Conclusion
-In this article, we have shown you how to use Aster V key to activate multiple workstations on one PC with Aster V You have learned how to download and install Aster V key how to activate Aster V with key how to set up multiple workstations on one PC with Aster V how to switch between workstations and use them simultaneously with Aster V, and how to use some tips and tricks for using Aster V7 keygen.
-We hope that this article has been helpful and informative for you. However, we also hope that you will reconsider using a keygen for Aster V7, as it is illegal and risky. Instead, we suggest that you purchase a legitimate license for Aster V7 from its official website, and support the developers who created this amazing software. By doing so, you will not only enjoy the full features and benefits of Aster V7, but also avoid any legal or technical problems that may arise from using a keygen.
-If you are interested in buying a license for Aster V7, you can visit its official website at https://www.ibik.ru/ and choose the best option for you. You can also find more information and support about Aster V7 on its website.
-Thank you for reading this article. We hope that you have learned something new and useful today. If you have any questions or feedback, please feel free to leave a comment below. We would love to hear from you.
-FAQs
-Here are some frequently asked questions about Aster V7 keygen:
--
-
- What is Aster V7? -
- What is a keygen? -
- Is using a keygen legal? -
- Where can I download Aster V7 keygen? -
- How can I buy a license for Aster V7? -
Aster V7 is a software program that allows you to create multiple independent workspaces on a single PC. You can use different applications and tasks on each workspace simultaneously without interfering with each other. You can also share your PC with other users by connecting multiple monitors, keyboards, mice, and speakers to it.
-A keygen is a small program that generates a valid license key for a software product. By using a keygen, you can bypass the activation process and use the software for free.
-No, using a keygen is illegal. It violates the copyright and intellectual property rights of the software developers. It also exposes your PC to viruses or malware that may harm it or compromise your privacy.
-You can find many websites that offer Aster V7 keygen for free download, but be careful as some of them may be fake or malicious. To avoid getting infected by viruses or malware, you should only download Aster V7 keygen from trusted sources.
-You can buy a license for Aster V7 from its official website at https://www.ibik.ru/. You can choose the best option for you depending on how many workspaces you want to create and how long you want to use them.
--
-
\ No newline at end of file diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Call Of Duty Black Ops 2 Crack File Download.md b/spaces/1gistliPinn/ChatGPT4/Examples/Call Of Duty Black Ops 2 Crack File Download.md deleted file mode 100644 index 0bb710d6047a4d8d64ecf92b3bf8912d8514f565..0000000000000000000000000000000000000000 --- a/spaces/1gistliPinn/ChatGPT4/Examples/Call Of Duty Black Ops 2 Crack File Download.md +++ /dev/null @@ -1,6 +0,0 @@ -
call of duty black ops 2 crack file download
Download File === https://imgfil.com/2uy1lx
- -Successful conversion of password encrypted OST files. Safe and fast scanning. Supports c... powered by Peatix : More than a ticket. 4d29de3e1b
-
-
- diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Catia P3 V5-6r2014 Free Crack 412.md b/spaces/1gistliPinn/ChatGPT4/Examples/Catia P3 V5-6r2014 Free Crack 412.md deleted file mode 100644 index 8b6dd49ddc30e10a658b35f545a01b120745a95f..0000000000000000000000000000000000000000 --- a/spaces/1gistliPinn/ChatGPT4/Examples/Catia P3 V5-6r2014 Free Crack 412.md +++ /dev/null @@ -1,6 +0,0 @@ -
catia p3 v5-6r2014 crack 412
Download Zip ⚙ https://imgfil.com/2uy1Xg
-
- d5da3c52bf
-
-
- diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Chief Architect X6 Crack Keygens.md b/spaces/1gistliPinn/ChatGPT4/Examples/Chief Architect X6 Crack Keygens.md deleted file mode 100644 index 613ee00d09361abf4c159df99aec451f4443df1e..0000000000000000000000000000000000000000 --- a/spaces/1gistliPinn/ChatGPT4/Examples/Chief Architect X6 Crack Keygens.md +++ /dev/null @@ -1,6 +0,0 @@ -
chief architect x6 crack keygens
DOWNLOAD ↔ https://imgfil.com/2uy0Nw
-
-Chief Architect Premier X6 serial numbers, cracks and keygens are presented here. No registration is needed. Just download and enjoy. 4d29de3e1b
-
-
- diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Adobe Flash Professional CS6 Whats New in the Latest Version?.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Adobe Flash Professional CS6 Whats New in the Latest Version?.md deleted file mode 100644 index 686db53e76edab2bb8d125db0a00525fa0f0a64f..0000000000000000000000000000000000000000 --- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Adobe Flash Professional CS6 Whats New in the Latest Version?.md +++ /dev/null @@ -1,227 +0,0 @@ - -
Introduction
-Adobe Flash Pro CS6 is a software that allows you to create animation and multimedia content for web, desktop, and mobile platforms. You can use it to design interactive experiences that present consistently across devices and browsers. You can also use it to create games, cartoons, banners, presentations, e-learning materials, and more.
-Some of the features of Adobe Flash Pro CS6 include:
-adobe flash pro cs6 free download
DOWNLOAD · https://urlin.us/2uT0D2
-
-
-
- Support for HTML5: You can use the Toolkit for CreateJS extension to export your content as JavaScript that can run on HTML5 canvas. -
- Sprite sheet generation: You can export your symbols and animation sequences as sprite sheets that help improve the gaming experience, workflow, and performance. -
- Wide platform and device support: You can reach Android and iOS devices by targeting the latest Adobe Flash Player and AIR runtimes. You can also create and deliver applications with a prepackaged Adobe AIR captive runtime for a better user experience. -
- Adobe AIR mobile simulation: You can simulate common mobile application interactions like screen orientation, touch gestures, and accelerometer to help speed up testing. -
- Stage 3D targeting: You can turbocharge rendering performance by using direct mode to leverage the open source Starling Framework for hardware-accelerated 2D content. -
Downloading and installing Adobe Flash Pro CS6
-If you want to use Adobe Flash Pro CS6 for free, you can download it from a Google Drive link that contains the setup file and the crack file. Here are the steps to download and install it:
--
-
- Click on the Google Drive link and download the Adobe.Flash.Professional.CS6.rar file. -
- Extract the rar file using a software like WinRAR or 7-Zip. -
- Open the extracted folder and run Set-up.exe as administrator. -
- Follow the on-screen instructions to complete the installation. When prompted to enter a serial number, enter any of the serial numbers provided in the Serial Key.txt file. -
- After the installation is finished, do not launch the program yet. -
- Copy the amtlib.dll file from the Crack folder and paste it in the installation directory (usually C:\Program Files\Adobe\Adobe Flash CS6). -
- Replace the existing file if asked. -
- You can now launch Adobe Flash Pro CS6 and enjoy using it for free. -
Getting started with Adobe Flash Pro CS6
-Now that you have installed Adobe Flash Pro CS6, you can start creating your own projects. Here are some basic steps to get you started:
-Creating a new document
-To create a new document in Adobe Flash Pro CS6, follow these steps:
--
-
- Launch Adobe Flash Pro CS6. -
- Select File > New or press Ctrl+N on your keyboard. -
- In the New Document dialog box, choose a document type from the tabs. You can choose from ActionScript 3.0, ActionScript 2.0, AIR for Desktop, AIR for Android, AIR for iOS, or HTML5 Canvas. -
- Click OK to create a new document with default settings or click Change to customize the settings such as the size, frame rate, background color, and ruler units of your document. -
Setting up the stage
-The stage is the rectangular area where you create and arrange the objects that appear in your animation. You can customize the appearance and behavior of the stage by using the Properties panel and the View menu. Here are some things you can do with the stage:
--
-
- Change the stage size: You can change the width and height of the stage by entering the values in the Size section of the Properties panel or by dragging the edges of the stage. -
- Change the stage color: You can change the background color of the stage by clicking on the color box in the Background Color section of the Properties panel and choosing a color from the color picker. -
- Change the stage alignment: You can change how the stage is aligned within the browser window by clicking on the Align button in the Align section of the Properties panel and choosing an alignment option from the drop-down menu. -
- Change the stage scale mode: You can change how the stage scales when the browser window is resized by clicking on the Scale button in the Scale section of the Properties panel and choosing a scale mode from the drop-down menu. The options are Show All, No Border, Exact Fit, and No Scale. -
- Zoom in or out of the stage: You can zoom in or out of the stage by using the Zoom tool from the Tools panel or by choosing a zoom level from the View > Magnification menu. -
- Show or hide rulers, guides, and grids: You can show or hide rulers, guides, and grids on the stage by choosing View > Rulers, View > Guides, or View > Grid. You can also customize their settings by choosing Edit > Preferences > Guides & Grid. -
Using the tools
-The Tools panel contains various tools that you can use to create and modify objects on the stage. You can access it by choosing Window > Tools or by pressing Ctrl+F2 on your keyboard. Here are some of the tools you can use:
-| Tool | Description |
|---|---|
| Selection tool | Lets you select and move objects on the stage. You can also use it to resize, rotate, skew, or distort objects by dragging their handles. |
| Subselection tool | Lets you select and edit individual anchor points and segments of an object. You can also use it to add or delete anchor points or convert them between corner and smooth points. |
| Free Transform tool | Lets you transform objects on the stage using various options such as scale, rotate, skew, distort, envelope, and perspective. You can also use it to flip or rotate objects in 3D space. |
| Lasso tool | Lets you select objects or parts of objects by drawing a freehand shape around them. You can also use it to select pixels in bitmap images. |
| Pen tool | Lets you draw straight or curved lines by placing anchor points on the stage. You can also use it to modify existing lines by adding, deleting, or moving anchor points. |
| Text tool | Lets you create and edit text on the stage. You can also use it to format text using various options such as font, size, color, alignment, and style. |
| Line tool | Lets you draw straight lines on the stage. You can also use it to set the stroke color, width, and style of the lines. |
| Oval tool | Lets you draw ovals and circles on the stage. You can also use it to set the fill and stroke color, width, and style of the ovals. |
| Rectangle tool | Lets you draw rectangles and squares on the stage. You can also use it to set the fill and stroke color, width, and style of the rectangles. You can also use it to adjust the corner radius of the rectangles. |
| Pencil tool | Lets you draw freehand lines on the stage. You can also use it to set the stroke color, width, and style of the lines. You can also use it to choose a drawing mode from straighten, smooth, or ink. |
| Brush tool | Lets you draw freehand shapes with a fill on the stage. You can also use it to set the fill color and style of the shapes. You can also use it to choose a brush size, shape, and mode from paint normal, paint fills, paint behind, paint selection, or paint inside. |
| Paint Bucket tool | Lets you fill an enclosed area or shape with a color on the stage. You can also use it to set the fill color and style of the area or shape. You can also use it to choose a fill mode from paint normal, paint fills, paint behind, paint selection, or paint inside. |
| Eyedropper tool | Lets you pick up a color from an object on the stage or from the color picker. You can also use it to apply the picked color to another object on the stage. |
| Eraser tool | Lets you erase parts of an object or a bitmap image on the stage. You can also use it to set the eraser mode from erase normal, erase fills, erase lines, or erase selected fills and lines. You can also use it to choose an eraser size and shape. |
| Hand tool | Lets you move the stage view by dragging it with your mouse. You can also use it to zoom in or out of the stage by holding down the Alt key and scrolling your mouse wheel. |
| Zoom tool | Lets you zoom in or out of a specific area on the stage by clicking or dragging your mouse. You can also use it to zoom out by holding down the Alt key and clicking your mouse. |
Creating animation with Adobe Flash Pro CS6
-One of the main features of Adobe Flash Pro CS6 is that you can create animation using various techniques such as frames, keyframes, layers, tweens, and symbols. Here are some basic concepts and steps to help you create animation with Adobe Flash Pro CS6:
-Frames and keyframes
-Frames are the basic units of time in an animation. Each frame represents a single image or state of your animation. Keyframes are special frames that mark the beginning or end of a change in your animation. You can create frames and keyframes by using the Timeline panel at the bottom of your screen. Here are some things you can do with frames and keyframes:
--
-
- Add frames: You can add frames by selecting a frame on the Timeline panel and choosing Insert > Timeline > Frame or pressing F5 on your keyboard. -
- Add keyframes: You can add keyframes by selecting a frame on the Timeline panel and choosing Insert > Timeline > Keyframe or pressing F6 on your keyboard. -
- Delete frames: You can delete frames by selecting them on the Timeline panel and choosing Edit > Timeline > Remove Frames or pressing Shift+F5 on your keyboard. -
- Copy and paste frames: You can copy and paste frames by selecting them on the Timeline panel and choosing Edit > Timeline > Copy Frames or Edit > Timeline > Paste Frames or pressing Ctrl+Alt+C or Ctrl+Alt+V on your keyboard. -
- Move frames: You can move frames by selecting them on the Timeline panel and dragging them to a new location. -
- Extend frames: You can extend frames by selecting them on the Timeline panel and dragging their right edge to a new position. -
- Insert blank keyframes: You can insert blank keyframes by selecting a frame on the Timeline panel and choosing Insert > Timeline > Blank Keyframe or pressing F7 on your keyboard. -
- Convert frames to keyframes: You can convert frames to keyframes by selecting them on the Timeline panel and choosing Modify > Timeline > Convert to Keyframes or pressing Ctrl+Alt+K on your keyboard. -
Layers
-Layers are the vertical stacks of frames on the Timeline panel that help you organize and control the visibility and order of your objects on the stage. You can create and manage layers by using the Layer panel at the bottom of your screen. Here are some things you can do with layers:
-adobe flash professional cs6 download
-adobe flash pro cs6 free trial
-adobe flash pro cs6 full version
-adobe flash pro cs6 crack
-adobe flash pro cs6 serial number
-adobe flash pro cs6 portable
-adobe flash pro cs6 tutorial
-adobe flash pro cs6 system requirements
-adobe flash pro cs6 animation
-adobe flash pro cs6 keygen
-adobe flash pro cs6 mac
-adobe flash pro cs6 offline installer
-adobe flash pro cs6 for windows 10
-adobe flash pro cs6 update
-adobe flash pro cs6 license key
-adobe flash pro cs6 iso
-adobe flash pro cs6 patch
-adobe flash pro cs6 online
-adobe flash pro cs6 features
-adobe flash pro cs6 activation code
-adobe flash pro cs6 rar
-adobe flash pro cs6 setup
-adobe flash pro cs6 software
-adobe flash pro cs6 toolkit for createjs
-adobe flash pro cs6 video editing
-adobe flash pro cs6 game development
-adobe flash pro cs6 classroom in a book pdf
-adobe flash pro cs6 ebook
-adobe flash pro cs6 templates
-adobe flash pro cs6 extensions
-adobe flash pro cs6 sprite sheet generator
-adobe flash pro cs6 export to html5
-adobe flash pro cs6 stage 3d targeting
-adobe flash pro cs6 air mobile simulation
-adobe flash pro cs6 prepackaged air application creation
-adobe flash pro cs6 wide platform and device support
-adobe flash pro cs6 actionscript 3.0 reference
-adobe flash pro cs6 bone tool tutorial
-adobe flash pro cs6 motion editor tutorial
-adobe flash pro cs6 motion presets tutorial
-adobe flash pro cs6 shape tween tutorial
-adobe flash pro cs6 classic tween tutorial
-adobe flash pro cs6 frame by frame animation tutorial
-adobe flash pro cs6 button tutorial
-adobe flash pro cs6 movie clip tutorial
-adobe flash pro cs6 symbol tutorial
-adobe flash pro cs6 text tool tutorial
-adobe flash pro cs6 mask layer tutorial
-adobe flash pro cs6 filters and blend modes tutorial
-
-
- Add layers: You can add layers by clicking on the New Layer button at the bottom of the Layer panel or by choosing Insert > Timeline > Layer. -
- Delete layers: You can delete layers by selecting them on the Layer panel and clicking on the Delete Layer button at the bottom of the Layer panel or by choosing Edit > Timeline > Remove Layer. -
- Rename layers: You can rename layers by double-clicking on their names on the Layer panel and typing a new name. -
- Lock layers: You can lock layers by clicking on the Lock icon next to their names on the Layer panel. This prevents you from accidentally modifying or selecting the objects on those layers. -
- Hide layers: You can hide layers by clicking on the Eye icon next to their names on the Layer panel. This makes the objects on those layers invisible on the stage and in the output. -
- Reorder layers: You can reorder layers by selecting them on the Layer panel and dragging them up or down to a new position. -
- Create layer folders: You can create layer folders by clicking on the New Folder button at the bottom of the Layer panel or by choosing Insert > Timeline > Folder. This helps you group related layers together and collapse or expand them as needed. -
- Create guide layers: You can create guide layers by right-clicking on a layer on the Layer panel and choosing Guide. This makes the objects on that layer visible only on the stage and not in the output. You can use guide layers to place reference images, sketches, or notes that help you design your animation. -
- Create mask layers: You can create mask layers by right-clicking on a layer on the Layer panel and choosing Mask. This makes the objects on that layer act as a mask that reveals or hides the objects on the layer below it. You can use mask layers to create effects such as spotlight, cutout, or transition. -
Tweens
-Tweens are a type of animation that lets you create smooth transitions between two or more keyframes. You can create tweens by using the Motion Editor panel at the bottom of your screen. There are two types of tweens in Adobe Flash Pro CS6: motion tweens and classic tweens. Here are some differences between them:
-| Motion tweens | Classic tweens |
|---|---|
| Use property keyframes to define changes in properties such as position, rotation, scale, color, and filters. | Use regular keyframes to define changes in properties such as position, rotation, scale, color, and filters. |
| Apply to symbols, text fields, groups, or instances. | Apply to symbols or instances only. |
| Use motion paths to define curved or complex paths for animation. | Use straight lines or shape hints to define curved or complex paths for animation. |
| Use eases to control the speed and acceleration of animation. | Use eases to control the speed and acceleration of animation. |
| Use 3D rotation and translation tools to create 3D effects. | Do not support 3D effects. |
Symbols
-Symbols are reusable objects that you can create and store in the Library panel at the right side of your screen. You can use symbols to save time and reduce file size by reusing them in different parts of your animation. There are three types of symbols in Adobe Flash Pro CS6: graphic symbols, button symbols, and movie clip symbols. Here are some differences between them:
-| Graphic symbols | Button symbols | Movie clip symbols | |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Contain static or animated graphics that play in sync with the main Timeline. | Contain graphics that change appearance based on user interaction such as mouse over, click, or release. | Contain graphics that play independently from li>Design your button states: You can design your button states by adding graphics or text to the four frames in the button symbol Timeline. The four frames correspond to the four states of the button: Up, Over, Down, and Hit. The Up state is how the button appears normally, the Over state is how the button appears when the mouse pointer is over it, the Down state is how the button appears when the mouse button is pressed, and the Hit state is the area that responds to mouse clicks. You can use any of the tools or symbols to create your button states.
-Using actions-Actions are commands that control the behavior of your project. You can use actions to add logic, interactivity, and functionality to your project. You can write actions using ActionScript, a scripting language that is based on JavaScript. You can access actions by using the Actions panel at the right side of your screen. Here are some things you can do with actions: -
Exporting and publishing your project with Adobe Flash Pro CS6-After you have finished creating your project with Adobe Flash Pro CS6, you can export and publish it in different formats and platforms. You can export your project as a SWF file or an HTML5 canvas file that can be viewed in a web browser. You can also publish your project as an AIR application that can be installed and run on desktop or mobile devices. Here are some basic steps to help you export and publish your project with Adobe Flash Pro CS6: -Exporting your project as a SWF file-A SWF file is a compressed file format that contains your project content and code. You can export your project as a SWF file by following these steps: -
You can view your SWF file in a web browser that has the Adobe Flash Player plugin installed. You can also embed your SWF file in an HTML page by using the Publish Settings dialog box. -Exporting your project as an HTML5 canvas file-An HTML5 canvas file is a JavaScript file that contains your project content and code converted to HTML5 standards. You can export your project as an HTML5 canvas file by following these steps: -
You can view your HTML5 canvas file in a web browser that supports the HTML5 canvas element. You can also embed your HTML5 canvas file in an HTML page by using the Publish Settings dialog box. -Publishing your project as an AIR application-An AIR application is a standalone application that contains your project content and code packaged with the Adobe AIR runtime. You can publish your project as an AIR application by following these steps: -
You can install and run your AIR application on desktop or mobile devices that have the Adobe AIR runtime installed. You can also distribute your AIR application through online stores or websites by using the appropriate installer files. -Conclusion-In this article, you learned how to use Adobe Flash Pro CS6 to create animation and multimedia content. You learned how to download, install, and use Adobe Flash Pro CS6 for free. You learned how to create and modify objects on the stage using various tools. You learned how to create animation using frames, keyframes, layers, tweens, and symbols. You learned how to add interactivity using code snippets, buttons, and actions. You learned how to export and publish your project in different formats and platforms. You also learned some useful resources and tips to help you master this software and create amazing projects. -FAQs-Here are some common questions and answers about Adobe Flash Pro CS6: -Q: Is Adobe Flash Pro CS6 still supported by Adobe?-A: No, Adobe Flash Pro CS6 is not supported by Adobe anymore. Adobe discontinued support for Flash Player on December 31, 2020. Adobe also recommends uninstalling Flash Player from your devices. However, you can still use Adobe Flash Pro CS6 to create content for other platforms such as HTML5 canvas or AIR applications. -Q: How can I learn more about Adobe Flash Pro CS6?-A: You can learn more about Adobe Flash Pro CS6 by visiting the official website, reading the user guide, watching the video tutorials or browsing the online forums. You can also take online courses or read books that teach you how to use Adobe Flash Pro CS6 for various purposes such as animation, game development, web design, and more. -Q: What are some alternatives to Adobe Flash Pro CS6?-A: Some alternatives to Adobe Flash Pro CS6 are: -
Q: How can I improve my skills in Adobe Flash Pro CS6?-A: You can improve your skills in Adobe Flash Pro CS6 by practicing regularly, experimenting with different features and techniques, and seeking feedback from others. You can also join online communities and groups that share tips, tutorials, and projects related to Adobe Flash Pro CS6. You can also participate in challenges and contests that test your creativity and skills in Adobe Flash Pro CS6. -Q: How can I troubleshoot problems in Adobe Flash Pro CS6?-A: You can troubleshoot problems in Adobe Flash Pro CS6 by following these steps: -
I hope you found this article helpful and informative. Thank you for reading! 197e85843d- - \ No newline at end of file diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Badminton League Mod APK with Unlimited Money and Coins.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Badminton League Mod APK with Unlimited Money and Coins.md deleted file mode 100644 index ac1b7cbadc5769348879c825d1f054be03727923..0000000000000000000000000000000000000000 --- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Badminton League Mod APK with Unlimited Money and Coins.md +++ /dev/null @@ -1,106 +0,0 @@ - - How to Download Badminton League Mod Apk-Badminton is a fun and exciting sport that can be played by anyone, anywhere. But if you want to take your badminton game to the next level, you might want to try Badminton League Mod Apk, a modified version of the popular badminton game app that gives you unlimited money, coins, and gems. With Badminton League Mod Apk, you can customize your character, unlock new rackets and outfits, upgrade your skills, and challenge your friends or other players online. In this article, we will show you how to download and install Badminton League Mod Apk on your Android device, as well as how to play it and some tips and tricks to win at badminton. -how to download badminton league mod apkDownload Zip ✅ https://urlin.us/2uST6j - What is Badminton League Mod Apk?-Badminton League is a 3D badminton game app that lets you play badminton with realistic physics and graphics. You can create your own character, choose your racket and outfit, and compete in various modes, such as tournament, league, or 1v1. You can also play with your friends or other players online in real-time matches. -Features of Badminton League Mod Apk-Badminton League Mod Apk is a modified version of the original game that gives you some extra features that are not available in the official version. Some of these features are: -
Benefits of Badminton League Mod Apk-Badminton League Mod Apk has some benefits that make it more enjoyable and fun than the original game. Some of these benefits are: -
How to Download and Install Badminton League Mod Apk-If you want to download and install Badminton League Mod Apk on your Android device, you need to follow these steps: -how to install badminton league mod apk on android Step 1: Enable Unknown Sources-Since Badminton League Mod Apk is not available on the Google Play Store, you need to enable unknown sources on your device settings. This will allow you to install apps from sources other than the official store. To do this, go to Settings > Security > Unknown Sources and toggle it on. -Step 2: Download Badminton League Mod Apk File-Next, you need to download the Badminton League Mod Apk file from a reliable source. You can use this link to download the latest version of the file. Make sure you have enough storage space on your device before downloading. -Step 3: Install Bad minton League Mod Apk File-After downloading the file, you need to install it on your device. To do this, locate the file in your file manager and tap on it. You will see a pop-up window asking you to confirm the installation. Tap on Install and wait for the process to finish. -Step 4: Launch Badminton League Mod Apk and Enjoy-Once the installation is done, you can launch the game from your app drawer or home screen. You will see a welcome screen with some instructions and options. You can choose your language, sign in with your Facebook account, or play as a guest. You can also adjust the sound and graphics settings. After that, you can start playing Badminton League Mod Apk and enjoy its features. -How to Play Badminton League Mod Apk-Badminton League Mod Apk is easy to play and has a simple interface. You can use the virtual joystick on the left side of the screen to move your character, and the buttons on the right side to hit the shuttlecock. You can also swipe on the screen to perform different shots, such as smash, drop, or lob. You can play in different modes, such as tournament, league, or 1v1. You can also play with your friends or other players online in real-time matches. -Basic Rules and Scoring System-The basic rules and scoring system of Badminton League Mod Apk are similar to the real badminton game. Here are some of them: -
Tips and Tricks to Win at Badminton-Badminton is a game of skill, speed, and strategy. Here are some tips and tricks to help you win at Badminton League Mod Apk: -
Conclusion-Badminton League Mod Apk is a great game for badminton lovers and casual gamers alike. It has realistic physics and graphics, various modes and features, and unlimited money, coins, and gems. You can download and install it easily on your Android device by following our guide above. You can also play it with your friends or other players online in real-time matches. If you want to enjoy badminton anytime, anywhere, Badminton League Mod Apk is the game for you. -FAQs-Here are some frequently asked questions about Badminton League Mod Apk: -
- - \ No newline at end of file diff --git a/spaces/1phancelerku/anime-remove-background/Download 6th Tamil Book PDF for Free - Samacheer Kalvi New Syllabus 2021 to 2022.md b/spaces/1phancelerku/anime-remove-background/Download 6th Tamil Book PDF for Free - Samacheer Kalvi New Syllabus 2021 to 2022.md deleted file mode 100644 index 3fc29083e4dab5eeedc11d6110dda138836af204..0000000000000000000000000000000000000000 --- a/spaces/1phancelerku/anime-remove-background/Download 6th Tamil Book PDF for Free - Samacheer Kalvi New Syllabus 2021 to 2022.md +++ /dev/null @@ -1,100 +0,0 @@ - - 6th Tamil Book PDF Download 2021 to 2022-If you are a student of class 6 in Tamil Nadu, you might be looking for the 6th Tamil book PDF download 2021 to 2022. The 6th Tamil book is one of the essential textbooks that you need to study the Tamil language and literature. In this article, we will tell you everything you need to know about the 6th Tamil book PDF download, including its benefits, challenges, and how to do it online. Read on to find out more. -6th tamil book pdf download 2021 to 2022Download File • https://jinyurl.com/2uNQJ4 - Introduction-What is the 6th Tamil book?-The 6th Tamil book is a textbook that covers the Tamil language and literature for class 6 students in Tamil Nadu. It is based on the new syllabus and curriculum that was announced by the Tamil Nadu State Council of Educational Research and Training (TNSCERT) for the academic year 2021 to 2022. The 6th Tamil book contains various chapters that teach you the basics of grammar, vocabulary, reading comprehension, writing skills, and literary appreciation. It also includes poems, stories, essays, and other forms of literature that showcase the rich culture and heritage of Tamil Nadu. -Why do you need to download the 6th Tamil book PDF?-You might be wondering why you need to download the 6th Tamil book PDF when you can get a printed copy from your school or bookstore. Well, there are many reasons why downloading the 6th Tamil book PDF can be beneficial for you. For instance, you might want to download the 6th Tamil book PDF if: -
How to download the 6th Tamil book PDF online?-Now that you know why you need to download the 6th Tamil book PDF, you might be wondering how to do it online. Well, there are many websites that offer free download of the 6th Tamil book PDF online. However, not all of them are reliable or safe. Therefore, you need to be careful and choose a trusted source for downloading the 6th Tamil book PDF online. Here are some of the steps that you can follow to download the 6th Tamil book PDF online: -6th standard tamil nadu revised text books 2020-2021 pdf
