There are different types of online levels in Geometry Dash World, depending on their difficulty, length, and style. Some of the most common types are:
- To play online levels in Geometry Dash World, you need to have some tips and tricks up your sleeve. Here are some of them:
- Another cool feature of Geometry Dash World is that you can customize your character with different icons and colors. You can also unlock secrets and achievements that will give you more options to personalize your character.
- You can choose from various icons and colors to change the appearance of your character. You can select an icon for your cube, ship, ball, UFO, wave, robot, or spider form. You can also select a primary color and a secondary color for your character. You can unlock more icons and colors by completing levels, quests, achievements, or secrets.
- You can unlock secrets and achievements by performing certain actions or finding hidden objects in the game. Some of these secrets and achievements are:
- Geometry Dash World is a fun and challenging game that will keep you entertained for hours. You can download and install the full apk version of the game to enjoy all the features without any limitations or ads. You can also play online levels created by other players and customize your character with different icons and colors. Geometry Dash World is a game that will test your skills, reflexes, and rhythm. Are you ready to dash into the world of geometry?
- If you are an iPhone, iPad or iPod touch user who wants to jailbreak your device running iOS 4.2.1, you might be interested in downloading Greenpois0n RC5 4.2.1 for Windows. This is a tool that allows you to jailbreak your device untethered, meaning that you don't have to connect it to a computer every time you reboot it.
-In this article, we will explain what Greenpois0n RC5 4.2.1 is, how to download it for Windows, and how to use it to jailbreak your device. We will also show you how to use Cydia, the jailbreak app store, where you can find many useful apps, tweaks and themes that are not available on the official App Store.
- Greenpois0n RC5 4.2.1 is a tool developed by the Chronic Dev Team, a group of hackers who specialize in jailbreaking iOS devices. Jailbreaking is a process that removes the restrictions imposed by Apple on its devices, allowing users to customize them and install apps that are not approved by Apple.
- Greenpois0n RC5 4.2.1 is designed to jailbreak iOS devices running iOS 4.2.1, which is an older version of iOS that was released in November 2010. It supports iPhone 4, iPhone 3GS, iPod touch 4G/3G/2G and iPad.
-One of the main features of Greenpois0n RC5 4.2.1 is that it can jailbreak iOS devices untethered, which means that you don't have to connect your device to a computer every time you reboot it or turn it off and on again. This makes your device more convenient and stable after jailbreaking.
- Of course, jailbreaking also has some risks and drawbacks, such as voiding your warranty, exposing your device to security threats, and causing instability or compatibility issues. Therefore, you should always backup your device before jailbreaking and follow the instructions carefully.
- If you are ready to jailbreak your device with Greenpois0n RC5 4.2.1, you will need to download the tool for Windows and follow the steps below.
- The first step is to backup your device using iTunes or iCloud. This will ensure that you don't lose any important data in case something goes wrong during the jailbreak process. To backup your device using iTunes, connect it to your PC and open iTunes. Then, click on the device icon in the upper left corner and select "Back Up Now". To backup your device using iCloud, go to Settings > iCloud > Backup and tap on "Back Up Now".
-After backing up your device, make sure you quit iTunes and any other programs that might interfere with the jailbreak process.
- The next step is to download Greenpois0n RC5 4.2.1 for Windows from the official website of the Chronic Dev Team. You can also use this mirror link if the official website is down or slow. The file size is about 16 MB and the file name is gp_win_rc5_b4.zip.
-After downloading the file, extract it to a folder on your desktop or any other location that is easy to access.
- The third step is to run Greenpois0n and follow the instructions on the screen. To do this, double-click on the greenpois0n.exe file that you extracted in the previous step. You will see a window like this:
-Before you click on "Prepare to Jailbreak (DFU)", make sure your device is turned off and connected to your PC via USB. Then, click on the button and follow the instructions to put your device into DFU mode. DFU mode is a special mode that allows your device to communicate with Greenpois0n and accept the jailbreak code. To enter DFU mode, you will need to press and hold the power and home buttons on your device for a certain amount of time.
-The instructions will tell you how long to press each button and when to release them. You will also see a countdown timer on the screen that will guide you through the process. If you do everything correctly, you will see a message saying "Ready to Jailbreak" and a button saying "Jailbreak". If not, you will see a message saying "Try Again" and a button saying "Retry". In that case, try again until you succeed.
-Once you are ready to jailbreak, click on the "Jailbreak" button and wait for Greenpois0n to do its magic. You will see some code running on your device's screen and a progress bar on your PC's screen. This may take a few minutes, so be patient and do not disconnect or interrupt your device.
- The final step is to install Cydia from the Loader app that Greenpois on will install on your device after the jailbreak. Cydia is the jailbreak app store, where you can find many apps, tweaks and themes that are not available on the official App Store.
-To install Cydia, go to your device's home screen and look for an icon that says "Loader". Tap on it and you will see a screen like this:
-Tap on the "Cydia" button and wait for the app to download and install. You may need to confirm some prompts or restart your device during the process. Once Cydia is installed, you will see its icon on your home screen. You can then delete the Loader app by tapping and holding on it and tapping on the "X" button.
- Now that you have Cydia on your device, you can start exploring the world of jailbreak apps, tweaks and themes. Here are some tips on how to use Cydia:
- Cydia is an app that allows you to browse and install software packages that are not available on the official App Store. These packages are created by independent developers and hackers who want to enhance or modify the iOS experience. Some of these packages are free, while others are paid or require a donation.
-Cydia works by accessing repositories, which are online sources that host the packages. There are many repositories that you can add to Cydia, each offering different kinds of packages. Some of the most popular repositories are BigBoss, ModMyi, ZodTTD & MacCiti, and Saurik's own repository.
- To access Cydia, simply tap on its icon on your home screen. You will see a screen like this:
-On the bottom of the screen, you will see five tabs: Home, Sections, Changes, Manage and Search. Here is what each tab does:
-You can now enjoy your new app, tweak or theme on your device. To uninstall a package from Cydia, simply go to the Manage tab > Packages > tap on the package name > tap on "Modify" > tap on "Remove".
- If you are a fan of fighting games, you must have heard of Mortal Kombat, one of the most iconic and brutal franchises in the genre. Mortal Kombat has been around since 1992, and it has evolved over the years with new characters, graphics, gameplay, and storylines. One of the latest and most popular entries in the series is Mortal Kombat XL, which was released in 2016 as an enhanced version of Mortal Kombat X.
- Mortal Kombat XL is a game that offers a lot of content, variety, and fun for both casual and hardcore players. It has a rich roster of fighters, each with their own unique abilities, moves, and fatalities. It has several game modes, such as story mode, arcade mode, online mode, and tower mode. It has stunning graphics, animations, and sound effects that make every fight feel realistic and immersive. And it has the signature gore and violence that make Mortal Kombat stand out from other fighting games.
-But what if you want to play Mortal Kombat XL on your Android device? Is it possible to enjoy this game on your smartphone or tablet? The answer is yes, thanks to the Mortal Kombat XL download APK. This is a file that allows you to install and run Mortal Kombat XL on your Android device without any hassle. In this article, we will show you how to download and install Mortal Kombat XL APK on your Android device, and how to enjoy it to the fullest.
- Mortal Kombat XL is an updated version of Mortal Kombat X, which was released in 2015. Mortal Kombat X is the tenth main installment in the Mortal Kombat series, and it continues the story of the previous games. It is set 25 years after the events of Mortal Kombat 9, and it features a new generation of fighters who have to face a new threat from the Outworld.
- Mortal Kombat XL has many features that make it one of the best fighting games ever made. Some of these features are:
- Mortal Kombat XL is an enhanced version of Mortal Kombat X that includes all the downloadable content (DLC) that was released for the original game. This means that Mortal Kombat XL has more characters, costumes, stages, and features than Mortal Kombat X. For example, Mortal Kombat XL has nine additional characters that were not available in Mortal Kombat X: Alien, Predator, Jason Voorhees, Leatherface, Bo' Rai Cho, Triborg, Tremor, Tanya, and Goro. It also has new costumes for some of the existing characters, such as Cyber Sub-Zero, Revenant Liu Kang, Revenant Kitana, Revenant Jax, Revenant Kung Lao, Dark Emperor Liu Kang, Dark Empress Kitana, and more. It also has new stages for some of the game modes, such as the Pit Stage for arcade mode and the Refugee Kamp Stage for online mode.
- If you already own Mortal Kombat X on your Android device, you can upgrade to Mortal Kombat XL by purchasing the XL Pack from the in-game store. This will give you access to all the DLC content that is included in Mortal Kombat XL. However, if you do not own Mortal Kombat X on your Android device, you can download and install Mortal Kombat XL APK directly from a trusted source online.
- If you want to play Mortal Kombat XL on your Android device, you will need to download and install Mortal Kombat XL APK from a reliable website. This is a file that contains the game data and allows you to run it on your device without any problems. However, before you do that, you will need to make sure that your device meets the requirements for running Mortal Kombat XL APK.
-Mortal Kombat XL APK is a large and demanding game that requires a powerful device to run smoothly and without errors. Here are some of the minimum requirements for running Mortal Kombat XL APK on your Android device:
- If your device meets these requirements, you can proceed to download and install Mortal Kombat XL APK on your Android device.
- Here are the steps for downloading and installing Mortal Kombat XL APK on your Android device:
- Mortal Kombat XL APK is a great way to enjoy Mortal Kombat XL on your Android device, but it also comes with some risks and challenges. Here are some tips for playing Mortal Kombat XL APK smoothly and safely:
- Mortal Kombat XL APK is a game that offers a lot of fun and excitement for anyone who loves fighting games. It has a lot of content, variety, and challenge that will keep you entertained for hours. Here are some tips on how to enjoy Mortal Kombat XL APK to the fullest:
- Mortal Kombat XL APK has a large and diverse roster of characters that you can choose from. Each character has their own strengths, weaknesses, styles, and personalities that make them unique and fun to play with. However, some characters may be better than others depending on your preferences and skills. Here are some of the best characters to use in Mortal Kombat XL APK:
- Mortal Kombat XL APK has several game modes that you can play and enjoy. Each game mode has its own objectives, rules, and rewards that make them different and fun. Here are some of the best game modes to play in Mortal Kombat XL APK:
- Mortal Kombat XL APK is a game that requires skill, strategy, and practice to master. It is not a game that you can win by button mashing or spamming moves. It is a game that rewards you for learning the mechanics, characters, combos, and tactics of the game. Here are some of the best tips and tricks to master Mortal Kombat XL APK:
-
-- Learn the basics: Before you jump into the game modes, make sure that you learn the basics of the game. Learn how to move, block, attack, grab, throw, break, counter, of the website before downloading and installing Mortal Kombat XL APK.
-
- Is Mortal Kombat XL APK legal?
-Mortal Kombat XL APK is legal to download and install from a legitimate website. However, some websites may offer pirated or cracked files that violate the intellectual property rights of the game developers. Therefore, you should always respect the law and the game developers by downloading and installing Mortal Kombat XL APK from an authorized website.
-- Is Mortal Kombat XL APK compatible with my device?
-Mortal Kombat XL APK is compatible with most Android devices that meet the minimum requirements for running the game. However, some devices may have issues or errors with the game due to different specifications or models. Therefore, you should always check the compatibility of your device with the game before downloading and installing Mortal Kombat XL APK.
-- How can I contact the support team of Mortal Kombat XL APK?
-If you have any questions, problems, or feedback about Mortal Kombat XL APK, you can contact the support team of the game by visiting their official website, social media pages, or email address. You can also check their online forums, FAQs, or guides for more information and help.
- 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Play Melon Playground on Your Mac with BlueStacks The Ultimate Android Emulator for PC and Mac.md b/spaces/congsaPfin/Manga-OCR/logs/Play Melon Playground on Your Mac with BlueStacks The Ultimate Android Emulator for PC and Mac.md
deleted file mode 100644
index c94403867274d2c4bed7906e48bdcc9d0f99557a..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Play Melon Playground on Your Mac with BlueStacks The Ultimate Android Emulator for PC and Mac.md
+++ /dev/null
@@ -1,133 +0,0 @@
-
-Can You Download Melon Playground on Mac?
-Melon Playground is a popular sandbox game that lets you unleash your creativity and imagination. You can use various items, weapons, and physics to create your own scenarios and experiments. But can you download Melon Playground on Mac? The answer is yes, but not directly. In this article, we will show you two ways to play Melon Playground on your Mac computer.
- What is Melon Playground?
-Melon Playground is a simulation game developed by TwentySeven, a studio based in Russia. It is available for Android devices on Google Play Store. The game has over 10 million downloads and a rating of 2.9 stars out of 5.
-can you download melon playground on mac
Download ✔✔✔ https://urlca.com/2uO6pB
- A sandbox game for Android devices
-Melon Playground is a sandbox game, which means that there is no fixed goal or objective. You can do whatever you want with the items and tools provided in the game. You can create your own scenes, characters, and stories. You can also destroy, explode, burn, freeze, or electrocute anything you see.
- Features and gameplay of Melon Playground
-Melon Playground has a wide variety of items at your disposal, such as melee weapons, guns, barrels, explosives, vehicles, animals, humans, robots, zombies, aliens, and more. You can also customize the items by changing their color, size, shape, texture, and properties. You can also use physics to make the items interact with each other in realistic or unrealistic ways.
-The game has a simple and intuitive interface that allows you to drag and drop items from the menu to the scene. You can also use gestures to rotate, zoom, or move the camera. You can also pause, resume, or reset the scene at any time. The game also has a screenshot and video recording feature that lets you capture and share your creations with others.
- How to Download Melon Playground on Mac?
-Since Melon Playground is an Android game, you cannot download it directly from the App Store or run it natively on your Mac. However, there are two ways to play Melon Playground on your Mac using either an Android emulator or a cloud gaming service.
- Option 1: Use an Android emulator
-An Android emulator is a software that simulates an Android device on your computer. It allows you to run Android apps and games on your Mac as if you were using an actual Android device.
-How to install melon playground on mac with bluestacks
-Melon playground app store download for mac
-Melon playground mac compatibility and requirements
-Melon playground simulation game for mac
-Melon playground sandbox game for mac
-Melon playground weapons and tools for mac
-Melon playground no ads subscription for mac
-Melon playground privacy policy and data usage for mac
-Melon playground developer and support for mac
-Melon playground reviews and ratings for mac
-Melon playground update and new features for mac
-Melon playground tips and tricks for mac
-Melon playground cheats and hacks for mac
-Melon playground gameplay and videos for mac
-Melon playground alternatives and similar games for mac
-Melon playground free download and play for mac
-Melon playground online and offline mode for mac
-Melon playground multiplayer and co-op mode for mac
-Melon playground custom scenarios and maps for mac
-Melon playground best weapons and tools for mac
-Melon playground bugs and glitches for mac
-Melon playground fixes and solutions for mac
-Melon playground system performance and optimization for mac
-Melon playground keyboard and mouse controls for mac
-Melon playground gamepad support and settings for mac
-Melon playground graphics and sound quality for mac
-Melon playground fun and relaxing game for mac
-Melon playground stress relief and outlet game for mac
-Melon playground destruction and chaos game for mac
-Melon playground explosions and fire effects for mac
-Melon playground ragdoll physics and animations for mac
-Melon playground barrels and grenades for mac
-Melon playground machine guns and rifles for mac
-Melon playground melee weapons and swords for mac
-Melon playground dummies and targets for mac
-Melon playground challenges and achievements for mac
-Melon playground leaderboards and rankings for mac
-Melon playground social media and community for mac
-Melon playground feedback and suggestions for mac
-Melon playground questions and answers for mac
-Is melon playground safe and secure for mac?
-Is melon playground compatible with macOS 11 or later?
-Is melon playground available on the Mac App Store?
-Is melon playground free or paid on the Mac App Store?
-Is melon playground worth downloading on the Mac App Store?
-Is melon playground fun and addictive on the Mac App Store?
-Is melon playground easy to install on the Mac App Store?
-Is melon playground updated regularly on the Mac App Store?
- What is an Android emulator and how does it work?
-An Android emulator is a software that creates a virtual environment that mimics the hardware and software of an Android device. It runs an Android operating system (OS) on your computer and lets you access the Google Play Store and other Android services. You can then download and install any Android app or game on your computer and run it using the emulator.
- Pros and cons of using an Android emulator
-Using an Android emulator has some advantages and disadvantages. Here are some of them:
Pros:
-
-- You can play Melon Playground and other Android games on your Mac without buying an Android device.
-- You can use your keyboard and mouse to control the game, which may be more comfortable and convenient than using a touchscreen.
-- You can customize the emulator settings to optimize the performance and graphics of the game according to your preferences and system specifications.
-
-Cons:
-
-- You need to download and install an Android emulator on your Mac, which may take up some storage space and memory.
-- You may experience some lag, glitches, or compatibility issues when running the game on the emulator, especially if your Mac is not powerful enough or if the emulator is not updated.
-- You may violate the terms and conditions of the game developer or the Google Play Store by using an emulator, which may result in a ban or a suspension of your account.
-
- Steps to download and install an Android emulator and Melon Playground on Mac
-There are many Android emulators available for Mac, such as BlueStacks, NoxPlayer, MEmu, LDPlayer, and more. You can choose any emulator that suits your needs and preferences. Here are the general steps to download and install an Android emulator and Melon Playground on Mac:
-
-- Go to the official website of the Android emulator you want to use and download the installer file for Mac.
-- Run the installer file and follow the instructions to install the emulator on your Mac.
-- Launch the emulator and sign in with your Google account. If you don't have one, you can create one for free.
-- Open the Google Play Store app on the emulator and search for Melon Playground. Alternatively, you can download the APK file of Melon Playground from a third-party source and drag and drop it to the emulator.
-- Click on the Install button to download and install Melon Playground on the emulator.
-- Once the installation is complete, you can launch Melon Playground from the emulator home screen or app drawer and start playing.
-
- Option 2: Use a cloud gaming service
-A cloud gaming service is a service that allows you to play games online without downloading or installing them on your device. It streams the game from a remote server to your device over the internet. You can play any game on any device as long as you have a stable internet connection and a compatible browser or app.
- What is a cloud gaming service and how does it work?
-A cloud gaming service is a service that uses cloud computing technology to run games on powerful servers and deliver them to your device via streaming. It works like Netflix or YouTube, but for games. You don't need to download or install anything on your device, you just need to access the service through a web browser or an app and choose the game you want to play. The service will then stream the game to your device in real-time, allowing you to control it with your keyboard, mouse, touchpad, or controller.
- Pros and cons of using a cloud gaming service
-Using a cloud gaming service has some advantages and disadvantages. Here are some of them:
-Pros:
-
-- You can play Melon Playground and other games on your Mac without downloading or installing anything on your device, saving storage space and memory.
-- You can play games that are not compatible with your device or operating system, such as Android games on Mac.
-- You can enjoy high-quality graphics and performance of games without worrying about your device's specifications or settings.
-
-Cons:
-
-- You need a fast and reliable internet connection to play games online without lag or interruption.
-- You may need to pay a subscription fee or buy credits to access some cloud gaming services or games.
-- You may not be able to access some features or functions of games that are available offline, such as saving progress, customizing settings, or playing multiplayer modes.
-
- Steps to sign up for a cloud gaming service and play Melon Playground online on Mac
-There are many cloud gaming services available online, such as Google Stadia, NVIDIA GeForce Now, Amazon Luna, Microsoft xCloud, Vortex, Shadow, and more. You can choose any service that offers Melon Playground or other games that you want to play. Here are the general steps to sign up for a cloud gaming service and play Melon Playground online on Mac:
-
-- Go to the official website of the cloud gaming service you want to use and create an account. You may need to provide your email, password, payment method, and other personal information.
-- Choose a subscription plan or buy credits that suit your budget and gaming needs. Some services may offer a free trial or a limited number of games for free.
-- Download and install the app of the cloud gaming service on your Mac, or access the service through a web browser that supports streaming, such as Chrome, Safari, or Firefox.
-- Launch the app or the browser and sign in with your account. You will see a library of games that you can play online.
-- Search for Melon Playground or browse the categories and genres to find it. Click on the Play button to start streaming the game to your Mac.
-- Enjoy playing Melon Playground online on your Mac with high-quality graphics and performance.
-
- Conclusion
-Melon Playground is a fun and creative sandbox game that lets you play with various items, weapons, and physics. However, since it is an Android game, you cannot download it directly on your Mac. You need to use either an Android emulator or a cloud gaming service to play Melon Playground on your Mac.
-Both options have their pros and cons, so you need to consider your preferences, budget, and internet connection before choosing one. If you want to play Melon Playground offline or customize the game settings, you may prefer using an Android emulator. If you want to play Melon Playground online or enjoy high-quality graphics and performance, you may prefer using a cloud gaming service.
-Whichever option you choose, we hope that this article has helped you learn how to download Melon Playground on Mac. Now you can enjoy creating and destroying anything you want with Melon Playground on your Mac computer.
- FAQs
-Is Melon Playground free to play?
-Yes, Melon Playground is free to download and play on Android devices. However, it may contain ads and in-app purchases that require real money. If you use an Android emulator or a cloud gaming service to play Melon Playground on Mac, you may also need to pay for the emulator or the service.
- Is Melon Playground safe to download and play?
-Yes, Melon Playground is safe to download and play if you get it from the official Google Play Store or a trusted third-party source. However, you should be careful when using an Android emulator or a cloud gaming service, as they may pose some security risks or violate some terms and conditions. You should always use a reputable emulator or service and protect your device and account with antivirus software and strong passwords.
- Is Melon Playground compatible with other devices?
-Melon Playground is compatible with most Android devices that have Android 4.4 or higher. However, some devices may not support the game or run it smoothly due to different specifications or settings. You can also play Melon Playground on other devices such as Windows PC, Mac, iOS, or Linux using an Android emulator or a cloud gaming service.
- Can I play Melon Playground offline?
-Yes, you can play Melon Playground offline on your Android device without an internet connection. However, you may not be able to access some features or functions of the game that require online services, such as updating the game, downloading new items, or sharing your creations. If you use an Android emulator or a cloud gaming service to play Melon Playground on Mac, you will need an internet connection to run the emulator or the service.
- Can I create my own items and scenarios in Melon Playground?
-Yes, you can create your own items and scenarios in Melon Playground using the customization tools provided in the game. You can change the color, size, shape, texture, and properties of any item in the game. You can also use physics to make the items interact with each other in realistic or unrealistic ways. You can then save your creations and share them with others through screenshots or videos.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Rise of the Kings Mod Apk OBB Build Your Empire and Defeat Your Enemies.md b/spaces/congsaPfin/Manga-OCR/logs/Rise of the Kings Mod Apk OBB Build Your Empire and Defeat Your Enemies.md
deleted file mode 100644
index fb84d089dc86398d04d8abd76ae275d5ecbec6e9..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Rise of the Kings Mod Apk OBB Build Your Empire and Defeat Your Enemies.md
+++ /dev/null
@@ -1,79 +0,0 @@
-
-Rise of the Kings Mod APK + OBB: A Guide for Strategy Game Lovers
-If you are a fan of strategy games, you might have heard of Rise of the Kings, a popular online multiplayer game that lets you build your own empire, recruit and train your army, forge alliances and fight enemies, and explore a vast world full of challenges and opportunities. In this article, we will tell you everything you need to know about Rise of the Kings, and how you can download and install Rise of the Kings Mod APK + OBB, a modified version of the game that gives you unlimited money, free VIP privileges, and no ads. Read on to find out more.
-rise of the kings mod apk + obb
Download ►►►►► https://urlca.com/2uOdYi
- What is Rise of the Kings?
-Rise of the Kings is a strategy game developed by ONEMT, a Chinese game studio that specializes in creating immersive and realistic games for mobile devices. The game was released in 2016 and has since attracted millions of players from all over the world. The game is set in a fantasy world where several kingdoms are vying for power and glory. You play as a lord who has to build your own empire, recruit and train your army, forge alliances and fight enemies, and explore a vast world full of challenges and opportunities.
- Features of Rise of the Kings
-Rise of the Kings has many features that make it one of the best strategy games on the market. Here are some of them:
- Build your empire
-You start with a small castle and some resources, and you have to expand your territory, upgrade your buildings, research new technologies, and manage your economy. You can choose from different types of buildings, such as farms, mines, barracks, workshops, academies, and more. You can also customize your castle with various decorations and designs.
- Recruit and train your army
-You can recruit different types of units, such as infantry, cavalry, archers, siege weapons, and more. You can also train them to improve their skills and abilities. You can also recruit legendary heroes who have unique talents and powers. You can equip them with weapons, armor, accessories, and mounts. You can also form teams with other players to create powerful formations.
- Forge alliances and fight enemies
-You can join or create an alliance with other players to cooperate and communicate with them. You can share resources, information, strategies, and troops with your allies. You can also participate in alliance events, such as wars, raids, rallies, quests, and more. You can also compete with other alliances for territory, resources, honor, and rewards. You can also fight against other players in PvP battles or against NPC enemies in PvE battles.
-Rise of the Kings Mod Apk 1.9.32 Full + OBB Data
-Download Rise of the Kings Mod Apk + OBB for Android
-How to Install Rise of the Kings Mod Apk + OBB on PC
-Rise of the Kings Mod Apk + OBB Unlimited Gems and Gold
-Rise of the Kings Mod Apk + OBB Latest Version 2023
-Rise of the Kings Mod Apk + OBB Offline Mode
-Rise of the Kings Mod Apk + OBB Hack and Cheats
-Rise of the Kings Mod Apk + OBB Gameplay and Review
-Rise of the Kings Mod Apk + OBB Free Download Link
-Rise of the Kings Mod Apk + OBB No Root Required
-Rise of the Kings Mod Apk + OBB Features and Benefits
-Rise of the Kings Mod Apk + OBB Tips and Tricks
-Rise of the Kings Mod Apk + OBB Best Strategy and Guide
-Rise of the Kings Mod Apk + OBB Compatible Devices and Requirements
-Rise of the Kings Mod Apk + OBB Update and Patch Notes
-Rise of the Kings Mod Apk + OBB Customer Support and Feedback
-Rise of the Kings Mod Apk + OBB Bug Fixes and Improvements
-Rise of the Kings Mod Apk + OBB Comparison and Alternatives
-Rise of the Kings Mod Apk + OBB Pros and Cons
-Rise of the Kings Mod Apk + OBB FAQ and Troubleshooting
-Rise of the Kings Mod Apk + OBB Forum and Community
-Rise of the Kings Mod Apk + OBB Wiki and Database
-Rise of the Kings Mod Apk + OBB Codes and Rewards
-Rise of the Kings Mod Apk + OBB Events and Promotions
-Rise of the Kings Mod Apk + OBB News and Updates
- Explore a vast world
-You can explore a vast world full of mysteries and surprises. You can discover new lands, resources, monsters, treasures, secrets, and more. You can also interact with other players in various ways, such as trading, chatting, gifting, spying, attacking, defending, and more. You can also experience different events and scenarios that change according to real-time situations.
- What is Rise of the Kings Mod APK + OBB?
-Rise of the Kings Mod APK + OBB is a modified version of the original game that gives you some advantages that are not available in the original game. These advantages include unlimited money, free VIP privileges, and no ads. With these benefits, you can enjoy the game without any limitations or interruptions. You can buy anything you want, access exclusive features, and play the game smoothly and comfortably.
- Benefits of Rise of the Kings Mod APK + OBB
-Here are some of the benefits of Rise of the Kings Mod APK + OBB that you can enjoy:
- Unlimited money
-Money is the main currency in the game that you can use to buy various items, such as resources, equipment, boosts, and more. With unlimited money, you can buy anything you want without worrying about running out of money. You can also speed up your progress and development by using money to upgrade your buildings, research new technologies, and train your army faster.
- Free VIP privileges
-VIP is a special status in the game that gives you access to exclusive features and benefits, such as extra resources, faster construction and research, more troops and heroes, and more. Normally, you have to pay real money to get VIP privileges or earn them by completing certain tasks. With Rise of the Kings Mod APK + OBB, you can get free VIP privileges without spending any money or doing any work. You can enjoy all the perks of being a VIP without any hassle.
- No ads
-Ads are annoying and distracting interruptions that can ruin your gaming experience. They can pop up at any time and force you to watch them or close them. They can also consume your data and battery life. With Rise of the Kings Mod APK + OBB, you can get rid of all the ads in the game and play the game without any interruptions or distractions. You can focus on your strategy and enjoy the game fully.
- How to download and install Rise of the Kings Mod APK + OBB?
-If you are interested in downloading and installing Rise of the Kings Mod APK + OBB, you need to follow some simple steps. Here are the steps you need to follow:
- Steps to download and install Rise of the Kings Mod APK + OBB
-Before you start, make sure you have enough storage space on your device and a stable internet connection.
- Download the files from a trusted source
-The first step is to download the files from a trusted source. You can find many websites that offer Rise of the Kings Mod APK + OBB files for free, but not all of them are safe and reliable. Some of them may contain viruses, malware, or spyware that can harm your device or steal your personal information. To avoid this, you should only download the files from a trusted source that has positive reviews and feedback from other users. You can use this link to download the files safely and securely.
- Enable unknown sources on your device
-The second step is to enable unknown sources on your device. This is a security setting that prevents you from installing apps from sources other than the official Google Play Store. Since Rise of the Kings Mod APK + OBB is not available on the Play Store, you need to enable unknown sources to install it on your device. To do this, go to your device settings > security > unknown sources > enable.
- Install the APK file and copy the OBB file to the Android/obb folder
-The third step is to install the APK file and copy the OBB file to the Android/obb folder. The APK file is the application file that contains the game data and code. The OBB file is the additional data file that contains the game graphics and sounds. To install the APK file, locate it in your device storage and tap on it. Follow the instructions on the screen to complete the installation. To copy the OBB file, locate it in your device storage and move it to the Android/obb folder. If you don't have this folder, create it manually.
- Launch the game and enjoy
-The final step is to launch the game and enjoy. To launch the game, go to your app drawer and tap on the Rise of the Kings icon. You will see the game loading screen and then the main menu. You can now enjoy the game with unlimited money, free VIP privileges, and no ads. You can also access all the features and content of the game without any restrictions or limitations.
- Conclusion
-Rise of the Kings is a strategy game that lets you build your own empire, recruit and train your army, forge alliances and fight enemies, and explore a vast world full of challenges and opportunities. It is a fun and addictive game that will keep you entertained for hours. However, if you want to enjoy the game without any limitations or interruptions, you should download and install Rise of the Kings Mod APK + OBB, a modified version of the game that gives you unlimited money, free VIP privileges, and no ads. With these benefits, you can buy anything you want, access exclusive features, and play the game smoothly and comfortably. To download and install Rise of the Kings Mod APK + OBB, you just need to follow some simple steps that we have explained in this article. We hope this article was helpful and informative for you. If you have any questions or feedback, feel free to leave a comment below.
- FAQs
-Here are some frequently asked questions about Rise of the Kings Mod APK + OBB:
- Is Rise of the Kings Mod APK + OBB safe to use?
-Yes, Rise of the Kings Mod APK + OBB is safe to use as long as you download it from a trusted source. We have provided a link to download the files safely and securely in this article. However, you should always be careful when downloading and installing any modded or hacked apps from unknown sources, as they may contain viruses, malware, or spyware that can harm your device or steal your personal information.
- Is Rise of the Kings Mod APK + OBB compatible with my device?
-Rise of the Kings Mod APK + OBB is compatible with most Android devices that run on Android 4.0.3 or higher. However, some devices may not support the game due to hardware or software limitations. To check if your device is compatible with the game, you can visit the official Google Play Store page of Rise of the Kings and see if your device is listed among the supported devices.
- Will I get banned for using Rise of the Kings Mod APK + OBB?
-There is a low risk of getting banned for using Rise of the Kings Mod APK + OBB, as the modded version does not interfere with the game servers or other players' accounts. However, you should always use the modded version at your own risk and discretion, as we cannot guarantee that it will work flawlessly or that it will not be detected by the game developers or moderators. If you want to avoid any potential issues or consequences, you should play the game with the original version.
- Can I update Rise of the Kings Mod APK + OBB?
-No, you cannot update Rise of the Kings Mod APK + OBB through the Google Play Store or any other official source. If you try to do so, you will lose all the benefits of the modded version and revert back to the original version. If you want to update the game, you will have to download and install the latest version of Rise of the Kings Mod APK + OBB from the same source that you downloaded it from. You may also have to uninstall the previous version of the game before installing the new one.
- Can I play Rise of the Kings Mod APK + OBB offline?
-No, you cannot play Rise of the Kings Mod APK + OBB offline, as the game requires an internet connection to run and function properly. The game is an online multiplayer game that connects you with other players from all over the world. You need an internet connection to access the game servers, chat with other players, participate in alliance events, and more. If you try to play the game offline, you will not be able to load the game or access any of its features.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/The Walking Dead How to Survive a Walker Attack.md b/spaces/congsaPfin/Manga-OCR/logs/The Walking Dead How to Survive a Walker Attack.md
deleted file mode 100644
index 16c3f4a5d5ef73843fc199730338d92c3a0166fe..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/The Walking Dead How to Survive a Walker Attack.md
+++ /dev/null
@@ -1,125 +0,0 @@
-
-The Walking Dead: A Guide to the Post-Apocalyptic Horror Series
- If you are a fan of horror, drama, and zombies, you might have heard of The Walking Dead, one of the most popular and acclaimed TV shows of the last decade. But what is The Walking Dead exactly, and why should you watch it? In this article, we will give you a comprehensive guide to the post-apocalyptic horror series, covering its origins, characters, themes, and more. Whether you are a newcomer or a longtime fan, we hope this article will help you enjoy The Walking Dead even more.
- What is The Walking Dead?
- The Walking Dead is a multimedia franchise that revolves around a group of survivors in a world overrun by zombies, or "walkers" as they are called in the series. The franchise consists of comic books, TV shows, video games, novels, webisodes, and movies. Here are some of the main components of the franchise:
-the walking dead
DOWNLOAD ❤❤❤ https://urlca.com/2uO6iZ
- The Walking Dead comic book series
- The original source material for The Walking Dead is a comic book series created by writer Robert Kirkman and artists Tony Moore and Charlie Adlard. The comic book series began in 2003 and ended in 2019, with 193 issues published. The comic book series follows the journey of Rick Grimes, a former sheriff's deputy who wakes up from a coma to find himself in a zombie apocalypse. He meets other survivors and forms a community with them, facing various threats from both the living and the dead. The comic book series is known for its dark, gritty, and realistic tone, as well as its shocking twists and deaths.
- The Walking Dead TV series
- The most popular adaptation of The Walking Dead is a TV series that premiered on AMC in 2010 and will conclude in 2022, with 11 seasons and 177 episodes. The TV series is developed by Frank Darabont and has several executive producers, including Kirkman, Gale Anne Hurd, David Alpert, Greg Nicotero, Scott M. Gimple, Angela Kang, and others. The TV series follows a similar storyline as the comic book series, but also introduces new characters, locations, and events. The TV series is praised for its compelling characters, performances, action sequences, makeup effects, and social commentary.
- The Walking Dead franchise
- Besides the comic book series and the TV series, The Walking Dead has expanded into a larger franchise that includes several spin-offs and movies. Some of the notable spin-offs are:
-
- Some of the upcoming movies are:
-
-- The Walking Dead, a trilogy of movies that will continue the story of Rick Grimes after his disappearance from the TV series.
-- Untitled Daryl and Carol Movie, a movie that will follow the adventures of Daryl Dixon and Carol Peletier after the end of the TV series.
-
- Who are the main characters of The Walking Dead?
- One of the strengths of The Walking Dead is its large and diverse cast of characters, who have different backgrounds, personalities, skills, and motivations. The characters evolve and change over time, as they face various challenges and dilemmas in the zombie apocalypse. Some of the main characters of The Walking Dead are:
- Rick Grimes
- Rick Grimes is the protagonist and leader of the group of survivors. He is a former sheriff's deputy who wakes up from a coma to find himself in a zombie apocalypse. He is determined to protect his family and friends, and to find a safe place to live. He is brave, loyal, resourceful, and compassionate, but also ruthless, pragmatic, and sometimes conflicted. He often struggles with his role as a leader, as he has to make difficult decisions that affect the lives of others. He is played by Andrew Lincoln in the TV series.
-The Walking Dead cast and crew
-The Walking Dead comic book series
-The Walking Dead spin-off shows
-The Walking Dead season 11 release date
-The Walking Dead zombies or walkers
-The Walking Dead Rick Grimes movies
-The Walking Dead best episodes and moments
-The Walking Dead merchandise and collectibles
-The Walking Dead fan theories and predictions
-The Walking Dead video games and apps
-The Walking Dead behind the scenes and trivia
-The Walking Dead crossover with Fear the Walking Dead
-The Walking Dead Negan and Lucille
-The Walking Dead Daryl Dixon and Carol Peletier
-The Walking Dead Michonne and her katana
-The Walking Dead Glenn Rhee and Maggie Greene
-The Walking Dead Carl Grimes and his eye patch
-The Walking Dead Morgan Jones and his stick
-The Walking Dead Eugene Porter and his mullet
-The Walking Dead Rosita Espinosa and her baby
-The Walking Dead Gabriel Stokes and his glasses
-The Walking Dead Aaron and his metal arm
-The Walking Dead Ezekiel and his tiger Shiva
-The Walking Dead Jerry and his axe
-The Walking Dead Sasha Williams and her sniper rifle
-The Walking Dead Tara Chambler and her sunglasses
-The Walking Dead Abraham Ford and his mustache
-The Walking Dead Hershel Greene and his farm
-The Walking Dead Shane Walsh and his betrayal
-The Walking Dead Lori Grimes and her pregnancy
-The Walking Dead Andrea and her gun skills
-The Walking Dead Merle Dixon and his knife hand
-The Walking Dead Dale Horvath and his RV
-The Walking Dead Sophia Peletier and her barn reveal
-The Walking Dead Beth Greene and her singing voice
-The Walking Dead Tyreese Williams and his hammer
-The Walking Dead Bob Stookey and his tainted meat
-The Walking Dead Noah and his revolving door death
-The Walking Dead Denise Cloyd and her arrow to the eye
-The Walking Dead Spencer Monroe and his guts spillage
-The Walking Dead Simon and his baseball bat swing
-The Walking Dead Jadis and her junkyard group
-The Walking Dead Enid and her JSS motto
-The Walking Dead Alpha and her Whisperers
-The Walking Dead Beta and his mask
-The Walking Dead Lydia and her mother issues
-The Walking Dead Yumiko and her lawyer background
-The Walking Dead Magna and her prison tattoos
-The Walking Dead Connie and her deafness
-The Walking Dead Princess and her pink jacket
- Daryl Dixon
- Daryl Dixon is one of the most popular and beloved characters of The Walking Dead. He is a skilled hunter, tracker, and fighter, who uses a crossbow as his signature weapon. He is loyal, brave, independent, and resilient, but also introverted, guarded, and sometimes volatile. He has a close bond with his brother Merle, who is often a source of conflict for him. He also develops a strong friendship with Carol Peletier, who helps him open up and heal from his past traumas. He is played by Norman Reedus in the TV series.
- Carol Peletier
- Carol Peletier is one of the longest-surviving characters of The Walking Dead. She starts off as a timid and abused housewife, who loses her husband and daughter in the zombie apocalypse. She then transforms into a strong, confident, and capable survivor, who is willing to do anything to protect her group. She is smart, resourceful, strategic, and compassionate, but also ruthless, cold, and sometimes manipulative. She has a close friendship with Daryl Dixon, who supports her through her losses and struggles. She is played by Melissa McBride in the TV series.
- Negan
- Negan is one of the most notorious and controversial characters of The Walking Dead. He is the leader of the Saviors, a large group of survivors who extort other communities for resources in exchange for protection from the walkers. He is charismatic, witty, sadistic, and violent, who uses a baseball bat wrapped in barbed wire named Lucille as his weapon of choice. He kills several members of Rick's group in a brutal way, sparking a war between them. He is later captured by Rick and imprisoned for years, until he redeems himself by helping them fight against other enemies. He is played by Jeffrey Dean Morgan in the TV series.
- What are the main themes of The Walking Dead?
- The Walking Dead is not just about zombies and gore. It is also about exploring various themes that are relevant to our society and humanity. Some of the main themes of The Walking Dead are:
- Survival
- The most obvious theme of The Walking Dead is survival. The characters have to survive not only from the walkers, but also from other humans who pose threats to them. They have to find food, water, shelter, weapons, medicine, and other resources to stay alive. They also have to deal with injuries, diseases, infections, hunger, thirst, fatigue, and stress. They have to adapt to different environments and situations, and overcome various obstacles and challenges. Survival is not easy or guaranteed in The Walking Dead, as many characters die or disappear along the way.
- Humanity
- Another theme of The Walking Dead is humanity. The characters have to question what it means to be human in a world where humanity seems to be lost or corrupted. They have to face moral dilemmas and ethical choices that test their values and principles. They have to balance their individual needs
and their group interests, and their personal feelings and their rational judgments. They have to cope with their emotions, such as fear, anger, grief, guilt, and hope. They have to maintain their sanity, dignity, and identity in a chaotic and cruel world. They have to find meaning and purpose in their existence, and to preserve their values and beliefs.
- Leadership
- A third theme of The Walking Dead is leadership. The characters have to decide who to follow and who to trust in a world where authority and order are gone or corrupted. They have to deal with different types of leaders, such as Rick Grimes, who is a democratic and benevolent leader, Negan, who is a tyrannical and oppressive leader, and the Governor, who is a charismatic and manipulative leader. They also have to face the challenges and responsibilities of being a leader themselves, such as making decisions, resolving conflicts, inspiring others, and facing consequences.
