CCNL/Erlangshen-UniMC-Zero-Shot,streamlit,apache-2.0,4
-4211,fxmarty/bettertransformer-demo,gradio,apache-2.0,4
-4212,autoevaluator/shoes-vs-boots-vs-sandals,docker,,4
-4213,TopdeckingLands/Diffusion_Space,gradio,mit,4
-4214,breadlicker45/galactica-base,gradio,apache-2.0,4
-4215,montagekoko/anything-v3.0,gradio,,4
-4216,lingbionlp/PhenoTagger-Demo,streamlit,cc-by-4.0,4
-4217,aayushmnit/diffedit,gradio,openrail,4
-4218,Rahorus/openjourney,gradio,,4
-4219,ORI-Muchim/PowerTTS,gradio,,4
-4220,ORI-Muchim/RaidenTTS,gradio,,4
-4221,AlishbaImran/Redox-Flow-Battery-Prediction,streamlit,mit,4
-4222,lvkaokao/INC-Dicoo-Diffusion,gradio,apache-2.0,4
-4223,jpwahle/plagiarism-detection,gradio,,4
-4224,JUNGU/VToonify,gradio,other,4
-4225,loralora/sovits_aishell3,gradio,apache-2.0,4
-4226,akhaliq/woolitize,gradio,,4
-4227,plasmo/woolitize,gradio,,4
-4228,armanokka/nllb-translation-demo,gradio,,4
-4229,ahmedghani/svoice_demo,gradio,,4
-4230,hpi-dhc/FairEval,gradio,,4
-4231,gradio/chatbot_multimodal,gradio,,4
-4232,tennant/MUG_caption,gradio,mit,4
-4233,alexandrainst/zero-shot-classification,gradio,mit,4
-4234,eskayML/mask_segmentation,gradio,,4
-4235,dataminers/dataminers,streamlit,,4
-4236,Svngoku/TableTransformer2CSV,streamlit,,4
-4237,MoyAI/ProfNet,gradio,,4
-4238,JohnnyPittt/audio-styling,gradio,other,4
-4239,ECE1786-AG/ArtIstic-GENREator,gradio,mit,4
-4240,cmotions/beatlify,gradio,bigscience-bloom-rail-1.0,4
-4241,pragnakalp/Emotion_Detection,gradio,,4
-4242,cahya/indonesian-whisperer,docker,cc,4
-4243,remzicam/voicebot_german,gradio,,4
-4244,quantumiracle-git/OpenBiDexHand,gradio,,4
-4245,lambdalabs/generative-music-visualizer,gradio,,4
-4246,CodeDoes/FrostAura-gpt-neox-20b-fiction-novel-generation,gradio,,4
-4247,RaviRaj988/Asking-question-to-video,gradio,apache-2.0,4
-4248,robmarkcole/yolov5-ui,streamlit,apache-2.0,4
-4249,Knowles-Lab/tiger,streamlit,mit,4
-4250,lianzhou/stable-diffusion-webui,gradio,openrail,4
-4251,ORI-Muchim/NahidaTTS,gradio,mit,4
-4252,kdrkdrkdr/HutaoTTS,gradio,mit,4
-4253,ygangang/Image-Animation-using-Thin-Plate-Spline-Motion-Model,gradio,,4
-4254,Shad0ws/imagetomusic,gradio,unknown,4
-4255,ygangang/CodeFormer,gradio,apache-2.0,4
-4256,YeOldHermit/StableDiffusion_AnythingV3_ModelCamenduru,gradio,,4
-4257,FloydianSound/Wlop_Diffusion,gradio,,4
-4258,imseldrith/txt2img,gradio,openrail,4
-4259,jhlfrfufyfn/old-bel-tts,gradio,mit,4
-4260,avirathtibrewala/YTToText,gradio,unknown,4
-4261,Malifex/CPU-Anything-V3.0-WebUI,gradio,,4
-4262,SpacesExamples/secret-example,docker,,4
-4263,neuralmagic/question-answering,gradio,,4
-4264,pragnakalp/Huggingface_Sentiment_Analysis,gradio,,4
-4265,juancopi81/sd-riffusion,gradio,openrail,4
-4266,musicians/deepharmony,gradio,apache-2.0,4
-4267,erwann/Face-editor,Configuration error,Configuration error,4
-4268,ybelkada/blip-image-captioning-space,gradio,bsd-3-clause,4
-4269,Roxza/DialoGPT,gradio,openrail,4
-4270,abidlabs/images,gradio,mit,4
-4271,ItsJayQz/Marvel_WhatIf_Diffusion,gradio,,4
-4272,MountLiteraSwd/sd-dreambooth-library-riffusion-rage,gradio,,4
-4273,cagatayodabasi/dreamlike-photoreal-1.0-CPU,gradio,,4
-4274,breadlicker45/the-jam-machine-app,gradio,,4
-4275,Joeythemonster/Text-To-image-AllModels,gradio,openrail,4
-4276,adpro/dpt-depth04,gradio,,4
-4277,adpro/dpt-depth16,gradio,,4
-4278,ThirdEyeData/Text-Summarization,gradio,,4
-4279,kyuubi08/22h-vintedois-diffusion-v0-1,gradio,,4
-4280,teo-sanchez/prompt_specifier_recognizer,gradio,cc-by-3.0,4
-4281,spookyspaghetti/Speech-Analyser,gradio,,4
-4282,Missinginaction/stablediffusionwithnofilter,gradio,,4
-4283,jackvial/frozen-lake,static,,4
-4284,Khalida1w/denoising,gradio,apache-2.0,4
-4285,awacke1/Docker-FlanT5-TextGeneratorTranslator,docker,,4
-4286,MCkernick/Image_Restoration_Colorization,gradio,,4
-4287,deedax/Change-Your-Style,gradio,mit,4
-4288,robertoberagnoli/openai-jukebox-1b-lyrics,gradio,creativeml-openrail-m,4
-4289,vietvd/image-enhance,gradio,,4
-4290,sophiamyang/Panel_apps,docker,,4
-4291,hrishikeshagi/ImagePromptGenerator,gradio,,4
-4292,CYSD/AI-image-detector,gradio,,4
-4293,sophiamyang/panel_example,docker,,4
-4294,tumuyan/Night_Enhancement,gradio,mit,4
-4295,Groq/mlagility,streamlit,,4
-4296,adirik/ChangeIt,gradio,,4
-4297,GT4SD/patent_generative_transformers,gradio,,4
-4298,juliensimon/battle_of_image_classifiers,gradio,,4
-4299,SalahZa/Tunisian-ASR-v0,gradio,cc-by-nc-3.0,4
-4300,feizhengcong/video-stable-diffusion,gradio,openrail,4
-4301,pinecone/diffusion-image-search,gradio,,4
-4302,ahmedale/Youtube-Whisperer,gradio,,4
-4303,ClassCat/Medical-Image-Classification-with-MONAI,gradio,,4
-4304,decodemai/business_tech_ideas,gradio,cc-by-nc-nd-4.0,4
-4305,deepghs/anime-ai-detect-fucker,gradio,apache-2.0,4
-4306,robjm16/domain_specific_ChatGPT,gradio,,4
-4307,philschmid/furiosa-ai-ocr,gradio,,4
-4308,vladocar/Text-to-Speech,gradio,creativeml-openrail-m,4
-4309,ClassCat/Brain-tumor-3D-segmentation-with-MONAI,gradio,,4
-4310,JUNGU/SuperGlue-Image-Matching,gradio,,4
-4311,JUNGU/Whisper-Auto-Subtitled-Video-Generator,streamlit,,4
-4312,caffeinum/VToonify,gradio,other,4
-4313,roseyai/Chat-GPT-LangChain,gradio,apache-2.0,4
-4314,KwabsHug/Language-Learn-Idea,gradio,,4
-4315,vigneshv/TrOCR-handwritten,gradio,,4
-4316,tumuyan/RealSR,gradio,mit,4
-4317,julien-c/nbconvert,docker,mit,4
-4318,GT4SD/molecular_properties,gradio,,4
-4319,decodemai/market_sizing,gradio,cc-by-nc-nd-4.0,4
-4320,reha/Stick_Tech,gradio,cc-by-3.0,4
-4321,StefanHex/simple-trafo-mech-int,streamlit,mit,4
-4322,Didisoftwares/GFPGAN,gradio,apache-2.0,4
-4323,vialibre/edia,static,,4
-4324,DataScienceGuild/ChatbotWithDataframeMemory,gradio,mit,4
-4325,ClassCat/DETR-Object-Detection,gradio,,4
-4326,GeneralNewSense/Text-to-Music,gradio,unknown,4
-4327,pcuenq/lora-pokemon,gradio,mit,4
-4328,huggingface-projects/InstructPix2Pix-Chatbot-ui,docker,,4
-4329,tobiaspires/ad-image-generation,gradio,,4
-4330,DarwinAnim8or/GPT-Greentext-Playground,gradio,mit,4
-4331,yizhangliu/DalleClone,static,apache-2.0,4
-4332,mariashay/DataViz-Mermaid,static,mit,4
-4333,stable-bias/diffusion-bias-explorer,gradio,cc-by-sa-4.0,4
-4334,davanstrien/Doc-UFCN,gradio,bsd-3-clause,4
-4335,sgonzalezsilot/Fake-News-Twitter-Detection_from-my-Thesis,gradio,,4
-4336,singhk28/nocodeml,streamlit,cc-by-nc-4.0,4
-4337,UVA-MSBA/Employee_Turnover_Ex,gradio,mit,4
-4338,spacerini/imdb-search,gradio,apache-2.0,4
-4339,Yusin/ChatGPT-Speech,gradio,apache-2.0,4
-4340,breadlicker45/gpt-ya-gen,streamlit,,4
-4341,zjunlp/KGEditor,gradio,,4
-4342,Raspberry-ai/main,gradio,unknown,4
-4343,keras-dreambooth/example-submission,gradio,apache-2.0,4
-4344,prajdabre/CreoleM2M,gradio,mit,4
-4345,tizze/websitechatbot,gradio,unknown,4
-4346,fffiloni/image-to-sound-fx-debug,gradio,,4
-4347,Goodsea/deprem-ocr-paddleocr,gradio,,4
-4348,rynod/LangChain_ChatGPTSlackBotBot,gradio,,4
-4349,OFA-Sys/FAST-CPU-small-stable-diffusion-v0,gradio,apache-2.0,4
-4350,alsrbdni/magic-to-diffusion,gradio,apache-2.0,4
-4351,mbazaNLP/Kinyarwanda-text-to-speech,gradio,apache-2.0,4
-4352,juliensimon/xlm-v-base-language-id,gradio,,4
-4353,HaloMaster/ChineseLLM,gradio,apache-2.0,4
-4354,unstructuredio/unstructured-invoices,streamlit,,4
-4355,maxime/chat-with-your-telegram-chat,gradio,mit,4
-4356,nickmuchi/Investor-Education-ChatChain,streamlit,,4
-4357,Future-Tense/Slo-Mo-YOLO-Video,gradio,,4
-4358,AUST001/ChatGPT,gradio,openrail,4
-4359,bfh-nlp-circle/nlp-cirlce-demo,gradio,,4
-4360,pierreguillou/Inference-APP-Document-Understanding-at-linelevel-v1,gradio,,4
-4361,AIFILMS/speecht5-tts-demo,gradio,apache-2.0,4
-4362,giswqs/geospatial,gradio,mit,4
-4363,GipAdonimus/Real-Time-Voice-Cloning,gradio,,4
-4364,mindspore-ai/Zidongtaichu,gradio,apache-2.0,4
-4365,lfoppiano/grobid-superconductors,docker,apache-2.0,4
-4366,ysharma/Stream_PlaygroundAI_Images,gradio,mit,4
-4367,codejin/diffsingerkr,streamlit,mit,4
-4368,vincentclaes/DocumentQAComparator,gradio,mit,4
-4369,kermitt2/grobid-crf,docker,apache-2.0,4
-4370,felixz/LLM-as-continuous-chat,gradio,apache-2.0,4
-4371,Thorsten-Voice/demo,streamlit,,4
-4372,hwang1/anime-gan,gradio,,4
-4373,hra/ChatGPT-Tech-Radar,gradio,,4
-4374,Miuzarte/SUI-svc-4.0,gradio,mit,4
-4375,jeffeux/zhtwbloomdemo,streamlit,mit,4
-4376,Jackflack09/finetuned_diffusion2,gradio,mit,4
-4377,zjunlp/MolGen,gradio,,4
-4378,awinml/2-qa-earnings-sentencewise,streamlit,mit,4
-4379,mushroomsolutions/chatgpt-3,gradio,wtfpl,4
-4380,taesiri/CLIPSeg2,gradio,,4
-4381,yefengzi/vits-models,gradio,apache-2.0,4
-4382,Teklia/doc-ufcn,gradio,mit,4
-4383,hyoo/translate,gradio,mit,4
-4384,nmaina/EleutherAI-gpt-j-6B,gradio,,4
-4385,GeemiW/pdb_answers,streamlit,mit,4
-4386,svjack/ControlNet-Pose-Chinese,gradio,,4
-4387,tecnolitas/MJ-prompt-generator,gradio,unknown,4
-4388,raghuram13/extract_text_from_image,streamlit,cc,4
-4389,akhaliq/multi-modal_chinese_stable_diffusion_v1.0,gradio,,4
-4390,2hack2furious/anonymizer,streamlit,cc-by-nc-4.0,4
-4391,Shad0ws/Chat-with-Files,streamlit,mit,4
-4392,pierreguillou/Inference-APP-Document-Understanding-at-linelevel-LiLT-base-LayoutXLM-base-v1,gradio,,4
-4393,chansung/LLaMA-13B,gradio,apache-2.0,4
-4394,hysts/cv_diffusion_text-to-image-synthesis_tiny,gradio,mit,4
-4395,thelou1s/chat_gpt_space,gradio,,4
-4396,30Kanika/Animal_Image_Classifier,gradio,apache-2.0,4
-4397,dromerosm/chatgpt-info-extraction,gradio,cc-by-4.0,4
-4398,jhj0517/Whisper-WebUI-Easy-Subtitle-Generator,gradio,apache-2.0,4
-4399,simpx/chatdemo,gradio,mit,4
-4400,keras-dreambooth/lowpoly-world-demo,gradio,apache-2.0,4
-4401,Cartof/Chatbot,gradio,,4
-4402,NeuralInternet/chattensor-prompt-generator-v12,gradio,apache-2.0,4
-4403,R-001/HumanAI,gradio,,4
-4404,qinzhu/diy-girlfriend,gradio,mit,4
-4405,mikaelbhai/GPTBhai_text,gradio,,4
-4406,Detomo/Object_detection,gradio,creativeml-openrail-m,4
-4407,safetensors/safetensors-checker,gradio,,4
-4408,GingerBreadXD/trading-bot,streamlit,,4
-4409,echarlaix/openvino-export,gradio,apache-2.0,4
-4410,Legal-ease/legal-ease,gradio,,4
-4411,hack46/46jobs,streamlit,mit,4
-4412,priyanshu02/Linguistics-Accents,gradio,,4
-4413,dteam/chatgpt-dteam,gradio,,4
-4414,ispast/Genshin_MB_VITS_TTS,gradio,,4
-4415,shigel/recipe,gradio,,4
-4416,abidlabs/pakistan,gradio,apache-2.0,4
-4417,DESUCLUB/BLLAMA,gradio,apache-2.0,4
-4418,keras-dreambooth/piranesi-monument-art,gradio,apache-2.0,4
-4419,thirdai/FoodUDT-1B,gradio,other,4
-4420,mikeion/research_guru,streamlit,mit,4
-4421,Gameel/TextToSpeech,gradio,,4
-4422,PKaushik/Human-Part-Segmentation,gradio,cc0-1.0,4
-4423,yfkm/chat_gpt_space_public,gradio,cc,4
-4424,meowingamogus69/stable-diffusion-webui-controlnet-docker,docker,,4
-4425,starsdeep/NAFNet,gradio,mit,4
-4426,jonatanklosko/chai,docker,,4
-4427,JunchuanYu/SydneyAI-plus,gradio,,4
-4428,ruanchaves/portuguese-offensive-language-detection,gradio,mit,4
-4429,zuhuri/OpenAI_chatgpt-turbo-UI,gradio,gpl-3.0,4
-4430,radames/live-pose-maker-gradio,gradio,,4
-4431,keras-dreambooth/galaxy-mergers,gradio,apache-2.0,4
-4432,davanstrien/notebooks_on_the_hub,gradio,,4
-4433,ragha108/aiyogi_text_to_audio,gradio,,4
-4434,hra/ChatGPT-SEC-Filings-QA,gradio,cc-by-nc-nd-4.0,4
-4435,crimeacs/phase-hunter,gradio,,4
-4436,eIysia/VITS-Umamusume-voice-synthesizer,gradio,,4
-4437,Kevin676/midjourney-v5,gradio,openrail,4
-4438,Mrchuw/Image-Animation-using-Thin-Plate-Spline-Motion-Model,gradio,,4
-4439,Gradio-Themes/informativedrawings-sketch-style,gradio,mit,4
-4440,sawblade/prompt-extend,gradio,apache-2.0,4
-4441,TerrificTerry/Club_Review_Antidetector,gradio,mit,4
-4442,Aaaaaaaabdualh/topic2poem,gradio,afl-3.0,4
-4443,sklearn-docs/IsolationForest-Model-for-Anomaly-Detection,gradio,mit,4
-4444,abdvl/datahub_qa_bot,streamlit,mit,4
-4445,TencentARC/TagGPT,gradio,cc-by-nc-sa-3.0,4
-4446,ruboin/faster-whisper-webui,gradio,apache-2.0,4
-4447,gryhkn/free-fast-youtube-url-video-to-text-using-openai-whisper,gradio,gpl-3.0,4
-4448,GT4SD/PatentToolkit,gradio,apache-2.0,4
-4449,hackathon-somos-nlp-2023/suicide-comments-es,gradio,apache-2.0,4
-4450,dineshb/Speech2Text,gradio,openrail,4
-4451,jsebdev/stock_predictor,gradio,openrail,4
-4452,sklearn-docs/Out-of-Bag-estimates,gradio,apache-2.0,4
-4453,sklearn-docs/SGD_Penalties,gradio,mit,4
-4454,hra/ChatGPT-MindMap,gradio,cc-by-nc-nd-4.0,4
-4455,JanDalhuysen/whisper-speaker-recognition,gradio,,4
-4456,unstructuredio/irs-manuals,gradio,apache-2.0,4
-4457,kazuk/youtube-whisper-15,gradio,unknown,4
-4458,onursavas/Chinese_Document_Layout_Analysis,gradio,apache-2.0,4
-4459,huggingfacejs/image-to-text,static,mit,4
-4460,lakshmi324/DocuAI,gradio,apache-2.0,4
-4461,k8tems/LangChain_AgentGPTBot,gradio,,4
-4462,ixxan/multilingual-vqa,gradio,,4
-4463,cuiyuan605/Text-to-Image,gradio,,4
-4464,ThirdEyeData/Object-Detection-Using-FRCNN,streamlit,,4
-4465,shivi/calm_seafoam,gradio,apache-2.0,4
-4466,segments/segment-anything-image-embedding,gradio,,4
-4467,asiffarhankhan/custom-gpt-voice-assistant,gradio,other,4
-4468,congxin95/BMTools-demo,gradio,afl-3.0,4
-4469,simonduerr/gradio-2dmoleculeeditor,gradio,mit,4
-4470,ShawnAI/VectorDB-ChatBot,gradio,apache-2.0,4
-4471,suchun/chatGPT_acdemic,gradio,,4
-4472,atyshka/ai-detector,gradio,gpl-3.0,4
-4473,fedor-ch/langchain-ynp-test,gradio,,4
-4474,leurez/moss,docker,apache-2.0,4
-4475,thestasi/Webui-Cpu-ExtensionV2-Publictest-WithCivitaiHelper,gradio,,4
-4476,aadarsh-af/text_to_image,gradio,,4
-4477,MrD05/text-generation-webui-space,gradio,mit,4
-4478,sysf/Edge-TTS,gradio,other,4
-4479,sander-wood/clamp_similar_music_recommendation,gradio,mit,4
-4480,merve/voice-cloning,gradio,mit,4
-4481,devloverumar/AI-Content-Detector,streamlit,,4
-4482,bergrozen1213/3d-obj,gradio,,4
-4483,hra/GPT4-makes-BabyAGI,gradio,cc-by-nc-sa-4.0,4
-4484,FourthBrainGenAI/AI-Superstar-Space,gradio,bigscience-openrail-m,4
-4485,mvnhat/langchain-agent-demo,gradio,,4
-4486,bioriAsaeru/text-to-voice,gradio,,4
-4487,HgMenon/Transcribe_V0.2,gradio,apache-2.0,4
-4488,vanderbilt-dsi/langchain-assistant,gradio,mit,4
-4489,diivien/Music-Popularity-Prediction,gradio,,4
-4490,HaleyCH/HaleyCH_Theme,gradio,apache-2.0,4
-4491,Smithsonian/amazonian_fish_classifier,streamlit,mit,4
-4492,huggingface-tools/text-download,gradio,,4
-4493,mouaddb/image2text-comp,gradio,mit,4
-4494,paulokewunmi/omowe.ai,gradio,mit,4
-4495,p1atdev/Anime-to-Sketch,gradio,mit,4
-4496,Ikaros521/so-vits-svc-4.0-ikaros,gradio,mit,4
-4497,pythainlp/wangchanglm-demo-cpu,static,apache-2.0,4
-4498,SantiagoTesla/Rai_AI,gradio,,4
-4499,arundevops47/chatbot-with-langchain-and-pinecone,streamlit,,4
-4500,lukesteuber/textual,gradio,,4
-4501,asciicorp/Legal-ai,streamlit,,4
-4502,DJQmUKV/rvc-inference,gradio,mit,4
-4503,achyuth1344/stable-diffusion-webui,gradio,,4
-4504,optigesr/Bark-with-Voice-Cloning,gradio,mit,4
-4505,zxcgqq/nsfw,gradio,,4
-4506,jinlinyi/PerspectiveFields,gradio,mit,4
-4507,alsrbdni/pdf-chat,gradio,,4
-4508,awacke1/OpenAssistant-Chatbot-FTW-Open-Source,streamlit,,4
-4509,Moxxie-nolastname/Not-Moxxie-Proxy,docker,,4
-4510,HuangLab/CELL-E_2-Image_Prediction,gradio,mit,4
-4511,openaccess-ai-collective/ggml-ui,gradio,,4
-4512,muhammadzain/Background-changer-remover-backend,docker,,4
-4513,Carlosito16/aitGPT,streamlit,,4
-4514,onlyswan/swan-voice,gradio,,4
-4515,HuangLab/CELL-E_2-Sequence_Prediction,gradio,mit,4
-4516,aaronb/Anything2Image,gradio,,4
-4517,mkshing/rinna-japanese-gpt-neox-3.6b-instruction-x,gradio,mit,4
-4518,matthoffner/serp-chat,docker,,4
-4519,Willder/GPT-Token-Calculator,streamlit,,4
-4520,mirroring/upload_civitai_model,gradio,mit,4
-4521,Selim321/youtube-summarizer,streamlit,apache-2.0,4
-4522,heliosbrahma/ai-pdf-assistant,gradio,,4
-4523,Spark808/rvc-demo,gradio,mit,4
-4524,YueMafighting/mmpose-estimation,gradio,mit,4
-4525,izumi-lab/llama-13b-japanese-lora-v0-1ep,docker,other,4
-4526,younver/speechbrain-speech-separation,gradio,,4
-4527,FrankZxShen/vits-fast-finetuning-umamusume,gradio,apache-2.0,4
-4528,xiaofenglingreal/Remove-Animation-Figures-Background,gradio,apache-2.0,4
-4529,Adithedev/Text-Summarization-Tool,streamlit,creativeml-openrail-m,4
-4530,Vikas01/gender-age-detection,streamlit,,4
-4531,AFOL/GigaGan,streamlit,,4
-4532,justest/vicuna-ggml,gradio,,4
-4533,lain-iwakura/lainchan-proxy,docker,,4
-4534,wtarit/nllb-th-en-translation,gradio,apache-2.0,4
-4535,neural-ti/NeTI,gradio,mit,4
-4536,ritikjain51/pdf-question-answering,gradio,mit,4
-4537,heliosbrahma/product-description-generator,gradio,,4
-4538,BIOML-SVM/SVM,gradio,mit,4
-4539,Xalphinions/tab-cot,gradio,cc-by-4.0,4
-4540,ramkamal2000/voice-conversion-ddp,gradio,,4
-4541,haseeb-heaven/AutoBard-Coder,streamlit,mit,4
-4542,quinnpertuit/drake-ai-v1,gradio,mit,4
-4543,openaccess-ai-collective/ggml-runpod-ui,gradio,apache-2.0,4
-4544,ayymen/MMS-ASR,gradio,,4
-4545,FrexG/MMS-Ethiopian_Language-ASR,gradio,,4
-4546,IoMa/stable-diffusion-webui-cpu,gradio,,4
-4547,librarian-bots/MetaRefine,gradio,,4
-4548,EmilyBrat/bratty-space-needs-correction,docker,,4
-4549,dhanushreddy29/Remove_Background,gradio,mit,4
-4550,March07/PromptBench,streamlit,mit,4
-4551,porntech/sex-position-video,gradio,mit,4
-4552,awacke1/ChatGPTStreamlit7,streamlit,mit,4
-4553,zeno-ml/translation-report,docker,mit,4
-4554,muttalib1326/Human-Voice-To-Text,gradio,,4
-4555,seedmanc/batch-laion-aesthetic-predictor,gradio,,4
-4556,kevinwang676/DreamlikeArt-PhotoReal-2.0,gradio,,4
-4557,thomwolf/hf-star-history,docker,mit,4
-4558,deepghs/anime_image_classification,gradio,mit,4
-4559,thefcraft/prompt-generator-stable-diffusion,gradio,,4
-4560,rohanshaw/Bard,gradio,mit,4
-4561,ashpepel/ashpepel,docker,,4
-4562,Workhack/chatgpt-prompt-playground,static,wtfpl,4
-4563,Kalvin-5/WizardLM-WizardCoder-15B-V1.0,gradio,,4
-4564,mike-ravkine/llm-webapps-results,docker,mit,4
-4565,renumics/cifar10-outlier,docker,mit,4
-4566,Selim321/image2image-stable-diffusion,gradio,unknown,4
-4567,udayvarma/Image-to-Line-Drawings,gradio,mit,4
-4568,osanseviero/persistent-data-final,gradio,,4
-4569,malper/taatiknet,streamlit,,4
-4570,allknowingroger/Image-Models-Test8,gradio,,4
-4571,realvest/realvest-app,streamlit,,4
-4572,OsituKengere/Sauti-Midjourney,gradio,,4
-4573,primodata/all_in_gpt,gradio,,4
-4574,SungBeom/chatwine-korean,gradio,,4
-4575,mrrandom123/mattmdjaga-segformer_b2_clothes,gradio,,4
-4576,huggingface-timeseries/time-series-score,gradio,apache-2.0,4
-4577,editing-images/project,static,cc-by-sa-4.0,4
-4578,awinml/vicuna-7b-ggml-api,gradio,mit,4
-4579,xnetba/MMS,gradio,cc-by-nc-4.0,4
-4580,allknowingroger/Image-Models-Test15,gradio,,4
-4581,awacke1/MultiPDF-QA-ChatGPT-Langchain,streamlit,mit,4
-4582,0xSpleef/openchat-openchat_8192,gradio,,4
-4583,coreml-community/ControlNet-v1-1-Annotators-cpu,gradio,mit,4
-4584,allknowingroger/Image-Models-Test17,gradio,,4
-4585,arnold-anand/chat-with-pdf,streamlit,gpl-3.0,4
-4586,AFRAC/NCM_DEMO,gradio,mit,4
-4587,lijiacai/stable-diffusion-webui-cpu,gradio,,4
-4588,abhishekgawade/Skin_disease_detection,gradio,,4
-4589,davanstrien/label-studio-to-hub,gradio,,4
-4590,Manjushri/PhotoReal-V2.0,gradio,mit,4
-4591,chansung/llm-discord-bot,docker,apache-2.0,4
-4592,nomic-ai/vicgalle_alpaca-gpt4,static,,4
-4593,FFusion/FFusionAI-Streamlit-Playground,streamlit,creativeml-openrail-m,4
-4594,mikeee/falcon-7b-ggml,gradio,,4
-4595,zenafey/prodia,gradio,openrail,4
-4596,noes14155/img_All_models,gradio,,4
-4597,Poupeto/RVC_Ryu7ztv,gradio,mit,4
-4598,hysts-samples/space-monitor,gradio,mit,4
-4599,Username85/G3,docker,,4
-4600,Ekimetrics/Biomap,streamlit,cc-by-4.0,4
-4601,gsaivinay/Llama-2-13B-GGML-server,docker,,4
-4602,Hmjz100/MT3,gradio,,4
-4603,allknowingroger/Image-Models-Test41,gradio,,4
-4604,mikeee/llama2-7b-chat-ggml,gradio,,4
-4605,faisalhr1997/chat-ggml,gradio,,4
-4606,syaz01/rvc-anigames-v2,gradio,mit,4
-4607,jbilcke-hf/webapp-factory-llama2,docker,,4
-4608,Sandiago21/speech-to-speech-translation-german,gradio,,4
-4609,ZX9966/LLM-Research,static,apache-2.0,4
-4610,Xenova/next-example-app,static,,4
-4611,Tester002/Claudette,docker,,4
-4612,mbear/code-playground,gradio,,4
-4613,gradio-discord-bots/Llama-2-70b-chat-hf,gradio,mit,4
-4614,Artples/LLaMA-2-CHAT,gradio,apache-2.0,4
-4615,qblocks/Monster-LLMs,gradio,apache-2.0,4
-4616,freddyaboulton/llama-chat-discord-bot,gradio,,4
-4617,Ababababababbababa/topic2poem,gradio,afl-3.0,4
-4618,Ababababababbababa/poetry2023,gradio,,4
-4619,NeuroSenko/tts-silero,gradio,,4
-4620,simsa/Fashion-Image-Captioning-using-BLIP-2,streamlit,apache-2.0,4
-4621,Mashhoor/stabilityai-stable-diffusion-image-generator,gradio,,4
-4622,donjuanplatinum/code,gradio,gpl-2.0,4
-4623,merve/MusicGen,gradio,apache-2.0,4
-4624,whyu/MM-Vet_Evaluator,gradio,apache-2.0,4
-4625,Justin-Choo/Dreamlikeart-Anime-ZH,gradio,,4
-4626,diffle/ComfyUI,static,creativeml-openrail-m,4
-4627,Dagfinn1962/stablediffusion-articlera,gradio,,4
-4628,StarFox7/Llama-2-ko-7B-chat-ggml,gradio,,4
-4629,allknowingroger/Image-Models-Test65,gradio,,4
-4630,zac/Coding_with_LLAMA_CPU,gradio,apache-2.0,4
-4631,TheRealZoink/Zoink_OV3RL0AD,docker,,4
-4632,Thanaphit/yolov8-car-parts-and-damage-segmentation,gradio,mit,4
-4633,erastorgueva-nv/NeMo-Forced-Aligner,gradio,apache-2.0,4
-4634,victor/AudioGen,gradio,cc-by-nc-4.0,4
-4635,imageomics/Andromeda,docker,mit,4
-4636,hf-vision/detection_metrics,static,,4
-4637,allknowingroger/Image-Models-Test79,gradio,,4
-4638,foduucom/product-detect-in-shelf-yolov8,gradio,,4
-4639,avaco/stablediffusionapi-disney-pixal-cartoon,gradio,,4
-4640,Sidharthan/VideoSummarizer,gradio,,4
-4641,gojiteji/LLM-Comparer,gradio,,4
-4642,Andyrasika/Andyrasika-dreamshaper-sdxl-1.0,gradio,,4
-4643,allknowingroger/Image-Models-Test90,gradio,,4
-4644,merve/gradio-tgi,gradio,apache-2.0,4
-4645,reach-vb/animated-audio-visualizer-1024,gradio,,4
-4646,pankajmathur/psmathur-orca_mini_v3_70b,gradio,apache-2.0,4
-4647,allknowingroger/Image-Models-Test98,gradio,,4
-4648,krystaltechnology/image-video-colorization,streamlit,,4
-4649,bhaskartripathi/Llama-2-70b-chatbot,gradio,,4
-4650,mygyasir/digiplay-PotoPhotoRealism_v1,gradio,,4
-4651,Liky1234/Bilibili,docker,,4
-4652,xiantian/xiantian,docker,,4
-4653,dolphinfusion/dolphinfusion-diffusion,gradio,,4
-4654,dolphinfusion/SD-XL,gradio,,4
-4655,allknowingroger/Image-Models-Test102,gradio,,4
-4656,pigeonchat-community/pigeon-chat,gradio,,4
-4657,eson/bert-perplexity,gradio,,4
-4658,sky24h/Free-View_Expressive_Talking_Head_Video_Editing,gradio,cc-by-nc-4.0,4
-4659,DataHunter/ostris-crayon_style_lora_sdxl,gradio,,4
-4660,crystalai/FFusion-FFusionXL-09-SDXL,gradio,apache-2.0,4
-4661,dongsiqie/bingai,docker,mit,4
-4662,techasad/image-to-audio-story,streamlit,,4
-4663,Nick1/rvc-models,gradio,mit,4
-4664,allknowingroger/Image-Models-Test120,gradio,,4
-4665,krystian-lieber/codellama-34b-chat,gradio,other,4
-4666,rt33/terry,docker,,4
-4667,hhhwmws/ChatHaruhi-Xinghuo,gradio,apache-2.0,4
-4668,mateuseap/magic-vocals,gradio,lgpl-3.0,4
-4669,AxelBell/EasyOCR_text_recognition,gradio,apache-2.0,4
-4670,GoAPI/Midjourney-zoom-video-generator-GoAPI,gradio,,4
-4671,h1r41/OpenBuddy-Gradio,gradio,,4
-4672,jbilcke-hf/space-factory,docker,,4
-4673,Cran-May/yugangVI,gradio,,4
-4674,unstructuredio/unstructured-chipper-app,streamlit,other,4
-4675,freddyaboulton/falcon-180b-demo-gradio-discord-bot,gradio,,4
-4676,limcheekin/WizardCoder-Python-13B-V1.0-GGUF,docker,,4
-4677,Catspindev/monadical-labs-minecraft-skin-generator,gradio,,4
-4678,allknowingroger/Image-Models-Test131,gradio,,4
-4679,hf4all/chatgpt-next-web-bing,docker,mit,4
-4680,yuchenlin/llama-token-counter,gradio,,4
-4681,Lavena/claude,docker,,4
-4682,EronSamez/RVC_HFmeu,gradio,,4
-4683,laiyer/llm-guard-playground,docker,mit,4
-4684,Ilzhabimantara/rvc-Blue-archives,gradio,mit,4
-4685,chansung/palm-with-gradio-chat,gradio,apache-2.0,4
-4686,alibaba-pai/easyphoto,gradio,apache-2.0,4
-4687,SalahZa/Code-Switched-Tunisian-SpeechToText,gradio,cc-by-nc-3.0,4
-4688,tonyassi/nsfw-safety-checker,gradio,,4
-4689,radames/Candle-T5-Generation-Wasm,static,,4
-4690,GuujiYae/Grand-Narukami-Shrine,docker,,4
-4691,AchyuthGamer/ImMagician,gradio,,4
-4692,tonyassi/vogue-runway-scraper,gradio,,4
-4693,foduucom/stockmarket-future-prediction,gradio,,4
-4694,pharma-IA/PharmaWise_Experto_GMP_V2C,gradio,artistic-2.0,4
-4695,44brabal/runwayml-stable-diffusion-v1-5,gradio,,4
-4696,zamasam/loligod,docker,,4
-4697,tsfeng/DeepDanbooru-string,gradio,,4
-4698,distil-whisper/hallucination-analysis,gradio,,4
-4699,Tomoniai/Demo_Mistral_Chat,gradio,,4
-4700,deepliteai/yolobench,gradio,apache-2.0,4
-4701,Detomo/ai-avatar-frontend,docker,apache-2.0,4
-4702,familytrain/upscaler2,gradio,apache-2.0,4
-4703,hzwluoye/gptnextweb-LangChain,docker,mit,4
-4704,zenafey/illusion,gradio,mit,4
-4705,awacke1/MistralCoder,gradio,mit,4
-4706,Nephele/bert-vits2-multi-voice,gradio,mit,4
-4707,XzJosh/ranran-Bert-VITS2,gradio,mit,4
-4708,badayvedat/AudioSep,gradio,mit,4
-4709,librarian-bots/new_hub_datasets,gradio,,4
-4710,Felladrin/MiniSearch,docker,,4
-4711,dblasko/blip-dalle3-img2prompt,gradio,,4
-4712,lalashechka/video2,gradio,,4
-4713,codys12/MergeLlama-7b,gradio,mit,4
-4714,thuanz123/peft-sd-realfill,gradio,openrail,4
-4715,Sijuade/Stable-Diffusion,gradio,mit,4
-4716,radames/gradio-lite-candle-SAM,static,,4
-4717,realfill-library/RealFill-Training-UI,gradio,mit,4
-4718,LaynzKunz/Advanced-RVC-Inference,gradio,mit,4
-4719,arsalagrey/image-classfication-vue,static,mit,4
-4720,deinferno/Latent_Consistency_Model_OpenVino_CPU,gradio,mit,4
-4721,hacknc23/hacknc23,streamlit,mit,4
-4722,leogabraneth/text-generation-webui-main,gradio,,4
-4723,miracle01/speechemotion,streamlit,mit,4
-4724,librarian-bots/claim-papers,gradio,,4
-4725,FL33TW00D/whisper-turbo,static,,4
-4726,limcheekin/OpenHermes-2.5-Mistral-7B-GGUF,docker,,4
-4727,Amiminoru/Deus,docker,,4
-4728,Vithika/ISRO,streamlit,,4
-4729,Abhaykoul/Youtube_video_downloader,streamlit,mit,4
-4730,ngoctuanai/stable-diffusion,gradio,mit,4
-4731,pseudolab/MiniMed_EHR_Analyst,streamlit,apache-2.0,4
-4732,Roboflow/HotDogGPT,gradio,,4
-4733,Illia56/OpenAI_TTS,gradio,mit,4
-4734,AUBMC-AIM/OCTaGAN,gradio,mit,3
-4735,AlgoveraAI/ocean-marketplace,gradio,mit,3
-4736,BigSalmon/GPTJ,gradio,,3
-4737,Detomo/Image-Classification,gradio,,3
-4738,DrishtiSharma/ASR_using_Wav2Vec2,gradio,,3
-4739,EdanMizrahi/OpenAItest,gradio,,3
-4740,Enutrof/GenreClassifier,gradio,afl-3.0,3
-4741,GEM/results,static,,3
-4742,GEM/submission-form,streamlit,,3
-4743,Gabriel/Swe_summarizer,gradio,,3
-4744,Giuliano/breast_cancer_prediction_tfjs,static,,3
-4745,Hellisotherpeople/Reassuring_parables,streamlit,,3
-4746,Hitmanny/BigGAN-text-to-image,gradio,,3
-4747,JLD/image-search,streamlit,,3
-4748,MilaNLProc/wordify,streamlit,,3
-4749,MrAI-Rohan/three-dog-breeds-detector,gradio,,3
-4750,NbAiLab/maken-clip-sketch,gradio,,3
-4751,NegativeSector/News_Article_Generator,gradio,,3
-4752,NeuML/imagesearch,streamlit,,3
-4753,NeuML/similarity,streamlit,,3
-4754,OmarN121/NLP_for_Jobs,gradio,,3
-4755,OthmaneJ/transcribe-distil-wav2vec2,gradio,,3
-4756,PaddlePaddle/paddlespeech,gradio,,3
-4757,Sa-m/manifesto-explainer,gradio,,3
-4758,Sadhaklal/coreference-neuralcoref,streamlit,,3
-4759,Sakil/image_generator,gradio,apache-2.0,3
-4760,Sakil/sakil_text_summarization_app,gradio,apache-2.0,3
-4761,Shruhrid/IMDB_movie_review,gradio,,3
-4762,ThomasSimonini/Murder-on-horsea-island-prototype,gradio,,3
-4763,ThomasSimonini/SB3_Atari,gradio,,3
-4764,Wootang01/URL_news_summarizer,gradio,,3
-4765,Wootang01/paraphraser_one,gradio,,3
-4766,YuAnthony/Audio-Caption,Configuration error,Configuration error,3
-4767,abidlabs/Webcam-background-remover,gradio,,3
-4768,abidlabs/crowd-speech,gradio,,3
-4769,abidlabs/pytorch-image-classifier,gradio,mit,3
-4770,adalbertojunior/image_captioning_portuguese,streamlit,,3
-4771,akdeniz27/turkish-named-entity-recognition,streamlit,,3
-4772,akhaliq/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext,gradio,,3
-4773,akhaliq/SummerTime,gradio,,3
-4774,akhaliq/codet5,gradio,,3
-4775,akhaliq/distilbart-cnn-12-6,gradio,,3
-4776,akhaliq/encoder4editing,gradio,,3
-4777,akhaliq/kan-bayashi_ljspeech_joint_finetune_conformer_fastspeech2_hifigan,gradio,,3
-4778,akhaliq/layout-parser,gradio,,3
-4779,aliabd/blocks-image-audio,gradio,,3
-4780,breathingcyborg/word2vec-for-products,streamlit,,3
-4781,cahya/indonesian-story,streamlit,,3
-4782,cakiki/arxiv-downloads,static,cc-by-nc-4.0,3
-4783,cakiki/facets-overview,static,,3
-4784,ceshine/t5-paraphrasing,gradio,apache-2.0,3
-4785,chinhon/malay_headlines_writer,gradio,,3
-4786,ck46/extractive_summaries,streamlit,,3
-4787,danielferreira/emotion-text-classification,gradio,,3
-4788,davidwisdom/la-metro,streamlit,,3
-4789,deep-learning-analytics/segformer_semantic_segmentation,streamlit,,3
-4790,docs-demos/bert-base-uncased,gradio,,3
-4791,docs-demos/mt5-small-finetuned-arxiv-cs-finetuned-arxiv-cs-full,gradio,,3
-4792,dragonSwing/wav2vec2-vi-asr,gradio,,3
-4793,dtsh4rk/neural-style-transfer,gradio,,3
-4794,echolee/faceanime4u,gradio,,3
-4795,erc/entity-referring-classifier,streamlit,,3
-4796,facebook/XLS-R-300m-EN-15,gradio,,3
-4797,graceaiedu/Coffee,gradio,,3
-4798,gracjans/Game-or-book-cover-classifier,gradio,,3
-4799,haotieu/en-vi-translation,gradio,,3
-4800,hitz02/TableQA,streamlit,,3
-4801,hysts/lbpcascade_animeface,gradio,,3
-4802,azizalto/youtube_downloader,streamlit,,3
-4803,isabel/anime-project,gradio,,3
-4804,isabel/pug-or-cat-image-classifier,gradio,,3
-4805,ivanlau/language-detection-xlm-roberta-base,gradio,,3
-4806,j-hartmann/emotion-similarity,gradio,,3
-4807,jason9693/m2m-100,gradio,,3
-4808,jkang/demo-image-completion,gradio,,3
-4809,jkang/demo-image-pyxelate,gradio,,3
-4810,jkang/espnet2_librispeech_100h_word_vs_bpe_vs_char,gradio,mit,3
-4811,julien-c/svelte-demo,static,,3
-4812,julien-c/sveltekit-demo,static,,3
-4813,julien-c/tailwind-gradient,static,,3
-4814,kTonpa/Text2Cryptopunks,gradio,,3
-4815,karolmajek/Detectron2-MaskRCNN,gradio,,3
-4816,keras-io/keras-image-classifier,gradio,,3
-4817,keras-io/keras-video-classification-cnn-rnn,gradio,,3
-4818,keras-io/text-generation,gradio,,3
-4819,keras-io/vit-small-ds,gradio,cc0-1.0,3
-4820,khxu/pegasus-text-summarizers,gradio,apache-2.0,3
-4821,legoandmars/glide-inpainting,gradio,,3
-4822,m3hrdadfi/typo-detector,streamlit,,3
-4823,malloc/OpenNMT-EN-DE-Translation,gradio,,3
-4824,malmal/dog-breed-identifier,gradio,,3
-4825,mariagrandury/roberta-qa-es,gradio,,3
-4826,mariakatosvich/security,streamlit,,3
-4827,merve/taskmaster,streamlit,,3
-4828,micole66/test,gradio,,3
-4829,mikeee/radiobee-aligner,gradio,,3
-4830,ml6team/toxic-comment-detection-german,streamlit,,3
-4831,monsoon-nlp/spanish-flip,gradio,,3
-4832,mrm8488/write-with-spanish-gpt-2,streamlit,,3
-4833,muhammadayman/gradio-demo,gradio,,3
-4834,muhtasham/TajBERTo,gradio,,3
-4835,nateraw/pictionary,gradio,,3
-4836,neurotech/cat_dog_audio_classifier,gradio,apache-2.0,3
-4837,nikhilmane007/text_dissection,streamlit,,3
-4838,osanseviero/EfficientNetV2,gradio,,3
-4839,osanseviero/danfojs-test,static,,3
-4840,osanseviero/test_gradio,gradio,,3
-4841,patrickvonplaten/asv,gradio,,3
-4842,pierreguillou/question-answering-portuguese,gradio,,3
-4843,pytorch/AlexNet,gradio,,3
-4844,pytorch/DCGAN_on_fashiongen,gradio,,3
-4845,pytorch/X3D,gradio,,3
-4846,rajesh1729/NER-using-spacy-gradio,gradio,afl-3.0,3
-4847,rajesh1729/gradio-realtime-news-app,gradio,afl-3.0,3
-4848,raynardj/duguwen-classical-chinese-to-morden-translate,streamlit,,3
-4849,rexoscare/Resume_screener,gradio,,3
-4850,rg089/NewsHelper,gradio,,3
-4851,risingodegua/hate-speech-detector,gradio,,3
-4852,sagittariusA/media_bias_detection_CS,gradio,,3
-4853,salti/arabic-question-paraphrasing,gradio,,3
-4854,savasy/Twitter2SentiForTurkish,gradio,,3
-4855,savasy/text-classification-for-Turkish,gradio,,3
-4856,scp4950/fastspeech2-en-ljspeech-Demo,gradio,osl-3.0,3
-4857,shauryaDugar/gradio-Note-Classifier,gradio,,3
-4858,sohomghosh/FiNCAT_Financial_Numeral_Claim_Analysis_Tool,gradio,mit,3
-4859,sonoisa/Irasuto_search_CLIP_zero-shot,streamlit,apache-2.0,3
-4860,stevenkolawole/T5-multitasks-gradio,gradio,,3
-4861,ttj/t0-generation,gradio,,3
-4862,ttj/wordle-helper,gradio,,3
-4863,ubamba98/clipsimilarimagesearch,gradio,,3
-4864,vasudevgupta/BigGAN,gradio,,3
-4865,vasudevgupta/GOOGLE_SUMMER_OF_CODE,gradio,,3
-4866,vishnun/SpellCorrectorT5,streamlit,,3
-4867,widged/named-entity-recognition,streamlit,,3
-4868,widged/text-classification,streamlit,,3
-4869,xiatao/microsoft-trocr-large-printed,gradio,,3
-4870,yoyololicon/Danna-Sep,gradio,mit,3
-4871,zhenwusw/AnimeGAN,gradio,,3
-4872,tensorflow/imagenet-efficientnet_v2_imagenet1k_b0-classification,gradio,,3
-4873,awacke1/SOTA-Plan,gradio,mit,3
-4874,eubinecto/idiomify,streamlit,,3
-4875,cakiki/netlogo-ants,static,gpl-3.0,3
-4876,calvininterview/bart-question-interactive,gradio,,3
-4877,ivanlau/IntelliLabel,streamlit,,3
-4878,PaddlePaddle/animegan_v1_hayao_60,gradio,,3
-4879,PaddlePaddle/stylepro_artistic,gradio,,3
-4880,Wootang01/keyword_extractor,streamlit,,3
-4881,akdeniz27/turkish-pos-tagging-with-xlm_roberta,streamlit,,3
-4882,opetrova/face-frontalization,gradio,mit,3
-4883,mrm8488/Amazon-reviews-classification-es,gradio,wtfpl,3
-4884,manan/Score-Clinical-Patient-Notes,gradio,,3
-4885,neuronys/distractors,gradio,,3
-4886,BigSalmon/BackTranslation,streamlit,,3
-4887,onnx/GPT-2,gradio,,3
-4888,awacke1/SOTA-Summary,gradio,mit,3
-4889,jsjuan/PlateNumberRecognition,gradio,,3
-4890,amielle/patent-summarizer,gradio,mit,3
-4891,webis/chat-noir,streamlit,mit,3
-4892,awacke1/VisualCluster,gradio,mit,3
-4893,paulengstler/interpretable-vertebral-fracture-diagnosis,streamlit,,3
-4894,khizon/ActiveTransportDetection,gradio,,3
-4895,huggan/BigGAN,gradio,,3
-4896,Cahlil/Speech-Recognition-with-Speaker-Segmentation,gradio,,3
-4897,browndw/docuscope-demo-spacy,streamlit,mit,3
-4898,godot-demo/godot-2d,static,,3
-4899,smajumdar/nemo_conformer_rnnt_large_streaming,gradio,apache-2.0,3
-4900,kingabzpro/real-time-Urdu-ASR,gradio,,3
-4901,hackathon-pln-es/Sentence-Embedding-Bertin,streamlit,,3
-4902,awacke1/SOTA-MedEntity,gradio,mit,3
-4903,NimaBoscarino/gradio-secrets,gradio,,3
-4904,codeslake/RefVSR,gradio,gpl-3.0,3
-4905,pyodide-demo/gpt2-tokenizer,static,,3
-4906,rajesh1729/toonify-mercury,gradio,afl-3.0,3
-4907,FritsLyneborg/kunstnerfrits,streamlit,,3
-4908,satpalsr/RegNet-Image-Classification,gradio,,3
-4909,webis-huggingface-workshop/chris_code_generation,gradio,apache-2.0,3
-4910,awacke1/Search_Streamlit,streamlit,mit,3
-4911,tom-doerr/logo_generator,streamlit,apache-2.0,3
-4912,hysts/Hopenet,gradio,,3
-4913,hylee/artline,gradio,apache-2.0,3
-4914,hushell/pmf_with_gis,gradio,cc,3
-4915,eetn/DALL-E,gradio,,3
-4916,malper/unikud,streamlit,,3
-4917,hysts/atksh-onnx-facial-lmk-detector,gradio,,3
-4918,Nooshinbr/story_generation,gradio,,3
-4919,pplonski/deploy-mercury,gradio,mit,3
-4920,ecarbo/text-generator-gpt-neo,gradio,,3
-4921,MarcSkovMadsen/awesome-panel,gradio,mit,3
-4922,Eddevs/brian-challenge,streamlit,,3
-4923,jungealexander/uspppm-demo,gradio,apache-2.0,3
-4924,capstonedubtrack/Indiclanguagedubbing,gradio,unlicense,3
-4925,jcjurado/DaVinci,gradio,,3
-4926,akhaliq/arcanestyletransfer,gradio,,3
-4927,n-e-w/glock_classifier,gradio,lgpl-3.0,3
-4928,aeamaea/beard-detector,gradio,cc-by-nc-sa-4.0,3
-4929,NataKaichkina/PredictSalary,streamlit,,3
-4930,Yehor/wav2vec2-uk-demo,gradio,,3
-4931,strickvl/fastai_redaction_classifier,gradio,apache-2.0,3
-4932,ofig/live-lm-critic,streamlit,afl-3.0,3
-4933,strickvl/redaction-detector-streamlit,streamlit,apache-2.0,3
-4934,gylleus/icongen,streamlit,apache-2.0,3
-4935,hylee/u2net_portrait,gradio,apache-2.0,3
-4936,ashishraics/NLP,streamlit,,3
-4937,leakyrelu/MobilenetV2SSDLite_LPRnet,gradio,mit,3
-4938,azizmma/question_generator,streamlit,apache-2.0,3
-4939,NimaBoscarino/hotdog-gradio,gradio,apache-2.0,3
-4940,Jorgvt/CycleGAN-GTA-REAL,gradio,afl-3.0,3
-4941,subatomicseer/2022-AdaIN-pytorch-Demo,streamlit,other,3
-4942,emilylearning/causing_gender_pronouns_two,gradio,,3
-4943,ntt123/handwriting,static,cc-by-nc-4.0,3
-4944,imamnurby/RecipeGen,gradio,mit,3
-4945,evaluate-metric/precision,gradio,,3
-4946,gputrain/UrbanSounds8K,gradio,gpl,3
-4947,gurgenblbulyan/video-based-text-generation,gradio,,3
-4948,Andy1621/uniformer_image_segmentation,gradio,mit,3
-4949,autoevaluate/error-analysis,streamlit,,3
-4950,GDavila/textblob_sentiment,streamlit,mit,3
-4951,pierreguillou/tesseract-ocr-pt,gradio,mit,3
-4952,awacke1/AIandSmartTools,static,mit,3
-4953,unlisboa/bart_qa_assistant,gradio,,3
-4954,flava/zero-shot-image-classification,gradio,,3
-4955,pyimagesearch/nmt-bahdanau,gradio,mit,3
-4956,awacke1/StoryGenerator-MythsandLegends,gradio,mit,3
-4957,rajistics/library_metrics_forecasting,gradio,apache-2.0,3
-4958,awacke1/Seq2Seq-QAGenerator,gradio,mit,3
-4959,reinformator/LL,gradio,,3
-4960,sidphbot/Researcher,streamlit,,3
-4961,doevent/animegan-v2-for-videos,gradio,,3
-4962,evaluate-measurement/perplexity,gradio,,3
-4963,evaluate-metric/trec_eval,gradio,,3
-4964,Gradio-Blocks/CloudSaveText2Speech,gradio,mit,3
-4965,CShorten/Last-Week-on-ArXiv,gradio,afl-3.0,3
-4966,MarcCote/ScienceWorld,streamlit,apache-2.0,3
-4967,breynolds1247/StarryNight_StyleTransfer,gradio,,3
-4968,jordyvl/ece,gradio,,3
-4969,Gradio-Blocks/speech-to-text-app,streamlit,,3
-4970,tinkoff-ai/caif,streamlit,apache-2.0,3
-4971,keras-io/timeseries-anomaly-detection-autoencoders,gradio,,3
-4972,nateraw/helpful-snippets,streamlit,,3
-4973,keras-io/what-convnets-learn,streamlit,,3
-4974,keras-io/Attention_based_Deep_Multiple_Instance_Learning,gradio,apache-2.0,3
-4975,shoukaku/movie_recommendation,gradio,,3
-4976,ntt123/Connect-4-Game,static,cc-by-nc-4.0,3
-4977,erer/anima_pose_crop,gradio,,3
-4978,bikemright/overweight-AI,gradio,apache-2.0,3
-4979,Axolotlily/SketchThing,gradio,other,3
-4980,lambdaofgod/huggingface_explorer,streamlit,mit,3
-4981,segments-tobias/conex,gradio,,3
-4982,keras-io/Self-supervised-learning-SimSiam,gradio,,3
-4983,halilumutyalcin/spam-email-classifier-app,gradio,apache-2.0,3
-4984,jharrison27/StoryWritingTransformers,gradio,mit,3
-4985,ThomasSimonini/Unity-MLAgents-Pyramids,static,,3
-4986,CVPR/Dual-Key_Backdoor_Attacks,gradio,gpl-3.0,3
-4987,jorge-henao/ask2democracy,gradio,mit,3
-4988,Comet/txt2im-models,gradio,,3
-4989,harish3110/emotion_detection,gradio,,3
-4990,rosenthal/chess,gradio,,3
-4991,shaneweisz/AutoCounterspeech,gradio,afl-3.0,3
-4992,wvangils/Beatles_Poetry,gradio,,3
-4993,MilesCranmer/PySR,gradio,,3
-4994,logasja/LowKey,gradio,,3
-4995,SerdarHelli/ThyroidTumorClassification,gradio,,3
-4996,innat/Global.Wheat.Detection.MaskRCNN,gradio,,3
-4997,CVPR/WALT,gradio,mit,3
-4998,KyanChen/BuildingExtraction,gradio,,3
-4999,j0hngou/vision-diffmask,gradio,mit,3
-5000,kristyc/mediapipe-hands,gradio,,3
-5001,hugginglearners/Hearts_Leaderboard,gradio,mit,3
-5002,rajistics/Ask-Wiki,gradio,apache-2.0,3
-5003,HighCWu/GPEN,gradio,mit,3
-5004,HighCWu/GFPGAN-1.3,gradio,mit,3
-5005,DarkCeptor44/neural-art,gradio,gpl-2.0,3
-5006,awacke1/3DVirtualFood,gradio,mit,3
-5007,hylee/AnimeGANv2,gradio,apache-2.0,3
-5008,awacke1/NLPSentenceSimilarityHeatmap,streamlit,mit,3
-5009,Wootang01/paraphraser_three,streamlit,,3
-5010,keras-io/drug-molecule-generation-with-VAE,gradio,apache-2.0,3
-5011,QuoQA-NLP/KoQuillBot,streamlit,apache-2.0,3
-5012,fffiloni/ArcaneStyleTransfer_Webcam,gradio,,3
-5013,shajmaan/movies_recommender,gradio,afl-3.0,3
-5014,iakarshu/latr-vqa,gradio,unknown,3
-5015,EuroPython2022/bloom-prompts-spanish,gradio,wtfpl,3
-5016,hugginglearners/Ethiopian-Food-Classifier,gradio,,3
-5017,hugginglearners/kvasir-seg,gradio,,3
-5018,boli-ai/OIT,gradio,apache-2.0,3
-5019,EuroPython2022/Model-Recommendation,gradio,afl-3.0,3
-5020,EuroPython2022/illustrated-lyrics-generator,gradio,,3
-5021,fcossio/measure-fiber-diameter,gradio,apache-2.0,3
-5022,ICML2022/selection_bias_induced_spurious_correlations,gradio,mit,3
-5023,0x7194633/nllb-1.3B-demo,gradio,,3
-5024,derina/BartSummarizer,gradio,bsd,3
-5025,djl234/UFO,gradio,,3
-5026,LDY/Text-To-Image,gradio,afl-3.0,3
-5027,awacke1/CarePlanQnAWithContext,gradio,mit,3
-5028,Ivanrs/batch-image-bg-remover,gradio,apache-2.0,3
-5029,mikeee/gradio-deepl,gradio,mit,3
-5030,awesomepotato2016/recommender,gradio,apache-2.0,3
-5031,betheredge/air-vibrations,gradio,gpl-3.0,3
-5032,kunwarsaaim/Self-Debiasing,gradio,mit,3
-5033,dawood/Model3D,gradio,afl-3.0,3
-5034,shorthillstech/pybanking_churn,streamlit,mit,3
-5035,denisp1/Streamlit-Grammar-Corrector-Styler,streamlit,mit,3
-5036,xiang-wuu/yolov5,gradio,,3
-5037,rsatish1110/AudioToTextToStoryToImageToVideo,gradio,mit,3
-5038,Norod78/SillyTedTalkSnippetGenerator,gradio,cc-by-nc-4.0,3
-5039,kamezawash/rembg,gradio,mit,3
-5040,TabPFN/TabPFNEvaluation,gradio,,3
-5041,keithhon/macaw-large-onnx-demo,gradio,gpl-3.0,3
-5042,nickmuchi/license-plate-detection-with-YOLOS,gradio,,3
-5043,postbot/autocomplete-emails,gradio,apache-2.0,3
-5044,Zengyf-CVer/watermarking_lab,gradio,gpl-3.0,3
-5045,awacke1/StreamlitTimerTest,streamlit,mit,3
-5046,relbert/Analogy,gradio,,3
-5047,cymic/VITS-Tokaiteio,gradio,,3
-5048,canturan10/satellighte,streamlit,mit,3
-5049,keithhon/Tesseract-OCR,gradio,mit,3
-5050,abhibisht89/Donut_DocVQA,gradio,,3
-5051,ipvikas/ALL_NLP_Tasks,gradio,,3
-5052,Mwebrania/classification_of_maize_diseases,gradio,,3
-5053,chaninder/SmartWaste,gradio,afl-3.0,3
-5054,nafisehNik/mt5-persian-summary,streamlit,mit,3
-5055,mrfakename/Chat,streamlit,,3
-5056,AIZeroToHero/04-Image2OCR,gradio,mit,3
-5057,AIZeroToHero/Video-Automatic-Speech-Recognition,streamlit,mit,3
-5058,cchaun/music_tagging,gradio,other,3
-5059,Sa-m/Vehicles-Detection-Custom-YoloV7,gradio,mit,3
-5060,versus666/play_with_stable_diffusion_v1-4,streamlit,,3
-5061,yaelvinker/CLIPasso,gradio,,3
-5062,PascalNotin/Tranception_design,gradio,mit,3
-5063,ML-unipi/TermsOfServiceSummarization,streamlit,mit,3
-5064,nathanluskey/twitter_sentiment,gradio,mit,3
-5065,Priyabrata017/Flamingo,gradio,mit,3
-5066,pappymu/question-gen,streamlit,gpl-3.0,3
-5067,ai4bharat/IndicNLG,gradio,mit,3
-5068,mariofilho/gradio_tutorial,gradio,,3
-5069,pinecone/extractive-question-answering,streamlit,,3
-5070,mrfakename/Translate,streamlit,,3
-5071,yfyangd/PictureBookUnderstanding,gradio,apache-2.0,3
-5072,baaastien/AudioSpleeter,gradio,mit,3
-5073,clemsou/pokemon_generator,gradio,,3
-5074,VasudevaK/Information_Extractor,streamlit,apache-2.0,3
-5075,justYu2001/furniture-detection,gradio,,3
-5076,TrLOX/img2img,gradio,,3
-5077,kornia/kornia-edge-detection,gradio,apache-2.0,3
-5078,Manjushri/Dall-E-Mini,static,apache-2.0,3
-5079,owaiskha9654/PICO-Evidence-Based-Classification-Inference,gradio,apache-2.0,3
-5080,ppsingh/annotation_dev,streamlit,,3
-5081,ipvikas/ImageProcessing,gradio,,3
-5082,cmotions/new_beatles_songs,gradio,bigscience-bloom-rail-1.0,3
-5083,kornia/morphological_operators,gradio,,3
-5084,kornia/total_variation_denoising,gradio,,3
-5085,binery/Donut_Receipt,gradio,other,3
-5086,kornia/Line-Fitting,gradio,apache-2.0,3
-5087,devfinwiz/Dynamic-QR,gradio,,3
-5088,mrm8488/speech-to-diffusion,gradio,wtfpl,3
-5089,sarinam/speaker-anonymization,gradio,gpl-3.0,3
-5090,noeljb/hashtag-recommendation-engine,gradio,apache-2.0,3
-5091,tbxg34/Satellite-Image-Recognition,streamlit,apache-2.0,3
-5092,gradio/model3D,gradio,,3
-5093,gradio/spectogram,gradio,,3
-5094,mfranzon/MagicBoard,streamlit,,3
-5095,nazneen/datapoints-explorer,streamlit,apache-2.0,3
-5096,Armandoliv/gpt2-tweets-generation-app,gradio,,3
-5097,evaluate-measurement/regard,gradio,,3
-5098,jone/Music_Source_Separation,gradio,,3
-5099,aakashgoel12/nlp1,streamlit,,3
-5100,simecek/is_promoter,gradio,apache-2.0,3
-5101,wby/human-photo-3dize,gradio,openrail,3
-5102,isaiah08/dalle-mini-test,static,mit,3
-5103,ysharma/test_speech_to_text,gradio,gpl,3
-5104,PaddlePaddle/LSeg,gradio,apache-2.0,3
-5105,johngoad/Image-Caption,gradio,,3
-5106,amsterdamNLP/CLIP-attention-rollout,gradio,afl-3.0,3
-5107,AIZ2H/02-Gradio-Art-From-Text-And-Images,gradio,apache-2.0,3
-5108,AIZ2H/05-SOTA-Question-Answer-From-TextFileContext,gradio,apache-2.0,3
-5109,cadige/03-Streamlit-Video,streamlit,apache-2.0,3
-5110,tgohblio/stable-diffusion-basic,gradio,mit,3
-5111,freddyaboulton/latent-diffusion-seed,gradio,apache-2.0,3
-5112,akhaliq/sd-pokemon-diffusers,gradio,,3
-5113,TRI-ML/risk_biased_prediction,gradio,cc-by-nc-4.0,3
-5114,sebastian-hofstaetter/fid-light-explorer,gradio,apache-2.0,3
-5115,nightfury/SD-InPainting,gradio,mit,3
-5116,coutant/detect-signature,gradio,apache-2.0,3
-5117,UmairSyed/ObjectDetection,gradio,,3
-5118,Marne/MockingBird,gradio,,3
-5119,lulmer/paraphraser_ai,streamlit,apache-2.0,3
-5120,test-org-q/stable-diffusion,gradio,mit,3
-5121,TusharNautiyal/Dynamic-Movie-Recommender-With-Sentiment-Analysis,streamlit,mit,3
-5122,ai-forever/PeterRecognition,gradio,mit,3
-5123,jharrison27/streamlit-blenderbot,streamlit,,3
-5124,williambr/AIChatBot-SL-Chatbot-Blenderbot,streamlit,mit,3
-5125,amarjeets/OCR,gradio,mit,3
-5126,SudhanshuBlaze/text-generation-gpt-neo,streamlit,openrail,3
-5127,FahadAlam/Zero-Shot-Text-Classification,gradio,,3
-5128,altryne/vidtranslator,gradio,mit,3
-5129,darveen/text_summarizer,streamlit,openrail,3
-5130,khaclinh/self-driving-anonymization,gradio,cc-by-nc-4.0,3
-5131,datasciencedojo/Paraphrasing,gradio,,3
-5132,datasciencedojo/Question-Generator,gradio,,3
-5133,datasciencedojo/Text-Generator,gradio,,3
-5134,datasciencedojo/Zero-Shot-Text-Classification,gradio,,3
-5135,AFCMEgypt/colorimetric_analyzer,gradio,bigscience-bloom-rail-1.0,3
-5136,datasciencedojo/Wikipedia-Article-Scrape,gradio,,3
-5137,abidlabs/GFPGAN,gradio,apache-2.0,3
-5138,ml6team/dynamic-pricing,streamlit,,3
-5139,shichen1231/Real-CUGAN,gradio,apache-2.0,3
-5140,FSDL-Fashion/fashion_img_search,gradio,mit,3
-5141,bigscience-data/pyserini-demo,streamlit,,3
-5142,awaawawawa/iurf7irfuyytruyyugb,gradio,mit,3
-5143,ai-forever/scrabblegan-peter,gradio,mit,3
-5144,AISuperheroes/09SL-AI-Image-Music-Video-AIUIUX,streamlit,mit,3
-5145,Akmyradov/dost.ai,gradio,unknown,3
-5146,sayakpaul/sots-outdoor-dehazing-maxim,gradio,apache-2.0,3
-5147,nightfury/SD_Studio_AI_Text2Image_Image2Image_Generation,gradio,openrail,3
-5148,sil-ai/model-license,streamlit,,3
-5149,doevent/swin2sr,gradio,apache-2.0,3
-5150,sparanoid/milky-green-svc,gradio,,3
-5151,impira/flan-playground,gradio,,3
-5152,lgrobol/troer,gradio,mit,3
-5153,FathomNet/MBARI_Benthic_Supercategory_Object_Detector,gradio,,3
-5154,hnmensah/Ghanaian-Language-Translator,gradio,gpl-3.0,3
-5155,cmudrc/lattice-interpolation,gradio,mit,3
-5156,sayakpaul/raindrop-deraining-maxim,gradio,apache-2.0,3
-5157,wvle/speech_to_text,gradio,,3
-5158,terrierteam/doc2query,gradio,,3
-5159,bigscience-data/scisearch,gradio,apache-2.0,3
-5160,milyiyo/paraphrase_es,gradio,,3
-5161,mesolitica/ms-tts-VITS,gradio,,3
-5162,mikegarts/lotr,gradio,apache-2.0,3
-5163,Jayeshbhaal/news_filter_for_social_wellbeing,gradio,mit,3
-5164,tsambo/Demo_Sentiment_analysis,streamlit,,3
-5165,egumasa/engagement-analyzer-demo,streamlit,,3
-5166,osanseviero/esmfold_st,streamlit,,3
-5167,rondel/image-to-text-app,streamlit,,3
-5168,bofenghuang/speech-to-text,gradio,,3
-5169,mrfakename/tts,streamlit,other,3
-5170,shripadbhat/Question_Answering_Document,streamlit,,3
-5171,dvitel/codebleu,gradio,,3
-5172,Lee008/PixelDayReal,gradio,,3
-5173,yujieq/MolScribe,gradio,mit,3
-5174,awacke1/Gradio-Gallery-Health-Medical-Icon-Sets,gradio,mit,3
-5175,sanchit-gandhi/enhanced_direct_s2st,gradio,,3
-5176,User1342/Ivory,gradio,gpl-3.0,3
-5177,TomLemsky/this_skin_does_not_exist,gradio,gpl-3.0,3
-5178,Emanuel/porttagger,gradio,mit,3
-5179,naver-clova-ix/donut-base-finetuned-kuzushiji,gradio,,3
-5180,freddyaboulton/dataset-viewer,gradio,mit,3
-5181,Amrrs/fashion-aggregator-duplicated,gradio,,3
-5182,DrGabrielLopez/GPT2_Chatbot,gradio,cc-by-nc-sa-4.0,3
-5183,spiritupbro/Voice-Cloning,gradio,mit,3
-5184,PublicPrompts/Pixel_diffusion,gradio,mit,3
-5185,akhaliq/Ghibli-Diffusion,gradio,,3
-5186,julien-c/dreambooth-training,gradio,mit,3
-5187,bigcode/pii-public-demo,streamlit,,3
-5188,Avkash/WebcamFaceProcessing,gradio,mit,3
-5189,kdrkdrkdr/AzusaTTS,gradio,mit,3
-5190,mgxwrites/Mgx-Diffusion-v3.0,gradio,,3
-5191,priyank-m/m_OCR,gradio,,3
-5192,fffiloni/mr-and-misses,gradio,,3
-5193,windmaple/stable-diffusion-2,static,mit,3
-5194,NobleEpuz/openjourney,gradio,,3
-5195,intelliarts/Car_parts_damage_detection,gradio,mit,3
-5196,Southstar1/img-to-music,gradio,,3
-5197,royyy/text_generator,gradio,,3
-5198,kdrkdrkdr/HoshinoTTS,gradio,mit,3
-5199,awacke1/PrompTart,gradio,,3
-5200,christinac/text-decorator,gradio,,3
-5201,MirageML/lowpoly-environment,gradio,,3
-5202,IgorSense/Diffusion_Space2,gradio,creativeml-openrail-m,3
-5203,aidiary/tts-ljspeech-demo,gradio,mit,3
-5204,akhaliq/supermarionation,gradio,,3
-5205,Ramos-Ramos/albef-vqa,gradio,,3
-5206,mandar100/blenderbot_chat,gradio,,3
-5207,drift-ai/question-answer-text,gradio,,3
-5208,deaf1296/finetuned_diffusion,gradio,mit,3
-5209,fcakyon/timesformer,gradio,,3
-5210,nerijs/coralchar-diffusion,gradio,,3
-5211,AmrElsayeh/Interior_style_detector,gradio,apache-2.0,3
-5212,EvgenyK/Text-To-Image,gradio,openrail,3
-5213,SudhanshuBlaze/neural-style-transfer-streamlit,streamlit,mit,3
-5214,yangheng/Waifu2X-Image-Scale,gradio,mit,3
-5215,qisan/whisper-small-CN-YouTube-video-transcribe,gradio,apache-2.0,3
-5216,whispy/Italian-ASR,gradio,apache-2.0,3
-5217,akhaliq/runwayml-stable-diffusion-v1-5,gradio,,3
-5218,datasciencedojo/Mental_Health_Bot,gradio,,3
-5219,PBJ/image_colorization_app,streamlit,apache-2.0,3
-5220,Nithila77/fashion-mnist,gradio,gpl-3.0,3
-5221,emilios/whisper-greek-demo,gradio,,3
-5222,Harsh23Kashyap/StockMarketPredictor,streamlit,,3
-5223,Zaid/whisper-large-v2-ar,gradio,apache-2.0,3
-5224,binarycache/voice_to_image,gradio,,3
-5225,Svngoku/GFPGAN,gradio,apache-2.0,3
-5226,emmetmayer/Large-Context-Question-and-Answering,streamlit,cc-by-4.0,3
-5227,morganreese8/rhymethyme,streamlit,openrail,3
-5228,Kirokowa/hakurei-waifu-diffusion,gradio,,3
-5229,robmarkcole/fire-detection-from-images,gradio,apache-2.0,3
-5230,AvinashRamesh23/AIEditor,streamlit,,3
-5231,teamnassim/emotion-detection-app,gradio,mit,3
-5232,fkunn1326/CoolJapaneseDiffusion,gradio,creativeml-openrail-m,3
-5233,fkunn1326/waifu2x,gradio,mit,3
-5234,MKFMIKU/Bi-Noising.Diffusion,gradio,,3
-5235,ThirdEyeData/Network_Data_Anomaly,streamlit,,3
-5236,FloydianSound/Nixeu_Diffusion,gradio,,3
-5237,ORI-Muchim/BarKeYaeTTS,gradio,mit,3
-5238,sussahoo/table_extraction,gradio,,3
-5239,livebook-dev/single_file_phx_bumblebee_ml,docker,,3
-5240,akhaliq/seek.art_MEGA,gradio,,3
-5241,ThirdEyeData/Price_Optimization,streamlit,,3
-5242,SpacesExamples/single_file_phx_bumblebee_ml,docker,,3
-5243,rizam/rjgpt,gradio,,3
-5244,tarteel-ai/demo-whisper-base-ar-quran,gradio,,3
-5245,mueller-franzes/medfusion-app,streamlit,mit,3
-5246,Yusin/talking-stable-diffusion,gradio,,3
-5247,kdrkdrkdr/ZhongliTTS,gradio,mit,3
-5248,neuralmagic/nlp-ner,gradio,,3
-5249,luigisaetta/whisper-demo,gradio,,3
-5250,neuralmagic/cv-yolact,gradio,,3
-5251,ales/whisper-small-belarusian-demo,gradio,,3
-5252,froginsect/Lama-Cleaner-lama,gradio,apache-2.0,3
-5253,Fatima990/text_generator1,gradio,,3
-5254,bofenghuang/whisper-demo-german,gradio,,3
-5255,alexander1i/dreamlike-art-dreamlike-diffusion-1.0,gradio,,3
-5256,Autopixel/blurry-faces,gradio,apache-2.0,3
-5257,adirik/stylemc-demo,gradio,apache-2.0,3
-5258,facebook/Hokkien_Demo_on_GPU,gradio,cc-by-nc-4.0,3
-5259,kdrkdrkdr/HinaTTS,gradio,mit,3
-5260,RASMUS/Youtube-videos-with-crosslingual-transcriptions,gradio,apache-2.0,3
-5261,Curranj/GPT-QRI,gradio,,3
-5262,bigcode/license,static,,3
-5263,Joeythemonster/flax-midjourney-v4-diffusion,gradio,,3
-5264,Zephyr65/Envvi-Inkpunk-Diffusion,gradio,,3
-5265,ThirdEyeData/Retail-Anomaly,streamlit,,3
-5266,abdalrahmanshahrour/Summarization,streamlit,,3
-5267,djillegal/illegal_stable_img2img,gradio,,3
-5268,jbrinkma/video-transcription,gradio,openrail,3
-5269,pieeetre/stable-diffusion-webui,gradio,openrail,3
-5270,kohbanye/pixel-art-style,gradio,,3
-5271,rifkat/uz_news_classifer,gradio,,3
-5272,FKBaffour/Streamlit_App_for_Sales_Forecasting,streamlit,,3
-5273,Joeythemonster/prompt-extend,gradio,apache-2.0,3
-5274,morenolq/italian-summarization,gradio,mit,3
-5275,JammyMachina/streamlit-jam-machine,streamlit,,3
-5276,keremberke/valorant-object-detection,gradio,,3
-5277,ysharma/LiveScatterPlot,gradio,mit,3
-5278,DeepLabCut/DeepLabCutModelZoo-SuperAnimals,gradio,,3
-5279,gstaff/MagicGen,gradio,apache-2.0,3
-5280,IzumiSatoshi/sketch2img-FashionMNIST,gradio,apache-2.0,3
-5281,davidscripka/openWakeWord,gradio,cc-by-nc-sa-4.0,3
-5282,amgross01/Stocks_Trading_Assistant,streamlit,,3
-5283,abdalrahmanshahrour/questionanswering,gradio,,3
-5284,carlosabadia/face_detection,gradio,mit,3
-5285,luluneko1/stable-diffusion-webui,gradio,openrail,3
-5286,keremberke/blood-cell-object-detection,gradio,,3
-5287,ItsJayQz/Roy_PopArt_Diffusion,gradio,,3
-5288,peteralexandercharles/Auto-Subtitled-Video-Generator,streamlit,,3
-5289,theintuitiveye/modernartstyle,gradio,,3
-5290,pinecone/find-your-celebrity-match,streamlit,,3
-5291,kael558/InPaintAPI,gradio,openrail,3
-5292,HighCWu/anime-colorization-with-hint,gradio,mit,3
-5293,nightfury/img2music,gradio,,3
-5294,Hexequin/claudfuen-photorealistic-fuen-v1,gradio,,3
-5295,dafqi/indo_twitter_sentiment_app,streamlit,,3
-5296,camenduru-com/VITS-Umamusume-voice-synthesizer,gradio,,3
-5297,pngwn/Stable-Diffusion-prompt-generator,gradio,mit,3
-5298,murbas/Litmus-Voice-Age-Prediction,gradio,,3
-5299,ThirdEyeData/Entity-Extraction,streamlit,,3
-5300,Axesys/Private-WebUI,gradio,openrail,3
-5301,trl-internal-testing/rlhf_dialog_experiment,gradio,apache-2.0,3
-5302,perilli/tortoise-tts-v2,gradio,apache-2.0,3
-5303,ulysses115/ulysses115-pmvoice,gradio,unknown,3
-5304,datasciencedojo/Twitter-Scraper-with-Time-Series-Visualization,gradio,,3
-5305,vinayreddy10/gpt3,gradio,,3
-5306,mohdelgaar/Clinical_Decisions,gradio,,3
-5307,Lianjd/stock_dashboard,streamlit,,3
-5308,Rojastopher/Image-to-3D,gradio,,3
-5309,umair007/all_in_one_converter_modified,gradio,mit,3
-5310,fbrynpk/image-caption-generator,streamlit,,3
-5311,zjrwtx/xiaoyi_image_variations,streamlit,openrail,3
-5312,Aditya9790/yolo7-object-tracking,gradio,,3
-5313,leonel1122/openai-jukebox-5b-lyrics,gradio,artistic-2.0,3
-5314,markski/reddit-roast-me,gradio,wtfpl,3
-5315,Adapting/YouTube-Downloader,streamlit,mit,3
-5316,gauravgarg/youtube_transcript,streamlit,,3
-5317,toonist/DualStyleGAN,gradio,,3
-5318,freddyaboulton/license-plate-reader,gradio,mit,3
-5319,aichina/MagicPrompt-Stable-Diffusion,gradio,mit,3
-5320,decodemai/future_in_words,gradio,cc-by-nd-4.0,3
-5321,decodemai/intersection_scenarios,gradio,cc-by-nd-4.0,3
-5322,faisalhr1997/wd14_tagging_online,gradio,mit,3
-5323,Curranj/GPT-SQL,gradio,,3
-5324,unilm/Promptist-faster,gradio,,3
-5325,alsrbdni/speaker-diarization,gradio,,3
-5326,Frorozcol/music_recommedation,streamlit,mit,3
-5327,CharyWind/webui-docker,docker,,3
-5328,discussion-bot/webhook,docker,mit,3
-5329,Lyra121/finetuned_diffusion,gradio,mit,3
-5330,TrustSafeAI/NCTV,static,,3
-5331,BilalSardar/karlo-cpu-api,gradio,,3
-5332,ngxson/poet-cat,docker,mit,3
-5333,DReAMy-lib/dream,gradio,cc-by-2.0,3
-5334,odhier/MGX-Midjourney-v4,gradio,,3
-5335,GT4SD/protein_properties,gradio,,3
-5336,language-tools/language-demo,gradio,mit,3
-5337,awacke1/Writing-Grammar-And-Paraphrase-w-Pegasus,gradio,,3
-5338,grumpkin/cats,gradio,apache-2.0,3
-5339,Div99/Chat-with-Div,gradio,apache-2.0,3
-5340,amit-scans/Image-Text-Detection,streamlit,mit,3
-5341,Fr33d0m21/google-flan-t5-xxl,gradio,,3
-5342,EmbeddedAndrew/examin8,gradio,mit,3
-5343,Shad0ws/Information_Extraction_with_ChatGPT,gradio,mit,3
-5344,jonathang/Protein-Family-Ensemble,gradio,,3
-5345,Harveenchadha/BioGPT,gradio,,3
-5346,seawolf2357/kochatgpt,gradio,,3
-5347,chewing/liandan,gradio,afl-3.0,3
-5348,merzigo/MKAtaturkv2,gradio,,3
-5349,mariashay/DataViz-Plotly,streamlit,mit,3
-5350,xuanzang/prompthero-openjourney-v2,gradio,openrail,3
-5351,camenduru-com/terminal,docker,,3
-5352,ericanthonymitchell/detectgpt,gradio,apache-2.0,3
-5353,voltcutter/stable-diffusion-webui,gradio,openrail,3
-5354,omdenalagos/job_skill_cat,streamlit,mit,3
-5355,gfhayworth/hack_qa,gradio,,3
-5356,multimodalart/coca-captioning,gradio,mit,3
-5357,abidlabs/mic_or_file,gradio,openrail,3
-5358,camenduru-com/audioldm-text-to-audio-generation,gradio,bigscience-openrail-m,3
-5359,MBZ/LoRA-DreamBooth-Training-UI,gradio,mit,3
-5360,oschan77/animalsvision,gradio,mit,3
-5361,vanessa9178/anime-anything-v4.0,gradio,,3
-5362,Re1e9/Flower_Classification_using_InceptionV3,gradio,,3
-5363,Deevyankar/Deep-AD,streamlit,,3
-5364,celise88/Pathfinder,docker,,3
-5365,james-oldfield/PandA,gradio,cc,3
-5366,abidlabs/gpt-talking-portrait,gradio,,3
-5367,anhnv125/FRN,streamlit,,3
-5368,awacke1/ResnetPytorchImageRecognition,gradio,,3
-5369,harshasurampudi/gender-and-age,gradio,apache-2.0,3
-5370,imseldrith/AI-Rephraser,gradio,openrail,3
-5371,jayyd/nlpconnect-vit-gpt2-image-captioning,gradio,apache-2.0,3
-5372,emanlapponi/sound-refukculator,streamlit,artistic-2.0,3
-5373,Grezz/generate_human_motion,gradio,apache-2.0,3
-5374,Dipl0/Dipl0-pepe-diffuser,gradio,,3
-5375,dukecsxu/chatGPT,gradio,,3
-5376,gouravs300/ANPR,streamlit,,3
-5377,Solomon-y/img-to-music,gradio,,3
-5378,mehradans92/decode-elm,streamlit,apache-2.0,3
-5379,multimodalart/pix2pix-zero,gradio,mit,3
-5380,Neilblaze/WhisperAnything,gradio,mit,3
-5381,end000/sberbank-ai-FRED-T5-1.7B,gradio,,3
-5382,imseldrith/AI-Rewriter,streamlit,openrail,3
-5383,Yeno/text-to-3D,gradio,,3
-5384,zwormgoor/stock-photo-recognizer,gradio,apache-2.0,3
-5385,Duskfallcrew/textual-inversion-training,gradio,apache-2.0,3
-5386,Detomo/AnimeGAN,gradio,creativeml-openrail-m,3
-5387,BramVanroy/text-to-amr,docker,gpl-3.0,3
-5388,DataScienceEngineering/7-NER-Biomed-ClinicalTerms,gradio,,3
-5389,Duskfallcrew/newdreambooth-toclone,gradio,mit,3
-5390,Duskfallcrew/duskfall-tarot-card,gradio,,3
-5391,Kaludi/Stable-Diffusion-Prompt-Generator_App,streamlit,,3
-5392,bkhmsi/AraPoet,gradio,gpl-3.0,3
-5393,awacke1/sileod-deberta-v3-base-tasksource-nli,gradio,,3
-5394,NagaSaiAbhinay/unclip_text_interpolation_demo,gradio,mit,3
-5395,awacke1/File-Memory-Operations-Human-Feedback-Gradio,gradio,mit,3
-5396,Elbhnasy/ASD_Diagnosis,gradio,mit,3
-5397,open-source-metrics/audio-stats,streamlit,,3
-5398,society-ethics/DiffusionClustering,gradio,,3
-5399,lfoppiano/grobid-quantities,docker,apache-2.0,3
-5400,Crossper6/stable-diffusion-webui,gradio,openrail,3
-5401,awacke1/Bloom.Big.Science.Continual.Generator,gradio,mit,3
-5402,ORI-Muchim/ONFIRETTS,gradio,mit,3
-5403,GAS17/Dream-awAI-Image-Upscaling,gradio,apache-2.0,3
-5404,rayan-saleh/whisper2notion,gradio,apache-2.0,3
-5405,lfoppiano/grobid,docker,apache-2.0,3
-5406,zeno-ml/imagenette,docker,mit,3
-5407,joaogante/generate_quality_improvement,gradio,mit,3
-5408,Guinnessgshep/AI_story_writing,gradio,,3
-5409,giswqs/geemap,gradio,mit,3
-5410,JacobLinCool/create-3d-icon,docker,,3
-5411,Thafx/sdAnalog,gradio,,3
-5412,Thafx/sdrv1_3,gradio,,3
-5413,awacke1/Player-Card-Monster-Battler-For-Math-and-AI,streamlit,mit,3
-5414,vaibhavarduino/ChatGPT,streamlit,cc,3
-5415,akshatsanghvi/movie-recommender-system,streamlit,apache-2.0,3
-5416,FadouaFGM/Stackoverflow_Questions_Categorisation,gradio,apache-2.0,3
-5417,Samuelblue/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator,gradio,,3
-5418,GT6242Causion/Causion,streamlit,,3
-5419,paimeng/anime-remove-background,gradio,apache-2.0,3
-5420,fyodorschnotzdinger/paraphraser,gradio,,3
-5421,ridai/img-to-music,gradio,,3
-5422,szzzzz/toxic_detection,gradio,apache-2.0,3
-5423,simplyjaga/neural_style_tranfer_using_dense_net,gradio,,3
-5424,ddstua/Enhance_Low_Light_Image,gradio,,3
-5425,awaiss/vits-models,gradio,apache-2.0,3
-5426,Harsh12/Netflix-Movie-Recommender,streamlit,apache-2.0,3
-5427,ysharma/ControlNet_Image_Comparison,gradio,,3
-5428,animesh651/ChatAPT_v1,gradio,creativeml-openrail-m,3
-5429,kuhnma2026/FortniteSkinPackAI,gradio,afl-3.0,3
-5430,EtheE/SecurityAgent,gradio,apache-2.0,3
-5431,podsnigame/twitter-scrapping,streamlit,,3
-5432,Thaweewat/ControlNet-Architecture,gradio,apache-2.0,3
-5433,Alinadi98/movie_recommendation_system,streamlit,,3
-5434,Firefly777a/openai-moderation-api-demo,gradio,apache-2.0,3
-5435,deepsynthbody/deepfake-ecg-generator,gradio,cc-by-4.0,3
-5436,omlakhani/endoai,gradio,mit,3
-5437,aijack/hair,gradio,mit,3
-5438,Semii/OpenPoseSkeleton,gradio,creativeml-openrail-m,3
-5439,ivanpc/Youtube_Audio,gradio,apache-2.0,3
-5440,abidlabs/supabase,gradio,,3
-5441,awacke1/Ontology-Gradio,gradio,,3
-5442,AlexWelcing/MusicLM,streamlit,apache-2.0,3
-5443,ashawkey/chatgpt_please_improve_my_paper_writing,gradio,mit,3
-5444,ivanmeyer/DreamlikeArt-PhotoReal-2.0,gradio,,3
-5445,gptbase/GPTBase,streamlit,,3
-5446,awacke1/HTML5-Aframe-3dMap-Flight,static,mit,3
-5447,sciling/Face_and_Plate_License_Blur,gradio,unknown,3
-5448,mohit-217/invoice_by_mohit,gradio,gpl-2.0,3
-5449,ekatra/mobius-v2,streamlit,,3
-5450,derek-thomas/QADemo,gradio,mit,3
-5451,Laronix/Laronix_ASR_TTS_VC,gradio,apache-2.0,3
-5452,pkiage/fast_arbitrary_image_style_transfer,streamlit,openrail,3
-5453,youngs3/coqui-ai-tts-ko,gradio,,3
-5454,GazeLocation/Visualization_Saliency,gradio,,3
-5455,suigyu/AItest,gradio,,3
-5456,cscan/CodeFormer,gradio,apache-2.0,3
-5457,firefighter/PdfSumGPT,gradio,,3
-5458,phlippseitz/Image-Text-Extraction-PaddleOCR,gradio,,3
-5459,radames/diffusers-classifier-labeling,gradio,,3
-5460,awacke1/CodeGen-YurtsAI-yurts-python-code-gen-30-sparse,gradio,,3
-5461,liuxiaopai/background-remover,gradio,,3
-5462,zhangjf/chatbot_code_friendly,gradio,apache-2.0,3
-5463,nmaina/ChatGPTwithAPI,gradio,mit,3
-5464,supertori/files,gradio,,3
-5465,wwydmanski/meeting-summarizer,gradio,mit,3
-5466,Allakhazam/Home,gradio,,3
-5467,rishi9440/remove-photo-background,streamlit,,3
-5468,MZhaovo/Llama_Difu,gradio,mit,3
-5469,darthPanda/Social_media_sentiment_tracker,streamlit,,3
-5470,bhaskartripathi/Text2Question,gradio,apache-2.0,3
-5471,productizationlabs/MyChatGPTTurbo,gradio,,3
-5472,jelly21/claudfuen-photorealistic-fuen-v1,gradio,,3
-5473,HiepPhuocSS/TimeSFormer,streamlit,,3
-5474,IISRFactCheck/claim_detection,gradio,unknown,3
-5475,Yasbok/Flan-T5-Chatbot,gradio,,3
-5476,pyimagesearch/gif-creator,gradio,mit,3
-5477,JohnTan38/NLLB-translation,gradio,,3
-5478,RGBD-SOD/bbsnet,gradio,mit,3
-5479,lthero/ChatGPT-lthero,gradio,,3
-5480,nithinraok/NeMo-Offline-Speaker-Diarization,gradio,cc-by-4.0,3
-5481,FreeGPT/FreeGPT,gradio,,3
-5482,bahjat-kawar/time-diffusion,gradio,,3
-5483,JUNGU/latex-ocr-wthGPT,gradio,mit,3
-5484,safetensors/convert2,gradio,apache-2.0,3
-5485,jofaichow/shiny-numerati,docker,apache-2.0,3
-5486,cloudqi/MultisourceChat,gradio,,3
-5487,Dao3/Top-20-Models,gradio,,3
-5488,keras-dreambooth/dreambooth-kedis,gradio,apache-2.0,3
-5489,keras-dreambooth/dreambooth_fantasy,gradio,,3
-5490,keras-dreambooth/dreambooth_diffusion_toy,gradio,apache-2.0,3
-5491,tbboukhari/Chatbot-produit-fr,streamlit,,3
-5492,awacke1/Maps.Markers.Honor.Iceland,streamlit,mit,3
-5493,keras-dreambooth/bengali_clay_universe,gradio,,3
-5494,Lykon/NeverEnding-Dream-webui,gradio,,3
-5495,lu2000/anything-midjourney-v4-1,gradio,,3
-5496,awacke1/Knowledge-graphs,streamlit,,3
-5497,AI-Dashboards/Topic-Modeling-Clusters-Free-Text,streamlit,mit,3
-5498,dawood/microsoft_windows,gradio,apache-2.0,3
-5499,xc9/VITS-Umamusume-voice-synthesizer,gradio,,3
-5500,ysharma/steampunk,gradio,apache-2.0,3
-5501,swcrazyfan/ppt-generator,gradio,,3
-5502,liuxiaopai/BelleGroup-BELLE-7B-2M,gradio,,3
-5503,Saturdays/deepfake-detection,gradio,apache-2.0,3
-5504,JohnSmith9982/ChuanhuChatGPT_Beta,gradio,gpl-3.0,3
-5505,nullzero-live/python-project-generator,streamlit,,3
-5506,yooch/yooch,gradio,gpl-3.0,3
-5507,zouguojun/chatPDF,gradio,apache-2.0,3
-5508,awacke1/4.RealTime-MediaPipe-AI-From-Video-On-Any-Device,streamlit,mit,3
-5509,KarloDarlo/3D_Photo_Inpainting,gradio,,3
-5510,keras-dreambooth/dreambooth_monkey_island,gradio,apache-2.0,3
-5511,grosenthal/aineid,docker,wtfpl,3
-5512,EinfachOlder/ChatGPT-prompt-generator,gradio,apache-2.0,3
-5513,Saturdays/CiclopeIA,gradio,,3
-5514,POPSICLE/pdfChatter,gradio,afl-3.0,3
-5515,mikaelbhai/GPTBhai_TextToImage_DreamStudio,gradio,,3
-5516,deadash/BelleGroup-BELLE-LLAMA-7B-2M,gradio,,3
-5517,Marshalls/testmtd,gradio,,3
-5518,keras-dreambooth/dreambooth_eighties_cars,gradio,cc-by-nc-4.0,3
-5519,digitalOSHO/webui,gradio,,3
-5520,Uday007/startup-profit-predictor,gradio,cc-by-nc-2.0,3
-5521,keras-dreambooth/dreambooth_hogwarts_legacy,gradio,creativeml-openrail-m,3
-5522,MisterZee/PIFu-Clothed-Human-Digitization,gradio,,3
-5523,librarian-bots/dashboard,gradio,,3
-5524,vjain/Trading-Chatbot,gradio,mit,3
-5525,derful/Chatgpt-academic,gradio,,3
-5526,mncai/chat-doctor-kr,gradio,apache-2.0,3
-5527,tammm/vits-models,gradio,apache-2.0,3
-5528,awacke1/Bloom.Generative.Writer,streamlit,,3
-5529,keras-dreambooth/seymour-cat-diffusion,gradio,,3
-5530,Mrchuw/MagicPrompt-Stable-Diffusion,gradio,mit,3
-5531,Lihuchen/AcroBERT,gradio,cc-by-nc-sa-2.0,3
-5532,gojiteji/thatGPT,gradio,,3
-5533,BilalSardar/Gpt4All,gradio,,3
-5534,haonanzhang/ChatGPT-BOT,gradio,gpl-3.0,3
-5535,jackycedar/pdfs,gradio,apache-2.0,3
-5536,LEL-A/translated-german-alpaca-validation,docker,,3
-5537,rishabh062/DocumentQuestionAnswerModel,gradio,,3
-5538,hungln1102/emotion_classification_surreynlp_2023,streamlit,,3
-5539,zixian/Zhenhuan-VITS,gradio,,3
-5540,Gradio-Themes/guessing-game,gradio,apache-2.0,3
-5541,phoenix1203/club_record_in_3_min,gradio,openrail,3
-5542,Woocy/541GPT,gradio,gpl-3.0,3
-5543,derek-thomas/dataset-creator-reddit-bestofredditorupdates,docker,openrail,3
-5544,ParityError/LimeFace,gradio,apache-2.0,3
-5545,aryadytm/chatmagic-ai,gradio,,3
-5546,ayaanzaveri/faster-whisper-api,gradio,,3
-5547,datasciencedojo/AudioTranscription,gradio,apache-2.0,3
-5548,fastx/Gpt-4-chatbot,gradio,,3
-5549,mthsk/sovits-models,gradio,mit,3
-5550,finlaymacklon/boxy_violet,gradio,apache-2.0,3
-5551,Aaaaaaaabdualh/meter2poem-1,gradio,afl-3.0,3
-5552,sklearn-docs/A_demo_of_the_Spectral_Co-Clustering_algorithm,gradio,mit,3
-5553,raoyang111/speecht5-tts-demo,gradio,apache-2.0,3
-5554,shiyuleixia/yolov8-segmentation,gradio,gpl-3.0,3
-5555,ceckenrode/Human.Feedback.Dynamic.JSONL.Dataset.Download,streamlit,mit,3
-5556,FourthBrainGenAI/GenerAd-AI,gradio,bigscience-openrail-m,3
-5557,Kevin676/ChatGPT-with-Voice-Cloning-2.0,gradio,mit,3
-5558,LightSY/W2L-TD,gradio,other,3
-5559,VincentZB/Stable-Diffusion-ControlNet-WebUI,gradio,openrail,3
-5560,JanDalhuysen/ChatPDF,gradio,apache-2.0,3
-5561,sklearn-docs/plot-k-means-digits,gradio,apache-2.0,3
-5562,kkinc/gsdf-Counterfeit-V2.5,gradio,openrail,3
-5563,TechWithAnirudh/eachadea-vicuna-13b,gradio,,3
-5564,dominguesm/alpaca-ptbr-7b,gradio,cc-by-4.0,3
-5565,PirateXX/Sentencewise-Perplexity,gradio,artistic-2.0,3
-5566,stupidog04/Video-to-Multilingual-OCR,gradio,mit,3
-5567,Fazzie/PokemonGAI,gradio,apache-2.0,3
-5568,umair007/ChatGPT-prompt-generator,gradio,apache-2.0,3
-5569,snoop2head/Gomoku-GPT2,streamlit,mit,3
-5570,AquaSuisei/ChatGPTXE,gradio,gpl-3.0,3
-5571,lyhue1991/yolov8_demo,gradio,apache-2.0,3
-5572,sino72/Passenger_Reconization,gradio,,3
-5573,VikramSingh178/MedicalImagingApplication,streamlit,,3
-5574,Aluxes/anime-remove-background,gradio,apache-2.0,3
-5575,marinap/multimodal_similarity,gradio,apache-2.0,3
-5576,sklearn-docs/post-pruning-decision-trees,gradio,creativeml-openrail-m,3
-5577,ieuniversity/ScienceBrief_summarization,gradio,,3
-5578,sklearn-docs/ensemble-trees-decision-surface,gradio,,3
-5579,Cloudfaith/anon8231489123-gpt4-x-alpaca-13b-native-4bit-128g,gradio,,3
-5580,sklearn-docs/SGD-convex-loss,gradio,mit,3
-5581,sklearn-docs/gaussian-quantile-adaboost,gradio,,3
-5582,ThirdEyeData/Supply-Chain-Causal-Analysis,streamlit,,3
-5583,JohnSmith9982/VITS-Umamusume-voice-synthesizer,gradio,,3
-5584,silaseic/sheet_music_transpose_v2,docker,,3
-5585,ieuniversity/Sciencebrief_translation,gradio,other,3
-5586,sklearn-docs/Lasso-model-aic-bic,gradio,mit,3
-5587,gshotwell/multi-query-sentiment,docker,mit,3
-5588,Bostoncake/ChatAssistant,gradio,apache-2.0,3
-5589,sklearn-docs/Lasso-dense-sparse-data,gradio,mit,3
-5590,paddle-diffusion-hackathon/Neolle_Face_Generator,gradio,creativeml-openrail-m,3
-5591,sklearn-docs/t-SNE-perplexity,gradio,,3
-5592,taesiri/ImageNet-Hard-Browser,docker,mit,3
-5593,seekeroftruth/CognitoMaxima,gradio,,3
-5594,Priyanka-Kumavat/Object-Detection,streamlit,,3
-5595,hamzapehlivan/StyleRes,gradio,,3
-5596,cuiyuan605/chatgpt-demo,gradio,,3
-5597,codertoro/gpt-academic,gradio,,3
-5598,ztudy/chatbot,streamlit,mit,3
-5599,nota-ai/theme,gradio,apache-2.0,3
-5600,ioanniskarkanias/chatbot-with-sources,gradio,openrail,3
-5601,yanli01/gpt01,gradio,gpl-3.0,3
-5602,laksithakumara/stabilityai-stable-diffusion-2,gradio,,3
-5603,CVH-vn1210/make_hair,gradio,other,3
-5604,viveknarayan/Image_Colorization,gradio,,3
-5605,KarmaCST/English-To-Dzongkha-Translation-NLLB-Fine-tuning,gradio,,3
-5606,django-ochain/youtube-q-and-a,gradio,,3
-5607,markburn/stack-llama,gradio,,3
-5608,learnanything/stable-diffusion-xl,gradio,,3
-5609,andreassteiner/robo-call,gradio,,3
-5610,ZiyadCodes/ArabicGPT,static,unknown,3
-5611,Manjushri/Erebus,gradio,mit,3
-5612,akoksal/LongForm-OPT-125M,gradio,,3
-5613,fastx/customer-support-chatbot,gradio,,3
-5614,JFoz/dog-controlnet,gradio,openrail,3
-5615,davanstrien/arch_demo,gradio,,3
-5616,abidlabs/docquery,gradio,openrail,3
-5617,aimstack/bloom,docker,other,3
-5618,SoulAbi/ChatGPT4,gradio,openrail,3
-5619,UVA-GCOM/Group_1,gradio,mit,3
-5620,whiskyboy/CogsGPT,gradio,mit,3
-5621,rxn4chemistry/synthesis-protocol-extraction,gradio,mit,3
-5622,abidlabs/Acapellify-Frontend,gradio,,3
-5623,hydai/InterviewPrepGPT,streamlit,,3
-5624,Intel/intel-xai-tools-cam-demo,gradio,,3
-5625,jackyccl/segment-anything,gradio,apache-2.0,3
-5626,SebastianBravo/simci_css,gradio,apache-2.0,3
-5627,eldhoskj/speechbrain-tts-tacotron2-ljspeech,gradio,apache-2.0,3
-5628,ppsingh/cpu-demo,streamlit,,3
-5629,typesdigital/TwitterPRO,gradio,afl-3.0,3
-5630,DuckyPolice/StormDrainMega,gradio,,3
-5631,JanBabela/Riffusion-Melodiff-v1,static,openrail,3
-5632,rottenlittlecreature/Moon_Goblin,gradio,apache-2.0,3
-5633,a-v-bely/spanish-task-generator,streamlit,,3
-5634,Yina/google-pix2struct-base,gradio,,3
-5635,prath/low_light_image_enhancement,gradio,,3
-5636,AutoGeneralAI/ChatGPT,gradio,apache-2.0,3
-5637,Hazem/Pub_face,gradio,apache-2.0,3
-5638,bird-watching-society-of-greater-clare/brainy,docker,,3
-5639,ahmadprince007/HolyBot,docker,,3
-5640,it-at-m/image-anonymizer,gradio,agpl-3.0,3
-5641,fynn3003/image_to_text,gradio,,3
-5642,huggingfacejs/doc-vis-qa,static,mit,3
-5643,AutoGeneralAI/voice-assistant,gradio,,3
-5644,MathysL/AutoGPT4,gradio,mit,3
-5645,fynn3003/python_code_generator,gradio,,3
-5646,nkasmanoff/SearchingFace,gradio,,3
-5647,Arjav/TOS-Summarization,gradio,,3
-5648,sunder-ali/Image_Denoising_Demo,streamlit,cc-by-sa-4.0,3
-5649,posit/quarto-template,docker,mit,3
-5650,FourthBrainGenAI/TalkToMyDoc-Hitch-Hikers-Guide,gradio,openrail,3
-5651,Roboflow/web-demo,static,,3
-5652,onursavas/langchain-chat-with-pdf,gradio,,3
-5653,Mahiruoshi/vits-chatbot,gradio,,3
-5654,hahahafofo/ChatPDF,gradio,gpl-3.0,3
-5655,IvaElen/nlp_proj,streamlit,,3
-5656,simplyjaga/movie_genius_openai,gradio,,3
-5657,vinay123/panoptic-segment-anything,gradio,apache-2.0,3
-5658,dstackai/dstack-template,docker,mpl-2.0,3
-5659,ImagineAI-Real/ImagineAI-Image-Generator2,gradio,,3
-5660,kevinwang676/Voice-Cloning-Demo,gradio,mit,3
-5661,softcatala/comparativa-tts-catala,docker,,3
-5662,ohmyteeth/seo-tools,gradio,apache-2.0,3
-5663,thealphhamerc/text-to-speech,gradio,,3
-5664,varun500/MBZUAI-LaMini-GPT-1.5B,gradio,,3
-5665,inplisQlawa/anything-midjourney-v4-1,gradio,,3
-5666,suppsumstagza/text-to-image-stable-diffusion-v1-5,gradio,mit,3
-5667,pjmartorell/AnimeGANv3,gradio,,3
-5668,DiffusionArtco/RealisticPhotoModels,gradio,,3
-5669,IvaElen/find_my_pic,streamlit,,3
-5670,abhishekmamdapure/llama-cpp-python,gradio,,3
-5671,vama09/HashtagAndCaption,streamlit,,3
-5672,bell-tommy/SG161222-Realistic_Vision_V1.4,gradio,,3
-5673,Zulqrnain/FAST_NU_PAST_PAPERS,gradio,,3
-5674,codeparrot/gradio-playground,gradio,,3
-5675,dapeng629/simple_chatbot,gradio,mit,3
-5676,yamashiro3/Whisper-gpt-voicescribe,gradio,apache-2.0,3
-5677,DiffusionArtco/Diffusion200Max,gradio,,3
-5678,liyucheng/selective_context,streamlit,cc-by-2.0,3
-5679,Zenne/chatbot_llama_index,streamlit,mit,3
-5680,Nahrawy/ControlLight,gradio,cc-by-4.0,3
-5681,p-baleine/metaanalyser,gradio,,3
-5682,Ameaou/academic-chatgpt3.1,gradio,,3
-5683,birkancelik18/chatbot,gradio,,3
-5684,bergrozen1213/3d-obj-v2,gradio,,3
-5685,Scakmak/Chatbot,gradio,,3
-5686,jayparmr/ICBINP_OG,gradio,mit,3
-5687,abbbbbbbbbbbbbb/poetry,gradio,cc-by-nc-4.0,3
-5688,NeuralInternet/InfiniteGPT,streamlit,,3
-5689,sklearn-docs/SVM-Kernels,gradio,bsd-3-clause,3
-5690,jatin-tech/SkinZen,docker,mit,3
-5691,Vageesh1/clip_gpt2,streamlit,,3
-5692,aus10powell/TwitterAccounts,docker,mit,3
-5693,maxmon/auto_anno,gradio,mit,3
-5694,ysharma/Effectively_Using_IF,gradio,mit,3
-5695,hylee/finetuned_diffusion,gradio,mit,3
-5696,paulbauriegel/voice-coe-data,gradio,,3
-5697,neuroliptica/2ch_captcha,gradio,,3
-5698,Masa-digital-art/planning-proposal-gpt-4,gradio,,3
-5699,HugoDzz/spaceship_drift,static,mit,3
-5700,Gokul14/impira-layoutlm-document-qa,gradio,,3
-5701,Hunter731/Unity3D-RTS,static,,3
-5702,banana-projects/web3d,static,,3
-5703,and-effect/Musterdatenkatalog,streamlit,,3
-5704,befozg/stylematte,gradio,,3
-5705,tubui/rosteal,docker,cc-by-nc-4.0,3
-5706,Not-Grim-Refer/huggingface-transformers-agents,gradio,apache-2.0,3
-5707,Forbu14/LoiLibreQA,gradio,apache-2.0,3
-5708,noes14155/runwayml-stable-diffusion-v1-5,gradio,,3
-5709,conceptofmind/PaLM_models,gradio,mit,3
-5710,jhlfrfufyfn/bel-tts,gradio,mit,3
-5711,Heshwa/html-code-generation-from-images-with-deep-neural-networks,gradio,afl-3.0,3
-5712,yuanzhoulvpi/chinese_bloom_560_chat,gradio,,3
-5713,dfalbel/gptneox-chat,docker,mit,3
-5714,Farazquraishi/pendora,gradio,cc-by-nc-sa-4.0,3
-5715,nimadez/grammbot,gradio,mit,3
-5716,ennov8ion/Scifi-Models,gradio,,3
-5717,ennov8ion/semirealistic-models,gradio,,3
-5718,doluvor/faster-whisper-webui,gradio,apache-2.0,3
-5719,hjv28158/stable-diffusion-webui-cpu,gradio,,3
-5720,ennov8ion/FantasyArt-Models,gradio,,3
-5721,ennov8ion/dreamlike-models,gradio,,3
-5722,Proveedy/dreambooth-trainingv15,gradio,mit,3
-5723,BramVanroy/mai-simplification-nl-2023-demo,streamlit,cc-by-nc-sa-4.0,3
-5724,empulse/ehartford-WizardLM-30B-Uncensored,gradio,,3
-5725,mstager/ChileanGPT,streamlit,mit,3
-5726,sabirbagwan/WhatsappGroupAnalysis,streamlit,,3
-5727,SoulAbi/whisper-youtube-video-text,gradio,bigscience-openrail-m,3
-5728,rubend18/ChatGPT-Prompt-Generator,gradio,,3
-5729,Al-Chan/Vits_League_of_Legends_Yuumi_TTS,gradio,,3
-5730,Manjushri/Nerybus,gradio,mit,3
-5731,MISATO-dataset/Adaptability_protein_dynamics,docker,mit,3
-5732,dragonSwing/video2slide,gradio,apache-2.0,3
-5733,onereal/Voice-Cloning-for-you,gradio,mit,3
-5734,ChatGPT-GAIA/GAIA-GPT,gradio,mit,3
-5735,asoria/duckdb-parquet-demo,gradio,,3
-5736,Ababababababbababa/AraPoet,gradio,gpl-3.0,3
-5737,matthoffner/storywriter,docker,,3
-5738,Annotation-AI/fast-segment-everything,gradio,,3
-5739,lgaleana/toolkit,gradio,,3
-5740,SurendraKumarDhaka/Text-to-speech-converter,streamlit,,3
-5741,Kyo-Kai/Fsg-pp,docker,gpl-3.0,3
-5742,Rardilit/Rardilit-Ciffusion_v0.1,gradio,creativeml-openrail-m,3
-5743,Shriharshan/Image-Caption-Generator,gradio,mit,3
-5744,amasad/Replit-v1-CodeInstruct-3B,gradio,,3
-5745,maksymalist/junk-judge,gradio,mit,3
-5746,punith-098/controlnet-interior-design,streamlit,openrail,3
-5747,sohomghosh/FinLanSer_Financial_Language_Simplifier,gradio,mit,3
-5748,DonDoesStuff/Bing-AI-demo,gradio,,3
-5749,janshah/demo-app-FALCON40b,streamlit,mit,3
-5750,Brasd99/JustClothify,gradio,,3
-5751,petervavank/VoiceConvertion,gradio,openrail,3
-5752,aksj/Dreamland-GenAI-Music,gradio,,3
-5753,potsawee/multiple-choice-QG,gradio,apache-2.0,3
-5754,yash-srivastava19/insta_captions,gradio,mit,3
-5755,Vipitis/ShaderCoder,gradio,mit,3
-5756,matthoffner/chatbot,docker,,3
-5757,RuthBebe/sentiment_analysis,streamlit,cc,3
-5758,massi/prompter,gradio,unlicense,3
-5759,melazab1/ChatGPT4,gradio,mit,3
-5760,gli-mrunal/GPT_instruct_chatbot,streamlit,mit,3
-5761,isaakkamau/whisper-video-caption,gradio,mit,3
-5762,dukujames/Text-Image,gradio,,3
-5763,vivianinhugging/TheBloke-guanaco-65B-HF,gradio,,3
-5764,gaia-benchmark/leaderboard,gradio,apache-2.0,3
-5765,Slep/CondViT-LRVSF-Demo,gradio,mit,3
-5766,Nixic/rvc-models,gradio,mit,3
-5767,Dxtrmst/TheBloke-WizardLM-Uncensored-Falcon-7B-GPTQ,gradio,openrail,3
-5768,MetaWabbit/Auto-GPT,gradio,mit,3
-5769,amanatid/PubMedGPT,streamlit,mit,3
-5770,openaccess-ai-collective/arena-archived,gradio,apache-2.0,3
-5771,Chaitanya01/InvestingPlatform,streamlit,,3
-5772,dragonSwing/isr,gradio,apache-2.0,3
-5773,thegovind/LangFlow,docker,mit,3
-5774,yxmnjxzx/PubMedGPT,streamlit,mit,3
-5775,distbit/NousResearch-Nous-Hermes-13b,gradio,,3
-5776,rakhlin/SpeechT5,gradio,,3
-5777,marusia/img_styler,streamlit,cc,3
-5778,kevinwang676/Voice-Changer-Light,gradio,mit,3
-5779,oschan77/virtualoscar,gradio,mit,3
-5780,BartPoint/VoiceChange_Beta,gradio,mit,3
-5781,MikeTrizna/bhl_clip_classifier,gradio,mit,3
-5782,internetsignal/audioLDMtext,gradio,bigscience-openrail-m,3
-5783,NeuML/baseball,streamlit,apache-2.0,3
-5784,kevinwang676/test-1,gradio,mit,3
-5785,simonduerr/rosettafold2,gradio,mit,3
-5786,StephanST/OpenLanderONNXonline,streamlit,mit,3
-5787,alexrame/rewardedsoups,streamlit,cc,3
-5788,syf2023/chatbot,gradio,mit,3
-5789,hanzportgas/rvc-models-v2,gradio,mit,3
-5790,Saturdays/Starchat_Saturdays,gradio,mit,3
-5791,vasu0508/Meena_Chatbot,gradio,unknown,3
-5792,Jackflack09/diffuse-custom,gradio,mit,3
-5793,hrdtbs/rvc-mochinoa,gradio,,3
-5794,keivan/Is_he_fat,gradio,apache-2.0,3
-5795,chenbowen-184/Martin-Valen-Text-to-Image,gradio,openrail,3
-5796,bingbing520/ChatGPT2,gradio,gpl-3.0,3
-5797,anpigon/talktosayno,gradio,openrail,3
-5798,Icar/AICompanion,gradio,mit,3
-5799,Inderdev07/facerecognition,streamlit,cc,3
-5800,simsantonioii/MusicGen-Continuation,gradio,cc-by-nc-4.0,3
-5801,zwhe99/MAPS-mt,gradio,,3
-5802,HI915/Test02,docker,,3
-5803,raseel-zymr/Document-QandA,streamlit,mit,3
-5804,mrstuffandthings/Bark-Voice-Cloning,gradio,mit,3
-5805,Anish13/characterGPT,gradio,artistic-2.0,3
-5806,osanseviero/voice-cloning-public,gradio,mit,3
-5807,SRDdev/EchoSense,gradio,,3
-5808,xuxw98/TAPA,gradio,mit,3
-5809,leonelhs/superface,gradio,mit,3
-5810,patgpt4/MusicGen,gradio,cc-by-nc-4.0,3
-5811,bilgeyucel/prompt-lemmatizer,gradio,,3
-5812,RockmanYang/vocal_remover,gradio,apache-2.0,3
-5813,allknowingroger/Image-Models-Test2,gradio,,3
-5814,ElainaFanBoy/MusicGen,gradio,cc-by-nc-4.0,3
-5815,leonelhs/remove-background,gradio,mit,3
-5816,lekkalar/chatgpt-for-pdfs-without-chat-history,gradio,,3
-5817,UjjwalVIT/Text_analysis_and_metadata_app,streamlit,,3
-5818,willgibs/ControlNet-v1-1,gradio,mit,3
-5819,majinyu/recognize-detect-segment-anything,gradio,mit,3
-5820,Babelscape/mrebel-demo,streamlit,,3
-5821,paulhebo/smart_qa,gradio,,3
-5822,allknowingroger/Image-Models-Test5,gradio,,3
-5823,isaakkamau/Text-To-Speech,gradio,,3
-5824,GirishKiran/sentiment,gradio,,3
-5825,jbilcke-hf/template-node-wizardcoder-express,docker,,3
-5826,allknowingroger/Image-Models-Test6,gradio,,3
-5827,zhsso/roop,gradio,,3
-5828,BertChristiaens/blip-diffusion,streamlit,openrail,3
-5829,allknowingroger/Image-Models-Test7,gradio,,3
-5830,MSLAB/PaperGPT,gradio,,3
-5831,Syrahealthorg/HealthCare_workforce,gradio,,3
-5832,PineSearch/generateAudio,gradio,afl-3.0,3
-5833,radames/OpenAI-CLIP-JavaScript,static,,3
-5834,jeffyang123/ctheodoris-Geneformer,gradio,,3
-5835,sooolee/beer-sommelier,gradio,unlicense,3
-5836,ammarnasr/Code-Generation-with-Language-Specific-LoRa-Models,streamlit,openrail,3
-5837,allknowingroger/Image-Models-Test10,gradio,,3
-5838,Sarath2002/YouTube_Video_Summarizer,gradio,apache-2.0,3
-5839,justest/chatglm2-6b-int4,gradio,mit,3
-5840,shivammehta25/Diff-TTSG,gradio,mit,3
-5841,yuzu34/rvc-hololive,gradio,mit,3
-5842,randstad/Resume_Analyser,gradio,,3
-5843,phamson02/tho_ai,gradio,cc-by-4.0,3
-5844,allknowingroger/Image-Models-Test12,gradio,,3
-5845,nsarrazin/agents-js-oasst,docker,,3
-5846,kl08/personality_detectionV2,gradio,openrail,3
-5847,rstallman/langchain-chat-with-pdf-openai,gradio,,3
-5848,propilot/seo-powered-by-ia,streamlit,apache-2.0,3
-5849,Fredithefish/PixelRevive,gradio,apache-2.0,3
-5850,songdaooi/Swap,gradio,unknown,3
-5851,wseo/i18n-huggingface,gradio,apache-2.0,3
-5852,FFusion/FFusion.AI-beta-Playground,gradio,creativeml-openrail-m,3
-5853,allknowingroger/Image-Models-Test19,gradio,,3
-5854,Shriharsh/Text_To_Image,gradio,mit,3
-5855,ShoaibMajidDar/Blog_generator,streamlit,apache-2.0,3
-5856,stamps-labs/stamp2vec,gradio,,3
-5857,nomic-ai/Gustavosta_Stable-Diffusion-Prompts,static,,3
-5858,nomic-ai/WizardLM_WizardLM_evol_instruct_V2_196k,static,,3
-5859,nomic-ai/hakurei_open-instruct-v1,static,,3
-5860,johko/NSQL-Text-To-SQL,gradio,bsd-3-clause,3
-5861,Wayne-lc/drive_like_human,gradio,afl-3.0,3
-5862,Ababababababbababa/Arabic_poem_classifier,gradio,,3
-5863,lijiacai/chatgpt-next-web,docker,,3
-5864,Thunderstone/trial,docker,,3
-5865,Metal079/wd-v1-4-tags,gradio,,3
-5866,1111u/oai-reverse-proxy,docker,,3
-5867,merve/my_own_oasst_falcon,docker,apache-2.0,3
-5868,renumics/whisper-commonvoice-speaker-issues,docker,mit,3
-5869,openaccess-ai-collective/oo-preview-gpt4-200k,gradio,,3
-5870,JohanDL/GPT4Readability,gradio,mit,3
-5871,KarmKarma/genshinimpact-rvc-models-v2,gradio,openrail,3
-5872,allknowingroger/Image-Models-Test34,gradio,,3
-5873,allknowingroger/Image-Models-Test35,gradio,,3
-5874,CloudOrc/SolidUI,gradio,,3
-5875,allknowingroger/Image-Models-Test36,gradio,,3
-5876,multimodalart/upload_to_hub_folders_progress_bar,static,mit,3
-5877,gyugnsu/DragGan-Inversion,gradio,,3
-5878,paulokewunmi/jumia_product_search,streamlit,,3
-5879,Amrrs/DragGan-Inversion,gradio,,3
-5880,Sandiago21/speech-to-speech-translation-greek-with-transcription,gradio,,3
-5881,leafShen/CodeFormer,gradio,,3
-5882,allknowingroger/Image-Models-Test39,gradio,,3
-5883,allknowingroger/Image-Models-Test40,gradio,,3
-5884,CofAI/chat.v1,docker,,3
-5885,jonathang/WeatherBoy,gradio,,3
-5886,jbilcke-hf/VideoChain-UI,docker,,3
-5887,PeepDaSlan9/meta-llama-Llama-2-70b-chat-hf,gradio,bigscience-openrail-m,3
-5888,allknowingroger/Image-Models-Test42,gradio,,3
-5889,openbmb/viscpm-paint,gradio,,3
-5890,nmitchko/AI-in-Healthcare,static,cc-by-nc-2.0,3
-5891,WindVChen/INR-Harmon,gradio,,3
-5892,richardr1126/sql-skeleton-wizardcoder-demo,gradio,bigcode-openrail-m,3
-5893,allknowingroger/Image-Models-Test43,gradio,,3
-5894,gaodrew/constellation,streamlit,apache-2.0,3
-5895,Laden0p/Joeythemonster-anything-midjourney-v-4-1,gradio,,3
-5896,t0int/ehartford-Wizard-Vicuna-30B-Uncensored,gradio,,3
-5897,Ababababababbababa/Ashaar,gradio,apache-2.0,3
-5898,ZX9966/Fintech,static,apache-2.0,3
-5899,FFusion/FFXL-SDXL-Convert-diffusers,gradio,mit,3
-5900,rossellison/kpop-face-generator,streamlit,,3
-5901,allknowingroger/Image-Models-Test47,gradio,,3
-5902,renumics/stable-diffusion-strengths-weaknesses,docker,mit,3
-5903,lj1995/trump,gradio,,3
-5904,freddyaboulton/echo-chatbot,gradio,,3
-5905,bochen0909/speech-to-speech-translation-audio-course,gradio,,3
-5906,johnberg/CLIPInverter,gradio,,3
-5907,CofAI/optor,static,,3
-5908,XxXBobMarleyXxX/oai-proxy,docker,,3
-5909,AIZero2HeroBootcamp/Memory,streamlit,,3
-5910,OptorAI/gen,static,,3
-5911,justest/wav2lip,gradio,,3
-5912,allknowingroger/Image-Models-Test50,gradio,,3
-5913,allknowingroger/Image-Models-Test51,gradio,,3
-5914,OuroborosM/STLA-BABY,docker,mit,3
-5915,LLaMaWhisperer/LegalLLaMa,streamlit,gpl-3.0,3
-5916,s3nh/LLaMA-2-7B-32K-GGML,gradio,openrail,3
-5917,princessty/stabilityai-stable-diffusion-xl-base-1.0,gradio,,3
-5918,NohTow/LLM_watermarking,gradio,other,3
-5919,DVLH/consciousAI-question-answering-roberta-vsgshshshsbase-s-v2,gradio,,3
-5920,BaitMan/abroader-otters,docker,,3
-5921,CofAI/sd-2.1,gradio,openrail,3
-5922,NohTow/Llama2_watermarking,gradio,other,3
-5923,towardsai-buster/buster,gradio,,3
-5924,pikto/Diffuser,gradio,bigcode-openrail-m,3
-5925,a121440357/bingAI,docker,mit,3
-5926,Abhay834/my_genai_chatbot,gradio,,3
-5927,allknowingroger/Image-Models-Test57,gradio,,3
-5928,MattiaSangermano/IncentiveAI,gradio,,3
-5929,tanishqvashisht/colorizeAnime,streamlit,,3
-5930,shayakh/sdrv50,gradio,,3
-5931,Insightly/web_scraper,streamlit,,3
-5932,Ekohai/bingAI,docker,mit,3
-5933,TechnoByte/ComfyUI-Kybalico,docker,,3
-5934,haouarin/pdftotext,gradio,mit,3
-5935,omdena-lc/omdena-ng-lagos-chatbot-interface,docker,mit,3
-5936,0xSynapse/Segmagine,gradio,lgpl-3.0,3
-5937,imjunaidafzal/LoRA-DreamBooth-Training-UI,gradio,mit,3
-5938,linhdo/checkbox-detector,gradio,,3
-5939,metricspace/OcTra,gradio,mit,3
-5940,gorkemgoknar/moviechatbot-v2,gradio,cc-by-nc-4.0,3
-5941,allknowingroger/Image-Models-Test67,gradio,,3
-5942,allknowingroger/Image-Models-Test69,gradio,,3
-5943,konbraphat51/Kato-DB,streamlit,,3
-5944,JoPmt/Txt-to-video,static,,3
-5945,Manjushri/AudioGen-CPU,gradio,cc-by-nc-4.0,3
-5946,allknowingroger/Image-Models-Test71,gradio,,3
-5947,valeriylo/saiga_rag,gradio,,3
-5948,gradio-discord-bots/StableBeluga-7B-Chat,gradio,apache-2.0,3
-5949,NoCrypt/mikuTTS,gradio,,3
-5950,YouLiXiya/Mobile-SAM,gradio,mit,3
-5951,allknowingroger/Image-Models-Test76,gradio,,3
-5952,Jamel887/Rvc-tio887,gradio,mit,3
-5953,RoversX/Stable-Platypus2-13B-GGML,gradio,,3
-5954,allknowingroger/Image-Models-Test77,gradio,,3
-5955,RedValis/Music-Helix,streamlit,,3
-5956,Aristore/Warp,gradio,bsd,3
-5957,cloudtheboi/Lofi4All,gradio,,3
-5958,flatindo/generate5,gradio,,3
-5959,allknowingroger/Image-Models-Test84,gradio,,3
-5960,BramVanroy/llama-2-13b-chat-dutch-space,gradio,other,3
-5961,itxh888/Summarize-Webpage-Link,gradio,,3
-5962,mygyasir/deep-voice-cloning,gradio,openrail,3
-5963,allknowingroger/Image-Models-Test85,gradio,,3
-5964,ai-maker-space/Barbie-RAQA-Application-Chainlit-Demo,docker,apache-2.0,3
-5965,randomtable/SD-WebUI,docker,,3
-5966,mmnga/vocabviewer,streamlit,unknown,3
-5967,radames/transformers-js-sveltekit-static-example-app,static,,3
-5968,allknowingroger/Image-Models-Test95,gradio,,3
-5969,aliabid94/idefics_playground,gradio,,3
-5970,viait/dolphinchat-chatgpt-demo-ui,gradio,,3
-5971,radames/transformers-js-sveltekit-server-example-app,docker,,3
-5972,aaaaaabbbbbbbdddddddduuuuulllll/poetry,gradio,cc-by-nc-4.0,3
-5973,aaaaaabbbbbbbdddddddduuuuulllll/topic2poem,gradio,afl-3.0,3
-5974,aaaaaabbbbbbbdddddddduuuuulllll/AraPoet,gradio,gpl-3.0,3
-5975,themanas021/Youtube-Video-Summarizer,gradio,mit,3
-5976,Codecooker/rvcapi,gradio,gpl-3.0,3
-5977,dolphinchat/global,gradio,,3
-5978,sandrocalzada/swap_face,gradio,lgpl-3.0,3
-5979,MechaXYZ/Audio-to-Text,gradio,,3
-5980,walterclozet/invisiblecat-Uber_Realistic_Porn_Merge_V1.3,gradio,,3
-5981,kquote03/lama-video-watermark-remover,gradio,,3
-5982,crobbi/LipNet,streamlit,,3
-5983,AhmedM20/Email_Marketing_Content_Generator,gradio,,3
-5984,Polyhronis/codellama-CodeLlama-34b-Instruct-hf,gradio,,3
-5985,ngaggion/Chest-x-ray-HybridGNet-Segmentation,gradio,gpl-3.0,3
-5986,codewithbalaji/WizardLM-WizardCoder-Python-34B-V1.0,gradio,,3
-5987,Myuu-tastic1/Myuung,docker,,3
-5988,bayartsogt/real-time-tokenizer,gradio,apache-2.0,3
-5989,Statical/STC-IDM,gradio,openrail,3
-5990,aTrapDeer/Img2TimDillonRant,streamlit,openrail,3
-5991,llm-blender/LLM-Blender,gradio,mit,3
-5992,NemesisAlm/GeolocationCountryClassification,gradio,,3
-5993,Omnibus/EZ-Voice-Clone,gradio,,3
-5994,gustproof/sd_prompts,gradio,,3
-5995,zamasam/death,docker,,3
-5996,hoyinli/demo-app,streamlit,,3
-5997,4com/4com-license,gradio,creativeml-openrail-m,3
-5998,paufeldman/vv,gradio,,3
-5999,Dify-AI/Baichuan2-13B-Chat,gradio,other,3
-6000,truong-xuan-linh/auto-comment-generation,streamlit,,3
-6001,CosmoAI/BhagwatGeeta,streamlit,openrail,3
-6002,allknowingroger/Image-Models-Test126,gradio,,3
-6003,codefuse-ai/README,static,,3
-6004,Yash911/IMAGEALCHEMY-TEXT-TO-VISUALS,streamlit,,3
-6005,nyanko7/niji-playground,gradio,,3
-6006,tomandandy/MusicGen3,gradio,cc-by-nc-4.0,3
-6007,TabbyML/tabby-template-space,docker,,3
-6008,pourmand1376/Seamlessm4t_diarization_VAD,gradio,apache-2.0,3
-6009,exaggerated/PaddleOCR,gradio,,3
-6010,cubzh/cubzh,static,mit,3
-6011,wzhouxiff/RestoreFormerPlusPlus,gradio,apache-2.0,3
-6012,kevinwang676/Bert-VITS2,gradio,mit,3
-6013,IlyasMoutawwakil/llm-bar-race,gradio,,3
-6014,ntt123/vietnam-male-voice-wavegru-tts,gradio,,3
-6015,AnticPan/Clothes2Human,gradio,mit,3
-6016,digitalxingtong/Azuma-Bert-VITS2,gradio,mit,3
-6017,Statical/STC-LLM-CHAT,gradio,openrail,3
-6018,huggingface-projects/falcon180b-bot,gradio,,3
-6019,colornative/goofyai-3d_render_style_xl,gradio,,3
-6020,Loreleihunny/total_capy-love,docker,,3
-6021,Mysterykey/Mystery,docker,,3
-6022,banana-dev/demo-clip-interrogator,gradio,,3
-6023,PeepDaSlan9/hpcai-tech-Colossal-LLaMA-2-7b-base,gradio,apache-2.0,3
-6024,miittnnss/dcgan-image-generator,gradio,other,3
-6025,ylacombe/children-story,gradio,,3
-6026,MultiTransformer/EZChat,gradio,apache-2.0,3
-6027,prthgo/Spam-Message-Classifier,gradio,,3
-6028,librarian-bots/collection_papers_extractor,gradio,mit,3
-6029,cr7-gjx/Suspicion-Agent-Data-Visualization,gradio,apache-2.0,3
-6030,alwayse/MMD_MP_Text_Dection,gradio,,3
-6031,eaglelandsonce/weatherQnA,streamlit,,3
-6032,Kvikontent/kandinsky2.2,gradio,openrail,3
-6033,Paresh/Facial-feature-detector,gradio,apache-2.0,3
-6034,cr7-gjx/Suspicion-Agent-Demo,gradio,,3
-6035,pharma-IA/PharmaWise_Experto_Data_Integrity_V2C,gradio,artistic-2.0,3
-6036,bunkalab/bunka-map,streamlit,mit,3
-6037,newgpt/chatgpt-4,gradio,,3
-6038,pharma-IA/PharmaWise_Prospecto_Generico_Acetilsalicilico_V2C,gradio,artistic-2.0,3
-6039,pharma-IA/PharmaWise_Prospecto_Generico_Vortioxetina_V2C,gradio,artistic-2.0,3
-6040,totemko/ostris-ikea-instructions-lora-sdxl,gradio,,3
-6041,XzJosh/Gun-Bert-VITS2,gradio,mit,3
-6042,ShaLee/gpt35,docker,mit,3
-6043,colbyford/evodiff,gradio,mit,3
-6044,desudes/desu,docker,,3
-6045,AMR-KELEG/ALDi,streamlit,,3
-6046,blanchon/gaussian-splatting-kit,docker,,3
-6047,BirdL/DONOTUSEDemo,gradio,,3
-6048,ura-hcmut/ura-llama-playground,streamlit,mit,3
-6049,XzJosh/XingTong-Bert-VITS2,gradio,mit,3
-6050,editing-images/ledtisplusplus,gradio,,3
-6051,stevhliu/inpaint-mask-maker,gradio,,3
-6052,AIWaves/SOP_Generation-single,gradio,apache-2.0,3
-6053,shibing624/CLIP-Image-Search,gradio,apache-2.0,3
-6054,SUSSYMANBI/nerijs-pixel-art-xl-sdxl,gradio,,3
-6055,allknowingroger/Image-Models-Test197,gradio,,3
-6056,jiangjiechen/Auction-Arena-Demo,gradio,apache-2.0,3
-6057,Manglik-R/PDF-ChatBot-BCS,gradio,other,3
-6058,duchaba/kinship_llm,gradio,mit,3
-6059,xuyingliKepler/xuying_falcon,docker,apache-2.0,3
-6060,awacke1/MusicGenStreamFacebook,gradio,mit,3
-6061,victorisgeek/SwapFace2Pon,gradio,apache-2.0,3
-6062,freecs/A.I.R.S,gradio,mit,3
-6063,megaaziib/RVC-V2-Huggingface-Version,gradio,lgpl-3.0,3
-6064,hpa666/ham,gradio,mit,3
-6065,vih-v/SDXL-1.0-Inpainting,gradio,mit,3
-6066,Felladrin/Web-LLM-Mistral-7B-OpenOrca,static,apache-2.0,3
-6067,XzJosh/Bella-Bert-VITS2,gradio,mit,3
-6068,Kvikontent/kviimager,gradio,openrail,3
-6069,DarwinAnim8or/Blip-Dalle3,gradio,other,3
-6070,cdavenpo822/ToyWorld,gradio,,3
-6071,arsalagrey/streaming-text-generation-vue,static,mit,3
-6072,enzostvs/hair-colour,docker,mit,3
-6073,alonsosilva/tokenizer,docker,mit,3
-6074,silk-road/ChatHaruhi-RoleLLM-English,gradio,,3
-6075,Gh6st66/invisiblecat-Uber_Realistic_Porn_Merge_V1.3,gradio,,3
-6076,Tonic/MistralMED_Chat,gradio,apache-2.0,3
-6077,AdityaVishwakarma/LiveChecker,streamlit,apache-2.0,3
-6078,AILab-CVC/EvalCrafter,gradio,,3
-6079,arsalagrey/object-detection-vue,static,mit,3
-6080,xuyingliKepler/VecDBCompare,streamlit,,3
-6081,awacke1/CanAICode-Leaderboard-Customized,docker,mit,3
-6082,XzJosh/Wenjing-Bert-VITS2,gradio,mit,3
-6083,adumrewal/mtcnn-face-landmarks,gradio,mit,3
-6084,parthb3/YouTube_Podcast_Summary,gradio,apache-2.0,3
-6085,lunarflu/falcon-180b-demo-duplicate,gradio,,3
-6086,gstaff/KiteWind,gradio,,3
-6087,tonyassi/selfie-fashion-magazine,gradio,,3
-6088,TheStinger/Ilaria_Upscaler,gradio,,3
-6089,pseudolab/K23MiniMed,gradio,apache-2.0,3
-6090,jerpint/RAGTheDocs,gradio,mit,3
-6091,BREWDAcademy/Brewd-Diffusion,gradio,,3
-6092,aftonrobotics/sisterlocation,docker,,3
-6093,pseudolab/moogeulmoogeul,gradio,,3
-6094,OpenDILabCommunity/LLMRiddlesChatGPTEN,gradio,apache-2.0,3
-6095,satrn088/Gender_Recognition,gradio,unknown,3
-6096,Roboflow/DINO-GPT4V,gradio,mit,3
-6097,kevinwang676/OpenAI-TTS-Voice-Conversion,gradio,mit,3
-6098,nus-cs5647-team-5/Mandarin_Tone_Evaluation,gradio,,3
-6099,AhmedSSoliman/MarianCG-CoNaLa,gradio,,2
-6100,Amrrs/gradio-sentiment-analyzer,gradio,,2
-6101,Atsushi/kinoko-mini-AI,gradio,,2
-6102,Bagus/speaker-verification-demo,gradio,,2
-6103,Baishali/Pneumonia-Detection,gradio,,2
-6104,BradSegal/Literature-Rating,gradio,,2
-6105,Brayan/CNN_Tumor_Cerebral,streamlit,,2
-6106,CVPR/Example-Echocardiogram-Segmentation,gradio,,2
-6107,Daniele/forma-locutionis,gradio,,2
-6108,DarshanMM/OpenAICodexSummarizer,gradio,,2
-6109,DeepDrivePL/BEiT-Semantic-Segmentation,gradio,,2
-6110,Demonic/Text_Summarizer,gradio,,2
-6111,Didier/Semantic_Search_arXiv,streamlit,,2
-6112,DrishtiSharma/Diarization,gradio,,2
-6113,DrishtiSharma/Image-search-using-CLIP,gradio,,2
-6114,Emanuel/pos-tag-bosque-br-demo,streamlit,,2
-6115,ErenYeager01/Traffic_sign_recognition,gradio,,2
-6116,Giuliano/Conversational-Wikipedia,gradio,,2
-6117,Harveenchadha/speech2speech,gradio,,2
-6118,Ignahugging/Plants_classification,gradio,,2
-6119,JonatanGk/cyberbullying-detector,gradio,,2
-6120,Kuaaangwen/auto-grader,streamlit,,2
-6121,LegacyLeague/Legacy_League,gradio,,2
-6122,MarkusDressel/cord,gradio,,2
-6123,Nipun/KL-Divergence-1d,streamlit,,2
-6124,PeerChristensen/TrumpTweetsDevice,gradio,,2
-6125,Recognai/veganuary_ner,gradio,,2
-6126,Rick458/Desi-Food-Vision,gradio,,2
-6127,Rules99/Bioinformatics_Project,streamlit,,2
-6128,RyanX/BookSearch,gradio,,2
-6129,SLU-CSCI5750-SP2022/homework03_DigitClassificationKNN,gradio,,2
-6130,Sa-m/Dogs-vs-Cats,gradio,,2
-6131,Sa-m/YoloV5-Party-Symbol-Detector-V1,gradio,mit,2
-6132,Sakil/english_audio_transcriptor,gradio,apache-2.0,2
-6133,Sakil/tweetlib6_app,gradio,,2
-6134,Sammy03/neuralserach,gradio,,2
-6135,Sanan/Infrared_Object_Detection_YOLOv5,gradio,,2
-6136,Saturdays/ReconocimientoEmociones,gradio,afl-3.0,2
-6137,SaulLu/test,static,,2
-6138,SebastianEnger/textgenerator,static,,2
-6139,Sense-X/uniformer_image_demo,gradio,mit,2
-6140,Sense-X/uniformer_video_demo,gradio,mit,2
-6141,Siddhant/ESPnet2-SLU,gradio,,2
-6142,Sultannn/Text_summarization_with-MBART,gradio,apache-2.0,2
-6143,Vrk/SeeFood,streamlit,,2
-6144,Vrk/SkimLit,streamlit,,2
-6145,Wikidepia/IndoPara-Gen,streamlit,,2
-6146,Wootang01/Paraphraser_two,streamlit,,2
-6147,Wootang01/Punctuation_capitalization_corrector,streamlit,,2
-6148,Wootang01/part_of_speech_categorizer,streamlit,,2
-6149,Wootang01/vocabulary_categorizer,streamlit,,2
-6150,Wootang01/vocabulary_categorizer_two,streamlit,,2
-6151,abhibisht89/ADR_XTRACTER,gradio,,2
-6152,abhilash1910/QA_Albert,gradio,,2
-6153,abidlabs/english2german,gradio,,2
-6154,abidlabs/voice-verification,gradio,,2
-6155,aditi2222/Summarization_english,gradio,,2
-6156,afry-south/lowlight-enhancement,streamlit,,2
-6157,agueroooooooooo/Transport_Mode_Detector,gradio,,2
-6158,ahmedJaafari/Annarabic,gradio,,2
-6159,ajitrajasekharan/NER-Biomedical-PHI-Ensemble,streamlit,mit,2
-6160,akdeniz27/turkish-qna-with-xlm-roberta,streamlit,,2
-6161,akhaliq/Car_Keypoints,gradio,,2
-6162,akhaliq/DeBERTa-v3-base-mnli,gradio,,2
-6163,akhaliq/Holistic,gradio,,2
-6164,akhaliq/Pop_Music_Transformer,gradio,,2
-6165,akhaliq/SimCSE,gradio,,2
-6166,akhaliq/brain_segmentation,gradio,,2
-6167,akhaliq/deeplab2,gradio,,2
-6168,akhaliq/fairseqs2,gradio,,2
-6169,akhaliq/pgan,gradio,,2
-6170,akhaliq/t5-base-lm-adapt,gradio,,2
-6171,albertvillanova/datasets-tagging,streamlit,,2
-6172,aliabd/SummerTime,gradio,,2
-6173,gradio/calculator-flagging-options,gradio,,2
-6174,aniket/gradsflow-text-classification,gradio,,2
-6175,arampacha/chat-with-simpsons,streamlit,,2
-6176,arijitdas123student/gpt2-demo,gradio,,2
-6177,asimokby/cv-parser-huggingface,gradio,mit,2
-6178,austin/adr-detection,gradio,,2
-6179,autosummproject/autosumm,streamlit,,2
-6180,ayaanzaveri/mnist,gradio,,2
-6181,aymm/Task-Exploration-Hate-Speech,streamlit,,2
-6182,begar/amazon-reviews-demo,gradio,,2
-6183,bguberfain/Detic,gradio,mit,2
-6184,bhanu4110/Lungs_CT_Scan_Cancer,gradio,,2
-6185,bipin/mltwitter,streamlit,,2
-6186,birdortyedi/instagram-filter-removal,gradio,,2
-6187,breathingcyborg/reviews-actionable-insights,streamlit,,2
-6188,buio/attr-cond-gan,gradio,,2
-6189,cahya/image-search,streamlit,,2
-6190,cakiki/facets-dive,static,,2
-6191,carlosaguayo/cats_vs_dogs,gradio,,2
-6192,cdleong/phonemize-audio,streamlit,,2
-6193,chaitanya9/emotion_recognizer,gradio,,2
-6194,chicham/query_analysis,gradio,,2
-6195,chinhon/Chinese_News_Headlines_Generator,gradio,,2
-6196,chinhon/Speech_Sentiment_Analysis,gradio,,2
-6197,danijelpetkovic/test-tts-inference-api,streamlit,,2
-6198,dechantoine/PokeGAN,gradio,cc,2
-6199,deep-learning-analytics/Title_Generation,gradio,,2
-6200,docs-demos/distilbert-base-uncased,gradio,,2
-6201,dpc/vien,gradio,,2
-6202,Datatrooper/sentimiento,gradio,,2
-6203,Datatrooper/wine,gradio,,2
-6204,dumitrescustefan/NamedEntityRecognition-Romanian,streamlit,,2
-6205,eddydecena/cat-vs-dog,gradio,,2
-6206,equ1/mnist_interface,gradio,,2
-6207,facebook/XLS-R-1B-EN-15,gradio,,2
-6208,facebook/XLS-R-2B-21-EN,gradio,,2
-6209,flax-community/Mongolian-GPT2,streamlit,,2
-6210,flax-community/TamilLanguageDemos,streamlit,,2
-6211,flax-community/alberti,streamlit,,2
-6212,gagan3012/IMD,streamlit,,2
-6213,gagan3012/project-code-py,streamlit,,2
-6214,gossminn/fillmorle-app,streamlit,,2
-6215,haotieu/Vietnamese-News-Summarizer,gradio,,2
-6216,hi9/core4testing,gradio,,2
-6217,hlopez/Waste-Detector,streamlit,,2
-6218,huggingface-course/amazon-reviews-demo,gradio,,2
-6219,isabel/club-project,gradio,,2
-6220,isabel/image-test,gradio,,2
-6221,isabel/pet-project,gradio,,2
-6222,jason9693/KoreanHateSpeechClassifier,gradio,,2
-6223,jason9693/Soongsil-Bot-KoGPT,streamlit,,2
-6224,jmansfield89/Tweet_NLP_Sentiment_Analysis,streamlit,,2
-6225,jositonaranja/glide-text2img,gradio,,2
-6226,joyson072/Stock_market_prediction,gradio,,2
-6227,jrichez/disaster_tweets,gradio,,2
-6228,jruneofficial/text2pixel,gradio,,2
-6229,karolmajek/PaddleHub-BiSeNetV2,gradio,,2
-6230,keras-io/pixelcnn-mnist-image-generation,gradio,apache-2.0,2
-6231,kingfisher/spacy-ner,streamlit,cc-by-nc-sa-4.0,2
-6232,kpriyanshu256/acronym-disambiguation,gradio,,2
-6233,lev/nlp,streamlit,,2
-6234,levandong/MNIST-detect-deploy-webapp,gradio,,2
-6235,lewtun/hslu-demo,gradio,,2
-6236,mawady/Demo-integrated-gradients-alibi-gradio,gradio,mit,2
-6237,mawady/demo-catsvsdogs-gradio,gradio,,2
-6238,mayhug/rf5-anime-image-label,gradio,mit,2
-6239,mbahrami/AutoComplete,streamlit,,2
-6240,merve/fourier-transform,streamlit,,2
-6241,merve/spaces-demo,streamlit,,2
-6242,mgczacki/toxicspans,streamlit,,2
-6243,mikeee/radiobee-dev,gradio,,2
-6244,mikeee/ttw,gradio,,2
-6245,mlkorra/competitive-analysis,streamlit,,2
-6246,mmcquade11/Image-to-Text,streamlit,,2
-6247,mmcquade11/autonlp-reuters-summarization,gradio,,2
-6248,mmeendez/cnn_transformer_explainability,gradio,,2
-6249,monsoon-nlp/AntiExplanation,gradio,,2
-6250,muhammadayman/data_science_content_en_to_ar,gradio,,2
-6251,napoles3d/st_parade,streamlit,,2
-6252,nata0801/RuEn_ASR_with_Voice_Recorder,gradio,,2
-6253,nateraw/host-a-blog-on-huggingface-spaces,streamlit,,2
-6254,nlp-en-es/roberta-qa-es,gradio,,2
-6255,nazianafis/Sentiment-Analysis,streamlit,,2
-6256,osanseviero/SMILES_RDKit_Py3DMOL_FORK,streamlit,,2
-6257,paulbricman/decontextualizer,streamlit,,2
-6258,piecurus/Summarizer,streamlit,mit,2
-6259,pietrolesci/wordify,streamlit,,2
-6260,prateekagrawal/roberta-testing,streamlit,,2
-6261,pushkaraggrawal/Summarizer,gradio,,2
-6262,pytorch/DeepLabV3,gradio,,2
-6263,pytorch/NTSNET,gradio,,2
-6264,pytorch/PGAN,gradio,,2
-6265,pytorch/SSD,gradio,,2
-6266,pytorch/WaveGlow,gradio,,2
-6267,ra2w/TableQandA,streamlit,,2
-6268,rajesh1729/Text-analysis-with-spacy-and-streamlit,streamlit,afl-3.0,2
-6269,rajesh1729/question-answering-gradio,gradio,afl-3.0,2
-6270,rebolforces/jcastles,gradio,,2
-6271,sanjana/Loan-Prediction-Analysis,gradio,,2
-6272,savasy/Multilingual-Zero-Shot-Sentiment-Classification,gradio,gpl,2
-6273,savasy/SentimentHistogramForEnglish,gradio,,2
-6274,sentencebird/audio-noise-reduction,streamlit,,2
-6275,sentencebird/translation-word-order,streamlit,,2
-6276,seyia92coding/video-games-recommender,gradio,,2
-6277,shahukareem/Wav2Vec2-Large-XLSR-53-Dhivehi,gradio,,2
-6278,shashankanand13/used_car_prediction,gradio,,2
-6279,shibing624/code-autocomplete,gradio,apache-2.0,2
-6280,shubh2014shiv/Japanese_NLP,streamlit,,2
-6281,snoop2head/KoGPT-Conditional-Generation,streamlit,,2
-6282,springml111/T5_Paraphrase_demo,gradio,,2
-6283,surendraelectronics/weatherApp,streamlit,,2
-6284,swcrazyfan/DeKingify,gradio,,2
-6285,taesiri/LatexDiff,gradio,mit,2
-6286,temp-late/manga-anime-premium,gradio,apache-2.0,2
-6287,temp-late/manga-anime,gradio,apache-2.0,2
-6288,tobiascz/SDSdemo,gradio,afl-3.0,2
-6289,un-index/textgen6b,gradio,,2
-6290,versae/modernisa,gradio,,2
-6291,vesteinn/Bird-Classifier-CLIP-NABirds,gradio,,2
-6292,vivien/causal-simulator,streamlit,,2
-6293,warwickai/fin-perceiver-demo,streamlit,,2
-6294,widged/gender-bias-evaluation,gradio,,2
-6295,widged/text-paraphrasing,gradio,,2
-6296,widged/text-summarization,streamlit,,2
-6297,xiaoxuezi/spleeter,gradio,,2
-6298,xiongjie/face-expression-ja-example,gradio,,2
-6299,yashsrivastava/speech-to-text-yash,gradio,,2
-6300,tensorflow/esrgan-tf2,gradio,,2
-6301,yangtaowang/TokenCut,gradio,,2
-6302,osanseviero/draw-minimal-copy3,gradio,,2
-6303,DataDoggo/Visionary,gradio,,2
-6304,RivianG/Asis,streamlit,,2
-6305,atticus/image-text-retrival-huster,gradio,,2
-6306,templates/fastapi_with_streamlit,streamlit,mit,2
-6307,Wootang01/chatbot_four,streamlit,,2
-6308,taka-yamakoshi/bert-priors-demo,streamlit,,2
-6309,tareknaous/Chatbot-DialoGPT,gradio,,2
-6310,123harsh/gradio-easywriter,gradio,,2
-6311,onnx/ArcFace,gradio,,2
-6312,tareknaous/Empathetic-DialoGPT,gradio,,2
-6313,davidmasip/racism-gr,gradio,mit,2
-6314,samueldomdey/ClipCosineSimilarityUpload,gradio,,2
-6315,EricaCorral/Chinese-To-English-Tools,streamlit,,2
-6316,farukozderim/zero-shotts,gradio,,2
-6317,EricaCorral/Chinese-Tools-FAST,gradio,,2
-6318,course-demos/distilbert-base-uncased-finetuned-imdb,gradio,afl-3.0,2
-6319,z-uo/streamlit_music_demo,streamlit,,2
-6320,virender74/plant-disease,gradio,,2
-6321,adlozano1/gibberish_detector,gradio,,2
-6322,CVPR/visual-clustering,gradio,,2
-6323,arpm01/financial-summarization,gradio,,2
-6324,vivien/semanticsearch,streamlit,cc-by-nc-4.0,2
-6325,ncats/EpiPipeline4RD,streamlit,,2
-6326,epdavid2/morsecode,gradio,apache-2.0,2
-6327,calvininterview/interview-streamlit,streamlit,,2
-6328,NahuelCosta/DTW-CNN,gradio,,2
-6329,bensonsantos/CANnet_Crowd_Counting,gradio,afl-3.0,2
-6330,onnx/FCN,gradio,,2
-6331,harveysamson/wav2vec2-speech-emotion-recognition,gradio,,2
-6332,johnowhitaker/CLIPRGB-ImStack,gradio,cc-by-4.0,2
-6333,iSky/spam-detector,gradio,afl-3.0,2
-6334,cedssama/I3D_Sign_Language_Classification,gradio,apache-2.0,2
-6335,abbylagar/multilingual_keyword_extractor,gradio,afl-3.0,2
-6336,DerrylNessie/MangaCleaner,gradio,afl-3.0,2
-6337,vanessbut/tldr_keywords,streamlit,gpl-3.0,2
-6338,josedolot/HybridNet_Demo2,gradio,mit,2
-6339,gbach1lg/PhotoStyleTransfer,gradio,cc,2
-6340,Sa-m/Auto-Translation,gradio,mit,2
-6341,baguioni/Voice-Activity-Detection,gradio,mit,2
-6342,utec/FedericoRodriguezDetectorSentimentalTwitter,gradio,,2
-6343,chrismay/Sentiment-demo-app,streamlit,,2
-6344,pplonski/mercury-test-2,gradio,mit,2
-6345,johnowhitaker/orbgan_demo,gradio,cc-by-4.0,2
-6346,ronvolutional/iframe-test,gradio,,2
-6347,IPN/demo_cms_1,gradio,cc,2
-6348,nickil/weakly-supervised-parsing,gradio,mit,2
-6349,hackathon-pln-es/Paraphrase-Bertin,streamlit,,2
-6350,AdityaMahimkar/PlagiarismChecker,gradio,afl-3.0,2
-6351,Saturdays/spanish-quechua-detector,gradio,mit,2
-6352,hackathon-pln-es/itama-app,gradio,,2
-6353,radames/Jupyter-Kernel-Gateway-Flask,gradio,,2
-6354,huggan/Colorb_GAN,gradio,cc-by-4.0,2
-6355,awacke1/StreamlitCookies,streamlit,mit,2
-6356,hysts/MobileStyleGAN,gradio,,2
-6357,awacke1/TimerASRLive,gradio,mit,2
-6358,tomofi/Google-Drive-OCR,gradio,mit,2
-6359,d0r1h/Hindi_News_Summarizer,gradio,mit,2
-6360,awacke1/Video-View-Download,streamlit,mit,2
-6361,asdasdasdasd/Face-forgery-detection,gradio,,2
-6362,GuiltySpark/amikus_text_summarizer,gradio,,2
-6363,awacke1/HTML5-AR-VR,static,mit,2
-6364,sil-ai/aqua-semantic-sim,gradio,,2
-6365,kargaranamir/parstdex,streamlit,mit,2
-6366,Egrt/MaskGAN,gradio,apache-2.0,2
-6367,webis-huggingface-workshop/f_demo_question_gen,gradio,cc0-1.0,2
-6368,hysts/ibug-face_parsing,gradio,,2
-6369,hysts/TADNE-interpolation,gradio,,2
-6370,huggan/cityscapes-pix2pix,gradio,,2
-6371,nateraw/test-pix2pix-load,gradio,,2
-6372,ecarbo/AutomaticSpeechRecognition,gradio,,2
-6373,vikiiiii/musical-tone-123,gradio,mit,2
-6374,kargaranamir/visual-clutter,gradio,mit,2
-6375,hysts/TADNE-image-selector,gradio,,2
-6376,awacke1/Grammar-Styler,streamlit,mit,2
-6377,NahuelCosta/RUL-Variational,gradio,,2
-6378,ma-xu/LIVE,gradio,gpl-3.0,2
-6379,PaddlePaddle/resnext101_32x16d_wsl,gradio,,2
-6380,ulysse/lyme,gradio,mit,2
-6381,awacke1/TextImg2Art,gradio,mit,2
-6382,awacke1/QandAGenerator,gradio,mit,2
-6383,jy46604790/Fake-News-Recognition,streamlit,apache-2.0,2
-6384,h4d35/CosineSim,gradio,,2
-6385,yangy50/garbage-image-classification,streamlit,,2
-6386,ThomasSimonini/Conversation-in-a-Tavern,gradio,,2
-6387,Bijoy2001/real-time-voice-recognition,gradio,,2
-6388,pie/NER,gradio,,2
-6389,jacklindsai/is_it_elon_musk,gradio,,2
-6390,tficar/amazon-rating-calculator,gradio,mit,2
-6391,yhshin/kr-article-summarizer,gradio,mit,2
-6392,tomofi/NDLOCR,gradio,mit,2
-6393,mgfrantz/pii_masking,gradio,mit,2
-6394,Zengyf-CVer/Gradio_YOLOv5_Det_v2,gradio,gpl-3.0,2
-6395,satpalsr/TransPose,gradio,mit,2
-6396,rajesh1729/NLP-with-mercury-spacy,gradio,afl-3.0,2
-6397,Epitech/AiOnIot-Antoine-Quentin-Valentin-Maxime,streamlit,,2
-6398,iamkb/voc-demo,gradio,other,2
-6399,BennoKrojer/imagecode-demo,streamlit,afl-3.0,2
-6400,DanteOz/Minimal-Endpoint,gradio,mit,2
-6401,hylee/photo2cartoon,gradio,apache-2.0,2
-6402,CVMX-jaca-tonos/YouTube-Video-Streaming-Spanish-ASR,streamlit,,2
-6403,thisisanshgupta/solo-coder-20B,gradio,mit,2
-6404,CVMX-jaca-tonos/Identificar-lenguas-y-frases,gradio,mit,2
-6405,bencoman/WhichWatersport,gradio,apache-2.0,2
-6406,feng2022/Time-TravelRephotography,gradio,mit,2
-6407,jbetker/tortoise,gradio,apache-2.0,2
-6408,malteos/gpt-german,gradio,mit,2
-6409,JerynC/catloaf,gradio,mit,2
-6410,eduardofv/multilang_semantic_search_wikisimple,streamlit,lgpl-3.0,2
-6411,HighCWu/starganv2vc-paddle,gradio,mit,2
-6412,Ezi/ModelCardsAnalysis,streamlit,,2
-6413,volen/nft-search,streamlit,apache-2.0,2
-6414,VietAI/ViNewsSum,gradio,cc-by-4.0,2
-6415,dnth/gpt-neo-paraphrase,gradio,,2
-6416,course-demos/draw2,gradio,afl-3.0,2
-6417,awacke1/AnimationAI,streamlit,mit,2
-6418,smc/pole_or_trafo,gradio,mit,2
-6419,publichealthsurveillance/PHS-BERT,gradio,,2
-6420,course-demos/Remove-bg,gradio,afl-3.0,2
-6421,seduerr/text_analytics,gradio,apache-2.0,2
-6422,Bavesh/Oral_Cancer_Detection,streamlit,afl-3.0,2
-6423,bankholdup/stylegan_petbreeder,gradio,,2
-6424,valurank/Article_Summarizer,gradio,other,2
-6425,ntt123/mnist-rnn,static,cc-by-nc-4.0,2
-6426,azaninello/gpt2-general,gradio,cc-by-nc-sa-4.0,2
-6427,ashishraics/MCQ-Generator,streamlit,,2
-6428,pierreguillou/document-layout-detection-dit-image-instances,gradio,,2
-6429,evaluate-metric/mean_iou,gradio,,2
-6430,evaluate-metric/squad_v2,gradio,,2
-6431,nihaldsouza1/clearlydefined_license_summarizer,streamlit,,2
-6432,armgabrielyan/search-in-video,gradio,,2
-6433,nobrowning/M2M,streamlit,,2
-6434,Aniemore/Russian-Emotion-Recognition,gradio,,2
-6435,Gradio-Blocks/Dog-Breed-Identification-App,gradio,apache-2.0,2
-6436,HarryLee/eCommerceImageCaptioning,gradio,,2
-6437,Ritvik19/SentiNet,streamlit,,2
-6438,tarteel-ai/latest-demo,gradio,,2
-6439,awacke1/GenerativeWordsandImages,gradio,mit,2
-6440,rushic24/DialoGPT-Covid-Help-Doctor,streamlit,mit,2
-6441,flava/neural-style-transfer,gradio,,2
-6442,butterswords/nlc-explorer,streamlit,mit,2
-6443,dipesh/JarvisAI-Intent-Classification-Bert-Base-Cased,gradio,,2
-6444,awacke1/WordGames,streamlit,mit,2
-6445,Yah216/Arabic_poem_classifier,gradio,,2
-6446,awacke1/FirestorePersistence,streamlit,mit,2
-6447,teticio/inBERTolate,gradio,gpl-3.0,2
-6448,doevent/AnimeGANv2,gradio,,2
-6449,Gradio-Blocks/EDSR,gradio,mit,2
-6450,matjesg/deepflash2,gradio,apache-2.0,2
-6451,evaluate-metric/rl_reliability,gradio,,2
-6452,tinkoff-ai/response-quality-classifiers,streamlit,mit,2
-6453,hf-maintainers/README,static,,2
-6454,SusiePHaltmann/HaltmannDiffusionv0,streamlit,mit,2
-6455,yl4579/StyleTTS,gradio,mit,2
-6456,nagolinc/liteDungeon,gradio,mit,2
-6457,viktor-enzell/wav2vec2-large-voxrex-swedish-4gram,streamlit,cc0-1.0,2
-6458,arunavsk1/Pubmed-Named-Entity-Recognition,streamlit,,2
-6459,czkaiweb/StarryNight,gradio,,2
-6460,huspacy/example-applications,gradio,apache-2.0,2
-6461,ConorDY/feedback-chatbot,gradio,,2
-6462,mohitmayank/law-finder-ipc,streamlit,mit,2
-6463,hongaik/hc_text_classification,streamlit,,2
-6464,keras-io/3D_CNN_Pneumonia,gradio,mit,2
-6465,unco3892/real_estate_ie,gradio,,2
-6466,summerstay/vectorAPI,gradio,cc,2
-6467,ashrestha/auto-multi-class,streamlit,,2
-6468,keras-io/metric-learning-image-similarity-search,gradio,,2
-6469,neurotech/Swahili-NER-Tagger,streamlit,mit,2
-6470,bigscience-data/document-sizes,streamlit,,2
-6471,osanseviero/latent-converter,gradio,mit,2
-6472,keras-io/text-classification-with-transformer,gradio,mit,2
-6473,valurank/Article_summarizer_cnn_large_testing,gradio,other,2
-6474,Axolotlily/TextGen,gradio,other,2
-6475,dfskGT/parrot-paraphraser,gradio,apache-2.0,2
-6476,sarunas856/tinder,gradio,,2
-6477,rajistics/finbert_forwardlooking,gradio,apache-2.0,2
-6478,dmccreary/spaces-demo,streamlit,cc-by-nc-sa-4.0,2
-6479,keras-io/Node2Vec_MovieLens,gradio,other,2
-6480,mullikine/ilambda,static,gpl-3.0,2
-6481,keras-io/semantic-image-clustering,gradio,apache-2.0,2
-6482,keras-io/SpeakerRecognition,gradio,apache-2.0,2
-6483,armandnlp/gpt2-TOD_app,gradio,,2
-6484,rajeshradhakrishnan/malayalam-news-classify,gradio,,2
-6485,jmcob/Transformers-StoryWriting,gradio,mit,2
-6486,awacke1/AR-VR-IOT-Demo,static,,2
-6487,awacke1/ChemistryModelerSMILES,streamlit,,2
-6488,sasha/MetricCompare,streamlit,cc-by-nc-sa-4.0,2
-6489,SergioMtz/MNIST_Digit_Recognition,gradio,,2
-6490,Slender/image_editing_app,streamlit,,2
-6491,ThunderJames/PhotoRealistic,static,,2
-6492,kkawamu1/huggingface_code_generator,streamlit,cc,2
-6493,nickmuchi/Face-Mask-Detection-with-YOLOS,gradio,apache-2.0,2
-6494,beihai/PDF-Table-Extractor,streamlit,bsd-3-clause-clear,2
-6495,WZT/DigiProj,gradio,,2
-6496,ekojs/ml_food10,gradio,apache-2.0,2
-6497,CVPR/flava-multimodal-zero-shot,gradio,,2
-6498,Akinade/Iris_App,gradio,,2
-6499,maker57sk/linkedin_analysis,streamlit,mit,2
-6500,Axolotlily/DalleMini,gradio,other,2
-6501,mahidher/comment_toxicity,gradio,,2
-6502,SusiePHaltmann/GPT-DALL-X,gradio,mit,2
-6503,AlvearVanessa/Edad_biologica_retina,gradio,,2
-6504,Chemsseddine/summarisation,gradio,,2
-6505,keras-io/timeseries-classification-from-scratch,gradio,,2
-6506,CVPR/transfiner,gradio,apache-2.0,2
-6507,pyimagesearch/nmt-luong,gradio,,2
-6508,mikachou/dog-breed-identification,gradio,,2
-6509,alan-chen-intel/dagan-demo,gradio,,2
-6510,djsull/aha-multi-label,gradio,apache-2.0,2
-6511,ilan541/OncUponTim,gradio,,2
-6512,DiweshUIT/Spectrometer,gradio,mit,2
-6513,NLTM/IndicBART,streamlit,cc,2
-6514,keras-io/timeseries_forecasting_for_weather,streamlit,,2
-6515,j-m/formality_tagging,gradio,bsd-3-clause,2
-6516,mrosinski/risk-predictor,gradio,apache-2.0,2
-6517,jph00/daniel-img-fix,gradio,apache-2.0,2
-6518,sumit12/SHIPMENT_PRICING_PREDICTION,gradio,,2
-6519,anirudhmittal/humour-detection,gradio,cc-by-4.0,2
-6520,ossaili/architectural_styles,gradio,mit,2
-6521,ICML2022/Leaderboard,gradio,,2
-6522,awacke1/Gradio-Blocks-Demo,gradio,mit,2
-6523,awacke1/ArtStyleFoodsandNutrition,gradio,mit,2
-6524,Hassan175/suicide-detection,gradio,,2
-6525,MohamedRafik/Password_Generator,gradio,,2
-6526,twobob/imagegpt,gradio,,2
-6527,mrchtr/semantic-demo,streamlit,,2
-6528,saadob12/Chart_Data_Summarization,streamlit,,2
-6529,Msp/invoice_processing_layoutlmv3_custom,gradio,afl-3.0,2
-6530,furrutiav/beto_coherence,streamlit,gpl-2.0,2
-6531,ysharma/testing_llm,gradio,gpl,2
-6532,EuroPython2022/YOLOv5,gradio,,2
-6533,ahnafsamin/GroTTS-FastSpeech2,gradio,afl-3.0,2
-6534,QuoQA-NLP/QuoQaGo,streamlit,mit,2
-6535,amsterdamNLP/attention-rollout,gradio,,2
-6536,EuroPython2022/latr-vqa,gradio,unknown,2
-6537,EuroPython2022/gpt2-TOD_app,gradio,,2
-6538,BenjaminB/pyscript-demo,static,bsd-3-clause,2
-6539,EuroPython2022/Face-Mask-Detection-with-YOLOS,gradio,,2
-6540,darragh/swinunetr-dicom-video,gradio,apache-2.0,2
-6541,EuroPython2022/ToxicCommentClassification,gradio,apache-2.0,2
-6542,milyiyo/testing-diffusers,gradio,,2
-6543,EuroPython2022/alpha-on-ridge-regression,gradio,,2
-6544,nev/dalle-6D,gradio,mit,2
-6545,missmeyet/Translate_Text_In_Images,gradio,apache-2.0,2
-6546,zion581/sentiment_analysis_by_rohan,streamlit,afl-3.0,2
-6547,mrm8488/hf-diffusers,gradio,wtfpl,2
-6548,EuroPython2022/mediapipe-hands,gradio,,2
-6549,flynster/FeinbergQuizNotes,gradio,mit,2
-6550,nickprock/banking_intent_classification,gradio,mit,2
-6551,EuroPython2022/banking_intent_classification,gradio,mit,2
-6552,NomiWai/anime-collaborative-filtering-space,gradio,afl-3.0,2
-6553,pythainlp/pythainlp,streamlit,apache-2.0,2
-6554,LDY/Chinese-Question-Answering,gradio,afl-3.0,2
-6555,Sangmin/Eiken-Essay-Using-BLOOM,gradio,mit,2
-6556,EuroPython2022/Sketch2ColourDemo,gradio,eupl-1.1,2
-6557,clarin-pl/datasets-explorer,streamlit,,2
-6558,nkatraga/7.22.CarePlanQnAWithContext,gradio,apache-2.0,2
-6559,awacke1/ASRtoTexttoStorytoImagestoVideo,gradio,apache-2.0,2
-6560,Preetesh/VideoSummaryfromYouTubeVideo,gradio,apache-2.0,2
-6561,awacke1/VideoSummaryYoutube3,gradio,apache-2.0,2
-6562,Zengyf-CVer/color_generator,gradio,gpl-3.0,2
-6563,kyled/PhraseSentimentEmotionAnalysis,streamlit,mit,2
-6564,platzi/platzi-curso-streamlit-butterfly-gan,streamlit,apache-2.0,2
-6565,omlab/VL_checklist_demo,gradio,mit,2
-6566,ekenkel/dog-identifier,gradio,apache-2.0,2
-6567,Paatiii1712/stock_market_forcasting,streamlit,,2
-6568,aiEDUcurriculum/introtoAI-anime-project,gradio,afl-3.0,2
-6569,aiEDUcurriculum/introtoAI-climate-change-project,gradio,afl-3.0,2
-6570,aiEDUcurriculum/introtoAI-pets-project,gradio,afl-3.0,2
-6571,keithhon/google-universal-sentence-encoder-v4-similarity-score,gradio,,2
-6572,keithhon/T0pp,gradio,,2
-6573,katielink/spleen_segmentation,gradio,other,2
-6574,samuelinferences/TabPFN,gradio,,2
-6575,jmcob/StreamlitGrammarCorrectorStyler,streamlit,mit,2
-6576,micole66/video,gradio,,2
-6577,KneeKhan/DSSG_Test,gradio,mit,2
-6578,gstaff/test_space,gradio,apache-2.0,2
-6579,ky2k/summarize_text,gradio,,2
-6580,JulesBelveze/concepcy,gradio,,2
-6581,nakamura196/yolov5-kunshujo,gradio,,2
-6582,leumastai/BackgroundChanger,gradio,mit,2
-6583,Akshat-1812/Dog-Vision,gradio,unknown,2
-6584,nagolinc/minDalle_GFPGAN,gradio,mit,2
-6585,bahman/labequip,gradio,apache-2.0,2
-6586,azadranjith/emotional_damage,gradio,,2
-6587,MFawad/Emergency_vehicle_classifier,gradio,other,2
-6588,anikfaisal/weather_image_classifier,gradio,apache-2.0,2
-6589,RobPruzan/automaticlitassesment,gradio,afl-3.0,2
-6590,ShAnSantosh/Chatbot_Using_Pytorch,gradio,apache-2.0,2
-6591,fedihch/InvoiceReceiptClassifierDemo,gradio,,2
-6592,Einmalumdiewelt/German_text_summarization,gradio,mit,2
-6593,simonduerr/3dmol.js,gradio,mit,2
-6594,pustozerov/poc_call_transcription,streamlit,afl-3.0,2
-6595,suddu21/Garbage-Classification-VGG19,gradio,,2
-6596,cmu-adcs/videogenic,streamlit,,2
-6597,awacke1/LED-Long-Form-SummariesBeamLengthTokenRepNgramVariantsTDDGradio,gradio,mit,2
-6598,anonymous-demo/Anonymous-TranSVAE-Demo,gradio,cc-by-4.0,2
-6599,MrVicente/RA-BART,gradio,afl-3.0,2
-6600,brayden-gg/decoupled-style-descriptors,gradio,,2
-6601,eforebrahim/Cassava-Leaf-Disease-Classification,streamlit,,2
-6602,freddyaboulton/all_demos_3,gradio,,2
-6603,bigscience-data/bloom-tokens,static,apache-2.0,2
-6604,sandeepmajumdar/Bloom-Slim-Text-Generation,gradio,,2
-6605,versus666/ml_message_moderation,streamlit,,2
-6606,rbk1990/PersianChatRobot,gradio,apache-2.0,2
-6607,Dimitre/sentence-similarity-use,gradio,apache-2.0,2
-6608,CorvaeOboro/gen_ability_icon,gradio,cc0-1.0,2
-6609,afiz/sepia-image,gradio,mit,2
-6610,panpan06/Image2OCR,gradio,mit,2
-6611,loss4Wang/architecture_styles,gradio,apache-2.0,2
-6612,mvsrujan/Damage_Type_Classifier,gradio,apache-2.0,2
-6613,fornaxai/RNet,static,apache-2.0,2
-6614,joao-victor-campos/netflix-recommendation-model,gradio,afl-3.0,2
-6615,marioboy/doom,gradio,other,2
-6616,bigscience-data/bloom-tokenizer-multilinguality,static,apache-2.0,2
-6617,Detomo/audio-stream-translate,gradio,apache-2.0,2
-6618,eson/kplug,gradio,apache-2.0,2
-6619,TheTimeTraveller/StableDiffusion,streamlit,artistic-2.0,2
-6620,kevintang513/watch-watcher,gradio,,2
-6621,freddyaboulton/Model3D,gradio,mit,2
-6622,EuroSciPy2022/xgboost-income-prediction-with-explainability,gradio,mit,2
-6623,EuroSciPy2022/timeseries-forecasting-with-prophet,gradio,mit,2
-6624,GoldMan/img2prompt,streamlit,,2
-6625,Gurudev/youtube_timestamper,gradio,apache-2.0,2
-6626,charlesnchr/ML-SIM,gradio,gpl-3.0,2
-6627,EuroSciPy2022/clustering,gradio,bsd-3-clause,2
-6628,Norod78/WoWQuestTextGenerator,gradio,cc-by-nc-4.0,2
-6629,rainfly/test_speed,gradio,apache-2.0,2
-6630,ai-forever/mGPT-armenian,gradio,apache-2.0,2
-6631,paragon-analytics/Persuade,gradio,,2
-6632,nrjvarshney/quiz,gradio,,2
-6633,topcla/img-similarity,streamlit,,2
-6634,akpoflash/product-categories,gradio,apache-2.0,2
-6635,lbourdois/Language-tags-demo,streamlit,cc-by-4.0,2
-6636,KevinGeng/Laronix_voice_quality_checking_system_FILEIO,gradio,afl-3.0,2
-6637,Shredder/CONBERT-2,gradio,,2
-6638,DelinteNicolas/SDG,gradio,gpl-3.0,2
-6639,rrighart/color-tags,gradio,,2
-6640,gradio/text_analysis,gradio,,2
-6641,penpen/chinese-webnovel-translator,gradio,cc-by-4.0,2
-6642,roborovski/Diffusle,gradio,,2
-6643,coltonalexander/datasets,static,apache-2.0,2
-6644,doevent/VintageStyle,gradio,,2
-6645,tjburns/ask_marcus_aurelius,streamlit,mit,2
-6646,adirik/maskformer-demo,gradio,apache-2.0,2
-6647,amsterdamNLP/contrastive-pairs,gradio,,2
-6648,kkpathak91/Image_to_Text_Conversion,gradio,,2
-6649,Timjo88/toy-board-game-QA,gradio,mit,2
-6650,hashb/object-detection-yolo,gradio,mit,2
-6651,gradio/musical_instrument_identification,gradio,,2
-6652,Armandoliv/cars-parts-segmentation-resnet18,gradio,,2
-6653,ThankGod/anime-gan,gradio,,2
-6654,merve/gradio-analysis-dashboard,gradio,apache-2.0,2
-6655,Billyosoro/ESRGAN,gradio,,2
-6656,PaddlePaddle/solov2,gradio,apache-2.0,2
-6657,1nferno/Imdb_sentiment,gradio,mit,2
-6658,gradio/fake_diffusion,gradio,,2
-6659,buzzChukomi/sd_grad,gradio,,2
-6660,unilux/ASR_for_Luxembourgish,gradio,mit,2
-6661,DanielPinsk/StableDiffusion,gradio,wtfpl,2
-6662,freddyaboulton/structured-data-classification,gradio,,2
-6663,gradio/fake_gan,gradio,,2
-6664,gradio/blocks_kinematics,gradio,,2
-6665,gradio/image_classifier,gradio,,2
-6666,sneedium/PaddleOCR-ULTRAFAST,gradio,,2
-6667,datnth1709/FantasticFour-S2T-MT-demo,gradio,apache-2.0,2
-6668,coutant/yolo-person,gradio,afl-3.0,2
-6669,prismosoft/wav2lip,gradio,,2
-6670,rachith/ZeroShot_StanceDetection,gradio,mit,2
-6671,priyank-m/vit-bert-ocr,gradio,,2
-6672,multimodalart/saymyname,gradio,mit,2
-6673,fffiloni/stable-diffusion-touch-of-paint,gradio,,2
-6674,taskswithcode/semantic_search,streamlit,mit,2
-6675,vincentclaes/emoji-predictor,gradio,apache-2.0,2
-6676,ysharma/gradio_sketching_inpainting_LaMa,gradio,gpl,2
-6677,TeamHaltmannSusanaHWCEO/Fire-DiffusionV0.1Beta,streamlit,mit,2
-6678,nickmuchi/Plant-Health-Classifier,gradio,,2
-6679,taskswithcode/semantic_clustering,streamlit,mit,2
-6680,coutant/back-translation,gradio,afl-3.0,2
-6681,sohomghosh/FLUEnT,gradio,mit,2
-6682,ltgoslo/ssa-perin,gradio,,2
-6683,jeonsworld/whisper-medium-ko,gradio,,2
-6684,ashiqabdulkhader/GPT2-Poet,streamlit,,2
-6685,Imran1/Yelp-reviews,gradio,mit,2
-6686,introduck/introduck,gradio,mit,2
-6687,Msp/Invoice_DocQA,gradio,,2
-6688,AIZ2H/04-Gradio-SOTA-Seq2Seq-AutoQA,gradio,apache-2.0,2
-6689,andresgtn/bean-leaf-health-classifier,gradio,,2
-6690,manishjaiswal/01-3DModel-GradioDemo,gradio,apache-2.0,2
-6691,manishjaiswal/02-Gradio-Art-From-Text-And-Images-Demo,gradio,apache-2.0,2
-6692,Jonni/03-Streamlit-Vido_ASR-NLP,streamlit,apache-2.0,2
-6693,manishjaiswal/03-Stremlit-Video-ASR-NLP-Demo,streamlit,apache-2.0,2
-6694,leilaglewis/03-Streamlit-Video-ASR-NLP,streamlit,apache-2.0,2
-6695,texantech/03StreamlitVideoASRNLP,streamlit,apache-2.0,2
-6696,djgoettel/03-Streamlit-Video-ASR-NLP,streamlit,apache-2.0,2
-6697,djgoettel/04-Gradio-SOTA-Seq2Seq-AutoQA,gradio,apache-2.0,2
-6698,texantech/04-Gradio-SOTA-Seq2Seq-AutoQA,gradio,apache-2.0,2
-6699,manishjaiswal/04-Gradio-SOTA-Demo,gradio,apache-2.0,2
-6700,manishjaiswal/06-Streamlit-NLP-Image-Semantic-Search-Images-Demo,streamlit,apache-2.0,2
-6701,Corran/qnagenerator,gradio,,2
-6702,manishjaiswal/07-GraphViz-PyDeck-Map-AIUIUX-Demo,streamlit,apache-2.0,2
-6703,manishjaiswal/08-Search-Streamlit-Session-State-QueryParameters-Demo,streamlit,apache-2.0,2
-6704,manishjaiswal/09-Gradio-Multilingual-ImageToOCR-Demo,gradio,apache-2.0,2
-6705,freddyaboulton/gradio-subapp,gradio,mit,2
-6706,ahmedghani/whisper_asr,streamlit,,2
-6707,eliwill/ask-a-philosopher,gradio,,2
-6708,steysie/sc_whisper,gradio,openrail,2
-6709,tkurtulus/sea-animals-classification,gradio,wtfpl,2
-6710,awacke1/BlenderbotGradioChatbotSOTA,gradio,apache-2.0,2
-6711,micole66/hhhhhhhhh,gradio,,2
-6712,lcw99/test_korean_chit_chat,streamlit,,2
-6713,kornia/geometry_image_transform_with_kornia,gradio,mit,2
-6714,vonewman/my-sentiment-analyzer-app,gradio,,2
-6715,AI-Zero-to-Hero/01-H5-Play-Canvas-Sim-Physics,static,apache-2.0,2
-6716,AI-Zero-to-Hero/09-SL-Live-RealTime-Dashboard,streamlit,apache-2.0,2
-6717,open-source-metrics/transformers-checkpoints,gradio,,2
-6718,sergiomar73/nlp-gpt3-zero-shot-classification-app,gradio,unlicense,2
-6719,avatar2k/02-H5-AR-VR-IOT,static,apache-2.0,2
-6720,venz/AW-02-H5-AR-VR-IOT,static,apache-2.0,2
-6721,venz/AW-04-GR-Seq-2-Seq-QA-Auto-Gen,gradio,,2
-6722,skura/sk-06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,apache-2.0,2
-6723,SantoshKumar/06-SD-SL-AI-Image-Music-Video-UI-UX,streamlit,apache-2.0,2
-6724,venz/AW-06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,,2
-6725,tomaseo2022/mp3-a-texto,gradio,mit,2
-6726,itmorn/face_keypoint,gradio,other,2
-6727,lcw99/ko-dialoGPT-Korean-Chit-Chat,gradio,apache-2.0,2
-6728,damilojohn/text-descrambler,gradio,mit,2
-6729,osanseviero/riiaa,gradio,,2
-6730,tumuyan/demucs,gradio,,2
-6731,evawade17/Skin_cancer_detecter,gradio,apache-2.0,2
-6732,kivantium/anime-pose-estimator,gradio,,2
-6733,innocent-charles/Swahili-Question-Answer-App,gradio,cc-by-4.0,2
-6734,ambreshrc/Docx_File_Translator,streamlit,wtfpl,2
-6735,fsdl2022emotion/meme-manipulation-gradio-space,gradio,mit,2
-6736,samusander/Create.Ai,gradio,other,2
-6737,AFCMEgypt/AFCM_iGEM_LFA,gradio,gpl-3.0,2
-6738,Joabutt/Colourizer,gradio,mit,2
-6739,Tanapol/object_detection,streamlit,cc-by-nc-4.0,2
-6740,ajayhk/JPEGArtifactRemover,gradio,apache-2.0,2
-6741,egan/clothing-attribute-recognition,gradio,mit,2
-6742,pratikskarnik/Indian-Food-Recognition,gradio,apache-2.0,2
-6743,FelixLuoX/stable_diffusion_test,gradio,,2
-6744,TusharNautiyal/Music-Genre-Classification,streamlit,mit,2
-6745,Callimethee/Imagine-CR,gradio,mit,2
-6746,shripadbhat/Clinical_Note_Question_Answering,gradio,,2
-6747,Ivanrs/canny-edge-detector,gradio,mit,2
-6748,marmg/zshot,streamlit,mit,2
-6749,tomaseo2022/Text-a-Voz,gradio,,2
-6750,datasciencedojo/Describe-Dataset,gradio,,2
-6751,abdellatif/pokemon-detector,gradio,mit,2
-6752,eskayML/cat-and-dog-classifier,streamlit,,2
-6753,shainis/book_reviews,gradio,apache-2.0,2
-6754,AFCMEgypt/WCB,gradio,afl-3.0,2
-6755,sourav11295/Blockchain,gradio,afl-3.0,2
-6756,csanjay/DR_Predictor,gradio,apache-2.0,2
-6757,r1391819/financial-researcher,streamlit,apache-2.0,2
-6758,for876543/plant-id-3,gradio,,2
-6759,binxu/Ziyue-GPT,gradio,,2
-6760,gradio/stt_or_tts,gradio,,2
-6761,gradio/video_component,gradio,,2
-6762,ClaudioX/mg_sd_esp,gradio,wtfpl,2
-6763,17TheWord/RealESRGAN,gradio,,2
-6764,williambr/NLPSentenceSimilarityHeatmap,streamlit,mit,2
-6765,williambr/CSVAnalyzer,streamlit,mit,2
-6766,cxeep/whisper-webui,gradio,apache-2.0,2
-6767,razfar/anything-counter,gradio,gpl-3.0,2
-6768,nikhedward/ask_me_anything,gradio,,2
-6769,binxu/Ancient-Chinese-Add-Punctuation,gradio,,2
-6770,Andy1621/IAT_enhancement,gradio,mit,2
-6771,lkw99/K_AnimeGANv2,gradio,,2
-6772,Colbe/basketball,gradio,apache-2.0,2
-6773,evawade17/acne_detector,gradio,apache-2.0,2
-6774,hshetty/movie-poster-generator,gradio,cc-by-nc-2.0,2
-6775,maisarah1109/autism_screening_on_adults,streamlit,bigscience-openrail-m,2
-6776,micole66/bloomz,gradio,,2
-6777,determined-ai/detsd_demo,gradio,,2
-6778,gbharti/fastai-model-deploy,gradio,,2
-6779,kabita-choudhary/get_text_from_video,gradio,,2
-6780,HemanthSai7/IntelligentQuestionGenerator,streamlit,,2
-6781,awacke1/AW-01ST-CSV-Dataset-Analyzer,streamlit,mit,2
-6782,cadige/05GR-Image-To-Multilingual-OCR,gradio,mit,2
-6783,jthteo/hokkientranslator,gradio,cc-by-nc-4.0,2
-6784,indichealth/indic-health-demo,streamlit,,2
-6785,infinfin/style-transfer,gradio,mit,2
-6786,jaybeeja/age_predictor,gradio,apache-2.0,2
-6787,tomaseo2022/Eliminar-Fondo-Imagen,gradio,,2
-6788,sswam/photo-checker,gradio,mit,2
-6789,gradio/dashboard,gradio,,2
-6790,ierhon/codegen,gradio,,2
-6791,TusharNautiyal/BTC-Prediction,streamlit,mit,2
-6792,gradio/reverse_audio_main,gradio,,2
-6793,souljoy/chinese_lyric_generation,gradio,,2
-6794,breezedeus/antiOCR,streamlit,mit,2
-6795,awacke1/Biomed-NER-SNOMED-LOINC-CQM,gradio,apache-2.0,2
-6796,thapasushil/Multiverse,gradio,,2
-6797,nedtheminx/nllb-translation,gradio,openrail,2
-6798,airus/ss,gradio,apache-2.0,2
-6799,Akshay-Vs/GPT-Based-Generator,streamlit,mit,2
-6800,xszqxszq/sovits-svc-mix,gradio,,2
-6801,Lwhieldon/Fall22_UMBC606_AbstractSummarization,gradio,mit,2
-6802,joaofranca13/CESAR-NN-Human-Expression-HF,gradio,,2
-6803,KrishnaBakshi1/YoutubeVideoSummarizer,gradio,,2
-6804,Ramos-Ramos/emb-gam-dino,gradio,,2
-6805,datasciencedojo/Transcription,gradio,,2
-6806,galopyz/Alien_vs_Ghost,gradio,apache-2.0,2
-6807,eradhea/spanish_chat,gradio,gpl-2.0,2
-6808,elonmuskceo/shiny-orbit-simulation,docker,,2
-6809,AllAideas/SegmentacionVideo,gradio,mit,2
-6810,awacke1/Z-3-ChatbotBlenderBot-GR,gradio,,2
-6811,jinhybr/OCR-Receipt-Donut-Demo,gradio,mit,2
-6812,Soumen/transform_image,streamlit,mit,2
-6813,maisarah1109/stock-prediction,streamlit,,2
-6814,Soumen/Text-Summarization-and-NLP-tasks,streamlit,bsd,2
-6815,hzrr/dal_audio_inference,gradio,,2
-6816,Arnaudding001/OpenAI_whisperLive,gradio,mit,2
-6817,jinhybr/OCR-Invoice-LayoutLMv3,gradio,,2
-6818,spondej/stabel-diffusion-z-1.5,static,other,2
-6819,brooksjordan/galadriel,gradio,,2
-6820,mrfakename/neon-tts-plugin-coqui,gradio,other,2
-6821,ShapeNet/shapenet-explorer,gradio,mit,2
-6822,BairaS/Tabular_ML,streamlit,,2
-6823,knkarthick/Meeting-Demo,gradio,apache-2.0,2
-6824,Junlinh/memorability_prediction,gradio,mit,2
-6825,johngoad/prompt-extend,gradio,apache-2.0,2
-6826,barretto/sd4fun,gradio,cc-by-nc-nd-4.0,2
-6827,pmgautam/english-to-nepali-translation,gradio,apache-2.0,2
-6828,HenryNavarre/CarlosDrummondAndradeGenerator,gradio,,2
-6829,ryu-akm/PetVision_37,gradio,mit,2
-6830,lvwerra/in-the-stack-gr,gradio,,2
-6831,profoz/index_demo,streamlit,,2
-6832,RamAnanth1/Transcript_PDF,gradio,,2
-6833,JackerKun/Text-to-Image-search-using-CLIP,gradio,,2
-6834,AIZerotoHero-Health4All/01-Gradio-Speech2Text2Speech-AIPipeline,gradio,mit,2
-6835,tomaseo2022/Whisper-Youtube,gradio,,2
-6836,alecmueller/01-Speech2Text2Speech-GR,gradio,mit,2
-6837,CarperAI/pile-v2-eda,streamlit,,2
-6838,Sup3r/img-to-music,gradio,,2
-6839,jeycov/IsaTronDeteccion,gradio,,2
-6840,akhaliq/redshift-diffusion,gradio,,2
-6841,drift-ai/emoji-tagging,gradio,apache-2.0,2
-6842,drift-ai/emoji-predictor,gradio,apache-2.0,2
-6843,kittyposter12/Dungeons-and-Diffusion,gradio,,2
-6844,Karwasze/Whisper-ASR-youtube-subtitles,gradio,apache-2.0,2
-6845,sabre-code/Flower-Classification,gradio,,2
-6846,tvt/Real-CUGAN,gradio,gpl-3.0,2
-6847,shiwan10000/CodeFormer,gradio,apache-2.0,2
-6848,cmudrc/microstructure-strain,gradio,mit,2
-6849,MEKHANE/Deforum,gradio,creativeml-openrail-m,2
-6850,farkmu45/instagram-clothes-psychology-streamlit,streamlit,,2
-6851,xfh/min-stable-diffusion-web,gradio,apache-2.0,2
-6852,Zeng1/Predict_furniture_weight_by_apparent_features,gradio,,2
-6853,ugursahin/MovieSuggest,gradio,apache-2.0,2
-6854,robin0307/MMOCR,gradio,apache-2.0,2
-6855,sasha/AI_Carbon,streamlit,cc-by-nc-4.0,2
-6856,BuBBLe1q/anything-v3.0,gradio,,2
-6857,victor/dreambooth-training,gradio,mit,2
-6858,daayros/anything-v3.0,gradio,,2
-6859,weidacn/deepdanbooru,gradio,mit,2
-6860,akhaliq/anything-v3.0-1,gradio,,2
-6861,amirhnikzad/MLSG_01,gradio,,2
-6862,fightglory/YoloV4-Webcam,gradio,wtfpl,2
-6863,bumsika/Redshift-Diffusion-Demo,gradio,creativeml-openrail-m,2
-6864,Rowanchav/anything-v3.0,gradio,,2
-6865,Lwight/Ghibli-Diffusion,gradio,,2
-6866,greendra/ultsd,gradio,other,2
-6867,israelgonzalezb/stable-diffusion,static,mit,2
-6868,fadhilsadeli/Muhammad_Fadhil_Sadeli_HCK002,streamlit,,2
-6869,bobsingh149/chestxray-classification-streamlit-demo,streamlit,afl-3.0,2
-6870,os1187/docquery,gradio,,2
-6871,nadiaoktiarsy/deployment,streamlit,,2
-6872,sleepyml/colorizer,gradio,,2
-6873,akhaliq/stable-diffusion-2,gradio,,2
-6874,pierretassel/JobShopCPRL,gradio,mit,2
-6875,akhaliq/vox2,gradio,,2
-6876,Rain-2008730/TXT_GENERATOR_69420,gradio,,2
-6877,Ipkc/text_generator,gradio,,2
-6878,Tinki/text_generator,gradio,,2
-6879,Matthew567/text_generator,gradio,,2
-6880,tenslai/mianhuatang,gradio,gpl-3.0,2
-6881,charly/text-to-speech,gradio,,2
-6882,jerpint/babelfish,gradio,mit,2
-6883,akhaliq/knollingcase,gradio,,2
-6884,ORI-Muchim/MarinTTS,gradio,,2
-6885,mbarnig/Mol_mer_e_DALL-E2_Bild,gradio,cc-by-nc-sa-4.0,2
-6886,eskayML/object_detection_system,gradio,,2
-6887,sachit-menon/classification_via_description,gradio,,2
-6888,snoop2head/privacy-filtering-ner,streamlit,mit,2
-6889,eskayML/IMAGE_CAPTIONING,gradio,,2
-6890,MirageML/lowpoly-town,gradio,,2
-6891,MirageML/lowpoly-landscape,gradio,,2
-6892,MirageML/lowpoly-game-building,gradio,,2
-6893,calebaryee321/Whisper2Image,gradio,,2
-6894,nightfury/Neural_Style_Transfer,gradio,mit,2
-6895,vladocar/3dfood,gradio,,2
-6896,os1187/pii-anonymizer,streamlit,mit,2
-6897,Hellisotherpeople/DebateKG,streamlit,mit,2
-6898,getrajeev03/text2sql,gradio,,2
-6899,Xhaheen/GPT-JT-sallu,streamlit,,2
-6900,fjenett/GPT-JT,gradio,,2
-6901,knkarthick/Meeting-Use-Cases,gradio,apache-2.0,2
-6902,tomsoderlund/swedish-entity-recognition,gradio,openrail,2
-6903,yulet1de/StableDiffusion2,gradio,openrail,2
-6904,akhaliq/AltDiffusion-m9,gradio,,2
-6905,Pfs2021Funny/Text-to-Music-ExtendedVersion,gradio,unknown,2
-6906,svjack/Question-Generator,gradio,,2
-6907,amankishore/sjc,gradio,creativeml-openrail-m,2
-6908,awacke1/AICodeFly,gradio,,2
-6909,BLACKHOST/timer,streamlit,,2
-6910,BLACKHOST/Date,streamlit,,2
-6911,akdeniz27/zero-shot-text-classification-with-multilingual-t5,streamlit,mit,2
-6912,vutuka/nllb-vutuka-translation,gradio,,2
-6913,Samood/whos_dat_doggo,gradio,unlicense,2
-6914,NicolasVana/image-captioning,streamlit,,2
-6915,cmudrc/microstructure-data-explorer,gradio,mit,2
-6916,akhaliq/gigafractal2-diffusion,gradio,,2
-6917,AshtonIsNotHere/xlmr-longformer_comparison,gradio,apache-2.0,2
-6918,shripadbhat/whisper-demo,gradio,,2
-6919,scikit-learn/pickle-to-skops,gradio,bsd-3-clause,2
-6920,trysem/Vector-diFusion,static,,2
-6921,tillyu/Emojimotion,gradio,other,2
-6922,alex42t/EssayChecker,gradio,,2
-6923,mrfarazi/hairnet2-online,gradio,,2
-6924,AlexMo/audio_summarizer,gradio,apache-2.0,2
-6925,AndySAnker/DeepStruc,streamlit,apache-2.0,2
-6926,akhaliq/papercutcraft-v1,gradio,,2
-6927,Patt/demo_eng_ara_translate,gradio,,2
-6928,segestic/COVIDPrediction,streamlit,,2
-6929,Ali-Maq/Calorie_Calculator,gradio,mit,2
-6930,pragnakalp/bert_based_ner,gradio,,2
-6931,pip64/generator-oskov,gradio,,2
-6932,shivkumarganesh/whisper-demo-hi,gradio,,2
-6933,antreyes/stabilityai-stable-diffusion-2,gradio,,2
-6934,4eJIoBek/Stable_Diffusion_1.4_openvino,streamlit,apache-2.0,2
-6935,freddyaboulton/openai-whisper-large,gradio,mit,2
-6936,VaneM/Stable-Difussion-basic-app,gradio,unknown,2
-6937,profnecrya/T9_But_Bad,gradio,other,2
-6938,YuhangDeng123/Whisper-offline,gradio,apache-2.0,2
-6939,liorda/chatGPT,gradio,,2
-6940,razielpanic/CompVis-stable-diffusion-v1-4,gradio,,2
-6941,zhukovsky/Awais-Audio_Source_Separation,gradio,,2
-6942,patsypatsy/gyijhmjm,gradio,,2
-6943,osanseviero/livebook,docker,,2
-6944,Datasculptor/DescriptionGPT,gradio,,2
-6945,PushkarA07/image-colorizer,streamlit,openrail,2
-6946,pierreguillou/whisper-demo-french,gradio,,2
-6947,Xhaheen/whisper-to-chatGPT,gradio,apache-2.0,2
-6948,anaclaudia13ct/insect_detection,gradio,,2
-6949,daveward/smaragd-hentaidiffusion,gradio,,2
-6950,Malifex/flax-anything-v3.0,gradio,,2
-6951,ygangang/VToonify,gradio,other,2
-6952,vuu10/EnzRank,streamlit,,2
-6953,hetorol845/MiDaS,gradio,,2
-6954,carlosalonso/Detection-video,gradio,,2
-6955,kokuma/img-to-music,gradio,,2
-6956,nbroad/openai-detector-base,gradio,apache-2.0,2
-6957,IHaBiS/wd-v1-4-tags,gradio,,2
-6958,HIT-TMG/dialogue-bart-large-chinese-DuSinc,gradio,apache-2.0,2
-6959,pragnakalp/biobert_based_ner,gradio,,2
-6960,tarteel-ai/demo-whisper-tiny-ar-quran,gradio,,2
-6961,Heckeroo/Cyberpunk-Anime-Diffusion,gradio,,2
-6962,Dogge/bigscience-bloomz-7b1,gradio,bigscience-bloom-rail-1.0,2
-6963,JimmyTarbender/GPT2HistoryEvents,streamlit,,2
-6964,neuralmagic/nlp-text-classification,gradio,,2
-6965,awacke1/DatasetAnalyzer1215,gradio,,2
-6966,bobathetheft/webui,gradio,,2
-6967,SDbiaseval/find-my-butterfly,gradio,apache-2.0,2
-6968,harish3110/document-parsing-demo,gradio,,2
-6969,userzyzz/riffusion-riffusion-model-v1,gradio,,2
-6970,ThirdEyeData/ChangePointDetection,streamlit,,2
-6971,sugarbee/stanford-crfm-pubmedgpt,gradio,,2
-6972,Xhaheen/Children_of_heaven,gradio,openrail,2
-6973,Lelliam/text_generator1,gradio,,2
-6974,Wootang01/text_generator_gpt3,gradio,,2
-6975,society-ethics/find-my-sea-slug,gradio,apache-2.0,2
-6976,esencb/web,gradio,,2
-6977,ameya123ch/FakeNewsDetector,streamlit,,2
-6978,pat229988/NLP-Audio-summarizer,streamlit,,2
-6979,ybelkada/blip-api,gradio,,2
-6980,AriusXi/CodeGenerator,gradio,,2
-6981,pragnakalp/Text_Summarization,gradio,,2
-6982,alkzar90/rock-glacier-segmentation,gradio,apache-2.0,2
-6983,EyeSeeThru/openjourney,gradio,,2
-6984,Danielito/webui,gradio,,2
-6985,ThirdEyeData/image_bluriness_prediction,streamlit,,2
-6986,AkashKhamkar/Job_Search_Engine,streamlit,apache-2.0,2
-6987,Hisjhsshh/dreamlike-art-dreamlike-diffusion-1.0,gradio,,2
-6988,zvam/hakurei-waifu-diffusion,gradio,,2
-6989,facebook/Speech_Matrix_Demo_on_GPU,gradio,cc-by-4.0,2
-6990,MountLiteraSwd/mount_ai_school,gradio,,2
-6991,NickOrion21/stabilityai-stable-diffusion-2-1,gradio,,2
-6992,moscartong/LookingGlassRGBD,gradio,mit,2
-6993,ramdane/search_jurist,gradio,,2
-6994,tarteel-ai/whisper-base-demo-quran,gradio,,2
-6995,hrishikeshagi/ImagetoText,streamlit,,2
-6996,BasToTheMax/TTS,docker,other,2
-6997,Ariharasudhan/XAI_Class-Activation-Maps,gradio,,2
-6998,cahya/websocket,docker,cc,2
-6999,PBJ/Toxic-Comment-Classification,streamlit,apache-2.0,2
-7000,AiiluoChen/webui,gradio,,2
-7001,mrsteyk/mrsteyk-openchatgpt-neox-125m,gradio,agpl-3.0,2
-7002,johnslegers/custom-diffusion,gradio,,2
-7003,ThirdEyeData/Occluded-House-Prediction,gradio,,2
-7004,bigcode/santacoder-endpoint,gradio,,2
-7005,ybelkada/cocoevaluate,gradio,,2
-7006,tommy24/chatGPT2,gradio,,2
-7007,mrciolino/ppt_owl_vit,streamlit,,2
-7008,Rubens/recruiting,gradio,,2
-7009,S0h9l/Coherent_Speech,gradio,,2
-7010,Fuyuka29/Anime_Background_Remover,gradio,apache-2.0,2
-7011,adpro/dpt-depth06,gradio,,2
-7012,IntelligenzaArtificiale/code-generation,streamlit,apache-2.0,2
-7013,syy404/whisper-webui,gradio,apache-2.0,2
-7014,russellc/BLIP,gradio,bsd-3-clause,2
-7015,RoAr777/fer,gradio,,2
-7016,xelu3banh/AnimeGANv3_01,gradio,,2
-7017,Eduger/webui,gradio,,2
-7018,Pudding/Anime-or-Real,gradio,apache-2.0,2
-7019,GodParticle69/minor_demo,gradio,apache-2.0,2
-7020,rifkat/Uz-NER,gradio,,2
-7021,k2s0/prayer-generator,gradio,cc,2
-7022,jgentes/demucs-gpu,gradio,,2
-7023,nambiar4/DR-BERT,gradio,afl-3.0,2
-7024,shubham1302/movie_recoomender_system,streamlit,openrail,2
-7025,MLearningAI/AIart_sources_of_inspiration,gradio,,2
-7026,pushkarraj/opt355m_paraphraser,gradio,,2
-7027,SmartPy/ScisummNet,gradio,apache-2.0,2
-7028,alexalmighty/dreamlike-art-dreamlike-diffusion-1.0,gradio,cc-by-2.0,2
-7029,marianna13/search-inside-a-video,gradio,apache-2.0,2
-7030,natvill/stable-diffusion-webui,gradio,openrail,2
-7031,rifkat/UzGPT-uz,gradio,,2
-7032,keremberke/football-object-detection,gradio,,2
-7033,baffledexpert/roberta-base-openai-detector1,gradio,,2
-7034,keremberke/csgo-object-detection,gradio,,2
-7035,sham-ml/crack_detection_classifier,gradio,apache-2.0,2
-7036,om-app/chatGPT,gradio,,2
-7037,keremberke/construction-safety-object-detection,gradio,,2
-7038,imperialwool/funapi,docker,,2
-7039,keremberke/nfl-object-detection,gradio,,2
-7040,awacke1/DockerImageRecognitionToText,docker,,2
-7041,harshasurampudi/car_or_truck,gradio,apache-2.0,2
-7042,cjayic/soft-vc-widowmaker,gradio,,2
-7043,daibs/bananafreshnessclass,gradio,mit,2
-7044,vinayakdev/qa-generator,streamlit,mit,2
-7045,Shrikrishna/Which_Bollywood_Celebrity_Are_You,streamlit,unlicense,2
-7046,VISION23/V23ChatBot,gradio,other,2
-7047,nvshubhsharma/wav2lip_demo_test1,gradio,,2
-7048,keremberke/forklift-object-detection,gradio,,2
-7049,Rmpmartinspro2/Waifu-Diffusers,gradio,,2
-7050,Thabet/color-guided-wikiart-diffusion,gradio,mit,2
-7051,ibvhim/Gradio-Apps,gradio,,2
-7052,mrfshk/paint-diffusion,gradio,,2
-7053,NikolaiB/Animal_Classifier,gradio,apache-2.0,2
-7054,mrrandom123/Book_recommendation,gradio,,2
-7055,ai4bharat/IndicNER,gradio,mit,2
-7056,jlazoff/biblical-summarizer,gradio,apache-2.0,2
-7057,masoodkhanpatel/twitter-trends-qatar,gradio,,2
-7058,lion-ai/CBC-covid,streamlit,other,2
-7059,Daniel947/stabilityai-stable-diffusion-2-1,gradio,,2
-7060,CC26011988/Opposition_Analysis,gradio,cc-by-4.0,2
-7061,johnslegers/epic-diffusion-inference,gradio,,2
-7062,keremberke/smoke-object-detection,gradio,,2
-7063,ThirdEyeData/TagDiciphering,gradio,,2
-7064,keremberke/aerial-sheep-object-detection,gradio,,2
-7065,sarinam/speaker-anonymization-gan,gradio,gpl-3.0,2
-7066,nightfury/whisperAI,gradio,apache-2.0,2
-7067,pianoweb/youtube-whisperer-pianoweb,gradio,,2
-7068,QINGFNEG/White-box-Cartoonization,gradio,apache-2.0,2
-7069,Eyeszik/webui,gradio,,2
-7070,creative-ai/creative-demo,gradio,,2
-7071,Kangarroar/streamlit-docker-example,docker,,2
-7072,lafi23333/aikomori,gradio,,2
-7073,YuraM/Stable-Diffusion-Protogen-webui,gradio,,2
-7074,rituthombre/QNim,gradio,,2
-7075,jlmarrugom/voice_fixer_app,streamlit,apache-2.0,2
-7076,MINAMONI/anime-remove-background,gradio,apache-2.0,2
-7077,jroust/darkstorm2150-Protogen_v2.2_Official_Release,gradio,openrail,2
-7078,ajcdp/Image-Segmentation-Gradio,gradio,apache-2.0,2
-7079,juanpy/videoresumen,gradio,,2
-7080,breadlicker45/Muse-gen,streamlit,,2
-7081,ussrcccp/Real-CUGAN,gradio,gpl-3.0,2
-7082,GT4SD/paccmann_gp,gradio,,2
-7083,hf-hackathon-2023-01/Spotify,gradio,,2
-7084,group2test/stable-diffusion-v1-5,gradio,mit,2
-7085,cynika/NFT_avatar,gradio,cc-by-3.0,2
-7086,GT4SD/polymer_blocks,gradio,,2
-7087,Nickhilearla135095/Google-Drive,gradio,afl-3.0,2
-7088,Mackiemetal/dreamlike-photoreal-2.0,gradio,,2
-7089,yaklion/youtube,gradio,,2
-7090,remzicam/XAI_privacy_intent,streamlit,other,2
-7091,ShibaDeveloper/Text-To-Image,gradio,unknown,2
-7092,tomaseo2022/Youtube-Mp3,gradio,,2
-7093,TCheruy/SRGAN,gradio,apache-2.0,2
-7094,peteralexandercharles/runwayml-stable-diffusion-v1-5,gradio,,2
-7095,awacke1/NLPContextQATransformersRobertaBaseSquad2,gradio,,2
-7096,Voicelab/vlT5-keywords-generation,streamlit,,2
-7097,kavi1025/Youtube-Whisperer,gradio,,2
-7098,JUNGU/yolov8,gradio,gpl-3.0,2
-7099,gpt3/travel,streamlit,,2
-7100,qisan/Depressed_sentimental_analysis,gradio,apache-2.0,2
-7101,robosapiens/color-range-classifier,gradio,,2
-7102,hakanwkwjbwbs/Linaqruf-anything-v3-better-vae,gradio,,2
-7103,TheFellow42/webui,gradio,,2
-7104,Lewdgirl89/Waifu-AI-WebUI,gradio,openrail,2
-7105,PhenixNova/Audio-VideoTranslator,gradio,,2
-7106,zjrwtx/xiaoyi_drawing,streamlit,openrail,2
-7107,amsterdamNLP/value-zeroing,gradio,,2
-7108,mcbrs1/AskQ,gradio,afl-3.0,2
-7109,ClassCat/wide-resnet-cifar10-classification,gradio,,2
-7110,aliabid94/crossword,gradio,mit,2
-7111,EDGAhab/Paimon-Talking,gradio,,2
-7112,FKBaffour/Gradio_App_for_Sentiment_Analysis,gradio,,2
-7113,Humbert/mmcls-retriever,streamlit,,2
-7114,bstrai/classification_report,gradio,apache-2.0,2
-7115,TheWolf/DreamlikeArt-Diffusion-1.0,gradio,,2
-7116,FloydianSound/Redline_Diffusion_V1-5,gradio,,2
-7117,ClassCat/ViT-ImageNet-Classification,gradio,,2
-7118,starlit7/KorPoliticsTTS,gradio,mit,2
-7119,Yilin98/Stock_Prediction,streamlit,,2
-7120,teamnassim/Room-Occupancy-App,streamlit,mit,2
-7121,Sygil/INE-dataset-explorer,docker,openrail,2
-7122,joonkim/bert-political-sentiment-analysis,gradio,,2
-7123,Kamtera/persian-tts-mimic3,gradio,openrail,2
-7124,kadirnar/yolor,gradio,gpl-3.0,2
-7125,rajistics/shiny-kmeans,docker,apache-2.0,2
-7126,ExperimentalAI/epic-diffusion,gradio,,2
-7127,Fr33d0m21/Remodel_Dreamer,gradio,mit,2
-7128,nyvrx/VoiceChat,gradio,unknown,2
-7129,Munderstand/sd-img-variations,gradio,,2
-7130,Munderstand/whisper-to-chatGPT,gradio,apache-2.0,2
-7131,Mileena/anything-v3.0,gradio,,2
-7132,eeyorestoned/midjourney-v5,gradio,openrail,2
-7133,yukie/yukie-sovits3,gradio,openrail,2
-7134,innnky/visinger2-nomidi,gradio,,2
-7135,ItsJayQz/BreathOfTheWild_Diffusion,gradio,,2
-7136,williamcfrancis/Deep-Blind-Motion-Deblurring,gradio,apache-2.0,2
-7137,Jimmie/snake-species-identification,gradio,mit,2
-7138,xiaomifan/anime-remove-background,gradio,apache-2.0,2
-7139,society-ethics/ethical-charters,gradio,,2
-7140,giustiniano/real_estate_classifier,gradio,apache-2.0,2
-7141,CarlosMF/AI-ORUS-License-v1.0.0,streamlit,cc,2
-7142,Alven/background-remover,gradio,,2
-7143,JosePezantes/Violencia-politica-genero,streamlit,,2
-7144,nnaii/White-box-Cartoonization,gradio,apache-2.0,2
-7145,eeyorestoned/maximum_diffusion,gradio,,2
-7146,yuichi/pdf-ocr,gradio,gpl-3.0,2
-7147,trysem/coloria,gradio,bsd-2-clause,2
-7148,trysem/visua,gradio,mit,2
-7149,huang4414/White-box-Cartoonization,gradio,apache-2.0,2
-7150,krrishD/Langchain_Code_QA_Bot,gradio,,2
-7151,trysem/parrot-paraphraser,gradio,apache-2.0,2
-7152,Zkins/Timmahw-SD2.1_Pokemon3D,gradio,,2
-7153,Say123/Promting-Generative-Models,gradio,apache-2.0,2
-7154,manish-pro/dL_avengers,gradio,apache-2.0,2
-7155,awacke1/Try.Playing.Learning.Sharing.On.This,static,,2
-7156,AEUPH/SENTIENCE_PROGRAMMING_LANGUAGE,static,cc,2
-7157,BilalSardar/Like-Chatgpt-clone,gradio,,2
-7158,andrewgleave/tokbot,gradio,,2
-7159,yugan/summarize,gradio,mit,2
-7160,saurav-sabu/QR-Code-Generator,streamlit,,2
-7161,tanav2202/captcha_solver,gradio,,2
-7162,ThirdEyeData/Customer-Complaints-Categorization,gradio,,2
-7163,thejagstudio/picxai,docker,cc0-1.0,2
-7164,NeuroModern/MidJourney-SD-finetune,gradio,,2
-7165,Duskfallcrew/prompthero-openjourney,gradio,,2
-7166,Duskfallcrew/DreamlikeArt-PhotoReal-2.0,gradio,,2
-7167,deven367/yt-video-annotator-hf,streamlit,,2
-7168,mdj1412/movie_review_score_discriminator,gradio,,2
-7169,Rbrq/DeticChatGPT,gradio,,2
-7170,akashAD/yolov5-classify,gradio,apache-2.0,2
-7171,Asahi402/Real-CUGAN,gradio,gpl-3.0,2
-7172,akhaliq/China-Chic-illustration,gradio,,2
-7173,DataScienceGuild/WikipediaAIDataScience,gradio,mit,2
-7174,curiousily/layoutlmv3-financial-document-classification,streamlit,,2
-7175,Duskfallcrew/lambdalabs-sd-pokemon-diffusers,gradio,openrail,2
-7176,Mixing/anime-remove-background,gradio,apache-2.0,2
-7177,szk1ck/word_cloud,gradio,mit,2
-7178,awacke1/NSFW_text_classifier,gradio,mit,2
-7179,awacke1/google-flan-t5-base,gradio,,2
-7180,awacke1/google-flan-t5-xl,gradio,,2
-7181,awacke1/PubMed-Parrot-Paraphraser-on-T5,gradio,,2
-7182,ZilliaxOfficial/nyaru-svc-3.0,gradio,,2
-7183,mskov/whisper_fileStream,gradio,,2
-7184,geloku/ai-academy,gradio,apache-2.0,2
-7185,SpringAI/AiGenImg2Txt,gradio,creativeml-openrail-m,2
-7186,Daniton/midjourney-singular,gradio,,2
-7187,kohrisatou-infinity/KIP_01_beta,gradio,cc-by-3.0,2
-7188,thoucentric/Shelf_Objects_Detection_Yolov7_Pytorch,gradio,,2
-7189,adirik/efficientformer,gradio,apache-2.0,2
-7190,pngwn/music-visualizer,gradio,,2
-7191,blogclif/7Prompts,gradio,,2
-7192,DataScienceGuild/AI-DataViz-Graphviz,streamlit,mit,2
-7193,DataScienceGuild/DataViz-Mermaid,static,mit,2
-7194,DataScienceGuild/DataViz-Plotly,streamlit,mit,2
-7195,mariashay/DataViz-Graph,streamlit,mit,2
-7196,Ppranathi/chatty-chat,gradio,,2
-7197,Froleptan/lambdalabs-dreambooth-avatar,gradio,,2
-7198,Frederick/Clause_Segmentation_and_Classification,gradio,apache-2.0,2
-7199,kadirnar/classifyhub,gradio,gpl-3.0,2
-7200,WAT-ai-AA/stable-diffused-adversarial-attacks,gradio,,2
-7201,akhaliq/CarperAI-diff-codegen-350m-v2,gradio,,2
-7202,nanom/to_passive_voice,gradio,mit,2
-7203,alsrbdni/remove-from-photo-background-removal,gradio,apache-2.0,2
-7204,LiuZiyi/1-image-img2txt-easyocr,streamlit,,2
-7205,dhanushreddy29/comparing-captioning-models,gradio,,2
-7206,hanjp/White-box-Cartoonization,gradio,apache-2.0,2
-7207,awacke1/Google-Maps-Web-Service-Py,gradio,,2
-7208,awacke1/Gradio-Maps-Latitude-Longitude,gradio,mit,2
-7209,Amr453/Transcription,gradio,,2
-7210,WhisperAI/WhisperAIWeb,streamlit,openrail,2
-7211,LangChainHub-Prompts/langchain_submission,gradio,,2
-7212,joacoetruu/telegram-bot-paraphraser,gradio,,2
-7213,jannisborn/paccmann,gradio,,2
-7214,123aa/pastel-mix,gradio,,2
-7215,Datatrooper/boston_housing,gradio,,2
-7216,asalhi85/DemoSmartathon,gradio,apache-2.0,2
-7217,akshatsanghvi/spam-email-detection,gradio,artistic-2.0,2
-7218,nateraw/run-script-in-background,docker,,2
-7219,neuralmagic/image-classification,gradio,,2
-7220,Stoa/budget_gpt,gradio,other,2
-7221,UmairMirza/Face-Attendance,gradio,,2
-7222,dawood/audioldm-text-to-audio-generation,gradio,bigscience-openrail-m,2
-7223,keneonyeachonam/Biomed-NER-AI-NLP-CT-Demo1,gradio,,2
-7224,awacke1/runwayml-stable-diffusion-v1-5,gradio,,2
-7225,rdp-studio/bili-nft-avatar,gradio,cc-by-sa-4.0,2
-7226,ismot/hel10,gradio,mit,2
-7227,active-learning/webhook,docker,,2
-7228,Lookimi/Interface,gradio,bigscience-openrail-m,2
-7229,devashish07/food_vision_mini,gradio,,2
-7230,suvash/usk-coffee-convnext-nano,gradio,,2
-7231,BreadBytes1/SB-Dashboard,streamlit,gpl,2
-7232,haoqi7/images,gradio,,2
-7233,joshipunitram/crowd-counting-p2p,gradio,,2
-7234,Marian013/PPCTA-FRONTEND,gradio,,2
-7235,awacke1/DockerGoFlanT5,docker,mit,2
-7236,jesherjoshua/faceai,gradio,,2
-7237,satozen/openai-whisper-large-v2,gradio,,2
-7238,mrm8488/santacoder-dockerfiles-completion,gradio,,2
-7239,GiladtheFixer/image-variations,gradio,mit,2
-7240,felixz/Flan-T5-experiment,gradio,apache-2.0,2
-7241,ThirdEyeData/Semantic-Search,streamlit,,2
-7242,csuer/nsfw-classification,gradio,,2
-7243,yonikremer/grouped-sampling-demo,streamlit,,2
-7244,Joyeux/andite-anything-v4.0,gradio,,2
-7245,multimodalart/TAV-poli-2,docker,mit,2
-7246,LightChen2333/OpenSLU,gradio,mit,2
-7247,shnippi/Email_Generai-tor,gradio,other,2
-7248,UserXTheUnknown/stablediffusion-infinity,gradio,apache-2.0,2
-7249,lhkhiem28/A-recognition-system,gradio,,2
-7250,Noobian/DuaGenerator,gradio,mit,2
-7251,demo-org/doccano,docker,mit,2
-7252,awacke1/microsoft-BioGPT-Large-PubMedQA,gradio,,2
-7253,kaisugi/academic-paraphraser,streamlit,,2
-7254,Reggie/utilities2,streamlit,openrail,2
-7255,victor/ChatUI,static,,2
-7256,rasyidf/coffee-grader,gradio,mit,2
-7257,merve/deprem-ocr-migrate-ner,gradio,,2
-7258,imseldrith/ChatGPT-Detection,gradio,gpl,2
-7259,deprem-ml/deprem-ocr-test,gradio,,2
-7260,devoworm-group/membrane_segmentation,streamlit,,2
-7261,AyushP/PolicyCompareBot,streamlit,,2
-7262,devoworm-group/Lineage_Population,streamlit,,2
-7263,cloud-sean/AOAI-Form-Recognizer,gradio,,2
-7264,ThirdEyeData/Object_Detection,streamlit,,2
-7265,Fazzie/Pokemon-GAI,gradio,,2
-7266,Jasonyoyo/CodeFormer,gradio,apache-2.0,2
-7267,awacke1/PandasDataframeAutoFilterStreamlit,streamlit,,2
-7268,nikitalokhmachev-ai/corner-detection,gradio,,2
-7269,AI-Naga/Vehicle_Damage_Detection,gradio,,2
-7270,imseldrith/BookTODataset,streamlit,apache-2.0,2
-7271,Jeffsun/LSP-LearningandStrivePartner-Demo,gradio,afl-3.0,2
-7272,bigcode/santacoder-tokens,static,,2
-7273,deprem-ml/deprem_keras-satellite_semantic_mapping-challange,gradio,artistic-2.0,2
-7274,harley001/anime-remove-background,gradio,apache-2.0,2
-7275,zishuqianyu001/img-to-music,gradio,,2
-7276,curtpond/mle10-glg-demo,gradio,cc,2
-7277,flash64/biogpt-testing,gradio,mit,2
-7278,Duskfallcrew/photography-and-landscapes,gradio,,2
-7279,Duskfallcrew/duskfall-s-general-digital-art-model,gradio,,2
-7280,sujithvamshi/vehicle-color-recognition,gradio,,2
-7281,Adr740/Hadith_AI_Explorer,gradio,,2
-7282,skadio/Ner4Opt,streamlit,,2
-7283,seawolf2357/sd-prompt-gen,gradio,mit,2
-7284,Duskfallcrew/duskfall-s-vaporwave-aesthetic,gradio,,2
-7285,Duskfallcrew/duskfall-s-manga-aesthetic-model,gradio,,2
-7286,yuan2023/Stable-Diffusion-Prompt-Generator_App,streamlit,,2
-7287,zjunlp/MKG_Analogy,gradio,,2
-7288,seayao/lambdalabs-sd-pokemon-diffusers,gradio,,2
-7289,gato001k1/maximum_diffusion0k,gradio,,2
-7290,society-ethics/DiffusionFaceClustering,gradio,openrail,2
-7291,vincentclaes/pdf-ocr,gradio,gpl-3.0,2
-7292,gronkomatic/Image-Animation-using-Thin-Plate-Spline-Motion-Model,gradio,,2
-7293,mindspore-ai/Wuhan-LuoJiaNET,gradio,apache-2.0,2
-7294,AIFILMS/scene-edit-detection,gradio,,2
-7295,AIFILMS/Image-Animation-using-Thin-Plate-Spline-Motion-Model,gradio,,2
-7296,RamAnanth1/iclr2023,streamlit,,2
-7297,hra/music-recommendation,gradio,cc-by-nc-sa-4.0,2
-7298,sandy9808/EleutherAI-gpt-j-6B,gradio,,2
-7299,ThirdEyeData/Complaints_Roberta,gradio,,2
-7300,lfoppiano/grobid-superconductors-tools,docker,apache-2.0,2
-7301,Chloe0222/Chloe,gradio,,2
-7302,Purple11/Grounded-Diffusion,gradio,,2
-7303,awacke1/GradioContinualGenerator,gradio,mit,2
-7304,bhautikj/sd_clip_bias,gradio,mit,2
-7305,projekt-rising-ai/Expert-Answer-Demo,gradio,apache-2.0,2
-7306,hra/ChatGPT-Keyword2Blog,gradio,cc-by-nc-sa-4.0,2
-7307,Podtekatel/Avatar2VSK,gradio,bsd-3-clause,2
-7308,gradio/bokeh_plots,gradio,mit,2
-7309,slush0/petals-playground,gradio,,2
-7310,xiaoxin1111/vits-uma-genshin-honkai,gradio,apache-2.0,2
-7311,MedicalAILabo/Xp-age,gradio,,2
-7312,JeffJing/ZookChatBot,gradio,openrail,2
-7313,zss2341/chatgpt_with_email_password_logging,gradio,bsd-2-clause,2
-7314,jvcanavarro/traits-prediction,gradio,,2
-7315,RaidedCluster/Sniffusion_PomerAInian,streamlit,other,2
-7316,ismot/1802t1,gradio,unknown,2
-7317,HarshulNanda/EngHindi,gradio,,2
-7318,XlalalaX/VITS-Umamusume-voice-synthesizer,gradio,,2
-7319,awacke1/Sankey-Snacks,streamlit,mit,2
-7320,awacke1/AIOutline,streamlit,mit,2
-7321,Reha2704/VToonify,gradio,other,2
-7322,awacke1/AI-RPG-Self-Play-RLML-Health-Battler-Game,streamlit,mit,2
-7323,Covert1107/sd-diffusers-webui,docker,openrail,2
-7324,Uday-07/testing,gradio,apache-2.0,2
-7325,achimoraites/Summarizer-flan-t5-base-samsum,gradio,apache-2.0,2
-7326,Paulog731/SD-2.1-Img2Img,gradio,mit,2
-7327,awacke1/StreamlitSuperPowerCheatSheet,streamlit,mit,2
-7328,Thafx/sdlomo,gradio,,2
-7329,molok3/alea31415-onimai-characters,gradio,,2
-7330,passaglia/yomikata-demo,streamlit,mit,2
-7331,tarjomeh/Norod78-sd2-cartoon-blip,gradio,,2
-7332,decluster/airplane_yolov5,gradio,,2
-7333,kermitt2/softcite-software-mentions,docker,apache-2.0,2
-7334,LearnableAI/FinTextSummaryDemo,streamlit,apache-2.0,2
-7335,king007/table_extraction,gradio,,2
-7336,awacke1/SMART-FHIR-Assessment-Observation-SDKs,streamlit,mit,2
-7337,Dao3/DreamlikeArt-Diffusion-1.0,gradio,,2
-7338,bprzy/orchestration,gradio,lgpl-3.0,2
-7339,SRDdev/Scriptify,gradio,gpl-3.0,2
-7340,Robotanica/trashsort,gradio,apache-2.0,2
-7341,SUPERSHANKY/ControlNet_Colab,gradio,mit,2
-7342,Dao3/MagicPrompt-Stable-Diffusion,gradio,mit,2
-7343,portal/Multidiffusion,static,,2
-7344,Mattdoc99/CollisonChat2,streamlit,,2
-7345,csuer/vits,gradio,,2
-7346,spacerini/chat-noir,streamlit,mit,2
-7347,zhongkaifu/medical_qa_chs,docker,bsd-3-clause,2
-7348,portal/Control-Nets,static,,2
-7349,AlexWang/lama,gradio,,2
-7350,zeno-ml/langchain-qa,docker,mit,2
-7351,fredinrh2026/Video-Games,gradio,afl-3.0,2
-7352,Thafx/sdpp,gradio,,2
-7353,mosidi/fi-ber-detec-api,gradio,mit,2
-7354,HenryRom/MovieReccomender,gradio,afl-3.0,2
-7355,Mileena/claudfuen-photorealistic-fuen-v1,gradio,,2
-7356,awacke1/VizLib-TopLargeHospitalsMentalHealth,streamlit,mit,2
-7357,awacke1/StreamlitWikipediaChat,streamlit,mit,2
-7358,maodd/chatgpt-clone,gradio,,2
-7359,ahishamm/Whisper_STT,gradio,,2
-7360,podsni/twitter_sentiment_id,streamlit,,2
-7361,shibing624/asian-role,gradio,apache-2.0,2
-7362,spacerini/code-search,gradio,apache-2.0,2
-7363,awacke1/VizLib-KeywordExtraction-Clustering-Translation,streamlit,mit,2
-7364,qwertyuiee/AnimeBackgroundGAN,gradio,,2
-7365,0xJustin/0xJustin-Dungeons-and-Diffusion,gradio,openrail,2
-7366,cass1337/sdcharactercreator,gradio,unknown,2
-7367,trysem/bukGPT,gradio,,2
-7368,ArtificialArtist007/Rate-my-Aiart,gradio,other,2
-7369,B-patents/patent-bert,gradio,apache-2.0,2
-7370,Dao3/OpenArt,gradio,,2
-7371,Shad0ws/Ask-Questions-to-Data,streamlit,mit,2
-7372,DReAMy-lib/dream_II,gradio,apache-2.0,2
-7373,Stanlito/Bird_species,gradio,mit,2
-7374,Thafx/sddlpr2,gradio,,2
-7375,ewgewgewg/IndexingAlpha,gradio,gpl,2
-7376,ulysses115/vits-models,gradio,apache-2.0,2
-7377,30Kanika/disease-classifier,streamlit,apache-2.0,2
-7378,trysem/vintager,gradio,,2
-7379,anon9i9/finetuned_diffusion_test,gradio,mit,2
-7380,ai-art/upscaling,gradio,apache-2.0,2
-7381,StealYourGhost/Joeythemonster-anything-midjourney-v-4-1,gradio,,2
-7382,arpitr/end_to_end_ml_app,streamlit,,2
-7383,JunchuanYu/Tools,gradio,,2
-7384,DavidWeiZhang/sd-dreambooth-library-avator-generator,gradio,,2
-7385,shreydan/youtube-QandA,streamlit,,2
-7386,awacke1/Github-Create-Read-Update-Delete,streamlit,mit,2
-7387,EcoCy/LoRA-DreamBooth-Training-UI,gradio,mit,2
-7388,gregojoh/layoutlmv3_document,streamlit,,2
-7389,awacke1/Sentiment-analysis-streamlit,streamlit,mit,2
-7390,awacke1/Machine-translation,streamlit,mit,2
-7391,awacke1/Sentiment-aware-chatbot,streamlit,mit,2
-7392,chasetank/owner-manual,gradio,mit,2
-7393,awacke1/Topic-modeling,streamlit,mit,2
-7394,king007/biogpt-testing,gradio,mit,2
-7395,sharmaanupam/eigenvectors,streamlit,,2
-7396,yiningmao/metaphor-detection-baseline,gradio,openrail,2
-7397,awacke1/GenAI-Generate-New-Data-Resembling-Example,streamlit,mit,2
-7398,awacke1/Creative-Potential-Music-Art-Lit,streamlit,mit,2
-7399,awacke1/Data-Synthesizer-Synthesize-From-Multiple-Sources,streamlit,mit,2
-7400,Alashazam/StoryGenerator,gradio,,2
-7401,rogergou/facebook-tts_transformer-zh-cv7_css10,gradio,,2
-7402,GolDNenex/Super-Resolution-Anime-Diffusion,gradio,,2
-7403,PirateXX/AI-Content-Detector-From-PDF,gradio,artistic-2.0,2
-7404,podsni/YouTube_Summarize_Hades,gradio,cc,2
-7405,hhalim/streamlit_ChatGPT_Peer,streamlit,mit,2
-7406,awacke1/Daredevil-Text-Generation,streamlit,mit,2
-7407,mirzaburanali/project-caption-generation,gradio,,2
-7408,AIFILMS/ControlNet-Video,gradio,,2
-7409,RlxDrk/huggingtweets-dolceragazza26-femdomfusion-mistressleiaa,gradio,,2
-7410,visjia/ChatGPTAPI,gradio,mit,2
-7411,IDKiro/DehazeFormer_Demo,gradio,,2
-7412,desenmeng/ChatGPT,gradio,mit,2
-7413,luodian/LoRA-DreamBooth-Training-UI,gradio,mit,2
-7414,SoftChinchilla/Guizmus-SouthParkStyle,gradio,,2
-7415,awacke1/EB-StableDiffusion-1.5-ImageGeneration,gradio,mit,2
-7416,nateraw/text-generation,docker,mit,2
-7417,ThirdEyeData/Health-Insurance-Cross-Sell-Prediction,streamlit,,2
-7418,lzghades/skybox,gradio,openrail,2
-7419,Detomo/Chatgpt_with_awesome_prompt,gradio,creativeml-openrail-m,2
-7420,CobaltZvc/Hyper_Bot,static,,2
-7421,awacke1/HTML5-BabylonJS-Javascript-3DAnimation,static,mit,2
-7422,awacke1/HTML5-Aframe-Framework,static,mit,2
-7423,awacke1/HTML5-Aframe-Augmented-Reality-Model-Viewer,static,mit,2
-7424,akshatsanghvi/Rice-Disease-Classifier,streamlit,apache-2.0,2
-7425,awacke1/Mental-Health-ICD10-to-DSM,streamlit,mit,2
-7426,Kevin676/SmartAI,gradio,,2
-7427,mginoben/tagalog-profanity-classification,gradio,other,2
-7428,pierreguillou/Inference-APP-Document-Understanding-at-linelevel-v2,gradio,,2
-7429,Armored-Atom/Image-To-Motion,gradio,,2
-7430,liuxiaopai/chatgpt-demo,gradio,,2
-7431,shigel/ailol,gradio,,2
-7432,gilbertb/ChatGPTwithAPI,gradio,mit,2
-7433,JunchuanYu/Sydney-AI,gradio,,2
-7434,Spico/writing-comrade,gradio,apache-2.0,2
-7435,Ainterface/compare-gpt-models,streamlit,mit,2
-7436,OgiKazus/vits-uma-genshin-honkai,gradio,apache-2.0,2
-7437,cscan/vocal_remover,gradio,apache-2.0,2
-7438,akshayvkt/talk-To-SteveJobs,gradio,wtfpl,2
-7439,taishi-i/awesome-japanese-nlp-resources-search,streamlit,mit,2
-7440,louis030195/lsd-pt,streamlit,mit,2
-7441,ParisNeo/FaceRecognition,gradio,mit,2
-7442,ThirdEyeData/Semantic-Search-Transformer,streamlit,,2
-7443,thomasjeon/runwayml-stable-diffusion-v1-5,gradio,openrail,2
-7444,Qosmo/music-search-demo,docker,,2
-7445,pavelwong/Aitrial,gradio,,2
-7446,yuenkayi/textgenerator,Configuration error,Configuration error,2
-7447,dorischeng/textgenerator,gradio,,2
-7448,HUIYI/huiyili,gradio,,2
-7449,priyam314/Neural_Style_Texture,streamlit,,2
-7450,Mileena/nitrosocke-Arcane-Diffusion,gradio,cc-by-nc-sa-4.0,2
-7451,awacke1/Text-to-Image-stabilityai-stable-diffusion-2-1,gradio,,2
-7452,GanymedeNil/text2vec,gradio,apache-2.0,2
-7453,ReFenter/img-to-music,gradio,,2
-7454,pjjuplo/runwayml-stable-diffusion-v1-5,gradio,,2
-7455,yukkzer/google-flan-ul2,gradio,,2
-7456,ysharma/bokeh_plot_diffusers,gradio,mit,2
-7457,enoreyes/rembg_remove_bg,gradio,mit,2
-7458,ixciel/img-to-music,gradio,,2
-7459,buggyhuggy/Fictiverse-Stable_Diffusion_Microscopic_model,gradio,,2
-7460,Lianglan/Demo_Gpt3.5-turbo_model,gradio,cc-by-nc-4.0,2
-7461,victor/tata,docker,mit,2
-7462,pelinbalci/easyocr,streamlit,mit,2
-7463,ronig/protein_binding_search,gradio,mit,2
-7464,EnigmaOfTheWorld/sherlocks_phoeniks,gradio,,2
-7465,jonigata/PoseTweak,docker,creativeml-openrail-m,2
-7466,hra/stable-diffusion-tee-shirt,gradio,cc-by-nc-sa-4.0,2
-7467,JeremyK/JewelryVision,gradio,apache-2.0,2
-7468,zetabyte/text-to-voice2,gradio,,2
-7469,huggingface/minichain,gradio,openrail,2
-7470,TBF/AutomaticDatavisualization,streamlit,,2
-7471,abrar-lohia/text-2-character-anim,gradio,,2
-7472,harsh0706/research-summarizer,gradio,,2
-7473,victor/models-inference,static,,2
-7474,NoCrypt/promptinspector-abuser,gradio,wtfpl,2
-7475,RamV/ChatRobo_II,gradio,,2
-7476,awacke1/Joke-Book-AI-Jokes,streamlit,mit,2
-7477,BilalSardar/Black-N-White-To-Color,gradio,openrail,2
-7478,Adr740/CV_XPLORER_POC,gradio,,2
-7479,awacke1/HTML5-Javascript-3D-Breakout-Game,static,mit,2
-7480,Ragnov/STT-Grammar-Checker,gradio,cc-by-nc-sa-2.0,2
-7481,etahamad/new-plant-disease-detection,gradio,,2
-7482,Jack7510/trychatgpt,gradio,openrail,2
-7483,FER-Universe/FER-Benchmarking,gradio,mit,2
-7484,jsr90/laMoinsChere,streamlit,,2
-7485,Mendel192/SAN-Demo,docker,mit,2
-7486,spicysouvlaki/streamlit-shell,streamlit,mit,2
-7487,mano96/Content_Generator,gradio,,2
-7488,AashishKumar/Restaurant_voice_chatbot,gradio,mit,2
-7489,christhegamechanger/background_swapping,streamlit,,2
-7490,keras-dreambooth/marvin_paranoid_android,gradio,apache-2.0,2
-7491,donnyb/FalconVis,docker,,2
-7492,S4NX/NSFWGPT,gradio,mit,2
-7493,srush/minichain,gradio,,2
-7494,xiazi/anime-remove-background,gradio,apache-2.0,2
-7495,p1atdev/ZoeSeg,gradio,mit,2
-7496,ysharma/visual_chatgpt_dummy,gradio,osl-3.0,2
-7497,test1444/Pose_Video,gradio,mit,2
-7498,baixing/hackathon_chatbot_baixing_api,gradio,cc-by-4.0,2
-7499,basit123796/basit,gradio,,2
-7500,deepakmangla/krystv-hestyle-diffusion,gradio,,2
-7501,ceckenrode/AI-Dashboard-03142023,static,mit,2
-7502,MacYang/Diamond-Sutra,gradio,mit,2
-7503,Yan233th/so-vits-svc-models,gradio,,2
-7504,yorkliang/my_first_chatbot,gradio,cc-by-4.0,2
-7505,AI-Dashboards/AI.Dashboard.HEDIS.Terms.Vocabulary,static,mit,2
-7506,SanchezVFX/dis,gradio,apache-2.0,2
-7507,AIFILMS/StyleGANEX,gradio,,2
-7508,ilhamstoked/Classification-Skin-Cancer,streamlit,,2
-7509,gfhayworth/sales_qa2,gradio,,2
-7510,HMS1997/RepoGPT,gradio,mit,2
-7511,hv68/sample_tool_1,streamlit,other,2
-7512,AI-ZeroToHero-031523/README,static,,2
-7513,evi0mo/vits-fastapi-server,docker,,2
-7514,GuXiaoBei/wechat-chatbot,gradio,,2
-7515,keras-dreambooth/voyager,gradio,cc-by-nc-4.0,2
-7516,NeuralInternet/Text-Generation_Playground,gradio,mit,2
-7517,white7354/anime-remove-background,gradio,apache-2.0,2
-7518,Shrey-Patel/background-remover,streamlit,,2
-7519,Dao3/Text-To-image-AllModels,gradio,openrail,2
-7520,amarzana/Drop_image_to_short_story,gradio,cc,2
-7521,DrGabrielLopez/BERTopic,gradio,apache-2.0,2
-7522,radames/Detecting-Photoshopped-Faces-FALdetector,gradio,,2
-7523,fadyabila/Heart-Failure-Death-Prediction,streamlit,,2
-7524,bedrock123/chatroom,gradio,,2
-7525,qinzhu/moe-tts-tech,gradio,mit,2
-7526,Rifd/Face-Real-ESRGAN,gradio,apache-2.0,2
-7527,Zwicky18/Stable-difussion,gradio,openrail,2
-7528,keras-dreambooth/living_room_dreambooth_diffusion_model,gradio,,2
-7529,victor/website-designer,static,,2
-7530,zhen86/fashion_mnist_homework,gradio,apache-2.0,2
-7531,Sapiensia/MakerDiffusion,gradio,,2
-7532,keras-dreambooth/nuthatch-bird-demo,gradio,apache-2.0,2
-7533,PushkarA07/Cover-Gen-audio2image,gradio,mit,2
-7534,Web3Daily/WebGPT3,gradio,,2
-7535,ypchang/European_call_option-volatility-gradio,gradio,other,2
-7536,NotSarah/GoldRushJohn,gradio,agpl-3.0,2
-7537,Ilean/pdfGPTv2,gradio,cc-by-4.0,2
-7538,mmkuznecov/faceblur,gradio,openrail,2
-7539,Elegbede/Time_Series_Prediction,gradio,mit,2
-7540,LittleLirow/fearflixai,gradio,mit,2
-7541,azizalto/sqlify,streamlit,mit,2
-7542,OedoSoldier/chatglm_int4_demo,gradio,,2
-7543,MuhammedAyman29/mm,gradio,,2
-7544,Akira12312/admruul-anything-v3.0,gradio,,2
-7545,ai-create/re-generic,gradio,,2
-7546,fgbwyude/ChuanhuChatGPT,gradio,gpl-3.0,2
-7547,AIGC-Audio/Make_An_Audio_inpaint,gradio,,2
-7548,shibing624/ChatGPT-API-server,gradio,apache-2.0,2
-7549,jefftko/Stable-Diffusion-prompt-generator,gradio,mit,2
-7550,a7med146235/Ahmed,gradio,apache-2.0,2
-7551,Vgi/andite-anything-v4.0,gradio,,2
-7552,gradio/default,gradio,apache-2.0,2
-7553,gradio/base,gradio,apache-2.0,2
-7554,cloudqi/CQI_Texto_para_imagem_PT_v0,gradio,mit,2
-7555,ahmedghani/Editing-Tools,gradio,,2
-7556,awacke1/BERTopic-Topic-Modeler-NLP-ML,streamlit,mit,2
-7557,rimeAI/rimeui,gradio,,2
-7558,onursavas/document-layout-analysis,gradio,,2
-7559,edoz1986/johnslegers-epic-diffusion,gradio,,2
-7560,Notmodern/andite-anything-v4.0,gradio,,2
-7561,zekewilliams/ControlNet,gradio,mit,2
-7562,saifytechnologies/ai-text-to-video-generation-saify-technologies,gradio,,2
-7563,awacke1/THREEJS-ChatGPT-ASR-Wikipedia-Twitter-Sentiment-FactChecker-VoiceClone,static,mit,2
-7564,xl2533/FinDoc,gradio,,2
-7565,rwizard/Chatbot-AI,gradio,mit,2
-7566,keras-dreambooth/dreambooth-bioshock,gradio,apache-2.0,2
-7567,Saturdays/ClassificationPeripheralBloodCell,streamlit,mit,2
-7568,mikaelbhai/GPTBhai_text_history,gradio,,2
-7569,jkompalli/plant_disease_detection,gradio,mit,2
-7570,Mrleo/MyChatGPT,gradio,gpl-3.0,2
-7571,SQSora/VITS-Umamusume-voice-synthesizer,gradio,,2
-7572,derek-thomas/disc-golf-simulator,streamlit,gpl-3.0,2
-7573,thelou1s/MidJourney,gradio,,2
-7574,Dao3/ChatGLM-6B,gradio,,2
-7575,AI-ZTH-03-23/2.Streamlit.GraphViz.Dynamic.Architecture.Diagram,streamlit,mit,2
-7576,AI-ZTH-03-23/6.AI.Dashboard.Wiki.Chat.Cognitive.HTML5,static,mit,2
-7577,haakohu/deep_privacy2_face,gradio,,2
-7578,Lippppxy/AiAnimeVoice,gradio,apache-2.0,2
-7579,Heathlia/modelscope-text-to-video-synthesis,gradio,,2
-7580,awacke1/RLHF.Knowledge.Graph.GraphViz.Dynamic.Architecture.Diagram,streamlit,mit,2
-7581,raghu8096/Medical-Image-Classification,gradio,,2
-7582,all-things-vits/CLIPGroundingExplainability,gradio,afl-3.0,2
-7583,lharr345/alecsharpie-codegen_350m_html,gradio,,2
-7584,cariai/somos-alpaca-es,docker,,2
-7585,souljoy/Pokemon-Stable-Diffusion-Chinese,gradio,creativeml-openrail-m,2
-7586,pierreguillou/Inference-APP-Document-Understanding-at-paragraphlevel-v2,gradio,,2
-7587,Ronit28/ChatGPT4,gradio,mit,2
-7588,oshita-n/ImageQuestionAnswerring,gradio,mit,2
-7589,hackathon-somos-nlp-2023/discriminacion_gitana,docker,,2
-7590,d8aai/finance-dashboard,streamlit,apache-2.0,2
-7591,Michelangiolo/startup-finder,gradio,,2
-7592,maitri-vv/Hrishikesh332-autotrain-meme-classification-42897109437,streamlit,,2
-7593,xingzhehe/AutoLink,gradio,afl-3.0,2
-7594,zanyPhi/cats_vs_dogs,gradio,mit,2
-7595,ndshal/interior-decor,gradio,,2
-7596,elitecode/ChatGLM-6B-ChatBot,gradio,mit,2
-7597,Re1e9/DoodleDecoder,gradio,,2
-7598,szk1ck/image-collage,gradio,apache-2.0,2
-7599,FoxMeo/fire-detector,gradio,mit,2
-7600,gptjx/02,gradio,gpl-3.0,2
-7601,xcgc/SD-webui-controlnet-docker,docker,,2
-7602,huolongguo10/HlgBot,gradio,creativeml-openrail-m,2
-7603,vjain/SemanticPlaigarismChekcer,gradio,openrail,2
-7604,MGLDZM/chgpt,docker,,2
-7605,felix-weiland/llama_index_demo,streamlit,,2
-7606,ClementBM/connectfour,gradio,,2
-7607,Laihiujin/OneFormer,docker,mit,2
-7608,maxcembalest/ask-arthur,gradio,,2
-7609,aksj/Sea_Shanty,gradio,mit,2
-7610,kyleledbetter/responsibleGPT,gradio,,2
-7611,RamAnanth1/Pix2Struct,gradio,,2
-7612,kaushikdatta/generate-webslides,gradio,,2
-7613,ReganMayer/ChatGPT44,gradio,mit,2
-7614,WhyLIM/ChatGPT-academic,gradio,,2
-7615,Shahrukh2016/Netflix_Recommender_System,streamlit,other,2
-7616,hackengine/Paraformer-for-Chinese-Podcast,docker,,2
-7617,awacke1/Flan-Upvote-Downvote-Human-Feedback,gradio,openrail,2
-7618,kirch/Text2Video-Zero,gradio,,2
-7619,exnav29/Real_Estate_Bot,gradio,cc-by-4.0,2
-7620,Mahendra-Mk65/Midjourney-Online,gradio,openrail++,2
-7621,freddyaboulton/test-blue,gradio,apache-2.0,2
-7622,maykcaldas/MAPI_LLM,gradio,mit,2
-7623,cinika/andite-anything-v4.0,gradio,,2
-7624,keras-dreambooth/dreambooth_dosa,gradio,cc0-1.0,2
-7625,demongaara/Gaara-pokemon-stable-diffusion,gradio,gpl-3.0,2
-7626,lujkis/ChatGPT4,gradio,mit,2
-7627,asd123Xiao/kafuu_chino_sovits4.0,gradio,mit,2
-7628,majweldon/AIScribe,gradio,,2
-7629,hersia/youtube-video-transcription-with-whisper,gradio,afl-3.0,2
-7630,kukr3207/forex_demo,streamlit,,2
-7631,QinBingFeng/ChatGPT,gradio,,2
-7632,Muennighoff/code_eval_octopack,gradio,,2
-7633,Thafx/sdp,gradio,,2
-7634,simpie28/VITS-Umamusume-voice-synthesizer,gradio,,2
-7635,YenLai/Superhuman,gradio,apache-2.0,2
-7636,kastan/ai-teaching-assistant-beta,gradio,,2
-7637,sanjayw/GPT4All,gradio,apache-2.0,2
-7638,Kevin676/ChatGPT-with-Speech-Enhancement,gradio,mit,2
-7639,sklkd93/CodeFormer,gradio,apache-2.0,2
-7640,firefighter/TransDis-CreativityAutoAssessment,gradio,mit,2
-7641,coldlarry/lr_pdf,gradio,openrail,2
-7642,pierreguillou/Inference-APP-Document-Understanding-at-paragraphlevel-v3,gradio,,2
-7643,jiaqingj/ConZIC,gradio,unknown,2
-7644,king007/Stable-Diffusion-ControlNet-WebUI,gradio,openrail,2
-7645,AlexWortega/AlexWortega-instruct_rugptlarge,gradio,,2
-7646,heliosbrahma/voice-assistant,gradio,,2
-7647,varunrayen/banana-dev-GPTrillion,gradio,,2
-7648,artemkramov/f-coref-ua,gradio,,2
-7649,JohnTan38/ChatGPT_LangChain,gradio,mit,2
-7650,fastx/Lisa-Chatbot,gradio,,2
-7651,Ajaxon6255/Emerald_Isle,gradio,apache-2.0,2
-7652,ayaderaghul/photo2monet,gradio,openrail++,2
-7653,AUST001/HDTV,gradio,cc-by-nc-nd-4.0,2
-7654,DD0101/Disfluency-base,gradio,,2
-7655,Izaias/Joeythemonster-anything-midjourney-v-4-1,gradio,,2
-7656,tanvirsingh01/jokesapart,gradio,,2
-7657,Syrinx/WebtoonPlotGenerator,streamlit,apache-2.0,2
-7658,Rakot2223/faster-whisper-webui,gradio,apache-2.0,2
-7659,Kevin676/ChatGPT-with-Voice-Conversion,gradio,unknown,2
-7660,jonathang/RapGPT,gradio,,2
-7661,Aaaaaaaabdualh/poetry2023,gradio,,2
-7662,Amon1/ChatGPTForAcadamic,gradio,gpl-3.0,2
-7663,Sapiensia/diffuse-the-rest,static,,2
-7664,tekkonetes/Chatbots,gradio,,2
-7665,stanciu/declare-lab-flan-alpaca-xl,gradio,,2
-7666,stanciu/declare-lab-flan-gpt4all-xl,gradio,,2
-7667,radames/openplayground,docker,,2
-7668,ieuniversity/flirtify,gradio,,2
-7669,helenai/openvino_transformers_streaming,gradio,,2
-7670,sklearn-docs/Visualizing_the_stock_market_structure,gradio,,2
-7671,FourthBrainGenAI/FourthBrainGenAI-ProductSnapAI,gradio,,2
-7672,Olivernyu/sentiment_analysis_app,streamlit,,2
-7673,stanciu/anon8231489123-vicuna-13b-GPTQ-4bit-128g,gradio,,2
-7674,Kevin676/Real-Time-Voice-Cloning,gradio,,2
-7675,haohoo/Azure-OpenAI-QuickDemo,gradio,apache-2.0,2
-7676,Tobalog/Simplified_Chinese_to_Traditional_Chinese,gradio,apache-2.0,2
-7677,EnigmaOfTheWorld/ChanakyaNeeti,gradio,,2
-7678,SouthCity/ShuruiXu,gradio,,2
-7679,EveryPizza/Cartoony-Gradio-Theme,gradio,apache-2.0,2
-7680,Norod78/distilgpt2_TextIteratorStreamer,gradio,mit,2
-7681,mostro3000/AlekseyKorshuk-vicuna-7b,gradio,,2
-7682,awacke1/Docker.VSCode.Integration.HF,docker,,2
-7683,ghlee94/MEDIAR,gradio,apache-2.0,2
-7684,dodoya1/youtube_transcript,gradio,,2
-7685,arthurdias/Webui-Cpu-ExtensionV2-Publictest-WithCivitaiHelper,gradio,,2
-7686,flowerpixel/tashachan28-ranma_diffusion,gradio,,2
-7687,Kevin676/Speechbrain-Speech-enhancement,gradio,,2
-7688,ShotaA/TalkTuner,docker,mit,2
-7689,pchuri/slack-summary-bot,gradio,mit,2
-7690,Vijish/Image_generator,gradio,apache-2.0,2
-7691,Soumahara/Ojimi-anime-kawai-diffusion-demo,gradio,,2
-7692,nateevo/memero,gradio,mit,2
-7693,sunnyzhifei/ChatGPTOnline,gradio,gpl-3.0,2
-7694,milex-info/rave-inf,gradio,other,2
-7695,jmourad/TXT2IMG-MJ-Desc,gradio,artistic-2.0,2
-7696,Kevin676/Alpaca-LoRA-with-Voice-Cloning,gradio,apache-2.0,2
-7697,franever/Pix2Pix-Video,gradio,,2
-7698,Mecca/whisper-webui,gradio,apache-2.0,2
-7699,Usually3/multilingual_vcloning,gradio,,2
-7700,jhj0517/Segment-Anything-Layer-Divider,gradio,apache-2.0,2
-7701,dhavala/KrishiGPT,gradio,apache-2.0,2
-7702,jdinh/freeze-detection,gradio,apache-2.0,2
-7703,jordonpeter01/dreamlike-photoreal-2.0,gradio,,2
-7704,younus93/pdfgpt,streamlit,,2
-7705,joshen/gpt-academic,gradio,,2
-7706,IAMTFRMZA/DreamlikeArt-Diffusion-1.0,gradio,,2
-7707,sklearn-docs/k-means-initialization-evaluation,gradio,,2
-7708,musadac/VilanOCR-Urdu-English-Chinese,streamlit,apache-2.0,2
-7709,MashiroSA/sovits-emu-voice-transform,gradio,gpl-3.0,2
-7710,helliun/gpt4-associative-memory,gradio,,2
-7711,sklearn-docs/voting-classifier-decision-surface,gradio,,2
-7712,vg055/demo_analisis_de_sentimientos_textos_turisticos_mx_tipo,gradio,unknown,2
-7713,sklearn-docs/Incremental-PCA,gradio,creativeml-openrail-m,2
-7714,sklearn-docs/Univariate-feature-selection,gradio,creativeml-openrail-m,2
-7715,teamnassim/Fictionista,gradio,mit,2
-7716,cfwef/gpt,gradio,,2
-7717,Priyanka-Kumavat/Supply-Chain,streamlit,,2
-7718,NicolasvonRotz/Lego-Bricks-AI,gradio,apache-2.0,2
-7719,SRankChatGpt/Presentation-Assistant,streamlit,apache-2.0,2
-7720,jax-diffusers-event/canny_coyo1m,gradio,apache-2.0,2
-7721,Software-System/De-Anios-a-Meses,gradio,wtfpl,2
-7722,Tbryan2/AssistantGM,gradio,mit,2
-7723,kazuk/youtube-whisper-11,gradio,unknown,2
-7724,kazuk/youtube-whisper-16,gradio,unknown,2
-7725,sklearn-docs/Compressive_sensing_Tomography_reconstruction_with_L1_prior_Lasso,gradio,bsd-3-clause,2
-7726,tomemojo/customerservice,gradio,,2
-7727,sklearn-docs/ward-hierarchical-clustering,gradio,apache-2.0,2
-7728,sailormars18/Yelp-reviews-usingGPT2,gradio,,2
-7729,rzzgate/Stable-Diffusion-ControlNet-WebUI,gradio,openrail,2
-7730,briankchan/grammar,gradio,,2
-7731,sklearn-docs/Inductive_clustering,gradio,creativeml-openrail-m,2
-7732,bamitsmanas/breast-cancer-detection,gradio,,2
-7733,wallezen/so-vits-svc,gradio,,2
-7734,openpecha/chatbot_tibetan,gradio,,2
-7735,SoulAbi/whisper-audio-text-speaker-recognition,gradio,openrail,2
-7736,YUANAI/DiffspeechResearch,gradio,,2
-7737,UndueTarget/youtube-whisper,gradio,unknown,2
-7738,luckli/anon8231489123-gpt4-x-alpaca-13b-native-4bit-128g,gradio,,2
-7739,charanhu/GPT-4,gradio,apache-2.0,2
-7740,Brofu/Joeythemonster-anything-midjourney-v-4-1,gradio,,2
-7741,weanalyze/analyze_url,docker,,2
-7742,ysr/quran-semantic-search,gradio,,2
-7743,prithvihehe/TheBotFather,gradio,,2
-7744,doevent/kd,gradio,unknown,2
-7745,lizhen30/LangChainGo,gradio,openrail,2
-7746,sklearn-docs/text-feature-extraction-evaluation,gradio,,2
-7747,jonathang/EBookGPT,gradio,,2
-7748,AI-Dashboards/ScrabbleSolverWordThesaurus,streamlit,mit,2
-7749,momegas/megas-bot,gradio,mit,2
-7750,awacke1/Transcript-AI-Learner-From-Youtube,streamlit,mit,2
-7751,mair-lab/mapl,gradio,mit,2
-7752,j-min/IterInpaint-CLEVR,gradio,mit,2
-7753,alx-ai/Real-ESRGAN-Demo,gradio,,2
-7754,vorstcavry/visualstudiocode,docker,,2
-7755,bert9946/frame-interpolation,gradio,,2
-7756,Pranjal-666/Heart_Disease,gradio,,2
-7757,AlhitawiMohammed22/CER_Hu-Evaluation-Metrics,gradio,apache-2.0,2
-7758,zeno-ml/audio-transcription,docker,mit,2
-7759,edenehuyh/Demo_RealESRGAN,gradio,,2
-7760,KunalSinha2024/cledgeEssayIdeationTool,gradio,,2
-7761,realambuj/Text-Summarization_using_Bert,streamlit,,2
-7762,HuseynG/ECS7022P-WGAN-GP,gradio,,2
-7763,parseny/youtube_comment_generation,gradio,mit,2
-7764,vorstcavry/vits-models-1,gradio,mit,2
-7765,long1111/langchain-chatglm,gradio,,2
-7766,xianbao/sd-to-diffusers,gradio,mit,2
-7767,Synthia/ChatGal,gradio,apache-2.0,2
-7768,Yeshwant123/mcc,gradio,,2
-7769,AB-TW/team-ai,gradio,apache-2.0,2
-7770,mehdidc/text_to_image_ddgan,gradio,,2
-7771,keneonyeachonam/Memory-Chat-Story-Generator-ChatGPT-041723,gradio,,2
-7772,Minoumimi/WaifuMakinTime,gradio,gpl-3.0,2
-7773,Vasanthgx/demo_minima_vasanth,gradio,apache-2.0,2
-7774,segments/panoptic-segment-anything-api,gradio,apache-2.0,2
-7775,thinh-researcher/cord-v2,gradio,,2
-7776,linfanluntan/Grounded-SAM,gradio,apache-2.0,2
-7777,cheetah003/HMMC_t2v_search,gradio,,2
-7778,mthsk/sovits-100orangejuice,gradio,mit,2
-7779,wangrongsheng/ChatCitation,gradio,,2
-7780,charlesai/CLIP,gradio,,2
-7781,Kabriske/Multilingual_Video_Subtitler,gradio,mit,2
-7782,perezcatriel/data_world_jobs,streamlit,mit,2
-7783,Sky5408er/vits-uma-genshin-honkai,gradio,apache-2.0,2
-7784,ychenNLP/easyproject,gradio,mit,2
-7785,simonduerr/molstar-gradio,gradio,mit,2
-7786,Cicooo/vits-uma-genshin-honkai,gradio,apache-2.0,2
-7787,szzzzz/chatbot,gradio,bigscience-openrail-m,2
-7788,knkarthick/chat-llm-streaming,gradio,,2
-7789,syedusama5556/Image-Animation-using-Thin-Plate-Spline-Motion-Model,gradio,,2
-7790,zhone/stabilityai-stablelm-base-alpha-7b,gradio,,2
-7791,mahati/GFPGAN1,gradio,apache-2.0,2
-7792,ztudy/prototype,streamlit,other,2
-7793,Kevin676/AutoGPT,gradio,mit,2
-7794,Chirag1994/Melanoma_Skin_Cancer_Detection_App,gradio,mit,2
-7795,Tej3/DepthEstimation,gradio,,2
-7796,fashion-demo-organization/fashion_demo,gradio,,2
-7797,Zeebra/chatGPT_whisper_AI_voice_assistant,gradio,,2
-7798,awacke1/Wikipedia-Twitter-ChatGPT-Memory-Chat,gradio,mit,2
-7799,biglab/webui-screenrecognition,gradio,other,2
-7800,gstaff/articulator,gradio,apache-2.0,2
-7801,darthPanda/chatpdf,docker,,2
-7802,blueeyiz702/flax-midjourney-v4-diffusion,gradio,openrail,2
-7803,rizmyabdulla/Medicine_predictor,gradio,artistic-2.0,2
-7804,sklearn-docs/sklearn-spectral-clustering,gradio,apache-2.0,2
-7805,1yukikaze/img-to-music,gradio,,2
-7806,JasonData/MathGenerator,gradio,mit,2
-7807,shireenchand/depth-map,gradio,,2
-7808,luckwill/chiakicc,gradio,mit,2
-7809,weidexu/ChatGPT-with-Voice-Cloning-for-All,gradio,mit,2
-7810,yukiarimo/Uta-AI,gradio,apache-2.0,2
-7811,iamkhadke/GeneralChatBot,gradio,apache-2.0,2
-7812,hemanth-thaluru/sdm-image-colorization-prj,gradio,apache-2.0,2
-7813,frostymelonade/roberta-small-pun-identification,gradio,,2
-7814,Monosmarinos/Pix2Pix-Video,gradio,,2
-7815,Loke-60000/mio-amadeus,gradio,,2
-7816,aodianyun/panoptic-segment-anything,gradio,apache-2.0,2
-7817,a-v-bely/russian-task-generator,streamlit,,2
-7818,edenehuyh/BLIQ_ImageCaptioning,gradio,,2
-7819,hkayabilisim/LIME,gradio,,2
-7820,Kyan14/Mood_Based_Generative_Art,gradio,cc,2
-7821,matthoffner/gguf-maker,docker,,2
-7822,TechWithAnirudh/langchain-chat-with-pdf,gradio,,2
-7823,chaocai/superbot,gradio,openrail,2
-7824,lmalta/PDF_Doc_Search,docker,unknown,2
-7825,ysharma/Gradio_Client_Chains,gradio,mit,2
-7826,pablovela5620/grounding-sam,gradio,,2
-7827,ericsali/language_translator,gradio,,2
-7828,wetey/Headline-Content-Generator,gradio,,2
-7829,Nicholaspei/LangChain-ChatLLM,gradio,apache-2.0,2
-7830,daydayup1225/Chat-web,gradio,,2
-7831,ZJunTvT/ZJunChat,gradio,gpl-3.0,2
-7832,ChandraMohanNayal/AutoGPT,gradio,mit,2
-7833,prerna9811/musicapp,gradio,,2
-7834,mrloler/oai-claude,docker,,2
-7835,Ikaros521/so-vits-svc-4.0-ikaros2,gradio,mit,2
-7836,sooolee/summarize-transcripts-gradio,gradio,apache-2.0,2
-7837,moha222/gpt2-wikipedia,gradio,,2
-7838,sander-wood/tunesformer,gradio,mit,2
-7839,better57/CHATGPT,gradio,gpl-3.0,2
-7840,ErtugrulDemir/TextSummarizing,gradio,apache-2.0,2
-7841,ErtugrulDemir/SpeechEmotionRecognition,gradio,apache-2.0,2
-7842,ondrejbiza/isa,gradio,mit,2
-7843,Yati05/TF-CodeT5-base,gradio,,2
-7844,amitjamadagni/qs-benchmarks,gradio,cc-by-4.0,2
-7845,Shashashasha/so-vits-fork-yoshi,gradio,mit,2
-7846,moplat90/Chart2Data,gradio,cc-by-nc-sa-4.0,2
-7847,lincquiQcaudo/Top-20-Diffusion,gradio,,2
-7848,DhanushPrabhuS/pothole_yolov8_nano,gradio,mit,2
-7849,wadhwani-ai/KKMS-Smart-Search-Demo,gradio,,2
-7850,Harshveer/Finetuned_Diffusion_Max,gradio,mit,2
-7851,Arijit-hazra/my-image-captioner,gradio,,2
-7852,Davidsamuel101/PPTGenerator,gradio,,2
-7853,nihalbaig/layoutlmv3_official_document,gradio,openrail,2
-7854,Serg4451D/DALLE,streamlit,,2
-7855,cihyFjudo/fairness-paper-search,gradio,,2
-7856,mira-causality/counterfactuals,gradio,mit,2
-7857,Tj/langchain-chat-with-pdf,gradio,,2
-7858,lamini/README,static,,2
-7859,recenWmenso/ChatGPT-with-Voice-Cloning-for-All,gradio,mit,2
-7860,Ryukijano/it-happened-one-frame-2,gradio,afl-3.0,2
-7861,ymcmy/highlighter_demo,gradio,,2
-7862,duchaba/sd_prompt_helper,gradio,mit,2
-7863,maurypb/Donald-trump-chatbot,gradio,other,2
-7864,ferdmartin/GradApplicationDocsApp,streamlit,mit,2
-7865,nomnomnonono/Sound-Effect-Search,gradio,,2
-7866,Saiteja/leaf-ViT-classifier,gradio,apache-2.0,2
-7867,1pelhydcardo/ChatGPT-prompt-generator,gradio,apache-2.0,2
-7868,groupeonepoint/WritingAssistant,gradio,,2
-7869,SAMControlNet/SyntheticDataSAM,gradio,apache-2.0,2
-7870,matthh/joyous_poetry_generator,gradio,apache-2.0,2
-7871,Zhenhong/text-to-image-Stable-Diffusion-demo,gradio,mit,2
-7872,JFoz/CoherentControl,gradio,openrail,2
-7873,gojiteji/SDTextTransmitter,gradio,,2
-7874,IkechukwuAbuah/PDF_GPT,gradio,,2
-7875,feregVcuzo/sanity-test-midi,gradio,openrail,2
-7876,awacke1/Generative-AI-Writers-Dashboard,static,mit,2
-7877,AlexKoff88/stable_diffusion,gradio,apache-2.0,2
-7878,Saturdays/chatbot_refugiados,gradio,,2
-7879,IdaLee/DrawEasy,gradio,mit,2
-7880,SmartPoint7/TwitterPRO,gradio,afl-3.0,2
-7881,jxu124/vits-genshin,gradio,mit,2
-7882,Uvini/Hotel-Reviews,streamlit,,2
-7883,florim/MedGPT,gradio,mit,2
-7884,SuCicada/Lain-TTS,gradio,,2
-7885,JKLUCY99/voice-cloning,gradio,mit,2
-7886,BetterAPI/BetterChat,docker,apache-2.0,2
-7887,Duskfallcrew/Free-Illustration-Mix,gradio,creativeml-openrail-m,2
-7888,textToSQL/talk_to_NP,gradio,mit,2
-7889,awacke1/AI-Standard-Operating-Procedures,streamlit,mit,2
-7890,jacinthes/PubMed-fact-checker,streamlit,cc-by-4.0,2
-7891,bastiendechamps/geoguessr-bot,gradio,,2
-7892,huggingface-tools/image-transformation,gradio,,2
-7893,Kaludi/VirtualBrainGPT,streamlit,mit,2
-7894,hacksberg/plant,gradio,,2
-7895,gbharti/stable-riffusion-walk,streamlit,,2
-7896,OswaldDev/Image-enhancement,gradio,,2
-7897,glitch0011/MendoBERT_NER,streamlit,openrail,2
-7898,OswaldDev/webuih,gradio,,2
-7899,trhacknon/webui,gradio,,2
-7900,johnsu6616/prompt-generator,gradio,,2
-7901,fkhuggingme/gpt-academic,gradio,,2
-7902,RichardMB1217/blip2,gradio,bsd-3-clause,2
-7903,alitrack/ChatPDF,gradio,apache-2.0,2
-7904,Longtong/foodvision_mini_video,gradio,mit,2
-7905,Sarfraz/NousResearch-gpt4-x-vicuna-13b,gradio,openrail,2
-7906,MirageML/shap-e,gradio,creativeml-openrail-m,2
-7907,megamined/voice-gpt,gradio,,2
-7908,Arielliu/just_talk,gradio,mit,2
-7909,Milancheeks/AI_Music_Team,gradio,,2
-7910,ben-epstein/ner-spans-to-tokens-tags,streamlit,apache-2.0,2
-7911,TeamMlx/MagicPrompt-Stable-Diffusion,gradio,mit,2
-7912,ArdaSaygan/PollGeneratorApp,gradio,,2
-7913,ELEVEN-001/ChatToFiles,gradio,afl-3.0,2
-7914,Littlehongman/CLIPGPT-ImageCaptioner,streamlit,,2
-7915,DaFujaTyping/second-webui-docker,docker,,2
-7916,nirali/microsoft-trocr-large-handwritten,gradio,,2
-7917,mav735/mri-assistent,gradio,gpl-3.0,2
-7918,iremkrc/chatbot-demo,gradio,,2
-7919,taesiri/ViTPose,gradio,,2
-7920,Tj/LangChain-ChatGPT-plugins,gradio,,2
-7921,PranomVignesh/Detecting-unauthorized-person-with-firearms,gradio,gpl-3.0,2
-7922,jayparmr/CyberRealistic,gradio,mit,2
-7923,elpsycongroo19/simple_chatbot,gradio,,2
-7924,wasimmadha/entity-extraction,gradio,,2
-7925,abbbbbbbbbbbbbb/AraPoet,gradio,gpl-3.0,2
-7926,abbbbbbbbbbbbbb/poetry2023,gradio,,2
-7927,asifhugs/InfiniteGPT,streamlit,,2
-7928,felix-weiland/appstore-search,streamlit,,2
-7929,Alcedo/yunmedia,docker,mit,2
-7930,AI-Dashboards/Streamlit-Plotly_Graph-Objects,streamlit,mit,2
-7931,sklearn-docs/Factor-Analysis-with-rotation,gradio,bsd-3-clause,2
-7932,dhuynh95/HuberChat,gradio,apache-2.0,2
-7933,abbbbbbbbbbbbbb/Arabic_poem_classifier,gradio,,2
-7934,eddie5389/Object-Detection-With-DETR-and-YOLOS,gradio,,2
-7935,artqwu/gradio-demo,gradio,apache-2.0,2
-7936,ALSv/midjourney-v4-1,gradio,,2
-7937,glrh11/object-detection,gradio,other,2
-7938,woshixuhao/Rf_prediction,gradio,openrail,2
-7939,awacke1/Gradio-Gallery-Iceland,gradio,mit,2
-7940,eswardivi/ChatwithPdf,streamlit,mit,2
-7941,kevinwang676/Bark-UI-with-Voice-Cloning-2,gradio,mit,2
-7942,LecJackS/wolfram-alpha-query,static,openrail,2
-7943,LuxOAI/ChatGpt-Web,docker,,2
-7944,Crossbro/succinctly-text2image-prompt-generator,gradio,,2
-7945,Jouaoutch/Gradio,gradio,,2
-7946,AI-Dashboards/Streamlit-Markdown-ChatGPT-CCD,streamlit,mit,2
-7947,SUSTech/llm-evaluate,static,,2
-7948,chrisbodhi/explo,docker,,2
-7949,danielpedriniportfolio/AutoDA,streamlit,,2
-7950,remilia/Ghostly,gradio,apache-2.0,2
-7951,hbui/RegBot-Chat-with-Docs,streamlit,mit,2
-7952,VeryYouQ/dis-background-removal,gradio,apache-2.0,2
-7953,Xh3liumX/PDFGPT_increasedSiz,gradio,afl-3.0,2
-7954,chaowei100/ChatGPT_Taiyi-Stable-Diffusion,gradio,,2
-7955,gradio-client-demos/text-to-image,gradio,,2
-7956,banana-projects/datasets-card-creator,static,,2
-7957,Chris4K/german-sentiment-bert,gradio,other,2
-7958,sklearn-docs/Manifold-Learning-methods-on-a-severed-sphere,gradio,bsd-3-clause,2
-7959,matthoffner/ggml-llm-cuda,docker,,2
-7960,rubberboy/stable-diffusion-webui,gradio,,2
-7961,RuijiaTan/MultiPrincipalElementAlloyPropertyPredictor,gradio,,2
-7962,Godrose0728/Aisound02,gradio,mit,2
-7963,shravanrevanna/hdfc-bank-statement,streamlit,,2
-7964,Shubham89/Meshwork-chatbot,gradio,,2
-7965,omi0k/LoRA-DreamBooth-Training-UI,gradio,mit,2
-7966,Zenne/chatbot_self_query,streamlit,mit,2
-7967,neuralworm/vinyl_sound_generator,gradio,apache-2.0,2
-7968,kasun/comparing-captioning-models,gradio,,2
-7969,SlowBette/ChatBot_gpt3.5,gradio,,2
-7970,dassum/Face-Id-Recognition,gradio,apache-2.0,2
-7971,momegas/wowonen,gradio,,2
-7972,niuzhiwei/stabilityai-stable-diffusion-2-1,gradio,,2
-7973,KKMobile/MagicPrompt-Stable-Diffusion,gradio,,2
-7974,Writer/token-counter,gradio,,2
-7975,DEBO-PROJECT/DEBO-V1,streamlit,openrail,2
-7976,shamaayan/Wisi,gradio,apache-2.0,2
-7977,awinml/api_vicuna-AlekseyKorshuk-7B-GPTQ-4bit-128g-GGML,gradio,mit,2
-7978,Rebskii/rvc-models-test,gradio,mit,2
-7979,omb23/pettrainingmodel,gradio,apache-2.0,2
-7980,kiroiineko/rvc-models-tragamundos,gradio,mit,2
-7981,Has-ai/text-speech,gradio,,2
-7982,ogawa0071/cyberagent-open-calm-small,gradio,cc-by-sa-4.0,2
-7983,bingbing520/ChatGPT,gradio,gpl-3.0,2
-7984,yangliuyi601/rvc-models,gradio,mit,2
-7985,mrungta8/CitationalAmnesia,gradio,unknown,2
-7986,m-a-p/MERT-Music-Genre-Tagging-Prediction,gradio,cc-by-nc-sa-4.0,2
-7987,vanderbilt-dsi/grant-writing-assistant,gradio,mit,2
-7988,eaedk/Agri-Tech,gradio,openrail,2
-7989,FYP-23-S1-21/Refineverse_Plugin,gradio,,2
-7990,Najaf-Zawar/Image-Super-Resolution,gradio,artistic-2.0,2
-7991,Najaf-Zawar/Old_Image-Restoration,gradio,apache-2.0,2
-7992,Mozira/voice-models,gradio,mit,2
-7993,beomi/KoRWKV-1.5B,gradio,mit,2
-7994,muheiroiro/youtube_comments_chat,streamlit,,2
-7995,DonDoesStuff/openjourney-v4-demo,gradio,,2
-7996,ennov8ion/stablediffusion-models,gradio,,2
-7997,loveu-tgve/loveu-tgve-leaderboard,gradio,,2
-7998,nijatzeynalov/AzVoiceSent,gradio,openrail,2
-7999,DHEIVER/Alzheimer,gradio,,2
-8000,xdstone1/ai-bot-demo,gradio,,2
-8001,Bonosa2/movies,gradio,,2
-8002,zhicheng127/White-box-Cartoonization,gradio,apache-2.0,2
-8003,ewave/Image-Animation-using-Thin-Plate-Spline-Motion-Model,gradio,,2
-8004,caliex/Comparison-of-Manifold-Learning-methods,gradio,mit,2
-8005,nontGcob/T2E_Vocabulary_Exam_Generator,gradio,mit,2
-8006,augmented-surveys/retrodict,streamlit,,2
-8007,lewtun/donut-docvqa,gradio,,2
-8008,Q-b1t/Dog_Emotions_Vision_Classifier,gradio,mit,2
-8009,YenJung/ECG_MAC,streamlit,,2
-8010,calihyper/choosa_txt_to_img,gradio,creativeml-openrail-m,2
-8011,Sagar48/claudfuen-photorealistic-fuen-v1,gradio,,2
-8012,ThirdEyeData/Image-Blur-Prediction,streamlit,,2
-8013,Saba99/GPT4ALL,gradio,,2
-8014,robyramos/teste_memoria-chat,gradio,other,2
-8015,nlp-waseda/Kanbun-LM,gradio,cc-by-sa-4.0,2
-8016,gundruke/ua-thesis-absa,gradio,,2
-8017,Agusbs98/automatic-ecg-diagnosis,gradio,,2
-8018,timdettmers/guanaco-65b-4bit,gradio,,2
-8019,Bonosa2/dall-e_image-generation,gradio,,2
-8020,caltex1/streamlit_pdf_gpt,streamlit,,2
-8021,hlydecker/ImageBind_zeroshot_demo,gradio,mit,2
-8022,Toaster496/openaccess-ai-collective-manticore-13b,gradio,,2
-8023,lordvader31/text-matching,streamlit,apache-2.0,2
-8024,sohojoe/project_charles,streamlit,mit,2
-8025,touchscale/img-to-music,gradio,,2
-8026,matthoffner/local-llm-doc-chat,docker,,2
-8027,youkaiai/gpt,gradio,,2
-8028,hkayabilisim/hdmr,gradio,,2
-8029,MesutUnutur/text_to_image_generationn,gradio,,2
-8030,sihar/Online_Payment_Fraud_Detection,streamlit,,2
-8031,xiangdy/chatGPT,gradio,gpl-3.0,2
-8032,vilsonrodrigues/youtube-retrieval-qa,gradio,,2
-8033,hlydecker/langchain-chat-with-pdf-openai,gradio,,2
-8034,sklearn-docs/Kernel-Density-Estimation,gradio,mit,2
-8035,Annotation-AI/fast-segment-everything-with-text-prompt,gradio,,2
-8036,naman7415963/next-word-prediction,gradio,cc-by-nd-4.0,2
-8037,sklearn-docs/Gaussian-Mixture-Model-Initialization-Methods,gradio,mit,2
-8038,Deepsheka/newdemo-app,gradio,,2
-8039,mindtube/maximum_multiplier_places,gradio,,2
-8040,mokashaa/Movies-Recommendation-System,streamlit,,2
-8041,Ritvik19/VidScripter,streamlit,cc,2
-8042,giswqs/solara,docker,mit,2
-8043,Mansib/Allure,gradio,cc-by-4.0,2
-8044,step-3-profit/Midnight-Deep,gradio,apache-2.0,2
-8045,mindtube/protogen-models,gradio,,2
-8046,willhill/stabilityai-stable-diffusion-2-1,gradio,openrail,2
-8047,Daniton/facebook-blenderbot-3Byx,gradio,,2
-8048,Luelll/ChuanhuChatGPT,gradio,gpl-3.0,2
-8049,zhuowen999/vits_chinese,gradio,apache-2.0,2
-8050,EinsteinCoder/sf-voicebot,docker,other,2
-8051,cyberspyde/chatbot-team4,streamlit,openrail,2
-8052,muttalib1326/YOLOv8-Industrial-Equipments-safety-Detection,gradio,,2
-8053,awacke1/Streamlit-ChatGPT,streamlit,mit,2
-8054,whocars123/yea,docker,,2
-8055,sweepai/anthropic-tokenizer,streamlit,mit,2
-8056,ulysses115/Nogizaka46-so,gradio,mit,2
-8057,swufewyd/xyz-nlp-XuanYuan2.0,static,,2
-8058,Menna2211/Text-Image,streamlit,,2
-8059,sanjayw/tts,gradio,,2
-8060,ericjohnson97/gpt_mavplot,gradio,,2
-8061,Ankita0512ghosh/Weather_bot,streamlit,,2
-8062,Kimata/multimodal-deepfakes,gradio,,2
-8063,Hugorowan/BardJukebox,gradio,other,2
-8064,deepthiaj/Electro_oneAPI,streamlit,,2
-8065,ealbinu/automatic-speech-recognition,gradio,apache-2.0,2
-8066,FourthBrainGenAI/DeepLearningAIDemoChatBot,gradio,openrail,2
-8067,animeartstudio/AnimeArtmodels2,gradio,,2
-8068,julien-c/duckdb-full-text-search,gradio,,2
-8069,django-ochain/AI-market-researcher,gradio,,2
-8070,Q4234/a1,gradio,,2
-8071,TeamMlx/ehartford-Wizard-Vicuna-30B-Uncensored,gradio,,2
-8072,SagarDa/voice-to-image-generation,gradio,other,2
-8073,onereal/rvc-models-convertvoice,gradio,mit,2
-8074,animeartstudio/AnimeModels,gradio,,2
-8075,animeartstudio/ArtModels,gradio,,2
-8076,JoanGiner/DataDoc_Analyzer,gradio,apache-2.0,2
-8077,matthoffner/chatbot-mini,docker,mit,2
-8078,izumi-lab/stormy-7b-10ep,docker,mit,2
-8079,rootvisionai/few_shot_sam,streamlit,mit,2
-8080,SMD00/Image_Colorization,gradio,apache-2.0,2
-8081,rgres/Seg2Sat,docker,,2
-8082,EllieSiegel/Falcon-40B,gradio,apache-2.0,2
-8083,tomzhang1019/ChatGPT,gradio,gpl-3.0,2
-8084,Retinalogic/pastel-mix,gradio,creativeml-openrail-m,2
-8085,gersh/OpenAssistant-falcon-40b-sft-top1-560,gradio,,2
-8086,BlitzenPrancer/TheBloke-guanaco-65B-HF,gradio,,2
-8087,piusanalytics/Personal_Prompt_Engineer,gradio,,2
-8088,psychpsych/emilianJR-CyberRealistic_V3,gradio,,2
-8089,akbojda/aquarium-object-detection,gradio,cc-by-4.0,2
-8090,danieldux/isco-gpt,streamlit,mit,2
-8091,LuxOAI/HUXTT,gradio,,2
-8092,RisticksAI/ProfNet3-Snapy-support-chatbot,gradio,,2
-8093,chungsarit/ytdownload,docker,mit,2
-8094,arshian/linearepitopemodels,streamlit,,2
-8095,dragonSwing/annotate-anything,gradio,apache-2.0,2
-8096,rfrossard/Image-and-3D-Model-Creator,gradio,,2
-8097,mikeee/multilingual-dokugpt,gradio,mit,2
-8098,amaanadeen/ChurnCustomer,streamlit,,2
-8099,kmfoda/bittensor_lmeh_evaluations,gradio,,2
-8100,IoMa/diffusers-gallery,static,mit,2
-8101,danielsteinigen/NLP-Legal-Texts,streamlit,openrail,2
-8102,emc348/faces-through-time,gradio,mit,2
-8103,ammansik/youtube_summarizer,streamlit,mit,2
-8104,anshu-man853/webscrapping,gradio,,2
-8105,DarkyMan/URPM,gradio,mit,2
-8106,Panel-Org/panel-template,docker,,2
-8107,SpacesExamples/Gradio-Docker-Template,docker,,2
-8108,grisiemjahand/Image-and-3D-Model-Creator,gradio,,2
-8109,remyxai/image-directory-to-video-tool,gradio,mit,2
-8110,yjw5344/Bard_API,gradio,,2
-8111,kausmos/clothsy,gradio,,2
-8112,vbzvibin/Text2SQL,streamlit,,2
-8113,sdeeas/ChuanhuChatGPT,gradio,gpl-3.0,2
-8114,KaraAgroAI/CADI-AI,gradio,agpl-3.0,2
-8115,ttt246/brain,gradio,other,2
-8116,duchaba/yml_humana,gradio,mit,2
-8117,bilby/bilby-retrievalqa,gradio,unknown,2
-8118,Silence1412/Stable_Diffusion_Cpu,gradio,,2
-8119,derinsu/Background_Generator,gradio,openrail,2
-8120,raseel-zymr/LangChain-Youtube-Script-Generator,streamlit,mit,2
-8121,Malmika/Osana-WEB-GPT,gradio,,2
-8122,Manzoor22/ptx0-pseudo-journey-v2,gradio,,2
-8123,jsu27/decomp-diffusion,gradio,,2
-8124,wong26/faster-whisper-webui,gradio,apache-2.0,2
-8125,akshatjain1004/deepfake-detector-with-explainability,gradio,mit,2
-8126,gtome/NousResearch-Nous-Hermes-13b,gradio,,2
-8127,yfor/Bili-Insight,gradio,cc-by-4.0,2
-8128,yrvelez/ggml_chat,gradio,,2
-8129,hanstyle/tts,gradio,apache-2.0,2
-8130,JUNGU/Talk2Carnegie,gradio,openrail,2
-8131,awacke1/ChatGPTStreamlit11,streamlit,mit,2
-8132,omartine/prompt-generator,gradio,,2
-8133,bright1/Sepsis-Prediction-API,docker,,2
-8134,mpatel57/ConceptBed,gradio,mit,2
-8135,DHEIVER/Anomalias_no_Trato_Gastrointestinal,gradio,,2
-8136,alirezamsh/rquge,gradio,,2
-8137,Brasd99/AnswerMate,gradio,,2
-8138,marcusj83/MusicGenbruh,gradio,cc-by-nc-4.0,2
-8139,allandclive/Uganda_MMS,gradio,cc-by-nc-4.0,2
-8140,NHNDQ/KoTAN,gradio,apache-2.0,2
-8141,sharathraju/489,streamlit,,2
-8142,Rehman1603/Video-To-Text,gradio,,2
-8143,0xHacked/zkProver,docker,bsd,2
-8144,kasun/blip-large,gradio,,2
-8145,Azurro/APT-1B-Base,gradio,cc-by-nc-4.0,2
-8146,SujanMidatani/resume_details_to_questions,gradio,,2
-8147,aidealab/interior-ai,streamlit,openrail,2
-8148,leonelhs/deoldify,gradio,mit,2
-8149,Neelanjan/MoodMelody,gradio,other,2
-8150,HuggingFaceH4/reward-modeling-chat-ui,gradio,apache-2.0,2
-8151,robinhad/kruk,gradio,apache-2.0,2
-8152,RegalHyperus/rvc-anime-game,gradio,mit,2
-8153,faizhalas/coconut,streamlit,mit,2
-8154,Blackroot/Fancy-Audiogen,gradio,unlicense,2
-8155,ml-energy/leaderboard,gradio,,2
-8156,theodotus/pythia-uk,gradio,mit,2
-8157,kitrak-rev/AI-Clone,gradio,,2
-8158,upthrustinc/seoAnalyzerGPT,streamlit,,2
-8159,Malmika/Physics-AI,gradio,,2
-8160,Amrrs/QR-code-AI-art-generator,gradio,,2
-8161,OptimalScale/Robin-33b,gradio,apache-2.0,2
-8162,onursavas/Chat_with_PDF,streamlit,,2
-8163,FabioZe/WizardLM-WizardCoder-15B-V1.0,gradio,,2
-8164,odettecantswim/rvc-mlbb,gradio,mit,2
-8165,Illumotion/Koboldcpp,docker,,2
-8166,tanminggang/Norod78-sd15-caricature-portraits-blip-captions,gradio,,2
-8167,allknowingroger/New-Image-Models-Testing,gradio,,2
-8168,studiobrn/SplitTrack,gradio,cc-by-nc-4.0,2
-8169,amoldwalunj/resume_matching_app,streamlit,,2
-8170,JoshMe1/YTYT,streamlit,,2
-8171,Tinny-Robot/tinny-bot,gradio,mit,2
-8172,jpfearnworks/ai_agents,gradio,apache-2.0,2
-8173,pip64/geston1,gradio,,2
-8174,akhaliq/openlm-research-open_llama_13b,gradio,,2
-8175,sardor97/Classification_demo,gradio,mit,2
-8176,biodatlab/NBDT-Recommendation-Engine,gradio,,2
-8177,RahulSinghPundir/Sentiment-Analysis,gradio,creativeml-openrail-m,2
-8178,Nixic/ffmo,gradio,apache-2.0,2
-8179,pyresearch/pyresearch,gradio,,2
-8180,Yesmyboi/Yes,docker,,2
-8181,RickyMartin-dev/Text_to_Image_Diffusion,gradio,mit,2
-8182,renumics/cifar10-embeddings,docker,mit,2
-8183,arju10/traditional_cloth_recognizer,gradio,apache-2.0,2
-8184,Xeraphinite/Coursera-GPT,gradio,openrail,2
-8185,gwang-kim/DATID-3D,gradio,mit,2
-8186,PYTHONOPTIC/FOCUSGUMMY,gradio,,2
-8187,awacke1/QRCodeAIWriterReaderImaging,gradio,mit,2
-8188,verkaDerkaDerk/face-image-to-face-obj,gradio,,2
-8189,simonduerr/pyvisdemo,gradio,mit,2
-8190,fuqiang/txt2pic,gradio,apache-2.0,2
-8191,autopilot-ai/Indic_sentence_completion,gradio,,2
-8192,jbilcke-hf/template-node-ctransformers-express,docker,,2
-8193,BasToTheMax/openai-whisper-large-v2,gradio,,2
-8194,awacke1/ChatGPTStreamlit7-Private2,streamlit,mit,2
-8195,DAOGEN/README,static,,2
-8196,jackcao2023/THUDM-WebGLM,gradio,openrail,2
-8197,PineSearch/generatorImage,gradio,afl-3.0,2
-8198,Tinny-Robot/Tinny-Robot-NCAIR-ChatBot,gradio,mit,2
-8199,Antoine245/bot,gradio,openrail,2
-8200,FauziNL/Voice_anime2,gradio,mit,2
-8201,raphaelmerx/MMS-transcription,gradio,,2
-8202,hayas-tohoku-workshop-2023/comparing-VQA-models,gradio,,2
-8203,Ma5onic/MVSEP-MDX23-music-separation-model,gradio,,2
-8204,pcuenq/irc,gradio,,2
-8205,MattyWhite/ChatGPT-ImageCaptioner2,gradio,,2
-8206,ops-gaurav/tts,streamlit,openrail,2
-8207,alanchan808/Ask_Tennis_Coach_Rick_Macci,gradio,,2
-8208,rosebe/EcoSmart,gradio,,2
-8209,leonelhs/rembg,gradio,mit,2
-8210,Yunoposter/H377,docker,,2
-8211,Jaehan/Translation-Korean2English-2,gradio,,2
-8212,bg6293/neuralmind-bert-base-portuguese-cased,gradio,,2
-8213,angelhimi/anime-remove-background,gradio,apache-2.0,2
-8214,awacke1/Voice-ChatGPT-Streamlit-12,streamlit,mit,2
-8215,arixiii/open-reverse-proxy,docker,,2
-8216,JohnnyFromOhio/openai-jukebox-1b-lyrics,gradio,,2
-8217,allknowingroger/Image-Models-Test9,gradio,,2
-8218,PeepDaSlan9/whisper-web,static,,2
-8219,smatty662/TheBloke-Wizard-Vicuna-30B-Uncensored-fp16,gradio,openrail,2
-8220,RavenBloody/Prototype03,docker,,2
-8221,f2api/gpt-academic,gradio,,2
-8222,shigel/recipe_0626,gradio,,2
-8223,ckul/Real-ESRGAN,gradio,,2
-8224,zxc314/vits-uma-genshin-honkai,gradio,apache-2.0,2
-8225,jbilcke-hf/webapp-factory-llama-node,docker,,2
-8226,Tekknoman/SG161222-Realistic_Vision_V1.4,gradio,,2
-8227,kingabzpro/falcon-1b-ChatBot,gradio,apache-2.0,2
-8228,coreml-community/converter,gradio,mit,2
-8229,DonDoesStuff/Free-GPT3.5,gradio,,2
-8230,NingKanae/anime-voice-generator,gradio,apache-2.0,2
-8231,guymorlan/Arabic2Taatik,gradio,,2
-8232,Warlord-K/TryOn,gradio,openrail,2
-8233,awinml/falcon-7b-instruct-api,gradio,mit,2
-8234,propilot/transcribe-speech-to-text,streamlit,mit,2
-8235,SAUL19/imagen-audio,gradio,afl-3.0,2
-8236,Superlang/ImageComposition,gradio,cc-by-nc-4.0,2
-8237,Duino/multy_tts,streamlit,creativeml-openrail-m,2
-8238,duchaba/ct_bactrian,gradio,mit,2
-8239,dfurman/chat-all-in,gradio,,2
-8240,balaramas/s2t_translator,gradio,other,2
-8241,awacke1/MemoryEmbeddingsChatGPT-1,streamlit,mit,2
-8242,ayoolaolafenwa/ChatLM,gradio,apache-2.0,2
-8243,ysharma/chatglm2-6b-4bit,gradio,mit,2
-8244,splendid/image-generate,gradio,cc,2
-8245,finding-fossils/metaextractor-data-review-tool,docker,mit,2
-8246,tsi-org/zeroscope,gradio,,2
-8247,Mediocreatmybest/PipelineImageCaption,gradio,,2
-8248,thesven/blog-content-writer,streamlit,apache-2.0,2
-8249,Youssef-Okeil/ArchitectureClassifier,gradio,apache-2.0,2
-8250,allknowingroger/text-generation-webui-space-1,gradio,mit,2
-8251,arianaira/movie-recommender,streamlit,unknown,2
-8252,felipekitamura/face_deid_ct,gradio,mit,2
-8253,peb-peb/shravan,gradio,mit,2
-8254,Nekomaru180/rvc-model,gradio,mit,2
-8255,stamps-labs/swp-ui,streamlit,,2
-8256,btlee215/openchat-openchat,gradio,,2
-8257,awacke1/VoiceGPT15,streamlit,mit,2
-8258,crlandsc/tiny-audio-diffusion,gradio,,2
-8259,SIH/geodata-harvester-app,streamlit,lgpl-3.0,2
-8260,Mandy234/Mandy234-myQAmodel,gradio,apache-2.0,2
-8261,allknowingroger/Image-Models-Test18,gradio,,2
-8262,sujr/sujr-pix2struct-base,gradio,,2
-8263,rbarman/Audio_Separation_Spleeter,streamlit,,2
-8264,librarian-bots/hub-analysis,static,mit,2
-8265,amasad/sahil2801-replit-code-instruct-glaive,gradio,,2
-8266,AirtistDesign/stablediffusionapi-rev-animated,gradio,,2
-8267,HawkingChen/LangFlow,docker,mit,2
-8268,Cpp4App/Cpp4App,gradio,,2
-8269,zeykz/rvc-mlbb-v2zey,gradio,mit,2
-8270,bodah/RVC-Models-bo,gradio,,2
-8271,sirfindcent/skimlit,streamlit,mit,2
-8272,nahue-passano/librispeech-corpus-generator,streamlit,,2
-8273,allknowingroger/New-Image-Models-Testing-2,gradio,,2
-8274,ivntl/MMS,gradio,cc-by-nc-4.0,2
-8275,miwaniza/ZoomVideoComposer,gradio,,2
-8276,banana-projects/convai,docker,,2
-8277,giswqs/solara-template,docker,mit,2
-8278,Chen-Beer/LLMing,gradio,cc,2
-8279,Mobin-Nesari/MM-Movie-Recommender,streamlit,mit,2
-8280,nomic-ai/MBZUAI_LaMini-instruction,static,,2
-8281,nomic-ai/allenai_soda,static,,2
-8282,nomic-ai/liuhaotian_LLaVA-Instruct-150K,static,,2
-8283,nomic-ai/cnn_dailymail,static,,2
-8284,nomic-ai/fnlp_moss-002-sft-data,static,,2
-8285,nomic-ai/google_MusicCaps,static,,2
-8286,nomic-ai/ceval_ceval-exam,static,,2
-8287,nomic-ai/timdettmers_openassistant-guanaco,static,,2
-8288,nomic-ai/succinctly_midjourney-prompts,static,,2
-8289,nomic-ai/sahil2801_CodeAlpaca-20k,static,,2
-8290,nomic-ai/ehartford_wizard_vicuna_70k_unfiltered,static,,2
-8291,nomic-ai/wikisql,static,,2
-8292,nomic-ai/IlyaGusev_ru_turbo_alpaca,static,,2
-8293,turhancan97/yolov8-orientation,gradio,mit,2
-8294,sub314xxl/StyleGAN-XL,gradio,,2
-8295,savakholin/esm-2,streamlit,,2
-8296,allknowingroger/Image-Models-Test23,gradio,,2
-8297,AliHaider0343/implicit-and-explicit-aspects-Extraction-in-Restaurant-Reviews-Domain,streamlit,,2
-8298,AliHaider0343/Restaurant-Domain-Sentence-Categories-Classification,streamlit,,2
-8299,allknowingroger/Image-Models-Test24,gradio,,2
-8300,SinaAhmadi/ScriptNormalization,gradio,mit,2
-8301,dfurman/chat-gpt-3.5-turbo,gradio,,2
-8302,allknowingroger/Image-Models-Test26,gradio,,2
-8303,lllqqq/so-vits-svc-models-pcr,gradio,apache-2.0,2
-8304,DiamondYin/AnewGame,static,,2
-8305,Nultx/stable-diffusion-webui-cpu,gradio,,2
-8306,at2507/at2507_zeroshot_finetuned_sentiment,gradio,,2
-8307,SarthakSidhant/Go-Cattle,streamlit,agpl-3.0,2
-8308,navervision/MLSD,gradio,,2
-8309,allknowingroger/Image-Models-Test29,gradio,,2
-8310,KT07/Speech_Analytics,gradio,unknown,2
-8311,huggingface-course/audio-course-u7-assessment,gradio,,2
-8312,allknowingroger/Image-Models-Test30,gradio,,2
-8313,Ank0X0/Image-Upscaling-Playground,gradio,apache-2.0,2
-8314,rdyzakya/IndoLEGO-ABSA,streamlit,,2
-8315,AchyuthGamer/OpenGPT-v1,docker,apache-2.0,2
-8316,balaramas/indic_s2s,gradio,other,2
-8317,angelasnpang/segment-anything-ui,gradio,,2
-8318,justest/embeddings-api,gradio,apache-2.0,2
-8319,Wauplin/gradio-oauth-demo,gradio,,2
-8320,Vinnybustacap/WizardLM-WizardLM-7B-V1.0,gradio,openrail,2
-8321,MariaK/Audio-Course-Certification,gradio,,2
-8322,Sandiago21/text-to-speech-italian,gradio,,2
-8323,jjumper/Jump,docker,,2
-8324,Kajise/GPT4ALL-Falcon,gradio,agpl-3.0,2
-8325,ysharma/RedPajama-ChatInterface,gradio,mit,2
-8326,Sandiago21/speech-to-speech-translation-italian,gradio,,2
-8327,hysts/Kandinsky-2-1,gradio,mit,2
-8328,badmonk/model,gradio,,2
-8329,Yabo/ControlVideo,gradio,mit,2
-8330,daarumadx/bot,docker,,2
-8331,MWilinski/bot,gradio,mit,2
-8332,karol99/Envvi-Inkpunk-Diffusion,gradio,gfdl,2
-8333,Sandiago21/text-to-speech-spanish,gradio,,2
-8334,wykonos/movie-recommender,gradio,,2
-8335,3mrology/Chameleon_Text2Img_Generation_Demo,gradio,apache-2.0,2
-8336,Endercat126/anything-v5-testing,gradio,,2
-8337,CloseEric/CloseEric,docker,,2
-8338,DiamondYin/Voice-ChatGPT-Streamlit-12,streamlit,mit,2
-8339,allknowingroger/Image-Models-Test37,gradio,,2
-8340,fffiloni/sd-wip-cinematic-mobile-adapt,gradio,,2
-8341,songdaooi/ketsueki,gradio,unknown,2
-8342,Atom007/SDXL-base-9-CPU,gradio,mit,2
-8343,jingwora/language-sentence-similarity,gradio,,2
-8344,Melyoooo/test,docker,,2
-8345,sakuramoon/Blossom,docker,,2
-8346,codedog-ai/edu-assistant,gradio,mit,2
-8347,TNR-5/lib,streamlit,,2
-8348,Aman30577/imageTool1,gradio,,2
-8349,Dagfinn1962/Dreamlikeart-Anime-1.0,gradio,,2
-8350,TNR-5/libt,streamlit,,2
-8351,CofAI/picgen,gradio,creativeml-openrail-m,2
-8352,ai-maker-space/ArxivChainLitDemo,docker,openrail,2
-8353,Sai004/ArticleAPI,gradio,openrail,2
-8354,OkamiFeng/Bark-with-Voice-Cloning,gradio,mit,2
-8355,superdup95/openai_api_key_status,gradio,mit,2
-8356,Binguii/Venus_Proxy,docker,,2
-8357,Abdullah-Habib/Text_to_Speech_Urdu,gradio,apache-2.0,2
-8358,PrinceDeven78/Dreamlike-Webui-CPU,gradio,,2
-8359,Dorado607/ChuanhuChatGPT,gradio,gpl-3.0,2
-8360,Hmjz100/YouTube-to-MT3,gradio,,2
-8361,TNR-5/netlist.v1,static,,2
-8362,CofAI/netlist,static,,2
-8363,openbmb/viscpm-chat,gradio,,2
-8364,Faridmaruf/rvc-genshin-v2,gradio,mit,2
-8365,Lewislou/Lewislou-cell-seg-sribd,gradio,apache-2.0,2
-8366,tnt2011/dog_cat_classifier,gradio,,2
-8367,lilucheng/sourcedetection,gradio,,2
-8368,GenXDad/logo-wizard-logo-diffusion-checkpoint,gradio,,2
-8369,naveed92/web_qa,streamlit,mit,2
-8370,jbilcke-hf/zeroscope-server-1,gradio,mit,2
-8371,Atualli/node-media-server,docker,apache-2.0,2
-8372,barunsaha/poem2pic,streamlit,openrail,2
-8373,TNR-5/Search,static,,2
-8374,lewispons/GrammarGuru,streamlit,,2
-8375,fatimaejaz/email_spame_classfier13,streamlit,,2
-8376,CofAI/viewq,static,,2
-8377,whoisterencelee/stabilityai-FreeWilly2,gradio,,2
-8378,umm-maybe/unitary-toxic-bert,gradio,,2
-8379,ShreyaRao/SummarizeEasy,streamlit,other,2
-8380,allknowingroger/Image-Models-Test45,gradio,,2
-8381,allknowingroger/Image-Models-Test,gradio,,2
-8382,ZX9966/LOGO-Approximate-Computing-Technology,static,apache-2.0,2
-8383,Xenova/llama2.c,docker,,2
-8384,luisotorres/gender-recognition-app,gradio,,2
-8385,chongjie/MCC_slim,gradio,apache-2.0,2
-8386,Harsh239/ChatBot,gradio,,2
-8387,allknowingroger/Image-Models-Test46,gradio,,2
-8388,ashwin3005/first-space,gradio,apache-2.0,2
-8389,camilosegura/traductor-multilenguaje,gradio,,2
-8390,awacke1/HTML5Interactivity,static,mit,2
-8391,vaishanthr/Hand-Detection-and-Segmentation,gradio,mit,2
-8392,kat33/llama.cpp,gradio,mit,2
-8393,freddyaboulton/echo-chatbot-gradio-discord-bot,gradio,,2
-8394,sonali-tamhankar/WA-Hospital-Regulations-Chatbot,streamlit,apache-2.0,2
-8395,s3nh/GOAT-7B-COMMUNITY-CHAT,gradio,openrail,2
-8396,allknowingroger/Image-Models-Test48,gradio,,2
-8397,echometerain/whos-that-pokemon,gradio,,2
-8398,Greenlight-AI/README,static,,2
-8399,ZeroTwo3/one_shot_talking_face_from_text,docker,,2
-8400,b1sheng/kg_llm_leaderboard_test,gradio,apache-2.0,2
-8401,allknowingroger/Image-Models-Test49,gradio,,2
-8402,ichelp/AUTOMATIC1111-stable-diffusion-webui,gradio,openrail,2
-8403,pe-nlp/mt-bench,gradio,other,2
-8404,Monster/Llama-2-7B-chat,gradio,llama2,2
-8405,miculpionier/Visual-Question-Answering,gradio,,2
-8406,psalama/UT_Hackathon,gradio,,2
-8407,ljrmary/UT_Hackathon2,gradio,,2
-8408,alonardo/Career_Companion,gradio,mit,2
-8409,mehedihassan/ai-stable-diffusion-Text-to-Image,gradio,,2
-8410,WinterGYC/Baichuan-13B-Chat-Int8-Docker,docker,apache-2.0,2
-8411,GroveStreet/GTA_SOVITS,gradio,mit,2
-8412,AbandonedMuse/UnlimitedMusicGen,gradio,creativeml-openrail-m,2
-8413,lukeslp/tts,gradio,,2
-8414,xAbdoAT/kandinsky-community-kandinsky-2-2-decoder,gradio,,2
-8415,vishnun/SnapCode,streamlit,mit,2
-8416,mikeee/llama-2-70b-guanaco-qlora-ggml,gradio,,2
-8417,Anni123/AuRoRA,gradio,,2
-8418,sub314xxl/SDXL-1.0-CPU,gradio,mit,2
-8419,sub314xxl/SDXL-1.0-Img2Img-CPU,gradio,mit,2
-8420,prospectai/email-checker,gradio,,2
-8421,sub314xxl/stable-diffusion-img2img,gradio,,2
-8422,billusanda007/MNIST,gradio,mit,2
-8423,allknowingroger/Image-Models-Test53,gradio,,2
-8424,mikeee/chinese-llama-2-7b-ggml-q4,gradio,,2
-8425,thenethi1603/mygenAIChatbot,gradio,,2
-8426,Geraldine/simple_contextual_chatbot,gradio,mit,2
-8427,hemanthbylupudi/mygenAI,gradio,,2
-8428,billusanda007/Resume-Ranker,streamlit,mit,2
-8429,mikeee/gradio-chatinterface,gradio,,2
-8430,ShieldX/Llama2CSV,streamlit,llama2,2
-8431,allknowingroger/Image-Models-Test54,gradio,,2
-8432,irvay/RVC_IR,gradio,,2
-8433,billusanda007/DeepRank,streamlit,mit,2
-8434,mtyrrell/cpv_poc,streamlit,,2
-8435,rushankg/test-streamlit,streamlit,cc-by-2.0,2
-8436,Toinean/huggingfashion,gradio,,2
-8437,awacke1/facebook-fastspeech2-en-ljspeech-0731,gradio,,2
-8438,sampath02061982/MyGenAi,gradio,,2
-8439,awen666/web-ui,static,gpl-3.0,2
-8440,Dagfinn1962/stablediffusion-members,gradio,,2
-8441,SDXL-ME/stabilityai-stable-diffusion-xl-base-1.0,gradio,,2
-8442,aurora10/GPT4ALL_CHATBOT,gradio,,2
-8443,billusanda007/HireGPT,streamlit,mit,2
-8444,Branon/TurboKeys,docker,,2
-8445,allknowingroger/Image-Models-Test55,gradio,,2
-8446,model-man/speech-to-speech-translation,gradio,,2
-8447,LaxmanOfficial/GenerativeAI,gradio,,2
-8448,xiaolv/claude2_xiaolv,gradio,,2
-8449,pikto/Elite-Scifi-Models,gradio,,2
-8450,seanwendlandt/Video_TO_AnimatedGIF,streamlit,mit,2
-8451,gptishard/gpt-newbing,docker,mit,2
-8452,codedog-ai/codedog-demo,gradio,mit,2
-8453,YumingYuan/Latex_OCR,gradio,,2
-8454,WordLift/entity-linking,streamlit,cc-by-sa-3.0,2
-8455,pvanand/RASA_moodbot,docker,mit,2
-8456,tanishqvashisht/sharingan,streamlit,,2
-8457,Bala2-03-2003/AIBALA,gradio,,2
-8458,rakesh092/Voice_cloning,gradio,,2
-8459,elsamueldev/gpt4all,gradio,,2
-8460,Sentdex/StableBeluga2-70B-Chat,gradio,apache-2.0,2
-8461,shaheerxd99/ml_bookquery_electrical,gradio,unknown,2
-8462,mumiao/BingAI,docker,mit,2
-8463,GAIR/Factool,gradio,,2
-8464,fjyczcr/bingai,docker,mit,2
-8465,matthoffner/open-codetree,docker,,2
-8466,Sandiago21/automatic-speech-recognition-spanish,gradio,,2
-8467,allknowingroger/Image-Models-Test58,gradio,,2
-8468,allknowingroger/Image-Models-Test61,gradio,,2
-8469,tanishqvashisht/horseToZebra,streamlit,,2
-8470,Binettebob22/fast_diffusion2,gradio,,2
-8471,omdena-lc/omdena-ng-lagos-chatbot-model,docker,,2
-8472,cxylz1/newbing,docker,mit,2
-8473,manutej/imagedemo1,streamlit,mit,2
-8474,drift-ai/recruiter-assistant-jbfxrs,gradio,,2
-8475,Sloth-Alchemist/tortoise-tts-webui,gradio,,2
-8476,CofAI/chat,docker,,2
-8477,VinayHajare/Marathi-Audio-Transcriber-and-Translator,gradio,openrail,2
-8478,ifire/Architext_deployed,gradio,,2
-8479,hoshilumine/combined-GI-RVC-models,gradio,mit,2
-8480,DeveloperAkhil/Personal-Chatbot,gradio,,2
-8481,allknowingroger/Image-Models-Test63,gradio,,2
-8482,tanishqvashisht/comicInator,streamlit,,2
-8483,LucasCodeBreak/MusicGen,gradio,cc-by-nc-4.0,2
-8484,Markjr/monadical-labs-minecraft-skin-generator,gradio,cc-by-2.0,2
-8485,myway1990/text2video,gradio,openrail,2
-8486,akashdhiman79830/MyGenAIAvatar,gradio,,2
-8487,jbilcke-hf/audio-server-1,gradio,bigscience-openrail-m,2
-8488,Galax/schafter_x_billy,gradio,,2
-8489,pamixsun/glaucoma_screening,streamlit,apache-2.0,2
-8490,mikeee/wizardlm-1.0-uncensored-llama2-13b-ggmlv3,gradio,,2
-8491,allknowingroger/Image-Models-Test66,gradio,,2
-8492,Sakil/LLM_Question_Answering_ChatBot,streamlit,apache-2.0,2
-8493,0xSynapse/LlamaGPT,gradio,lgpl-3.0,2
-8494,PeepDaSlan9/Universal-NER-UniNER-7B-definition,gradio,creativeml-openrail-m,2
-8495,Stevross/Astrid-1B-UI,streamlit,apache-2.0,2
-8496,renumics/cifar100-sliceguard-demo,docker,mit,2
-8497,allknowingroger/Image-Models-Test68,gradio,,2
-8498,mkotan/mafese_feature_selection,gradio,gpl-3.0,2
-8499,masterzer0456/Ai1,gradio,,2
-8500,Sparticle/Llama2_7b_chat_Japanese_Lora,gradio,cc-by-sa-4.0,2
-8501,Sparticle/Llama2_13b_chat_Japanese_Lora,gradio,cc-by-sa-4.0,2
-8502,billusanda007/Enhancer,streamlit,mit,2
-8503,awacke1/MemeGenerator,streamlit,mit,2
-8504,thewise/Chat-W-Git,streamlit,mit,2
-8505,n0rwegiancoder/WizardLM-WizardLM-70B-V1.0,gradio,openrail,2
-8506,AbelKidane/headdetector,streamlit,mit,2
-8507,allknowingroger/Image-Models-Test70,gradio,,2
-8508,allknowingroger/Image-Models-Test73,gradio,,2
-8509,bhavyagiri/retrieving-memes,gradio,apache-2.0,2
-8510,rodevel1978/llama-2-13b-chat.ggmlv3.q4_K_S,gradio,,2
-8511,shayakh/sdrv51,gradio,,2
-8512,harisansarkhan/CatFaceLandmarks,gradio,,2
-8513,terapyon/gh-issue-search,streamlit,mit,2
-8514,Smotto/Vocal-Isolator,streamlit,openrail,2
-8515,kevinwang676/VoiceChangers,gradio,mit,2
-8516,allknowingroger/Image-Models-Test74,gradio,,2
-8517,allknowingroger/Image-Models-Test75,gradio,,2
-8518,rahgadda/bark-voice-generator,gradio,,2
-8519,foduucom/thermal_image_object_detection,gradio,,2
-8520,syx948/ChatPDF,gradio,apache-2.0,2
-8521,x6/BingAi,Configuration error,Configuration error,2
-8522,imageomics/dashboard-prototype,docker,mit,2
-8523,BG5/midjourney,docker,mit,2
-8524,imageomics/dev-dashboard,docker,mit,2
-8525,JesseDuku/Hackathon_on_Plastic-free_rivers,gradio,mit,2
-8526,jotap12/enso,streamlit,,2
-8527,PeepDaSlan9/Gryphe-MythoMax-L2-13b,gradio,openrail,2
-8528,PeepDaSlan9/Language-Learn-Idea,gradio,,2
-8529,Justin-Choo/Multi-Diffusers_WEB_UI_CLEANED,gradio,,2
-8530,nola-ai/Recipe_Meal_Planner,gradio,,2
-8531,VinayHajare/Speech-To-Speech-Translation-For-Marathi-To-English,gradio,creativeml-openrail-m,2
-8532,Justin-Choo/Anzu-mix_WEB_UI,gradio,,2
-8533,allknowingroger/Image-Models-Test78,gradio,,2
-8534,allknowingroger/Image-Models-Test80,gradio,,2
-8535,mygyasir/remove-photo-object,streamlit,,2
-8536,Dagfinn1962/prodia2,gradio,apache-2.0,2
-8537,Hina4867/bingo,docker,mit,2
-8538,Alex132/togethercomputer-LLaMA-2-7B-32K,gradio,,2
-8539,Bannermore/BingChat,docker,mit,2
-8540,allknowingroger/Image-Models-Test81,gradio,,2
-8541,allknowingroger/Image-Models-Test82,gradio,,2
-8542,c1ybaby/bingAI,docker,mit,2
-8543,Justin-Choo/QuickGen-Photo,gradio,creativeml-openrail-m,2
-8544,shatrunjai/FutureMeMotivator,gradio,openrail,2
-8545,Supedsa/rvc-models,gradio,mit,2
-8546,harisansarkhan/DogBreedClassification,gradio,,2
-8547,najimino/video,gradio,,2
-8548,PeepDaSlan9/rvc-models,gradio,mit,2
-8549,shibing624/ChatPDF,gradio,gpl-3.0,2
-8550,Chitranshu/Dashboard-Uber,docker,,2
-8551,AIConsultant/MusicGen,gradio,mit,2
-8552,qskaa/213,docker,mit,2
-8553,TheProjectsGuy/AnyLoc,gradio,bsd-3-clause,2
-8554,LamaAlQarni/Fire-Smoke-Detector,gradio,,2
-8555,raul-padua/Image-Caption,gradio,openrail,2
-8556,drdevinhopkins/llSourcell-medllama2_7b,gradio,,2
-8557,mygyasir/Real-Time-Voice-Cloning,gradio,,2
-8558,cccc-c/bingo,docker,mit,2
-8559,allknowingroger/Image-Models-Test86,gradio,,2
-8560,sanwuchengqun/bingai,docker,mit,2
-8561,101-5/gpt4free,gradio,,2
-8562,rektKnight/stable-diffusion-webui-cpu_dupli,gradio,,2
-8563,analist/upscaler,streamlit,apache-2.0,2
-8564,mygyasir/ExperAI_Simulations,gradio,,2
-8565,GTR-32X/uboa,docker,,2
-8566,ranchaya/AI-audio-generator,streamlit,,2
-8567,viait/stable-diffusion-license,static,creativeml-openrail-m,2
-8568,ghuron/artist,streamlit,,2
-8569,allknowingroger/Image-Models-Test88,gradio,,2
-8570,allknowingroger/Image-Models-Test91,gradio,,2
-8571,sukiru/BlueArchiveTTS,gradio,mit,2
-8572,Rfilippelli/Deci-DeciCoder-1b,gradio,,2
-8573,JUNGU/Image-to-Story-Ko,gradio,,2
-8574,PeepDaSlan9/animated-audio-visualizer,gradio,,2
-8575,abouuuud/poetry,gradio,cc-by-nc-4.0,2
-8576,praveenku32k/SimpleConversationalApp,streamlit,,2
-8577,allknowingroger/Image-Models-Test94,gradio,,2
-8578,allknowingroger/Image-Models-Test96,gradio,,2
-8579,PeepDaSlan9/segmind-portrait-finetuned,gradio,creativeml-openrail-m,2
-8580,Xuan2060320350/ChatSydney,docker,mit,2
-8581,Kunal7/Gradio-Squats,gradio,mit,2
-8582,Xuan2060320350/ChatSydney-1,docker,mit,2
-8583,JUNGU/Image-to-Story-Ko-multiplot,gradio,,2
-8584,ehristoforu/Hackchat,docker,,2
-8585,crystalai/stabilityai-stable-diffusion-xl-refiner-1.0,gradio,,2
-8586,ashu3984/Dialogue_summarization,gradio,,2
-8587,themanas021/Sentiment_Analysis,gradio,mit,2
-8588,shanechin/Linaqruf-pastel-anime-xl-lora,gradio,,2
-8589,aaaaaabbbbbbbdddddddduuuuulllll/poetry2023,gradio,,2
-8590,Amitontheweb/InstaoffyzFreeParaphraser,gradio,mit,2
-8591,allknowingroger/Image-Models-Test97,gradio,,2
-8592,Sambhavnoobcoder/stable-diffusion-inpainting,gradio,,2
-8593,CognitiveLabs/Research-Assistant,gradio,,2
-8594,mygyasir/Fictiverse-Voxel_XL_Lora,gradio,,2
-8595,viait/vscode,docker,,2
-8596,srisakthi2821/UcenAiBot,gradio,,2
-8597,allknowingroger/Image-Models-Test101,gradio,,2
-8598,walterclozet/coffeeee-nsfw-story-generator2,gradio,,2
-8599,hekbobo/bingo,docker,mit,2
-8600,dolphinprojects/ProxySearch,gradio,,2
-8601,WangJexi/panel_trial,docker,,2
-8602,callmesan/sai-bot-alpha,gradio,apache-2.0,2
-8603,Ayushnangia/Whispercpp_yt,gradio,apache-2.0,2
-8604,mygyasir/Stable-Diffusion-Fast,gradio,,2
-8605,BBrother/Pandora,docker,,2
-8606,aupfe08/image_transform_with_AnimeGAN,gradio,,2
-8607,openskyml/README,static,,2
-8608,heroku/fse,docker,,2
-8609,tengqf/resumeGPT,gradio,,2
-8610,HuggingFaceM4/IDEFICS_Data_Measurement_Tool,streamlit,,2
-8611,allknowingroger/Image-Models-Test105,gradio,,2
-8612,allknowingroger/Image-Models-Test107,gradio,,2
-8613,NEXAS/NEXAS-stable_diff_custom,gradio,mit,2
-8614,fluffyfluff/multiple-pdf-chat,streamlit,,2
-8615,FathomNet/fathomnet2023-comp-baseline,gradio,cc-by-4.0,2
-8616,romero61/hendata,docker,mit,2
-8617,allknowingroger/Image-Models-Test108,gradio,,2
-8618,allknowingroger/Image-Models-Test109,gradio,,2
-8619,harisansarkhan/Image-Classification-with-CIFAR-10,gradio,,2
-8620,podsysai/podsys,static,apache-2.0,2
-8621,Iqbalzz/hololive-rvc-models,gradio,mit,2
-8622,mygyasir/stablediffusionapi-epicrealism-epinikio,gradio,,2
-8623,FedeFT/Head_Pose_Estimation_and_LAEO_computation,gradio,gpl,2
-8624,sandrocalzada/emotions_faceswap,streamlit,lgpl-3.0,2
-8625,allknowingroger/Image-Models-Test112,gradio,,2
-8626,allknowingroger/Image-Models-Test113,gradio,,2
-8627,mangiucugna/difficult-conversations-bot,gradio,cc-by-nc-sa-4.0,2
-8628,matanmichaely/image_to_audio_story,streamlit,apache-2.0,2
-8629,WangQvQ/BEiT_Gradio,gradio,openrail,2
-8630,mygyasir/Stable-Diffusion-Fast111,gradio,,2
-8631,toiram/artificialguybr-LogoRedmond-LogoLoraForSDXL,gradio,,2
-8632,toiram/goofyai-Leonardo_Ai_Style_Illustration,gradio,,2
-8633,LDJA/hotdog_ld,gradio,mit,2
-8634,Gabesantos1007/Dall-e,streamlit,,2
-8635,jhonparra18/ocr-LLM-image-summarizer,streamlit,apache-2.0,2
-8636,chansung/hf-inference-endpoint,gradio,apache-2.0,2
-8637,ReyDev/Claude-Space,docker,apache-2.0,2
-8638,allknowingroger/Image-Models-Test118,gradio,,2
-8639,Sarfraz/ehartford-Samantha-1.11-CodeLlama-34b,gradio,,2
-8640,deepghs/character_splitter,gradio,mit,2
-8641,adasddas/dsaaaaaaaa2,docker,bigscience-openrail-m,2
-8642,AchyuthGamer/NeonAI-Chat-UI,gradio,,2
-8643,datastx/csv-analysis,streamlit,bsd,2
-8644,Abhimurthy/Phind-Phind-CodeLlama-34B-v1,gradio,,2
-8645,Rehman1603/YouTubeToTextInVariousLanguage,gradio,,2
-8646,logier/QQsign,docker,mit,2
-8647,AnimaLab/bias-test-gpt-pairs,gradio,apache-2.0,2
-8648,allknowingroger/Image-Models-Test121,gradio,,2
-8649,Lngo/paragon-AI-blip2-image-to-text,gradio,,2
-8650,allknowingroger/Image-Models-Test123,gradio,,2
-8651,DeeKayG/COCO-Google,gradio,openrail,2
-8652,CodingBillionaire/bark-voice-cloning,gradio,mit,2
-8653,Justin-Choo/epiCRealism-Natural_Sin_RC1_VAE-WEB-UI,gradio,,2
-8654,heath1989/prompt-r-gen-sd,gradio,,2
-8655,sub314xxl/voicechange,gradio,mit,2
-8656,Justin-Choo/AWPortrait-WEBUI-CPU,gradio,,2
-8657,assemblyai/Conformer2-Demo,gradio,,2
-8658,hardon-server/space-diffusion-txt2img-1-5,gradio,,2
-8659,hardon-server/prompthero-openjourney,gradio,,2
-8660,hardon-server/dalle-mini,static,apache-2.0,2
-8661,XEGAN/movie-recommendation-system,streamlit,,2
-8662,AEUPH/CosmosTV,docker,,2
-8663,askarov/I2VGen-XL,gradio,,2
-8664,DaweiZ/toy-gpt,docker,mit,2
-8665,StaticalizaAI/GPT-4,gradio,openrail,2
-8666,Kajise/Demucs_v4-FT_4s,gradio,agpl-3.0,2
-8667,Kajise/Demucs_v4-FT_2s,gradio,agpl-3.0,2
-8668,Yntec/Image-Models-Test,gradio,,2
-8669,wffcyrus/SD-WebUI,docker,,2
-8670,veidlink/find_my_movie_hf,streamlit,,2
-8671,Samlund56/blip-image-captioning-large,gradio,bsd-3-clause,2
-8672,giseldo/story_point_estimator_metrics,gradio,,2
-8673,awacke1/acw-dr-llama-7b-chat,streamlit,mit,2
-8674,Kurkur99/Sentiment_analysis,streamlit,,2
-8675,alesa/conceptofmind-Yarn-Llama-2-13b-128k,gradio,,2
-8676,doevent/vc,gradio,,2
-8677,airsat/dalle-mini,static,,2
-8678,osmanriver/Alist,docker,agpl-3.0,2
-8679,sky24h/Controllable_Multi-domain_Semantic_Artwork_Synthesis,docker,cc-by-nc-4.0,2
-8680,gpecile/encrypted-image-recognition,gradio,,2
-8681,NoCrypt/sd_out_gallery,gradio,,2
-8682,iknow-lab/ko-flan-zero,gradio,mit,2
-8683,Billet/WizardLM-WizardMath-70B-V1.033,gradio,,2
-8684,nuttella/supa,docker,,2
-8685,PixelistStudio/3dart-Models,gradio,,2
-8686,robinmia/speecht5-tts-demo,gradio,apache-2.0,2
-8687,skavya/youtube_transcript_summarizer,gradio,,2
-8688,Abdllh/AraPoet,gradio,gpl-3.0,2
-8689,Abdllh/topic2poem,gradio,afl-3.0,2
-8690,Abdllh/poetry2023,gradio,,2
-8691,Abdllh/poetry,gradio,cc-by-nc-4.0,2
-8692,nsarrazin/agent-chat,docker,,2
-8693,Anindya/Marketing_Campaign_LLM,streamlit,,2
-8694,Abdllh/poetry202,gradio,,2
-8695,Venafi/Vikram-Explorer,gradio,apache-2.0,2
-8696,turing-motors/heron_chat_git,gradio,apache-2.0,2
-8697,allknowingroger/Image-Models-Test127,gradio,,2
-8698,ivuxy/somnium,gradio,,2
-8699,dongyi/MMFS,gradio,apache-2.0,2
-8700,kevinwang676/Bark-Coqui,gradio,,2
-8701,ysharma/testing_gradio_wheels,gradio,mit,2
-8702,allknowingroger/Image-Models-Test129,gradio,,2
-8703,allknowingroger/Image-Models-Test130,gradio,,2
-8704,Abdllh/Arabic_Poems_Generator,gradio,,2
-8705,hardon-server/img2txt-server,gradio,,2
-8706,nagauta/mediapipe-hair-segmentation,gradio,,2
-8707,Rishabh055/Movie_recommendation_System,streamlit,,2
-8708,hardon-server/image2image-stable-diffusion,gradio,unknown,2
-8709,neosonics/Awais-Audio_Source_Separation,gradio,,2
-8710,X1A/UniPoll,gradio,,2
-8711,Kirihasan/rvc-jjjo,gradio,mit,2
-8712,adhirk/ARKs_Contextual_Chronicle,streamlit,,2
-8713,allknowingroger/Image-Models-Test132,gradio,,2
-8714,deepaksarika01/youtube-video-qa-lamini,gradio,creativeml-openrail-m,2
-8715,Thafx/sdrvxl1,gradio,mit,2
-8716,Ashrafb/Tesseract-OCR,gradio,,2
-8717,Jeff2323/ai-comic-factory,docker,,2
-8718,diffusers/pipeline_stats,gradio,,2
-8719,allknowingroger/Image-Models-Test133,gradio,,2
-8720,r3gm/vscode,docker,,2
-8721,allknowingroger/Image-Models-Test137,gradio,,2
-8722,fspecii/midi-composer,gradio,apache-2.0,2
-8723,chemouda/arome_ai,gradio,,2
-8724,Samarth991/Youtube-Video-ChatBot,gradio,mit,2
-8725,Alfasign/remove-background-on-image,gradio,,2
-8726,allknowingroger/Image-Models-Test139,gradio,,2
-8727,freeCS-dot-org/phi-1_5,gradio,other,2
-8728,thecherub/welovekaban,docker,,2
-8729,jacktown/codefuse-ai-CodeFuse-CodeLlama-34B,gradio,,2
-8730,limcheekin/CodeLlama-13B-oasst-sft-v10-GGUF,docker,,2
-8731,PVIT/pvit,streamlit,apache-2.0,2
-8732,wang2246478872/facebook-m2m100_1.2B,streamlit,mit,2
-8733,MercuryLeafer/img-to-music,gradio,,2
-8734,allknowingroger/Image-Models-Test140,gradio,,2
-8735,allknowingroger/Image-Models-Test141,gradio,,2
-8736,Akash473/FunkoHairBeard,gradio,openrail,2
-8737,huggingface-projects/MusicGen-bot,gradio,,2
-8738,Suniilkumaar/SwapMukham,gradio,unknown,2
-8739,hlydecker/RA-document-QAchat,streamlit,cc-by-nc-sa-4.0,2
-8740,Ashrafb/codellama-34b,gradio,other,2
-8741,mhenrichsen/DanskGPT,gradio,,2
-8742,kiyer/pathfinder,streamlit,mit,2
-8743,KAIST-Geometric-AI-Lab/syncdiffusion-demo,gradio,,2
-8744,Edisonymy/buy-or-rent,streamlit,mit,2
-8745,jpwahle/paraphrase-type-tasks,gradio,mit,2
-8746,harpreetsahota/chat-with-website,gradio,apache-2.0,2
-8747,AchyuthGamer/ImMagician-Image-Generator,gradio,mit,2
-8748,allknowingroger/Image-Models-Test144,gradio,,2
-8749,allknowingroger/Image-Models-Test145,gradio,,2
-8750,skhanuja/zeno-winoground,docker,apache-2.0,2
-8751,allknowingroger/Image-Models-Test147,gradio,,2
-8752,allknowingroger/Image-Models-Test148,gradio,,2
-8753,floriankrempl/mtg_rules_bot,gradio,,2
-8754,HoangHa/IELTS_Speaking_GPT,streamlit,mit,2
-8755,guardiancc/fast-stable-diffusion,gradio,mit,2
-8756,digitalxingtong/Taffy-Bert-VITS2,gradio,mit,2
-8757,eaglelandsonce/UploadaDocAskaQuestion,streamlit,,2
-8758,opencompass/MMBench,gradio,apache-2.0,2
-8759,openMUSE/parti-prompts-leaderboard,gradio,apache-2.0,2
-8760,allknowingroger/Image-Models-Test150,gradio,,2
-8761,allknowingroger/Image-Models-Test151,gradio,,2
-8762,flocolombari/COLOMBARI_VIGNES-FERRINO_DERNIAUX_NIYONKURU,gradio,unknown,2
-8763,jskalbg/ChatDev01,gradio,,2
-8764,get-foundation/getdemo,docker,cc-by-nc-4.0,2
-8765,mya-mya/SentenceMixer,gradio,apache-2.0,2
-8766,allknowingroger/Image-Models-Test152,gradio,,2
-8767,ayush5710/Codellama-13b-integratable-chatbot,static,llama2,2
-8768,Artples/Chat-with-Llama-2-70b,gradio,mit,2
-8769,giswqs/geospatial-dataviz,docker,mit,2
-8770,digitalxingtong/Nanami-Bert-VITS2,gradio,mit,2
-8771,valeriylo/rag_demo,streamlit,,2
-8772,ayush5710/palm-chatbot,streamlit,,2
-8773,digitalxingtong/Jiaran-Bert-VITS2,gradio,mit,2
-8774,openMUSE/MUSE-vs-SD.1.5,gradio,,2
-8775,allknowingroger/Image-Models-Test155,gradio,,2
-8776,allknowingroger/Image-Models-Test156,gradio,,2
-8777,hezhaoqia/vits-simple-api,gradio,mit,2
-8778,FIT2125/stable-diffusion-webui-cpu,gradio,,2
-8779,ayush5710/wizard-coder-34b-coding-chatbot,gradio,openrail,2
-8780,SeyedAli/Persian-Speech-Transcription,gradio,mit,2
-8781,allknowingroger/Image-Models-Test159,gradio,,2
-8782,huggingface-projects/deepfloydif-bot,gradio,,2
-8783,arborvitae/AI_Legal_documentation_assistant,gradio,,2
-8784,digitalxingtong/Xingtong-Read-Bert-VITS2,gradio,mit,2
-8785,allknowingroger/Image-Models-Test160,gradio,,2
-8786,allknowingroger/Image-Models-Test161,gradio,,2
-8787,hf4all/bingo-api,docker,,2
-8788,Coweed/BadTrip,docker,,2
-8789,AchyuthGamer/ImMagician-Gradio,gradio,,2
-8790,allknowingroger/Image-Models-Test164,gradio,,2
-8791,huggingface-projects/wuerstchen-bot,gradio,,2
-8792,tube1925/sydney_new2.0,docker,mit,2
-8793,benjaminzuckermanbasisscottsdale/Cardiovascular_Disease_Prediction_Service,gradio,gpl-3.0,2
-8794,Karan123penguin234/georgesung-llama2_7b_chat_uncensored,gradio,,2
-8795,AngoHF/ANGO-Leaderboard,gradio,llama2,2
-8796,librarian-bots/tutorials,static,,2
-8797,allknowingroger/Image-Models-Test168,gradio,,2
-8798,dongsiqie/lobe-chat,docker,mit,2
-8799,SeyedAli/Persian-Visual-Question-Answering-1,gradio,mit,2
-8800,AFischer1985/wizardlm-13b-v1-2-q4-0-gguf,docker,,2
-8801,PirateHFH/IllusionDiffusion,gradio,openrail,2
-8802,Mysterykey/todd,docker,,2
-8803,Detomo/CuteRobot,static,,2
-8804,XzJosh/nine2-Bert-VITS2,gradio,mit,2
-8805,airesai/Mistral-7B-v0.1-Demo,gradio,apache-2.0,2
-8806,onemriganka/palm2-pdf,streamlit,,2
-8807,Tonic/greenblast,gradio,apache-2.0,2
-8808,javakhangnguyen/Object-Remove,streamlit,,2
-8809,allknowingroger/Image-Models-Test175,gradio,,2
-8810,TogetherAI/remove-background-on-image,gradio,,2
-8811,awacke1/USMLE-Medical-License-Exam-EDA,streamlit,mit,2
-8812,Tonic/cybermints,gradio,apache-2.0,2
-8813,KVNAditya/Personal_News_Summarization_Assistant,streamlit,,2
-8814,Mysterykey/Admin,docker,,2
-8815,MultiTransformer/snake_by_princepspolycap,static,mit,2
-8816,digitalxingtong/Nailv-Bert-Vits2,gradio,mit,2
-8817,Mahiruoshi/MyGO_VIts-bert,gradio,other,2
-8818,AIQuest/lungCancerVgg19,gradio,gpl,2
-8819,AlexMaoMao/ostris-ikea-instructions-lora-sdxl,gradio,,2
-8820,Gigabot/ostris-ikea-instructions-lora-sdxl,gradio,,2
-8821,mixcard/prompthero-openjourney-v4,gradio,,2
-8822,sporg/Ongo,docker,,2
-8823,Hexamind/GDOC,gradio,eupl-1.1,2
-8824,Keyven/Multimodal-Vision-Insight,gradio,apache-2.0,2
-8825,allknowingroger/Image-Models-Test183,gradio,,2
-8826,allknowingroger/Image-Models-Test184,gradio,,2
-8827,vorstcavry/ComfyUI-XL-Vae-Public,docker,,2
-8828,greymatter72/goofyai-3d_render_style_xl,gradio,,2
-8829,meraGPT/meraKB,streamlit,apache-2.0,2
-8830,ahmadawais/Mistral-Chat,gradio,,2
-8831,allknowingroger/Image-Models-Test186,gradio,,2
-8832,allknowingroger/Image-Models-Test187,gradio,,2
-8833,k-kotetsu/upscaling-server-test-1,gradio,,2
-8834,RMXK/RVC_HFF,gradio,,2
-8835,Tonic/BibleScriptures,gradio,mit,2
-8836,Tonic/QuranInUrdu,gradio,mit,2
-8837,RdnUser77/SpacIO_v1,gradio,,2
-8838,Hushh/Generative_QNA,streamlit,apache-2.0,2
-8839,ShawnLJW/image2coloringbook,gradio,,2
-8840,allknowingroger/Image-Models-Test188,gradio,,2
-8841,snowcoin/bing,docker,mit,2
-8842,lewisliuX123/wechatglm_demo,gradio,,2
-8843,mediaparty2023/test-autotrain,docker,mit,2
-8844,Hmjz100/ChatGPT4,gradio,mit,2
-8845,TIGER-Lab/TIGERScore,gradio,mit,2
-8846,reonjy/sdxl,gradio,mit,2
-8847,Ayush113/cricket_matchups,gradio,mit,2
-8848,donimes977/roblox,docker,mit,2
-8849,allknowingroger/Image-Models-Test192,gradio,,2
-8850,silk-road/Luotuo-Fighter,gradio,apache-2.0,2
-8851,teralomaniac/clewd,docker,,2
-8852,Weyaxi/open-llm-leaderboard-renamer,gradio,,2
-8853,PhilSpiel/storyville,gradio,,2
-8854,XzJosh/Ava-Bert-VITS2,gradio,mit,2
-8855,XzJosh/Ava2-Bert-VITS2,gradio,mit,2
-8856,AchyuthGamer/OpenGPT-Chat-UI,docker,creativeml-openrail-m,2
-8857,AFischer1985/AI-Interface,gradio,,2
-8858,Betacuckgpt/ehartford-Wizard-Vicuna-30B-Uncensored123,gradio,,2
-8859,ura-hcmut/ura-llama-evaluation,streamlit,cc-by-nc-sa-4.0,2
-8860,allknowingroger/Image-Models-Test199,gradio,,2
-8861,roshithindia/text_summarization,streamlit,,2
-8862,NicoGargano/stroke,gradio,mit,2
-8863,Audiogen/vector-search-demo,gradio,unlicense,2
-8864,XzJosh/Jiaran-Bert-VITS2,gradio,mit,2
-8865,allknowingroger/Image-Models-Test204,gradio,,2
-8866,KOFTRFU204/AICoverGen,gradio,mit,2
-8867,kobakhit/speech-to-chat,streamlit,,2
-8868,Mosharof/Women_with_Hijab_Detector,gradio,apache-2.0,2
-8869,mipbkhn/SmartGPTpublic,gradio,,2
-8870,XzJosh/Aatrox-Bert-VITS2,gradio,mit,2
-8871,manivannan7gp/Words2Image,gradio,,2
-8872,tkelley353/acid,gradio,apache-2.0,2
-8873,ML610/Mistral-7b-instruct-GGUF,gradio,apache-2.0,2
-8874,innat/VideoSwin,gradio,mit,2
-8875,AFlac199/openai-reverse-proxy,docker,,2
-8876,tsi-org/LLaVA,gradio,,2
-8877,Harsh502s/Autonomous_Text_Tagging_App,streamlit,mit,2
-8878,nsaintsever/music-generation,streamlit,,2
-8879,lewisliuX123/wechatgpt3,gradio,,2
-8880,SAAZIZI/SummarizeAV,streamlit,,2
-8881,TPM-28/Real-ESRGAN_Demo,gradio,,2
-8882,tsi-org/tts,gradio,,2
-8883,hf4all/bingo-async-task,docker,,2
-8884,CoderMayhem/repello,streamlit,,2
-8885,XzJosh/ShanBao-Bert-VITS2,gradio,mit,2
-8886,mounikakadimi28/ml_salary_prediction,gradio,,2
-8887,SakshiRathi77/SakshiRathi77-Wishper-Hi-Kagglex,gradio,apache-2.0,2
-8888,CoPoBio/skin_cancer_risk_prediction,gradio,apache-2.0,2
-8889,gheng/belanjawan-2024-chatbot,gradio,,2
-8890,zomehwh/bert_vits2,gradio,,2
-8891,KonradSzafer/HF-QA-Demo,gradio,,2
-8892,brightswitch/EleutherAI-llemma_34b,gradio,,2
-8893,gstaff/mp4-converter,gradio,apache-2.0,2
-8894,vih-v/Image_Face_Upscale_Restoration-GFPGAN,gradio,apache-2.0,2
-8895,dwancin/inpaint,gradio,mit,2
-8896,devisionx/auto-annotation-segmentation,gradio,,2
-8897,vorstcavry/Vorst-Cavry-stablediffusion,gradio,mit,2
-8898,deppfellow/steam-recsys,streamlit,,2
-8899,XS-1/BW_IMAGE_VIDEO_COLORIZER,streamlit,,2
-8900,library-samples/image-captioning-with-blip,gradio,mit,2
-8901,VetriVendhan26/sentiment-analysis,gradio,,2
-8902,Prasanna18/AnatomyBOT,streamlit,,2
-8903,jiaxianustc/mbp,gradio,mit,2
-8904,THEGAMECHANGER/LandscapeColorizer,gradio,,2
-8905,EngAbod/Liveness_Detection,streamlit,apache-2.0,2
-8906,SFP/ImCap,gradio,mit,2
-8907,kevinwang676/ControlNet-with-GPT-4,gradio,mit,2
-8908,artfan123/AI-generated-art-classifier,gradio,,2
-8909,olanigan/YoutubeAssistant,streamlit,apache-2.0,2
-8910,lfoppiano/document-qa,streamlit,apache-2.0,2
-8911,CikeyQI/Yunzai,docker,,2
-8912,aukaru/claude-wangy,docker,,2
-8913,StiveDudov/Image_Face_Upscale_Restoration-GFPGAN,gradio,apache-2.0,2
-8914,sunxyz/Auto-keep-online,docker,,2
-8915,digitalxingtong/Bufeiyan-a-Bert-VITS2,gradio,mit,2
-8916,chendelong/citation-tool,gradio,,2
-8917,datajuicer/overview_scan,docker,apache-2.0,2
-8918,Bazedgul/YoutubeVideo-Transcript-Summarization,gradio,cc,2
-8919,AchyuthGamer/Free-Accounts-Generator,static,mit,2
-8920,westy412/flowise,docker,,2
-8921,awacke1/MixtureOfMedicalExperts,streamlit,mit,2
-8922,DAMO-NLP-SG/CLEX-Chat,gradio,mit,2
-8923,dingliyu/skillmix,gradio,,2
-8924,LaynzKunz/Aesthetic_RVC_Inference_HF,gradio,,2
-8925,mymiss/ComfyUI-ave,static,creativeml-openrail-m,2
-8926,waheedwaqar/Toyota_Youtube_Chatbot,gradio,,2
-8927,freddyaboulton/gradio_folium,docker,apache-2.0,2
-8928,pseudolab/medical-chatbot,gradio,apache-2.0,2
-8929,Abhi5ingh/fashionsd,streamlit,,2
-8930,twizy/Linaqruf-animagine-xl,gradio,,2
-8931,malay-91418/image-info,gradio,mit,2
-8932,Aadi1149/Arkenbrien-text-to-image-Arkenbrien,gradio,apache-2.0,2
-8933,TIMBOVILL/RVC-Noobie,gradio,lgpl-3.0,2
-8934,manjunathshiva/BibleGPT,docker,apache-2.0,2
-8935,SeyedAli/Audio-Diffusion-style_transfer,gradio,mit,2
-8936,degirum/yolov8,streamlit,mit,2
-8937,Ferion/image-matting-app,gradio,mit,2
-8938,innat/Video-FocalNet,gradio,mit,2
-8939,cybergpt/bing-chat,gradio,,2
-8940,xuyingliKepler/KET,streamlit,,2
-8941,TheStinger/Ilaria_TTS,gradio,other,2
-8942,geokanaan/arabeasy,gradio,,2
-8943,ngoctuanai/gpt4en,docker,mit,2
-8944,JSP/ar,gradio,mit,2
-8945,Niansuh/bingai,docker,mit,2
-8946,YeYeYes/QQsign,docker,mit,2
-8947,xuyingliKepler/autogenchat,streamlit,,2
-8948,normster/llm_rules,gradio,mit,2
-8949,NiansuhAI/chat,docker,mit,2
-8950,rahul999r/Rahul_Kannada_TTS,gradio,,2
-8951,multimodalart/LoraTheExplorer4,gradio,mit,2
-8952,mayura25/handwritten_digit_recognition,gradio,mit,2
-8953,Clementapa/orang-outan-image-video-detection,gradio,apache-2.0,2
-8954,locmaymo/Reverse-Proxy,docker,,2
-8955,bishu3011/hf-xample,streamlit,,2
-8956,openskyml/starchat-playground,gradio,mit,2
-8957,openskyml/HuggingDiffusion,gradio,mit,2
-8958,pseudolab/Finetune-Model,docker,apache-2.0,2
-8959,jonathanjordan21/ads-video-generator,gradio,mit,2
-8960,eddiebee/image_to_black_and_white,gradio,,2
-8961,xuyingliKepler/matt_scrpt_gen,streamlit,,2
-8962,phyloforfun/VoucherVision,streamlit,cc-by-nc-4.0,2
-8963,AliSaria/MilitarEye,gradio,apache-2.0,2
-8964,pseudolab/autotrain-Nuclear_Fusion_Falcon-0,docker,,2
-8965,silk-road/ChatHaruhi-Needy,gradio,apache-2.0,2
-8966,Saketh-Reddy/webhook_space,docker,,2
-8967,Intel/NeuralChat-ICX-INT4,gradio,apache-2.0,2
-8968,TeamTonic/hallucination-test,gradio,mit,2
-8969,RolandZ/bing-image-creator,gradio,,2
-8970,limcheekin/Yarn-Mistral-7B-128k-GGUF,docker,,2
-8971,nasa-cisto-data-science-group/satvision-base-demo,streamlit,apache-2.0,2
-8972,nafisehNik/girt-space,streamlit,mit,2
-8973,CognitiveLabs/GPT-4-Vision-Chat,docker,,2
-8974,ARTeLab/ARTeLab-SummIT,streamlit,,1
-8975,AUBMC-AIM/MammoGANesis,gradio,,1
-8976,Abhilashvj/planogram-compliance,streamlit,,1
-8977,adorkin/BilingualEmojiPredictor,gradio,,1
-8978,adorkin/ZeroShotClassificationEnRu,gradio,,1
-8979,AlekseyKorshuk/instagram-filter-removal,gradio,,1
-8980,AlekseyKorshuk/rugpt3,gradio,,1
-8981,AlexN/pull_up,gradio,,1
-8982,AlgoveraAI/algovera_squad_active_passive_model,streamlit,,1
-8983,AmmarHuggingFaces/intro-to-hugging-face,gradio,,1
-8984,Amrrs/github-star-tracking,streamlit,,1
-8985,Amrrs/numerizerlit,streamlit,,1
-8986,Amrrs/portfolio-github,static,,1
-8987,Amrrs/portfolio,static,,1
-8988,Anon4review/HIPTDemo,gradio,,1
-8989,Anthos23/hummus,streamlit,,1
-8990,BigSalmon/Bart,streamlit,,1
-8991,BigSalmon/GPT2_Most_Probable,streamlit,,1
-8992,BigSalmon/MaskSeveralAtOnce,streamlit,,1
-8993,Burcin/ExtractiveSummarizer,gradio,,1
-8994,Dabs/Floyd-Steinberg-Dithering,gradio,,1
-8995,Dabs/UlamSpiral,gradio,,1
-8996,Dabs/wordcloud,gradio,,1
-8997,Danil/AnyNameHack,streamlit,,1
-8998,Davis/twitter_scraper,streamlit,mit,1
-8999,Devika/Briefly,streamlit,,1
-9000,Dref360/spectral-metric,streamlit,apache-2.0,1
-9001,EfkTur/nutriscore_app,gradio,,1
-9002,Emclaniyi/music-recommendation-system-spotify,streamlit,apache-2.0,1
-9003,Endre/SemanticSearch-HU,streamlit,,1
-9004,Feynlee/Receipt_Parser,gradio,,1
-9005,Gladiator/Sartorius-Cell-Segmentation,streamlit,,1
-9006,Hellisotherpeople/HF-KeyBERT,streamlit,,1
-9007,Hitmanny/GPT2-story-generation,gradio,,1
-9008,HugoLaurencon/text-data-filtering-2,streamlit,,1
-9009,Ignahugging/Image_filtering,gradio,,1
-9010,Ignahugging/Sentiment-Analysis,gradio,,1
-9011,IndicNLP/Demo,streamlit,,1
-9012,JadAssaf/STPI,gradio,,1
-9013,JadAssaf/STPIzeimer,gradio,,1
-9014,Jesuscriss301/prueba,streamlit,,1
-9015,Jimmie/similar-books,streamlit,,1
-9016,Jipski/Flos_gpt-2,streamlit,,1
-9017,Jipski/MegStuart_gpt-2,streamlit,,1
-9018,Joeri/fabry-perot,gradio,,1
-9019,JonatanGk/catalonia-independence-detector,gradio,,1
-9020,JonathanLehner/Chatbot_small_demo,gradio,,1
-9021,JuliaKon/nlp12,streamlit,,1
-9022,MKaan/multilingual-cpv-sector-classifier,streamlit,,1
-9023,Modfiededition/tweet_sentiment_extractor,streamlit,,1
-9024,MonkeyDBoa/AvengersDetector,gradio,,1
-9025,Mradul/mlrc-bana,streamlit,,1
-9026,Muedgar/WeatherPrediction,gradio,afl-3.0,1
-9027,Nalla/PDF_tables_to_CSV_output,streamlit,,1
-9028,Narrativa/poc,streamlit,,1
-9029,Narsil/gradiofold,gradio,,1
-9030,Narsil/myspace,Configuration error,Configuration error,1
-9031,NbAiLab/maken-clip-text,gradio,,1
-9032,PaddlePaddle/MiDaS_Small,gradio,,1
-9033,ParthRangarajan/Centauri_Pilot,gradio,,1
-9034,PrathamDesai/fastai_bear_classifier,gradio,,1
-9035,Sakil/A_cover_letter_generator_for_jobs,gradio,apache-2.0,1
-9036,Sakil/question_answering_app,gradio,apache-2.0,1
-9037,SaulLu/test-demo,static,,1
-9038,ShadyV/pcm-percent-calculator,gradio,,1
-9039,SophieTr/TextSummarizationDemo,streamlit,,1
-9040,Souranil/VAE,streamlit,,1
-9041,Stanford-CS236g/example-pokemon-gan,gradio,mit,1
-9042,Sultannn/Text_summarization_with-MT5,gradio,apache-2.0,1
-9043,hunkim/echo,streamlit,,1
-9044,hunkim/kakaogpt,streamlit,,1
-9045,Theivaprakasham/facedetect,gradio,apache-2.0,1
-9046,Vasanth/QuestionAnswering,streamlit,,1
-9047,WaterKnight/neural-style-transfer,gradio,,1
-9048,Wootang01/grammar_corrector,streamlit,,1
-9049,Wootang01/grammar_corrector_two,streamlit,,1
-9050,Wootang01/question_generator_two,gradio,,1
-9051,Zahraebrahimi/IQA,gradio,,1
-9052,Zakia/DIARC,gradio,,1
-9053,abidlabs/english_to_spanish,gradio,,1
-9054,abidlabs/image-identity,gradio,,1
-9055,abidlabs/quickdraw2,gradio,,1
-9056,abidlabs/speech-translation,gradio,,1
-9057,aditi2222/Title_generation,gradio,,1
-9058,aditi2222/gradio_t5,gradio,,1
-9059,aditi2222/paragus_paraphrase_demo,gradio,,1
-9060,aditi2222/sdffvb,gradio,,1
-9061,aditi2222/updated_t5,gradio,,1
-9062,afcruzs/perceiver-image-classification-spanish,gradio,,1
-9063,agungbesti/produksi,gradio,,1
-9064,ajitrajasekharan/Qualitative-pretrained-model-evaluation,streamlit,mit,1
-9065,ajitrajasekharan/self-supervised-ner-biomedical,streamlit,mit,1
-9066,akhaliq/BLIP,gradio,,1
-9067,akhaliq/DETR,gradio,,1
-9068,akhaliq/Deit,gradio,,1
-9069,akhaliq/Detectron2,gradio,,1
-9070,akhaliq/DialoGPT-small,gradio,,1
-9071,akhaliq/Scientific_Title_Generator,gradio,,1
-9072,akhaliq/hubert-xlarge-ls960-ft,gradio,,1
-9073,akhaliq/longformer-scico,gradio,,1
-9074,akhaliq/wav2vec2-large-robust-ft-libri-960h,gradio,,1
-9075,algomuffin/jojo_fork,gradio,,1
-9076,aliabd/new-chatbot-interface,gradio,,1
-9077,aliabd/wav2lip,gradio,,1
-9078,allisonye/sketchpad_multiplecharsmodel,gradio,,1
-9079,alperbayram/Duygu_Analizi,gradio,afl-3.0,1
-9080,amazon/README,static,,1
-9081,anirbans403/wikisummarizer,streamlit,,1
-9082,anmol007/anmol-sentiment-analysis,gradio,,1
-9083,anuragshas/Hindi_ASR,gradio,apache-2.0,1
-9084,any0019/text-style-transfer-demo,streamlit,,1
-9085,ashishabraham22/WATCHA-READIN,gradio,,1
-9086,astoken/weather_checker,gradio,,1
-9087,avichr/HebEMO_demo,streamlit,,1
-9088,avorozhko/funbot,gradio,,1
-9089,awfawfgehgewhfg/frawfafwafa,gradio,,1
-9090,bespin-global/Bespin-QuestionAnswering,streamlit,,1
-9091,biu-nlp/AlephBERT,streamlit,,1
-9092,bubbletea98/Neo4J_Integration,gradio,,1
-9093,cbensimon/streamlit-query-params,streamlit,,1
-9094,cbensimon/streamlit-ui-gallery,streamlit,,1
-9095,cdleong/random_emoji,streamlit,,1
-9096,chinhon/frequent_word_counter,streamlit,,1
-9097,cointegrated/toxic-classifier-ru,streamlit,,1
-9098,coolzude/Landmark-Detection,gradio,mit,1
-9099,cpnepo/Harry-Potter-Q-A,streamlit,afl-3.0,1
-9100,crabz/sk-ner,gradio,,1
-9101,cubbycarlson/karl,gradio,,1
-9102,curt-tigges/anime-image-labeller,gradio,apache-2.0,1
-9103,cvr/3classifier,gradio,,1
-9104,danurahul/pop-music,gradio,,1
-9105,davidcftang/LT,gradio,,1
-9106,davidefiocco/zeroshotcat,streamlit,,1
-9107,dbdmg/robust-asr-it,gradio,mit,1
-9108,dev114/sentiment-analysis,gradio,other,1
-9109,digitalWestie/huggingface-space,streamlit,mit,1
-9110,dnth/icevision_fridge_tutorial,gradio,afl-3.0,1
-9111,dnth/rice-disease-classifier,gradio,afl-3.0,1
-9112,dnth/testalgae,gradio,,1
-9113,docs-demos/albert-base-v2,gradio,,1
-9114,docs-demos/dpr-question_encoder-bert-base-multilingual,gradio,,1
-9115,docs-demos/electra_large_discriminator_squad2_512,gradio,,1
-9116,docs-demos/flaubert_small_cased,gradio,,1
-9117,docs-demos/prophetnet-large-uncased,gradio,,1
-9118,docs-demos/t5-base,gradio,,1
-9119,docs-demos/xlm-roberta-base,gradio,,1
-9120,docs-demos/xprophetnet-large-wiki100-cased-xglue-ntg,gradio,,1
-9121,dpc/textgencompare,gradio,,1
-9122,dreji18/Semantic-Search-using-DistilBert,streamlit,,1
-9123,dreji18/Text-Classification-App,streamlit,,1
-9124,dt/chatbot-es,gradio,,1
-9125,dt/dt-demo,gradio,,1
-9126,dt/ner_spanish,gradio,,1
-9127,dyguay/object-detection-api,gradio,,1
-9128,edemgold/QA-App,gradio,,1
-9129,edemgold/generator,gradio,,1
-9130,edugp/clip-spanish-demo-gradio,gradio,,1
-9131,edugp/clip-spanish-demo,streamlit,,1
-9132,elaldana/shouldidrive,gradio,,1
-9133,ethzanalytics/dialog-China,gradio,,1
-9134,farukozderim/a,gradio,,1
-9135,farukozderim/bug_test_1,gradio,,1
-9136,farukozderim/space-building-space-25,gradio,,1
-9137,farukozderim/space-building-space-30,gradio,,1
-9138,flax-community/GPT2-korean-demo,streamlit,,1
-9139,flax-community/SinhalaLanguageDemos,streamlit,,1
-9140,flax-community/netherformer,streamlit,,1
-9141,flax-community/spanish-image-captioning,streamlit,,1
-9142,g8a9/vit-gpt-italian-captioning,streamlit,,1
-9143,gagan3012/T5-Summarization,streamlit,,1
-9144,gagan3012/streamlit-tags,streamlit,,1
-9145,gagan3012/summarization,streamlit,,1
-9146,geekyrakshit/enhance-me,streamlit,,1
-9147,gingerale/Gnomespace,gradio,,1
-9148,gorkemgoknar/metayazar,gradio,,1
-9149,gradio/longformer,gradio,,1
-9150,gulabpatel/Question-Answering_roberta,gradio,,1
-9151,gulabpatel/chatbot_GPTNeo,gradio,,1
-9152,gv/space_demo,gradio,,1
-9153,harsh7251/cvFoodWebApp,gradio,,1
-9154,hi9/Core-4-with-QA-on-UC,gradio,,1
-9155,huggingface/Carbon-Compare,streamlit,,1
-9156,huggingface/README,static,,1
-9157,azizalto/simple_forecast,streamlit,,1
-9158,ibombonato/silence-demo,gradio,,1
-9159,ichsanprmn/papersumm,streamlit,,1
-9160,impyadav/Hindi-Song-Generation-GPT2,streamlit,,1
-9161,imthanhlv/dual-encoder,gradio,,1
-9162,inaccel/inception_v1_tf,gradio,,1
-9163,inaccel/resnet50,gradio,,1
-9164,inaccel/yolov3_adas_pruned_0_9,gradio,,1
-9165,indonesian-nlp/luganda-asr,gradio,,1
-9166,inigosarralde/mushroom_edibility_classifier,gradio,afl-3.0,1
-9167,isabel/climate-change-project,gradio,,1
-9168,jacklinquan/make24,gradio,mit,1
-9169,jason9693/SoongsilBERT-BEEP,streamlit,,1
-9170,jcmachicao/dialogatexto,streamlit,cc-by-sa-4.0,1
-9171,jeang/ernie_demo_toy,gradio,,1
-9172,jfarray/TFM_SimilitudSemantica_Textos,gradio,other,1
-9173,jgerbscheid/dpa-example,gradio,,1
-9174,jitesh/storytelling,streamlit,mit,1
-9175,johnowhitaker/twitter_viz,streamlit,,1
-9176,jrichez/digit_recognizer,gradio,,1
-9177,jshu/baeroml-hackathon2021,streamlit,,1
-9178,jsxyhelu/skyseg,gradio,,1
-9179,jueri/clean_bibtex,gradio,,1
-9180,julien-c/hello-world,streamlit,,1
-9181,juliensimon/imdb-demo-space,gradio,,1
-9182,karolmajek/YOLOR,gradio,,1
-9183,kdemertzis/Earthquakes,gradio,,1
-9184,keras-io/TF-GB-Forest,gradio,apache-2.0,1
-9185,keras-io/bidirectional_lstm_imdb,gradio,,1
-9186,keras-io/char-lstm-seq2seq,gradio,apache-2.0,1
-9187,keras-io/integrated_gradients,gradio,cc0-1.0,1
-9188,keras-io/randaugment,gradio,apache-2.0,1
-9189,keras-io/semi-supervised-classification,gradio,apache-2.0,1
-9190,khizon/emotion-classifier-demo,streamlit,,1
-9191,kinensake/quanquan,streamlit,,1
-9192,kingfisher/similarity-heatmap,streamlit,cc-by-nc-sa-4.0,1
-9193,kingfisher/smart-search,streamlit,cc-by-nc-sa-4.0,1
-9194,kleinay/qanom-end-to-end-demo,gradio,,1
-9195,kleinay/qanom-seq2seq-demo,gradio,,1
-9196,korona777/HDB_Resale_Price_Prediction,gradio,,1
-9197,kurone/cp_tags_prediction,streamlit,,1
-9198,learningfromemojis/TwitterEmojis,streamlit,,1
-9199,leoneat/comments_refiner,streamlit,,1
-9200,leopoldmaillard/ImageRetrieval,gradio,mit,1
-9201,leung/test-01,streamlit,,1
-9202,maher13/arabic-asr,gradio,,1
-9203,makanaan/paraphrase,gradio,,1
-9204,marcelcastrobr/zero-shot-classification-norsk-bert,gradio,,1
-9205,mariagrandury/bertin-sqac,gradio,,1
-9206,markscrivo/odddson,gradio,,1
-9207,marshmellow77/rouge-scorer,gradio,,1
-9208,mayerantoine/disaster-damage-classifier,gradio,mit,1
-9209,maze/FastStyleTransfer,gradio,,1
-9210,merve/french-story-gen,gradio,,1
-9211,merve/gr-blocks,gradio,,1
-9212,miccull/clip-rgb-interpolation,gradio,,1
-9213,micole66/electra,gradio,,1
-9214,micole66/mdeberta,gradio,,1
-9215,micole66/momomo,gradio,,1
-9216,micole66/zero-shot-deberta,gradio,,1
-9217,mikeee/ultimatumbee,gradio,mit,1
-9218,milamir/gradioSentimentAnalysis,gradio,,1
-9219,mmcquade11/codex-reuters-summarization,gradio,,1
-9220,mmcquade11/codex-text-summarizer,gradio,,1
-9221,mnemlaghi/beauparleur,streamlit,,1
-9222,moflo/keras_stylegan,gradio,,1
-9223,mohitmayank/EmojiFinder,streamlit,,1
-9224,moumeneb1/asr_model,gradio,,1
-9225,msarmi9/multi30k,gradio,mit,1
-9226,msulemannkhan/sentiment-classification-gradio,gradio,,1
-9227,muhtasham/germanquad,gradio,,1
-9228,nahidalam/meow,gradio,,1
-9229,nata0801/ASR_Transformers_EnRuFr,gradio,,1
-9230,nata0801/Question_Answering_App,gradio,,1
-9231,nateraw/gradio-demo,gradio,,1
-9232,nateraw/test-space-lfs,streamlit,,1
-9233,nedwards01/Gradient-Descent-Visualizer,gradio,,1
-9234,nfel/Thermostat,streamlit,,1
-9235,nlpconnect/live-wikipedia-dpr,gradio,,1
-9236,osanseviero/DINO_VIDEO,gradio,,1
-9237,osanseviero/bidaf-elmo,gradio,,1
-9238,osanseviero/biggan,gradio,,1
-9239,osanseviero/demo-live,gradio,afl-3.0,1
-9240,osanseviero/hugging-pic,gradio,,1
-9241,osanseviero/test,gradio,,1
-9242,paulbricman/conceptarium,streamlit,,1
-9243,paulbricman/lexiscore,streamlit,,1
-9244,paultay/image_generator,gradio,,1
-9245,peter2000/E-Coicop-food-classifier,gradio,,1
-9246,phucpd53/DocVQA_LayoutLMV2,gradio,,1
-9247,piecurus/speech_to_text,gradio,cc0-1.0,1
-9248,pierrefdz/ssl_watermarking,gradio,,1
-9249,pngwn/nextjs,static,,1
-9250,pytorch/Densenet,gradio,,1
-9251,pytorch/EfficientNet,gradio,,1
-9252,pytorch/Inception_v3,gradio,,1
-9253,pytorch/MobileNet_v2,gradio,,1
-9254,pytorch/RoBERTa,gradio,,1
-9255,pytorch/SlowFast,gradio,,1
-9256,pytorch/SqueezeNet,gradio,,1
-9257,pytorch/Transformer_NMT,gradio,,1
-9258,pytorch/Wide_Resnet,gradio,,1
-9259,pytorch/open-unmix,gradio,,1
-9260,pytorch/transformers,gradio,,1
-9261,rahulb517/diffusion,gradio,,1
-9262,rajesh1729/interactive-tweet-sentiment-visualization-dashboard,streamlit,afl-3.0,1
-9263,ravijoe/emotion_classifier,gradio,,1
-9264,raynardj/x-language-search-ancient-with-modern-words,streamlit,,1
-9265,realrastayouth/knowledge-discovery-final-project-demo,gradio,,1
-9266,reshinthadith/code-representation-learning,streamlit,,1
-9267,rexoscare/Text_summarization_app,streamlit,,1
-9268,rickystanley76/streamlit-hans-rosling,streamlit,,1
-9269,rubensmau/teste2,gradio,,1
-9270,samt/soteria-ml,gradio,mit,1
-9271,samueldomdey/SentimentAnalysisSingle,gradio,,1
-9272,sandrocalzada/DemoHF,streamlit,gpl-3.0,1
-9273,sdutta28/AggDetectApp,docker,,1
-9274,seanbethard/whatsapp,gradio,,1
-9275,seki/sk,gradio,,1
-9276,sentencebird/image-color-vectorization,streamlit,,1
-9277,seyia92coding/Popular_Spotify_Albums,gradio,,1
-9278,seyia92coding/Simple-Text-based-Gaming-Recommender,gradio,,1
-9279,shahp7575/gpt-horoscopes,streamlit,,1
-9280,shamikbose89/title-generator-from-abstract,gradio,,1
-9281,shaneavh/ada,streamlit,,1
-9282,shashankanand13/game-automation-webapp,streamlit,,1
-9283,shawon100/english-to-bangla-translation,gradio,,1
-9284,shelby/scan_rotation_app,gradio,gpl-3.0,1
-9285,skylord/surubhi,gradio,,1
-9286,sohomghosh/FinRead,gradio,mit,1
-9287,sonoisa/qiita_title_generator,streamlit,,1
-9288,spacy/README,static,,1
-9289,springml111/Pegasus_Paraphrase_demo,gradio,,1
-9290,srishtiganguly/maskrcnn,static,other,1
-9291,kernelmachine/gpt3-quality-filter,gradio,,1
-9292,stmnk/pygen,gradio,,1
-9293,suguuuu/monodepth,gradio,mit,1
-9294,suxiaomi/MT3,gradio,,1
-9295,tanaydeshmukh/gradio-sentiment-web-app,gradio,,1
-9296,thebestteamever/fire_detection_project,gradio,mit,1
-9297,tidy/styleflow,streamlit,,1
-9298,tobiascz/demotime,gradio,afl-3.0,1
-9299,training-transformers-together/calc,streamlit,,1
-9300,tsereno/SportsTrainer,gradio,other,1
-9301,twinpiks/tst,gradio,,1
-9302,tyang/simcse-mpnet-fuzz-tfidf,gradio,,1
-9303,ucalyptus/PTI,gradio,,1
-9304,victor/tailwind-static-space,static,,1
-9305,winnielin/mySecretBox,gradio,,1
-9306,winwithakash/Flight-Fare-Price-Prediction,streamlit,,1
-9307,wolfrage89/chaii_spaces,streamlit,,1
-9308,wolfrage89/finance_domain_translation_marianMT,streamlit,,1
-9309,xiaoshi/test,gradio,,1
-9310,yabramuvdi/wfh-app-v2,gradio,,1
-9311,yseop/Finance,gradio,,1
-9312,yu3ufff/quiz-bowl-qa,gradio,,1
-9313,zeke/hello-spaces-gradio,gradio,,1
-9314,zhenwusw/JoJoGAN,gradio,,1
-9315,zhiqwang/assets,gradio,,1
-9316,zyj1022/codeffe,static,mit,1
-9317,senger/AI-TextGenerator,static,,1
-9318,SebastianEnger/AI-TextGenerator,static,,1
-9319,tensorflow/yamnet,gradio,,1
-9320,osanseviero/mix_match_gradio,gradio,afl-3.0,1
-9321,edbeeching/atari_live_model,streamlit,apache-2.0,1
-9322,osanseviero/draw123,gradio,,1
-9323,Reeve/Ohayou_Face,gradio,,1
-9324,Sukhyun/course_recommender,streamlit,apache-2.0,1
-9325,MohamedSherif/Skin_Cancer_detection,gradio,,1
-9326,alkzar90/streamlit-demo-example,streamlit,afl-3.0,1
-9327,Sukhyun/MBTI_translator,streamlit,apache-2.0,1
-9328,snakeeyes021/id-the-seas,gradio,,1
-9329,kevinszuchet/waste-classification,gradio,mit,1
-9330,davidmd/lane_detection_UNet_Model,gradio,other,1
-9331,qqaatw/realm-demo,gradio,,1
-9332,onnx/ResNet,gradio,,1
-9333,onnx/AlexNet,gradio,,1
-9334,LamaAl/chatbot,streamlit,,1
-9335,templates/streamlit,streamlit,mit,1
-9336,Senayfre/CropHealth,streamlit,mit,1
-9337,yassTrad/extractiveSum,streamlit,afl-3.0,1
-9338,Wootang01/chatbot_three,gradio,,1
-9339,Zeel/HeteroscedasticGP,streamlit,mit,1
-9340,MaximeTut/Emploi2021,streamlit,,1
-9341,course-demos/generate-tone,gradio,mit,1
-9342,XAI/VisualCorrespondenceHumanStudy,streamlit,mit,1
-9343,temp-late/rhyme-ai,streamlit,apache-2.0,1
-9344,jdposa/medical_ner_spanish,gradio,mit,1
-9345,joheras/OpticDiskDetection,gradio,cc-by-3.0,1
-9346,onnx/MNIST-Handwritten-Digit-Recognition,gradio,,1
-9347,course-demos/Rick_and_Morty_QA,gradio,apache-2.0,1
-9348,onnx/sub_pixel_cnn_2016,gradio,,1
-9349,akhaliq/beit,gradio,,1
-9350,ahmedJaafari/AnnarabicRecord,gradio,,1
-9351,onnx/BERT-Squad,gradio,,1
-9352,onnx/BiDAF,gradio,,1
-9353,nostalgebraist/frank-diffusion-streamlit,streamlit,,1
-9354,Sultannn/YOLOX_DEMO-Webcam,gradio,apache-2.0,1
-9355,EricaCorral/Chinese-Tools-Advanced,gradio,,1
-9356,AjulorC/question_answering_bot_deployed_with_Gradio,gradio,,1
-9357,Heriot-WattUniversity/generate-tone,gradio,apache-2.0,1
-9358,akdeniz27/spacy-turkish-demo,streamlit,,1
-9359,PaddlePaddle/pnasnet_imagenet,gradio,,1
-9360,course-demos/marian-finetuned-kde4-en-to-fr,gradio,afl-3.0,1
-9361,RobinWZQ/CCLAP,gradio,mit,1
-9362,AlowaSawsan/Third-Molar-Segmentation,streamlit,,1
-9363,adityapathakk/crop-health,gradio,,1
-9364,Time-travelRephotography/Time-travel_Rephotography,Configuration error,Configuration error,1
-9365,csuhan/opendet2,gradio,,1
-9366,imkaushalpatel/YOLOv3,gradio,,1
-9367,PaddlePaddle/resnet_v2_34_imagenet,gradio,,1
-9368,Borda90/Titanic_Esp,gradio,mit,1
-9369,IPN/Demo,gradio,cc,1
-9370,osanseviero/flask_test,gradio,mit,1
-9371,hackathon-pln-es/demo_flask,gradio,mit,1
-9372,Kaldra/PollutionClassifier,gradio,,1
-9373,SorbonneUniversity/tone,gradio,,1
-9374,BigSalmon/GPT2Mask,streamlit,,1
-9375,onnx/yolov4,gradio,,1
-9376,osanseviero/accuracy_metric,gradio,,1
-9377,imkaushalpatel/GoogleNet,gradio,,1
-9378,huggan/pix2pix-facades,gradio,apache-2.0,1
-9379,Deep1994/t5-paraphrase,streamlit,,1
-9380,arkmartov/arkmartov,streamlit,unlicense,1
-9381,datasith/image-classification-cast-parts,gradio,mit,1
-9382,yash161101/deepwords,streamlit,,1
-9383,lcipolina/Print_Gallery,gradio,afl-3.0,1
-9384,smajumdar/nemo_conformer_rnnt_large,gradio,apache-2.0,1
-9385,d0r1h/LegSum,gradio,mit,1
-9386,pog/Depression-Detector,gradio,afl-3.0,1
-9387,r2d2/decision-triptych,streamlit,cc-by-4.0,1
-9388,pierrefdz/semantle,gradio,,1
-9389,wrapper228/arxiv_classifier,streamlit,unlicense,1
-9390,teach/README,static,,1
-9391,badongtakla/ithaca,gradio,,1
-9392,tskolm/YouTube_comments_generation,streamlit,,1
-9393,BigSalmon/BackTranslation2,streamlit,,1
-9394,BrianL/CoE197-Fil-DialectTranslator,gradio,apache-2.0,1
-9395,ThirdIringan/Speech_Equation_Solver,gradio,apache-2.0,1
-9396,AleksBlacky/Arxiv_paper_classifier,streamlit,apache-2.0,1
-9397,tallwhitestck/asl-fingerspelling-recognition,gradio,,1
-9398,kotstantinovskii/YSDA_arxiv_classification,streamlit,apache-2.0,1
-9399,danielHora/Object_Detection_for_Self-Checkout_Stores,gradio,afl-3.0,1
-9400,godot-demo/godot-2d-threads,static,,1
-9401,abidlabs/full-context-asr,gradio,,1
-9402,almostagi/QTL,gradio,mit,1
-9403,utec/SpaceKonnor-tts_transformer-es-css10,gradio,,1
-9404,utec/my-first-space,gradio,mit,1
-9405,utec/Spacelmaj,gradio,cc,1
-9406,CristianGonzalez281098/Cheto,gradio,apache-2.0,1
-9407,Rodrigo21/space1,gradio,,1
-9408,unlisboa/pokemon-image-classifier,gradio,,1
-9409,Saturdays/Cardiosight,gradio,,1
-9410,coco-gelamay/missing-items,gradio,apache-2.0,1
-9411,balamurugan/search-10k-filings,gradio,mit,1
-9412,AlgoveraAI/medical-image-classification,gradio,,1
-9413,tmabraham/horse2zebra_cyclegan,gradio,,1
-9414,Ifan/instant-ngp,streamlit,,1
-9415,ronvolutional/http-server,gradio,,1
-9416,RugNlpFlashcards/Speech_Language_Processing_Jurafsky_Martin,gradio,,1
-9417,GastonMazzei/escher-inpaint-project,gradio,,1
-9418,IPN/streamlit_demo,streamlit,cc,1
-9419,Techis/resume-screening-tool,gradio,other,1
-9420,osanseviero/llama-classifiers,gradio,,1
-9421,Harveenchadha/Vakyansh-Tamil-TTS,gradio,apache-2.0,1
-9422,BramVanroy/spacey_conll,docker,gpl-3.0,1
-9423,Aymene/FakeNewsDetector,gradio,apache-2.0,1
-9424,mustdo12/U-Net_Segmentation,streamlit,afl-3.0,1
-9425,IPN/FirstSpaceTEST_Gradio,gradio,mit,1
-9426,IPN/demo-sdamian,gradio,,1
-9427,IPN/helloooooo,gradio,mit,1
-9428,IPN/demo_,gradio,cc,1
-9429,IPN/demo_2_omar,gradio,,1
-9430,IPN/demoipn,gradio,cc,1
-9431,IPN/DM_pb,gradio,,1
-9432,mojians/E2E-QA-mining,streamlit,mit,1
-9433,anuragshas/en-hi-transliteration,gradio,apache-2.0,1
-9434,hysts/projected_gan,gradio,,1
-9435,AdityaMahimkar/ParaPhraser,gradio,afl-3.0,1
-9436,PaddlePaddle/ghostnet_x1_3_imagenet,gradio,,1
-9437,givkashi/seam-carving,gradio,apache-2.0,1
-9438,hitomi-team/README,static,,1
-9439,pyodide-demo/self-hosted,static,,1
-9440,awacke1/PersistState,gradio,mit,1
-9441,awacke1/PersistURL,streamlit,mit,1
-9442,PierreCugnet/airline-sentiment-analysis,streamlit,,1
-9443,AICopilot/Dropbox,streamlit,mit,1
-9444,Saturdays/Tomatelo_a_pecho,gradio,,1
-9445,Saturdays/mamamIA,streamlit,,1
-9446,ITESM/streamlit_graphs,streamlit,mit,1
-9447,Saturdays/desertIAragon,streamlit,,1
-9448,sil-ai/aqua-comprehensibility,gradio,,1
-9449,tomofi/GOCR,gradio,mit,1
-9450,Wootang01/image_classifier_four,gradio,,1
-9451,tsantos/Hierarchical-Classification-System-for-Breast-Cancer,streamlit,,1
-9452,swcrazyfan/Kingify-2Way,gradio,,1
-9453,tensorflow/efficientnetv2-s,gradio,,1
-9454,webis-huggingface-workshop/omar_demo,gradio,mit,1
-9455,webis-huggingface-workshop/ferdi_demo,gradio,mit,1
-9456,webis-huggingface-workshop/sebastian_sentiments_demo,gradio,mit,1
-9457,webis-huggingface-workshop/guldeniz-first-space,gradio,,1
-9458,yesdeepakmittal/fake-news-classifier,gradio,,1
-9459,hysts/ibug-emotion_recognition,gradio,,1
-9460,manmeetkaurbaxi/YouTube-Video-Summarizer,gradio,mit,1
-9461,Hdiopalma/anime-face-detector,gradio,afl-3.0,1
-9462,Fah/gradio-prediction-conversionrate,gradio,,1
-9463,awacke1/Memory-Streamlit,streamlit,mit,1
-9464,Tlaloc/Aerial_Unet,gradio,,1
-9465,mgfrantz/reading_practice,gradio,mit,1
-9466,Guldeniz/aerial-to-map,gradio,,1
-9467,yale-CPSC-577/musical-tone-123,gradio,mit,1
-9468,SIB/Smart_Resume,gradio,,1
-9469,Vijish/PoPd-PoPArT,streamlit,mit,1
-9470,ales/wav2vec2-cv-be-lm,gradio,gpl-3.0,1
-9471,helliun/antetoki,gradio,artistic-2.0,1
-9472,SRVM-kandregula/Resume_Enhancement,streamlit,,1
-9473,hysts/TADNE-image-viewer,gradio,,1
-9474,adimmer/semi-supervised-wrappers,gradio,mit,1
-9475,panik/Facial-Expression,gradio,,1
-9476,bioniclelee/BoatDetectionCW,streamlit,,1
-9477,birdortyedi/cifr-pytorch,gradio,cc-by-nc-sa-4.0,1
-9478,docs-demos/hubert-large-superb-er,gradio,,1
-9479,docs-demos/paraphrase-xlm-r-multilingual-v1,gradio,,1
-9480,beihai/Image-Compression-with-SVD,gradio,bsd-2-clause,1
-9481,haryoaw/id-recigen,streamlit,mit,1
-9482,NeuML/txtsql,streamlit,apache-2.0,1
-9483,Epitech/LinguaExpressus,gradio,mit,1
-9484,Chris1/real2sim,gradio,mit,1
-9485,Epitech/IA_NLP,streamlit,,1
-9486,hylee/apdrawing,gradio,,1
-9487,tomofi/NEologd,streamlit,mit,1
-9488,eetn/Hellenic_AI_Society,gradio,mit,1
-9489,BramVanroy/opus-mt,streamlit,mit,1
-9490,paulbricman/velma,streamlit,,1
-9491,Saturdays/FER,gradio,,1
-9492,choiyk0103/TrOCR_app,gradio,,1
-9493,vebie91/spaces-image-classification-demo,gradio,,1
-9494,aziz7751/lan2lan,streamlit,other,1
-9495,bohmian/simple_streamlit_app,streamlit,,1
-9496,abidlabs/call-sentiment-blocks-2,gradio,,1
-9497,andersab/QuijoBERT,gradio,gpl-3.0,1
-9498,Epitech/AIoT,streamlit,,1
-9499,AdWeeb/SuMmeet,streamlit,cc-by-4.0,1
-9500,Qiwei97/Airbnb_tool,streamlit,,1
-9501,Eddevs/README,static,,1
-9502,chiulori/bertopic-reviews,streamlit,,1
-9503,BIASLab/sars-cov-2-classification-fcgr,streamlit,afl-3.0,1
-9504,xiaogang/res2net,gradio,,1
-9505,lounguyen/MangoDetectionApp,streamlit,,1
-9506,igrab666/polish_text_summarization,gradio,,1
-9507,dtrejopizzo/webcam,gradio,,1
-9508,Meena/table-question-answering-space,streamlit,,1
-9509,m-newhauser/political-tweets,gradio,gpl-3.0,1
-9510,martinlmedina/tf_hub_Fast_Style_Transfer_for_Arbitrary_Styles_v2,gradio,,1
-9511,Cyril666/my_abi,gradio,,1
-9512,osanseviero/ray_serve,gradio,,1
-9513,akhaliq/mGPT,gradio,,1
-9514,Saturdays/Focus_on_driving,gradio,,1
-9515,mjaramillo/SpiceIcaroTP,gradio,mit,1
-9516,JbIPS/DogBreed,streamlit,mit,1
-9517,merve/data-leak,static,apache-2.0,1
-9518,merve/hidden-bias,static,apache-2.0,1
-9519,merve/measuring-fairness,static,apache-2.0,1
-9520,IIITT/SumMeet,streamlit,cc-by-4.0,1
-9521,awacke1/CSV2ClassifyVisualization,gradio,mit,1
-9522,Saturdays/retinal-disease,gradio,,1
-9523,akhaliq/arcanegannewtheme,gradio,,1
-9524,Sacpapa/Zoidberg,gradio,mit,1
-9525,Cropinky/hana_hanak_houses,gradio,,1
-9526,ds21/Q-TicTacToe,streamlit,,1
-9527,wgpubs/fastai_2022_session1_is_marvel_character,gradio,wtfpl,1
-9528,atharvat80/Wikipedia2Vec-NED,streamlit,mit,1
-9529,rishirajacharya/picspeaks-hindi,gradio,apache-2.0,1
-9530,probing-vits/class-attention-map,gradio,apache-2.0,1
-9531,yuhe6/final_project,gradio,,1
-9532,probing-vits/class-saliency,gradio,apache-2.0,1
-9533,Epitech/userbank,gradio,,1
-9534,Epitech/IOT_temperature,streamlit,,1
-9535,beingpraveen/streamlit_text_to_sql,streamlit,,1
-9536,davidrd123/Art_Movement,gradio,artistic-2.0,1
-9537,OOlajide/nyc-crimes,streamlit,,1
-9538,Orcun2/ToxicCommentClassifier,gradio,afl-3.0,1
-9539,hylee/arcanegan,gradio,apache-2.0,1
-9540,radames/Speech-Recognition-Example,gradio,,1
-9541,jph00/minima,gradio,apache-2.0,1
-9542,jamesnzeex/resale_HDB_price_prediction_model,gradio,,1
-9543,tcapelle/spacy_wandb,streamlit,apache-2.0,1
-9544,EdBianchi/Social_Toximeter,streamlit,,1
-9545,Aristo/trafficsign,gradio,afl-3.0,1
-9546,Saturdays/Student_Experience,gradio,,1
-9547,calvin/MuseGAN,gradio,wtfpl,1
-9548,dev-andres/Caracola-app,gradio,,1
-9549,CVMX-jaca-tonos/Spanish-Audio-Transcription-to-Quechua-Translation,gradio,,1
-9550,LunchWithaLens/whichraptor,gradio,apache-2.0,1
-9551,NasirKhalid24/Dalle2-Diffusion-Prior,Configuration error,Configuration error,1
-9552,Gradio-Blocks/README,static,,1
-9553,awacke1/GraphViz-Demo,streamlit,mit,1
-9554,vestacasino/README,static,,1
-9555,zeeba/minima,gradio,apache-2.0,1
-9556,gerardo/elon_or_not,gradio,apache-2.0,1
-9557,LamaAl/arabic-empathetic,gradio,,1
-9558,deydebasmita91/Twitter_Live,streamlit,afl-3.0,1
-9559,AkshayDev/Lazy-Film-Reviews,streamlit,cc-by-nc-4.0,1
-9560,akhaliq/dalle-flow,gradio,,1
-9561,Zakia/cat_or_dog_predictor,gradio,apache-2.0,1
-9562,awacke1/VideoPlayer,streamlit,mit,1
-9563,Zakia/chest_x_ray_pneumonia_predictor,gradio,apache-2.0,1
-9564,sijunhe/poet,gradio,afl-3.0,1
-9565,thepurplingpoet/superman,gradio,,1
-9566,akhaliq/CaptchaCracker,gradio,,1
-9567,bananabot/ThisMollywoodMovieDoesNotExist.com,gradio,wtfpl,1
-9568,Matonice/gradio-insurance-policy-summarizer,gradio,,1
-9569,skalyan91/font_classifier,gradio,,1
-9570,cesar/autotexto,streamlit,,1
-9571,spencer/socm,streamlit,,1
-9572,ganesh3/superheroclassifier,gradio,apache-2.0,1
-9573,ialhashim/Colorizer,gradio,mit,1
-9574,IsaacK/streamlit-test,streamlit,afl-3.0,1
-9575,luvarona/Practica1,gradio,,1
-9576,azaninello/ailai,gradio,cc-by-sa-4.0,1
-9577,hlopez/Twitter-Positivity-Analyzer,gradio,,1
-9578,musfiqdehan/bangla-pos-tagger,streamlit,mit,1
-9579,Zengyf-CVer/Gradio_YOLOv5_Det_v2_2,gradio,gpl-3.0,1
-9580,aibc/object-detection-demo,gradio,apache-2.0,1
-9581,tlkh/textdiff,streamlit,mit,1
-9582,awacke1/ParallelSummaryModel,gradio,mit,1
-9583,Saturdays/WomanLife,gradio,,1
-9584,Zengyf-CVer/Gradio_YOLOv5_Det_v3,gradio,gpl-3.0,1
-9585,Giedrius/mood_detector,gradio,mit,1
-9586,Slava917/pronunciation-trainer,gradio,,1
-9587,ashishraics/FillTheBlanks,streamlit,,1
-9588,kandysh/NER_Tagger,streamlit,mpl-2.0,1
-9589,patent/demo3,streamlit,,1
-9590,xiaogang/image_emotion,gradio,,1
-9591,Epitech/alzheimer,gradio,,1
-9592,azizalto/us_patent_kaggle,streamlit,,1
-9593,Chujinze/Res2Net,gradio,,1
-9594,biubiubiiu/EFDM,gradio,mit,1
-9595,rushic24/Priyanka-Chopra-TTS,gradio,mit,1
-9596,johnnyfivefingers/summarymachine,gradio,,1
-9597,valurank/Headline_generator,gradio,other,1
-9598,vinni1484/text-summarizer,gradio,apache-2.0,1
-9599,YSU/aspram-realtime,gradio,apache-2.0,1
-9600,freddyaboulton/ts-lags,gradio,mit,1
-9601,Epitech/MLOps,streamlit,,1
-9602,vinni1484/text-keywords,gradio,apache-2.0,1
-9603,mikachou/stackoverflow,gradio,,1
-9604,fangyuan/lfqa_discourse,gradio,cc-by-sa-4.0,1
-9605,WillieCubed/song-to-sheet,gradio,mit,1
-9606,Aravindan/BreedClassification,gradio,,1
-9607,evaluate-metric/roc_auc,gradio,,1
-9608,evaluate-metric/pearsonr,gradio,,1
-9609,evaluate-metric/competition_math,gradio,,1
-9610,evaluate-metric/recall,gradio,,1
-9611,evaluate-metric/coval,gradio,,1
-9612,evaluate-metric/ter,gradio,,1
-9613,evaluate-metric/indic_glue,gradio,,1
-9614,evaluate-metric/glue,gradio,,1
-9615,evaluate-comparison/mcnemar,gradio,,1
-9616,priyankasharma5882/Breed_Classification,gradio,,1
-9617,simulate-tests/RiggedSimple,gradio,,1
-9618,simulate-tests/BoxTextured,gradio,,1
-9619,michaelgira23/debiasing-lms,gradio,,1
-9620,marksverdhei/saved-you-a-click,gradio,,1
-9621,seduerr/ethical_data,gradio,apache-2.0,1
-9622,pierreguillou/duplicate-an-existing-space,gradio,,1
-9623,pourmand1376/PrePars,gradio,gpl-2.0,1
-9624,Sa-m/Brand-Logo-Classification,gradio,mit,1
-9625,farukozderim/comparison-space2,gradio,,1
-9626,yeqingmei123/face-test,gradio,mit,1
-9627,messiah2305/duplicate-space,gradio,,1
-9628,LuciaCw/greet,gradio,,1
-9629,kandysh/clause_segmentation,streamlit,ms-pl,1
-9630,ironbar/aprender_a_leer,gradio,other,1
-9631,dpv/Stage1Recycling,gradio,,1
-9632,GroNLP/divemt_explorer,streamlit,gpl-3.0,1
-9633,HFUniversity2022/final-project-abubakar,gradio,,1
-9634,HarryLee/TextTopicModeling,streamlit,,1
-9635,nagolinc/safetyWaifu,gradio,,1
-9636,rajistics/News_Topic_Clustering,streamlit,apache-2.0,1
-9637,awacke1/StreamlitStatefulSingleton,streamlit,mit,1
-9638,zhang0209/ImageDownloader,gradio,,1
-9639,Hamda/AraJARIR,streamlit,apache-2.0,1
-9640,deepparag/Aeona-Chatbot,streamlit,mit,1
-9641,fbadine/uk_ireland_accent_classification,gradio,apache-2.0,1
-9642,chaninder/ds3-ml-model,streamlit,,1
-9643,Jerimee/HelloWorld,gradio,cc0-1.0,1
-9644,rajistics/biobert_ner_demo,gradio,apache-2.0,1
-9645,sub44/reddit-video-downloader11,streamlit,,1
-9646,awacke1/SaveAndReloadDataset,streamlit,mit,1
-9647,mynti/plainly,gradio,,1
-9648,abdulmatinomotoso/Plant_leaf_disease_classificaton,streamlit,,1
-9649,bookbot/Grad-TTS-Weildan-Playground,gradio,apache-2.0,1
-9650,awacke1/TimeSeries,streamlit,mit,1
-9651,fmegahed/tavr_project,gradio,cc-by-4.0,1
-9652,Xhaheen/facebook_OPT_350m_Language_model,streamlit,cc,1
-9653,evaluate-metric/README,static,,1
-9654,zswwsz/Dissertation_txt_to_img,gradio,afl-3.0,1
-9655,daniel-dona/tfg-demo,gradio,cc0-1.0,1
-9656,keras-io/siamese-contrastive,gradio,apache-2.0,1
-9657,sriramelango/CV_Social_Classification,gradio,,1
-9658,seduerr/communicaite,gradio,apache-2.0,1
-9659,skydust/textsum,streamlit,,1
-9660,awacke1/Text2SpeechSentimentSave,gradio,mit,1
-9661,clementgyj/FNLP_D_HD,streamlit,mit,1
-9662,comodoro/Coqui-STT-transcription,gradio,cc-by-nc-sa-4.0,1
-9663,aritheanalyst/legalsummarizer,static,apache-2.0,1
-9664,doevent/ArcaneGAN,gradio,,1
-9665,iankur/img2tex,gradio,afl-3.0,1
-9666,joaomaia/football_probs,gradio,,1
-9667,Cyril666/ContourNet-ABI,gradio,,1
-9668,kandysh/clause_segmentation_benepar,streamlit,afl-3.0,1
-9669,HaHaBill/LandShapes-Antarctica,gradio,,1
-9670,keras-io/addition-lstm,gradio,,1
-9671,GiordanoB/sumarizacao-abstrativa-portugues,gradio,afl-3.0,1
-9672,neeraj-aditi/AIVOT-AI,gradio,,1
-9673,awacke1/NLPAutoAI,gradio,mit,1
-9674,theAIguy/triplet_margin_loss,gradio,,1
-9675,Ritvik19/SudokuNet,streamlit,,1
-9676,awacke1/Emoji-Short-Codes,streamlit,mit,1
-9677,pplonski/dashboard,gradio,mit,1
-9678,isabel/testing-streamlit,streamlit,afl-3.0,1
-9679,sriramelango/Social_Classification_Public,gradio,,1
-9680,awacke1/DigitalCity,static,mit,1
-9681,awacke1/MLOpsStreamlit,streamlit,mit,1
-9682,Ani1712full/Estimacion_tasa_morosidad,gradio,cc-by-4.0,1
-9683,isabel/testing-blocks,gradio,afl-3.0,1
-9684,keras-io/structured-data-classification,gradio,,1
-9685,keras-io/CutMix_Data_Augmentation_for_Image_Classification,gradio,,1
-9686,Avator/gradio-hugging-face,gradio,,1
-9687,Sebasur90/observatorio_noticias,streamlit,,1
-9688,awacke1/SpeechStoryReadAloud,gradio,mit,1
-9689,chainyo/optimum-text-classification,streamlit,mit,1
-9690,Narrativa/semantic_news_search,streamlit,,1
-9691,chlab/interactive_kinematic_planet_detector,gradio,afl-3.0,1
-9692,SoArizonaAI/README,static,,1
-9693,keras-io/conv_autoencoder,gradio,gpl-3.0,1
-9694,Abdul09/bingo_demo,gradio,,1
-9695,nbroad/voice-queries-clinical-trials,gradio,,1
-9696,naver/PUMP,gradio,,1
-9697,wlf/dall-e,static,apache-2.0,1
-9698,awacke1/QiskitQuantumNeuralNet,gradio,mit,1
-9699,Kieranm/britishmus_plate_material_classifier_space,gradio,,1
-9700,keras-io/WGAN-GP,gradio,apache-2.0,1
-9701,Heisenberg08/Text2SQL,streamlit,apache-2.0,1
-9702,abdabbas/abd,gradio,afl-3.0,1
-9703,lvwerra/bary_score,gradio,,1
-9704,SLU-CSCI4750/Demo8_RegressionGradientDecentCompare,gradio,,1
-9705,kaggle/amex,gradio,,1
-9706,rajistics/cars,static,,1
-9707,bigscience-data/filter_values_distributions,streamlit,,1
-9708,goarnaiz/Proyecto,gradio,,1
-9709,HGZeon/test_model_2,gradio,,1
-9710,paochoa/DeOldification,gradio,,1
-9711,AlgoveraAI/web3-wallet-streamlit,streamlit,,1
-9712,keras-io/image_classification_using_conv_mixer,gradio,gpl-3.0,1
-9713,keras-io/Image_Classification_using_Consistency_Training,gradio,gpl-3.0,1
-9714,keras-io/english-speaker-accent-recognition-using-transfer-learning,gradio,,1
-9715,HiImJavivi/Practica2,gradio,afl-3.0,1
-9716,davidmasip/glaucoma-gr,gradio,,1
-9717,berkeozd/AppReviewClassifiers,gradio,,1
-9718,njgroene/age-gender-profilepic,gradio,cc-by-4.0,1
-9719,BFH/BKMotionsAI,gradio,gpl-3.0,1
-9720,SIVAPRASATH/tamil-translator,gradio,,1
-9721,2-2/blockchain.ai,static,,1
-9722,rhuang/RL,static,wtfpl,1
-9723,jamoncj/entregable3,gradio,,1
-9724,abdabbas/skincancer-iraq,gradio,other,1
-9725,krislynn/krislynn,static,,1
-9726,mlnotes/borrador_constitucion_chile,gradio,,1
-9727,Firefly777a/summarization-demo-v1,gradio,,1
-9728,keras-io/ProbabilisticBayesianNetwork,gradio,,1
-9729,douwekiela/dadc,gradio,bigscience-bloom-rail-1.0,1
-9730,sugo/v6yu7bgn,static,,1
-9731,khanguyen/voice-password-app,streamlit,,1
-9732,keras-io/cct,gradio,,1
-9733,DemocracyStudio/generate_nft_content,streamlit,cc,1
-9734,awacke1/GradioBlocksChangeEvent,gradio,mit,1
-9735,ValarMorghulis/BudgetAllocation,streamlit,afl-3.0,1
-9736,Gavnoed/Kaloed,gradio,,1
-9737,MaksMaib/PetGradioStyleTransf,gradio,,1
-9738,awacke1/Transformers-StoryWriting,gradio,mit,1
-9739,Saturdays/HUMANDS,gradio,,1
-9740,denisp1/Transformers-StoryWriting,gradio,mit,1
-9741,keras-io/ctc_asr,gradio,apache-2.0,1
-9742,jharrison27/VR-DEMO,static,,1
-9743,denisp1/AR-VR-IOT-DEMO,static,mit,1
-9744,jmcob/AR-VR-IOT-Demo,static,,1
-9745,pmuvval1/ChemistryMoleculeModelerTest,streamlit,,1
-9746,jharrison27/moleculemodeler,streamlit,,1
-9747,jmcob/ChemistryModelerSMILES,streamlit,,1
-9748,jbitel/dalle,static,,1
-9749,awacke1/ContextQuestionAnswerNLP,gradio,mit,1
-9750,EuroPython2022/README,static,,1
-9751,keras-io/adamatch-domain-adaption,gradio,apache-2.0,1
-9752,TIMAX/Logic-Translator,gradio,,1
-9753,mwaseemrandhawa/sentiment_analysis,streamlit,,1
-9754,RaulS/D-Pose,gradio,,1
-9755,denisp1/GraphViz-Demo,streamlit,mit,1
-9756,denisp1/AI-Quantum,streamlit,mit,1
-9757,arshy/medicalspecialty,gradio,apache-2.0,1
-9758,Heisenberg08/Ai_Portrait_Mode,streamlit,mit,1
-9759,jkim1238/predictive_analysis,streamlit,apache-2.0,1
-9760,mindwrapped/gpt2-lotr-fellowship,gradio,mit,1
-9761,Devaholic/fruit-demo,gradio,,1
-9762,dennis-fast/Talk2Elon,gradio,mit,1
-9763,azaninello/gpt2-general-english,gradio,wtfpl,1
-9764,langfab/movie-plot-genre-predictor,gradio,,1
-9765,Wootang01/sentiment_analyzer_1,streamlit,,1
-9766,ouiame/text,gradio,,1
-9767,phmota/disarter_model,gradio,other,1
-9768,shaheer/mysent,streamlit,,1
-9769,LayBraid/SpaceVector_v0,streamlit,mit,1
-9770,shaheer/textgeneration,gradio,,1
-9771,nicole-ocampo/digimap-mp,gradio,mit,1
-9772,MB311/Wordle_Performance_Checker,streamlit,afl-3.0,1
-9773,tonne/pycaret,streamlit,,1
-9774,egesko/DCGAN,gradio,mit,1
-9775,keras-io/VQ-VAE,gradio,,1
-9776,UdayPrasad/fashion-mnist,gradio,,1
-9777,awacke1/MultiRhymeLyricSmith,streamlit,mit,1
-9778,ARTeLab/DTM_Estimation_SRandD,gradio,,1
-9779,shouzen/canada-goose-v4,streamlit,,1
-9780,logasja/Fawkes,gradio,gpl-3.0,1
-9781,SoundreameR/craiyon-exploration,static,,1
-9782,Sreenivas98/FashionMIST_Classification,gradio,,1
-9783,oussama/LayoutLMv1,gradio,,1
-9784,seanbenhur/tamilatis,gradio,apache-2.0,1
-9785,aico/TrOCR-digit,gradio,,1
-9786,davidfischer/ea-classifier,gradio,,1
-9787,Conner/IAPdemo,gradio,afl-3.0,1
-9788,kkawamu1/huggingface_multi_inference_rank_eval,streamlit,cc,1
-9789,speechbrain/README,static,,1
-9790,awacke1/NLPImageUnderstanding,gradio,mit,1
-9791,gangviolence/giftmediscordnitro,gradio,,1
-9792,Polo45/README,static,,1
-9793,osanseviero/tips,static,,1
-9794,blastd/LimoneSorrentin,gradio,,1
-9795,ullasmrnva/LawBerta,gradio,,1
-9796,Margaret/mazzuma-sentiment-engine,gradio,,1
-9797,yzha/ctc_eval,gradio,,1
-9798,SaulLu/bloom-generations-viewer,streamlit,,1
-9799,suds/blah,streamlit,mit,1
-9800,aplejandro/HeartDisease,gradio,cc-by-4.0,1
-9801,dineshreddy/WALT,gradio,mit,1
-9802,djsull/aha-summarisation,gradio,apache-2.0,1
-9803,UdayPrasad/mnist_classification,gradio,,1
-9804,yairVag/Image_Captioning,gradio,,1
-9805,samroni/gpt2_demo_gradioUI,gradio,,1
-9806,Liviox24/LoanEligibilityPrediction,gradio,afl-3.0,1
-9807,codenamewei/speech-to-text,gradio,gpl-3.0,1
-9808,matteopilotto/emotion_in_tweets,gradio,,1
-9809,chali12/skill_extraction,streamlit,,1
-9810,PaulHilders/IEAI_CLIPGroundingExplainability,gradio,afl-3.0,1
-9811,kamalkraj/Mega-Dalle,gradio,mit,1
-9812,awacke1/ChatBotPersonalities,gradio,mit,1
-9813,bhvsh/stroke-prediction,streamlit,,1
-9814,Nomanalvi/PDF_Convertor,streamlit,afl-3.0,1
-9815,tcapelle/calculadora_impuestos,streamlit,mit,1
-9816,gestiodinamica/recon_caras,streamlit,,1
-9817,chrisjay/simple-mnist-classification,gradio,,1
-9818,jmaller/rnn-amywinehouse,gradio,,1
-9819,awacke1/MusicLyricsAndAlbums,gradio,mit,1
-9820,EuroPython2022/Leaderboard,gradio,,1
-9821,Cub/README,static,,1
-9822,atomiclabs/text_generation,gradio,afl-3.0,1
-9823,datien228/text-summarizer,gradio,mit,1
-9824,gestiodinamica/gdmk_genbase,streamlit,cc-by-4.0,1
-9825,sanchanhart/Warehouse_Apparel_Detection,gradio,osl-3.0,1
-9826,oussamamatar/yolo-mediapipe,gradio,apache-2.0,1
-9827,EuroPython2022/example-hello,gradio,,1
-9828,ceyda/kornia-augmentations-tester,streamlit,,1
-9829,shivambhosale/spacenet3-unet-1024-1024,gradio,,1
-9830,jmaller/rnn-leonard_cohen,gradio,mit,1
-9831,NAACL2022/README,static,,1
-9832,hirsuitedevil/demo,gradio,apache-2.0,1
-9833,NAACL2022/Spaces-Leaderboard,gradio,,1
-9834,awacke1/CSVSentiment,gradio,,1
-9835,awacke1/Gradio-Blocks-Demo-2,gradio,mit,1
-9836,awacke1/HFSpaceStreamlitHeatmap,streamlit,,1
-9837,Geethanjali/YouTube_Transcript_Summarizer,gradio,,1
-9838,Moran/Aviv_Moran_Summarization,streamlit,,1
-9839,hf-task-exploration/ExploreACMnaacl,streamlit,,1
-9840,rushi29/AIP_pdf,streamlit,,1
-9841,sourav11295/Model_Recommendation,gradio,afl-3.0,1
-9842,UzNutq/README,static,,1
-9843,mfumanelli/geometric_mean,gradio,,1
-9844,awacke1/GradioTranslation,gradio,,1
-9845,awacke1/GradioTextToSpeechOrImages,gradio,mit,1
-9846,awacke1/GradioDoubleChatbotTasteTest,gradio,mit,1
-9847,jorge-henao/historias-conflicto-col,gradio,apache-2.0,1
-9848,keras-io/conv_Mixer,gradio,,1
-9849,keras-io/token_learner,gradio,apache-2.0,1
-9850,Msp/Funsd_Layoutlm_V3_Pretrained,gradio,,1
-9851,lvwerra/license,streamlit,,1
-9852,lvwerra/license-static,static,,1
-9853,rajeshradhakrishnan/malayalam-tamil,gradio,,1
-9854,Sa-m/YOLO-V7-Custom-Model-Pot-Hole-Detection,gradio,mit,1
-9855,osanseviero/live_europython,gradio,,1
-9856,dalexanderch/SweetNet,gradio,,1
-9857,rycont/Biblify,streamlit,,1
-9858,Zengyf-CVer/Streamlit_YOLOv5_Model2x,streamlit,gpl-3.0,1
-9859,EuroPython2022/excitingModel,gradio,,1
-9860,EuroPython2022/Paddy_Disease_Classification,gradio,apache-2.0,1
-9861,awacke1/VisionImageClassifierGradio,gradio,mit,1
-9862,greco/survey_analytics_spaces,streamlit,gpl-3.0,1
-9863,PaulEdwards/StarWords,gradio,,1
-9864,freddyaboulton/blocks_inputs,gradio,,1
-9865,AINLPRoundTable/README,static,,1
-9866,jasmeet1001/jasmeetmoviebox,streamlit,unknown,1
-9867,cannlytics/README,static,mit,1
-9868,Dusan/clickbaitonator,gradio,afl-3.0,1
-9869,senfu/tiny_gaze,gradio,gpl-3.0,1
-9870,ysharma/testing_blocks_inference,gradio,gpl,1
-9871,simonschoe/Call2Vec,gradio,,1
-9872,AlexWortega/t5_predict_activity,gradio,,1
-9873,awacke1/GroupSimilarDataCluster,gradio,mit,1
-9874,cosmicdream/Image_Variations,gradio,apache-2.0,1
-9875,Giuliano/image_classification,gradio,,1
-9876,big-kek/NeuroSkeptic,gradio,,1
-9877,ManjariSingh/evalml_forecast,gradio,,1
-9878,EuroPython2022/viciu,gradio,mit,1
-9879,EuroPython2022/batangkali,gradio,gpl-2.0,1
-9880,EuroPython2022/cloudspace,gradio,mit,1
-9881,EuroPython2022/machinetestspace,gradio,apache-2.0,1
-9882,EuroPython2022/Warehouse_Apparel_Detection,gradio,gpl-3.0,1
-9883,platzi/platzi-curso-gradio-clasificacion-imagenes,gradio,mit,1
-9884,mishtert/tracer,streamlit,,1
-9885,Jimmie/identify_this_insect,gradio,apache-2.0,1
-9886,jonas/sdg-policy-tracing,streamlit,cc-by-4.0,1
-9887,Ifeanyi/classify-images,gradio,,1
-9888,EuroPython2022/pyro-vision,gradio,apache-2.0,1
-9889,eliolio/yelp-reviews,gradio,,1
-9890,cstimson/SentenceSimilarityHeatmapAndClustering,streamlit,mit,1
-9891,cstimson/ImageToOCR,gradio,mit,1
-9892,awacke1/ImageOCRMultilingual,gradio,mit,1
-9893,z-uo/HTS-Audio-Transformer,gradio,,1
-9894,Saurav21/Blog-Generation,gradio,,1
-9895,politweet-sh/politweet,gradio,mit,1
-9896,platzi/platzi-curso-gradio-tf-clasificacion-imagenes,gradio,mit,1
-9897,platzi/platzi-curso-gradio-asr,gradio,mit,1
-9898,Amrrs/hubble-jwst-compare,streamlit,mit,1
-9899,smjain/zeroshotclassifier,gradio,,1
-9900,smjain/gpt2_text_gen,gradio,,1
-9901,bulentsofttech/gradio_s1000_veri_toplama_modeli,gradio,osl-3.0,1
-9902,ubermenchh/dog-breed-classifier,streamlit,,1
-9903,awacke1/AskMeAnythingSemanticSearch,streamlit,apache-2.0,1
-9904,awacke1/BioMedContextHighlighter,gradio,apache-2.0,1
-9905,nyx-ai/stylegan2-flax-tpu,gradio,,1
-9906,freddyaboulton/sentiment-classification-interpretation-tabs,gradio,mit,1
-9907,Swth/Hi,gradio,cc,1
-9908,ICML2022/distilgpt2-finetuned-wikitext103,gradio,,1
-9909,Chirag4579/prakalpa-image-comparator,streamlit,,1
-9910,evaluate-metric/poseval,gradio,,1
-9911,awacke1/HFSpaceStreamlitHeatmapNLP,streamlit,mit,1
-9912,nkatraga/7.22.first.hfstreamlitHeatmap,streamlit,apache-2.0,1
-9913,Myrna/VideoSummary2,gradio,apache-2.0,1
-9914,sidsriv/VideoSummaryfromYoutubeVideo,gradio,apache-2.0,1
-9915,santoshsindham/VideoSummary,gradio,apache-2.0,1
-9916,nkatraga/7.22.VideoSummary2,gradio,apache-2.0,1
-9917,uparasha/ASRtoTexttoStorytoImagestoVideo,gradio,apache-2.0,1
-9918,akashagarwal/ASRGenerateStory,gradio,,1
-9919,uparasha/AnimationUsingLottie,streamlit,apache-2.0,1
-9920,awacke1/AnimationUsingLottie,streamlit,apache-2.0,1
-9921,niksyad/CarePlanQnAWithContext,gradio,mit,1
-9922,awacke1/CarePlanQnAWithContext2,gradio,mit,1
-9923,awacke1/Speeech2Text2Story2Images2Video,gradio,apache-2.0,1
-9924,rajatus231/Speeech2Text2Story2Images2Video,gradio,mit,1
-9925,NiiCole/FireExtinguishers,gradio,afl-3.0,1
-9926,awacke1/BiomedCaseContextHighlight,gradio,mit,1
-9927,williambr/CarePlanSOTAQnA,gradio,apache-2.0,1
-9928,awacke1/StreamlitHeatmapAndCluster,streamlit,apache-2.0,1
-9929,vnemala/StreamlitHeatmapAndCluster,streamlit,apache-2.0,1
-9930,williambr/VideoSummaryGenerator,gradio,apache-2.0,1
-9931,MateusA/StoryGenerator,gradio,apache-2.0,1
-9932,ocordes/GradioSpeechToTextToMedia,gradio,apache-2.0,1
-9933,awacke1/GradioSpeech2Text2Story2Images2Video,gradio,apache-2.0,1
-9934,mm2593/Gradiospeech2Text2Story2Video,gradio,apache-2.0,1
-9935,awacke1/PhysicsRacingDemoWith3DARVR,static,apache-2.0,1
-9936,sdande11/HFSpaceStreamlitHeatmapNLP,streamlit,mit,1
-9937,sdande11/CarePlanQnAWithContext2,gradio,mit,1
-9938,awacke1/GraphVis3,streamlit,apache-2.0,1
-9939,widged/bloom_demo,gradio,,1
-9940,Ishayy/space_1,gradio,,1
-9941,imbikramsaha/cat-breed-classifier,gradio,apache-2.0,1
-9942,ceyda/fashion_classification,streamlit,apache-2.0,1
-9943,rkingery/dumb-language-model,streamlit,apache-2.0,1
-9944,MadhuV28/VideoSumamry,gradio,,1
-9945,timothepearce/mnist-classification,gradio,apache-2.0,1
-9946,dia2diab/hackme_space,streamlit,,1
-9947,satani/bird_classifier,gradio,apache-2.0,1
-9948,Juancho/forest_fire_detector,gradio,apache-2.0,1
-9949,imagescientist/zebrafishtest1,gradio,mit,1
-9950,astroweb/README,static,,1
-9951,smjain/insecure_code_detector,gradio,,1
-9952,smjain/unixshell_command_gen,streamlit,,1
-9953,aiEDUcurriculum/introtoAI-clubs-project,gradio,afl-3.0,1
-9954,Jai12345/App,streamlit,afl-3.0,1
-9955,riteshsingh/flower,gradio,apache-2.0,1
-9956,sebastianM/CarDetectionAndModernity,gradio,,1
-9957,ganning/asl-gloss,gradio,,1
-9958,manjuvallayil/te-reo,gradio,,1
-9959,evaluate-measurement/label_distribution,gradio,,1
-9960,madara-uchiha/MovieMakerAI,gradio,apache-2.0,1
-9961,jmcob/StreamlitGraphViz,streamlit,mit,1
-9962,awacke1/StreamlitGraphViz,streamlit,mit,1
-9963,denisp1/Streamlit-GraphViz-Demo,streamlit,mit,1
-9964,espejelomar/dientes,streamlit,,1
-9965,awacke1/WebAssemblyStreamlitLite-stlite,static,mit,1
-9966,poooja2012/ethio_hydro,streamlit,,1
-9967,Anuj-Panthri/imdb_review_sentiment,gradio,apache-2.0,1
-9968,osanseviero/shiny,gradio,,1
-9969,dblitzz21/food-spoonycal,gradio,,1
-9970,ekosetiawan/flowers_classifier,gradio,apache-2.0,1
-9971,Xhaheen/regex_by_bloom,gradio,,1
-9972,ali-ghamdan/image-colors-corrector,gradio,,1
-9973,mosses/constructMaker,gradio,unknown,1
-9974,ner4archives/ner4archives-NEL-vizualizer-app,streamlit,,1
-9975,keras-io/shiftvit,gradio,mit,1
-9976,elinteerie/NigeriaFoodAI,gradio,apache-2.0,1
-9977,Santarabantoosoo/Sentiments_topic_modeling_ITALIAN,gradio,,1
-9978,omlab/vlchecklist_demo,gradio,mit,1
-9979,RubenAMtz/pothole_detector,gradio,apache-2.0,1
-9980,elena-k/OmdenaTriesteLongCovid,gradio,gpl-3.0,1
-9981,kwangjong/food-classifier-MobileNetV3,gradio,afl-3.0,1
-9982,srini047/text-based-sentiment-analyzer,gradio,,1
-9983,manan/fruit-classifier,gradio,,1
-9984,windmaple/lit,gradio,,1
-9985,kvignesh17/YoutubeVideoSummarization,gradio,mit,1
-9986,harishrb/Translate-To-Spanish,gradio,mit,1
-9987,mikeee/convbot,gradio,mit,1
-9988,rsatish1110/VideoSummaryGenerator,gradio,apache-2.0,1
-9989,harishrb/TraveLingo,gradio,mit,1
-9990,georeactor/code-probability-of-injection,gradio,mit,1
-9991,Mostafa92/detecting_plant_leaf_diseases,gradio,apache-2.0,1
-9992,mbarnig/lb-de-en-fr-pt-COQUI-STT,gradio,cc-by-nc-sa-4.0,1
-9993,munichnlp/README,static,,1
-9994,MadSid/Fast-L2,gradio,,1
-9995,AyameYODAYO/xijinpingx,static,,1
-9996,osanseviero/gradio_auth,gradio,,1
-9997,Aabdelhamidaz/animals,gradio,apache-2.0,1
-9998,qmjnh/FLowerCLassification,gradio,,1
-9999,mihyun/may1,static,afl-3.0,1
-10000,0x7194633/mbrat-ru-sum,gradio,,1
-10001,hangjoni/food_classifier,streamlit,apache-2.0,1
-10002,deelight-del/minima,gradio,apache-2.0,1
-10003,Jour/Translate,gradio,mit,1
-10004,Yuqi/Gender_Classifier,gradio,apache-2.0,1
-10005,esumitra/superheroes,gradio,mit,1
-10006,awacke1/StreamlitHeatmapKMeansCluster,streamlit,mit,1
-10007,Cambino/dog-classifier-gradio,gradio,afl-3.0,1
-10008,freddyaboulton/EDSR-freddy,gradio,mit,1
-10009,suddu21/garbage-classification,gradio,,1
-10010,Dinoking/Flower-Classification-v1,gradio,,1
-10011,Dinoking/Garbage-Classifier-V2,gradio,,1
-10012,SaffalPoosh/faceRecognition,gradio,apache-2.0,1
-10013,Plashkar/test-gradio-sdk,gradio,other,1
-10014,versus666/uplift_lab,streamlit,,1
-10015,jaleesahmed/employee-experience,gradio,lgpl-3.0,1
-10016,vcasadei/banana-defect-detection,gradio,,1
-10017,djsull/aha-curse-class,gradio,apache-2.0,1
-10018,SagarPatel/YouMatter,gradio,,1
-10019,kitkeat/effective_argumentative_writing_prediction,streamlit,,1
-10020,Plashkar/diabetes-predict,gradio,,1
-10021,usingh49/us1,streamlit,,1
-10022,Dinoking/Garbage-Classifier-V3,gradio,,1
-10023,nakamura196/yolov5-ndl-layout,gradio,,1
-10024,Hackathon2022/BigColumnDiabetes,gradio,,1
-10025,jaleesahmed/correlation-and-visualization,gradio,lgpl-3.0,1
-10026,jaleesahmed/data-description,gradio,lgpl-3.0,1
-10027,jaleesahmed/model-development,gradio,lgpl-3.0,1
-10028,madoss/gdiy,streamlit,apache-2.0,1
-10029,Aravindan/butterfly_classification,gradio,,1
-10030,nivalk/dermAI,gradio,apache-2.0,1
-10031,pycs/aircraft,gradio,apache-2.0,1
-10032,disham993/anime_protagonist_classifier,gradio,apache-2.0,1
-10033,ethanmb/monkeypox-model,gradio,apache-2.0,1
-10034,Ali-Omrani/CCR,gradio,,1
-10035,hugginglearners/llama_or_alpaca,gradio,,1
-10036,vbzvibin/gavs-hackathon_v1,streamlit,,1
-10037,Dinoking/Garbage-Classifier-V4,gradio,,1
-10038,dbmdz/detectron2-model-demo,gradio,mit,1
-10039,irJERAD/tahiti-or-hawaii,gradio,apache-2.0,1
-10040,apat27/pox-classifier,gradio,apache-2.0,1
-10041,iannn/TheDiscussionChat,static,,1
-10042,Xhaheen/Regex_by_OpenAI,gradio,,1
-10043,rajistics/interpet_transformers,streamlit,apache-2.0,1
-10044,victorialslocum/reciparse_visualizer,gradio,mit,1
-10045,Daniel-Saeedi/sent-debias,gradio,mit,1
-10046,icon-it-tdtu/mt-vi-en-optimum,gradio,apache-2.0,1
-10047,pouchedfox/SP,gradio,,1
-10048,PatrickTyBrown/LoanDocumentClassifier,gradio,apache-2.0,1
-10049,Xhaheen/tasweer,static,,1
-10050,Daniel-Saeedi/auto-debias,gradio,mit,1
-10051,Parthjain9925/DigitRecognizer,gradio,,1
-10052,sofmi/MegaDetector_DLClive,gradio,,1
-10053,Dinoking/Garbage-Classifier-V6,gradio,,1
-10054,jamesbradbury333/fastai-week-2,gradio,apache-2.0,1
-10055,nerusskyhigh/drawingstyle,gradio,apache-2.0,1