Benefits of downloading the 6th Tamil book PDF-Access the latest syllabus and curriculum-One of the main benefits of downloading the 6th Tamil book PDF is that you can access the latest syllabus and curriculum that is prescribed by the TNSCERT for the academic year 2021 to 2022. This way, you can ensure that you are studying the most relevant and updated topics and concepts that are required for your class 6 education. You can also compare the old and new syllabus and curriculum to see what changes have been made and how they affect your learning outcomes. -Study anytime and anywhere-Another benefit of downloading the 6th Tamil book PDF is that you can study anytime and anywhere without depending on a physical copy of the book. You can access the book from your smartphone, tablet, laptop, or desktop and read it whenever you want. You can also study offline by saving the file on your device or cloud storage. This way, you can avoid missing out on any important lessons or assignments due to lack of availability or accessibility of the book. -Save money and paper-A third benefit of downloading the 6th Tamil book PDF is that you can save money and paper by avoiding buying or printing a hard copy of the book. You can download the book for free from various websites and use it as many times as you want. You can also share it with your friends or classmates who need it. By doing so, you can reduce the cost of education and also contribute to environmental conservation by saving paper and ink. -Prepare for exams and assessments-A fourth benefit of downloading the 6th Tamil book PDF is that you can prepare for your exams and assessments by revising the chapters and practicing the exercises online. You can easily access the book from your device or cloud storage and review the key points and summaries of each chapter. You can also test your knowledge and skills by solving the questions and activities given at the end of each chapter. You can also refer to other online resources such as sample papers, mock tests, previous year papers, etc. to enhance your preparation. -Challenges of downloading the 6th Tamil book PDF-Internet connectivity and speed-One of the main challenges of downloading the 6th Tamil book PDF is that you need a good internet connection and speed to do it online. If you have a slow or unstable internet connection, you might face difficulties in downloading the file or opening it with a PDF reader or browser. You might also experience interruptions or errors during the download process that might affect the quality or completeness of the file. Therefore, you need to ensure that you have a reliable and fast internet connection before downloading the 6th Tamil book PDF online. -Storage space and compatibility-Another challenge of downloading the 6th Tamil book PDF is that you need enough storage space and compatibility on your device or cloud storage to save and access the file. The 6th Tamil book PDF file might be large in size and require a lot of space on your device or cloud storage. If you have limited space or memory on your device or cloud storage, you might not be able to download or save the file properly. You might also need a compatible PDF reader or browser to open and view the file on your device or cloud storage. If you have an incompatible PDF reader or browser, you might not be able to see or read the contents of the file clearly. -Quality and accuracy of the PDF files-A third challenge of downloading the 6th Tamil book PDF is that you need to check the quality and accuracy of the PDF files that you download online. Not all websites that offer free download of the 6th Tamil book PDF online are trustworthy or authentic. Some of them might provide low-quality or inaccurate PDF files that might contain errors, omissions, or distortions. Some of them might also provide outdated or obsolete PDF files that might not match the latest syllabus and curriculum. Therefore, you need to verify the quality and accuracy of the PDF files that you download online by checking the source, date, and content of the files. -Security and privacy issues-A fourth challenge of downloading the 6th Tamil book PDF is that you need to be aware of the security and privacy issues that might arise from downloading the file online. Some websites that offer free download of the 6th Tamil book PDF online might not have proper security measures or encryption to protect the file from hackers, viruses, or malware. Some of them might also have hidden or malicious links or ads that might redirect you to unsafe or inappropriate sites or download unwanted or harmful software on your device or cloud storage. Therefore, you need to be careful and cautious when downloading the 6th Tamil book PDF online and avoid clicking on any suspicious or unknown links or ads. -Conclusion-Downloading the 6th Tamil book PDF online can be a great way to study the Tamil language and literature for class 6 students in Tamil Nadu. It can help you access the latest syllabus and curriculum, study anytime and anywhere, save money and paper, and prepare for exams and assessments. However, it can also pose some challenges such as internet connectivity and speed, storage space and compatibility, quality and accuracy of the PDF files, and security and privacy issues. Therefore, you need to weigh the pros and cons of downloading the 6th Tamil book PDF online and choose a reliable and safe source for doing so. We hope this article has helped you understand everything you need to know about the 6th Tamil book PDF download 2021 to 2022. -FAQs-Here are some of the frequently asked questions about the 6th Tamil book PDF download 2021 to 2022: -
The official website for downloading the 6th Tamil book PDF online is [TNSCERT], which is the official portal of the Tamil Nadu State Council of Educational Research and Training. You can find all the textbooks for class 1 to 12 in various subjects and mediums on this website. -If you want to download the 6th Tamil book PDF offline, you can visit your nearest school or bookstore and ask for a CD or DVD that contains the PDF file of the book. You can also ask your teacher or friend who has already downloaded the file to share it with you via a pen drive or email. -If you want to print the 6th Tamil book PDF, you can open the file with a PDF reader or browser and select the print option from the menu. You can also adjust the settings such as page size, orientation, margins, etc. before printing. However, we recommend that you avoid printing the 6th Tamil book PDF as it might waste paper and ink and harm the environment. You can instead use the digital version of the book on your device or cloud storage. -If you want to edit or annotate the 6th Tamil book PDF, you can use a PDF editor or annotator software or app that allows you to modify, highlight, comment, or draw on the PDF file. You can also use online tools such as [PDFescape] or [PDF Candy] that let you edit or annotate the PDF file for free. -If you want to convert the 6th Tamil book PDF to other formats such as Word, Excel, PowerPoint, etc., you can use a PDF converter software or app that allows you to change the format of the PDF file. You can also use online tools such as [Smallpdf] or [ILovePDF] that let you convert the PDF file to other formats for free. -- - \ No newline at end of file diff --git a/spaces/1phancelerku/anime-remove-background/Drive Through Highway Traffic with Stunning 3D Graphics in Traffic Racer Pro Car Games.md b/spaces/1phancelerku/anime-remove-background/Drive Through Highway Traffic with Stunning 3D Graphics in Traffic Racer Pro Car Games.md deleted file mode 100644 index 3549ecdb98a0e6ad5083fc855ef0a8efada01560..0000000000000000000000000000000000000000 --- a/spaces/1phancelerku/anime-remove-background/Drive Through Highway Traffic with Stunning 3D Graphics in Traffic Racer Pro Car Games.md +++ /dev/null @@ -1,134 +0,0 @@ - - Traffic Racer Pro: Car Games - A Review-If you are looking for a thrilling and realistic car racing game that will keep you entertained for hours, you might want to check out Traffic Racer Pro. This game is a milestone in the genre of endless car racing games, where you can drive through highway traffic, upgrade and tune cars, participate in online races, and more. In this article, we will review the game and tell you everything you need to know about it. -What is Traffic Racer Pro?-Traffic Racer Pro is a car racing game developed by TOJGAMES, a studio that specializes in car racing games and driving simulators. The game was released in 2021 and has been downloaded by over 1 million players worldwide. The game features stunning 3D graphics, smooth and realistic car handling, extreme car driving in highway traffic, easy to learn and drive controls, 3D realistic car interior views, endless game mode, different locations and cars to choose from, realistic car controls, 40+ different cars to choose from, advanced car customization through paint, decals, wheels, etc., online multiplayer mode, career mode, and more. -traffic racer pro car game downloadDownload File 🗹 https://jinyurl.com/2uNJT3 - How to download and install Traffic Racer Pro?-Traffic Racer Pro is available for both Android and iOS devices. You can download it from the Google Play Store or the App Store depending on your device. The game is free to play but it contains ads and in-app purchases that you can disable or buy if you want. The game requires an internet connection to play online multiplayer mode. -To install the game on your device, follow these steps - Open the Google Play Store or the App Store on your device and search for Traffic Racer Pro. - Tap on the game icon and then tap on the Install or Get button. - Wait for the game to download and install on your device. - Once the game is installed, tap on the Open or Play button to launch the game. - Enjoy playing Traffic Racer Pro! -How to play Traffic Racer Pro?-Traffic Racer Pro is easy to play but hard to master. The game has two modes: endless and career. In endless mode, you can drive as long as you can without crashing into other cars or obstacles. In career mode, you can complete various missions and challenges to earn coins and cash. You can use the coins and cash to buy and upgrade new cars and locations. -The game has four control options: tilt, touch, steering wheel, and buttons. You can choose the one that suits you best from the settings menu. You can also adjust the sensitivity, sound, graphics, and language settings from there. To accelerate, you can either tap on the gas pedal or use the auto-acceleration option. To brake, you can tap on the brake pedal or use the auto-brake option. To steer, you can either tilt your device, touch the screen, use the steering wheel, or use the buttons. -The game has four camera views: first person, third person, hood, and rear. You can switch between them by tapping on the camera icon. You can also use the horn, headlights, and indicators by tapping on their icons. To perform a nitro boost, you can tap on the nitro icon or swipe up on the screen. -The game has different traffic scenarios: light, medium, heavy, and extreme. You can choose the one that you prefer from the main menu. The more traffic there is, the more difficult it is to drive but also the more points you get. You can also choose between different weather conditions: sunny, rainy, foggy, and snowy. The weather affects the visibility and handling of your car. -traffic racer pro extreme car driving tour The game has different locations: city, desert, snow, forest, and night. You can unlock them by completing certain missions or by paying with coins or cash. Each location has its own scenery and challenges. -The game has different goals: distance, speed, time, overtaking, near miss, etc. You can see your current goal on the top of the screen. You can also see your speedometer, score multiplier, nitro meter, distance traveled, time elapsed, coins earned, and cash earned on the screen. -What are the benefits of playing Traffic Racer Pro?-Traffic Racer Pro is a fun and exciting game that will keep you hooked for hours. Here are some of the benefits of playing it: -
What are the drawbacks of playing Traffic Racer Pro?-Traffic Racer Pro is not a perfect game and it has some drawbacks that you should be aware of. Here are some of the drawbacks of playing it: -
How to customize your car in Traffic Racer Pro?-Traffic Racer Pro allows you to customize your car in various ways. You can change the appearance and performance of your car to suit your preferences and style. Here are some of the options for customizing your car: -
To customize your car, you need to go to the garage menu and select the car that you want to modify. Then, you can choose from the different tabs such as paint, wheels, upgrade, and tune. You can see the changes in real time on the screen. You can also test drive your car before saving the changes. How to join online multiplayer mode in Traffic Racer Pro?-Traffic Racer Pro also has an online multiplayer mode where you can race against other players from around the world. You can join the online multiplayer mode by tapping on the multiplayer icon on the main menu. You can choose between two modes: quick race and tournament. -In quick race mode, you can join a random race with up to 8 players. You can choose the traffic scenario, weather condition, and location of the race. You can also see the names, ranks, and cars of the other players. The race lasts for 3 minutes and the player with the highest score wins. -In tournament mode, you can join a seasonal competition with up to 100 players. You can choose the traffic scenario, weather condition, and location of the race. You can also see the names, ranks, and cars of the other players. The race lasts for 5 minutes and the player with the highest score wins. You can also earn trophies and rewards based on your performance. -To play online multiplayer mode, you need to have a stable internet connection and a registered account. You can create an account by tapping on the profile icon on the main menu and entering your username, email, and password. You can also log in with your Facebook or Google account. -How to earn coins and cash in Traffic Racer Pro?-Coins and cash are the two currencies in Traffic Racer Pro. You can use them to buy and upgrade new cars and locations. You can earn coins and cash by playing the game or by watching videos. Here are some of the ways to earn coins and cash in Traffic Racer Pro: -
How to unlock new cars and locations in Traffic Racer Pro?-Traffic Racer Pro has 40+ different cars and 5 different locations that you can unlock by playing the game. Each car and location has its own price, specifications, and requirements. Here are some of the ways to unlock new cars and locations in Traffic Racer Pro: -
How to contact the developers of Traffic Racer Pro?-If you have any questions, suggestions, feedback, or issues with Traffic Racer Pro, you can contact the developers of the game by using the following methods: -
The developers of Traffic Racer Pro are very responsive and friendly and they appreciate your feedback and support. They are constantly working on improving the game and adding new features and content. -What are some alternatives to Traffic Racer Pro?-If you enjoy playing Traffic Racer Pro, you might also like some other car racing games that are similar or different in some aspects. Here are some of the alternatives to Traffic Racer Pro that you can try: -
Conclusion-Traffic Racer Pro is a car racing game that will give you an adrenaline rush and a sense of adventure. You can drive through highway traffic, upgrade and tune cars, participate in online races, and more. The game has stunning 3D graphics, smooth and realistic car handling, easy to learn and drive controls, 3D realistic car interior views, endless game mode, different locations and cars to choose from, realistic car controls, 40+ different cars to choose from, advanced car customization through paint, decals, wheels etc., online multiplayer mode , career mode ,and more. -If you are looking for a thrilling and realistic car racing game that will keep you entertained for hours , you should download Traffic Racer Pro today. You will not regret it! -FAQs-Q1: Is Traffic Racer Pro free to play?-A1: Yes , Traffic Racer Pro is free to play but it contains ads and in-app purchases that you can disable or buy if you want. -Q2: Is Traffic Racer Pro compatible with my device?-A2: It depends on your device's specifications and operating system. The game requires Android 4.4 or higher or iOS 9.0 or higher to run smoothly. -Q3: Is Traffic Racer Pro safe to download?-A3: Yes , but make sure you download it from a trusted source such as the Google Play Store or the App Store. Do not download it from unknown or suspicious websites or links. -Q4: Is Traffic Racer Pro updated regularly?-A4: Yes , the developers are constantly working on improving the game and adding new features and content. You can check the latest updates on the game's page on the Google Play Store or the App Store or on their social media accounts. -Q5: Is Traffic Racer Pro addictive?-A5: It can be, so play responsibly and take breaks. The game is very fun and exciting, but it can also be distracting and time-consuming. Do not let the game interfere with your daily life, work, or studies. 401be4b1e0- - \ No newline at end of file diff --git a/spaces/4RiZ4/stabilityai-stable-diffusion-2/app.py b/spaces/4RiZ4/stabilityai-stable-diffusion-2/app.py deleted file mode 100644 index d2782cea00b1bfcd22df7c204d9e52a6baf46ac2..0000000000000000000000000000000000000000 --- a/spaces/4RiZ4/stabilityai-stable-diffusion-2/app.py +++ /dev/null @@ -1,3 +0,0 @@ -import gradio as gr - -gr.Interface.load("models/stabilityai/stable-diffusion-2").launch() \ No newline at end of file diff --git a/spaces/4Taps/SadTalker/src/facerender/animate.py b/spaces/4Taps/SadTalker/src/facerender/animate.py deleted file mode 100644 index be2d62ebaeffe06a8dee1e268d832690b1937320..0000000000000000000000000000000000000000 --- a/spaces/4Taps/SadTalker/src/facerender/animate.py +++ /dev/null @@ -1,182 +0,0 @@ -import os -import cv2 -import yaml -import numpy as np -import warnings -from skimage import img_as_ubyte -warnings.filterwarnings('ignore') - -import imageio -import torch - -from src.facerender.modules.keypoint_detector import HEEstimator, KPDetector -from src.facerender.modules.mapping import MappingNet -from src.facerender.modules.generator import OcclusionAwareGenerator, OcclusionAwareSPADEGenerator -from src.facerender.modules.make_animation import make_animation - -from pydub import AudioSegment -from src.utils.face_enhancer import enhancer as face_enhancer - - -class AnimateFromCoeff(): - - def __init__(self, free_view_checkpoint, mapping_checkpoint, - config_path, device): - - with open(config_path) as f: - config = yaml.safe_load(f) - - generator = OcclusionAwareSPADEGenerator(**config['model_params']['generator_params'], - **config['model_params']['common_params']) - kp_extractor = KPDetector(**config['model_params']['kp_detector_params'], - **config['model_params']['common_params']) - mapping = MappingNet(**config['model_params']['mapping_params']) - - - generator.to(device) - kp_extractor.to(device) - mapping.to(device) - for param in generator.parameters(): - param.requires_grad = False - for param in kp_extractor.parameters(): - param.requires_grad = False - for param in mapping.parameters(): - param.requires_grad = False - - if free_view_checkpoint is not None: - self.load_cpk_facevid2vid(free_view_checkpoint, kp_detector=kp_extractor, generator=generator) - else: - raise AttributeError("Checkpoint should be specified for video head pose estimator.") - - if mapping_checkpoint is not None: - self.load_cpk_mapping(mapping_checkpoint, mapping=mapping) - else: - raise AttributeError("Checkpoint should be specified for video head pose estimator.") - - self.kp_extractor = kp_extractor - self.generator = generator - self.mapping = mapping - - self.kp_extractor.eval() - self.generator.eval() - self.mapping.eval() - - self.device = device - - def load_cpk_facevid2vid(self, checkpoint_path, generator=None, discriminator=None, - kp_detector=None, he_estimator=None, optimizer_generator=None, - optimizer_discriminator=None, optimizer_kp_detector=None, - optimizer_he_estimator=None, device="cpu"): - checkpoint = torch.load(checkpoint_path, map_location=torch.device(device)) - if generator is not None: - generator.load_state_dict(checkpoint['generator']) - if kp_detector is not None: - kp_detector.load_state_dict(checkpoint['kp_detector']) - if he_estimator is not None: - he_estimator.load_state_dict(checkpoint['he_estimator']) - if discriminator is not None: - try: - discriminator.load_state_dict(checkpoint['discriminator']) - except: - print ('No discriminator in the state-dict. Dicriminator will be randomly initialized') - if optimizer_generator is not None: - optimizer_generator.load_state_dict(checkpoint['optimizer_generator']) - if optimizer_discriminator is not None: - try: - optimizer_discriminator.load_state_dict(checkpoint['optimizer_discriminator']) - except RuntimeError as e: - print ('No discriminator optimizer in the state-dict. Optimizer will be not initialized') - if optimizer_kp_detector is not None: - optimizer_kp_detector.load_state_dict(checkpoint['optimizer_kp_detector']) - if optimizer_he_estimator is not None: - optimizer_he_estimator.load_state_dict(checkpoint['optimizer_he_estimator']) - - return checkpoint['epoch'] - - def load_cpk_mapping(self, checkpoint_path, mapping=None, discriminator=None, - optimizer_mapping=None, optimizer_discriminator=None, device='cpu'): - checkpoint = torch.load(checkpoint_path, map_location=torch.device(device)) - if mapping is not None: - mapping.load_state_dict(checkpoint['mapping']) - if discriminator is not None: - discriminator.load_state_dict(checkpoint['discriminator']) - if optimizer_mapping is not None: - optimizer_mapping.load_state_dict(checkpoint['optimizer_mapping']) - if optimizer_discriminator is not None: - optimizer_discriminator.load_state_dict(checkpoint['optimizer_discriminator']) - - return checkpoint['epoch'] - - def generate(self, x, video_save_dir, enhancer=None, original_size=None): - - source_image=x['source_image'].type(torch.FloatTensor) - source_semantics=x['source_semantics'].type(torch.FloatTensor) - target_semantics=x['target_semantics_list'].type(torch.FloatTensor) - yaw_c_seq = x['yaw_c_seq'].type(torch.FloatTensor) - pitch_c_seq = x['pitch_c_seq'].type(torch.FloatTensor) - roll_c_seq = x['roll_c_seq'].type(torch.FloatTensor) - source_image=source_image.to(self.device) - source_semantics=source_semantics.to(self.device) - target_semantics=target_semantics.to(self.device) - yaw_c_seq = x['yaw_c_seq'].to(self.device) - pitch_c_seq = x['pitch_c_seq'].to(self.device) - roll_c_seq = x['roll_c_seq'].to(self.device) - - frame_num = x['frame_num'] - - predictions_video = make_animation(source_image, source_semantics, target_semantics, - self.generator, self.kp_extractor, self.mapping, - yaw_c_seq, pitch_c_seq, roll_c_seq, use_exp = True,) - - predictions_video = predictions_video.reshape((-1,)+predictions_video.shape[2:]) - predictions_video = predictions_video[:frame_num] - - video = [] - for idx in range(predictions_video.shape[0]): - image = predictions_video[idx] - image = np.transpose(image.data.cpu().numpy(), [1, 2, 0]).astype(np.float32) - video.append(image) - result = img_as_ubyte(video) - - ### the generated video is 256x256, so we keep the aspect ratio, - if original_size: - result = [ cv2.resize(result_i,(256, int(256.0 * original_size[1]/original_size[0]) )) for result_i in result ] - - video_name = x['video_name'] + '.mp4' - path = os.path.join(video_save_dir, 'temp_'+video_name) - imageio.mimsave(path, result, fps=float(25)) - - if enhancer: - video_name_enhancer = x['video_name'] + '_enhanced.mp4' - av_path_enhancer = os.path.join(video_save_dir, video_name_enhancer) - enhanced_path = os.path.join(video_save_dir, 'temp_'+video_name_enhancer) - enhanced_images = face_enhancer(result, method=enhancer) - - if original_size: - enhanced_images = [ cv2.resize(result_i,(256, int(256.0 * original_size[1]/original_size[0]) )) for result_i in enhanced_images ] - - imageio.mimsave(enhanced_path, enhanced_images, fps=float(25)) - - av_path = os.path.join(video_save_dir, video_name) - audio_path = x['audio_path'] - audio_name = os.path.splitext(os.path.split(audio_path)[-1])[0] - new_audio_path = os.path.join(video_save_dir, audio_name+'.wav') - start_time = 0 - sound = AudioSegment.from_mp3(audio_path) - frames = frame_num - end_time = start_time + frames*1/25*1000 - word1=sound.set_frame_rate(16000) - word = word1[start_time:end_time] - word.export(new_audio_path, format="wav") - - cmd = r'ffmpeg -y -i "%s" -i "%s" -vcodec copy "%s"' % (path, new_audio_path, av_path) - os.system(cmd) - - if enhancer: - cmd = r'ffmpeg -y -i "%s" -i "%s" -vcodec copy "%s"' % (enhanced_path, new_audio_path, av_path_enhancer) - os.system(cmd) - os.remove(enhanced_path) - - os.remove(path) - os.remove(new_audio_path) - diff --git a/spaces/801artistry/RVC801/infer/modules/vc/__init__.py b/spaces/801artistry/RVC801/infer/modules/vc/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/AICODER009/food_detection/README.md b/spaces/AICODER009/food_detection/README.md deleted file mode 100644 index 51de341dbf077412cfc75b8b8bdd98b61d6bce71..0000000000000000000000000000000000000000 --- a/spaces/AICODER009/food_detection/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Food Detection -emoji: 📉 -colorFrom: gray -colorTo: red -sdk: gradio -sdk_version: 3.29.0 -app_file: app.py -pinned: false -license: mit ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/AIWaves/SOP_Generation-single/Component/ExtraComponent.py b/spaces/AIWaves/SOP_Generation-single/Component/ExtraComponent.py deleted file mode 100644 index 3ae6d6728434d03e8a7194befe0cc1be14b6653f..0000000000000000000000000000000000000000 --- a/spaces/AIWaves/SOP_Generation-single/Component/ExtraComponent.py +++ /dev/null @@ -1,128 +0,0 @@ -from .ToolComponent import ToolComponent -import json -from utils import flatten_dict,get_embedding,matching_category,search_with_api,limit_keys,limit_values -import os - - -class CategoryRequirementsComponent(ToolComponent): - def __init__(self, information_path): - super().__init__() - self.information_dataset = [] - self.leaf_name = [] - for toy_path in information_path: - with open(toy_path, encoding="utf-8") as json_file: - data = json.load(json_file) - for d in data: - if "/" in d["cat_leaf_name"]: - leaf_names = d["cat_leaf_name"].split("/") + [d["cat_leaf_name"]] - else: - leaf_names = [d["cat_leaf_name"]] - for name in leaf_names: - self.leaf_name.append(name) - new_d = d.copy() - new_d["cat_leaf_name"] = name - new_d["information"] = flatten_dict(new_d["information"]) - self.information_dataset.append(new_d) - - self.target_embbeding = get_embedding( - self.leaf_name - ) - - def search_information(self, category, information_dataset): - knowledge = {} - for d in information_dataset: - if category == d["cat_leaf_name"]: - knowledge = d["information"] - knowledge = { - key: value - for key, value in knowledge.items() - if (value and key != "相关分类") - } - break - return knowledge - - def func(self, agent): - prompt = "" - messages = agent.long_term_memory - outputdict = {} - functions = [ - { - "name": "search_information", - "description": "根据用户所需要购买商品的种类跟用户的需求去寻找用户所需要的商品", - "parameters": { - "type": "object", - "properties": { - "category": { - "type": "string", - "description": "用户现在所需要的商品类别,比如纸尿布,笔记本电脑等,注意,只能有一个", - }, - "requirements": { - "type": "string", - "description": "用户现在的需求,比如说便宜,安踏品牌等等,可以有多个需求,中间以“ ”分隔", - }, - }, - "required": ["category", "requirements"], - }, - } - ] - - response = agent.LLM.get_response( - messages, - None, - None, - functions=functions, - stream=False, - function_call={"name": "search_information"}, - ) - response_message = json.loads(response["function_call"]["arguments"]) - category = ( - response_message["category"] if response_message["category"] else None - ) - requirements = ( - response_message["requirements"] - if response_message["requirements"] - else category - ) - if not (category or requirements): - return {} - - topk_result = matching_category( - category, self.leaf_name, None, self.target_embbeding, top_k=3 - ) - - top1_score = topk_result[1][0] - request_items, top_category = search_with_api(requirements, category) - - - MIN_CATEGORY_SIM = eval(os.environ["MIN_CATEGORY_SIM"] - ) if "MIN_CATEGORY_SIM" in os.environ else 0.7 - - if top1_score > MIN_CATEGORY_SIM: - agent.environment.shared_memory["category"] = topk_result[0][0] - category = topk_result[0][0] - information = self.search_information( - topk_result[0][0], self.information_dataset - ) - information = limit_keys(information, 3) - information = limit_values(information, 2) - prompt += f"""你需要知道的是:用户目前选择的商品是{category},该商品信息为{information}。你需要根据这些商品信息来详细介绍商品,比如详细介绍商品有哪些品牌,有哪些分类等等,并且询问用户是否有更多的需求。""" - if category in top_category: - top_category.remove(category) - - recommend = "\n经过搜索后,推荐商品如下:\n" - prompt += "筛选出的商品如下:\n" - - for i, request_item in enumerate(request_items): - - itemTitle = request_item["itemTitle"] - itemPrice = request_item["itemPrice"] - itemPicUrl = request_item["itemPicUrl"] - recommend += f"[{i}.商品名称:{itemTitle},商品价格:{float(itemPrice)/100}]({itemPicUrl})\n" - prompt += f"[{i}.商品名称:{itemTitle},商品价格:{float(itemPrice)/100}]\n" - outputdict["recommend"] = recommend - print(recommend) - else: - prompt += f"""你需要知道的是:用户目前选择的商品是{category},而我们店里没有这类商品,但是我们店里有一些近似商品,如{top_category},{topk_result[0][0]},你需要对这些近似商品进行介绍,并引导用户购买""" - outputdict["prompt"] = prompt - return outputdict - diff --git a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_0_ClothesDetection/mmyolo/configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py b/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_0_ClothesDetection/mmyolo/configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py deleted file mode 100644 index d2ef324ed097a30d5a04fba2bb85641e7857f353..0000000000000000000000000000000000000000 --- a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_0_ClothesDetection/mmyolo/configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py +++ /dev/null @@ -1,79 +0,0 @@ -_base_ = './yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py' - -# ========================modified parameters====================== -deepen_factor = 0.67 -widen_factor = 0.75 -lr_factor = 0.1 -affine_scale = 0.9 -loss_cls_weight = 0.3 -loss_obj_weight = 0.7 -mixup_prob = 0.1 - -# =======================Unmodified in most cases================== -num_classes = _base_.num_classes -num_det_layers = _base_.num_det_layers -img_scale = _base_.img_scale - -model = dict( - backbone=dict( - deepen_factor=deepen_factor, - widen_factor=widen_factor, - ), - neck=dict( - deepen_factor=deepen_factor, - widen_factor=widen_factor, - ), - bbox_head=dict( - head_module=dict(widen_factor=widen_factor), - loss_cls=dict(loss_weight=loss_cls_weight * - (num_classes / 80 * 3 / num_det_layers)), - loss_obj=dict(loss_weight=loss_obj_weight * - ((img_scale[0] / 640)**2 * 3 / num_det_layers)))) - -pre_transform = _base_.pre_transform -albu_train_transforms = _base_.albu_train_transforms - -mosaic_affine_pipeline = [ - dict( - type='Mosaic', - img_scale=img_scale, - pad_val=114.0, - pre_transform=pre_transform), - dict( - type='YOLOv5RandomAffine', - max_rotate_degree=0.0, - max_shear_degree=0.0, - scaling_ratio_range=(1 - affine_scale, 1 + affine_scale), - # img_scale is (width, height) - border=(-img_scale[0] // 2, -img_scale[1] // 2), - border_val=(114, 114, 114)) -] - -# enable mixup -train_pipeline = [ - *pre_transform, *mosaic_affine_pipeline, - dict( - type='YOLOv5MixUp', - prob=mixup_prob, - pre_transform=[*pre_transform, *mosaic_affine_pipeline]), - dict( - type='mmdet.Albu', - transforms=albu_train_transforms, - bbox_params=dict( - type='BboxParams', - format='pascal_voc', - label_fields=['gt_bboxes_labels', 'gt_ignore_flags']), - keymap={ - 'img': 'image', - 'gt_bboxes': 'bboxes' - }), - dict(type='YOLOv5HSVRandomAug'), - dict(type='mmdet.RandomFlip', prob=0.5), - dict( - type='mmdet.PackDetInputs', - meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip', - 'flip_direction')) -] - -train_dataloader = dict(dataset=dict(pipeline=train_pipeline)) -default_hooks = dict(param_scheduler=dict(lr_factor=lr_factor)) diff --git a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/configs/_base_/models/resnet34.py b/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/configs/_base_/models/resnet34.py deleted file mode 100644 index 100ee286bead6b5dd88f1752660e8ab9d0498e37..0000000000000000000000000000000000000000 --- a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/configs/_base_/models/resnet34.py +++ /dev/null @@ -1,17 +0,0 @@ -# model settings -model = dict( - type='ImageClassifier', - backbone=dict( - type='ResNet', - depth=34, - num_stages=4, - out_indices=(3, ), - style='pytorch'), - neck=dict(type='GlobalAveragePooling'), - head=dict( - type='LinearClsHead', - num_classes=1000, - in_channels=512, - loss=dict(type='CrossEntropyLoss', loss_weight=1.0), - topk=(1, 5), - )) diff --git a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/work_dirs/shufflenet-v2-1x_4xb32_2000e_3c_noF/__init__.py b/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/work_dirs/shufflenet-v2-1x_4xb32_2000e_3c_noF/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/Aashiue/speech_to_text/README.md b/spaces/Aashiue/speech_to_text/README.md deleted file mode 100644 index 02f5eab8fb36dadddcf57b9f15cdb1c83bc882b4..0000000000000000000000000000000000000000 --- a/spaces/Aashiue/speech_to_text/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Speech To Text -emoji: 📚 -colorFrom: gray -colorTo: blue -sdk: gradio -sdk_version: 3.3 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Adeeb-F/AI-Genrated-Image-Detector/README.md b/spaces/Adeeb-F/AI-Genrated-Image-Detector/README.md deleted file mode 100644 index 0673dddb6775858a2db873d2c9ddf537b3167c2c..0000000000000000000000000000000000000000 --- a/spaces/Adeeb-F/AI-Genrated-Image-Detector/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: AI Genrated Image Detector -emoji: 👁 -colorFrom: red -colorTo: indigo -sdk: gradio -sdk_version: 3.36.1 -app_file: app.py -pinned: false -license: gpl-3.0 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Afnaan/chatbots/README.md b/spaces/Afnaan/chatbots/README.md deleted file mode 100644 index 23f873018c4748242d02ef6195e34076ef1b856c..0000000000000000000000000000000000000000 --- a/spaces/Afnaan/chatbots/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Chatbots -emoji: 🏢 -colorFrom: yellow -colorTo: blue -sdk: gradio -sdk_version: 3.24.1 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/dots/Factory.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/dots/Factory.js deleted file mode 100644 index ac9a10ec258a5ecbafaf3e67bf78fb9cf9db9eb0..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/dots/Factory.js +++ /dev/null @@ -1,13 +0,0 @@ -import Dots from './Dots.js'; -import ObjectFactory from '../ObjectFactory.js'; -import SetValue from '../../../plugins/utils/object/SetValue.js'; - -ObjectFactory.register('dots', function (config) { - var gameObject = new Dots(this.scene, config); - this.scene.add.existing(gameObject); - return gameObject; -}); - -SetValue(window, 'RexPlugins.Spinner.Dots', Dots); - -export default Dots; \ No newline at end of file diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/los/Factory.d.ts b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/los/Factory.d.ts deleted file mode 100644 index 7c8335e714242d07b7db3a47298d6fff7ee78920..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/spinner/los/Factory.d.ts +++ /dev/null @@ -1,6 +0,0 @@ -import Los from './Los'; -import Base from '../base/Base'; - -export default function Factory( - config?: Base.IConfig -): Los; \ No newline at end of file diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/intouching/Factory.d.ts b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/intouching/Factory.d.ts deleted file mode 100644 index b2179188715c8c8d246c767978ec7f9df7e6c314..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/intouching/Factory.d.ts +++ /dev/null @@ -1,7 +0,0 @@ -// import * as Phaser from 'phaser'; -import InTouching from './InTouching'; - -export default function ( - gameObject: Phaser.GameObjects.GameObject, - config?: InTouching.IConfig -): InTouching; \ No newline at end of file diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sides/defaultcallbacks/FadeCallbacks.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sides/defaultcallbacks/FadeCallbacks.js deleted file mode 100644 index 85edf013f137ac10ba5714c90c90f7035642268f..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/sides/defaultcallbacks/FadeCallbacks.js +++ /dev/null @@ -1,26 +0,0 @@ -var GetShowCallback = function (duration, alpha) { - if (alpha === undefined) { - alpha = 1; - } - return function (child, key, sides, reset) { - if (key !== 'panel') { - sides.fadeChild(child, ((reset) ? 0 : duration), alpha); - } - } -} - -var GetHideCallback = function (duration, alpha) { - if (alpha === undefined) { - alpha = 0; - } - return function (child, key, sides, reset) { - if (key !== 'panel') { - sides.fadeChild(child, ((reset) ? 