- Morality
- A fourth theme of The Walking Dead is morality. The characters have to determine what is right and wrong in a world where morality seems to be relative or irrelevant. They have to confront the ethical implications of their actions and choices, such as killing, stealing, lying, betraying, sacrificing, and forgiving. They have to deal with the moral gray areas and ambiguities that arise in the zombie apocalypse, such as whether to kill walkers or spare them, whether to help strangers or ignore them, whether to cooperate with other groups or compete with them, and whether to follow the rules or break them.
- Why should you watch The Walking Dead?
- Now that you know what The Walking Dead is about, you might be wondering why you should watch it. Here are some of the reasons why The Walking Dead is worth watching:
- The Walking Dead is thrilling and suspenseful
- If you like horror and action, you will love The Walking Dead. The series is full of thrilling and suspenseful scenes that will keep you on the edge of your seat. You will witness the characters fighting against hordes of walkers, escaping from dangerous situations, encountering new enemies, and facing unexpected twists. You will also enjoy the stunning visuals, sound effects, and music that create a tense and immersive atmosphere.
- The Walking Dead is emotional and character-driven
- If you like drama and character development, you will love The Walking Dead. The series is not just about zombies and violence. It is also about the human stories and relationships that emerge in the zombie apocalypse. You will get to know the characters deeply, their backgrounds, personalities, motivations, and goals. You will care about them, root for them, cry for them, and sometimes hate them. You will also witness their growth and change over time, as they face various challenges and dilemmas.
- The Walking Dead is creative and diverse
- If you like creativity and diversity, you will love The Walking Dead. The series is not just a repetitive or predictable show. It is constantly evolving and expanding its scope and scale. You will explore different settings and locations, such as Atlanta, Hershel's farm, the prison, Terminus, Alexandria, the Kingdom, the Hilltop, the Sanctuary , and Oceanside. You will meet different groups and communities, such as the Survivors, the Saviors, the Whisperers, the Commonwealth, and the CRM. You will encounter different types of walkers, such as the roamers, the lurkers, the herd, the spiked, and the radioactive. You will also enjoy the various spin-offs and movies that expand the universe and explore new stories and characters.
- How to watch The Walking Dead?
- If you are interested in watching The Walking Dead, you might be wondering how to do it. Here are some of the ways you can watch The Walking Dead:
- The Walking Dead streaming platforms
- The easiest way to watch The Walking Dead is to stream it online. You can find all the episodes of the TV series on various streaming platforms, such as Netflix, Hulu, Amazon Prime Video, AMC+, and others. You can also find some of the spin-offs and movies on these platforms, or on other platforms, such as YouTube, iTunes, Google Play, and others. You can choose the platform that suits your preferences and budget, and enjoy The Walking Dead anytime and anywhere.
- The Walking Dead spin-offs and movies
- Another way to watch The Walking Dead is to watch its spin-offs and movies. You can find some of the spin-offs on the same streaming platforms as the TV series, or on other platforms, such as AMC's website or app. You can also find some of the movies on these platforms, or on other platforms, such as theaters or cable TV. You can choose the spin-off or movie that interests you, and enjoy a different perspective or experience of The Walking Dead.
- Conclusion
- In conclusion, The Walking Dead is a post-apocalyptic horror series that has captivated millions of fans around the world. It is a franchise that consists of comic books, TV shows, video games, novels, webisodes, and movies. It is a series that features a large and diverse cast of characters, who have to survive in a world overrun by zombies and other threats. It is a series that explores various themes that are relevant to our society and humanity. It is a series that is thrilling, emotional, creative, and diverse. It is a series that you should watch if you are a fan of horror, drama, and zombies.
- Here are some FAQs about The Walking Dead:
-
-- Q: When will The Walking Dead end?
-- A: The Walking Dead TV series will end in 2022, with its 11th and final season. However, the franchise will continue with its spin-offs and movies.
-- Q: How faithful is The Walking Dead TV series to the comic book series?
-- A: The Walking Dead TV series is based on the comic book series, but it also deviates from it in many ways. Some of the differences include new characters, locations, events, deaths, and endings.
-- Q: Who are the Whisperers?
-- A: The Whisperers are one of the main antagonists of The Walking Dead. They are a group of survivors who wear walker skins to blend in with them and to communicate with them. They are led by Alpha and Beta.
-- Q: What is CRM?
-- A: CRM is an acronym for Civic Republic Military. It is a mysterious and powerful organization that has access to advanced technology and resources. It is involved in the disappearance of Rick Grimes and the experiments on walkers.
-- Q: What is Lucille?
-- A: Lucille is the name of Negan's baseball bat wrapped in barbed wire. It is also the name of his late wife, who died of cancer before the zombie apocalypse.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/cooelf/Multimodal-CoT/timm/models/vision_transformer_hybrid.py b/spaces/cooelf/Multimodal-CoT/timm/models/vision_transformer_hybrid.py
deleted file mode 100644
index d5f0a5377ec9492c5ed55ceb3ce5a4378cbb8e3c..0000000000000000000000000000000000000000
--- a/spaces/cooelf/Multimodal-CoT/timm/models/vision_transformer_hybrid.py
+++ /dev/null
@@ -1,363 +0,0 @@
-""" Hybrid Vision Transformer (ViT) in PyTorch
-
-A PyTorch implement of the Hybrid Vision Transformers as described in:
-
-'An Image Is Worth 16 x 16 Words: Transformers for Image Recognition at Scale'
- - https://arxiv.org/abs/2010.11929
-
-`How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers`
- - https://arxiv.org/abs/2106.TODO
-
-NOTE These hybrid model definitions depend on code in vision_transformer.py.
-They were moved here to keep file sizes sane.
-
-Hacked together by / Copyright 2021 Ross Wightman
-"""
-from copy import deepcopy
-from functools import partial
-
-import torch
-import torch.nn as nn
-
-from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
-from .layers import StdConv2dSame, StdConv2d, to_2tuple
-from .resnet import resnet26d, resnet50d
-from .resnetv2 import ResNetV2, create_resnetv2_stem
-from .registry import register_model
-from timm.models.vision_transformer import _create_vision_transformer
-
-
-def _cfg(url='', **kwargs):
- return {
- 'url': url,
- 'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
- 'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
- 'mean': (0.5, 0.5, 0.5), 'std': (0.5, 0.5, 0.5),
- 'first_conv': 'patch_embed.backbone.stem.conv', 'classifier': 'head',
- **kwargs
- }
-
-
-default_cfgs = {
- # hybrid in-1k models (weights from official JAX impl where they exist)
- 'vit_tiny_r_s16_p8_224': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/'
- 'R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_224.npz',
- first_conv='patch_embed.backbone.conv'),
- 'vit_tiny_r_s16_p8_384': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/'
- 'R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz',
- first_conv='patch_embed.backbone.conv', input_size=(3, 384, 384), crop_pct=1.0),
- 'vit_small_r26_s32_224': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/'
- 'R26_S_32-i21k-300ep-lr_0.001-aug_light0-wd_0.03-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.03-res_224.npz',
- ),
- 'vit_small_r26_s32_384': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/'
- 'R26_S_32-i21k-300ep-lr_0.001-aug_medium2-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz',
- input_size=(3, 384, 384), crop_pct=1.0),
- 'vit_base_r26_s32_224': _cfg(),
- 'vit_base_r50_s16_224': _cfg(),
- 'vit_base_r50_s16_384': _cfg(
- url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_resnet50_384-9fd3c705.pth',
- input_size=(3, 384, 384), crop_pct=1.0),
- 'vit_large_r50_s32_224': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/'
- 'R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_224.npz'
- ),
- 'vit_large_r50_s32_384': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/'
- 'R50_L_32-i21k-300ep-lr_0.001-aug_medium2-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz',
- input_size=(3, 384, 384), crop_pct=1.0
- ),
-
- # hybrid in-21k models (weights from official Google JAX impl where they exist)
- 'vit_tiny_r_s16_p8_224_in21k': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz',
- num_classes=21843, crop_pct=0.9, first_conv='patch_embed.backbone.conv'),
- 'vit_small_r26_s32_224_in21k': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_medium2-wd_0.03-do_0.0-sd_0.0.npz',
- num_classes=21843, crop_pct=0.9),
- 'vit_base_r50_s16_224_in21k': _cfg(
- url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_resnet50_224_in21k-6f7c7740.pth',
- num_classes=21843, crop_pct=0.9),
- 'vit_large_r50_s32_224_in21k': _cfg(
- url='https://storage.googleapis.com/vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium2-wd_0.1-do_0.0-sd_0.0.npz',
- num_classes=21843, crop_pct=0.9),
-
- # hybrid models (using timm resnet backbones)
- 'vit_small_resnet26d_224': _cfg(
- mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD, first_conv='patch_embed.backbone.conv1.0'),
- 'vit_small_resnet50d_s16_224': _cfg(
- mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD, first_conv='patch_embed.backbone.conv1.0'),
- 'vit_base_resnet26d_224': _cfg(
- mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD, first_conv='patch_embed.backbone.conv1.0'),
- 'vit_base_resnet50d_224': _cfg(
- mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD, first_conv='patch_embed.backbone.conv1.0'),
-}
-
-
-class HybridEmbed(nn.Module):
- """ CNN Feature Map Embedding
- Extract feature map from CNN, flatten, project to embedding dim.
- """
- def __init__(self, backbone, img_size=224, patch_size=1, feature_size=None, in_chans=3, embed_dim=768):
- super().__init__()
- assert isinstance(backbone, nn.Module)
- img_size = to_2tuple(img_size)
- patch_size = to_2tuple(patch_size)
- self.img_size = img_size
- self.patch_size = patch_size
- self.backbone = backbone
- if feature_size is None:
- with torch.no_grad():
- # NOTE Most reliable way of determining output dims is to run forward pass
- training = backbone.training
- if training:
- backbone.eval()
- o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))
- if isinstance(o, (list, tuple)):
- o = o[-1] # last feature if backbone outputs list/tuple of features
- feature_size = o.shape[-2:]
- feature_dim = o.shape[1]
- backbone.train(training)
- else:
- feature_size = to_2tuple(feature_size)
- if hasattr(self.backbone, 'feature_info'):
- feature_dim = self.backbone.feature_info.channels()[-1]
- else:
- feature_dim = self.backbone.num_features
- assert feature_size[0] % patch_size[0] == 0 and feature_size[1] % patch_size[1] == 0
- self.grid_size = (feature_size[0] // patch_size[0], feature_size[1] // patch_size[1])
- self.num_patches = self.grid_size[0] * self.grid_size[1]
- self.proj = nn.Conv2d(feature_dim, embed_dim, kernel_size=patch_size, stride=patch_size)
-
- def forward(self, x):
- x = self.backbone(x)
- if isinstance(x, (list, tuple)):
- x = x[-1] # last feature if backbone outputs list/tuple of features
- x = self.proj(x).flatten(2).transpose(1, 2)
- return x
-
-
-def _create_vision_transformer_hybrid(variant, backbone, pretrained=False, **kwargs):
- embed_layer = partial(HybridEmbed, backbone=backbone)
- kwargs.setdefault('patch_size', 1) # default patch size for hybrid models if not set
- return _create_vision_transformer(
- variant, pretrained=pretrained, embed_layer=embed_layer, default_cfg=default_cfgs[variant], **kwargs)
-
-
-def _resnetv2(layers=(3, 4, 9), **kwargs):
- """ ResNet-V2 backbone helper"""
- padding_same = kwargs.get('padding_same', True)
- stem_type = 'same' if padding_same else ''
- conv_layer = partial(StdConv2dSame, eps=1e-8) if padding_same else partial(StdConv2d, eps=1e-8)
- if len(layers):
- backbone = ResNetV2(
- layers=layers, num_classes=0, global_pool='', in_chans=kwargs.get('in_chans', 3),
- preact=False, stem_type=stem_type, conv_layer=conv_layer)
- else:
- backbone = create_resnetv2_stem(
- kwargs.get('in_chans', 3), stem_type=stem_type, preact=False, conv_layer=conv_layer)
- return backbone
-
-
-@register_model
-def vit_tiny_r_s16_p8_224(pretrained=False, **kwargs):
- """ R+ViT-Ti/S16 w/ 8x8 patch hybrid @ 224 x 224.
- """
- backbone = _resnetv2(layers=(), **kwargs)
- model_kwargs = dict(patch_size=8, embed_dim=192, depth=12, num_heads=3, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_tiny_r_s16_p8_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_tiny_r_s16_p8_384(pretrained=False, **kwargs):
- """ R+ViT-Ti/S16 w/ 8x8 patch hybrid @ 384 x 384.
- """
- backbone = _resnetv2(layers=(), **kwargs)
- model_kwargs = dict(patch_size=8, embed_dim=192, depth=12, num_heads=3, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_tiny_r_s16_p8_384', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_small_r26_s32_224(pretrained=False, **kwargs):
- """ R26+ViT-S/S32 hybrid.
- """
- backbone = _resnetv2((2, 2, 2, 2), **kwargs)
- model_kwargs = dict(embed_dim=384, depth=12, num_heads=6, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_small_r26_s32_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_small_r26_s32_384(pretrained=False, **kwargs):
- """ R26+ViT-S/S32 hybrid.
- """
- backbone = _resnetv2((2, 2, 2, 2), **kwargs)
- model_kwargs = dict(embed_dim=384, depth=12, num_heads=6, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_small_r26_s32_384', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_base_r26_s32_224(pretrained=False, **kwargs):
- """ R26+ViT-B/S32 hybrid.
- """
- backbone = _resnetv2((2, 2, 2, 2), **kwargs)
- model_kwargs = dict(embed_dim=768, depth=12, num_heads=12, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_base_r26_s32_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_base_r50_s16_224(pretrained=False, **kwargs):
- """ R50+ViT-B/S16 hybrid from original paper (https://arxiv.org/abs/2010.11929).
- """
- backbone = _resnetv2((3, 4, 9), **kwargs)
- model_kwargs = dict(embed_dim=768, depth=12, num_heads=12, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_base_r50_s16_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_base_r50_s16_384(pretrained=False, **kwargs):
- """ R50+ViT-B/16 hybrid from original paper (https://arxiv.org/abs/2010.11929).
- ImageNet-1k weights fine-tuned from in21k @ 384x384, source https://github.com/google-research/vision_transformer.
- """
- backbone = _resnetv2((3, 4, 9), **kwargs)
- model_kwargs = dict(embed_dim=768, depth=12, num_heads=12, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_base_r50_s16_384', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_base_resnet50_384(pretrained=False, **kwargs):
- # DEPRECATED this is forwarding to model def above for backwards compatibility
- return vit_base_r50_s16_384(pretrained=pretrained, **kwargs)
-
-
-@register_model
-def vit_large_r50_s32_224(pretrained=False, **kwargs):
- """ R50+ViT-L/S32 hybrid.
- """
- backbone = _resnetv2((3, 4, 6, 3), **kwargs)
- model_kwargs = dict(embed_dim=1024, depth=24, num_heads=16, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_large_r50_s32_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_large_r50_s32_384(pretrained=False, **kwargs):
- """ R50+ViT-L/S32 hybrid.
- """
- backbone = _resnetv2((3, 4, 6, 3), **kwargs)
- model_kwargs = dict(embed_dim=1024, depth=24, num_heads=16, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_large_r50_s32_384', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_tiny_r_s16_p8_224_in21k(pretrained=False, **kwargs):
- """ R+ViT-Ti/S16 w/ 8x8 patch hybrid. ImageNet-21k.
- """
- backbone = _resnetv2(layers=(), **kwargs)
- model_kwargs = dict(patch_size=8, embed_dim=192, depth=12, num_heads=3, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_tiny_r_s16_p8_224_in21k', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_small_r26_s32_224_in21k(pretrained=False, **kwargs):
- """ R26+ViT-S/S32 hybrid. ImageNet-21k.
- """
- backbone = _resnetv2((2, 2, 2, 2), **kwargs)
- model_kwargs = dict(embed_dim=384, depth=12, num_heads=6, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_small_r26_s32_224_in21k', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_base_r50_s16_224_in21k(pretrained=False, **kwargs):
- """ R50+ViT-B/16 hybrid model from original paper (https://arxiv.org/abs/2010.11929).
- ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
- """
- backbone = _resnetv2(layers=(3, 4, 9), **kwargs)
- model_kwargs = dict(embed_dim=768, depth=12, num_heads=12, representation_size=768, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_base_r50_s16_224_in21k', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_base_resnet50_224_in21k(pretrained=False, **kwargs):
- # DEPRECATED this is forwarding to model def above for backwards compatibility
- return vit_base_r50_s16_224_in21k(pretrained=pretrained, **kwargs)
-
-
-@register_model
-def vit_large_r50_s32_224_in21k(pretrained=False, **kwargs):
- """ R50+ViT-L/S32 hybrid. ImageNet-21k.
- """
- backbone = _resnetv2((3, 4, 6, 3), **kwargs)
- model_kwargs = dict(embed_dim=1024, depth=24, num_heads=16, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_large_r50_s32_224_in21k', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_small_resnet26d_224(pretrained=False, **kwargs):
- """ Custom ViT small hybrid w/ ResNet26D stride 32. No pretrained weights.
- """
- backbone = resnet26d(pretrained=pretrained, in_chans=kwargs.get('in_chans', 3), features_only=True, out_indices=[4])
- model_kwargs = dict(embed_dim=768, depth=8, num_heads=8, mlp_ratio=3, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_small_resnet26d_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_small_resnet50d_s16_224(pretrained=False, **kwargs):
- """ Custom ViT small hybrid w/ ResNet50D 3-stages, stride 16. No pretrained weights.
- """
- backbone = resnet50d(pretrained=pretrained, in_chans=kwargs.get('in_chans', 3), features_only=True, out_indices=[3])
- model_kwargs = dict(embed_dim=768, depth=8, num_heads=8, mlp_ratio=3, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_small_resnet50d_s16_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_base_resnet26d_224(pretrained=False, **kwargs):
- """ Custom ViT base hybrid w/ ResNet26D stride 32. No pretrained weights.
- """
- backbone = resnet26d(pretrained=pretrained, in_chans=kwargs.get('in_chans', 3), features_only=True, out_indices=[4])
- model_kwargs = dict(embed_dim=768, depth=12, num_heads=12, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_base_resnet26d_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
-
-
-@register_model
-def vit_base_resnet50d_224(pretrained=False, **kwargs):
- """ Custom ViT base hybrid w/ ResNet50D stride 32. No pretrained weights.
- """
- backbone = resnet50d(pretrained=pretrained, in_chans=kwargs.get('in_chans', 3), features_only=True, out_indices=[4])
- model_kwargs = dict(embed_dim=768, depth=12, num_heads=12, **kwargs)
- model = _create_vision_transformer_hybrid(
- 'vit_base_resnet50d_224', backbone=backbone, pretrained=pretrained, **model_kwargs)
- return model
\ No newline at end of file
diff --git a/spaces/cooelf/Multimodal-CoT/timm/utils/__init__.py b/spaces/cooelf/Multimodal-CoT/timm/utils/__init__.py
deleted file mode 100644
index d02e62d2d0ce62e594393014208e28c3ace5318b..0000000000000000000000000000000000000000
--- a/spaces/cooelf/Multimodal-CoT/timm/utils/__init__.py
+++ /dev/null
@@ -1,13 +0,0 @@
-from .agc import adaptive_clip_grad
-from .checkpoint_saver import CheckpointSaver
-from .clip_grad import dispatch_clip_grad
-from .cuda import ApexScaler, NativeScaler
-from .distributed import distribute_bn, reduce_tensor
-from .jit import set_jit_legacy
-from .log import setup_default_logging, FormatterNoInfo
-from .metrics import AverageMeter, accuracy
-from .misc import natural_key, add_bool_arg
-from .model import unwrap_model, get_state_dict
-from .model_ema import ModelEma, ModelEmaV2
-from .random import random_seed
-from .summary import update_summary, get_outdir
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmseg/models/decode_heads/aspp_head.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmseg/models/decode_heads/aspp_head.py
deleted file mode 100644
index 3c0aadb2b097a604d96ba1c99c05663b7884b6e0..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/mmpkg/mmseg/models/decode_heads/aspp_head.py
+++ /dev/null
@@ -1,107 +0,0 @@
-import torch
-import torch.nn as nn
-from annotator.mmpkg.mmcv.cnn import ConvModule
-
-from annotator.mmpkg.mmseg.ops import resize
-from ..builder import HEADS
-from .decode_head import BaseDecodeHead
-
-
-class ASPPModule(nn.ModuleList):
- """Atrous Spatial Pyramid Pooling (ASPP) Module.
-
- Args:
- dilations (tuple[int]): Dilation rate of each layer.
- in_channels (int): Input channels.
- channels (int): Channels after modules, before conv_seg.
- conv_cfg (dict|None): Config of conv layers.
- norm_cfg (dict|None): Config of norm layers.
- act_cfg (dict): Config of activation layers.
- """
-
- def __init__(self, dilations, in_channels, channels, conv_cfg, norm_cfg,
- act_cfg):
- super(ASPPModule, self).__init__()
- self.dilations = dilations
- self.in_channels = in_channels
- self.channels = channels
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.act_cfg = act_cfg
- for dilation in dilations:
- self.append(
- ConvModule(
- self.in_channels,
- self.channels,
- 1 if dilation == 1 else 3,
- dilation=dilation,
- padding=0 if dilation == 1 else dilation,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg))
-
- def forward(self, x):
- """Forward function."""
- aspp_outs = []
- for aspp_module in self:
- aspp_outs.append(aspp_module(x))
-
- return aspp_outs
-
-
-@HEADS.register_module()
-class ASPPHead(BaseDecodeHead):
- """Rethinking Atrous Convolution for Semantic Image Segmentation.
-
- This head is the implementation of `DeepLabV3
- `_.
-
- Args:
- dilations (tuple[int]): Dilation rates for ASPP module.
- Default: (1, 6, 12, 18).
- """
-
- def __init__(self, dilations=(1, 6, 12, 18), **kwargs):
- super(ASPPHead, self).__init__(**kwargs)
- assert isinstance(dilations, (list, tuple))
- self.dilations = dilations
- self.image_pool = nn.Sequential(
- nn.AdaptiveAvgPool2d(1),
- ConvModule(
- self.in_channels,
- self.channels,
- 1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg))
- self.aspp_modules = ASPPModule(
- dilations,
- self.in_channels,
- self.channels,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
- self.bottleneck = ConvModule(
- (len(dilations) + 1) * self.channels,
- self.channels,
- 3,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
-
- def forward(self, inputs):
- """Forward function."""
- x = self._transform_inputs(inputs)
- aspp_outs = [
- resize(
- self.image_pool(x),
- size=x.size()[2:],
- mode='bilinear',
- align_corners=self.align_corners)
- ]
- aspp_outs.extend(self.aspp_modules(x))
- aspp_outs = torch.cat(aspp_outs, dim=1)
- output = self.bottleneck(aspp_outs)
- output = self.cls_seg(output)
- return output
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/oneformer/data/datasets/__init__.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/oneformer/data/datasets/__init__.py
deleted file mode 100644
index 59ce30713f63d056107b2a06ecd434eb27a30b7d..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/oneformer/data/datasets/__init__.py
+++ /dev/null
@@ -1,7 +0,0 @@
-from . import (
- register_ade20k_panoptic,
- register_cityscapes_panoptic,
- register_coco_panoptic_annos_semseg,
- register_ade20k_instance,
- register_coco_panoptic2instance,
-)
diff --git a/spaces/cymic/Talking_Head_Anime_3/tha3/nn/separable_conv.py b/spaces/cymic/Talking_Head_Anime_3/tha3/nn/separable_conv.py
deleted file mode 100644
index e33bce3c25aa279e7a7fbb0a7998a3f3788e4c25..0000000000000000000000000000000000000000
--- a/spaces/cymic/Talking_Head_Anime_3/tha3/nn/separable_conv.py
+++ /dev/null
@@ -1,119 +0,0 @@
-from typing import Optional
-
-from torch.nn import Sequential, Conv2d, ConvTranspose2d, Module
-
-from tha3.nn.normalization import NormalizationLayerFactory
-from tha3.nn.util import BlockArgs, wrap_conv_or_linear_module
-
-
-def create_separable_conv3(in_channels: int, out_channels: int,
- bias: bool = False,
- initialization_method='he',
- use_spectral_norm: bool = False) -> Module:
- return Sequential(
- wrap_conv_or_linear_module(
- Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1, bias=False, groups=in_channels),
- initialization_method,
- use_spectral_norm),
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
- initialization_method,
- use_spectral_norm))
-
-
-def create_separable_conv7(in_channels: int, out_channels: int,
- bias: bool = False,
- initialization_method='he',
- use_spectral_norm: bool = False) -> Module:
- return Sequential(
- wrap_conv_or_linear_module(
- Conv2d(in_channels, in_channels, kernel_size=7, stride=1, padding=3, bias=False, groups=in_channels),
- initialization_method,
- use_spectral_norm),
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
- initialization_method,
- use_spectral_norm))
-
-
-def create_separable_conv3_block(
- in_channels: int, out_channels: int, block_args: Optional[BlockArgs] = None):
- if block_args is None:
- block_args = BlockArgs()
- return Sequential(
- wrap_conv_or_linear_module(
- Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1, bias=False, groups=in_channels),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- NormalizationLayerFactory.resolve_2d(block_args.normalization_layer_factory).create(out_channels, affine=True),
- block_args.nonlinearity_factory.create())
-
-
-def create_separable_conv7_block(
- in_channels: int, out_channels: int, block_args: Optional[BlockArgs] = None):
- if block_args is None:
- block_args = BlockArgs()
- return Sequential(
- wrap_conv_or_linear_module(
- Conv2d(in_channels, in_channels, kernel_size=7, stride=1, padding=3, bias=False, groups=in_channels),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- NormalizationLayerFactory.resolve_2d(block_args.normalization_layer_factory).create(out_channels, affine=True),
- block_args.nonlinearity_factory.create())
-
-
-def create_separable_downsample_block(
- in_channels: int, out_channels: int, is_output_1x1: bool, block_args: Optional[BlockArgs] = None):
- if block_args is None:
- block_args = BlockArgs()
- if is_output_1x1:
- return Sequential(
- wrap_conv_or_linear_module(
- Conv2d(in_channels, in_channels, kernel_size=4, stride=2, padding=1, bias=False, groups=in_channels),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- block_args.nonlinearity_factory.create())
- else:
- return Sequential(
- wrap_conv_or_linear_module(
- Conv2d(in_channels, in_channels, kernel_size=4, stride=2, padding=1, bias=False, groups=in_channels),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- NormalizationLayerFactory.resolve_2d(block_args.normalization_layer_factory)
- .create(out_channels, affine=True),
- block_args.nonlinearity_factory.create())
-
-
-def create_separable_upsample_block(
- in_channels: int, out_channels: int, block_args: Optional[BlockArgs] = None):
- if block_args is None:
- block_args = BlockArgs()
- return Sequential(
- wrap_conv_or_linear_module(
- ConvTranspose2d(
- in_channels, in_channels, kernel_size=4, stride=2, padding=1, bias=False, groups=in_channels),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- wrap_conv_or_linear_module(
- Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
- block_args.initialization_method,
- block_args.use_spectral_norm),
- NormalizationLayerFactory.resolve_2d(block_args.normalization_layer_factory)
- .create(out_channels, affine=True),
- block_args.nonlinearity_factory.create())
diff --git a/spaces/darkartsaibwd/Envvi-Inkpunk-Diffusion/README.md b/spaces/darkartsaibwd/Envvi-Inkpunk-Diffusion/README.md
deleted file mode 100644
index 50c55a51990d9b9881b7d512e52772fac537ee52..0000000000000000000000000000000000000000
--- a/spaces/darkartsaibwd/Envvi-Inkpunk-Diffusion/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Envvi Inkpunk Diffusion
-emoji: 🏃
-colorFrom: purple
-colorTo: green
-sdk: gradio
-sdk_version: 3.24.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/dawood17/SayBot_Enchancer/CodeFormer/basicsr/utils/options.py b/spaces/dawood17/SayBot_Enchancer/CodeFormer/basicsr/utils/options.py
deleted file mode 100644
index db490e4aa52e26fde31959fd74c2cef3af2ecf76..0000000000000000000000000000000000000000
--- a/spaces/dawood17/SayBot_Enchancer/CodeFormer/basicsr/utils/options.py
+++ /dev/null
@@ -1,108 +0,0 @@
-import yaml
-import time
-from collections import OrderedDict
-from os import path as osp
-from basicsr.utils.misc import get_time_str
-
-def ordered_yaml():
- """Support OrderedDict for yaml.
-
- Returns:
- yaml Loader and Dumper.
- """
- try:
- from yaml import CDumper as Dumper
- from yaml import CLoader as Loader
- except ImportError:
- from yaml import Dumper, Loader
-
- _mapping_tag = yaml.resolver.BaseResolver.DEFAULT_MAPPING_TAG
-
- def dict_representer(dumper, data):
- return dumper.represent_dict(data.items())
-
- def dict_constructor(loader, node):
- return OrderedDict(loader.construct_pairs(node))
-
- Dumper.add_representer(OrderedDict, dict_representer)
- Loader.add_constructor(_mapping_tag, dict_constructor)
- return Loader, Dumper
-
-
-def parse(opt_path, root_path, is_train=True):
- """Parse option file.
-
- Args:
- opt_path (str): Option file path.
- is_train (str): Indicate whether in training or not. Default: True.
-
- Returns:
- (dict): Options.
- """
- with open(opt_path, mode='r') as f:
- Loader, _ = ordered_yaml()
- opt = yaml.load(f, Loader=Loader)
-
- opt['is_train'] = is_train
-
- # opt['name'] = f"{get_time_str()}_{opt['name']}"
- if opt['path'].get('resume_state', None): # Shangchen added
- resume_state_path = opt['path'].get('resume_state')
- opt['name'] = resume_state_path.split("/")[-3]
- else:
- opt['name'] = f"{get_time_str()}_{opt['name']}"
-
-
- # datasets
- for phase, dataset in opt['datasets'].items():
- # for several datasets, e.g., test_1, test_2
- phase = phase.split('_')[0]
- dataset['phase'] = phase
- if 'scale' in opt:
- dataset['scale'] = opt['scale']
- if dataset.get('dataroot_gt') is not None:
- dataset['dataroot_gt'] = osp.expanduser(dataset['dataroot_gt'])
- if dataset.get('dataroot_lq') is not None:
- dataset['dataroot_lq'] = osp.expanduser(dataset['dataroot_lq'])
-
- # paths
- for key, val in opt['path'].items():
- if (val is not None) and ('resume_state' in key or 'pretrain_network' in key):
- opt['path'][key] = osp.expanduser(val)
-
- if is_train:
- experiments_root = osp.join(root_path, 'experiments', opt['name'])
- opt['path']['experiments_root'] = experiments_root
- opt['path']['models'] = osp.join(experiments_root, 'models')
- opt['path']['training_states'] = osp.join(experiments_root, 'training_states')
- opt['path']['log'] = experiments_root
- opt['path']['visualization'] = osp.join(experiments_root, 'visualization')
-
- else: # test
- results_root = osp.join(root_path, 'results', opt['name'])
- opt['path']['results_root'] = results_root
- opt['path']['log'] = results_root
- opt['path']['visualization'] = osp.join(results_root, 'visualization')
-
- return opt
-
-
-def dict2str(opt, indent_level=1):
- """dict to string for printing options.
-
- Args:
- opt (dict): Option dict.
- indent_level (int): Indent level. Default: 1.
-
- Return:
- (str): Option string for printing.
- """
- msg = '\n'
- for k, v in opt.items():
- if isinstance(v, dict):
- msg += ' ' * (indent_level * 2) + k + ':['
- msg += dict2str(v, indent_level + 1)
- msg += ' ' * (indent_level * 2) + ']\n'
- else:
- msg += ' ' * (indent_level * 2) + k + ': ' + str(v) + '\n'
- return msg
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/altair/vegalite/v5/data.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/altair/vegalite/v5/data.py
deleted file mode 100644
index 703dffb3246a32f4734f0653dfcc1aaa0d1d23f9..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/altair/vegalite/v5/data.py
+++ /dev/null
@@ -1,43 +0,0 @@
-from ..data import (
- MaxRowsError,
- curry,
- default_data_transformer,
- limit_rows,
- pipe,
- sample,
- to_csv,
- to_json,
- to_values,
- DataTransformerRegistry,
-)
-
-
-# ==============================================================================
-# VegaLite 5 data transformers
-# ==============================================================================
-
-
-ENTRY_POINT_GROUP = "altair.vegalite.v5.data_transformer" # type: str
-
-
-data_transformers = DataTransformerRegistry(
- entry_point_group=ENTRY_POINT_GROUP
-) # type: DataTransformerRegistry
-data_transformers.register("default", default_data_transformer)
-data_transformers.register("json", to_json)
-data_transformers.register("csv", to_csv)
-data_transformers.enable("default")
-
-
-__all__ = (
- "MaxRowsError",
- "curry",
- "default_data_transformer",
- "limit_rows",
- "pipe",
- "sample",
- "to_csv",
- "to_json",
- "to_values",
- "data_transformers",
-)
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio_client/utils.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio_client/utils.py
deleted file mode 100644
index 850e6f8882bd3295a01c9285b136dc54c3daa7d3..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio_client/utils.py
+++ /dev/null
@@ -1,575 +0,0 @@
-from __future__ import annotations
-
-import asyncio
-import base64
-import json
-import mimetypes
-import os
-import pkgutil
-import secrets
-import shutil
-import tempfile
-import warnings
-from concurrent.futures import CancelledError
-from dataclasses import dataclass, field
-from datetime import datetime
-from enum import Enum
-from pathlib import Path
-from threading import Lock
-from typing import Any, Callable, Optional
-
-import fsspec.asyn
-import httpx
-import huggingface_hub
-import requests
-from huggingface_hub import SpaceStage
-from websockets.legacy.protocol import WebSocketCommonProtocol
-
-API_URL = "api/predict/"
-WS_URL = "queue/join"
-UPLOAD_URL = "upload"
-CONFIG_URL = "config"
-API_INFO_URL = "info"
-RAW_API_INFO_URL = "info?serialize=False"
-SPACE_FETCHER_URL = "https://gradio-space-api-fetcher-v2.hf.space/api"
-RESET_URL = "reset"
-SPACE_URL = "https://hf.space/{}"
-
-SKIP_COMPONENTS = {
- "state",
- "row",
- "column",
- "tabs",
- "tab",
- "tabitem",
- "box",
- "form",
- "accordion",
- "group",
- "interpretation",
- "dataset",
-}
-STATE_COMPONENT = "state"
-INVALID_RUNTIME = [
- SpaceStage.NO_APP_FILE,
- SpaceStage.CONFIG_ERROR,
- SpaceStage.BUILD_ERROR,
- SpaceStage.RUNTIME_ERROR,
- SpaceStage.PAUSED,
-]
-
-__version__ = (pkgutil.get_data(__name__, "version.txt") or b"").decode("ascii").strip()
-
-
-class TooManyRequestsError(Exception):
- """Raised when the API returns a 429 status code."""
-
- pass
-
-
-class QueueError(Exception):
- """Raised when the queue is full or there is an issue adding a job to the queue."""
-
- pass
-
-
-class InvalidAPIEndpointError(Exception):
- """Raised when the API endpoint is invalid."""
-
- pass
-
-
-class SpaceDuplicationError(Exception):
- """Raised when something goes wrong with a Space Duplication."""
-
- pass
-
-
-class Status(Enum):
- """Status codes presented to client users."""
-
- STARTING = "STARTING"
- JOINING_QUEUE = "JOINING_QUEUE"
- QUEUE_FULL = "QUEUE_FULL"
- IN_QUEUE = "IN_QUEUE"
- SENDING_DATA = "SENDING_DATA"
- PROCESSING = "PROCESSING"
- ITERATING = "ITERATING"
- PROGRESS = "PROGRESS"
- FINISHED = "FINISHED"
- CANCELLED = "CANCELLED"
-
- @staticmethod
- def ordering(status: Status) -> int:
- """Order of messages. Helpful for testing."""
- order = [
- Status.STARTING,
- Status.JOINING_QUEUE,
- Status.QUEUE_FULL,
- Status.IN_QUEUE,
- Status.SENDING_DATA,
- Status.PROCESSING,
- Status.PROGRESS,
- Status.ITERATING,
- Status.FINISHED,
- Status.CANCELLED,
- ]
- return order.index(status)
-
- def __lt__(self, other: Status):
- return self.ordering(self) < self.ordering(other)
-
- @staticmethod
- def msg_to_status(msg: str) -> Status:
- """Map the raw message from the backend to the status code presented to users."""
- return {
- "send_hash": Status.JOINING_QUEUE,
- "queue_full": Status.QUEUE_FULL,
- "estimation": Status.IN_QUEUE,
- "send_data": Status.SENDING_DATA,
- "process_starts": Status.PROCESSING,
- "process_generating": Status.ITERATING,
- "process_completed": Status.FINISHED,
- "progress": Status.PROGRESS,
- }[msg]
-
-
-@dataclass
-class ProgressUnit:
- index: Optional[int]
- length: Optional[int]
- unit: Optional[str]
- progress: Optional[float]
- desc: Optional[str]
-
- @classmethod
- def from_ws_msg(cls, data: list[dict]) -> list[ProgressUnit]:
- return [
- cls(
- index=d.get("index"),
- length=d.get("length"),
- unit=d.get("unit"),
- progress=d.get("progress"),
- desc=d.get("desc"),
- )
- for d in data
- ]
-
-
-@dataclass
-class StatusUpdate:
- """Update message sent from the worker thread to the Job on the main thread."""
-
- code: Status
- rank: int | None
- queue_size: int | None
- eta: float | None
- success: bool | None
- time: datetime | None
- progress_data: list[ProgressUnit] | None
-
-
-def create_initial_status_update():
- return StatusUpdate(
- code=Status.STARTING,
- rank=None,
- queue_size=None,
- eta=None,
- success=None,
- time=datetime.now(),
- progress_data=None,
- )
-
-
-@dataclass
-class JobStatus:
- """The job status.
-
- Keeps track of the latest status update and intermediate outputs (not yet implements).
- """
-
- latest_status: StatusUpdate = field(default_factory=create_initial_status_update)
- outputs: list[Any] = field(default_factory=list)
-
-
-@dataclass
-class Communicator:
- """Helper class to help communicate between the worker thread and main thread."""
-
- lock: Lock
- job: JobStatus
- prediction_processor: Callable[..., tuple]
- reset_url: str
- should_cancel: bool = False
-
-
-########################
-# Network utils
-########################
-
-
-def is_http_url_like(possible_url: str) -> bool:
- """
- Check if the given string looks like an HTTP(S) URL.
- """
- return possible_url.startswith(("http://", "https://"))
-
-
-def probe_url(possible_url: str) -> bool:
- """
- Probe the given URL to see if it responds with a 200 status code (to HEAD, then to GET).
- """
- headers = {"User-Agent": "gradio (https://gradio.app/; team@gradio.app)"}
- try:
- with requests.session() as sess:
- head_request = sess.head(possible_url, headers=headers)
- if head_request.status_code == 405:
- return sess.get(possible_url, headers=headers).ok
- return head_request.ok
- except Exception:
- return False
-
-
-def is_valid_url(possible_url: str) -> bool:
- """
- Check if the given string is a valid URL.
- """
- warnings.warn(
- "is_valid_url should not be used. "
- "Use is_http_url_like() and probe_url(), as suitable, instead.",
- )
- return is_http_url_like(possible_url) and probe_url(possible_url)
-
-
-async def get_pred_from_ws(
- websocket: WebSocketCommonProtocol,
- data: str,
- hash_data: str,
- helper: Communicator | None = None,
-) -> dict[str, Any]:
- completed = False
- resp = {}
- while not completed:
- # Receive message in the background so that we can
- # cancel even while running a long pred
- task = asyncio.create_task(websocket.recv())
- while not task.done():
- if helper:
- with helper.lock:
- if helper.should_cancel:
- # Need to reset the iterator state since the client
- # will not reset the session
- async with httpx.AsyncClient() as http:
- reset = http.post(
- helper.reset_url, json=json.loads(hash_data)
- )
- # Retrieve cancel exception from task
- # otherwise will get nasty warning in console
- task.cancel()
- await asyncio.gather(task, reset, return_exceptions=True)
- raise CancelledError()
- # Need to suspend this coroutine so that task actually runs
- await asyncio.sleep(0.01)
- msg = task.result()
- resp = json.loads(msg)
- if helper:
- with helper.lock:
- has_progress = "progress_data" in resp
- status_update = StatusUpdate(
- code=Status.msg_to_status(resp["msg"]),
- queue_size=resp.get("queue_size"),
- rank=resp.get("rank", None),
- success=resp.get("success"),
- time=datetime.now(),
- eta=resp.get("rank_eta"),
- progress_data=ProgressUnit.from_ws_msg(resp["progress_data"])
- if has_progress
- else None,
- )
- output = resp.get("output", {}).get("data", [])
- if output and status_update.code != Status.FINISHED:
- try:
- result = helper.prediction_processor(*output)
- except Exception as e:
- result = [e]
- helper.job.outputs.append(result)
- helper.job.latest_status = status_update
- if resp["msg"] == "queue_full":
- raise QueueError("Queue is full! Please try again.")