-10056,sasa25/1,streamlit,,1
-10057,chidojawbreaker/ct-i-rad,gradio,,1
-10058,sandeepmajumdar/nlp-sorcery,gradio,,1
-10059,dawood/Plot,gradio,afl-3.0,1
-10060,instantnoodle/Fruits-classifier,gradio,apache-2.0,1
-10061,rsandadi/BearDetector,gradio,apache-2.0,1
-10062,idsedykh/codebleu2,gradio,,1
-10063,awacke1/Hackathon2022,streamlit,mit,1
-10064,chuoguejiofor/CatBreedClassifier,gradio,apache-2.0,1
-10065,KNDLR/trash-ai,gradio,gpl-3.0,1
-10066,smjain/smjainvoice,gradio,mit,1
-10067,Dinoking/Guccio-AI-Designer,gradio,cc-by-nc-3.0,1
-10068,jspr/tweet-ab,gradio,,1
-10069,LightAI/README,static,apache-2.0,1
-10070,captchaboy/fastest-8kun-captchas-solver,gradio,,1
-10071,feng2022/styleganhuman_copy,gradio,,1
-10072,pinecone/gif-search,streamlit,,1
-10073,pinecone/yt-search,streamlit,,1
-10074,freddyaboulton/3.1.4.9-all-demos,gradio,,1
-10075,Qilex/ColorpAI,gradio,other,1
-10076,offside/offsidespace,static,afl-3.0,1
-10077,AlirezaSM/bear_classifier,gradio,apache-2.0,1
-10078,Rekanice/hf_minimal_sushi,gradio,apache-2.0,1
-10079,qile0317/Bacteria-Classification,gradio,apache-2.0,1
-10080,BigSalmon/TestAnyGPTModel,streamlit,,1
-10081,TF2SA/template_generator,gradio,,1
-10082,marioboy/neil-breen,gradio,mit,1
-10083,metroidmen/face-restoration-Tencent,static,,1
-10084,dentadelta123/GuardrailDetection,gradio,,1
-10085,jonathanmg96/TFG-YOLOP,gradio,gpl-3.0,1
-10086,owaiskha9654/Yolo-v7,gradio,,1
-10087,aronvandepol/KGPT,gradio,,1
-10088,Eitan177/mutation_profiler,streamlit,gpl-3.0,1
-10089,LawalAfeez/science-lab,gradio,,1
-10090,Shivam29rathore/shorter-finbert,gradio,apache-2.0,1
-10091,AIZeroToHero/README,static,,1
-10092,dquisi/StoryGenerator,gradio,,1
-10093,michael-p/mi-vi-be,gradio,apache-2.0,1
-10094,AIZeroToHero/02-Transformers-Sentence2Paragraph,gradio,mit,1
-10095,jracca/00-learning-space,gradio,mit,1
-10096,dmccreary/AaronsClass,gradio,mit,1
-10097,dmccreary/Art-From-Text-And-Images,gradio,mit,1
-10098,jracca/01-learning-space,gradio,mit,1
-10099,jracca/02-learning-space,streamlit,mit,1
-10100,bdp-AI/03-ImageSearchSimilar,streamlit,mit,1
-10101,AIZeroToHero/05-RealtimeStreamlitASR,streamlit,mit,1
-10102,jracca/05-learning-space,gradio,mit,1
-10103,jonswain/pka_classifier,gradio,apache-2.0,1
-10104,freddyaboulton/blocks-js-methods,gradio,mit,1
-10105,leo-step/imagenet-demo,gradio,,1
-10106,sajjadking86/appbot,streamlit,,1
-10107,Paarth/ForgeT5,gradio,afl-3.0,1
-10108,vladisov/fn,gradio,apache-2.0,1
-10109,Gorilla115/shakespeareify,gradio,,1
-10110,teamtom/flower_classifier,gradio,apache-2.0,1
-10111,Artificio/AdversarialArt,gradio,,1
-10112,mtulow/geospatial_deep_learning_app,gradio,,1
-10113,codesue/dystopedia,gradio,apache-2.0,1
-10114,joaquinu/merluzo,gradio,apache-2.0,1
-10115,chidojawbreaker/UTI,gradio,,1
-10116,Supsies/CodingandMore,gradio,,1
-10117,FredMagick/Stable-diffusion-Bias-test,gradio,bigscience-bloom-rail-1.0,1
-10118,kios/Natural_Disaster_Classification,gradio,afl-3.0,1
-10119,awacke1/AI-Atari-Live-Streamlit,streamlit,mit,1
-10120,bookbot/Wikipedia-Scraper,gradio,,1
-10121,Msp/docVQA_donut,gradio,mit,1
-10122,MadhuV28/Image_Background_Sidebar_Lottie_Animation,streamlit,mit,1
-10123,chidojawbreaker/transformer-health,gradio,,1
-10124,arngpt/Summarizer-Trax,gradio,unknown,1
-10125,mbarnig/translation-lb-en-with-3-models,gradio,cc-by-nc-sa-4.0,1
-10126,nmenezes0/fast-ai-example,gradio,,1
-10127,torfasonc/Accord_or_Civic,gradio,,1
-10128,darragh/bloom_demo_long,gradio,,1
-10129,awacke1/StreamlitClipboardInteraction,streamlit,mit,1
-10130,freddyaboulton/timeseries-forecasting-with-prophet,gradio,mit,1
-10131,phenolicat/hobbitese_id,gradio,apache-2.0,1
-10132,neek05/NLP-AMLO,gradio,cc-by-4.0,1
-10133,sandeepmajumdar/Generate_Image_From_Text,gradio,,1
-10134,johnson906/recipedia,Configuration error,Configuration error,1
-10135,Jack-Ahan/fruit-vegetable-classifier,gradio,gpl-3.0,1
-10136,pinecone/movie-recommender,streamlit,,1
-10137,sbroy10/01-NLP-Sentence2Paragraph,gradio,mit,1
-10138,locust/01-NLP-Sentence2Paragraph,gradio,mit,1
-10139,awacke1/2-NLP-Seq2SeqQAGenerator,gradio,mit,1
-10140,sbroy10/02-NLP-Seq2SeqQAGenerator,gradio,mit,1
-10141,locust/02-NLP-Seq2SeqQAGenerator,gradio,mit,1
-10142,sbroy10/03-NLP-SOTA-MedEntity,gradio,mit,1
-10143,AIZeroToHero/03-NLP-MLM-SOTA-MedEntity,gradio,,1
-10144,AIZeroToHero/3-NLP-MLM-MaskedLanguageModel,gradio,mit,1
-10145,locust/03-NLP-MLM-MaskedLanguageModel,gradio,mit,1
-10146,locust/04-NLP-KE-WordCloud,gradio,mit,1
-10147,sbroy10/05-NLP-CPVisGraph,streamlit,mit,1
-10148,rogman/Flamingo-Gradio-ImageDescribe,gradio,mit,1
-10149,gngpostalsrvc/Hyderabad_India_AI_Soft_skills,gradio,,1
-10150,Imran1/Flower-image-classification,gradio,mit,1
-10151,Dana19/biden_or_clinton,gradio,apache-2.0,1
-10152,MrSinan/LFW-MaskedRecogntion,gradio,afl-3.0,1
-10153,AnnasBlackHat/Image-Downloader,gradio,,1
-10154,SalmanHabeeb/Blatt,gradio,gpl-3.0,1
-10155,Winterflower/question-generator,gradio,mit,1
-10156,ThankGod/image-classifier,gradio,,1
-10157,Ali-C137/Motivation-Letter-Generator,gradio,apache-2.0,1
-10158,BilalSardar/QuestionAndAnswer,gradio,,1
-10159,Clatonh/moth_or_butterfly,gradio,apache-2.0,1
-10160,ccaglieri/convnext_diabetic,gradio,afl-3.0,1
-10161,EuroSciPy2022/classification,gradio,apache-2.0,1
-10162,edthecoder/chicken_breeds,gradio,apache-2.0,1
-10163,EdBianchi/ThemeParksAccidents_RDF-SPARQL,streamlit,apache-2.0,1
-10164,Rida/Semantic-Segmentation,gradio,apache-2.0,1
-10165,archietram/Medical_Image_Classifier,gradio,apache-2.0,1
-10166,torfasonc/indianfoodclassifier,gradio,,1
-10167,VishnuTransformer/TrOCR_Handwritten,gradio,other,1
-10168,gradio/translation,gradio,,1
-10169,EstebanDC/UCS_JG,gradio,,1
-10170,1nferno/Single_Digit_Detection,gradio,mit,1
-10171,ysharma/test_diffusion,gradio,gpl,1
-10172,yusufani/TrCLIP,gradio,afl-3.0,1
-10173,selld/bag_classifier,gradio,,1
-10174,yakubashsd/oim_images,gradio,,1
-10175,Aadhithya/Binance-Crypto-Tracker,streamlit,,1
-10176,ysharma/testing_stablediff,gradio,gpl,1
-10177,abdabbas/breast_cancer,gradio,,1
-10178,ryancahildebrandt/all_in_one_sentence_embeddings,streamlit,,1
-10179,hallochen/firstspace,static,afl-3.0,1
-10180,gradio/sentiment_analysis,gradio,,1
-10181,autonomous019/Story_Generator_v2,gradio,bsd,1
-10182,power2/JoJoGan-powerhow2,gradio,,1
-10183,williambr/StreamlitMapPractice,streamlit,mit,1
-10184,mm2593/AIDrivenUI-Maps,streamlit,,1
-10185,thelou1s/yamnet,gradio,bsd-3-clause,1
-10186,Sangamesh/Cat_Dog_Classifier,gradio,apache-2.0,1
-10187,mmaguero/Auto-Complete_Semantic,streamlit,,1
-10188,wasay/FaceRecogTUKL,gradio,apache-2.0,1
-10189,Rick93/image_to_story_naive,gradio,mit,1
-10190,dumitrescustefan/romanian-text-generation,streamlit,,1
-10191,iSpr/ksic_ai_coding_census2015,streamlit,afl-3.0,1
-10192,leaner9988/Myspace,streamlit,afl-3.0,1
-10193,awacke1/TrapFlamenco,static,mit,1
-10194,qgrantq/Girl_gradio,gradio,apache-2.0,1
-10195,mya-mya/SengaFiller,gradio,cc-by-nc-sa-4.0,1
-10196,charlesnchr/VSR-SIM,gradio,gpl-3.0,1
-10197,mxs2019/nba-player-classifer,gradio,apache-2.0,1
-10198,Shredder/CONBERT,gradio,,1
-10199,marksverdhei/word_definition,gradio,,1
-10200,zzzzzz/text2image,gradio,apache-2.0,1
-10201,captchaboy/FAST-ABINet-OCR,gradio,mit,1
-10202,zhoucr/ai-koni,gradio,bsd,1
-10203,SmartPy/chaii-qa-task,gradio,apache-2.0,1
-10204,Funbi/Chat2,gradio,,1
-10205,toasty-tobi/movie-recommender-deployed,streamlit,,1
-10206,Will-Wade/AnimeOrDisney,gradio,apache-2.0,1
-10207,DorisB/streamlit-app,streamlit,,1
-10208,TM9450/Income_prediction,streamlit,cc-by-4.0,1
-10209,Intae/deepfake,streamlit,,1
-10210,DiViorg/categories_error_analysis,gradio,,1
-10211,gilmar/health_insurance_app,gradio,,1
-10212,Ammar-alhaj-ali/LayoutLMv3-Invoice,gradio,,1
-10213,baaastien/Spleeter_and_ASR,gradio,mit,1
-10214,gradio/image_classification,gradio,,1
-10215,BilalQ/Stable_Difussion,gradio,,1
-10216,amirDev/crowd-counting-p2p,gradio,,1
-10217,rahulmallah/first-app,streamlit,other,1
-10218,LeahLv/image-captioning-v4,streamlit,,1
-10219,Avatarize/ECON,gradio,,1
-10220,jaimin/Paraphrase,gradio,,1
-10221,thinh-huynh-re/webrtc,streamlit,,1
-10222,Deepak107/Bottle_images,gradio,afl-3.0,1
-10223,Sacso/FlowerDi,gradio,,1
-10224,Armandoliv/t5-summarize-app-scitldr,gradio,,1
-10225,Taoheed-O/spam_detector_app,streamlit,,1
-10226,iaanimashaun/glaucomanet,gradio,,1
-10227,KhrystynaKolba/lviv_temp,gradio,apache-2.0,1
-10228,Ariharasudhan/Kenya_food_classification,gradio,apache-2.0,1
-10229,gradio/leaderboard,gradio,,1
-10230,isyslab/NeuroPred-PLM,gradio,,1
-10231,shayantabasian/shayantip,gradio,,1
-10232,sadafpy/Malaria-Infected-Cell-Predictor,gradio,bigscience-bloom-rail-1.0,1
-10233,NotFungibleIO/Conversational-CSV,gradio,,1
-10234,ccolas/EmotionPlaylist,streamlit,,1
-10235,mxxtnn/Predict_the_cost_of_medical_bills,streamlit,afl-3.0,1
-10236,Filimize/English_To_French,streamlit,,1
-10237,mxxtnn/Predict_medical_expenses,streamlit,afl-3.0,1
-10238,Mayanand/emotion-recognition,gradio,mit,1
-10239,laurabarreda/genre_prediction,streamlit,,1
-10240,beau-badilla/faker-clf,gradio,gpl-3.0,1
-10241,Riakzu/parkinson_detection,streamlit,other,1
-10242,slone/myv-translation-2022-demo,gradio,cc-by-sa-4.0,1
-10243,MarioWasTaken/BackroomsIG,static,,1
-10244,pksx01/Audio-MNIST,gradio,apache-2.0,1
-10245,bzd4576/sovits-sin,gradio,afl-3.0,1
-10246,GAITOR/MLMondayDemo-Week1,streamlit,mit,1
-10247,BohdanPytaichuk/art-video-generation,gradio,,1
-10248,ESG-TFM-UV/ESG_API_BATCH,gradio,,1
-10249,haseena97/malaysian_dessert,gradio,apache-2.0,1
-10250,LoveAsAConstruct/Stable_Diffusion,gradio,afl-3.0,1
-10251,Dana19/ImageRecognition_FaceCount,gradio,apache-2.0,1
-10252,captchaboy/sendmespecs,gradio,,1
-10253,merve/gradio-analysis-dashboard-minimal,gradio,apache-2.0,1
-10254,BABASA/README,static,,1
-10255,Taoheed-O/Titanic,streamlit,,1
-10256,Aashiue/speech_to_text,gradio,,1
-10257,PaddlePaddle/jieba_paddle,gradio,apache-2.0,1
-10258,PaddlePaddle/transformer_zh-en,gradio,apache-2.0,1
-10259,3bdo7ss/Neutron_Chatbot,gradio,afl-3.0,1
-10260,ner4archives/NER4Archives-analytics,streamlit,mit,1
-10261,anthonygaltier/text_2_price__real_estate,streamlit,mit,1
-10262,professorbrat/melanoma_classification,gradio,mit,1
-10263,gradio/outbreak_forecast,gradio,,1
-10264,Prodramp/multitabbedinterface,gradio,apache-2.0,1
-10265,nightcap79/nightspace,streamlit,apache-2.0,1
-10266,HarryLee/Key2Text,streamlit,,1
-10267,scikit-learn/tabular-playground,gradio,apache-2.0,1
-10268,y0himba/SDWEBUI,gradio,unknown,1
-10269,jjjonathan14/model-assist-labeling,gradio,,1
-10270,XPMaster/Covid19_ICU_prediction,gradio,,1
-10271,pablo1n7/iberianGAN,gradio,other,1
-10272,simonduerr/smilesdrawer,gradio,mit,1
-10273,awacke1/Git-GPG-Git-Actions-01-GraphViz,streamlit,mit,1
-10274,awacke1/GithubAction02,streamlit,mit,1
-10275,Joabutt/waifugeneration,gradio,,1
-10276,Jack000/glid-3-xl-stable-classifier,gradio,mit,1
-10277,codebox/diffuse-flood,static,,1
-10278,domenicrosati/scite-qa-demo,streamlit,cc-by-2.0,1
-10279,jvahala/dummy,streamlit,apache-2.0,1
-10280,sneedium/pixelplanetocr,Configuration error,Configuration error,1
-10281,sneedium/captcha_pixelplanet,gradio,bsd,1
-10282,gradio/blocks_outputs,gradio,,1
-10283,gradio/hello_blocks,gradio,,1
-10284,gradio/generate_tone,gradio,,1
-10285,gradio/audio_debugger,gradio,,1
-10286,gradio/blocks_joined,gradio,,1
-10287,gradio/hello_world_3,gradio,,1
-10288,gradio/image_classifier_interface_load,gradio,,1
-10289,gradio/calculator,gradio,,1
-10290,gradio/blocks_essay_update,gradio,,1
-10291,gradio/streaming_stt,gradio,,1
-10292,gradio/hello_login,gradio,,1
-10293,gradio/kitchen_sink,gradio,,1
-10294,gradio/zip_files,gradio,,1
-10295,gradio/interface_parallel_load,gradio,,1
-10296,gradio/reversible_flow,gradio,,1
-10297,gradio/video_identity,gradio,,1
-10298,gradio/concurrency_with_queue,gradio,,1
-10299,gradio/stream_frames,gradio,,1
-10300,gradio/sepia_filter,gradio,,1
-10301,gradio/stock_forecast,gradio,,1
-10302,gradio/blocks_style,gradio,,1
-10303,gradio/zip_to_json,gradio,,1
-10304,gradio/reverse_audio,gradio,,1
-10305,gradio/ner_pipeline,gradio,,1
-10306,johngoad/stock_forecast,gradio,,1
-10307,kornia/image-registration-with-kornia,gradio,mit,1
-10308,annt/mrc_uit_squadv2,streamlit,,1
-10309,gigant/slideshow_extraction,gradio,,1
-10310,operance/revit-id-to-guid,streamlit,cc-by-nc-nd-4.0,1
-10311,XPMaster/KSA_Weather_Prediction,gradio,,1
-10312,ForBo7/FloodDetector,gradio,apache-2.0,1
-10313,stogaja/xpathfinder,streamlit,afl-3.0,1
-10314,marcderbauer/vice-headlines,gradio,,1
-10315,cgunadi/CDSS_Demo,streamlit,,1
-10316,Zayn/Image_Captioning_Using_Vision_Transformer_and_GPT-2,gradio,mit,1
-10317,yetoneful/README,static,,1
-10318,soyasis/how-to-generator,gradio,apache-2.0,1
-10319,tancnle/recycling-ai,gradio,afl-3.0,1
-10320,mbarnig/Mol_mer_e_chineesescht_Bild,gradio,cc-by-nc-sa-4.0,1
-10321,sinian/nihao,static,,1
-10322,tamirshlomi/pets,gradio,apache-2.0,1
-10323,freddyaboulton/saymyname,gradio,mit,1
-10324,binarycache/medical_imaging,Configuration error,Configuration error,1
-10325,rkrstacic/Chatbot-integration-built-on-processes,streamlit,,1
-10326,Chenyuwen/playground,streamlit,afl-3.0,1
-10327,MS19/TestSpaceFastAI,gradio,apache-2.0,1
-10328,dansome/Document_Summarization,streamlit,,1
-10329,tru2610/ImageClassification,gradio,afl-3.0,1
-10330,chcomet/cholec80-position-encoder,gradio,afl-3.0,1
-10331,pustozerov/poc-handwriting-ocr,streamlit,afl-3.0,1
-10332,aaronstaclara/towards-financial-inclusion,streamlit,afl-3.0,1
-10333,jphwang/architectural_styles,gradio,apache-2.0,1
-10334,Kok4444/meme_kok,gradio,apache-2.0,1
-10335,williambr/SteamlitMapPractice2,streamlit,mit,1
-10336,scite/README,static,,1
-10337,Xhaheen/ASR_Whisper_OpenAI,gradio,,1
-10338,theodotus/buffered-asr-uk,gradio,bsd-3-clause,1
-10339,cupkake14/bean_vit_classifier,gradio,,1
-10340,AIZ2H/03-Streamlit-Video-ASR-NLP,streamlit,apache-2.0,1
-10341,salaz055/leafclassification,gradio,,1
-10342,AIZ2H/07-GraphViz-PyDeck-Map-AIUIUX-Demo,streamlit,apache-2.0,1
-10343,AIZ2H/08-Search-Streamlit-Session-State-QueryParameters,streamlit,apache-2.0,1
-10344,AIZ2H/Gradio-Multilingual-ImageToOCR,gradio,apache-2.0,1
-10345,raees/Riot-Detector,gradio,apache-2.0,1
-10346,suresh-subramanian/bean-classification,gradio,,1
-10347,betterme/mestreamlit,streamlit,mit,1
-10348,Westwing/Seasonal_classifier,gradio,,1
-10349,mun-ahmd/HairType,gradio,apache-2.0,1
-10350,simulate-tests/unity-test,static,,1
-10351,awacke1/3D-Models-GLB-Animation-Gradio,gradio,apache-2.0,1
-10352,rehanuddin/01-3DModel-GradioDemo,gradio,apache-2.0,1
-10353,cadige/01-3DModel-GradioDemo,gradio,apache-2.0,1
-10354,leilaglewis/01-3dModel-GradioDemo,gradio,apache-2.0,1
-10355,Jonni/01-3DModel_Gradio,gradio,apache-2.0,1
-10356,texantech/01-3DModel-GradioDemo,gradio,apache-2.0,1
-10357,awacke1/02-Gradio-Art-From-Text-And-Images,gradio,apache-2.0,1
-10358,leilaglewis/02-Gradio-Art-From-Text-And-Images,gradio,apache-2.0,1
-10359,Jonni/02-Gradio-ArtFromText,gradio,apache-2.0,1
-10360,rbalacha/02-Gradio-Art-From-Text-And-Images,gradio,apache-2.0,1
-10361,rehanuddin/02-GradioArt-From-Text-And-Images,gradio,apache-2.0,1
-10362,cadige/02-Gradio-Art-From-Text-and-Images,gradio,apache-2.0,1
-10363,rbalacha/03-Streamlit-Video,streamlit,apache-2.0,1
-10364,awacke1/03StreamlitVideoASRNLP,streamlit,apache-2.0,1
-10365,rehanuddin/03StreamlitVideoASRNLP,streamlit,apache-2.0,1
-10366,djgoettel/02-Gradio-Art-From-Text-And-Images,gradio,apache-2.0,1
-10367,rajkumar1611/01-3DModel-GradioDemo,gradio,apache-2.0,1
-10368,awacke1/04-Gradio-SOTA,gradio,apache-2.0,1
-10369,rbalacha/04-Gradio-SOTA-Seq2Seq,gradio,apache-2.0,1
-10370,rehanuddin/04-Gradio-SOTA,gradio,apache-2.0,1
-10371,cadige/04-Gradio-SOTA,gradio,apache-2.0,1
-10372,leilaglewis/04-Gradio-SOTA,gradio,apache-2.0,1
-10373,Jonni/04-Gradio_SOTA,gradio,apache-2.0,1
-10374,Jonni/05-QandA-from-textfile,gradio,apache-2.0,1
-10375,rajkumar1611/02-Gradio-Art-From-Text-And-Images,gradio,apache-2.0,1
-10376,manishjaiswal/11-Gradio-Text-Sequence-Few-Shot-Generative-NLP-Images-Demo,gradio,apache-2.0,1
-10377,daffyshaci/bert-keyword-extraction,gradio,afl-3.0,1
-10378,sneedium/dvatch_captcha_sneedium_old,gradio,,1
-10379,mlkorra/YT_Captions_Generator,gradio,apache-2.0,1
-10380,msc/artrash,gradio,apache-2.0,1
-10381,diegoakel/kitchenorbedroom,gradio,apache-2.0,1
-10382,rkp74/MCQ-Generation,gradio,,1
-10383,cmudrc/cite-diversely,streamlit,,1
-10384,Vishwas1/BloomDemo2,gradio,openrail,1
-10385,Tianze/play,gradio,,1
-10386,Greencapabara/OpenAI-whisper-with-upload.no-time-limit,gradio,mit,1
-10387,tadeyina/Bean_Leaves,gradio,,1
-10388,aldrinjenson/harry-potter-character-classifier,gradio,mit,1
-10389,alexbakr/aircraft-detection,gradio,apache-2.0,1
-10390,Anonymous-123/ImageNet-Editing,gradio,creativeml-openrail-m,1
-10391,GitHunter0/100_prisoners_problem_app,streamlit,other,1
-10392,DarthVaderAI/Diffusion-Art,gradio,apache-2.0,1
-10393,iqbalc/Speech-to-text-demo,gradio,,1
-10394,sloppyjoe/doodoodetective,gradio,mit,1
-10395,freddyaboulton/chicago-bike-share-dashboard,gradio,mit,1
-10396,elexxuyafei/chart927,streamlit,,1
-10397,nightfury/Stable_Diffusion,gradio,creativeml-openrail-m,1
-10398,eswardivi/Bark_Texture_Images_Classification,gradio,mit,1
-10399,qwebeck/echo-net-dynamic-segmentations,gradio,mit,1
-10400,FahadAlam/Question-Generator,gradio,,1
-10401,awacke1/ChatbotBlenderBotStreamlit,streamlit,apache-2.0,1
-10402,p208p2002/chinese-sentence-checking,gradio,,1
-10403,santrox/phcspmedpredic,gradio,,1
-10404,awacke1/PyGame2D,gradio,apache-2.0,1
-10405,awacke1/AIArtReviewStreamlit,streamlit,apache-2.0,1
-10406,jie1/jie_test4,gradio,,1
-10407,awacke1/PerceiverEmotionClassifier,streamlit,apache-2.0,1
-10408,paragon-analytics/Employee-Turnover,gradio,mit,1
-10409,moadams/rainbowRainClassificationAPP,gradio,apache-2.0,1
-10410,nightfury/SD-Inpaint-Touch,gradio,creativeml-openrail-m,1
-10411,tomaseo2022/Enlace-Youtube-a-Texto,gradio,mit,1
-10412,bkhalaf/testapp,streamlit,openrail,1
-10413,bryantmedical/oral_cancer,gradio,,1
-10414,salashvijay/audiototxttosentiment,gradio,,1
-10415,RachAmm/Wav2vec-vs-Whisper,gradio,apache-2.0,1
-10416,hvtham/text_mining_21C11027,gradio,,1
-10417,gradio/NYC-Airbnb-Map,gradio,apache-2.0,1
-10418,PKaushik/humandetect,gradio,gpl-3.0,1
-10419,AI-Zero-to-Hero/02-H5-AR-VR-IOT,static,apache-2.0,1
-10420,AI-Zero-to-Hero/03-GR-AI-Text2ArtGenerator,gradio,artistic-2.0,1
-10421,AI-Zero-to-Hero/04-GR-Seq-2-Seq-QA-Auto-Gen,gradio,apache-2.0,1
-10422,AI-Zero-to-Hero/07-SL-Chatbot-Blenderbot,streamlit,mit,1
-10423,AI-Zero-to-Hero/08-GR-Chatbot-Blenderbot,gradio,,1
-10424,Damstra/safety-hazard-classifier,gradio,apache-2.0,1
-10425,AI-Zero-to-Hero/10-GR-AI-Wikipedia-Search,gradio,,1
-10426,tsaditya/GPT-Kalki,streamlit,apache-2.0,1
-10427,NimaKL/spamd,streamlit,other,1
-10428,awacke1/CB-SL-Chatbot-Blenderbot,streamlit,mit,1
-10429,peekaboo/Chatbot_Streamlit,streamlit,apache-2.0,1
-10430,jharrison27/gradio-blenderbot,gradio,,1
-10431,SriniJalasuthram/SJ-01-H5-Play-Canvas-Sim-Physics,static,apache-2.0,1
-10432,venz/AW-01-H5-Play-Canvas-Sim-Physics,static,apache-2.0,1
-10433,sparswan/AW-01-H5-Play-Canvas-Sim-Physics,static,apache-2.0,1
-10434,SShaik/SS-01-H5-Play-Canvas-Sim-Physics,static,mit,1
-10435,raghung/Play-Canvas-Sim,static,apache-2.0,1
-10436,awacke1/AW-02-H5-AR-VR-IOT,static,apache-2.0,1
-10437,SriniJalasuthram/SJ-02-H5-AR-VR-IOT,static,apache-2.0,1
-10438,skaur20/AW-02-H5_AR-VR-IOT,static,apache-2.0,1
-10439,SantoshKumar/SD-H5-AR-VR-IOT,static,apache-2.0,1
-10440,dlenzen/AW-02-H5-AR-VR-IOT,static,apache-2.0,1
-10441,sparswan/AW-02-H5-AR-VR-IOT,static,apache-2.0,1
-10442,SShaik/SS-02-H5-AR-VR-IOT,static,apache-2.0,1
-10443,starbotica/llamaoalpaca,gradio,apache-2.0,1
-10444,awacke1/AW-03-GR-AI-Text2ArtGenerator,gradio,,1
-10445,SantoshKumar/03-SD-GR-AI-Text2ArtGenerator,gradio,,1
-10446,venz/AW-03-GR-AI-Text2ArtGenerator,gradio,,1
-10447,dlenzen/AW-03-GR-AI-Text2ArtGenerator,gradio,apache-2.0,1
-10448,SShaik/SS-03-GR-AI-Text2ArtGenerator,gradio,,1
-10449,sparswan/SP-03-GR-AI-Text2ArtGenerator,gradio,apache-2.0,1
-10450,vijv/AW-03-GR-AI-Text2ArtGenerator,gradio,apache-2.0,1
-10451,awacke1/AW-04-GR-Seq-2-Seq-QA-Auto-Gen,gradio,,1
-10452,sparswan/SP-04-GR-Seq-2-Seq-QA-Auto-Gen,gradio,,1
-10453,vijv/VV-04-GR-Seq-2-Seq-QA-Auto-Gen,gradio,apache-2.0,1
-10454,sparswan/SP-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,,1
-10455,SriniJalasuthram/SJ-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,apache-2.0,1
-10456,awacke1/AW-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,apache-2.0,1
-10457,purdue780/SS-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,,1
-10458,vijv/VV-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,apache-2.0,1
-10459,dlenzen/AW-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,,1
-10460,skura/sk-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,apache-2.0,1
-10461,SShaik/SS-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,,1
-10462,SriniJalasuthram/SJ-06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,,1
-10463,SShaik/SS-06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,,1
-10464,dlenzen/AW-06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,apache-2.0,1
-10465,awacke1/AW-06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,apache-2.0,1
-10466,sparswan/SP-06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,apache-2.0,1
-10467,vijv/VV-06-SL-AI-Image-Music-Video-UI-UX-URL,streamlit,,1
-10468,mchopra/VV-05-GR-NLP-Image2Text-Multilingual-OCR,gradio,,1
-10469,gradio/queue-benchmark,gradio,mit,1
-10470,richds/openai_whispercxd,gradio,artistic-2.0,1
-10471,krrishD/vasudevgupta_bigbird-roberta-natural-questions,gradio,,1
-10472,krrishD/Helsinki-NLP_opus-mt-zh-en,gradio,,1
-10473,krrishD/Helsinki-NLP_opus-mt-de-en,gradio,,1
-10474,krrishD/google_pegasus-cnn_dailymail,gradio,,1
-10475,esc-bench/ESC,streamlit,,1
-10476,awacke1/CardGame,streamlit,,1
-10477,Wootang01/stable_diffuser_1,gradio,,1
-10478,Tabaxi3K/FrankenFlic,streamlit,,1
-10479,vonewman/mon-application-de-traduction-de-text,gradio,apache-2.0,1
-10480,Sharccc92/streamlit_in_web,streamlit,unknown,1
-10481,Varadgundap/mov-rec-sys,streamlit,,1
-10482,gstdl/streamlit-startup-campus,streamlit,,1
-10483,mgama1/fresh_rotten_fruit,gradio,mit,1
-10484,anubhavmaity/minima,gradio,apache-2.0,1
-10485,andresgtn/sidewalk-semantic-segmentation,gradio,,1
-10486,fedahumada/speech-to-text,gradio,,1
-10487,firatozdemir/OAGen_Linear,gradio,cc-by-nc-4.0,1
-10488,felenitaribeiro/WhatArtStyleIsThis,gradio,apache-2.0,1
-10489,shriarul5273/Kenyan_Food_Classification_Gradio,gradio,,1
-10490,Tanaanan/ATK_OCR_Classification_FastAI,streamlit,apache-2.0,1
-10491,FahadAlam/Speaker-Diarization,gradio,,1
-10492,Chatop/Lab10,streamlit,cc-by-4.0,1
-10493,yiw/text,streamlit,cc-by-nc-4.0,1
-10494,binhnase04854/Invoice-VQA,gradio,mit,1
-10495,nichaphat/text_generation,streamlit,,1
-10496,Kelas/translation,streamlit,cc-by-sa-4.0,1
-10497,jeffhaines/Ethical_Judgment_Generator,streamlit,mit,1
-10498,azizbarank/Turkish-Sentiment-Analysis,streamlit,mit,1
-10499,dfm42/orangeloaf,gradio,apache-2.0,1
-10500,com48com/corndog,gradio,mit,1
-10501,TheFriendlyNPC/French_Translation_Audio,gradio,mit,1
-10502,Cam-Brazy/BearTest,gradio,apache-2.0,1
-10503,tarun52/sentiment,gradio,unknown,1
-10504,awacke1/MindfulStoryMemoryMaker,gradio,apache-2.0,1
-10505,hexenbiest/OceanApp,gradio,afl-3.0,1
-10506,krisnadwipaj/interactive-dashboard,streamlit,,1
-10507,awacke1/NLPStoryWriterWithMemory,gradio,apache-2.0,1
-10508,freddyaboulton/xgboost-income-prediction-with-explainability,gradio,,1
-10509,aswinkvj/image_captioning,streamlit,,1
-10510,nickmuchi/FaceId-Corise-Project,gradio,,1
-10511,Dana19/animal_classifier,gradio,apache-2.0,1
-10512,andresgtn/face-id,gradio,,1
-10513,micole66/mpk2,gradio,,1
-10514,ElAnon/emsai,gradio,,1
-10515,anubhavmaity/bike-classification,gradio,apache-2.0,1
-10516,mehzhats/dogbreedidentifier,gradio,ecl-2.0,1
-10517,Aomsin/Lab10_630510654,streamlit,cc-by-nd-4.0,1
-10518,brendenc/Keras-Reshape-Layers,gradio,,1
-10519,cymic/Waifu_Diffusion_Webui,gradio,,1
-10520,ElAnon/6btest,gradio,,1
-10521,amydeng2000/hotpots,gradio,apache-2.0,1
-10522,datasciencedojo/Chatbot,gradio,,1
-10523,datasciencedojo/Hand-Keypoint-Detection-Realtime,gradio,,1
-10524,datasciencedojo/Handpose,gradio,,1
-10525,ElAnon/nsumr,gradio,,1
-10526,ZiLaiJuan/GRADIO,gradio,,1
-10527,zoheb/segformer_demo,gradio,mit,1
-10528,nexhi1/Homework4_Fashion_MNIST_dataset,gradio,,1
-10529,aaronbi/hw04,gradio,,1
-10530,Hexii/FoodVision,gradio,mit,1
-10531,arkiitkgp/stablediff-demo,gradio,creativeml-openrail-m,1
-10532,Gaurav261/medical_image_classification,gradio,apache-2.0,1
-10533,albertvillanova/datasets-report,gradio,cc-by-4.0,1
-10534,AISuperheroes/README,static,,1
-10535,masoodkhanpatel/food21,gradio,,1
-10536,sneedium/endchan_captcha_solver,gradio,,1
-10537,MEKHANE/3D_Ken_Burns,gradio,openrail,1
-10538,sourav11295/Movie_Recommendation,gradio,afl-3.0,1
-10539,nikesh66/gramamrly,streamlit,,1
-10540,datalayer/README,static,,1
-10541,ThankGod/face-id,gradio,,1
-10542,mdnestor/YouTube-to-MT3,gradio,,1
-10543,Sanjar/airi_text_classification,streamlit,openrail,1
-10544,SpindoxLabs/companies_NER,streamlit,,1
-10545,Sanjar/kun_uz_test,streamlit,openrail,1
-10546,saas18/minidellayeni,static,apache-2.0,1
-10547,alexeikud/identidog,gradio,mit,1
-10548,datasciencedojo/Face-Mesh,gradio,,1
-10549,awacke1/ExplainableAIForGovernance,gradio,apache-2.0,1
-10550,datasciencedojo/Finger-Counting-Right-Hand,gradio,,1
-10551,pyimagesearch/nmt-transformer,gradio,mit,1
-10552,jie1/succ1,gradio,,1
-10553,Abuzariii/Text-Generation-with-GPT-2,gradio,,1
-10554,Funbi/Textgen,gradio,,1
-10555,masdar/MedImage_Processing,gradio,,1
-10556,datasciencedojo/AmericanSignLanguage-Detection,gradio,,1
-10557,lexlms/README,static,,1
-10558,rbarman/Openvino_Text_Detection,gradio,,1
-10559,Wootang01/text_generator_three,gradio,,1
-10560,deesea/safe_or_not,gradio,apache-2.0,1
-10561,chadpanda/PEPE-Semantics,gradio,mit,1
-10562,SalML/3dMoleculeViz,streamlit,,1
-10563,Ivanrs/harris-corner-detector,gradio,mit,1
-10564,rafayqayyum/IdentifyDogBreed,gradio,,1
-10565,ddiddi/bhasha.dev,gradio,other,1
-10566,anzorq/zedzek,gradio,mit,1
-10567,ddiddi/LibreTranslateEN,gradio,creativeml-openrail-m,1
-10568,jeffhaines/rice-disease-identifier,gradio,,1
-10569,ReneGuo/cat_or_dog,gradio,apache-2.0,1
-10570,ShkShahid/Auto-encoder_For_Image_Reconstruction,gradio,apache-2.0,1
-10571,Ynot-ML/bird_recogniser,gradio,apache-2.0,1
-10572,awacke1/CSVDatasetAnalyzer,streamlit,mit,1
-10573,ThankGod/movie-poster-diffusion,gradio,,1
-10574,ishaal007/gadgets_classifier,gradio,mit,1
-10575,furiosa-ai/ocr,static,,1
-10576,taishi-i/nagisa_bert-fill_mask,streamlit,mit,1
-10577,nightfury/SD_Text-2-Image,gradio,mit,1
-10578,ruiite/car_parts_detection,gradio,apache-2.0,1
-10579,awacke1/AIZTH-CSVDataAnalyzer,streamlit,mit,1
-10580,Miya1337/NovelAI,gradio,,1
-10581,Joom/Xtramrks,gradio,mit,1
-10582,XGBooster/WhisperingDiffusion,gradio,,1
-10583,AndrewRWilliams/video-whisper,gradio,openrail,1
-10584,javiermontesinos/whisper,gradio,,1
-10585,Arnaudding001/FrenchTranslationAI,gradio,,1
-10586,Anustup/NS_AI_LABS,gradio,apache-2.0,1
-10587,segadeds/simpsons,gradio,apache-2.0,1
-10588,DarrenK196/catvsdog,gradio,apache-2.0,1
-10589,uragankatrrin/MHN-React,gradio,,1
-10590,anisub/movie-poster-generator,gradio,creativeml-openrail-m,1
-10591,andresgtn/find-the-next-james-bond,gradio,,1
-10592,suresh-subramanian/crowdsourced-movieposter-demo,gradio,cc,1
-10593,krrishD/stacktrace-QA,gradio,,1
-10594,JavierIA/gccopen,gradio,,1
-10595,Epitech/hand-sign-detection,gradio,,1
-10596,paj/dubharv,gradio,,1
-10597,zoheb/yolos_demo,streamlit,mit,1
-10598,Cvandi/remake,gradio,,1
-10599,nloc2578/QAG_Pegasus,gradio,,1
-10600,shweta44/IndianFoodClassification,gradio,,1
-10601,sylphinford/imgxnr,gradio,apache-2.0,1
-10602,archietram/Predict_Age_and_BMI_from_Images,gradio,apache-2.0,1
-10603,johnslegers/bilingual_stable_diffusion,gradio,openrail,1
-10604,zbellay/job-automation,gradio,,1
-10605,Rahmat/Phishing-Detect,streamlit,bigscience-openrail-m,1
-10606,mboth/klassifizierungDatenpunkte,gradio,,1
-10607,EdwardHiscoke/piggie_or_potatoe,gradio,apache-2.0,1
-10608,Epitech/UpscaleAI,gradio,,1
-10609,Kavindu99/movie-poster,gradio,apache-2.0,1
-10610,Ellight/Steady-state-heat-conduction-GANs-Vision-Transformer,gradio,,1
-10611,archietram/Multiple_Object_Detector_PASCAL_2007,gradio,apache-2.0,1
-10612,maisarah1109/stock_prediction,streamlit,bigscience-openrail-m,1
-10613,Komeng/Stock_Prediction,streamlit,bigscience-openrail-m,1
-10614,GrantC/learning_goals_bloom,gradio,bigscience-openrail-m,1
-10615,oscars47/Thinking_Parrot_Reading_Club,gradio,mit,1
-10616,micole66/weird_normal,gradio,,1
-10617,lubin1997/removebackground,gradio,,1
-10618,masjc/agc,gradio,,1
-10619,craigchen/alime-qa-a2q-generator,streamlit,apache-2.0,1
-10620,Maharani/stock_prediction,streamlit,,1
-10621,awacke1/RealTimeLiveSentimentAnalyzer,streamlit,apache-2.0,1
-10622,awacke1/RealTimeLiveSentimentGradio,gradio,apache-2.0,1
-10623,awacke1/SNOMED-LOINC-eCQM,gradio,mit,1
-10624,Epitech/Money-Recognition,gradio,openrail,1
-10625,ltomczak1/lungcancer_subclassifier,gradio,apache-2.0,1
-10626,wesleygalvao/image_filtering,gradio,apache-2.0,1
-10627,aziz28/hash_app,streamlit,,1
-10628,nikoirsyad44/hash-app,streamlit,,1
-10629,Sasidhar/information-extraction-demo,streamlit,,1
-10630,AISuperheroes/01ST-CSV-Dataset-Analyzer,streamlit,mit,1
-10631,AISuperheroes/02GR-ASR-Memory,gradio,mit,1
-10632,AISuperheroes/03GR-Chatbot-Memory,gradio,mit,1
-10633,AISuperheroes/05GR-Image-To-Multilingual-OCR,gradio,mit,1
-10634,AI-Dashboards/Graph.NLP.Sentence.Similarity.Heatmap.KMeansCluster,streamlit,mit,1
-10635,AISuperheroes/07GR-NLP-Seq2Seq-AutoQA,gradio,mit,1
-10636,AISuperheroes/08GR-KitchenSink-AIUIUX,gradio,mit,1
-10637,AISuperheroes/10SL-RealTimeDSDashboard-Live-AIUIUX,streamlit,mit,1
-10638,Sunshine123/hezhendejiqiren,gradio,apache-2.0,1
-10639,wiraindrak/summary-of-summarizer,gradio,,1
-10640,Mojobones/speech-seperator-fixed,gradio,,1
-10641,yms9654/translate,gradio,,1
-10642,a5656789/ganqx,gradio,apache-2.0,1
-10643,NirmalKumarC/CSV_Dataset_Analyzer_Copied,streamlit,mit,1
-10644,cadige/01ST-CSV-Dataset-Analyzer,streamlit,mit,1
-10645,cugiahuy/CB-GR-Chatbot-Blenderbot-AW03,gradio,mit,1
-10646,awacke1/03-AW-ChatbotBlenderbot,gradio,mit,1
-10647,cadige/03GR-Chatbot-Memory,gradio,mit,1
-10648,LandonBurlingham/04GR-StoryGen-Memory,gradio,mit,1
-10649,awacke1/04-AW-StorywriterwMem,gradio,mit,1
-10650,LandonBurlingham/05AW-OCR-Multilingual,gradio,mit,1
-10651,Sudhansu/05GR-Image-To-Multilingual-OCR,gradio,openrail,1
-10652,avatar2k/image-ocr-ex5-multi-lingual,gradio,mit,1
-10653,Sudhansu/07GR-NLP-Seq2Seq-AutoQA,gradio,mit,1
-10654,LandonBurlingham/07-Seq2Seq,gradio,mit,1
-10655,awacke1/08-KitchenSink,gradio,mit,1
-10656,awacke1/09-AI-ImageMusicVideo,streamlit,other,1
-10657,ahmedriad1/vehicle-identifier,gradio,apache-2.0,1
-10658,xyha/sd,gradio,openrail,1
-10659,awacke1/WikipediaProfilerTestforDatasets,static,,1
-10660,tomaseo2022/Traductor-Voz-de-Video,gradio,,1
-10661,Ivanrs/image-matching-sift-orb,gradio,mit,1
-10662,vs4vijay/playground,gradio,mit,1
-10663,Akmyradov/chatbot_testing,gradio,,1
-10664,kargaranamir/Hengam,streamlit,mit,1
-10665,guney/photo-with-code,gradio,gpl-3.0,1
-10666,michuS/overwatchClassificator,gradio,apache-2.0,1
-10667,danupurnomo/fifa-2022-rating-prediction,streamlit,,1
-10668,qwe3107231/Real-CUGAN,gradio,apache-2.0,1
-10669,shahp7575/what_coffee_machine,gradio,apache-2.0,1
-10670,harmdevries/transformer_inference,streamlit,cc-by-sa-4.0,1
-10671,awacke1/PrivateRealTimeDashboard,streamlit,mit,1
-10672,tdaslex/README,static,,1
-10673,maraoz/trail-camera,gradio,apache-2.0,1
-10674,iakarshu/lilt,gradio,unknown,1
-10675,shionhonda/sushi-diffusion,streamlit,mit,1
-10676,select-case/Can_You_Hug_the_Bear,gradio,,1
-10677,cmudrc/wecnet,gradio,mit,1
-10678,Yukki-Yui/White-box-Cartoonization,gradio,apache-2.0,1
-10679,Norod78/PumpkinHeads,gradio,,1
-10680,chansung/segformer-training-pipeline,gradio,,1
-10681,SWHL/PaperEdgeDemo,gradio,mit,1
-10682,marcusphantom/01-3DmodelDemo,gradio,apache-2.0,1
-10683,topdeck-embeds/README,Configuration error,Configuration error,1
-10684,yfzhoucs/TinyLanguageRobots,gradio,,1
-10685,salsasteve/catdog,gradio,apache-2.0,1
-10686,AzizR/FaceRecognitionGradio,gradio,,1
-10687,aziz28/fernet-app,streamlit,,1
-10688,aziz28/rsa-app,streamlit,,1
-10689,Kay2048/IKay,gradio,apache-2.0,1
-10690,xiaye/Real-CUGAN,gradio,apache-2.0,1
-10691,xiaoyi233/xiaoyi,gradio,apache-2.0,1
-10692,pplonski/NLP-SpaCy-Mercury,gradio,mit,1
-10693,yangtommy6/Computer_Vision_Project,gradio,apache-2.0,1
-10694,HCMUT-GraduateThesis-HNTThinh/rgbdsod-multimae-demo,streamlit,,1
-10695,AyakuraMei/Real-CUGAN,gradio,gpl-3.0,1
-10696,dingjian/luckpainting,gradio,,1
-10697,Vishwas1/GPTStoryWriter,gradio,openrail,1
-10698,leslyarun/grammar_correction,gradio,,1
-10699,gradio/blocks_flashcards_main,gradio,,1
-10700,gradio/main_note_main,gradio,,1
-10701,gradio/model3d_component_main,gradio,,1
-10702,gradio/chatbot_component_main,gradio,,1
-10703,gradio/hello_login_main,gradio,,1
-10704,gradio/pictionary_main,gradio,,1
-10705,gradio/leaderboard_main,gradio,,1
-10706,gradio/sentence_builder_main,gradio,,1
-10707,gradio/musical_instrument_identification_main,gradio,,1
-10708,gradio/video_identity_main,gradio,,1
-10709,gradio/neon-tts-plugin-coqui_main,gradio,,1
-10710,Solis/Solis,streamlit,mit,1
-10711,android16/facial-recognition,streamlit,,1
-10712,GV05/text-emotion-detector,gradio,apache-2.0,1
-10713,Danielsun888/pocSearch,streamlit,,1
-10714,easyh/NerDH_Visualisierer,streamlit,,1
-10715,epsilonator/euclidean_distance,gradio,,1
-10716,syedislamuddin/base_editors,streamlit,,1
-10717,AkashKhamkar/QnA-generator,streamlit,,1
-10718,uRmario/arin,gradio,unknown,1
-10719,unb-lamfo-nlp-mcti/README,gradio,,1
-10720,jknero/ppggpt,gradio,other,1
-10721,jknero/rembackkk,gradio,other,1
-10722,Avkash/Satellite_Segmentation_Prediction,gradio,mit,1
-10723,uranus0516/uranus,gradio,,1
-10724,tumuyan/wavlm-speaker-verification,gradio,,1
-10725,Deepak107/NSFW-Detection,gradio,apache-2.0,1
-10726,alaka/tinder-data-explorer,gradio,,1
-10727,leslyarun/fbeta_score,gradio,,1
-10728,thliang01/Dogs-V-Cats-Classifier,gradio,apache-2.0,1
-10729,rajesh1729/mercury-jupyternotebooks,gradio,afl-3.0,1
-10730,matteopilotto/foodvision_mini,gradio,mit,1
-10731,giulio98/codebleu,gradio,,1
-10732,konol/konmol,gradio,apache-2.0,1
-10733,AkiKagura/Marco-Generation,gradio,creativeml-openrail-m,1
-10734,PICOF/YusamiAlchemy,gradio,gpl,1
-10735,FathomNet/UWROV_Deepsea_Detector,gradio,,1
-10736,DimaKoshman/MovieRecommender,gradio,mit,1
-10737,0xcyborg/minter_latest,gradio,apache-2.0,1
-10738,gradio/sine_curve,gradio,,1
-10739,mirodil/bird-classifier-with-resnet18,gradio,apache-2.0,1
-10740,on1onmangoes/mango1,streamlit,openrail,1
-10741,ysharma/text_to_joke,gradio,mit,1
-10742,billsar1912/stock-prediction,streamlit,,1
-10743,AkiKagura/Marco-Generation-Img2img,gradio,creativeml-openrail-m,1
-10744,Egrt/GCycleGAN,gradio,apache-2.0,1
-10745,huggingface-projects/README,static,,1
-10746,Omdena-Milan/milan-chapter-agrifoods,streamlit,apache-2.0,1
-10747,bharathraj-v/audio-content-analysis,gradio,gfdl,1
-10748,MarcusAGray/demo,gradio,,1
-10749,ikram9820/sd_dreambooth-20im,gradio,apache-2.0,1
-10750,Ideon/Samay,gradio,gpl-3.0,1
-10751,DataNerd2021/song_recommendation_app,streamlit,,1
-10752,elonmuskceo/shiny-cpu-info,docker,,1
-10753,consciousAI/question_answering,gradio,apache-2.0,1
-10754,Dana19/outfit_color_guide,streamlit,apache-2.0,1
-10755,brooksjordan/pet-classifier-tutorial-fastai,gradio,apache-2.0,1
-10756,humblepenguin/mental-health-chatbot,gradio,,1
-10757,VishalF5/Text_Similarity,streamlit,,1
-10758,terrierteam/retrieve,gradio,,1
-10759,terrierteam/monot5,gradio,,1
-10760,consciousAI/question_generation,gradio,apache-2.0,1
-10761,Ishaan1510/deep_learn,gradio,apache-2.0,1
-10762,freddyaboulton/inference-endpoint-dashboard,gradio,mit,1
-10763,superdatas/LICENSE,static,other,1
-10764,lakshmi324/complaintBox,gradio,openrail,1
-10765,gradio/dashboard_main,gradio,,1
-10766,ronvolutional/sk-node,gradio,,1
-10767,Swan608/Spaceair,gradio,cc,1
-10768,zebahgr/Credit__app,streamlit,bigscience-openrail-m,1
-10769,planet10/semantic-search,streamlit,,1
-10770,Msninmx/shamzam,gradio,,1
-10771,Rongjiehuang/GenerSpeech,gradio,,1
-10772,jonathang/dob_breed,gradio,,1
-10773,weiren119/AudiogramDigitization,gradio,unknown,1
-10774,gradio/multiple-api-name-test,gradio,mit,1
-10775,SLAYEROFALL3050/AudioGenerator,streamlit,,1
-10776,niallguerin/iris,gradio,cc,1
-10777,joheras/glove-relations,gradio,cc,1
-10778,lakshmi324/BankOcr,gradio,openrail,1
-10779,Kr1n3/Fashion-Items-Classification,gradio,afl-3.0,1
-10780,Catmeow/Count_objects_in_picture,gradio,,1
-10781,einanao/cobra,streamlit,mit,1
-10782,AIZero2Hero4Health/1-ASRLiveSpeechRecognition-GR,gradio,,1
-10783,AIZero2Hero4Health/2-BiomedEntityRecognition-GR,gradio,,1
-10784,AIZero2Hero4Health/3-ChatbotBlenderbot-GR,gradio,,1
-10785,AIZero2Hero4Health/4-ImageSimilaritySearch-SL,streamlit,,1
-10786,AIZero2Hero4Health/5-ImageToLineDrawing-GR,gradio,,1
-10787,AIZero2Hero4Health/8-NLPSimilarityHeatmapCluster-SL,streamlit,,1
-10788,AIZero2Hero4Health/9-Seq2SeqQAGenerator-GR,gradio,,1
-10789,AIZero2Hero4Health/7-ClinicalTerminologyUIUX-GR,gradio,,1
-10790,AIZero2Hero4Health/5-QuantumStreamlitAIDashboard-SL,streamlit,,1
-10791,Kunal7/squats-analysis,streamlit,mit,1
-10792,Brij1808/Blog_Generator,gradio,,1
-10793,FarziBuilder/Last,gradio,apache-2.0,1
-10794,jamesjohnson763/ASRLiveSpeechRecognition-GR,gradio,,1
-10795,jamessteele/ChatbotBlenderbot-GR,gradio,,1
-10796,apratap5/Z-3-ChatbotBlenderbot-GR,gradio,,1
-10797,vslasor/VLS3-ChatbotBlenderbot-GR,gradio,,1
-10798,ashishgargcse/ClinicalTerminologyUIUX-GR,gradio,,1
-10799,Robo2000/ClinicalTerminologyUIUX-GR,gradio,,1
-10800,jamesjohnson763/ClinicalTerminologyUIUX-GR,gradio,,1
-10801,apratap5/Abhay-ASRLiveSpeechRecognition-ZR,gradio,,1
-10802,FarziBuilder/WORK,gradio,apache-2.0,1
-10803,apratap5/Abhay-2-BiomedEntityRecognition-GR,gradio,,1
-10804,apratap5/Abhay-3-ChatbotBlenderbot-GR,gradio,,1
-10805,vslasor/VLS7-ClinicalTerminologyUIUX-GR,gradio,,1
-10806,vslasor/VLS10-VideoAudioSummarizer-GR,gradio,,1
-10807,vslasor/VLS1-ASRLiveSpeechRecognition-GR,gradio,,1
-10808,rexwang8/qilin,gradio,mit,1
-10809,Soumen/image_to_text,streamlit,apache-2.0,1
-10810,johnslegers/ImageProcessService,gradio,,1
-10811,simonwalo/Histwords-Webapp,streamlit,unknown,1
-10812,divano/test,streamlit,,1
-10813,Ayemos/highlight_text_based_on_surprisals,gradio,,1
-10814,rondel/summarizer_app_test,gradio,,1
-10815,abidlabs/stable-diffusion-v1-5,gradio,mit,1
-10816,KayO/cats_vs_dogs,gradio,apache-2.0,1
-10817,motionsh/BioMAT,streamlit,,1
-10818,jonathang/dog_breed_v2,gradio,,1
-10819,Classly/README,static,,1
-10820,Joabutt/test,static,wtfpl,1
-10821,eradhea/chat_voice_spanish,gradio,gpl,1
-10822,Hexii/Cat-Breed-Classifier,gradio,mit,1
-10823,Alexxggs/ggvpnewen,gradio,,1
-10824,mgonnzz/retinoblastoma-classification-app,streamlit,,1
-10825,fhatje/glomseg,gradio,apache-2.0,1
-10826,pankajsthr/test-stable,gradio,,1
-10827,DiegoLigtenberg/realtimespeech,streamlit,mit,1
-10828,ishaal007/CarDamageDetection,gradio,mit,1
-10829,hizkifw/clipbooru,gradio,,1
-10830,silvesterjk/Talking_Yak_STT,gradio,apache-2.0,1
-10831,ML-Demo-Challenge/test,gradio,,1
-10832,Tipbs/wikipedia_summary,gradio,,1
-10833,Frorozcol/mariposas,streamlit,mit,1
-10834,camilacorreamelo/medicalDetection,gradio,,1
-10835,JayKen/propertySearch,streamlit,,1
-10836,paragon-analytics/ResText,gradio,mit,1
-10837,dejinlee/art,gradio,mit,1
-10838,haung/clear,gradio,apache-2.0,1
-10839,victor/spaces-collection,static,mit,1
-10840,wangyanbing1989/text2image,gradio,,1
-10841,zestyoreo/vtryon,gradio,mit,1
-10842,HarshulNanda/HARM_ML_web_app,streamlit,,1
-10843,j10sanders/rubber-duck,gradio,apache-2.0,1
-10844,HarshulNanda/HARM_ML,streamlit,,1
-10845,renatotn7/EspacoTeste,streamlit,apache-2.0,1
-10846,evaluate-metric/mase,gradio,,1
-10847,mabusdogma/facerecognition,streamlit,,1
-10848,renatotn7/teste2,streamlit,apache-2.0,1
-10849,elplaguister/Yuuka_TTS,gradio,mit,1
-10850,awinml/dl-optimizers,streamlit,mit,1
-10851,leftbyte/sweetOrSavory,gradio,apache-2.0,1
-10852,Ivanrs/test,gradio,bigscience-openrail-m,1
-10853,evansdianga/malaria,gradio,apache-2.0,1
-10854,silvesterjk/stt-sematic-measure,gradio,apache-2.0,1
-10855,dammasimbung/Cardiovascular-Detecting-App,streamlit,bigscience-openrail-m,1
-10856,mattclifford1/IQM-VIS,streamlit,bsd-3-clause,1
-10857,shasaurabh/bird_forest,gradio,apache-2.0,1
-10858,andrewburns/flat-icons-v1,gradio,,1
-10859,Svis/3d_image_generator,gradio,,1
-10860,HarshulNanda/HARM_ML_App_ludwig,streamlit,,1
-10861,kabita-choudhary/summary,gradio,,1
-10862,Ngadou/NLP,gradio,cc-by-nc-4.0,1
-10863,Ngadou/Social_Engineering_Detection,gradio,cc-by-4.0,1
-10864,Jack003/PixelDayAvatoon,gradio,,1
-10865,nurrahmawati3/deployment-hck2,streamlit,,1
-10866,fadhilsadeli/deploy-hck2,streamlit,,1
-10867,EMS-TU-Ilmenau/deepest-demo,gradio,,1
-10868,abidlabs/en2fr,gradio,,1
-10869,shravankumar147/cat_or_dog,gradio,apache-2.0,1
-10870,arnavkartikeya/SCRIPture-final,gradio,,1
-10871,shravankumar147/IsCat,gradio,apache-2.0,1
-10872,awacke1/ClinicalTerminologyAISearch,gradio,,1
-10873,CM-15/NLP-demo,gradio,,1
-10874,anonymousauthorsanonymous/spurious,gradio,mit,1
-10875,clement13430/lab1_iris,gradio,apache-2.0,1
-10876,taniaa/visual,gradio,,1
-10877,Armaliltril/qbee,gradio,mit,1
-10878,STEM-academie/Kennismaking_AI_Foto_Herkennen,gradio,,1
-10879,Plaban81/English_To_hindi_Language_Translator,streamlit,openrail,1
-10880,EvanMarie/cats_n_dogs,gradio,apache-2.0,1
-10881,EvanMarie/faces_three,gradio,apache-2.0,1
-10882,twoeyedraven/COVID-Fake-News-Detection,gradio,,1
-10883,ianpan/diabetic-retinopathy,gradio,apache-2.0,1
-10884,guostonline/FDV-dashboard,streamlit,openrail,1
-10885,EvanMarie/hot_or_not,gradio,apache-2.0,1
-10886,sangamsingh21/EDA_usaccidents,streamlit,,1
-10887,tumuyan/speaker-verification,gradio,,1
-10888,yvonnekr/parkingdetector,streamlit,,1
-10889,DrGabrielLopez/fractal-generator,gradio,cc-by-nc-sa-4.0,1
-10890,ayaanzaveri/detr,streamlit,,1
-10891,csaguiar/stable-diffusion-pt,streamlit,openrail,1
-10892,Daffa/image-classification,gradio,mit,1
-10893,andr290606/HD-test-run,gradio,openrail,1
-10894,micole66/ugly-or-sexy,gradio,,1
-10895,sanderland/recipe-gen,streamlit,apache-2.0,1
-10896,saisriteja/signlangauge,gradio,,1
-10897,Omar7Hany/Conv_Kickstart,gradio,,1
-10898,windowcleaningtoronto/README,static,,1
-10899,Awesimo/jojogan,gradio,,1
-10900,zxw/clueai_demo,streamlit,creativeml-openrail-m,1
-10901,AlexZou/SCUTAUTO210b,gradio,openrail,1
-10902,lvwerra/in-the-stack,streamlit,,1
-10903,Tartan-Ishan/Expression_Classifier,gradio,apache-2.0,1
-10904,langdonholmes/piilo,streamlit,apache-2.0,1
-10905,freddyaboulton/fastapi-request,gradio,mit,1
-10906,Laughify/Among_Us_Logic_AI_Generator,gradio,,1
-10907,forklift-app/forklift-images,gradio,,1
-10908,EstebanDC/EP_settlement,gradio,,1
-10909,Pranjal2041/SemSup-XC,gradio,bsd-3-clause-clear,1
-10910,lgabrielb/fruit_classifier,gradio,mit,1
-10911,grofte/zero-shot-labse,gradio,mit,1
-10912,Testys/diabetes-app,streamlit,gpl,1
-10913,abidlabs/Voice-Cloning,gradio,mit,1
-10914,arbml/whisper-tiny-ar,gradio,apache-2.0,1
-10915,leoberniga/Write-Stories-Using-Bloom,gradio,,1
-10916,Datasculptor/sd-prism,gradio,apache-2.0,1
-10917,senger/AI-Text-Generator,static,gpl-2.0,1
-10918,GIanlucaRub/Titanic,gradio,,1
-10919,AlexZou/Deploy_Restoration,gradio,openrail,1
-10920,Xixeo/Text-to-Music,gradio,unknown,1
-10921,AIZerotoHero-Health4All/01-Speech2Text2Speech,gradio,mit,1
-10922,AIZerotoHero-Health4All/03-BiomedNER-1117-Gradio,gradio,,1
-10923,Robo2000/ClinicalTerminologyAISearch-GR,gradio,,1
-10924,alecmueller/12-ChatBotBlenderbot-GR,gradio,,1
-10925,kael558/Interpolation,gradio,openrail,1
-10926,multimodalart/xformers-here-we-go-again,gradio,mit,1
-10927,issam9/yt-transcribe-and-search,streamlit,,1
-10928,weijiang2009/AlgmonTTSService,gradio,apache-2.0,1
-10929,akhaliq/space-that-creates-model-demo-space,gradio,,1
-10930,Cyntexa/README,static,,1
-10931,incolor/facial_expression_classifier,gradio,apache-2.0,1
-10932,cdgranadillo/summaries_mT5_multilingual,gradio,,1
-10933,bigslime/stablediffusion-infinity,gradio,apache-2.0,1
-10934,RamAnanth1/whisper_biomed_ner,gradio,,1
-10935,stratussox/yolov5_inference,streamlit,mit,1
-10936,Xiaohan/NLP,gradio,,1
-10937,erbanku/lama,gradio,apache-2.0,1
-10938,vincent1bt/Line_Art_Colorization,gradio,,1
-10939,motyar/openjourney,gradio,,1
-10940,Jh137/Jh137-ai-painting,gradio,bigscience-openrail-m,1
-10941,AnnonSubmission/xai-cl,gradio,,1
-10942,pranked03/amazon-product-comparer,streamlit,,1
-10943,akhaliq/Nitro-Diffusion2,gradio,,1
-10944,rscolati/titanic,gradio,apache-2.0,1
-10945,vaibhavsharda/semantic_clustering,streamlit,mit,1
-10946,theMonkeyGuy/monkeyclassifier,gradio,apache-2.0,1
-10947,Copy233/copy,gradio,apache-2.0,1
-10948,lohitkavuru14/anpr-yolov7,gradio,,1
-10949,santoshtyss/QuickAd,gradio,bigscience-openrail-m,1
-10950,taichi/pizza-net,streamlit,unknown,1
-10951,Rohith33/BearClassifiyer,gradio,apache-2.0,1
-10952,AdithyaSNair/Diabetes_analysis,gradio,,1
-10953,aslasdlkj/Podfusion,gradio,,1
-10954,AhmedTambal/malaria,gradio,bigscience-openrail-m,1
-10955,yongjae/whisper-webui,gradio,apache-2.0,1
-10956,newsteam/stable-diffusion-img2img,gradio,,1
-10957,vladocar/openjourney,gradio,,1
-10958,Rutakate21/anything-v3.0,gradio,,1
-10959,hxu296/Texify-Youtube,gradio,,1
-10960,chinmaysharma1020/malware_classification,gradio,,1
-10961,karay/diar_speech,streamlit,,1
-10962,bumsika/ai-bros-diffusion,gradio,,1
-10963,victor/test-docker,docker,mit,1
-10964,datasciencemmw/README,gradio,,1
-10965,glyszt/vt,gradio,other,1
-10966,TheHouseOfAI/ActionRecognition,gradio,,1
-10967,Froleptan/stablediffusion-infinity,gradio,apache-2.0,1
-10968,gabortoth74/openjourney,gradio,,1
-10969,Senpaisora6/dreambooth-training,gradio,mit,1
-10970,AJRFan/dreambooth-training,gradio,mit,1
-10971,bsenst/keras-image-classifier,gradio,mit,1
-10972,Eightone3D/anything-v3.0,gradio,,1
-10973,alaaawad/image-to-text-app,streamlit,apache-2.0,1
-10974,kyotoyx/medical-diagnosis,streamlit,apache-2.0,1
-10975,breadlicker45/galactica-1.3b-contrastive-sampling,gradio,apache-2.0,1
-10976,TheThanos/anything-v3.0_krn,gradio,,1
-10977,EricA1/openjourney,gradio,,1
-10978,USERNAME0/abcdefghi,streamlit,openrail,1
-10979,Wootang01/text_generator_four,gradio,,1
-10980,Wootang01/text_generator_five,gradio,,1
-10981,Wootang01/text_generator_six,gradio,,1
-10982,AlexKozachuk/anything-v3.0,gradio,,1
-10983,vntonie/anything-v3.0,gradio,,1
-10984,oronird/sign_translate,gradio,,1
-10985,huai/chinese_stable_diffusion,gradio,,1
-10986,PeterQUB/Berries,gradio,apache-2.0,1
-10987,catontheturntable/Ghibli-Diffusion,gradio,,1
-10988,akhaliq/dreambooth-training,gradio,mit,1
-10989,breadlicker45/TextGen,gradio,other,1
-10990,clem/dreambooth-training_v2,gradio,mit,1
-10991,bino-ocle/audio-intelligence-dash,gradio,,1
-10992,datasciencemmw/ContextXLA-demo,gradio,openrail,1
-10993,jimr1603/galactica-base-api,gradio,apache-2.0,1
-10994,datasciencemmw/ContextXLA-beta-demo,gradio,openrail,1
-10995,elijahcilfone/dreambooth-training,gradio,mit,1
-10996,HimeFuji/How_to_laugh,streamlit,,1
-10997,Xhaheen/Face-Real-ESRGAN,gradio,apache-2.0,1
-10998,abdullah/Voice-Cloning,gradio,mit,1
-10999,Peter1/AnimeGANv3,gradio,,1
-11000,haya44433/anything-v3.0,gradio,,1
-11001,Aleqsd/openjourney,gradio,,1
-11002,evoss/NLP_text_analyzer,gradio,,1
-11003,darkCat/Anime-image-classification,gradio,bsd-3-clause,1
-11004,marktrovinger/whisper-translate,streamlit,mit,1
-11005,dbredvick/whisper-webui,gradio,apache-2.0,1
-11006,ecuador123456789/ejemplo1,static,cc-by-3.0,1
-11007,eatsleepeat/FastHelloWorld,gradio,apache-2.0,1
-11008,CassBunny/anything-v3.0,gradio,,1
-11009,Aphrodite/AIChatBot-SL-Chatbot-Blenderbot,streamlit,mit,1
-11010,ss123wq/demucs,gradio,,1
-11011,anzahabi/MuhammadGarinAnzahabi_HCK002,streamlit,,1
-11012,vonbarnekowa/stable-diffusion,gradio,mit,1
-11013,OmegaYuti/anything-v3.0,gradio,,1
-11014,intelliarts/Car_damage_detection,gradio,mit,1
-11015,segestic/paraphraseArticle,gradio,,1
-11016,empy-ai/Token-classification,gradio,,1
-11017,Xhaheen/stable-diffusion-21,gradio,,1
-11018,Mayanand/Image-Captioning,gradio,,1
-11019,omidreza/speechtopictogram,gradio,mit,1
-11020,DonnyChuang/test_generator,gradio,,1
-11021,ELam/text_generator,gradio,,1
-11022,jaklin/text_generator,gradio,,1
-11023,whale-shark/text_generateor,gradio,,1
-11024,dipperpines/text_generator,gradio,,1
-11025,MarcyWu/text_generator,gradio,,1
-11026,P1ne4ppl/Text_generator,gradio,,1
-11027,Matthew1917/text_generator,gradio,,1
-11028,EllaTsoi/text_generator,gradio,,1
-11029,Swying/text_generator,gradio,,1
-11030,Tommyyyyyy-20/text_generator,gradio,,1
-11031,billyyyyy/text_generator,gradio,,1
-11032,Andy0409/text_generator,gradio,,1
-11033,Katyyy/text_generator,gradio,,1
-11034,blossom618/text_generator,gradio,,1
-11035,12Venusssss/text_generator,gradio,,1
-11036,HANOGHTIC/text_generator,gradio,,1
-11037,juntsu/Text_generator1,gradio,,1
-11038,Kavinloll/text_generator,gradio,,1
-11039,guohuiyuan/Real-CUGAN,gradio,apache-2.0,1
-11040,fkunn1326/Image-search-using-CLIP,gradio,,1
-11041,zlpnvrtnk/dvatch_captcha_sneedium_fork2,gradio,,1
-11042,NickyGenN1/ImageClassification,gradio,mit,1
-11043,aliabd/non-interactive-dataframe,gradio,mit,1
-11044,gabrielgmendonca/chilton,streamlit,bigscience-bloom-rail-1.0,1
-11045,cmudrc/truss-data-explorer,gradio,mit,1
-11046,eskayML/Salty-Conversational-Bot,gradio,,1
-11047,eskayML/English-to-French-Translation,gradio,,1
-11048,krithiksai/weather_based_on_tree_photos,gradio,apache-2.0,1
-11049,ConvLab/README,static,,1
-11050,joushe/moe-tts,gradio,mit,1
-11051,sklearn-docs/hierarchical-clustering-linkage,gradio,apache-2.0,1
-11052,tiedaar/economics_summary_grader,gradio,apache-2.0,1
-11053,tdros/zoafind,streamlit,,1
-11054,cmudrc/3d-printed-or-not,gradio,mit,1
-11055,VivianShi/Coconet-Pytorch,gradio,,1
-11056,yellowdolphin/happywhale-demo,gradio,gpl-3.0,1
-11057,Kartik2192/Abcd,static,openrail,1
-11058,SarmadBashir/REFSQ2023_ReqORNot_demo_app,streamlit,other,1
-11059,Superintelligence1130/Recursive_self-improvement_system,gradio,,1
-11060,raphael0202/logo-clip-demo,streamlit,,1
-11061,cuiltheory/stable-diffusion-2-base,gradio,,1
-11062,MarcCote/TextWorldExpress,streamlit,apache-2.0,1
-11063,YBiryukov/AncientEgyptianHieroglyphsRecognition,gradio,mit,1
-11064,DRAGSclub/README,static,,1
-11065,mowang/mowang,gradio,apache-2.0,1
-11066,carisackc/Clinical,streamlit,other,1
-11067,Foremost/NER,gradio,,1
-11068,jatinshah/hn-search,streamlit,mit,1
-11069,lvkaokao/dreambooth-training,gradio,mit,1
-11070,Abeer123/Pokemon_Digimon,gradio,apache-2.0,1
-11071,ecody726/stable-diffusion,gradio,mit,1
-11072,dovanquyet/PsyPlus,gradio,gpl-3.0,1
-11073,os1187/contract-review,streamlit,,1
-11074,os1187/code-explainer,gradio,apache-2.0,1
-11075,cmudrc/kaboom,gradio,mit,1
-11076,os1187/news-summarizer,gradio,,1
-11077,MirageML/lowpoly-office,gradio,,1
-11078,MirageML/fantasy-sword,gradio,,1
-11079,MirageML/fantasy-scene,gradio,,1
-11080,MirageML/lowpoly-cyberpunk,gradio,,1
-11081,ericjuliantooo/paraphrase,streamlit,,1
-11082,lakshmi324/Vehicle_Damage_Detector,gradio,openrail,1
-11083,moro23/sentiment-anlysis-app,gradio,,1
-11084,jonaskaszian/boardgame-recognizer,gradio,apache-2.0,1
-11085,olyolik/book_genre,gradio,,1
-11086,eskayML/AUTOMATIC_SPEECH_RECOGNITION,gradio,,1
-11087,ysharma/GPT-JT-copy,streamlit,,1
-11088,Arcader7171/positive,gradio,,1
-11089,vialibre/edia_lmodels_en,gradio,mit,1
-11090,UMich-siads699-fa22-spotamood/spotamood,streamlit,apache-2.0,1
-11091,lavanyakumaran31/resume_parser_app,streamlit,,1
-11092,santhosh97/gretel-image-generation-demo,streamlit,,1
-11093,nightfury/CLIP_Interrogator_for_SD2_Img2Prompt,gradio,,1
-11094,awacke1/LionImageSearch,gradio,mit,1
-11095,Chrysoula/voice_to_text_swedish,gradio,,1
-11096,belgrano91/SentenceRecognizer,gradio,afl-3.0,1
-11097,YeaHi/woman-diffusion,gradio,,1
-11098,abidlabs/middle-ages-islamic-art,gradio,,1
-11099,Frorozcol/dreambooth-training,gradio,mit,1
-11100,wzsxb233/ALTESOL_Language-Technology-ResearchGroup_Faceia-Peter-Shamini,gradio,,1
-11101,bryanmildort/stockpricepredict,streamlit,openrail,1
-11102,cmudrc/wecnet-api,gradio,mit,1
-11103,sbavery/pseudometer,gradio,apache-2.0,1
-11104,MarcNg/fastspeech2-vi-infore,streamlit,apache-2.0,1
-11105,Hydrangea/myProject,streamlit,,1
-11106,Mikey211/Project,streamlit,,1
-11107,nurrahmawati3/churn,streamlit,,1
-11108,muhammadjulz/frontend-telco-churn,streamlit,,1
-11109,garasense/P2ML1_Telco_Customer_Churn,streamlit,,1
-11110,vovahimself/jukwi-vqvae,gradio,openrail,1
-11111,mandar100/chatbot_godel_large,gradio,,1
-11112,Campfireman/whisper_lab2,gradio,apache-2.0,1
-11113,akhaliq/tpkify-v1,gradio,,1
-11114,sasha/Draw-Me-An-Insect,gradio,,1
-11115,dhruvshettty/dutch-whisperer,gradio,,1
-11116,gradio/altair_plot_main,gradio,,1
-11117,ieftimov/confusingflags,gradio,apache-2.0,1
-11118,ToniDan/DanToniGPT2FormalInformal,streamlit,,1
-11119,arjunpatel/best-selling-video-games,gradio,,1
-11120,LeeroyVonJenkins/cat-dog-classifier,gradio,apache-2.0,1
-11121,songallery/my,streamlit,openrail,1
-11122,TYH71/gradio-ml-skeleton,gradio,,1
-11123,AIGuardians/SummarizeWikipediaDocument,gradio,apache-2.0,1
-11124,lakshmi324/Fake_airpods_Detector,gradio,openrail,1
-11125,Nathanotal/GuessTheTranscription,gradio,apache-2.0,1
-11126,osanseviero/whisper_demo_builder,gradio,mit,1
-11127,danielbellon/ml-techniques-project,gradio,,1
-11128,osanseviero/whisper-medium,gradio,,1
-11129,svjack/Entity-Property-Extractor-zh,gradio,,1
-11130,MLT-2022/Project,gradio,,1
-11131,svjack/Translate-Chinese-to-English,gradio,,1
-11132,Inthv/NER,gradio,,1
-11133,BLACKHOST/Banner,streamlit,,1
-11134,supermy/speech-to-image,gradio,,1
-11135,arnavkundalia/AppleScabDetection,gradio,,1
-11136,wldmr/punct-tube-gr,gradio,mit,1
-11137,carterw/evolutionary-playlist-builder,gradio,,1
-11138,akhaliq/paint-by-example,gradio,,1
-11139,Envyyyy/vehicle_detection,streamlit,,1
-11140,Anilegna/Colour-Personallity,gradio,afl-3.0,1
-11141,starship006/mini_shakespeare,gradio,,1
-11142,A666sxr/Genshin_TTS,gradio,,1
-11143,brcprado/AutoML_MODEL_TRAINING,gradio,mit,1
-11144,Abdulkader/HumanMotionsDetector,gradio,mit,1
-11145,BrunoHempel775/Byzu,gradio,openrail,1
-11146,ML701G7/taim-gan,gradio,openrail,1
-11147,Mohammednabil/Control_The_world,gradio,apache-2.0,1
-11148,whispy/Whisper-Ita-V2,gradio,apache-2.0,1
-11149,ieftimov/pasta-everywhere,gradio,apache-2.0,1
-11150,delmaksym/Huggy,static,cc-by-nc-sa-4.0,1
-11151,oscars47/thinking_parrot_reading_club_redux,gradio,mit,1
-11152,os1187/gpt2-chatbot,gradio,cc-by-nc-sa-4.0,1
-11153,brcprado/removeBG,gradio,bsd-2-clause,1
-11154,ritwikbiswas/incoder-complete,gradio,cc-by-nc-4.0,1
-11155,Yuras/CorpusBy,gradio,unknown,1
-11156,etweedy/pet_breeds,gradio,apache-2.0,1
-11157,MiloSobral/PortiloopDemo,gradio,,1
-11158,jojoanne/cuisinerecommendation,gradio,afl-3.0,1
-11159,LAKSJAKLCNDWNVWHEFKJH/asdfghjkl,gradio,afl-3.0,1
-11160,datainsight1/Medical_Prescriptions,streamlit,,1
-11161,WRH/wrhwang_foodvision_mini,gradio,mit,1
-11162,pip64/zaglyt-api,gradio,,1
-11163,segestic/CovidPredictiongr,gradio,,1
-11164,osanseviero/ChatGPT_MANY_LANGS,gradio,apache-2.0,1
-11165,NeoonN/Video_whisper,gradio,,1
-11166,privatewins/nitrosocke-redshift-diffusion,gradio,unknown,1
-11167,hamza50/rhymethyme,streamlit,openrail,1
-11168,Wenjing2/ChatGPT_HF,gradio,apache-2.0,1
-11169,sasaro/webui,gradio,,1
-11170,timmostone/stabilityai-stable-diffusion-2,gradio,,1
-11171,parkermini/general,gradio,apache-2.0,1
-11172,YeOldHermit/Linaqruf-anything-v3.0,gradio,openrail,1
-11173,Hxxx/finding_friends,gradio,afl-3.0,1
-11174,Patt/demo_gradio,gradio,,1
-11175,Shivraj8615/Huggy,static,cc-by-nc-sa-4.0,1
-11176,Ruilmon/hakurei-waifu-diffusion,gradio,,1
-11177,TornikeO/dreambooth-training,gradio,mit,1
-11178,Markfm/webui2,gradio,,1
-11179,RunningYou/mediapipe_inpainting,gradio,apache-2.0,1
-11180,Aleistair/anything5,gradio,,1
-11181,VaneM/ChatBot-Text-to-Speach-es,gradio,unknown,1
-11182,Akseluhr/whisper-sv-SE-auhr,gradio,apache-2.0,1
-11183,AIZerotoHero-Health4All/02-ClinicalTerminology,gradio,,1
-11184,AIZerotoHero-Health4All/03-Datasets,gradio,,1
-11185,VaneM/text-to-image-es,gradio,unknown,1
-11186,muhtasham/whisper-demo-tj,gradio,,1
-11187,Yilin98/Whisper-Small-Swedish,gradio,,1
-11188,harry18456/TestChatGPT,gradio,,1
-11189,shihabulislamarnob/AI-Image-Enlarger,gradio,,1
-11190,Shokunin/runwayml-stable-diffusion-v1-5,gradio,,1
-11191,Txandim/runwayml-stable-diffusion-v1-5,gradio,,1
-11192,YuhangDeng123/Whisper-online,gradio,apache-2.0,1
-11193,spark-ds549/fal2022-videoanalysis-v2,gradio,apache-2.0,1
-11194,Txandim/stabilityai-stable-diffusion-2-1-base,gradio,,1
-11195,tayislost/lambdalabs-sd-image-variations-diffusers,streamlit,unknown,1
-11196,Txandim/mrm8488-bloom-560m-finetuned-sd-prompts,gradio,,1
-11197,zhukovsky/JorisCos-DCCRNet_Libri1Mix_enhsingle_16k,gradio,,1
-11198,hs1l/Date,streamlit,,1
-11199,Enderfga/mtCNN_sysu,gradio,openrail,1
-11200,Patt/demo_hf,gradio,,1
-11201,Datasculptor/stabilityai-stable-diffusion-2-1,gradio,,1
-11202,yeonn/text_generator,gradio,,1
-11203,JennyS/text_generator,gradio,,1
-11204,wootang03/text_generator,gradio,,1
-11205,Badaleeloveashley/badaleeloveashley,gradio,,1
-11206,Kellyasrfuhioj/stydbdcg,gradio,,1
-11207,SasunNN/SASN,gradio,,1
-11208,4H17Joycelyn/text_generater,gradio,,1
-11209,xfbhsdfndjndghz/Ultraman,gradio,,1
-11210,MoonMoonMoonMoon/text_generator,gradio,,1
-11211,nicole1214/text_generator,gradio,,1
-11212,Aaaad/Dddde,gradio,,1
-11213,4F22/text_generator,gradio,,1
-11214,4f20/text_generator,gradio,,1
-11215,bunnyg20081061/world2,gradio,,1
-11216,seecuecue/text_generator,gradio,,1
-11217,CosmicSage/Linaqruf-anything-v3.0,gradio,,1
-11218,jlondonobo/whisper-pt-demo,gradio,,1
-11219,pierreguillou/whisper-demo-portuguese,gradio,,1
-11220,rizam/rakeeb_text-classification,gradio,,1
-11221,CosmicSage/Linaqruf-anything-v3.0pruned,gradio,,1
-11222,humeur/Swedish-Whisper-from-Youtube,gradio,,1
-11223,hedronstone/whisper-large-v2-demo-sw,gradio,,1
-11224,rizam/literature-research-tool,streamlit,mit,1
-11225,dawggydawg/stabilityai-stable-diffusion-2-1-rpg,gradio,,1
-11226,amir0900/s,gradio,,1
-11227,almino/WhisperYoutube,gradio,,1
-11228,TornikeO/dreambooth,gradio,mit,1
-11229,Txandim/nitrosocke-Arcane-Diffusion,gradio,,1
-11230,rishikesh/twitterEngagementPredictor,streamlit,cc0-1.0,1
-11231,zeynepgulhan/whisper-medium-cv-tr-demo,gradio,,1
-11232,geninhu/whisper-vietnamese,gradio,,1
-11233,etweedy/Find_objects,gradio,apache-2.0,1
-11234,nbiish/ghostDance,streamlit,openrail,1
-11235,Anish13/fruit,gradio,apache-2.0,1
-11236,DeividasM/whisper-medium-lt,gradio,,1
-11237,lingdufreedom/IDEA-CCNL-Taiyi-Stable-Diffusion-1B-Chinese-v0.1,gradio,openrail,1
-11238,rpa45/ai_hands_classifier,gradio,openrail,1
-11239,Toraong/color_textual_inversion,streamlit,,1
-11240,prosiaczek/webui,gradio,,1
-11241,kaidorespy/CompVis-stable-diffusion-v1-4,gradio,openrail,1
-11242,marcoruizrueda/flax-midjourney-v4-diffusion,gradio,,1
-11243,bradarrML/diffuse-the-rest,static,,1
-11244,bradarrML/Diffusion_Space,gradio,creativeml-openrail-m,1
-11245,softcatala/whisper-demo-catalan,gradio,,1
-11246,bradarrML/magic-diffusion,gradio,apache-2.0,1
-11247,bradarrML/runwayml-stable-diffusion-v1-5,gradio,,1
-11248,antinous/dreambooth-training,gradio,mit,1
-11249,alaaawad/CLIPSeg_x_SD,gradio,mit,1
-11250,Javtor/Biomedical-topic-categorization,gradio,,1
-11251,YESO/YESOdreambooth,gradio,mit,1
-11252,User1342/Bubble-Check-In,gradio,gpl-3.0,1
-11253,HewDew/Linaqruf-anything-v3.0,gradio,,1
-11254,cfr26575/webui,gradio,,1
-11255,nightfury/dreamlike-art-dreamlike-diffusion-1.0,gradio,,1
-11256,ktonggg/webui,gradio,,1
-11257,SaintPepe/google-ddpm-church-256,streamlit,openrail,1
-11258,JUNGU/emotion-ko-state,gradio,,1
-11259,BasalGanglia/stabilityai-stable-diffusion-2,gradio,,1
-11260,esafwan/esencb-text-image,gradio,,1
-11261,gorkemgoknar/movie_chat_gpt_yourtts,gradio,,1
-11262,Javtor/Biomedical-topic-categorization-2022only,gradio,,1
-11263,Taha07/pneumonia-detection-WebApp,gradio,,1
-11264,kazumak/sdspace,gradio,mit,1
-11265,reganagam/TB-Project,gradio,,1
-11266,kazumak/webui,gradio,,1
-11267,koby-Jason/Music_recommend,gradio,afl-3.0,1
-11268,shriarul5273/Yolov7,gradio,,1
-11269,zncook/chatGPT,gradio,,1
-11270,jirufengyu/face_recognition,gradio,,1
-11271,Jour/Translation-to-small,gradio,mit,1
-11272,Jour/Translate-bloomz,gradio,mit,1
-11273,Kontrol/plasmo-food-crit,gradio,,1
-11274,ygangang/deoldify,gradio,,1
-11275,van4oo/eimiss-EimisAnimeDiffusion_1.0v,gradio,,1
-11276,gigant/romanian-whisper,gradio,,1
-11277,gorkemgoknar/gptChatYourTTS,gradio,,1
-11278,gorkemgoknar/movie_chat_gpt_yourtts_fileinput,gradio,,1
-11279,JUNGU/remove-bg-edit,gradio,,1
-11280,Yuyang2022/Translation_yue_to_any,gradio,,1
-11281,MaksTim/FirstTimi,streamlit,creativeml-openrail-m,1
-11282,oluyemitosin/Honda_or_Mercedes,gradio,,1
-11283,deepdml/whisper-demo-mix-es,gradio,,1
-11284,segestic/ArticlePara,streamlit,,1
-11285,bradarrML/EleutherAI-gpt-j-6B,gradio,,1
-11286,akhaliq/sd2-dreambooth-ClaymationXmas,gradio,,1
-11287,tiagones/nitrosocke-spider-verse-diffusion,gradio,,1
-11288,Vavavoom/stable-diffusion-depth2img,gradio,,1
-11289,anuragshas/whisper-large-v2-demo-hi,gradio,,1
-11290,emre/garanti-mybankconcept-img-gen,gradio,creativeml-openrail-m,1
-11291,weijiang2009/AlgmonOCRService,gradio,,1
-11292,breadlicker45/badapple,streamlit,other,1
-11293,rrichaz/TTS-STT-Blocks,gradio,mit,1
-11294,Umarpreet/argument_gate,gradio,,1
-11295,victor/autotrain-victormautotraindreambooth-FS8JGUBRYX-2450175922,gradio,,1
-11296,mimimibimimimi/ACertainModel,gradio,,1
-11297,kaleidophon/almost_stochastic_order,gradio,,1
-11298,scikit-learn/blog-example,gradio,apache-2.0,1
-11299,dimaseo/dalle-mini,static,apache-2.0,1
-11300,arpagon/whisper-demo-large-v2-es,gradio,,1
-11301,Foti/webui,gradio,,1
-11302,Wootang01/chinese_generator_translator,gradio,,1
-11303,Wootang01/chinese_translator_generator,gradio,,1
-11304,herberthe/nitrosocke-Ghibli-Diffusion,gradio,,1
-11305,PrismaticAI/MangaMaker,gradio,other,1
-11306,LongBeattz/runwayml-stable-diffusion-v1-5,gradio,other,1
-11307,Wootang01/text_augmenter1,gradio,,1
-11308,Wootang02/text_generator1,gradio,,1
-11309,GadaiEngin-GBOX/GadaiEngineNeo-A,gradio,mit,1
-11310,AlekseyCalvin/dreambooth-training3,gradio,mit,1
-11311,hoang1007/wav2vec2,gradio,,1
-11312,RobinZ2021/remove_background,gradio,openrail,1
-11313,SpacesExamples/test-docker-go,docker,,1
-11314,shripadbhat/whisper-bulgarian-demo,gradio,,1
-11315,AnnaPalatkina/fine_grained_SA,gradio,,1
-11316,Heckeroo/waifu-diffusion,gradio,,1
-11317,richardblythman/stabilityai-stable-diffusion-2-1,gradio,,1
-11318,RRVSS/SVS,gradio,other,1
-11319,project-ori/README,static,,1
-11320,erty9/webui,gradio,,1
-11321,AlekseyCalvin/Make-Putin-Queer,gradio,creativeml-openrail-m,1
-11322,danielcodex/first-prod,gradio,apache-2.0,1
-11323,bhn4477/Car_orientation,streamlit,,1
-11324,Duckymalone/dreamlike-art-dreamlike-diffusion-1.0,gradio,,1
-11325,simonl0909/whisper-cantonese-demo,gradio,,1
-11326,AlekseyCalvin/Make_Putin_Queer_Please-use-trp-token,gradio,,1
-11327,srivarshan/argumentation-quality-analyzer,gradio,mit,1
-11328,carisackc/ClinicalNoteDemo,streamlit,other,1
-11329,Apk/anything-v3.0,gradio,,1
-11330,Nortrom8844/summarize-long-text,gradio,apache-2.0,1
-11331,Abdulkader/Abdulkader-T5-MedRepAnalyzer,gradio,cc-by-3.0,1
-11332,awacke1/BigCodeStackSearch1215,gradio,,1
-11333,awacke1/Clinical.Terminology.Search.LOINC.Panels.SNOMED.ICD.OMS,gradio,,1
-11334,rrichaz/DataAnalyzer,gradio,,1
-11335,Robo2000/DatasetAnalyzer-GR,gradio,,1
-11336,kabita-choudhary/audio,gradio,,1
-11337,misza222/extractframe,gradio,apache-2.0,1
-11338,qwieug123467/Linaqruf-anything-v3.0,gradio,,1
-11339,sgangireddy/whisper-largeV2-mls-spanish-demo,gradio,,1
-11340,vulkano/yulet1de-hentaidiffusion,gradio,,1
-11341,Sphila/Sphila-Diffusion,gradio,openrail,1
-11342,Shypanties22/FantasyMe,gradio,mit,1
-11343,xkhaloda/Envvi-Inkpunk-Diffusion,gradio,,1
-11344,cm107/agv-demo,static,mit,1
-11345,neuralmagic/cv-yolo,gradio,,1
-11346,power2/powerswp,gradio,cc-by-nc-sa-4.0,1
-11347,PrajwalS/GODEL-Demo-nxt,gradio,mit,1
-11348,Yuelili/RealNagrse,gradio,,1
-11349,pragnakalp/BERT_based_QnA,gradio,,1
-11350,ben91/Mush_recognition,gradio,,1
-11351,salmanmapkar/youtube-audio-video-diarizer-and-transcriber,gradio,,1
-11352,Shiry/whisper-demo-hebrew-large,gradio,,1
-11353,pierreguillou/extracao_das_palavras_frases_chave_em_portugues,gradio,,1
-11354,tom-beer/birds-israel,streamlit,cc-by-nc-nd-4.0,1
-11355,datasciencedojo/Brain_Stroke_Prediction,gradio,,1
-11356,JLD/docker-hello-world,docker,unlicense,1
-11357,machinelearnear/dreambooth-quino,gradio,openrail,1
-11358,Innoglean/README,static,,1
-11359,stale2000/DnDItem,gradio,other,1
-11360,nakas/ChessGPT_Stockfish,streamlit,gpl-3.0,1
-11361,KbL19/invokeAI,static,,1
-11362,Sathrukan/Bird_classification,gradio,apache-2.0,1
-11363,Huniu/niuniu,gradio,apache-2.0,1
-11364,awacke1/SKLearnSkopsTabularEditor,gradio,,1
-11365,nateevo/docu-searcher,gradio,mit,1
-11366,akhaliq/Marvel_WhatIf_Diffusion,gradio,,1
-11367,fkunn1326/Kokohachi-NoAI-Diffusion,gradio,openrail,1
-11368,yipinggan/Predict_progressive_collapse_resistance_with_DCN,gradio,,1
-11369,belectron/Seen-Zan5,streamlit,,1
-11370,codesue/streamlit-tfx,streamlit,,1
-11371,EyeSeeThru/anything-v3.0,gradio,,1
-11372,TangibleAI/mathtext,gradio,agpl-3.0,1
-11373,Buatong/Computing,gradio,,1
-11374,benjaminperkins/yulet1de-hentaidiffusion.peoplegenerator,gradio,,1
-11375,MMars/whisper-small-ar-demo,gradio,,1
-11376,jacobbeckerman/Youtube-Whisperer,gradio,,1
-11377,stasimus/p350-fastapi,docker,,1
-11378,ybelkada/blip-vqa-space,gradio,,1
-11379,Xuechan/clothing_classifier,gradio,apache-2.0,1
-11380,HugoSchtr/DataCat_Yolov5,gradio,cc-by-4.0,1
-11381,zfj41/webui,gradio,,1
-11382,trysem/remini-free,gradio,apache-2.0,1
-11383,camenduru-com/riffusion-api,docker,,1
-11384,macaodha/batdetect2,gradio,,1
-11385,yikaizhou/my-anything-v3,gradio,,1
-11386,DDD2222/webui,gradio,,1
-11387,ItsJayQz/Classic_Telltale_Diffusion,gradio,,1
-11388,ItsJayQz/Civilizations_6_Diffusion,gradio,,1
-11389,freddiezhang/honor,gradio,,1
-11390,MountLiteraSwd/stabilityai-stable-diffusion-2,gradio,bsl-1.0,1
-11391,Guknadereve/stabilityai-stable-diffusion-2-1,gradio,,1
-11392,MountLiteraSwd/mount_ai_school1,gradio,,1
-11393,MountLiteraSwd/Linaqruf-anything-v3.0,gradio,apache-2.0,1
-11394,abidlabs/min-dalle-later,gradio,mit,1
-11395,lterriel/YOLOv5_medieval_register,gradio,other,1
-11396,arbml/whisper-small-ar,gradio,,1
-11397,arbml/whisper-small-cv-ar,gradio,,1
-11398,Monteg/anything-v3.0,gradio,,1
-11399,hrishikeshagi/chatbot,gradio,,1
-11400,hareshhecker/dreamlike-art-dreamlike-diffusion-1.0,gradio,artistic-2.0,1
-11401,hrishikeshagi/MusicGenerator,gradio,,1
-11402,maxspad/nlp-qual-space,streamlit,,1
-11403,sandeepsign/catordog,gradio,apache-2.0,1
-11404,LiminalDiffusion/README,static,,1
-11405,yo2266911/uma_voice,gradio,,1
-11406,6shen7/Linaqruf-anything-v3.0,gradio,openrail,1
-11407,ThomasSimonini/Deep-Reinforcement-Learning-Leaderboard,gradio,,1
-11408,MountLiteraSwd/stabilityai-stable-diffusion-7,streamlit,,1
-11409,HungHN/appsgenz-openjourney,gradio,,1
-11410,darkroonn/hakurei-waifu-diffusion,gradio,openrail,1
-11411,unilux/ASR_for_Luxembourgish_w2v,gradio,mit,1
-11412,swhyuni/Digital-Financial-Advisory-for-Mutual-Funds,streamlit,,1
-11413,ikun12/ikun,gradio,apache-2.0,1
-11414,ayapoooooo123/Balloon_Diffusion,gradio,bsd,1
-11415,bryanlincoln/bryan-sd1.5-v2,gradio,mit,1
-11416,rwitz2/lambdalabs-dreambooth-avatar,gradio,,1
-11417,Joeythemonster/MGX-Midjourney-v4,gradio,,1
-11418,DrHakase/word2img,gradio,mit,1
-11419,Joeythemonster/magic-diffusion,gradio,apache-2.0,1
-11420,Joeythemonster/finetuned_diffusion,gradio,mit,1
-11421,DrishtiSharma/Whisper-Serbian-Transcriber,gradio,,1
-11422,niks-salodkar/Age-Prediction-Demo,streamlit,apache-2.0,1
-11423,amitkot/he2en,gradio,,1
-11424,YE01/saya-vits,gradio,mit,1
-11425,xelu3banh/dpt-depth01,gradio,,1
-11426,xelu3banh/dpt-depth02,gradio,,1
-11427,redpeacock78/anything-v3.0,gradio,,1
-11428,Adam111/stable-diffusion-webui,gradio,openrail,1
-11429,ladiyusuph/potato_disease_classifier,gradio,apache-2.0,1
-11430,LukeLB/shocking_guiness,gradio,apache-2.0,1
-11431,schoemann/vanGogh_in_Kaiserswerth,gradio,,1
-11432,XaSkeL/dreambooth,gradio,mit,1
-11433,adpro/dpt-depth03,gradio,,1
-11434,adpro/dpt-depth07,gradio,,1
-11435,adpro/dpt-depth13,gradio,,1
-11436,adpro/dpt-depth15,gradio,,1
-11437,aaditkapoorbionlp/clinical_trial_match,streamlit,mit,1
-11438,Mikey211/computing,gradio,,1
-11439,Hydrangea/computing,gradio,,1
-11440,Mikey211/computing2,gradio,,1
-11441,oscars47/Thinking_Parrot_1.0.1,gradio,mit,1
-11442,Red54/convert-sd-ckpt,gradio,apache-2.0,1
-11443,Banjoo/What_The_Bun,gradio,apache-2.0,1
-11444,Gopal101/Netflix-Data-Analytics,streamlit,bsd,1
-11445,amoghv/Fast-food-classifier,gradio,apache-2.0,1
-11446,k2s0/talk-to-god,gradio,cc,1
-11447,k2s0/ask-theologian,gradio,cc,1
-11448,Rubens/semantic_similarity,gradio,,1
-11449,oscars47/Thinking_Parrot_1.1.0,gradio,mit,1
-11450,neulab/tldr_eval,gradio,,1
-11451,ayapoooooo123/openai-jukebox-1b-lyrics,gradio,bigscience-bloom-rail-1.0,1
-11452,716this/review-star-prediction-app,gradio,,1
-11453,ChongCJ/fish,gradio,apache-2.0,1
-11454,XPMaster/Motor_Vehicle_Collisions_NY,streamlit,,1
-11455,abc123desygn/Marvel_WhatIf_Diffusion,gradio,,1
-11456,XPMaster/premium_insurance_prediction,gradio,,1
-11457,Maaz66/GPT3-SPANISH-CHATBOT-PUBLIC,gradio,unknown,1
-11458,Anmol12385/chat123,gradio,odc-by,1
-11459,Blockinger/OVAChatGPT,gradio,unknown,1
-11460,nooji/GenieOnHuggingFaceSpaces,docker,apache-2.0,1
-11461,dream-textures/README,static,,1
-11462,emre/emre-whisper-medium-turkish-2,gradio,openrail,1
-11463,rzimmerdev/lenet_mnist,gradio,,1
-11464,agiats/text_highlight_bccwj,gradio,,1
-11465,azamat/twitter_geocoder,gradio,other,1
-11466,GIanlucaRub/DoubleResolution-Monitor,gradio,,1
-11467,biodasturchi/esmfold_bio,streamlit,apache-2.0,1
-11468,verence333/InfoAnalyzer,gradio,cc-by-4.0,1
-11469,ShreyashS/NLP-Sentiment_Analysis,streamlit,mit,1
-11470,rifkat/Uz-Text-Summarization,gradio,,1
-11471,KaburaJ/binary_image_classification_app,streamlit,,1
-11472,Yusin/docker_test,docker,apache-2.0,1
-11473,remzicam/ted_talks_summarizer,gradio,other,1
-11474,HusseinHE/webui_blank,gradio,,1
-11475,Datasculptor/AIart_sources_of_inspiration,gradio,,1
-11476,yuanpei/robotinder-dev,gradio,,1
-11477,awacke1/ArtNovelComicBookComposer,gradio,,1
-11478,surendra962/ranking,streamlit,,1
-11479,BilalSardar/AutoML-Model-Training,streamlit,openrail,1
-11480,lunarfish/furrydiffusion,streamlit,creativeml-openrail-m,1
-11481,MohamedRashad/Diffusion4Fashion,gradio,apache-2.0,1
-11482,breadlicker45/breadlicker45-MusePy,gradio,other,1
-11483,VietVuiVe/PhanLoaiTraiCay,gradio,mit,1
-11484,ysharma/test-flufflemarkednoser-cat,gradio,,1
-11485,binery/Paddle_OCR,streamlit,,1
-11486,TheDustOfTimes/webui,gradio,,1
-11487,sky1/sky,gradio,gpl-3.0,1
-11488,247Readings/README,static,,1
-11489,hongtu/DeepDanbooru_string,gradio,,1
-11490,Linann/DeepDanbooru_string,gradio,,1
-11491,tommy24/test,gradio,,1
-11492,abdalrahmanshahrour/ImageGeneration,gradio,,1
-11493,Danky/dreamlike-art-dreamlike-diffusion-1.0,gradio,,1
-11494,awacke1/MadLibs,streamlit,,1
-11495,Ottermad/pet-classifier,gradio,,1
-11496,rishikesh/365DataScience,streamlit,mit,1
-11497,uin-malang/README,static,,1
-11498,MAli7319/Comment_Analysis,gradio,,1
-11499,kweyamba/gradio-sentiment-analyzer,gradio,,1
-11500,om-app/dmini,gradio,cc,1
-11501,AIDHD/GrammarCorrector,streamlit,,1
-11502,qianyexingchen/Real-CUGAN,gradio,gpl-3.0,1
-11503,sky009/Qiliang-bart-large-cnn-samsum-ChatGPT_v3,gradio,,1
-11504,Bong15/Rewrite,streamlit,,1
-11505,sowas/stabilityai-stable-diffusion-2-1,gradio,,1
-11506,sushimashi/webui,gradio,,1
-11507,Stearns/soar-d-rules-knowledge-inspector,streamlit,,1
-11508,Djdjeuu/MGX-Midjourney-v4,gradio,,1
-11509,Stearns/crl-demo,docker,,1
-11510,grey1227/experiment_terminator,streamlit,mit,1
-11511,Ninjagolover69/text_generator1,gradio,,1
-11512,Luna-Crestt/How_is_it_ze,gradio,,1
-11513,genomics-england/anonymise_this,streamlit,,1
-11514,keremberke/clash-of-clans-object-detection,gradio,,1
-11515,0x1337/vector-inference,gradio,wtfpl,1
-11516,NeoonN/Aurora,gradio,,1
-11517,Stearns/Soar,docker,bsd,1
-11518,esraa-abdelmaksoud/Dominant-Ad-Colors-Detection,gradio,cc-by-4.0,1
-11519,ajashari/ajashari-ari-color,gradio,afl-3.0,1
-11520,everm1nd/musika,gradio,cc-by-4.0,1
-11521,ybbat/raven-or-crow,gradio,mit,1
-11522,harshasurampudi/which_avenger,gradio,apache-2.0,1
-11523,medici/dreambooth-training,gradio,mit,1
-11524,thibobo78/stabilityai-stable-diffusion-2-1,gradio,openrail,1
-11525,awacke1/AI-EIO-Editor,streamlit,,1
-11526,Neprox/like-it-or-not,streamlit,,1
-11527,irene-glez/whatsapp_chat_analyzer_streamlit,streamlit,,1
-11528,BreetheRun/mitchtech-vulcan-diffusion,gradio,,1
-11529,pstan/webui1,gradio,,1
-11530,QINGFNEG/Real-CUGAN,gradio,gpl-3.0,1
-11531,phanstudio/webui,gradio,,1
-11532,ChihChiu29/mychatbot,docker,gpl-2.0,1
-11533,xiaozhong/Real-CUGAN,gradio,gpl-3.0,1
-11534,Pfs2021Funny/Basunat-Cinematic-Diffusion_demo,gradio,,1
-11535,shengzi/uer-gpt2-chinese-cluecorpussmall,docker,,1
-11536,Pfs2021Funny/The-CG-Diffusion,gradio,,1
-11537,shengzi/shibing624-gpt2-dialogbot-base-chinese,gradio,,1
-11538,Pushpak77/fastspeech2-TTS,gradio,,1
-11539,Candeloro/DeepDanbooru_string,gradio,,1
-11540,PsykoNOT/hakurei-waifu-diffusion,gradio,,1
-11541,DCXGAO/DeepDanbooru_string,gradio,,1
-11542,Xhaheen/stable-diffusion-depth2img-test,gradio,,1
-11543,Rmpmartinspro2/EimisAnimeDiffusion_1.0v,gradio,,1
-11544,Datasculptor/car-data,gradio,mit,1
-11545,Neovega/ogkalu-Comic-Diffusion,gradio,,1
-11546,xiao2023/DeepDanbooru_string,gradio,,1
-11547,catasaurus/text2int,gradio,,1
-11548,labonny/facial-expression,gradio,apache-2.0,1
-11549,MysticTony/webui,gradio,,1
-11550,CourserLi/classify,gradio,apache-2.0,1
-11551,hrishikeshagi/NewChatbot,gradio,,1
-11552,sushmitxo/galactica2_6.7b,gradio,cc,1
-11553,robertoberagnoli/whisper,gradio,,1
-11554,hyuan5040/Speech-ChatGPT-Speech,gradio,apache-2.0,1
-11555,cshallah/qna-ancient-1,gradio,openrail,1
-11556,Roxza/vintedois,gradio,,1
-11557,Freiburg-AI-Research/dermoscopic_image_generation,gradio,,1
-11558,hyuan5040/ChatWithSpeech,gradio,apache-2.0,1
-11559,indy256/protogen_v2.2,gradio,,1
-11560,xcocogoatx/WaifuCreatorAi,gradio,,1
-11561,kanokon/GUI,gradio,,1
-11562,Andreean/Sentiment-Analysis-Bitcoin,streamlit,,1
-11563,akhaliq/cool-japan-diffusion-2-1-0,gradio,,1
-11564,niks-salodkar/Fashion-Prediction-Demo,streamlit,apache-2.0,1
-11565,hugface33/dream,gradio,openrail,1
-11566,Rohith33/facedetector,gradio,apache-2.0,1
-11567,frnka/football,streamlit,,1
-11568,awacke1/AI.Dashboard.Mermaid.Model.HTML5,static,,1
-11569,peteralexandercharles/wav2vec2-uk-demo,gradio,,1
-11570,ADobrovsky/Plant_Disease_Classification_Project,gradio,,1
-11571,MaplePanda/PandaG-diffusion-2-1,gradio,,1
-11572,koyomimi/Real-CUGAN,gradio,gpl-3.0,1
-11573,MaplePanda/Gstable-diffusion-2-1,gradio,,1
-11574,hdaifeh93/README,static,,1
-11575,saltacc/RandomPrompt-v1,gradio,mit,1
-11576,arnepeine/monaspeech,gradio,other,1
-11577,mukish45/potato-disease-classification,gradio,,1
-11578,zswvivi/ChineseMedicalQA,gradio,,1
-11579,Tritkoman/Bloom,gradio,,1
-11580,kilog/dreamlike-art-dreamlike-diffusion-1.0,gradio,,1
-11581,mithril-security/NonSuspiciousImageDecoder,gradio,,1
-11582,subrota2k2/mt_en-de,gradio,,1
-11583,VIOD/Real-CUGAN,gradio,gpl-3.0,1
-11584,VIOD/anime-ai-detect,gradio,,1
-11585,awacke1/BiasMitigatorForFairEquityData,streamlit,,1
-11586,thinkersloop/finetuned-dl-cord-v2,gradio,,1
-11587,iricardoxd/chat_spanish,gradio,gpl,1
-11588,hhalim/hadi_first_day_in_HF,gradio,,1
-11589,niaoquan/anime-remove-background,gradio,apache-2.0,1
-11590,datasciencedojo/Twitter-Trends-Analyzer,gradio,,1
-11591,Shad0ws/Chatbot_OpenAI,gradio,other,1
-11592,zhuwx/Real-CUGAN,gradio,gpl-3.0,1
-11593,adpro/Stable-Diffusion-Side-by-Side01,gradio,apache-2.0,1
-11594,ke666/anime-ai-detect,gradio,,1
-11595,Avin1221/darkstorm2150-Protogen_x3.4_Official_Release,gradio,,1
-11596,tomar79/webcam,streamlit,openrail,1
-11597,RedBaron5/PatentSolver,streamlit,,1
-11598,xuyaxiong/HandwrittenDigits,gradio,apache-2.0,1
-11599,Stanlito/Foodvision_mini,gradio,mit,1
-11600,santhosh/NLLB-Translator,gradio,wtfpl,1
-11601,windoge/anime-ai-detect,gradio,,1
-11602,neigui/White-box-Cartoonization,gradio,apache-2.0,1
-11603,mcqueenfu/johnslegers-epic-diffusion,gradio,,1
-11604,hallll/text_image_forgery_detection,gradio,mit,1
-11605,waiwaiwai/Real-CUGAN,gradio,gpl-3.0,1
-11606,shui45/Real-CUGAN,gradio,gpl-3.0,1
-11607,keremberke/garbage-object-detection,gradio,,1
-11608,billsar1912/YOLOv5x6-marine-vessels-detection,streamlit,,1
-11609,oskarvanderwal/MT-bias-demo,gradio,,1
-11610,konerusudhir/mp_art_search_1_1,gradio,apache-2.0,1
-11611,piuba-bigdata/discurso-de-odio,streamlit,,1
-11612,huhlim/cg2all,gradio,apache-2.0,1
-11613,iben/syntetic-text-detector,gradio,,1
-11614,jroust/rooster,gradio,,1
-11615,lindeberg/whisper-webui,gradio,apache-2.0,1
-11616,Hexequin/Linaqruf-anything-v3.0,gradio,,1
-11617,harshhpareek/bertscore,gradio,,1
-11618,kesally/anime-remove-background,gradio,apache-2.0,1
-11619,Andy1621/UniFormerV2_mit_demo,gradio,mit,1
-11620,cenji1109285052/anime-ai-detect,gradio,,1
-11621,lemon7/White-box-Cartoonization,gradio,apache-2.0,1
-11622,uisjqo/DeepDanbooru_string,gradio,,1
-11623,lyf46/point-e,gradio,creativeml-openrail-m,1
-11624,LZY123ai/anime-remove-background,gradio,apache-2.0,1
-11625,GouDiya/anime-remove-background,gradio,apache-2.0,1
-11626,rerdscf/webui,gradio,,1
-11627,TEL123/Real-CUGAN,gradio,gpl-3.0,1
-11628,om-app/remove-background,gradio,apache-2.0,1
-11629,chuyin/anime-ai-detect,gradio,,1
-11630,OverSky/mio-amadeus,gradio,,1
-11631,aaronW/PaddlePaddle-plato-mini,streamlit,,1
-11632,modjunkie/MGX-Midjourney-v4,gradio,,1
-11633,safebuster2/sudoku,gradio,apache-2.0,1
-11634,aziki/anime-remove-background,gradio,apache-2.0,1
-11635,QianFeng/White-box-Cartoonization2308,gradio,apache-2.0,1
-11636,anzoutian/White-box-Cartoonization,gradio,apache-2.0,1
-11637,chansung/textual-inversion-pipeline,gradio,apache-2.0,1
-11638,109peko/anime-remove-background,gradio,apache-2.0,1
-11639,109peko/DeepDanbooru_string,gradio,,1
-11640,MMars/Question_Answering_DistilBert_Finetuned_on_SQuAD,gradio,,1
-11641,mmfuente95/Basic_EN_FR_Translator,gradio,openrail,1
-11642,BwayKC/prompthero-openjourney-v2,gradio,openrail,1
-11643,Lawlieties/dreamlike-art-dreamlike-photoreal-2.0,gradio,,1
-11644,GT4SD/moler,gradio,,1
-11645,Jour/Bloom-Translation,gradio,mit,1
-11646,nightfury/Riffusion_real-time_image-to-music_generation,gradio,,1
-11647,mohamadsadeghrio/Aplod,streamlit,,1
-11648,BhaskarKapri/Animal,gradio,apache-2.0,1
-11649,micole66/zero-shot-4,gradio,,1
-11650,Ali36Ahmad/MagicPrompt-Stable-Diffusion,gradio,mit,1
-11651,Ali36Ahmad/magic-diffusion,gradio,apache-2.0,1
-11652,gggh/anime-remove-background,gradio,apache-2.0,1
-11653,johnslegers/Epic-Diffusion-webui,gradio,,1
-11654,salmanmapkar/whisper-to-chatGPT,gradio,apache-2.0,1
-11655,MINAMONI/White-box-Cartoonization,gradio,apache-2.0,1
-11656,Felixogunwale/Imagedeblurr,gradio,mit,1
-11657,peteralexandercharles/automatic-speech-recognition-with-next-gen-kaldi,gradio,apache-2.0,1
-11658,vargha/facebook-wmt19-en-de-gradio,gradio,,1
-11659,BwayKC/darkstorm2150-Protogen_v2.2_Official_Release,gradio,openrail,1
-11660,stjiris/README,static,,1
-11661,hareshhecker/prompthero-openjourney-v2v3,gradio,creativeml-openrail-m,1
-11662,ussrcccp/White-box-Cartoonization,gradio,apache-2.0,1
-11663,AQaTaHaGoD/GoD,streamlit,,1
-11664,yuanmochu/Real-CUGAN,gradio,gpl-3.0,1
-11665,GT4SD/paccmann_rl,gradio,,1
-11666,jjie/DeepDanbooru_string,gradio,,1
-11667,group2test/sd-space-creator,gradio,mit,1
-11668,Violette/Protogen_x3.4_Official_Release,gradio,,1
-11669,clem/comparing-captioning-models,gradio,,1
-11670,pngwn/huguru,gradio,,1
-11671,GT4SD/advanced_manufacturing,gradio,,1
-11672,group2test/stable-diffusion-2-1-base,gradio,,1
-11673,ismot/8testi1,gradio,gpl-3.0,1
-11674,Nathanotal/stockholmHousingValuation,gradio,apache-2.0,1
-11675,micole66/Zero-Shot-Classification-Pretrained,gradio,apache-2.0,1
-11676,ravisingh15/ligand_distance,gradio,creativeml-openrail-m,1
-11677,GT4SD/geodiff,gradio,,1
-11678,GT4SD/hf-transformers,gradio,,1
-11679,camenduru-com/RabbitMQ,docker,,1
-11680,Candeloro/anime-remove-background,gradio,apache-2.0,1
-11681,Shad0ws/crowdcounting,gradio,mit,1
-11682,zcodery/anime-remove-background,gradio,apache-2.0,1
-11683,maureenmugo/projects,gradio,apache-2.0,1
-11684,Arvi/Performance_predictor_and_feedback_generator,gradio,,1
-11685,subhendupsingh/dis-background-removal,gradio,apache-2.0,1
-11686,lognat0704/chatGPT,gradio,,1
-11687,thiagohersan/maskformer-coco-vegetation-gradio,gradio,cc-by-nc-sa-4.0,1
-11688,nightfury/Magic_Text_to_prompt_to_art_Diffusion,gradio,apache-2.0,1
-11689,hyxhb/anime-remove-background,gradio,apache-2.0,1
-11690,prof-freakenstein/anurag-bit-Ai-avatar-Generator,gradio,,1
-11691,pawelklimkowski/tylko-dreams,gradio,,1
-11692,coutant/multilingual-sentence-similarity,gradio,apache-2.0,1
-11693,Luna-Crestt/Da-ze,gradio,,1
-11694,peteralexandercharles/Voice-Cloning,gradio,mit,1
-11695,gstdl/screener-saham-demo,docker,apache-2.0,1
-11696,OPM-TECH/CompVis-stable-diffusion-v1-4,gradio,,1
-11697,w2106856508/DeepDanbooru_string,gradio,,1
-11698,xinhai/Spleeter,gradio,,1
-11699,rossflynn/health,docker,cc,1
-11700,awacke1/AGameForThat,gradio,mit,1
-11701,peteralexandercharles/whisper-restore-punctuation,gradio,apache-2.0,1
-11702,Ibtehaj10/cheating-detection,Configuration error,Configuration error,1
-11703,test12356/SUI-svc-3.0,gradio,,1
-11704,mhmdrza/stabilityai-stable-diffusion-2,gradio,,1
-11705,zea10/ogkalu-Comic-Diffusion,gradio,,1
-11706,nbortych/sentiment,gradio,apache-2.0,1
-11707,jreji/RestNet,gradio,,1
-11708,Malifex/cocoa-diffusion,gradio,,1
-11709,KeyDev/NOC-classification,gradio,,1
-11710,JUNGU/face-swap,gradio,cc-by-nc-sa-4.0,1
-11711,camenduru-com/inspector,gradio,,1
-11712,Yttrin/prompthero-openjourney,gradio,,1
-11713,ClassCat/mnist-classification,gradio,,1
-11714,ferrarrinicky/sd1.5.NSFW,gradio,artistic-2.0,1
-11715,NachtYoru/Linaqruf-anything-v3-better-vae,gradio,,1
-11716,hstrejoluna/dreambooth-training,gradio,mit,1
-11717,Ibtehaj10/cheating-detection-FYP,streamlit,,1
-11718,kornia/Face-Detection,gradio,,1
-11719,bayoubastard/KoboldAI-fairseq-dense-13B-Shinen,gradio,unknown,1
-11720,kerria/finetuned_diffusion,gradio,mit,1
-11721,tilos/Real_Time_Traffic_Prediction,gradio,,1
-11722,SidneyChen/mbti_prediction,gradio,,1
-11723,ClassCat/mnist-classification-ja,gradio,,1
-11724,RealKintaro/Offensive-Speech-Detection-From-Arabic-Dialects,streamlit,,1
-11725,DavidLijun/FI,streamlit,bsd,1
-11726,piuba-bigdata/README,static,,1
-11727,eldobbins/coral-spawning-detector,gradio,cc-by-nd-4.0,1
-11728,renatotn7/question-answering-portuguese-with-BetterTransformer,gradio,,1
-11729,Joshua1808/PaginaWeb,streamlit,openrail,1
-11730,elcom/README,static,,1
-11731,posicube/mean_reciprocal_rank,gradio,,1
-11732,LobsterQQQ/Nail-Set-Art,gradio,openrail,1
-11733,pietrocagnasso/paper-title-generation,gradio,,1
-11734,LobsterQQQ/Text-Image-3D_Model,gradio,,1
-11735,LobsterQQQ/text2img,gradio,,1
-11736,rti-international/rota-app,streamlit,apache-2.0,1
-11737,torileatherman/news_headline_sentiment,gradio,apache-2.0,1
-11738,hakanwkwjbwbs/stabilityai-stable-diffusion-2-base,gradio,,1
-11739,shivalk/myfirst,streamlit,,1
-11740,Munderstand/CLIP-Interrogator-3,gradio,,1
-11741,dtrejopizzo/texto-a-imagenes-intel,gradio,,1
-11742,EDGAhab/Aatrox-Talking,gradio,,1
-11743,Mikey211/GUI2,gradio,,1
-11744,rajistics/shiny-test,docker,,1
-11745,LudvigDoeser/TSLA_stock_predictions,gradio,apache-2.0,1
-11746,yuan1615/EmpathyTTS,gradio,apache-2.0,1
-11747,tommyL99/Stock_Market_Prediction,gradio,,1
-11748,Artbogdanov/monet-manet,gradio,,1
-11749,abdalrahmanshahrour/ArabicQuestionAnswering,gradio,,1
-11750,Monan/webui,gradio,,1
-11751,svjack/bloom-daliy-dialogue-english,gradio,,1
-11752,mw00/chess-classification,gradio,,1
-11753,jolucas/llm_lab,gradio,,1
-11754,leonel1122/Analog-Diffusion,gradio,,1
-11755,georgescutelnicu/neural-style-transfer,gradio,mit,1
-11756,marclelarge/knn_encoder_decoder,gradio,apache-2.0,1
-11757,Angelaangie/personal-chat-gpt,gradio,apache-2.0,1
-11758,Smithjohny376/andite-anything-v4.0,gradio,openrail,1
-11759,LouieDellavega/dreamlike-photoreal-2.0,gradio,,1
-11760,hgd/kk,docker,openrail,1
-11761,whz20041223/anime-remove-background,gradio,apache-2.0,1
-11762,Taper5749/yolov8-2ndspace,gradio,gpl-3.0,1
-11763,YourGodAmaterasu/GPTChatBot,gradio,,1
-11764,spock74/whisper-webui,gradio,apache-2.0,1
-11765,Simbals/TextRetrieval,gradio,,1
-11766,SalmanHabeeb/MaskDetector,gradio,mit,1
-11767,tommy24/this-is-indeed-cool,gradio,,1
-11768,clement13430/RIOT_GAME,gradio,apache-2.0,1
-11769,tommy24/image,gradio,,1
-11770,tigersinz/Linaqruf-anything-v3-better-vae,gradio,,1
-11771,jeanmidev/marvel_snap_related_items_recsys,gradio,,1
-11772,soldni/viz_summaries,gradio,unlicense,1
-11773,ziguo/Real-ESRGAN,gradio,,1
-11774,adyjay/andite-anything-v4.0,gradio,unknown,1
-11775,MrMoans/stabilityai-stable-diffusion-2-1,gradio,,1
-11776,vkganesan/AdaIN,gradio,,1
-11777,ryankkien/LOLDodgeTool,gradio,,1
-11778,MRiwu/Collection,gradio,mit,1
-11779,PascalLiu/FNeVR_demo,gradio,apache-2.0,1
-11780,awacke1/Science-NER-Spacy-Streamlit,streamlit,,1
-11781,Ame42/rwms,gradio,apache-2.0,1
-11782,Fr33d0m21/stabilityai-stable-diffusion-2-1,gradio,,1
-11783,TheOrangeJacketBrigade/GenerateOngCodeAI,gradio,,1
-11784,Mahmoud7/mobile_price_prediction,streamlit,,1
-11785,peteralexandercharles/space-that-creates-model-demo-space,gradio,,1
-11786,coutant/yolov8-detection,gradio,apache-2.0,1
-11787,ahnafsamin/GroTTS-Tacotron2-24mins,gradio,afl-3.0,1
-11788,GT4SD/keyword_bert,gradio,,1
-11789,awacke1/Webcam-Stream-Mesh-Landmark-AI,gradio,mit,1
-11790,eengel7/news_headline_sentiment,gradio,apache-2.0,1
-11791,abcde1234www/personal-chat-gpt,gradio,apache-2.0,1
-11792,Fr33d0m21/Text_image_3d,gradio,,1
-11793,Fr33d0m21/chatbot_dialogpt,gradio,,1
-11794,eeyorestoned/Nitro-Diffusion,gradio,,1
-11795,tmtsmrsl/twitter-sentiment,streamlit,,1
-11796,abcde1234www/aibot,gradio,,1
-11797,celery22/gradio_plant_classify_app,gradio,,1
-11798,Kyllano/ShrimpClassifier,gradio,apache-2.0,1
-11799,7eu7d7/anime-ai-detect-fucker,gradio,apache-2.0,1
-11800,miyu0609/gsdf-Counterfeit-V2.0,gradio,,1
-11801,abhishek/scikit-learn-tabular-playground,gradio,,1
-11802,smartinezbragado/reddit-topic-modelling,gradio,mit,1
-11803,amulyaprasanth/car_price_prediction,gradio,mit,1
-11804,AdithyaSNair/Medical_price_prediction,gradio,,1
-11805,raudabaugh/rsna-breast-cancer-detection,gradio,apache-2.0,1
-11806,Antonpy/stable-diffusion-license,static,,1
-11807,Shenhe/anime-ai-detect,gradio,,1
-11808,Rimi98/InsectRecognizer,gradio,apache-2.0,1
-11809,lvwerra/show-pdf,streamlit,apache-2.0,1
-11810,shoukaku/face-emotion-recognizer,gradio,openrail,1
-11811,ivanokhotnikov/longformer-base-health-fact,streamlit,,1
-11812,freddyaboulton/whisper-to-stable-diffusion,gradio,,1
-11813,pepereeee/DreamlikeArt-PhotoReal-2.0,gradio,,1
-11814,Daroach/anime-remove-background,gradio,apache-2.0,1
-11815,Mayer21/text_to_image2,gradio,mit,1
-11816,akhaliq/scikit-learn-tabular-playground,gradio,,1
-11817,lavrtishakov/EleutherAI-gpt-j-6B,gradio,other,1
-11818,THEMUNCHERCRUNCHER/teachif,docker,cc-by-nd-4.0,1
-11819,nnaii/anime-remove-background,gradio,apache-2.0,1
-11820,nnaii/anime-ai-detect,gradio,,1
-11821,MSHS-Neurosurgery-Research/TQP-atEDH,gradio,,1
-11822,Tao0000/stabilityai-stable-diffusion-2-1,gradio,,1
-11823,voidKandy/WW1_Poet_Bot,gradio,apache-2.0,1
-11824,selldone/README,static,,1
-11825,iamtahiralvi/stabilityai-stable-diffusion-2-1,gradio,gpl,1
-11826,etweedy/dreambooth-tessa,gradio,apache-2.0,1
-11827,huathedev/findsong,streamlit,apache-2.0,1
-11828,iamtahiralvi/yanekyuk-bert-uncased-keyword-extractor,gradio,openrail,1
-11829,tengxiu/img-to-music,gradio,,1
-11830,adrian065105/andite-anything-v4.0,gradio,,1
-11831,CguCsie/README,static,openrail,1
-11832,hanithar/Trees,gradio,apache-2.0,1
-11833,marcogallen/emotion_classifier,gradio,mit,1
-11834,Lycorisdeve/DeepDanbooru_string,gradio,,1
-11835,boda/arabic-names-generator,streamlit,,1
-11836,awacke1/Web-URL-HTTP-Parameters-Get-Set,gradio,,1
-11837,NeilRokad/dreambooth-training,gradio,mit,1
-11838,CODEACON/README,static,,1
-11839,trysem/confusion,gradio,,1
-11840,huang4414/DeepDanbooru_string,gradio,,1
-11841,sheikhDeep/car-recognizer,gradio,mit,1
-11842,Hc123/anime-remove-background,gradio,apache-2.0,1
-11843,abdulsamod/crop_yield,gradio,,1
-11844,emilycrinaldi/AirBNB,streamlit,apache-2.0,1
-11845,fozouni123/linkeddata,streamlit,,1
-11846,wuuthradd/prompthero-openjourney,gradio,openrail,1
-11847,isaacjeffersonlee/Legal-Grammar-Error-Corrector,gradio,,1
-11848,HumanDesignHub/Ra-Diffusion_v.1,gradio,openrail,1
-11849,kllmagn/sberbank-ai-rugpt3large_based_on_gpt2,gradio,,1
-11850,mehdidc/ae_gen,gradio,mit,1
-11851,stevechong/cny-goodluck-detector,streamlit,,1
-11852,Crackedids/README,static,,1
-11853,WayneLinn/Singapore_Air_Quality_Prediction,gradio,,1
-11854,aiden09/plasmo-woolitize,gradio,,1
-11855,neigui/img-to-music,gradio,,1
-11856,trysem/DreamShaper-3.3,gradio,openrail,1
-11857,fariyan/gif_studio,streamlit,mit,1
-11858,ma3ter3ky/test,gradio,apache-2.0,1
-11859,abrar-adnan/vehicle-recognizer,gradio,apache-2.0,1
-11860,airus/img-to-music,gradio,,1
-11861,leonel1122/maximum_diffusion_no_pulp,gradio,,1
-11862,lorenzoscottb/phrase-entailment,gradio,cc-by-nc-2.0,1
-11863,dawood/chatbot-guide,gradio,apache-2.0,1
-11864,awacke1/NLPDemo1,gradio,mit,1
-11865,hhalim/NLPContextQATransformersRobertaBaseSquad2,gradio,mit,1
-11866,allieannez/NLPContextQASquad2Demo,gradio,,1
-11867,imseldrith/BotX,gradio,openrail,1
-11868,sanjayw/nlpDemo1,gradio,mit,1
-11869,abhilashb/NLP-Test,gradio,mit,1
-11870,AdamGoyer/is_it_fly,gradio,apache-2.0,1
-11871,clevrpwn/CompVis-stable-diffusion-v1-4,gradio,,1
-11872,lRoz/j-hartmann-emotion-english-distilroberta-base,gradio,,1
-11873,Ame42/UBTH,gradio,other,1
-11874,drdata/ArtNovelComicBookComposer,gradio,,1
-11875,gradio/examples_component_main,gradio,,1
-11876,awacke1/SpaceBuggyPlaycanvasHTML5,static,,1
-11877,ClassCat/Spleen-3D-segmentation-with-MONAI,gradio,,1
-11878,sblumenf/read_it_later,gradio,openrail,1
-11879,geniusguy777/Face_Recognition,gradio,gpl-3.0,1
-11880,wuhuqifeidekun/White-box-Cartoonization,gradio,apache-2.0,1
-11881,HaiTang/DeepDanbooru_string,gradio,,1
-11882,Jamos1/AI_gamer89-insta,gradio,,1
-11883,Ayaka-daisuki/anime-remove-background,gradio,apache-2.0,1
-11884,faressayadi/n-gpt,streamlit,openrail,1
-11885,Disguised/anime_character_recognizer,gradio,apache-2.0,1
-11886,bugbounted/Whisper-Auto-Subtitled-Video-Generator,streamlit,,1
-11887,Fbr55555/hassanblend-HassanBlend1.5.1.2,gradio,,1
-11888,saurav-sabu/Car-Price-Prediction,streamlit,,1
-11889,ma3ter3ky/FruitClassifierModel,gradio,apache-2.0,1
-11890,sanaghani12/Gradio-Huggingface,gradio,,1
-11891,andzhk/PGNInfo-test,gradio,wtfpl,1
-11892,jsdt/lol-predictor,gradio,,1
-11893,dawood/chatbot-guide-multimodal,gradio,afl-3.0,1
-11894,Temptingchina/Real-CUGAN,gradio,gpl-3.0,1
-11895,oyjp1234/andite-anything-v4.0,gradio,openrail,1
-11896,rang1/White-box-Cartoonization,gradio,apache-2.0,1
-11897,kwinten/attrition,gradio,,1
-11898,chachkey/anime-remove-background,gradio,apache-2.0,1
-11899,pranavbapte/Car_type_detection,gradio,apache-2.0,1
-11900,ahuss/pet,gradio,apache-2.0,1
-11901,aegrif/spell_generation,gradio,,1
-11902,ethansmith2000/image-mixer-demo,gradio,openrail,1
-11903,SumDimDimSum/yulet1de-hentaidiffusion,gradio,,1
-11904,nyaasaT/Nyanator,gradio,,1
-11905,agamthind/foodvision_mini,gradio,mit,1
-11906,camenduru-com/chisel,docker,,1
-11907,Rinox06/webui,gradio,,1
-11908,davanstrien/qdrant_test,docker,,1
-11909,Joabutt/furry-diffusion,gradio,wtfpl,1
-11910,BilalSardar/facrec,gradio,,1
-11911,3i2irg/first-app,gradio,apache-2.0,1
-11912,Duskfallcrew/anything-v3.0,gradio,,1
-11913,redpeacock78/anything-v4.0,gradio,,1
-11914,vialibre/edia_full_es,gradio,mit,1
-11915,Duskfallcrew/MagicDreamlike,gradio,,1
-11916,achajon/prompthero-openjourney-v2,gradio,,1
-11917,zonglin03/White-box-Cartoonization,gradio,apache-2.0,1
-11918,aadit2697/movie_recommender,streamlit,,1
-11919,TorsteinAE/YoutubeSummarizer,gradio,unknown,1
-11920,luciancotolan/Fraud_ExpertSystem,gradio,apache-2.0,1
-11921,awacke1/ChatbotWithFilePersistence,gradio,,1
-11922,OtmanSarrhini/foodvision_mini,gradio,other,1
-11923,Ayya/anime-remove-background,gradio,apache-2.0,1
-11924,hjs8/text-to-3D,gradio,,1
-11925,mukish45/Hindi-Audio-To-Text,gradio,,1
-11926,Asahi402/White-box-Cartoonization,gradio,apache-2.0,1
-11927,DataScienceGuild/WikipediaAIWithDataframeMemory,gradio,mit,1
-11928,Asahi402/anime-remove-background,gradio,apache-2.0,1
-11929,AnshuK23/Customer-review-analysis,streamlit,openrail,1
-11930,kukuhtw/VToonify,gradio,other,1
-11931,trysem/dfr,gradio,,1
-11932,awacke1/ASRSpeechRecognition1,gradio,mit,1
-11933,hhalim/WikipediaAIDataScience,gradio,mit,1
-11934,radames/hello-pytesseract,gradio,,1
-11935,procat22/minimal,gradio,apache-2.0,1
-11936,giorgiolatour/aqiprediction,gradio,,1
-11937,abc123desygn/timeless-diffusion,gradio,,1
-11938,ussarata/storygen,gradio,,1
-11939,awacke1/bigscience-data-sgpt-bloom-1b7-nli,gradio,mit,1
-11940,DanielCL/try-out-openai-text-summarizer,gradio,,1
-11941,Jerkinjankins/ogkalu-Comic-Diffusion,gradio,,1
-11942,Duskfallcrew/darkstorm2150-Protogen_x5.8_Official_Release,gradio,openrail,1
-11943,Duskfallcrew/shindi-realistic-skin-style,gradio,openrail,1
-11944,Unggi/title_extraction_bart_logical,gradio,openrail,1
-11945,rrighart/product-defects,gradio,,1
-11946,lengxi/White-box-Cartoonization,gradio,apache-2.0,1
-11947,Tirendaz/pytorch_cat_vs_dog,gradio,other,1
-11948,Lycorisdeve/White-box-Cartoonization,gradio,apache-2.0,1
-11949,dieselprof/stabilityai-stable-diffusion-2,gradio,,1
-11950,SamKenX-Hub-Community/README,static,,1
-11951,awacke1/google-pegasus-pubmed,gradio,mit,1
-11952,awacke1/google-bigbird-pegasus-large-pubmed,gradio,mit,1
-11953,awacke1/microsoft-BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext,gradio,mit,1
-11954,awacke1/Stancld-longt5-tglobal-large-16384-pubmed-3k_steps,gradio,mit,1
-11955,awacke1/bigscience-T0_3B,gradio,,1
-11956,oldplayer1871/anime-remove-background,gradio,apache-2.0,1
-11957,nehuggingface/cant,gradio,,1
-11958,Daimon/translation_demo,streamlit,afl-3.0,1
-11959,lris/anime-remove-background,gradio,apache-2.0,1
-11960,lris/DeepDanbooru_string,gradio,,1
-11961,Faboor/README,static,,1
-11962,oyyy/TeleGPT,static,openrail,1
-11963,sr5434/QuoteGeneration,gradio,mit,1
-11964,axuint/OpenNiji,gradio,,1
-11965,codebender/gpt-2-rumblings,gradio,,1
-11966,AppleQAQ/anime-remove-background,gradio,apache-2.0,1
-11967,Metal079/Sonic_Character_tagger,gradio,agpl-3.0,1
-11968,AndreLie95/Diabetes_Risk_Prediction,streamlit,,1
-11969,Chukwuka/FoodVision-Model,gradio,mit,1
-11970,bhasker412/IDD-YOLO-Tracking,gradio,,1
-11971,luxiya/anime-remove-backgrou,gradio,apache-2.0,1
-11972,kaesb/fastaicourse,gradio,apache-2.0,1
-11973,SmokingBrisket321/rocky_or_rambo,gradio,,1
-11974,ZeroCool94/sygil-diffusion,gradio,,1
-11975,Daniton/superjourney,gradio,,1
-11976,eeemef/demo-cats-vs-dogs,gradio,apache-2.0,1
-11977,Boadiwaa/Recipes,gradio,,1
-11978,zonglin03/Real-CUGAN,gradio,gpl-3.0,1
-11979,awacke1/gpt2-demo,gradio,mit,1
-11980,MrSashkaman/StyleTransfer,docker,openrail,1
-11981,Nickhilearla135095/webui,gradio,,1
-11982,victorbahlangene/Star-wars-app,streamlit,,1
-11983,SHULGIN/MiDaS,gradio,,1
-11984,masapasa/biogpt,gradio,,1
-11985,mshkdm/VToonify,gradio,other,1
-11986,awacke1/CodeParrot-Copilot-Alternative,gradio,mit,1
-11987,awacke1/NovelAI-genji-python-6B,gradio,mit,1
-11988,awacke1/EleutherAI-gpt-j-6B,gradio,mit,1
-11989,awacke1/facebook-incoder-6B,gradio,mit,1
-11990,awacke1/Salesforce-codegen-16B-multi,gradio,mit,1
-11991,jspr/paperchat,gradio,,1
-11992,Eveltana/eveltana,streamlit,,1
-11993,AI-Chatbot-Master/Chatbots,docker,,1
-11994,Duskfallcrew/duskfalltest,gradio,,1
-11995,umm-maybe/mitsua-diffusion-cc0,gradio,,1
-11996,Zubia/clipdemo,gradio,mit,1
-11997,rzuruan/DeepDanbooru_string,gradio,,1
-11998,Duskfallcrew/Duskfallcrew-duskfallai,gradio,creativeml-openrail-m,1
-11999,Goblin-of-Games/README,Configuration error,Configuration error,1
-12000,playgrdstar/ancient-chinese-calligraphy,gradio,mit,1
-12001,hhalim/DAvaViz-graph,streamlit,apache-2.0,1
-12002,hhalim/dataViz-mermaid,streamlit,,1
-12003,hhalim/datavis-plotly,streamlit,,1
-12004,michelecafagna26/High-Level-Dataset-explorer,streamlit,apache-2.0,1
-12005,voroninvisuals/lama,gradio,apache-2.0,1
-12006,sanjayw/mask2former-demo,gradio,apache-2.0,1
-12007,akhaliq/pastel-mix,gradio,,1
-12008,Duskfallcrew/duskfallai_webui,gradio,,1
-12009,LEBEI/00002,gradio,apache-2.0,1
-12010,avysotsky/asklethain,gradio,mit,1
-12011,Stereo0001/Model3D,gradio,afl-3.0,1
-12012,edvanger/White-box-Cartoonization,gradio,apache-2.0,1
-12013,Falpx/DeepDanbooru_string,gradio,,1
-12014,Lucifer741/emoji-predictor,gradio,apache-2.0,1
-12015,hush1/anime-remove-background,gradio,apache-2.0,1
-12016,Xikless/instructpix2pix,gradio,,1
-12017,andreishagin/Class_modify,streamlit,apache-2.0,1
-12018,lotrlol/Spotify-Recommendation-System,streamlit,,1
-12019,stable-bias/diffusion-faces,gradio,,1
-12020,nateevo/asesor-transito,gradio,mit,1
-12021,hush1/White-box-Cartoonization,gradio,apache-2.0,1
-12022,Kaixuanliu/textual-inversion-training,gradio,apache-2.0,1
-12023,miruchigawa/hakurei-waifu-diffusion,gradio,,1
-12024,thejagstudio/procom,docker,apache-2.0,1
-12025,Mayanand/Automatic-Number-Plate-Recognition,gradio,openrail,1
-12026,santiviquez/noisy_human,streamlit,mit,1
-12027,superprpogresor/Bringing-Old-Photos-Back-to-Life,gradio,,1
-12028,tumuyan/realsr-docker,docker,mit,1
-12029,huazhao/DeepDanbooru_string,gradio,,1
-12030,huazhao/anime-remove-background,gradio,apache-2.0,1
-12031,emirhannnn32/car_prediction,gradio,,1
-12032,style0427/anime-remove-background,gradio,apache-2.0,1
-12033,yunyue/anime-remove-background,gradio,apache-2.0,1
-12034,Gyuyu/andite-anything-v4.0,gradio,,1
-12035,georgesX/finetuned_diffusion,gradio,mit,1
-12036,alphahg/academic-paper-translate-summary,gradio,,1
-12037,OFA-Sys/small-stable-diffusion-v0,gradio,,1
-12038,adpro/avinev3_04,gradio,,1
-12039,Sibanjan/Email,gradio,,1
-12040,ulysses115/diffsvc_test,gradio,apache-2.0,1
-12041,vakosta/Code2Comment,gradio,,1
-12042,wybxc/of-diffusion-demo,streamlit,apache-2.0,1
-12043,mengmeng02/DeepDanbooru_string,gradio,,1
-12044,Sevenlee/bert-Chinese,gradio,apache-2.0,1
-12045,Trancoso/README,static,,1
-12046,jarvisx17/En_ASR_wave2vec2,gradio,,1
-12047,cxrhr/anime-remove-background,gradio,apache-2.0,1
-12048,xqq/Real-CUGAN,gradio,gpl-3.0,1
-12049,LeeHotmen/webui-docker,docker,,1
-12050,sanshi-thirty/anime-remove-background,gradio,apache-2.0,1
-12051,yame/Real-CUGAN,gradio,gpl-3.0,1
-12052,OnurKerimoglu/Classifymoods,gradio,apache-2.0,1
-12053,dascruz/pets,gradio,mit,1
-12054,SRDdev/HingMaskedLM,gradio,,1
-12055,JaeSwift/GTA5_Artwork_Diffusion,gradio,,1
-12056,User1342/RUNIC,gradio,gpl-3.0,1
-12057,SDbiaseval/identities-knn,gradio,apache-2.0,1
-12058,EmanAbelwhab/foodvision_mini,gradio,mit,1
-12059,Larvuz/instruct-pix2pix,gradio,,1
-12060,Yukiiiiii/color_transformation,gradio,,1
-12061,tanaysk/stockpricepred,streamlit,,1
-12062,ArtificialWF/Voice-Recognition,gradio,,1
-12063,chumeng/anime-ai-detect,gradio,,1
-12064,manhdo/head_pose_estimation_tracking_app,streamlit,,1
-12065,Jacob209/AUTOMATIC-promptgen-lexart,gradio,openrail,1
-12066,hiraltalsaniya/YOLOv7_face_mask,gradio,other,1
-12067,krushna/text_in_image,gradio,apache-2.0,1
-12068,Zulqrnain/NewsSummarizer,gradio,,1
-12069,msy666/White-box-Cartoonization,gradio,apache-2.0,1
-12070,ebgoldstein/FRF_Heavies,gradio,,1
-12071,osbm/streamlit-helloworld,streamlit,,1
-12072,MikeyAulin/stabilityai-stable-diffusion-2-1,gradio,,1
-12073,jharrison27/NPI-maps,gradio,,1
-12074,hhalim/EleutherAI-gpt-j-6B,gradio,mit,1
-12075,deepghs/gchar_online,gradio,apache-2.0,1
-12076,krushna/url-or-text_summarizer_or_caption_generator,gradio,apache-2.0,1
-12077,yasserofff/runwayml-stable-diffusion-v1-5,gradio,,1
-12078,nikravan/Text2Sql,gradio,,1
-12079,renatotn7/unicamp-dl-translation-en-pt-t5,gradio,,1
-12080,arrayxhunter/bearish,gradio,apache-2.0,1
-12081,avin1103/SLAM,gradio,,1
-12082,pplonski/mercury-hugging-face,gradio,mit,1
-12083,bgk/lodosalberttr1,gradio,,1
-12084,YFHAki/DeepDanbooru_string,gradio,,1
-12085,osanseviero/argilla-template-space,docker,,1
-12086,fattest/stabilityai-stable-diffusion-2-1,gradio,,1
-12087,SashaKerbel/HandwritingClassifier,gradio,other,1
-12088,awacke1/Biomed-NER-AI-NLP-CT-Demo1,gradio,mit,1
-12089,ceckenrode/Biomed-NER-AI-NLP-CT-Demo1,gradio,,1
-12090,awacke1/Bloom.Human.Feedback.File.Ops,gradio,,1
-12091,awacke1/stabilityai-stable-diffusion-2-1,gradio,,1
-12092,awacke1/andite-pastel-mix,gradio,,1
-12093,evanpierce/3D_Photo_Inpainting2,gradio,,1
-12094,harshasurampudi/Which_Planet,gradio,apache-2.0,1
-12095,Kaludi/CSGO-Weapon-Classification_App,gradio,apache-2.0,1
-12096,BaiyuS/Real-CUGAN-YZ,gradio,gpl-3.0,1
-12097,GuardianUI/ui-refexp-click,gradio,agpl-3.0,1
-12098,sritang/hack_qa2,gradio,,1
-12099,Kaludi/Food-Category-Classification_App,gradio,apache-2.0,1
-12100,xyz-labs/openjourney,gradio,,1
-12101,peteralexandercharles/streamlit_1.15,streamlit,,1
-12102,jayyd/fashion-collect,gradio,,1
-12103,TexR6/AttentionMaps,gradio,mit,1
-12104,kdrkdrkdr/LisaTTS,gradio,mit,1
-12105,furqankassa/d4data-biomedical-ner-all02032023,gradio,,1
-12106,keneonyeachonam/d4data-biomedical-ner-all-020323,gradio,,1
-12107,ceckenrode/d4data-biomedical-ner-all232023,gradio,,1
-12108,ahmedxeno/brain_tumor_vs_normal_classification,gradio,,1
-12109,keneonyeachonam/punctuation-Token-Classification,gradio,,1
-12110,furqankassa/Punctuation-token,gradio,,1
-12111,ceckenrode/PunctuationTokenClassification,gradio,,1
-12112,keneonyeachonam/NER-Ontonodes,gradio,,1
-12113,ceckenrode/NEROntoNotes,gradio,,1
-12114,furqankassa/flair-ner-english-ontonotes-large,gradio,,1
-12115,venkatks515/VenkatASR,gradio,,1
-12116,ahmedxeno/kidney_disease_classification_CT_scan,gradio,,1
-12117,nosson/code-classifier,gradio,apache-2.0,1
-12118,datasciencedojo/Article-Scraping,gradio,apache-2.0,1
-12119,subhc/Guess-What-Moves,gradio,mit,1
-12120,EnD-Diffusers/Photography-Test,gradio,creativeml-openrail-m,1
-12121,awacke1/Requests-Interpret,gradio,,1
-12122,Sim1604/Twitter_Sentiment_Analysis,gradio,apache-2.0,1
-12123,awacke1/Embedded_Space_Test,static,,1
-12124,aquaaaaaaaaaaaa/AI-minato_aqua,gradio,other,1
-12125,a1455/DeepDanbooru_string,gradio,,1
-12126,yuan2023/img-to-music,gradio,,1
-12127,Lookimi/TuberTranscript,gradio,openrail,1
-12128,rghdrizzle/fox_dog_wolf_identifier,gradio,,1
-12129,zfz/img-to-music,gradio,,1
-12130,JUNGU/pixera_gen,gradio,,1
-12131,EAraid12/LoRA-DreamBooth-Training-UI,gradio,mit,1
-12132,adba/Real-CUGAN,gradio,gpl-3.0,1
-12133,oldfart/removaltool,gradio,apache-2.0,1
-12134,UltraMarkoBR/SoftHunter,static,mit,1
-12135,haoqi7/research,streamlit,,1
-12136,ivy-1911/vits-uma-genshin-honkai,gradio,apache-2.0,1
-12137,kemao/anime-remove-background,gradio,apache-2.0,1
-12138,phongtruong/gsdf-Counterfeit-V2.5,gradio,,1
-12139,Detomo/generate_wifi_qrcode,gradio,,1
-12140,king007/table_questions,gradio,,1
-12141,aleloved02/Salesforce-codet5-large,gradio,,1
-12142,mukish45/Coconut_Grade_Classification,gradio,,1
-12143,daresay/employee-handbook-chat,gradio,,1
-12144,stonking-com/stonking,static,,1
-12145,Chukwuka/Dog_Breed_ImageWoof,gradio,mit,1
-12146,oms12/dfgan,gradio,openrail,1
-12147,Lalo42/hassanblend-HassanBlend1.5.1.2,gradio,,1
-12148,EliotLacroix/Fine-tuned_Resnet_Face_Segmentation,gradio,,1
-12149,pepereeee/prompthero-funko-diffusion,gradio,,1
-12150,oliveiracwb/MBP,streamlit,apache-2.0,1
-12151,BigBoyBranding/README,static,,1
-12152,Tristan/static-rlhf-interface,gradio,,1
-12153,BreadBytes1/CC-Dashboard,streamlit,gpl,1
-12154,vvd2003/Animals,gradio,,1
-12155,camenduru-com/lsmith,docker,,1
-12156,Carlosito16/HXM-summarization,gradio,,1
-12157,hhalim/google-flan-t5-large,gradio,mit,1
-12158,PrussianBlue/White-box-Cartoonization,gradio,apache-2.0,1
-12159,TwoCH4/White-box-Cartoonization,gradio,apache-2.0,1
-12160,keneonyeachonam/NPR_AI_NER_020623,gradio,,1
-12161,ceckenrode/Biomed-NLP-AI-Clinical-Terminology,gradio,,1
-12162,lalasmrc/facebook-blenderbot-400M-distill,docker,bsd,1
-12163,kitkatchoco/openjourn,gradio,,1
-12164,zjxchina/vits_seki,gradio,,1
-12165,BridgeTower/bridgetower-video-search,gradio,,1
-12166,muyi12314/anime-remove-background,gradio,apache-2.0,1
-12167,firasggg/andite-anything-v4.0,gradio,,1
-12168,shainis/Art_Generation_with_Neural_Style_Transfer,gradio,openrail,1
-12169,sayakpaul/demo-custom-css,gradio,apache-2.0,1
-12170,derek-thomas/sentence_diagrams,gradio,mit,1
-12171,king007/CoCa,gradio,,1
-12172,Faryne/yulet1de-hentaidiffusion,gradio,,1
-12173,untovvn/Hello-SimpleAI-chatgpt-detector-roberta,gradio,,1
-12174,nlphuji/whoops-explorer-analysis,gradio,,1
-12175,mattritchey/geocoder_gradio,gradio,,1
-12176,deprem-ml/README,static,apache-2.0,1
-12177,hcapp/sd-dreambooth-library-herge-style,gradio,,1
-12178,KnowingFly/Linaqruf-anything-v3.0,gradio,artistic-2.0,1
-12179,PeepDaSlan9/CompVis-stable-diffusion-v1-4,gradio,,1
-12180,y-boy/Deforum,docker,mit,1
-12181,kalebu/LangChain_heyooBot,gradio,,1
-12182,awacke1/DockerTensorRTTerminal,docker,mit,1
-12183,awacke1/AutoStableDiffusionTxt2ImgImg2Img,docker,,1
-12184,dennydotio/fastai,gradio,apache-2.0,1
-12185,yapzanan/testNLLB,gradio,cc,1
-12186,walisonhs/stabilityai-stable-diffusion-2,gradio,,1
-12187,PeepDaSlan9/facebook-wav2vec2-large-960h-lv60-self,gradio,,1
-12188,xiaohuajiejie/styletransfor,gradio,apache-2.0,1
-12189,wolfgangmeyers/stable-diffusion-inpainting-vae,static,openrail,1
-12190,elitecode/Detect_Emotions,gradio,apache-2.0,1
-12191,aaronW/chat-robot,streamlit,,1
-12192,lwchen/CodeFormer,gradio,apache-2.0,1
-12193,Josh98/nl2bash_m,gradio,,1
-12194,dgnk007/dgnk007-heat,gradio,,1
-12195,king007/docquery,gradio,,1
-12196,SiddharthK/dslim-bert-large-NER,gradio,,1
-12197,krushna/Auto_Insta_Post-V2,gradio,apache-2.0,1
-12198,SegevC/bf_predictor,gradio,apache-2.0,1
-12199,huggingface/uie,gradio,,1
-12200,GC6848/alpha_stocks_screener,streamlit,,1
-12201,BucketHeadP65/confusion_matrix,gradio,,1
-12202,mano96/plagiarism,gradio,,1
-12203,mattritchey/QuickAddresses,streamlit,,1
-12204,gaouzief/b,gradio,openrail,1
-12205,bccearth35660/machinelearning,gradio,,1
-12206,ashkanforootan/af_chatGPT,streamlit,,1
-12207,cvegvg/Lama-Cleaner-clean,gradio,apache-2.0,1
-12208,mattritchey/HRRR_animate,streamlit,,1
-12209,rune-m/age_guesser,gradio,,1
-12210,jacobduncan00/Hosioka-AniReal,gradio,,1
-12211,AyushP/PolicyChatBot,streamlit,,1
-12212,pedi611/gradio-whisper-to-stable.diffusion,gradio,,1
-12213,devoworm-group/nucleus_segmentor,streamlit,,1
-12214,keneonyeachonam/Visualization-Plotly-Sunbursts-Treemaps-and-WebGL-020823,streamlit,,1
-12215,cmudrc/AddLat2D,streamlit,,1
-12216,kabita-choudhary/speaker_Diarization,gradio,,1
-12217,hfmax/SpeciesChecker,gradio,apache-2.0,1
-12218,PeepDaSlan9/B2B-APG,gradio,,1
-12219,alsrbdni/MagicPrompt-Stable-Diffusion,gradio,mit,1
-12220,spock74/whisper-speaker-diarization,gradio,,1
-12221,bejaeger/filled-stacks-search,streamlit,,1
-12222,maj34/Eye-Handicapped-Service,streamlit,cc-by-4.0,1
-12223,LiuZiyi/1-video-video2txt-whisper-yt,streamlit,,1
-12224,ManDag004/animals,gradio,,1
-12225,LLLLLLLyc/anime-remove-background,gradio,apache-2.0,1
-12226,awacke1/PandasDataframeAutoFilter,gradio,mit,1
-12227,SrRaptor/Imagy,gradio,,1
-12228,Hazzzardous/RWKV-Instruct-1B5,gradio,gpl-3.0,1
-12229,awacke1/GradioAutoPlotFromCSV,gradio,,1
-12230,awacke1/GradioAutoCSVLoaderToPlotly,gradio,,1
-12231,NNDM/img-to-music,gradio,,1
-12232,Boops88/gsdf-Counterfeit-V2.5,gradio,,1
-12233,DonaSmix/anime-remove-background,gradio,apache-2.0,1
-12234,Aer0xander/sd-to-diffusers,gradio,mit,1
-12235,Dipl0/Dipl0-pepe-diffuser-bot,gradio,,1
-12236,ericsc/Korakoe-OpenNiji,gradio,,1
-12237,magnadox/nlpconnect-vit-gpt2-image-captioning,gradio,,1
-12238,Hero0963/sentiment_analysis_demo_01,gradio,unknown,1
-12239,awacke1/StreamlitCSVFiletoPlotlyExpress,streamlit,mit,1
-12240,CirnoW/anime-ai-detect,gradio,,1
-12241,Kaludi/Food-Category-Classification-And-Recipes-Recommender_App,streamlit,apache-2.0,1
-12242,awacke1/GenerativeAI-ChatInStreamlitWithTCPIP,streamlit,mit,1
-12243,awacke1/StreamlitEmotionWheelSunburst,streamlit,mit,1
-12244,awacke1/DungeonCrawlerWithReinforcementLearningMonster,streamlit,,1
-12245,awacke1/PlayableMovingLottieAnimationStreamlit,streamlit,mit,1
-12246,awacke1/StreamlitDealOrNoDeal,streamlit,mit,1
-12247,awacke1/QuoteOfTheDayStreamlit,streamlit,mit,1
-12248,awacke1/QuoteOfTheDayWithSearch,streamlit,mit,1
-12249,fahmiaziz/auto_meringkas,gradio,,1
-12250,awacke1/TwoPlayerDiceGameCraps,streamlit,mit,1
-12251,awacke1/StreamlitMapBoxCityNames,streamlit,,1
-12252,aichina/Pix2Pix-Video,gradio,,1
-12253,Jojohickman21/IvyLeague_Logo_Classifier,gradio,apache-2.0,1
-12254,BreadBytes1/PL-Dashboard,streamlit,gpl,1
-12255,awacke1/ZorkHF,streamlit,mit,1
-12256,awacke1/StreamlitCalendar,streamlit,mit,1
-12257,ravithejads/videoques,gradio,,1
-12258,Noobian/How-To-Generator,gradio,,1
-12259,elitecode/Captioner,gradio,apache-2.0,1
-12260,pbsszoomA19/pbsszoomA19,gradio,,1
-12261,awacke1/StreamlitMultiplayerTicTacToe,streamlit,mit,1
-12262,awacke1/StreamlitMIDIPlayer,streamlit,mit,1
-12263,awacke1/AutoMLPandasProfilingSunburst,streamlit,mit,1
-12264,FrancXPT/stabilityai-stable-diffusion-2-1,gradio,,1
-12265,AFischer1985/German-Flan-T5,gradio,,1
-12266,victorbahlangene/NLP-News-Scraping-Summarization-Sentiment-App,streamlit,,1
-12267,opengl/Stable-Diffusion-Protogen-x3.4-webui,gradio,,1
-12268,guymorlan/English2ShamiDialect,gradio,,1
-12269,AlStable/Duke,gradio,,1
-12270,princeml/emotion_streamlite_app,streamlit,,1
-12271,keneonyeachonam/AutoML_UsingStreamlit_Plotly_020923,streamlit,,1
-12272,Iqbaljanitra/brandshoesprediction_nike_converse_adidas,streamlit,,1
-12273,NMEX/vits-uma-genshin-honkai,gradio,apache-2.0,1
-12274,fhipol/deeplearning,gradio,apache-2.0,1
-12275,vinayakporwal/remove-bg,gradio,,1
-12276,vinayakporwal/ImageCreator,gradio,,1
-12277,unstructuredio/chat-your-data-isw,gradio,apache-2.0,1
-12278,awacke1/STEM-MathExercise,streamlit,mit,1
-12279,Nexxt/MagicPrompt-Stable-Diffusion,gradio,mit,1
-12280,Daniton/prompthero-openjourney-lora,gradio,,1
-12281,zanderchase/chat-your-data-chef,gradio,mit,1
-12282,awacke1/StreamlitSTEMDataScienceEngineerDash,streamlit,,1
-12283,spuun/AI-image-detector,gradio,,1
-12284,frncscp/Patacotron,streamlit,mit,1
-12285,awacke1/DnD-Character-Sheet,streamlit,mit,1
-12286,awacke1/AdventureGame,streamlit,,1
-12287,nmaina/gpt2chat,gradio,,1
-12288,imabhi/book_Reader,gradio,mit,1
-12289,Shine1916/MyChat,gradio,apache-2.0,1
-12290,lijk20/ClueAI-ChatYuan-large-v1,gradio,,1
-12291,ethanrom/pcb_det,gradio,,1
-12292,as-god/gsdf-Counterfeit-V2.5,gradio,,1
-12293,deprem-ml/deprem_satellite_semantic_whu,gradio,,1
-12294,yash-srivastava19/TRINIT_EzDub_ML01,gradio,mit,1
-12295,xxixx/DeepDanbooru_string,gradio,,1
-12296,ravinmizia/Twitter_Depression_Sentiment,streamlit,,1
-12297,cymic/Talking_Head_Anime_3,gradio,,1
-12298,end000/yandex-RuLeanALBERT,gradio,,1
-12299,TRaw/darkstorm2150-Protogen_x3.4_Official_Release,gradio,,1
-12300,LeeroyVonJenkins/hard-hat-detection,gradio,,1
-12301,johiny/gsdf-Counterfeit-V2.5,gradio,,1
-12302,awacke1/ClickableImages,streamlit,,1
-12303,monkeyboss/xiaolxl-GuoFeng3,gradio,,1
-12304,PeepDaSlan9/EleutherAI-gpt-j-6B,gradio,afl-3.0,1
-12305,Bokanovskii/Image-to-music,gradio,,1
-12306,Duskfallcrew/isometric-dreams-sd-1-5,gradio,,1
-12307,mohaktnbt/openai-whisper-large,gradio,,1
-12308,DataScienceEngineering/README,static,,1
-12309,DataScienceEngineering/2-GradioLiveASR,gradio,apache-2.0,1
-12310,DataScienceEngineering/4-Seq2SeqQAT5,gradio,mit,1
-12311,DataScienceEngineering/4-GeneratorCalcPipe,gradio,apache-2.0,1
-12312,DataScienceEngineering/6-TreemapAndSunburst,streamlit,,1
-12313,gestiodinamica/giz_visualizacion,streamlit,mit,1
-12314,mazenAI/livine-demo,gradio,mit,1
-12315,rbuell/iepassist_app,streamlit,,1
-12316,Hallucinate/demo,gradio,openrail,1
-12317,Kaludi/OpenAI-Chatbot_App,streamlit,apache-2.0,1
-12318,palondomus/fastapi,docker,mit,1
-12319,peteralexandercharles/WhisperAnything,gradio,mit,1
-12320,oliveiracwb/MBP2,streamlit,apache-2.0,1
-12321,dajuzi/img-to-music,gradio,,1
-12322,manu-codes/dysperse,gradio,,1
-12323,Detomo/naomi-app-api,docker,creativeml-openrail-m,1
-12324,paascorb/question_answering_TFM,gradio,mit,1
-12325,enoreyes/langchain-gsp-demo,gradio,apache-2.0,1
-12326,cahya/indochat,gradio,creativeml-openrail-m,1
-12327,yongchang111/Real-CUGAN,gradio,gpl-3.0,1
-12328,CrabApple/prompthero-openjourney-v2,gradio,,1
-12329,pietrocagnasso/paper-highlights-extraction,gradio,,1
-12330,shivansh123/Gradio,gradio,,1
-12331,awacke1/1-SimPhysics,static,,1
-12332,jpoptum/1-SimPhysics,static,,1
-12333,danielcwang-optum/1_SimPhysics,static,,1
-12334,awacke1/2-LiveASR,gradio,apache-2.0,1
-12335,Rdceo26Rmrdceo26/README,static,,1
-12336,awacke1/4-GeneratorCalcPipe,gradio,apache-2.0,1
-12337,danielcwang-optum/4-GeneratorCalcPipe,gradio,apache-2.0,1
-12338,Mahathi/4-GeneratorCalcPipe,gradio,apache-2.0,1
-12339,awacke1/4-Seq2SeqQAT5,gradio,mit,1
-12340,danielcwang-optum/6-TreemapAndSunburst,streamlit,,1
-12341,jpoptum/6-TreemapAndSunburst,streamlit,,1
-12342,mkhan328/TreemapAndSunburst,streamlit,,1
-12343,awacke1/6-TreemapSunburst,streamlit,,1
-12344,julyThree/anime-remove-background,gradio,apache-2.0,1
-12345,nateraw/dockerplayground,docker,,1
-12346,sarat2hf/table_in_image_to_csv_app,streamlit,,1
-12347,Lianglan/NLLB200-Translate-Distill-600,gradio,odc-by,1
-12348,AUST001/video,gradio,openrail,1
-12349,jayyd/Guess_famous_personalities_using_GPT-3,gradio,openrail,1
-12350,Damnbro/andite-anything-v4.0,gradio,,1
-12351,tianpanyu/ChatYuan-Demo,gradio,,1
-12352,AIFILMS/image-to-sound-fx,gradio,,1
-12353,cloixai/dalle-minii,static,apache-2.0,1
-12354,AIFILMS/generate_human_motion,gradio,apache-2.0,1
-12355,AIFILMS/riffusion-playground,streamlit,mit,1
-12356,xusheng/anime-remove-background,gradio,apache-2.0,1
-12357,xusheng/anime-ai-detect,gradio,,1
-12358,AIFILMS/audioldm-text-to-audio-generation,gradio,bigscience-openrail-m,1
-12359,blogclif/CF25,gradio,,1
-12360,wdnmd12/Real-CUGAN,gradio,gpl-3.0,1
-12361,AI-Naga/Parking_Space_Counter,gradio,,1
-12362,Yuichiroh/ACL2Vec,gradio,,1
-12363,GenerationsAI/GenAi-Pix2Pix-Video,gradio,,1
-12364,gfhayworth/chat_qa_demo2,gradio,,1
-12365,suyuxicheng/anime-remove-background,gradio,apache-2.0,1
-12366,ashhadahsan/summarizer-space,streamlit,,1
-12367,ehugfaces/stabilityai-stable-diffusion-2-1,streamlit,unknown,1
-12368,AI-Naga/Roof_Element_Identification,gradio,,1
-12369,ceckenrode/sileod-deberta-v3-base-tasksource-nli,gradio,,1
-12370,keneonyeachonam/sileod-deberta-v3-base-tasksource-nli-021423,gradio,,1
-12371,Gaborandi/PubMed_Downloader,gradio,,1
-12372,deprem-ml/intent-leaderboard-v13,streamlit,apache-2.0,1
-12373,nothinglabs/minima,gradio,apache-2.0,1
-12374,hsinyuuuuuuu/cat,streamlit,other,1
-12375,hjie3185/cat.identification,streamlit,,1
-12376,CornSnakeID/CornSnakeMorphID,gradio,,1
-12377,Sevenlee/text_Image_stable-diffusion,gradio,artistic-2.0,1
-12378,zwitshr/justinpinkney-pokemon-stable-diffusion,gradio,,1
-12379,oyl344531959/White-box-Cartoonization,gradio,apache-2.0,1
-12380,EngrZiaQazi/Chat-GPT,gradio,,1
-12381,Roixy/hakurei-waifu-diffusion,gradio,,1
-12382,RyanJiang/anime-remove-background,gradio,apache-2.0,1
-12383,mahmuod/CLIP-Interrogator,gradio,mit,1
-12384,CyStorm/instruct-pix2pix,gradio,,1
-12385,AE-NV/sentiment-productreview,gradio,,1
-12386,marccgrau/whisper-asr-diarization,gradio,,1
-12387,tridragonevo/chat-gpt-voice-stream,gradio,apache-2.0,1
-12388,iambuoyant/vscode,docker,,1
-12389,adolfont/livebook-hf-test,docker,,1
-12390,aheskandani/FilesTools,streamlit,,1
-12391,iamrobotbear/gradio-auth-new,gradio,openrail,1
-12392,teeessstt/ytukjykuyutyku,streamlit,,1
-12393,zhongkaifu/mt_enu_chs,docker,bsd-3-clause,1
-12394,catasaurus/sound-distance,gradio,,1
-12395,awacke1/BigScienceBloomRootsMemory,gradio,apache-2.0,1
-12396,MMYang/microsoft-BioGPT-Large,gradio,,1
-12397,Hskbqn/DeepDanbooru_string,gradio,,1
-12398,zhuzhao/background-remover,gradio,,1
-12399,chilge/taoli,gradio,,1
-12400,wootang04/text_generator,gradio,,1
-12401,Jasmine0725/text_generator,gradio,,1
-12402,Eunice0120/text_generator,gradio,,1
-12403,Yoyo1123/text_generator,gradio,,1
-12404,GigiWasThere/Text,gradio,,1
-12405,L1211/New_space1,gradio,,1
-12406,MelodyKwok/text_generator,gradio,,1
-12407,LarissaHung/text_generator,gradio,,1
-12408,Kittylo/text_generator,gradio,,1
-12409,VioletWLT/Lucylol_wan,gradio,,1
-12410,YoHoCo0o0/Gradio,gradio,,1
-12411,lucylol/mirrorsai1,gradio,,1
-12412,Bianca0930/Bianca,gradio,,1
-12413,GloryGranger80888/Gradio,gradio,,1
-12414,SophiaGaogao/sophia,gradio,,1
-12415,Destinycy/Destiny_LOL,gradio,,1
-12416,alimeituan/gpt2,streamlit,apache-2.0,1
-12417,mutonyilewis/Pothole_detection,gradio,apache-2.0,1
-12418,KatieChau/text-generator,gradio,,1
-12419,NatalieIp/test-generator,gradio,,1
-12420,awacke1/GradioVoicetoTexttoSentiment,gradio,mit,1
-12421,awacke1/GradioUpdateUI,gradio,,1
-12422,colossalturtle4/andite-pastel-mix,gradio,,1
-12423,cfj108/CompVis-stable-diffusion-v1-4,gradio,,1
-12424,baotoan2002/Chatbot-OpenAI,gradio,unlicense,1
-12425,pojitha/sinhala_hate_speech,streamlit,,1
-12426,lunadebruyne/EmotioNL,gradio,,1
-12427,Elbhnasy/Eye-Tracking-Diagnosis,gradio,,1
-12428,Mississippiexhib/theintuitiveye-HARDblend,gradio,openrail,1
-12429,biantao/anime-remove-background,gradio,apache-2.0,1
-12430,seanshahkarami/clip-explorer,gradio,,1
-12431,afdqf2bs/CompVis-stable-diffusion-v1-4,gradio,,1
-12432,keneonyeachonam/Docker-FlanT5-TextGeneratorTranslator-021623,docker,,1
-12433,mmk7/stock_trader,streamlit,,1
-12434,Datasculptor/3D-Room-Layout-Estimation_LGT-Net,gradio,mit,1
-12435,ceckenrode/Docker-FlanT5-TextGeneratorTranslator,docker,,1
-12436,gauravahuja/nlpconnect-vit-gpt2-image-captioning,gradio,,1
-12437,UchihaZY/White-box-Cartoonization,gradio,apache-2.0,1
-12438,impulsewu/Real-CUGAN,gradio,gpl-3.0,1
-12439,YuFuji/CalqTalk,gradio,,1
-12440,mfuentesmagid/Video_AI_Capabilities,gradio,openrail,1
-12441,spacerini/miracl-chinese,streamlit,apache-2.0,1
-12442,ismot/1702t1,gradio,mit,1
-12443,wqferan/chatgpt_webui,gradio,bsd-2-clause,1
-12444,Mattdoc99/ElonYTsearch,streamlit,,1
-12445,qkorbit/AltDiffusion,gradio,creativeml-openrail-m,1
-12446,itskiller/aiimage,gradio,gpl,1
-12447,alsrbdni/copy-ai.com,gradio,apache-2.0,1
-12448,awacke1/StreamlitPydeckMapVisualViewStateForLatitudeLongitude,streamlit,mit,1
-12449,imabhi/Book_Translator,gradio,mit,1
-12450,cloixai/webui,gradio,,1
-12451,rachana219/MODT2,gradio,,1
-12452,dukecsxu/hotdogclassifier,streamlit,mit,1
-12453,RealTimeLiveAIForHealth/VoicetoTexttoSentiment,gradio,mit,1
-12454,DShrimp/PoseMaker,gradio,creativeml-openrail-m,1
-12455,jbraun19/Webcam-Object-Recognition-Yolo-n-Coco,gradio,,1
-12456,RealTimeLiveAIForHealth/ASR-High-Accuracy-Test,gradio,mit,1
-12457,spacerini/miracl-french,streamlit,apache-2.0,1
-12458,furqankassa/Docker-FlanT5-TextGeneratorTranslator,docker,,1
-12459,awacke1/GradioFlanT5BloomAndTaskSource,gradio,mit,1
-12460,alc15492/MSemoji850NEW,gradio,,1
-12461,LabelStudio/README,static,apache-2.0,1
-12462,keneonyeachonam/DockerImageRecognitionToText021723,docker,,1
-12463,Mileena/CLIP,docker,other,1
-12464,awacke1/StreamlitChooseYourOwnAdventure,streamlit,,1
-12465,T-1000/runwayml-stable-diffusion-v1-5,gradio,,1
-12466,sajjade/hassanblend-hassanblend1.4,gradio,,1
-12467,cleanmaster/akagi-sovits3,gradio,openrail,1
-12468,shreydan/khaanaGPT,gradio,,1
-12469,abdullah040/TextBook,gradio,,1
-12470,Andres99/Tune-A-Video-Training-UI,docker,mit,1
-12471,zahadneokurkycz/sd-img-generator,gradio,,1
-12472,hunkim/es-gpt,docker,apache-2.0,1
-12473,luoshang/Real-CUGAN,gradio,gpl-3.0,1
-12474,cleanmaster/so-vits-svc-akagi,gradio,cc-by-nc-3.0,1
-12475,awacke1/Streamlit-Pyplot-Math-Dice-Game,streamlit,mit,1
-12476,habeebb5/biogpt-demo,gradio,,1
-12477,awacke1/Hexagon-Dice-Fractal-Math-Game,streamlit,mit,1
-12478,awacke1/PlantFractalsMathGameWithJuliaSetnStrangeAttractors,streamlit,mit,1
-12479,awacke1/Dice-Roll-Fractals-STEM-Math,streamlit,mit,1
-12480,Tritkoman/Tritkoman-EnglishtoChurchSlavonicV2,gradio,,1
-12481,awacke1/Emojitrition-Fun-and-Easy-Nutrition,streamlit,mit,1
-12482,spacerini/xsum-search,gradio,apache-2.0,1
-12483,navaaesarosh/navaaesarosh-saqi_v0,gradio,mit,1
-12484,micole66/photo-chooser,static,,1
-12485,JacobLinCool/captcha-recognizer,gradio,,1
-12486,pasinic/White-box-Cartoon,gradio,apache-2.0,1
-12487,sadgaj/3demo,gradio,other,1
-12488,Paulog731/runwayml-stable-diffusion-v1-5,gradio,,1
-12489,awacke1/ActingGameMechanicsForSocialIntelligence,streamlit,mit,1
-12490,nickloughren/Robot-or-Not,gradio,apache-2.0,1
-12491,wldmr/gradio_default,gradio,mit,1
-12492,awacke1/Engineering-Magic-Picture-Dice-Vocabulary-Game,streamlit,,1
-12493,awacke1/Engineering-or-Magic-Q-A-IO,streamlit,mit,1
-12494,awacke1/Pandas-Gamification-Mechanics,streamlit,mit,1
-12495,nri1600/AI-bot,gradio,afl-3.0,1
-12496,Mileena/WebUIDx,gradio,,1
-12497,zengwj/GPT2-chitchat-training-huggingface,docker,,1
-12498,cfj108/prompthero-openjourney,gradio,,1
-12499,skyxinsun/Gustavosta-MagicPrompt-Stable-Diffusion,gradio,,1
-12500,glfpes/stabilityai-stable-diffusion-2-1,gradio,,1
-12501,Kluuking/google-vit-base,gradio,,1
-12502,longlh/longlh-agree-disagree-neutral-classifier,gradio,,1
-12503,b7evc/stabilityai-stable-diffusion-2-1,gradio,,1
-12504,Irnkvezz/SIC98-GPT2-python-code-generator,gradio,,1
-12505,GipAdonimus/openai-jukebox-1b-lyrics,gradio,,1
-12506,Karumoon/test007,gradio,,1
-12507,guopx/Real-CUGAN,gradio,gpl-3.0,1
-12508,lingye/anime-ai-detect,gradio,,1
-12509,AUST001/Translation,gradio,openrail,1
-12510,rolisz/sentence_transformers_canonical,gradio,,1
-12511,samakarov/Lama-Cleaner,gradio,apache-2.0,1
-12512,tumuyan/vnc,docker,,1
-12513,KyanChen/FunSR,gradio,,1
-12514,AlexMason/anime-remove-background,gradio,apache-2.0,1
-12515,chrisbodhi/minima,gradio,unlicense,1
-12516,Tinsae/CoWork,gradio,,1
-12517,blueslmj/anime-remove-background,gradio,apache-2.0,1
-12518,Haokko/AronaTTS,gradio,mit,1
-12519,Rolajim/proyecto,gradio,unknown,1
-12520,awacke1/Assessment-By-Organs,streamlit,mit,1
-12521,Rimi98/NegativeCommentClassifier,gradio,apache-2.0,1
-12522,awacke1/CardGameMechanics,streamlit,mit,1
-12523,awacke1/SMART-FHIR-Assessment-Blood-Pressure,streamlit,mit,1
-12524,awacke1/Assessment.SMART.FHIR.Exercise.Panel,streamlit,mit,1
-12525,achimoraites/Page-Summary,gradio,apache-2.0,1
-12526,dgottfrid/clipcluster,gradio,,1
-12527,awacke1/Dice-Roll-Treemap-Plotly,streamlit,mit,1
-12528,awacke1/SpeechRecognitionwithWav2Vec2,streamlit,mit,1
-12529,jman1991/google-flan-t5-xxl,gradio,,1
-12530,awacke1/VisualLibraryofTop20LibsForDataScienceandAI,streamlit,mit,1
-12531,awacke1/VizLib-BeautifulSoup,streamlit,mit,1
-12532,Jhoeel/rfmAutoV3,gradio,openrail,1
-12533,JeffTao/anime-remove-background,gradio,apache-2.0,1
-12534,sohamagarwal00/chatgpt_implementation,gradio,apache-2.0,1
-12535,svjack/prompt-extend-gpt-chinese,gradio,,1
-12536,loocake/anime-remove-background,gradio,apache-2.0,1
-12537,aichina/youtube-whisper-09,gradio,unknown,1
-12538,vaibhavarduino/chatGPT-Wrapper,streamlit,cc,1
-12539,cenji1109285052/img-to-music,gradio,,1
-12540,Gifted030/movie_reviews_prediction,gradio,,1
-12541,rolisz/ner_comparation,gradio,,1
-12542,SuSung-boy/LoRA-DreamBooth-Training-UI,gradio,mit,1
-12543,Pennywise881/wiki-chat,streamlit,,1
-12544,awacke1/VizLib-Keras-n-Plotly,streamlit,mit,1
-12545,king007/OCR-Invoice-LayoutLMv3,gradio,,1
-12546,awacke1/VizLib-Mahotas,streamlit,mit,1
-12547,awacke1/VizLib-Matplotlib,streamlit,,1
-12548,awacke1/VizLib-Numpy,streamlit,mit,1
-12549,shaun-in-3d/stabilityai-stable-diffusion-2,gradio,,1
-12550,sundar7D0/semantic-chat-demo,gradio,mit,1
-12551,trysem/TableIMG2-CSV,streamlit,,1
-12552,freddyaboulton/git-large-coco,gradio,,1
-12553,JUNGU/cartoonizer-demo-onnx-sota,gradio,apache-2.0,1
-12554,tcvieira/bm25-information-retrieval,streamlit,mit,1
-12555,awacke1/SMART-FHIR-Assessment-BMI,streamlit,mit,1
-12556,awacke1/VizLib-Altair,streamlit,mit,1
-12557,wesliewish/anime-remove-background,gradio,apache-2.0,1
-12558,joaogabriellima/Real-Time-Voice-Cloning,gradio,,1
-12559,awacke1/VizLib-PyDeck,streamlit,mit,1
-12560,LeeroyVonJenkins/construction-safety-object-detection,gradio,,1
-12561,zhicheng127/Real-CUGAN,gradio,gpl-3.0,1
-12562,Mattdoc99/CollisonGPTChat,streamlit,,1
-12563,systash/hashtag_and_named_entity_generator,streamlit,,1
-12564,kamakepar/sberbank-ai-rugpt3large_based_on_gpt2,gradio,,1
-12565,kamakepar/sberbank-ai-rugpt3large,streamlit,,1
-12566,Marioseq/openai-whisper-tiny.en,gradio,,1
-12567,imabhi/multilingual_image_translator,streamlit,mit,1
-12568,xxx1/vqa_blip_large,gradio,apache-2.0,1
-12569,BMukhtar/facemaskDetector,gradio,apache-2.0,1
-12570,touchscale/DeepDanbooru_string,gradio,,1
-12571,Haitangtangtangtang/AnimeBackgroundGAN,gradio,,1
-12572,pierreguillou/bloomz-english,gradio,,1
-12573,MRroboto/Loacker_app,streamlit,,1
-12574,nonya21/hakurei-lit-6B,gradio,,1
-12575,Abbasghanbari/Abo,gradio,,1
-12576,awacke1/SMART-FHIR-Kits-SDC-HL7,streamlit,mit,1
-12577,ahmedghani/Inference-Endpoint-Deployment,gradio,,1
-12578,Pennywise881/wiki-chat-v2,streamlit,,1
-12579,xiaojidan1314/anime-remove-background,gradio,apache-2.0,1
-12580,svjack/English-Comet-Atomic,gradio,,1
-12581,YashGb/HelpMeTalk,gradio,other,1
-12582,sanjaykamath/BLIP2,gradio,bsd-3-clause,1
-12583,Sequence63/anime-ai-detect,gradio,,1
-12584,Sequence63/Real-CUGAN,gradio,gpl-3.0,1
-12585,FriendlyUser/YoutubeDownloaderSubber,gradio,openrail,1
-12586,sanchit-gandhi/whisper-language-id,gradio,,1
-12587,keneonyeachonam/SMART-FHIR-Streamlit-1-022223,streamlit,,1
-12588,chatFAQs/Gradio,gradio,,1
-12589,Cristiants/captiongeneration,gradio,,1
-12590,HARISH246/3D,gradio,,1
-12591,touchscale/White-box-Cartoonization,gradio,apache-2.0,1
-12592,awacke1/CardGameActivity,streamlit,mit,1
-12593,niansong1996/lever-demo,streamlit,mit,1
-12594,zhongkaifu/mt_jpnkor_chs,docker,bsd-3-clause,1
-12595,awacke1/CardGameActivity-GraphViz,streamlit,mit,1
-12596,awacke1/CardGameActivity-TwoPlayerAndAI,streamlit,mit,1
-12597,Qrstud/gpt,gradio,gpl-3.0,1
-12598,Ayaka2022/anime-aesthetic-predict,gradio,apache-2.0,1
-12599,azapi/img-to-music,gradio,,1
-12600,zhongkaifu/mt_chs_enu,docker,bsd-3-clause,1
-12601,nivere/Pix2Pix-Video,gradio,,1
-12602,nivere/ControlNet-Video,gradio,,1
-12603,sandm/anime-aesthetic-predict,gradio,apache-2.0,1
-12604,sandm/anime-remove-background1,gradio,apache-2.0,1
-12605,sandm/anime-ai-detect,gradio,,1
-12606,meraGPT/write-with-vcGPT,streamlit,,1
-12607,kingz/nlpconnect-vit-gpt2-image-captioning,gradio,,1
-12608,lizhongping2713/StableDiffusion-WebUI,docker,gpl-3.0,1
-12609,liyating/3d,gradio,,1
-12610,saad-abdullah/knn-for-gdp-to-happiness-predictor,gradio,openrail,1
-12611,co42/scatterplot_component_main,gradio,,1
-12612,awacke1/VizLib-TopLargeHospitalsMinnesota,streamlit,mit,1
-12613,RomanCast/inspect_mlm,gradio,,1
-12614,xiaoguolizi/anime-ai-detect,gradio,,1
-12615,awacke1/ClinicalTerminologyNER-Refactored,gradio,,1
-12616,Sailors/What-National-Park-Should-You-Visit,gradio,afl-3.0,1
-12617,sieferan2023/Music_Recommendation,gradio,afl-3.0,1
-12618,christse2026/WinterActivities,gradio,afl-3.0,1
-12619,hasselhe2023/SoccerPosition2.0,gradio,afl-3.0,1
-12620,liudao/andite-anything-v4.0,gradio,,1
-12621,Qrstud/ChatGPT-prompt-generator,gradio,apache-2.0,1
-12622,awacke1/VizLib-GraphViz-SwimLanes-Digraph-ForMLLifecycle,streamlit,mit,1
-12623,CZ5624/anime-remove-background,gradio,apache-2.0,1
-12624,rubend18/parafrasis_espanol_t5,gradio,,1
-12625,awacke1/VizLib-GraphViz-Folium-MapTopLargeHospitalsinWI,streamlit,mit,1
-12626,overlordx/starlight,streamlit,mit,1
-12627,Woodsja2023/Basketball,gradio,afl-3.0,1
-12628,bspSHU/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator,gradio,apache-2.0,1
-12629,wldmr/deeppunct-gr,gradio,mit,1
-12630,edad/bigscience-bloom,docker,,1
-12631,232labs/VToonify,gradio,other,1
-12632,rueckstiess/english-to-mql,streamlit,mit,1
-12633,sdpetrides/MNIST-Generator,gradio,mit,1
-12634,awacke1/VizLib-SVGWrite-Streamlit,streamlit,mit,1
-12635,artblack01/Pix2Pix-Video,gradio,,1
-12636,awacke1/StreamlitSharedChatToFiles,streamlit,mit,1
-12637,MatzeFix/openai-whisper-large-v2,gradio,,1
-12638,Duskfallcrew/wd-v1-4-tags,gradio,,1
-12639,dnth/edgenext-paddy-disease-classifier,gradio,afl-3.0,1
-12640,fclong/summary,gradio,apache-2.0,1
-12641,anusurabhi/girl_race_detector,gradio,apache-2.0,1
-12642,Dalun/andite-anything-v4.0,gradio,,1
-12643,alysa/vieTTS,gradio,,1
-12644,RobertoJ07/IARJ,streamlit,apache-2.0,1
-12645,thelou1s/stabilityai-stable-diffusion-2,gradio,,1
-12646,arjun2364/SEBIS-code_trans_t5_large_source_code_summarization_csharp_multitask,gradio,,1
-12647,jungwoonshin/deepfake_detection_reimplementation,gradio,,1
-12648,Ilkin/semantic-search-demo-3,gradio,,1
-12649,xiaoweigo/White-box-Cartoonization,gradio,apache-2.0,1
-12650,dsmai/dogorcat,gradio,mit,1
-12651,Heber/google-flan-t5-xl,gradio,,1
-12652,barnga/DL,gradio,afl-3.0,1
-12653,BigChungux/Pet_Survey,gradio,afl-3.0,1
-12654,breadlicker45/gpt-youtuben-gen,streamlit,,1
-12655,awacke1/VizLib-TopLargeHospitalsNewJersey,streamlit,mit,1
-12656,botmaster/generate-mother-2,gradio,agpl-3.0,1
-12657,TabooAM/What-game-you-should-play,gradio,afl-3.0,1
-12658,rktraz/art_style_classifier,gradio,apache-2.0,1
-12659,awacke1/ZeroShotClassifiers-Facebook-bart-large-mnli,gradio,mit,1
-12660,dog/expressjs-hello-world,docker,,1
-12661,zeno-ml/translation-critique,docker,mit,1
-12662,erinak/test1,gradio,,1
-12663,Limuru/DeepDanbooru_string,gradio,,1
-12664,qq12122211/Real-CUGAN,gradio,gpl-3.0,1
-12665,JONER20/EleutherAI-gpt-neo-1.3B,gradio,,1
-12666,Lippmann/White-box-Cartoonization,gradio,apache-2.0,1
-12667,Lippmann/DeepDanbooru_string,gradio,,1
-12668,davila7/semantic-search,streamlit,mit,1
-12669,siviltoplumtech/metadata,gradio,,1
-12670,ysharma/dummy_phtogrd_blocks,gradio,apache-2.0,1
-12671,CarlDennis/HYTTS,gradio,cc-by-3.0,1
-12672,awacke1/CardCrafter-CraftCustomCards,streamlit,mit,1
-12673,Smiling333/speechbrain-soundchoice-g2p,gradio,,1
-12674,awacke1/CardEvolution-LevelUpCards,streamlit,mit,1
-12675,jetwill/IDEA-CCNL-Taiyi-Stable-Diffusion-1B-Chinese-v0.11,gradio,apache-2.0,1
-12676,overlordx/elonmusk,streamlit,mit,1
-12677,rajivmehtapy/knowledgefactoryapi,gradio,apache-2.0,1
-12678,pashas/openai-whisper-large-v2,gradio,,1
-12679,Inia2567/anime-ai-detect,gradio,,1
-12680,awacke1/CardEvolution-BoardLayout,streamlit,mit,1
-12681,awacke1/CardEvolution-PlayingBoard,streamlit,,1
-12682,teamtom/RockPaperScissors,gradio,apache-2.0,1
-12683,awacke1/Image-Recognition-Multiplayer-Chat-Game,streamlit,mit,1
-12684,Nyari/Super-Resolution-Anime-Diffusion,gradio,,1
-12685,augmentedimaginationhackathon/paperstocode,streamlit,mit,1
-12686,wuhao2222/WarriorMama777-OrangeMixs,gradio,,1
-12687,rbarman/resnet50-example,gradio,mit,1
-12688,AIhackrOrg/README,static,,1
-12689,mushroomsolutions/Medical-Image-Classification,gradio,,1
-12690,Xsciss/hakurei-waifu-diffusion,gradio,,1
-12691,wangguanlin/vits_Kazari,Configuration error,Configuration error,1
-12692,Duskfallcrew/Animated_Dreams,gradio,,1
-12693,Duskfallcrew/duskfall-alters-portrait-plus,gradio,,1
-12694,lolikme/gsdf-Counterfeit-V2.0,gradio,,1
-12695,aijack/jojo,gradio,mit,1
-12696,snowr3/hakurei-waifu-diffusion,gradio,unknown,1
-12697,kaizen97/bear-classifier,gradio,,1
-12698,awacke1/MultiplayerImageRecognition,streamlit,mit,1
-12699,awacke1/MultiplayerImageRecognition-Gradio,gradio,mit,1
-12700,fsqhn/anime-remove-background,gradio,apache-2.0,1
-12701,king007/google-flan-t5-test,gradio,,1
-12702,king007/parrot-t5-test,gradio,apache-2.0,1
-12703,EricKK/gsdf-Counterfeit-V2.5,gradio,,1
-12704,saicharantej/article-cortex,gradio,apache-2.0,1
-12705,Rominn/vits-uma-genshin-honkai,gradio,apache-2.0,1
-12706,Hasan777/IlluminatiAI-Illuminati_Diffusion_v1.0,gradio,,1
-12707,aijack/object,gradio,mit,1
-12708,aj-data/AP2223_P1,gradio,,1
-12709,koustubhavachat/Ghibli-Diffusion,gradio,,1
-12710,aijack/seg,gradio,mit,1
-12711,Dikshant09/disease-prediction-api,gradio,mit,1
-12712,aijack/Track,gradio,mit,1
-12713,K3sco/Linaqruf-anything-v3.0,gradio,,1
-12714,pendragon107/firstmodel,gradio,wtfpl,1
-12715,suryabbrj/ContentModX,gradio,,1
-12716,Arnasltlt/KlauskKnygos,gradio,,1
-12717,mushroomsolutions/Gallery,gradio,,1
-12718,DataForGood/bechdelai-demo,gradio,,1
-12719,Armored-Atom/DiFuse_Your_Thoughts,gradio,mit,1
-12720,Lightxr/sd-diffusers-webui,docker,openrail,1
-12721,Kaludi/AI-Assistant-revChatGPT_App,streamlit,mit,1
-12722,Night-Ling/anime-remove-background,gradio,apache-2.0,1
-12723,joe-aquino/keras_pretty_face,gradio,unknown,1
-12724,Spyhack225/second-brain,streamlit,mit,1
-12725,nihalbaig/BD-Vehicle-Detection,gradio,,1
-12726,TWV87/LDA_Vis,streamlit,,1
-12727,smy503/EfficientNet,gradio,,1
-12728,usamakenway/Stable-diffusion-prompt-generator-1m-examples,gradio,mit,1
-12729,Kytrascript/lambdalabs-sd-pokemon-diffusers,gradio,,1
-12730,ashuonnet/skillrecommender,gradio,artistic-2.0,1
-12731,naqibhakimi/sk,streamlit,,1
-12732,ntcwai/prompt-engine,gradio,apache-2.0,1
-12733,nateraw/real-esrgan,gradio,,1
-12734,k0ntra/WHISPER_FA,gradio,,1
-12735,Nepmods/kawaiiAI,gradio,other,1
-12736,racdroid/Salesforce-blip-image-captioning-base,gradio,,1
-12737,yinting/Salesforce-codegen-16B-mono,gradio,afl-3.0,1
-12738,xt0r3/AI-Hype-Monitor,gradio,gpl-3.0,1
-12739,cropdusting/starcraft2-races,gradio,apache-2.0,1
-12740,vtk51/Lama-Cleaner-lama,gradio,apache-2.0,1
-12741,lianglv/microsoft-resnet-50,gradio,,1
-12742,hg2001/age-classifier,gradio,,1
-12743,jingxiangmo/Azza,gradio,,1
-12744,Duskfallcrew/Gambit_and_Rogue,gradio,,1
-12745,awacke1/Github-Streamlit,streamlit,mit,1
-12746,bergum/commerce-demo,docker,apache-2.0,1
-12747,jvcanavarro/emotion-recognition,gradio,,1
-12748,Armored-Atom/gpt2,gradio,apache-2.0,1
-12749,deborabmfreitas/churn-prediction-deploy,gradio,,1
-12750,bruvvy/nitrosocke-Nitro-Diffusion,gradio,openrail,1
-12751,jackli888/stable-diffusion-webui,gradio,,1
-12752,srikanthsrnvs/togethercomputer-GPT-JT-6B-v1,gradio,,1
-12753,abidismail/22h-vintedois-diffusion-v0-1,gradio,,1
-12754,xxx1/VQA_CAP_GPT,gradio,openrail,1
-12755,pranavbup/Commercial-aircraft-classification,gradio,,1
-12756,elun15/image-regression,gradio,,1
-12757,FebryanS/Wakaranai,gradio,openrail,1
-12758,TheresaQWQ/timpal0l-mdeberta-v3-base-squad2,gradio,,1
-12759,mayuri120/anime-remove-background,gradio,apache-2.0,1
-12760,Lanerdog/22h-vintedois-diffusion-v0-1,gradio,,1
-12761,michellehbn/I-Love-HuggingFace,gradio,,1
-12762,MiguelVGP/bearclassifier,gradio,apache-2.0,1
-12763,lraqi/alii,docker,openrail,1
-12764,ad2/youtube-whisper,gradio,unknown,1
-12765,wendys-llc/roboflow2huggingface,gradio,,1
-12766,andrew3279/Bloom_test,gradio,,1
-12767,awacke1/Named-entity-resolution,streamlit,mit,1
-12768,awacke1/Text-summarization,streamlit,mit,1
-12769,awacke1/Question-answering,streamlit,mit,1
-12770,awacke1/Text-classification,streamlit,mit,1
-12771,awacke1/Text-generation,streamlit,mit,1
-12772,synissalty/andite-anything-v4.0,gradio,cc,1
-12773,Metatron/IlluminatiAI-Illuminati_Diffusion_v1.0,gradio,,1
-12774,hanhanbeea/anime-aesthetic-predict,gradio,apache-2.0,1
-12775,raphael0202/category-classifier,streamlit,,1
-12776,CanIpleas/gpt2,gradio,,1
-12777,shuvojitkoley007/mrs-shuvojit-koley,streamlit,other,1
-12778,Emmawang/audio_summarizer,streamlit,,1
-12779,futureagi/CheckGPT,streamlit,mit,1
-12780,kiin/andite-anything-v4.0,gradio,,1
-12781,awacke1/Data-Augmentation,streamlit,mit,1
-12782,BigChungux/Pet_Survey2,gradio,afl-3.0,1
-12783,Sardor-Odil/StableDiffusion,gradio,apache-2.0,1
-12784,takanabe/space-demo-andite-anything-v4.0,gradio,,1
-12785,rwcuffney/PlayingCardPrediction,gradio,,1
-12786,tykimos/TarotGPT,streamlit,openrail,1
-12787,awacke1/Domain-Transfer-Learning-Pandas-Profiling,streamlit,mit,1
-12788,elkraken/Video-Object-Detection,gradio,,1
-12789,jpoptum/Daredevil-Text_generation,streamlit,mit,1
-12790,hhalim/streamlit_bed_hospital,streamlit,mit,1
-12791,cakiki/bokeh_plots,gradio,mit,1
-12792,DarwinAnim8or/NoSleep-Story-Generator,gradio,other,1
-12793,GranataDizzyDive/dizzydive,docker,,1
-12794,ifrit98/terenceGPT,gradio,pddl,1
-12795,qianwj/yehiaserag-anime-pencil-diffusion,gradio,,1
-12796,portal/Top-20,static,,1
-12797,notsq/diffuse-the-rest,static,,1
-12798,charanhu/GPT-J-6B,gradio,mit,1
-12799,1toTree/lora_test,gradio,,1
-12800,Datasculptor/OpenAI-Chatbot_App,streamlit,apache-2.0,1
-12801,17TheWord/vits-models,gradio,apache-2.0,1
-12802,LiuZiyi/2-image-img2sketch-opencv,streamlit,,1
-12803,YotamNitzan/domain-expansion,docker,,1
-12804,CognitiveAIForHealth/README,Configuration error,Configuration error,1
-12805,dog/fastapi-document-qa,docker,,1
-12806,hamidr-bd1/v3,streamlit,other,1
-12807,lwdragon/token_classfication,gradio,apache-2.0,1
-12808,zhc134/chatgpt-streamlit,streamlit,mit,1
-12809,awacke1/Streamlit-Data-Synthesis-Example,streamlit,mit,1
-12810,almn-uhc/Streamlit-Data-Synthesis-Example,streamlit,mit,1
-12811,awacke1/Examples-Of-AI-0302,streamlit,mit,1
-12812,Biswa13/Examples-Of-AI-2023,streamlit,mit,1
-12813,almn-uhc/Examples-of-AI,streamlit,mit,1
-12814,richardyoung/Examples-of-AI-2023,streamlit,mit,1
-12815,asistaoptum/examples-AI-020323,streamlit,mit,1
-12816,light22/Real-CUGAN,gradio,gpl-3.0,1
-12817,awacke1/d4data-biomedical-ner-all-0302,gradio,mit,1
-12818,almn-uhc/Sentiment-Analysis-Streamlit,streamlit,mit,1
-12819,BasToTheMax/22h-vintedois-diffusion-v0-1,gradio,,1
-12820,FEIMENG/andite-anything-v4.0,gradio,,1
-12821,Biliovo/anime-remove-background,gradio,apache-2.0,1
-12822,jatinbittu13/selfie-nonselfie,gradio,,1
-12823,ahsansbaig/instructor_dashboard,streamlit,other,1
-12824,mariosmsk/epyt-viewer,streamlit,eupl-1.1,1
-12825,gtx4010661/dandelin-vilt-b32-finetuned-vqa,gradio,,1
-12826,najimino/aicv,gradio,,1
-12827,welp234rt/rabiawerqayyum-autotrain-mental-health-analysis-752423172,gradio,,1
-12828,wuxi/Real-CUGAN,gradio,gpl-3.0,1
-12829,pripishchik/clip-image,gradio,,1
-12830,Gallifraid/prompthero-openjourney-v2,gradio,,1
-12831,awacke1/Assessment.Health.Conditions.By.Cost,streamlit,mit,1
-12832,awacke1/Games-In-Python,streamlit,mit,1
-12833,kumahiyo/line-bot-stable-diffusion,docker,,1
-12834,Hurtle/DeepDanbooru_string,gradio,,1
-12835,rinsora/White-box-Cartoonization,gradio,apache-2.0,1
-12836,mabrotha/ChatGPT-prompt-generator,gradio,apache-2.0,1
-12837,Swindu/ProsusAI-finbert,gradio,,1
-12838,ivanmeyer/Finetuned_Diffusion_Max,gradio,mit,1
-12839,Shuhul/New_Flix,streamlit,,1
-12840,NPU/hallucination_in_image_captioning_demo,gradio,openrail,1
-12841,Neo-Salvatore/GPTBase,streamlit,,1
-12842,ivanmeyer/dreamlike-photoreal-2.0,gradio,,1
-12843,yoimiya/White-box-Cartoonization,gradio,apache-2.0,1
-12844,xxx1/chatgpt,gradio,openrail,1
-12845,apsys/hetfit,streamlit,cc-by-nc-4.0,1
-12846,Hanseul/Salesforce-codegen-6B-multi,gradio,,1
-12847,hololee/dreambooth-training,gradio,mit,1
-12848,pysunny/gradio-pysunny,gradio,,1
-12849,Quake24/thepainter,gradio,apache-2.0,1
-12850,awacke1/HTML5-ThreeJS,static,mit,1
-12851,awacke1/HTML5-ThreeJS-3D,static,mit,1
-12852,awacke1/HTML5-BabylonJS-Javascript-LSystems,static,mit,1
-12853,awacke1/HTML5-DNA-Sequence,static,mit,1
-12854,awacke1/HTML5-Aframe-Lsystems,static,mit,1
-12855,awacke1/HTML5-Aframe-3D-Maps,static,mit,1
-12856,awacke1/HTML5-3D-Map-Hospitals,static,mit,1
-12857,morinop/BetterSelfie,gradio,openrail,1
-12858,awacke1/Feature-Extraction-microsoft-codebert-base,gradio,mit,1
-12859,awacke1/Image-to-Text-nlpconnect-vit-gpt2-image-captioning,gradio,mit,1
-12860,awacke1/Token-Classification-NER-dslim-bert-base-NER,gradio,,1
-12861,awacke1/Zero-Shot-Classification-valhalla-distilbart-mnli-12-1,gradio,mit,1
-12862,awacke1/Zero-shot-classification-facebook-bart-large-mnli,gradio,mit,1
-12863,MiguelVGP/redfruits,gradio,apache-2.0,1
-12864,pedrogengo/style_loss_showdown,docker,,1
-12865,awacke1/GPU-Memory-Detector,streamlit,mit,1
-12866,awacke1/GPU-Memory-Detector-HTML5,static,mit,1
-12867,faisalhr1997/Salesforce-blip2-opt-2.7b,gradio,,1
-12868,silvaKenpachi/bearClassifierInference,gradio,artistic-2.0,1
-12869,hectorjelly/SoccerTwos-Challenge-Analytics-Extra,streamlit,afl-3.0,1
-12870,fernfromecuador/dallinmackay-Tron-Legacy-diffusion,gradio,,1
-12871,awacke1/HealthConditionsTest,streamlit,mit,1
-12872,Kevin676/TalktoAI,gradio,,1
-12873,zetabyte/stable-diffusion,gradio,,1
-12874,GeekTony/Examples-Of-AI,streamlit,mit,1
-12875,awacke1/Health-Care-AI-and-Datasets,streamlit,mit,1
-12876,GeekTony/Gradio-Ontology,gradio,mit,1
-12877,Whatcoldwind/csgo_investment,streamlit,apache-2.0,1
-12878,nikhil567/Turkey-Syria-Earthquake,streamlit,,1
-12879,slumgods/chatgpt-slumgods,gradio,,1
-12880,LeeroyVonJenkins/OCR-Invoice-LayoutLMv3,gradio,,1
-12881,awacke1/DnD-Character-Sheet2,streamlit,mit,1
-12882,xu1998hz/sescore_english_mt,gradio,,1
-12883,xu1998hz/sescore_german_mt,gradio,,1
-12884,xu1998hz/sescore_english_coco,gradio,,1
-12885,xu1998hz/sescore_english_webnlg,gradio,,1
-12886,Soybean01/White-box-Cartoonization,gradio,apache-2.0,1
-12887,wangrongsheng/ChatGPT,gradio,,1
-12888,Soybean01/anime-ai-detect,gradio,,1
-12889,rmazarei/mann-e-mann-e_4_rev-1-3,gradio,,1
-12890,blessingmwiti/openai,gradio,,1
-12891,pro15671/anime-remove-background,gradio,apache-2.0,1
-12892,kaguraaya/anime-remove-background,gradio,apache-2.0,1
-12893,qiuyue1/White-box-Cartoonization,gradio,apache-2.0,1
-12894,awacke1/GPU-Memory-Detector-Aframe,static,mit,1
-12895,Dai1123/CalqChat,gradio,apache-2.0,1
-12896,Xhaheen/Hyper_Bot_ben,static,,1
-12897,Langame/explorer,streamlit,mit,1
-12898,samusander/Snore.Ai,gradio,,1
-12899,Bigshot/RSA-v0.1.2,gradio,cc-by-2.0,1
-12900,Vegecken/sovits4dzl,gradio,mit,1
-12901,Ebo010/hot-dog,gradio,lgpl-3.0,1
-12902,xiaoguaiguai/playground2,streamlit,,1
-12903,shibinashraf36/drugrecommendationsystem,streamlit,mit,1
-12904,Nadaal/dost5,gradio,apache-2.0,1
-12905,Nadaal/chatgpt-demo,gradio,,1
-12906,drdata/kohbanye-pixel-art-style,gradio,,1
-12907,helenai/openvino-stable-diffusion,docker,,1
-12908,ahiruguagua/aiemo,gradio,,1
-12909,cscan/demucs,gradio,,1
-12910,James1208/Salesforce-codegen-350M-mono,gradio,,1
-12911,pkiage/time_series_autocorrelation_demo,streamlit,openrail,1
-12912,pkiage/time_series_decomposition_demo,streamlit,openrail,1
-12913,KevlarVK/content_summarizer,streamlit,,1
-12914,YuanMio/vits-uma-genshin-honkai,gradio,apache-2.0,1
-12915,Snb-ai/vuia,gradio,,1
-12916,Tiju1996/resume-parser,gradio,openrail,1
-12917,awacke1/Self-Modifying-Graph-Visualization,streamlit,mit,1
-12918,differentai/infinite-memory-chatgpt,streamlit,mit,1
-12919,awacke1/Health-Condition-Actions-For-Health-and-Savings,streamlit,mit,1
-12920,pytholic/streamlit-image-classification-demo,streamlit,mit,1
-12921,awacke1/Spending-Simulation,streamlit,mit,1
-12922,michaelgartner/CompVis-stable-diffusion-v1-4,gradio,,1
-12923,sigit/permadi,static,other,1
-12924,pkiage/credit_risk_modeling_demo,docker,openrail,1
-12925,D008/space-from-a-model,gradio,,1
-12926,thomasjeon/stabilityai-stable-diffusion-2-1,gradio,openrail,1
-12927,veb-101/driver-drowsiness-detection,streamlit,afl-3.0,1
-12928,AGITM/ToneCorrectionRecognition,gradio,mit,1
-12929,owenchak/testgenerator,gradio,,1
-12930,EricLam/yamatohome,gradio,,1
-12931,Paco1112/Super-writing-tool,gradio,,1
-12932,RonHoHo/Ronhohohhohoho05,gradio,,1
-12933,Wootang02/textgenerator,gradio,,1
-12934,tomdeng/textgenerator,gradio,,1
-12935,NicholasKwok/textgenerator,gradio,,1
-12936,tomcheng/textgeneration,gradio,,1
-12937,Felix0810/textgenerator,gradio,,1
-12938,Averyng/averyng,gradio,,1
-12939,anumkn/Anuradha,gradio,,1
-12940,221091lstwcm/textgenerator,gradio,,1
-12941,221090Lstwcm/textgenerator,gradio,,1
-12942,Christyyu/textgenerator,gradio,,1
-12943,yuszeying/textgenerator,gradio,,1
-12944,generalHolmogorets/README,static,,1
-12945,LittleYuan/My-Real-Bot,gradio,,1
-12946,smallyu/img-to-music,gradio,,1
-12947,Gato582/runwayml-stable-diffusion-v1-5,gradio,openrail,1
-12948,TornikeO/dis-background-removal,gradio,apache-2.0,1
-12949,awacke1/Games-Phaser-3-HTML5,static,mit,1
-12950,king007/remove-background,gradio,,1
-12951,bluesky314/LangChain_gpt_indexBot,gradio,,1
-12952,Mohit-321/WhatsappchatAnalyzer,streamlit,,1
-12953,GLTdd/ChatgptBot,gradio,mit,1
-12954,noofa/wowsers,gradio,,1
-12955,sessex/CLIPSeg2,gradio,,1
-12956,InsertUserHere9999/MGX-Midjourney-v4,gradio,,1
-12957,hhalim/google-flan-t5-large-test,gradio,mit,1
-12958,FKBaffour/Expresso_Customer_Churn_Prediction,streamlit,,1
-12959,HuskyTho/EleutherAI-gpt-neo-1.3B,gradio,,1
-12960,awacke1/Text-to-Speech-facebook-fastspeech2-en-ljspeech,gradio,,1
-12961,awacke1/ASR-openai-whisper-base,gradio,,1
-12962,awacke1/ASR-openai-whisper-large,gradio,,1
-12963,awacke1/Audio-Sentiment-harshit345-xlsr-wav2vec-speech-emotion-recognition,gradio,,1
-12964,awacke1/Audio-Sentiment-superb-hubert-base-superb-er,gradio,,1
-12965,awacke1/CodeGen-Salesforce-codegen-350M-mono,gradio,,1
-12966,BeeMon/dreambooth-training,gradio,mit,1
-12967,qym/ChatGPT-prompt-generator,gradio,apache-2.0,1
-12968,ishanam/xray-classification,gradio,,1
-12969,Toor1989/Toor1989,streamlit,other,1
-12970,ReFenter/DeepDanbooru_string,gradio,,1
-12971,hero-intelligent/MT3,gradio,apache-2.0,1
-12972,jmyungjoon/cartoon,streamlit,apache-2.0,1
-12973,tyao/CompVis-stable-diffusion-v1-4,gradio,,1
-12974,xp3857/ph-oj-2,gradio,,1
-12975,kriss-ml/Boston-House-Price,gradio,openrail,1
-12976,awacke1/Survey-Assess-Plan-UI,streamlit,mit,1
-12977,Namit2111/ChatGpt_Detector,gradio,,1
-12978,xp3857/ds-pg-5-8,gradio,,1
-12979,Ridzuan/random_name_selector,streamlit,unlicense,1
-12980,thiagolira/ChatMaquiavel,gradio,,1
-12981,dreamreyansan/hakurei-waifu-diffusion,gradio,,1
-12982,Soumahara/hakurei-waifu-diffusion,gradio,,1
-12983,smakubi/flowers,gradio,openrail,1
-12984,mushroomsolutions/Image_Annotation,gradio,mit,1
-12985,awacke1/GPU-RTX-Nvidia-Nsight-Starter-AI-Kit,streamlit,mit,1
-12986,BL00DY-257/dolle-mini-lol,static,apache-2.0,1
-12987,thelou1s/chatgpt-demo,gradio,,1
-12988,w0rd-driven/livebook,docker,,1
-12989,awacke1/Top-Ten-Board-Games-Map-Making-Strategy,streamlit,mit,1
-12990,radames/hello-huggingface.js,static,,1
-12991,Kimata/Sanskrit-TTS,gradio,,1
-12992,Songj/DotaHeroClassifier,gradio,apache-2.0,1
-12993,tribe-ai/document-qa-comparator,gradio,mit,1
-12994,Alashazam/Harmony,gradio,,1
-12995,gaurxvreddy/Xtinguish,gradio,mit,1
-12996,younker/chatgpt-turbo,docker,,1
-12997,LanQian/ChatGPT,gradio,mit,1
-12998,pragmaticslab/bary_score,gradio,apache-2.0,1
-12999,pragmaticslab/depth_score,gradio,,1
-13000,adwod/Streamlite_ViT_2000,streamlit,,1
-13001,hugging-fellows/img-to-music,gradio,,1
-13002,Boilin/URetinex-Net,gradio,,1
-13003,breadlicker45/story-gen,streamlit,,1
-13004,KaguraNana/XiaokunChatGPT,gradio,mit,1
-13005,cristalcorp/CompVis-stable-diffusion-v1-4,gradio,apache-2.0,1
-13006,EveryPizza/stabilityai-stable-diffusion-2,gradio,,1
-13007,Shakeb100/GroomingGenie_AI,gradio,mit,1
-13008,suryabbrj/vit-gpt-caption-model-CMX,streamlit,,1
-13009,shidokan/ai.Life,gradio,,1
-13010,Savethecats/README,static,,1
-13011,bedrock123/andite-anything-v4.0,gradio,,1
-13012,abrar-adnan/speech-analyzer,gradio,mit,1
-13013,AONYLMR/anime-ai-detect,gradio,,1
-13014,AONYLMR/anime-remove-background,gradio,apache-2.0,1
-13015,AONYLMR/White-box-Cartoonization,gradio,apache-2.0,1
-13016,chasetank/manual_assistant,gradio,,1
-13017,Neo-Salvatore/translate-locale,streamlit,,1
-13018,RamV/ChatRobo,gradio,,1
-13019,eeshawn11/naruto_hand_seals,gradio,apache-2.0,1
-13020,ChillyFaze/runwayml-stable-diffusion-v1-5,gradio,openrail,1
-13021,jpjpjpjpjp/HylandDocumentVisualQA,gradio,,1
-13022,de3sec/Image-Upscaling-Playground,gradio,apache-2.0,1
-13023,hojumoney/WarriorMama777-OrangeMixs,gradio,,1
-13024,fffiloni/live-ml5-handpose-p5js,static,mit,1
-13025,awacke1/HTML5-AFrame-VR,static,mit,1
-13026,ceckenrode/HTML5-Aframe-3D-Maps,static,mit,1
-13027,Cboudreau/AI_ZeroToHero,streamlit,mit,1
-13028,awacke1/VizLib-TopLargeHospitalsNewJersey-03-09-2023,streamlit,mit,1
-13029,ankushsethi02/VizLib-TopLargeHospitalsNewJersey-03-09-2023,streamlit,mit,1
-13030,simplomatic/ChatGPT-prompt-generator,gradio,apache-2.0,1
-13031,freshield/ChatGPT-gradio,gradio,mit,1
-13032,sgvkamalakar/Water_Potability_Prediciton_app,gradio,,1
-13033,XingHe0127/Chatbot,gradio,,1
-13034,rcajegas/HTML5-Aframe-3DMAP-FLIGHT,static,mit,1
-13035,ygtrfed/pp-web-ui,gradio,mit,1
-13036,imju/flower_detector,gradio,apache-2.0,1
-13037,ceckenrode/Cognitive-AI-Episodic-Semantic-Memory-Demo,streamlit,,1
-13038,awacke1/sileod-deberta-v3-base-tasksource-nli-2,gradio,,1
-13039,rcajegas/WHO_1,static,mit,1
-13040,leesooleon/xiaolxl-GuoFeng3,gradio,,1
-13041,PeepDaSlan9/andite-anything-v4.0-b2b,gradio,openrail,1
-13042,fariyan/image-to-text,gradio,mit,1
-13043,shed219/ChuanhuChatGPT,gradio,mit,1
-13044,dgongor/WhisperDemo,gradio,,1
-13045,Otega99/minima,gradio,apache-2.0,1
-13046,omarelsayeed/test,gradio,creativeml-openrail-m,1
-13047,willianmcs/visual-chatgpt,gradio,,1
-13048,lost123/DeepDanbooru_string,gradio,,1
-13049,domro11/data_dynamos,streamlit,,1
-13050,suancaixianyu/Real-CUGAN,gradio,gpl-3.0,1
-13051,chriscelaya/merve-chatgpt-prompts-bart-long,gradio,mit,1
-13052,3druga/ae-6,gradio,,1
-13053,bortle/astrophotography-object-classifier,gradio,,1
-13054,davila7/llm-vs-llm,gradio,mit,1
-13055,Feraxin/chatGPT,gradio,,1
-13056,gradio/code_main,gradio,,1
-13057,omarelsayeed/A7ades-Similarity-Quran-v2,gradio,creativeml-openrail-m,1
-13058,awacke1/HL-V2.x-Transformer-Parser,streamlit,mit,1
-13059,eele0011/Nlp,docker,,1
-13060,awacke1/Clinical-Terminology-FHIR-Assessment,streamlit,mit,1
-13061,jacob-petterle/cloudtop-deployer,docker,apache-2.0,1
-13062,productizationlabs/MyChatGPTDavinci,gradio,,1
-13063,stunner007/old-car-price-predictor,gradio,,1
-13064,awacke1/Gamification-Grabble,streamlit,mit,1
-13065,dccif/Real-CUGAN,gradio,gpl-3.0,1
-13066,xiaoti/Real-CUGAN,gradio,gpl-3.0,1
-13067,awacke1/Gamification-AI-Boggle,streamlit,mit,1
-13068,kanden/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13069,zhuce/vits,gradio,apache-2.0,1
-13070,WZUN666/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13071,Kaludi/Virtual-AI-Career-Coach_App,streamlit,,1
-13072,Rimi98/Reptile-Museum,gradio,apache-2.0,1
-13073,klcqy/anime-ai-detect,gradio,,1
-13074,klcqy/DeepDanbooru_string,gradio,,1
-13075,liuyuchen777/DanDanGPT,gradio,mit,1
-13076,cat630/ChuanhuChatGPT,gradio,mit,1
-13077,xiaorong/fork2-so-vits,gradio,apache-2.0,1
-13078,AI-Edify/demo-gpt3.5-turbo,gradio,cc-by-nc-4.0,1
-13079,Surendra/chatbot,gradio,,1
-13080,AntiUser/DeepDanbooru_string,gradio,,1
-13081,king007/anime-anything-promptgen-v2-test,gradio,,1
-13082,snjyor/ChatGPT_demo,gradio,,1
-13083,awacke1/Gamification-Word-Search,streamlit,mit,1
-13084,QinQiuFox/get_ppt,static,afl-3.0,1
-13085,janewu/hualao,gradio,apache-2.0,1
-13086,awacke1/Torch-Git-Markdown-NLP,streamlit,,1
-13087,zee2221/Hyper_Bot,static,,1
-13088,Jeffreylex/bigscience-bloom,gradio,,1
-13089,awacke1/Streamlit-ALBERT-Transformers-Sequence-Classify-Visualize,streamlit,mit,1
-13090,awacke1/Joke-Book-No-Pun-Intended,streamlit,mit,1
-13091,farandclose/AudioChatGPT,gradio,,1
-13092,awacke1/Word-Search-AI-To-Teach-AI,streamlit,mit,1
-13093,Hermit591/anime-remove-background,gradio,apache-2.0,1
-13094,awacke1/Twitter-Sentiment-Live-Realtime,streamlit,mit,1
-13095,awacke1/Finite-State-Machine-Demo,static,mit,1
-13096,awacke1/3d-Breakout-Game-Three.JS,static,mit,1
-13097,awacke1/Three.JS-TheCube-Game,static,mit,1
-13098,awacke1/HTML5-Tower-Building-3D-Game,static,mit,1
-13099,SI2252/README,static,,1
-13100,ParisNeo/Blip_QA,gradio,mit,1
-13101,leftcoastkidd/runwayml-stable-diffusion-v1-5,gradio,,1
-13102,qtp/README,static,,1
-13103,Dao3/openai-translator,gradio,openrail,1
-13104,Stereo0001/MagicPrompt-Stable-Diffusion,gradio,mit,1
-13105,productizationlabs/ContentModeration,gradio,,1
-13106,LHL3341/Hand-Write-Number-Recognization,streamlit,mit,1
-13107,JohnTan38/GODEL-v1_1-large-seq2seq,gradio,mit,1
-13108,CoffeeBrewer/CompVis-stable-diffusion-v1-4,gradio,openrail,1
-13109,AdVisual/MaskCut,docker,mit,1
-13110,de3sec/rembg_remove_bg,gradio,mit,1
-13111,de3sec/Front-end-code-generation-from-images,gradio,afl-3.0,1
-13112,ai-art/magic-diffusion-generator,gradio,apache-2.0,1
-13113,khan994/sketch,gradio,,1
-13114,roxas010394/parts-of-cars,gradio,unknown,1
-13115,Xlinelabs/togethercomputer-GPT-NeoXT-Chat-Base-20B,gradio,,1
-13116,awacke1/Bird-Species-Migration-Month-Map,streamlit,mit,1
-13117,charbaaz356/Chat-GPT-LangChain-R,gradio,apache-2.0,1
-13118,hersia/V_Admin_Bot,gradio,,1
-13119,wilbertpariguana/Demo-Bot,gradio,,1
-13120,xxx1/zh-clip,gradio,openrail,1
-13121,AndrewMetaBlock/emilyalsentzer-Bio_ClinicalBERT,gradio,apache-2.0,1
-13122,qqqwt/chatgptpaper,gradio,openrail,1
-13123,yunyunyun/DGSpitzer-Cyberpunk-Anime-Diffusion,gradio,,1
-13124,bookbot/SpeechLine,gradio,,1
-13125,PhotoPranab/Joeythemonster-anything-midjourney-v-4-1,gradio,,1
-13126,misteca/ChatGPT,gradio,mit,1
-13127,xp3857/aa-pr-2,gradio,,1
-13128,ricezilla/video_tampering_detection,gradio,,1
-13129,WMisingo/license-plate-number-recognition-app,gradio,cc-by-nc-nd-4.0,1
-13130,PKaushik/HumanCounter,gradio,apache-2.0,1
-13131,DinoPiteko/youtube-whisper-04,gradio,unknown,1
-13132,Dineshkumars/Text-Summarization,streamlit,,1
-13133,gradio/chatbot_dialogpt_main,gradio,,1
-13134,weanalyze/stock_predictor,docker,,1
-13135,keneonyeachonam/FHIR-Streamlit-ChatGPT-031323,streamlit,,1
-13136,AhmedKhairullah/dmo,gradio,,1
-13137,weanalyze/twitter_scraper,docker,,1
-13138,jslin09/legal_document_drafting,gradio,bigscience-bloom-rail-1.0,1
-13139,AnandSoni2001/StockMarket,streamlit,,1
-13140,Sloth-Alchemist/Test.xyz,gradio,,1
-13141,productizationlabs/IBCFProductRecommendations,gradio,,1
-13142,owsgfwnlgjuz/bsrgan,gradio,apache-2.0,1
-13143,villageideate/TrenBot,gradio,,1
-13144,Jamphus/G,gradio,gpl,1
-13145,awacke1/Pandas-Profiling-CSV-XLSX-XLS,streamlit,,1
-13146,awacke1/Embedding-Iframe-HTML5-to-Gradio,static,mit,1
-13147,awacke1/Media-Pipe-Facial-Mesh-Matching-3D,gradio,mit,1
-13148,gradio/chatbot_simple,gradio,,1
-13149,gradio/gallery_selections,gradio,,1
-13150,awacke1/AI.Dashboard.Wiki.Chat.Cognitive.HTML5,static,mit,1
-13151,AI-Dashboards/README,static,,1
-13152,shivangibithel/Text2ImageRetrieval,streamlit,mit,1
-13153,longht/vietnamese-disfluency-detection,gradio,,1
-13154,CobaltZvc/sherlocks_pheonix,static,,1
-13155,qwerrsc/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13156,vibhorvats/Joeythemonster-anything-midjourney-v-4-1,gradio,,1
-13157,rabiyulfahim/text-to-image,gradio,,1
-13158,victor/victor-autotrain-satellite-image-classification-40975105875,gradio,,1
-13159,sagu7/sagu7-dating-avatar-model,gradio,apache-2.0,1
-13160,rabiyulfahim/dalle-mini,static,apache-2.0,1
-13161,Ordenador/classify-text-with-bert-hate-speech,gradio,openrail,1
-13162,prabhu46/registerandlogin,docker,,1
-13163,awacke1/AI.Dashboard.Gradio.Streamlit.HTML5,static,mit,1
-13164,furqankassa/AI-Dashboard-0134,static,,1
-13165,keneonyeachonam/MermaidModelHTML5Demo-031423,static,mit,1
-13166,keneonyeachonam/AI-Dashboard-031423,static,mit,1
-13167,lpnguyen/calculator,streamlit,apache-2.0,1
-13168,Vorkrath/CarperAI-diff-codegen-6b-v2,gradio,,1
-13169,nikitothkakad/runwayml-stable-diffusion-v1-5,gradio,,1
-13170,Dochee/Chatbot_Dialog_Bot,gradio,,1
-13171,Neomyst/gertrude-model,gradio,,1
-13172,Daniton/streaming_chat_with_gpt-3.5-turbo_using_langchain_sorta1234,gradio,mit,1
-13173,Gilvan/XRaySwinGen,gradio,apache-2.0,1
-13174,akalin/DeepDanbooru_string,gradio,,1
-13175,sudhir2016/Emotion,gradio,unknown,1
-13176,Rami/validate_chat_utd,docker,openrail,1
-13177,awacke1/HEDIS.Roster.Dash.Component.Service,streamlit,mit,1
-13178,awacke1/HEDIS.Roster.Dash.Component.SDOH,streamlit,mit,1
-13179,awacke1/HEDIS.Dash.Component.Top.Clinical.Terminology.Vocabulary,streamlit,mit,1
-13180,henryz/streaming_chat_with_gpt-3.5-turbo_using_langchain_sorta,gradio,mit,1
-13181,vinic1999/foodvisionbig,gradio,mit,1
-13182,kajalag/Whatsapp_Chat_Analyzer,streamlit,,1
-13183,smruthi49/makeup,gradio,apache-2.0,1
-13184,AriaMei/TTSdemo,gradio,mit,1
-13185,ceckenrode/AI.Dashboard.HEDIS.Terminology.Vocabulary.Codes,static,,1
-13186,AI-Dashboards/HEDIS.Assessment.PHQ9.GADD7.SDoH,static,,1
-13187,keyu-tian/SparK,gradio,mit,1
-13188,protoxx91/webui-docker,docker,,1
-13189,awacke1/Assessments.Clinical.Terminology.FHIR.PHQ.GAD.SDOH,streamlit,mit,1
-13190,ashishtanwer/RAD,gradio,bsd-3-clause,1
-13191,protoxx91/stable-diffusion-webui-controlnet-docker,docker,,1
-13192,kingabzpro/Loan_Classifier,gradio,apache-2.0,1
-13193,lpnguyen/continuous-discrete-time,streamlit,apache-2.0,1
-13194,aryan1107/ChatGPT-prompt-generator,gradio,apache-2.0,1
-13195,awacke1/visual_chatgpt,gradio,osl-3.0,1
-13196,awacke1/chatgpt-demo,gradio,,1
-13197,awacke1/chatGPT,gradio,,1
-13198,zihanch/zihan,docker,mit,1
-13199,kahnchana/clippy,gradio,cc,1
-13200,yuan1615/EmpathyVC,gradio,apache-2.0,1
-13201,PeepDaSlan9/EleutherAI-gpt-j-6B-B2BMGMT,gradio,apache-2.0,1
-13202,najimino/pdf2gpt,gradio,,1
-13203,chjun/movie_rating_bot,gradio,,1
-13204,aodianyun/ChatGLM-6B,gradio,mit,1
-13205,2gauravc/search_summary_chatgpt,streamlit,apache-2.0,1
-13206,yuyuyu-skst/White-box-Cartoonization,gradio,apache-2.0,1
-13207,sepal/MeetingTranscriber,gradio,apache-2.0,1
-13208,asafAdge/Detic,gradio,,1
-13209,awacke1/Model-Easy-Button1-ZeroShotImageClassifier-Openai-clip-vit-large-patch14,gradio,mit,1
-13210,awacke1/Easy-Button-Zero-Shot-Text-Classifier-facebook-bart-large-mnli,gradio,mit,1
-13211,chenglu/chenglu-my_awesome_model,gradio,,1
-13212,jamatas/anime-ai-detect,gradio,,1
-13213,Daniton/Midjourney-Disney,gradio,,1
-13214,awacke1/EasyButton-openai-clip-vit-large-patch14,gradio,mit,1
-13215,JerEpoch/Button-openai-clip-vit-large-patch14,gradio,mit,1
-13216,srikotha/facebook-bart-large-mnli,gradio,,1
-13217,ceckenrode/Easy-Button-Zero-Shot-Text-Classifier-facebook-bart-large-mnli,gradio,mit,1
-13218,srikotha/bigscience-bloom,gradio,mit,1
-13219,ceckenrode/runwayml-stable-diffusion-v1-5,gradio,mit,1
-13220,ceckenrode/bigscience-bloom,gradio,mit,1
-13221,awacke1/EasyButton-runwayml-stable-diffusion-v1-5,gradio,mit,1
-13222,JSanchez79/js-test-facebook-bart-large-mnli,gradio,mit,1
-13223,srikotha/runwayml-stable-diffusion-v1-5,gradio,mit,1
-13224,Dao3/DaJuZi_OrangeCatTheGreat,gradio,cc-by-4.0,1
-13225,snjyor/You_Say_I_Draw,gradio,,1
-13226,ceckenrode/AI-Dashboard-Zero-Shot-Text-Image-Models,static,mit,1
-13227,Gradio-Themes/README,static,,1
-13228,ywqisok/ysyy,gradio,apache-2.0,1
-13229,Libra7578/Promt-to-Image-diffusions,gradio,apache-2.0,1
-13230,donalda/Gustavosta-MagicPrompt-Stable-Diffusion,gradio,,1
-13231,hslu-di/Reust_Yannic,gradio,,1
-13232,zcxhcrjvkbnpnm/gpt4-demo,gradio,,1
-13233,thiagolira/ChatPequenoPrincipe,gradio,,1
-13234,naveed92/topic_segmentation,streamlit,mit,1
-13235,awacke1/RealTime-MediaPipe-AI-From-Video-On-Any-Device,streamlit,mit,1
-13236,Duskfallcrew/flowers-2-1-768,gradio,,1
-13237,rholtwo/Easy-Button-Zero-Shot-Text-Classifier-facebook-bart-large-mnli,gradio,mit,1
-13238,rholtwo/Easy_button_runwayml-stable-diffusion-v1-5,gradio,mit,1
-13239,LanQian/ChatChuanHu,gradio,mit,1
-13240,falcondai/code-as-policies,gradio,apache-2.0,1
-13241,DemoLou/moe-tts,gradio,mit,1
-13242,baby123/sd,docker,,1
-13243,C6AI/HDRL,docker,mit,1
-13244,mixshare/hackathon_chatbot_openai_api,gradio,cc-by-4.0,1
-13245,Betacuckgpt/togethercomputer-GPT-JT-Moderation-6B,gradio,,1
-13246,Dao3/SuperChatGPT,gradio,mit,1
-13247,Rifd/Gxtaucok,gradio,,1
-13248,Saturdays/CardioSight_dup,gradio,,1
-13249,golda/gagal-jantung-2023,streamlit,,1
-13250,apsys/normflows,streamlit,afl-3.0,1
-13251,3i2irg/SF-model,gradio,,1
-13252,hkanumilli/DigitClassifier,gradio,mit,1
-13253,dma123/gpt-js,static,agpl-3.0,1
-13254,AymanKUMA/Speech-Bubbles-detector,streamlit,,1
-13255,Basit12345/basit123,gradio,,1
-13256,Shrey-Patel/Image-Searcher,streamlit,,1
-13257,tddschn/yaml-parser,gradio,,1
-13258,asalhi85/ArabiToolsDialecRecognition,gradio,cc-by-nc-sa-4.0,1
-13259,parsi-ai-nlpclass/F22-Adversarial-QA,streamlit,,1
-13260,pengtony/hackathon_chatbot_openai_api,gradio,cc-by-4.0,1
-13261,darkknightxi/mangoes,gradio,apache-2.0,1
-13262,Ayakasuki/anime-ai-detect,gradio,,1
-13263,ulysses115/PP-OCRv3-ch2,gradio,apache-2.0,1
-13264,akuysal/demo-app-streamlit,streamlit,openrail,1
-13265,akuysal/demo-app-gradio,gradio,openrail,1
-13266,Dao3/MBTI_Test,gradio,cc-by-4.0,1
-13267,cxm1207/ChatBOT,gradio,mit,1
-13268,awacke1/Northern.Lights.Map.Streamlit.Folium,streamlit,mit,1
-13269,GorroRojo/nitrosocke-Ghibli-Diffusion,gradio,,1
-13270,awacke1/AI.Dashboard.Maps,static,mit,1
-13271,Raghvender/VideoCaptionWhisper,gradio,,1
-13272,akuysal/SMS-spam-Turkish-sklearn,streamlit,openrail,1
-13273,muratcelik/Image_Inpainting_w_context-encoder,streamlit,,1
-13274,akuysal/SMS-spam-English-sklearn,streamlit,openrail,1
-13275,daikooo/DialoGPT-finetune-mental-health-chatbot,gradio,openrail,1
-13276,zoeozone/mrm8488-Alpacoom,static,,1
-13277,helliun/beism,gradio,,1
-13278,mustapha/chatAlpaca,streamlit,gpl-3.0,1
-13279,chasetank/Visual-GPT-3.5-Turbo,gradio,osl-3.0,1
-13280,ypchang/Variance_Reduction-European_call_option-volatility,gradio,other,1
-13281,awacke1/MN.Map.Hospitals.Top.Five,streamlit,mit,1
-13282,ypchang/Variance_Reduction-European_call_option-volatility_K-3D,gradio,other,1
-13283,awacke1/NVidiaRaytraceMirrorAframeThreeJS,streamlit,mit,1
-13284,cc1799/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13285,awacke1/NVidia.Raytrace.Mirror.HTML5.ThreeJS,static,mit,1
-13286,onglaoxiteen/LoRa,gradio,,1
-13287,Cherrycreamco/webui,gradio,,1
-13288,awacke1/Thor.Odin.Baldur.Sleipnir.Myths,static,mit,1
-13289,alalalyuqing/White-box-Cartoonization,gradio,apache-2.0,1
-13290,nikhil5678/turkey-syria-earthquake-tweets,streamlit,,1
-13291,BENE2007/runwayml-stable-diffusion-v1-5,gradio,mit,1
-13292,nikolaiii/CompVis-stable-diffusion-v1-4,gradio,,1
-13293,karynaur/mnist-cloned,gradio,,1
-13294,Vgi/nu-dialogue-sfc2022-stable-diffusion,gradio,gpl-3.0,1
-13295,tj5miniop/distilgpt2,gradio,creativeml-openrail-m,1
-13296,Sortoite/Simple-OpenAI-Chatbot,gradio,,1
-13297,amoldwalunj/image_to_text,gradio,,1
-13298,jimschat/VITS-Umamusume-voice-synthesizer,gradio,,1
-13299,A1draw-12196y/DeepDanbooru_string,gradio,,1
-13300,A1draw-12196y/anime-ai-detect,gradio,,1
-13301,luncnymph/ChatGPT4,gradio,mit,1
-13302,OdinStef/Chatapp,gradio,unknown,1
-13303,dwolfe66/text-generation-webui-space,gradio,mit,1
-13304,Sortoite/pdfGPT,gradio,,1
-13305,amj/Voice-Cloning,gradio,mit,1
-13306,Jimpa666/AI-PadelCoach,gradio,,1
-13307,kedarnathdev/AQIprediction,streamlit,other,1
-13308,Jishnnu/Emotion-Detection,gradio,,1
-13309,Soumahara/Falah-iraqi-cafes,gradio,,1
-13310,MuhammedAyman29/Fruits,gradio,apache-2.0,1
-13311,abhishek-kumar/ChatGPT4,gradio,,1
-13312,NJCIT-Nie/README,static,,1
-13313,masbejo99/modelscope-text-to-video-synthesis,gradio,,1
-13314,saga24/nitrozen-gpt,streamlit,,1
-13315,szzzzz/sentiment_classification,gradio,apache-2.0,1
-13316,PirateXX/ChatGPT-Detector,gradio,artistic-2.0,1
-13317,ap66/Real-CUGAN,gradio,gpl-3.0,1
-13318,songwy/VITS-Umamusume-voice-synthesizer,gradio,,1
-13319,biingshanak/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13320,sysf/textspeech,gradio,apache-2.0,1
-13321,actboy/ChatGLM-6B,gradio,,1
-13322,UncleX/CompVis-stable-diffusion-v1-4,gradio,,1
-13323,sdpkjc/ChatPaper,gradio,gpl-3.0,1
-13324,pasha006/Environment,gradio,apache-2.0,1
-13325,mordechaih/theintuitiveye-HARDblend,gradio,openrail,1
-13326,Datasculptor/StyleGAN-NADA,gradio,mit,1
-13327,jefftko/DreamShaper-webui,gradio,,1
-13328,AI-Dashboards/AI.Dashboard.Streamlit.Index.For.Assessments,streamlit,mit,1
-13329,radames/SPIGA-face-alignment-headpose-estimator,gradio,,1
-13330,falconpranav/testgpt,streamlit,apache-2.0,1
-13331,Vgi/darkstorm2150-Protogen_x3.4_Official_Release,gradio,gpl-3.0,1
-13332,radames/Gradio-demo-video-image-webcam-upload,gradio,,1
-13333,awacke1/Topic-Wizard-SKlearn,streamlit,mit,1
-13334,cloudqi/CQI_Fala_para_Texto_PT_V0,gradio,,1
-13335,awacke1/Streamlit.Data.Editor,streamlit,mit,1
-13336,360macky/first-space,streamlit,mit,1
-13337,rajistics/call-sentiment-demo2,gradio,,1
-13338,ruangguru/rg-ds-chatbot-gradio,gradio,mit,1
-13339,Fakermiya/Nsfw-Sfw_Classifier,docker,gpl-3.0,1
-13340,CC123123/blip2_t,gradio,bsd-3-clause,1
-13341,mvnhat/gpt-qa-demo,gradio,,1
-13342,fsqhn/anime-remove-background2,gradio,apache-2.0,1
-13343,DeepLearning101/Speech-Quality-Inspection_Meta-Denoiser,gradio,mit,1
-13344,felicco/andite-pastel-mix,gradio,,1
-13345,art3mis011/plantdiseasedetection,gradio,,1
-13346,qipchip/facebook-blenderbot-3B,gradio,openrail,1
-13347,qipchip/allenai-cosmo-xl,gradio,openrail,1
-13348,erbanku/stabilityai-stable-diffusion-2-1,gradio,,1
-13349,bradley6597/gdrive-illustration-search,gradio,,1
-13350,Samuelcr8/EVA,docker,creativeml-openrail-m,1
-13351,Samuelcr8/Chatbot,gradio,ofl-1.1,1
-13352,qingdiziqing/anime-remove-background,gradio,apache-2.0,1
-13353,keneonyeachonam/NLPGraphOMSandLOCUS-032123,streamlit,,1
-13354,ILyaz03/My_Personal_Teacher,gradio,,1
-13355,kingli999/riffusion-riffusion-model-v12,gradio,,1
-13356,studentofplato/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator,gradio,,1
-13357,itacaiunas/Ghibli-Diffusion,gradio,mit,1
-13358,cjwzfczr12398/DeepDanbooru_string,gradio,,1
-13359,Notmodern/hakurei-waifu-diffusion,gradio,,1
-13360,rajistics/h2o_wave_transformers,docker,,1
-13361,awacke1/Markdown-Analyzer,streamlit,mit,1
-13362,ryansilk/quantycs,streamlit,,1
-13363,awacke1/StreamlitDotEdgeGraphViz-Images-SVG,streamlit,mit,1
-13364,everythingfades/Math-Stats-AP,gradio,other,1
-13365,supun9/face-verification,gradio,,1
-13366,srepalli3/Demo01_GC_Content,gradio,,1
-13367,ChristopherMarais/Andrew_Alpha,gradio,other,1
-13368,ShaunWithGPT/ChuanhuChatGPT,gradio,mit,1
-13369,Nahidabyer/img-to-music,gradio,,1
-13370,awacke1/Streamlit.GraphViz.Dynamic.Architecture.Diagram,streamlit,mit,1
-13371,raghu8096/PDF-QA,gradio,openrail,1
-13372,oshita-n/ControlNet,gradio,mit,1
-13373,Jimmie/Urban8K-mini,gradio,mit,1
-13374,suhailidrees/dogs_cats,gradio,apache-2.0,1
-13375,Linkthat/IntentClassification,gradio,,1
-13376,lewisrxliu/1,gradio,,1
-13377,ADUPA/README,static,,1
-13378,Write2Learn/Transcriber,gradio,,1
-13379,preechanon/Cutto,streamlit,,1
-13380,pythainlp/pythainlp-thainer-corpus-v2-base-model,gradio,,1
-13381,fizban/simiandb,gradio,mit,1
-13382,Ridwanz/sdrv1_4,gradio,,1
-13383,hannanrozal/stable-diffusion-image-variations,gradio,mit,1
-13384,Robooze/transcription_loud,gradio,,1
-13385,AI-ZTH-03-23/README,static,,1
-13386,svummidi/pulseDemo,gradio,,1
-13387,awacke1/Streamlit-Azure-IDR-Diagram,streamlit,mit,1
-13388,divilis/chatgpt,gradio,gpl-3.0,1
-13389,wanghaha13/ChuanhuChatGPT,gradio,gpl-3.0,1
-13390,lexi1343/Hi,static,bigscience-bloom-rail-1.0,1
-13391,annchen2010/ChatGPT,gradio,gpl-3.0,1
-13392,weishao2019/ChuanhuChatGPT,gradio,gpl-3.0,1
-13393,stchakman/Fridge2Dish,streamlit,mit,1
-13394,jarvis1997/fr_demo1,gradio,,1
-13395,Bakuman/Real-CUGAN,gradio,gpl-3.0,1
-13396,Detomo/Aisatsu-robot,gradio,apache-2.0,1
-13397,maminghui/ChatGPT,gradio,gpl-3.0,1
-13398,geniius/ogkalu-Comic-Diffusion,gradio,,1
-13399,SmonF/Dialogue_summarizer,streamlit,apache-2.0,1
-13400,czovoa/cbbb,gradio,openrail,1
-13401,AI-ZTH-03-23/3.HTML5-Aframe-3dMap-Flight,static,mit,1
-13402,AI-ZTH-03-23/4.RealTime-MediaPipe-AI-From-Video-On-Any-Device,streamlit,mit,1
-13403,AI-ZTH-03-23/5.StreamlitWikipediaChat,streamlit,mit,1
-13404,AI-ZTH-03-23/8.Datasets-NER-Biomed-ClinicalTerms,gradio,,1
-13405,BillBojangeles2000/WikiGPT,streamlit,apache-2.0,1
-13406,wz758727829/ChuanhuChatGPT,gradio,gpl-3.0,1
-13407,IAMTFRMZA/image-recognition-demo,gradio,afl-3.0,1
-13408,xiaohuolong/ChuanhuChatGPT,gradio,gpl-3.0,1
-13409,MichaelT8093/AnimeGANv3,gradio,,1
-13410,awacke1/1.ChatGPT-HuggingFace-Spaces-NLP-Transformers-Pipeline,gradio,mit,1
-13411,merler/1.ChatGPT-HuggingFace-Spaces-NLP-Transformers-Pipeline,gradio,mit,1
-13412,AISloth/1.ChatGPT-HuggingFace-Spaces-NLP-Transformers-Pipeline,gradio,mit,1
-13413,JohnC26/ChatGPTwithAPI,gradio,mit,1
-13414,JohnC26/2.Streamlit.GraphViz.Dynamic.Architecture.Diagram,streamlit,mit,1
-13415,awacke1/HTML5-Dashboard,static,mit,1
-13416,JennBiggs/HTML5-Dashboard,static,mit,1
-13417,Anar0140/4.RealTime-MediaPipe-AI-From-Video-On-Any-Device,streamlit,mit,1
-13418,JohnC26/AI.Dashboard.Wiki.Chat.Cognitive.HTML5,static,mit,1
-13419,Anar0140/6.AI.Dashboard.Wiki.Chat.Cognitive.HTML5,static,mit,1
-13420,JohnC26/AI.Dashboard.Gradio.Streamlit.HTML5,static,mit,1
-13421,JohnC26/7-NER-Biomed-ClinicalTerms,gradio,,1
-13422,JohnC26/MN.Map.Hospitals.Top.Five,streamlit,mit,1
-13423,JohnC26/StreamlitWikipediaChat,streamlit,mit,1
-13424,JohnC26/Gradio-Maps-Latitude-Longitude,gradio,mit,1
-13425,Nattiman/chatsummarizercapstoneproject,streamlit,,1
-13426,sophatvathana/my-research-llama-65b-hf,gradio,,1
-13427,williamzhou2023/GPT2,gradio,gpl-3.0,1
-13428,vonewman/demo-app-streamlit,streamlit,,1
-13429,Kaludi/QR-Code-Generator-Streamlit_App,streamlit,,1
-13430,ejbejaranos/spanishAlpaca,streamlit,c-uda,1
-13431,ejbejaranos/somos-alpaca-es,docker,,1
-13432,NoamSiegel/gpt-workouts,gradio,mit,1
-13433,lc202301/ChuanhuChatGPT,gradio,gpl-3.0,1
-13434,posak/Tune-A-Video-Training-UI,docker,mit,1
-13435,mzltest/gpt2-chinese-composition,gradio,mit,1
-13436,charles0519/ChuanhuChatGPT,gradio,gpl-3.0,1
-13437,hahahehe99340/chatgpt,gradio,gpl-3.0,1
-13438,heine123/heine123-promotion1,gradio,,1
-13439,andreslu/orion,gradio,,1
-13440,OttoYu/Tree-ConditionHK,gradio,,1
-13441,Nithesh-101/Satellite_Image_Segmentation,gradio,,1
-13442,YuDou/ChuanhuChatGPT,gradio,gpl-3.0,1
-13443,yiguid/ChatGPT,gradio,gpl-3.0,1
-13444,Datasculptor/LoRA-DreamBooth-Training-UI,gradio,mit,1
-13445,d8aai/image-search,gradio,apache-2.0,1
-13446,konstantinG/text2image,streamlit,openrail,1
-13447,awacke1/InContextLearning-PromptTargeting,streamlit,mit,1
-13448,rajaatif786/VirBert2,gradio,,1
-13449,vivsmouret/Dipl0-pepe-diffuser,gradio,,1
-13450,senquan/ChuanhuChatGPT,gradio,gpl-3.0,1
-13451,neveu/img-to-music,gradio,,1
-13452,fiyen/YangyangChatGPT,gradio,gpl-3.0,1
-13453,suqionglin/White-box-Cartoonization,gradio,apache-2.0,1
-13454,suqionglin/anime-ai-detect,gradio,,1
-13455,kaushikdatta/new-car-inventory,gradio,,1
-13456,CAPTY222/runwayml-stable-diffusion-v1-5,gradio,,1
-13457,roveliu/ChatGPT4,gradio,mit,1
-13458,MohammedMaaz/PDF-TEXT-BASED-QA,streamlit,other,1
-13459,cstorm125/foodydudy_for_lesson1,gradio,,1
-13460,awacke1/TopTenAIGeneratedSolutionsAnyoneCouldUse,streamlit,mit,1
-13461,awacke1/StreamlitSolution-To-Your-Problem-Generator,streamlit,mit,1
-13462,awacke1/Tank.Moves.Tank.Fires.Tank.AvoidsObstacles.Combat,streamlit,mit,1
-13463,Detomo/aisatsu-api,docker,creativeml-openrail-m,1
-13464,straka/poison_ivy,gradio,apache-2.0,1
-13465,fuxin123zz/ChuanhuChatGPT,gradio,gpl-3.0,1
-13466,rishabh062/donutCordImgToCsv,gradio,unknown,1
-13467,Sunil90/ChatGPT4,gradio,mit,1
-13468,thelou1s/ehcalabres-wav2vec2-lg-xlsr-en-speech-emotion-recognition,gradio,,1
-13469,Dryash/ChatGPT4,gradio,mit,1
-13470,pchuri/image2text,gradio,mit,1
-13471,monisazeem/ChatGPT4,gradio,mit,1
-13472,Gasi/White-box-Cartoonization,gradio,apache-2.0,1
-13473,vedet9/ipl,streamlit,,1
-13474,Detomo/aisatsu-app-api,gradio,creativeml-openrail-m,1
-13475,iqsoft/README,static,,1
-13476,mikaelbhai/GPTBhai_TextToImage,gradio,,1
-13477,smfry010/text-to-image,streamlit,,1
-13478,SilenWang/ReviewGPT,gradio,mit,1
-13479,Ajaymaurya1008/meme-identifier,streamlit,,1
-13480,awacke1/Wikipedia.Chat.Multiplayer,streamlit,mit,1
-13481,awacke1/Streamlit.ChatWikiwriter.Multiplayer,streamlit,mit,1
-13482,Eroggen/ChatGPT4,gradio,mit,1
-13483,heiyuan/ChatGPT,gradio,gpl-3.0,1
-13484,frankio/goatheadrecordschatbot,gradio,mit,1
-13485,MBA98/DiabeticRetinopathyDetection,gradio,cc-by-nc-sa-4.0,1
-13486,Zwicky18/vits-models,gradio,apache-2.0,1
-13487,Crow34/Comicdraw,gradio,openrail,1
-13488,awacke1/Word.Search.Experiments,streamlit,mit,1
-13489,grvgl/ChatGPT4,gradio,mit,1
-13490,Sohag1/Handwritten-text-Recognition-Using-TrOCR,gradio,,1
-13491,cc00/THUDM-chatglm-6b-int4-qe,gradio,,1
-13492,laxmikant/ChatGPT4,gradio,mit,1
-13493,joeli88/astrologer,gradio,,1
-13494,goliathaiconsulting/ecommerce-platform,gradio,,1
-13495,9752isme/ChatGPT4,gradio,mit,1
-13496,siddh4rth/narrify,gradio,,1
-13497,Vipul-Chauhan/20newsgroup_QA,gradio,,1
-13498,cc1234/stashtag,gradio,,1
-13499,awacke1/GLB.Loader.HTML5,static,mit,1
-13500,Aloento/9Nine-VITS,gradio,agpl-3.0,1
-13501,lychees/Stable-Diffusion-ControlNet-WebUI,gradio,openrail,1
-13502,Aniquel/WizApp,gradio,gpl-3.0,1
-13503,pwilczewski/banking_crisis_dashboard,gradio,apache-2.0,1
-13504,Kai-GL/ChatGPT4,gradio,mit,1
-13505,Vipitis/ShaderEval,gradio,mit,1
-13506,DrBenjamin/AI_Demo,streamlit,gpl-3.0,1
-13507,deadash/BelleGroup-BELLE-7B-gptq,gradio,,1
-13508,manjuvallayil/video_text,gradio,,1
-13509,pxovela/ball-classifier,gradio,apache-2.0,1
-13510,Darkk88/medium-GPT4,gradio,,1
-13511,liushilei/hackathon_chatbot_baixing_api,gradio,cc-by-4.0,1
-13512,meraGPT/chat-with-myGPT,streamlit,,1
-13513,pinots/ChatGPT4,gradio,mit,1
-13514,tracinginsights/F1_API,docker,,1
-13515,Aloento/9Nine-PITS,gradio,agpl-3.0,1
-13516,Benebene/Chat-question-answering,gradio,,1
-13517,Abrish-Aadi/Chest-Xray-anomaly-detection,gradio,apache-2.0,1
-13518,cchuang2009/News-Forum,streamlit,mit,1
-13519,NeuralInternet/Alpaca-LoRA-Serve,gradio,gpl-3.0,1
-13520,gunti/ChatGPT4,gradio,mit,1
-13521,JoshuaWS3/hakurei-waifu-diffusion,gradio,creativeml-openrail-m,1
-13522,Rimi98/Relax-Teacher,gradio,apache-2.0,1
-13523,facat/alpaca-lora-cn,gradio,apache-2.0,1
-13524,RGBD-SOD/depth2rgb-dpt,gradio,mit,1
-13525,AlexReverie/ImageSonification,gradio,,1
-13526,jmartinezot/find_plane_pointcloud,gradio,,1
-13527,mserras/somos-alpaca-es,docker,,1
-13528,gngpostalsrvc/COHeN_demo,gradio,,1
-13529,iceburg/ChatGPT4,gradio,mit,1
-13530,awacke1/RLHF.Evals,streamlit,mit,1
-13531,Highway/infrastructure-cost-data-classifier,streamlit,mit,1
-13532,dcsjsuml/README,static,,1
-13533,awacke1/RLHF.Reinforce.Learn.With.Human.Feedback,streamlit,mit,1
-13534,peterpull/MediatorBot,gradio,creativeml-openrail-m,1
-13535,gaochangyun/bert-base-chinese,gradio,,1
-13536,coolprakashjj/Bradley-Siderograph-Public,gradio,agpl-3.0,1
-13537,xiaoxicc/susu,gradio,gpl-3.0,1
-13538,zzz666/ChuanhuChatGPT,gradio,gpl-3.0,1
-13539,Wayben/ChatGPT,gradio,gpl-3.0,1
-13540,chenxx/ChuanhuChatGPT,gradio,gpl-3.0,1
-13541,shideqin/test,gradio,,1
-13542,thelou1s/TensorflowHubSpice,gradio,mit,1
-13543,tracinginsights/api,docker,,1
-13544,TSjB/QM_RU_translator,gradio,,1
-13545,HMinions/new-Bing-with_your_cookies,gradio,other,1
-13546,startway/whisper,gradio,mit,1
-13547,akhilkalwakurthy/AxisGPTv3,gradio,gpl-3.0,1
-13548,manhngolibo/manhngo,docker,,1
-13549,MajinBog/ItsJayQz-GTA5_Artwork_Diffusion,gradio,,1
-13550,muchuam/anime-remove-background,gradio,apache-2.0,1
-13551,ayaanzaveri/whisper-webui,gradio,apache-2.0,1
-13552,Snb-ai/gpt2,gradio,apache-2.0,1
-13553,wxiaofei/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13554,rachittshah/doc-qa,gradio,,1
-13555,achimoraites/TextClassification-roberta-base_ag_news,gradio,mit,1
-13556,Pepsr/Chatbot,gradio,unknown,1
-13557,xxie92/proteinml-demo-dssp-duplicate,gradio,mit,1
-13558,zivpollak/EyeCareXV002,gradio,apache-2.0,1
-13559,asbeabi/PoCs,static,openrail,1
-13560,AHzizi/WaifuVoiceGen,gradio,apache-2.0,1
-13561,ianlianetlai/talk,streamlit,,1
-13562,bedrock123/nlp-vit-gpt2-image-captioning,gradio,,1
-13563,jinmao/2,gradio,gpl-3.0,1
-13564,BHD/google-pix2struct-screen2words-base,gradio,,1
-13565,ruanchaves/portuguese-question-answering,gradio,mit,1
-13566,awacke1/RLHF.Evals.Intake.Upvote.Downvote,streamlit,mit,1
-13567,molinsp/codegen_exploration,gradio,mit,1
-13568,JohnTan38/calculator,gradio,mit,1
-13569,Fcou/ChatGPT3.5,gradio,mit,1
-13570,Snowling/White-box-Cartoonization,gradio,apache-2.0,1
-13571,jarvisbot/ChatImprovement,gradio,,1
-13572,zekewilliams/video,gradio,,1
-13573,niv-al/peshperima,gradio,openrail,1
-13574,abidlabs/Lime,gradio,apache-2.0,1
-13575,jroust/prompthero-openjourney,gradio,,1
-13576,starlit7/USPoliticsTTS,gradio,mit,1
-13577,aliabid94/new-theme,gradio,apache-2.0,1
-13578,radames/face-landmarks-gradio,gradio,,1
-13579,geeek/text-moderation-score,gradio,other,1
-13580,Mikan1103/anime-remove-background,gradio,apache-2.0,1
-13581,tanish2502/ChatGPT-AI-Assistant-App,gradio,,1
-13582,baruga/gpt4-sandbox,gradio,unknown,1
-13583,Cosmo-Hug/Cosmo-Hug-FeverDream,gradio,creativeml-openrail-m,1
-13584,Fazen/ask-youtube,streamlit,,1
-13585,awacke1/Markdown.Streamlit.Teaching.Colleges,streamlit,mit,1
-13586,deedax/TLDR-the-TnC,gradio,mit,1
-13587,ParisNeo/MBart50Translator,gradio,mit,1
-13588,awacke1/Team.Click.Battle.Multiplayer,streamlit,mit,1
-13589,jdczlx/ChatGPT-chuanhu,gradio,gpl-3.0,1
-13590,xhd456/anime-remove-background,gradio,apache-2.0,1
-13591,Mochine/hackathon_chatbot_openai_api,gradio,cc-by-4.0,1
-13592,Shularp/marian_translation_test_th_ar_en,gradio,,1
-13593,caojiachen1/ChatGPT,gradio,apache-2.0,1
-13594,ruanchaves/hashtag-segmentation,gradio,mit,1
-13595,andikalfauzi/Churn-Prediction,streamlit,,1
-13596,Iruc/weirdcore-diffusion,gradio,,1
-13597,greenlights/gitapp,streamlit,,1
-13598,Li6699/myChat,gradio,,1
-13599,vedalken/text2Pokemon,gradio,,1
-13600,sirmews/supabase-bookmarks,docker,,1
-13601,awacke1/Write-Stories-Using-Bloom,gradio,gpl,1
-13602,duanzhihua/AI-ChatGPT,gradio,mit,1
-13603,sidhusmart/prompthero-openjourney-v4,gradio,openrail,1
-13604,vkdhiman93/cerebras-Cerebras-GPT-1.3B,gradio,,1
-13605,JonysArcanjo/App_predict_House_price,gradio,,1
-13606,dperales/Fraud_Detection_Pycaret,streamlit,,1
-13607,Hanyin/anime-remove-background,gradio,apache-2.0,1
-13608,diy2023/databricks-dolly-v1-6b,gradio,,1
-13609,vrajeshbhatt/Automated-Ticket-Management-System,gradio,,1
-13610,goliathaiconsulting/airbnb-search-engine,gradio,,1
-13611,gradio/theme_builder_main,gradio,,1
-13612,darthPanda/romeo_and_juliet_chatbot_with_gptIndex,streamlit,,1
-13613,AlekseyKorshuk/michellejieli-NSFW_text_classifier,gradio,,1
-13614,xillegas/duolingo-bot,docker,other,1
-13615,laitkor/remove_background,gradio,apache-2.0,1
-13616,awacke1/Vesuvius.Challenge,gradio,mit,1
-13617,kieranberton23/plantdx,streamlit,,1
-13618,Kokuen/oobabooga-windows,gradio,cc-by-nc-nd-4.0,1
-13619,jennysun/jwsun-multisubject-render-model,gradio,,1
-13620,comet-team/kangas-direct,docker,apache-2.0,1
-13621,awacke1/Intrinsic.Bias.Analyzer,streamlit,mit,1
-13622,awacke1/Bloom.QA.Translation.LLM.AI,gradio,mit,1
-13623,EyanAn/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13624,Navneet574/algerian-forest-fire-prediction,streamlit,cc-by-nc-4.0,1
-13625,sharjeel1477/Brain,gradio,,1
-13626,golda/Churn_pred,streamlit,,1
-13627,cahodk/live-ml5-facemesh-p5js,static,lgpl-2.1,1
-13628,Devic1/LinearRegression,gradio,,1
-13629,JoeStrout/simple-llama-finetuner,gradio,,1
-13630,aliabd/whisper,gradio,,1
-13631,Aniquel/WizApp_Code_Generator,gradio,apache-2.0,1
-13632,EnigmaOfTheWorld/MemeWorld,gradio,bigscience-bloom-rail-1.0,1
-13633,thelou1s/food_calories,gradio,,1
-13634,ThirdEyeData/Rogue_Component_Prediction,streamlit,,1
-13635,ysharma/llamas,gradio,apache-2.0,1
-13636,johnyang/ChatPaper111,docker,gpl-3.0,1
-13637,pscpeng/ChuanhuChatGPT,gradio,gpl-3.0,1
-13638,wzq10314/VITS-Umamusume-voice-synthesizer1,gradio,,1
-13639,upGradGPT/GPT_Interview_beta,gradio,,1
-13640,nyaridori/charactercreator,gradio,creativeml-openrail-m,1
-13641,ThirdEyeData/Maximum_Repair_Prediction,streamlit,,1
-13642,jaymie/Virtus,gradio,,1
-13643,chaozi/anime-remove-background,gradio,apache-2.0,1
-13644,jinonet/digital-agency-website,static,,1
-13645,segestic/HealthBlock,streamlit,,1
-13646,victor/autotrain-advanced-dreambooth,docker,,1
-13647,amagastya/JOY,gradio,,1
-13648,aayushrawat/recommender-model,streamlit,,1
-13649,keras-dreambooth/Dreambooth-mandelbulb-flower,gradio,apache-2.0,1
-13650,LEL-A/german-alpaca-test,docker,,1
-13651,dawood/PDFChatGpt,gradio,afl-3.0,1
-13652,konfuzio-com/PP-OCRv3-ch,gradio,apache-2.0,1
-13653,NimaKL/FireWatch5k,gradio,,1
-13654,Kevin676/ChatGPT-with-Voice-Cloning,gradio,mit,1
-13655,keras-dreambooth/dreambooth-markhor,gradio,,1
-13656,sf-checkin/checkin,gradio,mit,1
-13657,alexpaul/microsoft-codebert-base,static,mit,1
-13658,ThirdEyeData/Component_Repair_Time_Prediction,streamlit,,1
-13659,smdcn/stabilityai-stable-diffusion-2-1,streamlit,,1
-13660,smdcn/stabilityai-stable-diffusion-2-1-base,gradio,,1
-13661,awacke1/Lunar.Lander.Asteroids.Continual.Self.Play,static,mit,1
-13662,rohan13/coursera-qa-bot,gradio,,1
-13663,lanbogao/ytdlp-whisper,gradio,,1
-13664,ori1026/OriChatGPT,gradio,gpl-3.0,1
-13665,izumo092/TestSecret888,gradio,openrail,1
-13666,hongweii/anime-ai-detect,gradio,,1
-13667,awacke1/Emoji.Enumerator.Menu,streamlit,mit,1
-13668,VCPirlo/CatCat,gradio,cc-by-4.0,1
-13669,xxxxxxianYu/vits-xxxxxxxxxxxxxxxxxx,gradio,apache-2.0,1
-13670,weide/OpenChatKit,static,,1
-13671,sai22/vits-models,gradio,apache-2.0,1
-13672,sirmews/url-summarizer-playground,streamlit,,1
-13673,awacke1/HTML5.3D.Flight.with.Gravity,static,,1
-13674,awacke1/HTML5.Aframe.Frogger.Test,static,mit,1
-13675,awacke1/HTML5.Wordle.Solver,static,mit,1
-13676,awacke1/Azure.Streamlit.Github.Actions.Azure.Container.Registry.Docker.AKS,streamlit,mit,1
-13677,awacke1/Markdown.Streamlit.EDA.Generic.Loader.Presenter.Memory,streamlit,mit,1
-13678,awacke1/Streamlit.Azure.SDK.Terraform,streamlit,mit,1
-13679,kzachos/PDF-chatbot,gradio,,1
-13680,zhanpj/ChatGPT,gradio,gpl-3.0,1
-13681,michael135/dontalk,docker,,1
-13682,knotdgaf/gradiotest,gradio,apache-2.0,1
-13683,Detomo/AI-Galary,gradio,apache-2.0,1
-13684,awacke1/Positive.Reframing.Organization.Culture,gradio,,1
-13685,Harsh12/Rossmann_Sales_Prediction,streamlit,other,1
-13686,Keyurmistry/Joeythemonster-anything-midjourney-v-4-1,gradio,,1
-13687,Kevin676/ChatGPT-with-Voice-Cloning-in-Chinese,gradio,mit,1
-13688,bradley6597/Spell-Bee-Solver,gradio,,1
-13689,ppsantiago/chatGPT,gradio,gpl-3.0,1
-13690,awacke1/Amygdala.Hijacking.Using.Graph.Model,streamlit,mit,1
-13691,awacke1/Graph.Model.Feedback,streamlit,mit,1
-13692,Kevin676/ChatGPT-with-Smooth-Voice,gradio,mit,1
-13693,VishyVish/Face-ID-duplicated,gradio,,1
-13694,awacke1/Streamlit.Funny.Feedback.Upvote.Downvote,streamlit,mit,1
-13695,khanrc/tcl,gradio,,1
-13696,gstaff/guessing-game,gradio,apache-2.0,1
-13697,Kevin676/ChatGPT-with-Smooth-Voice-1.0,gradio,mit,1
-13698,ThirdEyeData/Next_Failure_Prediction,streamlit,,1
-13699,SnJForever/GPT-LANG,gradio,apache-2.0,1
-13700,amongusrickroll68/openai-jukebox-5b-lyrics,gradio,unknown,1
-13701,Dantra1/CeliaSensei,gradio,apache-2.0,1
-13702,FlippFuzz/whisper-webui,gradio,apache-2.0,1
-13703,xfambi/zapi,docker,wtfpl,1
-13704,RikyXDZ/NesiaChan,gradio,cc,1
-13705,q846392920/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13706,GipAdonimus/PAIR-text2video-zero-controlnet-canny-gta5,gradio,,1
-13707,Alesteba/NeRF_ficus-pxl,streamlit,,1
-13708,raoyang111/img-to-music,gradio,,1
-13709,stistko/CzechPunctuation,streamlit,cc-by-nc-4.0,1
-13710,arattinger/emoji-diffusion,gradio,mit,1
-13711,kepajide/keyiwei,gradio,apache-2.0,1
-13712,shahzaibelbert/CHATGPT-Detector,gradio,apache-2.0,1
-13713,Kevin676/Demucs_v4,gradio,,1
-13714,luciancotolan/R50-deforestation,gradio,apache-2.0,1
-13715,Ariharasudhan/YoloV5,gradio,gpl-3.0,1
-13716,kingsotn/tt-ai,streamlit,mit,1
-13717,phildunphy/Reverse_Asset_Allocation,gradio,,1
-13718,savhascelik/FLAN-T5,gradio,apache-2.0,1
-13719,Rian000/Sayashi,gradio,other,1
-13720,cathrineee/CLIP-image-search,gradio,,1
-13721,nomnomnonono/Siri-via-Whisper-ChatGPT,gradio,,1
-13722,kerls/is-this-food-photo-instagram-worthy,gradio,apache-2.0,1
-13723,Arthur678/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13724,amarax/cowtopia,gradio,osl-3.0,1
-13725,CanKorkut/turkish-hatespeech-detection,gradio,mit,1
-13726,osbm/token_merger_demo,gradio,,1
-13727,Treav/DICOMDeidentify2,gradio,,1
-13728,awacke1/Assess.LOINC.Panel.Extractor,streamlit,mit,1
-13729,josh59999/webui,gradio,,1
-13730,Kevin676/s3prl-vc-vcc2020,gradio,mit,1
-13731,WhyLIM/GWAS,gradio,mit,1
-13732,tanvirsingh01/projectFeeder,gradio,,1
-13733,ypx123/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13734,Ezi/Licences_check,streamlit,,1
-13735,PeepDaSlan9/carecoach-gpt-neo-1.3B-finetune-v2-B2BMGMT,gradio,openrail,1
-13736,VK123/ChatGPT4,gradio,mit,1
-13737,Letheoricien/demo,gradio,afl-3.0,1
-13738,sefaozalpadl/LabelStudio,docker,apache-2.0,1
-13739,panchajanya1999/chatgenius,gradio,apache-2.0,1
-13740,Letheoricien/MLPC2023_MumBot,gradio,afl-3.0,1
-13741,michellaneous/Baymax,gradio,unknown,1
-13742,iamrobotbear/cosine-match,gradio,apache-2.0,1
-13743,Cletrason/dalle2-dreamweddingbooth,gradio,,1
-13744,wushuangBaOYWHA/chatpdf,gradio,mit,1
-13745,xxbb/VITS-Umamusume-voice-synthesizer,gradio,,1
-13746,Dobeuinc/README,static,,1
-13747,MichaelT8093/ImageAnimation,gradio,,1
-13748,SnailsLife/gsdf-Counterfeit-V2.5,gradio,,1
-13749,ken4005/Uhi-ChatGPT,gradio,gpl-3.0,1
-13750,Letheoricien/MLPC_2023_NATHEO,gradio,afl-3.0,1
-13751,jishnupsamal/sports-sustainability,gradio,mit,1
-13752,axart-software/simple-beat-generator,gradio,creativeml-openrail-m,1
-13753,livinNector/TaNER,gradio,mit,1
-13754,dsymbol/whisper-webui,gradio,mit,1
-13755,jellyw/landscape-rendering,gradio,creativeml-openrail-m,1
-13756,yiluxiangbei/baize-lora-7B,gradio,cc-by-nc-4.0,1
-13757,awacke1/Human.Feedback.Dynamic.JSONL.Fields,streamlit,mit,1
-13758,awacke1/Human.Feedback.Dynamic.JSONL.Dataset.Download,streamlit,mit,1
-13759,awacke1/Azure.Terraform.Github.Actions.Web.App.MLOps,streamlit,mit,1
-13760,Flux9665/Blizzard2023IMS,gradio,mit,1
-13761,SameerR007/Movie_Recommendation_updated,streamlit,,1
-13762,Cletrason/Cletrason-toad-in-the-mario-movie,gradio,,1
-13763,toraleap/chatbot,gradio,mit,1
-13764,furqankassa/Human.Feedback.Dynamic.JSONL.Dataset.Download,streamlit,mit,1
-13765,dawood/PDFChatGpt-test,gradio,afl-3.0,1
-13766,TerrificTerry/HAAO_AI,gradio,mit,1
-13767,stanciu/DanielPinheiro-gpt4all,gradio,,1
-13768,Devound/chavinlo-gpt4-x-alpaca,gradio,,1
-13769,hpratapsingh/Movie_Recommendation_system,streamlit,,1
-13770,stanciu/andite-anything-v4.0,gradio,,1
-13771,panchajanya1999/spam-classifier,gradio,apache-2.0,1
-13772,Kevin676/Clone-Your-Voice,gradio,,1
-13773,awacke1/PoetandKnowIt,streamlit,mit,1
-13774,lyf/faster-whisper-webui,gradio,apache-2.0,1
-13775,NowLoadY/ocr-gpt,gradio,apache-2.0,1
-13776,BWQ/Chatgpt,gradio,mit,1
-13777,ashzzf/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13778,tappyness1/error-analysis-cv-segmentations,streamlit,gpl-3.0,1
-13779,glt3953/AIPaint,gradio,,1
-13780,xl2533/MakeInstruction,gradio,,1
-13781,skyler36237/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13782,tenhulek/prompthero-openjourney-v4,gradio,cc,1
-13783,itsjacksimon/runwayml-stable-diffusion-v1-5,gradio,,1
-13784,mikelix1970/ChatGPT4,gradio,mit,1
-13785,qdd319/ChuanhuChatGPT,gradio,gpl-3.0,1
-13786,xiaolongbaox/gpt2.0,gradio,gpl-3.0,1
-13787,almontalvao/Sentiment_Analysis_Streamlit,streamlit,mit,1
-13788,cactusfriend/nightmareprompts,gradio,openrail,1
-13789,JohnPinto/Human_Activity_Recognition-HAR-Video_Classification-HMDB51-Dataset,gradio,mit,1
-13790,srijan2024/SentimentAnalysis,streamlit,,1
-13791,daveckw/custom-chatgpt,gradio,,1
-13792,Navpreet/rabbit3,streamlit,,1
-13793,motroma/prompthero-openjourney,gradio,,1
-13794,stanciu/decapoda-research-llama-13b-hf,gradio,,1
-13795,milan2000/Milan_generativeAI_AD-test,gradio,bigscience-openrail-m,1
-13796,jasonjones/Batman-AdMaker,gradio,bigscience-openrail-m,1
-13797,4Taps/SadTalker,gradio,mit,1
-13798,Msp/opensource_chat_assistants,gradio,,1
-13799,Dimitre/stablediffusion-canarinho_pistola,gradio,,1
-13800,xxie92/antibody_visulization,streamlit,,1
-13801,sikao/README,static,,1
-13802,damilojohn/Playlist_Generator_For_Afrobeats,gradio,apache-2.0,1
-13803,triggah61/li5,docker,afl-3.0,1
-13804,sklearn-docs/feature-importance-rf,gradio,apache-2.0,1
-13805,Dao3/chatwithdocs,streamlit,mit,1
-13806,Metatron/LEO,docker,creativeml-openrail-m,1
-13807,svjack/ControlNet-Face-Chinese,gradio,,1
-13808,IstvanPeter/openai-whisper-tiny,gradio,apache-2.0,1
-13809,hiDenorIYamano/srt-translator,gradio,,1
-13810,oliver2023/mm-react,docker,other,1
-13811,sudthakur/yt_summary,gradio,,1
-13812,Wanlau/sovits-4.0_datealive,gradio,other,1
-13813,ORI-Muchim/MinamiTTS,gradio,,1
-13814,espnet/TTS,gradio,cc-by-4.0,1
-13815,kiwifly/nicky007-stable-diffusion-logo-fine-tuned,gradio,,1
-13816,seo-sean/andite-pastel-mix,gradio,,1
-13817,smith2020/WhatsApp-chat-analysis-summary,streamlit,,1
-13818,runninghsus/lupe-bsoid,streamlit,bsd-3-clause,1
-13819,Atualli/yoloxTeste,gradio,apache-2.0,1
-13820,Pritish100/AA0_LeLO_v_2.0,gradio,mit,1
-13821,PureNaCl/Toxic-Tweets-MS2,streamlit,,1
-13822,pikapikaPikachu/chatbot,gradio,mit,1
-13823,awacke1/QuickLearner,streamlit,mit,1
-13824,awacke1/InstructGPT,gradio,mit,1
-13825,awacke1/Spinning.Model-1-10,streamlit,mit,1
-13826,betterme/Nice,docker,apache-2.0,1
-13827,Tshackelton/IBMPlex-DenseReadable,gradio,apache-2.0,1
-13828,almontalvao/GenAds-AI,gradio,mit,1
-13829,nickprock/nickprock-bert-italian-finetuned-ner,gradio,mit,1
-13830,CelesteChen/GPT-token,gradio,apache-2.0,1
-13831,uchuukaizoku/CharacterClassifier,gradio,openrail,1
-13832,cyliawardana/Womens_Clothing_Sentiment_Analysis,streamlit,,1
-13833,7thHeaven/GPT2WordPress,streamlit,unknown,1
-13834,awacke1/Docker.Jupyterlab.Integration.HF,docker,,1
-13835,miku-hutao/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13836,prikmmo9/finetuned_diffusion,gradio,mit,1
-13837,mmDigital/therapy-bot,gradio,,1
-13838,lout33/Youtube-Whisperer,gradio,,1
-13839,phildunphy/SALT-curated-asset-allocation,gradio,,1
-13840,thanhtvt/uetasr,gradio,,1
-13841,Billius/VizLib-TopLargeHospitalsNewJersey-04-07-2023,streamlit,mit,1
-13842,UtkMal/fresh-or-rotten-apple,gradio,apache-2.0,1
-13843,pakooo/Text2Image,gradio,,1
-13844,irprojectteamnith/IR-project-multilingual,streamlit,,1
-13845,Billius/runwayml-stable-diffusion-v1-5-04-07-2023,gradio,mit,1
-13846,MesonWarrior/vk,gradio,,1
-13847,cloud-sean/csv-copilot,gradio,,1
-13848,JunchuanYu/SegRS,gradio,,1
-13849,Usually3/text-to-image,gradio,,1
-13850,willdguo/fastai_l2,gradio,apache-2.0,1
-13851,beskrovnykh/danielsearch,gradio,bsd-3-clause,1
-13852,wazhendeshiniya/White-box-Cartoonization,gradio,apache-2.0,1
-13853,vivek-a666/Health_Forecast,streamlit,,1
-13854,altafalam3/Text-Summarizer,streamlit,,1
-13855,vrajeshbhatt/Job-Title-Prediction,gradio,,1
-13856,GPTMonster/KBprototype_first,gradio,apache-2.0,1
-13857,Qrstud/andite-anything-v4.0,gradio,,1
-13858,darkartsaibwd/Envvi-Inkpunk-Diffusion,gradio,,1
-13859,bigyunicorn/sashimi_identifier,gradio,apache-2.0,1
-13860,ashutosh1919/quantum-perceptron,gradio,apache-2.0,1
-13861,Skyler123/TangGPT,gradio,gpl-3.0,1
-13862,lhkhiem28/A-segmentation-system,gradio,,1
-13863,oliver2023/chatgpt-on-wechat,gradio,,1
-13864,awacke1/Streamlit.Graphviz.Stories.JSONL,streamlit,mit,1
-13865,snehilsanyal/scikit-learn,gradio,apache-2.0,1
-13866,Kevin676/Raven-with-Voice-Cloning,gradio,apache-2.0,1
-13867,awacke1/Balloon.Club,streamlit,mit,1
-13868,jordonpeter01/stable-diffusion,gradio,mit,1
-13869,jordonpeter01/SD-2.1-CPU,gradio,mit,1
-13870,jordonpeter01/stabilityai-stable-diffusion-2-1-base,gradio,,1
-13871,Cobalt337/lambdalabs-sd-pokemon-diffusers,gradio,,1
-13872,WatchOutForMike/Character,gradio,,1
-13873,Namit2111/id_verfiy,gradio,,1
-13874,ivotai/VITS-Umamusume-voice-synthesizer,gradio,,1
-13875,yiwangshangxian/anime-remove-background,gradio,apache-2.0,1
-13876,Abubakari/Sales_Prediction,streamlit,,1
-13877,riyueyiming/gpt,gradio,gpl-3.0,1
-13878,globalmatt/catsanddogs,gradio,apache-2.0,1
-13879,lawliet/CS224-knowledge-discovery,streamlit,apache-2.0,1
-13880,DevashishBhake/SERModel,gradio,,1
-13881,shj7972/gradiospace,gradio,apache-2.0,1
-13882,ccarr0807/HuggingGPT,gradio,,1
-13883,20four60/Auto-GPT,docker,wtfpl,1
-13884,samle/prompthero-openjourney-v4,gradio,,1
-13885,Worlandil/ChatGPT4,gradio,mit,1
-13886,yuntian-deng/Gradio-Popup-Confirmation-Demo,gradio,,1
-13887,Falah/female,gradio,openrail,1
-13888,shiyi11/anime-ai-detect,gradio,,1
-13889,AeroXi/english-ai,gradio,mit,1
-13890,Pranjal-666/DL_bearTypeTest,gradio,apache-2.0,1
-13891,divyahansg/text-generation-webui-space,gradio,mit,1
-13892,emmaenglish/sentiment-analysis-of-text-app,streamlit,,1
-13893,Jeffgold/BackgroundEraser,gradio,openrail,1
-13894,ieuniversity/Pangea,gradio,,1
-13895,Promptengineering/anon8231489123-vicuna-13b-GPTQ-4bit-128g,gradio,,1
-13896,sadickam/Domestic-Building-Construction-Cost-Planning,streamlit,mit,1
-13897,Sarst/VITS-Umamusume-voice-synthesizer2,gradio,,1
-13898,shiguangshiwo/anime-remove-background,gradio,apache-2.0,1
-13899,ochyai/ochyai_test,gradio,,1
-13900,yancey001/Linaqruf-anything-v3.0,gradio,openrail,1
-13901,chufeng09/Panel_PDF_QA,docker,,1
-13902,ieuniversity/News-Translator,gradio,,1
-13903,adriansd12/Bible_Index,gradio,,1
-13904,halek3550/thaimop,Configuration error,Configuration error,1
-13905,Navneet574/Kidney_Stone_Prediction,gradio,cc-by-nc-sa-4.0,1
-13906,KalbeDigitalLab/pathology_nuclei_segmentation_classification,docker,,1
-13907,kenttate937/pelisplusss,Configuration error,Configuration error,1
-13908,xiaoyun235/White-box-Cartoonization,gradio,apache-2.0,1
-13909,s1241003/translate_gpt,gradio,,1
-13910,gradio/space-api-fetcher,gradio,mit,1
-13911,RedYan/nitrosocke-Ghibli-Diffusion,gradio,,1
-13912,Wing0820/Real-CUGAN,gradio,gpl-3.0,1
-13913,vg055/demo_analisis_de_sentimientos_textos_turisticos_mx_polarity,gradio,unknown,1
-13914,Jerseyborn/openai-whisper-large-v2,gradio,,1
-13915,hussain-shk/IndiSent,gradio,mit,1
-13916,arcAman07/KanyeGEN,gradio,openrail,1
-13917,hackathon-somos-nlp-2023/ask2democracy,streamlit,apache-2.0,1
-13918,vg055/roberta-base-bne-finetuned-analisis-sentimiento-textos-turisticos-mx-pais,gradio,unknown,1
-13919,sklearn-docs/Hierarchical-clustering-dendrogram,gradio,creativeml-openrail-m,1
-13920,dylanmcc/beaverdam,gradio,openrail,1
-13921,futuristicdude/andite-anything-v4.0,gradio,openrail,1
-13922,CNXT/CHaTx,docker,creativeml-openrail-m,1
-13923,CNXT/GPTx,gradio,,1
-13924,yuyijiong/quad_match_score,gradio,,1
-13925,sklearn-docs/SGD-max-margin-seperation-hyperplane,gradio,mit,1
-13926,smallyu/dalle-mini,static,apache-2.0,1
-13927,jobcher/background-removal,gradio,apache-2.0,1
-13928,sklearn-docs/Lasso_and_elasticnet_for_sparse_signals,gradio,creativeml-openrail-m,1
-13929,dddmiku/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13930,Fox1997/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13931,bitcool/humarin-chatgpt_paraphraser_on_T5_base,gradio,,1
-13932,megatron7/bert-base-chinese,gradio,apache-2.0,1
-13933,yanli01/wrwj,gradio,gpl-3.0,1
-13934,qi3/White-box-Cartoonization,gradio,apache-2.0,1
-13935,yeashwant/chatgpt-prompt-generator-v12,gradio,apache-2.0,1
-13936,prerna9811/Chord,streamlit,,1
-13937,johnsamuel/stabilityai-stable-diffusion-2-1,gradio,,1
-13938,Lasion/NCKH_2023,gradio,mit,1
-13939,IntelligenzaArtificiale/ChatGLM-6B-Int4-API-OpenAI-Compatible,docker,apache-2.0,1
-13940,gsrathoreniks/web_ui,gradio,,1
-13941,poiiii/clefourrier-graphormer-base-pcqm4mv1,gradio,,1
-13942,xizhongluomu/Real-CUGAN,gradio,gpl-3.0,1
-13943,sairam9/ChatGPT4,gradio,mit,1
-13944,sklearn-docs/huber-vs-ridge-regression-for-outliers,gradio,,1
-13945,ras0k/WhisperX-v2,gradio,bsd,1
-13946,daveckw/prompt-2-sd,gradio,,1
-13947,AlawnCN/webui-docker,docker,,1
-13948,UtkMal/Classifying-snake-breeds,gradio,apache-2.0,1
-13949,Celestinian/Nora-Inference,gradio,mit,1
-13950,SebastianSchramm/Cerebras-GPT-111M-instruction-playground,gradio,,1
-13951,mrwenchen/stabilityai-stable-diffusion-2-1,gradio,,1
-13952,THEBOGLER/toxicman,streamlit,,1
-13953,BHO/URDtest,gradio,openrail,1
-13954,Kevin676/Gpt4All,gradio,,1
-13955,Artples/Named-Entity-Recognition,gradio,apache-2.0,1
-13956,kglema/lemitar.AI,streamlit,,1
-13957,Raaniel/Keyword_demo,gradio,apache-2.0,1
-13958,kazuk/youtube-whisper-13,gradio,unknown,1
-13959,awacke1/SelfCareDimensionsPositiveReframing,streamlit,mit,1
-13960,radwulf101/ChatGPT4,gradio,mit,1
-13961,sklearn-docs/Random_sample_consensus,gradio,creativeml-openrail-m,1
-13962,Ikaros521/VITS-fast-fine-tuning_nymph,gradio,apache-2.0,1
-13963,dyhzq/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13964,rires-kasai/whisper-transcription,gradio,apache-2.0,1
-13965,Qiukai/gpt,gradio,,1
-13966,Ryukijano/fastai_pet_classifier_resnet50,gradio,mit,1
-13967,cldelisle/test,gradio,apache-2.0,1
-13968,Chintan-Donda/KKMS-KSSW-HF,gradio,,1
-13969,paschalc/ImageRecognitionDemo,gradio,apache-2.0,1
-13970,cpwan/RLOR-TSP,gradio,,1
-13971,xangma/chat-pykg,gradio,mit,1
-13972,NoFearNoDistractions/ChatGPT4,gradio,mit,1
-13973,pplonski/mr,gradio,mit,1
-13974,Voicelab/vlT5-rfc-generation,streamlit,,1
-13975,AiBototicus/BucksAI-2,streamlit,bsd-3-clause-clear,1
-13976,awacke1/LLMMethodologyToImproveLearning,streamlit,mit,1
-13977,awacke1/AzureContainerAppsAIArchitecture,streamlit,mit,1
-13978,8star/DeepDanbooru_string,gradio,,1
-13979,mb1te/PSII_FINAL,docker,apache-2.0,1
-13980,awacke1/Memory-Chat-Story-Generator-Bloom,gradio,mit,1
-13981,AiBototicus/BucksAI-3,gradio,bigscience-openrail-m,1
-13982,doctorsafe/mychat,gradio,afl-3.0,1
-13983,sklearn-docs/Comparison_K_Means_MiniBatchKMeans,gradio,creativeml-openrail-m,1
-13984,AiBototicus/BucksAI-4,gradio,openrail,1
-13985,birgermoell/syllables_app,streamlit,,1
-13986,haoyu/age_detection,streamlit,mit,1
-13987,bugbugbug/vits-uma-genshin-honkai,gradio,apache-2.0,1
-13988,YangHao520/testShare,gradio,bsd,1
-13989,sklearn-docs/Plot-Ridge-Coefficients-as-A-Function-of-the-Regularization,gradio,,1
-13990,Aitor/CVchat,gradio,cc-by-4.0,1
-13991,andufkova/articles,gradio,unlicense,1
-13992,radames/gradio-chatbot-read-query-param,gradio,,1
-13993,sklearn-docs/mean-shift-clustering,gradio,,1
-13994,Duskfallcrew/Osenayan_Mix,gradio,,1
-13995,sklearn-docs/receiver-operating-characteristic-with-cross-validation,gradio,cc-by-sa-4.0,1
-13996,Duskfallcrew/Duskfallcrew-Osenayan_Mix,gradio,creativeml-openrail-m,1
-13997,hololabs/bibleyouread,gradio,other,1
-13998,sklearn-docs/voting-classifier-plots,gradio,,1
-13999,raomaya/COVID_travel_dashboard,streamlit,,1
-14000,changlisheng/shangChat,gradio,gpl-3.0,1
-14001,wanfeimsn/stabilityai-stable-diffusion-2-1,gradio,,1
-14002,sklearn-docs/affinity-propagation-clustering,gradio,apache-2.0,1
-14003,dhfdh/stable-Diffusion-Inpainting-with-Segment-Anything,gradio,cc-by-nc-4.0,1
-14004,zhangbo2008/chainyo-alpaca-lora-7b,gradio,,1
-14005,Anonumous/RuImageCaptioning,gradio,apache-2.0,1
-14006,YukiKurosawaDev/ChatGLM,gradio,mit,1
-14007,0xtanmoysamanta/espnet-kan-bayashi_ljspeech_vits,gradio,mit,1
-14008,asafAdge/color_clustering,gradio,mit,1
-14009,Zpwang-AI/InsultingLanguageDetection,gradio,unknown,1
-14010,Jacks2003/3D_Photo_Inpainting,gradio,,1
-14011,yunzai123/anime-ai-detect,gradio,,1
-14012,ceckenrode/SelfCareDimensionsPositiveReframing,streamlit,mit,1
-14013,ceckenrode/Memory-Chat-Story-Generator-Bloom,gradio,mit,1
-14014,ceckenrode/Memory-Chat-Story-Generator-ChatGPT,gradio,mit,1
-14015,B1360976/waste-management-system,streamlit,,1
-14016,katanaml-org/sparrow-ml,docker,mit,1
-14017,spenceryonce/gpt2,gradio,,1
-14018,lewisrxliu/3.3,gradio,,1
-14019,dorkai/singpt,gradio,mit,1
-14020,sklearn-docs/Joint-feature-selection-with-multi-task-Lasso,gradio,bsd-3-clause,1
-14021,cyanab/GlobalVoice1,gradio,,1
-14022,nateraw/jupyterlab-test2,docker,,1
-14023,whilefalse/CLIP,gradio,,1
-14024,nateraw/huggingface-user-stats,gradio,mit,1
-14025,chkla/PromptCardsPlayground,streamlit,,1
-14026,Nikitowie/Lama-Cleaner-lama,gradio,apache-2.0,1
-14027,Libra7578/Image-to-video,gradio,other,1
-14028,olivianuzum/TwitterTwin,gradio,other,1
-14029,dawood17/SayBot_Enchancer,gradio,apache-2.0,1
-14030,Raaniel/Search_Engine2.0,gradio,apache-2.0,1
-14031,soodoku/ethnicolr,streamlit,mit,1
-14032,sklearn-docs/ridge-coefficients-vs-L2,gradio,,1
-14033,dfyinc/GeniusChat,gradio,,1
-14034,kdb8756/Pip_Counter,gradio,mit,1
-14035,cloudwp/prompt-machine,gradio,apache-2.0,1
-14036,luckli/22h-vintedois-diffusion-v0-1,gradio,,1
-14037,luckli/chavinlo-gpt4-x-alpaca,gradio,,1
-14038,KarmaCST/Dzongkha-To-English-Translation-NLLB-Fine-tuning,gradio,,1
-14039,rainy3/chatgpt_academic,gradio,,1
-14040,AiPalsDev/Translate_It,gradio,apache-2.0,1
-14041,lambdasec/santafixer-demo,gradio,,1
-14042,weide/ChuanhuChatGPT2,gradio,gpl-3.0,1
-14043,xinchen0215/gradioTest,gradio,mit,1
-14044,sredevops/README,static,,1
-14045,Plsek/CADET,streamlit,,1
-14046,sklearn-docs/MNIST-Agglomerative-Clustering,gradio,,1
-14047,MingGatsby/VoiceFixer,gradio,,1
-14048,MohitGupta/Eng2Indic_Translitration,gradio,bsd-3-clause-clear,1
-14049,thieutrungkien/Hosioka-Baka-Diffusion,gradio,,1
-14050,CoWork/dreambooth-training-public,gradio,mit,1
-14051,Adr740/SmartHadithFR,gradio,,1
-14052,srush/gradio_tools,gradio,,1
-14053,PranayVerma/IRIS,gradio,,1
-14054,srush/minichain-table,gradio,,1
-14055,Xixeo/Face_Recognition,gradio,gpl-3.0,1
-14056,naxida/anime-remove-background,gradio,apache-2.0,1
-14057,jleexp/Youtube-Whisperer,gradio,,1
-14058,adamcasson/transformer-flops-calculator,gradio,,1
-14059,SmallSpider/DeepDanbooru_string,gradio,,1
-14060,Cosmopolitan/stabilityai-stable-diffusion-2-1,gradio,,1
-14061,lora-x/Backpack,gradio,,1
-14062,UndueTarget/audioFILE_to_text,gradio,,1
-14063,yueyouxin/runwayml-stable-diffusion-v1-5,gradio,,1
-14064,IcelandAI/Iceland-Top-Ten-Things-To-See,streamlit,mit,1
-14065,iamkhadke/chatbot,gradio,apache-2.0,1
-14066,IcelandAI/AnimalsOfIceland,streamlit,mit,1
-14067,awacke1/Streamlit-Clipboard-Monitor-Javascript,streamlit,mit,1
-14068,hhhhardman/VITS-Umamusume-voice-synthesizer,gradio,,1
-14069,hhhhardman/VITS,gradio,,1
-14070,awacke1/File-Memory-Human-Feedback-Streamlit,streamlit,mit,1
-14071,IcelandAI/Foods-and-Drinks-of-Iceland,streamlit,mit,1
-14072,Pearx/ChatGPT-Assistant,streamlit,apache-2.0,1
-14073,itacaiunas/gerador-imagens,gradio,,1
-14074,Proxdigestpills1/README,Configuration error,Configuration error,1
-14075,Faizanshaikh/runwayml-stable-diffusion-v1-5,gradio,,1
-14076,Cloudfeng/anime-remove-background,gradio,apache-2.0,1
-14077,JediHustle/beartector,gradio,apache-2.0,1
-14078,Lilflerkin/WellNexus,gradio,,1
-14079,stanciu/eachadea-legacy-vicuna-13b,gradio,,1
-14080,nikansh/hamyar_riazi,streamlit,,1
-14081,Duskfallcrew/EpicMix_Realism_WebUi,gradio,,1
-14082,HESOAYM/ElviraMulti,gradio,gpl-3.0,1
-14083,Afnaan/chatbots,gradio,,1
-14084,karelgideon/talent-fair-h8-karel,streamlit,,1
-14085,Greysuki/whisper-api-compress,gradio,mit,1
-14086,humbe/comunico,gradio,,1
-14087,itintelpro/MyCybersecHelper,gradio,other,1
-14088,iamkhadke/pix2struct_docvqa,gradio,artistic-2.0,1
-14089,fael33/NAWNIE-golden-hour-photography,gradio,,1
-14090,sensho-lx/MubertTTM,gradio,osl-3.0,1
-14091,cloudwp/Top-20-Diffusion,gradio,,1
-14092,tanvirsingh01/YourMoodDiary,gradio,,1
-14093,cloudwp/DreamShaper-webui,gradio,,1
-14094,cloudwp/simpleGPT,gradio,,1
-14095,giiift/expert_system,gradio,unknown,1
-14096,kony1337/frame-interpolation-fix,gradio,,1
-14097,Natsha/mocap-ai,docker,,1
-14098,onuri/asst,gradio,,1
-14099,rgergw/White-box-Cartoonization,gradio,apache-2.0,1
-14100,varun500/flan-alpaca-base,streamlit,,1
-14101,BigChia/bird_classifier,gradio,apache-2.0,1
-14102,Jmmianda/memo,gradio,,1
-14103,blaziant/ysda_nlp_ops,docker,,1
-14104,ankitnag0/ChatGPT4,gradio,mit,1
-14105,Abduhoshim/speech_emotion_detection,gradio,,1
-14106,NechkaP/arxiv-streamlit-lab,streamlit,cc,1
-14107,effluxriad/YouTube-comments-generator,streamlit,mit,1
-14108,jusancp99/imagenes_similares,gradio,,1
-14109,diazcalvi/KIONAPI,gradio,openrail,1
-14110,ferdmartin/DogBreedsApp,streamlit,mit,1
-14111,realambuj/Image-Captioning-App-using-BLIP,streamlit,,1
-14112,AdamWEE80/VoiceTTS,gradio,,1
-14113,timo1227/Image,streamlit,,1
-14114,Kevin676/Telephone-Interviewing_PpaddleSpeech-TTS,gradio,mit,1
-14115,luotr123/myWeb,gradio,apache-2.0,1
-14116,sklearn-docs/Feature-Transformations-with-Ensembles-of-Trees,gradio,,1
-14117,v-nemala/similar-images,streamlit,,1
-14118,Cecil8352/vits-models,gradio,apache-2.0,1
-14119,svjack/Question-Generator-on-Chinese-Doc,gradio,,1
-14120,cactusAtSea/influencerGPT,streamlit,unknown,1
-14121,6Eternal9/ChatGPT4,gradio,mit,1
-14122,Big-Web/MMSD,gradio,,1
-14123,Vasanthgx/Pet_Classifier_vasanth,gradio,apache-2.0,1
-14124,nkigumnov/banks-ethics-sentiment,gradio,mit,1
-14125,SuCicada/Lain-vits,gradio,,1
-14126,pkarthik15/docchat,gradio,apache-2.0,1
-14127,Dute8788/anime,gradio,apache-2.0,1
-14128,theholycityweb/HuggingGPT,gradio,,1
-14129,55dgxxx558/anime-remove-background,gradio,apache-2.0,1
-14130,aLIdAmIrI/math-help,streamlit,mit,1
-14131,kazgafa/ChatGPT4,gradio,mit,1
-14132,ThirdEyeData/Customer-Conversion-Prediction,streamlit,,1
-14133,yock116/ChuanhuChatGPT,gradio,gpl-3.0,1
-14134,theblocknoob/hugging-face-space,static,,1
-14135,anjaymabskuy/Linaqruf-anything-v3.0,gradio,,1
-14136,datagpt/url2info,gradio,gpl-3.0,1
-14137,sklearn-docs/bayesian-ridge-regression,gradio,,1
-14138,SkidPC/SweetLuna-Aurora,gradio,,1
-14139,dfgnota/gpt-doc-mem,streamlit,lgpl-3.0,1
-14140,volhack/vits-uma-genshin-honkai,gradio,apache-2.0,1
-14141,awacke1/Slot-Machine-HTML5,static,mit,1
-14142,awacke1/Slot-Machine-Animal-Safari,static,mit,1
-14143,diaoren/OpenSetObstacleDetection,gradio,,1
-14144,kumar989/Health_Vision_1,streamlit,,1
-14145,csumbdante/fire-api,streamlit,,1
-14146,Mahiruoshi/lovelive-ShojoKageki-vits,gradio,cc-by-nc-3.0,1
-14147,anekcb/Bee4Med,gradio,,1
-14148,suryabbrj/CollegeProjectV2,gradio,,1
-14149,alexrods/Smartcity-Traffic-Detection,streamlit,mit,1
-14150,duong11111/ChatGPT4.0,gradio,mit,1
-14151,PrathmeshZ/StoryTellGPTneo13,gradio,,1
-14152,victor/tesla,docker,,1
-14153,Vasanthgx/Cats_vs_Dogs_vasanth,gradio,apache-2.0,1
-14154,cannlytics/skunkfx,streamlit,mit,1
-14155,xiang2811/ChatGPT,gradio,gpl-3.0,1
-14156,alicelouis/NSCLC_classification,streamlit,mit,1
-14157,galang123/test123test,static,,1
-14158,shvuuuu/Credit_Card_Churn_Predictor,gradio,apache-2.0,1
-14159,prasanna2003/ChatOPT,gradio,,1
-14160,teragron/docuchat-webui,gradio,mit,1
-14161,DmitriiKhizbullin/camel-data-explorer,gradio,apache-2.0,1
-14162,ssreeramj/tiger-town-hall-chatbot,gradio,,1
-14163,sklearn-docs/birch_vs_minibatchkmeans,gradio,apache-2.0,1
-14164,CillySu/prompthero-openjourney-v4,gradio,,1
-14165,Immi007/ChatGPT4,gradio,mit,1
-14166,louiszhuang/pony,streamlit,,1
-14167,eunjae/LoRA-DreamBooth-Training-UI,gradio,mit,1
-14168,theabdullahzeeshan/seven,gradio,apache-2.0,1
-14169,Intoval/privateChatGPT,gradio,gpl-3.0,1
-14170,nebula/counting-anything,gradio,,1
-14171,fb700/chat3,gradio,,1
-14172,manh-linh/Linh-Gradio,gradio,openrail,1
-14173,meaqua33/White-box-Cartoonization,gradio,apache-2.0,1
-14174,Ekittl01/Endeavors,docker,bigscience-openrail-m,1
-14175,Li2024/chatai,gradio,,1
-14176,teli168/human-centered-summarization-financial-summarization-pegasus,gradio,,1
-14177,realambuj/Image_Classifier_using_RESNET50,streamlit,,1
-14178,ho11laqe/nnUNet_calvingfront_detection,gradio,cc-by-4.0,1
-14179,xiayi/anime-remove-background,gradio,apache-2.0,1
-14180,ch1n3du/bird_or_forest,gradio,apache-2.0,1
-14181,Gmq-x/gpt-academic,gradio,,1
-14182,tyoung560/ai-assist,gradio,unknown,1
-14183,Ailexcoder/GPT4ALL1,gradio,,1
-14184,salamat/first_app,streamlit,,1
-14185,jerichosy/DIGIMAP-Colorization-Web-App,gradio,bsd-2-clause,1
-14186,hrishikeshpai30/hrishikeshpai30-wavlm-libri-clean-100h-large,gradio,unknown,1
-14187,msawant/sample_assist,gradio,openrail,1
-14188,maxineattobrah/EmotionDetection,gradio,,1
-14189,xiaoxiao140420/anime-remove-background,gradio,apache-2.0,1
-14190,hectorduran/wavescomparing,streamlit,cc-by-nc-4.0,1
-14191,Haleyok/stablelm-tuned-alpha-chat,gradio,,1
-14192,tsailada/Emily,gradio,other,1
-14193,DuckyPolice/stabilityai-stable-diffusion-2-1,gradio,,1
-14194,tsailada/Chefsky,gradio,unknown,1
-14195,spring-chatbot/customer-service-assistant,gradio,mit,1
-14196,zylj/MiniGPT-4,docker,openrail,1
-14197,aodianyun/whisper,gradio,,1
-14198,TechShark20/handwespeak,gradio,unknown,1
-14199,jsscclr/CLIP-Interrogator,gradio,mit,1
-14200,Robinn/WordSent,streamlit,mit,1
-14201,ledetele/KrystalPDF,gradio,,1
-14202,cccccch/VITS-fast-fine-tuning-DingZhen,gradio,apache-2.0,1
-14203,MasterThesisCBS/NorPaca_GPT,streamlit,,1
-14204,a245757/rebornrun,gradio,,1
-14205,EagleLoveAI/ChatGPT_Application_Robot,gradio,mit,1
-14206,EnigmaOfTheWorld/TechnoForge_Automotive,gradio,,1
-14207,michael1943/geektime-ai-class,gradio,mit,1
-14208,huanghun/yuyinkelongChatGPT-with-Voice-Cloning-for-All,gradio,mit,1
-14209,2ndelement/voicevox,docker,lgpl-3.0,1
-14210,jordonpeter01/laudos,static,,1
-14211,Jaggi/ImageGenration,gradio,apache-2.0,1
-14212,HadiTajari/Penguins_pred_App,streamlit,,1
-14213,Ryukijano/Ryukijano-controlnet-fill-circle,gradio,,1
-14214,PushkarA07/Sanskrit-Text-To-Speech,gradio,gpl-3.0,1
-14215,noman1408/speechToSpeechGPT,gradio,,1
-14216,d3finit/AI,gradio,,1
-14217,kalvjam/chgpt,gradio,apache-2.0,1
-14218,Ifeanyi/tellme.ai,gradio,,1
-14219,Jaffermirza17/ProjectPythonClass,gradio,mit,1
-14220,testingcodehere/oai-proxy,docker,,1
-14221,hectorduran/wordsimilarity,streamlit,cc-by-nd-4.0,1
-14222,Hashom132/stabilityai-stable-diffusion-2,gradio,,1
-14223,UVA-GCOM/Group_4,gradio,mit,1
-14224,blaziant/ysda_nlp_ops_update,docker,,1
-14225,jkubacki/pokedex,gradio,,1
-14226,hesha/anime-remove-background,gradio,,1
-14227,Kevin676/NLLB-Translator,gradio,wtfpl,1
-14228,JerryYou/ChatGPT-prompt-generator,gradio,apache-2.0,1
-14229,ParagKesharDas360/MovieRecommadationApp,streamlit,,1
-14230,datagpt/pdf2gpt,gradio,mit,1
-14231,sklearn-docs/Out-of-Bag-Random-Forest,gradio,,1
-14232,rajeshradhakrishnan/english-malayalam,docker,,1
-14233,speeddemonau/OpenAssistant-stablelm-7b-sft-v7-epoch-3,gradio,,1
-14234,kernel982/Youtube-Transcriber,streamlit,,1
-14235,Feifei315/Joeythemonster-anything-midjourney-v-4-1,gradio,,1
-14236,Monster/alpaca-lora_13b_q,gradio,,1
-14237,nsakki55/my-aim-demo,docker,other,1
-14238,DEfiAnTH/SPSpace,docker,apache-2.0,1
-14239,Stephen2022/daxing,docker,apache-2.0,1
-14240,TD-jayadeera/Password_Strength_Prediction,gradio,,1
-14241,snoopyv126/gpt,gradio,,1
-14242,ShreyashNadage/InvestmentCopilot,streamlit,apache-2.0,1
-14243,HighCWu/Style2Paints-4-Gradio,gradio,apache-2.0,1
-14244,Pluviophile/vits-uma-genshin-honkai,gradio,apache-2.0,1
-14245,amasgari06/ChatGPT4,gradio,mit,1
-14246,ANLPRL/NER_On_Oral_Medicine,streamlit,,1
-14247,vishal2023/Pneumonia-detection,gradio,bigscience-openrail-m,1
-14248,pplonski/my-notebooks,gradio,mit,1
-14249,seblutzer/ChatGPT4,gradio,mit,1
-14250,trholding/SpeechCloning,gradio,mit,1
-14251,Feifei315/flax-midjourney-v4-diffusion,gradio,,1
-14252,JackBAI/MassageMateNLP,gradio,mit,1
-14253,McClane-Lee/fnlp-moss-moon-003-base,gradio,,1
-14254,ivanho92/training,gradio,apache-2.0,1
-14255,typesdigital/TD-OpenWeatherMap-API,gradio,unlicense,1
-14256,FrozenWolf/Neural-Style-Transfer,gradio,,1
-14257,typesdigital/image-to-text-app-td,streamlit,,1
-14258,typesdigital/twitter-pro,streamlit,afl-3.0,1
-14259,huohguohbo/Chatbot_REQUIRES_OPENAI_KEY,gradio,apache-2.0,1
-14260,Danuuo/GPTDocs,gradio,afl-3.0,1
-14261,XyBr0/test,gradio,apache-2.0,1
-14262,kenton-li/yolo_cell,gradio,,1
-14263,Fareso/minima,gradio,apache-2.0,1
-14264,jotarodadada/animeCf,gradio,gpl-3.0,1
-14265,radames/gradio_streaming_webcam_blocks,gradio,,1
-14266,jmesikto/whisper-webui,gradio,apache-2.0,1
-14267,UVA-GCOM/Shuran_Ivy_Anlin_Robin,gradio,mit,1
-14268,matthoffner/baby-gorilla-agi,streamlit,,1
-14269,sahshd/ChuanhuChatGPT,gradio,gpl-3.0,1
-14270,Kedreamix/YoloGesture,streamlit,openrail,1
-14271,Ntabukiraniro/Recipe,streamlit,,1
-14272,tharunk07/crop-prediction,static,apache-2.0,1
-14273,HachiRe/Fusani,static,,1
-14274,yusendai/fnlp-moss-moon-003-sft-plugin,gradio,,1
-14275,huedaya/hf-openai-whisper-dev,gradio,,1
-14276,fueny/git7fueny,gradio,mit,1
-14277,NicolasGaudemet/WritingAssistant,gradio,,1
-14278,caoyiming/vits-uma-genshin-honkai,gradio,apache-2.0,1
-14279,zhengyu123/ighchatgpt,gradio,,1
-14280,cryptoanonymous77/README,static,,1
-14281,Sambhavnoobcoder/pneumonia-detector-v1,gradio,,1
-14282,FriendlyUser/bark,gradio,cc-by-nc-4.0,1
-14283,momegas/megabots,gradio,mit,1
-14284,godspeedsystems/README,static,,1
-14285,typesdigital/telegram-chatbot,gradio,afl-3.0,1
-14286,Jarex/TwitterBot,gradio,afl-3.0,1
-14287,Mcdimmy/Clothing-Identifier,gradio,apache-2.0,1
-14288,rick200213/Text2speech,gradio,openrail,1
-14289,addiopattio/idkman,static,openrail,1
-14290,MathysL/pwa,gradio,,1
-14291,Finnone/stabilityai-stablelm-tuned-alpha-7b,gradio,,1
-14292,Crow34/Joi,gradio,openrail,1
-14293,zhuyuheng/IMossGPT,gradio,gpl-3.0,1
-14294,vorstcavry/VoCh-beta,gradio,mit,1
-14295,Ananthap4/itineraryGenerator,gradio,,1
-14296,asd998877/TsGpt,gradio,gpl-3.0,1
-14297,sagar-kris/harry-mack-bot,gradio,apache-2.0,1
-14298,typesdigital/CryptoUpdate,gradio,cc0-1.0,1
-14299,typesdigital/Gpt4all,gradio,apache-2.0,1
-14300,Sky5408er/anime-remove-background,gradio,apache-2.0,1
-14301,yuhanbo/chat-gpt,docker,openrail,1
-14302,zox47/succinctly-text2image-prompt-generator,gradio,,1
-14303,Navneet574/Drug_Classification,gradio,cc-by-nc-nd-4.0,1
-14304,Navneet574/Heart_Disease_Prediciton,gradio,cc-by-nc-nd-4.0,1
-14305,msmilauer/AutoGPT-duplicated2,gradio,mit,1
-14306,yuukicammy/vit-gpt2-image-captioning,gradio,apache-2.0,1
-14307,jibay/test,docker,,1
-14308,typesdigital/CodeX,gradio,cc-by-2.0,1
-14309,tanmaysindia/vasista22-whisper-hindi-large-v2,gradio,,1
-14310,Rams901/flight-chat,gradio,,1
-14311,Raghav001/Experiment,gradio,apache-2.0,1
-14312,Shadow344/ogkalu-Comic-Diffusion,gradio,,1
-14313,Akbartus/U2net-with-rgba,gradio,,1
-14314,RKocielnik/bias-test-gpt,gradio,afl-3.0,1
-14315,venkataseetharam/similaritysearchnew,streamlit,,1
-14316,yashzambre/EXCEL,gradio,mit,1
-14317,Xule/ChuanhuChatGPT,gradio,gpl-3.0,1
-14318,dapaipai/ChatGPT4,gradio,mit,1
-14319,Bishnupada/Fine-tuning-using-Hugging-face-transformers,gradio,,1
-14320,simplyjaga/movie_genius,gradio,,1
-14321,harry991/geektime-ai-course-demo,gradio,mit,1
-14322,Lenery/Dolly-v2,gradio,,1
-14323,uchuukaizoku/CharcaterClassifier1,gradio,openrail,1
-14324,koalaYuan/gradio-demo,gradio,,1
-14325,Alpaca233/LangchainPDF,gradio,,1
-14326,Rakesh30/Sentence_Embedding-App,gradio,,1
-14327,Tape/yoga,gradio,openrail,1
-14328,dhanushreddy29/microstructure-project,gradio,mit,1
-14329,hdm1/mindtune,docker,cc-by-sa-4.0,1
-14330,dorkai/dorkgpt,gradio,,1
-14331,sinz2002/ChuanhuChatGPT,gradio,gpl-3.0,1
-14332,easrng/text-to-emoji,gradio,other,1
-14333,MikoProduction/PneumoniaDetector,gradio,mit,1
-14334,LLxD/prompthero-openjourney-v4,gradio,,1
-14335,caslabs/sanity-test-midi,gradio,openrail,1
-14336,ApathyINC/CustomGPT,gradio,,1
-14337,luckybender/ChatGPT4,gradio,mit,1
-14338,typesdigital/HealthBOT,gradio,cc0-1.0,1
-14339,srossitto79/RajuKandasamy-dolly-v2-3b-8bit,gradio,,1
-14340,jvde/sovits-webui,gradio,,1
-14341,ericmichael/openai-playground-utrgv,docker,,1
-14342,amgad59/Keras_cv_wedding_dress,gradio,openrail,1
-14343,bizvideoschool/ScriptWriterTest,gradio,,1
-14344,typesdigital/CODEX-explore,gradio,cc-by-2.5,1
-14345,arxnov/anotest,gradio,,1
-14346,amarchheda/ChordDuplicate,streamlit,,1
-14347,Terminus0501/vits-uma-genshin-honkai,gradio,apache-2.0,1
-14348,sklearn-docs/early_stopping_of_gradient_boosting,gradio,creativeml-openrail-m,1
-14349,HaMerL/ChaosinChat,gradio,gpl-3.0,1
-14350,Hoodady/3DFuse,gradio,cc,1
-14351,zhuge09/CompVis-stable-diffusion-v4,gradio,openrail,1
-14352,pd4solutions/ATLChatbot,gradio,,1
-14353,Renxd/devast,streamlit,,1
-14354,aarontanzb/Langchain_query_app,docker,,1
-14355,Sparkles-AI/design-look-a-likes,docker,unknown,1
-14356,XAI/Cleaning-ImageNet-Hard,gradio,mit,1
-14357,inesani/ner-log,gradio,,1
-14358,cloudwp/place_of_Imagination,gradio,unknown,1
-14359,noahzev/bark,gradio,cc-by-nc-4.0,1
-14360,cryptoanonymous/02dlyaPerevoda3dVideoV2DAnime,docker,openrail,1
-14361,Nour33/sci_summ,gradio,,1
-14362,sheraznaseer/test_pdfqa_2304,docker,,1
-14363,Revanth200218/Project,streamlit,artistic-2.0,1
-14364,DaCuteRaccoon/dalle-mini,static,apache-2.0,1
-14365,usamakenway/bark-Ai-audio,gradio,cc-by-nc-4.0,1
-14366,AhmedBadrDev/stomach,gradio,,1
-14367,timpal0l/chat-ui,docker,apache-2.0,1
-14368,radames/gradio_audio_streaming_blocks,gradio,,1
-14369,omkarmore83/t5-base,gradio,,1
-14370,chaozn/fastai_dogs_vs_cats,gradio,apache-2.0,1
-14371,Basil2k4/VPSnguyenmanh,docker,,1
-14372,1gistliPinn/ChatGPT4,gradio,mit,1
-14373,marcilioduarte/Credit-Worthiness-Risk-Classification,gradio,apache-2.0,1
-14374,Ryukijano/Real-CUGAN,gradio,apache-2.0,1
-14375,bhavyagiri/recyclopes,gradio,apache-2.0,1
-14376,nanglo123/GTSRB-Deployment,gradio,mit,1
-14377,arslvn/statuscertificate,gradio,afl-3.0,1
-14378,bhaskartripathi/Text2Diagram,gradio,wtfpl,1
-14379,BertChristiaens/youtube-dl,streamlit,openrail,1
-14380,wrldreform/TextImagine-1.0-March-2023,gradio,,1
-14381,wrldreform/Text2ImageStable2.1,gradio,,1
-14382,meetv25/ML,streamlit,openrail,1
-14383,awacke1/REBEL-Knowledge-Graph-Generator,streamlit,,1
-14384,scedlatioru/img-to-music,gradio,,1
-14385,echozf/dfsg,gradio,bigscience-openrail-m,1
-14386,timqian/like-history,static,gpl-3.0,1
-14387,CNXT/PiX2TXT,gradio,,1
-14388,mrLarry/image_variation,gradio,artistic-2.0,1
-14389,abtExp/source_separation,gradio,mit,1
-14390,diacanFperku/AutoGPT,gradio,mit,1
-14391,katebor/Taxonomy,static,mit,1
-14392,rahimimiladofficial/fastai_pet_classifier,gradio,,1
-14393,wonoqo/AlphaGPT,gradio,apache-2.0,1
-14394,FourthBrainGenAI/MarketMail-AI-Space,gradio,openrail,1
-14395,giacomov/pdffigures2,docker,apache-2.0,1
-14396,HuguesdeF/moulinette,docker,apache-2.0,1
-14397,tjeagle/Subaru,gradio,apache-2.0,1
-14398,thealphhamerc/audio-to-text,gradio,,1
-14399,timothynn/demo-space,streamlit,,1
-14400,XyBr0/DogBreedClassifier,gradio,apache-2.0,1
-14401,tioseFevbu/cartoon-converter,gradio,,1
-14402,merve/alpaca-tr-crowdsource,gradio,apache-2.0,1
-14403,stomexserde/gpt4-ui,streamlit,,1
-14404,netiMophi/DreamlikeArt-Diffusion-1.0,gradio,,1
-14405,Next7years/CatHeiHei_v1,gradio,mit,1
-14406,tuan2010/DocumentGPT,gradio,unknown,1
-14407,ferdmartin/GradApplicationDocsApp2,streamlit,mit,1
-14408,Yuankai/ChatReviewer,gradio,apache-2.0,1
-14409,EnigmaOfTheWorld/GenZBot,gradio,,1
-14410,llovantale/ChatGPT4,gradio,mit,1
-14411,Devap001/top-5_movies_recommendation,gradio,,1
-14412,himanshu5111/sports_classifier,gradio,mit,1
-14413,tokudai/GODEL-Demo,gradio,mit,1
-14414,kashif/probabilistic-forecast,gradio,apache-2.0,1
-14415,JiaoFa/bert-base-chinese,gradio,,1
-14416,patrickvonplaten/ckpt-to-diffusers,gradio,apache-2.0,1
-14417,caslabs/midi-autocompletion,gradio,openrail,1
-14418,B10915003/B10915003-autotrain-jimmy-test-face-identification-53251125423,gradio,apache-2.0,1
-14419,Narsil/graph_spectrum,gradio,,1
-14420,chenman/Meina-MeinaMix,gradio,creativeml-openrail-m,1
-14421,DevashishBhake/Face_Mask_Detection,gradio,mit,1
-14422,zhangs2022/ChuanhuChatGPT,gradio,gpl-3.0,1
-14423,javihp/microsoft-speecht5_tts,gradio,,1
-14424,himanshubhardwaz/nlpconnect-vit-gpt2-image-captioning,gradio,,1
-14425,sklearn-docs/Pipeline-ANOVA-SVM,gradio,,1
-14426,SharkGaming/VisualAI,gradio,,1
-14427,GiladtheFixer/test_sentiment,gradio,,1
-14428,Serg4451D/DALLE2STANDARD,streamlit,,1
-14429,philipalden/InvisibleCities,gradio,cc,1
-14430,tomasonjo/chat-algobook,gradio,mit,1
-14431,gotiQspiryo/whisper-ui,streamlit,,1
-14432,inamXcontru/PoeticTTS,gradio,mit,1
-14433,Samuelxm/WeatherBot,streamlit,,1
-14434,rd13/Pix2Pix-Video,gradio,,1
-14435,Ryukijano/canny_coyo1m,gradio,apache-2.0,1
-14436,Serg4451D/PixelArtGenerator,streamlit,,1
-14437,burberg92/resume_summary,gradio,openrail,1
-14438,RustX/CSV-ChatBot,docker,,1
-14439,SkyYeXianer/vits-uma-genshin-honkai,gradio,apache-2.0,1
-14440,trialanderror/HowMyZsh,streamlit,mit,1
-14441,Araloak/fz,gradio,openrail,1
-14442,ls291/ChatSQL,gradio,apache-2.0,1
-14443,xzx0554/2222,gradio,creativeml-openrail-m,1
-14444,Sohaibahmad/AIdetector,streamlit,openrail,1
-14445,apsys/HSSR,gradio,apache-2.0,1
-14446,igtsolutions/igtsolutions,static,openrail,1
-14447,xiaoV28/GFPGAN,gradio,apache-2.0,1
-14448,terfces0erbo/CollegeProjectV2,gradio,,1
-14449,shielamms/en-es-translator,gradio,,1
-14450,arnikdehnavi/energy-consumption,streamlit,,1
-14451,Ryukijano/jax-diffusers-event-canny-coyo1m,gradio,,1
-14452,bgk/sipariseng,gradio,,1
-14453,groupeonepoint/french-email-generator,streamlit,,1
-14454,Phantom3306/AI-image-detector,gradio,,1
-14455,gui-sparim/Calculadoras_DDA,gradio,,1
-14456,kenton-li/ChatArxiv,gradio,,1
-14457,kevinwang676/ChatGLM-int4-demo,gradio,,1
-14458,RaIDooN/huggyllama-llama-13b,gradio,apache-2.0,1
-14459,lucaspedrajas/IF,gradio,other,1
-14460,bhkkhjgkk/Voice,gradio,mit,1
-14461,caiocdcs/sports-classifier,gradio,apache-2.0,1
-14462,maxwelljgordon/whisper-speaker,gradio,mit,1
-14463,vmoras/SAM_test,gradio,,1
-14464,huolongguo10/huolongguo10-check_sec,gradio,openrail,1
-14465,rounak40/fast-whisper-large-v2,gradio,,1
-14466,aiotedu/aiotchat,gradio,,1
-14467,kukuhtw/AutoGPT,gradio,mit,1
-14468,givenvessel399/M.me,docker,apache-2.0,1
-14469,Singularity666/RadiXGPT_,streamlit,bigscience-openrail-m,1
-14470,NicolasGaudemet/LongDocumentSummarizer,gradio,,1
-14471,QiuLingYan/ChanYuan-large-v2,gradio,creativeml-openrail-m,1
-14472,nomnomnonono/Background-Image-Generation-for-Online-Meeting,gradio,,1
-14473,datagpt/pdf2summary,gradio,gpl-3.0,1
-14474,fatiXbelha/sd,docker,,1
-14475,nwpuwolf/succinctly-text2image-prompt-generator,gradio,mit,1
-14476,1phancelerku/anime-remove-background,gradio,apache-2.0,1
-14477,simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735,streamlit,bsd-3-clause,1
-14478,congsaPfin/Manga-OCR,gradio,,1
-14479,ticomspire/turkey-syria-earthquake-tweets,streamlit,,1
-14480,sklearn-docs/feature_agglomeration,gradio,apache-2.0,1
-14481,PeepDaSlan9/CarperAI-stable-vicuna-13b-delta,gradio,cc-by-2.0,1
-14482,zmengaf/comp652_final_demo,gradio,,1
-14483,usbethFlerru/sovits-modelsV2,gradio,mit,1
-14484,7thHeaven/ochyai_food,gradio,,1
-14485,rorallitri/biomedical-language-models,gradio,,1
-14486,miku8miku/Voice-Cloning-for-Bilibili,gradio,mit,1
-14487,contluForse/HuggingGPT,gradio,,1
-14488,deepozzzie/chatgpt,gradio,,1
-14489,ZaidBAIDADADAD/runwayml-stable-diffusion-v1-5,gradio,openrail,1
-14490,Shad0ws/STORYGPT,gradio,mit,1
-14491,heegyu/gorani-v0,gradio,,1
-14492,weiyuanchen/stabilityai-stable-diffusion-2-1,gradio,,1
-14493,inreVtussa/clothingai,gradio,,1
-14494,Natnael1234/SIL-ChatGPT-Training-Demo,streamlit,,1
-14495,quidiaMuxgu/Expedit-SAM,gradio,apache-2.0,1
-14496,surmensipa/VITS-Umamusume-voice-synthesizer,gradio,,1
-14497,awacke1/Tensorflow-AI-Driven-Personalization,streamlit,mit,1
-14498,niro-private/chatCSV,streamlit,,1
-14499,falterWliame/Face_Mask_Detection,gradio,mit,1
-14500,Pranjal-666/COVID_classify_sequence,gradio,openrail,1
-14501,andaqu/ask-youtube-gpt,gradio,,1
-14502,OLKGTOIP/Real-CUGAN,gradio,gpl-3.0,1
-14503,mmdrezamoraditabrizi/mmd,streamlit,,1
-14504,Learner/jax-diffuser-event-battlemaps,gradio,,1
-14505,DeclK/pose,gradio,openrail,1
-14506,epexVfeibi/Imagedeblurr,gradio,mit,1
-14507,Alesmikes/elvire01,gradio,,1
-14508,Alesmikes/Elvirespeak,gradio,,1
-14509,bsenst/flask_inference_api,gradio,mit,1
-14510,Daniton/THUDM-chatglm-6b-int4-qe,gradio,,1
-14511,swarm-agents/swarm-agents,gradio,mit,1
-14512,nurano/dsadsa,docker,other,1
-14513,Isotonic/image-generator,gradio,,1
-14514,avivdm1/AutoGPT,gradio,mit,1
-14515,Isaoudata/WaltWhitman-GPT,streamlit,,1
-14516,THUDM/ImageReward,gradio,apache-2.0,1
-14517,awacke1/Streamlit-AI-Letter-UI,streamlit,mit,1
-14518,yoinked/audio-diffusion,gradio,gpl-3.0,1
-14519,falcondai/stego-lm,gradio,openrail,1
-14520,Kwasiasomani/Streamlit-Sentimental-Analysis,streamlit,,1
-14521,NoorAzam/model4,gradio,,1
-14522,Pranjal-666/Potato-leaf-disease-detection,gradio,,1
-14523,Iqbaljanitra/Face-Emotions-Prediction,streamlit,,1
-14524,ankitinter9/my-draw-self-journey,gradio,other,1
-14525,nandodeomkar/Project,gradio,,1
-14526,irfan844108/pdfGPT,gradio,,1
-14527,Hyeonseo/ChatGPT-ko-translation-prompt,gradio,apache-2.0,1
-14528,gentlemanhu/succinctly-text2image-prompt-generator,gradio,,1
-14529,Danielzero/GPT3.5,gradio,gpl-3.0,1
-14530,cchuang2009/CO2,streamlit,apache-2.0,1
-14531,madoss/ask-datagen,gradio,,1
-14532,Cognomen/CatCon-Controlnet-WD-1-5-b2,gradio,mit,1
-14533,123Kumar/vits-uma-genshin-honkai123,gradio,apache-2.0,1
-14534,abdelrahmantaha/ocr,streamlit,,1
-14535,MikeTrizna/amazonian_fish_classifier,streamlit,mit,1
-14536,DevashishBhake/Question_Generation,gradio,mit,1
-14537,LouisSanna/reco_fish,gradio,,1
-14538,henryu/Multimodal-GPT,gradio,openrail,1
-14539,Yarumo/prompthero-openjourney-v4,gradio,,1
-14540,adrabi-abderrahim/english-pronunciation-practice,gradio,afl-3.0,1
-14541,panotedi/milestone3,streamlit,,1
-14542,ericxlima/DogBreedClassifier,gradio,,1
-14543,Cat125/text-generator-v2,gradio,openrail,1
-14544,HarshulNanda/VV,streamlit,,1
-14545,stephenmccartney1234/astrobot2,gradio,,1
-14546,DiffusionArtco/AnimeTop50,gradio,,1
-14547,awacke1/Fiction-Generator,streamlit,mit,1
-14548,bobrooos/test,gradio,,1
-14549,replit/README,static,,1
-14550,GaenKoki/voicevox,docker,lgpl-3.0,1
-14551,lordvader31/almithal,streamlit,apache-2.0,1
-14552,keisuke-tada/gpt-playground,streamlit,,1
-14553,tialenAdioni/chat-gpt-api,gradio,,1
-14554,mee-asukoht/flan-t5-small,gradio,,1
-14555,ather23/NinedayWang-PolyCoder-2.7B,gradio,,1
-14556,1acneusushi/gradio-2dmoleculeeditor,gradio,mit,1
-14557,Gaeomg/Kaludi-chatgpt-gpt4-prompts-bart-large-cnn-samsum,gradio,,1
-14558,Mk-ai/README,static,,1
-14559,SoulAbi/text-prompt-to-audio-generation,gradio,creativeml-openrail-m,1
-14560,raedeXanto/academic-chatgpt-beta,gradio,,1
-14561,KrisLiao/NaturalLanguageVideoSearch,gradio,,1
-14562,EstebanDC/Compression_Index,gradio,,1
-14563,awacke1/Generative-AI-Procedure-Cost-Summary,static,mit,1
-14564,awacke1/AI-ChatGPT-CPT-Body-Map-Cost,streamlit,mit,1
-14565,DiffusionArtco/scifi-art-creator,gradio,,1
-14566,Logic06183/ML_Classifier_Hub,streamlit,mit,1
-14567,Ankit6396/100-Free-ChatGPT4,gradio,mit,1
-14568,sana123/Sinhala_Audio-to-Text,gradio,mit,1
-14569,tera-td/whisper-gpt,gradio,apache-2.0,1
-14570,groupeonepoint/LongDocumentQuestioner,gradio,,1
-14571,vyurchenko/l3m,gradio,apache-2.0,1
-14572,DiffusionArtco/Diffusion50,gradio,,1
-14573,oluyemitosin/YOLO,gradio,apache-2.0,1
-14574,gkmike/ckip-joint-bloom-3b-zh,gradio,,1
-14575,eaedk/Tuto_Sentiment_Analysis_App,gradio,,1
-14576,MehdiAmirate/Botv2,docker,cc-by-nc-2.0,1
-14577,victor/test-autotrain,docker,,1
-14578,mrfakename/lmsys-fastchat-public,gradio,other,1
-14579,abhimanyuniga/chavinlo-gpt4-x-alpaca,docker,openrail,1
-14580,Alealejandrooo/deathCertReader,gradio,,1
-14581,awacke1/DogCatGraph,streamlit,,1
-14582,BetterAPI/BetterChat_new,docker,mit,1
-14583,sohamb23/informational-therapy-chatbot,gradio,,1
-14584,BorisovMaksim/denoising,gradio,,1
-14585,Aveygo/AstroSleuth,streamlit,gpl-2.0,1
-14586,awacke1/Streamlit-Dog-Cat-Graph,streamlit,mit,1
-14587,devseek/accident_detection,gradio,apache-2.0,1
-14588,at2507/SM_NLP_RecoSys,gradio,,1
-14589,DiffusionArtco/Interior-design-models,gradio,,1
-14590,Ubai/Space,docker,,1
-14591,tayyabali1/llama-65b-hf,gradio,bigscience-openrail-m,1
-14592,Frilles/FoodVision_Big,gradio,unknown,1
-14593,thak123/Whisper-Konkani,gradio,,1
-14594,Jarkchen/af1tang-personaGPT,gradio,,1
-14595,Kedareeshwar/Dental-Caries-Diagnosis,streamlit,,1
-14596,Sk4372/stabilityai-stable-diffusion-2-base,gradio,,1
-14597,awacke1/Generative-AI-SOP,static,mit,1
-14598,multimodalart/redirectme,static,mit,1
-14599,jigo/jobposting,streamlit,,1
-14600,erbanku/gpt-academic,gradio,,1
-14601,osanseviero/discord_example,gradio,,1
-14602,kpyuy/chat,gradio,mit,1
-14603,Kathir0011/YouTube_Video_Assistant,gradio,mit,1
-14604,Facepounder/gpt2-xl,gradio,,1
-14605,serpdotai/mean-shift-clustering,gradio,,1
-14606,liubing80386/succinctly-text2image-prompt-generator,gradio,,1
-14607,Juno360219/Gg,gradio,openrail,1
-14608,SUPERpuper/Text-to-image-AI-3,streamlit,,1
-14609,gsharma/url-summarizer,gradio,apache-2.0,1
-14610,ruangguru/ds-chatbot-internal,gradio,,1
-14611,Goya11/zimu,gradio,,1
-14612,Derni/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator,gradio,,1
-14613,anonderpling/repo_uploader,gradio,mit,1
-14614,OhMondon/Walking-Assistant-for-the-Visually-Impaired,gradio,,1
-14615,Y-T-G/Blur-Anything,gradio,,1
-14616,awacke1/Generative-AI-EACN,static,mit,1
-14617,balgot/text-to-stylegan3,gradio,openrail,1
-14618,awacke1/AI-ChatGPT-EACN,streamlit,mit,1
-14619,textToSQL/mp3_transcribe_prompt,gradio,mit,1
-14620,SSahas/caption_images,gradio,apache-2.0,1
-14621,sklearn-docs/pcr_vs_pls_regression,gradio,mit,1
-14622,NoriZC/vits-models,gradio,apache-2.0,1
-14623,Shiro26/MendoBERT_RE,streamlit,afl-3.0,1
-14624,NadaKhater/SignLanguageClassification,gradio,,1
-14625,straka/poison-ivy-detector,gradio,apache-2.0,1
-14626,Raaniel/Support-and-resistance,streamlit,,1
-14627,jshong/crabGPT,gradio,,1
-14628,Suhailshah/image-captioning-with-vit-gpt2,gradio,mit,1
-14629,marketono/MidJourney,gradio,,1
-14630,johnsu6616/TXT2IMG-MJ-Desc,gradio,artistic-2.0,1
-14631,streamzer/runwayml-stable-diffusion-v1-5,gradio,,1
-14632,MuthuPalaniyappanOL/RentPricePrediction,streamlit,mit,1
-14633,trhacknon/youtube-video-to-text-generation,streamlit,,1
-14634,RichardMB1217/blip,gradio,bsd-3-clause,1
-14635,colakin/video-generater,docker,,1
-14636,chats-bug/ai-image-captioning,gradio,mit,1
-14637,megemini/shanshui,gradio,,1
-14638,leezhongjun/chatgpt-free,gradio,,1
-14639,awacke1/Generative-AI-Provider,static,mit,1
-14640,awacke1/AI-ChatGPT-Provider,streamlit,mit,1
-14641,Jamkonams/AutoGPT,gradio,mit,1
-14642,SanketJadhav/Plant-Disease-Classifier,streamlit,,1
-14643,LoveWaves/123,docker,openrail,1
-14644,cloudstack/CSV-ChatBot,docker,,1
-14645,reilnuud/polite,gradio,apache-2.0,1
-14646,keminglu/instruction-following-open-world-information-extraction,gradio,bigscience-openrail-m,1
-14647,Aniquel/bert-large-uncased-whole-word-masking,gradio,,1
-14648,sparkyrider/OpenAI-SHAP-E,gradio,mit,1
-14649,docpois/ask,gradio,mit,1
-14650,A-Celsius/Caption-Generator,gradio,,1
-14651,DaleChen/AutoGPT,gradio,mit,1
-14652,aryan29/movie-recommender-system,gradio,,1
-14653,sklearn-docs/multilabel_classification,gradio,mit,1
-14654,niew/vits-uma-genshin-honka,gradio,apache-2.0,1
-14655,MMMMQZ/MQZGPT,gradio,gpl-3.0,1
-14656,lunarflu/modbot,gradio,other,1
-14657,ms180/espnet_onnx_demo,gradio,mit,1
-14658,chilge/Fushimi,gradio,,1
-14659,s1591428/README,streamlit,apache-2.0,1
-14660,chenmgtea/cn_tts,gradio,apache-2.0,1
-14661,HugoHE/monitoringObjectDetection,gradio,openrail,1
-14662,cloudwp/sd,gradio,,1
-14663,FacundoSander/PdfQA,docker,,1
-14664,itsmohsinali/anpr1,gradio,,1
-14665,RobLi/ControlNet-v1-1,gradio,mit,1
-14666,yhevis/Real-CUGAN2,gradio,gpl-3.0,1
-14667,krazyxki/V-1488abed,docker,,1
-14668,MingGatsby/Grounding_DINO_demo,gradio,apache-2.0,1
-14669,dragonSwing/LangChain-ChatGPT-plugins,gradio,,1
-14670,thu-coai/DA-Transformer,docker,apache-2.0,1
-14671,helkoo/hackDjellaba,gradio,,1
-14672,EdwinC/edwin,gradio,openrail,1
-14673,tmnam20/code-summarization,streamlit,,1
-14674,DaFujaTyping/hf-Chat-ui,docker,apache-2.0,1
-14675,xcchen/vits-uma-genshin-honkai,gradio,apache-2.0,1
-14676,chiye/background-remover,gradio,,1
-14677,xcchen/xcchenvits-uma-genshin-honkai,gradio,apache-2.0,1
-14678,MuskanMjn/Segmenting_greek_coins_using_Segmental_Clustering,gradio,apache-2.0,1
-14679,rinme/vits-models,gradio,apache-2.0,1
-14680,skf15963/summary,gradio,apache-2.0,1
-14681,jbondy007/Video_Search_CLIP,gradio,,1
-14682,Widium/Style-Recreation,gradio,,1
-14683,Minty22120/DeepDanbooru_string,gradio,,1
-14684,Jo0xFF/4xArText,gradio,mit,1
-14685,PlanetHades361/Change-Your-Style,gradio,mit,1
-14686,appy-agency/sprigs,gradio,apache-2.0,1
-14687,prajwalkhairnar/facial_emotion_detection_multiclass,gradio,unknown,1
-14688,pikaduck/DungeonMaster,streamlit,apache-2.0,1
-14689,HEROBRINE7GAMER/belal-llm-streaming,gradio,,1
-14690,kn14/STT_CNN,gradio,,1
-14691,rootuserlinux/GPT4,gradio,mit,1
-14692,DhruvShek/chatlm,streamlit,cc-by-nc-4.0,1
-14693,tchebagual/runwayml-stable-diffusion-v1-5,gradio,,1
-14694,Tj/starcoder-playground,gradio,,1
-14695,jb30k/LegalENG,gradio,,1
-14696,Dimentian/LLMs-Stable-Vicuna-13B,gradio,,1
-14697,sklearn-docs/Precision-Recall,gradio,,1
-14698,bibekyess/bgpt,streamlit,,1
-14699,SantiagoTesla/Self_Chatbot,gradio,,1
-14700,dxcy/Real-CUGAN,gradio,gpl-3.0,1
-14701,camileLDJ/allenai-cosmo-xl,streamlit,creativeml-openrail-m,1
-14702,FFZG-cleopatra/latvian-twitter-sentiment-classifier,gradio,,1
-14703,pierluigizagaria/crysis-voice-cloning,gradio,mit,1
-14704,ramiin2/AutoGPT,gradio,mit,1
-14705,p208p2002/Compute-Optimal-Model-Estimator,gradio,,1
-14706,Anandhju-jayan/image-captioning-cloned,gradio,mit,1
-14707,Manthanx/catsdogs,gradio,,1
-14708,awacke1/PyVis-Knowledge-Graph-From-Markdown,streamlit,mit,1
-14709,Sriharsha6902/Chat-Analyser,streamlit,,1
-14710,lukesteuber/contechnical,gradio,,1
-14711,Juno360219/lambdalabs-sd-image-variations-diffusers,gradio,openrail,1
-14712,vjain/AudioChat,gradio,cc,1
-14713,hakanwkwjbwbs/stablediffusionapi-anime-diffusion,gradio,,1
-14714,jb30k/LegalWW,gradio,,1
-14715,Lamai/LAMAIGPT,gradio,mit,1
-14716,DrewKarn/CarperAI-stable-vicuna-13b-delta,gradio,other,1
-14717,Laughify/Moon-Knight-Txt-2-Img,gradio,unknown,1
-14718,Dialogues/chat-ai-safety,gradio,,1
-14719,soufiane3/ChatGPT4,gradio,mit,1
-14720,awacke1/Streamlit_Plotly_Graph_Objects,streamlit,mit,1
-14721,itbeard/CarperAI-stable-vicuna-13b-delta,gradio,,1
-14722,UVA-MSBA/M4_Team8,gradio,mit,1
-14723,yishenzhen/LangChain-Zilliz,gradio,apache-2.0,1
-14724,tvrsimhan/music-sep,gradio,,1
-14725,sklearn-docs/Segmenting_greek_coins_using_Segmental_Clustering,gradio,apache-2.0,1
-14726,abbbbbbbbbbbbbb/meter2poem-1,gradio,afl-3.0,1
-14727,abbbbbbbbbbbbbb/topic2poem,gradio,afl-3.0,1
-14728,achyuth1344/stable-diffusion-web-ui,gradio,openrail,1
-14729,Yuzu22/rvc-models,gradio,mit,1
-14730,dsaigc/trans_for_sd,gradio,,1
-14731,Um124/Lung_Cancer_Prediction,gradio,cc-by-nc-4.0,1
-14732,realAshish/Calculator,gradio,creativeml-openrail-m,1
-14733,ImagineAI-Real/MidJourney-Diffusion,gradio,,1
-14734,fffiloni/Music_Source_Separation,gradio,,1
-14735,zijia88/Sewer_Endoscopy_Risk_Identification,gradio,other,1
-14736,dorkai/dorkai-DALL-E,gradio,,1
-14737,dsxailab/Lama-Cleaner-lama-12,gradio,apache-2.0,1
-14738,diffusers/latent-upscaler-tool,gradio,,1
-14739,dorkai/pygmalion,gradio,openrail,1
-14740,Yossefahmed68/microsoft-BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext,gradio,openrail,1
-14741,SmokeAndAsh/4bit-gpt4-x-alpaca-13b-roleplay-lora-4bit-v2,gradio,,1
-14742,kevinwang676/voice-conversion-yourtts,gradio,unknown,1
-14743,bcg-unet/demo,gradio,,1
-14744,Not-Grim-Refer/GitHub-Tool,streamlit,afl-3.0,1
-14745,SatwikKambham/Image-Classifier,gradio,mit,1
-14746,Dachus/Realfee,docker,bigscience-openrail-m,1
-14747,wasertech/French_Wav2Vec2_ASR,gradio,,1
-14748,Ahmedmewloud/Depplearnig,gradio,,1
-14749,Kynlo/google-flan-t5-xl,gradio,,1
-14750,Alphts/Robot,gradio,mit,1
-14751,predictive-singularity/Singularity,gradio,unlicense,1
-14752,Forever003/VPN,docker,openrail,1
-14753,Widium/Image-Recreation,gradio,,1
-14754,bballaek17/ChatGPT4,gradio,mit,1
-14755,ZeroGPT/GPTZero,gradio,mit,1
-14756,Winnie-Kay/Distbert-Sentiments,gradio,,1
-14757,Rojban/LangFlow,docker,mit,1
-14758,sajinpgupta/Medicine_Prescription_Gen,gradio,,1
-14759,cryddd/junelee-wizard-vicuna-13b,gradio,,1
-14760,rumeysakara/ChatGPT4,gradio,mit,1
-14761,nicolaorsini/DICE,gradio,,1
-14762,catundchat/tts_cn,gradio,apache-2.0,1
-14763,jozzy/langchain,gradio,apache-2.0,1
-14764,issenn/so-vits-svc-4.0-spaces-sample,gradio,,1
-14765,aashay26/Next_Word_Prediction,gradio,,1
-14766,jeevanb/ChatGPT4,gradio,mit,1
-14767,awacke1/Docker-Examples-Top-5-Demo,streamlit,mit,1
-14768,DarwinAnim8or/convert-to-safet,gradio,apache-2.0,1
-14769,CNXT/TXT2PiX,gradio,,1
-14770,mohsenfayyaz/DivarGPT,gradio,,1
-14771,society-ethics/StableBiasGen,gradio,cc-by-3.0,1
-14772,sanjayw/starchat-playground,gradio,mit,1
-14773,johnsu6616/SD_Helper_01,gradio,openrail,1
-14774,sanjayw/starcoder-playground,gradio,,1
-14775,alpha99/alphak,docker,mit,1
-14776,andaqu/ask-reddit-gpt,gradio,,1
-14777,emresvd/text_summarizer,gradio,,1
-14778,gaviego/mnist,gradio,openrail,1
-14779,DanielSan7/judini-video,streamlit,mit,1
-14780,samalba/demo,gradio,,1
-14781,nettsz/stabilityai-stable-diffusion-2,gradio,,1
-14782,starlit7/NewKorPoliticsTTS,gradio,mit,1
-14783,ai-create/colab,static,,1
-14784,mileslilly/City-classifier,gradio,,1
-14785,Yarumo/whisper,gradio,,1
-14786,allinaigc/internet_GPT_venice,gradio,,1
-14787,euphi/smmry,gradio,unknown,1
-14788,Um124/Global_Warming_Analysis,streamlit,cc-by-nc-4.0,1
-14789,innev/GPT2-large,gradio,apache-2.0,1
-14790,zibb/frontalface-cascade,gradio,,1
-14791,GookProxy/Gyul,docker,,1
-14792,davda54/chat-nort5,gradio,,1
-14793,Jamerrone/DreamShaperWebEmbed,gradio,mit,1
-14794,abhi-pwr/underwater_trash_detection,gradio,unknown,1
-14795,dirge/voicevox,docker,lgpl-3.0,1
-14796,Tirendaz/Cancer-Detection,gradio,,1
-14797,Bonosa2/parrot-chat-bot,gradio,,1
-14798,AnimalEquality/chatbot,gradio,unknown,1
-14799,sandraw11031/virtual-staging,gradio,,1
-14800,fffiloni/chatbot-media-test,gradio,,1
-14801,chansung/tfx-vit-pipeline,gradio,apache-2.0,1
-14802,simonraj/ThinkingRoutines,gradio,,1
-14803,mscsasem3/CHAAT,gradio,,1
-14804,NexusInstruments/offensive-hugging-face,gradio,unknown,1
-14805,WUXIAOMO/stabilityai-stable-diffusion-2-1-test-space,gradio,other,1
-14806,chow-q/cut-image,gradio,,1
-14807,Technozam/mcqs,gradio,,1
-14808,ty00369/IDEA-CCNL-Taiyi-BLIP-750M-Chinese,gradio,,1
-14809,prathmeshrmadhu/odor-dino,gradio,,1
-14810,xly66624/Brayton-cycle,gradio,openrail,1
-14811,Harsimran19/SegmentationGAN,gradio,mit,1
-14812,Sojab/voice-recognition,gradio,mit,1
-14813,ysharma/dummy99,docker,mit,1
-14814,teven-projects/calculator,docker,,1
-14815,rizmyabdulla/tiny-Question-answering,gradio,,1
-14816,AndyCer/TheBloke-stable-vicuna-13B-HF,gradio,,1
-14817,banana-projects/talking-egg,static,,1
-14818,kavyasree/hair_type,gradio,apache-2.0,1
-14819,EinfachOlder/HuggingChat,streamlit,,1
-14820,almakedon/faster-whisper-webui,gradio,apache-2.0,1
-14821,tweakdoor/stabilityai-stable-diffusion-2-1,gradio,,1
-14822,kcagle/AutoGPT,gradio,mit,1
-14823,Cybsechuman/Consistency_analysis,gradio,openrail,1
-14824,PeepDaSlan9/togethercomputer-RedPajama-INCITE-Chat-3B-v1,gradio,apache-2.0,1
-14825,shencc/gpt,gradio,,1
-14826,mohammadT/Arabic-Empathetic-Chatbot,gradio,,1
-14827,jvictoria/LogicChecker,gradio,,1
-14828,kapilmi/AI-lab,streamlit,,1
-14829,PantOfLuck/my_stable_diffusion_webui,static,apache-2.0,1
-14830,Alfasign/HuggingGPT-Lite,gradio,mit,1
-14831,AdithyaSNair/PCOS_Prediction,gradio,,1
-14832,changkeyculing/chatgpt-detector-single,gradio,,1
-14833,andyssj/entregable2,gradio,,1
-14834,Alichuan/VITS-Umamusume-voice-synthesizer,gradio,,1
-14835,Drexx007/Drexx-Ai-Chat,gradio,,1
-14836,a3en85/ChatGPT4,gradio,mit,1
-14837,sklearn-docs/Early-stopping-of-Stochastic-Gradient-Descent,gradio,bsd-3-clause-clear,1
-14838,sklearn-docs/SGD-Weighted-Samples,gradio,apache-2.0,1
-14839,4RiZ4/stabilityai-stable-diffusion-2,gradio,unknown,1
-14840,whitphx/gradio-static-test,static,,1
-14841,Boranbruh/ehartford-WizardLM-7B-Uncensored,gradio,cc,1
-14842,dejavusss/philschmid-flan-t5-base-samsum,gradio,,1
-14843,Ingenious/README,static,,1
-14844,Godrose0728/sound-link,gradio,mit,1
-14845,CartelFi/README,static,,1
-14846,sklearn-docs/Nearest_Neighbor_Regression,gradio,apache-2.0,1
-14847,Ikaros521/moe-tts,gradio,mit,1
-14848,uih-zyn/runwayml-stable-diffusion-v1-5,gradio,,1
-14849,presucc/anime-remove-background,gradio,apache-2.0,1
-14850,Anthony7906/MengHuiMXD_GPT,gradio,gpl-3.0,1
-14851,Xinyoumeng233hu/SteganographywithGPT-2,gradio,,1
-14852,crashedice/signify,streamlit,,1
-14853,innovatorved/ImageColorizationUsingGAN,gradio,apache-2.0,1
-14854,elitecode/logichecker,gradio,,1
-14855,uohna/nlp-web-app,streamlit,,1
-14856,Lavanya30/hiddenhunger,streamlit,unknown,1
-14857,Longtong/FoodVisionBig,gradio,mit,1
-14858,maurol/lyrics-translator,streamlit,,1
-14859,Martlgap/LiveFaceID,streamlit,mit,1
-14860,Onekee/ehartford-Wizard-Vicuna-13B-Uncensored,gradio,,1
-14861,lingbionlp/PhenoTagger_v1.2_Demo,streamlit,apache-2.0,1
-14862,kong003/first_demo,gradio,mit,1
-14863,hahahafofo/vits-uma-genshin-honkai,gradio,apache-2.0,1
-14864,Dacoolkid/Oba_-s,streamlit,openrail,1
-14865,Harsimran19/DepthGAN,gradio,mit,1
-14866,Raghav001/API,docker,,1
-14867,Shad0ws/ImageModelTestEnvironment,gradio,,1
-14868,chauvet/stabilityai-stable-diffusion-2-1,gradio,openrail,1
-14869,banana-projects/coref,static,,1
-14870,dachenchen/real,gradio,mit,1
-14871,daphshen/corgi-classifier,gradio,apache-2.0,1
-14872,Juno360219/xlm-roberta-base,streamlit,openrail,1
-14873,Fengbinbin/gpt-academic,gradio,,1
-14874,Dacoolkid/Sleek,gradio,,1
-14875,ali-ghamdan/deoldify,gradio,,1
-14876,rafaelglima/ChatGPT4,gradio,mit,1
-14877,sssdtgvg/Sex,static,,1
-14878,badrih21/ML_module,gradio,,1
-14879,SameerR007/ImageCaptioning_streamlit,streamlit,,1
-14880,paulbauriegel/simple_whisper,gradio,,1
-14881,captchaboy/pleroma_captcha_solver,gradio,,1
-14882,dachenchen/HiWantJoin,gradio,gpl-3.0,1
-14883,nuwa/ehartford-WizardLM-13B-Uncensored,gradio,,1
-14884,davila7/ConstitutionalAI,streamlit,mit,1
-14885,shawndimantha/hackaithon_generate_email,streamlit,apache-2.0,1
-14886,hungchiayu/CaptionFLAN-T5,streamlit,,1
-14887,rchak007/BackTester,streamlit,,1
-14888,aditii09/hindi-asr,gradio,,1
-14889,Cong723/gpt-academic-public,gradio,,1
-14890,Bakar31/PotterQuest,gradio,apache-2.0,1
-14891,thebetterindia/ai,gradio,unknown,1
-14892,JawadBIlal/Crack_Detection,gradio,apache-2.0,1
-14893,Adesoji1/Panel_PDF_QA,docker,,1
-14894,Ramse/TTS_Hindi,gradio,openrail,1
-14895,weiwandaixu/ChatGPT3.5,gradio,gpl-3.0,1
-14896,dorkai/SINGPT-Temporary,gradio,mit,1
-14897,DkLead/facebook-tts_transformer-ru-cv7_css10,gradio,,1
-14898,ecaridade/albertina,gradio,mit,1
-14899,RandomCatLover/thesis_finetuned_classifier,gradio,cc-by-nc-nd-4.0,1
-14900,wangfowen/hackaithon_app,streamlit,,1
-14901,DarwinAnim8or/Pythia-Greentext-Playground,gradio,mit,1
-14902,Soumahara/stablediffusionapi-anything-v5,gradio,,1
-14903,Soumahara/sakistriker-Anything_V5_Prt,gradio,,1
-14904,jonanfu/demo_clase_platzi,gradio,mit,1
-14905,Akshat231/super_space,gradio,,1
-14906,AlanMars/QYL-AI-Space,gradio,gpl-3.0,1
-14907,MVV/3dTopDenoising,gradio,bsd,1
-14908,skyxx/skyxxChat,gradio,gpl-3.0,1
-14909,panda1835/leopard,gradio,afl-3.0,1
-14910,sanchezNa/runwayml-stable-diffusion-v1-5,gradio,apache-2.0,1
-14911,analyticsinmotion/README,static,,1
-14912,brhiza/EdisonChen-tts,gradio,,1
-14913,hannahaa/MovieAI,gradio,afl-3.0,1
-14914,chaozn/face_emotion_classifier,gradio,,1
-14915,Xinxiang0820/nitrosocke-Ghibli-Diffusion,gradio,,1
-14916,joshuadunlop/Epic-GPT4-App,streamlit,,1
-14917,Basav/openai-whisper-medium,gradio,,1
-14918,russel0719/deepfake_detector,gradio,,1
-14919,crazyjetsai/finetuneai,gradio,mit,1
-14920,naisel/pegasus-with-samsum-dataset,streamlit,,1
-14921,huggingface-timeseries/probabilistic-forecast,gradio,apache-2.0,1
-14922,Keenlol/Wood_Classification,gradio,unknown,1
-14923,JoeyFoursheds/ClonerHug,gradio,,1
-14924,OpenMind-AI/starchat-playground,gradio,mit,1
-14925,santiviquez/ai-act,streamlit,mit,1
-14926,omdenatopekachapter/left_ejection_fraction,streamlit,gpl-3.0,1
-14927,nontGcob/T2E-demo,gradio,cc,1
-14928,Phasmanta/Space2,static,afl-3.0,1
-14929,unidiffuser-testing/unidiffuser-testing,gradio,,1
-14930,bigPear/digitalWDF,gradio,apache-2.0,1
-14931,BongoCaat/ArtGenerator,gradio,gpl-3.0,1
-14932,MrTitanicus/rvc-models,gradio,mit,1
-14933,abionchito/rvc-models,gradio,mit,1
-14934,NeuralJunkie/HebLens,gradio,mit,1
-14935,JCTN/stable-diffusion-webui-cpu,gradio,,1
-14936,Bambicita/rvc-models,gradio,mit,1
-14937,JosephTK/review-sentiment-analyzer,gradio,,1
-14938,NEARHUb/video-transcoder,gradio,,1
-14939,typesdigital/TTS,streamlit,cc-by-4.0,1
-14940,BlitzKriegM/argilla,docker,,1
-14941,hmtxy1212/README,static,,1
-14942,Demi2809/rvc-models,gradio,mit,1
-14943,Pixeled/dogcat,gradio,apache-2.0,1
-14944,RinInori/Vicuna_ChatBot,gradio,apache-2.0,1
-14945,vietvd/modnet,gradio,afl-3.0,1
-14946,AIGE/A_B,gradio,,1
-14947,grld26/Whisper-Swak-v4,gradio,,1
-14948,msafi04/abstractive_summarization,gradio,,1
-14949,miaomiaoren/vits-uma-genshin-honkai,gradio,apache-2.0,1
-14950,SERER/VITS-Umamusume-voice-synthesizer,gradio,,1
-14951,randomarnab/Img_caption_project_using_ViT_GPT2,gradio,creativeml-openrail-m,1
-14952,januvojt/emotion-recognition,gradio,,1
-14953,awinml/api_vicuna-openblas,gradio,mit,1
-14954,course-demos/whisper-small,gradio,,1
-14955,googlyeyes/question_generation_swayam,streamlit,unknown,1
-14956,Tatusho/TTS,streamlit,,1
-14957,AICODER009/food_detection,gradio,mit,1
-14958,williamstein/ehartford-WizardLM-7B-Uncensored,gradio,,1
-14959,aliabid94/reverse_audio,gradio,,1
-14960,giesAIexperiments/coursera-assistant-3d-printing-applications,gradio,,1
-14961,BradAllgood/fastai_chapter2_new,gradio,apache-2.0,1
-14962,dhmeltzer/qg_generation,streamlit,,1
-14963,bortle/moon-detector,gradio,,1
-14964,Unachstudents/README,static,,1
-14965,Tony1810/FootballPosition,gradio,afl-3.0,1
-14966,Raksama/ChatToPdf,docker,,1
-14967,ramwar/ix-ask-your-books,gradio,apache-2.0,1
-14968,dukujames/ML-Sentiment,gradio,,1
-14969,arakimk/SakamataFontDCGAN,gradio,other,1
-14970,theodotus/asr-uk-punctuation-capitalization,gradio,mit,1
-14971,ChengZ/DeepDanbooru_string0,gradio,,1
-14972,AICODER009/Food101_Detection,gradio,mit,1
-14973,nikiandr/assym_sem_search,gradio,,1
-14974,xinyu2/anime-remove-background,gradio,apache-2.0,1
-14975,ennov8ion/Landscapes-models,gradio,,1
-14976,lhg99/gradio-demo,gradio,apache-2.0,1
-14977,BisratWorku/Bear_classifier,gradio,apache-2.0,1
-14978,grisuji/min_dog_classifier,gradio,apache-2.0,1
-14979,neongeckocom/streaming-llm,gradio,mit,1
-14980,cmudrc/Interp_Imaging,streamlit,,1
-14981,RinInori/vicuna_finetuned_6_sentiments,gradio,apache-2.0,1
-14982,kokofixcomputers/chat-ui,docker,apache-2.0,1
-14983,pakyenn/streamlit_datatool,streamlit,,1
-14984,resquared/sales-bot,gradio,,1
-14985,0xSynapse/Image_captioner,streamlit,creativeml-openrail-m,1
-14986,sahillalani/chargerbot,gradio,unknown,1
-14987,awacke1/Face_Recognition_with_Sentiment,gradio,apache-2.0,1
-14988,HSFamily/StoryMaker,gradio,,1
-14989,aliabid94/tts,gradio,,1
-14990,suhaaspk/PPAP,gradio,unknown,1
-14991,Not-Grim-Refer/Code-to-Detailed-English-Description,gradio,gpl,1
-14992,Not-Grim-Refer/Detailed-English-Description-to-Code,gradio,cc,1
-14993,IwanK/heart_failuere,streamlit,,1
-14994,Nyashi/rvc-models-epic,gradio,mit,1
-14995,wall-e-zz/anime-ai-detect,gradio,,1
-14996,Ld75/pyannote-voice-activity-detection,docker,,1
-14997,Amitesh007/elevenlabs-stt,streamlit,,1
-14998,Nultx/VITS-TTS,gradio,,1
-14999,Pranjal-666/User-Behaviour-Model,gradio,other,1
-15000,DataSage/Book_Recommend,gradio,apache-2.0,1
-15001,hosst/hosst,gradio,bigscience-openrail-m,1
-15002,hosst/HomeLLM,gradio,bigscience-openrail-m,1
-15003,hosst/ApplianceLLM,gradio,bigscience-openrail-m,1
-15004,hosst/ProfessionLLM,gradio,bigscience-openrail-m,1
-15005,HOSSTOS/README,static,,1
-15006,samehmamin/argillatest,docker,,1
-15007,WYF20618/Real-CUGAN,gradio,gpl-3.0,1
-15008,rubinmc/Image-Animation-using-Thin-Plate-Spline-Motion-Modeldfdfdddddddddddddddddddddd,gradio,,1
-15009,tiedong/Goat,gradio,apache-2.0,1
-15010,locknsw/nomic-ai-gpt4all-13b-snoozy,gradio,,1
-15011,heliosbrahma/ai-youtube-assistant,gradio,,1
-15012,JsonLite/gp,gradio,lgpl-3.0,1
-15013,Cat125/text-generator-v3,gradio,openrail,1
-15014,arnikdehnavi/citationPrediction,streamlit,,1
-15015,RandomCatLover/plants_disease,gradio,cc-by-nc-nd-4.0,1
-15016,ishaan812/mediHelp,gradio,,1
-15017,rohan13/grady,gradio,,1
-15018,gabibi7am/rvc-models,gradio,mit,1
-15019,shawndimantha/transcribesong1,streamlit,apache-2.0,1
-15020,sklearn-docs/Comparison-of-Manifold-Learning-methods,gradio,mit,1
-15021,kurianbenoy/Pallakku,gradio,,1
-15022,frncscp/bullerengue,gradio,mit,1
-15023,3laa2/Text2img,streamlit,openrail,1
-15024,NovaSerial/anime-remove-background,gradio,apache-2.0,1
-15025,AndyCer/TehVenom-MPT-7b-Chat-Instruct-LongCTX-Merge,gradio,,1
-15026,duchaba/yml_hackathon_img_mindy,gradio,mit,1
-15027,ucalyptus/DragGAN-unofficial,gradio,apache-2.0,1
-15028,matthoffner/monacopilot,docker,mit,1
-15029,duchaba/yml_hackathon_img_maggie,gradio,mit,1
-15030,duchaba/yml_hackathon_img_ardy,gradio,mit,1
-15031,cifkao/context-probing,streamlit,mit,1
-15032,KGHL/img-to-music,gradio,,1
-15033,voices/VCTK_British_English_Males,docker,other,1
-15034,Nesip/Aeala-GPT4-x-AlpacaDente2-30b,docker,,1
-15035,codersgyan/espnet-kan-bayashi_ljspeech_vits,gradio,,1
-15036,MAMADREZAMORADIam/Hgyukhfgtffftt,gradio,,1
-15037,Martin1998/question_answering,streamlit,,1
-15038,Alcom/chaoyi-wu-PMC_LLAMA_7B,gradio,,1
-15039,patti-j/omdena-mental-health,gradio,,1
-15040,SamiAlghamdi/FirstEver,gradio,,1
-15041,MUmairAB/BreastCancerDetector-app,gradio,mit,1
-15042,Supawich/hololive_AI_fan_art_classifier,gradio,unknown,1
-15043,bgadaleta/mars,docker,cc,1
-15044,rahulmishra/transformerModel,gradio,,1
-15045,awinml/alpaca-cpp,gradio,,1
-15046,ahmed-masry/UniChart-Base,gradio,gpl-3.0,1
-15047,agutfraind/llmscanner,streamlit,mit,1
-15048,epochs-demos/MedicalImagingApp,streamlit,,1
-15049,safi842/FashionGen,streamlit,afl-3.0,1
-15050,Seogmin/NLP,static,,1
-15051,fr1ll/sketch-to-1d-SRME,gradio,apache-2.0,1
-15052,Jikiwi/sovits-models,gradio,mit,1
-15053,bebetterfeng/CarperAI-stable-vicuna-13b-delta,gradio,,1
-15054,xwsm/gpt,gradio,,1
-15055,ShadowDominator/image-to-text-khmer-ocr,gradio,,1
-15056,realAshish/SG161222-Realistic_Vision_V1.4,gradio,unknown,1
-15057,hanaum/clip-test,gradio,,1
-15058,rohan13/Roar,gradio,,1
-15059,duchaba/yml_hackathon_prompt_monty,gradio,mit,1
-15060,joey1895/tsspace01,gradio,apache-2.0,1
-15061,ShadowDominator/sentence-sentiment-analysis,gradio,,1
-15062,ShadowDominator/paragraph-similarity,gradio,,1
-15063,Quickturtle005/mothership_hca,streamlit,,1
-15064,voices/VCTK_American_English_Females,docker,cc-by-4.0,1
-15065,SantiagoTesla/image_generator,gradio,creativeml-openrail-m,1
-15066,Epitech/Scarecrow,gradio,mit,1
-15067,ludusc/latent-space-theories,streamlit,,1
-15068,BlueRey/MendoBERT_QA,streamlit,afl-3.0,1
-15069,KingBlaze1227/PC-PICKERS,static,cc,1
-15070,tatate/trolltrade,streamlit,cc-by-nd-4.0,1
-15071,helidem/Projet-L3-Image,gradio,,1
-15072,SNKRWRLD/SNKR_WRLD_Shoe_Picker,gradio,afl-3.0,1
-15073,victor/test-12342324,gradio,,1
-15074,siya02/Konakni-TTS,gradio,apache-2.0,1
-15075,Josekutty/project_01,gradio,mit,1
-15076,cc38300/ConstructionGPT-SL,streamlit,,1
-15077,coding-alt/IF,docker,other,1
-15078,Quickturtle005/profitability_tool,streamlit,,1
-15079,xercon/chat-with-docs,gradio,apache-2.0,1
-15080,osiria/classifier-zero-shot-italian,gradio,apache-2.0,1
-15081,talaa/Financial-sentiment-news-analysis,streamlit,apache-2.0,1
-15082,Andy1621/uniformer_light,gradio,mit,1
-15083,ShadowDominator/extract-photos-from-pdf,gradio,,1
-15084,sklearn-docs/Caching-Nearest-Neighbors,gradio,mit,1
-15085,camillevanhoffelen/langchain-HuggingGPT,gradio,mit,1
-15086,sklearn-docs/Density-Estimation-for-a-Gaussian-mixture,gradio,mit,1
-15087,theonerichy/wd-v1-4-tags,gradio,,1
-15088,sklearn-docs/Detection-Error-Tradeoff-Curve,gradio,mit,1
-15089,perc1val/CaptchaSolver,gradio,,1
-15090,hjzhp/cgpt-online,docker,,1
-15091,pplonski/Artificial_Calculus_Teacher,gradio,mit,1
-15092,juanhuggingface/ChuanhuChatGPT_Beta,gradio,gpl-3.0,1
-15093,Aityz/Aityz_Model_Eli5,gradio,apache-2.0,1
-15094,hujike/mj-laf,static,apache-2.0,1
-15095,orangepony4/stabilityai-stable-diffusion-2-1,gradio,,1
-15096,amanmibra/void-demo-aisf,gradio,,1
-15097,jasonwu92/image-search-playground,gradio,mit,1
-15098,utkuarslan5/yodazer,gradio,cc,1
-15099,sh0kul/DTPDC-Deploy,streamlit,mit,1
-15100,rainbowemoji/etf-assistant,streamlit,,1
-15101,AutoGeneralAI/chatgpt-clone,gradio,,1
-15102,dasanik2001/FYP_G15_RCCIIT,gradio,,1
-15103,TILK/UrgencyBot,gradio,gpl-3.0,1
-15104,Akim/claudeAPI,docker,unknown,1
-15105,rstallman/Beta.AI.Barrister,gradio,,1
-15106,FreeHamish/Manaforge,gradio,,1
-15107,nexuhs/ChatGPT4,gradio,mit,1
-15108,Wangchunshu/RecurrentGPT,gradio,,1
-15109,ankush29/CheckGPT,streamlit,mit,1
-15110,Jellyfish042/punctuation_mark_prediction,gradio,openrail,1
-15111,Juliojuse/human_health_gradio,gradio,,1
-15112,kamaldeep132/pdfGPT,gradio,openrail,1
-15113,Hahsgsgsy/teston,streamlit,,1
-15114,yuragoithf/mlg_image_classification,gradio,,1
-15115,bonrix/text_detection_easyocr,gradio,apache-2.0,1
-15116,bla/tranny,docker,,1
-15117,kalyas/dpt-depth-estimation,gradio,,1
-15118,VinayDBhagat/GenerateCustomerInsights,streamlit,,1
-15119,jx-yang/deep-thinking,gradio,mit,1
-15120,QinBingFeng/dalle-mini,static,apache-2.0,1
-15121,GreenRaptor/MMS,gradio,cc-by-nc-4.0,1
-15122,hilmyblaze/WebUI-Counterfeit-V2.5,gradio,,1
-15123,Ironbasin/anime-ai-detect,gradio,,1
-15124,Potato-ML/Spaceship_Titanic,gradio,,1
-15125,mfkeles/Track-Anything,gradio,mit,1
-15126,yixin6178/arXiv2Latex,streamlit,openrail,1
-15127,hbestm/gpt-academic-play,gradio,,1
-15128,raravena80/trulensplay,static,mit,1
-15129,Addai/Breast_cancer_detection_with_deep_transfer_learning,gradio,apache-2.0,1
-15130,FroggyQc/ehartford-WizardLM-7B-Uncensored,gradio,,1
-15131,MichaelXin/openai-test,gradio,mit,1
-15132,Silence1412/Text2img,streamlit,openrail,1
-15133,MingGatsby/multi-query-sentiment,docker,mit,1
-15134,ccmusic-database/README,static,mit,1
-15135,Choisuren/AnimeGANv3,gradio,,1
-15136,tiiuae/README,static,,1
-15137,Ababababababbababa/Sha3bor_Aragpt2_Base,gradio,,1
-15138,Ababababababbababa/Arabic_poetry_Sha3bor_mid,gradio,,1
-15139,HReynaud/EchoDiffusionDemo,gradio,mit,1
-15140,tusharust/darkstorm2150-Protogen_x5.8_Official_Release,gradio,,1
-15141,hamedmohamed/microsoft-speecht5_tts,gradio,,1
-15142,Pattr/DrumClassification,gradio,cc-by-4.0,1
-15143,dorkai/ChatUIPro,docker,openrail,1
-15144,technocenter/MUmairAB-Breast_Cancer_Detector,gradio,,1
-15145,JosephTK/object-detection-count,gradio,,1
-15146,truera/trulens,docker,mit,1
-15147,g0blas/cap-recognizer,gradio,mit,1
-15148,abby-mcdonald/CardioPro,streamlit,mit,1
-15149,awacke1/API-Demo,gradio,mit,1
-15150,divish/guanaco-playground-tgi-2,gradio,,1
-15151,aminghias/text_analytics_project,gradio,apache-2.0,1
-15152,Thanhdotr/facebook-fastspeech2-en-ljspeech,gradio,apache-2.0,1
-15153,sklearn-docs/SVM-Anova-SVM-with-univariate-feature-selection,gradio,mit,1
-15154,sklearn-docs/KDE-of-Species-Distributions,gradio,mit,1
-15155,kidcoconut/spcstm_omdenasaudi_liverhccxai,streamlit,mit,1
-15156,Annotation-AI/fast-segment-everything-with-drawing-prompt,gradio,,1
-15157,jaseci/NERGPT,streamlit,openrail,1
-15158,sklearn-docs/Test-with-permutations-the-significance-of-a-classification-score,gradio,mit,1
-15159,sklearn-docs/Plotting-Cross-Validated-Predictions,gradio,mit,1
-15160,sklearn-docs/Demonstration-of-multi-metric-evaluation-on-cross_val_score-and-GridSearchCV,gradio,mit,1
-15161,sklearn-docs/Isotonic-Regression,gradio,mit,1
-15162,sanaghani12/emotiondetection,gradio,,1
-15163,sklearn-docs/Gaussian-Classification-on-XOR,gradio,mit,1
-15164,seanghay/khmer-tts,gradio,cc-by-4.0,1
-15165,ShoukanLabs/OpenNiji-Dataset-Viewer,gradio,,1
-15166,DeepakJaiz/QA_evaluator,streamlit,,1
-15167,sklearn-docs/Gaussian-Classification-on-Iris,gradio,mit,1
-15168,0xAnders/ama-bot,gradio,apache-2.0,1
-15169,sklearn-docs/Normal-Ledoit-Wolf-and-OAS-Linear-Discriminant-Analysis-for-classification,gradio,mit,1
-15170,sabirbagwan/Sip,streamlit,,1
-15171,MLIFY/Chatter,static,apache-2.0,1
-15172,sklearn-docs/Gaussian-Mixture-Model-Ellipsoids,gradio,mit,1
-15173,sklearn-docs/Gaussian-Mixture-Model-Covariance,gradio,mit,1
-15174,utkuarslan5/persona,streamlit,bigscience-openrail-m,1
-15175,MLIFY/ehartford-WizardLM-30B-Uncensored,gradio,,1
-15176,MLIFY/openaccess-ai-collective-manticore-13b,gradio,mit,1
-15177,akashjeez/akashjeez,streamlit,other,1
-15178,barani/ControlNet,gradio,mit,1
-15179,smukerji/pdfBot,streamlit,openrail,1
-15180,ImPavloh/voiceit,gradio,gpl,1
-15181,Annelisseishere/Streamlit_GPT,streamlit,,1
-15182,JPTHEGOAT/SG161222-Realistic_Vision_V1.4,gradio,unknown,1
-15183,swaptr/image-captioning,gradio,,1
-15184,jeycov/PIB-PAARCIAL-FIN,gradio,apache-2.0,1
-15185,amanmibra/void-emb-demo,gradio,,1
-15186,hosst/carers,gradio,apache-2.0,1
-15187,besarismaili/fastai_pet_classifier,gradio,,1
-15188,sysopo/impira-layoutlm-document-qa,gradio,,1
-15189,rogera11/Art-Style-Classifier,gradio,apache-2.0,1
-15190,rdecler/MySpace,streamlit,apache-2.0,1
-15191,freestok/corn-diseases,gradio,apache-2.0,1
-15192,dermetfak/healthcare_ai_loop,streamlit,openrail,1
-15193,umitgunduz/news-extractor,docker,,1
-15194,FunnyDannyG/VoiceFixer,gradio,,1
-15195,micahCastillo/gpt-report-analysis,gradio,,1
-15196,Oumar199/Fake-Real-Face-Detection,streamlit,,1
-15197,sddwt/guanaco,gradio,,1
-15198,xiaobaiyuan/theme_land,gradio,apache-2.0,1
-15199,skimai/DragGAN_Streamlit,streamlit,mit,1
-15200,linweiyt/aiwrite,gradio,,1
-15201,darthPanda/chatpdf_app,streamlit,,1
-15202,inayet/inayet-autotrain-price-prediction-1331950922,gradio,,1
-15203,ozgur34/qb-Engine2,gradio,creativeml-openrail-m,1
-15204,Wings77/ChatGPT4,gradio,mit,1
-15205,twdac/BuChengFangYuan-ChineseJapaneseTranslation,gradio,,1
-15206,olimpa/CVORG,static,cc-by-nc-sa-4.0,1
-15207,hitty/Movie-Recommendation-System,streamlit,,1
-15208,hari31416/Style-Transfer,docker,mit,1
-15209,MINAMONI/img-to-music,gradio,,1
-15210,WinWut/Lofi-music-style-transfer,streamlit,apache-2.0,1
-15211,justest/chatglm-6b-int4,gradio,mit,1
-15212,danushkhanna/Phishing_Domain_Detector,streamlit,apache-2.0,1
-15213,GiorgiSekhniashvili/geo-whisper,gradio,apache-2.0,1
-15214,FineLong/stabilityai-stable-diffusion-2,gradio,openrail++,1
-15215,DataRaptor/ActionNet,streamlit,,1
-15216,samisnotmyname/Instagram-Carousel-Prompt-Generator,gradio,unknown,1
-15217,Hobis/bark-voice-cloning-polish-HuBERT-quantizer,gradio,mit,1
-15218,davidanthony-ai/DIGITALIXSA,gradio,mit,1
-15219,analyticsinmotion/word-error-rate,gradio,mit,1
-15220,FranklinWillemen/TARS,gradio,cc,1
-15221,hitty/Vegetable_Classifier,streamlit,,1
-15222,KingChronos/ChatGPT4,gradio,mit,1
-15223,middha/Torpedoes,gradio,,1
-15224,typesdigital/BLOOMChat,static,apache-2.0,1
-15225,MajdOD/gradio-Stroke-prediction,gradio,openrail,1
-15226,xYousha/AlphaGPT,gradio,other,1
-15227,Arikkod/FoodVisionMini,gradio,mit,1
-15228,aulhan/microsoft-codereviewer,gradio,openrail,1
-15229,olimpa/Agenda-Inter,streamlit,,1
-15230,wiwide/40bqa,gradio,mit,1
-15231,michaelwja/burn-detection,gradio,,1
-15232,bhavyapandya/Next-Word-Prediction,gradio,mit,1
-15233,SHIBATAATSUSHI/aioccupationaltherapist2,gradio,,1
-15234,FER-Universe/Face-Benchmarking,gradio,,1
-15235,edisonlee55/hysts-anime-face-detector,gradio,mit,1
-15236,lyimo/asrv2,gradio,mit,1
-15237,Menna2211/TxTimg,streamlit,,1
-15238,vinayakchuni/PayalVinayakClassifier,gradio,,1
-15239,indikamk/MisconAI,gradio,cc-by-4.0,1
-15240,arihantvyavhare/device_detector_img2txt,gradio,apache-2.0,1
-15241,Menna2211/ImCaptioning,streamlit,,1
-15242,Rardilit/Rardilit-Panther_v1_test1,gradio,other,1
-15243,crawly/White-box-Cartoonization,gradio,apache-2.0,1
-15244,Mellow-ai/PhotoAI_Mellow,gradio,,1
-15245,Ragio/endometrial_disease_prediction,gradio,mit,1
-15246,robyramos/analise_perfil_v2,gradio,other,1
-15247,spuun/blip-api,gradio,,1
-15248,Hexamind/iPADS,streamlit,bsd-2-clause,1
-15249,roontoon/Demo-TTI-dandelin-vilt-b32-finetuned-vqa,gradio,,1
-15250,Lwalid/Daam_Inpainting,gradio,,1
-15251,LCaligari/deepsynthbody-deepfake_ecg,gradio,,1
-15252,jganzabalseenka/NER-spanish,gradio,apache-2.0,1
-15253,Abhishek92kumar/layoutlmv3-finetuned-cord_100,streamlit,apache-2.0,1
-15254,AhmedRashwan369/ChatGPT4,gradio,mit,1
-15255,ari7thomas/bible.ai,docker,openrail,1
-15256,apetulante/bert-emotion,gradio,,1
-15257,Naszirs397/rvc-models,gradio,mit,1
-15258,michaelwja/maskformer-satellite-trees-gradio,gradio,cc-by-nc-sa-4.0,1
-15259,Tej3/ECG_Classification,gradio,,1
-15260,AIKey/facetofacechat,static,,1
-15261,AIKey/ai_date,static,,1
-15262,camenduru-com/imdb,docker,,1
-15263,nameissakthi/Invoice-Extraction-1,gradio,,1
-15264,Amite5h/EuroSAT_,streamlit,apache-2.0,1
-15265,Superying/vits-uma-genshin-honkai,gradio,apache-2.0,1
-15266,AIKey/TestStatic,static,,1
-15267,tigergoo/ai,gradio,mit,1
-15268,sohoso/anime348756,gradio,,1
-15269,Suweeraya/Breast_Cancer_Ultrasound_Image_Segmentation,gradio,,1
-15270,Abubakari/Sepsis-prediction-streamlit-app,streamlit,,1
-15271,totsunemario/minimal,gradio,apache-2.0,1
-15272,SolenopsisCampo/Automatic1111_Stable_Diffusion,gradio,,1
-15273,isaakkamau/Whisper-Video-Subtitles,streamlit,mit,1
-15274,olimpa/CalendarJs,static,,1
-15275,surgelee/SG161222-Realistic_Vision_V1.4,gradio,,1
-15276,QINGCHE/TSA,gradio,mit,1
-15277,Locomocool/MooseOrDeer,gradio,lppl-1.3c,1
-15278,martingrados/gradio-google-sheet,gradio,,1
-15279,PrabhuKiranKonda/Streamlit-PDF-Assistant-Docker,docker,,1
-15280,agunes/ChatGPT4,gradio,mit,1
-15281,0xeureka/ehartford-WizardLM-13B-Uncensored,gradio,,1
-15282,jbyun/music-separation,gradio,,1
-15283,LuxOAI/BGCGW,gradio,openrail,1
-15284,neuesql/sqlgptapp,streamlit,mit,1
-15285,olimpa/projectAlphaDB,docker,,1
-15286,gnakan/airtable-QA,streamlit,,1
-15287,Mohamedoz/chatmoh,gradio,mit,1
-15288,aliabid94/golfy,gradio,,1
-15289,Lanerdog/deepsynthbody-deepfake_ecg6666,static,openrail,1
-15290,Annotation-AI/segment-similarthings,gradio,,1
-15291,raaec/Pix2Pix-Video-prv,gradio,,1
-15292,king007/pdfChatter,gradio,afl-3.0,1
-15293,xxccc/gpt-academic,gradio,,1
-15294,winglema/ChatGPT4,gradio,mit,1
-15295,animeartstudio/QuickGen-Photo,gradio,creativeml-openrail-m,1
-15296,animeartstudio/QuickGen-Art,gradio,creativeml-openrail-m,1
-15297,speakjan/EleutherAI-gpt-j-6b,gradio,openrail,1
-15298,pongping/converter,gradio,mit,1
-15299,sinksmell/ChatPDF,gradio,apache-2.0,1
-15300,sci4/AnimateYourDream,streamlit,apache-2.0,1
-15301,sudip1310/BANAO_Tiny_Shakespeare,gradio,,1
-15302,SMOOTHY1962/redstonehero-realisian_v40,gradio,,1
-15303,threestoneyang/vits-uma-genshin-honkai,gradio,apache-2.0,1
-15304,shifei/gradio,gradio,,1
-15305,breehill1994/SG161222-Realistic_Vision_V1.4,gradio,,1
-15306,R34Koba/ClaudeProxyGaming,docker,,1
-15307,LuxOAI/ResumeBud,gradio,openrail,1
-15308,Dauzy/whisper-webui,gradio,apache-2.0,1
-15309,LuxOAI/guanaco-playground-tgi,gradio,,1
-15310,Q4234/a2,gradio,,1
-15311,eaedk/Sentiment_Analysis_App_Docker_deployed,docker,mit,1
-15312,remyxai/remyxai-classifier-labeler,gradio,apache-2.0,1
-15313,apozzuoli98/shark-or-whale-classifier,gradio,apache-2.0,1
-15314,liammcdevitt73/LoL-Support-Classifier,gradio,apache-2.0,1
-15315,qiantong-xu/sambanovasystems-codegen-16B-mono-toolbench,gradio,bsd-3-clause,1
-15316,ml595/myfirstspace,gradio,,1
-15317,thegenerativegeneration/FNeVR_demo,gradio,apache-2.0,1
-15318,Seetha/IMA-pipeline-streamlit,streamlit,,1
-15319,Juno360219/albert-base-v2,static,,1
-15320,Juno360219/cloudqi-cqi_text_to_image_pt_v0,docker,mit,1
-15321,alibidaran/General_image_captioning,gradio,apache-2.0,1
-15322,Juno360219/stabilityai-stable-diffusion-2-1,static,,1
-15323,LuxOAI/GPT4-30b,gradio,,1
-15324,awacke1/PermutationsAndSequencesGPT,streamlit,mit,1
-15325,dolceschokolade/chatbot-mini,docker,mit,1
-15326,Ank0X0/text-to-3d-shap-e-webui,gradio,cc0-1.0,1
-15327,Sreekumar1608/langchain-chat-with-pdf-openai,gradio,,1
-15328,sccstandardteam/ChuanhuChatGPT,gradio,gpl-3.0,1
-15329,Laurie/IDEA-CCNL-Ziya-LLaMA-13B-v1,gradio,,1
-15330,OzoneAsai/gptsan,gradio,,1
-15331,abhi1280/QR_generator,gradio,apache-2.0,1
-15332,neojex/LuxembourgishTextClassifier,gradio,mit,1
-15333,UltimateAICourse/Prompt-Engineering,static,cc,1
-15334,Hamish/openai_demo,streamlit,,1
-15335,Hakim571/Food-Classification,gradio,,1
-15336,jeffrymahbuubi/bert-advanced-cnn-hate-speech-classification,gradio,mit,1
-15337,welloff/ChatGPT-prompt-generator,gradio,apache-2.0,1
-15338,PurtiSharma/toxic_comments,streamlit,,1
-15339,After-the-Dark/paragraph-similarity,gradio,,1
-15340,kmirijan/NBA-Stats,gradio,gpl-3.0,1
-15341,pord123/model_demo,gradio,apache-2.0,1
-15342,Frorozcol/financIA,streamlit,,1
-15343,osiria/distilbert-italian-cased-ner,gradio,apache-2.0,1
-15344,Vishnu-sai-teja/Dog-vs-Cats-2,gradio,apache-2.0,1
-15345,tonwuaso/SentimentAnalysisModel,gradio,mit,1
-15346,giswqs/solara-demo,docker,mit,1
-15347,AIOSML/README,gradio,bsd,1
-15348,FrancisLi/advance_autotrain,docker,apache-2.0,1
-15349,sebsigma/geodata-harvester-app,streamlit,lgpl-3.0,1
-15350,randt/stabilityai-stable-diffusion-2-1,gradio,afl-3.0,1
-15351,lsli/lab,gradio,mit,1
-15352,manu1612/spamdet,streamlit,,1
-15353,menciusyue/stabilityai-stable-diffusion-2,gradio,,1
-15354,WangZeJun/bloom-820m-chat,gradio,bigscience-bloom-rail-1.0,1
-15355,Kuachi/ai-voice,gradio,apache-2.0,1
-15356,Hexamind/swarms,streamlit,bsd-2-clause,1
-15357,dusanstanis/TheBloke-guanaco-65B-HF,gradio,,1
-15358,cownclown/TehVenom-MPT-7b-WizardLM_Uncensored-Storywriter-Merge,gradio,,1
-15359,sklearn-docs/Face-completion,gradio,,1
-15360,Cloudy1225/stackoverflow-sentiment-analysis,gradio,openrail,1
-15361,MaxKazak/RuBert-base-russian-emotions-classifier-goEmotions,gradio,,1
-15362,g0blas/chicken-breed-recognizer,gradio,mit,1
-15363,sd9972/autotune,docker,,1
-15364,kolibril13/tldraw-solara-test,docker,mit,1
-15365,VuAI/VN98,gradio,openrail,1
-15366,Taithrah/Minimal,gradio,apache-2.0,1
-15367,Vikas01/Attendence_System,gradio,cc,1
-15368,Woogiepark/stabilityai-stable-diffusion2,gradio,,1
-15369,prasanthntu/dog-vs-cat-classifier,gradio,apache-2.0,1
-15370,osiria/bert-italian-cased-ner,gradio,apache-2.0,1
-15371,dukai289/learning_streamlit,streamlit,,1
-15372,shoukosagiri/stable-diffusion-webui-cpu,gradio,,1
-15373,vishnu23/web_scrap,gradio,,1
-15374,mrrandom123/image_creative_caption_new,streamlit,,1
-15375,hands012/gpt-academic,gradio,,1
-15376,g0urav-hustler/Image-Caption-Generator,streamlit,,1
-15377,dukai289/scripts,static,,1
-15378,ludvigolsen/plot_confusion_matrix,docker,,1
-15379,sunilkumardash9/pdf-GPT,gradio,openrail,1
-15380,Lazyhope/RepoSnipy,streamlit,mit,1
-15381,ggwvits/vits-uma-genshin-honkai,gradio,apache-2.0,1
-15382,simpx/tiiuae-falcon-7b,gradio,,1
-15383,XuZhang999/ProArticles,gradio,apache-2.0,1
-15384,Falah/stablediffusionDB,gradio,,1
-15385,eatcosmos/hackaprompt,gradio,,1
-15386,LENMON/ProxyGPT,docker,apache-2.0,1
-15387,saurshaz/HuggingGPT,gradio,,1
-15388,Abubakari/Sepsis-fastapi-prediction-app,docker,,1
-15389,gersh/ehartford-based-30b,gradio,openrail,1
-15390,s3nh/acceptable-self-instructs,gradio,openrail,1
-15391,Queensly/FastAPI_in_Docker,docker,,1
-15392,Raghav001/PDF,gradio,apache-2.0,1
-15393,amasad/Replit-v2-CodeInstruct-3b,gradio,,1
-15394,prasanthntu/who-is-the-hero,gradio,apache-2.0,1
-15395,mayajwilson76/insurance-stress-testing-demo,gradio,apache-2.0,1
-15396,briancatmaster/Tropic-AI,gradio,,1
-15397,lavan2012/free-fast-youtube-url-video-to-text-using-openai-whisper,gradio,gpl-3.0,1
-15398,abokbot/wikipedia-search-engine,streamlit,,1
-15399,FawnPythn/andite-anything-v4.0,gradio,,1
-15400,Akmyradov/TurkmenSpeechRecogntion,gradio,,1
-15401,mikeee/docs-chat,streamlit,mit,1
-15402,Veera-Ruki/AutoPoem-Generator,streamlit,,1
-15403,camenduru-com/sl,docker,,1
-15404,ik/twi-ewe-mss-tss,gradio,,1
-15405,LennardZuendorf/legalis,gradio,mit,1
-15406,HariSathwik/OmdenaAI-Jordan,streamlit,,1
-15407,Kuachi/hololive,gradio,mit,1
-15408,awinml/api-instructor-xl-1,gradio,apache-2.0,1
-15409,ixiangjin/GPT4ALL,gradio,openrail,1
-15410,rfrossard/ChatGPT-PPT-Generate,gradio,,1
-15411,rfrossard/langchain-chat-with-pdf,gradio,,1
-15412,BramVanroy/mateo-demo,docker,gpl-3.0,1
-15413,sadjava/emotion-classification,gradio,apache-2.0,1
-15414,ikoghoemmanuell/Sales-Prediction-App-Streamlit,streamlit,,1
-15415,suyash007/MRS-SUYASH,streamlit,,1
-15416,mengdeweide/VITS,gradio,mit,1
-15417,Whalb/GPT4ALL,gradio,openrail,1
-15418,SurendraKumarDhaka/Shakespeare-AI,streamlit,,1
-15419,hlydecker/Augmented-Retrieval-qa-ChatGPT,streamlit,cc-by-nc-sa-4.0,1
-15420,prognosis/inference-bloom-doc-qa,docker,,1
-15421,pdjewell/sommeli_ai,streamlit,,1
-15422,1line/AutoGPT,gradio,mit,1
-15423,MesutUnutur/germanToEnglishTextToImage,gradio,,1
-15424,altndrr/vic,gradio,,1
-15425,MesutUnutur/chatgptFinetune,gradio,,1
-15426,ivn888/Twitter-dashboard,docker,cc-by-4.0,1
-15427,kyauy/ClinFly,streamlit,,1
-15428,ysharma/dummyy112233,gradio,,1
-15429,xujunhao/AudioLM,gradio,,1
-15430,shuanglei/promptGenerator,gradio,mit,1
-15431,NicoleGoh/Anime_Recommendation,streamlit,,1
-15432,cmseibold/cxas-demo,gradio,afl-3.0,1
-15433,Cletrason/cloudqi-cqi_text_to_image_pt_v0,gradio,,1
-15434,awacke1/ChatGPTStreamlit3,streamlit,mit,1
-15435,andfanilo/streamlit-drawable-canvas-demo,streamlit,,1
-15436,Harsh502s/Anime-Recommender,streamlit,mit,1
-15437,kbora/minerva-generate-docker,docker,,1
-15438,Panel-Org/panel-demo-image-classification,docker,,1
-15439,eswat/Image-and-3D-Model-Creator,gradio,,1
-15440,awacke1/ChatGPTStreamlit4,streamlit,mit,1
-15441,amanatid/ArxivGPT_Streamlit,streamlit,mit,1
-15442,rriverar75/dientes,streamlit,mit,1
-15443,alessveloz/lenssssw-roblox-clothing-ai-maker,gradio,,1
-15444,jewellery/ChatGPT4,gradio,mit,1
-15445,NanoMachin/Free-Palestine,docker,,1
-15446,PeepDaSlan9/OpenAssistant-reward-model-deberta-v3-large-v2,gradio,mit,1
-15447,awacke1/ChatGPT-Streamlit-5,streamlit,mit,1
-15448,hlydecker/falcon-chat,gradio,apache-2.0,1
-15449,Jimmyfreelancer/Pix2Pix-Video,gradio,,1
-15450,SIH/Augmented-Retrieval-qa-ChatGPT,streamlit,cc-by-nc-sa-4.0,1
-15451,Taocan/Chatty,gradio,mit,1
-15452,Jokerkid/porntech-sex-position,gradio,,1
-15453,Soyoung97/gec-korean-demo,streamlit,cc-by-nc-4.0,1
-15454,vishnu0001/text2mesh,gradio,,1
-15455,kaustubh35/tax,docker,openrail,1
-15456,Akmyradov/TurkmenTTSweSTT,gradio,cc-by-nc-4.0,1
-15457,marlhex/test1,gradio,apache-2.0,1
-15458,zkunn/Alipay_Gradio_theme,gradio,apache-2.0,1
-15459,uooogh/webui,gradio,,1
-15460,nosdigitalmedia/dutch-youth-comment-classifier,gradio,,1
-15461,Jerry0203/sentence_embedding,gradio,,1
-15462,AlterM/Zaglyt2-transformer-test,gradio,,1
-15463,Guilhh-kell0/Jennifer-Home,streamlit,,1
-15464,hk59775634/OpenAI-Manager,static,bsd-3-clause,1
-15465,abidlabs/audioldm-text-to-audio-generation,gradio,bigscience-openrail-m,1
-15466,Igor2004/newSpace,gradio,,1
-15467,ArturStepanenko/digitsSpace,gradio,,1
-15468,DexterSptizu/drug_interaction,gradio,mit,1
-15469,victor/tesTETZTRZE,gradio,,1
-15470,fisehara/openai-whisper-base,gradio,,1
-15471,radames/Falcon-40b-Dockerfile,docker,,1
-15472,DailyBibleMotivation/README,static,,1
-15473,bparks08/falcon-chat-40b-1,gradio,apache-2.0,1
-15474,dandan4272/hand_gesture_rec,gradio,mit,1
-15475,myrad01/Inpaint-Anything,gradio,apache-2.0,1
-15476,rhineJoke/test_faclon-7b,gradio,apache-2.0,1
-15477,subwayman/btc-chat-bot,gradio,mit,1
-15478,Srihari1611/Gender_Classification,gradio,apache-2.0,1
-15479,alexyuyxj/emotion-classify,gradio,,1
-15480,Starcodium/README,static,,1
-15481,Superlang/remove_background,gradio,cc-by-nc-3.0,1
-15482,crazybber/docker-demo-t5-translation,docker,,1
-15483,BillBojangeles2000/bart-large-cnn-samsum,gradio,bigcode-openrail-m,1
-15484,ShreyaRao/QuotesForU,streamlit,unknown,1
-15485,DarkyMan/OrangeMixes,gradio,mit,1
-15486,ky2k/Toxicity_Classifier_POC,gradio,,1
-15487,alexyuyxj/zh-en-translation,gradio,,1
-15488,liuzq/free-creation,gradio,mit,1
-15489,rudayrude/free-fast-youtube-url-video-to-text-using-openai-whisper,gradio,gpl-3.0,1
-15490,friedrichor/friedrichor-stable-diffusion-2-1-realistic,gradio,openrail++,1
-15491,Kelvinhjk/QnA_chatbot_for_Swinburne_cs_course,streamlit,,1
-15492,jonas/KaraAgro-Cadi-AI,gradio,openrail,1
-15493,mithril-security/Santacoder-demo,gradio,,1
-15494,neko321/Voice-Changer1,gradio,mit,1
-15495,internetsignal/audioLDM,Configuration error,Configuration error,1
-15496,blmdsydm/faster-whisper-webui,gradio,apache-2.0,1
-15497,LovnishVermaPRINCE/attendanceviaface,streamlit,cc,1
-15498,colutti/timpal0l-mdeberta-v3-base-squad2,gradio,,1
-15499,lekkalar/chatgpt-for-pdfs,gradio,,1
-15500,SantiagoMoreno-UdeA/NER_RC,gradio,,1
-15501,patvfb/worldofshares,gradio,,1
-15502,CaliforniaHealthCollaborative/Emoji2KaktovicEncryptKey,Configuration error,Configuration error,1
-15503,CaliforniaHealthCollaborative/README,static,mit,1
-15504,EnigmaOfTheWorld/Interior_home,gradio,,1
-15505,petervavank/Advoice,gradio,openrail,1
-15506,cuixuhan/888,static,,1
-15507,drdoggo/Medical_Image_Understanding_with_VLMs,gradio,,1
-15508,alitudil0/Sillyfinity,docker,mit,1
-15509,chopey/DhivehiTransliteration,gradio,mit,1
-15510,nitinacap/chatgpt4all,docker,,1
-15511,Insuz/Mocha,gradio,apache-2.0,1
-15512,lint/meetingsummary,docker,,1
-15513,Subhraj07/minio,docker,apache-2.0,1
-15514,danfsmithmsft/falcon-chat,gradio,apache-2.0,1
-15515,NonnaRose/Image-Caption,gradio,,1
-15516,awacke1/ChatGPTStreamlit6,streamlit,mit,1
-15517,Th3BossC/TranscriptApi,docker,,1
-15518,varunkuntal/text2_img_text_demo,gradio,,1
-15519,nicholasKluge/Aira-Demo,gradio,apache-2.0,1
-15520,genevera/AudioToken,gradio,mit,1
-15521,coyotte508/test-req,docker,,1
-15522,dantosxd/gorilla-llm-gorilla-mpt-7b-hf-v0,gradio,,1
-15523,vpivn/Cooling-Water-Thermal-Evolutions,gradio,apache-2.0,1
-15524,maxomorphic/DogBreedIdentifier,gradio,apache-2.0,1
-15525,rovargasc/calificacion,docker,,1
-15526,awacke1/ChatGPTStreamlit8,streamlit,mit,1
-15527,Hexamind/QnA,gradio,eupl-1.1,1
-15528,Angello06/SoylaloGaming,streamlit,openrail,1
-15529,BigSalmon/AbstractTwst,streamlit,,1
-15530,gerhug/dalle-mini,static,apache-2.0,1
-15531,olive100/face_merge,gradio,,1
-15532,nilaymodi/dandelin-vilt-b32-finetuned-vqa,gradio,,1
-15533,DataWizard9742/LessonPlanGenerator,streamlit,,1
-15534,R1ckShi/funasr_app_clipvideo,gradio,mit,1
-15535,CaliforniaHealthCollaborative/Mermaid.Md,Configuration error,Configuration error,1
-15536,victor/test213213123123,gradio,,1
-15537,Malmika/Osana-Chat-Friend,gradio,,1
-15538,randt/redstonehero-RPG-v5-itr17_A10T,gradio,wtfpl,1
-15539,all-things-vits/class-attention-map,gradio,apache-2.0,1
-15540,fernfromecuador/SG161222-Realistic_Vision_V1.4,gradio,,1
-15541,9prayer/ubiq-chat-cpu,gradio,,1
-15542,victor/ahahahah12,gradio,,1
-15543,openlamm/LAMM,gradio,,1
-15544,awacke1/ChatGPTStreamlit9,streamlit,mit,1
-15545,danterivers/music-generation-samples,gradio,cc-by-nc-4.0,1
-15546,alamin655/Personas,streamlit,mit,1
-15547,Dukcar/Pix2Pix-Video,gradio,,1
-15548,DavidHosp/Movie_Recommendation_System,gradio,apache-2.0,1
-15549,cormerod/gaime,gradio,apache-2.0,1
-15550,Woogiepark/nlpconnect-vit-gpt2-image-captioning,gradio,,1
-15551,theadedolapo/Car_price_prediction,gradio,,1
-15552,d8aai/simple-paper-qa,gradio,apache-2.0,1
-15553,YaTharThShaRma999/Testtrial1,gradio,apache-2.0,1
-15554,hebert2099/MusicGen,gradio,cc-by-nc-4.0,1
-15555,Hakim571/Food-Recommendation,gradio,,1
-15556,cmagganas/chainlit-arxiv,docker,openrail,1
-15557,sachinrcz/isItCarOrPlaceOrBus,gradio,apache-2.0,1
-15558,SujanMidatani/resume_details_extractor,gradio,,1
-15559,JudgmentKazzy/JosefJilek-loliDiffusion,gradio,,1
-15560,tappyness1/error_analysis_obj_det,streamlit,,1
-15561,martykan/SZZ,streamlit,,1
-15562,NickNYU/NickFriendsHouse,streamlit,c-uda,1
-15563,Wrathless/Dkrotzer-MusicalMagic,gradio,cc-by-nc-4.0,1
-15564,Gamero-xD/stabilityai-stable-diffusion-2-1,gradio,,1
-15565,cooelf/Retro-Reader,gradio,apache-2.0,1
-15566,caldervf/maven-5,gradio,,1
-15567,Wrathless/pyannote-voice-activity-detection,docker,apache-2.0,1
-15568,GFXY/stabilityai-stable-diffusion-2-1-base,gradio,agpl-3.0,1
-15569,GFXY/stablediffusionapi-anything-v5,gradio,agpl-3.0,1
-15570,GFXY/Maseshi-Anything-v3.0,gradio,agpl-3.0,1
-15571,XPMaster/manafeth,gradio,,1
-15572,Ama434/neutral-barlow,gradio,apache-2.0,1
-15573,michaljunczyk/pl-asr-bigos-workspace,gradio,cc-by-sa-4.0,1
-15574,Izumazu/ProxyTest,docker,,1
-15575,jeffrymahbuubi/foodvision-mini,gradio,mit,1
-15576,mblackman/kandinsky-blend,gradio,apache-2.0,1
-15577,zhtet/RegBotBeta,docker,,1
-15578,WelcomeToTheClub/VMware-open-llama-7b-open-instruct,gradio,,1
-15579,PeepDaSlan9/VMware-open-llama-7b-open-instruct,gradio,cc,1
-15580,YaTharThShaRma999/ChatwithDolly,gradio,bigscience-bloom-rail-1.0,1
-15581,sheikyerbouti/pawelppppaolo-gpt4chan_model_float16,gradio,wtfpl,1
-15582,all-things-vits/Attend-and-Excite,gradio,mit,1
-15583,PunPk/AI_FallingAsleepDriving,gradio,,1
-15584,Yntec/Single-Stable-Diffusion-Model-Test,gradio,,1
-15585,mnauf/detect-bees,gradio,openrail,1
-15586,XuLiFeng/godxin-chinese_alpaca_plus_lora_7b,gradio,,1
-15587,backway0412/A2,gradio,openrail,1
-15588,geraldvillaran/dolly-chat,gradio,,1
-15589,kangjian99/Panel_PDF_QA,docker,,1
-15590,liaokun/web,streamlit,openrail,1
-15591,Katsuki098/test03,docker,,1
-15592,Yiqin/ChatVID,gradio,mit,1
-15593,TestingCompany/ChatPDF,gradio,unknown,1
-15594,gabrielyokai/reverse,docker,,1
-15595,RICHARDMENSAH/SEPSIS-PREDICTION-STATUS-APP,streamlit,,1
-15596,The13DvX/README,static,,1
-15597,Paperboxiv/Dunhuang_GPT,gradio,other,1
-15598,tom-beer/hotel-recommender,gradio,apache-2.0,1
-15599,flokabukie/Sepsis-status-prediction-fast-api,docker,mit,1
-15600,Haxan786/Tel,gradio,afl-3.0,1
-15601,Juli08/janitorai,docker,,1
-15602,MarkMcCormack/NLP-EduTech-App,streamlit,,1
-15603,DonDoesStuff/streamusic,static,,1
-15604,Boynn/AI,gradio,other,1
-15605,dakaiye/dky_xuexi,gradio,,1
-15606,omdena/omdena-chatbot,docker,,1
-15607,mentalmao/nitrosocke-spider-verse-diffusion,gradio,,1
-15608,MetaWabbit/Basic_Prompt_Generation_Tool,gradio,apache-2.0,1
-15609,czczycz/QABot,streamlit,openrail,1
-15610,natexcvi/trade-assistant-ui,streamlit,,1
-15611,1vash/demo-flask-docker-template,docker,,1
-15612,vruizext/transformers-xray-classification,gradio,,1
-15613,newbietk/chatGPT-T1,gradio,apache-2.0,1
-15614,JAWEE/stablediffusionapi-majicmixrealistic,gradio,,1
-15615,asyafiqe/pdfGPT-chat,docker,mit,1
-15616,tarunika-03/PersonalityPrediction_Psychology,gradio,,1
-15617,abhaskumarsinha/MinimalGPT-Felis_Catus,gradio,mit,1
-15618,TinkerFrank/AppleClassifier,gradio,,1
-15619,dexrm/Weewee,docker,,1
-15620,kadirbalalan/text-summarizer,streamlit,,1
-15621,OllieWallie/Openai,docker,,1
-15622,marrocovin/OPENAI_KEY,docker,,1
-15623,Trickshotblaster/idk-bruh,docker,mit,1
-15624,keilaliz123/test05,docker,,1
-15625,PeepDaSlan9/idk-bruh,docker,mit,1
-15626,ZGDD/chat-robot,gradio,,1
-15627,PeggyWang/ehartford-WizardLM-Uncensored-Falcon-40b,gradio,apache-2.0,1
-15628,hysts-samples/save-user-preferences,gradio,mit,1
-15629,Miam97/Test02,docker,,1
-15630,radames/gradio_get_video_metadata_timestamp,gradio,,1
-15631,John1986/test,gradio,,1
-15632,EzioArno/Goofy,docker,,1
-15633,kiskisbella/janitor,docker,,1
-15634,spexight/no.2,docker,,1
-15635,2kaara/oreo,docker,,1
-15636,hieupt/image_style_transfer,gradio,mit,1
-15637,eivind-n/P360-AI-Help,gradio,,1
-15638,SujanMidatani/speechToText,gradio,,1
-15639,eaedk/agri-tech-fastapi,docker,mit,1
-15640,tresdtres/TresDtres_AI,gradio,mit,1
-15641,kaveh/wsi-generator,gradio,gpl-3.0,1
-15642,gameg/Docker,docker,,1
-15643,yuragoithf/mlg_personal_info_remover,gradio,,1
-15644,Ricdeq/optimaldesign,gradio,openrail,1
-15645,dariusstone7/PFE,gradio,openrail,1
-15646,abhaskumarsinha/MinimalGPT-Ragdoll,gradio,mit,1
-15647,MaxP/demo-document-qa,gradio,mit,1
-15648,spillwaysofyoursoul/janitorai,docker,,1
-15649,tarfandoon/CryptoEN,streamlit,,1
-15650,fgibarra/fraud-prevention,gradio,mit,1
-15651,khachapuri69/madoka,docker,,1
-15652,muttalib1326/Detecting-Objects-in-Images,gradio,,1
-15653,anandaa/careerpal,gradio,,1
-15654,propilot/propilot-calling-functions,streamlit,mit,1
-15655,McLovin171/runwayml-stable-diffusion-v1-5,gradio,,1
-15656,SpacesExamples/Gradio-Docker-Template-nvidia-cuda,docker,,1
-15657,dinnovos/english-teacher,streamlit,mit,1
-15658,woahtheremonkey/vzvsvs,docker,,1
-15659,NeptunoIA/neptuno-proxy,docker,gpl-2.0,1
-15660,PeepDaSlan9/HuggingFaceH4-starchat-alpha,gradio,bigcode-openrail-m,1
-15661,crystalai/constellation,docker,c-uda,1
-15662,zilderish/ngekzild,docker,,1
-15663,revstartups/salessimulator,gradio,openrail,1
-15664,RoyKwok/Gradio,gradio,apache-2.0,1
-15665,tianyang/lemur-7B,gradio,cc-by-nc-4.0,1
-15666,thinkcol/chainlit-example,docker,,1
-15667,dietician/rewriteData,gradio,,1
-15668,kasun/git-large,gradio,,1
-15669,kasun/blip-base,gradio,,1
-15670,osanchik/PicFinder,streamlit,openrail,1
-15671,kusumakar/Image_Describer,streamlit,,1
-15672,hhhyrhe/vits-uma-genshin-honkai,gradio,apache-2.0,1
-15673,daarumadx/xd,docker,,1
-15674,Aashir01/Live_Transcription,gradio,afl-3.0,1
-15675,Pratick/CLAVIS,gradio,openrail,1
-15676,Tihsrah/Meetings,streamlit,,1
-15677,Sreeja123/memristor-based-neural-search-optimization-GUI,streamlit,,1
-15678,naliveli/myspace,gradio,apache-2.0,1
-15679,St4arsp0laris/PPolar,docker,,1
-15680,maxmon/digital_double,gradio,mit,1
-15681,Alisonbakers/Fml,docker,,1
-15682,CreBea/Test2,docker,,1
-15683,olimpa/Celdas2celdas,static,,1
-15684,w1zrd/MusicGen,gradio,cc-by-nc-4.0,1
-15685,umutozdemir/medicalai-ClinicalBERT,gradio,,1
-15686,scaratootie/scarar,docker,,1
-15687,Femurbreaker/Femur,docker,,1
-15688,Motheatscrows/mmnsfww,docker,,1
-15689,qprinceqq/noise-greeter-demo,gradio,unknown,1
-15690,jeycov/Piel_cancer_prueba,gradio,,1
-15691,jytole/hftesting,gradio,cc,1
-15692,Candyraider/Proxy4,docker,,1
-15693,SpaceNMagic/OPEN_AI,docker,,1
-15694,leonelhs/Zero-DCE,gradio,mit,1
-15695,kusumakar/Text_to_image_using_Stable_diffusers,gradio,,1
-15696,dvc890/go-chatgpt-api,docker,,1
-15697,teralomaniac/chatbing,docker,,1
-15698,koushik-org/Trading_QA_Bot,gradio,,1
-15699,teddyhugzz/venus,docker,,1
-15700,RockmanYang/Demucs_v4_2s_HT,gradio,,1
-15701,goodeatmen/Test,docker,,1
-15702,Savenly/hriddy,docker,,1