0 : duration), alpha); - } - } -} - -export default { - show: GetShowCallback, - hide: GetHideCallback -} \ No newline at end of file diff --git a/spaces/Alpaca233/SadTalker/src/gradio_demo.py b/spaces/Alpaca233/SadTalker/src/gradio_demo.py deleted file mode 100644 index 1e70005831b9f29dc3c7f39642364bc325a4c8a4..0000000000000000000000000000000000000000 --- a/spaces/Alpaca233/SadTalker/src/gradio_demo.py +++ /dev/null @@ -1,155 +0,0 @@ -import torch, uuid -import os, sys, shutil -from src.utils.preprocess import CropAndExtract -from src.test_audio2coeff import Audio2Coeff -from src.facerender.animate import AnimateFromCoeff -from src.generate_batch import get_data -from src.generate_facerender_batch import get_facerender_data - -from src.utils.init_path import init_path - -from pydub import AudioSegment - - -def mp3_to_wav(mp3_filename,wav_filename,frame_rate): - mp3_file = AudioSegment.from_file(file=mp3_filename) - mp3_file.set_frame_rate(frame_rate).export(wav_filename,format="wav") - - -class SadTalker(): - - def __init__(self, checkpoint_path='checkpoints', config_path='src/config', lazy_load=False): - - if torch.cuda.is_available() : - device = "cuda" - else: - device = "cpu" - - self.device = device - - os.environ['TORCH_HOME']= checkpoint_path - - self.checkpoint_path = checkpoint_path - self.config_path = config_path - - - def test(self, source_image, driven_audio, preprocess='crop', - still_mode=False, use_enhancer=False, batch_size=1, size=256, - pose_style = 0, exp_scale=1.0, - use_ref_video = False, - ref_video = None, - ref_info = None, - use_idle_mode = False, - length_of_audio = 0, use_blink=True, - result_dir='./results/'): - - self.sadtalker_paths = init_path(self.checkpoint_path, self.config_path, size, False, preprocess) - print(self.sadtalker_paths) - - self.audio_to_coeff = Audio2Coeff(self.sadtalker_paths, self.device) - self.preprocess_model = CropAndExtract(self.sadtalker_paths, self.device) - self.animate_from_coeff = AnimateFromCoeff(self.sadtalker_paths, self.device) - - time_tag = str(uuid.uuid4()) - save_dir = os.path.join(result_dir, time_tag) - os.makedirs(save_dir, exist_ok=True) - - input_dir = os.path.join(save_dir, 'input') - os.makedirs(input_dir, exist_ok=True) - - print(source_image) - pic_path = os.path.join(input_dir, os.path.basename(source_image)) - shutil.move(source_image, input_dir) - - if driven_audio is not None and os.path.isfile(driven_audio): - audio_path = os.path.join(input_dir, os.path.basename(driven_audio)) - - #### mp3 to wav - if '.mp3' in audio_path: - mp3_to_wav(driven_audio, audio_path.replace('.mp3', '.wav'), 16000) - audio_path = audio_path.replace('.mp3', '.wav') - else: - shutil.move(driven_audio, input_dir) - - elif use_idle_mode: - audio_path = os.path.join(input_dir, 'idlemode_'+str(length_of_audio)+'.wav') ## generate audio from this new audio_path - from pydub import AudioSegment - one_sec_segment = AudioSegment.silent(duration=1000*length_of_audio) #duration in milliseconds - one_sec_segment.export(audio_path, format="wav") - else: - print(use_ref_video, ref_info) - assert use_ref_video == True and ref_info == 'all' - - if use_ref_video and ref_info == 'all': # full ref mode - ref_video_videoname = os.path.basename(ref_video) - audio_path = os.path.join(save_dir, ref_video_videoname+'.wav') - print('new audiopath:',audio_path) - # if ref_video contains audio, set the audio from ref_video. - cmd = r"ffmpeg -y -hide_banner -loglevel error -i %s %s"%(ref_video, audio_path) - os.system(cmd) - - os.makedirs(save_dir, exist_ok=True) - - #crop image and extract 3dmm from image - first_frame_dir = os.path.join(save_dir, 'first_frame_dir') - os.makedirs(first_frame_dir, exist_ok=True) - first_coeff_path, crop_pic_path, crop_info = self.preprocess_model.generate(pic_path, first_frame_dir, preprocess, True, size) - - if first_coeff_path is None: - raise AttributeError("No face is detected") - - if use_ref_video: - print('using ref video for genreation') - ref_video_videoname = os.path.splitext(os.path.split(ref_video)[-1])[0] - ref_video_frame_dir = os.path.join(save_dir, ref_video_videoname) - os.makedirs(ref_video_frame_dir, exist_ok=True) - print('3DMM Extraction for the reference video providing pose') - ref_video_coeff_path, _, _ = self.preprocess_model.generate(ref_video, ref_video_frame_dir, preprocess, source_image_flag=False) - else: - ref_video_coeff_path = None - - if use_ref_video: - if ref_info == 'pose': - ref_pose_coeff_path = ref_video_coeff_path - ref_eyeblink_coeff_path = None - elif ref_info == 'blink': - ref_pose_coeff_path = None - ref_eyeblink_coeff_path = ref_video_coeff_path - elif ref_info == 'pose+blink': - ref_pose_coeff_path = ref_video_coeff_path - ref_eyeblink_coeff_path = ref_video_coeff_path - elif ref_info == 'all': - ref_pose_coeff_path = None - ref_eyeblink_coeff_path = None - else: - raise('error in refinfo') - else: - ref_pose_coeff_path = None - ref_eyeblink_coeff_path = None - - #audio2ceoff - if use_ref_video and ref_info == 'all': - coeff_path = ref_video_coeff_path # self.audio_to_coeff.generate(batch, save_dir, pose_style, ref_pose_coeff_path) - else: - batch = get_data(first_coeff_path, audio_path, self.device, ref_eyeblink_coeff_path=ref_eyeblink_coeff_path, still=still_mode, idlemode=use_idle_mode, length_of_audio=length_of_audio, use_blink=use_blink) # longer audio? - coeff_path = self.audio_to_coeff.generate(batch, save_dir, pose_style, ref_pose_coeff_path) - - #coeff2video - data = get_facerender_data(coeff_path, crop_pic_path, first_coeff_path, audio_path, batch_size, still_mode=still_mode, preprocess=preprocess, size=size, expression_scale = exp_scale) - return_path = self.animate_from_coeff.generate(data, save_dir, pic_path, crop_info, enhancer='gfpgan' if use_enhancer else None, preprocess=preprocess, img_size=size) - video_name = data['video_name'] - print(f'The generated video is named {video_name} in {save_dir}') - - del self.preprocess_model - del self.audio_to_coeff - del self.animate_from_coeff - - if torch.cuda.is_available(): - torch.cuda.empty_cache() - torch.cuda.synchronize() - - import gc; gc.collect() - - return return_path - - \ No newline at end of file diff --git a/spaces/Ameaou/academic-chatgpt3.1/request_llm/bridge_chatgpt.py b/spaces/Ameaou/academic-chatgpt3.1/request_llm/bridge_chatgpt.py deleted file mode 100644 index 8c915c2a1c8701d08a4cd05f5d0c80683d0cd346..0000000000000000000000000000000000000000 --- a/spaces/Ameaou/academic-chatgpt3.1/request_llm/bridge_chatgpt.py +++ /dev/null @@ -1,272 +0,0 @@ -# 借鉴了 https://github.com/GaiZhenbiao/ChuanhuChatGPT 项目 - -""" - 该文件中主要包含三个函数 - - 不具备多线程能力的函数: - 1. predict: 正常对话时使用,具备完备的交互功能,不可多线程 - - 具备多线程调用能力的函数 - 2. predict_no_ui:高级实验性功能模块调用,不会实时显示在界面上,参数简单,可以多线程并行,方便实现复杂的功能逻辑 - 3. predict_no_ui_long_connection:在实验过程中发现调用predict_no_ui处理长文档时,和openai的连接容易断掉,这个函数用stream的方式解决这个问题,同样支持多线程 -""" - -import json -import time -import gradio as gr -import logging -import traceback -import requests -import importlib - -# config_private.py放自己的秘密如API和代理网址 -# 读取时首先看是否存在私密的config_private配置文件(不受git管控),如果有,则覆盖原config文件 -from toolbox import get_conf, update_ui, is_any_api_key, select_api_key -proxies, API_KEY, TIMEOUT_SECONDS, MAX_RETRY = \ - get_conf('proxies', 'API_KEY', 'TIMEOUT_SECONDS', 'MAX_RETRY') - -timeout_bot_msg = '[Local Message] Request timeout. Network error. Please check proxy settings in config.py.' + \ - '网络错误,检查代理服务器是否可用,以及代理设置的格式是否正确,格式须是[协议]://[地址]:[端口],缺一不可。' - -def get_full_error(chunk, stream_response): - """ - 获取完整的从Openai返回的报错 - """ - while True: - try: - chunk += next(stream_response) - except: - break - return chunk - - -def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="", observe_window=None, console_slience=False): - """ - 发送至chatGPT,等待回复,一次性完成,不显示中间过程。但内部用stream的方法避免中途网线被掐。 - inputs: - 是本次问询的输入 - sys_prompt: - 系统静默prompt - llm_kwargs: - chatGPT的内部调优参数 - history: - 是之前的对话列表 - observe_window = None: - 用于负责跨越线程传递已经输出的部分,大部分时候仅仅为了fancy的视觉效果,留空即可。observe_window[0]:观测窗。observe_window[1]:看门狗 - """ - watch_dog_patience = 5 # 看门狗的耐心, 设置5秒即可 - headers, payload = generate_payload(inputs, llm_kwargs, history, system_prompt=sys_prompt, stream=True) - retry = 0 - while True: - try: - # make a POST request to the API endpoint, stream=False - from .bridge_all import model_info - endpoint = model_info[llm_kwargs['llm_model']]['endpoint'] - response = requests.post(endpoint, headers=headers, proxies=proxies, - json=payload, stream=True, timeout=TIMEOUT_SECONDS); break - except requests.exceptions.ReadTimeout as e: - retry += 1 - traceback.print_exc() - if retry > MAX_RETRY: raise TimeoutError - if MAX_RETRY!=0: print(f'请求超时,正在重试 ({retry}/{MAX_RETRY}) ……') - - stream_response = response.iter_lines() - result = '' - while True: - try: chunk = next(stream_response).decode() - except StopIteration: - break - except requests.exceptions.ConnectionError: - chunk = next(stream_response).decode() # 失败了,重试一次?再失败就没办法了。 - if len(chunk)==0: continue - if not chunk.startswith('data:'): - error_msg = get_full_error(chunk.encode('utf8'), stream_response).decode() - if "reduce the length" in error_msg: - raise ConnectionAbortedError("OpenAI拒绝了请求:" + error_msg) - else: - raise RuntimeError("OpenAI拒绝了请求:" + error_msg) - if ('data: [DONE]' in chunk): break # api2d 正常完成 - json_data = json.loads(chunk.lstrip('data:'))['choices'][0] - delta = json_data["delta"] - if len(delta) == 0: break - if "role" in delta: continue - if "content" in delta: - result += delta["content"] - if not console_slience: print(delta["content"], end='') - if observe_window is not None: - # 观测窗,把已经获取的数据显示出去 - if len(observe_window) >= 1: observe_window[0] += delta["content"] - # 看门狗,如果超过期限没有喂狗,则终止 - if len(observe_window) >= 2: - if (time.time()-observe_window[1]) > watch_dog_patience: - raise RuntimeError("用户取消了程序。") - else: raise RuntimeError("意外Json结构:"+delta) - if json_data['finish_reason'] == 'length': - raise ConnectionAbortedError("正常结束,但显示Token不足,导致输出不完整,请削减单次输入的文本量。") - return result - - -def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream = True, additional_fn=None): - """ - 发送至chatGPT,流式获取输出。 - 用于基础的对话功能。 - inputs 是本次问询的输入 - top_p, temperature是chatGPT的内部调优参数 - history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误) - chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容 - additional_fn代表点击的哪个按钮,按钮见functional.py - """ - if is_any_api_key(inputs): - chatbot._cookies['api_key'] = inputs - chatbot.append(("输入已识别为openai的api_key", "api_key已导入")) - yield from update_ui(chatbot=chatbot, history=history, msg="api_key已导入") # 刷新界面 - return - elif not is_any_api_key(chatbot._cookies['api_key']): - chatbot.append((inputs, "缺少api_key。\n\n1. 临时解决方案:直接在输入区键入api_key,然后回车提交。\n\n2. 长效解决方案:在config.py中配置。")) - yield from update_ui(chatbot=chatbot, history=history, msg="缺少api_key") # 刷新界面 - return - - if additional_fn is not None: - import core_functional - importlib.reload(core_functional) # 热更新prompt - core_functional = core_functional.get_core_functions() - if "PreProcess" in core_functional[additional_fn]: inputs = core_functional[additional_fn]["PreProcess"](inputs) # 获取预处理函数(如果有的话) - inputs = core_functional[additional_fn]["Prefix"] + inputs + core_functional[additional_fn]["Suffix"] - - raw_input = inputs - logging.info(f'[raw_input] {raw_input}') - chatbot.append((inputs, "")) - yield from update_ui(chatbot=chatbot, history=history, msg="等待响应") # 刷新界面 - - try: - headers, payload = generate_payload(inputs, llm_kwargs, history, system_prompt, stream) - except RuntimeError as e: - chatbot[-1] = (inputs, f"您提供的api-key不满足要求,不包含任何可用于{llm_kwargs['llm_model']}的api-key。") - yield from update_ui(chatbot=chatbot, history=history, msg="api-key不满足要求") # 刷新界面 - return - - history.append(inputs); history.append(" ") - - retry = 0 - while True: - try: - # make a POST request to the API endpoint, stream=True - from .bridge_all import model_info - endpoint = model_info[llm_kwargs['llm_model']]['endpoint'] - response = requests.post(endpoint, headers=headers, proxies=proxies, - json=payload, stream=True, timeout=TIMEOUT_SECONDS);break - except: - retry += 1 - chatbot[-1] = ((chatbot[-1][0], timeout_bot_msg)) - retry_msg = f",正在重试 ({retry}/{MAX_RETRY}) ……" if MAX_RETRY > 0 else "" - yield from update_ui(chatbot=chatbot, history=history, msg="请求超时"+retry_msg) # 刷新界面 - if retry > MAX_RETRY: raise TimeoutError - - gpt_replying_buffer = "" - - is_head_of_the_stream = True - if stream: - stream_response = response.iter_lines() - while True: - chunk = next(stream_response) - # print(chunk.decode()[6:]) - if is_head_of_the_stream and (r'"object":"error"' not in chunk.decode()): - # 数据流的第一帧不携带content - is_head_of_the_stream = False; continue - - if chunk: - try: - chunk_decoded = chunk.decode() - # 前者API2D的 - if ('data: [DONE]' in chunk_decoded) or (len(json.loads(chunk_decoded[6:])['choices'][0]["delta"]) == 0): - # 判定为数据流的结束,gpt_replying_buffer也写完了 - logging.info(f'[response] {gpt_replying_buffer}') - break - # 处理数据流的主体 - chunkjson = json.loads(chunk_decoded[6:]) - status_text = f"finish_reason: {chunkjson['choices'][0]['finish_reason']}" - # 如果这里抛出异常,一般是文本过长,详情见get_full_error的输出 - gpt_replying_buffer = gpt_replying_buffer + json.loads(chunk_decoded[6:])['choices'][0]["delta"]["content"] - history[-1] = gpt_replying_buffer - chatbot[-1] = (history[-2], history[-1]) - yield from update_ui(chatbot=chatbot, history=history, msg=status_text) # 刷新界面 - - except Exception as e: - traceback.print_exc() - yield from update_ui(chatbot=chatbot, history=history, msg="Json解析不合常规") # 刷新界面 - chunk = get_full_error(chunk, stream_response) - chunk_decoded = chunk.decode() - error_msg = chunk_decoded - if "reduce the length" in error_msg: - chatbot[-1] = (chatbot[-1][0], "[Local Message] Reduce the length. 本次输入过长,或历史数据过长. 历史缓存数据现已释放,您可以请再次尝试.") - history = [] # 清除历史 - elif "does not exist" in error_msg: - chatbot[-1] = (chatbot[-1][0], f"[Local Message] Model {llm_kwargs['llm_model']} does not exist. 模型不存在,或者您没有获得体验资格.") - elif "Incorrect API key" in error_msg: - chatbot[-1] = (chatbot[-1][0], "[Local Message] Incorrect API key. OpenAI以提供了不正确的API_KEY为由,拒绝服务.") - elif "exceeded your current quota" in error_msg: - chatbot[-1] = (chatbot[-1][0], "[Local Message] You exceeded your current quota. OpenAI以账户额度不足为由,拒绝服务.") - elif "bad forward key" in error_msg: - chatbot[-1] = (chatbot[-1][0], "[Local Message] Bad forward key. API2D账户额度不足.") - else: - from toolbox import regular_txt_to_markdown - tb_str = '```\n' + traceback.format_exc() + '```' - chatbot[-1] = (chatbot[-1][0], f"[Local Message] 异常 \n\n{tb_str} \n\n{regular_txt_to_markdown(chunk_decoded[4:])}") - yield from update_ui(chatbot=chatbot, history=history, msg="Json异常" + error_msg) # 刷新界面 - return - -def generate_payload(inputs, llm_kwargs, history, system_prompt, stream): - """ - 整合所有信息,选择LLM模型,生成http请求,为发送请求做准备 - """ - if not is_any_api_key(llm_kwargs['api_key']): - raise AssertionError("你提供了错误的API_KEY。\n\n1. 临时解决方案:直接在输入区键入api_key,然后回车提交。\n\n2. 长效解决方案:在config.py中配置。") - - api_key = select_api_key(llm_kwargs['api_key'], llm_kwargs['llm_model']) - - headers = { - "Content-Type": "application/json", - "Authorization": f"Bearer {api_key}" - } - - conversation_cnt = len(history) // 2 - - messages = [{"role": "system", "content": system_prompt}] - if conversation_cnt: - for index in range(0, 2*conversation_cnt, 2): - what_i_have_asked = {} - what_i_have_asked["role"] = "user" - what_i_have_asked["content"] = history[index] - what_gpt_answer = {} - what_gpt_answer["role"] = "assistant" - what_gpt_answer["content"] = history[index+1] - if what_i_have_asked["content"] != "": - if what_gpt_answer["content"] == "": continue - if what_gpt_answer["content"] == timeout_bot_msg: continue - messages.append(what_i_have_asked) - messages.append(what_gpt_answer) - else: - messages[-1]['content'] = what_gpt_answer['content'] - - what_i_ask_now = {} - what_i_ask_now["role"] = "user" - what_i_ask_now["content"] = inputs - messages.append(what_i_ask_now) - - payload = { - "model": llm_kwargs['llm_model'].strip('api2d-'), - "messages": messages, - "temperature": llm_kwargs['temperature'], # 1.0, - "top_p": llm_kwargs['top_p'], # 1.0, - "n": 1, - "stream": stream, - "presence_penalty": 0, - "frequency_penalty": 0, - } - try: - print(f" {llm_kwargs['llm_model']} : {conversation_cnt} : {inputs[:100]} ..........") - except: - print('输入中可能存在乱码。') - return headers,payload - - diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/versatile_diffusion/__init__.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/versatile_diffusion/__init__.py deleted file mode 100644 index abf9dcff59dbc922dcc7063a1e73560679a23696..0000000000000000000000000000000000000000 --- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/versatile_diffusion/__init__.py +++ /dev/null @@ -1,24 +0,0 @@ -from ...utils import ( - OptionalDependencyNotAvailable, - is_torch_available, - is_transformers_available, - is_transformers_version, -) - - -try: - if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.25.0")): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - from ...utils.dummy_torch_and_transformers_objects import ( - VersatileDiffusionDualGuidedPipeline, - VersatileDiffusionImageVariationPipeline, - VersatileDiffusionPipeline, - VersatileDiffusionTextToImagePipeline, - ) -else: - from .modeling_text_unet import UNetFlatConditionModel - from .pipeline_versatile_diffusion import VersatileDiffusionPipeline - from .pipeline_versatile_diffusion_dual_guided import VersatileDiffusionDualGuidedPipeline - from .pipeline_versatile_diffusion_image_variation import VersatileDiffusionImageVariationPipeline - from .pipeline_versatile_diffusion_text_to_image import VersatileDiffusionTextToImagePipeline diff --git a/spaces/Andy1621/uniformer_image_detection/configs/gn+ws/mask_rcnn_r101_fpn_gn_ws-all_2x_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/gn+ws/mask_rcnn_r101_fpn_gn_ws-all_2x_coco.py deleted file mode 100644 index 4be68176d2ed6f9b209823187f1367d204fe67d1..0000000000000000000000000000000000000000 --- a/spaces/Andy1621/uniformer_image_detection/configs/gn+ws/mask_rcnn_r101_fpn_gn_ws-all_2x_coco.py +++ /dev/null @@ -1,3 +0,0 @@ -_base_ = './mask_rcnn_r50_fpn_gn_ws-all_2x_coco.py' -model = dict( - pretrained='open-mmlab://jhu/resnet101_gn_ws', backbone=dict(depth=101)) diff --git a/spaces/Andy1621/uniformer_image_detection/configs/grid_rcnn/README.md b/spaces/Andy1621/uniformer_image_detection/configs/grid_rcnn/README.md deleted file mode 100644 index a1e83525d50650e303b0acce7bdbff01ef1a357c..0000000000000000000000000000000000000000 --- a/spaces/Andy1621/uniformer_image_detection/configs/grid_rcnn/README.md +++ /dev/null @@ -1,35 +0,0 @@ -# Grid R-CNN - -## Introduction - -[ALGORITHM] - -```latex -@inproceedings{lu2019grid, - title={Grid r-cnn}, - author={Lu, Xin and Li, Buyu and Yue, Yuxin and Li, Quanquan and Yan, Junjie}, - booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, - year={2019} -} - -@article{lu2019grid, - title={Grid R-CNN Plus: Faster and Better}, - author={Lu, Xin and Li, Buyu and Yue, Yuxin and Li, Quanquan and Yan, Junjie}, - journal={arXiv preprint arXiv:1906.05688}, - year={2019} -} -``` - -## Results and Models - -| Backbone | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download | -|:-----------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:| -| R-50 | 2x | 5.1 | 15.0 | 40.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco/grid_rcnn_r50_fpn_gn-head_2x_coco_20200130-6cca8223.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco/grid_rcnn_r50_fpn_gn-head_2x_coco_20200130_221140.log.json) | -| R-101 | 2x | 7.0 | 12.6 | 41.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco/grid_rcnn_r101_fpn_gn-head_2x_coco_20200309-d6eca030.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco/grid_rcnn_r101_fpn_gn-head_2x_coco_20200309_164224.log.json) | -| X-101-32x4d | 2x | 8.3 | 10.8 | 42.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco_20200130-d8f0e3ff.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco_20200130_215413.log.json) | -| X-101-64x4d | 2x | 11.3 | 7.7 | 43.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco.py) | [model](http://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco_20200204-ec76a754.pth) | [log](http://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco_20200204_080641.log.json) | - -**Notes:** - -- All models are trained with 8 GPUs instead of 32 GPUs in the original paper. -- The warming up lasts for 1 epoch and `2x` here indicates 25 epochs. diff --git a/spaces/Andy1621/uniformer_image_detection/configs/hrnet/cascade_mask_rcnn_hrnetv2p_w18_20e_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/hrnet/cascade_mask_rcnn_hrnetv2p_w18_20e_coco.py deleted file mode 100644 index e8df265edefee1b7e5892fe373c1c0f80f59bf7b..0000000000000000000000000000000000000000 --- a/spaces/Andy1621/uniformer_image_detection/configs/hrnet/cascade_mask_rcnn_hrnetv2p_w18_20e_coco.py +++ /dev/null @@ -1,10 +0,0 @@ -_base_ = './cascade_mask_rcnn_hrnetv2p_w32_20e_coco.py' -# model settings -model = dict( - pretrained='open-mmlab://msra/hrnetv2_w18', - backbone=dict( - extra=dict( - stage2=dict(num_channels=(18, 36)), - stage3=dict(num_channels=(18, 36, 72)), - stage4=dict(num_channels=(18, 36, 72, 144)))), - neck=dict(type='HRFPN', in_channels=[18, 36, 72, 144], out_channels=256)) diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/hrnet/fcn_hr48_480x480_40k_pascal_context.py b/spaces/Andy1621/uniformer_image_segmentation/configs/hrnet/fcn_hr48_480x480_40k_pascal_context.py deleted file mode 100644 index 0e2d96cb6ce7249852cb1d9b36a2f24bdce00199..0000000000000000000000000000000000000000 --- a/spaces/Andy1621/uniformer_image_segmentation/configs/hrnet/fcn_hr48_480x480_40k_pascal_context.py +++ /dev/null @@ -1,10 +0,0 @@ -_base_ = './fcn_hr18_480x480_40k_pascal_context.py' -model = dict( - pretrained='open-mmlab://msra/hrnetv2_w48', - backbone=dict( - extra=dict( - stage2=dict(num_channels=(48, 96)), - stage3=dict(num_channels=(48, 96, 192)), - stage4=dict(num_channels=(48, 96, 192, 384)))), - decode_head=dict( - in_channels=[48, 96, 192, 384], channels=sum([48, 96, 192, 384]))) diff --git a/spaces/AnnasBlackHat/Image-Similarity/src/similarity/model_implements/mobilenet_v3.py b/spaces/AnnasBlackHat/Image-Similarity/src/similarity/model_implements/mobilenet_v3.py deleted file mode 100644 index 53b6770039bb4c077691aa578352d35427869119..0000000000000000000000000000000000000000 --- a/spaces/AnnasBlackHat/Image-Similarity/src/similarity/model_implements/mobilenet_v3.py +++ /dev/null @@ -1,14 +0,0 @@ -import tensorflow_hub as hub -import numpy as np - -class ModelnetV3(): - def __init__(self): - module_handle = "https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5" - self.module = hub.load(module_handle) - - def extract_feature(self, imgs): - print('getting with ModelnetV3...') - features = [] - for img in imgs: - features.append(np.squeeze(self.module(img))) - return features \ No newline at end of file diff --git a/spaces/Anthony7906/MengHuiMXD_GPT/modules/webui_locale.py b/spaces/Anthony7906/MengHuiMXD_GPT/modules/webui_locale.py deleted file mode 100644 index 1ce4d97b9b41cbb2d9be3fdadc4c85f6ef897604..0000000000000000000000000000000000000000 --- a/spaces/Anthony7906/MengHuiMXD_GPT/modules/webui_locale.py +++ /dev/null @@ -1,26 +0,0 @@ -import os -import locale -import commentjson as json - -class I18nAuto: - def __init__(self): - if os.path.exists("config.json"): - with open("config.json", "r", encoding='utf-8') as f: - config = json.load(f) - else: - config = {} - lang_config = config.get("language", "auto") - language = os.environ.get("LANGUAGE", lang_config) - if language == "auto": - language = locale.getdefaultlocale()[0] # get the language code of the system (ex. zh_CN) - self.language_map = {} - self.file_is_exists = os.path.isfile(f"./locale/{language}.json") - if self.file_is_exists: - with open(f"./locale/{language}.json", "r", encoding="utf-8") as f: - self.language_map.update(json.load(f)) - - def __call__(self, key): - if self.file_is_exists and key in self.language_map: - return self.language_map[key] - else: - return key diff --git a/spaces/AriaMei/TTSdemo/commons.py b/spaces/AriaMei/TTSdemo/commons.py deleted file mode 100644 index 9ad0444b61cbadaa388619986c2889c707d873ce..0000000000000000000000000000000000000000 --- a/spaces/AriaMei/TTSdemo/commons.py +++ /dev/null @@ -1,161 +0,0 @@ -import math -import numpy as np -import torch -from torch import nn -from torch.nn import functional as F - - -def init_weights(m, mean=0.0, std=0.01): - classname = m.__class__.__name__ - if classname.find("Conv") != -1: - m.weight.data.normal_(mean, std) - - -def get_padding(kernel_size, dilation=1): - return int((kernel_size*dilation - dilation)/2) - - -def convert_pad_shape(pad_shape): - l = pad_shape[::-1] - pad_shape = [item for sublist in l for item in sublist] - return pad_shape - - -def intersperse(lst, item): - result = [item] * (len(lst) * 2 + 1) - result[1::2] = lst - return result - - -def kl_divergence(m_p, logs_p, m_q, logs_q): - """KL(P||Q)""" - kl = (logs_q - logs_p) - 0.5 - kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q) - return kl - - -def rand_gumbel(shape): - """Sample from the Gumbel distribution, protect from overflows.""" - uniform_samples = torch.rand(shape) * 0.99998 + 0.00001 - return -torch.log(-torch.log(uniform_samples)) - - -def rand_gumbel_like(x): - g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device) - return g - - -def slice_segments(x, ids_str, segment_size=4): - ret = torch.zeros_like(x[:, :, :segment_size]) - for i in range(x.size(0)): - idx_str = ids_str[i] - idx_end = idx_str + segment_size - ret[i] = x[i, :, idx_str:idx_end] - return ret - - -def rand_slice_segments(x, x_lengths=None, segment_size=4): - b, d, t = x.size() - if x_lengths is None: - x_lengths = t - ids_str_max = x_lengths - segment_size + 1 - ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long) - ret = slice_segments(x, ids_str, segment_size) - return ret, ids_str - - -def get_timing_signal_1d( - length, channels, min_timescale=1.0, max_timescale=1.0e4): - position = torch.arange(length, dtype=torch.float) - num_timescales = channels // 2 - log_timescale_increment = ( - math.log(float(max_timescale) / float(min_timescale)) / - (num_timescales - 1)) - inv_timescales = min_timescale * torch.exp( - torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment) - scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1) - signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0) - signal = F.pad(signal, [0, 0, 0, channels % 2]) - signal = signal.view(1, channels, length) - return signal - - -def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4): - b, channels, length = x.size() - signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale) - return x + signal.to(dtype=x.dtype, device=x.device) - - -def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1): - b, channels, length = x.size() - signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale) - return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis) - - -def subsequent_mask(length): - mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0) - return mask - - -@torch.jit.script -def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels): - n_channels_int = n_channels[0] - in_act = input_a + input_b - t_act = torch.tanh(in_act[:, :n_channels_int, :]) - s_act = torch.sigmoid(in_act[:, n_channels_int:, :]) - acts = t_act * s_act - return acts - - -def convert_pad_shape(pad_shape): - l = pad_shape[::-1] - pad_shape = [item for sublist in l for item in sublist] - return pad_shape - - -def shift_1d(x): - x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1] - return x - - -def sequence_mask(length, max_length=None): - if max_length is None: - max_length = length.max() - x = torch.arange(max_length, dtype=length.dtype, device=length.device) - return x.unsqueeze(0) < length.unsqueeze(1) - - -def generate_path(duration, mask): - """ - duration: [b, 1, t_x] - mask: [b, 1, t_y, t_x] - """ - device = duration.device - - b, _, t_y, t_x = mask.shape - cum_duration = torch.cumsum(duration, -1) - - cum_duration_flat = cum_duration.view(b * t_x) - path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype) - path = path.view(b, t_x, t_y) - path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1] - path = path.unsqueeze(1).transpose(2,3) * mask - return path - - -def clip_grad_value_(parameters, clip_value, norm_type=2): - if isinstance(parameters, torch.Tensor): - parameters = [parameters] - parameters = list(filter(lambda p: p.grad is not None, parameters)) - norm_type = float(norm_type) - if clip_value is not None: - clip_value = float(clip_value) - - total_norm = 0 - for p in parameters: - param_norm = p.grad.data.norm(norm_type) - total_norm += param_norm.item() ** norm_type - if clip_value is not None: - p.grad.data.clamp_(min=-clip_value, max=clip_value) - total_norm = total_norm ** (1. / norm_type) - return total_norm diff --git a/spaces/Artrajz/vits-simple-api/vits/text/cleaners.py b/spaces/Artrajz/vits-simple-api/vits/text/cleaners.py deleted file mode 100644 index e1c71cb43e308f365de7a4444ca3ae51f617446f..0000000000000000000000000000000000000000 --- a/spaces/Artrajz/vits-simple-api/vits/text/cleaners.py +++ /dev/null @@ -1,278 +0,0 @@ -import re -import config -from unidecode import unidecode -from phonemizer import phonemize -from phonemizer.backend.espeak.wrapper import EspeakWrapper - -ESPEAK_LIBRARY = getattr(config, "ESPEAK_LIBRARY", "") -if ESPEAK_LIBRARY != "": - EspeakWrapper.set_library(ESPEAK_LIBRARY) - -# List of (regular expression, replacement) pairs for abbreviations: -_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [ - ('mrs', 'misess'), - ('mr', 'mister'), - ('dr', 'doctor'), - ('st', 'saint'), - ('co', 'company'), - ('jr', 'junior'), - ('maj', 'major'), - ('gen', 'general'), - ('drs', 'doctors'), - ('rev', 'reverend'), - ('lt', 'lieutenant'), - ('hon', 'honorable'), - ('sgt', 'sergeant'), - ('capt', 'captain'), - ('esq', 'esquire'), - ('ltd', 'limited'), - ('col', 'colonel'), - ('ft', 'fort'), -]] - - -def expand_abbreviations(text): - for regex, replacement in _abbreviations: - text = re.sub(regex, replacement, text) - return text - - -def transliteration_cleaners(text): - '''Pipeline for non-English text that transliterates to ASCII.''' - text = unidecode(text) - text = text.lower() - text = re.sub(r'\s+', ' ', text) - text = expand_abbreviations(text) - return text - - -# for English text -def english_cleaners(text): - '''Pipeline for English text, including abbreviation expansion.''' - text = re.sub(r'\[EN\](.*?)\[EN\]', lambda x: transliteration_cleaners(x.group(1)) + ' ', text) - phonemes = phonemize(text, language='en-us', backend='espeak', strip=True) - return phonemes - - -# for non-English text that can be transliterated to ASCII -def english_cleaners2(text): - '''Pipeline for English text, including abbreviation expansion. + punctuation + stress''' - text = re.sub(r'\[EN\](.*?)\[EN\]', lambda x: transliteration_cleaners(x.group(1)) + ' ', text) - phonemes = phonemize(text, language='en-us', backend='espeak', strip=True, preserve_punctuation=True, - with_stress=True) - return phonemes - - -def japanese_cleaners(text): - from vits.text.japanese import japanese_to_romaji_with_accent - - def clean(text): - text = japanese_to_romaji_with_accent(text) - text = re.sub(r'([A-Za-z])$', r'\1.', text) - return text - - text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: clean(x.group(1)) + ' ', text) - return text - - -def japanese_cleaners2(text): - return japanese_cleaners(text).replace('ts', 'ʦ').replace('...', '…') - - -def korean_cleaners(text): - '''Pipeline for Korean text''' - from vits.text.korean import latin_to_hangul, number_to_hangul, divide_hangul - - def clean(text): - text = latin_to_hangul(text) - text = number_to_hangul(text) - text = divide_hangul(text) - text = re.sub(r'([\u3131-\u3163])$', r'\1.', text) - return text - - text = re.sub(r'\[KO\](.*?)\[KO\]', lambda x: clean(x.group(1)) + ' ', text) - return text - - -def chinese_cleaners(text): - '''Pipeline for Chinese text''' - from vits.text.mandarin import number_to_chinese, chinese_to_bopomofo, latin_to_bopomofo, symbols_to_chinese - - def clean(text): - text = symbols_to_chinese(text) - text = number_to_chinese(text) - text = chinese_to_bopomofo(text) - text = latin_to_bopomofo(text) - text = re.sub(r'([ˉˊˇˋ˙])$', r'\1。', text) - return text - - text = re.sub(r'\[ZH\](.*?)\[ZH\]', lambda x: clean(x.group(1)) + ' ', text) - return text - - -def zh_ja_mixture_cleaners(text): - from vits.text.mandarin import chinese_to_romaji - from vits.text.japanese import japanese_to_romaji_with_accent - text = re.sub(r'\[ZH\](.*?)\[ZH\]', - lambda x: chinese_to_romaji(x.group(1)) + ' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_romaji_with_accent( - x.group(1)).replace('ts', 'ʦ').replace('u', 'ɯ').replace('...', '…') + ' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def sanskrit_cleaners(text): - text = text.replace('॥', '।').replace('ॐ', 'ओम्') - text = re.sub(r'([^।])$', r'\1।', text) - return text - - -def cjks_cleaners(text): - from vits.text.mandarin import chinese_to_lazy_ipa - from vits.text.japanese import japanese_to_ipa - from vits.text.korean import korean_to_lazy_ipa - from vits.text.sanskrit import devanagari_to_ipa - from vits.text.english import english_to_lazy_ipa - text = re.sub(r'\[ZH\](.*?)\[ZH\]', - lambda x: chinese_to_lazy_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', - lambda x: japanese_to_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[KO\](.*?)\[KO\]', - lambda x: korean_to_lazy_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[SA\](.*?)\[SA\]', - lambda x: devanagari_to_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', - lambda x: english_to_lazy_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def cjke_cleaners(text): - from vits.text.mandarin import chinese_to_lazy_ipa - from vits.text.japanese import japanese_to_ipa - from vits.text.korean import korean_to_ipa - from vits.text.english import english_to_ipa2 - text = re.sub(r'\[ZH\](.*?)\[ZH\]', lambda x: chinese_to_lazy_ipa(x.group(1)).replace( - 'ʧ', 'tʃ').replace('ʦ', 'ts').replace('ɥan', 'ɥæn') + ' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_ipa(x.group(1)).replace('ʧ', 'tʃ').replace( - 'ʦ', 'ts').replace('ɥan', 'ɥæn').replace('ʥ', 'dz') + ' ', text) - text = re.sub(r'\[KO\](.*?)\[KO\]', - lambda x: korean_to_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', lambda x: english_to_ipa2(x.group(1)).replace('ɑ', 'a').replace( - 'ɔ', 'o').replace('ɛ', 'e').replace('ɪ', 'i').replace('ʊ', 'u') + ' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def cjke_cleaners2(text): - from vits.text.mandarin import chinese_to_ipa - from vits.text.japanese import japanese_to_ipa2 - from vits.text.korean import korean_to_ipa - from vits.text.english import english_to_ipa2 - text = re.sub(r'\[ZH\](.*?)\[ZH\]', - lambda x: chinese_to_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', - lambda x: japanese_to_ipa2(x.group(1)) + ' ', text) - text = re.sub(r'\[KO\](.*?)\[KO\]', - lambda x: korean_to_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', - lambda x: english_to_ipa2(x.group(1)) + ' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def cje_cleaners(text): - from vits.text.mandarin import chinese_to_lazy_ipa - from vits.text.japanese import japanese_to_ipa - from vits.text.english import english_to_ipa2 - text = re.sub(r'\[ZH\](.*?)\[ZH\]', lambda x: chinese_to_lazy_ipa(x.group(1)).replace( - 'ʧ', 'tʃ').replace('ʦ', 'ts').replace('ɥan', 'ɥæn') + ' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_ipa(x.group(1)).replace('ʧ', 'tʃ').replace( - 'ʦ', 'ts').replace('ɥan', 'ɥæn').replace('ʥ', 'dz') + ' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', lambda x: english_to_ipa2(x.group(1)).replace('ɑ', 'a').replace( - 'ɔ', 'o').replace('ɛ', 'e').replace('ɪ', 'i').replace('ʊ', 'u') + ' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def cje_cleaners2(text): - from vits.text.mandarin import chinese_to_ipa - from vits.text.japanese import japanese_to_ipa2 - from vits.text.english import english_to_ipa2 - text = re.sub(r'\[ZH\](.*?)\[ZH\]', - lambda x: chinese_to_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', - lambda x: japanese_to_ipa2(x.group(1)) + ' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', - lambda x: english_to_ipa2(x.group(1)) + ' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def thai_cleaners(text): - from vits.text.thai import num_to_thai, latin_to_thai - - def clean(text): - text = num_to_thai(text) - text = latin_to_thai(text) - return text - - text = re.sub(r'\[TH\](.*?)\[TH\]', lambda x: clean(x.group(1)) + ' ', text) - return text - - -def shanghainese_cleaners(text): - from vits.text.shanghainese import shanghainese_to_ipa - - def clean(text): - text = shanghainese_to_ipa(text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - text = re.sub(r'\[SH\](.*?)\[SH\]', lambda x: clean(x.group(1)) + ' ', text) - return text - - -def chinese_dialect_cleaners(text): - from vits.text.mandarin import chinese_to_ipa2 - from vits.text.japanese import japanese_to_ipa3 - from vits.text.shanghainese import shanghainese_to_ipa - from vits.text.cantonese import cantonese_to_ipa - from vits.text.english import english_to_lazy_ipa2 - from vits.text.ngu_dialect import ngu_dialect_to_ipa - text = re.sub(r'\[ZH\](.