- if resp["msg"] == "send_hash":
- await websocket.send(hash_data)
- elif resp["msg"] == "send_data":
- await websocket.send(data)
- completed = resp["msg"] == "process_completed"
- return resp["output"]
-
-
-########################
-# Data processing utils
-########################
-
-
-def download_tmp_copy_of_file(
- url_path: str, hf_token: str | None = None, dir: str | None = None
-) -> str:
- if dir is not None:
- os.makedirs(dir, exist_ok=True)
- headers = {"Authorization": "Bearer " + hf_token} if hf_token else {}
- directory = Path(dir or tempfile.gettempdir()) / secrets.token_hex(20)
- directory.mkdir(exist_ok=True, parents=True)
- file_path = directory / Path(url_path).name
-
- with requests.get(url_path, headers=headers, stream=True) as r:
- r.raise_for_status()
- with open(file_path, "wb") as f:
- shutil.copyfileobj(r.raw, f)
- return str(file_path.resolve())
-
-
-def create_tmp_copy_of_file(file_path: str, dir: str | None = None) -> str:
- directory = Path(dir or tempfile.gettempdir()) / secrets.token_hex(20)
- directory.mkdir(exist_ok=True, parents=True)
- dest = directory / Path(file_path).name
- shutil.copy2(file_path, dest)
- return str(dest.resolve())
-
-
-def get_mimetype(filename: str) -> str | None:
- if filename.endswith(".vtt"):
- return "text/vtt"
- mimetype = mimetypes.guess_type(filename)[0]
- if mimetype is not None:
- mimetype = mimetype.replace("x-wav", "wav").replace("x-flac", "flac")
- return mimetype
-
-
-def get_extension(encoding: str) -> str | None:
- encoding = encoding.replace("audio/wav", "audio/x-wav")
- type = mimetypes.guess_type(encoding)[0]
- if type == "audio/flac": # flac is not supported by mimetypes
- return "flac"
- elif type is None:
- return None
- extension = mimetypes.guess_extension(type)
- if extension is not None and extension.startswith("."):
- extension = extension[1:]
- return extension
-
-
-def encode_file_to_base64(f: str | Path):
- with open(f, "rb") as file:
- encoded_string = base64.b64encode(file.read())
- base64_str = str(encoded_string, "utf-8")
- mimetype = get_mimetype(str(f))
- return (
- "data:"
- + (mimetype if mimetype is not None else "")
- + ";base64,"
- + base64_str
- )
-
-
-def encode_url_to_base64(url: str):
- resp = requests.get(url)
- resp.raise_for_status()
- encoded_string = base64.b64encode(resp.content)
- base64_str = str(encoded_string, "utf-8")
- mimetype = get_mimetype(url)
- return (
- "data:" + (mimetype if mimetype is not None else "") + ";base64," + base64_str
- )
-
-
-def encode_url_or_file_to_base64(path: str | Path):
- path = str(path)
- if is_http_url_like(path):
- return encode_url_to_base64(path)
- return encode_file_to_base64(path)
-
-
-def decode_base64_to_binary(encoding: str) -> tuple[bytes, str | None]:
- extension = get_extension(encoding)
- data = encoding.rsplit(",", 1)[-1]
- return base64.b64decode(data), extension
-
-
-def strip_invalid_filename_characters(filename: str, max_bytes: int = 200) -> str:
- """Strips invalid characters from a filename and ensures that the file_length is less than `max_bytes` bytes."""
- filename = "".join([char for char in filename if char.isalnum() or char in "._- "])
- filename_len = len(filename.encode())
- if filename_len > max_bytes:
- while filename_len > max_bytes:
- if len(filename) == 0:
- break
- filename = filename[:-1]
- filename_len = len(filename.encode())
- return filename
-
-
-def sanitize_parameter_names(original_name: str) -> str:
- """Cleans up a Python parameter name to make the API info more readable."""
- return (
- "".join([char for char in original_name if char.isalnum() or char in " _"])
- .replace(" ", "_")
- .lower()
- )
-
-
-def decode_base64_to_file(
- encoding: str,
- file_path: str | None = None,
- dir: str | Path | None = None,
- prefix: str | None = None,
-):
- directory = Path(dir or tempfile.gettempdir()) / secrets.token_hex(20)
- directory.mkdir(exist_ok=True, parents=True)
- data, extension = decode_base64_to_binary(encoding)
- if file_path is not None and prefix is None:
- filename = Path(file_path).name
- prefix = filename
- if "." in filename:
- prefix = filename[0 : filename.index(".")]
- extension = filename[filename.index(".") + 1 :]
-
- if prefix is not None:
- prefix = strip_invalid_filename_characters(prefix)
-
- if extension is None:
- file_obj = tempfile.NamedTemporaryFile(
- delete=False, prefix=prefix, dir=directory
- )
- else:
- file_obj = tempfile.NamedTemporaryFile(
- delete=False,
- prefix=prefix,
- suffix="." + extension,
- dir=directory,
- )
- file_obj.write(data)
- file_obj.flush()
- return file_obj
-
-
-def dict_or_str_to_json_file(jsn: str | dict | list, dir: str | Path | None = None):
- if dir is not None:
- os.makedirs(dir, exist_ok=True)
-
- file_obj = tempfile.NamedTemporaryFile(
- delete=False, suffix=".json", dir=dir, mode="w+"
- )
- if isinstance(jsn, str):
- jsn = json.loads(jsn)
- json.dump(jsn, file_obj)
- file_obj.flush()
- return file_obj
-
-
-def file_to_json(file_path: str | Path) -> dict | list:
- with open(file_path) as f:
- return json.load(f)
-
-
-###########################
-# HuggingFace Hub API Utils
-###########################
-def set_space_timeout(
- space_id: str,
- hf_token: str | None = None,
- timeout_in_seconds: int = 300,
-):
- headers = huggingface_hub.utils.build_hf_headers(
- token=hf_token,
- library_name="gradio_client",
- library_version=__version__,
- )
- req = requests.post(
- f"https://huggingface.co/api/spaces/{space_id}/sleeptime",
- json={"seconds": timeout_in_seconds},
- headers=headers,
- )
- try:
- huggingface_hub.utils.hf_raise_for_status(req)
- except huggingface_hub.utils.HfHubHTTPError as err:
- raise SpaceDuplicationError(
- f"Could not set sleep timeout on duplicated Space. Please visit {SPACE_URL.format(space_id)} "
- "to set a timeout manually to reduce billing charges."
- ) from err
-
-
-########################
-# Misc utils
-########################
-
-
-def synchronize_async(func: Callable, *args, **kwargs) -> Any:
- """
- Runs async functions in sync scopes. Can be used in any scope.
-
- Example:
- if inspect.iscoroutinefunction(block_fn.fn):
- predictions = utils.synchronize_async(block_fn.fn, *processed_input)
-
- Args:
- func:
- *args:
- **kwargs:
- """
- return fsspec.asyn.sync(fsspec.asyn.get_loop(), func, *args, **kwargs) # type: ignore
-
-
-class APIInfoParseError(ValueError):
- pass
-
-
-def get_type(schema: dict):
- if "type" in schema:
- return schema["type"]
- elif schema.get("oneOf"):
- return "oneOf"
- elif schema.get("anyOf"):
- return "anyOf"
- else:
- raise APIInfoParseError(f"Cannot parse type for {schema}")
-
-
-def json_schema_to_python_type(schema: Any) -> str:
- """Convert the json schema into a python type hint"""
- type_ = get_type(schema)
- if type_ == {}:
- if "json" in schema["description"]:
- return "Dict[Any, Any]"
- else:
- return "Any"
- elif type_ == "null":
- return "None"
- elif type_ == "integer":
- return "int"
- elif type_ == "string":
- return "str"
- elif type_ == "boolean":
- return "bool"
- elif type_ == "number":
- return "int | float"
- elif type_ == "array":
- items = schema.get("items")
- if "prefixItems" in items:
- elements = ", ".join(
- [json_schema_to_python_type(i) for i in items["prefixItems"]]
- )
- return f"Tuple[{elements}]"
- else:
- elements = json_schema_to_python_type(items)
- return f"List[{elements}]"
- elif type_ == "object":
- des = ", ".join(
- [
- f"{n}: {json_schema_to_python_type(v)} ({v.get('description')})"
- for n, v in schema["properties"].items()
- ]
- )
- return f"Dict({des})"
- elif type_ in ["oneOf", "anyOf"]:
- desc = " | ".join([json_schema_to_python_type(i) for i in schema[type_]])
- return desc
- else:
- raise APIInfoParseError(f"Cannot parse schema {schema}")
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/huggingface_hub/commands/scan_cache.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/huggingface_hub/commands/scan_cache.py
deleted file mode 100644
index ff26fa9de50f607ca78a24c5041010b4d629c148..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/huggingface_hub/commands/scan_cache.py
+++ /dev/null
@@ -1,138 +0,0 @@
-# coding=utf-8
-# Copyright 2022-present, the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Contains command to scan the HF cache directory.
-
-Usage:
- huggingface-cli scan-cache
- huggingface-cli scan-cache -v
- huggingface-cli scan-cache -vvv
- huggingface-cli scan-cache --dir ~/.cache/huggingface/hub
-"""
-import time
-from argparse import _SubParsersAction
-from typing import Optional
-
-from ..utils import CacheNotFound, HFCacheInfo, scan_cache_dir
-from . import BaseHuggingfaceCLICommand
-from ._cli_utils import ANSI, tabulate
-
-
-class ScanCacheCommand(BaseHuggingfaceCLICommand):
- @staticmethod
- def register_subcommand(parser: _SubParsersAction):
- scan_cache_parser = parser.add_parser("scan-cache", help="Scan cache directory.")
-
- scan_cache_parser.add_argument(
- "--dir",
- type=str,
- default=None,
- help="cache directory to scan (optional). Default to the default HuggingFace cache.",
- )
- scan_cache_parser.add_argument(
- "-v",
- "--verbose",
- action="count",
- default=0,
- help="show a more verbose output",
- )
- scan_cache_parser.set_defaults(func=ScanCacheCommand)
-
- def __init__(self, args):
- self.verbosity: int = args.verbose
- self.cache_dir: Optional[str] = args.dir
-
- def run(self):
- try:
- t0 = time.time()
- hf_cache_info = scan_cache_dir(self.cache_dir)
- t1 = time.time()
- except CacheNotFound as exc:
- cache_dir = exc.cache_dir
- print(f"Cache directory not found: {cache_dir}")
- return
-
- self._print_hf_cache_info_as_table(hf_cache_info)
-
- print(
- f"\nDone in {round(t1-t0,1)}s. Scanned {len(hf_cache_info.repos)} repo(s)"
- f" for a total of {ANSI.red(hf_cache_info.size_on_disk_str)}."
- )
- if len(hf_cache_info.warnings) > 0:
- message = f"Got {len(hf_cache_info.warnings)} warning(s) while scanning."
- if self.verbosity >= 3:
- print(ANSI.gray(message))
- for warning in hf_cache_info.warnings:
- print(ANSI.gray(warning))
- else:
- print(ANSI.gray(message + " Use -vvv to print details."))
-
- def _print_hf_cache_info_as_table(self, hf_cache_info: HFCacheInfo) -> None:
- if self.verbosity == 0:
- print(
- tabulate(
- rows=[
- [
- repo.repo_id,
- repo.repo_type,
- "{:>12}".format(repo.size_on_disk_str),
- repo.nb_files,
- repo.last_accessed_str,
- repo.last_modified_str,
- ", ".join(sorted(repo.refs)),
- str(repo.repo_path),
- ]
- for repo in sorted(hf_cache_info.repos, key=lambda repo: repo.repo_path)
- ],
- headers=[
- "REPO ID",
- "REPO TYPE",
- "SIZE ON DISK",
- "NB FILES",
- "LAST_ACCESSED",
- "LAST_MODIFIED",
- "REFS",
- "LOCAL PATH",
- ],
- )
- )
- else:
- print(
- tabulate(
- rows=[
- [
- repo.repo_id,
- repo.repo_type,
- revision.commit_hash,
- "{:>12}".format(revision.size_on_disk_str),
- revision.nb_files,
- revision.last_modified_str,
- ", ".join(sorted(revision.refs)),
- str(revision.snapshot_path),
- ]
- for repo in sorted(hf_cache_info.repos, key=lambda repo: repo.repo_path)
- for revision in sorted(repo.revisions, key=lambda revision: revision.commit_hash)
- ],
- headers=[
- "REPO ID",
- "REPO TYPE",
- "REVISION",
- "SIZE ON DISK",
- "NB FILES",
- "LAST_MODIFIED",
- "REFS",
- "LOCAL PATH",
- ],
- )
- )
diff --git a/spaces/derek-thomas/RAGDemo/backend/semantic_search.py b/spaces/derek-thomas/RAGDemo/backend/semantic_search.py
deleted file mode 100644
index 653cf44d4d345fe165b229babaec744cf774d476..0000000000000000000000000000000000000000
--- a/spaces/derek-thomas/RAGDemo/backend/semantic_search.py
+++ /dev/null
@@ -1,31 +0,0 @@
-import time
-import logging
-from qdrant_haystack import QdrantDocumentStore
-from haystack.nodes import EmbeddingRetriever
-from pathlib import Path
-
-# Setting up the logging
-logging.basicConfig(level=logging.INFO)
-logger = logging.getLogger(__name__)
-
-# Start the timer for loading the QdrantDocumentStore
-start_time = time.perf_counter()
-
-proj_dir = Path(__file__).parents[1]
-qd_document_store = QdrantDocumentStore(path=str(proj_dir/'Qdrant'), index='RAGDemo')
-
-# Log the time taken to load the QdrantDocumentStore
-document_store_loading_time = time.perf_counter() - start_time
-logger.info(f"Time taken to load QdrantDocumentStore: {document_store_loading_time:.6f} seconds")
-
-# Start the timer for loading the EmbeddingRetriever
-start_time = time.perf_counter()
-
-qd_retriever = EmbeddingRetriever(document_store=qd_document_store,
- embedding_model="BAAI/bge-base-en-v1.5",
- model_format="sentence_transformers",
- use_gpu=False)
-
-# Log the time taken to load the EmbeddingRetriever
-retriever_loading_time = time.perf_counter() - start_time
-logger.info(f"Time taken to load EmbeddingRetriever: {retriever_loading_time:.6f} seconds")
diff --git a/spaces/dhof/shapetest/README.md b/spaces/dhof/shapetest/README.md
deleted file mode 100644
index 28c652015c6a0211f7d9edebd73b9131214eec98..0000000000000000000000000000000000000000
--- a/spaces/dhof/shapetest/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
----
-title: Shap-E
-emoji: 🧢
-colorFrom: yellow
-colorTo: blue
-sdk: gradio
-sdk_version: 3.28.3
-python_version: 3.10.11
-app_file: app.py
-pinned: false
-license: mit
-duplicated_from: hysts/Shap-E
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/diacanFperku/AutoGPT/Easeus Partition Master Key 13.8 Technician Portable BETTER.md b/spaces/diacanFperku/AutoGPT/Easeus Partition Master Key 13.8 Technician Portable BETTER.md
deleted file mode 100644
index 406b9c6c76958e8d3d869b68ba320828f8d96e8c..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Easeus Partition Master Key 13.8 Technician Portable BETTER.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Easeus partition master key 13.8 Technician Portable
Download File 🔗 https://gohhs.com/2uFVrA
-
-EaseUS Partition Master Technician is an all-in-one partition... ... EaseUS Partition Master 13.8 Technician + crack (key gen). ... Partition Master 14.0 Technician Edition + Free + Pro + Rus + WinPE Bootable CD + Portable. 4d29de3e1b
-
-
-
diff --git a/spaces/diacanFperku/AutoGPT/Interviu Olvido Hormigos Pdf 131.md b/spaces/diacanFperku/AutoGPT/Interviu Olvido Hormigos Pdf 131.md
deleted file mode 100644
index 86b7f7733b03a34e7a2ece21bc6e4a269838cb88..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Interviu Olvido Hormigos Pdf 131.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Interviu Olvido Hormigos Pdf 131
DOWNLOAD ✒ ✒ ✒ https://gohhs.com/2uFUaX
-
-Olvido Hormigos (2017) Interviú Nº2149 ... Formatos disponibles. Descargue como PDF o lea en lÃnea desde Scribd. Marcar según contenido . 4d29de3e1b
-
-
-
diff --git a/spaces/diacanFperku/AutoGPT/Magix Video Pro X5 Keygen Download BEST.md b/spaces/diacanFperku/AutoGPT/Magix Video Pro X5 Keygen Download BEST.md
deleted file mode 100644
index cda70b50d303e0b8e40fa3e0ed26f326282dde60..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Magix Video Pro X5 Keygen Download BEST.md
+++ /dev/null
@@ -1,22 +0,0 @@
-Magix Video Pro X5 Keygen Download
Download File ››››› https://gohhs.com/2uFTlC
-
-This software helps you to make beautiful videos and movies of your life. You can edit all your favorite clips, short video clips, long video clip, HD-video clip, or movies of your life. This software is a free and powerful video editing software. It has a powerful editing tool with many features. More, you can add special effects, like Black and White, Sepia, Red-Eye Remover, Photo Filter, Special Effects. And many more you can also use the video editor software.
-
-MAGIX Video Pro X13 19.0.1.141 Crack is a powerful video editing software. It has powerful and easy to use editing tools for basic video editing needs. You can trim, crop, add effects, and apply transitions. You can save your video as an AVI, MPEG, MPG, and WMV files format. More, you can burn it on DVD, upload on YouTube, or save as a PDF file. In the other hand, this is a fast video editing software. More, it also has some other advanced features and functions. So that you can edit more powerful videos. This software is a smart software and you can also use it at your laptop, PC, or Windows.
-
-MAGIX Video Pro X13 Torrent Full Version Free Download
-
-MAGIX Video Pro X13 19.0.1.141 Crack is a powerful and advanced video editing software for PC, Mac, Android, iPhone, iPad, or IPhone OS. It is a powerful video editor for users. More, it is a fast video editor for Windows, Windows Mac, IOS, and Android users. So, this is a powerful software for a beginner and experienced user. It is one of the best video editor and free video editor software. It helps you to make a beautiful video. More, it has powerful video editing features and tools. Also, you can add your favorite clips or songs in your video. It has a powerful editing tool with many features and powerful tools. More, you can also make a video of your life. It can also edit movies and videos. It has a powerful video editing tool for editing your video clips, short video clips, long video clips, and HD video clips.
-
-MAGIX Video Pro X13 19.0.1.141 Crack Features:
-
-It is a powerful and efficient video editor software.
-
-It helps you to edit your video.
-
-It has powerful editing tools with many features.
-
-It is a smart video editing software 4fefd39f24
-
-
-
diff --git a/spaces/diagaiwei/ir_chinese_medqa/colbert/trainer.py b/spaces/diagaiwei/ir_chinese_medqa/colbert/trainer.py
deleted file mode 100644
index 0b0ac566577c016ff1dade2a90266764c1c6dafe..0000000000000000000000000000000000000000
--- a/spaces/diagaiwei/ir_chinese_medqa/colbert/trainer.py
+++ /dev/null
@@ -1,36 +0,0 @@
-from colbert.infra.run import Run
-from colbert.infra.launcher import Launcher
-from colbert.infra.config import ColBERTConfig, RunConfig
-
-from colbert.training.training import train
-
-
-class Trainer:
- def __init__(self, triples, queries, collection, config=None):
- self.config = ColBERTConfig.from_existing(config, Run().config)
-
- self.triples = triples
- self.queries = queries
- self.collection = collection
-
- def configure(self, **kw_args):
- self.config.configure(**kw_args)
-
- def train(self, checkpoint='bert-base-uncased'):
- """
- Note that config.checkpoint is ignored. Only the supplied checkpoint here is used.
- """
-
- # Resources don't come from the config object. They come from the input parameters.
- # TODO: After the API stabilizes, make this "self.config.assign()" to emphasize this distinction.
- self.configure(triples=self.triples, queries=self.queries, collection=self.collection)
- self.configure(checkpoint=checkpoint)
-
- launcher = Launcher(train)
-
- self._best_checkpoint_path = launcher.launch(self.config, self.triples, self.queries, self.collection)
-
-
- def best_checkpoint_path(self):
- return self._best_checkpoint_path
-
diff --git a/spaces/dineshreddy/WALT/mmdet/core/bbox/samplers/sampling_result.py b/spaces/dineshreddy/WALT/mmdet/core/bbox/samplers/sampling_result.py
deleted file mode 100644
index 419a8e39a3c307a7cd9cfd0565a20037ded0d646..0000000000000000000000000000000000000000
--- a/spaces/dineshreddy/WALT/mmdet/core/bbox/samplers/sampling_result.py
+++ /dev/null
@@ -1,152 +0,0 @@
-import torch
-
-from mmdet.utils import util_mixins
-
-
-class SamplingResult(util_mixins.NiceRepr):
- """Bbox sampling result.
-
- Example:
- >>> # xdoctest: +IGNORE_WANT
- >>> from mmdet.core.bbox.samplers.sampling_result import * # NOQA
- >>> self = SamplingResult.random(rng=10)
- >>> print(f'self = {self}')
- self =
- """
-
- def __init__(self, pos_inds, neg_inds, bboxes, gt_bboxes, assign_result,
- gt_flags):
- self.pos_inds = pos_inds
- self.neg_inds = neg_inds
- self.pos_bboxes = bboxes[pos_inds]
- self.neg_bboxes = bboxes[neg_inds]
- self.pos_is_gt = gt_flags[pos_inds]
-
- self.num_gts = gt_bboxes.shape[0]
- self.pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
-
- if gt_bboxes.numel() == 0:
- # hack for index error case
- assert self.pos_assigned_gt_inds.numel() == 0
- self.pos_gt_bboxes = torch.empty_like(gt_bboxes).view(-1, 4)
- else:
- if len(gt_bboxes.shape) < 2:
- gt_bboxes = gt_bboxes.view(-1, 4)
-
- self.pos_gt_bboxes = gt_bboxes[self.pos_assigned_gt_inds, :]
-
- if assign_result.labels is not None:
- self.pos_gt_labels = assign_result.labels[pos_inds]
- else:
- self.pos_gt_labels = None
-
- @property
- def bboxes(self):
- """torch.Tensor: concatenated positive and negative boxes"""
- return torch.cat([self.pos_bboxes, self.neg_bboxes])
-
- def to(self, device):
- """Change the device of the data inplace.
-
- Example:
- >>> self = SamplingResult.random()
- >>> print(f'self = {self.to(None)}')
- >>> # xdoctest: +REQUIRES(--gpu)
- >>> print(f'self = {self.to(0)}')
- """
- _dict = self.__dict__
- for key, value in _dict.items():
- if isinstance(value, torch.Tensor):
- _dict[key] = value.to(device)
- return self
-
- def __nice__(self):
- data = self.info.copy()
- data['pos_bboxes'] = data.pop('pos_bboxes').shape
- data['neg_bboxes'] = data.pop('neg_bboxes').shape
- parts = [f"'{k}': {v!r}" for k, v in sorted(data.items())]
- body = ' ' + ',\n '.join(parts)
- return '{\n' + body + '\n}'
-
- @property
- def info(self):
- """Returns a dictionary of info about the object."""
- return {
- 'pos_inds': self.pos_inds,
- 'neg_inds': self.neg_inds,
- 'pos_bboxes': self.pos_bboxes,
- 'neg_bboxes': self.neg_bboxes,
- 'pos_is_gt': self.pos_is_gt,
- 'num_gts': self.num_gts,
- 'pos_assigned_gt_inds': self.pos_assigned_gt_inds,
- }
-
- @classmethod
- def random(cls, rng=None, **kwargs):
- """
- Args:
- rng (None | int | numpy.random.RandomState): seed or state.
- kwargs (keyword arguments):
- - num_preds: number of predicted boxes
- - num_gts: number of true boxes
- - p_ignore (float): probability of a predicted box assinged to \
- an ignored truth.
- - p_assigned (float): probability of a predicted box not being \
- assigned.
- - p_use_label (float | bool): with labels or not.
-
- Returns:
- :obj:`SamplingResult`: Randomly generated sampling result.
-
- Example:
- >>> from mmdet.core.bbox.samplers.sampling_result import * # NOQA
- >>> self = SamplingResult.random()
- >>> print(self.__dict__)
- """
- from mmdet.core.bbox.samplers.random_sampler import RandomSampler
- from mmdet.core.bbox.assigners.assign_result import AssignResult
- from mmdet.core.bbox import demodata
- rng = demodata.ensure_rng(rng)
-
- # make probabalistic?
- num = 32
- pos_fraction = 0.5
- neg_pos_ub = -1
-
- assign_result = AssignResult.random(rng=rng, **kwargs)
-
- # Note we could just compute an assignment
- bboxes = demodata.random_boxes(assign_result.num_preds, rng=rng)
- gt_bboxes = demodata.random_boxes(assign_result.num_gts, rng=rng)
-
- if rng.rand() > 0.2:
- # sometimes algorithms squeeze their data, be robust to that
- gt_bboxes = gt_bboxes.squeeze()
- bboxes = bboxes.squeeze()
-
- if assign_result.labels is None:
- gt_labels = None
- else:
- gt_labels = None # todo
-
- if gt_labels is None:
- add_gt_as_proposals = False
- else:
- add_gt_as_proposals = True # make probabalistic?
-
- sampler = RandomSampler(
- num,
- pos_fraction,
- neg_pos_ub=neg_pos_ub,
- add_gt_as_proposals=add_gt_as_proposals,
- rng=rng)
- self = sampler.sample(assign_result, bboxes, gt_bboxes, gt_labels)
- return self
diff --git a/spaces/dineshreddy/WALT/mmdet/models/backbones/hrnet.py b/spaces/dineshreddy/WALT/mmdet/models/backbones/hrnet.py
deleted file mode 100644
index c0fd0a974192231506aa68b1e1719f618b78a1b3..0000000000000000000000000000000000000000
--- a/spaces/dineshreddy/WALT/mmdet/models/backbones/hrnet.py
+++ /dev/null
@@ -1,537 +0,0 @@
-import torch.nn as nn
-from mmcv.cnn import (build_conv_layer, build_norm_layer, constant_init,
- kaiming_init)
-from mmcv.runner import load_checkpoint
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmdet.utils import get_root_logger
-from ..builder import BACKBONES
-from .resnet import BasicBlock, Bottleneck
-
-
-class HRModule(nn.Module):
- """High-Resolution Module for HRNet.
-
- In this module, every branch has 4 BasicBlocks/Bottlenecks. Fusion/Exchange
- is in this module.
- """
-
- def __init__(self,
- num_branches,
- blocks,
- num_blocks,
- in_channels,
- num_channels,
- multiscale_output=True,
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN')):
- super(HRModule, self).__init__()
- self._check_branches(num_branches, num_blocks, in_channels,
- num_channels)
-
- self.in_channels = in_channels
- self.num_branches = num_branches
-
- self.multiscale_output = multiscale_output
- self.norm_cfg = norm_cfg
- self.conv_cfg = conv_cfg
- self.with_cp = with_cp
- self.branches = self._make_branches(num_branches, blocks, num_blocks,
- num_channels)
- self.fuse_layers = self._make_fuse_layers()
- self.relu = nn.ReLU(inplace=False)
-
- def _check_branches(self, num_branches, num_blocks, in_channels,
- num_channels):
- if num_branches != len(num_blocks):
- error_msg = f'NUM_BRANCHES({num_branches}) ' \
- f'!= NUM_BLOCKS({len(num_blocks)})'
- raise ValueError(error_msg)
-
- if num_branches != len(num_channels):
- error_msg = f'NUM_BRANCHES({num_branches}) ' \
- f'!= NUM_CHANNELS({len(num_channels)})'
- raise ValueError(error_msg)
-
- if num_branches != len(in_channels):
- error_msg = f'NUM_BRANCHES({num_branches}) ' \
- f'!= NUM_INCHANNELS({len(in_channels)})'
- raise ValueError(error_msg)
-
- def _make_one_branch(self,
- branch_index,
- block,
- num_blocks,
- num_channels,
- stride=1):
- downsample = None
- if stride != 1 or \
- self.in_channels[branch_index] != \
- num_channels[branch_index] * block.expansion:
- downsample = nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- self.in_channels[branch_index],
- num_channels[branch_index] * block.expansion,
- kernel_size=1,
- stride=stride,
- bias=False),
- build_norm_layer(self.norm_cfg, num_channels[branch_index] *
- block.expansion)[1])
-
- layers = []
- layers.append(
- block(
- self.in_channels[branch_index],
- num_channels[branch_index],
- stride,
- downsample=downsample,
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
- self.in_channels[branch_index] = \
- num_channels[branch_index] * block.expansion
- for i in range(1, num_blocks[branch_index]):
- layers.append(
- block(
- self.in_channels[branch_index],
- num_channels[branch_index],
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
-
- return nn.Sequential(*layers)
-
- def _make_branches(self, num_branches, block, num_blocks, num_channels):
- branches = []
-
- for i in range(num_branches):
- branches.append(
- self._make_one_branch(i, block, num_blocks, num_channels))
-
- return nn.ModuleList(branches)
-
- def _make_fuse_layers(self):
- if self.num_branches == 1:
- return None
-
- num_branches = self.num_branches
- in_channels = self.in_channels
- fuse_layers = []
- num_out_branches = num_branches if self.multiscale_output else 1
- for i in range(num_out_branches):
- fuse_layer = []
- for j in range(num_branches):
- if j > i:
- fuse_layer.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[i],
- kernel_size=1,
- stride=1,
- padding=0,
- bias=False),
- build_norm_layer(self.norm_cfg, in_channels[i])[1],
- nn.Upsample(
- scale_factor=2**(j - i), mode='nearest')))
- elif j == i:
- fuse_layer.append(None)
- else:
- conv_downsamples = []
- for k in range(i - j):
- if k == i - j - 1:
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[i],
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg,
- in_channels[i])[1]))
- else:
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels[j],
- in_channels[j],
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg,
- in_channels[j])[1],
- nn.ReLU(inplace=False)))
- fuse_layer.append(nn.Sequential(*conv_downsamples))
- fuse_layers.append(nn.ModuleList(fuse_layer))
-
- return nn.ModuleList(fuse_layers)
-
- def forward(self, x):
- """Forward function."""
- if self.num_branches == 1:
- return [self.branches[0](x[0])]
-
- for i in range(self.num_branches):
- x[i] = self.branches[i](x[i])
-
- x_fuse = []
- for i in range(len(self.fuse_layers)):
- y = 0
- for j in range(self.num_branches):
- if i == j:
- y += x[j]
- else:
- y += self.fuse_layers[i][j](x[j])
- x_fuse.append(self.relu(y))
- return x_fuse
-
-
-@BACKBONES.register_module()
-class HRNet(nn.Module):
- """HRNet backbone.
-
- High-Resolution Representations for Labeling Pixels and Regions
- arXiv: https://arxiv.org/abs/1904.04514
-
- Args:
- extra (dict): detailed configuration for each stage of HRNet.
- in_channels (int): Number of input image channels. Default: 3.
- conv_cfg (dict): dictionary to construct and config conv layer.
- norm_cfg (dict): dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- zero_init_residual (bool): whether to use zero init for last norm layer
- in resblocks to let them behave as identity.
-
- Example:
- >>> from mmdet.models import HRNet
- >>> import torch
- >>> extra = dict(
- >>> stage1=dict(
- >>> num_modules=1,
- >>> num_branches=1,
- >>> block='BOTTLENECK',
- >>> num_blocks=(4, ),
- >>> num_channels=(64, )),
- >>> stage2=dict(
- >>> num_modules=1,
- >>> num_branches=2,
- >>> block='BASIC',
- >>> num_blocks=(4, 4),
- >>> num_channels=(32, 64)),
- >>> stage3=dict(
- >>> num_modules=4,
- >>> num_branches=3,
- >>> block='BASIC',
- >>> num_blocks=(4, 4, 4),
- >>> num_channels=(32, 64, 128)),
- >>> stage4=dict(
- >>> num_modules=3,
- >>> num_branches=4,
- >>> block='BASIC',
- >>> num_blocks=(4, 4, 4, 4),
- >>> num_channels=(32, 64, 128, 256)))
- >>> self = HRNet(extra, in_channels=1)
- >>> self.eval()
- >>> inputs = torch.rand(1, 1, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 32, 8, 8)
- (1, 64, 4, 4)
- (1, 128, 2, 2)
- (1, 256, 1, 1)
- """
-
- blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
-
- def __init__(self,
- extra,
- in_channels=3,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- norm_eval=True,
- with_cp=False,
- zero_init_residual=False):
- super(HRNet, self).__init__()
- self.extra = extra
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.norm_eval = norm_eval
- self.with_cp = with_cp
- self.zero_init_residual = zero_init_residual
-
- # stem net
- self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
- self.norm2_name, norm2 = build_norm_layer(self.norm_cfg, 64, postfix=2)
-
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- 64,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False)
-
- self.add_module(self.norm1_name, norm1)
- self.conv2 = build_conv_layer(
- self.conv_cfg,
- 64,
- 64,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False)
-
- self.add_module(self.norm2_name, norm2)
- self.relu = nn.ReLU(inplace=True)
-
- # stage 1
- self.stage1_cfg = self.extra['stage1']
- num_channels = self.stage1_cfg['num_channels'][0]
- block_type = self.stage1_cfg['block']
- num_blocks = self.stage1_cfg['num_blocks'][0]
-
- block = self.blocks_dict[block_type]
- stage1_out_channels = num_channels * block.expansion
- self.layer1 = self._make_layer(block, 64, num_channels, num_blocks)
-
- # stage 2
- self.stage2_cfg = self.extra['stage2']
- num_channels = self.stage2_cfg['num_channels']
- block_type = self.stage2_cfg['block']
-
- block = self.blocks_dict[block_type]
- num_channels = [channel * block.expansion for channel in num_channels]
- self.transition1 = self._make_transition_layer([stage1_out_channels],
- num_channels)
- self.stage2, pre_stage_channels = self._make_stage(
- self.stage2_cfg, num_channels)
-
- # stage 3
- self.stage3_cfg = self.extra['stage3']
- num_channels = self.stage3_cfg['num_channels']
- block_type = self.stage3_cfg['block']
-
- block = self.blocks_dict[block_type]
- num_channels = [channel * block.expansion for channel in num_channels]
- self.transition2 = self._make_transition_layer(pre_stage_channels,
- num_channels)
- self.stage3, pre_stage_channels = self._make_stage(
- self.stage3_cfg, num_channels)
-
- # stage 4
- self.stage4_cfg = self.extra['stage4']
- num_channels = self.stage4_cfg['num_channels']
- block_type = self.stage4_cfg['block']
-
- block = self.blocks_dict[block_type]
- num_channels = [channel * block.expansion for channel in num_channels]
- self.transition3 = self._make_transition_layer(pre_stage_channels,
- num_channels)
- self.stage4, pre_stage_channels = self._make_stage(
- self.stage4_cfg, num_channels)
-
- @property
- def norm1(self):
- """nn.Module: the normalization layer named "norm1" """
- return getattr(self, self.norm1_name)
-
- @property
- def norm2(self):
- """nn.Module: the normalization layer named "norm2" """
- return getattr(self, self.norm2_name)
-
- def _make_transition_layer(self, num_channels_pre_layer,
- num_channels_cur_layer):
- num_branches_cur = len(num_channels_cur_layer)
- num_branches_pre = len(num_channels_pre_layer)
-
- transition_layers = []
- for i in range(num_branches_cur):
- if i < num_branches_pre:
- if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
- transition_layers.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- num_channels_pre_layer[i],
- num_channels_cur_layer[i],
- kernel_size=3,
- stride=1,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg,
- num_channels_cur_layer[i])[1],
- nn.ReLU(inplace=True)))
- else:
- transition_layers.append(None)
- else:
- conv_downsamples = []
- for j in range(i + 1 - num_branches_pre):
- in_channels = num_channels_pre_layer[-1]
- out_channels = num_channels_cur_layer[i] \
- if j == i - num_branches_pre else in_channels
- conv_downsamples.append(
- nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- in_channels,
- out_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False),
- build_norm_layer(self.norm_cfg, out_channels)[1],
- nn.ReLU(inplace=True)))
- transition_layers.append(nn.Sequential(*conv_downsamples))
-
- return nn.ModuleList(transition_layers)
-
- def _make_layer(self, block, inplanes, planes, blocks, stride=1):
- downsample = None
- if stride != 1 or inplanes != planes * block.expansion:
- downsample = nn.Sequential(
- build_conv_layer(
- self.conv_cfg,
- inplanes,
- planes * block.expansion,
- kernel_size=1,
- stride=stride,
- bias=False),
- build_norm_layer(self.norm_cfg, planes * block.expansion)[1])
-
- layers = []
- layers.append(
- block(
- inplanes,
- planes,
- stride,
- downsample=downsample,
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
- inplanes = planes * block.expansion
- for i in range(1, blocks):
- layers.append(
- block(
- inplanes,
- planes,
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
-
- return nn.Sequential(*layers)
-
- def _make_stage(self, layer_config, in_channels, multiscale_output=True):
- num_modules = layer_config['num_modules']
- num_branches = layer_config['num_branches']
- num_blocks = layer_config['num_blocks']
- num_channels = layer_config['num_channels']
- block = self.blocks_dict[layer_config['block']]
-
- hr_modules = []
- for i in range(num_modules):
- # multi_scale_output is only used for the last module
- if not multiscale_output and i == num_modules - 1:
- reset_multiscale_output = False
- else:
- reset_multiscale_output = True
-
- hr_modules.append(
- HRModule(
- num_branches,
- block,
- num_blocks,
- in_channels,
- num_channels,
- reset_multiscale_output,
- with_cp=self.with_cp,
- norm_cfg=self.norm_cfg,
- conv_cfg=self.conv_cfg))
-
- return nn.Sequential(*hr_modules), in_channels
-
- def init_weights(self, pretrained=None):
- """Initialize the weights in backbone.
-
- Args:
- pretrained (str, optional): Path to pre-trained weights.
- Defaults to None.
- """
- if isinstance(pretrained, str):
- logger = get_root_logger()
- load_checkpoint(self, pretrained, strict=False, logger=logger)
- elif pretrained is None:
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- kaiming_init(m)
- elif isinstance(m, (_BatchNorm, nn.GroupNorm)):
- constant_init(m, 1)
-
- if self.zero_init_residual:
- for m in self.modules():
- if isinstance(m, Bottleneck):
- constant_init(m.norm3, 0)
- elif isinstance(m, BasicBlock):
- constant_init(m.norm2, 0)
- else:
- raise TypeError('pretrained must be a str or None')
-
- def forward(self, x):
- """Forward function."""
- x = self.conv1(x)
- x = self.norm1(x)
- x = self.relu(x)
- x = self.conv2(x)
- x = self.norm2(x)
- x = self.relu(x)
- x = self.layer1(x)
-
- x_list = []
- for i in range(self.stage2_cfg['num_branches']):
- if self.transition1[i] is not None:
- x_list.append(self.transition1[i](x))
- else:
- x_list.append(x)
- y_list = self.stage2(x_list)
-
- x_list = []
- for i in range(self.stage3_cfg['num_branches']):
- if self.transition2[i] is not None:
- x_list.append(self.transition2[i](y_list[-1]))
- else:
- x_list.append(y_list[i])
- y_list = self.stage3(x_list)
-
- x_list = []
- for i in range(self.stage4_cfg['num_branches']):
- if self.transition3[i] is not None:
- x_list.append(self.transition3[i](y_list[-1]))
- else:
- x_list.append(y_list[i])
- y_list = self.stage4(x_list)
-
- return y_list
-
- def train(self, mode=True):
- """Convert the model into training mode will keeping the normalization
- layer freezed."""