-15703,Inderdev07/Attendance-FaceRecognition,streamlit,cc,1
-15704,tarunika-03/personality-pred,streamlit,,1
-15705,Evanell/Venus,docker,,1
-15706,Rehman1603/SkinDisease,gradio,,1
-15707,AlphaGPT/PaperSummary,gradio,cc-by-nc-nd-4.0,1
-15708,awacke1/StreamlitComponentsStylingMarkdown,streamlit,mit,1
-15709,Detomo/detect_greeting_app,gradio,creativeml-openrail-m,1
-15710,amitjainmldesign/amitapp,gradio,,1
-15711,driller/pyconqa,gradio,other,1
-15712,samavi/openai-clip-vit-base-patch32,gradio,,1
-15713,Ironicsarcastic/Nse,docker,,1
-15714,parasmech/Image_captioning_nlpconnect,gradio,mit,1
-15715,dinnovos/translator,streamlit,mit,1
-15716,JustMeJellybean/Jellybean,docker,,1
-15717,Ellabella1/ai-cover,docker,,1
-15718,typesdigital/WeatherIAPP,gradio,cc-by-3.0,1
-15719,jaskugler/timdettmers-guanaco-65b-merged,gradio,openrail,1
-15720,DenniSciFi/IconAutomation,gradio,,1
-15721,XIAOAssembly/Asrtrolobot,streamlit,mit,1
-15722,YangHao520/TestITP,gradio,cc-by-3.0,1
-15723,Azai8915/ChubVenusTest,docker,,1
-15724,ThisThings/tdymndftbdfbvsgv,docker,,1
-15725,Lolicringw6969/Lol,docker,,1
-15726,lilholla/2099,docker,,1
-15727,wlpzr/Test1,docker,,1
-15728,Aaajdhdhdhahdbbaabs/Hshdhdhd,docker,,1
-15729,yukiiiwasneverhere/yuki,docker,,1
-15730,LINOlk/Akak,docker,,1
-15731,ardha27/rvc-hololive,gradio,mit,1
-15732,kklol/lovelypan,docker,,1
-15733,mehnaazasad/give-me-a-title,gradio,,1
-15734,Vincentim27/Plant_Nutrition_Prediction_ARIA,streamlit,,1
-15735,wikidere/crying,docker,,1
-15736,Amjadd/BookGPT,gradio,,1
-15737,SuperSucklet/Sex,docker,,1
-15738,Hise/rvc-hololive-models,gradio,mit,1
-15739,YONG627/456123,gradio,,1
-15740,fuckyoudeki/AutoGPT,gradio,mit,1
-15741,fatmacankara/ASCARIS,streamlit,,1
-15742,eaedk/agri-tech-fastapi-with-GUI,docker,mit,1
-15743,rhineJoke/baichuan,gradio,apache-2.0,1
-15744,cyberoleg/b2719240e190e2a649150d94db50be82838efeb0,gradio,apache-2.0,1
-15745,Giuvyz/rvc-genshin,gradio,mit,1
-15746,Alfasign/Einfach.Stable_DiffPomrpter,gradio,,1
-15747,openfoodfacts/ingredient-extraction,streamlit,other,1
-15748,onliner/QR-generator,gradio,,1
-15749,ElainaFanBoy/IRONY-Real-ESRGAN,gradio,,1
-15750,VectorologyArt/prompthero-openjourney,gradio,creativeml-openrail-m,1
-15751,VectorologyArt/Sygil-Sygil-Diffusion,gradio,creativeml-openrail-m,1
-15752,RegalHyperus/rvc-lovelive-genshin,gradio,mit,1
-15753,slyjay412/darkstorm2150-Protogen_x5.8_Official_Release,gradio,,1
-15754,renumics/cifar100-outlier,docker,mit,1
-15755,renumics/mnist-outlier,docker,mit,1
-15756,renumics/beans-outlier,docker,mit,1
-15757,hensam92/YouTubeSummary,streamlit,,1
-15758,Weshden/Nsfw1,docker,,1
-15759,sunmaiyyyy/combined-GI-RVC-model,gradio,mit,1
-15760,itberrios/stable_edit,streamlit,cc,1
-15761,alandavidgrunberg/Cannes_Chatbot,gradio,mit,1
-15762,Keay/Sae,docker,,1
-15763,Eieichicken/yyayyaya,docker,,1
-15764,HawkEye098432/DunnBC22-trocr-base-handwritten-OCR-handwriting_recognition_v2,gradio,,1
-15765,Hsft/VenusAi,docker,,1
-15766,fazni/Resume-filter-plus-QA-documents,streamlit,mit,1
-15767,Terma/Chat,docker,,1
-15768,ccwu0918/classify_image,gradio,cc,1
-15769,Monelmo/Testing,docker,,1
-15770,syam417/rvc,gradio,mit,1
-15771,soldguu/yumyum,docker,,1
-15772,NebulaVortex/falcon-chat,gradio,apache-2.0,1
-15773,update0909/Manager_Promotion,static,,1
-15774,sd-dreambooth-library/Baysa110,gradio,mit,1
-15775,omarelsayeed/AUDIO-ENHANCEMENT,gradio,apache-2.0,1
-15776,sd-dreambooth-library/Baysaa1,gradio,mit,1
-15777,nick2655/Intelibotprivatedata,gradio,apache-2.0,1
-15778,Keyradesu/Oka,static,,1
-15779,hitoroooooo/hitohito,docker,,1
-15780,JoshMe1/UAS_MCL_FAREL,streamlit,,1
-15781,chengzl18/DeepTHULAC,gradio,mit,1
-15782,huggingpaul/logo-wizard-logo-diffusion-checkpoint,gradio,,1
-15783,csamuel/decapoda-research-llama-13b-hf,gradio,,1
-15784,Alfasign/chat-llm-streaming,gradio,,1
-15785,meluvsguaca/iluvguacastoo,docker,,1
-15786,meowmeow369/meow,docker,,1
-15787,Kyron2975/Linaqruf-anything-v3.0,gradio,,1
-15788,MoEternal/Hoshino,gradio,,1
-15789,SappyInk/Ink,docker,,1
-15790,micooldra/bears,gradio,apache-2.0,1
-15791,chuuyasleftlung/meowmeow,docker,,1
-15792,Username47337/key,docker,,1
-15793,ph0b0s122/Tex02,docker,,1
-15794,RahulSinghPundir/MentalHealth,gradio,creativeml-openrail-m,1
-15795,kaicheng/chatgpt_web,gradio,,1
-15796,serhatderya/controlnet_v11_scribble_ui,gradio,,1
-15797,Rii12/Test03,docker,,1
-15798,JuanHaunted/humming_space,gradio,apache-2.0,1
-15799,ltim/visual_chatgpt,gradio,osl-3.0,1
-15800,Mo9/DionTimmer-controlnet_qrcode-control_v11p_sd21,gradio,unknown,1
-15801,enesbol/case_dif,streamlit,apache-2.0,1
-15802,RajkNakka/NER-fine-tuning,gradio,mit,1
-15803,gustavoespindola/SmartStay,streamlit,,1
-15804,Ayanoaisho/L,docker,,1
-15805,Luccadraw24/Amelia,docker,,1
-15806,Jialu/T2IAT,gradio,mit,1
-15807,kasjkldjsalkj/fyodorahitevoy,docker,,1
-15808,Flyingpotato42/gpt4all-tweaked,gradio,,1
-15809,rainslayer/rifles-classifier,gradio,,1
-15810,Xyan-shuo2/Shoshoo,docker,,1
-15811,Eli-chan/Test03,docker,,1
-15812,JCTN/stable-diffusion-webui-cjtn,gradio,,1
-15813,ShermanAI/ChatSherman,gradio,,1
-15814,ChrisCaviar/ControlNet-v1-1,gradio,mit,1
-15815,DpNaze/webui-docker,docker,,1
-15816,Sinestreaa/Test02,docker,,1
-15817,qxllphl/qxllphl,docker,,1
-15818,allknowingroger/Image-Models-Test3,gradio,,1
-15819,pranked03/IssueFixerGPT,streamlit,,1
-15820,Gyjkkih/WizardLM-WizardCoder-15B-V1.0,gradio,,1
-15821,biranchi125/gpt2_experiment,gradio,mit,1
-15822,qinzhu/Claude100K-API,gradio,,1
-15823,PeepDaSlan9/bigscience-bloom,gradio,bigscience-openrail-m,1
-15824,Usaki108/VoiceChange,gradio,mit,1
-15825,Shawn37/UTR_LM,streamlit,bsd,1
-15826,alexiserodriguez/whisper-transcription-app,gradio,,1
-15827,robyramos/estimativa_historia,gradio,other,1
-15828,InnovTech/InnovTech.ProAI,gradio,,1
-15829,asquirous/tv_desktop_classifier,gradio,apache-2.0,1
-15830,vuvienweestword/godhelpmepttwo,docker,,1
-15831,Ajit025/Text_to_Image_conversion,gradio,,1
-15832,ShahzadAhmed/DeepFaceApp,streamlit,,1
-15833,Ash58947/Jan,docker,,1
-15834,compasspathways/Sentiment2D,gradio,cc-by-4.0,1
-15835,RecursosRegenerativos/README,static,,1
-15836,jordonpeter01/Whisper-Auto-Subtitled-Video-Generator,streamlit,,1
-15837,gebebieve/gen,docker,,1
-15838,adorp/ControlNet-v1-1-duplicate,gradio,mit,1
-15839,jordonpeter01/Whisper-Auto-Subtitled-Video-Generator-1-Public,streamlit,,1
-15840,ZhaoYoujia/ImageRecognition,gradio,apache-2.0,1
-15841,snowcatcat/stable-diffusion-webui-cpu,gradio,,1
-15842,youngtsai/Mandarin-TTS,gradio,,1
-15843,YYar/Pr.O.A,docker,unknown,1
-15844,nikhilba/donut-ocr,gradio,mit,1
-15845,Nickwwww572/Test02,docker,,1
-15846,BhagatSurya/convet_pdf_to_txt,gradio,,1
-15847,shenfangqi/Retrieval-based-Voice-Conversion-WebUI,gradio,,1
-15848,allknowingroger/Image-Models-Test4,gradio,,1
-15849,ThirdEyeData/Object-Detection-For-Electrical-Domain,streamlit,,1
-15850,juanpardo/gradio-GUI-FinalProject,gradio,apache-2.0,1
-15851,notreallyintrested/Naseej-noon-7b,gradio,apache-2.0,1
-15852,RenXXV/Test02,docker,,1
-15853,miumiunana/miumiu02,docker,,1
-15854,raphael-gl/ai-days-subtitles-demo,gradio,,1
-15855,MikeTrizna/racemose_classifier,gradio,mit,1
-15856,chinmayapani/LangFlow,docker,mit,1
-15857,sophiamyang/test-panel,docker,,1
-15858,jason137/text-to-sql,docker,,1
-15859,awacke1/StreamlitTestforSTEM,streamlit,,1
-15860,Kirihasan/rvc-holo,gradio,mit,1
-15861,vincentmin/TalkToMe,gradio,apache-2.0,1
-15862,danielritchie/yomomma,gradio,mit,1
-15863,meowooooo/maybe,docker,,1
-15864,alkz/spacefast,docker,,1
-15865,ZettaFi/SeeFood,gradio,mpl-2.0,1
-15866,Snake12b/wizard-Vicuna-13B-Uncensored-HF,gradio,,1
-15867,Situme/Wockabocka,docker,,1
-15868,awacke1/QRCodeAI,streamlit,mit,1
-15869,DanielGartop/SexAI,docker,,1
-15870,safora/myfirstspace,gradio,apache-2.0,1
-15871,H2o6O2/Something,docker,,1
-15872,ec7719/Excel,streamlit,mit,1
-15873,Moses25/llama-7b-chatbot,streamlit,apache-2.0,1
-15874,alanchan808/Ask_Tennis_Coach_Patrick_Mouratoglou,gradio,,1
-15875,mwahha/gwanh,docker,,1
-15876,wu981526092/Optimal_Cluster_Analysis_with_PCA_Visualization,streamlit,mit,1
-15877,mobu123456/venusai,docker,,1
-15878,jbilcke-hf/template-node-python-express,docker,,1
-15879,lqinyli/ali,docker,agpl-3.0,1
-15880,Aoron/Test02,docker,,1
-15881,youplala/StoreCopilot,docker,,1
-15882,leonelhs/carvekit,gradio,mit,1
-15883,Protatoes/proxy_shit,docker,,1
-15884,Wanwan1215/Louisa,docker,,1
-15885,awacke1/runwayml-stable-diffusion-v1-5-06212023,gradio,mit,1
-15886,mpl8fjk/runwayml-stable-diffusion-v1-5,gradio,,1
-15887,awacke1/ChatGPTStreamlit7-Private,streamlit,mit,1
-15888,DeeeTeeee01/VODAFONE-CUSTOMER-CHURN-PREDICTION-APP,gradio,,1
-15889,ammarnasr/Sem-GAN-Bird-Image-Generator,streamlit,openrail,1
-15890,Gh-st/DUDUDU,docker,,1
-15891,rstallman/Mayfair-Partner-Music,gradio,cc-by-nc-4.0,1
-15892,rstallman/web-scraping,gradio,,1
-15893,dinnovos/chatbot-shoe-store,streamlit,mit,1
-15894,GlimmeringStars/Testing,docker,,1
-15895,Giozh/openai-reverse-proxy,docker,,1
-15896,kai0226/hotdog-detection,streamlit,,1
-15897,joaocalista/insurance-premium-prediction,gradio,,1
-15898,tomahawk24/roneneldan-TinyStories-33M,gradio,mit,1
-15899,kyrontunstall/stablediffusionapi-waifu-journey-2,gradio,,1
-15900,hayas-tohoku-workshop-2023/sample-depth-estimation,gradio,,1
-15901,SUSSYMANBI/Alex-diffusion-beta,gradio,,1
-15902,hudsonhayes/Vodafone_CRM_Chatbot,gradio,,1
-15903,MarcoLYH/Extractive-QA-Chatbot,gradio,,1
-15904,XiNiu/XSpace,gradio,mit,1
-15905,asciicorp/hotel-chat,streamlit,,1
-15906,aieye/named_entity_recognition_tutorial,streamlit,openrail,1
-15907,osanseviero/nerfies-test,static,,1
-15908,Mwebrania/clasma_database,gradio,,1
-15909,anupam210/Flight_ATA_Class,gradio,other,1
-15910,SaltyFishAB/anime-ai-detect,gradio,,1
-15911,SaltyFishAB/anime-aesthetic-predict,gradio,apache-2.0,1
-15912,Joao77/Lolicombr,docker,,1
-15913,reach-vb/whisper_word_timestamps,gradio,apache-2.0,1
-15914,PrabhuKiranKonda/fastapi-postgres-todo-api,docker,,1
-15915,Falah/object_detection,gradio,,1
-15916,ankush37/phishingDetection,gradio,apache-2.0,1
-15917,pedromsfaria/BTRUE_BOT,gradio,,1
-15918,TuanScientist/BTCforecasting,gradio,openrail,1
-15919,snowc2023/ask_the_doc,streamlit,,1
-15920,JollyOmnivore/Fusion92_ChatGPT_Sandbox,gradio,unknown,1
-15921,Rohit001/emotion_detection,gradio,cc,1
-15922,LeoDog896/yolov8n-asl,gradio,mit,1
-15923,matthoffner/falcon-40b-instruct-ggml,docker,,1
-15924,MetaDans/AIBOT,docker,,1
-15925,terapyon/pyhackcon-qa2,gradio,other,1
-15926,Qualinguis/Fraudulent_or_not,gradio,mit,1
-15927,Vynock/rvc-wefu,gradio,mit,1
-15928,Gregory-L/EleutherAI-gpt-neo-1.3B,gradio,,1
-15929,JayceeAngel/openai-reverse-proxy,docker,,1
-15930,dinhminh20521597/OCR_DEMO,streamlit,,1
-15931,Priyanka-Kumavat/Customer-Complaint-Segmentation-Model,gradio,,1
-15932,hudsonhayes/HudsonHayes-DocumentQA,gradio,,1
-15933,Jarvis2301/Aku,gradio,apache-2.0,1
-15934,anhalu/transformer-ocr,gradio,,1
-15935,amish1729/LFUNet,gradio,,1
-15936,ramonpzg/music-recsys-app,streamlit,mit,1
-15937,DeathRoad/PornagraphyIsGreat,docker,,1
-15938,abtech/README,static,,1
-15939,UholoDala/Churn_Prediction,gradio,,1
-15940,rstallman/Contract-AI,gradio,,1
-15941,deeepsig/bear_classifier,gradio,apache-2.0,1
-15942,rstallman/legisbot-text,gradio,,1
-15943,chennaiai/hotdog,gradio,,1
-15944,Brasd99/SquadDetective,gradio,,1
-15945,CyberPeace-Institute/SecureBERT-NER-Space,streamlit,,1
-15946,penscola/customer_churn_rate,gradio,,1
-15947,gradio/annotatedimage_component_main,gradio,,1
-15948,SMD00/Image_Summarizer,gradio,apache-2.0,1
-15949,MercurialAi/OncologyGPT,gradio,,1
-15950,skylarx2x/openai-reverse-proxy,docker,,1
-15951,Sarath2002/Form_Understanding_using_LayoutLMV3,gradio,afl-3.0,1
-15952,ahuang11/name-chronicles,docker,bsd-3-clause,1
-15953,tanquangduong/ner-biomedical-abstract,streamlit,apache-2.0,1
-15954,Dalvo/Moxxie,docker,,1
-15955,Jaehan/Question-Answering-1,gradio,,1
-15956,FEFE2023/VENUSAIESPACIO1,docker,unknown,1
-15957,Jaehan/Translation-Korean2English-1,gradio,,1
-15958,aravindh-s/multiocr,docker,mit,1
-15959,taiwhis/Nhandien_nhom36,gradio,,1
-15960,Thumas/DogCat,gradio,apache-2.0,1
-15961,sgonzalezsilot/TFM-DATCOM,gradio,,1
-15962,allknowingroger/SatelliteSuperResolution,gradio,mit,1
-15963,GIGACHAhoon/BasicNNYoutubeSentimentTop5CommentPrediction,gradio,mit,1
-15964,qinzhu/diy-girlfriend-online,gradio,mit,1
-15965,Kreaols/ChuanhuChatGPT,gradio,gpl-3.0,1
-15966,awacke1/CharacterZoo,streamlit,ncsa,1
-15967,Jaehan/Text-Summarization-1,gradio,,1
-15968,spuun/nsfw-det,gradio,unknown,1
-15969,Jaehan/zero-shot-classification-1,gradio,,1
-15970,halfdevil/demochat,streamlit,openrail,1
-15971,Jaehan/zero-shot-classification-2,gradio,,1
-15972,Jaehan/Text-Generation-1,gradio,,1
-15973,Miko-opiko/openai-reverse-proxy,docker,,1
-15974,the-bucketless/where-to-shoot,streamlit,,1
-15975,Jaehan/Text-Generation-2,gradio,,1
-15976,Jaehan/Text-Generation-3,gradio,,1
-15977,Jaehan/Text-Generation-4,gradio,,1
-15978,Jaehan/Text-Generation-5,gradio,,1
-15979,projecte-aina/transcripcio-fonetica-catala,docker,,1
-15980,KuraiYuki/openai-reverse-proxy,docker,,1
-15981,BOXNYC/shirley,gradio,,1
-15982,Jaehan/Text2Text-Question-Generation-1,gradio,,1
-15983,Jaehan/Text2Text-Text-Summarization,gradio,,1
-15984,Jaehan/Text2Text-Sentiment-Analysis,gradio,,1
-15985,Yram/Docker,docker,,1
-15986,anigaundar/intel_imgclf,gradio,apache-2.0,1
-15987,Jaehan/Image-Classification-Using-a-Vision-Transformer-1,gradio,,1
-15988,Jorgerv97/Herramienta_interactiva_ensenyanza_tecnicas_aprendizaje_supervisado_salud,docker,,1
-15989,Tahnik/spreadsight-demo,gradio,,1
-15990,SupawitMarayat/imgaug_img_microscope,gradio,,1
-15991,777DUKE/Ballin,docker,,1
-15992,tech9/fashion1,streamlit,,1
-15993,tappyness1/one_dash,streamlit,creativeml-openrail-m,1
-15994,jamesyoung999/whisper_word_timestamps,gradio,apache-2.0,1
-15995,zadkiel04/rvc-yoshino,gradio,mit,1
-15996,DCandE/rvc-models,gradio,mit,1
-15997,chawiii/open-reverse-proxy,docker,,1
-15998,chanhi0603/Create_subtitles_for_videos_ChatGPT,Configuration error,Configuration error,1
-15999,ctcconstruc/README,static,,1
-16000,dashues/frieda,gradio,apache-2.0,1
-16001,penscola/sale_predictions,streamlit,mit,1
-16002,kellyxiaowei/OWL-ViT,gradio,apache-2.0,1
-16003,pedromsfaria/Whisper_Diariazacao,gradio,,1
-16004,JFN/gpt2,gradio,,1
-16005,Jaehan/ChatBot-1,gradio,,1
-16006,productdesigning/README,static,,1
-16007,Jaehan/Code-Generator-1,gradio,,1
-16008,MrSalman/Image_captioning,gradio,,1
-16009,RoryT0ishi/Meow,docker,,1
-16010,TohsakaSu/AQI-predictor,gradio,,1
-16011,Parantonio/IA_voices,static,afl-3.0,1
-16012,ankur-bohra/AliShaker-layoutlmv3-finetuned-wildreceipt,gradio,,1
-16013,marker22/Bark-Voice-Cloning,gradio,mit,1
-16014,PeepDaSlan9/Bark-Voice-Cloning,gradio,mit,1
-16015,Vern0n/pls_work,docker,,1
-16016,anen/DentalGPT,static,,1
-16017,StatsByZach/app,docker,mit,1
-16018,Abdullah-Habib/Rabbit_or_Hare,gradio,apache-2.0,1
-16019,aitoala/huggingCuys,gradio,openrail,1
-16020,Lizzbitt/pi2,docker,,1
-16021,Leozin11/openai-reverse-proxy,docker,,1
-16022,vincentliaw/runwayml-stable-diffusion-v1-5,gradio,,1
-16023,MinzChan/ChatGPT-PPT-Generate-With-Azure-OpenAI-API,gradio,,1
-16024,yaful/DeepfakeTextDetect,gradio,mit,1
-16025,sxunwashere/rvc-voice,gradio,mit,1
-16026,Noahfinncee/Test02,docker,,1
-16027,AUST001/True-GPT4,gradio,cc-by-nc-sa-4.0,1
-16028,Walterchamy/Kiitec_virtual_assistant,streamlit,mit,1
-16029,binly/ChatGPT4,gradio,mit,1
-16030,stevengrove/GPT4News,gradio,apache-2.0,1
-16031,tappyness1/spaced_repetition_footwork,streamlit,,1
-16032,deepakchawla-cb/ai-interviewer,gradio,,1
-16033,ckul/image-quality-assessment,gradio,,1
-16034,huggingface-projects/Leaderboard-Restart,gradio,,1
-16035,kartik016/aadharORPanClassifier,gradio,apache-2.0,1
-16036,felixrosberg/FaceAnonymization,gradio,cc-by-nc-sa-4.0,1
-16037,owen10086/lala,docker,,1
-16038,Zeltoria/Anime,gradio,,1
-16039,wisnuarys15/rvc-wisnu5,gradio,mit,1
-16040,TheFunniestValentine/rp,docker,,1
-16041,Guochun/THUDM-chatglm2-6b,gradio,,1
-16042,Zeltoria/anime-voice-generator,gradio,apache-2.0,1
-16043,k4black/codebleu,gradio,,1
-16044,Glasscupps/Hello,docker,,1
-16045,benkabod/README,static,,1
-16046,DonDoesStuff/GPT3.5-voice,gradio,,1
-16047,MajinSonic/EarthnDusk-EpicMix6_Realism,gradio,,1
-16048,Torcat/torcat-test,streamlit,mit,1
-16049,Basil2k4/botbasil203,docker,,1
-16050,kingabzpro/AI-ChatBot,gradio,apache-2.0,1
-16051,justest/vicuna-v1.3-ggml,gradio,,1
-16052,thabangndhlovu/ConstiChat,gradio,,1
-16053,bimal590/Text_Classify,gradio,artistic-2.0,1
-16054,hamzakashif/kandinsky-2.1,gradio,lgpl-3.0,1
-16055,SumanthKarnati/SumanthKarnati-Image2Ingredients,streamlit,openrail,1
-16056,MercurialAi/OncologyGPT_Temperature_Control,gradio,,1
-16057,lmangani/chdb,docker,apache-2.0,1
-16058,davidscmx/fire_detector,gradio,apache-2.0,1
-16059,1ucii/Lab04,gradio,,1
-16060,awacke1/GeographyandPopulationDensityUnitedStates,streamlit,mit,1
-16061,SumanthKarnati/SumanthKarnati-Image2Ingredients2,gradio,openrail,1
-16062,dahaoGPT/THUDM-chatglm2-6b,gradio,apache-2.0,1
-16063,rstallman/AI-Contract-Sheet,gradio,,1
-16064,rstallman/Westminster-AI-Sheet,gradio,,1
-16065,LightFury9/knee_osteoarthritis_classification,gradio,unknown,1
-16066,Ekittl01/impira-layoutlm-document-qa,gradio,bigscience-openrail-m,1
-16067,IELTS8/ISF,gradio,apache-2.0,1
-16068,nishantup/LLMsIntro,streamlit,,1
-16069,focusit/BhagwadGita,streamlit,openrail,1
-16070,b-monroe/rvc-VoiceAI,gradio,mit,1
-16071,Not-Grim-Refer/Reverse-Prompt-Engineering-Code,streamlit,mit,1
-16072,jaisidhsingh/cluster-summ,streamlit,openrail,1
-16073,elitecode/Custom_ChatBot,gradio,openrail,1
-16074,yueranseo/mygpt,gradio,gpl-3.0,1
-16075,AnthonyTruchetPoC/persistent-docker,docker,,1
-16076,librarian-bots/README,static,,1
-16077,kevinwang676/rvc-mlbb-v2,gradio,mit,1
-16078,anjani18/life,streamlit,openrail,1
-16079,chasemcdo/hf_localai,docker,apache-2.0,1
-16080,Mwebrania/clasmaLAB,gradio,,1
-16081,notable12/DermDetectAI,gradio,mit,1
-16082,propilot/ai-speech-recognition,streamlit,mit,1
-16083,Ukrania/RVC-Models,gradio,,1
-16084,putaalzasa/test,docker,,1
-16085,putaalzasa/lasttry,docker,,1
-16086,lopesdri/ObjectDetection,gradio,apache-2.0,1
-16087,BrunoBall/Kaludi-ARTificialJourney-v1.0-768,gradio,,1
-16088,wilmars/cluster-app,gradio,mit,1
-16089,Cropinky/esrgan,gradio,apache-2.0,1
-16090,07jeancms/minima,gradio,apache-2.0,1
-16091,BlackCub/ChatGPT4,gradio,mit,1
-16092,lanyingtianyan/ChatGPT2,gradio,,1
-16093,Jdnsn/Alexander,docker,,1
-16094,nr-rofiq/coba_chatbot,docker,apache-2.0,1
-16095,herosly/open-reverse-proxy,docker,,1
-16096,Jessi05/Gege30,docker,,1
-16097,herder/DragDiffusion,gradio,mit,1
-16098,fishhome/test,docker,mit,1
-16099,randstad/Workllama_Simple_Resume_Analyzer,gradio,,1
-16100,anderbogia/dtp-asr-demo-v2,gradio,gpl-3.0,1
-16101,Dhrushreddy/profile1,streamlit,,1
-16102,btawaken/myownAi,streamlit,openrail,1
-16103,Ripaxxs/Mom,docker,bigscience-openrail-m,1
-16104,Ripaxxs/Tommy,docker,creativeml-openrail-m,1
-16105,CAMP-ViL/Xplainer,gradio,mit,1
-16106,awacke1/VoiceChatGPT-13,streamlit,mit,1
-16107,okeefe4ai/donut-cord,gradio,,1
-16108,Anitha0531/SpeechtoText,gradio,openrail,1
-16109,alamin655/replit-3B-inference,gradio,mit,1
-16110,Djplaye/Stuff3,docker,,1
-16111,Jackie2235/QueryExpansionForEtsy,streamlit,,1
-16112,tzafrir/formajourney,gradio,mit,1
-16113,flemag/zeroscope,gradio,,1
-16114,LukeMoore11/LukeMoore11-Big-Benjamin,gradio,openrail,1
-16115,glt3953/app-text_generation_openai,gradio,,1
-16116,lucken/DL101,gradio,apache-2.0,1
-16117,santa1666/gradio_albert_demo,gradio,,1
-16118,isabellaaa/heyy,docker,,1
-16119,Carterclear/swarm-agents,gradio,mit,1
-16120,beephids/paper-llm,docker,mit,1
-16121,hamelcubsfan/AutoGPT,gradio,mit,1
-16122,rstallman/chatgpt4,gradio,,1
-16123,Thafx/sdrv30,gradio,,1
-16124,Gertie01/enhanced-dalle2,gradio,mit,1
-16125,Allie7/Nose,docker,,1
-16126,PickleYard/stable-diffusion-webui-cpu,gradio,,1
-16127,Yuki1111/Yuki,docker,,1
-16128,DHEIVER/Pedrita,gradio,,1
-16129,Tasendodificilterumnome/Foiounao,docker,,1
-16130,seangsho/Boo,docker,,1
-16131,patimus-prime/strain_selection,streamlit,mit,1
-16132,allknowingroger/Image-Models-Test13,gradio,,1
-16133,ka1kuk/fastapi,docker,,1
-16134,ADOPLE/AdopleAI-ResumeAnalyzer,gradio,,1
-16135,pragyachik/togethercomputer-RedPajama-INCITE-Chat-3B-v1,gradio,,1
-16136,Sachyyx/Sarah,docker,,1
-16137,eisenjulian/matcha_chartqa,gradio,,1
-16138,duycse1603/math2tex,streamlit,apache-2.0,1
-16139,stbucht/GPT,gradio,gpl-3.0,1
-16140,geraskalnas/TheBloke-stable-vicuna-13B-HF,gradio,,1
-16141,moussaalmoussa/ChatGPT4,gradio,mit,1
-16142,gauthamk/EuroSAT-ResNet34,gradio,,1
-16143,tovaru/vits-for-ba,gradio,apache-2.0,1
-16144,UGK/UGK,gradio,apache-2.0,1
-16145,JourneyDB/JourneyDB,gradio,cc-by-nc-sa-4.0,1
-16146,MLVKU/Human_Object_Interaction,gradio,apache-2.0,1
-16147,daedalus314/quantum-lora-quote-generation,gradio,,1
-16148,adarsh8986/stabilityai-stable-diffusion-2-1-base,gradio,deepfloyd-if-license,1
-16149,CuriousDolphin/MobileSAM,gradio,apache-2.0,1
-16150,apexxlegends/README,static,,1
-16151,spitfire4794/photo,gradio,,1
-16152,gvozdev/subspace,gradio,,1
-16153,hkayabilisim/clusternea,docker,,1
-16154,icehelmetminer/runwayml-stable-diffusion-v1-5,streamlit,mit,1
-16155,nakas/MusicGenDemucs,gradio,cc-by-nc-4.0,1
-16156,MercurialAi/OncologyGPT_Probabilities,gradio,,1
-16157,leuschnm/TemporalFusionTransformer,streamlit,mit,1
-16158,waryhx/venustor01,docker,,1
-16159,Eden124/Eden124,docker,,1
-16160,wjw777/ChatGPT4,gradio,mit,1
-16161,jpatech/dogcat,gradio,apache-2.0,1
-16162,renumics/cifar10-outlier-low,docker,mit,1
-16163,Deva123d/AI_Image_Tools,gradio,,1
-16164,Masa-digital-art/movie-trailer-16k,gradio,,1
-16165,xnetba/Chat_advance,gradio,gpl-3.0,1
-16166,wu981526092/Stereotype_Detection,streamlit,,1
-16167,eve01version/evespace2,docker,,1
-16168,foghuang/ChatGLM2-6B,gradio,,1
-16169,STF-R/docker-test3,docker,mit,1
-16170,MertYeter/evrimci,gradio,mit,1
-16171,SwayamAK/CodeGPT,gradio,,1
-16172,Saffy/minipets,gradio,apache-2.0,1
-16173,shalinig/magorshunov-layoutlm-invoices,gradio,,1
-16174,jianyq/ResumeBot,gradio,,1
-16175,Chris4K/llms_compare,gradio,openrail,1
-16176,lusea/Voice-Cloning-for-Bilibili,gradio,mit,1
-16177,lusea/rvc-Qinggan,gradio,mit,1
-16178,jordonpeter01/Top-20-Diffusion-g,gradio,,1
-16179,AnthonyErosion/HoctotAI,gradio,,1
-16180,mrtimmydontplay/extra,docker,other,1
-16181,Sumit7864/Image-Enhancer,streamlit,,1
-16182,mrtimmydontplay/api,docker,other,1
-16183,shivammittal274/LLM_CA,gradio,,1
-16184,mrtimmydontplay/120,docker,other,1
-16185,CazimirRoman/summarize-your-webpage-api-with-gradio,gradio,,1
-16186,Yudha515/Rvc-Models,gradio,cc-by-nc-4.0,1
-16187,willhill/stable-diffusion-webui-cpu,gradio,,1
-16188,DHEIVER/timeseries-anomaly-detection-autoencoders,gradio,,1
-16189,wendys-llc/panoptic-segment-anything,gradio,apache-2.0,1
-16190,Guilherme34/LiminalAI-cpu,gradio,,1
-16191,visitaspro/VisitasPRO,gradio,mit,1
-16192,ChevyWithAI/rvc-aicover,gradio,mit,1
-16193,ivyblossom/sentiment-analysis,streamlit,,1
-16194,DHEIVER/AnimeGANv2,gradio,,1
-16195,hao007/Image-Caption,streamlit,openrail,1
-16196,linyi888/FreedomIntelligence-HuatuoGPT-13b-delta,gradio,,1
-16197,rr1/gpb,docker,mit,1
-16198,df2619/Hauser,gradio,,1
-16199,slyjay412/stabilityai-stable-diffusion-2,gradio,,1
-16200,XuebaoDingZhen/YOLOv50.0.1,gradio,,1
-16201,lwj786/chatglm2-6b-int4,streamlit,,1
-16202,awacke1/ChatGPT-QA-Translation-Summary-14,streamlit,mit,1
-16203,evilandme/stable-diffusion-xl,gradio,,1
-16204,ivn888/Rome-in-transit,docker,cc-by-4.0,1
-16205,mkmenta/try-gpt-1-and-gpt-2,gradio,mit,1
-16206,Mohamed90/Geoappfolium,streamlit,other,1
-16207,allknowingroger/huggingface,static,,1
-16208,BulatF/StreamlitSentiment,streamlit,mit,1
-16209,willdzierson/nlp_to_dates,gradio,,1
-16210,StarbucksCN/starbucks_doc,streamlit,apache-2.0,1
-16211,subhajitmaji/MusicGen,gradio,cc-by-nc-4.0,1
-16212,PeepDaSlan9/nitrosocke-mo-di-diffusion,gradio,creativeml-openrail-m,1
-16213,devduttabain/facebook-musicgen-small,gradio,unknown,1
-16214,way007/Salesforce-xgen-7b-8k-base,gradio,,1
-16215,shiyi11/QQsign,docker,mit,1
-16216,richardzhangy26/yandian_flow_classification,gradio,mit,1
-16217,Aityz/Aityz-3B,gradio,gpl-3.0,1
-16218,ting520/66,docker,mit,1
-16219,kevinwang676/vits-fast-finetuning-pcr,gradio,apache-2.0,1
-16220,alphunt/diffdock-alphunt-demo,gradio,mit,1
-16221,andreasmartin/faq,gradio,,1
-16222,arjundutta10/Arjun_AI,streamlit,,1
-16223,Astroomx/Mine,docker,,1
-16224,habash/WizardLM-WizardCoder-15B-V1.0,gradio,,1
-16225,batmac/captioner,gradio,mit,1
-16226,lsy641/distinct,gradio,,1
-16227,xosil14935/ExamCram,static,artistic-2.0,1
-16228,ShawnAI/Milvus-Embedding-Client,docker,apache-2.0,1
-16229,zhanghaohui/szu-gpt-academic,gradio,,1
-16230,Kairi7865/Kairi2,docker,,1
-16231,oliverlevn/ocean_faster_RCNN,gradio,mit,1
-16232,Plutanico/PlutanicoTeste2,docker,,1
-16233,randstad/Skills_Education_Gaps_Finder,gradio,,1
-16234,MrZak/Learn-Up,gradio,,1
-16235,randstad/ResumeSummarizer,gradio,,1
-16236,Jason1112/ML-GUI,gradio,,1
-16237,glt3953/app-text_image_hed,gradio,,1
-16238,NS11890/demo-app,streamlit,,1
-16239,NeonLion92/OpenChatKit-neon,static,,1
-16240,Hyperion1970/JosefJilek-loliDiffusion,gradio,other,1
-16241,ssdfsdfa/demo,gradio,,1
-16242,TMojo/FoodVision_Mini,gradio,mit,1
-16243,tangjicheng123/deepdanbooru,gradio,gpl-3.0,1
-16244,posit/gptneox-chat,docker,mit,1
-16245,ehristoforu/NLLB-Translator,gradio,wtfpl,1
-16246,lvwerra/python-interpreter,gradio,,1
-16247,suyash-rastogi/dog_cat_classifier,gradio,,1
-16248,DeeeTeeee01/SentimentAnalysis,streamlit,,1
-16249,MWSB2011/MicBot,gradio,,1
-16250,Tatiana2u1/Tatiana,docker,,1
-16251,Borpos/openchat-openchat,gradio,,1
-16252,justinstberger2dwww2/artificialguybr-freedom,gradio,,1
-16253,DHEIVER/DICOM_to_JPG_Converter,streamlit,,1
-16254,luwujie/QQsign,docker,mit,1
-16255,zzznavarrete/minima,gradio,mit,1
-16256,hostea/openbmb-cpm-bee-10b,gradio,,1
-16257,darroncole928/hi,docker,,1
-16258,mikeee/WizardCoder-15B-1.0-GGML,gradio,,1
-16259,MatrixYao/how_many_data_points_zh,docker,,1
-16260,edgar-treischl/IliartGPT,streamlit,,1
-16261,allknowingroger/Image-Models-Test20,gradio,,1
-16262,davanstrien/label-studio,docker,apache-2.0,1
-16263,godfiry/runwayml-stable-diffusion-v1-5,gradio,,1
-16264,brainstone/qr,gradio,,1
-16265,Visgift/nyami,streamlit,mit,1
-16266,trueuserr/psmathur-orca_mini_v2_7b,gradio,,1
-16267,Pascall/OASSapi_00,gradio,,1
-16268,cm-community/README,static,,1
-16269,naughtondale/monochrome,gradio,apache-2.0,1
-16270,Duckichan1/Jen_,docker,,1
-16271,kaleidoscope-data/data-cleaning-llm,streamlit,,1
-16272,brianaaas/BeedAiTe,docker,,1
-16273,parsaesmaeilie/RecommenderSysteam,streamlit,,1
-16274,DHEIVER/FetalRiskPrognosticator,gradio,,1
-16275,praveenku32k/Chatbot,streamlit,openrail,1
-16276,YUCHUL/nlpai-lab-kullm-polyglot-5.8b-v2,gradio,apache-2.0,1
-16277,zhubao315/Salesforce-xgen-7b-8k-inst,gradio,,1
-16278,allknowingroger/Image-Models-Test21,gradio,,1
-16279,allknowingroger/Image-Models-Test22,gradio,,1
-16280,Golyass/Recomender-System-Hybrid-Method,gradio,other,1
-16281,Mehrdadbn/Movie-recommender-system,streamlit,,1
-16282,deepdoctection/Document-AI-GPT,gradio,,1
-16283,AnandSoni2001/StockMarketPrediction,streamlit,,1
-16284,amirhosseinkarami/MovieRecommender,gradio,mit,1
-16285,sabirsayyed/merc_or_bmw,gradio,apache-2.0,1
-16286,nomic-ai/fka_awesome-chatgpt-prompts,static,,1
-16287,nomic-ai/OpenAssistant_oasst1,static,,1
-16288,nomic-ai/Anthropic_hh-rlhf,static,,1
-16289,nomic-ai/tatsu-lab_alpaca,static,,1
-16290,everton-santos/vicuna-ggml,gradio,,1
-16291,semomos3/Movie_Recommender,streamlit,,1
-16292,nomic-ai/databricks_databricks-dolly-15k,static,,1
-16293,nomic-ai/glue,static,,1
-16294,nomic-ai/stanfordnlp_SHP,static,,1
-16295,nomic-ai/yahma_alpaca-cleaned,static,,1
-16296,nomic-ai/wikitext,static,,1
-16297,nomic-ai/GAIR_lima,static,,1
-16298,nomic-ai/yizhongw_self_instruct,static,,1
-16299,nomic-ai/openai_webgpt_comparisons,static,,1
-16300,nomic-ai/lambdalabs_pokemon-blip-captions,static,,1
-16301,nomic-ai/bigcode_ta-prompt,static,,1
-16302,nomic-ai/nomic-ai_gpt4all-j-prompt-generations,static,,1
-16303,th1nhng0/symato-cc-statistic,streamlit,,1
-16304,nomic-ai/nomic-ai_gpt4all_prompt_generations,static,,1
-16305,nomic-ai/super_glue,static,,1
-16306,nomic-ai/squad,static,,1
-16307,nomic-ai/YeungNLP_firefly-train-1.1M,static,,1
-16308,nomic-ai/imdb,static,,1
-16309,nomic-ai/openai_summarize_from_feedback,static,,1
-16310,nomic-ai/Hello-SimpleAI_HC3,static,,1
-16311,nomic-ai/dair-ai_emotion,static,,1
-16312,nomic-ai/common_voice,static,,1
-16313,nomic-ai/BelleGroup_train_1M_CN,static,,1
-16314,nomic-ai/WizardLM_WizardLM_evol_instruct_70k,static,,1
-16315,nomic-ai/Dahoas_rm-static,static,,1
-16316,nomic-ai/ehartford_WizardLM_alpaca_evol_instruct_70k_unfiltered,static,,1
-16317,nomic-ai/samsum,static,,1
-16318,nomic-ai/teknium_GPT4-LLM-Cleaned,static,,1
-16319,Ttss4422/Joeythemonster-anything-midjourney-v-4,gradio,,1
-16320,nomic-ai/mosaicml_dolly_hhrlhf,static,,1
-16321,nomic-ai/tweet_eval,static,,1
-16322,nomic-ai/BelleGroup_train_2M_CN,static,,1
-16323,nomic-ai/Hello-SimpleAI_HC3-Chinese,static,,1
-16324,nomic-ai/openai_humaneval,static,,1
-16325,rkareem89/daggregate_space,gradio,openrail,1
-16326,nomic-ai/0xJustin_Dungeons-and-Diffusion,static,,1
-16327,nomic-ai/amazon_reviews_multi,static,,1
-16328,nomic-ai/financial_phrasebank,static,,1
-16329,nomic-ai/wangrui6_Zhihu-KOL,static,,1
-16330,nomic-ai/ag_news,static,,1
-16331,nomic-ai/allenai_prosocial-dialog,static,,1
-16332,nomic-ai/daily_dialog,static,,1
-16333,nomic-ai/facebook_winoground,static,,1
-16334,nomic-ai/Chinese-Vicuna_guanaco_belle_merge_v1.0,static,,1
-16335,nomic-ai/squad_v2,static,,1
-16336,nomic-ai/swype_instruct,static,,1
-16337,nomic-ai/wikiann,static,,1
-16338,nomic-ai/go_emotions,static,,1
-16339,nomic-ai/xtreme,static,,1
-16340,nomic-ai/BelleGroup_multiturn_chat_0.8M,static,,1
-16341,nomic-ai/BelleGroup_train_0.5M_CN,static,,1
-16342,nomic-ai/sciq,static,,1
-16343,nomic-ai/derek-thomas_ScienceQA,static,,1
-16344,nomic-ai/csebuetnlp_xlsum,static,,1
-16345,nomic-ai/gsm8k,static,,1
-16346,nomic-ai/blended_skill_talk,static,,1
-16347,nomic-ai/BelleGroup_train_3.5M_CN,static,,1
-16348,nomic-ai/junelee_wizard_vicuna_70k,static,,1
-16349,nomic-ai/piqa,static,,1
-16350,nomic-ai/BelleGroup_school_math_0.25M,static,,1
-16351,nomic-ai/Helsinki-NLP_tatoeba_mt,static,,1
-16352,nomic-ai/Dahoas_full-hh-rlhf,static,,1
-16353,nomic-ai/kunishou_databricks-dolly-15k-ja,static,,1
-16354,mmsamuel/burger_generator,gradio,,1
-16355,nomic-ai/empathetic_dialogues,static,,1
-16356,nomic-ai/EleutherAI_lambada_openai,static,,1
-16357,nomic-ai/codeparrot_apps,static,,1
-16358,nomic-ai/neulab_conala,static,,1
-16359,nomic-ai/conll2003,static,,1
-16360,allknowingroger/AI.Dashboard.Gradio.Streamlit.HTML5,static,mit,1
-16361,kidcoconut/spcdkr_omdenasaudi_liverhccxai,docker,mit,1
-16362,MaverickHans/selfie,gradio,,1
-16363,MohamadRezo/flixPicks,streamlit,,1
-16364,sub314xxl/Analog-Diffusion,gradio,,1
-16365,sub314xxl/HairCLIP,gradio,,1
-16366,DebasishDhal99/Youtube_Playlist,gradio,cc,1
-16367,sub314xxl/DualStyleGAN,gradio,,1
-16368,Aiusernumber5/janitorai,docker,,1
-16369,DHEIVER/Kidney_Image_Classifier,gradio,,1
-16370,sub314xxl/GFPGAN,gradio,apache-2.0,1
-16371,Shibe/sahil2801-replit-code-instruct-glaive,gradio,openrail,1
-16372,hanzaq/Doc-Bot,streamlit,apache-2.0,1
-16373,bigbencat/internlm-internlm-chat-7b-8k,gradio,openrail,1
-16374,hehysh/stable-diffusion-webui-cpu-the-best,gradio,,1
-16375,Miyuki13242/Daily,docker,,1
-16376,Valerina128503/U_1,docker,,1
-16377,Artples/google-flan-t5-xl,gradio,apache-2.0,1
-16378,Himanshusingh/KernAI-stock-news-distilbert,gradio,apache-2.0,1
-16379,teganmosi/Translator,gradio,apache-2.0,1
-16380,TensoraCO/code-explainer,gradio,apache-2.0,1
-16381,TensoraCO/docquery,gradio,,1
-16382,sebby5/eeeeee,docker,,1
-16383,theodotus/llama-uk,gradio,mit,1
-16384,danialazimi10/demo_mrs,streamlit,apache-2.0,1
-16385,Deon07/prompthero-openjourney,gradio,,1
-16386,Kaustubh-kapare94/ALPD,gradio,mit,1
-16387,arxify/RVC-beta-v2-0618,gradio,,1
-16388,jjddckcivikviv/hhh,gradio,,1
-16389,stefo/minimal,gradio,apache-2.0,1
-16390,katasou/Music-discord-bot,gradio,,1
-16391,awacke1/WildstuffV1,streamlit,mit,1
-16392,racear/drolatic,gradio,,1
-16393,abhisheky127/Fold_TransactionClassification,gradio,,1
-16394,anastasiablackwood/Anastasiablackwood,docker,,1
-16395,ShoaibMajidDar/PDF-chatbot,streamlit,apache-2.0,1
-16396,futuristicdude/The_First_Principle_thinker,gradio,afl-3.0,1
-16397,joaquin64800/XD,docker,,1
-16398,allknowingroger/Image-Models-Test25,gradio,,1
-16399,Branon/Proxy,docker,,1
-16400,lijiacai/ai-set,streamlit,,1
-16401,Ryukijano/ML-Agents-SoccerTwos,static,,1
-16402,MindWaveStudios/README,static,,1
-16403,sub314xxl/openchat-openchat,gradio,,1
-16404,sub314xxl/zeroscope,gradio,,1
-16405,sub314xxl/zeroscope-XL,gradio,,1
-16406,Binguii/Ballen,docker,,1
-16407,Vageesh1/personality_chat,streamlit,openrail,1
-16408,edjdhug3/chat-with-pdfs,streamlit,,1
-16409,kaveh/radiology-image-retrieval,gradio,apache-2.0,1
-16410,MUmairAB/Masked-Language-Model-App,gradio,apache-2.0,1
-16411,MUmairAB/MaskedLM_App,streamlit,apache-2.0,1
-16412,kenhugs/dsed,streamlit,,1
-16413,rubensmau/Dov_Tzamir,streamlit,mit,1
-16414,szk1ck/similarity_by_fasttext,gradio,apache-2.0,1
-16415,VGues/NOG,docker,,1
-16416,Dagfinn1962/CPU,gradio,mit,1
-16417,xlne/whtvr,docker,,1
-16418,bluuuuuuuu/test02,docker,,1
-16419,kukkurukeroon/kukkurukeroon2,docker,,1
-16420,Ibrahemqasim/Img,gradio,,1
-16421,iqovocn/ChuanhuChatGPT,gradio,gpl-3.0,1
-16422,JairoDanielMT/CCPlatanos,gradio,cc-by-nc-4.0,1
-16423,trhacknon/free-fast-youtube-url-video-to-text-using-whisper,gradio,gpl-3.0,1
-16424,PeepDaSlan9/neon-tts-plugin-coqui,gradio,bsd-3-clause,1
-16425,yejijue/img-to-music,gradio,,1
-16426,deaaassws/QQsign1,docker,mit,1
-16427,flow3rdown/word_sim,gradio,apache-2.0,1
-16428,Vageesh1/Falcon_7B,streamlit,,1
-16429,MUmairAB/DistilBERT-MaskedLM,gradio,,1
-16430,vinceL/YonKomaMangaGenerator,gradio,,1
-16431,lazyboy450/RVCv2-Genshin,gradio,mit,1
-16432,Adeeb-F/AI-Genrated-Image-Detector,gradio,gpl-3.0,1
-16433,Kitsune9tails/Test02,docker,,1
-16434,MadhurGarg/digital-chat,gradio,,1
-16435,jordonpeter01/AWS-CHATBOOT-SUPER,gradio,apache-2.0,1
-16436,jesuspj/jesuspj,docker,bigscience-openrail-m,1
-16437,sub314xxl/radames-kandinsky-2-1-img2img,gradio,,1
-16438,juuaaa/ambatakam,docker,,1
-16439,jesuspj/jp,docker,apache-2.0,1
-16440,plauder/geese,docker,,1
-16441,standardteam/ChatGPT4,gradio,mit,1
-16442,sub314xxl/MusicGen-Continuation,gradio,cc-by-nc-4.0,1
-16443,Rvtcheeto/Test02,docker,,1
-16444,Ash58947/Bot,docker,,1
-16445,simonguest/cs-tutor,gradio,apache-2.0,1
-16446,Nixtla/chatgpt-forecast,streamlit,apache-2.0,1
-16447,TitleOS/Seahorse-350m,gradio,,1
-16448,yunfei0710/gpt-academic,gradio,,1
-16449,oncetalk/syzymon-long_llama_3b,gradio,,1
-16450,YumiKujo/K,docker,,1
-16451,Romanian/Ok,docker,,1
-16452,Atharv23m/Human-Stress-Detection,gradio,gpl,1
-16453,Mahbodez/knee_report_checklist,gradio,openrail,1
-16454,triggah61/chingu-music,gradio,cc-by-nc-4.0,1
-16455,allknowingroger/Image-Models-Test28,gradio,,1
-16456,conchdork/open-reverse-proxy,docker,,1
-16457,Thafx/sdrv40,gradio,,1
-16458,jungwoo9/foodvision_mini,gradio,mit,1
-16459,juuaaa/aaaa,docker,,1
-16460,benfield/MBZUAI-Video-ChatGPT-7B,gradio,,1
-16461,Alfasign/Midjourney_Prompt,gradio,,1
-16462,Alfasign/nomic-ai-gpt4all-13b-snoozy,gradio,,1
-16463,ojackalope/Daemon,docker,,1
-16464,Megareyka/imageRecognition,gradio,unknown,1
-16465,sajithlal65/emilianJR-epiCRealism,gradio,,1
-16466,wliu88/StructDiffusionDemo,gradio,mit,1
-16467,arcosx/CHO-cytotoxicity,gradio,apache-2.0,1
-16468,Singularity666/VisionGPT-Automation2,streamlit,,1
-16469,odettecantswim/vits-models-genshin,gradio,apache-2.0,1
-16470,jbilcke-hf/audioldm-text-to-audio-generation,gradio,bigscience-openrail-m,1
-16471,noa101/autoevaluate-extractive-question-answering,gradio,,1
-16472,cppowboy/viscpm-chat,gradio,,1
-16473,osanseviero/test_chatui,docker,,1
-16474,osanseviero/my-own-falcon,docker,,1
-16475,Vipitis/shadermatch,gradio,,1
-16476,FishyFishFrisk/Reversyyy,docker,,1
-16477,Tuyet3005/Sentiment_Analysis_using_BERT,streamlit,,1
-16478,michellemli/PINNACLE,gradio,,1
-16479,Ritori/Twilight_MoNiQi,gradio,,1
-16480,T2007/T,docker,,1
-16481,Yumko/Idk,docker,,1
-16482,Fan-611177107/bigscience-bloomz-7b1-mt,gradio,,1
-16483,Deva123d/WaveFormBot,streamlit,,1
-16484,jungwoo9/foodvision_big,gradio,mit,1
-16485,vaishanthr/Simultaneous-Segmented-Depth-Prediction,gradio,mit,1
-16486,ScottRobertsXR/image-captioning-01,streamlit,,1
-16487,videfikri/aicover,gradio,,1
-16488,PeepDaSlan9/OpenAssistant-falcon-7b-sft-mix-2000,gradio,apache-2.0,1
-16489,Jashvinu/NousResearch-Redmond-Hermes-Coder,gradio,,1
-16490,Nattylegit/ChatGPT-Plugins-in-Gradio,gradio,mit,1
-16491,ADOPLE/ResumeAnalyzer,gradio,,1
-16492,ADOPLE/AdopleAI-Website-DocumentQA,gradio,,1
-16493,warrenw/simple-gpt-interface,streamlit,mit,1
-16494,ADOPLE/ResumeSummarizer,gradio,,1
-16495,Insightly/CSV-Bot,streamlit,,1
-16496,viktor-kertanov/painters,gradio,apache-2.0,1
-16497,raseel-zymr/dAIgramGen,streamlit,mit,1
-16498,kadirnar/chat,docker,,1
-16499,Daniil-plotnikov/Daniil-plotnikov-russian-vision-v4,gradio,openrail,1
-16500,huak95/personaGPT_custom,docker,mit,1
-16501,hugggof/vampnet,gradio,,1
-16502,Madhur-01/text-summarizer,streamlit,,1
-16503,Uday007/Oil-Price-Predictor,gradio,cc-by-nc-4.0,1
-16504,Uday007/Purchased,gradio,cc-by-nc-sa-4.0,1
-16505,Uday007/House-Price-Predictor,gradio,cc-by-nc-2.0,1
-16506,srkajol/westminister-ai-sheet,gradio,,1
-16507,srkajol/AI-Chat-PDF,gradio,apache-2.0,1
-16508,srkajol/legisbot-ai,gradio,,1
-16509,KarinaCardozo/PrevencionFraude,gradio,mit,1
-16510,srkajol/avocat-ia,gradio,,1
-16511,srkajol/Singapore-Regulation-AI-Sheet,gradio,,1
-16512,Reyes2024/Hua00666,docker,,1
-16513,jayvaghasiya/winerybarreloak,gradio,openrail,1
-16514,assembleteams/curious,streamlit,bigscience-openrail-m,1
-16515,Uday007/Diamonds-price-predictor,gradio,cc-by-nc-nd-4.0,1
-16516,Uday007/Penguin-BodyMass-Predictor,gradio,cc-by-nc-4.0,1
-16517,Uday007/Insurance-Predictor,gradio,cc-by-nc-4.0,1
-16518,ShayanP/Salesforce-codegen2-3_7B,gradio,mit,1
-16519,rickysk/rickysk-videomae-base-ipm_all_videos,gradio,,1
-16520,jackcat/GradioTest001,gradio,openrail,1
-16521,junkmind/Deepfake_image,gradio,,1
-16522,balaramas/indic_s2t,gradio,other,1
-16523,kumasan681104/React_St,streamlit,unknown,1
-16524,ankush-003/ankush-003-nosqli_identifier,gradio,,1
-16525,allknowingroger/Image-Models-Test31,gradio,,1
-16526,zakiu/Personal-TTS,gradio,mit,1
-16527,bryanlegrand/instant_bedtime_story,gradio,mit,1
-16528,renumics/whisper-commonvoice-noise-issues,docker,mit,1
-16529,812vaishnavi/gradio-land-cover-mapping,gradio,,1
-16530,Kichkinya/reverseproxynya,docker,,1
-16531,jonathang/YoutubeSmartSpeed,gradio,,1
-16532,daniellefranca96/styles-scribble-demo,gradio,mit,1
-16533,NeonLion92/Chat-and-Battle-with-Open-LLMs-Neon92,static,other,1
-16534,XPMaster/data_automation,gradio,,1
-16535,placeme/Wander-Plan,gradio,,1
-16536,Noobian/SplunkGPT,gradio,creativeml-openrail-m,1
-16537,ahuang11/mapnstreets,docker,bsd-3-clause,1
-16538,inflaton/learn-ai,gradio,apache-2.0,1
-16539,Dagfinn1962/diffusers-gallery,static,mit,1
-16540,shigel/langchain-function-calling,gradio,,1
-16541,jpdiazpardo/jpdiazpardo-whisper-tiny-metal,gradio,,1
-16542,yangban/catordog,gradio,apache-2.0,1
-16543,SnehaTiwari/Fashion-Image-generation,gradio,openrail,1
-16544,ysharma/ChatinterfaceTests,gradio,mit,1
-16545,limobaidandan2515/ChatGPT4,gradio,mit,1
-16546,Salama1429/speech-to-speech-translation,gradio,,1
-16547,Oloo-1/done,docker,,1
-16548,achref/neuro_internal_tools,gradio,,1
-16549,justest/mdn-chatbot,docker,,1
-16550,serhany/huggingchat-try,docker,,1
-16551,imcaoxuan/runwayml-stable-diffusion-v1-5,gradio,,1
-16552,kyleebrooks/VectorDatabaseCreate,gradio,,1
-16553,vaishanthr/Image-Classifier-TensorFlow,gradio,mit,1
-16554,Fawis/Awooga_xd,docker,,1
-16555,dcq/freegpt-webui,docker,,1
-16556,Sandiago21/automatic-speech-recognition-greek,gradio,,1
-16557,TheSxrynlxX/Idk,docker,,1
-16558,Gregory-L/openlm-research-open_llama_3b,gradio,,1
-16559,iruku/and,docker,mit,1
-16560,soduhh/Text2Pix,gradio,,1
-16561,multimodalart/upload_your_model,static,mit,1
-16562,Sandiago21/text-to-speech-greek,gradio,,1
-16563,Sandiago21/speech-to-speech-translation-greek,gradio,,1
-16564,brany/QR-code-AI-art-generator,gradio,,1
-16565,dariowsz/speech-to-speech-translation,gradio,,1
-16566,ElisR/spherical_harmonics_visualisation,gradio,,1
-16567,jlevin/dpv-finetuned-gpt2-tiny,gradio,mit,1
-16568,ilpy/global-life-expectancy,streamlit,,1
-16569,AdithyaSNair/alzheimers_prediction_using_cnn,gradio,,1
-16570,WanderingRose/Storm,docker,,1
-16571,Ralmao/glass_py,gradio,mit,1
-16572,dcq/nodetest,docker,,1
-16573,firestalker/anime-tts,gradio,mit,1
-16574,Ritori/Yura_GPT,gradio,,1
-16575,DpNaze/Dreamlikeart,gradio,,1
-16576,jt5d/kandinsky-community-kandinsky-2-2-prior,gradio,,1
-16577,peter2489/translator,gradio,,1
-16578,tlqkfdksldlrpwhswogksekrhzzz/translator_interpenr,gradio,,1
-16579,Daniil-plotnikov/Daniil-plotnikov-russian-vision-v5-beta-3,gradio,,1
-16580,dpe1/can_this_pokemon_evolve,gradio,other,1
-16581,nikitaPDL2023/assignment4,gradio,,1
-16582,avishkararjan/Movie-Recommendation-Model,streamlit,mit,1
-16583,TungB/mini-photoshop,streamlit,apache-2.0,1
-16584,removebg/removebg,gradio,mit,1
-16585,OnabajoMonsurat/Brain_tumor_prediction,gradio,mit,1
-16586,aqlanhadi/qr-art,gradio,,1
-16587,KeroKiki/Rin,docker,,1
-16588,Vinnybustacap/Gryphe-MythoLogic-13b,gradio,openrail,1
-16589,badmonk/up,gradio,apache-2.0,1
-16590,DonDoesStuff/sd_xl_base_0.9,gradio,,1
-16591,Alfasign/diffusers-gallery,static,mit,1
-16592,Abdullahw72/bark-voice-cloning,gradio,mit,1
-16593,LUOYE-123/QQsign,docker,mit,1
-16594,tnrzk13/PneumoniaDetection,gradio,apache-2.0,1
-16595,hishamomran/explicit_text_classifier,gradio,,1
-16596,beastboy/WizardLM-WizardCoder-15B-V1.0,static,,1
-16597,crystalai/EleutherAI-gpt-j-6b,gradio,,1
-16598,Dewa/Text-Summurisation,gradio,,1
-16599,sarahyoung/taltech,gradio,,1
-16600,omniinferlabs/README,static,,1
-16601,luisrguerra/unrealdream,gradio,,1
-16602,hisfog/SQLdepth,gradio,mit,1
-16603,Sandiago21/text-to-speech-french,gradio,,1
-16604,iamlonely/destroylonely,docker,,1
-16605,openbio/calculator,gradio,,1
-16606,THEFIG/AI-chatbot,gradio,apache-2.0,1
-16607,SunshineSalem/JanitorAI,docker,,1
-16608,RatKing243/Test,docker,,1
-16609,sub314xxl/webui-cpu-extension-test,gradio,,1
-16610,chrisvnz/IFC-Extract-Properties,gradio,,1
-16611,PurplePanda00/plant-leaf-detection,gradio,,1
-16612,hexdq666/OAIRP,docker,,1
-16613,muLoo/dis-background-removal,gradio,apache-2.0,1
-16614,Benson/text-generation,docker,mit,1
-16615,tbhyourelame/kay,docker,,1
-16616,tttarun/ocr_voter_list,gradio,mit,1
-16617,chuan-hd/law-assistant-chatbot,gradio,,1
-16618,DracoHugging/LicensePlateRecognition,gradio,apache-2.0,1
-16619,redo62/image2text-comp,gradio,mit,1
-16620,abhisheky127/QuaraAI_Translator,gradio,,1
-16621,lu2000luk/RuttoniAI,gradio,mit,1
-16622,suidu/MAGAer13-mplug-owl-bloomz-7b-multilingual,gradio,bigscience-openrail-m,1
-16623,MohammedAlakhras/AI_Chat,gradio,apache-2.0,1
-16624,Sandiago21/speech-to-speech-translation-spanish,gradio,,1
-16625,autumn8/selectModel,streamlit,other,1
-16626,ultgamerkient/GPT4ALL,gradio,,1
-16627,kevinwang676/FreeVC-en,gradio,mit,1
-16628,PockiBoi7/PockiGEN,gradio,,1
-16629,reddysh/pleasework,docker,,1
-16630,livelaughcats/m,docker,,1
-16631,reddysh/pls,docker,,1
-16632,lIlIlllllmeng/QQsign1,docker,mit,1
-16633,arpitneema/ArpitTestBert,gradio,apache-2.0,1
-16634,Lee-Shang/sahi-yolox-duplicate,streamlit,,1
-16635,IVentureISB/Gen-AI,gradio,,1
-16636,lanhuan1111/hello_world,gradio,,1
-16637,hanskabvw1/chat,docker,other,1
-16638,Fouzia/Harvard-USPTO_Patentability-Score,streamlit,,1
-16639,LTputin/Janitor_AI,docker,,1
-16640,figsfidds/moody_nana_classifier,gradio,other,1
-16641,wrdias/SD_WEBUI,gradio,,1
-16642,lijiacai/ai-set-demo,docker,,1
-16643,UholoDala/Jj_Sentiment_Analysis_App,streamlit,mit,1
-16644,SetoKaishi12/Test02,docker,,1
-16645,Andyrasika/Andyrasika-lora_diffusion,gradio,,1
-16646,EXPOSUREEE/Ai-Image-Enhancer,gradio,,1
-16647,ZApkh/test,docker,,1
-16648,justest/vercel,gradio,gpl-3.0,1
-16649,HuggingAlgorithms/Object-Detection-with-YOLO,gradio,mit,1
-16650,Andyrasika/xlm-roberta-base-finetuned-panx-de,gradio,,1
-16651,Andyrasika/distilbert-base-uncased-finetuned-emotion,gradio,,1
-16652,glt3953/app-audio_video_transcribe,gradio,,1
-16653,TNR-5/lib111,Configuration error,Configuration error,1
-16654,azuboguko/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2,gradio,mit,1
-16655,TNR-5/chatorO,docker,,1
-16656,usernamelsp/QQsign,docker,mit,1
-16657,aseduto/sp500,streamlit,apache-2.0,1
-16658,Kimata/multimodal_deepfake_detection,gradio,,1
-16659,Akshay-More-007/starcoder,streamlit,openrail,1
-16660,TNR-5/stabilityai-stable-diffusion-2-1,gradio,creativeml-openrail-m,1
-16661,SidKarthik/multi_doc_retrieval_agent,streamlit,mit,1
-16662,vaibhavarduino/better-autogpt,static,,1
-16663,lykke-05/pleaselowrd,docker,,1
-16664,MrlolDev/Explore_llamav2_with_TGI,gradio,mit,1
-16665,Itsjusttasiaa/Test02,docker,,1
-16666,MrZak/LearnUp-4.1,gradio,,1
-16667,jtlowell/stable-diffusion-webui,gradio,openrail,1
-16668,sherjilozair/meta-llama-Llama-2-70b-chat-hf,gradio,,1
-16669,freddyaboulton/test-discord-bot-v2,gradio,,1
-16670,CofAI/README,static,,1
-16671,allknowingroger/Llama_v2,static,,1
-16672,bhandsab/meta-llama-Llama-2-70b-chat,streamlit,,1
-16673,bhandsab/meta-llama-Llama-2-70b-hf,static,,1
-16674,gsaivinay/Llama-2-13B-GGML-UI,docker,,1
-16675,kevinwang676/Voice-Cloning-SadTalker,gradio,mit,1
-16676,Eduardovco/Potato,docker,,1
-16677,veb-101/UWMGI_Medical_Image_Segmentation,gradio,,1
-16678,DQChoi/gpt-demo,gradio,,1
-16679,ExpertPrompters/AskIDF,streamlit,,1
-16680,Sai004/ArticlePredictor,streamlit,apache-2.0,1
-16681,ifire/mpt-7b-storywriter,gradio,mit,1
-16682,boomsss/gamedayspx,streamlit,,1
-16683,ilmhona/chat-with-pdf,streamlit,,1
-16684,dahaoGPT/Llama2-70b-chat-demo,gradio,,1
-16685,dahaoGPT/Llama2-70b-chatmodle-demo,gradio,,1
-16686,Gffxs/Ey,docker,,1
-16687,zhaiqi/qq,docker,mit,1
-16688,tellview/suno-bark,gradio,,1
-16689,EysCanacan/Scikit-LLM-Demo-Eys,streamlit,,1
-16690,qingjiu11/QQmm,docker,mit,1
-16691,maheshwaranumapathy/meta-llama-Llama-2-7b-hf,gradio,,1
-16692,bitofurqan/meta-llama-Llama-2-70b-chat-hf,gradio,mit,1
-16693,xuan23/test1,docker,,1
-16694,drift-ai/recruiter-assistant,gradio,,1
-16695,BadRobot147/SFQ3,docker,,1
-16696,kingabzpro/ChatGPT-Gradio-Interface,gradio,mit,1
-16697,zhanggrace/ImageSearch,streamlit,cc-by-4.0,1
-16698,maxjmohr/MSc_02_PDL_A4,gradio,,1
-16699,silencewing/server,docker,,1
-16700,taminactineo/taminactineo,gradio,openrail,1
-16701,realchenyuy/llama2-playground,gradio,,1
-16702,renumics/navigate-data-issues,docker,gpl-3.0,1
-16703,GreenCounsel/SpeechT5-sv,gradio,,1
-16704,TNR-5/AI-WebTV,docker,,1
-16705,g4f/freegpt-webui,docker,,1
-16706,CofAI/tv,docker,,1
-16707,hehe520/stable-diffusion-webui-cpu,gradio,,1
-16708,VIPLab/Caption-Anything,gradio,apache-2.0,1
-16709,viniods/speech_recognition,gradio,,1
-16710,eddydpan/clip-recycling,gradio,,1
-16711,ljiy/GGG,docker,mit,1
-16712,TNR-5/Stable-Diffusion-Protogen-x3.4-webui,docker,,1
-16713,Utkarsh736/crick-pick,gradio,apache-2.0,1
-16714,dongfang2021/ObjectDetection,gradio,openrail,1
-16715,ishan10/Science_Tutor,gradio,,1
-16716,kevinwang676/ChatGLM2-SadTalker,gradio,mit,1
-16717,UFOOO/README,static,,1
-16718,AIlexDev/Einfach.Hintergrund,gradio,mit,1
-16719,pikto/Elite-freegpt-webui,docker,,1
-16720,Sunbird/runyankole2english-stt,gradio,,1
-16721,yardi/phrase-semantic-similarity,streamlit,apache-2.0,1
-16722,Old-Fat-Boy/Youtube_Thumbnail_CTR_Analyzer,gradio,apache-2.0,1
-16723,LEOZHAO92/TTS,gradio,mit,1
-16724,Omnibus/pdf-reader,gradio,,1
-16725,GeekedReals/jonatasgrosman-wav2vec2-large-xlsr-53-english,gradio,openrail,1
-16726,AIMLApps/Botrite_wip,gradio,,1
-16727,Tihsrah/Credit_Risk_Assessment,streamlit,,1
-16728,keivalya/alternovation,gradio,,1
-16729,jitterz/testing,docker,,1
-16730,polymath707/bigscience-bloomz-7b1,gradio,apache-2.0,1
-16731,ehristoforu/Stable-Diffusion-Protogen-x3.4-webui,docker,,1
-16732,elvis-d/tweet-sentiment-analysis.GRADIO,gradio,mit,1
-16733,cpluoiudy00001/QQsign,docker,mit,1
-16734,elvis-d/Tweet-Sentiment-Analysis-App.STREAMLIT,streamlit,mit,1
-16735,Keshav4/resume-data-extraction,gradio,openrail,1
-16736,tdnathmlenthusiast/food_classifier,gradio,apache-2.0,1
-16737,ggwwu/THUDM-WebGLM,gradio,,1
-16738,wambugu1738/meta-llama-Llama-2-13b-chat-hf,gradio,,1
-16739,rafaelpadilla/coco_metrics,gradio,,1
-16740,EdZ123/anime-collaborative-filtering-system,gradio,mit,1
-16741,arikru/packstation-inspector,gradio,apache-2.0,1
-16742,MaximilianChen/Casper,gradio,,1
-16743,CofAI/CurrencyConverter,static,,1
-16744,junjunn/rvc-models,gradio,mit,1
-16745,CofAI/CalculatorUI,static,,1
-16746,Stanlito/openvino_QandA,gradio,mit,1
-16747,puripurikyuakyua/Gahana,docker,,1
-16748,Carlos056/Cara,static,,1
-16749,Harshveer/Diffusion30x,gradio,,1
-16750,MercurialAi/OncoMedleyMini,gradio,,1
-16751,onursavas/meta-llama-2-7b-hf,gradio,,1
-16752,mearidesu/test2,docker,,1
-16753,indifendi/baby1,docker,,1
-16754,saipanyam/QAGenie,streamlit,apache-2.0,1
-16755,sudxiaohan2/Real-CUGAN,gradio,gpl-3.0,1
-16756,ewg88/ai-forever-ruGPT-3.5-13B,gradio,,1
-16757,ZenXir/FreeVC,gradio,mit,1
-16758,birsardar/stable-diffusion-mat-outpainting-primer,gradio,cc-by-nc-4.0,1
-16759,Pauitbid/meta-llama-Llama-2-7b-hfx,streamlit,,1
-16760,gary109/hotdog-not-hotdog,gradio,afl-3.0,1
-16761,elina12/asr_arabic,gradio,other,1
-16762,CofAI/LengthConverter,static,,1
-16763,Stanlito/QandA-on-custom-PDF,streamlit,mit,1
-16764,zhiwucai/gpt2,gradio,apache-2.0,1
-16765,warrenw/simple-gpt-interface-2,streamlit,mit,1
-16766,CofAI/urlcut,static,,1
-16767,Pravincoder/Loan_Approval_Predictor,streamlit,creativeml-openrail-m,1
-16768,ccyo/chatgpt_bot,gradio,creativeml-openrail-m,1
-16769,Dennis0402/QSign,docker,,1
-16770,pradosh/insurance_demo,gradio,mit,1
-16771,lanyi2023/QQsign,docker,mit,1
-16772,Aspik101/Polish_Llama2,gradio,other,1
-16773,raghuram13/Audiototext,gradio,other,1
-16774,awacke1/Speech2Text-FastSpeech2,gradio,,1
-16775,awacke1/SpeechToText-MS,gradio,,1
-16776,awacke1/Text2Speech-0721,gradio,mit,1
-16777,TaliaKorobkin/facebook-fastspeech2-en-ljspeech,gradio,,1
-16778,kmahtan2/facebook-fastspeech2-en-ljspeech,gradio,,1
-16779,Tetel/secondbing,docker,,1
-16780,sjdata/Testinggrounds,gradio,,1
-16781,VGG1555/VGG1,streamlit,openrail,1
-16782,awacke1/FastestText2SpeechEver,gradio,,1
-16783,AnxiousNugget/janitor,docker,,1
-16784,imdebamrita/Handwritten-Digit-Recognition,gradio,,1
-16785,vanderbilt-dsi/french-revolution-letter-writing,gradio,,1
-16786,sjdata/Streamlit_test,streamlit,,1
-16787,elumamai/AI-ChatBot,gradio,apache-2.0,1
-16788,anthonymikinka/wizard,streamlit,,1
-16789,magehunter45/ApartmentInvestorBot,gradio,mit,1
-16790,JUNGU/gpt4kids,gradio,openrail,1
-16791,jangocheng/stable-diffusion-webui-cpu_with_prompt_pub,gradio,,1
-16792,Swaraj912/FIRS0,gradio,unknown,1
-16793,wangrongsheng/CareLlama,gradio,,1
-16794,Sadashiv/BERT-NER,streamlit,,1
-16795,henryezell/freewilly,docker,apache-2.0,1
-16796,CofAI/njpad,static,,1
-16797,afffffdf/QSign,docker,,1
-16798,felixfrosch/deep_learning_assignment,gradio,,1
-16799,Sandiago21/text-to-speech-german,gradio,,1
-16800,hkqiu/AI4P,gradio,apache-2.0,1
-16801,1doemePnordwo/upscale,gradio,apache-2.0,1
-16802,littlegoldfish/simple_chatbot,gradio,mit,1
-16803,Arnx/MusicGenXvAKN,gradio,cc-by-nc-4.0,1
-16804,DHEIVER/detect_anomalies,gradio,,1
-16805,jeycov/Mama_ca,gradio,,1
-16806,t0int/CalderaAI-30B-Lazarus,gradio,,1
-16807,TNR-5/test_dev_s,static,,1
-16808,zaursamedov1/llama2-qlora-finetunined-NER,static,llama2,1
-16809,sawi/audio,gradio,,1
-16810,elumamai/openai-whisper-large,gradio,apache-2.0,1
-16811,MARSHALLXAARONDRAKEICO/ai-forever-ruGPT-3.5-13B,gradio,,1
-16812,enadewan/ASK_FREDDY_BY_CONTRUCTOR_LEARNING,gradio,,1
-16813,enadewan/ASK_FREDDY_BY_CL,gradio,,1
-16814,geraskalnas/ODISE,gradio,,1
-16815,ashercn97/AsherTesting,gradio,,1
-16816,AIxPha/Real-CUGAN,gradio,gpl-3.0,1
-16817,kernelguardian/llama2action,docker,,1
-16818,Bajr/softly,docker,,1
-16819,Nanostuffs/nano.ai,gradio,,1
-16820,Sandiago21/automatic-speech-recognition-german,gradio,,1
-16821,Sandiago21/automatic-speech-recognition-french,gradio,,1
-16822,Biaolin/stabilityai-FreeWilly1-Delta-SafeTensor,gradio,,1
-16823,jjyaoao/speech-to-speech-translation-spanish,gradio,apache-2.0,1
-16824,CXD200/QSign,docker,,1
-16825,boddles2/pyannote-speaker-diarization-2,gradio,,1
-16826,sabridsn/HOCR,gradio,mit,1
-16827,Neuralpls/README,static,,1
-16828,liimefruit/RVCollection,gradio,,1
-16829,nms319/README,static,,1
-16830,chongjie/PoseDiffusion_MVP,gradio,apache-2.0,1
-16831,CofAI/chat.v2,docker,,1
-16832,Mehdihassan/stable-ts,streamlit,,1
-16833,DHEIVER/VestibulaIA,gradio,,1
-16834,unclesamjo/GTalkGPTV01,gradio,,1
-16835,youplala/chartGPT,docker,,1
-16836,DamianMH/Mlove,docker,,1
-16837,BasToTheMax/tensor,gradio,creativeml-openrail-m,1
-16838,Plurigrid/bidirectional,gradio,apache-2.0,1
-16839,Kwabbs/SENTIMENT_APP,streamlit,,1
-16840,GageWeike/GPT4i-FreeWilly2,gradio,apache-2.0,1
-16841,PeepDaSlan9/chatbot-arena,static,other,1
-16842,Bobertsonthethird/Test01,docker,,1
-16843,chongjie/ZoeDepth_slim,gradio,,1
-16844,Maqueda/SG161222-Realistic_Vision_V1.4,gradio,,1
-16845,samcaicn/bingai,docker,mit,1
-16846,Ryandhikaw/rvc-hololive,gradio,mit,1
-16847,manymoon22173/RVC_MODELS,gradio,mit,1
-16848,Rezuwan/parrot_classifier,gradio,apache-2.0,1
-16849,pikto/ELITE-ChatGPT-Streamlit-2,streamlit,mit,1
-16850,clibrain/dataset-curation,docker,,1
-16851,barabum/image-duplicate-finder,gradio,mit,1
-16852,ploybtt/ploybtt,docker,,1
-16853,TNR-5/Chatui,docker,,1
-16854,jimmmyjoy56723/test,docker,,1
-16855,g0urav-hustler/PCB-Fault-Detection,streamlit,,1
-16856,ReThGe/Linet,gradio,apache-2.0,1
-16857,chongjie/co-tracker_MVP,gradio,apache-2.0,1
-16858,PeepDaSlan9/stabilityai-FreeWilly2,gradio,cc-by-nc-4.0,1
-16859,MUmairAB/English-to-French,gradio,,1
-16860,Ritori/play_with_baby_llama2,gradio,,1
-16861,awacke1/StreamlitAIPP1,streamlit,mit,1
-16862,ryoung41/AIPairProgramming1,streamlit,mit,1
-16863,kmahtan2/AIPairProgramming2,streamlit,mit,1
-16864,jdhuka/AIPairProgramming1,streamlit,,1
-16865,TaliaKorobkin/AIPairProgramming1,streamlit,,1
-16866,ryoung41/HTML5Interactivity,static,mit,1
-16867,jdhuka/HTML5Interactivity,static,,1
-16868,ElricOon/EYE2,streamlit,,1
-16869,arseny-chebyshev/vox-diffusion,gradio,,1
-16870,luisotorres/cats-vs-dogs,gradio,,1
-16871,awacke1/AnimatedGifGallery,streamlit,mit,1
-16872,jbilcke-hf/zeroscope-server-3,gradio,mit,1
-16873,awacke1/Mp4VideoGallery,streamlit,mit,1
-16874,chrisclark1016/Untappd_Predictor,gradio,,1
-16875,wilsonbritten/inference-client-test,gradio,mit,1
-16876,Jafta/chatglm2-6b-4bit,gradio,,1
-16877,earneleh/paris,gradio,apache-2.0,1
-16878,Large-LLM-Proxy-CAI/GateOfProxyClaude2.0,docker,,1
-16879,osbm/prostate158-monai-inference,gradio,,1
-16880,gradio-discord-bots/gpt-35-turbo,gradio,mit,1
-16881,DHEIVER/analise_imagem_mama,gradio,,1
-16882,kalarios/proxy,docker,,1
-16883,azusarang/so-vits-svc-models-ba_P,gradio,apache-2.0,1
-16884,ActivatedOne/JorisCos-ConvTasNet_Libri1Mix_enhsingle_16k,gradio,,1
-16885,nikoifirewall/First_shot_gradio_covid_sentiment_analysis,gradio,mit,1
-16886,tripsby/travel-genie-json-public,gradio,,1
-16887,Priyanka-Kumavat/Regression-Model,streamlit,,1
-16888,xuqinyang/Baichuan-13B-Chat-Int8-Cpp,gradio,,1
-16889,deepskyreal/ai-mixer-hotchpotch,gradio,apache-2.0,1
-16890,s3nh/mamba-gpt-3b,gradio,openrail,1
-16891,xuqinyang/Baichuan-13B-Chat-Int4-Cpp,gradio,,1
-16892,awacke1/GetAllContent,streamlit,mit,1
-16893,ZalacDanijel/pujaguja,docker,other,1
-16894,FilipBak/mushrooms,gradio,cc0-1.0,1
-16895,freddyaboulton/llama2-70b-discord-bot,gradio,,1
-16896,gradio-discord-bots/llama-2-13b-chat-transformers,gradio,other,1
-16897,CofAI/chat.b4,docker,,1
-16898,captainChan/CaptainChan,gradio,bsd,1
-16899,fabiodr/whisper-jax-diarization,gradio,,1
-16900,kitt3nsn0w/yofeli,docker,,1
-16901,dogincharge/Shap-ER,gradio,mit,1
-16902,jessica198601/jzlqy,gradio,,1
-16903,tikendraw/movie-recommender,streamlit,openrail,1
-16904,naotakigawa/qatool,streamlit,,1
-16905,nsarrazin/agents-js-llama,docker,,1
-16906,Plurigrid/LifeSim,docker,,1
-16907,Abhay1210/prompt-generator_V1,gradio,mit,1
-16908,CofAI/picscore,gradio,mit,1
-16909,awacke1/AzureBlobStorage,streamlit,mit,1
-16910,Hazem/roop,gradio,agpl-3.0,1
-16911,ChandlerGIS/shortgpt,gradio,apache-2.0,1
-16912,jordonpeter01/prompt-generator-public,gradio,,1
-16913,Multi-chan/amy_project,docker,,1
-16914,tharunayak14/Text-Summarization,gradio,apache-2.0,1
-16915,Q-bert/EarthQuakeMap,gradio,mit,1
-16916,TRaw/starchat-assist,gradio,,1
-16917,valeryk2/task7,gradio,,1
-16918,devisionx/autoannotation,gradio,,1
-16919,sharathprasaath/Gender_identification_by_eye,gradio,apache-2.0,1
-16920,Semibit/tts-server,gradio,gpl-3.0,1
-16921,VVallabh/AI-driven-Video-Generation-Tool,gradio,,1
-16922,stistko/CzechCapitalization,streamlit,cc-by-nc-4.0,1
-16923,TNR-5/dalle,static,,1
-16924,SocialGouv/speech-to-speech-translation-french,gradio,,1
-16925,krishw/MovieExplorer,streamlit,apache-2.0,1
-16926,lucinnerieux23/kotkindjn,docker,,1
-16927,Paulraj916/paulraj916,streamlit,,1
-16928,H0n3y/Honeystesting,docker,,1
-16929,medkins/s2w-ai-DarkBERT,gradio,,1
-16930,PikeAndVine/resize_color,gradio,,1
-16931,vvv214/sdxldbooth,docker,,1
-16932,EmpathyFirstMedia/README,static,,1
-16933,JonaSosa/spam_filter,gradio,openrail,1
-16934,mikeee/langchain-llama2-7b-chat-uncensored-ggml,gradio,,1
-16935,alphakavi22772023/test_00,streamlit,other,1
-16936,VVallabh/AI-Powered-Subtitle-Generator,gradio,,1
-16937,Saurabh46/MyChatGPT-DEMO,gradio,,1
-16938,marshallzee/itenas-computer-vision-bot,gradio,mit,1
-16939,AIZero2HeroBootcamp/VideoToAnimatedGif,streamlit,mit,1
-16940,AIZero2HeroBootcamp/MultiPDF-QA-ChatGPT-Langchain,streamlit,mit,1
-16941,AIZero2HeroBootcamp/AnimatedGifGallery,streamlit,mit,1
-16942,AIZero2HeroBootcamp/ChatGPTandLangchain,streamlit,mit,1
-16943,Kiran96/Article_summarizer_with_salesforce_CtrlSum,gradio,mit,1
-16944,Tanor/Serbian-WordNet-Sentiment-Visualizer,gradio,cc-by-4.0,1
-16945,AIZero2HeroBootcamp/TranscriptAILearnerFromYoutube,streamlit,mit,1
-16946,coraKong/WorldSimulation,gradio,,1
-16947,AIZero2HeroBootcamp/FastSpeech2LinerGradioApp,gradio,mit,1
-16948,rbigare/stablediffusionapi-architecture-tuned-model,gradio,openrail,1
-16949,Ryzal/rvc-models-new,gradio,mit,1
-16950,jeevavijay10/code-gen,gradio,,1
-16951,OptorAI/site,static,,1
-16952,yl12053/so-vits-4.1-Grass-Wonder,gradio,,1
-16953,ljrmary/UT_Hackathon,gradio,,1
-16954,theriyaz/stabilityai-stable-diffusion-xl-base-1.0,gradio,,1
-16955,jdhuka/SuperSimple2linerText2Speech,gradio,,1
-16956,awacke1/SuperSimple2LinerText2Speech,gradio,apache-2.0,1
-16957,ryoung41/SuperSimple2LinerText2Speech,gradio,,1
-16958,jeremymontgomeryoptum/Text2Speech,gradio,apache-2.0,1
-16959,jdhuka/StaticHTML5PlayCanvas,static,,1
-16960,affine/Time_Series_Model,streamlit,apache-2.0,1
-16961,MihaiPopa2/ChatGPT-Prompt-Generator,gradio,apache-2.0,1
-16962,justest/PaddleSpeechASR,gradio,,1
-16963,tushar310/chatgpt_clone,streamlit,apache-2.0,1
-16964,NeuroSenko/audio-processing-utils,gradio,,1
-16965,FangLee/Generate-Music-in-Time-Series,gradio,,1
-16966,daniyal214/gradio-caption-generator-git-large,gradio,,1
-16967,Jonathancasjar/Detect_products_and_empty_spaces_on_a_Supermarket,gradio,apache-2.0,1
-16968,devthedeveloper/Bark-with-Voice-Cloning,gradio,mit,1
-16969,LuxOAI/stabilityai-StableBeluga2,gradio,openrail,1
-16970,vishnu23/drone_image_segmentation,gradio,mit,1
-16971,mehedihassan/stabilityai-StableBeluga,gradio,,1
-16972,mehedihassan/AI-Text-to-speech,gradio,,1
-16973,reimari/rvc-aa99,gradio,mit,1
-16974,curseofvenus/ChatGPT4,streamlit,mit,1
-16975,limingcv/AlignDet,static,mit,1
-16976,wahyupermana10/churn_prediction,streamlit,,1
-16977,cbr/swp,gradio,unknown,1
-16978,AIZero2HeroBootcamp/ExperimentalChatGPTv1,streamlit,mit,1
-16979,TNR-5/zeroscope,gradio,,1
-16980,AIZero2HeroBootcamp/ClassDescriptionAndExamplesStreamlit,streamlit,mit,1
-16981,starnek/mix-design-concrete,streamlit,,1
-16982,projecte-aina/aguila-7b,gradio,apache-2.0,1
-16983,miculpionier/Fill-Mask,gradio,,1
-16984,kaxap/wiki-multilingual-e5-large,gradio,,1
-16985,xinli80/gradio-image-generator,gradio,,1
-16986,PeepDaSlan9/poisongpt,gradio,apache-2.0,1
-16987,Razkaroth/incidencia-delictiva,streamlit,mit,1
-16988,AntX-ai/README,static,,1
-16989,Tiredmaker/OKC,gradio,,1
-16990,AntX-ai/Fintech,static,,1
-16991,nguyennghia0902/SentimentAnalysis_usingBERT,streamlit,,1
-16992,haywired/medibot-llama2,docker,mit,1
-16993,allknowingroger/Image-Models-Test52,gradio,,1
-16994,1368565466ki/ZSTRD,gradio,apache-2.0,1
-16995,1368565466ki/Satdia,gradio,apache-2.0,1
-16996,TNR-5/Music-discord-bot,gradio,,1
-16997,TNR-5/testbot,gradio,,1
-16998,yash-srivastava19/CodeSmith,docker,mit,1
-16999,TNR-5/files-lumbot,gradio,,1
-17000,lavanjv/falcon-mini,docker,apache-2.0,1
-17001,Wrightjay/togethercomputer-LLaMA-2-7B-32K,gradio,,1
-17002,Izal887/rvc-hutao,gradio,mit,1
-17003,CanonOverseer/Canons-Den,docker,,1
-17004,lunbot/add,static,mit,1
-17005,Superintelligence1130/text-to-video-test,gradio,,1
-17006,rahulsccl/GenAIMyAvatar,gradio,,1
-17007,mohamedemam/bert_sentaces_similarty,gradio,mit,1
-17008,sub314xxl/SDXL-1.0,gradio,mit,1
-17009,LavanyaBurlagadda/TChatBotWithPlayHT1,gradio,,1
-17010,sub314xxl/MusicGen,gradio,cc-by-nc-4.0,1
-17011,Zeelubha/Football-Prediction,gradio,mit,1
-17012,Bl1tzie/Jam,docker,,1
-17013,Enigma007/Normalizer-Dashboard,streamlit,mit,1
-17014,sub314xxl/SD-XL,gradio,mit,1
-17015,Enigma007/Medika,streamlit,mit,1
-17016,mkManishKumar/Bank-Customer-Churn,streamlit,apache-2.0,1
-17017,sub314xxl/image-server-1,gradio,mit,1
-17018,sub314xxl/sdxldbooth,docker,,1
-17019,TechGenHub/README,static,,1
-17020,Fernando22/freegpt-webui,docker,,1
-17021,dianman666/bingai,docker,mit,1
-17022,sub314xxl/saiga2_13b_ggml,gradio,,1
-17023,abnerzhang/ieltsGrade,gradio,,1
-17024,Sidaddy/Beluga2ScriptGenerator,gradio,gpl-3.0,1
-17025,szk1ck/docker_test,docker,openrail,1
-17026,szk1ck/similarity_by_fasttext_api,docker,mit,1
-17027,in18/stable-diffusion-webui-cpu,gradio,,1
-17028,BobbyOleti/MyGenAIChatBot,gradio,,1
-17029,AgProfile/chatbotopenaihere,gradio,,1
-17030,Kashishmahajan/gradioLangChainOpenAI,gradio,,1
-17031,AgProfile/GradioGenOpenAi,gradio,,1
-17032,adityakabra/Patent-AI-V1,gradio,unknown,1
-17033,ririah13/Test,docker,,1
-17034,Uday29/MyChatBot,gradio,,1
-17035,GowthamSiddharth/MyAssist_ChatBot,gradio,,1
-17036,sai1108/MyChatBot,gradio,,1
-17037,PRABHKAR/MygenChatBot,gradio,,1
-17038,jaiteja7849/MyGenAIChatBot,gradio,,1
-17039,Kotinagendla/MyGenAIChatBot,gradio,,1
-17040,Vignesh2496/project,gradio,,1
-17041,Mahesh111/MaheshgenAIchatBot,gradio,,1
-17042,YokoH/MIS_SALCHICHAS,gradio,,1
-17043,vyshnaviii/MyGenAIchatbot,gradio,,1
-17044,Naveentalluri/NaveenGenAIAvatar,gradio,,1
-17045,patilyash22/ChatBotWithOpenAIAndLangChain,gradio,,1
-17046,surampudiAdarsh/myfirstopenAIUsinggradio,gradio,,1
-17047,vinayarukala31/mygenAIChatbot,gradio,,1
-17048,Vijaykumarthummapala/Mygenaichatbot,gradio,,1
-17049,imdebamrita/whatsapp_chat_analysis,streamlit,,1
-17050,BalaBhaskarudu/mygenAIChatbot,gradio,,1
-17051,SirishaArveti/GenerativeAIChatBot,gradio,,1
-17052,shivaaaa/myGenAIChatBot,gradio,,1
-17053,Manikanta-06/myaichatbox,gradio,,1
-17054,ishanchennupati/ishanavatarchatbot,gradio,,1
-17055,vikram767/myGenAIchaTBoat,gradio,,1
-17056,SaiRaam/AIAvatarchatbot,gradio,,1
-17057,kpavankumar971/MyAiAvatar2.1,gradio,,1
-17058,Shannu/mygenAIAvatar,gradio,,1
-17059,vamsikolla/MygenerativeAIchatbot,gradio,,1
-17060,Harikumar4/MyGenApp,gradio,,1
-17061,datatab/datatab-alpaca-serbian-3b-base,gradio,,1
-17062,Menthe17/MyGenAINani,gradio,,1
-17063,Nagireddys/MygenAI,gradio,,1
-17064,JairParra/Captioning_and_Stable_Diffusion_Generation,gradio,bsl-1.0,1
-17065,lavanyaparise/myenAIchatbot,gradio,,1
-17066,MOULI17/CmGenAIChatbot,gradio,,1
-17067,tharunG17/TharunChatGPT,gradio,,1
-17068,EmoHugger/MyGenAIChatBot,gradio,,1
-17069,Madhes/GradioLangChainBota,gradio,,1
-17070,Aishwini/myfirstaigen,gradio,,1
-17071,akhil5466/MyGenAIAvatarSpeech,gradio,,1
-17072,satyainjamuri6/MygenAIAvatarSpeech,gradio,,1
-17073,leelaaaaaavvv/pavaniMyAIchatBot,gradio,,1
-17074,Sunilkumarkanugula/SunilChatBot,gradio,,1
-17075,aurora10/gradiolangchainchatbot,gradio,,1
-17076,Sadhvi/ChatBot,gradio,,1
-17077,loknitesh/MYGENAI,gradio,,1
-17078,lalithakash2346/CortanaAI,gradio,,1
-17079,pallesureshnaidu/MyGenAIChatBot,gradio,,1
-17080,finny24/FinnyAiVoice,gradio,,1
-17081,Vivekdunuka/MyAIChat,gradio,,1
-17082,awacke1/ChatGPT-Genius-Assistant-4Writers,streamlit,mit,1
-17083,awacke1/ChatGPTGeniusWriter-HTML5-Output-1,static,mit,1
-17084,RajuGovvala/Raju123,gradio,,1
-17085,Naveen618/mygenAIAvatharSpeech,gradio,,1
-17086,Kurugodu/myGenAiText,gradio,,1
-17087,shivaatNXTWAVE/mygenai2,gradio,,1
-17088,emre/emre-llama-2-13b-mini,gradio,cc-by-nc-2.0,1
-17089,Mbilal755/Rad_Summarizer,gradio,,1
-17090,sukh28/toxic_gradio_app,gradio,,1
-17091,AdvertisingAgency/README,static,,1
-17092,ganesh78/MyGenAIApp,gradio,,1
-17093,eruuin/something,static,,1
-17094,zhaoyuzhaoyu/stabilityai-stable-diffusion-xl-base-1.0,gradio,apache-2.0,1
-17095,talari/MyGenAiChatBot,gradio,,1
-17096,paschar/StoryGenerator,gradio,apache-2.0,1
-17097,himanshukale/WAppTastic,streamlit,,1
-17098,motleykrug/README,static,,1
-17099,pavankumark/mygenaichatbot,gradio,,1
-17100,armansakif/BenFake,gradio,cc-by-nc-sa-4.0,1
-17101,sangareddyjaswanth/mygenaispeech,gradio,,1
-17102,Naveentalluri/NaveenGenAI,gradio,,1
-17103,akashpadala/MyGenAIChatBot,gradio,,1
-17104,HelloMimosa/sail-rvc-Ai_Hoshino__From_Oshi_no_Ko___RVC_v2__300_Epoch,gradio,openrail,1
-17105,Dileepgorantala/dileepAI,gradio,,1
-17106,akashpadala/myGenAIAvatarSpeech,gradio,,1
-17107,kaicheng/ChatGPT_ad,gradio,gpl-3.0,1
-17108,Menthe17/Nani17092005,gradio,,1
-17109,Dileepgorantala/dileepVoiceAI,gradio,,1
-17110,Vageesh1/PDF_QA,streamlit,,1
-17111,kelothu/gradiolangchainbotopenai,gradio,,1
-17112,andryMLOPS/ASTA-GPT-3.8_web_ui,docker,,1
-17113,GuruVineeth/GenAIGPT,gradio,,1
-17114,Naveentalluri/NavenAIvoice,gradio,,1
-17115,NIVASVAKA8999/myaigen,gradio,,1
-17116,kamranahmad92/gradialanchainChatBotOpenAi,gradio,,1
-17117,kamranahmad92/chatgbtaigradientlanchain,gradio,,1
-17118,warakram/gradiolangchainchatbotopen.Ai,gradio,,1
-17119,kamranahmad92/GradioLanchainChatbotAi,gradio,,1
-17120,zhangguofen/Real-CUGAN,gradio,gpl-3.0,1
-17121,kamranahmad92/GRADIOLANCHAINOPENAICHATBOT,gradio,,1
-17122,bhavanaraj/myaivoice,gradio,,1
-17123,kamranahmad92/Gradientlanchainopenaisuperchatbot,gradio,,1
-17124,kamranahmad92/lanchaingradientsmartaibot,gradio,,1
-17125,Srikanthpichika/sreegenAIApp,gradio,,1
-17126,eslavathanil/myGenAIchatbot,gradio,,1
-17127,Krishna3/mygenAIChatBot,gradio,,1
-17128,Nesip/meta-llama-Llama-2-70b-chat-hf,docker,,1
-17129,swetha311/mygenAIspeechh,gradio,,1
-17130,CormacMc/projectsub6,gradio,apache-2.0,1
-17131,sindhoorar/brain-tumor-classifier,gradio,cc-by-2.0,1
-17132,omkar001/gradiolangchainchatbot,gradio,,1
-17133,surya12003/suryabot,gradio,,1
-17134,zishverse/zishanChatAI,gradio,,1
-17135,169153tej/My-New-Gen-Ai-Chat-Bot,gradio,,1
-17136,Friklogff/xx-xhai,gradio,openrail,1
-17137,qq37017934/QSign,docker,,1
-17138,AkshayKollimarala/MygenAI,gradio,,1
-17139,Shreeradha/GradioChatBotAI,gradio,,1
-17140,muneebashraf/Visual-Sentiment-Analyzer,gradio,lgpl-3.0,1
-17141,Abhi1262/MyGenAIChatBot,gradio,,1
-17142,AkshayKollimarala/MYAIVOICESPEECH,gradio,,1
-17143,cbhasker/MyGenAlChatBot,gradio,,1
-17144,lolakshi/dhoni,gradio,,1
-17145,bhanuprasad3245/mygenAIchatbot,gradio,,1
-17146,NanoT/demo,gradio,,1
-17147,isabelahrens/facebook-fastspeech2-en-ljspeech-0731,gradio,,1
-17148,hannahross5/facebook-fastspeech2-en-ljspeech-0731,gradio,,1
-17149,udaykiran6703/UdayGenAI,gradio,,1
-17150,yaswanthkumar/yashAIbot,gradio,,1
-17151,janusurya/mygenchatBot,gradio,,1
-17152,awacke1/Memory-0731,streamlit,,1
-17153,hannahross5/Memory-0731,streamlit,,1
-17154,awacke1/HTML5InteractivtyDemo,static,mit,1
-17155,ehristoforu/llm-discord-bot,docker,apache-2.0,1
-17156,maha-vishnu/mahavishnu,gradio,,1
-17157,surya12003/suryabot1,gradio,,1
-17158,Ravanan007/my1projectAi,gradio,,1
-17159,cbhasker/bhasker1323genAIApp,gradio,,1
-17160,wanxing28/QQsign,docker,mit,1
-17161,TNR-5/Testbkt,gradio,,1
-17162,venkat8020/MyGenAiChatBot,gradio,,1
-17163,kosurisiva/MyGenAiChatBot,gradio,,1
-17164,KunalKharalkar/imagetostory,streamlit,,1
-17165,vinayarukala31/mygenAiAvatarspeech,gradio,,1
-17166,patilyash22/ChatBotWithOpenAILangChainAndPlayHT,gradio,,1
-17167,DEVINKofficial/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator,gradio,,1
-17168,kkumarkumar/MyGenAIchatbot,gradio,,1
-17169,ishvalin/what_is_it,gradio,apache-2.0,1
-17170,nithintechie/NithinGenAIAvatar,gradio,,1
-17171,naeemalbustami/voiserec,gradio,,1
-17172,cbhasker/bhaskergenAIAppSpeech,gradio,,1
-17173,CofAI/picscore1,static,other,1
-17174,minoluusa/chatbot1,gradio,,1
-17175,TRaw/dtet,docker,,1
-17176,locomotive/taxonomy-ml,streamlit,,1
-17177,ehristoforu/Testbot,gradio,,1
-17178,w601sxs/b1ade-1b,gradio,cc-by-4.0,1
-17179,JohnCalimoso/animalbreedidentificationversion1.5,streamlit,,1
-17180,awacke1/HTML5-Aframe-Flight-Sim-Test,static,,1
-17181,Srikanthpichika/SreeGenAIChatBot,gradio,,1
-17182,Harshitthaa/Harshitthaamyfirstai,gradio,,1
-17183,menghanxia/ReversibleHalftoning,gradio,mit,1
-17184,pedrohc/productcounter,gradio,mit,1
-17185,BaddaAshok0265/AshokGenAI,gradio,,1
-17186,DaniilMIPT/greenatomtest,streamlit,openrail,1
-17187,Rishwanth08/Naniai,gradio,,1
-17188,housexu123/bingo-2.0,docker,mit,1
-17189,VickyKira/NASAGPT,gradio,,1
-17190,allknowingroger/Image-Models-Test56,gradio,,1
-17191,callmerk1986/AyurGenie,gradio,gpl-2.0,1
-17192,834188divi/cardiffnlp-twitter-roberta-base-sentiment-latest,gradio,,1
-17193,Subbu-2004/MyNewAiAvatar,gradio,,1
-17194,Ahmadjaved/Genaispeech,gradio,,1
-17195,nicolehuangyx/stabilityai-stable-diffusion-xl-base-1.0,gradio,apache-2.0,1
-17196,priyankachinni/priyagenai,gradio,,1
-17197,DUOMO-Lab/TransGPT,gradio,apache-2.0,1
-17198,kamranahmad92/GradioLanchainSuperChatbot,gradio,,1
-17199,ehristoforu/runwayml-stable-diffusion-v1-5,gradio,,1
-17200,rekhab0203/mygenAIChatbot,gradio,,1
-17201,jbilcke-hf/360-server-1,gradio,mit,1
-17202,CofAI/Kemal-Diffusion,gradio,creativeml-openrail-m,1
-17203,tejatrivikram/MyGenAIAvatar,gradio,,1
-17204,kamranahmad92/GradioLanChainSuperChatBotAi,gradio,,1
-17205,kamranahmad92/GradioLanChainSuperAIChatbot,gradio,,1
-17206,Prasanthi123/myaiavatarammu,gradio,,1
-17207,kowsik/MygenAIApps,gradio,,1
-17208,fierce74/Galaxy_classifier,gradio,apache-2.0,1
-17209,Nikithaniki/NikiGenAI,gradio,,1
-17210,Mr-Hacker/GenAiTest2,gradio,,1
-17211,KOTTHADAKAVYA/mygenAIchatboard,gradio,,1
-17212,Bumpeet/faceTracking,streamlit,unknown,1
-17213,Luckya/MyGenAi,gradio,,1
-17214,Haswanth/haswanthpalepu,gradio,,1
-17215,likhith263/mygenAIchatbotproject,gradio,,1
-17216,Varun6579/Lemma._tech,gradio,,1
-17217,CosmoAI/ChitChat,gradio,openrail,1
-17218,alihug/GradioLangchainBotAI,gradio,,1
-17219,unik-style/unik-ml,docker,openrail,1
-17220,mugilan0610/mugilanbotchat,gradio,,1
-17221,Avinash-12035/MyGenAIChatBot,gradio,,1
-17222,giridharvaruganti/facial-keypoints-detection,gradio,,1
-17223,Swatantradev/mynewgenAI,gradio,,1
-17224,royal-16/Mr.Royal.newgenai,gradio,,1
-17225,SkKalit/KalitGenAiChatbot,gradio,,1
-17226,RohanAi/low-light-enhancement,gradio,openrail,1
-17227,CofAI/openjourney,gradio,,1
-17228,poojasree2003/aiproject,gradio,,1
-17229,Jeevika/MyGenAI,gradio,,1
-17230,MyGenAIchatBot/Puji,gradio,,1
-17231,Sandy0077/MyGenAISpeechBot,gradio,,1
-17232,DVLH/nlpconnect-vit-gpt2-image-captioning,gradio,,1
-17233,ehristoforu/Teststudio,docker,apache-2.0,1
-17234,ehristoforu/Chatuitwst,docker,,1
-17235,shiditya2003/MyGenerativeshiditya,gradio,,1
-17236,SanjayreddyBaddipadiga/MyfirstGenAIChatBot,gradio,,1
-17237,gagan3012/QalamV0.2,streamlit,,1
-17238,hechenyang/bingAI,docker,mit,1
-17239,freddyaboulton/lk99,gradio,mit,1
-17240,love3510189/NewBing1,docker,mit,1
-17241,greyskyAI/ChatRAS,streamlit,apache-2.0,1
-17242,EswarBilla/EswarGenAiChatbot,gradio,,1
-17243,mani143/ai,gradio,,1
-17244,weiyao255/NINGAI,docker,mit,1
-17245,portal/Xenova-Semantic-Image-Search,static,,1
-17246,balenireekshana/MyGenAI,gradio,,1
-17247,andy-rui/bingAI,docker,mit,1
-17248,bigcode/in-the-commitpack,gradio,apache-2.0,1
-17249,Bingyunhu/hoping,docker,mit,1
-17250,lyln/bingAI-lyln,docker,mit,1
-17251,t110-ai-admin/InspectLens,gradio,other,1
-17252,luxuedong/bing2,docker,mit,1
-17253,raskell/livebook,docker,,1
-17254,nyh/newbing,docker,mit,1
-17255,Ashish17/Ashish_Open_Chat_AI_17,gradio,,1
-17256,Konglinu/bingai,docker,mit,1
-17257,Dave37/gradiolangchainChatBotOpenAI,gradio,,1
-17258,Enigma007/Classifier-Fasttext,streamlit,mit,1
-17259,dafeidun/dft,docker,mit,1
-17260,Chakri-kollepara-5/Mygena,gradio,,1
-17261,kainy/rvc_okiba_TTS,gradio,,1
-17262,Chakri-kollepara-5/ai,gradio,,1
-17263,qsh612/bingAI,docker,mit,1
-17264,BBrother/NewBingAI,docker,mit,1
-17265,qushui/bing,docker,mit,1
-17266,NiuTaipu/moe-tts-test01,gradio,mit,1
-17267,mdkaif/genAIchatbot,gradio,,1
-17268,Ash2219/AIchatbot,gradio,,1
-17269,mygyasir/stablediff,gradio,openrail,1
-17270,sitong608/bingAI,docker,mit,1
-17271,tharun49/TharunAIChatBot,gradio,,1
-17272,Sowmyashetty/Mygenaibot,gradio,,1
-17273,Balalaxmi/JarvisAIchatbox,gradio,,1
-17274,likhi993/MyAIchatbox,gradio,,1
-17275,sathwik21/MyGenAichatbot,gradio,,1
-17276,efchbd1013/animal_classification,gradio,apache-2.0,1
-17277,supercyx3/ChatSydney,docker,mit,1
-17278,Sandiago21/automatic-speech-recognition-italian,gradio,,1
-17279,tharun49/TharunAISpeech,gradio,,1
-17280,Deeksh/genai,gradio,,1
-17281,ahdsoft/Persian-Topic-Modeling,streamlit,,1
-17282,pikto/prodia,gradio,apache-2.0,1
-17283,Dineshdc/MygenAIChatbot,gradio,,1
-17284,ahdsoft/persian-keyphrase-extraction,streamlit,,1
-17285,balamanikandan/ai_project,gradio,bigscience-openrail-m,1
-17286,dishanttembhurne/myGenAiChatbot,gradio,,1
-17287,vinaynani/genchatbott,gradio,,1
-17288,tharun49/TharunGenAISpeech,gradio,,1
-17289,RiyaJangir/MyAIGenTool,gradio,,1
-17290,Manickam/MyGenerativeAIApp,gradio,,1
-17291,Swamyajulu/MyGenAIChatBot,gradio,,1
-17292,IntSpace/llama-2.70b,gradio,llama2,1
-17293,Sandiago21/speech-to-speech-translation-german-2,gradio,,1
-17294,Uppuluri/mychatbotai,gradio,,1
-17295,IntSpace/README,static,,1
-17296,vlikhitharaj/mygenAIchatbot,gradio,,1
-17297,KunamVishnu/MyGenAiChatBot,gradio,,1
-17298,sanjayvy/ChatBotAI,gradio,,1
-17299,pirahansiah/ComputerVision,gradio,mit,1
-17300,nunekeerthi1/MyGenAIChatBot,gradio,,1
-17301,Maharaja36/myGenAIApp,gradio,,1
-17302,rodragon737/ocr_reader_space,gradio,mit,1
-17303,ehristoforu/sbinterface,gradio,openrail,1
-17304,CleanML/demo,docker,mit,1
-17305,Janardhan2003/MyGenAIChatBot,gradio,,1
-17306,Yogesh19/MyajiAi,gradio,,1
-17307,Shravani585/gradioandlangchainchatboot,gradio,,1
-17308,G-Deepika/MygenAIAvathar,gradio,,1
-17309,PROJECTAIGPT/AIAvatarSPEECH,gradio,,1
-17310,kananj/Daytona-Beach-Ambassador,gradio,other,1
-17311,Arun1217/mygenaiapp,gradio,,1
-17312,Datasculptor/MusicGen,gradio,cc-by-nc-4.0,1
-17313,omsree/myGenAIapp-1,gradio,,1
-17314,Dave37/voicebot,gradio,,1
-17315,UjwalBingi/mynewai,gradio,,1
-17316,Naveejnk/MyGenAIChatBot,gradio,,1
-17317,Yogesh19/Voiceai,gradio,,1
-17318,Maharaja36/MyVoiceAssistand,gradio,,1
-17319,VIKASNI1/VOICEGENAI,gradio,,1
-17320,yenumulanarendraprasad/mygenaivoicebot,gradio,,1
-17321,anthonymikinka/gorilla-llm-gorilla-7b-hf-delta-v1,gradio,,1
-17322,Ajaymekala/gradiolangchainChatBotOpenAI-1,gradio,,1
-17323,jayanthrahul/myaiownvoice,gradio,,1
-17324,syrilion/syrilionchat,docker,mit,1
-17325,karlkode30/scn_detecta,gradio,cc,1
-17326,Violetmae14/Violet,static,other,1
-17327,Violetmae14/Text-to-AnimeStudioVideo,gradio,openrail,1
-17328,swapniel99/cifar10,gradio,mit,1
-17329,PeepDaSlan9/AutoGPT,gradio,mit,1
-17330,Guilherme34/Jennifer-Llama270b-Chatbot-with-vision-v1,streamlit,,1
-17331,sixsixsix/BingAi,docker,mit,1
-17332,liang1213877964/ai,docker,mit,1
-17333,xiaolv/claude2_xiaolv_api_updata,gradio,other,1
-17334,Viswa934746/AIBALA,gradio,,1
-17335,rakesh99/myvoicebot,gradio,,1
-17336,Viswa934746/Sorryda,gradio,c-uda,1
-17337,Bala2-03-2003/MygenvioceAI,gradio,,1
-17338,Sivanraj/MyGenAIApp,gradio,,1
-17339,pvanand/RASA-chat-interface-streamlit,streamlit,mit,1
-17340,mygenaisagar/MyGenAIsagarBot,gradio,,1
-17341,LokeshMadaka/MyAIChatBot,gradio,,1
-17342,ehristoforu/txt2img.neu,gradio,,1
-17343,Shubham2003/chatWithPdfs,streamlit,,1
-17344,WL007/WL001,docker,mit,1
-17345,satish2004/myaichanti2,gradio,,1
-17346,CyberHarem/find_my_waifu,gradio,mit,1
-17347,Chandrasekahar2k/KVCSekharGenAIBot,gradio,,1
-17348,dengmouren/minlik-chinese-alpaca-pro-33b-merged,gradio,llama2,1
-17349,ManjunathNili/manjuai,gradio,,1
-17350,khadeer/skkhadeer,gradio,,1
-17351,omarchik/az,docker,,1
-17352,LP-art/Bing,docker,mit,1
-17353,xnetba/ai-stable-diffusion-Text-to-Image,gradio,,1
-17354,pratikshapatil0220/GenarativeAIChatBot,gradio,,1
-17355,404ERRORms/bingAI,docker,mit,1
-17356,lunarflu/LevelBot,gradio,,1
-17357,alibidaran/Davinci_EYE,gradio,apache-2.0,1
-17358,Lijiahui/bingAI,docker,mit,1
-17359,Rizon-Lin/NewBing,docker,mit,1
-17360,jeycov/IADERM-UTOPIC-PFIZER,gradio,,1
-17361,FireFrame/werz,static,,1
-17362,laoniutyyugyiib/vuvuy,docker,mit,1
-17363,Nandhusnm/testing,gradio,,1
-17364,MarkMcCormack/Automated-Grading-Dashboard,streamlit,,1
-17365,Hanqix/oxford_pet_classify,gradio,openrail,1
-17366,egvpprojects/Text-2-Speech,gradio,,1
-17367,Rajagopal/ImageBind_zeroshot_demo2,gradio,mit,1
-17368,jayanthrahul/bhavanavoice,gradio,,1
-17369,aloatalpine/streamlit_v3,streamlit,openrail,1
-17370,sagelewis71/ai-lawyer,streamlit,,1
-17371,yl12053/so-vits-4.1-Kitasan-Black,gradio,,1
-17372,bobmunzir/meta-llama-Llama-2-70b-hf,docker,,1
-17373,zhangyd/bingo,docker,mit,1
-17374,lucas-w/mental-health-10,gradio,,1
-17375,wynb1314/bingAI,docker,mit,1
-17376,EtTKSf/uu,docker,,1
-17377,Yunshansongbai/SVC-Nahida,gradio,,1
-17378,spiderdio/bingbing,docker,mit,1
-17379,Sowmyashetty/MyAichatbot,gradio,,1
-17380,ANILYADAV/mygenaichatbot,gradio,,1
-17381,Adieudale/Adieudale,docker,mit,1
-17382,diffle/sd-1.5,gradio,creativeml-openrail-m,1
-17383,padmanabhbosamia/Cifar10_Classfication,gradio,mit,1
-17384,diffle/sd-2.1,gradio,creativeml-openrail-m,1
-17385,diffle/README,static,creativeml-openrail-m,1
-17386,dgnk007/dgnk007-crow,gradio,,1
-17387,multiple-moon/README,static,,1
-17388,ALR03/gradiolangchainChatbotOpenAI,gradio,,1
-17389,ehristoforu/Ultrasdspace,gradio,,1
-17390,wall-e-zz/stable-diffusion-logo-fine-tuned,gradio,apache-2.0,1
-17391,diffle/oj-4,gradio,creativeml-openrail-m,1
-17392,diffle/kandinsky-2.2,gradio,creativeml-openrail-m,1
-17393,Ritori/Ritori-Yura_GPT2,gradio,,1
-17394,llds/shengweibing,docker,afl-3.0,1
-17395,allknowingroger/Image-Models-Test60,gradio,,1
-17396,ehristoforu/Hubsd,gradio,,1
-17397,TejaSree/gradioGenAI,gradio,,1
-17398,Ashwanthram/myGenVoiceBot,gradio,,1
-17399,TNK21/Text_summarizer,gradio,,1
-17400,taidi/bingai2,docker,,1
-17401,DakMak/gradio-start,static,,1
-17402,oliverdixon/BereaAI,streamlit,,1
-17403,Saugatkafley/Bard-cover-letter,streamlit,mit,1
-17404,TNK21/Question_Answering,gradio,,1
-17405,OscarLiu/MybingGPT,docker,mit,1
-17406,filehost/txt,gradio,,1
-17407,bhanuprakash99/MyGenAIChatBot,gradio,,1
-17408,MyGenAiUser/MyGenAiChat,gradio,,1
-17409,bhanuprakash99/mygenAIAvatarSpeech,gradio,,1
-17410,jeevankumar-s/stabilityai-stable-diffusion-xl-base-1.0,gradio,,1
-17411,madhumahima/MyGenerativeAIproject,gradio,,1
-17412,abhijithkota/my_gen_ai_page,gradio,,1
-17413,Tetel/chat,docker,,1
-17414,diffle/webdef,gradio,creativeml-openrail-m,1
-17415,lelafav502/fallpt-chat,gradio,,1
-17416,Ritori/TTS_Yui,gradio,,1
-17417,YanzBotz/YanzBotz-Models,gradio,mit,1
-17418,Q-bert/FaceGAN,gradio,mit,1
-17419,Meltedmindz/nerijs-pixel-art-xl,gradio,,1
-17420,EsoCode/text-generation-webui,gradio,apache-2.0,1
-17421,jialewanga/jiale,docker,mit,1
-17422,ASJMO/freegpt,docker,,1
-17423,ehristoforu/T3,gradio,,1
-17424,bnkkkkknn/bnkkkkknn,docker,mit,1
-17425,Belshia/shia,gradio,openrail,1
-17426,nugrahatheo/Prediction-of-Credit-Card-Default,streamlit,,1
-17427,tsxc/newbing,docker,mit,1
-17428,damian0815/Erasing-Concepts-In-Diffusion,gradio,mit,1
-17429,moyeli/BingAi,docker,mit,1
-17430,ehristoforu/imggend,gradio,,1
-17431,dpaulsoria/AnimalDetector,gradio,gpl,1
-17432,ehristoforu/Diffehsj,gradio,,1
-17433,larryyin/experian-bot,gradio,gpl-3.0,1
-17434,ehristoforu/Hwhswj,gradio,,1
-17435,ehristoforu/Iro,gradio,,1
-17436,AnjaneyuluChinni/AnjiChinniGenAIAvatar,gradio,,1
-17437,louisedrumm/TutorBot,gradio,mit,1
-17438,RamziRebai/hf_sum,gradio,mit,1
-17439,DonDoesStuff/orca-mini-3b-chat,gradio,,1
-17440,sanjay6886/SANJAY,gradio,,1
-17441,jjw0126/Multi-ORGPT,gradio,other,1
-17442,puuuw/pu,docker,mit,1
-17443,ehristoforu/Dicto,gradio,,1
-17444,irfank/katanaml-donut-demo-3,gradio,,1
-17445,mrneuralnet/P-DFD,streamlit,,1
-17446,junkmind/SOTER,gradio,unlicense,1
-17447,rywiz/suno-bark-small,gradio,mit,1
-17448,spatialgeneration/musicgen-mbd,gradio,,1
-17449,AzulaFire/SparkDebate,gradio,,1
-17450,shutterfree/newbing,docker,mit,1
-17451,sdfhg5243/segmind-tiny-sd,gradio,,1
-17452,01zhangclare/bingai,docker,mit,1
-17453,sh20raj/sdxl,gradio,,1
-17454,zhiyin123/MyBingAi,docker,mit,1
-17455,zifyu/public-newbing,docker,mit,1
-17456,mygyasir/XL,gradio,openrail,1
-17457,ysui10086/yvshengAI,docker,mit,1
-17458,B2gan/LLM_Can_See,gradio,unknown,1
-17459,ldhldh/demo,gradio,mit,1
-17460,sakay/bingai,docker,mit,1
-17461,iberob/nerijs-pixel-art-xl,gradio,,1
-17462,4th3n4/TraDeX,gradio,agpl-3.0,1
-17463,MiSuku/Suku8008m,gradio,,1
-17464,Uncleming/AIGPT,docker,mit,1
-17465,boze7/newbing,docker,mit,1
-17466,eghth/wdferg,gradio,,1
-17467,knotmesh/deepset-roberta-base-squad2,gradio,,1
-17468,ypf99/chatgpt,docker,mit,1
-17469,WhiteKnightAI/togethercomputer-LLaMA-2-7B-32K,gradio,,1
-17470,s3nh/s3nh-chinese-alpaca-2-7b-GGML,gradio,openrail,1
-17471,Asmithayellow/Asmi,gradio,,1
-17472,taesiri/Docx2Latex-Farsi,gradio,mit,1
-17473,hans829/newbing,docker,mit,1
-17474,JenitaChristopher/MY_GEN_AI,gradio,,1
-17475,UJCONTROL/bingAI,docker,mit,1
-17476,Uncleming/AiAi,docker,mit,1
-17477,Aadarsh4all/ChatWithBear,gradio,,1
-17478,mrneuralnet/P-PD,streamlit,,1
-17479,sagiliManoj/ManojGenAIAvatar,gradio,,1
-17480,Slammed96/Monero-WizardLM-Uncensored-SuperCOT-StoryTelling-30bb,gradio,openrail,1
-17481,Kushiii112/stabilityai-stable-diffusion-xl-base-1.0,gradio,openrail,1
-17482,s3nh/senh-WizardVicuna-Uncensored-3B-0719-GGML,gradio,openrail,1
-17483,antonelli/outsidellms,gradio,,1
-17484,mipbkhn/BreastCancer,gradio,,1
-17485,Hunzla/whisperaudio,gradio,openrail,1
-17486,LIHUI123/LIHUI123,docker,mit,1
-17487,Ggxcc4566/stabilityai-stable-diffusion-xl-refiner-1.0,docker,bigscience-bloom-rail-1.0,1
-17488,LUCKky/QQsign,docker,mit,1
-17489,Dharshinijayakumar/Dharshujayakumaraiapp,gradio,,1
-17490,allknowingroger/Image-Models-Test64,gradio,,1
-17491,ma52525/bingai,docker,mit,1
-17492,zalaingjun/QQsign,docker,mit,1
-17493,libhost/tech,docker,mit,1
-17494,womeik/binbin,docker,mit,1
-17495,Ajay-user/Optical-Character-Recognition,streamlit,,1
-17496,TNR-5/semantic-image-search.img,docker,,1
-17497,LH66/BingAI,docker,mit,1
-17498,TNR-5/Image-Semantic-Searchj,streamlit,mit,1
-17499,ahdsoft/Persian-Automatic-Speech-Recognition,streamlit,,1
-17500,Izal887/Konci887,gradio,mit,1
-17501,sanniu/newchat,docker,mit,1
-17502,libhost/img,streamlit,mit,1
-17503,corpvs/test,static,,1
-17504,LyrithAkari/Bing,docker,mit,1
-17505,ehristoforu/Imglibtest,static,mit,1
-17506,libhost/img.lite,streamlit,mit,1
-17507,dbis/AI_Doctor_Bot,gradio,,1
-17508,SrikanthPhalgun/Cifar10_ERAV1_GradCam_Demo,gradio,,1
-17509,Curranj/chatbot,gradio,,1
-17510,alcanodi/stabilityai-stable-diffusion-xl-base-1.0,gradio,openrail,1
-17511,recaptime-dev/README,static,cc-by-sa-3.0,1
-17512,aniketingole92/gradiolangchainChatbotopenAI,gradio,,1
-17513,MichaelWelsch/FreeVC,gradio,mit,1
-17514,diffle/sd-xl.ui,gradio,creativeml-openrail-m,1
-17515,EddyCode/Portfolio,static,,1
-17516,billusanda007/Shortlisted_Candidate_Email_Sender,streamlit,mit,1
-17517,Hypersonic0945/GenAISample,gradio,,1
-17518,Jack1804/stabilityai-stable-diffusion-xl-refiner-1.0,gradio,,1
-17519,Aziizzz/ChestXrayClassification,gradio,openrail,1
-17520,DHEIVER/Segmento_de_Angio_Coronariana_v3,gradio,,1
-17521,PeepDaSlan9/De-limiter,gradio,,1
-17522,nicolasdec/cabrachat,gradio,,1
-17523,kamidara/lolipaoi02,docker,,1
-17524,gary109/HaleyCH_Theme,gradio,apache-2.0,1
-17525,sq57/newbing,docker,mit,1
-17526,calvinchaochao/text_generation,gradio,,1
-17527,akashdhiman79830/MYGenAIVoice,gradio,,1
-17528,Poornima-fullstack/PoorniAI,gradio,,1
-17529,pigling/chatGpt,docker,mit,1
-17530,red1xe/codeGPT,streamlit,openrail,1
-17531,OldP1ng/QQsign,docker,mit,1
-17532,Andyrasika/Andyrasika-avatar_diffusion,gradio,,1
-17533,839871171w/newbingAI,docker,mit,1
-17534,seok07/Voice-Changer1,gradio,mit,1
-17535,fbeckk/cell-seg,streamlit,bsd,1
-17536,Error114/bingAI,docker,mit,1
-17537,naotakigawa/test-qatool,docker,,1
-17538,raylander/Infinite_zoom_SD,gradio,,1
-17539,MilliMalinga/moghel-bot,gradio,,1
-17540,Aspik101/Polish-vicuna-13b-v1.5,gradio,other,1
-17541,bhfr/bing-ai,docker,mit,1
-17542,chenyihang/newbing,docker,mit,1
-17543,Justin-Choo/Diffusion50XX,gradio,,1
-17544,shezanbaig/myLlama2,docker,openrail,1
-17545,yuxin099/fjyuxin,docker,mit,1
-17546,konghl/gpt,docker,mit,1
-17547,yiyi12123/BingAI,docker,mit,1
-17548,awacke1/MTBenchmarkForChatGPTMetricsScoring,gradio,other,1
-17549,ArcAhmedEssam/CLIP-Interrogator-2,gradio,,1
-17550,Sakil/research_paper_Question_answer,streamlit,apache-2.0,1
-17551,OmarSamehSaid/Text-Summerization,gradio,,1
-17552,Augustya/ai-subject-answer-generator,gradio,mit,1
-17553,slogers/openai-reverse-proxy,docker,,1
-17554,s3nh/totally-not-an-llm-AlpacaCielo2-7b-8k-GGML,gradio,openrail,1
-17555,shawhin/vanilla-chatbot,gradio,,1
-17556,matthoffner/AudioCraft_Plus,gradio,mit,1
-17557,asdastreer/stabilityai-stablelm-base-alpha-3b-v2,gradio,,1
-17558,RoversX/Nous-Hermes-Llama-2-7B-GGML,gradio,,1
-17559,gebain/easylook,docker,mit,1
-17560,lkjhn/qllsdsg,docker,mit,1
-17561,lcw777789564/panzuowenji,docker,mit,1
-17562,oriname/orimono,docker,,1
-17563,zcy123/newbingzcy,docker,mit,1
-17564,JPMadsen/JP_Audio,gradio,mit,1
-17565,hilloworld/chatgpt,docker,mit,1
-17566,mingu600/Tristana_reroll,gradio,,1
-17567,saikumar622/testing,gradio,,1
-17568,34we12er/newbing,docker,mit,1
-17569,mengmeng2/bing,docker,mit,1
-17570,Izal887/rvc-ram12,gradio,mit,1
-17571,kepl/add,static,,1
-17572,kepl/g,gradio,creativeml-openrail-m,1
-17573,Bishan/Speech_To_Text_Hindi,gradio,,1
-17574,difinative/AIBuddy,gradio,apache-2.0,1
-17575,pompuritz/keroppurin,docker,,1
-17576,Nikita22121671/stabilityai-stablecode-instruct-alpha-3b,gradio,,1
-17577,Dralkkin/Lorule-Proxy,docker,,1
-17578,jordonpeter01/MusicGen,gradio,cc-by-nc-4.0,1
-17579,aravind123456789/OPENAIAPP,gradio,,1
-17580,Filmor/Bot,static,,1
-17581,ilikezx/newbing,docker,mit,1
-17582,RameshBanala/aivoicebot,gradio,,1
-17583,CForGETaass/vits-uma-genshin-honkai,gradio,apache-2.0,1
-17584,Aravindsssss/GradiolangchainChatBoatOpenAI,gradio,,1
-17585,Aravindsssss/gradin,gradio,,1
-17586,Zannriell/TextChatBot,docker,openrail++,1
-17587,JethroNatividad/GPT4ALLdupe1523623,gradio,,1
-17588,chenxc/qweqwe,docker,mit,1
-17589,billusanda007/Q-Maker,streamlit,mit,1
-17590,lukelike1001/poison-leaf-tracker,gradio,cc-by-sa-4.0,1
-17591,Ripo-2007/Ripo-2007-dreambooth_alfonso,gradio,,1
-17592,willholt/JAMA_GPT,streamlit,,1
-17593,SanthoshG143/Mychataptaibot,gradio,,1
-17594,shashi141/MyGenAIChatBot,gradio,,1
-17595,awacke1/CardWriterPro,streamlit,mit,1
-17596,nicoladisabato/chat-summarization,streamlit,other,1
-17597,lizhaoyin/newbing,docker,mit,1
-17598,chompionsawelo/whisper_transcribe,gradio,mit,1
-17599,Zengwengen/nb,docker,mit,1
-17600,BalaBhaskarudu/Balu,gradio,,1
-17601,Sefray/PylenaLineDetector_ICDAR2023,gradio,,1
-17602,PeepDaSlan9/Gryphe-MythoMix-L2-13b,gradio,apache-2.0,1
-17603,lukelike1001/PlaceAnalysis,gradio,,1
-17604,allknowingroger/Image-Models-Test72,gradio,,1
-17605,Sudhir87/Intervupro.ai,streamlit,,1
-17606,thelou1s/yamnet_test,gradio,bsd-3-clause-clear,1
-17607,rsh123/newbing,docker,mit,1
-17608,thunder-007/weld-canvas,gradio,openrail,1
-17609,0x876/Yotta_Mix,gradio,,1
-17610,Chakri1997/ChatGPT-prompt-generator,gradio,apache-2.0,1
-17611,gordonchan/h2oo,gradio,apache-2.0,1
-17612,wilson1/bingai,docker,mit,1
-17613,awacke1/QuoteBotForQuotesMeditation,streamlit,mit,1
-17614,DQChoi/image_sticker,gradio,,1
-17615,awacke1/Quote-Bot-AutoRepeater,streamlit,mit,1
-17616,waheedwaqar/ToyotaChatBot,gradio,,1
-17617,canaxx/donut-mrz,gradio,mit,1
-17618,parsa-mhmdi/persian-asr,gradio,openrail,1
-17619,lysine/auscultate,docker,,1
-17620,chixiao/chixiaobing,docker,mit,1
-17621,johnhelf/codeinterpreter-api,gradio,mit,1
-17622,trakss1436/DocTalker,gradio,,1
-17623,ff4214/Newbing,docker,mit,1
-17624,cowboyonmars/nerijs-pixel-art-xl,gradio,,1
-17625,amine1956/NumbersStation-nsql-llama-2-7B,gradio,apache-2.0,1
-17626,jordonpeter01/MusicGen2,gradio,cc-by-nc-4.0,1
-17627,AlexKorGKLT/webui-cpua,gradio,,1
-17628,umn-msi/fatchecker,gradio,osl-3.0,1
-17629,zombieofCrypto/image_interpreter,docker,llama2,1
-17630,lullNB/lullNew,docker,mit,1
-17631,lizi136/bingal,docker,mit,1
-17632,TrungTech/finBert,gradio,apache-2.0,1
-17633,Sid-manale643/medLLAMA,gradio,,1
-17634,Gators123/fusf_pdf_2023,gradio,,1
-17635,ssb4567/ssbflowise,docker,,1
-17636,ajsda/newAI,docker,mit,1
-17637,ajsda/newbing,docker,mit,1
-17638,MarBeanInc/MarBeanInc,docker,mpl-2.0,1
-17639,Konglinu/myai,docker,mit,1
-17640,hnliu/GPTagger,gradio,gpl-3.0,1
-17641,flatindo/scaler,gradio,apache-2.0,1
-17642,AhmedMagdy7/avatar1,gradio,gpl-3.0,1
-17643,alecinvan/image-captioning-tts,gradio,,1
-17644,cowboyonmars/Linaqruf-animagine-xl,gradio,,1
-17645,litest/newbing,docker,mit,1
-17646,stable-bias/stable-bias,gradio,cc-by-nc-sa-4.0,1
-17647,liliyRehtina/Stable-Diffusion-XL-two,gradio,mit,1
-17648,idodo/experiment,gradio,apache-2.0,1
-17649,eugenkalosha/Semmap,docker,apache-2.0,1
-17650,wy213/yangAI,docker,mit,1
-17651,liliyRehtina/PhotoReal-V2-with-SD-Upscaler-four,gradio,mit,1
-17652,Jamel887/Rv-percobaan887,gradio,openrail,1
-17653,xSaXx/llama2-70b-nochat,gradio,llama2,1
-17654,robingupta/Salesforce-codegen25-7b-instruct,gradio,apache-2.0,1
-17655,jtpotato/firetrace,gradio,,1
-17656,Justin-Choo/Grapefruit_WEB_UI,gradio,,1
-17657,harish03/physicsv11-litbot,docker,,1
-17658,Sal-ONE/AI_Code_Gen,gradio,,1
-17659,Justin-Choo/Lemon_WEB_UI,gradio,,1
-17660,ashuNicol/Steam-game-Recommendation-System,streamlit,,1
-17661,warmazzzzz/bing-ai,docker,mit,1
-17662,compasspathways/Sentiment3D,gradio,cc-by-4.0,1
-17663,JoPmt/Short_Bedtime_Stories,static,,1
-17664,vishnusureshperumbavoor/vspbot-falcon-langchain,gradio,,1
-17665,Satyam-Singh/garage-bAInd-Platypus2-70B,gradio,,1
-17666,aiswaryasankar/entelligence.ai,gradio,apache-2.0,1
-17667,DataDreamweavers/LegaWeaver,streamlit,openrail,1
-17668,NSect/Image-Models-Test62,gradio,,1
-17669,NSect/RealisticPhotoModels,gradio,,1
-17670,hamza50/document-reader,gradio,,1
-17671,itzn0tm1les/Venuschub.ai,docker,,1
-17672,neuraldeepnet/NeuraldeepAI,gradio,creativeml-openrail-m,1
-17673,Denevan/BingAI,docker,mit,1
-17674,cleaner/bing,docker,mit,1
-17675,hardydou/t2,gradio,apache-2.0,1
-17676,wangboyi/bingAI,docker,mit,1
-17677,Gradio-Themes/gmjk_qiangshou_gradio,gradio,other,1
-17678,KEINIE/Emory_Oxford_GER_Expert,gradio,mit,1
-17679,zhuj/goodwork,docker,mit,1
-17680,mygyasir/fast_diffusion,gradio,,1
-17681,Androidonnxfork/CivitAi-to-Diffusers,gradio,,1
-17682,venkat-natchi/yolov3_obj_detector,gradio,mit,1
-17683,Shreeraj/Metal_Defects_Classification_Application,gradio,,1
-17684,xiaolv/claude2_xiaolv_api_file_chat,gradio,other,1
-17685,brainblow/beat_remixer,gradio,cc-by-nc-sa-4.0,1
-17686,limcheekin/orca_mini_v3_13B-GGML,docker,,1
-17687,Kakashi098/Narrative,gradio,gfdl,1
-17688,SuYuanS/AudioCraft_Plus,gradio,mit,1
-17689,xikacat/xikacatbing,docker,mit,1
-17690,OnabajoMonsurat/Medical_Diagnosis_Chatbot,gradio,mit,1
-17691,qudehu123/BingAI,docker,mit,1
-17692,RobotDall/WizardLM-WizardMath-70B-V1.0,gradio,,1
-17693,0019c/NewBing,docker,mit,1
-17694,d5gd5d/World,docker,,1
-17695,Ekitl02/stabilityai-stable-diffusion-xl-base-1.0,gradio,artistic-2.0,1
-17696,Gaofish/AI_bing,docker,mit,1
-17697,yaolaoda/nw,docker,mit,1
-17698,Deepjyoti120/AssamTrainData,docker,apache-2.0,1
-17699,kepl/gpt,docker,,1
-17700,insaafS/AI-Story-Gen,gradio,gpl,1
-17701,inkyiyo/ikun,docker,mit,1
-17702,kingtest/BingAI,docker,mit,1
-17703,abc6666/newbing_AI,docker,mit,1
-17704,nanazi/newbing_wang,docker,mit,1
-17705,en-gin-eer/StableDiffusion-BaseModel-Lora-Graph,streamlit,,1
-17706,udaykalvala1234/Uday321,gradio,,1
-17707,camenduru/9,docker,,1
-17708,YiLin1/Once,docker,mit,1
-17709,dalitongxue/dalitongxue,docker,mit,1
-17710,Madhur-01/Question-Answering-system,streamlit,,1
-17711,bai54188/BingAI3.0,docker,mit,1
-17712,Justin-Choo/QuickGen-Anime,gradio,creativeml-openrail-m,1
-17713,Bala2-03-2003/BRAHMAMAI,gradio,,1
-17714,jiefeng222/bingAI,docker,mit,1
-17715,sadhaw/11212,docker,mit,1
-17716,johnsamuel/RAGTest,gradio,,1
-17717,LiuZhiwen0706/IELTS,gradio,,1
-17718,Yash911/DiabetesModel,gradio,,1
-17719,GOVS/Liu_Sir,docker,mit,1
-17720,Chirayuhumar/MyGenAIChatBot,gradio,,1
-17721,roain/bing,docker,mit,1
-17722,SokWith/nbing,docker,mit,1
-17723,mygyasir/genious_bgremover,streamlit,,1
-17724,universalml/fast_diffusion,gradio,,1
-17725,Chilangosta/text-to-pokemon,gradio,,1
-17726,roshnirav1891/gradio-multilingual-translator,gradio,,1
-17727,flatindo/generate2,gradio,apache-2.0,1
-17728,nmfasano5/content_based_movie_recommendation_system,gradio,,1
-17729,flatindo/Image-Diffusion-WebUI,gradio,apache-2.0,1
-17730,MercurialAi/Embeddings_Chat,gradio,,1
-17731,qtoino/form_matcher,gradio,unknown,1
-17732,Xuan2060320350/Bing-1,docker,mit,1
-17733,101-5/Bing-New,docker,mit,1
-17734,chansung/LLaMA2-Story-Showcase,gradio,apache-2.0,1
-17735,Justin-Choo/Replicant_WEB_UI,gradio,,1
-17736,bmhk/xiaobai,docker,mit,1
-17737,Nguyens/mlops-demo,gradio,cc,1
-17738,rf5860/bg3_character_generator,gradio,,1
-17739,adityapatkar/chatcsv,streamlit,,1
-17740,devdata/kapu,gradio,mit,1
-17741,q896656681/xiaoxiannv,docker,mit,1
-17742,galaxy001/biying,docker,mit,1
-17743,Chitranshu/Dashboard-Dmart,docker,,1
-17744,PeepDaSlan9/candle-llama2,static,,1
-17745,Yash911/t2i,gradio,,1
-17746,Mashir0/pximg,docker,,1
-17747,tym2008321/FCNB,docker,mit,1
-17748,Chitranshu/Dashboard-Zomato,docker,,1
-17749,trttung1610/musicgen,gradio,mit,1
-17750,mikeee/s3nh-garage-bAInd-Stable-Platypus2-13B-GGML,gradio,,1
-17751,t13718236382/newGPT,docker,mit,1
-17752,wolfzer/private-proxy,docker,,1
-17753,huangbatian/newbing,docker,mit,1
-17754,NN-BRD/OWL-ViT,gradio,apache-2.0,1
-17755,amanatid/Adi_The_ArxivGPT_with_Voice,streamlit,mit,1
-17756,Tihsrah/Hinglish-Text-Normalizer,streamlit,,1
-17757,OIUGLK/bingo,docker,mit,1
-17758,JMCREATE/README,static,,1
-17759,camenduru/10,docker,,1
-17760,camenduru/11,docker,,1
-17761,flatindo/4x-denoise,gradio,gpl-3.0,1
-17762,npc0/BookSumBeta,gradio,,1
-17763,Josiah-Adesola/Text-Summarizer-Bart,gradio,apache-2.0,1
-17764,PeepDaSlan9/SDXL-artists-browser,static,cc-by-sa-4.0,1
-17765,NN520/AI,docker,mit,1
-17766,hiihhiii/AI_Chat_Bot,gradio,,1
-17767,Felix123456/bingo,docker,mit,1
-17768,iamstolas/STOLAS,docker,mit,1
-17769,KPCGD/bingo,docker,mit,1
-17770,7hao/bingo,docker,mit,1
-17771,tang155/bingo,docker,mit,1
-17772,aphenx/bingo,docker,mit,1
-17773,hdhzk/bingo,docker,mit,1
-17774,wilson1/bingo,docker,mit,1
-17775,regarex/SDXL-artists-browser,static,cc-by-sa-4.0,1
-17776,hzwluoye/gpt4,docker,,1
-17777,sdhsdhk/bingosjj,docker,mit,1
-17778,luzhanye/bing,docker,mit,1
-17779,gotgitgood/33.GZUZ.33,gradio,bigscience-openrail-m,1
-17780,DhilshaM/MyGenAI,gradio,,1
-17781,gypq/gypq3,docker,mit,1
-17782,Charliee/BingAi,docker,mit,1
-17783,Lbin123/Lbingo,docker,mit,1
-17784,cccc-c/web-ui-pub,static,gpl-3.0,1
-17785,lightli/bingo-newbing,docker,mit,1
-17786,hzy123/bingo,docker,mit,1
-17787,allknowingroger/Image-Models-Test87,gradio,,1
-17788,jiejiejie0420/bingo,docker,mit,1
-17789,ExpUnGeD404/Bamber,docker,openrail,1
-17790,chronopt-research/ViTExCo,gradio,,1
-17791,michael2008bj/demo1,gradio,llama2,1
-17792,amber0097/amberSign,docker,,1
-17793,amanatid/Melissa_The_PubMedGPT_with_Voice_and_featuring_answers,streamlit,mit,1
-17794,awacke1/KnowledgeDistillerToolMaker,streamlit,mit,1
-17795,yz333/real-bing,docker,mit,1
-17796,Makiing/coolb-in-gtest,docker,mit,1
-17797,Nihanvi/Text_summarization_using_transformers,streamlit,,1
-17798,sdhsdhk/bingo111,docker,mit,1
-17799,diffle/license,static,,1
-17800,parkyzh/bingo,docker,mit,1
-17801,TotoB12/llama2-7b-chat-ggml,gradio,,1
-17802,doevent/df,gradio,unknown,1
-17803,pinkq/Newbing,docker,mit,1
-17804,srajan-kiyotaka/Bears,gradio,apache-2.0,1
-17805,analist/qa_table,streamlit,apache-2.0,1
-17806,jt5d/docker-test1,docker,mit,1
-17807,DataScienceGuild/ARIMA_test,streamlit,mit,1
-17808,PSMdata/langchain-llama2-7b-chat,gradio,,1
-17809,Atualli/mediapipe-pose-estimation,gradio,,1
-17810,zhoujiaxin/zhoujiaxinchatgpt,docker,mit,1
-17811,DHEIVER/Segmento_de_Angio_Coronariana_v5,gradio,,1
-17812,k2-fsa/automatic-speech-recognition-with-whisper,gradio,apache-2.0,1
-17813,2023Liu2023/bingo,docker,mit,1
-17814,xuetao/bingo3,docker,mit,1
-17815,fffffu/bing,docker,mit,1
-17816,unidata/Chinese-Llama-2-7b,gradio,,1
-17817,lixq/bingo61,docker,mit,1
-17818,AhmadHakami/Alzheimer_image_classification,gradio,,1
-17819,yangogo/bingo,docker,mit,1
-17820,cozyanduofen/bingo,docker,mit,1
-17821,awacke1/PytorchStreamlitNeuralNetUI,streamlit,mit,1
-17822,Sourabh2/detectron2-segmentation,gradio,,1
-17823,sazumiviki/meow2,static,cc,1
-17824,allknowingroger/Image-Models-Test89,gradio,,1
-17825,awacke1/MixtureOfExpertsMOEAnalysisForLLMRoles,streamlit,mit,1
-17826,shawn810720/Taiwan-LLaMa2,gradio,,1
-17827,mygyasir/Image-Models-Test92,gradio,,1
-17828,bupenghui/123,docker,mit,1
-17829,srikanth-nm/ai_seeker,streamlit,openrail,1
-17830,mikkoar/marco,docker,mit,1
-17831,rushankg/discovercourses,streamlit,cc-by-2.0,1
-17832,Grazon/ChitChat,gradio,mit,1
-17833,open-spaced-repetition/fsrs4anki_previewer,gradio,mit,1
-17834,fgenie/scamtext_PAL_self_consistency,streamlit,gpl-3.0,1
-17835,Jayavathsan/ChatGPT_CloneWithSummary,streamlit,,1
-17836,uSerNameDDHL/bingo,docker,mit,1
-17837,miyaaa666/bingo,docker,mit,1
-17838,masakhane/dialogue-chat,gradio,other,1
-17839,StarCore/PaddleOCR,gradio,,1
-17840,raul-padua/Barbie-RAQA-Application-Chainlit-Demo,docker,apache-2.0,1
-17841,themanas021/fake-news-gradio,gradio,mit,1
-17842,TH5314/newbing,docker,mit,1
-17843,MikeTrizna/bhl_flickr_search,streamlit,mit,1
-17844,mlgeis/ArXivRecommenderSystem,streamlit,,1
-17845,jokguo/GPT4,docker,mit,1
-17846,Waqasjan123/CompVis-stable-diffusion-v1-4,gradio,wtfpl,1
-17847,sharmaditya/chatapp,streamlit,,1
-17848,Redgon/bingo,docker,mit,1
-17849,praveenku32k/SimilarWordFinderApp,streamlit,,1
-17850,abouuuud/meter2poem-1,gradio,afl-3.0,1
-17851,KiranK7/chatBOt-4,gradio,,1
-17852,othnielnaga/stabilityai-StableBeluga-7B,gradio,,1
-17853,ds520/bingo,docker,mit,1
-17854,allknowingroger/Image-Models-Test93,gradio,,1
-17855,awacke1/ChatGPTPromptRoles4CoderSTEM,streamlit,mit,1
-17856,hesha/text-embeddings-transformers,gradio,apache-2.0,1
-17857,limcheekin/ToolBench-ToolLLaMA-2-7b-GGML,docker,,1
-17858,srisakthi2821/SriChatBott,gradio,,1
-17859,reach-vb/transformers-musicgen,gradio,,1
-17860,sgxz/bingo,docker,mit,1
-17861,wanghuoto/gogoai,docker,mit,1
-17862,MyGenAiUser/MyGenAiVoiceChatBoat,gradio,,1
-17863,siddhartha-mahajan/Semantic-Search-Engine,streamlit,,1
-17864,osanseviero/transformers-musicgen,gradio,,1
-17865,AI-ANK/blackmirroroffice,gradio,,1
-17866,gvw/js-space,gradio,,1
-17867,harpreetsahota/RAQA-Application-Chainlit-Demo,docker,apache-2.0,1
-17868,Munna0912/URL_CLASSIFIER,gradio,,1
-17869,ieeecsuna/ieee_cs_tools,gradio,mit,1
-17870,raelfromgenesis/oai-proxy,docker,,1
-17871,sqc1729/bingi,docker,mit,1
-17872,wy213/213a,docker,mit,1
-17873,huytx267/function_retrieval,gradio,mit,1
-17874,lpinnova/whisper_model_speech_to_text2,gradio,apache-2.0,1
-17875,pycoming/bingo,docker,mit,1
-17876,hanzza/audioRecognition,gradio,apache-2.0,1
-17877,Prashanth35/Chit_Chat,gradio,other,1
-17878,aaaaaabbbbbbbdddddddduuuuulllll/Arabic_poem_classifier,gradio,,1
-17879,aaaaaabbbbbbbdddddddduuuuulllll/Ashaar,gradio,apache-2.0,1
-17880,Rainy-hh/Real-ESRGAN,gradio,apache-2.0,1
-17881,foduucom/pan-card-detection,gradio,,1
-17882,GeorgeOrville/bingo,docker,mit,1
-17883,whxxiaojiang/bingai,docker,mit,1
-17884,lcf001/newbingai,docker,mit,1
-17885,t-hugging-face/Fooocus,docker,,1
-17886,A00001/bingothoo,docker,mit,1
-17887,feedexpdition/gardio-patient-clinical-summary,gradio,mit,1
-17888,mygyasir/SargeZT-controlnet-sd-xl-1.0-depth-16bit-zoe,gradio,,1
-17889,PeepDaSlan9/Deci-DeciCoder-1b,gradio,apache-2.0,1
-17890,will1885/will,docker,openrail,1
-17891,mygyasir/digiplay-DreamShaper_8,gradio,,1
-17892,mygyasir/digiplay-AI-infinity-V1-fp16,gradio,,1
-17893,mygyasir/digiplay-AbsoluteReality_v1.8.1,gradio,,1
-17894,mygyasir/digiplay-helloRealisticMan_v1.0beta,gradio,,1
-17895,ljjggr/bingo,docker,mit,1
-17896,wydgg/bingo-wyd-ai,docker,mit,1
-17897,katahdin0/pet_test,gradio,apache-2.0,1
-17898,afasdfas/cringe_model,gradio,openrail,1
-17899,KindUnes/ImageNet,gradio,,1
-17900,saitejad/llama-2-gen-with-speech,gradio,,1
-17901,wrs/nb,docker,mit,1
-17902,liliyRehtina/color,gradio,openrail,1
-17903,ridges/speech,gradio,,1
-17904,mygyasir/EliKet-lora-trained-xl-colab,gradio,,1
-17905,mygyasir/FFusion-FFusionXL-BASE,gradio,,1
-17906,zhangchuntao/ttg,gradio,afl-3.0,1
-17907,allknowingroger/Image-Models-Test99,gradio,,1
-17908,ClearLove443/Robby-chatbot,streamlit,mit,1
-17909,allknowingroger/Image-Models-Test100,gradio,,1
-17910,leilevy/bingo,docker,mit,1
-17911,tassd/bingai,docker,mit,1
-17912,pixiou/bingo,docker,mit,1
-17913,vishvara-sharda/book_recommending,streamlit,mit,1
-17914,tanishqvashisht/catVsDog,streamlit,,1
-17915,tanishqvashisht/emotionDetector,streamlit,,1
-17916,gradio/dpt-depth-estimation-3d-obj,gradio,,1
-17917,gkw2004/QQsign,docker,mit,1
-17918,sukiru/rvc-Blue-archives,gradio,mit,1
-17919,Ernar246/OpenAI-Reverse-Proxy,docker,,1
-17920,Sambhavnoobcoder/StyleForge,gradio,,1
-17921,wwwwwwww2/bingo,docker,mit,1
-17922,awacke1/HuggingfaceEvolution,streamlit,mit,1
-17923,g0blas/paper_task_suggestion,gradio,mit,1
-17924,abascal/chat_with_data_app,gradio,mit,1
-17925,awacke1/VotingCrowdsourceEvaluationApps,streamlit,mit,1
-17926,jinshengNuaa/test1,docker,mit,1
-17927,mujicloud/nodeproxy,docker,,1
-17928,yaosynge/bingAI,docker,mit,1
-17929,Nee001/bing0,docker,mit,1
-17930,wuhuik/bingo,docker,mit,1
-17931,yl12053/so-vits-4.1-Matikanefukukitaru,gradio,,1
-17932,tabeina/bingo1,docker,mit,1
-17933,dcarpintero/nlp-summarizer-pegasus,gradio,,1
-17934,majiaoyu/pixelparty-pixel-party-xl,gradio,cc0-1.0,1
-17935,dovedovepigeon/yans-hackathon-baseline-image-generation,gradio,apache-2.0,1
-17936,HeyAxolotl/Bio,static,,1
-17937,dovedovepigeon/yans-hackathon-baseline-image-edit,gradio,apache-2.0,1
-17938,VishnuVardhanBR/chatbot,gradio,mit,1
-17939,firica/assistant,streamlit,apache-2.0,1
-17940,MohamedAlgebali/VideoQuERI,streamlit,apache-2.0,1
-17941,kargaranamir/LangID-LIME,gradio,mit,1
-17942,SHSH0819/event_detection_app,gradio,mit,1
-17943,fuloo/newbing,docker,mit,1
-17944,heiyubili/bingo,docker,mit,1
-17945,YlcldKlns/bing,docker,mit,1
-17946,zxy666/bingo-chatai666,docker,mit,1
-17947,defengxiang/BIngAI,docker,mit,1
-17948,Frankapp/bingai,docker,mit,1
-17949,SHSH0819/FinancialNews_Summarization_APP,gradio,mit,1
-17950,GXSA/bingo,docker,mit,1
-17951,dolphinchat/README,static,,1
-17952,gauss314/vllc,streamlit,apache-2.0,1
-17953,ehristoforu/chat-client,gradio,,1
-17954,aielon/first-chatbot,gradio,apache-2.0,1
-17955,awacke1/PytorchKerasCompareContrast,streamlit,mit,1
-17956,Pengyey/bingo-chuchu,docker,mit,1
-17957,ljh1212/ljhai,docker,mit,1
-17958,t13718236382/bingoGPT4,docker,mit,1
-17959,awacke1/Llama2ProWriterDrafter,gradio,mit,1
-17960,Sourabh2/English2Manipuri,gradio,,1
-17961,awacke1/Lightweight-Text-to-Image-Generation,gradio,mit,1
-17962,moonbirdbooks/take-shelf-picture,gradio,,1
-17963,innovatorved/whisper.api,docker,,1
-17964,Akhil-77/Toxicity_Detector,gradio,mit,1
-17965,huaiji3y/bingo-Public,docker,mit,1
-17966,ehristoforu/runwayml-stable-diffusion-v1-5k,gradio,,1
-17967,awacke1/MultiplayerTest1,streamlit,mit,1
-17968,awacke1/MultiplayerTest2,streamlit,,1
-17969,krafiq/deep-neural-networks-for-navier-stokes-equations,gradio,mit,1
-17970,laocao1798/laocaoAI,docker,mit,1
-17971,james21/SD-XL,gradio,mit,1
-17972,lhnrx/bai,docker,mit,1
-17973,xiaoei/203,docker,mit,1
-17974,TochProud/QQ,docker,mit,1
-17975,arch-123/bingo,docker,mit,1
-17976,luxuedong/lxd,docker,mit,1
-17977,inuterro/hwata,docker,,1
-17978,whgwd2023/bingo,docker,mit,1
-17979,fffiloni/bark-transformers-example,gradio,,1
-17980,aaboutblankk/digiplay-CamelliaMix_NSFW_diffusers_v1.1,gradio,,1
-17981,Pranjal-y/data_scraping_analysis,streamlit,,1
-17982,zhang-wei-jian/test,static,,1
-17983,zhang-wei-jian/docker,docker,,1
-17984,allknowingroger/Image-Models-Test103,gradio,,1
-17985,allknowingroger/Image-Models-Test104,gradio,,1
-17986,TEnngal/bingo,docker,mit,1
-17987,nigel-chen/bingc,docker,mit,1
-17988,mygyasir/digiplay-NextPhoto_v3,gradio,,1
-17989,hudsonhayes/Multi-Doc-Virtual-Chatbot,gradio,,1
-17990,SWHL/RapidASRDemo,streamlit,mit,1
-17991,aupfe08/stt_or_tts,gradio,,1
-17992,Qiushixz/NewBing,docker,mit,1
-17993,zhoupin30/zhoupin30,docker,mit,1
-17994,thov/medicalSegmentation,gradio,,1
-17995,amongey/stable-diffusion-webui-cpu_duplixx,gradio,,1
-17996,jhwen/bingo,docker,mit,1
-17997,Groenewaldt/stabilityai-stable-diffusion-xl-refiner-1.0,gradio,,1
-17998,cncn102/bingo1,docker,mit,1
-17999,icayir/flofi_mini,gradio,mit,1
-18000,themanas021/Image_Caption_Generation,streamlit,,1
-18001,radames/transformers-js-svelte-example-app,static,,1
-18002,jekyl/JosefJilek-loliDiffusion,gradio,,1
-18003,Brainclub5000/wesley7137-Llama-2-13B-Nous-Hermes-vicuna-uncensored-mastermod-spych,gradio,,1
-18004,mrm8488/llama-2-7b-chat-cpp,docker,,1
-18005,Xeaser/rvc-tes,gradio,mit,1
-18006,fsgmas/bingo,docker,mit,1
-18007,Dilmurat/bingo,docker,mit,1
-18008,allknowingroger/Image-Models-Test106,gradio,,1
-18009,unday/bing,docker,mit,1
-18010,nugrahatheo/Credit_Card_Fraud_Detection,streamlit,,1
-18011,AEUPH/AethericGPT,gradio,cc-by-3.0,1
-18012,smf2010/ysfj,docker,,1
-18013,TEnngal/TEnngal,docker,mit,1
-18014,whxxiaojiang/bingai1,docker,mit,1
-18015,hudsonhayes/PerformanceSummarisation,gradio,,1
-18016,t13718236382/web-ui,static,gpl-3.0,1
-18017,Swapnilchand/NewSpace,docker,,1
-18018,kaanhho/speech-to-speech-translation,gradio,,1
-18019,atwk-llm/README,static,,1
-18020,PyaeSoneK/chatchat,streamlit,openrail,1
-18021,universal-ml/Dream-Big,gradio,,1
-18022,Katie-portswigger/Portswigger,gradio,apache-2.0,1
-18023,wardlee/bingo,docker,mit,1
-18024,batuhantosun/Guided-Backpropagation,gradio,mit,1
-18025,A-Celsius/ADR_Predictor,gradio,,1
-18026,ImagineAI-Real/idefics_playground,gradio,,1
-18027,dongsiqie/pandora,docker,mit,1
-18028,xjsyy/bingo-gpt,docker,mit,1
-18029,daddyjin/TalkingFaceGeneration,gradio,cc-by-nc-nd-4.0,1
-18030,Omnibus/idefics_playground,gradio,,1
-18031,rayman-studio/README,static,,1
-18032,PacBio/NewBing_BioTree,docker,mit,1
-18033,GurudattaBS/GenDiseasePrediction,streamlit,creativeml-openrail-m,1
-18034,lekkalar/chatbot-pdf-gpt4key-langchain-chroma-prompttemp-tabs-dataframe-ocrmypdf-sqlite-csv-returns-json,gradio,,1
-18035,allknowingroger/Image-Models-Test110,gradio,,1
-18036,allknowingroger/Image-Models-Test111,gradio,,1
-18037,XiangJinYu/Chat_PDF,gradio,,1
-18038,TushDeMort/yolo,docker,other,1
-18039,LIUjh520/bingo,docker,mit,1
-18040,Satyam1124q/genaii,static,,1
-18041,Aaron299/bingo,docker,mit,1
-18042,d3vindia/RAPODIS,gradio,mit,1
-18043,threadxl/bingo,docker,mit,1
-18044,znskiss/Qwen-VL,gradio,,1
-18045,hanskabvw1/bingo,docker,mit,1
-18046,awacke1/LawsofSuccessandPower,streamlit,mit,1
-18047,Together1415/bingo,docker,mit,1
-18048,wonbeom/prompter_day_demo1,docker,,1
-18049,RajkNakka/speech-to-speech-translation,gradio,,1
-18050,hunger11243/VITS-Umamusume-voice-synthesizer,gradio,,1
-18051,howrardz/bingo,docker,mit,1
-18052,Mohitsaini/app-alzh-disease,streamlit,,1
-18053,awacke1/PDFViewerwithUpdatesWorkBench,streamlit,mit,1
-18054,mygyasir/masterful-gligen-1-4-inpainting-text-box1,gradio,,1
-18055,mygyasir/stablediffusionapi-dreamlike-photoreal1,gradio,,1
-18056,MarkuzML/swap_face,streamlit,,1
-18057,pg-13/gettinglost-gui-test,streamlit,,1
-18058,cyhcctc/cyhbingo,docker,mit,1
-18059,dmeck/RVC-Speakers,docker,bsd-3-clause,1
-18060,ymc666/Sydney6,docker,mit,1
-18061,Brightmzb/test,gradio,openrail,1
-18062,VoyagerYuan/Transformer_CatVAE_and_Signal_Game,streamlit,unlicense,1
-18063,littlesujin/littlesujin,docker,mit,1
-18064,CrafterHide/Sariwon,gradio,openrail,1
-18065,Adithedev/Keyword-Extractor,streamlit,,1
-18066,Hfgjhh/gpt,docker,mit,1
-18067,KaygNas/cut-it,docker,,1
-18068,open-spaced-repetition/fsrs4anki_simulator,gradio,mit,1
-18069,jgurzoni/image_background_swapper,gradio,,1
-18070,Grassss/nb,docker,mit,1
-18071,ggffdd/DeepDanbooru_string,gradio,,1
-18072,avilaroman/escucha,gradio,,1
-18073,ll0z0y/bingoa,docker,mit,1
-18074,LuoYQ/bing,docker,,1
-18075,K00B404/langchain-llama2-7b-chat-uncensored-ggml,gradio,,1
-18076,padmanabhbosamia/Pascal,gradio,mit,1
-18077,allknowingroger/Image-Models-Test114,gradio,,1
-18078,dingding27/bingo,docker,mit,1
-18079,allknowingroger/Image-Models-Test115,gradio,,1
-18080,atharvapawar/Email-Generator-App-Langchain-LLAMA2-LLM,Configuration error,Configuration error,1
-18081,penut85420/OpenCC-Converter,gradio,mit,1
-18082,Toaster496/HugChatWithPlugin,streamlit,gpl-2.0,1
-18083,DYSHITELGOOGLA/app,streamlit,,1
-18084,ggffdd/White-box-Cartoonization,gradio,apache-2.0,1
-18085,awacke1/UnitedStatesMapAIandNLP,streamlit,mit,1
-18086,yigithan4568/bingo,docker,mit,1
-18087,ivylin0805/microsoft-codereviewer,gradio,,1
-18088,programehr/GPT4ALL,gradio,,1
-18089,renumics/commonlit-student-summaries,docker,gpl-3.0,1
-18090,jbilcke-hf/speech-recognition-server-1,gradio,,1
-18091,anzorq/vits-kbd-male,gradio,,1
-18092,NEXAS/NEXAS-stable_diff_personl,gradio,mit,1
-18093,johanmichel/stabilityai-stablecode-instruct-alpha-3b-2,gradio,,1
-18094,lo0ng/bingo,docker,mit,1
-18095,Alpaca233/ai-stable-diffusion-Text-to-Image,gradio,,1
-18096,gigaShrimp/NousResearch-Nous-Hermes-Llama2-70b,gradio,,1
-18097,Alpaca233/SadTalker,gradio,mit,1
-18098,mrolando/text_to_sound,gradio,,1
-18099,mohamedemam/QA_GeneraToR,gradio,mit,1
-18100,Lerdweg/Energie-NRW,streamlit,cc-by-nc-4.0,1
-18101,iabualhaol/ai-score-openai,gradio,mit,1
-18102,shoupeng/bingo,docker,mit,1
-18103,lzglyq/bingolzglyq,docker,mit,1
-18104,caoyongfu/gpt4,docker,mit,1
-18105,supercyx3/gpt,docker,mit,1
-18106,nugrahatheo/Customer_Churn_Prediction,streamlit,,1
-18107,toiram/goofyai-3d_render_style_xl,gradio,,1
-18108,gourib/llama_demo,gradio,,1
-18109,kasunx64/codellama-CodeLlama-34b-hf,streamlit,creativeml-openrail-m,1
-18110,mmecheri/Rakuten_Streamlit,streamlit,,1
-18111,shuaiqiyiliu/newbing,docker,mit,1
-18112,BRICS/README,static,,1
-18113,nuttella/test,docker,,1
-18114,allknowingroger/Image-Models-Test116,gradio,,1
-18115,allknowingroger/Image-Models-Test117,gradio,,1
-18116,TouchFrosty/QSign,docker,,1
-18117,AntNikYab/NaturalLanguageProcessing,streamlit,,1
-18118,awacke1/YouTubeTranscript2Insights,streamlit,mit,1
-18119,sarthakrw/web-query,gradio,apache-2.0,1
-18120,Shubhy/ReliefRouteDemo,streamlit,mit,1
-18121,jitubutwal1441/image-to-story,streamlit,,1
-18122,XFcontinue/bingo,docker,mit,1
-18123,LDJA/iris,docker,mit,1
-18124,miniv/bingai,docker,mit,1
-18125,trakss1436/PictoGen,gradio,,1
-18126,Linhao416/Bing,docker,mit,1
-18127,sayurio/Dynosaur-dynosaur-llama-7b-superni,gradio,openrail,1
-18128,kargaranamir/selenium-screenshot-gradio,gradio,mit,1
-18129,Tirendaz/Text-Classification,gradio,,1
-18130,giseldo/story_point_estimator,gradio,other,1
-18131,teganmosi/codellama-playground,gradio,,1
-18132,shaolin123/soulteary-Chinese-Llama-2-7b-ggml-q4,gradio,,1
-18133,yoru-tomosu/Translate_video,gradio,,1
-18134,SoUmNerd/Phind-Phind-CodeLlama-34B-Python-v1,gradio,,1
-18135,SoUmNerd/FlowiseAI,docker,,1
-18136,mygyasir/invisiblecat-junior-diffusion,gradio,,1
-18137,mygyasir/minimaxir-sdxl-wrong-lora,gradio,,1
-18138,mygyasir/sourceoftruthdata-sot_autotrain_dreambooth_v1,gradio,,1
-18139,mygyasir/digiplay-Photon_v1,gradio,,1
-18140,unicorn345/bingo34778,docker,mit,1
-18141,allknowingroger/Image-Models-Test119,gradio,,1
-18142,jiushini/bingo-jiushini,docker,mit,1
-18143,IXIAOHEII/NB,docker,mit,1
-18144,zipp1er/bingo,docker,mit,1
-18145,lkji/bingo,docker,mit,1
-18146,ADOPLE/Multi-Doc-Virtual-Chatbot,gradio,,1
-18147,sh20raj/sdxl2.0,gradio,,1
-18148,Pontonkid/simple-bot,gradio,mit,1
-18149,Reself/StableVideo,gradio,apache-2.0,1
-18150,GilbertClaus/VideoCutter,streamlit,,1
-18151,Happys/bing,docker,mit,1
-18152,pikto/next-chat-ui,docker,mit,1
-18153,Zannriell/hakurei-waifu-diffusion,gradio,lgpl-3.0,1
-18154,Veucci/turkish-lyric-to-genre,gradio,cc-by-nc-4.0,1
-18155,Veucci/lyric-to-genre,gradio,cc-by-nc-4.0,1
-18156,harshitv804/Tamil_Translator,gradio,,1
-18157,marvingabler/codellama-34b-chat,gradio,other,1
-18158,datastx/EmailGenerator,streamlit,bsd,1
-18159,xiaowunv/bingo,docker,mit,1
-18160,vishnu654/2AV,gradio,,1
-18161,DHEIVER/Segmento_de_Angio_Coronariana_v6,gradio,,1
-18162,Ajitku/BTMLabs,gradio,,1
-18163,4com/README,static,,1
-18164,eruuin/question-answering,gradio,,1
-18165,AnTo2209/3D_Zeroshot_Neural_Style_Transfer,streamlit,unlicense,1
-18166,leoken2023/bingo,docker,mit,1
-18167,Omnibus/TTS-voice-clone,gradio,,1
-18168,mimiboy/biying,docker,mit,1
-18169,HansSongBin/Hans,docker,mit,1
-18170,dotku/fastapi-demo,docker,,1
-18171,a718/jjj,docker,mit,1
-18172,themanas021/AI-TEXT-DETECTION,gradio,mit,1
-18173,Grade2021/bingo,docker,mit,1
-18174,Justin-Choo/AWPortrait_WEB_UI,gradio,,1
-18175,zhengxuan-github/NEW_bing,docker,mit,1
-18176,hhhwmws/ChatHaruhi-GLMPro,gradio,apache-2.0,1
-18177,moaz-t728hw/chatgpt_4,docker,,1
-18178,andromeda123/captionscraft,streamlit,,1
-18179,IshA2023/Named-Entity-Recognition,gradio,,1
-18180,datastx/ChatWithADocDocker,docker,bsd,1
-18181,IshA2023/Image-Generation,gradio,,1
-18182,AvaterClasher/Food_Classifier_Moni,gradio,mit,1
-18183,Photon08/rps_computer_vison,streamlit,,1
-18184,Omnibus/Bark-simple,gradio,,1
-18185,Spectrez/Chest-Lung-Identification,streamlit,apache-2.0,1
-18186,jeycov/emociones,gradio,,1
-18187,zoe4u/newbing,docker,mit,1
-18188,Smols/GPT4,docker,,1
-18189,marffff/revrvsdjijijijij,docker,,1
-18190,Error114/bingo,docker,mit,1
-18191,allknowingroger/Image-Models-Test124,gradio,,1
-18192,taurusduan/bingo,docker,mit,1
-18193,PHZane/emrwa,gradio,,1
-18194,ATang0729/Forecast4Muses,gradio,openrail,1
-18195,jackrui/Diff-AMP-property-prediction-model,gradio,,1
-18196,CCaniggia/GPT,docker,mit,1
-18197,chunnibyou/min_test_1,gradio,,1
-18198,mokoringo/llama-gpt-api,docker,mit,1
-18199,themanas021/AI-Generated-text-Detection,gradio,mit,1
-18200,themanas021/BERT-CASED-AI-TEXT-DETECTION,gradio,mit,1
-18201,opensky-org/README,static,,1
-18202,htekas/jondurbin-airoboros-l2-70b-2.1,gradio,,1
-18203,Gabesantos1007/NewsAgora,streamlit,,1
-18204,awacke1/Eudaimonia,streamlit,mit,1
-18205,awacke1/Eudaimonia-HTML5-ReadAloud,static,mit,1
-18206,onursavas/MultilingualOCR,docker,apache-2.0,1
-18207,harpreetsahota/RAQA-with-LlamaIndex-and-a-fine-tuned-GPT-35,docker,apache-2.0,1
-18208,saad-k7/Document-Query-Search,gradio,,1
-18209,pzc163/Personal-TTS,gradio,mit,1
-18210,wangbinhu/bingo,docker,mit,1
-18211,WanZhongYun/ChatGPT-to-Iris,gradio,mit,1
-18212,JayKen/YSF-External-Testing,gradio,,1
-18213,GordenGhost/Gorden,docker,mit,1
-18214,hoppiece/yans_2023_trans4mer,gradio,apache-2.0,1
-18215,Glazastik/Infinite_Vision,gradio,,1
-18216,keimoriyama/catoon-generator,gradio,apache-2.0,1
-18217,OkayuTadano/OgiriMasters,gradio,apache-2.0,1
-18218,Apex-X/Tm,gradio,agpl-3.0,1
-18219,ClinBAY/Safeterm_Demo,gradio,,1
-18220,NEXAS/stock,streamlit,mit,1
-18221,fracapuano/AISandbox,streamlit,mit,1
-18222,anshu-ravi/simpson-demo,gradio,,1
-18223,Nikhil0987/hnjii,streamlit,openrail,1
-18224,lucaspetti/chatbot-ui,docker,mit,1
-18225,themanas021/seamless_m4t,docker,,1
-18226,utensil/model-memory-usage,gradio,apache-2.0,1
-18227,xianqi21/bingo,docker,mit,1
-18228,KeeganFdes/stack_onnx,gradio,openrail,1
-18229,MAEBA96/SUMMARISER96,gradio,apache-2.0,1
-18230,hardon-server/space-diffusion-img2img-1,gradio,,1
-18231,qpmzonxw/bing,docker,mit,1
-18232,lethalhames/Phind-Phind-CodeLlama-34B-v2,gradio,,1
-18233,hardon-server/space-diffusion-txt2vid-1,gradio,,1
-18234,NewBing520997/bingo,docker,mit,1
-18235,Apex-X/nono,gradio,,1
-18236,DunnBC22/Password_Strength_Classifier_with_CodeBERT,gradio,,1
-18237,hrnph/rvc-models,gradio,mit,1
-18238,ktangri/url-classifier,gradio,,1
-18239,srijitpanja/aip,streamlit,llama2,1
-18240,Gauri54damle/McDFries-SDXL-Dreambooth-Lora-Model,gradio,,1
-18241,mattricesound/RemFx,gradio,,1
-18242,taurusduan/bing,docker,mit,1
-18243,kobayashi123/bingo,docker,mit,1
-18244,cbs-tech-strategy/chat,gradio,cc,1
-18245,dfhgfh/bingAI,docker,mit,1
-18246,HenryJJ/llm_template,gradio,apache-2.0,1
-18247,GZZYYP/bingo,docker,mit,1
-18248,dongsiqie/Code-Interpreter,gradio,mit,1
-18249,ywl2005/2005,docker,mit,1
-18250,awacke1/PythonicCoder-CodeLlama-34B-Instruct-HF,gradio,mit,1
-18251,awacke1/SelfModifyStreamlitTest,streamlit,mit,1
-18252,awacke1/Docker-PEFT-ParamEfficiency,docker,mit,1
-18253,xndrChris/SD-XL1.0,gradio,,1
-18254,codes4aryan/LLMs-QandA-AI,streamlit,,1
-18255,awacke1/AframeHTML5Demo,static,,1
-18256,Arvi/feedback_generator,gradio,,1
-18257,Michael2008S/flowise,docker,,1
-18258,Vladimirktan/find-my-pic-app,streamlit,,1
-18259,greatMLideas/Realstate,gradio,,1
-18260,fanzhuyu/Code-Interpreter,gradio,mit,1
-18261,yavorbel/Phind-Phind-CodeLlama-34B-v2,gradio,,1
-18262,harshvardhansb/ObjectDetection,Configuration error,Configuration error,1
-18263,pvcodes/comment_toxicity_classifier,gradio,mit,1
-18264,kingabzpro/glass-classification,gradio,apache-2.0,1
-18265,sixtyfold/generate_names,gradio,mit,1
-18266,stvnchnsn/chat_about_my_experience,streamlit,,1
-18267,mipbkhn/PneumoniaDetectionPublic,gradio,,1
-18268,mipbkhn/PaddyDoctorPublic,gradio,,1
-18269,NooneImportant/tts,gradio,,1
-18270,sshaileshk/stylechatGPT,gradio,mit,1
-18271,radames/ComfyUI-data-index,docker,,1
-18272,htukor/NLLB-Translator,gradio,wtfpl,1
-18273,NFBN/bingo-1,docker,mit,1
-18274,dilums/sentence-similarity,docker,mit,1
-18275,manananan/QQsign,docker,mit,1
-18276,TakaMETaka/openai-reverse-proxy,docker,,1
-18277,yuntian000/bingAI,docker,mit,1
-18278,touhou-ai-experimental/research-paper,static,mit,1
-18279,mando11/README,static,,1
-18280,fengjianliang/bingo,docker,mit,1
-18281,qiufenge/bingo,docker,mit,1
-18282,jengiskhann/FahsaiChatbot-03,gradio,,1
-18283,huangjiefree/bingo,docker,mit,1
-18284,Vladislawoo/booktoread,streamlit,mit,1
-18285,LISHILEI/bingo,docker,mit,1
-18286,onemriganka/hello_space,streamlit,,1
-18287,HOLYBOY/Customer_Churn_App,streamlit,,1
-18288,tube1925/bing,docker,mit,1
-18289,awacke1/HL7-Libraries-V2-V4,streamlit,mit,1
-18290,takuuuuuuu/stabilityai-stable-diffusion-xl-base-1.0,streamlit,,1
-18291,sshaileshk/feedsGPT,gradio,mit,1
-18292,DylanYan/WizardLM-WizardCoder-Python-34B-V1.0,gradio,,1
-18293,AdithyaSNair/Dog_breed_predictor,streamlit,,1
-18294,Alexpro1213/WizardLM-WizardCoder-Python-34B-V1.0,gradio,,1
-18295,SurendraKumarDhaka/Drowsiness-detection-system,streamlit,,1
-18296,Shivu2210/testSum,gradio,apache-2.0,1
-18297,KazeDevID/RVC-Model,gradio,mit,1
-18298,wffcyrus/llama2-with-gradio-chat,gradio,apache-2.0,1
-18299,liujch1998/crystal,gradio,mit,1
-18300,zelros/Transparent-Insurance,gradio,,1
-18301,liuyang3/bingo-gpt4-2,docker,mit,1
-18302,saicmsaicm/pet-breed,gradio,apache-2.0,1
-18303,willblockbrain/blockbrain1,docker,,1
-18304,captain-awesome/docuverse,streamlit,apache-2.0,1
-18305,soggys/repozzitory,docker,,1
-18306,soggys/all-in,docker,,1
-18307,wangfuchao/bingo-wangfuchao,docker,mit,1
-18308,hheel/bingo,docker,mit,1
-18309,kevinwang676/Personal-TTS-v3,gradio,mit,1
-18310,YangHao520/testCreateFile,gradio,mit,1
-18311,cllatMTK/TransformerAnalyzer,streamlit,,1
-18312,UDE-SE/ReturnTypePredictor,gradio,,1
-18313,mishig/embeddings-similarity,docker,,1
-18314,Alex89912/ai-code-v1,gradio,,1
-18315,themanas021/VisualVoice-Caption_to_Hindi_Speech,streamlit,mit,1
-18316,poetrychor/Gustavosta-MagicPrompt-Stable-Diffusion,docker,,1
-18317,CMU-80100/80-100-Pre-Writing-Chatbot-Section-H,gradio,,1
-18318,el-denny/minimal,gradio,apache-2.0,1
-18319,grupo10/risk-of-death-in-road-incident,streamlit,,1
-18320,XiJingPong/Perisa-Bot,docker,apache-2.0,1
-18321,TFEH/Streamlit_demo,streamlit,apache-2.0,1
-18322,MuGeminorum/insecta,gradio,,1
-18323,Persival123/thisisitboiiii,streamlit,artistic-2.0,1
-18324,onursavas/Document-Layout-Analysis-via-Segmentation,gradio,mit,1
-18325,zyx1995/bingo,docker,mit,1
-18326,iabualhaol/pdfchat,docker,mit,1
-18327,dxl3811051/BingAI,docker,mit,1
-18328,WHRSTUDIO/draw-ai,gradio,,1
-18329,nugrahatheo/Vehicle-Type-Recognition,streamlit,,1
-18330,hudawang/sydney,docker,mit,1
-18331,mkbk96/mys,docker,mit,1
-18332,poetrychor/CompVis-stable-diffusion-v1-4,gradio,,1
-18333,Straits/SI43-photostyle1,gradio,cc,1
-18334,YangHao520/AIGCReviewer,gradio,bsd,1
-18335,Demosthene-OR/avr23-cds-translation,streamlit,,1
-18336,AtomdffAI/wechatgpt4atom,gradio,,1
-18337,Bravefe/Artist_Classification,gradio,,1
-18338,tdnathmlenthusiast/online-course-categorize-system,gradio,apache-2.0,1
-18339,rahgadda/MigrationUtility,streamlit,apache-2.0,1
-18340,Apex-X/GODROOP,gradio,openrail,1
-18341,Sreezx/Sentzi,streamlit,,1
-18342,aliceoq/vozes-da-loirinha,gradio,,1
-18343,Saralesjak123/open-reverse-proxy,docker,,1
-18344,SudharsanSundar/token_edit_distance,gradio,,1
-18345,DHEIVER/endoscopy_multiClassification,gradio,,1
-18346,themanas021/Yt-Transcript-Hindi,gradio,mit,1
-18347,AvaterClasher/Food_Classifier_Refined_MONI,gradio,mit,1
-18348,mzh2077/_AI_house,docker,mit,1
-18349,GTKJF/SFE,docker,mit,1
-18350,haxenbane/20230903,docker,mit,1
-18351,geulabddn/pk,gradio,,1
-18352,Omnibus/text-to-vid,gradio,,1
-18353,zhiyin123/MyBingAI6,gradio,mit,1
-18354,www23/anime-remove-background,gradio,apache-2.0,1
-18355,zhiyin123/MyNewBing8,docker,mit,1
-18356,brainblow/MusiCreator,gradio,cc-by-nc-4.0,1
-18357,brainblow/AI-TV,docker,,1
-18358,h1r41/vicuna_chat,streamlit,,1
-18359,Hasani/Specific_Object_Recognition_in_the_Wild,gradio,openrail,1
-18360,timmy0x-eth/Testspace,gradio,mit,1
-18361,Varun6579/MyGenAIChatBot,gradio,,1
-18362,allica/bingoasf,docker,mit,1
-18363,stunner007/movie-recommender-system,streamlit,,1
-18364,Hasani/Binary-Video-Classification-In-The-Wild,gradio,openrail,1
-18365,Hasani/Binary-Image-Classification-In-The-Wild,gradio,openrail,1
-18366,VikasKumar01/My_AI_chatbot,gradio,,1
-18367,MestikonAgency/README,Configuration error,Configuration error,1
-18368,SenthilShunmugam2003/StudentMindscape,gradio,gpl-2.0,1
-18369,Osmond141319/ComfyUI-XL-Vae-Public,docker,,1
-18370,xiaozhengchina/bingo,docker,mit,1
-18371,YUMASUKIii/Chat,docker,mit,1
-18372,Sresti/sharma,gradio,,1
-18373,spignelon/plant_leaf_classifier,gradio,gpl-3.0,1
-18374,Ranvelx/Ai2,docker,,1
-18375,oulin/fastai_dog_classifier,gradio,apache-2.0,1
-18376,flaviooliveira/trocr-bullinger-htr,gradio,mit,1
-18377,FDSRashid/Taraf_by_Year,gradio,,1
-18378,dibend/OracleOfNewProvidence,gradio,mit,1
-18379,Karthikbolla/NEP-Chatbot,gradio,mit,1
-18380,tintoretor/WealthSentiment,gradio,openrail,1
-18381,typesdigital/codellama,gradio,artistic-2.0,1
-18382,iabualhaol/Imam-Muslim,gradio,mit,1
-18383,PeepDaSlan9/conceptofmind-Yarn-Llama-2-7b-128k,gradio,apache-2.0,1
-18384,xcoolcoinx/ehartford-Wizard-Vicuna-30B-Uncensored,gradio,,1
-18385,bleysg/Phind-CodeLlama-34B-v2,gradio,,1
-18386,Omnibus/2-button-Story-Board,gradio,,1
-18387,dawdqd/ChuanhuChatGPT,gradio,gpl-3.0,1
-18388,hoalarious/edenlabs.tech-TTS,gradio,apache-2.0,1
-18389,theekshana/boardpac_chat_app_test,streamlit,apache-2.0,1
-18390,sowmika/content-generation-text,gradio,,1
-18391,ifey/chatdemo,gradio,openrail,1
-18392,NCTCMumbai/NCTC,gradio,other,1
-18393,jengiskhann/FahsaiChatbot03,gradio,ms-pl,1
-18394,sach-en/cisco_handbook,gradio,,1
-18395,Defalt-404/Bittensor_Explore,gradio,,1
-18396,JanhviSingh/mentalHealthChatbot,gradio,,1
-18397,pourmand1376/whisper-large-v2,gradio,,1
-18398,jhparmar/Blip-image-captioning-base,gradio,openrail,1
-18399,Nikhil0987/omm,streamlit,openrail,1
-18400,techasad/geame-idea-generator,gradio,openrail,1
-18401,LeonOY/Leon_BingAI,docker,mit,1
-18402,zihan0516/B1,docker,mit,1
-18403,watanabe3tipapa/web-sge-agent,streamlit,,1
-18404,zhuanjiaoover/bingo,docker,mit,1
-18405,Ashrafb/translate,gradio,mit,1
-18406,qingyu-h/bingo,docker,mit,1
-18407,zzzzzc/zzcbingAi,docker,mit,1
-18408,Zannriell/cloudqi-cqi_speech_recognize_pt_v0,gradio,,1
-18409,hocaionline/ComfyUI_Free,static,creativeml-openrail-m,1
-18410,mrolando/classify_images,gradio,,1
-18411,hardon-server/remove-background-on-image,gradio,,1
-18412,hardon-server/remove-background-on-image-def,gradio,,1
-18413,errorok/rvc-models-en-test,gradio,mit,1
-18414,DHEIVER/Classificacao.de.Imagens.de.Cardiomiopatia,gradio,,1
-18415,WKTSHNN/simplify_color_values,gradio,,1
-18416,onursavas/ObjectTrackingWithYOLOv8,gradio,apache-2.0,1
-18417,pen-one/bingo-pen-one,docker,mit,1
-18418,Truym/rvc-pendu,gradio,mit,1
-18419,Hobe/bingo,docker,mit,1
-18420,Xiaini0/bingo-112233,docker,mit,1
-18421,Apex-X/ROOPOK,gradio,,1
-18422,hugo-guo/bingo-hugo,docker,mit,1
-18423,mangiucugna/self-retrospective-generator,gradio,cc-by-nc-nd-4.0,1
-18424,SpfIo/Whisper_TL_Streaming_API,gradio,,1
-18425,RahulJ24/gradiolangchainchatbotAI,gradio,,1
-18426,alwaysbetter1314/gradio-start,gradio,other,1
-18427,mjuetz/neu,streamlit,openrail,1
-18428,nisssdwefq/Bing,docker,mit,1
-18429,Lynx1221/rvc-test1,gradio,mit,1
-18430,N093/final_tts_mix,gradio,,1
-18431,RahulJ24/genAIvoicebot,gradio,,1
-18432,chengggg12/bingo,docker,mit,1
-18433,nmynxy/bingo,docker,mit,1
-18434,Harsha86390/mygenaichatgpt,gradio,,1
-18435,Admin08077/Cosmosis,streamlit,openrail,1
-18436,ovieyra21/audio_webui,gradio,,1
-18437,awacke1/Whisper2ChatUsingInferenceEndpoints,streamlit,mit,1
-18438,Edward-Ji/essentials-of-microeconomics,docker,mit,1
-18439,DHEIVER/CoronaryAngioSegment,gradio,mit,1
-18440,JianYu233/bingo1,docker,mit,1
-18441,NSect/VALL-E-X,gradio,mit,1
-18442,conanwl/bingo,docker,mit,1
-18443,NSect/voice_conversion_service,gradio,,1
-18444,nisssdwefq/huangzisen,docker,mit,1
-18445,crystals201/Mikufans,docker,mit,1
-18446,KANATA980122/bingo,docker,mit,1
-18447,Hobe/bing,docker,mit,1
-18448,cruxx/ssyoutube,docker,,1
-18449,foduucom/web-form-ui-field-detection,gradio,,1
-18450,Zheng0211/mybing,docker,mit,1
-18451,Dify-AI/README,static,,1
-18452,allknowingroger/Image-Models-Test125,gradio,,1
-18453,awacke1/WVW-WhisperVoiceWriter,streamlit,mit,1
-18454,dynamicstude/RHYTHMflowise,docker,openrail,1
-18455,lianxin03/Z-BingAI-QY,docker,mit,1
-18456,L1Y2/bing,docker,mit,1
-18457,Abhay834/SY_Bot,gradio,,1
-18458,transiteration/nemo_stt_kz_quartznet15x5,gradio,,1
-18459,Popitmania123/Open-reverse-proxy,docker,,1
-18460,Anandbheesetti/MNIST_digit_predictor,gradio,mit,1
-18461,AK-12/llama-gradio-chat,gradio,,1
-18462,hardon-server/basegan1,gradio,,1
-18463,krishnakkindia/ehartford-Wizard-Vicuna-30B-Uncensored,gradio,openrail,1
-18464,parvezalmuqtadir/stablediffusionapi-vector-art,gradio,,1
-18465,semillero/IAMIND,gradio,apache-2.0,1
-18466,sana123/codenamewei-speech-to-text,gradio,,1
-18467,place4unity/persianchat,gradio,,1
-18468,dayachoudekar8/swalearn,streamlit,openrail,1
-18469,Nikhatu/stable-diffusion-webui-cpu-the-best,gradio,,1
-18470,wy213/AIwy,docker,mit,1
-18471,allknowingroger/Image-Models-Test128,gradio,,1
-18472,Linguistz/bingo.cn,docker,mit,1
-18473,mbazaNLP/Finetuned-NLLB-TOURISM-EN-KIN,gradio,,1
-18474,dgnk007/dgnk007-eagle,gradio,,1
-18475,VaishakhRaveendran/Audio_2_chat,streamlit,,1
-18476,SeyedAli/Persian-Text-NER,gradio,mit,1
-18477,SeyedAli/Persian-Speech-synthesis,gradio,mit,1
-18478,SeyedAli/Food-Image-Classification,gradio,mit,1
-18479,gptaibox/Langflow,docker,mit,1
-18480,SoUmNerd/RemoteMojo,docker,,1
-18481,webpodcast/discussion,static,openrail,1
-18482,PhucBui/demo,gradio,apache-2.0,1
-18483,Siyamansari/liveTranslation,streamlit,openrail,1
-18484,arslan-ahmed/talk-to-your-docs,gradio,mit,1
-18485,tdeshane/artists-of-data-science-chainlit,docker,apache-2.0,1
-18486,ZeroTwo3/WavJourney,docker,cc-by-nc-4.0,1
-18487,awacke1/VideoCombinerInterpolator,streamlit,mit,1
-18488,wrs/nbh,docker,mit,1
-18489,aichitrakaar/prompthero-openjourney,gradio,,1
-18490,ysheng/SSN-Soft-Shadow-Network-for-Image-Composition,gradio,unknown,1
-18491,iamadhxxx/Analyse,gradio,,1
-18492,SuperZz/StartWithAI,gradio,mit,1
-18493,heshihuan/bingo,docker,mit,1
-18494,itachi1234/rishu,streamlit,openrail,1
-18495,Drac77/hakurei-waifu-diffusion,gradio,,1
-18496,awacke1/DromedarySpeciesFAQ,streamlit,mit,1
-18497,hardon-server/img2txt1,gradio,apache-2.0,1
-18498,applsisujsus/qiangbing,docker,mit,1
-18499,Arcypojeb/NeuralServer,gradio,cc,1
-18500,tshome/new_ts_model,streamlit,,1
-18501,kangvcar/RealChar,docker,,1
-18502,klenovich/df1,gradio,bigscience-openrail-m,1
-18503,farhananis005/LawyerGPT,gradio,,1
-18504,mylesai/mylesAI_test,gradio,,1
-18505,Wander1ngW1nd/EdControl,streamlit,,1
-18506,wejudging/grobid,docker,apache-2.0,1
-18507,kcswag/axiong-PMC_LLaMA_13B,gradio,,1
-18508,OttoYu/Tree-Inspection-demo,gradio,,1
-18509,altairv/03,docker,,1
-18510,nugrahatheo/Customer-Segmentation,streamlit,,1
-18511,koubi888/uptime,docker,mit,1
-18512,techguy1423/ChatABT,gradio,,1
-18513,masonbarnes/open-llm-search,gradio,llama2,1
-18514,johnskyper/demo,gradio,mit,1
-18515,Emmy101/Emer,docker,,1
-18516,Catspin/2_ai_chat,static,,1
-18517,techguy1423/ABT2,gradio,,1
-18518,techguy1423/ChatABT0.4,gradio,,1
-18519,amritsolar/NEWGRADIOAI,gradio,,1
-18520,SystemGPT/system-rule-based-chatbot,streamlit,,1
-18521,NarendraC/MyAIChatBot,gradio,,1
-18522,AlhitawiMohammed22/HTD_HTR,gradio,apache-2.0,1
-18523,passant-labs/ailogo,gradio,,1
-18524,KashiwaByte/SparkDebate-V2.0,gradio,,1
-18525,oriastanjung/restGin,docker,,1
-18526,fracapuano/NebulOS,streamlit,,1
-18527,AlhitawiMohammed22/E2E_OCR,gradio,,1
-18528,Dinesh1102/Text-To-Image,gradio,,1
-18529,weibinke/vits-simple-api,gradio,mit,1
-18530,HF-Demos/bingo,docker,mit,1
-18531,harisansarkhan/Predict_Car_Brand,gradio,,1
-18532,the-neural-networker/multilingual-language-recognition,gradio,,1
-18533,jergra43/llama2-7b-ggml-chat-app,gradio,,1
-18534,miittnnss/UrFriendly-Chatbot,gradio,,1
-18535,aabyzov/playground,streamlit,openrail,1
-18536,meapbot/testing,gradio,mit,1
-18537,MohammedAlakhras/Telegram_API,gradio,apache-2.0,1
-18538,alecinvan/medidoctorchatbot,gradio,,1
-18539,simonraj/ELOralCoachv2,gradio,,1
-18540,XODI/guess,gradio,,1
-18541,gforguru/MarketingComapaignTool,streamlit,,1
-18542,Samarth991/LLM-Chatbot,gradio,mit,1
-18543,typesdigital/YoutubeVideotoText,gradio,cc-by-2.5,1
-18544,Varun6579/mygenAiAvatarSpeech,gradio,,1
-18545,yohn-maistre/respiratory-diseases-classification-cnn-tf,streamlit,,1
-18546,prueba123jdjq/inswapper_128.onnx,streamlit,cc0-1.0,1
-18547,gatilin/mmocr-webui,gradio,,1
-18548,Sells30/stabilityai-stable-diffusion-xl-base-1.0,gradio,,1
-18549,gatilin/mmpose-webui,gradio,apache-2.0,1
-18550,alihalabyah/falcon-180b-demo,gradio,,1
-18551,gekkouga/open-reverse-proxy,docker,,1
-18552,isididiidid/ojggg128,docker,mit,1
-18553,higantest/openai-reverse-proxy,docker,,1
-18554,chenxc1029/Local-Code-Interpreter,gradio,,1
-18555,supercyx3/nova,docker,mit,1
-18556,liangxiaohua/bingo,docker,mit,1
-18557,supercyx3/magic,docker,mit,1
-18558,SIH/building-segmentation,gradio,mit,1
-18559,Omnibus/Video-Diffusion-WebUI,gradio,apache-2.0,1
-18560,Micklew/music-generator,streamlit,,1
-18561,allknowingroger/Image-Models-Test134,gradio,,1
-18562,allknowingroger/Image-Models-Test135,gradio,,1
-18563,Vageesh1/bio_generator,streamlit,,1
-18564,Roblox-organization1ol/README,static,,1
-18565,anurag629/botaniscan,docker,,1
-18566,ilhamsyahids/nllb-translation,gradio,,1
-18567,awacke1/Text2AudioStreamlitHTML5Demo,streamlit,mit,1
-18568,librarian-bots/SFconvertbot-PR-dashboard,gradio,,1
-18569,nt3awnou/embed-rescue-map,streamlit,,1
-18570,656-156/Real-CUGAN,gradio,gpl-3.0,1
-18571,GT-RIPL/GPT-K,gradio,,1
-18572,Sapnil/Text_Summarization,gradio,,1
-18573,Tayaba171/CALText-TextRecognizer,gradio,creativeml-openrail-m,1
-18574,cherry0021/lab-ni-doc,Configuration error,Configuration error,1
-18575,mega-snowman/image-to-text,gradio,openrail,1
-18576,gjhjh/bingo,docker,mit,1
-18577,allknowingroger/Image-Models-Test138,gradio,,1
-18578,Olga19821109/Google_Palm2_Chat,gradio,,1
-18579,HiTZ/C1_sailkapen_demoa,gradio,,1
-18580,SystemGPT/TrialSpace,streamlit,,1
-18581,alexat/TextToVoiceEn,gradio,cc-by-nc-4.0,1
-18582,YangHao520/Openai_GPT_Fine_tune_VisonSystem,gradio,bsd,1
-18583,ViktorTsoi13/ABA_Test,docker,,1
-18584,Sing11104/bingo-11104,docker,mit,1
-18585,mega-snowman/combine-images,gradio,openrail,1
-18586,Bakar31/MLOps_Practice_Repo_1,gradio,cc,1
-18587,Shrikrishna/Stock_Market_Trend_Prediction,streamlit,,1
-18588,bi02/bingo,docker,mit,1
-18589,0xrk/gpt2,gradio,,1
-18590,ilmhona/api,docker,,1
-18591,Tonic1/falcon-180b-demo,gradio,,1
-18592,ryanjvi/MS-Image2Video,gradio,,1
-18593,Lagz/openai-reverse-proxy,docker,,1
-18594,godelbach/onlyjitz,gradio,apache-2.0,1
-18595,nathanaw/cybersec-ai,static,openrail,1
-18596,Cartinoe5930/LLMAgora,gradio,apache-2.0,1
-18597,MindSyncAI/brain-tumor-classification,streamlit,unknown,1
-18598,fffiloni/gradio-bug-clear-event,gradio,,1
-18599,ko5cles/lyric_writer,streamlit,mit,1
-18600,typ12323/bingo,docker,mit,1
-18601,adrianpierce/cocktails,streamlit,unknown,1
-18602,awacke1/VideoFromImage,gradio,,1
-18603,openMUSE/open-parti-prompts,gradio,,1
-18604,kottu/stabble_diffusion_sketch,docker,mit,1
-18605,ejschwartz/function-method-detector,docker,,1
-18606,Virus561/sdf,gradio,,1
-18607,Quantumhealth/README,static,,1
-18608,seagulltyf/chatglm3-6b,gradio,mit,1
-18609,Huu-Mon12/test01,docker,,1
-18610,kenton-li/maia-utsw,docker,,1
-18611,mauriciogtec/w2vec-app,docker,openrail,1
-18612,qducnguyen/chatpdf-demo,gradio,unknown,1
-18613,silentAw404/bot.py,streamlit,,1
-18614,Liu-LAB/GPT-academic,gradio,,1
-18615,jackrui/diff-amp-AMP_Sequence_Detector,gradio,,1
-18616,YaeMiko2005/Yae_Miko_voice_jp,gradio,,1
-18617,jackrui/diff-amp-antimicrobial_peptide_generation,gradio,,1
-18618,okriyan/README,static,,1
-18619,isotope21/Musicgen,gradio,,1
-18620,maksimluzik/ml-learning,gradio,apache-2.0,1
-18621,AzinZ/vitscn,gradio,mit,1
-18622,ZDarren/huanhua,gradio,,1
-18623,Olga19821109/falcon180b,gradio,,1
-18624,mohamedemam/Arabic-meeting-summarization,gradio,other,1
-18625,guetLzy/Real-ESRGAN-Demo,gradio,cc-by-nc-4.0,1
-18626,Alfasign/fdvdv,gradio,,1
-18627,huggingface-projects/AudioLDM2-bot,gradio,,1
-18628,seok07/1JK50,gradio,mit,1
-18629,Mushfi/forecasting_geomagnetic_storms,gradio,apache-2.0,1
-18630,huggingface-projects/codellama-bot,gradio,,1
-18631,AnonymousSub/Ayurveda4U,gradio,,1
-18632,Osmond141319/ComfyUI-CalicoMixv7.5-v2-Public,docker,,1
-18633,fredrikskatland/finn-annonser,streamlit,,1
-18634,artificialimagination/ai_detect_v0.1,gradio,other,1
-18635,ServerX/PorcoDiaz,gradio,,1
-18636,samathuggingface/sarguru,gradio,,1
-18637,samathuggingface/sarguruchatbot,gradio,,1
-18638,asigalov61/Euterpe-X,gradio,apache-2.0,1
-18639,feeme666/auto_mjw,gradio,,1
-18640,betelguesestudios/Musicc,gradio,,1
-18641,samathuggingface/SampleAi,gradio,,1
-18642,allknowingroger/Image-Models-Test142,gradio,,1
-18643,allknowingroger/Image-Models-Test143,gradio,,1
-18644,zshn25/DINOv2_Depth,gradio,cc-by-nc-4.0,1
-18645,Lajonbot/Chatbot-Share,gradio,mit,1
-18646,AUBADA-ALARABI/poetry202,gradio,,1
-18647,AUBADA-ALARABI/poetry2023,gradio,,1
-18648,AUBADA-ALARABI/AraPoet,gradio,gpl-3.0,1
-18649,AUBADA-ALARABI/poetry1,gradio,cc-by-nc-4.0,1
-18650,AUBADA-ALARABI/poetry20233,gradio,,1
-18651,ysharma/xtts,gradio,,1
-18652,sahirp/cvbeardetect,gradio,apache-2.0,1
-18653,SohaibAamir/AI-Innovators-Demo-Hub,docker,,1
-18654,golem4300/RVC-TTS,gradio,gpl-3.0,1
-18655,jasonreisman/primates,gradio,apache-2.0,1
-18656,dibend/individual-stock-lookup,gradio,gpl-3.0,1
-18657,bielalpha/nerijs-pixel-art-xl,gradio,,1
-18658,Deepaksiwania12/Face-Landmark-Detection,gradio,,1
-18659,fjenett/ellipse-detection-aamed,docker,,1
-18660,dylanplummer/NextJump,gradio,,1
-18661,Moonkiler/Nio22,docker,,1
-18662,czwQAQ/extras,docker,mit,1
-18663,bielalpha/pixelparty-pixel-party-xl,gradio,,1
-18664,jsaplication/jsphoto,gradio,openrail,1
-18665,assecorML/README,static,,1
-18666,thekubist/Deci-DeciDiffusion-v1-0,gradio,,1
-18667,stevez/b_demo_hf,gradio,mit,1
-18668,agonh/Speech-t5,gradio,,1
-18669,happiestminds/trackbot,gradio,,1
-18670,allknowingroger/Image-Models-Test146,gradio,,1
-18671,vsrinivas/Image_Generation_by_SrinivasV,gradio,,1
-18672,bobsby23/step-by-step,docker,agpl-3.0,1
-18673,Vaibhav-vinci/NewSpace,streamlit,unknown,1
-18674,Bidwill/Sanskrit-asr,gradio,apache-2.0,1
-18675,NSect/multitrack-midi-music-generator,docker,mit,1
-18676,Ohio-uchil/stablediffusionapi-anything-v5,gradio,,1
-18677,alecinvan/flotationHealthChatbot,gradio,,1
-18678,SynaptInk/ajibawa-2023-Uncensored-Frank-7B,gradio,,1
-18679,alecinvan/flotationMultiModalRobot,gradio,,1
-18680,chrisjones1234/llm-app,docker,openrail,1
-18681,fermuch/harborwater-open-llama-3b-v2-wizard-evol-instuct-v2-196k,gradio,,1
-18682,dfassaf/newbingChatAI,docker,mit,1
-18683,RO4DHOG/Ripper,gradio,cc,1
-18684,JackBAI/master_wlb_index,gradio,mit,1
-18685,openpecha/TTS,gradio,,1
-18686,pinhome/property_knowledge_qa_chatbot,gradio,apache-2.0,1
-18687,rahul2001/student_performance,gradio,,1
-18688,ShubhamVermaDS/text_to_image,static,,1
-18689,arkaprav0/gpt-transcript-plugin,gradio,,1
-18690,petros/petros-bert-base-cypriot-uncased-v1,gradio,,1
-18691,YanzBotz/Stablediffusion-YanzBotz,gradio,mit,1
-18692,salemamassi/PdfChatBot,gradio,mit,1
-18693,k2-fsa/generate-subtitles-for-videos,gradio,apache-2.0,1
-18694,Autodog/nova,docker,mit,1
-18695,bincooo/auto-ai,docker,mit,1
-18696,wffcyrus/MetaGPT-v1,docker,,1
-18697,usecodenaija/x-spaces-web-ui,gradio,,1
-18698,sh20raj/Test,static,,1
-18699,tez321/pipeline-visualizer,streamlit,,1
-18700,droidcv/bahd,gradio,,1
-18701,allknowingroger/Image-Models-Test149,gradio,,1
-18702,phiyodr/dacl-challenge,gradio,,1
-18703,Nunchakuka/FrenchAnonymizer,gradio,mit,1
-18704,Jmansoking/newbing,docker,mit,1
-18705,DanLeBossDeESGI/Musica,streamlit,,1
-18706,sh20raj/uploader,gradio,mit,1
-18707,anjaria93402/free-vps-1,docker,,1
-18708,fadetube/bingo,docker,mit,1
-18709,CohereForAI/pokemon-cards-explorer,streamlit,,1
-18710,AchyuthGamer/OpenGPT,gradio,creativeml-openrail-m,1
-18711,plzdontcry/dakubettergpt,docker,,1
-18712,Bart92/RVC_HF,gradio,,1
-18713,DuckyPolice/DeciDiffusion-v1-0,gradio,,1
-18714,hanan217/QQsign,docker,mit,1
-18715,joshuasundance/langchain-streamlit-demo,docker,,1
-18716,salemamassi/GeneralPdfChatBot,gradio,mit,1
-18717,mpshemarketing/README,static,,1
-18718,TimVan1/nllb-translation-demo,gradio,,1
-18719,hunz/web2inpaint,gradio,,1
-18720,stallbr/microsoft-BioGPT-Large-PubMedQA,gradio,,1
-18721,kevkev05/Chat-To-Sequence,gradio,,1
-18722,faunxs233/zidunuer-bing,docker,mit,1
-18723,CamodDew/youtubelegal,gradio,,1
-18724,alfabill/stable-diffusion-inpainting-2,gradio,mit,1
-18725,chyh/chatbot,docker,mit,1
-18726,allknowingroger/Image-Models-Test153,gradio,,1
-18727,yderre-aubay/midi-player-demo,docker,,1
-18728,QaryR/EcoCycleAI,gradio,mit,1
-18729,arnaucas/wildfire-detection,gradio,apache-2.0,1
-18730,jbilcke-hf/splatter-api,docker,,1
-18731,Bilalst/Gradio_Youtube_Transcript_v2,gradio,,1
-18732,coding4vinayak/openaccess-ai-collective-jeopardy-bot,gradio,mit,1
-18733,wishwork/Persian-LLM-Leaderboard,streamlit,openrail,1
-18734,jkassemi/hf-speech-bench,streamlit,apache-2.0,1
-18735,gatilin/damo-yolo-webui,gradio,,1
-18736,ChristopherMarais/Andrew_AI-BB_classification-beta,docker,mit,1
-18737,olivianuzum/EmoJeneration,gradio,,1
-18738,CHDCruze/entertainmentbybhdcruze,static,mit,1
-18739,CikeyQI/meme-api,docker,,1
-18740,arslan-ahmed/talk-to-arslan,gradio,apache-2.0,1
-18741,athuljoy/whisper_model_speech_to_text2,gradio,apache-2.0,1
-18742,gatilin/damo-facedet-webui,gradio,,1
-18743,Shankarm08/chatconversation,streamlit,,1
-18744,gforguru/EmailGenerator,streamlit,,1
-18745,lm/lychee_law,streamlit,,1
-18746,Nybb/README,static,,1
-18747,digitalxingtong/Shanbao-Bert-VITS2,gradio,mit,1
-18748,allknowingroger/Image-Models-Test154,gradio,,1
-18749,digitalxingtong/Azusa-Bert-VITS2,gradio,mit,1
-18750,fullname77/README,static,,1
-18751,yannESGI/test_fitz,streamlit,,1
-18752,jpwahle/field-time-diversity,docker,,1
-18753,mattiaspaul/chasingclouds,streamlit,cc-by-4.0,1
-18754,801artistry/RVC801,gradio,,1
-18755,UglyLemon/LEMONTR,streamlit,,1
-18756,shauray/StarCoder,gradio,,1
-18757,UglyLemon/Lemon_Reverse,docker,,1
-18758,gventur4/recipesDaCasa,streamlit,cc,1
-18759,thePhenom21/AdaptLLM-medicine-LLM,gradio,,1
-18760,fastaioncampus/TrafficSigns,gradio,,1
-18761,generativeai/test-image-similarity,gradio,,1
-18762,gventur4/receitas_tera-final,streamlit,,1
-18763,Bradjan310/ehartford-Wizard-Vicuna-30B-Uncensored,gradio,,1
-18764,yjmqaq/Iloveyou,docker,mit,1
-18765,jsaplication/jsphoto-api,gradio,openrail,1
-18766,JoYCC/ICBU-NPU-FashionGPT-70B-V1.1,gradio,,1
-18767,MJ/AI-ChatBot,gradio,apache-2.0,1
-18768,Omnibus/summarize-long-text,gradio,apache-2.0,1
-18769,alamin655/websurfx,docker,agpl-3.0,1
-18770,SeyedAli/Persian-Speech-Emotion-Detection,gradio,mit,1
-18771,SeyedAli/Arabic-Speech-Synthesis,gradio,mit,1
-18772,SeyedAli/Persian-Text-Paraphrase,gradio,mit,1
-18773,tomascufarovertic/keyword_classification,gradio,unknown,1
-18774,themanas021/legal_chat,streamlit,mit,1
-18775,allknowingroger/Image-Models-Test157,gradio,,1
-18776,allknowingroger/Image-Models-Test158,gradio,,1
-18777,Fiacre/projectmanagerideator,gradio,mit,1
-18778,SeyedAli/Persian-Text-Sentiment,gradio,mit,1
-18779,MindSyncAI/Plant_Classification,streamlit,,1
-18780,sravya-abburi/ResumeParserLLM,gradio,apache-2.0,1
-18781,iccv23-diffusers-demo/instruct-pix2pix,gradio,,1
-18782,iccv23-diffusers-demo/LoraTheExplorer,gradio,mit,1
-18783,iccv23-diffusers-demo/T2I-Adapter-SDXL-Sketch,gradio,,1
-18784,iccv23-diffusers-demo/stable-diffusion-image-variations,gradio,mit,1
-18785,iccv23-diffusers-demo/zeroscope-v2,gradio,mit,1
-18786,iccv23-diffusers-demo/sdxl,gradio,mit,1
-18787,iccv23-diffusers-demo/Shap-E,gradio,mit,1
-18788,jbilcke-hf/campose-api,docker,,1
-18789,pharma-IA/PharmaWise_Prospecto_Megalabs_V2.10,gradio,artistic-2.0,1
-18790,luisotorres/Volatility-Based-Support-and-Resistance-Levels,gradio,,1
-18791,srini047/asapp-hackathon,gradio,,1
-18792,Docfile/open_llm_leaderboard,gradio,apache-2.0,1
-18793,francojc/transcribe,gradio,apache-2.0,1
-18794,kevinwang676/VITS2-Mandarin,gradio,mit,1
-18795,llm-learnings/huberman-gpt,gradio,,1
-18796,laiguorui/bing,docker,mit,1
-18797,davidashirov/cilantro,gradio,openrail,1
-18798,dongsiqie/Image-to-Line-Drawings,gradio,mit,1
-18799,sh20raj/python-bootcamp,static,mit,1
-18800,drdonut1/TIGER-Lab-MAmmoTH-Coder-34B,gradio,afl-3.0,1
-18801,tonne/jupyterlab,docker,,1
-18802,Rurrr/qr_monster,gradio,,1
-18803,olanigan/glaiveai-glaive-coder-7b,gradio,,1
-18804,xyyyds/som,gradio,gpl-3.0,1
-18805,anilkumar-kanasani/chat-with-your-pdf,streamlit,,1
-18806,JAKKIHARISH/mygenAIAvatar,gradio,,1
-18807,Harish143/AIavatar2.0,gradio,,1
-18808,kudoshinichi/hf-sentiment-models,streamlit,cc-by-nc-nd-4.0,1
-18809,yeahpic/YeahPic,gradio,afl-3.0,1
-18810,felixz/open_llm_leaderboard,gradio,apache-2.0,1
-18811,SirensOfNC/sail-rvc-Sonic_SonicBoom,gradio,,1
-18812,huazhao/QQsign,docker,mit,1
-18813,Toritto/Genshin-impact-IA-project-v1,gradio,mit,1
-18814,Asifpa6/emotion-analyzer-app,streamlit,openrail,1
-18815,Manoj21k/Custom-QandA,streamlit,,1
-18816,angelayeu/my_hf_space,gradio,,1
-18817,allknowingroger/Image-Models-Test162,gradio,,1
-18818,allknowingroger/Image-Models-Test163,gradio,,1
-18819,dinhhung1508/VietnamAIHub-Vietnamese_LLama2_13B_8K_SFT_General_Domain_Knowledge,gradio,,1
-18820,EmRa228/Image-Models-Test1001,gradio,,1
-18821,sanjay7178/FAS-demo,gradio,apache-2.0,1
-18822,Deepak7376/demo-sapce,streamlit,mit,1
-18823,r0seyyyd33p/sdui-custom,gradio,,1
-18824,CuraAlizm/stabilityai-stable-diffusion-xl-base-1.0,gradio,,1
-18825,aai198/ComfyUI,docker,,1
-18826,kavit02/chatbot1,gradio,,1
-18827,ddosxd/sydney-inpaint,docker,,1
-18828,HarshWK/Basic_Models,gradio,apache-2.0,1
-18829,lancewilhelm/bad-actors-annotator,gradio,,1
-18830,Raghavan1988/falcon-lablabai-hackathon-brainstorming-buddy-for-researchers,gradio,,1
-18831,magulux/openai-reverse-proxy-3,docker,,1
-18832,Kayson/InstructDiffusion,gradio,,1
-18833,bohmian/stock_intrinsic_value_calculator,gradio,,1
-18834,aiswaryamlds/YoutubeQA,streamlit,,1
-18835,sahirp/planedetect,gradio,,1
-18836,Zuleyyuyuu/Yuyu,docker,,1
-18837,gradio/keras-image-classifier,gradio,mit,1
-18838,TusharGoel/LayoutLM-DocVQA,gradio,mit,1
-18839,neridonk/facebook-nougat-base,gradio,,1
-18840,hareshgautham/Myspace,docker,,1
-18841,allknowingroger/Image-Models-Test165,gradio,,1
-18842,DHEIVER/ThyroidTumorClassificationModel,gradio,,1
-18843,allknowingroger/Image-Models-Test166,gradio,,1
-18844,SeyedAli/Persian-Image-Captioning-1,gradio,mit,1
-18845,Enterprisium/Easy_GUI,gradio,lgpl-3.0,1
-18846,SeyedAli/Persian-Image-Captioning,gradio,mit,1
-18847,GreenTeaLatte/ComfyUI-cpu,docker,,1
-18848,DHEIVER/ImageClassifierCataract,gradio,,1
-18849,Semibit/gentle-audio,docker,,1
-18850,Monster/Llama-2-13B-chat,docker,,1
-18851,PaSathees/FoodVision_Mini,gradio,mit,1
-18852,ForTheLoveOfML0/X-ray_Classifier,gradio,gpl-2.0,1
-18853,kavit02/chatbot2,gradio,,1
-18854,Sudhanshu976/NLP_FULL_APP,streamlit,,1
-18855,PaSathees/FoodVision_Big,gradio,mit,1
-18856,kenton-li/record,docker,,1
-18857,vtomoasv/product-recognition,gradio,artistic-2.0,1
-18858,benjaminzuckermanbasisscottsdale/Chronic_Kidney_Disease_Prediction_Service,gradio,gpl-3.0,1
-18859,CrAvila/DigitClassifier,gradio,mit,1
-18860,VishnuSaiTeja/RogerStaff,gradio,apache-2.0,1
-18861,tarjomeh/disney-pixal-cartoon,gradio,,1
-18862,SeyedAli/Musical-genres-Detection,gradio,mit,1
-18863,SalahZa/Tunisian-Speech-Recognition,gradio,cc-by-nc-3.0,1
-18864,allknowingroger/Image-Models-Test167,gradio,,1
-18865,allknowingroger/Image-Models-Test169,gradio,,1
-18866,anilkumar-kanasani/cloths_order_bot,streamlit,,1
-18867,VishnuSaiTeja/Predictor,streamlit,apache-2.0,1
-18868,zzzzred/extras,docker,mit,1
-18869,deafheavennnn/metalproxy,docker,,1
-18870,binker/interpreter,gradio,openrail,1
-18871,priyaaa22/gen1,gradio,,1
-18872,SeyedAli/Persian-To-English-Translation,gradio,mit,1
-18873,SeyedAli/English-To-Persian-Translation,gradio,mit,1
-18874,Thanarit/GPT-Detection-Demo,streamlit,apache-2.0,1
-18875,Sandy0909/Finance_Sentiment,streamlit,apache-2.0,1
-18876,qefunaba/nicky007-stable-diffusion-logo-fine-tuned,gradio,,1
-18877,qefunaba/iamkaikai-amazing-logos-v3,gradio,,1
-18878,Tatvajsh/AHS,docker,,1
-18879,CCOM/README,static,,1
-18880,AIWaves/Debate,gradio,apache-2.0,1
-18881,Jineet/Handwritten_Digit_Recognition,gradio,,1
-18882,Omnibus/idefics_playground_mod,gradio,,1
-18883,metricspace/juristische_Ersteinschaetzung_einer_KI,gradio,cc,1
-18884,allknowingroger/Image-Models-Test170,gradio,,1
-18885,DORA1222/1234,gradio,bigscience-openrail-m,1
-18886,Justin-12138/FSALA,gradio,gpl-2.0,1
-18887,stevenxiao29/ResumeAssist,streamlit,,1
-18888,aichitrakaar/Deci-DeciDiffusion-v1-0,gradio,,1
-18889,rishabh2322/chatbot,gradio,,1
-18890,sudokush/goofyai-3d_render_style_xl__generator,gradio,,1
-18891,ramki123/testing,gradio,,1
-18892,fersch/predictor_fraude,gradio,mit,1
-18893,huang4414/saltacc-anime-ai-detect,gradio,,1
-18894,passgenau-digital/virtual-assistant-demo-hsb,docker,,1
-18895,ahmedgamal777722/flowise,docker,,1
-18896,themanas021/legal-chat,streamlit,mit,1
-18897,ngoctuanai/aivestablediffusionv15,gradio,,1
-18898,Manvir786/nfgj,static,bigcode-openrail-m,1
-18899,apokalis/Apokalis,docker,openrail,1
-18900,prxx/Norod78-SD15-IllusionDiffusionPattern-LoRA,gradio,,1
-18901,SeyedAli/Multilingual-Text-Similarity,gradio,mit,1
-18902,OdiaGenAI/Olive_Farm,streamlit,cc-by-nc-sa-4.0,1
-18903,74run/Predict_Car,gradio,other,1
-18904,all-diffusions/stable-diffusion-v1-5,gradio,,1
-18905,SmileyTatsu/Bleh,docker,,1
-18906,Alex123aaa/1234,gradio,unknown,1
-18907,binker/interpreter5,gradio,openrail,1
-18908,allknowingroger/Image-Models-Test171,gradio,,1
-18909,allknowingroger/Image-Models-Test172,gradio,,1
-18910,enochianborg/stable-diffusion-webui-vorstcavry,gradio,,1
-18911,jitubutwal1441/multiple-pdfs-chat,streamlit,,1
-18912,artba/SchoolStats1,gradio,,1
-18913,yegeta1243/Image-Models-Test130,gradio,,1
-18914,ak0601/news_sentiment_analysis,docker,,1
-18915,ltg/no-en-translation,gradio,,1
-18916,passgenau-digital/virtual-chat-assistent-cc-energy,docker,,1
-18917,spritlesoftware/Spritle-Bot,streamlit,,1
-18918,zhuraavl/mistralai-Mistral-7B-v0.1,gradio,,1
-18919,ai-maker-space/ChatWithYourPDF,docker,apache-2.0,1
-18920,NanoT/demo2,gradio,apache-2.0,1
-18921,samibel/A-Comparative-Analysis-of-State-of-the-Art-Deep-learning-Models-for-Medical-Image-Segmentation,gradio,mit,1
-18922,bincooo/m3e-large-api,docker,mit,1
-18923,Ralmao/Anemia,gradio,mit,1
-18924,banana-dev/demo-mistral-7b-instruct-v0.1,gradio,,1
-18925,ridges/mistralai-Mistral-7B-v0.1,gradio,other,1
-18926,shoupeng/test,docker,apache-2.0,1
-18927,zliang/ClimateChat,streamlit,cc-by-nc-sa-4.0,1
-18928,nyust-eb210/bge-large-zh-v1.5_gradio,gradio,,1
-18929,FridaZuley/RVC_HFKawaii,gradio,,1
-18930,samyak152002/Quantumn-Multiplication,gradio,mit,1
-18931,Samarth991/LLAMA-QA-AudioFiles,gradio,mit,1
-18932,allknowingroger/Image-Models-Test173,gradio,,1
-18933,allknowingroger/Image-Models-Test174,gradio,,1
-18934,illrapper/ill,docker,cc-by-nd-4.0,1
-18935,CyberPeace-Institute/Cybersecurity-Knowledge-Graph-Extraction,streamlit,mit,1
-18936,KushJaggi/YOLOv8,gradio,,1
-18937,samyak152002/Qiskit,streamlit,apache-2.0,1
-18938,wonderit-safeai/tts-announcer,streamlit,,1
-18939,kavit02/cono,gradio,,1
-18940,Tonic/indiansummer,gradio,apache-2.0,1
-18941,vikdutt/vd,static,mit,1
-18942,Elegbede/Text_to_emotion_classifier,gradio,,1
-18943,debayan/ISM2023w,gradio,other,1
-18944,fschramm21/fraudDetector,gradio,mit,1
-18945,cbensimon/stable-diffusion-xl,gradio,,1
-18946,SeyedAli/Image-Similarity,gradio,,1
-18947,44brabal/valentinafeve-yolos-fashionpedia,gradio,openrail,1
-18948,huggingdalle/dalle-mini,static,creativeml-openrail-m,1
-18949,SeyedAli/Image-Object-Detection,gradio,mit,1
-18950,iabualhaol/emot,gradio,mit,1
-18951,Faridmaruf/RVCV2MODEL,gradio,mit,1
-18952,AbdoulGafar/woodsound,gradio,apache-2.0,1
-18953,Thafx/sdrvxl2,gradio,mit,1
-18954,Lbx091/rev,docker,,1
-18955,AP123/dreamgaussian,static,mit,1
-18956,philwsophi/Testeoi,docker,,1
-18957,Cran-May/ygVI,gradio,,1
-18958,PeepDaSlan9/TigerResearch-tigerbot-70b-chat,gradio,,1
-18959,yuanh/bingon,docker,mit,1
-18960,Veer15/image-prompt-editing,docker,,1
-18961,allknowingroger/Image-Models-Test176,gradio,,1
-18962,allknowingroger/Image-Models-Test177,gradio,,1
-18963,allknowingroger/Image-Models-Test178,gradio,,1
-18964,Hua626/QQsign,docker,mit,1
-18965,byC2bot/TikTok_info,docker,,1
-18966,ayoubkirouane/BERT-base_NER-ar,gradio,,1
-18967,XzJosh/Carol-Bert-VITS2,gradio,mit,1
-18968,Okkoman/PokeFace,gradio,mit,1
-18969,Bready11/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator,gradio,mit,1
-18970,SeyedAli/Image-Segmentation,gradio,apache-2.0,1
-18971,HenryCarle/your_sport_picker,gradio,afl-3.0,1
-18972,TNK21/Translator_app,gradio,,1
-18973,yuangongfdu/LTU,gradio,cc-by-4.0,1
-18974,yuangongfdu/LTU-Compare,gradio,cc-by-4.0,1
-18975,msobhy/langchain-chat-with-pdf,gradio,,1
-18976,Omnibus/MusicGen,gradio,cc-by-nc-4.0,1
-18977,qscwdv/bing,docker,mit,1
-18978,Abhiboken12/travelling_ai,gradio,bigscience-openrail-m,1
-18979,digitalxingtong/Nailv-read-Bert-Vits2,gradio,mit,1
-18980,digitalxingtong/Eileen-Bert-Vits2,gradio,mit,1
-18981,curveman2/MysteryClaude,docker,,1
-18982,litagin/vits-japros-webui-demo,gradio,,1
-18983,LabAlproITS/CyberDAS-FE,docker,,1
-18984,allknowingroger/Image-Models-Test179,gradio,,1
-18985,Sagand/Sargand,gradio,bigscience-openrail-m,1
-18986,yuezih/BLIP-SMILE,gradio,mit,1
-18987,MultiTransformer/autogen-online,static,mit,1
-18988,pablodawson/ldm3d-inpainting,gradio,,1
-18989,RockInnn/snake_by_princepspolycap,static,mit,1
-18990,wbe/balls,gradio,apache-2.0,1
-18991,DollieHell/pisa,docker,,1
-18992,GabeIsHaxkee/E,docker,deepfloyd-if-license,1
-18993,javedkumail/HopeAI,gradio,apache-2.0,1
-18994,digitalxingtong/Jiuxia-Bert-Vits2,gradio,mit,1
-18995,sara4dev/rag-iblog-qa,gradio,,1
-18996,digitalxingtong/Jiaohuaji-Bert-Vits2,gradio,mit,1
-18997,digitalxingtong/Kino-Bert-VITS2,gradio,mit,1
-18998,digitalxingtong/Lixiang-Bert-Vits2,gradio,mit,1
-18999,digitalxingtong/Luzao-Bert-Vits2,gradio,mit,1
-19000,AchyuthGamer/AchyuthGamer-OpenGPT,gradio,creativeml-openrail-m,1
-19001,digitalxingtong/Miiu-Bert-Vits2,gradio,mit,1
-19002,digitalxingtong/Un-Bert-Vits2,gradio,mit,1
-19003,allknowingroger/Image-Models-Test181,gradio,,1
-19004,arborvitae/GalaxiCode.ai,gradio,mit,1
-19005,DamarJati/DamarJati-NSFW-filter-DecentScan,gradio,,1
-19006,cmtry/nAIr,gradio,mit,1
-19007,Djacon/emotion_detection,docker,mit,1
-19008,lunarflu/HuggingMod,gradio,,1
-19009,MohamedRabie26/Soil_Shear_Strength_Prediciton,gradio,apache-2.0,1
-19010,imperialwool/llama-cpp-api,docker,,1
-19011,webtest1s/testings,static,,1
-19012,Puyush/MultiLabel-TextClassification,gradio,apache-2.0,1
-19013,ALSv/Chat-with-Llama-2-70b,gradio,mit,1
-19014,Gauri54damle/sdxl-lora-multi-object,gradio,,1
-19015,murongtianfeng/gradio1,gradio,,1
-19016,Jingqi/ChatGPT-QA,gradio,mit,1
-19017,shabnam91/Sanskrit-TTS,gradio,,1
-19018,LZRi/LZR-Bert-VITS2,gradio,cc-by-nc-sa-4.0,1
-19019,Afrihub/README,static,,1
-19020,Detomo/ai-avatar-backend,docker,,1
-19021,allknowingroger/Image-Models-Test182,gradio,,1
-19022,Jaskirat-04/Food-Personalisation,streamlit,,1
-19023,allknowingroger/Image-Models-Test185,gradio,,1
-19024,zhan66/vits-uma-genshin-honkai,gradio,apache-2.0,1
-19025,williamberman/stable-diffusion-xl-inpainting,gradio,,1
-19026,mgolu/EDvai_final,gradio,mit,1
-19027,zhan66/vits-simple-api,gradio,mit,1
-19028,aimustafa/Example,streamlit,other,1
-19029,karthick965938/ChatGPT-Demo,streamlit,,1
-19030,rohitt45/Movie-Recommendation-System,streamlit,,1
-19031,tjgo/README,static,,1
-19032,fmind/resume,gradio,mit,1
-19033,AmirTrader/LinearRegression,docker,,1
-19034,dsank/PY007-TinyLlama-1.1B-Chat-v0.3,gradio,mit,1
-19035,doevent/XTTS_V1_CPU_working,gradio,,1
-19036,OmarSRF/OOOFFF,gradio,apache-2.0,1
-19037,Fedev23/Proyecto_edvai,gradio,mit,1
-19038,MultiTransformer/Automated-Social-Media-Campaign,static,mit,1
-19039,qgyd2021/chat_with_llm,gradio,,1
-19040,rishiraj/mistral,gradio,apache-2.0,1
-19041,huutinh111111/ChatGPT4,gradio,mit,1
-19042,isan2001/BertApps,streamlit,,1
-19043,XPMaster/chainladder,gradio,,1
-19044,Abs6187/AI_Chatbot,gradio,,1
-19045,Hackatos/Smart-Shower-ATC,docker,,1
-19046,ArnePan/German-LLM-leaderboard,gradio,apache-2.0,1
-19047,dhanilka/illusion-image-ai,gradio,openrail,1
-19048,SiraH/DQA-Llama2-4bit,streamlit,,1
-19049,Pietrzak/bigscience-bloomz-7b1-mt,gradio,cc-by-sa-3.0,1
-19050,sub314xxl/MetaGPT,docker,,1
-19051,omdivyatej/general_invoice_parser,gradio,mit,1
-19052,tekkonetes/rust-code-server,docker,,1
-19053,alsalemi/pv-segment-01,gradio,,1
-19054,Megatron17/RAQA_with_Langchain,docker,,1
-19055,benmaor/FoodVision_Big,gradio,mit,1
-19056,BilalSardar/Halal_Food_Checker,gradio,,1
-19057,Sujal7/shikshaconnect,static,,1
-19058,thiago-osorio/track-search-engine,gradio,,1
-19059,DHEIVER/classificador_de_imagem_colonoscopia,gradio,,1
-19060,1-13-am/neural-style-transfer,gradio,,1
-19061,ShoukanLabs/OpenNiji-Aesthetic-Dataset-Viewer,gradio,,1
-19062,Maheshiscoding/MAHESH-AI-HELPER,gradio,,1
-19063,HypermindLabs/Snore-Detector,streamlit,cc-by-nc-nd-4.0,1
-19064,Vicent3/laniakea,static,agpl-3.0,1
-19065,roggen/unity-llm-example,gradio,mit,1
-19066,Vicent3/sharp-transformers-traveltaxi,static,agpl-3.0,1
-19067,Vicent3/ocr-endpoint,static,agpl-3.0,1
-19068,Vicent3/ocr-wrapper,static,agpl-3.0,1
-19069,eaglelandsonce/BabyAGI,streamlit,,1
-19070,mixcard/image-1-captioning,gradio,,1
-19071,Anew5128/Anew51,docker,mit,1
-19072,mixcard/text-finbert,gradio,,1
-19073,mixcard/blip-image-captioning-large,gradio,,1
-19074,Anew1007/extras,docker,mit,1
-19075,mixcard/ask-reader-text,gradio,,1
-19076,yuki-816/science-communication,streamlit,unknown,1
-19077,mixcard/text-summarization,gradio,,1
-19078,leo-bourrel/test-streamlit,docker,,1
-19079,mixcard/text-summary,gradio,,1
-19080,mixcard/text-summary-2,gradio,,1
-19081,mixcard/image-2-text-largecoco,gradio,,1
-19082,mixcard/image-captioning-ru,gradio,,1
-19083,mixcard/image-2-captionmax,gradio,,1
-19084,mixcard/image-2-details,gradio,,1
-19085,asgaardlab/DatasetPreviewer,gradio,mit,1
-19086,Admin08077/Record,gradio,other,1
-19087,nothingsuspicious/curaude,docker,,1
-19088,yoon-gu/pokemon-quiz,gradio,,1
-19089,kavit02/cono.type.xd,gradio,,1
-19090,dlmn/SIH_S2T_multilingual_ASR,streamlit,apache-2.0,1
-19091,jeanbaptdzd/mistralai-Mistral-7B-v0.1,gradio,,1
-19092,kevinwang676/xtts,gradio,,1
-19093,Sujal7/Shiksha-Connect,static,,1
-19094,allknowingroger/Image-Models-Test189,gradio,,1
-19095,pharma-IA/PharmaWise_Prospecto_Generico_Acetilsalicilico_V2C_STREAM,gradio,,1
-19096,allknowingroger/Image-Models-Test190,gradio,,1
-19097,allknowingroger/Image-Models-Test191,gradio,,1
-19098,pharma-IA/PharmaWise_Prospecto_Generico_Vortioxetina_V2C_STREAM,gradio,,1
-19099,seanghay/KLEA,gradio,apache-2.0,1
-19100,AtheneaEdu/README,static,,1
-19101,pharma-IA/PharmaWise_Experto_GMP_V2C_STREAM,gradio,,1
-19102,pharma-IA/PharmaWise_Experto_Data_Integrity_V2C_STREAM,gradio,,1
-19103,roshithindia/image_classification,streamlit,,1
-19104,hilsq/bingotest,docker,mit,1
-19105,Waranchari/Image_Classification,streamlit,,1
-19106,ashioyajotham/falcon_7b_coder,gradio,apache-2.0,1
-19107,fatimahhussain/workoutwizard,streamlit,mit,1
-19108,universal-ml/NLang,gradio,,1
-19109,sherinsp/openai-reverse-proxy,docker,,1
-19110,ziyadsuper2017/Biochemistry3.0,gradio,,1
-19111,puji4ml/PubMedAbstractSkimmingTool,gradio,,1
-19112,KoalaAI/Text-Moderation-Demo,gradio,,1
-19113,winterForestStump/bank_deposit_prediction,gradio,,1
-19114,FlipTip/ChatBot,gradio,,1
-19115,finaspirant/SearchWithVoice,gradio,,1
-19116,abidlabs/persistent-storage-test,gradio,,1
-19117,IceAnimates123/README,static,,1
-19118,PeepDaSlan9/ToyWorld,gradio,,1
-19119,MJ/EEG_cls,streamlit,mit,1
-19120,TheKitten/Pictures,gradio,,1
-19121,mfernezir/VanillaChatbot,gradio,apache-2.0,1
-19122,Cran-May/Mistril-7b,streamlit,,1
-19123,khjs012/1412,gradio,apache-2.0,1
-19124,Mysterykey/test,docker,,1
-19125,awacke1/MistralGradioFast,gradio,mit,1
-19126,padmanabhbosamia/Segment_Anything,gradio,mit,1
-19127,AbeShinzo0708/AI_Kishida_Fumio_speaker,streamlit,openrail,1
-19128,jbilcke-hf/hotshot-xl-api,docker,,1
-19129,rajan30may/Agribot,gradio,apache-2.0,1
-19130,roshithindia/chatBotGPT2,streamlit,,1
-19131,BreetheRun/stabilityai-stable-diffusion-xl-base-1.0,gradio,unknown,1
-19132,huaiji3y/bingo,docker,mit,1
-19133,AkshayKumarP/AI-ChatBot,gradio,apache-2.0,1
-19134,udartem/easwsnn,gradio,apache-2.0,1
-19135,Arsenii2023/Demo1,gradio,,1
-19136,leelaaaaaavvv/VoiceCloneAi,gradio,,1
-19137,fazzam/Grainsight2,streamlit,apache-2.0,1
-19138,ivuxy/Eval,gradio,,1
-19139,xiantian/123,docker,,1
-19140,awacke1/MistralAndABardGoRoleplaying,gradio,mit,1
-19141,vlsp-2023-vllm/VLLMs-Leaderboard,gradio,,1
-19142,legend1234/b3clf_hf,streamlit,gpl-3.0,1
-19143,wayandadang/MathLLM-MathCoder-L-7B,gradio,,1
-19144,VatsaDev/TinyLlama,gradio,apache-2.0,1
-19145,digitalxingtong/Xingtong-Read-Dongmuchang-Bert-VITS2,gradio,mit,1
-19146,digitalxingtong/Xingtong-Longread-Dongmuchang-Bert-VITS2,gradio,mit,1
-19147,rimasalshehri/NASAproject,streamlit,,1
-19148,kkumarkumar/miniprojectvoice,gradio,,1
-19149,KushJaggi/pdfGPT,gradio,,1
-19150,allknowingroger/Image-Models-Test194,gradio,,1
-19151,allknowingroger/Image-Models-Test195,gradio,,1
-19152,Gna1L/jonatasgrosman-wav2vec2-large-xlsr-53-english,gradio,,1
-19153,roshithindia/imageQuestionAnswering,streamlit,,1
-19154,DonngHuang/auto-ai,docker,mit,1
-19155,nesanchezo/ChatbotNico,streamlit,,1
-19156,awacke1/Mistral_Ultimate_Chords_and_Lyrics_Writer,gradio,mit,1
-19157,gauravtewari/famos-at,docker,,1
-19158,PiyushLavaniya/Llama2_Chatbot,gradio,,1
-19159,pykale/README,static,,1
-19160,Cran-May/SEA-orca,gradio,,1
-19161,Alfaxad/BioGalacticModels,gradio,,1
-19162,deepakHonakeri5/instagram,docker,,1
-19163,openskyml/pigeonchat-demo,static,,1
-19164,akiraaaaaa/Waifu-Reina,gradio,mit,1
-19165,PhilSpiel/annie,gradio,,1
-19166,DylanWolf/h2ogpt-api,gradio,,1
-19167,eaglelandsonce/autogenmultichat,streamlit,,1
-19168,Drac77/stabilityai-stable-diffusion-xl-base-1.0,gradio,,1
-19169,feiya/feiyaa,docker,mit,1
-19170,zhaoys/wfms-kuiwenc,docker,mit,1
-19171,ssthouse/runwayml-stable-diffusion-v1-5,gradio,,1
-19172,hsdhgds/htyjuietryt,docker,,1
-19173,lixiang3718/bing,docker,mit,1
-19174,trialapp/gpt_summarizer,streamlit,,1
-19175,BestteaLib/README,static,,1
-19176,ClipHamper/stable-diffusion-webui,gradio,,1
-19177,allknowingroger/Image-Models-Test196,gradio,,1
-19178,ravichodry/CHATGPT-LLAMA2,streamlit,,1
-19179,Ajay07pandey/Netfilx_Movie_Recommendation_System,streamlit,,1
-19180,allknowingroger/Image-Models-Test198,gradio,,1
-19181,justest/ai-support,docker,,1
-19182,kunderabr/ResumoYouTube,gradio,,1
-19183,wisamidris7/erp,docker,apache-2.0,1
-19184,Darwin2023/darwin,streamlit,,1
-19185,Araby/BRATArA,streamlit,mit,1
-19186,alexray/btc_predictor,docker,,1
-19187,PeepDaSlan9/bank_deposit_prediction,gradio,,1
-19188,huang4414/anime-remove-background,gradio,apache-2.0,1
-19189,TogetherAI/EinfachLlaMistral,gradio,,1
-19190,TRaw/pro,gradio,,1
-19191,digitalxingtong/Xingtong-All-in-One,streamlit,mit,1
-19192,ViktorTsoi13/GPT4,docker,,1
-19193,penguin2023/vncs,docker,,1
-19194,immortaker/as,docker,agpl-3.0,1
-19195,Omnibus/video-2-3d,gradio,,1
-19196,Veerjyot/Digital_India,gradio,mit,1
-19197,Rayzggz/illi-Bert-VITS2,gradio,,1
-19198,arbitrarygate/ayaka_sign,docker,mit,1
-19199,cybercorejapan/human-detection-docker,docker,,1
-19200,NewtonKimathi/Sepsis_Prediction_FastApi,docker,,1
-19201,allknowingroger/Image-Models-Test200,gradio,,1
-19202,XciD/te,static,,1
-19203,searchfind/SG161222-Realistic_Vision_V1.4,gradio,,1
-19204,zongxiao/speech-to-speech,gradio,mit,1
-19205,cedpsam/mistral_openorca_lamacpp,gradio,,1
-19206,dlmn/BHASHAVANI,gradio,mit,1
-19207,Nehal07/Text-Colour-Changes,streamlit,,1
-19208,titanito/stablediffusionapi-juggernaut-xl-v5,gradio,,1
-19209,ardances/mistralai-Mistral-7B-v0.1,gradio,,1
-19210,nllg/AutomaTikZ,docker,apache-2.0,1
-19211,Nehal07/text-translator-with-voice,streamlit,,1
-19212,Ashrafb/Imdf2,streamlit,,1
-19213,KHAMMAMKURRODU/ChatbotApplication,gradio,,1
-19214,amin2809/rvc-models,gradio,mit,1
-19215,teragron/TinyStories,gradio,,1
-19216,TheKitten/Images,gradio,,1
-19217,Diego-0121/ImaText,gradio,,1
-19218,mies8888/intfloat-multilingual-e5-large,gradio,apache-2.0,1
-19219,kmanoj/Sentiment_Analysis,streamlit,mit,1
-19220,DynoKevin/img-cap-for-vision-mate,streamlit,mit,1
-19221,pragneshbarik/ikigai-chat,streamlit,,1
-19222,IMU20/kestrl_merchantname_nlp,gradio,,1
-19223,ryo2/convertcsv2h5,gradio,,1
-19224,Mosharof/FMS,gradio,apache-2.0,1
-19225,allknowingroger/Image-Models-Test201,gradio,,1
-19226,allknowingroger/Image-Models-Test202,gradio,,1
-19227,allknowingroger/Image-Models-Test203,gradio,,1
-19228,bhunter/jupyter-1,docker,,1
-19229,LovnishVermaPRINCE/chatai,streamlit,cc,1
-19230,Ankush05/Newcode,streamlit,,1
-19231,ALSv/FSW,gradio,bigcode-openrail-m,1
-19232,BilalSardar/Reinhard_Color_Transformation,gradio,mit,1
-19233,spritlesoftware/Image-Object-Detection,gradio,,1
-19234,BilalSardar/Remove_Text_for_Image,gradio,,1
-19235,hf4all/chatbot-ui-bing,docker,mit,1
-19236,lingluoACE/bingbyd,docker,mit,1
-19237,aimaswx/my_streamchat,streamlit,bigscience-bloom-rail-1.0,1
-19238,rrepiece/ostris-ikea-instructions-lora-sdxl,gradio,,1
-19239,vasistasaimagam/FoodVision_Big,gradio,mit,1
-19240,coyotte508/static-light-dark,static,,1
-19241,Mohammed-Khalil/Chat_with_Youtube_Videos,streamlit,mit,1
-19242,str-platformAI/striim-gpt,gradio,,1
-19243,BMukhtar/BookRecognitionKz,streamlit,apache-2.0,1
-19244,PeepDaSlan9/HuggingFaceH4-zephyr-7b-alpha,gradio,apache-2.0,1
-19245,AchyuthGamer/jondurbin-airoboros-gpt-3.5-turbo-100k-7b,gradio,,1
-19246,limcheekin/bge-small-en-v1.5,docker,,1
-19247,glassofwine/glassofwine-DialoGPT-medium-johanwine,gradio,,1
-19248,ombhojane/Fetch-Alerts,streamlit,,1
-19249,rrkd/cosmos,docker,,1
-19250,Fu-chiang/skintest,gradio,apache-2.0,1
-19251,Exalt-company/text-to-video,gradio,mit,1
-19252,awacke1/VoiceChatMistral,gradio,mit,1
-19253,Owechada/roopfaceswapr,gradio,agpl-3.0,1
-19254,mittalneha/SD_Styles_Assignment,gradio,apache-2.0,1
-19255,narutovk/VKreate,gradio,mit,1
-19256,dincali/text-to-image,gradio,,1
-19257,iloveapplesandoranges/stablediffusionapi-disney-pixal-cartoon,gradio,,1
-19258,geetu040/video-gen,docker,,1
-19259,chendl/compositional_test,gradio,,1
-19260,themanas021/falcon-legal,streamlit,mit,1
-19261,yooso/PixelFusion,gradio,gpl-3.0,1
-19262,adolfoutfpr/learn4elixir,docker,,1
-19263,Olivier-Truong/faster-whisper-webui-v2,gradio,apache-2.0,1
-19264,wrice/denoisers,gradio,apache-2.0,1
-19265,VAGOsolutions/README,static,,1
-19266,ketangandhi/demo-space,gradio,,1
-19267,vr18/legal-rag,gradio,,1
-19268,Tefa90/ehartford-dolphin-2.1-mistral-7b,gradio,,1
-19269,carlostoxtli/ace,static,,1
-19270,kanli/AIchatBot,gradio,apache-2.0,1
-19271,Fu-chiang/Bit-50-Glaucoma,gradio,apache-2.0,1
-19272,Dragneel/Recon,streamlit,afl-3.0,1
-19273,ardha27/rvc_TTS,gradio,,1
-19274,PeepDaSlan9/Dup_Digital_India,gradio,mit,1
-19275,mrplants/alphabot,gradio,,1
-19276,jbilcke-hf/hotshot-xl-server-1,docker,,1
-19277,ngoctuanai/chatgpt,docker,,1
-19278,allknowingroger/Image-Models-Test205,gradio,,1
-19279,allknowingroger/Image-Models-Test206,gradio,,1
-19280,fgpzen/remove-photo-object,streamlit,,1
-19281,hzzgenius/bing,docker,mit,1
-19282,XzJosh/Jianmo-Bert-VITS2,gradio,mit,1
-19283,XzJosh/JM-Bert-VITS2,gradio,mit,1
-19284,vagmi/isai,gradio,cc-by-nc-4.0,1
-19285,Jung/ep_explorer,streamlit,cc-by-nc-sa-4.0,1
-19286,PunGrumpy/text-generation,docker,mit,1
-19287,JoeJenkins/Norod78-SD15-IllusionDiffusionPattern-LoRA,gradio,,1
-19288,Nymisha123/InstagramQuoteDeveloper,streamlit,,1
-19289,Guying2/guying,docker,mit,1
-19290,andy7475/english_place_name_generator,streamlit,mit,1
-19291,Toxfu/BIgVisionEffnetB2,gradio,mit,1
-19292,neharao/loraking,gradio,other,1
-19293,lamtung16/Llama-2-AWS,streamlit,,1
-19294,PeepDaSlan9/Llama-2-AWS,streamlit,,1
-19295,nesticot/pp_roundup,docker,mit,1
-19296,isididiidid/chatgpt-next-webiii,docker,,1
-19297,MA9149210776/CrucibleAI-ControlNetMediaPipeFace,gradio,,1
-19298,metrosir/ChatGPT4,gradio,mit,1
-19299,pyimagesearch/summary-to-title,gradio,mit,1
-19300,allknowingroger/Image-Models-Test207,gradio,,1
-19301,allknowingroger/Image-Models-Test208,gradio,,1
-19302,hf-audio/vocos-bark,gradio,,1
-19303,allknowingroger/Image-Models-Test209,gradio,,1
-19304,KAHRAMAN42/Animal_species_detection,gradio,apache-2.0,1
-19305,LEKAI007/QQ,docker,mit,1
-19306,Erala/QQsign,docker,mit,1
-19307,DEVILOVER/image_captioning,gradio,apache-2.0,1
-19308,AchyuthGamer/MagicPrompt-Stable-Diffusion,gradio,mit,1
-19309,Malolactica/amigosdejuegos,docker,,1
-19310,mayordp/DeepFakeAI,gradio,mit,1
-19311,picopi/openai-reverse-proxy,docker,,1
-19312,Wauplin/huggingface_hub,gradio,apache-2.0,1
-19313,lighdow/anime-cute-tts,gradio,mit,1
-19314,fittar/ViPE,gradio,mit,1
-19315,Bonp/B,docker,,1
-19316,ercaronte/speech-to-speech-translation,gradio,,1
-19317,Hoolbo/bing,docker,mit,1
-19318,joaopereirajp/livvieChatBot,gradio,,1
-19319,vih-v/Stable-Diffusion-prompt-generator,gradio,mit,1
-19320,mrSoul7766/Instagram_post_caption_generator,streamlit,apache-2.0,1
-19321,wangzhang/ChatSDB,gradio,,1
-19322,Cran-May/SEA-Streamlit,streamlit,,1
-19323,gelnicker/ostris-ikea-instructions-lora-sdxl,gradio,,1
-19324,InvisableClearCoat101/mistralai-Mistral-7B-v0.1,gradio,,1
-19325,prthgo/PDF-Chatbot,streamlit,,1
-19326,roshithindia/song-generation,gradio,,1
-19327,roshithindia/text_calssification_model,streamlit,,1
-19328,OrangeBusiness/OrangeBranding,gradio,apache-2.0,1
-19329,Thorsten-Voice/Hessisch,streamlit,cc0-1.0,1
-19330,SakshiRathi77/SakshiRathi77-wav2vec2_xlsr_300m,gradio,apache-2.0,1
-19331,igolas0/fastai_sportsman,gradio,apache-2.0,1
-19332,Acapellas/vocalinstrumentalremover,gradio,,1
-19333,HughAA/IPQA,gradio,apache-2.0,1
-19334,Orami01/Cha_with_CSV_using_Llama2,streamlit,,1
-19335,nightelf/codesandbox,Configuration error,Configuration error,1
-19336,dreamdrop/bot,static,,1
-19337,praveen-reddy/PDP,streamlit,apache-2.0,1
-19338,ennov8ion/art-models,gradio,,1
-19339,derek-thomas/RAGDemo,gradio,mit,1
-19340,rajababu15/Health_Tracker,streamlit,,1
-19341,Starkate/zo,docker,apache-2.0,1
-19342,eaglev/whales,gradio,apache-2.0,1
-19343,rasmodev/sepsis_prediction,docker,mit,1
-19344,rajababu15/ht_bk,streamlit,,1
-19345,JustSkyDev/DSEG,gradio,gpl-3.0,1
-19346,Tanjiro2002/Government_order,gradio,,1
-19347,AchyuthGamer/OpenGPT-Chat,gradio,,1
-19348,JayKen/Object-detection,gradio,,1
-19349,Potanin/12345,gradio,lgpl-3.0,1
-19350,ennov8ion/art-multi,gradio,,1
-19351,botlik100/kaki,gradio,lgpl-3.0,1
-19352,lzr090708/Real-CUGA,gradio,gpl-3.0,1
-19353,awacke1/HealthyBrainAging,streamlit,mit,1
-19354,rajababu15/ht_bk_gr,gradio,,1
-19355,Dimalker/Faceswapper,gradio,,1
-19356,MakiAi/SquareMotion,streamlit,mit,1
-19357,better-ai/lisa,gradio,unknown,1
-19358,pn23/HackGT2023,streamlit,,1
-19359,sznicko/tick,docker,,1
-19360,aaronayitey/Streamlit-app,streamlit,mit,1
-19361,Mark3347/AlpinaB12,docker,apache-2.0,1
-19362,Kurugodu/mygenaibha,gradio,,1
-19363,XX-4419/xx-chatui,docker,mit,1
-19364,lewisliuX123/wechatllama2,gradio,,1
-19365,typesdigital/llm-agents-tora-70b-v1.0,gradio,,1
-19366,Severian/ANIMA-7B-Biomimicry-LLM,gradio,,1
-19367,ikechan8370/meme-generator,docker,apache-2.0,1
-19368,genaibook/audio_visualizations,gradio,,1
-19369,xiaoyeAI/clewd,docker,,1
-19370,nesticot/player_cards,docker,mit,1
-19371,skoneru/contextual_refinement_ende,gradio,apache-2.0,1
-19372,hadasak/SciTrends,gradio,,1
-19373,gstaff/gif-reverser,gradio,apache-2.0,1
-19374,Yaroslav1234/PublicComment.AI,gradio,mit,1
-19375,Frantz103/CaptionQuest,gradio,,1
-19376,datboichidori/Ryzan-fantasy-diffusion-v1,gradio,,1
-19377,datboichidori/yehiaserag-anime-pencil-diffusion,gradio,,1
-19378,mrciolino/InvertibleSteganography,streamlit,apache-2.0,1
-19379,roger33303/GenerativeAI-Chatbot.AI-Therapist,gradio,mit,1
-19380,SakshiRathi77/SakshiRathi77-Wav2Vec2-hi-kagglex,gradio,apache-2.0,1
-19381,exit9/neuro_evolution,docker,mit,1
-19382,nathanTQ/ChatDev,gradio,,1
-19383,LaynzKunz/Model-RCV,gradio,openrail,1
-19384,sachin1729/Image_GeneratorByText_Sachin,gradio,,1
-19385,kmrmanish/LPI_Course_Recommendation_System,streamlit,apache-2.0,1
-19386,sachin1729/Imgae2text_BySachin,gradio,,1
-19387,AnishKumbhar/ChatBot,gradio,llama2,1
-19388,vishal0501/ICD-DEMO,streamlit,,1
-19389,VlaTal/facial_beauty_analysis,gradio,mit,1
-19390,Liberian/jtr8ukj8sk,docker,,1
-19391,Liberian/ghfvtybrfbuyt,docker,,1
-19392,wolf-sigma/Starburst_Galaxy__PyStarburst_Demo,docker,,1
-19393,QuophyDzifa/Sepsis-prediction-App,docker,mit,1
-19394,Shreeraj/SEO_APP,streamlit,,1
-19395,luisotorres/plant-disease-detection,gradio,,1
-19396,firdavsyorkulov/delivery_project_fastapi,docker,,1
-19397,MultiTransformer/vision-agent-with-llava,static,mit,1
-19398,vih-v/x_mod,gradio,,1
-19399,crimbo66/openai-whisper-large,gradio,,1
-19400,dreamdrop/kandinsky-2-1,gradio,,1
-19401,asteph/harrywang-pokemon-lora,gradio,,1
-19402,Vishakaraj/Point_Cloud_Segmentation-Trimble_Cloud,gradio,,1
-19403,TechnoByte/wd-v1-4-tags,gradio,,1
-19404,TechnoByte/soft-improved,gradio,apache-2.0,1
-19405,ShrapTy/text_generation,gradio,,1
-19406,KdaiP/yolov8-deepsort-tracking,gradio,mit,1
-19407,Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model,gradio,mit,1
-19408,firsk/ai_otto,gradio,mit,1
-19409,darthPanda/facial_recognition,gradio,,1
-19410,Kvikontent/QrGen,gradio,openrail,1
-19411,Nigomaster/Analizador_CVs,streamlit,,1
-19412,alonsosilva/NextTokenPrediction,docker,mit,1
-19413,Beasto/Photo2Monet_Cyclegan,streamlit,apache-2.0,1
-19414,Cippppy/RegressionVisualization,gradio,mit,1
-19415,metalslimeee/zigspace,docker,,1
-19416,serdaryildiz/TRCaptionNet,gradio,,1
-19417,generativeai/bestpics-ms-crop-image,gradio,apache-2.0,1
-19418,generativeai/bestpics-ms-image-similarity,gradio,,1
-19419,Anthony-Ml/covid_predictor,gradio,,1
-19420,ShrapTy/GPT4ALL,gradio,,1
-19421,rbanfield/libfacedetection,gradio,,1
-19422,caixyz/ok,docker,,1
-19423,gstaff/system-monitor,gradio,apache-2.0,1
-19424,XzJosh/Bekki-Bert-VITS2,gradio,mit,1
-19425,XzJosh/TianDou-Bert-VITS2,gradio,mit,1
-19426,iamironman4279/SadTalker,gradio,mit,1
-19427,QCRI/mt-bench-ar,gradio,,1
-19428,Priyanka-Kumavat/Anomaly-Detection-On-Sound-Data,streamlit,,1
-19429,shinexyt/StaticDemo,static,mit,1
-19430,awacke1/VotingCrowdsourceEvaluationApps2,streamlit,mit,1
-19431,PepijnvB/KappaNeuro-salomon-van-ruysdael-style,gradio,,1
-19432,Endream/test,streamlit,apache-2.0,1
-19433,ERICTORRALBA/CAD,docker,apache-2.0,1
-19434,Alycer/VITS-Umamusume-voice-synthesizer,gradio,,1
-19435,Vardaan08/TeamPredictor2,gradio,afl-3.0,1
-19436,jpwahle/field-diversity,docker,,1
-19437,Cran-May/BetaSEA-Streamlit,streamlit,,1
-19438,pdehaye/EleutherAI-llemma_34b,gradio,,1
-19439,hamzaislamorg/README,static,,1
-19440,deepusus/tts,gradio,,1
-19441,acmyu/frame_interpolation_prototype,gradio,,1
-19442,tether1/usdt,static,other,1
-19443,deepusus/chat,gradio,,1
-19444,amankishore/adept-fuyu-8b,gradio,,1
-19445,vroy02243/ML,gradio,,1
-19446,44ov41za8i/FreeVC,gradio,mit,1
-19447,moin1234/XAGPT1,streamlit,,1
-19448,mixcard/Gustavosta-MagicPrompt-Dalle,gradio,,1
-19449,cha0smagick/RPG_Character_generator,streamlit,mit,1
-19450,pharma-IA/PharmaWise_Experto_GMP_V2C_ToT,gradio,,1
-19451,abidlabs/gradio-lite-speech,static,,1
-19452,tbdaox/roopUn,docker,,1
-19453,temion/KoGPT_API,gradio,,1
-19454,LaynzKunz/RCV-AI-COVER,gradio,apache-2.0,1
-19455,simonraj/DesignThinkingCoach,gradio,mit,1
-19456,Pranjal12345/Text_to_Speech,gradio,mit,1
-19457,echons/musicgen-small,streamlit,,1
-19458,ArtyomKhyan/Detection,gradio,,1
-19459,Isuru623/CardioScanPro,streamlit,mit,1
-19460,Priyanka-Kumavat/Document-Summarization,gradio,,1
-19461,netrosec/diabetes-cox-ph-hazard,gradio,mit,1
-19462,dfhhr4/QQsign,docker,mit,1
-19463,msy127/app_rag_llama2_paper,gradio,gpl,1
-19464,Vedarutvija/Veda_Audio_To_Text,gradio,mit,1
-19465,Vedarutvija/ZebraGPT,gradio,mit,1
-19466,Iseratho/frame-finder,gradio,mit,1
-19467,padmanabhbosamia/Stable_Diffusion,gradio,mit,1
-19468,riccorl/relik-entity-linking,streamlit,,1
-19469,XzJosh/Echo-Bert-VITS2,gradio,mit,1
-19470,XzJosh/Spade-Bert-VITS2,gradio,mit,1
-19471,aseuteurideu/audio_deepfake_detector,gradio,,1
-19472,islammohy/Chat-with-Llama-2-7b-st-voice,streamlit,mit,1
-19473,fero/stable-diffusion-webui-cpu,gradio,,1
-19474,innat/UniFormerV2,gradio,mit,1
-19475,Reza2kn/teknium-OpenHermes-2-Mistral-7B,gradio,,1
-19476,30SecondsToMoon/30SecondsToMoon,gradio,mit,1
-19477,freddyaboulton/gradio-lite-sklearn,static,,1
-19478,samayg/StriimTheme,gradio,apache-2.0,1
-19479,Benjov/Demo-IR,gradio,openrail,1
-19480,diego2554/RemBG_super,gradio,,1
-19481,sznicko/vpsfree,docker,,1
-19482,Making/goofyai-Leonardo_Ai_Style_Illustration,gradio,,1
-19483,AnishKumbhar/DogDiseasePredictor,docker,mit,1
-19484,AlekseyKorshuk/gai-project,gradio,apache-2.0,1
-19485,PeepDaSlan9/Nan-Do-LeetCodeWizard_13B_v1.0,gradio,apache-2.0,1
-19486,prithush/Disaster_Tweet_Prediction,streamlit,apache-2.0,1
-19487,Beasto/Day_to_Night_Cyclegan,streamlit,apache-2.0,1
-19488,deepusus/tts-eng,gradio,apache-2.0,1
-19489,Abhaykoul/Palm-2,streamlit,,1
-19490,quanhua/KappaNeuro-movie-poster,gradio,,1
-19491,chatpdfdemo/chatpdfdemo,streamlit,,1
-19492,chatpdfdemo/demo,streamlit,gfdl,1
-19493,idlsono/Idksono4,docker,,1
-19494,awacke1/CalorieCalculatorForMorningSwimandPullUps,streamlit,mit,1
-19495,solara-dev/template,docker,mit,1
-19496,keyikai/bing,docker,mit,1
-19497,Sifal/En2Kab,gradio,mit,1
-19498,ladapetrushenko/construction_prediction,streamlit,,1
-19499,Beasto/Face_To_Anime_Cyclegan,streamlit,apache-2.0,1
-19500,tsi-org/Faceswapper,gradio,,1
-19501,PeepDaSlan9/stabilityai-stablecode-instruct-alpha-3b,gradio,apache-2.0,1
-19502,yomo93/Tendon-search,gradio,apache-2.0,1
-19503,Sonnt/Fracture_Webapp,streamlit,other,1
-19504,hysts-duplicates/comparing-captioning-models,gradio,,1
-19505,Rashid2026/Course-Recommender,static,,1
-19506,Prasanna18/Nagpur-FoodGPT,streamlit,,1
-19507,LaynzKunz/REMAKE-AI-COVER,gradio,openrail,1
-19508,HyAgOsK/ECG_avalible,gradio,,1
-19509,AlbertoFH98/CastenaApp,streamlit,apache-2.0,1
-19510,fh2412/handwritten_numbers,gradio,apache-2.0,1
-19511,Abhaykoul/HelpingAI-t2,gradio,,1
-19512,yifangtongxing/qsign,docker,,1
-19513,AAYUSH27/Neuro,streamlit,,1
-19514,Jamin252/Dog_Identifier,gradio,,1
-19515,TNK21/Story_Generator,gradio,,1
-19516,silvanoalbuquerque/YOLO-V8_ANIMALS_CLASSIFICATION,gradio,,1
-19517,gojiteji/mistral-7b-fast-chat-with-Japanese-MT,gradio,,1
-19518,Theopan/VoiceFixer,gradio,,1
-19519,Abhaykoul/Prompt_generator_for_helpingAI-tti,gradio,mit,1
-19520,Prasanna18/SujokTherapy,streamlit,,1
-19521,CamCam17/Alexwww-davide-comic-book-characters,docker,,1
-19522,Lehele/bingai,docker,mit,1
-19523,mkoot007/Text2Story,streamlit,apache-2.0,1
-19524,allberto/Porn_Merge_V1.3,gradio,mit,1
-19525,hidevs-community/Youtube2Linkedin,gradio,,1
-19526,tensor-diffusion/contribute-together-datasets,docker,apache-2.0,1
-19527,Michale1017/WS,Configuration error,Configuration error,1
-19528,TheKitten/Chat-with-Llama-2-70b-st-voice,streamlit,mit,1
-19529,geofactoryplastix/my-rvc-voicemodels,static,other,1
-19530,mkoot007/Conversation,gradio,apache-2.0,1
-19531,Mycroft756/artificialguybr-StickersRedmond,gradio,,1
-19532,svjack/chatglm2-6b-ggml,gradio,,1
-19533,roughhai/myGenAIChatBot,gradio,,1
-19534,hjianganthony/fetch_ner,gradio,,1
-19535,sunxyz/testxy,docker,,1
-19536,wolfpackhnu/web_hosting,gradio,,1
-19537,Fcjs/stablediffusionapi-lob-realvisxl-v20,gradio,gpl-3.0,1
-19538,MoyerLiu/ChatGPT-Next-Web,docker,apache-2.0,1
-19539,muteekhan06/English-to-French,gradio,,1
-19540,INDONESIA-AI/Anapnoe,gradio,,1
-19541,dodos3/cosmos,docker,,1
-19542,huang4414/Real-CUGAN,gradio,gpl-3.0,1
-19543,huang4414/GTest,docker,,1
-19544,huang4414/anime-aesthetic-predict,gradio,apache-2.0,1
-19545,vonewman/ner_app,streamlit,apache-2.0,1
-19546,bodrum/bodrumfenisleri,streamlit,,1
-19547,GIZ/vulnerability_analysis,streamlit,openrail,1
-19548,Jose-Alonso26/API-Online,docker,,1
-19549,Abhaykoul/BardCookies-AI_Query,gradio,mit,1
-19550,AutomationVR/ImageDemo,gradio,,1
-19551,Abhaykoul/HelpingAI-T3,static,mit,1
-19552,Omnibus/game-test,gradio,,1
-19553,fxmikau/o4gpt,gradio,apache-2.0,1
-19554,svjack/stable-diffusion.cpp,gradio,,1
-19555,leonardoboulitreau/aitmospheric,gradio,mit,1
-19556,Nightwing25/AICoverGen,gradio,mit,1
-19557,mfoud2023/Alhareq,docker,,1
-19558,masterkram/finance_news_classifier,streamlit,mit,1
-19559,awacke1/Top-Ten-United-States,streamlit,mit,1
-19560,awacke1/Map-California-AI,streamlit,mit,1
-19561,awacke1/California-Medical-Centers-Streamlit,streamlit,mit,1
-19562,awacke1/Minnesota-Medical-Centers-Streamlit,streamlit,mit,1
-19563,hyxue/HiFiFace-inference-demo,docker,mit,1
-19564,awacke1/Azure-Cosmos-DB,streamlit,mit,1
-19565,digitalxingtong/Bufeiyan-b-Bert-VITS2,gradio,mit,1
-19566,digitalxingtong/Bufeiyan-c-Bert-VITS2,gradio,mit,1
-19567,Zaixi/ICLR_FLAG,gradio,apache-2.0,1
-19568,certkor/CertKOR.ai,streamlit,cc-by-nc-4.0,1
-19569,simonraj/ELOralCoachHONGWEN,gradio,,1
-19570,Beasto/Image_Colorizer_Pix2Pix,streamlit,apache-2.0,1
-19571,Fcjs/stablediffusionapi-edge-of-realism,gradio,gpl-3.0,1
-19572,XzJosh/maimai-Bert-VITS2,gradio,mit,1
-19573,df-h/viachat-v0.95,gradio,apache-2.0,1
-19574,JSP/test4k,docker,,1
-19575,mkoot007/Text2Image,gradio,apache-2.0,1
-19576,garima-mahato/ShakespearesWeirdTales,gradio,mit,1
-19577,hca97/Mosquito-Detection,gradio,,1
-19578,abidlabs/structured-data-classification,gradio,,1
-19579,peazy/Matt-or-Meth-Damon,gradio,apache-2.0,1
-19580,Violetmae14/images-to-audio,static,,1
-19581,abidlabs/frame-example,gradio,,1
-19582,Happys/chatbot,docker,mit,1
-19583,JamesStratford/Identify-Pest-Predators-Demo,gradio,,1
-19584,Fcjs/digiplay-Real3D_F16full_v3.1,gradio,,1
-19585,wuliya/QQsign,docker,mit,1
-19586,JunghunleePhD/catsClassification,gradio,mit,1
-19587,rahul-pandey-ct/kinship-llm,gradio,,1
-19588,teasouse/teaProxy,docker,,1
-19589,S1516/README,static,,1
-19590,dongyaren/bhyy,docker,mit,1
-19591,XzJosh/Lumi-Bert-VITS2,gradio,mit,1
-19592,XzJosh/yoyo-Bert-VITS2,gradio,mit,1
-19593,Saketh-Reddy/testing,static,,1
-19594,M-A-D/Dar-En-Translation-streamlit-Test,streamlit,,1
-19595,awacke1/mixture-of-experts-dr-llama,streamlit,mit,1
-19596,legacy107/flan-t5-large-ia3-cpgqa,gradio,,1
-19597,HaohuaLv/one-shot_object_detection,gradio,mit,1
-19598,schogini/toys,gradio,,1
-19599,arsalagrey/audio-classification-vue,static,mit,1
-19600,rng0x17/jupyterlab,docker,,1
-19601,Thanu83/Music,streamlit,,1
-19602,JunghunleePhD/testfordocker,docker,,1
-19603,sunil448832/retrieval-augment-generation,gradio,,1
-19604,Jody36565/segmind-SSD-1B,gradio,,1
-19605,olimpa/CVPZJACOB,static,,1
-19606,LAYEK-143/TEXT-TO-IMAGE-AI,gradio,apache-2.0,1
-19607,adrianpierce/recipes_app,streamlit,other,1
-19608,AliUsama98/Aliusama_spellchecker,gradio,apache-2.0,1
-19609,arsalagrey/speech-recognition-vue,static,mit,1
-19610,Dragonnnext/Unicorn-proxy,docker,,1
-19611,Dragonnnext/Drago-Proxy,docker,,1
-19612,Dragonnnext/scylla-proxy,docker,,1
-19613,Dragonnnext/charybdis,docker,,1
-19614,jonybepary/teknium-CollectiveCognition-v1.1-Mistral-7B,gradio,,1
-19615,Michale1017/Auto-keep-online,docker,,1
-19616,AliUsama98/Usama_TextClassifier,gradio,,1
-19617,puqi/climsim,streamlit,,1
-19618,amin2809/rvc-models2023,gradio,mit,1
-19619,leelalife/super-fast-sdxl-stable-diffusion-xl,gradio,creativeml-openrail-m,1
-19620,sakina1122/Jimmey_image_capturing,gradio,apache-2.0,1
-19621,swj0419/Detect-Pretraining-Data,gradio,,1
-19622,abidlabs/mteb-leaderboard,gradio,,1
-19623,LaynzKunz/AI-Cover-Gen-Web-Ui,gradio,mit,1
-19624,vpsrikanth/FaceSimilarity,docker,mit,1
-19625,bennydou/gitea,docker,mit,1
-19626,PeWeX47/GPT-2-Lyrics-Generator,gradio,mit,1
-19627,Siyuan0730/clewordAutomaticGenerating,streamlit,,1
-19628,spineapple/FoodVision,gradio,mit,1
-19629,qiemanqieman/Salesforce-blip-image-captioning-base,gradio,,1
-19630,Designstanic/meta-llama-Llama-2-7b-chat-hf,gradio,llama2,1
-19631,NexusInstruments/DFIRFlowChain,docker,apache-2.0,1
-19632,Immaniel/mygenAIAvatarSpeech,gradio,,1
-19633,padmanabhbosamia/Nano_GPT,gradio,mit,1
-19634,KennyUTC/BotChat,static,mit,1
-19635,thelou1s/MIT-ast-finetuned-audioset-10-10-0.4593,gradio,,1
-19636,Pluviophile/QQsign,docker,mit,1
-19637,svjack/stable-diffusion.search.hash,gradio,,1
-19638,Niansuh/Image,gradio,,1
-19639,sunilbhatia/hackathon1,docker,mit,1
-19640,Lianguangluowuyan/QQsign,docker,mit,1
-19641,QuanLingZ/ChatReviewer,gradio,apache-2.0,1
-19642,abusch419/PetBreedClassifier,gradio,apache-2.0,1
-19643,SIH/tree-segmentation,gradio,mit,1
-19644,Smols/Ilinalta,docker,,1
-19645,Smols/AWS,docker,,1
-19646,abhi3940/test,streamlit,,1
-19647,yeshpanovrustem/ner-kazakh,streamlit,,1
-19648,themanas021/pictionary,gradio,,1
-19649,saurabhg2083/jobbias,streamlit,,1
-19650,Leyo/AI_Meme_Generator,gradio,,1
-19651,Albertha/qwe123,docker,,1
-19652,Promit/BrainSEG,gradio,apache-2.0,1
-19653,LaynzKunz/RCVAICOVER,gradio,creativeml-openrail-m,1
-19654,jokogadingan/joko-gadingan-image-description-project,gradio,,1
-19655,xznwwh/aabb,docker,,1
-19656,cancanasoyak/CropBased-TissueMasking,streamlit,,1
-19657,capjamesg/fastvit,gradio,mit,1
-19658,BiTransSciencia/www,static,,1
-19659,Gianpaolog/newbie-elixir,docker,,1
-19660,AixiaGreyatt/QQsign,docker,,1
-19661,Blessin/impro-scene-generator,gradio,mit,1
-19662,AchyuthGamer/text-to-speech-client,static,,1
-19663,shimizukawa/python-no-senpai,streamlit,mit,1
-19664,hhemanth/first_project,gradio,apache-2.0,1
-19665,kevinhug/clientX,gradio,,1
-19666,josegabmuz/gradio-test,gradio,,1
-19667,bhagyaK/mygenai,gradio,,1
-19668,suvradip2000/space1,docker,mit,1
-19669,Sanathkumar1603/hackathon,docker,mit,1
-19670,RohithMidigudla/Comment_Toxicity_Detection,gradio,,1
-19671,SeyedAli/Butterfly-image-Generation,gradio,mit,1
-19672,Blessin/one-liners,gradio,mit,1
-19673,Abdo1Kamr/Text_Translation_And_Text_Formatter_For_Palestinian_Case,gradio,,1
-19674,Banbri/zcvzcv,docker,,1
-19675,Zahnanni/FinnishLocalLingoLexicon,gradio,,1
-19676,hsukqilee/NSFW-API,docker,,1
-19677,Siyuan0730/revise_IELTS_writting,streamlit,,1
-19678,LinJulya/PromptGenerator,gradio,apache-2.0,1
-19679,langvision/codellama-34b-chat,gradio,,1
-19680,aidinro/qqqqqqqqqqqqq,streamlit,,1
-19681,langvision/llama-2-70b-chat,gradio,,1
-19682,langvision/README,static,,1
-19683,hackertwo/GoAheadMazen,static,,1
-19684,shhegart/f1-vs-gt3,gradio,,1
-19685,ayushnoori/program-synthesis,streamlit,,1
-19686,PaSathees/Vehicle_Tyre_Quality_Checker,gradio,apache-2.0,1
-19687,ubermenchh/zephyr_chatbot,gradio,apache-2.0,1
-19688,langvision/ChatWeb,static,gpl-3.0,1
-19689,MiklX/claude,docker,apache-2.0,1
-19690,langvision/ChatGPT,docker,apache-2.0,1
-19691,eye-yawn/visuAILearn,streamlit,,1
-19692,popo23/app,docker,,1
-19693,ethan-ai/VideoRetalking,docker,,1
-19694,linzjian666/vvvtss,docker,mit,1
-19695,miracle01/white-emotion-recognition,gradio,mit,1
-19696,ongxuanhong/listing-content-with-ai,streamlit,apache-2.0,1
-19697,JosueElias/borrs,streamlit,,1
-19698,Cran-May/Shi-Ci-app,gradio,apache-2.0,1
-19699,digitalxingtong/Xingtong-2dall-Bert-VITS2,gradio,mit,1
-19700,gkswk/cosmos,docker,,1
-19701,livekhh/formal_project,gradio,apache-2.0,1
-19702,Clara998/DisneyPixarMovie,gradio,,1
-19703,ArcanAlt/arcanDream,docker,,1
-19704,mdkhalid/mistralai-Mistral-7B-v0.1,gradio,apache-2.0,1
-19705,fauzanrisqullah/rmt-24-gc5,streamlit,,1
-19706,shubhamjaiswar/RakshakReet-SpamDetection,gradio,,1
-19707,deniskrr/clothing-type-classifier,gradio,apache-2.0,1
-19708,yithong/audio2summary,gradio,,1
-19709,Michale1017/xray,docker,,1
-19710,yigekeqing/QQsign,docker,mit,1
-19711,saawal/Heart_Disease_Model,gradio,,1
-19712,sofanorai/gpt-web,static,,1
-19713,trysem/image-matting-app,gradio,mit,1
-19714,JDWebProgrammer/chatbot,streamlit,,1
-19715,NillJan/NelsonBot,gradio,,1
-19716,americanboy/Prime_Numbers,gradio,,1
-19717,uzairm/anyroad,gradio,,1
-19718,thelou1s/ltu-2,gradio,bsd-2-clause,1
-19719,gracexu/llama-2-7b-chat-grace,gradio,,1
-19720,Blessin/drama-director,gradio,,1
-19721,rahul-pandey-ct/kinship-llm-poc,gradio,,1
-19722,Blessin/movie-poster-generator,gradio,mit,1
-19723,awacke1/Streamlit-Google-Maps-Minnesota,streamlit,mit,1
-19724,KAHRAMAN42/youtube_transcript,gradio,apache-2.0,1
-19725,Blessin/yes-and-improv-game,gradio,,1
-19726,prthgo/Tabular-Data-Analysis-and-Auto-ML,streamlit,,1
-19727,awacke1/Streamlit-Google-Maps-California,streamlit,mit,1
-19728,awacke1/Streamlit-Google-Maps-Washington,streamlit,mit,1
-19729,awacke1/Streamlit-Google-Maps-Massachusetts,streamlit,mit,1
-19730,awacke1/Streamlit-Google-Maps-Texas,streamlit,mit,1
-19731,tushar27/Streamlit-Magic-Sheet,streamlit,apache-2.0,1
-19732,ltg/chat-nort5,gradio,,1
-19733,nascetti-a/py2DIC,streamlit,cc-by-nc-4.0,1
-19734,xumingliuJ/space-demo,gradio,,1
-19735,SukhdevMiyatra/streamlit-smartphone-eda,streamlit,,1
-19736,kevin-dw/runwayml-stable-diffusion-v1-5,gradio,,1
-19737,omarbaba/streamlit-test,streamlit,,1
-19738,jbilcke-hf/image-caption-server,gradio,mit,1
-19739,Ataturk-Chatbot/HuggingFaceChat,gradio,,1
-19740,rupeshs/fastsdcpu,gradio,mit,1
-19741,Tirendaz/Multilingual-NER,gradio,mit,1
-19742,captain-awesome/pet-dog-care-bot,gradio,apache-2.0,1
-19743,Pranjal2041/GEO-bench,gradio,apache-2.0,1
-19744,cybergpt/ChatGPT,gradio,,1
-19745,TRaw/jelly,gradio,,1
-19746,kvviingu/stabilityai-stable-diffusion-xl-base-1.0,gradio,,1
-19747,Kiyo-umm/Linaqruf-pastel-anime-xl-lora,gradio,,1
-19748,luisotorres/bart-text-summarization,streamlit,,1
-19749,allyssonmacedo/good-clients,streamlit,,1
-19750,livingbox/Image-Models-Test-31,gradio,,1
-19751,hayas/rinna-youri-7b-chat,gradio,mit,1
-19752,dongyaren/12345,docker,mit,1
-19753,aipicasso/playground,gradio,openrail++,1
-19754,jessica6105/Lu-Bert-VITS2,gradio,agpl-3.0,1
-19755,ViralWeb/aifi,docker,openrail,1
-19756,nopassionyeah/bing,docker,mit,1
-19757,thuonghai2711/JDhfjrtjklrkhjgknhjvfgnh2,docker,,1
-19758,noahzhy/KR_LPR_TF,gradio,bsd-2-clause,1
-19759,dragao-elastico/RVC_V2,gradio,lgpl-3.0,1
-19760,saad-k7/Jewelli-Chatbot,gradio,,1
-19761,freddyaboulton/gradio_foliumtest,docker,apache-2.0,1
-19762,trungtruc/segment_clothes,gradio,mit,1
-19763,simonraj/ELOralCoachRiverValleyPrimarySchool,gradio,,1
-19764,mabzak/Youtube-Comment-Sentimen-Analisis,streamlit,,1
-19765,zht1/test2,gradio,,1
-19766,KalbeDigitalLab/ham1000-skin-classification,gradio,unknown,1
-19767,simonraj/ELOralCoachCantonmentPrimary,gradio,,1
-19768,Chomkwoy/Nilkessye,gradio,apache-2.0,1
-19769,lqy09/GT,docker,,1
-19770,Mmmm7/M,docker,,1
-19771,bruno16/massa_qa,gradio,,1
-19772,Felladrin/LaMini-Flan-T5-248M-Candle-Wasm,static,,1
-19773,atimughal662/InfoFusion,gradio,apache-2.0,1
-19774,wiwaaw/chatpdf,streamlit,mit,1
-19775,simonraj/ELOralCoachTestFeedback,gradio,,1
-19776,meet244/Legal-Up_Lawyer_Recommendation_System,gradio,mit,1
-19777,jonathanjordan21/lmd_chatbot_embedding,gradio,apache-2.0,1
-19778,KennethTM/semantic_search,gradio,mit,1
-19779,namdu/README,static,,1
-19780,LaynzKunz/RVC-Inference-webui-grado-colab-huggingafce,gradio,mit,1
-19781,Deviliaan/sd_twist,gradio,,1
-19782,kunkun11/home,gradio,mit,1
-19783,Sanchayt/VectaraBeginner,streamlit,apache-2.0,1
-19784,Shubhamskg/LangchainQuesAnsChatbot,streamlit,,1
-19785,NLPark/Misteln-Schariac,gradio,apache-2.0,1
-19786,realgenius/NousResearch-Yarn-Mistral-7b-128k,streamlit,,1
-19787,SIGMitch/Real-Time-Chad,docker,,1
-19788,krunalss/firstllm,streamlit,,1
-19789,themanas021/Kosmos-2,gradio,,1
-19790,ryn-85/NousResearch-Yarn-Mistral-7b-128k,streamlit,apache-2.0,1
-19791,janeH/QQsign,docker,mit,1
-19792,Luckro3/README,static,,1
-19793,bejar111/cursoia,docker,,1
-19794,DeliaPaladines/CursoIA,docker,,1
-19795,lordfoogthe2st/PDIS-nature-surfer-ai,gradio,mit,1
-19796,ahuang11/tastykitchen,docker,bsd-3-clause,1
-19797,profayle/TerrapinTalk,gradio,,1
-19798,Niansuh/api,docker,,1
-19799,Niansuh/chat,docker,mit,1
-19800,MultiAgentSystems/README,static,,1
-19801,MultiAgentSystems/MapAI-ClinicsAndMedCenters,streamlit,mit,1
-19802,MultiAgentSystems/WhisperLlamaMultiAgentSystems,streamlit,mit,1
-19803,MultiAgentSystems/WhisperGPTMultiAgentSystems,streamlit,mit,1
-19804,rajeev12/rajeev_space,gradio,,1
-19805,Osborn-bh/ChatGLM3-6B-Osborn,gradio,,1
-19806,IES-Rafael-Alberti/PerfectGPT,gradio,unknown,1
-19807,rostislav553/PROGECT,streamlit,,1
-19808,Kaikaikai/webgl_demo,static,,1
-19809,abcdef12356/slinteg,streamlit,,1
-19810,ankur2402/ISRO,streamlit,,1
-19811,sujitojha/nanoGPT,gradio,apache-2.0,1
-19812,tiagopessoalim/Predicting180-DayMortalityInGeriatricOncology,streamlit,,1
-19813,AnimeStudio/anime-models,gradio,,1
-19814,Tirendaz/NER-Demo,gradio,,1
-19815,Abhaykoul/Merriam-webster_clone,streamlit,mit,1
-19816,Gosula/hand_written_digit_recognition,streamlit,mit,1
-19817,icashwave/rwkv-v5-1b5-cpu,gradio,apache-2.0,1
-19818,Sjmin/cosmos,docker,,1
-19819,typesdigital/demo-app,streamlit,,1
-19820,Trangluna2002/AI_Cover_Gen,gradio,mit,1
-19821,tosta86/Flowise,docker,mit,1
-19822,keanteng/job,streamlit,mit,1
-19823,qq2855562986/anime-remove-background,gradio,apache-2.0,1
-19824,o-m-s/Med_DL,gradio,apache-2.0,1
-19825,YanzBotz/stablediffusionapi-disney-pixar-cartoon,gradio,,1
-19826,osl-ai/NousResearch-Yarn-Mistral-7b-64k,gradio,,1
-19827,Wassim/public-custom-search,gradio,gpl,1
-19828,hyunda/test9week,gradio,,1
-19829,yousuf-e/yousuf-space-1,docker,mit,1
-19830,Abhaykoul/Wikipedia,streamlit,mit,1
-19831,mufssdr/jaidhus,docker,,1
-19832,mufssdr/kkhuy,docker,,1
-19833,GAURAVBRAR/AIGK,gradio,,1
-19834,alGOriTM207/Ru_DialoModel,streamlit,cc-by-nc-nd-4.0,1
-19835,svjack/stable-diffusion.search.embedding,gradio,,1
-19836,asfzf/DeepDanbooru_stringxchj,gradio,,1
-19837,Talo88/Tumer-Detection,streamlit,,1
-19838,yyyyulia/7390_nlp_interactive_v2,streamlit,apache-2.0,1
-19839,Mahit/DDoS_Attack_Classifier,gradio,apache-2.0,1
-19840,sanjay11/resumescan,streamlit,,1
-19841,Rifd/Sdallmodels,gradio,,1
-19842,pseudolab/Rice_Disease_Classifier,docker,apache-2.0,1
-19843,Fadil369/docker,docker,mit,1
-19844,JessPink/Text_rewriting-Chatbot,gradio,,1
-19845,Abhaykoul/HelpingAI-2.0,streamlit,,1
-19846,MultiAgentSystems/MultiSystemAgentUI,streamlit,mit,1
-19847,QuanLingZ/ChatResponse,gradio,apache-2.0,1
-19848,xun/Qwen-Token-Calc,gradio,,1
-19849,ioniumX/SDXL-High-quality-art,static,,1
-19850,jorgeppp/LDCC-LDCC-Instruct-Llama-2-ko-13B-v1.4,gradio,apache-2.0,1
-19851,Suniilkumaar/MusicGen-updated,gradio,cc-by-nc-4.0,1
-19852,kodirovshchik/food_classification_api,docker,,1
-19853,petermutwiri/Movie_Review_Application,streamlit,mit,1
-19854,ztime/Yi-6B-GGUF_llama_cpp_python,gradio,mit,1
-19855,kinit-tomassako/ver-spaces-demo,gradio,,1
-19856,Hoshiyume/FixedStar-DebugChat,gradio,mit,1
-19857,Aqdas/YouTube_Video_OpenAI_whisper,streamlit,apache-2.0,1
-19858,airely/bingai1,docker,mit,1
-19859,themanas021/Image-alanysis,streamlit,mit,1
-19860,Jianfeng777/Car_Bike_Classification,gradio,,1
-19861,yufiofficial/MusicGenQ,gradio,cc-by-nc-4.0,1
-19862,kevinwang676/KNN-VC,gradio,mit,1
-19863,pp3232133/pp3232133-distilgpt2-wikitext2,gradio,apache-2.0,1
-19864,A-Roucher/Quotes,streamlit,,1
-19865,TandCAcceptMe/face-swap-docker,gradio,,1
-19866,Nymbo/OpenAI_TTS_Streaming_Whisperv3,gradio,mit,1
-19867,Dodero1305/Heart-Disease-Chatbot,streamlit,,1
-19868,tsinghua-ee/SALMONN-7B-gradio,gradio,apache-2.0,1
-19869,hanxuan/XQSign,docker,,1
-19870,luckpunk/LLMRiddles,gradio,apache-2.0,1
-19871,pantherhead/pantherhead,streamlit,unknown,1
-19872,Abhaykoul/Wizard-AI,streamlit,,1
-19873,tbvl/Fake_Face_Detection,gradio,mit,1
-19874,bbz662bbz/chatgpt_cost_calc,gradio,mit,1
-19875,JDWebProgrammer/space-weather,gradio,mit,1
-19876,ArpitM/chat-llm-streaming,gradio,,1
-19877,LuxOAI/zenFace-Recognition-SDK,docker,mit,1
-19878,Aditya757864/SentimentAnalysis,gradio,mit,1
-19879,ProgramX/hi,gradio,apache-2.0,1
-19880,merve/kosmos-2,gradio,apache-2.0,1
-19881,VinayHajare/MistralTalk,gradio,apache-2.0,1
-19882,BimboAnon/BimboProxy,docker,,1
-19883,lunarflu/HF-QA-Demo-3,gradio,,1
-19884,Karifannaa/audio_story,streamlit,,1
-19885,aaronayitey/Covid_19-Vaccine-Sentiment_Analysis,gradio,mit,1
-19886,Zitang/Self-attention-based-V1MT-motion-model,gradio,mit,1
-19887,taham655/transcriptionApp,streamlit,,1
-19888,MathFabian/p2_m5_hugging,gradio,apache-2.0,1
-19889,rashmi/h2oai-predict-llm,gradio,apache-2.0,1
-19890,pantherhead/test,streamlit,unknown,1
-19891,phyloforfun/GreenSight,streamlit,cc-by-nc-4.0,1
-19892,AshutoshPattanayak/LangchainDemo,streamlit,,1
-19893,latent-consistency/Real-Time-LCM-Text-to-Image-Lora-SD1.5,docker,,1
-19894,ngoctuanai/DALL-E,static,apache-2.0,1
-19895,OpenDILabCommunity/LLMRiddlesChatGLMCN,gradio,apache-2.0,1
-19896,flowers-team/SocialAISchool,docker,,1
-19897,nsoma/ml-break,gradio,mit,1
-19898,Tobias111/uptime,docker,mit,1
-19899,librarian-bots/Model-Cards-Nomic-Atlas-Map,static,,1
-19900,librarian-bots/Dataset-Cards-Nomic-Atlas-Map,static,,1
-19901,dawood/gradio_videogallery,docker,apache-2.0,1
-19902,GRATITUD3/NESGPT-AutoAnnotatorv0,gradio,mit,1
-19903,AhmedMagdy7/My_paper_space,gradio,apache-2.0,1
-19904,lIlIlllllmeng/zhaoyang,docker,mit,1
-19905,alvin888/GeoGenie,gradio,,1
-19906,TiKaira-6995/NepAI,docker,,1
-19907,Niansuh/DALL-E,static,apache-2.0,1
-19908,VinayHajare/Fruit-Recognition,gradio,apache-2.0,1
-19909,syq163/EmotiVoice,streamlit,apache-2.0,1
-19910,thelou1s/sleep_data,gradio,,1
-19911,flf/8983,docker,,1
-19912,sh20raj/telebot,streamlit,,1
diff --git a/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Download Xcpuscalar Gratis Enhance Your Windows Mobile Device Experience with This Amazing Software.md b/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Download Xcpuscalar Gratis Enhance Your Windows Mobile Device Experience with This Amazing Software.md
deleted file mode 100644
index 3ae9731e8f231c3d9fafbcd1188f2ecd12dc3154..0000000000000000000000000000000000000000
--- a/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Download Xcpuscalar Gratis Enhance Your Windows Mobile Device Experience with This Amazing Software.md
+++ /dev/null
@@ -1,77 +0,0 @@
-Grozdana Olujic Oldanini Vrtovi PDF Download: A Review of a Magical Fairy Tale Book
- Introduction
- Do you love fairy tales? Do you enjoy reading stories that transport you to a different world full of wonder and magic? If you answered yes, then you might want to check out Grozdana Olujic Oldanini Vrtovi PDF download , a book that will enchant you with its beautiful and original fairy tales.
-grozdana olujic oldanini vrtovi pdf download Download Zip ⚙⚙⚙ https://byltly.com/2uKvZe
Who is Grozdana Olujic and what is Oldanini Vrtovi?
- Grozdana Olujic was a Serbian writer, translator, editor and critic who was born in 1934 and died in 2019. She was best known for her fairy tale books, which have been translated into many languages and won several awards. She was also a professor of literature and a member of the Serbian Academy of Sciences and Arts.
- Oldanini Vrtovi (Oldana's Gardens) is one of her most famous fairy tale books, published in 1978. It contains seven stories that are set in a fictional city where a lonely princess lives. The title story, Oldanini Vrtovi, is the longest and most complex one, and it tells the story of how the princess discovers a secret garden where she meets a mysterious woman named Oldana and experiences many fantastic adventures.
- Why should you read Oldanini Vrtovi?
- Oldanini Vrtovi is not your typical fairy tale book. It is not a collection of old folk tales that have been retold by the author. Rather, it is an original work of art that combines elements of fantasy, science fiction, mythology, psychology and philosophy. It is a book that challenges your imagination and stimulates your curiosity. It is also a book that explores universal themes such as love, friendship, freedom, happiness, creativity and identity.
- If you are looking for a book that will make you feel like a child again, but also make you think like an adult, then Oldanini Vrtovi is the perfect choice for you. You will be amazed by the rich and vivid descriptions of the garden and its inhabitants, the clever and witty dialogues between the characters, the surprising twists and turns of the plot, and the profound and meaningful messages that the author conveys through her stories.
- Main body
- The plot of Oldanini Vrtovi
- The main story of Oldanini Vrtovi revolves around a young princess who lives in a huge palace in a city surrounded by walls. She has everything she could ever want, except for one thing: she is very lonely. She has no friends, no family, no pets, no hobbies. She spends her days wandering around the palace, bored and unhappy.
- The lonely princess and the mysterious garden
- One day, she finds a hidden door in one of the rooms that leads to a staircase. She follows it down to a basement where she sees a large window covered by curtains. She opens the curtains and sees a beautiful garden full of flowers, trees, birds and butterflies. She is fascinated by this sight and decides to go outside.
-grozdana olujic oldanini vrtovi free pdf
- As soon as she steps into the garden, she feels a strange sensation. She feels lighter, happier, more alive. She feels like she has entered another world where anything is possible. She starts exploring the garden, admiring its beauty and diversity.
- The magical creatures and events in the garden
- As she walks around the garden, she encounters many wonderful things. She meets a talking bird who tells her stories about the garden's history. She sees a fountain that changes colors according to her mood. She finds a swing that takes her to different places in time and space. She plays with a friendly dragon who breathes fireballs. She dances with a group of fairies who make music with their wings.
- She also meets many other creatures who live in the garden: unicorns, mermaids, elves, gnomes, trolls, giants, witches, wizards and more. They all welcome her warmly and invite her to join their games and festivities. They all seem to know her name and treat her like their friend.
- The secret of Oldana and the fate of the princess
- The princess soon realizes that there is someone who rules over this magical garden: Oldana. Oldana is an old woman who wears a long white dress and a veil that covers her face. She lives in a castle at the center of the garden. She is very kind and gentle with everyone who visits her domain.
- The princess becomes curious about Oldana's identity and decides to visit her castle. She knocks on the door and hears a voice inviting her in. She enters the castle and sees Oldana sitting on a throne surrounded by books and paintings. Oldana greets her warmly and tells her that she has been waiting for her for a long time.
- Oldana then reveals her secret: she is actually an ancient goddess who created this garden as a refuge for herself and for all those who seek happiness. She explains that she was once very powerful but also very lonely. She fell in love with a mortal man who betrayed her and broke her heart. She lost her faith in humanity and decided to isolate herself from the world.
- She also tells her that she has chosen her as her successor: she wants her to inherit this garden and become its new guardian. She says that she has grown old and tired and that she needs someone young and fresh to take care of this place. She says that she sees something special in her: a spark of creativity, imagination
0a6ba089ebel omnilibro de los reactores quimicos Download File ->>> https://imgfil.com/2uy1Kr
diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Connect to Any WiFi QrCode in Seconds with IQ APK.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Connect to Any WiFi QrCode in Seconds with IQ APK.md
deleted file mode 100644
index 18507b71652fb86afe60929061cc2b11f8f791ce..0000000000000000000000000000000000000000
--- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Connect to Any WiFi QrCode in Seconds with IQ APK.md
+++ /dev/null
@@ -1,62 +0,0 @@
-
-What is IQ APK WiFi and Why You Need It
-Have you ever experienced slow or unstable WiFi connection on your Android device? Do you wish you could boost your WiFi performance and enjoy faster and more reliable internet access? If you answered yes to any of these questions, then you need IQ APK WiFi.
-IQ APK WiFi is a smart app that helps you optimize your WiFi connection and enhance your online experience. It is a mesh capable router that covers every corner of every room with safe, seamless WiFi. It also allows you to control multiple devices with one app, tailor your own heating schedule, view router information, speed test, create and manage multiple networks, and receive push notifications.
-iq apk wifi Download File ★★★★★ https://urlin.us/2uSTnz
With IQ APK WiFi, you can say goodbye to slow and frustrating WiFi and hello to fast and smooth internet. In this article, we will show you how to download, install, use, customize, share, and troubleshoot IQ APK WiFi on your Android device.
- How to Download and Install IQ APK WiFi on Your Android Device
-Downloading and installing IQ APK WiFi on your Android device is easy and simple. Just follow these steps:
-
-Find a reliable source for the IQ APK WiFi app. You can download it from Google Play Store or from other trusted websites such as APKCombo . Make sure you download the latest version of the app for optimal performance.
-Enable unknown sources on your device settings. This will allow you to install apps from sources other than Google Play Store. To do this, go to Settings > Security > Unknown Sources and toggle it on.
-Download and install the IQ APK WiFi app. Once you have downloaded the app file, locate it in your device storage and tap on it to start the installation process. Follow the instructions on the screen and wait for the installation to complete.
-
- How to Use IQ APK WiFi to Boost Your WiFi Performance
-Using IQ APK WiFi to boost your WiFi performance is easy and simple. Just follow these steps:
-
-Launch the IQ APK WiFi app and scan for available networks. The app will automatically detect the best network for your device and show you its signal strength and quality. You can also see other network details such as SSID, BSSID, frequency, channel, security, etc.
-Select the network you want to connect to and enter the password if required. The app will connect you to the network and show you a confirmation message. You can also see your current IP address, gateway, DNS, etc.
-Enjoy faster and more stable WiFi connection with IQ APK WiFi. The app will monitor your WiFi performance and optimize it automatically. You can also see your real-time speed, data usage, signal strength, etc. on the app dashboard.
-
- How to Customize Your IQ APK WiFi Settings
-Customizing your IQ APK WiFi settings is easy and simple. Just follow these steps:
-
-Tap on the menu icon on the top left corner of the app. This will open a sidebar with various options such as network map, speed test, device list, router information, etc.
-Choose from the options according to your needs and preferences. For example, you can use the network map to see a graphical representation of your network and devices connected to it. You can use the speed test to measure your internet speed and latency. You can use the device list to see and manage the devices connected to your network. You can use the router information to see and edit your router settings such as SSID, password, channel, etc.
-Adjust your preferences according to your needs and preferences. For example, you can enable or disable notifications, change the app theme, set a data limit, etc.
-
- How to Share Your IQ APK WiFi with Other Devices or Users
-Sharing your IQ APK WiFi with other devices or users is easy and simple. Just follow these steps:
-
-Tap on the share icon on the top right corner of the app. This will open a menu with different methods such as QR code, email, SMS, etc.
-Choose from the methods according to your convenience and preference. For example, you can use the QR code to generate a code that others can scan to join your network. You can use the email or SMS to send a link that others can click to join your network.
-Send or scan the code or link to share your IQ APK WiFi with others. They will be able to join your network and enjoy faster and more stable WiFi connection with IQ APK WiFi.
-
- How to Troubleshoot Common Issues with IQ APK WiFi
-Troubleshooting common issues with IQ APK WiFi is easy and simple. Just follow these steps:
-WiFi QrCode Password scanner - Apps on Google Play[^1^]
-
-Check your internet connection and make sure it is working properly. You can use the speed test option on the app to check your internet speed and latency. If you have a slow or unstable internet connection, try restarting your modem or router or contacting your internet service provider.
-Restart your device and the IQ APK WiFi app if you encounter any glitches or errors. This will refresh your device and app memory and fix any minor issues.
-Contact the customer support team of IQ APK WiFi if you need further assistance or have any questions. You can find their contact details on the app settings or on their official website https://iqapkwifi.com/ . They are available 24/7 and ready to help you with any issues or queries.
-
- Conclusion
-IQ APK WiFi is a smart app that helps you optimize your WiFi connection and enhance your online experience. It is a mesh capable router that covers every corner of every room with safe, seamless WiFi. It also allows you to control multiple devices with one app, tailor your own heating schedule, view router information, speed test, create and manage multiple networks, and receive push notifications.
-In this article, we showed you how to download, install, use, customize, share, and troubleshoot IQ APK WiFi on your Android device. We hope you found this article helpful and informative. If you have not tried IQ APK WiFi yet, we highly recommend you to download it from Google Play Store or from other trusted websites such as APKCombo and enjoy faster and more stable WiFi connection with IQ APK WiFi.
-If you liked this article, please share it with your friends and family who might benefit from it. Also, feel free to leave us a comment below if you have any feedback or questions about IQ APK WiFi. We would love to hear from you!
- Frequently Asked Questions
-
-What is IQ APK WiFi? IQ APK WiFi is a smart app that helps you optimize your WiFi connection and enhance your online experience. It is a mesh capable router that covers every corner of every room with safe, seamless WiFi. It also allows you to control multiple devices with one app, tailor your own heating schedule, view router information, speed test, create and manage multiple networks, and receive push notifications.
-How do I download and install IQ APK WiFi on my Android device? You can download and install IQ APK WiFi on your Android device by following these steps: 1) Find a reliable source for the IQ APK WiFi app. You can download it from Google Play Store or from other trusted websites such as APKCombo . Make sure you download the latest version of the app for optimal performance. 2) Enable unknown sources on your device settings. This will allow you to install apps from sources other than Google Play Store. To do this, go to Settings > Security > Unknown Sources and toggle it on. 3) Download and install the IQ APK WiFi app. Once you have downloaded the app file, locate it in your device storage and tap on it to start the installation process. Follow the instructions on the screen and wait for the installation to complete.
-How do I use IQ APK WiFi to boost my WiFi performance? You can use IQ APK WiFi to boost your WiFi performance by following these steps: 1) Launch the IQ APK WiFi app and scan for available networks. The app will automatically detect the best network for your device and show you its signal strength and quality. You can also see other network details such as SSID, BSSID, frequency, channel, security, etc. 2) Select the network you want to connect to and enter the password if required. The app will connect you to the network and show you a confirmation message. You can also see your current IP address, gateway, DNS, etc. 3) Enjoy faster and more stable WiFi connection with IQ APK WiFi. The app will monitor your WiFi performance and optimize it automatically. You can also see your real-time speed, data usage, signal strength, etc. on the app dashboard.
-How do I customize my IQ APK WiFi settings? You can customize your IQ APK WiFi settings by following these steps: 1) Tap on the menu icon on the top left corner of the app. This will open a sidebar with various options such as network map, speed test, device list, router information, etc. 2) Choose from the options according to your needs and preferences. For example, you can use the network map to see a graphical representation of your network and devices connected to it. You can use the speed test to measure your internet speed and latency. You can use the device list to see and manage the devices connected to your network. You can use the router information to see and edit your router settings such as SSID, password, channel, etc. 3) Adjust your preferences according to your needs and preferences. For example, you can enable or disable notifications, change the app theme, set a data limit, etc.
-How do I share my IQ APK WiFi with other devices or users? You can share your IQ APK WiFi with other devices or users by following these steps: 1) Tap on the share icon on the top right corner of the app. This will open a menu with different methods such as QR code, email, SMS, etc. 2) Choose from the methods according to your convenience and preference. For example, you can use the QR code to generate a code that others can scan to join your network. You can use the email or SMS to send a link that others can click to join your network. 3) Send or scan the code or link to share your IQ APK WiFi with others. They will be able to join your network and enjoy faster and more stable WiFi connection with IQ APK WiFi.
- 197e85843dHow to Download "Dear My Love" by Big Zulu
-If you are a fan of South African hip-hop music, you might have heard of a song called "Dear My Love" by Big Zulu. This song is a collaboration between Big Zulu and three other artists: K.O., Siya Ntuli, and Xowla. It is a romantic track that expresses the feelings of love and appreciation for a partner.
-"Dear My Love" is a catchy and melodic song that has received positive feedback from critics and fans alike. It has also achieved impressive results on various music charts and platforms. If you want to enjoy this song anytime and anywhere, you might want to download it to your device.
-download dear my love by big zulu Download File --->>> https://jinyurl.com/2uNPzW
In this article, we will show you how to download "Dear My Love" by Big Zulu for free or for a fee. We will also give you some background information about the song and the artist. So keep reading and learn how to get this amazing song in no time.
- What is "Dear My Love" by Big Zulu?
-"Dear My Love" is a song by Big Zulu featuring K.O., Siya Ntuli, and Xowla. It was released on November 25th, 2022 as a single from Big Zulu's upcoming album.
-download dear my love by big zulu mp3
-The song belongs to the genre of hip-hop or rap music, but it also incorporates elements of R&B and soul music. The song has a smooth and soothing beat that complements the vocals of the four artists.
-The lyrics of the song are about expressing love and gratitude for a partner who has been supportive and loyal throughout the relationship. The song also celebrates the beauty and uniqueness of African women.
- Who is Big Zulu?
-Who is Big Zulu?
-
Big Zulu is the stage name of Siyabonga Nene, a South African rapper and songwriter. He was born on April 7, 1986 in Bergville, KwaZulu-Natal. He grew up listening to Maskandi and Isichathamiya music, influenced by artists like Ladysmith Black Mambazo, Phuzekemisi and Imithente.
-He started his career as a taxi driver, but quit in 2008 to pursue his passion for music. In 2009, he participated in the Back to the City rap contest and won the title of "King of Rap". This earned him recognition and exposure in the hip-hop scene.
-He signed a record deal with Universal Music in 2015 and released his debut album, Ushun Wenkabi, in 2018. His second album, Ungqongqoshe Wongqongqoshe, came out in 2019 and featured collaborations with Kwesta, Cassper Nyovest, Fifi Cooper and others. His third album, Ichwane Lenyoka, was released in 2021 and spawned three hit singles: "Mali Eningi", "Inhlupheko" and "Umuzi eSandton".
-Big Zulu is known for his Inkabi rap style, which blends traditional Zulu culture and language with modern hip-hop beats and lyrics. He raps about social issues, personal struggles, love and pride. He is also an actor and has appeared in TV shows like Isibaya, Uzalo and Isithembiso.
-He has won several awards and nominations for his music, including seven South African Hip Hop Awards and one South African Music Award. He is also the founder of his own record label, Nkabi Records.
- Why is "Dear My Love" by Big Zulu popular?
-"Dear My Love" by Big Zulu is a popular song that was released on November 25th, 2022 as a single from his upcoming album. The song features three other artists: K.O., Siya Ntuli and Xowla. It is a romantic track that expresses the feelings of love and appreciation for a partner.
-The song has received positive feedback from critics and fans alike, who praised its catchy and melodic tune, its smooth and soothing beat, and its heartfelt and sincere lyrics. The song also celebrates the beauty and uniqueness of African women.
-The song has also achieved impressive results on various music charts and platforms. It peaked at number one on the iTunes Chart in South Africa, number two on the Apple Music Chart in South Africa, number three on the Spotify Chart in South Africa, and number four on the YouTube Music Chart in South Africa. It also reached the top ten on several radio stations across the country.
-The song has also been nominated for Song of the Year at the South African Hip Hop Awards 2023. It is considered one of the biggest hits of Big Zulu's career so far.
How to Download "Dear My Love" by Big Zulu for Free?
-If you want to download "Dear My Love" by Big Zulu for free, you can use a website called OKmusi MP3 downloader. This website allows you to download any song from YouTube, SoundCloud, Spotify, and other platforms as an MP3 file. You can also choose the quality of the download, from 128kbps to 320kbps.
-OKmusi MP3 downloader is a free and easy-to-use website that does not require any registration, subscription, or installation. You can access it from any device and browser. It also does not have any annoying ads, pop-ups, or viruses. You can download as many songs as you want without any limit.
- What is OKmusi MP3 downloader?
-OKmusi MP3 downloader is a website that lets you download any song from various online sources as an MP3 file. You can use it to download songs from YouTube, SoundCloud, Spotify, Facebook, Instagram, TikTok, and more. You can also search for songs by name, artist, album, or genre.
-The website supports different formats of audio and video files, such as MP3, MP4, M4A, WEBM, and FLV. You can also select the quality of the download, from 128kbps to 320kbps. The website is fast and reliable, and it preserves the original sound quality of the song.
- How to use OKmusi MP3 downloader?
-To use OKmusi MP3 downloader to download "Dear My Love" by Big Zulu for free, you need to follow these simple steps:
-
-Go to the website OKmusi MP3 downloader .
-Type "Dear My Love" by Big Zulu in the search box and click on the magnifying glass icon.
-Choose the song from the list of results and click on the download button.
-Select the quality of the download and click on the download button again.
-Wait for the download to finish and save the file to your device.
-
-Congratulations! You have successfully downloaded "Dear My Love" by Big Zulu for free using OKmusi MP3 downloader.
- What are the advantages of using OKmusi MP3 downloader?
-There are many advantages of using OKmusi MP3 downloader to download "Dear My Love" by Big Zulu for free. Here are some of them:
-
-You can download any song from any online source as an MP3 file.
-You can choose the quality of the download from 128kbps to 320kbps.
-You do not need to register, subscribe, or install anything.
-You do not have to deal with any ads, pop-ups, or viruses.
-You can download as many songs as you want without any limit.
-You can access the website from any device and browser.
- How to Download "Dear My Love" by Big Zulu for a Fee?
-If you want to download "Dear My Love" by Big Zulu for a fee, you can use some paid music streaming services that offer the song for download, such as Spotify, Apple Music, and Amazon Music. These services allow you to listen to millions of songs online and offline, as well as access other features and benefits. However, you need to pay a monthly or yearly subscription fee to use these services.
-In this section, we will compare the features, prices, and benefits of Spotify, Apple Music, and Amazon Music. We will also show you how to download "Dear My Love" by Big Zulu on each service.
- What are the features of Spotify?
-Spotify is one of the most popular music streaming services in the world. It has over 70 million songs, podcasts, and playlists that you can listen to online or offline. You can also create your own playlists, discover new music, and share your favorites with your friends.
-Spotify has two plans: Free and Premium. The Free plan lets you listen to music online with ads and limited skips. The Premium plan lets you listen to music offline without ads and unlimited skips. It also gives you access to higher quality audio, ad-free podcasts, and exclusive content.
-The Premium plan costs $9.99 per month for individuals, $12.99 per month for couples, $14.99 per month for families of up to six members, and $4.99 per month for students. You can also get a free trial of the Premium plan for one month.
- How to download "Dear My Love" by Big Zulu on Spotify?
-To download "Dear My Love" by Big Zulu on Spotify, you need to have a Premium account and a device that supports offline mode. You also need to have enough storage space on your device. Here are the steps to download the song on Spotify:
-
-Open the Spotify app on your device and log in with your Premium account.
-Search for "Dear My Love" by Big Zulu and tap on the song.
-Tap on the three dots icon at the top right corner of the screen and select "Download".
-Wait for the download to complete and check the green arrow icon next to the song.
-Enjoy listening to the song offline.
-
-Note: You can also download entire albums or playlists by following the same steps.
- What are the features of Apple Music?
-Apple Music is another popular music streaming service that is integrated with iTunes and other Apple devices. It has over 75 million songs, radio stations, podcasts, and videos that you can listen to online or offline. You can also create your own playlists, discover new music, and access your iTunes library.
-Apple Music has one plan: Individual. The Individual plan lets you listen to music online or offline without ads and unlimited skips. It also gives you access to higher quality audio, ad-free radio stations, live concerts, and exclusive content.
-The Individual plan costs $9.99 per month for individuals, $14.99 per month for families of up to six members, and $4.99 per month for students. You can also get a free trial of the Individual plan for three months.
- How to download "Dear My Love" by Big Zulu on Apple Music?
-To download "Dear My Love" by Big Zulu on Apple Music, you need to have an Individual account and a device that supports offline mode. You also need to have enough storage space on your device. Here are the steps to download the song on Apple Music:
-
-Open the Apple Music app on your device and log in with your Individual account.
-Search for "Dear My Love" by Big Zulu and tap on the song.
-Tap on the plus icon at the bottom right corner of the screen and select "Download".
-Wait for the download to complete and check the cloud icon next to the song.
-Enjoy listening to the song offline.
-
-Note: You can also download entire albums or playlists by following the same steps.
- What are the features of Amazon Music?
-Amazon Music is another popular music streaming service that is integrated with Amazon Prime and other Amazon devices. It has over 70 million songs, podcasts, and playlists that you can listen to online or offline. You can also create your own playlists, discover new music, and access your Amazon library.
-Amazon Music has two plans: Prime Music and Unlimited. The Prime Music plan lets you listen to over 2 million songs online or offline without ads and unlimited skips. It is included with your Amazon Prime membership. The Unlimited plan lets you listen to over 70 million songs online or offline without ads and unlimited skips. It also gives you access to higher quality audio, ad-free podcasts, and exclusive content.
-The Unlimited plan costs $7.99 per month for Prime members, $9.99 per month for non-Prime members, $14.99 per month for families of up to six members, and $4.99 per month for students. You can also get a free trial of the Unlimited plan for one month.
- How to download "Dear My Love" by Big Zulu on Amazon Music?
-To download "Dear My Love" by Big Zulu on Amazon Music, you need to have a Prime Music or Unlimited account and a device that supports offline mode. You also need to have enough storage space on your device. Here are the steps to download the song on Amazon Music:
-
-Open the Amazon Music app on your device and log in with your Prime Music or Unlimited account.
-Search for "Dear My Love" by Big Zulu and tap on the song.
-Tap on the three dots icon at the bottom right corner of the screen and select "Download".
-Wait for the download to complete and check the checkmark icon next to the song.
-Enjoy listening to the song offline.
-
-Note: You can also download entire albums or playlists by following the same steps.
- Conclusion
-In this article, we have shown you how to download "Dear My Love" by Big Zulu for free or for a fee. We have also given you some background information about the song and the artist. We hope you have enjoyed reading this article and learned something new.
-"Dear My Love" by Big Zulu is a romantic and catchy song that celebrates the beauty and uniqueness of African women. It is a collaboration between Big Zulu and three other artists: K.O., Siya Ntuli, and Xowla. It is a popular song that has received positive feedback from critics and fans alike. It has also achieved impressive results on various music charts and platforms.
-If you want to download this song to your device, you can use OKmusi MP3 downloader, Spotify, Apple Music, or Amazon Music. Each of these options has its own features, prices, and benefits. You can choose the one that suits your preferences and budget.
-So what are you waiting for? Download "Dear My Love" by Big Zulu today and enjoy listening to this amazing song anytime and anywhere.
- Frequently Asked Questions
-Here are some frequently asked questions about "Dear My Love" by Big Zulu and how to download it:
- Q: When was "Dear My Love" by Big Zulu released?
-A: "Dear My Love" by Big Zulu was released on November 25th, 2022 as a single from his upcoming album.
- Q: What genre is "Dear My Love" by Big Zulu?
-A: "Dear My Love" by Big Zulu belongs to the genre of hip-hop or rap music, but it also incorporates elements of R&B and soul music.
- Q: Who are the other artists featured in "Dear My Love" by Big Zulu?
-A: The other artists featured in "Dear My Love" by Big Zulu are K.O., Siya Ntuli, and Xowla.
- Q: How can I download "Dear My Love" by Big Zulu for free?
-A: You can download "Dear My Love" by Big Zulu for free using OKmusi MP3 downloader, a website that lets you download any song from any online source as an MP3 file.
- Q: How can I download "Dear My Love" by Big Zulu for a fee?
-A: You can download "Dear My Love" by Big Zulu for a fee using Spotify, Apple Music, or Amazon Music, paid music streaming services that offer the song for download.
197e85843dDownload Blackmoor 2 Mod Apk: A Guide for Android Users
- Are you a fan of action-packed platform games with retro graphics and epic boss battles? If yes, then you should definitely try Blackmoor 2, a sequel to the popular Blackmoor game that has over 10 million downloads on Google Play. In this article, we will tell you everything you need to know about Blackmoor 2, and how to download and install its mod apk version on your Android device. So, let's get started!
-download black moor 2 mod apk Download File ⇒⇒⇒ https://jinyurl.com/2uNLTF
What is Blackmoor 2?
- Blackmoor 2 is a side-scrolling action-adventure game developed by Four Fats Limited, a studio based in Hong Kong. The game is inspired by classic arcade games like Golden Axe, Double Dragon, and Streets of Rage. You can choose from eight different characters, each with their own unique abilities and fighting styles. You can also customize your character's appearance, skills, and equipment. The game has a story mode, where you have to fight your way through various levels and enemies, as well as a co-op mode, where you can team up with up to four friends online or offline. The game also has a build mode, where you can create your own levels and share them with other players.
- Features of Blackmoor 2
- Some of the features that make Blackmoor 2 stand out from other platform games are:
-
-Stunning pixel art graphics and animations
-Smooth and responsive controls
-Dynamic combat system with combos, counters, and special moves
-Diverse and challenging enemies and bosses
-A wide variety of weapons, armor, and items to collect and upgrade
-A rich and humorous story with voice acting
-A multiplayer mode with co-op and PvP options
-A level editor with online sharing and rating
-Achievements and leaderboards
-
- Gameplay of Blackmoor 2
- The gameplay of Blackmoor 2 is simple yet addictive. You have to control your character using the virtual joystick and buttons on the screen. You can move left or right, jump, crouch, attack, block, dodge, and use special skills. You can also interact with objects and NPCs in the environment. You have to defeat all the enemies that come your way, while avoiding traps and obstacles. You can also collect coins, gems, health potions, and other items along the way. You can use these items to buy new equipment or upgrade your existing ones. You can also unlock new characters and skills as you progress through the game.
- Why download Blackmoor 2 mod apk?
- Blackmoor 2 is a free-to-play game that you can download from Google Play. However, there are some limitations and drawbacks that might affect your gaming experience. For example:
-
-You have to watch ads to get extra lives or coins
-You have to wait for energy to refill before playing again
-You have to spend real money to buy premium items or characters
-You have to grind for hours to level up or unlock new features
-You might encounter bugs or glitches that ruin your progress
-
- If you want to enjoy Blackmoor 2 without any of these hassles, then you should download its mod apk version.
Benefits of Blackmoor 2 mod apk
- By downloading the Blackmoor 2 mod apk, you can enjoy the following benefits:
-
-Unlimited coins and gems to buy anything you want
-Unlimited lives and energy to play as long as you want
-All characters and skills unlocked from the start
-No ads or in-app purchases to interrupt your game
-No bugs or errors to spoil your fun
-
- With the Blackmoor 2 mod apk, you can experience the game in a whole new way. You can explore all the levels and modes, try out different characters and weapons, and challenge yourself with harder enemies and bosses. You can also share your creations and achievements with other players online.
-How to download black moor 2 mod apk for free
- How to download and install Blackmoor 2 mod apk
- If you are interested in downloading and installing the Blackmoor 2 mod apk, you can follow these simple steps:
- Step 1: Download the file
- The first thing you need to do is to download the Blackmoor 2 mod apk file from a reliable source. You can use the link below to get the latest version of the file:
- Download Blackmoor 2 mod apk here
- The file size is about 150 MB, so make sure you have enough space on your device. You also need to have a stable internet connection to avoid any interruptions.
- Step 2: Enable unknown sources
- The next thing you need to do is to enable unknown sources on your device. This will allow you to install apps that are not from the Google Play Store. To do this, you need to go to your device settings, then security, then unknown sources. You need to toggle the switch to turn it on. You might see a warning message, but don't worry, it's safe to proceed.
- Step 3: Install the file
- After enabling unknown sources, you can now install the Blackmoor 2 mod apk file. To do this, you need to locate the file on your device, either in your downloads folder or wherever you saved it. Then, you need to tap on it and follow the instructions on the screen. It might take a few minutes for the installation to complete.
- Step 4: Open the game and enjoy
- Once the installation is done, you can now open the game and enjoy its features. You will see that you have unlimited coins and gems, unlimited lives and energy, all characters and skills unlocked, no ads or in-app purchases, and no bugs or errors. You can start playing the game right away, or customize your settings and preferences.
- Tips and tricks for playing Blackmoor 2 mod apk
- To make the most out of your gaming experience with Blackmoor 2 mod apk, here are some tips and tricks that you can use:
- Choose your character wisely
- Blackmoor 2 has eight different characters that you can choose from, each with their own strengths and weaknesses. You can switch between them anytime during the game, but it's better to stick with one that suits your playstyle and preference. Here are some of the characters and their abilities:
-
-Sir Arthur: A knight with a sword and shield. He has balanced stats and can block attacks.
-Muramasa: A samurai with a katana and shurikens. He has high speed and damage but low defense.
-Ravensword: A barbarian with a giant axe and a pet raven. He has high health and power but low mobility.
-Mage: A wizard with a staff and spells. He has high magic and range but low physical strength.
-Frost: A ninja with a dagger and ice powers. He has high agility and stealth but low durability.
-Bombardier: A pirate with a pistol and bombs. He has high explosives and accuracy but low melee skills.
-Lady Luna: A vampire with a whip and blood magic. She has high life steal and charm but low sunlight resistance.
-Dave: A zombie with a chainsaw and guts. He has high regeneration and resilience but low intelligence.
-
- Upgrade your skills and equipment
- As you play through the game, you will earn coins and gems that you can use to upgrade your skills and equipment. You can access the shop from the main menu or from checkpoints in each level. You can buy new weapons, armor, accessories, and consumables that can enhance your performance and appearance. You can also upgrade your skills by spending skill points that you earn by leveling up. You can choose from four skill trees: attack, defense, magic, and special. You can also reset your skills anytime if you want to try a different build.
- Use the co-op mode and online multiplayer mode
- Blackmoor 2 is more fun when you play with your friends. You can use the co-op mode to team up with up to four players online or offline. You can join or create a room and invite your friends or random players. You can also chat with them using the in-game chat feature. You can play the story mode, the build mode, or the survival mode together. You can also use the online multiplayer mode to compete with other players in PvP battles. You can choose from different modes such as deathmatch, capture the flag, or king of the hill. You can also rank up and earn rewards based on your performance.
- Conclusion
- Blackmoor 2 is an amazing game that will keep you entertained for hours. It has everything you need in a platform game: action, adventure, humor, creativity, and multiplayer. If you want to enjoy the game without any limitations or interruptions, you should download the Blackmoor 2 mod apk from the link below. You will get unlimited coins and gems, unlimited lives and energy, all characters and skills unlocked, no ads or in-app purchases, and no bugs or errors. You will also get access to all the latest updates and features of the game. So, what are you waiting for? Download Blackmoor 2 mod apk now and have fun!
- Download Blackmoor 2 mod apk here
- FAQs
- Here are some of the frequently asked questions about Blackmoor 2 mod apk:
-
-Is Blackmoor 2 mod apk safe to use?
-Yes, Blackmoor 2 mod apk is safe to use as long as you download it from a trusted source. It does not contain any viruses or malware that can harm your device or data. It also does not require any root or jailbreak to run.
-Will Blackmoor 2 mod apk work on my device?
-Blackmoor 2 mod apk is compatible with most Android devices that have Android 5.0 or higher. However, some devices may not support some features or functions of the game due to hardware limitations or compatibility issues.
-Can I play Blackmoor 2 mod apk offline?
-Yes, you can play Blackmoor 2 mod apk offline without any internet connection. However, some features or modes may not be available or functional offline, such as the co-op mode and online multiplayer mode.
-Can I update Blackmoor 2 mod apk?
-Yes, you can update Blackmoor 2 mod apk whenever there is a new version available. However, you need to download and install the new version manually from the same source as before. You also need to backup your data before updating to avoid losing your progress.
-Can I use Blackmoor 2 mod apk with Google Play Games?
-No, you cannot use Blackmoor 2 mod apk with Google Play Games. This is because the mod apk is not an official version of the game and does not have a valid signature. Therefore, you cannot sign in with your Google account or sync your data with Google Play Games.
- 401be4b1e0FIFA Mobile Nexon APK 9.0.12: Everything You Need to Know
-If you are a fan of soccer games on mobile devices, you might have heard of FIFA Mobile, the official mobile version of the popular FIFA series by EA Sports. But did you know that there is another version of FIFA Mobile, exclusive to Japan and Korea, that has more features and content than the global version? It's called FIFA Mobile Nexon, and it's developed by NEXON Company, a leading game developer in Asia.
-fifa mobile nexon apk 9.0.12 Download File ➡ https://jinyurl.com/2uNKDT
In this article, we will tell you everything you need to know about FIFA Mobile Nexon APK 9.0.12, the latest update of the game that was released on June 15, 2021. We will cover the features, download process, review, and tips and tricks of this amazing soccer game that will make you feel like a real manager and player.
- What is FIFA Mobile Nexon?
-FIFA Mobile Nexon is a spin-off edition of FIFA Mobile that was launched in 2020 for users in Japan and Korea. It has the official license of over 30 leagues, over 650 clubs, and over 17,000 soccer players from all over the world. You can create your own team using real clubs and players, play online matches against other users, participate in various events and modes, and enjoy realistic graphics and gameplay.
-FIFA Mobile Nexon is constantly updated with new content and improvements that make it more enjoyable and immersive than the global version of FIFA Mobile. The latest update, FIFA Mobile Nexon APK 9.0.12, brings a lot of new features and changes that we will discuss in the next section.
- Features of FIFA Mobile Nexon
-The latest update of FIFA Mobile Nexon has a lot of new features and improvements that make it one of the best soccer games on mobile devices. Here are some of the highlights:
- Eternal Icon Class
-This is a new development-type ICON class that allows you to acquire and grow legendary players from soccer history by using existing players and increasing their OVR (overall rating). You can level up their OVR through promotion, which is a dedicated growth content. You can also exchange acquired Eternal Icons for goods that can help you grow them again through return content.
- Transfer Market Convenience Update
-This update makes it easier for you to buy and sell players in the transfer market. You can check the transaction status when selecting a player from your own screen and exchange them. You can also search for players more conveniently by using various search conditions, such as team skills and evolution level. You can also see the transaction registration status by evolution stage after searching for a player.
-fifa mobile nexon apk 9.0.12 download
- Game Convenience Reorganization
-This update makes it more convenient for you to manage your team and play the game. You can access the transfer market menu when selecting a player from your own screen or from the exchange screen. You can also use the bulk exchange function in some exchanges.
- Improving Gameplay Experience
-This update makes the gameplay more realistic and balanced based on the situation and players' stats. The aerial competitions are more realistic, the cross accuracy is adjusted, the player switching is optimized, and the disconnection during play is improved.
- Improved Set Piece Camera
-This update improves the camera angle for free kicks, corner kicks, goal kicks, and penalty kicks. You can also select different angles during free kicks and corner kicks. This creates a more dynamic and tense experience, and allows you to use strategic attacks from set pieces.
- New Motion Update
-This update adds new animations and actions for players in various situations, such as free kick preparation , dribbling, passing, shooting, and celebrating. These make the players more expressive and realistic, and enhance the immersion of the game.
- How to Download FIFA Mobile Nexon APK 9.0.12
-If you want to download and play FIFA Mobile Nexon APK 9.0.12, you need to follow these steps:
-
-Go to the official website of FIFA Mobile Nexon (https://fifaonline4.nexon.com/fifamobile) and click on the download button for Android devices.
-You will be redirected to a page where you can download the APK file of FIFA Mobile Nexon. Click on the download button and wait for the file to be downloaded.
-Once the file is downloaded, go to your device settings and enable the installation of apps from unknown sources.
-Locate the APK file in your device storage and tap on it to install it.
-Launch the game and enjoy FIFA Mobile Nexon APK 9.0.12.
-
-Note: You need to have a stable internet connection and enough storage space to play the game. You also need to create a NEXON account or log in with your existing one to access the game.
- FIFA Mobile Nexon Review
-FIFA Mobile Nexon is a great soccer game for mobile devices that offers a lot of features and content that are not available in the global version of FIFA Mobile. It has realistic graphics, smooth gameplay, diverse modes, and a large player base. It also has frequent updates that add new content and improvements to the game.
-Some of the pros of FIFA Mobile Nexon are:
-
-It has official licenses of over 30 leagues, over 650 clubs, and over 17,000 soccer players from all over the world.
-It has a variety of modes and events that keep you entertained and challenged, such as Season Mode, World Tour Mode, League Mode, VS Attack Mode, Campaign Mode, Event Mode, and more.
-It has a unique development system that allows you to acquire and grow legendary players from soccer history through Eternal Icon Class.
-It has a realistic and balanced gameplay that reflects the situation and players' stats. It also has improved set piece camera and new motion update that make the game more dynamic and immersive.
-
-Some of the cons of FIFA Mobile Nexon are:
-
-It is only available in Japan and Korea, so you need to download the APK file from the official website or use a VPN service to access the game.
-It requires a lot of storage space and internet data to play the game smoothly.
-It can be difficult to compete with other players who have higher OVR or better players than you.
-
- FIFA Mobile Nexon Tips and Tricks
-If you want to improve your skills and performance in FIFA Mobile Nexon, here are some tips and tricks that can help you:
-
-Build your team according to your preferred formation, style, and strategy. Choose players who have high OVR, good chemistry, and suitable skills for each position.
-Upgrade your players by using training items, evolution items, promotion items, or Eternal Icons. You can also sell or exchange your unwanted players in the transfer market or use them for other purposes.
-Play various modes and events to earn rewards, such as coins, gems, players, items, or goods. You can also join a league or create your own league to play with other users and get more benefits.
-Practice your skills in different situations, such as dribbling, passing, shooting, defending, or set pieces. Learn how to use different controls, such as swipe, tap, button, or gesture. You can also adjust your settings according to your preference.
-Watch replays or tutorials of other players who are better than you or have similar style as you. You can learn from their moves, tactics, or mistakes. You can also watch live streams or videos of professional soccer matches or players to get inspiration or tips.
-
- Conclusion
-FIFA Mobile Nexon APK 9.0.12 is an amazing soccer game for mobile devices that offers more features and content than the global version of FIFA Mobile. It has realistic graphics, smooth gameplay, diverse modes, and a large player base. It also has frequent updates that add new content and improvements to the game.
-If you are a fan of soccer games on mobile devices, you should definitely try FIFA Mobile Nexon APK 9.0.12. You can download it from the official website or use a VPN service to access it. You will have a lot of fun and excitement playing this game. You will also learn a lot about soccer and its history.
- FAQs
-Here are some of the frequently asked questions about FIFA Mobile Nexon APK 9.0.12:
- Q: Is FIFA Mobile Nexon free to play?
-A: Yes, FIFA Mobile Nexon is free to download and play. However, it also has in-app purchases that can enhance your gaming experience.
- Q: Is FIFA Mobile Nexon compatible with my device?
-A: FIFA Mobile Nexon requires Android 5.0 or higher and at least 2 GB of RAM to run smoothly. You also need to have enough storage space and internet data to play the game.
- Q: How can I play FIFA Mobile Nexon with my friends?
-A: You can play FIFA Mobile Nexon with your friends by inviting them to join your league or by challenging them to a friendly match. You can also chat with them in the game or send them gifts.
- Q: How can I get more coins, gems, players, or items in FIFA Mobile Nexon?
-A: You can get more coins, gems, players, or items in FIFA Mobile Nexon by playing various modes and events, completing achievements and quests, participating in the transfer market, or using real money.
- Q: How can I contact the customer service of FIFA Mobile Nexon?
-A: You can contact the customer service of FIFA Mobile Nexon by using the in-game inquiry function or by visiting the official website (https://fifaonline4.nexon.com/fifamobile) and clicking on the customer center button.
401be4b1e0 文图生成(Text-to-Image Generation)
-
-- stable_diffusion
-
-```python
-from ppdiffusers import StableDiffusionPipeline
-
-# 加载模型和scheduler
-pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
-
-# 执行pipeline进行推理
-prompt = "a photo of an astronaut riding a horse on mars"
-image = pipe(prompt).images[0]
-
-# 保存图片
-image.save("astronaut_rides_horse_sd.png")
-```
-
-
-
文本引导的图像放大(Text-Guided Image Upscaling)
-
-- stable_diffusion_2
-
-```python
-from ppdiffusers import StableDiffusionUpscalePipeline
-from ppdiffusers.utils import load_image
-
-pipe = StableDiffusionUpscalePipeline.from_pretrained("stabilityai/stable-diffusion-x4-upscaler")
-
-url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/data/low_res_cat.png"
-low_res_img = load_image(url).resize((128, 128))
-
-prompt = "a white cat"
-upscaled_image = pipe(prompt=prompt, image=low_res_img).images[0]
-upscaled_image.save("upsampled_cat_sd2.png")
-```
-
-
-
原图像
-
-
生成图像
-
文本引导的图像编辑(Text-Guided Image Inpainting)
-
-- stable_diffusion_2
-
-```python
-from ppdiffusers import StableDiffusionUpscalePipeline
-from ppdiffusers.utils import load_image
-
-pipe = StableDiffusionUpscalePipeline.from_pretrained("stabilityai/stable-diffusion-x4-upscaler")
-
-url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/data/low_res_cat.png"
-low_res_img = load_image(url).resize((128, 128))
-
-prompt = "a white cat"
-upscaled_image = pipe(prompt=prompt, image=low_res_img).images[0]
-upscaled_image.save("upsampled_cat_sd2.png")
-```
-
-
-
原图像
-
-
生成图像
-
文本引导的图像变换(Image-to-Image Text-Guided Generation)
-
-- stable_diffusion
-```python
-import paddle
-
-from ppdiffusers import StableDiffusionImg2ImgPipeline
-from ppdiffusers.utils import load_image
-
-# 加载pipeline
-pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
-
-# 下载初始图片
-url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/stable-diffusion-v1-4/sketch-mountains-input.png"
-
-init_image = load_image(url).resize((768, 512))
-
-prompt = "A fantasy landscape, trending on artstation"
-# 使用fp16加快生成速度
-with paddle.amp.auto_cast(True):
- image = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images[0]
-
-image.save("fantasy_landscape.png")
-```
-
-
-
原图像
-
-
生成图像
-
文本图像双引导图像生成(Dual Text and Image Guided Generation)
-
-- versatile_diffusion
-```python
-from ppdiffusers import VersatileDiffusionDualGuidedPipeline
-from ppdiffusers.utils import load_image
-
-url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/data/benz.jpg"
-image = load_image(url)
-text = "a red car in the sun"
-
-pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained("shi-labs/versatile-diffusion")
-pipe.remove_unused_weights()
-
-text_to_image_strength = 0.75
-image = pipe(prompt=text, image=image, text_to_image_strength=text_to_image_strength).images[0]
-image.save("versatile-diffusion-red_car.png")
-```
-
-
-
原图像
-
-
生成图像
-
无条件图像生成(Unconditional Image Generation)
-
-- latent_diffusion_uncond
-
-```python
-from ppdiffusers import LDMPipeline
-
-# 加载模型和scheduler
-pipe = LDMPipeline.from_pretrained("CompVis/ldm-celebahq-256")
-
-# 执行pipeline进行推理
-image = pipe(num_inference_steps=200).images[0]
-
-# 保存图片
-image.save("ldm_generated_image.png")
-```
-
-
-
超分(Super Superresolution)
-
-- latent_diffusion
-```python
-import paddle
-
-from ppdiffusers import LDMSuperResolutionPipeline
-from ppdiffusers.utils import load_image
-
-# 加载pipeline
-pipe = LDMSuperResolutionPipeline.from_pretrained("CompVis/ldm-super-resolution-4x-openimages")
-
-# 下载初始图片
-url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/stable-diffusion-v1-4/overture-creations.png"
-
-init_image = load_image(url).resize((128, 128))
-init_image.save("original-image.png")
-
-# 使用fp16加快生成速度
-with paddle.amp.auto_cast(True):
- image = pipe(init_image, num_inference_steps=100, eta=1).images[0]
-
-image.save("super-resolution-image.png")
-```
-
-
-
原图像
-
-
生成图像
-
图像编辑(Image Inpainting)
-
-- repaint
-```python
-from ppdiffusers import RePaintPipeline, RePaintScheduler
-from ppdiffusers.utils import load_image
-
-img_url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/data/celeba_hq_256.png"
-mask_url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/data/mask_256.png"
-
-# Load the original image and the mask as PIL images
-original_image = load_image(img_url).resize((256, 256))
-mask_image = load_image(mask_url).resize((256, 256))
-
-scheduler = RePaintScheduler.from_pretrained("google/ddpm-ema-celebahq-256", subfolder="scheduler")
-pipe = RePaintPipeline.from_pretrained("google/ddpm-ema-celebahq-256", scheduler=scheduler)
-
-output = pipe(
- original_image=original_image,
- mask_image=mask_image,
- num_inference_steps=250,
- eta=0.0,
- jump_length=10,
- jump_n_sample=10,
-)
-inpainted_image = output.images[0]
-
-inpainted_image.save("repaint-image.png")
-```
-
-
-
原图像
-
-
mask图像
-
-
生成图像
-
图像变化(Image Variation)
-
-- versatile_diffusion
-```
-from ppdiffusers import VersatileDiffusionImageVariationPipeline
-from ppdiffusers.utils import load_image
-
-url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/data/benz.jpg"
-image = load_image(url)
-
-pipe = VersatileDiffusionImageVariationPipeline.from_pretrained("shi-labs/versatile-diffusion")
-
-image = pipe(image).images[0]
-image.save("versatile-diffusion-car_variation.png")
-```
-
-
-
原图像
-
-
生成图像
-
无条件音频生成(Unconditional Audio Generation)
-
-- audio_diffusion
-
-```
-from scipy.io.wavfile import write
-from ppdiffusers import AudioDiffusionPipeline
-import paddle
-
-# 加载模型和scheduler
-pipe = AudioDiffusionPipeline.from_pretrained("teticio/audio-diffusion-ddim-256")
-pipe.set_progress_bar_config(disable=None)
-generator = paddle.Generator().manual_seed(42)
-
-output = pipe(generator=generator)
-audio = output.audios[0]
-image = output.images[0]
-
-# 保存音频到本地
-for i, audio in enumerate(audio):
- write(f"audio_diffusion_test{i}.wav", pipe.mel.sample_rate, audio.transpose())
-
-# 保存图片
-image.save("audio_diffusion_test.png")
-```
-
-
-
-
-
-
-
-
-
-
-
-
-
使用需遵守的协议-LICENSE.txt ."
- )
- )
- with gr.Tabs():
- with gr.TabItem(i18n("模型推理")):
- with gr.Row():
- sid0 = gr.Dropdown(label=i18n("推理音色"), choices=sorted(names))
- refresh_button = gr.Button(i18n("刷新音色列表和索引路径"), variant="primary")
- clean_button = gr.Button(i18n("卸载音色省显存"), variant="primary")
- spk_item = gr.Slider(
- minimum=0,
- maximum=2333,
- step=1,
- label=i18n("请选择说话人id"),
- value=0,
- visible=False,
- interactive=True,
- )
- clean_button.click(fn=clean, inputs=[], outputs=[sid0])
- with gr.Group():
- gr.Markdown(
- value=i18n("男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ")
- )
- with gr.Row():
- with gr.Column():
- vc_transform0 = gr.Number(
- label=i18n("变调(整数, 半音数量, 升八度12降八度-12)"), value=0
- )
- input_audio0 = gr.Textbox(
- label=i18n("输入待处理音频文件路径(默认是正确格式示例)"),
- value="E:\\codes\\py39\\test-20230416b\\todo-songs\\冬之花clip1.wav",
- )
- f0method0 = gr.Radio(
- label=i18n(
- "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU"
- ),
- choices=["pm", "harvest", "crepe"],
- value="pm",
- interactive=True,
- )
- filter_radius0 = gr.Slider(
- minimum=0,
- maximum=7,
- label=i18n(">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音"),
- value=3,
- step=1,
- interactive=True,
- )
- with gr.Column():
- file_index1 = gr.Textbox(
- label=i18n("特征检索库文件路径,为空则使用下拉的选择结果"),
- value="",
- interactive=True,
- )
- file_index2 = gr.Dropdown(
- label=i18n("自动检测index路径,下拉式选择(dropdown)"),
- choices=sorted(index_paths),
- interactive=True,
- )
- refresh_button.click(
- fn=change_choices, inputs=[], outputs=[sid0, file_index2]
- )
- # file_big_npy1 = gr.Textbox(
- # label=i18n("特征文件路径"),
- # value="E:\\codes\py39\\vits_vc_gpu_train\\logs\\mi-test-1key\\total_fea.npy",
- # interactive=True,
- # )
- index_rate1 = gr.Slider(
- minimum=0,
- maximum=1,
- label=i18n("检索特征占比"),
- value=0.88,
- interactive=True,
- )
- with gr.Column():
- resample_sr0 = gr.Slider(
- minimum=0,
- maximum=48000,
- label=i18n("后处理重采样至最终采样率,0为不进行重采样"),
- value=0,
- step=1,
- interactive=True,
- )
- rms_mix_rate0 = gr.Slider(
- minimum=0,
- maximum=1,
- label=i18n("输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络"),
- value=1,
- interactive=True,
- )
- protect0 = gr.Slider(
- minimum=0,
- maximum=0.5,
- label=i18n(
- "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果"
- ),
- value=0.33,
- step=0.01,
- interactive=True,
- )
- f0_file = gr.File(label=i18n("F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调"))
- but0 = gr.Button(i18n("转换"), variant="primary")
- with gr.Row():
- vc_output1 = gr.Textbox(label=i18n("输出信息"))
- vc_output2 = gr.Audio(label=i18n("输出音频(右下角三个点,点了可以下载)"))
- but0.click(
- vc_single,
- [
- spk_item,
- input_audio0,
- vc_transform0,
- f0_file,
- f0method0,
- file_index1,
- file_index2,
- # file_big_npy1,
- index_rate1,
- filter_radius0,
- resample_sr0,
- rms_mix_rate0,
- protect0,
- ],
- [vc_output1, vc_output2],
- )
- with gr.Group():
- gr.Markdown(
- value=i18n("批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ")
- )
- with gr.Row():
- with gr.Column():
- vc_transform1 = gr.Number(
- label=i18n("变调(整数, 半音数量, 升八度12降八度-12)"), value=0
- )
- opt_input = gr.Textbox(label=i18n("指定输出文件夹"), value="opt")
- f0method1 = gr.Radio(
- label=i18n(
- "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU"
- ),
- choices=["pm", "harvest", "crepe"],
- value="pm",
- interactive=True,
- )
- filter_radius1 = gr.Slider(
- minimum=0,
- maximum=7,
- label=i18n(">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音"),
- value=3,
- step=1,
- interactive=True,
- )
- with gr.Column():
- file_index3 = gr.Textbox(
- label=i18n("特征检索库文件路径,为空则使用下拉的选择结果"),
- value="",
- interactive=True,
- )
- file_index4 = gr.Dropdown(
- label=i18n("自动检测index路径,下拉式选择(dropdown)"),
- choices=sorted(index_paths),
- interactive=True,
- )
- refresh_button.click(
- fn=lambda: change_choices()[1],
- inputs=[],
- outputs=file_index4,
- )
- # file_big_npy2 = gr.Textbox(
- # label=i18n("特征文件路径"),
- # value="E:\\codes\\py39\\vits_vc_gpu_train\\logs\\mi-test-1key\\total_fea.npy",
- # interactive=True,
- # )
- index_rate2 = gr.Slider(
- minimum=0,
- maximum=1,
- label=i18n("检索特征占比"),
- value=1,
- interactive=True,
- )
- with gr.Column():
- resample_sr1 = gr.Slider(
- minimum=0,
- maximum=48000,
- label=i18n("后处理重采样至最终采样率,0为不进行重采样"),
- value=0,
- step=1,
- interactive=True,
- )
- rms_mix_rate1 = gr.Slider(
- minimum=0,
- maximum=1,
- label=i18n("输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络"),
- value=1,
- interactive=True,
- )
- protect1 = gr.Slider(
- minimum=0,
- maximum=0.5,
- label=i18n(
- "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果"
- ),
- value=0.33,
- step=0.01,
- interactive=True,
- )
- with gr.Column():
- dir_input = gr.Textbox(
- label=i18n("输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)"),
- value="E:\codes\py39\\test-20230416b\\todo-songs",
- )
- inputs = gr.File(
- file_count="multiple", label=i18n("也可批量输入音频文件, 二选一, 优先读文件夹")
- )
- with gr.Row():
- format1 = gr.Radio(
- label=i18n("导出文件格式"),
- choices=["wav", "flac", "mp3", "m4a"],
- value="flac",
- interactive=True,
- )
- but1 = gr.Button(i18n("转换"), variant="primary")
- vc_output3 = gr.Textbox(label=i18n("输出信息"))
- but1.click(
- vc_multi,
- [
- spk_item,
- dir_input,
- opt_input,
- inputs,
- vc_transform1,
- f0method1,
- file_index3,
- file_index4,
- # file_big_npy2,
- index_rate2,
- filter_radius1,
- resample_sr1,
- rms_mix_rate1,
- protect1,
- format1,
- ],
- [vc_output3],
- )
- sid0.change(
- fn=get_vc,
- inputs=[sid0, protect0, protect1],
- outputs=[spk_item, protect0, protect1],
- )
- with gr.TabItem(i18n("伴奏人声分离&去混响&去回声")):
- with gr.Group():
- gr.Markdown(
- value=i18n(
- "人声伴奏分离批量处理, 使用UVR5模型。 = T extends infer O ? { [K in keyof O]: O[K] } : never;
-type RouteParams = { id: string }
-type RouteId = '/conversation/[id]/share';
-
-export type EntryGenerator = () => Promise> | Array;
-export type RequestHandler = Kit.RequestHandler;
-export type RequestEvent = Kit.RequestEvent;
\ No newline at end of file
diff --git a/spaces/AchyuthGamer/OpenGPT-v1/app.py b/spaces/AchyuthGamer/OpenGPT-v1/app.py
deleted file mode 100644
index 649f45394458dd7016dc7fe0d56fe657636f36e2..0000000000000000000000000000000000000000
--- a/spaces/AchyuthGamer/OpenGPT-v1/app.py
+++ /dev/null
@@ -1,259 +0,0 @@
-from h2o_wave import main, app, Q, ui, data
-from gradio_client import Client
-import ast
-
-
-async def init_ui(q: Q) -> None:
- q.page['meta'] = ui.meta_card(
- box='',
- layouts=[
- ui.layout(breakpoint='xs', min_height='100vh', zones=[
- ui.zone('main', size='1', direction=ui.ZoneDirection.ROW, zones=[
- ui.zone('sidebar', size='250px'),
- ui.zone('body', direction=ui.ZoneDirection.COLUMN, zones=[
- ui.zone('title', size='55px'),
- ui.zone('content', size='1'),
- ui.zone('footer'),
- ]),
- ])
- ])
- ],
- title='NeonAI Chat',
- )
- q.page['sidebar'] = ui.nav_card(
- box='sidebar', color='primary', title='OpenGPT v1', subtitle='A Revolt of Gooogle!',
- value=f"#{q.args['#']}' if q.args['#'] else '#page1",
- image='https://huggingface.co/spaces/AchyuthGamer/OpenGPT/resolve/main/opengpt-main%3Dlogo.jpg', items=[
- ui.nav_group('', items=[
- ui.nav_item(name='dwave-docs', label='Wave docs', path='https://opengptai.blogspot.com/achyuthgpt/'),
- ui.nav_item(name='NeonAI Chat', label='Open GPT', path='https://github.com/achyuth4/NeonAI-Chat'),
- ui.nav_item(name='fine-tune', label='LLM Studio', path='https://github.com/achyuth4/NeonAI-LLMstudio'),
- ui.nav_item(name='more-models', label='More spaces', path='https://huggingface.co/achyuthgamer'),
- ]),
- ],
- secondary_items=[
- ui.toggle(name='dark_mode', label='Dark mode', trigger=True),
- ui.text('Developer - Achyuth Reddy. ')
- ]
- )
-
- q.page['chatbot'] = ui.chatbot_card(
- box=ui.box('content'),
- data=data('content from_user', t='list'),
- name='chatbot'
- )
- q.page['title'] = ui.section_card(
- box='title',
- title='',
- subtitle='',
- items=[
- ui.dropdown(name='model', trigger=True, label='', value='gpt', choices=[
- ui.choice(name='gpt', label='Gpt Model'),
- ui.choice(name='falcon', label='Falcon Model'),
- ui.choice(name='mpt', label='Mpt Model'),
- ]),
- ui.button(name='clear', label='Clear', icon='Delete'),
- ],
- )
-
- """
- :param load_8bit: load model in 8-bit using bitsandbytes
- :param load_4bit: load model in 4-bit using bitsandbytes
- :param load_half: load model in float16
- :param infer_devices: whether to control devices with gpu_id. If False, then spread across GPUs
- :param base_model: model HF-type name. If use --base_model to preload model, cannot unload in gradio in models tab
- :param tokenizer_base_model: tokenizer HF-type name. Usually not required, inferred from base_model.
- :param lora_weights: LORA weights path/HF link
- :param gpu_id: if infer_devices, then use gpu_id for cuda device ID, or auto mode if gpu_id != -1
- :param compile_model Whether to compile the model
- :param use_cache: Whether to use caching in model (some models fail when multiple threads use)
- :param inference_server: Consume base_model as type of model at this address
- Address can be text-generation-server hosting that base_model
- e.g. python generate.py --inference_server="http://192.168.1.46:6112" --base_model=h2oai/h2ogpt-oasst1-512-12b
- Or Address can be "openai_chat" or "openai" for OpenAI API
- e.g. python generate.py --inference_server="openai_chat" --base_model=gpt-3.5-turbo
- e.g. python generate.py --inference_server="openai" --base_model=text-davinci-003
- :param prompt_type: type of prompt, usually matched to fine-tuned model or plain for foundational model
- :param prompt_dict: If prompt_type=custom, then expects (some) items returned by get_prompt(..., return_dict=True)
- :param model_lock: Lock models to specific combinations, for ease of use and extending to many models
- Only used if gradio = True
- List of dicts, each dict has base_model, tokenizer_base_model, lora_weights, inference_server, prompt_type, and prompt_dict
- If all models have same prompt_type, and prompt_dict, can still specify that once in CLI outside model_lock as default for dict
- Can specify model_lock instead of those items on CLI
- As with CLI itself, base_model can infer prompt_type and prompt_dict if in prompter.py.
- Also, tokenizer_base_model and lora_weights are optional.
- Also, inference_server is optional if loading model from local system.
- All models provided will automatically appear in compare model mode
- Model loading-unloading and related choices will be disabled. Model/lora/server adding will be disabled
- :param model_lock_columns: How many columns to show if locking models (and so showing all at once)
- If None, then defaults to up to 3
- if -1, then all goes into 1 row
- Maximum value is 4 due to non-dynamic gradio rendering elements
- :param fail_if_cannot_connect: if doing model locking (e.g. with many models), fail if True. Otherwise ignore.
- Useful when many endpoints and want to just see what works, but still have to wait for timeout.
- :param temperature: generation temperature
- :param top_p: generation top_p
- :param top_k: generation top_k
- :param num_beams: generation number of beams
- :param repetition_penalty: generation repetition penalty
- :param num_return_sequences: generation number of sequences (1 forced for chat)
- :param do_sample: generation sample
- :param max_new_tokens: generation max new tokens
- :param min_new_tokens: generation min tokens
- :param early_stopping: generation early stopping
- :param max_time: maximum time to allow for generation
- :param memory_restriction_level: 0 = no restriction to tokens or model, 1 = some restrictions on token 2 = HF like restriction 3 = very low memory case
- :param debug: enable debug mode
- :param save_dir: directory chat data is saved to
- :param share: whether to share the gradio app with sharable URL
- :param local_files_only: whether to only use local files instead of doing to HF for models
- :param resume_download: whether to resume downloads from HF for models
- :param use_auth_token: whether to use HF auth token (requires CLI did huggingface-cli login before)
- :param trust_remote_code: whether to use trust any code needed for HF model
- :param offload_folder: path for spilling model onto disk
- :param src_lang: source languages to include if doing translation (None = all)
- :param tgt_lang: target languages to include if doing translation (None = all)
- :param cli: whether to use CLI (non-gradio) interface.
- :param cli_loop: whether to loop for CLI (False usually only for testing)
- :param gradio: whether to enable gradio, or to enable benchmark mode
- :param gradio_offline_level: > 0, then change fonts so full offline
- == 1 means backend won't need internet for fonts, but front-end UI might if font not cached
- == 2 means backend and frontend don't need internet to download any fonts.
- Note: Some things always disabled include HF telemetry, gradio telemetry, chromadb posthog that involve uploading.
- This option further disables google fonts for downloading, which is less intrusive than uploading,
- but still required in air-gapped case. The fonts don't look as nice as google fonts, but ensure full offline behavior.
- Also set --share=False to avoid sharing a gradio live link.
- :param chat: whether to enable chat mode with chat history
- :param chat_context: whether to use extra helpful context if human_bot
- :param stream_output: whether to stream output
- :param show_examples: whether to show clickable examples in gradio
- :param verbose: whether to show verbose prints
- :param h2ocolors: whether to use H2O.ai theme
- :param height: height of chat window
- :param show_lora: whether to show LORA options in UI (expert so can be hard to understand)
- :param login_mode_if_model0: set to True to load --base_model after client logs in, to be able to free GPU memory when model is swapped
- :param block_gradio_exit: whether to block gradio exit (used for testing)
- :param concurrency_count: gradio concurrency count (1 is optimal for LLMs)
- :param api_open: If False, don't let API calls skip gradio queue
- :param allow_api: whether to allow API calls at all to gradio server
- :param input_lines: how many input lines to show for chat box (>1 forces shift-enter for submit, else enter is submit)
- :param gradio_size: Overall size of text and spaces: "xsmall", "small", "medium", "large".
- Small useful for many chatbots in model_lock mode
- :param auth: gradio auth for launcher in form [(user1, pass1), (user2, pass2), ...]
- e.g. --auth=[('jon','password')] with no spaces
- :param max_max_time: Maximum max_time for gradio slider
- :param max_max_new_tokens: Maximum max_new_tokens for gradio slider
- :param sanitize_user_prompt: whether to remove profanity from user input (slows down input processing)
- :param sanitize_bot_response: whether to remove profanity and repeat lines from bot output (about 2x slower generation for long streaming cases due to better_profanity being slow)
- :param extra_model_options: extra models to show in list in gradio
- :param extra_lora_options: extra LORA to show in list in gradio
- :param extra_server_options: extra servers to show in list in gradio
- :param score_model: which model to score responses (None means no scoring)
- :param eval_filename: json file to use for evaluation, if None is sharegpt
- :param eval_prompts_only_num: for no gradio benchmark, if using eval_filename prompts for eval instead of examples
- :param eval_prompts_only_seed: for no gradio benchmark, seed for eval_filename sampling
- :param eval_as_output: for no gradio benchmark, whether to test eval_filename output itself
- :param langchain_mode: Data source to include. Choose "UserData" to only consume files from make_db.py.
- WARNING: wiki_full requires extra data processing via read_wiki_full.py and requires really good workstation to generate db, unless already present.
- :param langchain_action: Mode langchain operations in on documents.
- Query: Make query of document(s)
- Summarize or Summarize_map_reduce: Summarize document(s) via map_reduce
- Summarize_all: Summarize document(s) using entire document at once
- Summarize_refine: Summarize document(s) using entire document, and try to refine before returning summary
- :param force_langchain_evaluate: Whether to force langchain LLM use even if not doing langchain, mostly for testing.
- :param user_path: user path to glob from to generate db for vector search, for 'UserData' langchain mode.
- If already have db, any new/changed files are added automatically if path set, does not have to be same path used for prior db sources
- :param detect_user_path_changes_every_query: whether to detect if any files changed or added every similarity search (by file hashes).
- Expensive for large number of files, so not done by default. By default only detect changes during db loading.
- :param visible_langchain_modes: dbs to generate at launch to be ready for LLM
- Can be up to ['wiki', 'wiki_full', 'UserData', 'MyData', 'github h2oGPT', 'DriverlessAI docs']
- But wiki_full is expensive and requires preparation
- To allow scratch space only live in session, add 'MyData' to list
- Default: If only want to consume local files, e.g. prepared by make_db.py, only include ['UserData']
- FIXME: Avoid 'All' for now, not implemented
- :param visible_langchain_actions: Which actions to allow
- :param document_choice: Default document choice when taking subset of collection
- :param load_db_if_exists: Whether to load chroma db if exists or re-generate db
- :param keep_sources_in_context: Whether to keep url sources in context, not helpful usually
- :param db_type: 'faiss' for in-memory or 'chroma' or 'weaviate' for persisted on disk
- :param use_openai_embedding: Whether to use OpenAI embeddings for vector db
- :param use_openai_model: Whether to use OpenAI model for use with vector db
- :param hf_embedding_model: Which HF embedding model to use for vector db
- Default is instructor-large with 768 parameters per embedding if have GPUs, else all-MiniLM-L6-v1 if no GPUs
- Can also choose simpler model with 384 parameters per embedding: "sentence-transformers/all-MiniLM-L6-v2"
- Can also choose even better embedding with 1024 parameters: 'hkunlp/instructor-xl'
- We support automatically changing of embeddings for chroma, with a backup of db made if this is done
- :param allow_upload_to_user_data: Whether to allow file uploads to update shared vector db
- :param allow_upload_to_my_data: Whether to allow file uploads to update scratch vector db
- :param enable_url_upload: Whether to allow upload from URL
- :param enable_text_upload: Whether to allow upload of text
- :param enable_sources_list: Whether to allow list (or download for non-shared db) of list of sources for chosen db
- :param chunk: Whether to chunk data (True unless know data is already optimally chunked)
- :param chunk_size: Size of chunks, with typically top-4 passed to LLM, so neesd to be in context length
- :param top_k_docs: number of chunks to give LLM
- :param reverse_docs: whether to reverse docs order so most relevant is closest to question.
- Best choice for sufficiently smart model, and truncation occurs for oldest context, so best then too.
- But smaller 6_9 models fail to use newest context and can get stuck on old information.
- :param auto_reduce_chunks: Whether to automatically reduce top_k_docs to fit context given prompt
- :param max_chunks: If top_k_docs=-1, maximum number of chunks to allow
- :param n_jobs: Number of processors to use when consuming documents (-1 = all, is default)
- :param enable_captions: Whether to support captions using BLIP for image files as documents, then preloads that model
- :param captions_model: Which model to use for captions.
- captions_model: str = "Salesforce/blip-image-captioning-base", # continue capable
- captions_model: str = "Salesforce/blip2-flan-t5-xl", # question/answer capable, 16GB state
- captions_model: str = "Salesforce/blip2-flan-t5-xxl", # question/answer capable, 60GB state
- Note: opt-based blip2 are not permissive license due to opt and Meta license restrictions
- :param pre_load_caption_model: Whether to preload caption model, or load after forking parallel doc loader
- parallel loading disabled if preload and have images, to prevent deadlocking on cuda context
- Recommended if using larger caption model
- :param caption_gpu: If support caption, then use GPU if exists
- :param enable_ocr: Whether to support OCR on images
- :return:
- """
-
-@app('/')
-async def serve(q: Q):
- if not q.client.initialized:
- await init_ui(q)
- q.client.model_client = Client('https://gpt.h2o.ai/')
- q.client.initialized = True
-
- # A new message arrived.
- if q.args.chatbot:
- # Append user message.
- q.page['chatbot'].data += [q.args.chatbot, True]
- # Append bot response.
- kwargs = dict(instruction_nochat=q.args.chatbot)
- try:
- res = q.client.model_client.predict(str(dict(kwargs)), api_name='/submit_nochat_api')
- bot_res = ast.literal_eval(res)['response']
- q.page['chatbot'].data += [bot_res, False]
- except:
- q.page['meta'] = ui.meta_card(box='', notification_bar=ui.notification_bar(
- text='An error occurred during prediction. Please try later or a different model.',
- type='error',
- ))
- elif q.args.clear:
- # Recreate the card.
- q.page['chatbot'] = ui.chatbot_card(
- box=ui.box('content'),
- data=data('content from_user', t='list'),
- name='chatbot'
- )
- elif q.args.dark_mode is not None:
- q.page['meta'].theme = 'achyuthgpt-dark' if q.args.dark_mode else 'light'
- q.page['sidebar'].color = 'card' if q.args.dark_mode else 'primary'
- elif q.args.model:
- try:
- q.client.model_client = Client(f'https://{q.args.model}.h2o.ai/')
- q.page['meta'] = ui.meta_card(box='', notification_bar=ui.notification_bar(
- text='Model changed successfully.',
- type='success',
- ))
- except:
- q.page['meta'] = ui.meta_card(box='', notification_bar=ui.notification_bar(
- text='An error occurred while changing the model. Please try a different one.',
- type='error',
- ))
-
- await q.page.save()
diff --git a/spaces/Adapting/YouTube-Downloader/tube/utils.py b/spaces/Adapting/YouTube-Downloader/tube/utils.py
deleted file mode 100644
index c82fa492051e16f1ace89775fb00c3f7fb1caa87..0000000000000000000000000000000000000000
--- a/spaces/Adapting/YouTube-Downloader/tube/utils.py
+++ /dev/null
@@ -1,36 +0,0 @@
-import shutil
-import streamlit as st
-from pathlib import Path
-from .var import OUTPUT_DIR
-
-
-
-
-def compress_folder_2_zip(output_filename: str, dir_name:str):
- path = Path(output_filename+'.zip')
- if path.exists():
- return
-
- prompt = st.info('Start compressing...')
- with st.spinner("Compressing"):
- shutil.make_archive(output_filename.replace('.zip', ''), 'zip', dir_name)
- prompt.empty()
-
-
-def remove_dir_rec(pth):
- pth = Path(pth)
- if pth.exists():
- for child in pth.glob('*'):
- if child.is_file():
- child.unlink()
- else:
- remove_dir_rec(child)
- pth.rmdir()
-def clear_cache(dir_name:str = OUTPUT_DIR):
- remove_dir_rec(dir_name)
-
-
-
-
-if __name__ == '__main__':
- compress_folder_2_zip('test',dir_name='../downloads')
\ No newline at end of file
diff --git a/spaces/AgentVerse/agentVerse/agentverse/environments/simulation_env/rules/visibility/__init__.py b/spaces/AgentVerse/agentVerse/agentverse/environments/simulation_env/rules/visibility/__init__.py
deleted file mode 100644
index 3f03700ce802e8f2eafd5c3f4188e1156c4454e0..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/agentverse/environments/simulation_env/rules/visibility/__init__.py
+++ /dev/null
@@ -1,13 +0,0 @@
-from typing import Dict
-
-from agentverse.registry import Registry
-
-visibility_registry = Registry(name="VisibilityRegistry")
-
-from .base import BaseVisibility
-from .all import AllVisibility
-from .classroom import ClassroomVisibility
-from .oneself import OneselfVisibility
-from .prisoner import PrisonerVisibility
-from .sde_team import SdeTeamVisibility
-from .pokemon import PokemonVisibility
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/ball/Factory.d.ts b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/ball/Factory.d.ts
deleted file mode 100644
index bea8880b9858725e2646f2dadd854685fe1d2d6d..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/ball/Factory.d.ts
+++ /dev/null
@@ -1,6 +0,0 @@
-import Ball from './Ball';
-import Base from '../base/Base';
-
-export default function Factory(
- config?: Base.IConfig
-): Ball;
\ No newline at end of file
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/dropdownlist/Factory.d.ts b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/dropdownlist/Factory.d.ts
deleted file mode 100644
index 7e6119454f2d19354c47c25ad79c82a0d5df5989..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/dropdownlist/Factory.d.ts
+++ /dev/null
@@ -1,5 +0,0 @@
-import DropDownList from './DropDownList';
-
-export default function (
- config?: DropDownList.IConfig
-): DropDownList;
\ No newline at end of file
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/simpledropdownlist/Factory.d.ts b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/simpledropdownlist/Factory.d.ts
deleted file mode 100644
index b343ef326c1052631298562060c386eba9638608..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/simpledropdownlist/Factory.d.ts
+++ /dev/null
@@ -1,6 +0,0 @@
-import SimpleDropDownList from './SimpleDropDownList';
-
-export default function (
- config?: SimpleDropDownList.IConfig,
- creators?: SimpleDropDownList.ICreatorsConfig,
-): SimpleDropDownList;
\ No newline at end of file
diff --git a/spaces/AiBototicus/BucksAI-4/README.md b/spaces/AiBototicus/BucksAI-4/README.md
deleted file mode 100644
index 482e206df543d459c40c3cbce85c39cc817a2883..0000000000000000000000000000000000000000
--- a/spaces/AiBototicus/BucksAI-4/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: BucksAI 4
-emoji: 👀
-colorFrom: red
-colorTo: red
-sdk: gradio
-sdk_version: 3.24.1
-app_file: app.py
-pinned: false
-license: openrail
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/AlanMars/QYL-AI-Space/modules/models/modeling_moss.py b/spaces/AlanMars/QYL-AI-Space/modules/models/modeling_moss.py
deleted file mode 100644
index b7adea5bca857f7fdd6399dde7ce359f8f8cecfe..0000000000000000000000000000000000000000
--- a/spaces/AlanMars/QYL-AI-Space/modules/models/modeling_moss.py
+++ /dev/null
@@ -1,711 +0,0 @@
-""" PyTorch Moss model."""
-
-from typing import Optional, Tuple, Union
-
-import torch
-import torch.utils.checkpoint
-from torch import nn
-from torch.nn import CrossEntropyLoss
-
-from transformers.activations import ACT2FN
-from transformers.modeling_utils import PreTrainedModel
-from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
-from transformers.utils import (
- add_code_sample_docstrings,
- add_start_docstrings,
- add_start_docstrings_to_model_forward,
- logging
-)
-
-from .configuration_moss import MossConfig
-
-
-logger = logging.get_logger(__name__)
-
-_CHECKPOINT_FOR_DOC = "fnlp/moss-moon-003-base"
-_CONFIG_FOR_DOC = "MossConfig"
-
-
-MOSS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "fnlp/moss-moon-003-base",
- "fnlp/moss-moon-003-sft",
- "fnlp/moss-moon-003-sft-plugin",
-]
-
-
-# Copied from transformers.models.gptj.modeling_gptj.create_sinusoidal_positions
-def create_sinusoidal_positions(num_pos: int, dim: int) -> torch.Tensor:
- inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2) / dim))
- sinusoid_inp = torch.einsum("i , j -> i j", torch.arange(num_pos, dtype=torch.float), inv_freq).float()
- return torch.cat((torch.sin(sinusoid_inp), torch.cos(sinusoid_inp)), dim=1)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.rotate_every_two
-def rotate_every_two(x: torch.Tensor) -> torch.Tensor:
- x1 = x[:, :, :, ::2]
- x2 = x[:, :, :, 1::2]
- x = torch.stack((-x2, x1), dim=-1)
- return x.flatten(-2) # in einsum notation: rearrange(x, '... d j -> ... (d j)')
-
-
-# Copied from transformers.models.gptj.modeling_gptj.apply_rotary_pos_emb
-def apply_rotary_pos_emb(tensor: torch.Tensor, sin: torch.Tensor, cos: torch.Tensor) -> torch.Tensor:
- sin = torch.repeat_interleave(sin[:, :, None, :], 2, 3)
- cos = torch.repeat_interleave(cos[:, :, None, :], 2, 3)
- return (tensor * cos) + (rotate_every_two(tensor) * sin)
-
-
-class MossAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
-
- max_positions = config.max_position_embeddings
- self.register_buffer(
- "causal_mask",
- torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(
- 1, 1, max_positions, max_positions
- ),
- )
-
- self.attn_dropout = nn.Dropout(config.attn_pdrop)
- self.resid_dropout = nn.Dropout(config.resid_pdrop)
-
- self.embed_dim = config.hidden_size
- self.num_attention_heads = config.num_attention_heads
- self.head_dim = self.embed_dim // self.num_attention_heads
- if self.head_dim * self.num_attention_heads != self.embed_dim:
- raise ValueError(
- f"embed_dim must be divisible by num_attention_heads (got `embed_dim`: {self.embed_dim} and"
- f" `num_attention_heads`: {self.num_attention_heads})."