*?)\[ZH\]', - lambda x: chinese_to_ipa2(x.group(1)) + ' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', - lambda x: japanese_to_ipa3(x.group(1)).replace('Q', 'ʔ') + ' ', text) - text = re.sub(r'\[SH\](.*?)\[SH\]', lambda x: shanghainese_to_ipa(x.group(1)).replace('1', '˥˧').replace('5', - '˧˧˦').replace( - '6', '˩˩˧').replace('7', '˥').replace('8', '˩˨').replace('ᴀ', 'ɐ').replace('ᴇ', 'e') + ' ', text) - text = re.sub(r'\[GD\](.*?)\[GD\]', - lambda x: cantonese_to_ipa(x.group(1)) + ' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', - lambda x: english_to_lazy_ipa2(x.group(1)) + ' ', text) - text = re.sub(r'\[([A-Z]{2})\](.*?)\[\1\]', lambda x: ngu_dialect_to_ipa(x.group(2), x.group( - 1)).replace('ʣ', 'dz').replace('ʥ', 'dʑ').replace('ʦ', 'ts').replace('ʨ', 'tɕ') + ' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def bert_chinese_cleaners(text): - from vits.text import mandarin - matches = re.findall(r"\[ZH\](.*?)\[ZH\]", text) - text = "".join(matches) - if text[-1] not in [".", "。", ",", ","]: text += "." - text = mandarin.symbols_to_chinese(text) - text = mandarin.number_transform_to_chinese(text) - if not hasattr(bert_chinese_cleaners, "tts_front"): - bert_chinese_cleaners.tts_front = mandarin.VITS_PinYin_model() - tts_front = bert_chinese_cleaners.tts_front - cleaned_text, char_embeds = tts_front.chinese_to_phonemes(text) - return cleaned_text, char_embeds diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/urllib3/util/queue.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/urllib3/util/queue.py deleted file mode 100644 index 41784104ee4bd5796006d1052536325d52db1e8c..0000000000000000000000000000000000000000 --- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/urllib3/util/queue.py +++ /dev/null @@ -1,22 +0,0 @@ -import collections - -from ..packages import six -from ..packages.six.moves import queue - -if six.PY2: - # Queue is imported for side effects on MS Windows. See issue #229. - import Queue as _unused_module_Queue # noqa: F401 - - -class LifoQueue(queue.Queue): - def _init(self, _): - self.queue = collections.deque() - - def _qsize(self, len=len): - return len(self.queue) - - def _put(self, item): - self.queue.append(item) - - def _get(self): - return self.queue.pop() diff --git a/spaces/AtlasUnified/DeforumPromptGenerator/README.md b/spaces/AtlasUnified/DeforumPromptGenerator/README.md deleted file mode 100644 index e28adb3dcac80f7f491d08387a9e64a77e0463e1..0000000000000000000000000000000000000000 --- a/spaces/AtlasUnified/DeforumPromptGenerator/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: DeforumPromptGenerator -emoji: 💻 -colorFrom: red -colorTo: green -sdk: gradio -sdk_version: 3.28.3 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Audio-AGI/AudioSep/models/CLAP/open_clip/transform.py b/spaces/Audio-AGI/AudioSep/models/CLAP/open_clip/transform.py deleted file mode 100644 index 77aaa722c4a5544ac50de6df35d3e922f63b111d..0000000000000000000000000000000000000000 --- a/spaces/Audio-AGI/AudioSep/models/CLAP/open_clip/transform.py +++ /dev/null @@ -1,45 +0,0 @@ -from torchvision.transforms import ( - Normalize, - Compose, - RandomResizedCrop, - InterpolationMode, - ToTensor, - Resize, - CenterCrop, -) - - -def _convert_to_rgb(image): - return image.convert("RGB") - - -def image_transform( - image_size: int, - is_train: bool, - mean=(0.48145466, 0.4578275, 0.40821073), - std=(0.26862954, 0.26130258, 0.27577711), -): - normalize = Normalize(mean=mean, std=std) - if is_train: - return Compose( - [ - RandomResizedCrop( - image_size, - scale=(0.9, 1.0), - interpolation=InterpolationMode.BICUBIC, - ), - _convert_to_rgb, - ToTensor(), - normalize, - ] - ) - else: - return Compose( - [ - Resize(image_size, interpolation=InterpolationMode.BICUBIC), - CenterCrop(image_size), - _convert_to_rgb, - ToTensor(), - normalize, - ] - ) diff --git a/spaces/Audio-AGI/WavJourney/APIs.py b/spaces/Audio-AGI/WavJourney/APIs.py deleted file mode 100644 index fe09e15c93f5e8109c383606a6ce9111778f3809..0000000000000000000000000000000000000000 --- a/spaces/Audio-AGI/WavJourney/APIs.py +++ /dev/null @@ -1,202 +0,0 @@ -import os -import numpy as np -import requests -import yaml -import pyloudnorm as pyln -from scipy.io.wavfile import write -import torchaudio -from retrying import retry -from utils import get_service_port, get_service_url - - -os.environ['OPENBLAS_NUM_THREADS'] = '1' -SAMPLE_RATE = 32000 - - -with open('config.yaml', 'r') as file: - config = yaml.safe_load(file) - service_port = get_service_port() - localhost_addr = get_service_url() - enable_sr = config['Speech-Restoration']['Enable'] - -def LOUDNESS_NORM(audio, sr=32000, volumn=-25): - # peak normalize audio to -1 dB - peak_normalized_audio = pyln.normalize.peak(audio, -10.0) - # measure the loudness first - meter = pyln.Meter(sr) # create BS.1770 meter - loudness = meter.integrated_loudness(peak_normalized_audio) - # loudness normalize audio to -12 dB LUFS - normalized_audio = pyln.normalize.loudness(peak_normalized_audio, loudness, volumn) - return normalized_audio - - -def WRITE_AUDIO(wav, name=None, sr=SAMPLE_RATE): - """ - function: write audio numpy to .wav file - @params: - wav: np.array [samples] - """ - if name is None: - name = 'output.wav' - - if len(wav.shape) > 1: - wav = wav[0] - - # declipping - - max_value = np.max(np.abs(wav)) - if max_value > 1: - wav *= 0.9 / max_value - - # write audio - write(name, sr, np.round(wav*32767).astype(np.int16)) - - -def READ_AUDIO_NUMPY(wav, sr=SAMPLE_RATE): - """ - function: read audio numpy - return: np.array [samples] - """ - waveform, sample_rate = torchaudio.load(wav) - - if sample_rate != sr: - waveform = torchaudio.functional.resample(waveform, orig_freq=sample_rate, new_freq=sr) - - wav_numpy = waveform[0].numpy() - - return wav_numpy - - -def MIX(wavs=[['1.wav', 0.], ['2.wav', 10.]], out_wav='out.wav', sr=SAMPLE_RATE): - """ - wavs:[[wav_name, absolute_offset], ...] - """ - - max_length = max([int(wav[1]*sr + len(READ_AUDIO_NUMPY(wav[0]))) for wav in wavs]) - template_wav = np.zeros(max_length) - - for wav in wavs: - cur_name, cur_offset = wav - cur_wav = READ_AUDIO_NUMPY(cur_name) - cur_len = len(cur_wav) - cur_offset = int(cur_offset * sr) - - # mix - template_wav[cur_offset:cur_offset+cur_len] += cur_wav - - WRITE_AUDIO(template_wav, name=out_wav) - - -def CAT(wavs, out_wav='out.wav'): - """ - wavs: List of wav file ['1.wav', '2.wav', ...] - """ - wav_num = len(wavs) - - segment0 = READ_AUDIO_NUMPY(wavs[0]) - - cat_wav = segment0 - - if wav_num > 1: - for i in range(1, wav_num): - next_wav = READ_AUDIO_NUMPY(wavs[i]) - cat_wav = np.concatenate((cat_wav, next_wav), axis=-1) - - WRITE_AUDIO(cat_wav, name=out_wav) - - -def COMPUTE_LEN(wav): - wav= READ_AUDIO_NUMPY(wav) - return len(wav) / 32000 - - -@retry(stop_max_attempt_number=5, wait_fixed=2000) -def TTM(text, length=10, volume=-28, out_wav='out.wav'): - url = f'http://{localhost_addr}:{service_port}/generate_music' - data = { - 'text': f'{text}', - 'length': f'{length}', - 'volume': f'{volume}', - 'output_wav': f'{out_wav}', - } - - response = requests.post(url, json=data) - - if response.status_code == 200: - print('Success:', response.json()['message']) - else: - print('Error:', response.json()['API error']) - raise RuntimeError(response.json()['API error']) - -@retry(stop_max_attempt_number=5, wait_fixed=2000) -def TTA(text, length=5, volume=-35, out_wav='out.wav'): - url = f'http://{localhost_addr}:{service_port}/generate_audio' - data = { - 'text': f'{text}', - 'length': f'{length}', - 'volume': f'{volume}', - 'output_wav': f'{out_wav}', - } - - response = requests.post(url, json=data) - - if response.status_code == 200: - print('Success:', response.json()['message']) - else: - print('Error:', response.json()['API error']) - raise RuntimeError(response.json()['API error']) - - -@retry(stop_max_attempt_number=5, wait_fixed=2000) -def TTS(text, volume=-20, out_wav='out.wav', enhanced=enable_sr, speaker_id='', speaker_npz=''): - url = f'http://{localhost_addr}:{service_port}/generate_speech' - data = { - 'text': f'{text}', - 'speaker_id': f'{speaker_id}', - 'speaker_npz': f'{speaker_npz}', - 'volume': f'{volume}', - 'output_wav': f'{out_wav}', - } - - response = requests.post(url, json=data) - - if response.status_code == 200: - print('Success:', response.json()['message']) - else: - print('Error:', response.json()['API error']) - raise RuntimeError(response.json()['API error']) - - if enhanced: - SR(processfile=out_wav) - - -@retry(stop_max_attempt_number=5, wait_fixed=2000) -def SR(processfile): - url = f'http://{localhost_addr}:{service_port}/fix_audio' - data = {'processfile': f'{processfile}'} - - response = requests.post(url, json=data) - - if response.status_code == 200: - print('Success:', response.json()['message']) - else: - print('Error:', response.json()['API error']) - raise RuntimeError(response.json()['API error']) - - -@retry(stop_max_attempt_number=5, wait_fixed=2000) -def VP(wav_path, out_dir): - url = f'http://{localhost_addr}:{service_port}/parse_voice' - data = { - 'wav_path': f'{wav_path}', - 'out_dir':f'{out_dir}' - } - - response = requests.post(url, json=data) - - if response.status_code == 200: - print('Success:', response.json()['message']) - else: - print('Error:', response.json()['API error']) - raise RuntimeError(response.json()['API error']) - diff --git a/spaces/Averyng/averyng/app.py b/spaces/Averyng/averyng/app.py deleted file mode 100644 index bab1d8ba59a36d0a5555d2ffa7b349b113ec44fd..0000000000000000000000000000000000000000 --- a/spaces/Averyng/averyng/app.py +++ /dev/null @@ -1,3 +0,0 @@ -import gradio as gr - -gr.Interface.load("huggingface/EleutherAI/gpt-neo-2.7B",title="averyng",description="Input name and submit").launch() \ No newline at end of file diff --git a/spaces/BAAI/vid2vid-zero/vid2vid_zero/models/attention_2d.py b/spaces/BAAI/vid2vid-zero/vid2vid_zero/models/attention_2d.py deleted file mode 100644 index 3b9ecce1acfcef084b2b03a528c2812b50529048..0000000000000000000000000000000000000000 --- a/spaces/BAAI/vid2vid-zero/vid2vid_zero/models/attention_2d.py +++ /dev/null @@ -1,434 +0,0 @@ -# Adapted from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention.py - -from dataclasses import dataclass -from typing import Optional - -import torch -import torch.nn.functional as F -from torch import nn - -from diffusers.configuration_utils import ConfigMixin, register_to_config -from diffusers.modeling_utils import ModelMixin -from diffusers.utils import BaseOutput -from diffusers.utils.import_utils import is_xformers_available -from diffusers.models.attention import CrossAttention, FeedForward, AdaLayerNorm - -from einops import rearrange, repeat - - -@dataclass -class Transformer2DModelOutput(BaseOutput): - sample: torch.FloatTensor - - -if is_xformers_available(): - import xformers - import xformers.ops -else: - xformers = None - - -class Transformer2DModel(ModelMixin, ConfigMixin): - @register_to_config - def __init__( - self, - num_attention_heads: int = 16, - attention_head_dim: int = 88, - in_channels: Optional[int] = None, - num_layers: int = 1, - dropout: float = 0.0, - norm_num_groups: int = 32, - cross_attention_dim: Optional[int] = None, - attention_bias: bool = False, - sample_size: Optional[int] = None, - num_vector_embeds: Optional[int] = None, - activation_fn: str = "geglu", - num_embeds_ada_norm: Optional[int] = None, - use_linear_projection: bool = False, - only_cross_attention: bool = False, - upcast_attention: bool = False, - use_sc_attn: bool = False, - use_st_attn: bool = False, - ): - super().__init__() - self.use_linear_projection = use_linear_projection - self.num_attention_heads = num_attention_heads - self.attention_head_dim = attention_head_dim - inner_dim = num_attention_heads * attention_head_dim - - # 1. Transformer2DModel can process both standard continous images of shape `(batch_size, num_channels, width, height)` as well as quantized image embeddings of shape `(batch_size, num_image_vectors)` - # Define whether input is continuous or discrete depending on configuration - self.is_input_continuous = in_channels is not None - self.is_input_vectorized = num_vector_embeds is not None - - if self.is_input_continuous and self.is_input_vectorized: - raise ValueError( - f"Cannot define both `in_channels`: {in_channels} and `num_vector_embeds`: {num_vector_embeds}. Make" - " sure that either `in_channels` or `num_vector_embeds` is None." - ) - elif not self.is_input_continuous and not self.is_input_vectorized: - raise ValueError( - f"Has to define either `in_channels`: {in_channels} or `num_vector_embeds`: {num_vector_embeds}. Make" - " sure that either `in_channels` or `num_vector_embeds` is not None." - ) - - # 2. Define input layers - if self.is_input_continuous: - self.in_channels = in_channels - - self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True) - if use_linear_projection: - self.proj_in = nn.Linear(in_channels, inner_dim) - else: - self.proj_in = nn.Conv2d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0) - else: - raise NotImplementedError - - # Define transformers blocks - self.transformer_blocks = nn.ModuleList( - [ - BasicTransformerBlock( - inner_dim, - num_attention_heads, - attention_head_dim, - dropout=dropout, - cross_attention_dim=cross_attention_dim, - activation_fn=activation_fn, - num_embeds_ada_norm=num_embeds_ada_norm, - attention_bias=attention_bias, - only_cross_attention=only_cross_attention, - upcast_attention=upcast_attention, - use_sc_attn=use_sc_attn, - use_st_attn=True if (d == 0 and use_st_attn) else False , - ) - for d in range(num_layers) - ] - ) - - # 4. Define output layers - if use_linear_projection: - self.proj_out = nn.Linear(in_channels, inner_dim) - else: - self.proj_out = nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0) - - def forward(self, hidden_states, encoder_hidden_states=None, timestep=None, return_dict: bool = True, normal_infer: bool = False): - # Input - assert hidden_states.dim() == 5, f"Expected hidden_states to have ndim=5, but got ndim={hidden_states.dim()}." - video_length = hidden_states.shape[2] - hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") - encoder_hidden_states = repeat(encoder_hidden_states, 'b n c -> (b f) n c', f=video_length) - - batch, channel, height, weight = hidden_states.shape - residual = hidden_states - - hidden_states = self.norm(hidden_states) - if not self.use_linear_projection: - hidden_states = self.proj_in(hidden_states) - inner_dim = hidden_states.shape[1] - hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * weight, inner_dim) - else: - inner_dim = hidden_states.shape[1] - hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * weight, inner_dim) - hidden_states = self.proj_in(hidden_states) - - # Blocks - for block in self.transformer_blocks: - hidden_states = block( - hidden_states, - encoder_hidden_states=encoder_hidden_states, - timestep=timestep, - video_length=video_length, - normal_infer=normal_infer, - ) - - # Output - if not self.use_linear_projection: - hidden_states = ( - hidden_states.reshape(batch, height, weight, inner_dim).permute(0, 3, 1, 2).contiguous() - ) - hidden_states = self.proj_out(hidden_states) - else: - hidden_states = self.proj_out(hidden_states) - hidden_states = ( - hidden_states.reshape(batch, height, weight, inner_dim).permute(0, 3, 1, 2).contiguous() - ) - - output = hidden_states + residual - - output = rearrange(output, "(b f) c h w -> b c f h w", f=video_length) - if not return_dict: - return (output,) - - return Transformer2DModelOutput(sample=output) - - -class BasicTransformerBlock(nn.Module): - def __init__( - self, - dim: int, - num_attention_heads: int, - attention_head_dim: int, - dropout=0.0, - cross_attention_dim: Optional[int] = None, - activation_fn: str = "geglu", - num_embeds_ada_norm: Optional[int] = None, - attention_bias: bool = False, - only_cross_attention: bool = False, - upcast_attention: bool = False, - use_sc_attn: bool = False, - use_st_attn: bool = False, - ): - super().__init__() - self.only_cross_attention = only_cross_attention - self.use_ada_layer_norm = num_embeds_ada_norm is not None - - # Attn with temporal modeling - self.use_sc_attn = use_sc_attn - self.use_st_attn = use_st_attn - - attn_type = SparseCausalAttention if self.use_sc_attn else CrossAttention - attn_type = SpatialTemporalAttention if self.use_st_attn else attn_type - self.attn1 = attn_type( - query_dim=dim, - heads=num_attention_heads, - dim_head=attention_head_dim, - dropout=dropout, - bias=attention_bias, - cross_attention_dim=cross_attention_dim if only_cross_attention else None, - upcast_attention=upcast_attention, - ) # is a self-attention - self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn) - - # Cross-Attn - if cross_attention_dim is not None: - self.attn2 = CrossAttention( - query_dim=dim, - cross_attention_dim=cross_attention_dim, - heads=num_attention_heads, - dim_head=attention_head_dim, - dropout=dropout, - bias=attention_bias, - upcast_attention=upcast_attention, - ) # is self-attn if encoder_hidden_states is none - else: - self.attn2 = None - - self.norm1 = AdaLayerNorm(dim, num_embeds_ada_norm) if self.use_ada_layer_norm else nn.LayerNorm(dim) - - if cross_attention_dim is not None: - self.norm2 = AdaLayerNorm(dim, num_embeds_ada_norm) if self.use_ada_layer_norm else nn.LayerNorm(dim) - else: - self.norm2 = None - - # 3. Feed-forward - self.norm3 = nn.LayerNorm(dim) - - def set_use_memory_efficient_attention_xformers(self, use_memory_efficient_attention_xformers: bool): - if not is_xformers_available(): - print("Here is how to install it") - raise ModuleNotFoundError( - "Refer to https://github.com/facebookresearch/xformers for more information on how to install" - " xformers", - name="xformers", - ) - elif not torch.cuda.is_available(): - raise ValueError( - "torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is only" - " available for GPU " - ) - else: - try: - # Make sure we can run the memory efficient attention - _ = xformers.ops.memory_efficient_attention( - torch.randn((1, 2, 40), device="cuda"), - torch.randn((1, 2, 40), device="cuda"), - torch.randn((1, 2, 40), device="cuda"), - ) - except Exception as e: - raise e - self.attn1._use_memory_efficient_attention_xformers = use_memory_efficient_attention_xformers - if self.attn2 is not None: - self.attn2._use_memory_efficient_attention_xformers = use_memory_efficient_attention_xformers - # self.attn_temp._use_memory_efficient_attention_xformers = use_memory_efficient_attention_xformers - - def forward(self, hidden_states, encoder_hidden_states=None, timestep=None, attention_mask=None, video_length=None, normal_infer=False): - # SparseCausal-Attention - norm_hidden_states = ( - self.norm1(hidden_states, timestep) if self.use_ada_layer_norm else self.norm1(hidden_states) - ) - - if self.only_cross_attention: - hidden_states = ( - self.attn1(norm_hidden_states, encoder_hidden_states, attention_mask=attention_mask) + hidden_states - ) - else: - if self.use_sc_attn or self.use_st_attn: - hidden_states = self.attn1( - norm_hidden_states, attention_mask=attention_mask, video_length=video_length, normal_infer=normal_infer, - ) + hidden_states - else: - # shape of hidden_states: (b*f, len, dim) - hidden_states = self.attn1(norm_hidden_states, attention_mask=attention_mask) + hidden_states - - if self.attn2 is not None: - # Cross-Attention - norm_hidden_states = ( - self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states) - ) - hidden_states = ( - self.attn2( - norm_hidden_states, encoder_hidden_states=encoder_hidden_states, attention_mask=attention_mask - ) - + hidden_states - ) - - # Feed-forward - hidden_states = self.ff(self.norm3(hidden_states)) + hidden_states - - return hidden_states - - -class SparseCausalAttention(CrossAttention): - def forward_sc_attn(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None): - batch_size, sequence_length, _ = hidden_states.shape - - encoder_hidden_states = encoder_hidden_states - - if self.group_norm is not None: - hidden_states = self.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2) - - query = self.to_q(hidden_states) - dim = query.shape[-1] - query = self.reshape_heads_to_batch_dim(query) - - if self.added_kv_proj_dim is not None: - raise NotImplementedError - - encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states - key = self.to_k(encoder_hidden_states) - value = self.to_v(encoder_hidden_states) - - former_frame_index = torch.arange(video_length) - 1 - former_frame_index[0] = 0 - - key = rearrange(key, "(b f) d c -> b f d c", f=video_length) - key = torch.cat([key[:, [0] * video_length], key[:, former_frame_index]], dim=2) - key = rearrange(key, "b f d c -> (b f) d c") - - value = rearrange(value, "(b f) d c -> b f d c", f=video_length) - value = torch.cat([value[:, [0] * video_length], value[:, former_frame_index]], dim=2) - value = rearrange(value, "b f d c -> (b f) d c") - - key = self.reshape_heads_to_batch_dim(key) - value = self.reshape_heads_to_batch_dim(value) - - if attention_mask is not None: - if attention_mask.shape[-1] != query.shape[1]: - target_length = query.shape[1] - attention_mask = F.pad(attention_mask, (0, target_length), value=0.0) - attention_mask = attention_mask.repeat_interleave(self.heads, dim=0) - - # attention, what we cannot get enough of - if self._use_memory_efficient_attention_xformers: - hidden_states = self._memory_efficient_attention_xformers(query, key, value, attention_mask) - # Some versions of xformers return output in fp32, cast it back to the dtype of the input - hidden_states = hidden_states.to(query.dtype) - else: - if self._slice_size is None or query.shape[0] // self._slice_size == 1: - hidden_states = self._attention(query, key, value, attention_mask) - else: - hidden_states = self._sliced_attention(query, key, value, sequence_length, dim, attention_mask) - - # linear proj - hidden_states = self.to_out[0](hidden_states) - - # dropout - hidden_states = self.to_out[1](hidden_states) - return hidden_states - - def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None, normal_infer=False): - if normal_infer: - return super().forward( - hidden_states=hidden_states, - encoder_hidden_states=encoder_hidden_states, - attention_mask=attention_mask, - # video_length=video_length, - ) - else: - return self.forward_sc_attn( - hidden_states=hidden_states, - encoder_hidden_states=encoder_hidden_states, - attention_mask=attention_mask, - video_length=video_length, - ) - -class SpatialTemporalAttention(CrossAttention): - def forward_dense_attn(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None): - batch_size, sequence_length, _ = hidden_states.shape - - encoder_hidden_states = encoder_hidden_states - - if self.group_norm is not None: - hidden_states = self.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2) - - query = self.to_q(hidden_states) - dim = query.shape[-1] - query = self.reshape_heads_to_batch_dim(query) - - if self.added_kv_proj_dim is not None: - raise NotImplementedError - - encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states - key = self.to_k(encoder_hidden_states) - value = self.to_v(encoder_hidden_states) - - key = rearrange(key, "(b f) n d -> b f n d", f=video_length) - key = key.unsqueeze(1).repeat(1, video_length, 1, 1, 1) # (b f f n d) - key = rearrange(key, "b f g n d -> (b f) (g n) d") - - value = rearrange(value, "(b f) n d -> b f n d", f=video_length) - value = value.unsqueeze(1).repeat(1, video_length, 1, 1, 1) # (b f f n d) - value = rearrange(value, "b f g n d -> (b f) (g n) d") - - key = self.reshape_heads_to_batch_dim(key) - value = self.reshape_heads_to_batch_dim(value) - - if attention_mask is not None: - if attention_mask.shape[-1] != query.shape[1]: - target_length = query.shape[1] - attention_mask = F.pad(attention_mask, (0, target_length), value=0.0) - attention_mask = attention_mask.repeat_interleave(self.heads, dim=0) - - # attention, what we cannot get enough of - if self._use_memory_efficient_attention_xformers: - hidden_states = self._memory_efficient_attention_xformers(query, key, value, attention_mask) - # Some versions of xformers return output in fp32, cast it back to the dtype of the input - hidden_states = hidden_states.to(query.dtype) - else: - if self._slice_size is None or query.shape[0] // self._slice_size == 1: - hidden_states = self._attention(query, key, value, attention_mask) - else: - hidden_states = self._sliced_attention(query, key, value, sequence_length, dim, attention_mask) - - # linear proj - hidden_states = self.to_out[0](hidden_states) - - # dropout - hidden_states = self.to_out[1](hidden_states) - return hidden_states - - def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None, normal_infer=False): - if normal_infer: - return super().forward( - hidden_states=hidden_states, - encoder_hidden_states=encoder_hidden_states, - attention_mask=attention_mask, - # video_length=video_length, - ) - else: - return self.forward_dense_attn( - hidden_states=hidden_states, - encoder_hidden_states=encoder_hidden_states, - attention_mask=attention_mask, - video_length=video_length, - ) diff --git a/spaces/Bart92/RVC_HF/tools/rvc_for_realtime.py b/spaces/Bart92/RVC_HF/tools/rvc_for_realtime.py deleted file mode 100644 index f746cde4dfd9c3b87fe844304aa3a975d68b3433..0000000000000000000000000000000000000000 --- a/spaces/Bart92/RVC_HF/tools/rvc_for_realtime.py +++ /dev/null @@ -1,381 +0,0 @@ -import os -import sys -import traceback -import logging - -logger = logging.getLogger(__name__) - -from time import time as ttime - -import fairseq -import faiss -import numpy as np -import parselmouth -import pyworld -import scipy.signal as signal -import torch -import torch.nn as nn -import torch.nn.functional as F -import torchcrepe - -from infer.lib.infer_pack.models import ( - SynthesizerTrnMs256NSFsid, - SynthesizerTrnMs256NSFsid_nono, - SynthesizerTrnMs768NSFsid, - SynthesizerTrnMs768NSFsid_nono, -) - -now_dir = os.getcwd() -sys.path.append(now_dir) -from multiprocessing import Manager as M - -from configs.config import Config - -config = Config() - -mm = M() -if config.dml == True: - - def forward_dml(ctx, x, scale): - ctx.scale = scale - res = x.clone().detach() - return res - - fairseq.modules.grad_multiply.GradMultiply.forward = forward_dml - - -# config.device=torch.device("cpu")########强制cpu测试 -# config.is_half=False########强制cpu测试 -class RVC: - def __init__( - self, - key, - pth_path, - index_path, - index_rate, - n_cpu, - inp_q, - opt_q, - device, - last_rvc=None, - ) -> None: - """ - 初始化 - """ - try: - global config - self.inp_q = inp_q - self.opt_q = opt_q - # device="cpu"########强制cpu测试 - self.device = device - self.f0_up_key = key - self.time_step = 160 / 16000 * 1000 - self.f0_min = 50 - self.f0_max = 1100 - self.f0_mel_min = 1127 * np.log(1 + self.f0_min / 700) - self.f0_mel_max = 1127 * np.log(1 + self.f0_max / 700) - self.sr = 16000 - self.window = 160 - self.n_cpu = n_cpu - if index_rate != 0: - self.index = faiss.read_index(index_path) - self.big_npy = self.index.reconstruct_n(0, self.index.ntotal) - logger.info("Index search enabled") - self.pth_path = pth_path - self.index_path = index_path - self.index_rate = index_rate - - if last_rvc is None: - models, _, _ = fairseq.checkpoint_utils.load_model_ensemble_and_task( - ["assets/hubert/hubert_base.pt"], - suffix="", - ) - hubert_model = models[0] - hubert_model = hubert_model.to(device) - if config.is_half: - hubert_model = hubert_model.half() - else: - hubert_model = hubert_model.float() - hubert_model.eval() - self.model = hubert_model - else: - self.model = last_rvc.model - - if last_rvc is None or last_rvc.pth_path != self.pth_path: - cpt = torch.load(self.pth_path, map_location="cpu") - self.tgt_sr = cpt["config"][-1] - cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0] - self.if_f0 = cpt.get("f0", 1) - self.version = cpt.get("version", "v1") - if self.version == "v1": - if self.if_f0 == 1: - self.net_g = SynthesizerTrnMs256NSFsid( - *cpt["config"], is_half=config.is_half - ) - else: - self.net_g = SynthesizerTrnMs256NSFsid_nono(*cpt["config"]) - elif self.version == "v2": - if self.if_f0 == 1: - self.net_g = SynthesizerTrnMs768NSFsid( - *cpt["config"], is_half=config.is_half - ) - else: - self.net_g = SynthesizerTrnMs768NSFsid_nono(*cpt["config"]) - del self.net_g.enc_q - logger.debug(self.net_g.load_state_dict(cpt["weight"], strict=False)) - self.net_g.eval().to(device) - # print(2333333333,device,config.device,self.device)#net_g是device,hubert是config.device - if config.is_half: - self.net_g = self.net_g.half() - else: - self.net_g = self.net_g.float() - self.is_half = config.is_half - else: - self.tgt_sr = last_rvc.tgt_sr - self.if_f0 = last_rvc.if_f0 - self.version = last_rvc.version - self.net_g = last_rvc.net_g - self.is_half = last_rvc.is_half - - if last_rvc is not None and hasattr(last_rvc, "model_rmvpe"): - self.model_rmvpe = last_rvc.model_rmvpe - except: - logger.warn(traceback.format_exc()) - - def change_key(self, new_key): - self.f0_up_key = new_key - - def change_index_rate(self, new_index_rate): - if new_index_rate != 0 and self.index_rate == 0: - self.index = faiss.read_index(self.index_path) - self.big_npy = self.index.reconstruct_n(0, self.index.ntotal) - logger.info("Index search enabled") - self.index_rate = new_index_rate - - def get_f0_post(self, f0): - f0_min = self.f0_min - f0_max = self.f0_max - f0_mel_min = 1127 * np.log(1 + f0_min / 700) - f0_mel_max = 1127 * np.log(1 + f0_max / 700) - f0bak = f0.copy() - f0_mel = 1127 * np.log(1 + f0 / 700) - f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / ( - f0_mel_max - f0_mel_min - ) + 1 - f0_mel[f0_mel <= 1] = 1 - f0_mel[f0_mel > 255] = 255 - f0_coarse = np.rint(f0_mel).astype(np.int32) - return f0_coarse, f0bak - - def get_f0(self, x, f0_up_key, n_cpu, method="harvest"): - n_cpu = int(n_cpu) - if method == "crepe": - return self.get_f0_crepe(x, f0_up_key) - if method == "rmvpe": - return self.get_f0_rmvpe(x, f0_up_key) - if method == "pm": - p_len = x.shape[0] // 160 + 1 - f0 = ( - parselmouth.Sound(x, 16000) - .to_pitch_ac( - time_step=0.01, - voicing_threshold=0.6, - pitch_floor=50, - pitch_ceiling=1100, - ) - .selected_array["frequency"] - ) - - pad_size = (p_len - len(f0) + 1) // 2 - if pad_size > 0 or p_len - len(f0) - pad_size > 0: - # print(pad_size, p_len - len(f0) - pad_size) - f0 = np.pad( - f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant" - ) - - f0 *= pow(2, f0_up_key / 12) - return self.get_f0_post(f0) - if n_cpu == 1: - f0, t = pyworld.harvest( - x.astype(np.double), - fs=16000, - f0_ceil=1100, - f0_floor=50, - frame_period=10, - ) - f0 = signal.medfilt(f0, 3) - f0 *= pow(2, f0_up_key / 12) - return self.get_f0_post(f0) - f0bak = np.zeros(x.shape[0] // 160 + 1, dtype=np.float64) - length = len(x) - part_length = 160 * ((length // 160 - 1) // n_cpu + 1) - n_cpu = (length // 160 - 1) // (part_length // 160) + 1 - ts = ttime() - res_f0 = mm.dict() - for idx in range(n_cpu): - tail = part_length * (idx + 1) + 320 - if idx == 0: - self.inp_q.put((idx, x[:tail], res_f0, n_cpu, ts)) - else: - self.inp_q.put( - (idx, x[part_length * idx - 320 : tail], res_f0, n_cpu, ts) - ) - while 1: - res_ts = self.opt_q.get() - if res_ts == ts: - break - f0s = [i[1] for i in sorted(res_f0.items(), key=lambda x: x[0])] - for idx, f0 in enumerate(f0s): - if idx == 0: - f0 = f0[:-3] - elif idx != n_cpu - 1: - f0 = f0[2:-3] - else: - f0 = f0[2:] - f0bak[ - part_length * idx // 160 : part_length * idx // 160 + f0.shape[0] - ] = f0 - f0bak = signal.medfilt(f0bak, 3) - f0bak *= pow(2, f0_up_key / 12) - return self.get_f0_post(f0bak) - - def get_f0_crepe(self, x, f0_up_key): - if "privateuseone" in str(self.device): ###不支持dml,cpu又太慢用不成,拿pm顶替 - return self.get_f0(x, f0_up_key, 1, "pm") - audio = torch.tensor(np.copy(x))[None].float() - # print("using crepe,device:%s"%self.device) - f0, pd = torchcrepe.predict( - audio, - self.sr, - 160, - self.f0_min, - self.f0_max, - "full", - batch_size=512, - # device=self.device if self.device.type!="privateuseone" else "cpu",###crepe不用半精度全部是全精度所以不愁###cpu延迟高到没法用 - device=self.device, - return_periodicity=True, - ) - pd = torchcrepe.filter.median(pd, 3) - f0 = torchcrepe.filter.mean(f0, 3) - f0[pd < 0.1] = 0 - f0 = f0[0].cpu().numpy() - f0 *= pow(2, f0_up_key / 12) - return self.get_f0_post(f0) - - def get_f0_rmvpe(self, x, f0_up_key): - if hasattr(self, "model_rmvpe") == False: - from infer.lib.rmvpe import RMVPE - - logger.info("Loading rmvpe model") - self.model_rmvpe = RMVPE( - # "rmvpe.pt", is_half=self.is_half if self.device.type!="privateuseone" else False, device=self.device if self.device.type!="privateuseone"else "cpu"####dml时强制对rmvpe用cpu跑 - # "rmvpe.pt", is_half=False, device=self.device####dml配置 - # "rmvpe.pt", is_half=False, device="cpu"####锁定cpu配置 - "assets/rmvpe/rmvpe.pt", - is_half=self.is_half, - device=self.device, ####正常逻辑 - ) - # self.model_rmvpe = RMVPE("aug2_58000_half.pt", is_half=self.is_half, device=self.device) - f0 = self.model_rmvpe.infer_from_audio(x, thred=0.03) - f0 *= pow(2, f0_up_key / 12) - return self.get_f0_post(f0) - - def infer( - self, - feats: torch.Tensor, - indata: np.ndarray, - block_frame_16k, - rate, - cache_pitch, - cache_pitchf, - f0method, - ) -> np.ndarray: - feats = feats.view(1, -1) - if config.is_half: - feats = feats.half() - else: - feats = feats.float() - feats = feats.to(self.device) - t1 = ttime() - with torch.no_grad(): - padding_mask = torch.BoolTensor(feats.shape).to(self.device).fill_(False) - inputs = { - "source": feats, - "padding_mask": padding_mask, - "output_layer": 9 if self.version == "v1" else 12, - } - logits = self.model.extract_features(**inputs) - feats = ( - self.model.final_proj(logits[0]) if self.version == "v1" else logits[0] - ) - feats = F.pad(feats, (0, 0, 1, 0)) - t2 = ttime() - try: - if hasattr(self, "index") and self.index_rate != 0: - leng_replace_head = int(rate * feats[0].shape[0]) - npy = feats[0][-leng_replace_head:].cpu().numpy().astype("float32") - score, ix = self.index.search(npy, k=8) - weight = np.square(1 / score) - weight /= weight.sum(axis=1, keepdims=True) - npy = np.sum(self.big_npy[ix] * np.expand_dims(weight, axis=2), axis=1) - if config.is_half: - npy = npy.astype("float16") - feats[0][-leng_replace_head:] = ( - torch.from_numpy(npy).unsqueeze(0).to(self.device) * self.index_rate - + (1 - self.index_rate) * feats[0][-leng_replace_head:] - ) - else: - logger.warn("Index search FAILED or disabled") - except: - traceback.print_exc() - logger.warn("Index search FAILED") - feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1) - t3 = ttime() - if self.if_f0 == 1: - pitch, pitchf = self.get_f0(indata, self.f0_up_key, self.n_cpu, f0method) - start_frame = block_frame_16k // 160 - end_frame = len(cache_pitch) - (pitch.shape[0] - 4) + start_frame - cache_pitch[:] = np.append(cache_pitch[start_frame:end_frame], pitch[3:-1]) - cache_pitchf[:] = np.append( - cache_pitchf[start_frame:end_frame], pitchf[3:-1] - ) - p_len = min(feats.shape[1], 13000, cache_pitch.shape[0]) - else: - cache_pitch, cache_pitchf = None, None - p_len = min(feats.shape[1], 13000) - t4 = ttime() - feats = feats[:, :p_len, :] - if self.if_f0 == 1: - cache_pitch = cache_pitch[:p_len] - cache_pitchf = cache_pitchf[:p_len] - cache_pitch = torch.LongTensor(cache_pitch).unsqueeze(0).to(self.device) - cache_pitchf = torch.FloatTensor(cache_pitchf).unsqueeze(0).to(self.device) - p_len = torch.LongTensor([p_len]).to(self.device) - ii = 0 # sid - sid = torch.LongTensor([ii]).to(self.device) - with torch.no_grad(): - if self.if_f0 == 1: - # print(12222222222,feats.device,p_len.device,cache_pitch.device,cache_pitchf.device,sid.device,rate2) - infered_audio = ( - self.net_g.infer( - feats, p_len, cache_pitch, cache_pitchf, sid, rate - )[0][0, 0] - .data - .float() - ) - else: - infered_audio = ( - self.net_g.infer(feats, p_len, sid, rate)[0][0, 0] - .data - .float() - ) - t5 = ttime() - logger.info( - "Spent time: fea = %.2fs, index = %.2fs, f0 = %.2fs, model = %.2fs", - t2 - t1, - t3 - t2, - t4 - t3, - t5 - t4, - ) - return infered_audio \ No newline at end of file diff --git a/spaces/Benson/text-generation/Examples/Decision Mod Apk.md b/spaces/Benson/text-generation/Examples/Decision Mod Apk.md deleted file mode 100644 index b78f73f6f863e9b3408f84f4e7b8594adfcf4a5e..0000000000000000000000000000000000000000 --- a/spaces/Benson/text-generation/Examples/Decision Mod Apk.md +++ /dev/null @@ -1,47 +0,0 @@ - - Descargar King’s Choice Mod Apk y regla de su propio imperio!