- super(HRNet, self).train(mode)
- if mode and self.norm_eval:
- for m in self.modules():
- # trick: eval have effect on BatchNorm only
- if isinstance(m, _BatchNorm):
- m.eval()
diff --git a/spaces/dinhminh20521597/OCR_DEMO/configs/_base_/det_pipelines/panet_pipeline.py b/spaces/dinhminh20521597/OCR_DEMO/configs/_base_/det_pipelines/panet_pipeline.py
deleted file mode 100644
index eae50de4fab0536d114509854f9250c0d613cb3c..0000000000000000000000000000000000000000
--- a/spaces/dinhminh20521597/OCR_DEMO/configs/_base_/det_pipelines/panet_pipeline.py
+++ /dev/null
@@ -1,156 +0,0 @@
-img_norm_cfg = dict(
- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
-
-# for ctw1500
-img_scale_train_ctw1500 = [(3000, 640)]
-shrink_ratio_train_ctw1500 = (1.0, 0.7)
-target_size_train_ctw1500 = (640, 640)
-train_pipeline_ctw1500 = [
- dict(type='LoadImageFromFile', color_type='color_ignore_orientation'),
- dict(
- type='LoadTextAnnotations',
- with_bbox=True,
- with_mask=True,
- poly2mask=False),
- dict(type='ColorJitter', brightness=32.0 / 255, saturation=0.5),
- dict(type='Normalize', **img_norm_cfg),
- dict(
- type='ScaleAspectJitter',
- img_scale=img_scale_train_ctw1500,
- ratio_range=(0.7, 1.3),
- aspect_ratio_range=(0.9, 1.1),
- multiscale_mode='value',
- keep_ratio=False),
- # shrink_ratio is from big to small. The 1st must be 1.0
- dict(type='PANetTargets', shrink_ratio=shrink_ratio_train_ctw1500),
- dict(type='RandomFlip', flip_ratio=0.5, direction='horizontal'),
- dict(type='RandomRotateTextDet'),
- dict(
- type='RandomCropInstances',
- target_size=target_size_train_ctw1500,
- instance_key='gt_kernels'),
- dict(type='Pad', size_divisor=32),
- dict(
- type='CustomFormatBundle',
- keys=['gt_kernels', 'gt_mask'],
- visualize=dict(flag=False, boundary_key='gt_kernels')),
- dict(type='Collect', keys=['img', 'gt_kernels', 'gt_mask'])
-]
-
-img_scale_test_ctw1500 = (3000, 640)
-test_pipeline_ctw1500 = [
- dict(type='LoadImageFromFile', color_type='color_ignore_orientation'),
- dict(
- type='MultiScaleFlipAug',
- img_scale=img_scale_test_ctw1500, # used by Resize
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='Collect', keys=['img']),
- ])
-]
-
-# for icdar2015
-img_scale_train_icdar2015 = [(3000, 736)]
-shrink_ratio_train_icdar2015 = (1.0, 0.5)
-target_size_train_icdar2015 = (736, 736)
-train_pipeline_icdar2015 = [
- dict(type='LoadImageFromFile', color_type='color_ignore_orientation'),
- dict(
- type='LoadTextAnnotations',
- with_bbox=True,
- with_mask=True,
- poly2mask=False),
- dict(type='ColorJitter', brightness=32.0 / 255, saturation=0.5),
- dict(type='Normalize', **img_norm_cfg),
- dict(
- type='ScaleAspectJitter',
- img_scale=img_scale_train_icdar2015,
- ratio_range=(0.7, 1.3),
- aspect_ratio_range=(0.9, 1.1),
- multiscale_mode='value',
- keep_ratio=False),
- dict(type='PANetTargets', shrink_ratio=shrink_ratio_train_icdar2015),
- dict(type='RandomFlip', flip_ratio=0.5, direction='horizontal'),
- dict(type='RandomRotateTextDet'),
- dict(
- type='RandomCropInstances',
- target_size=target_size_train_icdar2015,
- instance_key='gt_kernels'),
- dict(type='Pad', size_divisor=32),
- dict(
- type='CustomFormatBundle',
- keys=['gt_kernels', 'gt_mask'],
- visualize=dict(flag=False, boundary_key='gt_kernels')),
- dict(type='Collect', keys=['img', 'gt_kernels', 'gt_mask'])
-]
-
-img_scale_test_icdar2015 = (1333, 736)
-test_pipeline_icdar2015 = [
- dict(type='LoadImageFromFile', color_type='color_ignore_orientation'),
- dict(
- type='MultiScaleFlipAug',
- img_scale=img_scale_test_icdar2015, # used by Resize
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='Collect', keys=['img']),
- ])
-]
-
-# for icdar2017
-img_scale_train_icdar2017 = [(3000, 800)]
-shrink_ratio_train_icdar2017 = (1.0, 0.5)
-target_size_train_icdar2017 = (800, 800)
-train_pipeline_icdar2017 = [
- dict(type='LoadImageFromFile', color_type='color_ignore_orientation'),
- dict(
- type='LoadTextAnnotations',
- with_bbox=True,
- with_mask=True,
- poly2mask=False),
- dict(type='ColorJitter', brightness=32.0 / 255, saturation=0.5),
- dict(type='Normalize', **img_norm_cfg),
- dict(
- type='ScaleAspectJitter',
- img_scale=img_scale_train_icdar2017,
- ratio_range=(0.7, 1.3),
- aspect_ratio_range=(0.9, 1.1),
- multiscale_mode='value',
- keep_ratio=False),
- dict(type='PANetTargets', shrink_ratio=shrink_ratio_train_icdar2017),
- dict(type='RandomFlip', flip_ratio=0.5, direction='horizontal'),
- dict(type='RandomRotateTextDet'),
- dict(
- type='RandomCropInstances',
- target_size=target_size_train_icdar2017,
- instance_key='gt_kernels'),
- dict(type='Pad', size_divisor=32),
- dict(
- type='CustomFormatBundle',
- keys=['gt_kernels', 'gt_mask'],
- visualize=dict(flag=False, boundary_key='gt_kernels')),
- dict(type='Collect', keys=['img', 'gt_kernels', 'gt_mask'])
-]
-
-img_scale_test_icdar2017 = (1333, 800)
-test_pipeline_icdar2017 = [
- dict(type='LoadImageFromFile', color_type='color_ignore_orientation'),
- dict(
- type='MultiScaleFlipAug',
- img_scale=img_scale_test_icdar2017, # used by Resize
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='Collect', keys=['img']),
- ])
-]
diff --git a/spaces/dirge/voicevox/speaker_info/7ffcb7ce-00ec-4bdc-82cd-45a8889e43ff/policy.md b/spaces/dirge/voicevox/speaker_info/7ffcb7ce-00ec-4bdc-82cd-45a8889e43ff/policy.md
deleted file mode 100644
index c9bcc2cea42f727c8e43c934fc38163144848882..0000000000000000000000000000000000000000
--- a/spaces/dirge/voicevox/speaker_info/7ffcb7ce-00ec-4bdc-82cd-45a8889e43ff/policy.md
+++ /dev/null
@@ -1,3 +0,0 @@
-dummy1 policy
-
-https://voicevox.hiroshiba.jp/
diff --git a/spaces/dmeck/RVC-Speakers/speakers/server/__init__.py b/spaces/dmeck/RVC-Speakers/speakers/server/__init__.py
deleted file mode 100644
index 0591109378f8c017c4a65acab9f496dfb28454c0..0000000000000000000000000000000000000000
--- a/spaces/dmeck/RVC-Speakers/speakers/server/__init__.py
+++ /dev/null
@@ -1,109 +0,0 @@
-from speakers.common.registry import registry
-from speakers.server.bootstrap.bootstrap_register import load_bootstrap, get_bootstrap
-
-from omegaconf import OmegaConf
-
-from speakers.common.utils import get_abs_path
-from oscrypto import util as crypto_utils
-
-import asyncio
-import time
-import os
-import sys
-import traceback
-
-import subprocess
-
-root_dir = os.path.dirname(os.path.abspath(__file__))
-registry.register_path("server_library_root", root_dir)
-# Time to wait for web client to send a request to /task-state request
-# before that web clients task gets removed from the queue
-WEB_CLIENT_TIMEOUT = -1
-# Time before finished tasks get removed from memory
-FINISHED_TASK_REMOVE_TIMEOUT = 1800
-
-
-def generate_nonce():
- return crypto_utils.rand_bytes(16).hex()
-
-
-def start_translator_client_proc(speakers_config_file: str, nonce: str = None):
- cmds = [
- sys.executable,
- '-m', 'speakers',
- '--mode', 'web_runner',
- '--speakers-config-file', speakers_config_file,
- '--nonce', nonce,
- ]
-
- proc = subprocess.Popen(cmds, cwd=f"{registry.get_path('library_root')}/../")
- return proc
-
-
-async def start_async_app(speakers_config_file: str, nonce: str = None):
- config = OmegaConf.load(get_abs_path(speakers_config_file))
- load_bootstrap(config=config.get("bootstrap"))
-
- runner_bootstrap_web = get_bootstrap("runner_bootstrap_web")
-
- runner_bootstrap_web.set_nonce(nonce=nonce)
- await runner_bootstrap_web.run()
- return runner_bootstrap_web
-
-
-async def dispatch(speakers_config_file: str, nonce: str = None):
-
- if nonce is None:
- nonce = os.getenv('MT_WEB_NONCE', generate_nonce())
-
- runner = await start_async_app(speakers_config_file=speakers_config_file, nonce=nonce)
- # Create client process
- print()
- client_process = start_translator_client_proc(speakers_config_file, nonce=nonce)
-
- try:
- while True:
- """任务队列状态维护"""
- await asyncio.sleep(1)
-
- # Restart client if OOM or similar errors occured
- if client_process.poll() is not None:
- print('Restarting translator process')
- if len(runner.ongoing_tasks) > 0:
- task_id = runner.ongoing_tasks.pop(0)
- state = runner.task_states[task_id]
- state['info'] = 'error'
- state['finished'] = True
- client_process = start_translator_client_proc(speakers_config_file=speakers_config_file)
-
- # Filter queued and finished tasks
- now = time.time()
- to_del_task_ids = set()
- for tid, s in runner.task_states.items():
- payload = runner.task_data[tid]
- # Remove finished tasks after 30 minutes
- if s['finished'] and now - payload.created_at > FINISHED_TASK_REMOVE_TIMEOUT:
- to_del_task_ids.add(tid)
-
- # Remove queued tasks without web client
- elif WEB_CLIENT_TIMEOUT >= 0:
- if tid not in runner.ongoing_tasks and not s['finished'] \
- and now - payload.requested_at > WEB_CLIENT_TIMEOUT:
- print('REMOVING TASK', tid)
- to_del_task_ids.add(tid)
- try:
- runner.queue.remove(tid)
- except Exception:
- pass
-
- for tid in to_del_task_ids:
- del runner.task_states[tid]
- del runner.task_data[tid]
-
- except:
- if client_process.poll() is None:
- # client_process.terminate()
- client_process.kill()
- await runner.destroy()
- traceback.print_exc()
- raise
diff --git a/spaces/duycse1603/math2tex/ScanSSD/layers/functions/detection.py b/spaces/duycse1603/math2tex/ScanSSD/layers/functions/detection.py
deleted file mode 100644
index 597aa7374786ec7400a76db3f3d8a5c46e92da5b..0000000000000000000000000000000000000000
--- a/spaces/duycse1603/math2tex/ScanSSD/layers/functions/detection.py
+++ /dev/null
@@ -1,68 +0,0 @@
-import torch
-from torch.autograd import Function
-from ..box_utils import decode, nms
-
-class Detect(Function):
- """At test time, Detect is the final layer of SSD. Decode location preds,
- apply non-maximum suppression to location predictions based on conf
- scores and threshold to a top_k number of output predictions for both
- confidence score and locations.
- """
- def __init__(self, cfg, num_classes, bkg_label, top_k, conf_thresh, nms_thresh):
- self.num_classes = num_classes
- self.background_label = bkg_label
- self.top_k = top_k
- # Parameters used in nms.
- self.nms_thresh = nms_thresh
- if nms_thresh <= 0:
- raise ValueError('nms_threshold must be non negative.')
- self.conf_thresh = conf_thresh
- self.variance = cfg['variance']
-
- # @staticmethod
- def forward(self, loc_data, conf_data, prior_data):
- """
- Args:
- loc_data: (tensor) Loc preds from loc layers
- Shape: [batch,num_priors*4]
- conf_data: (tensor) Shape: Conf preds from conf layers
- Shape: [batch*num_priors,num_classes]
- prior_data: (tensor) Prior boxes and variances from priorbox layers
- Shape: [1,num_priors,4]
- """
- # move to CPU
- loc_data = loc_data.cpu()
- conf_data = conf_data.cpu()
- prior_data = prior_data.cpu()
-
- num = loc_data.size(0) # batch size
- num_priors = prior_data.size(0)
- output = torch.zeros(num, self.num_classes, self.top_k, 5)
- conf_preds = conf_data.view(num, num_priors,
- self.num_classes).transpose(2, 1)
-
- # Decode predictions into bboxes.
- for i in range(num):
- decoded_boxes = decode(loc_data[i], prior_data, self.variance)
- # For each class, perform nms
- conf_scores = conf_preds[i].clone()
- #print('decoded boxes ', decoded_boxes)
- #print('conf scores', conf_scores)
- for cl in range(1, self.num_classes):
- c_mask = conf_scores[cl].gt(self.conf_thresh)
- scores = conf_scores[cl][c_mask]
- if scores.dim() == 0:
- continue
- l_mask = c_mask.unsqueeze(1).expand_as(decoded_boxes)
- boxes = decoded_boxes[l_mask].view(-1, 4)
- # idx of highest scoring and non-overlapping boxes per class
-
- ids, count = nms(boxes, scores, self.nms_thresh, self.top_k)
- output[i, cl, :count] = \
- torch.cat((scores[ids[:count]].unsqueeze(1),
- boxes[ids[:count]]), 1)
- flt = output.contiguous().view(num, -1, 5)
- _, idx = flt[:, :, 0].sort(1, descending=True)
- _, rank = idx.sort(1)
- flt[(rank < self.top_k).unsqueeze(-1).expand_as(flt)].fill_(0)
- return output, boxes, scores
diff --git a/spaces/ecarbo/text-generator-gpt-neo/app.py b/spaces/ecarbo/text-generator-gpt-neo/app.py
deleted file mode 100644
index e13b7461fda47629406c9dba813bb7ae01e19493..0000000000000000000000000000000000000000
--- a/spaces/ecarbo/text-generator-gpt-neo/app.py
+++ /dev/null
@@ -1,25 +0,0 @@
-from transformers import AutoTokenizer, AutoModelForCausalLM
-import torch
-import gradio as gr
-
-tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
-model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
-
-def text_generation(input_text, seed):
- input_ids = tokenizer(input_text, return_tensors="pt").input_ids
- torch.manual_seed(seed) # Max value: 18446744073709551615
- outputs = model.generate(input_ids, do_sample=True, min_length=50, max_length=200)
- generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
- return generated_text
-
-title = "Text Generator Demo GPT-Neo"
-description = "Text Generator Application by ecarbo"
-
-gr.Interface(
- text_generation,
- [gr.inputs.Textbox(lines=2, label="Enter input text"), gr.inputs.Number(default=10, label="Enter seed number")],
- [gr.outputs.Textbox(type="auto", label="Text Generated")],
- title=title,
- description=description,
- theme="huggingface"
-).launch()
\ No newline at end of file
diff --git a/spaces/editing-images/ai-halloween-photobooth/style.css b/spaces/editing-images/ai-halloween-photobooth/style.css
deleted file mode 100644
index 6c0d066f2b8e2f4234634daf7e6fa8b2b2c0fd2b..0000000000000000000000000000000000000000
--- a/spaces/editing-images/ai-halloween-photobooth/style.css
+++ /dev/null
@@ -1,153 +0,0 @@
-/*
-This CSS file is modified from:
-https://huggingface.co/spaces/DeepFloyd/IF/blob/main/style.css
-*/
-@import url('https://fonts.googleapis.com/css2?family=IBM+Plex+Sans:wght@400;700&display=swap');
-body gradio-app{
- background-image: url(https://i.imgur.com/gqXjjP0.jpg) !important;
- background-position: center -131px !important;
- background-size: 1480px !important;
- background-repeat: no-repeat !important;
- background-color: #000305 !important;
-}
-h1, h3 {
- text-align: center;
- font-family: 'IBM Plex Sans', sans-serif;
-}
-
-.gradio-container {
- font-family: 'IBM Plex Sans', sans-serif;
- padding-top: 0 !important;
- margin-top: -35px !important;
-}
-
-.gr-button {
- color: white;
- border-color: black;
- background: black;
-}
-
-input[type='range'] {
- accent-color: black;
-}
-
-.dark input[type='range'] {
- accent-color: #dfdfdf;
-}
-
-.container {
- max-width: 730px;
- margin: auto;
- padding-top: 1.5rem;
-}
-
-/*background-image: url("https://i.imgur.com/gqXjjP0.jpg");*/
-
-.gr-button:focus {
- border-color: rgb(147 197 253 / var(--tw-border-opacity));
- outline: none;
- box-shadow: var(--tw-ring-offset-shadow), var(--tw-ring-shadow), var(--tw-shadow, 0 0 #0000);
- --tw-border-opacity: 1;
- --tw-ring-offset-shadow: var(--tw-ring-inset) 0 0 0 var(--tw-ring-offset-width) var(--tw-ring-offset-color);
- --tw-ring-shadow: var(--tw-ring-inset) 0 0 0 calc(3px var(--tw-ring-offset-width)) var(--tw-ring-color);
- --tw-ring-color: rgb(191 219 254 / var(--tw-ring-opacity));
- --tw-ring-opacity: .5;
-}
-
-.gr-form {
- flex: 1 1 50%;
- border-top-right-radius: 0;
- border-bottom-right-radius: 0;
-}
-
-#prompt-container {
- gap: 0;
-}
-
-#prompt-text-input,
-#negative-prompt-text-input {
- padding: .45rem 0.625rem
-}
-
-/* #component-16 {
- border-top-width: 1px !important;
- margin-top: 1em
-} */
-
-.image_duplication {
- position: absolute;
- width: 100px;
- left: 50px
-}
-
-#component-0 {
- max-width: 1048px;
- margin: auto;
-}
-
-#share-btn-container {
- display: flex; padding-left: 0.5rem !important; padding-right: 0.5rem !important; background-color: #000000; justify-content: center; align-items: center; border-radius: 9999px !important; width: 13rem; margin-left: auto;
-}
-#share-btn {
- all: initial; color: #ffffff;font-weight: 600; cursor:pointer; font-family: 'IBM Plex Sans', sans-serif; margin-left: 0.5rem !important; padding-top: 0.25rem !important; padding-bottom: 0.25rem !important;
-}
-#share-btn * {
- all: unset;
-}
-#share-btn-container div:nth-child(-n+2){
- width: auto !important;
- min-height: 0px !important;
-}
-#share-btn-container .wrap {
- display: none !important;
-}
-#lora_image button{
-height: 126px; width: 100%
-}
-h3, h4{margin-top: 0 !important}
-#input_image img, #output_image img, #lora_image img{
- object-fit: cover
-}
-.output_column_reverse{
- flex-direction: column-reverse !important;
-}
-#total_box{
- background-color: rgba(0, 0, 0, 0.5);
- backdrop-filter: blur(5px);
- max-width: 850px;
- margin: 0 auto;
- margin-top: -10px;
-}
-*{transition: width 0.5s ease, height 0.5s ease, flex-grow 0.5s ease}
-#buttons_area{margin-top: 1em}
-#iccv_logo{display: block !important; margin-top: 1.5em}
-#iccv_logo h1{margin-bottom: .5em}
-#pick{margin-top: .8em}
-[aria-label="Edit"],[aria-label="Download"],[aria-label="Share"]{
- display: none !important;
-}
-h3 a{
- color: var(--body-text-color) !important;
-}
-@media print{
- body gradio-app {
- background-color: #000305 !important;
- background-image: url(https://i.imgur.com/gqXjjP0.jpg) !important;
- }
- @page {
- size: landscape;
- margin: 0 !important;
- }
- #input_image, #output_image{height: 356px !important}
- #buttons_area{display: none !important}
- h3{display: none !important}
- footer{display: none !important}
-
- [data-testid="block-label"],
- [aria-label="Edit"],
- [aria-label="Clear"],
- [aria-label="Download"] {
- display: none !important;
- }
- #pick{display: none !important}
-}
\ No newline at end of file
diff --git a/spaces/eetn/Hellenic_AI_Society/README.md b/spaces/eetn/Hellenic_AI_Society/README.md
deleted file mode 100644
index 51e4e4f0c7b6a73e0a1a82301c5d90c6a9595e80..0000000000000000000000000000000000000000
--- a/spaces/eetn/Hellenic_AI_Society/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Hellenic_AI_Society
-emoji: 🔥
-colorFrom: green
-colorTo: indigo
-sdk: gradio
-sdk_version: 2.9.4
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/eforebrahim/Cassava-Leaf-Disease-Classification/app.py b/spaces/eforebrahim/Cassava-Leaf-Disease-Classification/app.py
deleted file mode 100644
index a4ac4d612d8ff86469f5f19a1010b5d09fb1c721..0000000000000000000000000000000000000000
--- a/spaces/eforebrahim/Cassava-Leaf-Disease-Classification/app.py
+++ /dev/null
@@ -1,65 +0,0 @@
-import cv2
-import os
-import PIL.Image
-import numpy as np
-import streamlit as st
-import tensorflow as tf
-from tensorflow.keras.preprocessing import image
-from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2,preprocess_input as mobilenet_v2_preprocess_input
-
-model = tf.keras.models.load_model("model_cassava.hdf5")
-### load file
-# uploaded_file = st.file_uploader("Choose a image file", type="jpg")
-
-map_dict = {0: 'Cassava Bacterial Blight (CBB)',
- 1: 'Cassava Brown Streak Disease (CBSD)',
- 2: 'Cassava Green Mottle (CGM)',
- 3: 'Cassava Mosaic Disease (CMD)',
- 4: 'Healthy'}
-
-option = st.radio('', ['Choose a test image', 'Choose your own image'])
-if option == 'Choose your own image':
- uploaded_file = st.file_uploader("Choose a image file", type="jpg")
-
- if uploaded_file is not None:
- # Convert the file to an opencv image.
- file_bytes = np.asarray(bytearray(uploaded_file.read()), dtype=np.uint8)
- opencv_image = cv2.imdecode(file_bytes, 1)
- opencv_image = cv2.cvtColor(opencv_image, cv2.COLOR_BGR2RGB)
- resized = cv2.resize(opencv_image,(224,224))
- # Now do something with the image! For example, let's display it:
- st.image(opencv_image, channels="RGB")
-
- # resized = mobilenet_v2_preprocess_input(resized)
- img_reshape = resized[np.newaxis,...]
-
- Genrate_pred = st.button("Generate Prediction")
- if Genrate_pred:
- predictions_proba = model.predict(img_reshape).max()*100
- prediction = model.predict(img_reshape).argmax()
- st.title("Predicted Label for the image is {}".format(map_dict[prediction]))
- st.title("with a probability of" f" { '{:.2f}'.format(predictions_proba)}")
-
-else:
- test_images = os.listdir('train_images')
- test_image = st.selectbox('Please select a test image:', test_images)
- file_path = 'train_images/' + test_image
- with open(file_path, 'rb') as img_stream:
- file_bytes = np.asarray(bytearray(img_stream.read()), dtype=np.uint8)
- opencv_image = cv2.imdecode(file_bytes, 1)
- opencv_image = cv2.cvtColor(opencv_image, cv2.COLOR_BGR2RGB)
- resized = cv2.resize(opencv_image,(224,224))
- # Now do something with the image! For example, let's display it:
- st.image(opencv_image, channels="RGB")
-
- # resized = mobilenet_v2_preprocess_input(resized)
- img_reshape = resized[np.newaxis,...]
-
- Genrate_pred = st.button("Generate Prediction")
- if Genrate_pred:
- predictions_proba = model.predict(img_reshape).max()*100
- prediction = model.predict(img_reshape).argmax()
- st.title("Predicted Label for the image is {}".format(map_dict[prediction]))
- st.title("with a probability of" f" { '{:.2f}'.format(predictions_proba)}")
-
-
diff --git a/spaces/ekojs/ml_food10/app.py b/spaces/ekojs/ml_food10/app.py
deleted file mode 100644
index e0c19ddc6ece270805a5765e2bc9c81fd3c6345b..0000000000000000000000000000000000000000
--- a/spaces/ekojs/ml_food10/app.py
+++ /dev/null
@@ -1,245 +0,0 @@
-import gradio as gr
-from fastai.vision.all import *
-import skimage
-from torchvision.transforms import RandAugment
-
-class RandAugmentTransform(RandTransform):
- "A fastai transform handler/wrapper for RandAugment (https://arxiv.org/abs/1909.13719)"
- split_idx, order = None, 2
- def __init__(self): store_attr()
-
- def before_call(self, b, split_idx):
- self.idx = split_idx
- self.aug = RandAugment()
-
- def encodes(self, img: PILImage):
- return self.aug(img) if self.idx == 0 else img
-
-# Adapted from https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html
-class BasicResNetBlock(nn.Module):
- """Basic ResNet Block (no bottleneck) with GELU instead of RELU"""
- expansion: int = 1
-
- def __init__(
- self,
- inplanes: int,
- planes: int,
- stride: int = 1,
- downsample = None
- ) -> None:
- super().__init__()
- # Both self.conv1 and self.downsample layers downsample the input when stride != 1
- self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, padding=1, stride=stride, bias=False)
- self.bn1 = nn.BatchNorm2d(planes)
- self.gelu = nn.GELU()
- self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1, stride=1, bias=False)
- self.bn2 = nn.BatchNorm2d(planes)
- self.downsample = downsample
- self.stride = stride
-
- def forward(self, x: Tensor) -> Tensor:
- identity = x
-
- out = self.conv1(x)
- out = self.bn1(out)
- out = self.gelu(out)
-
- out = self.conv2(out)
- out = self.bn2(out)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
- out = self.gelu(out)
-
- return out
-
- # Adapted from https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html
-class ResNet(nn.Module):
- def __init__(
- self,
- block,
- layers,
- num_classes = 10,
- zero_init_residual = True,
- ) -> None:
- super().__init__()
-
- self.inplanes = 64
-
- self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
- self.bn1 = nn.BatchNorm2d(self.inplanes)
- self.gelu = nn.ReLU(inplace=True)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
- self.layer1 = self._make_layer(block, 64, layers[0])
- self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
- self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
- self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
- self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
- self.fc = nn.Linear(512, num_classes)
-
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- nn.init.kaiming_normal_(m.weight, mode="fan_out")
- elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
- nn.init.constant_(m.weight, 1)
- nn.init.constant_(m.bias, 0)
-
- # Zero-initialize the last BN in each residual branch,
- # so that the residual branch starts with zeros, and each residual block behaves like an identity.
- # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
- if zero_init_residual:
- for m in self.modules():
- if isinstance(m, BasicResNetBlock):
- nn.init.constant_(m.bn2.weight, 0)
-
- def _make_layer(
- self,
- block,
- planes: int,
- blocks: int,
- stride: int = 1,
- ) -> nn.Sequential:
- downsample = None
- if stride != 1 or self.inplanes != planes:
- downsample = nn.Sequential(
- nn.Conv2d(self.inplanes, planes, 1, stride, bias=False),
- nn.BatchNorm2d(planes),
- )
-
- layers = []
- layers.append(block(self.inplanes, planes, stride, downsample))
-
- self.inplanes = planes
-
- for _ in range(1, blocks):
- layers.append(block(self.inplanes, planes))
-
- return nn.Sequential(*layers)
-
- def forward(self, x: Tensor) -> Tensor:
- x = self.conv1(x)
- x = self.bn1(x)
- x = self.gelu(x)
- x = self.maxpool(x)
-
- x = self.layer1(x)
- x = self.layer2(x)
- x = self.layer3(x)
- x = self.layer4(x)
-
- x = self.avgpool(x)
- x = torch.flatten(x, 1)
- x = self.fc(x)
-
- return x
-
-class ResNetWithPatches(nn.Module):
- def __init__(
- self,
- block,
- layers,
- num_classes = 10,
- zero_init_residual = True,
- ) -> None:
- super().__init__()
-
- self.inplanes = 64
-
- # Patchify stem
- # self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
- # self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
- self.stem = nn.Conv2d(3, self.inplanes, kernel_size=4, stride=4)
- self.gelu = nn.ReLU(inplace=True)
- self.bn1 = nn.BatchNorm2d(self.inplanes)
-
- self.layer1 = self._make_layer(block, 64, layers[0])
- self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
- self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
- self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
- self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
- self.fc = nn.Linear(512, num_classes)
-
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- nn.init.kaiming_normal_(m.weight, mode="fan_out")
- elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
- nn.init.constant_(m.weight, 1)
- nn.init.constant_(m.bias, 0)
-
- # Zero-initialize the last BN in each residual branch,
- # so that the residual branch starts with zeros, and each residual block behaves like an identity.
- # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
- if zero_init_residual:
- for m in self.modules():
- if isinstance(m, BasicResNetBlock):
- nn.init.constant_(m.bn2.weight, 0)
-
- def _make_layer(
- self,
- block,
- planes: int,
- blocks: int,
- stride: int = 1,
- ) -> nn.Sequential:
- downsample = None
- if stride != 1 or self.inplanes != planes:
- downsample = nn.Sequential(
- nn.Conv2d(self.inplanes, planes, 1, stride, bias=False),
- nn.BatchNorm2d(planes),
- )
-
- layers = []
- layers.append(block(self.inplanes, planes, stride, downsample))
-
- self.inplanes = planes
-
- for _ in range(1, blocks):
- layers.append(block(self.inplanes, planes))
-
- return nn.Sequential(*layers)
-
- def forward(self, x: Tensor) -> Tensor:
- x = self.stem(x)
- x = self.gelu(x)
- x = self.bn1(x)
-
- x = self.layer1(x)
- x = self.layer2(x)
- x = self.layer3(x)
- x = self.layer4(x)
-
- x = self.avgpool(x)
- x = torch.flatten(x, 1)
- x = self.fc(x)
-
- return x
-
-learner = load_learner("ResNetPatches.pkl")
-
-labels = learner.dls.vocab
-
-
-def predict(img):
- img = PILImage(PILImage.create(img).resize((224, 224)))
- pred, pred_idx, probs = learner.predict(img)
- return {labels[i]: float(probs[i]) for i in range(len(labels))}
-
-
-title = "Food Classifier"
-description = "A ResNet34 model modified to use patches of images, trained to classify food items on a subset (10 classes) of the Food 101 dataset."
-article = "Relevant Resources
"
-examples = [["chicken_curry.jpg"], ["garlic_bread.jpg"], ["takoyaki.jpg"]]
-enable_queue = True
-
-gr.Interface(
- fn=predict,
- inputs=gr.inputs.Image(shape=(224, 224)),
- outputs=gr.outputs.Label(num_top_classes=3),
- title=title,
- description=description,
- article=article,
- examples=examples,
- enable_queue=enable_queue,
-).launch()
diff --git a/spaces/epexVfeibi/Imagedeblurr/!!BETTER!! Full Version Scriptcase 6 Serial Number.md b/spaces/epexVfeibi/Imagedeblurr/!!BETTER!! Full Version Scriptcase 6 Serial Number.md
deleted file mode 100644
index cf0988f4fbb38156b8d1de0dcee271acde962d1d..0000000000000000000000000000000000000000
--- a/spaces/epexVfeibi/Imagedeblurr/!!BETTER!! Full Version Scriptcase 6 Serial Number.md
+++ /dev/null
@@ -1,147 +0,0 @@
-
-Full Version Scriptcase 6 Serial Number: What You Need to Know
-
-If you are looking for a powerful and easy-to-use web development tool, you might have heard of Scriptcase. Scriptcase is a low-code platform that allows you to create web applications using only your browser. You can import data from spreadsheets, databases, or external sources, and generate forms, reports, charts, dashboards, and more.
-Full Version Scriptcase 6 Serial Number
DOWNLOAD … https://jinyurl.com/2uEpj5
-
-Scriptcase is compatible with various databases, such as MySQL, PostgreSQL, SQLite, Interbase, Firebird, MS Access, Oracle, SQL Server, DB2, SyBase, Informix, or ODBC layer. You can also customize your applications with your own business rules, using external libraries, programming IDE (Blank), Events, Macros, and other features.
-
-Scriptcase has different versions for different needs and budgets. You can choose from Express Edition, Professional Edition, Enterprise Edition, or Cloud Edition. Each version has different features and limitations. For example, the Express Edition is free but has a limit of 10 projects and 2 connections.
-
-But what if you want to get the full version of Scriptcase 6 with all the features and no limitations? You will need a valid serial number to activate it. A serial number is a unique code that identifies your license and allows you to use Scriptcase without restrictions.
-
-How to Get a Full Version Scriptcase 6 Serial Number
-
-There are two ways to get a full version Scriptcase 6 serial number: buying it or cracking it.
-
-The first option is to buy it from the official website of Scriptcase. You can choose the edition that suits your needs and pay with your credit card or PayPal. You will receive an email with your serial number and instructions on how to activate it. This is the legal and safe way to get a full version Scriptcase 6 serial number.
-
-The second option is to crack it. This means using a software or a tool that generates a fake serial number that bypasses the activation process of Scriptcase. This is an illegal and risky way to get a full version Scriptcase 6 serial number. You might find some websites or blogs that offer cracked versions of Scriptcase 6 or serial number generators. However, these are not reliable sources and might contain viruses, malware, or spyware that can harm your computer or steal your personal information. Moreover, you might face legal consequences for violating the terms and conditions of Scriptcase.
-
-Why You Should Avoid Cracking Scriptcase 6
-
-Cracking Scriptcase 6 might seem tempting if you want to save money or try it before buying it. However, there are many reasons why you should avoid cracking Scriptcase 6 and opt for the legal way instead.
-
-
-
-- Cracking Scriptcase 6 is illegal and unethical. You are breaking the law and disrespecting the work of the developers who created Scriptcase. You are also depriving them of their income and support.
-- Cracking Scriptcase 6 is unsafe and unreliable. You are exposing your computer and your data to potential threats from viruses, malware, or spyware that might come with the cracked version or the serial number generator. You are also risking losing your work or getting errors or bugs in your applications.
-- Cracking Scriptcase 6 is unprofessional and unproductive. You are missing out on the benefits of having a legitimate license of Scriptcase 6, such as updates, support, documentation, tutorials, community forums, and more. You are also limiting your opportunities and credibility as a web developer.
-
-
-Conclusion
-
-Scriptcase 6 is a great web development tool that can help you create web applications faster and easier. However, if you want to get the full version of Scriptcase 6 with all the features and no limitations, you need a valid serial number to activate it.
-
-The best way to get a full version Scriptcase 6 serial number is to buy it from the official website of Scriptcase. This is the legal and safe way to get a full version Scriptcase 6 serial number. You will also enjoy the benefits of having a legitimate license of Scriptcase 6.
-
-The worst way to get a full version Scriptcase 6 serial number is to crack it. This is an illegal and risky way to get a full version Scriptcase 6 serial number. You will also face the drawbacks of having a cracked version of Scriptcase 6.
-
-Therefore, we recommend you to avoid cracking Scriptcase 6 and opt for the legal way instead. This will ensure your security, quality, professionalism, and productivity as a web developer.
-How to Use Scriptcase 6
-
-Once you have activated your full version Scriptcase 6 serial number, you can start using Scriptcase 6 to create web applications. The process is simple and intuitive. You just need to follow these steps:
-
-
-- Create a new project or open an existing one.
-- Select the database connection that you want to use for your application.
-- Create a new application or edit an existing one. You can choose from different types of applications, such as Form, Grid, Chart, Calendar, Control, Report, Dashboard, etc.
-- Configure the settings and options of your application, such as layout, fields, buttons, events, validations, filters, etc.
-- Generate the source code of your application and run it in your browser.
-- Publish your application to a web server or export it to a file.
-
-
-Scriptcase 6 also provides you with tools and resources to help you with your web development. You can access the documentation, tutorials, videos, samples, forums, support, and more from the Scriptcase menu.
-
-Benefits of Using Scriptcase 6
-
-Using Scriptcase 6 with a full version serial number has many benefits for web developers. Here are some of them:
-
-
-- You can create web applications faster and easier than coding from scratch.
-- You can use a visual interface to design and develop your applications without writing a single line of code.
-- You can import data from different sources and generate applications based on them.
-- You can create responsive and cross-browser applications that work on any device and platform.
-- You can customize your applications with your own business rules and logic.
-- You can integrate your applications with external libraries and APIs.
-- You can collaborate with other developers on the same project using the cloud edition or the team development feature.
-- You can update and maintain your applications easily with the automatic versioning and backup system.
-
-
-Scriptcase 6 is a powerful and easy-to-use web development tool that can help you create web applications faster and easier. However, if you want to get the full version of Scriptcase 6 with all the features and no limitations, you need a valid serial number to activate it.
-
-The best way to get a full version Scriptcase 6 serial number is to buy it from the official website of Scriptcase. This is the legal and safe way to get a full version Scriptcase 6 serial number. You will also enjoy the benefits of having a legitimate license of Scriptcase 6.
-
-The worst way to get a full version Scriptcase 6 serial number is to crack it. This is an illegal and risky way to get a full version Scriptcase 6 serial number. You will also face the drawbacks of having a cracked version of Scriptcase 6.
-
-Therefore, we recommend you to avoid cracking Scriptcase 6 and opt for the legal way instead. This will ensure your security, quality, professionalism, and productivity as a web developer.
-How to Download and Install Scriptcase 6
-
-If you have bought a full version Scriptcase 6 serial number, you can download and install Scriptcase 6 on your computer or on a web server. The process is simple and straightforward. You just need to follow these steps:
-
-
-- Go to the official website of Scriptcase and log in with your email and password.
-- Go to the download section and choose the version that matches your operating system (Windows, Linux, or Mac).
-- Download the installer file and save it on your computer or on a web server.
-- Run the installer file and follow the instructions on the screen.
-- Enter your full version Scriptcase 6 serial number when prompted.
-- Finish the installation and launch Scriptcase 6.
-
-
-You can also watch the video tutorials on the website of Scriptcase to see how to download and install Scriptcase 6 step by step.
-
-How to Update and Upgrade Scriptcase 6
-
-If you have a full version Scriptcase 6 serial number, you can update and upgrade Scriptcase 6 to get the latest features and improvements. The process is easy and convenient. You just need to follow these steps:
-
-
-- Open Scriptcase 6 and go to Help > Check for updates.
-- If there are any updates available, click on Download and Install.
-- Wait for the updates to be downloaded and installed.
-- Restart Scriptcase 6 and enjoy the new features and improvements.
-
-
-If you want to upgrade your edition of Scriptcase 6, you can do so by going to the website of Scriptcase and choosing the edition that you want to upgrade to. You will need to pay the difference between your current edition and the new edition. You will receive an email with your new serial number and instructions on how to activate it.
-
-You can also watch the video tutorials on the website of Scriptcase to see how to update and upgrade Scriptcase 6 step by step.
-How to Troubleshoot Scriptcase 6
-
-If you encounter any problems or issues while using Scriptcase 6 with a full version serial number, you can troubleshoot them by following these steps:
-
-
-- Check the system requirements of Scriptcase 6 and make sure your computer or web server meets them.
-- Check the compatibility of Scriptcase 6 with your browser and make sure you are using the latest version.
-- Check the connection settings of Scriptcase 6 and make sure they are correct and valid.
-- Check the error logs of Scriptcase 6 and see if there are any messages or codes that indicate the cause of the problem.
-- Check the documentation and FAQ of Scriptcase 6 and see if there are any solutions or tips for your problem.
-- Contact the support team of Scriptcase 6 and report your problem with details and screenshots.
-
-
-You can also watch the video tutorials on the website of Scriptcase to see how to troubleshoot Scriptcase 6 step by step.
-
-How to Uninstall Scriptcase 6
-
-If you want to uninstall Scriptcase 6 from your computer or web server, you can do so by following these steps:
-
-
-- Backup your projects and data before uninstalling Scriptcase 6.
-- Go to the control panel of your computer or web server and find the program list.
-- Select Scriptcase 6 and click on Uninstall.
-- Follow the instructions on the screen to complete the uninstallation process.
-- Delete any remaining files or folders related to Scriptcase 6 from your computer or web server.
-
-
-You can also watch the video tutorials on the website of Scriptcase to see how to uninstall Scriptcase 6 step by step.
-Conclusion
-
-Scriptcase 6 is a powerful and easy-to-use web development tool that can help you create web applications faster and easier. However, if you want to get the full version of Scriptcase 6 with all the features and no limitations, you need a valid serial number to activate it.
-
-The best way to get a full version Scriptcase 6 serial number is to buy it from the official website of Scriptcase. This is the legal and safe way to get a full version Scriptcase 6 serial number. You will also enjoy the benefits of having a legitimate license of Scriptcase 6, such as updates, support, documentation, tutorials, community forums, and more.
-
-The worst way to get a full version Scriptcase 6 serial number is to crack it. This is an illegal and risky way to get a full version Scriptcase 6 serial number. You will also face the drawbacks of having a cracked version of Scriptcase 6, such as viruses, malware, spyware, errors, bugs, legal consequences, and more.
-
-Therefore, we recommend you to avoid cracking Scriptcase 6 and opt for the legal way instead. This will ensure your security, quality, professionalism, and productivity as a web developer.
-
-We hope this article has helped you to understand what Scriptcase 6 is and how to get a full version Scriptcase 6 serial number. If you have any questions or feedback, please feel free to contact us or leave a comment below.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/epexVfeibi/Imagedeblurr/!!TOP!! Download Tally Ees V6 3 Release 1 Crack Keygen.md b/spaces/epexVfeibi/Imagedeblurr/!!TOP!! Download Tally Ees V6 3 Release 1 Crack Keygen.md
deleted file mode 100644
index cb25045577f967a29d525cd31e263af689d4cb8c..0000000000000000000000000000000000000000
--- a/spaces/epexVfeibi/Imagedeblurr/!!TOP!! Download Tally Ees V6 3 Release 1 Crack Keygen.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Download Tally Ees V6 3 Release 1 Crack Keygen
DOWNLOAD === https://jinyurl.com/2uEpHK
-
-We suggest that you download and install the current product i.e. Tally ERP 9. To migrate your Tally 6.3 data to Tally ERP 9, you can follow the steps below or contact us if ... Tally ERP 9 is compatible with Windows XP SP2 or higher versions of the ... 1. Start TallyERP 9. 2. Click A: Activate Your License in the startup screen, ... 4d29de3e1b
-
-
-
diff --git a/spaces/eswat/Image-and-3D-Model-Creator/PIFu/README.md b/spaces/eswat/Image-and-3D-Model-Creator/PIFu/README.md
deleted file mode 100644
index 5eae12f2a370027de6c46fbf78ec68a1ecb1c01c..0000000000000000000000000000000000000000
--- a/spaces/eswat/Image-and-3D-Model-Creator/PIFu/README.md
+++ /dev/null
@@ -1,167 +0,0 @@
-# PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
-
-[](https://arxiv.org/abs/1905.05172) [](https://colab.research.google.com/drive/1GFSsqP2BWz4gtq0e-nki00ZHSirXwFyY)
-
-News:
-* \[2020/05/04\] Added EGL rendering option for training data generation. Now you can create your own training data with headless machines!
-* \[2020/04/13\] Demo with Google Colab (incl. visualization) is available. Special thanks to [@nanopoteto](https://github.com/nanopoteto)!!!