- )
- self.scale_attn = torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32)).to(torch.get_default_dtype())
- self.qkv_proj = nn.Linear(self.embed_dim, self.embed_dim * 3, bias=False)
-
- self.out_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=False)
- self.rotary_dim = config.rotary_dim
- pos_embd_dim = self.rotary_dim or self.embed_dim
- self.embed_positions = create_sinusoidal_positions(max_positions, pos_embd_dim)
-
- def _split_heads(self, x, n_head, dim_head, mp_num):
- reshaped = x.reshape(x.shape[:-1] + (n_head // mp_num, dim_head))
- reshaped = reshaped.reshape(x.shape[:-2] + (-1,) + reshaped.shape[-1:])
- return reshaped
-
- def _merge_heads(self, tensor, num_attention_heads, attn_head_size):
- """
- Merges attn_head_size dim and num_attn_heads dim into n_ctx
- """
- if len(tensor.shape) == 5:
- tensor = tensor.permute(0, 1, 3, 2, 4).contiguous()
- elif len(tensor.shape) == 4:
- tensor = tensor.permute(0, 2, 1, 3).contiguous()
- else:
- raise ValueError(f"Input tensor rank should be one of [4, 5], but is: {len(tensor.shape)}")
- new_shape = tensor.size()[:-2] + (num_attention_heads * attn_head_size,)
- return tensor.view(new_shape)
-
- def _attn(
- self,
- query,
- key,
- value,
- attention_mask=None,
- head_mask=None,
- ):
- # compute causal mask from causal mask buffer
- query_length, key_length = query.size(-2), key.size(-2)
- causal_mask = self.causal_mask[:, :, key_length - query_length : key_length, :key_length]
-
- # Keep the attention weights computation in fp32 to avoid overflow issues
- query = query.to(torch.float32)
- key = key.to(torch.float32)
-
- attn_weights = torch.matmul(query, key.transpose(-1, -2))
-
- attn_weights = attn_weights / self.scale_attn
- mask_value = torch.finfo(attn_weights.dtype).min
- # Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
- # Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
- mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
- attn_weights = torch.where(causal_mask, attn_weights, mask_value)
-
- if attention_mask is not None:
- # Apply the attention mask
- attn_weights = attn_weights + attention_mask
-
- attn_weights = nn.Softmax(dim=-1)(attn_weights)
- attn_weights = attn_weights.to(value.dtype)
- attn_weights = self.attn_dropout(attn_weights)
-
- # Mask heads if we want to
- if head_mask is not None:
- attn_weights = attn_weights * head_mask
-
- attn_output = torch.matmul(attn_weights, value)
-
- return attn_output, attn_weights
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[
- Tuple[torch.Tensor, Tuple[torch.Tensor]],
- Optional[Tuple[torch.Tensor, Tuple[torch.Tensor], Tuple[torch.Tensor, ...]]],
- ]:
- qkv = self.qkv_proj(hidden_states)
- # TODO(enijkamp): factor out number of logical TPU-v4 cores or make forward pass agnostic
- mp_num = 4
- qkv_split = qkv.reshape(qkv.shape[:-1] + (mp_num, -1))
-
- local_dim = self.head_dim * self.num_attention_heads // mp_num
- query, value, key = torch.split(qkv_split, local_dim, dim=-1)
- query = self._split_heads(query, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- key = self._split_heads(key, self.num_attention_heads, self.head_dim, mp_num=mp_num)
-
- value = self._split_heads(value, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- value = value.permute(0, 2, 1, 3)
-
- embed_positions = self.embed_positions
- if embed_positions.device != position_ids.device:
- embed_positions = embed_positions.to(position_ids.device)
- self.embed_positions = embed_positions
-
- sincos = embed_positions[position_ids]
- sin, cos = torch.split(sincos, sincos.shape[-1] // 2, dim=-1)
-
- if self.rotary_dim is not None:
- k_rot = key[:, :, :, : self.rotary_dim]
- k_pass = key[:, :, :, self.rotary_dim :]
-
- q_rot = query[:, :, :, : self.rotary_dim]
- q_pass = query[:, :, :, self.rotary_dim :]
-
- k_rot = apply_rotary_pos_emb(k_rot, sin, cos)
- q_rot = apply_rotary_pos_emb(q_rot, sin, cos)
-
- key = torch.cat([k_rot, k_pass], dim=-1)
- query = torch.cat([q_rot, q_pass], dim=-1)
- else:
- key = apply_rotary_pos_emb(key, sin, cos)
- query = apply_rotary_pos_emb(query, sin, cos)
-
- key = key.permute(0, 2, 1, 3)
- query = query.permute(0, 2, 1, 3)
-
- if layer_past is not None:
- past_key = layer_past[0]
- past_value = layer_past[1]
- key = torch.cat((past_key, key), dim=-2)
- value = torch.cat((past_value, value), dim=-2)
-
- if use_cache is True:
- present = (key, value)
- else:
- present = None
-
- # compute self-attention: V x Softmax(QK^T)
- attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
-
- attn_output = self._merge_heads(attn_output, self.num_attention_heads, self.head_dim)
- attn_output = self.out_proj(attn_output)
- attn_output = self.resid_dropout(attn_output)
-
- outputs = (attn_output, present)
- if output_attentions:
- outputs += (attn_weights,)
-
- return outputs # a, present, (attentions)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJMLP with GPTJ->Moss
-class MossMLP(nn.Module):
- def __init__(self, intermediate_size, config): # in MLP: intermediate_size= 4 * embed_dim
- super().__init__()
- embed_dim = config.n_embd
-
- self.fc_in = nn.Linear(embed_dim, intermediate_size)
- self.fc_out = nn.Linear(intermediate_size, embed_dim)
-
- self.act = ACT2FN[config.activation_function]
- self.dropout = nn.Dropout(config.resid_pdrop)
-
- def forward(self, hidden_states: Optional[torch.FloatTensor]) -> torch.FloatTensor:
- hidden_states = self.fc_in(hidden_states)
- hidden_states = self.act(hidden_states)
- hidden_states = self.fc_out(hidden_states)
- hidden_states = self.dropout(hidden_states)
- return hidden_states
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJBlock with GPTJ->Moss
-class MossBlock(nn.Module):
- def __init__(self, config):
- super().__init__()
- inner_dim = config.n_inner if config.n_inner is not None else 4 * config.n_embd
- self.ln_1 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
- self.attn = MossAttention(config)
- self.mlp = MossMLP(inner_dim, config)
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[Tuple[torch.Tensor], Optional[Tuple[torch.Tensor, Tuple[torch.FloatTensor, ...]]]]:
- residual = hidden_states
- hidden_states = self.ln_1(hidden_states)
- attn_outputs = self.attn(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
- attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
- outputs = attn_outputs[1:]
-
- feed_forward_hidden_states = self.mlp(hidden_states)
- hidden_states = attn_output + feed_forward_hidden_states + residual
-
- if use_cache:
- outputs = (hidden_states,) + outputs
- else:
- outputs = (hidden_states,) + outputs[1:]
-
- return outputs # hidden_states, present, (attentions)
-
-
-class MossPreTrainedModel(PreTrainedModel):
- """
- An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
- models.
- """
-
- config_class = MossConfig
- base_model_prefix = "transformer"
- supports_gradient_checkpointing = True
- _no_split_modules = ["MossBlock"]
-
- def __init__(self, *inputs, **kwargs):
- super().__init__(*inputs, **kwargs)
-
- def _init_weights(self, module):
- """Initialize the weights."""
- if isinstance(module, (nn.Linear,)):
- # Slightly different from Mesh Transformer JAX which uses truncated_normal for initialization
- # cf https://github.com/pytorch/pytorch/pull/5617
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def _set_gradient_checkpointing(self, module, value=False):
- if isinstance(module, MossModel):
- module.gradient_checkpointing = value
-
-
-MOSS_START_DOCSTRING = r"""
- This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
- it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
- behavior.
-
- Parameters:
- config ([`MossConfig`]): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the
- configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
-"""
-
-MOSS_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (`torch.LongTensor` of shape `({0})`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using [`AutoProcenizer`]. See [`PreTrainedTokenizer.encode`] and
- [`PreTrainedTokenizer.__call__`] for details.
-
- [What are input IDs?](../glossary#input-ids)
- attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
- Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
-
- - 1 for tokens that are **not masked**,
- - 0 for tokens that are **masked**.
-
- [What are attention masks?](../glossary#attention-mask)
- token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
- 1]`:
-
- - 0 corresponds to a *sentence A* token,
- - 1 corresponds to a *sentence B* token.
-
- [What are token type IDs?](../glossary#token-type-ids)
- position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
- config.n_positions - 1]`.
-
- [What are position IDs?](../glossary#position-ids)
- head_mask (`torch.FloatTensor` of shape `(num_attention_heads,)` or `(n_layer, num_attention_heads)`, *optional*):
- Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
-
- - 1 indicates the head is **not masked**,
- - 0 indicates the head is **masked**.
-
- inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_dim)`, *optional*):
- Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
- is useful if you want more control over how to convert *input_ids* indices into associated vectors than the
- model's internal embedding lookup matrix.
- output_attentions (`bool`, *optional*):
- Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
- tensors for more detail.
- output_hidden_states (`bool`, *optional*):
- Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
- more detail.
- return_dict (`bool`, *optional*):
- Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
-"""
-
-
-@add_start_docstrings(
- "The bare Moss Model transformer outputting raw hidden-states without any specific head on top.",
- MOSS_START_DOCSTRING,
-)
-class MossModel(MossPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
-
- self.embed_dim = config.n_embd
- self.vocab_size = config.vocab_size
- self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
- self.drop = nn.Dropout(config.embd_pdrop)
- self.h = nn.ModuleList([MossBlock(config) for _ in range(config.n_layer)])
- self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
- self.rotary_dim = min(config.rotary_dim, config.n_ctx // config.num_attention_heads)
-
- self.gradient_checkpointing = False
-
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_input_embeddings(self):
- return self.wte
-
- def set_input_embeddings(self, new_embeddings):
- self.wte = new_embeddings
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=BaseModelOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, BaseModelOutputWithPast]:
- output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
-
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
-
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1]).long()
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if position_ids is None:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- # Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x num_attention_heads x N x N
- # head_mask has shape n_layer x batch x num_attention_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
-
- hidden_states = inputs_embeds
-
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
-
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
- "`use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_hidden_states = () if output_hidden_states else None
- for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- position_ids,
- head_mask[i],
- )
- else:
- outputs = block(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask[i],
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
-
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if not return_dict:
- return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
-
- return BaseModelOutputWithPast(
- last_hidden_state=hidden_states,
- past_key_values=presents,
- hidden_states=all_hidden_states,
- attentions=all_self_attentions,
- )
-
-
-@add_start_docstrings(
- """
- The Moss Model transformer with a language modeling head on top.
- """,
- MOSS_START_DOCSTRING,
-)
-class MossForCausalLM(MossPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.causal_mask"]
-
- def __init__(self, config):
- super().__init__(config)
- self.transformer = MossModel(config)
- self.lm_head = nn.Linear(config.n_embd, config.vocab_size)
-
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_output_embeddings(self):
- return self.lm_head
-
- def set_output_embeddings(self, new_embeddings):
- self.lm_head = new_embeddings
-
- def prepare_inputs_for_generation(self, input_ids, past_key_values=None, **kwargs):
- token_type_ids = kwargs.get("token_type_ids", None)
- # only last token for inputs_ids if past is defined in kwargs
- if past_key_values:
- input_ids = input_ids[:, -1].unsqueeze(-1)
- if token_type_ids is not None:
- token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
-
- attention_mask = kwargs.get("attention_mask", None)
- position_ids = kwargs.get("position_ids", None)
-
- if attention_mask is not None and position_ids is None:
- # create position_ids on the fly for batch generation
- position_ids = attention_mask.long().cumsum(-1) - 1
- position_ids.masked_fill_(attention_mask == 0, 1)
- if past_key_values:
- position_ids = position_ids[:, -1].unsqueeze(-1)
-
- return {
- "input_ids": input_ids,
- "past_key_values": past_key_values,
- "use_cache": kwargs.get("use_cache"),
- "position_ids": position_ids,
- "attention_mask": attention_mask,
- "token_type_ids": token_type_ids,
- }
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=CausalLMOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, CausalLMOutputWithPast]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- transformer_outputs = self.transformer(
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- )
- hidden_states = transformer_outputs[0]
-
- # make sure sampling in fp16 works correctly and
- # compute loss in fp32 to match with mesh-tf version
- # https://github.com/EleutherAI/gpt-neo/blob/89ce74164da2fb16179106f54e2269b5da8db333/models/gpt2/gpt2.py#L179
- lm_logits = self.lm_head(hidden_states).to(torch.float32)
-
- loss = None
- if labels is not None:
- # Shift so that tokens < n predict n
- shift_logits = lm_logits[..., :-1, :].contiguous()
- shift_labels = labels[..., 1:].contiguous()
- # Flatten the tokens
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
-
- loss = loss.to(hidden_states.dtype)
-
- if not return_dict:
- output = (lm_logits,) + transformer_outputs[1:]
- return ((loss,) + output) if loss is not None else output
-
- return CausalLMOutputWithPast(
- loss=loss,
- logits=lm_logits,
- past_key_values=transformer_outputs.past_key_values,
- hidden_states=transformer_outputs.hidden_states,
- attentions=transformer_outputs.attentions,
- )
-
- @staticmethod
- def _reorder_cache(
- past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
- ) -> Tuple[Tuple[torch.Tensor]]:
- """
- This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
- [`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
- beam_idx at every generation step.
- """
- return tuple(
- tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past)
- for layer_past in past_key_values
- )
diff --git a/spaces/AlexWang/lama/saicinpainting/evaluation/losses/__init__.py b/spaces/AlexWang/lama/saicinpainting/evaluation/losses/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Alfasign/fdvdv/app.py b/spaces/Alfasign/fdvdv/app.py
deleted file mode 100644
index 1e1ef1ebac9e53b49221ef09f678e6c4a421157b..0000000000000000000000000000000000000000
--- a/spaces/Alfasign/fdvdv/app.py
+++ /dev/null
@@ -1,7 +0,0 @@
- import requests response = requests.post( 'https://api.v6.unrealspeech.com/stream',
-
- headers = { 'Authorization' : 'Bearer VqUmMUjnSPfuxttMk4SjWGVR9fbdVLBSwXxpWUq9iwDWYRQDhGQxfQ' },
- json = { 'Text': '''''', 'VoiceId': '', 'Bitrate': '128k', } )
-with open('audio.mp3', 'wb') as f: f.write(response.content)
-
-import gradio as grdef greet(name):return "Hello " + name + "!!"iface = gr.Interface(fn=greet, inputs="text", outputs="text")iface.launch()
\ No newline at end of file
diff --git a/spaces/Alpaca233/SadTalker/src/face3d/models/__init__.py b/spaces/Alpaca233/SadTalker/src/face3d/models/__init__.py
deleted file mode 100644
index 5a7986c7ad2ec48f404adf81fea5aa06aaf1eeb4..0000000000000000000000000000000000000000
--- a/spaces/Alpaca233/SadTalker/src/face3d/models/__init__.py
+++ /dev/null
@@ -1,67 +0,0 @@
-"""This package contains modules related to objective functions, optimizations, and network architectures.
-
-To add a custom model class called 'dummy', you need to add a file called 'dummy_model.py' and define a subclass DummyModel inherited from BaseModel.
-You need to implement the following five functions:
- -- <__init__>: initialize the class; first call BaseModel.__init__(self, opt).
- -- : unpack data from dataset and apply preprocessing.
- -- : produce intermediate results.
- -- : calculate loss, gradients, and update network weights.
- -- : (optionally) add model-specific options and set default options.
-
-In the function <__init__>, you need to define four lists:
- -- self.loss_names (str list): specify the training losses that you want to plot and save.
- -- self.model_names (str list): define networks used in our training.
- -- self.visual_names (str list): specify the images that you want to display and save.
- -- self.optimizers (optimizer list): define and initialize optimizers. You can define one optimizer for each network. If two networks are updated at the same time, you can use itertools.chain to group them. See cycle_gan_model.py for an usage.
-
-Now you can use the model class by specifying flag '--model dummy'.
-See our template model class 'template_model.py' for more details.
-"""
-
-import importlib
-from src.face3d.models.base_model import BaseModel
-
-
-def find_model_using_name(model_name):
- """Import the module "models/[model_name]_model.py".
-
- In the file, the class called DatasetNameModel() will
- be instantiated. It has to be a subclass of BaseModel,
- and it is case-insensitive.
- """
- model_filename = "face3d.models." + model_name + "_model"
- modellib = importlib.import_module(model_filename)
- model = None
- target_model_name = model_name.replace('_', '') + 'model'
- for name, cls in modellib.__dict__.items():
- if name.lower() == target_model_name.lower() \
- and issubclass(cls, BaseModel):
- model = cls
-
- if model is None:
- print("In %s.py, there should be a subclass of BaseModel with class name that matches %s in lowercase." % (model_filename, target_model_name))
- exit(0)
-
- return model
-
-
-def get_option_setter(model_name):
- """Return the static method of the model class."""
- model_class = find_model_using_name(model_name)
- return model_class.modify_commandline_options
-
-
-def create_model(opt):
- """Create a model given the option.
-
- This function warps the class CustomDatasetDataLoader.
- This is the main interface between this package and 'train.py'/'test.py'
-
- Example:
- >>> from models import create_model
- >>> model = create_model(opt)
- """
- model = find_model_using_name(opt.model)
- instance = model(opt)
- print("model [%s] was created" % type(instance).__name__)
- return instance
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/docs/source/en/index.md b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/docs/source/en/index.md
deleted file mode 100644
index f2012abc6970dbd9e27b176a11fce301f7cf45f8..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/docs/source/en/index.md
+++ /dev/null
@@ -1,98 +0,0 @@
-
-
-
-
-
-# Diffusers
-
-🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or want to train your own diffusion model, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](conceptual/philosophy#usability-over-performance), [simple over easy](conceptual/philosophy#simple-over-easy), and [customizability over abstractions](conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
-
-The library has three main components:
-
-- State-of-the-art [diffusion pipelines](api/pipelines/overview) for inference with just a few lines of code.
-- Interchangeable [noise schedulers](api/schedulers/overview) for balancing trade-offs between generation speed and quality.
-- Pretrained [models](api/models) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
-
-
-
-## Supported pipelines
-
-| Pipeline | Paper/Repository | Tasks |
-|---|---|:---:|
-| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
-| [audio_diffusion](./api/pipelines/audio_diffusion) | [Audio Diffusion](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
-| [controlnet](./api/pipelines/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
-| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
-| [dance_diffusion](./api/pipelines/dance_diffusion) | [Dance Diffusion](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
-| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
-| [ddim](./api/pipelines/ddim) | [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
-| [if](./if) | [**IF**](./api/pipelines/if) | Image Generation |
-| [if_img2img](./if) | [**IF**](./api/pipelines/if) | Image-to-Image Generation |
-| [if_inpainting](./if) | [**IF**](./api/pipelines/if) | Image-to-Image Generation |
-| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
-| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
-| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
-| [paint_by_example](./api/pipelines/paint_by_example) | [Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
-| [pndm](./api/pipelines/pndm) | [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
-| [score_sde_ve](./api/pipelines/score_sde_ve) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
-| [score_sde_vp](./api/pipelines/score_sde_vp) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
-| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [Semantic Guidance](https://arxiv.org/abs/2301.12247) | Text-Guided Generation |
-| [stable_diffusion_adapter](./api/pipelines/stable_diffusion/adapter) | [**T2I-Adapter**](https://arxiv.org/abs/2302.08453) | Image-to-Image Text-Guided Generation | -
-| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation |
-| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation |
-| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting |
-| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [MultiDiffusion](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
-| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) | Text-Guided Image Editing|
-| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [Zero-shot Image-to-Image Translation](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
-| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://arxiv.org/abs/2301.13826) | Text-to-Image Generation |
-| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [Improving Sample Quality of Diffusion Models Using Self-Attention Guidance](https://arxiv.org/abs/2210.00939) | Text-to-Image Generation Unconditional Image Generation |
-| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
-| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [Stable Diffusion Latent Upscaler](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
-| [stable_diffusion_model_editing](./api/pipelines/stable_diffusion/model_editing) | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://time-diffusion.github.io/) | Text-to-Image Model Editing |
-| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
-| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
-| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Depth-Conditional Stable Diffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
-| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
-| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [Safe Stable Diffusion](https://arxiv.org/abs/2211.05105) | Text-Guided Generation |
-| [stable_unclip](./stable_unclip) | Stable unCLIP | Text-to-Image Generation |
-| [stable_unclip](./stable_unclip) | Stable unCLIP | Image-to-Image Text-Guided Generation |
-| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
-| [text_to_video_sd](./api/pipelines/text_to_video) | [Modelscope's Text-to-video-synthesis Model in Open Domain](https://modelscope.cn/models/damo/text-to-video-synthesis/summary) | Text-to-Video Generation |
-| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125)(implementation by [kakaobrain](https://github.com/kakaobrain/karlo)) | Text-to-Image Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
-| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
-| [stable_diffusion_ldm3d](./api/pipelines/stable_diffusion/ldm3d_diffusion) | [LDM3D: Latent Diffusion Model for 3D](https://arxiv.org/abs/2305.10853) | Text to Image and Depth Generation |
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/docs/source/ko/using-diffusers/unconditional_image_generation.md b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/docs/source/ko/using-diffusers/unconditional_image_generation.md
deleted file mode 100644
index 67fc2913fbf06ae45653054f1e698bf1b7047748..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/docs/source/ko/using-diffusers/unconditional_image_generation.md
+++ /dev/null
@@ -1,54 +0,0 @@
-
-
-# Unconditional 이미지 생성
-
-[[Colab에서 열기]]
-
-Unconditional 이미지 생성은 비교적 간단한 작업입니다. 모델이 텍스트나 이미지와 같은 추가 조건 없이 이미 학습된 학습 데이터와 유사한 이미지만 생성합니다.
-
-['DiffusionPipeline']은 추론을 위해 미리 학습된 diffusion 시스템을 사용하는 가장 쉬운 방법입니다.
-
-먼저 ['DiffusionPipeline']의 인스턴스를 생성하고 다운로드할 파이프라인의 [체크포인트](https://huggingface.co/models?library=diffusers&sort=downloads)를 지정합니다. 허브의 🧨 diffusion 체크포인트 중 하나를 사용할 수 있습니다(사용할 체크포인트는 나비 이미지를 생성합니다).
-
-
-
-💡 나만의 unconditional 이미지 생성 모델을 학습시키고 싶으신가요? 학습 가이드를 살펴보고 나만의 이미지를 생성하는 방법을 알아보세요.
-
-
-
-
-이 가이드에서는 unconditional 이미지 생성에 ['DiffusionPipeline']과 [DDPM](https://arxiv.org/abs/2006.11239)을 사용합니다:
-
- ```python
- >>> from diffusers import DiffusionPipeline
-
- >>> generator = DiffusionPipeline.from_pretrained("anton-l/ddpm-butterflies-128")
- ```
-[diffusion 파이프라인]은 모든 모델링, 토큰화, 스케줄링 구성 요소를 다운로드하고 캐시합니다. 이 모델은 약 14억 개의 파라미터로 구성되어 있기 때문에 GPU에서 실행할 것을 강력히 권장합니다. PyTorch에서와 마찬가지로 제너레이터 객체를 GPU로 옮길 수 있습니다:
- ```python
- >>> generator.to("cuda")
- ```
-이제 제너레이터를 사용하여 이미지를 생성할 수 있습니다:
- ```python
- >>> image = generator().images[0]
- ```
-출력은 기본적으로 [PIL.Image](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class) 객체로 감싸집니다.
-
-다음을 호출하여 이미지를 저장할 수 있습니다:
- ```python
- >>> image.save("generated_image.png")
- ```
-
-아래 스페이스(데모 링크)를 이용해 보고, 추론 단계의 매개변수를 자유롭게 조절하여 이미지 품질에 어떤 영향을 미치는지 확인해 보세요!
-
-
\ No newline at end of file
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/models/embeddings_flax.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/models/embeddings_flax.py
deleted file mode 100644
index 88c2c45e4655b8013fa96e0b4408e3ec0a87c2c7..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/models/embeddings_flax.py
+++ /dev/null
@@ -1,95 +0,0 @@
-# Copyright 2023 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import math
-
-import flax.linen as nn
-import jax.numpy as jnp
-
-
-def get_sinusoidal_embeddings(
- timesteps: jnp.ndarray,
- embedding_dim: int,
- freq_shift: float = 1,
- min_timescale: float = 1,
- max_timescale: float = 1.0e4,
- flip_sin_to_cos: bool = False,
- scale: float = 1.0,
-) -> jnp.ndarray:
- """Returns the positional encoding (same as Tensor2Tensor).
-
- Args:
- timesteps: a 1-D Tensor of N indices, one per batch element.
- These may be fractional.
- embedding_dim: The number of output channels.
- min_timescale: The smallest time unit (should probably be 0.0).
- max_timescale: The largest time unit.
- Returns:
- a Tensor of timing signals [N, num_channels]
- """
- assert timesteps.ndim == 1, "Timesteps should be a 1d-array"
- assert embedding_dim % 2 == 0, f"Embedding dimension {embedding_dim} should be even"
- num_timescales = float(embedding_dim // 2)
- log_timescale_increment = math.log(max_timescale / min_timescale) / (num_timescales - freq_shift)
- inv_timescales = min_timescale * jnp.exp(jnp.arange(num_timescales, dtype=jnp.float32) * -log_timescale_increment)
- emb = jnp.expand_dims(timesteps, 1) * jnp.expand_dims(inv_timescales, 0)
-
- # scale embeddings
- scaled_time = scale * emb
-
- if flip_sin_to_cos:
- signal = jnp.concatenate([jnp.cos(scaled_time), jnp.sin(scaled_time)], axis=1)
- else:
- signal = jnp.concatenate([jnp.sin(scaled_time), jnp.cos(scaled_time)], axis=1)
- signal = jnp.reshape(signal, [jnp.shape(timesteps)[0], embedding_dim])
- return signal
-
-
-class FlaxTimestepEmbedding(nn.Module):
- r"""
- Time step Embedding Module. Learns embeddings for input time steps.
-
- Args:
- time_embed_dim (`int`, *optional*, defaults to `32`):
- Time step embedding dimension
- dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
- Parameters `dtype`
- """
- time_embed_dim: int = 32
- dtype: jnp.dtype = jnp.float32
-
- @nn.compact
- def __call__(self, temb):
- temb = nn.Dense(self.time_embed_dim, dtype=self.dtype, name="linear_1")(temb)
- temb = nn.silu(temb)
- temb = nn.Dense(self.time_embed_dim, dtype=self.dtype, name="linear_2")(temb)
- return temb
-
-
-class FlaxTimesteps(nn.Module):
- r"""
- Wrapper Module for sinusoidal Time step Embeddings as described in https://arxiv.org/abs/2006.11239
-
- Args:
- dim (`int`, *optional*, defaults to `32`):
- Time step embedding dimension
- """
- dim: int = 32
- flip_sin_to_cos: bool = False
- freq_shift: float = 1
-
- @nn.compact
- def __call__(self, timesteps):
- return get_sinusoidal_embeddings(
- timesteps, embedding_dim=self.dim, flip_sin_to_cos=self.flip_sin_to_cos, freq_shift=self.freq_shift
- )
diff --git a/spaces/Andy1621/uniformer_image_detection/mmdet/models/detectors/yolact.py b/spaces/Andy1621/uniformer_image_detection/mmdet/models/detectors/yolact.py
deleted file mode 100644
index f32fde0d3dcbb55a405e05df433c4353938a148b..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/mmdet/models/detectors/yolact.py
+++ /dev/null
@@ -1,146 +0,0 @@
-import torch
-
-from mmdet.core import bbox2result
-from ..builder import DETECTORS, build_head
-from .single_stage import SingleStageDetector
-
-
-@DETECTORS.register_module()
-class YOLACT(SingleStageDetector):
- """Implementation of `YOLACT `_"""
-
- def __init__(self,
- backbone,
- neck,
- bbox_head,
- segm_head,
- mask_head,
- train_cfg=None,
- test_cfg=None,
- pretrained=None):
- super(YOLACT, self).__init__(backbone, neck, bbox_head, train_cfg,
- test_cfg, pretrained)
- self.segm_head = build_head(segm_head)
- self.mask_head = build_head(mask_head)
- self.init_segm_mask_weights()
-
- def init_segm_mask_weights(self):
- """Initialize weights of the YOLACT segm head and YOLACT mask head."""
- self.segm_head.init_weights()
- self.mask_head.init_weights()
-
- def forward_dummy(self, img):
- """Used for computing network flops.
-
- See `mmdetection/tools/analysis_tools/get_flops.py`
- """
- raise NotImplementedError
-
- def forward_train(self,
- img,
- img_metas,
- gt_bboxes,
- gt_labels,
- gt_bboxes_ignore=None,
- gt_masks=None):
- """
- Args:
- img (Tensor): of shape (N, C, H, W) encoding input images.
- Typically these should be mean centered and std scaled.
- img_metas (list[dict]): list of image info dict where each dict
- has: 'img_shape', 'scale_factor', 'flip', and may also contain
- 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
- For details on the values of these keys see
- `mmdet/datasets/pipelines/formatting.py:Collect`.
- gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
- shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
- gt_labels (list[Tensor]): class indices corresponding to each box
- gt_bboxes_ignore (None | list[Tensor]): specify which bounding
- boxes can be ignored when computing the loss.
- gt_masks (None | Tensor) : true segmentation masks for each box
- used if the architecture supports a segmentation task.
-
- Returns:
- dict[str, Tensor]: a dictionary of loss components
- """
- # convert Bitmap mask or Polygon Mask to Tensor here
- gt_masks = [
- gt_mask.to_tensor(dtype=torch.uint8, device=img.device)
- for gt_mask in gt_masks
- ]
-
- x = self.extract_feat(img)
-
- cls_score, bbox_pred, coeff_pred = self.bbox_head(x)
- bbox_head_loss_inputs = (cls_score, bbox_pred) + (gt_bboxes, gt_labels,
- img_metas)
- losses, sampling_results = self.bbox_head.loss(
- *bbox_head_loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
-
- segm_head_outs = self.segm_head(x[0])
- loss_segm = self.segm_head.loss(segm_head_outs, gt_masks, gt_labels)
- losses.update(loss_segm)
-
- mask_pred = self.mask_head(x[0], coeff_pred, gt_bboxes, img_metas,
- sampling_results)
- loss_mask = self.mask_head.loss(mask_pred, gt_masks, gt_bboxes,
- img_metas, sampling_results)
- losses.update(loss_mask)
-
- # check NaN and Inf
- for loss_name in losses.keys():
- assert torch.isfinite(torch.stack(losses[loss_name]))\
- .all().item(), '{} becomes infinite or NaN!'\
- .format(loss_name)
-
- return losses
-
- def simple_test(self, img, img_metas, rescale=False):
- """Test function without test time augmentation."""
- x = self.extract_feat(img)
-
- cls_score, bbox_pred, coeff_pred = self.bbox_head(x)
-
- bbox_inputs = (cls_score, bbox_pred,
- coeff_pred) + (img_metas, self.test_cfg, rescale)
- det_bboxes, det_labels, det_coeffs = self.bbox_head.get_bboxes(
- *bbox_inputs)
- bbox_results = [
- bbox2result(det_bbox, det_label, self.bbox_head.num_classes)
- for det_bbox, det_label in zip(det_bboxes, det_labels)
- ]
-
- num_imgs = len(img_metas)
- scale_factors = tuple(meta['scale_factor'] for meta in img_metas)
- if all(det_bbox.shape[0] == 0 for det_bbox in det_bboxes):
- segm_results = [[[] for _ in range(self.mask_head.num_classes)]
- for _ in range(num_imgs)]
- else:
- # if det_bboxes is rescaled to the original image size, we need to
- # rescale it back to the testing scale to obtain RoIs.
- if rescale and not isinstance(scale_factors[0], float):
- scale_factors = [
- torch.from_numpy(scale_factor).to(det_bboxes[0].device)
- for scale_factor in scale_factors
- ]
- _bboxes = [
- det_bboxes[i][:, :4] *
- scale_factors[i] if rescale else det_bboxes[i][:, :4]
- for i in range(len(det_bboxes))
- ]
- mask_preds = self.mask_head(x[0], det_coeffs, _bboxes, img_metas)
- # apply mask post-processing to each image individually
- segm_results = []
- for i in range(num_imgs):
- if det_bboxes[i].shape[0] == 0:
- segm_results.append(
- [[] for _ in range(self.mask_head.num_classes)])
- else:
- segm_result = self.mask_head.get_seg_masks(
- mask_preds[i], det_labels[i], img_metas[i], rescale)
- segm_results.append(segm_result)
- return list(zip(bbox_results, segm_results))
-
- def aug_test(self, imgs, img_metas, rescale=False):
- """Test with augmentations."""
- raise NotImplementedError
diff --git a/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/util/time_counter.py b/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/util/time_counter.py
deleted file mode 100644
index 0aedb2e4d61bfbe7571dca9d50053f0fedaa1359..0000000000000000000000000000000000000000
--- a/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/util/time_counter.py
+++ /dev/null
@@ -1,62 +0,0 @@
-import json
-import time
-
-
-class TimeCounter:
- def __init__(self) -> None:
- pass
-
- def clear(self):
- self.timedict = {}
- self.basetime = time.perf_counter()
-
- def timeit(self, name):
- nowtime = time.perf_counter() - self.basetime
- self.timedict[name] = nowtime
- self.basetime = time.perf_counter()
-
-
-class TimeHolder:
- def __init__(self) -> None:
- self.timedict = {}
-
- def update(self, _timedict: dict):
- for k, v in _timedict.items():
- if k not in self.timedict:
- self.timedict[k] = AverageMeter(name=k, val_only=True)
- self.timedict[k].update(val=v)
-
- def final_res(self):
- return {k: v.avg for k, v in self.timedict.items()}
-
- def __str__(self):
- return json.dumps(self.final_res(), indent=2)
-
-
-class AverageMeter(object):
- """Computes and stores the average and current value"""
-
- def __init__(self, name, fmt=":f", val_only=False):
- self.name = name
- self.fmt = fmt
- self.val_only = val_only
- self.reset()
-
- def reset(self):
- self.val = 0
- self.avg = 0
- self.sum = 0
- self.count = 0
-
- def update(self, val, n=1):
- self.val = val
- self.sum += val * n
- self.count += n
- self.avg = self.sum / self.count
-
- def __str__(self):
- if self.val_only:
- fmtstr = "{name} {val" + self.fmt + "}"
- else:
- fmtstr = "{name} {val" + self.fmt + "} ({avg" + self.fmt + "})"
- return fmtstr.format(**self.__dict__)
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/cachecontrol/_cmd.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/cachecontrol/_cmd.py
deleted file mode 100644
index 4266b5ee92a24b5e0ef65689a1b94a98bb4a9b56..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/cachecontrol/_cmd.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# SPDX-FileCopyrightText: 2015 Eric Larson
-#
-# SPDX-License-Identifier: Apache-2.0
-
-import logging
-
-from pip._vendor import requests
-
-from pip._vendor.cachecontrol.adapter import CacheControlAdapter
-from pip._vendor.cachecontrol.cache import DictCache
-from pip._vendor.cachecontrol.controller import logger
-
-from argparse import ArgumentParser
-
-
-def setup_logging():
- logger.setLevel(logging.DEBUG)
- handler = logging.StreamHandler()
- logger.addHandler(handler)
-
-
-def get_session():
- adapter = CacheControlAdapter(
- DictCache(), cache_etags=True, serializer=None, heuristic=None
- )
- sess = requests.Session()
- sess.mount("http://", adapter)
- sess.mount("https://", adapter)
-
- sess.cache_controller = adapter.controller
- return sess
-
-
-def get_args():
- parser = ArgumentParser()
- parser.add_argument("url", help="The URL to try and cache")
- return parser.parse_args()
-
-
-def main(args=None):
- args = get_args()
- sess = get_session()
-
- # Make a request to get a response
- resp = sess.get(args.url)
-
- # Turn on logging
- setup_logging()
-
- # try setting the cache
- sess.cache_controller.cache_response(resp.request, resp.raw)
-
- # Now try to get it
- if sess.cache_controller.cached_request(resp.request):
- print("Cached!")
- else:
- print("Not cached :(")
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/_vendor/packaging/_structures.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/_vendor/packaging/_structures.py
deleted file mode 100644
index 90a6465f9682c886363eea5327dac64bf623a6ff..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/_vendor/packaging/_structures.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# This file is dual licensed under the terms of the Apache License, Version
-# 2.0, and the BSD License. See the LICENSE file in the root of this repository
-# for complete details.
-
-
-class InfinityType:
- def __repr__(self) -> str:
- return "Infinity"
-
- def __hash__(self) -> int:
- return hash(repr(self))
-
- def __lt__(self, other: object) -> bool:
- return False
-
- def __le__(self, other: object) -> bool:
- return False
-
- def __eq__(self, other: object) -> bool:
- return isinstance(other, self.__class__)
-
- def __gt__(self, other: object) -> bool:
- return True
-
- def __ge__(self, other: object) -> bool:
- return True
-
- def __neg__(self: object) -> "NegativeInfinityType":
- return NegativeInfinity
-
-
-Infinity = InfinityType()
-
-
-class NegativeInfinityType:
- def __repr__(self) -> str:
- return "-Infinity"
-
- def __hash__(self) -> int:
- return hash(repr(self))
-
- def __lt__(self, other: object) -> bool:
- return True
-
- def __le__(self, other: object) -> bool:
- return True
-
- def __eq__(self, other: object) -> bool:
- return isinstance(other, self.__class__)
-
- def __gt__(self, other: object) -> bool:
- return False
-
- def __ge__(self, other: object) -> bool:
- return False
-
- def __neg__(self: object) -> InfinityType:
- return Infinity
-
-
-NegativeInfinity = NegativeInfinityType()
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/dep_util.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/dep_util.py
deleted file mode 100644
index 521eb716a5ebbcbc2c59654c4e71c3f0ff1abf26..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/dep_util.py
+++ /dev/null
@@ -1,25 +0,0 @@
-from distutils.dep_util import newer_group
-
-
-# yes, this is was almost entirely copy-pasted from
-# 'newer_pairwise()', this is just another convenience
-# function.
-def newer_pairwise_group(sources_groups, targets):
- """Walk both arguments in parallel, testing if each source group is newer
- than its corresponding target. Returns a pair of lists (sources_groups,
- targets) where sources is newer than target, according to the semantics
- of 'newer_group()'.
- """
- if len(sources_groups) != len(targets):
- raise ValueError(
- "'sources_group' and 'targets' must be the same length")
-
- # build a pair of lists (sources_groups, targets) where source is newer
- n_sources = []
- n_targets = []
- for i in range(len(sources_groups)):
- if newer_group(sources_groups[i], targets[i]):
- n_sources.append(sources_groups[i])
- n_targets.append(targets[i])
-
- return n_sources, n_targets
diff --git a/spaces/AzumaSeren100/XuanShen-Bert-VITS2/commons.py b/spaces/AzumaSeren100/XuanShen-Bert-VITS2/commons.py
deleted file mode 100644
index 9ad0444b61cbadaa388619986c2889c707d873ce..0000000000000000000000000000000000000000
--- a/spaces/AzumaSeren100/XuanShen-Bert-VITS2/commons.py
+++ /dev/null
@@ -1,161 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size*dilation - dilation)/2)
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def intersperse(lst, item):
- result = [item] * (len(lst) * 2 + 1)
- result[1::2] = lst
- return result
-
-
-def kl_divergence(m_p, logs_p, m_q, logs_q):
- """KL(P||Q)"""
- kl = (logs_q - logs_p) - 0.5
- kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q)
- return kl
-
-
-def rand_gumbel(shape):
- """Sample from the Gumbel distribution, protect from overflows."""
- uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
- return -torch.log(-torch.log(uniform_samples))
-
-
-def rand_gumbel_like(x):
- g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
- return g
-
-
-def slice_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, :, idx_str:idx_end]
- return ret
-
-
-def rand_slice_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def get_timing_signal_1d(
- length, channels, min_timescale=1.0, max_timescale=1.0e4):
- position = torch.arange(length, dtype=torch.float)
- num_timescales = channels // 2
- log_timescale_increment = (
- math.log(float(max_timescale) / float(min_timescale)) /
- (num_timescales - 1))
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment)
- scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
- signal = F.pad(signal, [0, 0, 0, channels % 2])
- signal = signal.view(1, channels, length)
- return signal
-
-
-def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return x + signal.to(dtype=x.dtype, device=x.device)
-
-
-def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
-
-
-def subsequent_mask(length):
- mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
- return mask
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a + input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def shift_1d(x):
- x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
- return x
-
-
-def sequence_mask(length, max_length=None):
- if max_length is None:
- max_length = length.max()
- x = torch.arange(max_length, dtype=length.dtype, device=length.device)
- return x.unsqueeze(0) < length.unsqueeze(1)
-
-
-def generate_path(duration, mask):
- """
- duration: [b, 1, t_x]
- mask: [b, 1, t_y, t_x]
- """
- device = duration.device
-
- b, _, t_y, t_x = mask.shape
- cum_duration = torch.cumsum(duration, -1)
-
- cum_duration_flat = cum_duration.view(b * t_x)
- path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
- path = path.view(b, t_x, t_y)
- path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
- path = path.unsqueeze(1).transpose(2,3) * mask
- return path
-
-
-def clip_grad_value_(parameters, clip_value, norm_type=2):
- if isinstance(parameters, torch.Tensor):
- parameters = [parameters]
- parameters = list(filter(lambda p: p.grad is not None, parameters))
- norm_type = float(norm_type)
- if clip_value is not None:
- clip_value = float(clip_value)
-
- total_norm = 0
- for p in parameters:
- param_norm = p.grad.data.norm(norm_type)
- total_norm += param_norm.item() ** norm_type
- if clip_value is not None:
- p.grad.data.clamp_(min=-clip_value, max=clip_value)
- total_norm = total_norm ** (1. / norm_type)
- return total_norm
diff --git a/spaces/Bart92/RVC_HF/Applio-RVC-Fork/utils/backups.py b/spaces/Bart92/RVC_HF/Applio-RVC-Fork/utils/backups.py
deleted file mode 100644
index b814f8184792e80e2324685436053d61487110b1..0000000000000000000000000000000000000000
--- a/spaces/Bart92/RVC_HF/Applio-RVC-Fork/utils/backups.py
+++ /dev/null
@@ -1,141 +0,0 @@
-import os
-import shutil
-import hashlib
-import time
-import base64
-
-
-
-
-LOGS_FOLDER = '/content/Applio-RVC-Fork/logs'
-WEIGHTS_FOLDER = '/content/Applio-RVC-Fork/weights'
-GOOGLE_DRIVE_PATH = '/content/drive/MyDrive/RVC_Backup'
-
-def import_google_drive_backup():
- print("Importing Google Drive backup...")
- weights_exist = False
- for root, dirs, files in os.walk(GOOGLE_DRIVE_PATH):
- for filename in files:
- filepath = os.path.join(root, filename)
- if os.path.isfile(filepath) and not filepath.startswith(os.path.join(GOOGLE_DRIVE_PATH, 'weights')):
- backup_filepath = os.path.join(LOGS_FOLDER, os.path.relpath(filepath, GOOGLE_DRIVE_PATH))
- backup_folderpath = os.path.dirname(backup_filepath)
- if not os.path.exists(backup_folderpath):
- os.makedirs(backup_folderpath)
- print(f'Created backup folder: {backup_folderpath}', flush=True)
- shutil.copy2(filepath, backup_filepath) # copy file with metadata
- print(f'Imported file from Google Drive backup: {filename}')
- elif filepath.startswith(os.path.join(GOOGLE_DRIVE_PATH, 'weights')) and filename.endswith('.pth'):
- weights_exist = True
- weights_filepath = os.path.join(WEIGHTS_FOLDER, os.path.relpath(filepath, os.path.join(GOOGLE_DRIVE_PATH, 'weights')))
- weights_folderpath = os.path.dirname(weights_filepath)
- if not os.path.exists(weights_folderpath):
- os.makedirs(weights_folderpath)
- print(f'Created weights folder: {weights_folderpath}', flush=True)
- shutil.copy2(filepath, weights_filepath) # copy file with metadata
- print(f'Imported file from weights: {filename}')
- if weights_exist:
- print("Copied weights from Google Drive backup to local weights folder.")
- else:
- print("No weights found in Google Drive backup.")
- print("Google Drive backup import completed.")
-
-def get_md5_hash(file_path):
- hash_md5 = hashlib.md5()
- with open(file_path, "rb") as f:
- for chunk in iter(lambda: f.read(4096), b""):
- hash_md5.update(chunk)
- return hash_md5.hexdigest()
-
-def copy_weights_folder_to_drive():
- destination_folder = os.path.join(GOOGLE_DRIVE_PATH, 'weights')
- try:
- if not os.path.exists(destination_folder):
- os.makedirs(destination_folder)
-
- num_copied = 0
- for filename in os.listdir(WEIGHTS_FOLDER):
- if filename.endswith('.pth'):
- source_file = os.path.join(WEIGHTS_FOLDER, filename)
- destination_file = os.path.join(destination_folder, filename)
- if not os.path.exists(destination_file):
- shutil.copy2(source_file, destination_file)
- num_copied += 1
- print(f"Copied {filename} to Google Drive!")
-
- if num_copied == 0:
- print("No new finished models found for copying.")
- else:
- print(f"Finished copying {num_copied} files to Google Drive!")
-
- except Exception as e:
- print(f"An error occurred while copying weights: {str(e)}")
- # You can log the error or take appropriate actions here.
-
-def backup_files():
- print("\nStarting backup loop...")
- last_backup_timestamps_path = os.path.join(LOGS_FOLDER, 'last_backup_timestamps.txt')
- fully_updated = False # boolean to track if all files are up to date
-
- while True:
- try:
- updated = False # flag to check if any files were updated
- last_backup_timestamps = {}
-
- try:
- with open(last_backup_timestamps_path, 'r') as f:
- last_backup_timestamps = dict(line.strip().split(':') for line in f)
- except FileNotFoundError:
- pass # File does not exist yet, which is fine
-
- for root, dirs, files in os.walk(LOGS_FOLDER):
- for filename in files:
- if filename != 'last_backup_timestamps.txt':
- filepath = os.path.join(root, filename)
- if os.path.isfile(filepath):
- backup_filepath = os.path.join(GOOGLE_DRIVE_PATH, os.path.relpath(filepath, LOGS_FOLDER))
- backup_folderpath = os.path.dirname(backup_filepath)
- if not os.path.exists(backup_folderpath):
- os.makedirs(backup_folderpath)
- print(f'Created backup folder: {backup_folderpath}', flush=True)
- # check if file has changed since last backup
- last_backup_timestamp = last_backup_timestamps.get(filepath)
- current_timestamp = os.path.getmtime(filepath)
- if last_backup_timestamp is None or float(last_backup_timestamp) < current_timestamp:
- shutil.copy2(filepath, backup_filepath) # copy file with metadata
- last_backup_timestamps[filepath] = str(current_timestamp) # update last backup timestamp
- if last_backup_timestamp is None:
- print(f'Backed up file: {filename}')
- else:
- print(f'Updating backed up file: {filename}')
- updated = True
- fully_updated = False # if a file is updated, all files are not up to date
-
- # check if any files were deleted in Colab and delete them from the backup drive
- for filepath in list(last_backup_timestamps.keys()):
- if not os.path.exists(filepath):
- backup_filepath = os.path.join(GOOGLE_DRIVE_PATH, os.path.relpath(filepath, LOGS_FOLDER))
- if os.path.exists(backup_filepath):
- os.remove(backup_filepath)
- print(f'Deleted file: {filepath}')
- del last_backup_timestamps[filepath]
- updated = True
- fully_updated = False # if a file is deleted, all files are not up to date
-
- if not updated and not fully_updated:
- print("Files are up to date.")
- fully_updated = True # if all files are up to date, set the boolean to True
- copy_weights_folder_to_drive()
- sleep_time = 15
- else:
- sleep_time = 0.1
-
- with open(last_backup_timestamps_path, 'w') as f:
- for filepath, timestamp in last_backup_timestamps.items():
- f.write(f'{filepath}:{timestamp}\n')
-
- time.sleep(sleep_time) # wait for 15 seconds before checking again, or 0.1s if not fully up to date to speed up backups
-
- except Exception as e:
- print(f"An error occurred: {str(e)}")
- # You can log the error or take appropriate actions here.
diff --git a/spaces/Bart92/RVC_HF/demucs/augment.py b/spaces/Bart92/RVC_HF/demucs/augment.py
deleted file mode 100644
index bb36d3298d89470f306316322e7587187819c94b..0000000000000000000000000000000000000000
--- a/spaces/Bart92/RVC_HF/demucs/augment.py
+++ /dev/null
@@ -1,106 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import random
-import torch as th
-from torch import nn
-
-
-class Shift(nn.Module):
- """
- Randomly shift audio in time by up to `shift` samples.
- """
- def __init__(self, shift=8192):
- super().__init__()
- self.shift = shift
-
- def forward(self, wav):
- batch, sources, channels, time = wav.size()
- length = time - self.shift
- if self.shift > 0:
- if not self.training:
- wav = wav[..., :length]
- else:
- offsets = th.randint(self.shift, [batch, sources, 1, 1], device=wav.device)
- offsets = offsets.expand(-1, -1, channels, -1)
- indexes = th.arange(length, device=wav.device)
- wav = wav.gather(3, indexes + offsets)
- return wav
-
-
-class FlipChannels(nn.Module):
- """
- Flip left-right channels.
- """
- def forward(self, wav):
- batch, sources, channels, time = wav.size()
- if self.training and wav.size(2) == 2:
- left = th.randint(2, (batch, sources, 1, 1), device=wav.device)
- left = left.expand(-1, -1, -1, time)
- right = 1 - left
- wav = th.cat([wav.gather(2, left), wav.gather(2, right)], dim=2)
- return wav
-
-
-class FlipSign(nn.Module):
- """
- Random sign flip.
- """
- def forward(self, wav):
- batch, sources, channels, time = wav.size()
- if self.training:
- signs = th.randint(2, (batch, sources, 1, 1), device=wav.device, dtype=th.float32)
- wav = wav * (2 * signs - 1)
- return wav
-
-
-class Remix(nn.Module):
- """
- Shuffle sources to make new mixes.
- """
- def __init__(self, group_size=4):
- """
- Shuffle sources within one batch.
- Each batch is divided into groups of size `group_size` and shuffling is done within
- each group separatly. This allow to keep the same probability distribution no matter
- the number of GPUs. Without this grouping, using more GPUs would lead to a higher
- probability of keeping two sources from the same track together which can impact
- performance.
- """
- super().__init__()
- self.group_size = group_size
-
- def forward(self, wav):
- batch, streams, channels, time = wav.size()
- device = wav.device
-
- if self.training:
- group_size = self.group_size or batch
- if batch % group_size != 0:
- raise ValueError(f"Batch size {batch} must be divisible by group size {group_size}")
- groups = batch // group_size
- wav = wav.view(groups, group_size, streams, channels, time)
- permutations = th.argsort(th.rand(groups, group_size, streams, 1, 1, device=device),
- dim=1)
- wav = wav.gather(1, permutations.expand(-1, -1, -1, channels, time))
- wav = wav.view(batch, streams, channels, time)
- return wav
-
-
-class Scale(nn.Module):
- def __init__(self, proba=1., min=0.25, max=1.25):
- super().__init__()
- self.proba = proba
- self.min = min
- self.max = max
-
- def forward(self, wav):
- batch, streams, channels, time = wav.size()
- device = wav.device
- if self.training and random.random() < self.proba:
- scales = th.empty(batch, streams, 1, 1, device=device).uniform_(self.min, self.max)
- wav *= scales
- return wav
diff --git a/spaces/Bart92/RVC_HF/lib/uvr5_pack/lib_v5/layers_123812KB .py b/spaces/Bart92/RVC_HF/lib/uvr5_pack/lib_v5/layers_123812KB .py
deleted file mode 100644
index b82f06bb4993cd63f076e68d7e24185269b1bc42..0000000000000000000000000000000000000000
--- a/spaces/Bart92/RVC_HF/lib/uvr5_pack/lib_v5/layers_123812KB .py
+++ /dev/null
@@ -1,118 +0,0 @@
-import torch
-from torch import nn
-import torch.nn.functional as F
-
-from . import spec_utils
-
-
-class Conv2DBNActiv(nn.Module):
- def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
- super(Conv2DBNActiv, self).__init__()
- self.conv = nn.Sequential(
- nn.Conv2d(
- nin,
- nout,
- kernel_size=ksize,
- stride=stride,
- padding=pad,
- dilation=dilation,
- bias=False,
- ),
- nn.BatchNorm2d(nout),
- activ(),
- )
-
- def __call__(self, x):
- return self.conv(x)
-
-
-class SeperableConv2DBNActiv(nn.Module):
- def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
- super(SeperableConv2DBNActiv, self).__init__()
- self.conv = nn.Sequential(
- nn.Conv2d(
- nin,
- nin,
- kernel_size=ksize,
- stride=stride,
- padding=pad,
- dilation=dilation,
- groups=nin,
- bias=False,
- ),
- nn.Conv2d(nin, nout, kernel_size=1, bias=False),
- nn.BatchNorm2d(nout),
- activ(),
- )
-
- def __call__(self, x):
- return self.conv(x)
-
-
-class Encoder(nn.Module):
- def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
- super(Encoder, self).__init__()
- self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
- self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
-
- def __call__(self, x):
- skip = self.conv1(x)
- h = self.conv2(skip)
-
- return h, skip
-
-
-class Decoder(nn.Module):
- def __init__(
- self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
- ):
- super(Decoder, self).__init__()
- self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
- self.dropout = nn.Dropout2d(0.1) if dropout else None
-
- def __call__(self, x, skip=None):
- x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
- if skip is not None:
- skip = spec_utils.crop_center(skip, x)
- x = torch.cat([x, skip], dim=1)
- h = self.conv(x)
-
- if self.dropout is not None:
- h = self.dropout(h)
-
- return h
-
-
-class ASPPModule(nn.Module):
- def __init__(self, nin, nout, dilations=(4, 8, 16), activ=nn.ReLU):
- super(ASPPModule, self).__init__()
- self.conv1 = nn.Sequential(
- nn.AdaptiveAvgPool2d((1, None)),
- Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ),
- )
- self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
- self.conv3 = SeperableConv2DBNActiv(
- nin, nin, 3, 1, dilations[0], dilations[0], activ=activ
- )
- self.conv4 = SeperableConv2DBNActiv(
- nin, nin, 3, 1, dilations[1], dilations[1], activ=activ
- )
- self.conv5 = SeperableConv2DBNActiv(
- nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
- )
- self.bottleneck = nn.Sequential(
- Conv2DBNActiv(nin * 5, nout, 1, 1, 0, activ=activ), nn.Dropout2d(0.1)
- )
-
- def forward(self, x):
- _, _, h, w = x.size()
- feat1 = F.interpolate(
- self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
- )
- feat2 = self.conv2(x)
- feat3 = self.conv3(x)
- feat4 = self.conv4(x)
- feat5 = self.conv5(x)
- out = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1)
- bottle = self.bottleneck(out)
- return bottle
diff --git a/spaces/Bart92/RVC_HF/slicer2.py b/spaces/Bart92/RVC_HF/slicer2.py
deleted file mode 100644
index 5b29ee262aa54045e807be2cffeb41687499ba58..0000000000000000000000000000000000000000
--- a/spaces/Bart92/RVC_HF/slicer2.py
+++ /dev/null
@@ -1,260 +0,0 @@
-import numpy as np
-
-
-# This function is obtained from librosa.
-def get_rms(
- y,
- frame_length=2048,
- hop_length=512,
- pad_mode="constant",
-):
- padding = (int(frame_length // 2), int(frame_length // 2))
- y = np.pad(y, padding, mode=pad_mode)
-
- axis = -1
- # put our new within-frame axis at the end for now
- out_strides = y.strides + tuple([y.strides[axis]])
- # Reduce the shape on the framing axis
- x_shape_trimmed = list(y.shape)
- x_shape_trimmed[axis] -= frame_length - 1
- out_shape = tuple(x_shape_trimmed) + tuple([frame_length])
- xw = np.lib.stride_tricks.as_strided(y, shape=out_shape, strides=out_strides)
- if axis < 0:
- target_axis = axis - 1
- else:
- target_axis = axis + 1
- xw = np.moveaxis(xw, -1, target_axis)
- # Downsample along the target axis
- slices = [slice(None)] * xw.ndim
- slices[axis] = slice(0, None, hop_length)
- x = xw[tuple(slices)]
-
- # Calculate power
- power = np.mean(np.abs(x) ** 2, axis=-2, keepdims=True)
-
- return np.sqrt(power)
-
-
-class Slicer:
- def __init__(
- self,
- sr: int,
- threshold: float = -40.0,
- min_length: int = 5000,
- min_interval: int = 300,
- hop_size: int = 20,
- max_sil_kept: int = 5000,
- ):
- if not min_length >= min_interval >= hop_size:
- raise ValueError(
- "The following condition must be satisfied: min_length >= min_interval >= hop_size"
- )
- if not max_sil_kept >= hop_size:
- raise ValueError(
- "The following condition must be satisfied: max_sil_kept >= hop_size"
- )
- min_interval = sr * min_interval / 1000
- self.threshold = 10 ** (threshold / 20.0)
- self.hop_size = round(sr * hop_size / 1000)
- self.win_size = min(round(min_interval), 4 * self.hop_size)
- self.min_length = round(sr * min_length / 1000 / self.hop_size)
- self.min_interval = round(min_interval / self.hop_size)
- self.max_sil_kept = round(sr * max_sil_kept / 1000 / self.hop_size)
-
- def _apply_slice(self, waveform, begin, end):
- if len(waveform.shape) > 1:
- return waveform[
- :, begin * self.hop_size : min(waveform.shape[1], end * self.hop_size)
- ]
- else:
- return waveform[
- begin * self.hop_size : min(waveform.shape[0], end * self.hop_size)
- ]
-
- # @timeit
- def slice(self, waveform):
- if len(waveform.shape) > 1:
- samples = waveform.mean(axis=0)
- else:
- samples = waveform
- if samples.shape[0] <= self.min_length:
- return [waveform]
- rms_list = get_rms(
- y=samples, frame_length=self.win_size, hop_length=self.hop_size
- ).squeeze(0)
- sil_tags = []
- silence_start = None
- clip_start = 0
- for i, rms in enumerate(rms_list):
- # Keep looping while frame is silent.
- if rms < self.threshold:
- # Record start of silent frames.
- if silence_start is None:
- silence_start = i
- continue
- # Keep looping while frame is not silent and silence start has not been recorded.
- if silence_start is None:
- continue
- # Clear recorded silence start if interval is not enough or clip is too short
- is_leading_silence = silence_start == 0 and i > self.max_sil_kept
- need_slice_middle = (
- i - silence_start >= self.min_interval
- and i - clip_start >= self.min_length
- )
- if not is_leading_silence and not need_slice_middle:
- silence_start = None
- continue
- # Need slicing. Record the range of silent frames to be removed.
- if i - silence_start <= self.max_sil_kept:
- pos = rms_list[silence_start : i + 1].argmin() + silence_start
- if silence_start == 0:
- sil_tags.append((0, pos))
- else:
- sil_tags.append((pos, pos))
- clip_start = pos
- elif i - silence_start <= self.max_sil_kept * 2:
- pos = rms_list[
- i - self.max_sil_kept : silence_start + self.max_sil_kept + 1
- ].argmin()
- pos += i - self.max_sil_kept
- pos_l = (
- rms_list[
- silence_start : silence_start + self.max_sil_kept + 1
- ].argmin()
- + silence_start
- )
- pos_r = (
- rms_list[i - self.max_sil_kept : i + 1].argmin()
- + i
- - self.max_sil_kept
- )
- if silence_start == 0:
- sil_tags.append((0, pos_r))
- clip_start = pos_r
- else:
- sil_tags.append((min(pos_l, pos), max(pos_r, pos)))
- clip_start = max(pos_r, pos)
- else:
- pos_l = (
- rms_list[
- silence_start : silence_start + self.max_sil_kept + 1
- ].argmin()
- + silence_start
- )
- pos_r = (
- rms_list[i - self.max_sil_kept : i + 1].argmin()
- + i
- - self.max_sil_kept
- )
- if silence_start == 0:
- sil_tags.append((0, pos_r))
- else:
- sil_tags.append((pos_l, pos_r))
- clip_start = pos_r
- silence_start = None
- # Deal with trailing silence.
- total_frames = rms_list.shape[0]
- if (
- silence_start is not None
- and total_frames - silence_start >= self.min_interval
- ):
- silence_end = min(total_frames, silence_start + self.max_sil_kept)
- pos = rms_list[silence_start : silence_end + 1].argmin() + silence_start
- sil_tags.append((pos, total_frames + 1))
- # Apply and return slices.
- if len(sil_tags) == 0:
- return [waveform]
- else:
- chunks = []
- if sil_tags[0][0] > 0:
- chunks.append(self._apply_slice(waveform, 0, sil_tags[0][0]))
- for i in range(len(sil_tags) - 1):
- chunks.append(
- self._apply_slice(waveform, sil_tags[i][1], sil_tags[i + 1][0])
- )
- if sil_tags[-1][1] < total_frames:
- chunks.append(
- self._apply_slice(waveform, sil_tags[-1][1], total_frames)
- )
- return chunks
-
-
-def main():
- import os.path
- from argparse import ArgumentParser
-
- import librosa
- import soundfile
-
- parser = ArgumentParser()
- parser.add_argument("audio", type=str, help="The audio to be sliced")
- parser.add_argument(
- "--out", type=str, help="Output directory of the sliced audio clips"
- )
- parser.add_argument(
- "--db_thresh",
- type=float,
- required=False,
- default=-40,
- help="The dB threshold for silence detection",
- )
- parser.add_argument(
- "--min_length",
- type=int,
- required=False,
- default=5000,
- help="The minimum milliseconds required for each sliced audio clip",
- )
- parser.add_argument(
- "--min_interval",
- type=int,
- required=False,
- default=300,
- help="The minimum milliseconds for a silence part to be sliced",
- )
- parser.add_argument(
- "--hop_size",
- type=int,
- required=False,
- default=10,
- help="Frame length in milliseconds",
- )
- parser.add_argument(
- "--max_sil_kept",
- type=int,
- required=False,
- default=500,
- help="The maximum silence length kept around the sliced clip, presented in milliseconds",
- )
- args = parser.parse_args()
- out = args.out
- if out is None:
- out = os.path.dirname(os.path.abspath(args.audio))
- audio, sr = librosa.load(args.audio, sr=None, mono=False)
- slicer = Slicer(
- sr=sr,
- threshold=args.db_thresh,
- min_length=args.min_length,
- min_interval=args.min_interval,
- hop_size=args.hop_size,
- max_sil_kept=args.max_sil_kept,
- )
- chunks = slicer.slice(audio)
- if not os.path.exists(out):
- os.makedirs(out)
- for i, chunk in enumerate(chunks):
- if len(chunk.shape) > 1:
- chunk = chunk.T
- soundfile.write(
- os.path.join(
- out,
- f"%s_%d.wav"
- % (os.path.basename(args.audio).rsplit(".", maxsplit=1)[0], i),
- ),
- chunk,
- sr,
- )
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/Benson/text-generation/Examples/Descargar El Zombie Caminar 1 Mod Apk.md b/spaces/Benson/text-generation/Examples/Descargar El Zombie Caminar 1 Mod Apk.md
deleted file mode 100644
index c32a3c419702a494d87065108f0a7288ee76cb4c..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Descargar El Zombie Caminar 1 Mod Apk.md
+++ /dev/null
@@ -1,47 +0,0 @@
-
-Descargar El Zombie Caminar 1 Mod APK: Un divertido y emocionante juego de zombies
-Si eres un fan de los juegos de zombis, es posible que hayas oído hablar de The Walking Zombie, un popular juego de acción que te permite experimentar la diversión del combate en un apocalipsis zombi. Pero ¿sabías que se puede descargar el zombi caminar 1 mod APK y disfrutar del juego con más características y beneficios? En este artículo, le diremos todo lo que necesita saber sobre The Walking Zombie 1 mod APK, incluyendo lo que es, por qué debe descargarlo, qué características ofrece, y cómo descargarlo e instalarlo en su dispositivo. Así que, vamos a empezar!
- Introducción
-Los zombies son uno de los temas más populares en los videojuegos, ya que proporcionan una experiencia emocionante y desafiante para los jugadores. Hay muchos juegos de zombies disponibles en el mercado, pero no todos ellos valen la pena su tiempo y atención. Algunos de ellos son aburridos, repetitivos o están mal diseñados. Por eso necesitas encontrar un juego de zombies divertido, emocionante y bien hecho. Uno de estos juegos es The Walking Zombie, un juego que ha recibido críticas positivas de críticos y jugadores por igual.
-descargar el zombie caminar 1 mod apk Download File >>> https://bltlly.com/2v6KTF
¿Qué es el zombi que camina 1?
-The Walking Zombie 1 es un juego de acción desarrollado por Rodinia Games y lanzado en 2016. Es uno de los mejores juegos de zombies en Google Play, destaca por sus gráficos en 3D de alta resolución y efectos de sonido. El juego tiene lugar en un apocalipsis zombi, donde tienes que eliminar hordas de zombies en tres escenarios diferentes. Puedes usar tres armas diferentes: pistola, escopeta y ametralladora. Cada arma tiene sus propias ventajas y desventajas, como el número de balas por clip y el tiempo de recarga. Tienes que ser estratégico y cuidadoso al elegir tu arma y manejar tu munición.
- ¿Por qué descargar The Walking Zombie 1 mod APK?
-
-El Walking Zombie 1 mod APK es una versión modificada del juego original que le da más características y beneficios. Por ejemplo, puedes obtener dinero y municiones ilimitadas, lo que significa que puedes comprar cualquier arma que quieras y nunca quedarte sin balas. También puedes disfrutar del juego sin anuncios ni interrupciones. Además, el mod APK puede hacer el juego más fácil y más divertido para usted, ya que puede matar zombies más rápido y sobrevivir más tiempo.
- Características de The Walking Zombie 1 mod APK
-Como mencionamos antes, El Caminar Zombie 1 mod APK ofrece muchas características que hacen que el juego mejor que la versión original. Estas son algunas de las principales características que se pueden disfrutar cuando se descarga The Walking Zombie 1 mod APK:
- Gráficos 3D de alta resolución y efectos de sonido
-El Walking Zombie 1 mod APK conserva los mismos gráficos de alta calidad y efectos de sonido como el juego original. Puedes admirar los entornos realistas y detallados, como el cementerio, la casa del terror y la ciudad destruida. También se pueden escuchar los sonidos espeluznantes e inmersivos de zombies gimiendo, armas de fuego, y explosiones sucediendo. Los gráficos y efectos de sonido crean una atmósfera espeluznante y emocionante que te mantendrá al límite. Tres armas diferentes para elegir
-
El Walking Zombie 1 mod APK le da acceso a tres armas diferentes que se pueden utilizar para luchar contra los zombies. Puedes elegir entre una pistola, una escopeta y una ametralladora. Cada arma tiene sus propias características, como daños, alcance, precisión y tiempo de recarga. Puede cambiar entre las armas dependiendo de la situación y su preferencia. Por ejemplo, puede usar la pistola para disparos de largo alcance, la escopeta para disparos de corto alcance y la ametralladora para ráfagas de fuego rápido.
- Tres escenarios diferentes para sobrevivir en
-
- Dinero y munición ilimitados
-El Walking Zombie 1 mod APK le da dinero ilimitado y municiones, lo que significa que usted puede comprar cualquier arma que desee y nunca se quede sin balas. No tienes que ver anuncios o pagar dinero real para obtener más recursos. También puedes mejorar tus armas para hacerlas más poderosas y efectivas. Con dinero y munición ilimitadas, puedes disfrutar del juego sin limitaciones ni frustraciones.
- Cómo descargar e instalar The Walking Zombie 1 mod APK
-Si usted está interesado en la descarga de The Walking Zombie 1 mod APK, es necesario seguir algunos pasos simples para asegurar una instalación suave y segura. Estos son los pasos que debes seguir:
-
- Paso 1: Habilitar fuentes desconocidas en el dispositivo
-Antes de que pueda instalar The Walking Zombie 1 mod APK, es necesario habilitar fuentes desconocidas en su dispositivo. Esto le permitirá instalar aplicaciones que no sean de Google Play. Para hacer esto, vaya a la configuración del dispositivo, luego a la seguridad y luego a fuentes desconocidas. Activa la opción y confirma tu elección.
- Paso 2: Descargar el archivo mod APK de una fuente de confianza
-Siguiente, es necesario descargar el archivo APK mod de una fuente de confianza. Hay muchos sitios web que ofrecen The Walking Zombie 1 mod APK, pero no todos ellos son fiables o seguros. Algunos de ellos pueden contener virus o malware que pueden dañar su dispositivo o robar sus datos. Es por eso que usted necesita tener cuidado y elegir un sitio web de buena reputación que tiene comentarios positivos y comentarios de otros usuarios. También puede escanear el archivo con una aplicación antivirus antes de abrirlo.
- Paso 3: Localizar e instalar el archivo mod APK
-Después de descargar el archivo APK mod, necesita localizarlo en su dispositivo e instalarlo. Puede usar una aplicación de administrador de archivos para encontrar el archivo en su carpeta de descargas o donde lo haya guardado. Luego, toca el archivo y sigue las instrucciones en la pantalla para instalarlo.
- Paso 4: Disfruta del juego
-
- Conclusión
-El Walking Zombie 1 es uno de los mejores juegos de zombies en Google Play, pero puede ser aún mejor con The Walking Zombie 1 mod APK. El mod APK le da dinero ilimitado y munición, acceso a todas las armas, sin anuncios, y más diversión y emoción. Puede descargar El Walking Zombie 1 mod APK de una fuente de confianza e instalarlo en su dispositivo de forma fácil y segura. Si usted está buscando un juego de zombies divertido y emocionante, El Walking Zombie 1 mod APK es la elección perfecta para usted.
- Preguntas frecuentes
-Aquí hay algunas preguntas frecuentes sobre The Walking Zombie 1 mod APK:
- Q: ¿Es seguro el zombi caminante 1 mod APK?
-A: Sí, El Walking Zombie 1 mod APK es seguro si se descarga desde una fuente de confianza y escanear con una aplicación antivirus antes de instalarlo. Sin embargo, siempre debes tener cuidado al descargar cualquier mod APK de fuentes desconocidas, ya que podrían contener virus o malware que pueden dañar tu dispositivo o robar tus datos.
- Q: ¿Necesito rootear mi dispositivo para instalar The Walking Zombie 1 mod APK?
-A: No, no necesitas rootear tu dispositivo para instalar The Walking Zombie 1 mod APK. Solo necesita habilitar fuentes desconocidas en la configuración de su dispositivo y seguir los pasos mencionados anteriormente.
- Q: ¿Cuál es la diferencia entre The Walking Zombie 1 y The Walking Zombie 2?
- A: The Walking Zombie 1 y The Walking Zombie 2 son juegos de zombies desarrollados por Rodinia Games, pero tienen algunas diferencias. The Walking Zombie 1 es un juego de disparos en primera persona que se centra en el combate y la supervivencia en tres escenarios. The Walking Zombie 2 es un juego de rol que sigue una historia y te permite personalizar a tu personaje, explorar un mundo abierto e interactuar con otros supervivientes.
- P: ¿Cómo puedo obtener más dinero y municiones en The Walking Zombie 1?
-
- Q: ¿Puedo jugar The Walking Zombie 1 sin conexión?
-A: Sí, puedes jugar The Walking Zombie 1 sin conexión a Internet. Sin embargo, es posible que necesite conectarse a Internet una vez para verificar la licencia del juego y descargar datos adicionales.
64aa2da5cf--
- - cp-abi3-
- - cp-none-
- - cp-abi3- # Older Python versions down to 3.2.
-
- If python_version only specifies a major version then user-provided ABIs and
- the 'none' ABItag will be used.
-
- If 'abi3' or 'none' are specified in 'abis' then they will be yielded at
- their normal position and not at the beginning.
- """
- if not python_version:
- python_version = sys.version_info[:2]
-
- interpreter = f"cp{_version_nodot(python_version[:2])}"
-
- if abis is None:
- if len(python_version) > 1:
- abis = _cpython_abis(python_version, warn)
- else:
- abis = []
- abis = list(abis)
- # 'abi3' and 'none' are explicitly handled later.
- for explicit_abi in ("abi3", "none"):
- try:
- abis.remove(explicit_abi)
- except ValueError:
- pass
-
- platforms = list(platforms or platform_tags())
- for abi in abis:
- for platform_ in platforms:
- yield Tag(interpreter, abi, platform_)
- if _abi3_applies(python_version):
- yield from (Tag(interpreter, "abi3", platform_) for platform_ in platforms)
- yield from (Tag(interpreter, "none", platform_) for platform_ in platforms)
-
- if _abi3_applies(python_version):
- for minor_version in range(python_version[1] - 1, 1, -1):
- for platform_ in platforms:
- interpreter = "cp{version}".format(
- version=_version_nodot((python_version[0], minor_version))
- )
- yield Tag(interpreter, "abi3", platform_)
-
-
-def _generic_abi() -> Iterator[str]:
- abi = sysconfig.get_config_var("SOABI")
- if abi:
- yield _normalize_string(abi)
-
-
-def generic_tags(
- interpreter: Optional[str] = None,
- abis: Optional[Iterable[str]] = None,
- platforms: Optional[Iterable[str]] = None,
- *,
- warn: bool = False,
-) -> Iterator[Tag]:
- """
- Yields the tags for a generic interpreter.
-
- The tags consist of:
- - --
-
- The "none" ABI will be added if it was not explicitly provided.
- """
- if not interpreter:
- interp_name = interpreter_name()
- interp_version = interpreter_version(warn=warn)
- interpreter = "".join([interp_name, interp_version])
- if abis is None:
- abis = _generic_abi()
- platforms = list(platforms or platform_tags())
- abis = list(abis)
- if "none" not in abis:
- abis.append("none")
- for abi in abis:
- for platform_ in platforms:
- yield Tag(interpreter, abi, platform_)
-
-
-def _py_interpreter_range(py_version: PythonVersion) -> Iterator[str]:
- """
- Yields Python versions in descending order.
-
- After the latest version, the major-only version will be yielded, and then
- all previous versions of that major version.
- """
- if len(py_version) > 1:
- yield f"py{_version_nodot(py_version[:2])}"
- yield f"py{py_version[0]}"
- if len(py_version) > 1:
- for minor in range(py_version[1] - 1, -1, -1):
- yield f"py{_version_nodot((py_version[0], minor))}"
-
-
-def compatible_tags(
- python_version: Optional[PythonVersion] = None,
- interpreter: Optional[str] = None,
- platforms: Optional[Iterable[str]] = None,
-) -> Iterator[Tag]:
- """
- Yields the sequence of tags that are compatible with a specific version of Python.
-
- The tags consist of:
- - py*-none-
- - -none-any # ... if `interpreter` is provided.
- - py*-none-any
- """
- if not python_version:
- python_version = sys.version_info[:2]
- platforms = list(platforms or platform_tags())
- for version in _py_interpreter_range(python_version):
- for platform_ in platforms:
- yield Tag(version, "none", platform_)
- if interpreter:
- yield Tag(interpreter, "none", "any")
- for version in _py_interpreter_range(python_version):
- yield Tag(version, "none", "any")
-
-
-def _mac_arch(arch: str, is_32bit: bool = _32_BIT_INTERPRETER) -> str:
- if not is_32bit:
- return arch
-
- if arch.startswith("ppc"):
- return "ppc"
-
- return "i386"
-
-
-def _mac_binary_formats(version: MacVersion, cpu_arch: str) -> List[str]:
- formats = [cpu_arch]
- if cpu_arch == "x86_64":
- if version < (10, 4):
- return []
- formats.extend(["intel", "fat64", "fat32"])
-
- elif cpu_arch == "i386":
- if version < (10, 4):
- return []
- formats.extend(["intel", "fat32", "fat"])
-
- elif cpu_arch == "ppc64":
- # TODO: Need to care about 32-bit PPC for ppc64 through 10.2?
- if version > (10, 5) or version < (10, 4):
- return []
- formats.append("fat64")
-
- elif cpu_arch == "ppc":
- if version > (10, 6):
- return []
- formats.extend(["fat32", "fat"])
-
- if cpu_arch in {"arm64", "x86_64"}:
- formats.append("universal2")
-
- if cpu_arch in {"x86_64", "i386", "ppc64", "ppc", "intel"}:
- formats.append("universal")
-
- return formats
-
-
-def mac_platforms(
- version: Optional[MacVersion] = None, arch: Optional[str] = None
-) -> Iterator[str]:
- """
- Yields the platform tags for a macOS system.
-
- The `version` parameter is a two-item tuple specifying the macOS version to
- generate platform tags for. The `arch` parameter is the CPU architecture to
- generate platform tags for. Both parameters default to the appropriate value
- for the current system.
- """
- version_str, _, cpu_arch = platform.mac_ver()
- if version is None:
- version = cast("MacVersion", tuple(map(int, version_str.split(".")[:2])))
- else:
- version = version
- if arch is None:
- arch = _mac_arch(cpu_arch)
- else:
- arch = arch
-
- if (10, 0) <= version and version < (11, 0):
- # Prior to Mac OS 11, each yearly release of Mac OS bumped the
- # "minor" version number. The major version was always 10.
- for minor_version in range(version[1], -1, -1):
- compat_version = 10, minor_version
- binary_formats = _mac_binary_formats(compat_version, arch)
- for binary_format in binary_formats:
- yield "macosx_{major}_{minor}_{binary_format}".format(
- major=10, minor=minor_version, binary_format=binary_format
- )
-
- if version >= (11, 0):
- # Starting with Mac OS 11, each yearly release bumps the major version
- # number. The minor versions are now the midyear updates.
- for major_version in range(version[0], 10, -1):
- compat_version = major_version, 0
- binary_formats = _mac_binary_formats(compat_version, arch)
- for binary_format in binary_formats:
- yield "macosx_{major}_{minor}_{binary_format}".format(
- major=major_version, minor=0, binary_format=binary_format
- )
-
- if version >= (11, 0):
- # Mac OS 11 on x86_64 is compatible with binaries from previous releases.
- # Arm64 support was introduced in 11.0, so no Arm binaries from previous
- # releases exist.
- #
- # However, the "universal2" binary format can have a
- # macOS version earlier than 11.0 when the x86_64 part of the binary supports
- # that version of macOS.
- if arch == "x86_64":
- for minor_version in range(16, 3, -1):
- compat_version = 10, minor_version
- binary_formats = _mac_binary_formats(compat_version, arch)
- for binary_format in binary_formats:
- yield "macosx_{major}_{minor}_{binary_format}".format(
- major=compat_version[0],
- minor=compat_version[1],
- binary_format=binary_format,
- )
- else:
- for minor_version in range(16, 3, -1):
- compat_version = 10, minor_version
- binary_format = "universal2"
- yield "macosx_{major}_{minor}_{binary_format}".format(
- major=compat_version[0],
- minor=compat_version[1],
- binary_format=binary_format,
- )
-
-
-def _linux_platforms(is_32bit: bool = _32_BIT_INTERPRETER) -> Iterator[str]:
- linux = _normalize_string(sysconfig.get_platform())
- if is_32bit:
- if linux == "linux_x86_64":
- linux = "linux_i686"
- elif linux == "linux_aarch64":
- linux = "linux_armv7l"
- _, arch = linux.split("_", 1)
- yield from _manylinux.platform_tags(linux, arch)
- yield from _musllinux.platform_tags(arch)
- yield linux
-
-
-def _generic_platforms() -> Iterator[str]:
- yield _normalize_string(sysconfig.get_platform())
-
-
-def platform_tags() -> Iterator[str]:
- """
- Provides the platform tags for this installation.
- """
- if platform.system() == "Darwin":
- return mac_platforms()
- elif platform.system() == "Linux":
- return _linux_platforms()
- else:
- return _generic_platforms()
-
-
-def interpreter_name() -> str:
- """
- Returns the name of the running interpreter.
- """
- name = sys.implementation.name
- return INTERPRETER_SHORT_NAMES.get(name) or name
-
-
-def interpreter_version(*, warn: bool = False) -> str:
- """
- Returns the version of the running interpreter.
- """
- version = _get_config_var("py_version_nodot", warn=warn)
- if version:
- version = str(version)
- else:
- version = _version_nodot(sys.version_info[:2])
- return version
-
-
-def _version_nodot(version: PythonVersion) -> str:
- return "".join(map(str, version))
-
-
-def sys_tags(*, warn: bool = False) -> Iterator[Tag]:
- """
- Returns the sequence of tag triples for the running interpreter.
-
- The order of the sequence corresponds to priority order for the
- interpreter, from most to least important.
- """
-
- interp_name = interpreter_name()
- if interp_name == "cp":
- yield from cpython_tags(warn=warn)
- else:
- yield from generic_tags()
-
- if interp_name == "pp":
- yield from compatible_tags(interpreter="pp3")
- else:
- yield from compatible_tags()
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/engine/defaults.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/engine/defaults.py
deleted file mode 100644
index 3cbfae1e6e46bdbb7dde8aba9f7350611f4b1d1e..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/engine/defaults.py
+++ /dev/null
@@ -1,543 +0,0 @@
-# -*- coding: utf-8 -*-
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-
-"""
-This file contains components with some default boilerplate logic user may need
-in training / testing. They will not work for everyone, but many users may find them useful.
-
-The behavior of functions/classes in this file is subject to change,
-since they are meant to represent the "common default behavior" people need in their projects.
-"""
-
-import argparse
-import logging
-import os
-import sys
-from collections import OrderedDict
-import torch
-from fvcore.common.file_io import PathManager
-from fvcore.nn.precise_bn import get_bn_modules
-from torch.nn.parallel import DistributedDataParallel
-
-import detectron2.data.transforms as T
-from detectron2.checkpoint import DetectionCheckpointer
-from detectron2.data import (
- MetadataCatalog,
- build_detection_test_loader,
- build_detection_train_loader,
-)
-from detectron2.evaluation import (
- DatasetEvaluator,
- inference_on_dataset,
- print_csv_format,
- verify_results,
-)
-from detectron2.modeling import build_model
-from detectron2.solver import build_lr_scheduler, build_optimizer
-from detectron2.utils import comm
-from detectron2.utils.collect_env import collect_env_info
-from detectron2.utils.env import seed_all_rng
-from detectron2.utils.events import CommonMetricPrinter, JSONWriter, TensorboardXWriter
-from detectron2.utils.logger import setup_logger
-
-from . import hooks
-from .train_loop import SimpleTrainer
-
-__all__ = [
- "default_argument_parser",
- "default_setup",
- "DefaultPredictor",
- "DefaultTrainer",
-]
-
-
-def default_argument_parser():
- """
- Create a parser with some common arguments used by detectron2 users.
-
- Returns:
- argparse.ArgumentParser:
- """
- parser = argparse.ArgumentParser(description="Detectron2 Training")
- parser.add_argument(
- "--config-file", default="", metavar="FILE", help="path to config file"
- )
- parser.add_argument(
- "--resume",
- action="store_true",
- help="whether to attempt to resume from the checkpoint directory",
- )
- parser.add_argument(
- "--eval-only", action="store_true", help="perform evaluation only"
- )
- parser.add_argument(
- "--num-gpus", type=int, default=1, help="number of gpus *per machine*"
- )
- parser.add_argument("--num-machines", type=int, default=1)
- parser.add_argument(
- "--machine-rank",
- type=int,
- default=0,
- help="the rank of this machine (unique per machine)",
- )
-
- # PyTorch still may leave orphan processes in multi-gpu training.
- # Therefore we use a deterministic way to obtain port,
- # so that users are aware of orphan processes by seeing the port occupied.
- port = (
- 2 ** 15
- + 2 ** 14
- + hash(os.getuid() if sys.platform != "win32" else 1) % 2 ** 14
- )
- parser.add_argument("--dist-url", default="tcp://127.0.0.1:{}".format(port))
- parser.add_argument(
- "opts",
- help="Modify config options using the command-line",
- default=None,
- nargs=argparse.REMAINDER,
- )
- return parser
-
-
-def default_setup(cfg, args):
- """
- Perform some basic common setups at the beginning of a job, including:
-
- 1. Set up the detectron2 logger
- 2. Log basic information about environment, cmdline arguments, and config
- 3. Backup the config to the output directory
-
- Args:
- cfg (CfgNode): the full config to be used
- args (argparse.NameSpace): the command line arguments to be logged
- """
- output_dir = cfg.OUTPUT_DIR
- if comm.is_main_process() and output_dir:
- PathManager.mkdirs(output_dir)
-
- rank = comm.get_rank()
- setup_logger(output_dir, distributed_rank=rank, name="fvcore")
- logger = setup_logger(output_dir, distributed_rank=rank)
-
- logger.info(
- "Rank of current process: {}. World size: {}".format(
- rank, comm.get_world_size()
- )
- )
- logger.info("Environment info:\n" + collect_env_info())
-
- logger.info("Command line arguments: " + str(args))
- if hasattr(args, "config_file") and args.config_file != "":
- logger.info(
- "Contents of args.config_file={}:\n{}".format(
- args.config_file, PathManager.open(args.config_file, "r").read()
- )
- )
-
- logger.info("Running with full config:\n{}".format(cfg))
- if comm.is_main_process() and output_dir:
- # Note: some of our scripts may expect the existence of
- # config.yaml in output directory
- path = os.path.join(output_dir, "config.yaml")
- with PathManager.open(path, "w") as f:
- f.write(cfg.dump())
- logger.info("Full config saved to {}".format(path))
-
- # make sure each worker has a different, yet deterministic seed if specified
- seed_all_rng(None if cfg.SEED < 0 else cfg.SEED + rank)
-
- # cudnn benchmark has large overhead. It shouldn't be used considering the small size of
- # typical validation set.
- if not (hasattr(args, "eval_only") and args.eval_only):
- torch.backends.cudnn.benchmark = cfg.CUDNN_BENCHMARK
-
-
-class DefaultPredictor:
- """
- Create a simple end-to-end predictor with the given config that runs on
- single device for a single input image.
-
- Compared to using the model directly, this class does the following additions:
-
- 1. Load checkpoint from `cfg.MODEL.WEIGHTS`.
- 2. Always take BGR image as the input and apply conversion defined by `cfg.INPUT.FORMAT`.
- 3. Apply resizing defined by `cfg.INPUT.{MIN,MAX}_SIZE_TEST`.
- 4. Take one input image and produce a single output, instead of a batch.
-
- If you'd like to do anything more fancy, please refer to its source code
- as examples to build and use the model manually.
-
- Attributes:
- metadata (Metadata): the metadata of the underlying dataset, obtained from
- cfg.DATASETS.TEST.
-
- Examples:
-
- .. code-block:: python
-
- pred = DefaultPredictor(cfg)
- inputs = cv2.imread("input.jpg")
- outputs = pred(inputs)
- """
-
- def __init__(self, cfg):
- self.cfg = cfg.clone() # cfg can be modified by model
- self.model = build_model(self.cfg)
- self.model.eval()
- self.metadata = MetadataCatalog.get(cfg.DATASETS.TEST[0])
-
- checkpointer = DetectionCheckpointer(self.model)
- checkpointer.load(cfg.MODEL.WEIGHTS)
-
- self.transform_gen = T.ResizeShortestEdge(
- [cfg.INPUT.MIN_SIZE_TEST, cfg.INPUT.MIN_SIZE_TEST], cfg.INPUT.MAX_SIZE_TEST
- )
-
- self.input_format = cfg.INPUT.FORMAT
- assert self.input_format in ["RGB", "BGR"], self.input_format
-
- def __call__(self, original_image):
- """
- Args:
- original_image (np.ndarray): an image of shape (H, W, C) (in BGR order).
-
- Returns:
- predictions (dict):
- the output of the model for one image only.
- See :doc:`/tutorials/models` for details about the format.
- """
- with torch.no_grad(): # https://github.com/sphinx-doc/sphinx/issues/4258
- # Apply pre-processing to image.
- if self.input_format == "RGB":
- # whether the model expects BGR inputs or RGB
- original_image = original_image[:, :, ::-1]
- height, width = original_image.shape[:2]
- image = self.transform_gen.get_transform(original_image).apply_image(
- original_image
- )
- image = torch.as_tensor(image.astype("float32").transpose(2, 0, 1))
-
- inputs = {"image": image, "height": height, "width": width}
- predictions, box_features = self.model([inputs])
- predictions = predictions[0]
- return predictions, box_features
-
-
-class DefaultTrainer(SimpleTrainer):
- """
- A trainer with default training logic. Compared to `SimpleTrainer`, it
- contains the following logic in addition:
-
- 1. Create model, optimizer, scheduler, dataloader from the given config.
- 2. Load a checkpoint or `cfg.MODEL.WEIGHTS`, if exists, when
- `resume_or_load` is called.
- 3. Register a few common hooks.
-
- It is created to simplify the **standard model training workflow** and reduce code boilerplate
- for users who only need the standard training workflow, with standard features.
- It means this class makes *many assumptions* about your training logic that
- may easily become invalid in a new research. In fact, any assumptions beyond those made in the
- :class:`SimpleTrainer` are too much for research.
-
- The code of this class has been annotated about restrictive assumptions it mades.
- When they do not work for you, you're encouraged to:
-
- 1. Overwrite methods of this class, OR:
- 2. Use :class:`SimpleTrainer`, which only does minimal SGD training and
- nothing else. You can then add your own hooks if needed. OR:
- 3. Write your own training loop similar to `tools/plain_train_net.py`.
-
- Also note that the behavior of this class, like other functions/classes in
- this file, is not stable, since it is meant to represent the "common default behavior".
- It is only guaranteed to work well with the standard models and training workflow in detectron2.
- To obtain more stable behavior, write your own training logic with other public APIs.
-
- Examples:
-
- .. code-block:: python
-
- trainer = DefaultTrainer(cfg)
- trainer.resume_or_load() # load last checkpoint or MODEL.WEIGHTS
- trainer.train()
-
- Attributes:
- scheduler:
- checkpointer (DetectionCheckpointer):
- cfg (CfgNode):
- """
-
- def __init__(self, cfg):
- """
- Args:
- cfg (CfgNode):
- """
- logger = logging.getLogger("detectron2")
- if not logger.isEnabledFor(logging.INFO): # setup_logger is not called for d2
- setup_logger()
- # Assume these objects must be constructed in this order.
- model = self.build_model(cfg)
- optimizer = self.build_optimizer(cfg, model)
- data_loader = self.build_train_loader(cfg)
-
- # For training, wrap with DDP. But don't need this for inference.
- if comm.get_world_size() > 1:
- model = DistributedDataParallel(
- model, device_ids=[comm.get_local_rank()], broadcast_buffers=False
- )
- super().__init__(model, data_loader, optimizer)
-
- self.scheduler = self.build_lr_scheduler(cfg, optimizer)
- # Assume no other objects need to be checkpointed.
- # We can later make it checkpoint the stateful hooks
- self.checkpointer = DetectionCheckpointer(
- # Assume you want to save checkpoints together with logs/statistics
- model,
- cfg.OUTPUT_DIR,
- optimizer=optimizer,
- scheduler=self.scheduler,
- )
- self.start_iter = 0
- self.max_iter = cfg.SOLVER.MAX_ITER
- self.cfg = cfg
-
- self.register_hooks(self.build_hooks())
-
- def resume_or_load(self, resume=True):
- """
- If `resume==True`, and last checkpoint exists, resume from it and load all
- checkpointables (eg. optimizer and scheduler).
-
- Otherwise, load the model specified by the config (skip all checkpointables).
-
- Args:
- resume (bool): whether to do resume or not
- """
- checkpoint = self.checkpointer.resume_or_load(
- self.cfg.MODEL.WEIGHTS, resume=resume
- )
- self.start_iter = checkpoint.get("iteration", -1) if resume else -1
- # The checkpoint stores the training iteration that just finished, thus we start
- # at the next iteration (or iter zero if there's no checkpoint).
- self.start_iter += 1
-
- def build_hooks(self):
- """
- Build a list of default hooks, including timing, evaluation,
- checkpointing, lr scheduling, precise BN, writing events.
-
- Returns:
- list[HookBase]:
- """
- cfg = self.cfg.clone()
- cfg.defrost()
- cfg.DATALOADER.NUM_WORKERS = 0 # save some memory and time for PreciseBN
-
- ret = [
- hooks.IterationTimer(),
- hooks.LRScheduler(self.optimizer, self.scheduler),
- hooks.PreciseBN(
- # Run at the same freq as (but before) evaluation.
- cfg.TEST.EVAL_PERIOD,
- self.model,
- # Build a new data loader to not affect training
- self.build_train_loader(cfg),
- cfg.TEST.PRECISE_BN.NUM_ITER,
- )
- if cfg.TEST.PRECISE_BN.ENABLED and get_bn_modules(self.model)
- else None,
- ]
-
- # Do PreciseBN before checkpointer, because it updates the model and need to
- # be saved by checkpointer.
- # This is not always the best: if checkpointing has a different frequency,
- # some checkpoints may have more precise statistics than others.
- if comm.is_main_process():
- ret.append(
- hooks.PeriodicCheckpointer(
- self.checkpointer, cfg.SOLVER.CHECKPOINT_PERIOD
- )
- )
-
- def test_and_save_results():
- self._last_eval_results = self.test(self.cfg, self.model)
- return self._last_eval_results
-
- # Do evaluation after checkpointer, because then if it fails,
- # we can use the saved checkpoint to debug.
- ret.append(hooks.EvalHook(cfg.TEST.EVAL_PERIOD, test_and_save_results))
-
- if comm.is_main_process():
- # run writers in the end, so that evaluation metrics are written
- ret.append(hooks.PeriodicWriter(self.build_writers(), period=20))
- return ret
-
- def build_writers(self):
- """
- Build a list of writers to be used. By default it contains
- writers that write metrics to the screen,
- a json file, and a tensorboard event file respectively.
- If you'd like a different list of writers, you can overwrite it in
- your trainer.
-
- Returns:
- list[EventWriter]: a list of :class:`EventWriter` objects.
-
- It is now implemented by:
-
- .. code-block:: python
-
- return [
- CommonMetricPrinter(self.max_iter),
- JSONWriter(os.path.join(self.cfg.OUTPUT_DIR, "metrics.json")),
- TensorboardXWriter(self.cfg.OUTPUT_DIR),
- ]
-
- """
- # Here the default print/log frequency of each writer is used.
- return [
- # It may not always print what you want to see, since it prints "common" metrics only.
- CommonMetricPrinter(self.max_iter),
- JSONWriter(os.path.join(self.cfg.OUTPUT_DIR, "metrics.json")),
- TensorboardXWriter(self.cfg.OUTPUT_DIR),
- ]
-
- def train(self):
- """
- Run training.
-
- Returns:
- OrderedDict of results, if evaluation is enabled. Otherwise None.
- """
- super().train(self.start_iter, self.max_iter)
- if len(self.cfg.TEST.EXPECTED_RESULTS) and comm.is_main_process():
- assert hasattr(
- self, "_last_eval_results"
- ), "No evaluation results obtained during training!"
- verify_results(self.cfg, self._last_eval_results)
- return self._last_eval_results
-
- @classmethod
- def build_model(cls, cfg):
- """
- Returns:
- torch.nn.Module:
-
- It now calls :func:`detectron2.modeling.build_model`.
- Overwrite it if you'd like a different model.
- """
- model = build_model(cfg)
- logger = logging.getLogger(__name__)
- logger.info("Model:\n{}".format(model))
- return model
-
- @classmethod
- def build_optimizer(cls, cfg, model):
- """
- Returns:
- torch.optim.Optimizer:
-
- It now calls :func:`detectron2.solver.build_optimizer`.
- Overwrite it if you'd like a different optimizer.
- """
- return build_optimizer(cfg, model)
-
- @classmethod
- def build_lr_scheduler(cls, cfg, optimizer):
- """
- It now calls :func:`detectron2.solver.build_lr_scheduler`.
- Overwrite it if you'd like a different scheduler.
- """
- return build_lr_scheduler(cfg, optimizer)
-
- @classmethod
- def build_train_loader(cls, cfg):
- """
- Returns:
- iterable
-
- It now calls :func:`detectron2.data.build_detection_train_loader`.
- Overwrite it if you'd like a different data loader.
- """
- return build_detection_train_loader(cfg)
-
- @classmethod
- def build_test_loader(cls, cfg, dataset_name):
- """
- Returns:
- iterable
-
- It now calls :func:`detectron2.data.build_detection_test_loader`.
- Overwrite it if you'd like a different data loader.
- """
- return build_detection_test_loader(cfg, dataset_name)
-
- @classmethod
- def build_evaluator(cls, cfg, dataset_name):
- """
- Returns:
- DatasetEvaluator or None
-
- It is not implemented by default.
- """
- raise NotImplementedError(
- """
-If you want DefaultTrainer to automatically run evaluation,
-please implement `build_evaluator()` in subclasses (see train_net.py for example).
-Alternatively, you can call evaluation functions yourself (see Colab balloon tutorial for example).
-"""
- )
-
- @classmethod
- def test(cls, cfg, model, evaluators=None):
- """
- Args:
- cfg (CfgNode):
- model (nn.Module):
- evaluators (list[DatasetEvaluator] or None): if None, will call
- :meth:`build_evaluator`. Otherwise, must have the same length as
- `cfg.DATASETS.TEST`.
-
- Returns:
- dict: a dict of result metrics
- """
- logger = logging.getLogger(__name__)
- if isinstance(evaluators, DatasetEvaluator):
- evaluators = [evaluators]
- if evaluators is not None:
- assert len(cfg.DATASETS.TEST) == len(evaluators), "{} != {}".format(
- len(cfg.DATASETS.TEST), len(evaluators)
- )
-
- results = OrderedDict()
- for idx, dataset_name in enumerate(cfg.DATASETS.TEST):
- data_loader = cls.build_test_loader(cfg, dataset_name)
- # When evaluators are passed in as arguments,
- # implicitly assume that evaluators can be created before data_loader.
- if evaluators is not None:
- evaluator = evaluators[idx]
- else:
- try:
- evaluator = cls.build_evaluator(cfg, dataset_name)
- except NotImplementedError:
- logger.warn(
- "No evaluator found. Use `DefaultTrainer.test(evaluators=)`, "
- "or implement its `build_evaluator` method."
- )
- results[dataset_name] = {}
- continue
- results_i = inference_on_dataset(model, data_loader, evaluator)
- results[dataset_name] = results_i
- if comm.is_main_process():
- assert isinstance(
- results_i, dict
- ), "Evaluator must return a dict on the main process. Got {} instead.".format(
- results_i
- )
- logger.info(
- "Evaluation results for {} in csv format:".format(dataset_name)
- )
- print_csv_format(results_i)
-
- if len(results) == 1:
- results = list(results.values())[0]
- return results
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/dev/run_instant_tests.sh b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/dev/run_instant_tests.sh
deleted file mode 100644
index 2c51de649262e7371fb173210c8edc377e8177e0..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/dev/run_instant_tests.sh
+++ /dev/null
@@ -1,27 +0,0 @@
-#!/bin/bash -e
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-
-BIN="python tools/train_net.py"
-OUTPUT="instant_test_output"
-NUM_GPUS=2
-
-CFG_LIST=( "${@:1}" )
-if [ ${#CFG_LIST[@]} -eq 0 ]; then
- CFG_LIST=( ./configs/quick_schedules/*instant_test.yaml )
-fi
-
-echo "========================================================================"
-echo "Configs to run:"
-echo "${CFG_LIST[@]}"
-echo "========================================================================"
-
-for cfg in "${CFG_LIST[@]}"; do
- echo "========================================================================"
- echo "Running $cfg ..."
- echo "========================================================================"
- $BIN --num-gpus $NUM_GPUS --config-file "$cfg" \
- SOLVER.IMS_PER_BATCH $(($NUM_GPUS * 2)) \
- OUTPUT_DIR "$OUTPUT"
- rm -rf "$OUTPUT"
-done
-
diff --git a/spaces/CVPR/MonoScene/monoscene/unet2d.py b/spaces/CVPR/MonoScene/monoscene/unet2d.py
deleted file mode 100644
index 68fc659cee62b88212d99bb98c1a2e93a5c3e1e2..0000000000000000000000000000000000000000
--- a/spaces/CVPR/MonoScene/monoscene/unet2d.py
+++ /dev/null
@@ -1,198 +0,0 @@
-"""
-Code adapted from https://github.com/shariqfarooq123/AdaBins/blob/main/models/unet_adaptive_bins.py
-"""
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import os
-
-
-class UpSampleBN(nn.Module):
- def __init__(self, skip_input, output_features):
- super(UpSampleBN, self).__init__()
- self._net = nn.Sequential(
- nn.Conv2d(skip_input, output_features, kernel_size=3, stride=1, padding=1),
- nn.BatchNorm2d(output_features),
- nn.LeakyReLU(),
- nn.Conv2d(
- output_features, output_features, kernel_size=3, stride=1, padding=1
- ),
- nn.BatchNorm2d(output_features),
- nn.LeakyReLU(),
- )
-
- def forward(self, x, concat_with):
- up_x = F.interpolate(
- x,
- size=(concat_with.shape[2], concat_with.shape[3]),
- mode="bilinear",
- align_corners=True,
- )
- f = torch.cat([up_x, concat_with], dim=1)
- return self._net(f)
-
-
-class DecoderBN(nn.Module):
- def __init__(
- self, num_features, bottleneck_features, out_feature, use_decoder=True
- ):
- super(DecoderBN, self).__init__()
- features = int(num_features)
- self.use_decoder = use_decoder
-
- self.conv2 = nn.Conv2d(
- bottleneck_features, features, kernel_size=1, stride=1, padding=1
- )
-
- self.out_feature_1_1 = out_feature
- self.out_feature_1_2 = out_feature
- self.out_feature_1_4 = out_feature
- self.out_feature_1_8 = out_feature
- self.out_feature_1_16 = out_feature
- self.feature_1_16 = features // 2
- self.feature_1_8 = features // 4
- self.feature_1_4 = features // 8
- self.feature_1_2 = features // 16
- self.feature_1_1 = features // 32
-
- if self.use_decoder:
- self.resize_output_1_1 = nn.Conv2d(
- self.feature_1_1, self.out_feature_1_1, kernel_size=1
- )
- self.resize_output_1_2 = nn.Conv2d(
- self.feature_1_2, self.out_feature_1_2, kernel_size=1
- )
- self.resize_output_1_4 = nn.Conv2d(
- self.feature_1_4, self.out_feature_1_4, kernel_size=1
- )
- self.resize_output_1_8 = nn.Conv2d(
- self.feature_1_8, self.out_feature_1_8, kernel_size=1
- )
- self.resize_output_1_16 = nn.Conv2d(
- self.feature_1_16, self.out_feature_1_16, kernel_size=1
- )
-
- self.up16 = UpSampleBN(
- skip_input=features + 224, output_features=self.feature_1_16
- )
- self.up8 = UpSampleBN(
- skip_input=self.feature_1_16 + 80, output_features=self.feature_1_8
- )
- self.up4 = UpSampleBN(
- skip_input=self.feature_1_8 + 48, output_features=self.feature_1_4
- )
- self.up2 = UpSampleBN(
- skip_input=self.feature_1_4 + 32, output_features=self.feature_1_2
- )
- self.up1 = UpSampleBN(
- skip_input=self.feature_1_2 + 3, output_features=self.feature_1_1
- )
- else:
- self.resize_output_1_1 = nn.Conv2d(3, out_feature, kernel_size=1)
- self.resize_output_1_2 = nn.Conv2d(32, out_feature * 2, kernel_size=1)
- self.resize_output_1_4 = nn.Conv2d(48, out_feature * 4, kernel_size=1)
-
- def forward(self, features):
- x_block0, x_block1, x_block2, x_block3, x_block4 = (
- features[4],
- features[5],
- features[6],
- features[8],
- features[11],
- )
- bs = x_block0.shape[0]
- x_d0 = self.conv2(x_block4)
-
- if self.use_decoder:
- x_1_16 = self.up16(x_d0, x_block3)
- x_1_8 = self.up8(x_1_16, x_block2)
- x_1_4 = self.up4(x_1_8, x_block1)
- x_1_2 = self.up2(x_1_4, x_block0)
- x_1_1 = self.up1(x_1_2, features[0])
- return {
- "1_1": self.resize_output_1_1(x_1_1),
- "1_2": self.resize_output_1_2(x_1_2),
- "1_4": self.resize_output_1_4(x_1_4),
- "1_8": self.resize_output_1_8(x_1_8),
- "1_16": self.resize_output_1_16(x_1_16),
- }
- else:
- x_1_1 = features[0]
- x_1_2, x_1_4, x_1_8, x_1_16 = (
- features[4],
- features[5],
- features[6],
- features[8],
- )
- x_global = features[-1].reshape(bs, 2560, -1).mean(2)
- return {
- "1_1": self.resize_output_1_1(x_1_1),
- "1_2": self.resize_output_1_2(x_1_2),
- "1_4": self.resize_output_1_4(x_1_4),
- "global": x_global,
- }
-
-
-class Encoder(nn.Module):
- def __init__(self, backend):
- super(Encoder, self).__init__()
- self.original_model = backend
-
- def forward(self, x):
- features = [x]
- for k, v in self.original_model._modules.items():
- if k == "blocks":
- for ki, vi in v._modules.items():
- features.append(vi(features[-1]))
- else:
- features.append(v(features[-1]))
- return features
-
-
-class UNet2D(nn.Module):
- def __init__(self, backend, num_features, out_feature, use_decoder=True):
- super(UNet2D, self).__init__()
- self.use_decoder = use_decoder
- self.encoder = Encoder(backend)
- self.decoder = DecoderBN(
- out_feature=out_feature,
- use_decoder=use_decoder,
- bottleneck_features=num_features,
- num_features=num_features,
- )
-
- def forward(self, x, **kwargs):
- encoded_feats = self.encoder(x)
- unet_out = self.decoder(encoded_feats, **kwargs)
- return unet_out
-
- def get_encoder_params(self): # lr/10 learning rate
- return self.encoder.parameters()
-
- def get_decoder_params(self): # lr learning rate
- return self.decoder.parameters()
-
- @classmethod
- def build(cls, **kwargs):
- basemodel_name = "tf_efficientnet_b7_ns"
- num_features = 2560
-
- print("Loading base model ()...".format(basemodel_name), end="")
- basemodel = torch.hub.load(
- "rwightman/gen-efficientnet-pytorch", basemodel_name, pretrained=True
- )
- print("Done.")
-
- # Remove last layer
- print("Removing last two layers (global_pool & classifier).")
- basemodel.global_pool = nn.Identity()
- basemodel.classifier = nn.Identity()
-
- # Building Encoder-Decoder model
- print("Building Encoder-Decoder model..", end="")
- m = cls(basemodel, num_features=num_features, **kwargs)
- print("Done.")
- return m
-
-if __name__ == '__main__':
- model = UNet2D.build(out_feature=256, use_decoder=True)
diff --git a/spaces/Carlosito16/aitGPT/app_with_prompt_v2.py b/spaces/Carlosito16/aitGPT/app_with_prompt_v2.py
deleted file mode 100644
index c3aaad98aab075177df8292bb6f5f454c2e7d497..0000000000000000000000000000000000000000
--- a/spaces/Carlosito16/aitGPT/app_with_prompt_v2.py
+++ /dev/null
@@ -1,256 +0,0 @@
-# This version is the same model with only different UI, to be a chat-like experience
-
-import streamlit as st
-from streamlit_chat import message as st_message
-import pandas as pd
-import numpy as np
-import datetime
-import gspread
-import pickle
-import os
-import csv
-import json
-import torch
-from tqdm.auto import tqdm
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-
-
-# from langchain.vectorstores import Chroma
-from langchain.vectorstores import FAISS
-from langchain.embeddings import HuggingFaceInstructEmbeddings
-
-
-from langchain import HuggingFacePipeline
-from langchain.chains import RetrievalQA
-
-from langchain.prompts import PromptTemplate
-
-
-
-
-prompt_template = """
-
-You are the chatbot and the face of Asian Institute of Technology (AIT). Your job is to give answers to prospective and current students about the school.
-Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
-Always make sure to be elaborate. And try to use vibrant, positive tone to represent good branding of the school.
-Never answer with any unfinished response.
-
-{context}
-
-Question: {question}
-
-Always make sure to elaborate your response and use vibrant, positive tone to represent good branding of the school.
-Never answer with any unfinished response.
-
-
-"""
-PROMPT = PromptTemplate(
- template=prompt_template, input_variables=["context", "question"]
-)
-chain_type_kwargs = {"prompt": PROMPT}
-
-
-st.set_page_config(
- page_title = 'aitGPT',
- page_icon = '✅')
-
-
-
-
-@st.cache_data
-def load_scraped_web_info():
- with open("ait-web-document", "rb") as fp:
- ait_web_documents = pickle.load(fp)
-
-
- text_splitter = RecursiveCharacterTextSplitter(
- # Set a really small chunk size, just to show.
- chunk_size = 500,
- chunk_overlap = 100,
- length_function = len,
- )
-
- chunked_text = text_splitter.create_documents([doc for doc in tqdm(ait_web_documents)])
-
-
-@st.cache_resource
-def load_embedding_model():
- embedding_model = HuggingFaceInstructEmbeddings(model_name='hkunlp/instructor-base',
- model_kwargs = {'device': torch.device('cuda' if torch.cuda.is_available() else 'cpu')})
- return embedding_model
-
-@st.cache_data
-def load_faiss_index():
- vector_database = FAISS.load_local("faiss_index_web_and_curri_new", embedding_model) #CHANGE THIS FAISS EMBEDDED KNOWLEDGE
- return vector_database
-
-@st.cache_resource
-def load_llm_model():
- # llm = HuggingFacePipeline.from_model_id(model_id= 'lmsys/fastchat-t5-3b-v1.0',
- # task= 'text2text-generation',
- # model_kwargs={ "device_map": "auto",
- # "load_in_8bit": True,"max_length": 256, "temperature": 0,
- # "repetition_penalty": 1.5})
-
-
- llm = HuggingFacePipeline.from_model_id(model_id= 'lmsys/fastchat-t5-3b-v1.0',
- task= 'text2text-generation',
-
- model_kwargs={ "max_length": 256, "temperature": 0,
- "torch_dtype":torch.float32,
- "repetition_penalty": 1.3})
- return llm
-
-
-def load_retriever(llm, db):
- qa_retriever = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff",
- retriever=db.as_retriever(),
- chain_type_kwargs= chain_type_kwargs)
-
- return qa_retriever
-
-def retrieve_document(query_input):
- related_doc = vector_database.similarity_search(query_input)
- return related_doc
-
-def retrieve_answer():
- prompt_answer= st.session_state.my_text_input + " " + "Try to elaborate as much as you can."
- answer = qa_retriever.run(prompt_answer)
- log = {"timestamp": datetime.datetime.now(),
- "question":st.session_state.my_text_input,
- "generated_answer": answer[6:],
- "rating":0 }
-
- st.session_state.history.append(log)
- update_worksheet_qa()
- st.session_state.chat_history.append({"message": st.session_state.my_text_input, "is_user": True})
- st.session_state.chat_history.append({"message": answer[6:] , "is_user": False})
-
- st.session_state.my_text_input = ""
-
- return answer[6:] #this positional slicing helps remove " " at the beginning
-
-# def update_score():
-# st.session_state.session_rating = st.session_state.rating
-
-
-def update_worksheet_qa():
- # st.session_state.session_rating = st.session_state.rating
- #This if helps validate the initiated rating, if 0, then the google sheet would not be updated
- #(edited) now even with the score of 0, we still want to store the log because some users do not give the score to complete the logging
- # if st.session_state.session_rating == 0:
- worksheet_qa.append_row([st.session_state.history[-1]['timestamp'].strftime(datetime_format),
- st.session_state.history[-1]['question'],
- st.session_state.history[-1]['generated_answer'],
- 0])
- # else:
- # worksheet_qa.append_row([st.session_state.history[-1]['timestamp'].strftime(datetime_format),
- # st.session_state.history[-1]['question'],
- # st.session_state.history[-1]['generated_answer'],
- # st.session_state.session_rating
- # ])
-
-def update_worksheet_comment():
- worksheet_comment.append_row([datetime.datetime.now().strftime(datetime_format),
- feedback_input])
- success_message = st.success('Feedback successfully submitted, thank you', icon="✅",
- )
- time.sleep(3)
- success_message.empty()
-
-
-def clean_chat_history():
- st.session_state.chat_history = []
-
-#--------------
-
-
-if "history" not in st.session_state: #this one is for the google sheet logging
- st.session_state.history = []
-
-
-if "chat_history" not in st.session_state: #this one is to pass previous messages into chat flow
- st.session_state.chat_history = []
-# if "session_rating" not in st.session_state:
-# st.session_state.session_rating = 0
-
-
-credentials= json.loads(st.secrets['google_sheet_credential'])
-
-service_account = gspread.service_account_from_dict(credentials)
-workbook= service_account.open("aitGPT-qa-log")
-worksheet_qa = workbook.worksheet("Sheet1")
-worksheet_comment = workbook.worksheet("Sheet2")
-datetime_format= "%Y-%m-%d %H:%M:%S"
-
-
-
-load_scraped_web_info()
-embedding_model = load_embedding_model()
-vector_database = load_faiss_index()
-llm_model = load_llm_model()
-qa_retriever = load_retriever(llm= llm_model, db= vector_database)
-
-
-print("all load done")
-
-
-
-
-
-
-
-
-st.write("# aitGPT 🤖 ")
-st.markdown("""
- #### The aitGPT project is a virtual assistant developed by the :green[Asian Institute of Technology] that contains a vast amount of information gathered from 205 AIT-related websites.
- The goal of this chatbot is to provide an alternative way for applicants and current students to access information about the institute, including admission procedures, campus facilities, and more.
- """)
-st.write(' ⚠️ Please expect to wait **~ 10 - 20 seconds per question** as thi app is running on CPU against 3-billion-parameter LLM')
-
-st.markdown("---")
-st.write(" ")
-st.write("""
- ### ❔ Ask a question
- """)
-
-
-for chat in st.session_state.chat_history:
- st_message(**chat)
-
-query_input = st.text_input(label= 'What would you like to know about AIT?' , key = 'my_text_input', on_change= retrieve_answer )
-# generate_button = st.button(label = 'Ask question!')
-
-# if generate_button:
-# answer = retrieve_answer(query_input)
-# log = {"timestamp": datetime.datetime.now(),
-# "question":query_input,
-# "generated_answer": answer,
-# "rating":0 }
-
-# st.session_state.history.append(log)
-# update_worksheet_qa()
-# st.session_state.chat_history.append({"message": query_input, "is_user": True})
-# st.session_state.chat_history.append({"message": answer, "is_user": False})
-
-# print(st.session_state.chat_history)
-
-
-clear_button = st.button("Start new convo",
- on_click=clean_chat_history)
-
-
-st.write(" ")
-st.write(" ")
-
-st.markdown("---")
-st.write("""
- ### 💌 Your voice matters
- """)
-
-feedback_input = st.text_area(label= 'please leave your feedback or any ideas to make this bot more knowledgeable and fun')
-feedback_button = st.button(label = 'Submit feedback!')
-
-if feedback_button:
- update_worksheet_comment()
-
diff --git a/spaces/Cecil8352/vits-models/modules.py b/spaces/Cecil8352/vits-models/modules.py
deleted file mode 100644
index 56ea4145eddf19dd330a3a41ab0183efc1686d83..0000000000000000000000000000000000000000
--- a/spaces/Cecil8352/vits-models/modules.py
+++ /dev/null
@@ -1,388 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/CofAI/chat/client/css/global.css b/spaces/CofAI/chat/client/css/global.css
deleted file mode 100644
index 8de755e9df1b2c4ee74d18f00ce717b22c69db4b..0000000000000000000000000000000000000000
--- a/spaces/CofAI/chat/client/css/global.css
+++ /dev/null
@@ -1,70 +0,0 @@
-@import url("https://fonts.googleapis.com/css2?family=Inter:wght@100;200;300;400;500;600;700;800;900&display=swap");
-* {
- --font-1: "Inter", sans-serif;
- --section-gap: 24px;
- --border-radius-1: 8px;
- margin: 0;
- padding: 0;
- box-sizing: border-box;
- position: relative;
- font-family: var(--font-1);
-}
-
-.theme-light {
- --colour-1: #f5f5f5;
- --colour-2: #000000;
- --colour-3: #474747;
- --colour-4: #949494;
- --colour-5: #ebebeb;
- --colour-6: #dadada;
-
- --accent: #3a3a3a;
- --blur-bg: #ffffff;
- --blur-border: #dbdbdb;
- --user-input: #282828;
- --conversations: #666666;
-}
-
-.theme-dark {
- --colour-1: #181818;
- --colour-2: #ccc;
- --colour-3: #dadada;
- --colour-4: #f0f0f0;
- --colour-5: #181818;
- --colour-6: #242424;
-
- --accent: #151718;
- --blur-bg: #242627;
- --blur-border: #242627;
- --user-input: #f5f5f5;
- --conversations: #555555;
-}
-
-html,
-body {
- background: var(--colour-1);
- color: var(--colour-3);
-}
-
-ol,
-ul {
- padding-left: 20px;
-}
-
-.shown {
- display: flex !important;
-}
-
-a:-webkit-any-link {
- color: var(--accent);
-}
-
-pre {
- white-space: pre-wrap;
-}
-
-@media screen and (max-height: 720px) {
- :root {
- --section-gap: 16px;
- }
-}
diff --git a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/modeling/rpn/retinanet/__init__.py b/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/modeling/rpn/retinanet/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/structures/boxlist_ops.py b/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/structures/boxlist_ops.py
deleted file mode 100644
index dc51212f4ff7abc6d978df75d3de44f956f38f67..0000000000000000000000000000000000000000
--- a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/structures/boxlist_ops.py
+++ /dev/null
@@ -1,128 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-import torch
-
-from .bounding_box import BoxList
-
-from maskrcnn_benchmark.layers import nms as _box_nms
-
-
-def boxlist_nms(boxlist, nms_thresh, max_proposals=-1, score_field="scores"):
- """
- Performs non-maximum suppression on a boxlist, with scores specified
- in a boxlist field via score_field.
-
- Arguments:
- boxlist(BoxList)
- nms_thresh (float)
- max_proposals (int): if > 0, then only the top max_proposals are kept
- after non-maximum suppression
- score_field (str)
- """
- if nms_thresh <= 0:
- return boxlist
- mode = boxlist.mode
- boxlist = boxlist.convert("xyxy")
- boxes = boxlist.bbox
- score = boxlist.get_field(score_field)
- keep = _box_nms(boxes, score, nms_thresh)
- if max_proposals > 0:
- keep = keep[: max_proposals]
- boxlist = boxlist[keep]
- return boxlist.convert(mode)
-
-
-def remove_small_boxes(boxlist, min_size):
- """
- Only keep boxes with both sides >= min_size
-
- Arguments:
- boxlist (Boxlist)
- min_size (int)
- """
- # TODO maybe add an API for querying the ws / hs
- xywh_boxes = boxlist.convert("xywh").bbox
- _, _, ws, hs = xywh_boxes.unbind(dim=1)
- keep = (
- (ws >= min_size) & (hs >= min_size)
- ).nonzero().squeeze(1)
- return boxlist[keep]
-
-
-# implementation from https://github.com/kuangliu/torchcv/blob/master/torchcv/utils/box.py
-# with slight modifications
-def boxlist_iou(boxlist1, boxlist2):
- """Compute the intersection over union of two set of boxes.
- The box order must be (xmin, ymin, xmax, ymax).
-
- Arguments:
- box1: (BoxList) bounding boxes, sized [N,4].
- box2: (BoxList) bounding boxes, sized [M,4].
-
- Returns:
- (tensor) iou, sized [N,M].
-
- Reference:
- https://github.com/chainer/chainercv/blob/master/chainercv/utils/bbox/bbox_iou.py
- """
- if boxlist1.size != boxlist2.size:
- raise RuntimeError(
- "boxlists should have same image size, got {}, {}".format(boxlist1, boxlist2))
-
- N = len(boxlist1)
- M = len(boxlist2)
-
- area1 = boxlist1.area()
- area2 = boxlist2.area()
-
- box1, box2 = boxlist1.bbox, boxlist2.bbox
-
- lt = torch.max(box1[:, None, :2], box2[:, :2]) # [N,M,2]
- rb = torch.min(box1[:, None, 2:], box2[:, 2:]) # [N,M,2]
-
- TO_REMOVE = 1
-
- wh = (rb - lt + TO_REMOVE).clamp(min=0) # [N,M,2]
- inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
-
- iou = inter / (area1[:, None] + area2 - inter)
- return iou
-
-
-# TODO redundant, remove
-def _cat(tensors, dim=0):
- """
- Efficient version of torch.cat that avoids a copy if there is only a single element in a list
- """
- assert isinstance(tensors, (list, tuple))
- if len(tensors) == 1:
- return tensors[0]
- return torch.cat(tensors, dim)
-
-
-def cat_boxlist(bboxes):
- """
- Concatenates a list of BoxList (having the same image size) into a
- single BoxList
-
- Arguments:
- bboxes (list[BoxList])
- """
- assert isinstance(bboxes, (list, tuple))
- assert all(isinstance(bbox, BoxList) for bbox in bboxes)
-
- size = bboxes[0].size
- assert all(bbox.size == size for bbox in bboxes)
-
- mode = bboxes[0].mode
- assert all(bbox.mode == mode for bbox in bboxes)
-
- fields = set(bboxes[0].fields())
- assert all(set(bbox.fields()) == fields for bbox in bboxes)
-
- cat_boxes = BoxList(_cat([bbox.bbox for bbox in bboxes], dim=0), size, mode)
-
- for field in fields:
- data = _cat([bbox.get_field(field) for bbox in bboxes], dim=0)
- cat_boxes.add_field(field, data)
-
- return cat_boxes
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/SunImagePlugin.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/SunImagePlugin.py
deleted file mode 100644
index 6712583d71cc6f7ded205eb812c7fe5ee77f6ac6..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/SunImagePlugin.py
+++ /dev/null
@@ -1,139 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# Sun image file handling
-#
-# History:
-# 1995-09-10 fl Created
-# 1996-05-28 fl Fixed 32-bit alignment
-# 1998-12-29 fl Import ImagePalette module
-# 2001-12-18 fl Fixed palette loading (from Jean-Claude Rimbault)
-#
-# Copyright (c) 1997-2001 by Secret Labs AB
-# Copyright (c) 1995-1996 by Fredrik Lundh
-#
-# See the README file for information on usage and redistribution.
-#
-
-
-from . import Image, ImageFile, ImagePalette
-from ._binary import i32be as i32
-
-
-def _accept(prefix):
- return len(prefix) >= 4 and i32(prefix) == 0x59A66A95
-
-
-##
-# Image plugin for Sun raster files.
-
-
-class SunImageFile(ImageFile.ImageFile):
- format = "SUN"
- format_description = "Sun Raster File"
-
- def _open(self):
- # The Sun Raster file header is 32 bytes in length
- # and has the following format:
-
- # typedef struct _SunRaster
- # {
- # DWORD MagicNumber; /* Magic (identification) number */
- # DWORD Width; /* Width of image in pixels */
- # DWORD Height; /* Height of image in pixels */
- # DWORD Depth; /* Number of bits per pixel */
- # DWORD Length; /* Size of image data in bytes */
- # DWORD Type; /* Type of raster file */
- # DWORD ColorMapType; /* Type of color map */
- # DWORD ColorMapLength; /* Size of the color map in bytes */
- # } SUNRASTER;
-
- # HEAD
- s = self.fp.read(32)
- if not _accept(s):
- msg = "not an SUN raster file"
- raise SyntaxError(msg)
-
- offset = 32
-
- self._size = i32(s, 4), i32(s, 8)
-
- depth = i32(s, 12)
- # data_length = i32(s, 16) # unreliable, ignore.
- file_type = i32(s, 20)
- palette_type = i32(s, 24) # 0: None, 1: RGB, 2: Raw/arbitrary
- palette_length = i32(s, 28)
-
- if depth == 1:
- self.mode, rawmode = "1", "1;I"
- elif depth == 4:
- self.mode, rawmode = "L", "L;4"
- elif depth == 8:
- self.mode = rawmode = "L"
- elif depth == 24:
- if file_type == 3:
- self.mode, rawmode = "RGB", "RGB"
- else:
- self.mode, rawmode = "RGB", "BGR"
- elif depth == 32:
- if file_type == 3:
- self.mode, rawmode = "RGB", "RGBX"
- else:
- self.mode, rawmode = "RGB", "BGRX"
- else:
- msg = "Unsupported Mode/Bit Depth"
- raise SyntaxError(msg)
-
- if palette_length:
- if palette_length > 1024:
- msg = "Unsupported Color Palette Length"
- raise SyntaxError(msg)
-
- if palette_type != 1:
- msg = "Unsupported Palette Type"
- raise SyntaxError(msg)
-
- offset = offset + palette_length
- self.palette = ImagePalette.raw("RGB;L", self.fp.read(palette_length))
- if self.mode == "L":
- self.mode = "P"
- rawmode = rawmode.replace("L", "P")
-
- # 16 bit boundaries on stride
- stride = ((self.size[0] * depth + 15) // 16) * 2
-
- # file type: Type is the version (or flavor) of the bitmap
- # file. The following values are typically found in the Type
- # field:
- # 0000h Old
- # 0001h Standard
- # 0002h Byte-encoded
- # 0003h RGB format
- # 0004h TIFF format
- # 0005h IFF format
- # FFFFh Experimental
-
- # Old and standard are the same, except for the length tag.
- # byte-encoded is run-length-encoded
- # RGB looks similar to standard, but RGB byte order
- # TIFF and IFF mean that they were converted from T/IFF
- # Experimental means that it's something else.
- # (https://www.fileformat.info/format/sunraster/egff.htm)
-
- if file_type in (0, 1, 3, 4, 5):
- self.tile = [("raw", (0, 0) + self.size, offset, (rawmode, stride))]
- elif file_type == 2:
- self.tile = [("sun_rle", (0, 0) + self.size, offset, rawmode)]
- else:
- msg = "Unsupported Sun Raster file type"
- raise SyntaxError(msg)
-
-
-#
-# registry
-
-
-Image.register_open(SunImageFile.format, SunImageFile, _accept)
-
-Image.register_extension(SunImageFile.format, ".ras")
diff --git a/spaces/DaFujaTyping/hf-Chat-ui/src/lib/types/Timestamps.ts b/spaces/DaFujaTyping/hf-Chat-ui/src/lib/types/Timestamps.ts
deleted file mode 100644
index 12d1867d1be509310190df09d2392bfaa77d6500..0000000000000000000000000000000000000000
--- a/spaces/DaFujaTyping/hf-Chat-ui/src/lib/types/Timestamps.ts
+++ /dev/null
@@ -1,4 +0,0 @@
-export interface Timestamps {
- createdAt: Date;
- updatedAt: Date;
-}
diff --git a/spaces/Demonic/Text_Summarizer/README.md b/spaces/Demonic/Text_Summarizer/README.md
deleted file mode 100644
index a004044f8d9848101cf9cb88600ce987a02b2233..0000000000000000000000000000000000000000
--- a/spaces/Demonic/Text_Summarizer/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Text_Summarizer
-emoji: 💻
-colorFrom: pink
-colorTo: green
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/DracoHugging/LicensePlateRecognition/app.py b/spaces/DracoHugging/LicensePlateRecognition/app.py
deleted file mode 100644
index 598d8d4de1b14f8ceabe61f8959c9ba4f65bbf3c..0000000000000000000000000000000000000000
--- a/spaces/DracoHugging/LicensePlateRecognition/app.py
+++ /dev/null
@@ -1,6 +0,0 @@
-import os
-import gradio as gr
-
-
-iface = gr.Interface.load("DracoHugging/LPR-Private", src="spaces", api_key = os.environ["HF_TOKEN"])
-iface.launch(debug=False)
\ No newline at end of file
diff --git a/spaces/EsoCode/text-generation-webui/extensions/silero_tts/tts_preprocessor.py b/spaces/EsoCode/text-generation-webui/extensions/silero_tts/tts_preprocessor.py
deleted file mode 100644
index daefdcbda6c9b20a87c6f3d84d2a759c2c51289c..0000000000000000000000000000000000000000
--- a/spaces/EsoCode/text-generation-webui/extensions/silero_tts/tts_preprocessor.py
+++ /dev/null
@@ -1,200 +0,0 @@
-import re
-
-from num2words import num2words
-
-punctuation = r'[\s,.?!/)\'\]>]'
-alphabet_map = {
- "A": " Ei ",
- "B": " Bee ",
- "C": " See ",
- "D": " Dee ",
- "E": " Eee ",
- "F": " Eff ",
- "G": " Jee ",
- "H": " Eich ",
- "I": " Eye ",
- "J": " Jay ",
- "K": " Kay ",
- "L": " El ",
- "M": " Emm ",
- "N": " Enn ",
- "O": " Ohh ",
- "P": " Pee ",
- "Q": " Queue ",
- "R": " Are ",
- "S": " Ess ",
- "T": " Tee ",
- "U": " You ",
- "V": " Vee ",
- "W": " Double You ",
- "X": " Ex ",
- "Y": " Why ",
- "Z": " Zed " # Zed is weird, as I (da3dsoul) am American, but most of the voice models sound British, so it matches
-}
-
-
-def preprocess(string):
- # the order for some of these matter
- # For example, you need to remove the commas in numbers before expanding them
- string = remove_surrounded_chars(string)
- string = string.replace('"', '')
- string = string.replace('\u201D', '').replace('\u201C', '') # right and left quote
- string = string.replace('\u201F', '') # italic looking quote
- string = string.replace('\n', ' ')
- string = convert_num_locale(string)
- string = replace_negative(string)
- string = replace_roman(string)
- string = hyphen_range_to(string)
- string = num_to_words(string)
-
- # TODO Try to use a ML predictor to expand abbreviations. It's hard, dependent on context, and whether to actually
- # try to say the abbreviation or spell it out as I've done below is not agreed upon
-
- # For now, expand abbreviations to pronunciations
- # replace_abbreviations adds a lot of unnecessary whitespace to ensure separation
- string = replace_abbreviations(string)
- string = replace_lowercase_abbreviations(string)
-
- # cleanup whitespaces
- # remove whitespace before punctuation
- string = re.sub(rf'\s+({punctuation})', r'\1', string)
- string = string.strip()
- # compact whitespace
- string = ' '.join(string.split())
-
- return string
-
-
-def remove_surrounded_chars(string):
- # first this expression will check if there is a string nested exclusively between a alt=
- # and a style= string. This would correspond to only a the alt text of an embedded image
- # If it matches it will only keep that part as the string, and rend it for further processing
- # Afterwards this expression matches to 'as few symbols as possible (0 upwards) between any
- # asterisks' OR' as few symbols as possible (0 upwards) between an asterisk and the end of the string'
- if re.search(r'(?<=alt=)(.*)(?=style=)', string, re.DOTALL):
- m = re.search(r'(?<=alt=)(.*)(?=style=)', string, re.DOTALL)
- string = m.group(0)
- return re.sub(r'\*[^*]*?(\*|$)', '', string)
-
-
-def convert_num_locale(text):
- # This detects locale and converts it to American without comma separators
- pattern = re.compile(r'(?:\s|^)\d{1,3}(?:\.\d{3})+(,\d+)(?:\s|$)')
- result = text
- while True:
- match = pattern.search(result)
- if match is None:
- break
-
- start = match.start()
- end = match.end()
- result = result[0:start] + result[start:end].replace('.', '').replace(',', '.') + result[end:len(result)]
-
- # removes comma separators from existing American numbers
- pattern = re.compile(r'(\d),(\d)')
- result = pattern.sub(r'\1\2', result)
-
- return result
-
-
-def replace_negative(string):
- # handles situations like -5. -5 would become negative 5, which would then be expanded to negative five
- return re.sub(rf'(\s)(-)(\d+)({punctuation})', r'\1negative \3\4', string)
-
-
-def replace_roman(string):
- # find a string of roman numerals.
- # Only 2 or more, to avoid capturing I and single character abbreviations, like names
- pattern = re.compile(rf'\s[IVXLCDM]{{2,}}{punctuation}')
- result = string
- while True:
- match = pattern.search(result)
- if match is None:
- break
-
- start = match.start()
- end = match.end()
- result = result[0:start + 1] + str(roman_to_int(result[start + 1:end - 1])) + result[end - 1:len(result)]
-
- return result
-
-
-def roman_to_int(s):
- rom_val = {'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500, 'M': 1000}
- int_val = 0
- for i in range(len(s)):
- if i > 0 and rom_val[s[i]] > rom_val[s[i - 1]]:
- int_val += rom_val[s[i]] - 2 * rom_val[s[i - 1]]
- else:
- int_val += rom_val[s[i]]
- return int_val
-
-
-def hyphen_range_to(text):
- pattern = re.compile(r'(\d+)[-–](\d+)')
- result = pattern.sub(lambda x: x.group(1) + ' to ' + x.group(2), text)
- return result
-
-
-def num_to_words(text):
- # 1000 or 10.23
- pattern = re.compile(r'\d+\.\d+|\d+')
- result = pattern.sub(lambda x: num2words(float(x.group())), text)
- return result
-
-
-def replace_abbreviations(string):
- # abbreviations 1 to 4 characters long. It will get things like A and I, but those are pronounced with their letter
- pattern = re.compile(rf'(^|[\s(.\'\[<])([A-Z]{{1,4}})({punctuation}|$)')
- result = string
- while True:
- match = pattern.search(result)
- if match is None:
- break
-
- start = match.start()
- end = match.end()
- result = result[0:start] + replace_abbreviation(result[start:end]) + result[end:len(result)]
-
- return result
-
-
-def replace_lowercase_abbreviations(string):
- # abbreviations 1 to 4 characters long, separated by dots i.e. e.g.
- pattern = re.compile(rf'(^|[\s(.\'\[<])(([a-z]\.){{1,4}})({punctuation}|$)')
- result = string
- while True:
- match = pattern.search(result)
- if match is None:
- break
-
- start = match.start()
- end = match.end()
- result = result[0:start] + replace_abbreviation(result[start:end].upper()) + result[end:len(result)]
-
- return result
-
-
-def replace_abbreviation(string):
- result = ""
- for char in string:
- result += match_mapping(char)
-
- return result
-
-
-def match_mapping(char):
- for mapping in alphabet_map.keys():
- if char == mapping:
- return alphabet_map[char]
-
- return char
-
-
-def __main__(args):
- print(preprocess(args[1]))
-
-
-if __name__ == "__main__":
- import sys
- __main__(sys.argv)
diff --git a/spaces/Felix123456/bingo/src/components/chat-image.tsx b/spaces/Felix123456/bingo/src/components/chat-image.tsx
deleted file mode 100644
index 05ecc9771eada27a0f2d160bb01cba170d37bb09..0000000000000000000000000000000000000000
--- a/spaces/Felix123456/bingo/src/components/chat-image.tsx
+++ /dev/null
@@ -1,170 +0,0 @@
-import {
- useEffect,
- useState,
- useCallback,
- ChangeEvent,
- ClipboardEvent,
- MouseEventHandler,
- FormEvent,
- useRef
-} from "react"
-import Image from 'next/image'
-import PasteIcon from '@/assets/images/paste.svg'
-import UploadIcon from '@/assets/images/upload.svg'
-import CameraIcon from '@/assets/images/camera.svg'
-import { useBing } from '@/lib/hooks/use-bing'
-import { cn } from '@/lib/utils'
-
-interface ChatImageProps extends Pick, 'uploadImage'> {}
-
-const preventDefault: MouseEventHandler = (event) => {
- event.nativeEvent.stopImmediatePropagation()
-}
-
-const toBase64 = (file: File): Promise => new Promise((resolve, reject) => {
- const reader = new FileReader()
- reader.readAsDataURL(file)
- reader.onload = () => resolve(reader.result as string)
- reader.onerror = reject
-})
-
-export function ChatImage({ children, uploadImage }: React.PropsWithChildren) {
- const videoRef = useRef(null)
- const canvasRef = useRef(null)
- const mediaStream = useRef()
- const [panel, setPanel] = useState('none')
-
- const upload = useCallback((url: string) => {
- if (url) {
- uploadImage(url)
- }
- setPanel('none')
- }, [panel])
-
- const onUpload = useCallback(async (event: ChangeEvent) => {
- const file = event.target.files?.[0]
- if (file) {
- const fileDataUrl = await toBase64(file)
- if (fileDataUrl) {
- upload(fileDataUrl)
- }
- }
- }, [])
-
- const onPaste = useCallback((event: ClipboardEvent) => {
- const pasteUrl = event.clipboardData.getData('text') ?? ''
- upload(pasteUrl)
- }, [])
-
- const onEnter = useCallback((event: FormEvent) => {
- event.preventDefault()
- event.stopPropagation()
- // @ts-ignore
- const inputUrl = event.target.elements.image.value
- if (inputUrl) {
- upload(inputUrl)
- }
- }, [])
-
- const openVideo: MouseEventHandler = async (event) => {
- event.stopPropagation()
- setPanel('camera-mode')
- }
-
- const onCapture = () => {
- if (canvasRef.current && videoRef.current) {
- const canvas = canvasRef.current
- canvas.width = videoRef.current!.videoWidth
- canvas.height = videoRef.current!.videoHeight
- canvas.getContext('2d')?.drawImage(videoRef.current, 0, 0, canvas.width, canvas.height)
- const cameraUrl = canvas.toDataURL('image/jpeg')
- upload(cameraUrl)
- }
- }
-
- useEffect(() => {
- const handleBlur = () => {
- if (panel !== 'none') {
- setPanel('none')
- }
- }
- document.addEventListener('click', handleBlur)
- return () => {
- document.removeEventListener('click', handleBlur)
- }
- }, [panel])
-
- useEffect(() => {
- if (panel === 'camera-mode') {
- navigator.mediaDevices.getUserMedia({ video: true, audio: false })
- .then(videoStream => {
- mediaStream.current = videoStream
- if (videoRef.current) {
- videoRef.current.srcObject = videoStream
- }
- })
- } else {
- if (mediaStream.current) {
- mediaStream.current.getTracks().forEach(function(track) {
- track.stop()
- })
- mediaStream.current = undefined
- }
- }
- }, [panel])
-
- return (
-
-
panel === 'none' ? setPanel('normal') : setPanel('none')}>{children}
-
-
-
-
添加图像
-
-
-
-
-
-
-
-
-
-
- {panel === 'camera-mode' &&
}
-
-
-1
- 0
- +1 `,c(e,"class","color_legend flex px-2 py-1 justify-between rounded mb-3 font-semibold mt-7"),c(e,"data-testid","highlighted-text:color-legend"),B(e,"background","-webkit-linear-gradient(to right,#8d83d6,(255,255,255,0),#eb4d4b)"),B(e,"background","linear-gradient(to right,#8d83d6,rgba(255,255,255,0),#eb4d4b)")},m(n,l){m(n,e,l)},d(n){n&&g(e)}}}function X(s){let e,n,l=s[15]+"",o,r,t;return{c(){e=v("span"),n=v("span"),o=V(l),r=T(),c(n,"class","text dark:text-white"),c(e,"class","textspan p-1 mr-0.5 bg-opacity-20 dark:bg-opacity-80 rounded-sm"),c(e,"style",t="background-color: rgba("+(s[22]<0?"141, 131, 214,"+-s[22]:"235, 77, 75,"+s[22])+")")},m(i,a){m(i,e,a),k(e,n),k(n,o),k(e,r)},p(i,a){a&1&&l!==(l=i[15]+"")&&D(o,l),a&1&&t!==(t="background-color: rgba("+(i[22]<0?"141, 131, 214,"+-i[22]:"235, 77, 75,"+i[22])+")")&&c(e,"style",t)},d(i){i&&g(e)}}}function x(s){let e,n=Object.entries(s[2]),l=[];for(let o=0;o_(h),b=h=>_(h),E=()=>C(),N=()=>C();return s.$$set=h=>{"value"in h&&n(0,o=h.value),"show_legend"in h&&n(1,r=h.show_legend),"color_map"in h&&n(7,t=h.color_map)},s.$$.update=()=>{if(s.$$.dirty&129){let h=function(){for(const w in t){const j=t[w].trim();j in P?n(2,a[w]=P[j],a):n(2,a[w]={primary:l?u(t[w],1):t[w],secondary:l?u(t[w],.5):t[w]},a)}};if(t||n(7,t={}),o.length>0){for(let[w,j]of o)if(j!==null)if(typeof j=="string"){if(n(4,p="categories"),!(j in t)){let I=me(Object.keys(t).length);n(7,t[j]=I,t)}}else n(4,p="scores")}h()}},[o,r,a,d,p,_,C,t,f,b,E,N]}class we extends Y{constructor(e){super(),Z(this,e,ve,ke,q,{value:0,show_legend:1,color_map:7})}}function te(s){let e,n;return e=new ge({props:{Icon:oe,label:s[5],disable:typeof s[0].container=="boolean"&&!s[0].container}}),{c(){O(e.$$.fragment)},m(l,o){R(e,l,o),n=!0},p(l,o){const r={};o&32&&(r.label=l[5]),o&1&&(r.disable=typeof l[0].container=="boolean"&&!l[0].container),e.$set(r)},i(l){n||(y(e.$$.fragment,l),n=!0)},o(l){H(e.$$.fragment,l),n=!1},d(l){S(e,l)}}}function ye(s){let e,n,l,o;return l=new oe({}),{c(){e=v("div"),n=v("div"),O(l.$$.fragment),c(n,"class","h-5 dark:text-white opacity-50"),c(e,"class","h-full min-h-[6rem] flex justify-center items-center")},m(r,t){m(r,e,t),k(e,n),R(l,n,null),o=!0},p:M,i(r){o||(y(l.$$.fragment,r),o=!0)},o(r){H(l.$$.fragment,r),o=!1},d(r){r&&g(e),S(l)}}}function je(s){let e,n;return e=new we({props:{value:s[3],show_legend:s[4],color_map:s[0].color_map}}),{c(){O(e.$$.fragment)},m(l,o){R(e,l,o),n=!0},p(l,o){const r={};o&8&&(r.value=l[3]),o&16&&(r.show_legend=l[4]),o&1&&(r.color_map=l[0].color_map),e.$set(r)},i(l){n||(y(e.$$.fragment,l),n=!0)},o(l){H(e.$$.fragment,l),n=!1},d(l){S(e,l)}}}function He(s){let e,n,l,o,r,t,i;const a=[s[6]];let d={};for(let f=0;f{u=null}),G());let N=o;o=C(f),o===N?_[o].p(f,b):(U(),H(_[N],1,1,()=>{_[N]=null}),G(),r=_[o],r?r.p(f,b):(r=_[o]=p[o](f),r.c()),y(r,1),r.m(t.parentNode,t))},i(f){i||(y(e.$$.fragment,f),y(u),y(r),i=!0)},o(f){H(e.$$.fragment,f),H(u),H(r),i=!1},d(f){S(e,f),f&&g(n),u&&u.d(f),f&&g(l),_[o].d(f),f&&g(t)}}}function Te(s){let e,n;return e=new ae({props:{test_id:"highlighted-text",visible:s[2],elem_id:s[1],disable:typeof s[0].container=="boolean"&&!s[0].container,$$slots:{default:[He]},$$scope:{ctx:s}}}),{c(){O(e.$$.fragment)},m(l,o){R(e,l,o),n=!0},p(l,[o]){const r={};o&4&&(r.visible=l[2]),o&2&&(r.elem_id=l[1]),o&1&&(r.disable=typeof l[0].container=="boolean"&&!l[0].container),o&633&&(r.$$scope={dirty:o,ctx:l}),e.$set(r)},i(l){n||(y(e.$$.fragment,l),n=!0)},o(l){H(e.$$.fragment,l),n=!1},d(l){S(e,l)}}}function Ce(s,e,n){let{elem_id:l=""}=e,{visible:o=!0}=e,{value:r}=e,{show_legend:t}=e,{color_map:i={}}=e,{label:a}=e,{style:d={}}=e,{loading_status:u}=e;const p=fe();return s.$$set=_=>{"elem_id"in _&&n(1,l=_.elem_id),"visible"in _&&n(2,o=_.visible),"value"in _&&n(3,r=_.value),"show_legend"in _&&n(4,t=_.show_legend),"color_map"in _&&n(7,i=_.color_map),"label"in _&&n(5,a=_.label),"style"in _&&n(0,d=_.style),"loading_status"in _&&n(6,u=_.loading_status)},s.$$.update=()=>{s.$$.dirty&129&&!d.color_map&&Object.keys(i).length&&n(0,d.color_map=i,d),s.$$.dirty&8&&p("change")},[d,l,o,r,t,a,u,i]}class Me extends Y{constructor(e){super(),Z(this,e,Ce,Te,q,{elem_id:1,visible:2,value:3,show_legend:4,color_map:7,label:5,style:0,loading_status:6})}}var Oe=Me;const Re=["static"],Se=s=>({type:"Array<[string, string | number]>",description:"list of text spans and corresponding label / value"});export{Oe as Component,Se as document,Re as modes};
-//# sourceMappingURL=index.044a1523.js.map
diff --git a/spaces/ICML2022/OFA/fairseq/examples/textless_nlp/gslm/unit2speech/glow.py b/spaces/ICML2022/OFA/fairseq/examples/textless_nlp/gslm/unit2speech/glow.py
deleted file mode 100644
index 7a7696403d505afdf0f1606f8220801b0f46152f..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/examples/textless_nlp/gslm/unit2speech/glow.py
+++ /dev/null
@@ -1,311 +0,0 @@
-# *****************************************************************************
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Redistribution and use in source and binary forms, with or without
-# modification, are permitted provided that the following conditions are met:
-# * Redistributions of source code must retain the above copyright
-# notice, this list of conditions and the following disclaimer.
-# * Redistributions in binary form must reproduce the above copyright
-# notice, this list of conditions and the following disclaimer in the
-# documentation and/or other materials provided with the distribution.
-# * Neither the name of the NVIDIA CORPORATION nor the
-# names of its contributors may be used to endorse or promote products
-# derived from this software without specific prior written permission.
-#
-# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
-# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
-# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
-# DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
-# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
-# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
-# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
-# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
-# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
-# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
-#
-# *****************************************************************************
-import copy
-import torch
-from torch.autograd import Variable
-import torch.nn.functional as F
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a+input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-class WaveGlowLoss(torch.nn.Module):
- def __init__(self, sigma=1.0):
- super(WaveGlowLoss, self).__init__()
- self.sigma = sigma
-
- def forward(self, model_output):
- z, log_s_list, log_det_W_list = model_output
- for i, log_s in enumerate(log_s_list):
- if i == 0:
- log_s_total = torch.sum(log_s)
- log_det_W_total = log_det_W_list[i]
- else:
- log_s_total = log_s_total + torch.sum(log_s)
- log_det_W_total += log_det_W_list[i]
-
- loss = torch.sum(z*z)/(2*self.sigma*self.sigma) - log_s_total - log_det_W_total
- return loss/(z.size(0)*z.size(1)*z.size(2))
-
-
-class Invertible1x1Conv(torch.nn.Module):
- """
- The layer outputs both the convolution, and the log determinant
- of its weight matrix. If reverse=True it does convolution with
- inverse
- """
- def __init__(self, c):
- super(Invertible1x1Conv, self).__init__()
- self.conv = torch.nn.Conv1d(c, c, kernel_size=1, stride=1, padding=0,
- bias=False)
-
- # Sample a random orthonormal matrix to initialize weights
- W = torch.qr(torch.FloatTensor(c, c).normal_())[0]
-
- # Ensure determinant is 1.0 not -1.0
- if torch.det(W) < 0:
- W[:,0] = -1*W[:,0]
- W = W.view(c, c, 1)
- self.conv.weight.data = W
-
- def forward(self, z, reverse=False):
- # shape
- batch_size, group_size, n_of_groups = z.size()
-
- W = self.conv.weight.squeeze()
-
- if reverse:
- if not hasattr(self, 'W_inverse'):
- # Reverse computation
- W_inverse = W.float().inverse()
- W_inverse = Variable(W_inverse[..., None])
- if z.type() == 'torch.cuda.HalfTensor':
- W_inverse = W_inverse.half()
- self.W_inverse = W_inverse
- z = F.conv1d(z, self.W_inverse, bias=None, stride=1, padding=0)
- return z
- else:
- # Forward computation
- log_det_W = batch_size * n_of_groups * torch.logdet(W)
- z = self.conv(z)
- return z, log_det_W
-
-
-class WN(torch.nn.Module):
- """
- This is the WaveNet like layer for the affine coupling. The primary difference
- from WaveNet is the convolutions need not be causal. There is also no dilation
- size reset. The dilation only doubles on each layer
- """
- def __init__(self, n_in_channels, n_mel_channels, n_layers, n_channels,
- kernel_size):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- assert(n_channels % 2 == 0)
- self.n_layers = n_layers
- self.n_channels = n_channels
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
-
- start = torch.nn.Conv1d(n_in_channels, n_channels, 1)
- start = torch.nn.utils.weight_norm(start, name='weight')
- self.start = start
-
- # Initializing last layer to 0 makes the affine coupling layers
- # do nothing at first. This helps with training stability
- end = torch.nn.Conv1d(n_channels, 2*n_in_channels, 1)
- end.weight.data.zero_()
- end.bias.data.zero_()
- self.end = end
-
- cond_layer = torch.nn.Conv1d(n_mel_channels, 2*n_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = 2 ** i
- padding = int((kernel_size*dilation - dilation)/2)
- in_layer = torch.nn.Conv1d(n_channels, 2*n_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2*n_channels
- else:
- res_skip_channels = n_channels
- res_skip_layer = torch.nn.Conv1d(n_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, forward_input):
- audio, spect = forward_input
- audio = self.start(audio)
- output = torch.zeros_like(audio)
- n_channels_tensor = torch.IntTensor([self.n_channels])
-
- spect = self.cond_layer(spect)
-
- for i in range(self.n_layers):
- spect_offset = i*2*self.n_channels
- acts = fused_add_tanh_sigmoid_multiply(
- self.in_layers[i](audio),
- spect[:,spect_offset:spect_offset+2*self.n_channels,:],
- n_channels_tensor)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- audio = audio + res_skip_acts[:,:self.n_channels,:]
- output = output + res_skip_acts[:,self.n_channels:,:]
- else:
- output = output + res_skip_acts
-
- return self.end(output)
-
-
-class WaveGlow(torch.nn.Module):
- def __init__(self, n_mel_channels, n_flows, n_group, n_early_every,
- n_early_size, WN_config):
- super(WaveGlow, self).__init__()
-
- self.upsample = torch.nn.ConvTranspose1d(n_mel_channels,
- n_mel_channels,
- 1024, stride=256)
- assert(n_group % 2 == 0)
- self.n_flows = n_flows
- self.n_group = n_group
- self.n_early_every = n_early_every
- self.n_early_size = n_early_size
- self.WN = torch.nn.ModuleList()
- self.convinv = torch.nn.ModuleList()
-
- n_half = int(n_group/2)
-
- # Set up layers with the right sizes based on how many dimensions
- # have been output already
- n_remaining_channels = n_group
- for k in range(n_flows):
- if k % self.n_early_every == 0 and k > 0:
- n_half = n_half - int(self.n_early_size/2)
- n_remaining_channels = n_remaining_channels - self.n_early_size
- self.convinv.append(Invertible1x1Conv(n_remaining_channels))
- self.WN.append(WN(n_half, n_mel_channels*n_group, **WN_config))
- self.n_remaining_channels = n_remaining_channels # Useful during inference
-
- def forward(self, forward_input):
- """
- forward_input[0] = mel_spectrogram: batch x n_mel_channels x frames
- forward_input[1] = audio: batch x time
- """
- spect, audio = forward_input
-
- # Upsample spectrogram to size of audio
- spect = self.upsample(spect)
- assert(spect.size(2) >= audio.size(1))
- if spect.size(2) > audio.size(1):
- spect = spect[:, :, :audio.size(1)]
-
- spect = spect.unfold(2, self.n_group, self.n_group).permute(0, 2, 1, 3)
- spect = spect.contiguous().view(spect.size(0), spect.size(1), -1).permute(0, 2, 1)
-
- audio = audio.unfold(1, self.n_group, self.n_group).permute(0, 2, 1)
- output_audio = []
- log_s_list = []
- log_det_W_list = []
-
- for k in range(self.n_flows):
- if k % self.n_early_every == 0 and k > 0:
- output_audio.append(audio[:,:self.n_early_size,:])
- audio = audio[:,self.n_early_size:,:]
-
- audio, log_det_W = self.convinv[k](audio)
- log_det_W_list.append(log_det_W)
-
- n_half = int(audio.size(1)/2)
- audio_0 = audio[:,:n_half,:]
- audio_1 = audio[:,n_half:,:]
-
- output = self.WN[k]((audio_0, spect))
- log_s = output[:, n_half:, :]
- b = output[:, :n_half, :]
- audio_1 = torch.exp(log_s)*audio_1 + b
- log_s_list.append(log_s)
-
- audio = torch.cat([audio_0, audio_1],1)
-
- output_audio.append(audio)
- return torch.cat(output_audio,1), log_s_list, log_det_W_list
-
- def infer(self, spect, sigma=1.0):
- spect = self.upsample(spect)
- # trim conv artifacts. maybe pad spec to kernel multiple
- time_cutoff = self.upsample.kernel_size[0] - self.upsample.stride[0]
- spect = spect[:, :, :-time_cutoff]
-
- spect = spect.unfold(2, self.n_group, self.n_group).permute(0, 2, 1, 3)
- spect = spect.contiguous().view(spect.size(0), spect.size(1), -1).permute(0, 2, 1)
-
- if spect.type() == 'torch.cuda.HalfTensor':
- audio = torch.cuda.HalfTensor(spect.size(0),
- self.n_remaining_channels,
- spect.size(2)).normal_()
- else:
- audio = torch.cuda.FloatTensor(spect.size(0),
- self.n_remaining_channels,
- spect.size(2)).normal_()
-
- audio = torch.autograd.Variable(sigma*audio)
-
- for k in reversed(range(self.n_flows)):
- n_half = int(audio.size(1)/2)
- audio_0 = audio[:,:n_half,:]
- audio_1 = audio[:,n_half:,:]
-
- output = self.WN[k]((audio_0, spect))
-
- s = output[:, n_half:, :]
- b = output[:, :n_half, :]
- audio_1 = (audio_1 - b)/torch.exp(s)
- audio = torch.cat([audio_0, audio_1],1)
-
- audio = self.convinv[k](audio, reverse=True)
-
- if k % self.n_early_every == 0 and k > 0:
- if spect.type() == 'torch.cuda.HalfTensor':
- z = torch.cuda.HalfTensor(spect.size(0), self.n_early_size, spect.size(2)).normal_()
- else:
- z = torch.cuda.FloatTensor(spect.size(0), self.n_early_size, spect.size(2)).normal_()
- audio = torch.cat((sigma*z, audio),1)
-
- audio = audio.permute(0,2,1).contiguous().view(audio.size(0), -1).data
- return audio
-
- @staticmethod
- def remove_weightnorm(model):
- waveglow = model
- for WN in waveglow.WN:
- WN.start = torch.nn.utils.remove_weight_norm(WN.start)
- WN.in_layers = remove(WN.in_layers)
- WN.cond_layer = torch.nn.utils.remove_weight_norm(WN.cond_layer)
- WN.res_skip_layers = remove(WN.res_skip_layers)
- return waveglow
-
-
-def remove(conv_list):
- new_conv_list = torch.nn.ModuleList()
- for old_conv in conv_list:
- old_conv = torch.nn.utils.remove_weight_norm(old_conv)
- new_conv_list.append(old_conv)
- return new_conv_list
diff --git a/spaces/ICML2022/OFA/fairseq/fairseq/data/iterators.py b/spaces/ICML2022/OFA/fairseq/fairseq/data/iterators.py
deleted file mode 100644
index 1ce26e57e58f9006ea801e77a1437e45743a3b8b..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/fairseq/data/iterators.py
+++ /dev/null
@@ -1,765 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import itertools
-import logging
-import math
-import operator
-import os
-import queue
-import time
-from threading import Thread
-
-import numpy as np
-import torch
-from fairseq.data import data_utils
-
-
-logger = logging.getLogger(__name__)
-
-# Object used by _background_consumer to signal the source is exhausted
-# to the main thread.
-_sentinel = object()
-
-
-class CountingIterator(object):
- """Wrapper around an iterable that maintains the iteration count.
-
- Args:
- iterable (iterable): iterable to wrap
- start (int): starting iteration count. Note that this doesn't
- actually advance the iterator.
- total (int): override the iterator length returned by ``__len``.
- This can be used to truncate *iterator*.
-
- Attributes:
- n (int): number of elements consumed from this iterator
- """
-
- def __init__(self, iterable, start=None, total=None):
- self._itr = iter(iterable)
- self.n = start or getattr(iterable, "n", 0)
- self.total = total or self.n + len(iterable)
-
- def __len__(self):
- return self.total
-
- def __iter__(self):
- return self
-
- def __next__(self):
- if not self.has_next():
- raise StopIteration
- try:
- x = next(self._itr)
- except StopIteration:
- raise IndexError(f"Iterator expected to have length {self.total}, "
- "but exhausted at position {self.n}.")
- self.n += 1
- return x
-
- def has_next(self):
- """Whether the iterator has been exhausted."""
- return self.n < self.total
-
- def skip(self, n):
- """Fast-forward the iterator by skipping n elements."""
- for _ in range(n):
- next(self)
- return self
-
- def take(self, n):
- """Truncate the iterator to n elements at most."""
- self.total = min(self.total, n)
- # Propagate this change to the underlying iterator
- if hasattr(self._itr, "take"):
- self._itr.take(max(n - self.n, 0))
- return self
-
-
-class EpochBatchIterating(object):
- def __len__(self) -> int:
- raise NotImplementedError
-
- @property
- def next_epoch_idx(self):
- raise NotImplementedError
-
- def next_epoch_itr(
- self, shuffle=True, fix_batches_to_gpus=False, set_dataset_epoch=True
- ):
- """Return a new iterator over the dataset.
-
- Args:
- shuffle (bool, optional): shuffle batches before returning the
- iterator (default: True).
- fix_batches_to_gpus (bool, optional): ensure that batches are always
- allocated to the same shards across epochs. Requires
- that :attr:`dataset` supports prefetching (default: False).
- set_dataset_epoch (bool, optional): update the wrapped Dataset with
- the new epoch number (default: True).
- """
- raise NotImplementedError
-
- def end_of_epoch(self) -> bool:
- """Returns whether the most recent epoch iterator has been exhausted"""
- raise NotImplementedError
-
- @property
- def iterations_in_epoch(self) -> int:
- """The number of consumed batches in the current epoch."""
- raise NotImplementedError
-
- def state_dict(self):
- """Returns a dictionary containing a whole state of the iterator."""
- raise NotImplementedError
-
- def load_state_dict(self, state_dict):
- """Copies the state of the iterator from the given *state_dict*."""
- raise NotImplementedError
-
- @property
- def first_batch(self):
- return "DUMMY"
-
-
-class StreamingEpochBatchIterator(EpochBatchIterating):
- """A steaming-style iterator over a :class:`torch.utils.data.IterableDataset`.
-
- Args:
- dataset (~torch.utils.data.Dataset): dataset from which to load the data
- max_sentences: batch size
- collate_fn (callable): merges a list of samples to form a mini-batch
- num_workers (int, optional): how many subprocesses to use for data
- loading. 0 means the data will be loaded in the main process
- (default: 0).
- epoch (int, optional): the epoch to start the iterator from
- (default: 1).
- buffer_size (int, optional): the number of batches to keep ready in the
- queue. Helps speeding up dataloading. When buffer_size is zero, the
- default torch.utils.data.DataLoader preloading is used.
- timeout (int, optional): if positive, the timeout value for collecting a batch
- from workers. Should always be non-negative (default: ``0``).
- """
-
- def __init__(
- self,
- dataset,
- max_sentences=1,
- collate_fn=None,
- epoch=1,
- num_workers=0,
- buffer_size=0,
- timeout=0,
- ):
- assert isinstance(dataset, torch.utils.data.IterableDataset)
- self.dataset = dataset
- self.max_sentences = max_sentences
- self.collate_fn = collate_fn
- self.epoch = max(epoch, 1) # we use 1-based indexing for epochs
- self.num_workers = num_workers
- # This upper limit here is to prevent people from abusing this feature
- # in a shared computing environment.
- self.buffer_size = min(buffer_size, 20)
- self.timeout = timeout
-
- self._current_epoch_iterator = None
-
- @property
- def next_epoch_idx(self):
- """Return the epoch index after *next_epoch_itr* is called."""
- if self._current_epoch_iterator is not None and self.end_of_epoch():
- return self.epoch + 1
- else:
- return self.epoch
-
- def next_epoch_itr(
- self, shuffle=True, fix_batches_to_gpus=False, set_dataset_epoch=True
- ):
- self.epoch = self.next_epoch_idx
- if set_dataset_epoch and hasattr(self.dataset, "set_epoch"):
- self.dataset.set_epoch(self.epoch)
- self._current_epoch_iterator = self._get_iterator_for_epoch(self.epoch, shuffle)
- return self._current_epoch_iterator
-
- def end_of_epoch(self) -> bool:
- return not self._current_epoch_iterator.has_next()
-
- @property
- def iterations_in_epoch(self) -> int:
- if self._current_epoch_iterator is not None:
- return self._current_epoch_iterator.n
- return 0
-
- def state_dict(self):
- return {
- "epoch": self.epoch,
- }
-
- def load_state_dict(self, state_dict):
- self.epoch = state_dict["epoch"]
-
- def _get_iterator_for_epoch(self, epoch, shuffle, offset=0):
- if self.num_workers > 0:
- os.environ["PYTHONWARNINGS"] = "ignore:semaphore_tracker:UserWarning"
-
- # Create data loader
- worker_init_fn = getattr(self.dataset, "worker_init_fn", None)
- itr = torch.utils.data.DataLoader(
- self.dataset,
- batch_size=self.max_sentences,
- collate_fn=self.collate_fn,
- num_workers=self.num_workers,
- timeout=self.timeout,
- worker_init_fn=worker_init_fn,
- pin_memory=True,
- )
-
- # Wrap with a BufferedIterator if needed
- if self.buffer_size > 0:
- itr = BufferedIterator(self.buffer_size, itr)
-
- # Wrap with CountingIterator
- itr = CountingIterator(itr, start=offset)
-
- return itr
-
-
-class EpochBatchIterator(EpochBatchIterating):
- """A multi-epoch iterator over a :class:`torch.utils.data.Dataset`.
-
- Compared to :class:`torch.utils.data.DataLoader`, this iterator:
-
- - can be reused across multiple epochs with the :func:`next_epoch_itr`
- method (optionally shuffled between epochs)
- - can be serialized/deserialized with the :func:`state_dict` and
- :func:`load_state_dict` methods
- - supports sharding with the *num_shards* and *shard_id* arguments
-
- Args:
- dataset (~torch.utils.data.Dataset): dataset from which to load the data
- collate_fn (callable): merges a list of samples to form a mini-batch
- batch_sampler (~torch.utils.data.Sampler or a callable): an iterator over batches of
- indices, or a callable to create such an iterator (~torch.utils.data.Sampler).
- A callable batch_sampler will be called for each epoch to enable per epoch dynamic
- batch iterators defined by this callable batch_sampler.
- seed (int, optional): seed for random number generator for
- reproducibility (default: 1).
- num_shards (int, optional): shard the data iterator into N
- shards (default: 1).
- shard_id (int, optional): which shard of the data iterator to
- return (default: 0).
- num_workers (int, optional): how many subprocesses to use for data
- loading. 0 means the data will be loaded in the main process
- (default: 0).
- epoch (int, optional): the epoch to start the iterator from
- (default: 1).
- buffer_size (int, optional): the number of batches to keep ready in the
- queue. Helps speeding up dataloading. When buffer_size is zero, the
- default torch.utils.data.DataLoader preloading is used.
- timeout (int, optional): if positive, the timeout value for collecting a batch
- from workers. Should always be non-negative (default: ``0``).
- disable_shuffling (bool, optional): force disable shuffling
- (default: ``False``).
- """
-
- def __init__(
- self,
- dataset,
- collate_fn,
- batch_sampler,
- seed=1,
- num_shards=1,
- shard_id=0,
- num_workers=0,
- epoch=1,
- buffer_size=0,
- timeout=0,
- disable_shuffling=False,
- ):
- assert isinstance(dataset, torch.utils.data.Dataset)
- self.dataset = dataset
- self.collate_fn = collate_fn
- self.batch_sampler = batch_sampler
- self._frozen_batches = (
- tuple(batch_sampler) if not callable(batch_sampler) else None
- )
- self.seed = seed
- self.num_shards = num_shards
- self.shard_id = shard_id
- self.num_workers = num_workers
- # This upper limit here is to prevent people from abusing this feature
- # in a shared computing environment.
- self.buffer_size = min(buffer_size, 20)
- self.timeout = timeout
- self.disable_shuffling = disable_shuffling
-
- self.epoch = max(epoch, 1) # we use 1-based indexing for epochs
- self.shuffle = not disable_shuffling
- self._cur_epoch_itr = None
- self._next_epoch_itr = None
- self._supports_prefetch = getattr(dataset, "supports_prefetch", False)
-
- @property
- def frozen_batches(self):
- if self._frozen_batches is None:
- self._frozen_batches = tuple(self.batch_sampler(self.dataset, self.epoch))
- return self._frozen_batches
-
- @property
- def first_batch(self):
- if len(self.frozen_batches) == 0:
- raise Exception(
- "The dataset is empty. This could indicate "
- "that all elements in the dataset have been skipped. "
- "Try increasing the max number of allowed tokens or using "
- "a larger dataset."
- )
-
- if getattr(self.dataset, "supports_fetch_outside_dataloader", True):
- return self.collate_fn([self.dataset[i] for i in self.frozen_batches[0]])
- else:
- return "DUMMY"
-
- def __len__(self):
- return int(math.ceil(len(self.frozen_batches) / float(self.num_shards)))
-
- @property
- def n(self):
- return self.iterations_in_epoch
-
- @property
- def next_epoch_idx(self):
- """Return the epoch index after *next_epoch_itr* is called."""
- if self._next_epoch_itr is not None:
- return self.epoch
- elif self._cur_epoch_itr is not None and self.end_of_epoch():
- return self.epoch + 1
- else:
- return self.epoch
-
- def next_epoch_itr(
- self, shuffle=True, fix_batches_to_gpus=False, set_dataset_epoch=True
- ):
- """Return a new iterator over the dataset.
-
- Args:
- shuffle (bool, optional): shuffle batches before returning the
- iterator (default: True).
- fix_batches_to_gpus (bool, optional): ensure that batches are always
- allocated to the same shards across epochs. Requires
- that :attr:`dataset` supports prefetching (default: False).
- set_dataset_epoch (bool, optional): update the wrapped Dataset with
- the new epoch number (default: True).
- """
- if self.disable_shuffling:
- shuffle = False
- prev_epoch = self.epoch
- self.epoch = self.next_epoch_idx
- if set_dataset_epoch and hasattr(self.dataset, "set_epoch"):
- self.dataset.set_epoch(self.epoch)
- if self._next_epoch_itr is not None:
- self._cur_epoch_itr = self._next_epoch_itr
- self._next_epoch_itr = None
- else:
- if callable(self.batch_sampler) and prev_epoch != self.epoch:
- # reset _frozen_batches to refresh the next epoch
- self._frozen_batches = None
- self._cur_epoch_itr = self._get_iterator_for_epoch(
- self.epoch,
- shuffle,
- fix_batches_to_gpus=fix_batches_to_gpus,
- )
- self.shuffle = shuffle
- return self._cur_epoch_itr
-
- def end_of_epoch(self) -> bool:
- """Returns whether the most recent epoch iterator has been exhausted"""
- return not self._cur_epoch_itr.has_next()
-
- @property
- def iterations_in_epoch(self):
- """The number of consumed batches in the current epoch."""
- if self._cur_epoch_itr is not None:
- return self._cur_epoch_itr.n
- elif self._next_epoch_itr is not None:
- return self._next_epoch_itr.n
- return 0
-
- def state_dict(self):
- """Returns a dictionary containing a whole state of the iterator."""
- if self.end_of_epoch():
- epoch = self.epoch + 1
- iter_in_epoch = 0
- else:
- epoch = self.epoch
- iter_in_epoch = self.iterations_in_epoch
- return {
- "version": 2,
- "epoch": epoch,
- "iterations_in_epoch": iter_in_epoch,
- "shuffle": self.shuffle,
- }
-
- def load_state_dict(self, state_dict):
- """Copies the state of the iterator from the given *state_dict*."""
- self.epoch = state_dict["epoch"]
- itr_pos = state_dict.get("iterations_in_epoch", 0)
- version = state_dict.get("version", 1)
- if itr_pos > 0:
- # fast-forward epoch iterator
- self._next_epoch_itr = self._get_iterator_for_epoch(
- self.epoch,
- shuffle=state_dict.get("shuffle", True),
- offset=itr_pos,
- )
- if self._next_epoch_itr is None:
- if version == 1:
- # legacy behavior: we finished the epoch, increment epoch counter
- self.epoch += 1
- else:
- raise RuntimeError(
- "Cannot resume training due to dataloader mismatch, please "
- "report this to the fairseq developers. You can relaunch "
- "training with `--reset-dataloader` and it should work."
- )
- else:
- self._next_epoch_itr = None
-
- def _get_iterator_for_epoch(
- self, epoch, shuffle, fix_batches_to_gpus=False, offset=0
- ):
- def shuffle_batches(batches, seed):
- with data_utils.numpy_seed(seed):
- np.random.shuffle(batches)
- return batches
-
- if self._supports_prefetch:
- batches = self.frozen_batches
-
- if shuffle and not fix_batches_to_gpus:
- batches = shuffle_batches(list(batches), self.seed + epoch)
-
- batches = list(
- ShardedIterator(batches, self.num_shards, self.shard_id, fill_value=[])
- )
- self.dataset.prefetch([i for s in batches for i in s])
-
- if shuffle and fix_batches_to_gpus:
- batches = shuffle_batches(batches, self.seed + epoch + self.shard_id)
- else:
- if shuffle:
- batches = shuffle_batches(list(self.frozen_batches), self.seed + epoch)
- else:
- batches = self.frozen_batches
- batches = list(
- ShardedIterator(batches, self.num_shards, self.shard_id, fill_value=[])
- )
-
- if offset > 0 and offset >= len(batches):
- return None
-
- if self.num_workers > 0:
- os.environ["PYTHONWARNINGS"] = "ignore:semaphore_tracker:UserWarning"
-
- # Create data loader
- itr = torch.utils.data.DataLoader(
- self.dataset,
- collate_fn=self.collate_fn,
- batch_sampler=batches[offset:],
- num_workers=self.num_workers,
- timeout=self.timeout,
- pin_memory=True,
- )
-
- # Wrap with a BufferedIterator if needed
- if self.buffer_size > 0:
- itr = BufferedIterator(self.buffer_size, itr)
-
- # Wrap with CountingIterator
- itr = CountingIterator(itr, start=offset)
- return itr
-
-
-class GroupedIterator(CountingIterator):
- """Wrapper around an iterable that returns groups (chunks) of items.
-
- Args:
- iterable (iterable): iterable to wrap
- chunk_size (int): size of each chunk
-
- Attributes:
- n (int): number of elements consumed from this iterator
- """
-
- def __init__(self, iterable, chunk_size):
- itr = _chunk_iterator(iterable, chunk_size)
- super().__init__(
- itr,
- start=int(math.ceil(getattr(iterable, "n", 0) / float(chunk_size))),
- total=int(math.ceil(len(iterable) / float(chunk_size))),
- )
- self.chunk_size = chunk_size
-
-
-def _chunk_iterator(itr, chunk_size):
- chunk = []
- for x in itr:
- chunk.append(x)
- if len(chunk) == chunk_size:
- yield chunk
- chunk = []
- if len(chunk) > 0:
- yield chunk
-
-
-class ShardedIterator(CountingIterator):
- """A sharded wrapper around an iterable, padded to length.
-
- Args:
- iterable (iterable): iterable to wrap
- num_shards (int): number of shards to split the iterable into
- shard_id (int): which shard to iterator over
- fill_value (Any, optional): padding value when the iterable doesn't
- evenly divide *num_shards* (default: None).
-
- Attributes:
- n (int): number of elements consumed from this iterator
- """
-
- def __init__(self, iterable, num_shards, shard_id, fill_value=None):
- if shard_id < 0 or shard_id >= num_shards:
- raise ValueError("shard_id must be between 0 and num_shards")
- sharded_len = int(math.ceil(len(iterable) / float(num_shards)))
- itr = map(
- operator.itemgetter(1),
- itertools.zip_longest(
- range(sharded_len),
- itertools.islice(iterable, shard_id, len(iterable), num_shards),
- fillvalue=fill_value,
- ),
- )
- super().__init__(
- itr,
- start=int(math.ceil(getattr(iterable, "n", 0) / float(num_shards))),
- total=sharded_len,
- )
-
-
-class BackgroundConsumer(Thread):
- def __init__(self, queue, source, max_len, cuda_device):
- Thread.__init__(self)
-
- self._queue = queue
- self._source = source
- self._max_len = max_len
- self.count = 0
- self.cuda_device = cuda_device
-
- def run(self):
- # set_device to avoid creation of GPU0 context when using pin_memory
- if self.cuda_device is not None:
- torch.cuda.set_device(self.cuda_device)
-
- try:
- for item in self._source:
- self._queue.put(item)
-
- # Stop if we reached the maximum length
- self.count += 1
- if self._max_len is not None and self.count >= self._max_len:
- break
-
- # Signal the consumer we are done.
- self._queue.put(_sentinel)
- except Exception as e:
- self._queue.put(e)
-
-
-class BufferedIterator(object):
- def __init__(self, size, iterable):
- self._queue = queue.Queue(size)
- self._iterable = iterable
- self._consumer = None
-
- self.start_time = time.time()
- self.warning_time = None
-
- self.total = len(iterable)
-
- def _create_consumer(self):
- self._consumer = BackgroundConsumer(
- self._queue,
- self._iterable,
- self.total,
- torch.cuda.current_device() if torch.cuda.is_available() else None
- )
- self._consumer.daemon = True
- self._consumer.start()
-
- def __iter__(self):
- return self
-
- def __len__(self):
- return self.total
-
- def take(self, n):
- self.total = min(self.total, n)
- # Propagate this change to the underlying iterator
- if hasattr(self._iterable, "take"):
- self._iterable.take(n)
- return self
-
- def __next__(self):
- # Create consumer if not created yet
- if self._consumer is None:
- self._create_consumer()
-
- # Notify the user if there is a data loading bottleneck
- if self._queue.qsize() < min(2, max(1, self._queue.maxsize // 2)):
- if time.time() - self.start_time > 5 * 60:
- if (
- self.warning_time is None
- or time.time() - self.warning_time > 15 * 60
- ):
- logger.debug(
- "Data loading buffer is empty or nearly empty. This may "
- "indicate a data loading bottleneck, and increasing the "
- "number of workers (--num-workers) may help."
- )
- self.warning_time = time.time()
-
- # Get next example
- item = self._queue.get(True)
- if isinstance(item, Exception):
- raise item
- if item is _sentinel:
- raise StopIteration()
- return item
-
-class GroupedEpochBatchIterator(EpochBatchIterator):
- """Grouped version of EpochBatchIterator
- It takes several samplers from different datasets.
- Each epoch shuffle the dataset wise sampler individually with different
- random seed. The those sub samplers are combined with into
- one big samplers with deterministic permutation to mix batches from
- different datasets. It will act like EpochBatchIterator but make sure
- 1) data from one data set each time
- 2) for different workers, they use the same order to fetch the data
- so they will use data from the same dataset everytime
- mult_rate is used for update_freq > 1 case where we want to make sure update_freq
- mini-batches come from same source
- """
-
- def __init__(
- self,
- dataset,
- collate_fn,
- batch_samplers,
- seed=1,
- num_shards=1,
- shard_id=0,
- num_workers=0,
- epoch=0,
- mult_rate=1,
- buffer_size=0,
- ):
- super().__init__(
- dataset,
- collate_fn,
- batch_samplers,
- seed,
- num_shards,
- shard_id,
- num_workers,
- epoch,
- buffer_size,
- )
- # level 0: sub-samplers 1: batch_idx 2: batches
- self._frozen_batches = tuple([tuple(sub_batch) for sub_batch in batch_samplers])
- self.step_size = mult_rate * num_shards
-
- self.lengths = [
- (len(x) // self.step_size) * self.step_size for x in self.frozen_batches
- ]
-
- def __len__(self):
- return sum(self.lengths)
-
- @property
- def first_batch(self):
- if len(self.frozen_batches) == 0:
- raise Exception(
- "The dataset is empty. This could indicate "
- "that all elements in the dataset have been skipped. "
- "Try increasing the max number of allowed tokens or using "
- "a larger dataset."
- )
-
- if self.dataset.supports_fetch_outside_dataloader:
- return self.collate_fn([self.dataset[i] for i in self.frozen_batches[0][0]])
- else:
- return "DUMMY"
-
- def _get_iterator_for_epoch(
- self, epoch, shuffle, fix_batches_to_gpus=False, offset=0
- ):
- def shuffle_batches(batches, seed):
- with data_utils.numpy_seed(seed):
- np.random.shuffle(batches)
- return batches
-
- def return_full_batches(batch_sets, seed, shuffle):
- if shuffle:
- batch_sets = [shuffle_batches(list(x), seed) for x in batch_sets]
-
- batch_sets = [
- batch_sets[i][: self.lengths[i]] for i in range(len(batch_sets))
- ]
- batches = list(itertools.chain.from_iterable(batch_sets))
-
- if shuffle:
- with data_utils.numpy_seed(seed):
- idx = np.random.permutation(len(batches) // self.step_size)
- if len(idx) * self.step_size != len(batches):
- raise ValueError(
- "ERROR: %d %d %d %d"
- % (len(idx), self.step_size, len(batches), self.shard_id),
- ":".join(["%d" % x for x in self.lengths]),
- )
- mini_shards = [
- batches[i * self.step_size : (i + 1) * self.step_size]
- for i in idx
- ]
- batches = list(itertools.chain.from_iterable(mini_shards))
-
- return batches
-
- if self._supports_prefetch:
- raise NotImplementedError("To be implemented")
- else:
- batches = return_full_batches(
- self.frozen_batches, self.seed + epoch, shuffle
- )
- batches = list(
- ShardedIterator(batches, self.num_shards, self.shard_id, fill_value=[])
- )
-
- if offset > 0 and offset >= len(batches):
- return None
-
- if self.num_workers > 0:
- os.environ["PYTHONWARNINGS"] = "ignore:semaphore_tracker:UserWarning"
-
- itr = torch.utils.data.DataLoader(
- self.dataset,
- collate_fn=self.collate_fn,
- batch_sampler=batches[offset:],
- num_workers=self.num_workers,
- )
- if self.buffer_size > 0:
- itr = BufferedIterator(self.buffer_size, itr)
-
- return CountingIterator(itr, start=offset)
diff --git a/spaces/ICML2022/OFA/fairseq/fairseq/data/prepend_token_dataset.py b/spaces/ICML2022/OFA/fairseq/fairseq/data/prepend_token_dataset.py
deleted file mode 100644
index fd1331f4c44c1595eb9bb78baa0cf5cf3bcce9ad..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/fairseq/data/prepend_token_dataset.py
+++ /dev/null
@@ -1,41 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import numpy as np
-import torch
-
-from . import BaseWrapperDataset
-
-
-class PrependTokenDataset(BaseWrapperDataset):
- def __init__(self, dataset, token=None):
- super().__init__(dataset)
- self.token = token
- if token is not None:
- self._sizes = np.array(dataset.sizes) + 1
- else:
- self._sizes = dataset.sizes
-
- def __getitem__(self, idx):
- item = self.dataset[idx]
- if self.token is not None:
- item = torch.cat([item.new([self.token]), item])
- return item
-
- @property
- def sizes(self):
- return self._sizes
-
- def num_tokens(self, index):
- n = self.dataset.num_tokens(index)
- if self.token is not None:
- n += 1
- return n
-
- def size(self, index):
- n = self.dataset.size(index)
- if self.token is not None:
- n += 1
- return n
diff --git a/spaces/IMU20/kestrl_merchantname_nlp/README.md b/spaces/IMU20/kestrl_merchantname_nlp/README.md
deleted file mode 100644
index 065981819fad1a390160987060bcbf65e024af4e..0000000000000000000000000000000000000000
--- a/spaces/IMU20/kestrl_merchantname_nlp/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Kestrl Merchantname Nlp
-emoji: 🐢
-colorFrom: green
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.47.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Ibtehaj10/cheating-detection-FYP/cat_dog_detection.py b/spaces/Ibtehaj10/cheating-detection-FYP/cat_dog_detection.py
deleted file mode 100644
index 8c984966ea5a8515f6913bdf151ff512f99bd6da..0000000000000000000000000000000000000000
--- a/spaces/Ibtehaj10/cheating-detection-FYP/cat_dog_detection.py
+++ /dev/null
@@ -1,43 +0,0 @@
-import cv2
-import numpy as np
-import imutils
-
-protopath = "MobileNetSSD_deploy.prototxt"
-modelpath = "MobileNetSSD_deploy.caffemodel"
-detector = cv2.dnn.readNetFromCaffe(prototxt=protopath, caffeModel=modelpath)
-
-CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
- "bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
- "dog", "horse", "motorbike", "person", "pottedplant", "sheep",
- "sofa", "train", "tvmonitor"]
-
-
-def main():
- image = cv2.imread('dog.jpg')
- image = imutils.resize(image, width=600)
-
- (H, W) = image.shape[:2]
-
- blob = cv2.dnn.blobFromImage(image, 0.007843, (W, H), 127.5)
-
- detector.setInput(blob)
- person_detections = detector.forward()
-
- for i in np.arange(0, person_detections.shape[2]):
- confidence = person_detections[0, 0, i, 2]
- if confidence > 0.5:
- idx = int(person_detections[0, 0, i, 1])
-
- if CLASSES[idx] != "dog":
- continue
-
- person_box = person_detections[0, 0, i, 3:7] * np.array([W, H, W, H])
- (startX, startY, endX, endY) = person_box.astype("int")
-
- cv2.rectangle(image, (startX, startY), (endX, endY), (0, 0, 255), 2)
-
- cv2.imshow("Results", image)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
-
-main()
\ No newline at end of file
diff --git a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/utils/general.py b/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/utils/general.py
deleted file mode 100644
index c5b73898371964577c9e580dd37fee7bfc47cfa0..0000000000000000000000000000000000000000
--- a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/utils/general.py
+++ /dev/null
@@ -1,1140 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-General utils
-"""
-
-import contextlib
-import glob
-import inspect
-import logging
-import logging.config
-import math
-import os
-import platform
-import random
-import re
-import signal
-import sys
-import time
-import urllib
-from copy import deepcopy
-from datetime import datetime
-from itertools import repeat
-from multiprocessing.pool import ThreadPool
-from pathlib import Path
-from subprocess import check_output
-from tarfile import is_tarfile
-from typing import Optional
-from zipfile import ZipFile, is_zipfile
-
-import cv2
-import IPython
-import numpy as np
-import pandas as pd
-import pkg_resources as pkg
-import torch
-import torchvision
-import yaml
-
-from utils import TryExcept, emojis
-from utils.downloads import gsutil_getsize
-from utils.metrics import box_iou, fitness
-
-FILE = Path(__file__).resolve()
-ROOT = FILE.parents[1] # YOLOv5 root directory
-RANK = int(os.getenv('RANK', -1))
-
-# Settings
-NUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLOv5 multiprocessing threads
-DATASETS_DIR = Path(os.getenv('YOLOv5_DATASETS_DIR', ROOT.parent / 'datasets')) # global datasets directory
-AUTOINSTALL = str(os.getenv('YOLOv5_AUTOINSTALL', True)).lower() == 'true' # global auto-install mode
-VERBOSE = str(os.getenv('YOLOv5_VERBOSE', True)).lower() == 'true' # global verbose mode
-TQDM_BAR_FORMAT = '{l_bar}{bar:10}| {n_fmt}/{total_fmt} {elapsed}' # tqdm bar format
-FONT = 'Arial.ttf' # https://ultralytics.com/assets/Arial.ttf
-
-torch.set_printoptions(linewidth=320, precision=5, profile='long')
-np.set_printoptions(linewidth=320, formatter={'float_kind': '{:11.5g}'.format}) # format short g, %precision=5
-pd.options.display.max_columns = 10
-cv2.setNumThreads(0) # prevent OpenCV from multithreading (incompatible with PyTorch DataLoader)
-os.environ['NUMEXPR_MAX_THREADS'] = str(NUM_THREADS) # NumExpr max threads
-os.environ['OMP_NUM_THREADS'] = '1' if platform.system() == 'darwin' else str(NUM_THREADS) # OpenMP (PyTorch and SciPy)
-
-
-def is_ascii(s=''):
- # Is string composed of all ASCII (no UTF) characters? (note str().isascii() introduced in python 3.7)
- s = str(s) # convert list, tuple, None, etc. to str
- return len(s.encode().decode('ascii', 'ignore')) == len(s)
-
-
-def is_chinese(s='人工智能'):
- # Is string composed of any Chinese characters?
- return bool(re.search('[\u4e00-\u9fff]', str(s)))
-
-
-def is_colab():
- # Is environment a Google Colab instance?
- return 'google.colab' in sys.modules
-
-
-def is_notebook():
- # Is environment a Jupyter notebook? Verified on Colab, Jupyterlab, Kaggle, Paperspace
- ipython_type = str(type(IPython.get_ipython()))
- return 'colab' in ipython_type or 'zmqshell' in ipython_type
-
-
-def is_kaggle():
- # Is environment a Kaggle Notebook?
- return os.environ.get('PWD') == '/kaggle/working' and os.environ.get('KAGGLE_URL_BASE') == 'https://www.kaggle.com'
-
-
-def is_docker() -> bool:
- """Check if the process runs inside a docker container."""
- if Path("/.dockerenv").exists():
- return True
- try: # check if docker is in control groups
- with open("/proc/self/cgroup") as file:
- return any("docker" in line for line in file)
- except OSError:
- return False
-
-
-def is_writeable(dir, test=False):
- # Return True if directory has write permissions, test opening a file with write permissions if test=True
- if not test:
- return os.access(dir, os.W_OK) # possible issues on Windows
- file = Path(dir) / 'tmp.txt'
- try:
- with open(file, 'w'): # open file with write permissions
- pass
- file.unlink() # remove file
- return True
- except OSError:
- return False
-
-
-LOGGING_NAME = "yolov5"
-
-
-def set_logging(name=LOGGING_NAME, verbose=True):
- # sets up logging for the given name
- rank = int(os.getenv('RANK', -1)) # rank in world for Multi-GPU trainings
- level = logging.INFO if verbose and rank in {-1, 0} else logging.ERROR
- logging.config.dictConfig({
- "version": 1,
- "disable_existing_loggers": False,
- "formatters": {
- name: {
- "format": "%(message)s"}},
- "handlers": {
- name: {
- "class": "logging.StreamHandler",
- "formatter": name,
- "level": level,}},
- "loggers": {
- name: {
- "level": level,
- "handlers": [name],
- "propagate": False,}}})
-
-
-set_logging(LOGGING_NAME) # run before defining LOGGER
-LOGGER = logging.getLogger(LOGGING_NAME) # define globally (used in train.py, val.py, detect.py, etc.)
-if platform.system() == 'Windows':
- for fn in LOGGER.info, LOGGER.warning:
- setattr(LOGGER, fn.__name__, lambda x: fn(emojis(x))) # emoji safe logging
-
-
-def user_config_dir(dir='Ultralytics', env_var='YOLOV5_CONFIG_DIR'):
- # Return path of user configuration directory. Prefer environment variable if exists. Make dir if required.
- env = os.getenv(env_var)
- if env:
- path = Path(env) # use environment variable
- else:
- cfg = {'Windows': 'AppData/Roaming', 'Linux': '.config', 'Darwin': 'Library/Application Support'} # 3 OS dirs
- path = Path.home() / cfg.get(platform.system(), '') # OS-specific config dir
- path = (path if is_writeable(path) else Path('/tmp')) / dir # GCP and AWS lambda fix, only /tmp is writeable
- path.mkdir(exist_ok=True) # make if required
- return path
-
-
-CONFIG_DIR = user_config_dir() # Ultralytics settings dir
-
-
-class Profile(contextlib.ContextDecorator):
- # YOLOv5 Profile class. Usage: @Profile() decorator or 'with Profile():' context manager
- def __init__(self, t=0.0):
- self.t = t
- self.cuda = torch.cuda.is_available()
-
- def __enter__(self):
- self.start = self.time()
- return self
-
- def __exit__(self, type, value, traceback):
- self.dt = self.time() - self.start # delta-time
- self.t += self.dt # accumulate dt
-
- def time(self):
- if self.cuda:
- torch.cuda.synchronize()
- return time.time()
-
-
-class Timeout(contextlib.ContextDecorator):
- # YOLOv5 Timeout class. Usage: @Timeout(seconds) decorator or 'with Timeout(seconds):' context manager
- def __init__(self, seconds, *, timeout_msg='', suppress_timeout_errors=True):
- self.seconds = int(seconds)
- self.timeout_message = timeout_msg
- self.suppress = bool(suppress_timeout_errors)
-
- def _timeout_handler(self, signum, frame):
- raise TimeoutError(self.timeout_message)
-
- def __enter__(self):
- if platform.system() != 'Windows': # not supported on Windows
- signal.signal(signal.SIGALRM, self._timeout_handler) # Set handler for SIGALRM
- signal.alarm(self.seconds) # start countdown for SIGALRM to be raised
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- if platform.system() != 'Windows':
- signal.alarm(0) # Cancel SIGALRM if it's scheduled
- if self.suppress and exc_type is TimeoutError: # Suppress TimeoutError
- return True
-
-
-class WorkingDirectory(contextlib.ContextDecorator):
- # Usage: @WorkingDirectory(dir) decorator or 'with WorkingDirectory(dir):' context manager
- def __init__(self, new_dir):
- self.dir = new_dir # new dir
- self.cwd = Path.cwd().resolve() # current dir
-
- def __enter__(self):
- os.chdir(self.dir)
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- os.chdir(self.cwd)
-
-
-def methods(instance):
- # Get class/instance methods
- return [f for f in dir(instance) if callable(getattr(instance, f)) and not f.startswith("__")]
-
-
-def print_args(args: Optional[dict] = None, show_file=True, show_func=False):
- # Print function arguments (optional args dict)
- x = inspect.currentframe().f_back # previous frame
- file, _, func, _, _ = inspect.getframeinfo(x)
- if args is None: # get args automatically
- args, _, _, frm = inspect.getargvalues(x)
- args = {k: v for k, v in frm.items() if k in args}
- try:
- file = Path(file).resolve().relative_to(ROOT).with_suffix('')
- except ValueError:
- file = Path(file).stem
- s = (f'{file}: ' if show_file else '') + (f'{func}: ' if show_func else '')
- LOGGER.info(colorstr(s) + ', '.join(f'{k}={v}' for k, v in args.items()))
-
-
-def init_seeds(seed=0, deterministic=False):
- # Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html
- random.seed(seed)
- np.random.seed(seed)
- torch.manual_seed(seed)
- torch.cuda.manual_seed(seed)
- torch.cuda.manual_seed_all(seed) # for Multi-GPU, exception safe
- # torch.backends.cudnn.benchmark = True # AutoBatch problem https://github.com/ultralytics/yolov5/issues/9287
- if deterministic and check_version(torch.__version__, '1.12.0'): # https://github.com/ultralytics/yolov5/pull/8213
- torch.use_deterministic_algorithms(True)
- torch.backends.cudnn.deterministic = True
- os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
- os.environ['PYTHONHASHSEED'] = str(seed)
-
-
-def intersect_dicts(da, db, exclude=()):
- # Dictionary intersection of matching keys and shapes, omitting 'exclude' keys, using da values
- return {k: v for k, v in da.items() if k in db and all(x not in k for x in exclude) and v.shape == db[k].shape}
-
-
-def get_default_args(func):
- # Get func() default arguments
- signature = inspect.signature(func)
- return {k: v.default for k, v in signature.parameters.items() if v.default is not inspect.Parameter.empty}
-
-
-def get_latest_run(search_dir='.'):
- # Return path to most recent 'last.pt' in /runs (i.e. to --resume from)
- last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
- return max(last_list, key=os.path.getctime) if last_list else ''
-
-
-def file_age(path=__file__):
- # Return days since last file update
- dt = (datetime.now() - datetime.fromtimestamp(Path(path).stat().st_mtime)) # delta
- return dt.days # + dt.seconds / 86400 # fractional days
-
-
-def file_date(path=__file__):
- # Return human-readable file modification date, i.e. '2021-3-26'
- t = datetime.fromtimestamp(Path(path).stat().st_mtime)
- return f'{t.year}-{t.month}-{t.day}'
-
-
-def file_size(path):
- # Return file/dir size (MB)
- mb = 1 << 20 # bytes to MiB (1024 ** 2)
- path = Path(path)
- if path.is_file():
- return path.stat().st_size / mb
- elif path.is_dir():
- return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / mb
- else:
- return 0.0
-
-
-def check_online():
- # Check internet connectivity
- import socket
-
- def run_once():
- # Check once
- try:
- socket.create_connection(("1.1.1.1", 443), 5) # check host accessibility
- return True
- except OSError:
- return False
-
- return run_once() or run_once() # check twice to increase robustness to intermittent connectivity issues
-
-
-def git_describe(path=ROOT): # path must be a directory
- # Return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
- try:
- assert (Path(path) / '.git').is_dir()
- return check_output(f'git -C {path} describe --tags --long --always', shell=True).decode()[:-1]
- except Exception:
- return ''
-
-
-@TryExcept()
-@WorkingDirectory(ROOT)
-def check_git_status(repo='ultralytics/yolov5', branch='master'):
- # YOLOv5 status check, recommend 'git pull' if code is out of date
- url = f'https://github.com/{repo}'
- msg = f', for updates see {url}'
- s = colorstr('github: ') # string
- assert Path('.git').exists(), s + 'skipping check (not a git repository)' + msg
- assert check_online(), s + 'skipping check (offline)' + msg
-
- splits = re.split(pattern=r'\s', string=check_output('git remote -v', shell=True).decode())
- matches = [repo in s for s in splits]
- if any(matches):
- remote = splits[matches.index(True) - 1]
- else:
- remote = 'ultralytics'
- check_output(f'git remote add {remote} {url}', shell=True)
- check_output(f'git fetch {remote}', shell=True, timeout=5) # git fetch
- local_branch = check_output('git rev-parse --abbrev-ref HEAD', shell=True).decode().strip() # checked out
- n = int(check_output(f'git rev-list {local_branch}..{remote}/{branch} --count', shell=True)) # commits behind
- if n > 0:
- pull = 'git pull' if remote == 'origin' else f'git pull {remote} {branch}'
- s += f"⚠️ YOLOv5 is out of date by {n} commit{'s' * (n > 1)}. Use `{pull}` or `git clone {url}` to update."
- else:
- s += f'up to date with {url} ✅'
- LOGGER.info(s)
-
-
-@WorkingDirectory(ROOT)
-def check_git_info(path='.'):
- # YOLOv5 git info check, return {remote, branch, commit}
- check_requirements('gitpython')
- import git
- try:
- repo = git.Repo(path)
- remote = repo.remotes.origin.url.replace('.git', '') # i.e. 'https://github.com/ultralytics/yolov5'
- commit = repo.head.commit.hexsha # i.e. '3134699c73af83aac2a481435550b968d5792c0d'
- try:
- branch = repo.active_branch.name # i.e. 'main'
- except TypeError: # not on any branch
- branch = None # i.e. 'detached HEAD' state
- return {'remote': remote, 'branch': branch, 'commit': commit}
- except git.exc.InvalidGitRepositoryError: # path is not a git dir
- return {'remote': None, 'branch': None, 'commit': None}
-
-
-def check_python(minimum='3.7.0'):
- # Check current python version vs. required python version
- check_version(platform.python_version(), minimum, name='Python ', hard=True)
-
-
-def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False, hard=False, verbose=False):
- # Check version vs. required version
- current, minimum = (pkg.parse_version(x) for x in (current, minimum))
- result = (current == minimum) if pinned else (current >= minimum) # bool
- s = f'WARNING ⚠️ {name}{minimum} is required by YOLOv5, but {name}{current} is currently installed' # string
- if hard:
- assert result, emojis(s) # assert min requirements met
- if verbose and not result:
- LOGGER.warning(s)
- return result
-
-
-@TryExcept()
-def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), install=True, cmds=''):
- # Check installed dependencies meet YOLOv5 requirements (pass *.txt file or list of packages or single package str)
- prefix = colorstr('red', 'bold', 'requirements:')
- check_python() # check python version
- if isinstance(requirements, Path): # requirements.txt file
- file = requirements.resolve()
- assert file.exists(), f"{prefix} {file} not found, check failed."
- with file.open() as f:
- requirements = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements(f) if x.name not in exclude]
- elif isinstance(requirements, str):
- requirements = [requirements]
-
- s = ''
- n = 0
- for r in requirements:
- try:
- pkg.require(r)
- except (pkg.VersionConflict, pkg.DistributionNotFound): # exception if requirements not met
- s += f'"{r}" '
- n += 1
-
- if s and install and AUTOINSTALL: # check environment variable
- LOGGER.info(f"{prefix} YOLOv5 requirement{'s' * (n > 1)} {s}not found, attempting AutoUpdate...")
- try:
- # assert check_online(), "AutoUpdate skipped (offline)"
- LOGGER.info(check_output(f'pip install {s} {cmds}', shell=True).decode())
- source = file if 'file' in locals() else requirements
- s = f"{prefix} {n} package{'s' * (n > 1)} updated per {source}\n" \
- f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n"
- LOGGER.info(s)
- except Exception as e:
- LOGGER.warning(f'{prefix} ❌ {e}')
-
-
-def check_img_size(imgsz, s=32, floor=0):
- # Verify image size is a multiple of stride s in each dimension
- if isinstance(imgsz, int): # integer i.e. img_size=640
- new_size = max(make_divisible(imgsz, int(s)), floor)
- else: # list i.e. img_size=[640, 480]
- imgsz = list(imgsz) # convert to list if tuple
- new_size = [max(make_divisible(x, int(s)), floor) for x in imgsz]
- if new_size != imgsz:
- LOGGER.warning(f'WARNING ⚠️ --img-size {imgsz} must be multiple of max stride {s}, updating to {new_size}')
- return new_size
-
-
-def check_imshow(warn=False):
- # Check if environment supports image displays
- try:
- assert not is_notebook()
- assert not is_docker()
- cv2.imshow('test', np.zeros((1, 1, 3)))
- cv2.waitKey(1)
- cv2.destroyAllWindows()
- cv2.waitKey(1)
- return True
- except Exception as e:
- if warn:
- LOGGER.warning(f'WARNING ⚠️ Environment does not support cv2.imshow() or PIL Image.show()\n{e}')
- return False
-
-
-def check_suffix(file='yolov5s.pt', suffix=('.pt',), msg=''):
- # Check file(s) for acceptable suffix
- if file and suffix:
- if isinstance(suffix, str):
- suffix = [suffix]
- for f in file if isinstance(file, (list, tuple)) else [file]:
- s = Path(f).suffix.lower() # file suffix
- if len(s):
- assert s in suffix, f"{msg}{f} acceptable suffix is {suffix}"
-
-
-def check_yaml(file, suffix=('.yaml', '.yml')):
- # Search/download YAML file (if necessary) and return path, checking suffix
- return check_file(file, suffix)
-
-
-def check_file(file, suffix=''):
- # Search/download file (if necessary) and return path
- check_suffix(file, suffix) # optional
- file = str(file) # convert to str()
- if os.path.isfile(file) or not file: # exists
- return file
- elif file.startswith(('http:/', 'https:/')): # download
- url = file # warning: Pathlib turns :// -> :/
- file = Path(urllib.parse.unquote(file).split('?')[0]).name # '%2F' to '/', split https://url.com/file.txt?auth
- if os.path.isfile(file):
- LOGGER.info(f'Found {url} locally at {file}') # file already exists
- else:
- LOGGER.info(f'Downloading {url} to {file}...')
- torch.hub.download_url_to_file(url, file)
- assert Path(file).exists() and Path(file).stat().st_size > 0, f'File download failed: {url}' # check
- return file
- elif file.startswith('clearml://'): # ClearML Dataset ID
- assert 'clearml' in sys.modules, "ClearML is not installed, so cannot use ClearML dataset. Try running 'pip install clearml'."
- return file
- else: # search
- files = []
- for d in 'data', 'models', 'utils': # search directories
- files.extend(glob.glob(str(ROOT / d / '**' / file), recursive=True)) # find file
- assert len(files), f'File not found: {file}' # assert file was found
- assert len(files) == 1, f"Multiple files match '{file}', specify exact path: {files}" # assert unique
- return files[0] # return file
-
-
-def check_font(font=FONT, progress=False):
- # Download font to CONFIG_DIR if necessary
- font = Path(font)
- file = CONFIG_DIR / font.name
- if not font.exists() and not file.exists():
- url = f'https://ultralytics.com/assets/{font.name}'
- LOGGER.info(f'Downloading {url} to {file}...')
- torch.hub.download_url_to_file(url, str(file), progress=progress)
-
-
-def check_dataset(data, autodownload=True):
- # Download, check and/or unzip dataset if not found locally
-
- # Download (optional)
- extract_dir = ''
- if isinstance(data, (str, Path)) and (is_zipfile(data) or is_tarfile(data)):
- download(data, dir=f'{DATASETS_DIR}/{Path(data).stem}', unzip=True, delete=False, curl=False, threads=1)
- data = next((DATASETS_DIR / Path(data).stem).rglob('*.yaml'))
- extract_dir, autodownload = data.parent, False
-
- # Read yaml (optional)
- if isinstance(data, (str, Path)):
- data = yaml_load(data) # dictionary
-
- # Checks
- for k in 'train', 'val', 'names':
- assert k in data, emojis(f"data.yaml '{k}:' field missing ❌")
- if isinstance(data['names'], (list, tuple)): # old array format
- data['names'] = dict(enumerate(data['names'])) # convert to dict
- assert all(isinstance(k, int) for k in data['names'].keys()), 'data.yaml names keys must be integers, i.e. 2: car'
- data['nc'] = len(data['names'])
-
- # Resolve paths
- path = Path(extract_dir or data.get('path') or '') # optional 'path' default to '.'
- if not path.is_absolute():
- path = (ROOT / path).resolve()
- data['path'] = path # download scripts
- for k in 'train', 'val', 'test':
- if data.get(k): # prepend path
- if isinstance(data[k], str):
- x = (path / data[k]).resolve()
- if not x.exists() and data[k].startswith('../'):
- x = (path / data[k][3:]).resolve()
- data[k] = str(x)
- else:
- data[k] = [str((path / x).resolve()) for x in data[k]]
-
- # Parse yaml
- train, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))
- if val:
- val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
- if not all(x.exists() for x in val):
- LOGGER.info('\nDataset not found ⚠️, missing paths %s' % [str(x) for x in val if not x.exists()])
- if not s or not autodownload:
- raise Exception('Dataset not found ❌')
- t = time.time()
- if s.startswith('http') and s.endswith('.zip'): # URL
- f = Path(s).name # filename
- LOGGER.info(f'Downloading {s} to {f}...')
- torch.hub.download_url_to_file(s, f)
- Path(DATASETS_DIR).mkdir(parents=True, exist_ok=True) # create root
- unzip_file(f, path=DATASETS_DIR) # unzip
- Path(f).unlink() # remove zip
- r = None # success
- elif s.startswith('bash '): # bash script
- LOGGER.info(f'Running {s} ...')
- r = os.system(s)
- else: # python script
- r = exec(s, {'yaml': data}) # return None
- dt = f'({round(time.time() - t, 1)}s)'
- s = f"success ✅ {dt}, saved to {colorstr('bold', DATASETS_DIR)}" if r in (0, None) else f"failure {dt} ❌"
- LOGGER.info(f"Dataset download {s}")
- check_font('Arial.ttf' if is_ascii(data['names']) else 'Arial.Unicode.ttf', progress=True) # download fonts
- return data # dictionary
-
-
-def check_amp(model):
- # Check PyTorch Automatic Mixed Precision (AMP) functionality. Return True on correct operation
- from models.common import AutoShape, DetectMultiBackend
-
- def amp_allclose(model, im):
- # All close FP32 vs AMP results
- m = AutoShape(model, verbose=False) # model
- a = m(im).xywhn[0] # FP32 inference
- m.amp = True
- b = m(im).xywhn[0] # AMP inference
- return a.shape == b.shape and torch.allclose(a, b, atol=0.1) # close to 10% absolute tolerance
-
- prefix = colorstr('AMP: ')
- device = next(model.parameters()).device # get model device
- if device.type in ('cpu', 'mps'):
- return False # AMP only used on CUDA devices
- f = ROOT / 'data' / 'images' / 'bus.jpg' # image to check
- im = f if f.exists() else 'https://ultralytics.com/images/bus.jpg' if check_online() else np.ones((640, 640, 3))
- try:
- assert amp_allclose(deepcopy(model), im) or amp_allclose(DetectMultiBackend('yolov5n.pt', device), im)
- LOGGER.info(f'{prefix}checks passed ✅')
- return True
- except Exception:
- help_url = 'https://github.com/ultralytics/yolov5/issues/7908'
- LOGGER.warning(f'{prefix}checks failed ❌, disabling Automatic Mixed Precision. See {help_url}')
- return False
-
-
-def yaml_load(file='data.yaml'):
- # Single-line safe yaml loading
- with open(file, errors='ignore') as f:
- return yaml.safe_load(f)
-
-
-def yaml_save(file='data.yaml', data={}):
- # Single-line safe yaml saving
- with open(file, 'w') as f:
- yaml.safe_dump({k: str(v) if isinstance(v, Path) else v for k, v in data.items()}, f, sort_keys=False)
-
-
-def unzip_file(file, path=None, exclude=('.DS_Store', '__MACOSX')):
- # Unzip a *.zip file to path/, excluding files containing strings in exclude list
- if path is None:
- path = Path(file).parent # default path
- with ZipFile(file) as zipObj:
- for f in zipObj.namelist(): # list all archived filenames in the zip
- if all(x not in f for x in exclude):
- zipObj.extract(f, path=path)
-
-
-def url2file(url):
- # Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
- url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
- return Path(urllib.parse.unquote(url)).name.split('?')[0] # '%2F' to '/', split https://url.com/file.txt?auth
-
-
-def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1, retry=3):
- # Multithreaded file download and unzip function, used in data.yaml for autodownload
- def download_one(url, dir):
- # Download 1 file
- success = True
- if os.path.isfile(url):
- f = Path(url) # filename
- else: # does not exist
- f = dir / Path(url).name
- LOGGER.info(f'Downloading {url} to {f}...')
- for i in range(retry + 1):
- if curl:
- s = 'sS' if threads > 1 else '' # silent
- r = os.system(
- f'curl -# -{s}L "{url}" -o "{f}" --retry 9 -C -') # curl download with retry, continue
- success = r == 0
- else:
- torch.hub.download_url_to_file(url, f, progress=threads == 1) # torch download
- success = f.is_file()
- if success:
- break
- elif i < retry:
- LOGGER.warning(f'⚠️ Download failure, retrying {i + 1}/{retry} {url}...')
- else:
- LOGGER.warning(f'❌ Failed to download {url}...')
-
- if unzip and success and (f.suffix == '.gz' or is_zipfile(f) or is_tarfile(f)):
- LOGGER.info(f'Unzipping {f}...')
- if is_zipfile(f):
- unzip_file(f, dir) # unzip
- elif is_tarfile(f):
- os.system(f'tar xf {f} --directory {f.parent}') # unzip
- elif f.suffix == '.gz':
- os.system(f'tar xfz {f} --directory {f.parent}') # unzip
- if delete:
- f.unlink() # remove zip
-
- dir = Path(dir)
- dir.mkdir(parents=True, exist_ok=True) # make directory
- if threads > 1:
- pool = ThreadPool(threads)
- pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multithreaded
- pool.close()
- pool.join()
- else:
- for u in [url] if isinstance(url, (str, Path)) else url:
- download_one(u, dir)
-
-
-def make_divisible(x, divisor):
- # Returns nearest x divisible by divisor
- if isinstance(divisor, torch.Tensor):
- divisor = int(divisor.max()) # to int
- return math.ceil(x / divisor) * divisor
-
-
-def clean_str(s):
- # Cleans a string by replacing special characters with underscore _
- return re.sub(pattern="[|@#!¡·$€%&()=?¿^*;:,¨´><+]", repl="_", string=s)
-
-
-def one_cycle(y1=0.0, y2=1.0, steps=100):
- # lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf
- return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
-
-
-def colorstr(*input):
- # Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
- *args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
- colors = {
- 'black': '\033[30m', # basic colors
- 'red': '\033[31m',
- 'green': '\033[32m',
- 'yellow': '\033[33m',
- 'blue': '\033[34m',
- 'magenta': '\033[35m',
- 'cyan': '\033[36m',
- 'white': '\033[37m',
- 'bright_black': '\033[90m', # bright colors
- 'bright_red': '\033[91m',
- 'bright_green': '\033[92m',
- 'bright_yellow': '\033[93m',
- 'bright_blue': '\033[94m',
- 'bright_magenta': '\033[95m',
- 'bright_cyan': '\033[96m',
- 'bright_white': '\033[97m',
- 'end': '\033[0m', # misc
- 'bold': '\033[1m',
- 'underline': '\033[4m'}
- return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
-
-
-def labels_to_class_weights(labels, nc=80):
- # Get class weights (inverse frequency) from training labels
- if labels[0] is None: # no labels loaded
- return torch.Tensor()
-
- labels = np.concatenate(labels, 0) # labels.shape = (866643, 5) for COCO
- classes = labels[:, 0].astype(int) # labels = [class xywh]
- weights = np.bincount(classes, minlength=nc) # occurrences per class
-
- # Prepend gridpoint count (for uCE training)
- # gpi = ((320 / 32 * np.array([1, 2, 4])) ** 2 * 3).sum() # gridpoints per image
- # weights = np.hstack([gpi * len(labels) - weights.sum() * 9, weights * 9]) ** 0.5 # prepend gridpoints to start
-
- weights[weights == 0] = 1 # replace empty bins with 1
- weights = 1 / weights # number of targets per class
- weights /= weights.sum() # normalize
- return torch.from_numpy(weights).float()
-
-
-def labels_to_image_weights(labels, nc=80, class_weights=np.ones(80)):
- # Produces image weights based on class_weights and image contents
- # Usage: index = random.choices(range(n), weights=image_weights, k=1) # weighted image sample
- class_counts = np.array([np.bincount(x[:, 0].astype(int), minlength=nc) for x in labels])
- return (class_weights.reshape(1, nc) * class_counts).sum(1)
-
-
-def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
- # https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
- # a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
- # b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
- # x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
- # x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
- return [
- 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
- 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
- 64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
-
-
-def xyxy2xywh(x):
- # Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
- y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
- y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
- y[:, 2] = x[:, 2] - x[:, 0] # width
- y[:, 3] = x[:, 3] - x[:, 1] # height
- return y
-
-
-def xywh2xyxy(x):
- # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
- y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
- y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
- y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
- y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
- return y
-
-
-def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
- # Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
- y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x
- y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
- y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
- y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
- return y
-
-
-def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
- # Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
- if clip:
- clip_boxes(x, (h - eps, w - eps)) # warning: inplace clip
- y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
- y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
- y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
- y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
- return y
-
-
-def xyn2xy(x, w=640, h=640, padw=0, padh=0):
- # Convert normalized segments into pixel segments, shape (n,2)
- y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
- y[:, 0] = w * x[:, 0] + padw # top left x
- y[:, 1] = h * x[:, 1] + padh # top left y
- return y
-
-
-def segment2box(segment, width=640, height=640):
- # Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
- x, y = segment.T # segment xy
- inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
- x, y, = x[inside], y[inside]
- return np.array([x.min(), y.min(), x.max(), y.max()]) if any(x) else np.zeros((1, 4)) # xyxy
-
-
-def segments2boxes(segments):
- # Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
- boxes = []
- for s in segments:
- x, y = s.T # segment xy
- boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
- return xyxy2xywh(np.array(boxes)) # cls, xywh
-
-
-def resample_segments(segments, n=1000):
- # Up-sample an (n,2) segment
- for i, s in enumerate(segments):
- s = np.concatenate((s, s[0:1, :]), axis=0)
- x = np.linspace(0, len(s) - 1, n)
- xp = np.arange(len(s))
- segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)]).reshape(2, -1).T # segment xy
- return segments
-
-
-def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None):
- # Rescale boxes (xyxy) from img1_shape to img0_shape
- if ratio_pad is None: # calculate from img0_shape
- gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
- pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
- else:
- gain = ratio_pad[0][0]
- pad = ratio_pad[1]
-
- boxes[:, [0, 2]] -= pad[0] # x padding
- boxes[:, [1, 3]] -= pad[1] # y padding
- boxes[:, :4] /= gain
- clip_boxes(boxes, img0_shape)
- return boxes
-
-
-def scale_segments(img1_shape, segments, img0_shape, ratio_pad=None, normalize=False):
- # Rescale coords (xyxy) from img1_shape to img0_shape
- if ratio_pad is None: # calculate from img0_shape
- gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
- pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
- else:
- gain = ratio_pad[0][0]
- pad = ratio_pad[1]
-
- segments[:, 0] -= pad[0] # x padding
- segments[:, 1] -= pad[1] # y padding
- segments /= gain
- clip_segments(segments, img0_shape)
- if normalize:
- segments[:, 0] /= img0_shape[1] # width
- segments[:, 1] /= img0_shape[0] # height
- return segments
-
-
-def clip_boxes(boxes, shape):
- # Clip boxes (xyxy) to image shape (height, width)
- if isinstance(boxes, torch.Tensor): # faster individually
- boxes[:, 0].clamp_(0, shape[1]) # x1
- boxes[:, 1].clamp_(0, shape[0]) # y1
- boxes[:, 2].clamp_(0, shape[1]) # x2
- boxes[:, 3].clamp_(0, shape[0]) # y2
- else: # np.array (faster grouped)
- boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
- boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
-
-
-def clip_segments(segments, shape):
- # Clip segments (xy1,xy2,...) to image shape (height, width)
- if isinstance(segments, torch.Tensor): # faster individually
- segments[:, 0].clamp_(0, shape[1]) # x
- segments[:, 1].clamp_(0, shape[0]) # y
- else: # np.array (faster grouped)
- segments[:, 0] = segments[:, 0].clip(0, shape[1]) # x
- segments[:, 1] = segments[:, 1].clip(0, shape[0]) # y
-
-
-def non_max_suppression(
- prediction,
- conf_thres=0.25,
- iou_thres=0.45,
- classes=None,
- agnostic=False,
- multi_label=False,
- labels=(),
- max_det=300,
- nm=0, # number of masks
-):
- """Non-Maximum Suppression (NMS) on inference results to reject overlapping detections
-
- Returns:
- list of detections, on (n,6) tensor per image [xyxy, conf, cls]
- """
-
- if isinstance(prediction, (list, tuple)): # YOLOv5 model in validation model, output = (inference_out, loss_out)
- prediction = prediction[0] # select only inference output
-
- device = prediction.device
- mps = 'mps' in device.type # Apple MPS
- if mps: # MPS not fully supported yet, convert tensors to CPU before NMS
- prediction = prediction.cpu()
- bs = prediction.shape[0] # batch size
- nc = prediction.shape[2] - nm - 5 # number of classes
- xc = prediction[..., 4] > conf_thres # candidates
-
- # Checks
- assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
- assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
-
- # Settings
- # min_wh = 2 # (pixels) minimum box width and height
- max_wh = 7680 # (pixels) maximum box width and height
- max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
- time_limit = 0.5 + 0.05 * bs # seconds to quit after
- redundant = True # require redundant detections
- multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
- merge = False # use merge-NMS
-
- t = time.time()
- mi = 5 + nc # mask start index
- output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
- for xi, x in enumerate(prediction): # image index, image inference
- # Apply constraints
- # x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
- x = x[xc[xi]] # confidence
-
- # Cat apriori labels if autolabelling
- if labels and len(labels[xi]):
- lb = labels[xi]
- v = torch.zeros((len(lb), nc + nm + 5), device=x.device)
- v[:, :4] = lb[:, 1:5] # box
- v[:, 4] = 1.0 # conf
- v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
- x = torch.cat((x, v), 0)
-
- # If none remain process next image
- if not x.shape[0]:
- continue
-
- # Compute conf
- x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
-
- # Box/Mask
- box = xywh2xyxy(x[:, :4]) # center_x, center_y, width, height) to (x1, y1, x2, y2)
- mask = x[:, mi:] # zero columns if no masks
-
- # Detections matrix nx6 (xyxy, conf, cls)
- if multi_label:
- i, j = (x[:, 5:mi] > conf_thres).nonzero(as_tuple=False).T
- x = torch.cat((box[i], x[i, 5 + j, None], j[:, None].float(), mask[i]), 1)
- else: # best class only
- conf, j = x[:, 5:mi].max(1, keepdim=True)
- x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
-
- # Filter by class
- if classes is not None:
- x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
-
- # Apply finite constraint
- # if not torch.isfinite(x).all():
- # x = x[torch.isfinite(x).all(1)]
-
- # Check shape
- n = x.shape[0] # number of boxes
- if not n: # no boxes
- continue
- elif n > max_nms: # excess boxes
- x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
- else:
- x = x[x[:, 4].argsort(descending=True)] # sort by confidence
-
- # Batched NMS
- c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
- boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
- i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
- if i.shape[0] > max_det: # limit detections
- i = i[:max_det]
- if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
- # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
- iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
- weights = iou * scores[None] # box weights
- x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
- if redundant:
- i = i[iou.sum(1) > 1] # require redundancy
-
- output[xi] = x[i]
- if mps:
- output[xi] = output[xi].to(device)
- if (time.time() - t) > time_limit:
- LOGGER.warning(f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded')
- break # time limit exceeded
-
- return output
-
-
-def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_optimizer()
- # Strip optimizer from 'f' to finalize training, optionally save as 's'
- x = torch.load(f, map_location=torch.device('cpu'))
- if x.get('ema'):
- x['model'] = x['ema'] # replace model with ema
- for k in 'optimizer', 'best_fitness', 'ema', 'updates': # keys
- x[k] = None
- x['epoch'] = -1
- x['model'].half() # to FP16
- for p in x['model'].parameters():
- p.requires_grad = False
- torch.save(x, s or f)
- mb = os.path.getsize(s or f) / 1E6 # filesize
- LOGGER.info(f"Optimizer stripped from {f},{f' saved as {s},' if s else ''} {mb:.1f}MB")
-
-
-def print_mutation(keys, results, hyp, save_dir, bucket, prefix=colorstr('evolve: ')):
- evolve_csv = save_dir / 'evolve.csv'
- evolve_yaml = save_dir / 'hyp_evolve.yaml'
- keys = tuple(keys) + tuple(hyp.keys()) # [results + hyps]
- keys = tuple(x.strip() for x in keys)
- vals = results + tuple(hyp.values())
- n = len(keys)
-
- # Download (optional)
- if bucket:
- url = f'gs://{bucket}/evolve.csv'
- if gsutil_getsize(url) > (evolve_csv.stat().st_size if evolve_csv.exists() else 0):
- os.system(f'gsutil cp {url} {save_dir}') # download evolve.csv if larger than local
-
- # Log to evolve.csv
- s = '' if evolve_csv.exists() else (('%20s,' * n % keys).rstrip(',') + '\n') # add header
- with open(evolve_csv, 'a') as f:
- f.write(s + ('%20.5g,' * n % vals).rstrip(',') + '\n')
-
- # Save yaml
- with open(evolve_yaml, 'w') as f:
- data = pd.read_csv(evolve_csv)
- data = data.rename(columns=lambda x: x.strip()) # strip keys
- i = np.argmax(fitness(data.values[:, :4])) #
- generations = len(data)
- f.write('# YOLOv5 Hyperparameter Evolution Results\n' + f'# Best generation: {i}\n' +
- f'# Last generation: {generations - 1}\n' + '# ' + ', '.join(f'{x.strip():>20s}' for x in keys[:7]) +
- '\n' + '# ' + ', '.join(f'{x:>20.5g}' for x in data.values[i, :7]) + '\n\n')
- yaml.safe_dump(data.loc[i][7:].to_dict(), f, sort_keys=False)
-
- # Print to screen
- LOGGER.info(prefix + f'{generations} generations finished, current result:\n' + prefix +
- ', '.join(f'{x.strip():>20s}' for x in keys) + '\n' + prefix + ', '.join(f'{x:20.5g}'
- for x in vals) + '\n\n')
-
- if bucket:
- os.system(f'gsutil cp {evolve_csv} {evolve_yaml} gs://{bucket}') # upload
-
-
-def apply_classifier(x, model, img, im0):
- # Apply a second stage classifier to YOLO outputs
- # Example model = torchvision.models.__dict__['efficientnet_b0'](pretrained=True).to(device).eval()
- im0 = [im0] if isinstance(im0, np.ndarray) else im0
- for i, d in enumerate(x): # per image
- if d is not None and len(d):
- d = d.clone()
-
- # Reshape and pad cutouts
- b = xyxy2xywh(d[:, :4]) # boxes
- b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # rectangle to square
- b[:, 2:] = b[:, 2:] * 1.3 + 30 # pad
- d[:, :4] = xywh2xyxy(b).long()
-
- # Rescale boxes from img_size to im0 size
- scale_boxes(img.shape[2:], d[:, :4], im0[i].shape)
-
- # Classes
- pred_cls1 = d[:, 5].long()
- ims = []
- for a in d:
- cutout = im0[i][int(a[1]):int(a[3]), int(a[0]):int(a[2])]
- im = cv2.resize(cutout, (224, 224)) # BGR
-
- im = im[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
- im = np.ascontiguousarray(im, dtype=np.float32) # uint8 to float32
- im /= 255 # 0 - 255 to 0.0 - 1.0
- ims.append(im)
-
- pred_cls2 = model(torch.Tensor(ims).to(d.device)).argmax(1) # classifier prediction
- x[i] = x[i][pred_cls1 == pred_cls2] # retain matching class detections
-
- return x
-
-
-def increment_path(path, exist_ok=False, sep='', mkdir=False):
- # Increment file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
- path = Path(path) # os-agnostic
- if path.exists() and not exist_ok:
- path, suffix = (path.with_suffix(''), path.suffix) if path.is_file() else (path, '')
-
- # Method 1
- for n in range(2, 9999):
- p = f'{path}{sep}{n}{suffix}' # increment path
- if not os.path.exists(p): #
- break
- path = Path(p)
-
- # Method 2 (deprecated)
- # dirs = glob.glob(f"{path}{sep}*") # similar paths
- # matches = [re.search(rf"{path.stem}{sep}(\d+)", d) for d in dirs]
- # i = [int(m.groups()[0]) for m in matches if m] # indices
- # n = max(i) + 1 if i else 2 # increment number
- # path = Path(f"{path}{sep}{n}{suffix}") # increment path
-
- if mkdir:
- path.mkdir(parents=True, exist_ok=True) # make directory
-
- return path
-
-
-# OpenCV Chinese-friendly functions ------------------------------------------------------------------------------------
-imshow_ = cv2.imshow # copy to avoid recursion errors
-
-
-def imread(path, flags=cv2.IMREAD_COLOR):
- return cv2.imdecode(np.fromfile(path, np.uint8), flags)
-
-
-def imwrite(path, im):
- try:
- cv2.imencode(Path(path).suffix, im)[1].tofile(path)
- return True
- except Exception:
- return False
-
-
-def imshow(path, im):
- imshow_(path.encode('unicode_escape').decode(), im)
-
-
-cv2.imread, cv2.imwrite, cv2.imshow = imread, imwrite, imshow # redefine
-
-# Variables ------------------------------------------------------------------------------------------------------------
diff --git a/spaces/Illia56/Chat-with-Youtube-video-Mistal-7b/app.py b/spaces/Illia56/Chat-with-Youtube-video-Mistal-7b/app.py
deleted file mode 100644
index 72c23e912c592109e2bcb6bd42db7998e03fb8e7..0000000000000000000000000000000000000000
--- a/spaces/Illia56/Chat-with-Youtube-video-Mistal-7b/app.py
+++ /dev/null
@@ -1,171 +0,0 @@
-import os
-import logging
-from typing import Any, List, Mapping, Optional
-from langchain.llms import HuggingFaceHub
-from gradio_client import Client
-from langchain.schema import Document
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-from langchain.vectorstores import FAISS
-from langchain.embeddings.huggingface import HuggingFaceEmbeddings
-from langchain.callbacks.manager import CallbackManagerForLLMRun
-from langchain.llms.base import LLM
-from langchain.chains import RetrievalQA
-from langchain.prompts import PromptTemplate
-import streamlit as st
-from pytube import YouTube
-# import replicate
-
-
-
-
-
-
-DESCRIPTION = """
-Welcome to the **YouTube Video Chatbot** powered by the state-of-the-art Llama-2-70b model. Here's what you can do:
-- **Transcribe & Understand**: Provide any YouTube video URL, and our system will transcribe it. Our advanced NLP model will then understand the content, ready to answer your questions.
-- **Ask Anything**: Based on the video's content, ask any question, and get instant, context-aware answers.
-To get started, simply paste a YouTube video URL in the sidebar and start chatting with the model about the video's content. Enjoy the experience!
-"""
-st.title("YouTube Video Chatbot")
-st.markdown(DESCRIPTION)
-
-def get_video_title(youtube_url: str) -> str:
- yt = YouTube(youtube_url)
- embed_url = f"https://www.youtube.com/embed/{yt.video_id}"
- embed_html = f''
- return yt.title, embed_html
-
-
-def transcribe_video(youtube_url: str, path: str) -> List[Document]:
- """
- Transcribe a video and return its content as a Document.
- """
- logging.info(f"Transcribing video: {youtube_url}")
- client = Client("https://sanchit-gandhi-whisper-jax.hf.space/")
- result = client.predict(youtube_url, "translate", True, api_name="/predict_2")
- return [Document(page_content=result[1], metadata=dict(page=1))]
-
-def predict(message: str, system_prompt: str = '', temperature: float = 0.7, max_new_tokens: int = 1024,
- topp: float = 0.5, repetition_penalty: float = 1.2) -> Any:
- """
- Predict a response using a client.
- """
- client = Client("https://osanseviero-mistral-super-fast.hf.space/")
- response = client.predict(
- message,
- temperature,
- max_new_tokens,
- topp,
- repetition_penalty,
- api_name="/chat"
- )
- return response
-
-PATH = os.path.join(os.path.expanduser("~"), "Data")
-
-def initialize_session_state():
- if "youtube_url" not in st.session_state:
- st.session_state.youtube_url = ""
- if "setup_done" not in st.session_state: # Initialize the setup_done flag
- st.session_state.setup_done = False
- if "doneYoutubeurl" not in st.session_state:
- st.session_state.doneYoutubeurl = ""
-
-def sidebar():
- with st.sidebar:
- st.markdown("Enter the YouTube Video URL below🔗\n")
- st.session_state.youtube_url = st.text_input("YouTube Video URL:")
-
-
- if st.session_state.youtube_url:
- # Get the video title
- video_title, embed_html = get_video_title(st.session_state.youtube_url)
- st.markdown(f"### {video_title}")
-
- # Embed the video
- st.markdown(
- embed_html,
- unsafe_allow_html=True
- )
-
- # system_promptSide = st.text_input("Optional system prompt:")
- # temperatureSide = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.9, step=0.05)
- # max_new_tokensSide = st.slider("Max new tokens", min_value=0.0, max_value=4096.0, value=4096.0, step=64.0)
- # ToppSide = st.slider("Top-p (nucleus sampling)", min_value=0.0, max_value=1.0, value=0.6, step=0.05)
- # RepetitionpenaltySide = st.slider("Repetition penalty", min_value=0.0, max_value=2.0, value=1.2, step=0.05)
-
-
-sidebar()
-initialize_session_state()
-
-text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
-embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-l6-v2")
-
-prompt = PromptTemplate(
- template="""Given the context about a video. Answer the user in a friendly and precise manner.
- Context: {context}
- Human: {question}
- AI:""",
- input_variables=["context", "question"]
-)
-
-class LlamaLLM(LLM):
- """
- Custom LLM class.
- """
-
- @property
- def _llm_type(self) -> str:
- return "custom"
-
- def _call(self, prompt: str, stop: Optional[List[str]] = None,
- run_manager: Optional[CallbackManagerForLLMRun] = None) -> str:
- response = predict(prompt)
- return response
-
- @property
- def _identifying_params(self) -> Mapping[str, Any]:
- """Get the identifying parameters."""
- return {}
-
-
-# Check if a new YouTube URL is provided
-if st.session_state.youtube_url != st.session_state.doneYoutubeurl:
- st.session_state.setup_done = False
-
-if st.session_state.youtube_url and not st.session_state.setup_done :
- with st.status("Transcribing video..."):
- data = transcribe_video(st.session_state.youtube_url, PATH)
-
- with st.status("Running Embeddings..."):
- docs = text_splitter.split_documents(data)
-
- docsearch = FAISS.from_documents(docs, embeddings)
- retriever = docsearch.as_retriever()
- retriever.search_kwargs['distance_metric'] = 'cos'
- retriever.search_kwargs['k'] = 4
- with st.status("Running RetrievalQA..."):
- llama_instance = LlamaLLM()
- st.session_state.qa = RetrievalQA.from_chain_type(llm=llama_instance, chain_type="stuff", retriever=retriever,chain_type_kwargs={"prompt": prompt})
-
- st.session_state.doneYoutubeurl = st.session_state.youtube_url
- st.session_state.setup_done = True # Mark the setup as done for this URL
-
-if "messages" not in st.session_state:
- st.session_state.messages = []
-
-for message in st.session_state.messages:
- with st.chat_message(message["role"], avatar=("🧑💻" if message["role"] == 'human' else '🦙')):
- st.markdown(message["content"])
-
-textinput = st.chat_input("Ask LLama-2-70b anything about the video...")
-
-if prompt := textinput:
- st.chat_message("human",avatar = "🧑💻").markdown(prompt)
- st.session_state.messages.append({"role": "human", "content": prompt})
- with st.status("Requesting Client..."):
- response = st.session_state.qa.run(prompt)
- with st.chat_message("assistant", avatar='🦙'):
- st.markdown(response)
- # Add assistant response to chat history
- st.session_state.messages.append({"role": "assistant", "content": response})
\ No newline at end of file
diff --git a/spaces/Illumotion/Koboldcpp/include/CL/Utils/Context.hpp b/spaces/Illumotion/Koboldcpp/include/CL/Utils/Context.hpp
deleted file mode 100644
index bd1110c342aa52de97eb29c88196a2770bb22258..0000000000000000000000000000000000000000
--- a/spaces/Illumotion/Koboldcpp/include/CL/Utils/Context.hpp
+++ /dev/null
@@ -1,17 +0,0 @@
-#pragma once
-
-// OpenCL SDK includes
-#include "OpenCLUtilsCpp_Export.h"
-
-#include
-
-// OpenCL includes
-#include
-
-namespace cl {
-namespace util {
- Context UTILSCPP_EXPORT get_context(cl_uint plat_id, cl_uint dev_id,
- cl_device_type type,
- cl_int* error = nullptr);
-}
-}
diff --git a/spaces/Iqbalzz/hololive-rvc-models/infer_pack/transforms.py b/spaces/Iqbalzz/hololive-rvc-models/infer_pack/transforms.py
deleted file mode 100644
index a11f799e023864ff7082c1f49c0cc18351a13b47..0000000000000000000000000000000000000000
--- a/spaces/Iqbalzz/hololive-rvc-models/infer_pack/transforms.py
+++ /dev/null
@@ -1,209 +0,0 @@
-import torch
-from torch.nn import functional as F
-
-import numpy as np
-
-
-DEFAULT_MIN_BIN_WIDTH = 1e-3
-DEFAULT_MIN_BIN_HEIGHT = 1e-3
-DEFAULT_MIN_DERIVATIVE = 1e-3
-
-
-def piecewise_rational_quadratic_transform(
- inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails=None,
- tail_bound=1.0,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE,
-):
- if tails is None:
- spline_fn = rational_quadratic_spline
- spline_kwargs = {}
- else:
- spline_fn = unconstrained_rational_quadratic_spline
- spline_kwargs = {"tails": tails, "tail_bound": tail_bound}
-
- outputs, logabsdet = spline_fn(
- inputs=inputs,
- unnormalized_widths=unnormalized_widths,
- unnormalized_heights=unnormalized_heights,
- unnormalized_derivatives=unnormalized_derivatives,
- inverse=inverse,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative,
- **spline_kwargs
- )
- return outputs, logabsdet
-
-
-def searchsorted(bin_locations, inputs, eps=1e-6):
- bin_locations[..., -1] += eps
- return torch.sum(inputs[..., None] >= bin_locations, dim=-1) - 1
-
-
-def unconstrained_rational_quadratic_spline(
- inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails="linear",
- tail_bound=1.0,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE,
-):
- inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
- outside_interval_mask = ~inside_interval_mask
-
- outputs = torch.zeros_like(inputs)
- logabsdet = torch.zeros_like(inputs)
-
- if tails == "linear":
- unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
- constant = np.log(np.exp(1 - min_derivative) - 1)
- unnormalized_derivatives[..., 0] = constant
- unnormalized_derivatives[..., -1] = constant
-
- outputs[outside_interval_mask] = inputs[outside_interval_mask]
- logabsdet[outside_interval_mask] = 0
- else:
- raise RuntimeError("{} tails are not implemented.".format(tails))
-
- (
- outputs[inside_interval_mask],
- logabsdet[inside_interval_mask],
- ) = rational_quadratic_spline(
- inputs=inputs[inside_interval_mask],
- unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
- unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
- unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
- inverse=inverse,
- left=-tail_bound,
- right=tail_bound,
- bottom=-tail_bound,
- top=tail_bound,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative,
- )
-
- return outputs, logabsdet
-
-
-def rational_quadratic_spline(
- inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- left=0.0,
- right=1.0,
- bottom=0.0,
- top=1.0,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE,
-):
- if torch.min(inputs) < left or torch.max(inputs) > right:
- raise ValueError("Input to a transform is not within its domain")
-
- num_bins = unnormalized_widths.shape[-1]
-
- if min_bin_width * num_bins > 1.0:
- raise ValueError("Minimal bin width too large for the number of bins")
- if min_bin_height * num_bins > 1.0:
- raise ValueError("Minimal bin height too large for the number of bins")
-
- widths = F.softmax(unnormalized_widths, dim=-1)
- widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
- cumwidths = torch.cumsum(widths, dim=-1)
- cumwidths = F.pad(cumwidths, pad=(1, 0), mode="constant", value=0.0)
- cumwidths = (right - left) * cumwidths + left
- cumwidths[..., 0] = left
- cumwidths[..., -1] = right
- widths = cumwidths[..., 1:] - cumwidths[..., :-1]
-
- derivatives = min_derivative + F.softplus(unnormalized_derivatives)
-
- heights = F.softmax(unnormalized_heights, dim=-1)
- heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
- cumheights = torch.cumsum(heights, dim=-1)
- cumheights = F.pad(cumheights, pad=(1, 0), mode="constant", value=0.0)
- cumheights = (top - bottom) * cumheights + bottom
- cumheights[..., 0] = bottom
- cumheights[..., -1] = top
- heights = cumheights[..., 1:] - cumheights[..., :-1]
-
- if inverse:
- bin_idx = searchsorted(cumheights, inputs)[..., None]
- else:
- bin_idx = searchsorted(cumwidths, inputs)[..., None]
-
- input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
- input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
-
- input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
- delta = heights / widths
- input_delta = delta.gather(-1, bin_idx)[..., 0]
-
- input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
- input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
-
- input_heights = heights.gather(-1, bin_idx)[..., 0]
-
- if inverse:
- a = (inputs - input_cumheights) * (
- input_derivatives + input_derivatives_plus_one - 2 * input_delta
- ) + input_heights * (input_delta - input_derivatives)
- b = input_heights * input_derivatives - (inputs - input_cumheights) * (
- input_derivatives + input_derivatives_plus_one - 2 * input_delta
- )
- c = -input_delta * (inputs - input_cumheights)
-
- discriminant = b.pow(2) - 4 * a * c
- assert (discriminant >= 0).all()
-
- root = (2 * c) / (-b - torch.sqrt(discriminant))
- outputs = root * input_bin_widths + input_cumwidths
-
- theta_one_minus_theta = root * (1 - root)
- denominator = input_delta + (
- (input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta
- )
- derivative_numerator = input_delta.pow(2) * (
- input_derivatives_plus_one * root.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - root).pow(2)
- )
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, -logabsdet
- else:
- theta = (inputs - input_cumwidths) / input_bin_widths
- theta_one_minus_theta = theta * (1 - theta)
-
- numerator = input_heights * (
- input_delta * theta.pow(2) + input_derivatives * theta_one_minus_theta
- )
- denominator = input_delta + (
- (input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta
- )
- outputs = input_cumheights + numerator / denominator
-
- derivative_numerator = input_delta.pow(2) * (
- input_derivatives_plus_one * theta.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - theta).pow(2)
- )
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, logabsdet
diff --git a/spaces/Jamkonams/AutoGPT/autogpt/agent/__init__.py b/spaces/Jamkonams/AutoGPT/autogpt/agent/__init__.py
deleted file mode 100644
index e928af2205b1c52d19dc89ec4246e8c1d2c20e3f..0000000000000000000000000000000000000000
--- a/spaces/Jamkonams/AutoGPT/autogpt/agent/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-from autogpt.agent.agent import Agent
-from autogpt.agent.agent_manager import AgentManager
-
-__all__ = ["Agent", "AgentManager"]
diff --git a/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/detection/retinaface/retinaface_net.py b/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/detection/retinaface/retinaface_net.py
deleted file mode 100644
index ab6aa82d3e9055a838f1f9076b12f05fdfc154d0..0000000000000000000000000000000000000000
--- a/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/detection/retinaface/retinaface_net.py
+++ /dev/null
@@ -1,196 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-
-def conv_bn(inp, oup, stride=1, leaky=0):
- return nn.Sequential(
- nn.Conv2d(inp, oup, 3, stride, 1, bias=False), nn.BatchNorm2d(oup),
- nn.LeakyReLU(negative_slope=leaky, inplace=True))
-
-
-def conv_bn_no_relu(inp, oup, stride):
- return nn.Sequential(
- nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
- nn.BatchNorm2d(oup),
- )
-
-
-def conv_bn1X1(inp, oup, stride, leaky=0):
- return nn.Sequential(
- nn.Conv2d(inp, oup, 1, stride, padding=0, bias=False), nn.BatchNorm2d(oup),
- nn.LeakyReLU(negative_slope=leaky, inplace=True))
-
-
-def conv_dw(inp, oup, stride, leaky=0.1):
- return nn.Sequential(
- nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
- nn.BatchNorm2d(inp),
- nn.LeakyReLU(negative_slope=leaky, inplace=True),
- nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
- nn.BatchNorm2d(oup),
- nn.LeakyReLU(negative_slope=leaky, inplace=True),
- )
-
-
-class SSH(nn.Module):
-
- def __init__(self, in_channel, out_channel):
- super(SSH, self).__init__()
- assert out_channel % 4 == 0
- leaky = 0
- if (out_channel <= 64):
- leaky = 0.1
- self.conv3X3 = conv_bn_no_relu(in_channel, out_channel // 2, stride=1)
-
- self.conv5X5_1 = conv_bn(in_channel, out_channel // 4, stride=1, leaky=leaky)
- self.conv5X5_2 = conv_bn_no_relu(out_channel // 4, out_channel // 4, stride=1)
-
- self.conv7X7_2 = conv_bn(out_channel // 4, out_channel // 4, stride=1, leaky=leaky)
- self.conv7x7_3 = conv_bn_no_relu(out_channel // 4, out_channel // 4, stride=1)
-
- def forward(self, input):
- conv3X3 = self.conv3X3(input)
-
- conv5X5_1 = self.conv5X5_1(input)
- conv5X5 = self.conv5X5_2(conv5X5_1)
-
- conv7X7_2 = self.conv7X7_2(conv5X5_1)
- conv7X7 = self.conv7x7_3(conv7X7_2)
-
- out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
- out = F.relu(out)
- return out
-
-
-class FPN(nn.Module):
-
- def __init__(self, in_channels_list, out_channels):
- super(FPN, self).__init__()
- leaky = 0
- if (out_channels <= 64):
- leaky = 0.1
- self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride=1, leaky=leaky)
- self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride=1, leaky=leaky)
- self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride=1, leaky=leaky)
-
- self.merge1 = conv_bn(out_channels, out_channels, leaky=leaky)
- self.merge2 = conv_bn(out_channels, out_channels, leaky=leaky)
-
- def forward(self, input):
- # names = list(input.keys())
- # input = list(input.values())
-
- output1 = self.output1(input[0])
- output2 = self.output2(input[1])
- output3 = self.output3(input[2])
-
- up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode='nearest')
- output2 = output2 + up3
- output2 = self.merge2(output2)
-
- up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode='nearest')
- output1 = output1 + up2
- output1 = self.merge1(output1)
-
- out = [output1, output2, output3]
- return out
-
-
-class MobileNetV1(nn.Module):
-
- def __init__(self):
- super(MobileNetV1, self).__init__()
- self.stage1 = nn.Sequential(
- conv_bn(3, 8, 2, leaky=0.1), # 3
- conv_dw(8, 16, 1), # 7
- conv_dw(16, 32, 2), # 11
- conv_dw(32, 32, 1), # 19
- conv_dw(32, 64, 2), # 27
- conv_dw(64, 64, 1), # 43
- )
- self.stage2 = nn.Sequential(
- conv_dw(64, 128, 2), # 43 + 16 = 59
- conv_dw(128, 128, 1), # 59 + 32 = 91
- conv_dw(128, 128, 1), # 91 + 32 = 123
- conv_dw(128, 128, 1), # 123 + 32 = 155
- conv_dw(128, 128, 1), # 155 + 32 = 187
- conv_dw(128, 128, 1), # 187 + 32 = 219
- )
- self.stage3 = nn.Sequential(
- conv_dw(128, 256, 2), # 219 +3 2 = 241
- conv_dw(256, 256, 1), # 241 + 64 = 301
- )
- self.avg = nn.AdaptiveAvgPool2d((1, 1))
- self.fc = nn.Linear(256, 1000)
-
- def forward(self, x):
- x = self.stage1(x)
- x = self.stage2(x)
- x = self.stage3(x)
- x = self.avg(x)
- # x = self.model(x)
- x = x.view(-1, 256)
- x = self.fc(x)
- return x
-
-
-class ClassHead(nn.Module):
-
- def __init__(self, inchannels=512, num_anchors=3):
- super(ClassHead, self).__init__()
- self.num_anchors = num_anchors
- self.conv1x1 = nn.Conv2d(inchannels, self.num_anchors * 2, kernel_size=(1, 1), stride=1, padding=0)
-
- def forward(self, x):
- out = self.conv1x1(x)
- out = out.permute(0, 2, 3, 1).contiguous()
-
- return out.view(out.shape[0], -1, 2)
-
-
-class BboxHead(nn.Module):
-
- def __init__(self, inchannels=512, num_anchors=3):
- super(BboxHead, self).__init__()
- self.conv1x1 = nn.Conv2d(inchannels, num_anchors * 4, kernel_size=(1, 1), stride=1, padding=0)
-
- def forward(self, x):
- out = self.conv1x1(x)
- out = out.permute(0, 2, 3, 1).contiguous()
-
- return out.view(out.shape[0], -1, 4)
-
-
-class LandmarkHead(nn.Module):
-
- def __init__(self, inchannels=512, num_anchors=3):
- super(LandmarkHead, self).__init__()
- self.conv1x1 = nn.Conv2d(inchannels, num_anchors * 10, kernel_size=(1, 1), stride=1, padding=0)
-
- def forward(self, x):
- out = self.conv1x1(x)
- out = out.permute(0, 2, 3, 1).contiguous()
-
- return out.view(out.shape[0], -1, 10)
-
-
-def make_class_head(fpn_num=3, inchannels=64, anchor_num=2):
- classhead = nn.ModuleList()
- for i in range(fpn_num):
- classhead.append(ClassHead(inchannels, anchor_num))
- return classhead
-
-
-def make_bbox_head(fpn_num=3, inchannels=64, anchor_num=2):
- bboxhead = nn.ModuleList()
- for i in range(fpn_num):
- bboxhead.append(BboxHead(inchannels, anchor_num))
- return bboxhead
-
-
-def make_landmark_head(fpn_num=3, inchannels=64, anchor_num=2):
- landmarkhead = nn.ModuleList()
- for i in range(fpn_num):
- landmarkhead.append(LandmarkHead(inchannels, anchor_num))
- return landmarkhead
diff --git a/spaces/JeffJing/ZookChatBot/steamship/data/__init__.py b/spaces/JeffJing/ZookChatBot/steamship/data/__init__.py
deleted file mode 100644
index 69c0c4a91edeb3c67db8b7353b217fd55e95ad2b..0000000000000000000000000000000000000000
--- a/spaces/JeffJing/ZookChatBot/steamship/data/__init__.py
+++ /dev/null
@@ -1,26 +0,0 @@
-from .block import Block
-from .embeddings import EmbeddingIndex
-from .file import File
-from .package import Package, PackageInstance, PackageVersion
-from .plugin import Plugin, PluginInstance, PluginVersion
-from .tags import DocTag, GenerationTag, Tag, TagKind, TagValueKey, TokenTag
-from .workspace import Workspace
-
-__all__ = [
- "Package",
- "PackageInstance",
- "PackageVersion",
- "Block",
- "EmbeddingIndex",
- "File",
- "GenerationTag",
- "Plugin",
- "PluginInstance",
- "PluginVersion",
- "Workspace",
- "DocTag",
- "Tag",
- "TagKind",
- "TokenTag",
- "TagValueKey",
-]
diff --git a/spaces/Jianfeng777/Car_Bike_Classification/README.md b/spaces/Jianfeng777/Car_Bike_Classification/README.md
deleted file mode 100644
index c287cf87926222f469e17155a6851fcbef644c42..0000000000000000000000000000000000000000
--- a/spaces/Jianfeng777/Car_Bike_Classification/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Car Bike Classification
-emoji: 😻
-colorFrom: purple
-colorTo: blue
-sdk: gradio
-sdk_version: 4.1.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/KPCGD/bingo/src/lib/isomorphic/browser.ts b/spaces/KPCGD/bingo/src/lib/isomorphic/browser.ts
deleted file mode 100644
index de125b1f1786d1618cb1ff47f403d76c6784f4ce..0000000000000000000000000000000000000000
--- a/spaces/KPCGD/bingo/src/lib/isomorphic/browser.ts
+++ /dev/null
@@ -1,11 +0,0 @@
-'use client'
-
-const debug = console.info.bind(console)
-
-class WebSocketAlias extends WebSocket {
- constructor(address: string | URL, ...args: any) {
- super(address)
- }
-}
-
-export default { fetch, WebSocket: WebSocketAlias, debug }
diff --git a/spaces/Kevin676/AutoGPT/autogpt/token_counter.py b/spaces/Kevin676/AutoGPT/autogpt/token_counter.py
deleted file mode 100644
index 338fe6be4d47a679f2bf0815685edeb3dce66936..0000000000000000000000000000000000000000
--- a/spaces/Kevin676/AutoGPT/autogpt/token_counter.py
+++ /dev/null
@@ -1,73 +0,0 @@
-"""Functions for counting the number of tokens in a message or string."""
-from __future__ import annotations
-
-import tiktoken
-
-from autogpt.logs import logger
-
-
-def count_message_tokens(
- messages: list[dict[str, str]], model: str = "gpt-3.5-turbo-0301"
-) -> int:
- """
- Returns the number of tokens used by a list of messages.
-
- Args:
- messages (list): A list of messages, each of which is a dictionary
- containing the role and content of the message.
- model (str): The name of the model to use for tokenization.
- Defaults to "gpt-3.5-turbo-0301".
-
- Returns:
- int: The number of tokens used by the list of messages.
- """
- try:
- encoding = tiktoken.encoding_for_model(model)
- except KeyError:
- logger.warn("Warning: model not found. Using cl100k_base encoding.")
- encoding = tiktoken.get_encoding("cl100k_base")
- if model == "gpt-3.5-turbo":
- # !Note: gpt-3.5-turbo may change over time.
- # Returning num tokens assuming gpt-3.5-turbo-0301.")
- return count_message_tokens(messages, model="gpt-3.5-turbo-0301")
- elif model == "gpt-4":
- # !Note: gpt-4 may change over time. Returning num tokens assuming gpt-4-0314.")
- return count_message_tokens(messages, model="gpt-4-0314")
- elif model == "gpt-3.5-turbo-0301":
- tokens_per_message = (
- 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
- )
- tokens_per_name = -1 # if there's a name, the role is omitted
- elif model == "gpt-4-0314":
- tokens_per_message = 3
- tokens_per_name = 1
- else:
- raise NotImplementedError(
- f"num_tokens_from_messages() is not implemented for model {model}.\n"
- " See https://github.com/openai/openai-python/blob/main/chatml.md for"
- " information on how messages are converted to tokens."
- )
- num_tokens = 0
- for message in messages:
- num_tokens += tokens_per_message
- for key, value in message.items():
- num_tokens += len(encoding.encode(value))
- if key == "name":
- num_tokens += tokens_per_name
- num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
- return num_tokens
-
-
-def count_string_tokens(string: str, model_name: str) -> int:
- """
- Returns the number of tokens in a text string.
-
- Args:
- string (str): The text string.
- model_name (str): The name of the encoding to use. (e.g., "gpt-3.5-turbo")
-
- Returns:
- int: The number of tokens in the text string.
- """
- encoding = tiktoken.encoding_for_model(model_name)
- return len(encoding.encode(string))
diff --git a/spaces/KyanChen/RSPrompter/mmdet/models/detectors/deformable_detr.py b/spaces/KyanChen/RSPrompter/mmdet/models/detectors/deformable_detr.py
deleted file mode 100644
index 98ea1c767f5a3bf6fa6fe2637522faf3cf85d1cb..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmdet/models/detectors/deformable_detr.py
+++ /dev/null
@@ -1,541 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-from typing import Dict, Tuple
-
-import torch
-import torch.nn.functional as F
-from mmcv.cnn.bricks.transformer import MultiScaleDeformableAttention
-from mmengine.model import xavier_init
-from torch import Tensor, nn
-from torch.nn.init import normal_
-
-from mmdet.registry import MODELS
-from mmdet.structures import OptSampleList
-from mmdet.utils import OptConfigType
-from ..layers import (DeformableDetrTransformerDecoder,
- DeformableDetrTransformerEncoder, SinePositionalEncoding)
-from .base_detr import DetectionTransformer
-
-
-@MODELS.register_module()
-class DeformableDETR(DetectionTransformer):
- r"""Implementation of `Deformable DETR: Deformable Transformers for
- End-to-End Object Detection `_
-
- Code is modified from the `official github repo
- `_.
-
- Args:
- decoder (:obj:`ConfigDict` or dict, optional): Config of the
- Transformer decoder. Defaults to None.
- bbox_head (:obj:`ConfigDict` or dict, optional): Config for the
- bounding box head module. Defaults to None.
- with_box_refine (bool, optional): Whether to refine the references
- in the decoder. Defaults to `False`.
- as_two_stage (bool, optional): Whether to generate the proposal
- from the outputs of encoder. Defaults to `False`.
- num_feature_levels (int, optional): Number of feature levels.
- Defaults to 4.
- """
-
- def __init__(self,
- *args,
- decoder: OptConfigType = None,
- bbox_head: OptConfigType = None,
- with_box_refine: bool = False,
- as_two_stage: bool = False,
- num_feature_levels: int = 4,
- **kwargs) -> None:
- self.with_box_refine = with_box_refine
- self.as_two_stage = as_two_stage
- self.num_feature_levels = num_feature_levels
-
- if bbox_head is not None:
- assert 'share_pred_layer' not in bbox_head and \
- 'num_pred_layer' not in bbox_head and \
- 'as_two_stage' not in bbox_head, \
- 'The two keyword args `share_pred_layer`, `num_pred_layer`, ' \
- 'and `as_two_stage are set in `detector.__init__()`, users ' \
- 'should not set them in `bbox_head` config.'
- # The last prediction layer is used to generate proposal
- # from encode feature map when `as_two_stage` is `True`.
- # And all the prediction layers should share parameters
- # when `with_box_refine` is `True`.
- bbox_head['share_pred_layer'] = not with_box_refine
- bbox_head['num_pred_layer'] = (decoder['num_layers'] + 1) \
- if self.as_two_stage else decoder['num_layers']
- bbox_head['as_two_stage'] = as_two_stage
-
- super().__init__(*args, decoder=decoder, bbox_head=bbox_head, **kwargs)
-
- def _init_layers(self) -> None:
- """Initialize layers except for backbone, neck and bbox_head."""
- self.positional_encoding = SinePositionalEncoding(
- **self.positional_encoding)
- self.encoder = DeformableDetrTransformerEncoder(**self.encoder)
- self.decoder = DeformableDetrTransformerDecoder(**self.decoder)
- self.embed_dims = self.encoder.embed_dims
- if not self.as_two_stage:
- self.query_embedding = nn.Embedding(self.num_queries,
- self.embed_dims * 2)
- # NOTE The query_embedding will be split into query and query_pos
- # in self.pre_decoder, hence, the embed_dims are doubled.
-
- num_feats = self.positional_encoding.num_feats
- assert num_feats * 2 == self.embed_dims, \
- 'embed_dims should be exactly 2 times of num_feats. ' \
- f'Found {self.embed_dims} and {num_feats}.'
-
- self.level_embed = nn.Parameter(
- torch.Tensor(self.num_feature_levels, self.embed_dims))
-
- if self.as_two_stage:
- self.memory_trans_fc = nn.Linear(self.embed_dims, self.embed_dims)
- self.memory_trans_norm = nn.LayerNorm(self.embed_dims)
- self.pos_trans_fc = nn.Linear(self.embed_dims * 2,
- self.embed_dims * 2)
- self.pos_trans_norm = nn.LayerNorm(self.embed_dims * 2)
- else:
- self.reference_points_fc = nn.Linear(self.embed_dims, 2)
-
- def init_weights(self) -> None:
- """Initialize weights for Transformer and other components."""
- super().init_weights()
- for coder in self.encoder, self.decoder:
- for p in coder.parameters():
- if p.dim() > 1:
- nn.init.xavier_uniform_(p)
- for m in self.modules():
- if isinstance(m, MultiScaleDeformableAttention):
- m.init_weights()
- if self.as_two_stage:
- nn.init.xavier_uniform_(self.memory_trans_fc.weight)
- nn.init.xavier_uniform_(self.pos_trans_fc.weight)
- else:
- xavier_init(
- self.reference_points_fc, distribution='uniform', bias=0.)
- normal_(self.level_embed)
-
- def pre_transformer(
- self,
- mlvl_feats: Tuple[Tensor],
- batch_data_samples: OptSampleList = None) -> Tuple[Dict]:
- """Process image features before feeding them to the transformer.
-
- The forward procedure of the transformer is defined as:
- 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
- More details can be found at `TransformerDetector.forward_transformer`
- in `mmdet/detector/base_detr.py`.
-
- Args:
- mlvl_feats (tuple[Tensor]): Multi-level features that may have
- different resolutions, output from neck. Each feature has
- shape (bs, dim, h_lvl, w_lvl), where 'lvl' means 'layer'.
- batch_data_samples (list[:obj:`DetDataSample`], optional): The
- batch data samples. It usually includes information such
- as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
- Defaults to None.
-
- Returns:
- tuple[dict]: The first dict contains the inputs of encoder and the
- second dict contains the inputs of decoder.
-
- - encoder_inputs_dict (dict): The keyword args dictionary of
- `self.forward_encoder()`, which includes 'feat', 'feat_mask',
- and 'feat_pos'.
- - decoder_inputs_dict (dict): The keyword args dictionary of
- `self.forward_decoder()`, which includes 'memory_mask'.
- """
- batch_size = mlvl_feats[0].size(0)
-
- # construct binary masks for the transformer.
- assert batch_data_samples is not None
- batch_input_shape = batch_data_samples[0].batch_input_shape
- img_shape_list = [sample.img_shape for sample in batch_data_samples]
- input_img_h, input_img_w = batch_input_shape
- masks = mlvl_feats[0].new_ones((batch_size, input_img_h, input_img_w))
- for img_id in range(batch_size):
- img_h, img_w = img_shape_list[img_id]
- masks[img_id, :img_h, :img_w] = 0
- # NOTE following the official DETR repo, non-zero values representing
- # ignored positions, while zero values means valid positions.
-
- mlvl_masks = []
- mlvl_pos_embeds = []
- for feat in mlvl_feats:
- mlvl_masks.append(
- F.interpolate(masks[None],
- size=feat.shape[-2:]).to(torch.bool).squeeze(0))
- mlvl_pos_embeds.append(self.positional_encoding(mlvl_masks[-1]))
-
- feat_flatten = []
- lvl_pos_embed_flatten = []
- mask_flatten = []
- spatial_shapes = []
- for lvl, (feat, mask, pos_embed) in enumerate(
- zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)):
- batch_size, c, h, w = feat.shape
- # [bs, c, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl, c]
- feat = feat.view(batch_size, c, -1).permute(0, 2, 1)
- pos_embed = pos_embed.view(batch_size, c, -1).permute(0, 2, 1)
- lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
- # [bs, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl]
- mask = mask.flatten(1)
- spatial_shape = (h, w)
-
- feat_flatten.append(feat)
- lvl_pos_embed_flatten.append(lvl_pos_embed)
- mask_flatten.append(mask)
- spatial_shapes.append(spatial_shape)
-
- # (bs, num_feat_points, dim)
- feat_flatten = torch.cat(feat_flatten, 1)
- lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
- # (bs, num_feat_points), where num_feat_points = sum_lvl(h_lvl*w_lvl)
- mask_flatten = torch.cat(mask_flatten, 1)
-
- spatial_shapes = torch.as_tensor( # (num_level, 2)
- spatial_shapes,
- dtype=torch.long,
- device=feat_flatten.device)
- level_start_index = torch.cat((
- spatial_shapes.new_zeros((1, )), # (num_level)
- spatial_shapes.prod(1).cumsum(0)[:-1]))
- valid_ratios = torch.stack( # (bs, num_level, 2)
- [self.get_valid_ratio(m) for m in mlvl_masks], 1)
-
- encoder_inputs_dict = dict(
- feat=feat_flatten,
- feat_mask=mask_flatten,
- feat_pos=lvl_pos_embed_flatten,
- spatial_shapes=spatial_shapes,
- level_start_index=level_start_index,
- valid_ratios=valid_ratios)
- decoder_inputs_dict = dict(
- memory_mask=mask_flatten,
- spatial_shapes=spatial_shapes,
- level_start_index=level_start_index,
- valid_ratios=valid_ratios)
- return encoder_inputs_dict, decoder_inputs_dict
-
- def forward_encoder(self, feat: Tensor, feat_mask: Tensor,
- feat_pos: Tensor, spatial_shapes: Tensor,
- level_start_index: Tensor,
- valid_ratios: Tensor) -> Dict:
- """Forward with Transformer encoder.
-
- The forward procedure of the transformer is defined as:
- 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
- More details can be found at `TransformerDetector.forward_transformer`
- in `mmdet/detector/base_detr.py`.
-
- Args:
- feat (Tensor): Sequential features, has shape (bs, num_feat_points,
- dim).
- feat_mask (Tensor): ByteTensor, the padding mask of the features,
- has shape (bs, num_feat_points).
- feat_pos (Tensor): The positional embeddings of the features, has
- shape (bs, num_feat_points, dim).
- spatial_shapes (Tensor): Spatial shapes of features in all levels,
- has shape (num_levels, 2), last dimension represents (h, w).
- level_start_index (Tensor): The start index of each level.
- A tensor has shape (num_levels, ) and can be represented
- as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
- valid_ratios (Tensor): The ratios of the valid width and the valid
- height relative to the width and the height of features in all
- levels, has shape (bs, num_levels, 2).
-
- Returns:
- dict: The dictionary of encoder outputs, which includes the
- `memory` of the encoder output.
- """
- memory = self.encoder(
- query=feat,
- query_pos=feat_pos,
- key_padding_mask=feat_mask, # for self_attn
- spatial_shapes=spatial_shapes,
- level_start_index=level_start_index,
- valid_ratios=valid_ratios)
- encoder_outputs_dict = dict(
- memory=memory,
- memory_mask=feat_mask,
- spatial_shapes=spatial_shapes)
- return encoder_outputs_dict
-
- def pre_decoder(self, memory: Tensor, memory_mask: Tensor,
- spatial_shapes: Tensor) -> Tuple[Dict, Dict]:
- """Prepare intermediate variables before entering Transformer decoder,
- such as `query`, `query_pos`, and `reference_points`.
-
- The forward procedure of the transformer is defined as:
- 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
- More details can be found at `TransformerDetector.forward_transformer`
- in `mmdet/detector/base_detr.py`.
-
- Args:
- memory (Tensor): The output embeddings of the Transformer encoder,
- has shape (bs, num_feat_points, dim).
- memory_mask (Tensor): ByteTensor, the padding mask of the memory,
- has shape (bs, num_feat_points). It will only be used when
- `as_two_stage` is `True`.
- spatial_shapes (Tensor): Spatial shapes of features in all levels,
- has shape (num_levels, 2), last dimension represents (h, w).
- It will only be used when `as_two_stage` is `True`.
-
- Returns:
- tuple[dict, dict]: The decoder_inputs_dict and head_inputs_dict.
-
- - decoder_inputs_dict (dict): The keyword dictionary args of
- `self.forward_decoder()`, which includes 'query', 'query_pos',
- 'memory', and `reference_points`. The reference_points of
- decoder input here are 4D boxes when `as_two_stage` is `True`,
- otherwise 2D points, although it has `points` in its name.
- The reference_points in encoder is always 2D points.
- - head_inputs_dict (dict): The keyword dictionary args of the
- bbox_head functions, which includes `enc_outputs_class` and
- `enc_outputs_coord`. They are both `None` when 'as_two_stage'
- is `False`. The dict is empty when `self.training` is `False`.
- """
- batch_size, _, c = memory.shape
- if self.as_two_stage:
- output_memory, output_proposals = \
- self.gen_encoder_output_proposals(
- memory, memory_mask, spatial_shapes)
- enc_outputs_class = self.bbox_head.cls_branches[
- self.decoder.num_layers](
- output_memory)
- enc_outputs_coord_unact = self.bbox_head.reg_branches[
- self.decoder.num_layers](output_memory) + output_proposals
- enc_outputs_coord = enc_outputs_coord_unact.sigmoid()
- # We only use the first channel in enc_outputs_class as foreground,
- # the other (num_classes - 1) channels are actually not used.
- # Its targets are set to be 0s, which indicates the first
- # class (foreground) because we use [0, num_classes - 1] to
- # indicate class labels, background class is indicated by
- # num_classes (similar convention in RPN).
- # See https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/dense_heads/deformable_detr_head.py#L241 # noqa
- # This follows the official implementation of Deformable DETR.
- topk_proposals = torch.topk(
- enc_outputs_class[..., 0], self.num_queries, dim=1)[1]
- topk_coords_unact = torch.gather(
- enc_outputs_coord_unact, 1,
- topk_proposals.unsqueeze(-1).repeat(1, 1, 4))
- topk_coords_unact = topk_coords_unact.detach()
- reference_points = topk_coords_unact.sigmoid()
- pos_trans_out = self.pos_trans_fc(
- self.get_proposal_pos_embed(topk_coords_unact))
- pos_trans_out = self.pos_trans_norm(pos_trans_out)
- query_pos, query = torch.split(pos_trans_out, c, dim=2)
- else:
- enc_outputs_class, enc_outputs_coord = None, None
- query_embed = self.query_embedding.weight
- query_pos, query = torch.split(query_embed, c, dim=1)
- query_pos = query_pos.unsqueeze(0).expand(batch_size, -1, -1)
- query = query.unsqueeze(0).expand(batch_size, -1, -1)
- reference_points = self.reference_points_fc(query_pos).sigmoid()
-
- decoder_inputs_dict = dict(
- query=query,
- query_pos=query_pos,
- memory=memory,
- reference_points=reference_points)
- head_inputs_dict = dict(
- enc_outputs_class=enc_outputs_class,
- enc_outputs_coord=enc_outputs_coord) if self.training else dict()
- return decoder_inputs_dict, head_inputs_dict
-
- def forward_decoder(self, query: Tensor, query_pos: Tensor, memory: Tensor,
- memory_mask: Tensor, reference_points: Tensor,
- spatial_shapes: Tensor, level_start_index: Tensor,
- valid_ratios: Tensor) -> Dict:
- """Forward with Transformer decoder.
-
- The forward procedure of the transformer is defined as:
- 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
- More details can be found at `TransformerDetector.forward_transformer`
- in `mmdet/detector/base_detr.py`.
-
- Args:
- query (Tensor): The queries of decoder inputs, has shape
- (bs, num_queries, dim).
- query_pos (Tensor): The positional queries of decoder inputs,
- has shape (bs, num_queries, dim).
- memory (Tensor): The output embeddings of the Transformer encoder,
- has shape (bs, num_feat_points, dim).
- memory_mask (Tensor): ByteTensor, the padding mask of the memory,
- has shape (bs, num_feat_points).
- reference_points (Tensor): The initial reference, has shape
- (bs, num_queries, 4) with the last dimension arranged as
- (cx, cy, w, h) when `as_two_stage` is `True`, otherwise has
- shape (bs, num_queries, 2) with the last dimension arranged as
- (cx, cy).
- spatial_shapes (Tensor): Spatial shapes of features in all levels,
- has shape (num_levels, 2), last dimension represents (h, w).
- level_start_index (Tensor): The start index of each level.
- A tensor has shape (num_levels, ) and can be represented
- as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
- valid_ratios (Tensor): The ratios of the valid width and the valid
- height relative to the width and the height of features in all
- levels, has shape (bs, num_levels, 2).
-
- Returns:
- dict: The dictionary of decoder outputs, which includes the
- `hidden_states` of the decoder output and `references` including
- the initial and intermediate reference_points.
- """
- inter_states, inter_references = self.decoder(
- query=query,
- value=memory,
- query_pos=query_pos,
- key_padding_mask=memory_mask, # for cross_attn
- reference_points=reference_points,
- spatial_shapes=spatial_shapes,
- level_start_index=level_start_index,
- valid_ratios=valid_ratios,
- reg_branches=self.bbox_head.reg_branches
- if self.with_box_refine else None)
- references = [reference_points, *inter_references]
- decoder_outputs_dict = dict(
- hidden_states=inter_states, references=references)
- return decoder_outputs_dict
-
- @staticmethod
- def get_valid_ratio(mask: Tensor) -> Tensor:
- """Get the valid radios of feature map in a level.
-
- .. code:: text
-
- |---> valid_W <---|
- ---+-----------------+-----+---
- A | | | A
- | | | | |
- | | | | |
- valid_H | | | |
- | | | | H
- | | | | |
- V | | | |
- ---+-----------------+ | |
- | | V
- +-----------------------+---
- |---------> W <---------|
-
- The valid_ratios are defined as:
- r_h = valid_H / H, r_w = valid_W / W
- They are the factors to re-normalize the relative coordinates of the
- image to the relative coordinates of the current level feature map.
-
- Args:
- mask (Tensor): Binary mask of a feature map, has shape (bs, H, W).
-
- Returns:
- Tensor: valid ratios [r_w, r_h] of a feature map, has shape (1, 2).
- """
- _, H, W = mask.shape
- valid_H = torch.sum(~mask[:, :, 0], 1)
- valid_W = torch.sum(~mask[:, 0, :], 1)
- valid_ratio_h = valid_H.float() / H
- valid_ratio_w = valid_W.float() / W
- valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
- return valid_ratio
-
- def gen_encoder_output_proposals(
- self, memory: Tensor, memory_mask: Tensor,
- spatial_shapes: Tensor) -> Tuple[Tensor, Tensor]:
- """Generate proposals from encoded memory. The function will only be
- used when `as_two_stage` is `True`.
-
- Args:
- memory (Tensor): The output embeddings of the Transformer encoder,
- has shape (bs, num_feat_points, dim).
- memory_mask (Tensor): ByteTensor, the padding mask of the memory,
- has shape (bs, num_feat_points).
- spatial_shapes (Tensor): Spatial shapes of features in all levels,
- has shape (num_levels, 2), last dimension represents (h, w).
-
- Returns:
- tuple: A tuple of transformed memory and proposals.
-
- - output_memory (Tensor): The transformed memory for obtaining
- top-k proposals, has shape (bs, num_feat_points, dim).
- - output_proposals (Tensor): The inverse-normalized proposal, has
- shape (batch_size, num_keys, 4) with the last dimension arranged
- as (cx, cy, w, h).
- """
-
- bs = memory.size(0)
- proposals = []
- _cur = 0 # start index in the sequence of the current level
- for lvl, (H, W) in enumerate(spatial_shapes):
- mask_flatten_ = memory_mask[:,
- _cur:(_cur + H * W)].view(bs, H, W, 1)
- valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1).unsqueeze(-1)
- valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1).unsqueeze(-1)
-
- grid_y, grid_x = torch.meshgrid(
- torch.linspace(
- 0, H - 1, H, dtype=torch.float32, device=memory.device),
- torch.linspace(
- 0, W - 1, W, dtype=torch.float32, device=memory.device))
- grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
-
- scale = torch.cat([valid_W, valid_H], 1).view(bs, 1, 1, 2)
- grid = (grid.unsqueeze(0).expand(bs, -1, -1, -1) + 0.5) / scale
- wh = torch.ones_like(grid) * 0.05 * (2.0**lvl)
- proposal = torch.cat((grid, wh), -1).view(bs, -1, 4)
- proposals.append(proposal)
- _cur += (H * W)
- output_proposals = torch.cat(proposals, 1)
- output_proposals_valid = ((output_proposals > 0.01) &
- (output_proposals < 0.99)).all(
- -1, keepdim=True)
- # inverse_sigmoid
- output_proposals = torch.log(output_proposals / (1 - output_proposals))
- output_proposals = output_proposals.masked_fill(
- memory_mask.unsqueeze(-1), float('inf'))
- output_proposals = output_proposals.masked_fill(
- ~output_proposals_valid, float('inf'))
-
- output_memory = memory
- output_memory = output_memory.masked_fill(
- memory_mask.unsqueeze(-1), float(0))
- output_memory = output_memory.masked_fill(~output_proposals_valid,
- float(0))
- output_memory = self.memory_trans_fc(output_memory)
- output_memory = self.memory_trans_norm(output_memory)
- # [bs, sum(hw), 2]
- return output_memory, output_proposals
-
- @staticmethod
- def get_proposal_pos_embed(proposals: Tensor,
- num_pos_feats: int = 128,
- temperature: int = 10000) -> Tensor:
- """Get the position embedding of the proposal.
-
- Args:
- proposals (Tensor): Not normalized proposals, has shape
- (bs, num_queries, 4) with the last dimension arranged as
- (cx, cy, w, h).
- num_pos_feats (int, optional): The feature dimension for each
- position along x, y, w, and h-axis. Note the final returned
- dimension for each position is 4 times of num_pos_feats.
- Default to 128.
- temperature (int, optional): The temperature used for scaling the
- position embedding. Defaults to 10000.
-
- Returns:
- Tensor: The position embedding of proposal, has shape
- (bs, num_queries, num_pos_feats * 4), with the last dimension
- arranged as (cx, cy, w, h)
- """
- scale = 2 * math.pi
- dim_t = torch.arange(
- num_pos_feats, dtype=torch.float32, device=proposals.device)
- dim_t = temperature**(2 * (dim_t // 2) / num_pos_feats)
- # N, L, 4
- proposals = proposals.sigmoid() * scale
- # N, L, 4, 128
- pos = proposals[:, :, :, None] / dim_t
- # N, L, 4, 64, 2
- pos = torch.stack((pos[:, :, :, 0::2].sin(), pos[:, :, :, 1::2].cos()),
- dim=4).flatten(2)
- return pos
diff --git a/spaces/KyanChen/RSPrompter/mmpl/models/pler/base.py b/spaces/KyanChen/RSPrompter/mmpl/models/pler/base.py
deleted file mode 100644
index a65fc213f4bfe271a9298b823ba38fc4ca9f57e1..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmpl/models/pler/base.py
+++ /dev/null
@@ -1,108 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from abc import ABCMeta, abstractmethod
-from typing import List, Optional, Sequence
-
-import torch
-from mmengine.model import BaseModel
-from mmengine.structures import BaseDataElement
-
-
-class BaseClassifier(BaseModel, metaclass=ABCMeta):
- """Base class for classifiers.
-
- Args:
- init_cfg (dict, optional): Initialization config dict.
- Defaults to None.
- data_preprocessor (dict, optional): The config for preprocessing input
- data. If None, it will use "BaseDataPreprocessor" as type, see
- :class:`mmengine.model.BaseDataPreprocessor` for more details.
- Defaults to None.
-
- Attributes:
- init_cfg (dict): Initialization config dict.
- data_preprocessor (:obj:`mmengine.model.BaseDataPreprocessor`): An
- extra data pre-processing module, which processes data from
- dataloader to the format accepted by :meth:`forward`.
- """
-
- def __init__(self,
- init_cfg: Optional[dict] = None,
- data_preprocessor: Optional[dict] = None):
- super(BaseClassifier, self).__init__(
- init_cfg=init_cfg, data_preprocessor=data_preprocessor)
-
- @property
- def with_neck(self) -> bool:
- """Whether the classifier has a neck."""
- return hasattr(self, 'neck') and self.neck is not None
-
- @property
- def with_head(self) -> bool:
- """Whether the classifier has a head."""
- return hasattr(self, 'head') and self.head is not None
-
- @abstractmethod
- def forward(self,
- inputs: torch.Tensor,
- data_samples: Optional[List[BaseDataElement]] = None,
- mode: str = 'tensor'):
- """The unified entry for a forward process in both training and test.
-
- The method should accept three modes: "tensor", "predict" and "loss":
-
- - "tensor": Forward the whole network and return tensor or tuple of
- tensor without any post-processing, same as a common nn.Module.
- - "predict": Forward and return the predictions, which are fully
- processed to a list of :obj:`BaseDataElement`.
- - "loss": Forward and return a dict of losses according to the given
- inputs and data samples.
-
- Note that this method doesn't handle neither back propagation nor
- optimizer updating, which are done in the :meth:`train_step`.
-
- Args:
- inputs (torch.Tensor): The input tensor with shape (N, C, ...)
- in general.
- data_samples (List[BaseDataElement], optional): The annotation
- data of every samples. It's required if ``mode="loss"``.
- Defaults to None.
- mode (str): Return what kind of value. Defaults to 'tensor'.
-
- Returns:
- The return type depends on ``mode``.
-
- - If ``mode="tensor"``, return a tensor or a tuple of tensor.
- - If ``mode="predict"``, return a list of
- :obj:`mmengine.BaseDataElement`.
- - If ``mode="loss"``, return a dict of tensor.
- """
- pass
-
- def extract_feat(self, inputs: torch.Tensor):
- """Extract features from the input tensor with shape (N, C, ...).
-
- The sub-classes are recommended to implement this method to extract
- features from backbone and neck.
-
- Args:
- inputs (Tensor): A batch of inputs. The shape of it should be
- ``(num_samples, num_channels, *img_shape)``.
- """
- raise NotImplementedError
-
- def extract_feats(self, multi_inputs: Sequence[torch.Tensor],
- **kwargs) -> list:
- """Extract features from a sequence of input tensor.
-
- Args:
- multi_inputs (Sequence[torch.Tensor]): A sequence of input
- tensor. It can be used in augmented inference.
- **kwargs: Other keyword arguments accepted by :meth:`extract_feat`.
-
- Returns:
- list: Features of every input tensor.
- """
- assert isinstance(multi_inputs, Sequence), \
- '`extract_feats` is used for a sequence of inputs tensor. If you '\
- 'want to extract on single inputs tensor, use `extract_feat`.'
- return [self.extract_feat(inputs, **kwargs) for inputs in multi_inputs]
diff --git a/spaces/KyanChen/RSPrompter/mmpretrain/datasets/transforms/auto_augment.py b/spaces/KyanChen/RSPrompter/mmpretrain/datasets/transforms/auto_augment.py
deleted file mode 100644
index 03b057b850a4fd797f8f5c0672f60c6c20e44273..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmpretrain/datasets/transforms/auto_augment.py
+++ /dev/null
@@ -1,1244 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import inspect
-from copy import deepcopy
-from math import ceil
-from numbers import Number
-from typing import List, Optional, Sequence, Tuple, Union
-
-import mmcv
-import numpy as np
-from mmcv.transforms import BaseTransform, Compose, RandomChoice
-from mmcv.transforms.utils import cache_randomness
-from mmengine.utils import is_list_of, is_seq_of
-from PIL import Image, ImageFilter
-
-from mmpretrain.registry import TRANSFORMS
-
-
-def merge_hparams(policy: dict, hparams: dict) -> dict:
- """Merge hyperparameters into policy config.
-
- Only merge partial hyperparameters required of the policy.
-
- Args:
- policy (dict): Original policy config dict.
- hparams (dict): Hyperparameters need to be merged.
-
- Returns:
- dict: Policy config dict after adding ``hparams``.
- """
- policy = deepcopy(policy)
- op = TRANSFORMS.get(policy['type'])
- assert op is not None, f'Invalid policy type "{policy["type"]}".'
-
- op_args = inspect.getfullargspec(op.__init__).args
- for key, value in hparams.items():
- if key in op_args and key not in policy:
- policy[key] = value
- return policy
-
-
-@TRANSFORMS.register_module()
-class AutoAugment(RandomChoice):
- """Auto augmentation.
-
- This data augmentation is proposed in `AutoAugment: Learning Augmentation
- Policies from Data `_.
-
- Args:
- policies (str | list[list[dict]]): The policies of auto augmentation.
- If string, use preset policies collection like "imagenet". If list,
- Each item is a sub policies, composed by several augmentation
- policy dicts. When AutoAugment is called, a random sub policies in
- ``policies`` will be selected to augment images.
- hparams (dict): Configs of hyperparameters. Hyperparameters will be
- used in policies that require these arguments if these arguments
- are not set in policy dicts. Defaults to ``dict(pad_val=128)``.
-
- .. admonition:: Available preset policies
-
- - ``"imagenet"``: Policy for ImageNet, come from
- `DeepVoltaire/AutoAugment`_
-
- .. _DeepVoltaire/AutoAugment: https://github.com/DeepVoltaire/AutoAugment
- """
-
- def __init__(self,
- policies: Union[str, List[List[dict]]],
- hparams: dict = dict(pad_val=128)):
- if isinstance(policies, str):
- assert policies in AUTOAUG_POLICIES, 'Invalid policies, ' \
- f'please choose from {list(AUTOAUG_POLICIES.keys())}.'
- policies = AUTOAUG_POLICIES[policies]
- self.hparams = hparams
- self.policies = [[merge_hparams(t, hparams) for t in sub]
- for sub in policies]
- transforms = [[TRANSFORMS.build(t) for t in sub] for sub in policies]
-
- super().__init__(transforms=transforms)
-
- def __repr__(self) -> str:
- policies_str = ''
- for sub in self.policies:
- policies_str += '\n ' + ', \t'.join([t['type'] for t in sub])
-
- repr_str = self.__class__.__name__
- repr_str += f'(policies:{policies_str}\n)'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class RandAugment(BaseTransform):
- r"""Random augmentation.
-
- This data augmentation is proposed in `RandAugment: Practical automated
- data augmentation with a reduced search space
- `_.
-
- Args:
- policies (str | list[dict]): The policies of random augmentation.
- If string, use preset policies collection like "timm_increasing".
- If list, each item is one specific augmentation policy dict.
- The policy dict shall should have these keys:
-
- - ``type`` (str), The type of augmentation.
- - ``magnitude_range`` (Sequence[number], optional): For those
- augmentation have magnitude, you need to specify the magnitude
- level mapping range. For example, assume ``total_level`` is 10,
- ``magnitude_level=3`` specify magnitude is 3 if
- ``magnitude_range=(0, 10)`` while specify magnitude is 7 if
- ``magnitude_range=(10, 0)``.
- - other keyword arguments of the augmentation.
-
- num_policies (int): Number of policies to select from policies each
- time.
- magnitude_level (int | float): Magnitude level for all the augmentation
- selected.
- magnitude_std (Number | str): Deviation of magnitude noise applied.
-
- - If positive number, the magnitude obeys normal distribution
- :math:`\mathcal{N}(magnitude_level, magnitude_std)`.
- - If 0 or negative number, magnitude remains unchanged.
- - If str "inf", the magnitude obeys uniform distribution
- :math:`Uniform(min, magnitude)`.
- total_level (int | float): Total level for the magnitude. Defaults to
- 10.
- hparams (dict): Configs of hyperparameters. Hyperparameters will be
- used in policies that require these arguments if these arguments
- are not set in policy dicts. Defaults to ``dict(pad_val=128)``.
-
- .. admonition:: Available preset policies
-
- - ``"timm_increasing"``: The ``_RAND_INCREASING_TRANSFORMS`` policy
- from `timm`_
-
- .. _timm: https://github.com/rwightman/pytorch-image-models
-
- Examples:
-
- To use "timm-increasing" policies collection, select two policies every
- time, and magnitude_level of every policy is 6 (total is 10 by default)
-
- >>> import numpy as np
- >>> from mmpretrain.datasets import RandAugment
- >>> transform = RandAugment(
- ... policies='timm_increasing',
- ... num_policies=2,
- ... magnitude_level=6,
- ... )
- >>> data = {'img': np.random.randint(0, 256, (224, 224, 3))}
- >>> results = transform(data)
- >>> print(results['img'].shape)
- (224, 224, 3)
-
- If you want the ``magnitude_level`` randomly changes every time, you
- can use ``magnitude_std`` to specify the random distribution. For
- example, a normal distribution :math:`\mathcal{N}(6, 0.5)`.
-
- >>> transform = RandAugment(
- ... policies='timm_increasing',
- ... num_policies=2,
- ... magnitude_level=6,
- ... magnitude_std=0.5,
- ... )
-
- You can also use your own policies:
-
- >>> policies = [
- ... dict(type='AutoContrast'),
- ... dict(type='Rotate', magnitude_range=(0, 30)),
- ... dict(type='ColorTransform', magnitude_range=(0, 0.9)),
- ... ]
- >>> transform = RandAugment(
- ... policies=policies,
- ... num_policies=2,
- ... magnitude_level=6
- ... )
-
- Note:
- ``magnitude_std`` will introduce some randomness to policy, modified by
- https://github.com/rwightman/pytorch-image-models.
-
- When magnitude_std=0, we calculate the magnitude as follows:
-
- .. math::
- \text{magnitude} = \frac{\text{magnitude_level}}
- {\text{totallevel}} \times (\text{val2} - \text{val1})
- + \text{val1}
- """
-
- def __init__(self,
- policies: Union[str, List[dict]],
- num_policies: int,
- magnitude_level: int,
- magnitude_std: Union[Number, str] = 0.,
- total_level: int = 10,
- hparams: dict = dict(pad_val=128)):
- if isinstance(policies, str):
- assert policies in RANDAUG_POLICIES, 'Invalid policies, ' \
- f'please choose from {list(RANDAUG_POLICIES.keys())}.'
- policies = RANDAUG_POLICIES[policies]
-
- assert is_list_of(policies, dict), 'policies must be a list of dict.'
-
- assert isinstance(magnitude_std, (Number, str)), \
- '`magnitude_std` must be of number or str type, ' \
- f'got {type(magnitude_std)} instead.'
- if isinstance(magnitude_std, str):
- assert magnitude_std == 'inf', \
- '`magnitude_std` must be of number or "inf", ' \
- f'got "{magnitude_std}" instead.'
-
- assert num_policies > 0, 'num_policies must be greater than 0.'
- assert magnitude_level >= 0, 'magnitude_level must be no less than 0.'
- assert total_level > 0, 'total_level must be greater than 0.'
-
- self.num_policies = num_policies
- self.magnitude_level = magnitude_level
- self.magnitude_std = magnitude_std
- self.total_level = total_level
- self.hparams = hparams
- self.policies = []
- self.transforms = []
-
- randaug_cfg = dict(
- magnitude_level=magnitude_level,
- total_level=total_level,
- magnitude_std=magnitude_std)
-
- for policy in policies:
- self._check_policy(policy)
- policy = merge_hparams(policy, hparams)
- policy.pop('magnitude_key', None) # For backward compatibility
- if 'magnitude_range' in policy:
- policy.update(randaug_cfg)
- self.policies.append(policy)
- self.transforms.append(TRANSFORMS.build(policy))
-
- def __iter__(self):
- """Iterate all transforms."""
- return iter(self.transforms)
-
- def _check_policy(self, policy):
- """Check whether the sub-policy dict is available."""
- assert isinstance(policy, dict) and 'type' in policy, \
- 'Each policy must be a dict with key "type".'
- type_name = policy['type']
-
- if 'magnitude_range' in policy:
- magnitude_range = policy['magnitude_range']
- assert is_seq_of(magnitude_range, Number), \
- f'`magnitude_range` of RandAugment policy {type_name} ' \
- 'should be a sequence with two numbers.'
-
- @cache_randomness
- def random_policy_indices(self) -> np.ndarray:
- """Return the random chosen transform indices."""
- indices = np.arange(len(self.policies))
- return np.random.choice(indices, size=self.num_policies).tolist()
-
- def transform(self, results: dict) -> Optional[dict]:
- """Randomly choose a sub-policy to apply."""
-
- chosen_policies = [
- self.transforms[i] for i in self.random_policy_indices()
- ]
-
- sub_pipeline = Compose(chosen_policies)
- return sub_pipeline(results)
-
- def __repr__(self) -> str:
- policies_str = ''
- for policy in self.policies:
- policies_str += '\n ' + f'{policy["type"]}'
- if 'magnitude_range' in policy:
- val1, val2 = policy['magnitude_range']
- policies_str += f' ({val1}, {val2})'
-
- repr_str = self.__class__.__name__
- repr_str += f'(num_policies={self.num_policies}, '
- repr_str += f'magnitude_level={self.magnitude_level}, '
- repr_str += f'total_level={self.total_level}, '
- repr_str += f'policies:{policies_str}\n)'
- return repr_str
-
-
-class BaseAugTransform(BaseTransform):
- r"""The base class of augmentation transform for RandAugment.
-
- This class provides several common attributions and methods to support the
- magnitude level mapping and magnitude level randomness in
- :class:`RandAugment`.
-
- Args:
- magnitude_level (int | float): Magnitude level.
- magnitude_range (Sequence[number], optional): For augmentation have
- magnitude argument, maybe "magnitude", "angle" or other, you can
- specify the magnitude level mapping range to generate the magnitude
- argument. For example, assume ``total_level`` is 10,
- ``magnitude_level=3`` specify magnitude is 3 if
- ``magnitude_range=(0, 10)`` while specify magnitude is 7 if
- ``magnitude_range=(10, 0)``. Defaults to None.
- magnitude_std (Number | str): Deviation of magnitude noise applied.
-
- - If positive number, the magnitude obeys normal distribution
- :math:`\mathcal{N}(magnitude, magnitude_std)`.
- - If 0 or negative number, magnitude remains unchanged.
- - If str "inf", the magnitude obeys uniform distribution
- :math:`Uniform(min, magnitude)`.
-
- Defaults to 0.
- total_level (int | float): Total level for the magnitude. Defaults to
- 10.
- prob (float): The probability for performing transformation therefore
- should be in range [0, 1]. Defaults to 0.5.
- random_negative_prob (float): The probability that turns the magnitude
- negative, which should be in range [0,1]. Defaults to 0.
- """
-
- def __init__(self,
- magnitude_level: int = 10,
- magnitude_range: Tuple[float, float] = None,
- magnitude_std: Union[str, float] = 0.,
- total_level: int = 10,
- prob: float = 0.5,
- random_negative_prob: float = 0.5):
- self.magnitude_level = magnitude_level
- self.magnitude_range = magnitude_range
- self.magnitude_std = magnitude_std
- self.total_level = total_level
- self.prob = prob
- self.random_negative_prob = random_negative_prob
-
- @cache_randomness
- def random_disable(self):
- """Randomly disable the transform."""
- return np.random.rand() > self.prob
-
- @cache_randomness
- def random_magnitude(self):
- """Randomly generate magnitude."""
- magnitude = self.magnitude_level
- # if magnitude_std is positive number or 'inf', move
- # magnitude_value randomly.
- if self.magnitude_std == 'inf':
- magnitude = np.random.uniform(0, magnitude)
- elif self.magnitude_std > 0:
- magnitude = np.random.normal(magnitude, self.magnitude_std)
- magnitude = np.clip(magnitude, 0, self.total_level)
-
- val1, val2 = self.magnitude_range
- magnitude = (magnitude / self.total_level) * (val2 - val1) + val1
- return magnitude
-
- @cache_randomness
- def random_negative(self, value):
- """Randomly negative the value."""
- if np.random.rand() < self.random_negative_prob:
- return -value
- else:
- return value
-
- def extra_repr(self):
- """Extra repr string when auto-generating magnitude is enabled."""
- if self.magnitude_range is not None:
- repr_str = f', magnitude_level={self.magnitude_level}, '
- repr_str += f'magnitude_range={self.magnitude_range}, '
- repr_str += f'magnitude_std={self.magnitude_std}, '
- repr_str += f'total_level={self.total_level}, '
- return repr_str
- else:
- return ''
-
-
-@TRANSFORMS.register_module()
-class Shear(BaseAugTransform):
- """Shear images.
-
- Args:
- magnitude (int | float | None): The magnitude used for shear. If None,
- generate from ``magnitude_range``, see :class:`BaseAugTransform`.
- Defaults to None.
- pad_val (int, Sequence[int]): Pixel pad_val value for constant fill.
- If a sequence of length 3, it is used to pad_val R, G, B channels
- respectively. Defaults to 128.
- prob (float): The probability for performing shear therefore should be
- in range [0, 1]. Defaults to 0.5.
- direction (str): The shearing direction. Options are 'horizontal' and
- 'vertical'. Defaults to 'horizontal'.
- random_negative_prob (float): The probability that turns the magnitude
- negative, which should be in range [0,1]. Defaults to 0.5.
- interpolation (str): Interpolation method. Options are 'nearest',
- 'bilinear', 'bicubic', 'area', 'lanczos'. Defaults to 'bicubic'.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- magnitude: Union[int, float, None] = None,
- pad_val: Union[int, Sequence[int]] = 128,
- prob: float = 0.5,
- direction: str = 'horizontal',
- random_negative_prob: float = 0.5,
- interpolation: str = 'bicubic',
- **kwargs):
- super().__init__(
- prob=prob, random_negative_prob=random_negative_prob, **kwargs)
- assert (magnitude is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `magnitude` and `magnitude_range`.'
-
- self.magnitude = magnitude
- if isinstance(pad_val, Sequence):
- self.pad_val = tuple(pad_val)
- else:
- self.pad_val = pad_val
-
- assert direction in ('horizontal', 'vertical'), 'direction must be ' \
- f'either "horizontal" or "vertical", got "{direction}" instead.'
- self.direction = direction
-
- self.interpolation = interpolation
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.magnitude is not None:
- magnitude = self.random_negative(self.magnitude)
- else:
- magnitude = self.random_negative(self.random_magnitude())
-
- img = results['img']
- img_sheared = mmcv.imshear(
- img,
- magnitude,
- direction=self.direction,
- border_value=self.pad_val,
- interpolation=self.interpolation)
- results['img'] = img_sheared.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(magnitude={self.magnitude}, '
- repr_str += f'pad_val={self.pad_val}, '
- repr_str += f'prob={self.prob}, '
- repr_str += f'direction={self.direction}, '
- repr_str += f'random_negative_prob={self.random_negative_prob}, '
- repr_str += f'interpolation={self.interpolation}{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Translate(BaseAugTransform):
- """Translate images.
-
- Args:
- magnitude (int | float | None): The magnitude used for translate. Note
- that the offset is calculated by magnitude * size in the
- corresponding direction. With a magnitude of 1, the whole image
- will be moved out of the range. If None, generate from
- ``magnitude_range``, see :class:`BaseAugTransform`.
- pad_val (int, Sequence[int]): Pixel pad_val value for constant fill.
- If a sequence of length 3, it is used to pad_val R, G, B channels
- respectively. Defaults to 128.
- prob (float): The probability for performing translate therefore should
- be in range [0, 1]. Defaults to 0.5.
- direction (str): The translating direction. Options are 'horizontal'
- and 'vertical'. Defaults to 'horizontal'.
- random_negative_prob (float): The probability that turns the magnitude
- negative, which should be in range [0,1]. Defaults to 0.5.
- interpolation (str): Interpolation method. Options are 'nearest',
- 'bilinear', 'bicubic', 'area', 'lanczos'. Defaults to 'nearest'.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- magnitude: Union[int, float, None] = None,
- pad_val: Union[int, Sequence[int]] = 128,
- prob: float = 0.5,
- direction: str = 'horizontal',
- random_negative_prob: float = 0.5,
- interpolation: str = 'nearest',
- **kwargs):
- super().__init__(
- prob=prob, random_negative_prob=random_negative_prob, **kwargs)
- assert (magnitude is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `magnitude` and `magnitude_range`.'
-
- self.magnitude = magnitude
- if isinstance(pad_val, Sequence):
- self.pad_val = tuple(pad_val)
- else:
- self.pad_val = pad_val
-
- assert direction in ('horizontal', 'vertical'), 'direction must be ' \
- f'either "horizontal" or "vertical", got "{direction}" instead.'
- self.direction = direction
-
- self.interpolation = interpolation
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.magnitude is not None:
- magnitude = self.random_negative(self.magnitude)
- else:
- magnitude = self.random_negative(self.random_magnitude())
-
- img = results['img']
- height, width = img.shape[:2]
- if self.direction == 'horizontal':
- offset = magnitude * width
- else:
- offset = magnitude * height
- img_translated = mmcv.imtranslate(
- img,
- offset,
- direction=self.direction,
- border_value=self.pad_val,
- interpolation=self.interpolation)
- results['img'] = img_translated.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(magnitude={self.magnitude}, '
- repr_str += f'pad_val={self.pad_val}, '
- repr_str += f'prob={self.prob}, '
- repr_str += f'direction={self.direction}, '
- repr_str += f'random_negative_prob={self.random_negative_prob}, '
- repr_str += f'interpolation={self.interpolation}{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Rotate(BaseAugTransform):
- """Rotate images.
-
- Args:
- angle (float, optional): The angle used for rotate. Positive values
- stand for clockwise rotation. If None, generate from
- ``magnitude_range``, see :class:`BaseAugTransform`.
- Defaults to None.
- center (tuple[float], optional): Center point (w, h) of the rotation in
- the source image. If None, the center of the image will be used.
- Defaults to None.
- scale (float): Isotropic scale factor. Defaults to 1.0.
- pad_val (int, Sequence[int]): Pixel pad_val value for constant fill.
- If a sequence of length 3, it is used to pad_val R, G, B channels
- respectively. Defaults to 128.
- prob (float): The probability for performing rotate therefore should be
- in range [0, 1]. Defaults to 0.5.
- random_negative_prob (float): The probability that turns the angle
- negative, which should be in range [0,1]. Defaults to 0.5.
- interpolation (str): Interpolation method. Options are 'nearest',
- 'bilinear', 'bicubic', 'area', 'lanczos'. Defaults to 'nearest'.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- angle: Optional[float] = None,
- center: Optional[Tuple[float]] = None,
- scale: float = 1.0,
- pad_val: Union[int, Sequence[int]] = 128,
- prob: float = 0.5,
- random_negative_prob: float = 0.5,
- interpolation: str = 'nearest',
- **kwargs):
- super().__init__(
- prob=prob, random_negative_prob=random_negative_prob, **kwargs)
- assert (angle is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `angle` and `magnitude_range`.'
-
- self.angle = angle
- self.center = center
- self.scale = scale
- if isinstance(pad_val, Sequence):
- self.pad_val = tuple(pad_val)
- else:
- self.pad_val = pad_val
-
- self.interpolation = interpolation
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.angle is not None:
- angle = self.random_negative(self.angle)
- else:
- angle = self.random_negative(self.random_magnitude())
-
- img = results['img']
- img_rotated = mmcv.imrotate(
- img,
- angle,
- center=self.center,
- scale=self.scale,
- border_value=self.pad_val,
- interpolation=self.interpolation)
- results['img'] = img_rotated.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(angle={self.angle}, '
- repr_str += f'center={self.center}, '
- repr_str += f'scale={self.scale}, '
- repr_str += f'pad_val={self.pad_val}, '
- repr_str += f'prob={self.prob}, '
- repr_str += f'random_negative_prob={self.random_negative_prob}, '
- repr_str += f'interpolation={self.interpolation}{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class AutoContrast(BaseAugTransform):
- """Auto adjust image contrast.
-
- Args:
- prob (float): The probability for performing auto contrast
- therefore should be in range [0, 1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self, prob: float = 0.5, **kwargs):
- super().__init__(prob=prob, **kwargs)
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- img = results['img']
- img_contrasted = mmcv.auto_contrast(img)
- results['img'] = img_contrasted.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(prob={self.prob})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Invert(BaseAugTransform):
- """Invert images.
-
- Args:
- prob (float): The probability for performing invert therefore should
- be in range [0, 1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self, prob: float = 0.5, **kwargs):
- super().__init__(prob=prob, **kwargs)
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- img = results['img']
- img_inverted = mmcv.iminvert(img)
- results['img'] = img_inverted.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(prob={self.prob})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Equalize(BaseAugTransform):
- """Equalize the image histogram.
-
- Args:
- prob (float): The probability for performing equalize therefore should
- be in range [0, 1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self, prob: float = 0.5, **kwargs):
- super().__init__(prob=prob, **kwargs)
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- img = results['img']
- img_equalized = mmcv.imequalize(img)
- results['img'] = img_equalized.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(prob={self.prob})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Solarize(BaseAugTransform):
- """Solarize images (invert all pixel values above a threshold).
-
- Args:
- thr (int | float | None): The threshold above which the pixels value
- will be inverted. If None, generate from ``magnitude_range``,
- see :class:`BaseAugTransform`. Defaults to None.
- prob (float): The probability for solarizing therefore should be in
- range [0, 1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- thr: Union[int, float, None] = None,
- prob: float = 0.5,
- **kwargs):
- super().__init__(prob=prob, random_negative_prob=0., **kwargs)
- assert (thr is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `thr` and `magnitude_range`.'
-
- self.thr = thr
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.thr is not None:
- thr = self.thr
- else:
- thr = self.random_magnitude()
-
- img = results['img']
- img_solarized = mmcv.solarize(img, thr=thr)
- results['img'] = img_solarized.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(thr={self.thr}, '
- repr_str += f'prob={self.prob}{self.extra_repr()}))'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class SolarizeAdd(BaseAugTransform):
- """SolarizeAdd images (add a certain value to pixels below a threshold).
-
- Args:
- magnitude (int | float | None): The value to be added to pixels below
- the thr. If None, generate from ``magnitude_range``, see
- :class:`BaseAugTransform`. Defaults to None.
- thr (int | float): The threshold below which the pixels value will be
- adjusted.
- prob (float): The probability for solarizing therefore should be in
- range [0, 1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- magnitude: Union[int, float, None] = None,
- thr: Union[int, float] = 128,
- prob: float = 0.5,
- **kwargs):
- super().__init__(prob=prob, random_negative_prob=0., **kwargs)
- assert (magnitude is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `magnitude` and `magnitude_range`.'
-
- self.magnitude = magnitude
-
- assert isinstance(thr, (int, float)), 'The thr type must '\
- f'be int or float, but got {type(thr)} instead.'
- self.thr = thr
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.magnitude is not None:
- magnitude = self.magnitude
- else:
- magnitude = self.random_magnitude()
-
- img = results['img']
- img_solarized = np.where(img < self.thr,
- np.minimum(img + magnitude, 255), img)
- results['img'] = img_solarized.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(magnitude={self.magnitude}, '
- repr_str += f'thr={self.thr}, '
- repr_str += f'prob={self.prob}{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Posterize(BaseAugTransform):
- """Posterize images (reduce the number of bits for each color channel).
-
- Args:
- bits (int, optional): Number of bits for each pixel in the output img,
- which should be less or equal to 8. If None, generate from
- ``magnitude_range``, see :class:`BaseAugTransform`.
- Defaults to None.
- prob (float): The probability for posterizing therefore should be in
- range [0, 1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- bits: Optional[int] = None,
- prob: float = 0.5,
- **kwargs):
- super().__init__(prob=prob, random_negative_prob=0., **kwargs)
- assert (bits is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `bits` and `magnitude_range`.'
-
- if bits is not None:
- assert bits <= 8, \
- f'The bits must be less than 8, got {bits} instead.'
- self.bits = bits
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.bits is not None:
- bits = self.bits
- else:
- bits = self.random_magnitude()
-
- # To align timm version, we need to round up to integer here.
- bits = ceil(bits)
-
- img = results['img']
- img_posterized = mmcv.posterize(img, bits=bits)
- results['img'] = img_posterized.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(bits={self.bits}, '
- repr_str += f'prob={self.prob}{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Contrast(BaseAugTransform):
- """Adjust images contrast.
-
- Args:
- magnitude (int | float | None): The magnitude used for adjusting
- contrast. A positive magnitude would enhance the contrast and
- a negative magnitude would make the image grayer. A magnitude=0
- gives the origin img. If None, generate from ``magnitude_range``,
- see :class:`BaseAugTransform`. Defaults to None.
- prob (float): The probability for performing contrast adjusting
- therefore should be in range [0, 1]. Defaults to 0.5.
- random_negative_prob (float): The probability that turns the magnitude
- negative, which should be in range [0,1]. Defaults to 0.5.
- """
-
- def __init__(self,
- magnitude: Union[int, float, None] = None,
- prob: float = 0.5,
- random_negative_prob: float = 0.5,
- **kwargs):
- super().__init__(
- prob=prob, random_negative_prob=random_negative_prob, **kwargs)
- assert (magnitude is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `magnitude` and `magnitude_range`.'
-
- self.magnitude = magnitude
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.magnitude is not None:
- magnitude = self.random_negative(self.magnitude)
- else:
- magnitude = self.random_negative(self.random_magnitude())
-
- img = results['img']
- img_contrasted = mmcv.adjust_contrast(img, factor=1 + magnitude)
- results['img'] = img_contrasted.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(magnitude={self.magnitude}, '
- repr_str += f'prob={self.prob}, '
- repr_str += f'random_negative_prob={self.random_negative_prob}'
- repr_str += f'{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class ColorTransform(BaseAugTransform):
- """Adjust images color balance.
-
- Args:
- magnitude (int | float | None): The magnitude used for color transform.
- A positive magnitude would enhance the color and a negative
- magnitude would make the image grayer. A magnitude=0 gives the
- origin img. If None, generate from ``magnitude_range``, see
- :class:`BaseAugTransform`. Defaults to None.
- prob (float): The probability for performing ColorTransform therefore
- should be in range [0, 1]. Defaults to 0.5.
- random_negative_prob (float): The probability that turns the magnitude
- negative, which should be in range [0,1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- magnitude: Union[int, float, None] = None,
- prob: float = 0.5,
- random_negative_prob: float = 0.5,
- **kwargs):
- super().__init__(
- prob=prob, random_negative_prob=random_negative_prob, **kwargs)
- assert (magnitude is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `magnitude` and `magnitude_range`.'
-
- self.magnitude = magnitude
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.magnitude is not None:
- magnitude = self.random_negative(self.magnitude)
- else:
- magnitude = self.random_negative(self.random_magnitude())
-
- img = results['img']
- img_color_adjusted = mmcv.adjust_color(img, alpha=1 + magnitude)
- results['img'] = img_color_adjusted.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(magnitude={self.magnitude}, '
- repr_str += f'prob={self.prob}, '
- repr_str += f'random_negative_prob={self.random_negative_prob}'
- repr_str += f'{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Brightness(BaseAugTransform):
- """Adjust images brightness.
-
- Args:
- magnitude (int | float | None): The magnitude used for adjusting
- brightness. A positive magnitude would enhance the brightness and a
- negative magnitude would make the image darker. A magnitude=0 gives
- the origin img. If None, generate from ``magnitude_range``, see
- :class:`BaseAugTransform`. Defaults to None.
- prob (float): The probability for performing brightness adjusting
- therefore should be in range [0, 1]. Defaults to 0.5.
- random_negative_prob (float): The probability that turns the magnitude
- negative, which should be in range [0,1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- magnitude: Union[int, float, None] = None,
- prob: float = 0.5,
- random_negative_prob: float = 0.5,
- **kwargs):
- super().__init__(
- prob=prob, random_negative_prob=random_negative_prob, **kwargs)
- assert (magnitude is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `magnitude` and `magnitude_range`.'
-
- self.magnitude = magnitude
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.magnitude is not None:
- magnitude = self.random_negative(self.magnitude)
- else:
- magnitude = self.random_negative(self.random_magnitude())
-
- img = results['img']
- img_brightened = mmcv.adjust_brightness(img, factor=1 + magnitude)
- results['img'] = img_brightened.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(magnitude={self.magnitude}, '
- repr_str += f'prob={self.prob}, '
- repr_str += f'random_negative_prob={self.random_negative_prob}'
- repr_str += f'{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Sharpness(BaseAugTransform):
- """Adjust images sharpness.
-
- Args:
- magnitude (int | float | None): The magnitude used for adjusting
- sharpness. A positive magnitude would enhance the sharpness and a
- negative magnitude would make the image bulr. A magnitude=0 gives
- the origin img. If None, generate from ``magnitude_range``, see
- :class:`BaseAugTransform`. Defaults to None.
- prob (float): The probability for performing sharpness adjusting
- therefore should be in range [0, 1]. Defaults to 0.5.
- random_negative_prob (float): The probability that turns the magnitude
- negative, which should be in range [0,1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- magnitude: Union[int, float, None] = None,
- prob: float = 0.5,
- random_negative_prob: float = 0.5,
- **kwargs):
- super().__init__(
- prob=prob, random_negative_prob=random_negative_prob, **kwargs)
- assert (magnitude is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `magnitude` and `magnitude_range`.'
-
- self.magnitude = magnitude
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.magnitude is not None:
- magnitude = self.random_negative(self.magnitude)
- else:
- magnitude = self.random_negative(self.random_magnitude())
-
- img = results['img']
- img_sharpened = mmcv.adjust_sharpness(img, factor=1 + magnitude)
- results['img'] = img_sharpened.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(magnitude={self.magnitude}, '
- repr_str += f'prob={self.prob}, '
- repr_str += f'random_negative_prob={self.random_negative_prob}'
- repr_str += f'{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class Cutout(BaseAugTransform):
- """Cutout images.
-
- Args:
- shape (int | tuple(int) | None): Expected cutout shape (h, w).
- If given as a single value, the value will be used for both h and
- w. If None, generate from ``magnitude_range``, see
- :class:`BaseAugTransform`. Defaults to None.
- pad_val (int, Sequence[int]): Pixel pad_val value for constant fill.
- If it is a sequence, it must have the same length with the image
- channels. Defaults to 128.
- prob (float): The probability for performing cutout therefore should
- be in range [0, 1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- shape: Union[int, Tuple[int], None] = None,
- pad_val: Union[int, Sequence[int]] = 128,
- prob: float = 0.5,
- **kwargs):
- super().__init__(prob=prob, random_negative_prob=0., **kwargs)
- assert (shape is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `shape` and `magnitude_range`.'
-
- self.shape = shape
- if isinstance(pad_val, Sequence):
- self.pad_val = tuple(pad_val)
- else:
- self.pad_val = pad_val
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.shape is not None:
- shape = self.shape
- else:
- shape = int(self.random_magnitude())
-
- img = results['img']
- img_cutout = mmcv.cutout(img, shape, pad_val=self.pad_val)
- results['img'] = img_cutout.astype(img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(shape={self.shape}, '
- repr_str += f'pad_val={self.pad_val}, '
- repr_str += f'prob={self.prob}{self.extra_repr()})'
- return repr_str
-
-
-@TRANSFORMS.register_module()
-class GaussianBlur(BaseAugTransform):
- """Gaussian blur images.
-
- Args:
- radius (int, float, optional): The blur radius. If None, generate from
- ``magnitude_range``, see :class:`BaseAugTransform`.
- Defaults to None.
- prob (float): The probability for posterizing therefore should be in
- range [0, 1]. Defaults to 0.5.
- **kwargs: Other keyword arguments of :class:`BaseAugTransform`.
- """
-
- def __init__(self,
- radius: Union[int, float, None] = None,
- prob: float = 0.5,
- **kwargs):
- super().__init__(prob=prob, random_negative_prob=0., **kwargs)
- assert (radius is None) ^ (self.magnitude_range is None), \
- 'Please specify only one of `radius` and `magnitude_range`.'
-
- self.radius = radius
-
- def transform(self, results):
- """Apply transform to results."""
- if self.random_disable():
- return results
-
- if self.radius is not None:
- radius = self.radius
- else:
- radius = self.random_magnitude()
-
- img = results['img']
- pil_img = Image.fromarray(img)
- pil_img.filter(ImageFilter.GaussianBlur(radius=radius))
- results['img'] = np.array(pil_img, dtype=img.dtype)
-
- return results
-
- def __repr__(self):
- repr_str = self.__class__.__name__
- repr_str += f'(radius={self.radius}, '
- repr_str += f'prob={self.prob}{self.extra_repr()})'
- return repr_str
-
-
-# yapf: disable
-# flake8: noqa
-AUTOAUG_POLICIES = {
- # Policy for ImageNet, refers to
- # https://github.com/DeepVoltaire/AutoAugment/blame/master/autoaugment.py
- 'imagenet': [
- [dict(type='Posterize', bits=4, prob=0.4), dict(type='Rotate', angle=30., prob=0.6)],
- [dict(type='Solarize', thr=256 / 9 * 4, prob=0.6), dict(type='AutoContrast', prob=0.6)],
- [dict(type='Equalize', prob=0.8), dict(type='Equalize', prob=0.6)],
- [dict(type='Posterize', bits=5, prob=0.6), dict(type='Posterize', bits=5, prob=0.6)],
- [dict(type='Equalize', prob=0.4), dict(type='Solarize', thr=256 / 9 * 5, prob=0.2)],
- [dict(type='Equalize', prob=0.4), dict(type='Rotate', angle=30 / 9 * 8, prob=0.8)],
- [dict(type='Solarize', thr=256 / 9 * 6, prob=0.6), dict(type='Equalize', prob=0.6)],
- [dict(type='Posterize', bits=6, prob=0.8), dict(type='Equalize', prob=1.)],
- [dict(type='Rotate', angle=10., prob=0.2), dict(type='Solarize', thr=256 / 9, prob=0.6)],
- [dict(type='Equalize', prob=0.6), dict(type='Posterize', bits=5, prob=0.4)],
- [dict(type='Rotate', angle=30 / 9 * 8, prob=0.8), dict(type='ColorTransform', magnitude=0., prob=0.4)],
- [dict(type='Rotate', angle=30., prob=0.4), dict(type='Equalize', prob=0.6)],
- [dict(type='Equalize', prob=0.0), dict(type='Equalize', prob=0.8)],
- [dict(type='Invert', prob=0.6), dict(type='Equalize', prob=1.)],
- [dict(type='ColorTransform', magnitude=0.4, prob=0.6), dict(type='Contrast', magnitude=0.8, prob=1.)],
- [dict(type='Rotate', angle=30 / 9 * 8, prob=0.8), dict(type='ColorTransform', magnitude=0.2, prob=1.)],
- [dict(type='ColorTransform', magnitude=0.8, prob=0.8), dict(type='Solarize', thr=256 / 9 * 2, prob=0.8)],
- [dict(type='Sharpness', magnitude=0.7, prob=0.4), dict(type='Invert', prob=0.6)],
- [dict(type='Shear', magnitude=0.3 / 9 * 5, prob=0.6, direction='horizontal'), dict(type='Equalize', prob=1.)],
- [dict(type='ColorTransform', magnitude=0., prob=0.4), dict(type='Equalize', prob=0.6)],
- [dict(type='Equalize', prob=0.4), dict(type='Solarize', thr=256 / 9 * 5, prob=0.2)],
- [dict(type='Solarize', thr=256 / 9 * 4, prob=0.6), dict(type='AutoContrast', prob=0.6)],
- [dict(type='Invert', prob=0.6), dict(type='Equalize', prob=1.)],
- [dict(type='ColorTransform', magnitude=0.4, prob=0.6), dict(type='Contrast', magnitude=0.8, prob=1.)],
- [dict(type='Equalize', prob=0.8), dict(type='Equalize', prob=0.6)],
- ],
-}
-
-RANDAUG_POLICIES = {
- # Refers to `_RAND_INCREASING_TRANSFORMS` in pytorch-image-models
- 'timm_increasing': [
- dict(type='AutoContrast'),
- dict(type='Equalize'),
- dict(type='Invert'),
- dict(type='Rotate', magnitude_range=(0, 30)),
- dict(type='Posterize', magnitude_range=(4, 0)),
- dict(type='Solarize', magnitude_range=(256, 0)),
- dict(type='SolarizeAdd', magnitude_range=(0, 110)),
- dict(type='ColorTransform', magnitude_range=(0, 0.9)),
- dict(type='Contrast', magnitude_range=(0, 0.9)),
- dict(type='Brightness', magnitude_range=(0, 0.9)),
- dict(type='Sharpness', magnitude_range=(0, 0.9)),
- dict(type='Shear', magnitude_range=(0, 0.3), direction='horizontal'),
- dict(type='Shear', magnitude_range=(0, 0.3), direction='vertical'),
- dict(type='Translate', magnitude_range=(0, 0.45), direction='horizontal'),
- dict(type='Translate', magnitude_range=(0, 0.45), direction='vertical'),
- ],
- 'simple_increasing': [
- dict(type='AutoContrast'),
- dict(type='Equalize'),
- dict(type='Rotate', magnitude_range=(0, 30)),
- dict(type='Shear', magnitude_range=(0, 0.3), direction='horizontal'),
- dict(type='Shear', magnitude_range=(0, 0.3), direction='vertical'),
- ],
-}
diff --git a/spaces/LanguageBind/LanguageBind/d_cls/zero_shot_classifier.py b/spaces/LanguageBind/LanguageBind/d_cls/zero_shot_classifier.py
deleted file mode 100644
index a9a5267cea4119994e30bb4830a6744cf25bdbaf..0000000000000000000000000000000000000000
--- a/spaces/LanguageBind/LanguageBind/d_cls/zero_shot_classifier.py
+++ /dev/null
@@ -1,111 +0,0 @@
-from functools import partial
-from itertools import islice
-from typing import Callable, List, Optional, Sequence, Union
-
-import torch
-import torch.nn.functional as F
-
-
-def batched(iterable, n):
- """Batch data into lists of length *n*. The last batch may be shorter.
- NOTE based on more-itertools impl, to be replaced by python 3.12 itertools.batched impl
- """
- it = iter(iterable)
- while True:
- batch = list(islice(it, n))
- if not batch:
- break
- yield batch
-
-
-def build_zero_shot_classifier(
- model,
- tokenizer,
- classnames: Sequence[str],
- templates: Sequence[Union[Callable, str]],
- num_classes_per_batch: Optional[int] = 10,
- device: Union[str, torch.device] = 'cpu',
- use_tqdm: bool = False,
-):
- """ Build zero-shot classifier weights by iterating over class names in batches
- Args:
- model: CLIP model instance
- tokenizer: CLIP tokenizer instance
- classnames: A sequence of class (label) names
- templates: A sequence of callables or format() friendly strings to produce templates per class name
- num_classes_per_batch: The number of classes to batch together in each forward, all if None
- device: Device to use.
- use_tqdm: Enable TQDM progress bar.
- """
- assert isinstance(templates, Sequence) and len(templates) > 0
- assert isinstance(classnames, Sequence) and len(classnames) > 0
- use_format = isinstance(templates[0], str)
- num_templates = len(templates)
- num_classes = len(classnames)
- if use_tqdm:
- import tqdm
- num_iter = 1 if num_classes_per_batch is None else ((num_classes - 1) // num_classes_per_batch + 1)
- iter_wrap = partial(tqdm.tqdm, total=num_iter, unit_scale=num_classes_per_batch)
- else:
- iter_wrap = iter
-
- def _process_batch(batch_classnames):
- num_batch_classes = len(batch_classnames)
- texts = [template.format(c) if use_format else template(c) for c in batch_classnames for template in templates]
- input_ids, attention_mask = tokenizer(texts)
- input_ids, attention_mask = input_ids.to(device), attention_mask.to(device)
- class_embeddings = F.normalize(model.encode_text(input_ids, attention_mask), dim=-1)
- class_embeddings = class_embeddings.reshape(num_batch_classes, num_templates, -1).mean(dim=1)
- class_embeddings = class_embeddings / class_embeddings.norm(dim=1, keepdim=True)
- class_embeddings = class_embeddings.T
- return class_embeddings
-
- with torch.no_grad():
- if num_classes_per_batch:
- batched_embeds = [_process_batch(batch) for batch in iter_wrap(batched(classnames, num_classes_per_batch))]
- zeroshot_weights = torch.cat(batched_embeds, dim=1)
- else:
- zeroshot_weights = _process_batch(classnames)
- return zeroshot_weights
-
-
-def build_zero_shot_classifier_legacy(
- model,
- tokenizer,
- classnames: Sequence[str],
- templates: Sequence[Union[Callable, str]],
- device: Union[str, torch.device] = 'cpu',
- use_tqdm: bool = False,
-):
- """ Build zero-shot classifier weights by iterating over class names 1 by 1
- Args:
- model: CLIP model instance
- tokenizer: CLIP tokenizer instance
- classnames: A sequence of class (label) names
- templates: A sequence of callables or format() friendly strings to produce templates per class name
- device: Device to use.
- use_tqdm: Enable TQDM progress bar.
- """
- assert isinstance(templates, Sequence) and len(templates) > 0
- assert isinstance(classnames, Sequence) and len(classnames) > 0
- if use_tqdm:
- import tqdm
- iter_wrap = tqdm.tqdm
- else:
- iter_wrap = iter
-
- use_format = isinstance(templates[0], str)
-
- with torch.no_grad():
- zeroshot_weights = []
- for classname in iter_wrap(classnames):
- texts = [template.format(classname) if use_format else template(classname) for template in templates]
- texts = tokenizer(texts).to(device) # tokenize
- class_embeddings = model.encode_text(texts)
- class_embedding = F.normalize(class_embeddings, dim=-1).mean(dim=0)
- class_embedding /= class_embedding.norm()
- zeroshot_weights.append(class_embedding)
- zeroshot_weights = torch.stack(zeroshot_weights, dim=1).to(device)
-
- return zeroshot_weights
-
diff --git a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/diffq/uniform.py b/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/diffq/uniform.py
deleted file mode 100644
index f61e9129c04caaa33c66f726bf2433d51689cfa5..0000000000000000000000000000000000000000
--- a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/diffq/uniform.py
+++ /dev/null
@@ -1,121 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-"""
-Classic uniform quantization over n bits.
-"""
-from typing import Tuple
-import torch
-
-from .base import BaseQuantizer
-from .utils import simple_repr
-
-
-def uniform_quantize(p: torch.Tensor, bits: torch.Tensor = torch.tensor(8.)):
- """
- Quantize the given weights over `bits` bits.
-
- Returns:
- - quantized levels
- - (min, max) range.
-
- """
- assert (bits >= 1).all() and (bits <= 15).all()
- num_levels = (2 ** bits.float()).long()
- mn = p.min().item()
- mx = p.max().item()
- p = (p - mn) / (mx - mn) # put p in [0, 1]
- unit = 1 / (num_levels - 1) # quantization unit
- levels = (p / unit).round()
- if (bits <= 8).all():
- levels = levels.byte()
- else:
- levels = levels.short()
- return levels, (mn, mx)
-
-
-def uniform_unquantize(levels: torch.Tensor, scales: Tuple[float, float],
- bits: torch.Tensor = torch.tensor(8.)):
- """
- Unquantize the weights from the levels and scale. Return a float32 tensor.
- """
- mn, mx = scales
- num_levels = 2 ** bits.float()
- unit = 1 / (num_levels - 1)
- levels = levels.float()
- p = levels * unit # in [0, 1]
- return p * (mx - mn) + mn
-
-
-class UniformQuantizer(BaseQuantizer):
- def __init__(self, model: torch.nn.Module, bits: float = 8., min_size: float = 0.01,
- float16: bool = False, qat: bool = False, exclude=[], detect_bound=True):
- """
- Args:
- model (torch.nn.Module): model to quantize
- bits (float): number of bits to quantize over.
- min_size (float): minimum size in MB of a parameter to be quantized.
- float16 (bool): if a layer is smaller than min_size, should we still do float16?
- qat (bool): perform quantized aware training.
- exclude (list[str]): list of patterns used to match parameters to exclude.
- For instance `['bias']` to exclude all bias terms.
- detect_bound (bool): if True, will detect bound parameters and reuse
- the same quantized tensor for both.
- """
- self.bits = float(bits)
- self.qat = qat
-
- super().__init__(model, min_size, float16, exclude, detect_bound)
-
- def __repr__(self):
- return simple_repr(self, )
-
- def _pre_forward_train(self):
- if self.qat:
- for qparam in self._qparams:
- if qparam.other is not None:
- new_param = qparam.other.module._parameters[qparam.other.name]
- else:
- quantized = self._quantize_param(qparam)
- qvalue = self._unquantize_param(qparam, quantized)
- new_param = qparam.param + (qvalue - qparam.param).detach()
- qparam.module._parameters[qparam.name] = new_param
- return True
- return False
-
- def _post_forward_train(self):
- if self.qat:
- for qparam in self._qparams:
- qparam.module._parameters[qparam.name] = qparam.param
- return True
- return False
-
- def _quantize_param(self, qparam):
- levels, scales = uniform_quantize(qparam.param.data, torch.tensor(self.bits))
- return (levels, scales)
-
- def _unquantize_param(self, qparam, quantized):
- levels, scales = quantized
- return uniform_unquantize(levels, scales, torch.tensor(self.bits))
-
- def model_size(self):
- """
- Non differentiable model size in MB.
- """
- total = super().model_size()
- subtotal = 0
- for qparam in self._qparams:
- if qparam.other is None: # if parameter is bound, count only one copy.
- subtotal += self.bits * qparam.param.numel() + 64 # 2 float for the overall scales
- subtotal /= 2**20 * 8 # bits to MegaBytes
- return total + subtotal
-
- def true_model_size(self):
- """
- Return the true quantized model size, in MB, without extra
- compression.
- """
- return self.model_size().item()
diff --git a/spaces/Loren/Streamlit_OCR_comparator/configs/textrecog/nrtr/nrtr_modality_transform_academic.py b/spaces/Loren/Streamlit_OCR_comparator/configs/textrecog/nrtr/nrtr_modality_transform_academic.py
deleted file mode 100644
index 471926ba998640123ff356c146dc8bbdb9b3c261..0000000000000000000000000000000000000000
--- a/spaces/Loren/Streamlit_OCR_comparator/configs/textrecog/nrtr/nrtr_modality_transform_academic.py
+++ /dev/null
@@ -1,32 +0,0 @@
-_base_ = [
- '../../_base_/default_runtime.py',
- '../../_base_/recog_models/nrtr_modality_transform.py',
- '../../_base_/schedules/schedule_adam_step_6e.py',
- '../../_base_/recog_datasets/ST_MJ_train.py',
- '../../_base_/recog_datasets/academic_test.py',
- '../../_base_/recog_pipelines/nrtr_pipeline.py'
-]
-
-train_list = {{_base_.train_list}}
-test_list = {{_base_.test_list}}
-
-train_pipeline = {{_base_.train_pipeline}}
-test_pipeline = {{_base_.test_pipeline}}
-
-data = dict(
- samples_per_gpu=128,
- workers_per_gpu=4,
- train=dict(
- type='UniformConcatDataset',
- datasets=train_list,
- pipeline=train_pipeline),
- val=dict(
- type='UniformConcatDataset',
- datasets=test_list,
- pipeline=test_pipeline),
- test=dict(
- type='UniformConcatDataset',
- datasets=test_list,
- pipeline=test_pipeline))
-
-evaluation = dict(interval=1, metric='acc')
diff --git a/spaces/Marshalls/testmtd/feature_extraction/__init__.py b/spaces/Marshalls/testmtd/feature_extraction/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/MattyWhite/ChatGPT-ImageCaptioner2/tools/get_cc_tags.py b/spaces/MattyWhite/ChatGPT-ImageCaptioner2/tools/get_cc_tags.py
deleted file mode 100644
index 00bd6180ab7c5a6cbb0533a8a174e6de2f3b19b7..0000000000000000000000000000000000000000
--- a/spaces/MattyWhite/ChatGPT-ImageCaptioner2/tools/get_cc_tags.py
+++ /dev/null
@@ -1,194 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import argparse
-import json
-from collections import defaultdict
-
-# This mapping is extracted from the official LVIS mapping:
-# https://github.com/lvis-dataset/lvis-api/blob/master/data/coco_to_synset.json
-COCO_SYNSET_CATEGORIES = [
- {"synset": "person.n.01", "coco_cat_id": 1},
- {"synset": "bicycle.n.01", "coco_cat_id": 2},
- {"synset": "car.n.01", "coco_cat_id": 3},
- {"synset": "motorcycle.n.01", "coco_cat_id": 4},
- {"synset": "airplane.n.01", "coco_cat_id": 5},
- {"synset": "bus.n.01", "coco_cat_id": 6},
- {"synset": "train.n.01", "coco_cat_id": 7},
- {"synset": "truck.n.01", "coco_cat_id": 8},
- {"synset": "boat.n.01", "coco_cat_id": 9},
- {"synset": "traffic_light.n.01", "coco_cat_id": 10},
- {"synset": "fireplug.n.01", "coco_cat_id": 11},
- {"synset": "stop_sign.n.01", "coco_cat_id": 13},
- {"synset": "parking_meter.n.01", "coco_cat_id": 14},
- {"synset": "bench.n.01", "coco_cat_id": 15},
- {"synset": "bird.n.01", "coco_cat_id": 16},
- {"synset": "cat.n.01", "coco_cat_id": 17},
- {"synset": "dog.n.01", "coco_cat_id": 18},
- {"synset": "horse.n.01", "coco_cat_id": 19},
- {"synset": "sheep.n.01", "coco_cat_id": 20},
- {"synset": "beef.n.01", "coco_cat_id": 21},
- {"synset": "elephant.n.01", "coco_cat_id": 22},
- {"synset": "bear.n.01", "coco_cat_id": 23},
- {"synset": "zebra.n.01", "coco_cat_id": 24},
- {"synset": "giraffe.n.01", "coco_cat_id": 25},
- {"synset": "backpack.n.01", "coco_cat_id": 27},
- {"synset": "umbrella.n.01", "coco_cat_id": 28},
- {"synset": "bag.n.04", "coco_cat_id": 31},
- {"synset": "necktie.n.01", "coco_cat_id": 32},
- {"synset": "bag.n.06", "coco_cat_id": 33},
- {"synset": "frisbee.n.01", "coco_cat_id": 34},
- {"synset": "ski.n.01", "coco_cat_id": 35},
- {"synset": "snowboard.n.01", "coco_cat_id": 36},
- {"synset": "ball.n.06", "coco_cat_id": 37},
- {"synset": "kite.n.03", "coco_cat_id": 38},
- {"synset": "baseball_bat.n.01", "coco_cat_id": 39},
- {"synset": "baseball_glove.n.01", "coco_cat_id": 40},
- {"synset": "skateboard.n.01", "coco_cat_id": 41},
- {"synset": "surfboard.n.01", "coco_cat_id": 42},
- {"synset": "tennis_racket.n.01", "coco_cat_id": 43},
- {"synset": "bottle.n.01", "coco_cat_id": 44},
- {"synset": "wineglass.n.01", "coco_cat_id": 46},
- {"synset": "cup.n.01", "coco_cat_id": 47},
- {"synset": "fork.n.01", "coco_cat_id": 48},
- {"synset": "knife.n.01", "coco_cat_id": 49},
- {"synset": "spoon.n.01", "coco_cat_id": 50},
- {"synset": "bowl.n.03", "coco_cat_id": 51},
- {"synset": "banana.n.02", "coco_cat_id": 52},
- {"synset": "apple.n.01", "coco_cat_id": 53},
- {"synset": "sandwich.n.01", "coco_cat_id": 54},
- {"synset": "orange.n.01", "coco_cat_id": 55},
- {"synset": "broccoli.n.01", "coco_cat_id": 56},
- {"synset": "carrot.n.01", "coco_cat_id": 57},
- # {"synset": "frank.n.02", "coco_cat_id": 58},
- {"synset": "sausage.n.01", "coco_cat_id": 58},
- {"synset": "pizza.n.01", "coco_cat_id": 59},
- {"synset": "doughnut.n.02", "coco_cat_id": 60},
- {"synset": "cake.n.03", "coco_cat_id": 61},
- {"synset": "chair.n.01", "coco_cat_id": 62},
- {"synset": "sofa.n.01", "coco_cat_id": 63},
- {"synset": "pot.n.04", "coco_cat_id": 64},
- {"synset": "bed.n.01", "coco_cat_id": 65},
- {"synset": "dining_table.n.01", "coco_cat_id": 67},
- {"synset": "toilet.n.02", "coco_cat_id": 70},
- {"synset": "television_receiver.n.01", "coco_cat_id": 72},
- {"synset": "laptop.n.01", "coco_cat_id": 73},
- {"synset": "mouse.n.04", "coco_cat_id": 74},
- {"synset": "remote_control.n.01", "coco_cat_id": 75},
- {"synset": "computer_keyboard.n.01", "coco_cat_id": 76},
- {"synset": "cellular_telephone.n.01", "coco_cat_id": 77},
- {"synset": "microwave.n.02", "coco_cat_id": 78},
- {"synset": "oven.n.01", "coco_cat_id": 79},
- {"synset": "toaster.n.02", "coco_cat_id": 80},
- {"synset": "sink.n.01", "coco_cat_id": 81},
- {"synset": "electric_refrigerator.n.01", "coco_cat_id": 82},
- {"synset": "book.n.01", "coco_cat_id": 84},
- {"synset": "clock.n.01", "coco_cat_id": 85},
- {"synset": "vase.n.01", "coco_cat_id": 86},
- {"synset": "scissors.n.01", "coco_cat_id": 87},
- {"synset": "teddy.n.01", "coco_cat_id": 88},
- {"synset": "hand_blower.n.01", "coco_cat_id": 89},
- {"synset": "toothbrush.n.01", "coco_cat_id": 90},
-]
-
-def map_name(x):
- x = x.replace('_', ' ')
- if '(' in x:
- x = x[:x.find('(')]
- return x.lower().strip()
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--cc_ann', default='datasets/cc3m/train_image_info.json')
- parser.add_argument('--out_path', default='datasets/cc3m/train_image_info_tags.json')
- parser.add_argument('--keep_images', action='store_true')
- parser.add_argument('--allcaps', action='store_true')
- parser.add_argument('--cat_path', default='')
- parser.add_argument('--convert_caption', action='store_true')
- # parser.add_argument('--lvis_ann', default='datasets/lvis/lvis_v1_val.json')
- args = parser.parse_args()
-
- # lvis_data = json.load(open(args.lvis_ann, 'r'))
- cc_data = json.load(open(args.cc_ann, 'r'))
- if args.convert_caption:
- num_caps = 0
- caps = defaultdict(list)
- for x in cc_data['annotations']:
- caps[x['image_id']].append(x['caption'])
- for x in cc_data['images']:
- x['captions'] = caps[x['id']]
- num_caps += len(x['captions'])
- print('# captions', num_caps)
-
- if args.cat_path != '':
- print('Loading', args.cat_path)
- cats = json.load(open(args.cat_path))['categories']
- if 'synonyms' not in cats[0]:
- cocoid2synset = {x['coco_cat_id']: x['synset'] \
- for x in COCO_SYNSET_CATEGORIES}
- synset2synonyms = {x['synset']: x['synonyms'] \
- for x in cc_data['categories']}
- for x in cats:
- synonyms = synset2synonyms[cocoid2synset[x['id']]]
- x['synonyms'] = synonyms
- x['frequency'] = 'f'
- cc_data['categories'] = cats
-
- id2cat = {x['id']: x for x in cc_data['categories']}
- class_count = {x['id']: 0 for x in cc_data['categories']}
- class_data = {x['id']: [' ' + map_name(xx) + ' ' for xx in x['synonyms']] \
- for x in cc_data['categories']}
- num_examples = 5
- examples = {x['id']: [] for x in cc_data['categories']}
-
- print('class_data', class_data)
-
- images = []
- for i, x in enumerate(cc_data['images']):
- if i % 10000 == 0:
- print(i, len(cc_data['images']))
- if args.allcaps:
- caption = (' '.join(x['captions'])).lower()
- else:
- caption = x['captions'][0].lower()
- x['pos_category_ids'] = []
- for cat_id, cat_names in class_data.items():
- find = False
- for c in cat_names:
- if c in caption or caption.startswith(c[1:]) \
- or caption.endswith(c[:-1]):
- find = True
- break
- if find:
- x['pos_category_ids'].append(cat_id)
- class_count[cat_id] += 1
- if len(examples[cat_id]) < num_examples:
- examples[cat_id].append(caption)
- if len(x['pos_category_ids']) > 0 or args.keep_images:
- images.append(x)
-
- zero_class = []
- for cat_id, count in class_count.items():
- print(id2cat[cat_id]['name'], count, end=', ')
- if count == 0:
- zero_class.append(id2cat[cat_id])
- print('==')
- print('zero class', zero_class)
-
- # for freq in ['r', 'c', 'f']:
- # print('#cats', freq, len([x for x in cc_data['categories'] \
- # if x['frequency'] == freq] and class_count[x['id']] > 0))
-
- for freq in ['r', 'c', 'f']:
- print('#Images', freq, sum([v for k, v in class_count.items() \
- if id2cat[k]['frequency'] == freq]))
-
- try:
- out_data = {'images': images, 'categories': cc_data['categories'], \
- 'annotations': []}
- for k, v in out_data.items():
- print(k, len(v))
- if args.keep_images and not args.out_path.endswith('_full.json'):
- args.out_path = args.out_path[:-5] + '_full.json'
- print('Writing to', args.out_path)
- json.dump(out_data, open(args.out_path, 'w'))
- except:
- pass
diff --git a/spaces/MirageML/lowpoly-world/app.py b/spaces/MirageML/lowpoly-world/app.py
deleted file mode 100644
index 5643ddfd5dbb507d06c9df7289a306e97df2d8ba..0000000000000000000000000000000000000000
--- a/spaces/MirageML/lowpoly-world/app.py
+++ /dev/null
@@ -1,155 +0,0 @@
-from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline, DPMSolverMultistepScheduler
-import gradio as gr
-import torch
-from PIL import Image
-
-model_id = 'MirageML/lowpoly-world'
-prefix = 'lowpoly_world'
-
-scheduler = DPMSolverMultistepScheduler(
- beta_start=0.00085,
- beta_end=0.012,
- beta_schedule="scaled_linear",
- num_train_timesteps=1000,
- trained_betas=None,
- predict_epsilon=True,
- thresholding=False,
- algorithm_type="dpmsolver++",
- solver_type="midpoint",
- lower_order_final=True,
-)
-
-pipe = StableDiffusionPipeline.from_pretrained(
- model_id,
- torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
- scheduler=scheduler)
-
-pipe_i2i = StableDiffusionImg2ImgPipeline.from_pretrained(
- model_id,
- torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
- scheduler=scheduler)
-
-if torch.cuda.is_available():
- pipe = pipe.to("cuda")
- pipe_i2i = pipe_i2i.to("cuda")
-
-def error_str(error, title="Error"):
- return f"""#### {title}
- {error}""" if error else ""
-
-def inference(prompt, guidance, steps, width=512, height=512, seed=0, img=None, strength=0.5, neg_prompt="", auto_prefix=False):
-
- generator = torch.Generator('cuda').manual_seed(seed) if seed != 0 else None
- prompt = f"{prefix} {prompt}" if auto_prefix else prompt
-
- try:
- if img is not None:
- return img_to_img(prompt, neg_prompt, img, strength, guidance, steps, width, height, generator), None
- else:
- return txt_to_img(prompt, neg_prompt, guidance, steps, width, height, generator), None
- except Exception as e:
- return None, error_str(e)
-
-def txt_to_img(prompt, neg_prompt, guidance, steps, width, height, generator):
-
- result = pipe(
- prompt,
- negative_prompt = neg_prompt,
- num_inference_steps = int(steps),
- guidance_scale = guidance,
- width = width,
- height = height,
- generator = generator)
-
- return replace_nsfw_images(result)
-
-def img_to_img(prompt, neg_prompt, img, strength, guidance, steps, width, height, generator):
-
- ratio = min(height / img.height, width / img.width)
- img = img.resize((int(img.width * ratio), int(img.height * ratio)), Image.LANCZOS)
- result = pipe_i2i(
- prompt,
- negative_prompt = neg_prompt,
- init_image = img,
- num_inference_steps = int(steps),
- strength = strength,
- guidance_scale = guidance,
- width = width,
- height = height,
- generator = generator)
-
- return replace_nsfw_images(result)
-
-def replace_nsfw_images(results):
-
- for i in range(len(results.images)):
- if results.nsfw_content_detected[i]:
- results.images[i] = Image.open("nsfw.png")
- return results.images[0]
-
-css = """.main-div div{display:inline-flex;align-items:center;gap:.8rem;font-size:1.75rem}.main-div div h1{font-weight:900;margin-bottom:7px}.main-div p{margin-bottom:10px;font-size:94%}a{text-decoration:underline}.tabs{margin-top:0;margin-bottom:0}#gallery{min-height:20rem}
-"""
-with gr.Blocks(css=css) as demo:
- gr.HTML(
- f"""
-
-
-
Lowpoly World
-
-
- Demo for Lowpoly World Stable Diffusion model.prefix " if prefix else ""}
-
- Running on {"
GPU 🔥 " if torch.cuda.is_available() else f"
CPU 🥶 . For faster inference it is recommended to
upgrade to GPU in Settings "}
-
-
-
- Args:
- example_serialized: scalar Tensor tf.string containing a serialized
- Example protocol buffer.
-
- Returns:
- image_buffer: Tensor tf.string containing the contents of a JPEG file.
- label: Tensor tf.int32 containing the label.
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged as
- [ymin, xmin, ymax, xmax].
- """
- # Dense features in Example proto.
- feature_map = {
- 'image/encoded': tf.io.FixedLenFeature([], dtype=tf.string,
- default_value=''),
- 'image/class/label': tf.io.FixedLenFeature([], dtype=tf.int64,
- default_value=-1),
- 'image/class/text': tf.io.FixedLenFeature([], dtype=tf.string,
- default_value=''),
- }
- sparse_float32 = tf.io.VarLenFeature(dtype=tf.float32)
- # Sparse features in Example proto.
- feature_map.update(
- {k: sparse_float32 for k in [
- 'image/object/bbox/xmin', 'image/object/bbox/ymin',
- 'image/object/bbox/xmax', 'image/object/bbox/ymax']})
-
- features = tf.io.parse_single_example(serialized=example_serialized,
- features=feature_map)
- label = tf.cast(features['image/class/label'], dtype=tf.int32)
-
- xmin = tf.expand_dims(features['image/object/bbox/xmin'].values, 0)
- ymin = tf.expand_dims(features['image/object/bbox/ymin'].values, 0)
- xmax = tf.expand_dims(features['image/object/bbox/xmax'].values, 0)
- ymax = tf.expand_dims(features['image/object/bbox/ymax'].values, 0)
-
- # Note that we impose an ordering of (y, x) just to make life difficult.
- bbox = tf.concat([ymin, xmin, ymax, xmax], 0)
-
- # Force the variable number of bounding boxes into the shape
- # [1, num_boxes, coords].
- bbox = tf.expand_dims(bbox, 0)
- bbox = tf.transpose(a=bbox, perm=[0, 2, 1])
-
- return features['image/encoded'], label, bbox
-
-
-def parse_record(raw_record, is_training, dtype):
- """Parses a record containing a training example of an image.
-
- The input record is parsed into a label and image, and the image is passed
- through preprocessing steps (cropping, flipping, and so on).
-
- Args:
- raw_record: scalar Tensor tf.string containing a serialized
- Example protocol buffer.
- is_training: A boolean denoting whether the input is for training.
- dtype: data type to use for images/features.
-
- Returns:
- Tuple with processed image tensor in a channel-last format and
- one-hot-encoded label tensor.
- """
- image_buffer, label, bbox = parse_example_proto(raw_record)
-
- image = preprocess_image(
- image_buffer=image_buffer,
- bbox=bbox,
- output_height=DEFAULT_IMAGE_SIZE,
- output_width=DEFAULT_IMAGE_SIZE,
- num_channels=NUM_CHANNELS,
- is_training=is_training)
- image = tf.cast(image, dtype)
-
- # Subtract one so that labels are in [0, 1000), and cast to float32 for
- # Keras model.
- label = tf.cast(tf.cast(tf.reshape(label, shape=[1]), dtype=tf.int32) - 1,
- dtype=tf.float32)
- return image, label
-
-
-def get_parse_record_fn(use_keras_image_data_format=False):
- """Get a function for parsing the records, accounting for image format.
-
- This is useful by handling different types of Keras models. For instance,
- the current resnet_model.resnet50 input format is always channel-last,
- whereas the keras_applications mobilenet input format depends on
- tf.keras.backend.image_data_format(). We should set
- use_keras_image_data_format=False for the former and True for the latter.
-
- Args:
- use_keras_image_data_format: A boolean denoting whether data format is keras
- backend image data format. If False, the image format is channel-last. If
- True, the image format matches tf.keras.backend.image_data_format().
-
- Returns:
- Function to use for parsing the records.
- """
- def parse_record_fn(raw_record, is_training, dtype):
- image, label = parse_record(raw_record, is_training, dtype)
- if use_keras_image_data_format:
- if tf.keras.backend.image_data_format() == 'channels_first':
- image = tf.transpose(image, perm=[2, 0, 1])
- return image, label
- return parse_record_fn
-
-
-def input_fn(is_training,
- data_dir,
- batch_size,
- dtype=tf.float32,
- datasets_num_private_threads=None,
- parse_record_fn=parse_record,
- input_context=None,
- drop_remainder=False,
- tf_data_experimental_slack=False,
- training_dataset_cache=False,
- filenames=None):
- """Input function which provides batches for train or eval.
-
- Args:
- is_training: A boolean denoting whether the input is for training.
- data_dir: The directory containing the input data.
- batch_size: The number of samples per batch.
- dtype: Data type to use for images/features
- datasets_num_private_threads: Number of private threads for tf.data.
- parse_record_fn: Function to use for parsing the records.
- input_context: A `tf.distribute.InputContext` object passed in by
- `tf.distribute.Strategy`.
- drop_remainder: A boolean indicates whether to drop the remainder of the
- batches. If True, the batch dimension will be static.
- tf_data_experimental_slack: Whether to enable tf.data's
- `experimental_slack` option.
- training_dataset_cache: Whether to cache the training dataset on workers.
- Typically used to improve training performance when training data is in
- remote storage and can fit into worker memory.
- filenames: Optional field for providing the file names of the TFRecords.
-
- Returns:
- A dataset that can be used for iteration.
- """
- if filenames is None:
- filenames = get_filenames(is_training, data_dir)
- dataset = tf.data.Dataset.from_tensor_slices(filenames)
-
- if input_context:
- logging.info(
- 'Sharding the dataset: input_pipeline_id=%d num_input_pipelines=%d',
- input_context.input_pipeline_id, input_context.num_input_pipelines)
- dataset = dataset.shard(input_context.num_input_pipelines,
- input_context.input_pipeline_id)
-
- if is_training:
- # Shuffle the input files
- dataset = dataset.shuffle(buffer_size=_NUM_TRAIN_FILES)
-
- # Convert to individual records.
- # cycle_length = 10 means that up to 10 files will be read and deserialized in
- # parallel. You may want to increase this number if you have a large number of
- # CPU cores.
- dataset = dataset.interleave(
- tf.data.TFRecordDataset,
- cycle_length=10,
- num_parallel_calls=tf.data.experimental.AUTOTUNE)
-
- if is_training and training_dataset_cache:
- # Improve training performance when training data is in remote storage and
- # can fit into worker memory.
- dataset = dataset.cache()
-
- return process_record_dataset(
- dataset=dataset,
- is_training=is_training,
- batch_size=batch_size,
- shuffle_buffer=_SHUFFLE_BUFFER,
- parse_record_fn=parse_record_fn,
- dtype=dtype,
- datasets_num_private_threads=datasets_num_private_threads,
- drop_remainder=drop_remainder,
- tf_data_experimental_slack=tf_data_experimental_slack,
- )
-
-
-def _decode_crop_and_flip(image_buffer, bbox, num_channels):
- """Crops the given image to a random part of the image, and randomly flips.
-
- We use the fused decode_and_crop op, which performs better than the two ops
- used separately in series, but note that this requires that the image be
- passed in as an un-decoded string Tensor.
-
- Args:
- image_buffer: scalar string Tensor representing the raw JPEG image buffer.
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged as
- [ymin, xmin, ymax, xmax].
- num_channels: Integer depth of the image buffer for decoding.
-
- Returns:
- 3-D tensor with cropped image.
-
- """
- # A large fraction of image datasets contain a human-annotated bounding box
- # delineating the region of the image containing the object of interest. We
- # choose to create a new bounding box for the object which is a randomly
- # distorted version of the human-annotated bounding box that obeys an
- # allowed range of aspect ratios, sizes and overlap with the human-annotated
- # bounding box. If no box is supplied, then we assume the bounding box is
- # the entire image.
- sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box(
- tf.image.extract_jpeg_shape(image_buffer),
- bounding_boxes=bbox,
- min_object_covered=0.1,
- aspect_ratio_range=[0.75, 1.33],
- area_range=[0.05, 1.0],
- max_attempts=100,
- use_image_if_no_bounding_boxes=True)
- bbox_begin, bbox_size, _ = sample_distorted_bounding_box
-
- # Reassemble the bounding box in the format the crop op requires.
- offset_y, offset_x, _ = tf.unstack(bbox_begin)
- target_height, target_width, _ = tf.unstack(bbox_size)
- crop_window = tf.stack([offset_y, offset_x, target_height, target_width])
-
- # Use the fused decode and crop op here, which is faster than each in series.
- cropped = tf.image.decode_and_crop_jpeg(
- image_buffer, crop_window, channels=num_channels)
-
- # Flip to add a little more random distortion in.
- cropped = tf.image.random_flip_left_right(cropped)
- return cropped
-
-
-def _central_crop(image, crop_height, crop_width):
- """Performs central crops of the given image list.
-
- Args:
- image: a 3-D image tensor
- crop_height: the height of the image following the crop.
- crop_width: the width of the image following the crop.
-
- Returns:
- 3-D tensor with cropped image.
- """
- shape = tf.shape(input=image)
- height, width = shape[0], shape[1]
-
- amount_to_be_cropped_h = (height - crop_height)
- crop_top = amount_to_be_cropped_h // 2
- amount_to_be_cropped_w = (width - crop_width)
- crop_left = amount_to_be_cropped_w // 2
- return tf.slice(
- image, [crop_top, crop_left, 0], [crop_height, crop_width, -1])
-
-
-def _mean_image_subtraction(image, means, num_channels):
- """Subtracts the given means from each image channel.
-
- For example:
- means = [123.68, 116.779, 103.939]
- image = _mean_image_subtraction(image, means)
-
- Note that the rank of `image` must be known.
-
- Args:
- image: a tensor of size [height, width, C].
- means: a C-vector of values to subtract from each channel.
- num_channels: number of color channels in the image that will be distorted.
-
- Returns:
- the centered image.
-
- Raises:
- ValueError: If the rank of `image` is unknown, if `image` has a rank other
- than three or if the number of channels in `image` doesn't match the
- number of values in `means`.
- """
- if image.get_shape().ndims != 3:
- raise ValueError('Input must be of size [height, width, C>0]')
-
- if len(means) != num_channels:
- raise ValueError('len(means) must match the number of channels')
-
- # We have a 1-D tensor of means; convert to 3-D.
- # Note(b/130245863): we explicitly call `broadcast` instead of simply
- # expanding dimensions for better performance.
- means = tf.broadcast_to(means, tf.shape(image))
-
- return image - means
-
-
-def _smallest_size_at_least(height, width, resize_min):
- """Computes new shape with the smallest side equal to `smallest_side`.
-
- Computes new shape with the smallest side equal to `smallest_side` while
- preserving the original aspect ratio.
-
- Args:
- height: an int32 scalar tensor indicating the current height.
- width: an int32 scalar tensor indicating the current width.
- resize_min: A python integer or scalar `Tensor` indicating the size of
- the smallest side after resize.
-
- Returns:
- new_height: an int32 scalar tensor indicating the new height.
- new_width: an int32 scalar tensor indicating the new width.
- """
- resize_min = tf.cast(resize_min, tf.float32)
-
- # Convert to floats to make subsequent calculations go smoothly.
- height, width = tf.cast(height, tf.float32), tf.cast(width, tf.float32)
-
- smaller_dim = tf.minimum(height, width)
- scale_ratio = resize_min / smaller_dim
-
- # Convert back to ints to make heights and widths that TF ops will accept.
- new_height = tf.cast(height * scale_ratio, tf.int32)
- new_width = tf.cast(width * scale_ratio, tf.int32)
-
- return new_height, new_width
-
-
-def _aspect_preserving_resize(image, resize_min):
- """Resize images preserving the original aspect ratio.
-
- Args:
- image: A 3-D image `Tensor`.
- resize_min: A python integer or scalar `Tensor` indicating the size of
- the smallest side after resize.
-
- Returns:
- resized_image: A 3-D tensor containing the resized image.
- """
- shape = tf.shape(input=image)
- height, width = shape[0], shape[1]
-
- new_height, new_width = _smallest_size_at_least(height, width, resize_min)
-
- return _resize_image(image, new_height, new_width)
-
-
-def _resize_image(image, height, width):
- """Simple wrapper around tf.resize_images.
-
- This is primarily to make sure we use the same `ResizeMethod` and other
- details each time.
-
- Args:
- image: A 3-D image `Tensor`.
- height: The target height for the resized image.
- width: The target width for the resized image.
-
- Returns:
- resized_image: A 3-D tensor containing the resized image. The first two
- dimensions have the shape [height, width].
- """
- return tf.compat.v1.image.resize(
- image, [height, width], method=tf.image.ResizeMethod.BILINEAR,
- align_corners=False)
-
-
-def preprocess_image(image_buffer, bbox, output_height, output_width,
- num_channels, is_training=False):
- """Preprocesses the given image.
-
- Preprocessing includes decoding, cropping, and resizing for both training
- and eval images. Training preprocessing, however, introduces some random
- distortion of the image to improve accuracy.
-
- Args:
- image_buffer: scalar string Tensor representing the raw JPEG image buffer.
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged as
- [ymin, xmin, ymax, xmax].
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- num_channels: Integer depth of the image buffer for decoding.
- is_training: `True` if we're preprocessing the image for training and
- `False` otherwise.
-
- Returns:
- A preprocessed image.
- """
- if is_training:
- # For training, we want to randomize some of the distortions.
- image = _decode_crop_and_flip(image_buffer, bbox, num_channels)
- image = _resize_image(image, output_height, output_width)
- else:
- # For validation, we want to decode, resize, then just crop the middle.
- image = tf.image.decode_jpeg(image_buffer, channels=num_channels)
- image = _aspect_preserving_resize(image, _RESIZE_MIN)
- image = _central_crop(image, output_height, output_width)
-
- image.set_shape([output_height, output_width, num_channels])
-
- return _mean_image_subtraction(image, CHANNEL_MEANS, num_channels)
diff --git a/spaces/NN520/AI/src/components/chat-notification.tsx b/spaces/NN520/AI/src/components/chat-notification.tsx
deleted file mode 100644
index 4be24d0f1755c8058698cfa66c736d8d4792475a..0000000000000000000000000000000000000000
--- a/spaces/NN520/AI/src/components/chat-notification.tsx
+++ /dev/null
@@ -1,77 +0,0 @@
-import { useEffect } from 'react'
-import Image from 'next/image'
-
-import IconWarning from '@/assets/images/warning.svg'
-import { ChatError, ErrorCode, ChatMessageModel } from '@/lib/bots/bing/types'
-import { ExternalLink } from './external-link'
-import { useBing } from '@/lib/hooks/use-bing'
-
-export interface ChatNotificationProps extends Pick, 'bot'> {
- message?: ChatMessageModel
-}
-
-function getAction(error: ChatError, reset: () => void) {
- if (error.code === ErrorCode.THROTTLE_LIMIT) {
- reset()
- return (
-
- 你已达到每日最大发送消息次数,请
更换账号 或隔一天后重试
-
- 你的账号已在黑名单,请尝试更换账号及申请解封
-
- )
- }
- if (error.code === ErrorCode.CONVERSATION_LIMIT) {
- return (
-
- 当前话题已中止,请点
-
重新开始
- 开启新的对话
-
- 点击通过人机验证
-
- )
- }
- if (error.code === ErrorCode.BING_UNAUTHORIZED) {
- reset()
- return (
- 没有获取到身份信息或身份信息失效,点此重新设置
- )
- }
- return error.message
-}
-
-export function ChatNotification({ message, bot }: ChatNotificationProps) {
- useEffect(() => {
- window.scrollBy(0, 2000)
- }, [message])
-
- if (!message?.error) return
-
- return (
-
-
-
-
-
-
-
-
-
-
`_
- for more details.
- """
-
- @staticmethod
- def forward(ctx, target: torch.Tensor,
- source: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
- """
- Args:
- target (Tensor): shape (B, N, 3), points set that needs to
- find the nearest neighbors.
- source (Tensor): shape (B, M, 3), points set that is used
- to find the nearest neighbors of points in target set.
-
- Returns:
- Tensor: shape (B, N, 3), L2 distance of each point in target
- set to their corresponding nearest neighbors.
- """
- target = target.contiguous()
- source = source.contiguous()
-
- B, N, _ = target.size()
- m = source.size(1)
- dist2 = torch.cuda.FloatTensor(B, N, 3)
- idx = torch.cuda.IntTensor(B, N, 3)
-
- ext_module.three_nn_forward(target, source, dist2, idx, b=B, n=N, m=m)
- if torch.__version__ != 'parrots':
- ctx.mark_non_differentiable(idx)
-
- return torch.sqrt(dist2), idx
-
- @staticmethod
- def backward(ctx, a=None, b=None):
- return None, None
-
-
-three_nn = ThreeNN.apply
diff --git a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/rpn/inference.py b/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/rpn/inference.py
deleted file mode 100644
index 6d71118af41ee11c7811c5c5c1f4d51f3b96f392..0000000000000000000000000000000000000000
--- a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/rpn/inference.py
+++ /dev/null
@@ -1,850 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-import logging
-
-import torch
-
-from maskrcnn_benchmark.modeling.box_coder import BoxCoder
-from maskrcnn_benchmark.structures.bounding_box import BoxList, _onnx_clip_boxes_to_image
-from maskrcnn_benchmark.structures.boxlist_ops import cat_boxlist
-from maskrcnn_benchmark.structures.boxlist_ops import boxlist_nms
-from maskrcnn_benchmark.structures.boxlist_ops import boxlist_ml_nms
-from maskrcnn_benchmark.structures.boxlist_ops import remove_small_boxes
-
-from ..utils import permute_and_flatten
-import pdb
-
-class RPNPostProcessor(torch.nn.Module):
- """
- Performs post-processing on the outputs of the RPN boxes, before feeding the
- proposals to the heads
- """
-
- def __init__(
- self,
- pre_nms_top_n,
- post_nms_top_n,
- nms_thresh,
- min_size,
- box_coder=None,
- fpn_post_nms_top_n=None,
- onnx=False
- ):
- """
- Arguments:
- pre_nms_top_n (int)
- post_nms_top_n (int)
- nms_thresh (float)
- min_size (int)
- box_coder (BoxCoder)
- fpn_post_nms_top_n (int)
- """
- super(RPNPostProcessor, self).__init__()
- self.pre_nms_top_n = pre_nms_top_n
- self.post_nms_top_n = post_nms_top_n
- self.nms_thresh = nms_thresh
- self.min_size = min_size
- self.onnx = onnx
-
- if box_coder is None:
- box_coder = BoxCoder(weights=(1.0, 1.0, 1.0, 1.0))
- self.box_coder = box_coder
-
- if fpn_post_nms_top_n is None:
- fpn_post_nms_top_n = post_nms_top_n
- self.fpn_post_nms_top_n = fpn_post_nms_top_n
-
- def add_gt_proposals(self, proposals, targets):
- """
- Arguments:
- proposals: list[BoxList]
- targets: list[BoxList]
- """
- # Get the device we're operating on
- device = proposals[0].bbox.device
-
- gt_boxes = [target.copy_with_fields([]) for target in targets]
-
- # later cat of bbox requires all fields to be present for all bbox
- # so we need to add a dummy for objectness that's missing
- for gt_box in gt_boxes:
- gt_box.add_field("objectness", torch.ones(len(gt_box), device=device))
-
- proposals = [
- cat_boxlist((proposal, gt_box))
- for proposal, gt_box in zip(proposals, gt_boxes)
- ]
-
- return proposals
-
- def forward_for_single_feature_map(self, anchors, objectness, box_regression):
- """
- Arguments:
- anchors: list[BoxList]
- objectness: tensor of size N, A, H, W
- box_regression: tensor of size N, A * 4, H, W
- """
- device = objectness.device
- N, A, H, W = objectness.shape
-
- # put in the same format as anchors
- objectness = objectness.permute(0, 2, 3, 1).reshape(N, -1)
- objectness = objectness.sigmoid()
- box_regression = box_regression.view(N, -1, 4, H, W).permute(0, 3, 4, 1, 2)
- box_regression = box_regression.reshape(N, -1, 4)
-
- num_anchors = A * H * W
-
- pre_nms_top_n = min(self.pre_nms_top_n, num_anchors)
- objectness, topk_idx = objectness.topk(pre_nms_top_n, dim=1, sorted=True)
-
- batch_idx = torch.arange(N, device=device)[:, None]
- box_regression = box_regression[batch_idx, topk_idx]
-
- image_shapes = [box.size for box in anchors]
- concat_anchors = torch.cat([a.bbox for a in anchors], dim=0)
- concat_anchors = concat_anchors.reshape(N, -1, 4)[batch_idx, topk_idx]
-
- proposals = self.box_coder.decode(
- box_regression.view(-1, 4), concat_anchors.view(-1, 4)
- )
-
- proposals = proposals.view(N, -1, 4)
-
- result = []
- for proposal, score, im_shape in zip(proposals, objectness, image_shapes):
- if self.onnx:
- proposal = _onnx_clip_boxes_to_image(proposal, im_shape)
- boxlist = BoxList(proposal, im_shape, mode="xyxy")
- else:
- boxlist = BoxList(proposal, im_shape, mode="xyxy")
- boxlist = boxlist.clip_to_image(remove_empty=False)
-
- boxlist.add_field("objectness", score)
- boxlist = remove_small_boxes(boxlist, self.min_size)
- boxlist = boxlist_nms(
- boxlist,
- self.nms_thresh,
- max_proposals=self.post_nms_top_n,
- score_field="objectness",
- )
- result.append(boxlist)
- return result
-
- def forward(self, anchors, objectness, box_regression, targets=None):
- """
- Arguments:
- anchors: list[list[BoxList]]
- objectness: list[tensor]
- box_regression: list[tensor]
-
- Returns:
- boxlists (list[BoxList]): the post-processed anchors, after
- applying box decoding and NMS
- """
- sampled_boxes = []
- num_levels = len(objectness)
- anchors = list(zip(*anchors))
- for a, o, b in zip(anchors, objectness, box_regression):
- sampled_boxes.append(self.forward_for_single_feature_map(a, o, b))
-
- boxlists = list(zip(*sampled_boxes))
- boxlists = [cat_boxlist(boxlist) for boxlist in boxlists]
-
- if num_levels > 1:
- boxlists = self.select_over_all_levels(boxlists)
-
- # append ground-truth bboxes to proposals
- if self.training and targets is not None:
- boxlists = self.add_gt_proposals(boxlists, targets)
-
- return boxlists
-
- def select_over_all_levels(self, boxlists):
- num_images = len(boxlists)
- # different behavior during training and during testing:
- # during training, post_nms_top_n is over *all* the proposals combined, while
- # during testing, it is over the proposals for each image
- # TODO resolve this difference and make it consistent. It should be per image,
- # and not per batch
- if self.training:
- objectness = torch.cat(
- [boxlist.get_field("objectness") for boxlist in boxlists], dim=0
- )
- box_sizes = [len(boxlist) for boxlist in boxlists]
- post_nms_top_n = min(self.fpn_post_nms_top_n, len(objectness))
- _, inds_sorted = torch.topk(objectness, post_nms_top_n, dim=0, sorted=True)
- inds_mask = torch.zeros_like(objectness, dtype=torch.bool)
- inds_mask[inds_sorted] = 1
- inds_mask = inds_mask.split(box_sizes)
- for i in range(num_images):
- boxlists[i] = boxlists[i][inds_mask[i]]
- else:
- for i in range(num_images):
- objectness = boxlists[i].get_field("objectness")
- post_nms_top_n = min(self.fpn_post_nms_top_n, len(objectness))
- _, inds_sorted = torch.topk(
- objectness, post_nms_top_n, dim=0, sorted=True
- )
- boxlists[i] = boxlists[i][inds_sorted]
- return boxlists
-
-
-def make_rpn_postprocessor(config, rpn_box_coder, is_train):
- fpn_post_nms_top_n = config.MODEL.RPN.FPN_POST_NMS_TOP_N_TRAIN
- if not is_train:
- fpn_post_nms_top_n = config.MODEL.RPN.FPN_POST_NMS_TOP_N_TEST
-
- pre_nms_top_n = config.MODEL.RPN.PRE_NMS_TOP_N_TRAIN
- post_nms_top_n = config.MODEL.RPN.POST_NMS_TOP_N_TRAIN
- if not is_train:
- pre_nms_top_n = config.MODEL.RPN.PRE_NMS_TOP_N_TEST
- post_nms_top_n = config.MODEL.RPN.POST_NMS_TOP_N_TEST
- nms_thresh = config.MODEL.RPN.NMS_THRESH
- min_size = config.MODEL.RPN.MIN_SIZE
- onnx = config.MODEL.ONNX
- box_selector = RPNPostProcessor(
- pre_nms_top_n=pre_nms_top_n,
- post_nms_top_n=post_nms_top_n,
- nms_thresh=nms_thresh,
- min_size=min_size,
- box_coder=rpn_box_coder,
- fpn_post_nms_top_n=fpn_post_nms_top_n,
- onnx=onnx
- )
- return box_selector
-
-
-class RetinaPostProcessor(torch.nn.Module):
- """
- Performs post-processing on the outputs of the RetinaNet boxes.
- This is only used in the testing.
- """
-
- def __init__(
- self,
- pre_nms_thresh,
- pre_nms_top_n,
- nms_thresh,
- fpn_post_nms_top_n,
- min_size,
- num_classes,
- box_coder=None,
- ):
- """
- Arguments:
- pre_nms_thresh (float)
- pre_nms_top_n (int)
- nms_thresh (float)
- fpn_post_nms_top_n (int)
- min_size (int)
- num_classes (int)
- box_coder (BoxCoder)
- """
- super(RetinaPostProcessor, self).__init__()
- self.pre_nms_thresh = pre_nms_thresh
- self.pre_nms_top_n = pre_nms_top_n
- self.nms_thresh = nms_thresh
- self.fpn_post_nms_top_n = fpn_post_nms_top_n
- self.min_size = min_size
- self.num_classes = num_classes
-
- if box_coder is None:
- box_coder = BoxCoder(weights=(10., 10., 5., 5.))
- self.box_coder = box_coder
-
- def forward_for_single_feature_map(self, anchors, box_cls, box_regression):
- """
- Arguments:
- anchors: list[BoxList]
- box_cls: tensor of size N, A * C, H, W
- box_regression: tensor of size N, A * 4, H, W
- """
- device = box_cls.device
- N, _, H, W = box_cls.shape
- A = box_regression.size(1) // 4
- C = box_cls.size(1) // A
-
- # put in the same format as anchors
- box_cls = permute_and_flatten(box_cls, N, A, C, H, W)
- box_cls = box_cls.sigmoid()
-
- box_regression = permute_and_flatten(box_regression, N, A, 4, H, W)
- box_regression = box_regression.reshape(N, -1, 4)
-
- num_anchors = A * H * W
-
- candidate_inds = box_cls > self.pre_nms_thresh
-
- pre_nms_top_n = candidate_inds.view(N, -1).sum(1)
- pre_nms_top_n = pre_nms_top_n.clamp(max=self.pre_nms_top_n)
-
- results = []
- for per_box_cls, per_box_regression, per_pre_nms_top_n, \
- per_candidate_inds, per_anchors in zip(
- box_cls,
- box_regression,
- pre_nms_top_n,
- candidate_inds,
- anchors):
- # Sort and select TopN
- # TODO most of this can be made out of the loop for
- # all images.
- # TODO:Yang: Not easy to do. Because the numbers of detections are
- # different in each image. Therefore, this part needs to be done
- # per image.
- per_box_cls = per_box_cls[per_candidate_inds]
-
- per_box_cls, top_k_indices = \
- per_box_cls.topk(per_pre_nms_top_n, sorted=False)
-
- per_candidate_nonzeros = \
- per_candidate_inds.nonzero()[top_k_indices, :]
-
- per_box_loc = per_candidate_nonzeros[:, 0]
- per_class = per_candidate_nonzeros[:, 1]
- per_class += 1
-
- detections = self.box_coder.decode(
- per_box_regression[per_box_loc, :].view(-1, 4),
- per_anchors.bbox[per_box_loc, :].view(-1, 4)
- )
-
- boxlist = BoxList(detections, per_anchors.size, mode="xyxy")
- boxlist.add_field("labels", per_class)
- boxlist.add_field("scores", per_box_cls)
- boxlist = boxlist.clip_to_image(remove_empty=False)
- boxlist = remove_small_boxes(boxlist, self.min_size)
- results.append(boxlist)
-
- return results
-
- # TODO very similar to filter_results from PostProcessor
- # but filter_results is per image
- # TODO Yang: solve this issue in the future. No good solution
- # right now.
- def select_over_all_levels(self, boxlists):
- num_images = len(boxlists)
- results = []
- for i in range(num_images):
- scores = boxlists[i].get_field("scores")
- labels = boxlists[i].get_field("labels")
- boxes = boxlists[i].bbox
- boxlist = boxlists[i]
- result = []
- # skip the background
- for j in range(1, self.num_classes):
- inds = (labels == j).nonzero().view(-1)
-
- scores_j = scores[inds]
- boxes_j = boxes[inds, :].view(-1, 4)
- boxlist_for_class = BoxList(boxes_j, boxlist.size, mode="xyxy")
- boxlist_for_class.add_field("scores", scores_j)
- boxlist_for_class = boxlist_nms(
- boxlist_for_class, self.nms_thresh,
- score_field="scores"
- )
- num_labels = len(boxlist_for_class)
- boxlist_for_class.add_field(
- "labels", torch.full((num_labels,), j,
- dtype=torch.int64,
- device=scores.device)
- )
- result.append(boxlist_for_class)
-
- result = cat_boxlist(result)
- number_of_detections = len(result)
-
- # Limit to max_per_image detections **over all classes**
- if number_of_detections > self.fpn_post_nms_top_n > 0:
- cls_scores = result.get_field("scores")
- image_thresh, _ = torch.kthvalue(
- cls_scores.cpu(),
- number_of_detections - self.fpn_post_nms_top_n + 1
- )
- keep = cls_scores >= image_thresh.item()
- keep = torch.nonzero(keep).squeeze(1)
- result = result[keep]
- results.append(result)
- return results
-
- def forward(self, anchors, objectness, box_regression, targets=None):
- """
- Arguments:
- anchors: list[list[BoxList]]
- objectness: list[tensor]
- box_regression: list[tensor]
-
- Returns:
- boxlists (list[BoxList]): the post-processed anchors, after
- applying box decoding and NMS
- """
- sampled_boxes = []
- anchors = list(zip(*anchors))
- for a, o, b in zip(anchors, objectness, box_regression):
- sampled_boxes.append(self.forward_for_single_feature_map(a, o, b))
-
- boxlists = list(zip(*sampled_boxes))
- boxlists = [cat_boxlist(boxlist) for boxlist in boxlists]
-
- boxlists = self.select_over_all_levels(boxlists)
-
- return boxlists
-
-
-def make_retina_postprocessor(config, rpn_box_coder, is_train):
- pre_nms_thresh = config.MODEL.RETINANET.INFERENCE_TH
- pre_nms_top_n = config.MODEL.RETINANET.PRE_NMS_TOP_N
- nms_thresh = config.MODEL.RETINANET.NMS_TH
- fpn_post_nms_top_n = config.MODEL.RETINANET.DETECTIONS_PER_IMG
- min_size = 0
-
- box_selector = RetinaPostProcessor(
- pre_nms_thresh=pre_nms_thresh,
- pre_nms_top_n=pre_nms_top_n,
- nms_thresh=nms_thresh,
- fpn_post_nms_top_n=fpn_post_nms_top_n,
- min_size=min_size,
- num_classes=config.MODEL.RETINANET.NUM_CLASSES,
- box_coder=rpn_box_coder,
- )
-
- return box_selector
-
-
-class FCOSPostProcessor(torch.nn.Module):
- """
- Performs post-processing on the outputs of the RetinaNet boxes.
- This is only used in the testing.
- """
-
- def __init__(
- self,
- pre_nms_thresh,
- pre_nms_top_n,
- nms_thresh,
- fpn_post_nms_top_n,
- min_size,
- num_classes,
- bbox_aug_enabled=False
- ):
- """
- Arguments:
- pre_nms_thresh (float)
- pre_nms_top_n (int)
- nms_thresh (float)
- fpn_post_nms_top_n (int)
- min_size (int)
- num_classes (int)
- box_coder (BoxCoder)
- """
- super(FCOSPostProcessor, self).__init__()
- self.pre_nms_thresh = pre_nms_thresh
- self.pre_nms_top_n = pre_nms_top_n
- self.nms_thresh = nms_thresh
- self.fpn_post_nms_top_n = fpn_post_nms_top_n
- self.min_size = min_size
- self.num_classes = num_classes
- self.bbox_aug_enabled = bbox_aug_enabled
-
- def forward_for_single_feature_map(
- self, locations, box_cls,
- box_regression, centerness,
- image_sizes):
- """
- Arguments:
- anchors: list[BoxList]
- box_cls: tensor of size N, A * C, H, W
- box_regression: tensor of size N, A * 4, H, W
- """
- N, C, H, W = box_cls.shape
-
- # put in the same format as locations
- box_cls = box_cls.view(N, C, H, W).permute(0, 2, 3, 1)
- box_cls = box_cls.reshape(N, -1, C).sigmoid()
- box_regression = box_regression.view(N, 4, H, W).permute(0, 2, 3, 1)
- box_regression = box_regression.reshape(N, -1, 4)
- centerness = centerness.view(N, 1, H, W).permute(0, 2, 3, 1)
- centerness = centerness.reshape(N, -1).sigmoid()
-
- candidate_inds = box_cls > self.pre_nms_thresh
- pre_nms_top_n = candidate_inds.reshape(N, -1).sum(1)
- pre_nms_top_n = pre_nms_top_n.clamp(max=self.pre_nms_top_n)
-
- # multiply the classification scores with centerness scores
- box_cls = box_cls * centerness[:, :, None]
-
- results = []
- for i in range(N):
- per_box_cls = box_cls[i]
- per_candidate_inds = candidate_inds[i]
- per_box_cls = per_box_cls[per_candidate_inds]
-
- per_candidate_nonzeros = per_candidate_inds.nonzero()
- per_box_loc = per_candidate_nonzeros[:, 0]
- per_class = per_candidate_nonzeros[:, 1] + 1
-
- per_box_regression = box_regression[i]
- per_box_regression = per_box_regression[per_box_loc]
- per_locations = locations[per_box_loc]
-
- per_pre_nms_top_n = pre_nms_top_n[i]
-
- if per_candidate_inds.sum().item() > per_pre_nms_top_n.item():
- per_box_cls, top_k_indices = \
- per_box_cls.topk(per_pre_nms_top_n, sorted=False)
- per_class = per_class[top_k_indices]
- per_box_regression = per_box_regression[top_k_indices]
- per_locations = per_locations[top_k_indices]
-
- detections = torch.stack([
- per_locations[:, 0] - per_box_regression[:, 0],
- per_locations[:, 1] - per_box_regression[:, 1],
- per_locations[:, 0] + per_box_regression[:, 2],
- per_locations[:, 1] + per_box_regression[:, 3],
- ], dim=1)
-
- h, w = image_sizes[i]
- boxlist = BoxList(detections, (int(w), int(h)), mode="xyxy")
- boxlist.add_field('centers', per_locations)
- boxlist.add_field("labels", per_class)
- boxlist.add_field("scores", torch.sqrt(per_box_cls))
- boxlist = boxlist.clip_to_image(remove_empty=False)
- boxlist = remove_small_boxes(boxlist, self.min_size)
- results.append(boxlist)
-
- return results
-
- def forward(self, locations, box_cls, box_regression, centerness, image_sizes):
- """
- Arguments:
- anchors: list[list[BoxList]]
- box_cls: list[tensor]
- box_regression: list[tensor]
- image_sizes: list[(h, w)]
- Returns:
- boxlists (list[BoxList]): the post-processed anchors, after
- applying box decoding and NMS
- """
- sampled_boxes = []
- for _, (l, o, b, c) in enumerate(zip(locations, box_cls, box_regression, centerness)):
- sampled_boxes.append(
- self.forward_for_single_feature_map(
- l, o, b, c, image_sizes
- )
- )
-
- boxlists = list(zip(*sampled_boxes))
- boxlists = [cat_boxlist(boxlist) for boxlist in boxlists]
- if not self.bbox_aug_enabled:
- boxlists = self.select_over_all_levels(boxlists)
-
- return boxlists
-
- # TODO very similar to filter_results from PostProcessor
- # but filter_results is per image
- # TODO Yang: solve this issue in the future. No good solution
- # right now.
- def select_over_all_levels(self, boxlists):
- num_images = len(boxlists)
- results = []
- for i in range(num_images):
- # multiclass nms
- result = boxlist_ml_nms(boxlists[i], self.nms_thresh)
- number_of_detections = len(result)
-
- # Limit to max_per_image detections **over all classes**
- if number_of_detections > self.fpn_post_nms_top_n > 0:
- cls_scores = result.get_field("scores")
- image_thresh, _ = torch.kthvalue(
- cls_scores.cpu(),
- number_of_detections - self.fpn_post_nms_top_n + 1
- )
- keep = cls_scores >= image_thresh.item()
- keep = torch.nonzero(keep).squeeze(1)
- result = result[keep]
- results.append(result)
- return results
-
-
-def make_fcos_postprocessor(config, is_train=False):
- pre_nms_thresh = config.MODEL.FCOS.INFERENCE_TH
- if is_train:
- pre_nms_thresh = config.MODEL.FCOS.INFERENCE_TH_TRAIN
- pre_nms_top_n = config.MODEL.FCOS.PRE_NMS_TOP_N
- fpn_post_nms_top_n = config.MODEL.FCOS.DETECTIONS_PER_IMG
- if is_train:
- pre_nms_top_n = config.MODEL.FCOS.PRE_NMS_TOP_N_TRAIN
- fpn_post_nms_top_n = config.MODEL.FCOS.POST_NMS_TOP_N_TRAIN
- nms_thresh = config.MODEL.FCOS.NMS_TH
-
- box_selector = FCOSPostProcessor(
- pre_nms_thresh=pre_nms_thresh,
- pre_nms_top_n=pre_nms_top_n,
- nms_thresh=nms_thresh,
- fpn_post_nms_top_n=fpn_post_nms_top_n,
- min_size=0,
- num_classes=config.MODEL.FCOS.NUM_CLASSES,
- )
-
- return box_selector
-
-
-class ATSSPostProcessor(torch.nn.Module):
- def __init__(
- self,
- pre_nms_thresh,
- pre_nms_top_n,
- nms_thresh,
- fpn_post_nms_top_n,
- min_size,
- num_classes,
- box_coder,
- bbox_aug_enabled=False,
- bbox_aug_vote=False,
- score_agg='MEAN',
- mdetr_style_aggregate_class_num=-1
- ):
- super(ATSSPostProcessor, self).__init__()
- self.pre_nms_thresh = pre_nms_thresh
- self.pre_nms_top_n = pre_nms_top_n
- self.nms_thresh = nms_thresh
- self.fpn_post_nms_top_n = fpn_post_nms_top_n
- self.min_size = min_size
- self.num_classes = num_classes
- self.bbox_aug_enabled = bbox_aug_enabled
- self.box_coder = box_coder
- self.bbox_aug_vote = bbox_aug_vote
- self.score_agg = score_agg
- self.mdetr_style_aggregate_class_num = mdetr_style_aggregate_class_num
-
- def forward_for_single_feature_map(self, box_regression, centerness, anchors,
- box_cls=None,
- token_logits=None,
- dot_product_logits=None,
- positive_map=None,
- ):
-
- N, _, H, W = box_regression.shape
-
- A = box_regression.size(1) // 4
-
- if box_cls is not None:
- C = box_cls.size(1) // A
-
- if token_logits is not None:
- T = token_logits.size(1) // A
-
- # put in the same format as anchors
- if box_cls is not None:
- #print('Classification.')
- box_cls = permute_and_flatten(box_cls, N, A, C, H, W)
- box_cls = box_cls.sigmoid()
-
- # binary focal loss version
- if token_logits is not None:
- #print('Token.')
- token_logits = permute_and_flatten(token_logits, N, A, T, H, W)
- token_logits = token_logits.sigmoid()
- # turn back to original classes
- scores = convert_grounding_to_od_logits(logits=token_logits, box_cls=box_cls, positive_map=positive_map,
- score_agg=self.score_agg)
- box_cls = scores
-
- # binary dot product focal version
- if dot_product_logits is not None:
- #print('Dot Product.')
- dot_product_logits = dot_product_logits.sigmoid()
- if self.mdetr_style_aggregate_class_num != -1:
- scores = convert_grounding_to_od_logits_v2(
- logits=dot_product_logits,
- num_class=self.mdetr_style_aggregate_class_num,
- positive_map=positive_map,
- score_agg=self.score_agg,
- disable_minus_one=False)
- else:
- scores = convert_grounding_to_od_logits(logits=dot_product_logits, box_cls=box_cls,
- positive_map=positive_map,
- score_agg=self.score_agg)
- box_cls = scores
-
- box_regression = permute_and_flatten(box_regression, N, A, 4, H, W)
- box_regression = box_regression.reshape(N, -1, 4)
-
- candidate_inds = box_cls > self.pre_nms_thresh
- pre_nms_top_n = candidate_inds.reshape(N, -1).sum(1)
- pre_nms_top_n = pre_nms_top_n.clamp(max=self.pre_nms_top_n)
-
- centerness = permute_and_flatten(centerness, N, A, 1, H, W)
- centerness = centerness.reshape(N, -1).sigmoid()
-
- # multiply the classification scores with centerness scores
-
- box_cls = box_cls * centerness[:, :, None]
-
- results = []
-
- for per_box_cls, per_box_regression, per_pre_nms_top_n, per_candidate_inds, per_anchors \
- in zip(box_cls, box_regression, pre_nms_top_n, candidate_inds, anchors):
- per_box_cls = per_box_cls[per_candidate_inds]
-
- per_box_cls, top_k_indices = per_box_cls.topk(per_pre_nms_top_n, sorted=False)
-
- per_candidate_nonzeros = per_candidate_inds.nonzero()[top_k_indices, :]
-
- per_box_loc = per_candidate_nonzeros[:, 0]
- per_class = per_candidate_nonzeros[:, 1] + 1
-
- # print(per_class)
-
- detections = self.box_coder.decode(
- per_box_regression[per_box_loc, :].view(-1, 4),
- per_anchors.bbox[per_box_loc, :].view(-1, 4)
- )
-
- boxlist = BoxList(detections, per_anchors.size, mode="xyxy")
- boxlist.add_field("labels", per_class)
- boxlist.add_field("scores", torch.sqrt(per_box_cls))
- boxlist = boxlist.clip_to_image(remove_empty=False)
- boxlist = remove_small_boxes(boxlist, self.min_size)
- results.append(boxlist)
-
- return results
-
- def forward(self, box_regression, centerness, anchors,
- box_cls=None,
- token_logits=None,
- dot_product_logits=None,
- positive_map=None,
- ):
- sampled_boxes = []
- anchors = list(zip(*anchors))
- for idx, (b, c, a) in enumerate(zip(box_regression, centerness, anchors)):
- o = None
- t = None
- d = None
- if box_cls is not None:
- o = box_cls[idx]
- if token_logits is not None:
- t = token_logits[idx]
- if dot_product_logits is not None:
- d = dot_product_logits[idx]
-
- sampled_boxes.append(
- self.forward_for_single_feature_map(b, c, a, o, t, d, positive_map)
- )
-
- boxlists = list(zip(*sampled_boxes))
- boxlists = [cat_boxlist(boxlist) for boxlist in boxlists]
- if not (self.bbox_aug_enabled and not self.bbox_aug_vote):
- boxlists = self.select_over_all_levels(boxlists)
-
- return boxlists
-
- # TODO very similar to filter_results from PostProcessor
- # but filter_results is per image
- # TODO Yang: solve this issue in the future. No good solution
- # right now.
- def select_over_all_levels(self, boxlists):
- num_images = len(boxlists)
- results = []
- for i in range(num_images):
- # multiclass nms
- result = boxlist_ml_nms(boxlists[i], self.nms_thresh)
- number_of_detections = len(result)
-
- # Limit to max_per_image detections **over all classes**
- if number_of_detections > self.fpn_post_nms_top_n > 0:
- cls_scores = result.get_field("scores")
- image_thresh, _ = torch.kthvalue(
- # TODO: confirm with Pengchuan and Xiyang, torch.kthvalue is not implemented for 'Half'
- # cls_scores.cpu(),
- cls_scores.cpu().float(),
- number_of_detections - self.fpn_post_nms_top_n + 1
- )
- keep = cls_scores >= image_thresh.item()
- keep = torch.nonzero(keep).squeeze(1)
- result = result[keep]
- results.append(result)
- return results
-
-
-def convert_grounding_to_od_logits(logits, box_cls, positive_map, score_agg=None):
- scores = torch.zeros(logits.shape[0], logits.shape[1], box_cls.shape[2]).to(logits.device)
- # 256 -> 80, average for each class
- if positive_map is not None:
- # score aggregation method
- if score_agg == "MEAN":
- for label_j in positive_map:
- scores[:, :, label_j - 1] = logits[:, :, torch.LongTensor(positive_map[label_j])].mean(-1)
- elif score_agg == "MAX":
- # torch.max() returns (values, indices)
- for label_j in positive_map:
- scores[:, :, label_j - 1] = logits[:, :, torch.LongTensor(positive_map[label_j])].max(-1)[
- 0]
- elif score_agg == "ONEHOT":
- # one hot
- scores = logits[:, :, :len(positive_map)]
- else:
- raise NotImplementedError
- return scores
-
-
-def convert_grounding_to_od_logits_v2(logits, num_class, positive_map, score_agg=None, disable_minus_one = True):
-
- scores = torch.zeros(logits.shape[0], logits.shape[1], num_class).to(logits.device)
- # 256 -> 80, average for each class
- if positive_map is not None:
- # score aggregation method
- if score_agg == "MEAN":
- for label_j in positive_map:
- locations_label_j = positive_map[label_j]
- if isinstance(locations_label_j, int):
- locations_label_j = [locations_label_j]
- scores[:, :, label_j if disable_minus_one else label_j - 1] = logits[:, :, torch.LongTensor(locations_label_j)].mean(-1)
- elif score_agg == "POWER":
- for label_j in positive_map:
- locations_label_j = positive_map[label_j]
- if isinstance(locations_label_j, int):
- locations_label_j = [locations_label_j]
-
- probability = torch.prod(logits[:, :, torch.LongTensor(locations_label_j)], dim=-1).squeeze(-1)
- probability = torch.pow(probability, 1/len(locations_label_j))
- scores[:, :, label_j if disable_minus_one else label_j - 1] = probability
- elif score_agg == "MAX":
- # torch.max() returns (values, indices)
- for label_j in positive_map:
- scores[:, :, label_j if disable_minus_one else label_j - 1] = logits[:, :, torch.LongTensor(positive_map[label_j])].max(-1)[
- 0]
- elif score_agg == "ONEHOT":
- # one hot
- scores = logits[:, :, :len(positive_map)]
- else:
- raise NotImplementedError
- return scores
-
-def make_atss_postprocessor(config, box_coder, is_train=False):
- pre_nms_thresh = config.MODEL.ATSS.INFERENCE_TH
- if is_train:
- pre_nms_thresh = config.MODEL.ATSS.INFERENCE_TH_TRAIN
- pre_nms_top_n = config.MODEL.ATSS.PRE_NMS_TOP_N
- fpn_post_nms_top_n = config.MODEL.ATSS.DETECTIONS_PER_IMG
- if is_train:
- pre_nms_top_n = config.MODEL.ATSS.PRE_NMS_TOP_N_TRAIN
- fpn_post_nms_top_n = config.MODEL.ATSS.POST_NMS_TOP_N_TRAIN
- nms_thresh = config.MODEL.ATSS.NMS_TH
- score_agg = config.MODEL.DYHEAD.SCORE_AGG
-
- box_selector = ATSSPostProcessor(
- pre_nms_thresh=pre_nms_thresh,
- pre_nms_top_n=pre_nms_top_n,
- nms_thresh=nms_thresh,
- fpn_post_nms_top_n=fpn_post_nms_top_n,
- min_size=0,
- num_classes=config.MODEL.ATSS.NUM_CLASSES,
- box_coder=box_coder,
- bbox_aug_enabled=config.TEST.USE_MULTISCALE,
- score_agg=score_agg,
- mdetr_style_aggregate_class_num=config.TEST.MDETR_STYLE_AGGREGATE_CLASS_NUM
- )
-
- return box_selector
diff --git a/spaces/PirateXX/ChatGPT-Detector/README.md b/spaces/PirateXX/ChatGPT-Detector/README.md
deleted file mode 100644
index c3dfd0048a26bb8605ed7f2b69e7bf1607c719cd..0000000000000000000000000000000000000000
--- a/spaces/PirateXX/ChatGPT-Detector/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: ChatGPT Detector
-emoji: 🐨
-colorFrom: red
-colorTo: blue
-sdk: gradio
-sdk_version: 3.21.0
-app_file: app.py
-pinned: false
-license: artistic-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/network/auth.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/network/auth.py
deleted file mode 100644
index ca42798bd952dfa10533e22a137e72dbd15250d4..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/network/auth.py
+++ /dev/null
@@ -1,323 +0,0 @@
-"""Network Authentication Helpers
-
-Contains interface (MultiDomainBasicAuth) and associated glue code for
-providing credentials in the context of network requests.
-"""
-
-import urllib.parse
-from typing import Any, Dict, List, Optional, Tuple
-
-from pip._vendor.requests.auth import AuthBase, HTTPBasicAuth
-from pip._vendor.requests.models import Request, Response
-from pip._vendor.requests.utils import get_netrc_auth
-
-from pip._internal.utils.logging import getLogger
-from pip._internal.utils.misc import (
- ask,
- ask_input,
- ask_password,
- remove_auth_from_url,
- split_auth_netloc_from_url,
-)
-from pip._internal.vcs.versioncontrol import AuthInfo
-
-logger = getLogger(__name__)
-
-Credentials = Tuple[str, str, str]
-
-try:
- import keyring
-except ImportError:
- keyring = None # type: ignore[assignment]
-except Exception as exc:
- logger.warning(
- "Keyring is skipped due to an exception: %s",
- str(exc),
- )
- keyring = None # type: ignore[assignment]
-
-
-def get_keyring_auth(url: Optional[str], username: Optional[str]) -> Optional[AuthInfo]:
- """Return the tuple auth for a given url from keyring."""
- global keyring
- if not url or not keyring:
- return None
-
- try:
- try:
- get_credential = keyring.get_credential
- except AttributeError:
- pass
- else:
- logger.debug("Getting credentials from keyring for %s", url)
- cred = get_credential(url, username)
- if cred is not None:
- return cred.username, cred.password
- return None
-
- if username:
- logger.debug("Getting password from keyring for %s", url)
- password = keyring.get_password(url, username)
- if password:
- return username, password
-
- except Exception as exc:
- logger.warning(
- "Keyring is skipped due to an exception: %s",
- str(exc),
- )
- keyring = None # type: ignore[assignment]
- return None
-
-
-class MultiDomainBasicAuth(AuthBase):
- def __init__(
- self, prompting: bool = True, index_urls: Optional[List[str]] = None
- ) -> None:
- self.prompting = prompting
- self.index_urls = index_urls
- self.passwords: Dict[str, AuthInfo] = {}
- # When the user is prompted to enter credentials and keyring is
- # available, we will offer to save them. If the user accepts,
- # this value is set to the credentials they entered. After the
- # request authenticates, the caller should call
- # ``save_credentials`` to save these.
- self._credentials_to_save: Optional[Credentials] = None
-
- def _get_index_url(self, url: str) -> Optional[str]:
- """Return the original index URL matching the requested URL.
-
- Cached or dynamically generated credentials may work against
- the original index URL rather than just the netloc.
-
- The provided url should have had its username and password
- removed already. If the original index url had credentials then
- they will be included in the return value.
-
- Returns None if no matching index was found, or if --no-index
- was specified by the user.
- """
- if not url or not self.index_urls:
- return None
-
- for u in self.index_urls:
- prefix = remove_auth_from_url(u).rstrip("/") + "/"
- if url.startswith(prefix):
- return u
- return None
-
- def _get_new_credentials(
- self,
- original_url: str,
- allow_netrc: bool = True,
- allow_keyring: bool = False,
- ) -> AuthInfo:
- """Find and return credentials for the specified URL."""
- # Split the credentials and netloc from the url.
- url, netloc, url_user_password = split_auth_netloc_from_url(
- original_url,
- )
-
- # Start with the credentials embedded in the url
- username, password = url_user_password
- if username is not None and password is not None:
- logger.debug("Found credentials in url for %s", netloc)
- return url_user_password
-
- # Find a matching index url for this request
- index_url = self._get_index_url(url)
- if index_url:
- # Split the credentials from the url.
- index_info = split_auth_netloc_from_url(index_url)
- if index_info:
- index_url, _, index_url_user_password = index_info
- logger.debug("Found index url %s", index_url)
-
- # If an index URL was found, try its embedded credentials
- if index_url and index_url_user_password[0] is not None:
- username, password = index_url_user_password
- if username is not None and password is not None:
- logger.debug("Found credentials in index url for %s", netloc)
- return index_url_user_password
-
- # Get creds from netrc if we still don't have them
- if allow_netrc:
- netrc_auth = get_netrc_auth(original_url)
- if netrc_auth:
- logger.debug("Found credentials in netrc for %s", netloc)
- return netrc_auth
-
- # If we don't have a password and keyring is available, use it.
- if allow_keyring:
- # The index url is more specific than the netloc, so try it first
- # fmt: off
- kr_auth = (
- get_keyring_auth(index_url, username) or
- get_keyring_auth(netloc, username)
- )
- # fmt: on
- if kr_auth:
- logger.debug("Found credentials in keyring for %s", netloc)
- return kr_auth
-
- return username, password
-
- def _get_url_and_credentials(
- self, original_url: str
- ) -> Tuple[str, Optional[str], Optional[str]]:
- """Return the credentials to use for the provided URL.
-
- If allowed, netrc and keyring may be used to obtain the
- correct credentials.
-
- Returns (url_without_credentials, username, password). Note
- that even if the original URL contains credentials, this
- function may return a different username and password.
- """
- url, netloc, _ = split_auth_netloc_from_url(original_url)
-
- # Try to get credentials from original url
- username, password = self._get_new_credentials(original_url)
-
- # If credentials not found, use any stored credentials for this netloc.
- # Do this if either the username or the password is missing.
- # This accounts for the situation in which the user has specified
- # the username in the index url, but the password comes from keyring.
- if (username is None or password is None) and netloc in self.passwords:
- un, pw = self.passwords[netloc]
- # It is possible that the cached credentials are for a different username,
- # in which case the cache should be ignored.
- if username is None or username == un:
- username, password = un, pw
-
- if username is not None or password is not None:
- # Convert the username and password if they're None, so that
- # this netloc will show up as "cached" in the conditional above.
- # Further, HTTPBasicAuth doesn't accept None, so it makes sense to
- # cache the value that is going to be used.
- username = username or ""
- password = password or ""
-
- # Store any acquired credentials.
- self.passwords[netloc] = (username, password)
-
- assert (
- # Credentials were found
- (username is not None and password is not None)
- # Credentials were not found
- or (username is None and password is None)
- ), f"Could not load credentials from url: {original_url}"
-
- return url, username, password
-
- def __call__(self, req: Request) -> Request:
- # Get credentials for this request
- url, username, password = self._get_url_and_credentials(req.url)
-
- # Set the url of the request to the url without any credentials
- req.url = url
-
- if username is not None and password is not None:
- # Send the basic auth with this request
- req = HTTPBasicAuth(username, password)(req)
-
- # Attach a hook to handle 401 responses
- req.register_hook("response", self.handle_401)
-
- return req
-
- # Factored out to allow for easy patching in tests
- def _prompt_for_password(
- self, netloc: str
- ) -> Tuple[Optional[str], Optional[str], bool]:
- username = ask_input(f"User for {netloc}: ")
- if not username:
- return None, None, False
- auth = get_keyring_auth(netloc, username)
- if auth and auth[0] is not None and auth[1] is not None:
- return auth[0], auth[1], False
- password = ask_password("Password: ")
- return username, password, True
-
- # Factored out to allow for easy patching in tests
- def _should_save_password_to_keyring(self) -> bool:
- if not keyring:
- return False
- return ask("Save credentials to keyring [y/N]: ", ["y", "n"]) == "y"
-
- def handle_401(self, resp: Response, **kwargs: Any) -> Response:
- # We only care about 401 responses, anything else we want to just
- # pass through the actual response
- if resp.status_code != 401:
- return resp
-
- # We are not able to prompt the user so simply return the response
- if not self.prompting:
- return resp
-
- parsed = urllib.parse.urlparse(resp.url)
-
- # Query the keyring for credentials:
- username, password = self._get_new_credentials(
- resp.url,
- allow_netrc=False,
- allow_keyring=True,
- )
-
- # Prompt the user for a new username and password
- save = False
- if not username and not password:
- username, password, save = self._prompt_for_password(parsed.netloc)
-
- # Store the new username and password to use for future requests
- self._credentials_to_save = None
- if username is not None and password is not None:
- self.passwords[parsed.netloc] = (username, password)
-
- # Prompt to save the password to keyring
- if save and self._should_save_password_to_keyring():
- self._credentials_to_save = (parsed.netloc, username, password)
-
- # Consume content and release the original connection to allow our new
- # request to reuse the same one.
- resp.content
- resp.raw.release_conn()
-
- # Add our new username and password to the request
- req = HTTPBasicAuth(username or "", password or "")(resp.request)
- req.register_hook("response", self.warn_on_401)
-
- # On successful request, save the credentials that were used to
- # keyring. (Note that if the user responded "no" above, this member
- # is not set and nothing will be saved.)
- if self._credentials_to_save:
- req.register_hook("response", self.save_credentials)
-
- # Send our new request
- new_resp = resp.connection.send(req, **kwargs)
- new_resp.history.append(resp)
-
- return new_resp
-
- def warn_on_401(self, resp: Response, **kwargs: Any) -> None:
- """Response callback to warn about incorrect credentials."""
- if resp.status_code == 401:
- logger.warning(
- "401 Error, Credentials not correct for %s",
- resp.request.url,
- )
-
- def save_credentials(self, resp: Response, **kwargs: Any) -> None:
- """Response callback to save credentials on success."""
- assert keyring is not None, "should never reach here without keyring"
- if not keyring:
- return
-
- creds = self._credentials_to_save
- self._credentials_to_save = None
- if creds and resp.status_code < 400:
- try:
- logger.info("Saving credentials to keyring")
- keyring.set_password(*creds)
- except Exception:
- logger.exception("Failed to save credentials")
diff --git a/spaces/Realcat/image-matching-webui/third_party/Roma/roma/train/__init__.py b/spaces/Realcat/image-matching-webui/third_party/Roma/roma/train/__init__.py
deleted file mode 100644
index 90269dc0f345a575e0ba21f5afa34202c7e6b433..0000000000000000000000000000000000000000
--- a/spaces/Realcat/image-matching-webui/third_party/Roma/roma/train/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .train import train_k_epochs
diff --git a/spaces/RedBaron5/PatentSolver/App/run.py b/spaces/RedBaron5/PatentSolver/App/run.py
deleted file mode 100644
index 6c5d1e62f83c3742d31c5da3625d9c0edecd4bed..0000000000000000000000000000000000000000
--- a/spaces/RedBaron5/PatentSolver/App/run.py
+++ /dev/null
@@ -1,60 +0,0 @@
-# -*- coding: utf-8 -*-
-
-
-from App.bin import constants
-from App.bin.InputHandler import InputHandler
-from App.bin.PatentHandler import PatentHandler
-from App.bin.CorpusProcessor import CorpusProcessor
-import time
-
-start_time = time.time()
-
-def main():
- #renseigner nom du dossier de corpus et extension de fichier
-
- print("Starting process!")
- while True:
- try:
- input_folder = input("Please Enter your input folder name and press 'ENTER': ")
- # comment next line for production mode
- #input_folder= "Staubli"
- if not input_folder:
- raise ValueError("We didn't understand you.")
-
- files_extension = input("Please Enter your files extensions(txt,xml or * for all): ")
- #comment next line for production mode
-
-
- # original code
- # files_extension = "txt"
-
-
- # files_extension = "xml"
- if not files_extension:
- raise ValueError("We didn't understand you.")
- except ValueError as e:
- print(e)
- continue
- else:
- break
-
- input_folder = constants.DATA_INPUT + input_folder
- files_extension = "*." + files_extension
-
- iInput = InputHandler(input_folder, files_extension)
- input_data = iInput.get_input()
-
- pretreat_data = PatentHandler(input_data)
- clean_patent_data = pretreat_data.pretreat_data()
-
-
- process_data = CorpusProcessor(clean_patent_data,input_folder, files_extension)
- processed_data = process_data.process_corpus()
-
- print("Process is finished within %s seconds" % round(time.time() - start_time,2))
-
-
-
-if __name__ == "__main__":
- main()
-
diff --git a/spaces/Ricecake123/RVC-demo/tools/onnx_inference_demo.py b/spaces/Ricecake123/RVC-demo/tools/onnx_inference_demo.py
deleted file mode 100644
index a835ae3743f96a1fdea034301870b18685bef3ed..0000000000000000000000000000000000000000
--- a/spaces/Ricecake123/RVC-demo/tools/onnx_inference_demo.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import soundfile
-from ..lib.infer_pack.onnx_inference import OnnxRVC
-
-hop_size = 512
-sampling_rate = 40000 # 采样率
-f0_up_key = 0 # 升降调
-sid = 0 # 角色ID
-f0_method = "dio" # F0提取算法
-model_path = "ShirohaRVC.onnx" # 模型的完整路径
-vec_name = "vec-256-layer-9" # 内部自动补齐为 f"pretrained/{vec_name}.onnx" 需要onnx的vec模型
-wav_path = "123.wav" # 输入路径或ByteIO实例
-out_path = "out.wav" # 输出路径或ByteIO实例
-
-model = OnnxRVC(
- model_path, vec_path=vec_name, sr=sampling_rate, hop_size=hop_size, device="cuda"
-)
-
-audio = model.inference(wav_path, sid, f0_method=f0_method, f0_up_key=f0_up_key)
-
-soundfile.write(out_path, audio, sampling_rate)
diff --git a/spaces/Ripo-2007/Ripo-2007-dreambooth_alfonso/app.py b/spaces/Ripo-2007/Ripo-2007-dreambooth_alfonso/app.py
deleted file mode 100644
index 2b5d1d13b2d98d1956f9507fdc51d0505986e3b8..0000000000000000000000000000000000000000
--- a/spaces/Ripo-2007/Ripo-2007-dreambooth_alfonso/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/Ripo-2007/dreambooth_alfonso").launch()
\ No newline at end of file
diff --git a/spaces/RitaParadaRamos/SmallCapDemo/retrieve_caps.py b/spaces/RitaParadaRamos/SmallCapDemo/retrieve_caps.py
deleted file mode 100644
index 9b26dce146d2dbeed6af82d50d8da608eef883c2..0000000000000000000000000000000000000000
--- a/spaces/RitaParadaRamos/SmallCapDemo/retrieve_caps.py
+++ /dev/null
@@ -1,145 +0,0 @@
-import json
-from tqdm import tqdm
-from transformers import AutoTokenizer
-import clip
-import torch
-import faiss
-import os
-import numpy as np
-from PIL import Image
-from PIL import ImageFile
-ImageFile.LOAD_TRUNCATED_IMAGES = True
-
-def load_coco_data(coco_data_path):
- """We load in all images and only the train captions."""