-¿Te gustan los juegos de simulación histórica con elementos RPG? ¿Quieres experimentar la vida de un rey y tomar decisiones que afectan el destino de tu reino? ¿Quieres reclutar héroes legendarios y bellezas a tu lado y disfrutar de recursos ilimitados? Si usted respondió sí a cualquiera de estas preguntas, entonces usted debe descargar King’s Choice mod apk y comenzar su aventura real! -decision mod apkDOWNLOAD ⚡ https://bltlly.com/2v6Jud - ¿Qué es King’s Choice?-King’s Choice es un popular juego para móviles desarrollado por ONEMT. Es un juego de simulación histórico con elementos RPG, donde puedes jugar como rey de un país europeo medieval. Puede elegir entre diferentes países, como Inglaterra, Francia, Alemania, España y más. También puede personalizar su apariencia, nombre y título. -Un juego de simulación histórica con elementos RPG-Como rey, tienes que manejar tu reino, lidiar con asuntos políticos, expandir tu territorio y enfrentar varios desafíos. También puede interactuar con otros jugadores en tiempo real, unirse a alianzas, intercambiar recursos y participar en guerras. También puedes explorar el mapa del mundo, descubrir secretos y completar misiones. -Un juego donde puedes tomar decisiones que afectan la historia-Una de las características más interesantes de King’s Choice es que puedes tomar decisiones que afectan la historia y el resultado del juego. Puedes elegir cómo lidiar con diferentes situaciones, como rebeliones, invasiones, matrimonios, asesinatos y más. También puedes elegir cómo tratar a tus súbditos, aliados, enemigos y amantes. Tus elecciones determinarán tu reputación, popularidad, lealtad y romance. -Un juego donde se puede reclutar héroes legendarios y bellezas- -¿Por qué descargar King’s Choice mod apk?-Si usted es un fan de King’s Choice, usted puede preguntarse por qué usted debe descargar King’s Choice mod apk en lugar de jugar la versión original. Bueno, hay muchas razones por las que descargar King’s Choice mod apk es una buena idea. Aquí están algunos de ellos: - -Recursos ilimitados para actualizar tu reino-Una de las principales ventajas de descargar King’s Choice mod apk es que usted tendrá recursos ilimitados para actualizar su reino. Tendrás oro ilimitado, gemas, comida, madera, hierro y más. Puedes usarlos para construir y mejorar tus edificios, investigar tecnologías, entrenar tropas y más. No tendrás que preocuparte por quedarte sin recursos o gastar dinero real en ellos. -Funciones VIP gratuitas para disfrutar de más beneficios-Otro beneficio de la descarga de King’s Choice mod apk es que usted tendrá funciones VIP gratuitas para disfrutar de más beneficios. Tendrás el nivel VIP 15 desbloqueado desde el principio, lo que significa que tendrás acceso a privilegios exclusivos, como velocidad de construcción más rápida, recompensas más diarias, más sorteos gratis, más espacio de almacenamiento y más. También tendrás puntos VIP gratis para aumentar aún más tu nivel VIP. -No hay anuncios para interrumpir tu juego-Una ventaja final de la descarga de King’s Choice mod apk es que no tendrá ningún anuncio para interrumpir su juego. Los anuncios pueden ser molestos y distraer, especialmente cuando estás inmerso en un juego como King’s Choice. También pueden consumir tus datos y batería. Al descargar King’s Choice mod apk, no tendrás que lidiar con ningún anuncio. Puedes disfrutar del juego sin interrupciones o molestias. -Cómo descargar e instalar King’s Choice mod apk?-Si usted está convencido por los beneficios de la descarga de King’s Choice mod apk, usted puede preguntarse cómo descargar e instalar en su dispositivo. No te preocupes, es muy fácil y sencillo. Solo sigue estos pasos: - -El primer paso es descargar el archivo apk mod de una fuente de confianza. Usted puede encontrar muchos sitios web que ofrecen King’s Choice mod apk, pero no todos ellos son seguros y fiables. Algunos de ellos pueden contener virus, malware o spyware que pueden dañar su dispositivo o robar su información personal. Para evitar cualquier riesgo, usted debe descargar King’s Choice mod apk de un sitio web de buena reputación, como [este]. -Paso 2: Habilitar fuentes desconocidas en el dispositivo-El segundo paso es habilitar fuentes desconocidas en su dispositivo. Esto es necesario porque King’s Choice mod apk no está disponible en la tienda de aplicaciones oficial, por lo que tiene que instalarlo desde una fuente externa. Para hacer esto, debe ir a la configuración del dispositivo, luego a la seguridad, luego a fuentes desconocidas y luego activarla. Esto le permitirá instalar aplicaciones desde fuentes distintas de la tienda de aplicaciones. -Paso 3: Instalar el archivo apk mod y lanzar el juego-El tercer y último paso es instalar el archivo apk mod y lanzar el juego. Para hacer esto, usted tiene que localizar el archivo apk mod descargado en su dispositivo, a continuación, toque en él y siga las instrucciones. Llevará unos segundos instalar el juego en tu dispositivo. Una vez que se hace, se puede iniciar el juego y disfrutar de todas las características de King’s Choice mod apk. -Conclusión-King’s Choice es un juego divertido y adictivo que te permite experimentar la vida de un rey en la Europa medieval. Puedes tomar decisiones que afecten la historia, reclutar héroes legendarios y bellezas, administrar tu reino e interactuar con otros jugadores. Sin embargo, si quieres disfrutar del juego al máximo, usted debe descargar King’s Choice mod apk y obtener recursos ilimitados, características VIP gratis, y sin anuncios. Es fácil y seguro para descargar e instalar King’s Choice mod apk en su dispositivo. Solo tienes que seguir los pasos anteriores y empezar a gobernar su propio imperio! -Preguntas frecuentes-Aquí hay algunas preguntas frecuentes sobre King’s Choice mod apk: -
Sí, Elección del rey mod apk es seguro, siempre y cuando se descarga desde una fuente de confianza. No contiene ningún virus, malware o spyware que pueda dañar su dispositivo o robar su información personal. -Elección del rey mod apk es compatible con la mayoría de los dispositivos Android que tienen Android 4.4 o superior. Sin embargo, es posible que algunos dispositivos no admitan algunas características o funciones del juego. -No, no se le prohibió el uso de King’s Choice mod apk. El mod apk tiene características anti-van que impiden que el juego detecte cualquier modificación o trucos. Puedes jugar el juego sin ninguna preocupación. -Sí, puede actualizar apk Elección del rey mod cada vez que hay una nueva versión disponible. Sin embargo, tiene que descargar e instalar la nueva versión manualmente desde la misma fuente que antes. -No, no se puede jugar King’s Choice mod apk offline. El juego requiere una conexión a Internet para funcionar correctamente y acceder a todas las características. -- - \ No newline at end of file diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/models/__init__.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/models/__init__.py deleted file mode 100644 index 7855226e4b500142deef8fb247cd33a9a991d122..0000000000000000000000000000000000000000 --- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/models/__init__.py +++ /dev/null @@ -1,2 +0,0 @@ -"""A package that contains models that represent entities. -""" diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/style.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/style.py deleted file mode 100644 index 84abbc20599f034626779702abc2303901d83ee5..0000000000000000000000000000000000000000 --- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/style.py +++ /dev/null @@ -1,197 +0,0 @@ -""" - pygments.style - ~~~~~~~~~~~~~~ - - Basic style object. - - :copyright: Copyright 2006-2022 by the Pygments team, see AUTHORS. - :license: BSD, see LICENSE for details. -""" - -from pip._vendor.pygments.token import Token, STANDARD_TYPES - -# Default mapping of ansixxx to RGB colors. -_ansimap = { - # dark - 'ansiblack': '000000', - 'ansired': '7f0000', - 'ansigreen': '007f00', - 'ansiyellow': '7f7fe0', - 'ansiblue': '00007f', - 'ansimagenta': '7f007f', - 'ansicyan': '007f7f', - 'ansigray': 'e5e5e5', - # normal - 'ansibrightblack': '555555', - 'ansibrightred': 'ff0000', - 'ansibrightgreen': '00ff00', - 'ansibrightyellow': 'ffff00', - 'ansibrightblue': '0000ff', - 'ansibrightmagenta': 'ff00ff', - 'ansibrightcyan': '00ffff', - 'ansiwhite': 'ffffff', -} -# mapping of deprecated #ansixxx colors to new color names -_deprecated_ansicolors = { - # dark - '#ansiblack': 'ansiblack', - '#ansidarkred': 'ansired', - '#ansidarkgreen': 'ansigreen', - '#ansibrown': 'ansiyellow', - '#ansidarkblue': 'ansiblue', - '#ansipurple': 'ansimagenta', - '#ansiteal': 'ansicyan', - '#ansilightgray': 'ansigray', - # normal - '#ansidarkgray': 'ansibrightblack', - '#ansired': 'ansibrightred', - '#ansigreen': 'ansibrightgreen', - '#ansiyellow': 'ansibrightyellow', - '#ansiblue': 'ansibrightblue', - '#ansifuchsia': 'ansibrightmagenta', - '#ansiturquoise': 'ansibrightcyan', - '#ansiwhite': 'ansiwhite', -} -ansicolors = set(_ansimap) - - -class StyleMeta(type): - - def __new__(mcs, name, bases, dct): - obj = type.__new__(mcs, name, bases, dct) - for token in STANDARD_TYPES: - if token not in obj.styles: - obj.styles[token] = '' - - def colorformat(text): - if text in ansicolors: - return text - if text[0:1] == '#': - col = text[1:] - if len(col) == 6: - return col - elif len(col) == 3: - return col[0] * 2 + col[1] * 2 + col[2] * 2 - elif text == '': - return '' - elif text.startswith('var') or text.startswith('calc'): - return text - assert False, "wrong color format %r" % text - - _styles = obj._styles = {} - - for ttype in obj.styles: - for token in ttype.split(): - if token in _styles: - continue - ndef = _styles.get(token.parent, None) - styledefs = obj.styles.get(token, '').split() - if not ndef or token is None: - ndef = ['', 0, 0, 0, '', '', 0, 0, 0] - elif 'noinherit' in styledefs and token is not Token: - ndef = _styles[Token][:] - else: - ndef = ndef[:] - _styles[token] = ndef - for styledef in obj.styles.get(token, '').split(): - if styledef == 'noinherit': - pass - elif styledef == 'bold': - ndef[1] = 1 - elif styledef == 'nobold': - ndef[1] = 0 - elif styledef == 'italic': - ndef[2] = 1 - elif styledef == 'noitalic': - ndef[2] = 0 - elif styledef == 'underline': - ndef[3] = 1 - elif styledef == 'nounderline': - ndef[3] = 0 - elif styledef[:3] == 'bg:': - ndef[4] = colorformat(styledef[3:]) - elif styledef[:7] == 'border:': - ndef[5] = colorformat(styledef[7:]) - elif styledef == 'roman': - ndef[6] = 1 - elif styledef == 'sans': - ndef[7] = 1 - elif styledef == 'mono': - ndef[8] = 1 - else: - ndef[0] = colorformat(styledef) - - return obj - - def style_for_token(cls, token): - t = cls._styles[token] - ansicolor = bgansicolor = None - color = t[0] - if color in _deprecated_ansicolors: - color = _deprecated_ansicolors[color] - if color in ansicolors: - ansicolor = color - color = _ansimap[color] - bgcolor = t[4] - if bgcolor in _deprecated_ansicolors: - bgcolor = _deprecated_ansicolors[bgcolor] - if bgcolor in ansicolors: - bgansicolor = bgcolor - bgcolor = _ansimap[bgcolor] - - return { - 'color': color or None, - 'bold': bool(t[1]), - 'italic': bool(t[2]), - 'underline': bool(t[3]), - 'bgcolor': bgcolor or None, - 'border': t[5] or None, - 'roman': bool(t[6]) or None, - 'sans': bool(t[7]) or None, - 'mono': bool(t[8]) or None, - 'ansicolor': ansicolor, - 'bgansicolor': bgansicolor, - } - - def list_styles(cls): - return list(cls) - - def styles_token(cls, ttype): - return ttype in cls._styles - - def __iter__(cls): - for token in cls._styles: - yield token, cls.style_for_token(token) - - def __len__(cls): - return len(cls._styles) - - -class Style(metaclass=StyleMeta): - - #: overall background color (``None`` means transparent) - background_color = '#ffffff' - - #: highlight background color - highlight_color = '#ffffcc' - - #: line number font color - line_number_color = 'inherit' - - #: line number background color - line_number_background_color = 'transparent' - - #: special line number font color - line_number_special_color = '#000000' - - #: special line number background color - line_number_special_background_color = '#ffffc0' - - #: Style definitions for individual token types. - styles = {} - - # Attribute for lexers defined within Pygments. If set - # to True, the style is not shown in the style gallery - # on the website. This is intended for language-specific - # styles. - web_style_gallery_exclude = False diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/styles/__init__.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/styles/__init__.py deleted file mode 100644 index 44cc0efb086e82e562905efdfdd5e28580b56ecc..0000000000000000000000000000000000000000 --- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/styles/__init__.py +++ /dev/null @@ -1,97 +0,0 @@ -""" - pygments.styles - ~~~~~~~~~~~~~~~ - - Contains built-in styles. - - :copyright: Copyright 2006-2022 by the Pygments team, see AUTHORS. - :license: BSD, see LICENSE for details. -""" - -from pip._vendor.pygments.plugin import find_plugin_styles -from pip._vendor.pygments.util import ClassNotFound - - -#: Maps style names to 'submodule::classname'. -STYLE_MAP = { - 'default': 'default::DefaultStyle', - 'emacs': 'emacs::EmacsStyle', - 'friendly': 'friendly::FriendlyStyle', - 'friendly_grayscale': 'friendly_grayscale::FriendlyGrayscaleStyle', - 'colorful': 'colorful::ColorfulStyle', - 'autumn': 'autumn::AutumnStyle', - 'murphy': 'murphy::MurphyStyle', - 'manni': 'manni::ManniStyle', - 'material': 'material::MaterialStyle', - 'monokai': 'monokai::MonokaiStyle', - 'perldoc': 'perldoc::PerldocStyle', - 'pastie': 'pastie::PastieStyle', - 'borland': 'borland::BorlandStyle', - 'trac': 'trac::TracStyle', - 'native': 'native::NativeStyle', - 'fruity': 'fruity::FruityStyle', - 'bw': 'bw::BlackWhiteStyle', - 'vim': 'vim::VimStyle', - 'vs': 'vs::VisualStudioStyle', - 'tango': 'tango::TangoStyle', - 'rrt': 'rrt::RrtStyle', - 'xcode': 'xcode::XcodeStyle', - 'igor': 'igor::IgorStyle', - 'paraiso-light': 'paraiso_light::ParaisoLightStyle', - 'paraiso-dark': 'paraiso_dark::ParaisoDarkStyle', - 'lovelace': 'lovelace::LovelaceStyle', - 'algol': 'algol::AlgolStyle', - 'algol_nu': 'algol_nu::Algol_NuStyle', - 'arduino': 'arduino::ArduinoStyle', - 'rainbow_dash': 'rainbow_dash::RainbowDashStyle', - 'abap': 'abap::AbapStyle', - 'solarized-dark': 'solarized::SolarizedDarkStyle', - 'solarized-light': 'solarized::SolarizedLightStyle', - 'sas': 'sas::SasStyle', - 'staroffice' : 'staroffice::StarofficeStyle', - 'stata': 'stata_light::StataLightStyle', - 'stata-light': 'stata_light::StataLightStyle', - 'stata-dark': 'stata_dark::StataDarkStyle', - 'inkpot': 'inkpot::InkPotStyle', - 'zenburn': 'zenburn::ZenburnStyle', - 'gruvbox-dark': 'gruvbox::GruvboxDarkStyle', - 'gruvbox-light': 'gruvbox::GruvboxLightStyle', - 'dracula': 'dracula::DraculaStyle', - 'one-dark': 'onedark::OneDarkStyle', - 'lilypond' : 'lilypond::LilyPondStyle', - 'nord': 'nord::NordStyle', - 'nord-darker': 'nord::NordDarkerStyle', - 'github-dark': 'gh_dark::GhDarkStyle' -} - - -def get_style_by_name(name): - if name in STYLE_MAP: - mod, cls = STYLE_MAP[name].split('::') - builtin = "yes" - else: - for found_name, style in find_plugin_styles(): - if name == found_name: - return style - # perhaps it got dropped into our styles package - builtin = "" - mod = name - cls = name.title() + "Style" - - try: - mod = __import__('pygments.styles.' + mod, None, None, [cls]) - except ImportError: - raise ClassNotFound("Could not find style module %r" % mod + - (builtin and ", though it should be builtin") + ".") - try: - return getattr(mod, cls) - except AttributeError: - raise ClassNotFound("Could not find style class %r in style module." % cls) - - -def get_all_styles(): - """Return a generator for all styles by name, - both builtin and plugin.""" - yield from STYLE_MAP - for name, _ in find_plugin_styles(): - yield name diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/rich/syntax.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/rich/syntax.py deleted file mode 100644 index 25b226a3a986c507747c8b40dc17f7a8017e73e1..0000000000000000000000000000000000000000 --- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/rich/syntax.py +++ /dev/null @@ -1,950 +0,0 @@ -import os.path -import platform -import re -import sys -import textwrap -from abc import ABC, abstractmethod -from pathlib import Path -from typing import ( - Any, - Dict, - Iterable, - List, - NamedTuple, - Optional, - Sequence, - Set, - Tuple, - Type, - Union, -) - -from pip._vendor.pygments.lexer import Lexer -from pip._vendor.pygments.lexers import get_lexer_by_name, guess_lexer_for_filename -from pip._vendor.pygments.style import Style as PygmentsStyle -from pip._vendor.pygments.styles import get_style_by_name -from pip._vendor.pygments.token import ( - Comment, - Error, - Generic, - Keyword, - Name, - Number, - Operator, - String, - Token, - Whitespace, -) -from pip._vendor.pygments.util import ClassNotFound - -from pip._vendor.rich.containers import Lines -from pip._vendor.rich.padding import Padding, PaddingDimensions - -from ._loop import loop_first -from .cells import cell_len -from .color import Color, blend_rgb -from .console import Console, ConsoleOptions, JustifyMethod, RenderResult -from .jupyter import JupyterMixin -from .measure import Measurement -from .segment import Segment, Segments -from .style import Style, StyleType -from .text import Text - -TokenType = Tuple[str, ...] - -WINDOWS = platform.system() == "Windows" -DEFAULT_THEME = "monokai" - -# The following styles are based on https://github.com/pygments/pygments/blob/master/pygments/formatters/terminal.py -# A few modifications were made - -ANSI_LIGHT: Dict[TokenType, Style] = { - Token: Style(), - Whitespace: Style(color="white"), - Comment: Style(dim=True), - Comment.Preproc: Style(color="cyan"), - Keyword: Style(color="blue"), - Keyword.Type: Style(color="cyan"), - Operator.Word: Style(color="magenta"), - Name.Builtin: Style(color="cyan"), - Name.Function: Style(color="green"), - Name.Namespace: Style(color="cyan", underline=True), - Name.Class: Style(color="green", underline=True), - Name.Exception: Style(color="cyan"), - Name.Decorator: Style(color="magenta", bold=True), - Name.Variable: Style(color="red"), - Name.Constant: Style(color="red"), - Name.Attribute: Style(color="cyan"), - Name.Tag: Style(color="bright_blue"), - String: Style(color="yellow"), - Number: Style(color="blue"), - Generic.Deleted: Style(color="bright_red"), - Generic.Inserted: Style(color="green"), - Generic.Heading: Style(bold=True), - Generic.Subheading: Style(color="magenta", bold=True), - Generic.Prompt: Style(bold=True), - Generic.Error: Style(color="bright_red"), - Error: Style(color="red", underline=True), -} - -ANSI_DARK: Dict[TokenType, Style] = { - Token: Style(), - Whitespace: Style(color="bright_black"), - Comment: Style(dim=True), - Comment.Preproc: Style(color="bright_cyan"), - Keyword: Style(color="bright_blue"), - Keyword.Type: Style(color="bright_cyan"), - Operator.Word: Style(color="bright_magenta"), - Name.Builtin: Style(color="bright_cyan"), - Name.Function: Style(color="bright_green"), - Name.Namespace: Style(color="bright_cyan", underline=True), - Name.Class: Style(color="bright_green", underline=True), - Name.Exception: Style(color="bright_cyan"), - Name.Decorator: Style(color="bright_magenta", bold=True), - Name.Variable: Style(color="bright_red"), - Name.Constant: Style(color="bright_red"), - Name.Attribute: Style(color="bright_cyan"), - Name.Tag: Style(color="bright_blue"), - String: Style(color="yellow"), - Number: Style(color="bright_blue"), - Generic.Deleted: Style(color="bright_red"), - Generic.Inserted: Style(color="bright_green"), - Generic.Heading: Style(bold=True), - Generic.Subheading: Style(color="bright_magenta", bold=True), - Generic.Prompt: Style(bold=True), - Generic.Error: Style(color="bright_red"), - Error: Style(color="red", underline=True), -} - -RICH_SYNTAX_THEMES = {"ansi_light": ANSI_LIGHT, "ansi_dark": ANSI_DARK} -NUMBERS_COLUMN_DEFAULT_PADDING = 2 - - -class SyntaxTheme(ABC): - """Base class for a syntax theme.""" - - @abstractmethod - def get_style_for_token(self, token_type: TokenType) -> Style: - """Get a style for a given Pygments token.""" - raise NotImplementedError # pragma: no cover - - @abstractmethod - def get_background_style(self) -> Style: - """Get the background color.""" - raise NotImplementedError # pragma: no cover - - -class PygmentsSyntaxTheme(SyntaxTheme): - """Syntax theme that delegates to Pygments theme.""" - - def __init__(self, theme: Union[str, Type[PygmentsStyle]]) -> None: - self._style_cache: Dict[TokenType, Style] = {} - if isinstance(theme, str): - try: - self._pygments_style_class = get_style_by_name(theme) - except ClassNotFound: - self._pygments_style_class = get_style_by_name("default") - else: - self._pygments_style_class = theme - - self._background_color = self._pygments_style_class.background_color - self._background_style = Style(bgcolor=self._background_color) - - def get_style_for_token(self, token_type: TokenType) -> Style: - """Get a style from a Pygments class.""" - try: - return self._style_cache[token_type] - except KeyError: - try: - pygments_style = self._pygments_style_class.style_for_token(token_type) - except KeyError: - style = Style.null() - else: - color = pygments_style["color"] - bgcolor = pygments_style["bgcolor"] - style = Style( - color="#" + color if color else "#000000", - bgcolor="#" + bgcolor if bgcolor else self._background_color, - bold=pygments_style["bold"], - italic=pygments_style["italic"], - underline=pygments_style["underline"], - ) - self._style_cache[token_type] = style - return style - - def get_background_style(self) -> Style: - return self._background_style - - -class ANSISyntaxTheme(SyntaxTheme): - """Syntax theme to use standard colors.""" - - def __init__(self, style_map: Dict[TokenType, Style]) -> None: - self.style_map = style_map - self._missing_style = Style.null() - self._background_style = Style.null() - self._style_cache: Dict[TokenType, Style] = {} - - def get_style_for_token(self, token_type: TokenType) -> Style: - """Look up style in the style map.""" - try: - return self._style_cache[token_type] - except KeyError: - # Styles form a hierarchy - # We need to go from most to least specific - # e.g. ("foo", "bar", "baz") to ("foo", "bar") to ("foo",) - get_style = self.style_map.get - token = tuple(token_type) - style = self._missing_style - while token: - _style = get_style(token) - if _style is not None: - style = _style - break - token = token[:-1] - self._style_cache[token_type] = style - return style - - def get_background_style(self) -> Style: - return self._background_style - - -SyntaxPosition = Tuple[int, int] - - -class _SyntaxHighlightRange(NamedTuple): - """ - A range to highlight in a Syntax object. - `start` and `end` are 2-integers tuples, where the first integer is the line number - (starting from 1) and the second integer is the column index (starting from 0). - """ - - style: StyleType - start: SyntaxPosition - end: SyntaxPosition - - -class Syntax(JupyterMixin): - """Construct a Syntax object to render syntax highlighted code. - - Args: - code (str): Code to highlight. - lexer (Lexer | str): Lexer to use (see https://pygments.org/docs/lexers/) - theme (str, optional): Color theme, aka Pygments style (see https://pygments.org/docs/styles/#getting-a-list-of-available-styles). Defaults to "monokai". - dedent (bool, optional): Enable stripping of initial whitespace. Defaults to False. - line_numbers (bool, optional): Enable rendering of line numbers. Defaults to False. - start_line (int, optional): Starting number for line numbers. Defaults to 1. - line_range (Tuple[int | None, int | None], optional): If given should be a tuple of the start and end line to render. - A value of None in the tuple indicates the range is open in that direction. - highlight_lines (Set[int]): A set of line numbers to highlight. - code_width: Width of code to render (not including line numbers), or ``None`` to use all available width. - tab_size (int, optional): Size of tabs. Defaults to 4. - word_wrap (bool, optional): Enable word wrapping. - background_color (str, optional): Optional background color, or None to use theme color. Defaults to None. - indent_guides (bool, optional): Show indent guides. Defaults to False. - padding (PaddingDimensions): Padding to apply around the syntax. Defaults to 0 (no padding). - """ - - _pygments_style_class: Type[PygmentsStyle] - _theme: SyntaxTheme - - @classmethod - def get_theme(cls, name: Union[str, SyntaxTheme]) -> SyntaxTheme: - """Get a syntax theme instance.""" - if isinstance(name, SyntaxTheme): - return name - theme: SyntaxTheme - if name in RICH_SYNTAX_THEMES: - theme = ANSISyntaxTheme(RICH_SYNTAX_THEMES[name]) - else: - theme = PygmentsSyntaxTheme(name) - return theme - - def __init__( - self, - code: str, - lexer: Union[Lexer, str], - *, - theme: Union[str, SyntaxTheme] = DEFAULT_THEME, - dedent: bool = False, - line_numbers: bool = False, - start_line: int = 1, - line_range: Optional[Tuple[Optional[int], Optional[int]]] = None, - highlight_lines: Optional[Set[int]] = None, - code_width: Optional[int] = None, - tab_size: int = 4, - word_wrap: bool = False, - background_color: Optional[str] = None, - indent_guides: bool = False, - padding: PaddingDimensions = 0, - ) -> None: - self.code = code - self._lexer = lexer - self.dedent = dedent - self.line_numbers = line_numbers - self.start_line = start_line - self.line_range = line_range - self.highlight_lines = highlight_lines or set() - self.code_width = code_width - self.tab_size = tab_size - self.word_wrap = word_wrap - self.background_color = background_color - self.background_style = ( - Style(bgcolor=background_color) if background_color else Style() - ) - self.indent_guides = indent_guides - self.padding = padding - - self._theme = self.get_theme(theme) - self._stylized_ranges: List[_SyntaxHighlightRange] = [] - - @classmethod - def from_path( - cls, - path: str, - encoding: str = "utf-8", - lexer: Optional[Union[Lexer, str]] = None, - theme: Union[str, SyntaxTheme] = DEFAULT_THEME, - dedent: bool = False, - line_numbers: bool = False, - line_range: Optional[Tuple[int, int]] = None, - start_line: int = 1, - highlight_lines: Optional[Set[int]] = None, - code_width: Optional[int] = None, - tab_size: int = 4, - word_wrap: bool = False, - background_color: Optional[str] = None, - indent_guides: bool = False, - padding: PaddingDimensions = 0, - ) -> "Syntax": - """Construct a Syntax object from a file. - - Args: - path (str): Path to file to highlight. - encoding (str): Encoding of file. - lexer (str | Lexer, optional): Lexer to use. If None, lexer will be auto-detected from path/file content. - theme (str, optional): Color theme, aka Pygments style (see https://pygments.org/docs/styles/#getting-a-list-of-available-styles). Defaults to "emacs". - dedent (bool, optional): Enable stripping of initial whitespace. Defaults to True. - line_numbers (bool, optional): Enable rendering of line numbers. Defaults to False. - start_line (int, optional): Starting number for line numbers. Defaults to 1. - line_range (Tuple[int, int], optional): If given should be a tuple of the start and end line to render. - highlight_lines (Set[int]): A set of line numbers to highlight. - code_width: Width of code to render (not including line numbers), or ``None`` to use all available width. - tab_size (int, optional): Size of tabs. Defaults to 4. - word_wrap (bool, optional): Enable word wrapping of code. - background_color (str, optional): Optional background color, or None to use theme color. Defaults to None. - indent_guides (bool, optional): Show indent guides. Defaults to False. - padding (PaddingDimensions): Padding to apply around the syntax. Defaults to 0 (no padding). - - Returns: - [Syntax]: A Syntax object that may be printed to the console - """ - code = Path(path).read_text(encoding=encoding) - - if not lexer: - lexer = cls.guess_lexer(path, code=code) - - return cls( - code, - lexer, - theme=theme, - dedent=dedent, - line_numbers=line_numbers, - line_range=line_range, - start_line=start_line, - highlight_lines=highlight_lines, - code_width=code_width, - tab_size=tab_size, - word_wrap=word_wrap, - background_color=background_color, - indent_guides=indent_guides, - padding=padding, - ) - - @classmethod - def guess_lexer(cls, path: str, code: Optional[str] = None) -> str: - """Guess the alias of the Pygments lexer to use based on a path and an optional string of code. - If code is supplied, it will use a combination of the code and the filename to determine the - best lexer to use. For example, if the file is ``index.html`` and the file contains Django - templating syntax, then "html+django" will be returned. If the file is ``index.html``, and no - templating language is used, the "html" lexer will be used. If no string of code - is supplied, the lexer will be chosen based on the file extension.. - - Args: - path (AnyStr): The path to the file containing the code you wish to know the lexer for. - code (str, optional): Optional string of code that will be used as a fallback if no lexer - is found for the supplied path. - - Returns: - str: The name of the Pygments lexer that best matches the supplied path/code. - """ - lexer: Optional[Lexer] = None - lexer_name = "default" - if code: - try: - lexer = guess_lexer_for_filename(path, code) - except ClassNotFound: - pass - - if not lexer: - try: - _, ext = os.path.splitext(path) - if ext: - extension = ext.lstrip(".").lower() - lexer = get_lexer_by_name(extension) - except ClassNotFound: - pass - - if lexer: - if lexer.aliases: - lexer_name = lexer.aliases[0] - else: - lexer_name = lexer.name - - return lexer_name - - def _get_base_style(self) -> Style: - """Get the base style.""" - default_style = self._theme.get_background_style() + self.background_style - return default_style - - def _get_token_color(self, token_type: TokenType) -> Optional[Color]: - """Get a color (if any) for the given token. - - Args: - token_type (TokenType): A token type tuple from Pygments. - - Returns: - Optional[Color]: Color from theme, or None for no color. - """ - style = self._theme.get_style_for_token(token_type) - return style.color - - @property - def lexer(self) -> Optional[Lexer]: - """The lexer for this syntax, or None if no lexer was found. - - Tries to find the lexer by name if a string was passed to the constructor. - """ - - if isinstance(self._lexer, Lexer): - return self._lexer - try: - return get_lexer_by_name( - self._lexer, - stripnl=False, - ensurenl=True, - tabsize=self.tab_size, - ) - except ClassNotFound: - return None - - def highlight( - self, - code: str, - line_range: Optional[Tuple[Optional[int], Optional[int]]] = None, - ) -> Text: - """Highlight code and return a Text instance. - - Args: - code (str): Code to highlight. - line_range(Tuple[int, int], optional): Optional line range to highlight. - - Returns: - Text: A text instance containing highlighted syntax. - """ - - base_style = self._get_base_style() - justify: JustifyMethod = ( - "default" if base_style.transparent_background else "left" - ) - - text = Text( - justify=justify, - style=base_style, - tab_size=self.tab_size, - no_wrap=not self.word_wrap, - ) - _get_theme_style = self._theme.get_style_for_token - - lexer = self.lexer - - if lexer is None: - text.append(code) - else: - if line_range: - # More complicated path to only stylize a portion of the code - # This speeds up further operations as there are less spans to process - line_start, line_end = line_range - - def line_tokenize() -> Iterable[Tuple[Any, str]]: - """Split tokens to one per line.""" - assert lexer # required to make MyPy happy - we know lexer is not None at this point - - for token_type, token in lexer.get_tokens(code): - while token: - line_token, new_line, token = token.partition("\n") - yield token_type, line_token + new_line - - def tokens_to_spans() -> Iterable[Tuple[str, Optional[Style]]]: - """Convert tokens to spans.""" - tokens = iter(line_tokenize()) - line_no = 0 - _line_start = line_start - 1 if line_start else 0 - - # Skip over tokens until line start - while line_no < _line_start: - try: - _token_type, token = next(tokens) - except StopIteration: - break - yield (token, None) - if token.endswith("\n"): - line_no += 1 - # Generate spans until line end - for token_type, token in tokens: - yield (token, _get_theme_style(token_type)) - if token.endswith("\n"): - line_no += 1 - if line_end and line_no >= line_end: - break - - text.append_tokens(tokens_to_spans()) - - else: - text.append_tokens( - (token, _get_theme_style(token_type)) - for token_type, token in lexer.get_tokens(code) - ) - if self.background_color is not None: - text.stylize(f"on {self.background_color}") - - if self._stylized_ranges: - self._apply_stylized_ranges(text) - - return text - - def stylize_range( - self, style: StyleType, start: SyntaxPosition, end: SyntaxPosition - ) -> None: - """ - Adds a custom style on a part of the code, that will be applied to the syntax display when it's rendered. - Line numbers are 1-based, while column indexes are 0-based. - - Args: - style (StyleType): The style to apply. - start (Tuple[int, int]): The start of the range, in the form `[line number, column index]`. - end (Tuple[int, int]): The end of the range, in the form `[line number, column index]`. - """ - self._stylized_ranges.append(_SyntaxHighlightRange(style, start, end)) - - def _get_line_numbers_color(self, blend: float = 0.3) -> Color: - background_style = self._theme.get_background_style() + self.background_style - background_color = background_style.bgcolor - if background_color is None or background_color.is_system_defined: - return Color.default() - foreground_color = self._get_token_color(Token.Text) - if foreground_color is None or foreground_color.is_system_defined: - return foreground_color or Color.default() - new_color = blend_rgb( - background_color.get_truecolor(), - foreground_color.get_truecolor(), - cross_fade=blend, - ) - return Color.from_triplet(new_color) - - @property - def _numbers_column_width(self) -> int: - """Get the number of characters used to render the numbers column.""" - column_width = 0 - if self.line_numbers: - column_width = ( - len(str(self.start_line + self.code.count("\n"))) - + NUMBERS_COLUMN_DEFAULT_PADDING - ) - return column_width - - def _get_number_styles(self, console: Console) -> Tuple[Style, Style, Style]: - """Get background, number, and highlight styles for line numbers.""" - background_style = self._get_base_style() - if background_style.transparent_background: - return Style.null(), Style(dim=True), Style.null() - if console.color_system in ("256", "truecolor"): - number_style = Style.chain( - background_style, - self._theme.get_style_for_token(Token.Text), - Style(color=self._get_line_numbers_color()), - self.background_style, - ) - highlight_number_style = Style.chain( - background_style, - self._theme.get_style_for_token(Token.Text), - Style(bold=True, color=self._get_line_numbers_color(0.9)), - self.background_style, - ) - else: - number_style = background_style + Style(dim=True) - highlight_number_style = background_style + Style(dim=False) - return background_style, number_style, highlight_number_style - - def __rich_measure__( - self, console: "Console", options: "ConsoleOptions" - ) -> "Measurement": - - _, right, _, left = Padding.unpack(self.padding) - padding = left + right - if self.code_width is not None: - width = self.code_width + self._numbers_column_width + padding + 1 - return Measurement(self._numbers_column_width, width) - lines = self.code.splitlines() - width = ( - self._numbers_column_width - + padding - + (max(cell_len(line) for line in lines) if lines else 0) - ) - if self.line_numbers: - width += 1 - return Measurement(self._numbers_column_width, width) - - def __rich_console__( - self, console: Console, options: ConsoleOptions - ) -> RenderResult: - segments = Segments(self._get_syntax(console, options)) - if self.padding: - yield Padding( - segments, style=self._theme.get_background_style(), pad=self.padding - ) - else: - yield segments - - def _get_syntax( - self, - console: Console, - options: ConsoleOptions, - ) -> Iterable[Segment]: - """ - Get the Segments for the Syntax object, excluding any vertical/horizontal padding - """ - transparent_background = self._get_base_style().transparent_background - code_width = ( - ( - (options.max_width - self._numbers_column_width - 1) - if self.line_numbers - else options.max_width - ) - if self.code_width is None - else self.code_width - ) - - ends_on_nl, processed_code = self._process_code(self.code) - text = self.highlight(processed_code, self.line_range) - - if not self.line_numbers and not self.word_wrap and not self.line_range: - if not ends_on_nl: - text.remove_suffix("\n") - # Simple case of just rendering text - style = ( - self._get_base_style() - + self._theme.get_style_for_token(Comment) - + Style(dim=True) - + self.background_style - ) - if self.indent_guides and not options.ascii_only: - text = text.with_indent_guides(self.tab_size, style=style) - text.overflow = "crop" - if style.transparent_background: - yield from console.render( - text, options=options.update(width=code_width) - ) - else: - syntax_lines = console.render_lines( - text, - options.update(width=code_width, height=None, justify="left"), - style=self.background_style, - pad=True, - new_lines=True, - ) - for syntax_line in syntax_lines: - yield from syntax_line - return - - start_line, end_line = self.line_range or (None, None) - line_offset = 0 - if start_line: - line_offset = max(0, start_line - 1) - lines: Union[List[Text], Lines] = text.split("\n", allow_blank=ends_on_nl) - if self.line_range: - if line_offset > len(lines): - return - lines = lines[line_offset:end_line] - - if self.indent_guides and not options.ascii_only: - style = ( - self._get_base_style() - + self._theme.get_style_for_token(Comment) - + Style(dim=True) - + self.background_style - ) - lines = ( - Text("\n") - .join(lines) - .with_indent_guides(self.tab_size, style=style) - .split("\n", allow_blank=True) - ) - - numbers_column_width = self._numbers_column_width - render_options = options.update(width=code_width) - - highlight_line = self.highlight_lines.