-* \[2020/02/26\] License is updated to MIT license! Enjoy!
-
-This repository contains a pytorch implementation of "[PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization](https://arxiv.org/abs/1905.05172)".
-
-[Project Page](https://shunsukesaito.github.io/PIFu/)
-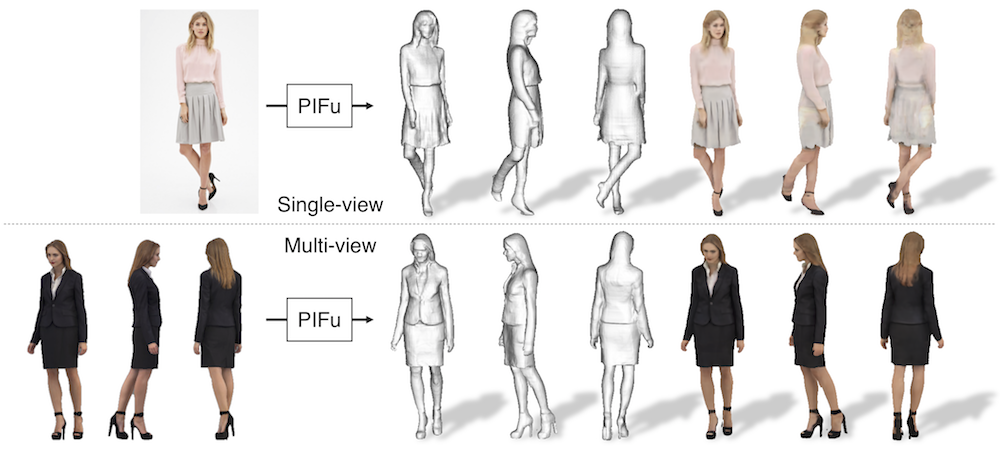
-
-If you find the code useful in your research, please consider citing the paper.
-
-```
-@InProceedings{saito2019pifu,
-author = {Saito, Shunsuke and Huang, Zeng and Natsume, Ryota and Morishima, Shigeo and Kanazawa, Angjoo and Li, Hao},
-title = {PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization},
-booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
-month = {October},
-year = {2019}
-}
-```
-
-
-This codebase provides:
-- test code
-- training code
-- data generation code
-
-## Requirements
-- Python 3
-- [PyTorch](https://pytorch.org/) tested on 1.4.0
-- json
-- PIL
-- skimage
-- tqdm
-- numpy
-- cv2
-
-for training and data generation
-- [trimesh](https://trimsh.org/) with [pyembree](https://github.com/scopatz/pyembree)
-- [pyexr](https://github.com/tvogels/pyexr)
-- PyOpenGL
-- freeglut (use `sudo apt-get install freeglut3-dev` for ubuntu users)
-- (optional) egl related packages for rendering with headless machines. (use `apt install libgl1-mesa-dri libegl1-mesa libgbm1` for ubuntu users)
-
-Warning: I found that outdated NVIDIA drivers may cause errors with EGL. If you want to try out the EGL version, please update your NVIDIA driver to the latest!!
-
-## Windows demo installation instuction
-
-- Install [miniconda](https://docs.conda.io/en/latest/miniconda.html)
-- Add `conda` to PATH
-- Install [git bash](https://git-scm.com/downloads)
-- Launch `Git\bin\bash.exe`
-- `eval "$(conda shell.bash hook)"` then `conda activate my_env` because of [this](https://github.com/conda/conda-build/issues/3371)
-- Automatic `env create -f environment.yml` (look [this](https://github.com/conda/conda/issues/3417))
-- OR manually setup [environment](https://towardsdatascience.com/a-guide-to-conda-environments-bc6180fc533)
- - `conda create —name pifu python` where `pifu` is name of your environment
- - `conda activate`
- - `conda install pytorch torchvision cudatoolkit=10.1 -c pytorch`
- - `conda install pillow`
- - `conda install scikit-image`
- - `conda install tqdm`
- - `conda install -c menpo opencv`
-- Download [wget.exe](https://eternallybored.org/misc/wget/)
-- Place it into `Git\mingw64\bin`
-- `sh ./scripts/download_trained_model.sh`
-- Remove background from your image ([this](https://www.remove.bg/), for example)
-- Create black-white mask .png
-- Replace original from sample_images/
-- Try it out - `sh ./scripts/test.sh`
-- Download [Meshlab](http://www.meshlab.net/) because of [this](https://github.com/shunsukesaito/PIFu/issues/1)
-- Open .obj file in Meshlab
-
-
-## Demo
-Warning: The released model is trained with mostly upright standing scans with weak perspectie projection and the pitch angle of 0 degree. Reconstruction quality may degrade for images highly deviated from trainining data.
-1. run the following script to download the pretrained models from the following link and copy them under `./PIFu/checkpoints/`.
-```
-sh ./scripts/download_trained_model.sh
-```
-
-2. run the following script. the script creates a textured `.obj` file under `./PIFu/eval_results/`. You may need to use `./apps/crop_img.py` to roughly align an input image and the corresponding mask to the training data for better performance. For background removal, you can use any off-the-shelf tools such as [removebg](https://www.remove.bg/).
-```
-sh ./scripts/test.sh
-```
-
-## Demo on Google Colab
-If you do not have a setup to run PIFu, we offer Google Colab version to give it a try, allowing you to run PIFu in the cloud, free of charge. Try our Colab demo using the following notebook:
-[](https://colab.research.google.com/drive/1GFSsqP2BWz4gtq0e-nki00ZHSirXwFyY)
-
-## Data Generation (Linux Only)
-While we are unable to release the full training data due to the restriction of commertial scans, we provide rendering code using free models in [RenderPeople](https://renderpeople.com/free-3d-people/).
-This tutorial uses `rp_dennis_posed_004` model. Please download the model from [this link](https://renderpeople.com/sample/free/rp_dennis_posed_004_OBJ.zip) and unzip the content under a folder named `rp_dennis_posed_004_OBJ`. The same process can be applied to other RenderPeople data.
-
-Warning: the following code becomes extremely slow without [pyembree](https://github.com/scopatz/pyembree). Please make sure you install pyembree.
-
-1. run the following script to compute spherical harmonics coefficients for [precomputed radiance transfer (PRT)](https://sites.fas.harvard.edu/~cs278/papers/prt.pdf). In a nutshell, PRT is used to account for accurate light transport including ambient occlusion without compromising online rendering time, which significantly improves the photorealism compared with [a common sperical harmonics rendering using surface normals](https://cseweb.ucsd.edu/~ravir/papers/envmap/envmap.pdf). This process has to be done once for each obj file.
-```
-python -m apps.prt_util -i {path_to_rp_dennis_posed_004_OBJ}
-```
-
-2. run the following script. Under the specified data path, the code creates folders named `GEO`, `RENDER`, `MASK`, `PARAM`, `UV_RENDER`, `UV_MASK`, `UV_NORMAL`, and `UV_POS`. Note that you may need to list validation subjects to exclude from training in `{path_to_training_data}/val.txt` (this tutorial has only one subject and leave it empty). If you wish to render images with headless servers equipped with NVIDIA GPU, add -e to enable EGL rendering.
-```
-python -m apps.render_data -i {path_to_rp_dennis_posed_004_OBJ} -o {path_to_training_data} [-e]
-```
-
-## Training (Linux Only)
-
-Warning: the following code becomes extremely slow without [pyembree](https://github.com/scopatz/pyembree). Please make sure you install pyembree.
-
-1. run the following script to train the shape module. The intermediate results and checkpoints are saved under `./results` and `./checkpoints` respectively. You can add `--batch_size` and `--num_sample_input` flags to adjust the batch size and the number of sampled points based on available GPU memory.
-```
-python -m apps.train_shape --dataroot {path_to_training_data} --random_flip --random_scale --random_trans
-```
-
-2. run the following script to train the color module.
-```
-python -m apps.train_color --dataroot {path_to_training_data} --num_sample_inout 0 --num_sample_color 5000 --sigma 0.1 --random_flip --random_scale --random_trans
-```
-
-## Related Research
-**[Monocular Real-Time Volumetric Performance Capture (ECCV 2020)](https://project-splinter.github.io/)**
-*Ruilong Li\*, Yuliang Xiu\*, Shunsuke Saito, Zeng Huang, Kyle Olszewski, Hao Li*
-
-The first real-time PIFu by accelerating reconstruction and rendering!!
-
-**[PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (CVPR 2020)](https://shunsukesaito.github.io/PIFuHD/)**
-*Shunsuke Saito, Tomas Simon, Jason Saragih, Hanbyul Joo*
-
-We further improve the quality of reconstruction by leveraging multi-level approach!
-
-**[ARCH: Animatable Reconstruction of Clothed Humans (CVPR 2020)](https://arxiv.org/pdf/2004.04572.pdf)**
-*Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, Tony Tung*
-
-Learning PIFu in canonical space for animatable avatar generation!
-
-**[Robust 3D Self-portraits in Seconds (CVPR 2020)](http://www.liuyebin.com/portrait/portrait.html)**
-*Zhe Li, Tao Yu, Chuanyu Pan, Zerong Zheng, Yebin Liu*
-
-They extend PIFu to RGBD + introduce "PIFusion" utilizing PIFu reconstruction for non-rigid fusion.
-
-**[Learning to Infer Implicit Surfaces without 3d Supervision (NeurIPS 2019)](http://papers.nips.cc/paper/9039-learning-to-infer-implicit-surfaces-without-3d-supervision.pdf)**
-*Shichen Liu, Shunsuke Saito, Weikai Chen, Hao Li*
-
-We answer to the question of "how can we learn implicit function if we don't have 3D ground truth?"
-
-**[SiCloPe: Silhouette-Based Clothed People (CVPR 2019, best paper finalist)](https://arxiv.org/pdf/1901.00049.pdf)**
-*Ryota Natsume\*, Shunsuke Saito\*, Zeng Huang, Weikai Chen, Chongyang Ma, Hao Li, Shigeo Morishima*
-
-Our first attempt to reconstruct 3D clothed human body with texture from a single image!
-
-**[Deep Volumetric Video from Very Sparse Multi-view Performance Capture (ECCV 2018)](http://openaccess.thecvf.com/content_ECCV_2018/papers/Zeng_Huang_Deep_Volumetric_Video_ECCV_2018_paper.pdf)**
-*Zeng Huang, Tianye Li, Weikai Chen, Yajie Zhao, Jun Xing, Chloe LeGendre, Linjie Luo, Chongyang Ma, Hao Li*
-
-Implict surface learning for sparse view human performance capture!
-
-------
-
-
-
-For commercial queries, please contact:
-
-Hao Li: hao@hao-li.com ccto: saitos@usc.edu Baker!!
diff --git a/spaces/eubinecto/idiomify/main_train.py b/spaces/eubinecto/idiomify/main_train.py
deleted file mode 100644
index ef24b27005bcdade3cc93d8c77adfe46ff04f843..0000000000000000000000000000000000000000
--- a/spaces/eubinecto/idiomify/main_train.py
+++ /dev/null
@@ -1,56 +0,0 @@
-import os
-import torch.cuda
-import wandb
-import argparse
-import pytorch_lightning as pl
-from termcolor import colored
-from pytorch_lightning.loggers import WandbLogger
-from transformers import BartForConditionalGeneration
-from idiomify.datamodules import IdiomifyDataModule
-from idiomify.fetchers import fetch_config, fetch_tokenizer
-from idiomify.models import Idiomifier
-from idiomify.paths import ROOT_DIR
-
-
-def main():
- parser = argparse.ArgumentParser()
- parser.add_argument("--num_workers", type=int, default=os.cpu_count())
- parser.add_argument("--log_every_n_steps", type=int, default=1)
- parser.add_argument("--fast_dev_run", action="store_true", default=False)
- parser.add_argument("--upload", dest='upload', action='store_true', default=False)
- args = parser.parse_args()
- config = fetch_config()['idiomifier']
- config.update(vars(args))
- if not config['upload']:
- print(colored("WARNING: YOU CHOSE NOT TO UPLOAD. NOTHING BUT LOGS WILL BE SAVED TO WANDB", color="red"))
- # prepare a pre-trained BART
- bart = BartForConditionalGeneration.from_pretrained(config['bart'])
- # prepare the datamodule
- with wandb.init(entity="eubinecto", project="idiomify", config=config) as run:
- tokenizer = fetch_tokenizer(config['tokenizer_ver'], run)
- bart.resize_token_embeddings(len(tokenizer)) # because new tokens are added, this process is necessary
- model = Idiomifier(bart, config['lr'], tokenizer.bos_token_id, tokenizer.pad_token_id)
- datamodule = IdiomifyDataModule(config, tokenizer, run)
- logger = WandbLogger(log_model=False)
- trainer = pl.Trainer(max_epochs=config['max_epochs'],
- fast_dev_run=config['fast_dev_run'],
- log_every_n_steps=config['log_every_n_steps'],
- gpus=torch.cuda.device_count(),
- default_root_dir=str(ROOT_DIR),
- enable_checkpointing=False,
- logger=logger)
- # start training
- trainer.fit(model=model, datamodule=datamodule)
- # upload the model to wandb only if the training is properly done #
- if not config['fast_dev_run'] and trainer.current_epoch == config['max_epochs'] - 1:
- ckpt_path = ROOT_DIR / "model.ckpt"
- trainer.save_checkpoint(str(ckpt_path))
- config['vocab_size'] = len(tokenizer) # this will be needed to fetch a pretrained idiomifier later
- artifact = wandb.Artifact(name="idiomifier", type="model", metadata=config)
- artifact.add_file(str(ckpt_path))
- run.log_artifact(artifact, aliases=["latest", config['ver']])
- os.remove(str(ckpt_path)) # make sure you remove it after you are done with uploading it
-
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/evoss/NLP_text_analyzer/app.py b/spaces/evoss/NLP_text_analyzer/app.py
deleted file mode 100644
index df2b45136606645bbe2253c96fd2abe160d927d8..0000000000000000000000000000000000000000
--- a/spaces/evoss/NLP_text_analyzer/app.py
+++ /dev/null
@@ -1,29 +0,0 @@
-import gradio as gr
-
-import spacy
-nlp = spacy.load('en_core_web_sm')
-
-
-def count_verbs(doc):
- verbs = 0
- for token in doc:
- if token.pos_ == "VERB":
- verbs += 1
- return verbs
-
-def greet(sent):
- doc = nlp(sent)
- nouns = 0
- for token in doc:
- if token.pos_ == "NOUN":
- nouns += 1
- verbs = count_verbs(doc)
- length = len(sent.split())
- return (f"Your sentence has {length} word(s).\n Your sentence has {nouns} noun(s).\n Your sentence has {verbs} verb(s).")
-
-
-
-iface = gr.Interface(fn=greet, inputs="text", outputs="text", examples = [
- ["The Moon's orbit around Earth takes a long time."],
- ["The smooth Borealis basin in the Northern Hemisphere covers 40%."]])
-iface.launch(debug=True)
\ No newline at end of file
diff --git a/spaces/facebook/StyleNeRF/training/networks.py b/spaces/facebook/StyleNeRF/training/networks.py
deleted file mode 100644
index f762ea468f7825d2f207fc6edb293088815f689b..0000000000000000000000000000000000000000
--- a/spaces/facebook/StyleNeRF/training/networks.py
+++ /dev/null
@@ -1,1563 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-
-# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-from pickle import NONE
-from re import X
-from sndhdr import whathdr
-import numpy as np
-import math
-import scipy.signal
-import scipy.optimize
-
-from numpy import core
-from numpy.lib.arraysetops import isin
-
-import torch
-import torch.nn.functional as F
-from torch.overrides import is_tensor_method_or_property
-from einops import repeat
-from dnnlib import camera, util, geometry
-from torch_utils import misc
-from torch_utils import persistence
-from torch_utils.ops import conv2d_resample
-from torch_utils.ops import upfirdn2d
-from torch_utils.ops import bias_act
-from torch_utils.ops import fma
-from torch_utils.ops import filtered_lrelu
-
-#----------------------------------------------------------------------------
-
-@misc.profiled_function
-def normalize_2nd_moment(x, dim=1, eps=1e-8):
- return x * (x.square().mean(dim=dim, keepdim=True) + eps).rsqrt()
-
-
-@misc.profiled_function
-def conv3d(x, w, up=1, down=1, padding=0, groups=1):
- if up > 1:
- x = F.interpolate(x, scale_factor=up, mode='trilinear', align_corners=True)
- x = F.conv3d(x, w, padding=padding, groups=groups)
- if down > 1:
- x = F.interpolate(x, scale_factor=1./float(down), mode='trilinear', align_corners=True)
- return x
-
-#----------------------------------------------------------------------------
-
-@misc.profiled_function
-def modulated_conv2d(
- x, # Input tensor of shape [batch_size, in_channels, in_height, in_width].
- weight, # Weight tensor of shape [out_channels, in_channels, kernel_height, kernel_width].
- styles, # Modulation coefficients of shape [batch_size, in_channels].
- noise = None, # Optional noise tensor to add to the output activations.
- up = 1, # Integer upsampling factor.
- down = 1, # Integer downsampling factor.
- padding = 0, # Padding with respect to the upsampled image.
- resample_filter = None, # Low-pass filter to apply when resampling activations. Must be prepared beforehand by calling upfirdn2d.setup_filter().
- demodulate = True, # Apply weight demodulation?
- flip_weight = True, # False = convolution, True = correlation (matches torch.nn.functional.conv2d) ????????
- fused_modconv = True, # Perform modulation, convolution, and demodulation as a single fused operation?
- mode = '2d', # modulated 2d/3d conv or MLP
- **unused,
-):
- batch_size = x.shape[0]
- if mode == '3d':
- _, in_channels, kd, kh, kw = weight.shape
- else:
- _, in_channels, kh, kw = weight.shape
-
- # Pre-normalize inputs to avoid FP16 overflow.
- if x.dtype == torch.float16 and demodulate:
- weight_sizes = in_channels * kh * kw if mode != '3d' else in_channels * kd * kh * kw
- weight = weight * (1 / np.sqrt(weight_sizes) / weight.norm(float('inf'), dim=[1,2,3], keepdim=True)) # max_Ikk
- styles = styles / styles.norm(float('inf'), dim=1, keepdim=True) # max_I
-
- # Calculate per-sample weights and demodulation coefficients.
- w = None
- dcoefs = None
- if mode != '3d':
- rsizes, ssizes = [-1, 1, 1], [2, 3, 4]
- else:
- rsizes, ssizes = [-1, 1, 1, 1], [2, 3, 4, 5]
-
- if demodulate or fused_modconv: # if not fused, skip
- w = weight.unsqueeze(0) * styles.reshape(batch_size, 1, *rsizes)
- if demodulate:
- dcoefs = (w.square().sum(dim=ssizes) + 1e-8).rsqrt() # [NO]
-
- if demodulate and fused_modconv:
- w = w * dcoefs.reshape(batch_size, *rsizes, 1) # [NOIkk] (batch_size, out_channels, in_channels, kernel_size, kernel_size)
-
- # Execute by scaling the activations before and after the convolution.
- if not fused_modconv:
- x = x * styles.to(x.dtype).reshape(batch_size, *rsizes)
- if mode == '2d':
- x = conv2d_resample.conv2d_resample(x=x, w=weight.to(x.dtype), f=resample_filter, up=up, down=down, padding=padding, flip_weight=flip_weight)
- elif mode == '3d':
- x = conv3d(x=x, w=weight.to(x.dtype), up=up, down=down, padding=padding)
- else:
- raise NotImplementedError
-
- if demodulate and noise is not None:
- x = fma.fma(x, dcoefs.to(x.dtype).reshape(batch_size, *rsizes), noise.to(x.dtype)) # fused multiply add
- elif demodulate:
- x = x * dcoefs.to(x.dtype).reshape(batch_size, *rsizes)
- elif noise is not None:
- x = x.add_(noise.to(x.dtype))
- return x
-
- # Execute as one fused op using grouped convolution.
- with misc.suppress_tracer_warnings(): # this value will be treated as a constant
- batch_size = int(batch_size)
-
- x = x.reshape(1, -1, *x.shape[2:])
- w = w.reshape(-1, *w.shape[2:])
- if mode == '2d':
- x = conv2d_resample.conv2d_resample(x=x, w=w.to(x.dtype), f=resample_filter, up=up, down=down, padding=padding, groups=batch_size, flip_weight=flip_weight)
- elif mode == '3d':
- x = conv3d(x=x, w=w.to(x.dtype), up=up, down=down, padding=padding, groups=batch_size)
- x = x.reshape(batch_size, -1, *x.shape[2:])
-
- if noise is not None:
- x = x.add_(noise)
- return x
-
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class FullyConnectedLayer(torch.nn.Module):
- def __init__(self,
- in_features, # Number of input features.
- out_features, # Number of output features.
- bias = True, # Apply additive bias before the activation function?
- activation = 'linear', # Activation function: 'relu', 'lrelu', etc.
- lr_multiplier = 1, # Learning rate multiplier.
- bias_init = 0, # Initial value for the additive bias.
- ):
- super().__init__()
- self.activation = activation
- self.weight = torch.nn.Parameter(torch.randn([out_features, in_features]) / lr_multiplier)
- self.bias = torch.nn.Parameter(torch.full([out_features], np.float32(bias_init))) if bias else None
- self.weight_gain = lr_multiplier / np.sqrt(in_features)
- self.bias_gain = lr_multiplier
-
- def forward(self, x):
- w = self.weight.to(x.dtype) * self.weight_gain
- b = self.bias
- if b is not None:
- b = b.to(x.dtype)
- if self.bias_gain != 1:
- b = b * self.bias_gain
-
- if self.activation == 'linear' and b is not None:
- x = torch.addmm(b.unsqueeze(0), x, w.t())
- else:
- x = x.matmul(w.t())
- x = bias_act.bias_act(x, b, act=self.activation)
- return x
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class Conv2dLayer(torch.nn.Module):
- def __init__(self,
- in_channels, # Number of input channels.
- out_channels, # Number of output channels.
- kernel_size, # Width and height of the convolution kernel.
- bias = True, # Apply additive bias before the activation function?
- activation = 'linear', # Activation function: 'relu', 'lrelu', etc.
- up = 1, # Integer upsampling factor.
- down = 1, # Integer downsampling factor.
- resample_filter = [1,3,3,1], # Low-pass filter to apply when resampling activations.
- conv_clamp = None, # Clamp the output to +-X, None = disable clamping.
- channels_last = False, # Expect the input to have memory_format=channels_last?
- trainable = True, # Update the weights of this layer during training?
- mode = '2d',
- **unused
- ):
- super().__init__()
- self.activation = activation
- self.up = up
- self.down = down
- self.conv_clamp = conv_clamp
- self.register_buffer('resample_filter', upfirdn2d.setup_filter(resample_filter))
- self.padding = kernel_size // 2
- self.weight_gain = 1 / np.sqrt(in_channels * (kernel_size ** 2))
- self.act_gain = bias_act.activation_funcs[activation].def_gain
- self.mode = mode
- weight_shape = [out_channels, in_channels, kernel_size, kernel_size]
- if mode == '3d':
- weight_shape += [kernel_size]
-
- memory_format = torch.channels_last if channels_last else torch.contiguous_format
- weight = torch.randn(weight_shape).to(memory_format=memory_format)
- bias = torch.zeros([out_channels]) if bias else None
- if trainable:
- self.weight = torch.nn.Parameter(weight)
- self.bias = torch.nn.Parameter(bias) if bias is not None else None
- else:
- self.register_buffer('weight', weight)
- if bias is not None:
- self.register_buffer('bias', bias)
- else:
- self.bias = None
-
- def forward(self, x, gain=1):
- w = self.weight * self.weight_gain
- b = self.bias.to(x.dtype) if self.bias is not None else None
- flip_weight = (self.up == 1) # slightly faster
-
- if self.mode == '2d':
- x = conv2d_resample.conv2d_resample(x=x, w=w.to(x.dtype), f=self.resample_filter, up=self.up, down=self.down, padding=self.padding, flip_weight=flip_weight)
- elif self.mode == '3d':
- x = conv3d(x=x, w=w.to(x.dtype), up=self.up, down=self.down, padding=self.padding)
-
- act_gain = self.act_gain * gain
- act_clamp = self.conv_clamp * gain if self.conv_clamp is not None else None
- x = bias_act.bias_act(x, b, act=self.activation, gain=act_gain, clamp=act_clamp)
- return x
-
-# ---------------------------------------------------------------------------
-
-@persistence.persistent_class
-class Blur(torch.nn.Module):
- def __init__(self):
- super().__init__()
- f = torch.Tensor([1, 2, 1])
- self.register_buffer('f', f)
-
- def forward(self, x):
- from kornia.filters import filter2d
- f = self.f
- f = f[None, None, :] * f [None, :, None]
- return filter2d(x, f, normalized=True)
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class MappingNetwork(torch.nn.Module):
- def __init__(self,
- z_dim, # Input latent (Z) dimensionality, 0 = no latent.
- c_dim, # Conditioning label (C) dimensionality, 0 = no label.
- w_dim, # Intermediate latent (W) dimensionality.
- num_ws, # Number of intermediate latents to output, None = do not broadcast.
- num_layers = 8, # Number of mapping layers.
- embed_features = None, # Label embedding dimensionality, None = same as w_dim.
- layer_features = None, # Number of intermediate features in the mapping layers, None = same as w_dim.
- activation = 'lrelu', # Activation function: 'relu', 'lrelu', etc.
- lr_multiplier = 0.01, # Learning rate multiplier for the mapping layers.
- w_avg_beta = 0.995, # Decay for tracking the moving average of W during training, None = do not track.
- **unused,
- ):
- super().__init__()
- self.z_dim = z_dim
- self.c_dim = c_dim
- self.w_dim = w_dim
- self.num_ws = num_ws
- self.num_layers = num_layers
- self.w_avg_beta = w_avg_beta
-
- if embed_features is None:
- embed_features = w_dim
- if c_dim == 0:
- embed_features = 0
- if layer_features is None:
- layer_features = w_dim
- features_list = [z_dim + embed_features] + [layer_features] * (num_layers - 1) + [w_dim]
-
- if c_dim > 0: # project label condition
- self.embed = FullyConnectedLayer(c_dim, embed_features)
- for idx in range(num_layers):
- in_features = features_list[idx]
- out_features = features_list[idx + 1]
- layer = FullyConnectedLayer(in_features, out_features, activation=activation, lr_multiplier=lr_multiplier)
- setattr(self, f'fc{idx}', layer)
-
- if num_ws is not None and w_avg_beta is not None:
- self.register_buffer('w_avg', torch.zeros([w_dim]))
-
- def forward(self, z=None, c=None, truncation_psi=1, truncation_cutoff=None, skip_w_avg_update=False, styles=None, **unused_kwargs):
- if styles is not None:
- return styles
-
- # Embed, normalize, and concat inputs.
- x = None
- with torch.autograd.profiler.record_function('input'):
- if self.z_dim > 0:
- misc.assert_shape(z, [None, self.z_dim])
- x = normalize_2nd_moment(z.to(torch.float32)) # normalize z to shpere
- if self.c_dim > 0:
- misc.assert_shape(c, [None, self.c_dim])
- y = normalize_2nd_moment(self.embed(c.to(torch.float32)))
- x = torch.cat([x, y], dim=1) if x is not None else y
-
- # Main layers.
- for idx in range(self.num_layers):
- layer = getattr(self, f'fc{idx}')
- x = layer(x)
-
- # Update moving average of W.
- if self.w_avg_beta is not None and self.training and not skip_w_avg_update:
- with torch.autograd.profiler.record_function('update_w_avg'):
- self.w_avg.copy_(x.detach().mean(dim=0).lerp(self.w_avg, self.w_avg_beta))
-
- # Broadcast.
- if self.num_ws is not None:
- with torch.autograd.profiler.record_function('broadcast'):
- x = x.unsqueeze(1).repeat([1, self.num_ws, 1])
-
- # Apply truncation.
- if truncation_psi != 1:
- with torch.autograd.profiler.record_function('truncate'):
- assert self.w_avg_beta is not None
- if self.num_ws is None or truncation_cutoff is None:
- x = self.w_avg.lerp(x, truncation_psi)
- else:
- x[:, :truncation_cutoff] = self.w_avg.lerp(x[:, :truncation_cutoff], truncation_psi)
- return x
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class SynthesisLayer(torch.nn.Module):
- def __init__(self,
- in_channels, # Number of input channels.
- out_channels, # Number of output channels.
- w_dim, # Intermediate latent (W) dimensionality.
- resolution, # Resolution of this layer.
- kernel_size = 3, # Convolution kernel size.
- up = 1, # Integer upsampling factor.
- use_noise = True, # Enable noise input?
- activation = 'lrelu', # Activation function: 'relu', 'lrelu', etc.
- resample_filter = [1,3,3,1], # Low-pass filter to apply when resampling activations.
- conv_clamp = None, # Clamp the output of convolution layers to +-X, None = disable clamping.
- channels_last = False, # Use channels_last format for the weights?
- upsample_mode = 'default', # [default, bilinear, ray_comm, ray_attn, ray_penc]
- use_group = False,
- magnitude_ema_beta = -1, # -1 means not using magnitude ema
- mode = '2d', # choose from 1d, 2d or 3d
- **unused_kwargs
- ):
- super().__init__()
- self.resolution = resolution
- self.up = up
- self.use_noise = use_noise
- self.activation = activation
- self.conv_clamp = conv_clamp
- self.upsample_mode = upsample_mode
- self.mode = mode
-
- self.register_buffer('resample_filter', upfirdn2d.setup_filter(resample_filter))
- if up == 2:
- if 'pixelshuffle' in upsample_mode:
- self.adapter = torch.nn.Sequential(
- Conv2dLayer(out_channels, out_channels // 4, kernel_size=1, activation=activation),
- Conv2dLayer(out_channels // 4, out_channels * 4, kernel_size=1, activation='linear'),
- )
- elif upsample_mode == 'liif':
- from dnnlib.geometry import get_grids, local_ensemble
- pi = get_grids(self.resolution//2, self.resolution//2, 'cpu', align=False).transpose(0,1)
- po = get_grids(self.resolution, self.resolution, 'cpu', align=False).transpose(0,1)
- diffs, coords, coeffs = local_ensemble(pi, po, self.resolution)
-
- self.diffs = torch.nn.Parameter(diffs, requires_grad=False)
- self.coords = torch.nn.Parameter(coords.float(), requires_grad=False)
- self.coeffs = torch.nn.Parameter(coeffs, requires_grad=False)
- add_dim = 2
- self.adapter = torch.nn.Sequential(
- Conv2dLayer(out_channels + add_dim, out_channels // 2, kernel_size=1, activation=activation),
- Conv2dLayer(out_channels // 2, out_channels, kernel_size=1, activation='linear'),
- )
- elif 'nn_cat' in upsample_mode:
- self.adapter = torch.nn.Sequential(
- Conv2dLayer(out_channels * 2, out_channels // 4, kernel_size=1, activation=activation),
- Conv2dLayer(out_channels // 4, out_channels, kernel_size=1, activation='linear'),
- )
- elif 'ada' in upsample_mode:
- self.adapter = torch.nn.Sequential(
- Conv2dLayer(out_channels, 8, kernel_size=1, activation=activation),
- Conv2dLayer(8, out_channels, kernel_size=1, activation='linear')
- )
- self.adapter[1].weight.data.zero_()
- if 'blur' in upsample_mode:
- self.blur = Blur()
-
- self.padding = kernel_size // 2
- self.groups = 2 if use_group else 1
- self.act_gain = bias_act.activation_funcs[activation].def_gain
- self.affine = FullyConnectedLayer(w_dim, in_channels, bias_init=1)
-
- memory_format = torch.channels_last if channels_last else torch.contiguous_format
- weight_sizes = [out_channels // self.groups, in_channels, kernel_size, kernel_size]
- if self.mode == '3d':
- weight_sizes += [kernel_size]
- weight = torch.randn(weight_sizes).to(memory_format=memory_format)
- self.weight = torch.nn.Parameter(weight)
-
- if use_noise:
- if self.mode == '2d':
- noise_sizes = [resolution, resolution]
- elif self.mode == '3d':
- noise_sizes = [resolution, resolution, resolution]
- else:
- raise NotImplementedError('not support for MLP')
- self.register_buffer('noise_const', torch.randn(noise_sizes)) # HACK: for safety reasons
- self.noise_strength = torch.nn.Parameter(torch.zeros([]))
- self.bias = torch.nn.Parameter(torch.zeros([out_channels]))
-
- self.magnitude_ema_beta = magnitude_ema_beta
- if magnitude_ema_beta > 0:
- self.register_buffer('w_avg', torch.ones([])) # TODO: name for compitibality
-
- def forward(self, x, w, noise_mode='random', fused_modconv=True, gain=1, skip_up=False, input_noise=None, **unused_kwargs):
- assert noise_mode in ['random', 'const', 'none']
- batch_size = x.size(0)
-
- if (self.magnitude_ema_beta > 0):
- if self.training: # updating EMA.
- with torch.autograd.profiler.record_function('update_magnitude_ema'):
- magnitude_cur = x.detach().to(torch.float32).square().mean()
- self.w_avg.copy_(magnitude_cur.lerp(self.w_avg, self.magnitude_ema_beta))
- input_gain = self.w_avg.rsqrt()
- x = x * input_gain
-
- styles = self.affine(w) # Batch x style_dim
- if styles.size(0) < x.size(0): # for repeating
- assert (x.size(0) // styles.size(0) * styles.size(0) == x.size(0))
- styles = repeat(styles, 'b c -> (b s) c', s=x.size(0) // styles.size(0))
- up = self.up if not skip_up else 1
- use_default = (self.upsample_mode == 'default')
- noise = None
- resample_filter = None
- if use_default and (up > 1):
- resample_filter = self.resample_filter
-
- if self.use_noise:
- if input_noise is not None:
- noise = input_noise * self.noise_strength
- elif noise_mode == 'random':
- noise_sizes = [x.shape[0], 1, up * x.shape[2], up * x.shape[3]]
- if self.mode == '3d':
- noise_sizes += [up * x.shape[4]]
- noise = torch.randn(noise_sizes, device=x.device) * self.noise_strength
- elif noise_mode == 'const':
- noise = self.noise_const * self.noise_strength
- if noise.shape[-1] < (up * x.shape[3]):
- noise = repeat(noise, 'h w -> h (s w)', s=up*x.shape[3]//noise.shape[-1])
-
- flip_weight = (up == 1) # slightly faster
- x = modulated_conv2d(
- x=x, weight=self.weight, styles=styles,
- noise=noise if (use_default and not skip_up) else None,
- up=up if use_default else 1,
- padding=self.padding,
- resample_filter=resample_filter,
- flip_weight=flip_weight,
- fused_modconv=fused_modconv,
- groups=self.groups,
- mode=self.mode
- )
-
- if (up == 2) and (not use_default):
- resolution = x.size(-1) * 2
- if 'bilinear' in self.upsample_mode:
- x = F.interpolate(x, size=(resolution, resolution), mode='bilinear', align_corners=True)
- elif 'nearest' in self.upsample_mode:
- x = F.interpolate(x, size=(resolution, resolution), mode='nearest')
- x = upfirdn2d.filter2d(x, self.resample_filter)
- elif 'bicubic' in self.upsample_mode:
- x = F.interpolate(x, size=(resolution, resolution), mode='bicubic', align_corners=True)
- elif 'pixelshuffle' in self.upsample_mode: # does not have rotation invariance
- x = F.interpolate(x, size=(resolution, resolution), mode='nearest') + torch.pixel_shuffle(self.adapter(x), 2)
- if not 'noblur' in self.upsample_mode:
- x = upfirdn2d.filter2d(x, self.resample_filter)
- elif 'nn_cat' in self.upsample_mode:
- x_pad = x.new_zeros(*x.size()[:2], x.size(-2)+2, x.size(-1)+2)
- x_pad[...,1:-1,1:-1] = x
- xl, xu, xd, xr = x_pad[..., 1:-1, :-2], x_pad[..., :-2, 1:-1], x_pad[..., 2:, 1:-1], x_pad[..., 1:-1, 2:]
- x1, x2, x3, x4 = xl + xu, xu + xr, xl + xd, xr + xd
- xb = torch.stack([x1, x2, x3, x4], 2) / 2
- xb = torch.pixel_shuffle(xb.view(xb.size(0), -1, xb.size(-2), xb.size(-1)), 2)
- xa = F.interpolate(x, size=(resolution, resolution), mode='nearest')
- x = xa + self.adapter(torch.cat([xa, xb], 1))
- if not 'noblur' in self.upsample_mode:
- x = upfirdn2d.filter2d(x, self.resample_filter)
- elif self.upsample_mode == 'liif': # this is an old version
- x = torch.stack([x[..., self.coords[j,:,:,0].long(), self.coords[j,:,:,1].long()] for j in range(4)], 0)
- d = self.diffs[:, None].type_as(x).repeat(1,batch_size,1,1,1).permute(0,1,4,2,3)
- x = self.adapter(torch.cat([x, d.type_as(x)], 2).reshape(batch_size*4,-1,*x.size()[-2:]))
- x = (x.reshape(4,batch_size,*x.size()[-3:]) * self.coeffs[:,None,None].type_as(x)).sum(0)
- else:
- raise NotImplementedError
-
- if up == 2:
- if 'ada' in self.upsample_mode:
- x = x + self.adapter(x)
- if 'blur' in self.upsample_mode:
- x = self.blur(x)
-
- if (noise is not None) and (not use_default) and (not skip_up):
- x = x.add_(noise.type_as(x))
-
- act_gain = self.act_gain * gain
- act_clamp = self.conv_clamp * gain if self.conv_clamp is not None else None
- x = bias_act.bias_act(x, self.bias.to(x.dtype), act=self.activation, gain=act_gain, clamp=act_clamp)
-
- return x
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class SynthesisLayer3(torch.nn.Module):
- """copy from the stylegan3 codebase with minor changes"""
- def __init__(self,
- w_dim, # Intermediate latent (W) dimensionality.
- is_torgb, # Is this the final ToRGB layer?
- is_critically_sampled, # Does this layer use critical sampling?
- use_fp16, # Does this layer use FP16?
-
- # Input & output specifications.
- in_channels, # Number of input channels.
- out_channels, # Number of output channels.
- in_size, # Input spatial size: int or [width, height].
- out_size, # Output spatial size: int or [width, height].
- in_sampling_rate, # Input sampling rate (s).
- out_sampling_rate, # Output sampling rate (s).
- in_cutoff, # Input cutoff frequency (f_c).
- out_cutoff, # Output cutoff frequency (f_c).
- in_half_width, # Input transition band half-width (f_h).
- out_half_width, # Output Transition band half-width (f_h).
-
- # Hyperparameters.
- kernel_size = 3, # Convolution kernel size. Ignored for final the ToRGB layer.
- filter_size = 6, # Low-pass filter size relative to the lower resolution when up/downsampling.
- lrelu_upsampling = 2, # Relative sampling rate for leaky ReLU. Ignored for final the ToRGB layer.
- use_radial_filters = False, # Use radially symmetric downsampling filter? Ignored for critically sampled layers.
- conv_clamp = 256, # Clamp the output to [-X, +X], None = disable clamping.
- magnitude_ema_beta = 0.999, # Decay rate for the moving average of input magnitudes.
-
- **unused_kwargs,
- ):
- super().__init__()
- self.w_dim = w_dim
- self.is_torgb = is_torgb
- self.is_critically_sampled = is_critically_sampled
- self.use_fp16 = use_fp16
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.in_size = np.broadcast_to(np.asarray(in_size), [2])
- self.out_size = np.broadcast_to(np.asarray(out_size), [2])
- self.in_sampling_rate = in_sampling_rate
- self.out_sampling_rate = out_sampling_rate
- self.tmp_sampling_rate = max(in_sampling_rate, out_sampling_rate) * (1 if is_torgb else lrelu_upsampling)
- self.in_cutoff = in_cutoff
- self.out_cutoff = out_cutoff
- self.in_half_width = in_half_width
- self.out_half_width = out_half_width
- self.conv_kernel = 1 if is_torgb else kernel_size
- self.conv_clamp = conv_clamp
- self.magnitude_ema_beta = magnitude_ema_beta
-
- # Setup parameters and buffers.
- self.affine = FullyConnectedLayer(self.w_dim, self.in_channels, bias_init=1)
- self.weight = torch.nn.Parameter(torch.randn([self.out_channels, self.in_channels, self.conv_kernel, self.conv_kernel]))
- self.bias = torch.nn.Parameter(torch.zeros([self.out_channels]))
- if magnitude_ema_beta > 0:
- self.register_buffer('w_avg', torch.ones([]))
-
- # Design upsampling filter.
- self.up_factor = int(np.rint(self.tmp_sampling_rate / self.in_sampling_rate))
- assert self.in_sampling_rate * self.up_factor == self.tmp_sampling_rate
- self.up_taps = filter_size * self.up_factor if self.up_factor > 1 and not self.is_torgb else 1
- self.register_buffer('up_filter', self.design_lowpass_filter(
- numtaps=self.up_taps, cutoff=self.in_cutoff, width=self.in_half_width*2, fs=self.tmp_sampling_rate))
-
- # Design downsampling filter.
- self.down_factor = int(np.rint(self.tmp_sampling_rate / self.out_sampling_rate))
- assert self.out_sampling_rate * self.down_factor == self.tmp_sampling_rate
- self.down_taps = filter_size * self.down_factor if self.down_factor > 1 and not self.is_torgb else 1
- self.down_radial = use_radial_filters and not self.is_critically_sampled
- self.register_buffer('down_filter', self.design_lowpass_filter(
- numtaps=self.down_taps, cutoff=self.out_cutoff, width=self.out_half_width*2, fs=self.tmp_sampling_rate, radial=self.down_radial))
-
- # Compute padding.