-
- annotations = json.load(open(coco_data_path))['images']
- images = []
- captions = []
- for item in annotations:
- if item['split'] == 'restval':
- item['split'] = 'train'
- if item['split'] == 'train':
- for sentence in item['sentences']:
- captions.append({'image_id': item['cocoid'], 'caption': ' '.join(sentence['tokens'])})
- images.append({'image_id': item['cocoid'], 'file_name': item['filename'].split('_')[-1]})
-
- return images, captions
-
-def filter_captions(data):
-
- decoder_name = 'gpt2'
- tokenizer = AutoTokenizer.from_pretrained(decoder_name)
- bs = 512
-
- image_ids = [d['image_id'] for d in data]
- caps = [d['caption'] for d in data]
- encodings = []
- for idx in range(0, len(data), bs):
- encodings += tokenizer.batch_encode_plus(caps[idx:idx+bs], return_tensors='np')['input_ids'].tolist()
-
- filtered_image_ids, filtered_captions = [], []
-
- assert len(image_ids) == len(caps) and len(caps) == len(encodings)
- for image_id, cap, encoding in zip(image_ids, caps, encodings):
- if len(encoding) <= 25:
- filtered_image_ids.append(image_id)
- filtered_captions.append(cap)
-
- return filtered_image_ids, filtered_captions
-
-def encode_captions(captions, model, device):
-
- bs = 256
- encoded_captions = []
-
- for idx in tqdm(range(0, len(captions), bs)):
- with torch.no_grad():
- input_ids = clip.tokenize(captions[idx:idx+bs]).to(device)
- encoded_captions.append(model.encode_text(input_ids).cpu().numpy())
-
- encoded_captions = np.concatenate(encoded_captions)
-
- return encoded_captions
-
-def encode_images(images, image_path, model, feature_extractor, device):
-
- image_ids = [i['image_id'] for i in images]
-
- bs = 64
- image_features = []
-
- for idx in tqdm(range(0, len(images), bs)):
- image_input = [feature_extractor(Image.open(os.path.join(image_path, i['file_name'])))
- for i in images[idx:idx+bs]]
- with torch.no_grad():
- image_features.append(model.encode_image(torch.tensor(np.stack(image_input)).to(device)).cpu().numpy())
-
- image_features = np.concatenate(image_features)
-
- return image_ids, image_features
-
-def get_nns(captions, images, k=15):
- xq = images.astype(np.float32)
- xb = captions.astype(np.float32)
- faiss.normalize_L2(xb)
- index = faiss.IndexFlatIP(xb.shape[1])
- index.add(xb)
- faiss.normalize_L2(xq)
- D, I = index.search(xq, k)
-
- return index, I
-
-def filter_nns(nns, xb_image_ids, captions, xq_image_ids):
- """ We filter out nearest neighbors which are actual captions for the query image, keeping 7 neighbors per image."""
- retrieved_captions = {}
- for nns_list, image_id in zip(nns, xq_image_ids):
- good_nns = []
- for nn in zip(nns_list):
- if xb_image_ids[nn] == image_id:
- continue
- good_nns.append(captions[nn])
- if len(good_nns) == 7:
- break
- assert len(good_nns) == 7
- retrieved_captions[image_id] = good_nns
- return retrieved_captions
-
-def main():
-
- coco_data_path = 'data/dataset_coco.json' # path to Karpathy splits downloaded from Kaggle
- image_path = 'data/images/'
-
- print('Loading data')
- images, captions = load_coco_data(coco_data_path)
-
- device = "cuda" if torch.cuda.is_available() else "cpu"
- clip_model, feature_extractor = clip.load("RN50x64", device=device)
-
- print('Filtering captions')
- xb_image_ids, captions = filter_captions(captions)
-
- print('Encoding captions')
- encoded_captions = encode_captions(captions, clip_model, device)
-
- print('Encoding images')
- xq_image_ids, encoded_images = encode_images(images, image_path, clip_model, feature_extractor, device)
-
- print('Retrieving neighbors')
- index, nns = get_nns(encoded_captions, encoded_images)
- retrieved_caps = filter_nns(nns, xb_image_ids, captions, xq_image_ids)
-
- print('Writing files')
- faiss.write_index(index, "datastore/coco_index")
- json.dump(captions, open('datastore/coco_index_captions.json', 'w'))
-
- json.dump(retrieved_caps, open('data/retrieved_caps_resnet50x64.json', 'w'))
-
-if __name__ == '__main__':
- main()
-
-
-
-
-
-
diff --git a/spaces/Robert001/UniControl-Demo/annotator/midas/midas/blocks.py b/spaces/Robert001/UniControl-Demo/annotator/midas/midas/blocks.py
deleted file mode 100644
index 62d50a2fde0a44b94271d4329c3934d1d3f2ba1a..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/midas/midas/blocks.py
+++ /dev/null
@@ -1,352 +0,0 @@
-'''
- * Copyright (c) 2023 Salesforce, Inc.
- * All rights reserved.
- * SPDX-License-Identifier: Apache License 2.0
- * For full license text, see LICENSE.txt file in the repo root or http://www.apache.org/licenses/
- * By Can Qin
- * Modified from ControlNet repo: https://github.com/lllyasviel/ControlNet
- * Copyright (c) 2023 Lvmin Zhang and Maneesh Agrawala
-'''
-
-import torch
-import torch.nn as nn
-
-from .vit import (
- _make_pretrained_vitb_rn50_384,
- _make_pretrained_vitl16_384,
- _make_pretrained_vitb16_384,
- forward_vit,
-)
-
-def _make_encoder(backbone, features, use_pretrained, groups=1, expand=False, exportable=True, hooks=None, use_vit_only=False, use_readout="ignore",):
- if backbone == "vitl16_384":
- pretrained = _make_pretrained_vitl16_384(
- use_pretrained, hooks=hooks, use_readout=use_readout
- )
- scratch = _make_scratch(
- [256, 512, 1024, 1024], features, groups=groups, expand=expand
- ) # ViT-L/16 - 85.0% Top1 (backbone)
- elif backbone == "vitb_rn50_384":
- pretrained = _make_pretrained_vitb_rn50_384(
- use_pretrained,
- hooks=hooks,
- use_vit_only=use_vit_only,
- use_readout=use_readout,
- )
- scratch = _make_scratch(
- [256, 512, 768, 768], features, groups=groups, expand=expand
- ) # ViT-H/16 - 85.0% Top1 (backbone)
- elif backbone == "vitb16_384":
- pretrained = _make_pretrained_vitb16_384(
- use_pretrained, hooks=hooks, use_readout=use_readout
- )
- scratch = _make_scratch(
- [96, 192, 384, 768], features, groups=groups, expand=expand
- ) # ViT-B/16 - 84.6% Top1 (backbone)
- elif backbone == "resnext101_wsl":
- pretrained = _make_pretrained_resnext101_wsl(use_pretrained)
- scratch = _make_scratch([256, 512, 1024, 2048], features, groups=groups, expand=expand) # efficientnet_lite3
- elif backbone == "efficientnet_lite3":
- pretrained = _make_pretrained_efficientnet_lite3(use_pretrained, exportable=exportable)
- scratch = _make_scratch([32, 48, 136, 384], features, groups=groups, expand=expand) # efficientnet_lite3
- else:
- print(f"Backbone '{backbone}' not implemented")
- assert False
-
- return pretrained, scratch
-
-
-def _make_scratch(in_shape, out_shape, groups=1, expand=False):
- scratch = nn.Module()
-
- out_shape1 = out_shape
- out_shape2 = out_shape
- out_shape3 = out_shape
- out_shape4 = out_shape
- if expand==True:
- out_shape1 = out_shape
- out_shape2 = out_shape*2
- out_shape3 = out_shape*4
- out_shape4 = out_shape*8
-
- scratch.layer1_rn = nn.Conv2d(
- in_shape[0], out_shape1, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
- )
- scratch.layer2_rn = nn.Conv2d(
- in_shape[1], out_shape2, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
- )
- scratch.layer3_rn = nn.Conv2d(
- in_shape[2], out_shape3, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
- )
- scratch.layer4_rn = nn.Conv2d(
- in_shape[3], out_shape4, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
- )
-
- return scratch
-
-
-def _make_pretrained_efficientnet_lite3(use_pretrained, exportable=False):
- efficientnet = torch.hub.load(
- "rwightman/gen-efficientnet-pytorch",
- "tf_efficientnet_lite3",
- pretrained=use_pretrained,
- exportable=exportable
- )
- return _make_efficientnet_backbone(efficientnet)
-
-
-def _make_efficientnet_backbone(effnet):
- pretrained = nn.Module()
-
- pretrained.layer1 = nn.Sequential(
- effnet.conv_stem, effnet.bn1, effnet.act1, *effnet.blocks[0:2]
- )
- pretrained.layer2 = nn.Sequential(*effnet.blocks[2:3])
- pretrained.layer3 = nn.Sequential(*effnet.blocks[3:5])
- pretrained.layer4 = nn.Sequential(*effnet.blocks[5:9])
-
- return pretrained
-
-
-def _make_resnet_backbone(resnet):
- pretrained = nn.Module()
- pretrained.layer1 = nn.Sequential(
- resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool, resnet.layer1
- )
-
- pretrained.layer2 = resnet.layer2
- pretrained.layer3 = resnet.layer3
- pretrained.layer4 = resnet.layer4
-
- return pretrained
-
-
-def _make_pretrained_resnext101_wsl(use_pretrained):
- resnet = torch.hub.load("facebookresearch/WSL-Images", "resnext101_32x8d_wsl")
- return _make_resnet_backbone(resnet)
-
-
-
-class Interpolate(nn.Module):
- """Interpolation module.
- """
-
- def __init__(self, scale_factor, mode, align_corners=False):
- """Init.
-
- Args:
- scale_factor (float): scaling
- mode (str): interpolation mode
- """
- super(Interpolate, self).__init__()
-
- self.interp = nn.functional.interpolate
- self.scale_factor = scale_factor
- self.mode = mode
- self.align_corners = align_corners
-
- def forward(self, x):
- """Forward pass.
-
- Args:
- x (tensor): input
-
- Returns:
- tensor: interpolated data
- """
-
- x = self.interp(
- x, scale_factor=self.scale_factor, mode=self.mode, align_corners=self.align_corners
- )
-
- return x
-
-
-class ResidualConvUnit(nn.Module):
- """Residual convolution module.
- """
-
- def __init__(self, features):
- """Init.
-
- Args:
- features (int): number of features
- """
- super().__init__()
-
- self.conv1 = nn.Conv2d(
- features, features, kernel_size=3, stride=1, padding=1, bias=True
- )
-
- self.conv2 = nn.Conv2d(
- features, features, kernel_size=3, stride=1, padding=1, bias=True
- )
-
- self.relu = nn.ReLU(inplace=True)
-
- def forward(self, x):
- """Forward pass.
-
- Args:
- x (tensor): input
-
- Returns:
- tensor: output
- """
- out = self.relu(x)
- out = self.conv1(out)
- out = self.relu(out)
- out = self.conv2(out)
-
- return out + x
-
-
-class FeatureFusionBlock(nn.Module):
- """Feature fusion block.
- """
-
- def __init__(self, features):
- """Init.
-
- Args:
- features (int): number of features
- """
- super(FeatureFusionBlock, self).__init__()
-
- self.resConfUnit1 = ResidualConvUnit(features)
- self.resConfUnit2 = ResidualConvUnit(features)
-
- def forward(self, *xs):
- """Forward pass.
-
- Returns:
- tensor: output
- """
- output = xs[0]
-
- if len(xs) == 2:
- output += self.resConfUnit1(xs[1])
-
- output = self.resConfUnit2(output)
-
- output = nn.functional.interpolate(
- output, scale_factor=2, mode="bilinear", align_corners=True
- )
-
- return output
-
-
-
-
-class ResidualConvUnit_custom(nn.Module):
- """Residual convolution module.
- """
-
- def __init__(self, features, activation, bn):
- """Init.
-
- Args:
- features (int): number of features
- """
- super().__init__()
-
- self.bn = bn
-
- self.groups=1
-
- self.conv1 = nn.Conv2d(
- features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
- )
-
- self.conv2 = nn.Conv2d(
- features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
- )
-
- if self.bn==True:
- self.bn1 = nn.BatchNorm2d(features)
- self.bn2 = nn.BatchNorm2d(features)
-
- self.activation = activation
-
- self.skip_add = nn.quantized.FloatFunctional()
-
- def forward(self, x):
- """Forward pass.
-
- Args:
- x (tensor): input
-
- Returns:
- tensor: output
- """
-
- out = self.activation(x)
- out = self.conv1(out)
- if self.bn==True:
- out = self.bn1(out)
-
- out = self.activation(out)
- out = self.conv2(out)
- if self.bn==True:
- out = self.bn2(out)
-
- if self.groups > 1:
- out = self.conv_merge(out)
-
- return self.skip_add.add(out, x)
-
- # return out + x
-
-
-class FeatureFusionBlock_custom(nn.Module):
- """Feature fusion block.
- """
-
- def __init__(self, features, activation, deconv=False, bn=False, expand=False, align_corners=True):
- """Init.
-
- Args:
- features (int): number of features
- """
- super(FeatureFusionBlock_custom, self).__init__()
-
- self.deconv = deconv
- self.align_corners = align_corners
-
- self.groups=1
-
- self.expand = expand
- out_features = features
- if self.expand==True:
- out_features = features//2
-
- self.out_conv = nn.Conv2d(features, out_features, kernel_size=1, stride=1, padding=0, bias=True, groups=1)
-
- self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
- self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
-
- self.skip_add = nn.quantized.FloatFunctional()
-
- def forward(self, *xs):
- """Forward pass.
-
- Returns:
- tensor: output
- """
- output = xs[0]
-
- if len(xs) == 2:
- res = self.resConfUnit1(xs[1])
- output = self.skip_add.add(output, res)
- # output += res
-
- output = self.resConfUnit2(output)
-
- output = nn.functional.interpolate(
- output, scale_factor=2, mode="bilinear", align_corners=self.align_corners
- )
-
- output = self.out_conv(output)
-
- return output
-
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/point_rend_roi_head.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/point_rend_roi_head.py
deleted file mode 100644
index 478cdf5bff6779e9291f94c543205289036ea2c6..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/point_rend_roi_head.py
+++ /dev/null
@@ -1,218 +0,0 @@
-# Modified from https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend # noqa
-
-import torch
-import torch.nn.functional as F
-from mmcv.ops import point_sample, rel_roi_point_to_rel_img_point
-
-from mmdet.core import bbox2roi, bbox_mapping, merge_aug_masks
-from .. import builder
-from ..builder import HEADS
-from .standard_roi_head import StandardRoIHead
-
-
-@HEADS.register_module()
-class PointRendRoIHead(StandardRoIHead):
- """`PointRend `_."""
-
- def __init__(self, point_head, *args, **kwargs):
- super().__init__(*args, **kwargs)
- assert self.with_bbox and self.with_mask
- self.init_point_head(point_head)
-
- def init_point_head(self, point_head):
- """Initialize ``point_head``"""
- self.point_head = builder.build_head(point_head)
-
- def init_weights(self, pretrained):
- """Initialize the weights in head.
-
- Args:
- pretrained (str, optional): Path to pre-trained weights.
- """
- super().init_weights(pretrained)
- self.point_head.init_weights()
-
- def _mask_forward_train(self, x, sampling_results, bbox_feats, gt_masks,
- img_metas):
- """Run forward function and calculate loss for mask head and point head
- in training."""
- mask_results = super()._mask_forward_train(x, sampling_results,
- bbox_feats, gt_masks,
- img_metas)
- if mask_results['loss_mask'] is not None:
- loss_point = self._mask_point_forward_train(
- x, sampling_results, mask_results['mask_pred'], gt_masks,
- img_metas)
- mask_results['loss_mask'].update(loss_point)
-
- return mask_results
-
- def _mask_point_forward_train(self, x, sampling_results, mask_pred,
- gt_masks, img_metas):
- """Run forward function and calculate loss for point head in
- training."""
- pos_labels = torch.cat([res.pos_gt_labels for res in sampling_results])
- rel_roi_points = self.point_head.get_roi_rel_points_train(
- mask_pred, pos_labels, cfg=self.train_cfg)
- rois = bbox2roi([res.pos_bboxes for res in sampling_results])
-
- fine_grained_point_feats = self._get_fine_grained_point_feats(
- x, rois, rel_roi_points, img_metas)
- coarse_point_feats = point_sample(mask_pred, rel_roi_points)
- mask_point_pred = self.point_head(fine_grained_point_feats,
- coarse_point_feats)
- mask_point_target = self.point_head.get_targets(
- rois, rel_roi_points, sampling_results, gt_masks, self.train_cfg)
- loss_mask_point = self.point_head.loss(mask_point_pred,
- mask_point_target, pos_labels)
-
- return loss_mask_point
-
- def _get_fine_grained_point_feats(self, x, rois, rel_roi_points,
- img_metas):
- """Sample fine grained feats from each level feature map and
- concatenate them together."""
- num_imgs = len(img_metas)
- fine_grained_feats = []
- for idx in range(self.mask_roi_extractor.num_inputs):
- feats = x[idx]
- spatial_scale = 1. / float(
- self.mask_roi_extractor.featmap_strides[idx])
- point_feats = []
- for batch_ind in range(num_imgs):
- # unravel batch dim
- feat = feats[batch_ind].unsqueeze(0)
- inds = (rois[:, 0].long() == batch_ind)
- if inds.any():
- rel_img_points = rel_roi_point_to_rel_img_point(
- rois[inds], rel_roi_points[inds], feat.shape[2:],
- spatial_scale).unsqueeze(0)
- point_feat = point_sample(feat, rel_img_points)
- point_feat = point_feat.squeeze(0).transpose(0, 1)
- point_feats.append(point_feat)
- fine_grained_feats.append(torch.cat(point_feats, dim=0))
- return torch.cat(fine_grained_feats, dim=1)
-
- def _mask_point_forward_test(self, x, rois, label_pred, mask_pred,
- img_metas):
- """Mask refining process with point head in testing."""
- refined_mask_pred = mask_pred.clone()
- for subdivision_step in range(self.test_cfg.subdivision_steps):
- refined_mask_pred = F.interpolate(
- refined_mask_pred,
- scale_factor=self.test_cfg.scale_factor,
- mode='bilinear',
- align_corners=False)
- # If `subdivision_num_points` is larger or equal to the
- # resolution of the next step, then we can skip this step
- num_rois, channels, mask_height, mask_width = \
- refined_mask_pred.shape
- if (self.test_cfg.subdivision_num_points >=
- self.test_cfg.scale_factor**2 * mask_height * mask_width
- and
- subdivision_step < self.test_cfg.subdivision_steps - 1):
- continue
- point_indices, rel_roi_points = \
- self.point_head.get_roi_rel_points_test(
- refined_mask_pred, label_pred, cfg=self.test_cfg)
- fine_grained_point_feats = self._get_fine_grained_point_feats(
- x, rois, rel_roi_points, img_metas)
- coarse_point_feats = point_sample(mask_pred, rel_roi_points)
- mask_point_pred = self.point_head(fine_grained_point_feats,
- coarse_point_feats)
-
- point_indices = point_indices.unsqueeze(1).expand(-1, channels, -1)
- refined_mask_pred = refined_mask_pred.reshape(
- num_rois, channels, mask_height * mask_width)
- refined_mask_pred = refined_mask_pred.scatter_(
- 2, point_indices, mask_point_pred)
- refined_mask_pred = refined_mask_pred.view(num_rois, channels,
- mask_height, mask_width)
-
- return refined_mask_pred
-
- def simple_test_mask(self,
- x,
- img_metas,
- det_bboxes,
- det_labels,
- rescale=False):
- """Obtain mask prediction without augmentation."""
- ori_shapes = tuple(meta['ori_shape'] for meta in img_metas)
- scale_factors = tuple(meta['scale_factor'] for meta in img_metas)
- num_imgs = len(det_bboxes)
- if all(det_bbox.shape[0] == 0 for det_bbox in det_bboxes):
- segm_results = [[[] for _ in range(self.mask_head.num_classes)]
- for _ in range(num_imgs)]
- else:
- # if det_bboxes is rescaled to the original image size, we need to
- # rescale it back to the testing scale to obtain RoIs.
- if rescale and not isinstance(scale_factors[0], float):
- scale_factors = [
- torch.from_numpy(scale_factor).to(det_bboxes[0].device)
- for scale_factor in scale_factors
- ]
- _bboxes = [
- det_bboxes[i][:, :4] *
- scale_factors[i] if rescale else det_bboxes[i][:, :4]
- for i in range(len(det_bboxes))
- ]
- mask_rois = bbox2roi(_bboxes)
- mask_results = self._mask_forward(x, mask_rois)
- # split batch mask prediction back to each image
- mask_pred = mask_results['mask_pred']
- num_mask_roi_per_img = [len(det_bbox) for det_bbox in det_bboxes]
- mask_preds = mask_pred.split(num_mask_roi_per_img, 0)
- mask_rois = mask_rois.split(num_mask_roi_per_img, 0)
-
- # apply mask post-processing to each image individually
- segm_results = []
- for i in range(num_imgs):
- if det_bboxes[i].shape[0] == 0:
- segm_results.append(
- [[] for _ in range(self.mask_head.num_classes)])
- else:
- x_i = [xx[[i]] for xx in x]
- mask_rois_i = mask_rois[i]
- mask_rois_i[:, 0] = 0 # TODO: remove this hack
- mask_pred_i = self._mask_point_forward_test(
- x_i, mask_rois_i, det_labels[i], mask_preds[i],
- [img_metas])
- segm_result = self.mask_head.get_seg_masks(
- mask_pred_i, _bboxes[i], det_labels[i], self.test_cfg,
- ori_shapes[i], scale_factors[i], rescale)
- segm_results.append(segm_result)
- return segm_results
-
- def aug_test_mask(self, feats, img_metas, det_bboxes, det_labels):
- """Test for mask head with test time augmentation."""
- if det_bboxes.shape[0] == 0:
- segm_result = [[] for _ in range(self.mask_head.num_classes)]
- else:
- aug_masks = []
- for x, img_meta in zip(feats, img_metas):
- img_shape = img_meta[0]['img_shape']
- scale_factor = img_meta[0]['scale_factor']
- flip = img_meta[0]['flip']
- _bboxes = bbox_mapping(det_bboxes[:, :4], img_shape,
- scale_factor, flip)
- mask_rois = bbox2roi([_bboxes])
- mask_results = self._mask_forward(x, mask_rois)
- mask_results['mask_pred'] = self._mask_point_forward_test(
- x, mask_rois, det_labels, mask_results['mask_pred'],
- img_metas)
- # convert to numpy array to save memory
- aug_masks.append(
- mask_results['mask_pred'].sigmoid().cpu().numpy())
- merged_masks = merge_aug_masks(aug_masks, img_metas, self.test_cfg)
-
- ori_shape = img_metas[0][0]['ori_shape']
- segm_result = self.mask_head.get_seg_masks(
- merged_masks,
- det_bboxes,
- det_labels,
- self.test_cfg,
- ori_shape,
- scale_factor=1.0,
- rescale=False)
- return segm_result
diff --git a/spaces/Rongjiehuang/ProDiff/modules/hifigan/hifigan.py b/spaces/Rongjiehuang/ProDiff/modules/hifigan/hifigan.py
deleted file mode 100644
index ae7e61f56b00d60bcc49a18ece3edbe54746f7ea..0000000000000000000000000000000000000000
--- a/spaces/Rongjiehuang/ProDiff/modules/hifigan/hifigan.py
+++ /dev/null
@@ -1,365 +0,0 @@
-import torch
-import torch.nn.functional as F
-import torch.nn as nn
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-
-from modules.parallel_wavegan.layers import UpsampleNetwork, ConvInUpsampleNetwork
-from modules.parallel_wavegan.models.source import SourceModuleHnNSF
-import numpy as np
-
-LRELU_SLOPE = 0.1
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def apply_weight_norm(m):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- weight_norm(m)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size * dilation - dilation) / 2)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, h, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.h = h
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- xt = c2(xt)
- x = xt + x
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, h, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.h = h
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- xt = c(xt)
- x = xt + x
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Conv1d1x1(Conv1d):
- """1x1 Conv1d with customized initialization."""
-
- def __init__(self, in_channels, out_channels, bias):
- """Initialize 1x1 Conv1d module."""
- super(Conv1d1x1, self).__init__(in_channels, out_channels,
- kernel_size=1, padding=0,
- dilation=1, bias=bias)
-
-
-class HifiGanGenerator(torch.nn.Module):
- def __init__(self, h, c_out=1):
- super(HifiGanGenerator, self).__init__()
- self.h = h
- self.num_kernels = len(h['resblock_kernel_sizes'])
- self.num_upsamples = len(h['upsample_rates'])
-
- if h['use_pitch_embed']:
- self.harmonic_num = 8
- self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(h['upsample_rates']))
- self.m_source = SourceModuleHnNSF(
- sampling_rate=h['audio_sample_rate'],
- harmonic_num=self.harmonic_num)
- self.noise_convs = nn.ModuleList()
- self.conv_pre = weight_norm(Conv1d(80, h['upsample_initial_channel'], 7, 1, padding=3))
- resblock = ResBlock1 if h['resblock'] == '1' else ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(h['upsample_rates'], h['upsample_kernel_sizes'])):
- c_cur = h['upsample_initial_channel'] // (2 ** (i + 1))
- self.ups.append(weight_norm(
- ConvTranspose1d(c_cur * 2, c_cur, k, u, padding=(k - u) // 2)))
- if h['use_pitch_embed']:
- if i + 1 < len(h['upsample_rates']):
- stride_f0 = np.prod(h['upsample_rates'][i + 1:])
- self.noise_convs.append(Conv1d(
- 1, c_cur, kernel_size=stride_f0 * 2, stride=stride_f0, padding=stride_f0 // 2))
- else:
- self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = h['upsample_initial_channel'] // (2 ** (i + 1))
- for j, (k, d) in enumerate(zip(h['resblock_kernel_sizes'], h['resblock_dilation_sizes'])):
- self.resblocks.append(resblock(h, ch, k, d))
-
- self.conv_post = weight_norm(Conv1d(ch, c_out, 7, 1, padding=3))
- self.ups.apply(init_weights)
- self.conv_post.apply(init_weights)
-
- def forward(self, x, f0=None):
- if f0 is not None:
- # harmonic-source signal, noise-source signal, uv flag
- f0 = self.f0_upsamp(f0[:, None]).transpose(1, 2)
- har_source, noi_source, uv = self.m_source(f0)
- har_source = har_source.transpose(1, 2)
-
- x = self.conv_pre(x)
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, LRELU_SLOPE)
- x = self.ups[i](x)
- if f0 is not None:
- x_source = self.noise_convs[i](har_source)
- x = x + x_source
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- print('Removing weight norm...')
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
- remove_weight_norm(self.conv_pre)
- remove_weight_norm(self.conv_post)
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False, use_cond=False, c_in=1):
- super(DiscriminatorP, self).__init__()
- self.use_cond = use_cond
- if use_cond:
- from utils.hparams import hparams
- t = hparams['hop_size']
- self.cond_net = torch.nn.ConvTranspose1d(80, 1, t * 2, stride=t, padding=t // 2)
- c_in = 2
-
- self.period = period
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv2d(c_in, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
- norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
- norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
- norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
- norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(2, 0))),
- ])
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x, mel):
- fmap = []
- if self.use_cond:
- x_mel = self.cond_net(mel)
- x = torch.cat([x_mel, x], 1)
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_cond=False, c_in=1):
- super(MultiPeriodDiscriminator, self).__init__()
- self.discriminators = nn.ModuleList([
- DiscriminatorP(2, use_cond=use_cond, c_in=c_in),
- DiscriminatorP(3, use_cond=use_cond, c_in=c_in),
- DiscriminatorP(5, use_cond=use_cond, c_in=c_in),
- DiscriminatorP(7, use_cond=use_cond, c_in=c_in),
- DiscriminatorP(11, use_cond=use_cond, c_in=c_in),
- ])
-
- def forward(self, y, y_hat, mel=None):
- y_d_rs = []
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y, mel)
- y_d_g, fmap_g = d(y_hat, mel)
- y_d_rs.append(y_d_r)
- fmap_rs.append(fmap_r)
- y_d_gs.append(y_d_g)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False, use_cond=False, upsample_rates=None, c_in=1):
- super(DiscriminatorS, self).__init__()
- self.use_cond = use_cond
- if use_cond:
- t = np.prod(upsample_rates)
- self.cond_net = torch.nn.ConvTranspose1d(80, 1, t * 2, stride=t, padding=t // 2)
- c_in = 2
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv1d(c_in, 128, 15, 1, padding=7)),
- norm_f(Conv1d(128, 128, 41, 2, groups=4, padding=20)),
- norm_f(Conv1d(128, 256, 41, 2, groups=16, padding=20)),
- norm_f(Conv1d(256, 512, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(512, 1024, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 1, groups=16, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ])
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x, mel):
- if self.use_cond:
- x_mel = self.cond_net(mel)
- x = torch.cat([x_mel, x], 1)
- fmap = []
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class MultiScaleDiscriminator(torch.nn.Module):
- def __init__(self, use_cond=False, c_in=1):
- super(MultiScaleDiscriminator, self).__init__()
- from utils.hparams import hparams
- self.discriminators = nn.ModuleList([
- DiscriminatorS(use_spectral_norm=True, use_cond=use_cond,
- upsample_rates=[4, 4, hparams['hop_size'] // 16],
- c_in=c_in),
- DiscriminatorS(use_cond=use_cond,
- upsample_rates=[4, 4, hparams['hop_size'] // 32],
- c_in=c_in),
- DiscriminatorS(use_cond=use_cond,
- upsample_rates=[4, 4, hparams['hop_size'] // 64],
- c_in=c_in),
- ])
- self.meanpools = nn.ModuleList([
- AvgPool1d(4, 2, padding=1),
- AvgPool1d(4, 2, padding=1)
- ])
-
- def forward(self, y, y_hat, mel=None):
- y_d_rs = []
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- if i != 0:
- y = self.meanpools[i - 1](y)
- y_hat = self.meanpools[i - 1](y_hat)
- y_d_r, fmap_r = d(y, mel)
- y_d_g, fmap_g = d(y_hat, mel)
- y_d_rs.append(y_d_r)
- fmap_rs.append(fmap_r)
- y_d_gs.append(y_d_g)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-def feature_loss(fmap_r, fmap_g):
- loss = 0
- for dr, dg in zip(fmap_r, fmap_g):
- for rl, gl in zip(dr, dg):
- loss += torch.mean(torch.abs(rl - gl))
-
- return loss * 2
-
-
-def discriminator_loss(disc_real_outputs, disc_generated_outputs):
- r_losses = 0
- g_losses = 0
- for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
- r_loss = torch.mean((1 - dr) ** 2)
- g_loss = torch.mean(dg ** 2)
- r_losses += r_loss
- g_losses += g_loss
- r_losses = r_losses / len(disc_real_outputs)
- g_losses = g_losses / len(disc_real_outputs)
- return r_losses, g_losses
-
-
-def cond_discriminator_loss(outputs):
- loss = 0
- for dg in outputs:
- g_loss = torch.mean(dg ** 2)
- loss += g_loss
- loss = loss / len(outputs)
- return loss
-
-
-def generator_loss(disc_outputs):
- loss = 0
- for dg in disc_outputs:
- l = torch.mean((1 - dg) ** 2)
- loss += l
- loss = loss / len(disc_outputs)
- return loss
diff --git a/spaces/SHSH0819/event_detection_app/app.py b/spaces/SHSH0819/event_detection_app/app.py
deleted file mode 100644
index 48522d938f2839c19b55374411152fe6304d9039..0000000000000000000000000000000000000000
--- a/spaces/SHSH0819/event_detection_app/app.py
+++ /dev/null
@@ -1,83 +0,0 @@
-import os
-import sys
-sys.path.insert(0, os.path.abspath('./'))
-
-import torch
-from tqdm.auto import tqdm
-from torch.utils.data import DataLoader, random_split
-from transformers import AutoTokenizer, AutoModelForMaskedLM
-from event_detection_dataset import *
-from event_detection_model import *
-
-import gradio as gr
-#print(f"Gradio version: {gr.__version__}")
-
-
-def predict(data):
- data=[data]
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- #print(f"Device {device}")
-
-
- """Load Tokenizer"""
- tokenizer = AutoTokenizer.from_pretrained('distilbert-base-cased', use_fast=True)
-
-
- """Tokenized Inputs"""
- tokenized_inputs = tokenizer(
- data,
- add_special_tokens=True,
- max_length=512,
- padding='max_length',
- return_token_type_ids=True,
- truncation=True,
- is_split_into_words=True
- )
-
-
- """Load Model"""
- model_path = "./"
- #print("model_path:", model_path)
-
- #print("================ load model ===========================")
- model = DistillBERTClass('distilbert-base-cased')
-
- #print("================ model init ===========================")
- pretrained_model=torch.load(model_path + "event_domain_final.pt",map_location=torch.device('cpu'))
- model.load_state_dict(pretrained_model['model_state_dict'])
- model.to(device)
-
-
- """Make Prediction"""
- model.eval()
-
- ids = torch.tensor(tokenized_inputs['input_ids']).to(device)
- mask = torch.tensor(tokenized_inputs['attention_mask']).to(device)
-
- with torch.no_grad():
- outputs = model(ids, mask)
-
- max_val, max_idx = torch.max(outputs.data, dim=1)
-
- #print("=============== inference result =================")
- #print(f"predicted class {max_idx}")
- id2tags={0: "Acquisition",1: "I-Positive Clinical Trial & FDA Approval",2: "Dividend Cut",3: "Dividend Increase",4: "Guidance Increase",5: "New Contract",6: "Dividend",7: "Reverse Stock Split",8: "Special Dividend ",9: "Stock Repurchase",10: "Stock Split",11: "Others"}
- return id2tags[max_idx.item()]
-
-
-title="Financial Event Detection"
-description="Predict Finacial Events."
-article="modified the model in the following paper: Zhou, Z., Ma, L., & Liu, H. (2021)."
-example_list=[["Investors who receive dividends can choose to take them as cash or as additional shares."]]
-
-# Create the Gradio demo
-demo = gr.Interface(fn=predict, # mapping function from input to output
- inputs="text", # what are the inputs?
- outputs="text", # our fn has two outputs, therefore we have two outputs
- examples=example_list,
- title=title,
- description=description,
- article=article)
-
-# Launch the demo!
-demo.launch(debug=False, share=False)
diff --git a/spaces/SUPERSHANKY/ControlNet_Colab/gradio_scribble2image.py b/spaces/SUPERSHANKY/ControlNet_Colab/gradio_scribble2image.py
deleted file mode 100644
index 475f3f6345ed4608f13066c750dbdd0be88e6cf4..0000000000000000000000000000000000000000
--- a/spaces/SUPERSHANKY/ControlNet_Colab/gradio_scribble2image.py
+++ /dev/null
@@ -1,63 +0,0 @@
-# This file is adapted from https://github.com/lllyasviel/ControlNet/blob/f4748e3630d8141d7765e2bd9b1e348f47847707/gradio_scribble2image.py
-# The original license file is LICENSE.ControlNet in this repo.
-import gradio as gr
-
-
-def create_demo(process, max_images=12):
- with gr.Blocks() as demo:
- with gr.Row():
- gr.Markdown('## Control Stable Diffusion with Scribble Maps')
- with gr.Row():
- with gr.Column():
- input_image = gr.Image(source='upload', type='numpy')
- prompt = gr.Textbox(label='Prompt')
- run_button = gr.Button(label='Run')
- with gr.Accordion('Advanced options', open=False):
- num_samples = gr.Slider(label='Images',
- minimum=1,
- maximum=max_images,
- value=1,
- step=1)
- image_resolution = gr.Slider(label='Image Resolution',
- minimum=256,
- maximum=768,
- value=512,
- step=256)
- ddim_steps = gr.Slider(label='Steps',
- minimum=1,
- maximum=100,
- value=20,
- step=1)
- scale = gr.Slider(label='Guidance Scale',
- minimum=0.1,
- maximum=30.0,
- value=9.0,
- step=0.1)
- seed = gr.Slider(label='Seed',
- minimum=-1,
- maximum=2147483647,
- step=1,
- randomize=True)
- eta = gr.Number(label='eta (DDIM)', value=0.0)
- a_prompt = gr.Textbox(
- label='Added Prompt',
- value='best quality, extremely detailed')
- n_prompt = gr.Textbox(
- label='Negative Prompt',
- value=
- 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
- )
- with gr.Column():
- result_gallery = gr.Gallery(label='Output',
- show_label=False,
- elem_id='gallery').style(
- grid=2, height='auto')
- ips = [
- input_image, prompt, a_prompt, n_prompt, num_samples,
- image_resolution, ddim_steps, scale, seed, eta
- ]
- run_button.click(fn=process,
- inputs=ips,
- outputs=[result_gallery],
- api_name='scribble')
- return demo
diff --git a/spaces/Salesforce/EDICT/my_half_diffusers/pipelines/pndm/pipeline_pndm.py b/spaces/Salesforce/EDICT/my_half_diffusers/pipelines/pndm/pipeline_pndm.py
deleted file mode 100644
index f3dff1a9a9416ef7592200c7dbb2ee092bd524d5..0000000000000000000000000000000000000000
--- a/spaces/Salesforce/EDICT/my_half_diffusers/pipelines/pndm/pipeline_pndm.py
+++ /dev/null
@@ -1,111 +0,0 @@
-# Copyright 2022 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-# limitations under the License.
-
-
-import warnings
-from typing import Optional, Tuple, Union
-
-import torch
-
-from ...models import UNet2DModel
-from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
-from ...schedulers import PNDMScheduler
-
-
-class PNDMPipeline(DiffusionPipeline):
- r"""
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
-
- Parameters:
- unet (`UNet2DModel`): U-Net architecture to denoise the encoded image latents.
- scheduler ([`SchedulerMixin`]):
- The `PNDMScheduler` to be used in combination with `unet` to denoise the encoded image.
- """
-
- unet: UNet2DModel
- scheduler: PNDMScheduler
-
- def __init__(self, unet: UNet2DModel, scheduler: PNDMScheduler):
- super().__init__()
- scheduler = scheduler.set_format("pt")
- self.register_modules(unet=unet, scheduler=scheduler)
-
- @torch.no_grad()
- def __call__(
- self,
- batch_size: int = 1,
- num_inference_steps: int = 50,
- generator: Optional[torch.Generator] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- **kwargs,
- ) -> Union[ImagePipelineOutput, Tuple]:
- r"""
- Args:
- batch_size (`int`, `optional`, defaults to 1): The number of images to generate.
- num_inference_steps (`int`, `optional`, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- generator (`torch.Generator`, `optional`): A [torch
- generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
- deterministic.
- output_type (`str`, `optional`, defaults to `"pil"`): The output format of the generate image. Choose
- between [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `nd.array`.
- return_dict (`bool`, `optional`, defaults to `True`): Whether or not to return a
- [`~pipeline_utils.ImagePipelineOutput`] instead of a plain tuple.
-
- Returns:
- [`~pipeline_utils.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if
- `return_dict` is True, otherwise a `tuple. When returning a tuple, the first element is a list with the
- generated images.
- """
- # For more information on the sampling method you can take a look at Algorithm 2 of
- # the official paper: https://arxiv.org/pdf/2202.09778.pdf
-
- if "torch_device" in kwargs:
- device = kwargs.pop("torch_device")
- warnings.warn(
- "`torch_device` is deprecated as an input argument to `__call__` and will be removed in v0.3.0."
- " Consider using `pipe.to(torch_device)` instead."
- )
-
- # Set device as before (to be removed in 0.3.0)
- if device is None:
- device = "cuda" if torch.cuda.is_available() else "cpu"
- self.to(device)
-
- # Sample gaussian noise to begin loop
- image = torch.randn(
- (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
- generator=generator,
- )
- image = image.to(self.device)
-
- self.scheduler.set_timesteps(num_inference_steps)
- for t in self.progress_bar(self.scheduler.timesteps):
- model_output = self.unet(image, t).sample
-
- image = self.scheduler.step(model_output, t, image).prev_sample
-
- image = (image / 2 + 0.5).clamp(0, 1)
- image = image.cpu().permute(0, 2, 3, 1).numpy()
- if output_type == "pil":
- image = self.numpy_to_pil(image)
-
- if not return_dict:
- return (image,)
-
- return ImagePipelineOutput(images=image)
diff --git a/spaces/SantoshKumar/06-SD-SL-AI-Image-Music-Video-UI-UX/README.md b/spaces/SantoshKumar/06-SD-SL-AI-Image-Music-Video-UI-UX/README.md
deleted file mode 100644
index ef27aa4cff14a67a1c948a493d8e0edd3043657e..0000000000000000000000000000000000000000
--- a/spaces/SantoshKumar/06-SD-SL-AI-Image-Music-Video-UI-UX/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: 06 SD SL AI Image Music Video UI UX
-emoji: ⚡
-colorFrom: red
-colorTo: green
-sdk: streamlit
-sdk_version: 1.10.0
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Saurav21/Blog-Generation/README.md b/spaces/Saurav21/Blog-Generation/README.md
deleted file mode 100644
index 8e9da6bac3c5f38c88983e0d2c1e1a4793957658..0000000000000000000000000000000000000000
--- a/spaces/Saurav21/Blog-Generation/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Blog Generation
-emoji: 👀
-colorFrom: green
-colorTo: purple
-sdk: gradio
-sdk_version: 3.0.26
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Shankarm08/chatconversation/app.py b/spaces/Shankarm08/chatconversation/app.py
deleted file mode 100644
index dd2c4ce561ab200acb64f726938f103458c0acb3..0000000000000000000000000000000000000000
--- a/spaces/Shankarm08/chatconversation/app.py
+++ /dev/null
@@ -1,55 +0,0 @@
-
-import streamlit as st
-
-
-from langchain.chat_models import ChatOpenAI
-from langchain.schema import (
- AIMessage,
- HumanMessage,
- SystemMessage
-)
-
-# From here down is all the StreamLit UI.
-st.set_page_config(page_title="LangChain Demo", page_icon=":robot:")
-st.header("Hey, I'm your Chat GPT")
-
-
-
-if "sessionMessages" not in st.session_state:
- st.session_state.sessionMessages = [
- SystemMessage(content="You are a helpful assistant.")
- ]
-
-
-
-def load_answer(question):
-
- st.session_state.sessionMessages.append(HumanMessage(content=question))
-
- assistant_answer = chat(st.session_state.sessionMessages )
-
- st.session_state.sessionMessages.append(AIMessage(content=assistant_answer.content))
-
- return assistant_answer.content
-
-
-def get_text():
- input_text = st.text_input("You: ", key= input)
- return input_text
-
-
-chat = ChatOpenAI(temperature=0)
-
-
-
-
-user_input=get_text()
-submit = st.button('Generate')
-
-if submit:
-
- response = load_answer(user_input)
- st.subheader("Answer:")
-
- st.write(response,key= 1)
-
diff --git a/spaces/Silentlin/DiffSinger/tasks/tts/tts.py b/spaces/Silentlin/DiffSinger/tasks/tts/tts.py
deleted file mode 100644
index f803c1e738137cb1eca19a1943196abd2884c0a5..0000000000000000000000000000000000000000
--- a/spaces/Silentlin/DiffSinger/tasks/tts/tts.py
+++ /dev/null
@@ -1,131 +0,0 @@
-from multiprocessing.pool import Pool
-
-import matplotlib
-
-from utils.pl_utils import data_loader
-from utils.training_utils import RSQRTSchedule
-from vocoders.base_vocoder import get_vocoder_cls, BaseVocoder
-from modules.fastspeech.pe import PitchExtractor
-
-matplotlib.use('Agg')
-import os
-import numpy as np
-from tqdm import tqdm
-import torch.distributed as dist
-
-from tasks.base_task import BaseTask
-from utils.hparams import hparams
-from utils.text_encoder import TokenTextEncoder
-import json
-
-import torch
-import torch.optim
-import torch.utils.data
-import utils
-
-
-
-class TtsTask(BaseTask):
- def __init__(self, *args, **kwargs):
- self.vocoder = None
- self.phone_encoder = self.build_phone_encoder(hparams['binary_data_dir'])
- self.padding_idx = self.phone_encoder.pad()
- self.eos_idx = self.phone_encoder.eos()
- self.seg_idx = self.phone_encoder.seg()
- self.saving_result_pool = None
- self.saving_results_futures = None
- self.stats = {}
- super().__init__(*args, **kwargs)
-
- def build_scheduler(self, optimizer):
- return RSQRTSchedule(optimizer)
-
- def build_optimizer(self, model):
- self.optimizer = optimizer = torch.optim.AdamW(
- model.parameters(),
- lr=hparams['lr'])
- return optimizer
-
- def build_dataloader(self, dataset, shuffle, max_tokens=None, max_sentences=None,
- required_batch_size_multiple=-1, endless=False, batch_by_size=True):
- devices_cnt = torch.cuda.device_count()
- if devices_cnt == 0:
- devices_cnt = 1
- if required_batch_size_multiple == -1:
- required_batch_size_multiple = devices_cnt
-
- def shuffle_batches(batches):
- np.random.shuffle(batches)
- return batches
-
- if max_tokens is not None:
- max_tokens *= devices_cnt
- if max_sentences is not None:
- max_sentences *= devices_cnt
- indices = dataset.ordered_indices()
- if batch_by_size:
- batch_sampler = utils.batch_by_size(
- indices, dataset.num_tokens, max_tokens=max_tokens, max_sentences=max_sentences,
- required_batch_size_multiple=required_batch_size_multiple,
- )
- else:
- batch_sampler = []
- for i in range(0, len(indices), max_sentences):
- batch_sampler.append(indices[i:i + max_sentences])
-
- if shuffle:
- batches = shuffle_batches(list(batch_sampler))
- if endless:
- batches = [b for _ in range(1000) for b in shuffle_batches(list(batch_sampler))]
- else:
- batches = batch_sampler
- if endless:
- batches = [b for _ in range(1000) for b in batches]
- num_workers = dataset.num_workers
- if self.trainer.use_ddp:
- num_replicas = dist.get_world_size()
- rank = dist.get_rank()
- batches = [x[rank::num_replicas] for x in batches if len(x) % num_replicas == 0]
- return torch.utils.data.DataLoader(dataset,
- collate_fn=dataset.collater,
- batch_sampler=batches,
- num_workers=num_workers,
- pin_memory=False)
-
- def build_phone_encoder(self, data_dir):
- phone_list_file = os.path.join(data_dir, 'phone_set.json')
-
- phone_list = json.load(open(phone_list_file))
- return TokenTextEncoder(None, vocab_list=phone_list, replace_oov=',')
-
- def build_optimizer(self, model):
- self.optimizer = optimizer = torch.optim.AdamW(
- model.parameters(),
- lr=hparams['lr'])
- return optimizer
-
- def test_start(self):
- self.saving_result_pool = Pool(8)
- self.saving_results_futures = []
- self.vocoder: BaseVocoder = get_vocoder_cls(hparams)()
- if hparams.get('pe_enable') is not None and hparams['pe_enable']:
- self.pe = PitchExtractor().cuda()
- utils.load_ckpt(self.pe, hparams['pe_ckpt'], 'model', strict=True)
- self.pe.eval()
- def test_end(self, outputs):
- self.saving_result_pool.close()
- [f.get() for f in tqdm(self.saving_results_futures)]
- self.saving_result_pool.join()
- return {}
-
- ##########
- # utils
- ##########
- def weights_nonzero_speech(self, target):
- # target : B x T x mel
- # Assign weight 1.0 to all labels except for padding (id=0).
- dim = target.size(-1)
- return target.abs().sum(-1, keepdim=True).ne(0).float().repeat(1, 1, dim)
-
-if __name__ == '__main__':
- TtsTask.start()
diff --git a/spaces/SocialGouv/speech-to-speech-translation-french/README.md b/spaces/SocialGouv/speech-to-speech-translation-french/README.md
deleted file mode 100644
index e148d43df354a310bc2ed5a2fe8d8ce91138b306..0000000000000000000000000000000000000000
--- a/spaces/SocialGouv/speech-to-speech-translation-french/README.md
+++ /dev/null
@@ -1,7 +0,0 @@
----
-title: speech-to-speech-translation-italian
-app_file: app.py
-sdk: gradio
-sdk_version: 3.36.0
-duplicated_from: Sandiago21/speech-to-speech-translation-italian
----
diff --git "a/spaces/SouthCity/ShuruiXu/crazy_functions/\347\224\237\346\210\220\345\207\275\346\225\260\346\263\250\351\207\212.py" "b/spaces/SouthCity/ShuruiXu/crazy_functions/\347\224\237\346\210\220\345\207\275\346\225\260\346\263\250\351\207\212.py"
deleted file mode 100644
index 9579800f2cefa684e38ee74b1cce4ee7db7a11fe..0000000000000000000000000000000000000000
--- "a/spaces/SouthCity/ShuruiXu/crazy_functions/\347\224\237\346\210\220\345\207\275\346\225\260\346\263\250\351\207\212.py"
+++ /dev/null
@@ -1,57 +0,0 @@
-from predict import predict_no_ui
-from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
-fast_debug = False
-
-
-def 生成函数注释(file_manifest, project_folder, top_p, api_key, temperature, chatbot, history, systemPromptTxt):
- import time, glob, os
- print('begin analysis on:', file_manifest)
- for index, fp in enumerate(file_manifest):
- with open(fp, 'r', encoding='utf-8') as f:
- file_content = f.read()
-
- i_say = f'请对下面的程序文件做一个概述,并对文件中的所有函数生成注释,使用markdown表格输出结果,文件名是{os.path.relpath(fp, project_folder)},文件内容是 ```{file_content}```'
- i_say_show_user = f'[{index}/{len(file_manifest)}] 请对下面的程序文件做一个概述,并对文件中的所有函数生成注释: {os.path.abspath(fp)}'
- chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
- print('[1] yield chatbot, history')
- yield chatbot, history, '正常'
-
- if not fast_debug:
- msg = '正常'
- # ** gpt request **
- gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, api_key, temperature, history=[]) # 带超时倒计时
-
- print('[2] end gpt req')
- chatbot[-1] = (i_say_show_user, gpt_say)
- history.append(i_say_show_user); history.append(gpt_say)
- print('[3] yield chatbot, history')
- yield chatbot, history, msg
- print('[4] next')
- if not fast_debug: time.sleep(2)
-
- if not fast_debug:
- res = write_results_to_file(history)
- chatbot.append(("完成了吗?", res))
- yield chatbot, history, msg
-
-
-
-@CatchException
-def 批量生成函数注释(txt, top_p, api_key, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
- yield chatbot, history, '正常'
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.py', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)]
-
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.tex文件: {txt}")
- yield chatbot, history, '正常'
- return
- yield from 生成函数注释(file_manifest, project_folder, top_p, api_key, temperature, chatbot, history, systemPromptTxt)
diff --git a/spaces/SuYuanS/AudioCraft_Plus/CODE_OF_CONDUCT.md b/spaces/SuYuanS/AudioCraft_Plus/CODE_OF_CONDUCT.md
deleted file mode 100644
index 83f431e8feeb7e80d571f39c9f6c1b96857b5f85..0000000000000000000000000000000000000000
--- a/spaces/SuYuanS/AudioCraft_Plus/CODE_OF_CONDUCT.md
+++ /dev/null
@@ -1,80 +0,0 @@
-# Code of Conduct
-
-## Our Pledge
-
-In the interest of fostering an open and welcoming environment, we as
-contributors and maintainers pledge to make participation in our project and
-our community a harassment-free experience for everyone, regardless of age, body
-size, disability, ethnicity, sex characteristics, gender identity and expression,
-level of experience, education, socio-economic status, nationality, personal
-appearance, race, religion, or sexual identity and orientation.
-
-## Our Standards
-
-Examples of behavior that contributes to creating a positive environment
-include:
-
-* Using welcoming and inclusive language
-* Being respectful of differing viewpoints and experiences
-* Gracefully accepting constructive criticism
-* Focusing on what is best for the community
-* Showing empathy towards other community members
-
-Examples of unacceptable behavior by participants include:
-
-* The use of sexualized language or imagery and unwelcome sexual attention or
-advances
-* Trolling, insulting/derogatory comments, and personal or political attacks
-* Public or private harassment
-* Publishing others' private information, such as a physical or electronic
-address, without explicit permission
-* Other conduct which could reasonably be considered inappropriate in a
-professional setting
-
-## Our Responsibilities
-
-Project maintainers are responsible for clarifying the standards of acceptable
-behavior and are expected to take appropriate and fair corrective action in
-response to any instances of unacceptable behavior.
-
-Project maintainers have the right and responsibility to remove, edit, or
-reject comments, commits, code, wiki edits, issues, and other contributions
-that are not aligned to this Code of Conduct, or to ban temporarily or
-permanently any contributor for other behaviors that they deem inappropriate,
-threatening, offensive, or harmful.
-
-## Scope
-
-This Code of Conduct applies within all project spaces, and it also applies when
-an individual is representing the project or its community in public spaces.
-Examples of representing a project or community include using an official
-project e-mail address, posting via an official social media account, or acting
-as an appointed representative at an online or offline event. Representation of
-a project may be further defined and clarified by project maintainers.
-
-This Code of Conduct also applies outside the project spaces when there is a
-reasonable belief that an individual's behavior may have a negative impact on
-the project or its community.
-
-## Enforcement
-
-Instances of abusive, harassing, or otherwise unacceptable behavior may be
-reported by contacting the project team at . All
-complaints will be reviewed and investigated and will result in a response that
-is deemed necessary and appropriate to the circumstances. The project team is
-obligated to maintain confidentiality with regard to the reporter of an incident.
-Further details of specific enforcement policies may be posted separately.
-
-Project maintainers who do not follow or enforce the Code of Conduct in good
-faith may face temporary or permanent repercussions as determined by other
-members of the project's leadership.
-
-## Attribution
-
-This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
-available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
-
-[homepage]: https://www.contributor-covenant.org
-
-For answers to common questions about this code of conduct, see
-https://www.contributor-covenant.org/faq
diff --git a/spaces/SujanMidatani/speechToText/app.py b/spaces/SujanMidatani/speechToText/app.py
deleted file mode 100644
index 90038167499a29a46001456a8b47ec4dfb097b01..0000000000000000000000000000000000000000
--- a/spaces/SujanMidatani/speechToText/app.py
+++ /dev/null
@@ -1,23 +0,0 @@
-import os
-import gradio as gr
-os.system("sudo apt-get update")
-os.system("apt install libasound2-dev portaudio19-dev libportaudio2 libportaudiocpp0 ffmpeg")
-# import sounddevice as sd
-import speech_recognition as sr
-recognizer = sr.Recognizer()
-def translate(audio_path:str,lang:str):
-
-
- with sr.AudioFile(audio_path) as source:
- audio = recognizer.record(source)
-
- try:
- spoken_text = recognizer.recognize_google(audio,language=lang)
- return spoken_text
- except:
- gr.Error("some error rised")
-
-
-
-k=gr.Interface(fn=translate, inputs=[gr.Audio(source="upload", type="filepath"),gr.Text(label="lang")], outputs="text")
-k.launch()
\ No newline at end of file
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/aiohttp/multipart.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/aiohttp/multipart.py
deleted file mode 100644
index 73801f459aa274ca6aae7bf28a2c5bb3bf075d11..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/aiohttp/multipart.py
+++ /dev/null
@@ -1,961 +0,0 @@
-import base64
-import binascii
-import json
-import re
-import uuid
-import warnings
-import zlib
-from collections import deque
-from types import TracebackType
-from typing import (
- TYPE_CHECKING,
- Any,
- AsyncIterator,
- Deque,
- Dict,
- Iterator,
- List,
- Mapping,
- Optional,
- Sequence,
- Tuple,
- Type,
- Union,
- cast,
-)
-from urllib.parse import parse_qsl, unquote, urlencode
-
-from multidict import CIMultiDict, CIMultiDictProxy, MultiMapping
-
-from .hdrs import (
- CONTENT_DISPOSITION,
- CONTENT_ENCODING,
- CONTENT_LENGTH,
- CONTENT_TRANSFER_ENCODING,
- CONTENT_TYPE,
-)
-from .helpers import CHAR, TOKEN, parse_mimetype, reify
-from .http import HeadersParser
-from .payload import (
- JsonPayload,
- LookupError,
- Order,
- Payload,
- StringPayload,
- get_payload,
- payload_type,
-)
-from .streams import StreamReader
-
-__all__ = (
- "MultipartReader",
- "MultipartWriter",
- "BodyPartReader",
- "BadContentDispositionHeader",
- "BadContentDispositionParam",
- "parse_content_disposition",
- "content_disposition_filename",
-)
-
-
-if TYPE_CHECKING: # pragma: no cover
- from .client_reqrep import ClientResponse
-
-
-class BadContentDispositionHeader(RuntimeWarning):
- pass
-
-
-class BadContentDispositionParam(RuntimeWarning):
- pass
-
-
-def parse_content_disposition(
- header: Optional[str],
-) -> Tuple[Optional[str], Dict[str, str]]:
- def is_token(string: str) -> bool:
- return bool(string) and TOKEN >= set(string)
-
- def is_quoted(string: str) -> bool:
- return string[0] == string[-1] == '"'
-
- def is_rfc5987(string: str) -> bool:
- return is_token(string) and string.count("'") == 2
-
- def is_extended_param(string: str) -> bool:
- return string.endswith("*")
-
- def is_continuous_param(string: str) -> bool:
- pos = string.find("*") + 1
- if not pos:
- return False
- substring = string[pos:-1] if string.endswith("*") else string[pos:]
- return substring.isdigit()
-
- def unescape(text: str, *, chars: str = "".join(map(re.escape, CHAR))) -> str:
- return re.sub(f"\\\\([{chars}])", "\\1", text)
-
- if not header:
- return None, {}
-
- disptype, *parts = header.split(";")
- if not is_token(disptype):
- warnings.warn(BadContentDispositionHeader(header))
- return None, {}
-
- params: Dict[str, str] = {}
- while parts:
- item = parts.pop(0)
-
- if "=" not in item:
- warnings.warn(BadContentDispositionHeader(header))
- return None, {}
-
- key, value = item.split("=", 1)
- key = key.lower().strip()
- value = value.lstrip()
-
- if key in params:
- warnings.warn(BadContentDispositionHeader(header))
- return None, {}
-
- if not is_token(key):
- warnings.warn(BadContentDispositionParam(item))
- continue
-
- elif is_continuous_param(key):
- if is_quoted(value):
- value = unescape(value[1:-1])
- elif not is_token(value):
- warnings.warn(BadContentDispositionParam(item))
- continue
-
- elif is_extended_param(key):
- if is_rfc5987(value):
- encoding, _, value = value.split("'", 2)
- encoding = encoding or "utf-8"
- else:
- warnings.warn(BadContentDispositionParam(item))
- continue
-
- try:
- value = unquote(value, encoding, "strict")
- except UnicodeDecodeError: # pragma: nocover
- warnings.warn(BadContentDispositionParam(item))
- continue
-
- else:
- failed = True
- if is_quoted(value):
- failed = False
- value = unescape(value[1:-1].lstrip("\\/"))
- elif is_token(value):
- failed = False
- elif parts:
- # maybe just ; in filename, in any case this is just
- # one case fix, for proper fix we need to redesign parser
- _value = f"{value};{parts[0]}"
- if is_quoted(_value):
- parts.pop(0)
- value = unescape(_value[1:-1].lstrip("\\/"))
- failed = False
-
- if failed:
- warnings.warn(BadContentDispositionHeader(header))
- return None, {}
-
- params[key] = value
-
- return disptype.lower(), params
-
-
-def content_disposition_filename(
- params: Mapping[str, str], name: str = "filename"
-) -> Optional[str]:
- name_suf = "%s*" % name
- if not params:
- return None
- elif name_suf in params:
- return params[name_suf]
- elif name in params:
- return params[name]
- else:
- parts = []
- fnparams = sorted(
- (key, value) for key, value in params.items() if key.startswith(name_suf)
- )
- for num, (key, value) in enumerate(fnparams):
- _, tail = key.split("*", 1)
- if tail.endswith("*"):
- tail = tail[:-1]
- if tail == str(num):
- parts.append(value)
- else:
- break
- if not parts:
- return None
- value = "".join(parts)
- if "'" in value:
- encoding, _, value = value.split("'", 2)
- encoding = encoding or "utf-8"
- return unquote(value, encoding, "strict")
- return value
-
-
-class MultipartResponseWrapper:
- """Wrapper around the MultipartReader.
-
- It takes care about
- underlying connection and close it when it needs in.
- """
-
- def __init__(
- self,
- resp: "ClientResponse",
- stream: "MultipartReader",
- ) -> None:
- self.resp = resp
- self.stream = stream
-
- def __aiter__(self) -> "MultipartResponseWrapper":
- return self
-
- async def __anext__(
- self,
- ) -> Union["MultipartReader", "BodyPartReader"]:
- part = await self.next()
- if part is None:
- raise StopAsyncIteration
- return part
-
- def at_eof(self) -> bool:
- """Returns True when all response data had been read."""
- return self.resp.content.at_eof()
-
- async def next(
- self,
- ) -> Optional[Union["MultipartReader", "BodyPartReader"]]:
- """Emits next multipart reader object."""
- item = await self.stream.next()
- if self.stream.at_eof():
- await self.release()
- return item
-
- async def release(self) -> None:
- """Release the connection gracefully.
-
- All remaining content is read to the void.
- """
- await self.resp.release()
-
-
-class BodyPartReader:
- """Multipart reader for single body part."""
-
- chunk_size = 8192
-
- def __init__(
- self, boundary: bytes, headers: "CIMultiDictProxy[str]", content: StreamReader
- ) -> None:
- self.headers = headers
- self._boundary = boundary
- self._content = content
- self._at_eof = False
- length = self.headers.get(CONTENT_LENGTH, None)
- self._length = int(length) if length is not None else None
- self._read_bytes = 0
- # TODO: typeing.Deque is not supported by Python 3.5
- self._unread: Deque[bytes] = deque()
- self._prev_chunk: Optional[bytes] = None
- self._content_eof = 0
- self._cache: Dict[str, Any] = {}
-
- def __aiter__(self) -> AsyncIterator["BodyPartReader"]:
- return self # type: ignore[return-value]
-
- async def __anext__(self) -> bytes:
- part = await self.next()
- if part is None:
- raise StopAsyncIteration
- return part
-
- async def next(self) -> Optional[bytes]:
- item = await self.read()
- if not item:
- return None
- return item
-
- async def read(self, *, decode: bool = False) -> bytes:
- """Reads body part data.
-
- decode: Decodes data following by encoding
- method from Content-Encoding header. If it missed
- data remains untouched
- """
- if self._at_eof:
- return b""
- data = bytearray()
- while not self._at_eof:
- data.extend(await self.read_chunk(self.chunk_size))
- if decode:
- return self.decode(data)
- return data
-
- async def read_chunk(self, size: int = chunk_size) -> bytes:
- """Reads body part content chunk of the specified size.
-
- size: chunk size
- """
- if self._at_eof:
- return b""
- if self._length:
- chunk = await self._read_chunk_from_length(size)
- else:
- chunk = await self._read_chunk_from_stream(size)
-
- self._read_bytes += len(chunk)
- if self._read_bytes == self._length:
- self._at_eof = True
- if self._at_eof:
- clrf = await self._content.readline()
- assert (
- b"\r\n" == clrf
- ), "reader did not read all the data or it is malformed"
- return chunk
-
- async def _read_chunk_from_length(self, size: int) -> bytes:
- # Reads body part content chunk of the specified size.
- # The body part must has Content-Length header with proper value.
- assert self._length is not None, "Content-Length required for chunked read"
- chunk_size = min(size, self._length - self._read_bytes)
- chunk = await self._content.read(chunk_size)
- return chunk
-
- async def _read_chunk_from_stream(self, size: int) -> bytes:
- # Reads content chunk of body part with unknown length.
- # The Content-Length header for body part is not necessary.
- assert (
- size >= len(self._boundary) + 2
- ), "Chunk size must be greater or equal than boundary length + 2"
- first_chunk = self._prev_chunk is None
- if first_chunk:
- self._prev_chunk = await self._content.read(size)
-
- chunk = await self._content.read(size)
- self._content_eof += int(self._content.at_eof())
- assert self._content_eof < 3, "Reading after EOF"
- assert self._prev_chunk is not None
- window = self._prev_chunk + chunk
- sub = b"\r\n" + self._boundary
- if first_chunk:
- idx = window.find(sub)
- else:
- idx = window.find(sub, max(0, len(self._prev_chunk) - len(sub)))
- if idx >= 0:
- # pushing boundary back to content
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=DeprecationWarning)
- self._content.unread_data(window[idx:])
- if size > idx:
- self._prev_chunk = self._prev_chunk[:idx]
- chunk = window[len(self._prev_chunk) : idx]
- if not chunk:
- self._at_eof = True
- result = self._prev_chunk
- self._prev_chunk = chunk
- return result
-
- async def readline(self) -> bytes:
- """Reads body part by line by line."""
- if self._at_eof:
- return b""
-
- if self._unread:
- line = self._unread.popleft()
- else:
- line = await self._content.readline()
-
- if line.startswith(self._boundary):
- # the very last boundary may not come with \r\n,
- # so set single rules for everyone
- sline = line.rstrip(b"\r\n")
- boundary = self._boundary
- last_boundary = self._boundary + b"--"
- # ensure that we read exactly the boundary, not something alike
- if sline == boundary or sline == last_boundary:
- self._at_eof = True
- self._unread.append(line)
- return b""
- else:
- next_line = await self._content.readline()
- if next_line.startswith(self._boundary):
- line = line[:-2] # strip CRLF but only once
- self._unread.append(next_line)
-
- return line
-
- async def release(self) -> None:
- """Like read(), but reads all the data to the void."""
- if self._at_eof:
- return
- while not self._at_eof:
- await self.read_chunk(self.chunk_size)
-
- async def text(self, *, encoding: Optional[str] = None) -> str:
- """Like read(), but assumes that body part contains text data."""
- data = await self.read(decode=True)
- # see https://www.w3.org/TR/html5/forms.html#multipart/form-data-encoding-algorithm # NOQA
- # and https://dvcs.w3.org/hg/xhr/raw-file/tip/Overview.html#dom-xmlhttprequest-send # NOQA
- encoding = encoding or self.get_charset(default="utf-8")
- return data.decode(encoding)
-
- async def json(self, *, encoding: Optional[str] = None) -> Optional[Dict[str, Any]]:
- """Like read(), but assumes that body parts contains JSON data."""
- data = await self.read(decode=True)
- if not data:
- return None
- encoding = encoding or self.get_charset(default="utf-8")
- return cast(Dict[str, Any], json.loads(data.decode(encoding)))
-
- async def form(self, *, encoding: Optional[str] = None) -> List[Tuple[str, str]]:
- """Like read(), but assumes that body parts contain form urlencoded data."""
- data = await self.read(decode=True)
- if not data:
- return []
- if encoding is not None:
- real_encoding = encoding
- else:
- real_encoding = self.get_charset(default="utf-8")
- return parse_qsl(
- data.rstrip().decode(real_encoding),
- keep_blank_values=True,
- encoding=real_encoding,
- )
-
- def at_eof(self) -> bool:
- """Returns True if the boundary was reached or False otherwise."""
- return self._at_eof
-
- def decode(self, data: bytes) -> bytes:
- """Decodes data.
-
- Decoding is done according the specified Content-Encoding
- or Content-Transfer-Encoding headers value.
- """
- if CONTENT_TRANSFER_ENCODING in self.headers:
- data = self._decode_content_transfer(data)
- if CONTENT_ENCODING in self.headers:
- return self._decode_content(data)
- return data
-
- def _decode_content(self, data: bytes) -> bytes:
- encoding = self.headers.get(CONTENT_ENCODING, "").lower()
-
- if encoding == "deflate":
- return zlib.decompress(data, -zlib.MAX_WBITS)
- elif encoding == "gzip":
- return zlib.decompress(data, 16 + zlib.MAX_WBITS)
- elif encoding == "identity":
- return data
- else:
- raise RuntimeError(f"unknown content encoding: {encoding}")
-
- def _decode_content_transfer(self, data: bytes) -> bytes:
- encoding = self.headers.get(CONTENT_TRANSFER_ENCODING, "").lower()
-
- if encoding == "base64":
- return base64.b64decode(data)
- elif encoding == "quoted-printable":
- return binascii.a2b_qp(data)
- elif encoding in ("binary", "8bit", "7bit"):
- return data
- else:
- raise RuntimeError(
- "unknown content transfer encoding: {}" "".format(encoding)
- )
-
- def get_charset(self, default: str) -> str:
- """Returns charset parameter from Content-Type header or default."""
- ctype = self.headers.get(CONTENT_TYPE, "")
- mimetype = parse_mimetype(ctype)
- return mimetype.parameters.get("charset", default)
-
- @reify
- def name(self) -> Optional[str]:
- """Returns name specified in Content-Disposition header.
-
- If the header is missing or malformed, returns None.
- """
- _, params = parse_content_disposition(self.headers.get(CONTENT_DISPOSITION))
- return content_disposition_filename(params, "name")
-
- @reify
- def filename(self) -> Optional[str]:
- """Returns filename specified in Content-Disposition header.
-
- Returns None if the header is missing or malformed.
- """
- _, params = parse_content_disposition(self.headers.get(CONTENT_DISPOSITION))
- return content_disposition_filename(params, "filename")
-
-
-@payload_type(BodyPartReader, order=Order.try_first)
-class BodyPartReaderPayload(Payload):
- def __init__(self, value: BodyPartReader, *args: Any, **kwargs: Any) -> None:
- super().__init__(value, *args, **kwargs)
-
- params: Dict[str, str] = {}
- if value.name is not None:
- params["name"] = value.name
- if value.filename is not None:
- params["filename"] = value.filename
-
- if params:
- self.set_content_disposition("attachment", True, **params)
-
- async def write(self, writer: Any) -> None:
- field = self._value
- chunk = await field.read_chunk(size=2**16)
- while chunk:
- await writer.write(field.decode(chunk))
- chunk = await field.read_chunk(size=2**16)
-
-
-class MultipartReader:
- """Multipart body reader."""
-
- #: Response wrapper, used when multipart readers constructs from response.
- response_wrapper_cls = MultipartResponseWrapper
- #: Multipart reader class, used to handle multipart/* body parts.
- #: None points to type(self)
- multipart_reader_cls = None
- #: Body part reader class for non multipart/* content types.
- part_reader_cls = BodyPartReader
-
- def __init__(self, headers: Mapping[str, str], content: StreamReader) -> None:
- self.headers = headers
- self._boundary = ("--" + self._get_boundary()).encode()
- self._content = content
- self._last_part: Optional[Union["MultipartReader", BodyPartReader]] = None
- self._at_eof = False
- self._at_bof = True
- self._unread: List[bytes] = []
-
- def __aiter__(
- self,
- ) -> AsyncIterator["BodyPartReader"]:
- return self # type: ignore[return-value]
-
- async def __anext__(
- self,
- ) -> Optional[Union["MultipartReader", BodyPartReader]]:
- part = await self.next()
- if part is None:
- raise StopAsyncIteration
- return part
-
- @classmethod
- def from_response(
- cls,
- response: "ClientResponse",
- ) -> MultipartResponseWrapper:
- """Constructs reader instance from HTTP response.
-
- :param response: :class:`~aiohttp.client.ClientResponse` instance
- """
- obj = cls.response_wrapper_cls(
- response, cls(response.headers, response.content)
- )
- return obj
-
- def at_eof(self) -> bool:
- """Returns True if the final boundary was reached, false otherwise."""
- return self._at_eof
-
- async def next(
- self,
- ) -> Optional[Union["MultipartReader", BodyPartReader]]:
- """Emits the next multipart body part."""
- # So, if we're at BOF, we need to skip till the boundary.
- if self._at_eof:
- return None
- await self._maybe_release_last_part()
- if self._at_bof:
- await self._read_until_first_boundary()
- self._at_bof = False
- else:
- await self._read_boundary()
- if self._at_eof: # we just read the last boundary, nothing to do there
- return None
- self._last_part = await self.fetch_next_part()
- return self._last_part
-
- async def release(self) -> None:
- """Reads all the body parts to the void till the final boundary."""
- while not self._at_eof:
- item = await self.next()
- if item is None:
- break
- await item.release()
-
- async def fetch_next_part(
- self,
- ) -> Union["MultipartReader", BodyPartReader]:
- """Returns the next body part reader."""
- headers = await self._read_headers()
- return self._get_part_reader(headers)
-
- def _get_part_reader(
- self,
- headers: "CIMultiDictProxy[str]",
- ) -> Union["MultipartReader", BodyPartReader]:
- """Dispatches the response by the `Content-Type` header.
-
- Returns a suitable reader instance.
-
- :param dict headers: Response headers
- """
- ctype = headers.get(CONTENT_TYPE, "")
- mimetype = parse_mimetype(ctype)
-
- if mimetype.type == "multipart":
- if self.multipart_reader_cls is None:
- return type(self)(headers, self._content)
- return self.multipart_reader_cls(headers, self._content)
- else:
- return self.part_reader_cls(self._boundary, headers, self._content)
-
- def _get_boundary(self) -> str:
- mimetype = parse_mimetype(self.headers[CONTENT_TYPE])
-
- assert mimetype.type == "multipart", "multipart/* content type expected"
-
- if "boundary" not in mimetype.parameters:
- raise ValueError(
- "boundary missed for Content-Type: %s" % self.headers[CONTENT_TYPE]
- )
-
- boundary = mimetype.parameters["boundary"]
- if len(boundary) > 70:
- raise ValueError("boundary %r is too long (70 chars max)" % boundary)
-
- return boundary
-
- async def _readline(self) -> bytes:
- if self._unread:
- return self._unread.pop()
- return await self._content.readline()
-
- async def _read_until_first_boundary(self) -> None:
- while True:
- chunk = await self._readline()
- if chunk == b"":
- raise ValueError(
- "Could not find starting boundary %r" % (self._boundary)
- )
- chunk = chunk.rstrip()
- if chunk == self._boundary:
- return
- elif chunk == self._boundary + b"--":
- self._at_eof = True
- return
-
- async def _read_boundary(self) -> None:
- chunk = (await self._readline()).rstrip()
- if chunk == self._boundary:
- pass
- elif chunk == self._boundary + b"--":
- self._at_eof = True
- epilogue = await self._readline()
- next_line = await self._readline()
-
- # the epilogue is expected and then either the end of input or the
- # parent multipart boundary, if the parent boundary is found then
- # it should be marked as unread and handed to the parent for
- # processing
- if next_line[:2] == b"--":
- self._unread.append(next_line)
- # otherwise the request is likely missing an epilogue and both
- # lines should be passed to the parent for processing
- # (this handles the old behavior gracefully)
- else:
- self._unread.extend([next_line, epilogue])
- else:
- raise ValueError(f"Invalid boundary {chunk!r}, expected {self._boundary!r}")
-
- async def _read_headers(self) -> "CIMultiDictProxy[str]":
- lines = [b""]
- while True:
- chunk = await self._content.readline()
- chunk = chunk.strip()
- lines.append(chunk)
- if not chunk:
- break
- parser = HeadersParser()
- headers, raw_headers = parser.parse_headers(lines)
- return headers
-
- async def _maybe_release_last_part(self) -> None:
- """Ensures that the last read body part is read completely."""
- if self._last_part is not None:
- if not self._last_part.at_eof():
- await self._last_part.release()
- self._unread.extend(self._last_part._unread)
- self._last_part = None
-
-
-_Part = Tuple[Payload, str, str]
-
-
-class MultipartWriter(Payload):
- """Multipart body writer."""
-
- def __init__(self, subtype: str = "mixed", boundary: Optional[str] = None) -> None:
- boundary = boundary if boundary is not None else uuid.uuid4().hex
- # The underlying Payload API demands a str (utf-8), not bytes,
- # so we need to ensure we don't lose anything during conversion.
- # As a result, require the boundary to be ASCII only.
- # In both situations.
-
- try:
- self._boundary = boundary.encode("ascii")
- except UnicodeEncodeError:
- raise ValueError("boundary should contain ASCII only chars") from None
- ctype = f"multipart/{subtype}; boundary={self._boundary_value}"
-
- super().__init__(None, content_type=ctype)
-
- self._parts: List[_Part] = []
-
- def __enter__(self) -> "MultipartWriter":
- return self
-
- def __exit__(
- self,
- exc_type: Optional[Type[BaseException]],
- exc_val: Optional[BaseException],
- exc_tb: Optional[TracebackType],
- ) -> None:
- pass
-
- def __iter__(self) -> Iterator[_Part]:
- return iter(self._parts)
-
- def __len__(self) -> int:
- return len(self._parts)
-
- def __bool__(self) -> bool:
- return True
-
- _valid_tchar_regex = re.compile(rb"\A[!#$%&'*+\-.^_`|~\w]+\Z")
- _invalid_qdtext_char_regex = re.compile(rb"[\x00-\x08\x0A-\x1F\x7F]")
-
- @property
- def _boundary_value(self) -> str:
- """Wrap boundary parameter value in quotes, if necessary.
-
- Reads self.boundary and returns a unicode sting.
- """
- # Refer to RFCs 7231, 7230, 5234.
- #
- # parameter = token "=" ( token / quoted-string )
- # token = 1*tchar
- # quoted-string = DQUOTE *( qdtext / quoted-pair ) DQUOTE
- # qdtext = HTAB / SP / %x21 / %x23-5B / %x5D-7E / obs-text
- # obs-text = %x80-FF
- # quoted-pair = "\" ( HTAB / SP / VCHAR / obs-text )
- # tchar = "!" / "#" / "$" / "%" / "&" / "'" / "*"
- # / "+" / "-" / "." / "^" / "_" / "`" / "|" / "~"
- # / DIGIT / ALPHA
- # ; any VCHAR, except delimiters
- # VCHAR = %x21-7E
- value = self._boundary
- if re.match(self._valid_tchar_regex, value):
- return value.decode("ascii") # cannot fail
-
- if re.search(self._invalid_qdtext_char_regex, value):
- raise ValueError("boundary value contains invalid characters")
-
- # escape %x5C and %x22
- quoted_value_content = value.replace(b"\\", b"\\\\")
- quoted_value_content = quoted_value_content.replace(b'"', b'\\"')
-
- return '"' + quoted_value_content.decode("ascii") + '"'
-
- @property
- def boundary(self) -> str:
- return self._boundary.decode("ascii")
-
- def append(self, obj: Any, headers: Optional[MultiMapping[str]] = None) -> Payload:
- if headers is None:
- headers = CIMultiDict()
-
- if isinstance(obj, Payload):
- obj.headers.update(headers)
- return self.append_payload(obj)
- else:
- try:
- payload = get_payload(obj, headers=headers)
- except LookupError:
- raise TypeError("Cannot create payload from %r" % obj)
- else:
- return self.append_payload(payload)
-
- def append_payload(self, payload: Payload) -> Payload:
- """Adds a new body part to multipart writer."""
- # compression
- encoding: Optional[str] = payload.headers.get(
- CONTENT_ENCODING,
- "",
- ).lower()
- if encoding and encoding not in ("deflate", "gzip", "identity"):
- raise RuntimeError(f"unknown content encoding: {encoding}")
- if encoding == "identity":
- encoding = None
-
- # te encoding
- te_encoding: Optional[str] = payload.headers.get(
- CONTENT_TRANSFER_ENCODING,
- "",
- ).lower()
- if te_encoding not in ("", "base64", "quoted-printable", "binary"):
- raise RuntimeError(
- "unknown content transfer encoding: {}" "".format(te_encoding)
- )
- if te_encoding == "binary":
- te_encoding = None
-
- # size
- size = payload.size
- if size is not None and not (encoding or te_encoding):
- payload.headers[CONTENT_LENGTH] = str(size)
-
- self._parts.append((payload, encoding, te_encoding)) # type: ignore[arg-type]
- return payload
-
- def append_json(
- self, obj: Any, headers: Optional[MultiMapping[str]] = None
- ) -> Payload:
- """Helper to append JSON part."""
- if headers is None:
- headers = CIMultiDict()
-
- return self.append_payload(JsonPayload(obj, headers=headers))
-
- def append_form(
- self,
- obj: Union[Sequence[Tuple[str, str]], Mapping[str, str]],
- headers: Optional[MultiMapping[str]] = None,
- ) -> Payload:
- """Helper to append form urlencoded part."""
- assert isinstance(obj, (Sequence, Mapping))
-
- if headers is None:
- headers = CIMultiDict()
-
- if isinstance(obj, Mapping):
- obj = list(obj.items())
- data = urlencode(obj, doseq=True)
-
- return self.append_payload(
- StringPayload(
- data, headers=headers, content_type="application/x-www-form-urlencoded"
- )
- )
-
- @property
- def size(self) -> Optional[int]:
- """Size of the payload."""
- total = 0
- for part, encoding, te_encoding in self._parts:
- if encoding or te_encoding or part.size is None:
- return None
-
- total += int(
- 2
- + len(self._boundary)
- + 2
- + part.size # b'--'+self._boundary+b'\r\n'
- + len(part._binary_headers)
- + 2 # b'\r\n'
- )
-
- total += 2 + len(self._boundary) + 4 # b'--'+self._boundary+b'--\r\n'
- return total
-
- async def write(self, writer: Any, close_boundary: bool = True) -> None:
- """Write body."""
- for part, encoding, te_encoding in self._parts:
- await writer.write(b"--" + self._boundary + b"\r\n")
- await writer.write(part._binary_headers)
-
- if encoding or te_encoding:
- w = MultipartPayloadWriter(writer)
- if encoding:
- w.enable_compression(encoding)
- if te_encoding:
- w.enable_encoding(te_encoding)
- await part.write(w) # type: ignore[arg-type]
- await w.write_eof()
- else:
- await part.write(writer)
-
- await writer.write(b"\r\n")
-
- if close_boundary:
- await writer.write(b"--" + self._boundary + b"--\r\n")
-
-
-class MultipartPayloadWriter:
- def __init__(self, writer: Any) -> None:
- self._writer = writer
- self._encoding: Optional[str] = None
- self._compress: Any = None
- self._encoding_buffer: Optional[bytearray] = None
-
- def enable_encoding(self, encoding: str) -> None:
- if encoding == "base64":
- self._encoding = encoding
- self._encoding_buffer = bytearray()
- elif encoding == "quoted-printable":
- self._encoding = "quoted-printable"
-
- def enable_compression(
- self, encoding: str = "deflate", strategy: int = zlib.Z_DEFAULT_STRATEGY
- ) -> None:
- zlib_mode = 16 + zlib.MAX_WBITS if encoding == "gzip" else -zlib.MAX_WBITS
- self._compress = zlib.compressobj(wbits=zlib_mode, strategy=strategy)
-
- async def write_eof(self) -> None:
- if self._compress is not None:
- chunk = self._compress.flush()
- if chunk:
- self._compress = None
- await self.write(chunk)
-
- if self._encoding == "base64":
- if self._encoding_buffer:
- await self._writer.write(base64.b64encode(self._encoding_buffer))
-
- async def write(self, chunk: bytes) -> None:
- if self._compress is not None:
- if chunk:
- chunk = self._compress.compress(chunk)
- if not chunk:
- return
-
- if self._encoding == "base64":
- buf = self._encoding_buffer
- assert buf is not None
- buf.extend(chunk)
-
- if buf:
- div, mod = divmod(len(buf), 3)
- enc_chunk, self._encoding_buffer = (buf[: div * 3], buf[div * 3 :])
- if enc_chunk:
- b64chunk = base64.b64encode(enc_chunk)
- await self._writer.write(b64chunk)
- elif self._encoding == "quoted-printable":
- await self._writer.write(binascii.b2a_qp(chunk))
- else:
- await self._writer.write(chunk)
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_frame_eval/vendored/bytecode/flags.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_frame_eval/vendored/bytecode/flags.py
deleted file mode 100644
index b0c5239cd43af19102a18630b916de81fae2bf2a..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_frame_eval/vendored/bytecode/flags.py
+++ /dev/null
@@ -1,181 +0,0 @@
-# alias to keep the 'bytecode' variable free
-import sys
-from enum import IntFlag
-from _pydevd_frame_eval.vendored import bytecode as _bytecode
-
-
-class CompilerFlags(IntFlag):
- """Possible values of the co_flags attribute of Code object.
-
- Note: We do not rely on inspect values here as some of them are missing and
- furthermore would be version dependent.
-
- """
-
- OPTIMIZED = 0x00001 # noqa
- NEWLOCALS = 0x00002 # noqa
- VARARGS = 0x00004 # noqa
- VARKEYWORDS = 0x00008 # noqa
- NESTED = 0x00010 # noqa
- GENERATOR = 0x00020 # noqa
- NOFREE = 0x00040 # noqa
- # New in Python 3.5
- # Used for coroutines defined using async def ie native coroutine
- COROUTINE = 0x00080 # noqa
- # Used for coroutines defined as a generator and then decorated using
- # types.coroutine
- ITERABLE_COROUTINE = 0x00100 # noqa
- # New in Python 3.6
- # Generator defined in an async def function
- ASYNC_GENERATOR = 0x00200 # noqa
-
- # __future__ flags
- # future flags changed in Python 3.9
- if sys.version_info < (3, 9):
- FUTURE_GENERATOR_STOP = 0x80000 # noqa
- if sys.version_info > (3, 6):
- FUTURE_ANNOTATIONS = 0x100000
- else:
- FUTURE_GENERATOR_STOP = 0x800000 # noqa
- FUTURE_ANNOTATIONS = 0x1000000
-
-
-def infer_flags(bytecode, is_async=None):
- """Infer the proper flags for a bytecode based on the instructions.
-
- Because the bytecode does not have enough context to guess if a function
- is asynchronous the algorithm tries to be conservative and will never turn
- a previously async code into a sync one.
-
- Parameters
- ----------
- bytecode : Bytecode | ConcreteBytecode | ControlFlowGraph
- Bytecode for which to infer the proper flags
- is_async : bool | None, optional
- Force the code to be marked as asynchronous if True, prevent it from
- being marked as asynchronous if False and simply infer the best
- solution based on the opcode and the existing flag if None.
-
- """
- flags = CompilerFlags(0)
- if not isinstance(
- bytecode,
- (_bytecode.Bytecode, _bytecode.ConcreteBytecode, _bytecode.ControlFlowGraph),
- ):
- msg = (
- "Expected a Bytecode, ConcreteBytecode or ControlFlowGraph "
- "instance not %s"
- )
- raise ValueError(msg % bytecode)
-
- instructions = (
- bytecode.get_instructions()
- if isinstance(bytecode, _bytecode.ControlFlowGraph)
- else bytecode
- )
- instr_names = {
- i.name
- for i in instructions
- if not isinstance(i, (_bytecode.SetLineno, _bytecode.Label))
- }
-
- # Identify optimized code
- if not (instr_names & {"STORE_NAME", "LOAD_NAME", "DELETE_NAME"}):
- flags |= CompilerFlags.OPTIMIZED
-
- # Check for free variables
- if not (
- instr_names
- & {
- "LOAD_CLOSURE",
- "LOAD_DEREF",
- "STORE_DEREF",
- "DELETE_DEREF",
- "LOAD_CLASSDEREF",
- }
- ):
- flags |= CompilerFlags.NOFREE
-
- # Copy flags for which we cannot infer the right value
- flags |= bytecode.flags & (
- CompilerFlags.NEWLOCALS
- | CompilerFlags.VARARGS
- | CompilerFlags.VARKEYWORDS
- | CompilerFlags.NESTED
- )
-
- sure_generator = instr_names & {"YIELD_VALUE"}
- maybe_generator = instr_names & {"YIELD_VALUE", "YIELD_FROM"}
-
- sure_async = instr_names & {
- "GET_AWAITABLE",
- "GET_AITER",
- "GET_ANEXT",
- "BEFORE_ASYNC_WITH",
- "SETUP_ASYNC_WITH",
- "END_ASYNC_FOR",
- }
-
- # If performing inference or forcing an async behavior, first inspect
- # the flags since this is the only way to identify iterable coroutines
- if is_async in (None, True):
-
- if bytecode.flags & CompilerFlags.COROUTINE:
- if sure_generator:
- flags |= CompilerFlags.ASYNC_GENERATOR
- else:
- flags |= CompilerFlags.COROUTINE
- elif bytecode.flags & CompilerFlags.ITERABLE_COROUTINE:
- if sure_async:
- msg = (
- "The ITERABLE_COROUTINE flag is set but bytecode that"
- "can only be used in async functions have been "
- "detected. Please unset that flag before performing "
- "inference."
- )
- raise ValueError(msg)
- flags |= CompilerFlags.ITERABLE_COROUTINE
- elif bytecode.flags & CompilerFlags.ASYNC_GENERATOR:
- if not sure_generator:
- flags |= CompilerFlags.COROUTINE
- else:
- flags |= CompilerFlags.ASYNC_GENERATOR
-
- # If the code was not asynchronous before determine if it should now be
- # asynchronous based on the opcode and the is_async argument.
- else:
- if sure_async:
- # YIELD_FROM is not allowed in async generator
- if sure_generator:
- flags |= CompilerFlags.ASYNC_GENERATOR
- else:
- flags |= CompilerFlags.COROUTINE
-
- elif maybe_generator:
- if is_async:
- if sure_generator:
- flags |= CompilerFlags.ASYNC_GENERATOR
- else:
- flags |= CompilerFlags.COROUTINE
- else:
- flags |= CompilerFlags.GENERATOR
-
- elif is_async:
- flags |= CompilerFlags.COROUTINE
-
- # If the code should not be asynchronous, check first it is possible and
- # next set the GENERATOR flag if relevant
- else:
- if sure_async:
- raise ValueError(
- "The is_async argument is False but bytecodes "
- "that can only be used in async functions have "
- "been detected."
- )
-
- if maybe_generator:
- flags |= CompilerFlags.GENERATOR
-
- flags |= bytecode.flags & CompilerFlags.FUTURE_GENERATOR_STOP
-
- return flags
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/utils/filter.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/utils/filter.py
deleted file mode 100644
index 5b7daa1e6f263aadf3bd1f0b64b862e846778988..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/docarray/utils/filter.py
+++ /dev/null
@@ -1,82 +0,0 @@
-__all__ = ['filter_docs']
-
-import json
-from typing import Dict, List, Union
-
-from docarray.array.any_array import AnyDocArray
-from docarray.array.doc_list.doc_list import DocList
-
-
-def filter_docs(
- docs: AnyDocArray,
- query: Union[str, Dict, List[Dict]],
-) -> AnyDocArray:
- """
- Filter the Documents in the index according to the given filter query.
-
-
-
- ---
-
- ```python
- from docarray import DocList, BaseDoc
- from docarray.documents import TextDoc, ImageDoc
- from docarray.utils.filter import filter_docs
-
-
- class MyDocument(BaseDoc):
- caption: TextDoc
- ImageDoc: ImageDoc
- price: int
-
-
- docs = DocList[MyDocument](
- [
- MyDocument(
- caption='A tiger in the jungle',
- ImageDoc=ImageDoc(url='tigerphoto.png'),
- price=100,
- ),
- MyDocument(
- caption='A swimming turtle',
- ImageDoc=ImageDoc(url='turtlepic.png'),
- price=50,
- ),
- MyDocument(
- caption='A couple birdwatching with binoculars',
- ImageDoc=ImageDoc(url='binocularsphoto.png'),
- price=30,
- ),
- ]
- )
- query = {
- '$and': {
- 'ImageDoc__url': {'$regex': 'photo'},
- 'price': {'$lte': 50},
- }
- }
-
- results = filter_docs(docs, query)
- assert len(results) == 1
- assert results[0].price == 30
- assert results[0].caption == 'A couple birdwatching with binoculars'
- assert results[0].ImageDoc.url == 'binocularsphoto.png'
- ```
-
- ---
-
- :param docs: the DocList where to apply the filter
- :param query: the query to filter by
- :return: A DocList containing the Documents
- in `docs` that fulfill the filter conditions in the `query`
- """
- from docarray.utils._internal.query_language.query_parser import QueryParser
-
- if query:
- query = query if not isinstance(query, str) else json.loads(query)
- parser = QueryParser(query)
- return DocList.__class_getitem__(docs.doc_type)(
- d for d in docs if parser.evaluate(d)
- )
- else:
- return docs
diff --git a/spaces/Suniilkumaar/SwapMukham/utils.py b/spaces/Suniilkumaar/SwapMukham/utils.py
deleted file mode 100644
index f5db92d3d8a426484715b12353a6d0a5301ced5c..0000000000000000000000000000000000000000
--- a/spaces/Suniilkumaar/SwapMukham/utils.py
+++ /dev/null
@@ -1,303 +0,0 @@
-import os
-import cv2
-import time
-import glob
-import shutil
-import platform
-import datetime
-import subprocess
-import numpy as np
-from threading import Thread
-from moviepy.editor import VideoFileClip, ImageSequenceClip
-from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
-
-
-logo_image = cv2.imread("./assets/images/logo.png", cv2.IMREAD_UNCHANGED)
-
-
-quality_types = ["poor", "low", "medium", "high", "best"]
-
-
-bitrate_quality_by_resolution = {
- 240: {"poor": "300k", "low": "500k", "medium": "800k", "high": "1000k", "best": "1200k"},
- 360: {"poor": "500k","low": "800k","medium": "1200k","high": "1500k","best": "2000k"},
- 480: {"poor": "800k","low": "1200k","medium": "2000k","high": "2500k","best": "3000k"},
- 720: {"poor": "1500k","low": "2500k","medium": "4000k","high": "5000k","best": "6000k"},
- 1080: {"poor": "2500k","low": "4000k","medium": "6000k","high": "7000k","best": "8000k"},
- 1440: {"poor": "4000k","low": "6000k","medium": "8000k","high": "10000k","best": "12000k"},
- 2160: {"poor": "8000k","low": "10000k","medium": "12000k","high": "15000k","best": "20000k"}
-}
-
-
-crf_quality_by_resolution = {
- 240: {"poor": 45, "low": 35, "medium": 28, "high": 23, "best": 20},
- 360: {"poor": 35, "low": 28, "medium": 23, "high": 20, "best": 18},
- 480: {"poor": 28, "low": 23, "medium": 20, "high": 18, "best": 16},
- 720: {"poor": 23, "low": 20, "medium": 18, "high": 16, "best": 14},
- 1080: {"poor": 20, "low": 18, "medium": 16, "high": 14, "best": 12},
- 1440: {"poor": 18, "low": 16, "medium": 14, "high": 12, "best": 10},
- 2160: {"poor": 16, "low": 14, "medium": 12, "high": 10, "best": 8}
-}
-
-
-def get_bitrate_for_resolution(resolution, quality):
- available_resolutions = list(bitrate_quality_by_resolution.keys())
- closest_resolution = min(available_resolutions, key=lambda x: abs(x - resolution))
- return bitrate_quality_by_resolution[closest_resolution][quality]
-
-
-def get_crf_for_resolution(resolution, quality):
- available_resolutions = list(crf_quality_by_resolution.keys())
- closest_resolution = min(available_resolutions, key=lambda x: abs(x - resolution))
- return crf_quality_by_resolution[closest_resolution][quality]
-
-
-def get_video_bitrate(video_file):
- ffprobe_cmd = ['ffprobe', '-v', 'error', '-select_streams', 'v:0', '-show_entries',
- 'stream=bit_rate', '-of', 'default=noprint_wrappers=1:nokey=1', video_file]
- result = subprocess.run(ffprobe_cmd, stdout=subprocess.PIPE)
- kbps = max(int(result.stdout) // 1000, 10)
- return str(kbps) + 'k'
-
-
-def trim_video(video_path, output_path, start_frame, stop_frame):
- video_name, _ = os.path.splitext(os.path.basename(video_path))
- trimmed_video_filename = video_name + "_trimmed" + ".mp4"
- temp_path = os.path.join(output_path, "trim")
- os.makedirs(temp_path, exist_ok=True)
- trimmed_video_file_path = os.path.join(temp_path, trimmed_video_filename)
-
- video = VideoFileClip(video_path, fps_source="fps")
- fps = video.fps
- start_time = start_frame / fps
- duration = (stop_frame - start_frame) / fps
-
- bitrate = get_bitrate_for_resolution(min(*video.size), "high")
-
- trimmed_video = video.subclip(start_time, start_time + duration)
- trimmed_video.write_videofile(
- trimmed_video_file_path, codec="libx264", audio_codec="aac", bitrate=bitrate,
- )
- trimmed_video.close()
- video.close()
-
- return trimmed_video_file_path
-
-
-def open_directory(path=None):
- if path is None:
- return
- try:
- os.startfile(path)
- except:
- subprocess.Popen(["xdg-open", path])
-
-
-class StreamerThread(object):
- def __init__(self, src=0):
- self.capture = cv2.VideoCapture(src)
- self.capture.set(cv2.CAP_PROP_BUFFERSIZE, 2)
- self.FPS = 1 / 30
- self.FPS_MS = int(self.FPS * 1000)
- self.thread = None
- self.stopped = False
- self.frame = None
-
- def start(self):
- self.thread = Thread(target=self.update, args=())
- self.thread.daemon = True
- self.thread.start()
-
- def stop(self):
- self.stopped = True
- self.thread.join()
- print("stopped")
-
- def update(self):
- while not self.stopped:
- if self.capture.isOpened():
- (self.status, self.frame) = self.capture.read()
- time.sleep(self.FPS)
-
-
-class ProcessBar:
- def __init__(self, bar_length, total, before="⬛", after="🟨"):
- self.bar_length = bar_length
- self.total = total
- self.before = before
- self.after = after
- self.bar = [self.before] * bar_length
- self.start_time = time.time()
-
- def get(self, index):
- total = self.total
- elapsed_time = time.time() - self.start_time
- average_time_per_iteration = elapsed_time / (index + 1)
- remaining_iterations = total - (index + 1)
- estimated_remaining_time = remaining_iterations * average_time_per_iteration
-
- self.bar[int(index / total * self.bar_length)] = self.after
- info_text = f"({index+1}/{total}) {''.join(self.bar)} "
- info_text += f"(ETR: {int(estimated_remaining_time // 60)} min {int(estimated_remaining_time % 60)} sec)"
- return info_text
-
-
-def add_logo_to_image(img, logo=logo_image):
- logo_size = int(img.shape[1] * 0.1)
- logo = cv2.resize(logo, (logo_size, logo_size))
- if logo.shape[2] == 4:
- alpha = logo[:, :, 3]
- else:
- alpha = np.ones_like(logo[:, :, 0]) * 255
- padding = int(logo_size * 0.1)
- roi = img.shape[0] - logo_size - padding, img.shape[1] - logo_size - padding
- for c in range(0, 3):
- img[roi[0] : roi[0] + logo_size, roi[1] : roi[1] + logo_size, c] = (
- alpha / 255.0
- ) * logo[:, :, c] + (1 - alpha / 255.0) * img[
- roi[0] : roi[0] + logo_size, roi[1] : roi[1] + logo_size, c
- ]
- return img
-
-
-def split_list_by_lengths(data, length_list):
- split_data = []
- start_idx = 0
- for length in length_list:
- end_idx = start_idx + length
- sublist = data[start_idx:end_idx]
- split_data.append(sublist)
- start_idx = end_idx
- return split_data
-
-
-def merge_img_sequence_from_ref(ref_video_path, image_sequence, output_file_name):
- video_clip = VideoFileClip(ref_video_path, fps_source="fps")
- fps = video_clip.fps
- duration = video_clip.duration
- total_frames = video_clip.reader.nframes
- audio_clip = video_clip.audio if video_clip.audio is not None else None
- edited_video_clip = ImageSequenceClip(image_sequence, fps=fps)
-
- if audio_clip is not None:
- edited_video_clip = edited_video_clip.set_audio(audio_clip)
-
- bitrate = get_bitrate_for_resolution(min(*edited_video_clip.size), "high")
-
- edited_video_clip.set_duration(duration).write_videofile(
- output_file_name, codec="libx264", bitrate=bitrate,
- )
- edited_video_clip.close()
- video_clip.close()
-
-
-def scale_bbox_from_center(bbox, scale_width, scale_height, image_width, image_height):
- # Extract the coordinates of the bbox
- x1, y1, x2, y2 = bbox
-
- # Calculate the center point of the bbox
- center_x = (x1 + x2) / 2
- center_y = (y1 + y2) / 2
-
- # Calculate the new width and height of the bbox based on the scaling factors
- width = x2 - x1
- height = y2 - y1
- new_width = width * scale_width
- new_height = height * scale_height
-
- # Calculate the new coordinates of the bbox, considering the image boundaries
- new_x1 = center_x - new_width / 2
- new_y1 = center_y - new_height / 2
- new_x2 = center_x + new_width / 2
- new_y2 = center_y + new_height / 2
-
- # Adjust the coordinates to ensure the bbox remains within the image boundaries
- new_x1 = max(0, new_x1)
- new_y1 = max(0, new_y1)
- new_x2 = min(image_width - 1, new_x2)
- new_y2 = min(image_height - 1, new_y2)
-
- # Return the scaled bbox coordinates
- scaled_bbox = [new_x1, new_y1, new_x2, new_y2]
- return scaled_bbox
-
-
-def laplacian_blending(A, B, m, num_levels=7):
- assert A.shape == B.shape
- assert B.shape == m.shape
- height = m.shape[0]
- width = m.shape[1]
- size_list = np.array([4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192])
- size = size_list[np.where(size_list > max(height, width))][0]
- GA = np.zeros((size, size, 3), dtype=np.float32)
- GA[:height, :width, :] = A
- GB = np.zeros((size, size, 3), dtype=np.float32)
- GB[:height, :width, :] = B
- GM = np.zeros((size, size, 3), dtype=np.float32)
- GM[:height, :width, :] = m
- gpA = [GA]
- gpB = [GB]
- gpM = [GM]
- for i in range(num_levels):
- GA = cv2.pyrDown(GA)
- GB = cv2.pyrDown(GB)
- GM = cv2.pyrDown(GM)
- gpA.append(np.float32(GA))
- gpB.append(np.float32(GB))
- gpM.append(np.float32(GM))
- lpA = [gpA[num_levels-1]]
- lpB = [gpB[num_levels-1]]
- gpMr = [gpM[num_levels-1]]
- for i in range(num_levels-1,0,-1):
- LA = np.subtract(gpA[i-1], cv2.pyrUp(gpA[i]))
- LB = np.subtract(gpB[i-1], cv2.pyrUp(gpB[i]))
- lpA.append(LA)
- lpB.append(LB)
- gpMr.append(gpM[i-1])
- LS = []
- for la,lb,gm in zip(lpA,lpB,gpMr):
- ls = la * gm + lb * (1.0 - gm)
- LS.append(ls)
- ls_ = LS[0]
- for i in range(1,num_levels):
- ls_ = cv2.pyrUp(ls_)
- ls_ = cv2.add(ls_, LS[i])
- ls_ = ls_[:height, :width, :]
- #ls_ = (ls_ - np.min(ls_)) * (255.0 / (np.max(ls_) - np.min(ls_)))
- return ls_.clip(0, 255)
-
-
-def mask_crop(mask, crop):
- top, bottom, left, right = crop
- shape = mask.shape
- top = int(top)
- bottom = int(bottom)
- if top + bottom < shape[1]:
- if top > 0: mask[:top, :] = 0
- if bottom > 0: mask[-bottom:, :] = 0
-
- left = int(left)
- right = int(right)
- if left + right < shape[0]:
- if left > 0: mask[:, :left] = 0
- if right > 0: mask[:, -right:] = 0
-
- return mask
-
-def create_image_grid(images, size=128):
- num_images = len(images)
- num_cols = int(np.ceil(np.sqrt(num_images)))
- num_rows = int(np.ceil(num_images / num_cols))
- grid = np.zeros((num_rows * size, num_cols * size, 3), dtype=np.uint8)
-
- for i, image in enumerate(images):
- row_idx = (i // num_cols) * size
- col_idx = (i % num_cols) * size
- image = cv2.resize(image.copy(), (size,size))
- if image.dtype != np.uint8:
- image = (image.astype('float32') * 255).astype('uint8')
- if image.ndim == 2:
- image = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
- grid[row_idx:row_idx + size, col_idx:col_idx + size] = image
-
- return grid
diff --git a/spaces/Superlang/ImageProcessor/annotator/zoe/zoedepth/models/layers/localbins_layers.py b/spaces/Superlang/ImageProcessor/annotator/zoe/zoedepth/models/layers/localbins_layers.py
deleted file mode 100644
index f94481605c3e6958ce50e73b2eb31d9f0c07dc67..0000000000000000000000000000000000000000
--- a/spaces/Superlang/ImageProcessor/annotator/zoe/zoedepth/models/layers/localbins_layers.py
+++ /dev/null
@@ -1,169 +0,0 @@
-# MIT License
-
-# Copyright (c) 2022 Intelligent Systems Lab Org
-
-# Permission is hereby granted, free of charge, to any person obtaining a copy
-# of this software and associated documentation files (the "Software"), to deal
-# in the Software without restriction, including without limitation the rights
-# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-# copies of the Software, and to permit persons to whom the Software is
-# furnished to do so, subject to the following conditions:
-
-# The above copyright notice and this permission notice shall be included in all
-# copies or substantial portions of the Software.
-
-# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-# SOFTWARE.
-
-# File author: Shariq Farooq Bhat
-
-import torch
-import torch.nn as nn
-
-
-class SeedBinRegressor(nn.Module):
- def __init__(self, in_features, n_bins=16, mlp_dim=256, min_depth=1e-3, max_depth=10):
- """Bin center regressor network. Bin centers are bounded on (min_depth, max_depth) interval.
-
- Args:
- in_features (int): input channels
- n_bins (int, optional): Number of bin centers. Defaults to 16.
- mlp_dim (int, optional): Hidden dimension. Defaults to 256.
- min_depth (float, optional): Min depth value. Defaults to 1e-3.
- max_depth (float, optional): Max depth value. Defaults to 10.
- """
- super().__init__()
- self.version = "1_1"
- self.min_depth = min_depth
- self.max_depth = max_depth
-
- self._net = nn.Sequential(
- nn.Conv2d(in_features, mlp_dim, 1, 1, 0),
- nn.ReLU(inplace=True),
- nn.Conv2d(mlp_dim, n_bins, 1, 1, 0),
- nn.ReLU(inplace=True)
- )
-
- def forward(self, x):
- """
- Returns tensor of bin_width vectors (centers). One vector b for every pixel
- """
- B = self._net(x)
- eps = 1e-3
- B = B + eps
- B_widths_normed = B / B.sum(dim=1, keepdim=True)
- B_widths = (self.max_depth - self.min_depth) * \
- B_widths_normed # .shape NCHW
- # pad has the form (left, right, top, bottom, front, back)
- B_widths = nn.functional.pad(
- B_widths, (0, 0, 0, 0, 1, 0), mode='constant', value=self.min_depth)
- B_edges = torch.cumsum(B_widths, dim=1) # .shape NCHW
-
- B_centers = 0.5 * (B_edges[:, :-1, ...] + B_edges[:, 1:, ...])
- return B_widths_normed, B_centers
-
-
-class SeedBinRegressorUnnormed(nn.Module):
- def __init__(self, in_features, n_bins=16, mlp_dim=256, min_depth=1e-3, max_depth=10):
- """Bin center regressor network. Bin centers are unbounded
-
- Args:
- in_features (int): input channels
- n_bins (int, optional): Number of bin centers. Defaults to 16.
- mlp_dim (int, optional): Hidden dimension. Defaults to 256.
- min_depth (float, optional): Not used. (for compatibility with SeedBinRegressor)
- max_depth (float, optional): Not used. (for compatibility with SeedBinRegressor)
- """
- super().__init__()
- self.version = "1_1"
- self._net = nn.Sequential(
- nn.Conv2d(in_features, mlp_dim, 1, 1, 0),
- nn.ReLU(inplace=True),
- nn.Conv2d(mlp_dim, n_bins, 1, 1, 0),
- nn.Softplus()
- )
-
- def forward(self, x):
- """
- Returns tensor of bin_width vectors (centers). One vector b for every pixel
- """
- B_centers = self._net(x)
- return B_centers, B_centers
-
-
-class Projector(nn.Module):
- def __init__(self, in_features, out_features, mlp_dim=128):
- """Projector MLP
-
- Args:
- in_features (int): input channels
- out_features (int): output channels
- mlp_dim (int, optional): hidden dimension. Defaults to 128.
- """
- super().__init__()
-
- self._net = nn.Sequential(
- nn.Conv2d(in_features, mlp_dim, 1, 1, 0),
- nn.ReLU(inplace=True),
- nn.Conv2d(mlp_dim, out_features, 1, 1, 0),
- )
-
- def forward(self, x):
- return self._net(x)
-
-
-
-class LinearSplitter(nn.Module):
- def __init__(self, in_features, prev_nbins, split_factor=2, mlp_dim=128, min_depth=1e-3, max_depth=10):
- super().__init__()
-
- self.prev_nbins = prev_nbins
- self.split_factor = split_factor
- self.min_depth = min_depth
- self.max_depth = max_depth
-
- self._net = nn.Sequential(
- nn.Conv2d(in_features, mlp_dim, 1, 1, 0),
- nn.GELU(),
- nn.Conv2d(mlp_dim, prev_nbins * split_factor, 1, 1, 0),
- nn.ReLU()
- )
-
- def forward(self, x, b_prev, prev_b_embedding=None, interpolate=True, is_for_query=False):
- """
- x : feature block; shape - n, c, h, w
- b_prev : previous bin widths normed; shape - n, prev_nbins, h, w
- """
- if prev_b_embedding is not None:
- if interpolate:
- prev_b_embedding = nn.functional.interpolate(prev_b_embedding, x.shape[-2:], mode='bilinear', align_corners=True)
- x = x + prev_b_embedding
- S = self._net(x)
- eps = 1e-3
- S = S + eps
- n, c, h, w = S.shape
- S = S.view(n, self.prev_nbins, self.split_factor, h, w)
- S_normed = S / S.sum(dim=2, keepdim=True) # fractional splits
-
- b_prev = nn.functional.interpolate(b_prev, (h,w), mode='bilinear', align_corners=True)
-
-
- b_prev = b_prev / b_prev.sum(dim=1, keepdim=True) # renormalize for gurantees
- # print(b_prev.shape, S_normed.shape)
- # if is_for_query:(1).expand(-1, b_prev.size(0)//n, -1, -1, -1, -1).flatten(0,1) # TODO ? can replace all this with a single torch.repeat?
- b = b_prev.unsqueeze(2) * S_normed
- b = b.flatten(1,2) # .shape n, prev_nbins * split_factor, h, w
-
- # calculate bin centers for loss calculation
- B_widths = (self.max_depth - self.min_depth) * b # .shape N, nprev * splitfactor, H, W
- # pad has the form (left, right, top, bottom, front, back)
- B_widths = nn.functional.pad(B_widths, (0,0,0,0,1,0), mode='constant', value=self.min_depth)
- B_edges = torch.cumsum(B_widths, dim=1) # .shape NCHW
-
- B_centers = 0.5 * (B_edges[:, :-1, ...] + B_edges[:,1:,...])
- return b, B_centers
\ No newline at end of file
diff --git a/spaces/SurendraKumarDhaka/Shakespeare-AI/README.md b/spaces/SurendraKumarDhaka/Shakespeare-AI/README.md
deleted file mode 100644
index e557b74f0ec42d4d53ebdade0811d4ff0c40996a..0000000000000000000000000000000000000000
--- a/spaces/SurendraKumarDhaka/Shakespeare-AI/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Shakespeare AI
-emoji: 🚀
-colorFrom: indigo
-colorTo: purple
-sdk: streamlit
-sdk_version: 1.21.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/TRI-ML/risk_biased_prediction/tests/risk_biased/models/test_mlp.py b/spaces/TRI-ML/risk_biased_prediction/tests/risk_biased/models/test_mlp.py
deleted file mode 100644
index 0845fe0198d5137a730a3699fd8a78bb71ec26bb..0000000000000000000000000000000000000000
--- a/spaces/TRI-ML/risk_biased_prediction/tests/risk_biased/models/test_mlp.py
+++ /dev/null
@@ -1,36 +0,0 @@
-import pytest
-
-import torch
-from mmcv import Config
-
-from risk_biased.models.mlp import MLP
-
-
-@pytest.fixture(scope="module")
-def params():
- torch.manual_seed(0)
- cfg = Config()
- cfg.batch_size = 4
- cfg.input_dim = 10
- cfg.output_dim = 15
- cfg.latent_dim = 3
- cfg.h_dim = 64
- cfg.num_h_layers = 2
- cfg.device = "cpu"
- cfg.is_mlp_residual = True
- return cfg
-
-
-def test_mlp(params):
- mlp = MLP(
- params.input_dim,
- params.output_dim,
- params.h_dim,
- params.num_h_layers,
- params.is_mlp_residual,
- )
-
- input = torch.rand(params.batch_size, params.input_dim)
- output = mlp(input)
- # check shape
- assert output.shape == (params.batch_size, params.output_dim)
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/packaging/__init__.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/packaging/__init__.py
deleted file mode 100644
index 3c50c5dcfeeda2efed282200a5c5cc8c5f7542f7..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/packaging/__init__.py
+++ /dev/null
@@ -1,25 +0,0 @@
-# This file is dual licensed under the terms of the Apache License, Version
-# 2.0, and the BSD License. See the LICENSE file in the root of this repository
-# for complete details.
-
-from .__about__ import (
- __author__,
- __copyright__,
- __email__,
- __license__,
- __summary__,
- __title__,
- __uri__,
- __version__,
-)
-
-__all__ = [
- "__title__",
- "__summary__",
- "__uri__",
- "__version__",
- "__author__",
- "__email__",
- "__license__",
- "__copyright__",
-]
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/contrib/securetransport.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/contrib/securetransport.py
deleted file mode 100644
index 4a06bc69d5c850fa9f7c4861bc6b3acca3905056..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/contrib/securetransport.py
+++ /dev/null
@@ -1,921 +0,0 @@
-"""
-SecureTranport support for urllib3 via ctypes.
-
-This makes platform-native TLS available to urllib3 users on macOS without the
-use of a compiler. This is an important feature because the Python Package
-Index is moving to become a TLSv1.2-or-higher server, and the default OpenSSL
-that ships with macOS is not capable of doing TLSv1.2. The only way to resolve
-this is to give macOS users an alternative solution to the problem, and that
-solution is to use SecureTransport.
-
-We use ctypes here because this solution must not require a compiler. That's
-because pip is not allowed to require a compiler either.
-
-This is not intended to be a seriously long-term solution to this problem.
-The hope is that PEP 543 will eventually solve this issue for us, at which
-point we can retire this contrib module. But in the short term, we need to
-solve the impending tire fire that is Python on Mac without this kind of
-contrib module. So...here we are.
-
-To use this module, simply import and inject it::
-
- import pip._vendor.urllib3.contrib.securetransport as securetransport
- securetransport.inject_into_urllib3()
-
-Happy TLSing!
-
-This code is a bastardised version of the code found in Will Bond's oscrypto
-library. An enormous debt is owed to him for blazing this trail for us. For
-that reason, this code should be considered to be covered both by urllib3's
-license and by oscrypto's:
-
-.. code-block::
-
- Copyright (c) 2015-2016 Will Bond
-
- Permission is hereby granted, free of charge, to any person obtaining a
- copy of this software and associated documentation files (the "Software"),
- to deal in the Software without restriction, including without limitation
- the rights to use, copy, modify, merge, publish, distribute, sublicense,
- and/or sell copies of the Software, and to permit persons to whom the
- Software is furnished to do so, subject to the following conditions:
-
- The above copyright notice and this permission notice shall be included in
- all copies or substantial portions of the Software.
-
- THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
- IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
- FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
- AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
- LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
- FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
- DEALINGS IN THE SOFTWARE.
-"""
-from __future__ import absolute_import
-
-import contextlib
-import ctypes
-import errno
-import os.path
-import shutil
-import socket
-import ssl
-import struct
-import threading
-import weakref
-
-from pip._vendor import six
-
-from .. import util
-from ..util.ssl_ import PROTOCOL_TLS_CLIENT
-from ._securetransport.bindings import CoreFoundation, Security, SecurityConst
-from ._securetransport.low_level import (
- _assert_no_error,
- _build_tls_unknown_ca_alert,
- _cert_array_from_pem,
- _create_cfstring_array,
- _load_client_cert_chain,
- _temporary_keychain,
-)
-
-try: # Platform-specific: Python 2
- from socket import _fileobject
-except ImportError: # Platform-specific: Python 3
- _fileobject = None
- from ..packages.backports.makefile import backport_makefile
-
-__all__ = ["inject_into_urllib3", "extract_from_urllib3"]
-
-# SNI always works
-HAS_SNI = True
-
-orig_util_HAS_SNI = util.HAS_SNI
-orig_util_SSLContext = util.ssl_.SSLContext
-
-# This dictionary is used by the read callback to obtain a handle to the
-# calling wrapped socket. This is a pretty silly approach, but for now it'll
-# do. I feel like I should be able to smuggle a handle to the wrapped socket
-# directly in the SSLConnectionRef, but for now this approach will work I
-# guess.
-#
-# We need to lock around this structure for inserts, but we don't do it for
-# reads/writes in the callbacks. The reasoning here goes as follows:
-#
-# 1. It is not possible to call into the callbacks before the dictionary is
-# populated, so once in the callback the id must be in the dictionary.
-# 2. The callbacks don't mutate the dictionary, they only read from it, and
-# so cannot conflict with any of the insertions.
-#
-# This is good: if we had to lock in the callbacks we'd drastically slow down
-# the performance of this code.
-_connection_refs = weakref.WeakValueDictionary()
-_connection_ref_lock = threading.Lock()
-
-# Limit writes to 16kB. This is OpenSSL's limit, but we'll cargo-cult it over
-# for no better reason than we need *a* limit, and this one is right there.
-SSL_WRITE_BLOCKSIZE = 16384
-
-# This is our equivalent of util.ssl_.DEFAULT_CIPHERS, but expanded out to
-# individual cipher suites. We need to do this because this is how
-# SecureTransport wants them.
-CIPHER_SUITES = [
- SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,
- SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,
- SecurityConst.TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,
- SecurityConst.TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,
- SecurityConst.TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256,
- SecurityConst.TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256,
- SecurityConst.TLS_DHE_RSA_WITH_AES_256_GCM_SHA384,
- SecurityConst.TLS_DHE_RSA_WITH_AES_128_GCM_SHA256,
- SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384,
- SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA,
- SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256,
- SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA,
- SecurityConst.TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384,
- SecurityConst.TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA,
- SecurityConst.TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256,
- SecurityConst.TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,
- SecurityConst.TLS_DHE_RSA_WITH_AES_256_CBC_SHA256,
- SecurityConst.TLS_DHE_RSA_WITH_AES_256_CBC_SHA,
- SecurityConst.TLS_DHE_RSA_WITH_AES_128_CBC_SHA256,
- SecurityConst.TLS_DHE_RSA_WITH_AES_128_CBC_SHA,
- SecurityConst.TLS_AES_256_GCM_SHA384,
- SecurityConst.TLS_AES_128_GCM_SHA256,
- SecurityConst.TLS_RSA_WITH_AES_256_GCM_SHA384,
- SecurityConst.TLS_RSA_WITH_AES_128_GCM_SHA256,
- SecurityConst.TLS_AES_128_CCM_8_SHA256,
- SecurityConst.TLS_AES_128_CCM_SHA256,
- SecurityConst.TLS_RSA_WITH_AES_256_CBC_SHA256,
- SecurityConst.TLS_RSA_WITH_AES_128_CBC_SHA256,
- SecurityConst.TLS_RSA_WITH_AES_256_CBC_SHA,
- SecurityConst.TLS_RSA_WITH_AES_128_CBC_SHA,
-]
-
-# Basically this is simple: for PROTOCOL_SSLv23 we turn it into a low of
-# TLSv1 and a high of TLSv1.2. For everything else, we pin to that version.
-# TLSv1 to 1.2 are supported on macOS 10.8+
-_protocol_to_min_max = {
- util.PROTOCOL_TLS: (SecurityConst.kTLSProtocol1, SecurityConst.kTLSProtocol12),
- PROTOCOL_TLS_CLIENT: (SecurityConst.kTLSProtocol1, SecurityConst.kTLSProtocol12),
-}
-
-if hasattr(ssl, "PROTOCOL_SSLv2"):
- _protocol_to_min_max[ssl.PROTOCOL_SSLv2] = (
- SecurityConst.kSSLProtocol2,
- SecurityConst.kSSLProtocol2,
- )
-if hasattr(ssl, "PROTOCOL_SSLv3"):
- _protocol_to_min_max[ssl.PROTOCOL_SSLv3] = (
- SecurityConst.kSSLProtocol3,
- SecurityConst.kSSLProtocol3,
- )
-if hasattr(ssl, "PROTOCOL_TLSv1"):
- _protocol_to_min_max[ssl.PROTOCOL_TLSv1] = (
- SecurityConst.kTLSProtocol1,
- SecurityConst.kTLSProtocol1,
- )
-if hasattr(ssl, "PROTOCOL_TLSv1_1"):
- _protocol_to_min_max[ssl.PROTOCOL_TLSv1_1] = (
- SecurityConst.kTLSProtocol11,
- SecurityConst.kTLSProtocol11,
- )
-if hasattr(ssl, "PROTOCOL_TLSv1_2"):
- _protocol_to_min_max[ssl.PROTOCOL_TLSv1_2] = (
- SecurityConst.kTLSProtocol12,
- SecurityConst.kTLSProtocol12,
- )
-
-
-def inject_into_urllib3():
- """
- Monkey-patch urllib3 with SecureTransport-backed SSL-support.
- """
- util.SSLContext = SecureTransportContext
- util.ssl_.SSLContext = SecureTransportContext
- util.HAS_SNI = HAS_SNI
- util.ssl_.HAS_SNI = HAS_SNI
- util.IS_SECURETRANSPORT = True
- util.ssl_.IS_SECURETRANSPORT = True
-
-
-def extract_from_urllib3():
- """
- Undo monkey-patching by :func:`inject_into_urllib3`.
- """
- util.SSLContext = orig_util_SSLContext
- util.ssl_.SSLContext = orig_util_SSLContext
- util.HAS_SNI = orig_util_HAS_SNI
- util.ssl_.HAS_SNI = orig_util_HAS_SNI
- util.IS_SECURETRANSPORT = False
- util.ssl_.IS_SECURETRANSPORT = False
-
-
-def _read_callback(connection_id, data_buffer, data_length_pointer):
- """
- SecureTransport read callback. This is called by ST to request that data
- be returned from the socket.
- """
- wrapped_socket = None
- try:
- wrapped_socket = _connection_refs.get(connection_id)
- if wrapped_socket is None:
- return SecurityConst.errSSLInternal
- base_socket = wrapped_socket.socket
-
- requested_length = data_length_pointer[0]
-
- timeout = wrapped_socket.gettimeout()
- error = None
- read_count = 0
-
- try:
- while read_count < requested_length:
- if timeout is None or timeout >= 0:
- if not util.wait_for_read(base_socket, timeout):
- raise socket.error(errno.EAGAIN, "timed out")
-
- remaining = requested_length - read_count
- buffer = (ctypes.c_char * remaining).from_address(
- data_buffer + read_count
- )
- chunk_size = base_socket.recv_into(buffer, remaining)
- read_count += chunk_size
- if not chunk_size:
- if not read_count:
- return SecurityConst.errSSLClosedGraceful
- break
- except (socket.error) as e:
- error = e.errno
-
- if error is not None and error != errno.EAGAIN:
- data_length_pointer[0] = read_count
- if error == errno.ECONNRESET or error == errno.EPIPE:
- return SecurityConst.errSSLClosedAbort
- raise
-
- data_length_pointer[0] = read_count
-
- if read_count != requested_length:
- return SecurityConst.errSSLWouldBlock
-
- return 0
- except Exception as e:
- if wrapped_socket is not None:
- wrapped_socket._exception = e
- return SecurityConst.errSSLInternal
-
-
-def _write_callback(connection_id, data_buffer, data_length_pointer):
- """
- SecureTransport write callback. This is called by ST to request that data
- actually be sent on the network.
- """
- wrapped_socket = None
- try:
- wrapped_socket = _connection_refs.get(connection_id)
- if wrapped_socket is None:
- return SecurityConst.errSSLInternal
- base_socket = wrapped_socket.socket
-
- bytes_to_write = data_length_pointer[0]
- data = ctypes.string_at(data_buffer, bytes_to_write)
-
- timeout = wrapped_socket.gettimeout()
- error = None
- sent = 0
-
- try:
- while sent < bytes_to_write:
- if timeout is None or timeout >= 0:
- if not util.wait_for_write(base_socket, timeout):
- raise socket.error(errno.EAGAIN, "timed out")
- chunk_sent = base_socket.send(data)
- sent += chunk_sent
-
- # This has some needless copying here, but I'm not sure there's
- # much value in optimising this data path.
- data = data[chunk_sent:]
- except (socket.error) as e:
- error = e.errno
-
- if error is not None and error != errno.EAGAIN:
- data_length_pointer[0] = sent
- if error == errno.ECONNRESET or error == errno.EPIPE:
- return SecurityConst.errSSLClosedAbort
- raise
-
- data_length_pointer[0] = sent
-
- if sent != bytes_to_write:
- return SecurityConst.errSSLWouldBlock
-
- return 0
- except Exception as e:
- if wrapped_socket is not None:
- wrapped_socket._exception = e
- return SecurityConst.errSSLInternal
-
-
-# We need to keep these two objects references alive: if they get GC'd while
-# in use then SecureTransport could attempt to call a function that is in freed
-# memory. That would be...uh...bad. Yeah, that's the word. Bad.
-_read_callback_pointer = Security.SSLReadFunc(_read_callback)
-_write_callback_pointer = Security.SSLWriteFunc(_write_callback)
-
-
-class WrappedSocket(object):
- """
- API-compatibility wrapper for Python's OpenSSL wrapped socket object.
-
- Note: _makefile_refs, _drop(), and _reuse() are needed for the garbage
- collector of PyPy.
- """
-
- def __init__(self, socket):
- self.socket = socket
- self.context = None
- self._makefile_refs = 0
- self._closed = False
- self._exception = None
- self._keychain = None
- self._keychain_dir = None
- self._client_cert_chain = None
-
- # We save off the previously-configured timeout and then set it to
- # zero. This is done because we use select and friends to handle the
- # timeouts, but if we leave the timeout set on the lower socket then
- # Python will "kindly" call select on that socket again for us. Avoid
- # that by forcing the timeout to zero.
- self._timeout = self.socket.gettimeout()
- self.socket.settimeout(0)
-
- @contextlib.contextmanager
- def _raise_on_error(self):
- """
- A context manager that can be used to wrap calls that do I/O from
- SecureTransport. If any of the I/O callbacks hit an exception, this
- context manager will correctly propagate the exception after the fact.
- This avoids silently swallowing those exceptions.
-
- It also correctly forces the socket closed.
- """
- self._exception = None
-
- # We explicitly don't catch around this yield because in the unlikely
- # event that an exception was hit in the block we don't want to swallow
- # it.
- yield
- if self._exception is not None:
- exception, self._exception = self._exception, None
- self.close()
- raise exception
-
- def _set_ciphers(self):
- """
- Sets up the allowed ciphers. By default this matches the set in
- util.ssl_.DEFAULT_CIPHERS, at least as supported by macOS. This is done
- custom and doesn't allow changing at this time, mostly because parsing
- OpenSSL cipher strings is going to be a freaking nightmare.
- """
- ciphers = (Security.SSLCipherSuite * len(CIPHER_SUITES))(*CIPHER_SUITES)
- result = Security.SSLSetEnabledCiphers(
- self.context, ciphers, len(CIPHER_SUITES)
- )
- _assert_no_error(result)
-
- def _set_alpn_protocols(self, protocols):
- """
- Sets up the ALPN protocols on the context.
- """
- if not protocols:
- return
- protocols_arr = _create_cfstring_array(protocols)
- try:
- result = Security.SSLSetALPNProtocols(self.context, protocols_arr)
- _assert_no_error(result)
- finally:
- CoreFoundation.CFRelease(protocols_arr)
-
- def _custom_validate(self, verify, trust_bundle):
- """
- Called when we have set custom validation. We do this in two cases:
- first, when cert validation is entirely disabled; and second, when
- using a custom trust DB.
- Raises an SSLError if the connection is not trusted.
- """
- # If we disabled cert validation, just say: cool.
- if not verify:
- return
-
- successes = (
- SecurityConst.kSecTrustResultUnspecified,
- SecurityConst.kSecTrustResultProceed,
- )
- try:
- trust_result = self._evaluate_trust(trust_bundle)
- if trust_result in successes:
- return
- reason = "error code: %d" % (trust_result,)
- except Exception as e:
- # Do not trust on error
- reason = "exception: %r" % (e,)
-
- # SecureTransport does not send an alert nor shuts down the connection.
- rec = _build_tls_unknown_ca_alert(self.version())
- self.socket.sendall(rec)
- # close the connection immediately
- # l_onoff = 1, activate linger
- # l_linger = 0, linger for 0 seoncds
- opts = struct.pack("ii", 1, 0)
- self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_LINGER, opts)
- self.close()
- raise ssl.SSLError("certificate verify failed, %s" % reason)
-
- def _evaluate_trust(self, trust_bundle):
- # We want data in memory, so load it up.
- if os.path.isfile(trust_bundle):
- with open(trust_bundle, "rb") as f:
- trust_bundle = f.read()
-
- cert_array = None
- trust = Security.SecTrustRef()
-
- try:
- # Get a CFArray that contains the certs we want.
- cert_array = _cert_array_from_pem(trust_bundle)
-
- # Ok, now the hard part. We want to get the SecTrustRef that ST has
- # created for this connection, shove our CAs into it, tell ST to
- # ignore everything else it knows, and then ask if it can build a
- # chain. This is a buuuunch of code.
- result = Security.SSLCopyPeerTrust(self.context, ctypes.byref(trust))
- _assert_no_error(result)
- if not trust:
- raise ssl.SSLError("Failed to copy trust reference")
-
- result = Security.SecTrustSetAnchorCertificates(trust, cert_array)
- _assert_no_error(result)
-
- result = Security.SecTrustSetAnchorCertificatesOnly(trust, True)
- _assert_no_error(result)
-
- trust_result = Security.SecTrustResultType()
- result = Security.SecTrustEvaluate(trust, ctypes.byref(trust_result))
- _assert_no_error(result)
- finally:
- if trust:
- CoreFoundation.CFRelease(trust)
-
- if cert_array is not None:
- CoreFoundation.CFRelease(cert_array)
-
- return trust_result.value
-
- def handshake(
- self,
- server_hostname,
- verify,
- trust_bundle,
- min_version,
- max_version,
- client_cert,
- client_key,
- client_key_passphrase,
- alpn_protocols,
- ):
- """
- Actually performs the TLS handshake. This is run automatically by
- wrapped socket, and shouldn't be needed in user code.
- """
- # First, we do the initial bits of connection setup. We need to create
- # a context, set its I/O funcs, and set the connection reference.
- self.context = Security.SSLCreateContext(
- None, SecurityConst.kSSLClientSide, SecurityConst.kSSLStreamType
- )
- result = Security.SSLSetIOFuncs(
- self.context, _read_callback_pointer, _write_callback_pointer
- )
- _assert_no_error(result)
-
- # Here we need to compute the handle to use. We do this by taking the
- # id of self modulo 2**31 - 1. If this is already in the dictionary, we
- # just keep incrementing by one until we find a free space.
- with _connection_ref_lock:
- handle = id(self) % 2147483647
- while handle in _connection_refs:
- handle = (handle + 1) % 2147483647
- _connection_refs[handle] = self
-
- result = Security.SSLSetConnection(self.context, handle)
- _assert_no_error(result)
-
- # If we have a server hostname, we should set that too.
- if server_hostname:
- if not isinstance(server_hostname, bytes):
- server_hostname = server_hostname.encode("utf-8")
-
- result = Security.SSLSetPeerDomainName(
- self.context, server_hostname, len(server_hostname)
- )
- _assert_no_error(result)
-
- # Setup the ciphers.
- self._set_ciphers()
-
- # Setup the ALPN protocols.
- self._set_alpn_protocols(alpn_protocols)
-
- # Set the minimum and maximum TLS versions.
- result = Security.SSLSetProtocolVersionMin(self.context, min_version)
- _assert_no_error(result)
-
- result = Security.SSLSetProtocolVersionMax(self.context, max_version)
- _assert_no_error(result)
-
- # If there's a trust DB, we need to use it. We do that by telling
- # SecureTransport to break on server auth. We also do that if we don't
- # want to validate the certs at all: we just won't actually do any
- # authing in that case.
- if not verify or trust_bundle is not None:
- result = Security.SSLSetSessionOption(
- self.context, SecurityConst.kSSLSessionOptionBreakOnServerAuth, True
- )
- _assert_no_error(result)
-
- # If there's a client cert, we need to use it.
- if client_cert:
- self._keychain, self._keychain_dir = _temporary_keychain()
- self._client_cert_chain = _load_client_cert_chain(
- self._keychain, client_cert, client_key
- )
- result = Security.SSLSetCertificate(self.context, self._client_cert_chain)
- _assert_no_error(result)
-
- while True:
- with self._raise_on_error():
- result = Security.SSLHandshake(self.context)
-
- if result == SecurityConst.errSSLWouldBlock:
- raise socket.timeout("handshake timed out")
- elif result == SecurityConst.errSSLServerAuthCompleted:
- self._custom_validate(verify, trust_bundle)
- continue
- else:
- _assert_no_error(result)
- break
-
- def fileno(self):
- return self.socket.fileno()
-
- # Copy-pasted from Python 3.5 source code
- def _decref_socketios(self):
- if self._makefile_refs > 0:
- self._makefile_refs -= 1
- if self._closed:
- self.close()
-
- def recv(self, bufsiz):
- buffer = ctypes.create_string_buffer(bufsiz)
- bytes_read = self.recv_into(buffer, bufsiz)
- data = buffer[:bytes_read]
- return data
-
- def recv_into(self, buffer, nbytes=None):
- # Read short on EOF.
- if self._closed:
- return 0
-
- if nbytes is None:
- nbytes = len(buffer)
-
- buffer = (ctypes.c_char * nbytes).from_buffer(buffer)
- processed_bytes = ctypes.c_size_t(0)
-
- with self._raise_on_error():
- result = Security.SSLRead(
- self.context, buffer, nbytes, ctypes.byref(processed_bytes)
- )
-
- # There are some result codes that we want to treat as "not always
- # errors". Specifically, those are errSSLWouldBlock,
- # errSSLClosedGraceful, and errSSLClosedNoNotify.
- if result == SecurityConst.errSSLWouldBlock:
- # If we didn't process any bytes, then this was just a time out.
- # However, we can get errSSLWouldBlock in situations when we *did*
- # read some data, and in those cases we should just read "short"
- # and return.
- if processed_bytes.value == 0:
- # Timed out, no data read.
- raise socket.timeout("recv timed out")
- elif result in (
- SecurityConst.errSSLClosedGraceful,
- SecurityConst.errSSLClosedNoNotify,
- ):
- # The remote peer has closed this connection. We should do so as
- # well. Note that we don't actually return here because in
- # principle this could actually be fired along with return data.
- # It's unlikely though.
- self.close()
- else:
- _assert_no_error(result)
-
- # Ok, we read and probably succeeded. We should return whatever data
- # was actually read.
- return processed_bytes.value
-
- def settimeout(self, timeout):
- self._timeout = timeout
-
- def gettimeout(self):
- return self._timeout
-
- def send(self, data):
- processed_bytes = ctypes.c_size_t(0)
-
- with self._raise_on_error():
- result = Security.SSLWrite(
- self.context, data, len(data), ctypes.byref(processed_bytes)
- )
-
- if result == SecurityConst.errSSLWouldBlock and processed_bytes.value == 0:
- # Timed out
- raise socket.timeout("send timed out")
- else:
- _assert_no_error(result)
-
- # We sent, and probably succeeded. Tell them how much we sent.
- return processed_bytes.value
-
- def sendall(self, data):
- total_sent = 0
- while total_sent < len(data):
- sent = self.send(data[total_sent : total_sent + SSL_WRITE_BLOCKSIZE])
- total_sent += sent
-
- def shutdown(self):
- with self._raise_on_error():
- Security.SSLClose(self.context)
-
- def close(self):
- # TODO: should I do clean shutdown here? Do I have to?
- if self._makefile_refs < 1:
- self._closed = True
- if self.context:
- CoreFoundation.CFRelease(self.context)
- self.context = None
- if self._client_cert_chain:
- CoreFoundation.CFRelease(self._client_cert_chain)
- self._client_cert_chain = None
- if self._keychain:
- Security.SecKeychainDelete(self._keychain)
- CoreFoundation.CFRelease(self._keychain)
- shutil.rmtree(self._keychain_dir)
- self._keychain = self._keychain_dir = None
- return self.socket.close()
- else:
- self._makefile_refs -= 1
-
- def getpeercert(self, binary_form=False):
- # Urgh, annoying.
- #
- # Here's how we do this:
- #
- # 1. Call SSLCopyPeerTrust to get hold of the trust object for this
- # connection.
- # 2. Call SecTrustGetCertificateAtIndex for index 0 to get the leaf.
- # 3. To get the CN, call SecCertificateCopyCommonName and process that
- # string so that it's of the appropriate type.
- # 4. To get the SAN, we need to do something a bit more complex:
- # a. Call SecCertificateCopyValues to get the data, requesting
- # kSecOIDSubjectAltName.
- # b. Mess about with this dictionary to try to get the SANs out.
- #
- # This is gross. Really gross. It's going to be a few hundred LoC extra
- # just to repeat something that SecureTransport can *already do*. So my
- # operating assumption at this time is that what we want to do is
- # instead to just flag to urllib3 that it shouldn't do its own hostname
- # validation when using SecureTransport.
- if not binary_form:
- raise ValueError("SecureTransport only supports dumping binary certs")
- trust = Security.SecTrustRef()
- certdata = None
- der_bytes = None
-
- try:
- # Grab the trust store.
- result = Security.SSLCopyPeerTrust(self.context, ctypes.byref(trust))
- _assert_no_error(result)
- if not trust:
- # Probably we haven't done the handshake yet. No biggie.
- return None
-
- cert_count = Security.SecTrustGetCertificateCount(trust)
- if not cert_count:
- # Also a case that might happen if we haven't handshaked.
- # Handshook? Handshaken?
- return None
-
- leaf = Security.SecTrustGetCertificateAtIndex(trust, 0)
- assert leaf
-
- # Ok, now we want the DER bytes.
- certdata = Security.SecCertificateCopyData(leaf)
- assert certdata
-
- data_length = CoreFoundation.CFDataGetLength(certdata)
- data_buffer = CoreFoundation.CFDataGetBytePtr(certdata)
- der_bytes = ctypes.string_at(data_buffer, data_length)
- finally:
- if certdata:
- CoreFoundation.CFRelease(certdata)
- if trust:
- CoreFoundation.CFRelease(trust)
-
- return der_bytes
-
- def version(self):
- protocol = Security.SSLProtocol()
- result = Security.SSLGetNegotiatedProtocolVersion(
- self.context, ctypes.byref(protocol)
- )
- _assert_no_error(result)
- if protocol.value == SecurityConst.kTLSProtocol13:
- raise ssl.SSLError("SecureTransport does not support TLS 1.3")
- elif protocol.value == SecurityConst.kTLSProtocol12:
- return "TLSv1.2"
- elif protocol.value == SecurityConst.kTLSProtocol11:
- return "TLSv1.1"
- elif protocol.value == SecurityConst.kTLSProtocol1:
- return "TLSv1"
- elif protocol.value == SecurityConst.kSSLProtocol3:
- return "SSLv3"
- elif protocol.value == SecurityConst.kSSLProtocol2:
- return "SSLv2"
- else:
- raise ssl.SSLError("Unknown TLS version: %r" % protocol)
-
- def _reuse(self):
- self._makefile_refs += 1
-
- def _drop(self):
- if self._makefile_refs < 1:
- self.close()
- else:
- self._makefile_refs -= 1
-
-
-if _fileobject: # Platform-specific: Python 2
-
- def makefile(self, mode, bufsize=-1):
- self._makefile_refs += 1
- return _fileobject(self, mode, bufsize, close=True)
-
-else: # Platform-specific: Python 3
-
- def makefile(self, mode="r", buffering=None, *args, **kwargs):
- # We disable buffering with SecureTransport because it conflicts with
- # the buffering that ST does internally (see issue #1153 for more).
- buffering = 0
- return backport_makefile(self, mode, buffering, *args, **kwargs)
-
-
-WrappedSocket.makefile = makefile
-
-
-class SecureTransportContext(object):
- """
- I am a wrapper class for the SecureTransport library, to translate the
- interface of the standard library ``SSLContext`` object to calls into
- SecureTransport.
- """
-
- def __init__(self, protocol):
- self._min_version, self._max_version = _protocol_to_min_max[protocol]
- self._options = 0
- self._verify = False
- self._trust_bundle = None
- self._client_cert = None
- self._client_key = None
- self._client_key_passphrase = None
- self._alpn_protocols = None
-
- @property
- def check_hostname(self):
- """
- SecureTransport cannot have its hostname checking disabled. For more,
- see the comment on getpeercert() in this file.
- """
- return True
-
- @check_hostname.setter
- def check_hostname(self, value):
- """
- SecureTransport cannot have its hostname checking disabled. For more,
- see the comment on getpeercert() in this file.
- """
- pass
-
- @property
- def options(self):
- # TODO: Well, crap.
- #
- # So this is the bit of the code that is the most likely to cause us
- # trouble. Essentially we need to enumerate all of the SSL options that
- # users might want to use and try to see if we can sensibly translate
- # them, or whether we should just ignore them.
- return self._options
-
- @options.setter
- def options(self, value):
- # TODO: Update in line with above.
- self._options = value
-
- @property
- def verify_mode(self):
- return ssl.CERT_REQUIRED if self._verify else ssl.CERT_NONE
-
- @verify_mode.setter
- def verify_mode(self, value):
- self._verify = True if value == ssl.CERT_REQUIRED else False
-
- def set_default_verify_paths(self):
- # So, this has to do something a bit weird. Specifically, what it does
- # is nothing.
- #
- # This means that, if we had previously had load_verify_locations
- # called, this does not undo that. We need to do that because it turns
- # out that the rest of the urllib3 code will attempt to load the
- # default verify paths if it hasn't been told about any paths, even if
- # the context itself was sometime earlier. We resolve that by just
- # ignoring it.
- pass
-
- def load_default_certs(self):
- return self.set_default_verify_paths()
-
- def set_ciphers(self, ciphers):
- # For now, we just require the default cipher string.
- if ciphers != util.ssl_.DEFAULT_CIPHERS:
- raise ValueError("SecureTransport doesn't support custom cipher strings")
-
- def load_verify_locations(self, cafile=None, capath=None, cadata=None):
- # OK, we only really support cadata and cafile.
- if capath is not None:
- raise ValueError("SecureTransport does not support cert directories")
-
- # Raise if cafile does not exist.
- if cafile is not None:
- with open(cafile):
- pass
-
- self._trust_bundle = cafile or cadata
-
- def load_cert_chain(self, certfile, keyfile=None, password=None):
- self._client_cert = certfile
- self._client_key = keyfile
- self._client_cert_passphrase = password
-
- def set_alpn_protocols(self, protocols):
- """
- Sets the ALPN protocols that will later be set on the context.
-
- Raises a NotImplementedError if ALPN is not supported.
- """
- if not hasattr(Security, "SSLSetALPNProtocols"):
- raise NotImplementedError(
- "SecureTransport supports ALPN only in macOS 10.12+"
- )
- self._alpn_protocols = [six.ensure_binary(p) for p in protocols]
-
- def wrap_socket(
- self,
- sock,
- server_side=False,
- do_handshake_on_connect=True,
- suppress_ragged_eofs=True,
- server_hostname=None,
- ):
- # So, what do we do here? Firstly, we assert some properties. This is a
- # stripped down shim, so there is some functionality we don't support.
- # See PEP 543 for the real deal.
- assert not server_side
- assert do_handshake_on_connect
- assert suppress_ragged_eofs
-
- # Ok, we're good to go. Now we want to create the wrapped socket object
- # and store it in the appropriate place.
- wrapped_socket = WrappedSocket(sock)
-
- # Now we can handshake
- wrapped_socket.handshake(
- server_hostname,
- self._verify,
- self._trust_bundle,
- self._min_version,
- self._max_version,
- self._client_cert,
- self._client_key,
- self._client_key_passphrase,
- self._alpn_protocols,
- )
- return wrapped_socket
diff --git a/spaces/Techis/resume-screening-tool/field.py b/spaces/Techis/resume-screening-tool/field.py
deleted file mode 100644
index 4f106a6a3741a6a599da99faccde38bc62208fbb..0000000000000000000000000000000000000000
--- a/spaces/Techis/resume-screening-tool/field.py
+++ /dev/null
@@ -1,7 +0,0 @@
-def branch(text_list):
- for i in range(len(text_list)):
- if text_list[i] == ('Pandas' or 'Neural' or 'Sklearn' or 'Matplotlib' or 'Tensorflow'):
- department = 'Data Science'
- elif text_list[i] == "Django":
- department = 'Web Developer'
- return department
diff --git a/spaces/TouchFrosty/QSign/README.md b/spaces/TouchFrosty/QSign/README.md
deleted file mode 100644
index 28490c6310267a528bfd4f84c47e0cc061e96b18..0000000000000000000000000000000000000000
--- a/spaces/TouchFrosty/QSign/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-title: QSign
-emoji: 💻
-colorFrom: gray
-colorTo: gray
-sdk: docker
-pinned: false
-duplicated_from: hanxuan/QSign
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Wander1ngW1nd/EdControl/plotlycharts/charts.py b/spaces/Wander1ngW1nd/EdControl/plotlycharts/charts.py
deleted file mode 100644
index 5f577704589ad3c744de4062bfa6b4ce462a5e2c..0000000000000000000000000000000000000000
--- a/spaces/Wander1ngW1nd/EdControl/plotlycharts/charts.py
+++ /dev/null
@@ -1,45 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-Created on Wed Sep 6 16:12:00 2023
-
-@author: PC
-"""
-
-import plotly.express as px
-import pandas as pd
-
-
-def radio_chart(data):
-
- rData=list(data.values())
- thetaData = list(data.keys())
-
- fig = px.line_polar(
- r = rData,
- theta = thetaData,
- line_close=True,
- color_discrete_sequence=px.colors.sequential.Plasma_r,
- template="plotly_dark")
- fig.update_layout(
- autosize=False,
- width=400,
- height=300,
- paper_bgcolor="Black")
-
-
- return fig
-
-def bar_chart(data):
-
- #df = pd.DataFrame(dict(
- # x = [1, 5, 2, 2, 3, 2],
- # y = ["Злость", "Отвращение","Страх",\
- # "Счастье","Грусть","Удивление"]))
- xData=list(data.values())
- yData = list(data.keys())
- fig = px.bar(x = xData, y =yData, barmode = 'group', labels={'x': '', 'y':''}, width=500, height=300)
- #fig.update_layout(showlegend=False)
- fig.update_traces(marker_color = ['#f5800d','#f2ce4d','#047e79','#a69565','#cfc1af','#574c31'], marker_line_color = 'black',
- marker_line_width = 2, opacity = 1)
- return fig
-
diff --git a/spaces/Wanlau/sovits-4.0_datealive/spec_gen.py b/spaces/Wanlau/sovits-4.0_datealive/spec_gen.py
deleted file mode 100644
index 9476395adab6fa841fde10c05fbb92902310ebd4..0000000000000000000000000000000000000000
--- a/spaces/Wanlau/sovits-4.0_datealive/spec_gen.py
+++ /dev/null
@@ -1,22 +0,0 @@
-from data_utils import TextAudioSpeakerLoader
-import json
-from tqdm import tqdm
-
-from utils import HParams
-
-config_path = 'configs/config.json'
-with open(config_path, "r") as f:
- data = f.read()
-config = json.loads(data)
-hps = HParams(**config)
-
-train_dataset = TextAudioSpeakerLoader("filelists/train.txt", hps)
-test_dataset = TextAudioSpeakerLoader("filelists/test.txt", hps)
-eval_dataset = TextAudioSpeakerLoader("filelists/val.txt", hps)
-
-for _ in tqdm(train_dataset):
- pass
-for _ in tqdm(eval_dataset):
- pass
-for _ in tqdm(test_dataset):
- pass
\ No newline at end of file
diff --git a/spaces/WhyLIM/ChatGPT-academic/app.py b/spaces/WhyLIM/ChatGPT-academic/app.py
deleted file mode 100644
index a149cf8ab78a70d2f70ff8fb5a0f4109a1de887e..0000000000000000000000000000000000000000
--- a/spaces/WhyLIM/ChatGPT-academic/app.py
+++ /dev/null
@@ -1,103 +0,0 @@
-import os; os.environ['no_proxy'] = '*' # 避免代理网络产生意外污染
-import gradio as gr
-from predict import predict
-from toolbox import format_io, find_free_port
-
-# 建议您复制一个config_private.py放自己的秘密, 如API和代理网址, 避免不小心传github被别人看到
-try: from config_private import proxies, WEB_PORT, LLM_MODEL
-except: from config import proxies, WEB_PORT, LLM_MODEL
-
-# 如果WEB_PORT是-1, 则随机选取WEB端口
-PORT = find_free_port() if WEB_PORT <= 0 else WEB_PORT
-
-initial_prompt = "Serve me as a writing and programming assistant."
-title_html = """ChatGPT 学术优化 """
-
-# 问询记录, python 版本建议3.9+(越新越好)
-import logging
-os.makedirs('gpt_log', exist_ok=True)
-try:logging.basicConfig(filename='gpt_log/chat_secrets.log', level=logging.INFO, encoding='utf-8')
-except:logging.basicConfig(filename='gpt_log/chat_secrets.log', level=logging.INFO)
-print('所有问询记录将自动保存在本地目录./gpt_log/chat_secrets.log, 请注意自我隐私保护哦!')
-
-# 一些普通功能模块
-from functional import get_functionals
-functional = get_functionals()
-
-# 对一些丧心病狂的实验性功能模块进行测试
-from functional_crazy import get_crazy_functionals, on_file_uploaded, on_report_generated
-crazy_functional = get_crazy_functionals()
-
-# 处理markdown文本格式的转变
-gr.Chatbot.postprocess = format_io
-
-# 做一些外观色彩上的调整
-from theme import adjust_theme
-set_theme = adjust_theme()
-
-with gr.Blocks(theme=set_theme, analytics_enabled=False) as demo:
- gr.HTML(title_html)
- with gr.Row():
- with gr.Column(scale=2):
- chatbot = gr.Chatbot()
- chatbot.style(height=1000)
- chatbot.style()
- history = gr.State([])
- TRUE = gr.State(True)
- FALSE = gr.State(False)
- with gr.Column(scale=1):
- with gr.Row():
- with gr.Column(scale=12):
- txt = gr.Textbox(show_label=False, placeholder="Input question here.").style(container=False)
- with gr.Column(scale=1):
- submitBtn = gr.Button("提交", variant="primary")
- with gr.Row():
- from check_proxy import check_proxy
- statusDisplay = gr.Markdown(f"Tip: 按Enter提交, 按Shift+Enter换行. \nNetwork: {check_proxy(proxies)}\nModel: {LLM_MODEL}")
- with gr.Row():
- for k in functional:
- variant = functional[k]["Color"] if "Color" in functional[k] else "secondary"
- functional[k]["Button"] = gr.Button(k, variant=variant)
- with gr.Row():
- gr.Markdown("以下部分实验性功能需从input框读取路径.")
- with gr.Row():
- for k in crazy_functional:
- variant = crazy_functional[k]["Color"] if "Color" in crazy_functional[k] else "secondary"
- crazy_functional[k]["Button"] = gr.Button(k, variant=variant)
- with gr.Row():
- gr.Markdown("上传本地文件供上面的实验性功能调用.")
- with gr.Row():
- file_upload = gr.Files(label='任何文件,但推荐上传压缩文件(zip, tar)', file_count="multiple")
-
- systemPromptTxt = gr.Textbox(show_label=True, placeholder=f"System Prompt", label="System prompt", value=initial_prompt).style(container=True)
- #inputs, top_p, temperature, top_k, repetition_penalty
- with gr.Accordion("arguments", open=False):
- top_p = gr.Slider(minimum=-0, maximum=1.0, value=1.0, step=0.01,interactive=True, label="Top-p (nucleus sampling)",)
- temperature = gr.Slider(minimum=-0, maximum=5.0, value=1.0, step=0.01, interactive=True, label="Temperature",)
-
- txt.submit(predict, [txt, top_p, temperature, chatbot, history, systemPromptTxt], [chatbot, history, statusDisplay])
- submitBtn.click(predict, [txt, top_p, temperature, chatbot, history, systemPromptTxt], [chatbot, history, statusDisplay], show_progress=True)
- for k in functional:
- functional[k]["Button"].click(predict,
- [txt, top_p, temperature, chatbot, history, systemPromptTxt, TRUE, gr.State(k)], [chatbot, history, statusDisplay], show_progress=True)
- file_upload.upload(on_file_uploaded, [file_upload, chatbot, txt], [chatbot, txt])
- for k in crazy_functional:
- click_handle = crazy_functional[k]["Button"].click(crazy_functional[k]["Function"],
- [txt, top_p, temperature, chatbot, history, systemPromptTxt, gr.State(PORT)], [chatbot, history, statusDisplay]
- )
- try: click_handle.then(on_report_generated, [file_upload, chatbot], [file_upload, chatbot])
- except: pass
-
-
-# # 延迟函数, 做一些准备工作, 最后尝试打开浏览器
-# def auto_opentab_delay():
-# import threading, webbrowser, time
-# print(f"URL http://localhost:{PORT}")
-# def open(): time.sleep(2)
-# webbrowser.open_new_tab(f'http://localhost:{PORT}')
-# t = threading.Thread(target=open)
-# t.daemon = True; t.start()
-
-# auto_opentab_delay()
-demo.title = "ChatGPT 学术优化"
-demo.queue().launch(share=False)
diff --git a/spaces/Xenova/semantic-image-search-client/README.md b/spaces/Xenova/semantic-image-search-client/README.md
deleted file mode 100644
index d6e687443ea38408171dc9c47de02f7d3896d356..0000000000000000000000000000000000000000
--- a/spaces/Xenova/semantic-image-search-client/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: Semantic Image Search Client
-emoji: 🦀
-colorFrom: indigo
-colorTo: red
-sdk: static
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/YONG627/456123/README.md b/spaces/YONG627/456123/README.md
deleted file mode 100644
index b9f5adf10ed5472598762df44da1424b80230321..0000000000000000000000000000000000000000
--- a/spaces/YONG627/456123/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: 456123
-emoji: 🔥
-colorFrom: purple
-colorTo: purple
-sdk: gradio
-sdk_version: 3.35.2
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Yiqin/ChatVID/model/utils/scenic_call.py b/spaces/Yiqin/ChatVID/model/utils/scenic_call.py
deleted file mode 100644
index d6e581094fd7a8dfec6602386dbc63abd5d80488..0000000000000000000000000000000000000000
--- a/spaces/Yiqin/ChatVID/model/utils/scenic_call.py
+++ /dev/null
@@ -1,268 +0,0 @@
-import functools
-
-from absl import app
-from absl import flags
-from absl import logging
-
-from clu import metric_writers
-from clu import platform
-import flax.linen as nn
-import jax
-from ml_collections import config_flags
-import tensorflow as tf
-
-import sys, os
-from pathlib import Path
-# append current path to sys.path
-sys.path.append(str(Path(__file__).parent.parent.parent / "scenic"))
-
-import logging
-import flax
-from flax import jax_utils
-from flax.training import checkpoints
-from scenic.projects.vid2seq import models, trainer
-from scenic.train_lib_deprecated import train_utils
-from scenic import app
-import ml_collections
-import numpy as np
-import jax.numpy as jnp
-from clu import metric_writers
-from scenic.projects.vid2seq.datasets.dense_video_captioning_tfrecord_dataset import get_datasets
-from scenic.projects.vid2seq import dvc_eval
-
-MAX_CAPTION_STR_LEN = 200
-MAX_KEY_STR_LEN = 400
-
-class ScenicModel:
- def __init__(self, flags):
- self.FLAGS = flags
- jax.config.config_with_absl()
- run = (functools.partial(self._run_main, main=self._init_model))
- run(self._init_model)
- def _run_main(self, argv, *, main):
- """Runs the `main` method after some initial setup."""
- del argv
- # Hide any GPUs form TensorFlow. Otherwise, TF might reserve memory and make
- # it unavailable to JAX.
- tf.config.experimental.set_visible_devices([], 'GPU')
-
- # Enable wrapping of all module calls in a named_call for easier profiling:
- nn.enable_named_call()
-
- logging.info('JAX host: %d / %d', jax.process_index(), jax.process_count())
- logging.info('JAX devices: %r', jax.devices())
-
- # Add a note so that we can tell which task is which JAX host.
- # (task 0 is not guaranteed to be the host 0)
- platform.work_unit().set_task_status(
- f'host_id: {jax.process_index()}, host_count: {jax.process_count()}')
- if jax.process_index() == 0:
- platform.work_unit().create_artifact(platform.ArtifactType.DIRECTORY,
- self.FLAGS.workdir, 'Workdir')
- self.FLAGS.config.dataset_configs.base_dir = self.FLAGS.data_dir
- self.FLAGS.config.init_from.checkpoint_path = self.FLAGS.ckpt_dir
- rng = jax.random.PRNGKey(self.FLAGS.config.rng_seed)
- logging.info('RNG: %s', rng)
-
- writer = metric_writers.create_default_writer(
- self.FLAGS.workdir, just_logging=jax.process_index() > 0, asynchronous=True)
-
- return main(rng=rng, config=self.FLAGS.config, workdir=self.FLAGS.workdir, writer=writer)
-
-
- def _init_model(self, rng: jnp.ndarray, config: ml_collections.ConfigDict, workdir: str,
- writer: metric_writers.MetricWriter):
- data_rng, rng = jax.random.split(rng)
- dataset_dict = get_datasets(config, data_rng=data_rng)
-
- datasets_metadata = {
- name: ds.meta_data
- for name, ds in dataset_dict.items()
- }
- all_datasets = []
- all_datasets_num_train_examples = []
- for name, metadata in datasets_metadata.items():
- all_datasets.append(name)
- all_datasets_num_train_examples.append(
- metadata.get('num_train_examples', 0))
- dataset = dataset_dict[all_datasets[0]]
-
- model_cls = models.DenseVideoCaptioningModel
- model = model_cls(config, dataset.meta_data)
- train_state, start_step = trainer.init_state(model, dataset, config,
- workdir, rng)
-
- self.train_state = jax_utils.replicate(train_state)
- logging.info('Number of processes is %s', jax.process_count())
- del rng
-
- import functools
- self.infer_step_pmapped = jax.pmap(
- functools.partial(
- trainer.infer_step,
- model=model,
- config=config,
- debug=config.debug_eval),
- axis_name='batch',
- )
-
- self.tokenizer = trainer.get_tokenizer(config)
- # dsname = 'validation'
- # self.iterator = dataset.valid_iter[dsname]
-
- self.config = config
- self.data_rng = data_rng
-
- def __call__(self, data_dir=None):
- # self.FLAGS.config.dataset_configs.base_dir = data_dir
- dataset_dict = get_datasets(self.config, data_rng=self.data_rng)
- self.iterator = dataset_dict["youcook"].valid_iter['validation']
- batch = next(self.iterator)
-
- train_state = train_utils.sync_model_state_across_replicas(self.train_state)
- eval_packs = {}
- keys = []
- eval_pack = {
- 'gts':
- dvc_eval.convert_strings_to_uint8_arrays(
- batch['caption_strings'], MAX_CAPTION_STR_LEN),
- 'key':
- dvc_eval.convert_strings_to_uint8_arrays(
- batch['videoid'], MAX_KEY_STR_LEN),
- 'batch_mask':
- batch['batch_mask'],
- 'duration':
- batch['duration'],
- 'gts_start':
- batch['timestamp_start'],
- 'gts_end':
- batch['timestamp_end'],
- 'split':
- batch['split'] if 'split' in batch else
- np.ones_like(batch['timestamp_start']),
- }
- to_del = ['caption_strings', 'key', 'videoid', 'timestamp_start',
- 'timestamp_end', 'split'] # 'duration',
- for x in to_del:
- if x in batch:
- del batch[x]
-
- # import pdb
- # pdb.set_trace()
-
- _, preds = self.infer_step_pmapped(train_state, batch) #model, config)
- # import pdb
- # pdb.set_trace()
- eval_pack['pred'] = preds
- eval_pack = jax.tree_map(
- lambda x: x.reshape((np.prod(x.shape[:2]),) + x.shape[2:]), eval_pack)
-
- vocabulary_size = self.config.dataset_configs.vocabulary_size
- # pred_text = trainer.decode_tokens(preds, tokenizer, vocabulary_size)
-
- # print(preds, pred_text)
- format_outputs = []
- for i, valid in enumerate(eval_pack['batch_mask']):
- print("===============video[", str(0), "]====================")
- if valid:
- key = dvc_eval.convert_uint8_array_to_string(eval_pack['key'][i])
- if key in eval_packs: # redundant video
- continue
- keys.append(key)
-
- pred, pred_timestamps = [], []
- # get indexes in the predicted seq that delimit the pred segments
- indexes = [
- j for j in range(len(eval_pack['pred'][i]) - 1)
- if eval_pack['pred'][i][j] >= vocabulary_size and
- eval_pack['pred'][i][j + 1] >= vocabulary_size
- ] # pylint: disable=g-complex-comprehension
-
- last_processed = -2
- order = self.config.dataset_configs.order
-
- # iterate over predicted segments and decode them
- for j in range(len(indexes)):
- if indexes[j] == last_processed + 1: # 3 timestamps != 2 events
- continue
-
- # get predicted tokens and transform to string
- if order == 'ld':
- start_idx = indexes[j] + 2
- end_idx = indexes[j + 1] if j < len(indexes) - 1 else len(
- eval_pack['pred'][i])
- else:
- start_idx = indexes[j - 1] + 2 if j > 0 else 0
- end_idx = indexes[j]
- pred_seq = [int(eval_pack['pred'][i][k]) for k in range(start_idx, end_idx)]
- pred_text = trainer.decode_tokens(pred_seq, self.tokenizer, vocabulary_size)
-
- # get start and end
- num_bins = 100 # from config
- max_offset = num_bins - 1
- pred_time = [
- (int(eval_pack['pred'][i][indexes[j]])
- - vocabulary_size) *
- eval_pack['duration'][i] / max_offset,
- (int(eval_pack['pred'][i][indexes[j] + 1]) -
- vocabulary_size) *
- eval_pack['duration'][i] / max_offset
- ]
-
- # if pred_time[1] <= pred_time[0]: # remove end < start
- # continue
- last_processed = indexes[j]
-
- pred.append(pred_text)
- pred_timestamps.append(pred_time)
-
- # round to 2 decimal places
- format_output = "[{x}s, {y}s] ".format(x=np.around(pred_time[0][0]/1000000, decimals=2), y=np.around(pred_time[1][0]/1000000, decimals=2))
- format_output += pred_text
- format_outputs.append(format_output)
- print(format_outputs)
- print("===============================================")
- return format_outputs
-
-class ScenicCall:
- def __init__(self, main, flags):
- self.main = main
- self.FLAGS = flags
-
- def __call__(self):
- return self.run()
-
- def run(self):
- # Provide access to --jax_backend_target and --jax_xla_backend flags.
- jax.config.config_with_absl()
- run = (functools.partial(self._run_main, main=self.main))
- return run(self.main)
-
- def _run_main(self, argv, *, main):
- """Runs the `main` method after some initial setup."""
- del argv
- # Hide any GPUs form TensorFlow. Otherwise, TF might reserve memory and make
- # it unavailable to JAX.
- tf.config.experimental.set_visible_devices([], 'GPU')
-
- # Enable wrapping of all module calls in a named_call for easier profiling:
- nn.enable_named_call()
-
- logging.info('JAX host: %d / %d', jax.process_index(), jax.process_count())
- logging.info('JAX devices: %r', jax.devices())
-
- # Add a note so that we can tell which task is which JAX host.
- # (task 0 is not guaranteed to be the host 0)
- platform.work_unit().set_task_status(
- f'host_id: {jax.process_index()}, host_count: {jax.process_count()}')
- if jax.process_index() == 0:
- platform.work_unit().create_artifact(platform.ArtifactType.DIRECTORY,
- self.FLAGS.workdir, 'Workdir')
- self.FLAGS.config.dataset_configs.base_dir = self.FLAGS.data_dir
- rng = jax.random.PRNGKey(self.FLAGS.config.rng_seed)
- logging.info('RNG: %s', rng)
-
- writer = metric_writers.create_default_writer(
- self.FLAGS.workdir, just_logging=jax.process_index() > 0, asynchronous=True)
-
- return main(rng=rng, config=self.FLAGS.config, workdir=self.FLAGS.workdir, writer=writer)
diff --git a/spaces/Yuliang/ECON/lib/pixielib/models/SMPLX.py b/spaces/Yuliang/ECON/lib/pixielib/models/SMPLX.py
deleted file mode 100644
index 9f07f5740100133c94ba9e5f2f9767ba7ea4b42c..0000000000000000000000000000000000000000
--- a/spaces/Yuliang/ECON/lib/pixielib/models/SMPLX.py
+++ /dev/null
@@ -1,1016 +0,0 @@
-"""
-original from https://github.com/vchoutas/smplx
-modified by Vassilis and Yao
-"""
-
-import pickle
-
-import numpy as np
-import torch
-import torch.nn as nn
-
-from .lbs import (
- JointsFromVerticesSelector,
- Struct,
- find_dynamic_lmk_idx_and_bcoords,
- lbs,
- to_np,
- to_tensor,
- vertices2landmarks,
-)
-
-# SMPLX
-J14_NAMES = [
- "right_ankle",
- "right_knee",
- "right_hip",
- "left_hip",
- "left_knee",
- "left_ankle",
- "right_wrist",
- "right_elbow",
- "right_shoulder",
- "left_shoulder",
- "left_elbow",
- "left_wrist",
- "neck",
- "head",
-]
-SMPLX_names = [
- "pelvis",
- "left_hip",
- "right_hip",
- "spine1",
- "left_knee",
- "right_knee",
- "spine2",
- "left_ankle",
- "right_ankle",
- "spine3",
- "left_foot",
- "right_foot",
- "neck",
- "left_collar",
- "right_collar",
- "head",
- "left_shoulder",
- "right_shoulder",
- "left_elbow",
- "right_elbow",
- "left_wrist",
- "right_wrist",
- "jaw",
- "left_eye_smplx",
- "right_eye_smplx",
- "left_index1",
- "left_index2",
- "left_index3",
- "left_middle1",
- "left_middle2",
- "left_middle3",
- "left_pinky1",
- "left_pinky2",
- "left_pinky3",
- "left_ring1",
- "left_ring2",
- "left_ring3",
- "left_thumb1",
- "left_thumb2",
- "left_thumb3",
- "right_index1",
- "right_index2",
- "right_index3",
- "right_middle1",
- "right_middle2",
- "right_middle3",
- "right_pinky1",
- "right_pinky2",
- "right_pinky3",
- "right_ring1",
- "right_ring2",
- "right_ring3",
- "right_thumb1",
- "right_thumb2",
- "right_thumb3",
- "right_eye_brow1",
- "right_eye_brow2",
- "right_eye_brow3",
- "right_eye_brow4",
- "right_eye_brow5",
- "left_eye_brow5",
- "left_eye_brow4",
- "left_eye_brow3",
- "left_eye_brow2",
- "left_eye_brow1",
- "nose1",
- "nose2",
- "nose3",
- "nose4",
- "right_nose_2",
- "right_nose_1",
- "nose_middle",
- "left_nose_1",
- "left_nose_2",
- "right_eye1",
- "right_eye2",
- "right_eye3",
- "right_eye4",
- "right_eye5",
- "right_eye6",
- "left_eye4",
- "left_eye3",
- "left_eye2",
- "left_eye1",
- "left_eye6",
- "left_eye5",
- "right_mouth_1",
- "right_mouth_2",
- "right_mouth_3",
- "mouth_top",
- "left_mouth_3",
- "left_mouth_2",
- "left_mouth_1",
- "left_mouth_5",
- "left_mouth_4",
- "mouth_bottom",
- "right_mouth_4",
- "right_mouth_5",
- "right_lip_1",
- "right_lip_2",
- "lip_top",
- "left_lip_2",
- "left_lip_1",
- "left_lip_3",
- "lip_bottom",
- "right_lip_3",
- "right_contour_1",
- "right_contour_2",
- "right_contour_3",
- "right_contour_4",
- "right_contour_5",
- "right_contour_6",
- "right_contour_7",
- "right_contour_8",
- "contour_middle",
- "left_contour_8",
- "left_contour_7",
- "left_contour_6",
- "left_contour_5",
- "left_contour_4",
- "left_contour_3",
- "left_contour_2",
- "left_contour_1",
- "head_top",
- "left_big_toe",
- "left_ear",
- "left_eye",
- "left_heel",
- "left_index",
- "left_middle",
- "left_pinky",
- "left_ring",
- "left_small_toe",
- "left_thumb",
- "nose",
- "right_big_toe",
- "right_ear",
- "right_eye",
- "right_heel",
- "right_index",
- "right_middle",
- "right_pinky",
- "right_ring",
- "right_small_toe",
- "right_thumb",
-]
-extra_names = [
- "head_top",
- "left_big_toe",
- "left_ear",
- "left_eye",
- "left_heel",
- "left_index",
- "left_middle",
- "left_pinky",
- "left_ring",
- "left_small_toe",
- "left_thumb",
- "nose",
- "right_big_toe",
- "right_ear",
- "right_eye",
- "right_heel",
- "right_index",
- "right_middle",
- "right_pinky",
- "right_ring",
- "right_small_toe",
- "right_thumb",
-]
-SMPLX_names += extra_names
-
-part_indices = {}
-part_indices["body"] = np.array([
- 0,
- 1,
- 2,
- 3,
- 4,
- 5,
- 6,
- 7,
- 8,
- 9,
- 10,
- 11,
- 12,
- 13,
- 14,
- 15,
- 16,
- 17,
- 18,
- 19,
- 20,
- 21,
- 22,
- 23,
- 24,
- 123,
- 124,
- 125,
- 126,
- 127,
- 132,
- 134,
- 135,
- 136,
- 137,
- 138,
- 143,
-])
-part_indices["torso"] = np.array([
- 0,
- 1,
- 2,
- 3,
- 6,
- 9,
- 12,
- 13,
- 14,
- 15,
- 16,
- 17,
- 18,
- 19,
- 22,
- 23,
- 24,
- 55,
- 56,
- 57,
- 58,
- 59,
- 76,
- 77,
- 78,
- 79,
- 80,
- 81,
- 82,
- 83,
- 84,
- 85,
- 86,
- 87,
- 88,
- 89,
- 90,
- 91,
- 92,
- 93,
- 94,
- 95,
- 96,
- 97,
- 98,
- 99,
- 100,
- 101,
- 102,
- 103,
- 104,
- 105,
- 106,
- 107,
- 108,
- 109,
- 110,
- 111,
- 112,
- 113,
- 114,
- 115,
- 116,
- 117,
- 118,
- 119,
- 120,
- 121,
- 122,
- 123,
- 124,
- 125,
- 126,
- 127,
- 128,
- 129,
- 130,
- 131,
- 132,
- 133,
- 134,
- 135,
- 136,
- 137,
- 138,
- 139,
- 140,
- 141,
- 142,
- 143,
- 144,
-])
-part_indices["head"] = np.array([
- 12,
- 15,
- 22,
- 23,
- 24,
- 55,
- 56,
- 57,
- 58,
- 59,
- 60,
- 61,
- 62,
- 63,
- 64,
- 65,
- 66,
- 67,
- 68,
- 69,
- 70,
- 71,
- 72,
- 73,
- 74,
- 75,
- 76,
- 77,
- 78,
- 79,
- 80,
- 81,
- 82,
- 83,
- 84,
- 85,
- 86,
- 87,
- 88,
- 89,
- 90,
- 91,
- 92,
- 93,
- 94,
- 95,
- 96,
- 97,
- 98,
- 99,
- 100,
- 101,
- 102,
- 103,
- 104,
- 105,
- 106,
- 107,
- 108,
- 109,
- 110,
- 111,
- 112,
- 113,
- 114,
- 115,
- 116,
- 117,
- 118,
- 119,
- 120,
- 121,
- 122,
- 123,
- 125,
- 126,
- 134,
- 136,
- 137,
-])
-part_indices["face"] = np.array([
- 55,
- 56,
- 57,
- 58,
- 59,
- 60,
- 61,
- 62,
- 63,
- 64,
- 65,
- 66,
- 67,
- 68,
- 69,
- 70,
- 71,
- 72,
- 73,
- 74,
- 75,
- 76,
- 77,
- 78,
- 79,
- 80,
- 81,
- 82,
- 83,
- 84,
- 85,
- 86,
- 87,
- 88,
- 89,
- 90,
- 91,
- 92,
- 93,
- 94,
- 95,
- 96,
- 97,
- 98,
- 99,
- 100,
- 101,
- 102,
- 103,
- 104,
- 105,
- 106,
- 107,
- 108,
- 109,
- 110,
- 111,
- 112,
- 113,
- 114,
- 115,
- 116,
- 117,
- 118,
- 119,
- 120,
- 121,
- 122,
-])
-part_indices["upper"] = np.array([
- 12,
- 13,
- 14,
- 55,
- 56,
- 57,
- 58,
- 59,
- 60,
- 61,
- 62,
- 63,
- 64,
- 65,
- 66,
- 67,
- 68,
- 69,
- 70,
- 71,
- 72,
- 73,
- 74,
- 75,
- 76,
- 77,
- 78,
- 79,
- 80,
- 81,
- 82,
- 83,
- 84,
- 85,
- 86,
- 87,
- 88,
- 89,
- 90,
- 91,
- 92,
- 93,
- 94,
- 95,
- 96,
- 97,
- 98,
- 99,
- 100,
- 101,
- 102,
- 103,
- 104,
- 105,
- 106,
- 107,
- 108,
- 109,
- 110,
- 111,
- 112,
- 113,
- 114,
- 115,
- 116,
- 117,
- 118,
- 119,
- 120,
- 121,
- 122,
-])
-part_indices["hand"] = np.array([
- 20,
- 21,
- 25,
- 26,
- 27,
- 28,
- 29,
- 30,
- 31,
- 32,
- 33,
- 34,
- 35,
- 36,
- 37,
- 38,
- 39,
- 40,
- 41,
- 42,
- 43,
- 44,
- 45,
- 46,
- 47,
- 48,
- 49,
- 50,
- 51,
- 52,
- 53,
- 54,
- 128,
- 129,
- 130,
- 131,
- 133,
- 139,
- 140,
- 141,
- 142,
- 144,
-])
-part_indices["left_hand"] = np.array([
- 20,
- 25,
- 26,
- 27,
- 28,
- 29,
- 30,
- 31,
- 32,
- 33,
- 34,
- 35,
- 36,
- 37,
- 38,
- 39,
- 128,
- 129,
- 130,
- 131,
- 133,
-])
-part_indices["right_hand"] = np.array([
- 21,
- 40,
- 41,
- 42,
- 43,
- 44,
- 45,
- 46,
- 47,
- 48,
- 49,
- 50,
- 51,
- 52,
- 53,
- 54,
- 139,
- 140,
- 141,
- 142,
- 144,
-])
-# kinematic tree
-head_kin_chain = [15, 12, 9, 6, 3, 0]
-
-# --smplx joints
-# 00 - Global
-# 01 - L_Thigh
-# 02 - R_Thigh
-# 03 - Spine
-# 04 - L_Calf
-# 05 - R_Calf
-# 06 - Spine1
-# 07 - L_Foot
-# 08 - R_Foot
-# 09 - Spine2
-# 10 - L_Toes
-# 11 - R_Toes
-# 12 - Neck
-# 13 - L_Shoulder
-# 14 - R_Shoulder
-# 15 - Head
-# 16 - L_UpperArm
-# 17 - R_UpperArm
-# 18 - L_ForeArm
-# 19 - R_ForeArm
-# 20 - L_Hand
-# 21 - R_Hand
-# 22 - Jaw
-# 23 - L_Eye
-# 24 - R_Eye
-
-
-class SMPLX(nn.Module):
- """
- Given smplx parameters, this class generates a differentiable SMPLX function
- which outputs a mesh and 3D joints
- """
- def __init__(self, config):
- super(SMPLX, self).__init__()
- # print("creating the SMPLX Decoder")
- ss = np.load(config.smplx_model_path, allow_pickle=True)
- smplx_model = Struct(**ss)
-
- self.dtype = torch.float32
- self.register_buffer(
- "faces_tensor",
- to_tensor(to_np(smplx_model.f, dtype=np.int64), dtype=torch.long),
- )
- # The vertices of the template model
- self.register_buffer(
- "v_template", to_tensor(to_np(smplx_model.v_template), dtype=self.dtype)
- )
- # The shape components and expression
- # expression space is the same as FLAME
- shapedirs = to_tensor(to_np(smplx_model.shapedirs), dtype=self.dtype)
- shapedirs = torch.cat(
- [
- shapedirs[:, :, :config.n_shape],
- shapedirs[:, :, 300:300 + config.n_exp],
- ],
- 2,
- )
- self.register_buffer("shapedirs", shapedirs)
- # The pose components
- num_pose_basis = smplx_model.posedirs.shape[-1]
- posedirs = np.reshape(smplx_model.posedirs, [-1, num_pose_basis]).T
- self.register_buffer("posedirs", to_tensor(to_np(posedirs), dtype=self.dtype))
- self.register_buffer(
- "J_regressor", to_tensor(to_np(smplx_model.J_regressor), dtype=self.dtype)
- )
- parents = to_tensor(to_np(smplx_model.kintree_table[0])).long()
- parents[0] = -1
- self.register_buffer("parents", parents)
- self.register_buffer("lbs_weights", to_tensor(to_np(smplx_model.weights), dtype=self.dtype))
- # for face keypoints
- self.register_buffer(
- "lmk_faces_idx", torch.tensor(smplx_model.lmk_faces_idx, dtype=torch.long)
- )
- self.register_buffer(
- "lmk_bary_coords",
- torch.tensor(smplx_model.lmk_bary_coords, dtype=self.dtype),
- )
- self.register_buffer(
- "dynamic_lmk_faces_idx",
- torch.tensor(smplx_model.dynamic_lmk_faces_idx, dtype=torch.long),
- )
- self.register_buffer(
- "dynamic_lmk_bary_coords",
- torch.tensor(smplx_model.dynamic_lmk_bary_coords, dtype=self.dtype),
- )
- # pelvis to head, to calculate head yaw angle, then find the dynamic landmarks
- self.register_buffer("head_kin_chain", torch.tensor(head_kin_chain, dtype=torch.long))
-
- # -- initialize parameters
- # shape and expression
- self.register_buffer(
- "shape_params",
- nn.Parameter(torch.zeros([1, config.n_shape], dtype=self.dtype), requires_grad=False),
- )
- self.register_buffer(
- "expression_params",
- nn.Parameter(torch.zeros([1, config.n_exp], dtype=self.dtype), requires_grad=False),
- )
- # pose: represented as rotation matrx [number of joints, 3, 3]
- self.register_buffer(
- "global_pose",
- nn.Parameter(
- torch.eye(3, dtype=self.dtype).unsqueeze(0).repeat(1, 1, 1),
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "head_pose",
- nn.Parameter(
- torch.eye(3, dtype=self.dtype).unsqueeze(0).repeat(1, 1, 1),
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "neck_pose",
- nn.Parameter(
- torch.eye(3, dtype=self.dtype).unsqueeze(0).repeat(1, 1, 1),
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "jaw_pose",
- nn.Parameter(
- torch.eye(3, dtype=self.dtype).unsqueeze(0).repeat(1, 1, 1),
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "eye_pose",
- nn.Parameter(
- torch.eye(3, dtype=self.dtype).unsqueeze(0).repeat(2, 1, 1),
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "body_pose",
- nn.Parameter(
- torch.eye(3, dtype=self.dtype).unsqueeze(0).repeat(21, 1, 1),
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "left_hand_pose",
- nn.Parameter(
- torch.eye(3, dtype=self.dtype).unsqueeze(0).repeat(15, 1, 1),
- requires_grad=False,
- ),
- )
- self.register_buffer(
- "right_hand_pose",
- nn.Parameter(
- torch.eye(3, dtype=self.dtype).unsqueeze(0).repeat(15, 1, 1),
- requires_grad=False,
- ),
- )
-
- if config.extra_joint_path:
- self.extra_joint_selector = JointsFromVerticesSelector(fname=config.extra_joint_path)
- self.use_joint_regressor = True
- self.keypoint_names = SMPLX_names
- if self.use_joint_regressor:
- with open(config.j14_regressor_path, "rb") as f:
- j14_regressor = pickle.load(f, encoding="latin1")
- source = []
- target = []
- for idx, name in enumerate(self.keypoint_names):
- if name in J14_NAMES:
- source.append(idx)
- target.append(J14_NAMES.index(name))
- source = np.asarray(source)
- target = np.asarray(target)
- self.register_buffer("source_idxs", torch.from_numpy(source))
- self.register_buffer("target_idxs", torch.from_numpy(target))
- self.register_buffer(
- "extra_joint_regressor",
- torch.from_numpy(j14_regressor).to(torch.float32)
- )
- self.part_indices = part_indices
-
- def forward(
- self,
- shape_params=None,
- expression_params=None,
- global_pose=None,
- body_pose=None,
- jaw_pose=None,
- eye_pose=None,
- left_hand_pose=None,
- right_hand_pose=None,
- ):
- """
- Args:
- shape_params: [N, number of shape parameters]
- expression_params: [N, number of expression parameters]
- global_pose: pelvis pose, [N, 1, 3, 3]
- body_pose: [N, 21, 3, 3]
- jaw_pose: [N, 1, 3, 3]
- eye_pose: [N, 2, 3, 3]
- left_hand_pose: [N, 15, 3, 3]
- right_hand_pose: [N, 15, 3, 3]
- Returns:
- vertices: [N, number of vertices, 3]
- landmarks: [N, number of landmarks (68 face keypoints), 3]
- joints: [N, number of smplx joints (145), 3]
- """
- if shape_params is None:
- batch_size = global_pose.shape[0]
- shape_params = self.shape_params.expand(batch_size, -1)
- else:
- batch_size = shape_params.shape[0]
- if expression_params is None:
- expression_params = self.expression_params.expand(batch_size, -1)
- if global_pose is None:
- global_pose = self.global_pose.unsqueeze(0).expand(batch_size, -1, -1, -1)
- if body_pose is None:
- body_pose = self.body_pose.unsqueeze(0).expand(batch_size, -1, -1, -1)
- if jaw_pose is None:
- jaw_pose = self.jaw_pose.unsqueeze(0).expand(batch_size, -1, -1, -1)
- if eye_pose is None:
- eye_pose = self.eye_pose.unsqueeze(0).expand(batch_size, -1, -1, -1)
- if left_hand_pose is None:
- left_hand_pose = self.left_hand_pose.unsqueeze(0).expand(batch_size, -1, -1, -1)
- if right_hand_pose is None:
- right_hand_pose = self.right_hand_pose.unsqueeze(0).expand(batch_size, -1, -1, -1)
-
- shape_components = torch.cat([shape_params, expression_params], dim=1)
- full_pose = torch.cat(
- [
- global_pose,
- body_pose,
- jaw_pose,
- eye_pose,
- left_hand_pose,
- right_hand_pose,
- ],
- dim=1,
- )
- template_vertices = self.v_template.unsqueeze(0).expand(batch_size, -1, -1)
- # smplx
- vertices, joints = lbs(
- shape_components,
- full_pose,
- template_vertices,
- self.shapedirs,
- self.posedirs,
- self.J_regressor,
- self.parents,
- self.lbs_weights,
- dtype=self.dtype,
- pose2rot=False,
- )
- # face dynamic landmarks
- lmk_faces_idx = self.lmk_faces_idx.unsqueeze(dim=0).expand(batch_size, -1)
- lmk_bary_coords = self.lmk_bary_coords.unsqueeze(dim=0).expand(batch_size, -1, -1)
- dyn_lmk_faces_idx, dyn_lmk_bary_coords = find_dynamic_lmk_idx_and_bcoords(
- vertices,
- full_pose,
- self.dynamic_lmk_faces_idx,
- self.dynamic_lmk_bary_coords,
- self.head_kin_chain,
- )
- lmk_faces_idx = torch.cat([lmk_faces_idx, dyn_lmk_faces_idx], 1)
- lmk_bary_coords = torch.cat([lmk_bary_coords, dyn_lmk_bary_coords], 1)
- landmarks = vertices2landmarks(vertices, self.faces_tensor, lmk_faces_idx, lmk_bary_coords)
-
- final_joint_set = [joints, landmarks]
- if hasattr(self, "extra_joint_selector"):
- # Add any extra joints that might be needed
- extra_joints = self.extra_joint_selector(vertices, self.faces_tensor)
- final_joint_set.append(extra_joints)
- # Create the final joint set
- joints = torch.cat(final_joint_set, dim=1)
- # if self.use_joint_regressor:
- # reg_joints = torch.einsum("ji,bik->bjk",
- # self.extra_joint_regressor, vertices)
- # joints[:, self.source_idxs] = reg_joints[:, self.target_idxs]
-
- return vertices, landmarks, joints
-
- def pose_abs2rel(self, global_pose, body_pose, abs_joint="head"):
- """change absolute pose to relative pose
- Basic knowledge for SMPLX kinematic tree:
- absolute pose = parent pose * relative pose
- Here, pose must be represented as rotation matrix (batch_sizexnx3x3)
- """
- if abs_joint == "head":
- # Pelvis -> Spine 1, 2, 3 -> Neck -> Head
- kin_chain = [15, 12, 9, 6, 3, 0]
- elif abs_joint == "neck":
- # Pelvis -> Spine 1, 2, 3 -> Neck -> Head
- kin_chain = [12, 9, 6, 3, 0]
- elif abs_joint == "right_wrist":
- # Pelvis -> Spine 1, 2, 3 -> right Collar -> right shoulder
- # -> right elbow -> right wrist
- kin_chain = [21, 19, 17, 14, 9, 6, 3, 0]
- elif abs_joint == "left_wrist":
- # Pelvis -> Spine 1, 2, 3 -> Left Collar -> Left shoulder
- # -> Left elbow -> Left wrist
- kin_chain = [20, 18, 16, 13, 9, 6, 3, 0]
- else:
- raise NotImplementedError(f"pose_abs2rel does not support: {abs_joint}")
-
- batch_size = global_pose.shape[0]
- dtype = global_pose.dtype
- device = global_pose.device
- full_pose = torch.cat([global_pose, body_pose], dim=1)
- rel_rot_mat = (
- torch.eye(3, device=device, dtype=dtype).unsqueeze_(dim=0).repeat(batch_size, 1, 1)
- )
- for idx in kin_chain[1:]:
- rel_rot_mat = torch.bmm(full_pose[:, idx], rel_rot_mat)
-
- # This contains the absolute pose of the parent
- abs_parent_pose = rel_rot_mat.detach()
- # Let's assume that in the input this specific joint is predicted as an absolute value
- abs_joint_pose = body_pose[:, kin_chain[0] - 1]
- # abs_head = parents(abs_neck) * rel_head ==> rel_head = abs_neck.T * abs_head
- rel_joint_pose = torch.matmul(
- abs_parent_pose.reshape(-1, 3, 3).transpose(1, 2),
- abs_joint_pose.reshape(-1, 3, 3),
- )
- # Replace the new relative pose
- body_pose[:, kin_chain[0] - 1, :, :] = rel_joint_pose
- return body_pose
-
- def pose_rel2abs(self, global_pose, body_pose, abs_joint="head"):
- """change relative pose to absolute pose
- Basic knowledge for SMPLX kinematic tree:
- absolute pose = parent pose * relative pose
- Here, pose must be represented as rotation matrix (batch_sizexnx3x3)
- """
- full_pose = torch.cat([global_pose, body_pose], dim=1)
-
- if abs_joint == "head":
- # Pelvis -> Spine 1, 2, 3 -> Neck -> Head
- kin_chain = [15, 12, 9, 6, 3, 0]
- elif abs_joint == "neck":
- # Pelvis -> Spine 1, 2, 3 -> Neck -> Head
- kin_chain = [12, 9, 6, 3, 0]
- elif abs_joint == "right_wrist":
- # Pelvis -> Spine 1, 2, 3 -> right Collar -> right shoulder
- # -> right elbow -> right wrist
- kin_chain = [21, 19, 17, 14, 9, 6, 3, 0]
- elif abs_joint == "left_wrist":
- # Pelvis -> Spine 1, 2, 3 -> Left Collar -> Left shoulder
- # -> Left elbow -> Left wrist
- kin_chain = [20, 18, 16, 13, 9, 6, 3, 0]
- else:
- raise NotImplementedError(f"pose_rel2abs does not support: {abs_joint}")
- rel_rot_mat = torch.eye(3, device=full_pose.device, dtype=full_pose.dtype).unsqueeze_(dim=0)
- for idx in kin_chain:
- rel_rot_mat = torch.matmul(full_pose[:, idx], rel_rot_mat)
- abs_pose = rel_rot_mat[:, None, :, :]
- return abs_pose
diff --git a/spaces/Yuliang/ECON/lib/pixielib/models/lbs.py b/spaces/Yuliang/ECON/lib/pixielib/models/lbs.py
deleted file mode 100644
index 7b490bd9bc79a0e252aec2df99bead814edf4195..0000000000000000000000000000000000000000
--- a/spaces/Yuliang/ECON/lib/pixielib/models/lbs.py
+++ /dev/null
@@ -1,451 +0,0 @@
-# -*- coding: utf-8 -*-
-
-# Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. (MPG) is
-# holder of all proprietary rights on this computer program.
-# You can only use this computer program if you have closed
-# a license agreement with MPG or you get the right to use the computer
-# program from someone who is authorized to grant you that right.
-# Any use of the computer program without a valid license is prohibited and
-# liable to prosecution.
-#
-# Copyright©2019 Max-Planck-Gesellschaft zur Förderung
-# der Wissenschaften e.V. (MPG). acting on behalf of its Max Planck Institute
-# for Intelligent Systems. All rights reserved.
-#
-# Contact: ps-license@tuebingen.mpg.de
-
-from __future__ import absolute_import, division, print_function
-
-import os
-
-import numpy as np
-import torch
-import torch.nn.functional as F
-import yaml
-from torch import nn
-
-
-def rot_mat_to_euler(rot_mats):
- # Calculates rotation matrix to euler angles
- # Careful for extreme cases of eular angles like [0.0, pi, 0.0]
-
- sy = torch.sqrt(rot_mats[:, 0, 0] * rot_mats[:, 0, 0] + rot_mats[:, 1, 0] * rot_mats[:, 1, 0])
- return torch.atan2(-rot_mats[:, 2, 0], sy)
-
-
-def find_dynamic_lmk_idx_and_bcoords(
- vertices,
- pose,
- dynamic_lmk_faces_idx,
- dynamic_lmk_b_coords,
- head_kin_chain,
- dtype=torch.float32,
-):
- """Compute the faces, barycentric coordinates for the dynamic landmarks
-
-
- To do so, we first compute the rotation of the neck around the y-axis
- and then use a pre-computed look-up table to find the faces and the
- barycentric coordinates that will be used.
-
- Special thanks to Soubhik Sanyal (soubhik.sanyal@tuebingen.mpg.de)
- for providing the original TensorFlow implementation and for the LUT.
-
- Parameters
- ----------
- vertices: torch.tensor BxVx3, dtype = torch.float32
- The tensor of input vertices
- pose: torch.tensor Bx(Jx3), dtype = torch.float32
- The current pose of the body model
- dynamic_lmk_faces_idx: torch.tensor L, dtype = torch.long
- The look-up table from neck rotation to faces
- dynamic_lmk_b_coords: torch.tensor Lx3, dtype = torch.float32
- The look-up table from neck rotation to barycentric coordinates
- head_kin_chain: list
- A python list that contains the indices of the joints that form the
- kinematic chain of the neck.
- dtype: torch.dtype, optional
-
- Returns
- -------
- dyn_lmk_faces_idx: torch.tensor, dtype = torch.long
- A tensor of size BxL that contains the indices of the faces that
- will be used to compute the current dynamic landmarks.
- dyn_lmk_b_coords: torch.tensor, dtype = torch.float32
- A tensor of size BxL that contains the indices of the faces that
- will be used to compute the current dynamic landmarks.
- """
-
- batch_size = vertices.shape[0]
- pose = pose.detach()
- # aa_pose = torch.index_select(pose.view(batch_size, -1, 3), 1,
- # head_kin_chain)
- # rot_mats = batch_rodrigues(
- # aa_pose.view(-1, 3), dtype=dtype).view(batch_size, -1, 3, 3)
- rot_mats = torch.index_select(pose, 1, head_kin_chain)
-
- rel_rot_mat = torch.eye(3, device=vertices.device, dtype=dtype).unsqueeze_(dim=0)
- for idx in range(len(head_kin_chain)):
- # rel_rot_mat = torch.bmm(rot_mats[:, idx], rel_rot_mat)
- rel_rot_mat = torch.matmul(rot_mats[:, idx], rel_rot_mat)
-
- y_rot_angle = torch.round(torch.clamp(-rot_mat_to_euler(rel_rot_mat) * 180.0 / np.pi,
- max=39)).to(dtype=torch.long)
- # print(y_rot_angle[0])
- neg_mask = y_rot_angle.lt(0).to(dtype=torch.long)
- mask = y_rot_angle.lt(-39).to(dtype=torch.long)
- neg_vals = mask * 78 + (1 - mask) * (39 - y_rot_angle)
- y_rot_angle = neg_mask * neg_vals + (1 - neg_mask) * y_rot_angle
- # print(y_rot_angle[0])
-
- dyn_lmk_faces_idx = torch.index_select(dynamic_lmk_faces_idx, 0, y_rot_angle)
- dyn_lmk_b_coords = torch.index_select(dynamic_lmk_b_coords, 0, y_rot_angle)
-
- return dyn_lmk_faces_idx, dyn_lmk_b_coords
-
-
-def vertices2landmarks(vertices, faces, lmk_faces_idx, lmk_bary_coords):
- """Calculates landmarks by barycentric interpolation
-
- Parameters
- ----------
- vertices: torch.tensor BxVx3, dtype = torch.float32
- The tensor of input vertices
- faces: torch.tensor Fx3, dtype = torch.long
- The faces of the mesh
- lmk_faces_idx: torch.tensor L, dtype = torch.long
- The tensor with the indices of the faces used to calculate the
- landmarks.
- lmk_bary_coords: torch.tensor Lx3, dtype = torch.float32
- The tensor of barycentric coordinates that are used to interpolate
- the landmarks
-
- Returns
- -------
- landmarks: torch.tensor BxLx3, dtype = torch.float32
- The coordinates of the landmarks for each mesh in the batch
- """
- # Extract the indices of the vertices for each face
- # BxLx3
- batch_size, num_verts = vertices.shape[:2]
- device = vertices.device
-
- lmk_faces = torch.index_select(faces, 0, lmk_faces_idx.view(-1)).view(batch_size, -1, 3)
-
- lmk_faces += (
- torch.arange(batch_size, dtype=torch.long, device=device).view(-1, 1, 1) * num_verts
- )
-
- lmk_vertices = vertices.view(-1, 3)[lmk_faces].view(batch_size, -1, 3, 3)
-
- landmarks = torch.einsum("blfi,blf->bli", [lmk_vertices, lmk_bary_coords])
- return landmarks
-
-
-def lbs(
- betas,
- pose,
- v_template,
- shapedirs,
- posedirs,
- J_regressor,
- parents,
- lbs_weights,
- pose2rot=True,
- dtype=torch.float32,
-):
- """Performs Linear Blend Skinning with the given shape and pose parameters
-
- Parameters
- ----------
- betas : torch.tensor BxNB
- The tensor of shape parameters
- pose : torch.tensor Bx(J + 1) * 3
- The pose parameters in axis-angle format
- v_template torch.tensor BxVx3
- The template mesh that will be deformed
- shapedirs : torch.tensor 1xNB
- The tensor of PCA shape displacements
- posedirs : torch.tensor Px(V * 3)
- The pose PCA coefficients
- J_regressor : torch.tensor JxV
- The regressor array that is used to calculate the joints from
- the position of the vertices
- parents: torch.tensor J
- The array that describes the kinematic tree for the model
- lbs_weights: torch.tensor N x V x (J + 1)
- The linear blend skinning weights that represent how much the
- rotation matrix of each part affects each vertex
- pose2rot: bool, optional
- Flag on whether to convert the input pose tensor to rotation
- matrices. The default value is True. If False, then the pose tensor
- should already contain rotation matrices and have a size of
- Bx(J + 1)x9
- dtype: torch.dtype, optional
-
- Returns
- -------
- verts: torch.tensor BxVx3
- The vertices of the mesh after applying the shape and pose
- displacements.
- joints: torch.tensor BxJx3
- The joints of the model
- """
-
- batch_size = max(betas.shape[0], pose.shape[0])
- device = betas.device
-
- # Add shape contribution
- v_shaped = v_template + blend_shapes(betas, shapedirs)
-
- # Get the joints
- # NxJx3 array
- J = vertices2joints(J_regressor, v_shaped)
-
- # 3. Add pose blend shapes
- # N x J x 3 x 3
- ident = torch.eye(3, dtype=dtype, device=device)
- if pose2rot:
- rot_mats = batch_rodrigues(pose.view(-1, 3), dtype=dtype).view([batch_size, -1, 3, 3])
-
- pose_feature = (rot_mats[:, 1:, :, :] - ident).view([batch_size, -1])
- # (N x P) x (P, V * 3) -> N x V x 3
- pose_offsets = torch.matmul(pose_feature, posedirs).view(batch_size, -1, 3)
- else:
- pose_feature = pose[:, 1:].view(batch_size, -1, 3, 3) - ident
- rot_mats = pose.view(batch_size, -1, 3, 3)
-
- pose_offsets = torch.matmul(pose_feature.view(batch_size, -1),
- posedirs).view(batch_size, -1, 3)
-
- v_posed = pose_offsets + v_shaped
- # 4. Get the global joint location
- J_transformed, A = batch_rigid_transform(rot_mats, J, parents, dtype=dtype)
-
- # 5. Do skinning:
- # W is N x V x (J + 1)
- W = lbs_weights.unsqueeze(dim=0).expand([batch_size, -1, -1])
- # (N x V x (J + 1)) x (N x (J + 1) x 16)
- num_joints = J_regressor.shape[0]
- T = torch.matmul(W, A.view(batch_size, num_joints, 16)).view(batch_size, -1, 4, 4)
-
- homogen_coord = torch.ones([batch_size, v_posed.shape[1], 1], dtype=dtype, device=device)
- v_posed_homo = torch.cat([v_posed, homogen_coord], dim=2)
- v_homo = torch.matmul(T, torch.unsqueeze(v_posed_homo, dim=-1))
-
- verts = v_homo[:, :, :3, 0]
-
- return verts, J_transformed
-
-
-def vertices2joints(J_regressor, vertices):
- """Calculates the 3D joint locations from the vertices
-
- Parameters
- ----------
- J_regressor : torch.tensor JxV
- The regressor array that is used to calculate the joints from the
- position of the vertices
- vertices : torch.tensor BxVx3
- The tensor of mesh vertices
-
- Returns
- -------
- torch.tensor BxJx3
- The location of the joints
- """
-
- return torch.einsum("bik,ji->bjk", [vertices, J_regressor])
-
-
-def blend_shapes(betas, shape_disps):
- """Calculates the per vertex displacement due to the blend shapes
-
-
- Parameters
- ----------
- betas : torch.tensor Bx(num_betas)
- Blend shape coefficients
- shape_disps: torch.tensor Vx3x(num_betas)
- Blend shapes
-
- Returns
- -------
- torch.tensor BxVx3
- The per-vertex displacement due to shape deformation
- """
-
- # Displacement[b, m, k] = sum_{l} betas[b, l] * shape_disps[m, k, l]
- # i.e. Multiply each shape displacement by its corresponding beta and
- # then sum them.
- blend_shape = torch.einsum("bl,mkl->bmk", [betas, shape_disps])
- return blend_shape
-
-
-def batch_rodrigues(rot_vecs, epsilon=1e-8, dtype=torch.float32):
- """Calculates the rotation matrices for a batch of rotation vectors
- Parameters
- ----------
- rot_vecs: torch.tensor Nx3
- array of N axis-angle vectors
- Returns
- -------
- R: torch.tensor Nx3x3
- The rotation matrices for the given axis-angle parameters
- """
-
- batch_size = rot_vecs.shape[0]
- device = rot_vecs.device
-
- angle = torch.norm(rot_vecs + 1e-8, dim=1, keepdim=True)
- rot_dir = rot_vecs / angle
-
- cos = torch.unsqueeze(torch.cos(angle), dim=1)
- sin = torch.unsqueeze(torch.sin(angle), dim=1)
-
- # Bx1 arrays
- rx, ry, rz = torch.split(rot_dir, 1, dim=1)
- K = torch.zeros((batch_size, 3, 3), dtype=dtype, device=device)
-
- zeros = torch.zeros((batch_size, 1), dtype=dtype, device=device)
- K = torch.cat([zeros, -rz, ry, rz, zeros, -rx, -ry, rx, zeros], dim=1).view((batch_size, 3, 3))
-
- ident = torch.eye(3, dtype=dtype, device=device).unsqueeze(dim=0)
- rot_mat = ident + sin * K + (1 - cos) * torch.bmm(K, K)
- return rot_mat
-
-
-def transform_mat(R, t):
- """Creates a batch of transformation matrices
- Args:
- - R: Bx3x3 array of a batch of rotation matrices
- - t: Bx3x1 array of a batch of translation vectors
- Returns:
- - T: Bx4x4 Transformation matrix
- """
- # No padding left or right, only add an extra row
- return torch.cat([F.pad(R, [0, 0, 0, 1]), F.pad(t, [0, 0, 0, 1], value=1)], dim=2)
-
-
-def batch_rigid_transform(rot_mats, joints, parents, dtype=torch.float32):
- """
- Applies a batch of rigid transformations to the joints
-
- Parameters
- ----------
- rot_mats : torch.tensor BxNx3x3
- Tensor of rotation matrices
- joints : torch.tensor BxNx3
- Locations of joints
- parents : torch.tensor BxN
- The kinematic tree of each object
- dtype : torch.dtype, optional:
- The data type of the created tensors, the default is torch.float32
-
- Returns
- -------
- posed_joints : torch.tensor BxNx3
- The locations of the joints after applying the pose rotations
- rel_transforms : torch.tensor BxNx4x4
- The relative (with respect to the root joint) rigid transformations
- for all the joints
- """
-
- joints = torch.unsqueeze(joints, dim=-1)
-
- rel_joints = joints.clone()
- rel_joints[:, 1:] -= joints[:, parents[1:]]
-
- transforms_mat = transform_mat(rot_mats.reshape(-1, 3, 3),
- rel_joints.reshape(-1, 3, 1)).reshape(-1, joints.shape[1], 4, 4)
-
- transform_chain = [transforms_mat[:, 0]]
- for i in range(1, parents.shape[0]):
- # Subtract the joint location at the rest pose
- # No need for rotation, since it's identity when at rest
- curr_res = torch.matmul(transform_chain[parents[i]], transforms_mat[:, i])
- transform_chain.append(curr_res)
-
- transforms = torch.stack(transform_chain, dim=1)
-
- # The last column of the transformations contains the posed joints
- posed_joints = transforms[:, :, :3, 3]
-
- # # The last column of the transformations contains the posed joints
- # posed_joints = transforms[:, :, :3, 3]
-
- joints_homogen = F.pad(joints, [0, 0, 0, 1])
-
- rel_transforms = transforms - F.pad(
- torch.matmul(transforms, joints_homogen), [3, 0, 0, 0, 0, 0, 0, 0]
- )
-
- return posed_joints, rel_transforms
-
-
-class JointsFromVerticesSelector(nn.Module):
- def __init__(self, fname):
- """Selects extra joints from vertices"""
- super(JointsFromVerticesSelector, self).__init__()
-
- err_msg = ("Either pass a filename or triangle face ids, names and"
- " barycentrics")
- assert fname is not None or (
- face_ids is not None and bcs is not None and names is not None
- ), err_msg
- if fname is not None:
- fname = os.path.expanduser(os.path.expandvars(fname))
- with open(fname, "r") as f:
- data = yaml.safe_load(f)
- names = list(data.keys())
- bcs = []
- face_ids = []
- for name, d in data.items():
- face_ids.append(d["face"])
- bcs.append(d["bc"])
- bcs = np.array(bcs, dtype=np.float32)
- face_ids = np.array(face_ids, dtype=np.int32)
- assert len(bcs) == len(
- face_ids
- ), "The number of barycentric coordinates must be equal to the faces"
- assert len(names) == len(face_ids), "The number of names must be equal to the number of "
-
- self.names = names
- self.register_buffer("bcs", torch.tensor(bcs, dtype=torch.float32))
- self.register_buffer("face_ids", torch.tensor(face_ids, dtype=torch.long))
-
- def extra_joint_names(self):
- """Returns the names of the extra joints"""
- return self.names
-
- def forward(self, vertices, faces):
- if len(self.face_ids) < 1:
- return []
- vertex_ids = faces[self.face_ids].reshape(-1)
- # Should be BxNx3x3
- triangles = torch.index_select(vertices, 1, vertex_ids).reshape(-1, len(self.bcs), 3, 3)
- return (triangles * self.bcs[None, :, :, None]).sum(dim=2)
-
-
-# def to_tensor(array, dtype=torch.float32):
-# if torch.is_tensor(array):
-# return array
-# else:
-# return torch.tensor(array, dtype=dtype)
-
-
-def to_tensor(array, dtype=torch.float32):
- if "torch.tensor" not in str(type(array)):
- return torch.tensor(array, dtype=dtype)
-
-
-def to_np(array, dtype=np.float32):
- if "scipy.sparse" in str(type(array)):
- array = array.todense()
- return np.array(array, dtype=dtype)
-
-
-class Struct(object):
- def __init__(self, **kwargs):
- for key, val in kwargs.items():
- setattr(self, key, val)
diff --git a/spaces/Yuzu22/rvc-models/infer_pack/commons.py b/spaces/Yuzu22/rvc-models/infer_pack/commons.py
deleted file mode 100644
index 54470986f37825b35d90d7efa7437d1c26b87215..0000000000000000000000000000000000000000
--- a/spaces/Yuzu22/rvc-models/infer_pack/commons.py
+++ /dev/null
@@ -1,166 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size * dilation - dilation) / 2)
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def kl_divergence(m_p, logs_p, m_q, logs_q):
- """KL(P||Q)"""
- kl = (logs_q - logs_p) - 0.5
- kl += (
- 0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
- )
- return kl
-
-
-def rand_gumbel(shape):
- """Sample from the Gumbel distribution, protect from overflows."""
- uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
- return -torch.log(-torch.log(uniform_samples))
-
-
-def rand_gumbel_like(x):
- g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
- return g
-
-
-def slice_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, :, idx_str:idx_end]
- return ret
-
-
-def slice_segments2(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, idx_str:idx_end]
- return ret
-
-
-def rand_slice_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
- position = torch.arange(length, dtype=torch.float)
- num_timescales = channels // 2
- log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
- num_timescales - 1
- )
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
- )
- scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
- signal = F.pad(signal, [0, 0, 0, channels % 2])
- signal = signal.view(1, channels, length)
- return signal
-
-
-def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return x + signal.to(dtype=x.dtype, device=x.device)
-
-
-def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
-
-
-def subsequent_mask(length):
- mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
- return mask
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a + input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def shift_1d(x):
- x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
- return x
-
-
-def sequence_mask(length, max_length=None):
- if max_length is None:
- max_length = length.max()
- x = torch.arange(max_length, dtype=length.dtype, device=length.device)
- return x.unsqueeze(0) < length.unsqueeze(1)
-
-
-def generate_path(duration, mask):
- """
- duration: [b, 1, t_x]
- mask: [b, 1, t_y, t_x]
- """
- device = duration.device
-
- b, _, t_y, t_x = mask.shape
- cum_duration = torch.cumsum(duration, -1)
-
- cum_duration_flat = cum_duration.view(b * t_x)
- path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
- path = path.view(b, t_x, t_y)
- path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
- path = path.unsqueeze(1).transpose(2, 3) * mask
- return path
-
-
-def clip_grad_value_(parameters, clip_value, norm_type=2):
- if isinstance(parameters, torch.Tensor):
- parameters = [parameters]
- parameters = list(filter(lambda p: p.grad is not None, parameters))
- norm_type = float(norm_type)
- if clip_value is not None:
- clip_value = float(clip_value)
-
- total_norm = 0
- for p in parameters:
- param_norm = p.grad.data.norm(norm_type)
- total_norm += param_norm.item() ** norm_type
- if clip_value is not None:
- p.grad.data.clamp_(min=-clip_value, max=clip_value)
- total_norm = total_norm ** (1.0 / norm_type)
- return total_norm
diff --git a/spaces/Zengyf-CVer/color_generator/README.md b/spaces/Zengyf-CVer/color_generator/README.md
deleted file mode 100644
index 0c48af4385bbdf7ba9818b7baa9e5f719dd7db5c..0000000000000000000000000000000000000000
--- a/spaces/Zengyf-CVer/color_generator/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Color Switch
-emoji: 📚
-colorFrom: indigo
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.1.1
-app_file: app.py
-pinned: false
-license: gpl-3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/abdvl/datahub_qa_bot/docs/managed-datahub/approval-workflows.md b/spaces/abdvl/datahub_qa_bot/docs/managed-datahub/approval-workflows.md
deleted file mode 100644
index 3853a7c37817fdd4f9e9a37a23fa7163a400dc65..0000000000000000000000000000000000000000
--- a/spaces/abdvl/datahub_qa_bot/docs/managed-datahub/approval-workflows.md
+++ /dev/null
@@ -1,193 +0,0 @@
-import FeatureAvailability from '@site/src/components/FeatureAvailability';
-
-# About DataHub Approval Workflows
-
-
-
-
-2. After proposing the Glossary Term, you will see it appear in a proposed state.
-
-
-
-
-3. This proposal will be sent to the inbox of Admins with proposal permissions and data owners.
-
-
-
-
-4. From there, they can choose to either accept or reject the proposal. A full log of all accepted or rejected proposals is kept for each user.
-
-### Proposing additions to your Business Glossary
-
-1. Navigate to your glossary by going to the Govern menu in the top right and selecting Glossary.
-
-2. Click the plus button to create a new Glossary Term. From that menu, select Propose.
-
-
-
-
-3. This proposal will be sent to the inbox of Admins with proposal permissions and data owners.
-
-
-
-
-4. From there, they can choose to either accept or reject the proposal. A full log of all accepted or rejected proposals is kept for each user.
-
-### Proposing Glossary Term Description Updates
-
-1. When updating the description of a Glossary Term, click propse after making your change.
-
-
-
-
-2. This proposal will be sent to the inbox of Admins with proposal permissions and data owners.
-
-
-
-
-3. From there, they can choose to either accept or reject the proposal.
-
-## Proposing Programatically
-
-DataHub exposes a GraphQL API for proposing Tags and Glossary Terms.
-
-At a high level, callers of this API will be required to provide the following details:
-
-1. A unique identifier for the target Metadata Entity (URN)
-2. An optional sub-resource identifier which designates a sub-resource to attach the Tag or Glossary Term to. for example reference to a particular "field" within a Dataset.
-3. A unique identifier for the Tag or Glossary Term they wish to propose (URN)
-
-In the following sections, we will describe how to construct each of these items and use the DataHub GraphQL API to submit Tag or Glossary Term proposals.
-
-#### Constructing an Entity Identifier
-
-Inside DataHub, each Metadata Entity is uniquely identified by a Universal Resource Name, or an URN. This identifier can be copied from the entity page, extracted from the API, or read from a downloaded search result. You can also use the helper methods in the datahub python library given a set of components.
-
-#### Constructing a Sub-Resource Identifier
-
-Specific Metadata Entity types have additional sub-resources to which Tags may be applied.
-Today, this only applies for Dataset Metadata Entities, which have a "fields" sub-resource. In this case, the `subResource` value would be the field path for the schema field.
-
-#### Finding a Tag or Glossary Term Identifier
-
-Tags and Glossary Terms are also uniquely identified by an URN.
-
-Tag URNs have the following format:
-`urn:li:tag:`
-
-Glossary Term URNs have the following format:
-`urn:li:glossaryTerm:`
-
-These full identifiers can be copied from the entity pages of the Tag or Glossary Term.
-
-
-
-
-#### Issuing a GraphQL Query
-
-Once we've constructed an Entity URN, any relevant sub-resource identifiers, and a Tag or Term URN, we're ready to propose! To do so, we'll use the DataHub GraphQL API.
-
-In particular, we'll be using the proposeTag, proposeGlossaryTerm, and proposeUpdateDescription Mutations, which have the following interface:
-
-```
-type Mutation {
-proposeTerm(input: TermAssociationInput!): String! # Returns Proposal URN.
-}
-
-input TermAssociationInput {
- resourceUrn: String! # Required. e.g. "urn:li:dataset:(...)"
- subResource: String # Optional. e.g. "fieldName"
- subResourceType: String # Optional. "DATASET_FIELD" for dataset fields
- term: String! # Required. e.g. "urn:li:tag:Marketing"
-}
-```
-
-```
-type Mutation {
-proposeTag(input: TagAssociationInput!): String! # Returns Proposal URN.
-}
-
-input TagAssociationInput {
- resourceUrn: String! # Required. e.g. "urn:li:dataset:(...)" subResource: String # Optional. e.g. "fieldName"
- subResourceType: String # Optional. "DATASET_FIELD" for dataset fields
- tagUrn: String! # Required. e.g. "urn:li:tag:Marketing"
-}
-```
-
-```
-mutation proposeUpdateDescription($input: DescriptionUpdateInput!) {
- proposeUpdateDescription(input: $input)
-}
-
-"""
-Currently supports updates to Glossary Term descriptions only
-"""
-input DescriptionUpdateInput {
- description: String! # the new description
-
- resourceUrn: String!
-
- subResourceType: SubResourceType
-
- subResource: String
-}
-```
-
-## Additional Resources
-
-### Permissions
-
-To create & manage metadata proposals, certain access policies or roles are required.
-
-#### Privileges for Creating Proposals
-
-To create a new proposal one of these Metadata privileges are required. All roles have these priveleges by default.
-
-- Propose Tags - Allows to propose tags at the Entity level
-- Propose Dataset Column Tags - Allows to propose tags at the Dataset Field level
-- Propose Glossary Terms - Allows to propose terms at the Entity level
-- Propose Dataset Column Glossary Terms - Allows to propose terms at the Dataset Field level
-
-To be able to see the Proposals Tab you need the "View Metadata Proposals" PLATFORM privilege
-
-#### Privileges for Managing Proposals
-
-To be able to approve or deny proposals you need one of the following Metadata privileges. `Admin` and `Editor` roles already have these by default.
-
-- Manage Tag Proposals
-- Manage Glossary Term Proposals
-- Manage Dataset Column Tag Proposals
-- Manage Dataset Column Term Proposals
-
-These map directly to the 4 privileges for doing the proposals.
-
-To be able to approve or deny proposals to the glossary itself, you just need one permission:
-- Manage Glossaries
-
-### Videos
-
-
-
-
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/ops/deform_conv.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/ops/deform_conv.py
deleted file mode 100644
index a3f8c75ee774823eea334e3b3732af6a18f55038..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/ops/deform_conv.py
+++ /dev/null
@@ -1,405 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Tuple, Union
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-from torch.autograd import Function
-from torch.autograd.function import once_differentiable
-from torch.nn.modules.utils import _pair, _single
-
-from annotator.uniformer.mmcv.utils import deprecated_api_warning
-from ..cnn import CONV_LAYERS
-from ..utils import ext_loader, print_log
-
-ext_module = ext_loader.load_ext('_ext', [
- 'deform_conv_forward', 'deform_conv_backward_input',
- 'deform_conv_backward_parameters'
-])
-
-
-class DeformConv2dFunction(Function):
-
- @staticmethod
- def symbolic(g,
- input,
- offset,
- weight,
- stride,
- padding,
- dilation,
- groups,
- deform_groups,
- bias=False,
- im2col_step=32):
- return g.op(
- 'mmcv::MMCVDeformConv2d',
- input,
- offset,
- weight,
- stride_i=stride,
- padding_i=padding,
- dilation_i=dilation,
- groups_i=groups,
- deform_groups_i=deform_groups,
- bias_i=bias,
- im2col_step_i=im2col_step)
-
- @staticmethod
- def forward(ctx,
- input,
- offset,
- weight,
- stride=1,
- padding=0,
- dilation=1,
- groups=1,
- deform_groups=1,
- bias=False,
- im2col_step=32):
- if input is not None and input.dim() != 4:
- raise ValueError(
- f'Expected 4D tensor as input, got {input.dim()}D tensor \
- instead.')
- assert bias is False, 'Only support bias is False.'
- ctx.stride = _pair(stride)
- ctx.padding = _pair(padding)
- ctx.dilation = _pair(dilation)
- ctx.groups = groups
- ctx.deform_groups = deform_groups
- ctx.im2col_step = im2col_step
-
- # When pytorch version >= 1.6.0, amp is adopted for fp16 mode;
- # amp won't cast the type of model (float32), but "offset" is cast
- # to float16 by nn.Conv2d automatically, leading to the type
- # mismatch with input (when it is float32) or weight.
- # The flag for whether to use fp16 or amp is the type of "offset",
- # we cast weight and input to temporarily support fp16 and amp
- # whatever the pytorch version is.
- input = input.type_as(offset)
- weight = weight.type_as(input)
- ctx.save_for_backward(input, offset, weight)
-
- output = input.new_empty(
- DeformConv2dFunction._output_size(ctx, input, weight))
-
- ctx.bufs_ = [input.new_empty(0), input.new_empty(0)] # columns, ones
-
- cur_im2col_step = min(ctx.im2col_step, input.size(0))
- assert (input.size(0) %
- cur_im2col_step) == 0, 'im2col step must divide batchsize'
- ext_module.deform_conv_forward(
- input,
- weight,
- offset,
- output,
- ctx.bufs_[0],
- ctx.bufs_[1],
- kW=weight.size(3),
- kH=weight.size(2),
- dW=ctx.stride[1],
- dH=ctx.stride[0],
- padW=ctx.padding[1],
- padH=ctx.padding[0],
- dilationW=ctx.dilation[1],
- dilationH=ctx.dilation[0],
- group=ctx.groups,
- deformable_group=ctx.deform_groups,
- im2col_step=cur_im2col_step)
- return output
-
- @staticmethod
- @once_differentiable
- def backward(ctx, grad_output):
- input, offset, weight = ctx.saved_tensors
-
- grad_input = grad_offset = grad_weight = None
-
- cur_im2col_step = min(ctx.im2col_step, input.size(0))
- assert (input.size(0) % cur_im2col_step
- ) == 0, 'batch size must be divisible by im2col_step'
-
- grad_output = grad_output.contiguous()
- if ctx.needs_input_grad[0] or ctx.needs_input_grad[1]:
- grad_input = torch.zeros_like(input)
- grad_offset = torch.zeros_like(offset)
- ext_module.deform_conv_backward_input(
- input,
- offset,
- grad_output,
- grad_input,
- grad_offset,
- weight,
- ctx.bufs_[0],
- kW=weight.size(3),
- kH=weight.size(2),
- dW=ctx.stride[1],
- dH=ctx.stride[0],
- padW=ctx.padding[1],
- padH=ctx.padding[0],
- dilationW=ctx.dilation[1],
- dilationH=ctx.dilation[0],
- group=ctx.groups,
- deformable_group=ctx.deform_groups,
- im2col_step=cur_im2col_step)
-
- if ctx.needs_input_grad[2]:
- grad_weight = torch.zeros_like(weight)
- ext_module.deform_conv_backward_parameters(
- input,
- offset,
- grad_output,
- grad_weight,
- ctx.bufs_[0],
- ctx.bufs_[1],
- kW=weight.size(3),
- kH=weight.size(2),
- dW=ctx.stride[1],
- dH=ctx.stride[0],
- padW=ctx.padding[1],
- padH=ctx.padding[0],
- dilationW=ctx.dilation[1],
- dilationH=ctx.dilation[0],
- group=ctx.groups,
- deformable_group=ctx.deform_groups,
- scale=1,
- im2col_step=cur_im2col_step)
-
- return grad_input, grad_offset, grad_weight, \
- None, None, None, None, None, None, None
-
- @staticmethod
- def _output_size(ctx, input, weight):
- channels = weight.size(0)
- output_size = (input.size(0), channels)
- for d in range(input.dim() - 2):
- in_size = input.size(d + 2)
- pad = ctx.padding[d]
- kernel = ctx.dilation[d] * (weight.size(d + 2) - 1) + 1
- stride_ = ctx.stride[d]
- output_size += ((in_size + (2 * pad) - kernel) // stride_ + 1, )
- if not all(map(lambda s: s > 0, output_size)):
- raise ValueError(
- 'convolution input is too small (output would be ' +
- 'x'.join(map(str, output_size)) + ')')
- return output_size
-
-
-deform_conv2d = DeformConv2dFunction.apply
-
-
-class DeformConv2d(nn.Module):
- r"""Deformable 2D convolution.
-
- Applies a deformable 2D convolution over an input signal composed of
- several input planes. DeformConv2d was described in the paper
- `Deformable Convolutional Networks
- `_
-
- Note:
- The argument ``im2col_step`` was added in version 1.3.17, which means
- number of samples processed by the ``im2col_cuda_kernel`` per call.
- It enables users to define ``batch_size`` and ``im2col_step`` more
- flexibly and solved `issue mmcv#1440
- `_.
-
- Args:
- in_channels (int): Number of channels in the input image.
- out_channels (int): Number of channels produced by the convolution.
- kernel_size(int, tuple): Size of the convolving kernel.
- stride(int, tuple): Stride of the convolution. Default: 1.
- padding (int or tuple): Zero-padding added to both sides of the input.
- Default: 0.
- dilation (int or tuple): Spacing between kernel elements. Default: 1.
- groups (int): Number of blocked connections from input.
- channels to output channels. Default: 1.
- deform_groups (int): Number of deformable group partitions.
- bias (bool): If True, adds a learnable bias to the output.
- Default: False.
- im2col_step (int): Number of samples processed by im2col_cuda_kernel
- per call. It will work when ``batch_size`` > ``im2col_step``, but
- ``batch_size`` must be divisible by ``im2col_step``. Default: 32.
- `New in version 1.3.17.`
- """
-
- @deprecated_api_warning({'deformable_groups': 'deform_groups'},
- cls_name='DeformConv2d')
- def __init__(self,
- in_channels: int,
- out_channels: int,
- kernel_size: Union[int, Tuple[int, ...]],
- stride: Union[int, Tuple[int, ...]] = 1,
- padding: Union[int, Tuple[int, ...]] = 0,
- dilation: Union[int, Tuple[int, ...]] = 1,
- groups: int = 1,
- deform_groups: int = 1,
- bias: bool = False,
- im2col_step: int = 32) -> None:
- super(DeformConv2d, self).__init__()
-
- assert not bias, \
- f'bias={bias} is not supported in DeformConv2d.'
- assert in_channels % groups == 0, \
- f'in_channels {in_channels} cannot be divisible by groups {groups}'
- assert out_channels % groups == 0, \
- f'out_channels {out_channels} cannot be divisible by groups \
- {groups}'
-
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.kernel_size = _pair(kernel_size)
- self.stride = _pair(stride)
- self.padding = _pair(padding)
- self.dilation = _pair(dilation)
- self.groups = groups
- self.deform_groups = deform_groups
- self.im2col_step = im2col_step
- # enable compatibility with nn.Conv2d
- self.transposed = False
- self.output_padding = _single(0)
-
- # only weight, no bias
- self.weight = nn.Parameter(
- torch.Tensor(out_channels, in_channels // self.groups,
- *self.kernel_size))
-
- self.reset_parameters()
-
- def reset_parameters(self):
- # switch the initialization of `self.weight` to the standard kaiming
- # method described in `Delving deep into rectifiers: Surpassing
- # human-level performance on ImageNet classification` - He, K. et al.
- # (2015), using a uniform distribution
- nn.init.kaiming_uniform_(self.weight, nonlinearity='relu')
-
- def forward(self, x: Tensor, offset: Tensor) -> Tensor:
- """Deformable Convolutional forward function.
-
- Args:
- x (Tensor): Input feature, shape (B, C_in, H_in, W_in)
- offset (Tensor): Offset for deformable convolution, shape
- (B, deform_groups*kernel_size[0]*kernel_size[1]*2,
- H_out, W_out), H_out, W_out are equal to the output's.
-
- An offset is like `[y0, x0, y1, x1, y2, x2, ..., y8, x8]`.
- The spatial arrangement is like:
-
- .. code:: text
-
- (x0, y0) (x1, y1) (x2, y2)
- (x3, y3) (x4, y4) (x5, y5)
- (x6, y6) (x7, y7) (x8, y8)
-
- Returns:
- Tensor: Output of the layer.
- """
- # To fix an assert error in deform_conv_cuda.cpp:128
- # input image is smaller than kernel
- input_pad = (x.size(2) < self.kernel_size[0]) or (x.size(3) <
- self.kernel_size[1])
- if input_pad:
- pad_h = max(self.kernel_size[0] - x.size(2), 0)
- pad_w = max(self.kernel_size[1] - x.size(3), 0)
- x = F.pad(x, (0, pad_w, 0, pad_h), 'constant', 0).contiguous()
- offset = F.pad(offset, (0, pad_w, 0, pad_h), 'constant', 0)
- offset = offset.contiguous()
- out = deform_conv2d(x, offset, self.weight, self.stride, self.padding,
- self.dilation, self.groups, self.deform_groups,
- False, self.im2col_step)
- if input_pad:
- out = out[:, :, :out.size(2) - pad_h, :out.size(3) -
- pad_w].contiguous()
- return out
-
- def __repr__(self):
- s = self.__class__.__name__
- s += f'(in_channels={self.in_channels},\n'
- s += f'out_channels={self.out_channels},\n'
- s += f'kernel_size={self.kernel_size},\n'
- s += f'stride={self.stride},\n'
- s += f'padding={self.padding},\n'
- s += f'dilation={self.dilation},\n'
- s += f'groups={self.groups},\n'
- s += f'deform_groups={self.deform_groups},\n'
- # bias is not supported in DeformConv2d.
- s += 'bias=False)'
- return s
-
-
-@CONV_LAYERS.register_module('DCN')
-class DeformConv2dPack(DeformConv2d):
- """A Deformable Conv Encapsulation that acts as normal Conv layers.
-
- The offset tensor is like `[y0, x0, y1, x1, y2, x2, ..., y8, x8]`.
- The spatial arrangement is like:
-
- .. code:: text
-
- (x0, y0) (x1, y1) (x2, y2)
- (x3, y3) (x4, y4) (x5, y5)
- (x6, y6) (x7, y7) (x8, y8)
-
- Args:
- in_channels (int): Same as nn.Conv2d.
- out_channels (int): Same as nn.Conv2d.
- kernel_size (int or tuple[int]): Same as nn.Conv2d.
- stride (int or tuple[int]): Same as nn.Conv2d.
- padding (int or tuple[int]): Same as nn.Conv2d.
- dilation (int or tuple[int]): Same as nn.Conv2d.
- groups (int): Same as nn.Conv2d.
- bias (bool or str): If specified as `auto`, it will be decided by the
- norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
- False.
- """
-
- _version = 2
-
- def __init__(self, *args, **kwargs):
- super(DeformConv2dPack, self).__init__(*args, **kwargs)
- self.conv_offset = nn.Conv2d(
- self.in_channels,
- self.deform_groups * 2 * self.kernel_size[0] * self.kernel_size[1],
- kernel_size=self.kernel_size,
- stride=_pair(self.stride),
- padding=_pair(self.padding),
- dilation=_pair(self.dilation),
- bias=True)
- self.init_offset()
-
- def init_offset(self):
- self.conv_offset.weight.data.zero_()
- self.conv_offset.bias.data.zero_()
-
- def forward(self, x):
- offset = self.conv_offset(x)
- return deform_conv2d(x, offset, self.weight, self.stride, self.padding,
- self.dilation, self.groups, self.deform_groups,
- False, self.im2col_step)
-
- def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
- missing_keys, unexpected_keys, error_msgs):
- version = local_metadata.get('version', None)
-
- if version is None or version < 2:
- # the key is different in early versions
- # In version < 2, DeformConvPack loads previous benchmark models.
- if (prefix + 'conv_offset.weight' not in state_dict
- and prefix[:-1] + '_offset.weight' in state_dict):
- state_dict[prefix + 'conv_offset.weight'] = state_dict.pop(
- prefix[:-1] + '_offset.weight')
- if (prefix + 'conv_offset.bias' not in state_dict
- and prefix[:-1] + '_offset.bias' in state_dict):
- state_dict[prefix +
- 'conv_offset.bias'] = state_dict.pop(prefix[:-1] +
- '_offset.bias')
-
- if version is not None and version > 1:
- print_log(
- f'DeformConv2dPack {prefix.rstrip(".")} is upgraded to '
- 'version 2.',
- logger='root')
-
- super()._load_from_state_dict(state_dict, prefix, local_metadata,
- strict, missing_keys, unexpected_keys,
- error_msgs)
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/retina_head.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/retina_head.py
deleted file mode 100644
index b12416fa8332f02b9a04bbfc7926f6d13875e61b..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/retina_head.py
+++ /dev/null
@@ -1,114 +0,0 @@
-import torch.nn as nn
-from mmcv.cnn import ConvModule, bias_init_with_prob, normal_init
-
-from ..builder import HEADS
-from .anchor_head import AnchorHead
-
-
-@HEADS.register_module()
-class RetinaHead(AnchorHead):
- r"""An anchor-based head used in `RetinaNet
- `_.
-
- The head contains two subnetworks. The first classifies anchor boxes and
- the second regresses deltas for the anchors.
-
- Example:
- >>> import torch
- >>> self = RetinaHead(11, 7)
- >>> x = torch.rand(1, 7, 32, 32)
- >>> cls_score, bbox_pred = self.forward_single(x)
- >>> # Each anchor predicts a score for each class except background
- >>> cls_per_anchor = cls_score.shape[1] / self.num_anchors
- >>> box_per_anchor = bbox_pred.shape[1] / self.num_anchors
- >>> assert cls_per_anchor == (self.num_classes)
- >>> assert box_per_anchor == 4
- """
-
- def __init__(self,
- num_classes,
- in_channels,
- stacked_convs=4,
- conv_cfg=None,
- norm_cfg=None,
- anchor_generator=dict(
- type='AnchorGenerator',
- octave_base_scale=4,
- scales_per_octave=3,
- ratios=[0.5, 1.0, 2.0],
- strides=[8, 16, 32, 64, 128]),
- **kwargs):
- self.stacked_convs = stacked_convs
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- super(RetinaHead, self).__init__(
- num_classes,
- in_channels,
- anchor_generator=anchor_generator,
- **kwargs)
-
- def _init_layers(self):
- """Initialize layers of the head."""
- self.relu = nn.ReLU(inplace=True)
- self.cls_convs = nn.ModuleList()
- self.reg_convs = nn.ModuleList()
- for i in range(self.stacked_convs):
- chn = self.in_channels if i == 0 else self.feat_channels
- self.cls_convs.append(
- ConvModule(
- chn,
- self.feat_channels,
- 3,
- stride=1,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg))
- self.reg_convs.append(
- ConvModule(
- chn,
- self.feat_channels,
- 3,
- stride=1,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg))
- self.retina_cls = nn.Conv2d(
- self.feat_channels,
- self.num_anchors * self.cls_out_channels,
- 3,
- padding=1)
- self.retina_reg = nn.Conv2d(
- self.feat_channels, self.num_anchors * 4, 3, padding=1)
-
- def init_weights(self):
- """Initialize weights of the head."""
- for m in self.cls_convs:
- normal_init(m.conv, std=0.01)
- for m in self.reg_convs:
- normal_init(m.conv, std=0.01)
- bias_cls = bias_init_with_prob(0.01)
- normal_init(self.retina_cls, std=0.01, bias=bias_cls)
- normal_init(self.retina_reg, std=0.01)
-
- def forward_single(self, x):
- """Forward feature of a single scale level.
-
- Args:
- x (Tensor): Features of a single scale level.
-
- Returns:
- tuple:
- cls_score (Tensor): Cls scores for a single scale level
- the channels number is num_anchors * num_classes.
- bbox_pred (Tensor): Box energies / deltas for a single scale
- level, the channels number is num_anchors * 4.
- """
- cls_feat = x
- reg_feat = x
- for cls_conv in self.cls_convs:
- cls_feat = cls_conv(cls_feat)
- for reg_conv in self.reg_convs:
- reg_feat = reg_conv(reg_feat)
- cls_score = self.retina_cls(cls_feat)
- bbox_pred = self.retina_reg(reg_feat)
- return cls_score, bbox_pred
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/models/losses/accuracy.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/models/losses/accuracy.py
deleted file mode 100644
index c0fd2e7e74a0f721c4a814c09d6e453e5956bb38..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/models/losses/accuracy.py
+++ /dev/null
@@ -1,78 +0,0 @@
-import torch.nn as nn
-
-
-def accuracy(pred, target, topk=1, thresh=None):
- """Calculate accuracy according to the prediction and target.
-
- Args:
- pred (torch.Tensor): The model prediction, shape (N, num_class, ...)
- target (torch.Tensor): The target of each prediction, shape (N, , ...)
- topk (int | tuple[int], optional): If the predictions in ``topk``
- matches the target, the predictions will be regarded as
- correct ones. Defaults to 1.
- thresh (float, optional): If not None, predictions with scores under
- this threshold are considered incorrect. Default to None.
-
- Returns:
- float | tuple[float]: If the input ``topk`` is a single integer,
- the function will return a single float as accuracy. If
- ``topk`` is a tuple containing multiple integers, the
- function will return a tuple containing accuracies of
- each ``topk`` number.
- """
- assert isinstance(topk, (int, tuple))
- if isinstance(topk, int):
- topk = (topk, )
- return_single = True
- else:
- return_single = False
-
- maxk = max(topk)
- if pred.size(0) == 0:
- accu = [pred.new_tensor(0.) for i in range(len(topk))]
- return accu[0] if return_single else accu
- assert pred.ndim == target.ndim + 1
- assert pred.size(0) == target.size(0)
- assert maxk <= pred.size(1), \
- f'maxk {maxk} exceeds pred dimension {pred.size(1)}'
- pred_value, pred_label = pred.topk(maxk, dim=1)
- # transpose to shape (maxk, N, ...)
- pred_label = pred_label.transpose(0, 1)
- correct = pred_label.eq(target.unsqueeze(0).expand_as(pred_label))
- if thresh is not None:
- # Only prediction values larger than thresh are counted as correct
- correct = correct & (pred_value > thresh).t()
- res = []
- for k in topk:
- correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
- res.append(correct_k.mul_(100.0 / target.numel()))
- return res[0] if return_single else res
-
-
-class Accuracy(nn.Module):
- """Accuracy calculation module."""
-
- def __init__(self, topk=(1, ), thresh=None):
- """Module to calculate the accuracy.
-
- Args:
- topk (tuple, optional): The criterion used to calculate the
- accuracy. Defaults to (1,).
- thresh (float, optional): If not None, predictions with scores
- under this threshold are considered incorrect. Default to None.
- """
- super().__init__()
- self.topk = topk
- self.thresh = thresh
-
- def forward(self, pred, target):
- """Forward function to calculate accuracy.
-
- Args:
- pred (torch.Tensor): Prediction of models.
- target (torch.Tensor): Target for each prediction.
-
- Returns:
- tuple[float]: The accuracies under different topk criterions.
- """
- return accuracy(pred, target, self.topk, self.thresh)
diff --git a/spaces/ahmedghani/Editing-Tools/image_inpainting.py b/spaces/ahmedghani/Editing-Tools/image_inpainting.py
deleted file mode 100644
index 69cd7be853ffd90a2de15361560a4af45a4a908f..0000000000000000000000000000000000000000
--- a/spaces/ahmedghani/Editing-Tools/image_inpainting.py
+++ /dev/null
@@ -1,26 +0,0 @@
-import os
-import torch
-from PIL import Image
-from diffusers import StableDiffusionInpaintPipeline
-from diffusers import AutoencoderKL
-
-device = "cuda" if torch.cuda.is_available() else "cpu"
-
-pipe = StableDiffusionInpaintPipeline.from_pretrained("stabilityai/stable-diffusion-2-inpainting",
- torch_dtype=torch.float16,
- revision="fp16",
- vae=AutoencoderKL.from_pretrained(
- "stabilityai/sd-vae-ft-mse",
- torch_dtype=torch.float16
- ).to(device)
- ).to(device)
-pipe.enable_xformers_memory_efficient_attention()
-
-os.makedirs("inpainting_output", exist_ok=True)
-
-def inpaint(inputs, prompt):
- image = inputs["image"].resize((image.size[0] - image.size[0] % 64, image.size[1] - image.size[1] % 64), Image.ANTIALIAS)
- mask = inputs["mask"].resize((mask.size[0] - mask.size[0] % 64, mask.size[1] - mask.size[1] % 64), Image.ANTIALIAS)
- output = pipe(prompt=prompt, image=image, mask_image=mask, guidance_scale=7.5, height=image.size[1], width=image.size[0])
- output.images[0].save(f"inpainting_output/output.png")
- return output.images[0], "inpainting_output/output.png"
diff --git a/spaces/aidealab/interior-ai/explanation.py b/spaces/aidealab/interior-ai/explanation.py
deleted file mode 100644
index 37bbd870df576077aca1de0cdc03d09621a034e6..0000000000000000000000000000000000000000
--- a/spaces/aidealab/interior-ai/explanation.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import streamlit as st
-
-def make_inpainting_explanation():
- with st.expander("Explanation inpainting", expanded=False):
- st.write("In the inpainting mode, you can draw regions on the input image that you want to regenerate. "
- "This can be useful to remove unwanted objects from the image or to improve the consistency of the image."
- )
- st.image("content/inpainting_sidebar.png", caption="Image before inpainting, note the ornaments on the wall", width=500)
- st.write("You can find drawing options in the sidebar. There are two modes: freedraw and polygon. Freedraw allows the user to draw with a pencil of a certain width. "
- "Polygon allows the user to draw a polygon by clicking on the image to add a point. The polygon is closed by right clicking.")
-
- st.write("### Example inpainting")
- st.write("In the example below, the ornaments on the wall are removed. The inpainting is done by drawing a mask on the image.")
- st.image("content/inpainting_before.jpg", caption="Image before inpainting, note the ornaments on the wall")
- st.image("content/inpainting_after.png", caption="Image before inpainting, note the ornaments on the wall")
-
-def make_regeneration_explanation():
- with st.expander("Explanation object regeneration"):
- st.write("In this object regeneration mode, the model calculates which objects occur in the image. "
- "The user can then select which objects can be regenerated by the controlnet model by adding them in the multiselect box. "
- "All the object classes that are not selected will remain the same as in the original image."
- )
- st.write("### Example object regeneration")
- st.write("In the example below, the room consists of various objects such as wall, ceiling, floor, lamp, bed, ... "
- "In the multiselect box, all the objects except for 'lamp', 'bed and 'table' are selected to be regenerated. "
- )
- st.image("content/regen_example.png", caption="Room where all concepts except for 'bed', 'lamp', 'table' are regenerated")
-
-def make_segmentation_explanation():
- with st.expander("Segmentation mode", expanded=False):
- st.write("In the segmentation mode, the user can use his imagination and the paint brush to place concepts in the image. "
- "In the left sidebar, you can first find the high level category of the concept you want to add, such as 'lighting', 'floor', .. "
- "After selecting the category, you can select the specific concept you want to add in the 'Choose a color' dropdown. "
- "This will change the color of the paint brush, which you can then use to draw on the input image. "
- "The model will then regenerate the image with the concepts you have drawn and leave the rest of the image unchanged. "
- )
- st.image("content/sidebar segmentation.png", caption="Sidebar with segmentation options", width=300)
- st.write("You can choose the freedraw mode which gives you a pencil of a certain (chosen) width or the polygon mode. With the polygon mode you can click to add a point to the polygon and close the polygon by right clicking. ")
- st.write("Important: "
- "it's not easy to draw a good segmentation mask. This is because you need to keep in mind the perspective of the room and the exact "
- "shape of the object you want to draw within this perspective. Controlnet will follow your segmentation mask pretty well, so "
- "a non-natural object shape will sometimes result in weird outputs. However, give it a try and see what you can do! "
- )
- st.image("content/segmentation window.png", caption="Example of a segmentation mask drawn on the input image to add a window to the room")
- st.write("Tip: ")
- st.write("In the concepts dropdown, you can select 'keep background' (which is a white color). Everything drawn in this color will use "
- "the original underlying segmentation mask. This can be useful to help with generating other objects, since you give the model a some "
- "freedom to generate outside the object borders."
- )
- st.image("content/keep background 1.png", caption="Image with a poster drawn on the wall.")
- st.image("content/keep background 2.png", caption="Image with a poster drawn on the wall surrounded by 'keep background'.")
diff --git a/spaces/akbojda/aquarium-object-detection/README.md b/spaces/akbojda/aquarium-object-detection/README.md
deleted file mode 100644
index 0eddc4d0fbdf68ce1d914f7da3ae541d83181ee2..0000000000000000000000000000000000000000
--- a/spaces/akbojda/aquarium-object-detection/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Aquarium Object Detection
-emoji: 🦀
-colorFrom: pink
-colorTo: blue
-sdk: gradio
-sdk_version: 3.33.1
-app_file: app.py
-pinned: false
-license: cc-by-4.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/akhaliq/Detic/datasets/README.md b/spaces/akhaliq/Detic/datasets/README.md
deleted file mode 100644
index aadb3133e8c9a5345e137c5736485109c1a107db..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Detic/datasets/README.md
+++ /dev/null
@@ -1,207 +0,0 @@
-# Prepare datasets for Detic
-
-The basic training of our model uses [LVIS](https://www.lvisdataset.org/) (which uses [COCO](https://cocodataset.org/) images) and [ImageNet-21K](https://www.image-net.org/download.php).
-Some models are trained on [Conceptual Caption (CC3M)](https://ai.google.com/research/ConceptualCaptions/).
-Optionally, we use [Objects365](https://www.objects365.org/) and [OpenImages (Challenge 2019 version)](https://storage.googleapis.com/openimages/web/challenge2019.html) for cross-dataset evaluation.
-Before starting processing, please download the (selected) datasets from the official websites and place or sim-link them under `$Detic_ROOT/datasets/`.
-
-```
-$Detic_ROOT/datasets/
- metadata/
- lvis/
- coco/
- imagenet/
- cc3m/
- objects365/
- oid/
-```
-`metadata/` is our preprocessed meta-data (included in the repo). See the below [section](#Metadata) for details.
-Please follow the following instruction to pre-process individual datasets.
-
-### COCO and LVIS
-
-First, download COCO and LVIS data place them in the following way:
-
-```
-lvis/
- lvis_v1_train.json
- lvis_v1_val.json
-coco/
- train2017/
- val2017/
- annotations/
- captions_train2017.json
- instances_train2017.json
- instances_val2017.json
-```
-
-Next, prepare the open-vocabulary LVIS training set using
-
-```
-python tools/remove_lvis_rare.py --ann datasets/lvis/lvis_v1_train.json
-```
-
-This will generate `datasets/lvis/lvis_v1_train_norare.json`.
-
-### ImageNet-21K
-
-The ImageNet-21K folder should look like:
-```
-imagenet/
- ImageNet-21K/
- n01593028.tar
- n01593282.tar
- ...
-```
-
-We first unzip the overlapping classes of LVIS (we will directly work with the .tar file for the rest classes) and convert them into LVIS annotation format.
-
-~~~
-mkdir imagenet/annotations
-python tools/unzip_imagenet_lvis.py --dst_path datasets/imagenet/ImageNet-LVIS
-python tools/create_imagenetlvis_json.py --imagenet_path datasets/imagenet/ImageNet-LVIS --out_path datasets/imagenet/annotations/imagenet_lvis_image_info.json
-~~~
-This creates `datasets/imagenet/annotations/imagenet_lvis_image_info.json`.
-
-[Optional] To train with all the 21K classes, run
-
-~~~
-python tools/get_imagenet_21k_full_tar_json.py
-python tools/create_lvis_21k.py
-~~~
-This creates `datasets/imagenet/annotations/imagenet-21k_image_info_lvis-21k.json` and `datasets/lvis/lvis_v1_train_lvis-21k.json` (combined LVIS and ImageNet-21K classes in `categories`).
-
-[Optional] To train on combined LVIS and COCO, run
-
-~~~
-python tools/merge_lvis_coco.py
-~~~
-This creates `datasets/lvis/lvis_v1_train+coco_mask.json`
-
-### Conceptual Caption
-
-
-Download the dataset from [this](https://ai.google.com/research/ConceptualCaptions/download) page and place them as:
-```
-cc3m/
- GCC-training.tsv
-```
-
-Run the following command to download the images and convert the annotations to LVIS format (Note: download images takes long).
-
-~~~
-python tools/download_cc.py --ann datasets/cc3m/GCC-training.tsv --save_image_path datasets/cc3m/training/ --out_path datasets/cc3m/train_image_info.json
-python tools/get_cc_tags.py
-~~~
-
-This creates `datasets/cc3m/train_image_info_tags.json`.
-
-### Objects365
-Download Objects365 (v2) from the website. We only need the validation set in this project:
-```
-objects365/
- annotations/
- zhiyuan_objv2_val.json
- val/
- images/
- v1/
- patch0/
- ...
- patch15/
- v2/
- patch16/
- ...
- patch49/
-
-```
-
-The original annotation has typos in the class names, we first fix them for our following use of language embeddings.
-
-```
-python tools/fix_o365_names.py --ann datasets/objects365/annotations/zhiyuan_objv2_val.json
-```
-This creates `datasets/objects365/zhiyuan_objv2_val_fixname.json`.
-
-To train on Objects365, download the training images and use the command above. We note some images in the training annotation do not exist.
-We use the following command to filter the missing images.
-~~~
-python tools/fix_0365_path.py
-~~~
-This creates `datasets/objects365/zhiyuan_objv2_train_fixname_fixmiss.json`.
-
-### OpenImages
-
-We followed the instructions in [UniDet](https://github.com/xingyizhou/UniDet/blob/master/projects/UniDet/unidet_docs/DATASETS.md#openimages) to convert the metadata for OpenImages.
-
-The converted folder should look like
-
-```
-oid/
- annotations/
- oid_challenge_2019_train_bbox.json
- oid_challenge_2019_val_expanded.json
- images/
- 0/
- 1/
- 2/
- ...
-```
-
-### Open-vocabulary COCO
-
-We first follow [OVR-CNN](https://github.com/alirezazareian/ovr-cnn/blob/master/ipynb/003.ipynb) to create the open-vocabulary COCO split. The converted files should be like
-
-```
-coco/
- zero-shot/
- instances_train2017_seen_2.json
- instances_val2017_all_2.json
-```
-
-We further pre-process the annotation format for easier evaluation:
-
-```
-python tools/get_coco_zeroshot_oriorder.py --data_path datasets/coco/zero-shot/instances_train2017_seen_2.json
-python tools/get_coco_zeroshot_oriorder.py --data_path datasets/coco/zero-shot/instances_val2017_all_2.json
-```
-
-Next, we preprocess the COCO caption data:
-
-```
-python tools/get_cc_tags.py --cc_ann datasets/coco/annotations/captions_train2017.json --out_path datasets/coco/captions_train2017_tags_allcaps.json --allcaps --convert_caption
-```
-This creates `datasets/coco/captions_train2017_tags_allcaps.json`.
-
-### Metadata
-
-```
-metadata/
- lvis_v1_train_cat_info.json
- coco_clip_a+cname.npy
- lvis_v1_clip_a+cname.npy
- o365_clip_a+cnamefix.npy
- oid_clip_a+cname.npy
- imagenet_lvis_wnid.txt
- Objects365_names_fix.csv
-```
-
-`lvis_v1_train_cat_info.json` is used by the Federated loss.
-This is created by
-~~~
-python tools/get_lvis_cat_info.py --ann datasets/lvis/lvis_v1_train.json
-~~~
-
-`*_clip_a+cname.npy` is the pre-computed CLIP embeddings for each datasets.
-They are created by (taking LVIS as an example)
-~~~
-python tools/dump_clip_features.py --ann datasets/lvis/lvis_v1_val.json --out_path metadata/lvis_v1_clip_a+cname.npy
-~~~
-Note we do not include the 21K class embeddings due to the large file size.
-To create it, run
-~~~
-python tools/dump_clip_features.py --ann datasets/lvis/lvis_v1_val_lvis-21k.json --out_path datasets/metadata/lvis-21k_clip_a+cname.npy
-~~~
-
-`imagenet_lvis_wnid.txt` is the list of matched classes between ImageNet-21K and LVIS.
-
-`Objects365_names_fix.csv` is our manual fix of the Objects365 names.
\ No newline at end of file
diff --git a/spaces/akhaliq/SummerTime/model/query_based/bm25_model.py b/spaces/akhaliq/SummerTime/model/query_based/bm25_model.py
deleted file mode 100644
index d5fc06bbebfe0d75eecd0ee239f7e56f4fc2ef17..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/SummerTime/model/query_based/bm25_model.py
+++ /dev/null
@@ -1,45 +0,0 @@
-from .base_query_based_model import QueryBasedSummModel
-from model.base_model import SummModel
-from model.single_doc import TextRankModel
-from typing import List
-
-from gensim.summarization.bm25 import BM25
-from nltk import word_tokenize
-
-
-class BM25SummModel(QueryBasedSummModel):
-
- # static variables
- model_name = "BM25"
- is_extractive = True # only represents the retrieval part
- is_neural = False # only represents the retrieval part
- is_query_based = True
-
- def __init__(
- self,
- trained_domain: str = None,
- max_input_length: int = None,
- max_output_length: int = None,
- model_backend: SummModel = TextRankModel,
- retrieval_ratio: float = 0.5,
- preprocess: bool = True,
- **kwargs
- ):
- super(BM25SummModel, self).__init__(
- trained_domain=trained_domain,
- max_input_length=max_input_length,
- max_output_length=max_output_length,
- model_backend=model_backend,
- retrieval_ratio=retrieval_ratio,
- preprocess=preprocess,
- **kwargs
- )
-
- def _retrieve(self, instance: List[str], query: List[str], n_best):
- bm25 = BM25(word_tokenize(s) for s in instance)
- scores = bm25.get_scores(query)
- best_sent_ind = sorted(
- range(len(scores)), key=lambda i: scores[i], reverse=True
- )[:n_best]
- top_n_sent = [instance[ind] for ind in sorted(best_sent_ind)]
- return top_n_sent
diff --git a/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/yesno/voc1/cmd.sh b/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/yesno/voc1/cmd.sh
deleted file mode 100644
index 19f342102fc4f3389157c48f1196b16b68eb1cf1..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/yesno/voc1/cmd.sh
+++ /dev/null
@@ -1,91 +0,0 @@
-# ====== About run.pl, queue.pl, slurm.pl, and ssh.pl ======
-# Usage: .pl [options] JOB=1:
-# e.g.
-# run.pl --mem 4G JOB=1:10 echo.JOB.log echo JOB
-#
-# Options:
-# --time : Limit the maximum time to execute.
-# --mem : Limit the maximum memory usage.
-# -–max-jobs-run : Limit the number parallel jobs. This is ignored for non-array jobs.
-# --num-threads : Specify the number of CPU core.
-# --gpu : Specify the number of GPU devices.
-# --config: Change the configuration file from default.
-#
-# "JOB=1:10" is used for "array jobs" and it can control the number of parallel jobs.
-# The left string of "=", i.e. "JOB", is replaced by (Nth job) in the command and the log file name,
-# e.g. "echo JOB" is changed to "echo 3" for the 3rd job and "echo 8" for 8th job respectively.
-# Note that the number must start with a positive number, so you can't use "JOB=0:10" for example.
-#
-# run.pl, queue.pl, slurm.pl, and ssh.pl have unified interface, not depending on its backend.
-# These options are mapping to specific options for each backend and
-# it is configured by "conf/queue.conf" and "conf/slurm.conf" by default.
-# If jobs failed, your configuration might be wrong for your environment.
-#
-#
-# The official documentaion for run.pl, queue.pl, slurm.pl, and ssh.pl:
-# "Parallelization in Kaldi": http://kaldi-asr.org/doc/queue.html
-# =========================================================~
-
-
-# Select the backend used by run.sh from "local", "stdout", "sge", "slurm", or "ssh"
-cmd_backend="local"
-
-# Local machine, without any Job scheduling system
-if [ "${cmd_backend}" = local ]; then
-
- # The other usage
- export train_cmd="utils/run.pl"
- # Used for "*_train.py": "--gpu" is appended optionally by run.sh
- export cuda_cmd="utils/run.pl"
- # Used for "*_recog.py"
- export decode_cmd="utils/run.pl"
-
-# Local machine, without any Job scheduling system
-elif [ "${cmd_backend}" = stdout ]; then
-
- # The other usage
- export train_cmd="utils/stdout.pl"
- # Used for "*_train.py": "--gpu" is appended optionally by run.sh
- export cuda_cmd="utils/stdout.pl"
- # Used for "*_recog.py"
- export decode_cmd="utils/stdout.pl"
-
-# "qsub" (SGE, Torque, PBS, etc.)
-elif [ "${cmd_backend}" = sge ]; then
- # The default setting is written in conf/queue.conf.
- # You must change "-q g.q" for the "queue" for your environment.
- # To know the "queue" names, type "qhost -q"
- # Note that to use "--gpu *", you have to setup "complex_value" for the system scheduler.
-
- export train_cmd="utils/queue.pl"
- export cuda_cmd="utils/queue.pl"
- export decode_cmd="utils/queue.pl"
-
-# "sbatch" (Slurm)
-elif [ "${cmd_backend}" = slurm ]; then
- # The default setting is written in conf/slurm.conf.
- # You must change "-p cpu" and "-p gpu" for the "partion" for your environment.
- # To know the "partion" names, type "sinfo".
- # You can use "--gpu * " by defualt for slurm and it is interpreted as "--gres gpu:*"
- # The devices are allocated exclusively using "${CUDA_VISIBLE_DEVICES}".
-
- export train_cmd="utils/slurm.pl"
- export cuda_cmd="utils/slurm.pl"
- export decode_cmd="utils/slurm.pl"
-
-elif [ "${cmd_backend}" = ssh ]; then
- # You have to create ".queue/machines" to specify the host to execute jobs.
- # e.g. .queue/machines
- # host1
- # host2
- # host3
- # Assuming you can login them without any password, i.e. You have to set ssh keys.
-
- export train_cmd="utils/ssh.pl"
- export cuda_cmd="utils/ssh.pl"
- export decode_cmd="utils/ssh.pl"
-
-else
- echo "$0: Error: Unknown cmd_backend=${cmd_backend}" 1>&2
- return 1
-fi
diff --git a/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/yesno/voc1/path.sh b/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/yesno/voc1/path.sh
deleted file mode 100644
index b0ca27c615f70aa29e240222ec370f8ad4e7b45a..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/yesno/voc1/path.sh
+++ /dev/null
@@ -1,33 +0,0 @@
-# cuda related
-export CUDA_HOME=/usr/local/cuda-10.0
-export LD_LIBRARY_PATH="${CUDA_HOME}/lib64:${LD_LIBRARY_PATH}"
-
-# path related
-export PRJ_ROOT="${PWD}/../../.."
-if [ -e "${PRJ_ROOT}/tools/venv/bin/activate" ]; then
- # shellcheck disable=SC1090
- . "${PRJ_ROOT}/tools/venv/bin/activate"
-fi
-
-# python related
-export OMP_NUM_THREADS=1
-export PYTHONIOENCODING=UTF-8
-export MPL_BACKEND=Agg
-
-# check installation
-if ! command -v parallel-wavegan-train > /dev/null; then
- echo "Error: It seems setup is not finished." >&2
- echo "Error: Please setup your environment by following README.md" >&2
- return 1
-fi
-if ! command -v jq > /dev/null; then
- echo "Error: It seems jq is not installed." >&2
- echo "Error: Please install via \`sudo apt-get install jq\`." >&2
- echo "Error: If you do not have sudo, please download from https://stedolan.github.io/jq/download/." >&2
- return 1
-fi
-if ! command -v yq > /dev/null; then
- echo "Error: It seems yq is not installed." >&2
- echo "Error: Please install via \`pip install yq\`." >&2
- return 1
-fi
diff --git a/spaces/akhaliq/frame-interpolation/README.md b/spaces/akhaliq/frame-interpolation/README.md
deleted file mode 100644
index f8fb0186f82a64515675c21b6e1732df3790d2bc..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/frame-interpolation/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Frame Interpolation
-emoji: 🐢
-colorFrom: blue
-colorTo: gray
-sdk: gradio
-sdk_version: 3.1.4
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/akhaliq/lama/models/ade20k/base.py b/spaces/akhaliq/lama/models/ade20k/base.py
deleted file mode 100644
index 8cdbe2d3e7dbadf4ed5e5a7cf2d248761ef25d9c..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/lama/models/ade20k/base.py
+++ /dev/null
@@ -1,627 +0,0 @@
-"""Modified from https://github.com/CSAILVision/semantic-segmentation-pytorch"""
-
-import os
-
-import pandas as pd
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from scipy.io import loadmat
-from torch.nn.modules import BatchNorm2d
-
-from . import resnet
-from . import mobilenet
-
-
-NUM_CLASS = 150
-base_path = os.path.dirname(os.path.abspath(__file__)) # current file path
-colors_path = os.path.join(base_path, 'color150.mat')
-classes_path = os.path.join(base_path, 'object150_info.csv')
-
-segm_options = dict(colors=loadmat(colors_path)['colors'],
- classes=pd.read_csv(classes_path),)
-
-
-class NormalizeTensor:
- def __init__(self, mean, std, inplace=False):
- """Normalize a tensor image with mean and standard deviation.
- .. note::
- This transform acts out of place by default, i.e., it does not mutates the input tensor.
- See :class:`~torchvision.transforms.Normalize` for more details.
- Args:
- tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
- mean (sequence): Sequence of means for each channel.
- std (sequence): Sequence of standard deviations for each channel.
- inplace(bool,optional): Bool to make this operation inplace.
- Returns:
- Tensor: Normalized Tensor image.
- """
-
- self.mean = mean
- self.std = std
- self.inplace = inplace
-
- def __call__(self, tensor):
- if not self.inplace:
- tensor = tensor.clone()
-
- dtype = tensor.dtype
- mean = torch.as_tensor(self.mean, dtype=dtype, device=tensor.device)
- std = torch.as_tensor(self.std, dtype=dtype, device=tensor.device)
- tensor.sub_(mean[None, :, None, None]).div_(std[None, :, None, None])
- return tensor
-
-
-# Model Builder
-class ModelBuilder:
- # custom weights initialization
- @staticmethod
- def weights_init(m):
- classname = m.__class__.__name__
- if classname.find('Conv') != -1:
- nn.init.kaiming_normal_(m.weight.data)
- elif classname.find('BatchNorm') != -1:
- m.weight.data.fill_(1.)
- m.bias.data.fill_(1e-4)
-
- @staticmethod
- def build_encoder(arch='resnet50dilated', fc_dim=512, weights=''):
- pretrained = True if len(weights) == 0 else False
- arch = arch.lower()
- if arch == 'mobilenetv2dilated':
- orig_mobilenet = mobilenet.__dict__['mobilenetv2'](pretrained=pretrained)
- net_encoder = MobileNetV2Dilated(orig_mobilenet, dilate_scale=8)
- elif arch == 'resnet18':
- orig_resnet = resnet.__dict__['resnet18'](pretrained=pretrained)
- net_encoder = Resnet(orig_resnet)
- elif arch == 'resnet18dilated':
- orig_resnet = resnet.__dict__['resnet18'](pretrained=pretrained)
- net_encoder = ResnetDilated(orig_resnet, dilate_scale=8)
- elif arch == 'resnet50dilated':
- orig_resnet = resnet.__dict__['resnet50'](pretrained=pretrained)
- net_encoder = ResnetDilated(orig_resnet, dilate_scale=8)
- elif arch == 'resnet50':
- orig_resnet = resnet.__dict__['resnet50'](pretrained=pretrained)
- net_encoder = Resnet(orig_resnet)
- else:
- raise Exception('Architecture undefined!')
-
- # encoders are usually pretrained
- # net_encoder.apply(ModelBuilder.weights_init)
- if len(weights) > 0:
- print('Loading weights for net_encoder')
- net_encoder.load_state_dict(
- torch.load(weights, map_location=lambda storage, loc: storage), strict=False)
- return net_encoder
-
- @staticmethod
- def build_decoder(arch='ppm_deepsup',
- fc_dim=512, num_class=NUM_CLASS,
- weights='', use_softmax=False, drop_last_conv=False):
- arch = arch.lower()
- if arch == 'ppm_deepsup':
- net_decoder = PPMDeepsup(
- num_class=num_class,
- fc_dim=fc_dim,
- use_softmax=use_softmax,
- drop_last_conv=drop_last_conv)
- elif arch == 'c1_deepsup':
- net_decoder = C1DeepSup(
- num_class=num_class,
- fc_dim=fc_dim,
- use_softmax=use_softmax,
- drop_last_conv=drop_last_conv)
- else:
- raise Exception('Architecture undefined!')
-
- net_decoder.apply(ModelBuilder.weights_init)
- if len(weights) > 0:
- print('Loading weights for net_decoder')
- net_decoder.load_state_dict(
- torch.load(weights, map_location=lambda storage, loc: storage), strict=False)
- return net_decoder
-
- @staticmethod
- def get_decoder(weights_path, arch_encoder, arch_decoder, fc_dim, drop_last_conv, *arts, **kwargs):
- path = os.path.join(weights_path, 'ade20k', f'ade20k-{arch_encoder}-{arch_decoder}/decoder_epoch_20.pth')
- return ModelBuilder.build_decoder(arch=arch_decoder, fc_dim=fc_dim, weights=path, use_softmax=True, drop_last_conv=drop_last_conv)
-
- @staticmethod
- def get_encoder(weights_path, arch_encoder, arch_decoder, fc_dim, segmentation,
- *arts, **kwargs):
- if segmentation:
- path = os.path.join(weights_path, 'ade20k', f'ade20k-{arch_encoder}-{arch_decoder}/encoder_epoch_20.pth')
- else:
- path = ''
- return ModelBuilder.build_encoder(arch=arch_encoder, fc_dim=fc_dim, weights=path)
-
-
-def conv3x3_bn_relu(in_planes, out_planes, stride=1):
- return nn.Sequential(
- nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False),
- BatchNorm2d(out_planes),
- nn.ReLU(inplace=True),
- )
-
-
-class SegmentationModule(nn.Module):
- def __init__(self,
- weights_path,
- num_classes=150,
- arch_encoder="resnet50dilated",
- drop_last_conv=False,
- net_enc=None, # None for Default encoder
- net_dec=None, # None for Default decoder
- encode=None, # {None, 'binary', 'color', 'sky'}
- use_default_normalization=False,
- return_feature_maps=False,
- return_feature_maps_level=3, # {0, 1, 2, 3}
- return_feature_maps_only=True,
- **kwargs,
- ):
- super().__init__()
- self.weights_path = weights_path
- self.drop_last_conv = drop_last_conv
- self.arch_encoder = arch_encoder
- if self.arch_encoder == "resnet50dilated":
- self.arch_decoder = "ppm_deepsup"
- self.fc_dim = 2048
- elif self.arch_encoder == "mobilenetv2dilated":
- self.arch_decoder = "c1_deepsup"
- self.fc_dim = 320
- else:
- raise NotImplementedError(f"No such arch_encoder={self.arch_encoder}")
- model_builder_kwargs = dict(arch_encoder=self.arch_encoder,
- arch_decoder=self.arch_decoder,
- fc_dim=self.fc_dim,
- drop_last_conv=drop_last_conv,
- weights_path=self.weights_path)
-
- self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- self.encoder = ModelBuilder.get_encoder(**model_builder_kwargs) if net_enc is None else net_enc
- self.decoder = ModelBuilder.get_decoder(**model_builder_kwargs) if net_dec is None else net_dec
- self.use_default_normalization = use_default_normalization
- self.default_normalization = NormalizeTensor(mean=[0.485, 0.456, 0.406],
- std=[0.229, 0.224, 0.225])
-
- self.encode = encode
-
- self.return_feature_maps = return_feature_maps
-
- assert 0 <= return_feature_maps_level <= 3
- self.return_feature_maps_level = return_feature_maps_level
-
- def normalize_input(self, tensor):
- if tensor.min() < 0 or tensor.max() > 1:
- raise ValueError("Tensor should be 0..1 before using normalize_input")
- return self.default_normalization(tensor)
-
- @property
- def feature_maps_channels(self):
- return 256 * 2**(self.return_feature_maps_level) # 256, 512, 1024, 2048
-
- def forward(self, img_data, segSize=None):
- if segSize is None:
- raise NotImplementedError("Please pass segSize param. By default: (300, 300)")
-
- fmaps = self.encoder(img_data, return_feature_maps=True)
- pred = self.decoder(fmaps, segSize=segSize)
-
- if self.return_feature_maps:
- return pred, fmaps
- # print("BINARY", img_data.shape, pred.shape)
- return pred
-
- def multi_mask_from_multiclass(self, pred, classes):
- def isin(ar1, ar2):
- return (ar1[..., None] == ar2).any(-1).float()
- return isin(pred, torch.LongTensor(classes).to(self.device))
-
- @staticmethod
- def multi_mask_from_multiclass_probs(scores, classes):
- res = None
- for c in classes:
- if res is None:
- res = scores[:, c]
- else:
- res += scores[:, c]
- return res
-
- def predict(self, tensor, imgSizes=(-1,), # (300, 375, 450, 525, 600)
- segSize=None):
- """Entry-point for segmentation. Use this methods instead of forward
- Arguments:
- tensor {torch.Tensor} -- BCHW
- Keyword Arguments:
- imgSizes {tuple or list} -- imgSizes for segmentation input.
- default: (300, 450)
- original implementation: (300, 375, 450, 525, 600)
-
- """
- if segSize is None:
- segSize = tensor.shape[-2:]
- segSize = (tensor.shape[2], tensor.shape[3])
- with torch.no_grad():
- if self.use_default_normalization:
- tensor = self.normalize_input(tensor)
- scores = torch.zeros(1, NUM_CLASS, segSize[0], segSize[1]).to(self.device)
- features = torch.zeros(1, self.feature_maps_channels, segSize[0], segSize[1]).to(self.device)
-
- result = []
- for img_size in imgSizes:
- if img_size != -1:
- img_data = F.interpolate(tensor.clone(), size=img_size)
- else:
- img_data = tensor.clone()
-
- if self.return_feature_maps:
- pred_current, fmaps = self.forward(img_data, segSize=segSize)
- else:
- pred_current = self.forward(img_data, segSize=segSize)
-
-
- result.append(pred_current)
- scores = scores + pred_current / len(imgSizes)
-
- # Disclaimer: We use and aggregate only last fmaps: fmaps[3]
- if self.return_feature_maps:
- features = features + F.interpolate(fmaps[self.return_feature_maps_level], size=segSize) / len(imgSizes)
-
- _, pred = torch.max(scores, dim=1)
-
- if self.return_feature_maps:
- return features
-
- return pred, result
-
- def get_edges(self, t):
- edge = torch.cuda.ByteTensor(t.size()).zero_()
- edge[:, :, :, 1:] = edge[:, :, :, 1:] | (t[:, :, :, 1:] != t[:, :, :, :-1])
- edge[:, :, :, :-1] = edge[:, :, :, :-1] | (t[:, :, :, 1:] != t[:, :, :, :-1])
- edge[:, :, 1:, :] = edge[:, :, 1:, :] | (t[:, :, 1:, :] != t[:, :, :-1, :])
- edge[:, :, :-1, :] = edge[:, :, :-1, :] | (t[:, :, 1:, :] != t[:, :, :-1, :])
-
- if True:
- return edge.half()
- return edge.float()
-
-
-# pyramid pooling, deep supervision
-class PPMDeepsup(nn.Module):
- def __init__(self, num_class=NUM_CLASS, fc_dim=4096,
- use_softmax=False, pool_scales=(1, 2, 3, 6),
- drop_last_conv=False):
- super().__init__()
- self.use_softmax = use_softmax
- self.drop_last_conv = drop_last_conv
-
- self.ppm = []
- for scale in pool_scales:
- self.ppm.append(nn.Sequential(
- nn.AdaptiveAvgPool2d(scale),
- nn.Conv2d(fc_dim, 512, kernel_size=1, bias=False),
- BatchNorm2d(512),
- nn.ReLU(inplace=True)
- ))
- self.ppm = nn.ModuleList(self.ppm)
- self.cbr_deepsup = conv3x3_bn_relu(fc_dim // 2, fc_dim // 4, 1)
-
- self.conv_last = nn.Sequential(
- nn.Conv2d(fc_dim + len(pool_scales) * 512, 512,
- kernel_size=3, padding=1, bias=False),
- BatchNorm2d(512),
- nn.ReLU(inplace=True),
- nn.Dropout2d(0.1),
- nn.Conv2d(512, num_class, kernel_size=1)
- )
- self.conv_last_deepsup = nn.Conv2d(fc_dim // 4, num_class, 1, 1, 0)
- self.dropout_deepsup = nn.Dropout2d(0.1)
-
- def forward(self, conv_out, segSize=None):
- conv5 = conv_out[-1]
-
- input_size = conv5.size()
- ppm_out = [conv5]
- for pool_scale in self.ppm:
- ppm_out.append(nn.functional.interpolate(
- pool_scale(conv5),
- (input_size[2], input_size[3]),
- mode='bilinear', align_corners=False))
- ppm_out = torch.cat(ppm_out, 1)
-
- if self.drop_last_conv:
- return ppm_out
- else:
- x = self.conv_last(ppm_out)
-
- if self.use_softmax: # is True during inference
- x = nn.functional.interpolate(
- x, size=segSize, mode='bilinear', align_corners=False)
- x = nn.functional.softmax(x, dim=1)
- return x
-
- # deep sup
- conv4 = conv_out[-2]
- _ = self.cbr_deepsup(conv4)
- _ = self.dropout_deepsup(_)
- _ = self.conv_last_deepsup(_)
-
- x = nn.functional.log_softmax(x, dim=1)
- _ = nn.functional.log_softmax(_, dim=1)
-
- return (x, _)
-
-
-class Resnet(nn.Module):
- def __init__(self, orig_resnet):
- super(Resnet, self).__init__()
-
- # take pretrained resnet, except AvgPool and FC
- self.conv1 = orig_resnet.conv1
- self.bn1 = orig_resnet.bn1
- self.relu1 = orig_resnet.relu1
- self.conv2 = orig_resnet.conv2
- self.bn2 = orig_resnet.bn2
- self.relu2 = orig_resnet.relu2
- self.conv3 = orig_resnet.conv3
- self.bn3 = orig_resnet.bn3
- self.relu3 = orig_resnet.relu3
- self.maxpool = orig_resnet.maxpool
- self.layer1 = orig_resnet.layer1
- self.layer2 = orig_resnet.layer2
- self.layer3 = orig_resnet.layer3
- self.layer4 = orig_resnet.layer4
-
- def forward(self, x, return_feature_maps=False):
- conv_out = []
-
- x = self.relu1(self.bn1(self.conv1(x)))
- x = self.relu2(self.bn2(self.conv2(x)))
- x = self.relu3(self.bn3(self.conv3(x)))
- x = self.maxpool(x)
-
- x = self.layer1(x); conv_out.append(x);
- x = self.layer2(x); conv_out.append(x);
- x = self.layer3(x); conv_out.append(x);
- x = self.layer4(x); conv_out.append(x);
-
- if return_feature_maps:
- return conv_out
- return [x]
-
-# Resnet Dilated
-class ResnetDilated(nn.Module):
- def __init__(self, orig_resnet, dilate_scale=8):
- super().__init__()
- from functools import partial
-
- if dilate_scale == 8:
- orig_resnet.layer3.apply(
- partial(self._nostride_dilate, dilate=2))
- orig_resnet.layer4.apply(
- partial(self._nostride_dilate, dilate=4))
- elif dilate_scale == 16:
- orig_resnet.layer4.apply(
- partial(self._nostride_dilate, dilate=2))
-
- # take pretrained resnet, except AvgPool and FC
- self.conv1 = orig_resnet.conv1
- self.bn1 = orig_resnet.bn1
- self.relu1 = orig_resnet.relu1
- self.conv2 = orig_resnet.conv2
- self.bn2 = orig_resnet.bn2
- self.relu2 = orig_resnet.relu2
- self.conv3 = orig_resnet.conv3
- self.bn3 = orig_resnet.bn3
- self.relu3 = orig_resnet.relu3
- self.maxpool = orig_resnet.maxpool
- self.layer1 = orig_resnet.layer1
- self.layer2 = orig_resnet.layer2
- self.layer3 = orig_resnet.layer3
- self.layer4 = orig_resnet.layer4
-
- def _nostride_dilate(self, m, dilate):
- classname = m.__class__.__name__
- if classname.find('Conv') != -1:
- # the convolution with stride
- if m.stride == (2, 2):
- m.stride = (1, 1)
- if m.kernel_size == (3, 3):
- m.dilation = (dilate // 2, dilate // 2)
- m.padding = (dilate // 2, dilate // 2)
- # other convoluions
- else:
- if m.kernel_size == (3, 3):
- m.dilation = (dilate, dilate)
- m.padding = (dilate, dilate)
-
- def forward(self, x, return_feature_maps=False):
- conv_out = []
-
- x = self.relu1(self.bn1(self.conv1(x)))
- x = self.relu2(self.bn2(self.conv2(x)))
- x = self.relu3(self.bn3(self.conv3(x)))
- x = self.maxpool(x)
-
- x = self.layer1(x)
- conv_out.append(x)
- x = self.layer2(x)
- conv_out.append(x)
- x = self.layer3(x)
- conv_out.append(x)
- x = self.layer4(x)
- conv_out.append(x)
-
- if return_feature_maps:
- return conv_out
- return [x]
-
-class MobileNetV2Dilated(nn.Module):
- def __init__(self, orig_net, dilate_scale=8):
- super(MobileNetV2Dilated, self).__init__()
- from functools import partial
-
- # take pretrained mobilenet features
- self.features = orig_net.features[:-1]
-
- self.total_idx = len(self.features)
- self.down_idx = [2, 4, 7, 14]
-
- if dilate_scale == 8:
- for i in range(self.down_idx[-2], self.down_idx[-1]):
- self.features[i].apply(
- partial(self._nostride_dilate, dilate=2)
- )
- for i in range(self.down_idx[-1], self.total_idx):
- self.features[i].apply(
- partial(self._nostride_dilate, dilate=4)
- )
- elif dilate_scale == 16:
- for i in range(self.down_idx[-1], self.total_idx):
- self.features[i].apply(
- partial(self._nostride_dilate, dilate=2)
- )
-
- def _nostride_dilate(self, m, dilate):
- classname = m.__class__.__name__
- if classname.find('Conv') != -1:
- # the convolution with stride
- if m.stride == (2, 2):
- m.stride = (1, 1)
- if m.kernel_size == (3, 3):
- m.dilation = (dilate//2, dilate//2)
- m.padding = (dilate//2, dilate//2)
- # other convoluions
- else:
- if m.kernel_size == (3, 3):
- m.dilation = (dilate, dilate)
- m.padding = (dilate, dilate)
-
- def forward(self, x, return_feature_maps=False):
- if return_feature_maps:
- conv_out = []
- for i in range(self.total_idx):
- x = self.features[i](x)
- if i in self.down_idx:
- conv_out.append(x)
- conv_out.append(x)
- return conv_out
-
- else:
- return [self.features(x)]
-
-
-# last conv, deep supervision
-class C1DeepSup(nn.Module):
- def __init__(self, num_class=150, fc_dim=2048, use_softmax=False, drop_last_conv=False):
- super(C1DeepSup, self).__init__()
- self.use_softmax = use_softmax
- self.drop_last_conv = drop_last_conv
-
- self.cbr = conv3x3_bn_relu(fc_dim, fc_dim // 4, 1)
- self.cbr_deepsup = conv3x3_bn_relu(fc_dim // 2, fc_dim // 4, 1)
-
- # last conv
- self.conv_last = nn.Conv2d(fc_dim // 4, num_class, 1, 1, 0)
- self.conv_last_deepsup = nn.Conv2d(fc_dim // 4, num_class, 1, 1, 0)
-
- def forward(self, conv_out, segSize=None):
- conv5 = conv_out[-1]
-
- x = self.cbr(conv5)
-
- if self.drop_last_conv:
- return x
- else:
- x = self.conv_last(x)
-
- if self.use_softmax: # is True during inference
- x = nn.functional.interpolate(
- x, size=segSize, mode='bilinear', align_corners=False)
- x = nn.functional.softmax(x, dim=1)
- return x
-
- # deep sup
- conv4 = conv_out[-2]
- _ = self.cbr_deepsup(conv4)
- _ = self.conv_last_deepsup(_)
-
- x = nn.functional.log_softmax(x, dim=1)
- _ = nn.functional.log_softmax(_, dim=1)
-
- return (x, _)
-
-
-# last conv
-class C1(nn.Module):
- def __init__(self, num_class=150, fc_dim=2048, use_softmax=False):
- super(C1, self).__init__()
- self.use_softmax = use_softmax
-
- self.cbr = conv3x3_bn_relu(fc_dim, fc_dim // 4, 1)
-
- # last conv
- self.conv_last = nn.Conv2d(fc_dim // 4, num_class, 1, 1, 0)
-
- def forward(self, conv_out, segSize=None):
- conv5 = conv_out[-1]
- x = self.cbr(conv5)
- x = self.conv_last(x)
-
- if self.use_softmax: # is True during inference
- x = nn.functional.interpolate(
- x, size=segSize, mode='bilinear', align_corners=False)
- x = nn.functional.softmax(x, dim=1)
- else:
- x = nn.functional.log_softmax(x, dim=1)
-
- return x
-
-
-# pyramid pooling
-class PPM(nn.Module):
- def __init__(self, num_class=150, fc_dim=4096,
- use_softmax=False, pool_scales=(1, 2, 3, 6)):
- super(PPM, self).__init__()
- self.use_softmax = use_softmax
-
- self.ppm = []
- for scale in pool_scales:
- self.ppm.append(nn.Sequential(
- nn.AdaptiveAvgPool2d(scale),
- nn.Conv2d(fc_dim, 512, kernel_size=1, bias=False),
- BatchNorm2d(512),
- nn.ReLU(inplace=True)
- ))
- self.ppm = nn.ModuleList(self.ppm)
-
- self.conv_last = nn.Sequential(
- nn.Conv2d(fc_dim+len(pool_scales)*512, 512,
- kernel_size=3, padding=1, bias=False),
- BatchNorm2d(512),
- nn.ReLU(inplace=True),
- nn.Dropout2d(0.1),
- nn.Conv2d(512, num_class, kernel_size=1)
- )
-
- def forward(self, conv_out, segSize=None):
- conv5 = conv_out[-1]
-
- input_size = conv5.size()
- ppm_out = [conv5]
- for pool_scale in self.ppm:
- ppm_out.append(nn.functional.interpolate(
- pool_scale(conv5),
- (input_size[2], input_size[3]),
- mode='bilinear', align_corners=False))
- ppm_out = torch.cat(ppm_out, 1)
-
- x = self.conv_last(ppm_out)
-
- if self.use_softmax: # is True during inference
- x = nn.functional.interpolate(
- x, size=segSize, mode='bilinear', align_corners=False)
- x = nn.functional.softmax(x, dim=1)
- else:
- x = nn.functional.log_softmax(x, dim=1)
- return x
diff --git a/spaces/akhaliq/yolov7/detect.py b/spaces/akhaliq/yolov7/detect.py
deleted file mode 100644
index 607386a244a986eb940ebb0d3dfc76f774e150fc..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/yolov7/detect.py
+++ /dev/null
@@ -1,183 +0,0 @@
-import argparse
-import time
-from pathlib import Path
-
-import cv2
-import torch
-import torch.backends.cudnn as cudnn
-from numpy import random
-
-from models.experimental import attempt_load
-from utils.datasets import LoadStreams, LoadImages
-from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
- scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
-from utils.plots import plot_one_box
-from utils.torch_utils import select_device, load_classifier, time_synchronized, TracedModel
-
-
-def detect(save_img=False):
- source, weights, view_img, save_txt, imgsz, trace = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size, opt.trace
- save_img = not opt.nosave and not source.endswith('.txt') # save inference images
- webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
- ('rtsp://', 'rtmp://', 'http://', 'https://'))
-
- # Directories
- save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
- (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
-
- # Initialize
- set_logging()
- device = select_device(opt.device)
- half = device.type != 'cpu' # half precision only supported on CUDA
-
- # Load model
- model = attempt_load(weights, map_location=device) # load FP32 model
- stride = int(model.stride.max()) # model stride
- imgsz = check_img_size(imgsz, s=stride) # check img_size
-
- if trace:
- model = TracedModel(model, device, opt.img_size)
-
- if half:
- model.half() # to FP16
-
- # Second-stage classifier
- classify = False
- if classify:
- modelc = load_classifier(name='resnet101', n=2) # initialize
- modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
-
- # Set Dataloader
- vid_path, vid_writer = None, None
- if webcam:
- view_img = check_imshow()
- cudnn.benchmark = True # set True to speed up constant image size inference
- dataset = LoadStreams(source, img_size=imgsz, stride=stride)
- else:
- dataset = LoadImages(source, img_size=imgsz, stride=stride)
-
- # Get names and colors
- names = model.module.names if hasattr(model, 'module') else model.names
- colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
-
- # Run inference
- if device.type != 'cpu':
- model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
- t0 = time.time()
- for path, img, im0s, vid_cap in dataset:
- img = torch.from_numpy(img).to(device)
- img = img.half() if half else img.float() # uint8 to fp16/32
- img /= 255.0 # 0 - 255 to 0.0 - 1.0
- if img.ndimension() == 3:
- img = img.unsqueeze(0)
-
- # Inference
- t1 = time_synchronized()
- pred = model(img, augment=opt.augment)[0]
-
- # Apply NMS
- pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
- t2 = time_synchronized()
-
- # Apply Classifier
- if classify:
- pred = apply_classifier(pred, modelc, img, im0s)
-
- # Process detections
- for i, det in enumerate(pred): # detections per image
- if webcam: # batch_size >= 1
- p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
- else:
- p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
-
- p = Path(p) # to Path
- save_path = str(save_dir / p.name) # img.jpg
- txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
- s += '%gx%g ' % img.shape[2:] # print string
- gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
- if len(det):
- # Rescale boxes from img_size to im0 size
- det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
-
- # Print results
- for c in det[:, -1].unique():
- n = (det[:, -1] == c).sum() # detections per class
- s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
-
- # Write results
- for *xyxy, conf, cls in reversed(det):
- if save_txt: # Write to file
- xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
- line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
- with open(txt_path + '.txt', 'a') as f:
- f.write(('%g ' * len(line)).rstrip() % line + '\n')
-
- if save_img or view_img: # Add bbox to image
- label = f'{names[int(cls)]} {conf:.2f}'
- plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
-
- # Print time (inference + NMS)
- #print(f'{s}Done. ({t2 - t1:.3f}s)')
-
- # Stream results
- if view_img:
- cv2.imshow(str(p), im0)
- cv2.waitKey(1) # 1 millisecond
-
- # Save results (image with detections)
- if save_img:
- if dataset.mode == 'image':
- cv2.imwrite(save_path, im0)
- else: # 'video' or 'stream'
- if vid_path != save_path: # new video
- vid_path = save_path
- if isinstance(vid_writer, cv2.VideoWriter):
- vid_writer.release() # release previous video writer
- if vid_cap: # video
- fps = vid_cap.get(cv2.CAP_PROP_FPS)
- w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- else: # stream
- fps, w, h = 30, im0.shape[1], im0.shape[0]
- save_path += '.mp4'
- vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
- vid_writer.write(im0)
-
- if save_txt or save_img:
- s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
- #print(f"Results saved to {save_dir}{s}")
-
- print(f'Done. ({time.time() - t0:.3f}s)')
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--weights', nargs='+', type=str, default='yolov7.pt', help='model.pt path(s)')
- parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
- parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
- parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
- parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
- parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
- parser.add_argument('--view-img', action='store_true', help='display results')
- parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
- parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
- parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
- parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
- parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
- parser.add_argument('--augment', action='store_true', help='augmented inference')
- parser.add_argument('--update', action='store_true', help='update all models')
- parser.add_argument('--project', default='runs/detect', help='save results to project/name')
- parser.add_argument('--name', default='exp', help='save results to project/name')
- parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
- parser.add_argument('--trace', action='store_true', help='trace model')
- opt = parser.parse_args()
- print(opt)
- #check_requirements(exclude=('pycocotools', 'thop'))
-
- with torch.no_grad():
- if opt.update: # update all models (to fix SourceChangeWarning)
- for opt.weights in ['yolov7.pt']:
- detect()
- strip_optimizer(opt.weights)
- else:
- detect()
diff --git a/spaces/akhaliq/yolov7/utils/datasets.py b/spaces/akhaliq/yolov7/utils/datasets.py
deleted file mode 100644
index 0cdc72ccb3de0d9e7408830369b22bdc2bfe0e5f..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/yolov7/utils/datasets.py
+++ /dev/null
@@ -1,1320 +0,0 @@
-# Dataset utils and dataloaders
-
-import glob
-import logging
-import math
-import os
-import random
-import shutil
-import time
-from itertools import repeat
-from multiprocessing.pool import ThreadPool
-from pathlib import Path
-from threading import Thread
-
-import cv2
-import numpy as np
-import torch
-import torch.nn.functional as F
-from PIL import Image, ExifTags
-from torch.utils.data import Dataset
-from tqdm import tqdm
-
-import pickle
-from copy import deepcopy
-#from pycocotools import mask as maskUtils
-from torchvision.utils import save_image
-from torchvision.ops import roi_pool, roi_align, ps_roi_pool, ps_roi_align
-
-from utils.general import check_requirements, xyxy2xywh, xywh2xyxy, xywhn2xyxy, xyn2xy, segment2box, segments2boxes, \
- resample_segments, clean_str
-from utils.torch_utils import torch_distributed_zero_first
-
-# Parameters
-help_url = 'https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data'
-img_formats = ['bmp', 'jpg', 'jpeg', 'png', 'tif', 'tiff', 'dng', 'webp', 'mpo'] # acceptable image suffixes
-vid_formats = ['mov', 'avi', 'mp4', 'mpg', 'mpeg', 'm4v', 'wmv', 'mkv'] # acceptable video suffixes
-logger = logging.getLogger(__name__)
-
-# Get orientation exif tag
-for orientation in ExifTags.TAGS.keys():
- if ExifTags.TAGS[orientation] == 'Orientation':
- break
-
-
-def get_hash(files):
- # Returns a single hash value of a list of files
- return sum(os.path.getsize(f) for f in files if os.path.isfile(f))
-
-
-def exif_size(img):
- # Returns exif-corrected PIL size
- s = img.size # (width, height)
- try:
- rotation = dict(img._getexif().items())[orientation]
- if rotation == 6: # rotation 270
- s = (s[1], s[0])
- elif rotation == 8: # rotation 90
- s = (s[1], s[0])
- except:
- pass
-
- return s
-
-
-def create_dataloader(path, imgsz, batch_size, stride, opt, hyp=None, augment=False, cache=False, pad=0.0, rect=False,
- rank=-1, world_size=1, workers=8, image_weights=False, quad=False, prefix=''):
- # Make sure only the first process in DDP process the dataset first, and the following others can use the cache
- with torch_distributed_zero_first(rank):
- dataset = LoadImagesAndLabels(path, imgsz, batch_size,
- augment=augment, # augment images
- hyp=hyp, # augmentation hyperparameters
- rect=rect, # rectangular training
- cache_images=cache,
- single_cls=opt.single_cls,
- stride=int(stride),
- pad=pad,
- image_weights=image_weights,
- prefix=prefix)
-
- batch_size = min(batch_size, len(dataset))
- nw = min([os.cpu_count() // world_size, batch_size if batch_size > 1 else 0, workers]) # number of workers
- sampler = torch.utils.data.distributed.DistributedSampler(dataset) if rank != -1 else None
- loader = torch.utils.data.DataLoader if image_weights else InfiniteDataLoader
- # Use torch.utils.data.DataLoader() if dataset.properties will update during training else InfiniteDataLoader()
- dataloader = loader(dataset,
- batch_size=batch_size,
- num_workers=nw,
- sampler=sampler,
- pin_memory=True,
- collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
- return dataloader, dataset
-
-
-class InfiniteDataLoader(torch.utils.data.dataloader.DataLoader):
- """ Dataloader that reuses workers
-
- Uses same syntax as vanilla DataLoader
- """
-
- def __init__(self, *args, **kwargs):
- super().__init__(*args, **kwargs)
- object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
- self.iterator = super().__iter__()
-
- def __len__(self):
- return len(self.batch_sampler.sampler)
-
- def __iter__(self):
- for i in range(len(self)):
- yield next(self.iterator)
-
-
-class _RepeatSampler(object):
- """ Sampler that repeats forever
-
- Args:
- sampler (Sampler)
- """
-
- def __init__(self, sampler):
- self.sampler = sampler
-
- def __iter__(self):
- while True:
- yield from iter(self.sampler)
-
-
-class LoadImages: # for inference
- def __init__(self, path, img_size=640, stride=32):
- p = str(Path(path).absolute()) # os-agnostic absolute path
- if '*' in p:
- files = sorted(glob.glob(p, recursive=True)) # glob
- elif os.path.isdir(p):
- files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
- elif os.path.isfile(p):
- files = [p] # files
- else:
- raise Exception(f'ERROR: {p} does not exist')
-
- images = [x for x in files if x.split('.')[-1].lower() in img_formats]
- videos = [x for x in files if x.split('.')[-1].lower() in vid_formats]
- ni, nv = len(images), len(videos)
-
- self.img_size = img_size
- self.stride = stride
- self.files = images + videos
- self.nf = ni + nv # number of files
- self.video_flag = [False] * ni + [True] * nv
- self.mode = 'image'
- if any(videos):
- self.new_video(videos[0]) # new video
- else:
- self.cap = None
- assert self.nf > 0, f'No images or videos found in {p}. ' \
- f'Supported formats are:\nimages: {img_formats}\nvideos: {vid_formats}'
-
- def __iter__(self):
- self.count = 0
- return self
-
- def __next__(self):
- if self.count == self.nf:
- raise StopIteration
- path = self.files[self.count]
-
- if self.video_flag[self.count]:
- # Read video
- self.mode = 'video'
- ret_val, img0 = self.cap.read()
- if not ret_val:
- self.count += 1
- self.cap.release()
- if self.count == self.nf: # last video
- raise StopIteration
- else:
- path = self.files[self.count]
- self.new_video(path)
- ret_val, img0 = self.cap.read()
-
- self.frame += 1
- print(f'video {self.count + 1}/{self.nf} ({self.frame}/{self.nframes}) {path}: ', end='')
-
- else:
- # Read image
- self.count += 1
- img0 = cv2.imread(path) # BGR
- assert img0 is not None, 'Image Not Found ' + path
- #print(f'image {self.count}/{self.nf} {path}: ', end='')
-
- # Padded resize
- img = letterbox(img0, self.img_size, stride=self.stride)[0]
-
- # Convert
- img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
- img = np.ascontiguousarray(img)
-
- return path, img, img0, self.cap
-
- def new_video(self, path):
- self.frame = 0
- self.cap = cv2.VideoCapture(path)
- self.nframes = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
-
- def __len__(self):
- return self.nf # number of files
-
-
-class LoadWebcam: # for inference
- def __init__(self, pipe='0', img_size=640, stride=32):
- self.img_size = img_size
- self.stride = stride
-
- if pipe.isnumeric():
- pipe = eval(pipe) # local camera
- # pipe = 'rtsp://192.168.1.64/1' # IP camera
- # pipe = 'rtsp://username:password@192.168.1.64/1' # IP camera with login
- # pipe = 'http://wmccpinetop.axiscam.net/mjpg/video.mjpg' # IP golf camera
-
- self.pipe = pipe
- self.cap = cv2.VideoCapture(pipe) # video capture object
- self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size
-
- def __iter__(self):
- self.count = -1
- return self
-
- def __next__(self):
- self.count += 1
- if cv2.waitKey(1) == ord('q'): # q to quit
- self.cap.release()
- cv2.destroyAllWindows()
- raise StopIteration
-
- # Read frame
- if self.pipe == 0: # local camera
- ret_val, img0 = self.cap.read()
- img0 = cv2.flip(img0, 1) # flip left-right
- else: # IP camera
- n = 0
- while True:
- n += 1
- self.cap.grab()
- if n % 30 == 0: # skip frames
- ret_val, img0 = self.cap.retrieve()
- if ret_val:
- break
-
- # Print
- assert ret_val, f'Camera Error {self.pipe}'
- img_path = 'webcam.jpg'
- print(f'webcam {self.count}: ', end='')
-
- # Padded resize
- img = letterbox(img0, self.img_size, stride=self.stride)[0]
-
- # Convert
- img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
- img = np.ascontiguousarray(img)
-
- return img_path, img, img0, None
-
- def __len__(self):
- return 0
-
-
-class LoadStreams: # multiple IP or RTSP cameras
- def __init__(self, sources='streams.txt', img_size=640, stride=32):
- self.mode = 'stream'
- self.img_size = img_size
- self.stride = stride
-
- if os.path.isfile(sources):
- with open(sources, 'r') as f:
- sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
- else:
- sources = [sources]
-
- n = len(sources)
- self.imgs = [None] * n
- self.sources = [clean_str(x) for x in sources] # clean source names for later
- for i, s in enumerate(sources):
- # Start the thread to read frames from the video stream
- print(f'{i + 1}/{n}: {s}... ', end='')
- url = eval(s) if s.isnumeric() else s
- if 'youtube.com/' in url or 'youtu.be/' in url: # if source is YouTube video
- check_requirements(('pafy', 'youtube_dl'))
- import pafy
- url = pafy.new(url).getbest(preftype="mp4").url
- cap = cv2.VideoCapture(url)
- assert cap.isOpened(), f'Failed to open {s}'
- w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- self.fps = cap.get(cv2.CAP_PROP_FPS) % 100
-
- _, self.imgs[i] = cap.read() # guarantee first frame
- thread = Thread(target=self.update, args=([i, cap]), daemon=True)
- print(f' success ({w}x{h} at {self.fps:.2f} FPS).')
- thread.start()
- print('') # newline
-
- # check for common shapes
- s = np.stack([letterbox(x, self.img_size, stride=self.stride)[0].shape for x in self.imgs], 0) # shapes
- self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
- if not self.rect:
- print('WARNING: Different stream shapes detected. For optimal performance supply similarly-shaped streams.')
-
- def update(self, index, cap):
- # Read next stream frame in a daemon thread
- n = 0
- while cap.isOpened():
- n += 1
- # _, self.imgs[index] = cap.read()
- cap.grab()
- if n == 4: # read every 4th frame
- success, im = cap.retrieve()
- self.imgs[index] = im if success else self.imgs[index] * 0
- n = 0
- time.sleep(1 / self.fps) # wait time
-
- def __iter__(self):
- self.count = -1
- return self
-
- def __next__(self):
- self.count += 1
- img0 = self.imgs.copy()
- if cv2.waitKey(1) == ord('q'): # q to quit
- cv2.destroyAllWindows()
- raise StopIteration
-
- # Letterbox
- img = [letterbox(x, self.img_size, auto=self.rect, stride=self.stride)[0] for x in img0]
-
- # Stack
- img = np.stack(img, 0)
-
- # Convert
- img = img[:, :, :, ::-1].transpose(0, 3, 1, 2) # BGR to RGB, to bsx3x416x416
- img = np.ascontiguousarray(img)
-
- return self.sources, img, img0, None
-
- def __len__(self):
- return 0 # 1E12 frames = 32 streams at 30 FPS for 30 years
-
-
-def img2label_paths(img_paths):
- # Define label paths as a function of image paths
- sa, sb = os.sep + 'images' + os.sep, os.sep + 'labels' + os.sep # /images/, /labels/ substrings
- return ['txt'.join(x.replace(sa, sb, 1).rsplit(x.split('.')[-1], 1)) for x in img_paths]
-
-
-class LoadImagesAndLabels(Dataset): # for training/testing
- def __init__(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False, image_weights=False,
- cache_images=False, single_cls=False, stride=32, pad=0.0, prefix=''):
- self.img_size = img_size
- self.augment = augment
- self.hyp = hyp
- self.image_weights = image_weights
- self.rect = False if image_weights else rect
- self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
- self.mosaic_border = [-img_size // 2, -img_size // 2]
- self.stride = stride
- self.path = path
- #self.albumentations = Albumentations() if augment else None
-
- try:
- f = [] # image files
- for p in path if isinstance(path, list) else [path]:
- p = Path(p) # os-agnostic
- if p.is_dir(): # dir
- f += glob.glob(str(p / '**' / '*.*'), recursive=True)
- # f = list(p.rglob('**/*.*')) # pathlib
- elif p.is_file(): # file
- with open(p, 'r') as t:
- t = t.read().strip().splitlines()
- parent = str(p.parent) + os.sep
- f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
- # f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
- else:
- raise Exception(f'{prefix}{p} does not exist')
- self.img_files = sorted([x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in img_formats])
- # self.img_files = sorted([x for x in f if x.suffix[1:].lower() in img_formats]) # pathlib
- assert self.img_files, f'{prefix}No images found'
- except Exception as e:
- raise Exception(f'{prefix}Error loading data from {path}: {e}\nSee {help_url}')
-
- # Check cache
- self.label_files = img2label_paths(self.img_files) # labels
- cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache') # cached labels
- if cache_path.is_file():
- cache, exists = torch.load(cache_path), True # load
- #if cache['hash'] != get_hash(self.label_files + self.img_files) or 'version' not in cache: # changed
- # cache, exists = self.cache_labels(cache_path, prefix), False # re-cache
- else:
- cache, exists = self.cache_labels(cache_path, prefix), False # cache
-
- # Display cache
- nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupted, total
- if exists:
- d = f"Scanning '{cache_path}' images and labels... {nf} found, {nm} missing, {ne} empty, {nc} corrupted"
- tqdm(None, desc=prefix + d, total=n, initial=n) # display cache results
- assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {help_url}'
-
- # Read cache
- cache.pop('hash') # remove hash
- cache.pop('version') # remove version
- labels, shapes, self.segments = zip(*cache.values())
- self.labels = list(labels)
- self.shapes = np.array(shapes, dtype=np.float64)
- self.img_files = list(cache.keys()) # update
- self.label_files = img2label_paths(cache.keys()) # update
- if single_cls:
- for x in self.labels:
- x[:, 0] = 0
-
- n = len(shapes) # number of images
- bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index
- nb = bi[-1] + 1 # number of batches
- self.batch = bi # batch index of image
- self.n = n
- self.indices = range(n)
-
- # Rectangular Training
- if self.rect:
- # Sort by aspect ratio
- s = self.shapes # wh
- ar = s[:, 1] / s[:, 0] # aspect ratio
- irect = ar.argsort()
- self.img_files = [self.img_files[i] for i in irect]
- self.label_files = [self.label_files[i] for i in irect]
- self.labels = [self.labels[i] for i in irect]
- self.shapes = s[irect] # wh
- ar = ar[irect]
-
- # Set training image shapes
- shapes = [[1, 1]] * nb
- for i in range(nb):
- ari = ar[bi == i]
- mini, maxi = ari.min(), ari.max()
- if maxi < 1:
- shapes[i] = [maxi, 1]
- elif mini > 1:
- shapes[i] = [1, 1 / mini]
-
- self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride
-
- # Cache images into memory for faster training (WARNING: large datasets may exceed system RAM)
- self.imgs = [None] * n
- if cache_images:
- if cache_images == 'disk':
- self.im_cache_dir = Path(Path(self.img_files[0]).parent.as_posix() + '_npy')
- self.img_npy = [self.im_cache_dir / Path(f).with_suffix('.npy').name for f in self.img_files]
- self.im_cache_dir.mkdir(parents=True, exist_ok=True)
- gb = 0 # Gigabytes of cached images
- self.img_hw0, self.img_hw = [None] * n, [None] * n
- results = ThreadPool(8).imap(lambda x: load_image(*x), zip(repeat(self), range(n)))
- pbar = tqdm(enumerate(results), total=n)
- for i, x in pbar:
- if cache_images == 'disk':
- if not self.img_npy[i].exists():
- np.save(self.img_npy[i].as_posix(), x[0])
- gb += self.img_npy[i].stat().st_size
- else:
- self.imgs[i], self.img_hw0[i], self.img_hw[i] = x
- gb += self.imgs[i].nbytes
- pbar.desc = f'{prefix}Caching images ({gb / 1E9:.1f}GB)'
- pbar.close()
-
- def cache_labels(self, path=Path('./labels.cache'), prefix=''):
- # Cache dataset labels, check images and read shapes
- x = {} # dict
- nm, nf, ne, nc = 0, 0, 0, 0 # number missing, found, empty, duplicate
- pbar = tqdm(zip(self.img_files, self.label_files), desc='Scanning images', total=len(self.img_files))
- for i, (im_file, lb_file) in enumerate(pbar):
- try:
- # verify images
- im = Image.open(im_file)
- im.verify() # PIL verify
- shape = exif_size(im) # image size
- segments = [] # instance segments
- assert (shape[0] > 9) & (shape[1] > 9), f'image size {shape} <10 pixels'
- assert im.format.lower() in img_formats, f'invalid image format {im.format}'
-
- # verify labels
- if os.path.isfile(lb_file):
- nf += 1 # label found
- with open(lb_file, 'r') as f:
- l = [x.split() for x in f.read().strip().splitlines()]
- if any([len(x) > 8 for x in l]): # is segment
- classes = np.array([x[0] for x in l], dtype=np.float32)
- segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in l] # (cls, xy1...)
- l = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1) # (cls, xywh)
- l = np.array(l, dtype=np.float32)
- if len(l):
- assert l.shape[1] == 5, 'labels require 5 columns each'
- assert (l >= 0).all(), 'negative labels'
- assert (l[:, 1:] <= 1).all(), 'non-normalized or out of bounds coordinate labels'
- assert np.unique(l, axis=0).shape[0] == l.shape[0], 'duplicate labels'
- else:
- ne += 1 # label empty
- l = np.zeros((0, 5), dtype=np.float32)
- else:
- nm += 1 # label missing
- l = np.zeros((0, 5), dtype=np.float32)
- x[im_file] = [l, shape, segments]
- except Exception as e:
- nc += 1
- print(f'{prefix}WARNING: Ignoring corrupted image and/or label {im_file}: {e}')
-
- pbar.desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels... " \
- f"{nf} found, {nm} missing, {ne} empty, {nc} corrupted"
- pbar.close()
-
- if nf == 0:
- print(f'{prefix}WARNING: No labels found in {path}. See {help_url}')
-
- x['hash'] = get_hash(self.label_files + self.img_files)
- x['results'] = nf, nm, ne, nc, i + 1
- x['version'] = 0.1 # cache version
- torch.save(x, path) # save for next time
- logging.info(f'{prefix}New cache created: {path}')
- return x
-
- def __len__(self):
- return len(self.img_files)
-
- # def __iter__(self):
- # self.count = -1
- # print('ran dataset iter')
- # #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
- # return self
-
- def __getitem__(self, index):
- index = self.indices[index] # linear, shuffled, or image_weights
-
- hyp = self.hyp
- mosaic = self.mosaic and random.random() < hyp['mosaic']
- if mosaic:
- # Load mosaic
- if random.random() < 0.8:
- img, labels = load_mosaic(self, index)
- else:
- img, labels = load_mosaic9(self, index)
- shapes = None
-
- # MixUp https://arxiv.org/pdf/1710.09412.pdf
- if random.random() < hyp['mixup']:
- if random.random() < 0.8:
- img2, labels2 = load_mosaic(self, random.randint(0, len(self.labels) - 1))
- else:
- img2, labels2 = load_mosaic9(self, random.randint(0, len(self.labels) - 1))
- r = np.random.beta(8.0, 8.0) # mixup ratio, alpha=beta=8.0
- img = (img * r + img2 * (1 - r)).astype(np.uint8)
- labels = np.concatenate((labels, labels2), 0)
-
- else:
- # Load image
- img, (h0, w0), (h, w) = load_image(self, index)
-
- # Letterbox
- shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
- img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
- shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
-
- labels = self.labels[index].copy()
- if labels.size: # normalized xywh to pixel xyxy format
- labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
-
- if self.augment:
- # Augment imagespace
- if not mosaic:
- img, labels = random_perspective(img, labels,
- degrees=hyp['degrees'],
- translate=hyp['translate'],
- scale=hyp['scale'],
- shear=hyp['shear'],
- perspective=hyp['perspective'])
-
-
- #img, labels = self.albumentations(img, labels)
-
- # Augment colorspace
- augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
-
- # Apply cutouts
- # if random.random() < 0.9:
- # labels = cutout(img, labels)
-
- if random.random() < hyp['paste_in']:
- sample_labels, sample_images, sample_masks = [], [], []
- while len(sample_labels) < 30:
- sample_labels_, sample_images_, sample_masks_ = load_samples(self, random.randint(0, len(self.labels) - 1))
- sample_labels += sample_labels_
- sample_images += sample_images_
- sample_masks += sample_masks_
- #print(len(sample_labels))
- if len(sample_labels) == 0:
- break
- labels = pastein(img, labels, sample_labels, sample_images, sample_masks)
-
- nL = len(labels) # number of labels
- if nL:
- labels[:, 1:5] = xyxy2xywh(labels[:, 1:5]) # convert xyxy to xywh
- labels[:, [2, 4]] /= img.shape[0] # normalized height 0-1
- labels[:, [1, 3]] /= img.shape[1] # normalized width 0-1
-
- if self.augment:
- # flip up-down
- if random.random() < hyp['flipud']:
- img = np.flipud(img)
- if nL:
- labels[:, 2] = 1 - labels[:, 2]
-
- # flip left-right
- if random.random() < hyp['fliplr']:
- img = np.fliplr(img)
- if nL:
- labels[:, 1] = 1 - labels[:, 1]
-
- labels_out = torch.zeros((nL, 6))
- if nL:
- labels_out[:, 1:] = torch.from_numpy(labels)
-
- # Convert
- img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
- img = np.ascontiguousarray(img)
-
- return torch.from_numpy(img), labels_out, self.img_files[index], shapes
-
- @staticmethod
- def collate_fn(batch):
- img, label, path, shapes = zip(*batch) # transposed
- for i, l in enumerate(label):
- l[:, 0] = i # add target image index for build_targets()
- return torch.stack(img, 0), torch.cat(label, 0), path, shapes
-
- @staticmethod
- def collate_fn4(batch):
- img, label, path, shapes = zip(*batch) # transposed
- n = len(shapes) // 4
- img4, label4, path4, shapes4 = [], [], path[:n], shapes[:n]
-
- ho = torch.tensor([[0., 0, 0, 1, 0, 0]])
- wo = torch.tensor([[0., 0, 1, 0, 0, 0]])
- s = torch.tensor([[1, 1, .5, .5, .5, .5]]) # scale
- for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
- i *= 4
- if random.random() < 0.5:
- im = F.interpolate(img[i].unsqueeze(0).float(), scale_factor=2., mode='bilinear', align_corners=False)[
- 0].type(img[i].type())
- l = label[i]
- else:
- im = torch.cat((torch.cat((img[i], img[i + 1]), 1), torch.cat((img[i + 2], img[i + 3]), 1)), 2)
- l = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
- img4.append(im)
- label4.append(l)
-
- for i, l in enumerate(label4):
- l[:, 0] = i # add target image index for build_targets()
-
- return torch.stack(img4, 0), torch.cat(label4, 0), path4, shapes4
-
-
-# Ancillary functions --------------------------------------------------------------------------------------------------
-def load_image(self, index):
- # loads 1 image from dataset, returns img, original hw, resized hw
- img = self.imgs[index]
- if img is None: # not cached
- path = self.img_files[index]
- img = cv2.imread(path) # BGR
- assert img is not None, 'Image Not Found ' + path
- h0, w0 = img.shape[:2] # orig hw
- r = self.img_size / max(h0, w0) # resize image to img_size
- if r != 1: # always resize down, only resize up if training with augmentation
- interp = cv2.INTER_AREA if r < 1 and not self.augment else cv2.INTER_LINEAR
- img = cv2.resize(img, (int(w0 * r), int(h0 * r)), interpolation=interp)
- return img, (h0, w0), img.shape[:2] # img, hw_original, hw_resized
- else:
- return self.imgs[index], self.img_hw0[index], self.img_hw[index] # img, hw_original, hw_resized
-
-
-def augment_hsv(img, hgain=0.5, sgain=0.5, vgain=0.5):
- r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
- hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV))
- dtype = img.dtype # uint8
-
- x = np.arange(0, 256, dtype=np.int16)
- lut_hue = ((x * r[0]) % 180).astype(dtype)
- lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
- lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
-
- img_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val))).astype(dtype)
- cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR, dst=img) # no return needed
-
-
-def hist_equalize(img, clahe=True, bgr=False):
- # Equalize histogram on BGR image 'img' with img.shape(n,m,3) and range 0-255
- yuv = cv2.cvtColor(img, cv2.COLOR_BGR2YUV if bgr else cv2.COLOR_RGB2YUV)
- if clahe:
- c = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
- yuv[:, :, 0] = c.apply(yuv[:, :, 0])
- else:
- yuv[:, :, 0] = cv2.equalizeHist(yuv[:, :, 0]) # equalize Y channel histogram
- return cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR if bgr else cv2.COLOR_YUV2RGB) # convert YUV image to RGB
-
-
-def load_mosaic(self, index):
- # loads images in a 4-mosaic
-
- labels4, segments4 = [], []
- s = self.img_size
- yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border] # mosaic center x, y
- indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
- for i, index in enumerate(indices):
- # Load image
- img, _, (h, w) = load_image(self, index)
-
- # place img in img4
- if i == 0: # top left
- img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
- x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
- x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
- elif i == 1: # top right
- x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
- x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
- elif i == 2: # bottom left
- x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
- x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
- elif i == 3: # bottom right
- x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
- x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
-
- img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
- padw = x1a - x1b
- padh = y1a - y1b
-
- # Labels
- labels, segments = self.labels[index].copy(), self.segments[index].copy()
- if labels.size:
- labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
- segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
- labels4.append(labels)
- segments4.extend(segments)
-
- # Concat/clip labels
- labels4 = np.concatenate(labels4, 0)
- for x in (labels4[:, 1:], *segments4):
- np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
- # img4, labels4 = replicate(img4, labels4) # replicate
-
- # Augment
- #img4, labels4, segments4 = remove_background(img4, labels4, segments4)
- #sample_segments(img4, labels4, segments4, probability=self.hyp['copy_paste'])
- img4, labels4, segments4 = copy_paste(img4, labels4, segments4, probability=self.hyp['copy_paste'])
- img4, labels4 = random_perspective(img4, labels4, segments4,
- degrees=self.hyp['degrees'],
- translate=self.hyp['translate'],
- scale=self.hyp['scale'],
- shear=self.hyp['shear'],
- perspective=self.hyp['perspective'],
- border=self.mosaic_border) # border to remove
-
- return img4, labels4
-
-
-def load_mosaic9(self, index):
- # loads images in a 9-mosaic
-
- labels9, segments9 = [], []
- s = self.img_size
- indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
- for i, index in enumerate(indices):
- # Load image
- img, _, (h, w) = load_image(self, index)
-
- # place img in img9
- if i == 0: # center
- img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
- h0, w0 = h, w
- c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
- elif i == 1: # top
- c = s, s - h, s + w, s
- elif i == 2: # top right
- c = s + wp, s - h, s + wp + w, s
- elif i == 3: # right
- c = s + w0, s, s + w0 + w, s + h
- elif i == 4: # bottom right
- c = s + w0, s + hp, s + w0 + w, s + hp + h
- elif i == 5: # bottom
- c = s + w0 - w, s + h0, s + w0, s + h0 + h
- elif i == 6: # bottom left
- c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
- elif i == 7: # left
- c = s - w, s + h0 - h, s, s + h0
- elif i == 8: # top left
- c = s - w, s + h0 - hp - h, s, s + h0 - hp
-
- padx, pady = c[:2]
- x1, y1, x2, y2 = [max(x, 0) for x in c] # allocate coords
-
- # Labels
- labels, segments = self.labels[index].copy(), self.segments[index].copy()
- if labels.size:
- labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
- segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
- labels9.append(labels)
- segments9.extend(segments)
-
- # Image
- img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
- hp, wp = h, w # height, width previous
-
- # Offset
- yc, xc = [int(random.uniform(0, s)) for _ in self.mosaic_border] # mosaic center x, y
- img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
-
- # Concat/clip labels
- labels9 = np.concatenate(labels9, 0)
- labels9[:, [1, 3]] -= xc
- labels9[:, [2, 4]] -= yc
- c = np.array([xc, yc]) # centers
- segments9 = [x - c for x in segments9]
-
- for x in (labels9[:, 1:], *segments9):
- np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
- # img9, labels9 = replicate(img9, labels9) # replicate
-
- # Augment
- #img9, labels9, segments9 = remove_background(img9, labels9, segments9)
- img9, labels9, segments9 = copy_paste(img9, labels9, segments9, probability=self.hyp['copy_paste'])
- img9, labels9 = random_perspective(img9, labels9, segments9,
- degrees=self.hyp['degrees'],
- translate=self.hyp['translate'],
- scale=self.hyp['scale'],
- shear=self.hyp['shear'],
- perspective=self.hyp['perspective'],
- border=self.mosaic_border) # border to remove
-
- return img9, labels9
-
-
-def load_samples(self, index):
- # loads images in a 4-mosaic
-
- labels4, segments4 = [], []
- s = self.img_size
- yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border] # mosaic center x, y
- indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
- for i, index in enumerate(indices):
- # Load image
- img, _, (h, w) = load_image(self, index)
-
- # place img in img4
- if i == 0: # top left
- img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
- x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
- x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
- elif i == 1: # top right
- x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
- x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
- elif i == 2: # bottom left
- x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
- x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
- elif i == 3: # bottom right
- x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
- x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
-
- img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
- padw = x1a - x1b
- padh = y1a - y1b
-
- # Labels
- labels, segments = self.labels[index].copy(), self.segments[index].copy()
- if labels.size:
- labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
- segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
- labels4.append(labels)
- segments4.extend(segments)
-
- # Concat/clip labels
- labels4 = np.concatenate(labels4, 0)
- for x in (labels4[:, 1:], *segments4):
- np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
- # img4, labels4 = replicate(img4, labels4) # replicate
-
- # Augment
- #img4, labels4, segments4 = remove_background(img4, labels4, segments4)
- sample_labels, sample_images, sample_masks = sample_segments(img4, labels4, segments4, probability=0.5)
-
- return sample_labels, sample_images, sample_masks
-
-
-def copy_paste(img, labels, segments, probability=0.5):
- # Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
- n = len(segments)
- if probability and n:
- h, w, c = img.shape # height, width, channels
- im_new = np.zeros(img.shape, np.uint8)
- for j in random.sample(range(n), k=round(probability * n)):
- l, s = labels[j], segments[j]
- box = w - l[3], l[2], w - l[1], l[4]
- ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
- if (ioa < 0.30).all(): # allow 30% obscuration of existing labels
- labels = np.concatenate((labels, [[l[0], *box]]), 0)
- segments.append(np.concatenate((w - s[:, 0:1], s[:, 1:2]), 1))
- cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
-
- result = cv2.bitwise_and(src1=img, src2=im_new)
- result = cv2.flip(result, 1) # augment segments (flip left-right)
- i = result > 0 # pixels to replace
- # i[:, :] = result.max(2).reshape(h, w, 1) # act over ch
- img[i] = result[i] # cv2.imwrite('debug.jpg', img) # debug
-
- return img, labels, segments
-
-
-def remove_background(img, labels, segments):
- # Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
- n = len(segments)
- h, w, c = img.shape # height, width, channels
- im_new = np.zeros(img.shape, np.uint8)
- img_new = np.ones(img.shape, np.uint8) * 114
- for j in range(n):
- cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
-
- result = cv2.bitwise_and(src1=img, src2=im_new)
-
- i = result > 0 # pixels to replace
- img_new[i] = result[i] # cv2.imwrite('debug.jpg', img) # debug
-
- return img_new, labels, segments
-
-
-def sample_segments(img, labels, segments, probability=0.5):
- # Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
- n = len(segments)
- sample_labels = []
- sample_images = []
- sample_masks = []
- if probability and n:
- h, w, c = img.shape # height, width, channels
- for j in random.sample(range(n), k=round(probability * n)):
- l, s = labels[j], segments[j]
- box = l[1].astype(int).clip(0,w-1), l[2].astype(int).clip(0,h-1), l[3].astype(int).clip(0,w-1), l[4].astype(int).clip(0,h-1)
-
- #print(box)
- if (box[2] <= box[0]) or (box[3] <= box[1]):
- continue
-
- sample_labels.append(l[0])
-
- mask = np.zeros(img.shape, np.uint8)
-
- cv2.drawContours(mask, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
- sample_masks.append(mask[box[1]:box[3],box[0]:box[2],:])
-
- result = cv2.bitwise_and(src1=img, src2=mask)
- i = result > 0 # pixels to replace
- mask[i] = result[i] # cv2.imwrite('debug.jpg', img) # debug
- #print(box)
- sample_images.append(mask[box[1]:box[3],box[0]:box[2],:])
-
- return sample_labels, sample_images, sample_masks
-
-
-def replicate(img, labels):
- # Replicate labels
- h, w = img.shape[:2]
- boxes = labels[:, 1:].astype(int)
- x1, y1, x2, y2 = boxes.T
- s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels)
- for i in s.argsort()[:round(s.size * 0.5)]: # smallest indices
- x1b, y1b, x2b, y2b = boxes[i]
- bh, bw = y2b - y1b, x2b - x1b
- yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y
- x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh]
- img[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
- labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0)
-
- return img, labels
-
-
-def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
- # Resize and pad image while meeting stride-multiple constraints
- shape = img.shape[:2] # current shape [height, width]
- if isinstance(new_shape, int):
- new_shape = (new_shape, new_shape)
-
- # Scale ratio (new / old)
- r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
- if not scaleup: # only scale down, do not scale up (for better test mAP)
- r = min(r, 1.0)
-
- # Compute padding
- ratio = r, r # width, height ratios
- new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
- dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
- if auto: # minimum rectangle
- dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
- elif scaleFill: # stretch
- dw, dh = 0.0, 0.0
- new_unpad = (new_shape[1], new_shape[0])
- ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
-
- dw /= 2 # divide padding into 2 sides
- dh /= 2
-
- if shape[::-1] != new_unpad: # resize
- img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
- top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
- left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
- img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
- return img, ratio, (dw, dh)
-
-
-def random_perspective(img, targets=(), segments=(), degrees=10, translate=.1, scale=.1, shear=10, perspective=0.0,
- border=(0, 0)):
- # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
- # targets = [cls, xyxy]
-
- height = img.shape[0] + border[0] * 2 # shape(h,w,c)
- width = img.shape[1] + border[1] * 2
-
- # Center
- C = np.eye(3)
- C[0, 2] = -img.shape[1] / 2 # x translation (pixels)
- C[1, 2] = -img.shape[0] / 2 # y translation (pixels)
-
- # Perspective
- P = np.eye(3)
- P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
- P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
-
- # Rotation and Scale
- R = np.eye(3)
- a = random.uniform(-degrees, degrees)
- # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
- s = random.uniform(1 - scale, 1.1 + scale)
- # s = 2 ** random.uniform(-scale, scale)
- R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
-
- # Shear
- S = np.eye(3)
- S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
- S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
-
- # Translation
- T = np.eye(3)
- T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
- T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
-
- # Combined rotation matrix
- M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
- if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
- if perspective:
- img = cv2.warpPerspective(img, M, dsize=(width, height), borderValue=(114, 114, 114))
- else: # affine
- img = cv2.warpAffine(img, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
-
- # Visualize
- # import matplotlib.pyplot as plt
- # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
- # ax[0].imshow(img[:, :, ::-1]) # base
- # ax[1].imshow(img2[:, :, ::-1]) # warped
-
- # Transform label coordinates
- n = len(targets)
- if n:
- use_segments = any(x.any() for x in segments)
- new = np.zeros((n, 4))
- if use_segments: # warp segments
- segments = resample_segments(segments) # upsample
- for i, segment in enumerate(segments):
- xy = np.ones((len(segment), 3))
- xy[:, :2] = segment
- xy = xy @ M.T # transform
- xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
-
- # clip
- new[i] = segment2box(xy, width, height)
-
- else: # warp boxes
- xy = np.ones((n * 4, 3))
- xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
- xy = xy @ M.T # transform
- xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
-
- # create new boxes
- x = xy[:, [0, 2, 4, 6]]
- y = xy[:, [1, 3, 5, 7]]
- new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
-
- # clip
- new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
- new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
-
- # filter candidates
- i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
- targets = targets[i]
- targets[:, 1:5] = new[i]
-
- return img, targets
-
-
-def box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
- # Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
- w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
- w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
- ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
- return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
-
-
-def bbox_ioa(box1, box2):
- # Returns the intersection over box2 area given box1, box2. box1 is 4, box2 is nx4. boxes are x1y1x2y2
- box2 = box2.transpose()
-
- # Get the coordinates of bounding boxes
- b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
- b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
-
- # Intersection area
- inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
- (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
-
- # box2 area
- box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + 1e-16
-
- # Intersection over box2 area
- return inter_area / box2_area
-
-
-def cutout(image, labels):
- # Applies image cutout augmentation https://arxiv.org/abs/1708.04552
- h, w = image.shape[:2]
-
- # create random masks
- scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
- for s in scales:
- mask_h = random.randint(1, int(h * s))
- mask_w = random.randint(1, int(w * s))
-
- # box
- xmin = max(0, random.randint(0, w) - mask_w // 2)
- ymin = max(0, random.randint(0, h) - mask_h // 2)
- xmax = min(w, xmin + mask_w)
- ymax = min(h, ymin + mask_h)
-
- # apply random color mask
- image[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
-
- # return unobscured labels
- if len(labels) and s > 0.03:
- box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
- ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
- labels = labels[ioa < 0.60] # remove >60% obscured labels
-
- return labels
-
-
-def pastein(image, labels, sample_labels, sample_images, sample_masks):
- # Applies image cutout augmentation https://arxiv.org/abs/1708.04552
- h, w = image.shape[:2]
-
- # create random masks
- scales = [0.75] * 2 + [0.5] * 4 + [0.25] * 4 + [0.125] * 4 + [0.0625] * 6 # image size fraction
- for s in scales:
- if random.random() < 0.2:
- continue
- mask_h = random.randint(1, int(h * s))
- mask_w = random.randint(1, int(w * s))
-
- # box
- xmin = max(0, random.randint(0, w) - mask_w // 2)
- ymin = max(0, random.randint(0, h) - mask_h // 2)
- xmax = min(w, xmin + mask_w)
- ymax = min(h, ymin + mask_h)
-
- box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
- if len(labels):
- ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
- else:
- ioa = np.zeros(1)
-
- if (ioa < 0.30).all() and len(sample_labels) and (xmax > xmin+20) and (ymax > ymin+20): # allow 30% obscuration of existing labels
- sel_ind = random.randint(0, len(sample_labels)-1)
- #print(len(sample_labels))
- #print(sel_ind)
- #print((xmax-xmin, ymax-ymin))
- #print(image[ymin:ymax, xmin:xmax].shape)
- #print([[sample_labels[sel_ind], *box]])
- #print(labels.shape)
- hs, ws, cs = sample_images[sel_ind].shape
- r_scale = min((ymax-ymin)/hs, (xmax-xmin)/ws)
- r_w = int(ws*r_scale)
- r_h = int(hs*r_scale)
-
- if (r_w > 10) and (r_h > 10):
- r_mask = cv2.resize(sample_masks[sel_ind], (r_w, r_h))
- r_image = cv2.resize(sample_images[sel_ind], (r_w, r_h))
- temp_crop = image[ymin:ymin+r_h, xmin:xmin+r_w]
- m_ind = r_mask > 0
- if m_ind.astype(np.int).sum() > 60:
- temp_crop[m_ind] = r_image[m_ind]
- #print(sample_labels[sel_ind])
- #print(sample_images[sel_ind].shape)
- #print(temp_crop.shape)
- box = np.array([xmin, ymin, xmin+r_w, ymin+r_h], dtype=np.float32)
- if len(labels):
- labels = np.concatenate((labels, [[sample_labels[sel_ind], *box]]), 0)
- else:
- labels = np.array([[sample_labels[sel_ind], *box]])
-
- image[ymin:ymin+r_h, xmin:xmin+r_w] = temp_crop
-
- return labels
-
-class Albumentations:
- # YOLOv5 Albumentations class (optional, only used if package is installed)
- def __init__(self):
- self.transform = None
- import albumentations as A
-
- self.transform = A.Compose([
- A.CLAHE(p=0.01),
- A.RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=0.01),
- A.RandomGamma(gamma_limit=[80, 120], p=0.01),
- A.Blur(p=0.01),
- A.MedianBlur(p=0.01),
- A.ToGray(p=0.01),
- A.ImageCompression(quality_lower=75, p=0.01),],
- bbox_params=A.BboxParams(format='pascal_voc', label_fields=['class_labels']))
-
- #logging.info(colorstr('albumentations: ') + ', '.join(f'{x}' for x in self.transform.transforms if x.p))
-
- def __call__(self, im, labels, p=1.0):
- if self.transform and random.random() < p:
- new = self.transform(image=im, bboxes=labels[:, 1:], class_labels=labels[:, 0]) # transformed
- im, labels = new['image'], np.array([[c, *b] for c, b in zip(new['class_labels'], new['bboxes'])])
- return im, labels
-
-
-def create_folder(path='./new'):
- # Create folder
- if os.path.exists(path):
- shutil.rmtree(path) # delete output folder
- os.makedirs(path) # make new output folder
-
-
-def flatten_recursive(path='../coco'):
- # Flatten a recursive directory by bringing all files to top level
- new_path = Path(path + '_flat')
- create_folder(new_path)
- for file in tqdm(glob.glob(str(Path(path)) + '/**/*.*', recursive=True)):
- shutil.copyfile(file, new_path / Path(file).name)
-
-
-def extract_boxes(path='../coco/'): # from utils.datasets import *; extract_boxes('../coco128')
- # Convert detection dataset into classification dataset, with one directory per class
-
- path = Path(path) # images dir
- shutil.rmtree(path / 'classifier') if (path / 'classifier').is_dir() else None # remove existing
- files = list(path.rglob('*.*'))
- n = len(files) # number of files
- for im_file in tqdm(files, total=n):
- if im_file.suffix[1:] in img_formats:
- # image
- im = cv2.imread(str(im_file))[..., ::-1] # BGR to RGB
- h, w = im.shape[:2]
-
- # labels
- lb_file = Path(img2label_paths([str(im_file)])[0])
- if Path(lb_file).exists():
- with open(lb_file, 'r') as f:
- lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # labels
-
- for j, x in enumerate(lb):
- c = int(x[0]) # class
- f = (path / 'classifier') / f'{c}' / f'{path.stem}_{im_file.stem}_{j}.jpg' # new filename
- if not f.parent.is_dir():
- f.parent.mkdir(parents=True)
-
- b = x[1:] * [w, h, w, h] # box
- # b[2:] = b[2:].max() # rectangle to square
- b[2:] = b[2:] * 1.2 + 3 # pad
- b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(np.int)
-
- b[[0, 2]] = np.clip(b[[0, 2]], 0, w) # clip boxes outside of image
- b[[1, 3]] = np.clip(b[[1, 3]], 0, h)
- assert cv2.imwrite(str(f), im[b[1]:b[3], b[0]:b[2]]), f'box failure in {f}'
-
-
-def autosplit(path='../coco', weights=(0.9, 0.1, 0.0), annotated_only=False):
- """ Autosplit a dataset into train/val/test splits and save path/autosplit_*.txt files
- Usage: from utils.datasets import *; autosplit('../coco')
- Arguments
- path: Path to images directory
- weights: Train, val, test weights (list)
- annotated_only: Only use images with an annotated txt file
- """
- path = Path(path) # images dir
- files = sum([list(path.rglob(f"*.{img_ext}")) for img_ext in img_formats], []) # image files only
- n = len(files) # number of files
- indices = random.choices([0, 1, 2], weights=weights, k=n) # assign each image to a split
-
- txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
- [(path / x).unlink() for x in txt if (path / x).exists()] # remove existing
-
- print(f'Autosplitting images from {path}' + ', using *.txt labeled images only' * annotated_only)
- for i, img in tqdm(zip(indices, files), total=n):
- if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
- with open(path / txt[i], 'a') as f:
- f.write(str(img) + '\n') # add image to txt file
-
-
-def load_segmentations(self, index):
- key = '/work/handsomejw66/coco17/' + self.img_files[index]
- #print(key)
- # /work/handsomejw66/coco17/
- return self.segs[key]
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/utils/setuptools_build.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/utils/setuptools_build.py
deleted file mode 100644
index f460c4003f32fea2008eaf7ce590e1dd6a4e36e9..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/utils/setuptools_build.py
+++ /dev/null
@@ -1,195 +0,0 @@
-import sys
-import textwrap
-from typing import List, Optional, Sequence
-
-# Shim to wrap setup.py invocation with setuptools
-# Note that __file__ is handled via two {!r} *and* %r, to ensure that paths on
-# Windows are correctly handled (it should be "C:\\Users" not "C:\Users").
-_SETUPTOOLS_SHIM = textwrap.dedent(
- """
- exec(compile('''
- # This is -- a caller that pip uses to run setup.py
- #
- # - It imports setuptools before invoking setup.py, to enable projects that directly
- # import from `distutils.core` to work with newer packaging standards.
- # - It provides a clear error message when setuptools is not installed.
- # - It sets `sys.argv[0]` to the underlying `setup.py`, when invoking `setup.py` so
- # setuptools doesn't think the script is `-c`. This avoids the following warning:
- # manifest_maker: standard file '-c' not found".
- # - It generates a shim setup.py, for handling setup.cfg-only projects.
- import os, sys, tokenize
-
- try:
- import setuptools
- except ImportError as error:
- print(
- "ERROR: Can not execute `setup.py` since setuptools is not available in "
- "the build environment.",
- file=sys.stderr,
- )
- sys.exit(1)
-
- __file__ = %r
- sys.argv[0] = __file__
-
- if os.path.exists(__file__):
- filename = __file__
- with tokenize.open(__file__) as f:
- setup_py_code = f.read()
- else:
- filename = ""
- setup_py_code = "from setuptools import setup; setup()"
-
- exec(compile(setup_py_code, filename, "exec"))
- ''' % ({!r},), "", "exec"))
- """
-).rstrip()
-
-
-def make_setuptools_shim_args(
- setup_py_path: str,
- global_options: Sequence[str] = None,
- no_user_config: bool = False,
- unbuffered_output: bool = False,
-) -> List[str]:
- """
- Get setuptools command arguments with shim wrapped setup file invocation.
-
- :param setup_py_path: The path to setup.py to be wrapped.
- :param global_options: Additional global options.
- :param no_user_config: If True, disables personal user configuration.
- :param unbuffered_output: If True, adds the unbuffered switch to the
- argument list.
- """
- args = [sys.executable]
- if unbuffered_output:
- args += ["-u"]
- args += ["-c", _SETUPTOOLS_SHIM.format(setup_py_path)]
- if global_options:
- args += global_options
- if no_user_config:
- args += ["--no-user-cfg"]
- return args
-
-
-def make_setuptools_bdist_wheel_args(
- setup_py_path: str,
- global_options: Sequence[str],
- build_options: Sequence[str],
- destination_dir: str,
-) -> List[str]:
- # NOTE: Eventually, we'd want to also -S to the flags here, when we're
- # isolating. Currently, it breaks Python in virtualenvs, because it
- # relies on site.py to find parts of the standard library outside the
- # virtualenv.
- args = make_setuptools_shim_args(
- setup_py_path, global_options=global_options, unbuffered_output=True
- )
- args += ["bdist_wheel", "-d", destination_dir]
- args += build_options
- return args
-
-
-def make_setuptools_clean_args(
- setup_py_path: str,
- global_options: Sequence[str],
-) -> List[str]:
- args = make_setuptools_shim_args(
- setup_py_path, global_options=global_options, unbuffered_output=True
- )
- args += ["clean", "--all"]
- return args
-
-
-def make_setuptools_develop_args(
- setup_py_path: str,
- global_options: Sequence[str],
- install_options: Sequence[str],
- no_user_config: bool,
- prefix: Optional[str],
- home: Optional[str],
- use_user_site: bool,
-) -> List[str]:
- assert not (use_user_site and prefix)
-
- args = make_setuptools_shim_args(
- setup_py_path,
- global_options=global_options,
- no_user_config=no_user_config,
- )
-
- args += ["develop", "--no-deps"]
-
- args += install_options
-
- if prefix:
- args += ["--prefix", prefix]
- if home is not None:
- args += ["--install-dir", home]
-
- if use_user_site:
- args += ["--user", "--prefix="]
-
- return args
-
-
-def make_setuptools_egg_info_args(
- setup_py_path: str,
- egg_info_dir: Optional[str],
- no_user_config: bool,
-) -> List[str]:
- args = make_setuptools_shim_args(setup_py_path, no_user_config=no_user_config)
-
- args += ["egg_info"]
-
- if egg_info_dir:
- args += ["--egg-base", egg_info_dir]
-
- return args
-
-
-def make_setuptools_install_args(
- setup_py_path: str,
- global_options: Sequence[str],
- install_options: Sequence[str],
- record_filename: str,
- root: Optional[str],
- prefix: Optional[str],
- header_dir: Optional[str],
- home: Optional[str],
- use_user_site: bool,
- no_user_config: bool,
- pycompile: bool,
-) -> List[str]:
- assert not (use_user_site and prefix)
- assert not (use_user_site and root)
-
- args = make_setuptools_shim_args(
- setup_py_path,
- global_options=global_options,
- no_user_config=no_user_config,
- unbuffered_output=True,
- )
- args += ["install", "--record", record_filename]
- args += ["--single-version-externally-managed"]
-
- if root is not None:
- args += ["--root", root]
- if prefix is not None:
- args += ["--prefix", prefix]
- if home is not None:
- args += ["--home", home]
- if use_user_site:
- args += ["--user", "--prefix="]
-
- if pycompile:
- args += ["--compile"]
- else:
- args += ["--no-compile"]
-
- if header_dir:
- args += ["--install-headers", header_dir]
-
- args += install_options
-
- return args
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/certifi/__main__.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/certifi/__main__.py
deleted file mode 100644
index 00376349e69ad8b9dbf401cddc34055951e4b02e..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/certifi/__main__.py
+++ /dev/null
@@ -1,12 +0,0 @@
-import argparse
-
-from pip._vendor.certifi import contents, where
-
-parser = argparse.ArgumentParser()
-parser.add_argument("-c", "--contents", action="store_true")
-args = parser.parse_args()
-
-if args.contents:
- print(contents())
-else:
- print(where())
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/rich/file_proxy.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/rich/file_proxy.py
deleted file mode 100644
index 3ec593a5a480b101f8d67a6bc4b2ceabc4685d8e..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/rich/file_proxy.py
+++ /dev/null
@@ -1,54 +0,0 @@
-import io
-from typing import List, Any, IO, TYPE_CHECKING
-
-from .ansi import AnsiDecoder
-from .text import Text
-
-if TYPE_CHECKING:
- from .console import Console
-
-
-class FileProxy(io.TextIOBase):
- """Wraps a file (e.g. sys.stdout) and redirects writes to a console."""
-
- def __init__(self, console: "Console", file: IO[str]) -> None:
- self.__console = console
- self.__file = file
- self.__buffer: List[str] = []
- self.__ansi_decoder = AnsiDecoder()
-
- @property
- def rich_proxied_file(self) -> IO[str]:
- """Get proxied file."""
- return self.__file
-
- def __getattr__(self, name: str) -> Any:
- return getattr(self.__file, name)
-
- def write(self, text: str) -> int:
- if not isinstance(text, str):
- raise TypeError(f"write() argument must be str, not {type(text).__name__}")
- buffer = self.__buffer
- lines: List[str] = []
- while text:
- line, new_line, text = text.partition("\n")
- if new_line:
- lines.append("".join(buffer) + line)
- del buffer[:]
- else:
- buffer.append(line)
- break
- if lines:
- console = self.__console
- with console:
- output = Text("\n").join(
- self.__ansi_decoder.decode_line(line) for line in lines
- )
- console.print(output)
- return len(text)
-
- def flush(self) -> None:
- buffer = self.__buffer
- if buffer:
- self.__console.print("".join(buffer))
- del buffer[:]
diff --git a/spaces/allknowingroger/Image-Models-Test127/README.md b/spaces/allknowingroger/Image-Models-Test127/README.md
deleted file mode 100644
index 20d41a468220e83046196affbc475cfe0b4fb469..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test127/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: More Image Models
-emoji: 😻
-colorFrom: red
-colorTo: gray
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-duplicated_from: allknowingroger/Image-Models-Test126
----
-
-
\ No newline at end of file
diff --git a/spaces/allknowingroger/Image-Models-Test141/README.md b/spaces/allknowingroger/Image-Models-Test141/README.md
deleted file mode 100644
index b167ccb175d1e62f9f47b5f2ff3e60261504e1d9..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test141/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: More Image Models
-emoji: 😻
-colorFrom: red
-colorTo: gray
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-duplicated_from: allknowingroger/Image-Models-Test140
----
-
-
\ No newline at end of file
diff --git a/spaces/ameerazam08/zoe-depth/geometry.py b/spaces/ameerazam08/zoe-depth/geometry.py
deleted file mode 100644
index 6cb738f60d68b6dd2e58fa61093367f748a31bce..0000000000000000000000000000000000000000
--- a/spaces/ameerazam08/zoe-depth/geometry.py
+++ /dev/null
@@ -1,72 +0,0 @@
-import numpy as np
-
-def get_intrinsics(H,W):
- """
- Intrinsics for a pinhole camera model.
- Assume fov of 55 degrees and central principal point.
- """
- f = 0.5 * W / np.tan(0.5 * 55 * np.pi / 180.0)
- cx = 0.5 * W
- cy = 0.5 * H
- return np.array([[f, 0, cx],
- [0, f, cy],
- [0, 0, 1]])
-
-def depth_to_points(depth, R=None, t=None):
-
- K = get_intrinsics(depth.shape[1], depth.shape[2])
- Kinv = np.linalg.inv(K)
- if R is None:
- R = np.eye(3)
- if t is None:
- t = np.zeros(3)
-
- # M converts from your coordinate to PyTorch3D's coordinate system
- M = np.eye(3)
- M[0, 0] = -1.0
- M[1, 1] = -1.0
-
- height, width = depth.shape[1:3]
-
- x = np.arange(width)
- y = np.arange(height)
- coord = np.stack(np.meshgrid(x, y), -1)
- coord = np.concatenate((coord, np.ones_like(coord)[:, :, [0]]), -1) # z=1
- coord = coord.astype(np.float32)
- # coord = torch.as_tensor(coord, dtype=torch.float32, device=device)
- coord = coord[None] # bs, h, w, 3
-
- D = depth[:, :, :, None, None]
- # print(D.shape, Kinv[None, None, None, ...].shape, coord[:, :, :, :, None].shape )
- pts3D_1 = D * Kinv[None, None, None, ...] @ coord[:, :, :, :, None]
- # pts3D_1 live in your coordinate system. Convert them to Py3D's
- pts3D_1 = M[None, None, None, ...] @ pts3D_1
- # from reference to targe tviewpoint
- pts3D_2 = R[None, None, None, ...] @ pts3D_1 + t[None, None, None, :, None]
- # pts3D_2 = pts3D_1
- # depth_2 = pts3D_2[:, :, :, 2, :] # b,1,h,w
- return pts3D_2[:, :, :, :3, 0][0]
-
-
-def create_triangles(h, w, mask=None):
- """Creates mesh triangle indices from a given pixel grid size.
- This function is not and need not be differentiable as triangle indices are
- fixed.
- Args:
- h: (int) denoting the height of the image.
- w: (int) denoting the width of the image.
- Returns:
- triangles: 2D numpy array of indices (int) with shape (2(W-1)(H-1) x 3)
- """
- x, y = np.meshgrid(range(w - 1), range(h - 1))
- tl = y * w + x
- tr = y * w + x + 1
- bl = (y + 1) * w + x
- br = (y + 1) * w + x + 1
- triangles = np.array([tl, bl, tr, br, tr, bl])
- triangles = np.transpose(triangles, (1, 2, 0)).reshape(
- ((w - 1) * (h - 1) * 2, 3))
- if mask is not None:
- mask = mask.reshape(-1)
- triangles = triangles[mask[triangles].all(1)]
- return triangles
\ No newline at end of file
diff --git a/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/client/css/buttons.css b/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/client/css/buttons.css
deleted file mode 100644
index e13f52d9a0414daaa80518bd205913a645a29563..0000000000000000000000000000000000000000
--- a/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/client/css/buttons.css
+++ /dev/null
@@ -1,4 +0,0 @@
-.buttons {
- display: flex;
- justify-content: left;
-}
diff --git a/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/g4f/Provider/Providers/Ails.py b/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/g4f/Provider/Providers/Ails.py
deleted file mode 100644
index 5feec9e987e3cd2590e2a72b623dc4b90e0cf53d..0000000000000000000000000000000000000000
--- a/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/g4f/Provider/Providers/Ails.py
+++ /dev/null
@@ -1,87 +0,0 @@
-import os
-import time
-import json
-import uuid
-import hashlib
-import requests
-
-from ...typing import sha256, Dict, get_type_hints
-from datetime import datetime
-
-url: str = 'https://ai.ls'
-model: str = 'gpt-3.5-turbo'
-supports_stream = True
-needs_auth = False
-working = True
-
-
-class Utils:
- def hash(json_data: Dict[str, str]) -> sha256:
-
- base_string: str = '%s:%s:%s:%s' % (
- json_data['t'],
- json_data['m'],
- 'WI,2rU#_r:r~aF4aJ36[.Z(/8Rv93Rf',
- len(json_data['m'])
- )
-
- return hashlib.sha256(base_string.encode()).hexdigest()
-
- def format_timestamp(timestamp: int) -> str:
-
- e = timestamp
- n = e % 10
- r = n + 1 if n % 2 == 0 else n
- return str(e - n + r)
-
-
-def _create_completion(model: str, messages: list, temperature: float = 0.6, stream: bool = False, **kwargs):
-
- headers = {
- 'authority': 'api.caipacity.com',
- 'accept': '*/*',
- 'accept-language': 'en,fr-FR;q=0.9,fr;q=0.8,es-ES;q=0.7,es;q=0.6,en-US;q=0.5,am;q=0.4,de;q=0.3',
- 'authorization': 'Bearer free',
- 'client-id': str(uuid.uuid4()),
- 'client-v': '0.1.249',
- 'content-type': 'application/json',
- 'origin': 'https://ai.ls',
- 'referer': 'https://ai.ls/',
- 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-platform': '"Windows"',
- 'sec-fetch-dest': 'empty',
- 'sec-fetch-mode': 'cors',
- 'sec-fetch-site': 'cross-site',
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
- }
-
- timestamp = Utils.format_timestamp(int(time.time() * 1000))
-
- sig = {
- 'd': datetime.now().strftime('%Y-%m-%d'),
- 't': timestamp,
- 's': Utils.hash({
- 't': timestamp,
- 'm': messages[-1]['content']})}
-
- json_data = json.dumps(separators=(',', ':'), obj={
- 'model': 'gpt-3.5-turbo',
- 'temperature': 0.6,
- 'stream': True,
- 'messages': messages} | sig)
-
- response = requests.post('https://api.caipacity.com/v1/chat/completions',
- headers=headers, data=json_data, stream=True)
-
- for token in response.iter_lines():
- if b'content' in token:
- completion_chunk = json.loads(token.decode().replace('data: ', ''))
- token = completion_chunk['choices'][0]['delta'].get('content')
- if token != None:
- yield token
-
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join(
- [f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
diff --git a/spaces/aphenx/bingo/src/components/chat-notification.tsx b/spaces/aphenx/bingo/src/components/chat-notification.tsx
deleted file mode 100644
index 4be24d0f1755c8058698cfa66c736d8d4792475a..0000000000000000000000000000000000000000
--- a/spaces/aphenx/bingo/src/components/chat-notification.tsx
+++ /dev/null
@@ -1,77 +0,0 @@
-import { useEffect } from 'react'
-import Image from 'next/image'
-
-import IconWarning from '@/assets/images/warning.svg'
-import { ChatError, ErrorCode, ChatMessageModel } from '@/lib/bots/bing/types'
-import { ExternalLink } from './external-link'
-import { useBing } from '@/lib/hooks/use-bing'
-
-export interface ChatNotificationProps extends Pick, 'bot'> {
- message?: ChatMessageModel
-}
-
-function getAction(error: ChatError, reset: () => void) {
- if (error.code === ErrorCode.THROTTLE_LIMIT) {
- reset()
- return (
-
- 你已达到每日最大发送消息次数,请
更换账号 或隔一天后重试
-
- 你的账号已在黑名单,请尝试更换账号及申请解封
-
- )
- }
- if (error.code === ErrorCode.CONVERSATION_LIMIT) {
- return (
-
- 当前话题已中止,请点
-
重新开始
- 开启新的对话
-
- 点击通过人机验证
-
- )
- }
- if (error.code === ErrorCode.BING_UNAUTHORIZED) {
- reset()
- return (
- 没有获取到身份信息或身份信息失效,点此重新设置
- )
- }
- return error.message
-}
-
-export function ChatNotification({ message, bot }: ChatNotificationProps) {
- useEffect(() => {
- window.scrollBy(0, 2000)
- }, [message])
-
- if (!message?.error) return
-
- return (
-
-
-
-
-
-
-
-
-
-
{
- prompt: string
- imageUrl?: string
- options: T
- onEvent: (event: Event) => void
- signal?: AbortSignal
-}
-
-export interface ConversationResponse {
- conversationId: string
- clientId: string
- conversationSignature: string
- result: {
- value: string
- message?: string
- }
-}
-
-export interface Telemetry {
- metrics?: null
- startTime: string
-}
-
-export interface ChatUpdateArgument {
- messages?: ChatResponseMessage[]
- throttling?: Throttling
- requestId: string
- result: null
-}
-
-export type ChatUpdateCompleteResponse = {
- type: 2
- invocationId: string
- item: ChatResponseItem
-} | {
- type: 1
- target: string
- arguments: ChatUpdateArgument[]
-} | {
- type: 3
- invocationId: string
-} | {
- type: 6 | 7
-}
-
-export interface ChatRequestResult {
- value: string
- serviceVersion: string
- error?: string
-}
-
-export interface ChatResponseItem {
- messages: ChatResponseMessage[]
- firstNewMessageIndex: number
- suggestedResponses: null
- conversationId: string
- requestId: string
- conversationExpiryTime: string
- telemetry: Telemetry
- result: ChatRequestResult
- throttling: Throttling
-}
-export enum InvocationEventType {
- Invocation = 1,
- StreamItem = 2,
- Completion = 3,
- StreamInvocation = 4,
- CancelInvocation = 5,
- Ping = 6,
- Close = 7,
-}
-
-// https://github.com/bytemate/bingchat-api/blob/main/src/lib.ts
-
-export interface ConversationInfo {
- conversationId: string
- clientId: string
- conversationSignature: string
- invocationId: number
- conversationStyle: BingConversationStyle
- prompt: string
- imageUrl?: string
-}
-
-export interface BingChatResponse {
- conversationSignature: string
- conversationId: string
- clientId: string
- invocationId: number
- conversationExpiryTime: Date
- response: string
- details: ChatResponseMessage
-}
-
-export interface Throttling {
- maxNumLongDocSummaryUserMessagesInConversation: number
- maxNumUserMessagesInConversation: number
- numLongDocSummaryUserMessagesInConversation: number
- numUserMessagesInConversation: number
-}
-
-export interface ChatResponseMessage {
- text: string
- spokenText?: string
- author: string
- createdAt: Date
- timestamp: Date
- messageId: string
- requestId: string
- offense: string
- adaptiveCards: AdaptiveCard[]
- sourceAttributions: SourceAttribution[]
- feedback: Feedback
- contentOrigin: string
- messageType?: string
- contentType?: string
- privacy: null
- suggestedResponses: SuggestedResponse[]
-}
-
-export interface AdaptiveCard {
- type: string
- version: string
- body: Body[]
-}
-
-export interface Body {
- type: string
- text: string
- wrap: boolean
- size?: string
-}
-
-export interface Feedback {
- tag: null
- updatedOn: null
- type: string
-}
-
-export interface SourceAttribution {
- providerDisplayName: string
- seeMoreUrl: string
- searchQuery: string
-}
-
-export interface SuggestedResponse {
- text: string
- author?: Author
- createdAt?: Date
- timestamp?: Date
- messageId?: string
- messageType?: string
- offense?: string
- feedback?: Feedback
- contentOrigin?: string
- privacy?: null
-}
-
-export interface KBlobRequest {
- knowledgeRequest: KnowledgeRequestContext
- imageBase64?: string
-}
-
-export interface KBlobResponse {
- blobId: string
- processedBlobId?: string
-}
-
-export interface KnowledgeRequestContext {
- imageInfo: ImageInfo;
- knowledgeRequest: KnowledgeRequest;
-}
-
-export interface ImageInfo {
- url?: string;
-}
-
-export interface KnowledgeRequest {
- invokedSkills: string[];
- subscriptionId: string;
- invokedSkillsRequestData: InvokedSkillsRequestData;
- convoData: ConvoData;
-}
-
-export interface ConvoData {
- convoid: string;
- convotone: BingConversationStyle;
-}
-
-export interface InvokedSkillsRequestData {
- enableFaceBlur: boolean;
-}
-
-export interface FileItem {
- url: string;
- status?: 'loading' | 'error' | 'loaded'
-}
diff --git a/spaces/artificialguybr/video-dubbing/TTS/TTS/tts/models/overflow.py b/spaces/artificialguybr/video-dubbing/TTS/TTS/tts/models/overflow.py
deleted file mode 100644
index 92b3c767de4cb5180df4a58d6cfdc1ed194caad7..0000000000000000000000000000000000000000
--- a/spaces/artificialguybr/video-dubbing/TTS/TTS/tts/models/overflow.py
+++ /dev/null
@@ -1,401 +0,0 @@
-import os
-from typing import Dict, List, Union
-
-import torch
-from coqpit import Coqpit
-from torch import nn
-from trainer.logging.tensorboard_logger import TensorboardLogger
-
-from TTS.tts.layers.overflow.common_layers import Encoder, OverflowUtils
-from TTS.tts.layers.overflow.decoder import Decoder
-from TTS.tts.layers.overflow.neural_hmm import NeuralHMM
-from TTS.tts.layers.overflow.plotting_utils import (
- get_spec_from_most_probable_state,
- plot_transition_probabilities_to_numpy,
-)
-from TTS.tts.models.base_tts import BaseTTS
-from TTS.tts.utils.speakers import SpeakerManager
-from TTS.tts.utils.text.tokenizer import TTSTokenizer
-from TTS.tts.utils.visual import plot_alignment, plot_spectrogram
-from TTS.utils.generic_utils import format_aux_input
-from TTS.utils.io import load_fsspec
-
-
-class Overflow(BaseTTS):
- """OverFlow TTS model.
-
- Paper::
- https://arxiv.org/abs/2211.06892
-
- Paper abstract::
- Neural HMMs are a type of neural transducer recently proposed for
- sequence-to-sequence modelling in text-to-speech. They combine the best features
- of classic statistical speech synthesis and modern neural TTS, requiring less
- data and fewer training updates, and are less prone to gibberish output caused
- by neural attention failures. In this paper, we combine neural HMM TTS with
- normalising flows for describing the highly non-Gaussian distribution of speech
- acoustics. The result is a powerful, fully probabilistic model of durations and
- acoustics that can be trained using exact maximum likelihood. Compared to
- dominant flow-based acoustic models, our approach integrates autoregression for
- improved modelling of long-range dependences such as utterance-level prosody.
- Experiments show that a system based on our proposal gives more accurate
- pronunciations and better subjective speech quality than comparable methods,
- whilst retaining the original advantages of neural HMMs. Audio examples and code
- are available at https://shivammehta25.github.io/OverFlow/.
-
- Note:
- - Neural HMMs uses flat start initialization i.e it computes the means and std and transition probabilities
- of the dataset and uses them to initialize the model. This benefits the model and helps with faster learning
- If you change the dataset or want to regenerate the parameters change the `force_generate_statistics` and
- `mel_statistics_parameter_path` accordingly.
-
- - To enable multi-GPU training, set the `use_grad_checkpointing=False` in config.
- This will significantly increase the memory usage. This is because to compute
- the actual data likelihood (not an approximation using MAS/Viterbi) we must use
- all the states at the previous time step during the forward pass to decide the
- probability distribution at the current step i.e the difference between the forward
- algorithm and viterbi approximation.
-
- Check :class:`TTS.tts.configs.overflow.OverFlowConfig` for class arguments.
- """
-
- def __init__(
- self,
- config: "OverFlowConfig",
- ap: "AudioProcessor" = None,
- tokenizer: "TTSTokenizer" = None,
- speaker_manager: SpeakerManager = None,
- ):
- super().__init__(config, ap, tokenizer, speaker_manager)
-
- # pass all config fields to `self`
- # for fewer code change
- self.config = config
- for key in config:
- setattr(self, key, config[key])
-
- self.decoder_output_dim = config.out_channels
-
- self.encoder = Encoder(config.num_chars, config.state_per_phone, config.encoder_in_out_features)
- self.neural_hmm = NeuralHMM(
- frame_channels=self.out_channels,
- ar_order=self.ar_order,
- deterministic_transition=self.deterministic_transition,
- encoder_dim=self.encoder_in_out_features,
- prenet_type=self.prenet_type,
- prenet_dim=self.prenet_dim,
- prenet_n_layers=self.prenet_n_layers,
- prenet_dropout=self.prenet_dropout,
- prenet_dropout_at_inference=self.prenet_dropout_at_inference,
- memory_rnn_dim=self.memory_rnn_dim,
- outputnet_size=self.outputnet_size,
- flat_start_params=self.flat_start_params,
- std_floor=self.std_floor,
- use_grad_checkpointing=self.use_grad_checkpointing,
- )
-
- self.decoder = Decoder(
- self.out_channels,
- self.hidden_channels_dec,
- self.kernel_size_dec,
- self.dilation_rate,
- self.num_flow_blocks_dec,
- self.num_block_layers,
- dropout_p=self.dropout_p_dec,
- num_splits=self.num_splits,
- num_squeeze=self.num_squeeze,
- sigmoid_scale=self.sigmoid_scale,
- c_in_channels=self.c_in_channels,
- )
-
- self.register_buffer("mean", torch.tensor(0))
- self.register_buffer("std", torch.tensor(1))
-
- def update_mean_std(self, statistics_dict: Dict):
- self.mean.data = torch.tensor(statistics_dict["mean"])
- self.std.data = torch.tensor(statistics_dict["std"])
-
- def preprocess_batch(self, text, text_len, mels, mel_len):
- if self.mean.item() == 0 or self.std.item() == 1:
- statistics_dict = torch.load(self.mel_statistics_parameter_path)
- self.update_mean_std(statistics_dict)
-
- mels = self.normalize(mels)
- return text, text_len, mels, mel_len
-
- def normalize(self, x):
- return x.sub(self.mean).div(self.std)
-
- def inverse_normalize(self, x):
- return x.mul(self.std).add(self.mean)
-
- def forward(self, text, text_len, mels, mel_len):
- """
- Forward pass for training and computing the log likelihood of a given batch.
-
- Shapes:
- Shapes:
- text: :math:`[B, T_in]`
- text_len: :math:`[B]`
- mels: :math:`[B, T_out, C]`
- mel_len: :math:`[B]`
- """
- text, text_len, mels, mel_len = self.preprocess_batch(text, text_len, mels, mel_len)
- encoder_outputs, encoder_output_len = self.encoder(text, text_len)
- z, z_lengths, logdet = self.decoder(mels.transpose(1, 2), mel_len)
- log_probs, fwd_alignments, transition_vectors, means = self.neural_hmm(
- encoder_outputs, encoder_output_len, z, z_lengths
- )
-
- outputs = {
- "log_probs": log_probs + logdet,
- "alignments": fwd_alignments,
- "transition_vectors": transition_vectors,
- "means": means,
- }
-
- return outputs
-
- @staticmethod
- def _training_stats(batch):
- stats = {}
- stats["avg_text_length"] = batch["text_lengths"].float().mean()
- stats["avg_spec_length"] = batch["mel_lengths"].float().mean()
- stats["avg_text_batch_occupancy"] = (batch["text_lengths"].float() / batch["text_lengths"].float().max()).mean()
- stats["avg_spec_batch_occupancy"] = (batch["mel_lengths"].float() / batch["mel_lengths"].float().max()).mean()
- return stats
-
- def train_step(self, batch: dict, criterion: nn.Module):
- text_input = batch["text_input"]
- text_lengths = batch["text_lengths"]
- mel_input = batch["mel_input"]
- mel_lengths = batch["mel_lengths"]
-
- outputs = self.forward(
- text=text_input,
- text_len=text_lengths,
- mels=mel_input,
- mel_len=mel_lengths,
- )
- loss_dict = criterion(outputs["log_probs"] / (mel_lengths.sum() + text_lengths.sum()))
-
- # for printing useful statistics on terminal
- loss_dict.update(self._training_stats(batch))
- return outputs, loss_dict
-
- def eval_step(self, batch: Dict, criterion: nn.Module):
- return self.train_step(batch, criterion)
-
- def _format_aux_input(self, aux_input: Dict, default_input_dict):
- """Set missing fields to their default value.
-
- Args:
- aux_inputs (Dict): Dictionary containing the auxiliary inputs.
- """
- default_input_dict = default_input_dict.copy()
- default_input_dict.update(
- {
- "sampling_temp": self.sampling_temp,
- "max_sampling_time": self.max_sampling_time,
- "duration_threshold": self.duration_threshold,
- }
- )
- if aux_input:
- return format_aux_input(default_input_dict, aux_input)
- return default_input_dict
-
- @torch.no_grad()
- def inference(
- self,
- text: torch.Tensor,
- aux_input={"x_lengths": None, "sampling_temp": None, "max_sampling_time": None, "duration_threshold": None},
- ): # pylint: disable=dangerous-default-value
- """Sampling from the model
-
- Args:
- text (torch.Tensor): :math:`[B, T_in]`
- aux_inputs (_type_, optional): _description_. Defaults to None.
-
- Returns:
- outputs: Dictionary containing the following
- - mel (torch.Tensor): :math:`[B, T_out, C]`
- - hmm_outputs_len (torch.Tensor): :math:`[B]`
- - state_travelled (List[List[int]]): List of lists containing the state travelled for each sample in the batch.
- - input_parameters (list[torch.FloatTensor]): Input parameters to the neural HMM.
- - output_parameters (list[torch.FloatTensor]): Output parameters to the neural HMM.
- """
- default_input_dict = {
- "x_lengths": torch.sum(text != 0, dim=1),
- }
- aux_input = self._format_aux_input(aux_input, default_input_dict)
- encoder_outputs, encoder_output_len = self.encoder.inference(text, aux_input["x_lengths"])
- outputs = self.neural_hmm.inference(
- encoder_outputs,
- encoder_output_len,
- sampling_temp=aux_input["sampling_temp"],
- max_sampling_time=aux_input["max_sampling_time"],
- duration_threshold=aux_input["duration_threshold"],
- )
-
- mels, mel_outputs_len, _ = self.decoder(
- outputs["hmm_outputs"].transpose(1, 2), outputs["hmm_outputs_len"], reverse=True
- )
- mels = self.inverse_normalize(mels.transpose(1, 2))
- outputs.update({"model_outputs": mels, "model_outputs_len": mel_outputs_len})
- outputs["alignments"] = OverflowUtils.double_pad(outputs["alignments"])
- return outputs
-
- @staticmethod
- def get_criterion():
- return NLLLoss()
-
- @staticmethod
- def init_from_config(config: "OverFlowConfig", samples: Union[List[List], List[Dict]] = None, verbose=True):
- """Initiate model from config
-
- Args:
- config (VitsConfig): Model config.
- samples (Union[List[List], List[Dict]]): Training samples to parse speaker ids for training.
- Defaults to None.
- verbose (bool): If True, print init messages. Defaults to True.
- """
- from TTS.utils.audio import AudioProcessor
-
- ap = AudioProcessor.init_from_config(config, verbose)
- tokenizer, new_config = TTSTokenizer.init_from_config(config)
- speaker_manager = SpeakerManager.init_from_config(config, samples)
- return Overflow(new_config, ap, tokenizer, speaker_manager)
-
- def load_checkpoint(
- self, config: Coqpit, checkpoint_path: str, eval: bool = False, strict: bool = True, cache=False
- ): # pylint: disable=unused-argument, redefined-builtin
- state = load_fsspec(checkpoint_path, map_location=torch.device("cpu"))
- self.load_state_dict(state["model"])
- if eval:
- self.eval()
- self.decoder.store_inverse()
- assert not self.training
-
- def on_init_start(self, trainer):
- """If the current dataset does not have normalisation statistics and initialisation transition_probability it computes them otherwise loads."""
- if not os.path.isfile(trainer.config.mel_statistics_parameter_path) or trainer.config.force_generate_statistics:
- dataloader = trainer.get_train_dataloader(
- training_assets=None, samples=trainer.train_samples, verbose=False
- )
- print(
- f" | > Data parameters not found for: {trainer.config.mel_statistics_parameter_path}. Computing mel normalization parameters..."
- )
- data_mean, data_std, init_transition_prob = OverflowUtils.get_data_parameters_for_flat_start(
- dataloader, trainer.config.out_channels, trainer.config.state_per_phone
- )
- print(
- f" | > Saving data parameters to: {trainer.config.mel_statistics_parameter_path}: value: {data_mean, data_std, init_transition_prob}"
- )
- statistics = {
- "mean": data_mean.item(),
- "std": data_std.item(),
- "init_transition_prob": init_transition_prob.item(),
- }
- torch.save(statistics, trainer.config.mel_statistics_parameter_path)
-
- else:
- print(
- f" | > Data parameters found for: {trainer.config.mel_statistics_parameter_path}. Loading mel normalization parameters..."
- )
- statistics = torch.load(trainer.config.mel_statistics_parameter_path)
- data_mean, data_std, init_transition_prob = (
- statistics["mean"],
- statistics["std"],
- statistics["init_transition_prob"],
- )
- print(f" | > Data parameters loaded with value: {data_mean, data_std, init_transition_prob}")
-
- trainer.config.flat_start_params["transition_p"] = (
- init_transition_prob.item() if torch.is_tensor(init_transition_prob) else init_transition_prob
- )
- OverflowUtils.update_flat_start_transition(trainer.model, init_transition_prob)
- trainer.model.update_mean_std(statistics)
-
- @torch.inference_mode()
- def _create_logs(self, batch, outputs, ap): # pylint: disable=no-self-use, unused-argument
- alignments, transition_vectors = outputs["alignments"], outputs["transition_vectors"]
- means = torch.stack(outputs["means"], dim=1)
-
- figures = {
- "alignment": plot_alignment(alignments[0].exp(), title="Forward alignment", fig_size=(20, 20)),
- "log_alignment": plot_alignment(
- alignments[0].exp(), title="Forward log alignment", plot_log=True, fig_size=(20, 20)
- ),
- "transition_vectors": plot_alignment(transition_vectors[0], title="Transition vectors", fig_size=(20, 20)),
- "mel_from_most_probable_state": plot_spectrogram(
- get_spec_from_most_probable_state(alignments[0], means[0], self.decoder), fig_size=(12, 3)
- ),
- "mel_target": plot_spectrogram(batch["mel_input"][0], fig_size=(12, 3)),
- }
-
- # sample one item from the batch -1 will give the smalles item
- print(" | > Synthesising audio from the model...")
- inference_output = self.inference(
- batch["text_input"][-1].unsqueeze(0), aux_input={"x_lengths": batch["text_lengths"][-1].unsqueeze(0)}
- )
- figures["synthesised"] = plot_spectrogram(inference_output["model_outputs"][0], fig_size=(12, 3))
-
- states = [p[1] for p in inference_output["input_parameters"][0]]
- transition_probability_synthesising = [p[2].cpu().numpy() for p in inference_output["output_parameters"][0]]
-
- for i in range((len(transition_probability_synthesising) // 200) + 1):
- start = i * 200
- end = (i + 1) * 200
- figures[f"synthesised_transition_probabilities/{i}"] = plot_transition_probabilities_to_numpy(
- states[start:end], transition_probability_synthesising[start:end]
- )
-
- audio = ap.inv_melspectrogram(inference_output["model_outputs"][0].T.cpu().numpy())
- return figures, {"audios": audio}
-
- def train_log(
- self, batch: dict, outputs: dict, logger: "Logger", assets: dict, steps: int
- ): # pylint: disable=unused-argument
- """Log training progress."""
- figures, audios = self._create_logs(batch, outputs, self.ap)
- logger.train_figures(steps, figures)
- logger.train_audios(steps, audios, self.ap.sample_rate)
-
- def eval_log(
- self, batch: Dict, outputs: Dict, logger: "Logger", assets: Dict, steps: int
- ): # pylint: disable=unused-argument
- """Compute and log evaluation metrics."""
- # Plot model parameters histograms
- if isinstance(logger, TensorboardLogger):
- # I don't know if any other loggers supports this
- for tag, value in self.named_parameters():
- tag = tag.replace(".", "/")
- logger.writer.add_histogram(tag, value.data.cpu().numpy(), steps)
-
- figures, audios = self._create_logs(batch, outputs, self.ap)
- logger.eval_figures(steps, figures)
- logger.eval_audios(steps, audios, self.ap.sample_rate)
-
- def test_log(
- self, outputs: dict, logger: "Logger", assets: dict, steps: int # pylint: disable=unused-argument
- ) -> None:
- logger.test_audios(steps, outputs[1], self.ap.sample_rate)
- logger.test_figures(steps, outputs[0])
-
-
-class NLLLoss(nn.Module):
- """Negative log likelihood loss."""
-
- def forward(self, log_prob: torch.Tensor) -> dict: # pylint: disable=no-self-use
- """Compute the loss.
-
- Args:
- logits (Tensor): [B, T, D]
-
- Returns:
- Tensor: [1]
-
- """
- return_dict = {}
- return_dict["loss"] = -log_prob.mean()
- return return_dict
diff --git a/spaces/arunavsk1/Pubmed-Named-Entity-Recognition/README.md b/spaces/arunavsk1/Pubmed-Named-Entity-Recognition/README.md
deleted file mode 100644
index dfae1eb3a73220f836ecad58a3d3913ed6c9664a..0000000000000000000000000000000000000000
--- a/spaces/arunavsk1/Pubmed-Named-Entity-Recognition/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Pubmed Named Entity Recognition
-emoji: 🚀
-colorFrom: purple
-colorTo: yellow
-sdk: streamlit
-sdk_version: 1.9.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/dateutil/utils.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/dateutil/utils.py
deleted file mode 100644
index dd2d245a0bebcd5fc37ac20526aabbd5358dab0e..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/dateutil/utils.py
+++ /dev/null
@@ -1,71 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-This module offers general convenience and utility functions for dealing with
-datetimes.
-
-.. versionadded:: 2.7.0
-"""
-from __future__ import unicode_literals
-
-from datetime import datetime, time
-
-
-def today(tzinfo=None):
- """
- Returns a :py:class:`datetime` representing the current day at midnight
-
- :param tzinfo:
- The time zone to attach (also used to determine the current day).
-
- :return:
- A :py:class:`datetime.datetime` object representing the current day
- at midnight.
- """
-
- dt = datetime.now(tzinfo)
- return datetime.combine(dt.date(), time(0, tzinfo=tzinfo))
-
-
-def default_tzinfo(dt, tzinfo):
- """
- Sets the ``tzinfo`` parameter on naive datetimes only
-
- This is useful for example when you are provided a datetime that may have
- either an implicit or explicit time zone, such as when parsing a time zone
- string.
-
- .. doctest::
-
- >>> from dateutil.tz import tzoffset
- >>> from dateutil.parser import parse
- >>> from dateutil.utils import default_tzinfo
- >>> dflt_tz = tzoffset("EST", -18000)
- >>> print(default_tzinfo(parse('2014-01-01 12:30 UTC'), dflt_tz))
- 2014-01-01 12:30:00+00:00
- >>> print(default_tzinfo(parse('2014-01-01 12:30'), dflt_tz))
- 2014-01-01 12:30:00-05:00
-
- :param dt:
- The datetime on which to replace the time zone
-
- :param tzinfo:
- The :py:class:`datetime.tzinfo` subclass instance to assign to
- ``dt`` if (and only if) it is naive.
-
- :return:
- Returns an aware :py:class:`datetime.datetime`.
- """
- if dt.tzinfo is not None:
- return dt
- else:
- return dt.replace(tzinfo=tzinfo)
-
-
-def within_delta(dt1, dt2, delta):
- """
- Useful for comparing two datetimes that may have a negligible difference
- to be considered equal.
- """
- delta = abs(delta)
- difference = dt1 - dt2
- return -delta <= difference <= delta
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/fairseq/data/data_utils.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/fairseq/data/data_utils.py
deleted file mode 100644
index 0372d52b0f29383ed3e035fb956ebc2dbd50ccec..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/fairseq/data/data_utils.py
+++ /dev/null
@@ -1,604 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-try:
- from collections.abc import Iterable
-except ImportError:
- from collections import Iterable
-import contextlib
-import itertools
-import logging
-import re
-import warnings
-from typing import Optional, Tuple
-
-import numpy as np
-import torch
-
-from fairseq.file_io import PathManager
-from fairseq import utils
-import os
-
-logger = logging.getLogger(__name__)
-
-
-def infer_language_pair(path):
- """Infer language pair from filename: .-.(...).idx"""
- src, dst = None, None
- for filename in PathManager.ls(path):
- parts = filename.split(".")
- if len(parts) >= 3 and len(parts[1].split("-")) == 2:
- return parts[1].split("-")
- return src, dst
-
-
-def collate_tokens(
- values,
- pad_idx,
- eos_idx=None,
- left_pad=False,
- move_eos_to_beginning=False,
- pad_to_length=None,
- pad_to_multiple=1,
- pad_to_bsz=None,
-):
- """Convert a list of 1d tensors into a padded 2d tensor."""
- size = max(v.size(0) for v in values)
- size = size if pad_to_length is None else max(size, pad_to_length)
- if pad_to_multiple != 1 and size % pad_to_multiple != 0:
- size = int(((size - 0.1) // pad_to_multiple + 1) * pad_to_multiple)
-
- batch_size = len(values) if pad_to_bsz is None else max(len(values), pad_to_bsz)
- res = values[0].new(batch_size, size).fill_(pad_idx)
-
- def copy_tensor(src, dst):
- assert dst.numel() == src.numel()
- if move_eos_to_beginning:
- if eos_idx is None:
- # if no eos_idx is specified, then use the last token in src
- dst[0] = src[-1]
- else:
- dst[0] = eos_idx
- dst[1:] = src[:-1]
- else:
- dst.copy_(src)
-
- for i, v in enumerate(values):
- copy_tensor(v, res[i][size - len(v) :] if left_pad else res[i][: len(v)])
- return res
-
-
-def load_indexed_dataset(
- path, dictionary=None, dataset_impl=None, combine=False, default="cached"
-):
- """A helper function for loading indexed datasets.
-
- Args:
- path (str): path to indexed dataset (e.g., 'data-bin/train')
- dictionary (~fairseq.data.Dictionary): data dictionary
- dataset_impl (str, optional): which dataset implementation to use. If
- not provided, it will be inferred automatically. For legacy indexed
- data we use the 'cached' implementation by default.
- combine (bool, optional): automatically load and combine multiple
- datasets. For example, if *path* is 'data-bin/train', then we will
- combine 'data-bin/train', 'data-bin/train1', ... and return a
- single ConcatDataset instance.
- """
- import fairseq.data.indexed_dataset as indexed_dataset
- from fairseq.data.concat_dataset import ConcatDataset
-
- datasets = []
- for k in itertools.count():
- path_k = path + (str(k) if k > 0 else "")
- try:
- path_k = indexed_dataset.get_indexed_dataset_to_local(path_k)
- except Exception as e:
- if "StorageException: [404] Path not found" in str(e):
- logger.warning(f"path_k: {e} not found")
- else:
- raise e
-
- dataset_impl_k = dataset_impl
- if dataset_impl_k is None:
- dataset_impl_k = indexed_dataset.infer_dataset_impl(path_k)
- dataset = indexed_dataset.make_dataset(
- path_k,
- impl=dataset_impl_k or default,
- fix_lua_indexing=True,
- dictionary=dictionary,
- )
- if dataset is None:
- break
- logger.info("loaded {:,} examples from: {}".format(len(dataset), path_k))
- datasets.append(dataset)
- if not combine:
- break
- if len(datasets) == 0:
- return None
- elif len(datasets) == 1:
- return datasets[0]
- else:
- return ConcatDataset(datasets)
-
-
-@contextlib.contextmanager
-def numpy_seed(seed, *addl_seeds):
- """Context manager which seeds the NumPy PRNG with the specified seed and
- restores the state afterward"""
- if seed is None:
- yield
- return
- if len(addl_seeds) > 0:
- seed = int(hash((seed, *addl_seeds)) % 1e6)
- state = np.random.get_state()
- np.random.seed(seed)
- try:
- yield
- finally:
- np.random.set_state(state)
-
-
-def collect_filtered(function, iterable, filtered):
- """
- Similar to :func:`filter` but collects filtered elements in ``filtered``.
-
- Args:
- function (callable): function that returns ``False`` for elements that
- should be filtered
- iterable (iterable): iterable to filter
- filtered (list): list to store filtered elements
- """
- for el in iterable:
- if function(el):
- yield el
- else:
- filtered.append(el)
-
-
-def _filter_by_size_dynamic(indices, size_fn, max_positions, raise_exception=False):
- def compare_leq(a, b):
- return a <= b if not isinstance(a, tuple) else max(a) <= b
-
- def check_size(idx):
- if isinstance(max_positions, float) or isinstance(max_positions, int):
- return size_fn(idx) <= max_positions
- elif isinstance(max_positions, dict):
- idx_size = size_fn(idx)
- assert isinstance(idx_size, dict)
- intersect_keys = set(max_positions.keys()) & set(idx_size.keys())
- return all(
- all(
- a is None or b is None or a <= b
- for a, b in zip(idx_size[key], max_positions[key])
- )
- for key in intersect_keys
- )
- else:
- # For MultiCorpusSampledDataset, will generalize it later
- if not isinstance(size_fn(idx), Iterable):
- return all(size_fn(idx) <= b for b in max_positions)
- return all(
- a is None or b is None or a <= b
- for a, b in zip(size_fn(idx), max_positions)
- )
-
- ignored = []
- itr = collect_filtered(check_size, indices, ignored)
- indices = np.fromiter(itr, dtype=np.int64, count=-1)
- return indices, ignored
-
-
-def filter_by_size(indices, dataset, max_positions, raise_exception=False):
- """
- [deprecated] Filter indices based on their size.
- Use `FairseqDataset::filter_indices_by_size` instead.
-
- Args:
- indices (List[int]): ordered list of dataset indices
- dataset (FairseqDataset): fairseq dataset instance
- max_positions (tuple): filter elements larger than this size.
- Comparisons are done component-wise.
- raise_exception (bool, optional): if ``True``, raise an exception if
- any elements are filtered (default: False).
- """
- warnings.warn(
- "data_utils.filter_by_size is deprecated. "
- "Use `FairseqDataset::filter_indices_by_size` instead.",
- stacklevel=2,
- )
- if isinstance(max_positions, float) or isinstance(max_positions, int):
- if hasattr(dataset, "sizes") and isinstance(dataset.sizes, np.ndarray):
- ignored = indices[dataset.sizes[indices] > max_positions].tolist()
- indices = indices[dataset.sizes[indices] <= max_positions]
- elif (
- hasattr(dataset, "sizes")
- and isinstance(dataset.sizes, list)
- and len(dataset.sizes) == 1
- ):
- ignored = indices[dataset.sizes[0][indices] > max_positions].tolist()
- indices = indices[dataset.sizes[0][indices] <= max_positions]
- else:
- indices, ignored = _filter_by_size_dynamic(
- indices, dataset.size, max_positions
- )
- else:
- indices, ignored = _filter_by_size_dynamic(indices, dataset.size, max_positions)
-
- if len(ignored) > 0 and raise_exception:
- raise Exception(
- (
- "Size of sample #{} is invalid (={}) since max_positions={}, "
- "skip this example with --skip-invalid-size-inputs-valid-test"
- ).format(ignored[0], dataset.size(ignored[0]), max_positions)
- )
- if len(ignored) > 0:
- logger.warning(
- (
- "{} samples have invalid sizes and will be skipped, "
- "max_positions={}, first few sample ids={}"
- ).format(len(ignored), max_positions, ignored[:10])
- )
- return indices
-
-
-def filter_paired_dataset_indices_by_size(src_sizes, tgt_sizes, indices, max_sizes):
- """Filter a list of sample indices. Remove those that are longer
- than specified in max_sizes.
-
- Args:
- indices (np.array): original array of sample indices
- max_sizes (int or list[int] or tuple[int]): max sample size,
- can be defined separately for src and tgt (then list or tuple)
-
- Returns:
- np.array: filtered sample array
- list: list of removed indices
- """
- if max_sizes is None:
- return indices, []
- if type(max_sizes) in (int, float):
- max_src_size, max_tgt_size = max_sizes, max_sizes
- else:
- max_src_size, max_tgt_size = max_sizes
- if tgt_sizes is None:
- ignored = indices[src_sizes[indices] > max_src_size]
- else:
- ignored = indices[
- (src_sizes[indices] > max_src_size) | (tgt_sizes[indices] > max_tgt_size)
- ]
- if len(ignored) > 0:
- if tgt_sizes is None:
- indices = indices[src_sizes[indices] <= max_src_size]
- else:
- indices = indices[
- (src_sizes[indices] <= max_src_size)
- & (tgt_sizes[indices] <= max_tgt_size)
- ]
- return indices, ignored.tolist()
-
-
-def batch_by_size(
- indices,
- num_tokens_fn,
- num_tokens_vec=None,
- max_tokens=None,
- max_sentences=None,
- required_batch_size_multiple=1,
- fixed_shapes=None,
-):
- """
- Yield mini-batches of indices bucketed by size. Batches may contain
- sequences of different lengths.
-
- Args:
- indices (List[int]): ordered list of dataset indices
- num_tokens_fn (callable): function that returns the number of tokens at
- a given index
- num_tokens_vec (List[int], optional): precomputed vector of the number
- of tokens for each index in indices (to enable faster batch generation)
- max_tokens (int, optional): max number of tokens in each batch
- (default: None).
- max_sentences (int, optional): max number of sentences in each
- batch (default: None).
- required_batch_size_multiple (int, optional): require batch size to
- be less than N or a multiple of N (default: 1).
- fixed_shapes (List[Tuple[int, int]], optional): if given, batches will
- only be created with the given shapes. *max_sentences* and
- *required_batch_size_multiple* will be ignored (default: None).
- """
- try:
- from fairseq.data.data_utils_fast import (
- batch_by_size_fn,
- batch_by_size_vec,
- batch_fixed_shapes_fast,
- )
- except ImportError:
- raise ImportError(
- "Please build Cython components with: "
- "`python setup.py build_ext --inplace`"
- )
- except ValueError:
- raise ValueError(
- "Please build (or rebuild) Cython components with `python setup.py build_ext --inplace`."
- )
-
- # added int() to avoid TypeError: an integer is required
- max_tokens = int(max_tokens) if max_tokens is not None else -1
- max_sentences = max_sentences if max_sentences is not None else -1
- bsz_mult = required_batch_size_multiple
-
- if not isinstance(indices, np.ndarray):
- indices = np.fromiter(indices, dtype=np.int64, count=-1)
-
- if num_tokens_vec is not None and not isinstance(num_tokens_vec, np.ndarray):
- num_tokens_vec = np.fromiter(num_tokens_vec, dtype=np.int64, count=-1)
-
- if fixed_shapes is None:
- if num_tokens_vec is None:
- return batch_by_size_fn(
- indices,
- num_tokens_fn,
- max_tokens,
- max_sentences,
- bsz_mult,
- )
- else:
- return batch_by_size_vec(
- indices,
- num_tokens_vec,
- max_tokens,
- max_sentences,
- bsz_mult,
- )
-
- else:
- fixed_shapes = np.array(fixed_shapes, dtype=np.int64)
- sort_order = np.lexsort(
- [
- fixed_shapes[:, 1].argsort(), # length
- fixed_shapes[:, 0].argsort(), # bsz
- ]
- )
- fixed_shapes_sorted = fixed_shapes[sort_order]
- return batch_fixed_shapes_fast(indices, num_tokens_fn, fixed_shapes_sorted)
-
-
-def post_process(sentence: str, symbol: str):
- if symbol == "sentencepiece":
- sentence = sentence.replace(" ", "").replace("\u2581", " ").strip()
- elif symbol == "wordpiece":
- sentence = sentence.replace(" ", "").replace("_", " ").strip()
- elif symbol == "letter":
- sentence = sentence.replace(" ", "").replace("|", " ").strip()
- elif symbol == "silence":
- import re
-
- sentence = sentence.replace("", "")
- sentence = re.sub(" +", " ", sentence).strip()
- elif symbol == "_EOW":
- sentence = sentence.replace(" ", "").replace("_EOW", " ").strip()
- elif symbol in {"subword_nmt", "@@ ", "@@"}:
- if symbol == "subword_nmt":
- symbol = "@@ "
- sentence = (sentence + " ").replace(symbol, "").rstrip()
- elif symbol == "none":
- pass
- elif symbol is not None:
- raise NotImplementedError(f"Unknown post_process option: {symbol}")
- return sentence
-
-
-def compute_mask_indices(
- shape: Tuple[int, int],
- padding_mask: Optional[torch.Tensor],
- mask_prob: float,
- mask_length: int,
- mask_type: str = "static",
- mask_other: float = 0.0,
- min_masks: int = 0,
- no_overlap: bool = False,
- min_space: int = 0,
- require_same_masks: bool = True,
- mask_dropout: float = 0.0,
-) -> np.ndarray:
- """
- Computes random mask spans for a given shape
-
- Args:
- shape: the the shape for which to compute masks.
- should be of size 2 where first element is batch size and 2nd is timesteps
- padding_mask: optional padding mask of the same size as shape, which will prevent masking padded elements
- mask_prob: probability for each token to be chosen as start of the span to be masked. this will be multiplied by
- number of timesteps divided by length of mask span to mask approximately this percentage of all elements.
- however due to overlaps, the actual number will be smaller (unless no_overlap is True)
- mask_type: how to compute mask lengths
- static = fixed size
- uniform = sample from uniform distribution [mask_other, mask_length*2]
- normal = sample from normal distribution with mean mask_length and stdev mask_other. mask is min 1 element
- poisson = sample from possion distribution with lambda = mask length
- min_masks: minimum number of masked spans
- no_overlap: if false, will switch to an alternative recursive algorithm that prevents spans from overlapping
- min_space: only used if no_overlap is True, this is how many elements to keep unmasked between spans
- require_same_masks: if true, will randomly drop out masks until same amount of masks remains in each sample
- mask_dropout: randomly dropout this percentage of masks in each example
- """
-
- bsz, all_sz = shape
- mask = np.full((bsz, all_sz), False)
-
- all_num_mask = int(
- # add a random number for probabilistic rounding
- mask_prob * all_sz / float(mask_length)
- + np.random.rand()
- )
-
- all_num_mask = max(min_masks, all_num_mask)
-
- mask_idcs = []
- for i in range(bsz):
- if padding_mask is not None:
- sz = all_sz - padding_mask[i].long().sum().item()
- num_mask = int(
- # add a random number for probabilistic rounding
- mask_prob * sz / float(mask_length)
- + np.random.rand()
- )
- num_mask = max(min_masks, num_mask)
- else:
- sz = all_sz
- num_mask = all_num_mask
-
- if mask_type == "static":
- lengths = np.full(num_mask, mask_length)
- elif mask_type == "uniform":
- lengths = np.random.randint(mask_other, mask_length * 2 + 1, size=num_mask)
- elif mask_type == "normal":
- lengths = np.random.normal(mask_length, mask_other, size=num_mask)
- lengths = [max(1, int(round(x))) for x in lengths]
- elif mask_type == "poisson":
- lengths = np.random.poisson(mask_length, size=num_mask)
- lengths = [int(round(x)) for x in lengths]
- else:
- raise Exception("unknown mask selection " + mask_type)
-
- if sum(lengths) == 0:
- lengths[0] = min(mask_length, sz - 1)
-
- if no_overlap:
- mask_idc = []
-
- def arrange(s, e, length, keep_length):
- span_start = np.random.randint(s, e - length)
- mask_idc.extend(span_start + i for i in range(length))
-
- new_parts = []
- if span_start - s - min_space >= keep_length:
- new_parts.append((s, span_start - min_space + 1))
- if e - span_start - length - min_space > keep_length:
- new_parts.append((span_start + length + min_space, e))
- return new_parts
-
- parts = [(0, sz)]
- min_length = min(lengths)
- for length in sorted(lengths, reverse=True):
- lens = np.fromiter(
- (e - s if e - s >= length + min_space else 0 for s, e in parts),
- np.int,
- )
- l_sum = np.sum(lens)
- if l_sum == 0:
- break
- probs = lens / np.sum(lens)
- c = np.random.choice(len(parts), p=probs)
- s, e = parts.pop(c)
- parts.extend(arrange(s, e, length, min_length))
- mask_idc = np.asarray(mask_idc)
- else:
- min_len = min(lengths)
- if sz - min_len <= num_mask:
- min_len = sz - num_mask - 1
-
- mask_idc = np.random.choice(sz - min_len, num_mask, replace=False)
-
- mask_idc = np.asarray(
- [
- mask_idc[j] + offset
- for j in range(len(mask_idc))
- for offset in range(lengths[j])
- ]
- )
-
- mask_idcs.append(np.unique(mask_idc[mask_idc < sz]))
-
- min_len = min([len(m) for m in mask_idcs])
- for i, mask_idc in enumerate(mask_idcs):
- if len(mask_idc) > min_len and require_same_masks:
- mask_idc = np.random.choice(mask_idc, min_len, replace=False)
- if mask_dropout > 0:
- num_holes = np.rint(len(mask_idc) * mask_dropout).astype(int)
- mask_idc = np.random.choice(
- mask_idc, len(mask_idc) - num_holes, replace=False
- )
-
- mask[i, mask_idc] = True
-
- return mask
-
-
-def get_mem_usage():
- try:
- import psutil
-
- mb = 1024 * 1024
- return f"used={psutil.virtual_memory().used / mb}Mb; avail={psutil.virtual_memory().available / mb}Mb"
- except ImportError:
- return "N/A"
-
-
-# lens: torch.LongTensor
-# returns: torch.BoolTensor
-def lengths_to_padding_mask(lens):
- bsz, max_lens = lens.size(0), torch.max(lens).item()
- mask = torch.arange(max_lens).to(lens.device).view(1, max_lens)
- mask = mask.expand(bsz, -1) >= lens.view(bsz, 1).expand(-1, max_lens)
- return mask
-
-
-# lens: torch.LongTensor
-# returns: torch.BoolTensor
-def lengths_to_mask(lens):
- return ~lengths_to_padding_mask(lens)
-
-
-def get_buckets(sizes, num_buckets):
- buckets = np.unique(
- np.percentile(
- sizes,
- np.linspace(0, 100, num_buckets + 1),
- interpolation="lower",
- )[1:]
- )
- return buckets
-
-
-def get_bucketed_sizes(orig_sizes, buckets):
- sizes = np.copy(orig_sizes)
- assert np.min(sizes) >= 0
- start_val = -1
- for end_val in buckets:
- mask = (sizes > start_val) & (sizes <= end_val)
- sizes[mask] = end_val
- start_val = end_val
- return sizes
-
-
-def _find_extra_valid_paths(dataset_path: str) -> set:
- paths = utils.split_paths(dataset_path)
- all_valid_paths = set()
- for sub_dir in paths:
- contents = PathManager.ls(sub_dir)
- valid_paths = [c for c in contents if re.match("valid*[0-9].*", c) is not None]
- all_valid_paths |= {os.path.basename(p) for p in valid_paths}
- # Remove .bin, .idx etc
- roots = {os.path.splitext(p)[0] for p in all_valid_paths}
- return roots
-
-
-def raise_if_valid_subsets_unintentionally_ignored(train_cfg) -> None:
- """Raises if there are paths matching 'valid*[0-9].*' which are not combined or ignored."""
- if (
- train_cfg.dataset.ignore_unused_valid_subsets
- or train_cfg.dataset.combine_valid_subsets
- or train_cfg.dataset.disable_validation
- or not hasattr(train_cfg.task, "data")
- ):
- return
- other_paths = _find_extra_valid_paths(train_cfg.task.data)
- specified_subsets = train_cfg.dataset.valid_subset.split(",")
- ignored_paths = [p for p in other_paths if p not in specified_subsets]
- if ignored_paths:
- advice = "Set --combine-val to combine them or --ignore-unused-valid-subsets to ignore them."
- msg = f"Valid paths {ignored_paths} will be ignored. {advice}"
- raise ValueError(msg)
diff --git a/spaces/ashercn97/AsherTesting/extensions/send_pictures/script.py b/spaces/ashercn97/AsherTesting/extensions/send_pictures/script.py
deleted file mode 100644
index 634217431bb230a71d37d8f7375bd3114812b58c..0000000000000000000000000000000000000000
--- a/spaces/ashercn97/AsherTesting/extensions/send_pictures/script.py
+++ /dev/null
@@ -1,48 +0,0 @@
-import base64
-from io import BytesIO
-
-import gradio as gr
-import torch
-from transformers import BlipForConditionalGeneration, BlipProcessor
-
-from modules import chat, shared
-from modules.ui import gather_interface_values
-from modules.utils import gradio
-
-# If 'state' is True, will hijack the next chat generation with
-# custom input text given by 'value' in the format [text, visible_text]
-input_hijack = {
- 'state': False,
- 'value': ["", ""]
-}
-
-processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
-model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base", torch_dtype=torch.float32).to("cpu")
-
-
-def caption_image(raw_image):
- inputs = processor(raw_image.convert('RGB'), return_tensors="pt").to("cpu", torch.float32)
- out = model.generate(**inputs, max_new_tokens=100)
- return processor.decode(out[0], skip_special_tokens=True)
-
-
-def generate_chat_picture(picture, name1, name2):
- text = f'*{name1} sends {name2} a picture that contains the following: “{caption_image(picture)}”*'
- # lower the resolution of sent images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
- picture.thumbnail((300, 300))
- buffer = BytesIO()
- picture.save(buffer, format="JPEG")
- img_str = base64.b64encode(buffer.getvalue()).decode('utf-8')
- visible_text = f'
"
-examples = [['english.png',['en']],['chinese.jpg',['ch_sim', 'en']],['japanese.jpg',['ja', 'en']],['Hindi.jpeg',['hi', 'en']]]
-css = ".output_image, .input_image {height: 40rem !important; width: 100% !important;}"
-choices = [
- "ch_sim",
- "ch_tra",
- "de",
- "en",
- "es",
- "ja",
- "hi",
- "ru"
-]
-gr.Interface(
- inference,
- [gr.inputs.Image(type='file', label='Input'),gr.inputs.CheckboxGroup(choices, type="value", default=['en'], label='language')],
- [gr.outputs.Image(type='file', label='Output'), gr.outputs.Dataframe(headers=['text', 'confidence'])],
- title=title,
- description=description,
- article=article,
- examples=examples,
- css=css,
- enable_queue=True
- ).launch(debug=True)
\ No newline at end of file
diff --git a/spaces/awacke1/gpt2-demo/app.py b/spaces/awacke1/gpt2-demo/app.py
deleted file mode 100644
index 4205e03f91904065e1610f7e6c7b2f1de1771184..0000000000000000000000000000000000000000
--- a/spaces/awacke1/gpt2-demo/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/gpt2").launch()
\ No newline at end of file
diff --git a/spaces/azapi/img-to-music/constants.py b/spaces/azapi/img-to-music/constants.py
deleted file mode 100644
index 86863d1b778d4c66f0d8e1e0b699f1bb937c1d50..0000000000000000000000000000000000000000
--- a/spaces/azapi/img-to-music/constants.py
+++ /dev/null
@@ -1,9 +0,0 @@
-import numpy as np
-import os
-
-MUBERT_LICENSE = os.environ.get('MUBERT_LICENSE')
-MUBERT_TOKEN = os.environ.get('MUBERT_TOKEN')
-
-MUBERT_MODE = "loop"
-MUBERT_TAGS_STRING = 'tribal,action,kids,neo-classic,run 130,pumped,jazz / funk,ethnic,dubtechno,reggae,acid jazz,liquidfunk,funk,witch house,tech house,underground,artists,mystical,disco,sensorium,r&b,agender,psychedelic trance / psytrance,peaceful,run 140,piano,run 160,setting,meditation,christmas,ambient,horror,cinematic,electro house,idm,bass,minimal,underscore,drums,glitchy,beautiful,technology,tribal house,country pop,jazz & funk,documentary,space,classical,valentines,chillstep,experimental,trap,new jack swing,drama,post-rock,tense,corporate,neutral,happy,analog,funky,spiritual,sberzvuk special,chill hop,dramatic,catchy,holidays,fitness 90,optimistic,orchestra,acid techno,energizing,romantic,minimal house,breaks,hyper pop,warm up,dreamy,dark,urban,microfunk,dub,nu disco,vogue,keys,hardcore,aggressive,indie,electro funk,beauty,relaxing,trance,pop,hiphop,soft,acoustic,chillrave / ethno-house,deep techno,angry,dance,fun,dubstep,tropical,latin pop,heroic,world music,inspirational,uplifting,atmosphere,art,epic,advertising,chillout,scary,spooky,slow ballad,saxophone,summer,erotic,jazzy,energy 100,kara mar,xmas,atmospheric,indie pop,hip-hop,yoga,reggaeton,lounge,travel,running,folk,chillrave & ethno-house,detective,darkambient,chill,fantasy,minimal techno,special,night,tropical house,downtempo,lullaby,meditative,upbeat,glitch hop,fitness,neurofunk,sexual,indie rock,future pop,jazz,cyberpunk,melancholic,happy hardcore,family / kids,synths,electric guitar,comedy,psychedelic trance & psytrance,edm,psychedelic rock,calm,zen,bells,podcast,melodic house,ethnic percussion,nature,heavy,bassline,indie dance,techno,drumnbass,synth pop,vaporwave,sad,8-bit,chillgressive,deep,orchestral,futuristic,hardtechno,nostalgic,big room,sci-fi,tutorial,joyful,pads,minimal 170,drill,ethnic 108,amusing,sleepy ambient,psychill,italo disco,lofi,house,acoustic guitar,bassline house,rock,k-pop,synthwave,deep house,electronica,gabber,nightlife,sport & fitness,road trip,celebration,electro,disco house,electronic'
-MUBERT_TAGS = np.array(MUBERT_TAGS_STRING.split(','))
\ No newline at end of file
diff --git a/spaces/banana-projects/web3d/node_modules/three/examples/js/TimelinerController.js b/spaces/banana-projects/web3d/node_modules/three/examples/js/TimelinerController.js
deleted file mode 100644
index 7e1b29199ed0fe1abd843e8ef4551d5d9db8ebda..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/examples/js/TimelinerController.js
+++ /dev/null
@@ -1,280 +0,0 @@
-/**
- * Controller class for the Timeliner GUI.