__contains__ - _Segment = Segment - new_line = _Segment("\n") - - line_pointer = "> " if options.legacy_windows else "❱ " - - ( - background_style, - number_style, - highlight_number_style, - ) = self._get_number_styles(console) - - for line_no, line in enumerate(lines, self.start_line + line_offset): - if self.word_wrap: - wrapped_lines = console.render_lines( - line, - render_options.update(height=None, justify="left"), - style=background_style, - pad=not transparent_background, - ) - else: - segments = list(line.render(console, end="")) - if options.no_wrap: - wrapped_lines = [segments] - else: - wrapped_lines = [ - _Segment.adjust_line_length( - segments, - render_options.max_width, - style=background_style, - pad=not transparent_background, - ) - ] - - if self.line_numbers: - wrapped_line_left_pad = _Segment( - " " * numbers_column_width + " ", background_style - ) - for first, wrapped_line in loop_first(wrapped_lines): - if first: - line_column = str(line_no).rjust(numbers_column_width - 2) + " " - if highlight_line(line_no): - yield _Segment(line_pointer, Style(color="red")) - yield _Segment(line_column, highlight_number_style) - else: - yield _Segment(" ", highlight_number_style) - yield _Segment(line_column, number_style) - else: - yield wrapped_line_left_pad - yield from wrapped_line - yield new_line - else: - for wrapped_line in wrapped_lines: - yield from wrapped_line - yield new_line - - def _apply_stylized_ranges(self, text: Text) -> None: - """ - Apply stylized ranges to a text instance, - using the given code to determine the right portion to apply the style to. - - Args: - text (Text): Text instance to apply the style to. - """ - code = text.plain - newlines_offsets = [ - # Let's add outer boundaries at each side of the list: - 0, - # N.B. using "\n" here is much faster than using metacharacters such as "^" or "\Z": - *[ - match.start() + 1 - for match in re.finditer("\n", code, flags=re.MULTILINE) - ], - len(code) + 1, - ] - - for stylized_range in self._stylized_ranges: - start = _get_code_index_for_syntax_position( - newlines_offsets, stylized_range.start - ) - end = _get_code_index_for_syntax_position( - newlines_offsets, stylized_range.end - ) - if start is not None and end is not None: - text.stylize(stylized_range.style, start, end) - - def _process_code(self, code: str) -> Tuple[bool, str]: - """ - Applies various processing to a raw code string - (normalises it so it always ends with a line return, dedents it if necessary, etc.) - - Args: - code (str): The raw code string to process - - Returns: - Tuple[bool, str]: the boolean indicates whether the raw code ends with a line return, - while the string is the processed code. - """ - ends_on_nl = code.endswith("\n") - processed_code = code if ends_on_nl else code + "\n" - processed_code = ( - textwrap.dedent(processed_code) if self.dedent else processed_code - ) - processed_code = processed_code.expandtabs(self.tab_size) - return ends_on_nl, processed_code - - -def _get_code_index_for_syntax_position( - newlines_offsets: Sequence[int], position: SyntaxPosition -) -> Optional[int]: - """ - Returns the index of the code string for the given positions. - - Args: - newlines_offsets (Sequence[int]): The offset of each newline character found in the code snippet. - position (SyntaxPosition): The position to search for. - - Returns: - Optional[int]: The index of the code string for this position, or `None` - if the given position's line number is out of range (if it's the column that is out of range - we silently clamp its value so that it reaches the end of the line) - """ - lines_count = len(newlines_offsets) - - line_number, column_index = position - if line_number > lines_count or len(newlines_offsets) < (line_number + 1): - return None # `line_number` is out of range - line_index = line_number - 1 - line_length = newlines_offsets[line_index + 1] - newlines_offsets[line_index] - 1 - # If `column_index` is out of range: let's silently clamp it: - column_index = min(line_length, column_index) - return newlines_offsets[line_index] + column_index - - -if __name__ == "__main__": # pragma: no cover - - import argparse - import sys - - parser = argparse.ArgumentParser( - description="Render syntax to the console with Rich" - ) - parser.add_argument( - "path", - metavar="PATH", - help="path to file, or - for stdin", - ) - parser.add_argument( - "-c", - "--force-color", - dest="force_color", - action="store_true", - default=None, - help="force color for non-terminals", - ) - parser.add_argument( - "-i", - "--indent-guides", - dest="indent_guides", - action="store_true", - default=False, - help="display indent guides", - ) - parser.add_argument( - "-l", - "--line-numbers", - dest="line_numbers", - action="store_true", - help="render line numbers", - ) - parser.add_argument( - "-w", - "--width", - type=int, - dest="width", - default=None, - help="width of output (default will auto-detect)", - ) - parser.add_argument( - "-r", - "--wrap", - dest="word_wrap", - action="store_true", - default=False, - help="word wrap long lines", - ) - parser.add_argument( - "-s", - "--soft-wrap", - action="store_true", - dest="soft_wrap", - default=False, - help="enable soft wrapping mode", - ) - parser.add_argument( - "-t", "--theme", dest="theme", default="monokai", help="pygments theme" - ) - parser.add_argument( - "-b", - "--background-color", - dest="background_color", - default=None, - help="Override background color", - ) - parser.add_argument( - "-x", - "--lexer", - default=None, - dest="lexer_name", - help="Lexer name", - ) - parser.add_argument( - "-p", "--padding", type=int, default=0, dest="padding", help="Padding" - ) - parser.add_argument( - "--highlight-line", - type=int, - default=None, - dest="highlight_line", - help="The line number (not index!) to highlight", - ) - args = parser.parse_args() - - from pip._vendor.rich.console import Console - - console = Console(force_terminal=args.force_color, width=args.width) - - if args.path == "-": - code = sys.stdin.read() - syntax = Syntax( - code=code, - lexer=args.lexer_name, - line_numbers=args.line_numbers, - word_wrap=args.word_wrap, - theme=args.theme, - background_color=args.background_color, - indent_guides=args.indent_guides, - padding=args.padding, - highlight_lines={args.highlight_line}, - ) - else: - syntax = Syntax.from_path( - args.path, - lexer=args.lexer_name, - line_numbers=args.line_numbers, - word_wrap=args.word_wrap, - theme=args.theme, - background_color=args.background_color, - indent_guides=args.indent_guides, - padding=args.padding, - highlight_lines={args.highlight_line}, - ) - console.print(syntax, soft_wrap=args.soft_wrap) diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/urllib3/util/ssltransport.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/urllib3/util/ssltransport.py deleted file mode 100644 index 4a7105d17916a7237f3df6e59d65ca82375f8803..0000000000000000000000000000000000000000 --- a/spaces/Big-Web/MMSD/env/Lib/site-packages/urllib3/util/ssltransport.py +++ /dev/null @@ -1,221 +0,0 @@ -import io -import socket -import ssl - -from ..exceptions import ProxySchemeUnsupported -from ..packages import six - -SSL_BLOCKSIZE = 16384 - - -class SSLTransport: - """ - The SSLTransport wraps an existing socket and establishes an SSL connection. - - Contrary to Python's implementation of SSLSocket, it allows you to chain - multiple TLS connections together. It's particularly useful if you need to - implement TLS within TLS. - - The class supports most of the socket API operations. - """ - - @staticmethod - def _validate_ssl_context_for_tls_in_tls(ssl_context): - """ - Raises a ProxySchemeUnsupported if the provided ssl_context can't be used - for TLS in TLS. - - The only requirement is that the ssl_context provides the 'wrap_bio' - methods. - """ - - if not hasattr(ssl_context, "wrap_bio"): - if six.PY2: - raise ProxySchemeUnsupported( - "TLS in TLS requires SSLContext.wrap_bio() which isn't " - "supported on Python 2" - ) - else: - raise ProxySchemeUnsupported( - "TLS in TLS requires SSLContext.wrap_bio() which isn't " - "available on non-native SSLContext" - ) - - def __init__( - self, socket, ssl_context, server_hostname=None, suppress_ragged_eofs=True - ): - """ - Create an SSLTransport around socket using the provided ssl_context. - """ - self.incoming = ssl.MemoryBIO() - self.outgoing = ssl.MemoryBIO() - - self.suppress_ragged_eofs = suppress_ragged_eofs - self.socket = socket - - self.sslobj = ssl_context.wrap_bio( - self.incoming, self.outgoing, server_hostname=server_hostname - ) - - # Perform initial handshake. - self._ssl_io_loop(self.sslobj.do_handshake) - - def __enter__(self): - return self - - def __exit__(self, *_): - self.close() - - def fileno(self): - return self.socket.fileno() - - def read(self, len=1024, buffer=None): - return self._wrap_ssl_read(len, buffer) - - def recv(self, len=1024, flags=0): - if flags != 0: - raise ValueError("non-zero flags not allowed in calls to recv") - return self._wrap_ssl_read(len) - - def recv_into(self, buffer, nbytes=None, flags=0): - if flags != 0: - raise ValueError("non-zero flags not allowed in calls to recv_into") - if buffer and (nbytes is None): - nbytes = len(buffer) - elif nbytes is None: - nbytes = 1024 - return self.read(nbytes, buffer) - - def sendall(self, data, flags=0): - if flags != 0: - raise ValueError("non-zero flags not allowed in calls to sendall") - count = 0 - with memoryview(data) as view, view.cast("B") as byte_view: - amount = len(byte_view) - while count < amount: - v = self.send(byte_view[count:]) - count += v - - def send(self, data, flags=0): - if flags != 0: - raise ValueError("non-zero flags not allowed in calls to send") - response = self._ssl_io_loop(self.sslobj.write, data) - return response - - def makefile( - self, mode="r", buffering=None, encoding=None, errors=None, newline=None - ): - """ - Python's httpclient uses makefile and buffered io when reading HTTP - messages and we need to support it. - - This is unfortunately a copy and paste of socket.py makefile with small - changes to point to the socket directly. - """ - if not set(mode) <= {"r", "w", "b"}: - raise ValueError("invalid mode %r (only r, w, b allowed)" % (mode,)) - - writing = "w" in mode - reading = "r" in mode or not writing - assert reading or writing - binary = "b" in mode - rawmode = "" - if reading: - rawmode += "r" - if writing: - rawmode += "w" - raw = socket.SocketIO(self, rawmode) - self.socket._io_refs += 1 - if buffering is None: - buffering = -1 - if buffering < 0: - buffering = io.DEFAULT_BUFFER_SIZE - if buffering == 0: - if not binary: - raise ValueError("unbuffered streams must be binary") - return raw - if reading and writing: - buffer = io.BufferedRWPair(raw, raw, buffering) - elif reading: - buffer = io.BufferedReader(raw, buffering) - else: - assert writing - buffer = io.BufferedWriter(raw, buffering) - if binary: - return buffer - text = io.TextIOWrapper(buffer, encoding, errors, newline) - text.mode = mode - return text - - def unwrap(self): - self._ssl_io_loop(self.sslobj.unwrap) - - def close(self): - self.socket.close() - - def getpeercert(self, binary_form=False): - return self.sslobj.getpeercert(binary_form) - - def version(self): - return self.sslobj.version() - - def cipher(self): - return self.sslobj.cipher() - - def selected_alpn_protocol(self): - return self.sslobj.selected_alpn_protocol() - - def selected_npn_protocol(self): - return self.sslobj.selected_npn_protocol() - - def shared_ciphers(self): - return self.sslobj.shared_ciphers() - - def compression(self): - return self.sslobj.compression() - - def settimeout(self, value): - self.socket.settimeout(value) - - def gettimeout(self): - return self.socket.gettimeout() - - def _decref_socketios(self): - self.socket._decref_socketios() - - def _wrap_ssl_read(self, len, buffer=None): - try: - return self._ssl_io_loop(self.sslobj.read, len, buffer) - except ssl.SSLError as e: - if e.errno == ssl.SSL_ERROR_EOF and self.suppress_ragged_eofs: - return 0 # eof, return 0. - else: - raise - - def _ssl_io_loop(self, func, *args): - """Performs an I/O loop between incoming/outgoing and the socket.""" - should_loop = True - ret = None - - while should_loop: - errno = None - try: - ret = func(*args) - except ssl.SSLError as e: - if e.errno not in (ssl.SSL_ERROR_WANT_READ, ssl.SSL_ERROR_WANT_WRITE): - # WANT_READ, and WANT_WRITE are expected, others are not. - raise e - errno = e.errno - - buf = self.outgoing.read() - self.socket.sendall(buf) - - if errno is None: - should_loop = False - elif errno == ssl.SSL_ERROR_WANT_READ: - buf = self.socket.recv(SSL_BLOCKSIZE) - if buf: - self.incoming.write(buf) - else: - self.incoming.write_eof() - return ret diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/utils/README.md b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/utils/README.md deleted file mode 100644 index 9765b24a730b77556104187ac3ef5439ab0859fd..0000000000000000000000000000000000000000 --- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/utils/README.md +++ /dev/null @@ -1,5 +0,0 @@ -# Utility functions - -This folder contain utility functions that are not used in the -core library, but are useful for building models or training -code using the config system. diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/utils/proc_dict_gqa.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/utils/proc_dict_gqa.py deleted file mode 100644 index a0bd67d273e8dc299d45ec8178df9407e05dc570..0000000000000000000000000000000000000000 --- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/openvqa/utils/proc_dict_gqa.py +++ /dev/null @@ -1,85 +0,0 @@ -# -------------------------------------------------------- -# mcan-vqa (Deep Modular Co-Attention Networks) -# Licensed under The MIT License [see LICENSE for details] -# Written by Yuhao Cui https://github.com/cuiyuhao1996 -# -------------------------------------------------------- - -import sys -sys.path.append('../') -from openvqa.utils.ans_punct import prep_ans -from openvqa.core.path_cfgs import PATH -import json, re - -path = PATH() - - -ques_dict_preread = { - 'train': json.load(open(path.RAW_PATH['gqa']['train'], 'r')), - 'val': json.load(open(path.RAW_PATH['gqa']['val'], 'r')), - 'testdev': json.load(open(path.RAW_PATH['gqa']['testdev'], 'r')), - 'test': json.load(open(path.RAW_PATH['gqa']['test'], 'r')), -} - -# Loading question word list -stat_ques_dict = { - **ques_dict_preread['train'], - **ques_dict_preread['val'], - **ques_dict_preread['testdev'], - **ques_dict_preread['test'], -} - -stat_ans_dict = { - **ques_dict_preread['train'], - **ques_dict_preread['val'], - **ques_dict_preread['testdev'], -} - - -def tokenize(stat_ques_dict): - token_to_ix = { - 'PAD': 0, - 'UNK': 1, - 'CLS': 2, - } - - max_token = 0 - for qid in stat_ques_dict: - ques = stat_ques_dict[qid]['question'] - words = re.sub( - r"([.,'!?\"()*#:;])", - '', - ques.lower() - ).replace('-', ' ').replace('/', ' ').split() - - if len(words) > max_token: - max_token = len(words) - - for word in words: - if word not in token_to_ix: - token_to_ix[word] = len(token_to_ix) - - return token_to_ix, max_token - - -def ans_stat(stat_ans_dict): - ans_to_ix = {} - ix_to_ans = {} - - for qid in stat_ans_dict: - ans = stat_ans_dict[qid]['answer'] - ans = prep_ans(ans) - - if ans not in ans_to_ix: - ix_to_ans[ans_to_ix.__len__()] = ans - ans_to_ix[ans] = ans_to_ix.__len__() - - return ans_to_ix, ix_to_ans - -token_to_ix, max_token = tokenize(stat_ques_dict) -ans_to_ix, ix_to_ans = ans_stat(stat_ans_dict) -# print(ans_to_ix) -# print(ix_to_ans) -# print(token_to_ix) -# print(token_to_ix.__len__()) -# print(max_token) -json.dump([ans_to_ix, ix_to_ans, token_to_ix, max_token], open('../openvqa/datasets/gqa/dicts.json', 'w')) diff --git a/spaces/CVPR/LIVE/model_download/yolov5_model_p5_n.sh b/spaces/CVPR/LIVE/model_download/yolov5_model_p5_n.sh deleted file mode 100644 index 2ff8cd2505a95c9f6469c47c3c890681f4df9ebe..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/model_download/yolov5_model_p5_n.sh +++ /dev/null @@ -1,4 +0,0 @@ -cd ./yolov5 - -# 下载YOLOv5模型 -wget -c -t 0 https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5n.pt \ No newline at end of file diff --git a/spaces/CVPR/LIVE/thrust/examples/include/timer.h b/spaces/CVPR/LIVE/thrust/examples/include/timer.h deleted file mode 100644 index c405195a17408a26b89285cada760d6a07f5d320..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/examples/include/timer.h +++ /dev/null @@ -1,112 +0,0 @@ -/* - * Copyright 2008-2009 NVIDIA Corporation - * - * Licensed under the Apache License, Version 2.0 (the "License"); - * you may not use this file except in compliance with the License. - * You may obtain a copy of the License at - * - * http://www.apache.org/licenses/LICENSE-2.0 - * - * Unless required by applicable law or agreed to in writing, software - * distributed under the License is distributed on an "AS IS" BASIS, - * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - * See the License for the specific language governing permissions and - * limitations under the License. - */ - -#pragma once - -// A simple timer class - -#ifdef __CUDACC__ - -// use CUDA's high-resolution timers when possible -#include
-
-
-
diff --git a/spaces/Cicooo/vits-uma-genshin-honkai/Docker/vits.sh b/spaces/Cicooo/vits-uma-genshin-honkai/Docker/vits.sh
deleted file mode 100644
index 2b87f26eda96d3800b73b4a21b210c78888a2299..0000000000000000000000000000000000000000
--- a/spaces/Cicooo/vits-uma-genshin-honkai/Docker/vits.sh
+++ /dev/null
@@ -1,20 +0,0 @@
-#!/bin/bash
-run() {
- echo -e "\033[32m已完成初始化,启动服务...\033[0m"
- python3 /app/vits-uma-genshin-honkai/app.py
-}
-install() {
- echo -e "\033[33m正在初始化:安装依赖....\033[0m"
- pip install -r /app/vits-uma-genshin-honkai/requirements.txt -i https://mirrors.ustc.edu.cn/pypi/web/simple
- echo -e "\033[33m正在下载模型....\033[0m"
- rm -f /app/vits-uma-genshin-honkai/model/G_953000.pth
- wget -O /app/vits-uma-genshin-honkai/model/G_953000.pth https://huggingface.co/spaces/ikechan8370/vits-uma-genshin-honkai/resolve/main/model/G_953000.pth
- echo -e "\033[32m初始化完成!\033[0m"
- run
-}
-
-if [ ! -f "/app/vits-uma-genshin-honkai/model/G_953000.pth" ] || [ "$(stat -c%s "/app/vits-uma-genshin-honkai/model/G_953000.pth")" -lt 10000 ]; then
- install
-else
- run
-fi
diff --git a/spaces/Cong723/gpt-academic-public/main.py b/spaces/Cong723/gpt-academic-public/main.py
deleted file mode 100644
index 5932b83ed9b3bffcfbcf613ec3175d253c674bd6..0000000000000000000000000000000000000000
--- a/spaces/Cong723/gpt-academic-public/main.py
+++ /dev/null
@@ -1,209 +0,0 @@
-import os; os.environ['no_proxy'] = '*' # 避免代理网络产生意外污染
-
-def main():
- import gradio as gr
- from request_llm.bridge_all import predict
- from toolbox import format_io, find_free_port, on_file_uploaded, on_report_generated, get_conf, ArgsGeneralWrapper, DummyWith
- # 建议您复制一个config_private.py放自己的秘密, 如API和代理网址, 避免不小心传github被别人看到
- proxies, WEB_PORT, LLM_MODEL, CONCURRENT_COUNT, AUTHENTICATION, CHATBOT_HEIGHT, LAYOUT, API_KEY, AVAIL_LLM_MODELS = \
- get_conf('proxies', 'WEB_PORT', 'LLM_MODEL', 'CONCURRENT_COUNT', 'AUTHENTICATION', 'CHATBOT_HEIGHT', 'LAYOUT', 'API_KEY', 'AVAIL_LLM_MODELS')
-
- # 如果WEB_PORT是-1, 则随机选取WEB端口
- PORT = find_free_port() if WEB_PORT <= 0 else WEB_PORT
- if not AUTHENTICATION: AUTHENTICATION = None
-
- from check_proxy import get_current_version
- initial_prompt = "Serve me as a writing and programming assistant."
- title_html = f"Welcome to your static Space!-You can modify this app directly by editing index.html in the Files and versions tab. -- Also don't forget to check the - Spaces documentation. - -ChatGPT 学术优化 {get_current_version()}" - description = """代码开源和更新[地址🚀](https://github.com/binary-husky/chatgpt_academic),感谢热情的[开发者们❤️](https://github.com/binary-husky/chatgpt_academic/graphs/contributors)""" - - # 问询记录, python 版本建议3.9+(越新越好) - import logging - os.makedirs("gpt_log", exist_ok=True) - try:logging.basicConfig(filename="gpt_log/chat_secrets.log", level=logging.INFO, encoding="utf-8") - except:logging.basicConfig(filename="gpt_log/chat_secrets.log", level=logging.INFO) - print("所有问询记录将自动保存在本地目录./gpt_log/chat_secrets.log, 请注意自我隐私保护哦!") - - # 一些普通功能模块 - from core_functional import get_core_functions - functional = get_core_functions() - - # 高级函数插件 - from crazy_functional import get_crazy_functions - crazy_fns = get_crazy_functions() - - # 处理markdown文本格式的转变 - gr.Chatbot.postprocess = format_io - - # 做一些外观色彩上的调整 - from theme import adjust_theme, advanced_css - set_theme = adjust_theme() - - # 代理与自动更新 - from check_proxy import check_proxy, auto_update, warm_up_modules - proxy_info = check_proxy(proxies) - - gr_L1 = lambda: gr.Row().style() - gr_L2 = lambda scale: gr.Column(scale=scale) - if LAYOUT == "TOP-DOWN": - gr_L1 = lambda: DummyWith() - gr_L2 = lambda scale: gr.Row() - CHATBOT_HEIGHT /= 2 - - cancel_handles = [] - with gr.Blocks(title="ChatGPT 学术优化", theme=set_theme, analytics_enabled=False, css=advanced_css) as demo: - gr.HTML(title_html) - gr.HTML('''切忌在“复制空间”(Duplicate Space)之前填入API_KEY或进行提问,否则您的API_KEY将极可能被空间所有者攫取! 支持任意数量的OpenAI的密钥和API2D的密钥共存,例如输入"OpenAI密钥1,API2D密钥2",然后提交,即可同时使用两种模型接口。
line 3 > - ] - subgraph { rank=same b c } - a:here -> b:there [dir=both arrowtail=diamond] - c -> b - d [shape=triangle] - d -> c [label=< -
... |+ method ... }>] - Class1[label = <{I/O class | + property ... |+ method ... }>] - edge [dir=back arrowtail=empty style=dashed] - Class1 -> System_1 [xlabel=implementation] - System_1 [label = <{System | + property ... |+ method ... }>] - "Shared resource" [label = <{Shared resource | + property ... |+ method ... }>] - edge [dir=back arrowtail=diamond] - "System_1" -> Subsystem_1 [xlabel="composition"] - Subsystem_1[label = <{Subsystem 1 | + property ... |+ method ... }>] - Subsystem_2[label = <{Subsystem 2 | + property ... |+ method ... }>] - Subsystem_3[label = <{Subsystem 3 | + property ... |+ method ... }>] - "System_1" -> Subsystem_2 - "System_1" -> Subsystem_3 - edge [xdir=back arrowtail=odiamond] - Subsystem_1 -> "Shared resource" [xlabel=aggregation] - {Subsystem_2 Subsystem_3 } -> "Shared resource" -} -''') - - - -st.graphviz_chart(''' -digraph G { - fontname="Helvetica,Arial,sans-serif" - node [fontname="Helvetica,Arial,sans-serif"] - edge [fontname="Helvetica,Arial,sans-serif"] - subgraph cluster_1 { - node [ style=filled,shape="box",fillcolor="antiquewhite:aquamarine" ]n5; - node [ shape="ellipse",fillcolor="bisque4:blue2" ]n4; - node [ shape="circle",fillcolor="cadetblue1:chocolate1" ]n3; - node [ shape="diamond",fillcolor="crimson:cyan4" ]n2; - node [ shape="triangle",fillcolor="deepskyblue2:firebrick" ]n1; - node [ shape="pentagon",fillcolor="gray24:gray88" ]n0; - label = "X11 Colors"; - } - subgraph cluster_2 { - node [ style=filled,shape="box",fillcolor="bisque:brown" ]n11; - node [ shape="ellipse",fillcolor="green:darkorchid" ]n10; - node [ shape="circle",fillcolor="deepskyblue:gold" ]n9; - node [ shape="diamond",fillcolor="lightseagreen:orangered" ]n8; - node [ shape="triangle",fillcolor="turquoise:salmon" ]n7; - node [ shape="pentagon",fillcolor="snow:black" ]n6; - label = "SVG Colors"; - } - subgraph cluster_3 { - node [ style=filled,shape="box",fillcolor="/accent3/1:/accent3/3" ]n17; - node [ shape="ellipse",fillcolor="/accent4/1:/accent4/4" ]n16; - node [ shape="circle",fillcolor="/accent5/1:/accent5/5" ]n15; - node [ shape="diamond",fillcolor="/accent6/1:/accent6/6" ]n14; - node [ shape="triangle",fillcolor="/accent7/1:/accent7/7" ]n13; - node [ shape="pentagon",fillcolor="/accent8/1:/accent8/8" ]n12; - label = "Brewer - accent"; - } - subgraph cluster_4 { - node [ style=filled,shape="box",fillcolor="/blues3/1:/blues3/2" ]n23; - node [ shape="ellipse",fillcolor="/blues4/1:/blues4/3" ]n22; - node [ shape="circle",fillcolor="/blues5/1:/blues5/4" ]n21; - node [ shape="diamond",fillcolor="/blues6/1:/blues6/5" ]n20; - node [ shape="triangle",fillcolor="/blues7/1:/blues7/6" ]n19; - node [ shape="pentagon",fillcolor="/blues8/1:/blues8/7" ]n18; - label = "Brewer - blues"; - } -n3 -> n9 -> n15 -> n21; -} -''') - -st.graphviz_chart(''' -digraph G {bgcolor="#0000FF44:#FF000044" gradientangle=90 - fontname="Helvetica,Arial,sans-serif" - node [fontname="Helvetica,Arial,sans-serif"] - edge [fontname="Helvetica,Arial,sans-serif"] - subgraph cluster_0 { - style=filled; - color=lightgrey; - fillcolor="darkgray:gold"; - gradientangle=0 - node [fillcolor="yellow:green" style=filled gradientangle=270] a0; - node [fillcolor="lightgreen:red"] a1; - node [fillcolor="lightskyblue:darkcyan"] a2; - node [fillcolor="cyan:lightslateblue"] a3; - a0 -> a1 -> a2 -> a3; - label = "process #1"; - } - subgraph cluster_1 { - node [fillcolor="yellow:magenta" - style=filled gradientangle=270] b0; - node [fillcolor="violet:darkcyan"] b1; - node [fillcolor="peachpuff:red"] b2; - node [fillcolor="mediumpurple:purple"] b3; - b0 -> b1 -> b2 -> b3; - label = "process #2"; - color=blue - fillcolor="darkgray:gold"; - gradientangle=0 - style=filled; - } - start -> a0; - start -> b0; - a1 -> b3; - b2 -> a3; - a3 -> a0; - a3 -> end; - b3 -> end; - start [shape=Mdiamond , - fillcolor="pink:red", - gradientangle=90, - style=radial]; - end [shape=Msquare, - fillcolor="lightyellow:orange", - style=radial, - gradientangle=90]; -} -''') - -st.graphviz_chart(''' -graph Color_wheel { - graph [ - layout = neato - label = "Color wheel, 33 colors.\nNeato layout" - labelloc = b - fontname = "Helvetica,Arial,sans-serif" - start = regular - normalize = 0 - ] - node [ - shape = circle - style = filled - color = "#00000088" - fontname = "Helvetica,Arial,sans-serif" - ] - edge [ - len = 2.7 - color = "#00000088" - fontname = "Helvetica,Arial,sans-serif" - ] - subgraph Dark { - node [fontcolor = white width = 1.4] - center [width = 1 style = invis shape = point] - center -- darkred [label = "0°/360°"] - darkred [fillcolor = darkred] - brown [fillcolor = brown] - brown -- center [label = "30°"] - olive [fillcolor = olive] - olive -- center [label = "60°"] - darkolivegreen [fillcolor = darkolivegreen fontsize = 10] - darkolivegreen -- center [label = "90°"] - darkgreen [fillcolor = darkgreen] - darkgreen -- center [label = "120°"] - "dark hue 0.416" [color = ".416 1 .6" fontcolor = white] - "dark hue 0.416" -- center [label = "150°"] - darkcyan [fillcolor = darkcyan] - darkcyan -- center [label = "180°"] - "dark hue 0.583" [color = ".583 1 .6" fontcolor = white] - "dark hue 0.583" -- center [label = "210°"] - darkblue [fillcolor = darkblue] - darkblue -- center [label = "240°"] - "dark hue 0.750" [color = ".750 1 .6"] - "dark hue 0.750" -- center [label = "270°"] - darkmagenta [fillcolor = darkmagenta] - darkmagenta -- center [label = "300°"] - "dark hue 0.916" [color = ".916 1 .6"] - "dark hue 0.916" -- center [label = "330°"] - } - subgraph Tue { - node [width = 1.3] - "hue 0.083" -- brown - "hue 0.083" [color = ".083 1 1"] - "hue 0.125" [color = ".125 1 1"] - "hue 0.166" -- olive - "hue 0.166" [color = ".166 1 1"] - "hue 0.208" [color = ".208 1 1"] - "hue 0.250" -- darkolivegreen - "hue 0.250" [color = ".250 1 1"] - "hue 0.291" [color = ".291 1 1"] - "hue 0.333" -- darkgreen - "hue 0.333" [color = ".333 1 1"] - "hue 0.375" [color = ".375 1 1"] - "hue 0.416" -- "dark hue 0.416" - "hue 0.416" [color = ".416 1 1"] - "hue 0.458" [color = ".458 1 1"] - "hue 0.500" -- darkcyan - "hue 0.500" [color = ".500 1 1"] - "hue 0.541" [color = ".541 1 1"] - node [fontcolor = white] - "hue 0.000" [color = ".000 1 1"] - "hue 0.000" -- darkred - "hue 0.041" [color = ".041 1 1"] - "hue 0.583" -- "dark hue 0.583" - "hue 0.583" [color = ".583 1 1"] - "hue 0.625" [color = ".625 1 1"] - "hue 0.666" -- darkblue - "hue 0.666" [color = ".666 1 1"] - "hue 0.708" [color = ".708 1 1"] - "hue 0.750" -- "dark hue 0.750" - "hue 0.750" [color = ".750 1 1"] - "hue 0.791" [color = ".791 1 1"] - "hue 0.833" -- darkmagenta - "hue 0.833" [color = ".833 1 1"] - "hue 0.875" [color = ".875 1 1"] - "hue 0.916" -- "dark hue 0.916" - "hue 0.916" [color = ".916 1 1"] - "hue 0.958" [color = ".958 1 1"] - edge [len = 1] - "hue 0.000" -- "hue 0.041" -- "hue 0.083" -- "hue 0.125" -- "hue 0.166" -- "hue 0.208" - "hue 0.208" -- "hue 0.250" -- "hue 0.291" -- "hue 0.333" -- "hue 0.375" -- "hue 0.416" - "hue 0.416" -- "hue 0.458" -- "hue 0.500" --"hue 0.541" -- "hue 0.583" -- "hue 0.625" - "hue 0.625" -- "hue 0.666" -- "hue 0.708" -- "hue 0.750" -- "hue 0.791" -- "hue 0.833" - "hue 0.833" -- "hue 0.875" -- "hue 0.916" -- "hue 0.958" -- "hue 0.000" - } - subgraph Main_colors { - node [width = 2 fontsize = 20] - red [fillcolor = red fontcolor = white] - orangered [fillcolor = orangered] - orange [fillcolor = orange] - gold [fillcolor = gold] - yellow [fillcolor = yellow] - yellowgreen [fillcolor = yellowgreen] - deeppink [fillcolor = deeppink fontcolor = white] - fuchsia [label = "fuchsia\nmagenta" fillcolor = fuchsia fontcolor = white] - purple [fillcolor = purple fontcolor = white] - blue [fillcolor = blue fontcolor = white] - cornflowerblue [fillcolor = cornflowerblue] - deepskyblue [fillcolor = deepskyblue] - aqua [fillcolor = aqua label = "aqua\ncyan"] - springgreen [fillcolor = springgreen] - green [fillcolor = green] - purple -- fuchsia -- deeppink -- red - cornflowerblue -- blue -- purple - cornflowerblue -- deepskyblue -- aqua [len = 1.7] - aqua -- springgreen -- green -- yellowgreen -- yellow - yellow -- gold -- orange -- orangered -- red [len = 1.6] - orange -- "hue 0.083" - deeppink -- "hue 0.916" - deeppink -- "hue 0.875" - red -- "hue 0.000" - yellowgreen -- "hue 0.250" - blue -- "hue 0.666" - yellow -- "hue 0.166" - gold -- "hue 0.125" - green -- "hue 0.333" - springgreen -- "hue 0.416" - aqua -- "hue 0.500" - cornflowerblue -- "hue 0.583" - deepskyblue -- "hue 0.541" - purple -- "hue 0.791" - purple -- "hue 0.750" - fuchsia -- "hue 0.833" - } - subgraph Light_colors { - node [width = 2 fontsize = 20] - node [shape = circle width = 1.8] - edge [len = 2.1] - pink [fillcolor = pink] - pink -- red - lightyellow [fillcolor = lightyellow] - lightyellow -- yellow - mediumpurple [fillcolor = mediumpurple] - mediumpurple -- purple - violet [fillcolor = violet] - violet -- fuchsia - hotpink [fillcolor = hotpink] - hotpink -- deeppink - "light hue 0.250" [color = ".250 .2 1"] - "light hue 0.250" -- yellowgreen - lightcyan [fillcolor = lightcyan] - lightcyan -- aqua - lightslateblue [fillcolor = lightslateblue] - lightslateblue -- blue - lightgreen [fillcolor = lightgreen] - lightgreen -- green - lightskyblue [fillcolor = lightskyblue] - lightskyblue -- deepskyblue - peachpuff [fillcolor = peachpuff] - peachpuff -- orange - "light hue 0.416" [color = ".416 .2 1"] - "light hue 0.416" -- springgreen - } - subgraph Tints { - node [width = 1] - edge [len = 2.4] - "hue 0 tint" -- pink - "hue 0 tint" [color = "0 .1 1"] - "hue 0.041 tint" [color = ".041 .1 1"] - "hue 0.083 tint" -- peachpuff - "hue 0.083 tint" [color = ".083 .1 1"] - "hue 0.125 tint" [color = ".125 .1 1"] - "hue 0.166 tint" -- lightyellow - "hue 0.166 tint" [color = ".166 .1 1"] - "hue 0.208 tint" [color = ".208 .1 1"] - "hue 0.250 tint" -- "light hue 0.250" - "hue 0.250 tint" [color = ".250 .1 1"] - "hue 0.291 tint" [color = ".291 .1 1"] - "hue 0.333 tint" -- lightgreen - "hue 0.333 tint" [color = ".333 .1 1"] - "hue 0.375 tint" [color = ".375 .1 1"] - "hue 0.416 tint" -- "light hue 0.416" - "hue 0.416 tint" [color = ".416 .1 1"] - "hue 0.458 tint" [color = ".458 .1 1"] - "hue 0.5 tint" -- lightcyan - "hue 0.5 tint" [color = ".5 .1 1"] - "hue 0.541 tint" -- lightskyblue - "hue 0.541 tint" [color = ".541 .1 1"] - "hue 0.583 tint" [color = ".583 .1 1"] - "hue 0.625 tint" [color = ".625 .1 1"] - "hue 0.666 tint" -- lightslateblue - "hue 0.666 tint" [color = ".666 .1 1"] - "hue 0.708 tint" [color = ".708 .1 1"] - "hue 0.750 tint" -- mediumpurple - "hue 0.750 tint" [color = ".750 .1 1"] - "hue 0.791 tint" [color = ".791 .1 1"] - "hue 0.833 tint" -- violet - "hue 0.833 tint" [color = ".833 .1 1"] - "hue 0.875 tint" [color = ".875 .1 1"] - "hue 0.916 tint" -- hotpink - "hue 0.916 tint" [color = ".916 .1 1"] - "hue 0.958 tint" [color = ".958 .1 1"] - edge [len = 2] - "hue 0 tint" -- "hue 0.041 tint" -- "hue 0.083 tint" -- "hue 0.125 tint" -- "hue 0.166 tint" -- "hue 0.208 tint" - "hue 0.208 tint" -- "hue 0.250 tint" -- "hue 0.291 tint" -- "hue 0.333 tint" -- "hue 0.375 tint" -- "hue 0.416 tint" - "hue 0.416 tint" -- "hue 0.458 tint" -- "hue 0.5 tint" --"hue 0.541 tint" -- "hue 0.583 tint" -- "hue 0.625 tint" - "hue 0.625 tint" -- "hue 0.666 tint" -- "hue 0.708 tint" -- "hue 0.750 tint" -- "hue 0.791 tint" -- "hue 0.833 tint" - "hue 0.833 tint" -- "hue 0.875 tint" -- "hue 0.916 tint" -- "hue 0.958 tint" -- "hue 0 tint" - } - } -''') \ No newline at end of file diff --git a/spaces/Dimitre/stablediffusion-canarinho_pistola/README.md b/spaces/Dimitre/stablediffusion-canarinho_pistola/README.md deleted file mode 100644 index 0f8dab44c8bac47578c44c541bade9944c92de47..0000000000000000000000000000000000000000 --- a/spaces/Dimitre/stablediffusion-canarinho_pistola/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Stablediffusion-canarinho Pistola -emoji: 🐨 -colorFrom: purple -colorTo: yellow -sdk: gradio -sdk_version: 3.24.1 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Dinoking/Guccio-AI-Designer/models/stylegan2/stylegan2-pytorch/generate.py