- pad_total = (self.out_size - 1) * self.down_factor + 1 # Desired output size before downsampling.
- pad_total -= (self.in_size + self.conv_kernel - 1) * self.up_factor # Input size after upsampling.
- pad_total += self.up_taps + self.down_taps - 2 # Size reduction caused by the filters.
- pad_lo = (pad_total + self.up_factor) // 2 # Shift sample locations according to the symmetric interpretation (Appendix C.3).
- pad_hi = pad_total - pad_lo
- self.padding = [int(pad_lo[0]), int(pad_hi[0]), int(pad_lo[1]), int(pad_hi[1])]
-
- def forward(self, x, w, noise_mode='random', force_fp32=False, **unused_kwargs):
- assert noise_mode in ['random', 'const', 'none'] # unused
- misc.assert_shape(x, [None, self.in_channels, int(self.in_size[1]), int(self.in_size[0])])
- misc.assert_shape(w, [x.shape[0], self.w_dim])
-
- # Track input magnitude.
- if (self.magnitude_ema_beta > 0):
- if self.training: # updating EMA.
- with torch.autograd.profiler.record_function('update_magnitude_ema'):
- magnitude_cur = x.detach().to(torch.float32).square().mean()
- self.w_avg.copy_(magnitude_cur.lerp(self.w_avg, self.magnitude_ema_beta))
- input_gain = self.w_avg.rsqrt()
- x = x * input_gain
-
- # Execute affine layer.
- styles = self.affine(w)
- if self.is_torgb:
- weight_gain = 1 / np.sqrt(self.in_channels * (self.conv_kernel ** 2))
- styles = styles * weight_gain
-
- # Execute modulated conv2d.
- dtype = torch.float16 if (self.use_fp16 and not force_fp32 and x.device.type == 'cuda') else torch.float32
- x = modulated_conv2d(x=x.to(dtype), weight=self.weight, styles=styles, padding=self.conv_kernel-1, up=1, fused_modconv=True)
-
- # Execute bias, filtered leaky ReLU, and clamping.
- gain = 1 if self.is_torgb else np.sqrt(2)
- slope = 1 if self.is_torgb else 0.2
- x = filtered_lrelu.filtered_lrelu(x=x, fu=self.up_filter, fd=self.down_filter, b=self.bias.to(x.dtype),
- up=self.up_factor, down=self.down_factor, padding=self.padding, gain=gain, slope=slope, clamp=self.conv_clamp)
-
- # Ensure correct shape and dtype.
- misc.assert_shape(x, [None, self.out_channels, int(self.out_size[1]), int(self.out_size[0])])
- assert x.dtype == dtype
- return x
-
- @staticmethod
- def design_lowpass_filter(numtaps, cutoff, width, fs, radial=False):
- assert numtaps >= 1
-
- # Identity filter.
- if numtaps == 1:
- return None
-
- # Separable Kaiser low-pass filter.
- if not radial:
- f = scipy.signal.firwin(numtaps=numtaps, cutoff=cutoff, width=width, fs=fs)
- return torch.as_tensor(f, dtype=torch.float32)
-
- # Radially symmetric jinc-based filter.
- x = (np.arange(numtaps) - (numtaps - 1) / 2) / fs
- r = np.hypot(*np.meshgrid(x, x))
- f = scipy.special.j1(2 * cutoff * (np.pi * r)) / (np.pi * r)
- beta = scipy.signal.kaiser_beta(scipy.signal.kaiser_atten(numtaps, width / (fs / 2)))
- w = np.kaiser(numtaps, beta)
- f *= np.outer(w, w)
- f /= np.sum(f)
- return torch.as_tensor(f, dtype=torch.float32)
-
- def extra_repr(self):
- return '\n'.join([
- f'w_dim={self.w_dim:d}, is_torgb={self.is_torgb},',
- f'is_critically_sampled={self.is_critically_sampled}, use_fp16={self.use_fp16},',
- f'in_sampling_rate={self.in_sampling_rate:g}, out_sampling_rate={self.out_sampling_rate:g},',
- f'in_cutoff={self.in_cutoff:g}, out_cutoff={self.out_cutoff:g},',
- f'in_half_width={self.in_half_width:g}, out_half_width={self.out_half_width:g},',
- f'in_size={list(self.in_size)}, out_size={list(self.out_size)},',
- f'in_channels={self.in_channels:d}, out_channels={self.out_channels:d}'])
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class ToRGBLayer(torch.nn.Module):
- def __init__(self, in_channels, out_channels, w_dim=0, kernel_size=1, conv_clamp=None, channels_last=False, mode='2d', **unused):
- super().__init__()
- self.conv_clamp = conv_clamp
- self.mode = mode
- weight_shape = [out_channels, in_channels, kernel_size, kernel_size]
- if mode == '3d':
- weight_shape += [kernel_size]
-
- if w_dim > 0:
- self.affine = FullyConnectedLayer(w_dim, in_channels, bias_init=1)
- memory_format = torch.channels_last if channels_last else torch.contiguous_format
- self.weight = torch.nn.Parameter(torch.randn(weight_shape).to(memory_format=memory_format))
- self.bias = torch.nn.Parameter(torch.zeros([out_channels]))
- self.weight_gain = 1 / np.sqrt(np.prod(weight_shape[1:]))
-
- else:
- assert kernel_size == 1, "does not support larger kernel sizes for now. used in NeRF"
- assert mode != '3d', "does not support 3D convolution for now"
-
- self.weight = torch.nn.Parameter(torch.Tensor(out_channels, in_channels))
- self.bias = torch.nn.Parameter(torch.Tensor(out_channels))
- self.weight_gain = 1.
-
- # initialization
- torch.nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
- fan_in, _ = torch.nn.init._calculate_fan_in_and_fan_out(self.weight)
- bound = 1 / math.sqrt(fan_in)
- torch.nn.init.uniform_(self.bias, -bound, bound)
-
- def forward(self, x, w=None, fused_modconv=True):
- if w is not None:
- styles = self.affine(w) * self.weight_gain
- if x.size(0) > styles.size(0):
- assert (x.size(0) // styles.size(0) * styles.size(0) == x.size(0))
- styles = repeat(styles, 'b c -> (b s) c', s=x.size(0) // styles.size(0))
- x = modulated_conv2d(x=x, weight=self.weight, styles=styles, demodulate=False, fused_modconv=fused_modconv, mode=self.mode)
- x = bias_act.bias_act(x, self.bias.to(x.dtype), clamp=self.conv_clamp)
- else:
- if x.ndim == 2:
- x = F.linear(x, self.weight, self.bias)
- else:
- x = F.conv2d(x, self.weight[:,:,None,None], self.bias)
- return x
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class SynthesisBlock(torch.nn.Module):
- def __init__(self,
- in_channels, # Number of input channels, 0 = first block.
- out_channels, # Number of output channels.
- w_dim, # Intermediate latent (W) dimensionality.
- resolution, # Resolution of this block.
- img_channels, # Number of output color channels.
- is_last, # Is this the last block?
- architecture = 'skip', # Architecture: 'orig', 'skip', 'resnet'.
- resample_filter = [1,3,3,1], # Low-pass filter to apply when resampling activations.
- conv_clamp = None, # Clamp the output of convolution layers to +-X, None = disable clamping.
- use_fp16 = False, # Use FP16 for this block?
- fp16_channels_last = False, # Use channels-last memory format with FP16?
- use_single_layer = False, # use only one instead of two synthesis layer
- disable_upsample = False,
- **layer_kwargs, # Arguments for SynthesisLayer.
- ):
- assert architecture in ['orig', 'skip', 'resnet']
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.w_dim = w_dim
- self.resolution = resolution
- self.img_channels = img_channels
- self.is_last = is_last
- self.architecture = architecture
- self.use_fp16 = use_fp16
- self.channels_last = (use_fp16 and fp16_channels_last)
- self.register_buffer('resample_filter', upfirdn2d.setup_filter(resample_filter))
- self.num_conv = 0
- self.num_torgb = 0
-
- self.groups = 1
- self.use_single_layer = use_single_layer
- self.margin = layer_kwargs.get('margin', 0)
- self.upsample_mode = layer_kwargs.get('upsample_mode', 'default')
- self.disable_upsample = disable_upsample
- self.mode = layer_kwargs.get('mode', '2d')
-
- if in_channels == 0:
- const_sizes = [out_channels, resolution, resolution]
- if self.mode == '3d':
- const_sizes = const_sizes + [resolution]
- self.const = torch.nn.Parameter(torch.randn(const_sizes))
-
- if in_channels != 0:
- self.conv0 = util.construct_class_by_name(
- class_name=layer_kwargs.get('layer_name', "training.networks.SynthesisLayer"),
- in_channels=in_channels, out_channels=out_channels,
- w_dim=w_dim, resolution=resolution,
- up=2 if (not disable_upsample) else 1,
- resample_filter=resample_filter, conv_clamp=conv_clamp,
- channels_last=self.channels_last, **layer_kwargs)
- self.num_conv += 1
-
- if not self.use_single_layer:
- self.conv1 = util.construct_class_by_name(
- class_name=layer_kwargs.get('layer_name', "training.networks.SynthesisLayer"),
- in_channels=out_channels, out_channels=out_channels,
- w_dim=w_dim, resolution=resolution,
- conv_clamp=conv_clamp, channels_last=self.channels_last, **layer_kwargs)
- self.num_conv += 1
-
- if is_last or architecture == 'skip':
- self.torgb = ToRGBLayer(
- out_channels, img_channels, w_dim=w_dim,
- conv_clamp=conv_clamp, channels_last=self.channels_last,
- groups=self.groups, mode=self.mode)
- self.num_torgb += 1
-
- if in_channels != 0 and architecture == 'resnet':
- self.skip = Conv2dLayer(
- in_channels, out_channels, kernel_size=1, bias=False, up=2,
- resample_filter=resample_filter,
- channels_last=self.channels_last,
- mode=self.mode)
-
- def forward(self, x, img, ws, force_fp32=False, fused_modconv=None, add_on=None, block_noise=None, disable_rgb=False, **layer_kwargs):
- misc.assert_shape(ws, [None, self.num_conv + self.num_torgb, self.w_dim])
- w_iter = iter(ws.unbind(dim=1))
- dtype = torch.float16 if (self.use_fp16 and x.device.type == 'cuda') and not force_fp32 else torch.float32
- memory_format = torch.channels_last if self.channels_last and not force_fp32 else torch.contiguous_format
- if fused_modconv is None:
- with misc.suppress_tracer_warnings(): # this value will be treated as a constant
- fused_modconv = (not self.training) and (dtype == torch.float32 or int(x.shape[0]) == 1)
-
- # Input.
- if self.in_channels == 0:
- x = self.const.to(dtype=dtype, memory_format=memory_format)
- x = x.unsqueeze(0).expand(ws.shape[0], *x.size())
- else:
- x = x.to(dtype=dtype, memory_format=memory_format)
-
- # Main layers.
- if add_on is not None:
- add_on = add_on.to(dtype=dtype, memory_format=memory_format)
-
- if self.in_channels == 0:
- if not self.use_single_layer:
- layer_kwargs['input_noise'] = block_noise[:,1:2] if block_noise is not None else None
- x = self.conv1(x, next(w_iter), fused_modconv=fused_modconv, **layer_kwargs)
-
- elif self.architecture == 'resnet':
- y = self.skip(x, gain=np.sqrt(0.5))
- layer_kwargs['input_noise'] = block_noise[:,0:1] if block_noise is not None else None
- x = self.conv0(x, next(w_iter), fused_modconv=fused_modconv, **layer_kwargs)
- if not self.use_single_layer:
- layer_kwargs['input_noise'] = block_noise[:,1:2] if block_noise is not None else None
- x = self.conv1(x, next(w_iter), fused_modconv=fused_modconv, gain=np.sqrt(0.5), **layer_kwargs)
- x = y.add_(x)
- else:
- layer_kwargs['input_noise'] = block_noise[:,0:1] if block_noise is not None else None
- x = self.conv0(x, next(w_iter), fused_modconv=fused_modconv, **layer_kwargs)
- if not self.use_single_layer:
- layer_kwargs['input_noise'] = block_noise[:,1:2] if block_noise is not None else None
- x = self.conv1(x, next(w_iter), fused_modconv=fused_modconv, **layer_kwargs)
-
- # ToRGB.
- if img is not None:
- if img.size(-1) * 2 == x.size(-1):
- if (self.upsample_mode == 'bilinear_all') or (self.upsample_mode == 'bilinear_ada'):
- img = F.interpolate(img, scale_factor=2, mode='bilinear', align_corners=True)
- else:
- img = upfirdn2d.upsample2d(img, self.resample_filter) # this is upsampling. Not sure about details and why they do this..
- elif img.size(-1) == x.size(-1):
- pass
- else:
- raise NotImplementedError
-
- if self.is_last or self.architecture == 'skip':
- if not disable_rgb:
- y = x if add_on is None else x + add_on
- y = self.torgb(y, next(w_iter), fused_modconv=fused_modconv)
- y = y.to(dtype=torch.float32, memory_format=torch.contiguous_format)
- img = img.add_(y) if img is not None else y
- else:
- img = None
-
- assert x.dtype == dtype
- assert img is None or img.dtype == torch.float32
- return x, img
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class SynthesisBlock3(torch.nn.Module):
- def __init__(self,
- in_channels, # Number of input channels, 0 = first block.
- out_channels, # Number of output channels.
- w_dim, # Intermediate latent (W) dimensionality.
- resolution, # Resolution of this block.
- img_channels, # Number of output color channels.
- block_id,
- stylegan3_hyperam,
- use_fp16 = False, # Use FP16 for this block?
- **layer_kwargs, # Arguments for SynthesisLayer.
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.w_dim = w_dim
- self.resolution = resolution
- self.img_channels = img_channels
- self.num_conv = 0
- self.num_torgb = 0
- self.use_fp16 = use_fp16
-
- is_critically_sampled = block_id == (len(stylegan3_hyperam['sampling_rates'][:-1]) // 2 - 1)
- sizes, sampling_rates, cutoffs, half_widths = \
- stylegan3_hyperam['sizes'], stylegan3_hyperam['sampling_rates'], \
- stylegan3_hyperam['cutoffs'], stylegan3_hyperam['half_widths']
-
- # each block has two layer
- prev = max(block_id * 2 - 1, 0)
- curr = block_id * 2
- self.conv0 = util.construct_class_by_name(
- class_name=layer_kwargs.get('layer_name', "training.networks.SynthesisLayer3"),
- w_dim=self.w_dim,
- is_torgb=False,
- is_critically_sampled=is_critically_sampled,
- use_fp16=use_fp16,
- in_channels=in_channels,
- out_channels=out_channels,
- in_size=int(sizes[prev]),
- out_size=int(sizes[curr]),
- in_sampling_rate=int(sampling_rates[prev]),
- out_sampling_rate=int(sampling_rates[curr]),
- in_cutoff=cutoffs[prev],
- out_cutoff=cutoffs[curr],
- in_half_width=half_widths[prev],
- out_half_width=half_widths[curr],
- use_radial_filters=True,
- **layer_kwargs)
- self.num_conv += 1
-
- prev = block_id * 2
- curr = block_id * 2 + 1
- self.conv1 = util.construct_class_by_name(
- class_name=layer_kwargs.get('layer_name', "training.networks.SynthesisLayer3"),
- w_dim=self.w_dim,
- is_torgb=False,
- is_critically_sampled=is_critically_sampled,
- use_fp16=use_fp16,
- in_channels=out_channels,
- out_channels=out_channels,
- in_size=int(sizes[prev]),
- out_size=int(sizes[curr]),
- in_sampling_rate=int(sampling_rates[prev]),
- out_sampling_rate=int(sampling_rates[curr]),
- in_cutoff=cutoffs[prev],
- out_cutoff=cutoffs[curr],
- in_half_width=half_widths[prev],
- out_half_width=half_widths[curr],
- use_radial_filters=True,
- **layer_kwargs)
- self.num_conv += 1
-
- # toRGB layer (used for progressive growing)
- self.torgb = ToRGBLayer(out_channels, img_channels, w_dim=w_dim)
- self.num_torgb += 1
-
- def forward(self, x, img, ws, force_fp32=False, add_on=None, disable_rgb=False, **layer_kwargs):
- w_iter = iter(ws.unbind(dim=1))
- dtype = torch.float16 if (self.use_fp16 and x.device.type == 'cuda') and not force_fp32 else torch.float32
- memory_format = torch.contiguous_format
-
- # Main layers.
- x = x.to(dtype=dtype, memory_format=memory_format)
- if add_on is not None:
- add_on = add_on.to(dtype=dtype, memory_format=memory_format)
-
- x = self.conv0(x, next(w_iter), **layer_kwargs)
- x = self.conv1(x, next(w_iter), **layer_kwargs)
-
- assert img is None, "currently not support."
- if not disable_rgb:
- y = x if add_on is None else x + add_on
- y = self.torgb(y, next(w_iter), fused_modconv=True)
- y = y.to(dtype=torch.float32, memory_format=torch.contiguous_format)
- img = y
-
- assert x.dtype == dtype
- assert img is None or img.dtype == torch.float32
- return x, img
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class SynthesisNetwork(torch.nn.Module):
- def __init__(self,
- w_dim, # Intermediate latent (W) dimensionality.
- img_resolution, # Output image resolution.
- img_channels, # Number of color channels.
- channel_base = 1, # Overall multiplier for the number of channels.
- channel_max = 512, # Maximum number of channels in any layer.
- num_fp16_res = 0, # Use FP16 for the N highest resolutions.
- **block_kwargs, # Arguments for SynthesisBlock.
- ):
- assert img_resolution >= 4 and img_resolution & (img_resolution - 1) == 0
- super().__init__()
- self.w_dim = w_dim
- self.img_resolution = img_resolution
- self.img_resolution_log2 = int(np.log2(img_resolution))
- self.img_channels = img_channels
- self.block_resolutions = [2 ** i for i in range(2, self.img_resolution_log2 + 1)]
-
- channel_base = int(channel_base * 32768)
- channels_dict = {res: min(channel_base // res, channel_max) for res in self.block_resolutions}
- fp16_resolution = max(2 ** (self.img_resolution_log2 + 1 - num_fp16_res), 8)
- self.channels_dict = channels_dict
-
- self.num_ws = 0
- for res in self.block_resolutions:
- in_channels = channels_dict[res // 2] if res > 4 else 0
- out_channels = channels_dict[res]
- use_fp16 = (res >= fp16_resolution)
- is_last = (res == self.img_resolution)
- block = util.construct_class_by_name(
- class_name=block_kwargs.get('block_name', "training.networks.SynthesisBlock"),
- in_channels=in_channels, out_channels=out_channels, w_dim=w_dim, resolution=res,
- img_channels=img_channels, is_last=is_last, use_fp16=use_fp16, **block_kwargs)
-
- self.num_ws += block.num_conv
- if is_last:
- self.num_ws += block.num_torgb
- setattr(self, f'b{res}', block)
-
- def forward(self, ws, **block_kwargs):
- block_ws = []
-
- # this part is to slice the style matrices (W) to each layer (conv/RGB)
- with torch.autograd.profiler.record_function('split_ws'):
- misc.assert_shape(ws, [None, self.num_ws, self.w_dim])
- ws = ws.to(torch.float32)
- w_idx = 0
- for res in self.block_resolutions:
- block = getattr(self, f'b{res}')
- block_ws.append(ws.narrow(1, w_idx, block.num_conv + block.num_torgb))
- w_idx += block.num_conv
-
- x = img = None
- for res, cur_ws in zip(self.block_resolutions, block_ws):
- block = getattr(self, f'b{res}')
- x, img = block(x, img, cur_ws, **block_kwargs)
- return img
-
- def get_current_resolution(self):
- return [self.img_resolution] # For compitibility
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class Generator(torch.nn.Module):
- def __init__(self,
- z_dim, # Input latent (Z) dimensionality.
- c_dim, # Conditioning label (C) dimensionality.
- w_dim, # Intermediate latent (W) dimensionality.
- img_resolution, # Output resolution.
- img_channels, # Number of output color channels.
- mapping_kwargs = {}, # Arguments for MappingNetwork.
- synthesis_kwargs = {}, # Arguments for SynthesisNetwork.
- encoder_kwargs = {}, # Arguments for Encoder (optional)
- ):
- super().__init__()
- self.z_dim = z_dim
- self.c_dim = c_dim
- self.w_dim = w_dim
- self.img_resolution = img_resolution
- self.img_channels = img_channels
- self.synthesis = util.construct_class_by_name(
- class_name=synthesis_kwargs.get('module_name', "training.networks.SynthesisNetwork"),
- w_dim=w_dim, img_resolution=img_resolution, img_channels=img_channels, **synthesis_kwargs)
- self.num_ws = self.synthesis.num_ws
- self.mapping = None
- self.encoder = None
-
- if len(mapping_kwargs) > 0: # Use mapping network
- self.mapping = util.construct_class_by_name(
- class_name=mapping_kwargs.get('module_name', "training.networks.MappingNetwork"),
- z_dim=z_dim, c_dim=c_dim, w_dim=w_dim, num_ws=self.num_ws, **mapping_kwargs)
-
- if len(encoder_kwargs) > 0: # Use Image-Encoder
- encoder_kwargs['model_kwargs'].update({'num_ws': self.num_ws, 'w_dim': self.w_dim})
- self.encoder = util.construct_class_by_name(
- img_resolution=img_resolution,
- img_channels=img_channels,
- **encoder_kwargs)
-
- def forward(self, z=None, c=None, styles=None, truncation_psi=1, truncation_cutoff=None, img=None, **synthesis_kwargs):
- if styles is None:
- assert z is not None
- if (self.encoder is not None) and (img is not None): #TODO: debug
- outputs = self.encoder(img)
- ws = outputs['ws']
- if ('camera' in outputs) and ('camera_mode' not in synthesis_kwargs):
- synthesis_kwargs['camera_RT'] = outputs['camera']
- else:
- ws = self.mapping(z, c, truncation_psi=truncation_psi, truncation_cutoff=truncation_cutoff, **synthesis_kwargs)
- else:
- ws = styles
-
- img = self.synthesis(ws, **synthesis_kwargs)
- return img
-
- def get_final_output(self, *args, **kwargs):
- img = self.forward(*args, **kwargs)
- if isinstance(img, list):
- return img[-1]
- elif isinstance(img, dict):
- return img['img']
- return img
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class DiscriminatorBlock(torch.nn.Module):
- def __init__(self,
- in_channels, # Number of input channels, 0 = first block.
- tmp_channels, # Number of intermediate channels.
- out_channels, # Number of output channels.
- resolution, # Resolution of this block.
- img_channels, # Number of input color channels.
- first_layer_idx, # Index of the first layer.
- architecture = 'resnet', # Architecture: 'orig', 'skip', 'resnet'.
- activation = 'lrelu', # Activation function: 'relu', 'lrelu', etc.
- resample_filter = [1,3,3,1], # Low-pass filter to apply when resampling activations.
- conv_clamp = None, # Clamp the output of convolution layers to +-X, None = disable clamping.
- use_fp16 = False, # Use FP16 for this block?
- fp16_channels_last = False, # Use channels-last memory format with FP16?
- freeze_layers = 0, # Freeze-D: Number of layers to freeze.
- ):
- assert in_channels in [0, tmp_channels]
- assert architecture in ['orig', 'skip', 'resnet']
- super().__init__()
- self.in_channels = in_channels
- self.resolution = resolution
- self.img_channels = img_channels
- self.first_layer_idx = first_layer_idx
- self.architecture = architecture
- self.use_fp16 = use_fp16
- self.channels_last = (use_fp16 and fp16_channels_last)
- self.register_buffer('resample_filter', upfirdn2d.setup_filter(resample_filter))
-
- self.num_layers = 0
- def trainable_gen():
- while True:
- layer_idx = self.first_layer_idx + self.num_layers
- trainable = (layer_idx >= freeze_layers)
- self.num_layers += 1
- yield trainable
- trainable_iter = trainable_gen()
-
- if in_channels == 0 or architecture == 'skip':
- self.fromrgb = Conv2dLayer(img_channels, tmp_channels, kernel_size=1, activation=activation,
- trainable=next(trainable_iter), conv_clamp=conv_clamp, channels_last=self.channels_last)
-
- self.conv0 = Conv2dLayer(tmp_channels, tmp_channels, kernel_size=3, activation=activation,
- trainable=next(trainable_iter), conv_clamp=conv_clamp, channels_last=self.channels_last)
-
- self.conv1 = Conv2dLayer(tmp_channels, out_channels, kernel_size=3, activation=activation, down=2,
- trainable=next(trainable_iter), resample_filter=resample_filter, conv_clamp=conv_clamp, channels_last=self.channels_last)
-
- if architecture == 'resnet':
- self.skip = Conv2dLayer(tmp_channels, out_channels, kernel_size=1, bias=False, down=2,
- trainable=next(trainable_iter), resample_filter=resample_filter, channels_last=self.channels_last)
-
- def forward(self, x, img, force_fp32=False, downsampler=None):
- dtype = torch.float16 if (self.use_fp16 and x.device.type == 'cuda') and not force_fp32 else torch.float32
- memory_format = torch.channels_last if self.channels_last and not force_fp32 else torch.contiguous_format
-
- # Input.
- if x is not None:
- misc.assert_shape(x, [None, self.in_channels, self.resolution, self.resolution])
- x = x.to(dtype=dtype, memory_format=memory_format)
-
- # FromRGB.
- if self.in_channels == 0 or self.architecture == 'skip':
- misc.assert_shape(img, [None, self.img_channels, self.resolution, self.resolution])
- img = img.to(dtype=dtype, memory_format=memory_format)
- y = self.fromrgb(img)
- x = x + y if x is not None else y
- if self.architecture != 'skip':
- img = None
- elif downsampler is not None:
- img = downsampler(img, 2)
- else:
- img = upfirdn2d.downsample2d(img, self.resample_filter)
-
- # Main layers.
- if self.architecture == 'resnet':
- y = self.skip(x, gain=np.sqrt(0.5))
- x = self.conv0(x)
- x = self.conv1(x, gain=np.sqrt(0.5))
- x = y.add_(x)
- else:
- x = self.conv0(x)
- x = self.conv1(x)
-
- assert x.dtype == dtype
- return x, img
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class MinibatchStdLayer(torch.nn.Module):
- def __init__(self, group_size, num_channels=1):
- super().__init__()
- self.group_size = group_size
- self.num_channels = num_channels
-
- def forward(self, x):
- N, C, H, W = x.shape
- with misc.suppress_tracer_warnings(): # as_tensor results are registered as constants
- G = torch.min(torch.as_tensor(self.group_size), torch.as_tensor(N)) if self.group_size is not None else N
- F = self.num_channels
- c = C // F
-
- y = x.reshape(G, -1, F, c, H, W) # [GnFcHW] Split minibatch N into n groups of size G, and channels C into F groups of size c.
- y = y - y.mean(dim=0) # [GnFcHW] Subtract mean over group.
- y = y.square().mean(dim=0) # [nFcHW] Calc variance over group.
- y = (y + 1e-8).sqrt() # [nFcHW] Calc stddev over group.
- y = y.mean(dim=[2,3,4]) # [nF] Take average over channels and pixels.
- y = y.reshape(-1, F, 1, 1) # [nF11] Add missing dimensions.
- y = y.repeat(G, 1, H, W) # [NFHW] Replicate over group and pixels.
- x = torch.cat([x, y], dim=1) # [NCHW] Append to input as new channels.
- return x
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class DiscriminatorEpilogue(torch.nn.Module):
- def __init__(self,
- in_channels, # Number of input channels.
- cmap_dim, # Dimensionality of mapped conditioning label, 0 = no label.
- resolution, # Resolution of this block.
- img_channels, # Number of input color channels.
- architecture = 'resnet', # Architecture: 'orig', 'skip', 'resnet'.
- mbstd_group_size = 4, # Group size for the minibatch standard deviation layer, None = entire minibatch.
- mbstd_num_channels = 1, # Number of features for the minibatch standard deviation layer, 0 = disable.
- activation = 'lrelu', # Activation function: 'relu', 'lrelu', etc.
- conv_clamp = None, # Clamp the output of convolution layers to +-X, None = disable clamping.
- final_channels = 1, # for classification it is always 1.
- ):
- assert architecture in ['orig', 'skip', 'resnet']
- super().__init__()
- self.in_channels = in_channels
- self.final_channels = final_channels
- self.cmap_dim = cmap_dim
- self.resolution = resolution
- self.img_channels = img_channels
- self.architecture = architecture
-
- if architecture == 'skip':
- self.fromrgb = Conv2dLayer(img_channels, in_channels, kernel_size=1, activation=activation)
- self.mbstd = MinibatchStdLayer(group_size=mbstd_group_size, num_channels=mbstd_num_channels) if mbstd_num_channels > 0 else None
- self.conv = Conv2dLayer(in_channels + mbstd_num_channels, in_channels, kernel_size=3, activation=activation, conv_clamp=conv_clamp)
- self.fc = FullyConnectedLayer(in_channels * (resolution ** 2), in_channels, activation=activation)
- self.out = FullyConnectedLayer(in_channels, final_channels if cmap_dim == 0 else cmap_dim)
-
- def forward(self, x, img, cmap, force_fp32=False):
- misc.assert_shape(x, [None, self.in_channels, self.resolution, self.resolution]) # [NCHW]
- _ = force_fp32 # unused
- dtype = torch.float32
- memory_format = torch.contiguous_format
-
- # FromRGB.
- x = x.to(dtype=dtype, memory_format=memory_format)
- if self.architecture == 'skip':
- misc.assert_shape(img, [None, self.img_channels, self.resolution, self.resolution])
- img = img.to(dtype=dtype, memory_format=memory_format)
- x = x + self.fromrgb(img)
-
- # Main layers.
- if self.mbstd is not None:
- x = self.mbstd(x)
- x = self.conv(x)
- x = self.fc(x.flatten(1))
- x = self.out(x)
-
- # Conditioning.
- if self.cmap_dim > 0:
- if not isinstance(cmap, list):
- cmap = [cmap] # in case of multiple conditions. a trick (TODO)
- x = [(x * c).sum(dim=1, keepdim=True) * (1 / np.sqrt(self.cmap_dim)) for c in cmap]
- x = sum(x) / len(cmap)
-
- assert x.dtype == dtype
- return x
-
-#----------------------------------------------------------------------------
-
-@persistence.persistent_class
-class Discriminator(torch.nn.Module): # The original StyleGAN2 discriminator
- def __init__(self,
- c_dim, # Conditioning label (C) dimensionality.
- img_resolution, # Input resolution.
- img_channels, # Number of input color channels.
- architecture = 'resnet', # Architecture: 'orig', 'skip', 'resnet'.
- channel_base = 32768, # Overall multiplier for the number of channels.
- channel_max = 512, # Maximum number of channels in any layer.
- num_fp16_res = 0, # Use FP16 for the N highest resolutions.
- conv_clamp = None, # Clamp the output of convolution layers to +-X, None = disable clamping.
- cmap_dim = None, # Dimensionality of mapped conditioning label, None = default.
- block_kwargs = {}, # Arguments for DiscriminatorBlock.
- mapping_kwargs = {}, # Arguments for MappingNetwork.
- epilogue_kwargs = {}, # Arguments for DiscriminatorEpilogue.
- ):
- super().__init__()
- self.c_dim = c_dim
- self.img_resolution = img_resolution
- self.img_resolution_log2 = int(np.log2(img_resolution))
- self.img_channels = img_channels
- self.block_resolutions = [2 ** i for i in range(self.img_resolution_log2, 2, -1)]
- channels_dict = {res: min(channel_base // res, channel_max) for res in self.block_resolutions + [4]}
- fp16_resolution = max(2 ** (self.img_resolution_log2 + 1 - num_fp16_res), 8)
-
- if cmap_dim is None:
- cmap_dim = channels_dict[4]
- if c_dim == 0:
- cmap_dim = 0
-
- common_kwargs = dict(img_channels=img_channels, architecture=architecture, conv_clamp=conv_clamp)
- cur_layer_idx = 0
- for res in self.block_resolutions:
- in_channels = channels_dict[res] if res < img_resolution else 0
- tmp_channels = channels_dict[res]
- out_channels = channels_dict[res // 2]
- use_fp16 = (res >= fp16_resolution)
- block = DiscriminatorBlock(in_channels, tmp_channels, out_channels, resolution=res,
- first_layer_idx=cur_layer_idx, use_fp16=use_fp16, **block_kwargs, **common_kwargs)
- setattr(self, f'b{res}', block)
- cur_layer_idx += block.num_layers
- if c_dim > 0:
- self.mapping = MappingNetwork(z_dim=0, c_dim=c_dim, w_dim=cmap_dim, num_ws=None, w_avg_beta=None, **mapping_kwargs)
- self.b4 = DiscriminatorEpilogue(channels_dict[4], cmap_dim=cmap_dim, resolution=4, **epilogue_kwargs, **common_kwargs)
-
- def forward(self, img, c, **block_kwargs):
- x = None
- if isinstance(img, dict):
- img = img['img']
- for res in self.block_resolutions:
- block = getattr(self, f'b{res}')
- x, img = block(x, img, **block_kwargs)
-
- cmap = None
- if self.c_dim > 0:
- cmap = self.mapping(None, c)
- x = self.b4(x, img, cmap)
- return x
-
-#----------------------------------------------------------------------------
-# encoders maybe used for inversion (not cleaned)
-
-@persistence.persistent_class
-class EncoderResBlock(torch.nn.Module):
- def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
- super().__init__()
-
- self.conv1 = Conv2dLayer(in_channel, in_channel, 3, activation='lrelu')
- self.conv2 = Conv2dLayer(in_channel, out_channel, 3, down=2, activation='lrelu')
- self.skip = Conv2dLayer(in_channel, out_channel, 1, down=2, activation='linear', bias=False)
-
- def forward(self, input):
- out = self.conv1(input)
- out = self.conv2(out)
- skip = self.skip(input)
- out = (out + skip) / math.sqrt(2)
- return out
-
-
-@persistence.persistent_class
-class EqualConv2d(torch.nn.Module):
- def __init__(
- self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
- ):
- super().__init__()
- new_scale = 1.0
- self.weight = torch.nn.Parameter(
- torch.randn(out_channel, in_channel, kernel_size, kernel_size) * new_scale
- )
- self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
- self.stride = stride
- self.padding = padding
- if bias:
- self.bias = torch.nn.Parameter(torch.zeros(out_channel))
- else:
- self.bias = None
-
- def forward(self, input):
- out = F.conv2d(
- input,
- self.weight * self.scale,
- bias=self.bias,
- stride=self.stride,
- padding=self.padding,
- )
- return out
-
- def __repr__(self):
- return (
- f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},'
- f' {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})'
- )
-
-
-@persistence.persistent_class
-class Encoder(torch.nn.Module):
- def __init__(self, size, n_latents, w_dim=512, add_dim=0, **unused):
- super().__init__()
-
- channels = {
- 4: 512,
- 8: 512,
- 16: 512,
- 32: 512,
- 64: 256,
- 128: 128,
- 256: 64,
- 512: 32,
- 1024: 16
- }
-
- self.w_dim = w_dim
- self.add_dim = add_dim
- log_size = int(math.log(size, 2))
-
- self.n_latents = n_latents
- convs = [Conv2dLayer(3, channels[size], 1)]
-
- in_channel = channels[size]
- for i in range(log_size, 2, -1):
- out_channel = channels[2 ** (i - 1)]
- convs.append(EncoderResBlock(in_channel, out_channel))
- in_channel = out_channel
-
- self.convs = torch.nn.Sequential(*convs)
- self.projector = EqualConv2d(in_channel, self.n_latents*self.w_dim + add_dim, 4, padding=0, bias=False)
-
- def forward(self, input):
- out = self.convs(input)
- out = self.projector(out)
- pws, pcm = out[:, :-2], out[:, -2:]
- pws = pws.view(len(input), self.n_latents, self.w_dim)
- pcm = pcm.view(len(input), self.add_dim)
- return pws, pcm
-
-
-@persistence.persistent_class
-class ResNetEncoder(torch.nn.Module):
- def __init__(self):
- super().__init__()
-
- import torchvision
- resnet_net = torchvision.models.resnet18(pretrained=True)
- modules = list(resnet_net.children())[:-1]
- self.convs = torch.nn.Sequential(*modules)
- self.requires_grad_(True)
- self.train()
-
- def preprocess_tensor(self, x):
- x = F.interpolate(x, size=(224, 224), mode='bicubic', align_corners=False)
- return x
-
- def forward(self, input):
- out = self.convs(self.preprocess_tensor(input))
- return out[:, :, 0, 0]
-
-
-@persistence.persistent_class
-class CLIPEncoder(torch.nn.Module):
- def __init__(self):
- super().__init__()
-
- import clip
- clip_net, _ = clip.load('ViT-B/32', device='cpu', jit=False)
- self.encoder = clip_net.visual
- for p in self.encoder.parameters():
- p.requires_grad_(True)
-
- def preprocess_tensor(self, x):
- import PIL.Image
- import torchvision.transforms.functional as TF
- x = x * 0.5 + 0.5 # mapping to 0~1
- x = TF.resize(x, size=224, interpolation=PIL.Image.BICUBIC)
- x = TF.normalize(x, (0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
- return x
-
- def forward(self, input):
- out = self.encoder(self.preprocess_tensor(input))
- return out
-
-
-# --------------------------------------------------------------------------------------------------- #
-# VolumeGAN thanks https://gist.github.com/justimyhxu/a96f5ac25480d733f3151adb8142d706
-
-@persistence.persistent_class
-class InstanceNormLayer3d(torch.nn.Module):
- """Implements instance normalization layer."""
- def __init__(self, num_features, epsilon=1e-8, affine=False):
- super().__init__()
- self.eps = epsilon
- self.affine = affine
- if self.affine:
- self.weight = torch.nn.Parameter(torch.Tensor(1, num_features,1,1,1))
- self.bias = torch.nn.Parameter(torch.Tensor(1, num_features,1,1,1))
- self.weight.data.uniform_()
- self.bias.data.zero_()
-
- def forward(self, x, weight=None, bias=None):
- x = x - torch.mean(x, dim=[2, 3, 4], keepdim=True)
- norm = torch.sqrt(
- torch.mean(x**2, dim=[2, 3, 4], keepdim=True) + self.eps)
- x = x / norm
- isnot_input_none = weight is not None and bias is not None
- assert (isnot_input_none and not self.affine) or (not isnot_input_none and self.affine)
- if self.affine:
- x = x*self.weight + self.bias
- else:
- x = x*weight + bias
- return x
-
-@persistence.persistent_class
-class FeatureVolume(torch.nn.Module):
- def __init__(
- self,
- feat_res=32,
- init_res=4,
- base_channels=256,
- output_channels=32,
- z_dim=256,
- use_mapping=True,
- **kwargs
- ):
- super().__init__()
- self.num_stages = int(np.log2(feat_res // init_res)) + 1
- self.use_mapping = use_mapping
-
- self.const = nn.Parameter(
- torch.ones(1, base_channels, init_res, init_res, init_res))
- inplanes = base_channels
- outplanes = base_channels
-
- self.stage_channels = []
- for i in range(self.num_stages):
- conv = nn.Conv3d(inplanes,
- outplanes,
- kernel_size=(3, 3, 3),
- padding=(1, 1, 1))
- self.stage_channels.append(outplanes)
- self.add_module(f'layer{i}', conv)
- instance_norm = InstanceNormLayer3d(num_features=outplanes, affine=not use_mapping)
-
- self.add_module(f'instance_norm{i}', instance_norm)
- inplanes = outplanes
- outplanes = max(outplanes // 2, output_channels)
- if i == self.num_stages - 1:
- outplanes = output_channels
-
- if self.use_mapping:
- self.mapping_network = CustomMappingNetwork(
- z_dim, 256,
- sum(self.stage_channels) * 2)
- self.upsample = UpsamplingLayer()
- self.lrelu = nn.LeakyReLU(negative_slope=0.2)
-
- def forward(self, z, **kwargs):
- if self.use_mapping:
- scales, shifts, style = self.mapping_network(z)
-
- x = self.const.repeat(z.shape[0], 1, 1, 1, 1)
- for idx in range(self.num_stages):
- if idx != 0:
- x = self.upsample(x)
- conv_layer = self.__getattr__(f'layer{idx}')
- x = conv_layer(x)
- instance_norm = self.__getattr__(f'instance_norm{idx}')
- if self.use_mapping:
- scale = scales[:, sum(self.stage_channels[:idx]):sum(self.stage_channels[:idx + 1])]
- shift = shifts[:, sum(self.stage_channels[:idx]):sum(self.stage_channels[:idx + 1])]
- scale = scale.view(scale.shape + (1, 1, 1))
- shift = shift.view(shift.shape + (1, 1, 1))
- else:
- scale, shift = None, None
- x = instance_norm(x, weight=scale, bias=shift)
- x = self.lrelu(x)
-
- return x
\ No newline at end of file
diff --git a/spaces/facebook/ov-seg/open_vocab_seg/utils/events.py b/spaces/facebook/ov-seg/open_vocab_seg/utils/events.py
deleted file mode 100644
index cbe82ce80a7110a1018167763ba3adc90f58faa0..0000000000000000000000000000000000000000
--- a/spaces/facebook/ov-seg/open_vocab_seg/utils/events.py
+++ /dev/null
@@ -1,121 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# Copyright (c) Meta Platforms, Inc. All Rights Reserved
-
-import os
-import wandb
-from detectron2.utils import comm
-from detectron2.utils.events import EventWriter, get_event_storage
-
-
-def setup_wandb(cfg, args):
- if comm.is_main_process():
- init_args = {
- k.lower(): v
- for k, v in cfg.WANDB.items()
- if isinstance(k, str) and k not in ["config", "name"]
- }
- # only include most related part to avoid too big table
- # TODO: add configurable params to select which part of `cfg` should be saved in config
- if "config_exclude_keys" in init_args:
- init_args["config"] = cfg
- init_args["config"]["cfg_file"] = args.config_file
- else:
- init_args["config"] = {
- "model": cfg.MODEL,
- "solver": cfg.SOLVER,
- "cfg_file": args.config_file,
- }
- if ("name" not in init_args) or (init_args["name"] is None):
- init_args["name"] = os.path.basename(args.config_file)
- wandb.init(**init_args)
-
-
-class BaseRule(object):
- def __call__(self, target):
- return target
-
-
-class IsIn(BaseRule):
- def __init__(self, keyword: str):
- self.keyword = keyword
-
- def __call__(self, target):
- return self.keyword in target
-
-
-class Prefix(BaseRule):
- def __init__(self, keyword: str):
- self.keyword = keyword
-
- def __call__(self, target):
- return "/".join([self.keyword, target])
-
-
-class WandbWriter(EventWriter):
- """
- Write all scalars to a tensorboard file.