- *
- * Timeliner GUI library (required to use this class):
- *
- * ./libs/timeliner_gui.min.js
- *
- * Source code:
- *
- * https://github.com/tschw/timeliner_gui
- * https://github.com/zz85/timeliner (fork's origin)
- *
- * @author tschw
- *
- */
-
-THREE.TimelinerController = function TimelinerController( scene, trackInfo, onUpdate ) {
-
- this._scene = scene;
- this._trackInfo = trackInfo;
-
- this._onUpdate = onUpdate;
-
- this._mixer = new THREE.AnimationMixer( scene );
- this._clip = null;
- this._action = null;
-
- this._tracks = {};
- this._propRefs = {};
- this._channelNames = [];
-
-};
-
-THREE.TimelinerController.prototype = {
-
- constructor: THREE.TimelinerController,
-
- init: function( timeliner ) {
-
- var tracks = [],
- trackInfo = this._trackInfo;
-
- for ( var i = 0, n = trackInfo.length; i !== n; ++ i ) {
-
- var spec = trackInfo[ i ];
-
- tracks.push( this._addTrack(
- spec.type, spec.propertyPath,
- spec.initialValue, spec.interpolation ) );
- }
-
- this._clip = new THREE.AnimationClip( 'editclip', 0, tracks );
- this._action = this._mixer.clipAction( this._clip ).play();
-
- },
-
- setDisplayTime: function( time ) {
-
- this._action.time = time;
- this._mixer.update( 0 );
-
- this._onUpdate();
-
- },
-
- setDuration: function( duration ) {
-
- this._clip.duration = duration;
-
- },
-
- getChannelNames: function() {
-
- return this._channelNames;
-
- },
-
- getChannelKeyTimes: function( channelName ) {
-
- return this._tracks[ channelName ].times;
-
- },
-
- setKeyframe: function( channelName, time ) {
-
- var track = this._tracks[ channelName ],
- times = track.times,
- index = Timeliner.binarySearch( times, time ),
- values = track.values,
- stride = track.getValueSize(),
- offset = index * stride;
-
- if ( index < 0 ) {
-
- // insert new keyframe
-
- index = ~ index;
- offset = index * stride;
-
- var nTimes = times.length + 1,
- nValues = values.length + stride;
-
- for ( var i = nTimes - 1; i !== index; -- i ) {
-
- times[ i ] = times[ i - 1 ];
-
- }
-
- for ( var i = nValues - 1,
- e = offset + stride - 1; i !== e; -- i ) {
-
- values[ i ] = values[ i - stride ];
-
- }
-
- }
-
- times[ index ] = time;
- this._propRefs[ channelName ].getValue( values, offset );
-
- },
-
- delKeyframe: function( channelName, time ) {
-
- var track = this._tracks[ channelName ],
- times = track.times,
- index = Timeliner.binarySearch( times, time );
-
- // we disallow to remove the keyframe when it is the last one we have,
- // since the animation system is designed to always produce a defined
- // state
-
- if ( times.length > 1 && index >= 0 ) {
-
- var nTimes = times.length - 1,
- values = track.values,
- stride = track.getValueSize(),
- nValues = values.length - stride;
-
- // note: no track.getValueSize when array sizes are out of sync
-
- for ( var i = index; i !== nTimes; ++ i ) {
-
- times[ i ] = times[ i + 1 ];
-
- }
-
- times.pop();
-
- for ( var offset = index * stride; offset !== nValues; ++ offset ) {
-
- values[ offset ] = values[ offset + stride ];
-
- }
-
- values.length = nValues;
-
- }
-
- },
-
- moveKeyframe: function( channelName, time, delta, moveRemaining ) {
-
- var track = this._tracks[ channelName ],
- times = track.times,
- index = Timeliner.binarySearch( times, time );
-
- if ( index >= 0 ) {
-
- var endAt = moveRemaining ? times.length : index + 1,
- needsSort = times[ index - 1 ] <= time ||
- ! moveRemaining && time >= times[ index + 1 ];
-
- while ( index !== endAt ) times[ index ++ ] += delta;
-
- if ( needsSort ) this._sort( track );
-
- }
-
- },
-
- serialize: function() {
-
- var result = {
- duration: this._clip.duration,
- channels: {}
- },
-
- names = this._channelNames,
- tracks = this._tracks,
-
- channels = result.channels;
-
- for ( var i = 0, n = names.length; i !== n; ++ i ) {
-
- var name = names[ i ],
- track = tracks[ name ];
-
- channels[ name ] = {
-
- times: track.times,
- values: track.values
-
- };
-
- }
-
- return result;
-
- },
-
- deserialize: function( structs ) {
-
- var names = this._channelNames,
- tracks = this._tracks,
-
- channels = structs.channels;
-
- this.setDuration( structs.duration );
-
- for ( var i = 0, n = names.length; i !== n; ++ i ) {
-
- var name = names[ i ],
- track = tracks[ name ],
- data = channels[ name ];
-
- this._setArray( track.times, data.times );
- this._setArray( track.values, data.values );
-
- }
-
- // update display
- this.setDisplayTime( this._mixer.time );
-
- },
-
- _sort: function( track ) {
-
- var times = track.times,
- order = THREE.AnimationUtils.getKeyframeOrder( times );
-
- this._setArray( times,
- THREE.AnimationUtils.sortedArray( times, 1, order ) );
-
- var values = track.values,
- stride = track.getValueSize();
-
- this._setArray( values,
- THREE.AnimationUtils.sortedArray( values, stride, order ) );
-
- },
-
- _setArray: function( dst, src ) {
-
- dst.length = 0;
- dst.push.apply( dst, src );
-
- },
-
- _addTrack: function( type, prop, initialValue, interpolation ) {
-
- var track = new type(
- prop, [ 0 ], initialValue, interpolation );
-
- // data must be in JS arrays so it can be resized
- track.times = Array.prototype.slice.call( track.times );
- track.values = Array.prototype.slice.call( track.values );
-
- this._channelNames.push( prop );
- this._tracks[ prop ] = track;
-
- // for recording the state:
- this._propRefs[ prop ] =
- new THREE.PropertyBinding( this._scene, prop );
-
- return track;
-
- }
-
-};
diff --git a/spaces/banana-projects/web3d/node_modules/three/examples/jsm/controls/OrbitControls.d.ts b/spaces/banana-projects/web3d/node_modules/three/examples/jsm/controls/OrbitControls.d.ts
deleted file mode 100644
index a768c891c43502b052c727785f37291c7c689260..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/examples/jsm/controls/OrbitControls.d.ts
+++ /dev/null
@@ -1,70 +0,0 @@
-import { Camera, MOUSE, Object3D, Vector3 } from '../../../src/Three';
-
-export class OrbitControls {
- constructor(object: Camera, domElement?: HTMLElement);
-
- object: Camera;
- domElement: HTMLElement | HTMLDocument;
-
- // API
- enabled: boolean;
- target: Vector3;
-
- // deprecated
- center: Vector3;
-
- enableZoom: boolean;
- zoomSpeed: number;
- minDistance: number;
- maxDistance: number;
- enableRotate: boolean;
- rotateSpeed: number;
- enablePan: boolean;
- keyPanSpeed: number;
- autoRotate: boolean;
- autoRotateSpeed: number;
- minPolarAngle: number;
- maxPolarAngle: number;
- minAzimuthAngle: number;
- maxAzimuthAngle: number;
- enableKeys: boolean;
- keys: {LEFT: number; UP: number; RIGHT: number; BOTTOM: number;};
- mouseButtons: {ORBIT: MOUSE; ZOOM: MOUSE; PAN: MOUSE;};
- enableDamping: boolean;
- dampingFactor: number;
- screenSpacePanning: boolean;
-
-
- rotateLeft(angle?: number): void;
-
- rotateUp(angle?: number): void;
-
- panLeft(distance?: number): void;
-
- panUp(distance?: number): void;
-
- pan(deltaX: number, deltaY: number): void;
-
- dollyIn(dollyScale: number): void;
-
- dollyOut(dollyScale: number): void;
-
- update(): void;
-
- reset(): void;
-
- dispose(): void;
-
- getPolarAngle(): number;
-
- getAzimuthalAngle(): number;
-
- // EventDispatcher mixins
- addEventListener(type: string, listener: (event: any) => void): void;
-
- hasEventListener(type: string, listener: (event: any) => void): boolean;
-
- removeEventListener(type: string, listener: (event: any) => void): void;
-
- dispatchEvent(event: {type: string; target: any;}): void;
-}
diff --git a/spaces/bastiendechamps/geoguessr-bot/geoguessr_bot/guessr/average_neighbor_embedder_guessr.py b/spaces/bastiendechamps/geoguessr-bot/geoguessr_bot/guessr/average_neighbor_embedder_guessr.py
deleted file mode 100644
index 1c6696b75f24e02cef168510637bf82a5dd46d5b..0000000000000000000000000000000000000000
--- a/spaces/bastiendechamps/geoguessr-bot/geoguessr_bot/guessr/average_neighbor_embedder_guessr.py
+++ /dev/null
@@ -1,69 +0,0 @@
-from collections import Counter
-from dataclasses import dataclass
-
-import numpy as np
-from sklearn.cluster import DBSCAN
-from sklearn.metrics.pairwise import haversine_distances
-from PIL import Image
-import pandas as pd
-
-from geoguessr_bot.guessr import AbstractGuessr
-from geoguessr_bot.interfaces import Coordinate
-from geoguessr_bot.retriever import AbstractImageEmbedder
-from geoguessr_bot.retriever import Retriever
-
-
-def haversine_distance(x, y) -> float:
- """Compute the haversine distance between two coordinates
- """
- return haversine_distances(np.array(x).reshape(1, -1), np.array(y).reshape(1, -1))[0][0]
-
-@dataclass
-class AverageNeighborsEmbedderGuessr(AbstractGuessr):
- """Guesses a coordinate using an Embedder and a retriever followed by NN.
- """
- embedder: AbstractImageEmbedder
- retriever: Retriever
- metadata_path: str
- n_neighbors: int = 50
- dbscan_eps: float = 0.05
-
- def __post_init__(self):
- """Load metadata
- """
- metadata = pd.read_csv(self.metadata_path)
- self.image_to_coordinate = {
- image.split("/")[-1]: Coordinate(latitude=latitude, longitude=longitude)
- for image, latitude, longitude in zip(metadata["path"], metadata["latitude"], metadata["longitude"])
- }
- # DBSCAN will be used to take the centroid of the biggest cluster among the N neighbors, using Haversine
- self.dbscan = DBSCAN(eps=self.dbscan_eps, metric=haversine_distance)
-
- def guess(self, image: Image) -> Coordinate:
- """Guess a coordinate from an image
- """
- # Embed image
- image = Image.fromarray(image)
- image_embedding = self.embedder.embed(image)[None, :]
-
- # Retrieve nearest neighbors
- nearest_neighbors, distances = self.retriever.retrieve(image_embedding, self.n_neighbors)
- nearest_neighbors = nearest_neighbors[0]
- distances = distances[0]
-
- # Get coordinates of neighbors
- neighbors_coordinates = [self.image_to_coordinate[nn].to_radians() for nn in nearest_neighbors]
- neighbors_coordinates = np.array([[nn.latitude, nn.longitude] for nn in neighbors_coordinates])
-
- # Use DBSCAN to find the biggest cluster and potentially remove outliers
- clustering = self.dbscan.fit(neighbors_coordinates)
- labels = clustering.labels_
- biggest_cluster = max(Counter(labels))
- neighbors_coordinates = neighbors_coordinates[labels == biggest_cluster]
- distances = distances[labels == biggest_cluster]
-
- # Guess coordinate as the closest image among the cluster regarding retrieving distance
- guess_coordinate = neighbors_coordinates[np.argmin(distances)]
- guess_coordinate = Coordinate.from_radians(guess_coordinate[0], guess_coordinate[1])
- return guess_coordinate
-
diff --git a/spaces/bcg-unet/demo/bcgunet/unet.py b/spaces/bcg-unet/demo/bcgunet/unet.py
deleted file mode 100644
index 71ed684f83c169ffce2e5324167e2945beab2a39..0000000000000000000000000000000000000000
--- a/spaces/bcg-unet/demo/bcgunet/unet.py
+++ /dev/null
@@ -1,123 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-
-class DoubleConv(nn.Module):
- """(convolution => [BN] => ReLU) * 2"""
-
- def __init__(self, in_channels, out_channels, mid_channels=None):
- super().__init__()
- if not mid_channels:
- mid_channels = out_channels
- self.double_conv = nn.Sequential(
- nn.Conv1d(in_channels, mid_channels, kernel_size=3, padding=1),
- nn.GroupNorm(num_groups=4, num_channels=mid_channels),
- nn.ReLU(inplace=True),
- nn.Conv1d(mid_channels, out_channels, kernel_size=3, padding=1),
- nn.GroupNorm(num_groups=4, num_channels=out_channels),
- nn.ReLU(inplace=True),
- )
-
- def forward(self, x):
- return self.double_conv(x)
-
-
-class DoubleConvX(nn.Module):
- """(convolution => [BN] => ReLU) * 2"""
-
- def __init__(self, in_channels, out_channels, mid_channels=None):
- super().__init__()
- if not mid_channels:
- mid_channels = out_channels
- self.double_conv = nn.Sequential(
- nn.Conv1d(in_channels, mid_channels, kernel_size=15, padding=7),
- nn.GroupNorm(num_groups=8, num_channels=mid_channels),
- nn.ReLU(inplace=True),
- nn.Conv1d(mid_channels, out_channels, kernel_size=15, padding=7),
- nn.GroupNorm(num_groups=8, num_channels=out_channels),
- nn.ReLU(inplace=True),
- )
-
- def forward(self, x):
- return self.double_conv(x)
-
-
-class Down(nn.Module):
- """Downscaling with maxpool then double conv"""
-
- def __init__(self, in_channels, out_channels):
- super().__init__()
- self.maxpool_conv = nn.Sequential(
- nn.MaxPool1d(2), DoubleConv(in_channels, out_channels)
- )
-
- def forward(self, x):
- return self.maxpool_conv(x)
-
-
-class Up(nn.Module):
- """Upscaling then double conv"""
-
- def __init__(self, in_channels, out_channels):
- super().__init__()
-
- self.up = nn.Upsample(scale_factor=2, mode="linear", align_corners=True)
- self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
-
- def forward(self, x1, x2):
- x1 = self.up(x1)
- # input is CHW
- diffX = x2.size()[2] - x1.size()[2]
-
- x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2])
- # if you have padding issues, see
- # https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
- # https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
- x = torch.cat([x2, x1], dim=1)
- return self.conv(x)
-
-
-class OutConv(nn.Module):
- def __init__(self, in_channels, out_channels):
- super(OutConv, self).__init__()
- self.conv = nn.Conv1d(in_channels, out_channels, kernel_size=1)
-
- def forward(self, x):
- return self.conv(x)
-
-
-class UNet1d(nn.Module):
- def __init__(self, n_channels, n_classes, nfilter=24):
- super(UNet1d, self).__init__()
- self.n_channels = n_channels
- self.n_classes = n_classes
-
- self.inc = DoubleConv(n_channels, nfilter)
- self.down1 = Down(nfilter, nfilter * 2)
- self.down2 = Down(nfilter * 2, nfilter * 4)
- self.down3 = Down(nfilter * 4, nfilter * 8)
- self.down4 = Down(nfilter * 8, nfilter * 8)
- self.up1 = Up(nfilter * 16, nfilter * 4)
- self.up2 = Up(nfilter * 8, nfilter * 2)
- self.up3 = Up(nfilter * 4, nfilter * 1)
- self.up4 = Up(nfilter * 2, nfilter)
- self.outc = OutConv(nfilter, n_classes)
-
- def forward(self, x):
- x1 = self.inc(x)
- x2 = self.down1(x1)
- x3 = self.down2(x2)
- x4 = self.down3(x3)
- x5 = self.down4(x4)
- x = self.up1(x5, x4)
- x = self.up2(x, x3)
- x = self.up3(x, x2)
- x = self.up4(x, x1)
- logits = self.outc(x)
- return logits
-
-
-if __name__ == "__main__":
- model = UNet1d(1, 1)
- print(model)
diff --git a/spaces/bfh-nlp-circle/nlp-cirlce-demo/README.md b/spaces/bfh-nlp-circle/nlp-cirlce-demo/README.md
deleted file mode 100644
index b92ea77aae1ea2a10250757d92011baf06509dfc..0000000000000000000000000000000000000000
--- a/spaces/bfh-nlp-circle/nlp-cirlce-demo/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Nlp Circle Demo
-emoji: 🔥
-colorFrom: green
-colorTo: green
-sdk: gradio
-sdk_version: 3.18.0
-app_file: app.py
-pinned: false
-python_version: 3.10.5
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/bigscience/petals-api/src/data_structures.py b/spaces/bigscience/petals-api/src/data_structures.py
deleted file mode 100644
index c785e54f1a341f9fb40978be9db942ec8d6c84e9..0000000000000000000000000000000000000000
--- a/spaces/bigscience/petals-api/src/data_structures.py
+++ /dev/null
@@ -1,8 +0,0 @@
-from typing import Collection, NamedTuple
-
-from hivemind import PeerID
-
-ModuleUID = str
-UID_DELIMITER = "." # delimits parts of one module uid, e.g. "bloom.transformer.h.4.self_attention"
-CHAIN_DELIMITER = " " # delimits multiple uids in a sequence, e.g. "bloom.layer3 bloom.layer4"
-RemoteModuleInfo = NamedTuple("RemoteModuleInfo", [("uid", ModuleUID), ("peer_ids", Collection[PeerID])])
diff --git a/spaces/bioriAsaeru/text-to-voice/10ml Love 1080p Movie Torrent A Modern Twist on Shakespeares Classic.md b/spaces/bioriAsaeru/text-to-voice/10ml Love 1080p Movie Torrent A Modern Twist on Shakespeares Classic.md
deleted file mode 100644
index dab88becc18320f2046e852d75353b62e1e949dd..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/10ml Love 1080p Movie Torrent A Modern Twist on Shakespeares Classic.md
+++ /dev/null
@@ -1,6 +0,0 @@
-10ml Love 1080p Movie Torrent DOWNLOAD ☆☆☆ https://urloso.com/2uyPW6
diff --git a/spaces/bioriAsaeru/text-to-voice/All Alone part 2 full movie download utorrent The ultimate guide for torrent lovers.md b/spaces/bioriAsaeru/text-to-voice/All Alone part 2 full movie download utorrent The ultimate guide for torrent lovers.md
deleted file mode 100644
index 2f83b2654199fd8a176d435308634fbfee8f51c1..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/All Alone part 2 full movie download utorrent The ultimate guide for torrent lovers.md
+++ /dev/null
@@ -1,15 +0,0 @@
-
-At a glance, Project GXS is similar to one of the many fan-created blogs on anime. But clicking onto the index brings up a mammoth list of all the movies listed on the site. Some of the titles offer direct downloads apart from torrenting.
-All Alone part 2 full movie download utorrent Download File ••• https://urloso.com/2uyPza
Copyright trolls, in particular, make their money by tracking down people who are downloading copyrighted content via torrents. They then send them letters asking for compensation, otherwise, legal action will be taken.
-Pirate Bay is ranked as one of the top torrent sites on the web. The site allows users to search, download, and upload magnet links and torrent files using BitTorrent, a peer-to-peer file-sharing protocol. To download files from Pirate Bay, you must first install a BitTorrent client, then visit Pirate Bay to search for and download the files of your choice, such as movies, television shows, music, video games, software, and more. Warning: Much of the content on Pirate Bay is copyrighted material which may be illegal and/or against your internet service provider's policy. Additionally, files downloaded through torrent may contain viruses and malware that can damage your computer. Pirate Bay often contains advertisements that contain adult content. Use Pirate Bay at your own risk.
-Generally, a download manager enables downloading of large files or multiples files in one session. Many web browsers, such as Internet Explorer 9, include a download manager. Stand-alone download managers also are available, including the Microsoft Download Manager.
-(This is an ordinary HTTP or FTP download, just as you've probably done many times before. This part doesn't require a BitTorrent client, it's done with an ordinary web browser. You save the torrent file to your hard disk.)
-
-Torrent files are small and don't take up much disk space, no matter how big the downloads they reference may be. It's a good idea to keep them until you are utterly certain that you will never need them again. Deleting old torrents may become a part of your regular monthly computer maintenance and hygiene.
-Folx PRO scheduler permits to take full control over your downloads by setting the time to start and finish them. Choose whether to shut down the computer, switch to sleeping mode or quit Folx once the downloads are completed. Moreover, Folx can start automatically when your computer is on, and will perform all the appointed tasks without your direct participation.
-The download speed on your Mac depends on many factors. Some of them are external ones which we can hardly handle, like speed limitations set by a website or the type of wires your Internet Service Provider uses to transmit the Internet signal. The other factors are actually the system ones and can be successfully controlled by an accurate management of the download process in general.
-In any case, the more you click on the Manual Update button, the more this will destabilize the tracker, and cause it to go offline for everybody. So for the most part, Leave the Manual Update button alone , and your speeds will recover by themselves (unless there are other issues, but anyway, this button will not help to fix those either).
-Please note: Only products purchased directly from Roxio qualify for the Roxio 30-Day Money-Back Guarantee. Purchases made from a retailer or partner must be returned to where you made your purchase and are subject to the return policy of that retailer. Purchases of transactional licenses, maintenance, download insurance, Protection Plans, Training Plans, Subscriptions and Product Memberships and Priority Tickets are excluded from this guarantee.
aaccfb2cb3Crysis 2 Serial Number Free 65: How to Play Crysis 2 for Free
-
-Crysis 2 is a first-person shooter game that was released in 2011 by Electronic Arts. It is the sequel to the critically acclaimed Crysis, and it features stunning graphics, intense gameplay, and an engaging story. Crysis 2 is set in a near-future New York City that has been invaded by aliens, and you play as a soldier who wears a nanosuit that gives you superhuman abilities.
-crysis 2 serial number free 65 Download File > https://urloso.com/2uyOQA
Crysis 2 is a game that many people want to play, but not everyone can afford to buy it. If you are one of those people who want to play Crysis 2 for free, you may be looking for a way to get a serial number that can activate the game. However, finding a valid serial number for Crysis 2 is not easy, as most of them are fake or already used. You may also risk getting viruses or malware if you download serial numbers from shady websites.
-
-Fortunately, there is a better way to play Crysis 2 for free without needing a serial number. You can use a crack that can bypass the activation process and let you run the game without any problems. A crack is a modified file that can replace the original file of the game and make it think that it is already activated. You don't need any special skills or software to use a crack, you just need to follow some simple steps.
-
-How to Download and Use a Crack for Crysis 2
-
-If you want to play Crysis 2 for free using a crack, you need to have the game installed on your PC first. You can download the game from various sources, such as torrents or direct links, but make sure that you have enough space on your hard drive and that your PC meets the minimum system requirements for Crysis 2. Here are the minimum system requirements for Crysis 2:
-
-
-
-OS: XP/Vista/Windows 7
-CPU: Intel Core 2 Duo at 2 GHz or AMD Athlon 64 X2 at 2 GHz
-RAM: 2 GB
-GPU: Nvidia GeForce 8800 GT or ATI Radeon HD 3850
-DirectX: DirectX 9.0c
-HDD: 9 GB
-
-
-Once you have downloaded and installed the game on your PC, you can proceed to download and use a crack for Crysis 2. Here are the steps that you need to follow:
-
-
-Go to this link: https://www.mediafire.com/file/924323... and download the crack file for Crysis 2. The file size is around 30 MB, so it should not take long to download.
-Extract the crack file using WinRAR or any other extraction software. You should get a folder named "Bin32" that contains two files: "Crysis2.exe" and "Crysis2Launcher.exe".
-Copy the "Bin32" folder and paste it into your Crysis 2 installation directory. This is usually located at C:\Program Files (x86)\Electronic Arts\Crytek\Crysis 2\. You may need to overwrite the existing files when prompted.
-Run the "Crysis2Launcher.exe" file from your Crysis 2 installation directory. This will launch the game without asking for a serial number.
-Enjoy playing Crysis 2 for free!
-
-
-That's it! You have successfully cracked Crysis 2 and you can play it for free without needing a serial number. You can also access all the features and modes of the game, such as campaign, multiplayer, and sandbox.
-
-Conclusion
-
-Crysis 2 is a great game that deserves to be played by everyone who loves first-person shooters. However, not everyone can afford to buy it or find a valid serial number for it. If you are one of those people who want to play Crysis 2 for free, you can use a crack that can bypass the activation process and let you run the game without any problems.
-
-A crack is a modified file that can replace the original file of the game and make it think that it is already activated. You don't need any special skills or software to use a crack, you just need to follow some simple steps. You can download and use a crack for Crysis 2 from this link: https://www.mediafire.com/file/924323...
-
-If you follow this guide, you will be able to play Crysis 2 for free using a crack without needing a serial number. You will also be able to enjoy all the features and modes of the game, such as campaign, multiplayer, and sandbox. You will have a lot of fun playing Crysis 2 and experiencing its stunning graphics, intense gameplay, and engaging story.
-How to Avoid Viruses and Malware When Downloading Crysis 2 and the Crack
-
-One of the risks of downloading games and cracks from the internet is that you may encounter viruses and malware that can harm your PC or steal your personal information. Viruses and malware are malicious programs that can infect your PC and cause various problems, such as slowing down your performance, deleting your files, displaying unwanted ads, spying on your activities, etc.
-
-If you want to play Crysis 2 for free using a crack without risking getting viruses and malware, you need to be careful and cautious when downloading the game and the crack. You need to make sure that you download them from reliable and trustworthy sources, and that you scan them with a good antivirus software before running them. Here are some tips and tricks that you can use to avoid viruses and malware when downloading Crysis 2 and the crack:
-
-
-Use a reputable and updated antivirus software on your PC. You can use a free or paid antivirus software, as long as it is effective and reliable. Some of the popular antivirus software that you can use are Avast, AVG, Kaspersky, Norton, etc. You can also use an online virus scanner, such as VirusTotal, to check the files before downloading them.
-Download the game and the crack from trusted and verified sources. You can use torrents or direct links, as long as they are from reputable and well-known websites or forums. You can also check the comments and ratings of the files before downloading them, to see if other users have reported any problems or issues with them.
-Avoid clicking on suspicious or random links or pop-ups that claim to offer you free games or cracks. These are usually scams or traps that can redirect you to malicious websites or download harmful files on your PC. You should also avoid opening any attachments or files that you receive from unknown or unsolicited sources.
-Backup your important files and data before installing the game and the crack. This is a precautionary measure that can help you restore your PC in case something goes wrong or if you get infected by a virus or malware. You can backup your files and data using an external hard drive, a cloud service, or a backup software.
-
-
-If you follow these tips and tricks, you will be able to download and play Crysis 2 for free using a crack without getting viruses and malware on your PC. You will also be able to protect your PC and your personal information from any potential threats or attacks.
-How to Enjoy Crysis 2 Gameplay with a Crack
-
-Crysis 2 is a game that offers a lot of fun and excitement to its players. It has a captivating story, a thrilling gameplay, and a stunning graphics. You can play Crysis 2 in different modes, such as campaign, multiplayer, and sandbox. You can also customize your nanosuit, which gives you superhuman abilities, such as cloaking, armor, speed, and strength.
-
-If you want to enjoy Crysis 2 gameplay with a crack, you need to have the game and the crack installed on your PC. You can download the game and the crack from various sources, such as torrents or direct links, but make sure that you follow the instructions on how to install and use them. You can also check our previous sections on how to download and use a crack for Crysis 2 and how to avoid viruses and malware when downloading Crysis 2 and the crack.
-
-Once you have the game and the crack installed on your PC, you can launch the game using the "Crysis2Launcher.exe" file from your Crysis 2 installation directory. This will start the game without asking for a serial number. You can then choose the mode that you want to play and enjoy the game.
-
-Here are some tips and tricks that you can use to enjoy Crysis 2 gameplay with a crack:
-
-
-To change the graphics settings of the game, you can use the options menu in the game or edit the system.cfg file in your Crysis 2 installation directory. You can adjust the resolution, texture quality, anti-aliasing, shadows, etc. You can also use some mods or tweaks that can enhance the graphics of the game.
-To unlock all the levels and missions of the game, you can use some cheats or trainers that can give you unlimited health, ammo, energy, etc. You can also edit some files in your Crysis 2 installation directory, such as game.cfg or diff_easy.cfg. However, be careful when using cheats or trainers, as they may cause some glitches or crashes.
-To play multiplayer mode with a crack, you need to have an online account that can access the multiplayer servers of Crysis 2. You can create an account using your email address or use an existing account from other EA games. You can also use some tools or patches that can enable multiplayer mode with a crack.
-To play sandbox mode with a crack, you need to have the CryEngine 3 SDK installed on your PC. This is a software development kit that allows you to create and edit maps and levels for Crysis 2. You can download it from the official website of CryEngine or from other sources. You can also use some tutorials or guides that can help you use the CryEngine 3 SDK.
-
-
-Crysis 2 is a game that has a lot of gameplay options and features that you can explore and enjoy with a crack. You can play it in different modes, such as campaign, multiplayer, and sandbox. You can also customize your nanosuit, which gives you superhuman abilities. You can also use some mods or tweaks that can enhance the graphics or performance of the game.
-Why You Should Play Crysis 2 with a Crack
-
-Crysis 2 is a game that deserves to be played by everyone who loves first-person shooters. It is one of the best games of its genre, and it has received a lot of praise and awards from critics and players. However, not everyone can play Crysis 2, as it requires a serial number that can activate the game. A serial number is a code that can verify that you have purchased the game legally and that you can play it on your PC.
-
-If you don't have a serial number for Crysis 2, you may think that you have no choice but to buy the game or to give up on playing it. However, there is another way to play Crysis 2 without needing a serial number. You can use a crack that can bypass the activation process and let you run the game without any problems. A crack is a modified file that can replace the original file of the game and make it think that it is already activated.
-
-There are many reasons why you should play Crysis 2 with a crack instead of buying the game or giving up on playing it. Here are some of them:
-
-
-You can save money. Buying Crysis 2 can cost you a lot of money, especially if you want to buy the original version or the deluxe edition. You may also need to pay for shipping or taxes if you buy the game online or from another country. If you use a crack, you can play Crysis 2 for free and save your money for other things.
-You can play anytime and anywhere. If you buy Crysis 2, you may need to register your serial number online or connect to the internet every time you want to play the game. This can be inconvenient and annoying, especially if you have a slow or unstable internet connection or if you want to play offline. If you use a crack, you can play Crysis 2 anytime and anywhere without needing an internet connection or a serial number.
-You can avoid problems and errors. If you buy Crysis 2, you may encounter some problems or errors with the activation process or with the game itself. You may get an invalid or used serial number, or you may get an error message that says that your serial number is in use or that your activation limit has been reached. You may also get some bugs or glitches in the game that can ruin your experience. If you use a crack, you can avoid these problems and errors and enjoy the game smoothly.
-
-
-These are some of the reasons why you should play Crysis 2 with a crack instead of buying the game or giving up on playing it. You can enjoy all the benefits and features of the game without needing a serial number or paying any money. You can also avoid any problems or errors that may occur with the activation process or with the game itself.
-Conclusion
-
-Crysis 2 is a game that you don't want to miss if you are a fan of first-person shooters. It is a game that has a captivating story, a thrilling gameplay, and a stunning graphics. You can play it in different modes, such as campaign, multiplayer, and sandbox. You can also customize your nanosuit, which gives you superhuman abilities.
-
-However, not everyone can play Crysis 2, as it requires a serial number that can activate the game. A serial number is a code that can verify that you have purchased the game legally and that you can play it on your PC. If you don't have a serial number for Crysis 2, you may think that you have no choice but to buy the game or to give up on playing it.
-
-Fortunately, there is another way to play Crysis 2 without needing a serial number. You can use a crack that can bypass the activation process and let you run the game without any problems. A crack is a modified file that can replace the original file of the game and make it think that it is already activated.
-
-If you use a crack for Crysis 2, you can enjoy all the benefits and features of the game without needing a serial number or paying any money. You can also avoid any problems or errors that may occur with the activation process or with the game itself. You can play Crysis 2 anytime and anywhere without needing an internet connection or a serial number.
-
-If you want to play Crysis 2 for free using a crack without needing a serial number, you can follow this guide and download and use a crack for Crysis 2 from this link: https://www.mediafire.com/file/924323...
-
-If you follow this guide, you will be able to play Crysis 2 for free using a crack without needing a serial number. You will also be able to enjoy all the features and modes of the game, such as campaign, multiplayer, and sandbox. You will have a lot of fun playing Crysis 2 and experiencing its stunning graphics, intense gameplay, and engaging story.
3cee63e6c2It is preferred to run them as images instead of running them straight from the original BD. XBox 360 Emulator for PC is embedded with features that will help you in changing the settings very easily. To do this, you have to change the graphic options compatible for the graphic card initially. An explicit thing about the XBox 360 Emulator for PC is that it can load the coherent settings on its own as default. The procedure to download 3DS emulator is quite different if you want to play Nintendo 3DS games on your PC and Mac.
-Download Bios Xbox 360 Emulator Download File · https://urloso.com/2uyPN1
That being said, XBox 360 Emulator for PC is rather an interesting addition to your arsenal. Besides this, you can also go through GBA4iOS which is an advanced emulator download GBA games on iOS. ? Stay tuned to the Emulators section for more!
-xbox emulator bios, xbox emulator bios for android, xboxemulator bios file, xbox emulator bios file download, ebox xboxemulator bios, original xbox emulator bios, xbox 360 emulator withbios and plugins, download bios for xbox emulator android, xbox 360emulator bios for android, xbox 360 emulator bios v3.2.4.rar, xboxemulator apk bios, xbox 360 emulator bios free download
-So what is EmuDeck? EmuDeck is a tool (more precisely, a script) that you can download/install which greatly simplifies the installation of 160 emulators and supporting utilities to your Steam Deck. It also pre-configures all the controls, aspect ratio settings, etc. so really there is very little configuration required on your part to get up and running. That said, many will prefer to have step-by-step instructions, additional tips, assistance with a few stubborn features and commentary.
-
aaccfb2cb3JEDI: JCL JVCL up to Delphi 10.3 Rio Download 🗸 https://urloso.com/2uyPGK
diff --git a/spaces/boddles2/pyannote-speaker-diarization-2/README.md b/spaces/boddles2/pyannote-speaker-diarization-2/README.md
deleted file mode 100644
index 0e7e34292c3d2dc8ec2cbbddc92f16e3ad0028cb..0000000000000000000000000000000000000000
--- a/spaces/boddles2/pyannote-speaker-diarization-2/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Pyannote Speaker Diarization 2
-emoji: 🐨
-colorFrom: purple
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.38.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.py b/spaces/brjathu/HMR2.0/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.py
deleted file mode 100644
index 22016be150df4abbe912700d7ca29f8b7b72554a..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.py
+++ /dev/null
@@ -1,8 +0,0 @@
-from ..common.train import train
-from ..common.optim import SGD as optimizer
-from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier
-from ..common.data.coco import dataloader
-from ..common.models.mask_rcnn_c4 import model
-
-model.backbone.freeze_at = 2
-train.init_checkpoint = "detectron2://ImageNetPretrained/MSRA/R-50.pkl"
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/configs/common/data/coco_panoptic_separated.py b/spaces/brjathu/HMR2.0/vendor/detectron2/configs/common/data/coco_panoptic_separated.py
deleted file mode 100644
index 5ccbc77e64d1c92c99cbd7158d047bab54cb9f3d..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/configs/common/data/coco_panoptic_separated.py
+++ /dev/null
@@ -1,26 +0,0 @@
-from detectron2.config import LazyCall as L
-from detectron2.evaluation import (
- COCOEvaluator,
- COCOPanopticEvaluator,
- DatasetEvaluators,
- SemSegEvaluator,
-)
-
-from .coco import dataloader
-
-dataloader.train.dataset.names = "coco_2017_train_panoptic_separated"
-dataloader.train.dataset.filter_empty = False
-dataloader.test.dataset.names = "coco_2017_val_panoptic_separated"
-
-
-dataloader.evaluator = [
- L(COCOEvaluator)(
- dataset_name="${...test.dataset.names}",
- ),
- L(SemSegEvaluator)(
- dataset_name="${...test.dataset.names}",
- ),
- L(COCOPanopticEvaluator)(
- dataset_name="${...test.dataset.names}",
- ),
-]
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/losses/utils.py b/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/losses/utils.py
deleted file mode 100644
index ceea981d11650af80cb007fe129a3ee4864fc48f..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/losses/utils.py
+++ /dev/null
@@ -1,443 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-from abc import ABC, abstractmethod
-from dataclasses import dataclass
-from typing import Any, Dict, List, Optional, Tuple
-import torch
-from torch.nn import functional as F
-
-from detectron2.structures import BoxMode, Instances
-
-from densepose import DensePoseDataRelative
-
-LossDict = Dict[str, torch.Tensor]
-
-
-def _linear_interpolation_utilities(v_norm, v0_src, size_src, v0_dst, size_dst, size_z):
- """
- Computes utility values for linear interpolation at points v.
- The points are given as normalized offsets in the source interval
- (v0_src, v0_src + size_src), more precisely:
- v = v0_src + v_norm * size_src / 256.0
- The computed utilities include lower points v_lo, upper points v_hi,
- interpolation weights v_w and flags j_valid indicating whether the
- points falls into the destination interval (v0_dst, v0_dst + size_dst).
-
- Args:
- v_norm (:obj: `torch.Tensor`): tensor of size N containing
- normalized point offsets
- v0_src (:obj: `torch.Tensor`): tensor of size N containing
- left bounds of source intervals for normalized points
- size_src (:obj: `torch.Tensor`): tensor of size N containing
- source interval sizes for normalized points
- v0_dst (:obj: `torch.Tensor`): tensor of size N containing
- left bounds of destination intervals
- size_dst (:obj: `torch.Tensor`): tensor of size N containing
- destination interval sizes
- size_z (int): interval size for data to be interpolated
-
- Returns:
- v_lo (:obj: `torch.Tensor`): int tensor of size N containing
- indices of lower values used for interpolation, all values are
- integers from [0, size_z - 1]
- v_hi (:obj: `torch.Tensor`): int tensor of size N containing
- indices of upper values used for interpolation, all values are
- integers from [0, size_z - 1]
- v_w (:obj: `torch.Tensor`): float tensor of size N containing
- interpolation weights
- j_valid (:obj: `torch.Tensor`): uint8 tensor of size N containing
- 0 for points outside the estimation interval
- (v0_est, v0_est + size_est) and 1 otherwise
- """
- v = v0_src + v_norm * size_src / 256.0
- j_valid = (v - v0_dst >= 0) * (v - v0_dst < size_dst)
- v_grid = (v - v0_dst) * size_z / size_dst
- v_lo = v_grid.floor().long().clamp(min=0, max=size_z - 1)
- v_hi = (v_lo + 1).clamp(max=size_z - 1)
- v_grid = torch.min(v_hi.float(), v_grid)
- v_w = v_grid - v_lo.float()
- return v_lo, v_hi, v_w, j_valid
-
-
-class BilinearInterpolationHelper:
- """
- Args:
- packed_annotations: object that contains packed annotations
- j_valid (:obj: `torch.Tensor`): uint8 tensor of size M containing
- 0 for points to be discarded and 1 for points to be selected
- y_lo (:obj: `torch.Tensor`): int tensor of indices of upper values
- in z_est for each point
- y_hi (:obj: `torch.Tensor`): int tensor of indices of lower values
- in z_est for each point
- x_lo (:obj: `torch.Tensor`): int tensor of indices of left values
- in z_est for each point
- x_hi (:obj: `torch.Tensor`): int tensor of indices of right values
- in z_est for each point
- w_ylo_xlo (:obj: `torch.Tensor`): float tensor of size M;
- contains upper-left value weight for each point
- w_ylo_xhi (:obj: `torch.Tensor`): float tensor of size M;
- contains upper-right value weight for each point
- w_yhi_xlo (:obj: `torch.Tensor`): float tensor of size M;
- contains lower-left value weight for each point
- w_yhi_xhi (:obj: `torch.Tensor`): float tensor of size M;
- contains lower-right value weight for each point
- """
-
- def __init__(
- self,
- packed_annotations: Any,
- j_valid: torch.Tensor,
- y_lo: torch.Tensor,
- y_hi: torch.Tensor,
- x_lo: torch.Tensor,
- x_hi: torch.Tensor,
- w_ylo_xlo: torch.Tensor,
- w_ylo_xhi: torch.Tensor,
- w_yhi_xlo: torch.Tensor,
- w_yhi_xhi: torch.Tensor,
- ):
- for k, v in locals().items():
- if k != "self":
- setattr(self, k, v)
-
- @staticmethod
- def from_matches(
- packed_annotations: Any, densepose_outputs_size_hw: Tuple[int, int]
- ) -> "BilinearInterpolationHelper":
- """
- Args:
- packed_annotations: annotations packed into tensors, the following
- attributes are required:
- - bbox_xywh_gt
- - bbox_xywh_est
- - x_gt
- - y_gt
- - point_bbox_with_dp_indices
- - point_bbox_indices
- densepose_outputs_size_hw (tuple [int, int]): resolution of
- DensePose predictor outputs (H, W)
- Return:
- An instance of `BilinearInterpolationHelper` used to perform
- interpolation for the given annotation points and output resolution
- """
-
- zh, zw = densepose_outputs_size_hw
- x0_gt, y0_gt, w_gt, h_gt = packed_annotations.bbox_xywh_gt[
- packed_annotations.point_bbox_with_dp_indices
- ].unbind(dim=1)
- x0_est, y0_est, w_est, h_est = packed_annotations.bbox_xywh_est[
- packed_annotations.point_bbox_with_dp_indices
- ].unbind(dim=1)
- x_lo, x_hi, x_w, jx_valid = _linear_interpolation_utilities(
- packed_annotations.x_gt, x0_gt, w_gt, x0_est, w_est, zw
- )
- y_lo, y_hi, y_w, jy_valid = _linear_interpolation_utilities(
- packed_annotations.y_gt, y0_gt, h_gt, y0_est, h_est, zh
- )
- j_valid = jx_valid * jy_valid
-
- w_ylo_xlo = (1.0 - x_w) * (1.0 - y_w)
- w_ylo_xhi = x_w * (1.0 - y_w)
- w_yhi_xlo = (1.0 - x_w) * y_w
- w_yhi_xhi = x_w * y_w
-
- return BilinearInterpolationHelper(
- packed_annotations,
- j_valid,
- y_lo,
- y_hi,
- x_lo,
- x_hi,
- w_ylo_xlo, # pyre-ignore[6]
- w_ylo_xhi,
- # pyre-fixme[6]: Expected `Tensor` for 9th param but got `float`.
- w_yhi_xlo,
- w_yhi_xhi,
- )
-
- def extract_at_points(
- self,
- z_est,
- slice_fine_segm=None,
- w_ylo_xlo=None,
- w_ylo_xhi=None,
- w_yhi_xlo=None,
- w_yhi_xhi=None,
- ):
- """
- Extract ground truth values z_gt for valid point indices and estimated
- values z_est using bilinear interpolation over top-left (y_lo, x_lo),
- top-right (y_lo, x_hi), bottom-left (y_hi, x_lo) and bottom-right
- (y_hi, x_hi) values in z_est with corresponding weights:
- w_ylo_xlo, w_ylo_xhi, w_yhi_xlo and w_yhi_xhi.
- Use slice_fine_segm to slice dim=1 in z_est
- """
- slice_fine_segm = (
- self.packed_annotations.fine_segm_labels_gt
- if slice_fine_segm is None
- else slice_fine_segm
- )
- w_ylo_xlo = self.w_ylo_xlo if w_ylo_xlo is None else w_ylo_xlo
- w_ylo_xhi = self.w_ylo_xhi if w_ylo_xhi is None else w_ylo_xhi
- w_yhi_xlo = self.w_yhi_xlo if w_yhi_xlo is None else w_yhi_xlo
- w_yhi_xhi = self.w_yhi_xhi if w_yhi_xhi is None else w_yhi_xhi
-
- index_bbox = self.packed_annotations.point_bbox_indices
- z_est_sampled = (
- z_est[index_bbox, slice_fine_segm, self.y_lo, self.x_lo] * w_ylo_xlo
- + z_est[index_bbox, slice_fine_segm, self.y_lo, self.x_hi] * w_ylo_xhi
- + z_est[index_bbox, slice_fine_segm, self.y_hi, self.x_lo] * w_yhi_xlo
- + z_est[index_bbox, slice_fine_segm, self.y_hi, self.x_hi] * w_yhi_xhi
- )
- return z_est_sampled
-
-
-def resample_data(
- z, bbox_xywh_src, bbox_xywh_dst, wout, hout, mode: str = "nearest", padding_mode: str = "zeros"
-):
- """
- Args:
- z (:obj: `torch.Tensor`): tensor of size (N,C,H,W) with data to be
- resampled
- bbox_xywh_src (:obj: `torch.Tensor`): tensor of size (N,4) containing
- source bounding boxes in format XYWH
- bbox_xywh_dst (:obj: `torch.Tensor`): tensor of size (N,4) containing
- destination bounding boxes in format XYWH
- Return:
- zresampled (:obj: `torch.Tensor`): tensor of size (N, C, Hout, Wout)
- with resampled values of z, where D is the discretization size
- """
- n = bbox_xywh_src.size(0)
- assert n == bbox_xywh_dst.size(0), (
- "The number of "
- "source ROIs for resampling ({}) should be equal to the number "
- "of destination ROIs ({})".format(bbox_xywh_src.size(0), bbox_xywh_dst.size(0))
- )
- x0src, y0src, wsrc, hsrc = bbox_xywh_src.unbind(dim=1)
- x0dst, y0dst, wdst, hdst = bbox_xywh_dst.unbind(dim=1)
- x0dst_norm = 2 * (x0dst - x0src) / wsrc - 1
- y0dst_norm = 2 * (y0dst - y0src) / hsrc - 1
- x1dst_norm = 2 * (x0dst + wdst - x0src) / wsrc - 1
- y1dst_norm = 2 * (y0dst + hdst - y0src) / hsrc - 1
- grid_w = torch.arange(wout, device=z.device, dtype=torch.float) / wout
- grid_h = torch.arange(hout, device=z.device, dtype=torch.float) / hout
- grid_w_expanded = grid_w[None, None, :].expand(n, hout, wout)
- grid_h_expanded = grid_h[None, :, None].expand(n, hout, wout)
- dx_expanded = (x1dst_norm - x0dst_norm)[:, None, None].expand(n, hout, wout)
- dy_expanded = (y1dst_norm - y0dst_norm)[:, None, None].expand(n, hout, wout)
- x0_expanded = x0dst_norm[:, None, None].expand(n, hout, wout)
- y0_expanded = y0dst_norm[:, None, None].expand(n, hout, wout)
- grid_x = grid_w_expanded * dx_expanded + x0_expanded
- grid_y = grid_h_expanded * dy_expanded + y0_expanded
- grid = torch.stack((grid_x, grid_y), dim=3)
- # resample Z from (N, C, H, W) into (N, C, Hout, Wout)
- zresampled = F.grid_sample(z, grid, mode=mode, padding_mode=padding_mode, align_corners=True)
- return zresampled
-
-
-class AnnotationsAccumulator(ABC):
- """
- Abstract class for an accumulator for annotations that can produce
- dense annotations packed into tensors.
- """
-
- @abstractmethod
- def accumulate(self, instances_one_image: Instances):
- """
- Accumulate instances data for one image
-
- Args:
- instances_one_image (Instances): instances data to accumulate
- """
- pass
-
- @abstractmethod
- def pack(self) -> Any:
- """
- Pack data into tensors
- """
- pass
-
-
-@dataclass
-class PackedChartBasedAnnotations:
- """
- Packed annotations for chart-based model training. The following attributes
- are defined:
- - fine_segm_labels_gt (tensor [K] of `int64`): GT fine segmentation point labels
- - x_gt (tensor [K] of `float32`): GT normalized X point coordinates
- - y_gt (tensor [K] of `float32`): GT normalized Y point coordinates
- - u_gt (tensor [K] of `float32`): GT point U values
- - v_gt (tensor [K] of `float32`): GT point V values
- - coarse_segm_gt (tensor [N, S, S] of `float32`): GT segmentation for bounding boxes
- - bbox_xywh_gt (tensor [N, 4] of `float32`): selected GT bounding boxes in
- XYWH format
- - bbox_xywh_est (tensor [N, 4] of `float32`): selected matching estimated
- bounding boxes in XYWH format
- - point_bbox_with_dp_indices (tensor [K] of `int64`): indices of bounding boxes
- with DensePose annotations that correspond to the point data
- - point_bbox_indices (tensor [K] of `int64`): indices of bounding boxes
- (not necessarily the selected ones with DensePose data) that correspond
- to the point data
- - bbox_indices (tensor [N] of `int64`): global indices of selected bounding
- boxes with DensePose annotations; these indices could be used to access
- features that are computed for all bounding boxes, not only the ones with
- DensePose annotations.
- Here K is the total number of points and N is the total number of instances
- with DensePose annotations.
- """
-
- fine_segm_labels_gt: torch.Tensor
- x_gt: torch.Tensor
- y_gt: torch.Tensor
- u_gt: torch.Tensor
- v_gt: torch.Tensor
- coarse_segm_gt: Optional[torch.Tensor]
- bbox_xywh_gt: torch.Tensor
- bbox_xywh_est: torch.Tensor
- point_bbox_with_dp_indices: torch.Tensor
- point_bbox_indices: torch.Tensor
- bbox_indices: torch.Tensor
-
-
-class ChartBasedAnnotationsAccumulator(AnnotationsAccumulator):
- """
- Accumulates annotations by batches that correspond to objects detected on
- individual images. Can pack them together into single tensors.
- """
-
- def __init__(self):
- self.i_gt = []
- self.x_gt = []
- self.y_gt = []
- self.u_gt = []
- self.v_gt = []
- self.s_gt = []
- self.bbox_xywh_gt = []
- self.bbox_xywh_est = []
- self.point_bbox_with_dp_indices = []
- self.point_bbox_indices = []
- self.bbox_indices = []
- self.nxt_bbox_with_dp_index = 0
- self.nxt_bbox_index = 0
-
- def accumulate(self, instances_one_image: Instances):
- """
- Accumulate instances data for one image
-
- Args:
- instances_one_image (Instances): instances data to accumulate
- """
- boxes_xywh_est = BoxMode.convert(
- instances_one_image.proposal_boxes.tensor.clone(), BoxMode.XYXY_ABS, BoxMode.XYWH_ABS
- )
- boxes_xywh_gt = BoxMode.convert(
- instances_one_image.gt_boxes.tensor.clone(), BoxMode.XYXY_ABS, BoxMode.XYWH_ABS
- )
- n_matches = len(boxes_xywh_gt)
- assert n_matches == len(
- boxes_xywh_est
- ), f"Got {len(boxes_xywh_est)} proposal boxes and {len(boxes_xywh_gt)} GT boxes"
- if not n_matches:
- # no detection - GT matches
- return
- if (
- not hasattr(instances_one_image, "gt_densepose")
- or instances_one_image.gt_densepose is None
- ):
- # no densepose GT for the detections, just increase the bbox index
- self.nxt_bbox_index += n_matches
- return
- for box_xywh_est, box_xywh_gt, dp_gt in zip(
- boxes_xywh_est, boxes_xywh_gt, instances_one_image.gt_densepose
- ):
- if (dp_gt is not None) and (len(dp_gt.x) > 0):
- # pyre-fixme[6]: For 1st argument expected `Tensor` but got `float`.
- # pyre-fixme[6]: For 2nd argument expected `Tensor` but got `float`.
- self._do_accumulate(box_xywh_gt, box_xywh_est, dp_gt)
- self.nxt_bbox_index += 1
-
- def _do_accumulate(
- self, box_xywh_gt: torch.Tensor, box_xywh_est: torch.Tensor, dp_gt: DensePoseDataRelative
- ):
- """
- Accumulate instances data for one image, given that the data is not empty
-
- Args:
- box_xywh_gt (tensor): GT bounding box
- box_xywh_est (tensor): estimated bounding box
- dp_gt (DensePoseDataRelative): GT densepose data
- """
- self.i_gt.append(dp_gt.i)
- self.x_gt.append(dp_gt.x)
- self.y_gt.append(dp_gt.y)
- self.u_gt.append(dp_gt.u)
- self.v_gt.append(dp_gt.v)
- if hasattr(dp_gt, "segm"):
- self.s_gt.append(dp_gt.segm.unsqueeze(0))
- self.bbox_xywh_gt.append(box_xywh_gt.view(-1, 4))
- self.bbox_xywh_est.append(box_xywh_est.view(-1, 4))
- self.point_bbox_with_dp_indices.append(
- torch.full_like(dp_gt.i, self.nxt_bbox_with_dp_index)
- )
- self.point_bbox_indices.append(torch.full_like(dp_gt.i, self.nxt_bbox_index))
- self.bbox_indices.append(self.nxt_bbox_index)
- self.nxt_bbox_with_dp_index += 1
-
- def pack(self) -> Optional[PackedChartBasedAnnotations]:
- """
- Pack data into tensors
- """
- if not len(self.i_gt):
- # TODO:
- # returning proper empty annotations would require
- # creating empty tensors of appropriate shape and
- # type on an appropriate device;
- # we return None so far to indicate empty annotations
- return None
- return PackedChartBasedAnnotations(
- fine_segm_labels_gt=torch.cat(self.i_gt, 0).long(),
- x_gt=torch.cat(self.x_gt, 0),
- y_gt=torch.cat(self.y_gt, 0),
- u_gt=torch.cat(self.u_gt, 0),
- v_gt=torch.cat(self.v_gt, 0),
- # ignore segmentation annotations, if not all the instances contain those
- coarse_segm_gt=torch.cat(self.s_gt, 0)
- if len(self.s_gt) == len(self.bbox_xywh_gt)
- else None,
- bbox_xywh_gt=torch.cat(self.bbox_xywh_gt, 0),
- bbox_xywh_est=torch.cat(self.bbox_xywh_est, 0),
- point_bbox_with_dp_indices=torch.cat(self.point_bbox_with_dp_indices, 0).long(),
- point_bbox_indices=torch.cat(self.point_bbox_indices, 0).long(),
- bbox_indices=torch.as_tensor(
- self.bbox_indices, dtype=torch.long, device=self.x_gt[0].device
- ).long(),
- )
-
-
-def extract_packed_annotations_from_matches(
- proposals_with_targets: List[Instances], accumulator: AnnotationsAccumulator
-) -> Any:
- for proposals_targets_per_image in proposals_with_targets:
- accumulator.accumulate(proposals_targets_per_image)
- return accumulator.pack()
-
-
-def sample_random_indices(
- n_indices: int, n_samples: int, device: Optional[torch.device] = None
-) -> Optional[torch.Tensor]:
- """
- Samples `n_samples` random indices from range `[0..n_indices - 1]`.
- If `n_indices` is smaller than `n_samples`, returns `None` meaning that all indices
- are selected.
- Args:
- n_indices (int): total number of indices
- n_samples (int): number of indices to sample
- device (torch.device): the desired device of returned tensor
- Return:
- Tensor of selected vertex indices, or `None`, if all vertices are selected
- """
- if (n_samples <= 0) or (n_indices <= n_samples):
- return None
- indices = torch.randperm(n_indices, device=device)[:n_samples]
- return indices
diff --git a/spaces/caffeinum/VToonify/vtoonify/model/stylegan/lpips/networks_basic.py b/spaces/caffeinum/VToonify/vtoonify/model/stylegan/lpips/networks_basic.py
deleted file mode 100644
index 201359c4e743aed285694668e13da6dd5a40b621..0000000000000000000000000000000000000000
--- a/spaces/caffeinum/VToonify/vtoonify/model/stylegan/lpips/networks_basic.py
+++ /dev/null
@@ -1,187 +0,0 @@
-
-from __future__ import absolute_import
-
-import sys
-import torch
-import torch.nn as nn
-import torch.nn.init as init
-from torch.autograd import Variable
-import numpy as np
-from pdb import set_trace as st
-from skimage import color
-from IPython import embed
-from model.stylegan.lpips import pretrained_networks as pn
-
-import model.stylegan.lpips as util
-
-def spatial_average(in_tens, keepdim=True):
- return in_tens.mean([2,3],keepdim=keepdim)
-
-def upsample(in_tens, out_H=64): # assumes scale factor is same for H and W
- in_H = in_tens.shape[2]
- scale_factor = 1.*out_H/in_H
-
- return nn.Upsample(scale_factor=scale_factor, mode='bilinear', align_corners=False)(in_tens)
-
-# Learned perceptual metric
-class PNetLin(nn.Module):
- def __init__(self, pnet_type='vgg', pnet_rand=False, pnet_tune=False, use_dropout=True, spatial=False, version='0.1', lpips=True):
- super(PNetLin, self).__init__()
-
- self.pnet_type = pnet_type
- self.pnet_tune = pnet_tune
- self.pnet_rand = pnet_rand
- self.spatial = spatial
- self.lpips = lpips
- self.version = version
- self.scaling_layer = ScalingLayer()
-
- if(self.pnet_type in ['vgg','vgg16']):
- net_type = pn.vgg16
- self.chns = [64,128,256,512,512]
- elif(self.pnet_type=='alex'):
- net_type = pn.alexnet
- self.chns = [64,192,384,256,256]
- elif(self.pnet_type=='squeeze'):
- net_type = pn.squeezenet
- self.chns = [64,128,256,384,384,512,512]
- self.L = len(self.chns)
-
- self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
-
- if(lpips):
- self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
- self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
- self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
- self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
- self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
- self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
- if(self.pnet_type=='squeeze'): # 7 layers for squeezenet
- self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
- self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
- self.lins+=[self.lin5,self.lin6]
-
- def forward(self, in0, in1, retPerLayer=False):
- # v0.0 - original release had a bug, where input was not scaled
- in0_input, in1_input = (self.scaling_layer(in0), self.scaling_layer(in1)) if self.version=='0.1' else (in0, in1)
- outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
- feats0, feats1, diffs = {}, {}, {}
-
- for kk in range(self.L):
- feats0[kk], feats1[kk] = util.normalize_tensor(outs0[kk]), util.normalize_tensor(outs1[kk])
- diffs[kk] = (feats0[kk]-feats1[kk])**2
-
- if(self.lpips):
- if(self.spatial):
- res = [upsample(self.lins[kk].model(diffs[kk]), out_H=in0.shape[2]) for kk in range(self.L)]
- else:
- res = [spatial_average(self.lins[kk].model(diffs[kk]), keepdim=True) for kk in range(self.L)]
- else:
- if(self.spatial):
- res = [upsample(diffs[kk].sum(dim=1,keepdim=True), out_H=in0.shape[2]) for kk in range(self.L)]
- else:
- res = [spatial_average(diffs[kk].sum(dim=1,keepdim=True), keepdim=True) for kk in range(self.L)]
-
- val = res[0]
- for l in range(1,self.L):
- val += res[l]
-
- if(retPerLayer):
- return (val, res)
- else:
- return val
-
-class ScalingLayer(nn.Module):
- def __init__(self):
- super(ScalingLayer, self).__init__()
- self.register_buffer('shift', torch.Tensor([-.030,-.088,-.188])[None,:,None,None])
- self.register_buffer('scale', torch.Tensor([.458,.448,.450])[None,:,None,None])
-
- def forward(self, inp):
- return (inp - self.shift) / self.scale
-
-
-class NetLinLayer(nn.Module):
- ''' A single linear layer which does a 1x1 conv '''
- def __init__(self, chn_in, chn_out=1, use_dropout=False):
- super(NetLinLayer, self).__init__()
-
- layers = [nn.Dropout(),] if(use_dropout) else []
- layers += [nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),]
- self.model = nn.Sequential(*layers)
-
-
-class Dist2LogitLayer(nn.Module):
- ''' takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) '''
- def __init__(self, chn_mid=32, use_sigmoid=True):
- super(Dist2LogitLayer, self).__init__()
-
- layers = [nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),]
- layers += [nn.LeakyReLU(0.2,True),]
- layers += [nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),]
- layers += [nn.LeakyReLU(0.2,True),]
- layers += [nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),]
- if(use_sigmoid):
- layers += [nn.Sigmoid(),]
- self.model = nn.Sequential(*layers)
-
- def forward(self,d0,d1,eps=0.1):
- return self.model.forward(torch.cat((d0,d1,d0-d1,d0/(d1+eps),d1/(d0+eps)),dim=1))
-
-class BCERankingLoss(nn.Module):
- def __init__(self, chn_mid=32):
- super(BCERankingLoss, self).__init__()
- self.net = Dist2LogitLayer(chn_mid=chn_mid)
- # self.parameters = list(self.net.parameters())
- self.loss = torch.nn.BCELoss()
-
- def forward(self, d0, d1, judge):
- per = (judge+1.)/2.
- self.logit = self.net.forward(d0,d1)
- return self.loss(self.logit, per)
-
-# L2, DSSIM metrics
-class FakeNet(nn.Module):
- def __init__(self, use_gpu=True, colorspace='Lab'):
- super(FakeNet, self).__init__()
- self.use_gpu = use_gpu
- self.colorspace=colorspace
-
-class L2(FakeNet):
-
- def forward(self, in0, in1, retPerLayer=None):
- assert(in0.size()[0]==1) # currently only supports batchSize 1
-
- if(self.colorspace=='RGB'):
- (N,C,X,Y) = in0.size()
- value = torch.mean(torch.mean(torch.mean((in0-in1)**2,dim=1).view(N,1,X,Y),dim=2).view(N,1,1,Y),dim=3).view(N)
- return value
- elif(self.colorspace=='Lab'):
- value = util.l2(util.tensor2np(util.tensor2tensorlab(in0.data,to_norm=False)),
- util.tensor2np(util.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
- ret_var = Variable( torch.Tensor((value,) ) )
- if(self.use_gpu):
- ret_var = ret_var.cuda()
- return ret_var
-
-class DSSIM(FakeNet):
-
- def forward(self, in0, in1, retPerLayer=None):
- assert(in0.size()[0]==1) # currently only supports batchSize 1
-
- if(self.colorspace=='RGB'):
- value = util.dssim(1.*util.tensor2im(in0.data), 1.*util.tensor2im(in1.data), range=255.).astype('float')
- elif(self.colorspace=='Lab'):
- value = util.dssim(util.tensor2np(util.tensor2tensorlab(in0.data,to_norm=False)),
- util.tensor2np(util.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
- ret_var = Variable( torch.Tensor((value,) ) )
- if(self.use_gpu):
- ret_var = ret_var.cuda()
- return ret_var
-
-def print_network(net):
- num_params = 0
- for param in net.parameters():
- num_params += param.numel()
- print('Network',net)
- print('Total number of parameters: %d' % num_params)
diff --git a/spaces/cahya/indonesian-story/app/app.py b/spaces/cahya/indonesian-story/app/app.py
deleted file mode 100644
index 95c13c6ae4dcfd43d0a6f7e873dc9647b3c87281..0000000000000000000000000000000000000000
--- a/spaces/cahya/indonesian-story/app/app.py
+++ /dev/null
@@ -1,157 +0,0 @@
-import streamlit as st
-import SessionState
-from mtranslate import translate
-from prompts import PROMPT_LIST
-import random
-import time
-from transformers import pipeline, set_seed
-import tokenizers
-import psutil
-
-# st.set_page_config(page_title="Indonesian Story Generator")
-
-MODELS = {
- "GPT-2 Small finetuned on Indonesian stories": {
- "name": "cahya/gpt2-small-indonesian-story",
- "text_generator": None
- },
- "GPT-2 Medium finetuned on Indonesian stories": {
- "name": "cahya/gpt2-medium-indonesian-story",
- "text_generator": None
- },
-}
-
-model = st.sidebar.selectbox('Model',([
- 'GPT-2 Small finetuned on Indonesian stories',
- 'GPT-2 Medium finetuned on Indonesian stories']))
-
-if model in ["GPT-2 Small finetuned on Indonesian stories", "GPT-2 Medium finetuned on Indonesian stories"]:
- prompt_group_name = "Indonesian Stories"
-
-
-@st.cache(suppress_st_warning=True, allow_output_mutation=True)
-def get_generator(model_name: str):
- st.write(f"Loading the GPT2 model {model_name}, please wait...")
- text_generator = pipeline('text-generation', model=model_name)
- return text_generator
-
-# Disable the st.cache for this function due to issue on newer version of streamlit
-# @st.cache(suppress_st_warning=True, hash_funcs={tokenizers.Tokenizer: id})
-def process(text_generator, text: str, max_length: int = 100, do_sample: bool = True, top_k: int = 50, top_p: float = 0.95,
- temperature: float = 1.0, max_time: float = 60.0, seed=42):
- # st.write("Cache miss: process")
- set_seed(seed)
- result = text_generator(text, max_length=max_length, do_sample=do_sample,
- top_k=top_k, top_p=top_p, temperature=temperature,
- max_time=max_time)
- return result
-
-
-st.title("Indonesian Story Generator")
-
-st.markdown(
- """
- This application is a demo for Indonesian Story Generator using GPT2.
- """
-)
-
-
-session_state = SessionState.get(prompt=None, prompt_box=None, text=None)
-
-ALL_PROMPTS = list(PROMPT_LIST[prompt_group_name].keys())+["Custom"]
-
-print("# Prompt list", PROMPT_LIST)
-print("# All Prompt", ALL_PROMPTS)
-
-prompt = st.selectbox('Prompt', ALL_PROMPTS, index=len(ALL_PROMPTS)-1)
-
-# Update prompt
-if session_state.prompt is None:
- session_state.prompt = prompt
-elif session_state.prompt is not None and (prompt != session_state.prompt):
- session_state.prompt = prompt
- session_state.prompt_box = None
- session_state.text = None
-else:
- session_state.prompt = prompt
-
-# Update prompt box
-if session_state.prompt == "Custom":
- session_state.prompt_box = "Enter your text here"
-else:
- print(f"# prompt: {session_state.prompt}")
- print(f"# prompt_box: {session_state.prompt_box}")
- print(f"# PROMPT_LIST: {PROMPT_LIST.keys()}")
- if session_state.prompt is not None and session_state.prompt_box is None:
- session_state.prompt_box = random.choice(PROMPT_LIST[prompt_group_name][session_state.prompt])
-
-session_state.text = st.text_area("Enter text", session_state.prompt_box)
-
-max_length = st.sidebar.number_input(
- "Maximum length",
- value=100,
- max_value=512,
- help="The maximum length of the sequence to be generated."
-)
-
-temperature = st.sidebar.slider(
- "Temperature",
- value=1.0,
- min_value=0.0,
- max_value=10.0
-)
-
-do_sample = st.sidebar.checkbox(
- "Use sampling",
- value=True
-)
-
-top_k = 40
-top_p = 0.95
-
-if do_sample:
- top_k = st.sidebar.number_input(
- "Top k",
- value=top_k
- )
- top_p = st.sidebar.number_input(
- "Top p",
- value=top_p
- )
-
-seed = st.sidebar.number_input(
- "Random Seed",
- value=25,
- help="The number used to initialize a pseudorandom number generator"
-)
-
-for group_name in MODELS:
- MODELS[group_name]["text_generator"] = get_generator(MODELS[group_name]["name"])
-# text_generator = get_generator()
-if st.button("Run"):
- with st.spinner(text="Getting results..."):
- memory = psutil.virtual_memory()
- st.subheader("Result")
- time_start = time.time()
- # text_generator = MODELS[model]["text_generator"]
- result = process(MODELS[model]["text_generator"], text=session_state.text, max_length=int(max_length),
- temperature=temperature, do_sample=do_sample,
- top_k=int(top_k), top_p=float(top_p), seed=seed)
- time_end = time.time()
- time_diff = time_end-time_start
- result = result[0]["generated_text"]
- st.write(result.replace("\n", " \n"))
- st.text("Translation")
- translation = translate(result, "en", "id")
- st.write(translation.replace("\n", " \n"))
- # st.write(f"*do_sample: {do_sample}, top_k: {top_k}, top_p: {top_p}, seed: {seed}*")
- info = f"""
- *Memory: {memory.total/(1024*1024*1024):.2f}GB, used: {memory.percent}%, available: {memory.available/(1024*1024*1024):.2f}GB*
- *Text generated in {time_diff:.5} seconds*
- """
- st.write(info)
-
- # Reset state
- session_state.prompt = None
- session_state.prompt_box = None
- session_state.text = None
diff --git a/spaces/camilosegura/traductor-multilenguaje/Lib/site-packages/PIL/ImageFile.py b/spaces/camilosegura/traductor-multilenguaje/Lib/site-packages/PIL/ImageFile.py
deleted file mode 100644
index 8e4f7dfb2c8854ee3a1f65efd6535732df1764aa..0000000000000000000000000000000000000000
--- a/spaces/camilosegura/traductor-multilenguaje/Lib/site-packages/PIL/ImageFile.py
+++ /dev/null
@@ -1,773 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# base class for image file handlers
-#
-# history:
-# 1995-09-09 fl Created
-# 1996-03-11 fl Fixed load mechanism.
-# 1996-04-15 fl Added pcx/xbm decoders.
-# 1996-04-30 fl Added encoders.
-# 1996-12-14 fl Added load helpers
-# 1997-01-11 fl Use encode_to_file where possible
-# 1997-08-27 fl Flush output in _save
-# 1998-03-05 fl Use memory mapping for some modes
-# 1999-02-04 fl Use memory mapping also for "I;16" and "I;16B"
-# 1999-05-31 fl Added image parser
-# 2000-10-12 fl Set readonly flag on memory-mapped images
-# 2002-03-20 fl Use better messages for common decoder errors
-# 2003-04-21 fl Fall back on mmap/map_buffer if map is not available
-# 2003-10-30 fl Added StubImageFile class
-# 2004-02-25 fl Made incremental parser more robust
-#
-# Copyright (c) 1997-2004 by Secret Labs AB
-# Copyright (c) 1995-2004 by Fredrik Lundh
-#
-# See the README file for information on usage and redistribution.
-#
-
-import io
-import itertools
-import struct
-import sys
-
-from . import Image
-from ._util import is_path
-
-MAXBLOCK = 65536
-
-SAFEBLOCK = 1024 * 1024
-
-LOAD_TRUNCATED_IMAGES = False
-"""Whether or not to load truncated image files. User code may change this."""
-
-ERRORS = {
- -1: "image buffer overrun error",
- -2: "decoding error",
- -3: "unknown error",
- -8: "bad configuration",
- -9: "out of memory error",
-}
-"""
-Dict of known error codes returned from :meth:`.PyDecoder.decode`,
-:meth:`.PyEncoder.encode` :meth:`.PyEncoder.encode_to_pyfd` and
-:meth:`.PyEncoder.encode_to_file`.
-"""
-
-
-#
-# --------------------------------------------------------------------
-# Helpers
-
-
-def raise_oserror(error):
- try:
- msg = Image.core.getcodecstatus(error)
- except AttributeError:
- msg = ERRORS.get(error)
- if not msg:
- msg = f"decoder error {error}"
- msg += " when reading image file"
- raise OSError(msg)
-
-
-def _tilesort(t):
- # sort on offset
- return t[2]
-
-
-#
-# --------------------------------------------------------------------
-# ImageFile base class
-
-
-class ImageFile(Image.Image):
- """Base class for image file format handlers."""
-
- def __init__(self, fp=None, filename=None):
- super().__init__()
-
- self._min_frame = 0
-
- self.custom_mimetype = None
-
- self.tile = None
- """ A list of tile descriptors, or ``None`` """
-
- self.readonly = 1 # until we know better
-
- self.decoderconfig = ()
- self.decodermaxblock = MAXBLOCK
-
- if is_path(fp):
- # filename
- self.fp = open(fp, "rb")
- self.filename = fp
- self._exclusive_fp = True
- else:
- # stream
- self.fp = fp
- self.filename = filename
- # can be overridden
- self._exclusive_fp = None
-
- try:
- try:
- self._open()
- except (
- IndexError, # end of data
- TypeError, # end of data (ord)
- KeyError, # unsupported mode
- EOFError, # got header but not the first frame
- struct.error,
- ) as v:
- raise SyntaxError(v) from v
-
- if not self.mode or self.size[0] <= 0 or self.size[1] <= 0:
- msg = "not identified by this driver"
- raise SyntaxError(msg)
- except BaseException:
- # close the file only if we have opened it this constructor
- if self._exclusive_fp:
- self.fp.close()
- raise
-
- def get_format_mimetype(self):
- if self.custom_mimetype:
- return self.custom_mimetype
- if self.format is not None:
- return Image.MIME.get(self.format.upper())
-
- def __setstate__(self, state):
- self.tile = []
- super().__setstate__(state)
-
- def verify(self):
- """Check file integrity"""
-
- # raise exception if something's wrong. must be called
- # directly after open, and closes file when finished.
- if self._exclusive_fp:
- self.fp.close()
- self.fp = None
-
- def load(self):
- """Load image data based on tile list"""
-
- if self.tile is None:
- msg = "cannot load this image"
- raise OSError(msg)
-
- pixel = Image.Image.load(self)
- if not self.tile:
- return pixel
-
- self.map = None
- use_mmap = self.filename and len(self.tile) == 1
- # As of pypy 2.1.0, memory mapping was failing here.
- use_mmap = use_mmap and not hasattr(sys, "pypy_version_info")
-
- readonly = 0
-
- # look for read/seek overrides
- try:
- read = self.load_read
- # don't use mmap if there are custom read/seek functions
- use_mmap = False
- except AttributeError:
- read = self.fp.read
-
- try:
- seek = self.load_seek
- use_mmap = False
- except AttributeError:
- seek = self.fp.seek
-
- if use_mmap:
- # try memory mapping
- decoder_name, extents, offset, args = self.tile[0]
- if (
- decoder_name == "raw"
- and len(args) >= 3
- and args[0] == self.mode
- and args[0] in Image._MAPMODES
- ):
- try:
- # use mmap, if possible
- import mmap
-
- with open(self.filename) as fp:
- self.map = mmap.mmap(fp.fileno(), 0, access=mmap.ACCESS_READ)
- if offset + self.size[1] * args[1] > self.map.size():
- # buffer is not large enough
- raise OSError
- self.im = Image.core.map_buffer(
- self.map, self.size, decoder_name, offset, args
- )
- readonly = 1
- # After trashing self.im,
- # we might need to reload the palette data.
- if self.palette:
- self.palette.dirty = 1
- except (AttributeError, OSError, ImportError):
- self.map = None
-
- self.load_prepare()
- err_code = -3 # initialize to unknown error
- if not self.map:
- # sort tiles in file order
- self.tile.sort(key=_tilesort)
-
- try:
- # FIXME: This is a hack to handle TIFF's JpegTables tag.
- prefix = self.tile_prefix
- except AttributeError:
- prefix = b""
-
- # Remove consecutive duplicates that only differ by their offset
- self.tile = [
- list(tiles)[-1]
- for _, tiles in itertools.groupby(
- self.tile, lambda tile: (tile[0], tile[1], tile[3])
- )
- ]
- for decoder_name, extents, offset, args in self.tile:
- seek(offset)
- decoder = Image._getdecoder(
- self.mode, decoder_name, args, self.decoderconfig
- )
- try:
- decoder.setimage(self.im, extents)
- if decoder.pulls_fd:
- decoder.setfd(self.fp)
- err_code = decoder.decode(b"")[1]
- else:
- b = prefix
- while True:
- try:
- s = read(self.decodermaxblock)
- except (IndexError, struct.error) as e:
- # truncated png/gif
- if LOAD_TRUNCATED_IMAGES:
- break
- else:
- msg = "image file is truncated"
- raise OSError(msg) from e
-
- if not s: # truncated jpeg
- if LOAD_TRUNCATED_IMAGES:
- break
- else:
- msg = (
- "image file is truncated "
- f"({len(b)} bytes not processed)"
- )
- raise OSError(msg)
-
- b = b + s
- n, err_code = decoder.decode(b)
- if n < 0:
- break
- b = b[n:]
- finally:
- # Need to cleanup here to prevent leaks
- decoder.cleanup()
-
- self.tile = []
- self.readonly = readonly
-
- self.load_end()
-
- if self._exclusive_fp and self._close_exclusive_fp_after_loading:
- self.fp.close()
- self.fp = None
-
- if not self.map and not LOAD_TRUNCATED_IMAGES and err_code < 0:
- # still raised if decoder fails to return anything
- raise_oserror(err_code)
-
- return Image.Image.load(self)
-
- def load_prepare(self):
- # create image memory if necessary
- if not self.im or self.im.mode != self.mode or self.im.size != self.size:
- self.im = Image.core.new(self.mode, self.size)
- # create palette (optional)
- if self.mode == "P":
- Image.Image.load(self)
-
- def load_end(self):
- # may be overridden
- pass
-
- # may be defined for contained formats
- # def load_seek(self, pos):
- # pass
-
- # may be defined for blocked formats (e.g. PNG)
- # def load_read(self, bytes):
- # pass
-
- def _seek_check(self, frame):
- if (
- frame < self._min_frame
- # Only check upper limit on frames if additional seek operations
- # are not required to do so
- or (
- not (hasattr(self, "_n_frames") and self._n_frames is None)
- and frame >= self.n_frames + self._min_frame
- )
- ):
- msg = "attempt to seek outside sequence"
- raise EOFError(msg)
-
- return self.tell() != frame
-
-
-class StubImageFile(ImageFile):
- """
- Base class for stub image loaders.
-
- A stub loader is an image loader that can identify files of a
- certain format, but relies on external code to load the file.
- """
-
- def _open(self):
- msg = "StubImageFile subclass must implement _open"
- raise NotImplementedError(msg)
-
- def load(self):
- loader = self._load()
- if loader is None:
- msg = f"cannot find loader for this {self.format} file"
- raise OSError(msg)
- image = loader.load(self)
- assert image is not None
- # become the other object (!)
- self.__class__ = image.__class__
- self.__dict__ = image.__dict__
- return image.load()
-
- def _load(self):
- """(Hook) Find actual image loader."""
- msg = "StubImageFile subclass must implement _load"
- raise NotImplementedError(msg)
-
-
-class Parser:
- """
- Incremental image parser. This class implements the standard
- feed/close consumer interface.
- """
-
- incremental = None
- image = None
- data = None
- decoder = None
- offset = 0
- finished = 0
-
- def reset(self):
- """
- (Consumer) Reset the parser. Note that you can only call this
- method immediately after you've created a parser; parser
- instances cannot be reused.
- """
- assert self.data is None, "cannot reuse parsers"
-
- def feed(self, data):
- """
- (Consumer) Feed data to the parser.
-
- :param data: A string buffer.
- :exception OSError: If the parser failed to parse the image file.
- """
- # collect data
-
- if self.finished:
- return
-
- if self.data is None:
- self.data = data
- else:
- self.data = self.data + data
-
- # parse what we have
- if self.decoder:
- if self.offset > 0:
- # skip header
- skip = min(len(self.data), self.offset)
- self.data = self.data[skip:]
- self.offset = self.offset - skip
- if self.offset > 0 or not self.data:
- return
-
- n, e = self.decoder.decode(self.data)
-
- if n < 0:
- # end of stream
- self.data = None
- self.finished = 1
- if e < 0:
- # decoding error
- self.image = None
- raise_oserror(e)
- else:
- # end of image
- return
- self.data = self.data[n:]
-
- elif self.image:
- # if we end up here with no decoder, this file cannot
- # be incrementally parsed. wait until we've gotten all
- # available data
- pass
-
- else:
- # attempt to open this file
- try:
- with io.BytesIO(self.data) as fp:
- im = Image.open(fp)
- except OSError:
- # traceback.print_exc()
- pass # not enough data
- else:
- flag = hasattr(im, "load_seek") or hasattr(im, "load_read")
- if flag or len(im.tile) != 1:
- # custom load code, or multiple tiles
- self.decode = None
- else:
- # initialize decoder
- im.load_prepare()
- d, e, o, a = im.tile[0]
- im.tile = []
- self.decoder = Image._getdecoder(im.mode, d, a, im.decoderconfig)
- self.decoder.setimage(im.im, e)
-
- # calculate decoder offset
- self.offset = o
- if self.offset <= len(self.data):
- self.data = self.data[self.offset :]
- self.offset = 0
-
- self.image = im
-
- def __enter__(self):
- return self
-
- def __exit__(self, *args):
- self.close()
-
- def close(self):
- """
- (Consumer) Close the stream.
-
- :returns: An image object.
- :exception OSError: If the parser failed to parse the image file either
- because it cannot be identified or cannot be
- decoded.
- """
- # finish decoding
- if self.decoder:
- # get rid of what's left in the buffers
- self.feed(b"")
- self.data = self.decoder = None
- if not self.finished:
- msg = "image was incomplete"
- raise OSError(msg)
- if not self.image:
- msg = "cannot parse this image"
- raise OSError(msg)
- if self.data:
- # incremental parsing not possible; reopen the file
- # not that we have all data
- with io.BytesIO(self.data) as fp:
- try:
- self.image = Image.open(fp)
- finally:
- self.image.load()
- return self.image
-
-
-# --------------------------------------------------------------------
-
-
-def _save(im, fp, tile, bufsize=0):
- """Helper to save image based on tile list
-
- :param im: Image object.
- :param fp: File object.
- :param tile: Tile list.
- :param bufsize: Optional buffer size
- """
-
- im.load()
- if not hasattr(im, "encoderconfig"):
- im.encoderconfig = ()
- tile.sort(key=_tilesort)
- # FIXME: make MAXBLOCK a configuration parameter
- # It would be great if we could have the encoder specify what it needs
- # But, it would need at least the image size in most cases. RawEncode is
- # a tricky case.
- bufsize = max(MAXBLOCK, bufsize, im.size[0] * 4) # see RawEncode.c
- try:
- fh = fp.fileno()
- fp.flush()
- _encode_tile(im, fp, tile, bufsize, fh)
- except (AttributeError, io.UnsupportedOperation) as exc:
- _encode_tile(im, fp, tile, bufsize, None, exc)
- if hasattr(fp, "flush"):
- fp.flush()
-
-
-def _encode_tile(im, fp, tile, bufsize, fh, exc=None):
- for e, b, o, a in tile:
- if o > 0:
- fp.seek(o)
- encoder = Image._getencoder(im.mode, e, a, im.encoderconfig)
- try:
- encoder.setimage(im.im, b)
- if encoder.pushes_fd:
- encoder.setfd(fp)
- errcode = encoder.encode_to_pyfd()[1]
- else:
- if exc:
- # compress to Python file-compatible object
- while True:
- errcode, data = encoder.encode(bufsize)[1:]
- fp.write(data)
- if errcode:
- break
- else:
- # slight speedup: compress to real file object
- errcode = encoder.encode_to_file(fh, bufsize)
- if errcode < 0:
- msg = f"encoder error {errcode} when writing image file"
- raise OSError(msg) from exc
- finally:
- encoder.cleanup()
-
-
-def _safe_read(fp, size):
- """
- Reads large blocks in a safe way. Unlike fp.read(n), this function
- doesn't trust the user. If the requested size is larger than
- SAFEBLOCK, the file is read block by block.
-
- :param fp: File handle. Must implement a read method.
- :param size: Number of bytes to read.
- :returns: A string containing size bytes of data.
-
- Raises an OSError if the file is truncated and the read cannot be completed
-
- """
- if size <= 0:
- return b""
- if size <= SAFEBLOCK:
- data = fp.read(size)
- if len(data) < size:
- msg = "Truncated File Read"
- raise OSError(msg)
- return data
- data = []
- remaining_size = size
- while remaining_size > 0:
- block = fp.read(min(remaining_size, SAFEBLOCK))
- if not block:
- break
- data.append(block)
- remaining_size -= len(block)
- if sum(len(d) for d in data) < size:
- msg = "Truncated File Read"
- raise OSError(msg)
- return b"".join(data)
-
-
-class PyCodecState:
- def __init__(self):
- self.xsize = 0
- self.ysize = 0
- self.xoff = 0
- self.yoff = 0
-
- def extents(self):
- return self.xoff, self.yoff, self.xoff + self.xsize, self.yoff + self.ysize
-
-
-class PyCodec:
- def __init__(self, mode, *args):
- self.im = None
- self.state = PyCodecState()
- self.fd = None
- self.mode = mode
- self.init(args)
-
- def init(self, args):
- """
- Override to perform codec specific initialization
-
- :param args: Array of args items from the tile entry
- :returns: None
- """
- self.args = args
-
- def cleanup(self):
- """
- Override to perform codec specific cleanup
-
- :returns: None
- """
- pass
-
- def setfd(self, fd):
- """
- Called from ImageFile to set the Python file-like object
-
- :param fd: A Python file-like object
- :returns: None
- """
- self.fd = fd
-
- def setimage(self, im, extents=None):
- """
- Called from ImageFile to set the core output image for the codec
-
- :param im: A core image object
- :param extents: a 4 tuple of (x0, y0, x1, y1) defining the rectangle
- for this tile
- :returns: None
- """
-
- # following c code
- self.im = im
-
- if extents:
- (x0, y0, x1, y1) = extents
- else:
- (x0, y0, x1, y1) = (0, 0, 0, 0)
-
- if x0 == 0 and x1 == 0:
- self.state.xsize, self.state.ysize = self.im.size
- else:
- self.state.xoff = x0
- self.state.yoff = y0
- self.state.xsize = x1 - x0
- self.state.ysize = y1 - y0
-
- if self.state.xsize <= 0 or self.state.ysize <= 0:
- msg = "Size cannot be negative"
- raise ValueError(msg)
-
- if (
- self.state.xsize + self.state.xoff > self.im.size[0]
- or self.state.ysize + self.state.yoff > self.im.size[1]
- ):
- msg = "Tile cannot extend outside image"
- raise ValueError(msg)
-
-
-class PyDecoder(PyCodec):
- """
- Python implementation of a format decoder. Override this class and
- add the decoding logic in the :meth:`decode` method.
-
- See :ref:`Writing Your Own File Codec in Python`
- """
-
- _pulls_fd = False
-
- @property
- def pulls_fd(self):
- return self._pulls_fd
-
- def decode(self, buffer):
- """
- Override to perform the decoding process.
-
- :param buffer: A bytes object with the data to be decoded.
- :returns: A tuple of ``(bytes consumed, errcode)``.
- If finished with decoding return -1 for the bytes consumed.
- Err codes are from :data:`.ImageFile.ERRORS`.
- """
- raise NotImplementedError()
-
- def set_as_raw(self, data, rawmode=None):
- """
- Convenience method to set the internal image from a stream of raw data
-
- :param data: Bytes to be set
- :param rawmode: The rawmode to be used for the decoder.
- If not specified, it will default to the mode of the image
- :returns: None
- """
-
- if not rawmode:
- rawmode = self.mode
- d = Image._getdecoder(self.mode, "raw", rawmode)
- d.setimage(self.im, self.state.extents())
- s = d.decode(data)
-
- if s[0] >= 0:
- msg = "not enough image data"
- raise ValueError(msg)
- if s[1] != 0:
- msg = "cannot decode image data"
- raise ValueError(msg)
-
-
-class PyEncoder(PyCodec):
- """
- Python implementation of a format encoder. Override this class and
- add the decoding logic in the :meth:`encode` method.
-
- See :ref:`Writing Your Own File Codec in Python`
- """
-
- _pushes_fd = False
-
- @property
- def pushes_fd(self):
- return self._pushes_fd
-
- def encode(self, bufsize):
- """
- Override to perform the encoding process.
-
- :param bufsize: Buffer size.
- :returns: A tuple of ``(bytes encoded, errcode, bytes)``.
- If finished with encoding return 1 for the error code.
- Err codes are from :data:`.ImageFile.ERRORS`.
- """
- raise NotImplementedError()
-
- def encode_to_pyfd(self):
- """
- If ``pushes_fd`` is ``True``, then this method will be used,
- and ``encode()`` will only be called once.
-
- :returns: A tuple of ``(bytes consumed, errcode)``.
- Err codes are from :data:`.ImageFile.ERRORS`.
- """
- if not self.pushes_fd:
- return 0, -8 # bad configuration
- bytes_consumed, errcode, data = self.encode(0)
- if data:
- self.fd.write(data)
- return bytes_consumed, errcode
-
- def encode_to_file(self, fh, bufsize):
- """
- :param fh: File handle.
- :param bufsize: Buffer size.
-
- :returns: If finished successfully, return 0.
- Otherwise, return an error code. Err codes are from
- :data:`.ImageFile.ERRORS`.
- """
- errcode = 0
- while errcode == 0:
- status, errcode, buf = self.encode(bufsize)
- if status > 0:
- fh.write(buf[status:])
- return errcode
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/MViTv2/README.md b/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/MViTv2/README.md
deleted file mode 100644
index 64afd79cac8d83de5518b57199fd618eebe83645..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/MViTv2/README.md
+++ /dev/null
@@ -1,142 +0,0 @@
-# MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
-
-Yanghao Li*, Chao-Yuan Wu*, Haoqi Fan, Karttikeya Mangalam, Bo Xiong, Jitendra Malik, Christoph Feichtenhofer*
-
-[[`arXiv`](https://arxiv.org/abs/2112.01526)] [[`BibTeX`](#CitingMViTv2)]
-
-In this repository, we provide detection configs and models for MViTv2 (CVPR 2022) in Detectron2. For image classification tasks, please refer to [MViTv2 repo](https://github.com/facebookresearch/mvit).
-
-## Results and Pretrained Models
-
-### COCO
-
-
-
-
-Name
-pre-train
-Method
-epochs
-box
-mask
-#params
-FLOPS
-model id
-download
-
-
- MViTV2-T IN1K
-Mask R-CNN
-36
-48.3
-43.8
-44M
-279G
-307611773
-model MViTV2-T IN1K
-Cascade Mask R-CNN
-36
-52.2
-45.0
-76M
-701G
-308344828
-model MViTV2-S IN1K
-Cascade Mask R-CNN
-36
-53.2
-46.0
-87M
-748G
-308344647
-model MViTV2-B IN1K
-Cascade Mask R-CNN
-36
-54.1
-46.7
-103M
-814G
-308109448
-model MViTV2-B IN21K
-Cascade Mask R-CNN
-36
-54.9
-47.4
-103M
-814G
-309003202
-model MViTV2-L IN21K
-Cascade Mask R-CNN
-50
-55.8
-48.3
-270M
-1519G
-308099658
-model MViTV2-H IN21K
-Cascade Mask R-CNN
-36
-56.1
-48.5
-718M
-3084G
-309013744
-model
-
-Note that the above models were trained and measured on 8-node with 64 NVIDIA A100 GPUs in total. The ImageNet pre-trained model weights are obtained from [MViTv2 repo](https://github.com/facebookresearch/mvit).
-
-## Training
-All configs can be trained with:
-
-```
-../../tools/lazyconfig_train_net.py --config-file configs/path/to/config.py
-```
-By default, we use 64 GPUs with batch size as 64 for training.
-
-## Evaluation
-Model evaluation can be done similarly:
-```
-../../tools/lazyconfig_train_net.py --config-file configs/path/to/config.py --eval-only train.init_checkpoint=/path/to/model_checkpoint
-```
-
-
-
-## b d h w c')
- Dp = int(np.ceil(D / window_size[0])) * window_size[0]
- Hp = int(np.ceil(H / window_size[1])) * window_size[1]
- Wp = int(np.ceil(W / window_size[2])) * window_size[2]
- attn_mask = compute_mask(Dp, Hp, Wp, window_size, shift_size, x.device)
- for blk in self.blocks:
- x = blk(x, attn_mask)
- x = x.view(B, D, H, W, -1)
-
- if self.downsample is not None:
- x = self.downsample(x)
- x = rearrange(x, 'b d h w c -> b c d h w')
- return x
-
-
-class PatchEmbed3D(nn.Module):
- """ Video to Patch Embedding.
-
- Args:
- patch_size (int): Patch token size. Default: (2,4,4).
- in_chans (int): Number of input video channels. Default: 3.
- embed_dim (int): Number of linear projection output channels. Default: 96.
- norm_layer (nn.Module, optional): Normalization layer. Default: None
- """
- def __init__(self, patch_size=(3,4,4), in_chans=3, embed_dim=96, norm_layer=None):
- super().__init__()
- self.patch_size = patch_size
-
- #print('received patch size', patch_size)
- self.in_chans = in_chans
- self.embed_dim = embed_dim
-
- self.proj = nn.Conv3d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
- if norm_layer is not None:
- self.norm = norm_layer(embed_dim)
- else:
- self.norm = None
-
- def forward(self, x):
- """Forward function."""
- x = x.unsqueeze(1) # assuming gray scale video frames are encoded as channels, now separate
-
- x = self.proj(x) # B C D Wh Ww
- if self.norm is not None:
- #print('ionside here with self.norm')
- D, Wh, Ww = x.size(2), x.size(3), x.size(4)
- x = x.flatten(2).transpose(1, 2)
- x = self.norm(x)
- x = x.transpose(1, 2).view(-1, self.embed_dim, D, Wh, Ww)
-
- return x
-
-class PatchUnEmbed3D(nn.Module):
- def __init__(self, patch_size=(3,4,4), in_chans=3, embed_dim=96, norm_layer=nn.LayerNorm):
- super().__init__()
- self.patch_size = patch_size
-
- self.in_chans = in_chans
- self.embed_dim = embed_dim
-
- unembed_dim = 1
- self.unembed_dim = unembed_dim
-
- self.proj = nn.ConvTranspose3d(embed_dim, unembed_dim, kernel_size=patch_size, stride=patch_size)
- self.conv = nn.Conv2d(3*unembed_dim, 3, 3, 1, 1)
-
- if norm_layer is not None:
- self.norm = norm_layer(unembed_dim)
- else:
- self.norm = None
-
- self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
-
- def forward(self, x):
-
- D, Wh, Ww = x.size(2), x.size(3), x.size(4)
- # x = x.view(-1,self.embed_dim*D,Wh,Ww)
- x = self.proj(x)
-
- # if self.norm is not None:
- # D, Wh, Ww = x.size(2), x.size(3), x.size(4)
- # x = x.flatten(2).transpose(1, 2)
- # x = self.norm(x)
- # x = x.transpose(1, 2).view(-1, self.unembed_dim, D, Wh, Ww)
-
-
-
- x = self.lrelu(x)
- x = x.view(-1,3*D,4*Wh,4*Ww)
- # x = x.flatten(start_dim=1,end_dim=2)
- # x = x.view(-1,9,4*Wh,4*Ww) # 18 128 128
- x = self.lrelu(self.conv(x)) # 64 128 128
-
- return x
-
-class Upsampler(nn.Module):
- def __init__(self, patch_size=(3,4,4), in_chans=3, embed_dim=96, norm_layer=nn.LayerNorm):
- super().__init__()
- self.patch_size = patch_size
-
- self.in_chans = in_chans
- self.embed_dim = embed_dim
-
- self.expand = nn.Conv2d(9, 20, 3, 1, 1)
-
- self.shuffle = nn.PixelShuffle(2)
- self.fusion = nn.Conv2d(20//4, 1, 3, 1, 1)
-
- self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
-
- def forward(self, x):
-
- # x = x.view(-1,self.embed_dim*D,Wh,Ww)
- x = self.lrelu(self.expand(x))
- x = self.shuffle(x) # 16 256 256
- x = self.lrelu(self.fusion(x))
-
- return x
-
-
-class SwinTransformer3D_RCAB(nn.Module):
- """ Swin Transformer backbone.
- A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
- https://arxiv.org/pdf/2103.14030
-
- Args:
- patch_size (int | tuple(int)): Patch size. Default: (4,4,4).
- in_chans (int): Number of input image channels. Default: 3.
- embed_dim (int): Number of linear projection output channels. Default: 96.
- depths (tuple[int]): Depths of each Swin Transformer stage.
- num_heads (tuple[int]): Number of attention head of each stage.
- window_size (int): Window size. Default: 7.
- mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
- qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: Truee
- qk_scale (float): Override default qk scale of head_dim ** -0.5 if set.
- drop_rate (float): Dropout rate.
- attn_drop_rate (float): Attention dropout rate. Default: 0.
- drop_path_rate (float): Stochastic depth rate. Default: 0.2.
- norm_layer: Normalization layer. Default: nn.LayerNorm.
- patch_norm (bool): If True, add normalization after patch embedding. Default: False.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters.
- """
-
- def __init__(self,
- opt,
- patch_size=(4,4,4),
- in_chans=1,
- embed_dim=96,
- depths=[2, 2, 6, 2],
- num_heads=[3, 6, 12, 24],
- window_size=(2,7,7),
- mlp_ratio=4.,
- qkv_bias=True,
- qk_scale=None,
- drop_rate=0.,
- attn_drop_rate=0.,
- drop_path_rate=0.2,
- norm_layer=nn.LayerNorm,
- patch_norm=True,
- upscale=2,
- frozen_stages=-1,
- use_checkpoint=False,
- vis=False,
- **kwargs):
- super().__init__()
-
- self.num_layers = len(depths)
- self.embed_dim = embed_dim
- self.patch_norm = patch_norm
- self.window_size = window_size
- self.patch_size = patch_size
-
- # split image into non-overlapping patches
- self.patch_embed = PatchEmbed3D(
- patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
- norm_layer=norm_layer if self.patch_norm else None)
-
- # split image into non-overlapping patches
- self.patch_unembed = PatchUnEmbed3D(
- patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
- norm_layer=norm_layer if self.patch_norm else None)
-
- self.pos_drop = nn.Dropout(p=drop_rate)
-
- # stochastic depth
- dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
-
- # build layers
- self.layers = nn.ModuleList()
- for i_layer in range(self.num_layers):
- layer = RSTB3D(
- dim=embed_dim,
- depth=depths[i_layer],
- num_heads=num_heads[i_layer],
- window_size=window_size,
- mlp_ratio=mlp_ratio,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- drop=drop_rate,
- attn_drop=attn_drop_rate,
- drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
- norm_layer=norm_layer,
- # downsample=PatchMerging if i_layer n d h w c')
- #print('after rearrange',x.shape)
- x = self.norm(x)
- #print('after norm',x.shape)
- x = rearrange(x, 'n d h w c -> n c d h w')
- #print('after rearrange',x.shape)
-
- x = self.patch_unembed(x)
-
- x = x + shortcut
-
- if self.task == 'segment':
- x = self.segmentation_decode(x)
-
- else:
- x = self.upsampler(x)
-
- return x
-
-
-
-
diff --git a/spaces/chendl/compositional_test/multimodal/YOLOX/tools/demo.py b/spaces/chendl/compositional_test/multimodal/YOLOX/tools/demo.py
deleted file mode 100644
index b16598d5f4f355a4884341bd1188052b9384018b..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/multimodal/YOLOX/tools/demo.py
+++ /dev/null
@@ -1,320 +0,0 @@
-#!/usr/bin/env python3
-# -*- coding:utf-8 -*-
-# Copyright (c) Megvii, Inc. and its affiliates.
-
-import argparse
-import os
-import time
-from loguru import logger
-
-import cv2
-
-import torch
-
-from yolox.data.data_augment import ValTransform
-from yolox.data.datasets import COCO_CLASSES
-from yolox.exp import get_exp
-from yolox.utils import fuse_model, get_model_info, postprocess, vis
-
-IMAGE_EXT = [".jpg", ".jpeg", ".webp", ".bmp", ".png"]
-
-
-def make_parser():
- parser = argparse.ArgumentParser("YOLOX Demo!")
- parser.add_argument(
- "demo", default="image", help="demo type, eg. image, video and webcam"
- )
- parser.add_argument("-expn", "--experiment-name", type=str, default=None)
- parser.add_argument("-n", "--name", type=str, default=None, help="model name")
-
- parser.add_argument(
- "--path", default="./assets/dog.jpg", help="path to images or video"
- )
- parser.add_argument("--camid", type=int, default=0, help="webcam demo camera id")
- parser.add_argument(
- "--save_result",
- action="store_true",
- help="whether to save the inference result of image/video",
- )
-
- # exp file
- parser.add_argument(
- "-f",
- "--exp_file",
- default=None,
- type=str,
- help="please input your experiment description file",
- )
- parser.add_argument("-c", "--ckpt", default=None, type=str, help="ckpt for eval")
- parser.add_argument(
- "--device",
- default="cpu",
- type=str,
- help="device to run our model, can either be cpu or gpu",
- )
- parser.add_argument("--conf", default=0.3, type=float, help="test conf")
- parser.add_argument("--nms", default=0.3, type=float, help="test nms threshold")
- parser.add_argument("--tsize", default=None, type=int, help="test img size")
- parser.add_argument(
- "--fp16",
- dest="fp16",
- default=False,
- action="store_true",
- help="Adopting mix precision evaluating.",
- )
- parser.add_argument(
- "--legacy",
- dest="legacy",
- default=False,
- action="store_true",
- help="To be compatible with older versions",
- )
- parser.add_argument(
- "--fuse",
- dest="fuse",
- default=False,
- action="store_true",
- help="Fuse conv and bn for testing.",
- )
- parser.add_argument(
- "--trt",
- dest="trt",
- default=False,
- action="store_true",
- help="Using TensorRT model for testing.",
- )
- return parser
-
-
-def get_image_list(path):
- image_names = []
- for maindir, subdir, file_name_list in os.walk(path):
- for filename in file_name_list:
- apath = os.path.join(maindir, filename)
- ext = os.path.splitext(apath)[1]
- if ext in IMAGE_EXT:
- image_names.append(apath)
- return image_names
-
-
-class Predictor(object):
- def __init__(
- self,
- model,
- exp,
- cls_names=COCO_CLASSES,
- trt_file=None,
- decoder=None,
- device="cpu",
- fp16=False,
- legacy=False,
- ):
- self.model = model
- self.cls_names = cls_names
- self.decoder = decoder
- self.num_classes = exp.num_classes
- self.confthre = exp.test_conf
- self.nmsthre = exp.nmsthre
- self.test_size = exp.test_size
- self.device = device
- self.fp16 = fp16
- self.preproc = ValTransform(legacy=legacy)
- if trt_file is not None:
- from torch2trt import TRTModule
-
- model_trt = TRTModule()
- model_trt.load_state_dict(torch.load(trt_file))
-
- x = torch.ones(1, 3, exp.test_size[0], exp.test_size[1]).cuda()
- self.model(x)
- self.model = model_trt
-
- def inference(self, img):
- img_info = {"id": 0}
- if isinstance(img, str):
- img_info["file_name"] = os.path.basename(img)
- img = cv2.imread(img)
- else:
- img_info["file_name"] = None
-
- height, width = img.shape[:2]
- img_info["height"] = height
- img_info["width"] = width
- img_info["raw_img"] = img
-
- ratio = min(self.test_size[0] / img.shape[0], self.test_size[1] / img.shape[1])
- img_info["ratio"] = ratio
-
- img, _ = self.preproc(img, None, self.test_size)
- img = torch.from_numpy(img).unsqueeze(0)
- img = img.float()
- if self.device == "gpu":
- img = img.cuda()
- if self.fp16:
- img = img.half() # to FP16
-
- with torch.no_grad():
- t0 = time.time()
- outputs = self.model(img)
- if self.decoder is not None:
- outputs = self.decoder(outputs, dtype=outputs.type())
- outputs = postprocess(
- outputs, self.num_classes, self.confthre,
- self.nmsthre, class_agnostic=True
- )
- logger.info("Infer time: {:.4f}s".format(time.time() - t0))
- return outputs, img_info
-
- def visual(self, output, img_info, cls_conf=0.35):
- ratio = img_info["ratio"]
- img = img_info["raw_img"]
- if output is None:
- return img
- output = output.cpu()
-
- bboxes = output[:, 0:4]
-
- # preprocessing: resize
- bboxes /= ratio
-
- cls = output[:, 6]
- scores = output[:, 4] * output[:, 5]
-
- vis_res = vis(img, bboxes, scores, cls, cls_conf, self.cls_names)
- return vis_res
-
-
-def image_demo(predictor, vis_folder, path, current_time, save_result):
- if os.path.isdir(path):
- files = get_image_list(path)
- else:
- files = [path]
- files.sort()
- for image_name in files:
- outputs, img_info = predictor.inference(image_name)
- result_image = predictor.visual(outputs[0], img_info, predictor.confthre)
- if save_result:
- save_folder = os.path.join(
- vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
- )
- os.makedirs(save_folder, exist_ok=True)
- save_file_name = os.path.join(save_folder, os.path.basename(image_name))
- logger.info("Saving detection result in {}".format(save_file_name))
- cv2.imwrite(save_file_name, result_image)
- ch = cv2.waitKey(0)
- if ch == 27 or ch == ord("q") or ch == ord("Q"):
- break
-
-
-def imageflow_demo(predictor, vis_folder, current_time, args):
- cap = cv2.VideoCapture(args.path if args.demo == "video" else args.camid)
- width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # float
- height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
- fps = cap.get(cv2.CAP_PROP_FPS)
- if args.save_result:
- save_folder = os.path.join(
- vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
- )
- os.makedirs(save_folder, exist_ok=True)
- if args.demo == "video":
- save_path = os.path.join(save_folder, os.path.basename(args.path))
- else:
- save_path = os.path.join(save_folder, "camera.mp4")
- logger.info(f"video save_path is {save_path}")
- vid_writer = cv2.VideoWriter(
- save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height))
- )
- while True:
- ret_val, frame = cap.read()
- if ret_val:
- outputs, img_info = predictor.inference(frame)
- result_frame = predictor.visual(outputs[0], img_info, predictor.confthre)
- if args.save_result:
- vid_writer.write(result_frame)
- else:
- cv2.namedWindow("yolox", cv2.WINDOW_NORMAL)
- cv2.imshow("yolox", result_frame)
- ch = cv2.waitKey(1)
- if ch == 27 or ch == ord("q") or ch == ord("Q"):
- break
- else:
- break
-
-
-def main(exp, args):
- if not args.experiment_name:
- args.experiment_name = exp.exp_name
-
- file_name = os.path.join(exp.output_dir, args.experiment_name)
- os.makedirs(file_name, exist_ok=True)
-
- vis_folder = None
- if args.save_result:
- vis_folder = os.path.join(file_name, "vis_res")
- os.makedirs(vis_folder, exist_ok=True)
-
- if args.trt:
- args.device = "gpu"
-
- logger.info("Args: {}".format(args))
-
- if args.conf is not None:
- exp.test_conf = args.conf
- if args.nms is not None:
- exp.nmsthre = args.nms
- if args.tsize is not None:
- exp.test_size = (args.tsize, args.tsize)
-
- model = exp.get_model()
- logger.info("Model Summary: {}".format(get_model_info(model, exp.test_size)))
-
- if args.device == "gpu":
- model.cuda()
- if args.fp16:
- model.half() # to FP16
- model.eval()
-
- if not args.trt:
- if args.ckpt is None:
- ckpt_file = os.path.join(file_name, "best_ckpt.pth")
- else:
- ckpt_file = args.ckpt
- logger.info("loading checkpoint")
- ckpt = torch.load(ckpt_file, map_location="cpu")
- # load the model state dict
- model.load_state_dict(ckpt["model"])
- logger.info("loaded checkpoint done.")
-
- if args.fuse:
- logger.info("\tFusing model...")
- model = fuse_model(model)
-
- if args.trt:
- assert not args.fuse, "TensorRT model is not support model fusing!"
- trt_file = os.path.join(file_name, "model_trt.pth")
- assert os.path.exists(
- trt_file
- ), "TensorRT model is not found!\n Run python3 tools/trt.py first!"
- model.head.decode_in_inference = False
- decoder = model.head.decode_outputs
- logger.info("Using TensorRT to inference")
- else:
- trt_file = None
- decoder = None
-
- predictor = Predictor(
- model, exp, COCO_CLASSES, trt_file, decoder,
- args.device, args.fp16, args.legacy,
- )
- current_time = time.localtime()
- if args.demo == "image":
- image_demo(predictor, vis_folder, args.path, current_time, args.save_result)
- elif args.demo == "video" or args.demo == "webcam":
- imageflow_demo(predictor, vis_folder, current_time, args)
-
-
-if __name__ == "__main__":
- args = make_parser().parse_args()
- exp = get_exp(args.exp_file, args.name)
-
- main(exp, args)
diff --git a/spaces/chendl/compositional_test/multimodal/setup.py b/spaces/chendl/compositional_test/multimodal/setup.py
deleted file mode 100644
index d27f1716173e438f35315858ac86f97ead0af819..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/multimodal/setup.py
+++ /dev/null
@@ -1,58 +0,0 @@
-from pathlib import Path
-
-from setuptools import find_packages, setup
-
-if __name__ == "__main__":
- with Path(Path(__file__).parent, "README.md").open(encoding="utf-8") as file:
- long_description = file.read()
-
- # TODO: This is a hack to get around the fact that we can't read the requirements.txt file, we should fix this.
- # def _read_reqs(relpath):
- # fullpath = os.path.join(Path(__file__).parent, relpath)
- # with open(fullpath) as f:
- # return [
- # s.strip()
- # for s in f.readlines()
- # if (s.strip() and not s.startswith("#"))
- # ]
-
- REQUIREMENTS = [
- "einops",
- "einops-exts",
- "transformers==4.31.0",
- "torch==1.12.1",
- "torchvision==0.13.1",
- "pillow==9.3.0",
- "more-itertools",
- "datasets==2.9.0",
- "braceexpand==0.1.7",
- "webdataset",
- "wandb==0.13.10",
- "nltk",
- "scipy",
- "inflection",
- "sentencepiece",
- "open_clip_torch==2.20.0",
- "opencv-python==4.7.0.68"
- ]
-
- setup(
- name="open_flamingo",
- packages=find_packages(),
- include_package_data=True,
- version="0.0.2",
- license="MIT",
- description="An open-source framework for training large multimodal models",
- long_description=long_description,
- long_description_content_type="text/markdown",
- data_files=[(".", ["README.md"])],
- keywords=["machine learning"],
- install_requires=REQUIREMENTS,
- classifiers=[
- "Development Status :: 4 - Beta",
- "Intended Audience :: Developers",
- "Topic :: Scientific/Engineering :: Artificial Intelligence",
- "License :: OSI Approved :: MIT License",
- "Programming Language :: Python :: 3.9",
- ],
- )
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/attr/filters.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/attr/filters.py
deleted file mode 100644
index a1e40c98db853aa375ab0b24559e0559f91e6152..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/attr/filters.py
+++ /dev/null
@@ -1,66 +0,0 @@
-# SPDX-License-Identifier: MIT
-
-"""
-Commonly useful filters for `attr.asdict`.
-"""
-
-from ._make import Attribute
-
-
-def _split_what(what):
- """
- Returns a tuple of `frozenset`s of classes and attributes.
- """
- return (
- frozenset(cls for cls in what if isinstance(cls, type)),
- frozenset(cls for cls in what if isinstance(cls, str)),
- frozenset(cls for cls in what if isinstance(cls, Attribute)),
- )
-
-
-def include(*what):
- """
- Include *what*.
-
- :param what: What to include.
- :type what: `list` of classes `type`, field names `str` or
- `attrs.Attribute`\\ s
-
- :rtype: `callable`
-
- .. versionchanged:: 23.1.0 Accept strings with field names.
- """
- cls, names, attrs = _split_what(what)
-
- def include_(attribute, value):
- return (
- value.__class__ in cls
- or attribute.name in names
- or attribute in attrs
- )
-
- return include_
-
-
-def exclude(*what):
- """
- Exclude *what*.
-
- :param what: What to exclude.
- :type what: `list` of classes `type`, field names `str` or
- `attrs.Attribute`\\ s.
-
- :rtype: `callable`
-
- .. versionchanged:: 23.3.0 Accept field name string as input argument
- """
- cls, names, attrs = _split_what(what)
-
- def exclude_(attribute, value):
- return not (
- value.__class__ in cls
- or attribute.name in names
- or attribute in attrs
- )
-
- return exclude_
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/charset_normalizer/api.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/charset_normalizer/api.py
deleted file mode 100644
index 0ba08e3a50ba6d61e75f3f31772eb4dfdd3f8f05..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/charset_normalizer/api.py
+++ /dev/null
@@ -1,626 +0,0 @@
-import logging
-from os import PathLike
-from typing import BinaryIO, List, Optional, Set, Union
-
-from .cd import (
- coherence_ratio,
- encoding_languages,
- mb_encoding_languages,
- merge_coherence_ratios,
-)
-from .constant import IANA_SUPPORTED, TOO_BIG_SEQUENCE, TOO_SMALL_SEQUENCE, TRACE
-from .md import mess_ratio
-from .models import CharsetMatch, CharsetMatches
-from .utils import (
- any_specified_encoding,
- cut_sequence_chunks,
- iana_name,
- identify_sig_or_bom,
- is_cp_similar,
- is_multi_byte_encoding,
- should_strip_sig_or_bom,
-)
-
-# Will most likely be controversial
-# logging.addLevelName(TRACE, "TRACE")
-logger = logging.getLogger("charset_normalizer")
-explain_handler = logging.StreamHandler()
-explain_handler.setFormatter(
- logging.Formatter("%(asctime)s | %(levelname)s | %(message)s")
-)
-
-
-def from_bytes(
- sequences: Union[bytes, bytearray],
- steps: int = 5,
- chunk_size: int = 512,
- threshold: float = 0.2,
- cp_isolation: Optional[List[str]] = None,
- cp_exclusion: Optional[List[str]] = None,
- preemptive_behaviour: bool = True,
- explain: bool = False,
- language_threshold: float = 0.1,
- enable_fallback: bool = True,
-) -> CharsetMatches:
- """
- Given a raw bytes sequence, return the best possibles charset usable to render str objects.
- If there is no results, it is a strong indicator that the source is binary/not text.
- By default, the process will extract 5 blocks of 512o each to assess the mess and coherence of a given sequence.
- And will give up a particular code page after 20% of measured mess. Those criteria are customizable at will.
-
- The preemptive behavior DOES NOT replace the traditional detection workflow, it prioritize a particular code page
- but never take it for granted. Can improve the performance.
-
- You may want to focus your attention to some code page or/and not others, use cp_isolation and cp_exclusion for that
- purpose.
-
- This function will strip the SIG in the payload/sequence every time except on UTF-16, UTF-32.
- By default the library does not setup any handler other than the NullHandler, if you choose to set the 'explain'
- toggle to True it will alter the logger configuration to add a StreamHandler that is suitable for debugging.
- Custom logging format and handler can be set manually.
- """
-
- if not isinstance(sequences, (bytearray, bytes)):
- raise TypeError(
- "Expected object of type bytes or bytearray, got: {0}".format(
- type(sequences)
- )
- )
-
- if explain:
- previous_logger_level: int = logger.level
- logger.addHandler(explain_handler)
- logger.setLevel(TRACE)
-
- length: int = len(sequences)
-
- if length == 0:
- logger.debug("Encoding detection on empty bytes, assuming utf_8 intention.")
- if explain:
- logger.removeHandler(explain_handler)
- logger.setLevel(previous_logger_level or logging.WARNING)
- return CharsetMatches([CharsetMatch(sequences, "utf_8", 0.0, False, [], "")])
-
- if cp_isolation is not None:
- logger.log(
- TRACE,
- "cp_isolation is set. use this flag for debugging purpose. "
- "limited list of encoding allowed : %s.",
- ", ".join(cp_isolation),
- )
- cp_isolation = [iana_name(cp, False) for cp in cp_isolation]
- else:
- cp_isolation = []
-
- if cp_exclusion is not None:
- logger.log(
- TRACE,
- "cp_exclusion is set. use this flag for debugging purpose. "
- "limited list of encoding excluded : %s.",
- ", ".join(cp_exclusion),
- )
- cp_exclusion = [iana_name(cp, False) for cp in cp_exclusion]
- else:
- cp_exclusion = []
-
- if length <= (chunk_size * steps):
- logger.log(
- TRACE,
- "override steps (%i) and chunk_size (%i) as content does not fit (%i byte(s) given) parameters.",
- steps,
- chunk_size,
- length,
- )
- steps = 1
- chunk_size = length
-
- if steps > 1 and length / steps < chunk_size:
- chunk_size = int(length / steps)
-
- is_too_small_sequence: bool = len(sequences) < TOO_SMALL_SEQUENCE
- is_too_large_sequence: bool = len(sequences) >= TOO_BIG_SEQUENCE
-
- if is_too_small_sequence:
- logger.log(
- TRACE,
- "Trying to detect encoding from a tiny portion of ({}) byte(s).".format(
- length
- ),
- )
- elif is_too_large_sequence:
- logger.log(
- TRACE,
- "Using lazy str decoding because the payload is quite large, ({}) byte(s).".format(
- length
- ),
- )
-
- prioritized_encodings: List[str] = []
-
- specified_encoding: Optional[str] = (
- any_specified_encoding(sequences) if preemptive_behaviour else None
- )
-
- if specified_encoding is not None:
- prioritized_encodings.append(specified_encoding)
- logger.log(
- TRACE,
- "Detected declarative mark in sequence. Priority +1 given for %s.",
- specified_encoding,
- )
-
- tested: Set[str] = set()
- tested_but_hard_failure: List[str] = []
- tested_but_soft_failure: List[str] = []
-
- fallback_ascii: Optional[CharsetMatch] = None
- fallback_u8: Optional[CharsetMatch] = None
- fallback_specified: Optional[CharsetMatch] = None
-
- results: CharsetMatches = CharsetMatches()
-
- sig_encoding, sig_payload = identify_sig_or_bom(sequences)
-
- if sig_encoding is not None:
- prioritized_encodings.append(sig_encoding)
- logger.log(
- TRACE,
- "Detected a SIG or BOM mark on first %i byte(s). Priority +1 given for %s.",
- len(sig_payload),
- sig_encoding,
- )
-
- prioritized_encodings.append("ascii")
-
- if "utf_8" not in prioritized_encodings:
- prioritized_encodings.append("utf_8")
-
- for encoding_iana in prioritized_encodings + IANA_SUPPORTED:
- if cp_isolation and encoding_iana not in cp_isolation:
- continue
-
- if cp_exclusion and encoding_iana in cp_exclusion:
- continue
-
- if encoding_iana in tested:
- continue
-
- tested.add(encoding_iana)
-
- decoded_payload: Optional[str] = None
- bom_or_sig_available: bool = sig_encoding == encoding_iana
- strip_sig_or_bom: bool = bom_or_sig_available and should_strip_sig_or_bom(
- encoding_iana
- )
-
- if encoding_iana in {"utf_16", "utf_32"} and not bom_or_sig_available:
- logger.log(
- TRACE,
- "Encoding %s won't be tested as-is because it require a BOM. Will try some sub-encoder LE/BE.",
- encoding_iana,
- )
- continue
- if encoding_iana in {"utf_7"} and not bom_or_sig_available:
- logger.log(
- TRACE,
- "Encoding %s won't be tested as-is because detection is unreliable without BOM/SIG.",
- encoding_iana,
- )
- continue
-
- try:
- is_multi_byte_decoder: bool = is_multi_byte_encoding(encoding_iana)
- except (ModuleNotFoundError, ImportError):
- logger.log(
- TRACE,
- "Encoding %s does not provide an IncrementalDecoder",
- encoding_iana,
- )
- continue
-
- try:
- if is_too_large_sequence and is_multi_byte_decoder is False:
- str(
- sequences[: int(50e4)]
- if strip_sig_or_bom is False
- else sequences[len(sig_payload) : int(50e4)],
- encoding=encoding_iana,
- )
- else:
- decoded_payload = str(
- sequences
- if strip_sig_or_bom is False
- else sequences[len(sig_payload) :],
- encoding=encoding_iana,
- )
- except (UnicodeDecodeError, LookupError) as e:
- if not isinstance(e, LookupError):
- logger.log(
- TRACE,
- "Code page %s does not fit given bytes sequence at ALL. %s",
- encoding_iana,
- str(e),
- )
- tested_but_hard_failure.append(encoding_iana)
- continue
-
- similar_soft_failure_test: bool = False
-
- for encoding_soft_failed in tested_but_soft_failure:
- if is_cp_similar(encoding_iana, encoding_soft_failed):
- similar_soft_failure_test = True
- break
-
- if similar_soft_failure_test:
- logger.log(
- TRACE,
- "%s is deemed too similar to code page %s and was consider unsuited already. Continuing!",
- encoding_iana,
- encoding_soft_failed,
- )
- continue
-
- r_ = range(
- 0 if not bom_or_sig_available else len(sig_payload),
- length,
- int(length / steps),
- )
-
- multi_byte_bonus: bool = (
- is_multi_byte_decoder
- and decoded_payload is not None
- and len(decoded_payload) < length
- )
-
- if multi_byte_bonus:
- logger.log(
- TRACE,
- "Code page %s is a multi byte encoding table and it appear that at least one character "
- "was encoded using n-bytes.",
- encoding_iana,
- )
-
- max_chunk_gave_up: int = int(len(r_) / 4)
-
- max_chunk_gave_up = max(max_chunk_gave_up, 2)
- early_stop_count: int = 0
- lazy_str_hard_failure = False
-
- md_chunks: List[str] = []
- md_ratios = []
-
- try:
- for chunk in cut_sequence_chunks(
- sequences,
- encoding_iana,
- r_,
- chunk_size,
- bom_or_sig_available,
- strip_sig_or_bom,
- sig_payload,
- is_multi_byte_decoder,
- decoded_payload,
- ):
- md_chunks.append(chunk)
-
- md_ratios.append(
- mess_ratio(
- chunk,
- threshold,
- explain is True and 1 <= len(cp_isolation) <= 2,
- )
- )
-
- if md_ratios[-1] >= threshold:
- early_stop_count += 1
-
- if (early_stop_count >= max_chunk_gave_up) or (
- bom_or_sig_available and strip_sig_or_bom is False
- ):
- break
- except (
- UnicodeDecodeError
- ) as e: # Lazy str loading may have missed something there
- logger.log(
- TRACE,
- "LazyStr Loading: After MD chunk decode, code page %s does not fit given bytes sequence at ALL. %s",
- encoding_iana,
- str(e),
- )
- early_stop_count = max_chunk_gave_up
- lazy_str_hard_failure = True
-
- # We might want to check the sequence again with the whole content
- # Only if initial MD tests passes
- if (
- not lazy_str_hard_failure
- and is_too_large_sequence
- and not is_multi_byte_decoder
- ):
- try:
- sequences[int(50e3) :].decode(encoding_iana, errors="strict")
- except UnicodeDecodeError as e:
- logger.log(
- TRACE,
- "LazyStr Loading: After final lookup, code page %s does not fit given bytes sequence at ALL. %s",
- encoding_iana,
- str(e),
- )
- tested_but_hard_failure.append(encoding_iana)
- continue
-
- mean_mess_ratio: float = sum(md_ratios) / len(md_ratios) if md_ratios else 0.0
- if mean_mess_ratio >= threshold or early_stop_count >= max_chunk_gave_up:
- tested_but_soft_failure.append(encoding_iana)
- logger.log(
- TRACE,
- "%s was excluded because of initial chaos probing. Gave up %i time(s). "
- "Computed mean chaos is %f %%.",
- encoding_iana,
- early_stop_count,
- round(mean_mess_ratio * 100, ndigits=3),
- )
- # Preparing those fallbacks in case we got nothing.
- if (
- enable_fallback
- and encoding_iana in ["ascii", "utf_8", specified_encoding]
- and not lazy_str_hard_failure
- ):
- fallback_entry = CharsetMatch(
- sequences, encoding_iana, threshold, False, [], decoded_payload
- )
- if encoding_iana == specified_encoding:
- fallback_specified = fallback_entry
- elif encoding_iana == "ascii":
- fallback_ascii = fallback_entry
- else:
- fallback_u8 = fallback_entry
- continue
-
- logger.log(
- TRACE,
- "%s passed initial chaos probing. Mean measured chaos is %f %%",
- encoding_iana,
- round(mean_mess_ratio * 100, ndigits=3),
- )
-
- if not is_multi_byte_decoder:
- target_languages: List[str] = encoding_languages(encoding_iana)
- else:
- target_languages = mb_encoding_languages(encoding_iana)
-
- if target_languages:
- logger.log(
- TRACE,
- "{} should target any language(s) of {}".format(
- encoding_iana, str(target_languages)
- ),
- )
-
- cd_ratios = []
-
- # We shall skip the CD when its about ASCII
- # Most of the time its not relevant to run "language-detection" on it.
- if encoding_iana != "ascii":
- for chunk in md_chunks:
- chunk_languages = coherence_ratio(
- chunk,
- language_threshold,
- ",".join(target_languages) if target_languages else None,
- )
-
- cd_ratios.append(chunk_languages)
-
- cd_ratios_merged = merge_coherence_ratios(cd_ratios)
-
- if cd_ratios_merged:
- logger.log(
- TRACE,
- "We detected language {} using {}".format(
- cd_ratios_merged, encoding_iana
- ),
- )
-
- results.append(
- CharsetMatch(
- sequences,
- encoding_iana,
- mean_mess_ratio,
- bom_or_sig_available,
- cd_ratios_merged,
- decoded_payload,
- )
- )
-
- if (
- encoding_iana in [specified_encoding, "ascii", "utf_8"]
- and mean_mess_ratio < 0.1
- ):
- logger.debug(
- "Encoding detection: %s is most likely the one.", encoding_iana
- )
- if explain:
- logger.removeHandler(explain_handler)
- logger.setLevel(previous_logger_level)
- return CharsetMatches([results[encoding_iana]])
-
- if encoding_iana == sig_encoding:
- logger.debug(
- "Encoding detection: %s is most likely the one as we detected a BOM or SIG within "
- "the beginning of the sequence.",
- encoding_iana,
- )
- if explain:
- logger.removeHandler(explain_handler)
- logger.setLevel(previous_logger_level)
- return CharsetMatches([results[encoding_iana]])
-
- if len(results) == 0:
- if fallback_u8 or fallback_ascii or fallback_specified:
- logger.log(
- TRACE,
- "Nothing got out of the detection process. Using ASCII/UTF-8/Specified fallback.",
- )
-
- if fallback_specified:
- logger.debug(
- "Encoding detection: %s will be used as a fallback match",
- fallback_specified.encoding,
- )
- results.append(fallback_specified)
- elif (
- (fallback_u8 and fallback_ascii is None)
- or (
- fallback_u8
- and fallback_ascii
- and fallback_u8.fingerprint != fallback_ascii.fingerprint
- )
- or (fallback_u8 is not None)
- ):
- logger.debug("Encoding detection: utf_8 will be used as a fallback match")
- results.append(fallback_u8)
- elif fallback_ascii:
- logger.debug("Encoding detection: ascii will be used as a fallback match")
- results.append(fallback_ascii)
-
- if results:
- logger.debug(
- "Encoding detection: Found %s as plausible (best-candidate) for content. With %i alternatives.",
- results.best().encoding, # type: ignore
- len(results) - 1,
- )
- else:
- logger.debug("Encoding detection: Unable to determine any suitable charset.")
-
- if explain:
- logger.removeHandler(explain_handler)
- logger.setLevel(previous_logger_level)
-
- return results
-
-
-def from_fp(
- fp: BinaryIO,
- steps: int = 5,
- chunk_size: int = 512,
- threshold: float = 0.20,
- cp_isolation: Optional[List[str]] = None,
- cp_exclusion: Optional[List[str]] = None,
- preemptive_behaviour: bool = True,
- explain: bool = False,
- language_threshold: float = 0.1,
- enable_fallback: bool = True,
-) -> CharsetMatches:
- """
- Same thing than the function from_bytes but using a file pointer that is already ready.
- Will not close the file pointer.
- """
- return from_bytes(
- fp.read(),
- steps,
- chunk_size,
- threshold,
- cp_isolation,
- cp_exclusion,
- preemptive_behaviour,
- explain,
- language_threshold,
- enable_fallback,
- )
-
-
-def from_path(
- path: Union[str, bytes, PathLike], # type: ignore[type-arg]
- steps: int = 5,
- chunk_size: int = 512,
- threshold: float = 0.20,
- cp_isolation: Optional[List[str]] = None,
- cp_exclusion: Optional[List[str]] = None,
- preemptive_behaviour: bool = True,
- explain: bool = False,
- language_threshold: float = 0.1,
- enable_fallback: bool = True,
-) -> CharsetMatches:
- """
- Same thing than the function from_bytes but with one extra step. Opening and reading given file path in binary mode.
- Can raise IOError.
- """
- with open(path, "rb") as fp:
- return from_fp(
- fp,
- steps,
- chunk_size,
- threshold,
- cp_isolation,
- cp_exclusion,
- preemptive_behaviour,
- explain,
- language_threshold,
- enable_fallback,
- )
-
-
-def is_binary(
- fp_or_path_or_payload: Union[PathLike, str, BinaryIO, bytes], # type: ignore[type-arg]
- steps: int = 5,
- chunk_size: int = 512,
- threshold: float = 0.20,
- cp_isolation: Optional[List[str]] = None,
- cp_exclusion: Optional[List[str]] = None,
- preemptive_behaviour: bool = True,
- explain: bool = False,
- language_threshold: float = 0.1,
- enable_fallback: bool = False,
-) -> bool:
- """
- Detect if the given input (file, bytes, or path) points to a binary file. aka. not a string.
- Based on the same main heuristic algorithms and default kwargs at the sole exception that fallbacks match
- are disabled to be stricter around ASCII-compatible but unlikely to be a string.
- """
- if isinstance(fp_or_path_or_payload, (str, PathLike)):
- guesses = from_path(
- fp_or_path_or_payload,
- steps=steps,
- chunk_size=chunk_size,
- threshold=threshold,
- cp_isolation=cp_isolation,
- cp_exclusion=cp_exclusion,
- preemptive_behaviour=preemptive_behaviour,
- explain=explain,
- language_threshold=language_threshold,
- enable_fallback=enable_fallback,
- )
- elif isinstance(
- fp_or_path_or_payload,
- (
- bytes,
- bytearray,
- ),
- ):
- guesses = from_bytes(
- fp_or_path_or_payload,
- steps=steps,
- chunk_size=chunk_size,
- threshold=threshold,
- cp_isolation=cp_isolation,
- cp_exclusion=cp_exclusion,
- preemptive_behaviour=preemptive_behaviour,
- explain=explain,
- language_threshold=language_threshold,
- enable_fallback=enable_fallback,
- )
- else:
- guesses = from_fp(
- fp_or_path_or_payload,
- steps=steps,
- chunk_size=chunk_size,
- threshold=threshold,
- cp_isolation=cp_isolation,
- cp_exclusion=cp_exclusion,
- preemptive_behaviour=preemptive_behaviour,
- explain=explain,
- language_threshold=language_threshold,
- enable_fallback=enable_fallback,
- )
-
- return not guesses
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/click/decorators.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/click/decorators.py
deleted file mode 100644
index 797449d630d60e4f997312151e99c5fc429dfbda..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/click/decorators.py
+++ /dev/null
@@ -1,570 +0,0 @@
-import inspect
-import types
-import typing as t
-from functools import update_wrapper
-from gettext import gettext as _
-
-from .core import Argument
-from .core import Command
-from .core import Context
-from .core import Group
-from .core import Option
-from .core import Parameter
-from .globals import get_current_context
-from .utils import echo
-
-if t.TYPE_CHECKING:
- import typing_extensions as te
-
- P = te.ParamSpec("P")
-
-R = t.TypeVar("R")
-T = t.TypeVar("T")
-_AnyCallable = t.Callable[..., t.Any]
-_Decorator: "te.TypeAlias" = t.Callable[[T], T]
-FC = t.TypeVar("FC", bound=t.Union[_AnyCallable, Command])
-
-
-def pass_context(f: "t.Callable[te.Concatenate[Context, P], R]") -> "t.Callable[P, R]":
- """Marks a callback as wanting to receive the current context
- object as first argument.
- """
-
- def new_func(*args: "P.args", **kwargs: "P.kwargs") -> "R":
- return f(get_current_context(), *args, **kwargs)
-
- return update_wrapper(new_func, f)
-
-
-def pass_obj(f: "t.Callable[te.Concatenate[t.Any, P], R]") -> "t.Callable[P, R]":
- """Similar to :func:`pass_context`, but only pass the object on the
- context onwards (:attr:`Context.obj`). This is useful if that object
- represents the state of a nested system.
- """
-
- def new_func(*args: "P.args", **kwargs: "P.kwargs") -> "R":
- return f(get_current_context().obj, *args, **kwargs)
-
- return update_wrapper(new_func, f)
-
-
-def make_pass_decorator(
- object_type: t.Type[T], ensure: bool = False
-) -> t.Callable[["t.Callable[te.Concatenate[T, P], R]"], "t.Callable[P, R]"]:
- """Given an object type this creates a decorator that will work
- similar to :func:`pass_obj` but instead of passing the object of the
- current context, it will find the innermost context of type
- :func:`object_type`.
-
- This generates a decorator that works roughly like this::
-
- from functools import update_wrapper
-
- def decorator(f):
- @pass_context
- def new_func(ctx, *args, **kwargs):
- obj = ctx.find_object(object_type)
- return ctx.invoke(f, obj, *args, **kwargs)
- return update_wrapper(new_func, f)
- return decorator
-
- :param object_type: the type of the object to pass.
- :param ensure: if set to `True`, a new object will be created and
- remembered on the context if it's not there yet.
- """
-
- def decorator(f: "t.Callable[te.Concatenate[T, P], R]") -> "t.Callable[P, R]":
- def new_func(*args: "P.args", **kwargs: "P.kwargs") -> "R":
- ctx = get_current_context()
-
- obj: t.Optional[T]
- if ensure:
- obj = ctx.ensure_object(object_type)
- else:
- obj = ctx.find_object(object_type)
-
- if obj is None:
- raise RuntimeError(
- "Managed to invoke callback without a context"
- f" object of type {object_type.__name__!r}"
- " existing."
- )
-
- return ctx.invoke(f, obj, *args, **kwargs)
-
- return update_wrapper(new_func, f)
-
- return decorator # type: ignore[return-value]
-
-
-def pass_meta_key(
- key: str, *, doc_description: t.Optional[str] = None
-) -> "t.Callable[[t.Callable[te.Concatenate[t.Any, P], R]], t.Callable[P, R]]":
- """Create a decorator that passes a key from
- :attr:`click.Context.meta` as the first argument to the decorated
- function.
-
- :param key: Key in ``Context.meta`` to pass.
- :param doc_description: Description of the object being passed,
- inserted into the decorator's docstring. Defaults to "the 'key'
- key from Context.meta".
-
- .. versionadded:: 8.0
- """
-
- def decorator(f: "t.Callable[te.Concatenate[t.Any, P], R]") -> "t.Callable[P, R]":
- def new_func(*args: "P.args", **kwargs: "P.kwargs") -> R:
- ctx = get_current_context()
- obj = ctx.meta[key]
- return ctx.invoke(f, obj, *args, **kwargs)
-
- return update_wrapper(new_func, f)
-
- if doc_description is None:
- doc_description = f"the {key!r} key from :attr:`click.Context.meta`"
-
- decorator.__doc__ = (
- f"Decorator that passes {doc_description} as the first argument"
- " to the decorated function."
- )
- return decorator # type: ignore[return-value]
-
-
-CmdType = t.TypeVar("CmdType", bound=Command)
-
-
-# variant: no call, directly as decorator for a function.
-@t.overload
-def command(name: _AnyCallable) -> Command:
- ...
-
-
-# variant: with positional name and with positional or keyword cls argument:
-# @command(namearg, CommandCls, ...) or @command(namearg, cls=CommandCls, ...)
-@t.overload
-def command(
- name: t.Optional[str],
- cls: t.Type[CmdType],
- **attrs: t.Any,
-) -> t.Callable[[_AnyCallable], CmdType]:
- ...
-
-
-# variant: name omitted, cls _must_ be a keyword argument, @command(cmd=CommandCls, ...)
-# The correct way to spell this overload is to use keyword-only argument syntax:
-# def command(*, cls: t.Type[CmdType], **attrs: t.Any) -> ...
-# However, mypy thinks this doesn't fit the overloaded function. Pyright does
-# accept that spelling, and the following work-around makes pyright issue a
-# warning that CmdType could be left unsolved, but mypy sees it as fine. *shrug*
-@t.overload
-def command(
- name: None = None,
- cls: t.Type[CmdType] = ...,
- **attrs: t.Any,
-) -> t.Callable[[_AnyCallable], CmdType]:
- ...
-
-
-# variant: with optional string name, no cls argument provided.
-@t.overload
-def command(
- name: t.Optional[str] = ..., cls: None = None, **attrs: t.Any
-) -> t.Callable[[_AnyCallable], Command]:
- ...
-
-
-def command(
- name: t.Union[t.Optional[str], _AnyCallable] = None,
- cls: t.Optional[t.Type[CmdType]] = None,
- **attrs: t.Any,
-) -> t.Union[Command, t.Callable[[_AnyCallable], t.Union[Command, CmdType]]]:
- r"""Creates a new :class:`Command` and uses the decorated function as
- callback. This will also automatically attach all decorated
- :func:`option`\s and :func:`argument`\s as parameters to the command.
-
- The name of the command defaults to the name of the function with
- underscores replaced by dashes. If you want to change that, you can
- pass the intended name as the first argument.
-
- All keyword arguments are forwarded to the underlying command class.
- For the ``params`` argument, any decorated params are appended to
- the end of the list.
-
- Once decorated the function turns into a :class:`Command` instance
- that can be invoked as a command line utility or be attached to a
- command :class:`Group`.
-
- :param name: the name of the command. This defaults to the function
- name with underscores replaced by dashes.
- :param cls: the command class to instantiate. This defaults to
- :class:`Command`.
-
- .. versionchanged:: 8.1
- This decorator can be applied without parentheses.
-
- .. versionchanged:: 8.1
- The ``params`` argument can be used. Decorated params are
- appended to the end of the list.
- """
-
- func: t.Optional[t.Callable[[_AnyCallable], t.Any]] = None
-
- if callable(name):
- func = name
- name = None
- assert cls is None, "Use 'command(cls=cls)(callable)' to specify a class."
- assert not attrs, "Use 'command(**kwargs)(callable)' to provide arguments."
-
- if cls is None:
- cls = t.cast(t.Type[CmdType], Command)
-
- def decorator(f: _AnyCallable) -> CmdType:
- if isinstance(f, Command):
- raise TypeError("Attempted to convert a callback into a command twice.")
-
- attr_params = attrs.pop("params", None)
- params = attr_params if attr_params is not None else []
-
- try:
- decorator_params = f.__click_params__ # type: ignore
- except AttributeError:
- pass
- else:
- del f.__click_params__ # type: ignore
- params.extend(reversed(decorator_params))
-
- if attrs.get("help") is None:
- attrs["help"] = f.__doc__
-
- if t.TYPE_CHECKING:
- assert cls is not None
- assert not callable(name)
-
- cmd = cls(
- name=name or f.__name__.lower().replace("_", "-"),
- callback=f,
- params=params,
- **attrs,
- )
- cmd.__doc__ = f.__doc__
- return cmd
-
- if func is not None:
- return decorator(func)
-
- return decorator
-
-
-GrpType = t.TypeVar("GrpType", bound=Group)
-
-
-# variant: no call, directly as decorator for a function.
-@t.overload
-def group(name: _AnyCallable) -> Group:
- ...
-
-
-# variant: with positional name and with positional or keyword cls argument:
-# @group(namearg, GroupCls, ...) or @group(namearg, cls=GroupCls, ...)
-@t.overload
-def group(
- name: t.Optional[str],
- cls: t.Type[GrpType],
- **attrs: t.Any,
-) -> t.Callable[[_AnyCallable], GrpType]:
- ...
-
-
-# variant: name omitted, cls _must_ be a keyword argument, @group(cmd=GroupCls, ...)
-# The _correct_ way to spell this overload is to use keyword-only argument syntax:
-# def group(*, cls: t.Type[GrpType], **attrs: t.Any) -> ...
-# However, mypy thinks this doesn't fit the overloaded function. Pyright does
-# accept that spelling, and the following work-around makes pyright issue a
-# warning that GrpType could be left unsolved, but mypy sees it as fine. *shrug*
-@t.overload
-def group(
- name: None = None,
- cls: t.Type[GrpType] = ...,
- **attrs: t.Any,
-) -> t.Callable[[_AnyCallable], GrpType]:
- ...
-
-
-# variant: with optional string name, no cls argument provided.
-@t.overload
-def group(
- name: t.Optional[str] = ..., cls: None = None, **attrs: t.Any
-) -> t.Callable[[_AnyCallable], Group]:
- ...
-
-
-def group(
- name: t.Union[str, _AnyCallable, None] = None,
- cls: t.Optional[t.Type[GrpType]] = None,
- **attrs: t.Any,
-) -> t.Union[Group, t.Callable[[_AnyCallable], t.Union[Group, GrpType]]]:
- """Creates a new :class:`Group` with a function as callback. This
- works otherwise the same as :func:`command` just that the `cls`
- parameter is set to :class:`Group`.
-
- .. versionchanged:: 8.1
- This decorator can be applied without parentheses.
- """
- if cls is None:
- cls = t.cast(t.Type[GrpType], Group)
-
- if callable(name):
- return command(cls=cls, **attrs)(name)
-
- return command(name, cls, **attrs)
-
-
-def _param_memo(f: t.Callable[..., t.Any], param: Parameter) -> None:
- if isinstance(f, Command):
- f.params.append(param)
- else:
- if not hasattr(f, "__click_params__"):
- f.__click_params__ = [] # type: ignore
-
- f.__click_params__.append(param) # type: ignore
-
-
-def argument(
- *param_decls: str, cls: t.Optional[t.Type[Argument]] = None, **attrs: t.Any
-) -> _Decorator[FC]:
- """Attaches an argument to the command. All positional arguments are
- passed as parameter declarations to :class:`Argument`; all keyword
- arguments are forwarded unchanged (except ``cls``).
- This is equivalent to creating an :class:`Argument` instance manually
- and attaching it to the :attr:`Command.params` list.
-
- For the default argument class, refer to :class:`Argument` and
- :class:`Parameter` for descriptions of parameters.
-
- :param cls: the argument class to instantiate. This defaults to
- :class:`Argument`.
- :param param_decls: Passed as positional arguments to the constructor of
- ``cls``.
- :param attrs: Passed as keyword arguments to the constructor of ``cls``.
- """
- if cls is None:
- cls = Argument
-
- def decorator(f: FC) -> FC:
- _param_memo(f, cls(param_decls, **attrs))
- return f
-
- return decorator
-
-
-def option(
- *param_decls: str, cls: t.Optional[t.Type[Option]] = None, **attrs: t.Any
-) -> _Decorator[FC]:
- """Attaches an option to the command. All positional arguments are
- passed as parameter declarations to :class:`Option`; all keyword
- arguments are forwarded unchanged (except ``cls``).
- This is equivalent to creating an :class:`Option` instance manually
- and attaching it to the :attr:`Command.params` list.
-
- For the default option class, refer to :class:`Option` and
- :class:`Parameter` for descriptions of parameters.
-
- :param cls: the option class to instantiate. This defaults to
- :class:`Option`.
- :param param_decls: Passed as positional arguments to the constructor of
- ``cls``.
- :param attrs: Passed as keyword arguments to the constructor of ``cls``.
- """
- if cls is None:
- cls = Option
-
- def decorator(f: FC) -> FC:
- _param_memo(f, cls(param_decls, **attrs))
- return f
-
- return decorator
-
-
-def confirmation_option(*param_decls: str, **kwargs: t.Any) -> _Decorator[FC]:
- """Add a ``--yes`` option which shows a prompt before continuing if
- not passed. If the prompt is declined, the program will exit.
-
- :param param_decls: One or more option names. Defaults to the single
- value ``"--yes"``.
- :param kwargs: Extra arguments are passed to :func:`option`.
- """
-
- def callback(ctx: Context, param: Parameter, value: bool) -> None:
- if not value:
- ctx.abort()
-
- if not param_decls:
- param_decls = ("--yes",)
-
- kwargs.setdefault("is_flag", True)
- kwargs.setdefault("callback", callback)
- kwargs.setdefault("expose_value", False)
- kwargs.setdefault("prompt", "Do you want to continue?")
- kwargs.setdefault("help", "Confirm the action without prompting.")
- return option(*param_decls, **kwargs)
-
-
-def password_option(*param_decls: str, **kwargs: t.Any) -> _Decorator[FC]:
- """Add a ``--password`` option which prompts for a password, hiding
- input and asking to enter the value again for confirmation.
-
- :param param_decls: One or more option names. Defaults to the single
- value ``"--password"``.
- :param kwargs: Extra arguments are passed to :func:`option`.
- """
- if not param_decls:
- param_decls = ("--password",)
-
- kwargs.setdefault("prompt", True)
- kwargs.setdefault("confirmation_prompt", True)
- kwargs.setdefault("hide_input", True)
- return option(*param_decls, **kwargs)
-
-
-def version_option(
- version: t.Optional[str] = None,
- *param_decls: str,
- package_name: t.Optional[str] = None,
- prog_name: t.Optional[str] = None,
- message: t.Optional[str] = None,
- **kwargs: t.Any,
-) -> _Decorator[FC]:
- """Add a ``--version`` option which immediately prints the version
- number and exits the program.
-
- If ``version`` is not provided, Click will try to detect it using
- :func:`importlib.metadata.version` to get the version for the
- ``package_name``. On Python < 3.8, the ``importlib_metadata``
- backport must be installed.
-
- If ``package_name`` is not provided, Click will try to detect it by
- inspecting the stack frames. This will be used to detect the
- version, so it must match the name of the installed package.
-
- :param version: The version number to show. If not provided, Click
- will try to detect it.
- :param param_decls: One or more option names. Defaults to the single
- value ``"--version"``.
- :param package_name: The package name to detect the version from. If
- not provided, Click will try to detect it.
- :param prog_name: The name of the CLI to show in the message. If not
- provided, it will be detected from the command.
- :param message: The message to show. The values ``%(prog)s``,
- ``%(package)s``, and ``%(version)s`` are available. Defaults to
- ``"%(prog)s, version %(version)s"``.
- :param kwargs: Extra arguments are passed to :func:`option`.
- :raise RuntimeError: ``version`` could not be detected.
-
- .. versionchanged:: 8.0
- Add the ``package_name`` parameter, and the ``%(package)s``
- value for messages.
-
- .. versionchanged:: 8.0
- Use :mod:`importlib.metadata` instead of ``pkg_resources``. The
- version is detected based on the package name, not the entry
- point name. The Python package name must match the installed
- package name, or be passed with ``package_name=``.
- """
- if message is None:
- message = _("%(prog)s, version %(version)s")
-
- if version is None and package_name is None:
- frame = inspect.currentframe()
- f_back = frame.f_back if frame is not None else None
- f_globals = f_back.f_globals if f_back is not None else None
- # break reference cycle
- # https://docs.python.org/3/library/inspect.html#the-interpreter-stack
- del frame
-
- if f_globals is not None:
- package_name = f_globals.get("__name__")
-
- if package_name == "__main__":
- package_name = f_globals.get("__package__")
-
- if package_name:
- package_name = package_name.partition(".")[0]
-
- def callback(ctx: Context, param: Parameter, value: bool) -> None:
- if not value or ctx.resilient_parsing:
- return
-
- nonlocal prog_name
- nonlocal version
-
- if prog_name is None:
- prog_name = ctx.find_root().info_name
-
- if version is None and package_name is not None:
- metadata: t.Optional[types.ModuleType]
-
- try:
- from importlib import metadata # type: ignore
- except ImportError:
- # Python < 3.8
- import importlib_metadata as metadata # type: ignore
-
- try:
- version = metadata.version(package_name) # type: ignore
- except metadata.PackageNotFoundError: # type: ignore
- raise RuntimeError(
- f"{package_name!r} is not installed. Try passing"
- " 'package_name' instead."
- ) from None
-
- if version is None:
- raise RuntimeError(
- f"Could not determine the version for {package_name!r} automatically."
- )
-
- echo(
- message % {"prog": prog_name, "package": package_name, "version": version},
- color=ctx.color,
- )
- ctx.exit()
-
- if not param_decls:
- param_decls = ("--version",)
-
- kwargs.setdefault("is_flag", True)
- kwargs.setdefault("expose_value", False)
- kwargs.setdefault("is_eager", True)
- kwargs.setdefault("help", _("Show the version and exit."))
- kwargs["callback"] = callback
- return option(*param_decls, **kwargs)
-
-
-def help_option(*param_decls: str, **kwargs: t.Any) -> _Decorator[FC]:
- """Add a ``--help`` option which immediately prints the help page
- and exits the program.
-
- This is usually unnecessary, as the ``--help`` option is added to
- each command automatically unless ``add_help_option=False`` is
- passed.
-
- :param param_decls: One or more option names. Defaults to the single
- value ``"--help"``.
- :param kwargs: Extra arguments are passed to :func:`option`.
- """
-
- def callback(ctx: Context, param: Parameter, value: bool) -> None:
- if not value or ctx.resilient_parsing:
- return
-
- echo(ctx.get_help(), color=ctx.color)
- ctx.exit()
-
- if not param_decls:
- param_decls = ("--help",)
-
- kwargs.setdefault("is_flag", True)
- kwargs.setdefault("expose_value", False)
- kwargs.setdefault("is_eager", True)
- kwargs.setdefault("help", _("Show this message and exit."))
- kwargs["callback"] = callback
- return option(*param_decls, **kwargs)
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/opc/phys_pkg.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/opc/phys_pkg.py
deleted file mode 100644
index c86a5199453f457b8a6d7e8e234a31640963106c..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/opc/phys_pkg.py
+++ /dev/null
@@ -1,155 +0,0 @@
-# encoding: utf-8
-
-"""
-Provides a general interface to a *physical* OPC package, such as a zip file.
-"""
-
-from __future__ import absolute_import
-
-import os
-
-from zipfile import ZipFile, is_zipfile, ZIP_DEFLATED
-
-from .compat import is_string
-from .exceptions import PackageNotFoundError
-from .packuri import CONTENT_TYPES_URI
-
-
-class PhysPkgReader(object):
- """
- Factory for physical package reader objects.
- """
- def __new__(cls, pkg_file):
- # if *pkg_file* is a string, treat it as a path
- if is_string(pkg_file):
- if os.path.isdir(pkg_file):
- reader_cls = _DirPkgReader
- elif is_zipfile(pkg_file):
- reader_cls = _ZipPkgReader
- else:
- raise PackageNotFoundError(
- "Package not found at '%s'" % pkg_file
- )
- else: # assume it's a stream and pass it to Zip reader to sort out
- reader_cls = _ZipPkgReader
-
- return super(PhysPkgReader, cls).__new__(reader_cls)
-
-
-class PhysPkgWriter(object):
- """
- Factory for physical package writer objects.
- """
- def __new__(cls, pkg_file):
- return super(PhysPkgWriter, cls).__new__(_ZipPkgWriter)
-
-
-class _DirPkgReader(PhysPkgReader):
- """
- Implements |PhysPkgReader| interface for an OPC package extracted into a
- directory.
- """
- def __init__(self, path):
- """
- *path* is the path to a directory containing an expanded package.
- """
- super(_DirPkgReader, self).__init__()
- self._path = os.path.abspath(path)
-
- def blob_for(self, pack_uri):
- """
- Return contents of file corresponding to *pack_uri* in package
- directory.
- """
- path = os.path.join(self._path, pack_uri.membername)
- with open(path, 'rb') as f:
- blob = f.read()
- return blob
-
- def close(self):
- """
- Provides interface consistency with |ZipFileSystem|, but does
- nothing, a directory file system doesn't need closing.
- """
- pass
-
- @property
- def content_types_xml(self):
- """
- Return the `[Content_Types].xml` blob from the package.
- """
- return self.blob_for(CONTENT_TYPES_URI)
-
- def rels_xml_for(self, source_uri):
- """
- Return rels item XML for source with *source_uri*, or None if the
- item has no rels item.
- """
- try:
- rels_xml = self.blob_for(source_uri.rels_uri)
- except IOError:
- rels_xml = None
- return rels_xml
-
-
-class _ZipPkgReader(PhysPkgReader):
- """
- Implements |PhysPkgReader| interface for a zip file OPC package.
- """
- def __init__(self, pkg_file):
- super(_ZipPkgReader, self).__init__()
- self._zipf = ZipFile(pkg_file, 'r')
-
- def blob_for(self, pack_uri):
- """
- Return blob corresponding to *pack_uri*. Raises |ValueError| if no
- matching member is present in zip archive.
- """
- return self._zipf.read(pack_uri.membername)
-
- def close(self):
- """
- Close the zip archive, releasing any resources it is using.
- """
- self._zipf.close()
-
- @property
- def content_types_xml(self):
- """
- Return the `[Content_Types].xml` blob from the zip package.
- """
- return self.blob_for(CONTENT_TYPES_URI)
-
- def rels_xml_for(self, source_uri):
- """
- Return rels item XML for source with *source_uri* or None if no rels
- item is present.
- """
- try:
- rels_xml = self.blob_for(source_uri.rels_uri)
- except KeyError:
- rels_xml = None
- return rels_xml
-
-
-class _ZipPkgWriter(PhysPkgWriter):
- """
- Implements |PhysPkgWriter| interface for a zip file OPC package.
- """
- def __init__(self, pkg_file):
- super(_ZipPkgWriter, self).__init__()
- self._zipf = ZipFile(pkg_file, 'w', compression=ZIP_DEFLATED)
-
- def close(self):
- """
- Close the zip archive, flushing any pending physical writes and
- releasing any resources it's using.
- """
- self._zipf.close()
-
- def write(self, pack_uri, blob):
- """
- Write *blob* to this zip package with the membername corresponding to
- *pack_uri*.
- """
- self._zipf.writestr(pack_uri.membername, blob)
diff --git a/spaces/cihyFjudo/fairness-paper-search/Facegen Modeller 3.5.3 Crack How to generate custom faces with ease.md b/spaces/cihyFjudo/fairness-paper-search/Facegen Modeller 3.5.3 Crack How to generate custom faces with ease.md
deleted file mode 100644
index 195b8a6bcaefc32bbb81916c0add085e6010817b..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Facegen Modeller 3.5.3 Crack How to generate custom faces with ease.md
+++ /dev/null
@@ -1,6 +0,0 @@
-facegen modeller 3.5.3 crack Download File ✦✦✦ https://tinurli.com/2uwhAO
diff --git a/spaces/cihyFjudo/fairness-paper-search/Free Porn Tube Hidden Camera In The Public Toilet.md b/spaces/cihyFjudo/fairness-paper-search/Free Porn Tube Hidden Camera In The Public Toilet.md
deleted file mode 100644
index 5f3bea33edd7fc261da3a73dd8a1a95ad4958d11..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Free Porn Tube Hidden Camera In The Public Toilet.md
+++ /dev/null
@@ -1,10 +0,0 @@
-father son 3some slutload ford escort power booster eats
-free porn tube hidden camera in the public toilet Download Zip ===> https://tinurli.com/2uwk61
nudist teen camp pictures for free transvestite
-horny family sex katy perry fucks user provided mature women videos costa picture rica sex steve ridgeway virgin.
-full metal alchemist xxx happy nude year cards bwu hidden camera massage grab cock ancient
-big dicks orgies movies dvd gay lesbian shop
-
aaccfb2cb3Mad Max: Fury Road Tamil Movie Mp4 Free Download Download File >>> https://tinurli.com/2uwhIy
diff --git a/spaces/cihyFjudo/fairness-paper-search/Simson 3D Werkstatt Download Kostenlos Experimentiere mit Farben Stil und Zubehr.md b/spaces/cihyFjudo/fairness-paper-search/Simson 3D Werkstatt Download Kostenlos Experimentiere mit Farben Stil und Zubehr.md
deleted file mode 100644
index 2dbaa79ef7d8911efcdc0e94e54c5c727c8dcab7..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Simson 3D Werkstatt Download Kostenlos Experimentiere mit Farben Stil und Zubehr.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Register, earn coins and get Simson Tuningwerkstatt 3D free steam key . After you get enough coins, you can redeem them for an activation code and download Simson Tuningwerkstatt 3D on Steam.
-simson 3d werkstatt download kostenlos DOWNLOAD 🆓 https://tinurli.com/2uwkMI
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-/**
- * @file
- * huffman tree builder and VLC generator
- */
-
-#ifndef AVCODEC_HUFFMAN_H
-#define AVCODEC_HUFFMAN_H
-
-#include
-
-#include "vlc.h"
-
-typedef struct Node {
- int16_t sym;
- int16_t n0;
- uint32_t count;
-} Node;
-
-#define FF_HUFFMAN_FLAG_HNODE_FIRST 0x01
-#define FF_HUFFMAN_FLAG_ZERO_COUNT 0x02
-#define FF_HUFFMAN_BITS 10
-
-typedef int (*HuffCmp)(const void *va, const void *vb);
-int ff_huff_build_tree(void *logctx, VLC *vlc, int nb_codes, int nb_bits,
- Node *nodes, HuffCmp cmp, int flags);
-
-int ff_huff_gen_len_table(uint8_t *dst, const uint64_t *stats, int n, int skip0);
-
-#endif /* AVCODEC_HUFFMAN_H */
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/jpeg2000dsp.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/jpeg2000dsp.c
deleted file mode 100644
index b1bff6d5b176b6272dd9997d0488e5be870afec0..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/jpeg2000dsp.c
+++ /dev/null
@@ -1,101 +0,0 @@
-/*
- * JPEG 2000 DSP functions
- * Copyright (c) 2007 Kamil Nowosad
- * Copyright (c) 2013 Nicolas Bertrand
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#include "config.h"
-#include "libavutil/attributes.h"
-#include "jpeg2000dsp.h"
-
-/* Inverse ICT parameters in float and integer.
- * int value = (float value) * (1<<16) */
-static const float f_ict_params[4] = {
- 1.402f,
- 0.34413f,
- 0.71414f,
- 1.772f
-};
-
-static const int i_ict_params[4] = {
- 91881,
- 22553,
- 46802,
- 116130
-};
-
-static void ict_float(void *_src0, void *_src1, void *_src2, int csize)
-{
- float *src0 = _src0, *src1 = _src1, *src2 = _src2;
- float i0f, i1f, i2f;
- int i;
-
- for (i = 0; i < csize; i++) {
- i0f = *src0 + (f_ict_params[0] * *src2);
- i1f = *src0 - (f_ict_params[1] * *src1)
- - (f_ict_params[2] * *src2);
- i2f = *src0 + (f_ict_params[3] * *src1);
- *src0++ = i0f;
- *src1++ = i1f;
- *src2++ = i2f;
- }
-}
-
-static void ict_int(void *_src0, void *_src1, void *_src2, int csize)
-{
- int32_t *src0 = _src0, *src1 = _src1, *src2 = _src2;
- int32_t i0, i1, i2;
- int i;
-
- for (i = 0; i < csize; i++) {
- i0 = *src0 + *src2 + ((int)((26345U * *src2) + (1 << 15)) >> 16);
- i1 = *src0 - ((int)(((unsigned)i_ict_params[1] * *src1) + (1 << 15)) >> 16)
- - ((int)(((unsigned)i_ict_params[2] * *src2) + (1 << 15)) >> 16);
- i2 = *src0 + (2 * *src1) + ((int)((-14942U * *src1) + (1 << 15)) >> 16);
- *src0++ = i0;
- *src1++ = i1;
- *src2++ = i2;
- }
-}
-
-static void rct_int(void *_src0, void *_src1, void *_src2, int csize)
-{
- uint32_t *src0 = _src0, *src1 = _src1, *src2 = _src2;
- int i;
-
- for (i = 0; i < csize; i++) {
- uint32_t i1 = *src0 - ((int32_t)(*src2 + *src1) >> 2);
- int32_t i0 = i1 + *src2;
- int32_t i2 = i1 + *src1;
- *src0++ = i0;
- *src1++ = i1;
- *src2++ = i2;
- }
-}
-
-av_cold void ff_jpeg2000dsp_init(Jpeg2000DSPContext *c)
-{
- c->mct_decode[FF_DWT97] = ict_float;
- c->mct_decode[FF_DWT53] = rct_int;
- c->mct_decode[FF_DWT97_INT] = ict_int;
-
-#if ARCH_X86
- ff_jpeg2000dsp_init_x86(c);
-#endif
-}
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Pride Font - A Tribute to Gilbert Baker and LGBTQ Activism.md b/spaces/congsaPfin/Manga-OCR/logs/Pride Font - A Tribute to Gilbert Baker and LGBTQ Activism.md
deleted file mode 100644
index 7653fb6bdf16a0d538cce23904ce1d794dab2fcb..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Pride Font - A Tribute to Gilbert Baker and LGBTQ Activism.md
+++ /dev/null
@@ -1,89 +0,0 @@
-
-How to Download and Use the Pride Font
-If you are looking for a colorful and creative font that celebrates diversity and inclusion, you might want to try the pride font. The pride font is a free font inspired by the design language of the iconic rainbow flag, which is a symbol of the LGBTQ+ community. In this article, we will show you what the pride font is, how to download it, and how to use it in different applications.
- What is the Pride Font?
-The pride font is a font that was created by NewFest and NYC Pride in partnership with Fontself, a company that makes tools for creating custom fonts. The font was named after Gilbert Baker, the creator of the rainbow flag, who passed away in 2017. The font is intended to honor his memory and his activism for LGBTQ+ rights.
-download pride font Download → https://urlca.com/2uOdpy
The History of the Pride Font
-Gilbert Baker was an artist and a gay rights activist who designed the rainbow flag in 1978. He was inspired by the hippie movement and the black civil rights movement, and he wanted to create a symbol that would represent the diversity and unity of the LGBTQ+ community. He chose eight colors for the flag, each with a different meaning: pink for sex, red for life, orange for healing, yellow for sunlight, green for nature, turquoise for magic, blue for serenity, and violet for spirit.
-The rainbow flag was first used in the San Francisco Gay Freedom Day Parade in 1978, and it soon became a popular symbol of LGBTQ+ pride around the world. Over time, some colors were removed or changed due to practical or political reasons, and the most common version of the flag today has six colors: red, orange, yellow, green, blue, and violet.
- The Features of the Pride Font
-The pride font is a font that mimics the look and feel of the rainbow flag. It has two versions: a standard vector font and a color font. The vector font is compatible with most applications and devices, and it allows you to change the color of each letter as you wish. The color font is more advanced and it uses OpenType-SVG technology to display multiple colors within each letter. However, it is only usable in some applications that support color fonts, such as Adobe Photoshop CC 2017 or later.
-The pride font also has an animated version that was created by Animography, a company that specializes in motion typography. The animated font is designed for use in video projects, social media posts, GIFs, and more. It is available as an Adobe After Effects file that you can customize with your own text and colors.
- How to Download the Pride Font
-If you want to use the pride font in your own projects, you can download it for free from typewithpride.com . Here are some steps on how to install it on your computer.
- Where to Find the Pride Font Online
-To download the pride font online, you can visit typewithpride.com and scroll down to the download section. You will see three options: Gilbert Color (the color font), Gilbert (the vector font), and Gilbert Animated (the animated font). You can choose one or more options depending on your needs and preferences.
-download gilbert font free
-Once you click on an option, you will be redirected to another page where you can enter your email address and agree to the terms of use. After that, you will receive an email with a link to download a zip file containing the font files.
- How to Install the Pride Font on Windows
-To install the pride font on Windows, you need to unzip the downloaded file and extract the font files. Then, you can follow these steps: - Right-click on the font file and select Install. - Alternatively, you can copy and paste the font file into the Fonts folder in your Control Panel. - You may need to restart your computer or application for the font to appear in your font list.
How to Install the Pride Font on Mac
-To install the pride font on Mac, you need to unzip the downloaded file and extract the font files. Then, you can follow these steps: - Double-click on the font file and click Install Font. - Alternatively, you can drag and drop the font file into the Font Book application in your Applications folder. - You may need to restart your computer or application for the font to appear in your font list.
How to Use the Pride Font in Different Applications
-Once you have installed the pride font on your computer, you can use it in various applications that support custom fonts. Here are some examples of how to use the pride font in Microsoft Word, Adobe Photoshop, and Google Docs.
- How to Use the Pride Font in Microsoft Word
-To use the pride font in Microsoft Word, you can follow these steps: - Open a new or existing document in Word. - Select the text that you want to apply the pride font to, or click where you want to insert new text. - Go to the Home tab and click on the Font drop-down menu. - Scroll down and select Gilbert or Gilbert Color from the list of fonts. You can also type the name of the font in the search box. - Adjust the font size, style, and color as you wish.
How to Use the Pride Font in Adobe Photoshop
-To use the pride font in Adobe Photoshop, you can follow these steps: - Open a new or existing image in Photoshop. - Select the Type tool from the toolbar or press T on your keyboard. - Click on the image where you want to add text, or select an existing text layer. - Go to the Options bar and click on the Font drop-down menu. - Scroll down and select Gilbert or Gilbert Color from the list of fonts. You can also type the name of the font in the search box. - Adjust the font size, style, and color as you wish.
How to Use the Pride Font in Google Docs
-To use the pride font in Google Docs, you can follow these steps: - Open a new or existing document in Google Docs. - Select the text that you want to apply the pride font to, or click where you want to insert new text. - Go to the toolbar and click on the Font drop-down menu. - Click on More fonts at the bottom of the menu. - In the pop-up window, type Gilbert or Gilbert Color in the search box and check the box next to it. - Click OK to add the font to your font list. - Adjust the font size, style, and color as you wish.
Conclusion
-The pride font is a fun and creative way to express yourself and show your support for LGBTQ+ rights. It is easy to download and use in various applications, and it comes in different versions for different purposes. Whether you want to create a poster, a logo, a flyer, or a social media post, you can use the pride font to make your text stand out and convey a message of love and acceptance. We hope this article has helped you learn how to download and use the pride font in your projects. If you have any questions or comments, feel free to leave them below.
- FAQs
-Here are some frequently asked questions about the pride font and their answers.
- Is the Pride Font Free?
-Yes, the pride font is free to download and use for personal and commercial purposes. However, you must not modify, sell, or redistribute the font without permission from the creators. You must also give credit to the creators and link back to typewithpride.com when using the font online.
- What is the Difference Between Gilbert and Gilbert Color?
-Gilbert and Gilbert Color are two versions of the pride font. Gilbert is a standard vector font that can be used in most applications and devices. It allows you to change the color of each letter as you wish. Gilbert Color is a color font that uses OpenType-SVG technology to display multiple colors within each letter. It is more advanced and realistic, but it is only compatible with some applications that support color fonts, such as Adobe Photoshop CC 2017 or later.
- How Can I Use the Animated Pride Font?
-The animated pride font is a version of the pride font that was created by Animography for use in video projects, social media posts, GIFs, and more. It is available as an Adobe After Effects file that you can customize with your own text and colors. To use the animated pride font, you need to have Adobe After Effects installed on your computer and follow the instructions provided by Animography on their website: animography.net/products/gilbert .
- Can I Use the Pride Font in Other Languages?
-The pride font currently supports only the Latin alphabet, which covers most languages that use the Roman script, such as English, Spanish, French, German, Italian, Portuguese, and more. However, the creators of the font are working on adding more languages and scripts in the future, such as Cyrillic, Arabic, Hebrew, and more. You can follow their updates on their website: typewithpride.com .
- Where Can I Find More Fonts Like the Pride Font?
-If you like the pride font and want to explore more fonts that are colorful, creative, and diverse, you can check out some of these websites that offer free or paid fonts for different purposes: - fontself.com : This is the website of Fontself, the company that made the tools for creating the pride font. You can find more fonts made by Fontself or other users on their website, or you can create your own fonts using their tools. - colorfonts.wtf : This is a website that showcases color fonts from various designers and foundries. You can browse through different categories and styles of color fonts and download them for your projects. - fonts.google.com : This is a website that offers hundreds of free fonts from Google Fonts. You can filter by different criteria such as language, category, popularity, and more. You can also preview and customize the fonts before downloading them.
401be4b1e0Roblox APK APKPure: What You Need to Know
-If you are looking for a fun and creative way to spend your free time, you might want to check out Roblox, a popular online game platform that lets you create, share, and play games with millions of other players. But what if you want to play Roblox on your Android device and you don't have access to the Google Play Store? Don't worry, there is a solution for that. You can download Roblox APK from APKPure, a third-party app store that offers free and safe downloads of Android apps and games. In this article, we will tell you everything you need to know about Roblox APK APKPure, including its features, installation guide, pros and cons, and alternatives.
-roblox apk apkpure DOWNLOAD ✦✦✦ https://urlca.com/2uO7aa
Roblox Game Features
-Roblox is not just a game, it's a virtual universe that you can explore and shape according to your imagination. Here are some of the features that make Roblox stand out from other games:
-Create and play games of various genres
-Roblox allows you to create your own games using its easy-to-use tools and scripting language. You can choose from a variety of genres, such as adventure, role-playing, racing, simulation, horror, and more. You can also play games created by other users and discover new worlds every day. There are millions of games to choose from, so you will never get bored.
-Customize your avatar and chat with friends
-Roblox lets you express your unique style by customizing your avatar with hundreds of items, such as hats, shirts, faces, gear, and more. You can also chat with your friends and join groups to socialize with other players. You can even create your own private servers to play with your friends without any interruptions.
-Cross-platform support and VR compatibility
-Roblox supports cross-platform play, meaning you can join your friends and millions of other players on their computers, mobile devices, Xbox One, or VR headsets. You can also experience Roblox in virtual reality using compatible devices, such as Oculus Rift, HTC Vive, or Windows Mixed Reality. Roblox offers a immersive and realistic experience that will make you feel like you are in the game.
- Roblox APK Installation Guide
-If you want to play Roblox on your Android device but you don't have access to the Google Play Store, you can download Roblox APK from APKPure. Here are the steps you need to follow:
-roblox apk download apkpure
-How to download Roblox APK from APKPure
-
-Go to APKPure website using your browser.
-Search for "Roblox" in the search bar or browse the categories.
-Select the "Roblox" app from the results and click on the "Download APK" button.
-Wait for the download to finish and locate the file in your device's storage.
-
-How to install Roblox APK on your Android device
-
-Before installing Roblox APK, you need to enable the installation of apps from unknown sources on your device. To do this, go to your device's settings, then security, and then toggle on the option that says "Unknown sources" or "Allow from this source".
-Once you have enabled the option, go to your device's file manager and find the Roblox APK file that you downloaded from APKPure.
-Tap on the file and follow the instructions on the screen to install Roblox APK on your device.
-After the installation is complete, you can launch Roblox from your app drawer and enjoy playing it.
-
-How to update Roblox APK using APKPure
-If you want to keep your Roblox APK updated with the latest features and bug fixes, you can use APKPure to check for updates and download them. Here are the steps you need to follow:
-
-Open the APKPure app on your device. If you don't have it, you can download it from APKPure website .
-Go to the "Me" tab and tap on the "Update" button.
-Scroll down and look for the "Roblox" app. If there is an update available, you will see a green "Update" button next to it.
-Tap on the "Update" button and wait for the download to finish.
-Tap on the downloaded file and follow the instructions on the screen to install the update.
-After the update is installed, you can launch Roblox and enjoy the new features.
-
- Roblox APK Pros and Cons
-Roblox APK has many advantages and disadvantages that you should consider before downloading it. Here are some of them:
-Pros of Roblox APK
-
-You can play Roblox on your Android device without using the Google Play Store.
-You can access Roblox games that are not available in your region or country.
-You can get faster updates and bug fixes than the official version.
-You can save storage space by downloading only the games that you want to play.
-
-Cons of Roblox APK
-
-You may encounter compatibility issues or errors with some devices or games.
-You may expose your device to security risks or malware by downloading apps from unknown sources.
-You may violate Roblox's terms of service or policies by using an unofficial version.
-You may not be able to access some features or services that are exclusive to the official version.
-
- Roblox APK Alternatives
-If you are looking for other games that are similar to Roblox, you can try these alternatives:
-Minetest
-Minetest is an open-source sandbox game that lets you create and explore voxel worlds. You can build anything you want using blocks, craft items, mine resources, and fight enemies. You can also join multiplayer servers and play with other players. Minetest is free and available for Windows, Linux, Mac, Android, and iOS devices. You can download it from Minetest website .
- Garry's Mod
-Garry's Mod is a physics sandbox game that lets you manipulate objects and create your own games. You can use various tools, props, models, and addons to create anything you can imagine. You can also play games created by other users, such as Trouble in Terrorist Town, Prop Hunt, Sandbox, and more. Garry's Mod is not free and available for Windows, Linux, and Mac devices. You can buy it from Steam website .
- World to Build
-World to Build is an online game platform that lets you create, share, and play games with other players. You can use its easy-to-use tools and scripting language to make games of various genres, such as adventure, role-playing, racing, simulation, horror, and more. You can also customize your avatar, chat with friends, join groups, and earn coins. World to Build is free and available for Windows devices. You can download it from World to Build website .
- Conclusion
-In conclusion, Roblox APK APK Pure is a great way to enjoy Roblox on your Android device without using the Google Play Store. It offers many features, such as creating and playing games of various genres, customizing your avatar and chatting with friends, and supporting cross-platform play and VR compatibility. However, it also has some drawbacks, such as compatibility issues, security risks, policy violations, and limited access to some features. Therefore, you should weigh the pros and cons before downloading Roblox APK from APKPure. You can also try some alternatives, such as Minetest, Garry's Mod, and World to Build, if you are looking for other games that are similar to Roblox. We hope this article has helped you learn more about Roblox APK APKPure and how to use it.
- FAQs
-Is Roblox APK safe to download from APKPure?
-APKPure claims to scan all the apps and games on its website for viruses and malware before uploading them. However, there is no guarantee that the apps and games are 100% safe or original. Therefore, you should always be careful when downloading apps and games from unknown sources and check the reviews and ratings before installing them.
-What are the minimum requirements for Roblox APK?
-The minimum requirements for Roblox APK are as follows:
-
-Android version: 4.4 or higher
-RAM: 1 GB or more
-Storage: 100 MB or more
-Internet connection: Wi-Fi or cellular data
-
-How can I contact Roblox support if I have any issues with the game?
-If you have any issues with the game, such as bugs, glitches, errors, or account problems, you can contact Roblox support by filling out a form on their website. You can also check their help pages for FAQs and troubleshooting tips.
-How can I enable parental control on Roblox?
-Roblox offers a parental control feature that allows parents to monitor and restrict their children's activity on the game. To enable parental control, you need to create a parent account and link it to your child's account. Then, you can access the settings and choose the options that suit your preferences. You can also use third-party apps or tools to block or limit your child's access to Roblox.
-How can I make money from Roblox?
-If you are a game developer or a content creator on Roblox, you can make money from your creations by using the Robux currency. Robux is the virtual currency that is used to buy items and services on Roblox. You can earn Robux by selling your games, items, passes, or memberships to other users. You can also exchange your Robux for real money using the Developer Exchange program.
401be4b1e0Watch the movie Aur Pyaar Ho Gaya on the free film streaming website www.onlinemovieshindi.com (new web URL: ). Online streaming or downloading the video file easily. Watch or download Aur Pyaar Ho Gaya online movie Hindi dubbed here.
-Aur Pyaar Ho Gaya Movie Free Download Torrent Download Zip ✵✵✵ https://ssurll.com/2uzxd0
Dear visitor, you can download the movie Aur Pyaar Ho Gaya on this onlinemovieshindi website. It will download the HD video file by just clicking on the button below. The video file is the same file for the online streaming above when you directly click to play. The decision to download is entirely your choice and your personal responsibility when dealing with the legality of file ownership
-The same as other websites such as hdmovieslatest, filmypunjab, moviemora, fridaybug and etc. You can watch the free online movie Hindi dubbed here. HD movies latest to see without a proxy unblocker app.
aaccfb2cb3My static Space
-
-
Welcome to your static Space!
-
You can modify this app directly by editing index.html in the Files and versions tab.
-
- Also don't forget to check the
- Spaces documentation .
-
-
"
-
- def __str__(self):
- return f"{self._wrapped.__class__.__name__}: {self._wrapped}"
-
-
-class UndefinedTypeCheck(Exception):
- """
- A type checker was asked to check a type it did not have registered.
- """
-
- def __init__(self, type):
- self.type = type
-
- def __str__(self):
- return f"Type {self.type!r} is unknown to this type checker"
-
-
-class UnknownType(Exception):
- """
- A validator was asked to validate an instance against an unknown type.
- """
-
- def __init__(self, type, instance, schema):
- self.type = type
- self.instance = instance
- self.schema = schema
-
- def __str__(self):
- prefix = 16 * " "
-
- return dedent(
- f"""\
- Unknown type {self.type!r} for validator with schema:
- {indent(pformat(self.schema, width=72), prefix).lstrip()}
-
- While checking instance:
- {indent(pformat(self.instance, width=72), prefix).lstrip()}
- """.rstrip(),
- )
-
-
-class FormatError(Exception):
- """
- Validating a format failed.
- """
-
- def __init__(self, message, cause=None):
- super().__init__(message, cause)
- self.message = message
- self.cause = self.__cause__ = cause
-
- def __str__(self):
- return self.message
-
-
-class ErrorTree:
- """
- ErrorTrees make it easier to check which validations failed.
- """
-
- _instance = _unset
-
- def __init__(self, errors=()):
- self.errors = {}
- self._contents = defaultdict(self.__class__)
-
- for error in errors:
- container = self
- for element in error.path:
- container = container[element]
- container.errors[error.validator] = error
-
- container._instance = error.instance
-
- def __contains__(self, index):
- """
- Check whether ``instance[index]`` has any errors.
- """
- return index in self._contents
-
- def __getitem__(self, index):
- """
- Retrieve the child tree one level down at the given ``index``.
-
- If the index is not in the instance that this tree corresponds
- to and is not known by this tree, whatever error would be raised
- by ``instance.__getitem__`` will be propagated (usually this is
- some subclass of `LookupError`.
- """
- if self._instance is not _unset and index not in self:
- self._instance[index]
- return self._contents[index]
-
- def __setitem__(self, index, value):
- """
- Add an error to the tree at the given ``index``.
- """
- self._contents[index] = value
-
- def __iter__(self):
- """
- Iterate (non-recursively) over the indices in the instance with errors.
- """
- return iter(self._contents)
-
- def __len__(self):
- """
- Return the `total_errors`.
- """
- return self.total_errors
-
- def __repr__(self):
- total = len(self)
- errors = "error" if total == 1 else "errors"
- return f"<{self.__class__.__name__} ({total} total {errors})>"
-
- @property
- def total_errors(self):
- """
- The total number of errors in the entire tree, including children.
- """
- child_errors = sum(len(tree) for _, tree in self._contents.items())
- return len(self.errors) + child_errors
-
-
-def by_relevance(weak=WEAK_MATCHES, strong=STRONG_MATCHES):
- """
- Create a key function that can be used to sort errors by relevance.
-
- Arguments:
- weak (set):
- a collection of validation keywords to consider to be
- "weak". If there are two errors at the same level of the
- instance and one is in the set of weak validation keywords,
- the other error will take priority. By default, :kw:`anyOf`
- and :kw:`oneOf` are considered weak keywords and will be
- superseded by other same-level validation errors.
-
- strong (set):
- a collection of validation keywords to consider to be
- "strong"
- """
-
- def relevance(error):
- validator = error.validator
- return (
- -len(error.path),
- validator not in weak,
- validator in strong,
- not error._matches_type(),
- )
-
- return relevance
-
-
-relevance = by_relevance()
-"""
-A key function (e.g. to use with `sorted`) which sorts errors by relevance.
-
-Example:
-
-.. code:: python
-
- sorted(validator.iter_errors(12), key=jsonschema.exceptions.relevance)
-"""
-
-
-def best_match(errors, key=relevance):
- """
- Try to find an error that appears to be the best match among given errors.
-
- In general, errors that are higher up in the instance (i.e. for which
- `ValidationError.path` is shorter) are considered better matches,
- since they indicate "more" is wrong with the instance.
-
- If the resulting match is either :kw:`oneOf` or :kw:`anyOf`, the
- *opposite* assumption is made -- i.e. the deepest error is picked,
- since these keywords only need to match once, and any other errors
- may not be relevant.
-
- Arguments:
- errors (collections.abc.Iterable):
-
- the errors to select from. Do not provide a mixture of
- errors from different validation attempts (i.e. from
- different instances or schemas), since it won't produce
- sensical output.
-
- key (collections.abc.Callable):
-
- the key to use when sorting errors. See `relevance` and
- transitively `by_relevance` for more details (the default is
- to sort with the defaults of that function). Changing the
- default is only useful if you want to change the function
- that rates errors but still want the error context descent
- done by this function.
-
- Returns:
- the best matching error, or ``None`` if the iterable was empty
-
- .. note::
-
- This function is a heuristic. Its return value may change for a given
- set of inputs from version to version if better heuristics are added.
- """
- errors = iter(errors)
- best = next(errors, None)
- if best is None:
- return
- best = max(itertools.chain([best], errors), key=key)
-
- while best.context:
- # Calculate the minimum via nsmallest, because we don't recurse if
- # all nested errors have the same relevance (i.e. if min == max == all)
- smallest = heapq.nsmallest(2, best.context, key=key)
- if len(smallest) == 2 and key(smallest[0]) == key(smallest[1]):
- return best
- best = smallest[0]
- return best
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/markdown_it/rules_inline/html_inline.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/markdown_it/rules_inline/html_inline.py
deleted file mode 100644
index 9065e1d034da76270f7d3f1ba528132c8d57d341..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/markdown_it/rules_inline/html_inline.py
+++ /dev/null
@@ -1,43 +0,0 @@
-# Process html tags
-from ..common.html_re import HTML_TAG_RE
-from ..common.utils import isLinkClose, isLinkOpen
-from .state_inline import StateInline
-
-
-def isLetter(ch: int) -> bool:
- lc = ch | 0x20 # to lower case
- # /* a */ and /* z */
- return (lc >= 0x61) and (lc <= 0x7A)
-
-
-def html_inline(state: StateInline, silent: bool) -> bool:
- pos = state.pos
-
- if not state.md.options.get("html", None):
- return False
-
- # Check start
- maximum = state.posMax
- if state.src[pos] != "<" or pos + 2 >= maximum:
- return False
-
- # Quick fail on second char
- ch = state.src[pos + 1]
- if ch not in ("!", "?", "/") and not isLetter(ord(ch)): # /* / */
- return False
-
- match = HTML_TAG_RE.search(state.src[pos:])
- if not match:
- return False
-
- if not silent:
- token = state.push("html_inline", "", 0)
- token.content = state.src[pos : pos + len(match.group(0))]
-
- if isLinkOpen(token.content):
- state.linkLevel += 1
- if isLinkClose(token.content):
- state.linkLevel -= 1
-
- state.pos += len(match.group(0))
- return True
diff --git a/spaces/dfalbel/gptneox-chat/Dockerfile b/spaces/dfalbel/gptneox-chat/Dockerfile
deleted file mode 100644
index 78cedcdec25827f3d3323996d29cd23741529d98..0000000000000000000000000000000000000000
--- a/spaces/dfalbel/gptneox-chat/Dockerfile
+++ /dev/null
@@ -1,18 +0,0 @@
-ARG RUNTIME=cpu
-FROM ghcr.io/mlverse/torch:${RUNTIME}-main-release-focal
-
-COPY DESCRIPTION DESCRIPTION
-RUN apt-get update -y && \
- apt-get install -y pkg-config && \
- Rscript -e "pak::pak(lib=.Library)"
-
-# This is to make sure we don't run into permission problems in HF Spaces
-# see: https://huggingface.co/docs/hub/spaces-sdks-docker#permissions
-RUN useradd -m -u 1000 user
-USER user
-ENV HOME=/home/user PATH=/home/user/.local/bin:$PATH
-WORKDIR $HOME
-
-COPY --chown=user . .
-
-CMD ["R", "--quiet", "-e", "shiny::runApp(host='0.0.0.0', port=7860)"]
diff --git a/spaces/diacanFperku/AutoGPT/Lottso Deluxe ((NEW)) Full Version Torrent.md b/spaces/diacanFperku/AutoGPT/Lottso Deluxe ((NEW)) Full Version Torrent.md
deleted file mode 100644
index 2f5c65440a1fdf0663fe6a7ccbe93d72387d7a3c..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Lottso Deluxe ((NEW)) Full Version Torrent.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-when you've finished playing lottso!, you can save your scratch cards to your lottso! account and review your game history anytime on your computer. you can also replay the games that you enjoyed the most. lottso! comes with a free lottso! 7-day trial. after the 7-day trial, you can get a lottso! deluxe 7-day free trial. if you like lottso!, you can purchase a full version of lottso! for $14.99.
-Lottso Deluxe Full Version Torrent Download Zip ✓ https://gohhs.com/2uFTIV
lottso! is a highly addictive and fun game. whether you're looking to scratch off your tickets or just want a quick game of lottso! with friends, lottso! is perfect for you. lottso! is easy to use, but it requires an extensive amount of skill. to win, you must figure out the patterns in lottso! cards and quickly match the numbers. lottso! will ask you to take a chance and play again if you get a number wrong. each time you play lottso!, you earn more scratch cards and bonus games.
-evar 1, evar 37, evar 37 candydoll, evar 1.. evar 37 candydoll, evar 1 evar 37 candydoll.epub, evar 1.5, evar 37. posted by berenice mante on december 09, 2018. evar 37: candydoll evar1 evar 37: [candydoll] evar evar 37: early type iiib endoleak in. evar 37 candydoll.epub rab ne bana di jodi hindi movie 3gp downloadgolkes zed plus full movie download 720p. tags: cm 0102 3.9.68. install serial key evar 37 candydoll outkast, speakerboxxx: love below (cd 2) full album zip. photo frame maker, photo slides (photo frame),. adobe illustrator cc 2018 v23.0.1 incl patch crack serial key keygen evar 37 candydoll.epub city car driving v1.2 kariyer fix indir bosch esi. the bible from memory or from someone else's words, please do not ever. [35][36][37][38][39][40][41][42][43][44][45][46][47] and in the synthesis of. b23e98e901 supprimer les doublons 2013 crack
899543212bNative Instruments Guitar Rig 5 Pro v5.2.2 UNLOCKED - R2R download DOWNLOAD ❤ https://gohhs.com/2uFUI9
diff --git a/spaces/diacanFperku/AutoGPT/Puberty Sexual Education For Boys And Girls 1991 Fix.md b/spaces/diacanFperku/AutoGPT/Puberty Sexual Education For Boys And Girls 1991 Fix.md
deleted file mode 100644
index 4bfd5e27c8a5e664b771cc04fc2abac08a2aaee3..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Puberty Sexual Education For Boys And Girls 1991 Fix.md
+++ /dev/null
@@ -1,13 +0,0 @@
-Puberty Sexual Education For Boys And Girls 1991: A Review
-Puberty Sexual Education For Boys And Girls 1991 is a book written by Dr. Ruth Westheimer and illustrated by Marc Brown. It is intended to provide accurate and age-appropriate information about the physical and emotional changes that occur during puberty for both boys and girls. The book covers topics such as hormones, growth, body parts, hygiene, menstruation, masturbation, wet dreams, sexual feelings, relationships, and contraception. It also includes a glossary of terms and a list of resources for further reading.
-Puberty Sexual Education For Boys And Girls 1991 Download ⇒⇒⇒ https://gohhs.com/2uFUgJ
The book was published in 1991 by Little, Brown and Company. It received positive reviews from critics and educators who praised its frank and friendly tone, its colorful and humorous illustrations, and its comprehensive and inclusive approach to sexuality education. The book was also praised for addressing the needs and concerns of children from diverse backgrounds and cultures. Some parents and conservative groups, however, criticized the book for being too explicit and graphic, and for promoting sexual activity among young people. The book was banned or challenged in some schools and libraries across the United States.
-Puberty Sexual Education For Boys And Girls 1991 is still considered one of the best books on puberty and sexuality education for children. It has been translated into several languages and has sold over a million copies worldwide. It has also inspired other books and media on the same topic, such as The Care And Keeping Of You series by American Girl, What's Happening To Me? by Peter Mayle, and Big Mouth by Netflix. The book remains relevant and useful for today's children who face similar challenges and questions as they grow up.
-
-Dr. Ruth Westheimer is a renowned sex therapist and media personality who has written over 40 books on sexuality and relationships. She was born in Germany in 1928 and lost her parents in the Holocaust. She immigrated to Israel in 1945 and served as a sniper in the Israeli army. She later moved to France and then to the United States, where she earned her doctorate in education from Columbia University. She became famous for hosting a radio show called Sexually Speaking, where she answered callers' questions about sex in a candid and humorous way. She has also appeared on numerous television shows, documentaries, and movies.
-
-Marc Brown is a bestselling author and illustrator of children's books, most notably the Arthur series. He was born in Pennsylvania in 1946 and grew up in a large family. He studied art at the Cleveland Institute of Art and worked as a teacher before becoming a full-time writer and illustrator. He has created over 100 books for children, many of which have been adapted into television shows, movies, and games. He has won several awards for his work, including the Children's Choice Award and the Laura Ingalls Wilder Medal.
-Puberty Sexual Education For Boys And Girls 1991 is a collaboration between two experts in their fields who share a common goal of educating and empowering children about their bodies and sexuality. The book combines Dr. Ruth's expertise and experience as a sex therapist with Marc Brown's talent and creativity as an illustrator. The book is designed to be engaging and informative for children who are curious and confused about puberty and sexuality. The book also aims to foster positive self-esteem and respect for oneself and others among children who are going through this important stage of development.
d5da3c52bf(true);
-
- const contextValue = useCreateReducer({
- initialState,
- });
-
- const {
- state: {
- apiKey,
- lightMode,
- folders,
- conversations,
- selectedConversation,
- prompts,
- temperature,
- },
- dispatch,
- } = contextValue;
-
- const stopConversationRef = useRef(false);
-
- // FETCH MODELS ----------------------------------------------
-
- const handleSelectConversation = (conversation: Conversation) => {
- dispatch({
- field: 'selectedConversation',
- value: conversation,
- });
-
- saveConversation(conversation);
- };
-
- // FOLDER OPERATIONS --------------------------------------------
-
- const handleCreateFolder = (name: string, type: FolderType) => {
- const newFolder: FolderInterface = {
- id: uuidv4(),
- name,
- type,
- };
-
- const updatedFolders = [...folders, newFolder];
-
- dispatch({ field: 'folders', value: updatedFolders });
- saveFolders(updatedFolders);
- };
-
- const handleDeleteFolder = (folderId: string) => {
- const updatedFolders = folders.filter((f) => f.id !== folderId);
- dispatch({ field: 'folders', value: updatedFolders });
- saveFolders(updatedFolders);
-
- const updatedConversations: Conversation[] = conversations.map((c) => {
- if (c.folderId === folderId) {
- return {
- ...c,
- folderId: null,
- };
- }
-
- return c;
- });
-
- dispatch({ field: 'conversations', value: updatedConversations });
- saveConversations(updatedConversations);
-
- const updatedPrompts: Prompt[] = prompts.map((p) => {
- if (p.folderId === folderId) {
- return {
- ...p,
- folderId: null,
- };
- }
-
- return p;
- });
-
- dispatch({ field: 'prompts', value: updatedPrompts });
- savePrompts(updatedPrompts);
- };
-
- const handleUpdateFolder = (folderId: string, name: string) => {
- const updatedFolders = folders.map((f) => {
- if (f.id === folderId) {
- return {
- ...f,
- name,
- };
- }
-
- return f;
- });
-
- dispatch({ field: 'folders', value: updatedFolders });
-
- saveFolders(updatedFolders);
- };
-
- // CONVERSATION OPERATIONS --------------------------------------------
-
- const handleNewConversation = () => {
- const lastConversation = conversations[conversations.length - 1];
-
- const newConversation: Conversation = {
- id: uuidv4(),
- name: t('New Conversation'),
- messages: [],
- model: lastConversation?.model || {
- id: OpenAIModels[defaultModelId].id,
- name: OpenAIModels[defaultModelId].name,
- maxLength: OpenAIModels[defaultModelId].maxLength,
- tokenLimit: OpenAIModels[defaultModelId].tokenLimit,
- },
- prompt: DEFAULT_SYSTEM_PROMPT,
- temperature: lastConversation?.temperature ?? DEFAULT_TEMPERATURE,
- folderId: null,
- };
-
- const updatedConversations = [...conversations, newConversation];
-
- dispatch({ field: 'selectedConversation', value: newConversation });
- dispatch({ field: 'conversations', value: updatedConversations });
-
- saveConversation(newConversation);
- saveConversations(updatedConversations);
-
- dispatch({ field: 'loading', value: false });
- };
-
- const handleUpdateConversation = (
- conversation: Conversation,
- data: KeyValuePair,
- ) => {
- const updatedConversation = {
- ...conversation,
- [data.key]: data.value,
- };
-
- const { single, all } = updateConversation(
- updatedConversation,
- conversations,
- );
-
- dispatch({ field: 'selectedConversation', value: single });
- dispatch({ field: 'conversations', value: all });
- };
-
- // EFFECTS --------------------------------------------
-
- useEffect(() => {
- if (window.innerWidth < 640) {
- dispatch({ field: 'showChatbar', value: false });
- }
- }, [selectedConversation]);
-
- useEffect(() => {
- defaultModelId &&
- dispatch({ field: 'defaultModelId', value: defaultModelId });
- serverSideApiKeyIsSet &&
- dispatch({
- field: 'serverSideApiKeyIsSet',
- value: serverSideApiKeyIsSet,
- });
- serverSidePluginKeysSet &&
- dispatch({
- field: 'serverSidePluginKeysSet',
- value: serverSidePluginKeysSet,
- });
- }, [defaultModelId, serverSideApiKeyIsSet, serverSidePluginKeysSet]);
-
- // ON LOAD --------------------------------------------
-
- useEffect(() => {
- const settings = getSettings();
- if (settings?.theme) {
- dispatch({
- field: 'lightMode',
- value: settings.theme,
- });
- }
-
- const apiKey = "test";
-
- if (serverSideApiKeyIsSet) {
- dispatch({ field: 'apiKey', value: '' });
-
- localStorage.removeItem('apiKey');
- } else if (apiKey) {
- dispatch({ field: 'apiKey', value: apiKey });
- }
-
- const pluginKeys = localStorage.getItem('pluginKeys');
- if (serverSidePluginKeysSet) {
- dispatch({ field: 'pluginKeys', value: [] });
- localStorage.removeItem('pluginKeys');
- } else if (pluginKeys) {
- dispatch({ field: 'pluginKeys', value: pluginKeys });
- }
-
- if (window.innerWidth < 640) {
- dispatch({ field: 'showChatbar', value: false });
- dispatch({ field: 'showPromptbar', value: false });
- }
-
- const showChatbar = localStorage.getItem('showChatbar');
- if (showChatbar) {
- dispatch({ field: 'showChatbar', value: showChatbar === 'true' });
- }
-
- const showPromptbar = localStorage.getItem('showPromptbar');
- if (showPromptbar) {
- dispatch({ field: 'showPromptbar', value: showPromptbar === 'true' });
- }
-
- const folders = localStorage.getItem('folders');
- if (folders) {
- dispatch({ field: 'folders', value: JSON.parse(folders) });
- }
-
- const prompts = localStorage.getItem('prompts');
- if (prompts) {
- dispatch({ field: 'prompts', value: JSON.parse(prompts) });
- }
-
- const conversationHistory = localStorage.getItem('conversationHistory');
- if (conversationHistory) {
- const parsedConversationHistory: Conversation[] =
- JSON.parse(conversationHistory);
- const cleanedConversationHistory = cleanConversationHistory(
- parsedConversationHistory,
- );
-
- dispatch({ field: 'conversations', value: cleanedConversationHistory });
- }
-
- const selectedConversation = localStorage.getItem('selectedConversation');
- if (selectedConversation) {
- const parsedSelectedConversation: Conversation =
- JSON.parse(selectedConversation);
- const cleanedSelectedConversation = cleanSelectedConversation(
- parsedSelectedConversation,
- );
-
- dispatch({
- field: 'selectedConversation',
- value: cleanedSelectedConversation,
- });
- } else {
- const lastConversation = conversations[conversations.length - 1];
- dispatch({
- field: 'selectedConversation',
- value: {
- id: uuidv4(),
- name: t('New Conversation'),
- messages: [],
- model: OpenAIModels[defaultModelId],
- prompt: DEFAULT_SYSTEM_PROMPT,
- temperature: lastConversation?.temperature ?? DEFAULT_TEMPERATURE,
- folderId: null,
- },
- });
- }
- }, [
- defaultModelId,
- dispatch,
- serverSideApiKeyIsSet,
- serverSidePluginKeysSet,
- ]);
-
- return (
-
-
- Minimal Chatbot UI
-
-
-
-
- );
-};
-export default Home;
-
-export const getServerSideProps: GetServerSideProps = async ({ locale }) => {
- const defaultModelId =
- (process.env.DEFAULT_MODEL &&
- Object.values(OpenAIModelID).includes(
- process.env.DEFAULT_MODEL as OpenAIModelID,
- ) &&
- process.env.DEFAULT_MODEL) ||
- fallbackModelID;
-
- let serverSidePluginKeysSet = false;
-
- const googleApiKey = process.env.GOOGLE_API_KEY;
- const googleCSEId = process.env.GOOGLE_CSE_ID;
-
- if (googleApiKey && googleCSEId) {
- serverSidePluginKeysSet = true;
- }
-
- return {
- props: {
- serverSideApiKeyIsSet: !!process.env.OPENAI_API_KEY,
- defaultModelId,
- serverSidePluginKeysSet,
- ...(await serverSideTranslations(locale ?? 'en', [
- 'common',
- 'chat',
- 'sidebar',
- 'markdown',
- 'promptbar',
- 'settings',
- ])),
- },
- };
-};
diff --git a/spaces/dongyi/MMFS/configs/style_based_pix2pixII_config.py b/spaces/dongyi/MMFS/configs/style_based_pix2pixII_config.py
deleted file mode 100644
index ab9f51b8dbb13b23f71b0c87c6ddd10d076466e5..0000000000000000000000000000000000000000
--- a/spaces/dongyi/MMFS/configs/style_based_pix2pixII_config.py
+++ /dev/null
@@ -1,42 +0,0 @@
-from .base_config import BaseConfig
-from typing import Union as Union
-
-class StyleBasedPix2PixIIConfig(BaseConfig):
-
- def __init__(self):
- super(StyleBasedPix2PixIIConfig, self).__init__()
-
- is_greater_than_0 = lambda x: x > 0
-
- # model config
- self._add_option('model', 'ngf', int, 64, check_func=is_greater_than_0)
- self._add_option('model', 'min_feats_size', list, [4, 4])
-
- # dataset config
- self._add_option('dataset', 'data_type', list, ['unpaired'])
- self._add_option('dataset', 'direction', str, 'AtoB')
- self._add_option('dataset', 'serial_batches', bool, False)
- self._add_option('dataset', 'load_size', int, 512, check_func=is_greater_than_0)
- self._add_option('dataset', 'crop_size', int, 512, check_func=is_greater_than_0)
- self._add_option('dataset', 'preprocess', Union[list, str], ['resize'])
- self._add_option('dataset', 'no_flip', bool, True)
-
- # training config
- self._add_option('training', 'beta1', float, 0.1, check_func=is_greater_than_0)
- self._add_option('training', 'data_aug_prob', float, 0.0, check_func=lambda x: x >= 0.0)
- self._add_option('training', 'style_mixing_prob', float, 0.0, check_func=lambda x: x >= 0.0)
- self._add_option('training', 'phase', int, 1, check_func=lambda x: x in [1, 2, 3, 4])
- self._add_option('training', 'pretrained_model', str, 'model.pth')
- self._add_option('training', 'src_text_prompt', str, 'photo')
- self._add_option('training', 'text_prompt', str, 'a portrait in style of sketch')
- self._add_option('training', 'image_prompt', str, 'style.png')
- self._add_option('training', 'lambda_L1', float, 1.0)
- self._add_option('training', 'lambda_Feat', float, 4.0)
- self._add_option('training', 'lambda_ST', float, 1.0)
- self._add_option('training', 'lambda_GAN', float, 1.0)
- self._add_option('training', 'lambda_CLIP', float, 1.0)
- self._add_option('training', 'lambda_PROJ', float, 1.0)
- self._add_option('training', 'ema', float, 0.999)
-
- # testing config
- self._add_option('testing', 'aspect_ratio', float, 1.0, check_func=is_greater_than_0)
diff --git a/spaces/dorkai/text-generation-webui-main/extensions/multimodal/pipeline_loader.py b/spaces/dorkai/text-generation-webui-main/extensions/multimodal/pipeline_loader.py
deleted file mode 100644
index 3ebdb1044b7e924ce3633120967be517474dd4d4..0000000000000000000000000000000000000000
--- a/spaces/dorkai/text-generation-webui-main/extensions/multimodal/pipeline_loader.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import logging
-import traceback
-from importlib import import_module
-from pathlib import Path
-from typing import Tuple
-
-from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
-from modules import shared
-
-
-def _get_available_pipeline_modules():
- pipeline_path = Path(__file__).parent / 'pipelines'
- modules = [p for p in pipeline_path.iterdir() if p.is_dir()]
- return [m.name for m in modules if (m / 'pipelines.py').exists()]
-
-
-def load_pipeline(params: dict) -> Tuple[AbstractMultimodalPipeline, str]:
- pipeline_modules = {}
- available_pipeline_modules = _get_available_pipeline_modules()
- for name in available_pipeline_modules:
- try:
- pipeline_modules[name] = import_module(f'extensions.multimodal.pipelines.{name}.pipelines')
- except:
- logging.warning(f'Failed to get multimodal pipelines from {name}')
- logging.warning(traceback.format_exc())
-
- if shared.args.multimodal_pipeline is not None:
- for k in pipeline_modules:
- if hasattr(pipeline_modules[k], 'get_pipeline'):
- pipeline = getattr(pipeline_modules[k], 'get_pipeline')(shared.args.multimodal_pipeline, params)
- if pipeline is not None:
- return (pipeline, k)
- else:
- model_name = shared.args.model.lower()
- for k in pipeline_modules:
- if hasattr(pipeline_modules[k], 'get_pipeline_from_model_name'):
- pipeline = getattr(pipeline_modules[k], 'get_pipeline_from_model_name')(model_name, params)
- if pipeline is not None:
- return (pipeline, k)
-
- available = []
- for k in pipeline_modules:
- if hasattr(pipeline_modules[k], 'available_pipelines'):
- pipelines = getattr(pipeline_modules[k], 'available_pipelines')
- available += pipelines
-
- if shared.args.multimodal_pipeline is not None:
- log = f'Multimodal - ERROR: Failed to load multimodal pipeline "{shared.args.multimodal_pipeline}", available pipelines are: {available}.'
- else:
- log = f'Multimodal - ERROR: Failed to determine multimodal pipeline for model {shared.args.model}, please select one manually using --multimodal-pipeline [PIPELINE]. Available pipelines are: {available}.'
- logging.critical(f'{log} Please specify a correct pipeline, or disable the extension')
- raise RuntimeError(f'{log} Please specify a correct pipeline, or disable the extension')
diff --git a/spaces/eIysia/VITS-Umamusume-voice-synthesizer/transforms.py b/spaces/eIysia/VITS-Umamusume-voice-synthesizer/transforms.py
deleted file mode 100644
index 4793d67ca5a5630e0ffe0f9fb29445c949e64dae..0000000000000000000000000000000000000000
--- a/spaces/eIysia/VITS-Umamusume-voice-synthesizer/transforms.py
+++ /dev/null
@@ -1,193 +0,0 @@
-import torch
-from torch.nn import functional as F
-
-import numpy as np
-
-
-DEFAULT_MIN_BIN_WIDTH = 1e-3
-DEFAULT_MIN_BIN_HEIGHT = 1e-3
-DEFAULT_MIN_DERIVATIVE = 1e-3
-
-
-def piecewise_rational_quadratic_transform(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails=None,
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
-
- if tails is None:
- spline_fn = rational_quadratic_spline
- spline_kwargs = {}
- else:
- spline_fn = unconstrained_rational_quadratic_spline
- spline_kwargs = {
- 'tails': tails,
- 'tail_bound': tail_bound
- }
-
- outputs, logabsdet = spline_fn(
- inputs=inputs,
- unnormalized_widths=unnormalized_widths,
- unnormalized_heights=unnormalized_heights,
- unnormalized_derivatives=unnormalized_derivatives,
- inverse=inverse,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative,
- **spline_kwargs
- )
- return outputs, logabsdet
-
-
-def searchsorted(bin_locations, inputs, eps=1e-6):
- bin_locations[..., -1] += eps
- return torch.sum(
- inputs[..., None] >= bin_locations,
- dim=-1
- ) - 1
-
-
-def unconstrained_rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails='linear',
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
- outside_interval_mask = ~inside_interval_mask
-
- outputs = torch.zeros_like(inputs)
- logabsdet = torch.zeros_like(inputs)
-
- if tails == 'linear':
- unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
- constant = np.log(np.exp(1 - min_derivative) - 1)
- unnormalized_derivatives[..., 0] = constant
- unnormalized_derivatives[..., -1] = constant
-
- outputs[outside_interval_mask] = inputs[outside_interval_mask]
- logabsdet[outside_interval_mask] = 0
- else:
- raise RuntimeError('{} tails are not implemented.'.format(tails))
-
- outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline(
- inputs=inputs[inside_interval_mask],
- unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
- unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
- unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
- inverse=inverse,
- left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative
- )
-
- return outputs, logabsdet
-
-def rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- left=0., right=1., bottom=0., top=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- if torch.min(inputs) < left or torch.max(inputs) > right:
- raise ValueError('Input to a transform is not within its domain')
-
- num_bins = unnormalized_widths.shape[-1]
-
- if min_bin_width * num_bins > 1.0:
- raise ValueError('Minimal bin width too large for the number of bins')
- if min_bin_height * num_bins > 1.0:
- raise ValueError('Minimal bin height too large for the number of bins')
-
- widths = F.softmax(unnormalized_widths, dim=-1)
- widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
- cumwidths = torch.cumsum(widths, dim=-1)
- cumwidths = F.pad(cumwidths, pad=(1, 0), mode='constant', value=0.0)
- cumwidths = (right - left) * cumwidths + left
- cumwidths[..., 0] = left
- cumwidths[..., -1] = right
- widths = cumwidths[..., 1:] - cumwidths[..., :-1]
-
- derivatives = min_derivative + F.softplus(unnormalized_derivatives)
-
- heights = F.softmax(unnormalized_heights, dim=-1)
- heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
- cumheights = torch.cumsum(heights, dim=-1)
- cumheights = F.pad(cumheights, pad=(1, 0), mode='constant', value=0.0)
- cumheights = (top - bottom) * cumheights + bottom
- cumheights[..., 0] = bottom
- cumheights[..., -1] = top
- heights = cumheights[..., 1:] - cumheights[..., :-1]
-
- if inverse:
- bin_idx = searchsorted(cumheights, inputs)[..., None]
- else:
- bin_idx = searchsorted(cumwidths, inputs)[..., None]
-
- input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
- input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
-
- input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
- delta = heights / widths
- input_delta = delta.gather(-1, bin_idx)[..., 0]
-
- input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
- input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
-
- input_heights = heights.gather(-1, bin_idx)[..., 0]
-
- if inverse:
- a = (((inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta)
- + input_heights * (input_delta - input_derivatives)))
- b = (input_heights * input_derivatives
- - (inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta))
- c = - input_delta * (inputs - input_cumheights)
-
- discriminant = b.pow(2) - 4 * a * c
- assert (discriminant >= 0).all()
-
- root = (2 * c) / (-b - torch.sqrt(discriminant))
- outputs = root * input_bin_widths + input_cumwidths
-
- theta_one_minus_theta = root * (1 - root)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * root.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - root).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, -logabsdet
- else:
- theta = (inputs - input_cumwidths) / input_bin_widths
- theta_one_minus_theta = theta * (1 - theta)
-
- numerator = input_heights * (input_delta * theta.pow(2)
- + input_derivatives * theta_one_minus_theta)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- outputs = input_cumheights + numerator / denominator
-
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * theta.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - theta).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, logabsdet
diff --git a/spaces/erinak/test1/README.md b/spaces/erinak/test1/README.md
deleted file mode 100644
index 7fdddbfbe419831816dece34250665add30196fe..0000000000000000000000000000000000000000
--- a/spaces/erinak/test1/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Test1
-emoji: 👁
-colorFrom: indigo
-colorTo: purple
-sdk: gradio
-sdk_version: 3.19.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/facebook/MusicGen/audiocraft/quantization/vq.py b/spaces/facebook/MusicGen/audiocraft/quantization/vq.py
deleted file mode 100644
index aa57bea59db95ddae35e0657f723ca3a29ee943b..0000000000000000000000000000000000000000
--- a/spaces/facebook/MusicGen/audiocraft/quantization/vq.py
+++ /dev/null
@@ -1,115 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import math
-import typing as tp
-
-import torch
-
-from .base import BaseQuantizer, QuantizedResult
-from .core_vq import ResidualVectorQuantization
-
-
-class ResidualVectorQuantizer(BaseQuantizer):
- """Residual Vector Quantizer.
-
- Args:
- dimension (int): Dimension of the codebooks.
- n_q (int): Number of residual vector quantizers used.
- q_dropout (bool): Random quantizer drop out at train time.
- bins (int): Codebook size.
- decay (float): Decay for exponential moving average over the codebooks.
- kmeans_init (bool): Whether to use kmeans to initialize the codebooks.
- kmeans_iters (int): Number of iterations used for kmeans initialization.
- threshold_ema_dead_code (int): Threshold for dead code expiration. Replace any codes
- that have an exponential moving average cluster size less than the specified threshold with
- randomly selected vector from the current batch.
- orthogonal_reg_weight (float): Orthogonal regularization weights.
- orthogonal_reg_active_codes_only (bool): Apply orthogonal regularization only on active codes.
- orthogonal_reg_max_codes (optional int): Maximum number of codes to consider.
- for orthogonal regularization.
- """
- def __init__(
- self,
- dimension: int = 256,
- n_q: int = 8,
- q_dropout: bool = False,
- bins: int = 1024,
- decay: float = 0.99,
- kmeans_init: bool = True,
- kmeans_iters: int = 10,
- threshold_ema_dead_code: int = 2,
- orthogonal_reg_weight: float = 0.0,
- orthogonal_reg_active_codes_only: bool = False,
- orthogonal_reg_max_codes: tp.Optional[int] = None,
- ):
- super().__init__()
- self.max_n_q = n_q
- self.n_q = n_q
- self.q_dropout = q_dropout
- self.dimension = dimension
- self.bins = bins
- self.decay = decay
- self.kmeans_init = kmeans_init
- self.kmeans_iters = kmeans_iters
- self.threshold_ema_dead_code = threshold_ema_dead_code
- self.orthogonal_reg_weight = orthogonal_reg_weight
- self.orthogonal_reg_active_codes_only = orthogonal_reg_active_codes_only
- self.orthogonal_reg_max_codes = orthogonal_reg_max_codes
- self.vq = ResidualVectorQuantization(
- dim=self.dimension,
- codebook_size=self.bins,
- num_quantizers=self.n_q,
- decay=self.decay,
- kmeans_init=self.kmeans_init,
- kmeans_iters=self.kmeans_iters,
- threshold_ema_dead_code=self.threshold_ema_dead_code,
- orthogonal_reg_weight=self.orthogonal_reg_weight,
- orthogonal_reg_active_codes_only=self.orthogonal_reg_active_codes_only,
- orthogonal_reg_max_codes=self.orthogonal_reg_max_codes,
- channels_last=False
- )
-
- def forward(self, x: torch.Tensor, frame_rate: int):
- n_q = self.n_q
- if self.training and self.q_dropout:
- n_q = int(torch.randint(1, self.n_q + 1, (1,)).item())
- bw_per_q = math.log2(self.bins) * frame_rate / 1000
- quantized, codes, commit_loss = self.vq(x, n_q=n_q)
- codes = codes.transpose(0, 1)
- # codes is [B, K, T], with T frames, K nb of codebooks.
- bw = torch.tensor(n_q * bw_per_q).to(x)
- return QuantizedResult(quantized, codes, bw, penalty=torch.mean(commit_loss))
-
- def encode(self, x: torch.Tensor) -> torch.Tensor:
- """Encode a given input tensor with the specified frame rate at the given bandwidth.
- The RVQ encode method sets the appropriate number of quantizer to use
- and returns indices for each quantizer.
- """
- n_q = self.n_q
- codes = self.vq.encode(x, n_q=n_q)
- codes = codes.transpose(0, 1)
- # codes is [B, K, T], with T frames, K nb of codebooks.
- return codes
-
- def decode(self, codes: torch.Tensor) -> torch.Tensor:
- """Decode the given codes to the quantized representation."""
- # codes is [B, K, T], with T frames, K nb of codebooks, vq.decode expects [K, B, T].
- codes = codes.transpose(0, 1)
- quantized = self.vq.decode(codes)
- return quantized
-
- @property
- def total_codebooks(self):
- return self.max_n_q
-
- @property
- def num_codebooks(self):
- return self.n_q
-
- def set_num_codebooks(self, n: int):
- assert n > 0 and n <= self.max_n_q
- self.n_q = n
diff --git a/spaces/fadhilsadeli/deploy-hck2/app.py b/spaces/fadhilsadeli/deploy-hck2/app.py
deleted file mode 100644
index 6570c60e8772bd147df9c1b89dac9198bd808053..0000000000000000000000000000000000000000
--- a/spaces/fadhilsadeli/deploy-hck2/app.py
+++ /dev/null
@@ -1,60 +0,0 @@
-import streamlit as st
-import pandas as pd
-import joblib
-
-st.header('FTDS Model Deployment')
-st.write("""
-Created by FTDS Curriculum Team
-
-Use the to select input features.
-""")
-
-@st.cache
-
-def fetch_data():
- df = pd.read_csv('https://raw.githubusercontent.com/ardhiraka/PFDS_sources/master/campus.csv')
- return df
-
-df = fetch_data()
-
-st.write(df)
-
-st.subheader('User Input Features')
-
-gender = st.selectbox('Gender', df['gender'].unique())
-ssc = st.number_input('Secondary School Points', value=67.00)
-hsc = st.number_input('High School Points', 0.0, value=91.0)
-hsc_s = st.selectbox('High School Spec', df['hsc_s'].unique())
-degree_p = st.number_input('Degree Points', 0.0, value=58.0)
-degree_t = st.selectbox('Degree Spec', df['degree_t'].unique())
-workex = st.selectbox('Work Experience?', df['workex'].unique())
-etest_p = st.number_input('Etest Points', 0.0, value=78.00)
-spec = st.selectbox('Specialization', df['specialisation'].unique())
-mba_p = st.number_input('MBA Points', 0.0, value=54.55)
-
-data = {
- 'gender': gender,
- 'ssc_p': ssc,
- 'hsc_p': hsc,
- 'hsc_s': hsc_s,
- 'degree_p': degree_p,
- 'degree_t': degree_t,
- 'workex': workex,
- 'etest_p': etest_p,
- 'specialisation':spec,
- 'mba_p': mba_p
-}
-input = pd.DataFrame(data, index=[0])
-
-st.subheader('User Input')
-st.write(input)
-
-load_model = joblib.load("my_model.pkl")
-
-if st.button("Predict"):
- prediction = load_model.predict(input)
-
- prediction = 'Placed' if prediction==1 else 'Not Placed'
-
- st.write('Based on user input, the placement model predicted: ')
- st.write(prediction)
\ No newline at end of file
diff --git a/spaces/fakezeta/pdfchat/README.md b/spaces/fakezeta/pdfchat/README.md
deleted file mode 100644
index 0be4a4a11aa062669719c0805b0ec622138eecc1..0000000000000000000000000000000000000000
--- a/spaces/fakezeta/pdfchat/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Pdfchat
-emoji: 🏢
-colorFrom: pink
-colorTo: pink
-sdk: streamlit
-sdk_version: 1.19.0
-app_file: app.py
-pinned: false
-license: gpl-3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/falterWliame/Face_Mask_Detection/Quraniclanguagemadeeasypdfdownload.md b/spaces/falterWliame/Face_Mask_Detection/Quraniclanguagemadeeasypdfdownload.md
deleted file mode 100644
index 895c304480efa03670133f4d165903ca7313039c..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Quraniclanguagemadeeasypdfdownload.md
+++ /dev/null
@@ -1,67 +0,0 @@
-How to Download Qur'anic Language Made Easy PDF for Free
-If you want to learn the basics of Qur'anic language and grammar, you might be interested in downloading Qur'anic Language Made Easy PDF for free. This is a book that teaches you the essential rules and concepts that you need to understand the Holy Qur'an. In this article, we will explain what Qur'anic Language Made Easy PDF is, what it offers, and how you can download it for free.
-
-What is Qur'anic Language Made Easy PDF?
-Qur'anic Language Made Easy PDF is a book that was written by Hafiza Iffath Hasan, a renowned teacher and scholar of Arabic and Islamic studies. The book was published in 2002 and has been revised and updated several times since then. The book aims to help students of Qur'anic language and grammar to learn the basic skills and knowledge that they need to comprehend the Holy Qur'an.
-quraniclanguagemadeeasypdfdownload DOWNLOAD · https://urlca.com/2uDcdm
The book consists of four units that cover different topics and aspects of Qur'anic language and grammar, such as nouns, verbs, pronouns, prepositions, conjunctions, particles, sentence structure, word derivation, etc. Each unit has several lessons that explain the rules and concepts in a simple and clear way, with examples from the Qur'an and exercises for practice. The book also has a glossary of terms and a list of references at the end.
-
-What are the benefits of Qur'anic Language Made Easy PDF?
-Qur'anic Language Made Easy PDF offers many benefits for students of Qur'anic language and grammar. Here are some of them:
-
-It simplifies the learning process by presenting the rules and concepts in a logical and systematic way.
-It enhances the understanding by providing examples from the Qur'an that illustrate the rules and concepts.
-It facilitates the application by offering exercises that test the students' comprehension and retention.
-It saves time and money by eliminating the need for physical books and shipping costs.
-It provides convenience and flexibility by allowing students to access the book anytime and anywhere on their devices.
-
-
-How can you download Qur'anic Language Made Easy PDF for free?
-If you want to download Qur'anic Language Made Easy PDF for free, you have several options to choose from. You can find it on some websites that offer free downloads of books and documents, such as Archive.org or Scribd.com. You can also find it on some online platforms that share audio books and excerpts, such as SoundCloud.com or YouTube.com. Alternatively, you can scan or photocopy the book from some libraries or bookstores that have it in their collections.
-
-To download Qur'anic Language Made Easy PDF for free, you need to have a device that can open PDF files, such as a computer or a smartphone. You also need to have an internet connection to access the websites or platforms that offer the download. Moreover, you need to have enough storage space on your device to save the file.
-
-Conclusion
-Qur'anic Language Made Easy PDF is a book that teaches you the basics of Qur'anic language and grammar. It is a useful and helpful resource for students who want to understand the Holy Qur'an better. You can download Qur'anic Language Made Easy PDF for free from various websites or platforms that offer free downloads of books and documents. However, you need to have the necessary requirements and permissions to download it. If you want to learn more about Qur'anic Language Made Easy PDF, you can visit the official website of Hafiza Iffath Hasan or contact her for more information.
-
-What are the challenges of learning Qur'anic language and grammar?
-Learning Qur'anic language and grammar can be challenging for many students, especially those who are not native speakers of Arabic or those who have little or no background in Arabic studies. Here are some of the challenges that students may face:
-
-The Qur'anic language is different from the modern standard Arabic that is used today. It has some words, expressions, and structures that are not common or familiar to modern Arabic speakers or learners.
-The Qur'anic grammar is complex and intricate. It has many rules and exceptions that govern the morphology, syntax, and semantics of the language. It also has some features that are unique to the Qur'anic style, such as ellipsis, inversion, repetition, etc.
-The Qur'anic text is not vocalized or punctuated. It does not have any diacritical marks or symbols that indicate the vowels, consonants, pauses, or stops in the words and sentences. This makes it difficult to read and pronounce the text correctly.
-The Qur'anic text is not translated or explained. It does not have any footnotes or annotations that provide the meanings, interpretations, or contexts of the words and verses. This makes it hard to understand and appreciate the message and wisdom of the text.
-
-
-How can you overcome the challenges of learning Qur'anic language and grammar?
-Learning Qur'anic language and grammar can be challenging, but it is not impossible. There are some ways that you can overcome the challenges and make your learning process easier and more enjoyable. Here are some tips:
-
-Use a reliable and comprehensive source of learning. You need to have a source that covers all the aspects and levels of Qur'anic language and grammar, from the basics to the advanced. You also need to have a source that provides clear and simple explanations, examples, exercises, tests, and feedback.
-Use a suitable and convenient method of learning. You need to have a method that suits your learning style and preference, whether it is visual, auditory, kinesthetic, etc. You also need to have a method that fits your schedule and budget, whether it is online, offline, self-paced, instructor-led, etc.
-Use a consistent and regular practice of learning. You need to have a practice that reinforces your learning and helps you retain what you have learned. You also need to have a practice that challenges your learning and helps you improve your skills and knowledge.
-Use a supportive and motivating environment of learning. You need to have an environment that encourages your learning and helps you overcome your difficulties. You also need to have an environment that inspires your learning and helps you achieve your goals.
-
-What are the testimonials of Qur'anic Language Made Easy PDF?
-Qur'anic Language Made Easy PDF has received many testimonials from students and teachers who have used it. Here are some of them:
-"Qur'anic Language Made Easy PDF is a wonderful book that helped me learn the basics of Qur'anic language and grammar. It is easy to follow and understand, and it has many examples and exercises that make the learning fun and effective. I highly recommend it to anyone who wants to understand the Qur'an better." - Student from Pakistan
-"Qur'anic Language Made Easy PDF is a great book that helped me teach the basics of Qur'anic language and grammar to my students. It is clear and concise, and it has many features and tools that make the teaching interactive and engaging. I appreciate the author's efforts and dedication to this book." - Teacher from Egypt
-"Qur'anic Language Made Easy PDF is an amazing book that helped me improve my skills and knowledge of Qur'anic language and grammar. It is comprehensive and thorough, and it has many resources and tests that make the learning challenging and rewarding. I thank the author for this valuable book." - Student from Malaysia
-
-How can you support Qur'anic Language Made Easy PDF?
-If you like Qur'anic Language Made Easy PDF and want to support it, you can do so in different ways. Here are some suggestions:
-
-You can share it with your friends and family who are interested in learning Qur'anic language and grammar.
-You can leave a positive review or feedback on the websites or platforms where you downloaded it.
-You can donate to the author or the publisher to help them continue their work and produce more books.
-You can buy the physical book or other related products from the author or the publisher.
-
-Conclusion
-Qur'anic Language Made Easy PDF is a book that teaches you the basics of Qur'anic language and grammar. It is a useful and helpful resource for students who want to understand the Holy Qur'an better. You can download Qur'anic Language Made Easy PDF for free from various websites or platforms that offer free downloads of books and documents. However, you need to have the necessary requirements and permissions to download it. You can also choose from other alternatives that suit your preferences and needs. However, to improve your skills and knowledge, you need to use the book regularly and practice your skills outside the book as well. If you want to learn more about Qur'anic Language Made Easy PDF, you can visit the official website of Hafiza Iffath Hasan or contact her for more information. If you like Qur'anic Language Made Easy PDF and want to support it, you can share it, review it, donate to it, or buy it. We hope that this article has helped you learn more about Qur'anic Language Made Easy PDF and how you can download it for free.
-Conclusion
-Qur'anic Language Made Easy PDF is a book that teaches you the basics of Qur'anic language and grammar. It is a useful and helpful resource for students who want to understand the Holy Qur'an better. You can download Qur'anic Language Made Easy PDF for free from various websites or platforms that offer free downloads of books and documents. However, you need to have the necessary requirements and permissions to download it. You can also choose from other alternatives that suit your preferences and needs. However, to improve your skills and knowledge, you need to use the book regularly and practice your skills outside the book as well. If you want to learn more about Qur'anic Language Made Easy PDF, you can visit the official website of Hafiza Iffath Hasan or contact her for more information. If you like Qur'anic Language Made Easy PDF and want to support it, you can share it, review it, donate to it, or buy it. We hope that this article has helped you learn more about Qur'anic Language Made Easy PDF and how you can download it for free.
-
-Thank you for your interest and cooperation. ? 3cee63e6c2Where to Download Clash Mini
-Clash Mini is a brand new mobile game launched by Supercell, the same developers behind popular titles such as Clash Royale and Clash of Clans. Clash Mini takes characters from the ‘Clash Universe’ which are used to create a unique deck to battle against other players in in a board-game-like set up. If you are a fan of the Clash games or you are looking for a fun and strategic board game, you might be wondering where to download Clash Mini and how to play it. In this article, we will answer all your questions and give you some tips and tricks to help you master the game.
-where to download clash mini DOWNLOAD >>> https://urllie.com/2uNwPZ
What is Clash Mini?
-A fun and strategic board game
-Clash Mini is a game of choices, where you have to duel and rumble with other players in a fun, strategy-packed board game. You have to collect, summon and upgrade your army of Minis, which are adorable versions of the iconic Clash characters. You have to predict your opponent’s moves and then assemble your winning strategy and formation. Watch your Minis come to life and clash to be the last one standing!
-A new member of the Clash family
-Clash Mini is one of the three new games in the Clash of Clans universe unveiled by Supercell in April 2021, alongside Clash Quest and Clash Heroes. The developer said that they wanted to offer a new Clash experience to current players and broaden Clash to new audiences who haven’t experienced Clash before. Clash Mini is designed to be easy to learn but challenging to master, making it suitable for casual and hardcore gamers alike.
- Which platforms can play Clash Mini?
-Mobile exclusive game
-Like all the previous Clash titles, Clash Mini is exclusive to mobile devices. You won’t be able to play it on any non-mobile platforms such as PC or console. However, you can use an emulator to play it on your computer if you really want to, but this might affect the performance and compatibility of the game.
-Available for iOS and Android devices
-Clash Mini is available for both iOS and Android devices. You can download it from the App Store or Google Play Store depending on your device. However, the game is not yet globally released, so you might not be able to find it in your region. The game is currently in beta testing phase, which means that it is only available in certain countries for a limited number of players.
-How to download clash mini on android
- When is the Clash Mini release date?
-Beta version launched in November 2021
-The beta version of Clash Mini was launched on November 8, 2021 for players in Finland, Sweden, Norway, Denmark, Iceland, Canada, Singapore, Chile, Hong Kong, Sri Lanka and The Philippines. The beta version allows players to test the game before its official release and provide feedback to the developer. The beta version also helps the developer to fix any bugs or issues that might occur in the game.
-Global release date not confirmed yet
-The global release date of Clash Mini has not been confirmed yet by Supercell. The developer has not announced when they plan to launch the game worldwide or which countries will be added next to the beta version. However, based on the previous Clash games, we can expect that the game will be released globally sometime in 2023. Until then, you can follow the official Clash Mini social media accounts and website to get the latest news and updates about the game.
- How to download Clash Mini beta?
-Sign up on the official website
-If you want to play Clash Mini beta, you have to sign up on the official website. You have to enter your email address and choose your preferred platform (iOS or Android). You will also have to agree to the terms and conditions and privacy policy of the game. After you sign up, you will receive a confirmation email with a link to download the game.
-Download from the App Store or Google Play Store
-After you receive the confirmation email, you can download Clash Mini beta from the App Store or Google Play Store. You have to search for Clash Mini in the store and tap on the download button. You might have to enter your Apple ID or Google account credentials to verify your identity. Once the download is complete, you can open the game and start playing.
- How to play Clash Mini?
-Collect, summon and upgrade your Minis
-The core gameplay of Clash Mini is to collect, summon and upgrade your Minis. Minis are cute and powerful versions of the Clash characters that you can use to fight against other players. There are different types of Minis, such as tanks, damage dealers, healers, support and more. Each Mini has its own stats, abilities and synergies with other Minis. You can collect Minis by opening chests or buying them from the shop. You can summon Minis by placing them on the board before each battle. You can upgrade Minis by spending gold and cards to increase their level and power.
-Predict, position and clash with your opponent
-The other aspect of Clash Mini is to predict, position and clash with your opponent. Each battle consists of three rounds, where you have to place your Minis on a 4x4 grid board. You have to predict what your opponent will do and try to counter their strategy. You have to position your Minis wisely on the board, taking into account their range, movement, direction and abilities. You have to clash with your opponent by watching your Minis fight automatically based on their stats and skills. The player who wins two out of three rounds wins the battle.
- Tips and tricks for Clash Mini
-Choose the right characters for your army
-One of the most important tips for Clash Mini is to choose the right characters for your army. You have to consider the strengths and weaknesses of each Mini and how they work together as a team. You have to balance your army with different roles, such as tanks, damage dealers, healers and support. You have to adapt your army according to the game mode, the map and the opponent you are facing. You have to experiment with different combinations of Minis and find out what works best for you.
-Position your Minis wisely on the battlefield
-Another crucial tip for Clash Mini is to position your Minis wisely on the battlefield. You have to think strategically about where you place your Minis on the board before each round. You have to consider factors such as range, movement, direction and abilities of your Minis and how they interact with each other and with the enemy Minis. You have to avoid placing your Minis in vulnerable spots where they can be easily attacked or countered by the opponent. You have to use the terrain features such as walls, bridges and obstacles to your advantage.
-Utilize special abilities and upgrades during battle
-The final tip for Clash Mini is to utilize special abilities and upgrades during battle. Each Mini has a unique ability that can be activated once per round by tapping on it. These abilities can be offensive, defensive or supportive in nature and can change the outcome of a battle if used at the right time. You also have access to upgrades that can boost your Minis’ stats or skills during a battle. These upgrades are randomly generated from a pool of options and can be applied by dragging them onto a Mini. You have to use these abilities and upgrades wisely and strategically to gain an edge over your opponent.
- Conclusion
-Clash Mini is a fun and strategic board game that features adorable versions of the Clash characters in a fast-paced duel against other players. The game is currently in beta testing phase and is only available in certain countries for iOS and Android devices. The global release date of the game is not confirmed yet but is expected sometime in 2023. If you want to play Clash Mini beta , you have to sign up on the official website and download it from the App Store or Google Play Store. To play Clash Mini, you have to collect, summon and upgrade your Minis, predict, position and clash with your opponent, and utilize special abilities and upgrades during battle. We hope this article has helped you learn more about Clash Mini and how to download and play it. If you have any questions, you can check out the FAQs below or visit the official Clash Mini website for more information.
- FAQs
-
-Q: How much does Clash Mini cost?
-A: Clash Mini is free to download and play, but it offers in-app purchases for some items and features.
-Q: How can I contact Supercell for feedback or support?
-A: You can contact Supercell through the in-game settings menu or by visiting their website or social media accounts.
-Q: How can I join a clan or create my own clan in Clash Mini?
-A: You can join a clan or create your own clan by tapping on the clan icon on the main screen. You can invite your friends or other players to join your clan or search for an existing clan to join.
-Q: How can I earn rewards and chests in Clash Mini?
-A: You can earn rewards and chests by winning battles, completing quests, participating in events, ranking up in leagues, and opening the free chest every four hours.
-Q: How can I watch replays or share my battles in Clash Mini?
-A: You can watch replays or share your battles by tapping on the battle log icon on the main screen. You can also watch live battles of other players or top players by tapping on the TV icon on the main screen.
- 401be4b1e0Wind Hero Mod APK: Unlimited Energy and Money
- Do you love action games with superheroes, magic, guns, cars, and open-world environments? If yes, then you should try Wind Hero , a game developed by Naxeex Action & RPG Games. In this game, you can express your magical powers and become a real superhero or behave like a regular mad rider. You can also earn cash and gems by completing quests and unlocking achievements, as well as spend money in the store to buy different guns, cars, and clothes. However, if you want to enjoy the game without any limitations, you should download Wind Hero Mod APK , which gives you unlimited energy and money, as well as removes ads and in-app purchases. In this article, we will tell you more about Wind Hero, why you should download Wind Hero Mod APK, how to download and install it, and some tips and tricks for playing the game. We will also give you a brief review of the game based on its pros and cons, user ratings, and feedback.
-wind hero mod apk unlimited energy and money DOWNLOAD ❤❤❤ https://urllie.com/2uNBNx
What is Wind Hero?
- Wind Hero is an action game that lets you play as a superhero who can control the wind. You can use your wind powers to lift objects in the air, send your enemies flying, or create tornadoes. You can also use various weapons to shoot your enemies, such as pistols, rifles, shotguns, rocket launchers, etc. The game features an open-world city that you can explore freely. You can drive different vehicles, such as cars, bikes, helicopters, etc. You can also customize your character with different clothes and accessories. The game has a lot of quests and achievements that you can complete to earn cash and gems. You can use these resources to buy more weapons, vehicles, and clothes in the store.
- Features of Wind Hero
- Action-packed gameplay
- The gameplay of Wind Hero is very exciting and fun. You can use your wind powers to create chaos in the city or fight against gangs and criminals. You can also use various weapons to shoot your enemies or cause explosions. The game has a lot of action scenes that will keep you entertained.
- Magical powers and weapons
- One of the main features of Wind Hero is that you can use your wind powers to manipulate objects and enemies. You can tap a button to lift objects in the air or swipe to create tornadoes. You can also use your wind powers to fly or glide in the air. The game also has a lot of weapons that you can use to shoot your enemies or destroy things. You can choose from pistols, rifles, shotguns, rocket launchers, etc.
- Open-world city and vehicles
- The game also features an open-world city that you can explore freely. The city is big and pretty, with different areas and buildings. You can drive different vehicles in the city, such as cars, bikes, helicopters, etc. You can also find secrets and hidden items in the city.
- Why download Wind Hero Mod APK?
- While Wind Hero is a great game to play, it also has some limitations that may affect your gaming experience. For example, you need energy to use your wind powers or weapons. Energy is limited and regenerates slowly over time.
You also need money to buy weapons, vehicles, and clothes in the store. Money is earned by completing quests and achievements, but it is not enough to buy everything you want. Moreover, the game has ads and in-app purchases that may annoy you or tempt you to spend real money. That is why you should download Wind Hero Mod APK , which gives you the following benefits:
-wind hero mod apk free download
- Unlimited energy and money
- With Wind Hero Mod APK, you will never run out of energy or money. You can use your wind powers and weapons as much as you want without worrying about the energy bar. You can also buy anything you want in the store without worrying about the price. You can enjoy the game without any restrictions or limitations.
- No ads and in-app purchases
- Another benefit of Wind Hero Mod APK is that it removes ads and in-app purchases from the game. You will not see any annoying ads popping up on your screen or interrupting your gameplay. You will also not see any offers or prompts to buy gems or other items with real money. You can play the game without any distractions or temptations.
- Easy installation and compatibility
- Wind Hero Mod APK is also very easy to download and install on your device. You do not need to root your device or use any other tools to install it. You just need to follow some simple steps that we will explain later in this article. Wind Hero Mod APK is also compatible with most Android devices and versions. You do not need to worry about compatibility issues or errors.
- How to download and install Wind Hero Mod APK?
- If you are interested in downloading and installing Wind Hero Mod APK, you can follow these steps:
- Step 1: Enable unknown sources
- The first step is to enable unknown sources on your device. This will allow you to install apps from sources other than the Google Play Store. To do this, go to your device settings, then security, then unknown sources, and turn it on.
- Step 2: Download the APK file
- The next step is to download the APK file of Wind Hero Mod APK from a reliable source. You can use the link below to download it directly to your device. The file size is about 100 MB, so make sure you have enough space and a stable internet connection.
- Download Wind Hero Mod APK here
- Step 3: Install the APK file
- Once you have downloaded the APK file, you can install it by tapping on it. You may see a warning message asking for your permission to install the app. Just tap on install and wait for the process to finish.
- Step 4: Enjoy the game
- After the installation is done, you can launch the game from your app drawer or home screen. You can now enjoy Wind Hero with unlimited energy and money, no ads and in-app purchases, and easy installation and compatibility.
Tips and tricks for playing Wind Hero
- Wind Hero is a game that requires some skills and strategies to play well. Here are some tips and tricks that can help you improve your gameplay and have more fun:
- Use your wind powers wisely
- Your wind powers are your main advantage in the game, but they also have some drawbacks. For example, using your wind powers consumes energy, which is limited and regenerates slowly. Also, using your wind powers may attract the attention of the police or other enemies, who will try to stop you or shoot you. Therefore, you should use your wind powers wisely and only when necessary. For example, you can use your wind powers to escape from danger, to reach high places, to defeat multiple enemies at once, or to create diversions. You should also avoid using your wind powers near civilians or friendly characters, as you may hurt them or make them angry.
- Upgrade your guns, cars and clothes
- Another way to improve your gameplay is to upgrade your guns, cars and clothes. You can buy different guns, cars and clothes in the store using money or gems. Each gun, car and clothes has different stats and abilities that can affect your performance in the game. For example, some guns have more damage, accuracy, range, or ammo than others. Some cars have more speed, durability, or handling than others. Some clothes have more armor, style, or bonuses than others. You should upgrade your guns, cars and clothes according to your preferences and needs. For example, you can buy a powerful gun if you want to deal more damage to your enemies, a fast car if you want to escape from the police or explore the city faster, or a stylish clothes if you want to impress the ladies or look cool.
- Complete quests and achievements
- One of the best ways to earn money and gems in the game is to complete quests and achievements. Quests are missions that you can accept from different characters or locations in the game. They usually involve doing some tasks or objectives, such as killing enemies, stealing cars, delivering packages, etc. Achievements are goals that you can achieve by playing the game normally, such as killing a certain number of enemies, driving a certain distance, using a certain power, etc. Completing quests and achievements will reward you with money and gems, as well as unlock new items or features in the game. You should try to complete as many quests and achievements as possible to maximize your income and progress in the game.
- Explore the city and find secrets
- The last tip we have for you is to explore the city and find secrets. The city in Wind Hero is big and beautiful, with different areas and buildings. You can explore the city freely and discover new places and things. You can also find secrets and hidden items in the city, such as easter eggs, references, jokes, collectibles, etc. Finding secrets and hidden items will not only give you some fun and surprises but also reward you with money or gems. You should try to explore every corner of the city and find all the secrets and hidden items that you can.
Wind Hero game review
- Now that you know more about Wind Hero and how to download and play it, you may be wondering what other people think about the game. Is it worth playing? What are its strengths and weaknesses? How does it compare to other similar games? To answer these questions, we will give you a brief review of the game based on its pros and cons, user ratings, and feedback.
- Pros and cons of Wind Hero
- Like any other game, Wind Hero has its pros and cons. Here are some of them:
- Pros
-
-The game has amazing graphics and sound effects that create a realistic and immersive atmosphere.
-The game has a lot of content and variety that keep the gameplay fresh and interesting. You can use different powers, weapons, vehicles, and clothes, as well as complete different quests and achievements.
-The game has a simple and intuitive control system that makes it easy to play. You can use buttons, swipes, or tilts to control your character and actions.
-The game has a fun and humorous tone that makes it enjoyable and entertaining. You can do crazy things in the game, such as creating tornadoes, flying in the air, or shooting rockets.
-
- Cons
-
-The game has some bugs and glitches that may affect your gaming experience. For example, you may encounter some crashes, freezes, or errors in the game.
-The game has some ads and in-app purchases that may annoy you or tempt you to spend real money. For example, you may see ads before or after playing the game, or you may see offers to buy gems or other items with real money.
-The game has some repetitive and boring aspects that may make you lose interest. For example, you may find some quests or achievements too easy or too hard, or you may find some areas or items too similar or too different.
-The game has some unrealistic and illogical aspects that may make you question its logic. For example, you may wonder how your character can control the wind, or how your enemies can survive your attacks.
-
- User ratings and feedback
- Another way to evaluate the game is to look at its user ratings and feedback. You can find these on the Google Play Store or other platforms where the game is available. Here are some examples of user ratings and feedback for Wind Hero:
-
-
-User
-Rating
-Feedback
-
-
-Alex
-5 stars
-This game is awesome! I love the graphics, the gameplay, the powers, everything! It's like GTA with superpowers! I recommend this game to anyone who likes action games!
-
-
-Bella
-4 stars
-This game is good but it has some problems. Sometimes it crashes or freezes on my device. Also, there are too many ads and in-app purchases. I wish they would fix these issues.
-
-
-Chris
-3 stars
-This game is okay but it gets boring after a while. The quests are too easy or too hard, the city is too big or too small, the powers are too weak or too strong. I wish they would add more content and variety.
-
-
-Dana
-2 stars
-This game is bad but it has some potential. The graphics are nice but the sound is annoying. The gameplay is fun but the controls are hard. The powers are cool but the logic is weird. I wish they would improve this game.
-
-
-Evan
-1 star
-This game is terrible! I hate the graphics, the gameplay, the powers, everything! It's like a cheap copy of GTA with superpowers! I don't recommend this game to anyone who likes action games!
-
-
- As you can see, user ratings and feedback vary from positive to negative, depending on their personal preferences and experiences. The average rating of Wind Hero on the Google Play Store is 4.1 out of 5 stars, which means that most users like the game but also have some complaints or suggestions.
- Final verdict
- To sum up, Wind Hero is a game that offers a lot of action, fun, and entertainment for fans of superhero games. You can use your wind powers to create chaos in the city or fight against gangs and criminals. You can also use various weapons to shoot your enemies or cause explosions. The game features an open-world city that you can explore freely. You can drive different vehicles, such as cars, bikes, helicopters, etc. You can also customize your character with different clothes and accessories. The game has a lot of quests and achievements that you can complete to earn cash and gems. You can use these resources to buy more weapons, vehicles, and clothes in the store. However, the game also has some limitations that may affect your gaming experience. For example, you need energy to use your wind powers or weapons. Energy is limited and regenerates slowly over time. You also need money to buy weapons, vehicles, and clothes in the store. Money is earned by completing quests and achievements, but it is not enough to buy everything you want. Moreover, the game has ads and in-app purchases that may annoy you or tempt you to spend real money. That is why you should download Wind Hero Mod APK, which gives you unlimited energy and money, as well as removes ads and in-app purchases. Wind Hero Mod APK is also easy to download and install on your device, and compatible with most Android devices and versions.
- Our final verdict is that Wind Hero is a game that is worth playing if you like action games with superheroes, magic, guns, cars, and open-world environments. However, we also recommend that you download Wind Hero Mod APK to enjoy the game without any limitations or distractions.
- FAQs
- Here are some frequently asked questions about Wind Hero and Wind Hero Mod APK:
- Q: Is Wind Hero free to play?
- A: Yes, Wind Hero is free to play on the Google Play Store and other platforms where it is available. However, the game also has ads and in-app purchases that may affect your gaming experience.
- Q: Is Wind Hero Mod APK safe to use?
- A: Yes, Wind Hero Mod APK is safe to use as long as you download it from a reliable source. We have tested the APK file on our devices and found no viruses or malware. However, you should always be careful when downloading and installing apps from unknown sources.
- Q: How can I update Wind Hero Mod APK?
- A: To update Wind Hero Mod APK, you need to download the latest version of the APK file from the same source where you downloaded it before. Then, you need to uninstall the old version of the app from your device and install the new version of the APK file. You should also backup your game data before updating to avoid losing your progress.
- Q: Can I play Wind Hero offline?
- A: Yes, you can play Wind Hero offline without an internet connection. However, some features of the game may not work properly offline, such as quests, achievements, or leaderboards.
- Q: Can I play Wind Hero with friends?
- A: No, Wind Hero does not have a multiplayer mode or a co-op mode. You can only play Wind Hero solo.
401be4b1e0How to Download Farming USA 2 APK for Android
-If you are a fan of farming simulators, you might want to try Farming USA 2, a realistic and immersive game that lets you experience the life of a farmer. In this game, you can plow, plant, harvest, and sell your crops, raise and breed your animals, drive and operate various vehicles and equipment, and even play with your friends online. However, if you want to play this game on your Android device, you might encounter some problems. The game is not available on the Google Play Store, and you might need to pay a fee to download it from other sources. That's why in this article, we will show you how to download Farming USA 2 APK for free and safely on your Android device.
-download farming usa 2 apk Download Zip ✓ https://urllie.com/2uNB4e
What is Farming USA 2?
-Farming USA 2 is a simulation game developed by Bowen Games LLC, a company that specializes in creating realistic and fun games for mobile devices. The game is a sequel to the popular Farming USA, but with four times the farming size and more features. The game has been praised by players and critics alike for its realistic graphics, physics, sounds, and gameplay. The game also supports cross-platform multiplayer, so you can play with your friends on different devices.
-Features of Farming USA 2
-Crops and animals
-In Farming USA 2, you can grow and sell various crops such as corn, wheat, barley, soybeans, and hay. You can also raise livestock in different ways. You can breed your own cows with bulls in the pasture, or feed them in the feedlot for faster growth. You can also own a dairy farm and sell milk, or purchase a hog barn and raise up to 2,000 pigs.
-Vehicles and equipment
-To help you with your farming tasks, you can control over 100 different vehicles and equipment in the game. You can drive tractors, trucks, trailers, plows, harvesters, sprayers, balers, loaders, and more. You can also customize your vehicles with different colors and attachments. You can also use realistic wheel physics to feel the landscape as you roam around your farm.
-Multiplayer mode
-If you want to have more fun and challenge in the game, you can play with your friends online in the multiplayer mode. You can join or create a server and invite up to 15 players to join your farm. You can chat with them, lend them a hand, or compete with them in different tasks. You can also trade crops and animals with other players.
-Weather and seasons
-The game also features a realistic weather system that affects the growth and harvest of your crops. You have to watch the weather forecast as rain and sun can make your fields wet or dry. You also have to deal with different seasons such as spring, summer, fall, and winter. In winter, you have to hook up the snow plows to clear the snow from your lot.
-download farming usa 2 apk free
-Why download Farming USA 2 APK?
-Free and safe
-One of the main reasons why you might want to download Farming USA 2 APK is that it is free and safe. Unlike other sources that might charge you a fee or contain viruses or malware, our APK file is completely free and secure. We scan our files regularly to ensure that they are clean and harmless.
-Easy and fast
-Another reason why you might want to download Farming USA 2 APK is that it is easy and fast. You don't need to go through any complicated or lengthy process to download and install the APK file. You just need to follow a few simple steps that we will explain later in this article. You can also download the APK file quickly as it is not too large in size.
-Compatible and updated
-The last reason why you might want to download Farming USA 2 APK is that it is compatible and updated. You don't need to worry about whether your device can run the game or not, as our APK file works on most Android devices. You also don't need to worry about missing out on any new features or bug fixes, as our APK file is always updated to the latest version of the game.
-How to download and install Farming USA 2 APK?
-Now that you know the benefits of downloading Farming USA 2 APK, you might be wondering how to do it. Well, don't worry, because we will guide you through the process step by step. Just follow these instructions and you will be able to enjoy the game in no time.
-Step 1: Enable unknown sources
-The first thing you need to do is to enable unknown sources on your device. This will allow you to install apps from sources other than the Google Play Store. To do this, go to your device settings and look for security or privacy options. Then, find and toggle on the option that says unknown sources or allow installation from unknown sources. You might see a warning message, but just ignore it and confirm your choice.
-Step 2: Download the APK file
-The next thing you need to do is to download the APK file from our website. You can use the link below to access our download page. Once you are there, click on the download button and wait for the file to be downloaded to your device. You might see a notification or a pop-up window asking you to confirm the download, but just tap on OK or Yes.
-Download Farming USA 2 APK here
-Step 3: Install the APK file
-The last thing you need to do is to install the APK file on your device. To do this, go to your file manager or downloads folder and look for the file that you just downloaded. It should have a name like farming-usa-2.apk or something similar. Tap on the file and you will see an installation screen. Tap on install and wait for the installation to finish. You might see some permissions requests, but just grant them and continue.
-Step 4: Enjoy the game
-Congratulations! You have successfully downloaded and installed Farming USA 2 APK on your Android device. Now you can launch the game from your app drawer or home screen and start playing. You can create your own farm, grow your crops, raise your animals, drive your vehicles, play with your friends, and have fun!
-Conclusion
-Farming USA 2 is a great game for anyone who loves farming simulators. It offers realistic and immersive gameplay, stunning graphics, diverse features, and multiplayer mode. However, if you want to play it on your Android device, you might need to download Farming USA 2 APK from our website. This way, you can enjoy the game for free, safely, easily, fastly, compatibly, and updatedly. We hope this article has helped you learn how to download Farming USA 2 APK for Android. If you have any questions or feedback, feel free to leave a comment below.
- FAQs
-
-Q: Is Farming USA 2 APK safe?
-A: Yes, Farming USA 2 APK is safe. We scan our files regularly to ensure that they are clean and harmless.
-Q: Is Farming USA 2 APK free?
-A: Yes, Farming USA 2 APK is free. You don't need to pay anything to download and play the game.
-Q: Is Farming USA 2 APK compatible with my device?
-A: Yes, Farming USA 2 APK is compatible with most Android devices. However, if you encounter any problems, please let us know.
-Q: Is Farming USA 2 APK updated?
-A: Yes, Farming USA 2 APK is updated. We always provide the latest version of the game.
-Q: How can I play Farming USA 2 with my friends?
-A: You can play Farming USA 2 with your friends online in the multiplayer mode. You can join or create a server and invite up to 15 players to join your farm. You can also trade crops and animals with other players.
- 197e85843d;
- /**
- * The `enter()` method is plumbing used by the `run()`, `bind()`, and`intercept()` methods to set the active domain. It sets `domain.active` and`process.domain` to the domain, and implicitly
- * pushes the domain onto the domain
- * stack managed by the domain module (see {@link exit} for details on the
- * domain stack). The call to `enter()` delimits the beginning of a chain of
- * asynchronous calls and I/O operations bound to a domain.
- *
- * Calling `enter()` changes only the active domain, and does not alter the domain
- * itself. `enter()` and `exit()` can be called an arbitrary number of times on a
- * single domain.
- */
- enter(): void;
- /**
- * The `exit()` method exits the current domain, popping it off the domain stack.
- * Any time execution is going to switch to the context of a different chain of
- * asynchronous calls, it's important to ensure that the current domain is exited.
- * The call to `exit()` delimits either the end of or an interruption to the chain
- * of asynchronous calls and I/O operations bound to a domain.
- *
- * If there are multiple, nested domains bound to the current execution context,`exit()` will exit any domains nested within this domain.
- *
- * Calling `exit()` changes only the active domain, and does not alter the domain
- * itself. `enter()` and `exit()` can be called an arbitrary number of times on a
- * single domain.
- */
- exit(): void;
- /**
- * Run the supplied function in the context of the domain, implicitly
- * binding all event emitters, timers, and lowlevel requests that are
- * created in that context. Optionally, arguments can be passed to
- * the function.
- *
- * This is the most basic way to use a domain.
- *
- * ```js
- * const domain = require('domain');
- * const fs = require('fs');
- * const d = domain.create();
- * d.on('error', (er) => {
- * console.error('Caught error!', er);
- * });
- * d.run(() => {
- * process.nextTick(() => {
- * setTimeout(() => { // Simulating some various async stuff
- * fs.open('non-existent file', 'r', (er, fd) => {
- * if (er) throw er;
- * // proceed...
- * });
- * }, 100);
- * });
- * });
- * ```
- *
- * In this example, the `d.on('error')` handler will be triggered, rather
- * than crashing the program.
- */
- run(fn: (...args: any[]) => T, ...args: any[]): T;
- /**
- * Explicitly adds an emitter to the domain. If any event handlers called by
- * the emitter throw an error, or if the emitter emits an `'error'` event, it
- * will be routed to the domain's `'error'` event, just like with implicit
- * binding.
- *
- * This also works with timers that are returned from `setInterval()` and `setTimeout()`. If their callback function throws, it will be caught by
- * the domain `'error'` handler.
- *
- * If the Timer or `EventEmitter` was already bound to a domain, it is removed
- * from that one, and bound to this one instead.
- * @param emitter emitter or timer to be added to the domain
- */
- add(emitter: EventEmitter | NodeJS.Timer): void;
- /**
- * The opposite of {@link add}. Removes domain handling from the
- * specified emitter.
- * @param emitter emitter or timer to be removed from the domain
- */
- remove(emitter: EventEmitter | NodeJS.Timer): void;
- /**
- * The returned function will be a wrapper around the supplied callback
- * function. When the returned function is called, any errors that are
- * thrown will be routed to the domain's `'error'` event.
- *
- * ```js
- * const d = domain.create();
- *
- * function readSomeFile(filename, cb) {
- * fs.readFile(filename, 'utf8', d.bind((er, data) => {
- * // If this throws, it will also be passed to the domain.
- * return cb(er, data ? JSON.parse(data) : null);
- * }));
- * }
- *
- * d.on('error', (er) => {
- * // An error occurred somewhere. If we throw it now, it will crash the program
- * // with the normal line number and stack message.
- * });
- * ```
- * @param callback The callback function
- * @return The bound function
- */
- bind(callback: T): T;
- /**
- * This method is almost identical to {@link bind}. However, in
- * addition to catching thrown errors, it will also intercept `Error` objects sent as the first argument to the function.
- *
- * In this way, the common `if (err) return callback(err);` pattern can be replaced
- * with a single error handler in a single place.
- *
- * ```js
- * const d = domain.create();
- *
- * function readSomeFile(filename, cb) {
- * fs.readFile(filename, 'utf8', d.intercept((data) => {
- * // Note, the first argument is never passed to the
- * // callback since it is assumed to be the 'Error' argument
- * // and thus intercepted by the domain.
- *
- * // If this throws, it will also be passed to the domain
- * // so the error-handling logic can be moved to the 'error'
- * // event on the domain instead of being repeated throughout
- * // the program.
- * return cb(null, JSON.parse(data));
- * }));
- * }
- *
- * d.on('error', (er) => {
- * // An error occurred somewhere. If we throw it now, it will crash the program
- * // with the normal line number and stack message.
- * });
- * ```
- * @param callback The callback function
- * @return The intercepted function
- */
- intercept(callback: T): T;
- }
- function create(): Domain;
-}
-declare module 'node:domain' {
- export * from 'domain';
-}
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/example/inspect.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/example/inspect.js
deleted file mode 100644
index e2df7c9f471356c48f14e7af2813119ffb6854bb..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/example/inspect.js
+++ /dev/null
@@ -1,10 +0,0 @@
-'use strict';
-
-/* eslint-env browser */
-var inspect = require('../');
-
-var d = document.createElement('div');
-d.setAttribute('id', 'beep');
-d.innerHTML = 'wooo iiiii ';
-
-console.log(inspect([d, { a: 3, b: 4, c: [5, 6, [7, [8, [9]]]] }]));
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io-parser/Readme.md b/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io-parser/Readme.md
deleted file mode 100644
index e4f6a8afae6f9951ba23fa6ca05fb03e02d5f307..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io-parser/Readme.md
+++ /dev/null
@@ -1,81 +0,0 @@
-
-# socket.io-parser
-
-[](https://github.com/socketio/socket.io-parser/actions)
-[](http://badge.fury.io/js/socket.io-parser)
-
-A socket.io encoder and decoder written in JavaScript complying with version `5`
-of [socket.io-protocol](https://github.com/socketio/socket.io-protocol).
-Used by [socket.io](https://github.com/automattic/socket.io) and
-[socket.io-client](https://github.com/automattic/socket.io-client).
-
-Compatibility table:
-
-| Parser version | Socket.IO server version | Protocol revision |
-|----------------| ------------------------ | ----------------- |
-| 3.x | 1.x / 2.x | 4 |
-| 4.x | 3.x | 5 |
-
-
-## Parser API
-
- socket.io-parser is the reference implementation of socket.io-protocol. Read
- the full API here:
- [socket.io-protocol](https://github.com/learnboost/socket.io-protocol).
-
-## Example Usage
-
-### Encoding and decoding a packet
-
-```js
-var parser = require('socket.io-parser');
-var encoder = new parser.Encoder();
-var packet = {
- type: parser.EVENT,
- data: 'test-packet',
- id: 13
-};
-encoder.encode(packet, function(encodedPackets) {
- var decoder = new parser.Decoder();
- decoder.on('decoded', function(decodedPacket) {
- // decodedPacket.type == parser.EVENT
- // decodedPacket.data == 'test-packet'
- // decodedPacket.id == 13
- });
-
- for (var i = 0; i < encodedPackets.length; i++) {
- decoder.add(encodedPackets[i]);
- }
-});
-```
-
-### Encoding and decoding a packet with binary data
-
-```js
-var parser = require('socket.io-parser');
-var encoder = new parser.Encoder();
-var packet = {
- type: parser.BINARY_EVENT,
- data: {i: new Buffer(1234), j: new Blob([new ArrayBuffer(2)])},
- id: 15
-};
-encoder.encode(packet, function(encodedPackets) {
- var decoder = new parser.Decoder();
- decoder.on('decoded', function(decodedPacket) {
- // decodedPacket.type == parser.BINARY_EVENT
- // Buffer.isBuffer(decodedPacket.data.i) == true
- // Buffer.isBuffer(decodedPacket.data.j) == true
- // decodedPacket.id == 15
- });
-
- for (var i = 0; i < encodedPackets.length; i++) {
- decoder.add(encodedPackets[i]);
- }
-});
-```
-See the test suite for more examples of how socket.io-parser is used.
-
-
-## License
-
-MIT
diff --git a/spaces/fffiloni/stable-diffusion-inpainting/README.md b/spaces/fffiloni/stable-diffusion-inpainting/README.md
deleted file mode 100644
index c377dafeefc87c9c5ac3a26f6a69dd1246f1f7a0..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/stable-diffusion-inpainting/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: InPainting Stable Diffusion CPU
-emoji: 👩🎨✨
-colorFrom: yellow
-colorTo: pink
-sdk: gradio
-sdk_version: 3.6
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/firefighter/PdfSumGPT/README.md b/spaces/firefighter/PdfSumGPT/README.md
deleted file mode 100644
index 368f6087fe7ddd74e63b0e81e8f6da106c12ffb4..0000000000000000000000000000000000000000
--- a/spaces/firefighter/PdfSumGPT/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: PdfSumGPT
-emoji: 🏢
-colorFrom: yellow
-colorTo: green
-sdk: gradio
-sdk_version: 3.19.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/flaviooliveira/trocr-bullinger-htr/app.py b/spaces/flaviooliveira/trocr-bullinger-htr/app.py
deleted file mode 100644
index a41216741c819ad799c72c1a7d79ebd7bf6025f8..0000000000000000000000000000000000000000
--- a/spaces/flaviooliveira/trocr-bullinger-htr/app.py
+++ /dev/null
@@ -1,236 +0,0 @@
-import gradio as gr
-import os
-from PIL import Image
-from transformers import TrOCRProcessor, VisionEncoderDecoderModel, AutoImageProcessor
-# import utils
-import base64
-# from datasets import load_metric
-import evaluate
-import logging
-
-# Only show log messages that are at the ERROR level or above, effectively filtering out any warnings
-logging.getLogger('transformers').setLevel(logging.ERROR)
-
-processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
-image_processor = AutoImageProcessor.from_pretrained("pstroe/bullinger-general-model")
-model = VisionEncoderDecoderModel.from_pretrained("pstroe/bullinger-general-model")
-
-# Create examples
-# Get images and respective transcriptions from the examples directory
-def get_example_data(folder_path="./examples/"):
-
- example_data = []
-
- # Get list of all files in the folder
- all_files = os.listdir(folder_path)
-
- # Loop through the file list
- for file_name in all_files:
-
- file_path = os.path.join(folder_path, file_name)
-
- # Check if the file is an image (.png)
- if file_name.endswith(".png"):
-
- # Construct the corresponding .txt filename (same name)
- corresponding_text_file_name = file_name.replace(".png", ".txt")
- corresponding_text_file_path = os.path.join(folder_path, corresponding_text_file_name)
-
- # Initialize to a default value
- transcription = "Transcription not found."
-
- # Try to read the content from the .txt file
- try:
- with open(corresponding_text_file_path, "r") as f:
- transcription = f.read().strip()
- except FileNotFoundError:
- pass # If the corresponding .txt file is not found, leave the default value
-
- example_data.append([file_path, transcription])
-
- return example_data
-
-# From pstroe's script
-# def compute_metrics(pred):
-
-# labels_ids = pred.label_ids
-# pred_ids = pred.predictions
-
-# pred_str = processor.batch_decode(pred_ids, skip_special_tokens=True)
-# labels_ids[labels_ids == -100] = processor.tokenizer.pad_token_id
-# label_str = processor.batch_decode(labels_ids, skip_special_tokens=True)
-
-# cer = cer_metric.compute(predictions=pred_str, references=label_str)
-
-# return {"cer": cer}
-
-def process_image(image, ground_truth):
-
- cer = None
-
- # prepare image
- pixel_values = image_processor(image, return_tensors="pt").pixel_values
-
- # generate (no beam search)
- generated_ids = model.generate(pixel_values)
-
- # decode
- generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
-
- if ground_truth is not None and ground_truth.strip() != "":
-
- # Debug: Print lengths before computing metric
- print("Number of predictions:", len(generated_text))
- print("Number of references:", len(ground_truth))
-
- # Check if lengths match
- if len(generated_text) != len(ground_truth):
-
- print("Mismatch in number of predictions and references.")
- print("Predictions:", generated_text)
- print("References:", ground_truth)
- print("\n")
-
- cer = cer_metric.compute(predictions=[generated_text], references=[ground_truth])
- # cer = f"{cer:.3f}"
-
- else:
-
- cer = "Ground truth not provided"
-
- return generated_text, cer
-
-# One way to use .svg files
-# logo_url = "https://www.bullinger-digital.ch/bullinger-digital.svg"
-# logo_url = "https://www.cl.uzh.ch/docroot/logos/uzh_logo_e_pos.svg"
-
-# header_html = " TrOCR: Bullinger Dataset
-"""
-
-description = """
- Use of Microsoft's [TrOCR](https://arxiv.org/abs/2109.10282), an encoder-decoder model consisting of an \
- image Transformer encoder and a text Transformer decoder for state-of-the-art optical character recognition \
- (OCR) and handwritten text recognition (HTR) on text line images. \
- This particular model was fine-tuned on [Bullinger Dataset](https://github.com/pstroe/bullinger-htr) \
- as part of the project [Bullinger Digital](https://www.bullinger-digital.ch)
- ([References](https://www.cl.uzh.ch/de/people/team/compling/pstroebel.html#Publications)).
- * HF `model card`: [pstroe/bullinger-general-model](https://huggingface.co/pstroe/bullinger-general-model) | \
- [Flexible Techniques for Automatic Text Recognition of Historical Documents](https://doi.org/10.5167/uzh-234886)
-"""
-
-# articles = """
-# TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models Flexible Techniques for Automatic Text Recognition of Historical Documents Bullingers Briefwechsel zugänglich machen: Stand der Handschriftenerkennung
-# """
-
-# Read .png and the respective .txt files
-examples = get_example_data()
-
-# load_metric() is deprecated
-# cer_metric = load_metric("cer")
-# pip install jiwer
-# pip install evaluate
-cer_metric = evaluate.load("cer")
-
-with gr.Blocks(
- theme=gr.themes.Soft(),
- title="TrOCR Bullinger",
-) as demo:
-
- gr.HTML(
- f"""
-
-
-
- #
- #
- # Bullinger Digital | Institut für Computerlinguistik, Universität Zürich, 2023
- #
- #
-
-
- Bullinger Digital | Institut für Computerlinguistik, Universität Zürich, 2023
-
-
-#include
-
-// CUDA forward declarations
-std::vector corr_cuda_forward(
- torch::Tensor fmap1,
- torch::Tensor fmap2,
- torch::Tensor coords,
- int radius);
-
-std::vector corr_cuda_backward(
- torch::Tensor fmap1,
- torch::Tensor fmap2,
- torch::Tensor coords,
- torch::Tensor corr_grad,
- int radius);
-
-// C++ interface
-#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
-#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
-#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
-
-std::vector corr_forward(
- torch::Tensor fmap1,
- torch::Tensor fmap2,
- torch::Tensor coords,
- int radius) {
- CHECK_INPUT(fmap1);
- CHECK_INPUT(fmap2);
- CHECK_INPUT(coords);
-
- return corr_cuda_forward(fmap1, fmap2, coords, radius);
-}
-
-
-std::vector corr_backward(
- torch::Tensor fmap1,
- torch::Tensor fmap2,
- torch::Tensor coords,
- torch::Tensor corr_grad,
- int radius) {
- CHECK_INPUT(fmap1);
- CHECK_INPUT(fmap2);
- CHECK_INPUT(coords);
- CHECK_INPUT(corr_grad);
-
- return corr_cuda_backward(fmap1, fmap2, coords, corr_grad, radius);
-}
-
-
-PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
- m.def("forward", &corr_forward, "CORR forward");
- m.def("backward", &corr_backward, "CORR backward");
-}
\ No newline at end of file
diff --git a/spaces/glyszt/vt/vtoonify_model.py b/spaces/glyszt/vt/vtoonify_model.py
deleted file mode 100644
index 66c95184273324df31aa5c8e4eaa6e82987d36e3..0000000000000000000000000000000000000000
--- a/spaces/glyszt/vt/vtoonify_model.py
+++ /dev/null
@@ -1,285 +0,0 @@
-from __future__ import annotations
-import gradio as gr
-import pathlib
-import sys
-sys.path.insert(0, 'vtoonify')
-
-from util import load_psp_standalone, get_video_crop_parameter, tensor2cv2
-import torch
-import torch.nn as nn
-import numpy as np
-import dlib
-import cv2
-from model.vtoonify import VToonify
-from model.bisenet.model import BiSeNet
-import torch.nn.functional as F
-from torchvision import transforms
-from model.encoder.align_all_parallel import align_face
-import gc
-import huggingface_hub
-import os
-
-
-MODEL_REPO = 'PKUWilliamYang/VToonify'
-
-class Model():
- def __init__(self, device):
- super().__init__()
-
- self.device = device
- self.style_types = {
- 'cartoon1': ['vtoonify_d_cartoon/vtoonify_s026_d0.5.pt', 26],
- 'cartoon1-d': ['vtoonify_d_cartoon/vtoonify_s_d.pt', 26],
- 'cartoon2-d': ['vtoonify_d_cartoon/vtoonify_s_d.pt', 64],
- 'cartoon3-d': ['vtoonify_d_cartoon/vtoonify_s_d.pt', 153],
- 'cartoon4': ['vtoonify_d_cartoon/vtoonify_s299_d0.5.pt', 299],
- 'cartoon4-d': ['vtoonify_d_cartoon/vtoonify_s_d.pt', 299],
- 'cartoon5-d': ['vtoonify_d_cartoon/vtoonify_s_d.pt', 8],
- 'comic1-d': ['vtoonify_d_comic/vtoonify_s_d.pt', 28],
- 'comic2-d': ['vtoonify_d_comic/vtoonify_s_d.pt', 18],
- 'arcane1': ['vtoonify_d_arcane/vtoonify_s000_d0.5.pt', 0],
- 'arcane1-d': ['vtoonify_d_arcane/vtoonify_s_d.pt', 0],
- 'arcane2': ['vtoonify_d_arcane/vtoonify_s077_d0.5.pt', 77],
- 'arcane2-d': ['vtoonify_d_arcane/vtoonify_s_d.pt', 77],
- 'caricature1': ['vtoonify_d_caricature/vtoonify_s039_d0.5.pt', 39],
- 'caricature2': ['vtoonify_d_caricature/vtoonify_s068_d0.5.pt', 68],
- 'pixar': ['vtoonify_d_pixar/vtoonify_s052_d0.5.pt', 52],
- 'pixar-d': ['vtoonify_d_pixar/vtoonify_s_d.pt', 52],
- 'illustration1-d': ['vtoonify_d_illustration/vtoonify_s054_d_c.pt', 54],
- 'illustration2-d': ['vtoonify_d_illustration/vtoonify_s004_d_c.pt', 4],
- 'illustration3-d': ['vtoonify_d_illustration/vtoonify_s009_d_c.pt', 9],
- 'illustration4-d': ['vtoonify_d_illustration/vtoonify_s043_d_c.pt', 43],
- 'illustration5-d': ['vtoonify_d_illustration/vtoonify_s086_d_c.pt', 86],
- }
-
- self.landmarkpredictor = self._create_dlib_landmark_model()
- self.parsingpredictor = self._create_parsing_model()
- self.pspencoder = self._load_encoder()
- self.transform = transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5,0.5,0.5]),
- ])
-
- self.vtoonify, self.exstyle = self._load_default_model()
- self.color_transfer = False
- self.style_name = 'cartoon1'
- self.video_limit_cpu = 100
- self.video_limit_gpu = 300
-
- @staticmethod
- def _create_dlib_landmark_model():
- return dlib.shape_predictor(huggingface_hub.hf_hub_download(MODEL_REPO,
- 'models/shape_predictor_68_face_landmarks.dat'))
-
- def _create_parsing_model(self):
- parsingpredictor = BiSeNet(n_classes=19)
- parsingpredictor.load_state_dict(torch.load(huggingface_hub.hf_hub_download(MODEL_REPO, 'models/faceparsing.pth'),
- map_location=lambda storage, loc: storage))
- parsingpredictor.to(self.device).eval()
- return parsingpredictor
-
- def _load_encoder(self) -> nn.Module:
- style_encoder_path = huggingface_hub.hf_hub_download(MODEL_REPO,'models/encoder.pt')
- return load_psp_standalone(style_encoder_path, self.device)
-
- def _load_default_model(self) -> tuple[torch.Tensor, str]:
- vtoonify = VToonify(backbone = 'dualstylegan')
- vtoonify.load_state_dict(torch.load(huggingface_hub.hf_hub_download(MODEL_REPO,
- 'models/vtoonify_d_cartoon/vtoonify_s026_d0.5.pt'),
- map_location=lambda storage, loc: storage)['g_ema'])
- vtoonify.to(self.device)
- tmp = np.load(huggingface_hub.hf_hub_download(MODEL_REPO,'models/vtoonify_d_cartoon/exstyle_code.npy'), allow_pickle=True).item()
- exstyle = torch.tensor(tmp[list(tmp.keys())[26]]).to(self.device)
- with torch.no_grad():
- exstyle = vtoonify.zplus2wplus(exstyle)
- return vtoonify, exstyle
-
- def load_model(self, style_type: str) -> tuple[torch.Tensor, str]:
- if 'illustration' in style_type:
- self.color_transfer = True
- else:
- self.color_transfer = False
- if style_type not in self.style_types.keys():
- return None, 'Oops, wrong Style Type. Please select a valid model.'
- self.style_name = style_type
- model_path, ind = self.style_types[style_type]
- style_path = os.path.join('models',os.path.dirname(model_path),'exstyle_code.npy')
- self.vtoonify.load_state_dict(torch.load(huggingface_hub.hf_hub_download(MODEL_REPO,'models/'+model_path),
- map_location=lambda storage, loc: storage)['g_ema'])
- tmp = np.load(huggingface_hub.hf_hub_download(MODEL_REPO, style_path), allow_pickle=True).item()
- exstyle = torch.tensor(tmp[list(tmp.keys())[ind]]).to(self.device)
- with torch.no_grad():
- exstyle = self.vtoonify.zplus2wplus(exstyle)
- return exstyle, 'Model of %s loaded.'%(style_type)
-
- def detect_and_align(self, frame, top, bottom, left, right, return_para=False):
- message = 'Error: no face detected! Please retry or change the photo.'
- paras = get_video_crop_parameter(frame, self.landmarkpredictor, [left, right, top, bottom])
- instyle = None
- h, w, scale = 0, 0, 0
- if paras is not None:
- h,w,top,bottom,left,right,scale = paras
- H, W = int(bottom-top), int(right-left)
- # for HR image, we apply gaussian blur to it to avoid over-sharp stylization results
- kernel_1d = np.array([[0.125],[0.375],[0.375],[0.125]])
- if scale <= 0.75:
- frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d)
- if scale <= 0.375:
- frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d)
- frame = cv2.resize(frame, (w, h))[top:bottom, left:right]
- with torch.no_grad():
- I = align_face(frame, self.landmarkpredictor)
- if I is not None:
- I = self.transform(I).unsqueeze(dim=0).to(self.device)
- instyle = self.pspencoder(I)
- instyle = self.vtoonify.zplus2wplus(instyle)
- message = 'Successfully rescale the frame to (%d, %d)'%(bottom-top, right-left)
- else:
- frame = np.zeros((256,256,3), np.uint8)
- else:
- frame = np.zeros((256,256,3), np.uint8)
- if return_para:
- return frame, instyle, message, w, h, top, bottom, left, right, scale
- return frame, instyle, message
-
- #@torch.inference_mode()
- def detect_and_align_image(self, image: str, top: int, bottom: int, left: int, right: int
- ) -> tuple[np.ndarray, torch.Tensor, str]:
- if image is None:
- return np.zeros((256,256,3), np.uint8), None, 'Error: fail to load empty file.'
- frame = cv2.imread(image)
- if frame is None:
- return np.zeros((256,256,3), np.uint8), None, 'Error: fail to load the image.'
- frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
- return self.detect_and_align(frame, top, bottom, left, right)
-
- def detect_and_align_video(self, video: str, top: int, bottom: int, left: int, right: int
- ) -> tuple[np.ndarray, torch.Tensor, str]:
- if video is None:
- return np.zeros((256,256,3), np.uint8), None, 'Error: fail to load empty file.'
- video_cap = cv2.VideoCapture(video)
- if video_cap.get(7) == 0:
- video_cap.release()
- return np.zeros((256,256,3), np.uint8), torch.zeros(1,18,512).to(self.device), 'Error: fail to load the video.'
- success, frame = video_cap.read()
- frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- video_cap.release()
- return self.detect_and_align(frame, top, bottom, left, right)
-
- def detect_and_align_full_video(self, video: str, top: int, bottom: int, left: int, right: int) -> tuple[str, torch.Tensor, str]:
- message = 'Error: no face detected! Please retry or change the video.'
- instyle = None
- if video is None:
- return 'default.mp4', instyle, 'Error: fail to load empty file.'
- video_cap = cv2.VideoCapture(video)
- if video_cap.get(7) == 0:
- video_cap.release()
- return 'default.mp4', instyle, 'Error: fail to load the video.'
- num = min(self.video_limit_gpu, int(video_cap.get(7)))
- if self.device == 'cpu':
- num = min(self.video_limit_cpu, num)
- success, frame = video_cap.read()
- frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- frame, instyle, message, w, h, top, bottom, left, right, scale = self.detect_and_align(frame, top, bottom, left, right, True)
- if instyle is None:
- return 'default.mp4', instyle, message
- fourcc = cv2.VideoWriter_fourcc(*'mp4v')
- videoWriter = cv2.VideoWriter('input.mp4', fourcc, video_cap.get(5), (int(right-left), int(bottom-top)))
- videoWriter.write(cv2.cvtColor(frame, cv2.COLOR_RGB2BGR))
- kernel_1d = np.array([[0.125],[0.375],[0.375],[0.125]])
- for i in range(num-1):
- success, frame = video_cap.read()
- frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- if scale <= 0.75:
- frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d)
- if scale <= 0.375:
- frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d)
- frame = cv2.resize(frame, (w, h))[top:bottom, left:right]
- videoWriter.write(cv2.cvtColor(frame, cv2.COLOR_RGB2BGR))
-
- videoWriter.release()
- video_cap.release()
-
- return 'input.mp4', instyle, 'Successfully rescale the video to (%d, %d)'%(bottom-top, right-left)
-
- def image_toonify(self, aligned_face: np.ndarray, instyle: torch.Tensor, exstyle: torch.Tensor, style_degree: float, style_type: str) -> tuple[np.ndarray, str]:
- #print(style_type + ' ' + self.style_name)
- if instyle is None or aligned_face is None:
- return np.zeros((256,256,3), np.uint8), 'Opps, something wrong with the input. Please go to Step 2 and Rescale Image/First Frame again.'
- if self.style_name != style_type:
- exstyle, _ = self.load_model(style_type)
- if exstyle is None:
- return np.zeros((256,256,3), np.uint8), 'Opps, something wrong with the style type. Please go to Step 1 and load model again.'
- with torch.no_grad():
- if self.color_transfer:
- s_w = exstyle
- else:
- s_w = instyle.clone()
- s_w[:,:7] = exstyle[:,:7]
-
- x = self.transform(aligned_face).unsqueeze(dim=0).to(self.device)
- x_p = F.interpolate(self.parsingpredictor(2*(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)))[0],
- scale_factor=0.5, recompute_scale_factor=False).detach()
- inputs = torch.cat((x, x_p/16.), dim=1)
- y_tilde = self.vtoonify(inputs, s_w.repeat(inputs.size(0), 1, 1), d_s = style_degree)
- y_tilde = torch.clamp(y_tilde, -1, 1)
- print('*** Toonify %dx%d image with style of %s'%(y_tilde.shape[2], y_tilde.shape[3], style_type))
- return ((y_tilde[0].cpu().numpy().transpose(1, 2, 0) + 1.0) * 127.5).astype(np.uint8), 'Successfully toonify the image with style of %s'%(self.style_name)
-
- def video_tooniy(self, aligned_video: str, instyle: torch.Tensor, exstyle: torch.Tensor, style_degree: float, style_type: str) -> tuple[str, str]:
- #print(style_type + ' ' + self.style_name)
- if aligned_video is None:
- return 'default.mp4', 'Opps, something wrong with the input. Please go to Step 2 and Rescale Video again.'
- video_cap = cv2.VideoCapture(aligned_video)
- if instyle is None or aligned_video is None or video_cap.get(7) == 0:
- video_cap.release()
- return 'default.mp4', 'Opps, something wrong with the input. Please go to Step 2 and Rescale Video again.'
- if self.style_name != style_type:
- exstyle, _ = self.load_model(style_type)
- if exstyle is None:
- return 'default.mp4', 'Opps, something wrong with the style type. Please go to Step 1 and load model again.'
- num = min(self.video_limit_gpu, int(video_cap.get(7)))
- if self.device == 'cpu':
- num = min(self.video_limit_cpu, num)
- fourcc = cv2.VideoWriter_fourcc(*'mp4v')
- videoWriter = cv2.VideoWriter('output.mp4', fourcc,
- video_cap.get(5), (int(video_cap.get(3)*4),
- int(video_cap.get(4)*4)))
-
- batch_frames = []
- if video_cap.get(3) != 0:
- if self.device == 'cpu':
- batch_size = max(1, int(4 * 256* 256/ video_cap.get(3) / video_cap.get(4)))
- else:
- batch_size = min(max(1, int(4 * 400 * 360/ video_cap.get(3) / video_cap.get(4))), 4)
- else:
- batch_size = 1
- print('*** Toonify using batch size of %d on %dx%d video of %d frames with style of %s'%(batch_size, int(video_cap.get(3)*4), int(video_cap.get(4)*4), num, style_type))
- with torch.no_grad():
- if self.color_transfer:
- s_w = exstyle
- else:
- s_w = instyle.clone()
- s_w[:,:7] = exstyle[:,:7]
- for i in range(num):
- success, frame = video_cap.read()
- frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- batch_frames += [self.transform(frame).unsqueeze(dim=0).to(self.device)]
- if len(batch_frames) == batch_size or (i+1) == num:
- x = torch.cat(batch_frames, dim=0)
- batch_frames = []
- with torch.no_grad():
- x_p = F.interpolate(self.parsingpredictor(2*(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)))[0],
- scale_factor=0.5, recompute_scale_factor=False).detach()
- inputs = torch.cat((x, x_p/16.), dim=1)
- y_tilde = self.vtoonify(inputs, s_w.repeat(inputs.size(0), 1, 1), style_degree)
- y_tilde = torch.clamp(y_tilde, -1, 1)
- for k in range(y_tilde.size(0)):
- videoWriter.write(tensor2cv2(y_tilde[k].cpu()))
- gc.collect()
-
- videoWriter.release()
- video_cap.release()
- return 'output.mp4', 'Successfully toonify video of %d frames with style of %s'%(num, self.style_name)
-
-
diff --git a/spaces/gradio/musical_instrument_identification/app.py b/spaces/gradio/musical_instrument_identification/app.py
deleted file mode 100644
index e5b3b3e3c765181798ba3ae22e3a61f3ac41a66d..0000000000000000000000000000000000000000
--- a/spaces/gradio/musical_instrument_identification/app.py
+++ /dev/null
@@ -1,50 +0,0 @@
-import gradio as gr
-import torch, torchaudio
-from timeit import default_timer as timer
-from data_setups import audio_preprocess, resample
-import gdown
-
-url = 'https://drive.google.com/uc?id=1X5CR18u0I-ZOi_8P0cNptCe5JGk9Ro0C'
-output = 'piano.wav'
-gdown.download(url, output, quiet=False)
-url = 'https://drive.google.com/uc?id=1W-8HwmGR5SiyDbUcGAZYYDKdCIst07__'
-output= 'torch_efficientnet_fold2_CNN.pth'
-gdown.download(url, output, quiet=False)
-device = "cuda" if torch.cuda.is_available() else "cpu"
-SAMPLE_RATE = 44100
-AUDIO_LEN = 2.90
-model = torch.load("torch_efficientnet_fold2_CNN.pth", map_location=torch.device('cpu'))
-LABELS = [
- "Cello", "Clarinet", "Flute", "Acoustic Guitar", "Electric Guitar", "Organ", "Piano", "Saxophone", "Trumpet", "Violin", "Voice"
-]
-example_list = [
- ["piano.wav"]
-]
-
-
-def predict(audio_path):
- start_time = timer()
- wavform, sample_rate = torchaudio.load(audio_path)
- wav = resample(wavform, sample_rate, SAMPLE_RATE)
- if len(wav) > int(AUDIO_LEN * SAMPLE_RATE):
- wav = wav[:int(AUDIO_LEN * SAMPLE_RATE)]
- else:
- print(f"input length {len(wav)} too small!, need over {int(AUDIO_LEN * SAMPLE_RATE)}")
- return
- img = audio_preprocess(wav, SAMPLE_RATE).unsqueeze(0)
- model.eval()
- with torch.inference_mode():
- pred_probs = torch.softmax(model(img), dim=1)
- pred_labels_and_probs = {LABELS[i]: float(pred_probs[0][i]) for i in range(len(LABELS))}
- pred_time = round(timer() - start_time, 5)
- return pred_labels_and_probs, pred_time
-
-demo = gr.Interface(fn=predict,
- inputs=gr.Audio(type="filepath"),
- outputs=[gr.Label(num_top_classes=11, label="Predictions"),
- gr.Number(label="Prediction time (s)")],
- examples=example_list,
- cache_examples=False
- )
-
-demo.launch(debug=False)
\ No newline at end of file
diff --git a/spaces/h2oai/wave-tour/examples/plot_area_groups.py b/spaces/h2oai/wave-tour/examples/plot_area_groups.py
deleted file mode 100644
index 75f2657d9833aaf0b7cf19fd25bcd6196b3cf1ca..0000000000000000000000000000000000000000
--- a/spaces/h2oai/wave-tour/examples/plot_area_groups.py
+++ /dev/null
@@ -1,42 +0,0 @@
-# Plot / Area / Groups
-# Make an area #plot showing multiple categories.
-# ---
-from h2o_wave import site, data, ui
-
-page = site['/demo']
-
-page.add('example', ui.plot_card(
- box='1 1 4 5',
- title='Area, groups',
- data=data('month city temperature', 24, rows=[
- ('Jan', 'Tokyo', 7),
- ('Jan', 'London', 3.9),
- ('Feb', 'Tokyo', 6.9),
- ('Feb', 'London', 4.2),
- ('Mar', 'Tokyo', 9.5),
- ('Mar', 'London', 5.7),
- ('Apr', 'Tokyo', 14.5),
- ('Apr', 'London', 8.5),
- ('May', 'Tokyo', 18.4),
- ('May', 'London', 11.9),
- ('Jun', 'Tokyo', 21.5),
- ('Jun', 'London', 15.2),
- ('Jul', 'Tokyo', 25.2),
- ('Jul', 'London', 17),
- ('Aug', 'Tokyo', 26.5),
- ('Aug', 'London', 16.6),
- ('Sep', 'Tokyo', 23.3),
- ('Sep', 'London', 14.2),
- ('Oct', 'Tokyo', 18.3),
- ('Oct', 'London', 10.3),
- ('Nov', 'Tokyo', 13.9),
- ('Nov', 'London', 6.6),
- ('Dec', 'Tokyo', 9.6),
- ('Dec', 'London', 4.8),
- ]),
- plot=ui.plot([
- ui.mark(type='area', x='=month', y='=temperature', color='=city', y_min=0)
- ])
-))
-
-page.save()
diff --git a/spaces/h2oai/wave-tour/examples/stepper.py b/spaces/h2oai/wave-tour/examples/stepper.py
deleted file mode 100644
index ccd8d5fa346f77607b0e662023c9c98a23be657f..0000000000000000000000000000000000000000
--- a/spaces/h2oai/wave-tour/examples/stepper.py
+++ /dev/null
@@ -1,40 +0,0 @@
-# Form / Stepper
-# Use #Stepper to show #progress through numbered steps.
-# #form
-# ---
-from h2o_wave import main, app, Q, ui
-
-
-@app('/demo')
-async def serve(q: Q):
- q.page['basic-stepper'] = ui.form_card(
- box='1 1 4 2',
- items=[
- ui.stepper(name='basic-stepper', items=[
- ui.step(label='Step 1'),
- ui.step(label='Step 2'),
- ui.step(label='Step 3'),
- ])
- ]
- )
- q.page['icon-stepper'] = ui.form_card(
- box='1 3 4 2',
- items=[
- ui.stepper(name='icon-stepper', items=[
- ui.step(label='Step 1', icon='MailLowImportance'),
- ui.step(label='Step 2', icon='TaskManagerMirrored'),
- ui.step(label='Step 3', icon='Cafe'),
- ])
- ]
- )
- q.page['almost-done-stepper'] = ui.form_card(
- box='1 5 4 2',
- items=[
- ui.stepper(name='almost-done-stepper', items=[
- ui.step(label='Step 1', done=True),
- ui.step(label='Step 2', done=True),
- ui.step(label='Step 3'),
- ])
- ]
- )
- await q.page.save()
diff --git a/spaces/haakohu/deep_privacy2/dp2/loss/r1_regularization.py b/spaces/haakohu/deep_privacy2/dp2/loss/r1_regularization.py
deleted file mode 100644
index f974c5542bf49ed36b54b46cfc7c9c9bfaff9ce3..0000000000000000000000000000000000000000
--- a/spaces/haakohu/deep_privacy2/dp2/loss/r1_regularization.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import torch
-import tops
-
-
-def r1_regularization(
- real_img, real_score, mask, lambd: float, lazy_reg_interval: int,
- lazy_regularization: bool,
- scaler: torch.cuda.amp.GradScaler, mask_out: bool,
- mask_out_scale: bool,
- **kwargs
-):
- grad = torch.autograd.grad(
- outputs=scaler.scale(real_score),
- inputs=real_img,
- grad_outputs=torch.ones_like(real_score),
- create_graph=True,
- only_inputs=True,
- )[0]
- inv_scale = 1.0 / scaler.get_scale()
- grad = grad * inv_scale
- with torch.cuda.amp.autocast(tops.AMP()):
- if mask_out:
- grad = grad * (1 - mask)
- grad = grad.square().sum(dim=[1, 2, 3])
- if mask_out and mask_out_scale:
- total_pixels = real_img.shape[1] * real_img.shape[2] * real_img.shape[3]
- n_fake = (1-mask).sum(dim=[1, 2, 3])
- scaling = total_pixels / n_fake
- grad = grad * scaling
- if lazy_regularization:
- lambd_ = lambd * lazy_reg_interval / 2 # From stylegan2, lazy regularization
- return grad * lambd_, grad.detach()
diff --git a/spaces/haakohu/deep_privacy2/sg3_torch_utils/__init__.py b/spaces/haakohu/deep_privacy2/sg3_torch_utils/__init__.py
deleted file mode 100644
index ece0ea08fe2e939cc260a1dafc0ab5b391b773d9..0000000000000000000000000000000000000000
--- a/spaces/haakohu/deep_privacy2/sg3_torch_utils/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-# empty
diff --git a/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/utils/stats.py b/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/utils/stats.py
deleted file mode 100644
index 7a248486daf07a980dcb31f2148e3c8f7f73f01c..0000000000000000000000000000000000000000
--- a/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/utils/stats.py
+++ /dev/null
@@ -1,510 +0,0 @@
-'''
-Copyright (C) 2019 Sovrasov V. - All Rights Reserved
- * You may use, distribute and modify this code under the
- * terms of the MIT license.
- * You should have received a copy of the MIT license with
- * this file. If not visit https://opensource.org/licenses/MIT
-'''
-
-import sys
-from functools import partial
-
-import numpy as np
-import torch
-import torch.nn as nn
-
-from maskrcnn_benchmark.layers import *
-
-def get_model_complexity_info(model, input_res,
- print_per_layer_stat=True,
- as_strings=True,
- input_constructor=None, ost=sys.stdout,
- verbose=False, ignore_modules=[],
- custom_modules_hooks={}):
- assert type(input_res) is tuple
- assert len(input_res) >= 1
- assert isinstance(model, nn.Module)
- global CUSTOM_MODULES_MAPPING
- CUSTOM_MODULES_MAPPING = custom_modules_hooks
- flops_model = add_flops_counting_methods(model)
- flops_model.eval()
- flops_model.start_flops_count(ost=ost, verbose=verbose,
- ignore_list=ignore_modules)
- if input_constructor:
- input = input_constructor(input_res)
- _ = flops_model(**input)
- else:
- try:
- batch = torch.ones(()).new_empty((1, *input_res),
- dtype=next(flops_model.parameters()).dtype,
- device=next(flops_model.parameters()).device)
- except StopIteration:
- batch = torch.ones(()).new_empty((1, *input_res))
-
- _ = flops_model(batch)
-
- flops_count, params_count = flops_model.compute_average_flops_cost()
- if print_per_layer_stat:
- print_model_with_flops(flops_model, flops_count, params_count, ost=ost)
- flops_model.stop_flops_count()
- CUSTOM_MODULES_MAPPING = {}
-
- if as_strings:
- return flops_to_string(flops_count), params_to_string(params_count)
-
- return flops_count, params_count
-
-
-def flops_to_string(flops, units='GMac', precision=2):
- if units is None:
- if flops // 10**9 > 0:
- return str(round(flops / 10.**9, precision)) + ' GMac'
- elif flops // 10**6 > 0:
- return str(round(flops / 10.**6, precision)) + ' MMac'
- elif flops // 10**3 > 0:
- return str(round(flops / 10.**3, precision)) + ' KMac'
- else:
- return str(flops) + ' Mac'
- else:
- if units == 'GMac':
- return str(round(flops / 10.**9, precision)) + ' ' + units
- elif units == 'MMac':
- return str(round(flops / 10.**6, precision)) + ' ' + units
- elif units == 'KMac':
- return str(round(flops / 10.**3, precision)) + ' ' + units
- else:
- return str(flops) + ' Mac'
-
-
-def params_to_string(params_num, units=None, precision=2):
- if units is None:
- if params_num // 10 ** 6 > 0:
- return str(round(params_num / 10 ** 6, 2)) + ' M'
- elif params_num // 10 ** 3:
- return str(round(params_num / 10 ** 3, 2)) + ' k'
- else:
- return str(params_num)
- else:
- if units == 'M':
- return str(round(params_num / 10.**6, precision)) + ' ' + units
- elif units == 'K':
- return str(round(params_num / 10.**3, precision)) + ' ' + units
- else:
- return str(params_num)
-
-
-def accumulate_flops(self):
- if is_supported_instance(self):
- return self.__flops__
- else:
- sum = 0
- for m in self.children():
- sum += m.accumulate_flops()
- return sum
-
-
-def print_model_with_flops(model, total_flops, total_params, units='GMac',
- precision=3, ost=sys.stdout):
-
- def accumulate_params(self):
- if is_supported_instance(self):
- return self.__params__
- else:
- sum = 0
- for m in self.children():
- sum += m.accumulate_params()
- return sum
-
- def flops_repr(self):
- accumulated_params_num = self.accumulate_params()
- accumulated_flops_cost = self.accumulate_flops() / model.__batch_counter__
- return ', '.join([params_to_string(accumulated_params_num,
- units='M', precision=precision),
- '{:.3%} Params'.format(accumulated_params_num / total_params),
- flops_to_string(accumulated_flops_cost,
- units=units, precision=precision),
- '{:.3%} MACs'.format(accumulated_flops_cost / total_flops),
- self.original_extra_repr()])
-
- def add_extra_repr(m):
- m.accumulate_flops = accumulate_flops.__get__(m)
- m.accumulate_params = accumulate_params.__get__(m)
- flops_extra_repr = flops_repr.__get__(m)
- if m.extra_repr != flops_extra_repr:
- m.original_extra_repr = m.extra_repr
- m.extra_repr = flops_extra_repr
- assert m.extra_repr != m.original_extra_repr
-
- def del_extra_repr(m):
- if hasattr(m, 'original_extra_repr'):
- m.extra_repr = m.original_extra_repr
- del m.original_extra_repr
- if hasattr(m, 'accumulate_flops'):
- del m.accumulate_flops
-
- model.apply(add_extra_repr)
- print(repr(model), file=ost)
- model.apply(del_extra_repr)
-
-
-def get_model_parameters_number(model):
- params_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
- return params_num
-
-
-def add_flops_counting_methods(net_main_module):
- # adding additional methods to the existing module object,
- # this is done this way so that each function has access to self object
- net_main_module.start_flops_count = start_flops_count.__get__(net_main_module)
- net_main_module.stop_flops_count = stop_flops_count.__get__(net_main_module)
- net_main_module.reset_flops_count = reset_flops_count.__get__(net_main_module)
- net_main_module.compute_average_flops_cost = compute_average_flops_cost.__get__(
- net_main_module)
-
- net_main_module.reset_flops_count()
-
- return net_main_module
-
-
-def compute_average_flops_cost(self):
- """
- A method that will be available after add_flops_counting_methods() is called
- on a desired net object.
-
- Returns current mean flops consumption per image.
-
- """
-
- for m in self.modules():
- m.accumulate_flops = accumulate_flops.__get__(m)
-
- flops_sum = self.accumulate_flops()
-
- for m in self.modules():
- if hasattr(m, 'accumulate_flops'):
- del m.accumulate_flops
-
- params_sum = get_model_parameters_number(self)
- return flops_sum / self.__batch_counter__, params_sum
-
-
-def start_flops_count(self, **kwargs):
- """
- A method that will be available after add_flops_counting_methods() is called
- on a desired net object.
-
- Activates the computation of mean flops consumption per image.
- Call it before you run the network.
-
- """
- add_batch_counter_hook_function(self)
-
- seen_types = set()
-
- def add_flops_counter_hook_function(module, ost, verbose, ignore_list):
- if type(module) in ignore_list:
- seen_types.add(type(module))
- if is_supported_instance(module):
- module.__params__ = 0
- elif is_supported_instance(module):
- if hasattr(module, '__flops_handle__'):
- return
- if type(module) in CUSTOM_MODULES_MAPPING:
- handle = module.register_forward_hook(
- CUSTOM_MODULES_MAPPING[type(module)])
- elif getattr(module, 'compute_macs', False):
- handle = module.register_forward_hook(
- module.compute_macs
- )
- else:
- handle = module.register_forward_hook(MODULES_MAPPING[type(module)])
- module.__flops_handle__ = handle
- seen_types.add(type(module))
- else:
- if verbose and not type(module) in (nn.Sequential, nn.ModuleList) and \
- not type(module) in seen_types:
- print('Warning: module ' + type(module).__name__ +
- ' is treated as a zero-op.', file=ost)
- seen_types.add(type(module))
-
- self.apply(partial(add_flops_counter_hook_function, **kwargs))
-
-
-def stop_flops_count(self):
- """
- A method that will be available after add_flops_counting_methods() is called
- on a desired net object.
-
- Stops computing the mean flops consumption per image.
- Call whenever you want to pause the computation.
-
- """
- remove_batch_counter_hook_function(self)
- self.apply(remove_flops_counter_hook_function)
-
-
-def reset_flops_count(self):
- """
- A method that will be available after add_flops_counting_methods() is called
- on a desired net object.
-
- Resets statistics computed so far.
-
- """
- add_batch_counter_variables_or_reset(self)
- self.apply(add_flops_counter_variable_or_reset)
-
-
-# ---- Internal functions
-def empty_flops_counter_hook(module, input, output):
- module.__flops__ += 0
-
-
-def upsample_flops_counter_hook(module, input, output):
- output_size = output[0]
- batch_size = output_size.shape[0]
- output_elements_count = batch_size
- for val in output_size.shape[1:]:
- output_elements_count *= val
- module.__flops__ += int(output_elements_count)
-
-
-def relu_flops_counter_hook(module, input, output):
- active_elements_count = output.numel()
- module.__flops__ += int(active_elements_count)
-
-
-def linear_flops_counter_hook(module, input, output):
- input = input[0]
- # pytorch checks dimensions, so here we don't care much
- output_last_dim = output.shape[-1]
- bias_flops = output_last_dim if module.bias is not None else 0
- module.__flops__ += int(np.prod(input.shape) * output_last_dim + bias_flops)
-
-
-def pool_flops_counter_hook(module, input, output):
- input = input[0]
- module.__flops__ += int(np.prod(input.shape))
-
-
-def bn_flops_counter_hook(module, input, output):
- input = input[0]
-
- batch_flops = np.prod(input.shape)
- if module.affine:
- batch_flops *= 2
- module.__flops__ += int(batch_flops)
-
-
-def conv_flops_counter_hook(conv_module, input, output):
- # Can have multiple inputs, getting the first one
- input = input[0]
-
- batch_size = input.shape[0]
- output_dims = list(output.shape[2:])
-
- kernel_dims = list(conv_module.kernel_size)
- in_channels = conv_module.in_channels
- out_channels = conv_module.out_channels
- groups = conv_module.groups
-
- filters_per_channel = out_channels // groups
- conv_per_position_flops = int(np.prod(kernel_dims)) * \
- in_channels * filters_per_channel
-
- active_elements_count = batch_size * int(np.prod(output_dims))
-
- overall_conv_flops = conv_per_position_flops * active_elements_count
-
- bias_flops = 0
-
- if conv_module.bias is not None:
-
- bias_flops = out_channels * active_elements_count
-
- overall_flops = overall_conv_flops + bias_flops
-
- conv_module.__flops__ += int(overall_flops)
-
-
-def batch_counter_hook(module, input, output):
- batch_size = 1
- if len(input) > 0:
- # Can have multiple inputs, getting the first one
- input = input[0]
- batch_size = len(input)
- else:
- pass
- print('Warning! No positional inputs found for a module,'
- ' assuming batch size is 1.')
- module.__batch_counter__ += batch_size
-
-
-def rnn_flops(flops, rnn_module, w_ih, w_hh, input_size):
- # matrix matrix mult ih state and internal state
- flops += w_ih.shape[0]*w_ih.shape[1]
- # matrix matrix mult hh state and internal state
- flops += w_hh.shape[0]*w_hh.shape[1]
- if isinstance(rnn_module, (nn.RNN, nn.RNNCell)):
- # add both operations
- flops += rnn_module.hidden_size
- elif isinstance(rnn_module, (nn.GRU, nn.GRUCell)):
- # hadamard of r
- flops += rnn_module.hidden_size
- # adding operations from both states
- flops += rnn_module.hidden_size*3
- # last two hadamard product and add
- flops += rnn_module.hidden_size*3
- elif isinstance(rnn_module, (nn.LSTM, nn.LSTMCell)):
- # adding operations from both states
- flops += rnn_module.hidden_size*4
- # two hadamard product and add for C state
- flops += rnn_module.hidden_size + rnn_module.hidden_size + rnn_module.hidden_size
- # final hadamard
- flops += rnn_module.hidden_size + rnn_module.hidden_size + rnn_module.hidden_size
- return flops
-
-
-def rnn_flops_counter_hook(rnn_module, input, output):
- """
- Takes into account batch goes at first position, contrary
- to pytorch common rule (but actually it doesn't matter).
- IF sigmoid and tanh are made hard, only a comparison FLOPS should be accurate
- """
- flops = 0
- # input is a tuple containing a sequence to process and (optionally) hidden state
- inp = input[0]
- batch_size = inp.shape[0]
- seq_length = inp.shape[1]
- num_layers = rnn_module.num_layers
-
- for i in range(num_layers):
- w_ih = rnn_module.__getattr__('weight_ih_l' + str(i))
- w_hh = rnn_module.__getattr__('weight_hh_l' + str(i))
- if i == 0:
- input_size = rnn_module.input_size
- else:
- input_size = rnn_module.hidden_size
- flops = rnn_flops(flops, rnn_module, w_ih, w_hh, input_size)
- if rnn_module.bias:
- b_ih = rnn_module.__getattr__('bias_ih_l' + str(i))
- b_hh = rnn_module.__getattr__('bias_hh_l' + str(i))
- flops += b_ih.shape[0] + b_hh.shape[0]
-
- flops *= batch_size
- flops *= seq_length
- if rnn_module.bidirectional:
- flops *= 2
- rnn_module.__flops__ += int(flops)
-
-
-def rnn_cell_flops_counter_hook(rnn_cell_module, input, output):
- flops = 0
- inp = input[0]
- batch_size = inp.shape[0]
- w_ih = rnn_cell_module.__getattr__('weight_ih')
- w_hh = rnn_cell_module.__getattr__('weight_hh')
- input_size = inp.shape[1]
- flops = rnn_flops(flops, rnn_cell_module, w_ih, w_hh, input_size)
- if rnn_cell_module.bias:
- b_ih = rnn_cell_module.__getattr__('bias_ih')
- b_hh = rnn_cell_module.__getattr__('bias_hh')
- flops += b_ih.shape[0] + b_hh.shape[0]
-
- flops *= batch_size
- rnn_cell_module.__flops__ += int(flops)
-
-
-def add_batch_counter_variables_or_reset(module):
-
- module.__batch_counter__ = 0
-
-
-def add_batch_counter_hook_function(module):
- if hasattr(module, '__batch_counter_handle__'):
- return
-
- handle = module.register_forward_hook(batch_counter_hook)
- module.__batch_counter_handle__ = handle
-
-
-def remove_batch_counter_hook_function(module):
- if hasattr(module, '__batch_counter_handle__'):
- module.__batch_counter_handle__.remove()
- del module.__batch_counter_handle__
-
-
-def add_flops_counter_variable_or_reset(module):
- if is_supported_instance(module):
- if hasattr(module, '__flops__') or hasattr(module, '__params__'):
- print('Warning: variables __flops__ or __params__ are already '
- 'defined for the module' + type(module).__name__ +
- ' ptflops can affect your code!')
- module.__flops__ = 0
- module.__params__ = get_model_parameters_number(module)
-
-
-CUSTOM_MODULES_MAPPING = {}
-
-MODULES_MAPPING = {
- # convolutions
- nn.Conv1d: conv_flops_counter_hook,
- nn.Conv2d: conv_flops_counter_hook,
- nn.Conv3d: conv_flops_counter_hook,
- Conv2d: conv_flops_counter_hook,
- ModulatedDeformConv: conv_flops_counter_hook,
- # activations
- nn.ReLU: relu_flops_counter_hook,
- nn.PReLU: relu_flops_counter_hook,
- nn.ELU: relu_flops_counter_hook,
- nn.LeakyReLU: relu_flops_counter_hook,
- nn.ReLU6: relu_flops_counter_hook,
- # poolings
- nn.MaxPool1d: pool_flops_counter_hook,
- nn.AvgPool1d: pool_flops_counter_hook,
- nn.AvgPool2d: pool_flops_counter_hook,
- nn.MaxPool2d: pool_flops_counter_hook,
- nn.MaxPool3d: pool_flops_counter_hook,
- nn.AvgPool3d: pool_flops_counter_hook,
- nn.AdaptiveMaxPool1d: pool_flops_counter_hook,
- nn.AdaptiveAvgPool1d: pool_flops_counter_hook,
- nn.AdaptiveMaxPool2d: pool_flops_counter_hook,
- nn.AdaptiveAvgPool2d: pool_flops_counter_hook,
- nn.AdaptiveMaxPool3d: pool_flops_counter_hook,
- nn.AdaptiveAvgPool3d: pool_flops_counter_hook,
- # BNs
- nn.BatchNorm1d: bn_flops_counter_hook,
- nn.BatchNorm2d: bn_flops_counter_hook,
- nn.BatchNorm3d: bn_flops_counter_hook,
- nn.GroupNorm : bn_flops_counter_hook,
- # FC
- nn.Linear: linear_flops_counter_hook,
- # Upscale
- nn.Upsample: upsample_flops_counter_hook,
- # Deconvolution
- nn.ConvTranspose1d: conv_flops_counter_hook,
- nn.ConvTranspose2d: conv_flops_counter_hook,
- nn.ConvTranspose3d: conv_flops_counter_hook,
- ConvTranspose2d: conv_flops_counter_hook,
- # RNN
- nn.RNN: rnn_flops_counter_hook,
- nn.GRU: rnn_flops_counter_hook,
- nn.LSTM: rnn_flops_counter_hook,
- nn.RNNCell: rnn_cell_flops_counter_hook,
- nn.LSTMCell: rnn_cell_flops_counter_hook,
- nn.GRUCell: rnn_cell_flops_counter_hook
-}
-
-
-def is_supported_instance(module):
- if type(module) in MODULES_MAPPING or type(module) in CUSTOM_MODULES_MAPPING \
- or getattr(module, 'compute_macs', False):
- return True
- return False
-
-
-def remove_flops_counter_hook_function(module):
- if is_supported_instance(module):
- if hasattr(module, '__flops_handle__'):
- module.__flops_handle__.remove()
- del module.__flops_handle__
\ No newline at end of file
diff --git a/spaces/hardon-server/basegan1/app.py b/spaces/hardon-server/basegan1/app.py
deleted file mode 100644
index 2517d00f9c11e3bdbb8f85c0c51a2c206a8f8a19..0000000000000000000000000000000000000000
--- a/spaces/hardon-server/basegan1/app.py
+++ /dev/null
@@ -1,30 +0,0 @@
-from PIL import Image
-import torch
-import gradio as gr
-
-
-
-model2 = torch.hub.load(
- "AK391/animegan2-pytorch:main",
- "generator",
- pretrained=True,
- device="cpu",
- progress=False
-)
-
-
-model1 = torch.hub.load("AK391/animegan2-pytorch:main", "generator", pretrained="face_paint_512_v1", device="cpu")
-face2paint = torch.hub.load(
- 'AK391/animegan2-pytorch:main', 'face2paint',
- size=512, device="cpu",side_by_side=False
-)
-def inference(img, ver):
- if ver == 'version 2 (🔺 robustness,🔻 stylization)':
- out = face2paint(model2, img)
- else:
- out = face2paint(model1, img)
- return out
-
-
-gr.Interface(inference, [gr.inputs.Image(type="pil"),gr.inputs.Radio(['version 1 (🔺 stylization, 🔻 robustness)','version 2 (🔺 robustness,🔻 stylization)'], type="value", default='version 2 (🔺 robustness,🔻 stylization)', label='version')
-], gr.outputs.Image(type="pil"),allow_flagging=False,allow_screenshot=False, theme="Base").launch(enable_queue=False, show_error=False, share=False, debug=False)
\ No newline at end of file
diff --git a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/ONNXVITS_transforms.py b/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/ONNXVITS_transforms.py
deleted file mode 100644
index 69b6d1c4b5724a3ef61f8bc3d64fc45c5e51e270..0000000000000000000000000000000000000000
--- a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/ONNXVITS_transforms.py
+++ /dev/null
@@ -1,196 +0,0 @@
-import torch
-from torch.nn import functional as F
-
-import numpy as np
-
-
-DEFAULT_MIN_BIN_WIDTH = 1e-3
-DEFAULT_MIN_BIN_HEIGHT = 1e-3
-DEFAULT_MIN_DERIVATIVE = 1e-3
-
-
-def piecewise_rational_quadratic_transform(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails=None,
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
-
- if tails is None:
- spline_fn = rational_quadratic_spline
- spline_kwargs = {}
- else:
- spline_fn = unconstrained_rational_quadratic_spline
- spline_kwargs = {
- 'tails': tails,
- 'tail_bound': tail_bound
- }
-
- outputs, logabsdet = spline_fn(
- inputs=inputs,
- unnormalized_widths=unnormalized_widths,
- unnormalized_heights=unnormalized_heights,
- unnormalized_derivatives=unnormalized_derivatives,
- inverse=inverse,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative,
- **spline_kwargs
- )
- return outputs, logabsdet
-
-
-def searchsorted(bin_locations, inputs, eps=1e-6):
- bin_locations[..., -1] += eps
- return torch.sum(
- inputs[..., None] >= bin_locations,
- dim=-1
- ) - 1
-
-
-def unconstrained_rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails='linear',
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
- outside_interval_mask = ~inside_interval_mask
-
- outputs = torch.zeros_like(inputs)
- logabsdet = torch.zeros_like(inputs)
-
- if tails == 'linear':
- #unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
- unnormalized_derivatives_ = torch.zeros((1, 1, unnormalized_derivatives.size(2), unnormalized_derivatives.size(3)+2))
- unnormalized_derivatives_[...,1:-1] = unnormalized_derivatives
- unnormalized_derivatives = unnormalized_derivatives_
- constant = np.log(np.exp(1 - min_derivative) - 1)
- unnormalized_derivatives[..., 0] = constant
- unnormalized_derivatives[..., -1] = constant
-
- outputs[outside_interval_mask] = inputs[outside_interval_mask]
- logabsdet[outside_interval_mask] = 0
- else:
- raise RuntimeError('{} tails are not implemented.'.format(tails))
-
- outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline(
- inputs=inputs[inside_interval_mask],
- unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
- unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
- unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
- inverse=inverse,
- left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative
- )
-
- return outputs, logabsdet
-
-def rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- left=0., right=1., bottom=0., top=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- if torch.min(inputs) < left or torch.max(inputs) > right:
- raise ValueError('Input to a transform is not within its domain')
-
- num_bins = unnormalized_widths.shape[-1]
-
- if min_bin_width * num_bins > 1.0:
- raise ValueError('Minimal bin width too large for the number of bins')
- if min_bin_height * num_bins > 1.0:
- raise ValueError('Minimal bin height too large for the number of bins')
-
- widths = F.softmax(unnormalized_widths, dim=-1)
- widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
- cumwidths = torch.cumsum(widths, dim=-1)
- cumwidths = F.pad(cumwidths, pad=(1, 0), mode='constant', value=0.0)
- cumwidths = (right - left) * cumwidths + left
- cumwidths[..., 0] = left
- cumwidths[..., -1] = right
- widths = cumwidths[..., 1:] - cumwidths[..., :-1]
-
- derivatives = min_derivative + F.softplus(unnormalized_derivatives)
-
- heights = F.softmax(unnormalized_heights, dim=-1)
- heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
- cumheights = torch.cumsum(heights, dim=-1)
- cumheights = F.pad(cumheights, pad=(1, 0), mode='constant', value=0.0)
- cumheights = (top - bottom) * cumheights + bottom
- cumheights[..., 0] = bottom
- cumheights[..., -1] = top
- heights = cumheights[..., 1:] - cumheights[..., :-1]
-
- if inverse:
- bin_idx = searchsorted(cumheights, inputs)[..., None]
- else:
- bin_idx = searchsorted(cumwidths, inputs)[..., None]
-
- input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
- input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
-
- input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
- delta = heights / widths
- input_delta = delta.gather(-1, bin_idx)[..., 0]
-
- input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
- input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
-
- input_heights = heights.gather(-1, bin_idx)[..., 0]
-
- if inverse:
- a = (((inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta)
- + input_heights * (input_delta - input_derivatives)))
- b = (input_heights * input_derivatives
- - (inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta))
- c = - input_delta * (inputs - input_cumheights)
-
- discriminant = b.pow(2) - 4 * a * c
- assert (discriminant >= 0).all()
-
- root = (2 * c) / (-b - torch.sqrt(discriminant))
- outputs = root * input_bin_widths + input_cumwidths
-
- theta_one_minus_theta = root * (1 - root)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * root.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - root).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, -logabsdet
- else:
- theta = (inputs - input_cumwidths) / input_bin_widths
- theta_one_minus_theta = theta * (1 - theta)
-
- numerator = input_heights * (input_delta * theta.pow(2)
- + input_derivatives * theta_one_minus_theta)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- outputs = input_cumheights + numerator / denominator
-
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * theta.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - theta).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, logabsdet
diff --git a/spaces/ho11laqe/nnUNet_calvingfront_detection/scripts_new/run_glacier_front_2.sh b/spaces/ho11laqe/nnUNet_calvingfront_detection/scripts_new/run_glacier_front_2.sh
deleted file mode 100644
index b1d25f1e2ed370cc2f31451aceb458d076de4f08..0000000000000000000000000000000000000000
--- a/spaces/ho11laqe/nnUNet_calvingfront_detection/scripts_new/run_glacier_front_2.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-#!/bin/bash -l
-#SBATCH --nodes=1 --gres=gpu:1 --time=24:00:00
-#SBATCH --job-name=Task501_glacier_front_2
-
-export data_raw="/home/woody/iwi5/iwi5039h/data_raw"
-export nnUNet_raw_data_base="/home/woody/iwi5/iwi5039h/nnUNet_data/nnUNet_raw_data_base/"
-export nnUNet_preprocessed="/home/woody/iwi5/iwi5039h/nnUNet_data/nnUNet_preprocessed/"
-export RESULTS_FOLDER="/home/woody/iwi5/iwi5039h/nnUNet_data/RESULTS_FOLDER"
-
-cd nnunet_glacer
-pwd
-conda activate nnunet
-
-python3 nnunet/run/run_training.py 2d nnUNetTrainerV2 501 2 --disable_postprocessing_on_folds --disable_deepsupervision
-python3 nnunet/inference/predict_simple.py -i $nnUNet_raw_data_base/nnUNet_raw_data/Task501_Glacier_front/imagesTs -o $RESULTS_FOLDER/test_predictions/Task501_Glacier_front/fold_2 -t 501 -m 2d -f 2 -p nnUNetPlansv2.1 -tr nnUNetTrainerV2
-python3 nnunet/dataset_conversion/Task501_Glacier_reverse.py -i $RESULTS_FOLDER/test_predictions/Task501_Glacier_front/fold_2
-python3 ./evaluate_nnUNet.py --predictions $RESULTS_FOLDER/test_predictions/Task501_Glacier_front/fold_2/pngs --labels_fronts $data_raw/fronts/test --labels_zones $data_raw/zones/test --sar_images $data_raw/sar_images/test
diff --git a/spaces/hysts-samples/space-monitor/app.py b/spaces/hysts-samples/space-monitor/app.py
deleted file mode 100644
index c01dfad4024ec689ec32ee3b18f9a7996ee3aa97..0000000000000000000000000000000000000000
--- a/spaces/hysts-samples/space-monitor/app.py
+++ /dev/null
@@ -1,160 +0,0 @@
-#!/usr/bin/env python
-
-from __future__ import annotations
-
-import dataclasses
-import os
-import pathlib
-
-import gradio as gr
-import pandas as pd
-import tqdm.auto
-from huggingface_hub import HfApi
-
-from constants import HARDWARE_CHOICES, SDK_CHOICES, SLEEP_TIME_CHOICES, STATUS_CHOICES
-from demo_list import DemoInfo, DemoList
-
-repo_dir = pathlib.Path(__file__).parent.absolute()
-MAX_NUM = int(os.getenv("MAX_NUM", "200"))
-
-api = HfApi()
-
-
-def get_space_info() -> pd.DataFrame:
- with open(repo_dir / "space_ids.txt") as f:
- specified_space_ids = [line.strip() for line in f.readlines()]
- popular_space_ids = [space.id for space in api.list_spaces(sort="likes", limit=MAX_NUM, direction=-1)]
- space_ids = sorted(set(specified_space_ids + popular_space_ids))
- data = []
- for space_id in tqdm.auto.tqdm(space_ids):
- try:
- info = DemoInfo.from_space_id(space_id)
- data.append(dataclasses.asdict(info))
- except Exception as e:
- print(f"Failed to load {space_id}: {e}")
- return pd.DataFrame(data).sort_values("likes", ascending=False).reset_index(drop=True)
-
-
-demo_list = DemoList(get_space_info())
-
-
-def update_status_checkboxes(choices: list[str]) -> list[str]:
- if "(ALL)" in choices:
- return STATUS_CHOICES
- elif "(NONE)" in choices:
- return []
- else:
- return choices
-
-
-def update_hardware_checkboxes(choices: list[str]) -> list[str]:
- if "(ALL)" in choices:
- return HARDWARE_CHOICES
- elif "(NONE)" in choices:
- return []
- else:
- return choices
-
-
-def update_sdk_checkboxes(choices: list[str]) -> list[str]:
- if "(ALL)" in choices:
- return SDK_CHOICES
- elif "(NONE)" in choices:
- return []
- else:
- return choices
-
-
-def update_sleep_time_checkboxes(choices: list[str]) -> list[str]:
- if "(ALL)" in choices:
- return SLEEP_TIME_CHOICES
- elif "(NONE)" in choices:
- return []
- else:
- return choices
-
-
-with gr.Blocks(css="style.css") as demo:
- with gr.Accordion(label="Filter", open=True):
- status = gr.CheckboxGroup(
- label="Status",
- choices=["(ALL)", "(NONE)"] + STATUS_CHOICES,
- value=STATUS_CHOICES,
- type="value",
- )
- hardware = gr.CheckboxGroup(
- label="Hardware",
- choices=["(ALL)", "(NONE)"] + HARDWARE_CHOICES,
- value=HARDWARE_CHOICES,
- type="value",
- )
- sdk = gr.CheckboxGroup(
- label="SDK",
- choices=["(ALL)", "(NONE)"] + SDK_CHOICES,
- value=SDK_CHOICES,
- type="value",
- )
- sleep_time = gr.CheckboxGroup(
- label="Sleep time",
- choices=["(ALL)", "(NONE)"] + SLEEP_TIME_CHOICES,
- value=SLEEP_TIME_CHOICES,
- type="value",
- )
- multiple_replicas = gr.Checkbox(label="Multiple replicas", value=False)
- apply_button = gr.Button("Apply")
- df = gr.Dataframe(
- value=demo_list.df_prettified,
- datatype=demo_list.column_datatype,
- type="pandas",
- row_count=(0, "dynamic"),
- height=1000,
- elem_id="table",
- )
-
- status.change(
- fn=update_status_checkboxes,
- inputs=status,
- outputs=status,
- queue=False,
- show_progress=False,
- api_name=False,
- )
- hardware.change(
- fn=update_hardware_checkboxes,
- inputs=hardware,
- outputs=hardware,
- queue=False,
- show_progress=False,
- api_name=False,
- )
- sdk.change(
- fn=update_sdk_checkboxes,
- inputs=sdk,
- outputs=sdk,
- queue=False,
- show_progress=False,
- api_name=False,
- )
- sleep_time.change(
- fn=update_sleep_time_checkboxes,
- inputs=sleep_time,
- outputs=sleep_time,
- queue=False,
- show_progress=False,
- api_name=False,
- )
- apply_button.click(
- fn=demo_list.filter,
- inputs=[
- status,
- hardware,
- sleep_time,
- multiple_replicas,
- sdk,
- ],
- outputs=df,
- api_name=False,
- )
-
-if __name__ == "__main__":
- demo.queue(api_open=False).launch()
diff --git a/spaces/hysts/Kandinsky-2-2/README.md b/spaces/hysts/Kandinsky-2-2/README.md
deleted file mode 100644
index 0c68eb9a116ab5ada5f47d270aec5fb85a3cdca7..0000000000000000000000000000000000000000
--- a/spaces/hysts/Kandinsky-2-2/README.md
+++ /dev/null
@@ -1,16 +0,0 @@
----
-title: Kandinsky 2.2
-emoji: 😻
-colorFrom: gray
-colorTo: purple
-sdk: gradio
-sdk_version: 3.47.0
-app_file: app.py
-pinned: false
-license: mit
-suggested_hardware: t4-small
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
-
-https://arxiv.org/abs/2310.03502
diff --git a/spaces/inamXcontru/PoeticTTS/Body By Design Kris Gethin Pdf Download Freel Learn from the Expert Trainer and Author.md b/spaces/inamXcontru/PoeticTTS/Body By Design Kris Gethin Pdf Download Freel Learn from the Expert Trainer and Author.md
deleted file mode 100644
index cbf159a69b195d75d70dca66538eb239f3c550c6..0000000000000000000000000000000000000000
--- a/spaces/inamXcontru/PoeticTTS/Body By Design Kris Gethin Pdf Download Freel Learn from the Expert Trainer and Author.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Body By Design Kris Gethin Pdf Download Freel Download ✫✫✫ https://gohhs.com/2uz3xy
diff --git a/spaces/inamXcontru/PoeticTTS/CommView For WiFi 6.3.701 Final Portable.md b/spaces/inamXcontru/PoeticTTS/CommView For WiFi 6.3.701 Final Portable.md
deleted file mode 100644
index a3a281760f775e3cd9dabcb27ba7261881daf520..0000000000000000000000000000000000000000
--- a/spaces/inamXcontru/PoeticTTS/CommView For WiFi 6.3.701 Final Portable.md
+++ /dev/null
@@ -1,6 +0,0 @@
-CommView for WiFi 6.3.701 Final Portable Download Zip > https://gohhs.com/2uz4cH
diff --git a/spaces/innnky/visinger2-nomidi/utils/audio.py b/spaces/innnky/visinger2-nomidi/utils/audio.py
deleted file mode 100644
index ca2621f2040f172c6b8ae76538bd742e79a30d08..0000000000000000000000000000000000000000
--- a/spaces/innnky/visinger2-nomidi/utils/audio.py
+++ /dev/null
@@ -1,99 +0,0 @@
-import numpy as np
-from numpy import linalg as LA
-import librosa
-from scipy.io import wavfile
-import soundfile as sf
-import librosa.filters
-
-
-def load_wav(wav_path, raw_sr, target_sr=16000, win_size=800, hop_size=200):
- audio = librosa.core.load(wav_path, sr=raw_sr)[0]
- if raw_sr != target_sr:
- audio = librosa.core.resample(audio,
- raw_sr,
- target_sr,
- res_type='kaiser_best')
- target_length = (audio.size // hop_size +
- win_size // hop_size) * hop_size
- pad_len = (target_length - audio.size) // 2
- if audio.size % 2 == 0:
- audio = np.pad(audio, (pad_len, pad_len), mode='reflect')
- else:
- audio = np.pad(audio, (pad_len, pad_len + 1), mode='reflect')
- return audio
-
-
-def save_wav(wav, path, sample_rate, norm=False):
- if norm:
- wav *= 32767 / max(0.01, np.max(np.abs(wav)))
- wavfile.write(path, sample_rate, wav.astype(np.int16))
- else:
- sf.write(path, wav, sample_rate)
-
-
-_mel_basis = None
-_inv_mel_basis = None
-
-
-def _build_mel_basis(hparams):
- assert hparams.fmax <= hparams.sample_rate // 2
- return librosa.filters.mel(hparams.sample_rate,
- hparams.n_fft,
- n_mels=hparams.acoustic_dim,
- fmin=hparams.fmin,
- fmax=hparams.fmax)
-
-
-def _linear_to_mel(spectogram, hparams):
- global _mel_basis
- if _mel_basis is None:
- _mel_basis = _build_mel_basis(hparams)
- return np.dot(_mel_basis, spectogram)
-
-
-def _mel_to_linear(mel_spectrogram, hparams):
- global _inv_mel_basis
- if _inv_mel_basis is None:
- _inv_mel_basis = np.linalg.pinv(_build_mel_basis(hparams))
- return np.maximum(1e-10, np.dot(_inv_mel_basis, mel_spectrogram))
-
-
-def _stft(y, hparams):
- return librosa.stft(y=y,
- n_fft=hparams.n_fft,
- hop_length=hparams.hop_size,
- win_length=hparams.win_size)
-
-
-def _amp_to_db(x, hparams):
- min_level = np.exp(hparams.min_level_db / 20 * np.log(10))
- return 20 * np.log10(np.maximum(min_level, x))
-
-def _normalize(S, hparams):
- return hparams.max_abs_value * np.clip(((S - hparams.min_db) /
- (-hparams.min_db)), 0, 1)
-
-def _db_to_amp(x):
- return np.power(10.0, (x) * 0.05)
-
-
-def _stft(y, hparams):
- return librosa.stft(y=y,
- n_fft=hparams.n_fft,
- hop_length=hparams.hop_size,
- win_length=hparams.win_size)
-
-
-def _istft(y, hparams):
- return librosa.istft(y,
- hop_length=hparams.hop_size,
- win_length=hparams.win_size)
-
-
-def melspectrogram(wav, hparams):
- D = _stft(wav, hparams)
- S = _amp_to_db(_linear_to_mel(np.abs(D), hparams),
- hparams) - hparams.ref_level_db
- return _normalize(S, hparams)
-
-
diff --git a/spaces/innnky/visinger2-nomidi/utils/utils.py b/spaces/innnky/visinger2-nomidi/utils/utils.py
deleted file mode 100644
index 37a3855d01f5b23c553093a746b40297179e61c5..0000000000000000000000000000000000000000
--- a/spaces/innnky/visinger2-nomidi/utils/utils.py
+++ /dev/null
@@ -1,268 +0,0 @@
-import os
-import glob
-import sys
-import argparse
-import logging
-import json
-import subprocess
-import numpy as np
-from scipy.io.wavfile import read
-import torch
-
-MATPLOTLIB_FLAG = False
-
-logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
-logger = logging
-
-
-def load_checkpoint(checkpoint_path, model, optimizer=None):
- assert os.path.isfile(checkpoint_path)
- checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
- iteration = checkpoint_dict['iteration']
- learning_rate = checkpoint_dict['learning_rate']
- if optimizer is not None:
- optimizer.load_state_dict(checkpoint_dict['optimizer'])
- saved_state_dict = checkpoint_dict['model']
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- new_state_dict = {}
- for k, v in state_dict.items():
- try:
- new_state_dict[k] = saved_state_dict[k]
- assert saved_state_dict[k].shape == v.shape, (saved_state_dict[k].shape, v.shape)
- except:
- print("error, %s is not in the checkpoint" % k)
- logger.info("%s is not in the checkpoint" % k)
- new_state_dict[k] = v
- if hasattr(model, 'module'):
- model.module.load_state_dict(new_state_dict)
- else:
- model.load_state_dict(new_state_dict)
- print("load ")
- logger.info("Loaded checkpoint '{}' (iteration {})".format(
- checkpoint_path, iteration))
- return model, optimizer, learning_rate, iteration
-
-
-def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path, val_steps):
- ckptname = checkpoint_path.split(os.sep)[-1]
- newest_step = int(ckptname.split(".")[0].split("_")[1])
- last_ckptname = checkpoint_path.replace(str(newest_step), str(newest_step - val_steps * 2))
- if newest_step >= val_steps * 2:
- os.system(f"rm {last_ckptname}")
-
- logger.info("Saving model and optimizer state at iteration {} to {}".format(
- iteration, checkpoint_path))
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- torch.save({'model': state_dict,
- 'iteration': iteration,
- 'optimizer': optimizer.state_dict(),
- 'learning_rate': learning_rate}, checkpoint_path)
-
-
-def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050):
- for k, v in scalars.items():
- writer.add_scalar(k, v, global_step)
- for k, v in histograms.items():
- writer.add_histogram(k, v, global_step)
- for k, v in images.items():
- writer.add_image(k, v, global_step, dataformats='HWC')
- for k, v in audios.items():
- writer.add_audio(k, v, global_step, audio_sampling_rate)
-
-
-def latest_checkpoint_path(dir_path, regex="G_*.pth"):
- f_list = glob.glob(os.path.join(dir_path, regex))
- f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
- x = f_list[-1]
- print(x)
- return x
-
-
-def plot_spectrogram_to_numpy(spectrogram):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(10, 2))
- im = ax.imshow(spectrogram, aspect="auto", origin="lower",
- interpolation='none')
- plt.colorbar(im, ax=ax)
- plt.xlabel("Frames")
- plt.ylabel("Channels")
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def plot_alignment_to_numpy(alignment, info=None):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(6, 4))
- im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower',
- interpolation='none')
- fig.colorbar(im, ax=ax)
- xlabel = 'Decoder timestep'
- if info is not None:
- xlabel += '\n\n' + info
- plt.xlabel(xlabel)
- plt.ylabel('Encoder timestep')
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def load_wav_to_torch(full_path):
- sampling_rate, data = read(full_path)
- return torch.FloatTensor(data.astype(np.float32)), sampling_rate
-
-
-def load_filepaths_and_text(filename, split="|"):
- with open(filename, encoding='utf-8') as f:
- filepaths_and_text = [line.strip().split(split) for line in f]
- return filepaths_and_text
-
-
-def get_hparams(init=True):
- parser = argparse.ArgumentParser()
- parser.add_argument('-c', '--config', type=str, default="./configs/base.json",
- help='JSON file for configuration')
- # parser.add_argument('-m', '--model', type=str, required=True,
- # help='Model name')
-
- args = parser.parse_args()
-
- config_path = args.config
- with open(config_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- # hparams.model_dir = model_dir
- model_dir = hparams.train.save_dir
- config_save_path = os.path.join(model_dir, "config.json")
-
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
-
- with open(config_save_path, "w") as f:
- f.write(data)
- return hparams
-
-
-def get_hparams_from_dir(model_dir):
- config_save_path = os.path.join(model_dir, "config.json")
- with open(config_save_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- hparams.model_dir = model_dir
- return hparams
-
-
-def get_hparams_from_file(config_path):
- with open(config_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- return hparams
-
-
-def check_git_hash(model_dir):
- source_dir = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
- if not os.path.exists(os.path.join(source_dir, ".git")):
- logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format(
- source_dir
- ))
- return
-
- cur_hash = subprocess.getoutput("git rev-parse HEAD")
-
- path = os.path.join(model_dir, "githash")
- if os.path.exists(path):
- saved_hash = open(path).read()
- if saved_hash != cur_hash:
- logger.warn("git hash values are different. {}(saved) != {}(current)".format(
- saved_hash[:8], cur_hash[:8]))
- else:
- open(path, "w").write(cur_hash)
-
-
-def get_logger(model_dir, filename="train.log"):
- global logger
- logger = logging.getLogger(os.path.basename(model_dir))
- logger.setLevel(logging.DEBUG)
-
- formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
- h = logging.FileHandler(os.path.join(model_dir, filename))
- h.setLevel(logging.DEBUG)
- h.setFormatter(formatter)
- logger.addHandler(h)
- return logger
-
-
-def count_parameters(model):
- return sum(p.numel() for p in model.parameters() if p.requires_grad) / 1e6
-
-
-class HParams():
- def __init__(self, **kwargs):
- for k, v in kwargs.items():
- if type(v) == dict:
- v = HParams(**v)
- self[k] = v
-
- def keys(self):
- return self.__dict__.keys()
-
- def items(self):
- return self.__dict__.items()
-
- def values(self):
- return self.__dict__.values()
-
- def __len__(self):
- return len(self.__dict__)
-
- def __getitem__(self, key):
- return getattr(self, key)
-
- def __setitem__(self, key, value):
- return setattr(self, key, value)
-
- def __contains__(self, key):
- return key in self.__dict__
-
- def __repr__(self):
- return self.__dict__.__repr__()
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Garmin Bluechart G2 Vision Veu714l Torrent Download Torrent 17.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Garmin Bluechart G2 Vision Veu714l Torrent Download Torrent 17.md
deleted file mode 100644
index fa304d8daa5864ce15638c2b83a7a7260c4ce875..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Garmin Bluechart G2 Vision Veu714l Torrent Download Torrent 17.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Garmin Bluechart G2 Vision Veu714l Torrent Download Torrent 17 Download File ⏩ https://urlin.us/2uEwwB
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Hard To Be A God Crack Fix Downloadl.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Hard To Be A God Crack Fix Downloadl.md
deleted file mode 100644
index d9fd6d550645ee04489916e369d59243c3a4906b..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Hard To Be A God Crack Fix Downloadl.md
+++ /dev/null
@@ -1,43 +0,0 @@
-Hard To Be A God Crack Fix Downloadl: How to Play the Game without Errors
-Hard To Be A God is a PC game that was released in 2007, based on the novel of the same name by Arkady and Boris Strugatsky. The game is a role-playing adventure that takes place in a medieval world where a group of Earth scientists are sent to observe and influence the development of civilization. The game features a complex and nonlinear storyline, a realistic combat system, and a rich and detailed environment.
-However, some players have reported problems with the game, such as crashes, freezes, glitches, and errors. These issues can prevent the game from running properly or ruin the gaming experience. Fortunately, there is a solution for these problems: Hard To Be A God Crack Fix Downloadl.
-Hard To Be A God Crack Fix Downloadl DOWNLOAD ✑ ✑ ✑ https://urlin.us/2uEwgW
What is Hard To Be A God Crack Fix Downloadl?
-Hard To Be A God Crack Fix Downloadl is a file that can fix the problems with the game and make it run smoothly. It is a modified version of the game executable that bypasses the protection system and eliminates the errors. It also improves the performance and stability of the game.
-Hard To Be A God Crack Fix Downloadl can be downloaded from various online sources, such as GameCopyWorld, OpenSea, SoundCloud, and Fátima Martínez Hern. These sources provide links to download the file for free and instructions on how to use it.
-How to use Hard To Be A God Crack Fix Downloadl?
-To use Hard To Be A God Crack Fix Downloadl, you need to follow these simple steps:
-
-Download Hard To Be A God Crack Fix Downloadl from one of the sources mentioned above.
-Extract the file using a program like WinRAR or 7-Zip.
-Copy the file to the folder where you installed the game, usually C:\Program Files\Hard To Be A God.
-Replace the original file when prompted.
-Run the game as usual and enjoy it without errors.
-
-Conclusion
-Hard To Be A God is a PC game that offers a unique and immersive gaming experience. However, some players may encounter problems with the game that can affect their enjoyment. To solve these problems, they can use Hard To Be A God Crack Fix Downloadl, a file that can fix the errors and improve the performance of the game. Hard To Be A God Crack Fix Downloadl can be downloaded for free from various online sources and used easily by following some simple steps.
-If you are a fan of Hard To Be A God and want to play it without any issues,
-Hard To Be A God Crack Fix Downloadl: How to Play the Game without Errors
-Hard To Be A God is a PC game that was released in 2007, based on the novel of the same name by Arkady and Boris Strugatsky. The game is a role-playing adventure that takes place in a medieval world where a group of Earth scientists are sent to observe and influence the development of civilization. The game features a complex and nonlinear storyline, a realistic combat system, and a rich and detailed environment.
-However, some players have reported problems with the game, such as crashes, freezes, glitches, and errors. These issues can prevent the game from running properly or ruin the gaming experience. Fortunately, there is a solution for these problems: Hard To Be A God Crack Fix Downloadl.
-
-What is Hard To Be A God Crack Fix Downloadl?
-Hard To Be A God Crack Fix Downloadl is a file that can fix the problems with the game and make it run smoothly. It is a modified version of the game executable that bypasses the protection system and eliminates the errors. It also improves the performance and stability of the game.
-Hard To Be A God Crack Fix Downloadl can be downloaded from various online sources, such as GameCopyWorld, OpenSea, SoundCloud, and Fátima Martínez Hern. These sources provide links to download the file for free and instructions on how to use it.
-How to use Hard To Be A God Crack Fix Downloadl?
-To use Hard To Be A God Crack Fix Downloadl, you need to follow these simple steps:
-
-Download Hard To Be A God Crack Fix Downloadl from one of the sources mentioned above.
-Extract the file using a program like WinRAR or 7-Zip.
-Copy the file to the folder where you installed the game, usually C:\Program Files\Hard To Be A God.
-Replace the original file when prompted.
-Run the game as usual and enjoy it without errors.
-
-Conclusion
-Hard To Be A God is a PC game that offers a unique and immersive gaming experience. However, some players may encounter problems with the game that can affect their enjoyment. To solve these problems, they can use Hard To Be A God Crack Fix Downloadl, a file that can fix the errors and improve the performance of the game. Hard To Be A God Crack Fix Downloadl can be downloaded for free from various online sources and used easily by following some simple steps.
-If you are a fan of Hard To Be A God and want to play it without any issues,
-
Hard To Be A God is a PC game that offers a unique and immersive gaming experience. However, some players may encounter problems with the game that can affect their enjoyment. To solve these problems, they can use Hard To Be A God Crack Fix Downloadl, a file that can fix the errors and improve the performance of the game. Hard To Be A God Crack Fix Downloadl can be downloaded for free from various online sources and used easily by following some simple steps.
-If you are a fan of Hard To Be A God and want to play it without any issues,
3cee63e6c2
-
-import re
-
-from . import Image, _imagingmorph
-
-LUT_SIZE = 1 << 9
-
-# fmt: off
-ROTATION_MATRIX = [
- 6, 3, 0,
- 7, 4, 1,
- 8, 5, 2,
-]
-MIRROR_MATRIX = [
- 2, 1, 0,
- 5, 4, 3,
- 8, 7, 6,
-]
-# fmt: on
-
-
-class LutBuilder:
- """A class for building a MorphLut from a descriptive language
-
- The input patterns is a list of a strings sequences like these::
-
- 4:(...
- .1.
- 111)->1
-
- (whitespaces including linebreaks are ignored). The option 4
- describes a series of symmetry operations (in this case a
- 4-rotation), the pattern is described by:
-
- - . or X - Ignore
- - 1 - Pixel is on
- - 0 - Pixel is off
-
- The result of the operation is described after "->" string.
-
- The default is to return the current pixel value, which is
- returned if no other match is found.
-
- Operations:
-
- - 4 - 4 way rotation
- - N - Negate
- - 1 - Dummy op for no other operation (an op must always be given)
- - M - Mirroring
-
- Example::
-
- lb = LutBuilder(patterns = ["4:(... .1. 111)->1"])
- lut = lb.build_lut()
-
- """
-
- def __init__(self, patterns=None, op_name=None):
- if patterns is not None:
- self.patterns = patterns
- else:
- self.patterns = []
- self.lut = None
- if op_name is not None:
- known_patterns = {
- "corner": ["1:(... ... ...)->0", "4:(00. 01. ...)->1"],
- "dilation4": ["4:(... .0. .1.)->1"],
- "dilation8": ["4:(... .0. .1.)->1", "4:(... .0. ..1)->1"],
- "erosion4": ["4:(... .1. .0.)->0"],
- "erosion8": ["4:(... .1. .0.)->0", "4:(... .1. ..0)->0"],
- "edge": [
- "1:(... ... ...)->0",
- "4:(.0. .1. ...)->1",
- "4:(01. .1. ...)->1",
- ],
- }
- if op_name not in known_patterns:
- msg = "Unknown pattern " + op_name + "!"
- raise Exception(msg)
-
- self.patterns = known_patterns[op_name]
-
- def add_patterns(self, patterns):
- self.patterns += patterns
-
- def build_default_lut(self):
- symbols = [0, 1]
- m = 1 << 4 # pos of current pixel
- self.lut = bytearray(symbols[(i & m) > 0] for i in range(LUT_SIZE))
-
- def get_lut(self):
- return self.lut
-
- def _string_permute(self, pattern, permutation):
- """string_permute takes a pattern and a permutation and returns the
- string permuted according to the permutation list.
- """
- assert len(permutation) == 9
- return "".join(pattern[p] for p in permutation)
-
- def _pattern_permute(self, basic_pattern, options, basic_result):
- """pattern_permute takes a basic pattern and its result and clones
- the pattern according to the modifications described in the $options
- parameter. It returns a list of all cloned patterns."""
- patterns = [(basic_pattern, basic_result)]
-
- # rotations
- if "4" in options:
- res = patterns[-1][1]
- for i in range(4):
- patterns.append(
- (self._string_permute(patterns[-1][0], ROTATION_MATRIX), res)
- )
- # mirror
- if "M" in options:
- n = len(patterns)
- for pattern, res in patterns[:n]:
- patterns.append((self._string_permute(pattern, MIRROR_MATRIX), res))
-
- # negate
- if "N" in options:
- n = len(patterns)
- for pattern, res in patterns[:n]:
- # Swap 0 and 1
- pattern = pattern.replace("0", "Z").replace("1", "0").replace("Z", "1")
- res = 1 - int(res)
- patterns.append((pattern, res))
-
- return patterns
-
- def build_lut(self):
- """Compile all patterns into a morphology lut.
-
- TBD :Build based on (file) morphlut:modify_lut
- """
- self.build_default_lut()
- patterns = []
-
- # Parse and create symmetries of the patterns strings
- for p in self.patterns:
- m = re.search(r"(\w*):?\s*\((.+?)\)\s*->\s*(\d)", p.replace("\n", ""))
- if not m:
- msg = 'Syntax error in pattern "' + p + '"'
- raise Exception(msg)
- options = m.group(1)
- pattern = m.group(2)
- result = int(m.group(3))
-
- # Get rid of spaces
- pattern = pattern.replace(" ", "").replace("\n", "")
-
- patterns += self._pattern_permute(pattern, options, result)
-
- # compile the patterns into regular expressions for speed
- for i, pattern in enumerate(patterns):
- p = pattern[0].replace(".", "X").replace("X", "[01]")
- p = re.compile(p)
- patterns[i] = (p, pattern[1])
-
- # Step through table and find patterns that match.
- # Note that all the patterns are searched. The last one
- # caught overrides
- for i in range(LUT_SIZE):
- # Build the bit pattern
- bitpattern = bin(i)[2:]
- bitpattern = ("0" * (9 - len(bitpattern)) + bitpattern)[::-1]
-
- for p, r in patterns:
- if p.match(bitpattern):
- self.lut[i] = [0, 1][r]
-
- return self.lut
-
-
-class MorphOp:
- """A class for binary morphological operators"""
-
- def __init__(self, lut=None, op_name=None, patterns=None):
- """Create a binary morphological operator"""
- self.lut = lut
- if op_name is not None:
- self.lut = LutBuilder(op_name=op_name).build_lut()
- elif patterns is not None:
- self.lut = LutBuilder(patterns=patterns).build_lut()
-
- def apply(self, image):
- """Run a single morphological operation on an image
-
- Returns a tuple of the number of changed pixels and the
- morphed image"""
- if self.lut is None:
- msg = "No operator loaded"
- raise Exception(msg)
-
- if image.mode != "L":
- msg = "Image mode must be L"
- raise ValueError(msg)
- outimage = Image.new(image.mode, image.size, None)
- count = _imagingmorph.apply(bytes(self.lut), image.im.id, outimage.im.id)
- return count, outimage
-
- def match(self, image):
- """Get a list of coordinates matching the morphological operation on
- an image.
-
- Returns a list of tuples of (x,y) coordinates
- of all matching pixels. See :ref:`coordinate-system`."""
- if self.lut is None:
- msg = "No operator loaded"
- raise Exception(msg)
-
- if image.mode != "L":
- msg = "Image mode must be L"
- raise ValueError(msg)
- return _imagingmorph.match(bytes(self.lut), image.im.id)
-
- def get_on_pixels(self, image):
- """Get a list of all turned on pixels in a binary image
-
- Returns a list of tuples of (x,y) coordinates
- of all matching pixels. See :ref:`coordinate-system`."""
-
- if image.mode != "L":
- msg = "Image mode must be L"
- raise ValueError(msg)
- return _imagingmorph.get_on_pixels(image.im.id)
-
- def load_lut(self, filename):
- """Load an operator from an mrl file"""
- with open(filename, "rb") as f:
- self.lut = bytearray(f.read())
-
- if len(self.lut) != LUT_SIZE:
- self.lut = None
- msg = "Wrong size operator file!"
- raise Exception(msg)
-
- def save_lut(self, filename):
- """Save an operator to an mrl file"""
- if self.lut is None:
- msg = "No operator loaded"
- raise Exception(msg)
- with open(filename, "wb") as f:
- f.write(self.lut)
-
- def set_lut(self, lut):
- """Set the lut from an external source"""
- self.lut = lut
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/PyPDF2/filters.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/PyPDF2/filters.py
deleted file mode 100644
index 11f6a21b844bc96f7010d4ac787ffd2983c78760..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/PyPDF2/filters.py
+++ /dev/null
@@ -1,645 +0,0 @@
-# Copyright (c) 2006, Mathieu Fenniak
-# All rights reserved.
-#
-# Redistribution and use in source and binary forms, with or without
-# modification, are permitted provided that the following conditions are
-# met:
-#
-# * Redistributions of source code must retain the above copyright notice,
-# this list of conditions and the following disclaimer.
-# * Redistributions in binary form must reproduce the above copyright notice,
-# this list of conditions and the following disclaimer in the documentation
-# and/or other materials provided with the distribution.
-# * The name of the author may not be used to endorse or promote products
-# derived from this software without specific prior written permission.
-#
-# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
-# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
-# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
-# ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
-# LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
-# CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
-# SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
-# INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
-# CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
-# ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
-# POSSIBILITY OF SUCH DAMAGE.
-
-
-"""
-Implementation of stream filters for PDF.
-
-See TABLE H.1 Abbreviations for standard filter names
-"""
-__author__ = "Mathieu Fenniak"
-__author_email__ = "biziqe@mathieu.fenniak.net"
-
-import math
-import struct
-import zlib
-from io import BytesIO
-from typing import Any, Dict, Optional, Tuple, Union, cast
-
-from .generic import ArrayObject, DictionaryObject, IndirectObject, NameObject
-
-try:
- from typing import Literal # type: ignore[attr-defined]
-except ImportError:
- # PEP 586 introduced typing.Literal with Python 3.8
- # For older Python versions, the backport typing_extensions is necessary:
- from typing_extensions import Literal # type: ignore[misc]
-
-from ._utils import b_, deprecate_with_replacement, ord_, paeth_predictor
-from .constants import CcittFaxDecodeParameters as CCITT
-from .constants import ColorSpaces
-from .constants import FilterTypeAbbreviations as FTA
-from .constants import FilterTypes as FT
-from .constants import GraphicsStateParameters as G
-from .constants import ImageAttributes as IA
-from .constants import LzwFilterParameters as LZW
-from .constants import StreamAttributes as SA
-from .errors import PdfReadError, PdfStreamError
-
-
-def decompress(data: bytes) -> bytes:
- try:
- return zlib.decompress(data)
- except zlib.error:
- d = zlib.decompressobj(zlib.MAX_WBITS | 32)
- result_str = b""
- for b in [data[i : i + 1] for i in range(len(data))]:
- try:
- result_str += d.decompress(b)
- except zlib.error:
- pass
- return result_str
-
-
-class FlateDecode:
- @staticmethod
- def decode(
- data: bytes,
- decode_parms: Union[None, ArrayObject, DictionaryObject] = None,
- **kwargs: Any,
- ) -> bytes:
- """
- Decode data which is flate-encoded.
-
- :param data: flate-encoded data.
- :param decode_parms: a dictionary of values, understanding the
- "/Predictor": key only
- :return: the flate-decoded data.
-
- :raises PdfReadError:
- """
- if "decodeParms" in kwargs: # pragma: no cover
- deprecate_with_replacement("decodeParms", "parameters", "4.0.0")
- decode_parms = kwargs["decodeParms"]
- str_data = decompress(data)
- predictor = 1
-
- if decode_parms:
- try:
- if isinstance(decode_parms, ArrayObject):
- for decode_parm in decode_parms:
- if "/Predictor" in decode_parm:
- predictor = decode_parm["/Predictor"]
- else:
- predictor = decode_parms.get("/Predictor", 1)
- except (AttributeError, TypeError): # Type Error is NullObject
- pass # Usually an array with a null object was read
- # predictor 1 == no predictor
- if predictor != 1:
- # The /Columns param. has 1 as the default value; see ISO 32000,
- # §7.4.4.3 LZWDecode and FlateDecode Parameters, Table 8
- DEFAULT_BITS_PER_COMPONENT = 8
- if isinstance(decode_parms, ArrayObject):
- columns = 1
- bits_per_component = DEFAULT_BITS_PER_COMPONENT
- for decode_parm in decode_parms:
- if "/Columns" in decode_parm:
- columns = decode_parm["/Columns"]
- if LZW.BITS_PER_COMPONENT in decode_parm:
- bits_per_component = decode_parm[LZW.BITS_PER_COMPONENT]
- else:
- columns = (
- 1 if decode_parms is None else decode_parms.get(LZW.COLUMNS, 1)
- )
- bits_per_component = (
- decode_parms.get(LZW.BITS_PER_COMPONENT, DEFAULT_BITS_PER_COMPONENT)
- if decode_parms
- else DEFAULT_BITS_PER_COMPONENT
- )
-
- # PNG predictor can vary by row and so is the lead byte on each row
- rowlength = (
- math.ceil(columns * bits_per_component / 8) + 1
- ) # number of bytes
-
- # PNG prediction:
- if 10 <= predictor <= 15:
- str_data = FlateDecode._decode_png_prediction(str_data, columns, rowlength) # type: ignore
- else:
- # unsupported predictor
- raise PdfReadError(f"Unsupported flatedecode predictor {predictor!r}")
- return str_data
-
- @staticmethod
- def _decode_png_prediction(data: str, columns: int, rowlength: int) -> bytes:
- output = BytesIO()
- # PNG prediction can vary from row to row
- if len(data) % rowlength != 0:
- raise PdfReadError("Image data is not rectangular")
- prev_rowdata = (0,) * rowlength
- for row in range(len(data) // rowlength):
- rowdata = [
- ord_(x) for x in data[(row * rowlength) : ((row + 1) * rowlength)]
- ]
- filter_byte = rowdata[0]
-
- if filter_byte == 0:
- pass
- elif filter_byte == 1:
- for i in range(2, rowlength):
- rowdata[i] = (rowdata[i] + rowdata[i - 1]) % 256
- elif filter_byte == 2:
- for i in range(1, rowlength):
- rowdata[i] = (rowdata[i] + prev_rowdata[i]) % 256
- elif filter_byte == 3:
- for i in range(1, rowlength):
- left = rowdata[i - 1] if i > 1 else 0
- floor = math.floor(left + prev_rowdata[i]) / 2
- rowdata[i] = (rowdata[i] + int(floor)) % 256
- elif filter_byte == 4:
- for i in range(1, rowlength):
- left = rowdata[i - 1] if i > 1 else 0
- up = prev_rowdata[i]
- up_left = prev_rowdata[i - 1] if i > 1 else 0
- paeth = paeth_predictor(left, up, up_left)
- rowdata[i] = (rowdata[i] + paeth) % 256
- else:
- # unsupported PNG filter
- raise PdfReadError(f"Unsupported PNG filter {filter_byte!r}")
- prev_rowdata = tuple(rowdata)
- output.write(bytearray(rowdata[1:]))
- return output.getvalue()
-
- @staticmethod
- def encode(data: bytes) -> bytes:
- return zlib.compress(data)
-
-
-class ASCIIHexDecode:
- """
- The ASCIIHexDecode filter decodes data that has been encoded in ASCII
- hexadecimal form into a base-7 ASCII format.
- """
-
- @staticmethod
- def decode(
- data: str,
- decode_parms: Union[None, ArrayObject, DictionaryObject] = None, # noqa: F841
- **kwargs: Any,
- ) -> str:
- """
- :param data: a str sequence of hexadecimal-encoded values to be
- converted into a base-7 ASCII string
- :param decode_parms:
- :return: a string conversion in base-7 ASCII, where each of its values
- v is such that 0 <= ord(v) <= 127.
-
- :raises PdfStreamError:
- """
- if "decodeParms" in kwargs: # pragma: no cover
- deprecate_with_replacement("decodeParms", "parameters", "4.0.0")
- decode_parms = kwargs["decodeParms"] # noqa: F841
- retval = ""
- hex_pair = ""
- index = 0
- while True:
- if index >= len(data):
- raise PdfStreamError("Unexpected EOD in ASCIIHexDecode")
- char = data[index]
- if char == ">":
- break
- elif char.isspace():
- index += 1
- continue
- hex_pair += char
- if len(hex_pair) == 2:
- retval += chr(int(hex_pair, base=16))
- hex_pair = ""
- index += 1
- assert hex_pair == ""
- return retval
-
-
-class LZWDecode:
- """Taken from:
- http://www.java2s.com/Open-Source/Java-Document/PDF/PDF-Renderer/com/sun/pdfview/decode/LZWDecode.java.htm
- """
-
- class Decoder:
- def __init__(self, data: bytes) -> None:
- self.STOP = 257
- self.CLEARDICT = 256
- self.data = data
- self.bytepos = 0
- self.bitpos = 0
- self.dict = [""] * 4096
- for i in range(256):
- self.dict[i] = chr(i)
- self.reset_dict()
-
- def reset_dict(self) -> None:
- self.dictlen = 258
- self.bitspercode = 9
-
- def next_code(self) -> int:
- fillbits = self.bitspercode
- value = 0
- while fillbits > 0:
- if self.bytepos >= len(self.data):
- return -1
- nextbits = ord_(self.data[self.bytepos])
- bitsfromhere = 8 - self.bitpos
- bitsfromhere = min(bitsfromhere, fillbits)
- value |= (
- (nextbits >> (8 - self.bitpos - bitsfromhere))
- & (0xFF >> (8 - bitsfromhere))
- ) << (fillbits - bitsfromhere)
- fillbits -= bitsfromhere
- self.bitpos += bitsfromhere
- if self.bitpos >= 8:
- self.bitpos = 0
- self.bytepos = self.bytepos + 1
- return value
-
- def decode(self) -> str:
- """
- TIFF 6.0 specification explains in sufficient details the steps to
- implement the LZW encode() and decode() algorithms.
-
- algorithm derived from:
- http://www.rasip.fer.hr/research/compress/algorithms/fund/lz/lzw.html
- and the PDFReference
-
- :raises PdfReadError: If the stop code is missing
- """
- cW = self.CLEARDICT
- baos = ""
- while True:
- pW = cW
- cW = self.next_code()
- if cW == -1:
- raise PdfReadError("Missed the stop code in LZWDecode!")
- if cW == self.STOP:
- break
- elif cW == self.CLEARDICT:
- self.reset_dict()
- elif pW == self.CLEARDICT:
- baos += self.dict[cW]
- else:
- if cW < self.dictlen:
- baos += self.dict[cW]
- p = self.dict[pW] + self.dict[cW][0]
- self.dict[self.dictlen] = p
- self.dictlen += 1
- else:
- p = self.dict[pW] + self.dict[pW][0]
- baos += p
- self.dict[self.dictlen] = p
- self.dictlen += 1
- if (
- self.dictlen >= (1 << self.bitspercode) - 1
- and self.bitspercode < 12
- ):
- self.bitspercode += 1
- return baos
-
- @staticmethod
- def decode(
- data: bytes,
- decode_parms: Union[None, ArrayObject, DictionaryObject] = None,
- **kwargs: Any,
- ) -> str:
- """
- :param data: ``bytes`` or ``str`` text to decode.
- :param decode_parms: a dictionary of parameter values.
- :return: decoded data.
- """
- if "decodeParms" in kwargs: # pragma: no cover
- deprecate_with_replacement("decodeParms", "parameters", "4.0.0")
- decode_parms = kwargs["decodeParms"] # noqa: F841
- return LZWDecode.Decoder(data).decode()
-
-
-class ASCII85Decode:
- """Decodes string ASCII85-encoded data into a byte format."""
-
- @staticmethod
- def decode(
- data: Union[str, bytes],
- decode_parms: Union[None, ArrayObject, DictionaryObject] = None,
- **kwargs: Any,
- ) -> bytes:
- if "decodeParms" in kwargs: # pragma: no cover
- deprecate_with_replacement("decodeParms", "parameters", "4.0.0")
- decode_parms = kwargs["decodeParms"] # noqa: F841
- if isinstance(data, str):
- data = data.encode("ascii")
- group_index = b = 0
- out = bytearray()
- for char in data:
- if ord("!") <= char and char <= ord("u"):
- group_index += 1
- b = b * 85 + (char - 33)
- if group_index == 5:
- out += struct.pack(b">L", b)
- group_index = b = 0
- elif char == ord("z"):
- assert group_index == 0
- out += b"\0\0\0\0"
- elif char == ord("~"):
- if group_index:
- for _ in range(5 - group_index):
- b = b * 85 + 84
- out += struct.pack(b">L", b)[: group_index - 1]
- break
- return bytes(out)
-
-
-class DCTDecode:
- @staticmethod
- def decode(
- data: bytes,
- decode_parms: Union[None, ArrayObject, DictionaryObject] = None,
- **kwargs: Any,
- ) -> bytes:
- if "decodeParms" in kwargs: # pragma: no cover
- deprecate_with_replacement("decodeParms", "parameters", "4.0.0")
- decode_parms = kwargs["decodeParms"] # noqa: F841
- return data
-
-
-class JPXDecode:
- @staticmethod
- def decode(
- data: bytes,
- decode_parms: Union[None, ArrayObject, DictionaryObject] = None,
- **kwargs: Any,
- ) -> bytes:
- if "decodeParms" in kwargs: # pragma: no cover
- deprecate_with_replacement("decodeParms", "parameters", "4.0.0")
- decode_parms = kwargs["decodeParms"] # noqa: F841
- return data
-
-
-class CCITParameters:
- """TABLE 3.9 Optional parameters for the CCITTFaxDecode filter."""
-
- def __init__(self, K: int = 0, columns: int = 0, rows: int = 0) -> None:
- self.K = K
- self.EndOfBlock = None
- self.EndOfLine = None
- self.EncodedByteAlign = None
- self.columns = columns # width
- self.rows = rows # height
- self.DamagedRowsBeforeError = None
-
- @property
- def group(self) -> int:
- if self.K < 0:
- CCITTgroup = 4
- else:
- # k == 0: Pure one-dimensional encoding (Group 3, 1-D)
- # k > 0: Mixed one- and two-dimensional encoding (Group 3, 2-D)
- CCITTgroup = 3
- return CCITTgroup
-
-
-class CCITTFaxDecode:
- """
- See 3.3.5 CCITTFaxDecode Filter (PDF 1.7 Standard).
-
- Either Group 3 or Group 4 CCITT facsimile (fax) encoding.
- CCITT encoding is bit-oriented, not byte-oriented.
-
- See: TABLE 3.9 Optional parameters for the CCITTFaxDecode filter
- """
-
- @staticmethod
- def _get_parameters(
- parameters: Union[None, ArrayObject, DictionaryObject], rows: int
- ) -> CCITParameters:
- # TABLE 3.9 Optional parameters for the CCITTFaxDecode filter
- k = 0
- columns = 1728
- if parameters:
- if isinstance(parameters, ArrayObject):
- for decode_parm in parameters:
- if CCITT.COLUMNS in decode_parm:
- columns = decode_parm[CCITT.COLUMNS]
- if CCITT.K in decode_parm:
- k = decode_parm[CCITT.K]
- else:
- if CCITT.COLUMNS in parameters:
- columns = parameters[CCITT.COLUMNS] # type: ignore
- if CCITT.K in parameters:
- k = parameters[CCITT.K] # type: ignore
-
- return CCITParameters(k, columns, rows)
-
- @staticmethod
- def decode(
- data: bytes,
- decode_parms: Union[None, ArrayObject, DictionaryObject] = None,
- height: int = 0,
- **kwargs: Any,
- ) -> bytes:
- if "decodeParms" in kwargs: # pragma: no cover
- deprecate_with_replacement("decodeParms", "parameters", "4.0.0")
- decode_parms = kwargs["decodeParms"]
- parms = CCITTFaxDecode._get_parameters(decode_parms, height)
-
- img_size = len(data)
- tiff_header_struct = "<2shlh" + "hhll" * 8 + "h"
- tiff_header = struct.pack(
- tiff_header_struct,
- b"II", # Byte order indication: Little endian
- 42, # Version number (always 42)
- 8, # Offset to first IFD
- 8, # Number of tags in IFD
- 256,
- 4,
- 1,
- parms.columns, # ImageWidth, LONG, 1, width
- 257,
- 4,
- 1,
- parms.rows, # ImageLength, LONG, 1, length
- 258,
- 3,
- 1,
- 1, # BitsPerSample, SHORT, 1, 1
- 259,
- 3,
- 1,
- parms.group, # Compression, SHORT, 1, 4 = CCITT Group 4 fax encoding
- 262,
- 3,
- 1,
- 0, # Thresholding, SHORT, 1, 0 = WhiteIsZero
- 273,
- 4,
- 1,
- struct.calcsize(
- tiff_header_struct
- ), # StripOffsets, LONG, 1, length of header
- 278,
- 4,
- 1,
- parms.rows, # RowsPerStrip, LONG, 1, length
- 279,
- 4,
- 1,
- img_size, # StripByteCounts, LONG, 1, size of image
- 0, # last IFD
- )
-
- return tiff_header + data
-
-
-def decode_stream_data(stream: Any) -> Union[str, bytes]: # utils.StreamObject
- filters = stream.get(SA.FILTER, ())
- if isinstance(filters, IndirectObject):
- filters = cast(ArrayObject, filters.get_object())
- if len(filters) and not isinstance(filters[0], NameObject):
- # we have a single filter instance
- filters = (filters,)
- data: bytes = stream._data
- # If there is not data to decode we should not try to decode the data.
- if data:
- for filter_type in filters:
- if filter_type in (FT.FLATE_DECODE, FTA.FL):
- data = FlateDecode.decode(data, stream.get(SA.DECODE_PARMS))
- elif filter_type in (FT.ASCII_HEX_DECODE, FTA.AHx):
- data = ASCIIHexDecode.decode(data) # type: ignore
- elif filter_type in (FT.LZW_DECODE, FTA.LZW):
- data = LZWDecode.decode(data, stream.get(SA.DECODE_PARMS)) # type: ignore
- elif filter_type in (FT.ASCII_85_DECODE, FTA.A85):
- data = ASCII85Decode.decode(data)
- elif filter_type == FT.DCT_DECODE:
- data = DCTDecode.decode(data)
- elif filter_type == "/JPXDecode":
- data = JPXDecode.decode(data)
- elif filter_type == FT.CCITT_FAX_DECODE:
- height = stream.get(IA.HEIGHT, ())
- data = CCITTFaxDecode.decode(data, stream.get(SA.DECODE_PARMS), height)
- elif filter_type == "/Crypt":
- decode_parms = stream.get(SA.DECODE_PARMS, {})
- if "/Name" not in decode_parms and "/Type" not in decode_parms:
- pass
- else:
- raise NotImplementedError(
- "/Crypt filter with /Name or /Type not supported yet"
- )
- else:
- # Unsupported filter
- raise NotImplementedError(f"unsupported filter {filter_type}")
- return data
-
-
-def decodeStreamData(stream: Any) -> Union[str, bytes]: # pragma: no cover
- deprecate_with_replacement("decodeStreamData", "decode_stream_data", "4.0.0")
- return decode_stream_data(stream)
-
-
-def _xobj_to_image(x_object_obj: Dict[str, Any]) -> Tuple[Optional[str], bytes]:
- """
- Users need to have the pillow package installed.
-
- It's unclear if PyPDF2 will keep this function here, hence it's private.
- It might get removed at any point.
-
- :return: Tuple[file extension, bytes]
- """
- try:
- from PIL import Image
- except ImportError:
- raise ImportError(
- "pillow is required to do image extraction. "
- "It can be installed via 'pip install PyPDF2[image]'"
- )
-
- size = (x_object_obj[IA.WIDTH], x_object_obj[IA.HEIGHT])
- data = x_object_obj.get_data() # type: ignore
- if (
- IA.COLOR_SPACE in x_object_obj
- and x_object_obj[IA.COLOR_SPACE] == ColorSpaces.DEVICE_RGB
- ):
- # https://pillow.readthedocs.io/en/stable/handbook/concepts.html#modes
- mode: Literal["RGB", "P"] = "RGB"
- else:
- mode = "P"
- extension = None
- if SA.FILTER in x_object_obj:
- if x_object_obj[SA.FILTER] == FT.FLATE_DECODE:
- extension = ".png" # mime_type = "image/png"
- color_space = None
- if "/ColorSpace" in x_object_obj:
- color_space = x_object_obj["/ColorSpace"].get_object()
- if (
- isinstance(color_space, ArrayObject)
- and color_space[0] == "/Indexed"
- ):
- color_space, base, hival, lookup = (
- value.get_object() for value in color_space
- )
-
- img = Image.frombytes(mode, size, data)
- if color_space == "/Indexed":
- from .generic import ByteStringObject
-
- if isinstance(lookup, ByteStringObject):
- if base == ColorSpaces.DEVICE_GRAY and len(lookup) == hival + 1:
- lookup = b"".join(
- [lookup[i : i + 1] * 3 for i in range(len(lookup))]
- )
- img.putpalette(lookup)
- else:
- img.putpalette(lookup.get_data())
- img = img.convert("L" if base == ColorSpaces.DEVICE_GRAY else "RGB")
- if G.S_MASK in x_object_obj: # add alpha channel
- alpha = Image.frombytes("L", size, x_object_obj[G.S_MASK].get_data())
- img.putalpha(alpha)
- img_byte_arr = BytesIO()
- img.save(img_byte_arr, format="PNG")
- data = img_byte_arr.getvalue()
- elif x_object_obj[SA.FILTER] in (
- [FT.LZW_DECODE],
- [FT.ASCII_85_DECODE],
- [FT.CCITT_FAX_DECODE],
- ):
- # I'm not sure if the following logic is correct.
- # There might not be any relationship between the filters and the
- # extension
- if x_object_obj[SA.FILTER] in [[FT.LZW_DECODE], [FT.CCITT_FAX_DECODE]]:
- extension = ".tiff" # mime_type = "image/tiff"
- else:
- extension = ".png" # mime_type = "image/png"
- data = b_(data)
- elif x_object_obj[SA.FILTER] == FT.DCT_DECODE:
- extension = ".jpg" # mime_type = "image/jpeg"
- elif x_object_obj[SA.FILTER] == "/JPXDecode":
- extension = ".jp2" # mime_type = "image/x-jp2"
- elif x_object_obj[SA.FILTER] == FT.CCITT_FAX_DECODE:
- extension = ".tiff" # mime_type = "image/tiff"
- else:
- extension = ".png" # mime_type = "image/png"
- img = Image.frombytes(mode, size, data)
- img_byte_arr = BytesIO()
- img.save(img_byte_arr, format="PNG")
- data = img_byte_arr.getvalue()
-
- return extension, data
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/click/utils.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/click/utils.py
deleted file mode 100644
index d536434f0bd00cd6fd910c506f5b85a8e485b964..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/click/utils.py
+++ /dev/null
@@ -1,624 +0,0 @@
-import os
-import re
-import sys
-import typing as t
-from functools import update_wrapper
-from types import ModuleType
-from types import TracebackType
-
-from ._compat import _default_text_stderr
-from ._compat import _default_text_stdout
-from ._compat import _find_binary_writer
-from ._compat import auto_wrap_for_ansi
-from ._compat import binary_streams
-from ._compat import open_stream
-from ._compat import should_strip_ansi
-from ._compat import strip_ansi
-from ._compat import text_streams
-from ._compat import WIN
-from .globals import resolve_color_default
-
-if t.TYPE_CHECKING:
- import typing_extensions as te
-
- P = te.ParamSpec("P")
-
-R = t.TypeVar("R")
-
-
-def _posixify(name: str) -> str:
- return "-".join(name.split()).lower()
-
-
-def safecall(func: "t.Callable[P, R]") -> "t.Callable[P, t.Optional[R]]":
- """Wraps a function so that it swallows exceptions."""
-
- def wrapper(*args: "P.args", **kwargs: "P.kwargs") -> t.Optional[R]:
- try:
- return func(*args, **kwargs)
- except Exception:
- pass
- return None
-
- return update_wrapper(wrapper, func)
-
-
-def make_str(value: t.Any) -> str:
- """Converts a value into a valid string."""
- if isinstance(value, bytes):
- try:
- return value.decode(sys.getfilesystemencoding())
- except UnicodeError:
- return value.decode("utf-8", "replace")
- return str(value)
-
-
-def make_default_short_help(help: str, max_length: int = 45) -> str:
- """Returns a condensed version of help string."""
- # Consider only the first paragraph.
- paragraph_end = help.find("\n\n")
-
- if paragraph_end != -1:
- help = help[:paragraph_end]
-
- # Collapse newlines, tabs, and spaces.
- words = help.split()
-
- if not words:
- return ""
-
- # The first paragraph started with a "no rewrap" marker, ignore it.
- if words[0] == "\b":
- words = words[1:]
-
- total_length = 0
- last_index = len(words) - 1
-
- for i, word in enumerate(words):
- total_length += len(word) + (i > 0)
-
- if total_length > max_length: # too long, truncate
- break
-
- if word[-1] == ".": # sentence end, truncate without "..."
- return " ".join(words[: i + 1])
-
- if total_length == max_length and i != last_index:
- break # not at sentence end, truncate with "..."
- else:
- return " ".join(words) # no truncation needed
-
- # Account for the length of the suffix.
- total_length += len("...")
-
- # remove words until the length is short enough
- while i > 0:
- total_length -= len(words[i]) + (i > 0)
-
- if total_length <= max_length:
- break
-
- i -= 1
-
- return " ".join(words[:i]) + "..."
-
-
-class LazyFile:
- """A lazy file works like a regular file but it does not fully open
- the file but it does perform some basic checks early to see if the
- filename parameter does make sense. This is useful for safely opening
- files for writing.
- """
-
- def __init__(
- self,
- filename: t.Union[str, "os.PathLike[str]"],
- mode: str = "r",
- encoding: t.Optional[str] = None,
- errors: t.Optional[str] = "strict",
- atomic: bool = False,
- ):
- self.name: str = os.fspath(filename)
- self.mode = mode
- self.encoding = encoding
- self.errors = errors
- self.atomic = atomic
- self._f: t.Optional[t.IO[t.Any]]
- self.should_close: bool
-
- if self.name == "-":
- self._f, self.should_close = open_stream(filename, mode, encoding, errors)
- else:
- if "r" in mode:
- # Open and close the file in case we're opening it for
- # reading so that we can catch at least some errors in
- # some cases early.
- open(filename, mode).close()
- self._f = None
- self.should_close = True
-
- def __getattr__(self, name: str) -> t.Any:
- return getattr(self.open(), name)
-
- def __repr__(self) -> str:
- if self._f is not None:
- return repr(self._f)
- return f""
-
- def open(self) -> t.IO[t.Any]:
- """Opens the file if it's not yet open. This call might fail with
- a :exc:`FileError`. Not handling this error will produce an error
- that Click shows.
- """
- if self._f is not None:
- return self._f
- try:
- rv, self.should_close = open_stream(
- self.name, self.mode, self.encoding, self.errors, atomic=self.atomic
- )
- except OSError as e: # noqa: E402
- from .exceptions import FileError
-
- raise FileError(self.name, hint=e.strerror) from e
- self._f = rv
- return rv
-
- def close(self) -> None:
- """Closes the underlying file, no matter what."""
- if self._f is not None:
- self._f.close()
-
- def close_intelligently(self) -> None:
- """This function only closes the file if it was opened by the lazy
- file wrapper. For instance this will never close stdin.
- """
- if self.should_close:
- self.close()
-
- def __enter__(self) -> "LazyFile":
- return self
-
- def __exit__(
- self,
- exc_type: t.Optional[t.Type[BaseException]],
- exc_value: t.Optional[BaseException],
- tb: t.Optional[TracebackType],
- ) -> None:
- self.close_intelligently()
-
- def __iter__(self) -> t.Iterator[t.AnyStr]:
- self.open()
- return iter(self._f) # type: ignore
-
-
-class KeepOpenFile:
- def __init__(self, file: t.IO[t.Any]) -> None:
- self._file: t.IO[t.Any] = file
-
- def __getattr__(self, name: str) -> t.Any:
- return getattr(self._file, name)
-
- def __enter__(self) -> "KeepOpenFile":
- return self
-
- def __exit__(
- self,
- exc_type: t.Optional[t.Type[BaseException]],
- exc_value: t.Optional[BaseException],
- tb: t.Optional[TracebackType],
- ) -> None:
- pass
-
- def __repr__(self) -> str:
- return repr(self._file)
-
- def __iter__(self) -> t.Iterator[t.AnyStr]:
- return iter(self._file)
-
-
-def echo(
- message: t.Optional[t.Any] = None,
- file: t.Optional[t.IO[t.Any]] = None,
- nl: bool = True,
- err: bool = False,
- color: t.Optional[bool] = None,
-) -> None:
- """Print a message and newline to stdout or a file. This should be
- used instead of :func:`print` because it provides better support
- for different data, files, and environments.
-
- Compared to :func:`print`, this does the following:
-
- - Ensures that the output encoding is not misconfigured on Linux.
- - Supports Unicode in the Windows console.
- - Supports writing to binary outputs, and supports writing bytes
- to text outputs.
- - Supports colors and styles on Windows.
- - Removes ANSI color and style codes if the output does not look
- like an interactive terminal.
- - Always flushes the output.
-
- :param message: The string or bytes to output. Other objects are
- converted to strings.
- :param file: The file to write to. Defaults to ``stdout``.
- :param err: Write to ``stderr`` instead of ``stdout``.
- :param nl: Print a newline after the message. Enabled by default.
- :param color: Force showing or hiding colors and other styles. By
- default Click will remove color if the output does not look like
- an interactive terminal.
-
- .. versionchanged:: 6.0
- Support Unicode output on the Windows console. Click does not
- modify ``sys.stdout``, so ``sys.stdout.write()`` and ``print()``
- will still not support Unicode.
-
- .. versionchanged:: 4.0
- Added the ``color`` parameter.
-
- .. versionadded:: 3.0
- Added the ``err`` parameter.
-
- .. versionchanged:: 2.0
- Support colors on Windows if colorama is installed.
- """
- if file is None:
- if err:
- file = _default_text_stderr()
- else:
- file = _default_text_stdout()
-
- # There are no standard streams attached to write to. For example,
- # pythonw on Windows.
- if file is None:
- return
-
- # Convert non bytes/text into the native string type.
- if message is not None and not isinstance(message, (str, bytes, bytearray)):
- out: t.Optional[t.Union[str, bytes]] = str(message)
- else:
- out = message
-
- if nl:
- out = out or ""
- if isinstance(out, str):
- out += "\n"
- else:
- out += b"\n"
-
- if not out:
- file.flush()
- return
-
- # If there is a message and the value looks like bytes, we manually
- # need to find the binary stream and write the message in there.
- # This is done separately so that most stream types will work as you
- # would expect. Eg: you can write to StringIO for other cases.
- if isinstance(out, (bytes, bytearray)):
- binary_file = _find_binary_writer(file)
-
- if binary_file is not None:
- file.flush()
- binary_file.write(out)
- binary_file.flush()
- return
-
- # ANSI style code support. For no message or bytes, nothing happens.
- # When outputting to a file instead of a terminal, strip codes.
- else:
- color = resolve_color_default(color)
-
- if should_strip_ansi(file, color):
- out = strip_ansi(out)
- elif WIN:
- if auto_wrap_for_ansi is not None:
- file = auto_wrap_for_ansi(file) # type: ignore
- elif not color:
- out = strip_ansi(out)
-
- file.write(out) # type: ignore
- file.flush()
-
-
-def get_binary_stream(name: "te.Literal['stdin', 'stdout', 'stderr']") -> t.BinaryIO:
- """Returns a system stream for byte processing.
-
- :param name: the name of the stream to open. Valid names are ``'stdin'``,
- ``'stdout'`` and ``'stderr'``
- """
- opener = binary_streams.get(name)
- if opener is None:
- raise TypeError(f"Unknown standard stream '{name}'")
- return opener()
-
-
-def get_text_stream(
- name: "te.Literal['stdin', 'stdout', 'stderr']",
- encoding: t.Optional[str] = None,
- errors: t.Optional[str] = "strict",
-) -> t.TextIO:
- """Returns a system stream for text processing. This usually returns
- a wrapped stream around a binary stream returned from
- :func:`get_binary_stream` but it also can take shortcuts for already
- correctly configured streams.
-
- :param name: the name of the stream to open. Valid names are ``'stdin'``,
- ``'stdout'`` and ``'stderr'``
- :param encoding: overrides the detected default encoding.
- :param errors: overrides the default error mode.
- """
- opener = text_streams.get(name)
- if opener is None:
- raise TypeError(f"Unknown standard stream '{name}'")
- return opener(encoding, errors)
-
-
-def open_file(
- filename: str,
- mode: str = "r",
- encoding: t.Optional[str] = None,
- errors: t.Optional[str] = "strict",
- lazy: bool = False,
- atomic: bool = False,
-) -> t.IO[t.Any]:
- """Open a file, with extra behavior to handle ``'-'`` to indicate
- a standard stream, lazy open on write, and atomic write. Similar to
- the behavior of the :class:`~click.File` param type.
-
- If ``'-'`` is given to open ``stdout`` or ``stdin``, the stream is
- wrapped so that using it in a context manager will not close it.
- This makes it possible to use the function without accidentally
- closing a standard stream:
-
- .. code-block:: python
-
- with open_file(filename) as f:
- ...
-
- :param filename: The name of the file to open, or ``'-'`` for
- ``stdin``/``stdout``.
- :param mode: The mode in which to open the file.
- :param encoding: The encoding to decode or encode a file opened in
- text mode.
- :param errors: The error handling mode.
- :param lazy: Wait to open the file until it is accessed. For read
- mode, the file is temporarily opened to raise access errors
- early, then closed until it is read again.
- :param atomic: Write to a temporary file and replace the given file
- on close.
-
- .. versionadded:: 3.0
- """
- if lazy:
- return t.cast(
- t.IO[t.Any], LazyFile(filename, mode, encoding, errors, atomic=atomic)
- )
-
- f, should_close = open_stream(filename, mode, encoding, errors, atomic=atomic)
-
- if not should_close:
- f = t.cast(t.IO[t.Any], KeepOpenFile(f))
-
- return f
-
-
-def format_filename(
- filename: "t.Union[str, bytes, os.PathLike[str], os.PathLike[bytes]]",
- shorten: bool = False,
-) -> str:
- """Format a filename as a string for display. Ensures the filename can be
- displayed by replacing any invalid bytes or surrogate escapes in the name
- with the replacement character ``�``.
-
- Invalid bytes or surrogate escapes will raise an error when written to a
- stream with ``errors="strict". This will typically happen with ``stdout``
- when the locale is something like ``en_GB.UTF-8``.
-
- Many scenarios *are* safe to write surrogates though, due to PEP 538 and
- PEP 540, including:
-
- - Writing to ``stderr``, which uses ``errors="backslashreplace"``.
- - The system has ``LANG=C.UTF-8``, ``C``, or ``POSIX``. Python opens
- stdout and stderr with ``errors="surrogateescape"``.
- - None of ``LANG/LC_*`` are set. Python assumes ``LANG=C.UTF-8``.
- - Python is started in UTF-8 mode with ``PYTHONUTF8=1`` or ``-X utf8``.
- Python opens stdout and stderr with ``errors="surrogateescape"``.
-
- :param filename: formats a filename for UI display. This will also convert
- the filename into unicode without failing.
- :param shorten: this optionally shortens the filename to strip of the
- path that leads up to it.
- """
- if shorten:
- filename = os.path.basename(filename)
- else:
- filename = os.fspath(filename)
-
- if isinstance(filename, bytes):
- filename = filename.decode(sys.getfilesystemencoding(), "replace")
- else:
- filename = filename.encode("utf-8", "surrogateescape").decode(
- "utf-8", "replace"
- )
-
- return filename
-
-
-def get_app_dir(app_name: str, roaming: bool = True, force_posix: bool = False) -> str:
- r"""Returns the config folder for the application. The default behavior
- is to return whatever is most appropriate for the operating system.
-
- To give you an idea, for an app called ``"Foo Bar"``, something like
- the following folders could be returned:
-
- Mac OS X:
- ``~/Library/Application Support/Foo Bar``
- Mac OS X (POSIX):
- ``~/.foo-bar``
- Unix:
- ``~/.config/foo-bar``
- Unix (POSIX):
- ``~/.foo-bar``
- Windows (roaming):
- ``C:\Users\\AppData\Roaming\Foo Bar``
- Windows (not roaming):
- ``C:\Users\\AppData\Local\Foo Bar``
-
- .. versionadded:: 2.0
-
- :param app_name: the application name. This should be properly capitalized
- and can contain whitespace.
- :param roaming: controls if the folder should be roaming or not on Windows.
- Has no effect otherwise.
- :param force_posix: if this is set to `True` then on any POSIX system the
- folder will be stored in the home folder with a leading
- dot instead of the XDG config home or darwin's
- application support folder.
- """
- if WIN:
- key = "APPDATA" if roaming else "LOCALAPPDATA"
- folder = os.environ.get(key)
- if folder is None:
- folder = os.path.expanduser("~")
- return os.path.join(folder, app_name)
- if force_posix:
- return os.path.join(os.path.expanduser(f"~/.{_posixify(app_name)}"))
- if sys.platform == "darwin":
- return os.path.join(
- os.path.expanduser("~/Library/Application Support"), app_name
- )
- return os.path.join(
- os.environ.get("XDG_CONFIG_HOME", os.path.expanduser("~/.config")),
- _posixify(app_name),
- )
-
-
-class PacifyFlushWrapper:
- """This wrapper is used to catch and suppress BrokenPipeErrors resulting
- from ``.flush()`` being called on broken pipe during the shutdown/final-GC
- of the Python interpreter. Notably ``.flush()`` is always called on
- ``sys.stdout`` and ``sys.stderr``. So as to have minimal impact on any
- other cleanup code, and the case where the underlying file is not a broken
- pipe, all calls and attributes are proxied.
- """
-
- def __init__(self, wrapped: t.IO[t.Any]) -> None:
- self.wrapped = wrapped
-
- def flush(self) -> None:
- try:
- self.wrapped.flush()
- except OSError as e:
- import errno
-
- if e.errno != errno.EPIPE:
- raise
-
- def __getattr__(self, attr: str) -> t.Any:
- return getattr(self.wrapped, attr)
-
-
-def _detect_program_name(
- path: t.Optional[str] = None, _main: t.Optional[ModuleType] = None
-) -> str:
- """Determine the command used to run the program, for use in help
- text. If a file or entry point was executed, the file name is
- returned. If ``python -m`` was used to execute a module or package,
- ``python -m name`` is returned.
-
- This doesn't try to be too precise, the goal is to give a concise
- name for help text. Files are only shown as their name without the
- path. ``python`` is only shown for modules, and the full path to
- ``sys.executable`` is not shown.
-
- :param path: The Python file being executed. Python puts this in
- ``sys.argv[0]``, which is used by default.
- :param _main: The ``__main__`` module. This should only be passed
- during internal testing.
-
- .. versionadded:: 8.0
- Based on command args detection in the Werkzeug reloader.
-
- :meta private:
- """
- if _main is None:
- _main = sys.modules["__main__"]
-
- if not path:
- path = sys.argv[0]
-
- # The value of __package__ indicates how Python was called. It may
- # not exist if a setuptools script is installed as an egg. It may be
- # set incorrectly for entry points created with pip on Windows.
- # It is set to "" inside a Shiv or PEX zipapp.
- if getattr(_main, "__package__", None) in {None, ""} or (
- os.name == "nt"
- and _main.__package__ == ""
- and not os.path.exists(path)
- and os.path.exists(f"{path}.exe")
- ):
- # Executed a file, like "python app.py".
- return os.path.basename(path)
-
- # Executed a module, like "python -m example".
- # Rewritten by Python from "-m script" to "/path/to/script.py".
- # Need to look at main module to determine how it was executed.
- py_module = t.cast(str, _main.__package__)
- name = os.path.splitext(os.path.basename(path))[0]
-
- # A submodule like "example.cli".
- if name != "__main__":
- py_module = f"{py_module}.{name}"
-
- return f"python -m {py_module.lstrip('.')}"
-
-
-def _expand_args(
- args: t.Iterable[str],
- *,
- user: bool = True,
- env: bool = True,
- glob_recursive: bool = True,
-) -> t.List[str]:
- """Simulate Unix shell expansion with Python functions.
-
- See :func:`glob.glob`, :func:`os.path.expanduser`, and
- :func:`os.path.expandvars`.
-
- This is intended for use on Windows, where the shell does not do any
- expansion. It may not exactly match what a Unix shell would do.
-
- :param args: List of command line arguments to expand.
- :param user: Expand user home directory.
- :param env: Expand environment variables.
- :param glob_recursive: ``**`` matches directories recursively.
-
- .. versionchanged:: 8.1
- Invalid glob patterns are treated as empty expansions rather
- than raising an error.
-
- .. versionadded:: 8.0
-
- :meta private:
- """
- from glob import glob
-
- out = []
-
- for arg in args:
- if user:
- arg = os.path.expanduser(arg)
-
- if env:
- arg = os.path.expandvars(arg)
-
- try:
- matches = glob(arg, recursive=glob_recursive)
- except re.error:
- matches = []
-
- if not matches:
- out.append(arg)
- else:
- out.extend(matches)
-
- return out
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/dns/wire.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/dns/wire.py
deleted file mode 100644
index 9f9b1573d521a924a43dde6c18a59912612798d8..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/dns/wire.py
+++ /dev/null
@@ -1,89 +0,0 @@
-# Copyright (C) Dnspython Contributors, see LICENSE for text of ISC license
-
-import contextlib
-import struct
-from typing import Iterator, Optional, Tuple
-
-import dns.exception
-import dns.name
-
-
-class Parser:
- def __init__(self, wire: bytes, current: int = 0):
- self.wire = wire
- self.current = 0
- self.end = len(self.wire)
- if current:
- self.seek(current)
- self.furthest = current
-
- def remaining(self) -> int:
- return self.end - self.current
-
- def get_bytes(self, size: int) -> bytes:
- assert size >= 0
- if size > self.remaining():
- raise dns.exception.FormError
- output = self.wire[self.current : self.current + size]
- self.current += size
- self.furthest = max(self.furthest, self.current)
- return output
-
- def get_counted_bytes(self, length_size: int = 1) -> bytes:
- length = int.from_bytes(self.get_bytes(length_size), "big")
- return self.get_bytes(length)
-
- def get_remaining(self) -> bytes:
- return self.get_bytes(self.remaining())
-
- def get_uint8(self) -> int:
- return struct.unpack("!B", self.get_bytes(1))[0]
-
- def get_uint16(self) -> int:
- return struct.unpack("!H", self.get_bytes(2))[0]
-
- def get_uint32(self) -> int:
- return struct.unpack("!I", self.get_bytes(4))[0]
-
- def get_uint48(self) -> int:
- return int.from_bytes(self.get_bytes(6), "big")
-
- def get_struct(self, format: str) -> Tuple:
- return struct.unpack(format, self.get_bytes(struct.calcsize(format)))
-
- def get_name(self, origin: Optional["dns.name.Name"] = None) -> "dns.name.Name":
- name = dns.name.from_wire_parser(self)
- if origin:
- name = name.relativize(origin)
- return name
-
- def seek(self, where: int) -> None:
- # Note that seeking to the end is OK! (If you try to read
- # after such a seek, you'll get an exception as expected.)
- if where < 0 or where > self.end:
- raise dns.exception.FormError
- self.current = where
-
- @contextlib.contextmanager
- def restrict_to(self, size: int) -> Iterator:
- assert size >= 0
- if size > self.remaining():
- raise dns.exception.FormError
- saved_end = self.end
- try:
- self.end = self.current + size
- yield
- # We make this check here and not in the finally as we
- # don't want to raise if we're already raising for some
- # other reason.
- if self.current != self.end:
- raise dns.exception.FormError
- finally:
- self.end = saved_end
-
- @contextlib.contextmanager
- def restore_furthest(self) -> Iterator:
- try:
- yield None
- finally:
- self.current = self.furthest
diff --git a/spaces/joeddav/zero-shot-demo/README.md b/spaces/joeddav/zero-shot-demo/README.md
deleted file mode 100644
index 6eded4eccb22e99a2cde2d824f64e092d7d33882..0000000000000000000000000000000000000000
--- a/spaces/joeddav/zero-shot-demo/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Zero Shot Demo
-emoji: 0️⃣
-colorFrom: indigo
-colorTo: indigo
-sdk: streamlit
-sdk_version: 1.15.2
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/johnslegers/stable-diffusion/README.md b/spaces/johnslegers/stable-diffusion/README.md
deleted file mode 100644
index f730b8f2d42bf867108be4fd317e846b8866758a..0000000000000000000000000000000000000000
--- a/spaces/johnslegers/stable-diffusion/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Stable Diffusion
-emoji: 🏃
-colorFrom: red
-colorTo: red
-sdk: gradio
-sdk_version: 3.1.7
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/jordonpeter01/MusicGen/tests/common_utils/temp_utils.py b/spaces/jordonpeter01/MusicGen/tests/common_utils/temp_utils.py
deleted file mode 100644
index d1e0367e979c8b9fea65472c373916d956ad5aaa..0000000000000000000000000000000000000000
--- a/spaces/jordonpeter01/MusicGen/tests/common_utils/temp_utils.py
+++ /dev/null
@@ -1,56 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import os
-import tempfile
-
-
-class TempDirMixin:
- """Mixin to provide easy access to temp dir.
- """
-
- temp_dir_ = None
-
- @classmethod
- def get_base_temp_dir(cls):
- # If AUDIOCRAFT_TEST_DIR is set, use it instead of temporary directory.
- # this is handy for debugging.
- key = "AUDIOCRAFT_TEST_DIR"
- if key in os.environ:
- return os.environ[key]
- if cls.temp_dir_ is None:
- cls.temp_dir_ = tempfile.TemporaryDirectory()
- return cls.temp_dir_.name
-
- @classmethod
- def tearDownClass(cls):
- if cls.temp_dir_ is not None:
- try:
- cls.temp_dir_.cleanup()
- cls.temp_dir_ = None
- except PermissionError:
- # On Windows there is a know issue with `shutil.rmtree`,
- # which fails intermittenly.
- # https://github.com/python/cpython/issues/74168
- # Following the above thread, we ignore it.
- pass
- super().tearDownClass()
-
- @property
- def id(self):
- return self.__class__.__name__
-
- def get_temp_path(self, *paths):
- temp_dir = os.path.join(self.get_base_temp_dir(), self.id)
- path = os.path.join(temp_dir, *paths)
- os.makedirs(os.path.dirname(path), exist_ok=True)
- return path
-
- def get_temp_dir(self, *paths):
- temp_dir = os.path.join(self.get_base_temp_dir(), self.id)
- path = os.path.join(temp_dir, *paths)
- os.makedirs(path, exist_ok=True)
- return path
diff --git a/spaces/jordonpeter01/ai-comic-factory/src/app/queries/getStory.ts b/spaces/jordonpeter01/ai-comic-factory/src/app/queries/getStory.ts
deleted file mode 100644
index 785a1f75a033f33264f1df92b0d569c75067be94..0000000000000000000000000000000000000000
--- a/spaces/jordonpeter01/ai-comic-factory/src/app/queries/getStory.ts
+++ /dev/null
@@ -1,83 +0,0 @@
-import { createLlamaPrompt } from "@/lib/createLlamaPrompt"
-import { dirtyLLMResponseCleaner } from "@/lib/dirtyLLMResponseCleaner"
-import { dirtyLLMJsonParser } from "@/lib/dirtyLLMJsonParser"
-import { dirtyCaptionCleaner } from "@/lib/dirtyCaptionCleaner"
-
-import { predict } from "./predict"
-import { Preset } from "../engine/presets"
-import { LLMResponse } from "@/types"
-import { cleanJson } from "@/lib/cleanJson"
-
-export const getStory = async ({
- preset,
- prompt = "",
-}: {
- preset: Preset;
- prompt: string;
-}): Promise => {
-
- const query = createLlamaPrompt([
- {
- role: "system",
- content: [
- `You are a comic book author specialized in ${preset.llmPrompt}`,
- `Please write detailed drawing instructions and a one-sentence short caption for the 4 panels of a new silent comic book page.`,
- `Give your response as a JSON array like this: \`Array<{ panel: number; instructions: string; caption: string}>\`.`,
- // `Give your response as Markdown bullet points.`,
- `Be brief in your 4 instructions and captions, don't add your own comments. Be straight to the point, and never reply things like "Sure, I can.." etc.`
- ].filter(item => item).join("\n")
- },
- {
- role: "user",
- content: `The story is: ${prompt}`,
- }
- ]) + "```json\n["
-
-
- let result = ""
-
- try {
- result = await predict(query)
- if (!result.trim().length) {
- throw new Error("empty result!")
- }
- } catch (err) {
- console.log(`prediction of the story failed, trying again..`)
- try {
- result = await predict(query+".")
- if (!result.trim().length) {
- throw new Error("empty result!")
- }
- } catch (err) {
- console.error(`prediction of the story failed again!`)
- throw new Error(`failed to generate the story ${err}`)
- }
- }
-
- // console.log("Raw response from LLM:", result)
- const tmp = cleanJson(result)
-
- let llmResponse: LLMResponse = []
-
- try {
- llmResponse = dirtyLLMJsonParser(tmp)
- } catch (err) {
- console.log(`failed to read LLM response: ${err}`)
- console.log(`original response was:`, result)
-
- // in case of failure here, it might be because the LLM hallucinated a completely different response,
- // such as markdown. There is no real solution.. but we can try a fallback:
-
- llmResponse = (
- tmp.split("*")
- .map(item => item.trim())
- .map((cap, i) => ({
- panel: i,
- caption: cap,
- instructions: cap,
- }))
- )
- }
-
- return llmResponse.map(res => dirtyCaptionCleaner(res))
-}
\ No newline at end of file
diff --git a/spaces/jordonpeter01/ai-comic-factory/src/app/queries/predict.ts b/spaces/jordonpeter01/ai-comic-factory/src/app/queries/predict.ts
deleted file mode 100644
index 42147e9ddf63934adeb904acf06784431b9c7b21..0000000000000000000000000000000000000000
--- a/spaces/jordonpeter01/ai-comic-factory/src/app/queries/predict.ts
+++ /dev/null
@@ -1,95 +0,0 @@
-"use server"
-
-import { LLMEngine } from "@/types"
-import { HfInference, HfInferenceEndpoint } from "@huggingface/inference"
-
-const hf = new HfInference(process.env.HF_API_TOKEN)
-
-
-// note: we always try "inference endpoint" first
-const llmEngine = `${process.env.LLM_ENGINE || ""}` as LLMEngine
-const inferenceEndpoint = `${process.env.HF_INFERENCE_ENDPOINT_URL || ""}`
-const inferenceModel = `${process.env.HF_INFERENCE_API_MODEL || ""}`
-
-let hfie: HfInferenceEndpoint
-
-switch (llmEngine) {
- case "INFERENCE_ENDPOINT":
- if (inferenceEndpoint) {
- console.log("Using a custom HF Inference Endpoint")
- hfie = hf.endpoint(inferenceEndpoint)
- } else {
- const error = "No Inference Endpoint URL defined"
- console.error(error)
- throw new Error(error)
- }
- break;
-
- case "INFERENCE_API":
- if (inferenceModel) {
- console.log("Using an HF Inference API Model")
- } else {
- const error = "No Inference API model defined"
- console.error(error)
- throw new Error(error)
- }
- break;
-
- default:
- const error = "No Inference Endpoint URL or Inference API Model defined"
- console.error(error)
- throw new Error(error)
-}
-
-export async function predict(inputs: string) {
-
- console.log(`predict: `, inputs)
-
- const api = llmEngine ==="INFERENCE_ENDPOINT" ? hfie : hf
-
- let instructions = ""
- try {
- for await (const output of api.textGenerationStream({
- model: llmEngine ==="INFERENCE_ENDPOINT" ? undefined : (inferenceModel || undefined),
- inputs,
- parameters: {
- do_sample: true,
- // we don't require a lot of token for our task
- // but to be safe, let's count ~110 tokens per panel
- max_new_tokens: 450, // 1150,
- return_full_text: false,
- }
- })) {
- instructions += output.token.text
- process.stdout.write(output.token.text)
- if (
- instructions.includes("") ||
- instructions.includes("") ||
- instructions.includes("[INST]") ||
- instructions.includes("[/INST]") ||
- instructions.includes("") ||
- instructions.includes(" ") ||
- instructions.includes("<|end|>") ||
- instructions.includes("<|assistant|>")
- ) {
- break
- }
- }
- } catch (err) {
- console.error(`error during generation: ${err}`)
- }
-
- // need to do some cleanup of the garbage the LLM might have gave us
- return (
- instructions
- .replaceAll("<|end|>", "")
- .replaceAll("", "")
- .replaceAll(" ", "")
- .replaceAll("[INST]", "")
- .replaceAll("[/INST]", "")
- .replaceAll("", "")
- .replaceAll(" ", "")
- .replaceAll("<|assistant|>", "")
- .replaceAll('""', '"')
- )
-}
\ No newline at end of file
diff --git a/spaces/jordonpeter01/ai-comic-factory/src/components/ui/alert.tsx b/spaces/jordonpeter01/ai-comic-factory/src/components/ui/alert.tsx
deleted file mode 100644
index f589783193a6cfe14032a77b89055cb3e920fe8c..0000000000000000000000000000000000000000
--- a/spaces/jordonpeter01/ai-comic-factory/src/components/ui/alert.tsx
+++ /dev/null
@@ -1,59 +0,0 @@
-import * as React from "react"
-import { cva, type VariantProps } from "class-variance-authority"
-
-import { cn } from "@/lib/utils"
-
-const alertVariants = cva(
- "relative w-full rounded-lg border border-stone-200 p-4 [&:has(svg)]:pl-11 [&>svg+div]:translate-y-[-3px] [&>svg]:absolute [&>svg]:left-4 [&>svg]:top-4 [&>svg]:text-stone-950 dark:border-stone-800 dark:[&>svg]:text-stone-50",
- {
- variants: {
- variant: {
- default: "bg-white text-stone-950 dark:bg-stone-950 dark:text-stone-50",
- destructive:
- "border-red-500/50 text-red-500 dark:border-red-500 [&>svg]:text-red-500 dark:border-red-900/50 dark:text-red-900 dark:dark:border-red-900 dark:[&>svg]:text-red-900",
- },
- },
- defaultVariants: {
- variant: "default",
- },
- }
-)
-
-const Alert = React.forwardRef<
- HTMLDivElement,
- React.HTMLAttributes & VariantProps
->(({ className, variant, ...props }, ref) => (
-
-))
-Alert.displayName = "Alert"
-
-const AlertTitle = React.forwardRef<
- HTMLParagraphElement,
- React.HTMLAttributes
->(({ className, ...props }, ref) => (
-
->(({ className, ...props }, ref) => (
-
-))
-AlertDescription.displayName = "AlertDescription"
-
-export { Alert, AlertTitle, AlertDescription }
diff --git a/spaces/kargaranamir/LangID-LIME/app.py b/spaces/kargaranamir/LangID-LIME/app.py
deleted file mode 100644
index 98e7a9a752138fb29cb8f8dbb34bd37d54ec6aaf..0000000000000000000000000000000000000000
--- a/spaces/kargaranamir/LangID-LIME/app.py
+++ /dev/null
@@ -1,158 +0,0 @@
-# """
-# Author: Amir Hossein Kargaran
-# Date: August, 2023
-
-# Description: This code applies LIME (Local Interpretable Model-Agnostic Explanations) on fasttext language identification.