b/spaces/Dinoking/Guccio-AI-Designer/models/stylegan2/stylegan2-pytorch/generate.py deleted file mode 100644 index 4255c8cb0a16817b3f4d60783456bfa5cd15d018..0000000000000000000000000000000000000000 --- a/spaces/Dinoking/Guccio-AI-Designer/models/stylegan2/stylegan2-pytorch/generate.py +++ /dev/null @@ -1,55 +0,0 @@ -import argparse - -import torch -from torchvision import utils -from model import Generator -from tqdm import tqdm -def generate(args, g_ema, device, mean_latent): - - with torch.no_grad(): - g_ema.eval() - for i in tqdm(range(args.pics)): - sample_z = torch.randn(args.sample, args.latent, device=device) - - sample, _ = g_ema([sample_z], truncation=args.truncation, truncation_latent=mean_latent) - - utils.save_image( - sample, - f'sample/{str(i).zfill(6)}.png', - nrow=1, - normalize=True, - range=(-1, 1), - ) - -if __name__ == '__main__': - device = 'cuda' - - parser = argparse.ArgumentParser() - - parser.add_argument('--size', type=int, default=1024) - parser.add_argument('--sample', type=int, default=1) - parser.add_argument('--pics', type=int, default=20) - parser.add_argument('--truncation', type=float, default=1) - parser.add_argument('--truncation_mean', type=int, default=4096) - parser.add_argument('--ckpt', type=str, default="stylegan2-ffhq-config-f.pt") - parser.add_argument('--channel_multiplier', type=int, default=2) - - args = parser.parse_args() - - args.latent = 512 - args.n_mlp = 8 - - g_ema = Generator( - args.size, args.latent, args.n_mlp, channel_multiplier=args.channel_multiplier - ).to(device) - checkpoint = torch.load(args.ckpt) - - g_ema.load_state_dict(checkpoint['g_ema']) - - if args.truncation < 1: - with torch.no_grad(): - mean_latent = g_ema.mean_latent(args.truncation_mean) - else: - mean_latent = None - - generate(args, g_ema, device, mean_latent) diff --git a/spaces/DrGabrielLopez/BERTopic/README.md b/spaces/DrGabrielLopez/BERTopic/README.md deleted file mode 100644 index 4266f4c66573d84b8be6aa762f45f3d9113d5fc3..0000000000000000000000000000000000000000 --- a/spaces/DrGabrielLopez/BERTopic/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: BERTopic -emoji: 👁 -colorFrom: blue -colorTo: blue -sdk: gradio -sdk_version: 3.21.0 -app_file: app.py -pinned: false -license: apache-2.0 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Einmalumdiewelt/German_text_summarization/app.py b/spaces/Einmalumdiewelt/German_text_summarization/app.py deleted file mode 100644 index e89309fabc6bea700a0ae6925c6b0d8cc01fdb75..0000000000000000000000000000000000000000 --- a/spaces/Einmalumdiewelt/German_text_summarization/app.py +++ /dev/null @@ -1,105 +0,0 @@ -import gradio as gr -import torch - -from transformers import AutoTokenizer, AutoModelForSeq2SeqLM - -#"Google T5-base","Google MT5-small","Google Pegasus","Facebook Bart-large","Facebook DistilBART" -def summarize(inputs,model,summary_length): - prefix = "" - if model=="Google T5-base": - tokenizer = AutoTokenizer.from_pretrained("Einmalumdiewelt/T5-Base_GNAD") - model = AutoModelForSeq2SeqLM.from_pretrained("Einmalumdiewelt/T5-Base_GNAD") - prefix = "summarize: " - elif model=="Google Pegasus": - tokenizer = AutoTokenizer.from_pretrained("Einmalumdiewelt/PegasusXSUM_GNAD") - model = AutoModelForSeq2SeqLM.from_pretrained("Einmalumdiewelt/PegasusXSUM_GNAD") - elif model=="Facebook Bart-large": - tokenizer = AutoTokenizer.from_pretrained("Einmalumdiewelt/BART_large_CNN_GNAD") - model = AutoModelForSeq2SeqLM.from_pretrained("Einmalumdiewelt/BART_large_CNN_GNAD") - elif model=="Google MT5-small": - tokenizer = AutoTokenizer.from_pretrained("Einmalumdiewelt/MT5_small_sum-de_GNAD") - model = AutoModelForSeq2SeqLM.from_pretrained("Einmalumdiewelt/MT5_small_sum-de_GNAD") - prefix = "summarize: " - elif model=="Facebook DistilBART": - tokenizer = AutoTokenizer.from_pretrained("Einmalumdiewelt/DistilBART_CNN_GNAD") - model = AutoModelForSeq2SeqLM.from_pretrained("Einmalumdiewelt/DistilBART_CNN_GNAD") - - device = "cpu" - #"cuda" if torch.cuda.is_available() else "CPU" - model.to(device) - - - #print(str(inputs)) - print(str(prefix)+str(inputs)) - - #define model inputs - inputs = tokenizer( - prefix + inputs, - max_length=512, - truncation=True, - padding="max_length", - return_tensors='pt').to(device) - - - #generate preds - if summary_length==25: - # make sure models actually generate something - preds = model.generate(**inputs,max_length=summary_length+5,min_length=summary_length-20) - else: - preds = model.generate(**inputs,max_length=summary_length+25,min_length=summary_length-25) - #we decode the predictions to store them - decoded_predictions = tokenizer.batch_decode(preds, skip_special_tokens=True) - #return - return decoded_predictions[0] - -description = "Quickly summarize your German texts in a few sentences. \nOur algorithms were fine-tuned on high-quality German news articles and work best with a summarization length of about 75 tokens. Please note that inference can take up to 60 seconds, so feel free to look at some of the examples, first. All provided examples are out-of-sample texts from German news providers. They were not cherry-picked and reflect the real performance of our fine-tuned architectures." - -title = "State-of-the-art German \ntext summarization." - -examples = [ -["Keine einzige Zelle unseres Körpers kommt ohne sie aus: Proteine sind essenzielle Bausteine lebender Organismen. Ihr Bauplan ist in der DNA festgelegt. Zu den Proteinen gehören die Bestandteile des Immunsystems, etwa Antikörper, genauso wie Hormone, etwa Insulin, oder Enzyme, die beispielsweise im Dünndarm Milchzucker spalten und Milch verträglich machen. Wie genau ein Protein im Körper wirkt, hängt nicht nur von der Reihenfolge der Atome ab, aus denen es besteht – sondern auch von seiner Struktur: Die langen Ketten von Aminosäuren, aus denen Proteine zusammengesetzt sind, verknäulen sich zu komplexen 3D-Strukturen. Und deren Entschlüsselung gilt oft als mühsam und zeitaufwendig; dabei kommt vor allem die Methode der Röntgenkristallstrukturanalyse zum Einsatz. Bereits Ende vergangenen Jahres hatten Forscherinnen und Forscher der britischen Firma DeepMind, einer Tochter der Google-Holding Alphabet, aber einen Erfolg bei einem neuartigen Ansatz vermeldet. Eine von ihnen entwickelte künstliche Intelligenz (KI) namens AlphaFold kann demnach die Strukturen von Molekülen präzise vorhersagen. Nun hat das Team um Kathryn Tunyasuvunakool, John Jumper und Demis Hassabis von DeepMind die Anwendung des Verfahrens in einem Fachartikel im Magazin »Nature« vorgestellt. Entstanden ist eine frei zugängliche Datenbank, die viele Tausend Proteinstrukturen enthält. Diese sollen für Durchbrüche in der medizinischen Forschung genutzt werden, aber auch für die Pflanzenzucht – oder für die Entwicklung von Bakterien, die Plastik in der Umwelt zersetzen können. Abgedeckt ist dabei beinahe die komplette Menge aller 20.000 beim Menschen vorkommenden Proteine, das sogenannte Proteom, allerdings mit verschiedenen Genauigkeitsstufen. Dazu kommen Zehntausende weitere Proteine, die in anderen für die Forschung wichtigen Modellorganismen wie Mäusen, Fruchtfliegen oder Coli-Bakterien eine Rolle spielen. Die Kenntnis der Struktur ist so wichtig, weil sich auf diese Weise vorhersagen lässt, wie andere Moleküle an das Protein binden – also welche Wirkung ein bestimmter Stoff in der Praxis hat. »Wir glauben, dass es sich um das bisher vollständigste und genaueste Bild des menschlichen Proteoms handelt«, so Hassabis, der auch Chef von DeepMind ist. Seine Firma sei außerdem der Meinung, »dass diese Arbeit den bedeutendsten Beitrag darstellt, den Künstliche Intelligenz bisher zum Fortschritt des wissenschaftlichen Kenntnisstandes geleistet hat«. »Das wird unser Verständnis darüber revolutionieren, wie Leben funktioniert«, sagt Edith Heard vom Europäischen Laboratorium für Molekularbiologie (EMBL) in Heidelberg. »Die Anwendungsmöglichkeiten sind nur durch unsere Vorstellungskraft begrenzt.« Am EMBL wird die Datenbank der Proteinstrukturen in Zukunft betreut. Und Gira Bhabha, die sich an der New York University mit Zellbiologie beschäftigt, lobt die Zeitersparnis für Projekte in verschiedensten Bereichen der Forschung: »Egal, ob Sie Neurowissenschaften oder Immunologie studieren – was auch immer Ihr Fachgebiet der Biologie ist – dies kann nützlich sein.« chs/jme","Google T5-base",75], -["Keine einzige Zelle unseres Körpers kommt ohne sie aus: Proteine sind essenzielle Bausteine lebender Organismen. Ihr Bauplan ist in der DNA festgelegt. Zu den Proteinen gehören die Bestandteile des Immunsystems, etwa Antikörper, genauso wie Hormone, etwa Insulin, oder Enzyme, die beispielsweise im Dünndarm Milchzucker spalten und Milch verträglich machen. Wie genau ein Protein im Körper wirkt, hängt nicht nur von der Reihenfolge der Atome ab, aus denen es besteht – sondern auch von seiner Struktur: Die langen Ketten von Aminosäuren, aus denen Proteine zusammengesetzt sind, verknäulen sich zu komplexen 3D-Strukturen. Und deren Entschlüsselung gilt oft als mühsam und zeitaufwendig; dabei kommt vor allem die Methode der Röntgenkristallstrukturanalyse zum Einsatz. Bereits Ende vergangenen Jahres hatten Forscherinnen und Forscher der britischen Firma DeepMind, einer Tochter der Google-Holding Alphabet, aber einen Erfolg bei einem neuartigen Ansatz vermeldet. Eine von ihnen entwickelte künstliche Intelligenz (KI) namens AlphaFold kann demnach die Strukturen von Molekülen präzise vorhersagen. Nun hat das Team um Kathryn Tunyasuvunakool, John Jumper und Demis Hassabis von DeepMind die Anwendung des Verfahrens in einem Fachartikel im Magazin »Nature« vorgestellt. Entstanden ist eine frei zugängliche Datenbank, die viele Tausend Proteinstrukturen enthält. Diese sollen für Durchbrüche in der medizinischen Forschung genutzt werden, aber auch für die Pflanzenzucht – oder für die Entwicklung von Bakterien, die Plastik in der Umwelt zersetzen können. Abgedeckt ist dabei beinahe die komplette Menge aller 20.000 beim Menschen vorkommenden Proteine, das sogenannte Proteom, allerdings mit verschiedenen Genauigkeitsstufen. Dazu kommen Zehntausende weitere Proteine, die in anderen für die Forschung wichtigen Modellorganismen wie Mäusen, Fruchtfliegen oder Coli-Bakterien eine Rolle spielen. Die Kenntnis der Struktur ist so wichtig, weil sich auf diese Weise vorhersagen lässt, wie andere Moleküle an das Protein binden – also welche Wirkung ein bestimmter Stoff in der Praxis hat. »Wir glauben, dass es sich um das bisher vollständigste und genaueste Bild des menschlichen Proteoms handelt«, so Hassabis, der auch Chef von DeepMind ist. Seine Firma sei außerdem der Meinung, »dass diese Arbeit den bedeutendsten Beitrag darstellt, den Künstliche Intelligenz bisher zum Fortschritt des wissenschaftlichen Kenntnisstandes geleistet hat«. »Das wird unser Verständnis darüber revolutionieren, wie Leben funktioniert«, sagt Edith Heard vom Europäischen Laboratorium für Molekularbiologie (EMBL) in Heidelberg. »Die Anwendungsmöglichkeiten sind nur durch unsere Vorstellungskraft begrenzt.« Am EMBL wird die Datenbank der Proteinstrukturen in Zukunft betreut. Und Gira Bhabha, die sich an der New York University mit Zellbiologie beschäftigt, lobt die Zeitersparnis für Projekte in verschiedensten Bereichen der Forschung: »Egal, ob Sie Neurowissenschaften oder Immunologie studieren – was auch immer Ihr Fachgebiet der Biologie ist – dies kann nützlich sein.« chs/jme","Google Pegasus",75], -["Keine einzige Zelle unseres Körpers kommt ohne sie aus: Proteine sind essenzielle Bausteine lebender Organismen. Ihr Bauplan ist in der DNA festgelegt. Zu den Proteinen gehören die Bestandteile des Immunsystems, etwa Antikörper, genauso wie Hormone, etwa Insulin, oder Enzyme, die beispielsweise im Dünndarm Milchzucker spalten und Milch verträglich machen. Wie genau ein Protein im Körper wirkt, hängt nicht nur von der Reihenfolge der Atome ab, aus denen es besteht – sondern auch von seiner Struktur: Die langen Ketten von Aminosäuren, aus denen Proteine zusammengesetzt sind, verknäulen sich zu komplexen 3D-Strukturen. Und deren Entschlüsselung gilt oft als mühsam und zeitaufwendig; dabei kommt vor allem die Methode der Röntgenkristallstrukturanalyse zum Einsatz. Bereits Ende vergangenen Jahres hatten Forscherinnen und Forscher der britischen Firma DeepMind, einer Tochter der Google-Holding Alphabet, aber einen Erfolg bei einem neuartigen Ansatz vermeldet. Eine von ihnen entwickelte künstliche Intelligenz (KI) namens AlphaFold kann demnach die Strukturen von Molekülen präzise vorhersagen. Nun hat das Team um Kathryn Tunyasuvunakool, John Jumper und Demis Hassabis von DeepMind die Anwendung des Verfahrens in einem Fachartikel im Magazin »Nature« vorgestellt. Entstanden ist eine frei zugängliche Datenbank, die viele Tausend Proteinstrukturen enthält. Diese sollen für Durchbrüche in der medizinischen Forschung genutzt werden, aber auch für die Pflanzenzucht – oder für die Entwicklung von Bakterien, die Plastik in der Umwelt zersetzen können. Abgedeckt ist dabei beinahe die komplette Menge aller 20.000 beim Menschen vorkommenden Proteine, das sogenannte Proteom, allerdings mit verschiedenen Genauigkeitsstufen. Dazu kommen Zehntausende weitere Proteine, die in anderen für die Forschung wichtigen Modellorganismen wie Mäusen, Fruchtfliegen oder Coli-Bakterien eine Rolle spielen. Die Kenntnis der Struktur ist so wichtig, weil sich auf diese Weise vorhersagen lässt, wie andere Moleküle an das Protein binden – also welche Wirkung ein bestimmter Stoff in der Praxis hat. »Wir glauben, dass es sich um das bisher vollständigste und genaueste Bild des menschlichen Proteoms handelt«, so Hassabis, der auch Chef von DeepMind ist. Seine Firma sei außerdem der Meinung, »dass diese Arbeit den bedeutendsten Beitrag darstellt, den Künstliche Intelligenz bisher zum Fortschritt des wissenschaftlichen Kenntnisstandes geleistet hat«. »Das wird unser Verständnis darüber revolutionieren, wie Leben funktioniert«, sagt Edith Heard vom Europäischen Laboratorium für Molekularbiologie (EMBL) in Heidelberg. »Die Anwendungsmöglichkeiten sind nur durch unsere Vorstellungskraft begrenzt.« Am EMBL wird die Datenbank der Proteinstrukturen in Zukunft betreut. Und Gira Bhabha, die sich an der New York University mit Zellbiologie beschäftigt, lobt die Zeitersparnis für Projekte in verschiedensten Bereichen der Forschung: »Egal, ob Sie Neurowissenschaften oder Immunologie studieren – was auch immer Ihr Fachgebiet der Biologie ist – dies kann nützlich sein.« chs/jme","Google MT5-small",75], -["Keine einzige Zelle unseres Körpers kommt ohne sie aus: Proteine sind essenzielle Bausteine lebender Organismen. Ihr Bauplan ist in der DNA festgelegt. Zu den Proteinen gehören die Bestandteile des Immunsystems, etwa Antikörper, genauso wie Hormone, etwa Insulin, oder Enzyme, die beispielsweise im Dünndarm Milchzucker spalten und Milch verträglich machen. Wie genau ein Protein im Körper wirkt, hängt nicht nur von der Reihenfolge der Atome ab, aus denen es besteht – sondern auch von seiner Struktur: Die langen Ketten von Aminosäuren, aus denen Proteine zusammengesetzt sind, verknäulen sich zu komplexen 3D-Strukturen. Und deren Entschlüsselung gilt oft als mühsam und zeitaufwendig; dabei kommt vor allem die Methode der Röntgenkristallstrukturanalyse zum Einsatz. Bereits Ende vergangenen Jahres hatten Forscherinnen und Forscher der britischen Firma DeepMind, einer Tochter der Google-Holding Alphabet, aber einen Erfolg bei einem neuartigen Ansatz vermeldet. Eine von ihnen entwickelte künstliche Intelligenz (KI) namens AlphaFold kann demnach die Strukturen von Molekülen präzise vorhersagen. Nun hat das Team um Kathryn Tunyasuvunakool, John Jumper und Demis Hassabis von DeepMind die Anwendung des Verfahrens in einem Fachartikel im Magazin »Nature« vorgestellt. Entstanden ist eine frei zugängliche Datenbank, die viele Tausend Proteinstrukturen enthält. Diese sollen für Durchbrüche in der medizinischen Forschung genutzt werden, aber auch für die Pflanzenzucht – oder für die Entwicklung von Bakterien, die Plastik in der Umwelt zersetzen können. Abgedeckt ist dabei beinahe die komplette Menge aller 20.000 beim Menschen vorkommenden Proteine, das sogenannte Proteom, allerdings mit verschiedenen Genauigkeitsstufen. Dazu kommen Zehntausende weitere Proteine, die in anderen für die Forschung wichtigen Modellorganismen wie Mäusen, Fruchtfliegen oder Coli-Bakterien eine Rolle spielen. Die Kenntnis der Struktur ist so wichtig, weil sich auf diese Weise vorhersagen lässt, wie andere Moleküle an das Protein binden – also welche Wirkung ein bestimmter Stoff in der Praxis hat. »Wir glauben, dass es sich um das bisher vollständigste und genaueste Bild des menschlichen Proteoms handelt«, so Hassabis, der auch Chef von DeepMind ist. Seine Firma sei außerdem der Meinung, »dass diese Arbeit den bedeutendsten Beitrag darstellt, den Künstliche Intelligenz bisher zum Fortschritt des wissenschaftlichen Kenntnisstandes geleistet hat«. »Das wird unser Verständnis darüber revolutionieren, wie Leben funktioniert«, sagt Edith Heard vom Europäischen Laboratorium für Molekularbiologie (EMBL) in Heidelberg. »Die Anwendungsmöglichkeiten sind nur durch unsere Vorstellungskraft begrenzt.« Am EMBL wird die Datenbank der Proteinstrukturen in Zukunft betreut. Und Gira Bhabha, die sich an der New York University mit Zellbiologie beschäftigt, lobt die Zeitersparnis für Projekte in verschiedensten Bereichen der Forschung: »Egal, ob Sie Neurowissenschaften oder Immunologie studieren – was auch immer Ihr Fachgebiet der Biologie ist – dies kann nützlich sein.« chs/jme","Facebook Bart-large",75], -["Keine einzige Zelle unseres Körpers kommt ohne sie aus: Proteine sind essenzielle Bausteine lebender Organismen. Ihr Bauplan ist in der DNA festgelegt. Zu den Proteinen gehören die Bestandteile des Immunsystems, etwa Antikörper, genauso wie Hormone, etwa Insulin, oder Enzyme, die beispielsweise im Dünndarm Milchzucker spalten und Milch verträglich machen. Wie genau ein Protein im Körper wirkt, hängt nicht nur von der Reihenfolge der Atome ab, aus denen es besteht – sondern auch von seiner Struktur: Die langen Ketten von Aminosäuren, aus denen Proteine zusammengesetzt sind, verknäulen sich zu komplexen 3D-Strukturen. Und deren Entschlüsselung gilt oft als mühsam und zeitaufwendig; dabei kommt vor allem die Methode der Röntgenkristallstrukturanalyse zum Einsatz. Bereits Ende vergangenen Jahres hatten Forscherinnen und Forscher der britischen Firma DeepMind, einer Tochter der Google-Holding Alphabet, aber einen Erfolg bei einem neuartigen Ansatz vermeldet. Eine von ihnen entwickelte künstliche Intelligenz (KI) namens AlphaFold kann demnach die Strukturen von Molekülen präzise vorhersagen. Nun hat das Team um Kathryn Tunyasuvunakool, John Jumper und Demis Hassabis von DeepMind die Anwendung des Verfahrens in einem Fachartikel im Magazin »Nature« vorgestellt. Entstanden ist eine frei zugängliche Datenbank, die viele Tausend Proteinstrukturen enthält. Diese sollen für Durchbrüche in der medizinischen Forschung genutzt werden, aber auch für die Pflanzenzucht – oder für die Entwicklung von Bakterien, die Plastik in der Umwelt zersetzen können. Abgedeckt ist dabei beinahe die komplette Menge aller 20.000 beim Menschen vorkommenden Proteine, das sogenannte Proteom, allerdings mit verschiedenen Genauigkeitsstufen. Dazu kommen Zehntausende weitere Proteine, die in anderen für die Forschung wichtigen Modellorganismen wie Mäusen, Fruchtfliegen oder Coli-Bakterien eine Rolle spielen. Die Kenntnis der Struktur ist so wichtig, weil sich auf diese Weise vorhersagen lässt, wie andere Moleküle an das Protein binden – also welche Wirkung ein bestimmter Stoff in der Praxis hat. »Wir glauben, dass es sich um das bisher vollständigste und genaueste Bild des menschlichen Proteoms handelt«, so Hassabis, der auch Chef von DeepMind ist. Seine Firma sei außerdem der Meinung, »dass diese Arbeit den bedeutendsten Beitrag darstellt, den Künstliche Intelligenz bisher zum Fortschritt des wissenschaftlichen Kenntnisstandes geleistet hat«. »Das wird unser Verständnis darüber revolutionieren, wie Leben funktioniert«, sagt Edith Heard vom Europäischen Laboratorium für Molekularbiologie (EMBL) in Heidelberg. »Die Anwendungsmöglichkeiten sind nur durch unsere Vorstellungskraft begrenzt.« Am EMBL wird die Datenbank der Proteinstrukturen in Zukunft betreut. Und Gira Bhabha, die sich an der New York University mit Zellbiologie beschäftigt, lobt die Zeitersparnis für Projekte in verschiedensten Bereichen der Forschung: »Egal, ob Sie Neurowissenschaften oder Immunologie studieren – was auch immer Ihr Fachgebiet der Biologie ist – dies kann nützlich sein.« chs/jme","Facebook DistilBART",75], -["Der Insolvenzverwalter der Drogeriemarktkette Schlecker ist mit einer Schadensersatzklage in Millionenhöhe gegen frühere Lieferanten auch in der nächsten Instanz gescheitert. Nach Angaben von Verwalter Arndt Geiwitz wies das Oberlandesgericht Frankfurt die Berufung gegen ein vorangegangenes Urteil des Landgerichts zurück. Das Gericht bestätigte dies, nannte zunächst aber keine Details zu dem Fall. Geiwitz will nun Beschwerde beim Bundesgerichtshof in Karlsruhe einlegen, weil die OLG-Richter gegen ihre Entscheidung auch keine Revision zuließen.Geiwitz verlangt von den Drogerieartikel-Herstellern rund 212 Millionen Euro Schadensersatz. Die Drogeriemarktkette soll vor ihrer Insolvenz jahrelang zu viel bezahlt haben, weil die Hersteller sich abgesprochen hatten. Bundeskartellamt und EU-Kommission hatten deshalb schon Bußgelder verhängt. Geiwitz geht nun zivilrechtlich gegen die Kartelle vor.Geiwitz teilte mit, dass er von Anfang an auf langwierige und komplexe Prozesse durch die Instanzen eingestellt gewesen sei. Überraschend sei die Entscheidung aber, weil das Gericht noch vor wenigen Wochen in einem vergleichbaren Verfahren einer anderen Drogeriemarktkette zugunsten des Klägers einen Beweisbeschluss erlassen habe. \"Wir kämpfen mit den Kartellklagen primär für die Masse-Gläubiger und damit allen voran auch für die Schlecker-Mitarbeiterinnen und -Mitarbeiter wie auch für jeden Steuerzahler, da die Bundesagentur für Arbeit hohe Ansprüche hat\", sagte Geiwitz. Aktenzeichen: 11 U 98/18","Google T5-base",75], -["Der Insolvenzverwalter der Drogeriemarktkette Schlecker ist mit einer Schadensersatzklage in Millionenhöhe gegen frühere Lieferanten auch in der nächsten Instanz gescheitert. Nach Angaben von Verwalter Arndt Geiwitz wies das Oberlandesgericht Frankfurt die Berufung gegen ein vorangegangenes Urteil des Landgerichts zurück. Das Gericht bestätigte dies, nannte zunächst aber keine Details zu dem Fall. Geiwitz will nun Beschwerde beim Bundesgerichtshof in Karlsruhe einlegen, weil die OLG-Richter gegen ihre Entscheidung auch keine Revision zuließen.Geiwitz verlangt von den Drogerieartikel-Herstellern rund 212 Millionen Euro Schadensersatz. Die Drogeriemarktkette soll vor ihrer Insolvenz jahrelang zu viel bezahlt haben, weil die Hersteller sich abgesprochen hatten. Bundeskartellamt und EU-Kommission hatten deshalb schon Bußgelder verhängt. Geiwitz geht nun zivilrechtlich gegen die Kartelle vor.Geiwitz teilte mit, dass er von Anfang an auf langwierige und komplexe Prozesse durch die Instanzen eingestellt gewesen sei. Überraschend sei die Entscheidung aber, weil das Gericht noch vor wenigen Wochen in einem vergleichbaren Verfahren einer anderen Drogeriemarktkette zugunsten des Klägers einen Beweisbeschluss erlassen habe. \"Wir kämpfen mit den Kartellklagen primär für die Masse-Gläubiger und damit allen voran auch für die Schlecker-Mitarbeiterinnen und -Mitarbeiter wie auch für jeden Steuerzahler, da die Bundesagentur für Arbeit hohe Ansprüche hat\", sagte Geiwitz. Aktenzeichen: 11 U 98/18","Facebook Bart-large",75], -["Der Insolvenzverwalter der Drogeriemarktkette Schlecker ist mit einer Schadensersatzklage in Millionenhöhe gegen frühere Lieferanten auch in der nächsten Instanz gescheitert. Nach Angaben von Verwalter Arndt Geiwitz wies das Oberlandesgericht Frankfurt die Berufung gegen ein vorangegangenes Urteil des Landgerichts zurück. Das Gericht bestätigte dies, nannte zunächst aber keine Details zu dem Fall. Geiwitz will nun Beschwerde beim Bundesgerichtshof in Karlsruhe einlegen, weil die OLG-Richter gegen ihre Entscheidung auch keine Revision zuließen.Geiwitz verlangt von den Drogerieartikel-Herstellern rund 212 Millionen Euro Schadensersatz. Die Drogeriemarktkette soll vor ihrer Insolvenz jahrelang zu viel bezahlt haben, weil die Hersteller sich abgesprochen hatten. Bundeskartellamt und EU-Kommission hatten deshalb schon Bußgelder verhängt. Geiwitz geht nun zivilrechtlich gegen die Kartelle vor.Geiwitz teilte mit, dass er von Anfang an auf langwierige und komplexe Prozesse durch die Instanzen eingestellt gewesen sei. Überraschend sei die Entscheidung aber, weil das Gericht noch vor wenigen Wochen in einem vergleichbaren Verfahren einer anderen Drogeriemarktkette zugunsten des Klägers einen Beweisbeschluss erlassen habe. \"Wir kämpfen mit den Kartellklagen primär für die Masse-Gläubiger und damit allen voran auch für die Schlecker-Mitarbeiterinnen und -Mitarbeiter wie auch für jeden Steuerzahler, da die Bundesagentur für Arbeit hohe Ansprüche hat\", sagte Geiwitz. Aktenzeichen: 11 U 98/18","Google Pegasus",75], -["Der Insolvenzverwalter der Drogeriemarktkette Schlecker ist mit einer Schadensersatzklage in Millionenhöhe gegen frühere Lieferanten auch in der nächsten Instanz gescheitert. Nach Angaben von Verwalter Arndt Geiwitz wies das Oberlandesgericht Frankfurt die Berufung gegen ein vorangegangenes Urteil des Landgerichts zurück. Das Gericht bestätigte dies, nannte zunächst aber keine Details zu dem Fall. Geiwitz will nun Beschwerde beim Bundesgerichtshof in Karlsruhe einlegen, weil die OLG-Richter gegen ihre Entscheidung auch keine Revision zuließen.Geiwitz verlangt von den Drogerieartikel-Herstellern rund 212 Millionen Euro Schadensersatz. Die Drogeriemarktkette soll vor ihrer Insolvenz jahrelang zu viel bezahlt haben, weil die Hersteller sich abgesprochen hatten. Bundeskartellamt und EU-Kommission hatten deshalb schon Bußgelder verhängt. Geiwitz geht nun zivilrechtlich gegen die Kartelle vor.Geiwitz teilte mit, dass er von Anfang an auf langwierige und komplexe Prozesse durch die Instanzen eingestellt gewesen sei. Überraschend sei die Entscheidung aber, weil das Gericht noch vor wenigen Wochen in einem vergleichbaren Verfahren einer anderen Drogeriemarktkette zugunsten des Klägers einen Beweisbeschluss erlassen habe. \"Wir kämpfen mit den Kartellklagen primär für die Masse-Gläubiger und damit allen voran auch für die Schlecker-Mitarbeiterinnen und -Mitarbeiter wie auch für jeden Steuerzahler, da die Bundesagentur für Arbeit hohe Ansprüche hat\", sagte Geiwitz. Aktenzeichen: 11 U 98/18","Facebook DistilBART",75], -["Der Insolvenzverwalter der Drogeriemarktkette Schlecker ist mit einer Schadensersatzklage in Millionenhöhe gegen frühere Lieferanten auch in der nächsten Instanz gescheitert. Nach Angaben von Verwalter Arndt Geiwitz wies das Oberlandesgericht Frankfurt die Berufung gegen ein vorangegangenes Urteil des Landgerichts zurück. Das Gericht bestätigte dies, nannte zunächst aber keine Details zu dem Fall. Geiwitz will nun Beschwerde beim Bundesgerichtshof in Karlsruhe einlegen, weil die OLG-Richter gegen ihre Entscheidung auch keine Revision zuließen.Geiwitz verlangt von den Drogerieartikel-Herstellern rund 212 Millionen Euro Schadensersatz. Die Drogeriemarktkette soll vor ihrer Insolvenz jahrelang zu viel bezahlt haben, weil die Hersteller sich abgesprochen hatten. Bundeskartellamt und EU-Kommission hatten deshalb schon Bußgelder verhängt. Geiwitz geht nun zivilrechtlich gegen die Kartelle vor.Geiwitz teilte mit, dass er von Anfang an auf langwierige und komplexe Prozesse durch die Instanzen eingestellt gewesen sei. Überraschend sei die Entscheidung aber, weil das Gericht noch vor wenigen Wochen in einem vergleichbaren Verfahren einer anderen Drogeriemarktkette zugunsten des Klägers einen Beweisbeschluss erlassen habe. \"Wir kämpfen mit den Kartellklagen primär für die Masse-Gläubiger und damit allen voran auch für die Schlecker-Mitarbeiterinnen und -Mitarbeiter wie auch für jeden Steuerzahler, da die Bundesagentur für Arbeit hohe Ansprüche hat\", sagte Geiwitz. Aktenzeichen: 11 U 98/18","Google MT5-small",75], -["Der Schweizer Carlo Janka hat im südkoreanischen Jeongseon den Super-G gewonnen. Es war der erste Schweizer Sieg im alpinen Weltcup der Männer seit über einem Jahr und Jankas erster Super-G-Erfolg überhaupt. Während Andreas Sander auf den zehnten Rang fuhr, siegte der Riesenslalom-Olympiasieger von 2010 mit einer Zeit von 1:26,16 klar vor dem Italiener Christof Innerhofer (+0,82 Sekunden) und dem Österreicher Vincent Kriechmayr (+1,06). Janka hatte zuletzt im Januar 2015 die Kombination in Wengen gewonnen, davor aber vier Jahre lang gar nicht. Der 30-Jährige kämpft seit Jahren mit Rückenproblemen. Bei der Weltcup-Abfahrt zwei Wochen zuvor auf der Streif in Kitzbühel hatte er als Dritter überrascht. Der Super-G-Kurs auf der eigens für Olympia gebauten Strecke in Jeongseon erwies sich vor allem wegen der Sprünge als sehr tückisch. Zahlreiche Fahrer schieden aus, darunter auch Kjetil Jansrud aus Norwegen, der am Vortag die Abfahrt gewonnen hatte.Bei minus zwölf Grad und strahlendem Sonnenschein zog der deutsche Alpinchef Wolfgang Maier ein positives Fazit nach dem ersten Testlauf für die Winterspiele in zwei Jahren. \"Bis Olympia wird noch viel verändert, und wir müssen auch noch viel arbeiten, um beim Material mit diesen kalten Bedingungen zurecht zu kommen\", sagte Maier. \"Aber wir haben gesehen, dass wir uns im Spitzenbereich bewegen können.\"Ein Sonderlob gab es für die Veranstalter. \"Das war eine außergewöhnlich gute Piste\", betonte Maier. \"Dafür, dass es ein komplett neu aus dem Boden gestampftes Skigebiet ist, haben sie das wirklich gut gemacht. Im November stand hier nicht mal ein Lift.\" rae/dpa/sid","Google T5-base",75], -["Der Schweizer Carlo Janka hat im südkoreanischen Jeongseon den Super-G gewonnen. Es war der erste Schweizer Sieg im alpinen Weltcup der Männer seit über einem Jahr und Jankas erster Super-G-Erfolg überhaupt. Während Andreas Sander auf den zehnten Rang fuhr, siegte der Riesenslalom-Olympiasieger von 2010 mit einer Zeit von 1:26,16 klar vor dem Italiener Christof Innerhofer (+0,82 Sekunden) und dem Österreicher Vincent Kriechmayr (+1,06). Janka hatte zuletzt im Januar 2015 die Kombination in Wengen gewonnen, davor aber vier Jahre lang gar nicht. Der 30-Jährige kämpft seit Jahren mit Rückenproblemen. Bei der Weltcup-Abfahrt zwei Wochen zuvor auf der Streif in Kitzbühel hatte er als Dritter überrascht. Der Super-G-Kurs auf der eigens für Olympia gebauten Strecke in Jeongseon erwies sich vor allem wegen der Sprünge als sehr tückisch. Zahlreiche Fahrer schieden aus, darunter auch Kjetil Jansrud aus Norwegen, der am Vortag die Abfahrt gewonnen hatte.Bei minus zwölf Grad und strahlendem Sonnenschein zog der deutsche Alpinchef Wolfgang Maier ein positives Fazit nach dem ersten Testlauf für die Winterspiele in zwei Jahren. \"Bis Olympia wird noch viel verändert, und wir müssen auch noch viel arbeiten, um beim Material mit diesen kalten Bedingungen zurecht zu kommen\", sagte Maier. \"Aber wir haben gesehen, dass wir uns im Spitzenbereich bewegen können.\"Ein Sonderlob gab es für die Veranstalter. \"Das war eine außergewöhnlich gute Piste\", betonte Maier. \"Dafür, dass es ein komplett neu aus dem Boden gestampftes Skigebiet ist, haben sie das wirklich gut gemacht. Im November stand hier nicht mal ein Lift.\" rae/dpa/sid","Google Pegasus",75], -["Der Schweizer Carlo Janka hat im südkoreanischen Jeongseon den Super-G gewonnen. Es war der erste Schweizer Sieg im alpinen Weltcup der Männer seit über einem Jahr und Jankas erster Super-G-Erfolg überhaupt. Während Andreas Sander auf den zehnten Rang fuhr, siegte der Riesenslalom-Olympiasieger von 2010 mit einer Zeit von 1:26,16 klar vor dem Italiener Christof Innerhofer (+0,82 Sekunden) und dem Österreicher Vincent Kriechmayr (+1,06). Janka hatte zuletzt im Januar 2015 die Kombination in Wengen gewonnen, davor aber vier Jahre lang gar nicht. Der 30-Jährige kämpft seit Jahren mit Rückenproblemen. Bei der Weltcup-Abfahrt zwei Wochen zuvor auf der Streif in Kitzbühel hatte er als Dritter überrascht. Der Super-G-Kurs auf der eigens für Olympia gebauten Strecke in Jeongseon erwies sich vor allem wegen der Sprünge als sehr tückisch. Zahlreiche Fahrer schieden aus, darunter auch Kjetil Jansrud aus Norwegen, der am Vortag die Abfahrt gewonnen hatte.Bei minus zwölf Grad und strahlendem Sonnenschein zog der deutsche Alpinchef Wolfgang Maier ein positives Fazit nach dem ersten Testlauf für die Winterspiele in zwei Jahren. \"Bis Olympia wird noch viel verändert, und wir müssen auch noch viel arbeiten, um beim Material mit diesen kalten Bedingungen zurecht zu kommen\", sagte Maier. \"Aber wir haben gesehen, dass wir uns im Spitzenbereich bewegen können.\"Ein Sonderlob gab es für die Veranstalter. \"Das war eine außergewöhnlich gute Piste\", betonte Maier. \"Dafür, dass es ein komplett neu aus dem Boden gestampftes Skigebiet ist, haben sie das wirklich gut gemacht. Im November stand hier nicht mal ein Lift.\" rae/dpa/sid","Google MT5-small",75], -["Der Schweizer Carlo Janka hat im südkoreanischen Jeongseon den Super-G gewonnen. Es war der erste Schweizer Sieg im alpinen Weltcup der Männer seit über einem Jahr und Jankas erster Super-G-Erfolg überhaupt. Während Andreas Sander auf den zehnten Rang fuhr, siegte der Riesenslalom-Olympiasieger von 2010 mit einer Zeit von 1:26,16 klar vor dem Italiener Christof Innerhofer (+0,82 Sekunden) und dem Österreicher Vincent Kriechmayr (+1,06). Janka hatte zuletzt im Januar 2015 die Kombination in Wengen gewonnen, davor aber vier Jahre lang gar nicht. Der 30-Jährige kämpft seit Jahren mit Rückenproblemen. Bei der Weltcup-Abfahrt zwei Wochen zuvor auf der Streif in Kitzbühel hatte er als Dritter überrascht. Der Super-G-Kurs auf der eigens für Olympia gebauten Strecke in Jeongseon erwies sich vor allem wegen der Sprünge als sehr tückisch. Zahlreiche Fahrer schieden aus, darunter auch Kjetil Jansrud aus Norwegen, der am Vortag die Abfahrt gewonnen hatte.Bei minus zwölf Grad und strahlendem Sonnenschein zog der deutsche Alpinchef Wolfgang Maier ein positives Fazit nach dem ersten Testlauf für die Winterspiele in zwei Jahren. \"Bis Olympia wird noch viel verändert, und wir müssen auch noch viel arbeiten, um beim Material mit diesen kalten Bedingungen zurecht zu kommen\", sagte Maier. \"Aber wir haben gesehen, dass wir uns im Spitzenbereich bewegen können.\"Ein Sonderlob gab es für die Veranstalter. \"Das war eine außergewöhnlich gute Piste\", betonte Maier. \"Dafür, dass es ein komplett neu aus dem Boden gestampftes Skigebiet ist, haben sie das wirklich gut gemacht. Im November stand hier nicht mal ein Lift.\" rae/dpa/sid","Facebook DistilBART",75], -["Der Schweizer Carlo Janka hat im südkoreanischen Jeongseon den Super-G gewonnen. Es war der erste Schweizer Sieg im alpinen Weltcup der Männer seit über einem Jahr und Jankas erster Super-G-Erfolg überhaupt. Während Andreas Sander auf den zehnten Rang fuhr, siegte der Riesenslalom-Olympiasieger von 2010 mit einer Zeit von 1:26,16 klar vor dem Italiener Christof Innerhofer (+0,82 Sekunden) und dem Österreicher Vincent Kriechmayr (+1,06). Janka hatte zuletzt im Januar 2015 die Kombination in Wengen gewonnen, davor aber vier Jahre lang gar nicht. Der 30-Jährige kämpft seit Jahren mit Rückenproblemen. Bei der Weltcup-Abfahrt zwei Wochen zuvor auf der Streif in Kitzbühel hatte er als Dritter überrascht. Der Super-G-Kurs auf der eigens für Olympia gebauten Strecke in Jeongseon erwies sich vor allem wegen der Sprünge als sehr tückisch. Zahlreiche Fahrer schieden aus, darunter auch Kjetil Jansrud aus Norwegen, der am Vortag die Abfahrt gewonnen hatte.Bei minus zwölf Grad und strahlendem Sonnenschein zog der deutsche Alpinchef Wolfgang Maier ein positives Fazit nach dem ersten Testlauf für die Winterspiele in zwei Jahren. \"Bis Olympia wird noch viel verändert, und wir müssen auch noch viel arbeiten, um beim Material mit diesen kalten Bedingungen zurecht zu kommen\", sagte Maier. \"Aber wir haben gesehen, dass wir uns im Spitzenbereich bewegen können.