- """
-
- def __init__(self):
- """
- Args:
- log_dir (str): the directory to save the output events
- kwargs: other arguments passed to `torch.utils.tensorboard.SummaryWriter(...)`
- """
- self._last_write = -1
- self._group_rules = [
- (IsIn("/"), BaseRule()),
- (IsIn("loss"), Prefix("train")),
- ]
-
- def write(self):
-
- storage = get_event_storage()
-
- def _group_name(scalar_name):
- for (rule, op) in self._group_rules:
- if rule(scalar_name):
- return op(scalar_name)
- return scalar_name
-
- stats = {
- _group_name(name): scalars[0]
- for name, scalars in storage.latest().items()
- if scalars[1] > self._last_write
- }
- if len(stats) > 0:
- self._last_write = max([v[1] for k, v in storage.latest().items()])
-
- # storage.put_{image,histogram} is only meant to be used by
- # tensorboard writer. So we access its internal fields directly from here.
- if len(storage._vis_data) >= 1:
- stats["image"] = [
- wandb.Image(img, caption=img_name)
- for img_name, img, step_num in storage._vis_data
- ]
- # Storage stores all image data and rely on this writer to clear them.
- # As a result it assumes only one writer will use its image data.
- # An alternative design is to let storage store limited recent
- # data (e.g. only the most recent image) that all writers can access.
- # In that case a writer may not see all image data if its period is long.
- storage.clear_images()
-
- if len(storage._histograms) >= 1:
-
- def create_bar(tag, bucket_limits, bucket_counts, **kwargs):
- data = [
- [label, val] for (label, val) in zip(bucket_limits, bucket_counts)
- ]
- table = wandb.Table(data=data, columns=["label", "value"])
- return wandb.plot.bar(table, "label", "value", title=tag)
-
- stats["hist"] = [create_bar(**params) for params in storage._histograms]
-
- storage.clear_histograms()
-
- if len(stats) == 0:
- return
- wandb.log(stats, step=storage.iter)
-
- def close(self):
- wandb.finish()
diff --git a/spaces/falterWliame/Face_Mask_Detection/Download Driver Monitor Aoc 215lm00040.md b/spaces/falterWliame/Face_Mask_Detection/Download Driver Monitor Aoc 215lm00040.md
deleted file mode 100644
index f690799ee90637f5c88cb54f4959bcff9b6b1db0..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Download Driver Monitor Aoc 215lm00040.md
+++ /dev/null
@@ -1,14 +0,0 @@
-download driver monitor aoc 215lm00040
DOWNLOAD » https://urlca.com/2uDcic
-
-Results
-
-After installing the AOC official driver, the screen is not displayed and your computer is not able to communicate with the external monitor. Check your monitor and your computer manufacturer's website to ensure that the monitor is compatible with your computer.
-
-## 0.3. Run the driver setup utility to install the Universal drivers
-
-In this tutorial, we will install the Universal drivers for all AOC monitors. In this tutorial, we will install the Universal driver for the AOC monitor.
-
-1. Open the Device Manager by clicking on the Start button, selecting Control Panel, and then selecting Programs and Features. In the left pane, select View By and then select By Category. Select Hardware and Sound from the left pane and then select Device Manager from the middle pane. Expand the display driver list in the left pane and then select Display adapters from the middle pane. Select Universal from the list. If there 4fefd39f24
-
-
-
diff --git a/spaces/fatiXbelha/sd/Download FIFA Romania and get ready for the new 23 season with updated players kits and clubs.md b/spaces/fatiXbelha/sd/Download FIFA Romania and get ready for the new 23 season with updated players kits and clubs.md
deleted file mode 100644
index fbbdc5323e5001f315cde85b145904f6ac82223b..0000000000000000000000000000000000000000
--- a/spaces/fatiXbelha/sd/Download FIFA Romania and get ready for the new 23 season with updated players kits and clubs.md
+++ /dev/null
@@ -1,148 +0,0 @@
-
-Download FIFA Romania: How to Play the Ultimate Football Game with Your Favorite Romanian Teams and Players
- If you are a fan of football and you love Romania, you might be interested in downloading FIFA Romania, a modded version of the popular FIFA game that features Romanian teams, players, stadiums, and more. In this article, we will show you how to download FIFA Romania, how to play it, and why you should give it a try.
- Introduction
- What is FIFA Romania?
- FIFA Romania is a modification of the original FIFA game that adds Romanian elements to the game. It was created by a group of passionate Romanian fans who wanted to bring their country's football culture to the virtual world. FIFA Romania includes:
-download fifa romania
Download File ->>> https://urllie.com/2uNCdC
-
-- Over 40 Romanian teams from Liga 1, Liga 2, and Liga 3
-- Over 1000 Romanian players with realistic faces, attributes, and ratings
-- Over 20 Romanian stadiums with authentic details and atmosphere
-- Romanian commentators, chants, banners, logos, kits, and graphics
-- Romanian national team with updated roster and kits
-
- Why should you download FIFA Romania?
- Downloading FIFA Romania has many benefits for football lovers. Here are some of them:
-
-- You can play with your favorite Romanian teams and players in various game modes, such as career mode, tournament mode, or online mode
-- You can experience the thrill of the Romanian football league, with realistic fixtures, standings, and statistics
-- You can enjoy the authentic Romanian football atmosphere, with lively crowds, chants, and commentary
-- You can support the Romanian football community and show your patriotism
-- You can have fun and challenge yourself with a different and unique football game
-
- How to download FIFA Romania
- Requirements and compatibility
- To download FIFA Romania, you will need the following:
-
-- A PC or laptop with Windows operating system (Windows 7 or higher)
-- A copy of FIFA 14 or FIFA 15 installed on your device (you can buy it online or from a local store)
-- At least 10 GB of free disk space on your device
-- A stable internet connection for downloading and installing the mod
-- A compatible controller or keyboard for playing the game (optional)
-
- FIFA Romania is compatible with both FIFA 14 and FIFA 15 versions. However, some features may vary depending on the version you have. For example, FIFA 15 has better graphics and gameplay than FIFA 14, but FIFA 14 has more Romanian teams and players than FIFA 15.
- Steps to download and install FIFA Romania
- To download and install FIFA Romania, follow these steps:
-
-- Go to the official website of FIFA Romania (www.fifaromania.net) and register an account (it's free)
-- Log in to your account and go to the download section
-- Select the version of FIFA Romania that matches your version of FIFA (FIFA 14 or FIFA 15)
-- Download the mod file (it's a zip file that contains several folders)
-- Extract the mod file to a folder on your device (you can use WinRAR or any other extraction software)
-- Copy the contents of the extracted folder to the folder where you installed FIFA on your device (usually C:\Program Files\EA Sports\FIFA)
-- Run the game as administrator (right-click on the game icon and select "Run as administrator")
-- Enjoy playing FIFA Romania!
-
- Tips and tricks to optimize your gaming experience
- Here are some tips and tricks to make the most out of FIFA Romania:
-
-- Update your device drivers and software to ensure smooth performance and compatibility
-- Adjust the game settings according to your device specifications and preferences (you can change the resolution, graphics, sound, controls, etc.)
-- Backup your original FIFA files before installing the mod, in case you want to revert to the original game or uninstall the mod
-- Check the official website of FIFA Romania regularly for updates, patches, and news about the mod
-- Join the online community of FIFA Romania players and fans on social media, forums, and blogs, where you can share your feedback, suggestions, questions, and experiences
-
- How to play FIFA Romania
- Game modes and features
- FIFA Romania offers a variety of game modes and features that will keep you entertained and challenged. Here are some of them:
-
-- Career mode: You can create your own manager or player and lead your team to glory in the Romanian league or the international stage. You can also transfer players, negotiate contracts, scout talents, and manage your finances.
-- Tournament mode: You can choose from various tournaments, such as the Romanian Cup, the Romanian Super Cup, the UEFA Champions League, or the FIFA World Cup, and compete with other teams for the trophy.
-- Online mode: You can play online with other FIFA Romania players from around the world, either in friendly matches or in ranked matches. You can also join or create online leagues and tournaments with your friends or other players.
-- Ultimate team mode: You can create your own dream team by collecting and trading cards of players, managers, stadiums, kits, and more. You can also compete with other players' teams in various modes, such as seasons, tournaments, or drafts.
-- Skill games mode: You can practice and improve your skills in various aspects of the game, such as dribbling, passing, shooting, defending, or goalkeeping. You can also challenge yourself with different levels of difficulty and earn rewards.
-
- How to create and customize your own team
- If you want to create and customize your own team in FIFA Romania, you can do so by following these steps:
-
-- Go to the main menu and select "Customize"
-- Select "Create team"
-- Enter a name for your team and choose a country (you can choose Romania or any other country)
-- Select a league for your team (you can choose from Liga 1, Liga 2, Liga 3, or Rest of World)
-- Select a stadium for your team (you can choose from any of the Romanian stadiums or any other stadium)
-- Select a kit for your team (you can choose from any of the Romanian kits or any other kit)
-- Select a logo for your team (you can choose from any of the Romanian logos or any other logo)
-- Select a squad for your team (you can choose from any of the Romanian players or any other players)
-- Save your team and exit
-
- You can also edit or delete your team at any time by going to "Customize" > "Edit teams"
-download fifa romania apk
-download fifa romania 2023
-download fifa romania liga 1
-download fifa romania patch
-download fifa romania android
-download fifa romania pc
-download fifa romania mod
-download fifa romania 2022
-download fifa romania free
-download fifa romania online
-download fifa mobile romania
-download fifa 14 romania
-download fifa 21 romania
-download fifa 20 romania
-download fifa 19 romania
-download fifa 18 romania
-download fifa 17 romania
-download fifa 16 romania
-download fifa 15 romania
-download fifa 13 romania
-download ea sports fifa romania
-download jocuri fifa romania
-download liga 1 betano fifa romania
-download liga 2 casa pariurilor fifa romania
-download liga 3 fifa romania
-download echipe nationale fifa romania
-download comentariu in limba romana pentru fifa
-download stadioane romanesti pentru fifa
-download imnul national al romaniei pentru fifa
-download steaua bucuresti pentru fifa
-download dinamo bucuresti pentru fifa
-download rapid bucuresti pentru fifa
-download universitatea craiova pentru fifa
-download cfr cluj pentru fifa
-download fcsb pentru fifa
-download viitorul constanta pentru fifa
-download astra giurgiu pentru fifa
-download petrolul ploiesti pentru fifa
-download uta arad pentru fifa
-download chindia targoviste pentru fifa
- How to compete online and offline with other players
- If you want to compete online and offline with other players in FIFA Romania, you have several options:
-
-- If you want to play online with other FIFA Romania players from around the world, you can go to "Online" > "Seasons" or "Tournaments" and select a mode that suits you. You can also go to "Online" > "Match lobbies" and join or create a lobby with your preferred settings.
-- If you want to play online with your friends or other players that you know, you can go to "Online" > "Friendlies" and invite them to a match. You can also go to "Online" > "Custom games" and create a game with your own rules and settings.
-- If you want to play offline with another player on the same device, you can go to "Kick off" > "Match" and select a mode that suits you. You can also go to "Kick off" > "Custom games" and create a game with your own rules and settings.
-- If you want to play offline with another player on a different device, you can go to "Kick off" > "LAN Play" and connect your devices via LAN cable or Wi-Fi and select a mode that suits you. You can also go to "Kick off" > "Custom games" and create a game with your own rules and settings.
-
- Conclusion
- Summary of the main points
- In conclusion, FIFA Romania is a modded version of the original FIFA game that features Romanian teams, players, stadiums, and more. It is a fun and unique way to enjoy football and support Romania. To download FIFA Romania, you need to have FIFA 14 or FIFA 15 installed on your device, and then follow the steps to download and install the mod from the official website. You can play FIFA Romania in various game modes and features, such as career mode, tournament mode, online mode, ultimate team mode, or skill games mode. You can also create and customize your own team, and compete online and offline with other players.
- Call to action and invitation to share feedback
- If you are interested in downloading FIFA Romania, you can visit the official website (www.fifaromania.net) and register an account for free. You can also join the online community of FIFA Romania players and fans on social media, forums, and blogs, where you can share your feedback, suggestions, questions, and experiences. We hope you enjoy playing FIFA Romania and have a great time with your favorite Romanian teams and players. Thank you for reading this article and please share it with your friends if you found it helpful.
- FAQs
- Here are some frequently asked questions about FIFA Romania:
-
-- Is FIFA Romania legal and safe?
-Yes, FIFA Romania is legal and safe. It is a fan-made modification of the original FIFA game that does not violate any copyrights or trademarks of EA Sports or FIFA. It is also free of viruses, malware, or spyware.
-- Can I play FIFA Romania on other devices besides PC?
-No, FIFA Romania is only available for PC devices. It is not compatible with other devices such as consoles, mobile phones, or tablets.
-- Can I play FIFA Romania with other mods or patches?
-No, FIFA Romania is not compatible with other mods or patches. It is a standalone mod that requires a clean installation of FIFA 14 or FIFA 15. If you have other mods or patches installed on your device, you need to uninstall them before installing FIFA Romania.
-- Can I update FIFA Romania to the latest version of FIFA?
-No, FIFA Romania is only compatible with FIFA 14 or FIFA 15 versions. It is not compatible with newer versions of FIFA such as FIFA 16 or FIFA 17. If you want to play the latest version of FIFA, you need to buy it separately from EA Sports or from a local store.
-- Can I contact the developers of FIFA Romania for support or feedback?
-Yes, you can contact the developers of FIFA Romania for support or feedback. You can visit their official website (www.fifaromania.net) and use the contact form or the forum to send them a message. You can also follow them on social media (Facebook, Twitter, YouTube) and send them a message there.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/fatiXbelha/sd/Download Soul Knight APK dan Nikmati Gameplay Menarik di Game RPG Ini 2022.md b/spaces/fatiXbelha/sd/Download Soul Knight APK dan Nikmati Gameplay Menarik di Game RPG Ini 2022.md
deleted file mode 100644
index 7084106b2b12e4b1e7431156f28a69681977cbfd..0000000000000000000000000000000000000000
--- a/spaces/fatiXbelha/sd/Download Soul Knight APK dan Nikmati Gameplay Menarik di Game RPG Ini 2022.md
+++ /dev/null
@@ -1,133 +0,0 @@
-
-Download Soul Knight Versi Terbaru 2022: A Guide for Pixel Action Shoot'em Up Fans
-If you are a fan of pixel action shoot'em up games, you might have heard of Soul Knight, a popular game made by ChillyRoom Inc. © for Android, iOS, and Nintendo Switch. Soul Knight is a shooter game that features extremely easy and intuitive control, super smooth and enjoyable gameplay, mixed with rogue-like elements, that will get you hooked from the very first run!
-In this article, we will guide you on how to download Soul Knight versi terbaru 2022, the latest version of the game that was released on June 6th, 2023 for Android devices and May 15th, 2023 for iOS devices. We will also show you what's new in this version, how to play it, and why you should play it.
-download soul knight versi terbaru 2022
Download Zip ✦ https://urllie.com/2uNAub
-What's New in Soul Knight Versi Terbaru 2022?
-Soul Knight versi terbaru 2022 is the most updated version of the game that brings new features and improvements to enhance your gaming experience. Here are some of the highlights of this version:
-
-- New gift! Claim your gift from the mail: "Doodle Doo", the new skin of Rogue.
-- New hero! Meet Rosemary, a cute girl who loves gardening and has a special ability to grow plants.
-- New event! Travelogue of Rosemary Island, a new adventure mode where you can explore an island full of plants, animals, and secrets.
-- New weapons! More than 20 new weapons added, including Buddha's Palm, Iron Will Wavebreaker, Night Wanderer, etc.
-- New skins! More than 10 new skins added, including Bunny Girl of Assassin, Pirate of Knight, etc.
-- New pets! More than 10 new pets added, including Baby Dragon, Baby Phoenix, Baby Unicorn, etc.
-- New bosses! More than 5 new bosses added, including Giant Crab, Giant Octopus, Giant Shark, etc.
-- New achievements! More than 10 new achievements added, including Plant Lover, Island Explorer, Sea Monster Slayer, etc.
-- New languages! Added support for Arabic, Turkish, and Vietnamese languages.
-- Improved performance and stability. Fixed some bugs and glitches.
-
-As you can see, Soul Knight versi terbaru 2022 is packed with new content and updates that will make you want to play it more than ever. But how do you download it? Let's find out in the next section.
-How to Download Soul Knight Versi Terbaru 2022 for Android and iOS Devices?
-Downloading Soul Knight versi terbaru 2022 is very easy and simple. Just follow these steps:
-
-- Go to the official website of Soul Knight: https://www.chillyroom.com/
-- Click on the "Download" button on the top right corner of the screen.
-- Select your device type: Android or iOS.
-- You will be redirected to the Google Play Store or the App Store, depending on your device.
-- Click on the "Install" or "Get" button to download Soul Knight versi terbaru 2022 on your device.
-- Wait for the download and installation process to finish.
-- Launch the game and enjoy!
-
-Alternatively, you can also scan the QR code on the website to download Soul Knight versi terbaru 2022 directly on your device. Just make sure you have a QR code scanner app installed on your device.
-That's it! You have successfully downloaded Soul Knight versi terbaru 2022 on your device. Now, let's learn how to play it in the next section.
How to Play Soul Knight Versi Terbaru 2022?
-Soul Knight versi terbaru 2022 is a game that is easy to learn but hard to master. It is a game that requires skill, strategy, and luck. Here are some tips and tricks on how to play it and have fun:
-Choose Your Hero and Weapon
-One of the first things you need to do in Soul Knight versi terbaru 2022 is to choose your hero and weapon. There are more than 30 heroes to choose from, each with their own unique skills and stats. Some of the heroes are free, while others require gems or real money to unlock. You can also customize your hero's appearance with different skins.
-download soul knight mod apk versi terbaru 2022
-download soul knight update 5.2.2 versi terbaru 2022
-download soul knight game android versi terbaru 2022
-download soul knight hack unlimited gems versi terbaru 2022
-download soul knight offline rpg versi terbaru 2022
-download soul knight cheat menu versi terbaru 2022
-download soul knight latest version 2022 for free
-download soul knight new skins and weapons versi terbaru 2022
-download soul knight premium unlocked versi terbaru 2022
-download soul knight full version modded versi terbaru 2022
-download soul knight best roguelike game versi terbaru 2022
-download soul knight all characters and pets versi terbaru 2022
-download soul knight no ads and in-app purchases versi terbaru 2022
-download soul knight online multiplayer versi terbaru 2022
-download soul knight dungeon shooter versi terbaru 2022
-download soul knight pixel art graphics versi terbaru 2022
-download soul knight tips and tricks versi terbaru 2022
-download soul knight changelog and patch notes versi terbaru 2022
-download soul knight apk file for android versi terbaru 2022
-download soul knight apk + obb data versi terbaru 2022
-download soul knight apk mirror link versi terbaru 2022
-download soul knight apk pure source versi terbaru 2022
-download soul knight apk combo installer versi terbaru 2022
-download soul knight apk mod menu versi terbaru 2022
-download soul knight apk unlimited money and gems versi terbaru 2022
-download soul knight apk pro version versi terbaru 2022
-download soul knight apk latest update versi terbaru 2022
-download soul knight apk from google play store versi terbaru 2022
-download soul knight apk from official website versi terbaru 2022
-download soul knight apk from youtube video link versi terbaru 2022
-cara download soul knight di android versi terbaru 2022
-cara download soul knight mod gratis versi terbaru 2022
-cara download soul knight tanpa root versi terbaru 2022
-cara download soul knight dengan mudah dan cepat versi terbaru 2022
-cara download soul knight dari situs web resmi versi terbaru 2022
-cara download soul knight dari play store versi terbaru 2022
-cara download soul knight dari link alternatif versi terbaru 2022
-cara download soul knight dengan fitur lengkap versi terbaru 2022
-cara download soul knight dengan kualitas tinggi versi terbaru 2022
-cara download soul knight dengan ukuran kecil versi terbaru 2022
-review game soul knight untuk android versi terbaru 2022
-gameplay game soul knight di android versi terbaru 2022
-fitur game soul knight untuk android versi terbaru 2022
-kelebihan game soul knight untuk android versi terbaru 2022
-kekurangan game soul knight untuk android versi terbaru 2022
-tips bermain game soul knight di android versi terbaru 2022
-trik bermain game soul knight di android versi terbaru 2022
-cheat game soul knight di android versi terbaru 2022
-kode game soul knight di android versi terbaru 2022
-Each hero has a default weapon that they start with, but you can also find and use other weapons in the game. There are more than 300 weapons to collect, ranging from swords, guns, bows, lasers, rockets, etc. Each weapon has its own attributes, such as damage, fire rate, accuracy, etc. You can also upgrade your weapons with gold or gems to make them more powerful.
-Choosing the right hero and weapon for your play style and preference is crucial for your success in Soul Knight versi terbaru 2022. Experiment with different combinations and see what works best for you.
-Explore Randomly Generated Dungeons
-The main mode of Soul Knight versi terbaru 2022 is the dungeon mode, where you have to explore randomly generated dungeons and fight against various enemies and bosses. Each dungeon has a theme, such as forest, desert, ice, etc., and consists of several floors. Each floor has a number of rooms, where you can find enemies, chests, shops, statues, etc.
-Your goal is to clear all the rooms on each floor and reach the portal that leads to the next floor. Along the way, you can collect coins, gems, health potions, ammo boxes, etc., that will help you survive and progress. You can also find secrets and hidden rooms that may contain special items or surprises.
-The dungeons are randomly generated every time you play, so you never know what to expect. This adds an element of unpredictability and replayability to Soul Knight versi terbaru 2022. You have to be prepared for anything and adapt to different situations.
-Use Skills and Buffs Wisely
-Another important aspect of Soul Knight versi terbaru 2022 is the use of skills and buffs. Skills are special abilities that each hero has and can use in combat. Skills have a cooldown time before they can be used again. Some skills are offensive, such as shooting projectiles or summoning allies, while others are defensive, such as healing or shielding.
-Buffs are temporary effects that enhance your hero's performance in some way. Buffs can be obtained from statues, plants, potions, etc., and can affect your stats, such as health, damage, speed, etc., or give you special abilities, such as immunity, reflection, regeneration, etc.
-Using skills and buffs wisely can make a huge difference in your gameplay. You have to know when to use them and how to combine them for maximum effect. You also have to be careful not to use them too often or too recklessly, as they may have drawbacks or side effects.
Team Up with Friends Online or Offline
-One of the best features of Soul Knight versi terbaru 2022 is the multiplayer mode, where you can team up with your friends online or offline and play together. You can join or create a room online and invite up to three other players to join you. You can also use the local multiplayer mode and connect up to four devices via Wi-Fi or Bluetooth.
-Playing with your friends can make Soul Knight versi terbaru 2022 more fun and exciting, as you can cooperate and coordinate with each other, share items and resources, revive each other, and compete for the best score. You can also chat with your friends using the in-game voice or text chat feature.
-However, playing with your friends can also make Soul Knight versi terbaru 2022 more challenging and chaotic, as you have to deal with more enemies and bosses, friendly fire, limited screen space, and potential lag or connection issues. You also have to be careful not to steal or sabotage each other's items or buffs.
-Whether you prefer to play solo or with your friends, Soul Knight versi terbaru 2022 has something for everyone. You can choose the mode that suits your mood and preference.
-Why You Should Play Soul Knight Versi Terbaru 2022?
-By now, you might be wondering why you should play Soul Knight versi terbaru 2022. Well, there are many reasons why this game is worth your time and attention. Here are some of them:
-Fun and Engaging Gameplay
-Soul Knight versi terbaru 2022 offers a fun and engaging gameplay experience for pixel action shoot'em up fans. The game is fast-paced, smooth, and responsive, with easy and intuitive controls. The game is also varied, unpredictable, and replayable, with different heroes, weapons, dungeons, enemies, bosses, skills, buffs, etc. The game is also challenging, rewarding, and addictive, with different difficulty levels, achievements, leaderboards, etc.
-If you are looking for a game that will keep you entertained and hooked for hours, Soul Knight versi terbaru 2022 is the game for you.
-Beautiful Pixel Art and Music
-Soul Knight versi terbaru 2022 showcases a beautiful pixel art style and music that enhance the game's atmosphere. The game has a retro and nostalgic feel, with colorful and detailed graphics that capture the essence of pixel art. The game also has a catchy and upbeat soundtrack that matches the mood and theme of the game. The game also has a variety of sound effects that add to the immersion and realism of the game.
-If you are a fan of pixel art and music, Soul Knight versi terbaru 2022 is the game for you.
Challenging but Rewarding Difficulty
-Soul Knight versi terbaru 2022 offers a challenging but rewarding difficulty level that keeps you hooked and motivated. The game is not easy, as you have to face countless enemies and bosses that will test your skills and reflexes. The game is also not forgiving, as you have to start over from the beginning if you die. The game is also not predictable, as you have to deal with random dungeons and events that will change your gameplay.
-However, the game is also not impossible, as you have access to various resources and tools that will help you overcome the challenges. The game is also not boring, as you have different goals and rewards that will keep you interested and satisfied. The game is also not repetitive, as you have different strategies and styles that will keep you creative and curious.
-If you are looking for a game that will challenge you but also reward you, Soul Knight versi terbaru 2022 is the game for you.
-Diverse Game Modes and Features
-Soul Knight versi terbaru 2022 offers a diverse range of game modes and features that cater to different preferences and tastes. The game has a main dungeon mode, where you can explore different dungeons and fight against various enemies and bosses. The game also has an adventure mode, where you can embark on different quests and stories. The game also has a multiplayer mode, where you can play with your friends online or offline. The game also has a workshop mode, where you can create your own weapons and dungeons. The game also has a garden mode, where you can grow plants and harvest resources.
-If you are looking for a game that will offer you different options and possibilities, Soul Knight versi terbaru 2022 is the game for you.
-Conclusion
-Soul Knight versi terbaru 2022 is a pixel action shoot'em up game that features extremely easy and intuitive control, super smooth and enjoyable gameplay, mixed with rogue-like elements, that will get you hooked from the very first run!
-In this article, we have guided you on how to download Soul Knight versi terbaru 2022, the latest version of the game that brings new features and improvements to enhance your gaming experience. We have also shown you what's new in this version, how to play it, and why you should play it.
-Now that you know everything about Soul Knight versi terbaru 2022, what are you waiting for? Download it now and enjoy the pixel action shoot'em up adventure of your life!
-FAQs
-Here are some frequently asked questions and answers about Soul Knight versi terbaru 2022:
-
-- Is Soul Knight versi terbaru 2022 free to play?
-Yes, Soul Knight versi terbaru 2022 is free to play, but it contains some in-app purchases that can enhance your gameplay or unlock some premium content.
-- Is Soul Knight versi terbaru 2022 compatible with my device?
-Soul Knight versi terbaru 2022 is compatible with Android devices running Android 4.4 or higher, and iOS devices running iOS 9.0 or higher. It is also compatible with Nintendo Switch devices.
-- How can I save my progress in Soul Knight versi terbaru 2022?
-Soul Knight versi terbaru 2022 supports cloud saving, which means you can save your progress online and access it from any device. You just need to log in with your Google Play Games or Game Center account in the game settings.
-- How can I contact the developers of Soul Knight versi terbaru 2022?
-You can contact the developers of Soul Knight versi terbaru 2022 by sending an email to support@chillyroom.com, or by visiting their official website: https://www.chillyroom.com/.
-- Where can I find more information about Soul Knight versi terbaru 2022?
-You can find more information about Soul Knight versi terbaru 2022 by visiting their official website: https://www.chillyroom.com/, or by following their social media accounts: https://www.facebook.com/chillyroomsoulknight/, https://twitter.com/ChillyRoom, https://www.instagram.com/chillyroominc/.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/fb700/chatglm-fitness-RLHF/src/gradio_demo.py b/spaces/fb700/chatglm-fitness-RLHF/src/gradio_demo.py
deleted file mode 100644
index b1d2619fd9a67b37bea55bc91776afbcb3e50558..0000000000000000000000000000000000000000
--- a/spaces/fb700/chatglm-fitness-RLHF/src/gradio_demo.py
+++ /dev/null
@@ -1,170 +0,0 @@
-import torch, uuid
-import os, sys, shutil, platform
-from src.facerender.pirender_animate import AnimateFromCoeff_PIRender
-from src.utils.preprocess import CropAndExtract
-from src.test_audio2coeff import Audio2Coeff
-from src.facerender.animate import AnimateFromCoeff
-from src.generate_batch import get_data
-from src.generate_facerender_batch import get_facerender_data
-
-from src.utils.init_path import init_path
-
-from pydub import AudioSegment
-
-
-def mp3_to_wav(mp3_filename,wav_filename,frame_rate):
- mp3_file = AudioSegment.from_file(file=mp3_filename)
- mp3_file.set_frame_rate(frame_rate).export(wav_filename,format="wav")
-
-
-class SadTalker():
-
- def __init__(self, checkpoint_path='checkpoints', config_path='src/config', lazy_load=False):
-
- if torch.cuda.is_available():
- device = "cuda"
- elif platform.system() == 'Darwin': # macos
- device = "mps"
- else:
- device = "cpu"
-
- self.device = device
-
- os.environ['TORCH_HOME']= checkpoint_path
-
- self.checkpoint_path = checkpoint_path
- self.config_path = config_path
-
-
- def test(self, source_image, driven_audio, preprocess='crop',
- still_mode=False, use_enhancer=False, batch_size=1, size=256,
- pose_style = 0,
- facerender='facevid2vid',
- exp_scale=1.0,
- use_ref_video = False,
- ref_video = None,
- ref_info = None,
- use_idle_mode = False,
- length_of_audio = 0, use_blink=True,
- result_dir='./results/'):
-
- self.sadtalker_paths = init_path(self.checkpoint_path, self.config_path, size, False, preprocess)
- print(self.sadtalker_paths)
-
- self.audio_to_coeff = Audio2Coeff(self.sadtalker_paths, self.device)
- self.preprocess_model = CropAndExtract(self.sadtalker_paths, self.device)
-
- if facerender == 'facevid2vid' and self.device != 'mps':
- self.animate_from_coeff = AnimateFromCoeff(self.sadtalker_paths, self.device)
- elif facerender == 'pirender' or self.device == 'mps':
- self.animate_from_coeff = AnimateFromCoeff_PIRender(self.sadtalker_paths, self.device)
- facerender = 'pirender'
- else:
- raise(RuntimeError('Unknown model: {}'.format(facerender)))
-
-
- time_tag = str(uuid.uuid4())
- save_dir = os.path.join(result_dir, time_tag)
- os.makedirs(save_dir, exist_ok=True)
-
- input_dir = os.path.join(save_dir, 'input')
- os.makedirs(input_dir, exist_ok=True)
-
- print(source_image)
- pic_path = os.path.join(input_dir, os.path.basename(source_image))
- shutil.move(source_image, input_dir)
-
- if driven_audio is not None and os.path.isfile(driven_audio):
- audio_path = os.path.join(input_dir, os.path.basename(driven_audio))
-
- #### mp3 to wav
- if '.mp3' in audio_path:
- mp3_to_wav(driven_audio, audio_path.replace('.mp3', '.wav'), 16000)
- audio_path = audio_path.replace('.mp3', '.wav')
- else:
- shutil.move(driven_audio, input_dir)
-
- elif use_idle_mode:
- audio_path = os.path.join(input_dir, 'idlemode_'+str(length_of_audio)+'.wav') ## generate audio from this new audio_path
- from pydub import AudioSegment
- one_sec_segment = AudioSegment.silent(duration=1000*length_of_audio) #duration in milliseconds
- one_sec_segment.export(audio_path, format="wav")
- else:
- print(use_ref_video, ref_info)
- assert use_ref_video == True and ref_info == 'all'
-
- if use_ref_video and ref_info == 'all': # full ref mode
- ref_video_videoname = os.path.basename(ref_video)
- audio_path = os.path.join(save_dir, ref_video_videoname+'.wav')
- print('new audiopath:',audio_path)
- # if ref_video contains audio, set the audio from ref_video.
- cmd = r"ffmpeg -y -hide_banner -loglevel error -i %s %s"%(ref_video, audio_path)
- os.system(cmd)
-
- os.makedirs(save_dir, exist_ok=True)
-
- #crop image and extract 3dmm from image
- first_frame_dir = os.path.join(save_dir, 'first_frame_dir')
- os.makedirs(first_frame_dir, exist_ok=True)
- first_coeff_path, crop_pic_path, crop_info = self.preprocess_model.generate(pic_path, first_frame_dir, preprocess, True, size)
-
- if first_coeff_path is None:
- raise AttributeError("No face is detected")
-
- if use_ref_video:
- print('using ref video for genreation')
- ref_video_videoname = os.path.splitext(os.path.split(ref_video)[-1])[0]
- ref_video_frame_dir = os.path.join(save_dir, ref_video_videoname)
- os.makedirs(ref_video_frame_dir, exist_ok=True)
- print('3DMM Extraction for the reference video providing pose')
- ref_video_coeff_path, _, _ = self.preprocess_model.generate(ref_video, ref_video_frame_dir, preprocess, source_image_flag=False)
- else:
- ref_video_coeff_path = None
-
- if use_ref_video:
- if ref_info == 'pose':
- ref_pose_coeff_path = ref_video_coeff_path
- ref_eyeblink_coeff_path = None
- elif ref_info == 'blink':
- ref_pose_coeff_path = None
- ref_eyeblink_coeff_path = ref_video_coeff_path
- elif ref_info == 'pose+blink':
- ref_pose_coeff_path = ref_video_coeff_path
- ref_eyeblink_coeff_path = ref_video_coeff_path
- elif ref_info == 'all':
- ref_pose_coeff_path = None
- ref_eyeblink_coeff_path = None
- else:
- raise('error in refinfo')
- else:
- ref_pose_coeff_path = None
- ref_eyeblink_coeff_path = None
-
- #audio2ceoff
- if use_ref_video and ref_info == 'all':
- coeff_path = ref_video_coeff_path # self.audio_to_coeff.generate(batch, save_dir, pose_style, ref_pose_coeff_path)
- else:
- batch = get_data(first_coeff_path, audio_path, self.device, ref_eyeblink_coeff_path=ref_eyeblink_coeff_path, still=still_mode, \
- idlemode=use_idle_mode, length_of_audio=length_of_audio, use_blink=use_blink) # longer audio?
- coeff_path = self.audio_to_coeff.generate(batch, save_dir, pose_style, ref_pose_coeff_path)
-
- #coeff2video
- data = get_facerender_data(coeff_path, crop_pic_path, first_coeff_path, audio_path, batch_size, still_mode=still_mode, \
- preprocess=preprocess, size=size, expression_scale = exp_scale, facemodel=facerender)
- return_path = self.animate_from_coeff.generate(data, save_dir, pic_path, crop_info, enhancer='gfpgan' if use_enhancer else None, preprocess=preprocess, img_size=size)
- video_name = data['video_name']
- print(f'The generated video is named {video_name} in {save_dir}')
-
- del self.preprocess_model
- del self.audio_to_coeff
- del self.animate_from_coeff
-
- if torch.cuda.is_available():
- torch.cuda.empty_cache()
- torch.cuda.synchronize()
-
- import gc; gc.collect()
-
- return return_path
-
-
\ No newline at end of file
diff --git a/spaces/feng2022/styleganhuman_copy/torch_utils/op_edit/upfirdn2d.py b/spaces/feng2022/styleganhuman_copy/torch_utils/op_edit/upfirdn2d.py
deleted file mode 100644
index 874c09c5e98bee1ace64408aa31ec547dfe695a4..0000000000000000000000000000000000000000
--- a/spaces/feng2022/styleganhuman_copy/torch_utils/op_edit/upfirdn2d.py
+++ /dev/null
@@ -1,202 +0,0 @@
-# Copyright (c) SenseTime Research. All rights reserved.