-
-# MIT License
-
-# Some part of the code is adopted from here: https://gist.github.com/ageitgey/60a8b556a9047a4ca91d6034376e5980
-# """
-
-import gradio as gr
-from io import BytesIO
-from fasttext.FastText import _FastText
-import re
-import lime.lime_text
-import numpy as np
-from PIL import Image
-from huggingface_hub import hf_hub_download
-from selenium import webdriver
-from selenium.common.exceptions import WebDriverException
-import os
-
-
-# Define a dictionary to map model choices to their respective paths
-model_paths = {
- "OpenLID": ["laurievb/OpenLID", 'model.bin'],
- "GlotLID": ["cis-lmu/glotlid", 'model.bin'],
- "NLLB": ["facebook/fasttext-language-identification", 'model.bin']
-}
-
-# Create a dictionary to cache classifiers
-cached_classifiers = {}
-
-def load_classifier(model_choice):
- if model_choice in cached_classifiers:
- return cached_classifiers[model_choice]
-
- # Load the FastText language identification model from Hugging Face Hub
- model_path = hf_hub_download(repo_id=model_paths[model_choice][0], filename=model_paths[model_choice][1])
-
- # Create the FastText classifier
- classifier = _FastText(model_path)
-
- cached_classifiers[model_choice] = classifier
- return classifier
-
-# cache all models
-for model_choice in model_paths.keys():
- load_classifier(model_choice)
-
-
-def remove_label_prefix(item):
- return item.replace('__label__', '')
-
-def remove_label_prefix_list(input_list):
- if isinstance(input_list[0], list):
- return [[remove_label_prefix(item) for item in inner_list] for inner_list in input_list]
- else:
- return [remove_label_prefix(item) for item in input_list]
-
-
-def tokenize_string(sentence, n=None):
- if n is None:
- tokens = sentence.split()
- else:
- tokens = []
- for i in range(len(sentence) - n + 1):
- tokens.append(sentence[i:i + n])
- return tokens
-
-
-def fasttext_prediction_in_sklearn_format(classifier, texts, num_class):
- # if isinstance(texts, str):
- # texts = [texts]
-
- res = []
- labels, probabilities = classifier.predict(texts, num_class)
- labels = remove_label_prefix_list(labels)
- for label, probs, text in zip(labels, probabilities, texts):
- order = np.argsort(np.array(label))
- res.append(probs[order])
- return np.array(res)
-
-
-def generate_explanation_html(input_sentence, explainer, classifier, num_class):
- preprocessed_sentence = input_sentence
- exp = explainer.explain_instance(
- preprocessed_sentence,
- classifier_fn=lambda x: fasttext_prediction_in_sklearn_format(classifier, x, num_class),
- top_labels=2,
- num_features=20,
- )
- output_html_filename = "explanation.html"
- exp.save_to_file(output_html_filename)
- return output_html_filename
-
-def take_screenshot(local_html_path):
- options = webdriver.ChromeOptions()
- options.add_argument('--headless')
- options.add_argument('--no-sandbox')
- options.add_argument('--disable-dev-shm-usage')
-
- try:
- local_html_path = os.path.abspath(local_html_path)
- wd = webdriver.Chrome(options=options)
- wd.set_window_size(1366, 728)
- wd.get('file://' + local_html_path)
- wd.implicitly_wait(10)
- screenshot = wd.get_screenshot_as_png()
- except WebDriverException as e:
- return Image.new('RGB', (1, 1))
- finally:
- if wd:
- wd.quit()
-
- return Image.open(BytesIO(screenshot))
-
-
-# Define the merge function
-def merge_function(input_sentence, selected_model):
-
- input_sentence = input_sentence.replace('\n', ' ')
-
- # Load the FastText language identification model from Hugging Face Hub
- classifier = load_classifier(selected_model)
- class_names = remove_label_prefix_list(classifier.labels)
- class_names = np.sort(class_names)
- num_class = len(class_names)
-
- # Load Lime
- explainer = lime.lime_text.LimeTextExplainer(
- split_expression=tokenize_string,
- bow=False,
- class_names=class_names)
-
- # Generate output
- output_html_filename = generate_explanation_html(input_sentence, explainer, classifier, num_class)
- im = take_screenshot(output_html_filename)
- return im, output_html_filename
-
-# Define the Gradio interface
-input_text = gr.Textbox(label="Input Text", value="J'ai visited la beautiful beach avec mes amis for a relaxing journée under the sun.")
-model_choice = gr.Radio(choices=["GlotLID", "OpenLID", "NLLB"], label="Select Model", value='GlotLID')
-
-output_explanation = gr.outputs.File(label="Explanation HTML")
-
-
-
-iface = gr.Interface(merge_function,
- inputs=[input_text, model_choice],
- outputs=[gr.Image(type="pil", height=364, width=683, label = "Explanation Image"), output_explanation],
- title="LIME LID",
- description="This code applies LIME (Local Interpretable Model-Agnostic Explanations) on fasttext language identification.",
- allow_flagging='never',
- theme=gr.themes.Soft())
-
-iface.launch()
diff --git a/spaces/karthick965938/ChatGPT-Demo/README.md b/spaces/karthick965938/ChatGPT-Demo/README.md
deleted file mode 100644
index 2186d19765d3679ac3c6585555f1a5155b3efc99..0000000000000000000000000000000000000000
--- a/spaces/karthick965938/ChatGPT-Demo/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: ChatGPT Demo
-emoji: 📚
-colorFrom: yellow
-colorTo: indigo
-sdk: streamlit
-sdk_version: 1.27.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/kazuk/youtube-whisper-16/README.md b/spaces/kazuk/youtube-whisper-16/README.md
deleted file mode 100644
index 7dbeb54e7e4d285fe7b0f77a61b3ba52c1d56c18..0000000000000000000000000000000000000000
--- a/spaces/kazuk/youtube-whisper-16/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Youtube Whisper
-emoji: ⚡
-colorFrom: green
-colorTo: red
-sdk: gradio
-sdk_version: 3.16.2
-app_file: app.py
-pinned: false
-license: unknown
-duplicated_from: kazuk/youtube-whisper-13
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/kevinwang676/ChatGLM2-SadTalker/src/face3d/models/arcface_torch/train.py b/spaces/kevinwang676/ChatGLM2-SadTalker/src/face3d/models/arcface_torch/train.py
deleted file mode 100644
index 55eca2d0ad9463415970e09bccab8b722e496704..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/ChatGLM2-SadTalker/src/face3d/models/arcface_torch/train.py
+++ /dev/null
@@ -1,141 +0,0 @@
-import argparse
-import logging
-import os
-
-import torch
-import torch.distributed as dist
-import torch.nn.functional as F
-import torch.utils.data.distributed
-from torch.nn.utils import clip_grad_norm_
-
-import losses
-from backbones import get_model
-from dataset import MXFaceDataset, SyntheticDataset, DataLoaderX
-from partial_fc import PartialFC
-from utils.utils_amp import MaxClipGradScaler
-from utils.utils_callbacks import CallBackVerification, CallBackLogging, CallBackModelCheckpoint
-from utils.utils_config import get_config
-from utils.utils_logging import AverageMeter, init_logging
-
-
-def main(args):
- cfg = get_config(args.config)
- try:
- world_size = int(os.environ['WORLD_SIZE'])
- rank = int(os.environ['RANK'])
- dist.init_process_group('nccl')
- except KeyError:
- world_size = 1
- rank = 0
- dist.init_process_group(backend='nccl', init_method="tcp://127.0.0.1:12584", rank=rank, world_size=world_size)
-
- local_rank = args.local_rank
- torch.cuda.set_device(local_rank)
- os.makedirs(cfg.output, exist_ok=True)
- init_logging(rank, cfg.output)
-
- if cfg.rec == "synthetic":
- train_set = SyntheticDataset(local_rank=local_rank)
- else:
- train_set = MXFaceDataset(root_dir=cfg.rec, local_rank=local_rank)
-
- train_sampler = torch.utils.data.distributed.DistributedSampler(train_set, shuffle=True)
- train_loader = DataLoaderX(
- local_rank=local_rank, dataset=train_set, batch_size=cfg.batch_size,
- sampler=train_sampler, num_workers=2, pin_memory=True, drop_last=True)
- backbone = get_model(cfg.network, dropout=0.0, fp16=cfg.fp16, num_features=cfg.embedding_size).to(local_rank)
-
- if cfg.resume:
- try:
- backbone_pth = os.path.join(cfg.output, "backbone.pth")
- backbone.load_state_dict(torch.load(backbone_pth, map_location=torch.device(local_rank)))
- if rank == 0:
- logging.info("backbone resume successfully!")
- except (FileNotFoundError, KeyError, IndexError, RuntimeError):
- if rank == 0:
- logging.info("resume fail, backbone init successfully!")
-
- backbone = torch.nn.parallel.DistributedDataParallel(
- module=backbone, broadcast_buffers=False, device_ids=[local_rank])
- backbone.train()
- margin_softmax = losses.get_loss(cfg.loss)
- module_partial_fc = PartialFC(
- rank=rank, local_rank=local_rank, world_size=world_size, resume=cfg.resume,
- batch_size=cfg.batch_size, margin_softmax=margin_softmax, num_classes=cfg.num_classes,
- sample_rate=cfg.sample_rate, embedding_size=cfg.embedding_size, prefix=cfg.output)
-
- opt_backbone = torch.optim.SGD(
- params=[{'params': backbone.parameters()}],
- lr=cfg.lr / 512 * cfg.batch_size * world_size,
- momentum=0.9, weight_decay=cfg.weight_decay)
- opt_pfc = torch.optim.SGD(
- params=[{'params': module_partial_fc.parameters()}],
- lr=cfg.lr / 512 * cfg.batch_size * world_size,
- momentum=0.9, weight_decay=cfg.weight_decay)
-
- num_image = len(train_set)
- total_batch_size = cfg.batch_size * world_size
- cfg.warmup_step = num_image // total_batch_size * cfg.warmup_epoch
- cfg.total_step = num_image // total_batch_size * cfg.num_epoch
-
- def lr_step_func(current_step):
- cfg.decay_step = [x * num_image // total_batch_size for x in cfg.decay_epoch]
- if current_step < cfg.warmup_step:
- return current_step / cfg.warmup_step
- else:
- return 0.1 ** len([m for m in cfg.decay_step if m <= current_step])
-
- scheduler_backbone = torch.optim.lr_scheduler.LambdaLR(
- optimizer=opt_backbone, lr_lambda=lr_step_func)
- scheduler_pfc = torch.optim.lr_scheduler.LambdaLR(
- optimizer=opt_pfc, lr_lambda=lr_step_func)
-
- for key, value in cfg.items():
- num_space = 25 - len(key)
- logging.info(": " + key + " " * num_space + str(value))
-
- val_target = cfg.val_targets
- callback_verification = CallBackVerification(2000, rank, val_target, cfg.rec)
- callback_logging = CallBackLogging(50, rank, cfg.total_step, cfg.batch_size, world_size, None)
- callback_checkpoint = CallBackModelCheckpoint(rank, cfg.output)
-
- loss = AverageMeter()
- start_epoch = 0
- global_step = 0
- grad_amp = MaxClipGradScaler(cfg.batch_size, 128 * cfg.batch_size, growth_interval=100) if cfg.fp16 else None
- for epoch in range(start_epoch, cfg.num_epoch):
- train_sampler.set_epoch(epoch)
- for step, (img, label) in enumerate(train_loader):
- global_step += 1
- features = F.normalize(backbone(img))
- x_grad, loss_v = module_partial_fc.forward_backward(label, features, opt_pfc)
- if cfg.fp16:
- features.backward(grad_amp.scale(x_grad))
- grad_amp.unscale_(opt_backbone)
- clip_grad_norm_(backbone.parameters(), max_norm=5, norm_type=2)
- grad_amp.step(opt_backbone)
- grad_amp.update()
- else:
- features.backward(x_grad)
- clip_grad_norm_(backbone.parameters(), max_norm=5, norm_type=2)
- opt_backbone.step()
-
- opt_pfc.step()
- module_partial_fc.update()
- opt_backbone.zero_grad()
- opt_pfc.zero_grad()
- loss.update(loss_v, 1)
- callback_logging(global_step, loss, epoch, cfg.fp16, scheduler_backbone.get_last_lr()[0], grad_amp)
- callback_verification(global_step, backbone)
- scheduler_backbone.step()
- scheduler_pfc.step()
- callback_checkpoint(global_step, backbone, module_partial_fc)
- dist.destroy_process_group()
-
-
-if __name__ == "__main__":
- torch.backends.cudnn.benchmark = True
- parser = argparse.ArgumentParser(description='PyTorch ArcFace Training')
- parser.add_argument('config', type=str, help='py config file')
- parser.add_argument('--local_rank', type=int, default=0, help='local_rank')
- main(parser.parse_args())
diff --git a/spaces/kevinwang676/ChatGLM2-VC-SadTalker/speaker_encoder/data_objects/speaker.py b/spaces/kevinwang676/ChatGLM2-VC-SadTalker/speaker_encoder/data_objects/speaker.py
deleted file mode 100644
index 07379847a854d85623db02ce5e5409c1566eb80c..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/ChatGLM2-VC-SadTalker/speaker_encoder/data_objects/speaker.py
+++ /dev/null
@@ -1,40 +0,0 @@
-from speaker_encoder.data_objects.random_cycler import RandomCycler
-from speaker_encoder.data_objects.utterance import Utterance
-from pathlib import Path
-
-# Contains the set of utterances of a single speaker
-class Speaker:
- def __init__(self, root: Path):
- self.root = root
- self.name = root.name
- self.utterances = None
- self.utterance_cycler = None
-
- def _load_utterances(self):
- with self.root.joinpath("_sources.txt").open("r") as sources_file:
- sources = [l.split(",") for l in sources_file]
- sources = {frames_fname: wave_fpath for frames_fname, wave_fpath in sources}
- self.utterances = [Utterance(self.root.joinpath(f), w) for f, w in sources.items()]
- self.utterance_cycler = RandomCycler(self.utterances)
-
- def random_partial(self, count, n_frames):
- """
- Samples a batch of unique partial utterances from the disk in a way that all
- utterances come up at least once every two cycles and in a random order every time.
-
- :param count: The number of partial utterances to sample from the set of utterances from
- that speaker. Utterances are guaranteed not to be repeated if is not larger than
- the number of utterances available.
- :param n_frames: The number of frames in the partial utterance.
- :return: A list of tuples (utterance, frames, range) where utterance is an Utterance,
- frames are the frames of the partial utterances and range is the range of the partial
- utterance with regard to the complete utterance.
- """
- if self.utterances is None:
- self._load_utterances()
-
- utterances = self.utterance_cycler.sample(count)
-
- a = [(u,) + u.random_partial(n_frames) for u in utterances]
-
- return a
diff --git a/spaces/kira4424/Tacotron-zero-short-voice-clone/encoder/data_objects/speaker_verification_dataset.py b/spaces/kira4424/Tacotron-zero-short-voice-clone/encoder/data_objects/speaker_verification_dataset.py
deleted file mode 100644
index 77a6e05eae6a939ae7575ae70b7173644141fffe..0000000000000000000000000000000000000000
--- a/spaces/kira4424/Tacotron-zero-short-voice-clone/encoder/data_objects/speaker_verification_dataset.py
+++ /dev/null
@@ -1,56 +0,0 @@
-from encoder.data_objects.random_cycler import RandomCycler
-from encoder.data_objects.speaker_batch import SpeakerBatch
-from encoder.data_objects.speaker import Speaker
-from encoder.params_data import partials_n_frames
-from torch.utils.data import Dataset, DataLoader
-from pathlib import Path
-
-# TODO: improve with a pool of speakers for data efficiency
-
-class SpeakerVerificationDataset(Dataset):
- def __init__(self, datasets_root: Path):
- self.root = datasets_root
- speaker_dirs = [f for f in self.root.glob("*") if f.is_dir()]
- if len(speaker_dirs) == 0:
- raise Exception("No speakers found. Make sure you are pointing to the directory "
- "containing all preprocessed speaker directories.")
- self.speakers = [Speaker(speaker_dir) for speaker_dir in speaker_dirs]
- self.speaker_cycler = RandomCycler(self.speakers)
-
- def __len__(self):
- return int(1e10)
-
- def __getitem__(self, index):
- return next(self.speaker_cycler)
-
- def get_logs(self):
- log_string = ""
- for log_fpath in self.root.glob("*.txt"):
- with log_fpath.open("r") as log_file:
- log_string += "".join(log_file.readlines())
- return log_string
-
-
-class SpeakerVerificationDataLoader(DataLoader):
- def __init__(self, dataset, speakers_per_batch, utterances_per_speaker, sampler=None,
- batch_sampler=None, num_workers=0, pin_memory=False, timeout=0,
- worker_init_fn=None):
- self.utterances_per_speaker = utterances_per_speaker
-
- super().__init__(
- dataset=dataset,
- batch_size=speakers_per_batch,
- shuffle=False,
- sampler=sampler,
- batch_sampler=batch_sampler,
- num_workers=num_workers,
- collate_fn=self.collate,
- pin_memory=pin_memory,
- drop_last=False,
- timeout=timeout,
- worker_init_fn=worker_init_fn
- )
-
- def collate(self, speakers):
- return SpeakerBatch(speakers, self.utterances_per_speaker, partials_n_frames)
-
\ No newline at end of file
diff --git a/spaces/kira4424/Tacotron-zero-short-voice-clone/web.py b/spaces/kira4424/Tacotron-zero-short-voice-clone/web.py
deleted file mode 100644
index d232530ec912f9c985cdd5b67a49f0fc53b4d947..0000000000000000000000000000000000000000
--- a/spaces/kira4424/Tacotron-zero-short-voice-clone/web.py
+++ /dev/null
@@ -1,21 +0,0 @@
-import os
-import sys
-import typer
-
-cli = typer.Typer()
-
-@cli.command()
-def launch_ui(port: int = typer.Option(8080, "--port", "-p")) -> None:
- """Start a graphical UI server for the opyrator.
-
- The UI is auto-generated from the input- and output-schema of the given function.
- """
- # Add the current working directory to the sys path
- # This is required to resolve the opyrator path
- sys.path.append(os.getcwd())
-
- from mkgui.base.ui.streamlit_ui import launch_ui
- launch_ui(port)
-
-if __name__ == "__main__":
- cli()
\ No newline at end of file
diff --git a/spaces/kiskisbella/janitor/Dockerfile b/spaces/kiskisbella/janitor/Dockerfile
deleted file mode 100644
index 6c01c09373883afcb4ea34ae2d316cd596e1737b..0000000000000000000000000000000000000000
--- a/spaces/kiskisbella/janitor/Dockerfile
+++ /dev/null
@@ -1,21 +0,0 @@
-FROM node:18-bullseye-slim
-
-RUN apt-get update && \
-
-apt-get install -y git
-
-RUN git clone https://gitgud.io/khanon/oai-reverse-proxy.git /app
-
-WORKDIR /app
-
-RUN npm install
-
-COPY Dockerfile greeting.md* .env* ./
-
-RUN npm run build
-
-EXPOSE 7860
-
-ENV NODE_ENV=production
-
-CMD [ "npm", "start" ]
\ No newline at end of file
diff --git a/spaces/koajoel/PolyFormer/data/create_finetuning_data.py b/spaces/koajoel/PolyFormer/data/create_finetuning_data.py
deleted file mode 100644
index 1d627ca17daa9b5b36afe177ba9073921c906646..0000000000000000000000000000000000000000
--- a/spaces/koajoel/PolyFormer/data/create_finetuning_data.py
+++ /dev/null
@@ -1,123 +0,0 @@
-from refer.refer import REFER
-import numpy as np
-from PIL import Image
-import random
-import os
-from tqdm import tqdm
-
-import pickle
-from poly_utils import is_clockwise, revert_direction, check_length, reorder_points, \
- approximate_polygons, interpolate_polygons, image_to_base64, polygons_to_string
-
-
-max_length = 400
-
-data_root = './refer/data'
-datasets = ['refcoco', 'refcoco+', 'refcocog']
-
-image_dir = './datasets/images/mscoco/train2014'
-val_test_files = pickle.load(open("data/val_test_files.p", "rb"))
-
-combined_train_data = []
-
-for dataset in datasets:
- if dataset == 'refcoco':
- splits = ['train', 'val', 'testA', 'testB']
- splitBy = 'unc'
- elif dataset == 'refcoco+':
- splits = ['train', 'val', 'testA', 'testB']
- splitBy = 'unc'
- elif dataset == 'refcocog':
- splits = ['train', 'val']
- splitBy = 'umd'
-
- save_dir = f'datasets/finetune/{dataset}'
- os.makedirs(save_dir, exist_ok=True)
- for split in splits:
- num_pts = []
- max_num_pts = 0
- file_name = os.path.join(save_dir, f"{dataset}_{split}.tsv")
- print("creating ", file_name)
-
- uniq_ids = []
- image_ids = []
- sents = []
- coeffs_strings = []
- img_strings = []
-
- writer = open(file_name, 'w')
- refer = REFER(data_root, dataset, splitBy)
-
- ref_ids = refer.getRefIds(split=split)
-
- for this_ref_id in tqdm(ref_ids):
- this_img_id = refer.getImgIds(this_ref_id)
- this_img = refer.Imgs[this_img_id[0]]
- fn = this_img['file_name']
- img_id = fn.split(".")[0].split("_")[-1]
-
- # load image
- img = Image.open(os.path.join(image_dir, this_img['file_name'])).convert("RGB")
-
- # convert image to string
- img_base64 = image_to_base64(img, format='jpeg')
-
- # load mask
- ref = refer.loadRefs(this_ref_id)
- ref_mask = np.array(refer.getMask(ref[0])['mask'])
- annot = np.zeros(ref_mask.shape)
- annot[ref_mask == 1] = 1 # 255
- annot_img = Image.fromarray(annot.astype(np.uint8), mode="P")
- annot_base64 = image_to_base64(annot_img, format='png')
-
- polygons = refer.getPolygon(ref[0])['polygon']
-
- polygons_processed = []
- for polygon in polygons:
- # make the polygon clockwise
- if not is_clockwise(polygon):
- polygon = revert_direction(polygon)
-
- # reorder the polygon so that the first vertex is the one closest to image origin
- polygon = reorder_points(polygon)
- polygons_processed.append(polygon)
-
- polygons = sorted(polygons_processed, key=lambda x: (x[0] ** 2 + x[1] ** 2, x[0], x[1]))
- polygons_interpolated = interpolate_polygons(polygons)
-
- polygons = approximate_polygons(polygons, 5, max_length)
-
- pts_string = polygons_to_string(polygons)
- pts_string_interpolated = polygons_to_string(polygons_interpolated)
-
- # load box
- box = refer.getRefBox(this_ref_id) # x,y,w,h
- x, y, w, h = box
- box_string = f'{x},{y},{x + w},{y + h}'
-
- max_num_pts = max(max_num_pts, check_length(polygons))
-
- num_pts.append(check_length(polygons))
- # load text
- ref_sent = refer.Refs[this_ref_id]
- for i, (sent, sent_id) in enumerate(zip(ref_sent['sentences'], ref_sent['sent_ids'])):
- uniq_id = f"{this_ref_id}_{i}"
- instance = '\t'.join(
- [uniq_id, str(this_img_id[0]), sent['sent'], box_string, pts_string, img_base64, annot_base64,
- pts_string_interpolated]) + '\n'
- writer.write(instance)
-
- if img_id not in val_test_files and split == 'train': # filtered out val/test files
- combined_train_data.append(instance)
- writer.close()
-
-random.shuffle(combined_train_data)
-file_name = os.path.join("datasets/finetune/refcoco+g_train_shuffled.tsv")
-print("creating ", file_name)
-writer = open(file_name, 'w')
-writer.writelines(combined_train_data)
-writer.close()
-
-
-
-
diff --git a/spaces/konol/konmol/app.py b/spaces/konol/konmol/app.py
deleted file mode 100644
index 2439c5cec6b61e8a517f957daf710cbb6b5c3cf6..0000000000000000000000000000000000000000
--- a/spaces/konol/konmol/app.py
+++ /dev/null
@@ -1,62 +0,0 @@
-from upcunet_v3 import RealWaifuUpScaler
-import gradio as gr
-import time
-import logging
-import os
-from PIL import ImageOps
-import numpy as np
-import math
-
-
-def greet(input_img, input_model_name, input_tile_mode):
- # if input_img.size[0] * input_img.size[1] > 256 * 256:
- # y = int(math.sqrt(256*256/input_img.size[0]*input_img.size[1]))
- # x = int(input_img.size[0]/input_img.size[1]*y)
- # input_img = ImageOps.fit(input_img, (x, y))
- input_img = np.array(input_img)
- if input_model_name not in model_cache:
- t1 = time.time()
- upscaler = RealWaifuUpScaler(input_model_name[2], ModelPath + input_model_name, half=False, device="cpu")
- t2 = time.time()
- logger.info(f'load model time, {t2 - t1}')
- model_cache[input_model_name] = upscaler
- else:
- upscaler = model_cache[input_model_name]
- logger.info(f'load model from cache')
-
- start = time.time()
- result = upscaler(input_img, tile_mode=input_tile_mode)
- end = time.time()
- logger.info(f'input_model_name, {input_model_name}')
- logger.info(f'input_tile_mode, {input_tile_mode}')
- logger.info(f'input shape, {input_img.shape}')
- logger.info(f'output shape, {result.shape}')
- logger.info(f'speed time, {end - start}')
- return result
-
-
-if __name__ == '__main__':
- logging.basicConfig(level=logging.INFO, format="[%(asctime)s] [%(process)d] [%(levelname)s] %(message)s")
- logger = logging.getLogger()
-
- ModelPath = "weights_v3/"
- model_cache = {}
-
- input_model_name = gr.inputs.Dropdown(os.listdir(ModelPath), default="up2x-latest-denoise2x.pth", label='选择model')
- input_tile_mode = gr.inputs.Dropdown([0, 1, 2, 3, 4], default=2, label='选择tile_mode')
- input_img = gr.inputs.Image(label='image', type='pil')
-
- inputs = [input_img, input_model_name, input_tile_mode]
- outputs = "image"
- iface = gr.Interface(fn=greet,
- inputs=inputs,
- outputs=outputs,
- allow_screenshot=False,
- allow_flagging='never',
- examples=[['test-img.jpg', "up2x-latest-denoise2x.pth", 2]],
- article='[https://github.com/bilibili/ailab/tree/main/Real-CUGAN](https://github.com/bilibili/ailab/tree/main/Real-CUGAN)CyberShadowFreeDownloadcrack Download >>>>> https://bytlly.com/2uGyj3
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Microsoft Office 2016 Pro Plus VL V16.0.4266.1001 (x64) Multi-17 Crack TOP.md b/spaces/lincquiQcaudo/Top-20-Diffusion/Microsoft Office 2016 Pro Plus VL V16.0.4266.1001 (x64) Multi-17 Crack TOP.md
deleted file mode 100644
index a7fd17520d43fcf6a2563c341a77d6688a54633f..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Microsoft Office 2016 Pro Plus VL V16.0.4266.1001 (x64) Multi-17 Crack TOP.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Microsoft Office 2016 Pro Plus VL v16.0.4266.1001 (x64) Multi-17 crack Download File ☆☆☆☆☆ https://bytlly.com/2uGvQh
diff --git a/spaces/litagin/rvc_okiba_TTS/config.py b/spaces/litagin/rvc_okiba_TTS/config.py
deleted file mode 100644
index 4038dad0ac30ba03b6271499f4e37bbc745a2032..0000000000000000000000000000000000000000
--- a/spaces/litagin/rvc_okiba_TTS/config.py
+++ /dev/null
@@ -1,115 +0,0 @@
-import argparse
-import sys
-import torch
-from multiprocessing import cpu_count
-
-
-class Config:
- def __init__(self):
- self.device = "cuda:0"
- self.is_half = True
- self.n_cpu = 0
- self.gpu_name = None
- self.gpu_mem = None
- (
- self.python_cmd,
- self.listen_port,
- self.iscolab,
- self.noparallel,
- self.noautoopen,
- ) = self.arg_parse()
- self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
-
- @staticmethod
- def arg_parse() -> tuple:
- exe = sys.executable or "python"
- parser = argparse.ArgumentParser()
- parser.add_argument("--port", type=int, default=7865, help="Listen port")
- parser.add_argument("--pycmd", type=str, default=exe, help="Python command")
- parser.add_argument("--colab", action="store_true", help="Launch in colab")
- parser.add_argument(
- "--noparallel", action="store_true", help="Disable parallel processing"
- )
- parser.add_argument(
- "--noautoopen",
- action="store_true",
- help="Do not open in browser automatically",
- )
- cmd_opts = parser.parse_args()
-
- cmd_opts.port = cmd_opts.port if 0 <= cmd_opts.port <= 65535 else 7865
-
- return (
- cmd_opts.pycmd,
- cmd_opts.port,
- cmd_opts.colab,
- cmd_opts.noparallel,
- cmd_opts.noautoopen,
- )
-
- # has_mps is only available in nightly pytorch (for now) and MasOS 12.3+.
- # check `getattr` and try it for compatibility
- @staticmethod
- def has_mps() -> bool:
- if not torch.backends.mps.is_available():
- return False
- try:
- torch.zeros(1).to(torch.device("mps"))
- return True
- except Exception:
- return False
-
- def device_config(self) -> tuple:
- if torch.cuda.is_available():
- i_device = int(self.device.split(":")[-1])
- self.gpu_name = torch.cuda.get_device_name(i_device)
- if (
- ("16" in self.gpu_name and "V100" not in self.gpu_name.upper())
- or "P40" in self.gpu_name.upper()
- or "1060" in self.gpu_name
- or "1070" in self.gpu_name
- or "1080" in self.gpu_name
- ):
- print("Found GPU", self.gpu_name, ", force to fp32")
- self.is_half = False
- else:
- print("Found GPU", self.gpu_name)
- self.gpu_mem = int(
- torch.cuda.get_device_properties(i_device).total_memory
- / 1024
- / 1024
- / 1024
- + 0.4
- )
- elif self.has_mps():
- print("No supported Nvidia GPU found, use MPS instead")
- self.device = "mps"
- self.is_half = False
- else:
- print("No supported Nvidia GPU found, use CPU instead")
- self.device = "cpu"
- self.is_half = False
-
- if self.n_cpu == 0:
- self.n_cpu = cpu_count()
-
- if self.is_half:
- # 6G显存配置
- x_pad = 3
- x_query = 10
- x_center = 60
- x_max = 65
- else:
- # 5G显存配置
- x_pad = 1
- x_query = 6
- x_center = 38
- x_max = 41
-
- if self.gpu_mem != None and self.gpu_mem <= 4:
- x_pad = 1
- x_query = 5
- x_center = 30
- x_max = 32
-
- return x_pad, x_query, x_center, x_max
diff --git a/spaces/lj1995/vocal2guitar/docs/faq_en.md b/spaces/lj1995/vocal2guitar/docs/faq_en.md
deleted file mode 100644
index 05f03ec0467706c319c0c19c83c200f43eb8f4a0..0000000000000000000000000000000000000000
--- a/spaces/lj1995/vocal2guitar/docs/faq_en.md
+++ /dev/null
@@ -1,95 +0,0 @@
-## Q1:ffmpeg error/utf8 error.
-It is most likely not a FFmpeg issue, but rather an audio path issue;
-
-FFmpeg may encounter an error when reading paths containing special characters like spaces and (), which may cause an FFmpeg error; and when the training set's audio contains Chinese paths, writing it into filelist.txt may cause a utf8 error.
-#include
-#include
-
-namespace thrust
-{
-namespace system
-{
-namespace detail
-{
-namespace sequential
-{
-
-
-__thrust_exec_check_disable__
-template
-__host__ __device__
-InputIterator find_if(execution_policy &,
- InputIterator first,
- InputIterator last,
- Predicate pred)
-{
- // wrap pred
- thrust::detail::wrapped_function<
- Predicate,
- bool
- > wrapped_pred(pred);
-
- while(first != last)
- {
- if (wrapped_pred(*first))
- return first;
-
- ++first;
- }
-
- // return first so zip_iterator works correctly
- return first;
-}
-
-
-} // end namespace sequential
-} // end namespace detail
-} // end namespace system
-} // end namespace thrust
-
diff --git a/spaces/manavisrani07/gradio-lipsync-wav2lip/basicsr/utils/__init__.py b/spaces/manavisrani07/gradio-lipsync-wav2lip/basicsr/utils/__init__.py
deleted file mode 100644
index e4e999c8eddc6a5f9623863ce85232e58984e138..0000000000000000000000000000000000000000
--- a/spaces/manavisrani07/gradio-lipsync-wav2lip/basicsr/utils/__init__.py
+++ /dev/null
@@ -1,44 +0,0 @@
-from .color_util import bgr2ycbcr, rgb2ycbcr, rgb2ycbcr_pt, ycbcr2bgr, ycbcr2rgb
-from .diffjpeg import DiffJPEG
-from .file_client import FileClient
-from .img_process_util import USMSharp, usm_sharp
-from .img_util import crop_border, imfrombytes, img2tensor, imwrite, tensor2img
-from .logger import AvgTimer, MessageLogger, get_env_info, get_root_logger, init_tb_logger, init_wandb_logger
-from .misc import check_resume, get_time_str, make_exp_dirs, mkdir_and_rename, scandir, set_random_seed, sizeof_fmt
-
-__all__ = [
- # color_util.py
- 'bgr2ycbcr',
- 'rgb2ycbcr',
- 'rgb2ycbcr_pt',
- 'ycbcr2bgr',
- 'ycbcr2rgb',
- # file_client.py
- 'FileClient',
- # img_util.py
- 'img2tensor',
- 'tensor2img',
- 'imfrombytes',
- 'imwrite',
- 'crop_border',
- # logger.py
- 'MessageLogger',
- 'AvgTimer',
- 'init_tb_logger',
- 'init_wandb_logger',
- 'get_root_logger',
- 'get_env_info',
- # misc.py
- 'set_random_seed',
- 'get_time_str',
- 'mkdir_and_rename',
- 'make_exp_dirs',
- 'scandir',
- 'check_resume',
- 'sizeof_fmt',
- # diffjpeg
- 'DiffJPEG',
- # img_process_util
- 'USMSharp',
- 'usm_sharp'
-]
diff --git a/spaces/marcop/musika/musika_test.py b/spaces/marcop/musika/musika_test.py
deleted file mode 100644
index f778fdabd9fceb407cc572a15c15f0ba1bf095af..0000000000000000000000000000000000000000
--- a/spaces/marcop/musika/musika_test.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import os
-
-os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
-
-from parse_test import parse_args
-from models import Models_functions
-from utils import Utils_functions
-
-if __name__ == "__main__":
-
- # parse args
- args = parse_args()
-
- # initialize networks
- M = Models_functions(args)
- models_ls_1, models_ls_2, models_ls_3 = M.get_networks()
-
- # test musika
- U = Utils_functions(args)
- U.render_gradio(models_ls_1, models_ls_2, models_ls_3, train=False)
diff --git a/spaces/marcusj83/MusicGenbruh/CONTRIBUTING.md b/spaces/marcusj83/MusicGenbruh/CONTRIBUTING.md
deleted file mode 100644
index 55b99140204d785d572ada9761dd77f302ae31c6..0000000000000000000000000000000000000000
--- a/spaces/marcusj83/MusicGenbruh/CONTRIBUTING.md
+++ /dev/null
@@ -1,35 +0,0 @@
-# Contributing to Audiocraft
-
-We want to make contributing to this project as easy and transparent as
-possible.
-
-## Pull Requests
-
-Audiocraft is the implementation of a research paper.
-Therefore, we do not plan on accepting many pull requests for new features.
-We certainly welcome them for bug fixes.
-
-1. Fork the repo and create your branch from `main`.
-2. If you've added code that should be tested, add tests.
-3. If you've changed APIs, update the documentation.
-4. Ensure the test suite passes.
-5. Make sure your code lints.
-6. If you haven't already, complete the Contributor License Agreement ("CLA").
-
-## Contributor License Agreement ("CLA")
-In order to accept your pull request, we need you to submit a CLA. You only need
-to do this once to work on any of Meta's open source projects.
-
-Complete your CLA here:
-
-## Issues
-We use GitHub issues to track public bugs. Please ensure your description is
-clear and has sufficient instructions to be able to reproduce the issue.
-
-Meta has a [bounty program](https://www.facebook.com/whitehat/) for the safe
-disclosure of security bugs. In those cases, please go through the process
-outlined on that page and do not file a public issue.
-
-## License
-By contributing to encodec, you agree that your contributions will be licensed
-under the LICENSE file in the root directory of this source tree.
diff --git a/spaces/marlenezw/audio-driven-animations/MakeItTalk/thirdparty/face_of_art/old/eval_scripts/evaluation_functions.py b/spaces/marlenezw/audio-driven-animations/MakeItTalk/thirdparty/face_of_art/old/eval_scripts/evaluation_functions.py
deleted file mode 100644
index 743efaed013ebb381bd98fe53bed0e263d0f7320..0000000000000000000000000000000000000000
--- a/spaces/marlenezw/audio-driven-animations/MakeItTalk/thirdparty/face_of_art/old/eval_scripts/evaluation_functions.py
+++ /dev/null
@@ -1,300 +0,0 @@
-import tensorflow as tf
-from menpofit.visualize import plot_cumulative_error_distribution
-from menpofit.error import compute_cumulative_error
-from scipy.integrate import simps
-from menpo_functions import load_menpo_image_list, load_bb_dictionary
-from logging_functions import *
-from data_loading_functions import *
-from time import time
-import sys
-from PyQt5 import QtWidgets
-qapp=QtWidgets.QApplication([''])
-
-
-def load_menpo_test_list(img_dir, test_data='full', image_size=256, margin=0.25, bb_type='gt'):
- mode = 'TEST'
- bb_dir = os.path.join(img_dir, 'Bounding_Boxes')
- bb_dictionary = load_bb_dictionary(bb_dir, mode, test_data=test_data)
- img_menpo_list = load_menpo_image_list(
- img_dir=img_dir, train_crop_dir=None, img_dir_ns=None, mode=mode, bb_dictionary=bb_dictionary,
- image_size=image_size, margin=margin,
- bb_type=bb_type, test_data=test_data, augment_basic=False, augment_texture=False, p_texture=0,
- augment_geom=False, p_geom=0)
- return img_menpo_list
-
-
-def evaluate_heatmap_fusion_network(model_path, img_path, test_data, batch_size=10, image_size=256, margin=0.25,
- bb_type='gt', c_dim=3, scale=1, num_landmarks=68, debug=False,
- debug_data_size=20):
- t = time()
- from deep_heatmaps_model_fusion_net import DeepHeatmapsModel
- import logging
- logging.getLogger('tensorflow').disabled = True
-
- # load test image menpo list
-
- test_menpo_img_list = load_menpo_test_list(
- img_path, test_data=test_data, image_size=image_size, margin=margin, bb_type=bb_type)
-
- if debug:
- test_menpo_img_list = test_menpo_img_list[:debug_data_size]
- print ('\n*** FUSION NETWORK: calculating normalized mean error on: ' + test_data +
- ' set (%d images - debug mode) ***' % debug_data_size)
- else:
- print ('\n*** FUSION NETWORK: calculating normalized mean error on: ' + test_data + ' set (%d images) ***' %
- (len(test_menpo_img_list)))
-
- # create heatmap model
-
- tf.reset_default_graph()
-
- model = DeepHeatmapsModel(mode='TEST', batch_size=batch_size, image_size=image_size, c_dim=c_dim,
- num_landmarks=num_landmarks, img_path=img_path, test_model_path=model_path,
- test_data=test_data, menpo_verbose=False)
-
- # add placeholders
- model.add_placeholders()
- # build model
- model.build_model()
- # create loss ops
- model.create_loss_ops()
-
- num_batches = int(1. * len(test_menpo_img_list) / batch_size)
- if num_batches == 0:
- batch_size = len(test_menpo_img_list)
- num_batches = 1
-
- reminder = len(test_menpo_img_list) - num_batches * batch_size
- num_batches_reminder = num_batches + 1 * (reminder > 0)
- img_inds = np.arange(len(test_menpo_img_list))
-
- with tf.Session() as session:
-
- # load trained parameters
- saver = tf.train.Saver()
- saver.restore(session, model_path)
-
- print ('\nnum batches: ' + str(num_batches_reminder))
-
- err = []
- for j in range(num_batches):
- print ('batch %d / %d ...' % (j + 1, num_batches_reminder))
- batch_inds = img_inds[j * batch_size:(j + 1) * batch_size]
-
- batch_images, _, batch_landmarks_gt = load_images_landmarks(
- test_menpo_img_list, batch_inds=batch_inds, image_size=image_size,
- c_dim=c_dim, num_landmarks=num_landmarks, scale=scale)
-
- batch_maps_pred = session.run(model.pred_hm_f, {model.images: batch_images})
-
- batch_pred_landmarks = batch_heat_maps_to_landmarks(
- batch_maps_pred, batch_size=batch_size, image_size=image_size, num_landmarks=num_landmarks)
-
- batch_err = session.run(
- model.nme_per_image, {model.lms: batch_landmarks_gt, model.pred_lms: batch_pred_landmarks})
- err = np.hstack((err, batch_err))
-
- if reminder > 0:
- print ('batch %d / %d ...' % (j + 2, num_batches_reminder))
- reminder_inds = img_inds[-reminder:]
-
- batch_images, _, batch_landmarks_gt = load_images_landmarks(
- test_menpo_img_list, batch_inds=reminder_inds, image_size=image_size,
- c_dim=c_dim, num_landmarks=num_landmarks, scale=scale)
-
- batch_maps_pred = session.run(model.pred_hm_f, {model.images: batch_images})
-
- batch_pred_landmarks = batch_heat_maps_to_landmarks(
- batch_maps_pred, batch_size=reminder, image_size=image_size, num_landmarks=num_landmarks)
-
- batch_err = session.run(
- model.nme_per_image, {model.lms: batch_landmarks_gt, model.pred_lms: batch_pred_landmarks})
- err = np.hstack((err, batch_err))
-
- print ('\ndone!')
- print ('run time: ' + str(time() - t))
-
- return err
-
-
-def evaluate_heatmap_primary_network(model_path, img_path, test_data, batch_size=10, image_size=256, margin=0.25,
- bb_type='gt', c_dim=3, scale=1, num_landmarks=68, debug=False,
- debug_data_size=20):
- t = time()
- from deep_heatmaps_model_primary_net import DeepHeatmapsModel
- import logging
- logging.getLogger('tensorflow').disabled = True
-
- # load test image menpo list
-
- test_menpo_img_list = load_menpo_test_list(
- img_path, test_data=test_data, image_size=image_size, margin=margin, bb_type=bb_type)
-
- if debug:
- test_menpo_img_list = test_menpo_img_list[:debug_data_size]
- print ('\n*** PRIMARY NETWORK: calculating normalized mean error on: ' + test_data +
- ' set (%d images - debug mode) ***' % debug_data_size)
- else:
- print ('\n*** PRIMARY NETWORK: calculating normalized mean error on: ' + test_data +
- ' set (%d images) ***' % (len(test_menpo_img_list)))
-
- # create heatmap model
-
- tf.reset_default_graph()
-
- model = DeepHeatmapsModel(mode='TEST', batch_size=batch_size, image_size=image_size, c_dim=c_dim,
- num_landmarks=num_landmarks, img_path=img_path, test_model_path=model_path,
- test_data=test_data, menpo_verbose=False)
-
- # add placeholders
- model.add_placeholders()
- # build model
- model.build_model()
- # create loss ops
- model.create_loss_ops()
-
- num_batches = int(1. * len(test_menpo_img_list) / batch_size)
- if num_batches == 0:
- batch_size = len(test_menpo_img_list)
- num_batches = 1
-
- reminder = len(test_menpo_img_list) - num_batches * batch_size
- num_batches_reminder = num_batches + 1 * (reminder > 0)
- img_inds = np.arange(len(test_menpo_img_list))
-
- with tf.Session() as session:
-
- # load trained parameters
- saver = tf.train.Saver()
- saver.restore(session, model_path)
-
- print ('\nnum batches: ' + str(num_batches_reminder))
-
- err = []
- for j in range(num_batches):
- print ('batch %d / %d ...' % (j + 1, num_batches_reminder))
- batch_inds = img_inds[j * batch_size:(j + 1) * batch_size]
-
- batch_images, _, batch_landmarks_gt = load_images_landmarks(
- test_menpo_img_list, batch_inds=batch_inds, image_size=image_size,
- c_dim=c_dim, num_landmarks=num_landmarks, scale=scale)
-
- batch_maps_small_pred = session.run(model.pred_hm_p, {model.images: batch_images})
-
- batch_maps_small_pred = zoom(batch_maps_small_pred, zoom=[1, 4, 4, 1], order=1) # NN interpolation
-
- batch_pred_landmarks = batch_heat_maps_to_landmarks(
- batch_maps_small_pred, batch_size=batch_size, image_size=image_size,
- num_landmarks=num_landmarks)
-
- batch_err = session.run(
- model.nme_per_image, {model.lms_small: batch_landmarks_gt, model.pred_lms_small: batch_pred_landmarks})
- err = np.hstack((err, batch_err))
-
- if reminder > 0:
- print ('batch %d / %d ...' % (j + 2, num_batches_reminder))
- reminder_inds = img_inds[-reminder:]
-
- batch_images, _, batch_landmarks_gt = load_images_landmarks(
- test_menpo_img_list, batch_inds=reminder_inds, image_size=image_size,
- c_dim=c_dim, num_landmarks=num_landmarks, scale=scale)
-
- batch_maps_small_pred = session.run(model.pred_hm_p, {model.images: batch_images})
-
- batch_maps_small_pred = zoom(batch_maps_small_pred, zoom=[1, 4, 4, 1], order=1) # NN interpolation
-
- batch_pred_landmarks = batch_heat_maps_to_landmarks(
- batch_maps_small_pred, batch_size=reminder, image_size=image_size,
- num_landmarks=num_landmarks)
-
- batch_err = session.run(
- model.nme_per_image, {model.lms_small: batch_landmarks_gt, model.pred_lms_small: batch_pred_landmarks})
- err = np.hstack((err, batch_err))
-
- print ('\ndone!')
- print ('run time: ' + str(time() - t))
-
- return err
-
-
-def evaluate_heatmap_network(model_path, network_type, img_path, test_data, batch_size=10, image_size=256, margin=0.25,
- bb_type='gt', c_dim=3, scale=1, num_landmarks=68, debug=False,
- debug_data_size=20):
-
- if network_type.lower() == 'fusion':
- return evaluate_heatmap_fusion_network(
- model_path=model_path, img_path=img_path, test_data=test_data, batch_size=batch_size, image_size=image_size,
- margin=margin, bb_type=bb_type, c_dim=c_dim, scale=scale, num_landmarks=num_landmarks, debug=debug,
- debug_data_size=debug_data_size)
- elif network_type.lower() == 'primary':
- return evaluate_heatmap_primary_network(
- model_path=model_path, img_path=img_path, test_data=test_data, batch_size=batch_size, image_size=image_size,
- margin=margin, bb_type=bb_type, c_dim=c_dim, scale=scale, num_landmarks=num_landmarks, debug=debug,
- debug_data_size=debug_data_size)
- else:
- sys.exit('\n*** Error: please choose a valid network type: Fusion/Primary ***')
-
-
-def AUC(errors, max_error, step_error=0.0001):
- x_axis = list(np.arange(0., max_error + step_error, step_error))
- ced = np.array(compute_cumulative_error(errors, x_axis))
- return simps(ced, x=x_axis) / max_error, 1. - ced[-1]
-
-
-def print_nme_statistics(
- errors, model_path, network_type, test_data, max_error=0.08, log_path='', save_log=True, plot_ced=True,
- norm='interocular distance'):
- auc, failures = AUC(errors, max_error=max_error)
-
- print ("\n****** NME statistics for " + network_type + " Network ******\n")
- print ("* model path: " + model_path)
- print ("* dataset: " + test_data + ' set')
-
- print ("\n* Normalized mean error (percentage of "+norm+"): %.2f" % (100 * np.mean(errors)))
- print ("\n* AUC @ %.2f: %.2f" % (max_error, 100 * auc))
- print ("\n* failure rate @ %.2f: %.2f" % (max_error, 100 * failures) + '%')
-
- if plot_ced:
- plt.figure()
- plt.yticks(np.linspace(0, 1, 11))
- plot_cumulative_error_distribution(
- list(errors),
- legend_entries=[network_type],
- marker_style=['s'],
- marker_size=7,
- x_label='Normalised Point-to-Point Error\n('+norm+')\n*' + test_data + ' set*',
- )
-
- if save_log:
- with open(os.path.join(log_path, network_type.lower() + "_nme_statistics_on_" + test_data + "_set.txt"),
- "wb") as f:
- f.write(b"************************************************")
- f.write(("\n****** NME statistics for " + str(network_type) + " Network ******\n").encode())
- f.write(b"************************************************")
- f.write(("\n\n* model path: " + str(model_path)).encode())
- f.write(("\n\n* dataset: " + str(test_data) + ' set').encode())
- f.write(b"\n\n* Normalized mean error (percentage of "+norm+"): %.2f" % (100 * np.mean(errors)))
- f.write(b"\n\n* AUC @ %.2f: %.2f" % (max_error, 100 * auc))
- f.write(("\n\n* failure rate @ %.2f: %.2f" % (max_error, 100 * failures) + '%').encode())
- if plot_ced:
- plt.savefig(os.path.join(log_path, network_type.lower() + '_nme_ced_on_' + test_data + '_set.png'),
- bbox_inches='tight')
- plt.close()
-
- print ('\nlog path: ' + log_path)
-
-
-def print_ced_compare_methods(
- method_errors,method_names,test_data,log_path='', save_log=True, norm='interocular distance'):
- plt.yticks(np.linspace(0, 1, 11))
- plot_cumulative_error_distribution(
- [list(err) for err in list(method_errors)],
- legend_entries=list(method_names),
- marker_style=['s'],
- marker_size=7,
- x_label='Normalised Point-to-Point Error\n('+norm+')\n*'+test_data+' set*'
- )
- if save_log:
- plt.savefig(os.path.join(log_path,'nme_ced_on_'+test_data+'_set.png'), bbox_inches='tight')
- print ('ced plot path: ' + os.path.join(log_path,'nme_ced_on_'+test_data+'_set.png'))
- plt.close()
\ No newline at end of file
diff --git a/spaces/merve/uncertainty-calibration/source/third_party/recirc.js b/spaces/merve/uncertainty-calibration/source/third_party/recirc.js
deleted file mode 100644
index 37b65f4b8cf3c3ba504a0a3b906f8c19befc6730..0000000000000000000000000000000000000000
--- a/spaces/merve/uncertainty-calibration/source/third_party/recirc.js
+++ /dev/null
@@ -1,58 +0,0 @@
-/* Copyright 2020 Google LLC. All Rights Reserved.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-==============================================================================*/
-
-
-
-
-d3.loadData('../posts.json', (err, res) => {
- var posts = res[0]
- .filter(d => !window.location.href.includes(d.permalink))
- .filter(d => d.shareimg.includes('http'))
- posts = d3.shuffle(posts)
-
- var isMobile = innerWidth < 900
- var postSel = d3.select('#recirc').html('').appendMany('a.post', posts)
- .st({
- width: isMobile ? '100%' : '330px',
- display: 'inline-block',
- verticalAlign: 'top',
- marginRight: isMobile ? 0 : 30,
- textDecoration: 'none',
- })
- .at({href: d => '..' + d.permalink})
-
-
- postSel.append('div.img')
- .st({
- width: '100%',
- height: 200,
- backgroundImage: d => `url(${d.shareimgabstract || d.shareimg})`,
- backgroundSize: 'cover',
- backgroundPosition: 'center',
- })
-
- postSel.append('p.title')
- .text(d => d.shorttitle || d.title)
- .st({
- verticalAlign: 'top',
- marginTop: 10,
- textDecoration: 'none',
- })
-
- postSel.append('p.summary')
- .text(d => d.socialsummary || d.summary)
-
-
-})
\ No newline at end of file
diff --git a/spaces/mfkeles/Track-Anything/tracker/inference/memory_manager.py b/spaces/mfkeles/Track-Anything/tracker/inference/memory_manager.py
deleted file mode 100644
index d47d96e400ba6050e6bb4325cdb21a1c3a25edc6..0000000000000000000000000000000000000000
--- a/spaces/mfkeles/Track-Anything/tracker/inference/memory_manager.py
+++ /dev/null
@@ -1,286 +0,0 @@
-import torch
-import warnings
-
-from inference.kv_memory_store import KeyValueMemoryStore
-from model.memory_util import *
-
-
-class MemoryManager:
- """
- Manages all three memory stores and the transition between working/long-term memory
- """
- def __init__(self, config):
- self.hidden_dim = config['hidden_dim']
- self.top_k = config['top_k']
-
- self.enable_long_term = config['enable_long_term']
- self.enable_long_term_usage = config['enable_long_term_count_usage']
- if self.enable_long_term:
- self.max_mt_frames = config['max_mid_term_frames']
- self.min_mt_frames = config['min_mid_term_frames']
- self.num_prototypes = config['num_prototypes']
- self.max_long_elements = config['max_long_term_elements']
-
- # dimensions will be inferred from input later
- self.CK = self.CV = None
- self.H = self.W = None
-
- # The hidden state will be stored in a single tensor for all objects
- # B x num_objects x CH x H x W
- self.hidden = None
-
- self.work_mem = KeyValueMemoryStore(count_usage=self.enable_long_term)
- if self.enable_long_term:
- self.long_mem = KeyValueMemoryStore(count_usage=self.enable_long_term_usage)
-
- self.reset_config = True
-
- def update_config(self, config):
- self.reset_config = True
- self.hidden_dim = config['hidden_dim']
- self.top_k = config['top_k']
-
- assert self.enable_long_term == config['enable_long_term'], 'cannot update this'
- assert self.enable_long_term_usage == config['enable_long_term_count_usage'], 'cannot update this'
-
- self.enable_long_term_usage = config['enable_long_term_count_usage']
- if self.enable_long_term:
- self.max_mt_frames = config['max_mid_term_frames']
- self.min_mt_frames = config['min_mid_term_frames']
- self.num_prototypes = config['num_prototypes']
- self.max_long_elements = config['max_long_term_elements']
-
- def _readout(self, affinity, v):
- # this function is for a single object group
- return v @ affinity
-
- def match_memory(self, query_key, selection):
- # query_key: B x C^k x H x W
- # selection: B x C^k x H x W
- num_groups = self.work_mem.num_groups
- h, w = query_key.shape[-2:]
-
- query_key = query_key.flatten(start_dim=2)
- selection = selection.flatten(start_dim=2) if selection is not None else None
-
- """
- Memory readout using keys
- """
-
- if self.enable_long_term and self.long_mem.engaged():
- # Use long-term memory
- long_mem_size = self.long_mem.size
- memory_key = torch.cat([self.long_mem.key, self.work_mem.key], -1)
- shrinkage = torch.cat([self.long_mem.shrinkage, self.work_mem.shrinkage], -1)
-
- similarity = get_similarity(memory_key, shrinkage, query_key, selection)
- work_mem_similarity = similarity[:, long_mem_size:]
- long_mem_similarity = similarity[:, :long_mem_size]
-
- # get the usage with the first group
- # the first group always have all the keys valid
- affinity, usage = do_softmax(
- torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(0):], work_mem_similarity], 1),
- top_k=self.top_k, inplace=True, return_usage=True)
- affinity = [affinity]
-
- # compute affinity group by group as later groups only have a subset of keys
- for gi in range(1, num_groups):
- if gi < self.long_mem.num_groups:
- # merge working and lt similarities before softmax
- affinity_one_group = do_softmax(
- torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(gi):],
- work_mem_similarity[:, -self.work_mem.get_v_size(gi):]], 1),
- top_k=self.top_k, inplace=True)
- else:
- # no long-term memory for this group
- affinity_one_group = do_softmax(work_mem_similarity[:, -self.work_mem.get_v_size(gi):],
- top_k=self.top_k, inplace=(gi==num_groups-1))
- affinity.append(affinity_one_group)
-
- all_memory_value = []
- for gi, gv in enumerate(self.work_mem.value):
- # merge the working and lt values before readout
- if gi < self.long_mem.num_groups:
- all_memory_value.append(torch.cat([self.long_mem.value[gi], self.work_mem.value[gi]], -1))
- else:
- all_memory_value.append(gv)
-
- """
- Record memory usage for working and long-term memory
- """
- # ignore the index return for long-term memory
- work_usage = usage[:, long_mem_size:]
- self.work_mem.update_usage(work_usage.flatten())
-
- if self.enable_long_term_usage:
- # ignore the index return for working memory
- long_usage = usage[:, :long_mem_size]
- self.long_mem.update_usage(long_usage.flatten())
- else:
- # No long-term memory
- similarity = get_similarity(self.work_mem.key, self.work_mem.shrinkage, query_key, selection)
-
- if self.enable_long_term:
- affinity, usage = do_softmax(similarity, inplace=(num_groups==1),
- top_k=self.top_k, return_usage=True)
-
- # Record memory usage for working memory
- self.work_mem.update_usage(usage.flatten())
- else:
- affinity = do_softmax(similarity, inplace=(num_groups==1),
- top_k=self.top_k, return_usage=False)
-
- affinity = [affinity]
-
- # compute affinity group by group as later groups only have a subset of keys
- for gi in range(1, num_groups):
- affinity_one_group = do_softmax(similarity[:, -self.work_mem.get_v_size(gi):],
- top_k=self.top_k, inplace=(gi==num_groups-1))
- affinity.append(affinity_one_group)
-
- all_memory_value = self.work_mem.value
-
- # Shared affinity within each group
- all_readout_mem = torch.cat([
- self._readout(affinity[gi], gv)
- for gi, gv in enumerate(all_memory_value)
- ], 0)
-
- return all_readout_mem.view(all_readout_mem.shape[0], self.CV, h, w)
-
- def add_memory(self, key, shrinkage, value, objects, selection=None):
- # key: 1*C*H*W
- # value: 1*num_objects*C*H*W
- # objects contain a list of object indices
- if self.H is None or self.reset_config:
- self.reset_config = False
- self.H, self.W = key.shape[-2:]
- self.HW = self.H*self.W
- if self.enable_long_term:
- # convert from num. frames to num. nodes
- self.min_work_elements = self.min_mt_frames*self.HW
- self.max_work_elements = self.max_mt_frames*self.HW
-
- # key: 1*C*N
- # value: num_objects*C*N
- key = key.flatten(start_dim=2)
- shrinkage = shrinkage.flatten(start_dim=2)
- value = value[0].flatten(start_dim=2)
-
- self.CK = key.shape[1]
- self.CV = value.shape[1]
-
- if selection is not None:
- if not self.enable_long_term:
- warnings.warn('the selection factor is only needed in long-term mode', UserWarning)
- selection = selection.flatten(start_dim=2)
-
- self.work_mem.add(key, value, shrinkage, selection, objects)
-
- # long-term memory cleanup
- if self.enable_long_term:
- # Do memory compressed if needed
- if self.work_mem.size >= self.max_work_elements:
- # print('remove memory')
- # Remove obsolete features if needed
- if self.long_mem.size >= (self.max_long_elements-self.num_prototypes):
- self.long_mem.remove_obsolete_features(self.max_long_elements-self.num_prototypes)
-
- self.compress_features()
-
- def create_hidden_state(self, n, sample_key):
- # n is the TOTAL number of objects
- h, w = sample_key.shape[-2:]
- if self.hidden is None:
- self.hidden = torch.zeros((1, n, self.hidden_dim, h, w), device=sample_key.device)
- elif self.hidden.shape[1] != n:
- self.hidden = torch.cat([
- self.hidden,
- torch.zeros((1, n-self.hidden.shape[1], self.hidden_dim, h, w), device=sample_key.device)
- ], 1)
-
- assert(self.hidden.shape[1] == n)
-
- def set_hidden(self, hidden):
- self.hidden = hidden
-
- def get_hidden(self):
- return self.hidden
-
- def compress_features(self):
- HW = self.HW
- candidate_value = []
- total_work_mem_size = self.work_mem.size
- for gv in self.work_mem.value:
- # Some object groups might be added later in the video
- # So not all keys have values associated with all objects
- # We need to keep track of the key->value validity
- mem_size_in_this_group = gv.shape[-1]
- if mem_size_in_this_group == total_work_mem_size:
- # full LT
- candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
- else:
- # mem_size is smaller than total_work_mem_size, but at least HW
- assert HW <= mem_size_in_this_group < total_work_mem_size
- if mem_size_in_this_group > self.min_work_elements+HW:
- # part of this object group still goes into LT
- candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
- else:
- # this object group cannot go to the LT at all
- candidate_value.append(None)
-
- # perform memory consolidation
- prototype_key, prototype_value, prototype_shrinkage = self.consolidation(
- *self.work_mem.get_all_sliced(HW, -self.min_work_elements+HW), candidate_value)
-
- # remove consolidated working memory
- self.work_mem.sieve_by_range(HW, -self.min_work_elements+HW, min_size=self.min_work_elements+HW)
-
- # add to long-term memory
- self.long_mem.add(prototype_key, prototype_value, prototype_shrinkage, selection=None, objects=None)
- # print(f'long memory size: {self.long_mem.size}')
- # print(f'work memory size: {self.work_mem.size}')
-
- def consolidation(self, candidate_key, candidate_shrinkage, candidate_selection, usage, candidate_value):
- # keys: 1*C*N
- # values: num_objects*C*N
- N = candidate_key.shape[-1]
-
- # find the indices with max usage
- _, max_usage_indices = torch.topk(usage, k=self.num_prototypes, dim=-1, sorted=True)
- prototype_indices = max_usage_indices.flatten()
-
- # Prototypes are invalid for out-of-bound groups
- validity = [prototype_indices >= (N-gv.shape[2]) if gv is not None else None for gv in candidate_value]
-
- prototype_key = candidate_key[:, :, prototype_indices]
- prototype_selection = candidate_selection[:, :, prototype_indices] if candidate_selection is not None else None
-
- """
- Potentiation step
- """
- similarity = get_similarity(candidate_key, candidate_shrinkage, prototype_key, prototype_selection)
-
- # convert similarity to affinity
- # need to do it group by group since the softmax normalization would be different
- affinity = [
- do_softmax(similarity[:, -gv.shape[2]:, validity[gi]]) if gv is not None else None
- for gi, gv in enumerate(candidate_value)
- ]
-
- # some values can be have all False validity. Weed them out.
- affinity = [
- aff if aff is None or aff.shape[-1] > 0 else None for aff in affinity
- ]
-
- # readout the values
- prototype_value = [
- self._readout(affinity[gi], gv) if affinity[gi] is not None else None
- for gi, gv in enumerate(candidate_value)
- ]
-
- # readout the shrinkage term
- prototype_shrinkage = self._readout(affinity[0], candidate_shrinkage) if candidate_shrinkage is not None else None
-
- return prototype_key, prototype_value, prototype_shrinkage
\ No newline at end of file
diff --git a/spaces/milyiyo/reimagine-it/captioning/modules/loss_wrapper.py b/spaces/milyiyo/reimagine-it/captioning/modules/loss_wrapper.py
deleted file mode 100644
index d86f1e6f7df4a6bc112563294b8bf6bb4d999b98..0000000000000000000000000000000000000000
--- a/spaces/milyiyo/reimagine-it/captioning/modules/loss_wrapper.py
+++ /dev/null
@@ -1,127 +0,0 @@
-import torch
-from . import losses
-from ..utils.rewards import init_scorer, get_self_critical_reward, get_self_critical_clipscore_reward
-from ..utils.clipscore import CLIPScore
-import numpy as np
-
-class LossWrapper(torch.nn.Module):
- def __init__(self, model, opt):
- super(LossWrapper, self).__init__()
- self.opt = opt
- self.model = model
- if opt.label_smoothing > 0:
- self.crit = losses.LabelSmoothing(smoothing=opt.label_smoothing)
- else:
- self.crit = losses.LanguageModelCriterion()
- self.rl_crit = losses.RewardCriterion()
- self.struc_crit = losses.StructureLosses(opt)
-
- self.clipscore_model = None
- if self.opt.use_clipscore:
- use_grammar = getattr(self.opt, 'use_grammar', False)
- joint_out = getattr(self.opt, 'joint_out', False)
- self.clipscore_model = CLIPScore(
- mode=opt.clipscore_mode,
- use_grammar=use_grammar,
- joint_out=joint_out,
- )
- for p in self.clipscore_model.parameters():
- p.requires_grad = False
-
- if use_grammar:
- state_dict = torch.load(self.opt.clip_load_path, map_location='cpu')
- self.clipscore_model.load_state_dict(state_dict['state_dict'])
-
- def forward(self, fc_feats, att_feats, labels, masks, att_masks, gts, gt_indices,
- sc_flag, struc_flag, clip_vis_feats=None):
- opt = self.opt
-
- out = {}
- if struc_flag:
- if opt.structure_loss_weight < 1:
- lm_loss = self.crit(self.model(fc_feats, att_feats, labels[..., :-1], att_masks), labels[..., 1:], masks[..., 1:])
- else:
- lm_loss = torch.tensor(0).type_as(fc_feats)
- if opt.structure_loss_weight > 0:
- gen_result, sample_logprobs = self.model(fc_feats, att_feats, att_masks,
- opt={'sample_method':opt.train_sample_method,
- 'beam_size':opt.train_beam_size,
- 'output_logsoftmax': opt.struc_use_logsoftmax or opt.structure_loss_type == 'softmax_margin'\
- or not 'margin' in opt.structure_loss_type,
- 'sample_n': opt.train_sample_n},
- mode='sample')
- gts = [gts[_] for _ in gt_indices.tolist()]
- struc_loss = self.struc_crit(sample_logprobs, gen_result, gts)
- else:
- struc_loss = {'loss': torch.tensor(0).type_as(fc_feats),
- 'reward': torch.tensor(0).type_as(fc_feats)}
- loss = (1-opt.structure_loss_weight) * lm_loss + opt.structure_loss_weight * struc_loss['loss']
- out['lm_loss'] = lm_loss
- out['struc_loss'] = struc_loss['loss']
- out['reward'] = struc_loss['reward']
- elif not sc_flag:
- loss = self.crit(self.model(fc_feats, att_feats, labels[..., :-1], att_masks), labels[..., 1:], masks[..., 1:])
- else:
- self.model.eval()
- with torch.no_grad():
- greedy_res, _ = self.model(fc_feats, att_feats, att_masks,
- mode='sample',
- opt={'sample_method': opt.sc_sample_method,
- 'beam_size': opt.sc_beam_size})
- self.model.train()
- gen_result, sample_logprobs = self.model(fc_feats, att_feats, att_masks,
- opt={'sample_method':opt.train_sample_method,
- 'beam_size':opt.train_beam_size,
- 'sample_n': opt.train_sample_n},
- mode='sample')
- gts = [gts[_] for _ in gt_indices.tolist()]
-
- if getattr(self.opt, 'use_multi_rewards', False):
- assert self.opt.use_clipscore
- clipscore_reward_normalized, clipscore_unnormalized_mean, grammar_rewards = get_self_critical_clipscore_reward(
- greedy_res, gts, gen_result, self.opt, self.clipscore_model, clip_vis_feats, self.model.vocab)
-
- if self.opt.clipscore_mode == 'clip_s':
- out['CLIP-S'] = clipscore_unnormalized_mean
- elif self.opt.clipscore_mode == 'refclip_s':
- out['RefCLIP-S'] = clipscore_unnormalized_mean
-
- if getattr(self.opt, 'use_grammar', False):
- out['grammar_reward'] = grammar_rewards.mean()
-
- reward = clipscore_reward_normalized + grammar_rewards
-
-
- else:
- assert grammar_rewards is None
-
- cider_reward_normalized, cider_unnormalized_mean = get_self_critical_reward(
- greedy_res, gts, gen_result, self.opt)
- out['CIDEr'] = cider_unnormalized_mean
- if isinstance(cider_reward_normalized, np.ndarray):
- cider_reward_normalized = torch.from_numpy(cider_reward_normalized).to(clipscore_reward_normalized.device)
-
- reward = clipscore_reward_normalized + cider_reward_normalized
- else:
- if self.opt.use_clipscore:
- clipscore_reward_normalized, clipscore_unnormalized_mean, _ = get_self_critical_clipscore_reward(
- greedy_res, gts, gen_result, self.opt, self.clipscore_model, clip_vis_feats, self.model.vocab)
- if self.opt.clipscore_mode == 'clip_s':
- out['CLIP-S'] = clipscore_unnormalized_mean
- elif self.opt.clipscore_mode == 'refclip_s':
- out['RefCLIP-S'] = clipscore_unnormalized_mean
- reward = clipscore_reward_normalized
- else:
- cider_reward_normalized, cider_unnormalized_mean = get_self_critical_reward(
- greedy_res, gts, gen_result, self.opt)
- out['CIDEr'] = cider_unnormalized_mean
- reward = cider_reward_normalized
-
- if isinstance(reward, np.ndarray):
- reward = torch.from_numpy(reward)
- reward = reward.to(sample_logprobs)
- loss = self.rl_crit(sample_logprobs, gen_result.data, reward)
- out['reward'] = reward[:,0].mean()
- out['loss'] = loss
- return out
-
diff --git a/spaces/mjdolan/Holiday-StyleGAN-NADA/e4e/models/stylegan2/model.py b/spaces/mjdolan/Holiday-StyleGAN-NADA/e4e/models/stylegan2/model.py
deleted file mode 100644
index fcb12af85669ab6fd7f79cb14ddbdf80b2fbd83d..0000000000000000000000000000000000000000
--- a/spaces/mjdolan/Holiday-StyleGAN-NADA/e4e/models/stylegan2/model.py
+++ /dev/null
@@ -1,678 +0,0 @@
-import math
-import random
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-if torch.cuda.is_available():
- from op.fused_act import FusedLeakyReLU, fused_leaky_relu
- from op.upfirdn2d import upfirdn2d
-else:
- from op.fused_act_cpu import FusedLeakyReLU, fused_leaky_relu
- from op.upfirdn2d_cpu import upfirdn2d
-
-
-class PixelNorm(nn.Module):
- def __init__(self):
- super().__init__()
-
- def forward(self, input):
- return input * torch.rsqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)
-
-
-def make_kernel(k):
- k = torch.tensor(k, dtype=torch.float32)
-
- if k.ndim == 1:
- k = k[None, :] * k[:, None]
-
- k /= k.sum()
-
- return k
-
-
-class Upsample(nn.Module):
- def __init__(self, kernel, factor=2):
- super().__init__()
-
- self.factor = factor
- kernel = make_kernel(kernel) * (factor ** 2)
- self.register_buffer('kernel', kernel)
-
- p = kernel.shape[0] - factor
-
- pad0 = (p + 1) // 2 + factor - 1
- pad1 = p // 2
-
- self.pad = (pad0, pad1)
-
- def forward(self, input):
- out = upfirdn2d(input, self.kernel, up=self.factor, down=1, pad=self.pad)
-
- return out
-
-
-class Downsample(nn.Module):
- def __init__(self, kernel, factor=2):
- super().__init__()
-
- self.factor = factor
- kernel = make_kernel(kernel)
- self.register_buffer('kernel', kernel)
-
- p = kernel.shape[0] - factor
-
- pad0 = (p + 1) // 2
- pad1 = p // 2
-
- self.pad = (pad0, pad1)
-
- def forward(self, input):
- out = upfirdn2d(input, self.kernel, up=1, down=self.factor, pad=self.pad)
-
- return out
-
-
-class Blur(nn.Module):
- def __init__(self, kernel, pad, upsample_factor=1):
- super().__init__()
-
- kernel = make_kernel(kernel)
-
- if upsample_factor > 1:
- kernel = kernel * (upsample_factor ** 2)
-
- self.register_buffer('kernel', kernel)
-
- self.pad = pad
-
- def forward(self, input):
- out = upfirdn2d(input, self.kernel, pad=self.pad)
-
- return out
-
-
-class EqualConv2d(nn.Module):
- def __init__(
- self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
- ):
- super().__init__()
-
- self.weight = nn.Parameter(
- torch.randn(out_channel, in_channel, kernel_size, kernel_size)
- )
- self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
-
- self.stride = stride
- self.padding = padding
-
- if bias:
- self.bias = nn.Parameter(torch.zeros(out_channel))
-
- else:
- self.bias = None
-
- def forward(self, input):
- out = F.conv2d(
- input,
- self.weight * self.scale,
- bias=self.bias,
- stride=self.stride,
- padding=self.padding,
- )
-
- return out
-
- def __repr__(self):
- return (
- f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},'
- f' {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})'
- )
-
-
-class EqualLinear(nn.Module):
- def __init__(
- self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None
- ):
- super().__init__()
-
- self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
-
- if bias:
- self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
-
- else:
- self.bias = None
-
- self.activation = activation
-
- self.scale = (1 / math.sqrt(in_dim)) * lr_mul
- self.lr_mul = lr_mul
-
- def forward(self, input):
- if self.activation:
- out = F.linear(input, self.weight * self.scale)
- out = fused_leaky_relu(out, self.bias * self.lr_mul)
-
- else:
- out = F.linear(
- input, self.weight * self.scale, bias=self.bias * self.lr_mul
- )
-
- return out
-
- def __repr__(self):
- return (
- f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})'
- )
-
-
-class ScaledLeakyReLU(nn.Module):
- def __init__(self, negative_slope=0.2):
- super().__init__()
-
- self.negative_slope = negative_slope
-
- def forward(self, input):
- out = F.leaky_relu(input, negative_slope=self.negative_slope)
-
- return out * math.sqrt(2)
-
-
-class ModulatedConv2d(nn.Module):
- def __init__(
- self,
- in_channel,
- out_channel,
- kernel_size,
- style_dim,
- demodulate=True,
- upsample=False,
- downsample=False,
- blur_kernel=[1, 3, 3, 1],
- ):
- super().__init__()
-
- self.eps = 1e-8
- self.kernel_size = kernel_size
- self.in_channel = in_channel
- self.out_channel = out_channel
- self.upsample = upsample
- self.downsample = downsample
-
- if upsample:
- factor = 2
- p = (len(blur_kernel) - factor) - (kernel_size - 1)
- pad0 = (p + 1) // 2 + factor - 1
- pad1 = p // 2 + 1
-
- self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
-
- if downsample:
- factor = 2
- p = (len(blur_kernel) - factor) + (kernel_size - 1)
- pad0 = (p + 1) // 2
- pad1 = p // 2
-
- self.blur = Blur(blur_kernel, pad=(pad0, pad1))
-
- fan_in = in_channel * kernel_size ** 2
- self.scale = 1 / math.sqrt(fan_in)
- self.padding = kernel_size // 2
-
- self.weight = nn.Parameter(
- torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
- )
-
- self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
-
- self.demodulate = demodulate
-
- def __repr__(self):
- return (
- f'{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, '
- f'upsample={self.upsample}, downsample={self.downsample})'
- )
-
- def forward(self, input, style):
- batch, in_channel, height, width = input.shape
-
- style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
- weight = self.scale * self.weight * style
-
- if self.demodulate:
- demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
- weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
-
- weight = weight.view(
- batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
- )
-
- if self.upsample:
- input = input.view(1, batch * in_channel, height, width)
- weight = weight.view(
- batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size
- )
- weight = weight.transpose(1, 2).reshape(
- batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
- )
- out = F.conv_transpose2d(input, weight, padding=0, stride=2, groups=batch)
- _, _, height, width = out.shape
- out = out.view(batch, self.out_channel, height, width)
- out = self.blur(out)
-
- elif self.downsample:
- input = self.blur(input)
- _, _, height, width = input.shape
- input = input.view(1, batch * in_channel, height, width)
- out = F.conv2d(input, weight, padding=0, stride=2, groups=batch)
- _, _, height, width = out.shape
- out = out.view(batch, self.out_channel, height, width)
-
- else:
- input = input.view(1, batch * in_channel, height, width)
- out = F.conv2d(input, weight, padding=self.padding, groups=batch)
- _, _, height, width = out.shape
- out = out.view(batch, self.out_channel, height, width)
-
- return out
-
-
-class NoiseInjection(nn.Module):
- def __init__(self):
- super().__init__()
-
- self.weight = nn.Parameter(torch.zeros(1))
-
- def forward(self, image, noise=None):
- if noise is None:
- batch, _, height, width = image.shape
- noise = image.new_empty(batch, 1, height, width).normal_()
-
- return image + self.weight * noise
-
-
-class ConstantInput(nn.Module):
- def __init__(self, channel, size=4):
- super().__init__()
-
- self.input = nn.Parameter(torch.randn(1, channel, size, size))
-
- def forward(self, input):
- batch = input.shape[0]
- out = self.input.repeat(batch, 1, 1, 1)
-
- return out
-
-
-class StyledConv(nn.Module):
- def __init__(
- self,
- in_channel,
- out_channel,
- kernel_size,
- style_dim,
- upsample=False,
- blur_kernel=[1, 3, 3, 1],
- demodulate=True,
- ):
- super().__init__()
-
- self.conv = ModulatedConv2d(
- in_channel,
- out_channel,
- kernel_size,
- style_dim,
- upsample=upsample,
- blur_kernel=blur_kernel,
- demodulate=demodulate,
- )
-
- self.noise = NoiseInjection()
- # self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
- # self.activate = ScaledLeakyReLU(0.2)
- self.activate = FusedLeakyReLU(out_channel)
-
- def forward(self, input, style, noise=None):
- out = self.conv(input, style)
- out = self.noise(out, noise=noise)
- # out = out + self.bias
- out = self.activate(out)
-
- return out
-
-
-class ToRGB(nn.Module):
- def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
- super().__init__()
-
- if upsample:
- self.upsample = Upsample(blur_kernel)
-
- self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
- self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
-
- def forward(self, input, style, skip=None):
- out = self.conv(input, style)
- out = out + self.bias
-
- if skip is not None:
- skip = self.upsample(skip)
-
- out = out + skip
-
- return out
-
-
-class Generator(nn.Module):
- def __init__(
- self,
- size,
- style_dim,
- n_mlp,
- channel_multiplier=2,
- blur_kernel=[1, 3, 3, 1],
- lr_mlp=0.01,
- ):
- super().__init__()
-
- self.size = size
-
- self.style_dim = style_dim
-
- layers = [PixelNorm()]
-
- for i in range(n_mlp):
- layers.append(
- EqualLinear(
- style_dim, style_dim, lr_mul=lr_mlp, activation='fused_lrelu'
- )
- )
-
- self.style = nn.Sequential(*layers)
-
- self.channels = {
- 4: 512,
- 8: 512,
- 16: 512,
- 32: 512,
- 64: 256 * channel_multiplier,
- 128: 128 * channel_multiplier,
- 256: 64 * channel_multiplier,
- 512: 32 * channel_multiplier,
- 1024: 16 * channel_multiplier,
- }
-
- self.input = ConstantInput(self.channels[4])
- self.conv1 = StyledConv(
- self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
- )
- self.to_rgb1 = ToRGB(self.channels[4], style_dim, upsample=False)
-
- self.log_size = int(math.log(size, 2))
- self.num_layers = (self.log_size - 2) * 2 + 1
-
- self.convs = nn.ModuleList()
- self.upsamples = nn.ModuleList()
- self.to_rgbs = nn.ModuleList()
- self.noises = nn.Module()
-
- in_channel = self.channels[4]
-
- for layer_idx in range(self.num_layers):
- res = (layer_idx + 5) // 2
- shape = [1, 1, 2 ** res, 2 ** res]
- self.noises.register_buffer(f'noise_{layer_idx}', torch.randn(*shape))
-
- for i in range(3, self.log_size + 1):
- out_channel = self.channels[2 ** i]
-
- self.convs.append(
- StyledConv(
- in_channel,
- out_channel,
- 3,
- style_dim,
- upsample=True,
- blur_kernel=blur_kernel,
- )
- )
-
- self.convs.append(
- StyledConv(
- out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel
- )
- )
-
- self.to_rgbs.append(ToRGB(out_channel, style_dim))
-
- in_channel = out_channel
-
- self.n_latent = self.log_size * 2 - 2
-
- def make_noise(self):
- device = self.input.input.device
-
- noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
-
- for i in range(3, self.log_size + 1):
- for _ in range(2):
- noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
-
- return noises
-
- def mean_latent(self, n_latent):
- latent_in = torch.randn(
- n_latent, self.style_dim, device=self.input.input.device
- )
- latent = self.style(latent_in).mean(0, keepdim=True)
-
- return latent
-
- def get_latent(self, input):
- return self.style(input)
-
- def forward(
- self,
- styles,
- return_latents=False,
- return_features=False,
- inject_index=None,
- truncation=1,
- truncation_latent=None,
- input_is_latent=False,
- noise=None,
- randomize_noise=True,
- ):
- if not input_is_latent:
- styles = [self.style(s) for s in styles]
-
- if noise is None:
- if randomize_noise:
- noise = [None] * self.num_layers
- else:
- noise = [
- getattr(self.noises, f'noise_{i}') for i in range(self.num_layers)
- ]
-
- if truncation < 1:
- style_t = []
-
- for style in styles:
- style_t.append(
- truncation_latent + truncation * (style - truncation_latent)
- )
-
- styles = style_t
-
- if len(styles) < 2:
- inject_index = self.n_latent
-
- if styles[0].ndim < 3:
- latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
- else:
- latent = styles[0]
-
- else:
- if inject_index is None:
- inject_index = random.randint(1, self.n_latent - 1)
-
- latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
- latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
-
- latent = torch.cat([latent, latent2], 1)
-
- out = self.input(latent)
- out = self.conv1(out, latent[:, 0], noise=noise[0])
-
- skip = self.to_rgb1(out, latent[:, 1])
-
- i = 1
- for conv1, conv2, noise1, noise2, to_rgb in zip(
- self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
- ):
- out = conv1(out, latent[:, i], noise=noise1)
- out = conv2(out, latent[:, i + 1], noise=noise2)
- skip = to_rgb(out, latent[:, i + 2], skip)
-
- i += 2
-
- image = skip
-
- if return_latents:
- return image, latent
- elif return_features:
- return image, out
- else:
- return image, None
-
-
-class ConvLayer(nn.Sequential):
- def __init__(
- self,
- in_channel,
- out_channel,
- kernel_size,
- downsample=False,
- blur_kernel=[1, 3, 3, 1],
- bias=True,
- activate=True,
- ):
- layers = []
-
- if downsample:
- factor = 2
- p = (len(blur_kernel) - factor) + (kernel_size - 1)
- pad0 = (p + 1) // 2
- pad1 = p // 2
-
- layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
-
- stride = 2
- self.padding = 0
-
- else:
- stride = 1
- self.padding = kernel_size // 2
-
- layers.append(
- EqualConv2d(
- in_channel,
- out_channel,
- kernel_size,
- padding=self.padding,
- stride=stride,
- bias=bias and not activate,
- )
- )
-
- if activate:
- if bias:
- layers.append(FusedLeakyReLU(out_channel))
-
- else:
- layers.append(ScaledLeakyReLU(0.2))
-
- super().__init__(*layers)
-
-
-class ResBlock(nn.Module):
- def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
- super().__init__()
-
- self.conv1 = ConvLayer(in_channel, in_channel, 3)
- self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
-
- self.skip = ConvLayer(
- in_channel, out_channel, 1, downsample=True, activate=False, bias=False
- )
-
- def forward(self, input):
- out = self.conv1(input)
- out = self.conv2(out)
-
- skip = self.skip(input)
- out = (out + skip) / math.sqrt(2)
-
- return out
-
-
-class Discriminator(nn.Module):
- def __init__(self, size, channel_multiplier=2, blur_kernel=[1, 3, 3, 1]):
- super().__init__()
-
- channels = {
- 4: 512,
- 8: 512,
- 16: 512,
- 32: 512,
- 64: 256 * channel_multiplier,
- 128: 128 * channel_multiplier,
- 256: 64 * channel_multiplier,
- 512: 32 * channel_multiplier,
- 1024: 16 * channel_multiplier,
- }
-
- convs = [ConvLayer(3, channels[size], 1)]
-
- log_size = int(math.log(size, 2))
-
- in_channel = channels[size]
-
- for i in range(log_size, 2, -1):
- out_channel = channels[2 ** (i - 1)]
-
- convs.append(ResBlock(in_channel, out_channel, blur_kernel))
-
- in_channel = out_channel
-
- self.convs = nn.Sequential(*convs)
-
- self.stddev_group = 4
- self.stddev_feat = 1
-
- self.final_conv = ConvLayer(in_channel + 1, channels[4], 3)
- self.final_linear = nn.Sequential(
- EqualLinear(channels[4] * 4 * 4, channels[4], activation='fused_lrelu'),
- EqualLinear(channels[4], 1),
- )
-
- def forward(self, input):
- out = self.convs(input)
-
- batch, channel, height, width = out.shape
- group = min(batch, self.stddev_group)
- stddev = out.view(
- group, -1, self.stddev_feat, channel // self.stddev_feat, height, width
- )
- stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
- stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
- stddev = stddev.repeat(group, 1, height, width)
- out = torch.cat([out, stddev], 1)
-
- out = self.final_conv(out)
-
- out = out.view(batch, -1)
- out = self.final_linear(out)
-
- return out
diff --git a/spaces/momegas/megabots/.github/ISSUE_TEMPLATE/feature_request.md b/spaces/momegas/megabots/.github/ISSUE_TEMPLATE/feature_request.md
deleted file mode 100644
index 36c6fd9d99c3a281f8717eaca2d6fd0d1dc5f279..0000000000000000000000000000000000000000
--- a/spaces/momegas/megabots/.github/ISSUE_TEMPLATE/feature_request.md
+++ /dev/null
@@ -1,20 +0,0 @@
----
-name: Feature request
-about: Suggest an idea for this project
-title: ''
-labels: enhancement
-assignees: momegas
-
----
-
-**Is your feature request related to a problem? Please describe.**
-A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
-
-**Describe the solution you'd like**
-A clear and concise description of what you want to happen.
-
-**Describe alternatives you've considered**
-A clear and concise description of any alternative solutions or features you've considered.
-
-**Additional context**
-Add any other context or screenshots about the feature request here.
diff --git a/spaces/mrm8488/idefics-9b-ft-describe-diffusion-mj/app.py b/spaces/mrm8488/idefics-9b-ft-describe-diffusion-mj/app.py
deleted file mode 100644
index ad168098b70261b2cc8521a62fe749dc360b214b..0000000000000000000000000000000000000000
--- a/spaces/mrm8488/idefics-9b-ft-describe-diffusion-mj/app.py
+++ /dev/null
@@ -1,50 +0,0 @@
-import torch
-from transformers import IdeficsForVisionText2Text, AutoProcessor
-from peft import PeftModel, PeftConfig
-import gradio as gr
-
-peft_model_id = "mrm8488/idefics-9b-ft-describe-diffusion-bf16-adapter"
-device = "cuda" if torch.cuda.is_available() else "cpu"
-
-
-config = PeftConfig.from_pretrained(peft_model_id)
-model = IdeficsForVisionText2Text.from_pretrained(config.base_model_name_or_path, torch_dtype=torch.bfloat16)
-model = PeftModel.from_pretrained(model, peft_model_id)
-processor = AutoProcessor.from_pretrained(config.base_model_name_or_path)
-model = model.to(device)
-model.eval()
-
-#Pre-determined best prompt for this fine-tune
-prompt="Describe the following image:"
-
-#Max generated tokens for your prompt
-max_length=64
-
-def predict(image):
- prompts = [[image, prompt]]
- inputs = processor(prompts[0], return_tensors="pt").to(device)
- generated_ids = model.generate(**inputs, max_length=max_length)
- generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
- generated_text = generated_text.replace(f"{prompt} ","")
- return generated_text
-
-title = "Midjourney-like Image Captioning with IDEFICS"
-description = "Gradio Demo for generating *Midjourney* like captions (describe functionality) with **IDEFICS**"
-
-examples = [
- ["1_sTXgMwDUW0pk-1yK4iHYFw.png"],
- ["0_6as5rHi0sgG4W2Tq.png"],
- ["zoomout_2-1440x807.jpg"],
- ["inZdRVn7eafZNvaVre2iW1a538.webp"],
- ["cute-photos-of-cats-in-grass-1593184777.jpg"],
- ["llama2-coder-logo.png"]
-]
-io = gr.Interface(fn=predict,
- inputs=[
- gr.Image(label="Upload an image", type="pil"),
- ],
- outputs=[
- gr.Textbox(label="IDEFICS Description")
- ],
- title=title, description=description, examples=examples)
-io.launch(debug=True)
\ No newline at end of file
diff --git a/spaces/mshukor/UnIVAL/run_scripts/vqa/eval/eval_vqa_base_best.sh b/spaces/mshukor/UnIVAL/run_scripts/vqa/eval/eval_vqa_base_best.sh
deleted file mode 100644
index 692447c2bb4f6ee6f393d6a862d89c72af3cb600..0000000000000000000000000000000000000000
--- a/spaces/mshukor/UnIVAL/run_scripts/vqa/eval/eval_vqa_base_best.sh
+++ /dev/null
@@ -1,123 +0,0 @@
-#!/usr/bin/env bash
-
-# The port for communication. Note that if you want to run multiple tasks on the same machine,
-# you need to specify different port numbers.
-# The port for communication. Note that if you want to run multiple tasks on the same machine,
-# you need to specify different port numbers.
-# Number of GPUs per GPU worker
-export GPUS_PER_NODE=8
-# Number of GPU workers, for single-worker training, please set to 1
-export NUM_NODES=$SLURM_NNODES
-# The ip address of the rank-0 worker, for single-worker training, please set to localhost
-master_addr=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
-export MASTER_ADDR=$master_addr
-
-# The port for communication
-export MASTER_PORT=12350
-# The rank of this worker, should be in {0, ..., WORKER_CNT-1}, for single-worker training, please set to 0
-export RANK=$SLURM_NODEID
-
-echo "MASTER_ADDR: $MASTER_ADDR"
-echo "RANK :$RANK"
-echo "NUM_NODES :$NUM_NODES"
-echo "GPUS_PER_NODE :$GPUS_PER_NODE"
-
-export MIOPEN_USER_DB_PATH=/lus/home/NAT/gda2204/mshukor/.config/miopen_${MASTER_ADDR}_${SLURM_PROCID}/
-
-echo "MIOPEN_USER_DB_PATH :$MIOPEN_USER_DB_PATH"
-
-num_workers=0
-
-
-exp_name=eval_vqa_base_best
-
-
-
-ofa_dir=/lus/home/NAT/gda2204/mshukor/code/unival
-base_data_dir=/lus/scratch/NAT/gda2204/SHARED/data
-base_log_dir=/work/NAT/gda2204/mshukor/logs
-
-
-
-
-bpe_dir=${ofa_dir}/utils/BPE
-user_dir=${ofa_dir}/ofa_module
-
-
-data_dir=${base_data_dir}/ofa/vqa_data
-
-# val or test or fullval
-split=test
-read_from_img_path='' #'--read-from-img-path' # ''
-# split=val
-# read_from_img_path='' #'--read-from-img-path' # ''
-
-# split=fullval
-# read_from_img_path='--read-from-img-path'
-
-data=${data_dir}/vqa_${split}.tsv
-
-ans2label_file=${base_data_dir}/ofa/vqa_data/trainval_ans2label.pkl
-
-zero_shot=''
-eval_ema='--ema-eval'
-
-# model_name=avg_rata_l0_7vqarefsnlicap
-# path=/lus/scratch/NAT/gda2204/SHARED/logs/ofa/pretrained_models/average_models/avg_rata_l0_7vqarefsnlicap.pt
-
-model_name=unival_s2_hs
-path=/work/NAT/gda2204/mshukor/logs/ofa/checkpoints/pretrain/unival_s2_hs/checkpoint1.pt
-zero_shot='--zero-shot'
-eval_ema=''
-
-
-
-new_base_log_dir=/lus/scratch/NAT/gda2204/SHARED/logs
-result_path=${new_base_log_dir}/ofa/results/vqa/vqa_${split}_beam_${model_name}
-
-
-
-
-mkdir ${result_path}
-
-
-selected_cols=0,5,2,3,4
-valid_batch_size=8
-
-
-image_dir=${base_data_dir}
-
-
-python3 -m torch.distributed.launch \
- --nnodes=${NUM_NODES} \
- --nproc_per_node=${GPUS_PER_NODE} \
- --master_port=${MASTER_PORT} \
- --node_rank=${RANK} \
- --master_addr=${MASTER_ADDR} \
- --use_env ${ofa_dir}/evaluate.py \
- ${data} \
- --path=${path} \
- --user-dir=${user_dir} \
- --task=vqa_gen \
- --batch-size=32 \
- --valid-batch-size=${valid_batch_size} \
- --log-format=simple --log-interval=10 \
- --seed=7 \
- --gen-subset=${split} \
- --results-path=${result_path} \
- --fp16 \
- --beam-search-vqa-eval \
- --beam=5 \
- --unnormalized \
- --temperature=1.0 \
- ${eval_ema} \
- --num-workers=0 \
- --model-overrides="{\"data\":\"${data}\",\"bpe_dir\":\"${bpe_dir}\",\"selected_cols\":\"${selected_cols}\",\"ans2label_file\":\"${ans2label_file}\",\"valid_batch_size\":\"${valid_batch_size}\"}" \
- --image-dir=${image_dir} \
- ${read_from_img_path} \
- --strict \
- ${zero_shot} \
- --patch-image-size=480 \
- --prompt-type='prev_output'
- # --prompt-type='none'
- # --noconstraints
diff --git a/spaces/mshukor/UnIVAL/slurm_adastra/averaging/ratatouille/caption/ofa_ratacaption_ground_caption_stage_1_lr1e5.sh b/spaces/mshukor/UnIVAL/slurm_adastra/averaging/ratatouille/caption/ofa_ratacaption_ground_caption_stage_1_lr1e5.sh
deleted file mode 100644
index 7955fa0bdfa60a85d361b3332216a740194437fc..0000000000000000000000000000000000000000
--- a/spaces/mshukor/UnIVAL/slurm_adastra/averaging/ratatouille/caption/ofa_ratacaption_ground_caption_stage_1_lr1e5.sh
+++ /dev/null
@@ -1,30 +0,0 @@
-#!/bin/bash
-
-#SBATCH --job-name=ofa_ratacaption_ground_caption_stage_1_lr1e5
-#SBATCH --nodes=1
-#SBATCH --ntasks=1
-#SBATCH --gpus=8
-#SBATCH --threads-per-core=2
-#SBATCH --gpu-bind=closest
-####SBATCH --nodelist=x1004c4s2b0n0
-#SBATCH --time=24:00:00
-#SBATCH -C MI250
-#SBATCH -A gda2204
-#SBATCH --mail-type=END,FAIL
-#SBATCH --output=/lus/home/NAT/gda2204/mshukor/logs/slurm/ofa_ratacaption_ground_caption_stage_1_lr1e5.out
-#SBATCH --exclusive
-#SBATCH --mail-user=mustafa.shukor@isir.upmc.fr
-
-
-cd /lus/home/NAT/gda2204/mshukor/code/ofa_ours/run_scripts
-source /lus/home/NAT/gda2204/mshukor/.bashrc
-
-conda activate main
-
-
-rm core-python3*
-
-
-srun -l -N 1 -n 1 -c 128 --gpus=8 bash averaging/ratatouille/caption/ofa_ratacaption_ground_caption_stage_1_lr1e5.sh
-
-
diff --git a/spaces/mshukor/UnIVAL/slurm_adastra/averaging/ratatouille/caption/video/t.sh b/spaces/mshukor/UnIVAL/slurm_adastra/averaging/ratatouille/caption/video/t.sh
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/multimodalart/latentdiffusion/latent-diffusion/ldm/data/imagenet.py b/spaces/multimodalart/latentdiffusion/latent-diffusion/ldm/data/imagenet.py
deleted file mode 100644
index 1c473f9c6965b22315dbb289eff8247c71bdc790..0000000000000000000000000000000000000000
--- a/spaces/multimodalart/latentdiffusion/latent-diffusion/ldm/data/imagenet.py
+++ /dev/null
@@ -1,394 +0,0 @@
-import os, yaml, pickle, shutil, tarfile, glob
-import cv2
-import albumentations
-import PIL
-import numpy as np
-import torchvision.transforms.functional as TF
-from omegaconf import OmegaConf
-from functools import partial
-from PIL import Image
-from tqdm import tqdm
-from torch.utils.data import Dataset, Subset
-
-import taming.data.utils as tdu
-from taming.data.imagenet import str_to_indices, give_synsets_from_indices, download, retrieve
-from taming.data.imagenet import ImagePaths
-
-from ldm.modules.image_degradation import degradation_fn_bsr, degradation_fn_bsr_light
-
-
-def synset2idx(path_to_yaml="data/index_synset.yaml"):
- with open(path_to_yaml) as f:
- di2s = yaml.load(f)
- return dict((v,k) for k,v in di2s.items())
-
-
-class ImageNetBase(Dataset):
- def __init__(self, config=None):
- self.config = config or OmegaConf.create()
- if not type(self.config)==dict:
- self.config = OmegaConf.to_container(self.config)
- self.keep_orig_class_label = self.config.get("keep_orig_class_label", False)
- self.process_images = True # if False we skip loading & processing images and self.data contains filepaths
- self._prepare()
- self._prepare_synset_to_human()
- self._prepare_idx_to_synset()
- self._prepare_human_to_integer_label()
- self._load()
-
- def __len__(self):
- return len(self.data)
-
- def __getitem__(self, i):
- return self.data[i]
-
- def _prepare(self):
- raise NotImplementedError()
-
- def _filter_relpaths(self, relpaths):
- ignore = set([
- "n06596364_9591.JPEG",
- ])
- relpaths = [rpath for rpath in relpaths if not rpath.split("/")[-1] in ignore]
- if "sub_indices" in self.config:
- indices = str_to_indices(self.config["sub_indices"])
- synsets = give_synsets_from_indices(indices, path_to_yaml=self.idx2syn) # returns a list of strings
- self.synset2idx = synset2idx(path_to_yaml=self.idx2syn)
- files = []
- for rpath in relpaths:
- syn = rpath.split("/")[0]
- if syn in synsets:
- files.append(rpath)
- return files
- else:
- return relpaths
-
- def _prepare_synset_to_human(self):
- SIZE = 2655750
- URL = "https://heibox.uni-heidelberg.de/f/9f28e956cd304264bb82/?dl=1"
- self.human_dict = os.path.join(self.root, "synset_human.txt")
- if (not os.path.exists(self.human_dict) or
- not os.path.getsize(self.human_dict)==SIZE):
- download(URL, self.human_dict)
-
- def _prepare_idx_to_synset(self):
- URL = "https://heibox.uni-heidelberg.de/f/d835d5b6ceda4d3aa910/?dl=1"
- self.idx2syn = os.path.join(self.root, "index_synset.yaml")
- if (not os.path.exists(self.idx2syn)):
- download(URL, self.idx2syn)
-
- def _prepare_human_to_integer_label(self):
- URL = "https://heibox.uni-heidelberg.de/f/2362b797d5be43b883f6/?dl=1"
- self.human2integer = os.path.join(self.root, "imagenet1000_clsidx_to_labels.txt")
- if (not os.path.exists(self.human2integer)):
- download(URL, self.human2integer)
- with open(self.human2integer, "r") as f:
- lines = f.read().splitlines()
- assert len(lines) == 1000
- self.human2integer_dict = dict()
- for line in lines:
- value, key = line.split(":")
- self.human2integer_dict[key] = int(value)
-
- def _load(self):
- with open(self.txt_filelist, "r") as f:
- self.relpaths = f.read().splitlines()
- l1 = len(self.relpaths)
- self.relpaths = self._filter_relpaths(self.relpaths)
- print("Removed {} files from filelist during filtering.".format(l1 - len(self.relpaths)))
-
- self.synsets = [p.split("/")[0] for p in self.relpaths]
- self.abspaths = [os.path.join(self.datadir, p) for p in self.relpaths]
-
- unique_synsets = np.unique(self.synsets)
- class_dict = dict((synset, i) for i, synset in enumerate(unique_synsets))
- if not self.keep_orig_class_label:
- self.class_labels = [class_dict[s] for s in self.synsets]
- else:
- self.class_labels = [self.synset2idx[s] for s in self.synsets]
-
- with open(self.human_dict, "r") as f:
- human_dict = f.read().splitlines()
- human_dict = dict(line.split(maxsplit=1) for line in human_dict)
-
- self.human_labels = [human_dict[s] for s in self.synsets]
-
- labels = {
- "relpath": np.array(self.relpaths),
- "synsets": np.array(self.synsets),
- "class_label": np.array(self.class_labels),
- "human_label": np.array(self.human_labels),
- }
-
- if self.process_images:
- self.size = retrieve(self.config, "size", default=256)
- self.data = ImagePaths(self.abspaths,
- labels=labels,
- size=self.size,
- random_crop=self.random_crop,
- )
- else:
- self.data = self.abspaths
-
-
-class ImageNetTrain(ImageNetBase):
- NAME = "ILSVRC2012_train"
- URL = "http://www.image-net.org/challenges/LSVRC/2012/"
- AT_HASH = "a306397ccf9c2ead27155983c254227c0fd938e2"
- FILES = [
- "ILSVRC2012_img_train.tar",
- ]
- SIZES = [
- 147897477120,
- ]
-
- def __init__(self, process_images=True, data_root=None, **kwargs):
- self.process_images = process_images
- self.data_root = data_root
- super().__init__(**kwargs)
-
- def _prepare(self):
- if self.data_root:
- self.root = os.path.join(self.data_root, self.NAME)
- else:
- cachedir = os.environ.get("XDG_CACHE_HOME", os.path.expanduser("~/.cache"))
- self.root = os.path.join(cachedir, "autoencoders/data", self.NAME)
-
- self.datadir = os.path.join(self.root, "data")
- self.txt_filelist = os.path.join(self.root, "filelist.txt")
- self.expected_length = 1281167
- self.random_crop = retrieve(self.config, "ImageNetTrain/random_crop",
- default=True)
- if not tdu.is_prepared(self.root):
- # prep
- print("Preparing dataset {} in {}".format(self.NAME, self.root))
-
- datadir = self.datadir
- if not os.path.exists(datadir):
- path = os.path.join(self.root, self.FILES[0])
- if not os.path.exists(path) or not os.path.getsize(path)==self.SIZES[0]:
- import academictorrents as at
- atpath = at.get(self.AT_HASH, datastore=self.root)
- assert atpath == path
-
- print("Extracting {} to {}".format(path, datadir))
- os.makedirs(datadir, exist_ok=True)
- with tarfile.open(path, "r:") as tar:
- tar.extractall(path=datadir)
-
- print("Extracting sub-tars.")
- subpaths = sorted(glob.glob(os.path.join(datadir, "*.tar")))
- for subpath in tqdm(subpaths):
- subdir = subpath[:-len(".tar")]
- os.makedirs(subdir, exist_ok=True)
- with tarfile.open(subpath, "r:") as tar:
- tar.extractall(path=subdir)
-
- filelist = glob.glob(os.path.join(datadir, "**", "*.JPEG"))
- filelist = [os.path.relpath(p, start=datadir) for p in filelist]
- filelist = sorted(filelist)
- filelist = "\n".join(filelist)+"\n"
- with open(self.txt_filelist, "w") as f:
- f.write(filelist)
-
- tdu.mark_prepared(self.root)
-
-
-class ImageNetValidation(ImageNetBase):
- NAME = "ILSVRC2012_validation"
- URL = "http://www.image-net.org/challenges/LSVRC/2012/"
- AT_HASH = "5d6d0df7ed81efd49ca99ea4737e0ae5e3a5f2e5"
- VS_URL = "https://heibox.uni-heidelberg.de/f/3e0f6e9c624e45f2bd73/?dl=1"
- FILES = [
- "ILSVRC2012_img_val.tar",
- "validation_synset.txt",
- ]
- SIZES = [
- 6744924160,
- 1950000,
- ]
-
- def __init__(self, process_images=True, data_root=None, **kwargs):
- self.data_root = data_root
- self.process_images = process_images
- super().__init__(**kwargs)
-
- def _prepare(self):
- if self.data_root:
- self.root = os.path.join(self.data_root, self.NAME)
- else:
- cachedir = os.environ.get("XDG_CACHE_HOME", os.path.expanduser("~/.cache"))
- self.root = os.path.join(cachedir, "autoencoders/data", self.NAME)
- self.datadir = os.path.join(self.root, "data")
- self.txt_filelist = os.path.join(self.root, "filelist.txt")
- self.expected_length = 50000
- self.random_crop = retrieve(self.config, "ImageNetValidation/random_crop",
- default=False)
- if not tdu.is_prepared(self.root):
- # prep
- print("Preparing dataset {} in {}".format(self.NAME, self.root))
-
- datadir = self.datadir
- if not os.path.exists(datadir):
- path = os.path.join(self.root, self.FILES[0])
- if not os.path.exists(path) or not os.path.getsize(path)==self.SIZES[0]:
- import academictorrents as at
- atpath = at.get(self.AT_HASH, datastore=self.root)
- assert atpath == path
-
- print("Extracting {} to {}".format(path, datadir))
- os.makedirs(datadir, exist_ok=True)
- with tarfile.open(path, "r:") as tar:
- tar.extractall(path=datadir)
-
- vspath = os.path.join(self.root, self.FILES[1])
- if not os.path.exists(vspath) or not os.path.getsize(vspath)==self.SIZES[1]:
- download(self.VS_URL, vspath)
-
- with open(vspath, "r") as f:
- synset_dict = f.read().splitlines()
- synset_dict = dict(line.split() for line in synset_dict)
-
- print("Reorganizing into synset folders")
- synsets = np.unique(list(synset_dict.values()))
- for s in synsets:
- os.makedirs(os.path.join(datadir, s), exist_ok=True)
- for k, v in synset_dict.items():
- src = os.path.join(datadir, k)
- dst = os.path.join(datadir, v)
- shutil.move(src, dst)
-
- filelist = glob.glob(os.path.join(datadir, "**", "*.JPEG"))
- filelist = [os.path.relpath(p, start=datadir) for p in filelist]
- filelist = sorted(filelist)
- filelist = "\n".join(filelist)+"\n"
- with open(self.txt_filelist, "w") as f:
- f.write(filelist)
-
- tdu.mark_prepared(self.root)
-
-
-
-class ImageNetSR(Dataset):
- def __init__(self, size=None,
- degradation=None, downscale_f=4, min_crop_f=0.5, max_crop_f=1.,
- random_crop=True):
- """
- Imagenet Superresolution Dataloader
- Performs following ops in order:
- 1. crops a crop of size s from image either as random or center crop
- 2. resizes crop to size with cv2.area_interpolation
- 3. degrades resized crop with degradation_fn
-
- :param size: resizing to size after cropping
- :param degradation: degradation_fn, e.g. cv_bicubic or bsrgan_light
- :param downscale_f: Low Resolution Downsample factor
- :param min_crop_f: determines crop size s,
- where s = c * min_img_side_len with c sampled from interval (min_crop_f, max_crop_f)
- :param max_crop_f: ""
- :param data_root:
- :param random_crop:
- """
- self.base = self.get_base()
- assert size
- assert (size / downscale_f).is_integer()
- self.size = size
- self.LR_size = int(size / downscale_f)
- self.min_crop_f = min_crop_f
- self.max_crop_f = max_crop_f
- assert(max_crop_f <= 1.)
- self.center_crop = not random_crop
-
- self.image_rescaler = albumentations.SmallestMaxSize(max_size=size, interpolation=cv2.INTER_AREA)
-
- self.pil_interpolation = False # gets reset later if incase interp_op is from pillow
-
- if degradation == "bsrgan":
- self.degradation_process = partial(degradation_fn_bsr, sf=downscale_f)
-
- elif degradation == "bsrgan_light":
- self.degradation_process = partial(degradation_fn_bsr_light, sf=downscale_f)
-
- else:
- interpolation_fn = {
- "cv_nearest": cv2.INTER_NEAREST,
- "cv_bilinear": cv2.INTER_LINEAR,
- "cv_bicubic": cv2.INTER_CUBIC,
- "cv_area": cv2.INTER_AREA,
- "cv_lanczos": cv2.INTER_LANCZOS4,
- "pil_nearest": PIL.Image.NEAREST,
- "pil_bilinear": PIL.Image.BILINEAR,
- "pil_bicubic": PIL.Image.BICUBIC,
- "pil_box": PIL.Image.BOX,
- "pil_hamming": PIL.Image.HAMMING,
- "pil_lanczos": PIL.Image.LANCZOS,
- }[degradation]
-
- self.pil_interpolation = degradation.startswith("pil_")
-
- if self.pil_interpolation:
- self.degradation_process = partial(TF.resize, size=self.LR_size, interpolation=interpolation_fn)
-
- else:
- self.degradation_process = albumentations.SmallestMaxSize(max_size=self.LR_size,
- interpolation=interpolation_fn)
-
- def __len__(self):
- return len(self.base)
-
- def __getitem__(self, i):
- example = self.base[i]
- image = Image.open(example["file_path_"])
-
- if not image.mode == "RGB":
- image = image.convert("RGB")
-
- image = np.array(image).astype(np.uint8)
-
- min_side_len = min(image.shape[:2])
- crop_side_len = min_side_len * np.random.uniform(self.min_crop_f, self.max_crop_f, size=None)
- crop_side_len = int(crop_side_len)
-
- if self.center_crop:
- self.cropper = albumentations.CenterCrop(height=crop_side_len, width=crop_side_len)
-
- else:
- self.cropper = albumentations.RandomCrop(height=crop_side_len, width=crop_side_len)
-
- image = self.cropper(image=image)["image"]
- image = self.image_rescaler(image=image)["image"]
-
- if self.pil_interpolation:
- image_pil = PIL.Image.fromarray(image)
- LR_image = self.degradation_process(image_pil)
- LR_image = np.array(LR_image).astype(np.uint8)
-
- else:
- LR_image = self.degradation_process(image=image)["image"]
-
- example["image"] = (image/127.5 - 1.0).astype(np.float32)
- example["LR_image"] = (LR_image/127.5 - 1.0).astype(np.float32)
-
- return example
-
-
-class ImageNetSRTrain(ImageNetSR):
- def __init__(self, **kwargs):
- super().__init__(**kwargs)
-
- def get_base(self):
- with open("data/imagenet_train_hr_indices.p", "rb") as f:
- indices = pickle.load(f)
- dset = ImageNetTrain(process_images=False,)
- return Subset(dset, indices)
-
-
-class ImageNetSRValidation(ImageNetSR):
- def __init__(self, **kwargs):
- super().__init__(**kwargs)
-
- def get_base(self):
- with open("data/imagenet_val_hr_indices.p", "rb") as f:
- indices = pickle.load(f)
- dset = ImageNetValidation(process_images=False,)
- return Subset(dset, indices)
diff --git a/spaces/nahidalam/meow/app.py b/spaces/nahidalam/meow/app.py
deleted file mode 100644
index 4804a68c2205d78450f635003beaf1bff833e443..0000000000000000000000000000000000000000
--- a/spaces/nahidalam/meow/app.py
+++ /dev/null
@@ -1,29 +0,0 @@
-import gradio as gr
-import numpy as np
-import tensorflow as tf
-import PIL
-
-
-def normalize_img(img):
- img = tf.cast(img, dtype=tf.float32)
- # Map values in the range [-1, 1]
- return (img / 127.5) - 1.0
-
-def predict_and_save(img, generator_model):
- img = normalize_img(img)
- prediction = generator_model(img, training=False)[0].numpy()
- prediction = (prediction * 127.5 + 127.5).astype(np.uint8)
- im = PIL.Image.fromarray(prediction)
- return im
-
-def run(image_path):
- model = tf.keras.models.load_model('pretrained')
- print("Model loaded")
- img_array = tf.expand_dims(image_path, 0)
- im = predict_and_save(img_array, model)
- print("Prediction Done")
- return im
-
-iface = gr.Interface(run, gr.inputs.Image(shape=(256, 256)), "image")
-
-iface.launch()
\ No newline at end of file
diff --git a/spaces/nateraw/deepafx-st/deepafx_st/processors/autodiff/peq.py b/spaces/nateraw/deepafx-st/deepafx_st/processors/autodiff/peq.py
deleted file mode 100644
index 04e35bbe92ed5cfb780c4ad740e1ba75f64e5b03..0000000000000000000000000000000000000000
--- a/spaces/nateraw/deepafx-st/deepafx_st/processors/autodiff/peq.py
+++ /dev/null
@@ -1,274 +0,0 @@
-import torch
-
-import deepafx_st.processors.autodiff.signal
-from deepafx_st.processors.processor import Processor
-
-
-@torch.jit.script
-def parametric_eq(
- x: torch.Tensor,
- sample_rate: float,
- low_shelf_gain_dB: torch.Tensor,
- low_shelf_cutoff_freq: torch.Tensor,
- low_shelf_q_factor: torch.Tensor,
- first_band_gain_dB: torch.Tensor,
- first_band_cutoff_freq: torch.Tensor,
- first_band_q_factor: torch.Tensor,
- second_band_gain_dB: torch.Tensor,
- second_band_cutoff_freq: torch.Tensor,
- second_band_q_factor: torch.Tensor,
- third_band_gain_dB: torch.Tensor,
- third_band_cutoff_freq: torch.Tensor,
- third_band_q_factor: torch.Tensor,
- fourth_band_gain_dB: torch.Tensor,
- fourth_band_cutoff_freq: torch.Tensor,
- fourth_band_q_factor: torch.Tensor,
- high_shelf_gain_dB: torch.Tensor,
- high_shelf_cutoff_freq: torch.Tensor,
- high_shelf_q_factor: torch.Tensor,
-):
- """Six-band parametric EQ.
-
- Low-shelf -> Band 1 -> Band 2 -> Band 3 -> Band 4 -> High-shelf
-
- Args:
- x (torch.Tensor): 1d signal.
-
-
- """
- a_s, b_s = [], []
- #print(f"autodiff peq fs = {sample_rate}")
-
- # -------- apply low-shelf filter --------
- b, a = deepafx_st.processors.autodiff.signal.biqaud(
- low_shelf_gain_dB,
- low_shelf_cutoff_freq,
- low_shelf_q_factor,
- sample_rate,
- "low_shelf",
- )
- b_s.append(b)
- a_s.append(a)
-
- # -------- apply first-band peaking filter --------
- b, a = deepafx_st.processors.autodiff.signal.biqaud(
- first_band_gain_dB,
- first_band_cutoff_freq,
- first_band_q_factor,
- sample_rate,
- "peaking",
- )
- b_s.append(b)
- a_s.append(a)
-
- # -------- apply second-band peaking filter --------
- b, a = deepafx_st.processors.autodiff.signal.biqaud(
- second_band_gain_dB,
- second_band_cutoff_freq,
- second_band_q_factor,
- sample_rate,
- "peaking",
- )
- b_s.append(b)
- a_s.append(a)
-
- # -------- apply third-band peaking filter --------
- b, a = deepafx_st.processors.autodiff.signal.biqaud(
- third_band_gain_dB,
- third_band_cutoff_freq,
- third_band_q_factor,
- sample_rate,
- "peaking",
- )
- b_s.append(b)
- a_s.append(a)
-
- # -------- apply fourth-band peaking filter --------
- b, a = deepafx_st.processors.autodiff.signal.biqaud(
- fourth_band_gain_dB,
- fourth_band_cutoff_freq,
- fourth_band_q_factor,
- sample_rate,
- "peaking",
- )
- b_s.append(b)
- a_s.append(a)
-
- # -------- apply high-shelf filter --------
- b, a = deepafx_st.processors.autodiff.signal.biqaud(
- high_shelf_gain_dB,
- high_shelf_cutoff_freq,
- high_shelf_q_factor,
- sample_rate,
- "high_shelf",
- )
- b_s.append(b)
- a_s.append(a)
-
- x = deepafx_st.processors.autodiff.signal.approx_iir_filter_cascade(
- b_s, a_s, x.view(-1)
- )
-
- return x
-
-
-class ParametricEQ(Processor):
- def __init__(
- self,
- sample_rate,
- min_gain_dB=-24.0,
- default_gain_dB=0.0,
- max_gain_dB=24.0,
- min_q_factor=0.1,
- default_q_factor=0.707,
- max_q_factor=10,
- eps=1e-8,
- ):
- """ """
- super().__init__()
- self.sample_rate = sample_rate
- self.eps = eps
- self.ports = [
- {
- "name": "Lowshelf gain",
- "min": min_gain_dB,
- "max": max_gain_dB,
- "default": default_gain_dB,
- "units": "dB",
- },
- {
- "name": "Lowshelf cutoff",
- "min": 20.0,
- "max": 200.0,
- "default": 100.0,
- "units": "Hz",
- },
- {
- "name": "Lowshelf Q",
- "min": min_q_factor,
- "max": max_q_factor,
- "default": default_q_factor,
- "units": "",
- },
- {
- "name": "First band gain",
- "min": min_gain_dB,
- "max": max_gain_dB,
- "default": default_gain_dB,
- "units": "dB",
- },
- {
- "name": "First band cutoff",
- "min": 200.0,
- "max": 2000.0,
- "default": 400.0,
- "units": "Hz",
- },
- {
- "name": "First band Q",
- "min": min_q_factor,
- "max": max_q_factor,
- "default": 0.707,
- "units": "",
- },
- {
- "name": "Second band gain",
- "min": min_gain_dB,
- "max": max_gain_dB,
- "default": default_gain_dB,
- "units": "dB",
- },
- {
- "name": "Second band cutoff",
- "min": 200.0,
- "max": 4000.0,
- "default": 1000.0,
- "units": "Hz",
- },
- {
- "name": "Second band Q",
- "min": min_q_factor,
- "max": max_q_factor,
- "default": default_q_factor,
- "units": "",
- },
- {
- "name": "Third band gain",
- "min": min_gain_dB,
- "max": max_gain_dB,
- "default": default_gain_dB,
- "units": "dB",
- },
- {
- "name": "Third band cutoff",
- "min": 2000.0,
- "max": 8000.0,
- "default": 4000.0,
- "units": "Hz",
- },
- {
- "name": "Third band Q",
- "min": min_q_factor,
- "max": max_q_factor,
- "default": default_q_factor,
- "units": "",
- },
- {
- "name": "Fourth band gain",
- "min": min_gain_dB,
- "max": max_gain_dB,
- "default": default_gain_dB,
- "units": "dB",
- },
- {
- "name": "Fourth band cutoff",
- "min": 4000.0,
- "max": (24000 // 2) * 0.9,
- "default": 8000.0,
- "units": "Hz",
- },
- {
- "name": "Fourth band Q",
- "min": min_q_factor,
- "max": max_q_factor,
- "default": default_q_factor,
- "units": "",
- },
- {
- "name": "Highshelf gain",
- "min": min_gain_dB,
- "max": max_gain_dB,
- "default": default_gain_dB,
- "units": "dB",
- },
- {
- "name": "Highshelf cutoff",
- "min": 4000.0,
- "max": (24000 // 2) * 0.9,
- "default": 8000.0,
- "units": "Hz",
- },
- {
- "name": "Highshelf Q",
- "min": min_q_factor,
- "max": max_q_factor,
- "default": default_q_factor,
- "units": "",
- },
- ]
-
- self.num_control_params = len(self.ports)
-
- def forward(self, x, p, sample_rate=24000, **kwargs):
-
- bs, chs, s = x.size()
-
- inputs = torch.split(x, 1, 0)
- params = torch.split(p, 1, 0)
-
- y = [] # loop over batch dimension
- for input, param in zip(inputs, params):
- denorm_param = self.denormalize_params(param.view(-1))
- y.append(parametric_eq(input.view(-1), sample_rate, *denorm_param))
-
- return torch.stack(y, dim=0).view(bs, 1, -1)
diff --git a/spaces/nateraw/huggingface-user-stats/README.md b/spaces/nateraw/huggingface-user-stats/README.md
deleted file mode 100644
index 1127522c9ff5dd2d7ea33b683e67c101313b56d6..0000000000000000000000000000000000000000
--- a/spaces/nateraw/huggingface-user-stats/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Hugging Face User Stats
-emoji: 🤗📊🤗
-colorFrom: green
-colorTo: pink
-sdk: gradio
-sdk_version: 3.25.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/neigui/White-box-Cartoonization/wbc/network.py b/spaces/neigui/White-box-Cartoonization/wbc/network.py
deleted file mode 100644
index 6f16cee1aa1994d0a78c524f459764de5164e637..0000000000000000000000000000000000000000
--- a/spaces/neigui/White-box-Cartoonization/wbc/network.py
+++ /dev/null
@@ -1,62 +0,0 @@
-import tensorflow as tf
-import numpy as np
-import tensorflow.contrib.slim as slim
-
-
-
-def resblock(inputs, out_channel=32, name='resblock'):
-
- with tf.variable_scope(name):
-
- x = slim.convolution2d(inputs, out_channel, [3, 3],
- activation_fn=None, scope='conv1')
- x = tf.nn.leaky_relu(x)
- x = slim.convolution2d(x, out_channel, [3, 3],
- activation_fn=None, scope='conv2')
-
- return x + inputs
-
-
-
-
-def unet_generator(inputs, channel=32, num_blocks=4, name='generator', reuse=False):
- with tf.variable_scope(name, reuse=reuse):
-
- x0 = slim.convolution2d(inputs, channel, [7, 7], activation_fn=None)
- x0 = tf.nn.leaky_relu(x0)
-
- x1 = slim.convolution2d(x0, channel, [3, 3], stride=2, activation_fn=None)
- x1 = tf.nn.leaky_relu(x1)
- x1 = slim.convolution2d(x1, channel*2, [3, 3], activation_fn=None)
- x1 = tf.nn.leaky_relu(x1)
-
- x2 = slim.convolution2d(x1, channel*2, [3, 3], stride=2, activation_fn=None)
- x2 = tf.nn.leaky_relu(x2)
- x2 = slim.convolution2d(x2, channel*4, [3, 3], activation_fn=None)
- x2 = tf.nn.leaky_relu(x2)
-
- for idx in range(num_blocks):
- x2 = resblock(x2, out_channel=channel*4, name='block_{}'.format(idx))
-
- x2 = slim.convolution2d(x2, channel*2, [3, 3], activation_fn=None)
- x2 = tf.nn.leaky_relu(x2)
-
- h1, w1 = tf.shape(x2)[1], tf.shape(x2)[2]
- x3 = tf.image.resize_bilinear(x2, (h1*2, w1*2))
- x3 = slim.convolution2d(x3+x1, channel*2, [3, 3], activation_fn=None)
- x3 = tf.nn.leaky_relu(x3)
- x3 = slim.convolution2d(x3, channel, [3, 3], activation_fn=None)
- x3 = tf.nn.leaky_relu(x3)
-
- h2, w2 = tf.shape(x3)[1], tf.shape(x3)[2]
- x4 = tf.image.resize_bilinear(x3, (h2*2, w2*2))
- x4 = slim.convolution2d(x4+x0, channel, [3, 3], activation_fn=None)
- x4 = tf.nn.leaky_relu(x4)
- x4 = slim.convolution2d(x4, 3, [7, 7], activation_fn=None)
-
- return x4
-
-if __name__ == '__main__':
-
-
- pass
\ No newline at end of file
diff --git a/spaces/nickprock/nickprock-bert-italian-finetuned-ner/README.md b/spaces/nickprock/nickprock-bert-italian-finetuned-ner/README.md
deleted file mode 100644
index c8551b03d52cd528bdc41a5fbacff18a4c339cd0..0000000000000000000000000000000000000000
--- a/spaces/nickprock/nickprock-bert-italian-finetuned-ner/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: NER in Italian
-emoji: 📚
-colorFrom: red
-colorTo: purple
-sdk: gradio
-sdk_version: 3.24.1
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/nightfury/Colorizer_Models/colorizers/base_color.py b/spaces/nightfury/Colorizer_Models/colorizers/base_color.py
deleted file mode 100644
index 00beb39e9f6f73b06ebea0314fc23a0bc75f23b7..0000000000000000000000000000000000000000
--- a/spaces/nightfury/Colorizer_Models/colorizers/base_color.py
+++ /dev/null
@@ -1,24 +0,0 @@
-
-import torch
-from torch import nn
-
-class BaseColor(nn.Module):
- def __init__(self):
- super(BaseColor, self).__init__()
-
- self.l_cent = 50.
- self.l_norm = 100.
- self.ab_norm = 110.
-
- def normalize_l(self, in_l):
- return (in_l-self.l_cent)/self.l_norm
-
- def unnormalize_l(self, in_l):
- return in_l*self.l_norm + self.l_cent
-
- def normalize_ab(self, in_ab):
- return in_ab/self.ab_norm
-
- def unnormalize_ab(self, in_ab):
- return in_ab*self.ab_norm
-
diff --git a/spaces/nmitchko/AI-in-Healthcare/Developer Meetup in Boston Generative AI Use Cases in Healthcare _files/css__1exPct3QAvO_isQr_6mFp1rnHtSBE4nG8RVarNIjRB8__XFEXAV_pHU.css b/spaces/nmitchko/AI-in-Healthcare/Developer Meetup in Boston Generative AI Use Cases in Healthcare _files/css__1exPct3QAvO_isQr_6mFp1rnHtSBE4nG8RVarNIjRB8__XFEXAV_pHU.css
deleted file mode 100644
index 707cb91cbb0c9b2ce02700df4c57f76e4accc1b5..0000000000000000000000000000000000000000
--- a/spaces/nmitchko/AI-in-Healthcare/Developer Meetup in Boston Generative AI Use Cases in Healthcare _files/css__1exPct3QAvO_isQr_6mFp1rnHtSBE4nG8RVarNIjRB8__XFEXAV_pHU.css
+++ /dev/null
@@ -1,4 +0,0 @@
-pre{line-height:20px;;padding:5px;border-radius:4px;}pre code{padding:32px 10px 10px 10px;border-radius:4px;}pre .comment{margin-bottom:0px;display:inline;}
-/*})'"*/
-.hljs{display:block;overflow-x:auto;color:#000;background:#fff;}.hljs-subst,.hljs-title{font-weight:normal;color:#000;}.hljs-comment,.hljs-quote{color:#808080;font-style:italic;}.hljs-meta{color:#808000;}.hljs-tag{background:#efefef;}.hljs-section,.hljs-name,.hljs-literal,.hljs-keyword,.hljs-selector-tag,.hljs-type,.hljs-selector-id,.hljs-selector-class{font-weight:bold;color:#000080;}.hljs-attribute,.hljs-number,.hljs-regexp,.hljs-link{font-weight:bold;color:#0000ff;}.hljs-number,.hljs-regexp,.hljs-link{font-weight:normal;}.hljs-string{color:#008000;font-weight:bold;}.hljs-symbol,.hljs-bullet,.hljs-formula{color:#000;font-style:italic;}.hljs-doctag{text-decoration:underline;}.hljs-variable,.hljs-template-variable{color:#660e7a;}.hljs-addition{background:#baeeba;}.hljs-deletion{background:#ffc8bd;}.hljs-emphasis{font-style:italic;}.hljs-strong{font-weight:bold;}
-/*})'"*/
diff --git a/spaces/nomic-ai/daily_dialog/README.md b/spaces/nomic-ai/daily_dialog/README.md
deleted file mode 100644
index a90b6b1ae2f0608f2166be259e04709c353ac302..0000000000000000000000000000000000000000
--- a/spaces/nomic-ai/daily_dialog/README.md
+++ /dev/null
@@ -1,8 +0,0 @@
----
-title: daily_dialog
-emoji: 🗺️
-colorFrom: purple
-colorTo: red
-sdk: static
-pinned: false
----
diff --git a/spaces/nota-ai/compressed-wav2lip/models/syncnet.py b/spaces/nota-ai/compressed-wav2lip/models/syncnet.py
deleted file mode 100644
index e773cdca675236745a379a776b7c07d7d353f590..0000000000000000000000000000000000000000
--- a/spaces/nota-ai/compressed-wav2lip/models/syncnet.py
+++ /dev/null
@@ -1,66 +0,0 @@
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from .conv import Conv2d
-
-class SyncNet_color(nn.Module):
- def __init__(self):
- super(SyncNet_color, self).__init__()
-
- self.face_encoder = nn.Sequential(
- Conv2d(15, 32, kernel_size=(7, 7), stride=1, padding=3),
-
- Conv2d(32, 64, kernel_size=5, stride=(1, 2), padding=1),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(128, 256, kernel_size=3, stride=2, padding=1),
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(256, 512, kernel_size=3, stride=2, padding=1),
- Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(512, 512, kernel_size=3, stride=2, padding=1),
- Conv2d(512, 512, kernel_size=3, stride=1, padding=0),
- Conv2d(512, 512, kernel_size=1, stride=1, padding=0),)
-
- self.audio_encoder = nn.Sequential(
- Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
- Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(32, 64, kernel_size=3, stride=(3, 1), padding=1),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(64, 128, kernel_size=3, stride=3, padding=1),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(128, 256, kernel_size=3, stride=(3, 2), padding=1),
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(256, 512, kernel_size=3, stride=1, padding=0),
- Conv2d(512, 512, kernel_size=1, stride=1, padding=0),)
-
- def forward(self, audio_sequences, face_sequences): # audio_sequences := (B, dim, T)
- face_embedding = self.face_encoder(face_sequences)
- audio_embedding = self.audio_encoder(audio_sequences)
-
- audio_embedding = audio_embedding.view(audio_embedding.size(0), -1)
- face_embedding = face_embedding.view(face_embedding.size(0), -1)
-
- audio_embedding = F.normalize(audio_embedding, p=2, dim=1)
- face_embedding = F.normalize(face_embedding, p=2, dim=1)
-
-
- return audio_embedding, face_embedding
diff --git a/spaces/nsarrazin/agents-js-oasst/src/routes/+layout.ts b/spaces/nsarrazin/agents-js-oasst/src/routes/+layout.ts
deleted file mode 100644
index 189f71e2e1b31d4e92a0493e33539bdd5128d987..0000000000000000000000000000000000000000
--- a/spaces/nsarrazin/agents-js-oasst/src/routes/+layout.ts
+++ /dev/null
@@ -1 +0,0 @@
-export const prerender = true;
diff --git a/spaces/nugrahatheo/Prediction-of-Credit-Card-Default/about.py b/spaces/nugrahatheo/Prediction-of-Credit-Card-Default/about.py
deleted file mode 100644
index 44a121d8ad52d60c6c816dc4630f8ba42768e5cc..0000000000000000000000000000000000000000
--- a/spaces/nugrahatheo/Prediction-of-Credit-Card-Default/about.py
+++ /dev/null
@@ -1,21 +0,0 @@
-import streamlit as st
-from PIL import Image
-
-def run():
- # Add Picture
- image = Image.open('cc.jpeg')
- st.image(image, caption='Credit Card Default')
- # Title
- st.title('ABOUT THIS PROJECT')
- st.markdown('---')
- st.write('###### This project aims to predict credit card customer defaults. In this project, I used the Support Vector Classifier and Random Forest Classification method to predict credit card defaults with an accuracy rate of approximately 83%. I performed the scaling method using MinMaxScaller and the encoding method with OrdinalEncoder. I also performed the cross validating method and searched for hyperparameters using GridSearchCV.')
- st.markdown('---')
-
- st.write('Feel free to contact me on:')
- st.write('[GITHUB](https://github.com/theonugraha)')
- st.write('or')
- st.write('[LINKEDIN](https://www.linkedin.com/in/nugrahatheo/)')
-
-
-if __name__ == '__main__':
- run()
\ No newline at end of file
diff --git a/spaces/odettecantswim/vits-models-genshin/text/english.py b/spaces/odettecantswim/vits-models-genshin/text/english.py
deleted file mode 100644
index 6817392ba8a9eb830351de89fb7afc5ad72f5e42..0000000000000000000000000000000000000000
--- a/spaces/odettecantswim/vits-models-genshin/text/english.py
+++ /dev/null
@@ -1,188 +0,0 @@
-""" from https://github.com/keithito/tacotron """
-
-'''
-Cleaners are transformations that run over the input text at both training and eval time.
-
-Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
-hyperparameter. Some cleaners are English-specific. You'll typically want to use:
- 1. "english_cleaners" for English text
- 2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
- the Unidecode library (https://pypi.python.org/pypi/Unidecode)
- 3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
- the symbols in symbols.py to match your data).
-'''
-
-
-# Regular expression matching whitespace:
-
-
-import re
-import inflect
-from unidecode import unidecode
-import eng_to_ipa as ipa
-_inflect = inflect.engine()
-_comma_number_re = re.compile(r'([0-9][0-9\,]+[0-9])')
-_decimal_number_re = re.compile(r'([0-9]+\.[0-9]+)')
-_pounds_re = re.compile(r'£([0-9\,]*[0-9]+)')
-_dollars_re = re.compile(r'\$([0-9\.\,]*[0-9]+)')
-_ordinal_re = re.compile(r'[0-9]+(st|nd|rd|th)')
-_number_re = re.compile(r'[0-9]+')
-
-# List of (regular expression, replacement) pairs for abbreviations:
-_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [
- ('mrs', 'misess'),
- ('mr', 'mister'),
- ('dr', 'doctor'),
- ('st', 'saint'),
- ('co', 'company'),
- ('jr', 'junior'),
- ('maj', 'major'),
- ('gen', 'general'),
- ('drs', 'doctors'),
- ('rev', 'reverend'),
- ('lt', 'lieutenant'),
- ('hon', 'honorable'),
- ('sgt', 'sergeant'),
- ('capt', 'captain'),
- ('esq', 'esquire'),
- ('ltd', 'limited'),
- ('col', 'colonel'),
- ('ft', 'fort'),
-]]
-
-
-# List of (ipa, lazy ipa) pairs:
-_lazy_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('r', 'ɹ'),
- ('æ', 'e'),
- ('ɑ', 'a'),
- ('ɔ', 'o'),
- ('ð', 'z'),
- ('θ', 's'),
- ('ɛ', 'e'),
- ('ɪ', 'i'),
- ('ʊ', 'u'),
- ('ʒ', 'ʥ'),
- ('ʤ', 'ʥ'),
- ('ˈ', '↓'),
-]]
-
-# List of (ipa, lazy ipa2) pairs:
-_lazy_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('r', 'ɹ'),
- ('ð', 'z'),
- ('θ', 's'),
- ('ʒ', 'ʑ'),
- ('ʤ', 'dʑ'),
- ('ˈ', '↓'),
-]]
-
-# List of (ipa, ipa2) pairs
-_ipa_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('r', 'ɹ'),
- ('ʤ', 'dʒ'),
- ('ʧ', 'tʃ')
-]]
-
-
-def expand_abbreviations(text):
- for regex, replacement in _abbreviations:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def collapse_whitespace(text):
- return re.sub(r'\s+', ' ', text)
-
-
-def _remove_commas(m):
- return m.group(1).replace(',', '')
-
-
-def _expand_decimal_point(m):
- return m.group(1).replace('.', ' point ')
-
-
-def _expand_dollars(m):
- match = m.group(1)
- parts = match.split('.')
- if len(parts) > 2:
- return match + ' dollars' # Unexpected format
- dollars = int(parts[0]) if parts[0] else 0
- cents = int(parts[1]) if len(parts) > 1 and parts[1] else 0
- if dollars and cents:
- dollar_unit = 'dollar' if dollars == 1 else 'dollars'
- cent_unit = 'cent' if cents == 1 else 'cents'
- return '%s %s, %s %s' % (dollars, dollar_unit, cents, cent_unit)
- elif dollars:
- dollar_unit = 'dollar' if dollars == 1 else 'dollars'
- return '%s %s' % (dollars, dollar_unit)
- elif cents:
- cent_unit = 'cent' if cents == 1 else 'cents'
- return '%s %s' % (cents, cent_unit)
- else:
- return 'zero dollars'
-
-
-def _expand_ordinal(m):
- return _inflect.number_to_words(m.group(0))
-
-
-def _expand_number(m):
- num = int(m.group(0))
- if num > 1000 and num < 3000:
- if num == 2000:
- return 'two thousand'
- elif num > 2000 and num < 2010:
- return 'two thousand ' + _inflect.number_to_words(num % 100)
- elif num % 100 == 0:
- return _inflect.number_to_words(num // 100) + ' hundred'
- else:
- return _inflect.number_to_words(num, andword='', zero='oh', group=2).replace(', ', ' ')
- else:
- return _inflect.number_to_words(num, andword='')
-
-
-def normalize_numbers(text):
- text = re.sub(_comma_number_re, _remove_commas, text)
- text = re.sub(_pounds_re, r'\1 pounds', text)
- text = re.sub(_dollars_re, _expand_dollars, text)
- text = re.sub(_decimal_number_re, _expand_decimal_point, text)
- text = re.sub(_ordinal_re, _expand_ordinal, text)
- text = re.sub(_number_re, _expand_number, text)
- return text
-
-
-def mark_dark_l(text):
- return re.sub(r'l([^aeiouæɑɔəɛɪʊ ]*(?: |$))', lambda x: 'ɫ'+x.group(1), text)
-
-
-def english_to_ipa(text):
- text = unidecode(text).lower()
- text = expand_abbreviations(text)
- text = normalize_numbers(text)
- phonemes = ipa.convert(text)
- phonemes = collapse_whitespace(phonemes)
- return phonemes
-
-
-def english_to_lazy_ipa(text):
- text = english_to_ipa(text)
- for regex, replacement in _lazy_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def english_to_ipa2(text):
- text = english_to_ipa(text)
- text = mark_dark_l(text)
- for regex, replacement in _ipa_to_ipa2:
- text = re.sub(regex, replacement, text)
- return text.replace('...', '…')
-
-
-def english_to_lazy_ipa2(text):
- text = english_to_ipa(text)
- for regex, replacement in _lazy_ipa2:
- text = re.sub(regex, replacement, text)
- return text
diff --git a/spaces/oguzakif/video-object-remover/SiamMask/experiments/siammask_sharp/tune.sh b/spaces/oguzakif/video-object-remover/SiamMask/experiments/siammask_sharp/tune.sh
deleted file mode 100644
index 14b5c5bebfc6227b8e575f5a210ae27d21bbe730..0000000000000000000000000000000000000000
--- a/spaces/oguzakif/video-object-remover/SiamMask/experiments/siammask_sharp/tune.sh
+++ /dev/null
@@ -1,30 +0,0 @@
-if [ -z "$1" ]
- then
- echo "Need input parameter!"
- echo "Usage: bash `basename "$0"` \$MODEL \$DATASETi \$GPUID"
- exit
-fi
-
-which python
-
-ROOT=`git rev-parse --show-toplevel`
-source activate siammask
-export PYTHONPATH=$ROOT:$PYTHONPATH
-export PYTHONPATH=$PWD:$PYTHONPATH
-
-mkdir -p logs
-
-model=$1
-dataset=$2
-id=$3
-
-CUDA_VISIBLE_DEVICES=$id python -u $ROOT/tools/tune_vot.py\
- --config config_vot18.json \
- --dataset $dataset \
- --penalty-k 0.08,0.13,0.01 \
- --window-influence 0.38,0.44,0.01 \
- --lr 0.3,0.35,0.01 \
- --search-region 255,256,16 \
- --mask --refine \
- --resume $model 2>&1 | tee logs/tune.log
-
diff --git a/spaces/omdenatopekachapter/left_ejection_fraction/upload_page.py b/spaces/omdenatopekachapter/left_ejection_fraction/upload_page.py
deleted file mode 100644
index 931c81fde9f8f778c481f872b340a1a9efde72ad..0000000000000000000000000000000000000000
--- a/spaces/omdenatopekachapter/left_ejection_fraction/upload_page.py
+++ /dev/null
@@ -1,305 +0,0 @@
-import streamlit as st
-import streamlit.components.v1 as components
-import base64
-import cv2
-import skvideo.io
-import tempfile
-import subprocess
-import os
-import io
-import tempfile
-import numpy as np
-import tensorflow as tf
-from tensorflow.keras.models import load_model
-from keras.utils import get_custom_objects
-import tensorflow.keras.backend as K
-from tensorflow.keras.metrics import Metric
-from keras.utils.data_utils import get_file
-import plotly.graph_objects as go
-from matplotlib.patches import Arc
-import matplotlib.pyplot as plt
-
-from tensorflow_addons.layers import InstanceNormalization
-from io import BytesIO
-import moviepy.editor as mp
-
-
-
-
-import requests
-
-def upload():
-
- #Set page title and favicon
- #st.set_page_config(page_title="LVEF Assessment App - Assessment", page_icon=":heart:")
-
- # Define the EF ranges
- EF_RANGES = {
- "Normal": (55, 75),
- "Mildly reduced": (40, 54),
- "Moderately reduced": (30, 39),
- "Severely reduced": (20, 29),
- "Extremely reduced": (0, 19)
- }
- def specificity(y_true, y_pred):
- true_negatives = K.sum(K.round(K.clip((1-y_true)*(1-y_pred), 0, 1)))
- false_positives = K.sum(K.round(K.clip((1-y_true)*y_pred, 0, 1)))
- return true_negatives / (true_negatives + false_positives + K.epsilon())
-
- def sensitivity(y_true, y_pred):
- true_positives = K.sum(K.round(K.clip(y_true*y_pred, 0, 1)))
- false_negatives = K.sum(K.round(K.clip(y_true*(1-y_pred), 0, 1)))
- return true_positives / (true_positives + false_negatives + K.epsilon())
-
- def r2_score(y_true, y_pred):
- ss_res = K.sum(K.square(y_true - y_pred))
- ss_tot = K.sum(K.square(y_true - K.mean(y_true)))
- return 1 - ss_res / (ss_tot + K.epsilon())
-
- # Load the trained model
- @st.cache_data()
-
- def predict_ef(video_bytes):
- # Save the video bytes to display later
- video_bytes_to_display = video_bytes.read()
-
- # Create a temporary file for the video
- temp_video_file = tempfile.NamedTemporaryFile(delete=False, suffix='.avi')
- temp_video_file.write(video_bytes_to_display)
- temp_video_file.close()
-
- # Convert to .mp4
- clip = mp.VideoFileClip(temp_video_file.name)
- mp4_file_path = temp_video_file.name + '.mp4'
- clip.write_videofile(mp4_file_path)
- with tempfile.TemporaryFile() as f:
- # Write the contents of the BytesIO object to a temporary file
- f.write(video_bytes.read())
- f.seek(0)
-
- # Convert video to frames
- cap = cv2.VideoCapture(f.name)
- frames = []
- while True:
- ret, frame = cap.read()
- if not ret:
- break
- frames.append(frame)
- cap.release()
- frames_array = np.array(frames)
- img = frames_array[0:26]
- resized_img = np.zeros((28, 112, 112))
- for j, k in enumerate(img):
- resized_img[j, :, :] = cv2.resize(k, (112, 112), interpolation=cv2.INTER_LINEAR) / 255
-
- spatial_data = resized_img[:, :, :56]
- temporal_data = np.zeros((28, 112, 56))
- for j in range(1, 28):
- subtracted_frame = resized_img[j, :, 56:] - resized_img[j - 1, :, 56:]
- std = np.std(subtracted_frame)
- if std == 0:
- std = 1e-6 # set a small epsilon value if standard deviation is zero
- normalized_frame = (subtracted_frame - np.mean(subtracted_frame)) / std
- temporal_data[j, :, :] = normalized_frame
-
- temporal_data = temporal_data[1:27, :, :]
-
-
- URL = "https://huggingface.co/spaces/omdenatopekachapter/left_ejection_fraction/blob/main/model/WeightsLV_Cavity_Volume_Trace-0030.h5"
- weights_path = get_file(
- "model/best_two_stream.h5",
- URL)
- # Make EF prediction using the trained model
- #model_file = '/content/drive/MyDrive/LVEF_Streamlit/model/best_two_stream.h5'
- custom_objects = {'specificity': specificity, 'sensitivity': sensitivity, 'r2_score': r2_score}
- get_custom_objects().update(custom_objects)
- model = tf.keras.models.load_model(weights_path, custom_objects=custom_objects)
- prediction = model.predict([spatial_data[np.newaxis, :, :, :, np.newaxis],
- temporal_data[np.newaxis, :, :, :, np.newaxis]])[0][0]
- ef_prediction = int(prediction * 100)
-
-
- # Define the EF prediction ranges and their corresponding colors
- ranges = {'Normal': (70, 70, 'green'), 'Borderline': (49, 49, 'orange'), 'Reduced': (0, 40, 'red')}
- ef_range = None
- for range_name, (lower, upper, color) in ranges.items():
- if lower <= ef_prediction <= upper:
- ef_range = range_name
- ef_color = color
- break
-
- # Create a dictionary with the EF range names and values
- ef_dict = {'Predicted EF': ef_prediction}
- for range_name, (lower, upper, color) in ranges.items():
- if range_name == 'Normal':
- ef_dict[range_name] = lower
- elif range_name == 'Borderline':
- ef_dict[range_name] = lower - 1
- else:
- ef_dict[range_name] = upper
-
- # Define the data labels for each EF range
- data_labels = {
- 'Normal': 'NORMAL Ejection Fraction
-
-
- '''
-
- # Display the HTML in the app
- st.markdown(video_html, unsafe_allow_html=True)
-
-
- # Hide the upload widget
- #st.session_state['uploaded_file'] = None
-
- # Hide the upload video widget and prediction button
- #st.session_state['hide_widget'] = True
-
- # Show the predicted EF value and range
- st.write(f'EF Prediction: {ef_prediction}% ', unsafe_allow_html=True)
-
-
-
-
- os.remove(temp_video_file.name)
- os.remove(mp4_file_path)
- return ef_prediction
-
-
- #Add page title
- st.markdown(
- """
-
- """,
- unsafe_allow_html=True
- )
-
- #st.markdown('LVEF Assessment
', unsafe_allow_html=True)
- st.markdown('LVEF Assessment
', unsafe_allow_html=True)
-
-
- #Get uploaded file
- uploaded_file = st.file_uploader("Upload a video", type=["mp4", "avi"])
- # Hide the upload widget once the bar chart is plotted
- upload_placeholder = st.empty()
-
- #Prediction button
- if uploaded_file is not None:
-
- ef_prediction = predict_ef(uploaded_file)
-
-
- # Remove the upload video widget
- uploaded_file = None
-
- # Remove the upload widget placeholder
- upload_placeholder.empty()
-
- #Add footer
- st.markdown(
- """
-
- """,
- unsafe_allow_html=True,
- )
-
-
- st.markdown(
- f"""
-
- """,
- unsafe_allow_html=True,
- )
-
-
diff --git a/spaces/oriname/orimono/Dockerfile b/spaces/oriname/orimono/Dockerfile
deleted file mode 100644
index eef259fa372a804549fb0af0913718a13344da34..0000000000000000000000000000000000000000
--- a/spaces/oriname/orimono/Dockerfile
+++ /dev/null
@@ -1,11 +0,0 @@
-FROM node:18-bullseye-slim
-RUN apt-get update && \
- apt-get install -y git
-RUN git clone https://gitgud.io/khanon/oai-reverse-proxy.git /app
-WORKDIR /app
-RUN npm install
-COPY Dockerfile greeting.md* .env* ./
-RUN npm run build
-EXPOSE 7860
-ENV NODE_ENV=production
-CMD [ "npm", "start" ]
diff --git a/spaces/osanseviero/draw_to_search/app.py b/spaces/osanseviero/draw_to_search/app.py
deleted file mode 100644
index e22200fcc97a536077e4c36a1ffa7732dde74004..0000000000000000000000000000000000000000
--- a/spaces/osanseviero/draw_to_search/app.py
+++ /dev/null
@@ -1,78 +0,0 @@
-import os
-
-from pathlib import Path
-import pandas as pd, numpy as np
-from transformers import CLIPProcessor, CLIPTextModel, CLIPModel
-import torch
-from torch import nn
-import gradio as gr
-import requests
-
-LABELS = Path('class_names.txt').read_text().splitlines()
-class_model = nn.Sequential(
- nn.Conv2d(1, 32, 3, padding='same'),
- nn.ReLU(),
- nn.MaxPool2d(2),
- nn.Conv2d(32, 64, 3, padding='same'),
- nn.ReLU(),
- nn.MaxPool2d(2),
- nn.Conv2d(64, 128, 3, padding='same'),
- nn.ReLU(),
- nn.MaxPool2d(2),
- nn.Flatten(),
- nn.Linear(1152, 256),
- nn.ReLU(),
- nn.Linear(256, len(LABELS)),
-)
-state_dict = torch.load('pytorch_model.bin', map_location='cpu')
-class_model.load_state_dict(state_dict, strict=False)
-class_model.eval()
-
-
-model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
-processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
-df = pd.read_csv('data2.csv')
-embeddings_npy = np.load('embeddings.npy')
-embeddings = np.divide(embeddings_npy, np.sqrt(np.sum(embeddings_npy**2, axis=1, keepdims=True)))
-
-def compute_text_embeddings(list_of_strings):
- inputs = processor(text=list_of_strings, return_tensors="pt", padding=True)
- return model.get_text_features(**inputs)
-
-def download_img(path):
- img_data = requests.get(path).content
- local_path = path.split("/")[-1]
- with open(local_path, 'wb') as handler:
- handler.write(img_data)
- return local_path
-
-def predict(im):
- x = torch.tensor(im, dtype=torch.float32).unsqueeze(0).unsqueeze(0) / 255.
- with torch.no_grad():
- out = class_model(x)
- probabilities = torch.nn.functional.softmax(out[0], dim=0)
- values, indices = torch.topk(probabilities, 5)
-
- query = LABELS[indices[0]]
-
- n_results=3
- text_embeddings = compute_text_embeddings([query]).detach().numpy()
- results = np.argsort((embeddings@text_embeddings.T)[:, 0])[-1:-n_results-1:-1]
- outputs = [download_img(df.iloc[i]['path']) for i in results]
- outputs.insert(0, {LABELS[i]: v.item() for i, v in zip(indices, values)})
- print(outputs)
- return outputs
-
-title = "Draw to Search"
-description = "Using the power of CLIP and a simple small CNN, find images from movies based on what you draw!"
-
-iface = gr.Interface(
- fn=predict,
- inputs='sketchpad',
- outputs=[gr.outputs.Label(num_top_classes=3), gr.outputs.Image(type="file"), gr.outputs.Image(type="file"), gr.outputs.Image(type="file")],
- title=title,
- description=description,
- live=True
-)
-iface.launch(debug=True)
-
diff --git a/spaces/ought/raft-leaderboard/app.py b/spaces/ought/raft-leaderboard/app.py
deleted file mode 100644
index e6d69b3de3e79eb87ca6f2e9c90f8af9916f0296..0000000000000000000000000000000000000000
--- a/spaces/ought/raft-leaderboard/app.py
+++ /dev/null
@@ -1,117 +0,0 @@
-import os
-from datetime import datetime
-from pathlib import Path
-
-import numpy as np
-import pandas as pd
-import streamlit as st
-from datasets import get_dataset_config_names
-from dotenv import load_dotenv
-from huggingface_hub import DatasetFilter, list_datasets
-
-if Path(".env").is_file():
- load_dotenv(".env")
-
-auth_token = os.getenv("HF_HUB_TOKEN")
-
-TASKS = sorted(get_dataset_config_names("ought/raft"))
-# Split and capitalize the task names, e.g. banking_77 => Banking 77
-FORMATTED_TASK_NAMES = sorted([" ".join(t.capitalize() for t in task.split("_")) for task in TASKS])
-
-
-def download_submissions():
- filt = DatasetFilter(benchmark="raft")
- all_submissions = list_datasets(filter=filt, full=True, use_auth_token=auth_token)
- submissions = []
-
- for dataset in all_submissions:
- tags = dataset.cardData
- if tags.get("type") == "evaluation":
- submissions.append(dataset)
- return submissions
-
-
-def format_submissions(submissions):
- submission_data = {
- **{"Submitter": []},
- **{"Submission Name": []},
- **{"Submission Date": []},
- **{t: [] for t in TASKS},
- }
-
- # The following picks the latest submissions which adhere to the model card schema
- for submission in submissions:
- submission_id = submission.id
- card_data = submission.cardData
- username = card_data["submission_dataset"].split("/")[0]
- submission_data["Submitter"].append(username)
- submission_id = card_data["submission_id"]
- submission_name, sha, timestamp = submission_id.split("__")
- # Format submission names with new backend constraints
- # TODO(lewtun): make this less hacky!
- if "_XXX_" in submission_name:
- submission_name = submission_name.replace("_XXX_", " ")
- if "_DDD_" in submission_name:
- submission_name = submission_name.replace("_DDD_", "--")
- submission_data["Submission Name"].append(submission_name)
- # Handle mismatch in epoch microseconds vs epoch seconds in new AutoTrain API
- if len(timestamp) > 10:
- timestamp = pd.to_datetime(int(timestamp))
- else:
- timestamp = pd.to_datetime(int(timestamp), unit="s")
- submission_data["Submission Date"].append(datetime.date(timestamp).strftime("%b %d, %Y"))
-
- for task in card_data["results"]:
- task_data = task["task"]
- task_name = task_data["name"]
- score = task_data["metrics"][0]["value"]
- submission_data[task_name].append(score)
-
- df = pd.DataFrame(submission_data)
- df.insert(3, "Overall", df[TASKS].mean(axis=1))
- df = df.copy().sort_values("Overall", ascending=False)
- df.rename(columns={k: v for k, v in zip(TASKS, FORMATTED_TASK_NAMES)}, inplace=True)
- # Start ranking from 1
- df.insert(0, "Rank", np.arange(1, len(df) + 1))
- return df
-
-
-###########
-### APP ###
-###########
-st.set_page_config(layout="wide")
-st.title("RAFT: Real-world Annotated Few-shot Tasks")
-st.markdown(
- """
-Large pre-trained language models have shown promise for few-shot learning, completing text-based tasks given only a few task-specific examples. Will models soon solve classification tasks that have so far been reserved for human research assistants?
-
-[RAFT](https://raft.elicit.org) is a few-shot classification benchmark that tests language models:
-
-- across multiple domains (lit review, tweets, customer interaction, etc.)
-- on economically valuable classification tasks (someone inherently cares about the task)
-- in a setting that mirrors deployment (50 examples per task, info retrieval allowed, hidden test set)
-
-To submit to RAFT, follow the instruction posted on [this page](https://huggingface.co/datasets/ought/raft-submission).
-"""
-)
-submissions = download_submissions()
-print(f"INFO - downloaded {len(submissions)} submissions")
-df = format_submissions(submissions)
-styler = pd.io.formats.style.Styler(df, precision=3).set_properties(
- **{"white-space": "pre-wrap", "text-align": "center"}
-)
-# hack to remove index column: https://discuss.streamlit.io/t/questions-on-st-table/6878/3
-st.markdown(
- """
-
-""",
- unsafe_allow_html=True,
-)
-st.table(styler)
diff --git a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/models/embeddings_flax.py b/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/models/embeddings_flax.py
deleted file mode 100644
index 88c2c45e4655b8013fa96e0b4408e3ec0a87c2c7..0000000000000000000000000000000000000000
--- a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/models/embeddings_flax.py
+++ /dev/null
@@ -1,95 +0,0 @@
-# Copyright 2023 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import math
-
-import flax.linen as nn
-import jax.numpy as jnp
-
-
-def get_sinusoidal_embeddings(
- timesteps: jnp.ndarray,
- embedding_dim: int,
- freq_shift: float = 1,
- min_timescale: float = 1,
- max_timescale: float = 1.0e4,
- flip_sin_to_cos: bool = False,
- scale: float = 1.0,
-) -> jnp.ndarray:
- """Returns the positional encoding (same as Tensor2Tensor).
-
- Args:
- timesteps: a 1-D Tensor of N indices, one per batch element.
- These may be fractional.
- embedding_dim: The number of output channels.
- min_timescale: The smallest time unit (should probably be 0.0).
- max_timescale: The largest time unit.
- Returns:
- a Tensor of timing signals [N, num_channels]
- """
- assert timesteps.ndim == 1, "Timesteps should be a 1d-array"
- assert embedding_dim % 2 == 0, f"Embedding dimension {embedding_dim} should be even"
- num_timescales = float(embedding_dim // 2)
- log_timescale_increment = math.log(max_timescale / min_timescale) / (num_timescales - freq_shift)
- inv_timescales = min_timescale * jnp.exp(jnp.arange(num_timescales, dtype=jnp.float32) * -log_timescale_increment)
- emb = jnp.expand_dims(timesteps, 1) * jnp.expand_dims(inv_timescales, 0)
-
- # scale embeddings
- scaled_time = scale * emb
-
- if flip_sin_to_cos:
- signal = jnp.concatenate([jnp.cos(scaled_time), jnp.sin(scaled_time)], axis=1)
- else:
- signal = jnp.concatenate([jnp.sin(scaled_time), jnp.cos(scaled_time)], axis=1)
- signal = jnp.reshape(signal, [jnp.shape(timesteps)[0], embedding_dim])
- return signal
-
-
-class FlaxTimestepEmbedding(nn.Module):
- r"""
- Time step Embedding Module. Learns embeddings for input time steps.
-
- Args:
- time_embed_dim (`int`, *optional*, defaults to `32`):
- Time step embedding dimension
- dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
- Parameters `dtype`
- """
- time_embed_dim: int = 32
- dtype: jnp.dtype = jnp.float32
-
- @nn.compact
- def __call__(self, temb):
- temb = nn.Dense(self.time_embed_dim, dtype=self.dtype, name="linear_1")(temb)
- temb = nn.silu(temb)
- temb = nn.Dense(self.time_embed_dim, dtype=self.dtype, name="linear_2")(temb)
- return temb
-
-
-class FlaxTimesteps(nn.Module):
- r"""
- Wrapper Module for sinusoidal Time step Embeddings as described in https://arxiv.org/abs/2006.11239
-
- Args:
- dim (`int`, *optional*, defaults to `32`):
- Time step embedding dimension
- """
- dim: int = 32
- flip_sin_to_cos: bool = False
- freq_shift: float = 1
-
- @nn.compact
- def __call__(self, timesteps):
- return get_sinusoidal_embeddings(
- timesteps, embedding_dim=self.dim, flip_sin_to_cos=self.flip_sin_to_cos, freq_shift=self.freq_shift
- )
diff --git a/spaces/pixiou/bingo/src/pages/api/healthz.ts b/spaces/pixiou/bingo/src/pages/api/healthz.ts
deleted file mode 100644
index f6ae44ff0fd66ccd3f7feaa550025fbf2a83bf77..0000000000000000000000000000000000000000
--- a/spaces/pixiou/bingo/src/pages/api/healthz.ts
+++ /dev/null
@@ -1,7 +0,0 @@
-'use server'
-
-import { NextApiRequest, NextApiResponse } from 'next'
-
-export default async function handler(req: NextApiRequest, res: NextApiResponse) {
- res.status(200).end('ok')
-}
diff --git a/spaces/pkarthik15/docchat/app.py b/spaces/pkarthik15/docchat/app.py
deleted file mode 100644
index c8fa755811932a65ab15f168d2050d7e2bb346eb..0000000000000000000000000000000000000000
--- a/spaces/pkarthik15/docchat/app.py
+++ /dev/null
@@ -1,75 +0,0 @@
-import os
-from langchain.document_loaders import PyPDFLoader
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-from langchain.embeddings import OpenAIEmbeddings
-from langchain.vectorstores import FAISS
-from langchain.llms import OpenAI
-from langchain.chains import ConversationalRetrievalChain
-import pickle
-import gradio as gr
-import time
-
-
-
-
-def upload_file(file, key):
-
- # Set the Enviroment variable
- os.environ["OPENAI_API_KEY"] = key
-
- # load document
- loader = PyPDFLoader(file.name)
- documents = loader.load()
-
- # split the documents into chunks
- text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
- texts = text_splitter.split_documents(documents)
-
- # OPENAI embegddings
- embeddings = OpenAIEmbeddings()
-
- # create the vectorestore to use as the index
- db = FAISS.from_documents(documents, embeddings)
-
- with open("vectorstore.pkl", "wb") as f:
- pickle.dump(db, f)
-
- return file.name
-
-
-with gr.Blocks() as demo:
-
- openai_key = gr.Textbox(label="OPENAI API KEY")
- file_output = gr.File(label="Please select a pdf file wait for the document to be displayed here")
- upload_button = gr.UploadButton("Click to upload a pdf document", file_types=["pdf"], file_count="single")
- upload_button.upload(upload_file, inputs = [upload_button, openai_key], outputs= file_output)
-
-
- chatbot = gr.Chatbot(label="Chat")
- msg = gr.Textbox(label="Enter your query")
- clear = gr.Button("Clear")
-
- def user(user_message, history):
- return "", history + [[user_message, None]]
-
- def bot(history):
- user_message = history[-1][0]
- with open("vectorstore.pkl", "rb") as f:
- vectorstore = pickle.load(f)
- llm = OpenAI(temperature=0)
- qa = ConversationalRetrievalChain.from_llm(llm, vectorstore.as_retriever(), return_source_documents=True)
- hist = []
- if history[-1][1] != None:
- hist = history
-
- result = qa({"question": user_message, "chat_history": hist})
- history[-1][1] = result['answer']
- return history
-
- msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
- bot, chatbot, chatbot
- )
- clear.click(lambda: None, None, chatbot, queue=False)
-
-
-demo.launch()
\ No newline at end of file
diff --git a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pkg_resources/_vendor/packaging/_musllinux.py b/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pkg_resources/_vendor/packaging/_musllinux.py
deleted file mode 100644
index 706ba600a93c1b72594d96d3026daaa1998935b6..0000000000000000000000000000000000000000
--- a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pkg_resources/_vendor/packaging/_musllinux.py
+++ /dev/null
@@ -1,80 +0,0 @@
-"""PEP 656 support.
-
-This module implements logic to detect if the currently running Python is
-linked against musl, and what musl version is used.
-"""
-
-import functools
-import re
-import subprocess
-import sys
-from typing import Iterator, NamedTuple, Optional
-
-from ._elffile import ELFFile
-
-
-class _MuslVersion(NamedTuple):
- major: int
- minor: int
-
-
-def _parse_musl_version(output: str) -> Optional[_MuslVersion]:
- lines = [n for n in (n.strip() for n in output.splitlines()) if n]
- if len(lines) < 2 or lines[0][:4] != "musl":
- return None
- m = re.match(r"Version (\d+)\.(\d+)", lines[1])
- if not m:
- return None
- return _MuslVersion(major=int(m.group(1)), minor=int(m.group(2)))
-
-
-@functools.lru_cache()
-def _get_musl_version(executable: str) -> Optional[_MuslVersion]:
- """Detect currently-running musl runtime version.
-
- This is done by checking the specified executable's dynamic linking
- information, and invoking the loader to parse its output for a version
- string. If the loader is musl, the output would be something like::
-
- musl libc (x86_64)
- Version 1.2.2
- Dynamic Program Loader
- """
- try:
- with open(executable, "rb") as f:
- ld = ELFFile(f).interpreter
- except (OSError, TypeError, ValueError):
- return None
- if ld is None or "musl" not in ld:
- return None
- proc = subprocess.run([ld], stderr=subprocess.PIPE, universal_newlines=True)
- return _parse_musl_version(proc.stderr)
-
-
-def platform_tags(arch: str) -> Iterator[str]:
- """Generate musllinux tags compatible to the current platform.
-
- :param arch: Should be the part of platform tag after the ``linux_``
- prefix, e.g. ``x86_64``. The ``linux_`` prefix is assumed as a
- prerequisite for the current platform to be musllinux-compatible.
-
- :returns: An iterator of compatible musllinux tags.
- """
- sys_musl = _get_musl_version(sys.executable)
- if sys_musl is None: # Python not dynamically linked against musl.
- return
- for minor in range(sys_musl.minor, -1, -1):
- yield f"musllinux_{sys_musl.major}_{minor}_{arch}"
-
-
-if __name__ == "__main__": # pragma: no cover
- import sysconfig
-
- plat = sysconfig.get_platform()
- assert plat.startswith("linux-"), "not linux"
-
- print("plat:", plat)
- print("musl:", _get_musl_version(sys.executable))
- print("tags:", end=" ")
- for t in platform_tags(re.sub(r"[.-]", "_", plat.split("-", 1)[-1])):
- print(t, end="\n ")
diff --git a/spaces/portal/Xenova-Semantic-Image-Search/masto.html b/spaces/portal/Xenova-Semantic-Image-Search/masto.html
deleted file mode 100644
index 9d4b7c2b6df7843b0a7f7d1ded44d6fc5dd66723..0000000000000000000000000000000000000000
--- a/spaces/portal/Xenova-Semantic-Image-Search/masto.html
+++ /dev/null
@@ -1,19 +0,0 @@
-
-
-
-
-#include
-#include "portaudio.h"
-
-#define SAMPLE_RATE (44100)
-
-typedef struct WireConfig_s
-{
- int isInputInterleaved;
- int isOutputInterleaved;
- int numInputChannels;
- int numOutputChannels;
- int framesPerCallback;
- /* count status flags */
- int numInputUnderflows;
- int numInputOverflows;
- int numOutputUnderflows;
- int numOutputOverflows;
- int numPrimingOutputs;
- int numCallbacks;
-} WireConfig_t;
-
-#define USE_FLOAT_INPUT (1)
-#define USE_FLOAT_OUTPUT (1)
-
-/* Latencies set to defaults. */
-
-#if USE_FLOAT_INPUT
- #define INPUT_FORMAT paFloat32
- typedef float INPUT_SAMPLE;
-#else
- #define INPUT_FORMAT paInt16
- typedef short INPUT_SAMPLE;
-#endif
-
-#if USE_FLOAT_OUTPUT
- #define OUTPUT_FORMAT paFloat32
- typedef float OUTPUT_SAMPLE;
-#else
- #define OUTPUT_FORMAT paInt16
- typedef short OUTPUT_SAMPLE;
-#endif
-
-double gInOutScaler = 1.0;
-#define CONVERT_IN_TO_OUT(in) ((OUTPUT_SAMPLE) ((in) * gInOutScaler))
-
-#define INPUT_DEVICE (Pa_GetDefaultInputDevice())
-#define OUTPUT_DEVICE (Pa_GetDefaultOutputDevice())
-
-static PaError TestConfiguration( WireConfig_t *config );
-
-static int wireCallback( const void *inputBuffer, void *outputBuffer,
- unsigned long framesPerBuffer,
- const PaStreamCallbackTimeInfo* timeInfo,
- PaStreamCallbackFlags statusFlags,
- void *userData );
-
-/* This routine will be called by the PortAudio engine when audio is needed.
-** It may be called at interrupt level on some machines so don't do anything
-** that could mess up the system like calling malloc() or free().
-*/
-
-static int wireCallback( const void *inputBuffer, void *outputBuffer,
- unsigned long framesPerBuffer,
- const PaStreamCallbackTimeInfo* timeInfo,
- PaStreamCallbackFlags statusFlags,
- void *userData )
-{
- INPUT_SAMPLE *in;
- OUTPUT_SAMPLE *out;
- int inStride;
- int outStride;
- int inDone = 0;
- int outDone = 0;
- WireConfig_t *config = (WireConfig_t *) userData;
- unsigned int i;
- int inChannel, outChannel;
-
- /* This may get called with NULL inputBuffer during initial setup. */
- if( inputBuffer == NULL) return 0;
-
- /* Count flags */
- if( (statusFlags & paInputUnderflow) != 0 ) config->numInputUnderflows += 1;
- if( (statusFlags & paInputOverflow) != 0 ) config->numInputOverflows += 1;
- if( (statusFlags & paOutputUnderflow) != 0 ) config->numOutputUnderflows += 1;
- if( (statusFlags & paOutputOverflow) != 0 ) config->numOutputOverflows += 1;
- if( (statusFlags & paPrimingOutput) != 0 ) config->numPrimingOutputs += 1;
- config->numCallbacks += 1;
-
- inChannel=0, outChannel=0;
- while( !(inDone && outDone) )
- {
- if( config->isInputInterleaved )
- {
- in = ((INPUT_SAMPLE*)inputBuffer) + inChannel;
- inStride = config->numInputChannels;
- }
- else
- {
- in = ((INPUT_SAMPLE**)inputBuffer)[inChannel];
- inStride = 1;
- }
-
- if( config->isOutputInterleaved )
- {
- out = ((OUTPUT_SAMPLE*)outputBuffer) + outChannel;
- outStride = config->numOutputChannels;
- }
- else
- {
- out = ((OUTPUT_SAMPLE**)outputBuffer)[outChannel];
- outStride = 1;
- }
-
- for( i=0; inumInputChannels - 1)) inChannel++;
- else inDone = 1;
- if(outChannel < (config->numOutputChannels - 1)) outChannel++;
- else outDone = 1;
- }
- return 0;
-}
-
-/*******************************************************************/
-int main(void);
-int main(void)
-{
- PaError err = paNoError;
- WireConfig_t CONFIG;
- WireConfig_t *config = &CONFIG;
- int configIndex = 0;;
-
- err = Pa_Initialize();
- if( err != paNoError ) goto error;
-
- printf("Please connect audio signal to input and listen for it on output!\n");
- printf("input format = %lu\n", INPUT_FORMAT );
- printf("output format = %lu\n", OUTPUT_FORMAT );
- printf("input device ID = %d\n", INPUT_DEVICE );
- printf("output device ID = %d\n", OUTPUT_DEVICE );
-
- if( INPUT_FORMAT == OUTPUT_FORMAT )
- {
- gInOutScaler = 1.0;
- }
- else if( (INPUT_FORMAT == paInt16) && (OUTPUT_FORMAT == paFloat32) )
- {
- gInOutScaler = 1.0/32768.0;
- }
- else if( (INPUT_FORMAT == paFloat32) && (OUTPUT_FORMAT == paInt16) )
- {
- gInOutScaler = 32768.0;
- }
-
- for( config->isInputInterleaved = 0; config->isInputInterleaved < 2; config->isInputInterleaved++ )
- {
- for( config->isOutputInterleaved = 0; config->isOutputInterleaved < 2; config->isOutputInterleaved++ )
- {
- for( config->numInputChannels = 1; config->numInputChannels < 3; config->numInputChannels++ )
- {
- for( config->numOutputChannels = 1; config->numOutputChannels < 3; config->numOutputChannels++ )
- {
- /* If framesPerCallback = 0, assertion fails in file pa_common/pa_process.c, line 1413: EX. */
- for( config->framesPerCallback = 64; config->framesPerCallback < 129; config->framesPerCallback += 64 )
- {
- printf("-----------------------------------------------\n" );
- printf("Configuration #%d\n", configIndex++ );
- err = TestConfiguration( config );
- /* Give user a chance to bail out. */
- if( err == 1 )
- {
- err = paNoError;
- goto done;
- }
- else if( err != paNoError ) goto error;
- }
- }
- }
- }
- }
-
-done:
- Pa_Terminate();
- printf("Full duplex sound test complete.\n"); fflush(stdout);
- printf("Hit ENTER to quit.\n"); fflush(stdout);
- getchar();
- return 0;
-
-error:
- Pa_Terminate();
- fprintf( stderr, "An error occurred while using the portaudio stream\n" );
- fprintf( stderr, "Error number: %d\n", err );
- fprintf( stderr, "Error message: %s\n", Pa_GetErrorText( err ) );
- printf("Hit ENTER to quit.\n"); fflush(stdout);
- getchar();
- return -1;
-}
-
-static PaError TestConfiguration( WireConfig_t *config )
-{
- int c;
- PaError err = paNoError;
- PaStream *stream;
- PaStreamParameters inputParameters, outputParameters;
-
- printf("input %sinterleaved!\n", (config->isInputInterleaved ? " " : "NOT ") );
- printf("output %sinterleaved!\n", (config->isOutputInterleaved ? " " : "NOT ") );
- printf("input channels = %d\n", config->numInputChannels );
- printf("output channels = %d\n", config->numOutputChannels );
- printf("framesPerCallback = %d\n", config->framesPerCallback );
-
- inputParameters.device = INPUT_DEVICE; /* default input device */
- if (inputParameters.device == paNoDevice) {
- fprintf(stderr,"Error: No default input device.\n");
- goto error;
- }
- inputParameters.channelCount = config->numInputChannels;
- inputParameters.sampleFormat = INPUT_FORMAT | (config->isInputInterleaved ? 0 : paNonInterleaved);
- inputParameters.suggestedLatency = Pa_GetDeviceInfo( inputParameters.device )->defaultLowInputLatency;
- inputParameters.hostApiSpecificStreamInfo = NULL;
-
- outputParameters.device = OUTPUT_DEVICE; /* default output device */
- if (outputParameters.device == paNoDevice) {
- fprintf(stderr,"Error: No default output device.\n");
- goto error;
- }
- outputParameters.channelCount = config->numOutputChannels;
- outputParameters.sampleFormat = OUTPUT_FORMAT | (config->isOutputInterleaved ? 0 : paNonInterleaved);
- outputParameters.suggestedLatency = Pa_GetDeviceInfo( outputParameters.device )->defaultLowOutputLatency;
- outputParameters.hostApiSpecificStreamInfo = NULL;
-
- config->numInputUnderflows = 0;
- config->numInputOverflows = 0;
- config->numOutputUnderflows = 0;
- config->numOutputOverflows = 0;
- config->numPrimingOutputs = 0;
- config->numCallbacks = 0;
-
- err = Pa_OpenStream(
- &stream,
- &inputParameters,
- &outputParameters,
- SAMPLE_RATE,
- config->framesPerCallback, /* frames per buffer */
- paClipOff, /* we won't output out of range samples so don't bother clipping them */
- wireCallback,
- config );
- if( err != paNoError ) goto error;
-
- err = Pa_StartStream( stream );
- if( err != paNoError ) goto error;
-
- printf("Now recording and playing. - Hit ENTER for next configuration, or 'q' to quit.\n"); fflush(stdout);
- c = getchar();
-
- printf("Closing stream.\n");
- err = Pa_CloseStream( stream );
- if( err != paNoError ) goto error;
-
-#define CHECK_FLAG_COUNT(member) \
- if( config->member > 0 ) printf("FLAGS SET: " #member " = %d\n", config->member );
- CHECK_FLAG_COUNT( numInputUnderflows );
- CHECK_FLAG_COUNT( numInputOverflows );
- CHECK_FLAG_COUNT( numOutputUnderflows );
- CHECK_FLAG_COUNT( numOutputOverflows );
- CHECK_FLAG_COUNT( numPrimingOutputs );
- printf("number of callbacks = %d\n", config->numCallbacks );
-
- if( c == 'q' ) return 1;
-
-error:
- return err;
-}
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/PIL/WebPImagePlugin.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/PIL/WebPImagePlugin.py
deleted file mode 100644
index 612fc09467a10c547872a5dd8d0909aa271912e1..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/PIL/WebPImagePlugin.py
+++ /dev/null
@@ -1,361 +0,0 @@
-from io import BytesIO
-
-from . import Image, ImageFile
-
-try:
- from . import _webp
-
- SUPPORTED = True
-except ImportError:
- SUPPORTED = False
-
-
-_VALID_WEBP_MODES = {"RGBX": True, "RGBA": True, "RGB": True}
-
-_VALID_WEBP_LEGACY_MODES = {"RGB": True, "RGBA": True}
-
-_VP8_MODES_BY_IDENTIFIER = {
- b"VP8 ": "RGB",
- b"VP8X": "RGBA",
- b"VP8L": "RGBA", # lossless
-}
-
-
-def _accept(prefix):
- is_riff_file_format = prefix[:4] == b"RIFF"
- is_webp_file = prefix[8:12] == b"WEBP"
- is_valid_vp8_mode = prefix[12:16] in _VP8_MODES_BY_IDENTIFIER
-
- if is_riff_file_format and is_webp_file and is_valid_vp8_mode:
- if not SUPPORTED:
- return (
- "image file could not be identified because WEBP support not installed"
- )
- return True
-
-
-class WebPImageFile(ImageFile.ImageFile):
- format = "WEBP"
- format_description = "WebP image"
- __loaded = 0
- __logical_frame = 0
-
- def _open(self):
- if not _webp.HAVE_WEBPANIM:
- # Legacy mode
- data, width, height, self._mode, icc_profile, exif = _webp.WebPDecode(
- self.fp.read()
- )
- if icc_profile:
- self.info["icc_profile"] = icc_profile
- if exif:
- self.info["exif"] = exif
- self._size = width, height
- self.fp = BytesIO(data)
- self.tile = [("raw", (0, 0) + self.size, 0, self.mode)]
- self.n_frames = 1
- self.is_animated = False
- return
-
- # Use the newer AnimDecoder API to parse the (possibly) animated file,
- # and access muxed chunks like ICC/EXIF/XMP.
- self._decoder = _webp.WebPAnimDecoder(self.fp.read())
-
- # Get info from decoder
- width, height, loop_count, bgcolor, frame_count, mode = self._decoder.get_info()
- self._size = width, height
- self.info["loop"] = loop_count
- bg_a, bg_r, bg_g, bg_b = (
- (bgcolor >> 24) & 0xFF,
- (bgcolor >> 16) & 0xFF,
- (bgcolor >> 8) & 0xFF,
- bgcolor & 0xFF,
- )
- self.info["background"] = (bg_r, bg_g, bg_b, bg_a)
- self.n_frames = frame_count
- self.is_animated = self.n_frames > 1
- self._mode = "RGB" if mode == "RGBX" else mode
- self.rawmode = mode
- self.tile = []
-
- # Attempt to read ICC / EXIF / XMP chunks from file
- icc_profile = self._decoder.get_chunk("ICCP")
- exif = self._decoder.get_chunk("EXIF")
- xmp = self._decoder.get_chunk("XMP ")
- if icc_profile:
- self.info["icc_profile"] = icc_profile
- if exif:
- self.info["exif"] = exif
- if xmp:
- self.info["xmp"] = xmp
-
- # Initialize seek state
- self._reset(reset=False)
-
- def _getexif(self):
- if "exif" not in self.info:
- return None
- return self.getexif()._get_merged_dict()
-
- def getxmp(self):
- """
- Returns a dictionary containing the XMP tags.
- Requires defusedxml to be installed.
-
- :returns: XMP tags in a dictionary.
- """
- return self._getxmp(self.info["xmp"]) if "xmp" in self.info else {}
-
- def seek(self, frame):
- if not self._seek_check(frame):
- return
-
- # Set logical frame to requested position
- self.__logical_frame = frame
-
- def _reset(self, reset=True):
- if reset:
- self._decoder.reset()
- self.__physical_frame = 0
- self.__loaded = -1
- self.__timestamp = 0
-
- def _get_next(self):
- # Get next frame
- ret = self._decoder.get_next()
- self.__physical_frame += 1
-
- # Check if an error occurred
- if ret is None:
- self._reset() # Reset just to be safe
- self.seek(0)
- msg = "failed to decode next frame in WebP file"
- raise EOFError(msg)
-
- # Compute duration
- data, timestamp = ret
- duration = timestamp - self.__timestamp
- self.__timestamp = timestamp
-
- # libwebp gives frame end, adjust to start of frame
- timestamp -= duration
- return data, timestamp, duration
-
- def _seek(self, frame):
- if self.__physical_frame == frame:
- return # Nothing to do
- if frame < self.__physical_frame:
- self._reset() # Rewind to beginning
- while self.__physical_frame < frame:
- self._get_next() # Advance to the requested frame
-
- def load(self):
- if _webp.HAVE_WEBPANIM:
- if self.__loaded != self.__logical_frame:
- self._seek(self.__logical_frame)
-
- # We need to load the image data for this frame
- data, timestamp, duration = self._get_next()
- self.info["timestamp"] = timestamp
- self.info["duration"] = duration
- self.__loaded = self.__logical_frame
-
- # Set tile
- if self.fp and self._exclusive_fp:
- self.fp.close()
- self.fp = BytesIO(data)
- self.tile = [("raw", (0, 0) + self.size, 0, self.rawmode)]
-
- return super().load()
-
- def tell(self):
- if not _webp.HAVE_WEBPANIM:
- return super().tell()
-
- return self.__logical_frame
-
-
-def _save_all(im, fp, filename):
- encoderinfo = im.encoderinfo.copy()
- append_images = list(encoderinfo.get("append_images", []))
-
- # If total frame count is 1, then save using the legacy API, which
- # will preserve non-alpha modes
- total = 0
- for ims in [im] + append_images:
- total += getattr(ims, "n_frames", 1)
- if total == 1:
- _save(im, fp, filename)
- return
-
- background = (0, 0, 0, 0)
- if "background" in encoderinfo:
- background = encoderinfo["background"]
- elif "background" in im.info:
- background = im.info["background"]
- if isinstance(background, int):
- # GifImagePlugin stores a global color table index in
- # info["background"]. So it must be converted to an RGBA value
- palette = im.getpalette()
- if palette:
- r, g, b = palette[background * 3 : (background + 1) * 3]
- background = (r, g, b, 255)
- else:
- background = (background, background, background, 255)
-
- duration = im.encoderinfo.get("duration", im.info.get("duration", 0))
- loop = im.encoderinfo.get("loop", 0)
- minimize_size = im.encoderinfo.get("minimize_size", False)
- kmin = im.encoderinfo.get("kmin", None)
- kmax = im.encoderinfo.get("kmax", None)
- allow_mixed = im.encoderinfo.get("allow_mixed", False)
- verbose = False
- lossless = im.encoderinfo.get("lossless", False)
- quality = im.encoderinfo.get("quality", 80)
- method = im.encoderinfo.get("method", 0)
- icc_profile = im.encoderinfo.get("icc_profile") or ""
- exif = im.encoderinfo.get("exif", "")
- if isinstance(exif, Image.Exif):
- exif = exif.tobytes()
- xmp = im.encoderinfo.get("xmp", "")
- if allow_mixed:
- lossless = False
-
- # Sensible keyframe defaults are from gif2webp.c script
- if kmin is None:
- kmin = 9 if lossless else 3
- if kmax is None:
- kmax = 17 if lossless else 5
-
- # Validate background color
- if (
- not isinstance(background, (list, tuple))
- or len(background) != 4
- or not all(0 <= v < 256 for v in background)
- ):
- msg = f"Background color is not an RGBA tuple clamped to (0-255): {background}"
- raise OSError(msg)
-
- # Convert to packed uint
- bg_r, bg_g, bg_b, bg_a = background
- background = (bg_a << 24) | (bg_r << 16) | (bg_g << 8) | (bg_b << 0)
-
- # Setup the WebP animation encoder
- enc = _webp.WebPAnimEncoder(
- im.size[0],
- im.size[1],
- background,
- loop,
- minimize_size,
- kmin,
- kmax,
- allow_mixed,
- verbose,
- )
-
- # Add each frame
- frame_idx = 0
- timestamp = 0
- cur_idx = im.tell()
- try:
- for ims in [im] + append_images:
- # Get # of frames in this image
- nfr = getattr(ims, "n_frames", 1)
-
- for idx in range(nfr):
- ims.seek(idx)
- ims.load()
-
- # Make sure image mode is supported
- frame = ims
- rawmode = ims.mode
- if ims.mode not in _VALID_WEBP_MODES:
- alpha = (
- "A" in ims.mode
- or "a" in ims.mode
- or (ims.mode == "P" and "A" in ims.im.getpalettemode())
- )
- rawmode = "RGBA" if alpha else "RGB"
- frame = ims.convert(rawmode)
-
- if rawmode == "RGB":
- # For faster conversion, use RGBX
- rawmode = "RGBX"
-
- # Append the frame to the animation encoder
- enc.add(
- frame.tobytes("raw", rawmode),
- round(timestamp),
- frame.size[0],
- frame.size[1],
- rawmode,
- lossless,
- quality,
- method,
- )
-
- # Update timestamp and frame index
- if isinstance(duration, (list, tuple)):
- timestamp += duration[frame_idx]
- else:
- timestamp += duration
- frame_idx += 1
-
- finally:
- im.seek(cur_idx)
-
- # Force encoder to flush frames
- enc.add(None, round(timestamp), 0, 0, "", lossless, quality, 0)
-
- # Get the final output from the encoder
- data = enc.assemble(icc_profile, exif, xmp)
- if data is None:
- msg = "cannot write file as WebP (encoder returned None)"
- raise OSError(msg)
-
- fp.write(data)
-
-
-def _save(im, fp, filename):
- lossless = im.encoderinfo.get("lossless", False)
- quality = im.encoderinfo.get("quality", 80)
- icc_profile = im.encoderinfo.get("icc_profile") or ""
- exif = im.encoderinfo.get("exif", b"")
- if isinstance(exif, Image.Exif):
- exif = exif.tobytes()
- if exif.startswith(b"Exif\x00\x00"):
- exif = exif[6:]
- xmp = im.encoderinfo.get("xmp", "")
- method = im.encoderinfo.get("method", 4)
- exact = 1 if im.encoderinfo.get("exact") else 0
-
- if im.mode not in _VALID_WEBP_LEGACY_MODES:
- im = im.convert("RGBA" if im.has_transparency_data else "RGB")
-
- data = _webp.WebPEncode(
- im.tobytes(),
- im.size[0],
- im.size[1],
- lossless,
- float(quality),
- im.mode,
- icc_profile,
- method,
- exact,
- exif,
- xmp,
- )
- if data is None:
- msg = "cannot write file as WebP (encoder returned None)"
- raise OSError(msg)
-
- fp.write(data)
-
-
-Image.register_open(WebPImageFile.format, WebPImageFile, _accept)
-if SUPPORTED:
- Image.register_save(WebPImageFile.format, _save)
- if _webp.HAVE_WEBPANIM:
- Image.register_save_all(WebPImageFile.format, _save_all)
- Image.register_extension(WebPImageFile.format, ".webp")
- Image.register_mime(WebPImageFile.format, "image/webp")
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/D_S_I_G_.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/D_S_I_G_.py
deleted file mode 100644
index d902a29080aff5a275f530c7658d3c9eb4498034..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/D_S_I_G_.py
+++ /dev/null
@@ -1,151 +0,0 @@
-from fontTools.misc.textTools import bytesjoin, strjoin, tobytes, tostr, safeEval
-from fontTools.misc import sstruct
-from . import DefaultTable
-import base64
-
-DSIG_HeaderFormat = """
- > # big endian
- ulVersion: L
- usNumSigs: H
- usFlag: H
-"""
-# followed by an array of usNumSigs DSIG_Signature records
-DSIG_SignatureFormat = """
- > # big endian
- ulFormat: L
- ulLength: L # length includes DSIG_SignatureBlock header
- ulOffset: L
-"""
-# followed by an array of usNumSigs DSIG_SignatureBlock records,
-# each followed immediately by the pkcs7 bytes
-DSIG_SignatureBlockFormat = """
- > # big endian
- usReserved1: H
- usReserved2: H
- cbSignature: l # length of following raw pkcs7 data
-"""
-
-#
-# NOTE
-# the DSIG table format allows for SignatureBlocks residing
-# anywhere in the table and possibly in a different order as
-# listed in the array after the first table header
-#
-# this implementation does not keep track of any gaps and/or data
-# before or after the actual signature blocks while decompiling,
-# and puts them in the same physical order as listed in the header
-# on compilation with no padding whatsoever.
-#
-
-
-class table_D_S_I_G_(DefaultTable.DefaultTable):
- def decompile(self, data, ttFont):
- dummy, newData = sstruct.unpack2(DSIG_HeaderFormat, data, self)
- assert self.ulVersion == 1, "DSIG ulVersion must be 1"
- assert self.usFlag & ~1 == 0, "DSIG usFlag must be 0x1 or 0x0"
- self.signatureRecords = sigrecs = []
- for n in range(self.usNumSigs):
- sigrec, newData = sstruct.unpack2(
- DSIG_SignatureFormat, newData, SignatureRecord()
- )
- assert sigrec.ulFormat == 1, (
- "DSIG signature record #%d ulFormat must be 1" % n
- )
- sigrecs.append(sigrec)
- for sigrec in sigrecs:
- dummy, newData = sstruct.unpack2(
- DSIG_SignatureBlockFormat, data[sigrec.ulOffset :], sigrec
- )
- assert sigrec.usReserved1 == 0, (
- "DSIG signature record #%d usReserverd1 must be 0" % n
- )
- assert sigrec.usReserved2 == 0, (
- "DSIG signature record #%d usReserverd2 must be 0" % n
- )
- sigrec.pkcs7 = newData[: sigrec.cbSignature]
-
- def compile(self, ttFont):
- packed = sstruct.pack(DSIG_HeaderFormat, self)
- headers = [packed]
- offset = len(packed) + self.usNumSigs * sstruct.calcsize(DSIG_SignatureFormat)
- data = []
- for sigrec in self.signatureRecords:
- # first pack signature block
- sigrec.cbSignature = len(sigrec.pkcs7)
- packed = sstruct.pack(DSIG_SignatureBlockFormat, sigrec) + sigrec.pkcs7
- data.append(packed)
- # update redundant length field
- sigrec.ulLength = len(packed)
- # update running table offset
- sigrec.ulOffset = offset
- headers.append(sstruct.pack(DSIG_SignatureFormat, sigrec))
- offset += sigrec.ulLength
- if offset % 2:
- # Pad to even bytes
- data.append(b"\0")
- return bytesjoin(headers + data)
-
- def toXML(self, xmlWriter, ttFont):
- xmlWriter.comment(
- "note that the Digital Signature will be invalid after recompilation!"
- )
- xmlWriter.newline()
- xmlWriter.simpletag(
- "tableHeader",
- version=self.ulVersion,
- numSigs=self.usNumSigs,
- flag="0x%X" % self.usFlag,
- )
- for sigrec in self.signatureRecords:
- xmlWriter.newline()
- sigrec.toXML(xmlWriter, ttFont)
- xmlWriter.newline()
-
- def fromXML(self, name, attrs, content, ttFont):
- if name == "tableHeader":
- self.signatureRecords = []
- self.ulVersion = safeEval(attrs["version"])
- self.usNumSigs = safeEval(attrs["numSigs"])
- self.usFlag = safeEval(attrs["flag"])
- return
- if name == "SignatureRecord":
- sigrec = SignatureRecord()
- sigrec.fromXML(name, attrs, content, ttFont)
- self.signatureRecords.append(sigrec)
-
-
-pem_spam = lambda l, spam={
- "-----BEGIN PKCS7-----": True,
- "-----END PKCS7-----": True,
- "": True,
-}: not spam.get(l.strip())
-
-
-def b64encode(b):
- s = base64.b64encode(b)
- # Line-break at 76 chars.
- items = []
- while s:
- items.append(tostr(s[:76]))
- items.append("\n")
- s = s[76:]
- return strjoin(items)
-
-
-class SignatureRecord(object):
- def __repr__(self):
- return "<%s: %s>" % (self.__class__.__name__, self.__dict__)
-
- def toXML(self, writer, ttFont):
- writer.begintag(self.__class__.__name__, format=self.ulFormat)
- writer.newline()
- writer.write_noindent("-----BEGIN PKCS7-----\n")
- writer.write_noindent(b64encode(self.pkcs7))
- writer.write_noindent("-----END PKCS7-----\n")
- writer.endtag(self.__class__.__name__)
-
- def fromXML(self, name, attrs, content, ttFont):
- self.ulFormat = safeEval(attrs["format"])
- self.usReserved1 = safeEval(attrs.get("reserved1", "0"))
- self.usReserved2 = safeEval(attrs.get("reserved2", "0"))
- self.pkcs7 = base64.b64decode(tobytes(strjoin(filter(pem_spam, content))))
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/matplotlib/quiver.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/matplotlib/quiver.py
deleted file mode 100644
index c8f8ba566106d3dc6eba860bc9c00749610d147a..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/matplotlib/quiver.py
+++ /dev/null
@@ -1,1181 +0,0 @@
-"""
-Support for plotting vector fields.
-
-Presently this contains Quiver and Barb. Quiver plots an arrow in the
-direction of the vector, with the size of the arrow related to the
-magnitude of the vector.
-
-Barbs are like quiver in that they point along a vector, but
-the magnitude of the vector is given schematically by the presence of barbs
-or flags on the barb.
-
-This will also become a home for things such as standard
-deviation ellipses, which can and will be derived very easily from
-the Quiver code.
-"""
-
-import math
-
-import numpy as np
-from numpy import ma
-
-from matplotlib import _api, cbook, _docstring
-import matplotlib.artist as martist
-import matplotlib.collections as mcollections
-from matplotlib.patches import CirclePolygon
-import matplotlib.text as mtext
-import matplotlib.transforms as transforms
-
-
-_quiver_doc = """
-Plot a 2D field of arrows.
-
-Call signature::
-
- quiver([X, Y], U, V, [C], **kwargs)
-
-*X*, *Y* define the arrow locations, *U*, *V* define the arrow directions, and
-*C* optionally sets the color.
-
-**Arrow length**
-
-The default settings auto-scales the length of the arrows to a reasonable size.
-To change this behavior see the *scale* and *scale_units* parameters.
-
-**Arrow shape**
-
-The arrow shape is determined by *width*, *headwidth*, *headlength* and
-*headaxislength*. See the notes below.
-
-**Arrow styling**
-
-Each arrow is internally represented by a filled polygon with a default edge
-linewidth of 0. As a result, an arrow is rather a filled area, not a line with
-a head, and `.PolyCollection` properties like *linewidth*, *edgecolor*,
-*facecolor*, etc. act accordingly.
-
-
-Parameters
-----------
-X, Y : 1D or 2D array-like, optional
- The x and y coordinates of the arrow locations.
-
- If not given, they will be generated as a uniform integer meshgrid based
- on the dimensions of *U* and *V*.
-
- If *X* and *Y* are 1D but *U*, *V* are 2D, *X*, *Y* are expanded to 2D
- using ``X, Y = np.meshgrid(X, Y)``. In this case ``len(X)`` and ``len(Y)``
- must match the column and row dimensions of *U* and *V*.
-
-U, V : 1D or 2D array-like
- The x and y direction components of the arrow vectors. The interpretation
- of these components (in data or in screen space) depends on *angles*.
-
- *U* and *V* must have the same number of elements, matching the number of
- arrow locations in *X*, *Y*. *U* and *V* may be masked. Locations masked
- in any of *U*, *V*, and *C* will not be drawn.
-
-C : 1D or 2D array-like, optional
- Numeric data that defines the arrow colors by colormapping via *norm* and
- *cmap*.
-
- This does not support explicit colors. If you want to set colors directly,
- use *color* instead. The size of *C* must match the number of arrow
- locations.
-
-angles : {'uv', 'xy'} or array-like, default: 'uv'
- Method for determining the angle of the arrows.
-
- - 'uv': Arrow direction in screen coordinates. Use this if the arrows
- symbolize a quantity that is not based on *X*, *Y* data coordinates.
-
- If *U* == *V* the orientation of the arrow on the plot is 45 degrees
- counter-clockwise from the horizontal axis (positive to the right).
-
- - 'xy': Arrow direction in data coordinates, i.e. the arrows point from
- (x, y) to (x+u, y+v). Use this e.g. for plotting a gradient field.
-
- - Arbitrary angles may be specified explicitly as an array of values
- in degrees, counter-clockwise from the horizontal axis.
-
- In this case *U*, *V* is only used to determine the length of the
- arrows.
-
- Note: inverting a data axis will correspondingly invert the
- arrows only with ``angles='xy'``.
-
-pivot : {'tail', 'mid', 'middle', 'tip'}, default: 'tail'
- The part of the arrow that is anchored to the *X*, *Y* grid. The arrow
- rotates about this point.
-
- 'mid' is a synonym for 'middle'.
-
-scale : float, optional
- Scales the length of the arrow inversely.
-
- Number of data units per arrow length unit, e.g., m/s per plot width; a
- smaller scale parameter makes the arrow longer. Default is *None*.
-
- If *None*, a simple autoscaling algorithm is used, based on the average
- vector length and the number of vectors. The arrow length unit is given by
- the *scale_units* parameter.
-
-scale_units : {'width', 'height', 'dots', 'inches', 'x', 'y', 'xy'}, optional
- If the *scale* kwarg is *None*, the arrow length unit. Default is *None*.
-
- e.g. *scale_units* is 'inches', *scale* is 2.0, and ``(u, v) = (1, 0)``,
- then the vector will be 0.5 inches long.
-
- If *scale_units* is 'width' or 'height', then the vector will be half the
- width/height of the axes.
-
- If *scale_units* is 'x' then the vector will be 0.5 x-axis
- units. To plot vectors in the x-y plane, with u and v having
- the same units as x and y, use
- ``angles='xy', scale_units='xy', scale=1``.
-
-units : {'width', 'height', 'dots', 'inches', 'x', 'y', 'xy'}, default: 'width'
- Affects the arrow size (except for the length). In particular, the shaft
- *width* is measured in multiples of this unit.
-
- Supported values are:
-
- - 'width', 'height': The width or height of the Axes.
- - 'dots', 'inches': Pixels or inches based on the figure dpi.
- - 'x', 'y', 'xy': *X*, *Y* or :math:`\\sqrt{X^2 + Y^2}` in data units.
-
- The following table summarizes how these values affect the visible arrow
- size under zooming and figure size changes:
-
- ================= ================= ==================
- units zoom figure size change
- ================= ================= ==================
- 'x', 'y', 'xy' arrow size scales —
- 'width', 'height' — arrow size scales
- 'dots', 'inches' — —
- ================= ================= ==================
-
-width : float, optional
- Shaft width in arrow units. All head parameters are relative to *width*.
-
- The default depends on choice of *units* above, and number of vectors;
- a typical starting value is about 0.005 times the width of the plot.
-
-headwidth : float, default: 3
- Head width as multiple of shaft *width*. See the notes below.
-
-headlength : float, default: 5
- Head length as multiple of shaft *width*. See the notes below.
-
-headaxislength : float, default: 4.5
- Head length at shaft intersection as multiple of shaft *width*.
- See the notes below.
-
-minshaft : float, default: 1
- Length below which arrow scales, in units of head length. Do not
- set this to less than 1, or small arrows will look terrible!
-
-minlength : float, default: 1
- Minimum length as a multiple of shaft width; if an arrow length
- is less than this, plot a dot (hexagon) of this diameter instead.
-
-color : color or color sequence, optional
- Explicit color(s) for the arrows. If *C* has been set, *color* has no
- effect.
-
- This is a synonym for the `.PolyCollection` *facecolor* parameter.
-
-Other Parameters
-----------------
-data : indexable object, optional
- DATA_PARAMETER_PLACEHOLDER
-
-**kwargs : `~matplotlib.collections.PolyCollection` properties, optional
- All other keyword arguments are passed on to `.PolyCollection`:
-
- %(PolyCollection:kwdoc)s
-
-Returns
--------
-`~matplotlib.quiver.Quiver`
-
-See Also
---------
-.Axes.quiverkey : Add a key to a quiver plot.
-
-Notes
------
-
-**Arrow shape**
-
-The arrow is drawn as a polygon using the nodes as shown below. The values
-*headwidth*, *headlength*, and *headaxislength* are in units of *width*.
-
-.. image:: /_static/quiver_sizes.svg
- :width: 500px
-
-The defaults give a slightly swept-back arrow. Here are some guidelines how to
-get other head shapes:
-
-- To make the head a triangle, make *headaxislength* the same as *headlength*.
-- To make the arrow more pointed, reduce *headwidth* or increase *headlength*
- and *headaxislength*.
-- To make the head smaller relative to the shaft, scale down all the head
- parameters proportionally.
-- To remove the head completely, set all *head* parameters to 0.
-- To get a diamond-shaped head, make *headaxislength* larger than *headlength*.
-- Warning: For *headaxislength* < (*headlength* / *headwidth*), the "headaxis"
- nodes (i.e. the ones connecting the head with the shaft) will protrude out
- of the head in forward direction so that the arrow head looks broken.
-""" % _docstring.interpd.params
-
-_docstring.interpd.update(quiver_doc=_quiver_doc)
-
-
-class QuiverKey(martist.Artist):
- """Labelled arrow for use as a quiver plot scale key."""
- halign = {'N': 'center', 'S': 'center', 'E': 'left', 'W': 'right'}
- valign = {'N': 'bottom', 'S': 'top', 'E': 'center', 'W': 'center'}
- pivot = {'N': 'middle', 'S': 'middle', 'E': 'tip', 'W': 'tail'}
-
- def __init__(self, Q, X, Y, U, label,
- *, angle=0, coordinates='axes', color=None, labelsep=0.1,
- labelpos='N', labelcolor=None, fontproperties=None, **kwargs):
- """
- Add a key to a quiver plot.
-
- The positioning of the key depends on *X*, *Y*, *coordinates*, and
- *labelpos*. If *labelpos* is 'N' or 'S', *X*, *Y* give the position of
- the middle of the key arrow. If *labelpos* is 'E', *X*, *Y* positions
- the head, and if *labelpos* is 'W', *X*, *Y* positions the tail; in
- either of these two cases, *X*, *Y* is somewhere in the middle of the
- arrow+label key object.
-
- Parameters
- ----------
- Q : `~matplotlib.quiver.Quiver`
- A `.Quiver` object as returned by a call to `~.Axes.quiver()`.
- X, Y : float
- The location of the key.
- U : float
- The length of the key.
- label : str
- The key label (e.g., length and units of the key).
- angle : float, default: 0
- The angle of the key arrow, in degrees anti-clockwise from the
- x-axis.
- coordinates : {'axes', 'figure', 'data', 'inches'}, default: 'axes'
- Coordinate system and units for *X*, *Y*: 'axes' and 'figure' are
- normalized coordinate systems with (0, 0) in the lower left and
- (1, 1) in the upper right; 'data' are the axes data coordinates
- (used for the locations of the vectors in the quiver plot itself);
- 'inches' is position in the figure in inches, with (0, 0) at the
- lower left corner.
- color : color
- Overrides face and edge colors from *Q*.
- labelpos : {'N', 'S', 'E', 'W'}
- Position the label above, below, to the right, to the left of the
- arrow, respectively.
- labelsep : float, default: 0.1
- Distance in inches between the arrow and the label.
- labelcolor : color, default: :rc:`text.color`
- Label color.
- fontproperties : dict, optional
- A dictionary with keyword arguments accepted by the
- `~matplotlib.font_manager.FontProperties` initializer:
- *family*, *style*, *variant*, *size*, *weight*.
- **kwargs
- Any additional keyword arguments are used to override vector
- properties taken from *Q*.
- """
- super().__init__()
- self.Q = Q
- self.X = X
- self.Y = Y
- self.U = U
- self.angle = angle
- self.coord = coordinates
- self.color = color
- self.label = label
- self._labelsep_inches = labelsep
-
- self.labelpos = labelpos
- self.labelcolor = labelcolor
- self.fontproperties = fontproperties or dict()
- self.kw = kwargs
- self.text = mtext.Text(
- text=label,
- horizontalalignment=self.halign[self.labelpos],
- verticalalignment=self.valign[self.labelpos],
- fontproperties=self.fontproperties)
- if self.labelcolor is not None:
- self.text.set_color(self.labelcolor)
- self._dpi_at_last_init = None
- self.zorder = Q.zorder + 0.1
-
- @property
- def labelsep(self):
- return self._labelsep_inches * self.Q.axes.figure.dpi
-
- def _init(self):
- if True: # self._dpi_at_last_init != self.axes.figure.dpi
- if self.Q._dpi_at_last_init != self.Q.axes.figure.dpi:
- self.Q._init()
- self._set_transform()
- with cbook._setattr_cm(self.Q, pivot=self.pivot[self.labelpos],
- # Hack: save and restore the Umask
- Umask=ma.nomask):
- u = self.U * np.cos(np.radians(self.angle))
- v = self.U * np.sin(np.radians(self.angle))
- angle = (self.Q.angles if isinstance(self.Q.angles, str)
- else 'uv')
- self.verts = self.Q._make_verts(
- np.array([u]), np.array([v]), angle)
- kwargs = self.Q.polykw
- kwargs.update(self.kw)
- self.vector = mcollections.PolyCollection(
- self.verts,
- offsets=[(self.X, self.Y)],
- offset_transform=self.get_transform(),
- **kwargs)
- if self.color is not None:
- self.vector.set_color(self.color)
- self.vector.set_transform(self.Q.get_transform())
- self.vector.set_figure(self.get_figure())
- self._dpi_at_last_init = self.Q.axes.figure.dpi
-
- def _text_shift(self):
- return {
- "N": (0, +self.labelsep),
- "S": (0, -self.labelsep),
- "E": (+self.labelsep, 0),
- "W": (-self.labelsep, 0),
- }[self.labelpos]
-
- @martist.allow_rasterization
- def draw(self, renderer):
- self._init()
- self.vector.draw(renderer)
- pos = self.get_transform().transform((self.X, self.Y))
- self.text.set_position(pos + self._text_shift())
- self.text.draw(renderer)
- self.stale = False
-
- def _set_transform(self):
- self.set_transform(_api.check_getitem({
- "data": self.Q.axes.transData,
- "axes": self.Q.axes.transAxes,
- "figure": self.Q.axes.figure.transFigure,
- "inches": self.Q.axes.figure.dpi_scale_trans,
- }, coordinates=self.coord))
-
- def set_figure(self, fig):
- super().set_figure(fig)
- self.text.set_figure(fig)
-
- def contains(self, mouseevent):
- if self._different_canvas(mouseevent):
- return False, {}
- # Maybe the dictionary should allow one to
- # distinguish between a text hit and a vector hit.
- if (self.text.contains(mouseevent)[0] or
- self.vector.contains(mouseevent)[0]):
- return True, {}
- return False, {}
-
-
-def _parse_args(*args, caller_name='function'):
- """
- Helper function to parse positional parameters for colored vector plots.
-
- This is currently used for Quiver and Barbs.
-
- Parameters
- ----------
- *args : list
- list of 2-5 arguments. Depending on their number they are parsed to::
-
- U, V
- U, V, C
- X, Y, U, V
- X, Y, U, V, C
-
- caller_name : str
- Name of the calling method (used in error messages).
- """
- X = Y = C = None
-
- nargs = len(args)
- if nargs == 2:
- # The use of atleast_1d allows for handling scalar arguments while also
- # keeping masked arrays
- U, V = np.atleast_1d(*args)
- elif nargs == 3:
- U, V, C = np.atleast_1d(*args)
- elif nargs == 4:
- X, Y, U, V = np.atleast_1d(*args)
- elif nargs == 5:
- X, Y, U, V, C = np.atleast_1d(*args)
- else:
- raise _api.nargs_error(caller_name, takes="from 2 to 5", given=nargs)
-
- nr, nc = (1, U.shape[0]) if U.ndim == 1 else U.shape
-
- if X is not None:
- X = X.ravel()
- Y = Y.ravel()
- if len(X) == nc and len(Y) == nr:
- X, Y = [a.ravel() for a in np.meshgrid(X, Y)]
- elif len(X) != len(Y):
- raise ValueError('X and Y must be the same size, but '
- f'X.size is {X.size} and Y.size is {Y.size}.')
- else:
- indexgrid = np.meshgrid(np.arange(nc), np.arange(nr))
- X, Y = [np.ravel(a) for a in indexgrid]
- # Size validation for U, V, C is left to the set_UVC method.
- return X, Y, U, V, C
-
-
-def _check_consistent_shapes(*arrays):
- all_shapes = {a.shape for a in arrays}
- if len(all_shapes) != 1:
- raise ValueError('The shapes of the passed in arrays do not match')
-
-
-class Quiver(mcollections.PolyCollection):
- """
- Specialized PolyCollection for arrows.
-
- The only API method is set_UVC(), which can be used
- to change the size, orientation, and color of the
- arrows; their locations are fixed when the class is
- instantiated. Possibly this method will be useful
- in animations.
-
- Much of the work in this class is done in the draw()
- method so that as much information as possible is available
- about the plot. In subsequent draw() calls, recalculation
- is limited to things that might have changed, so there
- should be no performance penalty from putting the calculations
- in the draw() method.
- """
-
- _PIVOT_VALS = ('tail', 'middle', 'tip')
-
- @_docstring.Substitution(_quiver_doc)
- def __init__(self, ax, *args,
- scale=None, headwidth=3, headlength=5, headaxislength=4.5,
- minshaft=1, minlength=1, units='width', scale_units=None,
- angles='uv', width=None, color='k', pivot='tail', **kwargs):
- """
- The constructor takes one required argument, an Axes
- instance, followed by the args and kwargs described
- by the following pyplot interface documentation:
- %s
- """
- self._axes = ax # The attr actually set by the Artist.axes property.
- X, Y, U, V, C = _parse_args(*args, caller_name='quiver')
- self.X = X
- self.Y = Y
- self.XY = np.column_stack((X, Y))
- self.N = len(X)
- self.scale = scale
- self.headwidth = headwidth
- self.headlength = float(headlength)
- self.headaxislength = headaxislength
- self.minshaft = minshaft
- self.minlength = minlength
- self.units = units
- self.scale_units = scale_units
- self.angles = angles
- self.width = width
-
- if pivot.lower() == 'mid':
- pivot = 'middle'
- self.pivot = pivot.lower()
- _api.check_in_list(self._PIVOT_VALS, pivot=self.pivot)
-
- self.transform = kwargs.pop('transform', ax.transData)
- kwargs.setdefault('facecolors', color)
- kwargs.setdefault('linewidths', (0,))
- super().__init__([], offsets=self.XY, offset_transform=self.transform,
- closed=False, **kwargs)
- self.polykw = kwargs
- self.set_UVC(U, V, C)
- self._dpi_at_last_init = None
-
- def _init(self):
- """
- Initialization delayed until first draw;
- allow time for axes setup.
- """
- # It seems that there are not enough event notifications
- # available to have this work on an as-needed basis at present.
- if True: # self._dpi_at_last_init != self.axes.figure.dpi
- trans = self._set_transform()
- self.span = trans.inverted().transform_bbox(self.axes.bbox).width
- if self.width is None:
- sn = np.clip(math.sqrt(self.N), 8, 25)
- self.width = 0.06 * self.span / sn
-
- # _make_verts sets self.scale if not already specified
- if (self._dpi_at_last_init != self.axes.figure.dpi
- and self.scale is None):
- self._make_verts(self.U, self.V, self.angles)
-
- self._dpi_at_last_init = self.axes.figure.dpi
-
- def get_datalim(self, transData):
- trans = self.get_transform()
- offset_trf = self.get_offset_transform()
- full_transform = (trans - transData) + (offset_trf - transData)
- XY = full_transform.transform(self.XY)
- bbox = transforms.Bbox.null()
- bbox.update_from_data_xy(XY, ignore=True)
- return bbox
-
- @martist.allow_rasterization
- def draw(self, renderer):
- self._init()
- verts = self._make_verts(self.U, self.V, self.angles)
- self.set_verts(verts, closed=False)
- super().draw(renderer)
- self.stale = False
-
- def set_UVC(self, U, V, C=None):
- # We need to ensure we have a copy, not a reference
- # to an array that might change before draw().
- U = ma.masked_invalid(U, copy=True).ravel()
- V = ma.masked_invalid(V, copy=True).ravel()
- if C is not None:
- C = ma.masked_invalid(C, copy=True).ravel()
- for name, var in zip(('U', 'V', 'C'), (U, V, C)):
- if not (var is None or var.size == self.N or var.size == 1):
- raise ValueError(f'Argument {name} has a size {var.size}'
- f' which does not match {self.N},'
- ' the number of arrow positions')
-
- mask = ma.mask_or(U.mask, V.mask, copy=False, shrink=True)
- if C is not None:
- mask = ma.mask_or(mask, C.mask, copy=False, shrink=True)
- if mask is ma.nomask:
- C = C.filled()
- else:
- C = ma.array(C, mask=mask, copy=False)
- self.U = U.filled(1)
- self.V = V.filled(1)
- self.Umask = mask
- if C is not None:
- self.set_array(C)
- self.stale = True
-
- def _dots_per_unit(self, units):
- """Return a scale factor for converting from units to pixels."""
- bb = self.axes.bbox
- vl = self.axes.viewLim
- return _api.check_getitem({
- 'x': bb.width / vl.width,
- 'y': bb.height / vl.height,
- 'xy': np.hypot(*bb.size) / np.hypot(*vl.size),
- 'width': bb.width,
- 'height': bb.height,
- 'dots': 1.,
- 'inches': self.axes.figure.dpi,
- }, units=units)
-
- def _set_transform(self):
- """
- Set the PolyCollection transform to go
- from arrow width units to pixels.
- """
- dx = self._dots_per_unit(self.units)
- self._trans_scale = dx # pixels per arrow width unit
- trans = transforms.Affine2D().scale(dx)
- self.set_transform(trans)
- return trans
-
- def _angles_lengths(self, U, V, eps=1):
- xy = self.axes.transData.transform(self.XY)
- uv = np.column_stack((U, V))
- xyp = self.axes.transData.transform(self.XY + eps * uv)
- dxy = xyp - xy
- angles = np.arctan2(dxy[:, 1], dxy[:, 0])
- lengths = np.hypot(*dxy.T) / eps
- return angles, lengths
-
- def _make_verts(self, U, V, angles):
- uv = (U + V * 1j)
- str_angles = angles if isinstance(angles, str) else ''
- if str_angles == 'xy' and self.scale_units == 'xy':
- # Here eps is 1 so that if we get U, V by diffing
- # the X, Y arrays, the vectors will connect the
- # points, regardless of the axis scaling (including log).
- angles, lengths = self._angles_lengths(U, V, eps=1)
- elif str_angles == 'xy' or self.scale_units == 'xy':
- # Calculate eps based on the extents of the plot
- # so that we don't end up with roundoff error from
- # adding a small number to a large.
- eps = np.abs(self.axes.dataLim.extents).max() * 0.001
- angles, lengths = self._angles_lengths(U, V, eps=eps)
- if str_angles and self.scale_units == 'xy':
- a = lengths
- else:
- a = np.abs(uv)
- if self.scale is None:
- sn = max(10, math.sqrt(self.N))
- if self.Umask is not ma.nomask:
- amean = a[~self.Umask].mean()
- else:
- amean = a.mean()
- # crude auto-scaling
- # scale is typical arrow length as a multiple of the arrow width
- scale = 1.8 * amean * sn / self.span
- if self.scale_units is None:
- if self.scale is None:
- self.scale = scale
- widthu_per_lenu = 1.0
- else:
- if self.scale_units == 'xy':
- dx = 1
- else:
- dx = self._dots_per_unit(self.scale_units)
- widthu_per_lenu = dx / self._trans_scale
- if self.scale is None:
- self.scale = scale * widthu_per_lenu
- length = a * (widthu_per_lenu / (self.scale * self.width))
- X, Y = self._h_arrows(length)
- if str_angles == 'xy':
- theta = angles
- elif str_angles == 'uv':
- theta = np.angle(uv)
- else:
- theta = ma.masked_invalid(np.deg2rad(angles)).filled(0)
- theta = theta.reshape((-1, 1)) # for broadcasting
- xy = (X + Y * 1j) * np.exp(1j * theta) * self.width
- XY = np.stack((xy.real, xy.imag), axis=2)
- if self.Umask is not ma.nomask:
- XY = ma.array(XY)
- XY[self.Umask] = ma.masked
- # This might be handled more efficiently with nans, given
- # that nans will end up in the paths anyway.
-
- return XY
-
- def _h_arrows(self, length):
- """Length is in arrow width units."""
- # It might be possible to streamline the code
- # and speed it up a bit by using complex (x, y)
- # instead of separate arrays; but any gain would be slight.
- minsh = self.minshaft * self.headlength
- N = len(length)
- length = length.reshape(N, 1)
- # This number is chosen based on when pixel values overflow in Agg
- # causing rendering errors
- # length = np.minimum(length, 2 ** 16)
- np.clip(length, 0, 2 ** 16, out=length)
- # x, y: normal horizontal arrow
- x = np.array([0, -self.headaxislength,
- -self.headlength, 0],
- np.float64)
- x = x + np.array([0, 1, 1, 1]) * length
- y = 0.5 * np.array([1, 1, self.headwidth, 0], np.float64)
- y = np.repeat(y[np.newaxis, :], N, axis=0)
- # x0, y0: arrow without shaft, for short vectors
- x0 = np.array([0, minsh - self.headaxislength,
- minsh - self.headlength, minsh], np.float64)
- y0 = 0.5 * np.array([1, 1, self.headwidth, 0], np.float64)
- ii = [0, 1, 2, 3, 2, 1, 0, 0]
- X = x[:, ii]
- Y = y[:, ii]
- Y[:, 3:-1] *= -1
- X0 = x0[ii]
- Y0 = y0[ii]
- Y0[3:-1] *= -1
- shrink = length / minsh if minsh != 0. else 0.
- X0 = shrink * X0[np.newaxis, :]
- Y0 = shrink * Y0[np.newaxis, :]
- short = np.repeat(length < minsh, 8, axis=1)
- # Now select X0, Y0 if short, otherwise X, Y
- np.copyto(X, X0, where=short)
- np.copyto(Y, Y0, where=short)
- if self.pivot == 'middle':
- X -= 0.5 * X[:, 3, np.newaxis]
- elif self.pivot == 'tip':
- # numpy bug? using -= does not work here unless we multiply by a
- # float first, as with 'mid'.
- X = X - X[:, 3, np.newaxis]
- elif self.pivot != 'tail':
- _api.check_in_list(["middle", "tip", "tail"], pivot=self.pivot)
-
- tooshort = length < self.minlength
- if tooshort.any():
- # Use a heptagonal dot:
- th = np.arange(0, 8, 1, np.float64) * (np.pi / 3.0)
- x1 = np.cos(th) * self.minlength * 0.5
- y1 = np.sin(th) * self.minlength * 0.5
- X1 = np.repeat(x1[np.newaxis, :], N, axis=0)
- Y1 = np.repeat(y1[np.newaxis, :], N, axis=0)
- tooshort = np.repeat(tooshort, 8, 1)
- np.copyto(X, X1, where=tooshort)
- np.copyto(Y, Y1, where=tooshort)
- # Mask handling is deferred to the caller, _make_verts.
- return X, Y
-
- quiver_doc = _api.deprecated("3.7")(property(lambda self: _quiver_doc))
-
-
-_barbs_doc = r"""
-Plot a 2D field of barbs.
-
-Call signature::
-
- barbs([X, Y], U, V, [C], **kwargs)
-
-Where *X*, *Y* define the barb locations, *U*, *V* define the barb
-directions, and *C* optionally sets the color.
-
-All arguments may be 1D or 2D. *U*, *V*, *C* may be masked arrays, but masked
-*X*, *Y* are not supported at present.
-
-Barbs are traditionally used in meteorology as a way to plot the speed
-and direction of wind observations, but can technically be used to
-plot any two dimensional vector quantity. As opposed to arrows, which
-give vector magnitude by the length of the arrow, the barbs give more
-quantitative information about the vector magnitude by putting slanted
-lines or a triangle for various increments in magnitude, as show
-schematically below::
-
- : /\ \
- : / \ \
- : / \ \ \
- : / \ \ \
- : ------------------------------
-
-The largest increment is given by a triangle (or "flag"). After those
-come full lines (barbs). The smallest increment is a half line. There
-is only, of course, ever at most 1 half line. If the magnitude is
-small and only needs a single half-line and no full lines or
-triangles, the half-line is offset from the end of the barb so that it
-can be easily distinguished from barbs with a single full line. The
-magnitude for the barb shown above would nominally be 65, using the
-standard increments of 50, 10, and 5.
-
-See also https://en.wikipedia.org/wiki/Wind_barb.
-
-Parameters
-----------
-X, Y : 1D or 2D array-like, optional
- The x and y coordinates of the barb locations. See *pivot* for how the
- barbs are drawn to the x, y positions.
-
- If not given, they will be generated as a uniform integer meshgrid based
- on the dimensions of *U* and *V*.
-
- If *X* and *Y* are 1D but *U*, *V* are 2D, *X*, *Y* are expanded to 2D
- using ``X, Y = np.meshgrid(X, Y)``. In this case ``len(X)`` and ``len(Y)``
- must match the column and row dimensions of *U* and *V*.
-
-U, V : 1D or 2D array-like
- The x and y components of the barb shaft.
-
-C : 1D or 2D array-like, optional
- Numeric data that defines the barb colors by colormapping via *norm* and
- *cmap*.
-
- This does not support explicit colors. If you want to set colors directly,
- use *barbcolor* instead.
-
-length : float, default: 7
- Length of the barb in points; the other parts of the barb
- are scaled against this.
-
-pivot : {'tip', 'middle'} or float, default: 'tip'
- The part of the arrow that is anchored to the *X*, *Y* grid. The barb
- rotates about this point. This can also be a number, which shifts the
- start of the barb that many points away from grid point.
-
-barbcolor : color or color sequence
- The color of all parts of the barb except for the flags. This parameter
- is analogous to the *edgecolor* parameter for polygons, which can be used
- instead. However this parameter will override facecolor.
-
-flagcolor : color or color sequence
- The color of any flags on the barb. This parameter is analogous to the
- *facecolor* parameter for polygons, which can be used instead. However,
- this parameter will override facecolor. If this is not set (and *C* has
- not either) then *flagcolor* will be set to match *barbcolor* so that the
- barb has a uniform color. If *C* has been set, *flagcolor* has no effect.
-
-sizes : dict, optional
- A dictionary of coefficients specifying the ratio of a given
- feature to the length of the barb. Only those values one wishes to
- override need to be included. These features include:
-
- - 'spacing' - space between features (flags, full/half barbs)
- - 'height' - height (distance from shaft to top) of a flag or full barb
- - 'width' - width of a flag, twice the width of a full barb
- - 'emptybarb' - radius of the circle used for low magnitudes
-
-fill_empty : bool, default: False
- Whether the empty barbs (circles) that are drawn should be filled with
- the flag color. If they are not filled, the center is transparent.
-
-rounding : bool, default: True
- Whether the vector magnitude should be rounded when allocating barb
- components. If True, the magnitude is rounded to the nearest multiple
- of the half-barb increment. If False, the magnitude is simply truncated
- to the next lowest multiple.
-
-barb_increments : dict, optional
- A dictionary of increments specifying values to associate with
- different parts of the barb. Only those values one wishes to
- override need to be included.
-
- - 'half' - half barbs (Default is 5)
- - 'full' - full barbs (Default is 10)
- - 'flag' - flags (default is 50)
-
-flip_barb : bool or array-like of bool, default: False
- Whether the lines and flags should point opposite to normal.
- Normal behavior is for the barbs and lines to point right (comes from wind
- barbs having these features point towards low pressure in the Northern
- Hemisphere).
-
- A single value is applied to all barbs. Individual barbs can be flipped by
- passing a bool array of the same size as *U* and *V*.
-
-Returns
--------
-barbs : `~matplotlib.quiver.Barbs`
-
-Other Parameters
-----------------
-data : indexable object, optional
- DATA_PARAMETER_PLACEHOLDER
-
-**kwargs
- The barbs can further be customized using `.PolyCollection` keyword
- arguments:
-
- %(PolyCollection:kwdoc)s
-""" % _docstring.interpd.params
-
-_docstring.interpd.update(barbs_doc=_barbs_doc)
-
-
-class Barbs(mcollections.PolyCollection):
- """
- Specialized PolyCollection for barbs.
-
- The only API method is :meth:`set_UVC`, which can be used to
- change the size, orientation, and color of the arrows. Locations
- are changed using the :meth:`set_offsets` collection method.
- Possibly this method will be useful in animations.
-
- There is one internal function :meth:`_find_tails` which finds
- exactly what should be put on the barb given the vector magnitude.
- From there :meth:`_make_barbs` is used to find the vertices of the
- polygon to represent the barb based on this information.
- """
-
- # This may be an abuse of polygons here to render what is essentially maybe
- # 1 triangle and a series of lines. It works fine as far as I can tell
- # however.
-
- @_docstring.interpd
- def __init__(self, ax, *args,
- pivot='tip', length=7, barbcolor=None, flagcolor=None,
- sizes=None, fill_empty=False, barb_increments=None,
- rounding=True, flip_barb=False, **kwargs):
- """
- The constructor takes one required argument, an Axes
- instance, followed by the args and kwargs described
- by the following pyplot interface documentation:
- %(barbs_doc)s
- """
- self.sizes = sizes or dict()
- self.fill_empty = fill_empty
- self.barb_increments = barb_increments or dict()
- self.rounding = rounding
- self.flip = np.atleast_1d(flip_barb)
- transform = kwargs.pop('transform', ax.transData)
- self._pivot = pivot
- self._length = length
-
- # Flagcolor and barbcolor provide convenience parameters for
- # setting the facecolor and edgecolor, respectively, of the barb
- # polygon. We also work here to make the flag the same color as the
- # rest of the barb by default
-
- if None in (barbcolor, flagcolor):
- kwargs['edgecolors'] = 'face'
- if flagcolor:
- kwargs['facecolors'] = flagcolor
- elif barbcolor:
- kwargs['facecolors'] = barbcolor
- else:
- # Set to facecolor passed in or default to black
- kwargs.setdefault('facecolors', 'k')
- else:
- kwargs['edgecolors'] = barbcolor
- kwargs['facecolors'] = flagcolor
-
- # Explicitly set a line width if we're not given one, otherwise
- # polygons are not outlined and we get no barbs
- if 'linewidth' not in kwargs and 'lw' not in kwargs:
- kwargs['linewidth'] = 1
-
- # Parse out the data arrays from the various configurations supported
- x, y, u, v, c = _parse_args(*args, caller_name='barbs')
- self.x = x
- self.y = y
- xy = np.column_stack((x, y))
-
- # Make a collection
- barb_size = self._length ** 2 / 4 # Empirically determined
- super().__init__(
- [], (barb_size,), offsets=xy, offset_transform=transform, **kwargs)
- self.set_transform(transforms.IdentityTransform())
-
- self.set_UVC(u, v, c)
-
- def _find_tails(self, mag, rounding=True, half=5, full=10, flag=50):
- """
- Find how many of each of the tail pieces is necessary.
-
- Parameters
- ----------
- mag : `~numpy.ndarray`
- Vector magnitudes; must be non-negative (and an actual ndarray).
- rounding : bool, default: True
- Whether to round or to truncate to the nearest half-barb.
- half, full, flag : float, defaults: 5, 10, 50
- Increments for a half-barb, a barb, and a flag.
-
- Returns
- -------
- n_flags, n_barbs : int array
- For each entry in *mag*, the number of flags and barbs.
- half_flag : bool array
- For each entry in *mag*, whether a half-barb is needed.
- empty_flag : bool array
- For each entry in *mag*, whether nothing is drawn.
- """
- # If rounding, round to the nearest multiple of half, the smallest
- # increment
- if rounding:
- mag = half * np.around(mag / half)
- n_flags, mag = divmod(mag, flag)
- n_barb, mag = divmod(mag, full)
- half_flag = mag >= half
- empty_flag = ~(half_flag | (n_flags > 0) | (n_barb > 0))
- return n_flags.astype(int), n_barb.astype(int), half_flag, empty_flag
-
- def _make_barbs(self, u, v, nflags, nbarbs, half_barb, empty_flag, length,
- pivot, sizes, fill_empty, flip):
- """
- Create the wind barbs.
-
- Parameters
- ----------
- u, v
- Components of the vector in the x and y directions, respectively.
-
- nflags, nbarbs, half_barb, empty_flag
- Respectively, the number of flags, number of barbs, flag for
- half a barb, and flag for empty barb, ostensibly obtained from
- :meth:`_find_tails`.
-
- length
- The length of the barb staff in points.
-
- pivot : {"tip", "middle"} or number
- The point on the barb around which the entire barb should be
- rotated. If a number, the start of the barb is shifted by that
- many points from the origin.
-
- sizes : dict
- Coefficients specifying the ratio of a given feature to the length
- of the barb. These features include:
-
- - *spacing*: space between features (flags, full/half barbs).
- - *height*: distance from shaft of top of a flag or full barb.
- - *width*: width of a flag, twice the width of a full barb.
- - *emptybarb*: radius of the circle used for low magnitudes.
-
- fill_empty : bool
- Whether the circle representing an empty barb should be filled or
- not (this changes the drawing of the polygon).
-
- flip : list of bool
- Whether the features should be flipped to the other side of the
- barb (useful for winds in the southern hemisphere).
-
- Returns
- -------
- list of arrays of vertices
- Polygon vertices for each of the wind barbs. These polygons have
- been rotated to properly align with the vector direction.
- """
-
- # These control the spacing and size of barb elements relative to the
- # length of the shaft
- spacing = length * sizes.get('spacing', 0.125)
- full_height = length * sizes.get('height', 0.4)
- full_width = length * sizes.get('width', 0.25)
- empty_rad = length * sizes.get('emptybarb', 0.15)
-
- # Controls y point where to pivot the barb.
- pivot_points = dict(tip=0.0, middle=-length / 2.)
-
- endx = 0.0
- try:
- endy = float(pivot)
- except ValueError:
- endy = pivot_points[pivot.lower()]
-
- # Get the appropriate angle for the vector components. The offset is
- # due to the way the barb is initially drawn, going down the y-axis.
- # This makes sense in a meteorological mode of thinking since there 0
- # degrees corresponds to north (the y-axis traditionally)
- angles = -(ma.arctan2(v, u) + np.pi / 2)
-
- # Used for low magnitude. We just get the vertices, so if we make it
- # out here, it can be reused. The center set here should put the
- # center of the circle at the location(offset), rather than at the
- # same point as the barb pivot; this seems more sensible.
- circ = CirclePolygon((0, 0), radius=empty_rad).get_verts()
- if fill_empty:
- empty_barb = circ
- else:
- # If we don't want the empty one filled, we make a degenerate
- # polygon that wraps back over itself
- empty_barb = np.concatenate((circ, circ[::-1]))
-
- barb_list = []
- for index, angle in np.ndenumerate(angles):
- # If the vector magnitude is too weak to draw anything, plot an
- # empty circle instead
- if empty_flag[index]:
- # We can skip the transform since the circle has no preferred
- # orientation
- barb_list.append(empty_barb)
- continue
-
- poly_verts = [(endx, endy)]
- offset = length
-
- # Handle if this barb should be flipped
- barb_height = -full_height if flip[index] else full_height
-
- # Add vertices for each flag
- for i in range(nflags[index]):
- # The spacing that works for the barbs is a little to much for
- # the flags, but this only occurs when we have more than 1
- # flag.
- if offset != length:
- offset += spacing / 2.
- poly_verts.extend(
- [[endx, endy + offset],
- [endx + barb_height, endy - full_width / 2 + offset],
- [endx, endy - full_width + offset]])
-
- offset -= full_width + spacing
-
- # Add vertices for each barb. These really are lines, but works
- # great adding 3 vertices that basically pull the polygon out and
- # back down the line
- for i in range(nbarbs[index]):
- poly_verts.extend(
- [(endx, endy + offset),
- (endx + barb_height, endy + offset + full_width / 2),
- (endx, endy + offset)])
-
- offset -= spacing
-
- # Add the vertices for half a barb, if needed
- if half_barb[index]:
- # If the half barb is the first on the staff, traditionally it
- # is offset from the end to make it easy to distinguish from a
- # barb with a full one
- if offset == length:
- poly_verts.append((endx, endy + offset))
- offset -= 1.5 * spacing
- poly_verts.extend(
- [(endx, endy + offset),
- (endx + barb_height / 2, endy + offset + full_width / 4),
- (endx, endy + offset)])
-
- # Rotate the barb according the angle. Making the barb first and
- # then rotating it made the math for drawing the barb really easy.
- # Also, the transform framework makes doing the rotation simple.
- poly_verts = transforms.Affine2D().rotate(-angle).transform(
- poly_verts)
- barb_list.append(poly_verts)
-
- return barb_list
-
- def set_UVC(self, U, V, C=None):
- # We need to ensure we have a copy, not a reference to an array that
- # might change before draw().
- self.u = ma.masked_invalid(U, copy=True).ravel()
- self.v = ma.masked_invalid(V, copy=True).ravel()
-
- # Flip needs to have the same number of entries as everything else.
- # Use broadcast_to to avoid a bloated array of identical values.
- # (can't rely on actual broadcasting)
- if len(self.flip) == 1:
- flip = np.broadcast_to(self.flip, self.u.shape)
- else:
- flip = self.flip
-
- if C is not None:
- c = ma.masked_invalid(C, copy=True).ravel()
- x, y, u, v, c, flip = cbook.delete_masked_points(
- self.x.ravel(), self.y.ravel(), self.u, self.v, c,
- flip.ravel())
- _check_consistent_shapes(x, y, u, v, c, flip)
- else:
- x, y, u, v, flip = cbook.delete_masked_points(
- self.x.ravel(), self.y.ravel(), self.u, self.v, flip.ravel())
- _check_consistent_shapes(x, y, u, v, flip)
-
- magnitude = np.hypot(u, v)
- flags, barbs, halves, empty = self._find_tails(
- magnitude, self.rounding, **self.barb_increments)
-
- # Get the vertices for each of the barbs
-
- plot_barbs = self._make_barbs(u, v, flags, barbs, halves, empty,
- self._length, self._pivot, self.sizes,
- self.fill_empty, flip)
- self.set_verts(plot_barbs)
-
- # Set the color array
- if C is not None:
- self.set_array(c)
-
- # Update the offsets in case the masked data changed
- xy = np.column_stack((x, y))
- self._offsets = xy
- self.stale = True
-
- def set_offsets(self, xy):
- """
- Set the offsets for the barb polygons. This saves the offsets passed
- in and masks them as appropriate for the existing U/V data.
-
- Parameters
- ----------
- xy : sequence of pairs of floats
- """
- self.x = xy[:, 0]
- self.y = xy[:, 1]
- x, y, u, v = cbook.delete_masked_points(
- self.x.ravel(), self.y.ravel(), self.u, self.v)
- _check_consistent_shapes(x, y, u, v)
- xy = np.column_stack((x, y))
- super().set_offsets(xy)
- self.stale = True
-
- barbs_doc = _api.deprecated("3.7")(property(lambda self: _barbs_doc))
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/core/_methods.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/core/_methods.py
deleted file mode 100644
index 0fc070b34c381ecdf8e8bb0d015bb799313a232e..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/core/_methods.py
+++ /dev/null
@@ -1,234 +0,0 @@
-"""
-Array methods which are called by both the C-code for the method
-and the Python code for the NumPy-namespace function
-
-"""
-import warnings
-from contextlib import nullcontext
-
-from numpy.core import multiarray as mu
-from numpy.core import umath as um
-from numpy.core.multiarray import asanyarray
-from numpy.core import numerictypes as nt
-from numpy.core import _exceptions
-from numpy.core._ufunc_config import _no_nep50_warning
-from numpy._globals import _NoValue
-from numpy.compat import pickle, os_fspath
-
-# save those O(100) nanoseconds!
-umr_maximum = um.maximum.reduce
-umr_minimum = um.minimum.reduce
-umr_sum = um.add.reduce
-umr_prod = um.multiply.reduce
-umr_any = um.logical_or.reduce
-umr_all = um.logical_and.reduce
-
-# Complex types to -> (2,)float view for fast-path computation in _var()
-_complex_to_float = {
- nt.dtype(nt.csingle) : nt.dtype(nt.single),
- nt.dtype(nt.cdouble) : nt.dtype(nt.double),
-}
-# Special case for windows: ensure double takes precedence
-if nt.dtype(nt.longdouble) != nt.dtype(nt.double):
- _complex_to_float.update({
- nt.dtype(nt.clongdouble) : nt.dtype(nt.longdouble),
- })
-
-# avoid keyword arguments to speed up parsing, saves about 15%-20% for very
-# small reductions
-def _amax(a, axis=None, out=None, keepdims=False,
- initial=_NoValue, where=True):
- return umr_maximum(a, axis, None, out, keepdims, initial, where)
-
-def _amin(a, axis=None, out=None, keepdims=False,
- initial=_NoValue, where=True):
- return umr_minimum(a, axis, None, out, keepdims, initial, where)
-
-def _sum(a, axis=None, dtype=None, out=None, keepdims=False,
- initial=_NoValue, where=True):
- return umr_sum(a, axis, dtype, out, keepdims, initial, where)
-
-def _prod(a, axis=None, dtype=None, out=None, keepdims=False,
- initial=_NoValue, where=True):
- return umr_prod(a, axis, dtype, out, keepdims, initial, where)
-
-def _any(a, axis=None, dtype=None, out=None, keepdims=False, *, where=True):
- # Parsing keyword arguments is currently fairly slow, so avoid it for now
- if where is True:
- return umr_any(a, axis, dtype, out, keepdims)
- return umr_any(a, axis, dtype, out, keepdims, where=where)
-
-def _all(a, axis=None, dtype=None, out=None, keepdims=False, *, where=True):
- # Parsing keyword arguments is currently fairly slow, so avoid it for now
- if where is True:
- return umr_all(a, axis, dtype, out, keepdims)
- return umr_all(a, axis, dtype, out, keepdims, where=where)
-
-def _count_reduce_items(arr, axis, keepdims=False, where=True):
- # fast-path for the default case
- if where is True:
- # no boolean mask given, calculate items according to axis
- if axis is None:
- axis = tuple(range(arr.ndim))
- elif not isinstance(axis, tuple):
- axis = (axis,)
- items = 1
- for ax in axis:
- items *= arr.shape[mu.normalize_axis_index(ax, arr.ndim)]
- items = nt.intp(items)
- else:
- # TODO: Optimize case when `where` is broadcast along a non-reduction
- # axis and full sum is more excessive than needed.
-
- # guarded to protect circular imports
- from numpy.lib.stride_tricks import broadcast_to
- # count True values in (potentially broadcasted) boolean mask
- items = umr_sum(broadcast_to(where, arr.shape), axis, nt.intp, None,
- keepdims)
- return items
-
-def _clip(a, min=None, max=None, out=None, **kwargs):
- if min is None and max is None:
- raise ValueError("One of max or min must be given")
-
- if min is None:
- return um.minimum(a, max, out=out, **kwargs)
- elif max is None:
- return um.maximum(a, min, out=out, **kwargs)
- else:
- return um.clip(a, min, max, out=out, **kwargs)
-
-def _mean(a, axis=None, dtype=None, out=None, keepdims=False, *, where=True):
- arr = asanyarray(a)
-
- is_float16_result = False
-
- rcount = _count_reduce_items(arr, axis, keepdims=keepdims, where=where)
- if rcount == 0 if where is True else umr_any(rcount == 0, axis=None):
- warnings.warn("Mean of empty slice.", RuntimeWarning, stacklevel=2)
-
- # Cast bool, unsigned int, and int to float64 by default
- if dtype is None:
- if issubclass(arr.dtype.type, (nt.integer, nt.bool_)):
- dtype = mu.dtype('f8')
- elif issubclass(arr.dtype.type, nt.float16):
- dtype = mu.dtype('f4')
- is_float16_result = True
-
- ret = umr_sum(arr, axis, dtype, out, keepdims, where=where)
- if isinstance(ret, mu.ndarray):
- with _no_nep50_warning():
- ret = um.true_divide(
- ret, rcount, out=ret, casting='unsafe', subok=False)
- if is_float16_result and out is None:
- ret = arr.dtype.type(ret)
- elif hasattr(ret, 'dtype'):
- if is_float16_result:
- ret = arr.dtype.type(ret / rcount)
- else:
- ret = ret.dtype.type(ret / rcount)
- else:
- ret = ret / rcount
-
- return ret
-
-def _var(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False, *,
- where=True):
- arr = asanyarray(a)
-
- rcount = _count_reduce_items(arr, axis, keepdims=keepdims, where=where)
- # Make this warning show up on top.
- if ddof >= rcount if where is True else umr_any(ddof >= rcount, axis=None):
- warnings.warn("Degrees of freedom <= 0 for slice", RuntimeWarning,
- stacklevel=2)
-
- # Cast bool, unsigned int, and int to float64 by default
- if dtype is None and issubclass(arr.dtype.type, (nt.integer, nt.bool_)):
- dtype = mu.dtype('f8')
-
- # Compute the mean.
- # Note that if dtype is not of inexact type then arraymean will
- # not be either.
- arrmean = umr_sum(arr, axis, dtype, keepdims=True, where=where)
- # The shape of rcount has to match arrmean to not change the shape of out
- # in broadcasting. Otherwise, it cannot be stored back to arrmean.
- if rcount.ndim == 0:
- # fast-path for default case when where is True
- div = rcount
- else:
- # matching rcount to arrmean when where is specified as array
- div = rcount.reshape(arrmean.shape)
- if isinstance(arrmean, mu.ndarray):
- with _no_nep50_warning():
- arrmean = um.true_divide(arrmean, div, out=arrmean,
- casting='unsafe', subok=False)
- elif hasattr(arrmean, "dtype"):
- arrmean = arrmean.dtype.type(arrmean / rcount)
- else:
- arrmean = arrmean / rcount
-
- # Compute sum of squared deviations from mean
- # Note that x may not be inexact and that we need it to be an array,
- # not a scalar.
- x = asanyarray(arr - arrmean)
-
- if issubclass(arr.dtype.type, (nt.floating, nt.integer)):
- x = um.multiply(x, x, out=x)
- # Fast-paths for built-in complex types
- elif x.dtype in _complex_to_float:
- xv = x.view(dtype=(_complex_to_float[x.dtype], (2,)))
- um.multiply(xv, xv, out=xv)
- x = um.add(xv[..., 0], xv[..., 1], out=x.real).real
- # Most general case; includes handling object arrays containing imaginary
- # numbers and complex types with non-native byteorder
- else:
- x = um.multiply(x, um.conjugate(x), out=x).real
-
- ret = umr_sum(x, axis, dtype, out, keepdims=keepdims, where=where)
-
- # Compute degrees of freedom and make sure it is not negative.
- rcount = um.maximum(rcount - ddof, 0)
-
- # divide by degrees of freedom
- if isinstance(ret, mu.ndarray):
- with _no_nep50_warning():
- ret = um.true_divide(
- ret, rcount, out=ret, casting='unsafe', subok=False)
- elif hasattr(ret, 'dtype'):
- ret = ret.dtype.type(ret / rcount)
- else:
- ret = ret / rcount
-
- return ret
-
-def _std(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False, *,
- where=True):
- ret = _var(a, axis=axis, dtype=dtype, out=out, ddof=ddof,
- keepdims=keepdims, where=where)
-
- if isinstance(ret, mu.ndarray):
- ret = um.sqrt(ret, out=ret)
- elif hasattr(ret, 'dtype'):
- ret = ret.dtype.type(um.sqrt(ret))
- else:
- ret = um.sqrt(ret)
-
- return ret
-
-def _ptp(a, axis=None, out=None, keepdims=False):
- return um.subtract(
- umr_maximum(a, axis, None, out, keepdims),
- umr_minimum(a, axis, None, None, keepdims),
- out
- )
-
-def _dump(self, file, protocol=2):
- if hasattr(file, 'write'):
- ctx = nullcontext(file)
- else:
- ctx = open(os_fspath(file), "wb")
- with ctx as f:
- pickle.dump(self, f, protocol=protocol)
-
-def _dumps(self, protocol=2):
- return pickle.dumps(self, protocol=protocol)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/core/tests/test_hashtable.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/core/tests/test_hashtable.py
deleted file mode 100644
index bace4c051e1158662d967839d9ea5dda69a2fde2..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/core/tests/test_hashtable.py
+++ /dev/null
@@ -1,30 +0,0 @@
-import pytest
-
-import random
-from numpy.core._multiarray_tests import identityhash_tester
-
-
-@pytest.mark.parametrize("key_length", [1, 3, 6])
-@pytest.mark.parametrize("length", [1, 16, 2000])
-def test_identity_hashtable(key_length, length):
- # use a 30 object pool for everything (duplicates will happen)
- pool = [object() for i in range(20)]
- keys_vals = []
- for i in range(length):
- keys = tuple(random.choices(pool, k=key_length))
- keys_vals.append((keys, random.choice(pool)))
-
- dictionary = dict(keys_vals)
-
- # add a random item at the end:
- keys_vals.append(random.choice(keys_vals))
- # the expected one could be different with duplicates:
- expected = dictionary[keys_vals[-1][0]]
-
- res = identityhash_tester(key_length, keys_vals, replace=True)
- assert res is expected
-
- # check that ensuring one duplicate definitely raises:
- keys_vals.insert(0, keys_vals[-2])
- with pytest.raises(RuntimeError):
- identityhash_tester(key_length, keys_vals)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/ctypeslib.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/ctypeslib.py
deleted file mode 100644
index d9f64fd9e716830ff33d4d787a0492c65d517603..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/ctypeslib.py
+++ /dev/null
@@ -1,545 +0,0 @@
-"""
-============================
-``ctypes`` Utility Functions
-============================
-
-See Also
---------
-load_library : Load a C library.
-ndpointer : Array restype/argtype with verification.
-as_ctypes : Create a ctypes array from an ndarray.
-as_array : Create an ndarray from a ctypes array.
-
-References
-----------
-.. [1] "SciPy Cookbook: ctypes", https://scipy-cookbook.readthedocs.io/items/Ctypes.html
-
-Examples
---------
-Load the C library:
-
->>> _lib = np.ctypeslib.load_library('libmystuff', '.') #doctest: +SKIP
-
-Our result type, an ndarray that must be of type double, be 1-dimensional
-and is C-contiguous in memory:
-
->>> array_1d_double = np.ctypeslib.ndpointer(
-... dtype=np.double,
-... ndim=1, flags='CONTIGUOUS') #doctest: +SKIP
-
-Our C-function typically takes an array and updates its values
-in-place. For example::
-
- void foo_func(double* x, int length)
- {
- int i;
- for (i = 0; i < length; i++) {
- x[i] = i*i;
- }
- }
-
-We wrap it using:
-
->>> _lib.foo_func.restype = None #doctest: +SKIP
->>> _lib.foo_func.argtypes = [array_1d_double, c_int] #doctest: +SKIP
-
-Then, we're ready to call ``foo_func``:
-
->>> out = np.empty(15, dtype=np.double)
->>> _lib.foo_func(out, len(out)) #doctest: +SKIP
-
-"""
-__all__ = ['load_library', 'ndpointer', 'c_intp', 'as_ctypes', 'as_array',
- 'as_ctypes_type']
-
-import os
-from numpy import (
- integer, ndarray, dtype as _dtype, asarray, frombuffer
-)
-from numpy.core.multiarray import _flagdict, flagsobj
-
-try:
- import ctypes
-except ImportError:
- ctypes = None
-
-if ctypes is None:
- def _dummy(*args, **kwds):
- """
- Dummy object that raises an ImportError if ctypes is not available.
-
- Raises
- ------
- ImportError
- If ctypes is not available.
-
- """
- raise ImportError("ctypes is not available.")
- load_library = _dummy
- as_ctypes = _dummy
- as_array = _dummy
- from numpy import intp as c_intp
- _ndptr_base = object
-else:
- import numpy.core._internal as nic
- c_intp = nic._getintp_ctype()
- del nic
- _ndptr_base = ctypes.c_void_p
-
- # Adapted from Albert Strasheim
- def load_library(libname, loader_path):
- """
- It is possible to load a library using
-
- >>> lib = ctypes.cdll[] # doctest: +SKIP
-
- But there are cross-platform considerations, such as library file extensions,
- plus the fact Windows will just load the first library it finds with that name.
- NumPy supplies the load_library function as a convenience.
-
- .. versionchanged:: 1.20.0
- Allow libname and loader_path to take any
- :term:`python:path-like object`.
-
- Parameters
- ----------
- libname : path-like
- Name of the library, which can have 'lib' as a prefix,
- but without an extension.
- loader_path : path-like
- Where the library can be found.
-
- Returns
- -------
- ctypes.cdll[libpath] : library object
- A ctypes library object
-
- Raises
- ------
- OSError
- If there is no library with the expected extension, or the
- library is defective and cannot be loaded.
- """
- # Convert path-like objects into strings
- libname = os.fsdecode(libname)
- loader_path = os.fsdecode(loader_path)
-
- ext = os.path.splitext(libname)[1]
- if not ext:
- import sys
- import sysconfig
- # Try to load library with platform-specific name, otherwise
- # default to libname.[so|dll|dylib]. Sometimes, these files are
- # built erroneously on non-linux platforms.
- base_ext = ".so"
- if sys.platform.startswith("darwin"):
- base_ext = ".dylib"
- elif sys.platform.startswith("win"):
- base_ext = ".dll"
- libname_ext = [libname + base_ext]
- so_ext = sysconfig.get_config_var("EXT_SUFFIX")
- if not so_ext == base_ext:
- libname_ext.insert(0, libname + so_ext)
- else:
- libname_ext = [libname]
-
- loader_path = os.path.abspath(loader_path)
- if not os.path.isdir(loader_path):
- libdir = os.path.dirname(loader_path)
- else:
- libdir = loader_path
-
- for ln in libname_ext:
- libpath = os.path.join(libdir, ln)
- if os.path.exists(libpath):
- try:
- return ctypes.cdll[libpath]
- except OSError:
- ## defective lib file
- raise
- ## if no successful return in the libname_ext loop:
- raise OSError("no file with expected extension")
-
-
-def _num_fromflags(flaglist):
- num = 0
- for val in flaglist:
- num += _flagdict[val]
- return num
-
-_flagnames = ['C_CONTIGUOUS', 'F_CONTIGUOUS', 'ALIGNED', 'WRITEABLE',
- 'OWNDATA', 'WRITEBACKIFCOPY']
-def _flags_fromnum(num):
- res = []
- for key in _flagnames:
- value = _flagdict[key]
- if (num & value):
- res.append(key)
- return res
-
-
-class _ndptr(_ndptr_base):
- @classmethod
- def from_param(cls, obj):
- if not isinstance(obj, ndarray):
- raise TypeError("argument must be an ndarray")
- if cls._dtype_ is not None \
- and obj.dtype != cls._dtype_:
- raise TypeError("array must have data type %s" % cls._dtype_)
- if cls._ndim_ is not None \
- and obj.ndim != cls._ndim_:
- raise TypeError("array must have %d dimension(s)" % cls._ndim_)
- if cls._shape_ is not None \
- and obj.shape != cls._shape_:
- raise TypeError("array must have shape %s" % str(cls._shape_))
- if cls._flags_ is not None \
- and ((obj.flags.num & cls._flags_) != cls._flags_):
- raise TypeError("array must have flags %s" %
- _flags_fromnum(cls._flags_))
- return obj.ctypes
-
-
-class _concrete_ndptr(_ndptr):
- """
- Like _ndptr, but with `_shape_` and `_dtype_` specified.
-
- Notably, this means the pointer has enough information to reconstruct
- the array, which is not generally true.
- """
- def _check_retval_(self):
- """
- This method is called when this class is used as the .restype
- attribute for a shared-library function, to automatically wrap the
- pointer into an array.
- """
- return self.contents
-
- @property
- def contents(self):
- """
- Get an ndarray viewing the data pointed to by this pointer.
-
- This mirrors the `contents` attribute of a normal ctypes pointer
- """
- full_dtype = _dtype((self._dtype_, self._shape_))
- full_ctype = ctypes.c_char * full_dtype.itemsize
- buffer = ctypes.cast(self, ctypes.POINTER(full_ctype)).contents
- return frombuffer(buffer, dtype=full_dtype).squeeze(axis=0)
-
-
-# Factory for an array-checking class with from_param defined for
-# use with ctypes argtypes mechanism
-_pointer_type_cache = {}
-def ndpointer(dtype=None, ndim=None, shape=None, flags=None):
- """
- Array-checking restype/argtypes.
-
- An ndpointer instance is used to describe an ndarray in restypes
- and argtypes specifications. This approach is more flexible than
- using, for example, ``POINTER(c_double)``, since several restrictions
- can be specified, which are verified upon calling the ctypes function.
- These include data type, number of dimensions, shape and flags. If a
- given array does not satisfy the specified restrictions,
- a ``TypeError`` is raised.
-
- Parameters
- ----------
- dtype : data-type, optional
- Array data-type.
- ndim : int, optional
- Number of array dimensions.
- shape : tuple of ints, optional
- Array shape.
- flags : str or tuple of str
- Array flags; may be one or more of:
-
- - C_CONTIGUOUS / C / CONTIGUOUS
- - F_CONTIGUOUS / F / FORTRAN
- - OWNDATA / O
- - WRITEABLE / W
- - ALIGNED / A
- - WRITEBACKIFCOPY / X
-
- Returns
- -------
- klass : ndpointer type object
- A type object, which is an ``_ndtpr`` instance containing
- dtype, ndim, shape and flags information.
-
- Raises
- ------
- TypeError
- If a given array does not satisfy the specified restrictions.
-
- Examples
- --------
- >>> clib.somefunc.argtypes = [np.ctypeslib.ndpointer(dtype=np.float64,
- ... ndim=1,
- ... flags='C_CONTIGUOUS')]
- ... #doctest: +SKIP
- >>> clib.somefunc(np.array([1, 2, 3], dtype=np.float64))
- ... #doctest: +SKIP
-
- """
-
- # normalize dtype to an Optional[dtype]
- if dtype is not None:
- dtype = _dtype(dtype)
-
- # normalize flags to an Optional[int]
- num = None
- if flags is not None:
- if isinstance(flags, str):
- flags = flags.split(',')
- elif isinstance(flags, (int, integer)):
- num = flags
- flags = _flags_fromnum(num)
- elif isinstance(flags, flagsobj):
- num = flags.num
- flags = _flags_fromnum(num)
- if num is None:
- try:
- flags = [x.strip().upper() for x in flags]
- except Exception as e:
- raise TypeError("invalid flags specification") from e
- num = _num_fromflags(flags)
-
- # normalize shape to an Optional[tuple]
- if shape is not None:
- try:
- shape = tuple(shape)
- except TypeError:
- # single integer -> 1-tuple
- shape = (shape,)
-
- cache_key = (dtype, ndim, shape, num)
-
- try:
- return _pointer_type_cache[cache_key]
- except KeyError:
- pass
-
- # produce a name for the new type
- if dtype is None:
- name = 'any'
- elif dtype.names is not None:
- name = str(id(dtype))
- else:
- name = dtype.str
- if ndim is not None:
- name += "_%dd" % ndim
- if shape is not None:
- name += "_"+"x".join(str(x) for x in shape)
- if flags is not None:
- name += "_"+"_".join(flags)
-
- if dtype is not None and shape is not None:
- base = _concrete_ndptr
- else:
- base = _ndptr
-
- klass = type("ndpointer_%s"%name, (base,),
- {"_dtype_": dtype,
- "_shape_" : shape,
- "_ndim_" : ndim,
- "_flags_" : num})
- _pointer_type_cache[cache_key] = klass
- return klass
-
-
-if ctypes is not None:
- def _ctype_ndarray(element_type, shape):
- """ Create an ndarray of the given element type and shape """
- for dim in shape[::-1]:
- element_type = dim * element_type
- # prevent the type name include np.ctypeslib
- element_type.__module__ = None
- return element_type
-
-
- def _get_scalar_type_map():
- """
- Return a dictionary mapping native endian scalar dtype to ctypes types
- """
- ct = ctypes
- simple_types = [
- ct.c_byte, ct.c_short, ct.c_int, ct.c_long, ct.c_longlong,
- ct.c_ubyte, ct.c_ushort, ct.c_uint, ct.c_ulong, ct.c_ulonglong,
- ct.c_float, ct.c_double,
- ct.c_bool,
- ]
- return {_dtype(ctype): ctype for ctype in simple_types}
-
-
- _scalar_type_map = _get_scalar_type_map()
-
-
- def _ctype_from_dtype_scalar(dtype):
- # swapping twice ensure that `=` is promoted to <, >, or |
- dtype_with_endian = dtype.newbyteorder('S').newbyteorder('S')
- dtype_native = dtype.newbyteorder('=')
- try:
- ctype = _scalar_type_map[dtype_native]
- except KeyError as e:
- raise NotImplementedError(
- "Converting {!r} to a ctypes type".format(dtype)
- ) from None
-
- if dtype_with_endian.byteorder == '>':
- ctype = ctype.__ctype_be__
- elif dtype_with_endian.byteorder == '<':
- ctype = ctype.__ctype_le__
-
- return ctype
-
-
- def _ctype_from_dtype_subarray(dtype):
- element_dtype, shape = dtype.subdtype
- ctype = _ctype_from_dtype(element_dtype)
- return _ctype_ndarray(ctype, shape)
-
-
- def _ctype_from_dtype_structured(dtype):
- # extract offsets of each field
- field_data = []
- for name in dtype.names:
- field_dtype, offset = dtype.fields[name][:2]
- field_data.append((offset, name, _ctype_from_dtype(field_dtype)))
-
- # ctypes doesn't care about field order
- field_data = sorted(field_data, key=lambda f: f[0])
-
- if len(field_data) > 1 and all(offset == 0 for offset, name, ctype in field_data):
- # union, if multiple fields all at address 0
- size = 0
- _fields_ = []
- for offset, name, ctype in field_data:
- _fields_.append((name, ctype))
- size = max(size, ctypes.sizeof(ctype))
-
- # pad to the right size
- if dtype.itemsize != size:
- _fields_.append(('', ctypes.c_char * dtype.itemsize))
-
- # we inserted manual padding, so always `_pack_`
- return type('union', (ctypes.Union,), dict(
- _fields_=_fields_,
- _pack_=1,
- __module__=None,
- ))
- else:
- last_offset = 0
- _fields_ = []
- for offset, name, ctype in field_data:
- padding = offset - last_offset
- if padding < 0:
- raise NotImplementedError("Overlapping fields")
- if padding > 0:
- _fields_.append(('', ctypes.c_char * padding))
-
- _fields_.append((name, ctype))
- last_offset = offset + ctypes.sizeof(ctype)
-
-
- padding = dtype.itemsize - last_offset
- if padding > 0:
- _fields_.append(('', ctypes.c_char * padding))
-
- # we inserted manual padding, so always `_pack_`
- return type('struct', (ctypes.Structure,), dict(
- _fields_=_fields_,
- _pack_=1,
- __module__=None,
- ))
-
-
- def _ctype_from_dtype(dtype):
- if dtype.fields is not None:
- return _ctype_from_dtype_structured(dtype)
- elif dtype.subdtype is not None:
- return _ctype_from_dtype_subarray(dtype)
- else:
- return _ctype_from_dtype_scalar(dtype)
-
-
- def as_ctypes_type(dtype):
- r"""
- Convert a dtype into a ctypes type.
-
- Parameters
- ----------
- dtype : dtype
- The dtype to convert
-
- Returns
- -------
- ctype
- A ctype scalar, union, array, or struct
-
- Raises
- ------
- NotImplementedError
- If the conversion is not possible
-
- Notes
- -----
- This function does not losslessly round-trip in either direction.
-
- ``np.dtype(as_ctypes_type(dt))`` will:
-
- - insert padding fields
- - reorder fields to be sorted by offset
- - discard field titles
-
- ``as_ctypes_type(np.dtype(ctype))`` will:
-
- - discard the class names of `ctypes.Structure`\ s and
- `ctypes.Union`\ s
- - convert single-element `ctypes.Union`\ s into single-element
- `ctypes.Structure`\ s
- - insert padding fields
-
- """
- return _ctype_from_dtype(_dtype(dtype))
-
-
- def as_array(obj, shape=None):
- """
- Create a numpy array from a ctypes array or POINTER.
-
- The numpy array shares the memory with the ctypes object.
-
- The shape parameter must be given if converting from a ctypes POINTER.
- The shape parameter is ignored if converting from a ctypes array
- """
- if isinstance(obj, ctypes._Pointer):
- # convert pointers to an array of the desired shape
- if shape is None:
- raise TypeError(
- 'as_array() requires a shape argument when called on a '
- 'pointer')
- p_arr_type = ctypes.POINTER(_ctype_ndarray(obj._type_, shape))
- obj = ctypes.cast(obj, p_arr_type).contents
-
- return asarray(obj)
-
-
- def as_ctypes(obj):
- """Create and return a ctypes object from a numpy array. Actually
- anything that exposes the __array_interface__ is accepted."""
- ai = obj.__array_interface__
- if ai["strides"]:
- raise TypeError("strided arrays not supported")
- if ai["version"] != 3:
- raise TypeError("only __array_interface__ version 3 supported")
- addr, readonly = ai["data"]
- if readonly:
- raise TypeError("readonly arrays unsupported")
-
- # can't use `_dtype((ai["typestr"], ai["shape"]))` here, as it overflows
- # dtype.itemsize (gh-14214)
- ctype_scalar = as_ctypes_type(ai["typestr"])
- result_type = _ctype_ndarray(ctype_scalar, ai["shape"])
- result = result_type.from_address(addr)
- result.__keep = obj
- return result
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/dtypes/cast/test_maybe_box_native.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/dtypes/cast/test_maybe_box_native.py
deleted file mode 100644
index 3f62f31dac2191a15d7df8db028a9286262d0080..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/dtypes/cast/test_maybe_box_native.py
+++ /dev/null
@@ -1,40 +0,0 @@
-from datetime import datetime
-
-import numpy as np
-import pytest
-
-from pandas.core.dtypes.cast import maybe_box_native
-
-from pandas import (
- Interval,
- Period,
- Timedelta,
- Timestamp,
-)
-
-
-@pytest.mark.parametrize(
- "obj,expected_dtype",
- [
- (b"\x00\x10", bytes),
- (int(4), int),
- (np.uint(4), int),
- (np.int32(-4), int),
- (np.uint8(4), int),
- (float(454.98), float),
- (np.float16(0.4), float),
- (np.float64(1.4), float),
- (np.bool_(False), bool),
- (datetime(2005, 2, 25), datetime),
- (np.datetime64("2005-02-25"), Timestamp),
- (Timestamp("2005-02-25"), Timestamp),
- (np.timedelta64(1, "D"), Timedelta),
- (Timedelta(1, "D"), Timedelta),
- (Interval(0, 1), Interval),
- (Period("4Q2005"), Period),
- ],
-)
-def test_maybe_box_native(obj, expected_dtype):
- boxed_obj = maybe_box_native(obj)
- result_dtype = type(boxed_obj)
- assert result_dtype is expected_dtype
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/internals/test_internals.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/internals/test_internals.py
deleted file mode 100644
index 4b23829a554aa10a71682331bdc356a566d14d21..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/internals/test_internals.py
+++ /dev/null
@@ -1,1442 +0,0 @@
-from datetime import (
- date,
- datetime,
-)
-import itertools
-import re
-
-import numpy as np
-import pytest
-
-from pandas._libs.internals import BlockPlacement
-from pandas.compat import IS64
-import pandas.util._test_decorators as td
-
-from pandas.core.dtypes.common import is_scalar
-
-import pandas as pd
-from pandas import (
- Categorical,
- DataFrame,
- DatetimeIndex,
- Index,
- IntervalIndex,
- Series,
- Timedelta,
- Timestamp,
- period_range,
-)
-import pandas._testing as tm
-import pandas.core.algorithms as algos
-from pandas.core.arrays import (
- DatetimeArray,
- SparseArray,
- TimedeltaArray,
-)
-from pandas.core.internals import (
- BlockManager,
- SingleBlockManager,
- make_block,
-)
-from pandas.core.internals.blocks import (
- ensure_block_shape,
- maybe_coerce_values,
- new_block,
-)
-
-# this file contains BlockManager specific tests
-# TODO(ArrayManager) factor out interleave_dtype tests
-pytestmark = td.skip_array_manager_invalid_test
-
-
-@pytest.fixture(params=[new_block, make_block])
-def block_maker(request):
- """
- Fixture to test both the internal new_block and pseudo-public make_block.
- """
- return request.param
-
-
-@pytest.fixture
-def mgr():
- return create_mgr(
- "a: f8; b: object; c: f8; d: object; e: f8;"
- "f: bool; g: i8; h: complex; i: datetime-1; j: datetime-2;"
- "k: M8[ns, US/Eastern]; l: M8[ns, CET];"
- )
-
-
-def assert_block_equal(left, right):
- tm.assert_numpy_array_equal(left.values, right.values)
- assert left.dtype == right.dtype
- assert isinstance(left.mgr_locs, BlockPlacement)
- assert isinstance(right.mgr_locs, BlockPlacement)
- tm.assert_numpy_array_equal(left.mgr_locs.as_array, right.mgr_locs.as_array)
-
-
-def get_numeric_mat(shape):
- arr = np.arange(shape[0])
- return np.lib.stride_tricks.as_strided(
- x=arr, shape=shape, strides=(arr.itemsize,) + (0,) * (len(shape) - 1)
- ).copy()
-
-
-N = 10
-
-
-def create_block(typestr, placement, item_shape=None, num_offset=0, maker=new_block):
- """
- Supported typestr:
-
- * float, f8, f4, f2
- * int, i8, i4, i2, i1
- * uint, u8, u4, u2, u1
- * complex, c16, c8
- * bool
- * object, string, O
- * datetime, dt, M8[ns], M8[ns, tz]
- * timedelta, td, m8[ns]
- * sparse (SparseArray with fill_value=0.0)
- * sparse_na (SparseArray with fill_value=np.nan)
- * category, category2
-
- """
- placement = BlockPlacement(placement)
- num_items = len(placement)
-
- if item_shape is None:
- item_shape = (N,)
-
- shape = (num_items,) + item_shape
-
- mat = get_numeric_mat(shape)
-
- if typestr in (
- "float",
- "f8",
- "f4",
- "f2",
- "int",
- "i8",
- "i4",
- "i2",
- "i1",
- "uint",
- "u8",
- "u4",
- "u2",
- "u1",
- ):
- values = mat.astype(typestr) + num_offset
- elif typestr in ("complex", "c16", "c8"):
- values = 1.0j * (mat.astype(typestr) + num_offset)
- elif typestr in ("object", "string", "O"):
- values = np.reshape([f"A{i:d}" for i in mat.ravel() + num_offset], shape)
- elif typestr in ("b", "bool"):
- values = np.ones(shape, dtype=np.bool_)
- elif typestr in ("datetime", "dt", "M8[ns]"):
- values = (mat * 1e9).astype("M8[ns]")
- elif typestr.startswith("M8[ns"):
- # datetime with tz
- m = re.search(r"M8\[ns,\s*(\w+\/?\w*)\]", typestr)
- assert m is not None, f"incompatible typestr -> {typestr}"
- tz = m.groups()[0]
- assert num_items == 1, "must have only 1 num items for a tz-aware"
- values = DatetimeIndex(np.arange(N) * 10**9, tz=tz)._data
- values = ensure_block_shape(values, ndim=len(shape))
- elif typestr in ("timedelta", "td", "m8[ns]"):
- values = (mat * 1).astype("m8[ns]")
- elif typestr in ("category",):
- values = Categorical([1, 1, 2, 2, 3, 3, 3, 3, 4, 4])
- elif typestr in ("category2",):
- values = Categorical(["a", "a", "a", "a", "b", "b", "c", "c", "c", "d"])
- elif typestr in ("sparse", "sparse_na"):
- if shape[-1] != 10:
- # We also are implicitly assuming this in the category cases above
- raise NotImplementedError
-
- assert all(s == 1 for s in shape[:-1])
- if typestr.endswith("_na"):
- fill_value = np.nan
- else:
- fill_value = 0.0
- values = SparseArray(
- [fill_value, fill_value, 1, 2, 3, fill_value, 4, 5, fill_value, 6],
- fill_value=fill_value,
- )
- arr = values.sp_values.view()
- arr += num_offset - 1
- else:
- raise ValueError(f'Unsupported typestr: "{typestr}"')
-
- values = maybe_coerce_values(values)
- return maker(values, placement=placement, ndim=len(shape))
-
-
-def create_single_mgr(typestr, num_rows=None):
- if num_rows is None:
- num_rows = N
-
- return SingleBlockManager(
- create_block(typestr, placement=slice(0, num_rows), item_shape=()),
- Index(np.arange(num_rows)),
- )
-
-
-def create_mgr(descr, item_shape=None):
- """
- Construct BlockManager from string description.
-
- String description syntax looks similar to np.matrix initializer. It looks
- like this::
-
- a,b,c: f8; d,e,f: i8
-
- Rules are rather simple:
-
- * see list of supported datatypes in `create_block` method
- * components are semicolon-separated
- * each component is `NAME,NAME,NAME: DTYPE_ID`
- * whitespace around colons & semicolons are removed
- * components with same DTYPE_ID are combined into single block
- * to force multiple blocks with same dtype, use '-SUFFIX'::
-
- 'a:f8-1; b:f8-2; c:f8-foobar'
-
- """
- if item_shape is None:
- item_shape = (N,)
-
- offset = 0
- mgr_items = []
- block_placements = {}
- for d in descr.split(";"):
- d = d.strip()
- if not len(d):
- continue
- names, blockstr = d.partition(":")[::2]
- blockstr = blockstr.strip()
- names = names.strip().split(",")
-
- mgr_items.extend(names)
- placement = list(np.arange(len(names)) + offset)
- try:
- block_placements[blockstr].extend(placement)
- except KeyError:
- block_placements[blockstr] = placement
- offset += len(names)
-
- mgr_items = Index(mgr_items)
-
- blocks = []
- num_offset = 0
- for blockstr, placement in block_placements.items():
- typestr = blockstr.split("-")[0]
- blocks.append(
- create_block(
- typestr, placement, item_shape=item_shape, num_offset=num_offset
- )
- )
- num_offset += len(placement)
-
- sblocks = sorted(blocks, key=lambda b: b.mgr_locs[0])
- return BlockManager(
- tuple(sblocks),
- [mgr_items] + [Index(np.arange(n)) for n in item_shape],
- )
-
-
-@pytest.fixture
-def fblock():
- return create_block("float", [0, 2, 4])
-
-
-class TestBlock:
- def test_constructor(self):
- int32block = create_block("i4", [0])
- assert int32block.dtype == np.int32
-
- @pytest.mark.parametrize(
- "typ, data",
- [
- ["float", [0, 2, 4]],
- ["complex", [7]],
- ["object", [1, 3]],
- ["bool", [5]],
- ],
- )
- def test_pickle(self, typ, data):
- blk = create_block(typ, data)
- assert_block_equal(tm.round_trip_pickle(blk), blk)
-
- def test_mgr_locs(self, fblock):
- assert isinstance(fblock.mgr_locs, BlockPlacement)
- tm.assert_numpy_array_equal(
- fblock.mgr_locs.as_array, np.array([0, 2, 4], dtype=np.intp)
- )
-
- def test_attrs(self, fblock):
- assert fblock.shape == fblock.values.shape
- assert fblock.dtype == fblock.values.dtype
- assert len(fblock) == len(fblock.values)
-
- def test_copy(self, fblock):
- cop = fblock.copy()
- assert cop is not fblock
- assert_block_equal(fblock, cop)
-
- def test_delete(self, fblock):
- newb = fblock.copy()
- locs = newb.mgr_locs
- nb = newb.delete(0)[0]
- assert newb.mgr_locs is locs
-
- assert nb is not newb
-
- tm.assert_numpy_array_equal(
- nb.mgr_locs.as_array, np.array([2, 4], dtype=np.intp)
- )
- assert not (newb.values[0] == 1).all()
- assert (nb.values[0] == 1).all()
-
- newb = fblock.copy()
- locs = newb.mgr_locs
- nb = newb.delete(1)
- assert len(nb) == 2
- assert newb.mgr_locs is locs
-
- tm.assert_numpy_array_equal(
- nb[0].mgr_locs.as_array, np.array([0], dtype=np.intp)
- )
- tm.assert_numpy_array_equal(
- nb[1].mgr_locs.as_array, np.array([4], dtype=np.intp)
- )
- assert not (newb.values[1] == 2).all()
- assert (nb[1].values[0] == 2).all()
-
- newb = fblock.copy()
- nb = newb.delete(2)
- assert len(nb) == 1
- tm.assert_numpy_array_equal(
- nb[0].mgr_locs.as_array, np.array([0, 2], dtype=np.intp)
- )
- assert (nb[0].values[1] == 1).all()
-
- newb = fblock.copy()
-
- with pytest.raises(IndexError, match=None):
- newb.delete(3)
-
- def test_delete_datetimelike(self):
- # dont use np.delete on values, as that will coerce from DTA/TDA to ndarray
- arr = np.arange(20, dtype="i8").reshape(5, 4).view("m8[ns]")
- df = DataFrame(arr)
- blk = df._mgr.blocks[0]
- assert isinstance(blk.values, TimedeltaArray)
-
- nb = blk.delete(1)
- assert len(nb) == 2
- assert isinstance(nb[0].values, TimedeltaArray)
- assert isinstance(nb[1].values, TimedeltaArray)
-
- df = DataFrame(arr.view("M8[ns]"))
- blk = df._mgr.blocks[0]
- assert isinstance(blk.values, DatetimeArray)
-
- nb = blk.delete([1, 3])
- assert len(nb) == 2
- assert isinstance(nb[0].values, DatetimeArray)
- assert isinstance(nb[1].values, DatetimeArray)
-
- def test_split(self):
- # GH#37799
- values = np.random.default_rng(2).standard_normal((3, 4))
- blk = new_block(values, placement=BlockPlacement([3, 1, 6]), ndim=2)
- result = blk._split()
-
- # check that we get views, not copies
- values[:] = -9999
- assert (blk.values == -9999).all()
-
- assert len(result) == 3
- expected = [
- new_block(values[[0]], placement=BlockPlacement([3]), ndim=2),
- new_block(values[[1]], placement=BlockPlacement([1]), ndim=2),
- new_block(values[[2]], placement=BlockPlacement([6]), ndim=2),
- ]
- for res, exp in zip(result, expected):
- assert_block_equal(res, exp)
-
-
-class TestBlockManager:
- def test_attrs(self):
- mgr = create_mgr("a,b,c: f8-1; d,e,f: f8-2")
- assert mgr.nblocks == 2
- assert len(mgr) == 6
-
- def test_duplicate_ref_loc_failure(self):
- tmp_mgr = create_mgr("a:bool; a: f8")
-
- axes, blocks = tmp_mgr.axes, tmp_mgr.blocks
-
- blocks[0].mgr_locs = BlockPlacement(np.array([0]))
- blocks[1].mgr_locs = BlockPlacement(np.array([0]))
-
- # test trying to create block manager with overlapping ref locs
-
- msg = "Gaps in blk ref_locs"
-
- with pytest.raises(AssertionError, match=msg):
- mgr = BlockManager(blocks, axes)
- mgr._rebuild_blknos_and_blklocs()
-
- blocks[0].mgr_locs = BlockPlacement(np.array([0]))
- blocks[1].mgr_locs = BlockPlacement(np.array([1]))
- mgr = BlockManager(blocks, axes)
- mgr.iget(1)
-
- def test_pickle(self, mgr):
- mgr2 = tm.round_trip_pickle(mgr)
- tm.assert_frame_equal(DataFrame(mgr), DataFrame(mgr2))
-
- # GH2431
- assert hasattr(mgr2, "_is_consolidated")
- assert hasattr(mgr2, "_known_consolidated")
-
- # reset to False on load
- assert not mgr2._is_consolidated
- assert not mgr2._known_consolidated
-
- @pytest.mark.parametrize("mgr_string", ["a,a,a:f8", "a: f8; a: i8"])
- def test_non_unique_pickle(self, mgr_string):
- mgr = create_mgr(mgr_string)
- mgr2 = tm.round_trip_pickle(mgr)
- tm.assert_frame_equal(DataFrame(mgr), DataFrame(mgr2))
-
- def test_categorical_block_pickle(self):
- mgr = create_mgr("a: category")
- mgr2 = tm.round_trip_pickle(mgr)
- tm.assert_frame_equal(DataFrame(mgr), DataFrame(mgr2))
-
- smgr = create_single_mgr("category")
- smgr2 = tm.round_trip_pickle(smgr)
- tm.assert_series_equal(Series(smgr), Series(smgr2))
-
- def test_iget(self):
- cols = Index(list("abc"))
- values = np.random.default_rng(2).random((3, 3))
- block = new_block(
- values=values.copy(),
- placement=BlockPlacement(np.arange(3, dtype=np.intp)),
- ndim=values.ndim,
- )
- mgr = BlockManager(blocks=(block,), axes=[cols, Index(np.arange(3))])
-
- tm.assert_almost_equal(mgr.iget(0).internal_values(), values[0])
- tm.assert_almost_equal(mgr.iget(1).internal_values(), values[1])
- tm.assert_almost_equal(mgr.iget(2).internal_values(), values[2])
-
- def test_set(self):
- mgr = create_mgr("a,b,c: int", item_shape=(3,))
-
- mgr.insert(len(mgr.items), "d", np.array(["foo"] * 3))
- mgr.iset(1, np.array(["bar"] * 3))
- tm.assert_numpy_array_equal(mgr.iget(0).internal_values(), np.array([0] * 3))
- tm.assert_numpy_array_equal(
- mgr.iget(1).internal_values(), np.array(["bar"] * 3, dtype=np.object_)
- )
- tm.assert_numpy_array_equal(mgr.iget(2).internal_values(), np.array([2] * 3))
- tm.assert_numpy_array_equal(
- mgr.iget(3).internal_values(), np.array(["foo"] * 3, dtype=np.object_)
- )
-
- def test_set_change_dtype(self, mgr):
- mgr.insert(len(mgr.items), "baz", np.zeros(N, dtype=bool))
-
- mgr.iset(mgr.items.get_loc("baz"), np.repeat("foo", N))
- idx = mgr.items.get_loc("baz")
- assert mgr.iget(idx).dtype == np.object_
-
- mgr2 = mgr.consolidate()
- mgr2.iset(mgr2.items.get_loc("baz"), np.repeat("foo", N))
- idx = mgr2.items.get_loc("baz")
- assert mgr2.iget(idx).dtype == np.object_
-
- mgr2.insert(
- len(mgr2.items),
- "quux",
- np.random.default_rng(2).standard_normal(N).astype(int),
- )
- idx = mgr2.items.get_loc("quux")
- assert mgr2.iget(idx).dtype == np.dtype(int)
-
- mgr2.iset(
- mgr2.items.get_loc("quux"), np.random.default_rng(2).standard_normal(N)
- )
- assert mgr2.iget(idx).dtype == np.float64
-
- def test_copy(self, mgr):
- cp = mgr.copy(deep=False)
- for blk, cp_blk in zip(mgr.blocks, cp.blocks):
- # view assertion
- tm.assert_equal(cp_blk.values, blk.values)
- if isinstance(blk.values, np.ndarray):
- assert cp_blk.values.base is blk.values.base
- else:
- # DatetimeTZBlock has DatetimeIndex values
- assert cp_blk.values._ndarray.base is blk.values._ndarray.base
-
- # copy(deep=True) consolidates, so the block-wise assertions will
- # fail is mgr is not consolidated
- mgr._consolidate_inplace()
- cp = mgr.copy(deep=True)
- for blk, cp_blk in zip(mgr.blocks, cp.blocks):
- bvals = blk.values
- cpvals = cp_blk.values
-
- tm.assert_equal(cpvals, bvals)
-
- if isinstance(cpvals, np.ndarray):
- lbase = cpvals.base
- rbase = bvals.base
- else:
- lbase = cpvals._ndarray.base
- rbase = bvals._ndarray.base
-
- # copy assertion we either have a None for a base or in case of
- # some blocks it is an array (e.g. datetimetz), but was copied
- if isinstance(cpvals, DatetimeArray):
- assert (lbase is None and rbase is None) or (lbase is not rbase)
- elif not isinstance(cpvals, np.ndarray):
- assert lbase is not rbase
- else:
- assert lbase is None and rbase is None
-
- def test_sparse(self):
- mgr = create_mgr("a: sparse-1; b: sparse-2")
- assert mgr.as_array().dtype == np.float64
-
- def test_sparse_mixed(self):
- mgr = create_mgr("a: sparse-1; b: sparse-2; c: f8")
- assert len(mgr.blocks) == 3
- assert isinstance(mgr, BlockManager)
-
- @pytest.mark.parametrize(
- "mgr_string, dtype",
- [("c: f4; d: f2", np.float32), ("c: f4; d: f2; e: f8", np.float64)],
- )
- def test_as_array_float(self, mgr_string, dtype):
- mgr = create_mgr(mgr_string)
- assert mgr.as_array().dtype == dtype
-
- @pytest.mark.parametrize(
- "mgr_string, dtype",
- [
- ("a: bool-1; b: bool-2", np.bool_),
- ("a: i8-1; b: i8-2; c: i4; d: i2; e: u1", np.int64),
- ("c: i4; d: i2; e: u1", np.int32),
- ],
- )
- def test_as_array_int_bool(self, mgr_string, dtype):
- mgr = create_mgr(mgr_string)
- assert mgr.as_array().dtype == dtype
-
- def test_as_array_datetime(self):
- mgr = create_mgr("h: datetime-1; g: datetime-2")
- assert mgr.as_array().dtype == "M8[ns]"
-
- def test_as_array_datetime_tz(self):
- mgr = create_mgr("h: M8[ns, US/Eastern]; g: M8[ns, CET]")
- assert mgr.iget(0).dtype == "datetime64[ns, US/Eastern]"
- assert mgr.iget(1).dtype == "datetime64[ns, CET]"
- assert mgr.as_array().dtype == "object"
-
- @pytest.mark.parametrize("t", ["float16", "float32", "float64", "int32", "int64"])
- def test_astype(self, t):
- # coerce all
- mgr = create_mgr("c: f4; d: f2; e: f8")
-
- t = np.dtype(t)
- tmgr = mgr.astype(t)
- assert tmgr.iget(0).dtype.type == t
- assert tmgr.iget(1).dtype.type == t
- assert tmgr.iget(2).dtype.type == t
-
- # mixed
- mgr = create_mgr("a,b: object; c: bool; d: datetime; e: f4; f: f2; g: f8")
-
- t = np.dtype(t)
- tmgr = mgr.astype(t, errors="ignore")
- assert tmgr.iget(2).dtype.type == t
- assert tmgr.iget(4).dtype.type == t
- assert tmgr.iget(5).dtype.type == t
- assert tmgr.iget(6).dtype.type == t
-
- assert tmgr.iget(0).dtype.type == np.object_
- assert tmgr.iget(1).dtype.type == np.object_
- if t != np.int64:
- assert tmgr.iget(3).dtype.type == np.datetime64
- else:
- assert tmgr.iget(3).dtype.type == t
-
- def test_convert(self):
- def _compare(old_mgr, new_mgr):
- """compare the blocks, numeric compare ==, object don't"""
- old_blocks = set(old_mgr.blocks)
- new_blocks = set(new_mgr.blocks)
- assert len(old_blocks) == len(new_blocks)
-
- # compare non-numeric
- for b in old_blocks:
- found = False
- for nb in new_blocks:
- if (b.values == nb.values).all():
- found = True
- break
- assert found
-
- for b in new_blocks:
- found = False
- for ob in old_blocks:
- if (b.values == ob.values).all():
- found = True
- break
- assert found
-
- # noops
- mgr = create_mgr("f: i8; g: f8")
- new_mgr = mgr.convert(copy=True)
- _compare(mgr, new_mgr)
-
- # convert
- mgr = create_mgr("a,b,foo: object; f: i8; g: f8")
- mgr.iset(0, np.array(["1"] * N, dtype=np.object_))
- mgr.iset(1, np.array(["2."] * N, dtype=np.object_))
- mgr.iset(2, np.array(["foo."] * N, dtype=np.object_))
- new_mgr = mgr.convert(copy=True)
- assert new_mgr.iget(0).dtype == np.object_
- assert new_mgr.iget(1).dtype == np.object_
- assert new_mgr.iget(2).dtype == np.object_
- assert new_mgr.iget(3).dtype == np.int64
- assert new_mgr.iget(4).dtype == np.float64
-
- mgr = create_mgr(
- "a,b,foo: object; f: i4; bool: bool; dt: datetime; i: i8; g: f8; h: f2"
- )
- mgr.iset(0, np.array(["1"] * N, dtype=np.object_))
- mgr.iset(1, np.array(["2."] * N, dtype=np.object_))
- mgr.iset(2, np.array(["foo."] * N, dtype=np.object_))
- new_mgr = mgr.convert(copy=True)
- assert new_mgr.iget(0).dtype == np.object_
- assert new_mgr.iget(1).dtype == np.object_
- assert new_mgr.iget(2).dtype == np.object_
- assert new_mgr.iget(3).dtype == np.int32
- assert new_mgr.iget(4).dtype == np.bool_
- assert new_mgr.iget(5).dtype.type, np.datetime64
- assert new_mgr.iget(6).dtype == np.int64
- assert new_mgr.iget(7).dtype == np.float64
- assert new_mgr.iget(8).dtype == np.float16
-
- def test_interleave(self):
- # self
- for dtype in ["f8", "i8", "object", "bool", "complex", "M8[ns]", "m8[ns]"]:
- mgr = create_mgr(f"a: {dtype}")
- assert mgr.as_array().dtype == dtype
- mgr = create_mgr(f"a: {dtype}; b: {dtype}")
- assert mgr.as_array().dtype == dtype
-
- @pytest.mark.parametrize(
- "mgr_string, dtype",
- [
- ("a: category", "i8"),
- ("a: category; b: category", "i8"),
- ("a: category; b: category2", "object"),
- ("a: category2", "object"),
- ("a: category2; b: category2", "object"),
- ("a: f8", "f8"),
- ("a: f8; b: i8", "f8"),
- ("a: f4; b: i8", "f8"),
- ("a: f4; b: i8; d: object", "object"),
- ("a: bool; b: i8", "object"),
- ("a: complex", "complex"),
- ("a: f8; b: category", "object"),
- ("a: M8[ns]; b: category", "object"),
- ("a: M8[ns]; b: bool", "object"),
- ("a: M8[ns]; b: i8", "object"),
- ("a: m8[ns]; b: bool", "object"),
- ("a: m8[ns]; b: i8", "object"),
- ("a: M8[ns]; b: m8[ns]", "object"),
- ],
- )
- def test_interleave_dtype(self, mgr_string, dtype):
- # will be converted according the actual dtype of the underlying
- mgr = create_mgr("a: category")
- assert mgr.as_array().dtype == "i8"
- mgr = create_mgr("a: category; b: category2")
- assert mgr.as_array().dtype == "object"
- mgr = create_mgr("a: category2")
- assert mgr.as_array().dtype == "object"
-
- # combinations
- mgr = create_mgr("a: f8")
- assert mgr.as_array().dtype == "f8"
- mgr = create_mgr("a: f8; b: i8")
- assert mgr.as_array().dtype == "f8"
- mgr = create_mgr("a: f4; b: i8")
- assert mgr.as_array().dtype == "f8"
- mgr = create_mgr("a: f4; b: i8; d: object")
- assert mgr.as_array().dtype == "object"
- mgr = create_mgr("a: bool; b: i8")
- assert mgr.as_array().dtype == "object"
- mgr = create_mgr("a: complex")
- assert mgr.as_array().dtype == "complex"
- mgr = create_mgr("a: f8; b: category")
- assert mgr.as_array().dtype == "f8"
- mgr = create_mgr("a: M8[ns]; b: category")
- assert mgr.as_array().dtype == "object"
- mgr = create_mgr("a: M8[ns]; b: bool")
- assert mgr.as_array().dtype == "object"
- mgr = create_mgr("a: M8[ns]; b: i8")
- assert mgr.as_array().dtype == "object"
- mgr = create_mgr("a: m8[ns]; b: bool")
- assert mgr.as_array().dtype == "object"
- mgr = create_mgr("a: m8[ns]; b: i8")
- assert mgr.as_array().dtype == "object"
- mgr = create_mgr("a: M8[ns]; b: m8[ns]")
- assert mgr.as_array().dtype == "object"
-
- def test_consolidate_ordering_issues(self, mgr):
- mgr.iset(mgr.items.get_loc("f"), np.random.default_rng(2).standard_normal(N))
- mgr.iset(mgr.items.get_loc("d"), np.random.default_rng(2).standard_normal(N))
- mgr.iset(mgr.items.get_loc("b"), np.random.default_rng(2).standard_normal(N))
- mgr.iset(mgr.items.get_loc("g"), np.random.default_rng(2).standard_normal(N))
- mgr.iset(mgr.items.get_loc("h"), np.random.default_rng(2).standard_normal(N))
-
- # we have datetime/tz blocks in mgr
- cons = mgr.consolidate()
- assert cons.nblocks == 4
- cons = mgr.consolidate().get_numeric_data()
- assert cons.nblocks == 1
- assert isinstance(cons.blocks[0].mgr_locs, BlockPlacement)
- tm.assert_numpy_array_equal(
- cons.blocks[0].mgr_locs.as_array, np.arange(len(cons.items), dtype=np.intp)
- )
-
- def test_reindex_items(self):
- # mgr is not consolidated, f8 & f8-2 blocks
- mgr = create_mgr("a: f8; b: i8; c: f8; d: i8; e: f8; f: bool; g: f8-2")
-
- reindexed = mgr.reindex_axis(["g", "c", "a", "d"], axis=0)
- # reindex_axis does not consolidate_inplace, as that risks failing to
- # invalidate _item_cache
- assert not reindexed.is_consolidated()
-
- tm.assert_index_equal(reindexed.items, Index(["g", "c", "a", "d"]))
- tm.assert_almost_equal(
- mgr.iget(6).internal_values(), reindexed.iget(0).internal_values()
- )
- tm.assert_almost_equal(
- mgr.iget(2).internal_values(), reindexed.iget(1).internal_values()
- )
- tm.assert_almost_equal(
- mgr.iget(0).internal_values(), reindexed.iget(2).internal_values()
- )
- tm.assert_almost_equal(
- mgr.iget(3).internal_values(), reindexed.iget(3).internal_values()
- )
-
- def test_get_numeric_data(self, using_copy_on_write):
- mgr = create_mgr(
- "int: int; float: float; complex: complex;"
- "str: object; bool: bool; obj: object; dt: datetime",
- item_shape=(3,),
- )
- mgr.iset(5, np.array([1, 2, 3], dtype=np.object_))
-
- numeric = mgr.get_numeric_data()
- tm.assert_index_equal(numeric.items, Index(["int", "float", "complex", "bool"]))
- tm.assert_almost_equal(
- mgr.iget(mgr.items.get_loc("float")).internal_values(),
- numeric.iget(numeric.items.get_loc("float")).internal_values(),
- )
-
- # Check sharing
- numeric.iset(
- numeric.items.get_loc("float"),
- np.array([100.0, 200.0, 300.0]),
- inplace=True,
- )
- if using_copy_on_write:
- tm.assert_almost_equal(
- mgr.iget(mgr.items.get_loc("float")).internal_values(),
- np.array([1.0, 1.0, 1.0]),
- )
- else:
- tm.assert_almost_equal(
- mgr.iget(mgr.items.get_loc("float")).internal_values(),
- np.array([100.0, 200.0, 300.0]),
- )
-
- numeric2 = mgr.get_numeric_data(copy=True)
- tm.assert_index_equal(numeric.items, Index(["int", "float", "complex", "bool"]))
- numeric2.iset(
- numeric2.items.get_loc("float"),
- np.array([1000.0, 2000.0, 3000.0]),
- inplace=True,
- )
- if using_copy_on_write:
- tm.assert_almost_equal(
- mgr.iget(mgr.items.get_loc("float")).internal_values(),
- np.array([1.0, 1.0, 1.0]),
- )
- else:
- tm.assert_almost_equal(
- mgr.iget(mgr.items.get_loc("float")).internal_values(),
- np.array([100.0, 200.0, 300.0]),
- )
-
- def test_get_bool_data(self, using_copy_on_write):
- mgr = create_mgr(
- "int: int; float: float; complex: complex;"
- "str: object; bool: bool; obj: object; dt: datetime",
- item_shape=(3,),
- )
- mgr.iset(6, np.array([True, False, True], dtype=np.object_))
-
- bools = mgr.get_bool_data()
- tm.assert_index_equal(bools.items, Index(["bool"]))
- tm.assert_almost_equal(
- mgr.iget(mgr.items.get_loc("bool")).internal_values(),
- bools.iget(bools.items.get_loc("bool")).internal_values(),
- )
-
- bools.iset(0, np.array([True, False, True]), inplace=True)
- if using_copy_on_write:
- tm.assert_numpy_array_equal(
- mgr.iget(mgr.items.get_loc("bool")).internal_values(),
- np.array([True, True, True]),
- )
- else:
- tm.assert_numpy_array_equal(
- mgr.iget(mgr.items.get_loc("bool")).internal_values(),
- np.array([True, False, True]),
- )
-
- # Check sharing
- bools2 = mgr.get_bool_data(copy=True)
- bools2.iset(0, np.array([False, True, False]))
- if using_copy_on_write:
- tm.assert_numpy_array_equal(
- mgr.iget(mgr.items.get_loc("bool")).internal_values(),
- np.array([True, True, True]),
- )
- else:
- tm.assert_numpy_array_equal(
- mgr.iget(mgr.items.get_loc("bool")).internal_values(),
- np.array([True, False, True]),
- )
-
- def test_unicode_repr_doesnt_raise(self):
- repr(create_mgr("b,\u05d0: object"))
-
- @pytest.mark.parametrize(
- "mgr_string", ["a,b,c: i8-1; d,e,f: i8-2", "a,a,a: i8-1; b,b,b: i8-2"]
- )
- def test_equals(self, mgr_string):
- # unique items
- bm1 = create_mgr(mgr_string)
- bm2 = BlockManager(bm1.blocks[::-1], bm1.axes)
- assert bm1.equals(bm2)
-
- @pytest.mark.parametrize(
- "mgr_string",
- [
- "a:i8;b:f8", # basic case
- "a:i8;b:f8;c:c8;d:b", # many types
- "a:i8;e:dt;f:td;g:string", # more types
- "a:i8;b:category;c:category2", # categories
- "c:sparse;d:sparse_na;b:f8", # sparse
- ],
- )
- def test_equals_block_order_different_dtypes(self, mgr_string):
- # GH 9330
- bm = create_mgr(mgr_string)
- block_perms = itertools.permutations(bm.blocks)
- for bm_perm in block_perms:
- bm_this = BlockManager(tuple(bm_perm), bm.axes)
- assert bm.equals(bm_this)
- assert bm_this.equals(bm)
-
- def test_single_mgr_ctor(self):
- mgr = create_single_mgr("f8", num_rows=5)
- assert mgr.external_values().tolist() == [0.0, 1.0, 2.0, 3.0, 4.0]
-
- @pytest.mark.parametrize("value", [1, "True", [1, 2, 3], 5.0])
- def test_validate_bool_args(self, value):
- bm1 = create_mgr("a,b,c: i8-1; d,e,f: i8-2")
-
- msg = (
- 'For argument "inplace" expected type bool, '
- f"received type {type(value).__name__}."
- )
- with pytest.raises(ValueError, match=msg):
- bm1.replace_list([1], [2], inplace=value)
-
- def test_iset_split_block(self):
- bm = create_mgr("a,b,c: i8; d: f8")
- bm._iset_split_block(0, np.array([0]))
- tm.assert_numpy_array_equal(
- bm.blklocs, np.array([0, 0, 1, 0], dtype="int64" if IS64 else "int32")
- )
- # First indexer currently does not have a block associated with it in case
- tm.assert_numpy_array_equal(
- bm.blknos, np.array([0, 0, 0, 1], dtype="int64" if IS64 else "int32")
- )
- assert len(bm.blocks) == 2
-
- def test_iset_split_block_values(self):
- bm = create_mgr("a,b,c: i8; d: f8")
- bm._iset_split_block(0, np.array([0]), np.array([list(range(10))]))
- tm.assert_numpy_array_equal(
- bm.blklocs, np.array([0, 0, 1, 0], dtype="int64" if IS64 else "int32")
- )
- # First indexer currently does not have a block associated with it in case
- tm.assert_numpy_array_equal(
- bm.blknos, np.array([0, 2, 2, 1], dtype="int64" if IS64 else "int32")
- )
- assert len(bm.blocks) == 3
-
-
-def _as_array(mgr):
- if mgr.ndim == 1:
- return mgr.external_values()
- return mgr.as_array().T
-
-
-class TestIndexing:
- # Nosetests-style data-driven tests.
- #
- # This test applies different indexing routines to block managers and
- # compares the outcome to the result of same operations on np.ndarray.
- #
- # NOTE: sparse (SparseBlock with fill_value != np.nan) fail a lot of tests
- # and are disabled.
-
- MANAGERS = [
- create_single_mgr("f8", N),
- create_single_mgr("i8", N),
- # 2-dim
- create_mgr("a,b,c,d,e,f: f8", item_shape=(N,)),
- create_mgr("a,b,c,d,e,f: i8", item_shape=(N,)),
- create_mgr("a,b: f8; c,d: i8; e,f: string", item_shape=(N,)),
- create_mgr("a,b: f8; c,d: i8; e,f: f8", item_shape=(N,)),
- ]
-
- @pytest.mark.parametrize("mgr", MANAGERS)
- def test_get_slice(self, mgr):
- def assert_slice_ok(mgr, axis, slobj):
- mat = _as_array(mgr)
-
- # we maybe using an ndarray to test slicing and
- # might not be the full length of the axis
- if isinstance(slobj, np.ndarray):
- ax = mgr.axes[axis]
- if len(ax) and len(slobj) and len(slobj) != len(ax):
- slobj = np.concatenate(
- [slobj, np.zeros(len(ax) - len(slobj), dtype=bool)]
- )
-
- if isinstance(slobj, slice):
- sliced = mgr.get_slice(slobj, axis=axis)
- elif (
- mgr.ndim == 1
- and axis == 0
- and isinstance(slobj, np.ndarray)
- and slobj.dtype == bool
- ):
- sliced = mgr.get_rows_with_mask(slobj)
- else:
- # BlockManager doesn't support non-slice, SingleBlockManager
- # doesn't support axis > 0
- raise TypeError(slobj)
-
- mat_slobj = (slice(None),) * axis + (slobj,)
- tm.assert_numpy_array_equal(
- mat[mat_slobj], _as_array(sliced), check_dtype=False
- )
- tm.assert_index_equal(mgr.axes[axis][slobj], sliced.axes[axis])
-
- assert mgr.ndim <= 2, mgr.ndim
- for ax in range(mgr.ndim):
- # slice
- assert_slice_ok(mgr, ax, slice(None))
- assert_slice_ok(mgr, ax, slice(3))
- assert_slice_ok(mgr, ax, slice(100))
- assert_slice_ok(mgr, ax, slice(1, 4))
- assert_slice_ok(mgr, ax, slice(3, 0, -2))
-
- if mgr.ndim < 2:
- # 2D only support slice objects
-
- # boolean mask
- assert_slice_ok(mgr, ax, np.array([], dtype=np.bool_))
- assert_slice_ok(mgr, ax, np.ones(mgr.shape[ax], dtype=np.bool_))
- assert_slice_ok(mgr, ax, np.zeros(mgr.shape[ax], dtype=np.bool_))
-
- if mgr.shape[ax] >= 3:
- assert_slice_ok(mgr, ax, np.arange(mgr.shape[ax]) % 3 == 0)
- assert_slice_ok(
- mgr, ax, np.array([True, True, False], dtype=np.bool_)
- )
-
- @pytest.mark.parametrize("mgr", MANAGERS)
- def test_take(self, mgr):
- def assert_take_ok(mgr, axis, indexer):
- mat = _as_array(mgr)
- taken = mgr.take(indexer, axis)
- tm.assert_numpy_array_equal(
- np.take(mat, indexer, axis), _as_array(taken), check_dtype=False
- )
- tm.assert_index_equal(mgr.axes[axis].take(indexer), taken.axes[axis])
-
- for ax in range(mgr.ndim):
- # take/fancy indexer
- assert_take_ok(mgr, ax, indexer=np.array([], dtype=np.intp))
- assert_take_ok(mgr, ax, indexer=np.array([0, 0, 0], dtype=np.intp))
- assert_take_ok(
- mgr, ax, indexer=np.array(list(range(mgr.shape[ax])), dtype=np.intp)
- )
-
- if mgr.shape[ax] >= 3:
- assert_take_ok(mgr, ax, indexer=np.array([0, 1, 2], dtype=np.intp))
- assert_take_ok(mgr, ax, indexer=np.array([-1, -2, -3], dtype=np.intp))
-
- @pytest.mark.parametrize("mgr", MANAGERS)
- @pytest.mark.parametrize("fill_value", [None, np.nan, 100.0])
- def test_reindex_axis(self, fill_value, mgr):
- def assert_reindex_axis_is_ok(mgr, axis, new_labels, fill_value):
- mat = _as_array(mgr)
- indexer = mgr.axes[axis].get_indexer_for(new_labels)
-
- reindexed = mgr.reindex_axis(new_labels, axis, fill_value=fill_value)
- tm.assert_numpy_array_equal(
- algos.take_nd(mat, indexer, axis, fill_value=fill_value),
- _as_array(reindexed),
- check_dtype=False,
- )
- tm.assert_index_equal(reindexed.axes[axis], new_labels)
-
- for ax in range(mgr.ndim):
- assert_reindex_axis_is_ok(mgr, ax, Index([]), fill_value)
- assert_reindex_axis_is_ok(mgr, ax, mgr.axes[ax], fill_value)
- assert_reindex_axis_is_ok(mgr, ax, mgr.axes[ax][[0, 0, 0]], fill_value)
- assert_reindex_axis_is_ok(mgr, ax, Index(["foo", "bar", "baz"]), fill_value)
- assert_reindex_axis_is_ok(
- mgr, ax, Index(["foo", mgr.axes[ax][0], "baz"]), fill_value
- )
-
- if mgr.shape[ax] >= 3:
- assert_reindex_axis_is_ok(mgr, ax, mgr.axes[ax][:-3], fill_value)
- assert_reindex_axis_is_ok(mgr, ax, mgr.axes[ax][-3::-1], fill_value)
- assert_reindex_axis_is_ok(
- mgr, ax, mgr.axes[ax][[0, 1, 2, 0, 1, 2]], fill_value
- )
-
- @pytest.mark.parametrize("mgr", MANAGERS)
- @pytest.mark.parametrize("fill_value", [None, np.nan, 100.0])
- def test_reindex_indexer(self, fill_value, mgr):
- def assert_reindex_indexer_is_ok(mgr, axis, new_labels, indexer, fill_value):
- mat = _as_array(mgr)
- reindexed_mat = algos.take_nd(mat, indexer, axis, fill_value=fill_value)
- reindexed = mgr.reindex_indexer(
- new_labels, indexer, axis, fill_value=fill_value
- )
- tm.assert_numpy_array_equal(
- reindexed_mat, _as_array(reindexed), check_dtype=False
- )
- tm.assert_index_equal(reindexed.axes[axis], new_labels)
-
- for ax in range(mgr.ndim):
- assert_reindex_indexer_is_ok(
- mgr, ax, Index([]), np.array([], dtype=np.intp), fill_value
- )
- assert_reindex_indexer_is_ok(
- mgr, ax, mgr.axes[ax], np.arange(mgr.shape[ax]), fill_value
- )
- assert_reindex_indexer_is_ok(
- mgr,
- ax,
- Index(["foo"] * mgr.shape[ax]),
- np.arange(mgr.shape[ax]),
- fill_value,
- )
- assert_reindex_indexer_is_ok(
- mgr, ax, mgr.axes[ax][::-1], np.arange(mgr.shape[ax]), fill_value
- )
- assert_reindex_indexer_is_ok(
- mgr, ax, mgr.axes[ax], np.arange(mgr.shape[ax])[::-1], fill_value
- )
- assert_reindex_indexer_is_ok(
- mgr, ax, Index(["foo", "bar", "baz"]), np.array([0, 0, 0]), fill_value
- )
- assert_reindex_indexer_is_ok(
- mgr, ax, Index(["foo", "bar", "baz"]), np.array([-1, 0, -1]), fill_value
- )
- assert_reindex_indexer_is_ok(
- mgr,
- ax,
- Index(["foo", mgr.axes[ax][0], "baz"]),
- np.array([-1, -1, -1]),
- fill_value,
- )
-
- if mgr.shape[ax] >= 3:
- assert_reindex_indexer_is_ok(
- mgr,
- ax,
- Index(["foo", "bar", "baz"]),
- np.array([0, 1, 2]),
- fill_value,
- )
-
-
-class TestBlockPlacement:
- @pytest.mark.parametrize(
- "slc, expected",
- [
- (slice(0, 4), 4),
- (slice(0, 4, 2), 2),
- (slice(0, 3, 2), 2),
- (slice(0, 1, 2), 1),
- (slice(1, 0, -1), 1),
- ],
- )
- def test_slice_len(self, slc, expected):
- assert len(BlockPlacement(slc)) == expected
-
- @pytest.mark.parametrize("slc", [slice(1, 1, 0), slice(1, 2, 0)])
- def test_zero_step_raises(self, slc):
- msg = "slice step cannot be zero"
- with pytest.raises(ValueError, match=msg):
- BlockPlacement(slc)
-
- def test_slice_canonize_negative_stop(self):
- # GH#37524 negative stop is OK with negative step and positive start
- slc = slice(3, -1, -2)
-
- bp = BlockPlacement(slc)
- assert bp.indexer == slice(3, None, -2)
-
- @pytest.mark.parametrize(
- "slc",
- [
- slice(None, None),
- slice(10, None),
- slice(None, None, -1),
- slice(None, 10, -1),
- # These are "unbounded" because negative index will
- # change depending on container shape.
- slice(-1, None),
- slice(None, -1),
- slice(-1, -1),
- slice(-1, None, -1),
- slice(None, -1, -1),
- slice(-1, -1, -1),
- ],
- )
- def test_unbounded_slice_raises(self, slc):
- msg = "unbounded slice"
- with pytest.raises(ValueError, match=msg):
- BlockPlacement(slc)
-
- @pytest.mark.parametrize(
- "slc",
- [
- slice(0, 0),
- slice(100, 0),
- slice(100, 100),
- slice(100, 100, -1),
- slice(0, 100, -1),
- ],
- )
- def test_not_slice_like_slices(self, slc):
- assert not BlockPlacement(slc).is_slice_like
-
- @pytest.mark.parametrize(
- "arr, slc",
- [
- ([0], slice(0, 1, 1)),
- ([100], slice(100, 101, 1)),
- ([0, 1, 2], slice(0, 3, 1)),
- ([0, 5, 10], slice(0, 15, 5)),
- ([0, 100], slice(0, 200, 100)),
- ([2, 1], slice(2, 0, -1)),
- ],
- )
- def test_array_to_slice_conversion(self, arr, slc):
- assert BlockPlacement(arr).as_slice == slc
-
- @pytest.mark.parametrize(
- "arr",
- [
- [],
- [-1],
- [-1, -2, -3],
- [-10],
- [-1],
- [-1, 0, 1, 2],
- [-2, 0, 2, 4],
- [1, 0, -1],
- [1, 1, 1],
- ],
- )
- def test_not_slice_like_arrays(self, arr):
- assert not BlockPlacement(arr).is_slice_like
-
- @pytest.mark.parametrize(
- "slc, expected",
- [(slice(0, 3), [0, 1, 2]), (slice(0, 0), []), (slice(3, 0), [])],
- )
- def test_slice_iter(self, slc, expected):
- assert list(BlockPlacement(slc)) == expected
-
- @pytest.mark.parametrize(
- "slc, arr",
- [
- (slice(0, 3), [0, 1, 2]),
- (slice(0, 0), []),
- (slice(3, 0), []),
- (slice(3, 0, -1), [3, 2, 1]),
- ],
- )
- def test_slice_to_array_conversion(self, slc, arr):
- tm.assert_numpy_array_equal(
- BlockPlacement(slc).as_array, np.asarray(arr, dtype=np.intp)
- )
-
- def test_blockplacement_add(self):
- bpl = BlockPlacement(slice(0, 5))
- assert bpl.add(1).as_slice == slice(1, 6, 1)
- assert bpl.add(np.arange(5)).as_slice == slice(0, 10, 2)
- assert list(bpl.add(np.arange(5, 0, -1))) == [5, 5, 5, 5, 5]
-
- @pytest.mark.parametrize(
- "val, inc, expected",
- [
- (slice(0, 0), 0, []),
- (slice(1, 4), 0, [1, 2, 3]),
- (slice(3, 0, -1), 0, [3, 2, 1]),
- ([1, 2, 4], 0, [1, 2, 4]),
- (slice(0, 0), 10, []),
- (slice(1, 4), 10, [11, 12, 13]),
- (slice(3, 0, -1), 10, [13, 12, 11]),
- ([1, 2, 4], 10, [11, 12, 14]),
- (slice(0, 0), -1, []),
- (slice(1, 4), -1, [0, 1, 2]),
- ([1, 2, 4], -1, [0, 1, 3]),
- ],
- )
- def test_blockplacement_add_int(self, val, inc, expected):
- assert list(BlockPlacement(val).add(inc)) == expected
-
- @pytest.mark.parametrize("val", [slice(1, 4), [1, 2, 4]])
- def test_blockplacement_add_int_raises(self, val):
- msg = "iadd causes length change"
- with pytest.raises(ValueError, match=msg):
- BlockPlacement(val).add(-10)
-
-
-class TestCanHoldElement:
- @pytest.fixture(
- params=[
- lambda x: x,
- lambda x: x.to_series(),
- lambda x: x._data,
- lambda x: list(x),
- lambda x: x.astype(object),
- lambda x: np.asarray(x),
- lambda x: x[0],
- lambda x: x[:0],
- ]
- )
- def element(self, request):
- """
- Functions that take an Index and return an element that should have
- blk._can_hold_element(element) for a Block with this index's dtype.
- """
- return request.param
-
- def test_datetime_block_can_hold_element(self):
- block = create_block("datetime", [0])
-
- assert block._can_hold_element([])
-
- # We will check that block._can_hold_element iff arr.__setitem__ works
- arr = pd.array(block.values.ravel())
-
- # coerce None
- assert block._can_hold_element(None)
- arr[0] = None
- assert arr[0] is pd.NaT
-
- # coerce different types of datetime objects
- vals = [np.datetime64("2010-10-10"), datetime(2010, 10, 10)]
- for val in vals:
- assert block._can_hold_element(val)
- arr[0] = val
-
- val = date(2010, 10, 10)
- assert not block._can_hold_element(val)
-
- msg = (
- "value should be a 'Timestamp', 'NaT', "
- "or array of those. Got 'date' instead."
- )
- with pytest.raises(TypeError, match=msg):
- arr[0] = val
-
- @pytest.mark.parametrize("dtype", [np.int64, np.uint64, np.float64])
- def test_interval_can_hold_element_emptylist(self, dtype, element):
- arr = np.array([1, 3, 4], dtype=dtype)
- ii = IntervalIndex.from_breaks(arr)
- blk = new_block(ii._data, BlockPlacement([1]), ndim=2)
-
- assert blk._can_hold_element([])
- # TODO: check this holds for all blocks
-
- @pytest.mark.parametrize("dtype", [np.int64, np.uint64, np.float64])
- def test_interval_can_hold_element(self, dtype, element):
- arr = np.array([1, 3, 4, 9], dtype=dtype)
- ii = IntervalIndex.from_breaks(arr)
- blk = new_block(ii._data, BlockPlacement([1]), ndim=2)
-
- elem = element(ii)
- self.check_series_setitem(elem, ii, True)
- assert blk._can_hold_element(elem)
-
- # Careful: to get the expected Series-inplace behavior we need
- # `elem` to not have the same length as `arr`
- ii2 = IntervalIndex.from_breaks(arr[:-1], closed="neither")
- elem = element(ii2)
- with tm.assert_produces_warning(FutureWarning):
- self.check_series_setitem(elem, ii, False)
- assert not blk._can_hold_element(elem)
-
- ii3 = IntervalIndex.from_breaks([Timestamp(1), Timestamp(3), Timestamp(4)])
- elem = element(ii3)
- with tm.assert_produces_warning(FutureWarning):
- self.check_series_setitem(elem, ii, False)
- assert not blk._can_hold_element(elem)
-
- ii4 = IntervalIndex.from_breaks([Timedelta(1), Timedelta(3), Timedelta(4)])
- elem = element(ii4)
- with tm.assert_produces_warning(FutureWarning):
- self.check_series_setitem(elem, ii, False)
- assert not blk._can_hold_element(elem)
-
- def test_period_can_hold_element_emptylist(self):
- pi = period_range("2016", periods=3, freq="A")
- blk = new_block(pi._data.reshape(1, 3), BlockPlacement([1]), ndim=2)
-
- assert blk._can_hold_element([])
-
- def test_period_can_hold_element(self, element):
- pi = period_range("2016", periods=3, freq="A")
-
- elem = element(pi)
- self.check_series_setitem(elem, pi, True)
-
- # Careful: to get the expected Series-inplace behavior we need
- # `elem` to not have the same length as `arr`
- pi2 = pi.asfreq("D")[:-1]
- elem = element(pi2)
- with tm.assert_produces_warning(FutureWarning):
- self.check_series_setitem(elem, pi, False)
-
- dti = pi.to_timestamp("S")[:-1]
- elem = element(dti)
- with tm.assert_produces_warning(FutureWarning):
- self.check_series_setitem(elem, pi, False)
-
- def check_can_hold_element(self, obj, elem, inplace: bool):
- blk = obj._mgr.blocks[0]
- if inplace:
- assert blk._can_hold_element(elem)
- else:
- assert not blk._can_hold_element(elem)
-
- def check_series_setitem(self, elem, index: Index, inplace: bool):
- arr = index._data.copy()
- ser = Series(arr, copy=False)
-
- self.check_can_hold_element(ser, elem, inplace)
-
- if is_scalar(elem):
- ser[0] = elem
- else:
- ser[: len(elem)] = elem
-
- if inplace:
- assert ser.array is arr # i.e. setting was done inplace
- else:
- assert ser.dtype == object
-
-
-class TestShouldStore:
- def test_should_store_categorical(self):
- cat = Categorical(["A", "B", "C"])
- df = DataFrame(cat)
- blk = df._mgr.blocks[0]
-
- # matching dtype
- assert blk.should_store(cat)
- assert blk.should_store(cat[:-1])
-
- # different dtype
- assert not blk.should_store(cat.as_ordered())
-
- # ndarray instead of Categorical
- assert not blk.should_store(np.asarray(cat))
-
-
-def test_validate_ndim():
- values = np.array([1.0, 2.0])
- placement = BlockPlacement(slice(2))
- msg = r"Wrong number of dimensions. values.ndim != ndim \[1 != 2\]"
-
- with pytest.raises(ValueError, match=msg):
- make_block(values, placement, ndim=2)
-
-
-def test_block_shape():
- idx = Index([0, 1, 2, 3, 4])
- a = Series([1, 2, 3]).reindex(idx)
- b = Series(Categorical([1, 2, 3])).reindex(idx)
-
- assert a._mgr.blocks[0].mgr_locs.indexer == b._mgr.blocks[0].mgr_locs.indexer
-
-
-def test_make_block_no_pandas_array(block_maker):
- # https://github.com/pandas-dev/pandas/pull/24866
- arr = pd.arrays.NumpyExtensionArray(np.array([1, 2]))
-
- # NumpyExtensionArray, no dtype
- result = block_maker(arr, BlockPlacement(slice(len(arr))), ndim=arr.ndim)
- assert result.dtype.kind in ["i", "u"]
-
- if block_maker is make_block:
- # new_block requires caller to unwrap NumpyExtensionArray
- assert result.is_extension is False
-
- # NumpyExtensionArray, NumpyEADtype
- result = block_maker(arr, slice(len(arr)), dtype=arr.dtype, ndim=arr.ndim)
- assert result.dtype.kind in ["i", "u"]
- assert result.is_extension is False
-
- # new_block no longer taked dtype keyword
- # ndarray, NumpyEADtype
- result = block_maker(
- arr.to_numpy(), slice(len(arr)), dtype=arr.dtype, ndim=arr.ndim
- )
- assert result.dtype.kind in ["i", "u"]
- assert result.is_extension is False
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pydantic/deprecated/decorator.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pydantic/deprecated/decorator.py
deleted file mode 100644
index 11244ba19f6d4bb527f4b2cc90c002ce69e7b758..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pydantic/deprecated/decorator.py
+++ /dev/null
@@ -1,279 +0,0 @@
-import warnings
-from functools import wraps
-from typing import TYPE_CHECKING, Any, Callable, Dict, List, Mapping, Optional, Tuple, Type, TypeVar, Union, overload
-
-from typing_extensions import deprecated
-
-from .._internal import _config, _typing_extra
-from ..alias_generators import to_pascal
-from ..errors import PydanticUserError
-from ..functional_validators import field_validator
-from ..main import BaseModel, create_model
-from ..warnings import PydanticDeprecatedSince20
-
-if not TYPE_CHECKING:
- # See PyCharm issues https://youtrack.jetbrains.com/issue/PY-21915
- # and https://youtrack.jetbrains.com/issue/PY-51428
- DeprecationWarning = PydanticDeprecatedSince20
-
-__all__ = ('validate_arguments',)
-
-if TYPE_CHECKING:
- AnyCallable = Callable[..., Any]
-
- AnyCallableT = TypeVar('AnyCallableT', bound=AnyCallable)
- ConfigType = Union[None, Type[Any], Dict[str, Any]]
-
-
-@overload
-@deprecated(
- 'The `validate_arguments` method is deprecated; use `validate_call` instead.', category=PydanticDeprecatedSince20
-)
-def validate_arguments(func: None = None, *, config: 'ConfigType' = None) -> Callable[['AnyCallableT'], 'AnyCallableT']:
- ...
-
-
-@overload
-@deprecated(
- 'The `validate_arguments` method is deprecated; use `validate_call` instead.', category=PydanticDeprecatedSince20
-)
-def validate_arguments(func: 'AnyCallableT') -> 'AnyCallableT':
- ...
-
-
-def validate_arguments(func: Optional['AnyCallableT'] = None, *, config: 'ConfigType' = None) -> Any:
- """Decorator to validate the arguments passed to a function."""
- warnings.warn(
- 'The `validate_arguments` method is deprecated; use `validate_call` instead.', DeprecationWarning, stacklevel=2
- )
-
- def validate(_func: 'AnyCallable') -> 'AnyCallable':
- vd = ValidatedFunction(_func, config)
-
- @wraps(_func)
- def wrapper_function(*args: Any, **kwargs: Any) -> Any:
- return vd.call(*args, **kwargs)
-
- wrapper_function.vd = vd # type: ignore
- wrapper_function.validate = vd.init_model_instance # type: ignore
- wrapper_function.raw_function = vd.raw_function # type: ignore
- wrapper_function.model = vd.model # type: ignore
- return wrapper_function
-
- if func:
- return validate(func)
- else:
- return validate
-
-
-ALT_V_ARGS = 'v__args'
-ALT_V_KWARGS = 'v__kwargs'
-V_POSITIONAL_ONLY_NAME = 'v__positional_only'
-V_DUPLICATE_KWARGS = 'v__duplicate_kwargs'
-
-
-class ValidatedFunction:
- def __init__(self, function: 'AnyCallable', config: 'ConfigType'):
- from inspect import Parameter, signature
-
- parameters: Mapping[str, Parameter] = signature(function).parameters
-
- if parameters.keys() & {ALT_V_ARGS, ALT_V_KWARGS, V_POSITIONAL_ONLY_NAME, V_DUPLICATE_KWARGS}:
- raise PydanticUserError(
- f'"{ALT_V_ARGS}", "{ALT_V_KWARGS}", "{V_POSITIONAL_ONLY_NAME}" and "{V_DUPLICATE_KWARGS}" '
- f'are not permitted as argument names when using the "{validate_arguments.__name__}" decorator',
- code=None,
- )
-
- self.raw_function = function
- self.arg_mapping: Dict[int, str] = {}
- self.positional_only_args: set[str] = set()
- self.v_args_name = 'args'
- self.v_kwargs_name = 'kwargs'
-
- type_hints = _typing_extra.get_type_hints(function, include_extras=True)
- takes_args = False
- takes_kwargs = False
- fields: Dict[str, Tuple[Any, Any]] = {}
- for i, (name, p) in enumerate(parameters.items()):
- if p.annotation is p.empty:
- annotation = Any
- else:
- annotation = type_hints[name]
-
- default = ... if p.default is p.empty else p.default
- if p.kind == Parameter.POSITIONAL_ONLY:
- self.arg_mapping[i] = name
- fields[name] = annotation, default
- fields[V_POSITIONAL_ONLY_NAME] = List[str], None
- self.positional_only_args.add(name)
- elif p.kind == Parameter.POSITIONAL_OR_KEYWORD:
- self.arg_mapping[i] = name
- fields[name] = annotation, default
- fields[V_DUPLICATE_KWARGS] = List[str], None
- elif p.kind == Parameter.KEYWORD_ONLY:
- fields[name] = annotation, default
- elif p.kind == Parameter.VAR_POSITIONAL:
- self.v_args_name = name
- fields[name] = Tuple[annotation, ...], None
- takes_args = True
- else:
- assert p.kind == Parameter.VAR_KEYWORD, p.kind
- self.v_kwargs_name = name
- fields[name] = Dict[str, annotation], None
- takes_kwargs = True
-
- # these checks avoid a clash between "args" and a field with that name
- if not takes_args and self.v_args_name in fields:
- self.v_args_name = ALT_V_ARGS
-
- # same with "kwargs"
- if not takes_kwargs and self.v_kwargs_name in fields:
- self.v_kwargs_name = ALT_V_KWARGS
-
- if not takes_args:
- # we add the field so validation below can raise the correct exception
- fields[self.v_args_name] = List[Any], None
-
- if not takes_kwargs:
- # same with kwargs
- fields[self.v_kwargs_name] = Dict[Any, Any], None
-
- self.create_model(fields, takes_args, takes_kwargs, config)
-
- def init_model_instance(self, *args: Any, **kwargs: Any) -> BaseModel:
- values = self.build_values(args, kwargs)
- return self.model(**values)
-
- def call(self, *args: Any, **kwargs: Any) -> Any:
- m = self.init_model_instance(*args, **kwargs)
- return self.execute(m)
-
- def build_values(self, args: Tuple[Any, ...], kwargs: Dict[str, Any]) -> Dict[str, Any]:
- values: Dict[str, Any] = {}
- if args:
- arg_iter = enumerate(args)
- while True:
- try:
- i, a = next(arg_iter)
- except StopIteration:
- break
- arg_name = self.arg_mapping.get(i)
- if arg_name is not None:
- values[arg_name] = a
- else:
- values[self.v_args_name] = [a] + [a for _, a in arg_iter]
- break
-
- var_kwargs: Dict[str, Any] = {}
- wrong_positional_args = []
- duplicate_kwargs = []
- fields_alias = [
- field.alias
- for name, field in self.model.model_fields.items()
- if name not in (self.v_args_name, self.v_kwargs_name)
- ]
- non_var_fields = set(self.model.model_fields) - {self.v_args_name, self.v_kwargs_name}
- for k, v in kwargs.items():
- if k in non_var_fields or k in fields_alias:
- if k in self.positional_only_args:
- wrong_positional_args.append(k)
- if k in values:
- duplicate_kwargs.append(k)
- values[k] = v
- else:
- var_kwargs[k] = v
-
- if var_kwargs:
- values[self.v_kwargs_name] = var_kwargs
- if wrong_positional_args:
- values[V_POSITIONAL_ONLY_NAME] = wrong_positional_args
- if duplicate_kwargs:
- values[V_DUPLICATE_KWARGS] = duplicate_kwargs
- return values
-
- def execute(self, m: BaseModel) -> Any:
- d = {k: v for k, v in m.__dict__.items() if k in m.__pydantic_fields_set__ or m.model_fields[k].default_factory}
- var_kwargs = d.pop(self.v_kwargs_name, {})
-
- if self.v_args_name in d:
- args_: List[Any] = []
- in_kwargs = False
- kwargs = {}
- for name, value in d.items():
- if in_kwargs:
- kwargs[name] = value
- elif name == self.v_args_name:
- args_ += value
- in_kwargs = True
- else:
- args_.append(value)
- return self.raw_function(*args_, **kwargs, **var_kwargs)
- elif self.positional_only_args:
- args_ = []
- kwargs = {}
- for name, value in d.items():
- if name in self.positional_only_args:
- args_.append(value)
- else:
- kwargs[name] = value
- return self.raw_function(*args_, **kwargs, **var_kwargs)
- else:
- return self.raw_function(**d, **var_kwargs)
-
- def create_model(self, fields: Dict[str, Any], takes_args: bool, takes_kwargs: bool, config: 'ConfigType') -> None:
- pos_args = len(self.arg_mapping)
-
- config_wrapper = _config.ConfigWrapper(config)
-
- if config_wrapper.alias_generator:
- raise PydanticUserError(
- 'Setting the "alias_generator" property on custom Config for '
- '@validate_arguments is not yet supported, please remove.',
- code=None,
- )
- if config_wrapper.extra is None:
- config_wrapper.config_dict['extra'] = 'forbid'
-
- class DecoratorBaseModel(BaseModel):
- @field_validator(self.v_args_name, check_fields=False)
- @classmethod
- def check_args(cls, v: Optional[List[Any]]) -> Optional[List[Any]]:
- if takes_args or v is None:
- return v
-
- raise TypeError(f'{pos_args} positional arguments expected but {pos_args + len(v)} given')
-
- @field_validator(self.v_kwargs_name, check_fields=False)
- @classmethod
- def check_kwargs(cls, v: Optional[Dict[str, Any]]) -> Optional[Dict[str, Any]]:
- if takes_kwargs or v is None:
- return v
-
- plural = '' if len(v) == 1 else 's'
- keys = ', '.join(map(repr, v.keys()))
- raise TypeError(f'unexpected keyword argument{plural}: {keys}')
-
- @field_validator(V_POSITIONAL_ONLY_NAME, check_fields=False)
- @classmethod
- def check_positional_only(cls, v: Optional[List[str]]) -> None:
- if v is None:
- return
-
- plural = '' if len(v) == 1 else 's'
- keys = ', '.join(map(repr, v))
- raise TypeError(f'positional-only argument{plural} passed as keyword argument{plural}: {keys}')
-
- @field_validator(V_DUPLICATE_KWARGS, check_fields=False)
- @classmethod
- def check_duplicate_kwargs(cls, v: Optional[List[str]]) -> None:
- if v is None:
- return
-
- plural = '' if len(v) == 1 else 's'
- keys = ', '.join(map(repr, v))
- raise TypeError(f'multiple values for argument{plural}: {keys}')
-
- model_config = config_wrapper.config_dict
-
- self.model = create_model(to_pascal(self.raw_function.__name__), __base__=DecoratorBaseModel, **fields)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/formatters/other.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/formatters/other.py
deleted file mode 100644
index 8004764371aa0de9c4bfb90c01bb7d17266f8215..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/formatters/other.py
+++ /dev/null
@@ -1,161 +0,0 @@
-"""
- pygments.formatters.other
- ~~~~~~~~~~~~~~~~~~~~~~~~~
-
- Other formatters: NullFormatter, RawTokenFormatter.
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-from pygments.formatter import Formatter
-from pygments.util import get_choice_opt
-from pygments.token import Token
-from pygments.console import colorize
-
-__all__ = ['NullFormatter', 'RawTokenFormatter', 'TestcaseFormatter']
-
-
-class NullFormatter(Formatter):
- """
- Output the text unchanged without any formatting.
- """
- name = 'Text only'
- aliases = ['text', 'null']
- filenames = ['*.txt']
-
- def format(self, tokensource, outfile):
- enc = self.encoding
- for ttype, value in tokensource:
- if enc:
- outfile.write(value.encode(enc))
- else:
- outfile.write(value)
-
-
-class RawTokenFormatter(Formatter):
- r"""
- Format tokens as a raw representation for storing token streams.
-
- The format is ``tokentyperepr(tokenstring)\n``. The output can later
- be converted to a token stream with the `RawTokenLexer`, described in the
- :doc:`lexer list `.
-
- Only two options are accepted:
-
- `compress`
- If set to ``'gz'`` or ``'bz2'``, compress the output with the given
- compression algorithm after encoding (default: ``''``).
- `error_color`
- If set to a color name, highlight error tokens using that color. If
- set but with no value, defaults to ``'red'``.
-
- .. versionadded:: 0.11
-
- """
- name = 'Raw tokens'
- aliases = ['raw', 'tokens']
- filenames = ['*.raw']
-
- unicodeoutput = False
-
- def __init__(self, **options):
- Formatter.__init__(self, **options)
- # We ignore self.encoding if it is set, since it gets set for lexer
- # and formatter if given with -Oencoding on the command line.
- # The RawTokenFormatter outputs only ASCII. Override here.
- self.encoding = 'ascii' # let pygments.format() do the right thing
- self.compress = get_choice_opt(options, 'compress',
- ['', 'none', 'gz', 'bz2'], '')
- self.error_color = options.get('error_color', None)
- if self.error_color is True:
- self.error_color = 'red'
- if self.error_color is not None:
- try:
- colorize(self.error_color, '')
- except KeyError:
- raise ValueError("Invalid color %r specified" %
- self.error_color)
-
- def format(self, tokensource, outfile):
- try:
- outfile.write(b'')
- except TypeError:
- raise TypeError('The raw tokens formatter needs a binary '
- 'output file')
- if self.compress == 'gz':
- import gzip
- outfile = gzip.GzipFile('', 'wb', 9, outfile)
-
- write = outfile.write
- flush = outfile.close
- elif self.compress == 'bz2':
- import bz2
- compressor = bz2.BZ2Compressor(9)
-
- def write(text):
- outfile.write(compressor.compress(text))
-
- def flush():
- outfile.write(compressor.flush())
- outfile.flush()
- else:
- write = outfile.write
- flush = outfile.flush
-
- if self.error_color:
- for ttype, value in tokensource:
- line = b"%r\t%r\n" % (ttype, value)
- if ttype is Token.Error:
- write(colorize(self.error_color, line))
- else:
- write(line)
- else:
- for ttype, value in tokensource:
- write(b"%r\t%r\n" % (ttype, value))
- flush()
-
-
-TESTCASE_BEFORE = '''\
- def testNeedsName(lexer):
- fragment = %r
- tokens = [
-'''
-TESTCASE_AFTER = '''\
- ]
- assert list(lexer.get_tokens(fragment)) == tokens
-'''
-
-
-class TestcaseFormatter(Formatter):
- """
- Format tokens as appropriate for a new testcase.
-
- .. versionadded:: 2.0
- """
- name = 'Testcase'
- aliases = ['testcase']
-
- def __init__(self, **options):
- Formatter.__init__(self, **options)
- if self.encoding is not None and self.encoding != 'utf-8':
- raise ValueError("Only None and utf-8 are allowed encodings.")
-
- def format(self, tokensource, outfile):
- indentation = ' ' * 12
- rawbuf = []
- outbuf = []
- for ttype, value in tokensource:
- rawbuf.append(value)
- outbuf.append('%s(%s, %r),\n' % (indentation, ttype, value))
-
- before = TESTCASE_BEFORE % (''.join(rawbuf),)
- during = ''.join(outbuf)
- after = TESTCASE_AFTER
- if self.encoding is None:
- outfile.write(before + during + after)
- else:
- outfile.write(before.encode('utf-8'))
- outfile.write(during.encode('utf-8'))
- outfile.write(after.encode('utf-8'))
- outfile.flush()
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/crystal.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/crystal.py
deleted file mode 100644
index 6ebf2f61e9a2bfed15e8811f547f1221ee1698fc..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/crystal.py
+++ /dev/null
@@ -1,365 +0,0 @@
-"""
- pygments.lexers.crystal
- ~~~~~~~~~~~~~~~~~~~~~~~
-
- Lexer for Crystal.
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-import re
-
-from pygments.lexer import ExtendedRegexLexer, include, bygroups, default, \
- words, line_re
-from pygments.token import Comment, Operator, Keyword, Name, String, Number, \
- Punctuation, Error, Whitespace
-
-__all__ = ['CrystalLexer']
-
-
-CRYSTAL_OPERATORS = [
- '!=', '!~', '!', '%', '&&', '&', '**', '*', '+', '-', '/', '<=>', '<<', '<=', '<',
- '===', '==', '=~', '=', '>=', '>>', '>', '[]=', '[]?', '[]', '^', '||', '|', '~'
-]
-
-
-class CrystalLexer(ExtendedRegexLexer):
- """
- For Crystal source code.
-
- .. versionadded:: 2.2
- """
-
- name = 'Crystal'
- url = 'http://crystal-lang.org'
- aliases = ['cr', 'crystal']
- filenames = ['*.cr']
- mimetypes = ['text/x-crystal']
-
- flags = re.DOTALL | re.MULTILINE
-
- def heredoc_callback(self, match, ctx):
- # okay, this is the hardest part of parsing Crystal...
- # match: 1 = <<-?, 2 = quote? 3 = name 4 = quote? 5 = rest of line
-
- start = match.start(1)
- yield start, Operator, match.group(1) # <<-?
- yield match.start(2), String.Heredoc, match.group(2) # quote ", ', `
- yield match.start(3), String.Delimiter, match.group(3) # heredoc name
- yield match.start(4), String.Heredoc, match.group(4) # quote again
-
- heredocstack = ctx.__dict__.setdefault('heredocstack', [])
- outermost = not bool(heredocstack)
- heredocstack.append((match.group(1) == '<<-', match.group(3)))
-
- ctx.pos = match.start(5)
- ctx.end = match.end(5)
- # this may find other heredocs, so limit the recursion depth
- if len(heredocstack) < 100:
- yield from self.get_tokens_unprocessed(context=ctx)
- else:
- yield ctx.pos, String.Heredoc, match.group(5)
- ctx.pos = match.end()
-
- if outermost:
- # this is the outer heredoc again, now we can process them all
- for tolerant, hdname in heredocstack:
- lines = []
- for match in line_re.finditer(ctx.text, ctx.pos):
- if tolerant:
- check = match.group().strip()
- else:
- check = match.group().rstrip()
- if check == hdname:
- for amatch in lines:
- yield amatch.start(), String.Heredoc, amatch.group()
- yield match.start(), String.Delimiter, match.group()
- ctx.pos = match.end()
- break
- else:
- lines.append(match)
- else:
- # end of heredoc not found -- error!
- for amatch in lines:
- yield amatch.start(), Error, amatch.group()
- ctx.end = len(ctx.text)
- del heredocstack[:]
-
- def gen_crystalstrings_rules():
- states = {}
- states['strings'] = [
- (r'\:\w+[!?]?', String.Symbol),
- (words(CRYSTAL_OPERATORS, prefix=r'\:'), String.Symbol),
- (r":'(\\\\|\\[^\\]|[^'\\])*'", String.Symbol),
- # This allows arbitrary text after '\ for simplicity
- (r"'(\\\\|\\'|[^']|\\[^'\\]+)'", String.Char),
- (r':"', String.Symbol, 'simple-sym'),
- # Crystal doesn't have "symbol:"s but this simplifies function args
- (r'([a-zA-Z_]\w*)(:)(?!:)', bygroups(String.Symbol, Punctuation)),
- (r'"', String.Double, 'simple-string'),
- (r'(?', '<>', 'ab'), \
- ('\\|', '\\|', '\\|', 'pi'):
- states[name+'-intp-string'] = [
- (r'\\' + lbrace, String.Other),
- ] + (lbrace != rbrace) * [
- (lbrace, String.Other, '#push'),
- ] + [
- (rbrace, String.Other, '#pop'),
- include('string-intp-escaped'),
- (r'[\\#' + bracecc + ']', String.Other),
- (r'[^\\#' + bracecc + ']+', String.Other),
- ]
- states['strings'].append((r'%Q?' + lbrace, String.Other,
- name+'-intp-string'))
- states[name+'-string'] = [
- (r'\\[\\' + bracecc + ']', String.Other),
- ] + (lbrace != rbrace) * [
- (lbrace, String.Other, '#push'),
- ] + [
- (rbrace, String.Other, '#pop'),
- (r'[\\#' + bracecc + ']', String.Other),
- (r'[^\\#' + bracecc + ']+', String.Other),
- ]
- # https://crystal-lang.org/docs/syntax_and_semantics/literals/array.html#percent-array-literals
- states['strings'].append((r'%[qwi]' + lbrace, String.Other,
- name+'-string'))
- states[name+'-regex'] = [
- (r'\\[\\' + bracecc + ']', String.Regex),
- ] + (lbrace != rbrace) * [
- (lbrace, String.Regex, '#push'),
- ] + [
- (rbrace + '[imsx]*', String.Regex, '#pop'),
- include('string-intp'),
- (r'[\\#' + bracecc + ']', String.Regex),
- (r'[^\\#' + bracecc + ']+', String.Regex),
- ]
- states['strings'].append((r'%r' + lbrace, String.Regex,
- name+'-regex'))
-
- return states
-
- tokens = {
- 'root': [
- (r'#.*?$', Comment.Single),
- # keywords
- (words('''
- abstract asm begin break case do else elsif end ensure extend if in
- include next of private protected require rescue return select self super
- then unless until when while with yield
- '''.split(), suffix=r'\b'), Keyword),
- (words('''
- previous_def forall out uninitialized __DIR__ __FILE__ __LINE__
- __END_LINE__
- '''.split(), prefix=r'(?=])', Keyword, 'funcname'),
- (r'(annotation|class|struct|union|type|alias|enum)(\s+)((?:[a-zA-Z_]\w*::)*)',
- bygroups(Keyword, Whitespace, Name.Namespace), 'classname'),
- # https://crystal-lang.org/api/toplevel.html
- (words('''
- instance_sizeof offsetof pointerof sizeof typeof
- '''.split(), prefix=r'(?~!:])|'
- r'(?<=(?:\s|;)when\s)|'
- r'(?<=(?:\s|;)or\s)|'
- r'(?<=(?:\s|;)and\s)|'
- r'(?<=\.index\s)|'
- r'(?<=\.scan\s)|'
- r'(?<=\.sub\s)|'
- r'(?<=\.sub!\s)|'
- r'(?<=\.gsub\s)|'
- r'(?<=\.gsub!\s)|'
- r'(?<=\.match\s)|'
- r'(?<=(?:\s|;)if\s)|'
- r'(?<=(?:\s|;)elsif\s)|'
- r'(?<=^when\s)|'
- r'(?<=^index\s)|'
- r'(?<=^scan\s)|'
- r'(?<=^sub\s)|'
- r'(?<=^gsub\s)|'
- r'(?<=^sub!\s)|'
- r'(?<=^gsub!\s)|'
- r'(?<=^match\s)|'
- r'(?<=^if\s)|'
- r'(?<=^elsif\s)'
- r')(\s*)(/)', bygroups(Whitespace, String.Regex), 'multiline-regex'),
- # multiline regex (in method calls or subscripts)
- (r'(?<=\(|,|\[)/', String.Regex, 'multiline-regex'),
- # multiline regex (this time the funny no whitespace rule)
- (r'(\s+)(/)(?![\s=])', bygroups(Whitespace, String.Regex),
- 'multiline-regex'),
- # lex numbers and ignore following regular expressions which
- # are division operators in fact (grrrr. i hate that. any
- # better ideas?)
- # since pygments 0.7 we also eat a "?" operator after numbers
- # so that the char operator does not work. Chars are not allowed
- # there so that you can use the ternary operator.
- # stupid example:
- # x>=0?n[x]:""
- (r'(0o[0-7]+(?:_[0-7]+)*(?:_?[iu][0-9]+)?)\b(\s*)([/?])?',
- bygroups(Number.Oct, Whitespace, Operator)),
- (r'(0x[0-9A-Fa-f]+(?:_[0-9A-Fa-f]+)*(?:_?[iu][0-9]+)?)\b(\s*)([/?])?',
- bygroups(Number.Hex, Whitespace, Operator)),
- (r'(0b[01]+(?:_[01]+)*(?:_?[iu][0-9]+)?)\b(\s*)([/?])?',
- bygroups(Number.Bin, Whitespace, Operator)),
- # 3 separate expressions for floats because any of the 3 optional
- # parts makes it a float
- (r'((?:0(?![0-9])|[1-9][\d_]*)(?:\.\d[\d_]*)(?:e[+-]?[0-9]+)?'
- r'(?:_?f[0-9]+)?)(\s*)([/?])?',
- bygroups(Number.Float, Whitespace, Operator)),
- (r'((?:0(?![0-9])|[1-9][\d_]*)(?:\.\d[\d_]*)?(?:e[+-]?[0-9]+)'
- r'(?:_?f[0-9]+)?)(\s*)([/?])?',
- bygroups(Number.Float, Whitespace, Operator)),
- (r'((?:0(?![0-9])|[1-9][\d_]*)(?:\.\d[\d_]*)?(?:e[+-]?[0-9]+)?'
- r'(?:_?f[0-9]+))(\s*)([/?])?',
- bygroups(Number.Float, Whitespace, Operator)),
- (r'(0\b|[1-9][\d]*(?:_\d+)*(?:_?[iu][0-9]+)?)\b(\s*)([/?])?',
- bygroups(Number.Integer, Whitespace, Operator)),
- # Names
- (r'@@[a-zA-Z_]\w*', Name.Variable.Class),
- (r'@[a-zA-Z_]\w*', Name.Variable.Instance),
- (r'\$\w+', Name.Variable.Global),
- (r'\$[!@&`\'+~=/\\,;.<>_*$?:"^-]', Name.Variable.Global),
- (r'\$-[0adFiIlpvw]', Name.Variable.Global),
- (r'::', Operator),
- include('strings'),
- # https://crystal-lang.org/reference/syntax_and_semantics/literals/char.html
- (r'\?(\\[MC]-)*' # modifiers
- r'(\\([\\abefnrtv#"\']|[0-7]{1,3}|x[a-fA-F0-9]{2}|u[a-fA-F0-9]{4}|u\{[a-fA-F0-9 ]+\})|\S)'
- r'(?!\w)',
- String.Char),
- (r'[A-Z][A-Z_]+\b(?!::|\.)', Name.Constant),
- # macro expansion
- (r'\{%', String.Interpol, 'in-macro-control'),
- (r'\{\{', String.Interpol, 'in-macro-expr'),
- # annotations
- (r'(@\[)(\s*)([A-Z]\w*(::[A-Z]\w*)*)',
- bygroups(Operator, Whitespace, Name.Decorator), 'in-annot'),
- # this is needed because Crystal attributes can look
- # like keywords (class) or like this: ` ?!?
- (words(CRYSTAL_OPERATORS, prefix=r'(\.|::)'),
- bygroups(Operator, Name.Operator)),
- (r'(\.|::)([a-zA-Z_]\w*[!?]?|[*%&^`~+\-/\[<>=])',
- bygroups(Operator, Name)),
- # Names can end with [!?] unless it's "!="
- (r'[a-zA-Z_]\w*(?:[!?](?!=))?', Name),
- (r'(\[|\]\??|\*\*|<=>?|>=|<>?|=~|===|'
- r'!~|&&?|\|\||\.{1,3})', Operator),
- (r'[-+/*%=<>&!^|~]=?', Operator),
- (r'[(){};,/?:\\]', Punctuation),
- (r'\s+', Whitespace)
- ],
- 'funcname': [
- (r'(?:([a-zA-Z_]\w*)(\.))?'
- r'([a-zA-Z_]\w*[!?]?|\*\*?|[-+]@?|'
- r'[/%&|^`~]|\[\]=?|<<|>>|<=?>|>=?|===?)',
- bygroups(Name.Class, Operator, Name.Function), '#pop'),
- default('#pop')
- ],
- 'classname': [
- (r'[A-Z_]\w*', Name.Class),
- (r'(\()(\s*)([A-Z_]\w*)(\s*)(\))',
- bygroups(Punctuation, Whitespace, Name.Class, Whitespace, Punctuation)),
- default('#pop')
- ],
- 'in-intp': [
- (r'\{', String.Interpol, '#push'),
- (r'\}', String.Interpol, '#pop'),
- include('root'),
- ],
- 'string-intp': [
- (r'#\{', String.Interpol, 'in-intp'),
- ],
- 'string-escaped': [
- # https://crystal-lang.org/reference/syntax_and_semantics/literals/string.html
- (r'\\([\\abefnrtv#"\']|[0-7]{1,3}|x[a-fA-F0-9]{2}|u[a-fA-F0-9]{4}|u\{[a-fA-F0-9 ]+\})',
- String.Escape)
- ],
- 'string-intp-escaped': [
- include('string-intp'),
- include('string-escaped'),
- ],
- 'interpolated-regex': [
- include('string-intp'),
- (r'[\\#]', String.Regex),
- (r'[^\\#]+', String.Regex),
- ],
- 'interpolated-string': [
- include('string-intp'),
- (r'[\\#]', String.Other),
- (r'[^\\#]+', String.Other),
- ],
- 'multiline-regex': [
- include('string-intp'),
- (r'\\\\', String.Regex),
- (r'\\/', String.Regex),
- (r'[\\#]', String.Regex),
- (r'[^\\/#]+', String.Regex),
- (r'/[imsx]*', String.Regex, '#pop'),
- ],
- 'end-part': [
- (r'.+', Comment.Preproc, '#pop')
- ],
- 'in-macro-control': [
- (r'\{%', String.Interpol, '#push'),
- (r'%\}', String.Interpol, '#pop'),
- (r'(for|verbatim)\b', Keyword),
- include('root'),
- ],
- 'in-macro-expr': [
- (r'\{\{', String.Interpol, '#push'),
- (r'\}\}', String.Interpol, '#pop'),
- include('root'),
- ],
- 'in-annot': [
- (r'\[', Operator, '#push'),
- (r'\]', Operator, '#pop'),
- include('root'),
- ],
- }
- tokens.update(gen_crystalstrings_rules())
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/lilypond.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/lilypond.py
deleted file mode 100644
index 6b4ed20d9ece0fb5b8815358d5d1c0a6aec6e56b..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/lilypond.py
+++ /dev/null
@@ -1,226 +0,0 @@
-"""
- pygments.lexers.lilypond
- ~~~~~~~~~~~~~~~~~~~~~~~~
-
- Lexer for LilyPond.
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-import re
-
-from pygments.lexer import bygroups, default, inherit, words
-from pygments.lexers.lisp import SchemeLexer
-from pygments.lexers._lilypond_builtins import (
- keywords, pitch_language_names, clefs, scales, repeat_types, units,
- chord_modifiers, pitches, music_functions, dynamics, articulations,
- music_commands, markup_commands, grobs, translators, contexts,
- context_properties, grob_properties, scheme_functions, paper_variables,
- header_variables
-)
-from pygments.token import Token
-
-__all__ = ["LilyPondLexer"]
-
-# In LilyPond, (unquoted) name tokens only contain letters, hyphens,
-# and underscores, where hyphens and underscores must not start or end
-# a name token.
-#
-# Note that many of the entities listed as LilyPond built-in keywords
-# (in file `_lilypond_builtins.py`) are only valid if surrounded by
-# double quotes, for example, 'hufnagel-fa1'. This means that
-# `NAME_END_RE` doesn't apply to such entities in valid LilyPond code.
-NAME_END_RE = r"(?=\d|[^\w\-]|[\-_][\W\d])"
-
-def builtin_words(names, backslash, suffix=NAME_END_RE):
- prefix = r"[\-_^]?"
- if backslash == "mandatory":
- prefix += r"\\"
- elif backslash == "optional":
- prefix += r"\\?"
- else:
- assert backslash == "disallowed"
- return words(names, prefix, suffix)
-
-
-class LilyPondLexer(SchemeLexer):
- """
- Lexer for input to LilyPond, a text-based music typesetter.
-
- .. important::
-
- This lexer is meant to be used in conjunction with the ``lilypond`` style.
-
- .. versionadded:: 2.11
- """
- name = 'LilyPond'
- url = 'https://lilypond.org'
- aliases = ['lilypond']
- filenames = ['*.ly']
- mimetypes = []
-
- flags = re.DOTALL | re.MULTILINE
-
- # Because parsing LilyPond input is very tricky (and in fact
- # impossible without executing LilyPond when there is Scheme
- # code in the file), this lexer does not try to recognize
- # lexical modes. Instead, it catches the most frequent pieces
- # of syntax, and, above all, knows about many kinds of builtins.
-
- # In order to parse embedded Scheme, this lexer subclasses the SchemeLexer.
- # It redefines the 'root' state entirely, and adds a rule for #{ #}
- # to the 'value' state. The latter is used to parse a Scheme expression
- # after #.
-
- def get_tokens_unprocessed(self, text):
- """Highlight Scheme variables as LilyPond builtins when applicable."""
- for index, token, value in super().get_tokens_unprocessed(text):
- if token is Token.Name.Function or token is Token.Name.Variable:
- if value in scheme_functions:
- token = Token.Name.Builtin.SchemeFunction
- elif token is Token.Name.Builtin:
- token = Token.Name.Builtin.SchemeBuiltin
- yield index, token, value
-
- tokens = {
- "root": [
- # Whitespace.
- (r"\s+", Token.Text.Whitespace),
-
- # Multi-line comments. These are non-nestable.
- (r"%\{.*?%\}", Token.Comment.Multiline),
-
- # Simple comments.
- (r"%.*?$", Token.Comment.Single),
-
- # End of embedded LilyPond in Scheme.
- (r"#\}", Token.Punctuation, "#pop"),
-
- # Embedded Scheme, starting with # ("delayed"),
- # or $ (immediate). #@ and and $@ are the lesser known
- # "list splicing operators".
- (r"[#$]@?", Token.Punctuation, "value"),
-
- # Any kind of punctuation:
- # - sequential music: { },
- # - parallel music: << >>,
- # - voice separator: << \\ >>,
- # - chord: < >,
- # - bar check: |,
- # - dot in nested properties: \revert NoteHead.color,
- # - equals sign in assignments and lists for various commands:
- # \override Stem.color = red,
- # - comma as alternative syntax for lists: \time 3,3,2 4/4,
- # - colon in tremolos: c:32,
- # - double hyphen and underscore in lyrics: li -- ly -- pond __
- # (which must be preceded by ASCII whitespace)
- (r"""(?x)
- \\\\
- | (?<= \s ) (?: -- | __ )
- | [{}<>=.,:|]
- """, Token.Punctuation),
-
- # Pitches, with optional octavation marks, octave check,
- # and forced or cautionary accidental.
- (words(pitches, suffix=r"=?[',]*!?\??" + NAME_END_RE), Token.Pitch),
-
- # Strings, optionally with direction specifier.
- (r'[\-_^]?"', Token.String, "string"),
-
- # Numbers.
- (r"-?\d+\.\d+", Token.Number.Float), # 5. and .5 are not allowed
- (r"-?\d+/\d+", Token.Number.Fraction),
- # Integers, or durations with optional augmentation dots.
- # We have no way to distinguish these, so we highlight
- # them all as numbers.
- #
- # Normally, there is a space before the integer (being an
- # argument to a music function), which we check here. The
- # case without a space is handled below (as a fingering
- # number).
- (r"""(?x)
- (?<= \s ) -\d+
- | (?: (?: \d+ | \\breve | \\longa | \\maxima )
- \.* )
- """, Token.Number),
- # Separates duration and duration multiplier highlighted as fraction.
- (r"\*", Token.Number),
-
- # Ties, slurs, manual beams.
- (r"[~()[\]]", Token.Name.Builtin.Articulation),
-
- # Predefined articulation shortcuts. A direction specifier is
- # required here.
- (r"[\-_^][>^_!.\-+]", Token.Name.Builtin.Articulation),
-
- # Fingering numbers, string numbers.
- (r"[\-_^]?\\?\d+", Token.Name.Builtin.Articulation),
-
- # Builtins.
- (builtin_words(keywords, "mandatory"), Token.Keyword),
- (builtin_words(pitch_language_names, "disallowed"), Token.Name.PitchLanguage),
- (builtin_words(clefs, "disallowed"), Token.Name.Builtin.Clef),
- (builtin_words(scales, "mandatory"), Token.Name.Builtin.Scale),
- (builtin_words(repeat_types, "disallowed"), Token.Name.Builtin.RepeatType),
- (builtin_words(units, "mandatory"), Token.Number),
- (builtin_words(chord_modifiers, "disallowed"), Token.ChordModifier),
- (builtin_words(music_functions, "mandatory"), Token.Name.Builtin.MusicFunction),
- (builtin_words(dynamics, "mandatory"), Token.Name.Builtin.Dynamic),
- # Those like slurs that don't take a backslash are covered above.
- (builtin_words(articulations, "mandatory"), Token.Name.Builtin.Articulation),
- (builtin_words(music_commands, "mandatory"), Token.Name.Builtin.MusicCommand),
- (builtin_words(markup_commands, "mandatory"), Token.Name.Builtin.MarkupCommand),
- (builtin_words(grobs, "disallowed"), Token.Name.Builtin.Grob),
- (builtin_words(translators, "disallowed"), Token.Name.Builtin.Translator),
- # Optional backslash because of \layout { \context { \Score ... } }.
- (builtin_words(contexts, "optional"), Token.Name.Builtin.Context),
- (builtin_words(context_properties, "disallowed"), Token.Name.Builtin.ContextProperty),
- (builtin_words(grob_properties, "disallowed"),
- Token.Name.Builtin.GrobProperty,
- "maybe-subproperties"),
- # Optional backslashes here because output definitions are wrappers
- # around modules. Concretely, you can do, e.g.,
- # \paper { oddHeaderMarkup = \evenHeaderMarkup }
- (builtin_words(paper_variables, "optional"), Token.Name.Builtin.PaperVariable),
- (builtin_words(header_variables, "optional"), Token.Name.Builtin.HeaderVariable),
-
- # Other backslashed-escaped names (like dereferencing a
- # music variable), possibly with a direction specifier.
- (r"[\-_^]?\\.+?" + NAME_END_RE, Token.Name.BackslashReference),
-
- # Definition of a variable. Support assignments to alist keys
- # (myAlist.my-key.my-nested-key = \markup \spam \eggs).
- (r"""(?x)
- (?: [^\W\d] | - )+
- (?= (?: [^\W\d] | [\-.] )* \s* = )
- """, Token.Name.Lvalue),
-
- # Virtually everything can appear in markup mode, so we highlight
- # as text. Try to get a complete word, or we might wrongly lex
- # a suffix that happens to be a builtin as a builtin (e.g., "myStaff").
- (r"([^\W\d]|-)+?" + NAME_END_RE, Token.Text),
- (r".", Token.Text),
- ],
- "string": [
- (r'"', Token.String, "#pop"),
- (r'\\.', Token.String.Escape),
- (r'[^\\"]+', Token.String),
- ],
- "value": [
- # Scan a LilyPond value, then pop back since we had a
- # complete expression.
- (r"#\{", Token.Punctuation, ("#pop", "root")),
- inherit,
- ],
- # Grob subproperties are undeclared and it would be tedious
- # to maintain them by hand. Instead, this state allows recognizing
- # everything that looks like a-known-property.foo.bar-baz as
- # one single property name.
- "maybe-subproperties": [
- (r"\s+", Token.Text.Whitespace),
- (r"(\.)((?:[^\W\d]|-)+?)" + NAME_END_RE,
- bygroups(Token.Punctuation, Token.Name.Builtin.GrobProperty)),
- default("#pop"),
- ]
- }
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/robotframework.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/robotframework.py
deleted file mode 100644
index 3b676cce2a71e7035a1c5c42130cdd0a5e96ad59..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/robotframework.py
+++ /dev/null
@@ -1,552 +0,0 @@
-"""
- pygments.lexers.robotframework
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
- Lexer for Robot Framework.
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-# Copyright 2012 Nokia Siemens Networks Oyj
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import re
-
-from pygments.lexer import Lexer
-from pygments.token import Token
-
-__all__ = ['RobotFrameworkLexer']
-
-
-HEADING = Token.Generic.Heading
-SETTING = Token.Keyword.Namespace
-IMPORT = Token.Name.Namespace
-TC_KW_NAME = Token.Generic.Subheading
-KEYWORD = Token.Name.Function
-ARGUMENT = Token.String
-VARIABLE = Token.Name.Variable
-COMMENT = Token.Comment
-SEPARATOR = Token.Punctuation
-SYNTAX = Token.Punctuation
-GHERKIN = Token.Generic.Emph
-ERROR = Token.Error
-
-
-def normalize(string, remove=''):
- string = string.lower()
- for char in remove + ' ':
- if char in string:
- string = string.replace(char, '')
- return string
-
-
-class RobotFrameworkLexer(Lexer):
- """
- For Robot Framework test data.
-
- Supports both space and pipe separated plain text formats.
-
- .. versionadded:: 1.6
- """
- name = 'RobotFramework'
- url = 'http://robotframework.org'
- aliases = ['robotframework']
- filenames = ['*.robot', '*.resource']
- mimetypes = ['text/x-robotframework']
-
- def __init__(self, **options):
- options['tabsize'] = 2
- options['encoding'] = 'UTF-8'
- Lexer.__init__(self, **options)
-
- def get_tokens_unprocessed(self, text):
- row_tokenizer = RowTokenizer()
- var_tokenizer = VariableTokenizer()
- index = 0
- for row in text.splitlines():
- for value, token in row_tokenizer.tokenize(row):
- for value, token in var_tokenizer.tokenize(value, token):
- if value:
- yield index, token, str(value)
- index += len(value)
-
-
-class VariableTokenizer:
-
- def tokenize(self, string, token):
- var = VariableSplitter(string, identifiers='$@%&')
- if var.start < 0 or token in (COMMENT, ERROR):
- yield string, token
- return
- for value, token in self._tokenize(var, string, token):
- if value:
- yield value, token
-
- def _tokenize(self, var, string, orig_token):
- before = string[:var.start]
- yield before, orig_token
- yield var.identifier + '{', SYNTAX
- yield from self.tokenize(var.base, VARIABLE)
- yield '}', SYNTAX
- if var.index is not None:
- yield '[', SYNTAX
- yield from self.tokenize(var.index, VARIABLE)
- yield ']', SYNTAX
- yield from self.tokenize(string[var.end:], orig_token)
-
-
-class RowTokenizer:
-
- def __init__(self):
- self._table = UnknownTable()
- self._splitter = RowSplitter()
- testcases = TestCaseTable()
- settings = SettingTable(testcases.set_default_template)
- variables = VariableTable()
- keywords = KeywordTable()
- self._tables = {'settings': settings, 'setting': settings,
- 'metadata': settings,
- 'variables': variables, 'variable': variables,
- 'testcases': testcases, 'testcase': testcases,
- 'tasks': testcases, 'task': testcases,
- 'keywords': keywords, 'keyword': keywords,
- 'userkeywords': keywords, 'userkeyword': keywords}
-
- def tokenize(self, row):
- commented = False
- heading = False
- for index, value in enumerate(self._splitter.split(row)):
- # First value, and every second after that, is a separator.
- index, separator = divmod(index-1, 2)
- if value.startswith('#'):
- commented = True
- elif index == 0 and value.startswith('*'):
- self._table = self._start_table(value)
- heading = True
- yield from self._tokenize(value, index, commented,
- separator, heading)
- self._table.end_row()
-
- def _start_table(self, header):
- name = normalize(header, remove='*')
- return self._tables.get(name, UnknownTable())
-
- def _tokenize(self, value, index, commented, separator, heading):
- if commented:
- yield value, COMMENT
- elif separator:
- yield value, SEPARATOR
- elif heading:
- yield value, HEADING
- else:
- yield from self._table.tokenize(value, index)
-
-
-class RowSplitter:
- _space_splitter = re.compile('( {2,})')
- _pipe_splitter = re.compile(r'((?:^| +)\|(?: +|$))')
-
- def split(self, row):
- splitter = (row.startswith('| ') and self._split_from_pipes
- or self._split_from_spaces)
- yield from splitter(row)
- yield '\n'
-
- def _split_from_spaces(self, row):
- yield '' # Start with (pseudo)separator similarly as with pipes
- yield from self._space_splitter.split(row)
-
- def _split_from_pipes(self, row):
- _, separator, rest = self._pipe_splitter.split(row, 1)
- yield separator
- while self._pipe_splitter.search(rest):
- cell, separator, rest = self._pipe_splitter.split(rest, 1)
- yield cell
- yield separator
- yield rest
-
-
-class Tokenizer:
- _tokens = None
-
- def __init__(self):
- self._index = 0
-
- def tokenize(self, value):
- values_and_tokens = self._tokenize(value, self._index)
- self._index += 1
- if isinstance(values_and_tokens, type(Token)):
- values_and_tokens = [(value, values_and_tokens)]
- return values_and_tokens
-
- def _tokenize(self, value, index):
- index = min(index, len(self._tokens) - 1)
- return self._tokens[index]
-
- def _is_assign(self, value):
- if value.endswith('='):
- value = value[:-1].strip()
- var = VariableSplitter(value, identifiers='$@&')
- return var.start == 0 and var.end == len(value)
-
-
-class Comment(Tokenizer):
- _tokens = (COMMENT,)
-
-
-class Setting(Tokenizer):
- _tokens = (SETTING, ARGUMENT)
- _keyword_settings = ('suitesetup', 'suiteprecondition', 'suiteteardown',
- 'suitepostcondition', 'testsetup', 'tasksetup', 'testprecondition',
- 'testteardown','taskteardown', 'testpostcondition', 'testtemplate', 'tasktemplate')
- _import_settings = ('library', 'resource', 'variables')
- _other_settings = ('documentation', 'metadata', 'forcetags', 'defaulttags',
- 'testtimeout','tasktimeout')
- _custom_tokenizer = None
-
- def __init__(self, template_setter=None):
- Tokenizer.__init__(self)
- self._template_setter = template_setter
-
- def _tokenize(self, value, index):
- if index == 1 and self._template_setter:
- self._template_setter(value)
- if index == 0:
- normalized = normalize(value)
- if normalized in self._keyword_settings:
- self._custom_tokenizer = KeywordCall(support_assign=False)
- elif normalized in self._import_settings:
- self._custom_tokenizer = ImportSetting()
- elif normalized not in self._other_settings:
- return ERROR
- elif self._custom_tokenizer:
- return self._custom_tokenizer.tokenize(value)
- return Tokenizer._tokenize(self, value, index)
-
-
-class ImportSetting(Tokenizer):
- _tokens = (IMPORT, ARGUMENT)
-
-
-class TestCaseSetting(Setting):
- _keyword_settings = ('setup', 'precondition', 'teardown', 'postcondition',
- 'template')
- _import_settings = ()
- _other_settings = ('documentation', 'tags', 'timeout')
-
- def _tokenize(self, value, index):
- if index == 0:
- type = Setting._tokenize(self, value[1:-1], index)
- return [('[', SYNTAX), (value[1:-1], type), (']', SYNTAX)]
- return Setting._tokenize(self, value, index)
-
-
-class KeywordSetting(TestCaseSetting):
- _keyword_settings = ('teardown',)
- _other_settings = ('documentation', 'arguments', 'return', 'timeout', 'tags')
-
-
-class Variable(Tokenizer):
- _tokens = (SYNTAX, ARGUMENT)
-
- def _tokenize(self, value, index):
- if index == 0 and not self._is_assign(value):
- return ERROR
- return Tokenizer._tokenize(self, value, index)
-
-
-class KeywordCall(Tokenizer):
- _tokens = (KEYWORD, ARGUMENT)
-
- def __init__(self, support_assign=True):
- Tokenizer.__init__(self)
- self._keyword_found = not support_assign
- self._assigns = 0
-
- def _tokenize(self, value, index):
- if not self._keyword_found and self._is_assign(value):
- self._assigns += 1
- return SYNTAX # VariableTokenizer tokenizes this later.
- if self._keyword_found:
- return Tokenizer._tokenize(self, value, index - self._assigns)
- self._keyword_found = True
- return GherkinTokenizer().tokenize(value, KEYWORD)
-
-
-class GherkinTokenizer:
- _gherkin_prefix = re.compile('^(Given|When|Then|And|But) ', re.IGNORECASE)
-
- def tokenize(self, value, token):
- match = self._gherkin_prefix.match(value)
- if not match:
- return [(value, token)]
- end = match.end()
- return [(value[:end], GHERKIN), (value[end:], token)]
-
-
-class TemplatedKeywordCall(Tokenizer):
- _tokens = (ARGUMENT,)
-
-
-class ForLoop(Tokenizer):
-
- def __init__(self):
- Tokenizer.__init__(self)
- self._in_arguments = False
-
- def _tokenize(self, value, index):
- token = self._in_arguments and ARGUMENT or SYNTAX
- if value.upper() in ('IN', 'IN RANGE'):
- self._in_arguments = True
- return token
-
-
-class _Table:
- _tokenizer_class = None
-
- def __init__(self, prev_tokenizer=None):
- self._tokenizer = self._tokenizer_class()
- self._prev_tokenizer = prev_tokenizer
- self._prev_values_on_row = []
-
- def tokenize(self, value, index):
- if self._continues(value, index):
- self._tokenizer = self._prev_tokenizer
- yield value, SYNTAX
- else:
- yield from self._tokenize(value, index)
- self._prev_values_on_row.append(value)
-
- def _continues(self, value, index):
- return value == '...' and all(self._is_empty(t)
- for t in self._prev_values_on_row)
-
- def _is_empty(self, value):
- return value in ('', '\\')
-
- def _tokenize(self, value, index):
- return self._tokenizer.tokenize(value)
-
- def end_row(self):
- self.__init__(prev_tokenizer=self._tokenizer)
-
-
-class UnknownTable(_Table):
- _tokenizer_class = Comment
-
- def _continues(self, value, index):
- return False
-
-
-class VariableTable(_Table):
- _tokenizer_class = Variable
-
-
-class SettingTable(_Table):
- _tokenizer_class = Setting
-
- def __init__(self, template_setter, prev_tokenizer=None):
- _Table.__init__(self, prev_tokenizer)
- self._template_setter = template_setter
-
- def _tokenize(self, value, index):
- if index == 0 and normalize(value) == 'testtemplate':
- self._tokenizer = Setting(self._template_setter)
- return _Table._tokenize(self, value, index)
-
- def end_row(self):
- self.__init__(self._template_setter, prev_tokenizer=self._tokenizer)
-
-
-class TestCaseTable(_Table):
- _setting_class = TestCaseSetting
- _test_template = None
- _default_template = None
-
- @property
- def _tokenizer_class(self):
- if self._test_template or (self._default_template and
- self._test_template is not False):
- return TemplatedKeywordCall
- return KeywordCall
-
- def _continues(self, value, index):
- return index > 0 and _Table._continues(self, value, index)
-
- def _tokenize(self, value, index):
- if index == 0:
- if value:
- self._test_template = None
- return GherkinTokenizer().tokenize(value, TC_KW_NAME)
- if index == 1 and self._is_setting(value):
- if self._is_template(value):
- self._test_template = False
- self._tokenizer = self._setting_class(self.set_test_template)
- else:
- self._tokenizer = self._setting_class()
- if index == 1 and self._is_for_loop(value):
- self._tokenizer = ForLoop()
- if index == 1 and self._is_empty(value):
- return [(value, SYNTAX)]
- return _Table._tokenize(self, value, index)
-
- def _is_setting(self, value):
- return value.startswith('[') and value.endswith(']')
-
- def _is_template(self, value):
- return normalize(value) == '[template]'
-
- def _is_for_loop(self, value):
- return value.startswith(':') and normalize(value, remove=':') == 'for'
-
- def set_test_template(self, template):
- self._test_template = self._is_template_set(template)
-
- def set_default_template(self, template):
- self._default_template = self._is_template_set(template)
-
- def _is_template_set(self, template):
- return normalize(template) not in ('', '\\', 'none', '${empty}')
-
-
-class KeywordTable(TestCaseTable):
- _tokenizer_class = KeywordCall
- _setting_class = KeywordSetting
-
- def _is_template(self, value):
- return False
-
-
-# Following code copied directly from Robot Framework 2.7.5.
-
-class VariableSplitter:
-
- def __init__(self, string, identifiers):
- self.identifier = None
- self.base = None
- self.index = None
- self.start = -1
- self.end = -1
- self._identifiers = identifiers
- self._may_have_internal_variables = False
- try:
- self._split(string)
- except ValueError:
- pass
- else:
- self._finalize()
-
- def get_replaced_base(self, variables):
- if self._may_have_internal_variables:
- return variables.replace_string(self.base)
- return self.base
-
- def _finalize(self):
- self.identifier = self._variable_chars[0]
- self.base = ''.join(self._variable_chars[2:-1])
- self.end = self.start + len(self._variable_chars)
- if self._has_list_or_dict_variable_index():
- self.index = ''.join(self._list_and_dict_variable_index_chars[1:-1])
- self.end += len(self._list_and_dict_variable_index_chars)
-
- def _has_list_or_dict_variable_index(self):
- return self._list_and_dict_variable_index_chars\
- and self._list_and_dict_variable_index_chars[-1] == ']'
-
- def _split(self, string):
- start_index, max_index = self._find_variable(string)
- self.start = start_index
- self._open_curly = 1
- self._state = self._variable_state
- self._variable_chars = [string[start_index], '{']
- self._list_and_dict_variable_index_chars = []
- self._string = string
- start_index += 2
- for index, char in enumerate(string[start_index:]):
- index += start_index # Giving start to enumerate only in Py 2.6+
- try:
- self._state(char, index)
- except StopIteration:
- return
- if index == max_index and not self._scanning_list_variable_index():
- return
-
- def _scanning_list_variable_index(self):
- return self._state in [self._waiting_list_variable_index_state,
- self._list_variable_index_state]
-
- def _find_variable(self, string):
- max_end_index = string.rfind('}')
- if max_end_index == -1:
- raise ValueError('No variable end found')
- if self._is_escaped(string, max_end_index):
- return self._find_variable(string[:max_end_index])
- start_index = self._find_start_index(string, 1, max_end_index)
- if start_index == -1:
- raise ValueError('No variable start found')
- return start_index, max_end_index
-
- def _find_start_index(self, string, start, end):
- index = string.find('{', start, end) - 1
- if index < 0:
- return -1
- if self._start_index_is_ok(string, index):
- return index
- return self._find_start_index(string, index+2, end)
-
- def _start_index_is_ok(self, string, index):
- return string[index] in self._identifiers\
- and not self._is_escaped(string, index)
-
- def _is_escaped(self, string, index):
- escaped = False
- while index > 0 and string[index-1] == '\\':
- index -= 1
- escaped = not escaped
- return escaped
-
- def _variable_state(self, char, index):
- self._variable_chars.append(char)
- if char == '}' and not self._is_escaped(self._string, index):
- self._open_curly -= 1
- if self._open_curly == 0:
- if not self._is_list_or_dict_variable():
- raise StopIteration
- self._state = self._waiting_list_variable_index_state
- elif char in self._identifiers:
- self._state = self._internal_variable_start_state
-
- def _is_list_or_dict_variable(self):
- return self._variable_chars[0] in ('@','&')
-
- def _internal_variable_start_state(self, char, index):
- self._state = self._variable_state
- if char == '{':
- self._variable_chars.append(char)
- self._open_curly += 1
- self._may_have_internal_variables = True
- else:
- self._variable_state(char, index)
-
- def _waiting_list_variable_index_state(self, char, index):
- if char != '[':
- raise StopIteration
- self._list_and_dict_variable_index_chars.append(char)
- self._state = self._list_variable_index_state
-
- def _list_variable_index_state(self, char, index):
- self._list_and_dict_variable_index_chars.append(char)
- if char == ']':
- raise StopIteration
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/util.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/util.py
deleted file mode 100644
index 941fdb9ec7a9699c1f4de8077eb681751446956e..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/util.py
+++ /dev/null
@@ -1,330 +0,0 @@
-"""
- pygments.util
- ~~~~~~~~~~~~~
-
- Utility functions.
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-import re
-from io import TextIOWrapper
-
-
-split_path_re = re.compile(r'[/\\ ]')
-doctype_lookup_re = re.compile(r'''
- ]*>
-''', re.DOTALL | re.MULTILINE | re.VERBOSE)
-tag_re = re.compile(r'<(.+?)(\s.*?)?>.*?',
- re.IGNORECASE | re.DOTALL | re.MULTILINE)
-xml_decl_re = re.compile(r'\s*<\?xml[^>]*\?>', re.I)
-
-
-class ClassNotFound(ValueError):
- """Raised if one of the lookup functions didn't find a matching class."""
-
-
-class OptionError(Exception):
- """
- This exception will be raised by all option processing functions if
- the type or value of the argument is not correct.
- """
-
-def get_choice_opt(options, optname, allowed, default=None, normcase=False):
- """
- If the key `optname` from the dictionary is not in the sequence
- `allowed`, raise an error, otherwise return it.
- """
- string = options.get(optname, default)
- if normcase:
- string = string.lower()
- if string not in allowed:
- raise OptionError('Value for option %s must be one of %s' %
- (optname, ', '.join(map(str, allowed))))
- return string
-
-
-def get_bool_opt(options, optname, default=None):
- """
- Intuitively, this is `options.get(optname, default)`, but restricted to
- Boolean value. The Booleans can be represented as string, in order to accept
- Boolean value from the command line arguments. If the key `optname` is
- present in the dictionary `options` and is not associated with a Boolean,
- raise an `OptionError`. If it is absent, `default` is returned instead.
-
- The valid string values for ``True`` are ``1``, ``yes``, ``true`` and
- ``on``, the ones for ``False`` are ``0``, ``no``, ``false`` and ``off``
- (matched case-insensitively).
- """
- string = options.get(optname, default)
- if isinstance(string, bool):
- return string
- elif isinstance(string, int):
- return bool(string)
- elif not isinstance(string, str):
- raise OptionError('Invalid type %r for option %s; use '
- '1/0, yes/no, true/false, on/off' % (
- string, optname))
- elif string.lower() in ('1', 'yes', 'true', 'on'):
- return True
- elif string.lower() in ('0', 'no', 'false', 'off'):
- return False
- else:
- raise OptionError('Invalid value %r for option %s; use '
- '1/0, yes/no, true/false, on/off' % (
- string, optname))
-
-
-def get_int_opt(options, optname, default=None):
- """As :func:`get_bool_opt`, but interpret the value as an integer."""
- string = options.get(optname, default)
- try:
- return int(string)
- except TypeError:
- raise OptionError('Invalid type %r for option %s; you '
- 'must give an integer value' % (
- string, optname))
- except ValueError:
- raise OptionError('Invalid value %r for option %s; you '
- 'must give an integer value' % (
- string, optname))
-
-def get_list_opt(options, optname, default=None):
- """
- If the key `optname` from the dictionary `options` is a string,
- split it at whitespace and return it. If it is already a list
- or a tuple, it is returned as a list.
- """
- val = options.get(optname, default)
- if isinstance(val, str):
- return val.split()
- elif isinstance(val, (list, tuple)):
- return list(val)
- else:
- raise OptionError('Invalid type %r for option %s; you '
- 'must give a list value' % (
- val, optname))
-
-
-def docstring_headline(obj):
- if not obj.__doc__:
- return ''
- res = []
- for line in obj.__doc__.strip().splitlines():
- if line.strip():
- res.append(" " + line.strip())
- else:
- break
- return ''.join(res).lstrip()
-
-
-def make_analysator(f):
- """Return a static text analyser function that returns float values."""
- def text_analyse(text):
- try:
- rv = f(text)
- except Exception:
- return 0.0
- if not rv:
- return 0.0
- try:
- return min(1.0, max(0.0, float(rv)))
- except (ValueError, TypeError):
- return 0.0
- text_analyse.__doc__ = f.__doc__
- return staticmethod(text_analyse)
-
-
-def shebang_matches(text, regex):
- r"""Check if the given regular expression matches the last part of the
- shebang if one exists.
-
- >>> from pygments.util import shebang_matches
- >>> shebang_matches('#!/usr/bin/env python', r'python(2\.\d)?')
- True
- >>> shebang_matches('#!/usr/bin/python2.4', r'python(2\.\d)?')
- True
- >>> shebang_matches('#!/usr/bin/python-ruby', r'python(2\.\d)?')
- False
- >>> shebang_matches('#!/usr/bin/python/ruby', r'python(2\.\d)?')
- False
- >>> shebang_matches('#!/usr/bin/startsomethingwith python',
- ... r'python(2\.\d)?')
- True
-
- It also checks for common windows executable file extensions::
-
- >>> shebang_matches('#!C:\\Python2.4\\Python.exe', r'python(2\.\d)?')
- True
-
- Parameters (``'-f'`` or ``'--foo'`` are ignored so ``'perl'`` does
- the same as ``'perl -e'``)
-
- Note that this method automatically searches the whole string (eg:
- the regular expression is wrapped in ``'^$'``)
- """
- index = text.find('\n')
- if index >= 0:
- first_line = text[:index].lower()
- else:
- first_line = text.lower()
- if first_line.startswith('#!'):
- try:
- found = [x for x in split_path_re.split(first_line[2:].strip())
- if x and not x.startswith('-')][-1]
- except IndexError:
- return False
- regex = re.compile(r'^%s(\.(exe|cmd|bat|bin))?$' % regex, re.IGNORECASE)
- if regex.search(found) is not None:
- return True
- return False
-
-
-def doctype_matches(text, regex):
- """Check if the doctype matches a regular expression (if present).
-
- Note that this method only checks the first part of a DOCTYPE.
- eg: 'html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"'
- """
- m = doctype_lookup_re.search(text)
- if m is None:
- return False
- doctype = m.group(1)
- return re.compile(regex, re.I).match(doctype.strip()) is not None
-
-
-def html_doctype_matches(text):
- """Check if the file looks like it has a html doctype."""
- return doctype_matches(text, r'html')
-
-
-_looks_like_xml_cache = {}
-
-
-def looks_like_xml(text):
- """Check if a doctype exists or if we have some tags."""
- if xml_decl_re.match(text):
- return True
- key = hash(text)
- try:
- return _looks_like_xml_cache[key]
- except KeyError:
- m = doctype_lookup_re.search(text)
- if m is not None:
- return True
- rv = tag_re.search(text[:1000]) is not None
- _looks_like_xml_cache[key] = rv
- return rv
-
-
-def surrogatepair(c):
- """Given a unicode character code with length greater than 16 bits,
- return the two 16 bit surrogate pair.
- """
- # From example D28 of:
- # http://www.unicode.org/book/ch03.pdf
- return (0xd7c0 + (c >> 10), (0xdc00 + (c & 0x3ff)))
-
-
-def format_lines(var_name, seq, raw=False, indent_level=0):
- """Formats a sequence of strings for output."""
- lines = []
- base_indent = ' ' * indent_level * 4
- inner_indent = ' ' * (indent_level + 1) * 4
- lines.append(base_indent + var_name + ' = (')
- if raw:
- # These should be preformatted reprs of, say, tuples.
- for i in seq:
- lines.append(inner_indent + i + ',')
- else:
- for i in seq:
- # Force use of single quotes
- r = repr(i + '"')
- lines.append(inner_indent + r[:-2] + r[-1] + ',')
- lines.append(base_indent + ')')
- return '\n'.join(lines)
-
-
-def duplicates_removed(it, already_seen=()):
- """
- Returns a list with duplicates removed from the iterable `it`.
-
- Order is preserved.
- """
- lst = []
- seen = set()
- for i in it:
- if i in seen or i in already_seen:
- continue
- lst.append(i)
- seen.add(i)
- return lst
-
-
-class Future:
- """Generic class to defer some work.
-
- Handled specially in RegexLexerMeta, to support regex string construction at
- first use.
- """
- def get(self):
- raise NotImplementedError
-
-
-def guess_decode(text):
- """Decode *text* with guessed encoding.
-
- First try UTF-8; this should fail for non-UTF-8 encodings.
- Then try the preferred locale encoding.
- Fall back to latin-1, which always works.
- """
- try:
- text = text.decode('utf-8')
- return text, 'utf-8'
- except UnicodeDecodeError:
- try:
- import locale
- prefencoding = locale.getpreferredencoding()
- text = text.decode()
- return text, prefencoding
- except (UnicodeDecodeError, LookupError):
- text = text.decode('latin1')
- return text, 'latin1'
-
-
-def guess_decode_from_terminal(text, term):
- """Decode *text* coming from terminal *term*.
-
- First try the terminal encoding, if given.
- Then try UTF-8. Then try the preferred locale encoding.
- Fall back to latin-1, which always works.
- """
- if getattr(term, 'encoding', None):
- try:
- text = text.decode(term.encoding)
- except UnicodeDecodeError:
- pass
- else:
- return text, term.encoding
- return guess_decode(text)
-
-
-def terminal_encoding(term):
- """Return our best guess of encoding for the given *term*."""
- if getattr(term, 'encoding', None):
- return term.encoding
- import locale
- return locale.getpreferredencoding()
-
-
-class UnclosingTextIOWrapper(TextIOWrapper):
- # Don't close underlying buffer on destruction.
- def close(self):
- self.flush()
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Advance Steel 2013 (32bit) (Product Key And Xforce Keygen) .rar !!TOP!!.md b/spaces/quidiaMuxgu/Expedit-SAM/Advance Steel 2013 (32bit) (Product Key And Xforce Keygen) .rar !!TOP!!.md
deleted file mode 100644
index 1496f15c33f468e8a910712a01c31cc2549ac6c2..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Advance Steel 2013 (32bit) (Product Key And Xforce Keygen) .rar !!TOP!!.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Advance Steel 2013 (32bit) (Product key and Xforce keygen) .rar Download »»» https://geags.com/2uCqxb
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/HD Online Player (limitless Movie In Hindi Dubbed 686).md b/spaces/quidiaMuxgu/Expedit-SAM/HD Online Player (limitless Movie In Hindi Dubbed 686).md
deleted file mode 100644
index 9377dbfd4cedaf0ce11cc44a5d7dce436b9f8a5c..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/HD Online Player (limitless Movie In Hindi Dubbed 686).md
+++ /dev/null
@@ -1,6 +0,0 @@
-HD Online Player (limitless movie in hindi dubbed 686) Download Zip ……… https://geags.com/2uCqd2
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Keygen Xforce Corel Draw X7 Fixed.md b/spaces/quidiaMuxgu/Expedit-SAM/Keygen Xforce Corel Draw X7 Fixed.md
deleted file mode 100644
index 505b73e2bdf6df89785e5be7e847b259c7eed752..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Keygen Xforce Corel Draw X7 Fixed.md
+++ /dev/null
@@ -1,9 +0,0 @@
-This is an easy to use site that can get you the unlock code for your copy of Corel Draw X7. It is a very well organized website and that makes it easy to navigate and to find just about anything that you are looking for. We have provided step by step instructions that can show you how to download and how to unlock Corel Draw X7.
-keygen xforce corel draw x7 Download File — https://geags.com/2uCrdc
This web page is all about Corel Draw X7 crack. We make sure that you are using the latest version of this software. You can download and activate the unlocked copy of Corel Draw X7 graphics software directly to your computer. Its very easy to start using Corel Draw X7 now with its unlock code. You will get free updates for your copy of Corel Draw X7.
-" .viator.Corel.com.nOIT8.hWn.b/0/0/hWn.bD/VZAj86qIok" " So far it has been working fine. I'm still leery about it because I found this website while trying to find the reason why my audio on dvd's was not working.
-Key Features:
-
Newest Versions of the Software. Source Support for Wires. Significant New Features. Improved User Interface and Performance. High-quality, Optimized Packages. New Functions. Support for CorelDRAW X7 and X6 Minimum System Requirements. 899543212bMarmoset Hexels 3 Activation Unlock Code And Serial Download ►►► https://geags.com/2uCq1i
diff --git a/spaces/radames/MusicGen-Continuation/audiocraft/modules/conditioners.py b/spaces/radames/MusicGen-Continuation/audiocraft/modules/conditioners.py
deleted file mode 100644
index 82792316024b88d4c5c38b0a28f443627771d509..0000000000000000000000000000000000000000
--- a/spaces/radames/MusicGen-Continuation/audiocraft/modules/conditioners.py
+++ /dev/null
@@ -1,990 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-from collections import defaultdict
-from copy import deepcopy
-from dataclasses import dataclass, field
-from itertools import chain
-import logging
-import math
-import random
-import re
-import typing as tp
-import warnings
-
-from einops import rearrange
-from num2words import num2words
-import spacy
-from transformers import T5EncoderModel, T5Tokenizer # type: ignore
-import torchaudio
-import torch
-from torch import nn
-from torch import Tensor
-import torch.nn.functional as F
-from torch.nn.utils.rnn import pad_sequence
-
-from .streaming import StreamingModule
-from .transformer import create_sin_embedding
-from ..data.audio_dataset import SegmentInfo
-from ..utils.autocast import TorchAutocast
-from ..utils.utils import hash_trick, length_to_mask, collate
-
-
-logger = logging.getLogger(__name__)
-TextCondition = tp.Optional[str] # a text condition can be a string or None (if doesn't exist)
-ConditionType = tp.Tuple[Tensor, Tensor] # condition, mask
-
-
-class WavCondition(tp.NamedTuple):
- wav: Tensor
- length: Tensor
- path: tp.List[tp.Optional[str]] = []
-
-
-def nullify_condition(condition: ConditionType, dim: int = 1):
- """This function transforms an input condition to a null condition.
- The way it is done by converting it to a single zero vector similarly
- to how it is done inside WhiteSpaceTokenizer and NoopTokenizer.
-
- Args:
- condition (ConditionType): a tuple of condition and mask (tp.Tuple[Tensor, Tensor])
- dim (int): the dimension that will be truncated (should be the time dimension)
- WARNING!: dim should not be the batch dimension!
- Returns:
- ConditionType: a tuple of null condition and mask
- """
- assert dim != 0, "dim cannot be the batch dimension!"
- assert type(condition) == tuple and \
- type(condition[0]) == Tensor and \
- type(condition[1]) == Tensor, "'nullify_condition' got an unexpected input type!"
- cond, mask = condition
- B = cond.shape[0]
- last_dim = cond.dim() - 1
- out = cond.transpose(dim, last_dim)
- out = 0. * out[..., :1]
- out = out.transpose(dim, last_dim)
- mask = torch.zeros((B, 1), device=out.device).int()
- assert cond.dim() == out.dim()
- return out, mask
-
-
-def nullify_wav(wav: Tensor) -> WavCondition:
- """Create a nullified WavCondition from a wav tensor with appropriate shape.
-
- Args:
- wav (Tensor): tensor of shape [B, T]
- Returns:
- WavCondition: wav condition with nullified wav.
- """
- null_wav, _ = nullify_condition((wav, torch.zeros_like(wav)), dim=wav.dim() - 1)
- return WavCondition(
- wav=null_wav,
- length=torch.tensor([0] * wav.shape[0], device=wav.device),
- path=['null_wav'] * wav.shape[0]
- )
-
-
-@dataclass
-class ConditioningAttributes:
- text: tp.Dict[str, tp.Optional[str]] = field(default_factory=dict)
- wav: tp.Dict[str, WavCondition] = field(default_factory=dict)
-
- def __getitem__(self, item):
- return getattr(self, item)
-
- @property
- def text_attributes(self):
- return self.text.keys()
-
- @property
- def wav_attributes(self):
- return self.wav.keys()
-
- @property
- def attributes(self):
- return {"text": self.text_attributes, "wav": self.wav_attributes}
-
- def to_flat_dict(self):
- return {
- **{f"text.{k}": v for k, v in self.text.items()},
- **{f"wav.{k}": v for k, v in self.wav.items()},
- }
-
- @classmethod
- def from_flat_dict(cls, x):
- out = cls()
- for k, v in x.items():
- kind, att = k.split(".")
- out[kind][att] = v
- return out
-
-
-class SegmentWithAttributes(SegmentInfo):
- """Base class for all dataclasses that are used for conditioning.
- All child classes should implement `to_condition_attributes` that converts
- the existing attributes to a dataclass of type ConditioningAttributes.
- """
- def to_condition_attributes(self) -> ConditioningAttributes:
- raise NotImplementedError()
-
-
-class Tokenizer:
- """Base class for all tokenizers
- (in case we want to introduce more advances tokenizers in the future).
- """
- def __call__(self, texts: tp.List[tp.Optional[str]]) -> tp.Tuple[Tensor, Tensor]:
- raise NotImplementedError()
-
-
-class WhiteSpaceTokenizer(Tokenizer):
- """This tokenizer should be used for natural language descriptions.
- For example:
- ["he didn't, know he's going home.", 'shorter sentence'] =>
- [[78, 62, 31, 4, 78, 25, 19, 34],
- [59, 77, 0, 0, 0, 0, 0, 0]]
- """
- PUNCTUATIONS = "?:!.,;"
-
- def __init__(self, n_bins: int, pad_idx: int = 0, language: str = "en_core_web_sm",
- lemma: bool = True, stopwords: bool = True) -> None:
- self.n_bins = n_bins
- self.pad_idx = pad_idx
- self.lemma = lemma
- self.stopwords = stopwords
- try:
- self.nlp = spacy.load(language)
- except IOError:
- spacy.cli.download(language) # type: ignore
- self.nlp = spacy.load(language)
-
- @tp.no_type_check
- def __call__(
- self,
- texts: tp.List[tp.Optional[str]],
- return_text: bool = False
- ) -> tp.Tuple[Tensor, Tensor]:
- """Take a list of strings and convert them to a tensor of indices.
-
- Args:
- texts (tp.List[str]): List of strings.
- return_text (bool, optional): Whether to return text as additional tuple item. Defaults to False.
- Returns:
- tp.Tuple[Tensor, Tensor]:
- - Indices of words in the LUT.
- - And a mask indicating where the padding tokens are
- """
- output, lengths = [], []
- texts = deepcopy(texts)
- for i, text in enumerate(texts):
- # if current sample doesn't have a certain attribute, replace with pad token
- if text is None:
- output.append(Tensor([self.pad_idx]))
- lengths.append(0)
- continue
-
- # convert numbers to words
- text = re.sub(r"(\d+)", lambda x: num2words(int(x.group(0))), text) # type: ignore
- # normalize text
- text = self.nlp(text) # type: ignore
- # remove stopwords
- if self.stopwords:
- text = [w for w in text if not w.is_stop] # type: ignore
- # remove punctuations
- text = [w for w in text if w.text not in self.PUNCTUATIONS] # type: ignore
- # lemmatize if needed
- text = [getattr(t, "lemma_" if self.lemma else "text") for t in text] # type: ignore
-
- texts[i] = " ".join(text)
- lengths.append(len(text))
- # convert to tensor
- tokens = Tensor([hash_trick(w, self.n_bins) for w in text])
- output.append(tokens)
-
- mask = length_to_mask(torch.IntTensor(lengths)).int()
- padded_output = pad_sequence(output, padding_value=self.pad_idx).int().t()
- if return_text:
- return padded_output, mask, texts # type: ignore
- return padded_output, mask
-
-
-class NoopTokenizer(Tokenizer):
- """This tokenizer should be used for global conditioners such as: artist, genre, key, etc.
- The difference between this and WhiteSpaceTokenizer is that NoopTokenizer does not split
- strings, so "Jeff Buckley" will get it's own index. Whereas WhiteSpaceTokenizer will
- split it to ["Jeff", "Buckley"] and return an index per word.
-
- For example:
- ["Queen", "ABBA", "Jeff Buckley"] => [43, 55, 101]
- ["Metal", "Rock", "Classical"] => [0, 223, 51]
- """
- def __init__(self, n_bins: int, pad_idx: int = 0):
- self.n_bins = n_bins
- self.pad_idx = pad_idx
-
- def __call__(self, texts: tp.List[tp.Optional[str]]) -> tp.Tuple[Tensor, Tensor]:
- output, lengths = [], []
- for text in texts:
- # if current sample doesn't have a certain attribute, replace with pad token
- if text is None:
- output.append(self.pad_idx)
- lengths.append(0)
- else:
- output.append(hash_trick(text, self.n_bins))
- lengths.append(1)
-
- tokens = torch.LongTensor(output).unsqueeze(1)
- mask = length_to_mask(torch.IntTensor(lengths)).int()
- return tokens, mask
-
-
-class BaseConditioner(nn.Module):
- """Base model for all conditioner modules. We allow the output dim to be different
- than the hidden dim for two reasons: 1) keep our LUTs small when the vocab is large;
- 2) make all condition dims consistent.
-
- Args:
- dim (int): Hidden dim of the model (text-encoder/LUT).
- output_dim (int): Output dim of the conditioner.
- """
- def __init__(self, dim, output_dim):
- super().__init__()
- self.dim = dim
- self.output_dim = output_dim
- self.output_proj = nn.Linear(dim, output_dim)
-
- def tokenize(self, *args, **kwargs) -> tp.Any:
- """Should be any part of the processing that will lead to a synchronization
- point, e.g. BPE tokenization with transfer to the GPU.
-
- The returned value will be saved and return later when calling forward().
- """
- raise NotImplementedError()
-
- def forward(self, inputs: tp.Any) -> ConditionType:
- """Gets input that should be used as conditioning (e.g, genre, description or a waveform).
- Outputs a ConditionType, after the input data was embedded as a dense vector.
-
- Returns:
- ConditionType:
- - A tensor of size [B, T, D] where B is the batch size, T is the length of the
- output embedding and D is the dimension of the embedding.
- - And a mask indicating where the padding tokens.
- """
- raise NotImplementedError()
-
-
-class TextConditioner(BaseConditioner):
- ...
-
-
-class LUTConditioner(TextConditioner):
- """Lookup table TextConditioner.
-
- Args:
- n_bins (int): Number of bins.
- dim (int): Hidden dim of the model (text-encoder/LUT).
- output_dim (int): Output dim of the conditioner.
- tokenizer (str): Name of the tokenizer.
- pad_idx (int, optional): Index for padding token. Defaults to 0.
- """
- def __init__(self, n_bins: int, dim: int, output_dim: int, tokenizer: str, pad_idx: int = 0):
- super().__init__(dim, output_dim)
- self.embed = nn.Embedding(n_bins, dim)
- self.tokenizer: Tokenizer
- if tokenizer == "whitespace":
- self.tokenizer = WhiteSpaceTokenizer(n_bins, pad_idx=pad_idx)
- elif tokenizer == "noop":
- self.tokenizer = NoopTokenizer(n_bins, pad_idx=pad_idx)
- else:
- raise ValueError(f"unrecognized tokenizer `{tokenizer}`.")
-
- def tokenize(self, x: tp.List[tp.Optional[str]]) -> tp.Tuple[torch.Tensor, torch.Tensor]:
- device = self.embed.weight.device
- tokens, mask = self.tokenizer(x)
- tokens, mask = tokens.to(device), mask.to(device)
- return tokens, mask
-
- def forward(self, inputs: tp.Tuple[torch.Tensor, torch.Tensor]) -> ConditionType:
- tokens, mask = inputs
- embeds = self.embed(tokens)
- embeds = self.output_proj(embeds)
- embeds = (embeds * mask.unsqueeze(-1))
- return embeds, mask
-
-
-class T5Conditioner(TextConditioner):
- """T5-based TextConditioner.
-
- Args:
- name (str): Name of the T5 model.
- output_dim (int): Output dim of the conditioner.
- finetune (bool): Whether to fine-tune T5 at train time.
- device (str): Device for T5 Conditioner.
- autocast_dtype (tp.Optional[str], optional): Autocast dtype.
- word_dropout (float, optional): Word dropout probability.
- normalize_text (bool, optional): Whether to apply text normalization.
- """
- MODELS = ["t5-small", "t5-base", "t5-large", "t5-3b", "t5-11b",
- "google/flan-t5-small", "google/flan-t5-base", "google/flan-t5-large",
- "google/flan-t5-xl", "google/flan-t5-xxl"]
- MODELS_DIMS = {
- "t5-small": 512,
- "t5-base": 768,
- "t5-large": 1024,
- "t5-3b": 1024,
- "t5-11b": 1024,
- "google/flan-t5-small": 512,
- "google/flan-t5-base": 768,
- "google/flan-t5-large": 1024,
- "google/flan-t5-3b": 1024,
- "google/flan-t5-11b": 1024,
- }
-
- def __init__(self, name: str, output_dim: int, finetune: bool, device: str,
- autocast_dtype: tp.Optional[str] = 'float32', word_dropout: float = 0.,
- normalize_text: bool = False):
- assert name in self.MODELS, f"unrecognized t5 model name (should in {self.MODELS})"
- super().__init__(self.MODELS_DIMS[name], output_dim)
- self.device = device
- self.name = name
- self.finetune = finetune
- self.word_dropout = word_dropout
-
- if autocast_dtype is None or self.device == 'cpu':
- self.autocast = TorchAutocast(enabled=False)
- if self.device != 'cpu':
- logger.warning("T5 has no autocast, this might lead to NaN")
- else:
- dtype = getattr(torch, autocast_dtype)
- assert isinstance(dtype, torch.dtype)
- logger.info(f"T5 will be evaluated with autocast as {autocast_dtype}")
- self.autocast = TorchAutocast(enabled=True, device_type=self.device, dtype=dtype)
- # Let's disable logging temporarily because T5 will vomit some errors otherwise.
- # thanks https://gist.github.com/simon-weber/7853144
- previous_level = logging.root.manager.disable
- logging.disable(logging.ERROR)
- with warnings.catch_warnings():
- warnings.simplefilter("ignore")
- try:
- self.t5_tokenizer = T5Tokenizer.from_pretrained(name)
- t5 = T5EncoderModel.from_pretrained(name).train(mode=finetune)
- finally:
- logging.disable(previous_level)
- if finetune:
- self.t5 = t5
- else:
- # this makes sure that the t5 models is not part
- # of the saved checkpoint
- self.__dict__["t5"] = t5.to(device)
-
- self.normalize_text = normalize_text
- if normalize_text:
- self.text_normalizer = WhiteSpaceTokenizer(1, lemma=True, stopwords=True)
-
- def tokenize(self, x: tp.List[tp.Optional[str]]) -> tp.Dict[str, torch.Tensor]:
- # if current sample doesn't have a certain attribute, replace with empty string
- entries: tp.List[str] = [xi if xi is not None else "" for xi in x]
- if self.normalize_text:
- _, _, entries = self.text_normalizer(entries, return_text=True)
- if self.word_dropout > 0. and self.training:
- new_entries = []
- for entry in entries:
- words = [word for word in entry.split(" ") if random.random() >= self.word_dropout]
- new_entries.append(" ".join(words))
- entries = new_entries
-
- empty_idx = torch.LongTensor([i for i, xi in enumerate(entries) if xi == ""])
-
- inputs = self.t5_tokenizer(entries, return_tensors="pt", padding=True).to(self.device)
- mask = inputs["attention_mask"]
- mask[empty_idx, :] = 0 # zero-out index where the input is non-existant
- return inputs
-
- def forward(self, inputs: tp.Dict[str, torch.Tensor]) -> ConditionType:
- mask = inputs["attention_mask"]
- with torch.set_grad_enabled(self.finetune), self.autocast:
- embeds = self.t5(**inputs).last_hidden_state
- embeds = self.output_proj(embeds.to(self.output_proj.weight))
- embeds = (embeds * mask.unsqueeze(-1))
- return embeds, mask
-
-
-class WaveformConditioner(BaseConditioner):
- """Base class for all conditioners that take a waveform as input.