\"Ein Sonderlob gab es für die Veranstalter. \"Das war eine außergewöhnlich gute Piste\", betonte Maier. \"Dafür, dass es ein komplett neu aus dem Boden gestampftes Skigebiet ist, haben sie das wirklich gut gemacht. Im November stand hier nicht mal ein Lift.\" rae/dpa/sid","Facebook Bart-large",75]] - -#interface = gr.Interface.load("models/Einmalumdiewelt/T5-Base_GNAD", -# title=title, -# description=description, -# examples=examples) - -# text input box -txt=gr.Textbox(lines=15, label="Here's your German text:", placeholder="Paste your German text in here.") -# dropdown model selection -drop=gr.Dropdown(["Google T5-base","Google MT5-small","Google Pegasus","Facebook Bart-large","Facebook DistilBART"],label="Choose a fine-tuned architecture.") -# slider summary length selection -slide=gr.Slider(25, 150, step=25, label="Select a preferred summary length (+/- 25 tokens).", value=75) -# text output box -out=gr.Textbox(lines=5, label="Here's your summary:") - -interface = gr.Interface(summarize, - inputs=[ - txt, - # Selection of models for inference - drop, - # Length of summaries - slide], - # ouptut - outputs=out, - title=title, - description=description, - examples=examples) - -# launch interface -if __name__ == "__main__": - interface.launch(share=True) \ No newline at end of file diff --git a/spaces/EmRa228/Image-Models-Test1001/app.py b/spaces/EmRa228/Image-Models-Test1001/app.py deleted file mode 100644 index 9493a49eaded61e86310abde515c5a2bdce17950..0000000000000000000000000000000000000000 --- a/spaces/EmRa228/Image-Models-Test1001/app.py +++ /dev/null @@ -1,135 +0,0 @@ -import gradio as gr -import time - -models =[ - "digiplay/perfectlevel10", -# "usman0007/stablediffusion", -# "prompthero/openjourney-v4", -] - - -model_functions = {} -model_idx = 1 -for model_path in models: - try: - model_functions[model_idx] = gr.Interface.load(f"models/{model_path}", live=False, preprocess=True, postprocess=False) - except Exception as error: - def the_fn(txt): - return None - model_functions[model_idx] = gr.Interface(fn=the_fn, inputs=["text"], outputs=["image"]) - model_idx+=1 - - -def send_it_idx(idx): - def send_it_fn(prompt): - output = (model_functions.get(str(idx)) or model_functions.get(str(1)))(prompt) - return output - return send_it_fn - -def get_prompts(prompt_text): - return prompt_text - -def clear_it(val): - if int(val) != 0: - val = 0 - else: - val = 0 - pass - return val - -def all_task_end(cnt,t_stamp): - to = t_stamp + 60 - et = time.time() - if et > to and t_stamp != 0: - d = gr.update(value=0) - tog = gr.update(value=1) - #print(f'to: {to} et: {et}') - else: - if cnt != 0: - d = gr.update(value=et) - else: - d = gr.update(value=0) - tog = gr.update(value=0) - #print (f'passing: to: {to} et: {et}') - pass - return d, tog - -def all_task_start(): - print("\n\n\n\n\n\n\n") - t = time.gmtime() - t_stamp = time.time() - current_time = time.strftime("%H:%M:%S", t) - return gr.update(value=t_stamp), gr.update(value=t_stamp), gr.update(value=0) - -def clear_fn(): - nn = len(models) - return tuple([None, *[None for _ in range(nn)]]) - - - -with gr.Blocks(title="SD Models") as my_interface: - with gr.Column(scale=12): - # with gr.Row(): - # gr.Markdown("""- Primary prompt: 你想画的内容(英文单词,如 a cat, 加英文逗号效果更好;点 Improve 按钮进行完善)\n- Real prompt: 完善后的提示词,出现后再点右边的 Run 按钮开始运行""") - with gr.Row(): - with gr.Row(scale=6): - primary_prompt=gr.Textbox(label="Prompt", value="") - # real_prompt=gr.Textbox(label="Real prompt") - with gr.Row(scale=6): - # improve_prompts_btn=gr.Button("Improve") - with gr.Row(): - run=gr.Button("Run",variant="primary") - clear_btn=gr.Button("Clear") - with gr.Row(): - sd_outputs = {} - model_idx = 1 - for model_path in models: - with gr.Column(scale=3, min_width=320): - with gr.Box(): - sd_outputs[model_idx] = gr.Image(label=model_path) - pass - model_idx += 1 - pass - pass - - with gr.Row(visible=False): - start_box=gr.Number(interactive=False) - end_box=gr.Number(interactive=False) - tog_box=gr.Textbox(value=0,interactive=False) - - start_box.change( - all_task_end, - [start_box, end_box], - [start_box, tog_box], - every=1, - show_progress=False) - - primary_prompt.submit(all_task_start, None, [start_box, end_box, tog_box]) - run.click(all_task_start, None, [start_box, end_box, tog_box]) - runs_dict = {} - model_idx = 1 - for model_path in models: - runs_dict[model_idx] = run.click(model_functions[model_idx], inputs=[primary_prompt], outputs=[sd_outputs[model_idx]]) - model_idx += 1 - pass - pass - - # improve_prompts_btn_clicked=improve_prompts_btn.click( - # get_prompts, - # inputs=[primary_prompt], - # outputs=[primary_prompt], - # cancels=list(runs_dict.values())) - clear_btn.click( - clear_fn, - None, - [primary_prompt, *list(sd_outputs.values())], - cancels=[*list(runs_dict.values())]) - tog_box.change( - clear_it, - tog_box, - tog_box, - cancels=[*list(runs_dict.values())]) - -my_interface.queue(concurrency_count=600, status_update_rate=1) -my_interface.launch(inline=True, show_api=False) - \ No newline at end of file diff --git a/spaces/Enterprisium/Easy_GUI/i18n/locale_diff.py b/spaces/Enterprisium/Easy_GUI/i18n/locale_diff.py deleted file mode 100644 index 257277965e0866a86d0361863a8f1b408c4f71ab..0000000000000000000000000000000000000000 --- a/spaces/Enterprisium/Easy_GUI/i18n/locale_diff.py +++ /dev/null @@ -1,45 +0,0 @@ -import json -import os -from collections import OrderedDict - -# Define the standard file name -standard_file = "zh_CN.json" - -# Find all JSON files in the directory -dir_path = "./" -languages = [ - f for f in os.listdir(dir_path) if f.endswith(".json") and f != standard_file -] - -# Load the standard file -with open(standard_file, "r", encoding="utf-8") as f: - standard_data = json.load(f, object_pairs_hook=OrderedDict) - -# Loop through each language file -for lang_file in languages: - # Load the language file - with open(lang_file, "r", encoding="utf-8") as f: - lang_data = json.load(f, object_pairs_hook=OrderedDict) - - # Find the difference between the language file and the standard file - diff = set(standard_data.keys()) - set(lang_data.keys()) - - miss = set(lang_data.keys()) - set(standard_data.keys()) - - # Add any missing keys to the language file - for key in diff: - lang_data[key] = key - - # Del any extra keys to the language file - for key in miss: - del lang_data[key] - - # Sort the keys of the language file to match the order of the standard file - lang_data = OrderedDict( - sorted(lang_data.items(), key=lambda x: list(standard_data.keys()).index(x[0])) - ) - - # Save the updated language file - with open(lang_file, "w", encoding="utf-8") as f: - json.dump(lang_data, f, ensure_ascii=False, indent=4) - f.write("\n") diff --git a/spaces/EuroPython2022/mmocr-demo/configs/textrecog/satrn/README.md b/spaces/EuroPython2022/mmocr-demo/configs/textrecog/satrn/README.md deleted file mode 100644 index 4bb92f3fc9d37d0c1a9563769b645d20fc598eb2..0000000000000000000000000000000000000000 --- a/spaces/EuroPython2022/mmocr-demo/configs/textrecog/satrn/README.md +++ /dev/null @@ -1,51 +0,0 @@ -# SATRN - -> [On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention](https://arxiv.org/abs/1910.04396) - - - -## Abstract - -Scene text recognition (STR) is the task of recognizing character sequences in natural scenes. While there have been great advances in STR methods, current methods still fail to recognize texts in arbitrary shapes, such as heavily curved or rotated texts, which are abundant in daily life (e.g. restaurant signs, product labels, company logos, etc). This paper introduces a novel architecture to recognizing texts of arbitrary shapes, named Self-Attention Text Recognition Network (SATRN), which is inspired by the Transformer. SATRN utilizes the self-attention mechanism to describe two-dimensional (2D) spatial dependencies of characters in a scene text image. Exploiting the full-graph propagation of self-attention, SATRN can recognize texts with arbitrary arrangements and large inter-character spacing. As a result, SATRN outperforms existing STR models by a large margin of 5.7 pp on average in "irregular text" benchmarks. We provide empirical analyses that illustrate the inner mechanisms and the extent to which the model is applicable (e.g. rotated and multi-line text). We will open-source the code. - -
-
-
-## Dataset
-
-### Train Dataset
-
-| trainset | instance_num | repeat_num | source |
-| :-------: | :----------: | :--------: | :----: |
-| SynthText | 7266686 | 1 | synth |
-| Syn90k | 8919273 | 1 | synth |
-
-### Test Dataset
-
-| testset | instance_num | type |
-| :-----: | :----------: | :-------: |
-| IIIT5K | 3000 | regular |
-| SVT | 647 | regular |
-| IC13 | 1015 | regular |
-| IC15 | 2077 | irregular |
-| SVTP | 645 | irregular |
-| CT80 | 288 | irregular |
-
-## Results and Models
-
-| Methods | | Regular Text | | | | Irregular Text | | download |
-| :----------------------------------------------------: | :----: | :----------: | :--: | :-: | :--: | :------------: | :--: | :-------------------------------------------------------------------------------------------------: |
-| | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
-| [Satrn](/configs/textrecog/satrn/satrn_academic.py) | 96.1 | 93.5 | 95.7 | | 84.1 | 88.5 | 90.3 | [model](https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_academic_20211009-cb8b1580.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/satrn/20210809_093244.log.json) |
-| [Satrn_small](/configs/textrecog/satrn/satrn_small.py) | 94.7 | 91.3 | 95.4 | | 81.9 | 85.9 | 86.5 | [model](https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_small_20211009-2cf13355.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/satrn/20210811_053047.log.json) |
-
-## Citation
-
-```bibtex
-@article{junyeop2019recognizing,
- title={On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention},
- author={Junyeop Lee, Sungrae Park, Jeonghun Baek, Seong Joon Oh, Seonghyeon Kim, Hwalsuk Lee},
- year={2019}
-}
-```
diff --git a/spaces/Felixogunwale/Imagedeblurr/README.md b/spaces/Felixogunwale/Imagedeblurr/README.md
deleted file mode 100644
index 57b11e8dde4441b97cdc78423541a6b6a045ab84..0000000000000000000000000000000000000000
--- a/spaces/Felixogunwale/Imagedeblurr/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Imagedeblurr
-emoji: 🐨
-colorFrom: gray
-colorTo: indigo
-sdk: gradio
-sdk_version: 2.9.4
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/GEM/DatasetCardForm/datacards/gem.py b/spaces/GEM/DatasetCardForm/datacards/gem.py
deleted file mode 100644
index 76037857501a5454a9205c804320e680aa6267ce..0000000000000000000000000000000000000000
--- a/spaces/GEM/DatasetCardForm/datacards/gem.py
+++ /dev/null
@@ -1,134 +0,0 @@
-import streamlit as st
-
-from .streamlit_utils import make_text_input
-
-from .streamlit_utils import (
- make_multiselect,
- make_text_area,
- make_radio,
-)
-
-N_FIELDS_RATIONALE = 5
-N_FIELDS_CURATION = 6
-N_FIELDS_STARTING = 2
-
-N_FIELDS = N_FIELDS_RATIONALE + N_FIELDS_CURATION + N_FIELDS_STARTING
-
-
-def gem_page():
- st.session_state.card_dict["gem"] = st.session_state.card_dict.get("gem", {})
- with st.expander("Rationale", expanded=False):
- key_pref = ["gem", "rationale"]
- st.session_state.card_dict["gem"]["rationale"] = st.session_state.card_dict[
- "gem"
- ].get("rationale", {})
- make_text_area(
- label="What does this dataset contribute toward better generation evaluation and why is it part of GEM?",
- key_list=key_pref + ["contribution"],
- help="Describe briefly what makes this dataset an interesting target for NLG evaluations and why it is part of GEM",
- )
- make_radio(
- label="Do other datasets for the high level task exist?",
- options=["no", "yes"],
- key_list=key_pref + ["sole-task-dataset"],
- help="for example, is this the only summarization dataset proposed in GEM",
- )
- if "yes" in st.session_state.card_dict["gem"]["rationale"].get("sole-task-dataset", []):
- make_radio(
- label="Does this dataset cover other languages than other datasets for the same task?",
- options=["no", "yes"],
- key_list=key_pref + ["sole-language-task-dataset"],
- help="for example, is this the only summarization dataset proposed in GEM to have French text?",
- )
- make_text_area(
- label="What else sets this dataset apart from other similar datasets in GEM?",
- key_list=key_pref + ["distinction-description"],
- help="Describe briefly for each similar dataset (same task/languages) what sets this one apart",
- )
- else:
- st.session_state.card_dict["gem"]["rationale"]["sole-language-task-dataset"] = "N/A"
- st.session_state.card_dict["gem"]["rationale"]["distinction-description"] = "N/A"
-
- make_text_area(
- label="What aspect of model ability can be measured with this dataset?",
- key_list=key_pref + ["model-ability"],
- help="What kind of abilities should a model exhibit that performs well on the task of this dataset (e.g., reasoning capability, morphological inflection)?",
- )
-
- with st.expander("GEM Additional Curation", expanded=False):
- key_pref = ["gem", "curation"]
- st.session_state.card_dict["gem"]["curation"] = st.session_state.card_dict[
- "gem"
- ].get("curation", {})
- make_radio(
- label="Has the GEM version of the dataset been modified in any way (data, processing, splits) from the original curated data?",
- options=["no", "yes"],
- key_list=key_pref+["has-additional-curation"],
- )
- if st.session_state.card_dict["gem"]["curation"]["has-additional-curation"] == "yes":
- make_multiselect(
- label="What changes have been made to he original dataset?",
- options=["data points added", "data points removed", "data points modified", "annotations added", "other"],
- key_list=key_pref+["modification-types"],
- )
- make_text_area(
- label="For each of these changes, described them in more details and provided the intended purpose of the modification",
- key_list=key_pref+["modification-description"],
- )
- make_radio(
- label="Does GEM provide additional splits to the dataset?",
- options=["no", "yes"],
- key_list=key_pref+["has-additional-splits"],
- )
- if st.session_state.card_dict["gem"]["curation"]["has-additional-splits"] == "yes":
- make_text_area(
- label="Describe how the new splits were created",
- key_list=key_pref+["additional-splits-description"],
- )
- make_text_area(
- label="What aspects of the model's generation capacities were the splits created to test?",
- key_list=key_pref+["additional-splits-capacicites"],
- )
- else:
- st.session_state.card_dict["gem"]["curation"]["additional-splits-description"] = "N/A"
- st.session_state.card_dict["gem"]["curation"]["additional-splits-capacicites"] = "N/A"
- else:
- st.session_state.card_dict["gem"]["curation"]["modification-types"] = []
- st.session_state.card_dict["gem"]["curation"]["modification-description"] = "N/A"
- st.session_state.card_dict["gem"]["curation"]["has-additional-splits"] = "no"
- st.session_state.card_dict["gem"]["curation"]["additional-splits-description"] = "N/A"
- st.session_state.card_dict["gem"]["curation"]["additional-splits-capacicites"] = "N/A"
-
- with st.expander("Getting Started", expanded=False):
- key_pref = ["gem", "starting"]
- st.session_state.card_dict["gem"]["starting"] = st.session_state.card_dict[
- "gem"
- ].get("starting", {})
- make_text_area(
- label="Getting started with in-depth research on the task. Add relevant pointers to resources that researchers can consult when they want to get started digging deeper into the task.",
- key_list=key_pref + ["research-pointers"],
- help=" These can include blog posts, research papers, literature surveys, etc. You can also link to tutorials on the GEM website.",
- )
- make_text_area(
- label="Technical terms used in this card and the dataset and their definitions",
- key_list=key_pref + ["technical-terms"],
- help="Provide a brief definition of technical terms that are unique to this dataset",
- )
-
-
-
-def gem_summary():
- total_filled = sum(
- [len(dct) for dct in st.session_state.card_dict.get("gem", {}).values()]
- )
- with st.expander(
- f"Dataset in GEM Completion - {total_filled} of {N_FIELDS}", expanded=False
- ):
- completion_markdown = ""
- completion_markdown += (
- f"- **Overall completion:**\n - {total_filled} of {N_FIELDS} fields\n"
- )
- completion_markdown += f"- **Sub-section - Rationale:**\n - {len(st.session_state.card_dict.get('gem', {}).get('rationale', {}))} of {N_FIELDS_RATIONALE} fields\n"
- completion_markdown += f"- **Sub-section - GEM Additional Curation:**\n - {len(st.session_state.card_dict.get('gem', {}).get('curation', {}))} of {N_FIELDS_CURATION} fields\n"
- completion_markdown += f"- **Sub-section - Getting Started:**\n - {len(st.session_state.card_dict.get('gem', {}).get('starting', {}))} of {N_FIELDS_STARTING} fields\n"
- st.markdown(completion_markdown)
diff --git a/spaces/GXSA/bingo/src/components/chat-header.tsx b/spaces/GXSA/bingo/src/components/chat-header.tsx
deleted file mode 100644
index c6664b8dee61179f844d45c5bd650518fc2cb4c2..0000000000000000000000000000000000000000
--- a/spaces/GXSA/bingo/src/components/chat-header.tsx
+++ /dev/null
@@ -1,12 +0,0 @@
-import LogoIcon from '@/assets/images/logo.svg'
-import Image from 'next/image'
-
-export function ChatHeader() {
- return (
- 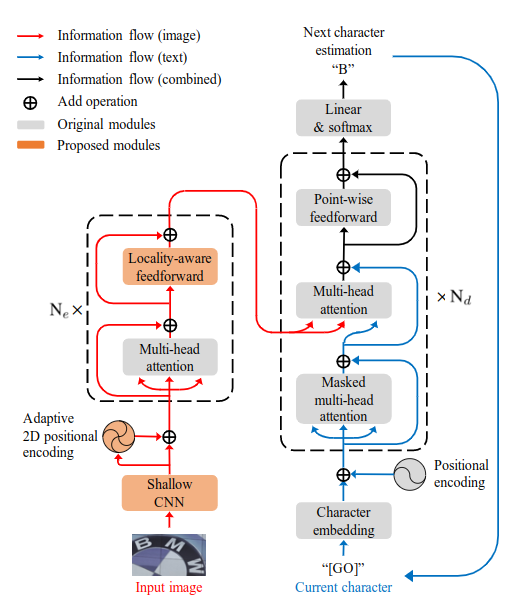 -
-
-
- )
-}
diff --git a/spaces/Gen-Sim/Gen-Sim/cliport/models/resnet_lat.py b/spaces/Gen-Sim/Gen-Sim/cliport/models/resnet_lat.py
deleted file mode 100644
index b7ca39891552f4eb51a5fe25776cb72d534126e6..0000000000000000000000000000000000000000
--- a/spaces/Gen-Sim/Gen-Sim/cliport/models/resnet_lat.py
+++ /dev/null
@@ -1,121 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-import cliport.utils.utils as utils
-
-from cliport.models.resnet import ConvBlock, IdentityBlock
-
-class ResNet45_10s(nn.Module):
- def __init__(self, input_shape, output_dim, cfg, device, preprocess):
- super(ResNet45_10s, self).__init__()
- self.input_shape = input_shape
- self.input_dim = input_shape[-1]
- self.output_dim = output_dim
- self.cfg = cfg
- self.device = device
- self.batchnorm = self.cfg['train']['batchnorm']
- self.preprocess = preprocess
- # import IPython; IPython.embed()
-
- self._make_layers()
-
- def _make_layers(self):
- # conv1
- self.conv1 = nn.Sequential(
- nn.Conv2d(self.input_dim, 64, stride=1, kernel_size=3, padding=1),
- nn.BatchNorm2d(64) if self.batchnorm else nn.Identity(),
- nn.ReLU(True),
- )
-
- # fcn
- self.layer1 = nn.Sequential(
- ConvBlock(64, [64, 64, 64], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- IdentityBlock(64, [64, 64, 64], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- )
-
- self.layer2 = nn.Sequential(
- ConvBlock(64, [128, 128, 128], kernel_size=3, stride=2, batchnorm=self.batchnorm),
- IdentityBlock(128, [128, 128, 128], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- )
-
- self.layer3 = nn.Sequential(
- ConvBlock(128, [256, 256, 256], kernel_size=3, stride=2, batchnorm=self.batchnorm),
- IdentityBlock(256, [256, 256, 256], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- )
-
- self.layer4 = nn.Sequential(
- ConvBlock(256, [512, 512, 512], kernel_size=3, stride=2, batchnorm=self.batchnorm),
- IdentityBlock(512, [512, 512, 512], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- )
-
- # self.layer5 = nn.Sequential(
- # ConvBlock(512, [1024, 1024, 1024], kernel_size=3, stride=2, batchnorm=self.batchnorm),
- # IdentityBlock(1024, [1024, 1024, 1024], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- # )
-
- # # head
- # self.layer6 = nn.Sequential(
- # ConvBlock(1024, [512, 512, 512], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- # IdentityBlock(512, [512, 512, 512], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- # nn.UpsamplingBilinear2d(scale_factor=2),
- # )
-
- self.layer7 = nn.Sequential(
- ConvBlock(512, [256, 256, 256], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- IdentityBlock(256, [256, 256, 256], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- nn.UpsamplingBilinear2d(scale_factor=2),
- )
-
- self.layer8 = nn.Sequential(
- ConvBlock(256, [128, 128, 128], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- IdentityBlock(128, [128, 128, 128], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- nn.UpsamplingBilinear2d(scale_factor=2),
- )
-
- self.layer9 = nn.Sequential(
- ConvBlock(128, [64, 64, 64], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- IdentityBlock(64, [64, 64, 64], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- nn.UpsamplingBilinear2d(scale_factor=2),
- )
-
- self.layer10 = nn.Sequential(
- ConvBlock(64, [32, 32, 32], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- IdentityBlock(32, [32, 32, 32], kernel_size=3, stride=1, batchnorm=self.batchnorm),
- nn.UpsamplingBilinear2d(scale_factor=2),
- )
-
- # conv2
- self.conv2 = nn.Sequential(
- ConvBlock(32, [16, 16, self.output_dim], kernel_size=3, stride=1,
- final_relu=False, batchnorm=self.batchnorm),
- IdentityBlock(self.output_dim, [16, 16, self.output_dim], kernel_size=3, stride=1,
- final_relu=False, batchnorm=self.batchnorm)
- )
-
- def forward(self, x):
- x = self.preprocess(x, dist='transporter')
- in_shape = x.shape
-
- # # encoder
- # for layer in [self.conv1, self.layer1, self.layer2, self.layer3, self.layer4, self.layer5]:
- # x = layer(x)
-
- # # decoder
- # im = []
- # for layer in [self.layer6, self.layer7, self.layer8, self.layer9, self.layer10, self.conv2]:
- # im.append(x)
- # x = layer(x)
-
- # encoder
- for layer in [self.conv1, self.layer1, self.layer2, self.layer3, self.layer4]:
- x = layer(x)
-
- # decoder
- im = []
- for layer in [self.layer7, self.layer8, self.layer9, self.layer10, self.conv2]:
- im.append(x)
- x = layer(x)
-
- x = F.interpolate(x, size=(in_shape[-2], in_shape[-1]), mode='bilinear')
- return x, im
\ No newline at end of file
diff --git a/spaces/GodParticle69/minor_demo/coco.py b/spaces/GodParticle69/minor_demo/coco.py
deleted file mode 100644
index 20d7429f3e6d75884beda29de4112475862c4fd8..0000000000000000000000000000000000000000
--- a/spaces/GodParticle69/minor_demo/coco.py
+++ /dev/null
@@ -1,522 +0,0 @@
-"""
-Mask R-CNN
-Configurations and data loading code for MS COCO.
-
-Copyright (c) 2017 Matterport, Inc.
-Licensed under the MIT License (see LICENSE for details)
-Written by Waleed Abdulla
-
-------------------------------------------------------------
-
-Usage: import the module (see Jupyter notebooks for examples), or run from
- the command line as such:
-
- # Train a new model starting from pre-trained COCO weights
- python3 coco.py train --dataset=/path/to/coco/ --model=coco
-
- # Train a new model starting from ImageNet weights
- python3 coco.py train --dataset=/path/to/coco/ --model=imagenet
-
- # Continue training a model that you had trained earlier
- python3 coco.py train --dataset=/path/to/coco/ --model=/path/to/weights.h5
-
- # Continue training the last model you trained
- python3 coco.py train --dataset=/path/to/coco/ --model=last
-
- # Run COCO evaluatoin on the last model you trained
- python3 coco.py evaluate --dataset=/path/to/coco/ --model=last
-"""
-
-import os
-import time
-import numpy as np
-
-# Download and install the Python COCO tools from https://github.com/waleedka/coco
-#
-# pip install git+https://github.com/waleedka/coco.git#subdirectory=PythonAPI
-#
-# That's a fork from the original https://github.com/pdollar/coco with a bug
-# fix for Python 3.
-# I submitted a pull request https://github.com/cocodataset/cocoapi/pull/50
-# If the PR is merged then use the original repo.
-# Note: Edit PythonAPI/Makefile and replace "python" with "python3".
-from pycocotools.coco import COCO
-from pycocotools.cocoeval import COCOeval
-from pycocotools import mask as maskUtils
-
-import zipfile
-import urllib.request
-import shutil
-
-from mrcnn.config import Config
-import mrcnn.utils as utils
-import mrcnn.model as modellib
-
-# Root directory of the project
-ROOT_DIR = os.getcwd()
-
-# Path to trained weights file
-COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
-
-# Directory to save logs and model checkpoints, if not provided
-# through the command line argument --logs
-DEFAULT_LOGS_DIR = os.path.join(ROOT_DIR, "logs")
-DEFAULT_DATASET_YEAR = "2014"
-
-############################################################
-# Configurations
-############################################################
-
-
-class CocoConfig(Config):
- """Configuration for training on MS COCO.
- Derives from the base Config class and overrides values specific
- to the COCO dataset.
- """
- # Give the configuration a recognizable name
- NAME = "coco"
-
- # We use a GPU with 12GB memory, which can fit two images.
- # Adjust down if you use a smaller GPU.
- IMAGES_PER_GPU = 2
-
- # Uncomment to train on 8 GPUs (default is 1)
- # GPU_COUNT = 8
-
- # Number of classes (including background)
- NUM_CLASSES = 1 + 80 # COCO has 80 classes
-
-
-############################################################
-# Dataset
-############################################################
-
-class CocoDataset(utils.Dataset):
- def load_coco(self, dataset_dir, subset, year=DEFAULT_DATASET_YEAR, class_ids=None,
- class_map=None, return_coco=False, auto_download=False):
- """Load a subset of the COCO dataset.
- dataset_dir: The root directory of the COCO dataset.
- subset: What to load (train, val, minival, valminusminival)
- year: What dataset year to load (2014, 2017) as a string, not an integer
- class_ids: If provided, only loads images that have the given classes.
- class_map: TODO: Not implemented yet. Supports maping classes from
- different datasets to the same class ID.
- return_coco: If True, returns the COCO object.
- auto_download: Automatically download and unzip MS-COCO images and annotations
- """
-
- if auto_download is True:
- self.auto_download(dataset_dir, subset, year)
-
- coco = COCO("{}/annotations/instances_{}{}.json".format(dataset_dir, subset, year))
- if subset == "minival" or subset == "valminusminival":
- subset = "val"
- image_dir = "{}/{}{}".format(dataset_dir, subset, year)
-
- # Load all classes or a subset?
- if not class_ids:
- # All classes
- class_ids = sorted(coco.getCatIds())
-
- # All images or a subset?
- if class_ids:
- image_ids = []
- for id in class_ids:
- image_ids.extend(list(coco.getImgIds(catIds=[id])))
- # Remove duplicates
- image_ids = list(set(image_ids))
- else:
- # All images
- image_ids = list(coco.imgs.keys())
-
- # Add classes
- for i in class_ids:
- self.add_class("coco", i, coco.loadCats(i)[0]["name"])
-
- # Add images
- for i in image_ids:
- self.add_image(
- "coco", image_id=i,
- path=os.path.join(image_dir, coco.imgs[i]['file_name']),
- width=coco.imgs[i]["width"],
- height=coco.imgs[i]["height"],
- annotations=coco.loadAnns(coco.getAnnIds(
- imgIds=[i], catIds=class_ids, iscrowd=None)))
- if return_coco:
- return coco
-
- def auto_download(self, dataDir, dataType, dataYear):
- """Download the COCO dataset/annotations if requested.
- dataDir: The root directory of the COCO dataset.
- dataType: What to load (train, val, minival, valminusminival)
- dataYear: What dataset year to load (2014, 2017) as a string, not an integer
- Note:
- For 2014, use "train", "val", "minival", or "valminusminival"
- For 2017, only "train" and "val" annotations are available
- """
-
- # Setup paths and file names
- if dataType == "minival" or dataType == "valminusminival":
- imgDir = "{}/{}{}".format(dataDir, "val", dataYear)
- imgZipFile = "{}/{}{}.zip".format(dataDir, "val", dataYear)
- imgURL = "http://images.cocodataset.org/zips/{}{}.zip".format("val", dataYear)
- else:
- imgDir = "{}/{}{}".format(dataDir, dataType, dataYear)
- imgZipFile = "{}/{}{}.zip".format(dataDir, dataType, dataYear)
- imgURL = "http://images.cocodataset.org/zips/{}{}.zip".format(dataType, dataYear)
- # print("Image paths:"); print(imgDir); print(imgZipFile); print(imgURL)
-
- # Create main folder if it doesn't exist yet
- if not os.path.exists(dataDir):
- os.makedirs(dataDir)
-
- # Download images if not available locally
- if not os.path.exists(imgDir):
- os.makedirs(imgDir)
- print("Downloading images to " + imgZipFile + " ...")
- with urllib.request.urlopen(imgURL) as resp, open(imgZipFile, 'wb') as out:
- shutil.copyfileobj(resp, out)
- print("... done downloading.")
- print("Unzipping " + imgZipFile)
- with zipfile.ZipFile(imgZipFile, "r") as zip_ref:
- zip_ref.extractall(dataDir)
- print("... done unzipping")
- print("Will use images in " + imgDir)
-
- # Setup annotations data paths
- annDir = "{}/annotations".format(dataDir)
- if dataType == "minival":
- annZipFile = "{}/instances_minival2014.json.zip".format(dataDir)
- annFile = "{}/instances_minival2014.json".format(annDir)
- annURL = "https://dl.dropboxusercontent.com/s/o43o90bna78omob/instances_minival2014.json.zip?dl=0"
- unZipDir = annDir
- elif dataType == "valminusminival":
- annZipFile = "{}/instances_valminusminival2014.json.zip".format(dataDir)
- annFile = "{}/instances_valminusminival2014.json".format(annDir)
- annURL = "https://dl.dropboxusercontent.com/s/s3tw5zcg7395368/instances_valminusminival2014.json.zip?dl=0"
- unZipDir = annDir
- else:
- annZipFile = "{}/annotations_trainval{}.zip".format(dataDir, dataYear)
- annFile = "{}/instances_{}{}.json".format(annDir, dataType, dataYear)
- annURL = "http://images.cocodataset.org/annotations/annotations_trainval{}.zip".format(dataYear)
- unZipDir = dataDir
- # print("Annotations paths:"); print(annDir); print(annFile); print(annZipFile); print(annURL)
-
- # Download annotations if not available locally
- if not os.path.exists(annDir):
- os.makedirs(annDir)
- if not os.path.exists(annFile):
- if not os.path.exists(annZipFile):
- print("Downloading zipped annotations to " + annZipFile + " ...")
- with urllib.request.urlopen(annURL) as resp, open(annZipFile, 'wb') as out:
- shutil.copyfileobj(resp, out)
- print("... done downloading.")
- print("Unzipping " + annZipFile)
- with zipfile.ZipFile(annZipFile, "r") as zip_ref:
- zip_ref.extractall(unZipDir)
- print("... done unzipping")
- print("Will use annotations in " + annFile)
-
- def load_mask(self, image_id):
- """Load instance masks for the given image.
-
- Different datasets use different ways to store masks. This
- function converts the different mask format to one format
- in the form of a bitmap [height, width, instances].
-
- Returns:
- masks: A bool array of shape [height, width, instance count] with
- one mask per instance.
- class_ids: a 1D array of class IDs of the instance masks.
- """
- # If not a COCO image, delegate to parent class.
- image_info = self.image_info[image_id]
- if image_info["source"] != "coco":
- return super(CocoDataset, self).load_mask(image_id)
-
- instance_masks = []
- class_ids = []
- annotations = self.image_info[image_id]["annotations"]
- # Build mask of shape [height, width, instance_count] and list
- # of class IDs that correspond to each channel of the mask.
- for annotation in annotations:
- class_id = self.map_source_class_id(
- "coco.{}".format(annotation['category_id']))
- if class_id:
- m = self.annToMask(annotation, image_info["height"],
- image_info["width"])
- # Some objects are so small that they're less than 1 pixel area
- # and end up rounded out. Skip those objects.
- if m.max() < 1:
- continue
- # Is it a crowd? If so, use a negative class ID.
- if annotation['iscrowd']:
- # Use negative class ID for crowds
- class_id *= -1
- # For crowd masks, annToMask() sometimes returns a mask
- # smaller than the given dimensions. If so, resize it.
- if m.shape[0] != image_info["height"] or m.shape[1] != image_info["width"]:
- m = np.ones([image_info["height"], image_info["width"]], dtype=bool)
- instance_masks.append(m)
- class_ids.append(class_id)
-
- # Pack instance masks into an array
- if class_ids:
- mask = np.stack(instance_masks, axis=2)
- class_ids = np.array(class_ids, dtype=np.int32)
- return mask, class_ids
- else:
- # Call super class to return an empty mask
- return super(CocoDataset, self).load_mask(image_id)
-
- def image_reference(self, image_id):
- """Return a link to the image in the COCO Website."""
- info = self.image_info[image_id]
- if info["source"] == "coco":
- return "http://cocodataset.org/#explore?id={}".format(info["id"])
- else:
- super(CocoDataset, self).image_reference(image_id)
-
- # The following two functions are from pycocotools with a few changes.
-
- def annToRLE(self, ann, height, width):
- """
- Convert annotation which can be polygons, uncompressed RLE to RLE.
- :return: binary mask (numpy 2D array)
- """
- segm = ann['segmentation']
- if isinstance(segm, list):
- # polygon -- a single object might consist of multiple parts
- # we merge all parts into one mask rle code
- rles = maskUtils.frPyObjects(segm, height, width)
- rle = maskUtils.merge(rles)
- elif isinstance(segm['counts'], list):
- # uncompressed RLE
- rle = maskUtils.frPyObjects(segm, height, width)
- else:
- # rle
- rle = ann['segmentation']
- return rle
-
- def annToMask(self, ann, height, width):
- """
- Convert annotation which can be polygons, uncompressed RLE, or RLE to binary mask.
- :return: binary mask (numpy 2D array)
- """
- rle = self.annToRLE(ann, height, width)
- m = maskUtils.decode(rle)
- return m
-
-
-############################################################
-# COCO Evaluation
-############################################################
-
-def build_coco_results(dataset, image_ids, rois, class_ids, scores, masks):
- """Arrange resutls to match COCO specs in http://cocodataset.org/#format
- """
- # If no results, return an empty list
- if rois is None:
- return []
-
- results = []
- for image_id in image_ids:
- # Loop through detections
- for i in range(rois.shape[0]):
- class_id = class_ids[i]
- score = scores[i]
- bbox = np.around(rois[i], 1)
- mask = masks[:, :, i]
-
- result = {
- "image_id": image_id,
- "category_id": dataset.get_source_class_id(class_id, "coco"),
- "bbox": [bbox[1], bbox[0], bbox[3] - bbox[1], bbox[2] - bbox[0]],
- "score": score,
- "segmentation": maskUtils.encode(np.asfortranarray(mask))
- }
- results.append(result)
- return results
-
-
-def evaluate_coco(model, dataset, coco, eval_type="bbox", limit=0, image_ids=None):
- """Runs official COCO evaluation.
- dataset: A Dataset object with valiadtion data
- eval_type: "bbox" or "segm" for bounding box or segmentation evaluation
- limit: if not 0, it's the number of images to use for evaluation
- """
- # Pick COCO images from the dataset
- image_ids = image_ids or dataset.image_ids
-
- # Limit to a subset
- if limit:
- image_ids = image_ids[:limit]
-
- # Get corresponding COCO image IDs.
- coco_image_ids = [dataset.image_info[id]["id"] for id in image_ids]
-
- t_prediction = 0
- t_start = time.time()
-
- results = []
- for i, image_id in enumerate(image_ids):
- # Load image
- image = dataset.load_image(image_id)
-
- # Run detection
- t = time.time()
- r = model.detect([image], verbose=0)[0]
- t_prediction += (time.time() - t)
-
- # Convert results to COCO format
- image_results = build_coco_results(dataset, coco_image_ids[i:i + 1],
- r["rois"], r["class_ids"],
- r["scores"], r["masks"])
- results.extend(image_results)
-
- # Load results. This modifies results with additional attributes.
- coco_results = coco.loadRes(results)
-
- # Evaluate
- cocoEval = COCOeval(coco, coco_results, eval_type)
- cocoEval.params.imgIds = coco_image_ids
- cocoEval.evaluate()
- cocoEval.accumulate()
- cocoEval.summarize()
-
- print("Prediction time: {}. Average {}/image".format(
- t_prediction, t_prediction / len(image_ids)))
- print("Total time: ", time.time() - t_start)
-
-
-############################################################
-# Training
-############################################################
-
-
-if __name__ == '__main__':
- import argparse
-
- # Parse command line arguments
- parser = argparse.ArgumentParser(
- description='Train Mask R-CNN on MS COCO.')
- parser.add_argument("command",
- metavar="欢迎使用新必应
- 由 AI 支持的网页版 Copilot
- | |||||||||||||||||||||||||||||||