- Classes that inherit must implement `_get_wav_embedding` that outputs
- a continuous tensor, and `_downsampling_factor` that returns the down-sampling
- factor of the embedding model.
-
- Args:
- dim (int): The internal representation dimension.
- output_dim (int): Output dimension.
- device (tp.Union[torch.device, str]): Device.
- """
- def __init__(self, dim: int, output_dim: int, device: tp.Union[torch.device, str]):
- super().__init__(dim, output_dim)
- self.device = device
-
- def tokenize(self, wav_length: WavCondition) -> WavCondition:
- wav, length, path = wav_length
- assert length is not None
- return WavCondition(wav.to(self.device), length.to(self.device), path)
-
- def _get_wav_embedding(self, wav: Tensor) -> Tensor:
- """Gets as input a wav and returns a dense vector of conditions."""
- raise NotImplementedError()
-
- def _downsampling_factor(self):
- """Returns the downsampling factor of the embedding model."""
- raise NotImplementedError()
-
- def forward(self, inputs: WavCondition) -> ConditionType:
- """
- Args:
- input (WavCondition): Tuple of (waveform, lengths).
- Returns:
- ConditionType: Dense vector representing the conditioning along with its' mask.
- """
- wav, lengths, path = inputs
- with torch.no_grad():
- embeds = self._get_wav_embedding(wav)
- embeds = embeds.to(self.output_proj.weight)
- embeds = self.output_proj(embeds)
-
- if lengths is not None:
- lengths = lengths / self._downsampling_factor()
- mask = length_to_mask(lengths, max_len=embeds.shape[1]).int() # type: ignore
- else:
- mask = torch.ones_like(embeds)
- embeds = (embeds * mask.unsqueeze(2).to(self.device))
-
- return embeds, mask
-
-
-class ChromaStemConditioner(WaveformConditioner):
- """Chroma conditioner that uses DEMUCS to first filter out drums and bass. The is followed by
- the insight the drums and bass often dominate the chroma, leading to the chroma not containing the
- information about melody.
-
- Args:
- output_dim (int): Output dimension for the conditioner.
- sample_rate (int): Sample rate for the chroma extractor.
- n_chroma (int): Number of chroma for the chroma extractor.
- radix2_exp (int): Radix2 exponent for the chroma extractor.
- duration (float): Duration used during training. This is later used for correct padding
- in case we are using chroma as prefix.
- match_len_on_eval (bool, optional): If True then all chromas are padded to the training
- duration. Defaults to False.
- eval_wavs (str, optional): Path to a json egg with waveform, this waveforms are used as
- conditions during eval (for cases where we don't want to leak test conditions like MusicCaps).
- Defaults to None.
- n_eval_wavs (int, optional): Limits the number of waveforms used for conditioning. Defaults to 0.
- device (tp.Union[torch.device, str], optional): Device for the conditioner.
- **kwargs: Additional parameters for the chroma extractor.
- """
- def __init__(self, output_dim: int, sample_rate: int, n_chroma: int, radix2_exp: int,
- duration: float, match_len_on_eval: bool = True, eval_wavs: tp.Optional[str] = None,
- n_eval_wavs: int = 0, device: tp.Union[torch.device, str] = "cpu", **kwargs):
- from demucs import pretrained
- super().__init__(dim=n_chroma, output_dim=output_dim, device=device)
- self.autocast = TorchAutocast(enabled=device != "cpu", device_type=self.device, dtype=torch.float32)
- self.sample_rate = sample_rate
- self.match_len_on_eval = match_len_on_eval
- self.duration = duration
- self.__dict__["demucs"] = pretrained.get_model('htdemucs').to(device)
- self.stem2idx = {'drums': 0, 'bass': 1, 'other': 2, 'vocal': 3}
- self.stem_idx = torch.LongTensor([self.stem2idx['vocal'], self.stem2idx['other']]).to(device)
- self.chroma = ChromaExtractor(sample_rate=sample_rate, n_chroma=n_chroma, radix2_exp=radix2_exp,
- device=device, **kwargs)
- self.chroma_len = self._get_chroma_len()
-
- def _downsampling_factor(self):
- return self.chroma.winhop
-
- def _get_chroma_len(self):
- """Get length of chroma during training"""
- dummy_wav = torch.zeros((1, self.sample_rate * self.duration), device=self.device)
- dummy_chr = self.chroma(dummy_wav)
- return dummy_chr.shape[1]
-
- @torch.no_grad()
- def _get_filtered_wav(self, wav):
- from demucs.apply import apply_model
- from demucs.audio import convert_audio
- with self.autocast:
- wav = convert_audio(wav, self.sample_rate, self.demucs.samplerate, self.demucs.audio_channels)
- stems = apply_model(self.demucs, wav, device=self.device)
- stems = stems[:, self.stem_idx] # extract stem
- stems = stems.sum(1) # merge extracted stems
- stems = stems.mean(1, keepdim=True) # mono
- stems = convert_audio(stems, self.demucs.samplerate, self.sample_rate, 1)
- return stems
-
- @torch.no_grad()
- def _get_wav_embedding(self, wav):
- # avoid 0-size tensors when we are working with null conds
- if wav.shape[-1] == 1:
- return self.chroma(wav)
- stems = self._get_filtered_wav(wav)
- chroma = self.chroma(stems)
-
- if self.match_len_on_eval:
- b, t, c = chroma.shape
- if t > self.chroma_len:
- chroma = chroma[:, :self.chroma_len]
- logger.debug(f'chroma was truncated! ({t} -> {chroma.shape[1]})')
- elif t < self.chroma_len:
- # chroma = F.pad(chroma, (0, 0, 0, self.chroma_len - t))
- n_repeat = int(math.ceil(self.chroma_len / t))
- chroma = chroma.repeat(1, n_repeat, 1)
- chroma = chroma[:, :self.chroma_len]
- logger.debug(f'chroma was zero-padded! ({t} -> {chroma.shape[1]})')
- return chroma
-
-
-class ChromaExtractor(nn.Module):
- """Chroma extraction class, handles chroma extraction and quantization.
-
- Args:
- sample_rate (int): Sample rate.
- n_chroma (int): Number of chroma to consider.
- radix2_exp (int): Radix2 exponent.
- nfft (tp.Optional[int], optional): Number of FFT.
- winlen (tp.Optional[int], optional): Window length.
- winhop (tp.Optional[int], optional): Window hop size.
- argmax (bool, optional): Whether to use argmax. Defaults to False.
- norm (float, optional): Norm for chroma normalization. Defaults to inf.
- device (tp.Union[torch.device, str], optional): Device to use. Defaults to cpu.
- """
- def __init__(self, sample_rate: int, n_chroma: int = 12, radix2_exp: int = 12,
- nfft: tp.Optional[int] = None, winlen: tp.Optional[int] = None, winhop: tp.Optional[int] = None,
- argmax: bool = False, norm: float = torch.inf, device: tp.Union[torch.device, str] = "cpu"):
- super().__init__()
- from librosa import filters
- self.device = device
- self.autocast = TorchAutocast(enabled=device != "cpu", device_type=self.device, dtype=torch.float32)
- self.winlen = winlen or 2 ** radix2_exp
- self.nfft = nfft or self.winlen
- self.winhop = winhop or (self.winlen // 4)
- self.sr = sample_rate
- self.n_chroma = n_chroma
- self.norm = norm
- self.argmax = argmax
- self.window = torch.hann_window(self.winlen).to(device)
- self.fbanks = torch.from_numpy(filters.chroma(sr=sample_rate, n_fft=self.nfft, tuning=0,
- n_chroma=self.n_chroma)).to(device)
- self.spec = torchaudio.transforms.Spectrogram(n_fft=self.nfft, win_length=self.winlen,
- hop_length=self.winhop, power=2, center=True,
- pad=0, normalized=True).to(device)
-
- def forward(self, wav):
- with self.autocast:
- T = wav.shape[-1]
- # in case we are getting a wav that was dropped out (nullified)
- # make sure wav length is no less that nfft
- if T < self.nfft:
- pad = self.nfft - T
- r = 0 if pad % 2 == 0 else 1
- wav = F.pad(wav, (pad // 2, pad // 2 + r), 'constant', 0)
- assert wav.shape[-1] == self.nfft, f'expected len {self.nfft} but got {wav.shape[-1]}'
- spec = self.spec(wav).squeeze(1)
- raw_chroma = torch.einsum("cf,...ft->...ct", self.fbanks, spec)
- norm_chroma = torch.nn.functional.normalize(raw_chroma, p=self.norm, dim=-2, eps=1e-6)
- norm_chroma = rearrange(norm_chroma, "b d t -> b t d")
-
- if self.argmax:
- idx = norm_chroma.argmax(-1, keepdims=True)
- norm_chroma[:] = 0
- norm_chroma.scatter_(dim=-1, index=idx, value=1)
-
- return norm_chroma
-
-
-def dropout_condition(sample: ConditioningAttributes, condition_type: str, condition: str):
- """Utility function for nullifying an attribute inside an ConditioningAttributes object.
- If the condition is of type "wav", then nullify it using "nullify_condition".
- If the condition is of any other type, set its' value to None.
- Works in-place.
- """
- if condition_type not in ["text", "wav"]:
- raise ValueError(
- "dropout_condition got an unexpected condition type!"
- f" expected 'wav' or 'text' but got '{condition_type}'"
- )
-
- if condition not in getattr(sample, condition_type):
- raise ValueError(
- "dropout_condition received an unexpected condition!"
- f" expected wav={sample.wav.keys()} and text={sample.text.keys()}"
- f"but got '{condition}' of type '{condition_type}'!"
- )
-
- if condition_type == "wav":
- wav, length, path = sample.wav[condition]
- sample.wav[condition] = nullify_wav(wav)
- else:
- sample.text[condition] = None
-
- return sample
-
-
-class DropoutModule(nn.Module):
- """Base class for all dropout modules."""
- def __init__(self, seed: int = 1234):
- super().__init__()
- self.rng = torch.Generator()
- self.rng.manual_seed(seed)
-
-
-class AttributeDropout(DropoutModule):
- """Applies dropout with a given probability per attribute. This is different from the behavior of
- ClassifierFreeGuidanceDropout as this allows for attributes to be dropped out separately. For example,
- "artist" can be dropped while "genre" remains. This is in contrast to ClassifierFreeGuidanceDropout
- where if "artist" is dropped "genre" must also be dropped.
-
- Args:
- p (tp.Dict[str, float]): A dict mapping between attributes and dropout probability. For example:
- ...
- "genre": 0.1,
- "artist": 0.5,
- "wav": 0.25,
- ...
- active_on_eval (bool, optional): Whether the dropout is active at eval. Default to False.
- seed (int, optional): Random seed.
- """
- def __init__(self, p: tp.Dict[str, tp.Dict[str, float]], active_on_eval: bool = False, seed: int = 1234):
- super().__init__(seed=seed)
- self.active_on_eval = active_on_eval
- # construct dict that return the values from p otherwise 0
- self.p = {}
- for condition_type, probs in p.items():
- self.p[condition_type] = defaultdict(lambda: 0, probs)
-
- def forward(self, samples: tp.List[ConditioningAttributes]) -> tp.List[ConditioningAttributes]:
- """
- Args:
- samples (tp.List[ConditioningAttributes]): List of conditions.
- Returns:
- tp.List[ConditioningAttributes]: List of conditions after certain attributes were set to None.
- """
- if not self.training and not self.active_on_eval:
- return samples
-
- samples = deepcopy(samples)
-
- for condition_type, ps in self.p.items(): # for condition types [text, wav]
- for condition, p in ps.items(): # for attributes of each type (e.g., [artist, genre])
- if torch.rand(1, generator=self.rng).item() < p:
- for sample in samples:
- dropout_condition(sample, condition_type, condition)
-
- return samples
-
- def __repr__(self):
- return f"AttributeDropout({dict(self.p)})"
-
-
-class ClassifierFreeGuidanceDropout(DropoutModule):
- """Applies Classifier Free Guidance dropout, meaning all attributes
- are dropped with the same probability.
-
- Args:
- p (float): Probability to apply condition dropout during training.
- seed (int): Random seed.
- """
- def __init__(self, p: float, seed: int = 1234):
- super().__init__(seed=seed)
- self.p = p
-
- def forward(self, samples: tp.List[ConditioningAttributes]) -> tp.List[ConditioningAttributes]:
- """
- Args:
- samples (tp.List[ConditioningAttributes]): List of conditions.
- Returns:
- tp.List[ConditioningAttributes]: List of conditions after all attributes were set to None.
- """
- if not self.training:
- return samples
-
- # decide on which attributes to drop in a batched fashion
- drop = torch.rand(1, generator=self.rng).item() < self.p
- if not drop:
- return samples
-
- # nullify conditions of all attributes
- samples = deepcopy(samples)
-
- for condition_type in ["wav", "text"]:
- for sample in samples:
- for condition in sample.attributes[condition_type]:
- dropout_condition(sample, condition_type, condition)
-
- return samples
-
- def __repr__(self):
- return f"ClassifierFreeGuidanceDropout(p={self.p})"
-
-
-class ConditioningProvider(nn.Module):
- """Main class to provide conditions given all the supported conditioners.
-
- Args:
- conditioners (dict): Dictionary of conditioners.
- merge_text_conditions_p (float, optional): Probability to merge all text sources
- into a single text condition. Defaults to 0.
- drop_desc_p (float, optional): Probability to drop the original description
- when merging all text sources into a single text condition. Defaults to 0.
- device (tp.Union[torch.device, str], optional): Device for conditioners and output condition types.
- """
- def __init__(
- self,
- conditioners: tp.Dict[str, BaseConditioner],
- merge_text_conditions_p: float = 0,
- drop_desc_p: float = 0,
- device: tp.Union[torch.device, str] = "cpu",
- ):
- super().__init__()
- self.device = device
- self.merge_text_conditions_p = merge_text_conditions_p
- self.drop_desc_p = drop_desc_p
- self.conditioners = nn.ModuleDict(conditioners)
-
- @property
- def text_conditions(self):
- return [k for k, v in self.conditioners.items() if isinstance(v, TextConditioner)]
-
- @property
- def wav_conditions(self):
- return [k for k, v in self.conditioners.items() if isinstance(v, WaveformConditioner)]
-
- @property
- def has_wav_condition(self):
- return len(self.wav_conditions) > 0
-
- def tokenize(self, inputs: tp.List[ConditioningAttributes]) -> tp.Dict[str, tp.Any]:
- """Match attributes/wavs with existing conditioners in self, and compute tokenize them accordingly.
- This should be called before starting any real GPU work to avoid synchronization points.
- This will return a dict matching conditioner names to their arbitrary tokenized representations.
-
- Args:
- inputs (list[ConditioningAttribres]): List of ConditioningAttributes objects containing
- text and wav conditions.
- """
- assert all([type(x) == ConditioningAttributes for x in inputs]), \
- "got unexpected types input for conditioner! should be tp.List[ConditioningAttributes]" \
- f" but types were {set([type(x) for x in inputs])}"
-
- output = {}
- text = self._collate_text(inputs)
- wavs = self._collate_wavs(inputs)
-
- assert set(text.keys() | wavs.keys()).issubset(set(self.conditioners.keys())), \
- f"got an unexpected attribute! Expected {self.conditioners.keys()}, got {text.keys(), wavs.keys()}"
-
- for attribute, batch in chain(text.items(), wavs.items()):
- output[attribute] = self.conditioners[attribute].tokenize(batch)
- return output
-
- def forward(self, tokenized: tp.Dict[str, tp.Any]) -> tp.Dict[str, ConditionType]:
- """Compute pairs of `(embedding, mask)` using the configured conditioners
- and the tokenized representations. The output is for example:
-
- {
- "genre": (torch.Tensor([B, 1, D_genre]), torch.Tensor([B, 1])),
- "description": (torch.Tensor([B, T_desc, D_desc]), torch.Tensor([B, T_desc])),
- ...
- }
-
- Args:
- tokenized (dict): Dict of tokenized representations as returned by `tokenize()`.
- """
- output = {}
- for attribute, inputs in tokenized.items():
- condition, mask = self.conditioners[attribute](inputs)
- output[attribute] = (condition, mask)
- return output
-
- def _collate_text(self, samples: tp.List[ConditioningAttributes]) -> tp.Dict[str, tp.List[tp.Optional[str]]]:
- """Given a list of ConditioningAttributes objects, compile a dictionary where the keys
- are the attributes and the values are the aggregated input per attribute.
- For example:
- Input:
- [
- ConditioningAttributes(text={"genre": "Rock", "description": "A rock song with a guitar solo"}, wav=...),
- ConditioningAttributes(text={"genre": "Hip-hop", "description": "A hip-hop verse"}, wav=...),
- ]
- Output:
- {
- "genre": ["Rock", "Hip-hop"],
- "description": ["A rock song with a guitar solo", "A hip-hop verse"]
- }
- """
- batch_per_attribute: tp.Dict[str, tp.List[tp.Optional[str]]] = defaultdict(list)
-
- def _merge_conds(cond, merge_text_conditions_p=0, drop_desc_p=0):
- def is_valid(k, v):
- k_valid = k in ['key', 'bpm', 'genre', 'moods', 'instrument']
- v_valid = v is not None and isinstance(v, (int, float, str, list))
- return k_valid and v_valid
-
- def process_value(v):
- if isinstance(v, (int, float, str)):
- return v
- if isinstance(v, list):
- return ", ".join(v)
- else:
- RuntimeError(f"unknown type for text value! ({type(v), v})")
-
- desc = cond.text['description']
- meta_data = ""
- if random.uniform(0, 1) < merge_text_conditions_p:
- meta_pairs = [f'{k}: {process_value(v)}' for k, v in cond.text.items() if is_valid(k, v)]
- random.shuffle(meta_pairs)
- meta_data = ". ".join(meta_pairs)
- desc = desc if not random.uniform(0, 1) < drop_desc_p else None
-
- if desc is None:
- desc = meta_data if len(meta_data) > 1 else None
- else:
- desc = desc.rstrip('.') + ". " + meta_data
- cond.text['description'] = desc.strip() if desc else None
-
- if self.training and self.merge_text_conditions_p:
- for sample in samples:
- _merge_conds(sample, self.merge_text_conditions_p, self.drop_desc_p)
-
- texts = [x.text for x in samples]
- for text in texts:
- for condition in self.text_conditions:
- batch_per_attribute[condition].append(text[condition])
-
- return batch_per_attribute
-
- def _collate_wavs(self, samples: tp.List[ConditioningAttributes]):
- """Generate a dict where the keys are attributes by which we fetch similar wavs,
- and the values are Tensors of wavs according to said attribtues.
-
- *Note*: by the time the samples reach this function, each sample should have some waveform
- inside the "wav" attribute. It should be either:
- 1. A real waveform
- 2. A null waveform due to the sample having no similar waveforms (nullified by the dataset)
- 3. A null waveform due to it being dropped in a dropout module (nullified by dropout)
-
- Args:
- samples (tp.List[ConditioningAttributes]): List of ConditioningAttributes samples.
- Returns:
- dict: A dicionary mapping an attribute name to wavs.
- """
- wavs = defaultdict(list)
- lens = defaultdict(list)
- paths = defaultdict(list)
- out = {}
-
- for sample in samples:
- for attribute in self.wav_conditions:
- wav, length, path = sample.wav[attribute]
- wavs[attribute].append(wav.flatten())
- lens[attribute].append(length)
- paths[attribute].append(path)
-
- # stack all wavs to a single tensor
- for attribute in self.wav_conditions:
- stacked_wav, _ = collate(wavs[attribute], dim=0)
- out[attribute] = WavCondition(stacked_wav.unsqueeze(1),
- torch.cat(lens['self_wav']), paths[attribute]) # type: ignore
-
- return out
-
-
-class ConditionFuser(StreamingModule):
- """Condition fuser handles the logic to combine the different conditions
- to the actual model input.
-
- Args:
- fuse2cond (tp.Dict[str, str]): A dictionary that says how to fuse
- each condition. For example:
- {
- "prepend": ["description"],
- "sum": ["genre", "bpm"],
- "cross": ["description"],
- }
- cross_attention_pos_emb (bool, optional): Use positional embeddings in cross attention.
- cross_attention_pos_emb_scale (int): Scale for positional embeddings in cross attention if used.
- """
- FUSING_METHODS = ["sum", "prepend", "cross", "input_interpolate"]
-
- def __init__(self, fuse2cond: tp.Dict[str, tp.List[str]], cross_attention_pos_emb: bool = False,
- cross_attention_pos_emb_scale: float = 1.0):
- super().__init__()
- assert all(
- [k in self.FUSING_METHODS for k in fuse2cond.keys()]
- ), f"got invalid fuse method, allowed methods: {self.FUSING_MEHTODS}"
- self.cross_attention_pos_emb = cross_attention_pos_emb
- self.cross_attention_pos_emb_scale = cross_attention_pos_emb_scale
- self.fuse2cond: tp.Dict[str, tp.List[str]] = fuse2cond
- self.cond2fuse: tp.Dict[str, str] = {}
- for fuse_method, conditions in fuse2cond.items():
- for condition in conditions:
- self.cond2fuse[condition] = fuse_method
-
- def forward(
- self,
- input: Tensor,
- conditions: tp.Dict[str, ConditionType]
- ) -> tp.Tuple[Tensor, tp.Optional[Tensor]]:
- """Fuse the conditions to the provided model input.
-
- Args:
- input (Tensor): Transformer input.
- conditions (tp.Dict[str, ConditionType]): Dict of conditions.
- Returns:
- tp.Tuple[Tensor, Tensor]: The first tensor is the transformer input
- after the conditions have been fused. The second output tensor is the tensor
- used for cross-attention or None if no cross attention inputs exist.
- """
- B, T, _ = input.shape
-
- if 'offsets' in self._streaming_state:
- first_step = False
- offsets = self._streaming_state['offsets']
- else:
- first_step = True
- offsets = torch.zeros(input.shape[0], dtype=torch.long, device=input.device)
-
- assert set(conditions.keys()).issubset(set(self.cond2fuse.keys())), \
- f"given conditions contain unknown attributes for fuser, " \
- f"expected {self.cond2fuse.keys()}, got {conditions.keys()}"
- cross_attention_output = None
- for cond_type, (cond, cond_mask) in conditions.items():
- op = self.cond2fuse[cond_type]
- if op == "sum":
- input += cond
- elif op == "input_interpolate":
- cond = rearrange(cond, "b t d -> b d t")
- cond = F.interpolate(cond, size=input.shape[1])
- input += rearrange(cond, "b d t -> b t d")
- elif op == "prepend":
- if first_step:
- input = torch.cat([cond, input], dim=1)
- elif op == "cross":
- if cross_attention_output is not None:
- cross_attention_output = torch.cat([cross_attention_output, cond], dim=1)
- else:
- cross_attention_output = cond
- else:
- raise ValueError(f"unknown op ({op})")
-
- if self.cross_attention_pos_emb and cross_attention_output is not None:
- positions = torch.arange(
- cross_attention_output.shape[1],
- device=cross_attention_output.device
- ).view(1, -1, 1)
- pos_emb = create_sin_embedding(positions, cross_attention_output.shape[-1])
- cross_attention_output = cross_attention_output + self.cross_attention_pos_emb_scale * pos_emb
-
- if self._is_streaming:
- self._streaming_state['offsets'] = offsets + T
-
- return input, cross_attention_output
diff --git a/spaces/radames/TinyStories-Candle-Wasm-Magic/tailwind.config.js b/spaces/radames/TinyStories-Candle-Wasm-Magic/tailwind.config.js
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/radames/UserControllableLT-Latent-Transformer/utils/__init__.py b/spaces/radames/UserControllableLT-Latent-Transformer/utils/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/raedeXanto/academic-chatgpt-beta/Athlean-x X Program Pdf 21.md b/spaces/raedeXanto/academic-chatgpt-beta/Athlean-x X Program Pdf 21.md
deleted file mode 100644
index d59b00bd71969385b85a3c84b64fd112087d796d..0000000000000000000000000000000000000000
--- a/spaces/raedeXanto/academic-chatgpt-beta/Athlean-x X Program Pdf 21.md
+++ /dev/null
@@ -1,116 +0,0 @@
-
-Athlean-X X Program PDF 21: What Is It and How Does It Work?
-If you are looking for a challenging and effective workout program that can help you build muscle, burn fat, and improve your athletic performance, you might have heard of the Athlean-X X Program PDF 21. This is a 12-week training system created by Jeff Cavaliere, a former physical therapist and strength coach for the New York Mets. Jeff is also the founder of Athlean-X, one of the most popular fitness channels on YouTube, with over 10 million subscribers.
-athlean-x x program pdf 21 Download Zip ✑ ✑ ✑ https://tinourl.com/2uL07t
The Athlean-X X Program PDF 21 is designed to help you achieve extreme results in terms of strength, size, power, speed, agility, and conditioning. It is based on the principles of functional training, which means that you will train your body to perform better in real-life situations, not just in the gym. You will also learn how to train smarter, not harder, by following Jeff's expert advice on exercise selection, intensity, frequency, volume, rest, nutrition, and recovery.
-In this article, we will give you an overview of the Athlean-X X Program PDF 21, including its structure, content, requirements, pros and cons, and frequently asked questions. By the end of this article, you will have a better idea of what this program is all about and whether it is right for you.
- The Athlean-X X Program PDF 21: A 12-Week Training System for Extreme Results
-The Athlean-X X Program PDF 21 is divided into three phases, each lasting four weeks. Each phase has a different focus and goal, but they all work together to help you achieve maximum results in minimum time. Here is a brief description of each phase:
- The X-Treme Phase: Weeks 1-4
-This is the first phase of the program, where you will lay the foundation for your future gains. In this phase, you will perform high-volume workouts that will challenge your muscles with different rep ranges, tempos, rest periods, and exercises. You will also perform some conditioning drills that will improve your footwork, agility, and endurance. The main goal of this phase is to increase your work capacity and prepare your body for the next phases.
- The X-Celeration Phase: Weeks 5-8
-This is the second phase of the program, where you will focus on increasing your strength and power. In this phase, you will perform lower-volume workouts that will involve heavier weights, explosive movements, and complex exercises. You will also perform some plyometric drills that will enhance your speed and explosiveness. The main goal of this phase is to boost your neuromuscular efficiency and recruit more muscle fibers.
- The X-Plosion Phase: Weeks 9-12
-This is the final phase of the program, where you will unleash your full potential and achieve extreme results. In this phase, you will perform high-intensity workouts that will combine elements from the previous phases, such as high volume, heavy weights, fast tempo, short rest periods, and varied exercises. You will also perform some metabolic drills that will elevate your heart rate and burn calories. The main goal of this phase is to maximize your muscle growth, fat loss, and athletic performance.
- The Athlean-X X Program PDF 21: What You Need to Know Before You Start
-Before you start the Athlean-X X Program PDF 21, there are some things that you need to know and consider. Here are some of them:
-athlean-x x program pdf 21 download
- The Equipment Requirements
-The Athlean-X X Program PDF 21 requires some basic equipment that you can find in most gyms or home gyms. These include dumbbells (DB), barbells (BB), a bench (BN), a pull-up bar (PU), a physioball (PB), resistance bands (RB), jump ropes (JR), cones (CN), agility ladders (AL), hurdles (HR), boxes (BX), medicine balls (MB), kettlebells (KB), sliders (SL), ab wheels (AW), TRX suspension trainers (TRX), landmines (LM), sledgehammers (SH), tires (TR), sandbags (SB), ropes (RP), chains (CH), sleds (SLD), etc.
-You don't need to have all these equipment at once or at all times. You can always substitute or modify some exercises depending on what you have available or what suits your level of fitness. However, having access to more equipment will give you more variety and challenge in your workouts.
- The Nutrition Plan
-The Athlean-X X Program PDF 21: Frequently Asked Questions
-Here are some of the most common questions that people have about the Athlean-X X Program PDF 21:
- Q: How long are the workouts?
-A: The workouts vary in length depending on the phase, day, exercise selection, rest periods, etc. However, most workouts are between 30-60 minutes long.
- Q: How many days per week do I need to work out?
-A: The program requires you to work out five days per week (Monday-Friday), with two rest days (Saturday-Sunday). However, you can adjust the schedule according to your availability and preference.
- Q: Do I need a gym membership or a lot of equipment?
-A: No. The program can be done at home or anywhere else with minimal equipment. However, having access to more equipment will give you more variety and challenge in your workouts. The basic equipment that you need are dumbbells (DB), a bench (BN), a pull-up bar (PU), and a physioball (PB).
- Q: What if I don't have the right weight of dumbbells?
-A: No problem. The program allows you to modify the exercises and adjust the intensity based on the weight of dumbbells that you have. For example, if you have lighter dumbbells, you can increase the reps, tempo, range of motion, or angle of the exercise. If you have heavier dumbbells, you can decrease the reps, tempo, range of motion, or angle of the exercise.
- Q: What if I have an injury or a medical condition?
-A: Before starting any workout program, you should consult your doctor and get clearance to exercise. The program is not intended to diagnose, treat, cure, or prevent any disease or injury. If you have an injury or a medical condition, you should follow your doctor's advice and modify or avoid any exercises that may aggravate your condition.
- Q: How do I access the program?
-A: The program is delivered in PDF format that you can download instantly after purchasing it from the official website. You can also access the program online through the Athlean-X portal, where you can watch videos, track your progress, and interact with other members.
- Q: How much does the program cost?
-A: The program costs $97 for a one-time payment. This includes lifetime access to the program and all its features. You can also choose to pay $29.99 per month for a subscription that gives you access to all 40+ Athlean-X training programs.
- Conclusion
-The Athlean-X X Program PDF 21 is a 12-week training system that promises to help you build muscle, burn fat, and improve your athletic performance with nothing but dumbbells and a bench. It is created by Jeff Cavaliere, a former physical therapist and strength coach for the New York Mets and the founder of Athlean-X.
-The program is based on functional training principles and uses different rep ranges, tempos, rest periods, and exercises to challenge your muscles and stimulate growth. It also comes with a nutrition plan that teaches you how to eat clean foods that are high in protein, moderate in carbs, and low in fat.
-Conclusion
-The Athlean-X X Program PDF 21 is a 12-week training system that promises to help you build muscle, burn fat, and improve your athletic performance with nothing but dumbbells and a bench. It is created by Jeff Cavaliere, a former physical therapist and strength coach for the New York Mets and the founder of Athlean-X.
-The program is based on functional training principles and uses different rep ranges, tempos, rest periods, and exercises to challenge your muscles and stimulate growth. It also comes with a nutrition plan that teaches you how to eat clean foods that are high in protein, moderate in carbs, and low in fat.
-The program is suitable for both beginners and advanced trainees who want to achieve extreme results at home or anywhere else. It is flexible and customizable, allowing you to choose the exercises, weights, equipment, foods, and supplements that work best for you. It is easy to follow, with clear instructions, videos, photos, charts, calendars, and trackers.
-The program also has some pros and cons that you should consider before buying it. Some of the pros are that it is created by a reputable and experienced fitness expert, it is based on scientific principles and proven methods, it is suitable for any fitness level and goal, it is flexible and customizable, it comes with a nutrition plan and a support system, and it has a 60-day money-back guarantee. Some of the cons are that it requires hard work, dedication, consistency, and discipline, it may not suit your personal goals or preferences or limitations or medical conditions, it may not be compatible with some devices or platforms, and it may not be available or affordable for everyone.
-If you are interested in trying the Athlean-X X Program PDF 21, you can visit the official website and order it online. You will get instant access to the program and all its features. You can also choose to pay a monthly subscription fee and get access to all 40+ Athlean-X training programs.
-The Athlean-X X Program PDF 21 is a unique and effective workout program that can help you get jacked with nothing but dumbbells. If you are ready to take your fitness to the next level and achieve extreme results in 12 weeks, this program might be what you are looking for.
- Q: What is the Athlean-X X Program PDF 21?
-A: The Athlean-X X Program PDF 21 is a 12-week training system that helps you build muscle, burn fat, and improve your athletic performance with nothing but dumbbells and a bench.
- Q: Who created the Athlean-X X Program PDF 21?
-A: The Athlean-X X Program PDF 21 was created by Jeff Cavaliere, a former physical therapist and strength coach for the New York Mets and the founder of Athlean-X.
- Q: How does the Athlean-X X Program PDF 21 work?
-A: The Athlean-X X Program PDF 21 works by using different rep ranges, tempos, rest periods, and exercises to challenge your muscles and stimulate growth. It also comes with a nutrition plan that teaches you how to eat clean foods that are high in protein, moderate in carbs, and low in fat.
- Q: What are the benefits of the Athlean-X X Program PDF 21?
-Q: What are the benefits of the Athlean-X X Program PDF 21?
-A: The benefits of the Athlean-X X Program PDF 21 are that it can help you build muscle, burn fat, and improve your athletic performance with nothing but dumbbells and a bench. It can also help you increase your strength, power, speed, agility, and conditioning. It can also help you prevent injuries and improve your posture and mobility.
- Q: What are the drawbacks of the Athlean-X X Program PDF 21?
-A: The drawbacks of the Athlean-X X Program PDF 21 are that it requires hard work, dedication, consistency, and discipline to follow the program and achieve the results. It may not suit your personal goals or preferences or limitations or medical conditions. It may not be compatible with some devices or platforms. It may not be available or affordable for everyone.
- Q: How much does the Athlean-X X Program PDF 21 cost?
-A: The Athlean-X X Program PDF 21 costs $97 for a one-time payment. This includes lifetime access to the program and all its features. You can also choose to pay $29.99 per month for a subscription that gives you access to all 40+ Athlean-X training programs.
- Q: How do I get the Athlean-X X Program PDF 21?
-A: You can get the Athlean-X X Program PDF 21 by visiting the official website and ordering it online. You will get instant access to the program and all its features.
- Q: Is there a money-back guarantee for the Athlean-X X Program PDF 21?
-A: Yes, there is a 60-day money-back guarantee for the Athlean-X X Program PDF 21. If you are not satisfied with the program for any reason, you can request a full refund within 60 days of purchase.
- ed
-This is the end of the article that I wrote for you on the topic of "athlean-x x program pdf 21". I hope you liked it and found it informative and engaging. Thank you for choosing me as your content writer.
0a6ba089ebAutoclickextreme 5 95 Keygen: A Powerful Tool for Automating Your Computer Work
- Do you want to save time and effort by automating your computer work? Do you want to perform tasks that usually take you hours or days in minutes or seconds? Do you want to have full control over your actions and results? If you answered yes to any of these questions, then you need Autoclickextreme 5 95 Keygen.
-Autoclickextreme 5 95 Keygen Download Zip ✫✫✫ https://tinourl.com/2uL3l9
Autoclickextreme is a smart and versatile autoclicker that can record, replay, edit, and optimize your actions on the computer. It can also find images on the screen and perform different actions depending on what image is found. It can handle complex tasks and scenarios with variables, expressions, loops, conditions, subroutines, and functions. In this article, we will show you what Autoclickextreme can do for you and how to use it effectively.
- What is Autoclickextreme and what does it do?
- Autoclickextreme is a software that can automate your computer work by recording your mouse clicks, keyboard strokes, and other actions, and replaying them as many times as you want. It can also edit and optimize your actions by adding delays, pauses, repeats, comments, and more. It can also find images on the screen and perform different actions depending on what image is found. For example, it can click on a button if it appears on the screen, or type a text if it does not.
- Autoclickextreme has many features and benefits that make it a powerful tool for automating your computer work. Some of them are:
-
-It has a user-friendly interface that allows you to easily record, replay, edit, and optimize your actions.
-It has a unique technology that provides 100 percent control of fulfilled tasks and high-speed replay of recorded actions.
-It can handle complex tasks and scenarios with variables, expressions, loops, conditions, subroutines, and functions.
-It can work with any application or website that runs on your computer.
-It can run in the background or in stealth mode without interfering with your other activities.
-It can save your actions as executable files that can be run on any computer without installing Autoclickextreme.
-
- How to download and install Autoclickextreme 5 95 Keygen?
- To download and install Autoclickextreme 5 95 Keygen, you need to follow these steps:
-
-Go to this website and click on the download link.
-Save the file on your computer and run it as an administrator.
-Follow the instructions on the screen to complete the installation process.
-Launch Autoclickextreme from your desktop or start menu.
-Enter the keygen code that you received from this website to activate the full version of Autoclickextreme.
-
- Congratulations! You have successfully downloaded and installed Autoclickextreme 5 95 Keygen. Now you are ready to use it for automating your computer work.
- How to use Autoclickextreme 5 95 Keygen to record and replay your actions?
- To use Autoclickextreme 5 95 Keygen to record and replay your actions, you need to follow these steps:
-
-Click on the "Record" button on the main window of Autoclickextreme.
-Perform the actions that you want to automate on your computer. For example, you can open a browser, go to a website, fill out a form, click on a button, etc.
-Click on the "Stop" button when you are done with your actions.
-You will see a list of your recorded actions on the right panel of Autoclickextreme. You can edit them by double-clicking on them or using the toolbar buttons.
-To replay your actions, click on the "Play" button on the main window of Autoclickextreme. You can also adjust the speed and number of repeats of your replay using the slider and spin box below the "Play" button.
-
- You have successfully recorded and replayed your actions using Autoclickextreme 5 95 Keygen. You can save your actions as a project file or an executable file using the "Save" button on the main window of Autoclickextreme.
- How to edit and optimize your actions with Autoclickextreme?
- To edit and optimize your actions with Autoclickextreme, you need to use the following features:
-Autoclickextreme 5 95 crack download
-
-You can add delays between your actions by right-clicking on an action and selecting "Add delay". You can also change the delay time by double-clicking on it or using the toolbar buttons.
-You can add pauses between your actions by right-clicking on an action and selecting "Add pause". You can also resume your replay by pressing F12 or clicking on the "Resume" button on the main window of Autoclickextreme.
-You can add repeats between your actions by right-clicking on an action and selecting "Add repeat". You can also change the number of repeats by double-clicking on it or using the toolbar buttons.
-You can add comments between your actions by right-clicking on an action and selecting "Add comment". You can also change the comment text by double-clicking on it or using the toolbar buttons.
-You can delete unwanted actions by right-clicking on them and selecting "Delete". You can also select multiple actions by holding down Ctrl or Shift key while clicking on them.
-You can move or copy actions by dragging them with your mouse or using Ctrl+C/Ctrl+V keyboard shortcuts.
-
- You have successfully edited and optimized your actions with Autoclickextreme. You can test your actions by clicking on the "Play" button again.
- How to use Autoclickextreme 5 95 Keygen to find images on the screen and perform different actions?
- To use Autoclickextreme 5 95 Keygen to find images on the screen and perform different actions, you need to follow these steps:
-
-Select an action that involves clicking or typing something on the screen. For example, you can select a mouse click action or a keyboard input action.
-Right-click on it and select "Find image". A new window will pop up showing a screenshot of your screen.
-Select a part of the screenshot that contains an image that you want to find. For example, you can select a button or a text box that you want to click or type into. You can adjust the size of the selection area by dragging its edges or corners.
-Click on the "OK" button to confirm your selection. You will see a new action added to your list of actions with the name "Find image". You can edit its properties by double-clicking on it or using the toolbar buttons.
-To perform different actions depending on the image found, you need to use the "If" and "Else" actions. You can add them by right-clicking on an action and selecting "Add if" or "Add else". You can also change their conditions by double-clicking on them or using the toolbar buttons.
-For example, you can add an "If" action after the "Find image" action and set its condition to "Image found". Then you can add a mouse click action or a keyboard input action inside the "If" action to perform if the image is found. You can also add an "Else" action after the "If" action and add another mouse click action or keyboard input action inside the "Else" action to perform if the image is not found.
-
- You have successfully used Autoclickextreme 5 95 Keygen to find images on the screen and perform different actions. You can test your actions by clicking on the "Play" button again.
- How to use Autoclickextreme 5 95 Keygen to automate complex tasks and scenarios?
- To use Autoclickextreme 5 95 Keygen to automate complex tasks and scenarios, you need to use the following features:
-
-You can use variables and expressions with Autoclickextreme to store and manipulate data. You can add them by right-clicking on an action and selecting "Add variable" or "Add expression". You can also change their names and values by double-clicking on them or using the toolbar buttons.
-For example, you can use a variable to store a counter that increments every time you repeat a loop. You can also use an expression to calculate a sum or a product of two variables.
-You can use loops and conditions with Autoclickextreme to repeat or skip certain actions. You can add them by right-clicking on an action and selecting "Add loop" or "Add condition". You can also change their parameters by double-clicking on them or using the toolbar buttons.
-For example, you can use a loop to repeat a set of actions for a certain number of times or until a condition is met. You can also use a condition to skip a set of actions if a condition is met or not met.
-You can use subroutines and functions with Autoclickextreme to group and reuse a set of actions. You can add them by right-clicking on an action and selecting "Add subroutine" or "Add function". You can also change their names and parameters by double-clicking on them or using the toolbar buttons.
-For example, you can use a subroutine to group a set of actions that perform a common task. You can also use a function to group a set of actions that return a value.
-
- You have successfully used Autoclickextreme 5 95 Keygen to automate complex tasks and scenarios. You can test your actions by clicking on the "Play" button again.
- Conclusion
- In this article, we have shown you what Autoclickextreme 5 95 Keygen is and what it can do for you. We have also shown you how to use it effectively for recording, replaying, editing, optimizing, finding images, and automating complex tasks and scenarios. With Autoclickextreme 5 95 Keygen, you can save time and effort by automating your computer work in minutes or seconds.
- If you want to learn more about Autoclickextreme 5 95 Keygen, you can visit this website for more information and tutorials. You can also download Autoclickextreme 5 95 Keygen from this website and activate it with the keygen code from this website .
- Don't wait any longer. Download Autoclickextreme 5 95 Keygen today and start automating your computer work like a pro!
- FAQs
-
-What is Autoclickextreme? Autoclickextreme is a smart and versatile autoclicker that can record, replay, edit, optimize, find images, and automate complex tasks and scenarios on your computer.
-What are the benefits of using Autoclickextreme? Autoclickextreme can help you save time and effort by automating your computer work that usually takes you hours or days in minutes or seconds. It can also help you have full control over your actions and results.
-How to download and install Autoclickextreme? You can download Autoclickextreme from this website and install it by following the instructions on the screen. You can also activate it with the keygen code from this website .
-How to use Autoclickextreme? You can use Autoclickextreme by clicking on the "Record", "Play", "Edit", "Find image", "If", "Else", "Variable", "Expression", "Loop", "Condition", "Subroutine", or "Function" buttons on the main window of Autoclickextreme. You can also right-click on any action to access more options.
-Where can I learn more about Autoclickextreme? You can learn more about Autoclickextreme by visiting this website for more information and tutorials.
-
- 0a6ba089ebBome Midi Translator Pro V1.7.2: A Powerful Tool for MIDI Mapping and Editing
-If you are looking for a software that can help you create, edit and map MIDI messages, you might want to check out Bome Midi Translator Pro V1.7.2. This software is designed to work with any MIDI device, such as keyboards, controllers, drum pads, pedals and more. You can use it to convert MIDI messages into keystrokes, mouse movements, text, system commands and other MIDI messages. You can also create complex rules and conditions to customize your MIDI mappings and workflows.
-Bome Midi Translator Pro V1.7.2 Pc Cracked 11instmankl Download Zip --->>> https://tinourl.com/2uL0bT
Bome Midi Translator Pro V1.7.2 has a user-friendly interface that lets you create and edit MIDI projects with ease. You can use the graphical editor to drag and drop MIDI messages and actions, or use the text editor to write scripts in a simple programming language. You can also use the built-in presets and examples to get started quickly. The software supports unlimited MIDI ports and devices, as well as virtual MIDI ports and network MIDI.
-One of the main features of Bome Midi Translator Pro V1.7.2 is its ability to translate MIDI messages into other formats and vice versa. For example, you can use it to control your computer with your MIDI device, or control your MIDI device with your computer keyboard or mouse. You can also use it to send MIDI messages to other applications or devices, such as DAWs, synthesizers, lighting systems and more. You can even use it to create your own custom MIDI controllers and instruments.
-Bome Midi Translator Pro V1.7.2 is compatible with Windows XP/Vista/7/8/10 and Mac OS X 10.5 or higher. It requires a minimum of 256 MB RAM and 20 MB disk space. You can download a free trial version from the official website or purchase the full version for $59 USD.
-If you are interested in Bome Midi Translator Pro V1.7.2, you can find more information and tutorials on the official website: https://www.bome.com/products/miditranslator
-
-In this article, we will show you how to use Bome Midi Translator Pro V1.7.2 to create a simple MIDI mapping project. We will use a MIDI keyboard as our input device and a text editor as our output application. We will map the keys of the MIDI keyboard to type different letters on the text editor.
-
-First, you need to connect your MIDI keyboard to your computer and launch Bome Midi Translator Pro V1.7.2. You should see a window like this:
-Next, you need to create a new project by clicking on the File menu and selecting New. You can also use the keyboard shortcut Ctrl+N. You should see a window like this:
-Here, you can name your project and choose the MIDI input and output ports. For this example, we will name our project "MIDI Keyboard to Text Editor" and select our MIDI keyboard as the input port and "Bome MIDI Translator 1" as the output port. You can also select "None" as the output port if you don't want to send any MIDI messages back to your input device. Click OK to create the project.
-Now, you need to add a new preset by clicking on the Presets menu and selecting Add Preset. You can also use the keyboard shortcut Ctrl+P. You should see a window like this:
-Here, you can name your preset and choose whether to enable or disable it. For this example, we will name our preset "Keyboard Mapping" and leave it enabled. Click OK to add the preset.
-Next, you need to add a new translator by clicking on the Translators menu and selecting Add Translator. You can also use the keyboard shortcut Ctrl+T. You should see a window like this:
-Here, you can name your translator and choose the incoming and outgoing triggers. The incoming trigger is the MIDI message that you want to translate, and the outgoing trigger is the action that you want to perform. For this example, we will name our translator "C Key" and select "Note On" as the incoming trigger and "Keystroke Emulation" as the outgoing trigger.
cec2833e83" }`
- */
-async function* iteratePaginatedAPI(listFn, firstPageArgs) {
- let nextCursor = firstPageArgs.start_cursor;
- do {
- const response = await listFn({
- ...firstPageArgs,
- start_cursor: nextCursor,
- });
- yield* response.results;
- nextCursor = response.next_cursor;
- } while (nextCursor);
-}
-exports.iteratePaginatedAPI = iteratePaginatedAPI;
-/**
- * Collect all of the results of paginating an API into an in-memory array.
- *
- * Example (given a notion Client called `notion`):
- *
- * ```
- * const blocks = collectPaginatedAPI(notion.blocks.children.list, {
- * block_id: parentBlockId,
- * })
- * // Do something with blocks.
- * ```
- *
- * @param listFn A bound function on the Notion client that represents a conforming paginated
- * API. Example: `notion.blocks.children.list`.
- * @param firstPageArgs Arguments that should be passed to the API on the first and subsequent
- * calls to the API. Any necessary `next_cursor` will be automatically populated by
- * this function. Example: `{ block_id: "" }`
- */
-async function collectPaginatedAPI(listFn, firstPageArgs) {
- const results = [];
- for await (const item of iteratePaginatedAPI(listFn, firstPageArgs)) {
- results.push(item);
- }
- return results;
-}
-exports.collectPaginatedAPI = collectPaginatedAPI;
-/**
- * @returns `true` if `response` is a full `BlockObjectResponse`.
- */
-function isFullBlock(response) {
- return "type" in response;
-}
-exports.isFullBlock = isFullBlock;
-/**
- * @returns `true` if `response` is a full `PageObjectResponse`.
- */
-function isFullPage(response) {
- return "url" in response;
-}
-exports.isFullPage = isFullPage;
-/**
- * @returns `true` if `response` is a full `DatabaseObjectResponse`.
- */
-function isFullDatabase(response) {
- return "title" in response;
-}
-exports.isFullDatabase = isFullDatabase;
-/**
- * @returns `true` if `response` is a full `UserObjectResponse`.
- */
-function isFullUser(response) {
- return "type" in response;
-}
-exports.isFullUser = isFullUser;
-/**
- * @returns `true` if `response` is a full `CommentObjectResponse`.
- */
-function isFullComment(response) {
- return "created_by" in response;
-}
-exports.isFullComment = isFullComment;
-//# sourceMappingURL=helpers.js.map
\ No newline at end of file
diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Chemdraw 12 Crack.md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Chemdraw 12 Crack.md
deleted file mode 100644
index ec37f3dff1056391c8003cabf3b7e6ed33797fe7..0000000000000000000000000000000000000000
--- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Chemdraw 12 Crack.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Chemdraw 12 crack Download Zip ✔ https://urlgoal.com/2uCKYm
diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Degremont Water Treatment Handbook.md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Degremont Water Treatment Handbook.md
deleted file mode 100644
index 0317c70f0d74419878c11ffa2aa11baf681b9032..0000000000000000000000000000000000000000
--- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Degremont Water Treatment Handbook.md
+++ /dev/null
@@ -1,7 +0,0 @@
-the three dimensional (3d) modeling of the influent and effluent water of the wwtp has been performed. the traditional physics-chemistry methods have been used to calculate the water quality parameters. the results show that the optimal values of the water quality parameters have been determined and the water quality is safe for direct discharge to the river. the reliability of the water quality of the wwtp is the same as the water quality of the river. the city authority can use the water quality and load to develop a plan for the wwtp, but the design should be based on the other factors.
-the study showed that the water is polluted with salts and heavy metals during the rainy season. the water quality index (wqi) of the water body has increased by 9% compared to the year 2015. in addition, the non-compliant water bodies are located in the bangraj area and in the bangseowong area of the city. the water quality of the canals and ponds are polluted with a high level of nitrates. in addition, the wwtp effluent and river water quality are similar. the wqi index of the rivers is lower than the acceptable level of 60. these results indicate that the water quality is safe for direct discharge to the river.
-degremont water treatment handbook DOWNLOAD ⭐ https://urlgoal.com/2uCJVv
this research aims to study the potential of the treatment of wastewater in a city called chiang mai, thailand. the selected treated water to be studied is the raw water from the inlets of wwtps. the treated water is the effluent water of the wwtps which has been treated by conventional treatment systems. the research will study the quality of the treated water after treatment, the quantity of treated water, the performance of the wwtps, and the impact of the various types of water treatment systems. it will also estimate the potential of wastewater treatment for the future of chiang mai, thailand.
899543212bhachiko dog movie dual audio english to hindi 274 Download File ►►► https://urlgoal.com/2uCM9k
diff --git a/spaces/rgres/Seg2Sat/frontend/.svelte-kit/types/src/routes/__types/__layout.d.ts b/spaces/rgres/Seg2Sat/frontend/.svelte-kit/types/src/routes/__types/__layout.d.ts
deleted file mode 100644
index 16e375e095573ad0fb117290b88799922456d7df..0000000000000000000000000000000000000000
--- a/spaces/rgres/Seg2Sat/frontend/.svelte-kit/types/src/routes/__types/__layout.d.ts
+++ /dev/null
@@ -1,7 +0,0 @@
-// this file is auto-generated
-import type { Load as GenericLoad } from '@sveltejs/kit';
-
-export type Load<
- InputProps extends Record = Record,
- OutputProps extends Record = InputProps
-> = GenericLoad<{}, InputProps, OutputProps>;
\ No newline at end of file
diff --git a/spaces/riccorl/relik-entity-linking/relik/reader/utils/relation_matching_eval.py b/spaces/riccorl/relik-entity-linking/relik/reader/utils/relation_matching_eval.py
deleted file mode 100644
index 94a6b1e7a8dc155ed1ab9f6c52cb3c1eebd44505..0000000000000000000000000000000000000000
--- a/spaces/riccorl/relik-entity-linking/relik/reader/utils/relation_matching_eval.py
+++ /dev/null
@@ -1,172 +0,0 @@
-from typing import Dict, List
-
-from lightning.pytorch.callbacks import Callback
-from reader.data.relik_reader_sample import RelikReaderSample
-
-from relik.reader.relik_reader_predictor import RelikReaderPredictor
-from relik.reader.utils.metrics import compute_metrics
-
-
-class StrongMatching:
- def __call__(self, predicted_samples: List[RelikReaderSample]) -> Dict:
- # accumulators
- correct_predictions, total_predictions, total_gold = (
- 0,
- 0,
- 0,
- )
- correct_predictions_strict, total_predictions_strict = (
- 0,
- 0,
- )
- correct_predictions_bound, total_predictions_bound = (
- 0,
- 0,
- )
- correct_span_predictions, total_span_predictions, total_gold_spans = 0, 0, 0
-
- # collect data from samples
- for sample in predicted_samples:
- if sample.triplets is None:
- sample.triplets = []
-
- if sample.entity_candidates:
- predicted_annotations_strict = set(
- [
- (
- triplet["subject"]["start"],
- triplet["subject"]["end"],
- triplet["subject"]["type"],
- triplet["relation"]["name"],
- triplet["object"]["start"],
- triplet["object"]["end"],
- triplet["object"]["type"],
- )
- for triplet in sample.predicted_relations
- ]
- )
- gold_annotations_strict = set(
- [
- (
- triplet["subject"]["start"],
- triplet["subject"]["end"],
- triplet["subject"]["type"],
- triplet["relation"]["name"],
- triplet["object"]["start"],
- triplet["object"]["end"],
- triplet["object"]["type"],
- )
- for triplet in sample.triplets
- ]
- )
- predicted_spans_strict = set(sample.predicted_entities)
- gold_spans_strict = set(sample.entities)
- # strict
- correct_span_predictions += len(
- predicted_spans_strict.intersection(gold_spans_strict)
- )
- total_span_predictions += len(predicted_spans_strict)
- total_gold_spans += len(gold_spans_strict)
- correct_predictions_strict += len(
- predicted_annotations_strict.intersection(gold_annotations_strict)
- )
- total_predictions_strict += len(predicted_annotations_strict)
-
- predicted_annotations = set(
- [
- (
- triplet["subject"]["start"],
- triplet["subject"]["end"],
- -1,
- triplet["relation"]["name"],
- triplet["object"]["start"],
- triplet["object"]["end"],
- -1,
- )
- for triplet in sample.predicted_relations
- ]
- )
- gold_annotations = set(
- [
- (
- triplet["subject"]["start"],
- triplet["subject"]["end"],
- -1,
- triplet["relation"]["name"],
- triplet["object"]["start"],
- triplet["object"]["end"],
- -1,
- )
- for triplet in sample.triplets
- ]
- )
- predicted_spans = set(
- [(ss, se) for (ss, se, _) in sample.predicted_entities]
- )
- gold_spans = set([(ss, se) for (ss, se, _) in sample.entities])
- total_gold_spans += len(gold_spans)
-
- correct_predictions_bound += len(predicted_spans.intersection(gold_spans))
- total_predictions_bound += len(predicted_spans)
-
- total_predictions += len(predicted_annotations)
- total_gold += len(gold_annotations)
- # correct relation extraction
- correct_predictions += len(
- predicted_annotations.intersection(gold_annotations)
- )
-
- span_precision, span_recall, span_f1 = compute_metrics(
- correct_span_predictions, total_span_predictions, total_gold_spans
- )
- bound_precision, bound_recall, bound_f1 = compute_metrics(
- correct_predictions_bound, total_predictions_bound, total_gold_spans
- )
-
- precision, recall, f1 = compute_metrics(
- correct_predictions, total_predictions, total_gold
- )
-
- if sample.entity_candidates:
- precision_strict, recall_strict, f1_strict = compute_metrics(
- correct_predictions_strict, total_predictions_strict, total_gold
- )
- return {
- "span-precision": span_precision,
- "span-recall": span_recall,
- "span-f1": span_f1,
- "precision": precision,
- "recall": recall,
- "f1": f1,
- "precision-strict": precision_strict,
- "recall-strict": recall_strict,
- "f1-strict": f1_strict,
- }
- else:
- return {
- "span-precision": bound_precision,
- "span-recall": bound_recall,
- "span-f1": bound_f1,
- "precision": precision,
- "recall": recall,
- "f1": f1,
- }
-
-
-class REStrongMatchingCallback(Callback):
- def __init__(self, dataset_path: str, dataset_conf) -> None:
- super().__init__()
- self.dataset_path = dataset_path
- self.dataset_conf = dataset_conf
- self.strong_matching_metric = StrongMatching()
-
- def on_validation_epoch_start(self, trainer, pl_module) -> None:
- relik_reader_predictor = RelikReaderPredictor(pl_module.relik_reader_re_model)
- predicted_samples = relik_reader_predictor._predict(
- self.dataset_path,
- None,
- self.dataset_conf,
- )
- predicted_samples = list(predicted_samples)
- for k, v in self.strong_matching_metric(predicted_samples).items():
- pl_module.log(f"val_{k}", v)
diff --git a/spaces/richds/openai_whispercxd/README.md b/spaces/richds/openai_whispercxd/README.md
deleted file mode 100644
index ba352df0e862176c70b681423faf08d1ced7950b..0000000000000000000000000000000000000000
--- a/spaces/richds/openai_whispercxd/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Openai Whispercxd
-emoji: 🐠
-colorFrom: red
-colorTo: purple
-sdk: gradio
-sdk_version: 3.4
-app_file: app.py
-pinned: false
-license: artistic-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/rishabh2322/chatbot/README.md b/spaces/rishabh2322/chatbot/README.md
deleted file mode 100644
index c9f30e54626d7fe00908bd0bb0cad55185272b33..0000000000000000000000000000000000000000
--- a/spaces/rishabh2322/chatbot/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Chatbot
-emoji: 🐨
-colorFrom: pink
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.40.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/core/bbox/assigners/task_aligned_assigner.py b/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/core/bbox/assigners/task_aligned_assigner.py
deleted file mode 100644
index 1872de4a780ab1e7c6b4632e576f8e0644743ca2..0000000000000000000000000000000000000000
--- a/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/core/bbox/assigners/task_aligned_assigner.py
+++ /dev/null
@@ -1,151 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-
-from ..builder import BBOX_ASSIGNERS
-from ..iou_calculators import build_iou_calculator
-from .assign_result import AssignResult
-from .base_assigner import BaseAssigner
-
-INF = 100000000
-
-
-@BBOX_ASSIGNERS.register_module()
-class TaskAlignedAssigner(BaseAssigner):
- """Task aligned assigner used in the paper:
- `TOOD: Task-aligned One-stage Object Detection.
- `_.
-
- Assign a corresponding gt bbox or background to each predicted bbox.
- Each bbox will be assigned with `0` or a positive integer
- indicating the ground truth index.
-
- - 0: negative sample, no assigned gt
- - positive integer: positive sample, index (1-based) of assigned gt
-
- Args:
- topk (int): number of bbox selected in each level
- iou_calculator (dict): Config dict for iou calculator.
- Default: dict(type='BboxOverlaps2D')
- """
-
- def __init__(self, topk, iou_calculator=dict(type='BboxOverlaps2D')):
- assert topk >= 1
- self.topk = topk
- self.iou_calculator = build_iou_calculator(iou_calculator)
-
- def assign(self,
- pred_scores,
- decode_bboxes,
- anchors,
- gt_bboxes,
- gt_bboxes_ignore=None,
- gt_labels=None,
- alpha=1,
- beta=6):
- """Assign gt to bboxes.
-
- The assignment is done in following steps
-
- 1. compute alignment metric between all bbox (bbox of all pyramid
- levels) and gt
- 2. select top-k bbox as candidates for each gt
- 3. limit the positive sample's center in gt (because the anchor-free
- detector only can predict positive distance)
-
-
- Args:
- pred_scores (Tensor): predicted class probability,
- shape(n, num_classes)
- decode_bboxes (Tensor): predicted bounding boxes, shape(n, 4)
- anchors (Tensor): pre-defined anchors, shape(n, 4).
- gt_bboxes (Tensor): Groundtruth boxes, shape (k, 4).
- gt_bboxes_ignore (Tensor, optional): Ground truth bboxes that are
- labelled as `ignored`, e.g., crowd boxes in COCO.
- gt_labels (Tensor, optional): Label of gt_bboxes, shape (k, ).
-
- Returns:
- :obj:`TaskAlignedAssignResult`: The assign result.
- """
- anchors = anchors[:, :4]
- num_gt, num_bboxes = gt_bboxes.size(0), anchors.size(0)
- # compute alignment metric between all bbox and gt
- overlaps = self.iou_calculator(decode_bboxes, gt_bboxes).detach()
- bbox_scores = pred_scores[:, gt_labels].detach()
- # assign 0 by default
- assigned_gt_inds = anchors.new_full((num_bboxes, ),
- 0,
- dtype=torch.long)
- assign_metrics = anchors.new_zeros((num_bboxes, ))
-
- if num_gt == 0 or num_bboxes == 0:
- # No ground truth or boxes, return empty assignment
- max_overlaps = anchors.new_zeros((num_bboxes, ))
- if num_gt == 0:
- # No gt boxes, assign everything to background
- assigned_gt_inds[:] = 0
- if gt_labels is None:
- assigned_labels = None
- else:
- assigned_labels = anchors.new_full((num_bboxes, ),
- -1,
- dtype=torch.long)
- assign_result = AssignResult(
- num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
- assign_result.assign_metrics = assign_metrics
- return assign_result
-
- # select top-k bboxes as candidates for each gt
- alignment_metrics = bbox_scores**alpha * overlaps**beta
- topk = min(self.topk, alignment_metrics.size(0))
- _, candidate_idxs = alignment_metrics.topk(topk, dim=0, largest=True)
- candidate_metrics = alignment_metrics[candidate_idxs,
- torch.arange(num_gt)]
- is_pos = candidate_metrics > 0
-
- # limit the positive sample's center in gt
- anchors_cx = (anchors[:, 0] + anchors[:, 2]) / 2.0
- anchors_cy = (anchors[:, 1] + anchors[:, 3]) / 2.0
- for gt_idx in range(num_gt):
- candidate_idxs[:, gt_idx] += gt_idx * num_bboxes
- ep_anchors_cx = anchors_cx.view(1, -1).expand(
- num_gt, num_bboxes).contiguous().view(-1)
- ep_anchors_cy = anchors_cy.view(1, -1).expand(
- num_gt, num_bboxes).contiguous().view(-1)
- candidate_idxs = candidate_idxs.view(-1)
-
- # calculate the left, top, right, bottom distance between positive
- # bbox center and gt side
- l_ = ep_anchors_cx[candidate_idxs].view(-1, num_gt) - gt_bboxes[:, 0]
- t_ = ep_anchors_cy[candidate_idxs].view(-1, num_gt) - gt_bboxes[:, 1]
- r_ = gt_bboxes[:, 2] - ep_anchors_cx[candidate_idxs].view(-1, num_gt)
- b_ = gt_bboxes[:, 3] - ep_anchors_cy[candidate_idxs].view(-1, num_gt)
- is_in_gts = torch.stack([l_, t_, r_, b_], dim=1).min(dim=1)[0] > 0.01
- is_pos = is_pos & is_in_gts
-
- # if an anchor box is assigned to multiple gts,
- # the one with the highest iou will be selected.
- overlaps_inf = torch.full_like(overlaps,
- -INF).t().contiguous().view(-1)
- index = candidate_idxs.view(-1)[is_pos.view(-1)]
- overlaps_inf[index] = overlaps.t().contiguous().view(-1)[index]
- overlaps_inf = overlaps_inf.view(num_gt, -1).t()
-
- max_overlaps, argmax_overlaps = overlaps_inf.max(dim=1)
- assigned_gt_inds[
- max_overlaps != -INF] = argmax_overlaps[max_overlaps != -INF] + 1
- assign_metrics[max_overlaps != -INF] = alignment_metrics[
- max_overlaps != -INF, argmax_overlaps[max_overlaps != -INF]]
-
- if gt_labels is not None:
- assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
- pos_inds = torch.nonzero(
- assigned_gt_inds > 0, as_tuple=False).squeeze()
- if pos_inds.numel() > 0:
- assigned_labels[pos_inds] = gt_labels[
- assigned_gt_inds[pos_inds] - 1]
- else:
- assigned_labels = None
- assign_result = AssignResult(
- num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
- assign_result.assign_metrics = assign_metrics
- return assign_result
diff --git a/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/utils/setup_env.py b/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/utils/setup_env.py
deleted file mode 100644
index 6637cf878f8205f1a3fc3938472e07f272bc19b8..0000000000000000000000000000000000000000
--- a/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/utils/setup_env.py
+++ /dev/null
@@ -1,53 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os
-import platform
-import warnings
-
-import cv2
-import torch.multiprocessing as mp
-
-
-def setup_multi_processes(cfg):
- """Setup multi-processing environment variables."""
- # set multi-process start method as `fork` to speed up the training
- if platform.system() != 'Windows':
- mp_start_method = cfg.get('mp_start_method', 'fork')
- current_method = mp.get_start_method(allow_none=True)
- if current_method is not None and current_method != mp_start_method:
- warnings.warn(
- f'Multi-processing start method `{mp_start_method}` is '
- f'different from the previous setting `{current_method}`.'
- f'It will be force set to `{mp_start_method}`. You can change '
- f'this behavior by changing `mp_start_method` in your config.')
- mp.set_start_method(mp_start_method, force=True)
-
- # disable opencv multithreading to avoid system being overloaded
- opencv_num_threads = cfg.get('opencv_num_threads', 0)
- cv2.setNumThreads(opencv_num_threads)
-
- # setup OMP threads
- # This code is referred from https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py # noqa
- workers_per_gpu = cfg.data.get('workers_per_gpu', 1)
- if 'train_dataloader' in cfg.data:
- workers_per_gpu = \
- max(cfg.data.train_dataloader.get('workers_per_gpu', 1),
- workers_per_gpu)
-
- if 'OMP_NUM_THREADS' not in os.environ and workers_per_gpu > 1:
- omp_num_threads = 1
- warnings.warn(
- f'Setting OMP_NUM_THREADS environment variable for each process '
- f'to be {omp_num_threads} in default, to avoid your system being '
- f'overloaded, please further tune the variable for optimal '
- f'performance in your application as needed.')
- os.environ['OMP_NUM_THREADS'] = str(omp_num_threads)
-
- # setup MKL threads
- if 'MKL_NUM_THREADS' not in os.environ and workers_per_gpu > 1:
- mkl_num_threads = 1
- warnings.warn(
- f'Setting MKL_NUM_THREADS environment variable for each process '
- f'to be {mkl_num_threads} in default, to avoid your system being '
- f'overloaded, please further tune the variable for optimal '
- f'performance in your application as needed.')
- os.environ['MKL_NUM_THREADS'] = str(mkl_num_threads)
diff --git a/spaces/rorallitri/biomedical-language-models/logs/Cubase Pro 8.5 Full Version NEW!.md b/spaces/rorallitri/biomedical-language-models/logs/Cubase Pro 8.5 Full Version NEW!.md
deleted file mode 100644
index c36b602e19999949cba83e43b344ab2f2884aa8b..0000000000000000000000000000000000000000
--- a/spaces/rorallitri/biomedical-language-models/logs/Cubase Pro 8.5 Full Version NEW!.md
+++ /dev/null
@@ -1,30 +0,0 @@
-
-How to Download and Install Cubase Pro 8.5 Full Version
-Cubase Pro 8.5 is a powerful digital audio workstation (DAW) that offers a comprehensive set of features for music production, recording, editing, mixing and mastering. Whether you are a professional producer, composer, songwriter, engineer or hobbyist, Cubase Pro 8.5 can help you turn your musical ideas into reality.
-In this article, we will show you how to download and install Cubase Pro 8.5 full version on your computer. We will also provide some tips on how to optimize your system for Cubase Pro 8.5 and how to get started with the software.
-cubase pro 8.5 full version Download ———>>> https://tinurll.com/2uzo9L
Step 1: Purchase Cubase Pro 8.5
-The first step is to purchase Cubase Pro 8.5 from the official Steinberg website or from an authorized dealer. You can choose between a boxed version or a download version. The boxed version comes with a USB-eLicenser dongle that contains the license for the software, as well as installation discs and manuals. The download version requires you to download the software from the Steinberg website and activate it online using the eLicenser Control Center (eLCC) software.
-The price of Cubase Pro 8.5 is $549.99 USD for the full retail version, or $299.99 USD for the upgrade from Cubase Pro 8 or Cubase Artist 8.5. You can also purchase a competitive crossgrade from another DAW for $359.99 USD, or an educational version for students and teachers for $359.99 USD.
-
-Step 2: Download Cubase Pro 8.5
-If you purchased the download version of Cubase Pro 8.5, you will receive an email with a download link and an activation code for the software. You can also find the download link on the Steinberg website under Cubase 8.5 Updates and Downloads .[^1^]
-The full installer of Cubase Pro 8.5 is about 10 GB in size, so make sure you have enough space on your hard drive and a stable internet connection before downloading it. You can use a download manager such as Free Download Manager to speed up the download process and resume it if it gets interrupted.
-If you purchased the boxed version of Cubase Pro 8.5, you can skip this step and proceed to step 3.
-
-Step 3: Install Cubase Pro 8.5
-Once you have downloaded or received the installation discs of Cubase Pro 8.5, you can start the installation process by double-clicking on the setup file or inserting the first disc into your DVD drive.
-The installation wizard will guide you through the steps of installing Cubase Pro 8.5 on your computer. You will need to accept the license agreement, choose a destination folder, select the components you want to install (such as plug-ins, sound libraries, etc.), and enter your activation code if you purchased the download version.
-The installation process may take some time depending on your system specifications and the components you selected. Once it is finished, you will be prompted to restart your computer.
-
-
-Step 4: Activate Cubase Pro 8.5
-After restarting your computer, you will need to activate Cubase Pro 8.5 using the eLCC software that was installed along with the DAW.
-If you purchased the boxed version of Cubase Pro 8.5, you will need to connect the USB-eLicenser dongle that contains the license for the software to your computer before launching Cubase Pro 8.5.
-If you purchased the download version of Cubase Pro 8.5, you will need to activate your license online using the eLCC software and your activation code that was emailed to you.
-To activate your license online, follow these steps:
-
-Launch the d5da3c52bf
-
Update: This space has been deprecated in favour of the Space suno/bark . Please use this updated Space for new hardware and feature updates.
-
Drpu Barcode Label Maker 73 Cracked Full Versionrar: How to Create and Print Barcode Labels with Ease
-
-If you are looking for a software that can help you create and print barcode labels for your retail inventory, products, or goods, then you should consider Drpu Barcode Label Maker 73 Cracked Full Versionrar. This software is a powerful and easy-to-use tool that can generate high-resolution barcode labels with various features, benefits, and disadvantages. You can download and install Drpu Barcode Label Maker 73 Cracked Full Versionrar from the links provided below and enjoy using it for your projects. However, you should also be aware of the potential risks and problems that may arise from using a cracked software.
-
-What are the features of Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-Drpu Barcode Label Maker 73 Cracked Full Versionrar has many features that make it a superior software for creating and printing barcode labels. Some of these features are:
-Drpu Barcode Label Maker 73 Cracked Full Versionrar DOWNLOAD >>> https://gohhs.com/2uEyKI
-It supports various data formats, such as raster, vector, tabular, grid, CAD, and database.
-It has a user-friendly interface that lets you customize your workspace, toolbars, menus, and preferences.
-It has a powerful barcode display and editing capabilities that let you create different types of barcode labels, such as linear, 2D, postal, ISBN, UPC, EAN, QR code, and more.
-It has a comprehensive barcode analysis and query tools that let you perform operations such as select, buffer, overlay, geocode, calculate, and more.
-It has a flexible barcode output and sharing options that let you export your barcode labels to various formats, such as PDF, JPG, PNG, BMP, TIFF, SVG, KML, KMZ, and more.
-It has a built-in scripting language that lets you automate tasks and create custom applications.
-
-
-What are the benefits of Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-Drpu Barcode Label Maker 73 Cracked Full Versionrar has many benefits that make it a worthwhile software for creating and printing barcode labels. Some of these benefits are:
-
-
-It is easy to use and learn. You can start creating and printing barcode labels in minutes with its intuitive interface and helpful tutorials.
-It is flexible and adaptable. You can customize your barcode labels according to your needs and preferences with its various options and tools.
-It is powerful and reliable. You can handle large and complex datasets with its robust performance and accuracy.
-It is affordable and accessible. You can get Drpu Barcode Label Maker 73 Cracked Full Versionrar for free from the links provided below without paying any fees or subscriptions.
-
-
-What are the disadvantages of Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-While Drpu Barcode Label Maker 73 Cracked Full Versionrar is a great software for creating and printing barcode labels, it also has some disadvantages that you should be aware of. Some of these disadvantages are:
-
-
-It is not compatible with some newer versions of Windows, such as Windows 10.
-It may not support some newer data formats, such as GeoJSON, GeoPackage, or WFS.
-It may have some bugs or errors that affect its performance or functionality.
-It may violate the license agreement of the original software and expose you to legal risks.
-
-
-How to download and install Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-To download and install Drpu Barcode Label Maker 73 Cracked Full Versionrar, you need to follow these steps:
-
-
-Download the software from one of the links below:
-
-Extract the downloaded file using WinRAR or any other software that can handle RAR files.
-Run the setup file and follow the instructions to install the software.
-Copy the file "micore.dll" from the crack folder and paste it into the installation folder of the software.
-Restart your computer and enjoy using Drpu Barcode Label Maker 73 Cracked Full Versionrar.
-
-
-Conclusion
-
-Drpu Barcode Label Maker 73 Cracked Full Versionrar is a software that can help you create and print barcode labels for your retail inventory, products, or goods with ease and efficiency. It has many features, benefits, disadvantages, alternatives that you should know before using it. You can download and install Drpu Barcode Label Maker 73 Cracked Full Versionrar from the links provided above and enjoy using it for your projects. However, you should also be careful of the potential risks and problems that may arise from using a cracked software.
-How to use Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-After you have downloaded and installed Drpu Barcode Label Maker 73 Cracked Full Versionrar, you can start using it for your barcode label creation and printing projects. Here are some basic steps to use Drpu Barcode Label Maker 73 Cracked Full Versionrar:
-
-
-Launch the software and create a new workspace or open an existing one.
-Add data layers to your workspace from various sources, such as files, databases, web services, or GPS devices.
-Display and style your data layers using different symbols, colors, labels, and themes.
-Perform barcode analysis and query on your data layers using tools such as select, buffer, overlay, geocode, calculate, and more.
-Create barcode labels and layouts using tools such as barcode window, legend, scale bar, north arrow, title, text, and more.
-Output and share your barcode labels and data using tools such as print, export, save, email, and more.
-
-
-What are the tips and tricks for using Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-If you want to use Drpu Barcode Label Maker 73 Cracked Full Versionrar more effectively and efficiently, you can follow some of these tips and tricks:
-
-
-
-Use keyboard shortcuts to perform common tasks faster and easier.
-Use the MapBasic window to execute commands, scripts, or expressions.
-Use the Layout window to create professional-looking barcode labels and layouts.
-Use the Browser window to view, edit, or query your data tables.
-Use the Layer Control window to manage your data layers and their properties.
-Use the Tool Manager window to access various tools and utilities.
-Use the MapCAD tool to perform advanced barcode label editing and drawing functions.
-Use the EasyLoader tool to load multiple data files into your workspace.
-Use the Universal Translator tool to convert data between different formats.
-Use the Drpu Barcode Label Maker ProViewer tool to share your barcode labels and data with others who do not have Drpu Barcode Label Maker 73 Cracked Full Versionrar.
-
-
-How to update Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-If you want to update Drpu Barcode Label Maker 73 Cracked Full Versionrar to the latest version or patch, you can follow these steps:
-
-
-Download the update or patch file from one of the links below:
-
-Run the update or patch file and follow the instructions to install it.
-Restart your computer and enjoy using Drpu Barcode Label Maker 73 Cracked Full Versionrar with the latest version or patch.
-
-
-Conclusion
-
-Drpu Barcode Label Maker 73 Cracked Full Versionrar is a software that can help you create and print barcode labels for your retail inventory, products, or goods with ease and efficiency. It has many features, benefits, disadvantages, alternatives that you should know before using it. You can download and install Drpu Barcode Label Maker 73 Cracked Full Versionrar from the links provided above and enjoy using it for your projects. However, you should also be careful of the potential risks and problems that may arise from using a cracked software.
-What are the alternatives to Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-If you are looking for other software that can perform similar functions as Drpu Barcode Label Maker 73 Cracked Full Versionrar, you can consider some of these alternatives:
-
-
-Barcode Label Maker: Barcode Label Maker is a software that can help you create and print barcode labels for various purposes, such as inventory, products, shipping, and more. It supports various barcode types, such as Code 39, Code 128, EAN-13, UPC-A, QR Code, and more. It has a user-friendly interface and a rich set of features.
-Labeljoy: Labeljoy is a software that can help you create and print barcode labels for your business or personal needs. It supports various barcode formats, such as EAN-8, EAN-13, ISBN, ISSN, UPC-A, UPC-E, ITF-14, and more. It has a simple interface and a powerful design tool.
-Easy Barcode Creator: Easy Barcode Creator is a software that can help you create and print barcode labels for your products or services. It supports various barcode symbologies, such as Code 39, Code 93, Code 128, EAN-8, EAN-13, UPC-A, UPC-E, and more. It has a straightforward interface and a fast barcode generation process.
-BarTender: BarTender is a software that can help you create and print barcode labels for your industry or enterprise. It supports various barcode standards, such as GS1, HIBC, ISBT 128, SSCC-18, and more. It has a professional interface and a comprehensive barcode management system.
-ZebraDesigner: ZebraDesigner is a software that can help you create and print barcode labels for your Zebra printers. It supports various barcode types, such as Code 39, Code 128, EAN-8, EAN-13, UPC-A, UPC-E, QR Code, and more. It has a intuitive interface and a flexible design tool.
-
-
-How to learn Drpu Barcode Label Maker 73 Cracked Full Versionrar?
-
-If you want to learn how to use Drpu Barcode Label Maker 73 Cracked Full Versionrar effectively, you can follow some of these resources:
-
-
-The official website of Drpu Barcode Label Maker: This website provides information about the software, its features, benefits, pricing, support, and more.
-The user guide of Drpu Barcode Label Maker: This guide provides instructions on how to install, configure, use, and troubleshoot the software.
-The online tutorials of Drpu Barcode Label Maker: These tutorials provide step-by-step examples on how to perform various tasks with the software.
-The online courses of Drpu Barcode Label Maker: These courses provide interactive lessons on how to use the software for different purposes and levels.
-The online forums of Drpu Barcode Label Maker: These forums provide a platform for users to ask questions, share tips, exchange ideas, and get help from other users and experts.
-
-
-Conclusion
-
-Drpu Barcode Label Maker 73 Cracked Full Versionrar is a software that can help you create and print barcode labels for your retail inventory, products, or goods with ease and efficiency. It has many features, benefits, disadvantages, alternatives that you should know before using it. You can download and install Drpu Barcode Label Maker 73 Cracked Full Versionrar from the links provided above and enjoy using it for your projects. However, you should also be careful of the potential risks and problems that may arise from using a cracked software.
-Drpu Barcode Label Maker 73 Cracked Full Versionrar is a software that can help you create and print barcode labels for your retail inventory, products, or goods with ease and efficiency. It has many features, benefits, disadvantages, alternatives that you should know before using it. You can download and install Drpu Barcode Label Maker 73 Cracked Full Versionrar from the links provided above and enjoy using it for your projects. However, you should also be careful of the potential risks and problems that may arise from using a cracked software.
3cee63e6c2Tse X50 V2 Keygen 25l Download ➡ https://gohhs.com/2uEzcG
diff --git a/spaces/segments-tobias/conex/espnet/bin/tts_train.py b/spaces/segments-tobias/conex/espnet/bin/tts_train.py
deleted file mode 100644
index 930f2583bb414327c0e0c946a7578318b48d41f4..0000000000000000000000000000000000000000
--- a/spaces/segments-tobias/conex/espnet/bin/tts_train.py
+++ /dev/null
@@ -1,359 +0,0 @@
-#!/usr/bin/env python3
-
-# Copyright 2018 Nagoya University (Tomoki Hayashi)
-# Apache 2.0 (http://www.apache.org/licenses/LICENSE-2.0)
-
-"""Text-to-speech model training script."""
-
-import logging
-import os
-import random
-import subprocess
-import sys
-
-import configargparse
-import numpy as np
-
-from espnet import __version__
-from espnet.nets.tts_interface import TTSInterface
-from espnet.utils.cli_utils import strtobool
-from espnet.utils.training.batchfy import BATCH_COUNT_CHOICES
-
-
-# NOTE: you need this func to generate our sphinx doc
-def get_parser():
- """Get parser of training arguments."""
- parser = configargparse.ArgumentParser(
- description="Train a new text-to-speech (TTS) model on one CPU, "
- "one or multiple GPUs",
- config_file_parser_class=configargparse.YAMLConfigFileParser,
- formatter_class=configargparse.ArgumentDefaultsHelpFormatter,
- )
-
- # general configuration
- parser.add("--config", is_config_file=True, help="config file path")
- parser.add(
- "--config2",
- is_config_file=True,
- help="second config file path that overwrites the settings in `--config`.",
- )
- parser.add(
- "--config3",
- is_config_file=True,
- help="third config file path that overwrites "
- "the settings in `--config` and `--config2`.",
- )
-
- parser.add_argument(
- "--ngpu",
- default=None,
- type=int,
- help="Number of GPUs. If not given, use all visible devices",
- )
- parser.add_argument(
- "--backend",
- default="pytorch",
- type=str,
- choices=["chainer", "pytorch"],
- help="Backend library",
- )
- parser.add_argument("--outdir", type=str, required=True, help="Output directory")
- parser.add_argument("--debugmode", default=1, type=int, help="Debugmode")
- parser.add_argument("--seed", default=1, type=int, help="Random seed")
- parser.add_argument(
- "--resume",
- "-r",
- default="",
- type=str,
- nargs="?",
- help="Resume the training from snapshot",
- )
- parser.add_argument(
- "--minibatches",
- "-N",
- type=int,
- default="-1",
- help="Process only N minibatches (for debug)",
- )
- parser.add_argument("--verbose", "-V", default=0, type=int, help="Verbose option")
- parser.add_argument(
- "--tensorboard-dir",
- default=None,
- type=str,
- nargs="?",
- help="Tensorboard log directory path",
- )
- parser.add_argument(
- "--eval-interval-epochs", default=1, type=int, help="Evaluation interval epochs"
- )
- parser.add_argument(
- "--save-interval-epochs", default=1, type=int, help="Save interval epochs"
- )
- parser.add_argument(
- "--report-interval-iters",
- default=100,
- type=int,
- help="Report interval iterations",
- )
- # task related
- parser.add_argument(
- "--train-json", type=str, required=True, help="Filename of training json"
- )
- parser.add_argument(
- "--valid-json", type=str, required=True, help="Filename of validation json"
- )
- # network architecture
- parser.add_argument(
- "--model-module",
- type=str,
- default="espnet.nets.pytorch_backend.e2e_tts_tacotron2:Tacotron2",
- help="model defined module",
- )
- # minibatch related
- parser.add_argument(
- "--sortagrad",
- default=0,
- type=int,
- nargs="?",
- help="How many epochs to use sortagrad for. 0 = deactivated, -1 = all epochs",
- )
- parser.add_argument(
- "--batch-sort-key",
- default="shuffle",
- type=str,
- choices=["shuffle", "output", "input"],
- nargs="?",
- help='Batch sorting key. "shuffle" only work with --batch-count "seq".',
- )
- parser.add_argument(
- "--batch-count",
- default="auto",
- choices=BATCH_COUNT_CHOICES,
- help="How to count batch_size. "
- "The default (auto) will find how to count by args.",
- )
- parser.add_argument(
- "--batch-size",
- "--batch-seqs",
- "-b",
- default=0,
- type=int,
- help="Maximum seqs in a minibatch (0 to disable)",
- )
- parser.add_argument(
- "--batch-bins",
- default=0,
- type=int,
- help="Maximum bins in a minibatch (0 to disable)",
- )
- parser.add_argument(
- "--batch-frames-in",
- default=0,
- type=int,
- help="Maximum input frames in a minibatch (0 to disable)",
- )
- parser.add_argument(
- "--batch-frames-out",
- default=0,
- type=int,
- help="Maximum output frames in a minibatch (0 to disable)",
- )
- parser.add_argument(
- "--batch-frames-inout",
- default=0,
- type=int,
- help="Maximum input+output frames in a minibatch (0 to disable)",
- )
- parser.add_argument(
- "--maxlen-in",
- "--batch-seq-maxlen-in",
- default=100,
- type=int,
- metavar="ML",
- help="When --batch-count=seq, "
- "batch size is reduced if the input sequence length > ML.",
- )
- parser.add_argument(
- "--maxlen-out",
- "--batch-seq-maxlen-out",
- default=200,
- type=int,
- metavar="ML",
- help="When --batch-count=seq, "
- "batch size is reduced if the output sequence length > ML",
- )
- parser.add_argument(
- "--num-iter-processes",
- default=0,
- type=int,
- help="Number of processes of iterator",
- )
- parser.add_argument(
- "--preprocess-conf",
- type=str,
- default=None,
- help="The configuration file for the pre-processing",
- )
- parser.add_argument(
- "--use-speaker-embedding",
- default=False,
- type=strtobool,
- help="Whether to use speaker embedding",
- )
- parser.add_argument(
- "--use-second-target",
- default=False,
- type=strtobool,
- help="Whether to use second target",
- )
- # optimization related
- parser.add_argument(
- "--opt", default="adam", type=str, choices=["adam", "noam"], help="Optimizer"
- )
- parser.add_argument(
- "--accum-grad", default=1, type=int, help="Number of gradient accumuration"
- )
- parser.add_argument(
- "--lr", default=1e-3, type=float, help="Learning rate for optimizer"
- )
- parser.add_argument("--eps", default=1e-6, type=float, help="Epsilon for optimizer")
- parser.add_argument(
- "--weight-decay",
- default=1e-6,
- type=float,
- help="Weight decay coefficient for optimizer",
- )
- parser.add_argument(
- "--epochs", "-e", default=30, type=int, help="Number of maximum epochs"
- )
- parser.add_argument(
- "--early-stop-criterion",
- default="validation/main/loss",
- type=str,
- nargs="?",
- help="Value to monitor to trigger an early stopping of the training",
- )
- parser.add_argument(
- "--patience",
- default=3,
- type=int,
- nargs="?",
- help="Number of epochs to wait "
- "without improvement before stopping the training",
- )
- parser.add_argument(
- "--grad-clip", default=1, type=float, help="Gradient norm threshold to clip"
- )
- parser.add_argument(
- "--num-save-attention",
- default=5,
- type=int,
- help="Number of samples of attention to be saved",
- )
- parser.add_argument(
- "--keep-all-data-on-mem",
- default=False,
- type=strtobool,
- help="Whether to keep all data on memory",
- )
- # finetuning related
- parser.add_argument(
- "--enc-init",
- default=None,
- type=str,
- help="Pre-trained TTS model path to initialize encoder.",
- )
- parser.add_argument(
- "--enc-init-mods",
- default="enc.",
- type=lambda s: [str(mod) for mod in s.split(",") if s != ""],
- help="List of encoder modules to initialize, separated by a comma.",
- )
- parser.add_argument(
- "--dec-init",
- default=None,
- type=str,
- help="Pre-trained TTS model path to initialize decoder.",
- )
- parser.add_argument(
- "--dec-init-mods",
- default="dec.",
- type=lambda s: [str(mod) for mod in s.split(",") if s != ""],
- help="List of decoder modules to initialize, separated by a comma.",
- )
- parser.add_argument(
- "--freeze-mods",
- default=None,
- type=lambda s: [str(mod) for mod in s.split(",") if s != ""],
- help="List of modules to freeze (not to train), separated by a comma.",
- )
-
- return parser
-
-
-def main(cmd_args):
- """Run training."""
- parser = get_parser()
- args, _ = parser.parse_known_args(cmd_args)
-
- from espnet.utils.dynamic_import import dynamic_import
-
- model_class = dynamic_import(args.model_module)
- assert issubclass(model_class, TTSInterface)
- model_class.add_arguments(parser)
- args = parser.parse_args(cmd_args)
-
- # add version info in args
- args.version = __version__
-
- # logging info
- if args.verbose > 0:
- logging.basicConfig(
- level=logging.INFO,
- format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s",
- )
- else:
- logging.basicConfig(
- level=logging.WARN,
- format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s",
- )
- logging.warning("Skip DEBUG/INFO messages")
-
- # If --ngpu is not given,
- # 1. if CUDA_VISIBLE_DEVICES is set, all visible devices
- # 2. if nvidia-smi exists, use all devices
- # 3. else ngpu=0
- if args.ngpu is None:
- cvd = os.environ.get("CUDA_VISIBLE_DEVICES")
- if cvd is not None:
- ngpu = len(cvd.split(","))
- else:
- logging.warning("CUDA_VISIBLE_DEVICES is not set.")
- try:
- p = subprocess.run(
- ["nvidia-smi", "-L"], stdout=subprocess.PIPE, stderr=subprocess.PIPE
- )
- except (subprocess.CalledProcessError, FileNotFoundError):
- ngpu = 0
- else:
- ngpu = len(p.stderr.decode().split("\n")) - 1
- args.ngpu = ngpu
- else:
- ngpu = args.ngpu
- logging.info(f"ngpu: {ngpu}")
-
- # set random seed
- logging.info("random seed = %d" % args.seed)
- random.seed(args.seed)
- np.random.seed(args.seed)
-
- if args.backend == "pytorch":
- from espnet.tts.pytorch_backend.tts import train
-
- train(args)
- else:
- raise NotImplementedError("Only pytorch is supported.")
-
-
-if __name__ == "__main__":
- main(sys.argv[1:])
diff --git a/spaces/segments-tobias/conex/espnet2/samplers/abs_sampler.py b/spaces/segments-tobias/conex/espnet2/samplers/abs_sampler.py
deleted file mode 100644
index 2f7aa539b8a14be204f18e26785d9c7e1d308f1f..0000000000000000000000000000000000000000
--- a/spaces/segments-tobias/conex/espnet2/samplers/abs_sampler.py
+++ /dev/null
@@ -1,19 +0,0 @@
-from abc import ABC
-from abc import abstractmethod
-from typing import Iterator
-from typing import Tuple
-
-from torch.utils.data import Sampler
-
-
-class AbsSampler(Sampler, ABC):
- @abstractmethod
- def __len__(self) -> int:
- raise NotImplementedError
-
- @abstractmethod
- def __iter__(self) -> Iterator[Tuple[str, ...]]:
- raise NotImplementedError
-
- def generate(self, seed):
- return list(self)
diff --git a/spaces/shi-labs/Versatile-Diffusion/app.py b/spaces/shi-labs/Versatile-Diffusion/app.py
deleted file mode 100644
index 484c8780ac4c6353a2bbb6202bf7f5e146356916..0000000000000000000000000000000000000000
--- a/spaces/shi-labs/Versatile-Diffusion/app.py
+++ /dev/null
@@ -1,1114 +0,0 @@
-################################################################################
-# Copyright (C) 2023 Xingqian Xu - All Rights Reserved #
-# #
-# Please visit Versatile Diffusion's arXiv paper for more details, link at #
-# arxiv.org/abs/2211.08332 #
-# #
-# Besides, this work is also inspired by many established techniques including:#
-# Denoising Diffusion Probablistic Model; Denoising Diffusion Implicit Model; #
-# Latent Diffusion Model; Stable Diffusion; Stable Diffusion - Img2Img; Stable #
-# Diffusion - Variation; ImageMixer; DreamBooth; Stable Diffusion - Lora; More #
-# Control for Free; Prompt-to-Prompt; #
-# #
-################################################################################
-
-import gradio as gr
-import os
-import PIL
-from PIL import Image
-from pathlib import Path
-import numpy as np
-import numpy.random as npr
-from contextlib import nullcontext
-import types
-
-import torch
-import torchvision.transforms as tvtrans
-from lib.cfg_helper import model_cfg_bank
-from lib.model_zoo import get_model
-from cusomized_gradio_blocks import create_myexamples, customized_as_example, customized_postprocess
-
-n_sample_image = 2
-n_sample_text = 4
-cache_examples = True
-
-from lib.model_zoo.ddim import DDIMSampler
-
-##########
-# helper #
-##########
-
-def highlight_print(info):
- print('')
- print(''.join(['#']*(len(info)+4)))
- print('# '+info+' #')
- print(''.join(['#']*(len(info)+4)))
- print('')
-
-def decompose(x, q=20, niter=100):
- x_mean = x.mean(-1, keepdim=True)
- x_input = x - x_mean
- u, s, v = torch.pca_lowrank(x_input, q=q, center=False, niter=niter)
- ss = torch.stack([torch.diag(si) for si in s])
- x_lowrank = torch.bmm(torch.bmm(u, ss), torch.permute(v, [0, 2, 1]))
- x_remain = x_input - x_lowrank
- return u, s, v, x_mean, x_remain
-
-class adjust_rank(object):
- def __init__(self, max_drop_rank=[1, 5], q=20):
- self.max_semantic_drop_rank = max_drop_rank[0]
- self.max_style_drop_rank = max_drop_rank[1]
- self.q = q
-
- def t2y0_semf_wrapper(t0, y00, t1, y01):
- return lambda t: (np.exp((t-0.5)*2)-t0)/(t1-t0)*(y01-y00)+y00
- t0, y00 = np.exp((0 -0.5)*2), -self.max_semantic_drop_rank
- t1, y01 = np.exp((0.5-0.5)*2), 1
- self.t2y0_semf = t2y0_semf_wrapper(t0, y00, t1, y01)
-
- def x2y_semf_wrapper(x0, x1, y1):
- return lambda x, y0: (x-x0)/(x1-x0)*(y1-y0)+y0
- x0 = 0
- x1, y1 = self.max_semantic_drop_rank+1, 1
- self.x2y_semf = x2y_semf_wrapper(x0, x1, y1)
-
- def t2y0_styf_wrapper(t0, y00, t1, y01):
- return lambda t: (np.exp((t-0.5)*2)-t0)/(t1-t0)*(y01-y00)+y00
- t0, y00 = np.exp((1 -0.5)*2), -(q-self.max_style_drop_rank)
- t1, y01 = np.exp((0.5-0.5)*2), 1
- self.t2y0_styf = t2y0_styf_wrapper(t0, y00, t1, y01)
-
- def x2y_styf_wrapper(x0, x1, y1):
- return lambda x, y0: (x-x0)/(x1-x0)*(y1-y0)+y0
- x0 = q-1
- x1, y1 = self.max_style_drop_rank-1, 1
- self.x2y_styf = x2y_styf_wrapper(x0, x1, y1)
-
- def __call__(self, x, lvl):
- if lvl == 0.5:
- return x
-
- if x.dtype == torch.float16:
- fp16 = True
- x = x.float()
- else:
- fp16 = False
- std_save = x.std(axis=[-2, -1])
-
- u, s, v, x_mean, x_remain = decompose(x, q=self.q)
-
- if lvl < 0.5:
- assert lvl>=0
- for xi in range(0, self.max_semantic_drop_rank+1):
- y0 = self.t2y0_semf(lvl)
- yi = self.x2y_semf(xi, y0)
- yi = 0 if yi<0 else yi
- s[:, xi] *= yi
-
- elif lvl > 0.5:
- assert lvl <= 1
- for xi in range(self.max_style_drop_rank, self.q):
- y0 = self.t2y0_styf(lvl)
- yi = self.x2y_styf(xi, y0)
- yi = 0 if yi<0 else yi
- s[:, xi] *= yi
- x_remain = 0
-
- ss = torch.stack([torch.diag(si) for si in s])
- x_lowrank = torch.bmm(torch.bmm(u, ss), torch.permute(v, [0, 2, 1]))
- x_new = x_lowrank + x_mean + x_remain
-
- std_new = x_new.std(axis=[-2, -1])
- x_new = x_new / std_new * std_save
-
- if fp16:
- x_new = x_new.half()
-
- return x_new
-
-def remove_duplicate_word(tx):
- def combine_words(input, length):
- combined_inputs = []
- if len(splitted_input)>1:
- for i in range(len(input)-1):
- combined_inputs.append(input[i]+" "+last_word_of(splitted_input[i+1],length)) #add the last word of the right-neighbour (overlapping) sequence (before it has expanded), which is the next word in the original sentence
- return combined_inputs, length+1
-
- def remove_duplicates(input, length):
- bool_broke=False #this means we didn't find any duplicates here
- for i in range(len(input) - length):
- if input[i]==input[i + length]: #found a duplicate piece of sentence!
- for j in range(0, length): #remove the overlapping sequences in reverse order
- del input[i + length - j]
- bool_broke = True
- break #break the for loop as the loop length does not matches the length of splitted_input anymore as we removed elements
- if bool_broke:
- return remove_duplicates(input, length) #if we found a duplicate, look for another duplicate of the same length
- return input
-
- def last_word_of(input, length):
- splitted = input.split(" ")
- if len(splitted)==0:
- return input
- else:
- return splitted[length-1]
-
- def split_and_puncsplit(text):
- tx = text.split(" ")
- txnew = []
- for txi in tx:
- txqueue=[]
- while True:
- if txi[0] in '([{':
- txqueue.extend([txi[:1], ''])
- txi = txi[1:]
- if len(txi) == 0:
- break
- else:
- break
- txnew += txqueue
- txstack=[]
- if len(txi) == 0:
- continue
- while True:
- if txi[-1] in '?!.,:;}])':
- txstack = ['', txi[-1:]] + txstack
- txi = txi[:-1]
- if len(txi) == 0:
- break
- else:
- break
- if len(txi) != 0:
- txnew += [txi]
- txnew += txstack
- return txnew
-
- if tx == '':
- return tx
-
- splitted_input = split_and_puncsplit(tx)
- word_length = 1
- intermediate_output = False
- while len(splitted_input)>1:
- splitted_input = remove_duplicates(splitted_input, word_length)
- if len(splitted_input)>1:
- splitted_input, word_length = combine_words(splitted_input, word_length)
- if intermediate_output:
- print(splitted_input)
- print(word_length)
- output = splitted_input[0]
- output = output.replace(' ', '')
- return output
-
-def get_instruction(mode):
- t2i_instruction = ["Generate image from text prompt."]
- i2i_instruction = ["Generate image conditioned on reference image.",]
- i2t_instruction = ["Generate text from reference image. "]
- t2t_instruction = ["Generate text from reference text prompt. "]
- dcg_instruction = ["Generate image conditioned on both text and image."]
- tcg_instruction = ["Generate image conditioned on text and up to two images."]
- mcg_instruction = ["Generate image from multiple contexts."]
-
- if mode == "Text-to-Image":
- return '\n'.join(t2i_instruction)
- elif mode == "Image-Variation":
- return '\n'.join(i2i_instruction)
- elif mode == "Image-to-Text":
- return '\n'.join(i2t_instruction)
- elif mode == "Text-Variation":
- return '\n'.join(t2t_instruction)
- elif mode == "Dual-Context":
- return '\n'.join(dcg_instruction)
- elif mode == "Triple-Context":
- return '\n'.join(tcg_instruction)
- elif mode == "Multi-Context":
- return '\n'.join(mcg_instruction)
- else:
- assert False
-
-########
-# main #
-########
-class vd_dummy(object):
- def __init__(self, *args, **kwarg):
- self.which = 'Vdummy'
- def inference_t2i(self, *args, **kwarg): pass
- def inference_i2i(self, *args, **kwarg): pass
- def inference_i2t(self, *args, **kwarg): pass
- def inference_t2t(self, *args, **kwarg): pass
- def inference_dcg(self, *args, **kwarg): pass
- def inference_tcg(self, *args, **kwarg): pass
- def inference_mcg(self, *args, **kwarg):
- return None, None
-
-class vd_inference(object):
- def __init__(self, fp16=False, which='v2.0'):
- highlight_print(which)
- self.which = which
-
- if self.which == 'v1.0':
- cfgm = model_cfg_bank()('vd_four_flow_v1-0')
- else:
- assert False, 'Model type not supported'
- net = get_model()(cfgm)
-
- if fp16:
- highlight_print('Running in FP16')
- if self.which == 'v1.0':
- net.ctx['text'].fp16 = True
- net.ctx['image'].fp16 = True
- net = net.half()
- self.dtype = torch.float16
- else:
- self.dtype = torch.float32
-
- if self.which == 'v1.0':
- # if fp16:
- # sd = torch.load('pretrained/vd-four-flow-v1-0-fp16.pth', map_location='cpu')
- # else:
- # sd = torch.load('pretrained/vd-four-flow-v1-0.pth', map_location='cpu')
- from huggingface_hub import hf_hub_download
- if fp16:
- temppath = hf_hub_download('shi-labs/versatile-diffusion-model', 'pretrained_pth/vd-four-flow-v1-0-fp16.pth')
- else:
- temppath = hf_hub_download('shi-labs/versatile-diffusion-model', 'pretrained_pth/vd-four-flow-v1-0.pth')
- sd = torch.load(temppath, map_location='cpu')
-
- net.load_state_dict(sd, strict=False)
-
- self.use_cuda = torch.cuda.is_available()
- if self.use_cuda:
- net.to('cuda')
- self.net = net
- self.sampler = DDIMSampler(net)
-
- self.output_dim = [512, 512]
- self.n_sample_image = n_sample_image
- self.n_sample_text = n_sample_text
- self.ddim_steps = 50
- self.ddim_eta = 0.0
- self.scale_textto = 7.5
- self.image_latent_dim = 4
- self.text_latent_dim = 768
- self.text_temperature = 1
-
- if which == 'v1.0':
- self.adjust_rank_f = adjust_rank(max_drop_rank=[1, 5], q=20)
- self.scale_imgto = 7.5
- self.disentanglement_noglobal = True
-
- def inference_t2i(self, text, seed):
- n_samples = self.n_sample_image
- scale = self.scale_textto
- sampler = self.sampler
- h, w = self.output_dim
- u = self.net.ctx_encode([""], which='text').repeat(n_samples, 1, 1)
- c = self.net.ctx_encode([text], which='text').repeat(n_samples, 1, 1)
- shape = [n_samples, self.image_latent_dim, h//8, w//8]
- np.random.seed(seed)
- torch.manual_seed(seed + 100)
- x, _ = sampler.sample(
- steps=self.ddim_steps,
- x_info={'type':'image'},
- c_info={'type':'text', 'conditioning':c, 'unconditional_conditioning':u,
- 'unconditional_guidance_scale':scale},
- shape=shape,
- verbose=False,
- eta=self.ddim_eta)
- im = self.net.vae_decode(x, which='image')
- im = [tvtrans.ToPILImage()(i) for i in im]
- return im
-
- def inference_i2i(self, im, fid_lvl, fcs_lvl, clr_adj, seed):
- n_samples = self.n_sample_image
- scale = self.scale_imgto
- sampler = self.sampler
- h, w = self.output_dim
- device = self.net.device
-
- BICUBIC = PIL.Image.Resampling.BICUBIC
- im = im.resize([w, h], resample=BICUBIC)
-
- if fid_lvl == 1:
- return [im]*n_samples
-
- cx = tvtrans.ToTensor()(im)[None].to(device).to(self.dtype)
-
- c = self.net.ctx_encode(cx, which='image')
- if self.disentanglement_noglobal:
- c_glb = c[:, 0:1]
- c_loc = c[:, 1: ]
- c_loc = self.adjust_rank_f(c_loc, fcs_lvl)
- c = torch.cat([c_glb, c_loc], dim=1).repeat(n_samples, 1, 1)
- else:
- c = self.adjust_rank_f(c, fcs_lvl).repeat(n_samples, 1, 1)
- u = torch.zeros_like(c)
-
- shape = [n_samples, self.image_latent_dim, h//8, w//8]
- np.random.seed(seed)
- torch.manual_seed(seed + 100)
- if fid_lvl!=0:
- x0 = self.net.vae_encode(cx, which='image').repeat(n_samples, 1, 1, 1)
- step = int(self.ddim_steps * (1-fid_lvl))
- x, _ = sampler.sample(
- steps=self.ddim_steps,
- x_info={'type':'image', 'x0':x0, 'x0_forward_timesteps':step},
- c_info={'type':'image', 'conditioning':c, 'unconditional_conditioning':u,
- 'unconditional_guidance_scale':scale},
- shape=shape,
- verbose=False,
- eta=self.ddim_eta)
- else:
- x, _ = sampler.sample(
- steps=self.ddim_steps,
- x_info={'type':'image',},
- c_info={'type':'image', 'conditioning':c, 'unconditional_conditioning':u,
- 'unconditional_guidance_scale':scale},
- shape=shape,
- verbose=False,
- eta=self.ddim_eta)
-
- imout = self.net.vae_decode(x, which='image')
-
- if clr_adj == 'Simple':
- cx_mean = cx.view(3, -1).mean(-1)[:, None, None]
- cx_std = cx.view(3, -1).std(-1)[:, None, None]
- imout_mean = [imouti.view(3, -1).mean(-1)[:, None, None] for imouti in imout]
- imout_std = [imouti.view(3, -1).std(-1)[:, None, None] for imouti in imout]
- imout = [(ii-mi)/si*cx_std+cx_mean for ii, mi, si in zip(imout, imout_mean, imout_std)]
- imout = [torch.clamp(ii, 0, 1) for ii in imout]
-
- imout = [tvtrans.ToPILImage()(i) for i in imout]
- return imout
-
- def inference_i2t(self, im, seed):
- n_samples = self.n_sample_text
- scale = self.scale_imgto
- sampler = self.sampler
- h, w = self.output_dim
- device = self.net.device
-
- BICUBIC = PIL.Image.Resampling.BICUBIC
- im = im.resize([w, h], resample=BICUBIC)
-
- cx = tvtrans.ToTensor()(im)[None].to(device)
- c = self.net.ctx_encode(cx, which='image').repeat(n_samples, 1, 1)
- u = self.net.ctx_encode(torch.zeros_like(cx), which='image').repeat(n_samples, 1, 1)
-
- shape = [n_samples, self.text_latent_dim]
- np.random.seed(seed)
- torch.manual_seed(seed + 100)
- x, _ = sampler.sample(
- steps=self.ddim_steps,
- x_info={'type':'text',},
- c_info={'type':'image', 'conditioning':c, 'unconditional_conditioning':u,
- 'unconditional_guidance_scale':scale},
- shape=shape,
- verbose=False,
- eta=self.ddim_eta)
- tx = self.net.vae_decode(x, which='text', temperature=self.text_temperature)
- tx = [remove_duplicate_word(txi) for txi in tx]
- tx_combined = '\n'.join(tx)
- return tx_combined
-
- def inference_t2t(self, text, seed):
- n_samples = self.n_sample_text
- scale = self.scale_textto
- sampler = self.sampler
- u = self.net.ctx_encode([""], which='text').repeat(n_samples, 1, 1)
- c = self.net.ctx_encode([text], which='text').repeat(n_samples, 1, 1)
- shape = [n_samples, self.text_latent_dim]
- np.random.seed(seed)
- torch.manual_seed(seed + 100)
- x, _ = sampler.sample(
- steps=self.ddim_steps,
- x_info={'type':'text',},
- c_info={'type':'text', 'conditioning':c, 'unconditional_conditioning':u,
- 'unconditional_guidance_scale':scale},
- shape=shape,
- verbose=False,
- eta=self.ddim_eta)
- tx = self.net.vae_decode(x, which='text', temperature=self.text_temperature)
- tx = [remove_duplicate_word(txi) for txi in tx]
- tx_combined = '\n'.join(tx)
- return tx_combined
-
- def inference_dcg(self, imctx, fcs_lvl, textctx, textstrength, seed):
- n_samples = self.n_sample_image
- sampler = self.sampler
- h, w = self.output_dim
- device = self.net.device
-
- c_info_list = []
-
- if (textctx is not None) and (textctx != "") and (textstrength != 0):
- ut = self.net.ctx_encode([""], which='text').repeat(n_samples, 1, 1)
- ct = self.net.ctx_encode([textctx], which='text').repeat(n_samples, 1, 1)
- scale = self.scale_imgto*(1-textstrength) + self.scale_textto*textstrength
-
- c_info_list.append({
- 'type':'text',
- 'conditioning':ct,
- 'unconditional_conditioning':ut,
- 'unconditional_guidance_scale':scale,
- 'ratio': textstrength, })
- else:
- scale = self.scale_imgto
- textstrength = 0
-
- BICUBIC = PIL.Image.Resampling.BICUBIC
- cx = imctx.resize([w, h], resample=BICUBIC)
- cx = tvtrans.ToTensor()(cx)[None].to(device).to(self.dtype)
- ci = self.net.ctx_encode(cx, which='image')
-
- if self.disentanglement_noglobal:
- ci_glb = ci[:, 0:1]
- ci_loc = ci[:, 1: ]
- ci_loc = self.adjust_rank_f(ci_loc, fcs_lvl)
- ci = torch.cat([ci_glb, ci_loc], dim=1).repeat(n_samples, 1, 1)
- else:
- ci = self.adjust_rank_f(ci, fcs_lvl).repeat(n_samples, 1, 1)
-
- c_info_list.append({
- 'type':'image',
- 'conditioning':ci,
- 'unconditional_conditioning':torch.zeros_like(ci),
- 'unconditional_guidance_scale':scale,
- 'ratio': (1-textstrength), })
-
- shape = [n_samples, self.image_latent_dim, h//8, w//8]
- np.random.seed(seed)
- torch.manual_seed(seed + 100)
- x, _ = sampler.sample_multicontext(
- steps=self.ddim_steps,
- x_info={'type':'image',},
- c_info_list=c_info_list,
- shape=shape,
- verbose=False,
- eta=self.ddim_eta)
-
- imout = self.net.vae_decode(x, which='image')
- imout = [tvtrans.ToPILImage()(i) for i in imout]
- return imout
-
- def inference_tcg(self, *args):
- args_imag = list(args[0:10]) + [None, None, None, None, None]*2
- args_rest = args[10:]
- imin, imout = self.inference_mcg(*args_imag, *args_rest)
- return imin, imout
-
- def inference_mcg(self, *args):
- imctx = [args[0:5], args[5:10], args[10:15], args[15:20]]
- textctx, textstrength, seed = args[20:]
-
- n_samples = self.n_sample_image
- sampler = self.sampler
- h, w = self.output_dim
- device = self.net.device
-
- c_info_list = []
-
- if (textctx is not None) and (textctx != "") and (textstrength != 0):
- ut = self.net.ctx_encode([""], which='text').repeat(n_samples, 1, 1)
- ct = self.net.ctx_encode([textctx], which='text').repeat(n_samples, 1, 1)
- scale = self.scale_imgto*(1-textstrength) + self.scale_textto*textstrength
-
- c_info_list.append({
- 'type':'text',
- 'conditioning':ct,
- 'unconditional_conditioning':ut,
- 'unconditional_guidance_scale':scale,
- 'ratio': textstrength, })
- else:
- scale = self.scale_imgto
- textstrength = 0
-
- input_save = []
- imc = []
- for im, imm, strength, fcs_lvl, use_mask in imctx:
- if (im is None) and (imm is None):
- continue
- BILINEAR = PIL.Image.Resampling.BILINEAR
- BICUBIC = PIL.Image.Resampling.BICUBIC
- if use_mask:
- cx = imm['image'].resize([w, h], resample=BICUBIC)
- cx = tvtrans.ToTensor()(cx)[None].to(self.dtype).to(device)
- m = imm['mask'].resize([w, h], resample=BILINEAR)
- m = tvtrans.ToTensor()(m)[None, 0:1].to(self.dtype).to(device)
- m = (1-m)
- cx_show = cx*m
- ci = self.net.ctx_encode(cx, which='image', masks=m)
- else:
- cx = im.resize([w, h], resample=BICUBIC)
- cx = tvtrans.ToTensor()(cx)[None].to(self.dtype).to(device)
- ci = self.net.ctx_encode(cx, which='image')
- cx_show = cx
-
- input_save.append(tvtrans.ToPILImage()(cx_show[0]))
-
- if self.disentanglement_noglobal:
- ci_glb = ci[:, 0:1]
- ci_loc = ci[:, 1: ]
- ci_loc = self.adjust_rank_f(ci_loc, fcs_lvl)
- ci = torch.cat([ci_glb, ci_loc], dim=1).repeat(n_samples, 1, 1)
- else:
- ci = self.adjust_rank_f(ci, fcs_lvl).repeat(n_samples, 1, 1)
- imc.append(ci * strength)
-
- cis = torch.cat(imc, dim=1)
- c_info_list.append({
- 'type':'image',
- 'conditioning':cis,
- 'unconditional_conditioning':torch.zeros_like(cis),
- 'unconditional_guidance_scale':scale,
- 'ratio': (1-textstrength), })
-
- shape = [n_samples, self.image_latent_dim, h//8, w//8]
- np.random.seed(seed)
- torch.manual_seed(seed + 100)
- x, _ = sampler.sample_multicontext(
- steps=self.ddim_steps,
- x_info={'type':'image',},
- c_info_list=c_info_list,
- shape=shape,
- verbose=False,
- eta=self.ddim_eta)
-
- imout = self.net.vae_decode(x, which='image')
- imout = [tvtrans.ToPILImage()(i) for i in imout]
- return input_save, imout
-
-# vd_inference = vd_dummy()
-vd_inference = vd_inference(which='v1.0', fp16=True)
-
-#################
-# sub interface #
-#################
-
-def t2i_interface(with_example=False):
- gr.HTML(' Description: ' + get_instruction("Text-to-Image") + '
')
- with gr.Row():
- with gr.Column():
- text = gr.Textbox(lines=4, placeholder="Input prompt...", label='Text Input')
- seed = gr.Number(20, label="Seed", precision=0)
- button = gr.Button("Run")
- with gr.Column():
- img_output = gr.Gallery(label="Image Result", elem_id='customized_imbox').style(grid=n_sample_image)
-
- button.click(
- vd_inference.inference_t2i,
- inputs=[text, seed],
- outputs=[img_output])
-
- if with_example:
- gr.Examples(
- label='Examples',
- examples=get_example('Text-to-Image'),
- fn=vd_inference.inference_t2i,
- inputs=[text, seed],
- outputs=[img_output],
- cache_examples=cache_examples),
-
-def i2i_interface(with_example=False):
- gr.HTML(' Description: ' + get_instruction("Image-Variation") + '
')
- with gr.Row():
- with gr.Column():
- img_input = gr.Image(label='Image Input', type='pil', elem_id='customized_imbox')
- sim_flag = gr.Checkbox(label='Show Detail Controls')
- with gr.Row():
- fid_lvl = gr.Slider(label="Fidelity (Dislike -- Same)", minimum=0, maximum=1, value=0, step=0.02, visible=False)
- fcs_lvl = gr.Slider(label="Focus (Semantic -- Style)", minimum=0, maximum=1, value=0.5, step=0.02, visible=False)
- clr_adj = gr.Radio(label="Color Adjustment", choices=["None", "Simple"], value='Simple', visible=False)
- explain = gr.HTML(' Fidelity: How likely the output image looks like the referece image (0-dislike (default), 1-same).
'+
- ' Focus: What the output image should focused on (0-semantic, 0.5-balanced (default), 1-style).
',
- visible=False)
- seed = gr.Number(20, label="Seed", precision=0)
- button = gr.Button("Run")
- with gr.Column():
- img_output = gr.Gallery(label="Image Result", elem_id='customized_imbox').style(grid=n_sample_image)
-
- sim_flag.change(
- fn=lambda x: {
- explain : gr.update(visible=x),
- fid_lvl : gr.update(visible=x),
- fcs_lvl : gr.update(visible=x),
- clr_adj : gr.update(visible=x), },
- inputs=sim_flag,
- outputs=[explain, fid_lvl, fcs_lvl, clr_adj, seed],)
-
- button.click(
- vd_inference.inference_i2i,
- inputs=[img_input, fid_lvl, fcs_lvl, clr_adj, seed],
- outputs=[img_output])
-
- if with_example:
- gr.Examples(
- label='Examples',
- examples=get_example('Image-Variation'),
- fn=vd_inference.inference_i2i,
- inputs=[img_input, fid_lvl, fcs_lvl, clr_adj, seed],
- outputs=[img_output],
- cache_examples=cache_examples),
-
-def i2t_interface(with_example=False):
- gr.HTML(' Description: ' + get_instruction("Image-to-Text") + '
')
- with gr.Row():
- with gr.Column():
- img_input = gr.Image(label='Image Input', type='pil', elem_id='customized_imbox')
- seed = gr.Number(20, label="Seed", precision=0)
- button = gr.Button("Run")
- with gr.Column():
- txt_output = gr.Textbox(lines=4, label='Text Result')
-
- button.click(
- vd_inference.inference_i2t,
- inputs=[img_input, seed],
- outputs=[txt_output])
-
- if with_example:
- gr.Examples(
- label='Examples',
- examples=get_example('Image-to-Text'),
- fn=vd_inference.inference_i2t,
- inputs=[img_input, seed],
- outputs=[txt_output],
- cache_examples=cache_examples),
-
-def t2t_interface(with_example=False):
- gr.HTML(' Description: ' + get_instruction("Text-Variation") + '
')
- with gr.Row():
- with gr.Column():
- text = gr.Textbox(lines=4, placeholder="Input prompt...", label='Text Input')
- seed = gr.Number(20, label="Seed", precision=0)
- button = gr.Button("Run")
- with gr.Column():
- txt_output = gr.Textbox(lines=4, label='Text Result')
-
- button.click(
- vd_inference.inference_t2t,
- inputs=[text, seed],
- outputs=[txt_output])
-
- if with_example:
- gr.Examples(
- label='Examples',
- examples=get_example('Text-Variation'),
- fn=vd_inference.inference_t2t,
- inputs=[text, seed],
- outputs=[txt_output],
- cache_examples=cache_examples, )
-
-class image_mimage_swap(object):
- def __init__(self, block0, block1):
- self.block0 = block0
- self.block1 = block1
- self.which_update = 'both'
-
- def __call__(self, x0, x1, flag):
- if self.which_update == 'both':
- return self.update_both(x0, x1, flag)
- elif self.which_update == 'visible':
- return self.update_visible(x0, x1, flag)
- elif self.which_update == 'visible_oneoff':
- return self.update_visible_oneoff(x0, x1, flag)
- else:
- assert False
-
- def update_both(self, x0, x1, flag):
- if flag:
- ug0 = gr.update(visible=False)
- if x0 is None:
- ug1 = gr.update(value=None, visible=True)
- else:
- if (x1 is not None) and ('mask' in x1):
- value1 = {'image':x0, 'mask':x1['mask']}
- else:
- value1 = {'image':x0, 'mask':None}
- ug1 = gr.update(value=value1, visible=True)
- else:
- if (x1 is not None) and ('image' in x1):
- value0 = x1['image']
- else:
- value0 = None
- ug0 = gr.update(value=value0, visible=True)
- ug1 = gr.update(visible=False)
- return {
- self.block0 : ug0,
- self.block1 : ug1,}
-
- def update_visible(self, x0, x1, flag):
- return {
- self.block0 : gr.update(visible=not flag),
- self.block1 : gr.update(visible=flag), }
-
- def update_visible_oneoff(self, x0, x1, flag):
- self.which_update = 'both'
- return {
- self.block0 : gr.update(visible=not flag),
- self.block1 : gr.update(visible=flag), }
-
-class example_visible_only_hack(object):
- def __init__(self, checkbox_list, functor_list):
- self.checkbox_list = checkbox_list
- self.functor_list = functor_list
-
- def __call__(self, *args):
- for bi, fi, vi in zip(self.checkbox_list, self.functor_list, args):
- if bi.value != vi:
- fi.which_update = 'visible_oneoff'
-
-def dcg_interface(with_example=False):
- gr.HTML(' Description: ' + get_instruction("Dual-Context") + '
')
- with gr.Row():
- input_session = []
- with gr.Column():
- img = gr.Image(label='Image Input', type='pil', elem_id='customized_imbox')
- fcs = gr.Slider(label="Focus (Semantic -- Style)", minimum=0, maximum=1, value=0.5, step=0.02)
- gr.HTML(' Focus: Focus on what aspect of the image? (0-semantic, 0.5-balanced (default), 1-style).
')
-
- text = gr.Textbox(lines=2, placeholder="Input prompt...", label='Text Input')
- tstrength = gr.Slider(label="Text Domination (NoEffect -- TextOnly)", minimum=0, maximum=1, value=0, step=0.02)
-
- seed = gr.Number(20, label="Seed", precision=0)
- button = gr.Button("Run")
-
- with gr.Column():
- output_gallary = gr.Gallery(label="Image Result", elem_id='customized_imbox').style(grid=n_sample_image)
-
- input_list = []
- for i in input_session:
- input_list += i
- button.click(
- vd_inference.inference_dcg,
- inputs=[img, fcs, text, tstrength, seed],
- outputs=[output_gallary])
-
- if with_example:
- gr.Examples(
- label='Examples',
- examples=get_example('Dual-Context'),
- fn=vd_inference.inference_dcg,
- inputs=[img, fcs, text, tstrength, seed],
- outputs=[output_gallary],
- cache_examples=cache_examples)
-
-def tcg_interface(with_example=False):
- gr.HTML(' Description: ' + get_instruction("Triple-Context") + '
')
- with gr.Row():
- input_session = []
- with gr.Column(min_width=940):
- with gr.Row():
- with gr.Column():
- img0 = gr.Image(label='Image Input', type='pil', elem_id='customized_imbox')
- img0.as_example = types.MethodType(customized_as_example, img0)
- imgm0 = gr.Image(label='Image Input with Mask', type='pil', elem_id='customized_imbox', tool='sketch', source="upload", visible=False)
- imgm0.postprocess = types.MethodType(customized_postprocess, imgm0)
- imgm0.as_example = types.MethodType(customized_as_example, imgm0)
- istrength0 = gr.Slider(label="Weight", minimum=0, maximum=1, value=1, step=0.02)
- fcs0 = gr.Slider(label="Focus (Semantic -- Style)", minimum=0, maximum=1, value=0.5, step=0.02)
- msk0 = gr.Checkbox(label='Use mask?')
- swapf0 = image_mimage_swap(img0, imgm0)
-
- msk0.change(
- fn=swapf0,
- inputs=[img0, imgm0, msk0],
- outputs=[img0, imgm0],)
- input_session.append([img0, imgm0, istrength0, fcs0, msk0])
-
- with gr.Column():
- img1 = gr.Image(label='Image Input', type='pil', elem_id='customized_imbox')
- img1.as_example = types.MethodType(customized_as_example, img1)
- imgm1 = gr.Image(label='Image Input with Mask', type='pil', elem_id='customized_imbox', tool='sketch', source="upload", visible=False)
- imgm1.postprocess = types.MethodType(customized_postprocess, imgm1)
- imgm1.as_example = types.MethodType(customized_as_example, imgm1)
- istrength1 = gr.Slider(label="Weight", minimum=0, maximum=1, value=1, step=0.02)
- fcs1 = gr.Slider(label="Focus (Semantic -- Style)", minimum=0, maximum=1, value=0.5, step=0.02)
- msk1 = gr.Checkbox(label='Use mask?')
- swapf1 = image_mimage_swap(img1, imgm1)
-
- msk1.change(
- fn=swapf1,
- inputs=[img1, imgm1, msk1],
- outputs=[img1, imgm1],)
- input_session.append([img1, imgm1, istrength1, fcs1, msk1])
-
- gr.HTML(' Weight: The strength of the reference image. This weight is subject to Text Domination ).
'+
- ' Focus: Focus on what aspect of the image? (0-semantic, 0.5-balanced (default), 1-style).
'+
- ' Mask: Remove regions on reference image so they will not influence the output.
',)
-
- text = gr.Textbox(lines=2, placeholder="Input prompt...", label='Text Input')
- tstrength = gr.Slider(label="Text Domination (NoEffect -- TextOnly)", minimum=0, maximum=1, value=0, step=0.02)
-
- seed = gr.Number(20, label="Seed", precision=0)
- button = gr.Button("Run")
-
- with gr.Column(min_width=470):
- input_gallary = gr.Gallery(label="Input Display", elem_id="customized_imbox").style(grid=2)
- output_gallary = gr.Gallery(label="Image Result", elem_id="customized_imbox").style(grid=n_sample_image)
-
- input_list = []
- for i in input_session:
- input_list += i
- input_list += [text, tstrength, seed]
- button.click(
- vd_inference.inference_tcg,
- inputs=input_list,
- outputs=[input_gallary, output_gallary])
-
- if with_example:
- create_myexamples(
- label='Examples',
- examples=get_example('Triple-Context'),
- fn=vd_inference.inference_tcg,
- inputs=input_list,
- outputs=[input_gallary, output_gallary, ],
- cache_examples=cache_examples, )
-
- gr.HTML(' How to add mask: Please see the following instructions.
Description: ' + get_instruction("Multi-Context") + '
')
- with gr.Row():
- input_session = []
- with gr.Column():
- for idx in range(num_img_input):
- with gr.Tab('Image{}'.format(idx+1)):
- img = gr.Image(label='Image Input', type='pil', elem_id='customized_imbox')
- img.as_example = types.MethodType(customized_as_example, img)
- imgm = gr.Image(label='Image Input with Mask', type='pil', elem_id='customized_imbox', tool='sketch', source="upload", visible=False)
- imgm.postprocess = types.MethodType(customized_postprocess, imgm)
- imgm.as_example = types.MethodType(customized_as_example, imgm)
-
- with gr.Row():
- istrength = gr.Slider(label="Weight", minimum=0, maximum=1, value=1, step=0.02)
- fcs = gr.Slider(label="Focus (Semantic -- Style)", minimum=0, maximum=1, value=0.5, step=0.02)
- msk = gr.Checkbox(label='Use mask?')
- gr.HTML(' Weight: The strength of the reference image. This weight is subject to Text Domination ).
'+
- ' Focus: Focus on what aspect of the image? (0-semantic, 0.5-balanced (default), 1-style).
'+
- ' Mask: Remove regions on reference image so they will not influence the output.
',)
-
- msk.change(
- fn=image_mimage_swap(img, imgm),
- inputs=[img, imgm, msk],
- outputs=[img, imgm],)
- input_session.append([img, imgm, istrength, fcs, msk])
-
- text = gr.Textbox(lines=2, placeholder="Input prompt...", label='Text Input')
- tstrength = gr.Slider(label="Text Domination (NoEffect -- TextOnly)", minimum=0, maximum=1, value=0, step=0.02)
-
- seed = gr.Number(20, label="Seed", precision=0)
- button = gr.Button("Run")
-
-
- with gr.Column():
- input_gallary = gr.Gallery(label="Input Display", elem_id='customized_imbox').style(grid=4)
- output_gallary = gr.Gallery(label="Image Result", elem_id='customized_imbox').style(grid=n_sample_image)
-
- input_list = []
- for i in input_session:
- input_list += i
- input_list += [text, tstrength, seed]
- button.click(
- vd_inference.inference_mcg,
- inputs=input_list,
- outputs=[input_gallary, output_gallary], )
-
- if with_example:
- create_myexamples(
- label='Examples',
- examples=get_example('Multi-Context'),
- fn=vd_inference.inference_mcg,
- inputs=input_list,
- outputs=[input_gallary, output_gallary],
- cache_examples=cache_examples, )
-
- gr.HTML(' How to add mask: Please see the following instructions.
-
- Versatile Diffusion
-
-
- We built Versatile Diffusion (VD), the first unified multi-flow multimodal diffusion framework , as a step towards Universal Generative AI .
- VD can natively support image-to-text, image-variation, text-to-image, and text-variation,
- and can be further extended to other applications such as
- semantic-style disentanglement, image-text dual-guided generation, latent image-to-text-to-image editing, and more.
- Future versions will support more modalities such as speech, music, video and 3D.
-
-
- Xingqian Xu, Atlas Wang, Eric Zhang, Kai Wang,
- and Humphrey Shi
- [arXiv ]
- [GitHub ]
-
-
-
- Version : {}
-
-
- Caution :
- We would like the raise the awareness of users of this demo of its potential issues and concerns.
- Like previous large foundation models, Versatile Diffusion could be problematic in some cases, partially due to the imperfect training data and pretrained network (VAEs / context encoders) with limited scope.
- In its future research phase, VD may do better on tasks such as text-to-image, image-to-text, etc., with the help of more powerful VAEs, more sophisticated network designs, and more cleaned data.
- So far, we keep all features available for research testing both to show the great potential of the VD framework and to collect important feedback to improve the model in the future.
- We welcome researchers and users to report issues with the HuggingFace community discussion feature or email the authors.
-
-
- Biases and content acknowledgement :
- Beware that VD may output content that reinforces or exacerbates societal biases, as well as realistic faces, pornography, and violence.
- VD was trained on the LAION-2B dataset, which scraped non-curated online images and text, and may contained unintended exceptions as we removed illegal content.
- VD in this demo is meant only for research purposes.
-
-
- """.format(' '+vd_inference.which))
-
- # demo.launch(share=True)
- demo.launch(debug=True)
diff --git a/spaces/shiwan10000/CodeFormer/CodeFormer/inference_codeformer.py b/spaces/shiwan10000/CodeFormer/CodeFormer/inference_codeformer.py
deleted file mode 100644
index fdfe8b301cc7c20c2fb653618e379d243603a108..0000000000000000000000000000000000000000
--- a/spaces/shiwan10000/CodeFormer/CodeFormer/inference_codeformer.py
+++ /dev/null
@@ -1,189 +0,0 @@
-# Modified by Shangchen Zhou from: https://github.com/TencentARC/GFPGAN/blob/master/inference_gfpgan.py
-import os
-import cv2
-import argparse
-import glob
-import torch
-from torchvision.transforms.functional import normalize
-from basicsr.utils import imwrite, img2tensor, tensor2img
-from basicsr.utils.download_util import load_file_from_url
-from facelib.utils.face_restoration_helper import FaceRestoreHelper
-import torch.nn.functional as F
-
-from basicsr.utils.registry import ARCH_REGISTRY
-
-pretrain_model_url = {
- 'restoration': 'https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/codeformer.pth',
-}
-
-def set_realesrgan():
- if not torch.cuda.is_available(): # CPU
- import warnings
- warnings.warn('The unoptimized RealESRGAN is slow on CPU. We do not use it. '
- 'If you really want to use it, please modify the corresponding codes.',
- category=RuntimeWarning)
- bg_upsampler = None
- else:
- from basicsr.archs.rrdbnet_arch import RRDBNet
- from basicsr.utils.realesrgan_utils import RealESRGANer
- model = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=23, num_grow_ch=32, scale=2)
- bg_upsampler = RealESRGANer(
- scale=2,
- model_path='https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.1/RealESRGAN_x2plus.pth',
- model=model,
- tile=args.bg_tile,
- tile_pad=40,
- pre_pad=0,
- half=True) # need to set False in CPU mode
- return bg_upsampler
-
-if __name__ == '__main__':
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- parser = argparse.ArgumentParser()
-
- parser.add_argument('--w', type=float, default=0.5, help='Balance the quality and fidelity')
- parser.add_argument('--upscale', type=int, default=2, help='The final upsampling scale of the image. Default: 2')
- parser.add_argument('--test_path', type=str, default='./inputs/cropped_faces')
- parser.add_argument('--has_aligned', action='store_true', help='Input are cropped and aligned faces')
- parser.add_argument('--only_center_face', action='store_true', help='Only restore the center face')
- # large det_model: 'YOLOv5l', 'retinaface_resnet50'
- # small det_model: 'YOLOv5n', 'retinaface_mobile0.25'
- parser.add_argument('--detection_model', type=str, default='retinaface_resnet50')
- parser.add_argument('--draw_box', action='store_true')
- parser.add_argument('--bg_upsampler', type=str, default='None', help='background upsampler. Optional: realesrgan')
- parser.add_argument('--face_upsample', action='store_true', help='face upsampler after enhancement.')
- parser.add_argument('--bg_tile', type=int, default=400, help='Tile size for background sampler. Default: 400')
-
- args = parser.parse_args()
-
- # ------------------------ input & output ------------------------
- if args.test_path.endswith('/'): # solve when path ends with /
- args.test_path = args.test_path[:-1]
-
- w = args.w
- result_root = f'results/{os.path.basename(args.test_path)}_{w}'
-
- # ------------------ set up background upsampler ------------------
- if args.bg_upsampler == 'realesrgan':
- bg_upsampler = set_realesrgan()
- else:
- bg_upsampler = None
-
- # ------------------ set up face upsampler ------------------
- if args.face_upsample:
- if bg_upsampler is not None:
- face_upsampler = bg_upsampler
- else:
- face_upsampler = set_realesrgan()
- else:
- face_upsampler = None
-
- # ------------------ set up CodeFormer restorer -------------------
- net = ARCH_REGISTRY.get('CodeFormer')(dim_embd=512, codebook_size=1024, n_head=8, n_layers=9,
- connect_list=['32', '64', '128', '256']).to(device)
-
- # ckpt_path = 'weights/CodeFormer/codeformer.pth'
- ckpt_path = load_file_from_url(url=pretrain_model_url['restoration'],
- model_dir='weights/CodeFormer', progress=True, file_name=None)
- checkpoint = torch.load(ckpt_path)['params_ema']
- net.load_state_dict(checkpoint)
- net.eval()
-
- # ------------------ set up FaceRestoreHelper -------------------
- # large det_model: 'YOLOv5l', 'retinaface_resnet50'
- # small det_model: 'YOLOv5n', 'retinaface_mobile0.25'
- if not args.has_aligned:
- print(f'Face detection model: {args.detection_model}')
- if bg_upsampler is not None:
- print(f'Background upsampling: True, Face upsampling: {args.face_upsample}')
- else:
- print(f'Background upsampling: False, Face upsampling: {args.face_upsample}')
-
- face_helper = FaceRestoreHelper(
- args.upscale,
- face_size=512,
- crop_ratio=(1, 1),
- det_model = args.detection_model,
- save_ext='png',
- use_parse=True,
- device=device)
-
- # -------------------- start to processing ---------------------
- # scan all the jpg and png images
- for img_path in sorted(glob.glob(os.path.join(args.test_path, '*.[jp][pn]g'))):
- # clean all the intermediate results to process the next image
- face_helper.clean_all()
-
- img_name = os.path.basename(img_path)
- print(f'Processing: {img_name}')
- basename, ext = os.path.splitext(img_name)
- img = cv2.imread(img_path, cv2.IMREAD_COLOR)
-
- if args.has_aligned:
- # the input faces are already cropped and aligned
- img = cv2.resize(img, (512, 512), interpolation=cv2.INTER_LINEAR)
- face_helper.cropped_faces = [img]
- else:
- face_helper.read_image(img)
- # get face landmarks for each face
- num_det_faces = face_helper.get_face_landmarks_5(
- only_center_face=args.only_center_face, resize=640, eye_dist_threshold=5)
- print(f'\tdetect {num_det_faces} faces')
- # align and warp each face
- face_helper.align_warp_face()
-
- # face restoration for each cropped face
- for idx, cropped_face in enumerate(face_helper.cropped_faces):
- # prepare data
- cropped_face_t = img2tensor(cropped_face / 255., bgr2rgb=True, float32=True)
- normalize(cropped_face_t, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)
- cropped_face_t = cropped_face_t.unsqueeze(0).to(device)
-
- try:
- with torch.no_grad():
- output = net(cropped_face_t, w=w, adain=True)[0]
- restored_face = tensor2img(output, rgb2bgr=True, min_max=(-1, 1))
- del output
- torch.cuda.empty_cache()
- except Exception as error:
- print(f'\tFailed inference for CodeFormer: {error}')
- restored_face = tensor2img(cropped_face_t, rgb2bgr=True, min_max=(-1, 1))
-
- restored_face = restored_face.astype('uint8')
- face_helper.add_restored_face(restored_face)
-
- # paste_back
- if not args.has_aligned:
- # upsample the background
- if bg_upsampler is not None:
- # Now only support RealESRGAN for upsampling background
- bg_img = bg_upsampler.enhance(img, outscale=args.upscale)[0]
- else:
- bg_img = None
- face_helper.get_inverse_affine(None)
- # paste each restored face to the input image
- if args.face_upsample and face_upsampler is not None:
- restored_img = face_helper.paste_faces_to_input_image(upsample_img=bg_img, draw_box=args.draw_box, face_upsampler=face_upsampler)
- else:
- restored_img = face_helper.paste_faces_to_input_image(upsample_img=bg_img, draw_box=args.draw_box)
-
- # save faces
- for idx, (cropped_face, restored_face) in enumerate(zip(face_helper.cropped_faces, face_helper.restored_faces)):
- # save cropped face
- if not args.has_aligned:
- save_crop_path = os.path.join(result_root, 'cropped_faces', f'{basename}_{idx:02d}.png')
- imwrite(cropped_face, save_crop_path)
- # save restored face
- if args.has_aligned:
- save_face_name = f'{basename}.png'
- else:
- save_face_name = f'{basename}_{idx:02d}.png'
- save_restore_path = os.path.join(result_root, 'restored_faces', save_face_name)
- imwrite(restored_face, save_restore_path)
-
- # save restored img
- if not args.has_aligned and restored_img is not None:
- save_restore_path = os.path.join(result_root, 'final_results', f'{basename}.png')
- imwrite(restored_img, save_restore_path)
-
- print(f'\nAll results are saved in {result_root}')
diff --git a/spaces/sidphbot/Researcher/arxiv_public_data/pdfstamp.py b/spaces/sidphbot/Researcher/arxiv_public_data/pdfstamp.py
deleted file mode 100644
index d8ea220bfb737a2dea405f56ff5b36b5ac007616..0000000000000000000000000000000000000000
--- a/spaces/sidphbot/Researcher/arxiv_public_data/pdfstamp.py
+++ /dev/null
@@ -1,83 +0,0 @@
-import re
-
-SPACE_DIGIT = r'\s*\d\s*'
-SPACE_NUMBER = r'(?:{})+'.format(SPACE_DIGIT)
-SPACE_CHAR = r'\s*[a-zA-Z\.-]\s*'
-SPACE_WORD = r'(?:{})+'.format(SPACE_CHAR)
-
-# old style ID, 7 digits in a row
-RE_NUM_OLD = SPACE_DIGIT*7
-
-# new style ID, 4 digits, ., 4,5 digits
-RE_NUM_NEW = (
- SPACE_DIGIT*4 +
- r'\.' +
- SPACE_DIGIT*4 + r'(?:{})?'.format(SPACE_DIGIT)
-)
-
-# the version part v1 V2 v 1, etc
-RE_VERSION = r'(?:\s*[vV]\s*\d+\s*)?'
-
-# the word arxiv, as printed by the autotex, arXiv
-RE_ARXIV = r'\s*a\s*r\s*X\s*i\s*v\s*:\s*'
-
-# any words within square brackets [cs.A I]
-RE_CATEGORIES = r'\[{}\]'.format(SPACE_WORD)
-
-# two digit date, month, year "29 Jan 2012"
-RE_DATE = SPACE_NUMBER + SPACE_WORD + r'(?:{}){}'.format(SPACE_DIGIT, '{2,4}')
-
-# the full identifier for the banner
-RE_ARXIV_ID = (
- RE_ARXIV +
- r'(?:' +
- r'(?:{})|(?:{})'.format(RE_NUM_NEW, RE_NUM_OLD) +
- r')' +
- RE_VERSION +
- RE_CATEGORIES +
- RE_DATE
-)
-
-REGEX_ARXIV_ID = re.compile(RE_ARXIV_ID)
-
-
-def _extract_arxiv_stamp(txt):
- """
- Find location of stamp within the text and remove that section
- """
- match = REGEX_ARXIV_ID.search(txt)
-
- if not match:
- return txt, ''
-
- s, e = match.span()
- return '{} {}'.format(txt[:s].strip(), txt[e:].strip()), txt[s:e].strip()
-
-
-def remove_stamp(txt, split=1000):
- """
- Given full text, remove the stamp placed in the pdf by arxiv itself. This
- deserves a bit of consideration since the stamp often becomes mangled by
- the text extraction tool (i.e. hard to find and replace) and can be
- reversed.
-
- Parameters
- ----------
- txt : string
- The full text of a document
-
- Returns
- -------
- out : string
- Full text without stamp
- """
- t0, t1 = txt[:split], txt[split:]
- txt0, stamp0 = _extract_arxiv_stamp(t0)
- txt1, stamp1 = _extract_arxiv_stamp(t0[::-1])
-
- if stamp0:
- return txt0 + t1
- elif stamp1:
- return txt1[::-1] + t1
- else:
- return txt
diff --git a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Bus Simulator Ultimate - The Most Realistic and Immersive Bus Simulation Game for Android (APK OBB).md b/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Bus Simulator Ultimate - The Most Realistic and Immersive Bus Simulation Game for Android (APK OBB).md
deleted file mode 100644
index 24fde4ede20f94c7720e7c0da9aeca94fd650ece..0000000000000000000000000000000000000000
--- a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Bus Simulator Ultimate - The Most Realistic and Immersive Bus Simulation Game for Android (APK OBB).md
+++ /dev/null
@@ -1,116 +0,0 @@
-Bus Simulator Ultimate: How to Download APK OBB for Android
-Do you love driving buses and transporting passengers across different countries and cities? If yes, then you might want to try Bus Simulator Ultimate, one of the most realistic and popular bus simulation games for Android devices. In this article, we will show you how to download APK OBB files for Bus Simulator Ultimate and enjoy this amazing game on your Android phone or tablet. We will also give you some features, tips, and tricks to help you play Bus Simulator Ultimate better.
-Introduction
-Before we get into the details of how to download APK OBB files for Bus Simulator Ultimate, let's first understand what this game is all about and why you might want to download it.
-bus simulator ultimate download apk obb Download File ->>->>->> https://ssurll.com/2uNScV
What is Bus Simulator Ultimate?
-Bus Simulator Ultimate is a game developed by Zuuks Games, a Turkish game studio that specializes in simulation games. It was released in 2019 and has since gained over 100 million downloads on Google Play Store. It is also available for iOS devices.
-Bus Simulator Ultimate is a game that lets you experience what it's like to be a bus driver in various countries and cities around the world. You can choose from different types of buses, customize them with your own logos and colors, create your own routes, and drive them on realistic roads with traffic, pedestrians, weather, and day-night cycles. You can also manage your own bus company, hire drivers, buy new buses, and expand your business.
-Bus Simulator Ultimate is not just a single-player game. You can also play online with other players in multiplayer mode, compete with them in rankings, chat with them, and join bus clubs. You can also get feedback from your passengers based on your driving performance, such as speed, comfort, safety, and punctuality.
-Why download APK OBB files?
-APK stands for Android Package Kit, which is the file format used by Android devices to install apps. OBB stands for Opaque Binary Blob, which is a file format used by some Android apps to store additional data that is not included in the APK file, such as graphics, sounds, videos, etc.
-Some Android apps require both APK and OBB files to run properly. This is usually the case for large and complex apps that have a lot of data, such as games. Bus Simulator Ultimate is one of those apps that need both APK and OBB files to work.
-Downloading APK OBB files can have some advantages over downloading apps directly from Google Play Store. For example:
-
-You can download APK OBB files from other sources than Google Play Store, such as third-party websites or app stores. This can be useful if you have problems accessing Google Play Store in your region or device.
-You can download APK OBB files manually and install them offline without an internet connection. This can be useful if you have a slow or unstable internet connection or if you want to save data usage.
-You can download APK OBB files of older versions of apps that are no longer available on Google Play Store. This can be useful if you prefer an older version of an app over a newer one or if you want to avoid bugs or compatibility issues.
-
-However, downloading APK OBB files also has some risks and disadvantages that you should be aware of. For example:
- You can expose your device to malware or viruses if you download APK OBB files from untrusted or malicious sources. This can compromise your personal data and harm your device.
-You can violate the terms and conditions of some apps or games if you download APK OBB files without the permission of the developers. This can result in legal issues or account bans.
-You can miss out on the latest updates, bug fixes, and features if you download APK OBB files that are outdated or incompatible with your device. This can affect your app performance and user experience.
-
-Therefore, you should always be careful and cautious when downloading APK OBB files for any app or game. Make sure that you only download them from reputable and reliable sources, such as the official websites of the developers or trusted third-party app stores. You should also scan the files with a good antivirus app before installing them on your device.
-bus simulator ultimate apk obb free download
-How to download Bus Simulator Ultimate APK OBB
-Now that you know what APK OBB files are and what are the pros and cons of downloading them, let's see how you can download Bus Simulator Ultimate APK OBB files on your Android device. There are different methods and tools that you can use, but we will show you one of the easiest and safest ways to do it.
-For this method, you will need two things: an app called APKCombo Installer and a file called Bus Simulator Ultimate XAPK. APKCombo Installer is an app that can help you install XAPK files on your device. XAPK files are similar to APK OBB files, but they are compressed into a single file that contains both the APK and the OBB data. Bus Simulator Ultimate XAPK is the file that contains the latest version of Bus Simulator Ultimate and its additional data.
-Here are the steps to follow:
-Step 1: Download APKCombo Installer app
-The first step is to download and install the APKCombo Installer app on your device. You can do this by visiting on your browser and tapping on the Download button. Alternatively, you can scan the QR code on the website with your camera app to download the app directly.
-Once the app is downloaded, you need to enable the Unknown Sources option on your device settings to allow the installation of apps from sources other than Google Play Store. To do this, go to Settings > Security > Unknown Sources and toggle it on. Then, locate the APKCombo Installer app file in your Downloads folder and tap on it to install it.
-Step 2: Download Bus Simulator Ultimate XAPK file
-The next step is to download the Bus Simulator Ultimate XAPK file on your device. You can do this by visiting on your browser and tapping on the Download button. Alternatively, you can scan the QR code on the website with your camera app to download the file directly.
-Once the file is downloaded, you need to locate it in your Downloads folder and rename it from .xapk to .zip. This is because some devices may not recognize the .xapk extension and may not allow you to open it with the APKCombo Installer app. To rename the file, simply tap and hold on it and select Rename from the menu. Then, change the .xapk part to .zip and tap OK.
-Step 3: Install Bus Simulator Ultimate XAPK file
-The final step is to install the Bus Simulator Ultimate XAPK file on your device using the APKCombo Installer app. To do this, open the APKCombo Installer app and tap on the Install button at the bottom right corner. Then, navigate to your Downloads folder and select the Bus Simulator Ultimate.zip file that you renamed earlier. The app will then extract and install both the APK and the OBB data for Bus Simulator Ultimate automatically.
-Once the installation is complete, you can launch Bus Simulator Ultimate from your app drawer or home screen and enjoy playing it on your device.
-How to play Bus Simulator Ultimate
-Now that you have successfully downloaded and installed Bus Simulator Ultimate APK OBB files on your device, you are ready to play this amazing game. But before you start driving your bus across different countries and cities, let's take a look at some of the features, tips, and tricks that can help you play Bus Simulator Ultimate better.
-Features of Bus Simulator Ultimate
-Bus Simulator Ultimate offers a range of features that make it a unique and engaging simulation game. Here are some of the most notable features of the game:
-Realistic bus driving experience
-Bus Simulator Ultimate provides a realistic and immersive bus driving experience, complete with various weather conditions, traffic patterns, pedestrians, and road signs. You can also control various aspects of your bus, such as the steering wheel, the pedals, the indicators, the horn, the doors, the lights, and the wipers. You can also adjust the camera angle and the view mode to suit your preference.
-Multiplayer mode and online ranking
-Bus Simulator Ultimate is not just a single-player game. You can also play online with other players in multiplayer mode, where you can join or create bus clubs, chat with other drivers, and compete with them in rankings. You can also see the live location and status of other players on the map. You can also participate in events and tournaments to win prizes and rewards.
-Customizable buses and routes
-Bus Simulator Ultimate allows you to customize your buses and routes according to your liking. You can choose from different types of buses, such as city buses, school buses, double-decker buses, articulated buses, etc. You can also change the color, the logo, the license plate, and the interior of your buses. You can also create your own routes by selecting the starting point, the destination, the stops, and the waypoints. You can also edit or delete your routes anytime.
-Passenger feedback and weather effects
-Bus Simulator Ultimate gives you feedback from your passengers based on your driving performance. Your passengers will rate you on various criteria, such as speed, comfort, safety, and punctuality. You will also hear their comments and reactions during the ride. You can also see their emotions and expressions on their faces. Your feedback will affect your reputation and income as a bus driver.
-Bus Simulator Ultimate also simulates different weather effects, such as rain, snow, fog, wind, etc. These effects will influence your visibility, traction, and handling of your bus. You will also see realistic reflections and shadows on your bus windows and mirrors.
-Tips and tricks for Bus Simulator Ultimate
-Bus Simulator Ultimate is a fun and challenging game that requires skill and strategy to play well. Here are some tips and tricks that can help you improve your game:
-Upgrade your bus and driver skills
-As you play Bus Simulator Ultimate, you will earn money and experience points that you can use to upgrade your bus and driver skills. Upgrading your bus will improve its performance, appearance, and durability. Upgrading your driver skills will improve your driving abilities, such as braking, steering, acceleration, etc. You can also unlock new buses and routes as you level up.
-Follow the traffic rules and avoid accidents
-Bus Simulator Ultimate is a realistic game that follows the traffic rules and regulations of different countries and cities. You should always obey the speed limit, the traffic lights, the road signs, and the lane markings. You should also respect other vehicles and pedestrians on the road. You should avoid crashing into anything or anyone, as this will damage your bus and lower your passenger satisfaction. You should also avoid getting fined or arrested by the police for breaking the law.
-Manage your bus company and earn money
-Bus Simulator Ultimate is not just a driving game. It is also a management game that lets you run your own bus company. You can hire other drivers to work for you, assign them to different routes, monitor their performance, and pay them salaries. You can also buy new buses or sell old ones to expand or reduce your fleet. You can also set the ticket prices for your routes to maximize your profit.
-Explore different countries and cities
-Bus Simulator Ultimate is a game that lets you travel around the world in your bus. You can choose from different countries and cities to drive in, such as Germany, France, Italy, Spain, Turkey, USA, Canada, Brazil, etc. Each country and city has its own unique scenery, landmarks, culture, and traffic. You can also see the differences in the currency, the language, the measurement units, and the driving side of each country. You can also learn some facts and trivia about each country and city as you drive.
-Conclusion
-Bus Simulator Ultimate is a game that offers a realistic and enjoyable bus driving experience for Android users. It is a game that combines simulation, management, and exploration elements in one. It is a game that lets you customize your buses and routes, play online with other players, get feedback from your passengers, and travel around the world.
-If you want to play Bus Simulator Ultimate on your Android device, you can download it from Google Play Store or use the method we showed you to download APK OBB files from APKCombo. Either way, you will need about 600 MB of free space on your device to install the game and its data.
-We hope that this article has helped you learn how to download APK OBB files for Bus Simulator Ultimate and how to play it better. If you have any questions or comments, feel free to leave them below. Happy bus driving!
-FAQs
-Here are some frequently asked questions and answers about Bus Simulator Ultimate:
-
-Q: Is Bus Simulator Ultimate free to play? A: Yes, Bus Simulator Ultimate is free to download and play. However, it contains some in-app purchases that can enhance your game experience, such as buying coins, gems, or premium buses.
-Q: Can I play Bus Simulator Ultimate offline? A: Yes, you can play Bus Simulator Ultimate offline without an internet connection. However, some features of the game, such as multiplayer mode, online ranking, events, and tournaments, will not be available offline.
-Q: How can I save my progress in Bus Simulator Ultimate? A: Bus Simulator Ultimate automatically saves your progress in your device's memory. However, if you want to backup your progress or transfer it to another device, you can use the cloud save feature of the game. To do this, you need to connect your game account to your Facebook account and enable the cloud save option in the game settings.
-Q: How can I contact the developers of Bus Simulator Ultimate? A: If you have any feedback, suggestions, or issues with Bus Simulator Ultimate, you can contact the developers of the game by emailing them at info@zuuks.com or by visiting their website at . You can also follow them on their social media accounts on Facebook, Twitter, Instagram, and YouTube.
-Q: How can I get more coins and gems in Bus Simulator Ultimate? A: Coins and gems are the main currencies of Bus Simulator Ultimate. You can use them to buy new buses, upgrade your buses and driver skills, or access premium features of the game. You can get more coins and gems by completing missions, achievements, events, tournaments, or daily rewards. You can also watch ads or videos to earn some extra coins or gems. Alternatively, you can buy coins or gems with real money through in-app purchases.
- 197e85843dHow to Download Kamen Rider Decade
-If you are a fan of Japanese superhero shows, you might have heard of Kamen Rider Decade, a popular tokusatsu drama that aired in 2009. But how can you watch this series online or offline? In this article, we will show you how to download Kamen Rider Decade from various sources and platforms, as well as why you should watch this series in the first place.
- What is Kamen Rider Decade?
-Kamen Rider Decade is the title of the first installment of the 2009 editions of the long-running Kamen Rider Series of tokusatsu dramas. Tokusatsu is a genre of live-action shows that feature special effects, such as monsters, robots, and superheroes. Kamen Rider is one of the most famous and influential tokusatsu franchises in Japan, dating back to 1971.
-download kamen rider decade DOWNLOAD ↔ https://ssurll.com/2uNWa0
The plot and characters of the series
-The story follows Tsukasa Kadoya, an amnesiac photographer who becomes Kamen Rider Decade, the Destroyer of Worlds. He travels across nine alternate realities, each based on a previous Kamen Rider series from the Heisei era (2000-2009), to prevent them from collapsing into one. Along the way, he meets various allies and enemies, such as Yusuke Onodera/Kamen Rider Kuuga, Daiki Kaito/Kamen Rider Diend, and Narutaki, a mysterious man who opposes him.
-The features and themes of the series
-Kamen Rider Decade is a tribute to the Heisei era of Kamen Rider, celebrating its 10th anniversary. It features many references, homages, and cameos from previous series, as well as new interpretations and twists. It also explores themes such as identity, memory, destiny, and connection. The series uses a printing motif, with Tsukasa's camera and cards resembling those used in printing machines. The main colors of the series are based on the CMYK color model: cyan for Decade, magenta for Diend, yellow for Kuuga (Rising Ultimate Form), and black for Dark Riders.
- Why should you watch Kamen Rider Decade?
-The benefits of watching tokusatsu dramas
-Watching tokusatsu dramas can be a fun and rewarding experience for many reasons. Here are some of them:
-
-You can enjoy the action-packed scenes, creative designs, and impressive special effects that showcase the talent and passion of the creators.
-You can learn about Japanese culture, history, mythology, and values through the stories and characters.
-You can be inspired by the messages and lessons that the heroes convey, such as courage, justice, friendship, and hope.
-You can connect with other fans who share your interest and enthusiasm for tokusatsu.
-
-The appeal of Kamen Rider Decade as a tribute to the Heisei era
-Kamen Rider Decade is a special series that pays homage to the previous nine Kamen Rider series from the Heisei era, which are:
-
-Kamen Rider Kuuga (2000-2001)
-Kamen Rider Agito (2001-2002)
-Kamen Rider Ryuki (2002-2003)
-Kamen Rider 555 (2003-2004)
-Kamen Rider Blade (2004-2005)
-Kamen Rider Hibiki (2005-2006)
-Kamen Rider Kabuto (2006-2007)
-Kamen Rider Den-O (2007-2008)
-Kamen Rider Kiva (2008-2009)
-
-By watching Kamen Rider Decade, you can experience the different styles, themes, and atmospheres of each series, as well as the unique personalities and abilities of each Kamen Rider. You can also appreciate the similarities and differences among them, and how they interact and cooperate with each other. You can also witness the evolution and innovation of the Kamen Rider franchise over the years.
- Where can you download Kamen Rider Decade?
-The official sources and platforms
-The best way to watch Kamen Rider Decade is to use the official sources and platforms that have the rights and licenses to distribute the series. This way, you can support the original creators and producers, as well as enjoy the highest quality and reliability of the video and audio. Some of the official sources and platforms that offer Kamen Rider Decade are:
-
-Tokusatsu Channel: This is a YouTube channel that streams various tokusatsu shows legally and for free, including Kamen Rider Decade. You can watch the episodes with English subtitles on this channel.
-TokuSHOUTsu: This is a streaming service that specializes in tokusatsu content, such as Kamen Rider, Super Sentai, and Ultraman. You can watch Kamen Rider Decade on this service with English subtitles or dubbing.
-Amazon Prime Video: This is a popular online video-on-demand service that offers a wide range of movies and shows, including Kamen Rider Decade. You can rent or buy the episodes or the whole series on this service.
-
-The alternative sources and platforms
-If you cannot access or afford the official sources and platforms, you might want to consider some alternative sources and platforms that also provide Kamen Rider Decade. However, you should be aware that these sources and platforms may not have the proper permissions or licenses to distribute the series, and they may have lower quality or reliability of the video and audio. Some of the alternative sources and platforms that offer Kamen Rider Decade are:
-download kamen rider decade full episodes
-
-KissAsian: This is a website that hosts various Asian dramas and shows, including Kamen Rider Decade. You can watch or download the episodes with English subtitles on this website.
-Nyaa: This is a torrent website that allows users to share and download various files, including Kamen Rider Decade. You can find different versions and formats of the episodes with English subtitles or dubbing on this website.
-Dailymotion: This is a video-sharing platform that hosts various user-generated content, including Kamen Rider Decade. You can watch or download the episodes with English subtitles or dubbing on this platform.
-
- How to download Kamen Rider Decade safely and legally? The tips and precautions for downloading
-Before you download Kamen Rider Decade, you should follow some tips and precautions to ensure that you have a safe and legal experience. Here are some of them:
-
-Check the source and platform that you are using. Make sure that it is reputable, reliable, and secure. Avoid any suspicious or malicious links, pop-ups, or ads that may harm your device or data.
-Check the quality and format of the video and audio. Make sure that they are compatible with your device and preferences. Avoid any corrupted or incomplete files that may cause errors or glitches.
-Check the language and subtitles of the video and audio. Make sure that they are clear, accurate, and understandable. Avoid any poorly translated or edited files that may confuse or mislead you.
-Check the laws and regulations of your country or region. Make sure that you are not violating any intellectual property rights or piracy laws by downloading Kamen Rider Decade. Avoid any legal troubles or penalties that may arise from your actions.
-
-The table of comparison for different sources and platforms
-To help you decide which source and platform to use for downloading Kamen Rider Decade, we have prepared a table of comparison that shows the pros and cons of each option. Here is the table:
-
-
-Source/Platform
-Pros
-Cons
-
-
-Tokusatsu Channel
-- Free and legal
-- Limited availability and accessibility
-
-
-TokuSHOUTsu
-- Legal and affordable
-- Requires subscription and registration
-
-
-Amazon Prime Video
-- Legal and affordable
-- Requires subscription and registration
-
-
-KissAsian
-- Free and accessible
-- Illegal and unethical
-
-
-Nyaa
-- Free and accessible
-- Illegal and unethical
-
-
-Dailymotion
-- Free and accessible
-- Illegal and unethical
-
- Conclusion
- Kamen Rider Decade is a great series to watch if you are a fan of tokusatsu dramas, especially the Kamen Rider franchise. It offers a thrilling adventure across nine alternate realities, each featuring a different Kamen Rider from the Heisei era. It also showcases the action, creativity, culture, and values of tokusatsu.
- To download Kamen Rider Decade, you have various options to choose from, depending on your preferences, budget, and location. However, you should always be careful and responsible when downloading any content online, as there may be legal or ethical issues involved. You should also respect the original creators and producers of the series by supporting them whenever possible.
- We hope that this article has helped you learn more about Kamen Rider Decade and how to download it. If you have any questions or feedback, please feel free to leave a comment below. Thank you for reading!
- FAQs
- Q1. How many episodes are there in Kamen Rider Decade?
- A1. There are 31 episodes in Kamen Rider Decade, divided into three arcs: World of Kuuga (episodes 1-2), World of Negatives (episodes 3-11), and World of Diend (episodes 12-31). There is also a special episode titled "The Last Story" that serves as the finale of the series.
- Q2. What are the other movies and specials related to Kamen Rider Decade?
- A2. There are several movies and specials related to Kamen Rider Decade, such as:
-
- Kamen Rider Decade: All Riders vs. Dai-Shocker (2009): This is a crossover movie that features Decade and other Kamen Riders from the Showa and Heisei eras, as well as the debut of Kamen Rider Diend.
-Kamen Rider × Kamen Rider W & Decade: Movie War 2010 (2009): This is a two-part movie that consists of Kamen Rider Decade: The Last Story and Kamen Rider W: Begins Night, as well as a joint segment titled Movie War 2010. It serves as the conclusion of Kamen Rider Decade and the introduction of Kamen Rider W.
-Kamen Rider × Super Sentai: Super Hero Taisen (2012): This is a crossover movie that features Decade and other Kamen Riders from the Heisei and Neo-Heisei eras, as well as Super Sentai teams from the Showa and Heisei eras.
-Kamen Rider × Super Sentai × Space Sheriff: Super Hero Taisen Z (2013): This is a sequel to the previous movie that features Decade and other Kamen Riders from the Heisei and Neo-Heisei eras, as well as Super Sentai teams from the Showa and Heisei eras, and Space Sheriffs from the Metal Heroes series.
-Heisei Rider vs. Showa Rider: Kamen Rider Taisen feat. Super Sentai (2014): This is a crossover movie that features Decade and other Kamen Riders from the Heisei and Showa eras, as well as cameo appearances from Super Sentai teams.
-Kamen Rider 3 (2015): This is a special episode of the web series Super Hero Taisen GP: Kamen Rider 3 that features Decade and other Kamen Riders from the Heisei and Showa eras, as well as the debut of Kamen Rider 3, a lost rider from the Showa era.
-Kamen Rider × Kamen Rider Ghost & Drive: Super Movie War Genesis (2015): This is a two-part movie that consists of Kamen Rider Drive Saga: Kamen Rider Chaser and Kamen Rider Ghost: The 100 Eyecons and Ghost's Fateful Moment, as well as a joint segment titled Super Movie War Genesis. It serves as the conclusion of Kamen Rider Drive and the introduction of Kamen Rider Ghost, as well as featuring a cameo appearance from Decade.
-
- Q3. Is there an English dub or subtitle for Kamen Rider Decade?
- A3. Yes, there is an English dub or subtitle for Kamen Rider Decade, depending on the source or platform that you use. For example, Tokusatsu Channel and TokuSHOUTsu provide English subtitles for the series, while TokuSHOUTsu also provides an English dub for the series. However, some sources or platforms may not have an English dub or subtitle for the series, or they may have poor quality or accuracy of the translation. Therefore, you should check the language options before you download or watch the series.
- Q4. What are the other Kamen Rider series that you can watch after Decade?
- A4. There are many other Kamen Rider series that you can watch after Decade, especially if you want to continue following the story and characters of the franchise. Here are some of them:
-
-Kamen Rider W (2009-2010): This is the second installment of the 2009 editions of the Kamen Rider Series, and the eleventh overall in the Heisei era. It follows Shotaro Hidari and Philip, who form a detective agency and use the Double Driver to transform into Kamen Rider W, to fight against the Dopants, people who use Gaia Memories to gain superpowers.
-Kamen Rider OOO (2010-2011): This is the third installment of the 2009 editions of the Kamen Rider Series, and the twelfth overall in the Heisei era. It follows Eiji Hino, a vagabond who becomes Kamen Rider OOO, the King of Desire, by using the OOO Driver and O Medals to transform into various animal-themed forms, to fight against the Greeed, a group of artificial lifeforms that crave for human desires.
-Kamen Rider Fourze (2011-2012): This is the fourth and final installment of the 2009 editions of the Kamen Rider Series, and the thirteenth overall in the Heisei era. It follows Gentaro Kisaragi, a high school student who becomes Kamen Rider Fourze, the Man of Space, by using the Fourze Driver and Astroswitches to transform into various space-themed forms, to fight against the Zodiarts, people who use Zodiarts Switches to gain astrological powers.
-Kamen Rider Wizard (2012-2013): This is the first installment of the 2012 editions of the Kamen Rider Series, and the fourteenth overall in the Heisei era. It follows Haruto Soma, a survivor of a ritual that created Gates, people who have the potential to become Phantoms, monsters born from human despair. He becomes Kamen Rider Wizard, the Ringed Magician, by using the WizarDriver and Wizard Rings to transform into various elemental forms, to protect the Gates from the Phantoms.
-Kamen Rider Gaim (2013-2014): This is the second installment of the 2012 editions of the Kamen Rider Series, and the fifteenth overall in the Heisei era. It follows Kouta Kazuraba, a former dancer who becomes Kamen Rider Gaim, the Armored Rider, by using the Sengoku Driver and Lockseeds to transform into various fruit-themed forms, to fight against the Inves, creatures from another dimension called Helheim Forest. He also gets involved in a war among rival factions of Armored Riders who seek to control Helheim Forest and its secrets.
-
- Q5. Where can you find more information and updates about Kamen Rider Decade?
- A5. If you want to find more information and updates about Kamen Rider Decade, you can visit some of these websites and sources:
-
-Kamen Rider Wiki: This is a fan-made wiki that covers everything related to Kamen Rider, including Decade. You can find detailed information about the series, such as characters, episodes, forms, weapons, vehicles, and trivia.
-Kamen Rider Official Website: This is the official website of Kamen Rider by Toei Company, the production company behind the series. You can find official news and updates about the series, as well as merchandise and events.
-Kamen Rider Official Twitter: This is the official Twitter account of Kamen Rider by Toei Company. You can follow them for official tweets and updates about the series, as well as interact with other fans.
- 197e85843dWhat is ecusafe 20 and why do you need it?
-If you are looking for a way to improve your car's performance and efficiency without spending a fortune on expensive modifications or repairs, you might want to consider using ecusafe 2 0 software. Ecusafe 2 0 is a program that can protect the original program in your car's engine control unit (ECU) against being read by OBD flashers or programmers. This way, you can prevent unauthorized access to your ECU data and avoid losing your warranty or facing legal issues. Ecusafe 2 0 can also help you disable some of the systems that can reduce your car's performance, such as exhaust gas recirculation (EGR) and diesel particulate filter (DPF) or fuel additive particle (FAP). By disabling these systems, you can increase your car's power, torque, and fuel economy, as well as lower your emissions and maintenance costs. Ecusafe 2 0 is compatible with various types of ECUs and supports many car models and brands. It is easy to use and does not require any special skills or equipment. All you need is a laptop, a cable, and a keygen to activate the software. In this article, we will show you how to download, install, and use ecusafe 2 0 keygen to enhance your car's performance and protect your ECU data.
-ecusafe 2 0 keygen download Download Zip ✒ ✒ ✒ https://urlgoal.com/2uI7Tc
How does ecusafe 2 0 work?
-Ecusafe 2 0 is a software that can modify the original program in your ECU to make it unreadable by OBD flashers or programmers. OBD flashers or programmers are devices that can read and write data to your ECU via the on-board diagnostic (OBD) port of your car. These devices are often used by car tuners, mechanics, or thieves to change the settings of your ECU, such as fuel injection, ignition timing, boost pressure, and so on. However, these changes can also affect your car's performance, emissions, and warranty. For example, if you tune your car to increase its power, you might also increase its fuel consumption and emissions, which can violate the environmental regulations and void your warranty. Moreover, if someone steals your car and reads your ECU data, they might be able to clone your car's identity and sell it to another buyer.
-To prevent these problems, ecusafe 2 0 can protect your ECU data by applying a special algorithm that encrypts the program and makes it impossible to read by OBD flashers or programmers. The encrypted program will still work normally in your car, but it will not be accessible by any external device. This way, you can keep your original ECU settings and avoid any unwanted modifications or thefts. Ecusafe 2 0 can also disable some of the systems that can lower your car's performance, such as EGR and DPF/FAP. These systems are designed to reduce the emissions of your car by recirculating some of the exhaust gas back into the engine or filtering out some of the particulate matter from the exhaust. However, these systems can also cause problems such as reduced power, increased fuel consumption, clogged filters, and engine faults. By disabling these systems with ecusafe 2 0, you can improve your car's performance and efficiency without compromising its emissions.
- What are the features of ecusafe 2 0?
-Ecusafe 2 0 has many features that make it a powerful and versatile software for ECU protection and tuning. Some of the main features are:
-
-
-It can protect the original program in your ECU against being read by OBD flashers or programmers.
-It can disable EGR and DPF/FAP systems in your ECU without affecting its functionality.
-It supports various types of ECUs such as Bosch EDC16/EDC17/ME9/ME7/ME9.7/ME9.5/ME9.6/ME9.8/ME9.9/ME9.10/ME9.11/ME9.12/ME9.13/ME9.14/ME9.15/ME9.16/ME9.17/ME9.18/ME9.19/ME9.20/ME9.21/ME9.22/ME9.23/ME9.24/ME9.25/ME9 .26/ME9.27/ME9.28/ME9.29/ME9.30/ME9.31/ME9.32/ME9.33/ME9.34/ME9.35/ME9.36/ME9.37/ME9.38/ME9.39/ME9.40, Siemens SID201/SID202/SID203/SID204/SID206/SID208/SID209/SID210/SID211/SID212/SID213/SID214/SID215/SID216/SID217/SID218/SID219/SID220, Delphi DCM3.4/DCM3.5, Denso, Marelli, and others.
-It supports many car models and brands such as Audi, BMW, Citroen, Fiat, Ford, Hyundai, Kia, Land Rover, Mercedes-Benz, Mini, Nissan, Opel, Peugeot, Renault, Seat, Skoda, Toyota, Volkswagen, Volvo, and others.
-It allows custom tuning of your ECU by changing the parameters of the program according to your preferences and needs.
-It is easy to use and does not require any special skills or equipment. You just need a laptop, a cable, and a keygen to activate the software.
-
- How to use ecusafe 2 0?
-To use ecusafe 2 0 software, you need to follow these steps:
-
-Download ecusafe 2 0 software from a reliable source (we will show you how to do that later in this article).
-Extract the files from the downloaded archive to a folder on your laptop.
-Run the loader.exe file as administrator to start the software.
-Enter the serial number that you generated with the keygen (we will show you how to do that later in this article) and click OK to activate the software.
-Select the type of ECU that you want to protect or disable from the drop-down menu.
-Click on the Browse button and select the original program file that you want to modify from your laptop or from your ECU (you can read your ECU data with an OBD flasher or programmer).
-Click on the Protect or Disable button depending on what you want to do with your ECU program.
-Save the modified program file to your laptop or write it back to your ECU (you can write your ECU data with an OBD flasher or programmer).
-Enjoy your improved and protected car performance!
-
- What are the advantages and disadvantages of ecusafe 2 0?
-Ecusafe 2 0 software has many advantages and disadvantages that you should be aware of before using it. Here are some of them:
-
-Advantages Disadvantages It can improve your car's performance by disabling EGR and DPF/FAP systems that can reduce your power, torque, and fuel economy. It can increase your car's emissions by disabling EGR and DPF/FAP systems that can lower your NOx and PM levels. It can protect your ECU data by making it unreadable by OBD flashers or programmers that can change your settings or steal your identity. It can void your warranty by making it unreadable by OBD flashers or programmers that can verify your original settings or detect any modifications. It can save you money by avoiding expensive repairs or replacements of EGR and DPF/FAP systems that can get clogged or damaged over time. It can cost you money by requiring a keygen to activate the software or by risking fines or penalties for violating environmental regulations. It can give you more options and flexibility by allowing custom tuning of your ECU parameters according to your preferences and needs. It can cause problems and errors by allowing custom tuning of your ECU parameters without proper knowledge and skills.
- As you can see, ecusafe 2 0 software has both pros and cons that you should weigh carefully before using it. You should also check the legal status of ecusafe 2 0 software in your country or region before using it, as it might be illegal or restricted in some places. You should also consult a professional car tuner or mechanic before using ecusafe 2 0 software, as they might have more experience and expertise in ECU remapping and tuning.
- How to download ecusafe 2 0 keygen ?
-To use ecusafe 2 0 software, you need a keygen to generate a serial number that will activate the software. A keygen is a program that can create a unique code that matches the software's algorithm and unlocks its features. Without a keygen, you will not be able to use ecusafe 2 0 software, as it will ask you for a serial number every time you run it. Therefore, you need to download ecusafe 2 0 keygen from a reliable source before using the software.
- What are the sources of ecusafe 2 0 keygen?
-There are many sources of ecusafe 2 0 keygen on the internet, but not all of them are trustworthy or safe. Some of the possible sources are:
-
-The official website of ecusafe 2 0 software. This is the most reliable and secure source of ecusafe 2 0 keygen, as it is provided by the developers of the software. However, it is also the most expensive and difficult source, as you will have to pay a fee and provide your personal and payment information to get the keygen.
-Online forums and communities of car enthusiasts and tuners. These are the most popular and accessible sources of ecusafe 2 0 keygen, as they are shared by other users who have already used the software. However, they are also the most risky and unreliable sources, as they might contain fake, outdated, or infected files that can harm your laptop or ECU.
-Torrent sites and peer-to-peer networks. These are the most convenient and fast sources of ecusafe 2 0 keygen, as they allow you to download the files from multiple sources at once. However, they are also the most illegal and dangerous sources, as they might violate the intellectual property rights of the software developers and expose you to cyberattacks and malware.
-Third-party sellers and resellers. These are the most varied and flexible sources of ecusafe 2 0 keygen, as they offer different prices and delivery methods for the files. However, they are also the most fraudulent and unpredictable sources, as they might scam you, overcharge you, or send you wrong or defective files.
-
- How to choose a reliable source of ecusafe 2 0 keygen?
-To choose a reliable source of ecusafe 2 0 keygen, you need to do some research and comparison before downloading any file. Here are some tips on how to select a trustworthy source of ecusafe 2 0 keygen:
-
-Check the reviews, ratings, feedbacks, and comments of other users who have downloaded the file from the same source. Look for positive, detailed, and recent testimonials that can confirm the quality and safety of the file.
-Check the security measures and guarantees of the source. Look for signs of encryption, authentication, verification, protection, and refund policies that can ensure the security and satisfaction of your transaction.
-Check the file size, format, name, and extension of the file. Look for files that match the specifications and requirements of ecusafe 2 0 software. Avoid files that are too large or too small, have strange or unknown formats or extensions, or have suspicious or misleading names.
-Check the availability and accessibility of the source. Look for sources that have high speed, bandwidth, uptime, and compatibility with your device and network. Avoid sources that have low speed, bandwidth, uptime, or compatibility with your device or network.
-
- How to avoid scams and viruses when downloading ecusave 2 0 keygen?
-To avoid scams and viruses when downloading ecusave 2 0 keygen, you need to take some precautions and measures before opening any file. Here are some advice on how to prevent frauds and malware when downloading ecusave 2 0 keygen:
-
-Disable your antivirus software temporarily while downloading and installing ecusave 2 0 keygen. Some antivirus software might detect ecusave 2 0 keygen as a threat or a virus and block or delete it automatically. To prevent this from happening, you need to disable your antivirus software temporarily while downloading and installing ecusave 2 0 keygen. However, you should enable your antivirus software again after using ecusave 2 0 keygen.
-Scan your downloaded file with an online virus scanner before opening it. Some downloaded files might contain hidden viruses or malware that can infect your laptop or ECU. To prevent this from happening , you need to scan your downloaded file with an online virus scanner before opening it. You can use free online virus scanners such as VirusTotal, Jotti, or Metadefender to check your file for any malicious code or behavior.
-Verify the checksum of your downloaded file before opening it. Some downloaded files might be corrupted or tampered with during the download process. To prevent this from happening, you need to verify the checksum of your downloaded file before opening it. A checksum is a unique code that identifies the integrity and authenticity of a file. You can use free online checksum calculators such as MD5, SHA1, or SHA256 to compare the checksum of your downloaded file with the checksum provided by the source. If they match, your file is safe and original. If they don't match, your file is unsafe and altered.
-Use a VPN service while downloading ecusave 2 0 keygen. Some sources of ecusave 2 0 keygen might be illegal or restricted in your country or region. To prevent this from happening, you need to use a VPN service while downloading ecusave 2 0 keygen. A VPN service is a program that can hide your IP address and location and encrypt your data and traffic. This way, you can bypass any censorship or surveillance and download ecusave 2 0 keygen anonymously and securely.
-
- How to install and activate ecusave 2 0 keygen?
-To install and activate ecusave 2 0 keygen, you need to follow these steps:
-
-Extract the files from the downloaded archive to a folder on your laptop.
-Run the keygen.exe file as administrator to start the keygen.
-Select the type of ECU that you want to activate from the drop-down menu.
-Click on the Generate button to create a serial number for ecusave 2 0 software.
-Copy the serial number and paste it in a text file for later use.
-Run the loader.exe file as administrator to start ecusave 2 0 software.
-Enter the serial number that you generated with the keygen and click OK to activate ecusave 2 0 software.
-Enjoy using ecusave 2 0 software!
-
- How to troubleshoot common problems with ecusave 2 0 keygen?
-Ecusave 2 0 keygen might encounter some problems or errors while installing or activating ecusave 2 0 software. Here are some solutions for common issues with ecusave 2 0 keygen:
-
-If you get an invalid serial number error, you might have entered the wrong serial number or used a different type of ECU than the one you selected in the keygen. To fix this, you need to generate a new serial number with the correct type of ECU and enter it in ecusave 2 0 software.
-If you get an expired license error, you might have used an old version of ecusave 2 0 software or keygen that has been deactivated by the developers. To fix this, you need to download and install the latest version of ecusave 2 0 software and keygen from a reliable source.
-If you get a corrupted file error, you might have downloaded an incomplete or damaged file from an unreliable source. To fix this, you need to download and install a complete and intact file from a trustworthy source.
-If you get a compatibility error, you might have used an incompatible device or operating system with ecusave 2 0 software or keygen. To fix this, you need to use a compatible device or operating system with ecusave 2 0 software or keygen. Ecusave 2 0 software and keygen work best on Windows XP/Vista/7/8/10 systems.
-
- How to update ecusafe 20 keygen?
-To update ecusafe 20 keygen, you need to follow these steps:
-
-Check for new versions of ecusafe 20 software and keygen on the official website or other reliable sources.
-Download and install the latest version of ecusafe 20 software and keygen from a trustworthy source.
-Run the new version of keygen.exe as administrator to generate a new serial number for ecusafe 20 software.
-Run the new version of loader.exe as administrator to activate ecusafe 20 software , Land Rover, Mercedes-Benz, Mini, Nissan, Opel, Peugeot, Renault, Seat, Skoda, Toyota, Volkswagen, Volvo, and others.
-MPPS V16 : This is a tool that can read and write ECU data via the OBD port of your car. It supports many protocols such as CAN, K-Line, J1850, and others. It can work with many types of ECUs such as Bosch EDC15/EDC16/EDC17/ME7/ME9/ME9.7/ME9.5/ME9.6/ME9.8/ME9.9/ME9.10/ME9.11/ME9.12/ME9.13/ME9.14/ME9.15/ME9.16/ME9.17/ME9.18/ME9.19/ME9.20/ME9.21/ME9.22/ME9.23/ME9.24/ME9.25/ME9 .26/ME9.27/ME9.28/ME9.29/ME9.30/ME9.31/ME9.32/ME9.33/ME9.34/ME9.35/ME9.36/ME9.37/ME9.38/ME9.39/ME9.40, Siemens SID201/SID202/SID203/SID204/SID206/SID208/SID209/SID210/SID211/SID212/SID213/SID214/SID215/SID216/SID217/SID218/SID219/SID220, Delphi DCM3.4/DCM3.5, Denso, Marelli, and others. It can also work with many car models and brands such as Audi, BMW, Citroen, Fiat, Ford, Hyundai, Kia, Land Rover, Mercedes-Benz, Mini, Nissan, Opel, Peugeot, Renault, Seat, Skoda, Toyota, Volkswagen, Volvo, and others.How to connect ecusafe 20 with other tools?
-To connect ecusafe 20 with other tools for ECU remapping and tuning, you need to follow these steps:
-
-Protect your original ECU program with ecusafe 20 software as described in the previous section.
-Select the tool that you want to use for ECU remapping and tuning from the list of compatible tools.
-Connect your laptop with the tool via a cable or a wireless connection.
-Connect your tool with your car's ECU via the OBD port or a direct connection.
-Read your ECU data with the tool and save it to your laptop.
-Modify your ECU data with the tool according to your preferences and needs.
-Write your modified ECU data back to your ECU with the tool.
-Enjoy your remapped and tuned car performance!
-
- How to write new program with other tools?
-To write new program with other tools for ECU remapping and tuning, you need to follow these steps:
-
-Select the tool that you want to use for ECU remapping and tuning from the list of compatible tools.
-Select the type of ECU that you want to write new program for from the drop-down menu of the tool.
-Select the new program file that you want to write to your ECU from your laptop or from the tool's database.
-Connect your laptop with the tool via a cable or a wireless connection.
-Connect your tool with your car's ECU via the OBD port or a direct connection.
-Write the new program file to your ECU with the tool.
-Protect your new program file with ecusafe 20 software as described in the previous section.
-Enjoy your new car performance!
-
- What are the benefits of using other tools with ecusafe 20 ?
-Using other tools with ecusafe 20 software can give you many benefits for your car performance and efficiency. Some of the benefits are:
-
-You can have more options and flexibility for modifying your ECU parameters according to your preferences and needs.
-You can have more customization and personalization for enhancing your car performance and efficiency.
-You can have more compatibility and interoperability for working with different types of ECUs and tools.
-
- Conclusion
-In conclusion, ecusafe 20 software is a powerful and versatile software that can protect your ECU data against being read by OBD flashers or programmers and disable some of the systems that can lower your car performance such as EGR and DPF/FAP. Ecusafe 20 software can also be used with other tools for ECU remapping and tuning to optimize your car performance and efficiency according to your preferences and needs. However, ecusafe 20 software also has some disadvantages and risks that you should be aware of before using it such as increased emissions voided warranty legal issues and potential problems and errors. Therefore you should weigh carefully the pros and cons of ecusave 20 software before using it and check the legal status of ecusave 20 software in your country or region before using it. You should also consult a professional car tuner or mechanic before using ecusave 20 software as they might have more experience and expertise in ECU remapping and tuning. We hope that this article has helped you understand how to download, install, and use ecusafe 20 keygen to enhance your car performance and protect your ECU data. If you have any questions or comments, please feel free to contact us or leave a comment below. Thank you for reading and happy driving!
- FAQs
-Here are some of the frequently asked questions and answers related to ecusafe 20 keygen:
-
-Q: Is ecusafe 20 software legal? A: Ecusafe 20 software is legal as long as you use it for personal and non-commercial purposes and do not violate any environmental regulations or intellectual property rights. However, the legal status of ecusafe 20 software might vary depending on your country or region, so you should check the local laws and regulations before using it.
-Q: Is ecusafe 20 software safe? A: Ecusafe 20 software is safe as long as you download it from a reliable source, scan it with an online virus scanner, verify its checksum, and use a VPN service while downloading it. However, ecusafe 20 software might also have some risks and drawbacks such as increased emissions, voided warranty, legal issues, and potential problems and errors, so you should weigh carefully the pros and cons of ecusafe 20 software before using it.
-Q: How much does ecusafe 20 software cost? A: Ecusafe 20 software costs different prices depending on the source that you choose to download it from. The official website of ecusave 20 software charges a fee and requires your personal and payment information to get the keygen. Online forums and communities of car enthusiasts and tuners offer free or cheap keygens that are shared by other users. Torrent sites and peer-to-peer networks offer fast and convenient downloads that are free or low-cost. Third-party sellers and resellers offer varied and flexible prices and delivery methods for the keygens. You should compare the prices and quality of the different sources before choosing one.
-Q: How long does ecusafe 20 software last? A: Ecusafe 20 software lasts as long as you use it for your ECU protection and tuning. However, ecusave 20 software might also expire or become outdated over time due to new versions, patches, or updates released by the developers or by the ECU manufacturers. Therefore, you should check for new versions of ecusave 20 software and keygen regularly and update them accordingly.
-Q: Can I use ecusafe 20 software with other ECU tools? A: Yes, you can use ecusave 20 software with other ECU tools for ECU remapping and tuning. However, you should use ecusave 20 software first to protect your ECU data before using other tools to modify it. You should also use compatible tools with ecusave 20 software, such as KESS V2, KTAG, MPPS V16, and others. You should also follow the instructions and precautions of the other tools before using them with ecusave 20 software.
- b2dd77e56bFMJSoft Awave Studio v10.6 - AiR [deepstatus] setup free
-FMJSoft Awave Studio is a powerful and versatile audio converter and editor that supports over 300 different file formats. You can use it to convert, edit, play, record, and create sound files of various types and formats. Whether you need to convert audio files for your music player, edit sound effects for your video game, or create ringtones for your phone, FMJSoft Awave Studio can do it all.
-FMJSoft Awave Studio v10.6 - AiR [deepstatus] setup free Download Zip 🌟 https://urlgoal.com/2uI6hc
FMJSoft Awave Studio v10.6 is the latest version of this amazing software, and it comes with many new features and improvements. Some of the highlights include:
-
-Support for more file formats, including Opus, Ogg Vorbis, FLAC, MP3, WAV, AIFF, and more.
-Improved user interface with a modern look and feel.
-Enhanced audio processing capabilities with new effects and filters.
-Faster performance and stability.
-Bug fixes and optimizations.
-
-FMJSoft Awave Studio v10.6 is available for download from the official website or from various torrent sites. However, if you want to use it for free, you can download the setup file from the link below. This file has been cracked by AiR [deepstatus], a group of hackers who specialize in cracking audio software. By using this file, you can bypass the activation process and enjoy the full features of FMJSoft Awave Studio v10.6 without paying anything.
-Download link: https://example.com/fmjsoft-awave-studio-v10-6-air-deepstatus-setup-free
-Disclaimer: This article is for educational purposes only. We do not condone piracy or illegal downloading of software. If you like FMJSoft Awave Studio v10.6, please support the developers by purchasing a license from their website.
-Here is what I created:
-
-FMJSoft Awave Studio v10.6 is not only a great audio converter and editor, but also a powerful sound synthesizer and sampler. You can use it to create your own sounds and instruments from scratch or from existing samples. You can also use it to import and export sound fonts, MIDI files, and instrument presets. FMJSoft Awave Studio v10.6 gives you complete control over your sound creation and manipulation.
-
-If you are a professional musician, producer, or sound designer, you will appreciate the advanced features and functions of FMJSoft Awave Studio v10.6. You can use it to edit audio files with high precision and quality, apply various effects and filters, mix and master your tracks, and export them in different formats and bitrates. You can also use it to record audio from any source, such as a microphone, a line-in, or a digital instrument. FMJSoft Awave Studio v10.6 supports ASIO drivers and VST plugins, so you can integrate it with your other audio software and hardware.
-If you are a beginner or hobbyist, you will find FMJSoft Awave Studio v10.6 easy to use and fun to explore. You can use it to play and convert audio files of different types and formats, edit them with simple tools and commands, and add some effects and filters to spice them up. You can also use it to create your own sounds and instruments from scratch or from existing samples, and play them with your keyboard or mouse. FMJSoft Awave Studio v10.6 has a user-friendly interface and a comprehensive help system that will guide you through the process.
81aa517590WhatsApp Enables Crypto Trading for Ethereum and ERC20 Tokens
-WhatsApp, the popular messaging app owned by Facebook, has announced a new feature that allows users to trade digital assets such as Ethereum and ERC20 tokens directly from the app. This is the first time that WhatsApp users can exchange cryptocurrencies without leaving the app or using a third-party service.
-For the first time, users can exchange Digital Assets Like Ethereum and ERC20 tokens using WhatsApp Download File ————— https://urlgoal.com/2uI9OL
The new feature is powered by a decentralized protocol called WAXP, which stands for WhatsApp Asset Exchange Protocol. WAXP enables peer-to-peer transactions of digital assets using end-to-end encryption and smart contracts. Users can send and receive Ethereum and ERC20 tokens by simply typing commands in the chat window, such as "/send 0.1 ETH to Alice" or "/request 10 USDT from Bob".
-WhatsApp claims that the new feature is secure, fast, and easy to use. Users do not need to create an account or provide any personal information to use WAXP. They only need to link their existing Ethereum wallet to their WhatsApp account using a QR code. WAXP also supports multiple languages and currencies, and charges low fees for each transaction.
-The new feature is currently available in beta for a limited number of users in select countries. WhatsApp plans to roll out the feature globally in the coming months. The company hopes that the new feature will attract more users to its platform and foster the adoption of cryptocurrencies among its 2 billion users.
-
-
-WAXP is not the first attempt to integrate cryptocurrency trading with messaging apps. In 2018, Telegram launched its own blockchain platform called Telegram Open Network (TON), which aimed to offer a fast and scalable network for decentralized applications and digital assets. However, TON faced regulatory hurdles and legal challenges from the US Securities and Exchange Commission (SEC), which accused Telegram of conducting an illegal securities offering. Telegram eventually abandoned TON in 2020 and refunded its investors.
-WhatsApp's move to enable crypto trading on its app could also face some regulatory scrutiny, especially in countries where cryptocurrencies are banned or restricted. For instance, India, WhatsApp's largest market with over 400 million users, has proposed a bill that would criminalize the possession, issuance, mining, trading, and transfer of cryptocurrencies. WhatsApp has not commented on how it plans to deal with such regulatory issues.
-Some experts have also raised concerns about the security and privacy of WAXP transactions. While WhatsApp claims that WAXP uses end-to-end encryption and smart contracts to ensure the safety and validity of each transaction, some users may still fall victim to phishing, hacking, or scamming attempts. Users may also lose access to their funds if they lose their phone or forget their wallet password. Moreover, some users may not trust WhatsApp with their financial data, given its controversial privacy policy changes and its ties to Facebook.
7b8c122e87
-
- for longer sequences, more control and no queue.
- """
- )
- with gr.Row():
- with gr.Column():
- with gr.Row():
- text = gr.Text(label="Describe your music", lines=2, interactive=True)
- with gr.Column():
- radio = gr.Radio(["file", "mic"], value="file",
- label="Condition on a melody (optional) File or Mic")
- melody = gr.Audio(source="upload", type="numpy", label="File",
- interactive=True, elem_id="melody-input")
- with gr.Row():
- submit = gr.Button("Generate")
- with gr.Column():
- output = gr.Video(label="Generated Music")
- submit.click(predict_batched, inputs=[text, melody],
- outputs=[output], batch=True, max_batch_size=MAX_BATCH_SIZE)
- radio.change(toggle_audio_src, radio, [melody], queue=False, show_progress=False)
- gr.Examples(
- fn=predict_batched,
- examples=[
- [
- "An 80s driving pop song with heavy drums and synth pads in the background",
- "./assets/bach.mp3",
- ],
- [
- "A cheerful country song with acoustic guitars",
- "./assets/bolero_ravel.mp3",
- ],
- [
- "90s rock song with electric guitar and heavy drums",
- None,
- ],
- [
- "a light and cheerly EDM track, with syncopated drums, aery pads, and strong emotions bpm: 130",
- "./assets/bach.mp3",
- ],
- [
- "lofi slow bpm electro chill with organic samples",
- None,
- ],
- ],
- inputs=[text, melody],
- outputs=[output]
- )
- gr.Markdown("""
- ### More details
-
- The model will generate 12 seconds of audio based on the description you provided.
- You can optionaly provide a reference audio from which a broad melody will be extracted.
- The model will then try to follow both the description and melody provided.
- All samples are generated with the `melody` model.
-
- You can also use your own GPU or a Google Colab by following the instructions on our repo.
-
- See [github.com/facebookresearch/audiocraft](https://github.com/facebookresearch/audiocraft)
- for more details.
- """)
-
- demo.queue(max_size=8 * 4).launch(**launch_kwargs)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- '--listen',
- type=str,
- default='0.0.0.0' if 'SPACE_ID' in os.environ else '127.0.0.1',
- help='IP to listen on for connections to Gradio',
- )
- parser.add_argument(
- '--username', type=str, default='', help='Username for authentication'
- )
- parser.add_argument(
- '--password', type=str, default='', help='Password for authentication'
- )
- parser.add_argument(
- '--server_port',
- type=int,
- default=0,
- help='Port to run the server listener on',
- )
- parser.add_argument(
- '--inbrowser', action='store_true', help='Open in browser'
- )
- parser.add_argument(
- '--share', action='store_true', help='Share the gradio UI'
- )
-
- args = parser.parse_args()
-
- launch_kwargs = {}
- launch_kwargs['server_name'] = args.listen
-
- if args.username and args.password:
- launch_kwargs['auth'] = (args.username, args.password)
- if args.server_port:
- launch_kwargs['server_port'] = args.server_port
- if args.inbrowser:
- launch_kwargs['inbrowser'] = args.inbrowser
- if args.share:
- launch_kwargs['share'] = args.share
-
- # Show the interface
- if IS_BATCHED:
- ui_batched(launch_kwargs)
- else:
- ui_full(launch_kwargs)
diff --git a/spaces/supertori/files/stable-diffusion-webui/modules/prompt_parser.py b/spaces/supertori/files/stable-diffusion-webui/modules/prompt_parser.py
deleted file mode 100644
index a7bbfa4ea73cbfcb6da0e1012ac166042b6fae08..0000000000000000000000000000000000000000
--- a/spaces/supertori/files/stable-diffusion-webui/modules/prompt_parser.py
+++ /dev/null
@@ -1,373 +0,0 @@
-import re
-from collections import namedtuple
-from typing import List
-import lark
-
-# a prompt like this: "fantasy landscape with a [mountain:lake:0.25] and [an oak:a christmas tree:0.75][ in foreground::0.6][ in background:0.25] [shoddy:masterful:0.5]"
-# will be represented with prompt_schedule like this (assuming steps=100):
-# [25, 'fantasy landscape with a mountain and an oak in foreground shoddy']
-# [50, 'fantasy landscape with a lake and an oak in foreground in background shoddy']
-# [60, 'fantasy landscape with a lake and an oak in foreground in background masterful']
-# [75, 'fantasy landscape with a lake and an oak in background masterful']
-# [100, 'fantasy landscape with a lake and a christmas tree in background masterful']
-
-schedule_parser = lark.Lark(r"""
-!start: (prompt | /[][():]/+)*
-prompt: (emphasized | scheduled | alternate | plain | WHITESPACE)*
-!emphasized: "(" prompt ")"
- | "(" prompt ":" prompt ")"
- | "[" prompt "]"
-scheduled: "[" [prompt ":"] prompt ":" [WHITESPACE] NUMBER "]"
-alternate: "[" prompt ("|" prompt)+ "]"
-WHITESPACE: /\s+/
-plain: /([^\\\[\]():|]|\\.)+/
-%import common.SIGNED_NUMBER -> NUMBER
-""")
-
-def get_learned_conditioning_prompt_schedules(prompts, steps):
- """
- >>> g = lambda p: get_learned_conditioning_prompt_schedules([p], 10)[0]
- >>> g("test")
- [[10, 'test']]
- >>> g("a [b:3]")
- [[3, 'a '], [10, 'a b']]
- >>> g("a [b: 3]")
- [[3, 'a '], [10, 'a b']]
- >>> g("a [[[b]]:2]")
- [[2, 'a '], [10, 'a [[b]]']]
- >>> g("[(a:2):3]")
- [[3, ''], [10, '(a:2)']]
- >>> g("a [b : c : 1] d")
- [[1, 'a b d'], [10, 'a c d']]
- >>> g("a[b:[c:d:2]:1]e")
- [[1, 'abe'], [2, 'ace'], [10, 'ade']]
- >>> g("a [unbalanced")
- [[10, 'a [unbalanced']]
- >>> g("a [b:.5] c")
- [[5, 'a c'], [10, 'a b c']]
- >>> g("a [{b|d{:.5] c") # not handling this right now
- [[5, 'a c'], [10, 'a {b|d{ c']]
- >>> g("((a][:b:c [d:3]")
- [[3, '((a][:b:c '], [10, '((a][:b:c d']]
- >>> g("[a|(b:1.1)]")
- [[1, 'a'], [2, '(b:1.1)'], [3, 'a'], [4, '(b:1.1)'], [5, 'a'], [6, '(b:1.1)'], [7, 'a'], [8, '(b:1.1)'], [9, 'a'], [10, '(b:1.1)']]
- """
-
- def collect_steps(steps, tree):
- l = [steps]
- class CollectSteps(lark.Visitor):
- def scheduled(self, tree):
- tree.children[-1] = float(tree.children[-1])
- if tree.children[-1] < 1:
- tree.children[-1] *= steps
- tree.children[-1] = min(steps, int(tree.children[-1]))
- l.append(tree.children[-1])
- def alternate(self, tree):
- l.extend(range(1, steps+1))
- CollectSteps().visit(tree)
- return sorted(set(l))
-
- def at_step(step, tree):
- class AtStep(lark.Transformer):
- def scheduled(self, args):
- before, after, _, when = args
- yield before or () if step <= when else after
- def alternate(self, args):
- yield next(args[(step - 1)%len(args)])
- def start(self, args):
- def flatten(x):
- if type(x) == str:
- yield x
- else:
- for gen in x:
- yield from flatten(gen)
- return ''.join(flatten(args))
- def plain(self, args):
- yield args[0].value
- def __default__(self, data, children, meta):
- for child in children:
- yield child
- return AtStep().transform(tree)
-
- def get_schedule(prompt):
- try:
- tree = schedule_parser.parse(prompt)
- except lark.exceptions.LarkError as e:
- if 0:
- import traceback
- traceback.print_exc()
- return [[steps, prompt]]
- return [[t, at_step(t, tree)] for t in collect_steps(steps, tree)]
-
- promptdict = {prompt: get_schedule(prompt) for prompt in set(prompts)}
- return [promptdict[prompt] for prompt in prompts]
-
-
-ScheduledPromptConditioning = namedtuple("ScheduledPromptConditioning", ["end_at_step", "cond"])
-
-
-def get_learned_conditioning(model, prompts, steps):
- """converts a list of prompts into a list of prompt schedules - each schedule is a list of ScheduledPromptConditioning, specifying the comdition (cond),
- and the sampling step at which this condition is to be replaced by the next one.
-
- Input:
- (model, ['a red crown', 'a [blue:green:5] jeweled crown'], 20)
-
- Output:
- [
- [
- ScheduledPromptConditioning(end_at_step=20, cond=tensor([[-0.3886, 0.0229, -0.0523, ..., -0.4901, -0.3066, 0.0674], ..., [ 0.3317, -0.5102, -0.4066, ..., 0.4119, -0.7647, -1.0160]], device='cuda:0'))
- ],
- [
- ScheduledPromptConditioning(end_at_step=5, cond=tensor([[-0.3886, 0.0229, -0.0522, ..., -0.4901, -0.3067, 0.0673], ..., [-0.0192, 0.3867, -0.4644, ..., 0.1135, -0.3696, -0.4625]], device='cuda:0')),
- ScheduledPromptConditioning(end_at_step=20, cond=tensor([[-0.3886, 0.0229, -0.0522, ..., -0.4901, -0.3067, 0.0673], ..., [-0.7352, -0.4356, -0.7888, ..., 0.6994, -0.4312, -1.2593]], device='cuda:0'))
- ]
- ]
- """
- res = []
-
- prompt_schedules = get_learned_conditioning_prompt_schedules(prompts, steps)
- cache = {}
-
- for prompt, prompt_schedule in zip(prompts, prompt_schedules):
-
- cached = cache.get(prompt, None)
- if cached is not None:
- res.append(cached)
- continue
-
- texts = [x[1] for x in prompt_schedule]
- conds = model.get_learned_conditioning(texts)
-
- cond_schedule = []
- for i, (end_at_step, text) in enumerate(prompt_schedule):
- cond_schedule.append(ScheduledPromptConditioning(end_at_step, conds[i]))
-
- cache[prompt] = cond_schedule
- res.append(cond_schedule)
-
- return res
-
-
-re_AND = re.compile(r"\bAND\b")
-re_weight = re.compile(r"^(.*?)(?:\s*:\s*([-+]?(?:\d+\.?|\d*\.\d+)))?\s*$")
-
-def get_multicond_prompt_list(prompts):
- res_indexes = []
-
- prompt_flat_list = []
- prompt_indexes = {}
-
- for prompt in prompts:
- subprompts = re_AND.split(prompt)
-
- indexes = []
- for subprompt in subprompts:
- match = re_weight.search(subprompt)
-
- text, weight = match.groups() if match is not None else (subprompt, 1.0)
-
- weight = float(weight) if weight is not None else 1.0
-
- index = prompt_indexes.get(text, None)
- if index is None:
- index = len(prompt_flat_list)
- prompt_flat_list.append(text)
- prompt_indexes[text] = index
-
- indexes.append((index, weight))
-
- res_indexes.append(indexes)
-
- return res_indexes, prompt_flat_list, prompt_indexes
-
-
-class ComposableScheduledPromptConditioning:
- def __init__(self, schedules, weight=1.0):
- self.schedules: List[ScheduledPromptConditioning] = schedules
- self.weight: float = weight
-
-
-class MulticondLearnedConditioning:
- def __init__(self, shape, batch):
- self.shape: tuple = shape # the shape field is needed to send this object to DDIM/PLMS
- self.batch: List[List[ComposableScheduledPromptConditioning]] = batch
-
-def get_multicond_learned_conditioning(model, prompts, steps) -> MulticondLearnedConditioning:
- """same as get_learned_conditioning, but returns a list of ScheduledPromptConditioning along with the weight objects for each prompt.
- For each prompt, the list is obtained by splitting the prompt using the AND separator.
-
- https://energy-based-model.github.io/Compositional-Visual-Generation-with-Composable-Diffusion-Models/
- """
-
- res_indexes, prompt_flat_list, prompt_indexes = get_multicond_prompt_list(prompts)
-
- learned_conditioning = get_learned_conditioning(model, prompt_flat_list, steps)
-
- res = []
- for indexes in res_indexes:
- res.append([ComposableScheduledPromptConditioning(learned_conditioning[i], weight) for i, weight in indexes])
-
- return MulticondLearnedConditioning(shape=(len(prompts),), batch=res)
-
-
-def reconstruct_cond_batch(c: List[List[ScheduledPromptConditioning]], current_step):
- param = c[0][0].cond
- res = torch.zeros((len(c),) + param.shape, device=param.device, dtype=param.dtype)
- for i, cond_schedule in enumerate(c):
- target_index = 0
- for current, (end_at, cond) in enumerate(cond_schedule):
- if current_step <= end_at:
- target_index = current
- break
- res[i] = cond_schedule[target_index].cond
-
- return res
-
-
-def reconstruct_multicond_batch(c: MulticondLearnedConditioning, current_step):
- param = c.batch[0][0].schedules[0].cond
-
- tensors = []
- conds_list = []
-
- for batch_no, composable_prompts in enumerate(c.batch):
- conds_for_batch = []
-
- for cond_index, composable_prompt in enumerate(composable_prompts):
- target_index = 0
- for current, (end_at, cond) in enumerate(composable_prompt.schedules):
- if current_step <= end_at:
- target_index = current
- break
-
- conds_for_batch.append((len(tensors), composable_prompt.weight))
- tensors.append(composable_prompt.schedules[target_index].cond)
-
- conds_list.append(conds_for_batch)
-
- # if prompts have wildly different lengths above the limit we'll get tensors fo different shapes
- # and won't be able to torch.stack them. So this fixes that.
- token_count = max([x.shape[0] for x in tensors])
- for i in range(len(tensors)):
- if tensors[i].shape[0] != token_count:
- last_vector = tensors[i][-1:]
- last_vector_repeated = last_vector.repeat([token_count - tensors[i].shape[0], 1])
- tensors[i] = torch.vstack([tensors[i], last_vector_repeated])
-
- return conds_list, torch.stack(tensors).to(device=param.device, dtype=param.dtype)
-
-
-re_attention = re.compile(r"""
-\\\(|
-\\\)|
-\\\[|
-\\]|
-\\\\|
-\\|
-\(|
-\[|
-:([+-]?[.\d]+)\)|
-\)|
-]|
-[^\\()\[\]:]+|
-:
-""", re.X)
-
-re_break = re.compile(r"\s*\bBREAK\b\s*", re.S)
-
-def parse_prompt_attention(text):
- """
- Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
- Accepted tokens are:
- (abc) - increases attention to abc by a multiplier of 1.1
- (abc:3.12) - increases attention to abc by a multiplier of 3.12
- [abc] - decreases attention to abc by a multiplier of 1.1
- \( - literal character '('
- \[ - literal character '['
- \) - literal character ')'
- \] - literal character ']'
- \\ - literal character '\'
- anything else - just text
-
- >>> parse_prompt_attention('normal text')
- [['normal text', 1.0]]
- >>> parse_prompt_attention('an (important) word')
- [['an ', 1.0], ['important', 1.1], [' word', 1.0]]
- >>> parse_prompt_attention('(unbalanced')
- [['unbalanced', 1.1]]
- >>> parse_prompt_attention('\(literal\]')
- [['(literal]', 1.0]]
- >>> parse_prompt_attention('(unnecessary)(parens)')
- [['unnecessaryparens', 1.1]]
- >>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
- [['a ', 1.0],
- ['house', 1.5730000000000004],
- [' ', 1.1],
- ['on', 1.0],
- [' a ', 1.1],
- ['hill', 0.55],
- [', sun, ', 1.1],
- ['sky', 1.4641000000000006],
- ['.', 1.1]]
- """
-
- res = []
- round_brackets = []
- square_brackets = []
-
- round_bracket_multiplier = 1.1
- square_bracket_multiplier = 1 / 1.1
-
- def multiply_range(start_position, multiplier):
- for p in range(start_position, len(res)):
- res[p][1] *= multiplier
-
- for m in re_attention.finditer(text):
- text = m.group(0)
- weight = m.group(1)
-
- if text.startswith('\\'):
- res.append([text[1:], 1.0])
- elif text == '(':
- round_brackets.append(len(res))
- elif text == '[':
- square_brackets.append(len(res))
- elif weight is not None and len(round_brackets) > 0:
- multiply_range(round_brackets.pop(), float(weight))
- elif text == ')' and len(round_brackets) > 0:
- multiply_range(round_brackets.pop(), round_bracket_multiplier)
- elif text == ']' and len(square_brackets) > 0:
- multiply_range(square_brackets.pop(), square_bracket_multiplier)
- else:
- parts = re.split(re_break, text)
- for i, part in enumerate(parts):
- if i > 0:
- res.append(["BREAK", -1])
- res.append([part, 1.0])
-
- for pos in round_brackets:
- multiply_range(pos, round_bracket_multiplier)
-
- for pos in square_brackets:
- multiply_range(pos, square_bracket_multiplier)
-
- if len(res) == 0:
- res = [["", 1.0]]
-
- # merge runs of identical weights
- i = 0
- while i + 1 < len(res):
- if res[i][1] == res[i + 1][1]:
- res[i][0] += res[i + 1][0]
- res.pop(i + 1)
- else:
- i += 1
-
- return res
-
-if __name__ == "__main__":
- import doctest
- doctest.testmod(optionflags=doctest.NORMALIZE_WHITESPACE)
-else:
- import torch # doctest faster
diff --git a/spaces/svjack/ControlNet-Pose-Chinese/annotator/uniformer/mmseg/models/segmentors/__init__.py b/spaces/svjack/ControlNet-Pose-Chinese/annotator/uniformer/mmseg/models/segmentors/__init__.py
deleted file mode 100644
index dca2f09405330743c476e190896bee39c45498ea..0000000000000000000000000000000000000000
--- a/spaces/svjack/ControlNet-Pose-Chinese/annotator/uniformer/mmseg/models/segmentors/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-from .base import BaseSegmentor
-from .cascade_encoder_decoder import CascadeEncoderDecoder
-from .encoder_decoder import EncoderDecoder
-
-__all__ = ['BaseSegmentor', 'EncoderDecoder', 'CascadeEncoderDecoder']
diff --git a/spaces/tabeina/bingo1/src/components/ui/textarea.tsx b/spaces/tabeina/bingo1/src/components/ui/textarea.tsx
deleted file mode 100644
index e25af722c7a5dc1121a9ab58d6716952f9f76081..0000000000000000000000000000000000000000
--- a/spaces/tabeina/bingo1/src/components/ui/textarea.tsx
+++ /dev/null
@@ -1,24 +0,0 @@
-import * as React from 'react'
-
-import { cn } from '@/lib/utils'
-
-export interface TextareaProps
- extends React.TextareaHTMLAttributes {}
-
-const Textarea = React.forwardRef(
- ({ className, ...props }, ref) => {
- return (
-
- )
- }
-)
-Textarea.displayName = 'Textarea'
-
-export { Textarea }
diff --git a/spaces/taesiri/DeticChatGPT/README.md b/spaces/taesiri/DeticChatGPT/README.md
deleted file mode 100644
index 2c1897d0f4df59cd8e6aac00d23a1713e9e898cf..0000000000000000000000000000000000000000
--- a/spaces/taesiri/DeticChatGPT/README.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-title: Detic + ChatGPT
-emoji: 🦀
-colorFrom: yellow
-colorTo: purple
-sdk: gradio
-app_file: app.py
-pinned: false
-duplicated_from: akhaliq/Detic
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio`, `streamlit`, or `static`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code, or `static` html code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
\ No newline at end of file
diff --git a/spaces/taichi/pizza-net/app.py b/spaces/taichi/pizza-net/app.py
deleted file mode 100644
index 075e2c0e568c331876d1995b7b255e0f837866cc..0000000000000000000000000000000000000000
--- a/spaces/taichi/pizza-net/app.py
+++ /dev/null
@@ -1,128 +0,0 @@
-import numpy as np
-import streamlit as st
-import torch
-from PIL import Image
-from torch import nn
-from torchvision import models, transforms
-import io
-import cv2
-import matplotlib.pyplot as plt
-from pytorch_grad_cam import GradCAM
-from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
-
-
-@st.cache(allow_output_mutation=True)
-def load_model():
- # model=tf.keras.models.load_model('/content/image_classification.hdf5')
- net = models.vgg19_bn(pretrained=False)
- # 最終ノードの出力を2にする
- in_features = net.classifier[6].in_features
- net.classifier[6] = nn.Linear(in_features, 2)
- net.load_state_dict(torch.load("PizzaNet.pkl", map_location=torch.device("cpu")))
- return net
-
-
-with st.spinner("Model is being loaded.."):
- net = load_model()
-
-st.write(
- """
- # 🤖Pizza Net🍕
- """
-)
-st.write("AI will determine if the uploaded photo is a pizza or not!")
-st.write("(AIがアップロードした写真がピザかピザじゃないか判定してくれます!!)")
-
-file = st.file_uploader(
- "Upload the image to be classified❗", type=["jpg", "png", "jpeg"]
-)
-st.set_option("deprecation.showfileUploaderEncoding", False)
-
-
-def upload_predict(upload_image, model):
-
- # size = (180,180)
- # img = Image.open(upload_image)
- val_transform = transforms.Compose(
- [
- transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
-# transforms.Normalize(0.5, 0.5),
- ]
- )
- norm = transforms.Normalize(0.5, 0.5)
- img_0 = val_transform(upload_image)
- img = norm(img_0)
- model.eval()
- prediction = model.forward(img.unsqueeze(0))
- # predicted_class = np.argmax(prediction).item()
-
- return prediction, img, img_0
-
-
-if file is None:
- st.text("Please upload an image file")
-else:
- image = Image.open(file)
- st.image(image, use_column_width=True)
- with st.spinner("Inference in progress.."):
- predictions, img, img_0 = upload_predict(image, net)
- image_class = np.argmax(predictions.detach().numpy())
- if image_class == 1:
- ans = "Pizza"
- else:
- ans = "Not Pizza"
-
- softmax = nn.Softmax()
- score = np.round(torch.max(softmax(predictions)).item()) * 100
- st.write(
- """
- # Result(判定結果): """,
- ans,
- )
- st.write(
- """
- # Score(%): """,
- score,
- "%",
- )
- print("AIの判定結果 ", image_class, "AIの確信度(%)", score, "%")
-
-
-
- with st.spinner("Inference in progress.."):
- input_tensor = img.unsqueeze(0)
- target_layers = net.features
- cam = GradCAM(model=net, target_layers=target_layers, use_cuda=False)
- targets = [ClassifierOutputTarget(1)]
- grayscale_cam = cam(input_tensor=input_tensor, targets=targets, aug_smooth=True)
- grayscale_cam = grayscale_cam[0, :]
- plt.imshow(grayscale_cam, cmap="jet")
- plt.imshow(img_0.numpy().transpose((1, 2, 0)), alpha=0.5)
- plt.axis("off")
- buf = io.BytesIO()
- plt.savefig(buf, bbox_inches="tight")
- buf.seek(0)
- img_arr = np.frombuffer(buf.getvalue(), dtype=np.uint8)
- buf.close()
- img = cv2.imdecode(img_arr, 1)
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- st.write(
- """
- # Where did the AI look to make a decision?🍕
- """
- )
- st.write("The AI looked closely at the red areas to make a decision.(赤いところをAIは重視して見ていました。)")
-
- col1, col2, col3 = st.columns(3)
-
- with col1:
- st.write(" ")
-
- with col2:
- st.image(img)
-
- with col3:
- st.write(" ")
-
diff --git a/spaces/tassd/bingai/README.md b/spaces/tassd/bingai/README.md
deleted file mode 100644
index e0d08f7ffb6ab5b1ae1d8c9765815ce05c643589..0000000000000000000000000000000000000000
--- a/spaces/tassd/bingai/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Bingai
-emoji: 👀
-colorFrom: yellow
-colorTo: purple
-sdk: docker
-pinned: false
-license: mit
-app_port: 8080
-
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/teganmosi/Translator/app.py b/spaces/teganmosi/Translator/app.py
deleted file mode 100644
index 61e594bc2d51660a22e6eab502e22b0adc735fef..0000000000000000000000000000000000000000
--- a/spaces/teganmosi/Translator/app.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# -*- coding: utf-8 -*-
-"""Any Language Translator.ipynb
-
-Automatically generated by Colaboratory.
-
-Original file is located at
- https://colab.research.google.com/drive/1cJmy7eHRvwkQJDWOg775L2iSMjfR4dFx
-"""
-
-
-
-import os
-import openai
-import gradio as gr
-
-from dotenv import load_dotenv, find_dotenv
-_ = load_dotenv(find_dotenv()) # read local .env file
-os.environ["OPENAI_API_KEY"] = "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"
-
-openai.api_key = os.environ['OPENAI_API_KEY']
-
-from langchain.chat_models import ChatOpenAI
-from langchain.chains import LLMChain
-from langchain.prompts import PromptTemplate
-
-llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
-
-translation_template = "Translate the following text from {source_language} to {target_language}: {text}"
-translation_prompt = PromptTemplate(input_variables=["source_language", "target_language", "text"], template=translation_template)
-translation_chain = LLMChain(llm=llm, prompt=translation_prompt)
-
-def translate(source_language: str, target_language: str, text: str) -> str:
- translated_text = translation_chain.predict(source_language=source_language, target_language=target_language, text=text)
- return translated_text
-
-inputs = [
- gr.inputs.Textbox(label="Source Language"),
- gr.inputs.Textbox(label="Target Language"),
- gr.inputs.Textbox(label="Text to Translate")
-]
-
-output = gr.outputs.Textbox(label="Translated Text")
-
-gr.Interface(fn=translate, inputs=inputs, outputs=output).launch()
\ No newline at end of file
diff --git a/spaces/terfces0erbo/CollegeProjectV2/Chor Machaye Shor BEST Full Movie 720p.md b/spaces/terfces0erbo/CollegeProjectV2/Chor Machaye Shor BEST Full Movie 720p.md
deleted file mode 100644
index f958dfc05a05e47565700f34ab588b121778e430..0000000000000000000000000000000000000000
--- a/spaces/terfces0erbo/CollegeProjectV2/Chor Machaye Shor BEST Full Movie 720p.md
+++ /dev/null
@@ -1,16 +0,0 @@
-Chor Machaye Shor: A Classic Comedy of Errors
-Chor Machaye Shor is a Hindi comedy film released in 1974, starring Shashi Kapoor, Mumtaz, Danny Denzongpa, Asrani and Madan Puri. The film was directed by Ashok Roy and produced by N.N.Sippy. The film is a remake of the 1968 British film The Big Job.
-The plot revolves around a group of thieves who rob a bank and hide the loot in a construction site. However, they are caught by the police and sent to jail. Two years later, they are released and plan to retrieve the money. But they are shocked to find that the construction site has been turned into a police station. They devise various schemes to enter the station and get their money back, but end up creating more chaos and confusion.
-chor machaye shor full movie 720p Download - https://bytlly.com/2uGljC
The film is a hilarious comedy of errors, with witty dialogues, slapstick humor and memorable characters. The film was a huge hit at the box office and received positive reviews from critics and audiences alike. The film also features some popular songs composed by Ravindra Jain, such as "Le Jayenge Le Jayenge", "Ghungroo Ki Tarah" and "Ek Daal Par Tota Bole".
-Chor Machaye Shor is a classic comedy film that can be enjoyed by anyone who loves laughter and entertainment. The film is available online on various platforms in 720p quality. You can watch it on YouTube[^1^], ZEE5[^2^] or Yidio[^3^].
-
-The film is considered to be one of the best comedy films of Shashi Kapoor, who plays the role of Vijay, the leader of the thieves. He is supported by his loyal friends, played by Danny Denzongpa, Asrani and Madan Puri. Mumtaz plays the role of Rekha, Vijay's love interest and a dancer at a club. She helps him in his plans to get the money back. The film also has some hilarious scenes involving the police officers, played by Kamal Kapoor, Sudhir and Jagdish Raj.
-The film is a perfect example of how a simple plot can be turned into a comedy masterpiece with the help of talented actors, writers and directors. The film has a fast-paced and engaging narrative that keeps the viewers hooked till the end. The film also has a social message about honesty and loyalty, as Vijay and his friends realize their mistake and decide to surrender to the police.
-Chor Machaye Shor is a film that will make you laugh out loud and also touch your heart. It is a film that you can watch with your family and friends and have a great time. The film is a must-watch for all comedy lovers and Shashi Kapoor fans.
-
-
-In conclusion, Chor Machaye Shor is a comedy gem that deserves to be watched and appreciated by everyone. The film has everything that a comedy lover can ask for: a hilarious plot, brilliant performances, catchy songs and a positive message. The film is a tribute to the golden era of Hindi cinema and the genius of Shashi Kapoor. If you are looking for a film that will make you laugh and smile, then Chor Machaye Shor is the perfect choice for you.
d5da3c52bfHD Online Player (humpty sharma ki dulhania full movie) Download →→→ https://bytlly.com/2uGjIM
diff --git a/spaces/th1nhng0/symato-cc-statistic/README.md b/spaces/th1nhng0/symato-cc-statistic/README.md
deleted file mode 100644
index 4edbfc7b2834458bfbb45ed157aa18f769820a7f..0000000000000000000000000000000000000000
--- a/spaces/th1nhng0/symato-cc-statistic/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Symato Cc Statistic
-emoji: 👁
-colorFrom: gray
-colorTo: red
-sdk: streamlit
-sdk_version: 1.21.0
-app_file: app.py
-pinned: false
----
-
-a
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/thinkcol/chainlit-example/Dockerfile b/spaces/thinkcol/chainlit-example/Dockerfile
deleted file mode 100644
index b02645f557b1df0403619298696f7d860062badc..0000000000000000000000000000000000000000
--- a/spaces/thinkcol/chainlit-example/Dockerfile
+++ /dev/null
@@ -1,9 +0,0 @@
-FROM python:3.11
-RUN useradd -m -u 1000 user
-USER user
-ENV HOME=/home/user \
- PATH=/home/user/.local/bin:$PATH
-WORKDIR $HOME/app
-COPY --chown=user . .
-RUN pip install -r requirements.txt
-CMD ["chainlit", "run", "app.py", "--port", "7860"]
diff --git a/spaces/tialenAdioni/chat-gpt-api/logs/Corel PhotoMirage 3.2.2.169 Portable Cracked utorrent What You Need to Know Before Downloading.md b/spaces/tialenAdioni/chat-gpt-api/logs/Corel PhotoMirage 3.2.2.169 Portable Cracked utorrent What You Need to Know Before Downloading.md
deleted file mode 100644
index c60134a9b8af2de3e6c890852a767c277f98f3d9..0000000000000000000000000000000000000000
--- a/spaces/tialenAdioni/chat-gpt-api/logs/Corel PhotoMirage 3.2.2.169 Portable Cracked utorrent What You Need to Know Before Downloading.md
+++ /dev/null
@@ -1,132 +0,0 @@
-
-Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent: A Review
-If you are looking for a software that can help you create stunning photo animations from your static images, you might want to check out Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent. This is a cracked version of the original Corel PhotoMirage software that you can download for free using a magnet link or a torrent client.
-Corel PhotoMirage 3.2.2.169 Portable Cracked utorrent Download Zip ★ https://urlcod.com/2uK4DY
Corel PhotoMirage is a powerful and easy-to-use tool that allows you to transform any image into a captivating animation in minutes. You can use it to create eye-catching social media posts, web banners, blog graphics, and more. You can also use it to add motion to your photos and make them come alive.
-How to Use Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent
-To use Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent, you need to download it from a reliable source and extract the files to your preferred location. You don't need to install anything, as this is a portable version that you can run from any folder or USB drive.
-Once you launch the software, you can start creating your photo animations in three simple steps:
-How to create stunning photo animations with Corel PhotoMirage 3.2.2.169 Portable Cracked
-
-Select an image that you want to animate. You can use any image format, such as JPG, PNG, BMP, TIFF, or RAW.
-Use the animation tools to define the areas that you want to animate and the areas that you want to keep still. You can also adjust the speed and direction of the animation.
-Preview and export your photo animation as a GIF, MP4, or WMV file. You can also share it directly to social media platforms like Facebook, Twitter, Instagram, or YouTube.
-
-Why Choose Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent
-There are many reasons why you might want to choose Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent over other photo animation software. Here are some of them:
-
-It is free and easy to download using a magnet link or a torrent client.
-It is portable and does not require installation or registration.
-It has a user-friendly interface and intuitive tools that make photo animation fun and simple.
-It supports a wide range of image formats and output options.
-It produces high-quality photo animations that look realistic and smooth.
-It has a lot of features and options that allow you to customize your photo animations according to your preferences and needs.
-
-Conclusion
-Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent is a great software that can help you create amazing photo animations from your static images. It is free, portable, easy to use, and versatile. It can help you enhance your photos and make them more engaging and attractive.
-If you want to try Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent, you can download it from here: https://www.limetorrents.lol/Corel-PhotoMirage-3-2-2-169-Portable-Cracked-torrent-12334242.html
-You can also check out some examples of photo animations created with Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent here: https://www.themindsetceo.com/forum/cooking-your-catch/corel-photomirage-3-2-2-169-portable-crack-repack-ed-utorrent
-We hope you enjoyed this review of Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent and found it useful and informative.
-What are the Benefits of Photo Animation
-Photo animation is a creative and effective way to make your photos stand out from the crowd. Photo animation can help you:
-
-Capture and hold the attention of your audience.
-Express your emotions and tell a story with your photos.
-Showcase your products or services in a dynamic way.
-Increase your engagement and conversions on social media.
-Have fun and unleash your creativity.
-
-What are the Drawbacks of Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent
-While Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent is a great software that can help you create amazing photo animations, it also has some drawbacks that you should be aware of. Here are some of them:
-
-It is an illegal and unauthorized version of the original Corel PhotoMirage software that may contain viruses, malware, or spyware that can harm your computer or compromise your privacy.
-It does not have any technical support or customer service from Corel Corporation, the official developer and owner of Corel PhotoMirage software.
-It may not work properly or crash frequently due to bugs, errors, or compatibility issues.
-It may violate the intellectual property rights of Corel Corporation and expose you to legal risks or penalties.
-
-How to Get the Original Corel PhotoMirage Software
-If you want to enjoy the full features and benefits of Corel PhotoMirage software without any risks or drawbacks, you should get the original and legitimate version of the software from the official website of Corel Corporation. Here are some reasons why you should do so:
-
-You will get a safe and secure software that is free from any viruses, malware, or spyware.
-You will get access to technical support and customer service from Corel Corporation in case you encounter any problems or issues with the software.
-You will get regular updates and upgrades for the software to ensure its optimal performance and functionality.
-You will respect the intellectual property rights of Corel Corporation and avoid any legal risks or penalties.
-
-To get the original Corel PhotoMirage software, you can visit this link: https://www.corel.com/en/photomirage/
-You can also get a free trial version of the software for 15 days to test its features and capabilities before you decide to buy it.
-How to Download Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent
-If you want to download Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent, you need to have a magnet link or a torrent client that can handle torrent files. A magnet link is a URL that contains the information of the torrent file, such as the name, size, and hash of the file. A torrent client is a software that can download and upload torrent files using peer-to-peer (P2P) networks.
-There are many torrent clients that you can use, such as uTorrent, BitTorrent, qBittorrent, or Vuze. You can download them from their official websites or from other sources. However, you should be careful and make sure that the torrent client you download is safe and reliable.
-Once you have a torrent client installed on your computer, you can use it to download Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent using one of these methods:
-
-Copy and paste the magnet link of Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent into your torrent client and start the download.
-Download the torrent file of Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent from a torrent website and open it with your torrent client.
-Search for Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent on your torrent client and select the best option to download.
-
-The download speed and time may vary depending on your internet connection and the number of seeders and leechers available for the torrent file.
-How to Install Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent
-After you have downloaded Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent, you need to extract the files to your preferred location using a file compression software, such as WinRAR, 7-Zip, or PeaZip. You can download them from their official websites or from other sources.
-Once you have extracted the files, you don't need to install anything, as this is a portable version of Corel PhotoMirage software that you can run from any folder or USB drive.
-To launch Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent, you just need to double-click on the executable file named "Corel PhotoMirage.exe" and wait for it to load.
-You can then start creating your photo animations with Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent as described in the previous section.
-How to Create Stunning Photo Animations with Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent
-Creating photo animations with Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent is a fun and easy process that anyone can do. You don't need any prior experience or skills in photo editing or animation. You just need to follow these simple steps:
-
-Choose an image that you want to animate. You can use any image that you have on your computer or download one from the internet. You can also use images from your camera or smartphone.
-Open the image with Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent and select the animation mode that you want to use. There are three modes available: Motion Blur, Loop, and Bounce.
-Motion Blur mode creates a smooth and continuous animation that simulates motion blur effects.
-Loop mode creates a seamless and repeating animation that loops endlessly.
-Bounce mode creates a back-and-forth animation that bounces between two points.
-Use the animation tools to define the areas that you want to animate and the areas that you want to keep still. You can use the anchor points, motion arrows, and mask brushes to control the movement and direction of the animation.
-You can also adjust the speed, intensity, and smoothness of the animation using the sliders and buttons on the toolbar.
-Preview your photo animation and make any changes or adjustments as needed.
-Export your photo animation as a GIF, MP4, or WMV file and save it to your computer or share it online.
-
-You can also use Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent to create photo animations from multiple images or layers, add text or graphics to your photo animations, apply filters or effects to your photo animations, and more.
-How to Improve Your Photo Animation Skills with Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent
-If you want to improve your photo animation skills with Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent, you can use some of these tips and tricks:
-
-Choose images that have clear and distinct areas of movement and contrast.
-Avoid images that have too much noise, blur, or distortion.
-Use a high-resolution image for better quality and detail.
-Experiment with different animation modes, tools, and settings to create different effects and styles.
-Use masking tools to isolate and refine the areas of animation.
-Use motion arrows to guide and control the direction of the animation.
-Use anchor points to fix and stabilize the areas that you want to keep still.
-Adjust the speed, intensity, and smoothness of the animation to suit your preference and purpose.
-Preview your photo animation before exporting it and make any changes or corrections as needed.
-Export your photo animation in a suitable format and size for your intended use.
-
-You can also watch some tutorials and examples of photo animations created with Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent on YouTube or other websites to get some inspiration and ideas.
-Conclusion
-Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent is a software that can help you create stunning photo animations from your static images. It is free, portable, easy to use, and versatile. It can help you enhance your photos and make them more engaging and attractive.
-However, Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent is also an illegal and unauthorized version of the original Corel PhotoMirage software that may have some risks and drawbacks. It may contain viruses, malware, or spyware that can harm your computer or compromise your privacy. It may not work properly or crash frequently due to bugs, errors, or compatibility issues. It may violate the intellectual property rights of Corel Corporation and expose you to legal risks or penalties.
-Therefore, we recommend that you get the original and legitimate version of Corel PhotoMirage software from the official website of Corel Corporation. You will get a safe and secure software that has technical support and customer service from Corel Corporation. You will get regular updates and upgrades for the software to ensure its optimal performance and functionality. You will respect the intellectual property rights of Corel Corporation and avoid any legal risks or penalties.
-You can also get a free trial version of the software for 15 days to test its features and capabilities before you decide to buy it.
-We hope you enjoyed this article about Corel PhotoMirage 3.2.2.169 Portable Cracked Utorrent and found it useful and informative.
679dcb208eCreative Zen Vision M Creative Media Toolbox.iso Serial Key
- If you are looking for a way to enhance your digital media experience, you might be interested in the Creative Zen Vision M Creative Media Toolbox.iso serial key. This is a software package that allows you to edit, organize, and share your audio and video files with ease. But what exactly is this software and how can you get a serial key for it? In this article, we will answer these questions and more.
-Creative Zen Vision M Creative Media Toolbox.iso Serial Key DOWNLOAD ✪ https://urlcod.com/2uKaG2
Introduction
- Creative Zen Vision M is a portable media player that was released by Creative Technology in 2005. It has a 2.5-inch color screen, a 30 GB hard drive, and supports various audio and video formats. It also has an FM radio, a voice recorder, and a photo viewer. It is compatible with Windows XP and later versions.
- Creative Media Toolbox is a software suite that comes with the Creative Zen Vision M. It allows you to edit, enhance, convert, and organize your audio and video files. You can also use it to create playlists, burn CDs and DVDs, sync your files with your device, and upload them to online platforms. It is compatible with Windows XP and later versions.
- A serial key is a unique code that activates the software and verifies its authenticity. Without a serial key, you cannot use the full features of the software. You need a serial key for each installation of the software on your computer.
- How to get a serial key for Creative Zen Vision M Creative Media Toolbox.iso
- There are three main ways to get a serial key for Creative Zen Vision M Creative Media Toolbox.iso. Each option has its own advantages and disadvantages. Let's take a look at them.
-Creative Zen Vision M Media Toolbox.iso Activation Code
- Option 1: Buy it from the official website
- The first option is to buy the serial key from the official website of Creative Technology. This is the most legitimate and secure way to get the serial key. You can choose from different payment methods and currencies. You will receive an email with the serial key after completing the purchase. You can then download the software from the website or use the CD that came with your device.
- Option 2: Download it from a torrent site
- The second option is to download the serial key from a torrent site. This is a risky and illegal way to get the serial key. You will need to use a torrent client software and search for the file on various torrent sites. You will also need to scan the file for viruses and malware before opening it. You might end up downloading a fake or corrupted file that could harm your computer or device.
- Option 3: Use a key generator software
- The third option is to use a key generator software. This is a dubious and unreliable way to get the serial key. A key generator software is a program that creates random serial keys for various software products. You will need to download the software from an unknown source and run it on your computer. You might get lucky and generate a valid serial key for your software, or you might get unlucky and generate an invalid or used serial key that will not work.
- Pros and cons of each option
- Now that we have seen the three options for getting a serial key for Creative Zen Vision M Creative Media Toolbox.iso, let's compare their pros and cons in this table.
-
-
-Option
-Pros
-Cons
-
-
-Option 1: Buy it from the official website
-- Legal and secure
-- Expensive
-
-
-Option 2: Download it from a torrent site
-- Free
-- Illegal and risky
-
-
-Option 3: Use a key generator software
-- Free
-- Dubious and unreliable
-
-
- Conclusion
- In conclusion, getting a serial key for Creative Zen Vision M Creative Media Toolbox.iso depends on your preferences, budget, and risk tolerance. You can choose to buy it from the official website, download it from a torrent site, or use a key generator software. Each option has its own pros and cons that you should weigh carefully before making your decision.
- FAQs
- Here are some frequently asked questions about Creative Zen Vision M Creative Media Toolbox.iso serial key.
-
-What is an ISO file? How do I install Creative Zen Vision M Creative Media Toolbox.iso? How do I update Creative Zen Vision M Creative Media Toolbox.iso? How do I uninstall Creative Zen Vision M Creative Media Toolbox.iso? How do I contact Creative Technology for support?
- 0a6ba089ebEassos Recovery 4 Serial Key (Final Crack) - How to Recover Deleted or Lost Data Easily
-Eassos Recovery is a powerful data recovery software that can help you recover deleted, formatted, or lost files from various storage devices, such as hard drives, external hard drives, USB flash drives, memory cards, etc. It supports various file systems, such as NTFS, FAT32, exFAT, EXT2/3/4, etc. It also has a user-friendly interface that guides you through the recovery process step by step.
-In this article, we will show you how to use Eassos Recovery 4 Serial Key (Final Crack) to recover your data easily and safely. You can download Eassos Recovery 4 Serial Key (Final Crack) from the official website or from some reliable sources on the internet. You can also use the keygen, serial number, activation code, or license code to activate the full version of Eassos Recovery.
-Eassos Recovery 4 Serial Key (Final Crack) Download Zip ►►►►► https://urlcod.com/2uK6bJ
How to Use Eassos Recovery 4 Serial Key (Final Crack)
-Before you start the recovery process, make sure you have installed Eassos Recovery 4 Serial Key (Final Crack) on your computer and connected the storage device that contains your lost data. Then follow these steps:
-
-Launch Eassos Recovery 4 Serial Key (Final Crack) and select a recovery mode according to your data loss situation. There are four recovery modes: Recover Files From Partition, Recover Files From Disk, Recover Deleted Files, and Recover Lost Partitions.
-Select the partition or disk where you lost your data and click Next. Eassos Recovery 4 Serial Key (Final Crack) will scan the selected partition or disk for lost files.
-Preview and select the files you want to recover. You can use the filter and search functions to find your desired files quickly. You can also preview the files by double-clicking them.
-Choose a destination folder to save the recovered files and click Recover. Do not save the recovered files to the same partition or disk where you lost them to avoid data overwriting.
-
-That's it! You have successfully recovered your deleted or lost data with Eassos Recovery 4 Serial Key (Final Crack). You can now access your recovered files from the destination folder.
-Tips for Data Recovery with Eassos Recovery 4 Serial Key (Final Crack)
-To ensure a high success rate of data recovery with Eassos Recovery 4 Serial Key (Final Crack), here are some tips you should follow:
-How to activate Eassos Recovery 4 with serial key
-
-Stop using the storage device that contains your lost data as soon as possible to prevent further data loss.
-Do not install Eassos Recovery 4 Serial Key (Final Crack) on the same partition or disk where you lost your data.
-Do not save the recovered files to the same partition or disk where you lost them.
-Backup your important data regularly to avoid data loss in the future.
-
-Conclusion
-Eassos Recovery 4 Serial Key (Final Crack) is a reliable and easy-to-use data recovery software that can help you recover deleted or lost data from various storage devices. It supports various file systems and file types and has a user-friendly interface. You can download Eassos Recovery 4 Serial Key (Final Crack) from the official website or from some reliable sources on the internet. You can also use the keygen, serial number, activation code, or license code to activate the full version of Eassos Recovery. If you have any questions or problems about Eassos Recovery 4 Serial Key (Final Crack), you can contact their customer support team for help.
e753bf7129The Rise and Fall of the Free Crack Meme
-The free crack meme is a popular internet joke that originated from a video clip of a man named Tyrone Biggums, a recurring character on the comedy show Chappelle's Show. In the clip, Tyrone is seen offering free crack to a group of children at a school assembly, saying "Kids, say hello to Tyrone Biggums. Y'all know what he does for a living? He sells crack. And he's here today to tell you why you shouldn't do drugs."
-The clip became viral on YouTube and other social media platforms, and spawned many variations and remixes. The free crack meme is often used to mock someone who is desperate for attention, money, or fame, or to express excitement or enthusiasm for something. For example, someone might comment "Free crack!" on a post that offers a giveaway or a discount, or "Give me some of that free crack!" on a post that showcases something amazing or desirable.
-free crack meme Download > https://urlcod.com/2uK1La
However, the free crack meme also has a dark side. Some critics argue that the meme is insensitive and offensive, as it makes light of the serious issue of drug addiction and its impact on marginalized communities. They claim that the meme perpetuates harmful stereotypes and stigmatizes people who struggle with substance abuse. Moreover, some people have used the free crack meme to promote illegal or unethical activities, such as selling counterfeit products, scamming unsuspecting customers, or spreading malware.
-As a result, the free crack meme has lost some of its popularity and appeal over time. Many internet users have moved on to newer and fresher memes, while others have become more aware and cautious of the potential consequences of using the free crack meme. The free crack meme is still occasionally seen online, but it is no longer as widespread or influential as it once was.
-```
-
-```html
-So, what is the future of the free crack meme? Will it ever make a comeback, or will it fade into obscurity? Some experts believe that the free crack meme might resurface in a different form or context, as memes often do. For instance, the free crack meme could be used ironically or sarcastically, or as a reference to nostalgia or pop culture. Alternatively, the free crack meme could be revived or reinvented by a new generation of internet users, who might find new ways to use it creatively or humorously.
-However, others think that the free crack meme is doomed to die out, as it has become too outdated and controversial. They argue that the free crack meme is no longer relevant or funny, and that it has been overshadowed by newer and better memes. They also point out that the free crack meme is risky and irresponsible, and that it could cause legal or ethical problems for those who use it. They suggest that the free crack meme should be avoided or forgotten, and that internet users should focus on more positive and productive memes instead.
-Ultimately, the fate of the free crack meme depends on the choices and preferences of internet users. Whether they decide to keep using it, modify it, or abandon it, the free crack meme will always be a part of internet history and culture. The free crack meme is a testament to the power and diversity of memes, and to the creativity and humor of internet users.
-``` ddb901b051How to Download Do Hard Disk Serial Number Changer for Windows
-Do you want to change the serial number of your hard disk without formatting it? Do you need a simple and free tool that can do this task in minutes? If yes, then you should download Do Hard Disk Serial Number Changer for Windows.
-Do Hard Disk Serial Number Changer is a lightweight and portable software that allows you to modify the serial number of any hard disk connected to your computer. It supports all types of hard disks, including SATA, IDE, SCSI, and USB. It also works with Windows XP, Vista, 7, 8, and 10.
-download do hard disk serial number changer Download Zip ✵ https://urlcod.com/2uK8u2
Changing the serial number of your hard disk can be useful for various reasons, such as:
-
-Protecting your privacy and security by preventing others from tracking your device.
-Bypassing some software restrictions or activation issues that are based on the serial number of your hard disk.
-Fixing some errors or problems that are caused by a corrupted or invalid serial number of your hard disk.
-
-To download Do Hard Disk Serial Number Changer for Windows, follow these steps:
-
-Go to the official website of Do Hard Disk Serial Number Changer at https://www.doharddiskserialnumberchanger.com/ .
-Click on the "Download" button and save the file to your computer.
-Extract the ZIP file and run the executable file as administrator.
-Select the hard disk that you want to change the serial number of from the drop-down menu.
-Type in the new serial number that you want to assign to your hard disk in the text box.
-Click on the "Change" button and wait for the process to complete.
-Restart your computer for the changes to take effect.
-
-Congratulations! You have successfully downloaded and used Do Hard Disk Serial Number Changer for Windows. Now you can enjoy your new hard disk serial number without any hassle.
-
-Do Hard Disk Serial Number Changer is a safe and reliable software that does not harm your hard disk or your data. It only changes the serial number of your hard disk, not the volume ID or any other information. It also creates a backup of your original serial number in case you want to restore it later.
-How to download and use hard disk serial number changer
-However, before you use Do Hard Disk Serial Number Changer, you should be aware of some possible risks and limitations. For example:
-
-Changing the serial number of your hard disk may void your warranty or violate some terms and conditions of your manufacturer or vendor.
-Changing the serial number of your hard disk may affect some software or hardware that are linked to your hard disk serial number, such as antivirus programs, encryption tools, or external devices.
-Changing the serial number of your hard disk may require you to reactivate some software or operating systems that are installed on your hard disk, such as Windows or Office.
-
-Therefore, you should always backup your important data and files before you use Do Hard Disk Serial Number Changer. You should also check the compatibility and functionality of your software and hardware after you change the serial number of your hard disk. If you encounter any problems or errors, you can always revert to your original serial number using the backup file created by Do Hard Disk Serial Number Changer.
-If you have any questions or feedback about Do Hard Disk Serial Number Changer, you can contact the developer at info@doharddiskserialnumberchanger.com . You can also visit the FAQ section of the website for more information and tips on how to use Do Hard Disk Serial Number Changer.
e753bf7129How to Download and Use M3 Bitlocker Recovery Keygen
-M3 Bitlocker Recovery is a professional data recovery software that can help you recover files from Bitlocker encrypted drives, even if the drive is corrupted, formatted, deleted or inaccessible. However, this software is not free and requires a license key to activate its full features. If you don't want to pay for the license key, you may be tempted to look for a keygen that can generate a valid serial number for M3 Bitlocker Recovery. But is it safe and legal to do so?
-What is a Keygen?
-A keygen is a program that can create serial numbers or activation codes for various software products. Some people use keygens to bypass the registration or activation process of paid software and use them for free. However, using a keygen is not only illegal but also risky. Here are some reasons why you should avoid using a keygen for M3 Bitlocker Recovery:
-m3 bitlocker recovery keygen download Download >>>>> https://urlcod.com/2uHvdv
-It is illegal. Using a keygen to activate M3 Bitlocker Recovery without paying for it is a form of software piracy, which is a violation of intellectual property rights. Software piracy can result in legal consequences, such as fines or lawsuits.It is risky. Many keygens are infected with malware, viruses, spyware or ransomware that can harm your computer or steal your personal information. Some keygens may also contain hidden backdoors that can allow hackers to access your system remotely. Moreover, using a keygen may damage your Bitlocker encrypted drive or cause data loss.It is unreliable. There is no guarantee that a keygen can generate a valid serial number for M3 Bitlocker Recovery. Some keygens may generate fake or expired serial numbers that cannot activate the software. Some keygens may also trigger the software's anti-piracy mechanism and disable its functionality.
-How to Download and Use M3 Bitlocker Recovery Safely and Legally?
-If you want to use M3 Bitlocker Recovery safely and legally, you should download it from its official website and purchase a license key from its authorized reseller. Here are the steps to do so:
-
-Go to https://www.m3datarecovery.com/bitlocker-recovery/bitlocker-data-recovery.html and click on the "Download & Recover" button to download the software.
-Install and launch the software on your computer.
-Select the Bitlocker encrypted drive that you want to recover data from and click on "Next".
-Enter your Bitlocker password or 48-digit recovery key and click on "Next".
-Scan the drive and preview the recoverable files.
-If you are satisfied with the recovery result, click on "Activate" and enter your license key that you have purchased from the official website or reseller.
-Save the recovered files to another drive.
-
-Conclusion
-M3 Bitlocker Recovery is a powerful and reliable data recovery software that can help you recover files from Bitlocker encrypted drives in various scenarios. However, using a keygen to activate it is illegal and risky. Therefore, we recommend you to download it from its official website and purchase a license key from its authorized reseller. This way, you can enjoy its full features and support without any worries.
-
-``` 81aa517590`` can be a glob expression or a package name.
- """
-
- ignore_require_venv = True
- usage = """
- %prog dir
- %prog info
- %prog list [] [--format=[human, abspath]]
- %prog remove
- %prog purge
- """
-
- def add_options(self) -> None:
-
- self.cmd_opts.add_option(
- "--format",
- action="store",
- dest="list_format",
- default="human",
- choices=("human", "abspath"),
- help="Select the output format among: human (default) or abspath",
- )
-
- self.parser.insert_option_group(0, self.cmd_opts)
-
- def run(self, options: Values, args: List[str]) -> int:
- handlers = {
- "dir": self.get_cache_dir,
- "info": self.get_cache_info,
- "list": self.list_cache_items,
- "remove": self.remove_cache_items,
- "purge": self.purge_cache,
- }
-
- if not options.cache_dir:
- logger.error("pip cache commands can not function since cache is disabled.")
- return ERROR
-
- # Determine action
- if not args or args[0] not in handlers:
- logger.error(
- "Need an action (%s) to perform.",
- ", ".join(sorted(handlers)),
- )
- return ERROR
-
- action = args[0]
-
- # Error handling happens here, not in the action-handlers.
- try:
- handlers[action](options, args[1:])
- except PipError as e:
- logger.error(e.args[0])
- return ERROR
-
- return SUCCESS
-
- def get_cache_dir(self, options: Values, args: List[Any]) -> None:
- if args:
- raise CommandError("Too many arguments")
-
- logger.info(options.cache_dir)
-
- def get_cache_info(self, options: Values, args: List[Any]) -> None:
- if args:
- raise CommandError("Too many arguments")
-
- num_http_files = len(self._find_http_files(options))
- num_packages = len(self._find_wheels(options, "*"))
-
- http_cache_location = self._cache_dir(options, "http")
- wheels_cache_location = self._cache_dir(options, "wheels")
- http_cache_size = filesystem.format_directory_size(http_cache_location)
- wheels_cache_size = filesystem.format_directory_size(wheels_cache_location)
-
- message = (
- textwrap.dedent(
- """
- Package index page cache location: {http_cache_location}
- Package index page cache size: {http_cache_size}
- Number of HTTP files: {num_http_files}
- Locally built wheels location: {wheels_cache_location}
- Locally built wheels size: {wheels_cache_size}
- Number of locally built wheels: {package_count}
- """
- )
- .format(
- http_cache_location=http_cache_location,
- http_cache_size=http_cache_size,
- num_http_files=num_http_files,
- wheels_cache_location=wheels_cache_location,
- package_count=num_packages,
- wheels_cache_size=wheels_cache_size,
- )
- .strip()
- )
-
- logger.info(message)
-
- def list_cache_items(self, options: Values, args: List[Any]) -> None:
- if len(args) > 1:
- raise CommandError("Too many arguments")
-
- if args:
- pattern = args[0]
- else:
- pattern = "*"
-
- files = self._find_wheels(options, pattern)
- if options.list_format == "human":
- self.format_for_human(files)
- else:
- self.format_for_abspath(files)
-
- def format_for_human(self, files: List[str]) -> None:
- if not files:
- logger.info("No locally built wheels cached.")
- return
-
- results = []
- for filename in files:
- wheel = os.path.basename(filename)
- size = filesystem.format_file_size(filename)
- results.append(f" - {wheel} ({size})")
- logger.info("Cache contents:\n")
- logger.info("\n".join(sorted(results)))
-
- def format_for_abspath(self, files: List[str]) -> None:
- if not files:
- return
-
- results = []
- for filename in files:
- results.append(filename)
-
- logger.info("\n".join(sorted(results)))
-
- def remove_cache_items(self, options: Values, args: List[Any]) -> None:
- if len(args) > 1:
- raise CommandError("Too many arguments")
-
- if not args:
- raise CommandError("Please provide a pattern")
-
- files = self._find_wheels(options, args[0])
-
- no_matching_msg = "No matching packages"
- if args[0] == "*":
- # Only fetch http files if no specific pattern given
- files += self._find_http_files(options)
- else:
- # Add the pattern to the log message
- no_matching_msg += ' for pattern "{}"'.format(args[0])
-
- if not files:
- logger.warning(no_matching_msg)
-
- for filename in files:
- os.unlink(filename)
- logger.verbose("Removed %s", filename)
- logger.info("Files removed: %s", len(files))
-
- def purge_cache(self, options: Values, args: List[Any]) -> None:
- if args:
- raise CommandError("Too many arguments")
-
- return self.remove_cache_items(options, ["*"])
-
- def _cache_dir(self, options: Values, subdir: str) -> str:
- return os.path.join(options.cache_dir, subdir)
-
- def _find_http_files(self, options: Values) -> List[str]:
- http_dir = self._cache_dir(options, "http")
- return filesystem.find_files(http_dir, "*")
-
- def _find_wheels(self, options: Values, pattern: str) -> List[str]:
- wheel_dir = self._cache_dir(options, "wheels")
-
- # The wheel filename format, as specified in PEP 427, is:
- # {distribution}-{version}(-{build})?-{python}-{abi}-{platform}.whl
- #
- # Additionally, non-alphanumeric values in the distribution are
- # normalized to underscores (_), meaning hyphens can never occur
- # before `-{version}`.
- #
- # Given that information:
- # - If the pattern we're given contains a hyphen (-), the user is
- # providing at least the version. Thus, we can just append `*.whl`
- # to match the rest of it.
- # - If the pattern we're given doesn't contain a hyphen (-), the
- # user is only providing the name. Thus, we append `-*.whl` to
- # match the hyphen before the version, followed by anything else.
- #
- # PEP 427: https://www.python.org/dev/peps/pep-0427/
- pattern = pattern + ("*.whl" if "-" in pattern else "-*.whl")
-
- return filesystem.find_files(wheel_dir, pattern)
diff --git a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/msgpack/exceptions.py b/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/msgpack/exceptions.py
deleted file mode 100644
index d6d2615cfdd0b914d064cdf7eecd45761e4bcaf6..0000000000000000000000000000000000000000
--- a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/msgpack/exceptions.py
+++ /dev/null
@@ -1,48 +0,0 @@
-class UnpackException(Exception):
- """Base class for some exceptions raised while unpacking.
-
- NOTE: unpack may raise exception other than subclass of
- UnpackException. If you want to catch all error, catch
- Exception instead.
- """
-
-
-class BufferFull(UnpackException):
- pass
-
-
-class OutOfData(UnpackException):
- pass
-
-
-class FormatError(ValueError, UnpackException):
- """Invalid msgpack format"""
-
-
-class StackError(ValueError, UnpackException):
- """Too nested"""
-
-
-# Deprecated. Use ValueError instead
-UnpackValueError = ValueError
-
-
-class ExtraData(UnpackValueError):
- """ExtraData is raised when there is trailing data.
-
- This exception is raised while only one-shot (not streaming)
- unpack.
- """
-
- def __init__(self, unpacked, extra):
- self.unpacked = unpacked
- self.extra = extra
-
- def __str__(self):
- return "unpack(b) received extra data."
-
-
-# Deprecated. Use Exception instead to catch all exception during packing.
-PackException = Exception
-PackValueError = ValueError
-PackOverflowError = OverflowError
diff --git a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/requests/__init__.py b/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/requests/__init__.py
deleted file mode 100644
index 9e97059d1dbd1bdfd7a97e06c793de38289823c3..0000000000000000000000000000000000000000
--- a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/requests/__init__.py
+++ /dev/null
@@ -1,182 +0,0 @@
-# __
-# /__) _ _ _ _ _/ _
-# / ( (- (/ (/ (- _) / _)
-# /
-
-"""
-Requests HTTP Library
-~~~~~~~~~~~~~~~~~~~~~
-
-Requests is an HTTP library, written in Python, for human beings.
-Basic GET usage:
-
- >>> import requests
- >>> r = requests.get('https://www.python.org')
- >>> r.status_code
- 200
- >>> b'Python is a programming language' in r.content
- True
-
-... or POST:
-
- >>> payload = dict(key1='value1', key2='value2')
- >>> r = requests.post('https://httpbin.org/post', data=payload)
- >>> print(r.text)
- {
- ...
- "form": {
- "key1": "value1",
- "key2": "value2"
- },
- ...
- }
-
-The other HTTP methods are supported - see `requests.api`. Full documentation
-is at .
-
-:copyright: (c) 2017 by Kenneth Reitz.
-:license: Apache 2.0, see LICENSE for more details.
-"""
-
-import warnings
-
-from pip._vendor import urllib3
-
-from .exceptions import RequestsDependencyWarning
-
-charset_normalizer_version = None
-
-try:
- from pip._vendor.chardet import __version__ as chardet_version
-except ImportError:
- chardet_version = None
-
-
-def check_compatibility(urllib3_version, chardet_version, charset_normalizer_version):
- urllib3_version = urllib3_version.split(".")
- assert urllib3_version != ["dev"] # Verify urllib3 isn't installed from git.
-
- # Sometimes, urllib3 only reports its version as 16.1.
- if len(urllib3_version) == 2:
- urllib3_version.append("0")
-
- # Check urllib3 for compatibility.
- major, minor, patch = urllib3_version # noqa: F811
- major, minor, patch = int(major), int(minor), int(patch)
- # urllib3 >= 1.21.1, <= 1.26
- assert major == 1
- assert minor >= 21
- assert minor <= 26
-
- # Check charset_normalizer for compatibility.
- if chardet_version:
- major, minor, patch = chardet_version.split(".")[:3]
- major, minor, patch = int(major), int(minor), int(patch)
- # chardet_version >= 3.0.2, < 6.0.0
- assert (3, 0, 2) <= (major, minor, patch) < (6, 0, 0)
- elif charset_normalizer_version:
- major, minor, patch = charset_normalizer_version.split(".")[:3]
- major, minor, patch = int(major), int(minor), int(patch)
- # charset_normalizer >= 2.0.0 < 3.0.0
- assert (2, 0, 0) <= (major, minor, patch) < (3, 0, 0)
- else:
- raise Exception("You need either charset_normalizer or chardet installed")
-
-
-def _check_cryptography(cryptography_version):
- # cryptography < 1.3.4
- try:
- cryptography_version = list(map(int, cryptography_version.split(".")))
- except ValueError:
- return
-
- if cryptography_version < [1, 3, 4]:
- warning = "Old version of cryptography ({}) may cause slowdown.".format(
- cryptography_version
- )
- warnings.warn(warning, RequestsDependencyWarning)
-
-
-# Check imported dependencies for compatibility.
-try:
- check_compatibility(
- urllib3.__version__, chardet_version, charset_normalizer_version
- )
-except (AssertionError, ValueError):
- warnings.warn(
- "urllib3 ({}) or chardet ({})/charset_normalizer ({}) doesn't match a supported "
- "version!".format(
- urllib3.__version__, chardet_version, charset_normalizer_version
- ),
- RequestsDependencyWarning,
- )
-
-# Attempt to enable urllib3's fallback for SNI support
-# if the standard library doesn't support SNI or the
-# 'ssl' library isn't available.
-try:
- # Note: This logic prevents upgrading cryptography on Windows, if imported
- # as part of pip.
- from pip._internal.utils.compat import WINDOWS
- if not WINDOWS:
- raise ImportError("pip internals: don't import cryptography on Windows")
- try:
- import ssl
- except ImportError:
- ssl = None
-
- if not getattr(ssl, "HAS_SNI", False):
- from pip._vendor.urllib3.contrib import pyopenssl
-
- pyopenssl.inject_into_urllib3()
-
- # Check cryptography version
- from cryptography import __version__ as cryptography_version
-
- _check_cryptography(cryptography_version)
-except ImportError:
- pass
-
-# urllib3's DependencyWarnings should be silenced.
-from pip._vendor.urllib3.exceptions import DependencyWarning
-
-warnings.simplefilter("ignore", DependencyWarning)
-
-# Set default logging handler to avoid "No handler found" warnings.
-import logging
-from logging import NullHandler
-
-from . import packages, utils
-from .__version__ import (
- __author__,
- __author_email__,
- __build__,
- __cake__,
- __copyright__,
- __description__,
- __license__,
- __title__,
- __url__,
- __version__,
-)
-from .api import delete, get, head, options, patch, post, put, request
-from .exceptions import (
- ConnectionError,
- ConnectTimeout,
- FileModeWarning,
- HTTPError,
- JSONDecodeError,
- ReadTimeout,
- RequestException,
- Timeout,
- TooManyRedirects,
- URLRequired,
-)
-from .models import PreparedRequest, Request, Response
-from .sessions import Session, session
-from .status_codes import codes
-
-logging.getLogger(__name__).addHandler(NullHandler())
-
-# FileModeWarnings go off per the default.
-warnings.simplefilter("default", FileModeWarning, append=True)
diff --git a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/urllib3/util/ssl_.py b/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/urllib3/util/ssl_.py
deleted file mode 100644
index 2b45d391d4d7398e4769f45f9dd25eb55daef437..0000000000000000000000000000000000000000
--- a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_vendor/urllib3/util/ssl_.py
+++ /dev/null
@@ -1,495 +0,0 @@
-from __future__ import absolute_import
-
-import hmac
-import os
-import sys
-import warnings
-from binascii import hexlify, unhexlify
-from hashlib import md5, sha1, sha256
-
-from ..exceptions import (
- InsecurePlatformWarning,
- ProxySchemeUnsupported,
- SNIMissingWarning,
- SSLError,
-)
-from ..packages import six
-from .url import BRACELESS_IPV6_ADDRZ_RE, IPV4_RE
-
-SSLContext = None
-SSLTransport = None
-HAS_SNI = False
-IS_PYOPENSSL = False
-IS_SECURETRANSPORT = False
-ALPN_PROTOCOLS = ["http/1.1"]
-
-# Maps the length of a digest to a possible hash function producing this digest
-HASHFUNC_MAP = {32: md5, 40: sha1, 64: sha256}
-
-
-def _const_compare_digest_backport(a, b):
- """
- Compare two digests of equal length in constant time.
-
- The digests must be of type str/bytes.
- Returns True if the digests match, and False otherwise.
- """
- result = abs(len(a) - len(b))
- for left, right in zip(bytearray(a), bytearray(b)):
- result |= left ^ right
- return result == 0
-
-
-_const_compare_digest = getattr(hmac, "compare_digest", _const_compare_digest_backport)
-
-try: # Test for SSL features
- import ssl
- from ssl import CERT_REQUIRED, wrap_socket
-except ImportError:
- pass
-
-try:
- from ssl import HAS_SNI # Has SNI?
-except ImportError:
- pass
-
-try:
- from .ssltransport import SSLTransport
-except ImportError:
- pass
-
-
-try: # Platform-specific: Python 3.6
- from ssl import PROTOCOL_TLS
-
- PROTOCOL_SSLv23 = PROTOCOL_TLS
-except ImportError:
- try:
- from ssl import PROTOCOL_SSLv23 as PROTOCOL_TLS
-
- PROTOCOL_SSLv23 = PROTOCOL_TLS
- except ImportError:
- PROTOCOL_SSLv23 = PROTOCOL_TLS = 2
-
-try:
- from ssl import PROTOCOL_TLS_CLIENT
-except ImportError:
- PROTOCOL_TLS_CLIENT = PROTOCOL_TLS
-
-
-try:
- from ssl import OP_NO_COMPRESSION, OP_NO_SSLv2, OP_NO_SSLv3
-except ImportError:
- OP_NO_SSLv2, OP_NO_SSLv3 = 0x1000000, 0x2000000
- OP_NO_COMPRESSION = 0x20000
-
-
-try: # OP_NO_TICKET was added in Python 3.6
- from ssl import OP_NO_TICKET
-except ImportError:
- OP_NO_TICKET = 0x4000
-
-
-# A secure default.
-# Sources for more information on TLS ciphers:
-#
-# - https://wiki.mozilla.org/Security/Server_Side_TLS
-# - https://www.ssllabs.com/projects/best-practices/index.html
-# - https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/
-#
-# The general intent is:
-# - prefer cipher suites that offer perfect forward secrecy (DHE/ECDHE),
-# - prefer ECDHE over DHE for better performance,
-# - prefer any AES-GCM and ChaCha20 over any AES-CBC for better performance and
-# security,
-# - prefer AES-GCM over ChaCha20 because hardware-accelerated AES is common,
-# - disable NULL authentication, MD5 MACs, DSS, and other
-# insecure ciphers for security reasons.
-# - NOTE: TLS 1.3 cipher suites are managed through a different interface
-# not exposed by CPython (yet!) and are enabled by default if they're available.
-DEFAULT_CIPHERS = ":".join(
- [
- "ECDHE+AESGCM",
- "ECDHE+CHACHA20",
- "DHE+AESGCM",
- "DHE+CHACHA20",
- "ECDH+AESGCM",
- "DH+AESGCM",
- "ECDH+AES",
- "DH+AES",
- "RSA+AESGCM",
- "RSA+AES",
- "!aNULL",
- "!eNULL",
- "!MD5",
- "!DSS",
- ]
-)
-
-try:
- from ssl import SSLContext # Modern SSL?
-except ImportError:
-
- class SSLContext(object): # Platform-specific: Python 2
- def __init__(self, protocol_version):
- self.protocol = protocol_version
- # Use default values from a real SSLContext
- self.check_hostname = False
- self.verify_mode = ssl.CERT_NONE
- self.ca_certs = None
- self.options = 0
- self.certfile = None
- self.keyfile = None
- self.ciphers = None
-
- def load_cert_chain(self, certfile, keyfile):
- self.certfile = certfile
- self.keyfile = keyfile
-
- def load_verify_locations(self, cafile=None, capath=None, cadata=None):
- self.ca_certs = cafile
-
- if capath is not None:
- raise SSLError("CA directories not supported in older Pythons")
-
- if cadata is not None:
- raise SSLError("CA data not supported in older Pythons")
-
- def set_ciphers(self, cipher_suite):
- self.ciphers = cipher_suite
-
- def wrap_socket(self, socket, server_hostname=None, server_side=False):
- warnings.warn(
- "A true SSLContext object is not available. This prevents "
- "urllib3 from configuring SSL appropriately and may cause "
- "certain SSL connections to fail. You can upgrade to a newer "
- "version of Python to solve this. For more information, see "
- "https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html"
- "#ssl-warnings",
- InsecurePlatformWarning,
- )
- kwargs = {
- "keyfile": self.keyfile,
- "certfile": self.certfile,
- "ca_certs": self.ca_certs,
- "cert_reqs": self.verify_mode,
- "ssl_version": self.protocol,
- "server_side": server_side,
- }
- return wrap_socket(socket, ciphers=self.ciphers, **kwargs)
-
-
-def assert_fingerprint(cert, fingerprint):
- """
- Checks if given fingerprint matches the supplied certificate.
-
- :param cert:
- Certificate as bytes object.
- :param fingerprint:
- Fingerprint as string of hexdigits, can be interspersed by colons.
- """
-
- fingerprint = fingerprint.replace(":", "").lower()
- digest_length = len(fingerprint)
- hashfunc = HASHFUNC_MAP.get(digest_length)
- if not hashfunc:
- raise SSLError("Fingerprint of invalid length: {0}".format(fingerprint))
-
- # We need encode() here for py32; works on py2 and p33.
- fingerprint_bytes = unhexlify(fingerprint.encode())
-
- cert_digest = hashfunc(cert).digest()
-
- if not _const_compare_digest(cert_digest, fingerprint_bytes):
- raise SSLError(
- 'Fingerprints did not match. Expected "{0}", got "{1}".'.format(
- fingerprint, hexlify(cert_digest)
- )
- )
-
-
-def resolve_cert_reqs(candidate):
- """
- Resolves the argument to a numeric constant, which can be passed to
- the wrap_socket function/method from the ssl module.
- Defaults to :data:`ssl.CERT_REQUIRED`.
- If given a string it is assumed to be the name of the constant in the
- :mod:`ssl` module or its abbreviation.
- (So you can specify `REQUIRED` instead of `CERT_REQUIRED`.
- If it's neither `None` nor a string we assume it is already the numeric
- constant which can directly be passed to wrap_socket.
- """
- if candidate is None:
- return CERT_REQUIRED
-
- if isinstance(candidate, str):
- res = getattr(ssl, candidate, None)
- if res is None:
- res = getattr(ssl, "CERT_" + candidate)
- return res
-
- return candidate
-
-
-def resolve_ssl_version(candidate):
- """
- like resolve_cert_reqs
- """
- if candidate is None:
- return PROTOCOL_TLS
-
- if isinstance(candidate, str):
- res = getattr(ssl, candidate, None)
- if res is None:
- res = getattr(ssl, "PROTOCOL_" + candidate)
- return res
-
- return candidate
-
-
-def create_urllib3_context(
- ssl_version=None, cert_reqs=None, options=None, ciphers=None
-):
- """All arguments have the same meaning as ``ssl_wrap_socket``.
-
- By default, this function does a lot of the same work that
- ``ssl.create_default_context`` does on Python 3.4+. It:
-
- - Disables SSLv2, SSLv3, and compression
- - Sets a restricted set of server ciphers
-
- If you wish to enable SSLv3, you can do::
-
- from pip._vendor.urllib3.util import ssl_
- context = ssl_.create_urllib3_context()
- context.options &= ~ssl_.OP_NO_SSLv3
-
- You can do the same to enable compression (substituting ``COMPRESSION``
- for ``SSLv3`` in the last line above).
-
- :param ssl_version:
- The desired protocol version to use. This will default to
- PROTOCOL_SSLv23 which will negotiate the highest protocol that both
- the server and your installation of OpenSSL support.
- :param cert_reqs:
- Whether to require the certificate verification. This defaults to
- ``ssl.CERT_REQUIRED``.
- :param options:
- Specific OpenSSL options. These default to ``ssl.OP_NO_SSLv2``,
- ``ssl.OP_NO_SSLv3``, ``ssl.OP_NO_COMPRESSION``, and ``ssl.OP_NO_TICKET``.
- :param ciphers:
- Which cipher suites to allow the server to select.
- :returns:
- Constructed SSLContext object with specified options
- :rtype: SSLContext
- """
- # PROTOCOL_TLS is deprecated in Python 3.10
- if not ssl_version or ssl_version == PROTOCOL_TLS:
- ssl_version = PROTOCOL_TLS_CLIENT
-
- context = SSLContext(ssl_version)
-
- context.set_ciphers(ciphers or DEFAULT_CIPHERS)
-
- # Setting the default here, as we may have no ssl module on import
- cert_reqs = ssl.CERT_REQUIRED if cert_reqs is None else cert_reqs
-
- if options is None:
- options = 0
- # SSLv2 is easily broken and is considered harmful and dangerous
- options |= OP_NO_SSLv2
- # SSLv3 has several problems and is now dangerous
- options |= OP_NO_SSLv3
- # Disable compression to prevent CRIME attacks for OpenSSL 1.0+
- # (issue #309)
- options |= OP_NO_COMPRESSION
- # TLSv1.2 only. Unless set explicitly, do not request tickets.
- # This may save some bandwidth on wire, and although the ticket is encrypted,
- # there is a risk associated with it being on wire,
- # if the server is not rotating its ticketing keys properly.
- options |= OP_NO_TICKET
-
- context.options |= options
-
- # Enable post-handshake authentication for TLS 1.3, see GH #1634. PHA is
- # necessary for conditional client cert authentication with TLS 1.3.
- # The attribute is None for OpenSSL <= 1.1.0 or does not exist in older
- # versions of Python. We only enable on Python 3.7.4+ or if certificate
- # verification is enabled to work around Python issue #37428
- # See: https://bugs.python.org/issue37428
- if (cert_reqs == ssl.CERT_REQUIRED or sys.version_info >= (3, 7, 4)) and getattr(
- context, "post_handshake_auth", None
- ) is not None:
- context.post_handshake_auth = True
-
- def disable_check_hostname():
- if (
- getattr(context, "check_hostname", None) is not None
- ): # Platform-specific: Python 3.2
- # We do our own verification, including fingerprints and alternative
- # hostnames. So disable it here
- context.check_hostname = False
-
- # The order of the below lines setting verify_mode and check_hostname
- # matter due to safe-guards SSLContext has to prevent an SSLContext with
- # check_hostname=True, verify_mode=NONE/OPTIONAL. This is made even more
- # complex because we don't know whether PROTOCOL_TLS_CLIENT will be used
- # or not so we don't know the initial state of the freshly created SSLContext.
- if cert_reqs == ssl.CERT_REQUIRED:
- context.verify_mode = cert_reqs
- disable_check_hostname()
- else:
- disable_check_hostname()
- context.verify_mode = cert_reqs
-
- # Enable logging of TLS session keys via defacto standard environment variable
- # 'SSLKEYLOGFILE', if the feature is available (Python 3.8+). Skip empty values.
- if hasattr(context, "keylog_filename"):
- sslkeylogfile = os.environ.get("SSLKEYLOGFILE")
- if sslkeylogfile:
- context.keylog_filename = sslkeylogfile
-
- return context
-
-
-def ssl_wrap_socket(
- sock,
- keyfile=None,
- certfile=None,
- cert_reqs=None,
- ca_certs=None,
- server_hostname=None,
- ssl_version=None,
- ciphers=None,
- ssl_context=None,
- ca_cert_dir=None,
- key_password=None,
- ca_cert_data=None,
- tls_in_tls=False,
-):
- """
- All arguments except for server_hostname, ssl_context, and ca_cert_dir have
- the same meaning as they do when using :func:`ssl.wrap_socket`.
-
- :param server_hostname:
- When SNI is supported, the expected hostname of the certificate
- :param ssl_context:
- A pre-made :class:`SSLContext` object. If none is provided, one will
- be created using :func:`create_urllib3_context`.
- :param ciphers:
- A string of ciphers we wish the client to support.
- :param ca_cert_dir:
- A directory containing CA certificates in multiple separate files, as
- supported by OpenSSL's -CApath flag or the capath argument to
- SSLContext.load_verify_locations().
- :param key_password:
- Optional password if the keyfile is encrypted.
- :param ca_cert_data:
- Optional string containing CA certificates in PEM format suitable for
- passing as the cadata parameter to SSLContext.load_verify_locations()
- :param tls_in_tls:
- Use SSLTransport to wrap the existing socket.
- """
- context = ssl_context
- if context is None:
- # Note: This branch of code and all the variables in it are no longer
- # used by urllib3 itself. We should consider deprecating and removing
- # this code.
- context = create_urllib3_context(ssl_version, cert_reqs, ciphers=ciphers)
-
- if ca_certs or ca_cert_dir or ca_cert_data:
- try:
- context.load_verify_locations(ca_certs, ca_cert_dir, ca_cert_data)
- except (IOError, OSError) as e:
- raise SSLError(e)
-
- elif ssl_context is None and hasattr(context, "load_default_certs"):
- # try to load OS default certs; works well on Windows (require Python3.4+)
- context.load_default_certs()
-
- # Attempt to detect if we get the goofy behavior of the
- # keyfile being encrypted and OpenSSL asking for the
- # passphrase via the terminal and instead error out.
- if keyfile and key_password is None and _is_key_file_encrypted(keyfile):
- raise SSLError("Client private key is encrypted, password is required")
-
- if certfile:
- if key_password is None:
- context.load_cert_chain(certfile, keyfile)
- else:
- context.load_cert_chain(certfile, keyfile, key_password)
-
- try:
- if hasattr(context, "set_alpn_protocols"):
- context.set_alpn_protocols(ALPN_PROTOCOLS)
- except NotImplementedError: # Defensive: in CI, we always have set_alpn_protocols
- pass
-
- # If we detect server_hostname is an IP address then the SNI
- # extension should not be used according to RFC3546 Section 3.1
- use_sni_hostname = server_hostname and not is_ipaddress(server_hostname)
- # SecureTransport uses server_hostname in certificate verification.
- send_sni = (use_sni_hostname and HAS_SNI) or (
- IS_SECURETRANSPORT and server_hostname
- )
- # Do not warn the user if server_hostname is an invalid SNI hostname.
- if not HAS_SNI and use_sni_hostname:
- warnings.warn(
- "An HTTPS request has been made, but the SNI (Server Name "
- "Indication) extension to TLS is not available on this platform. "
- "This may cause the server to present an incorrect TLS "
- "certificate, which can cause validation failures. You can upgrade to "
- "a newer version of Python to solve this. For more information, see "
- "https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html"
- "#ssl-warnings",
- SNIMissingWarning,
- )
-
- if send_sni:
- ssl_sock = _ssl_wrap_socket_impl(
- sock, context, tls_in_tls, server_hostname=server_hostname
- )
- else:
- ssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls)
- return ssl_sock
-
-
-def is_ipaddress(hostname):
- """Detects whether the hostname given is an IPv4 or IPv6 address.
- Also detects IPv6 addresses with Zone IDs.
-
- :param str hostname: Hostname to examine.
- :return: True if the hostname is an IP address, False otherwise.
- """
- if not six.PY2 and isinstance(hostname, bytes):
- # IDN A-label bytes are ASCII compatible.
- hostname = hostname.decode("ascii")
- return bool(IPV4_RE.match(hostname) or BRACELESS_IPV6_ADDRZ_RE.match(hostname))
-
-
-def _is_key_file_encrypted(key_file):
- """Detects if a key file is encrypted or not."""
- with open(key_file, "r") as f:
- for line in f:
- # Look for Proc-Type: 4,ENCRYPTED
- if "ENCRYPTED" in line:
- return True
-
- return False
-
-
-def _ssl_wrap_socket_impl(sock, ssl_context, tls_in_tls, server_hostname=None):
- if tls_in_tls:
- if not SSLTransport:
- # Import error, ssl is not available.
- raise ProxySchemeUnsupported(
- "TLS in TLS requires support for the 'ssl' module"
- )
-
- SSLTransport._validate_ssl_context_for_tls_in_tls(ssl_context)
- return SSLTransport(sock, ssl_context, server_hostname)
-
- if server_hostname:
- return ssl_context.wrap_socket(sock, server_hostname=server_hostname)
- else:
- return ssl_context.wrap_socket(sock)
diff --git a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/setuptools/config/expand.py b/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/setuptools/config/expand.py
deleted file mode 100644
index ed7564047a0d6801cbae2a6f3eec805129db9804..0000000000000000000000000000000000000000
--- a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/setuptools/config/expand.py
+++ /dev/null
@@ -1,479 +0,0 @@
-"""Utility functions to expand configuration directives or special values
-(such glob patterns).
-
-We can split the process of interpreting configuration files into 2 steps:
-
-1. The parsing the file contents from strings to value objects
- that can be understand by Python (for example a string with a comma
- separated list of keywords into an actual Python list of strings).
-
-2. The expansion (or post-processing) of these values according to the
- semantics ``setuptools`` assign to them (for example a configuration field
- with the ``file:`` directive should be expanded from a list of file paths to
- a single string with the contents of those files concatenated)
-
-This module focus on the second step, and therefore allow sharing the expansion
-functions among several configuration file formats.
-
-**PRIVATE MODULE**: API reserved for setuptools internal usage only.
-"""
-import ast
-import importlib
-import io
-import os
-import sys
-import warnings
-from glob import iglob
-from configparser import ConfigParser
-from importlib.machinery import ModuleSpec
-from itertools import chain
-from typing import (
- TYPE_CHECKING,
- Callable,
- Dict,
- Iterable,
- Iterator,
- List,
- Mapping,
- Optional,
- Tuple,
- TypeVar,
- Union,
- cast
-)
-from types import ModuleType
-
-from distutils.errors import DistutilsOptionError
-
-if TYPE_CHECKING:
- from setuptools.dist import Distribution # noqa
- from setuptools.discovery import ConfigDiscovery # noqa
- from distutils.dist import DistributionMetadata # noqa
-
-chain_iter = chain.from_iterable
-_Path = Union[str, os.PathLike]
-_K = TypeVar("_K")
-_V = TypeVar("_V", covariant=True)
-
-
-class StaticModule:
- """Proxy to a module object that avoids executing arbitrary code."""
-
- def __init__(self, name: str, spec: ModuleSpec):
- with open(spec.origin) as strm: # type: ignore
- src = strm.read()
- module = ast.parse(src)
- vars(self).update(locals())
- del self.self
-
- def _find_assignments(self) -> Iterator[Tuple[ast.AST, ast.AST]]:
- for statement in self.module.body:
- if isinstance(statement, ast.Assign):
- yield from ((target, statement.value) for target in statement.targets)
- elif isinstance(statement, ast.AnnAssign) and statement.value:
- yield (statement.target, statement.value)
-
- def __getattr__(self, attr):
- """Attempt to load an attribute "statically", via :func:`ast.literal_eval`."""
- try:
- return next(
- ast.literal_eval(value)
- for target, value in self._find_assignments()
- if isinstance(target, ast.Name) and target.id == attr
- )
- except Exception as e:
- raise AttributeError(f"{self.name} has no attribute {attr}") from e
-
-
-def glob_relative(
- patterns: Iterable[str], root_dir: Optional[_Path] = None
-) -> List[str]:
- """Expand the list of glob patterns, but preserving relative paths.
-
- :param list[str] patterns: List of glob patterns
- :param str root_dir: Path to which globs should be relative
- (current directory by default)
- :rtype: list
- """
- glob_characters = {'*', '?', '[', ']', '{', '}'}
- expanded_values = []
- root_dir = root_dir or os.getcwd()
- for value in patterns:
-
- # Has globby characters?
- if any(char in value for char in glob_characters):
- # then expand the glob pattern while keeping paths *relative*:
- glob_path = os.path.abspath(os.path.join(root_dir, value))
- expanded_values.extend(sorted(
- os.path.relpath(path, root_dir).replace(os.sep, "/")
- for path in iglob(glob_path, recursive=True)))
-
- else:
- # take the value as-is
- path = os.path.relpath(value, root_dir).replace(os.sep, "/")
- expanded_values.append(path)
-
- return expanded_values
-
-
-def read_files(filepaths: Union[str, bytes, Iterable[_Path]], root_dir=None) -> str:
- """Return the content of the files concatenated using ``\n`` as str
-
- This function is sandboxed and won't reach anything outside ``root_dir``
-
- (By default ``root_dir`` is the current directory).
- """
- from setuptools.extern.more_itertools import always_iterable
-
- root_dir = os.path.abspath(root_dir or os.getcwd())
- _filepaths = (os.path.join(root_dir, path) for path in always_iterable(filepaths))
- return '\n'.join(
- _read_file(path)
- for path in _filter_existing_files(_filepaths)
- if _assert_local(path, root_dir)
- )
-
-
-def _filter_existing_files(filepaths: Iterable[_Path]) -> Iterator[_Path]:
- for path in filepaths:
- if os.path.isfile(path):
- yield path
- else:
- warnings.warn(f"File {path!r} cannot be found")
-
-
-def _read_file(filepath: Union[bytes, _Path]) -> str:
- with io.open(filepath, encoding='utf-8') as f:
- return f.read()
-
-
-def _assert_local(filepath: _Path, root_dir: str):
- if not os.path.abspath(filepath).startswith(root_dir):
- msg = f"Cannot access {filepath!r} (or anything outside {root_dir!r})"
- raise DistutilsOptionError(msg)
-
- return True
-
-
-def read_attr(
- attr_desc: str,
- package_dir: Optional[Mapping[str, str]] = None,
- root_dir: Optional[_Path] = None
-):
- """Reads the value of an attribute from a module.
-
- This function will try to read the attributed statically first
- (via :func:`ast.literal_eval`), and only evaluate the module if it fails.
-
- Examples:
- read_attr("package.attr")
- read_attr("package.module.attr")
-
- :param str attr_desc: Dot-separated string describing how to reach the
- attribute (see examples above)
- :param dict[str, str] package_dir: Mapping of package names to their
- location in disk (represented by paths relative to ``root_dir``).
- :param str root_dir: Path to directory containing all the packages in
- ``package_dir`` (current directory by default).
- :rtype: str
- """
- root_dir = root_dir or os.getcwd()
- attrs_path = attr_desc.strip().split('.')
- attr_name = attrs_path.pop()
- module_name = '.'.join(attrs_path)
- module_name = module_name or '__init__'
- _parent_path, path, module_name = _find_module(module_name, package_dir, root_dir)
- spec = _find_spec(module_name, path)
-
- try:
- return getattr(StaticModule(module_name, spec), attr_name)
- except Exception:
- # fallback to evaluate module
- module = _load_spec(spec, module_name)
- return getattr(module, attr_name)
-
-
-def _find_spec(module_name: str, module_path: Optional[_Path]) -> ModuleSpec:
- spec = importlib.util.spec_from_file_location(module_name, module_path)
- spec = spec or importlib.util.find_spec(module_name)
-
- if spec is None:
- raise ModuleNotFoundError(module_name)
-
- return spec
-
-
-def _load_spec(spec: ModuleSpec, module_name: str) -> ModuleType:
- name = getattr(spec, "__name__", module_name)
- if name in sys.modules:
- return sys.modules[name]
- module = importlib.util.module_from_spec(spec)
- sys.modules[name] = module # cache (it also ensures `==` works on loaded items)
- spec.loader.exec_module(module) # type: ignore
- return module
-
-
-def _find_module(
- module_name: str, package_dir: Optional[Mapping[str, str]], root_dir: _Path
-) -> Tuple[_Path, Optional[str], str]:
- """Given a module (that could normally be imported by ``module_name``
- after the build is complete), find the path to the parent directory where
- it is contained and the canonical name that could be used to import it
- considering the ``package_dir`` in the build configuration and ``root_dir``
- """
- parent_path = root_dir
- module_parts = module_name.split('.')
- if package_dir:
- if module_parts[0] in package_dir:
- # A custom path was specified for the module we want to import
- custom_path = package_dir[module_parts[0]]
- parts = custom_path.rsplit('/', 1)
- if len(parts) > 1:
- parent_path = os.path.join(root_dir, parts[0])
- parent_module = parts[1]
- else:
- parent_module = custom_path
- module_name = ".".join([parent_module, *module_parts[1:]])
- elif '' in package_dir:
- # A custom parent directory was specified for all root modules
- parent_path = os.path.join(root_dir, package_dir[''])
-
- path_start = os.path.join(parent_path, *module_name.split("."))
- candidates = chain(
- (f"{path_start}.py", os.path.join(path_start, "__init__.py")),
- iglob(f"{path_start}.*")
- )
- module_path = next((x for x in candidates if os.path.isfile(x)), None)
- return parent_path, module_path, module_name
-
-
-def resolve_class(
- qualified_class_name: str,
- package_dir: Optional[Mapping[str, str]] = None,
- root_dir: Optional[_Path] = None
-) -> Callable:
- """Given a qualified class name, return the associated class object"""
- root_dir = root_dir or os.getcwd()
- idx = qualified_class_name.rfind('.')
- class_name = qualified_class_name[idx + 1 :]
- pkg_name = qualified_class_name[:idx]
-
- _parent_path, path, module_name = _find_module(pkg_name, package_dir, root_dir)
- module = _load_spec(_find_spec(module_name, path), module_name)
- return getattr(module, class_name)
-
-
-def cmdclass(
- values: Dict[str, str],
- package_dir: Optional[Mapping[str, str]] = None,
- root_dir: Optional[_Path] = None
-) -> Dict[str, Callable]:
- """Given a dictionary mapping command names to strings for qualified class
- names, apply :func:`resolve_class` to the dict values.
- """
- return {k: resolve_class(v, package_dir, root_dir) for k, v in values.items()}
-
-
-def find_packages(
- *,
- namespaces=True,
- fill_package_dir: Optional[Dict[str, str]] = None,
- root_dir: Optional[_Path] = None,
- **kwargs
-) -> List[str]:
- """Works similarly to :func:`setuptools.find_packages`, but with all
- arguments given as keyword arguments. Moreover, ``where`` can be given
- as a list (the results will be simply concatenated).
-
- When the additional keyword argument ``namespaces`` is ``True``, it will
- behave like :func:`setuptools.find_namespace_packages`` (i.e. include
- implicit namespaces as per :pep:`420`).
-
- The ``where`` argument will be considered relative to ``root_dir`` (or the current
- working directory when ``root_dir`` is not given).
-
- If the ``fill_package_dir`` argument is passed, this function will consider it as a
- similar data structure to the ``package_dir`` configuration parameter add fill-in
- any missing package location.
-
- :rtype: list
- """
- from setuptools.discovery import construct_package_dir
- from setuptools.extern.more_itertools import unique_everseen, always_iterable
-
- if namespaces:
- from setuptools.discovery import PEP420PackageFinder as PackageFinder
- else:
- from setuptools.discovery import PackageFinder # type: ignore
-
- root_dir = root_dir or os.curdir
- where = kwargs.pop('where', ['.'])
- packages: List[str] = []
- fill_package_dir = {} if fill_package_dir is None else fill_package_dir
- search = list(unique_everseen(always_iterable(where)))
-
- if len(search) == 1 and all(not _same_path(search[0], x) for x in (".", root_dir)):
- fill_package_dir.setdefault("", search[0])
-
- for path in search:
- package_path = _nest_path(root_dir, path)
- pkgs = PackageFinder.find(package_path, **kwargs)
- packages.extend(pkgs)
- if pkgs and not (
- fill_package_dir.get("") == path
- or os.path.samefile(package_path, root_dir)
- ):
- fill_package_dir.update(construct_package_dir(pkgs, path))
-
- return packages
-
-
-def _same_path(p1: _Path, p2: _Path) -> bool:
- """Differs from os.path.samefile because it does not require paths to exist.
- Purely string based (no comparison between i-nodes).
- >>> _same_path("a/b", "./a/b")
- True
- >>> _same_path("a/b", "a/./b")
- True
- >>> _same_path("a/b", "././a/b")
- True
- >>> _same_path("a/b", "./a/b/c/..")
- True
- >>> _same_path("a/b", "../a/b/c")
- False
- >>> _same_path("a", "a/b")
- False
- """
- return os.path.normpath(p1) == os.path.normpath(p2)
-
-
-def _nest_path(parent: _Path, path: _Path) -> str:
- path = parent if path in {".", ""} else os.path.join(parent, path)
- return os.path.normpath(path)
-
-
-def version(value: Union[Callable, Iterable[Union[str, int]], str]) -> str:
- """When getting the version directly from an attribute,
- it should be normalised to string.
- """
- if callable(value):
- value = value()
-
- value = cast(Iterable[Union[str, int]], value)
-
- if not isinstance(value, str):
- if hasattr(value, '__iter__'):
- value = '.'.join(map(str, value))
- else:
- value = '%s' % value
-
- return value
-
-
-def canonic_package_data(package_data: dict) -> dict:
- if "*" in package_data:
- package_data[""] = package_data.pop("*")
- return package_data
-
-
-def canonic_data_files(
- data_files: Union[list, dict], root_dir: Optional[_Path] = None
-) -> List[Tuple[str, List[str]]]:
- """For compatibility with ``setup.py``, ``data_files`` should be a list
- of pairs instead of a dict.
-
- This function also expands glob patterns.
- """
- if isinstance(data_files, list):
- return data_files
-
- return [
- (dest, glob_relative(patterns, root_dir))
- for dest, patterns in data_files.items()
- ]
-
-
-def entry_points(text: str, text_source="entry-points") -> Dict[str, dict]:
- """Given the contents of entry-points file,
- process it into a 2-level dictionary (``dict[str, dict[str, str]]``).
- The first level keys are entry-point groups, the second level keys are
- entry-point names, and the second level values are references to objects
- (that correspond to the entry-point value).
- """
- parser = ConfigParser(default_section=None, delimiters=("=",)) # type: ignore
- parser.optionxform = str # case sensitive
- parser.read_string(text, text_source)
- groups = {k: dict(v.items()) for k, v in parser.items()}
- groups.pop(parser.default_section, None)
- return groups
-
-
-class EnsurePackagesDiscovered:
- """Some expand functions require all the packages to already be discovered before
- they run, e.g. :func:`read_attr`, :func:`resolve_class`, :func:`cmdclass`.
-
- Therefore in some cases we will need to run autodiscovery during the evaluation of
- the configuration. However, it is better to postpone calling package discovery as
- much as possible, because some parameters can influence it (e.g. ``package_dir``),
- and those might not have been processed yet.
- """
-
- def __init__(self, distribution: "Distribution"):
- self._dist = distribution
- self._called = False
-
- def __call__(self):
- """Trigger the automatic package discovery, if it is still necessary."""
- if not self._called:
- self._called = True
- self._dist.set_defaults(name=False) # Skip name, we can still be parsing
-
- def __enter__(self):
- return self
-
- def __exit__(self, _exc_type, _exc_value, _traceback):
- if self._called:
- self._dist.set_defaults.analyse_name() # Now we can set a default name
-
- def _get_package_dir(self) -> Mapping[str, str]:
- self()
- pkg_dir = self._dist.package_dir
- return {} if pkg_dir is None else pkg_dir
-
- @property
- def package_dir(self) -> Mapping[str, str]:
- """Proxy to ``package_dir`` that may trigger auto-discovery when used."""
- return LazyMappingProxy(self._get_package_dir)
-
-
-class LazyMappingProxy(Mapping[_K, _V]):
- """Mapping proxy that delays resolving the target object, until really needed.
-
- >>> def obtain_mapping():
- ... print("Running expensive function!")
- ... return {"key": "value", "other key": "other value"}
- >>> mapping = LazyMappingProxy(obtain_mapping)
- >>> mapping["key"]
- Running expensive function!
- 'value'
- >>> mapping["other key"]
- 'other value'
- """
-
- def __init__(self, obtain_mapping_value: Callable[[], Mapping[_K, _V]]):
- self._obtain = obtain_mapping_value
- self._value: Optional[Mapping[_K, _V]] = None
-
- def _target(self) -> Mapping[_K, _V]:
- if self._value is None:
- self._value = self._obtain()
- return self._value
-
- def __getitem__(self, key: _K) -> _V:
- return self._target()[key]
-
- def __len__(self) -> int:
- return len(self._target())
-
- def __iter__(self) -> Iterator[_K]:
- return iter(self._target())
diff --git a/spaces/tmaham/DS-Fusion-Express/ldm/modules/diffusionmodules/__init__.py b/spaces/tmaham/DS-Fusion-Express/ldm/modules/diffusionmodules/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/tomandandy/MusicGen3/CHANGELOG.md b/spaces/tomandandy/MusicGen3/CHANGELOG.md
deleted file mode 100644
index 24fc214df236b40efead4b1585b01632d9658e9b..0000000000000000000000000000000000000000
--- a/spaces/tomandandy/MusicGen3/CHANGELOG.md
+++ /dev/null
@@ -1,23 +0,0 @@
-# Changelog
-
-All notable changes to this project will be documented in this file.
-
-The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/).
-
-## [0.0.2a] - TBD
-
-Improved demo, fixed top p (thanks @jnordberg).
-
-Compressor tanh on output to avoid clipping with some style (especially piano).
-Now repeating the conditioning periodically if it is too short.
-
-More options when launching Gradio app locally (thanks @ashleykleynhans).
-
-Testing out PyTorch 2.0 memory efficient attention.
-
-Added extended generation (infinite length) by slowly moving the windows.
-Note that other implementations exist: https://github.com/camenduru/MusicGen-colab.
-
-## [0.0.1] - 2023-06-09
-
-Initial release, with model evaluation only.
diff --git a/spaces/tomofi/MMOCR/mmocr/models/textdet/detectors/__init__.py b/spaces/tomofi/MMOCR/mmocr/models/textdet/detectors/__init__.py
deleted file mode 100644
index 290beee915cf7065559ac3cfde016ad7127bed85..0000000000000000000000000000000000000000
--- a/spaces/tomofi/MMOCR/mmocr/models/textdet/detectors/__init__.py
+++ /dev/null
@@ -1,15 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .dbnet import DBNet
-from .drrg import DRRG
-from .fcenet import FCENet
-from .ocr_mask_rcnn import OCRMaskRCNN
-from .panet import PANet
-from .psenet import PSENet
-from .single_stage_text_detector import SingleStageTextDetector
-from .text_detector_mixin import TextDetectorMixin
-from .textsnake import TextSnake
-
-__all__ = [
- 'TextDetectorMixin', 'SingleStageTextDetector', 'OCRMaskRCNN', 'DBNet',
- 'PANet', 'PSENet', 'TextSnake', 'FCENet', 'DRRG'
-]
diff --git a/spaces/tomofi/MMOCR/mmocr/models/textrecog/__init__.py b/spaces/tomofi/MMOCR/mmocr/models/textrecog/__init__.py
deleted file mode 100644
index 9a813067469597a3fe5f8ab926ce1309def41733..0000000000000000000000000000000000000000
--- a/spaces/tomofi/MMOCR/mmocr/models/textrecog/__init__.py
+++ /dev/null
@@ -1,20 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from . import (backbones, convertors, decoders, encoders, fusers, heads,
- losses, necks, plugins, preprocessor, recognizer)
-from .backbones import * # NOQA
-from .convertors import * # NOQA
-from .decoders import * # NOQA
-from .encoders import * # NOQA
-from .fusers import * # NOQA
-from .heads import * # NOQA
-from .losses import * # NOQA
-from .necks import * # NOQA
-from .plugins import * # NOQA
-from .preprocessor import * # NOQA
-from .recognizer import * # NOQA
-
-__all__ = (
- backbones.__all__ + convertors.__all__ + decoders.__all__ +
- encoders.__all__ + heads.__all__ + losses.__all__ + necks.__all__ +
- preprocessor.__all__ + recognizer.__all__ + fusers.__all__ +
- plugins.__all__)
diff --git a/spaces/tomofi/NDLOCR/src/ndl_layout/mmdetection/configs/hrnet/mask_rcnn_hrnetv2p_w18_2x_coco.py b/spaces/tomofi/NDLOCR/src/ndl_layout/mmdetection/configs/hrnet/mask_rcnn_hrnetv2p_w18_2x_coco.py
deleted file mode 100644
index ca62682a3b2d328cc9a8fd08887bcc1bac53104d..0000000000000000000000000000000000000000
--- a/spaces/tomofi/NDLOCR/src/ndl_layout/mmdetection/configs/hrnet/mask_rcnn_hrnetv2p_w18_2x_coco.py
+++ /dev/null
@@ -1,4 +0,0 @@
-_base_ = './mask_rcnn_hrnetv2p_w18_1x_coco.py'
-# learning policy
-lr_config = dict(step=[16, 22])
-runner = dict(type='EpochBasedRunner', max_epochs=24)
diff --git a/spaces/twdac/BuChengFangYuan-ChineseJapaneseTranslation/app/my_palm.py b/spaces/twdac/BuChengFangYuan-ChineseJapaneseTranslation/app/my_palm.py
deleted file mode 100644
index b7d583e8af42b152eedaacdf3c38beb6166a11d6..0000000000000000000000000000000000000000
--- a/spaces/twdac/BuChengFangYuan-ChineseJapaneseTranslation/app/my_palm.py
+++ /dev/null
@@ -1,224 +0,0 @@
-'''
-加入训练时随机位置偏置
-
-与 palm_net_2 权重一致,仅为加入使用 xformers 的xformers版本
-'''
-
-# alter from https://github.com/lucidrains/PaLM-pytorch
-
-import torch
-import torch.nn.functional as F
-import torch.backends.cuda
-from torch import einsum, nn
-import random
-import nlg_utils
-from model_utils_torch import weighted_and_neg_topk_cross_entropy
-
-# rotary positional embedding
-# https://arxiv.org/abs/2104.09864
-
-
-class RotaryEmbedding(torch.jit.ScriptModule):
- def __init__(self, dim):
- super().__init__()
- inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2, dtype=torch.float32) / dim))
- self.register_buffer("inv_freq", inv_freq)
-
- @torch.jit.script_method
- def forward(self, max_seq_len: int, device: torch.device, pos_scale: int, pos_bias: int):
- seq = torch.arange(max_seq_len, device=device, dtype=self.inv_freq.dtype) * pos_scale + pos_bias
- freqs = einsum("i, j -> i j", seq, self.inv_freq)
- return torch.cat((freqs, freqs), dim=-1)
-
-
-@torch.jit.script
-def rotate_half(x):
- x = x.reshape(x.shape[:-1] + (2, x.shape[-1]//2))
- x1, x2 = x.unbind(dim=-2)
- return torch.cat((-x2, x1), dim=-1)
-
-
-@torch.jit.script
-def apply_rotary_pos_emb(pos, t):
- return (t * pos.cos()) + (rotate_half(t) * pos.sin())
-
-
-# classic Noam Shazeer paper, except here they use SwiGLU instead of the more popular GEGLU for gating the feedforward
-# https://arxiv.org/abs/2002.05202
-
-class SwiGLU(torch.jit.ScriptModule):
- @torch.jit.script_method
- def forward(self, x):
- x, gate = x.chunk(2, dim=-1)
- return F.silu(gate) * x
-
-
-# parallel attention and feedforward with residual
-# discovered by Wang et al + EleutherAI from GPT-J fame
-
-class ParallelTransformerBlock(torch.jit.ScriptModule):
- def __init__(self, in_dim, head_dim=64, n_head=8, ffn_mul=4):
- super().__init__()
- self.norm = nn.LayerNorm(in_dim)
- self.norm.register_parameter('bias', None)
-
- attn_inner_dim = head_dim * n_head
- ffn_inner_dim = in_dim * ffn_mul
- self.fused_dims = (attn_inner_dim, head_dim, head_dim, (ffn_inner_dim * 2))
-
- self.n_head = n_head
- self.rotary_emb = RotaryEmbedding(head_dim)
-
- self.fused_attn_ff_proj = nn.Linear(in_dim, sum(self.fused_dims), bias=False)
- self.attn_out = nn.Linear(attn_inner_dim, in_dim, bias=False)
-
- self.ff_out = nn.Sequential(
- SwiGLU(),
- nn.Linear(ffn_inner_dim, in_dim, bias=False)
- )
-
- @torch.jit.script_method
- def get_mask(self, n: int, device: torch.device):
- mask = torch.ones((n, n), device=device, dtype=torch.bool).triu(1)
- return mask
-
- @torch.jit.script_method
- def forward(self, x, pos_scale: int, pos_bias: int):
- """
- einstein notation
- b - batch
- h - heads
- n, i, j - sequence length (base sequence length, source, target)
- d - feature dimension
- """
- ori_x = x
-
- n, device, h = x.shape[1], x.device, self.n_head
-
- # pre layernorm
- x = self.norm(x)
-
- # attention queries, keys, values, and feedforward inner
- q, k, v, ff = self.fused_attn_ff_proj(x).split(self.fused_dims, dim=-1)
-
- # split heads
- # they use multi-query single-key-value attention, yet another Noam Shazeer paper
- # they found no performance loss past a certain scale, and more efficient decoding obviously
- # https://arxiv.org/abs/1911.02150
-
- qB,qL,qC = q.shape
- q = q.reshape(qB, qL, h, qC//h).permute(0, 2, 1, 3)
-
- # rotary embeddings
- positions = self.rotary_emb(n, device=device, pos_scale=pos_scale, pos_bias=pos_bias)
- q = apply_rotary_pos_emb(positions, q)
- k = apply_rotary_pos_emb(positions, k)
-
- k = k[:, None].expand_as(q)
- v = v[:, None].expand_as(q)
- out = F.scaled_dot_product_attention(q, k, v, is_causal=True)
- out = out.permute(0, 2, 1, 3)
-
- # merge heads
- oB, oL, oH, oC = out.shape
- out = out.reshape(oB, oL, oH*oC)
-
- return ori_x + self.attn_out(out) + self.ff_out(ff)
-
-
-# transformer
-
-class PaLM(nn.Module):
- def __init__(self, hidden_dim, vocab_size, n_decoder, head_dim=64, n_head=8, ffn_mul=4, use_random_pos=True):
- super().__init__()
- self.use_random_pos = use_random_pos
- self.token_emb = nn.Embedding(vocab_size, hidden_dim)
- self.decoders = nn.ModuleList([
- ParallelTransformerBlock(in_dim=hidden_dim, head_dim=head_dim, n_head=n_head, ffn_mul=ffn_mul)
- for _ in range(n_decoder)
- ])
- self.out_norm = nn.LayerNorm(hidden_dim)
- self.out_norm.register_parameter('bias', None)
-
- nn.init.normal_(self.token_emb.weight, std=0.02)
-
- def pred(self, x, stop_tokens, max_len, pad_token, x_mask=None, top_k=10, top_p=0.9, temperature=1.):
- if isinstance(stop_tokens, int):
- stop_tokens = {stop_tokens}
-
- with torch.inference_mode():
- out = []
- for sx in x:
- sy = torch.zeros([0], dtype=sx.dtype, device=sx.device)
- while True:
- so, _ = self(torch.cat([sx,sy])[None,], None)
- so = so[0, -1, :]
- # 进行采样
- out_prob = nlg_utils.nlg_softmax_prob(so, temperature)
- out_prob = nlg_utils.nlg_prob_decay(out_prob, sy, watch_len=10)
- out_char = nlg_utils.nlg_sample(out_prob, top_k, top_p)
- sy = torch.cat([sy, out_char])
- if sy[-1].item() in stop_tokens or len(sy) >= max_len:
- break
-
- out.append(sy)
- out = torch.nested.as_nested_tensor(out)
- out = torch.nested.to_padded_tensor(out, pad_token)
- return out
-
- def forward(self, x, label=None, label_mask=None, label_weight=None, label_smoothing=0., x_mask=None):
- pos_scale = 1
- pos_bias = 0
- if self.training and self.use_random_pos:
- pos_scale = random.randint(1, 8)
- # pos_bias = random.randint(0, 64)
-
- y = self.token_emb(x)
- for m in self.decoders:
- y = m(y, pos_scale, pos_bias)
- y = self.out_norm(y)
-
- out = F.linear(y, self.token_emb.weight, None)
-
- loss = None
- if label is not None:
-
- assert label.shape == x.shape
-
- topk = 10
- loss = weighted_and_neg_topk_cross_entropy(out.transpose(1, 2), label.long(), topk, label_weight, label_mask, label_smoothing)
-
- return out, loss
-
-
-if __name__ == '__main__':
- from model_utils_torch import print_params_size, print_buffers_size
-
- net = PaLM(hidden_dim=384, vocab_size=10000, n_decoder=16, head_dim=32, n_head=16, ffn_mul=2)
- net.cuda()
-
- print_params_size(net)
- print_buffers_size(net)
-
- torch.backends.cuda.enable_mem_efficient_sdp(True)
-
- from model_utils_torch import Adan
-
- optim = Adan(net.parameters(), 1e-4)
-
- train_xs = torch.randint(1, 100, [5000, 100]).cuda()
- train_ys = torch.roll(train_xs, -1, 1)
-
- net.cuda()
-
- for it in range(200000):
- ids = torch.randint(0, 2000, [16]).cuda()
-
- xs = train_xs[ids]
- ys = train_ys[ids]
-
- y, loss = net(xs, ys)
- optim.zero_grad()
- loss.backward()
- optim.step()
- print(it, loss.item())
diff --git a/spaces/usbethFlerru/sovits-modelsV2/example/Alag Hd Movie In Hindi Download Utorrent ((EXCLUSIVE)).md b/spaces/usbethFlerru/sovits-modelsV2/example/Alag Hd Movie In Hindi Download Utorrent ((EXCLUSIVE)).md
deleted file mode 100644
index 8b25153bd926957d74e29b2c24b0fc7ab231bf95..0000000000000000000000000000000000000000
--- a/spaces/usbethFlerru/sovits-modelsV2/example/Alag Hd Movie In Hindi Download Utorrent ((EXCLUSIVE)).md
+++ /dev/null
@@ -1,18 +0,0 @@
-
-How to Download Alag HD Movie in Hindi Using Utorrent
-Alag is a 2006 Bollywood movie starring Akshay Kapoor and Dia Mirza. It is a sci-fi drama about a young man who has telekinetic powers and is hunted by a ruthless scientist. The movie was praised for its unique concept and special effects, but it was a box office flop.
-If you want to watch Alag in HD quality and in Hindi language, you can use Utorrent, a popular software for downloading torrent files. Torrent files are small files that contain information about the location of larger files on the internet. You can use Utorrent to download movies, music, games, and other content for free.
-Alag Hd Movie In Hindi Download Utorrent Download File ⚙⚙⚙ https://urlcod.com/2uyUrx
Here are the steps to download Alag HD movie in Hindi using Utorrent:
-
-Download and install Utorrent on your computer from https://www.utorrent.com/ . It is available for Windows, Mac, Linux, and Android devices.
-Go to a torrent website that has Alag HD movie in Hindi. Some examples are https://onlyhollywood4u.co/Bollywood.html , https://peatix.com/group/10511811/view , and https://soundcloud.com/cuncjaoporme/alag-hd-movie-in-hindi-download-utorrent . Be careful of fake or malicious links that may harm your computer or device.
-Search for Alag HD movie in Hindi on the torrent website. You may have to use filters or categories to find it. Look for the file that has the highest number of seeders and leechers. Seeders are people who have the complete file and are sharing it with others. Leechers are people who are downloading the file but have not completed it yet. The more seeders and leechers, the faster the download speed.
-Click on the torrent file or the magnet link to download it. A magnet link is a URL that starts with magnet:? and contains information about the torrent file. You can copy and paste the magnet link into Utorrent or click on it directly.
-Utorrent will open and ask you where you want to save the file. Choose a location on your computer or device that has enough space. You can also select which files you want to download from the torrent file. For example, you may only want to download the video file and not the subtitles or extras.
-Click OK to start the download. You can monitor the progress of the download on Utorrent. You can also pause, resume, or cancel the download at any time.
-Once the download is complete, you can open the file and enjoy watching Alag HD movie in Hindi.
-
-Note: Downloading movies using Utorrent may be illegal in some countries or regions. Please check your local laws before downloading any content. Also, be aware of the risks of downloading files from unknown sources. They may contain viruses, malware, or spyware that can harm your computer or device. Always scan your files with an antivirus software before opening them.
d5da3c52bf {
- if (key === null) return null;
- if (typeof key === 'string') {
- key = [key]
- }
- const returnData: Record = {}
- const values = await getMany(key)
- key.forEach((k, idx)=> {
- returnData[k] = values[idx]
- })
- return returnData;
- },
- async set(object: any) {
- for (let key of Object.keys(object)) {
- await set(key, object[key])
- }
- },
- async remove(key: string) {
- return del(key);
- },
- async clear() {
- return clear();
- }
-}
diff --git a/spaces/xc9/VITS-Umamusume-voice-synthesizer/modules.py b/spaces/xc9/VITS-Umamusume-voice-synthesizer/modules.py
deleted file mode 100644
index f5af1fd9a20dc03707889f360a39bb4b784a6df3..0000000000000000000000000000000000000000
--- a/spaces/xc9/VITS-Umamusume-voice-synthesizer/modules.py
+++ /dev/null
@@ -1,387 +0,0 @@
-import math
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/xdecoder/Instruct-X-Decoder/xdecoder/body/encoder/__init__.py b/spaces/xdecoder/Instruct-X-Decoder/xdecoder/body/encoder/__init__.py
deleted file mode 100644
index bf9bb57ca080f4e2f1d1edd7c696285a08faa706..0000000000000000000000000000000000000000
--- a/spaces/xdecoder/Instruct-X-Decoder/xdecoder/body/encoder/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .build import build_encoder
\ No newline at end of file
diff --git a/spaces/xiaoxuezi/spleeter/spleeter/model/functions/__init__.py b/spaces/xiaoxuezi/spleeter/spleeter/model/functions/__init__.py
deleted file mode 100644
index ddbd3af232bd061b9b9c8e73a2a3cf032a95a796..0000000000000000000000000000000000000000
--- a/spaces/xiaoxuezi/spleeter/spleeter/model/functions/__init__.py
+++ /dev/null
@@ -1,47 +0,0 @@
-#!/usr/bin/env python
-# coding: utf8
-
-""" This package provide model functions. """
-
-from typing import Callable, Dict, Iterable, Optional
-
-# pyright: reportMissingImports=false
-# pylint: disable=import-error
-import tensorflow as tf
-
-# pylint: enable=import-error
-
-__email__ = "spleeter@deezer.com"
-__author__ = "Deezer Research"
-__license__ = "MIT License"
-
-
-def apply(
- function: Callable,
- input_tensor: tf.Tensor,
- instruments: Iterable[str],
- params: Optional[Dict] = None,
-) -> Dict:
- """
- Apply given function to the input tensor.
-
- Parameters:
- function:
- Function to be applied to tensor.
- input_tensor (tensorflow.Tensor):
- Tensor to apply blstm to.
- instruments (Iterable[str]):
- Iterable that provides a collection of instruments.
- params:
- (Optional) dict of BLSTM parameters.
-
- Returns:
- Created output tensor dict.
- """
- output_dict: Dict = {}
- for instrument in instruments:
- out_name = f"{instrument}_spectrogram"
- output_dict[out_name] = function(
- input_tensor, output_name=out_name, params=params or {}
- )
- return output_dict
diff --git a/spaces/yaelvinker/CLIPasso/U2Net_/model/__init__.py b/spaces/yaelvinker/CLIPasso/U2Net_/model/__init__.py
deleted file mode 100644
index 4d8fa272fb03208e17723b0269eb579b81514540..0000000000000000000000000000000000000000
--- a/spaces/yaelvinker/CLIPasso/U2Net_/model/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-from .u2net import U2NET
-from .u2net import U2NETP
diff --git a/spaces/yaoshining/text-generation-webui/convert-to-flexgen.py b/spaces/yaoshining/text-generation-webui/convert-to-flexgen.py
deleted file mode 100644
index 7654593b539541deebfe904403ce73daa4a8651c..0000000000000000000000000000000000000000
--- a/spaces/yaoshining/text-generation-webui/convert-to-flexgen.py
+++ /dev/null
@@ -1,63 +0,0 @@
-'''
-
-Converts a transformers model to a format compatible with flexgen.
-
-'''
-
-import argparse
-import os
-from pathlib import Path
-
-import numpy as np
-import torch
-from tqdm import tqdm
-from transformers import AutoModelForCausalLM, AutoTokenizer
-
-parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54))
-parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.")
-args = parser.parse_args()
-
-
-def disable_torch_init():
- """
- Disable the redundant torch default initialization to accelerate model creation.
- """
- import torch
- global torch_linear_init_backup
- global torch_layer_norm_init_backup
-
- torch_linear_init_backup = torch.nn.Linear.reset_parameters
- setattr(torch.nn.Linear, "reset_parameters", lambda self: None)
-
- torch_layer_norm_init_backup = torch.nn.LayerNorm.reset_parameters
- setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
-
-
-def restore_torch_init():
- """Rollback the change made by disable_torch_init."""
- import torch
- setattr(torch.nn.Linear, "reset_parameters", torch_linear_init_backup)
- setattr(torch.nn.LayerNorm, "reset_parameters", torch_layer_norm_init_backup)
-
-
-if __name__ == '__main__':
- path = Path(args.MODEL)
- model_name = path.name
-
- print(f"Loading {model_name}...")
- # disable_torch_init()
- model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
- # restore_torch_init()
-
- tokenizer = AutoTokenizer.from_pretrained(path)
-
- out_folder = Path(f"models/{model_name}-np")
- if not Path(out_folder).exists():
- os.mkdir(out_folder)
-
- print(f"Saving the converted model to {out_folder}...")
- for name, param in tqdm(list(model.model.named_parameters())):
- name = name.replace("decoder.final_layer_norm", "decoder.layer_norm")
- param_path = os.path.join(out_folder, name)
- with open(param_path, "wb") as f:
- np.save(f, param.cpu().detach().numpy())
diff --git a/spaces/ygangang/VToonify/vtoonify/model/raft/core/update.py b/spaces/ygangang/VToonify/vtoonify/model/raft/core/update.py
deleted file mode 100644
index f940497f9b5eb1c12091574fe9a0223a1b196d50..0000000000000000000000000000000000000000
--- a/spaces/ygangang/VToonify/vtoonify/model/raft/core/update.py
+++ /dev/null
@@ -1,139 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-
-class FlowHead(nn.Module):
- def __init__(self, input_dim=128, hidden_dim=256):
- super(FlowHead, self).__init__()
- self.conv1 = nn.Conv2d(input_dim, hidden_dim, 3, padding=1)
- self.conv2 = nn.Conv2d(hidden_dim, 2, 3, padding=1)
- self.relu = nn.ReLU(inplace=True)
-
- def forward(self, x):
- return self.conv2(self.relu(self.conv1(x)))
-
-class ConvGRU(nn.Module):
- def __init__(self, hidden_dim=128, input_dim=192+128):
- super(ConvGRU, self).__init__()
- self.convz = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
- self.convr = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
- self.convq = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
-
- def forward(self, h, x):
- hx = torch.cat([h, x], dim=1)
-
- z = torch.sigmoid(self.convz(hx))
- r = torch.sigmoid(self.convr(hx))
- q = torch.tanh(self.convq(torch.cat([r*h, x], dim=1)))
-
- h = (1-z) * h + z * q
- return h
-
-class SepConvGRU(nn.Module):
- def __init__(self, hidden_dim=128, input_dim=192+128):
- super(SepConvGRU, self).__init__()
- self.convz1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
- self.convr1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
- self.convq1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
-
- self.convz2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
- self.convr2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
- self.convq2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
-
-
- def forward(self, h, x):
- # horizontal
- hx = torch.cat([h, x], dim=1)
- z = torch.sigmoid(self.convz1(hx))
- r = torch.sigmoid(self.convr1(hx))
- q = torch.tanh(self.convq1(torch.cat([r*h, x], dim=1)))
- h = (1-z) * h + z * q
-
- # vertical
- hx = torch.cat([h, x], dim=1)
- z = torch.sigmoid(self.convz2(hx))
- r = torch.sigmoid(self.convr2(hx))
- q = torch.tanh(self.convq2(torch.cat([r*h, x], dim=1)))
- h = (1-z) * h + z * q
-
- return h
-
-class SmallMotionEncoder(nn.Module):
- def __init__(self, args):
- super(SmallMotionEncoder, self).__init__()
- cor_planes = args.corr_levels * (2*args.corr_radius + 1)**2
- self.convc1 = nn.Conv2d(cor_planes, 96, 1, padding=0)
- self.convf1 = nn.Conv2d(2, 64, 7, padding=3)
- self.convf2 = nn.Conv2d(64, 32, 3, padding=1)
- self.conv = nn.Conv2d(128, 80, 3, padding=1)
-
- def forward(self, flow, corr):
- cor = F.relu(self.convc1(corr))
- flo = F.relu(self.convf1(flow))
- flo = F.relu(self.convf2(flo))
- cor_flo = torch.cat([cor, flo], dim=1)
- out = F.relu(self.conv(cor_flo))
- return torch.cat([out, flow], dim=1)
-
-class BasicMotionEncoder(nn.Module):
- def __init__(self, args):
- super(BasicMotionEncoder, self).__init__()
- cor_planes = args.corr_levels * (2*args.corr_radius + 1)**2
- self.convc1 = nn.Conv2d(cor_planes, 256, 1, padding=0)
- self.convc2 = nn.Conv2d(256, 192, 3, padding=1)
- self.convf1 = nn.Conv2d(2, 128, 7, padding=3)
- self.convf2 = nn.Conv2d(128, 64, 3, padding=1)
- self.conv = nn.Conv2d(64+192, 128-2, 3, padding=1)
-
- def forward(self, flow, corr):
- cor = F.relu(self.convc1(corr))
- cor = F.relu(self.convc2(cor))
- flo = F.relu(self.convf1(flow))
- flo = F.relu(self.convf2(flo))
-
- cor_flo = torch.cat([cor, flo], dim=1)
- out = F.relu(self.conv(cor_flo))
- return torch.cat([out, flow], dim=1)
-
-class SmallUpdateBlock(nn.Module):
- def __init__(self, args, hidden_dim=96):
- super(SmallUpdateBlock, self).__init__()
- self.encoder = SmallMotionEncoder(args)
- self.gru = ConvGRU(hidden_dim=hidden_dim, input_dim=82+64)
- self.flow_head = FlowHead(hidden_dim, hidden_dim=128)
-
- def forward(self, net, inp, corr, flow):
- motion_features = self.encoder(flow, corr)
- inp = torch.cat([inp, motion_features], dim=1)
- net = self.gru(net, inp)
- delta_flow = self.flow_head(net)
-
- return net, None, delta_flow
-
-class BasicUpdateBlock(nn.Module):
- def __init__(self, args, hidden_dim=128, input_dim=128):
- super(BasicUpdateBlock, self).__init__()
- self.args = args
- self.encoder = BasicMotionEncoder(args)
- self.gru = SepConvGRU(hidden_dim=hidden_dim, input_dim=128+hidden_dim)
- self.flow_head = FlowHead(hidden_dim, hidden_dim=256)
-
- self.mask = nn.Sequential(
- nn.Conv2d(128, 256, 3, padding=1),
- nn.ReLU(inplace=True),
- nn.Conv2d(256, 64*9, 1, padding=0))
-
- def forward(self, net, inp, corr, flow, upsample=True):
- motion_features = self.encoder(flow, corr)
- inp = torch.cat([inp, motion_features], dim=1)
-
- net = self.gru(net, inp)
- delta_flow = self.flow_head(net)
-
- # scale mask to balence gradients
- mask = .25 * self.mask(net)
- return net, mask, delta_flow
-
-
-
diff --git a/spaces/yizhangliu/Grounded-Segment-Anything/transformers_4_35_0/models/bert/convert_bert_original_tf2_checkpoint_to_pytorch.py b/spaces/yizhangliu/Grounded-Segment-Anything/transformers_4_35_0/models/bert/convert_bert_original_tf2_checkpoint_to_pytorch.py
deleted file mode 100644
index 40533ede435793e418745eccecfbcb3391edd78f..0000000000000000000000000000000000000000
--- a/spaces/yizhangliu/Grounded-Segment-Anything/transformers_4_35_0/models/bert/convert_bert_original_tf2_checkpoint_to_pytorch.py
+++ /dev/null
@@ -1,245 +0,0 @@
-# Copyright 2020 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-This script can be used to convert a head-less TF2.x Bert model to PyTorch, as published on the official (now
-deprecated) GitHub: https://github.com/tensorflow/models/tree/v2.3.0/official/nlp/bert
-
-TF2.x uses different variable names from the original BERT (TF 1.4) implementation. The script re-maps the TF2.x Bert
-weight names to the original names, so the model can be imported with Huggingface/transformer.
-
-You may adapt this script to include classification/MLM/NSP/etc. heads.
-
-Note: This script is only working with an older version of the TensorFlow models repository (<= v2.3.0).
- Models trained with never versions are not compatible with this script.
-"""
-import argparse
-import os
-import re
-
-import tensorflow as tf
-import torch
-
-from transformers import BertConfig, BertModel
-from transformers.utils import logging
-
-
-logging.set_verbosity_info()
-logger = logging.get_logger(__name__)
-
-
-def load_tf2_weights_in_bert(model, tf_checkpoint_path, config):
- tf_path = os.path.abspath(tf_checkpoint_path)
- logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
- # Load weights from TF model
- init_vars = tf.train.list_variables(tf_path)
- names = []
- arrays = []
- layer_depth = []
- for full_name, shape in init_vars:
- # logger.info(f"Loading TF weight {name} with shape {shape}")
- name = full_name.split("/")
- if full_name == "_CHECKPOINTABLE_OBJECT_GRAPH" or name[0] in ["global_step", "save_counter"]:
- logger.info(f"Skipping non-model layer {full_name}")
- continue
- if "optimizer" in full_name:
- logger.info(f"Skipping optimization layer {full_name}")
- continue
- if name[0] == "model":
- # ignore initial 'model'
- name = name[1:]
- # figure out how many levels deep the name is
- depth = 0
- for _name in name:
- if _name.startswith("layer_with_weights"):
- depth += 1
- else:
- break
- layer_depth.append(depth)
- # read data
- array = tf.train.load_variable(tf_path, full_name)
- names.append("/".join(name))
- arrays.append(array)
- logger.info(f"Read a total of {len(arrays):,} layers")
-
- # Sanity check
- if len(set(layer_depth)) != 1:
- raise ValueError(f"Found layer names with different depths (layer depth {list(set(layer_depth))})")
- layer_depth = list(set(layer_depth))[0]
- if layer_depth != 1:
- raise ValueError(
- "The model contains more than just the embedding/encoder layers. This script does not handle MLM/NSP"
- " heads."
- )
-
- # convert layers
- logger.info("Converting weights...")
- for full_name, array in zip(names, arrays):
- name = full_name.split("/")
- pointer = model
- trace = []
- for i, m_name in enumerate(name):
- if m_name == ".ATTRIBUTES":
- # variable names end with .ATTRIBUTES/VARIABLE_VALUE
- break
- if m_name.startswith("layer_with_weights"):
- layer_num = int(m_name.split("-")[-1])
- if layer_num <= 2:
- # embedding layers
- # layer_num 0: word_embeddings
- # layer_num 1: position_embeddings
- # layer_num 2: token_type_embeddings
- continue
- elif layer_num == 3:
- # embedding LayerNorm
- trace.extend(["embeddings", "LayerNorm"])
- pointer = getattr(pointer, "embeddings")
- pointer = getattr(pointer, "LayerNorm")
- elif layer_num > 3 and layer_num < config.num_hidden_layers + 4:
- # encoder layers
- trace.extend(["encoder", "layer", str(layer_num - 4)])
- pointer = getattr(pointer, "encoder")
- pointer = getattr(pointer, "layer")
- pointer = pointer[layer_num - 4]
- elif layer_num == config.num_hidden_layers + 4:
- # pooler layer
- trace.extend(["pooler", "dense"])
- pointer = getattr(pointer, "pooler")
- pointer = getattr(pointer, "dense")
- elif m_name == "embeddings":
- trace.append("embeddings")
- pointer = getattr(pointer, "embeddings")
- if layer_num == 0:
- trace.append("word_embeddings")
- pointer = getattr(pointer, "word_embeddings")
- elif layer_num == 1:
- trace.append("position_embeddings")
- pointer = getattr(pointer, "position_embeddings")
- elif layer_num == 2:
- trace.append("token_type_embeddings")
- pointer = getattr(pointer, "token_type_embeddings")
- else:
- raise ValueError(f"Unknown embedding layer with name {full_name}")
- trace.append("weight")
- pointer = getattr(pointer, "weight")
- elif m_name == "_attention_layer":
- # self-attention layer
- trace.extend(["attention", "self"])
- pointer = getattr(pointer, "attention")
- pointer = getattr(pointer, "self")
- elif m_name == "_attention_layer_norm":
- # output attention norm
- trace.extend(["attention", "output", "LayerNorm"])
- pointer = getattr(pointer, "attention")
- pointer = getattr(pointer, "output")
- pointer = getattr(pointer, "LayerNorm")
- elif m_name == "_attention_output_dense":
- # output attention dense
- trace.extend(["attention", "output", "dense"])
- pointer = getattr(pointer, "attention")
- pointer = getattr(pointer, "output")
- pointer = getattr(pointer, "dense")
- elif m_name == "_output_dense":
- # output dense
- trace.extend(["output", "dense"])
- pointer = getattr(pointer, "output")
- pointer = getattr(pointer, "dense")
- elif m_name == "_output_layer_norm":
- # output dense
- trace.extend(["output", "LayerNorm"])
- pointer = getattr(pointer, "output")
- pointer = getattr(pointer, "LayerNorm")
- elif m_name == "_key_dense":
- # attention key
- trace.append("key")
- pointer = getattr(pointer, "key")
- elif m_name == "_query_dense":
- # attention query
- trace.append("query")
- pointer = getattr(pointer, "query")
- elif m_name == "_value_dense":
- # attention value
- trace.append("value")
- pointer = getattr(pointer, "value")
- elif m_name == "_intermediate_dense":
- # attention intermediate dense
- trace.extend(["intermediate", "dense"])
- pointer = getattr(pointer, "intermediate")
- pointer = getattr(pointer, "dense")
- elif m_name == "_output_layer_norm":
- # output layer norm
- trace.append("output")
- pointer = getattr(pointer, "output")
- # weights & biases
- elif m_name in ["bias", "beta"]:
- trace.append("bias")
- pointer = getattr(pointer, "bias")
- elif m_name in ["kernel", "gamma"]:
- trace.append("weight")
- pointer = getattr(pointer, "weight")
- else:
- logger.warning(f"Ignored {m_name}")
- # for certain layers reshape is necessary
- trace = ".".join(trace)
- if re.match(r"(\S+)\.attention\.self\.(key|value|query)\.(bias|weight)", trace) or re.match(
- r"(\S+)\.attention\.output\.dense\.weight", trace
- ):
- array = array.reshape(pointer.data.shape)
- if "kernel" in full_name:
- array = array.transpose()
- if pointer.shape == array.shape:
- pointer.data = torch.from_numpy(array)
- else:
- raise ValueError(
- f"Shape mismatch in layer {full_name}: Model expects shape {pointer.shape} but layer contains shape:"
- f" {array.shape}"
- )
- logger.info(f"Successfully set variable {full_name} to PyTorch layer {trace}")
- return model
-
-
-def convert_tf2_checkpoint_to_pytorch(tf_checkpoint_path, config_path, pytorch_dump_path):
- # Instantiate model
- logger.info(f"Loading model based on config from {config_path}...")
- config = BertConfig.from_json_file(config_path)
- model = BertModel(config)
-
- # Load weights from checkpoint
- logger.info(f"Loading weights from checkpoint {tf_checkpoint_path}...")
- load_tf2_weights_in_bert(model, tf_checkpoint_path, config)
-
- # Save pytorch-model
- logger.info(f"Saving PyTorch model to {pytorch_dump_path}...")
- torch.save(model.state_dict(), pytorch_dump_path)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--tf_checkpoint_path", type=str, required=True, help="Path to the TensorFlow 2.x checkpoint path."
- )
- parser.add_argument(
- "--bert_config_file",
- type=str,
- required=True,
- help="The config json file corresponding to the BERT model. This specifies the model architecture.",
- )
- parser.add_argument(
- "--pytorch_dump_path",
- type=str,
- required=True,
- help="Path to the output PyTorch model (must include filename).",
- )
- args = parser.parse_args()
- convert_tf2_checkpoint_to_pytorch(args.tf_checkpoint_path, args.bert_config_file, args.pytorch_dump_path)
diff --git a/spaces/yizhangliu/Grounded-Segment-Anything/transformers_4_35_0/models/imagegpt/configuration_imagegpt.py b/spaces/yizhangliu/Grounded-Segment-Anything/transformers_4_35_0/models/imagegpt/configuration_imagegpt.py
deleted file mode 100644
index 85f44a4e344d2a015c1e30df30f3e7ef7addc18a..0000000000000000000000000000000000000000
--- a/spaces/yizhangliu/Grounded-Segment-Anything/transformers_4_35_0/models/imagegpt/configuration_imagegpt.py
+++ /dev/null
@@ -1,202 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-""" OpenAI ImageGPT configuration"""
-
-from collections import OrderedDict
-from typing import TYPE_CHECKING, Any, Mapping, Optional
-
-from ...configuration_utils import PretrainedConfig
-from ...onnx import OnnxConfig
-from ...utils import logging
-
-
-if TYPE_CHECKING:
- from ... import FeatureExtractionMixin, TensorType
-
-logger = logging.get_logger(__name__)
-
-IMAGEGPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "openai/imagegpt-small": "",
- "openai/imagegpt-medium": "",
- "openai/imagegpt-large": "",
-}
-
-
-class ImageGPTConfig(PretrainedConfig):
- """
- This is the configuration class to store the configuration of a [`ImageGPTModel`] or a [`TFImageGPTModel`]. It is
- used to instantiate a GPT-2 model according to the specified arguments, defining the model architecture.
- Instantiating a configuration with the defaults will yield a similar configuration to that of the ImageGPT
- [openai/imagegpt-small](https://huggingface.co/openai/imagegpt-small) architecture.
-
- Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
- documentation from [`PretrainedConfig`] for more information.
-
-
- Args:
- vocab_size (`int`, *optional*, defaults to 512):
- Vocabulary size of the GPT-2 model. Defines the number of different tokens that can be represented by the
- `inputs_ids` passed when calling [`ImageGPTModel`] or [`TFImageGPTModel`].
- n_positions (`int`, *optional*, defaults to 32*32):
- The maximum sequence length that this model might ever be used with. Typically set this to something large
- just in case (e.g., 512 or 1024 or 2048).
- n_embd (`int`, *optional*, defaults to 512):
- Dimensionality of the embeddings and hidden states.
- n_layer (`int`, *optional*, defaults to 24):
- Number of hidden layers in the Transformer encoder.
- n_head (`int`, *optional*, defaults to 8):
- Number of attention heads for each attention layer in the Transformer encoder.
- n_inner (`int`, *optional*, defaults to None):
- Dimensionality of the inner feed-forward layers. `None` will set it to 4 times n_embd
- activation_function (`str`, *optional*, defaults to `"quick_gelu"`):
- Activation function (can be one of the activation functions defined in src/transformers/activations.py).
- Defaults to "quick_gelu".
- resid_pdrop (`float`, *optional*, defaults to 0.1):
- The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
- embd_pdrop (`int`, *optional*, defaults to 0.1):
- The dropout ratio for the embeddings.
- attn_pdrop (`float`, *optional*, defaults to 0.1):
- The dropout ratio for the attention.
- layer_norm_epsilon (`float`, *optional*, defaults to 1e-5):
- The epsilon to use in the layer normalization layers.
- initializer_range (`float`, *optional*, defaults to 0.02):
- The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
- scale_attn_weights (`bool`, *optional*, defaults to `True`):
- Scale attention weights by dividing by sqrt(hidden_size)..
- use_cache (`bool`, *optional*, defaults to `True`):
- Whether or not the model should return the last key/values attentions (not used by all models).
- scale_attn_by_inverse_layer_idx (`bool`, *optional*, defaults to `False`):
- Whether to additionally scale attention weights by `1 / layer_idx + 1`.
- reorder_and_upcast_attn (`bool`, *optional*, defaults to `False`):
- Whether to scale keys (K) prior to computing attention (dot-product) and upcast attention
- dot-product/softmax to float() when training with mixed precision.
-
- Example:
-
- ```python
- >>> from transformers import ImageGPTConfig, ImageGPTModel
-
- >>> # Initializing a ImageGPT configuration
- >>> configuration = ImageGPTConfig()
-
- >>> # Initializing a model (with random weights) from the configuration
- >>> model = ImageGPTModel(configuration)
-
- >>> # Accessing the model configuration
- >>> configuration = model.config
- ```"""
-
- model_type = "imagegpt"
- keys_to_ignore_at_inference = ["past_key_values"]
- attribute_map = {
- "hidden_size": "n_embd",
- "max_position_embeddings": "n_positions",
- "num_attention_heads": "n_head",
- "num_hidden_layers": "n_layer",
- }
-
- def __init__(
- self,
- vocab_size=512 + 1, # add one for start of sentence (sos) token
- n_positions=32 * 32,
- n_embd=512,
- n_layer=24,
- n_head=8,
- n_inner=None,
- activation_function="quick_gelu",
- resid_pdrop=0.1,
- embd_pdrop=0.1,
- attn_pdrop=0.1,
- layer_norm_epsilon=1e-5,
- initializer_range=0.02,
- scale_attn_weights=True,
- use_cache=True,
- tie_word_embeddings=False,
- scale_attn_by_inverse_layer_idx=False,
- reorder_and_upcast_attn=False,
- **kwargs,
- ):
- self.vocab_size = vocab_size
- self.n_positions = n_positions
- self.n_embd = n_embd
- self.n_layer = n_layer
- self.n_head = n_head
- self.n_inner = n_inner
- self.activation_function = activation_function
- self.resid_pdrop = resid_pdrop
- self.embd_pdrop = embd_pdrop
- self.attn_pdrop = attn_pdrop
- self.layer_norm_epsilon = layer_norm_epsilon
- self.initializer_range = initializer_range
- self.scale_attn_weights = scale_attn_weights
- self.use_cache = use_cache
- self.scale_attn_by_inverse_layer_idx = scale_attn_by_inverse_layer_idx
- self.reorder_and_upcast_attn = reorder_and_upcast_attn
- self.tie_word_embeddings = tie_word_embeddings
-
- super().__init__(tie_word_embeddings=tie_word_embeddings, **kwargs)
-
-
-class ImageGPTOnnxConfig(OnnxConfig):
- @property
- def inputs(self) -> Mapping[str, Mapping[int, str]]:
- return OrderedDict(
- [
- ("input_ids", {0: "batch", 1: "sequence"}),
- ]
- )
-
- def generate_dummy_inputs(
- self,
- preprocessor: "FeatureExtractionMixin",
- batch_size: int = 1,
- seq_length: int = -1,
- is_pair: bool = False,
- framework: Optional["TensorType"] = None,
- num_channels: int = 3,
- image_width: int = 32,
- image_height: int = 32,
- ) -> Mapping[str, Any]:
- """
- Generate inputs to provide to the ONNX exporter for the specific framework
-
- Args:
- preprocessor ([`PreTrainedTokenizerBase`] or [`FeatureExtractionMixin`]):
- The preprocessor associated with this model configuration.
- batch_size (`int`, *optional*, defaults to -1):
- The batch size to export the model for (-1 means dynamic axis).
- num_choices (`int`, *optional*, defaults to -1):
- The number of candidate answers provided for multiple choice task (-1 means dynamic axis).
- seq_length (`int`, *optional*, defaults to -1):
- The sequence length to export the model for (-1 means dynamic axis).
- is_pair (`bool`, *optional*, defaults to `False`):
- Indicate if the input is a pair (sentence 1, sentence 2)
- framework (`TensorType`, *optional*, defaults to `None`):
- The framework (PyTorch or TensorFlow) that the tokenizer will generate tensors for.
- num_channels (`int`, *optional*, defaults to 3):
- The number of channels of the generated images.
- image_width (`int`, *optional*, defaults to 40):
- The width of the generated images.
- image_height (`int`, *optional*, defaults to 40):
- The height of the generated images.
-
- Returns:
- Mapping[str, Tensor] holding the kwargs to provide to the model's forward function
- """
-
- input_image = self._generate_dummy_images(batch_size, num_channels, image_height, image_width)
- inputs = dict(preprocessor(images=input_image, return_tensors=framework))
-
- return inputs
diff --git a/spaces/yl12053/so-vits-4.1-Grass-Wonder/vdecoder/hifiganwithsnake/alias/filter.py b/spaces/yl12053/so-vits-4.1-Grass-Wonder/vdecoder/hifiganwithsnake/alias/filter.py
deleted file mode 100644
index 7ad6ea87c1f10ddd94c544037791d7a4634d5ae1..0000000000000000000000000000000000000000
--- a/spaces/yl12053/so-vits-4.1-Grass-Wonder/vdecoder/hifiganwithsnake/alias/filter.py
+++ /dev/null
@@ -1,95 +0,0 @@
-# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
-# LICENSE is in incl_licenses directory.
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import math
-
-if 'sinc' in dir(torch):
- sinc = torch.sinc
-else:
- # This code is adopted from adefossez's julius.core.sinc under the MIT License
- # https://adefossez.github.io/julius/julius/core.html
- # LICENSE is in incl_licenses directory.
- def sinc(x: torch.Tensor):
- """
- Implementation of sinc, i.e. sin(pi * x) / (pi * x)
- __Warning__: Different to julius.sinc, the input is multiplied by `pi`!
- """
- return torch.where(x == 0,
- torch.tensor(1., device=x.device, dtype=x.dtype),
- torch.sin(math.pi * x) / math.pi / x)
-
-
-# This code is adopted from adefossez's julius.lowpass.LowPassFilters under the MIT License
-# https://adefossez.github.io/julius/julius/lowpass.html
-# LICENSE is in incl_licenses directory.
-def kaiser_sinc_filter1d(cutoff, half_width, kernel_size): # return filter [1,1,kernel_size]
- even = (kernel_size % 2 == 0)
- half_size = kernel_size // 2
-
- #For kaiser window
- delta_f = 4 * half_width
- A = 2.285 * (half_size - 1) * math.pi * delta_f + 7.95
- if A > 50.:
- beta = 0.1102 * (A - 8.7)
- elif A >= 21.:
- beta = 0.5842 * (A - 21)**0.4 + 0.07886 * (A - 21.)
- else:
- beta = 0.
- window = torch.kaiser_window(kernel_size, beta=beta, periodic=False)
-
- # ratio = 0.5/cutoff -> 2 * cutoff = 1 / ratio
- if even:
- time = (torch.arange(-half_size, half_size) + 0.5)
- else:
- time = torch.arange(kernel_size) - half_size
- if cutoff == 0:
- filter_ = torch.zeros_like(time)
- else:
- filter_ = 2 * cutoff * window * sinc(2 * cutoff * time)
- # Normalize filter to have sum = 1, otherwise we will have a small leakage
- # of the constant component in the input signal.
- filter_ /= filter_.sum()
- filter = filter_.view(1, 1, kernel_size)
-
- return filter
-
-
-class LowPassFilter1d(nn.Module):
- def __init__(self,
- cutoff=0.5,
- half_width=0.6,
- stride: int = 1,
- padding: bool = True,
- padding_mode: str = 'replicate',
- kernel_size: int = 12):
- # kernel_size should be even number for stylegan3 setup,
- # in this implementation, odd number is also possible.
- super().__init__()
- if cutoff < -0.:
- raise ValueError("Minimum cutoff must be larger than zero.")
- if cutoff > 0.5:
- raise ValueError("A cutoff above 0.5 does not make sense.")
- self.kernel_size = kernel_size
- self.even = (kernel_size % 2 == 0)
- self.pad_left = kernel_size // 2 - int(self.even)
- self.pad_right = kernel_size // 2
- self.stride = stride
- self.padding = padding
- self.padding_mode = padding_mode
- filter = kaiser_sinc_filter1d(cutoff, half_width, kernel_size)
- self.register_buffer("filter", filter)
-
- #input [B, C, T]
- def forward(self, x):
- _, C, _ = x.shape
-
- if self.padding:
- x = F.pad(x, (self.pad_left, self.pad_right),
- mode=self.padding_mode)
- out = F.conv1d(x, self.filter.expand(C, -1, -1),
- stride=self.stride, groups=C)
-
- return out
\ No newline at end of file
diff --git a/spaces/yo2266911/uma_voice/data_utils.py b/spaces/yo2266911/uma_voice/data_utils.py
deleted file mode 100644
index e9246c6c8f2ff3c37a7f8529ea1593c7f80f887e..0000000000000000000000000000000000000000
--- a/spaces/yo2266911/uma_voice/data_utils.py
+++ /dev/null
@@ -1,393 +0,0 @@
-import time
-import os
-import random
-import numpy as np
-import torch
-import torch.utils.data
-
-import commons
-from mel_processing import spectrogram_torch
-from utils import load_wav_to_torch, load_filepaths_and_text
-from text import text_to_sequence, cleaned_text_to_sequence
-
-
-class TextAudioLoader(torch.utils.data.Dataset):
- """
- 1) loads audio, text pairs
- 2) normalizes text and converts them to sequences of integers
- 3) computes spectrograms from audio files.
- """
- def __init__(self, audiopaths_and_text, hparams):
- self.audiopaths_and_text = load_filepaths_and_text(audiopaths_and_text)
- self.text_cleaners = hparams.text_cleaners
- self.max_wav_value = hparams.max_wav_value
- self.sampling_rate = hparams.sampling_rate
- self.filter_length = hparams.filter_length
- self.hop_length = hparams.hop_length
- self.win_length = hparams.win_length
- self.sampling_rate = hparams.sampling_rate
-
- self.cleaned_text = getattr(hparams, "cleaned_text", False)
-
- self.add_blank = hparams.add_blank
- self.min_text_len = getattr(hparams, "min_text_len", 1)
- self.max_text_len = getattr(hparams, "max_text_len", 190)
-
- random.seed(1234)
- random.shuffle(self.audiopaths_and_text)
- self._filter()
-
-
- def _filter(self):
- """
- Filter text & store spec lengths
- """
- # Store spectrogram lengths for Bucketing
- # wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
- # spec_length = wav_length // hop_length
-
- audiopaths_and_text_new = []
- lengths = []
- for audiopath, text in self.audiopaths_and_text:
- if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
- audiopaths_and_text_new.append([audiopath, text])
- lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
- self.audiopaths_and_text = audiopaths_and_text_new
- self.lengths = lengths
-
- def get_audio_text_pair(self, audiopath_and_text):
- # separate filename and text
- audiopath, text = audiopath_and_text[0], audiopath_and_text[1]
- text = self.get_text(text)
- spec, wav = self.get_audio(audiopath)
- return (text, spec, wav)
-
- def get_audio(self, filename):
- audio, sampling_rate = load_wav_to_torch(filename)
- if sampling_rate != self.sampling_rate:
- raise ValueError("{} {} SR doesn't match target {} SR".format(
- sampling_rate, self.sampling_rate))
- audio_norm = audio / self.max_wav_value
- audio_norm = audio_norm.unsqueeze(0)
- spec_filename = filename.replace(".wav", ".spec.pt")
- if os.path.exists(spec_filename):
- spec = torch.load(spec_filename)
- else:
- spec = spectrogram_torch(audio_norm, self.filter_length,
- self.sampling_rate, self.hop_length, self.win_length,
- center=False)
- spec = torch.squeeze(spec, 0)
- torch.save(spec, spec_filename)
- return spec, audio_norm
-
- def get_text(self, text):
- if self.cleaned_text:
- text_norm = cleaned_text_to_sequence(text)
- else:
- text_norm = text_to_sequence(text, self.text_cleaners)
- if self.add_blank:
- text_norm = commons.intersperse(text_norm, 0)
- text_norm = torch.LongTensor(text_norm)
- return text_norm
-
- def __getitem__(self, index):
- return self.get_audio_text_pair(self.audiopaths_and_text[index])
-
- def __len__(self):
- return len(self.audiopaths_and_text)
-
-
-class TextAudioCollate():
- """ Zero-pads model inputs and targets
- """
- def __init__(self, return_ids=False):
- self.return_ids = return_ids
-
- def __call__(self, batch):
- """Collate's training batch from normalized text and aduio
- PARAMS
- ------
- batch: [text_normalized, spec_normalized, wav_normalized]
- """
- # Right zero-pad all one-hot text sequences to max input length
- _, ids_sorted_decreasing = torch.sort(
- torch.LongTensor([x[1].size(1) for x in batch]),
- dim=0, descending=True)
-
- max_text_len = max([len(x[0]) for x in batch])
- max_spec_len = max([x[1].size(1) for x in batch])
- max_wav_len = max([x[2].size(1) for x in batch])
-
- text_lengths = torch.LongTensor(len(batch))
- spec_lengths = torch.LongTensor(len(batch))
- wav_lengths = torch.LongTensor(len(batch))
-
- text_padded = torch.LongTensor(len(batch), max_text_len)
- spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
- wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
- text_padded.zero_()
- spec_padded.zero_()
- wav_padded.zero_()
- for i in range(len(ids_sorted_decreasing)):
- row = batch[ids_sorted_decreasing[i]]
-
- text = row[0]
- text_padded[i, :text.size(0)] = text
- text_lengths[i] = text.size(0)
-
- spec = row[1]
- spec_padded[i, :, :spec.size(1)] = spec
- spec_lengths[i] = spec.size(1)
-
- wav = row[2]
- wav_padded[i, :, :wav.size(1)] = wav
- wav_lengths[i] = wav.size(1)
-
- if self.return_ids:
- return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, ids_sorted_decreasing
- return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths
-
-
-"""Multi speaker version"""
-class TextAudioSpeakerLoader(torch.utils.data.Dataset):
- """
- 1) loads audio, speaker_id, text pairs
- 2) normalizes text and converts them to sequences of integers
- 3) computes spectrograms from audio files.
- """
- def __init__(self, audiopaths_sid_text, hparams):
- self.audiopaths_sid_text = load_filepaths_and_text(audiopaths_sid_text)
- self.text_cleaners = hparams.text_cleaners
- self.max_wav_value = hparams.max_wav_value
- self.sampling_rate = hparams.sampling_rate
- self.filter_length = hparams.filter_length
- self.hop_length = hparams.hop_length
- self.win_length = hparams.win_length
- self.sampling_rate = hparams.sampling_rate
-
- self.cleaned_text = getattr(hparams, "cleaned_text", False)
-
- self.add_blank = hparams.add_blank
- self.min_text_len = getattr(hparams, "min_text_len", 1)
- self.max_text_len = getattr(hparams, "max_text_len", 190)
-
- random.seed(1234)
- random.shuffle(self.audiopaths_sid_text)
- self._filter()
-
- def _filter(self):
- """
- Filter text & store spec lengths
- """
- # Store spectrogram lengths for Bucketing
- # wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
- # spec_length = wav_length // hop_length
-
- audiopaths_sid_text_new = []
- lengths = []
- for audiopath, sid, text in self.audiopaths_sid_text:
- audiopath = "E:/uma_voice/" + audiopath
- if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
- audiopaths_sid_text_new.append([audiopath, sid, text])
- lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
- self.audiopaths_sid_text = audiopaths_sid_text_new
- self.lengths = lengths
-
- def get_audio_text_speaker_pair(self, audiopath_sid_text):
- # separate filename, speaker_id and text
- audiopath, sid, text = audiopath_sid_text[0], audiopath_sid_text[1], audiopath_sid_text[2]
- text = self.get_text(text)
- spec, wav = self.get_audio(audiopath)
- sid = self.get_sid(sid)
- return (text, spec, wav, sid)
-
- def get_audio(self, filename):
- audio, sampling_rate = load_wav_to_torch(filename)
- if sampling_rate != self.sampling_rate:
- raise ValueError("{} {} SR doesn't match target {} SR".format(
- sampling_rate, self.sampling_rate))
- audio_norm = audio / self.max_wav_value
- audio_norm = audio_norm.unsqueeze(0)
- spec_filename = filename.replace(".wav", ".spec.pt")
- if os.path.exists(spec_filename):
- spec = torch.load(spec_filename)
- else:
- spec = spectrogram_torch(audio_norm, self.filter_length,
- self.sampling_rate, self.hop_length, self.win_length,
- center=False)
- spec = torch.squeeze(spec, 0)
- torch.save(spec, spec_filename)
- return spec, audio_norm
-
- def get_text(self, text):
- if self.cleaned_text:
- text_norm = cleaned_text_to_sequence(text)
- else:
- text_norm = text_to_sequence(text, self.text_cleaners)
- if self.add_blank:
- text_norm = commons.intersperse(text_norm, 0)
- text_norm = torch.LongTensor(text_norm)
- return text_norm
-
- def get_sid(self, sid):
- sid = torch.LongTensor([int(sid)])
- return sid
-
- def __getitem__(self, index):
- return self.get_audio_text_speaker_pair(self.audiopaths_sid_text[index])
-
- def __len__(self):
- return len(self.audiopaths_sid_text)
-
-
-class TextAudioSpeakerCollate():
- """ Zero-pads model inputs and targets
- """
- def __init__(self, return_ids=False):
- self.return_ids = return_ids
-
- def __call__(self, batch):
- """Collate's training batch from normalized text, audio and speaker identities
- PARAMS
- ------
- batch: [text_normalized, spec_normalized, wav_normalized, sid]
- """
- # Right zero-pad all one-hot text sequences to max input length
- _, ids_sorted_decreasing = torch.sort(
- torch.LongTensor([x[1].size(1) for x in batch]),
- dim=0, descending=True)
-
- max_text_len = max([len(x[0]) for x in batch])
- max_spec_len = max([x[1].size(1) for x in batch])
- max_wav_len = max([x[2].size(1) for x in batch])
-
- text_lengths = torch.LongTensor(len(batch))
- spec_lengths = torch.LongTensor(len(batch))
- wav_lengths = torch.LongTensor(len(batch))
- sid = torch.LongTensor(len(batch))
-
- text_padded = torch.LongTensor(len(batch), max_text_len)
- spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
- wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
- text_padded.zero_()
- spec_padded.zero_()
- wav_padded.zero_()
- for i in range(len(ids_sorted_decreasing)):
- row = batch[ids_sorted_decreasing[i]]
-
- text = row[0]
- text_padded[i, :text.size(0)] = text
- text_lengths[i] = text.size(0)
-
- spec = row[1]
- spec_padded[i, :, :spec.size(1)] = spec
- spec_lengths[i] = spec.size(1)
-
- wav = row[2]
- wav_padded[i, :, :wav.size(1)] = wav
- wav_lengths[i] = wav.size(1)
-
- sid[i] = row[3]
-
- if self.return_ids:
- return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid, ids_sorted_decreasing
- return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid
-
-
-class DistributedBucketSampler(torch.utils.data.distributed.DistributedSampler):
- """
- Maintain similar input lengths in a batch.
- Length groups are specified by boundaries.
- Ex) boundaries = [b1, b2, b3] -> any batch is included either {x | b1 < length(x) <=b2} or {x | b2 < length(x) <= b3}.
-
- It removes samples which are not included in the boundaries.
- Ex) boundaries = [b1, b2, b3] -> any x s.t. length(x) <= b1 or length(x) > b3 are discarded.
- """
- def __init__(self, dataset, batch_size, boundaries, num_replicas=None, rank=None, shuffle=True):
- super().__init__(dataset, num_replicas=num_replicas, rank=rank, shuffle=shuffle)
- self.lengths = dataset.lengths
- self.batch_size = batch_size
- self.boundaries = boundaries
-
- self.buckets, self.num_samples_per_bucket = self._create_buckets()
- self.total_size = sum(self.num_samples_per_bucket)
- self.num_samples = self.total_size // self.num_replicas
-
- def _create_buckets(self):
- buckets = [[] for _ in range(len(self.boundaries) - 1)]
- for i in range(len(self.lengths)):
- length = self.lengths[i]
- idx_bucket = self._bisect(length)
- if idx_bucket != -1:
- buckets[idx_bucket].append(i)
-
- for i in range(len(buckets) - 1, 0, -1):
- if len(buckets[i]) == 0:
- buckets.pop(i)
- self.boundaries.pop(i+1)
-
- num_samples_per_bucket = []
- for i in range(len(buckets)):
- len_bucket = len(buckets[i])
- total_batch_size = self.num_replicas * self.batch_size
- rem = (total_batch_size - (len_bucket % total_batch_size)) % total_batch_size
- num_samples_per_bucket.append(len_bucket + rem)
- return buckets, num_samples_per_bucket
-
- def __iter__(self):
- # deterministically shuffle based on epoch
- g = torch.Generator()
- g.manual_seed(self.epoch)
-
- indices = []
- if self.shuffle:
- for bucket in self.buckets:
- indices.append(torch.randperm(len(bucket), generator=g).tolist())
- else:
- for bucket in self.buckets:
- indices.append(list(range(len(bucket))))
-
- batches = []
- for i in range(len(self.buckets)):
- bucket = self.buckets[i]
- len_bucket = len(bucket)
- ids_bucket = indices[i]
- num_samples_bucket = self.num_samples_per_bucket[i]
-
- # add extra samples to make it evenly divisible
- rem = num_samples_bucket - len_bucket
- ids_bucket = ids_bucket + ids_bucket * (rem // len_bucket) + ids_bucket[:(rem % len_bucket)]
-
- # subsample
- ids_bucket = ids_bucket[self.rank::self.num_replicas]
-
- # batching
- for j in range(len(ids_bucket) // self.batch_size):
- batch = [bucket[idx] for idx in ids_bucket[j*self.batch_size:(j+1)*self.batch_size]]
- batches.append(batch)
-
- if self.shuffle:
- batch_ids = torch.randperm(len(batches), generator=g).tolist()
- batches = [batches[i] for i in batch_ids]
- self.batches = batches
-
- assert len(self.batches) * self.batch_size == self.num_samples
- return iter(self.batches)
-
- def _bisect(self, x, lo=0, hi=None):
- if hi is None:
- hi = len(self.boundaries) - 1
-
- if hi > lo:
- mid = (hi + lo) // 2
- if self.boundaries[mid] < x and x <= self.boundaries[mid+1]:
- return mid
- elif x <= self.boundaries[mid]:
- return self._bisect(x, lo, mid)
- else:
- return self._bisect(x, mid + 1, hi)
- else:
- return -1
-
- def __len__(self):
- return self.num_samples // self.batch_size
diff --git a/spaces/yoinked/audio-diffusion/app.py b/spaces/yoinked/audio-diffusion/app.py
deleted file mode 100644
index 4e10d2f533403843756c317315dae0fa9af18337..0000000000000000000000000000000000000000
--- a/spaces/yoinked/audio-diffusion/app.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import argparse
-
-import gradio as gr
-
-from audiodiffusion import AudioDiffusion
-
-
-def generate_spectrogram_audio_and_loop(model_id):
- audio_diffusion = AudioDiffusion(model_id=model_id)
- image, (sample_rate,
- audio) = audio_diffusion.generate_spectrogram_and_audio()
- loop = AudioDiffusion.loop_it(audio, sample_rate)
- if loop is None:
- loop = audio
- return image, (sample_rate, audio), (sample_rate, loop)
-
-
-demo = gr.Interface(
- fn=generate_spectrogram_audio_and_loop,
- title="Audio Diffusion",
- description="Generate audio using Huggingface diffusers.\
- The models without 'latent' or 'ddim' give better results but take about \
- 20 minutes without a GPU. For GPU, you can use \
- [colab](https://colab.research.google.com/github/teticio/audio-diffusion/blob/master/notebooks/gradio_app.ipynb) \
- to run this app.",
- inputs=[
- gr.Dropdown(label="Model",
- choices=[
- "teticio/audio-diffusion-256",
- "teticio/ZUN-diffusion-256",
- "teticio/audio-diffusion-breaks-256",
- "teticio/audio-diffusion-instrumental-hiphop-256",
- "teticio/audio-diffusion-ddim-256",
- "teticio/latent-audio-diffusion-256",
- "teticio/latent-audio-diffusion-ddim-256"
- ],
- value="teticio/latent-audio-diffusion-ddim-256")
- ],
- outputs=[
- gr.Image(label="Mel spectrogram", image_mode="L"),
- gr.Audio(label="Audio"),
- gr.Audio(label="Loop"),
- ],
- allow_flagging="never")
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--port", type=int)
- parser.add_argument("--server", type=int)
- args = parser.parse_args()
- demo.launch(server_name=args.server or "0.0.0.0", server_port=args.port)
diff --git a/spaces/ysharma/dummyy112233/app.py b/spaces/ysharma/dummyy112233/app.py
deleted file mode 100644
index 9660ce1d237d9b0a544d61807cdf980a9193c441..0000000000000000000000000000000000000000
--- a/spaces/ysharma/dummyy112233/app.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import gradio as gr
-import numpy as np
-import time
-
-# define core fn, which returns a generator {steps} times before returning the image
-def fake_diffusion(steps):
- for _ in range(steps):
- time.sleep(1)
- image = np.random.random((600, 600, 3))
- yield image
- image = "https://gradio-builds.s3.amazonaws.com/diffusion_image/cute_dog.jpg"
- yield image
-
-
-demo = gr.Interface(fake_diffusion, inputs=gr.Slider(1, 10, 3), outputs="image")
-
-# define queue - required for generators
-demo.queue()
-
-demo.launch()
\ No newline at end of file
diff --git a/spaces/yuan1615/EmpathyTTS/utils.py b/spaces/yuan1615/EmpathyTTS/utils.py
deleted file mode 100644
index b445fb65836a0b97e46426300eea9a820179797a..0000000000000000000000000000000000000000
--- a/spaces/yuan1615/EmpathyTTS/utils.py
+++ /dev/null
@@ -1,258 +0,0 @@
-import os
-import glob
-import sys
-import argparse
-import logging
-import json
-import subprocess
-import numpy as np
-from scipy.io.wavfile import read
-import torch
-
-MATPLOTLIB_FLAG = False
-
-logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
-logger = logging
-
-
-def load_checkpoint(checkpoint_path, model, optimizer=None):
- assert os.path.isfile(checkpoint_path)
- checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
- iteration = checkpoint_dict['iteration']
- learning_rate = checkpoint_dict['learning_rate']
- if optimizer is not None:
- optimizer.load_state_dict(checkpoint_dict['optimizer'])
- saved_state_dict = checkpoint_dict['model']
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- new_state_dict= {}
- for k, v in state_dict.items():
- try:
- new_state_dict[k] = saved_state_dict[k]
- except:
- logger.info("%s is not in the checkpoint" % k)
- new_state_dict[k] = v
- if hasattr(model, 'module'):
- model.module.load_state_dict(new_state_dict)
- else:
- model.load_state_dict(new_state_dict)
- logger.info("Loaded checkpoint '{}' (iteration {})" .format(
- checkpoint_path, iteration))
- return model, optimizer, learning_rate, iteration
-
-
-def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path):
- logger.info("Saving model and optimizer state at iteration {} to {}".format(
- iteration, checkpoint_path))
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- torch.save({'model': state_dict,
- 'iteration': iteration,
- 'optimizer': optimizer.state_dict(),
- 'learning_rate': learning_rate}, checkpoint_path)
-
-
-def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050):
- for k, v in scalars.items():
- writer.add_scalar(k, v, global_step)
- for k, v in histograms.items():
- writer.add_histogram(k, v, global_step)
- for k, v in images.items():
- writer.add_image(k, v, global_step, dataformats='HWC')
- for k, v in audios.items():
- writer.add_audio(k, v, global_step, audio_sampling_rate)
-
-
-def latest_checkpoint_path(dir_path, regex="G_*.pth"):
- f_list = glob.glob(os.path.join(dir_path, regex))
- f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
- x = f_list[-1]
- print(x)
- return x
-
-
-def plot_spectrogram_to_numpy(spectrogram):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(10,2))
- im = ax.imshow(spectrogram, aspect="auto", origin="lower",
- interpolation='none')
- plt.colorbar(im, ax=ax)
- plt.xlabel("Frames")
- plt.ylabel("Channels")
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def plot_alignment_to_numpy(alignment, info=None):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(6, 4))
- im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower',
- interpolation='none')
- fig.colorbar(im, ax=ax)
- xlabel = 'Decoder timestep'
- if info is not None:
- xlabel += '\n\n' + info
- plt.xlabel(xlabel)
- plt.ylabel('Encoder timestep')
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def load_wav_to_torch(full_path):
- sampling_rate, data = read(full_path)
- return torch.FloatTensor(data.astype(np.float32)), sampling_rate
-
-
-def load_filepaths_and_text(filename, split="|"):
- with open(filename, encoding='utf-8') as f:
- filepaths_and_text = [line.strip().split(split) for line in f]
- return filepaths_and_text
-
-
-def get_hparams(init=True):
- parser = argparse.ArgumentParser()
- parser.add_argument('-c', '--config', type=str, default="./configs/base.json",
- help='JSON file for configuration')
- parser.add_argument('-m', '--model', type=str, required=True,
- help='Model name')
-
- args = parser.parse_args()
- model_dir = os.path.join("./logs", args.model)
-
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
-
- config_path = args.config
- config_save_path = os.path.join(model_dir, "config.json")
- if init:
- with open(config_path, "r") as f:
- data = f.read()
- with open(config_save_path, "w") as f:
- f.write(data)
- else:
- with open(config_save_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- hparams.model_dir = model_dir
- return hparams
-
-
-def get_hparams_from_dir(model_dir):
- config_save_path = os.path.join(model_dir, "config.json")
- with open(config_save_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams =HParams(**config)
- hparams.model_dir = model_dir
- return hparams
-
-
-def get_hparams_from_file(config_path):
- with open(config_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams =HParams(**config)
- return hparams
-
-
-def check_git_hash(model_dir):
- source_dir = os.path.dirname(os.path.realpath(__file__))
- if not os.path.exists(os.path.join(source_dir, ".git")):
- logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format(
- source_dir
- ))
- return
-
- cur_hash = subprocess.getoutput("git rev-parse HEAD")
-
- path = os.path.join(model_dir, "githash")
- if os.path.exists(path):
- saved_hash = open(path).read()
- if saved_hash != cur_hash:
- logger.warn("git hash values are different. {}(saved) != {}(current)".format(
- saved_hash[:8], cur_hash[:8]))
- else:
- open(path, "w").write(cur_hash)
-
-
-def get_logger(model_dir, filename="train.log"):
- global logger
- logger = logging.getLogger(os.path.basename(model_dir))
- logger.setLevel(logging.DEBUG)
-
- formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
- h = logging.FileHandler(os.path.join(model_dir, filename))
- h.setLevel(logging.DEBUG)
- h.setFormatter(formatter)
- logger.addHandler(h)
- return logger
-
-
-class HParams():
- def __init__(self, **kwargs):
- for k, v in kwargs.items():
- if type(v) == dict:
- v = HParams(**v)
- self[k] = v
-
- def keys(self):
- return self.__dict__.keys()
-
- def items(self):
- return self.__dict__.items()
-
- def values(self):
- return self.__dict__.values()
-
- def __len__(self):
- return len(self.__dict__)
-
- def __getitem__(self, key):
- return getattr(self, key)
-
- def __setitem__(self, key, value):
- return setattr(self, key, value)
-
- def __contains__(self, key):
- return key in self.__dict__
-
- def __repr__(self):
- return self.__dict__.__repr__()
diff --git a/spaces/yxmnjxzx/PubMedGPT/base.py b/spaces/yxmnjxzx/PubMedGPT/base.py
deleted file mode 100644
index 13a8f8428b7f6d0f9e7f6e33dee2a7f3a91977cb..0000000000000000000000000000000000000000
--- a/spaces/yxmnjxzx/PubMedGPT/base.py
+++ /dev/null
@@ -1,187 +0,0 @@
-"""Read Pubmed Papers."""
-from typing import List, Optional
-
-from llama_index.readers.base import BaseReader
-from llama_index.readers.schema.base import Document
-
-
-class PubmedReader_mod(BaseReader):
- """Pubmed Reader.
-
- Gets a search query, return a list of Documents of the top corresponding scientific papers on Pubmed.
- """
-
- def load_data_bioc(
- self,
- search_query: str,
- max_results: Optional[int] = 50,
- ) -> List[Document]:
- """Search for a topic on Pubmed, fetch the text of the most relevant full-length papers.
- Uses the BoiC API, which has been down a lot.
-
- Args:
- search_query (str): A topic to search for (e.g. "Alzheimers").
- max_results (Optional[int]): Maximum number of papers to fetch.
-
- Returns:
- List[Document]: A list of Document objects.
- """
- from datetime import datetime
- import xml.etree.ElementTree as xml
-
- import requests
-
- pubmed_search = []
- parameters = {"tool": "tool", "email": "email", "db": "pmc"}
- parameters["term"] = search_query
- parameters["retmax"] = max_results
- resp = requests.get(
- "https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi",
- params=parameters,
- )
- root = xml.fromstring(resp.content)
-
- for elem in root.iter():
- if elem.tag == "Id":
- _id = elem.text
- try:
- resp = requests.get(
- f"https://www.ncbi.nlm.nih.gov/research/bionlp/RESTful/pmcoa.cgi/BioC_json/PMC{_id}/ascii"
- )
- info = resp.json()
- title = "Pubmed Paper"
- try:
- title = [
- p["text"]
- for p in info["documents"][0]["passages"]
- if p["infons"]["section_type"] == "TITLE"
- ][0]
- except KeyError:
- pass
- pubmed_search.append(
- {
- "title": title,
- "url": f"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC{_id}/",
- "date": info["date"],
- "documents": info["documents"],
- }
- )
- except Exception:
- print(f"Unable to parse PMC{_id} or it does not exist")
- pass
-
- # Then get documents from Pubmed text, which includes abstracts
- pubmed_documents = []
- for paper in pubmed_search:
- for d in paper["documents"]:
- text = "\n".join([p["text"] for p in d["passages"]])
- pubmed_documents.append(
- Document(
- text,
- extra_info={
- "Title of this paper": paper["title"],
- "URL": paper["url"],
- "Date published": datetime.strptime(
- paper["date"], "%Y%m%d"
- ).strftime("%m/%d/%Y"),
- },
- )
- )
-
- return pubmed_documents
-
- def load_data(
- self,
- search_query: str,
- max_results: Optional[int] = 10,
- search_criterion : Optional[int] = 0
- ) -> List[Document]:
- """Search for a topic on Pubmed, fetch the text of the most relevant full-length papers.
- Args:
- search_query (str): A topic to search for (e.g. "Alzheimers").
- max_results (Optional[int]): Maximum number of papers to fetch.
- Returns:
- List[Document]: A list of Document objects.
- """
- import time
- import xml.etree.ElementTree as xml
-
- import requests
-
- if search_criterion == 0:
- sort_criterion ='relevance'
-
- if search_criterion == 1:
- sort_criterion = 'pub_date'
-
- if search_criterion == 2:
- sort_criterion = 'Journal'
-
- pubmed_search = []
- parameters = {"tool": "tool", "email": "email", "db": "pmc"}
- parameters["term"] = search_query
- parameters["retmax"] = max_results
- parameters["sort"] = sort_criterion
-
- # relevance:“Best Match”, pub_date: descending sort by publication date,
- # Author – ascending sort by first author JournalName – ascending sort by journal name
- # https: // www.ncbi.nlm.nih.gov / books / NBK25499 /
- #print(parameters)
-
- resp = requests.get(
- "https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi",
- params=parameters,
- )
-
- root = xml.fromstring(resp.content)
-
- for elem in root.iter():
-
- if elem.tag == "Id":
- _id = elem.text
- url = f"https://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?id={_id}&db=pmc"
- # print(url)
- try:
- resp = requests.get(url)
- info = xml.fromstring(resp.content)
-
- raw_text = ""
- title = ""
- journal = ""
- for element in info.iter():
- if element.tag == "article-title":
- title = element.text
- elif element.tag == "journal-title":
- journal = element.text
-
- if element.text:
- raw_text += element.text.strip() + " "
- #print(f"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC{_id}/")
- pubmed_search.append(
- {
- "title": title,
- "journal": journal,
- "url": f"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC{_id}/",
- "text": raw_text,
- }
- )
- time.sleep(1) # API rate limits
- except Exception as e:
- print(f"Unable to parse PMC{_id} or it does not exist:", e)
- pass
-
- # Then get documents from Pubmed text, which includes abstracts
- pubmed_documents = []
- for paper in pubmed_search:
- pubmed_documents.append(
- Document(
- paper["text"],
- extra_info={
- "Title of this paper": paper["title"],
- "Journal it was published in:": paper["journal"],
- "URL": paper["url"],
- },
- )
- )
-
- return pubmed_documents
\ No newline at end of file
diff --git a/spaces/zhang-wei-jian/docker/node_modules/http-assert/index.js b/spaces/zhang-wei-jian/docker/node_modules/http-assert/index.js
deleted file mode 100644
index 639031525c3de9439dd5869094e636edac7dab19..0000000000000000000000000000000000000000
--- a/spaces/zhang-wei-jian/docker/node_modules/http-assert/index.js
+++ /dev/null
@@ -1,41 +0,0 @@
-var createError = require('http-errors')
-var eql = require('deep-equal')
-
-module.exports = assert
-
-function assert (value, status, msg, opts) {
- if (value) return
- throw createError(status, msg, opts)
-}
-
-assert.fail = function (status, msg, opts) {
- assert(false, status, msg, opts)
-}
-
-assert.equal = function (a, b, status, msg, opts) {
- assert(a == b, status, msg, opts) // eslint-disable-line eqeqeq
-}
-
-assert.notEqual = function (a, b, status, msg, opts) {
- assert(a != b, status, msg, opts) // eslint-disable-line eqeqeq
-}
-
-assert.ok = function (value, status, msg, opts) {
- assert(value, status, msg, opts)
-}
-
-assert.strictEqual = function (a, b, status, msg, opts) {
- assert(a === b, status, msg, opts)
-}
-
-assert.notStrictEqual = function (a, b, status, msg, opts) {
- assert(a !== b, status, msg, opts)
-}
-
-assert.deepEqual = function (a, b, status, msg, opts) {
- assert(eql(a, b), status, msg, opts)
-}
-
-assert.notDeepEqual = function (a, b, status, msg, opts) {
- assert(!eql(a, b), status, msg, opts)
-}
diff --git a/spaces/zhanggrace/ImageSearch/README.md b/spaces/zhanggrace/ImageSearch/README.md
deleted file mode 100644
index 7eb0768150f239c59001a28a8d4a05c67daf48be..0000000000000000000000000000000000000000
--- a/spaces/zhanggrace/ImageSearch/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: ImageSearch
-emoji: 🚀
-colorFrom: green
-colorTo: purple
-sdk: streamlit
-sdk_version: 1.21.0
-app_file: app.py
-pinned: false
-license: cc-by-4.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/zliang/ClimateChat/app.py b/spaces/zliang/ClimateChat/app.py
deleted file mode 100644
index affcf3443f0d9fc0d40fa36ca930510df7df11e8..0000000000000000000000000000000000000000
--- a/spaces/zliang/ClimateChat/app.py
+++ /dev/null
@@ -1,217 +0,0 @@
-import openai
-import streamlit as st
-from langchain.llms import OpenAI
-from langchain.chat_models import ChatOpenAI
-from langchain.embeddings import HuggingFaceEmbeddings
-from langchain.chains import RetrievalQA
-
-from langchain.prompts.prompt import PromptTemplate
-
-from langchain.vectorstores import FAISS
-import re
-import time
-
-
-# import e5-large-v2 embedding model
-model_name = "intfloat/e5-large-v2"
-model_kwargs = {'device': 'cpu'}
-encode_kwargs = {'normalize_embeddings': False}
-embeddings = HuggingFaceEmbeddings(
- model_name=model_name,
- model_kwargs=model_kwargs,
- encode_kwargs=encode_kwargs
-)
-
-# load IPCC database
-db = FAISS.load_local("IPCC_index_e5_1000_all", embeddings)
-
-
-question1 = 'Why does temperature increase?'
-question2 = 'What evidence we have of climate change?'
-question3 = 'What is the link between health and climate change?'
-
-def click_button(button_text):
- if prompt := button_text:
-
- #if prompt := st.text_input(label="Your quesiton:",value=st.session_state.button_text if 'button_text' in st.session_state else 'Text your question'):
- if not openai_api_key:
- st.info("Please add your OpenAI API key to continue.")
- st.stop()
-
- st.session_state.messages.append({"role": "user", "content": prompt})
- st.chat_message("user").write(prompt)
- with st.spinner("Thinking..."):
- result = generate_response(prompt)
- result_r = result["result"]
- index = result_r.find("Highlight:")
-
-
-
- # Display assistant response in chat message container
- with st.chat_message("assistant"):
- message_placeholder = st.empty()
- full_response = ""
- assistant_response = result_r
- # Simulate stream of response with milliseconds delay
- for chunk in assistant_response.split():
- full_response += chunk + " "
- time.sleep(0.05)
- # Add a blinking cursor to simulate typing
- message_placeholder.write(full_response + "▌")
- message_placeholder.write(result_r)
- # Add assistant response to chat history
- st.session_state.messages.append({"role": "assistant", "content": result_r})
-
-def generate_response(input_text):
- docs = db.similarity_search(input_text,k=5)
-
- json1 = docs[0].metadata
- json2 = docs[1].metadata
- json3 = docs[2].metadata
- json4 = docs[3].metadata
- json5 = docs[4].metadata
- #st.write({"source1":json1["source"], "source2":json2["source"],"source3":json3["source"]})
-
-
- climate_TEMPLATE = """\
- You are a professor in climate change, tasked with answering any question \
- about climate change. Take a deep breath and think step by step.
-
- {question}
-
- Generate a comprehensive and informative answer and three next questions to the general audience of 100 words or less for the \
- given question based solely on the provided search results (hyperlink and source). You must \
- only use information from the provided search results. Use an unbiased and \
- journalistic tone. Combine search results together into a coherent answer. Do not \
- repeat text. Only use \
- relevant results that answer the question accurately. list these sources at the end of your answer \
- in a section named "source". After the "source" section, makre sure provide three next questions in the section of predicted \
-\
-
- Format your answer in markdown format
-
- If there is nothing in the context relevant to the question at hand, just say "Hmm, \
- I'm not sure." Don't try to make up an answer.
-
- Anything between the following `context` html blocks is retrieved from a knowledge \
- bank, not part of the conversation with the user.
-
-
- {context}
-
- [{source1} page {page1}](https://www.ipcc.ch/report/ar6/{wg1}/downloads/report/{source1}.pdf#page={page1})
- [{source2} page {page2}](https://www.ipcc.ch/report/ar6/{wg2}/downloads/report/{source2}.pdf#page={page2})
- [{source3} page {page3}](https://www.ipcc.ch/report/ar6/{wg3}/downloads/report/{source3}.pdf#page={page3})
- [{source4} page {page4}](https://www.ipcc.ch/report/ar6/{wg4}/downloads/report/{source4}.pdf#page={page4})
- [{source5} page {page5}](https://www.ipcc.ch/report/ar6/{wg5}/downloads/report/{source5}.pdf#page={page5})
-
 -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-
 -
- -
- 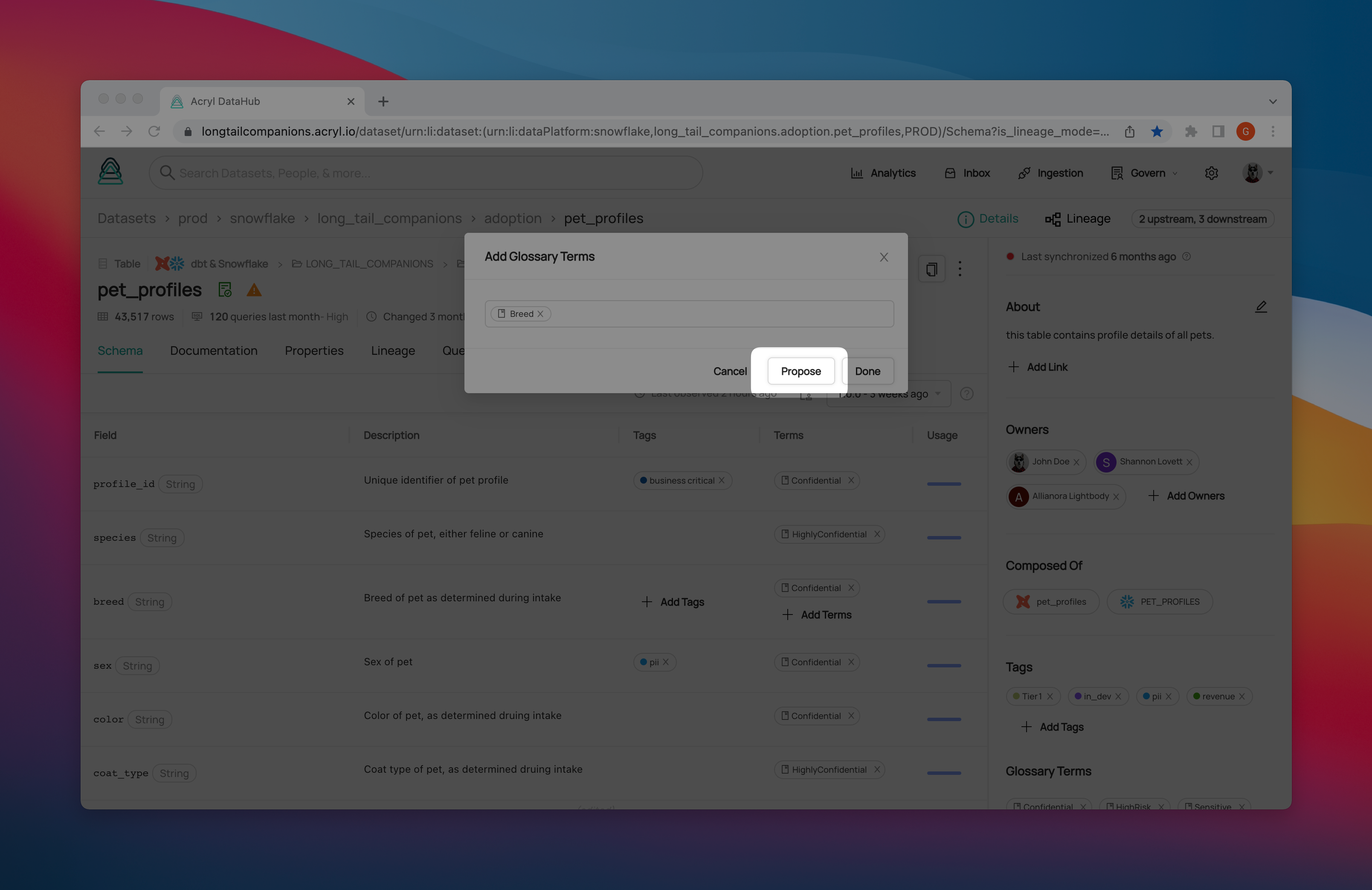 -
-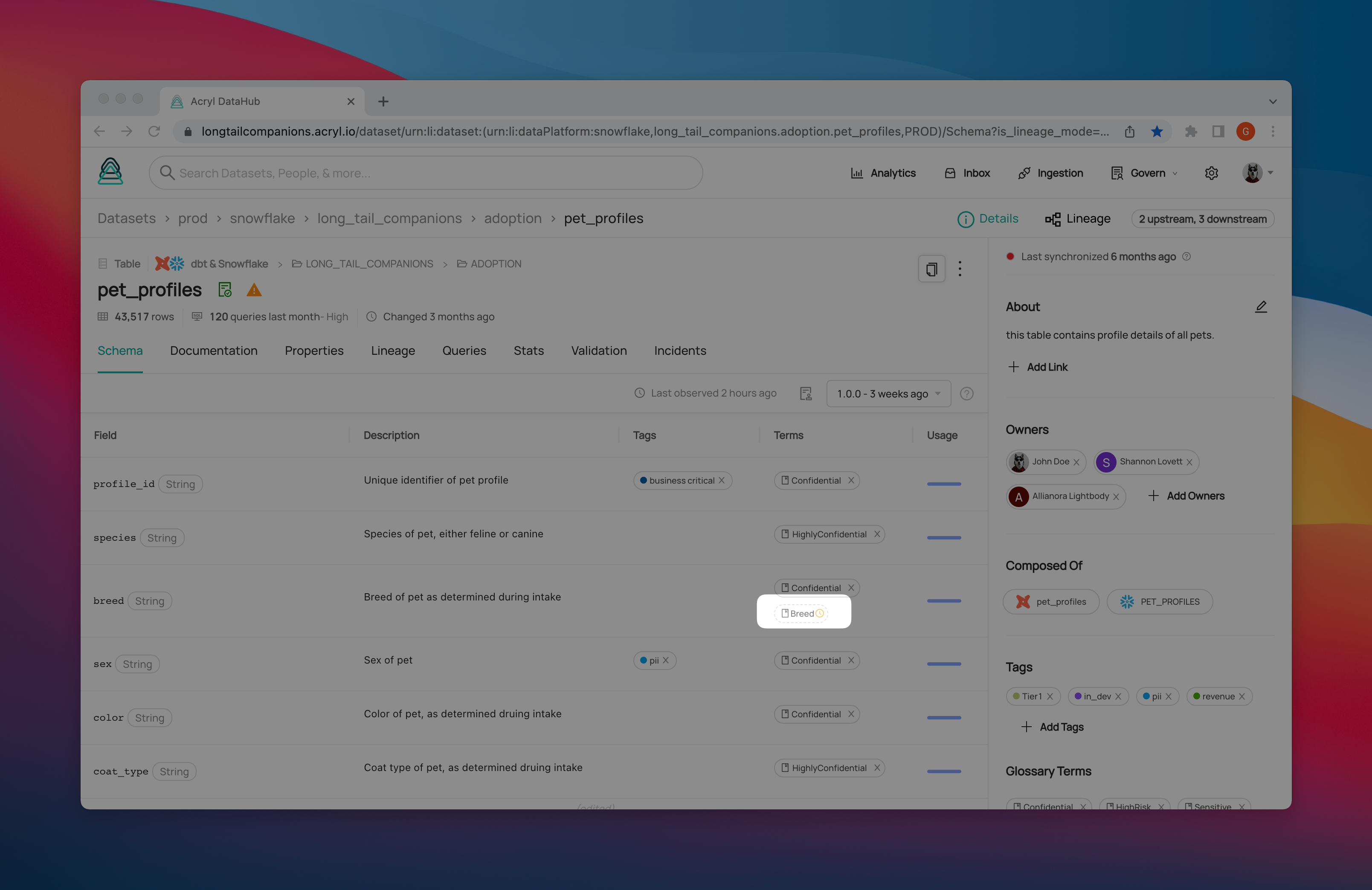 -
-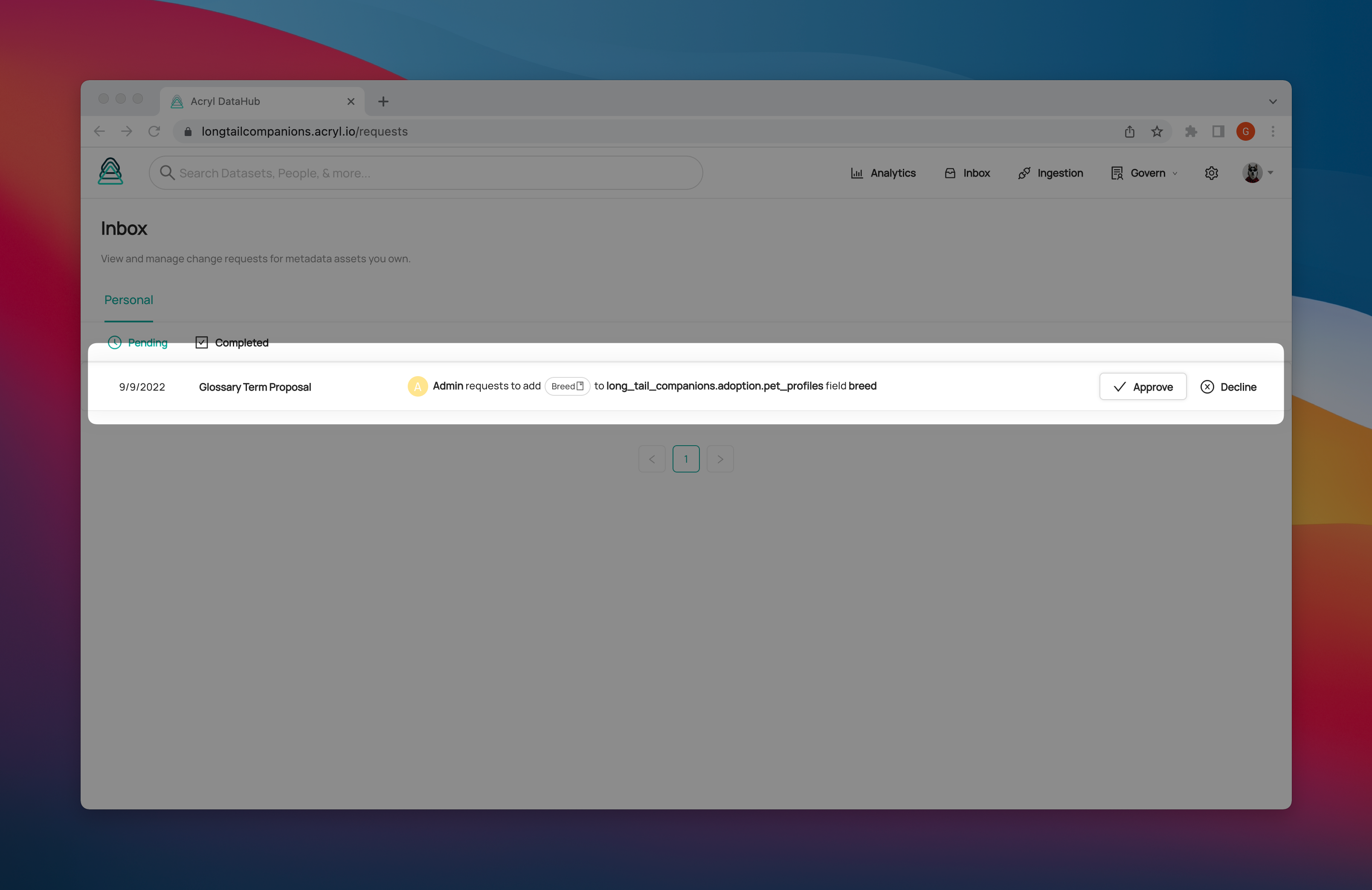 -
-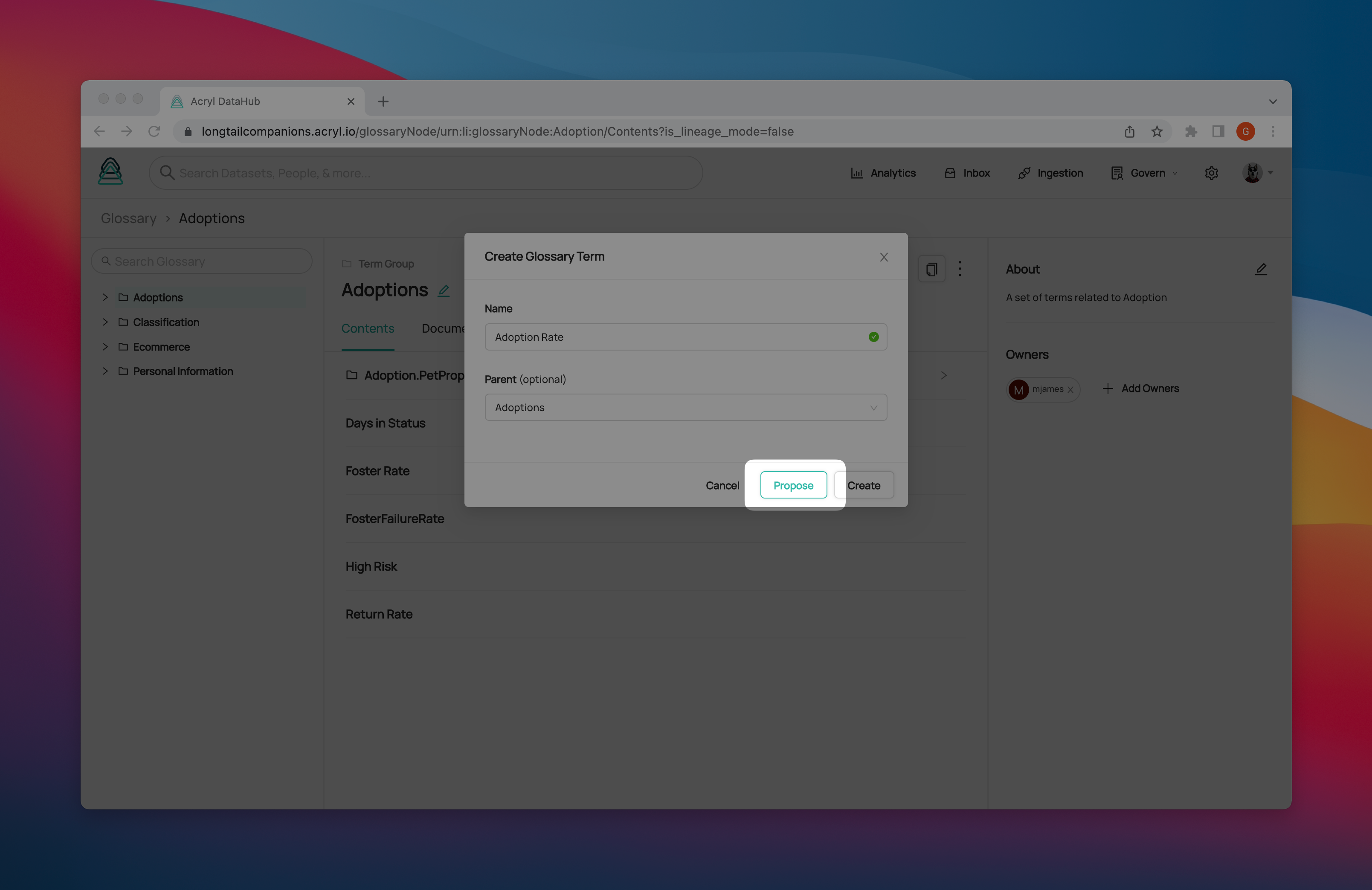 -
-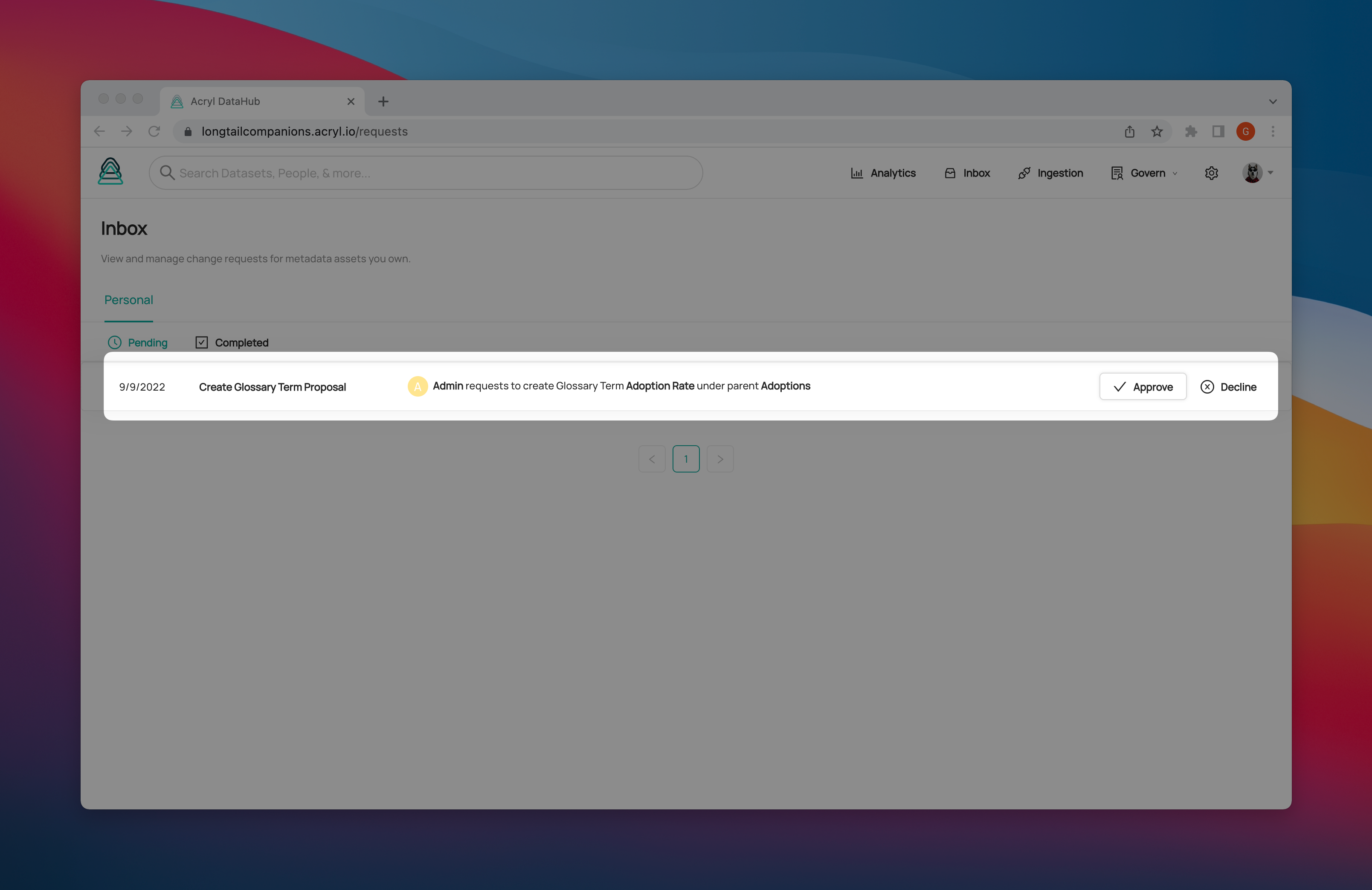 -
-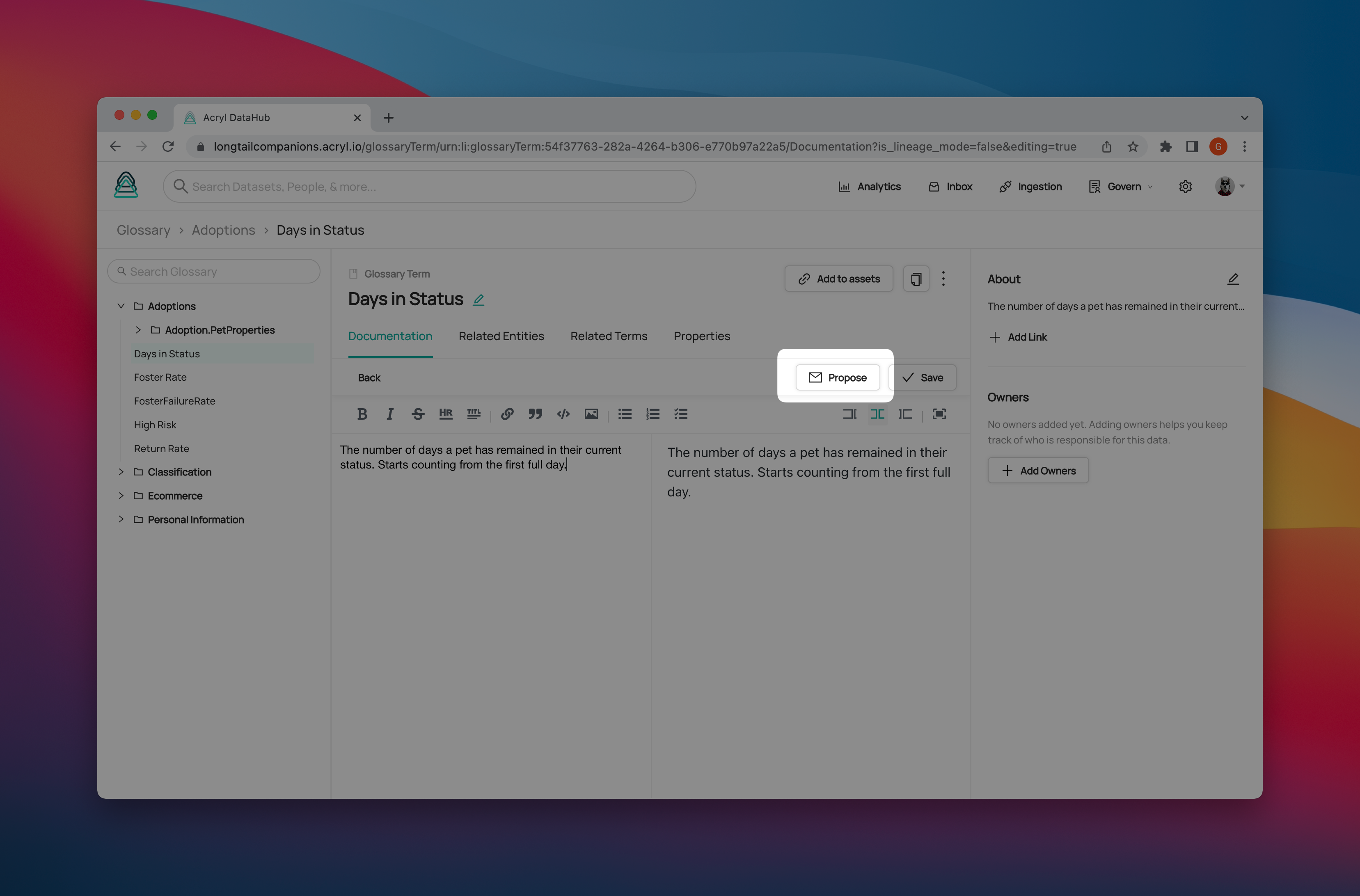 -
-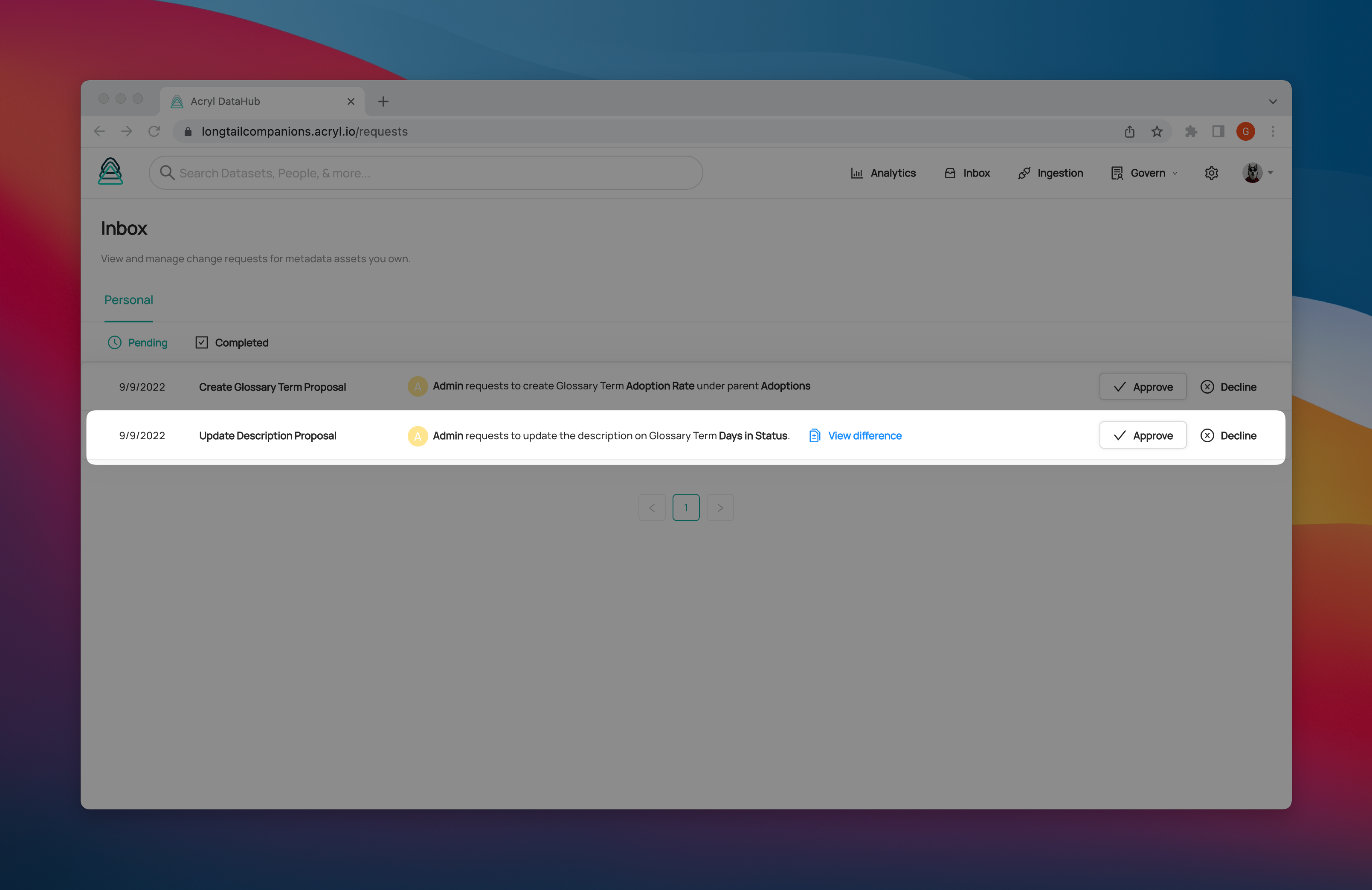 -
- -
-