-
-import os
-
-import torch
-from torch.nn import functional as F
-from torch.autograd import Function
-from torch.utils.cpp_extension import load
-
-
-module_path = os.path.dirname(__file__)
-upfirdn2d_op = load(
- "upfirdn2d",
- sources=[
- os.path.join(module_path, "upfirdn2d.cpp"),
- os.path.join(module_path, "upfirdn2d_kernel.cu"),
- ],
-)
-
-
-class UpFirDn2dBackward(Function):
- @staticmethod
- def forward(
- ctx, grad_output, kernel, grad_kernel, up, down, pad, g_pad, in_size, out_size
- ):
-
- up_x, up_y = up
- down_x, down_y = down
- g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1 = g_pad
-
- grad_output = grad_output.reshape(-1, out_size[0], out_size[1], 1)
-
- grad_input = upfirdn2d_op.upfirdn2d(
- grad_output,
- grad_kernel,
- down_x,
- down_y,
- up_x,
- up_y,
- g_pad_x0,
- g_pad_x1,
- g_pad_y0,
- g_pad_y1,
- )
- grad_input = grad_input.view(in_size[0], in_size[1], in_size[2], in_size[3])
-
- ctx.save_for_backward(kernel)
-
- pad_x0, pad_x1, pad_y0, pad_y1 = pad
-
- ctx.up_x = up_x
- ctx.up_y = up_y
- ctx.down_x = down_x
- ctx.down_y = down_y
- ctx.pad_x0 = pad_x0
- ctx.pad_x1 = pad_x1
- ctx.pad_y0 = pad_y0
- ctx.pad_y1 = pad_y1
- ctx.in_size = in_size
- ctx.out_size = out_size
-
- return grad_input
-
- @staticmethod
- def backward(ctx, gradgrad_input):
- (kernel,) = ctx.saved_tensors
-
- gradgrad_input = gradgrad_input.reshape(-1, ctx.in_size[2], ctx.in_size[3], 1)
-
- gradgrad_out = upfirdn2d_op.upfirdn2d(
- gradgrad_input,
- kernel,
- ctx.up_x,
- ctx.up_y,
- ctx.down_x,
- ctx.down_y,
- ctx.pad_x0,
- ctx.pad_x1,
- ctx.pad_y0,
- ctx.pad_y1,
- )
- # gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.out_size[0], ctx.out_size[1], ctx.in_size[3])
- gradgrad_out = gradgrad_out.view(
- ctx.in_size[0], ctx.in_size[1], ctx.out_size[0], ctx.out_size[1]
- )
-
- return gradgrad_out, None, None, None, None, None, None, None, None
-
-
-class UpFirDn2d(Function):
- @staticmethod
- def forward(ctx, input, kernel, up, down, pad):
- up_x, up_y = up
- down_x, down_y = down
- pad_x0, pad_x1, pad_y0, pad_y1 = pad
-
- kernel_h, kernel_w = kernel.shape
- batch, channel, in_h, in_w = input.shape
- ctx.in_size = input.shape
-
- input = input.reshape(-1, in_h, in_w, 1)
-
- ctx.save_for_backward(kernel, torch.flip(kernel, [0, 1]))
-
- out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
- out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
- ctx.out_size = (out_h, out_w)
-
- ctx.up = (up_x, up_y)
- ctx.down = (down_x, down_y)
- ctx.pad = (pad_x0, pad_x1, pad_y0, pad_y1)
-
- g_pad_x0 = kernel_w - pad_x0 - 1
- g_pad_y0 = kernel_h - pad_y0 - 1
- g_pad_x1 = in_w * up_x - out_w * down_x + pad_x0 - up_x + 1
- g_pad_y1 = in_h * up_y - out_h * down_y + pad_y0 - up_y + 1
-
- ctx.g_pad = (g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1)
-
- out = upfirdn2d_op.upfirdn2d(
- input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
- )
- # out = out.view(major, out_h, out_w, minor)
- out = out.view(-1, channel, out_h, out_w)
-
- return out
-
- @staticmethod
- def backward(ctx, grad_output):
- kernel, grad_kernel = ctx.saved_tensors
-
- grad_input = UpFirDn2dBackward.apply(
- grad_output,
- kernel,
- grad_kernel,
- ctx.up,
- ctx.down,
- ctx.pad,
- ctx.g_pad,
- ctx.in_size,
- ctx.out_size,
- )
-
- return grad_input, None, None, None, None
-
-
-def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
- if input.device.type == "cpu":
- out = upfirdn2d_native(
- input, kernel, up, up, down, down, pad[0], pad[1], pad[0], pad[1]
- )
-
- else:
- out = UpFirDn2d.apply(
- input, kernel, (up, up), (down, down), (pad[0], pad[1], pad[0], pad[1])
- )
-
- return out
-
-
-def upfirdn2d_native(
- input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
-):
- _, channel, in_h, in_w = input.shape
- input = input.reshape(-1, in_h, in_w, 1)
-
- _, in_h, in_w, minor = input.shape
- kernel_h, kernel_w = kernel.shape
-
- out = input.view(-1, in_h, 1, in_w, 1, minor)
- out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
- out = out.view(-1, in_h * up_y, in_w * up_x, minor)
-
- out = F.pad(
- out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)]
- )
- out = out[
- :,
- max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
- max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
- :,
- ]
-
- out = out.permute(0, 3, 1, 2)
- out = out.reshape(
- [-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1]
- )
- w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
- out = F.conv2d(out, w)
- out = out.reshape(
- -1,
- minor,
- in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
- in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
- )
- out = out.permute(0, 2, 3, 1)
- out = out[:, ::down_y, ::down_x, :]
-
- out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
- out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
-
- return out.view(-1, channel, out_h, out_w)
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/content-disposition/HISTORY.md b/spaces/fffiloni/controlnet-animation-doodle/node_modules/content-disposition/HISTORY.md
deleted file mode 100644
index 488effa0c9440f4e214102980665781a62ba7059..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/content-disposition/HISTORY.md
+++ /dev/null
@@ -1,60 +0,0 @@
-0.5.4 / 2021-12-10
-==================
-
- * deps: safe-buffer@5.2.1
-
-0.5.3 / 2018-12-17
-==================
-
- * Use `safe-buffer` for improved Buffer API
-
-0.5.2 / 2016-12-08
-==================
-
- * Fix `parse` to accept any linear whitespace character
-
-0.5.1 / 2016-01-17
-==================
-
- * perf: enable strict mode
-
-0.5.0 / 2014-10-11
-==================
-
- * Add `parse` function
-
-0.4.0 / 2014-09-21
-==================
-
- * Expand non-Unicode `filename` to the full ISO-8859-1 charset
-
-0.3.0 / 2014-09-20
-==================
-
- * Add `fallback` option
- * Add `type` option
-
-0.2.0 / 2014-09-19
-==================
-
- * Reduce ambiguity of file names with hex escape in buggy browsers
-
-0.1.2 / 2014-09-19
-==================
-
- * Fix periodic invalid Unicode filename header
-
-0.1.1 / 2014-09-19
-==================
-
- * Fix invalid characters appearing in `filename*` parameter
-
-0.1.0 / 2014-09-18
-==================
-
- * Make the `filename` argument optional
-
-0.0.0 / 2014-09-18
-==================
-
- * Initial release
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/test/shams/get-own-property-symbols.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/test/shams/get-own-property-symbols.js
deleted file mode 100644
index 9191b248baa14b9866da65ccf638b96b71c046e7..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/test/shams/get-own-property-symbols.js
+++ /dev/null
@@ -1,28 +0,0 @@
-'use strict';
-
-var test = require('tape');
-
-if (typeof Symbol === 'function' && typeof Symbol() === 'symbol') {
- test('has native Symbol support', function (t) {
- t.equal(typeof Symbol, 'function');
- t.equal(typeof Symbol(), 'symbol');
- t.end();
- });
- return;
-}
-
-var hasSymbols = require('../../shams');
-
-test('polyfilled Symbols', function (t) {
- /* eslint-disable global-require */
- t.equal(hasSymbols(), false, 'hasSymbols is false before polyfilling');
-
- require('get-own-property-symbols');
-
- require('../tests')(t);
-
- var hasSymbolsAfter = hasSymbols();
- t.equal(hasSymbolsAfter, true, 'hasSymbols is true after polyfilling');
- /* eslint-enable global-require */
- t.end();
-});
diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/video/io.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/video/io.py
deleted file mode 100644
index 9879154227f640c262853b92c219461c6f67ee8e..0000000000000000000000000000000000000000
--- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/video/io.py
+++ /dev/null
@@ -1,318 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import os.path as osp
-from collections import OrderedDict
-
-import cv2
-from cv2 import (CAP_PROP_FOURCC, CAP_PROP_FPS, CAP_PROP_FRAME_COUNT,
- CAP_PROP_FRAME_HEIGHT, CAP_PROP_FRAME_WIDTH,
- CAP_PROP_POS_FRAMES, VideoWriter_fourcc)
-
-from annotator.uniformer.mmcv.utils import (check_file_exist, mkdir_or_exist, scandir,
- track_progress)
-
-
-class Cache:
-
- def __init__(self, capacity):
- self._cache = OrderedDict()
- self._capacity = int(capacity)
- if capacity <= 0:
- raise ValueError('capacity must be a positive integer')
-
- @property
- def capacity(self):
- return self._capacity
-
- @property
- def size(self):
- return len(self._cache)
-
- def put(self, key, val):
- if key in self._cache:
- return
- if len(self._cache) >= self.capacity:
- self._cache.popitem(last=False)
- self._cache[key] = val
-
- def get(self, key, default=None):
- val = self._cache[key] if key in self._cache else default
- return val
-
-
-class VideoReader:
- """Video class with similar usage to a list object.
-
- This video warpper class provides convenient apis to access frames.
- There exists an issue of OpenCV's VideoCapture class that jumping to a
- certain frame may be inaccurate. It is fixed in this class by checking
- the position after jumping each time.
- Cache is used when decoding videos. So if the same frame is visited for
- the second time, there is no need to decode again if it is stored in the
- cache.
-
- :Example:
-
- >>> import annotator.uniformer.mmcv as mmcv
- >>> v = mmcv.VideoReader('sample.mp4')
- >>> len(v) # get the total frame number with `len()`
- 120
- >>> for img in v: # v is iterable
- >>> mmcv.imshow(img)
- >>> v[5] # get the 6th frame
- """
-
- def __init__(self, filename, cache_capacity=10):
- # Check whether the video path is a url
- if not filename.startswith(('https://', 'http://')):
- check_file_exist(filename, 'Video file not found: ' + filename)
- self._vcap = cv2.VideoCapture(filename)
- assert cache_capacity > 0
- self._cache = Cache(cache_capacity)
- self._position = 0
- # get basic info
- self._width = int(self._vcap.get(CAP_PROP_FRAME_WIDTH))
- self._height = int(self._vcap.get(CAP_PROP_FRAME_HEIGHT))
- self._fps = self._vcap.get(CAP_PROP_FPS)
- self._frame_cnt = int(self._vcap.get(CAP_PROP_FRAME_COUNT))
- self._fourcc = self._vcap.get(CAP_PROP_FOURCC)
-
- @property
- def vcap(self):
- """:obj:`cv2.VideoCapture`: The raw VideoCapture object."""
- return self._vcap
-
- @property
- def opened(self):
- """bool: Indicate whether the video is opened."""
- return self._vcap.isOpened()
-
- @property
- def width(self):
- """int: Width of video frames."""
- return self._width
-
- @property
- def height(self):
- """int: Height of video frames."""
- return self._height
-
- @property
- def resolution(self):
- """tuple: Video resolution (width, height)."""
- return (self._width, self._height)
-
- @property
- def fps(self):
- """float: FPS of the video."""
- return self._fps
-
- @property
- def frame_cnt(self):
- """int: Total frames of the video."""
- return self._frame_cnt
-
- @property
- def fourcc(self):
- """str: "Four character code" of the video."""
- return self._fourcc
-
- @property
- def position(self):
- """int: Current cursor position, indicating frame decoded."""
- return self._position
-
- def _get_real_position(self):
- return int(round(self._vcap.get(CAP_PROP_POS_FRAMES)))
-
- def _set_real_position(self, frame_id):
- self._vcap.set(CAP_PROP_POS_FRAMES, frame_id)
- pos = self._get_real_position()
- for _ in range(frame_id - pos):
- self._vcap.read()
- self._position = frame_id
-
- def read(self):
- """Read the next frame.
-
- If the next frame have been decoded before and in the cache, then
- return it directly, otherwise decode, cache and return it.
-
- Returns:
- ndarray or None: Return the frame if successful, otherwise None.
- """
- # pos = self._position
- if self._cache:
- img = self._cache.get(self._position)
- if img is not None:
- ret = True
- else:
- if self._position != self._get_real_position():
- self._set_real_position(self._position)
- ret, img = self._vcap.read()
- if ret:
- self._cache.put(self._position, img)
- else:
- ret, img = self._vcap.read()
- if ret:
- self._position += 1
- return img
-
- def get_frame(self, frame_id):
- """Get frame by index.
-
- Args:
- frame_id (int): Index of the expected frame, 0-based.
-
- Returns:
- ndarray or None: Return the frame if successful, otherwise None.
- """
- if frame_id < 0 or frame_id >= self._frame_cnt:
- raise IndexError(
- f'"frame_id" must be between 0 and {self._frame_cnt - 1}')
- if frame_id == self._position:
- return self.read()
- if self._cache:
- img = self._cache.get(frame_id)
- if img is not None:
- self._position = frame_id + 1
- return img
- self._set_real_position(frame_id)
- ret, img = self._vcap.read()
- if ret:
- if self._cache:
- self._cache.put(self._position, img)
- self._position += 1
- return img
-
- def current_frame(self):
- """Get the current frame (frame that is just visited).
-
- Returns:
- ndarray or None: If the video is fresh, return None, otherwise
- return the frame.
- """
- if self._position == 0:
- return None
- return self._cache.get(self._position - 1)
-
- def cvt2frames(self,
- frame_dir,
- file_start=0,
- filename_tmpl='{:06d}.jpg',
- start=0,
- max_num=0,
- show_progress=True):
- """Convert a video to frame images.
-
- Args:
- frame_dir (str): Output directory to store all the frame images.
- file_start (int): Filenames will start from the specified number.
- filename_tmpl (str): Filename template with the index as the
- placeholder.
- start (int): The starting frame index.
- max_num (int): Maximum number of frames to be written.
- show_progress (bool): Whether to show a progress bar.
- """
- mkdir_or_exist(frame_dir)
- if max_num == 0:
- task_num = self.frame_cnt - start
- else:
- task_num = min(self.frame_cnt - start, max_num)
- if task_num <= 0:
- raise ValueError('start must be less than total frame number')
- if start > 0:
- self._set_real_position(start)
-
- def write_frame(file_idx):
- img = self.read()
- if img is None:
- return
- filename = osp.join(frame_dir, filename_tmpl.format(file_idx))
- cv2.imwrite(filename, img)
-
- if show_progress:
- track_progress(write_frame, range(file_start,
- file_start + task_num))
- else:
- for i in range(task_num):
- write_frame(file_start + i)
-
- def __len__(self):
- return self.frame_cnt
-
- def __getitem__(self, index):
- if isinstance(index, slice):
- return [
- self.get_frame(i)
- for i in range(*index.indices(self.frame_cnt))
- ]
- # support negative indexing
- if index < 0:
- index += self.frame_cnt
- if index < 0:
- raise IndexError('index out of range')
- return self.get_frame(index)
-
- def __iter__(self):
- self._set_real_position(0)
- return self
-
- def __next__(self):
- img = self.read()
- if img is not None:
- return img
- else:
- raise StopIteration
-
- next = __next__
-
- def __enter__(self):
- return self
-
- def __exit__(self, exc_type, exc_value, traceback):
- self._vcap.release()
-
-
-def frames2video(frame_dir,
- video_file,
- fps=30,
- fourcc='XVID',
- filename_tmpl='{:06d}.jpg',
- start=0,
- end=0,
- show_progress=True):
- """Read the frame images from a directory and join them as a video.
-
- Args:
- frame_dir (str): The directory containing video frames.
- video_file (str): Output filename.
- fps (float): FPS of the output video.
- fourcc (str): Fourcc of the output video, this should be compatible
- with the output file type.
- filename_tmpl (str): Filename template with the index as the variable.
- start (int): Starting frame index.
- end (int): Ending frame index.
- show_progress (bool): Whether to show a progress bar.
- """
- if end == 0:
- ext = filename_tmpl.split('.')[-1]
- end = len([name for name in scandir(frame_dir, ext)])
- first_file = osp.join(frame_dir, filename_tmpl.format(start))
- check_file_exist(first_file, 'The start frame not found: ' + first_file)
- img = cv2.imread(first_file)
- height, width = img.shape[:2]
- resolution = (width, height)
- vwriter = cv2.VideoWriter(video_file, VideoWriter_fourcc(*fourcc), fps,
- resolution)
-
- def write_frame(file_idx):
- filename = osp.join(frame_dir, filename_tmpl.format(file_idx))
- img = cv2.imread(filename)
- vwriter.write(img)
-
- if show_progress:
- track_progress(write_frame, range(start, end))
- else:
- for i in range(start, end):
- write_frame(i)
- vwriter.release()
diff --git a/spaces/giswqs/solara-demo/pages/00_home.py b/spaces/giswqs/solara-demo/pages/00_home.py
deleted file mode 100644
index 7f177ca6f04afd20334d0efdee1d00b8539b0ef4..0000000000000000000000000000000000000000
--- a/spaces/giswqs/solara-demo/pages/00_home.py
+++ /dev/null
@@ -1,25 +0,0 @@
-import solara
-
-@solara.component
-def Page():
-
- markdown = """
- ## Solara for Geospatial Applications
-
- ### Introduction
-
- **A collection of [Solara](https://github.com/widgetti/solara) web apps for geospatial applications.**
-
- Just a proof-of-concept for now. Not all features are working yet. More features will be added in the future. Click on the menu above to see the other pages.
-
- - Web App:
- - GitHub:
- - Hugging Face:
-
- ### Demos
-
- 
-
- """
-
- solara.Markdown(markdown)
diff --git a/spaces/gotiQspiryo/whisper-ui/examples/Izotope Ozone Crack Mac.md b/spaces/gotiQspiryo/whisper-ui/examples/Izotope Ozone Crack Mac.md
deleted file mode 100644
index 6901f8e5c45453f2a9dc14e5df12df61b900a0f2..0000000000000000000000000000000000000000
--- a/spaces/gotiQspiryo/whisper-ui/examples/Izotope Ozone Crack Mac.md
+++ /dev/null
@@ -1,10 +0,0 @@
-
-for producers and music makers that have been using plugins to modify their track’s sound, ozone 9 promises a lot of improvements. ozone 9 gives you the ability to change the sound of your instrument by adjusting its balance, panning, resonances, and eq. adjust every instrument and every mic with an intuitive interface, whether you are recording, mixing, mastering, or simply sound designing.
-Izotope Ozone Crack Mac
Download File › https://urlgoal.com/2uyMwM
-ozone 9 also includes a new balance plugin, which lets you fine-tune the balance of your stereo mix or render a mono balance for your mix. set up your mix with a single click and balance to your heart’s content. a new spectrum analyzer and sender gui are also available.
-ozone 9 also includes more than 12 ozone-exclusive mastering processors. use the master assistant to fine-tune your eq and gain in real time. add harmonics, saturate, and noise reduction to your sound with the maximizer and peaking plugins. the new tonal balance control is perfect for balancing out vocals, drums, and low-frequency effects. you can even use a variable target to automatically balance the sound to the sound of a reference track.
-ozone 9 also includes a new sender workflow. it’s a new way to send your mixes to ozone. use the sender to send a stereo mix as mono, or send a mono mix as a stereo mix with a new panning. you can also send a kick and bass track separately and mix them to a mono file.
-ozone 9 also includes a new spectral analyzer plugin. it lets you fine-tune the sound of your stereo mix or render a mono balance for your mix. finally, ozone 9 offers a new integrated workflow for mixing and mastering. mix any combination of ozone and other plugins, or route individual plugins and buses via the daw’s mixer channels. this workflow allows you to spend more time creating and less time trying to learn the ins and outs of every vst.
- 899543212b
-
-
\ No newline at end of file
diff --git a/spaces/gradio/HuBERT/examples/speech_recognition/utils/wer_utils.py b/spaces/gradio/HuBERT/examples/speech_recognition/utils/wer_utils.py
deleted file mode 100644
index cf6f3d09ba41a46ad4d7968fb3c286dd53d15c38..0000000000000000000000000000000000000000
--- a/spaces/gradio/HuBERT/examples/speech_recognition/utils/wer_utils.py
+++ /dev/null
@@ -1,381 +0,0 @@
-#!/usr/bin/env python3
-
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from __future__ import absolute_import, division, print_function, unicode_literals
-
-import re
-from collections import deque
-from enum import Enum
-
-import numpy as np
-
-
-"""
- Utility modules for computation of Word Error Rate,
- Alignments, as well as more granular metrics like
- deletion, insersion and substitutions.
-"""
-
-
-class Code(Enum):
- match = 1
- substitution = 2
- insertion = 3
- deletion = 4
-
-
-class Token(object):
- def __init__(self, lbl="", st=np.nan, en=np.nan):
- if np.isnan(st):
- self.label, self.start, self.end = "", 0.0, 0.0
- else:
- self.label, self.start, self.end = lbl, st, en
-
-
-class AlignmentResult(object):
- def __init__(self, refs, hyps, codes, score):
- self.refs = refs # std::deque
- self.hyps = hyps # std::deque
- self.codes = codes # std::deque
- self.score = score # float
-
-
-def coordinate_to_offset(row, col, ncols):
- return int(row * ncols + col)
-
-
-def offset_to_row(offset, ncols):
- return int(offset / ncols)
-
-
-def offset_to_col(offset, ncols):
- return int(offset % ncols)
-
-
-def trimWhitespace(str):
- return re.sub(" +", " ", re.sub(" *$", "", re.sub("^ *", "", str)))
-
-
-def str2toks(str):
- pieces = trimWhitespace(str).split(" ")
- toks = []
- for p in pieces:
- toks.append(Token(p, 0.0, 0.0))
- return toks
-
-
-class EditDistance(object):
- def __init__(self, time_mediated):
- self.time_mediated_ = time_mediated
- self.scores_ = np.nan # Eigen::Matrix
- self.backtraces_ = (
- np.nan
- ) # Eigen::Matrix backtraces_;
- self.confusion_pairs_ = {}
-
- def cost(self, ref, hyp, code):
- if self.time_mediated_:
- if code == Code.match:
- return abs(ref.start - hyp.start) + abs(ref.end - hyp.end)
- elif code == Code.insertion:
- return hyp.end - hyp.start
- elif code == Code.deletion:
- return ref.end - ref.start
- else: # substitution
- return abs(ref.start - hyp.start) + abs(ref.end - hyp.end) + 0.1
- else:
- if code == Code.match:
- return 0
- elif code == Code.insertion or code == Code.deletion:
- return 3
- else: # substitution
- return 4
-
- def get_result(self, refs, hyps):
- res = AlignmentResult(refs=deque(), hyps=deque(), codes=deque(), score=np.nan)
-
- num_rows, num_cols = self.scores_.shape
- res.score = self.scores_[num_rows - 1, num_cols - 1]
-
- curr_offset = coordinate_to_offset(num_rows - 1, num_cols - 1, num_cols)
-
- while curr_offset != 0:
- curr_row = offset_to_row(curr_offset, num_cols)
- curr_col = offset_to_col(curr_offset, num_cols)
-
- prev_offset = self.backtraces_[curr_row, curr_col]
-
- prev_row = offset_to_row(prev_offset, num_cols)
- prev_col = offset_to_col(prev_offset, num_cols)
-
- res.refs.appendleft(curr_row - 1) # Note: this was .push_front() in C++
- res.hyps.appendleft(curr_col - 1)
- if curr_row - 1 == prev_row and curr_col == prev_col:
- res.codes.appendleft(Code.deletion)
- elif curr_row == prev_row and curr_col - 1 == prev_col:
- res.codes.appendleft(Code.insertion)
- else:
- # assert(curr_row - 1 == prev_row and curr_col - 1 == prev_col)
- ref_str = refs[res.refs[0]].label
- hyp_str = hyps[res.hyps[0]].label
-
- if ref_str == hyp_str:
- res.codes.appendleft(Code.match)
- else:
- res.codes.appendleft(Code.substitution)
-
- confusion_pair = "%s -> %s" % (ref_str, hyp_str)
- if confusion_pair not in self.confusion_pairs_:
- self.confusion_pairs_[confusion_pair] = 1
- else:
- self.confusion_pairs_[confusion_pair] += 1
-
- curr_offset = prev_offset
-
- return res
-
- def align(self, refs, hyps):
- if len(refs) == 0 and len(hyps) == 0:
- return np.nan
-
- # NOTE: we're not resetting the values in these matrices because every value
- # will be overridden in the loop below. If this assumption doesn't hold,
- # be sure to set all entries in self.scores_ and self.backtraces_ to 0.
- self.scores_ = np.zeros((len(refs) + 1, len(hyps) + 1))
- self.backtraces_ = np.zeros((len(refs) + 1, len(hyps) + 1))
-
- num_rows, num_cols = self.scores_.shape
-
- for i in range(num_rows):
- for j in range(num_cols):
- if i == 0 and j == 0:
- self.scores_[i, j] = 0.0
- self.backtraces_[i, j] = 0
- continue
-
- if i == 0:
- self.scores_[i, j] = self.scores_[i, j - 1] + self.cost(
- None, hyps[j - 1], Code.insertion
- )
- self.backtraces_[i, j] = coordinate_to_offset(i, j - 1, num_cols)
- continue
-
- if j == 0:
- self.scores_[i, j] = self.scores_[i - 1, j] + self.cost(
- refs[i - 1], None, Code.deletion
- )
- self.backtraces_[i, j] = coordinate_to_offset(i - 1, j, num_cols)
- continue
-
- # Below here both i and j are greater than 0
- ref = refs[i - 1]
- hyp = hyps[j - 1]
- best_score = self.scores_[i - 1, j - 1] + (
- self.cost(ref, hyp, Code.match)
- if (ref.label == hyp.label)
- else self.cost(ref, hyp, Code.substitution)
- )
-
- prev_row = i - 1
- prev_col = j - 1
- ins = self.scores_[i, j - 1] + self.cost(None, hyp, Code.insertion)
- if ins < best_score:
- best_score = ins
- prev_row = i
- prev_col = j - 1
-
- delt = self.scores_[i - 1, j] + self.cost(ref, None, Code.deletion)
- if delt < best_score:
- best_score = delt
- prev_row = i - 1
- prev_col = j
-
- self.scores_[i, j] = best_score
- self.backtraces_[i, j] = coordinate_to_offset(
- prev_row, prev_col, num_cols
- )
-
- return self.get_result(refs, hyps)
-
-
-class WERTransformer(object):
- def __init__(self, hyp_str, ref_str, verbose=True):
- self.ed_ = EditDistance(False)
- self.id2oracle_errs_ = {}
- self.utts_ = 0
- self.words_ = 0
- self.insertions_ = 0
- self.deletions_ = 0
- self.substitutions_ = 0
-
- self.process(["dummy_str", hyp_str, ref_str])
-
- if verbose:
- print("'%s' vs '%s'" % (hyp_str, ref_str))
- self.report_result()
-
- def process(self, input): # std::vector&& input
- if len(input) < 3:
- print(
- "Input must be of the form ... [ , got ",
- len(input),
- " inputs:",
- )
- return None
-
- # Align
- # std::vector hyps;
- # std::vector refs;
-
- hyps = str2toks(input[-2])
- refs = str2toks(input[-1])
-
- alignment = self.ed_.align(refs, hyps)
- if alignment is None:
- print("Alignment is null")
- return np.nan
-
- # Tally errors
- ins = 0
- dels = 0
- subs = 0
- for code in alignment.codes:
- if code == Code.substitution:
- subs += 1
- elif code == Code.insertion:
- ins += 1
- elif code == Code.deletion:
- dels += 1
-
- # Output
- row = input
- row.append(str(len(refs)))
- row.append(str(ins))
- row.append(str(dels))
- row.append(str(subs))
- # print(row)
-
- # Accumulate
- kIdIndex = 0
- kNBestSep = "/"
-
- pieces = input[kIdIndex].split(kNBestSep)
-
- if len(pieces) == 0:
- print(
- "Error splitting ",
- input[kIdIndex],
- " on '",
- kNBestSep,
- "', got empty list",
- )
- return np.nan
-
- id = pieces[0]
- if id not in self.id2oracle_errs_:
- self.utts_ += 1
- self.words_ += len(refs)
- self.insertions_ += ins
- self.deletions_ += dels
- self.substitutions_ += subs
- self.id2oracle_errs_[id] = [ins, dels, subs]
- else:
- curr_err = ins + dels + subs
- prev_err = np.sum(self.id2oracle_errs_[id])
- if curr_err < prev_err:
- self.id2oracle_errs_[id] = [ins, dels, subs]
-
- return 0
-
- def report_result(self):
- # print("---------- Summary ---------------")
- if self.words_ == 0:
- print("No words counted")
- return
-
- # 1-best
- best_wer = (
- 100.0
- * (self.insertions_ + self.deletions_ + self.substitutions_)
- / self.words_
- )
-
- print(
- "\tWER = %0.2f%% (%i utts, %i words, %0.2f%% ins, "
- "%0.2f%% dels, %0.2f%% subs)"
- % (
- best_wer,
- self.utts_,
- self.words_,
- 100.0 * self.insertions_ / self.words_,
- 100.0 * self.deletions_ / self.words_,
- 100.0 * self.substitutions_ / self.words_,
- )
- )
-
- def wer(self):
- if self.words_ == 0:
- wer = np.nan
- else:
- wer = (
- 100.0
- * (self.insertions_ + self.deletions_ + self.substitutions_)
- / self.words_
- )
- return wer
-
- def stats(self):
- if self.words_ == 0:
- stats = {}
- else:
- wer = (
- 100.0
- * (self.insertions_ + self.deletions_ + self.substitutions_)
- / self.words_
- )
- stats = dict(
- {
- "wer": wer,
- "utts": self.utts_,
- "numwords": self.words_,
- "ins": self.insertions_,
- "dels": self.deletions_,
- "subs": self.substitutions_,
- "confusion_pairs": self.ed_.confusion_pairs_,
- }
- )
- return stats
-
-
-def calc_wer(hyp_str, ref_str):
- t = WERTransformer(hyp_str, ref_str, verbose=0)
- return t.wer()
-
-
-def calc_wer_stats(hyp_str, ref_str):
- t = WERTransformer(hyp_str, ref_str, verbose=0)
- return t.stats()
-
-
-def get_wer_alignment_codes(hyp_str, ref_str):
- """
- INPUT: hypothesis string, reference string
- OUTPUT: List of alignment codes (intermediate results from WER computation)
- """
- t = WERTransformer(hyp_str, ref_str, verbose=0)
- return t.ed_.align(str2toks(ref_str), str2toks(hyp_str)).codes
-
-
-def merge_counts(x, y):
- # Merge two hashes which have 'counts' as their values
- # This can be used for example to merge confusion pair counts
- # conf_pairs = merge_counts(conf_pairs, stats['confusion_pairs'])
- for k, v in y.items():
- if k not in x:
- x[k] = 0
- x[k] += v
- return x
diff --git a/spaces/gradio/HuBERT/tests/test_dictionary.py b/spaces/gradio/HuBERT/tests/test_dictionary.py
deleted file mode 100644
index 81ce102f4f555822e36298034cdeb3d1c0650255..0000000000000000000000000000000000000000
--- a/spaces/gradio/HuBERT/tests/test_dictionary.py
+++ /dev/null
@@ -1,116 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import io
-import tempfile
-import unittest
-
-import torch
-from fairseq.data import Dictionary
-
-
-class TestDictionary(unittest.TestCase):
- def test_finalize(self):
- txt = [
- "A B C D",
- "B C D",
- "C D",
- "D",
- ]
- ref_ids1 = list(
- map(
- torch.IntTensor,
- [
- [4, 5, 6, 7, 2],
- [5, 6, 7, 2],
- [6, 7, 2],
- [7, 2],
- ],
- )
- )
- ref_ids2 = list(
- map(
- torch.IntTensor,
- [
- [7, 6, 5, 4, 2],
- [6, 5, 4, 2],
- [5, 4, 2],
- [4, 2],
- ],
- )
- )
-
- # build dictionary
- d = Dictionary()
- for line in txt:
- d.encode_line(line, add_if_not_exist=True)
-
- def get_ids(dictionary):
- ids = []
- for line in txt:
- ids.append(dictionary.encode_line(line, add_if_not_exist=False))
- return ids
-
- def assertMatch(ids, ref_ids):
- for toks, ref_toks in zip(ids, ref_ids):
- self.assertEqual(toks.size(), ref_toks.size())
- self.assertEqual(0, (toks != ref_toks).sum().item())
-
- ids = get_ids(d)
- assertMatch(ids, ref_ids1)
-
- # check finalized dictionary
- d.finalize()
- finalized_ids = get_ids(d)
- assertMatch(finalized_ids, ref_ids2)
-
- # write to disk and reload
- with tempfile.NamedTemporaryFile(mode="w") as tmp_dict:
- d.save(tmp_dict.name)
- d = Dictionary.load(tmp_dict.name)
- reload_ids = get_ids(d)
- assertMatch(reload_ids, ref_ids2)
- assertMatch(finalized_ids, reload_ids)
-
- def test_overwrite(self):
- # for example, Camembert overwrites , ] and
- dict_file = io.StringIO(
- " 999 #fairseq:overwrite\n"
- " 999 #fairseq:overwrite\n"
- " 999 #fairseq:overwrite\n"
- ", 999\n"
- "▁de 999\n"
- )
- d = Dictionary()
- d.add_from_file(dict_file)
- self.assertEqual(d.index(""), 1)
- self.assertEqual(d.index("foo"), 3)
- self.assertEqual(d.index(""), 4)
- self.assertEqual(d.index(""), 5)
- self.assertEqual(d.index(""), 6)
- self.assertEqual(d.index(","), 7)
- self.assertEqual(d.index("▁de"), 8)
-
- def test_no_overwrite(self):
- # for example, Camembert overwrites , and
- dict_file = io.StringIO(
- " 999\n" " 999\n" " 999\n" ", 999\n" "▁de 999\n"
- )
- d = Dictionary()
- with self.assertRaisesRegex(RuntimeError, "Duplicate"):
- d.add_from_file(dict_file)
-
- def test_space(self):
- # for example, character models treat space as a symbol
- dict_file = io.StringIO(" 999\n" "a 999\n" "b 999\n")
- d = Dictionary()
- d.add_from_file(dict_file)
- self.assertEqual(d.index(" "), 4)
- self.assertEqual(d.index("a"), 5)
- self.assertEqual(d.index("b"), 6)
-
-
-if __name__ == "__main__":
- unittest.main()
diff --git a/spaces/gstaff/MagicGen/colab-data-test/css/mtg.css b/spaces/gstaff/MagicGen/colab-data-test/css/mtg.css
deleted file mode 100644
index 535ffd300815eacedfca2c6bad4e17aa0f55f2ec..0000000000000000000000000000000000000000
--- a/spaces/gstaff/MagicGen/colab-data-test/css/mtg.css
+++ /dev/null
@@ -1,130 +0,0 @@
-* {margin: 0; padding: 0; box-sizing: border-box; }
-
-.card {background: #000; padding: 17px; height: 600px; width: 400px;
- margin: 100px auto;
-}
-.card-background {
- padding: 7px 8px 30px 7px;
- background-color: #69a;
- background-image:
- repeating-linear-gradient(140deg, transparent, rgba(255, 255, 255, 0.25) 1%, transparent 20%),
- repeating-linear-gradient(-30deg, transparent, transparent 8%, rgba(255, 255, 255, 0.4), transparent 9%),
- repeating-linear-gradient(-10deg, transparent, transparent 13%, rgba(0, 0, 0, 0.4), transparent 15%),
- repeating-linear-gradient(80deg, transparent, transparent 7.5%, rgba(0, 0, 0, 0.25), transparent 8%),
- repeating-linear-gradient(5deg, transparent, transparent 10.5%, rgba(255, 255, 255, 0.5), transparent 11%),
- repeating-linear-gradient(75deg, transparent, transparent 11.5%, rgba(255, 255, 255, 0.5), transparent 12%),
- repeating-radial-gradient(rgba(0, 0, 0, 0.2), rgba(0, 0, 0, 0.2) 1%, transparent 1%, transparent 5%);
- border-radius: 10px 10px 40px 40px;
- height: 500px;
-}
-
-.card-body {
- position: absolute;
- height: 109.4%;
- width: 350px;
- border: 2px solid rgba(0, 0, 0, 0.8);
- border-right: 2px solid #ddd;
- border-bottom: 2px solid #555;
- border-radius: 5px 5px 0 0;
- background: #ddd;
-
-}
-
-article {
- padding: 3px;
- width: 350px;
-}
-
-article > div {
- background: #ddd;
- position: relative;
- height: 200px;
- border: 2px solid #333;
- z-index: -1;
-}
-
-header {
- padding: 3px;
- background: #ddd;
- border-radius: 8px/20px;
- box-shadow: -2px 0 0 0 rgba(0, 0, 0, 0.8);
- position: relative;
- top: 200px; left: 0; right: 0;
-}
-header div {
- padding: 5px 8px 3px;
- background: radial-gradient(ellipse farthest-corner, #E0E7ED 50%, #BDC6CD);
- position: relative;
- border: 2px solid #000;
- border-radius: 10px/20px;
- box-shadow: inset 2px -3px 0 #aaa, inset -1px 1px 0 #fff;
- height: 33px;
-}
-header:first-child {top: 0; }
-header:first-child div {height: 34px; }
-
-#textBox {
- margin-top: 38px;
- padding: 10px 7px;
- top: 260px; bottom: 44px;
- border: 2px solid #999;
- border-bottom: 0 none;
- border-left: 0 none;
- background: #d3dddd;
-
-}
-
-#powerToughness {
- width: 4em;
- top: ; right: 21px; bottom: 28px; left: auto;
- text-align: center;
- box-shadow: -2px 1px 2px 0 rgba(0, 0, 0, 0.8);
-}
-#powerToughness div {
- padding: 4px 0 0;
- height: 23px;
- box-shadow: inset -2px 2px 1px #333, inset 1px -1px 0 #fff;
- border: 0 none;
- font-size: 21px;
-}
-
-footer {
- color: #ccc;
- font-family: sans-serif; font-size: 9px;
- position: relative;
- left: 25px; bottom: 10px; right: 25px;
- overflow: auto;
-}
-footer p {margin-bottom: 0.2em; letter-spacing: 0.18em; }
-
-.ms {
- position: relative;
- top: -22px;
- float: right;
-}
-
-h1 {font-size: 21px; line-height: 1em; }
-h2 {font-size: 18px; line-height: 1em; }
-h3 {
- padding-top: 2px;
- position: relative;
- right: 5px; top: 2px;
- width: 1.05em; height: 1.05em;
- background: #ddd;
- text-align: center;
- border-radius: 1em;
- line-height: 1em;
-}
-h4 {
- border-bottom: 14px solid #000;
- border-right: 7px solid transparent;
- border-left: 7px solid transparent;
- height: 0; width: 0;
- overflow: hidden;
- position: relative;
- right: 10px; top: 7px;
-}
-h6 {float: right; width: 60%; text-align: right; font-size: 8px; }
-p {margin-bottom: 0.6em; line-height: 1.1em; }
-blockquote {font-style: italic; }
-blockquote p {margin-bottom: 0; }
diff --git a/spaces/gulabpatel/Real-ESRGAN/realesrgan/train.py b/spaces/gulabpatel/Real-ESRGAN/realesrgan/train.py
deleted file mode 100644
index 8a9cec9ed80d9f362984779548dcec921a636a04..0000000000000000000000000000000000000000
--- a/spaces/gulabpatel/Real-ESRGAN/realesrgan/train.py
+++ /dev/null
@@ -1,11 +0,0 @@
-# flake8: noqa
-import os.path as osp
-from basicsr.train import train_pipeline
-
-import realesrgan.archs
-import realesrgan.data
-import realesrgan.models
-
-if __name__ == '__main__':
- root_path = osp.abspath(osp.join(__file__, osp.pardir, osp.pardir))
- train_pipeline(root_path)
diff --git a/spaces/gwang-kim/DATID-3D/eg3d/dataset_tool.py b/spaces/gwang-kim/DATID-3D/eg3d/dataset_tool.py
deleted file mode 100644
index a400f770fa477ef09adf4804235be4d67898765a..0000000000000000000000000000000000000000
--- a/spaces/gwang-kim/DATID-3D/eg3d/dataset_tool.py
+++ /dev/null
@@ -1,458 +0,0 @@
-# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
-#
-# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
-# property and proprietary rights in and to this material, related
-# documentation and any modifications thereto. Any use, reproduction,
-# disclosure or distribution of this material and related documentation
-# without an express license agreement from NVIDIA CORPORATION or
-# its affiliates is strictly prohibited.
-
-"""Tool for creating ZIP/PNG based datasets."""
-
-import functools
-import gzip
-import io
-import json
-import os
-import pickle
-import re
-import sys
-import tarfile
-import zipfile
-from pathlib import Path
-from typing import Callable, Optional, Tuple, Union
-
-import click
-import numpy as np
-import PIL.Image
-from tqdm import tqdm
-
-#----------------------------------------------------------------------------
-
-def error(msg):
- print('Error: ' + msg)
- sys.exit(1)
-
-#----------------------------------------------------------------------------
-
-def parse_tuple(s: str) -> Tuple[int, int]:
- '''Parse a 'M,N' or 'MxN' integer tuple.
-
- Example:
- '4x2' returns (4,2)
- '0,1' returns (0,1)
- '''
- if m := re.match(r'^(\d+)[x,](\d+)$', s):
- return (int(m.group(1)), int(m.group(2)))
- raise ValueError(f'cannot parse tuple {s}')
-
-#----------------------------------------------------------------------------
-
-def maybe_min(a: int, b: Optional[int]) -> int:
- if b is not None:
- return min(a, b)
- return a
-
-#----------------------------------------------------------------------------
-
-def file_ext(name: Union[str, Path]) -> str:
- return str(name).split('.')[-1]
-
-#----------------------------------------------------------------------------
-
-def is_image_ext(fname: Union[str, Path]) -> bool:
- ext = file_ext(fname).lower()
- return f'.{ext}' in PIL.Image.EXTENSION # type: ignore
-
-#----------------------------------------------------------------------------
-
-def open_image_folder(source_dir, *, max_images: Optional[int]):
- input_images = [str(f) for f in sorted(Path(source_dir).rglob('*')) if is_image_ext(f) and os.path.isfile(f)]
-
- # Load labels.
- labels = {}
- meta_fname = os.path.join(source_dir, 'dataset.json')
- if os.path.isfile(meta_fname):
- with open(meta_fname, 'r') as file:
- labels = json.load(file)['labels']
- if labels is not None:
- labels = { x[0]: x[1] for x in labels }
- else:
- labels = {}
-
- max_idx = maybe_min(len(input_images), max_images)
-
- def iterate_images():
- for idx, fname in enumerate(input_images):
- arch_fname = os.path.relpath(fname, source_dir)
- arch_fname = arch_fname.replace('\\', '/')
- img = np.array(PIL.Image.open(fname))
- yield dict(img=img, label=labels.get(arch_fname))
- if idx >= max_idx-1:
- break
- return max_idx, iterate_images()
-
-#----------------------------------------------------------------------------
-
-def open_image_zip(source, *, max_images: Optional[int]):
- with zipfile.ZipFile(source, mode='r') as z:
- input_images = [str(f) for f in sorted(z.namelist()) if is_image_ext(f)]
-
- # Load labels.
- labels = {}
- if 'dataset.json' in z.namelist():
- with z.open('dataset.json', 'r') as file:
- labels = json.load(file)['labels']
- if labels is not None:
- labels = { x[0]: x[1] for x in labels }
- else:
- labels = {}
-
- max_idx = maybe_min(len(input_images), max_images)
-
- def iterate_images():
- with zipfile.ZipFile(source, mode='r') as z:
- for idx, fname in enumerate(input_images):
- with z.open(fname, 'r') as file:
- img = PIL.Image.open(file) # type: ignore
- img = np.array(img)
- yield dict(img=img, label=labels.get(fname))
- if idx >= max_idx-1:
- break
- return max_idx, iterate_images()
-
-#----------------------------------------------------------------------------
-
-def open_lmdb(lmdb_dir: str, *, max_images: Optional[int]):
- import cv2 # pip install opencv-python # pylint: disable=import-error
- import lmdb # pip install lmdb # pylint: disable=import-error
-
- with lmdb.open(lmdb_dir, readonly=True, lock=False).begin(write=False) as txn:
- max_idx = maybe_min(txn.stat()['entries'], max_images)
-
- def iterate_images():
- with lmdb.open(lmdb_dir, readonly=True, lock=False).begin(write=False) as txn:
- for idx, (_key, value) in enumerate(txn.cursor()):
- try:
- try:
- img = cv2.imdecode(np.frombuffer(value, dtype=np.uint8), 1)
- if img is None:
- raise IOError('cv2.imdecode failed')
- img = img[:, :, ::-1] # BGR => RGB
- except IOError:
- img = np.array(PIL.Image.open(io.BytesIO(value)))
- yield dict(img=img, label=None)
- if idx >= max_idx-1:
- break
- except:
- print(sys.exc_info()[1])
-
- return max_idx, iterate_images()
-
-#----------------------------------------------------------------------------
-
-def open_cifar10(tarball: str, *, max_images: Optional[int]):
- images = []
- labels = []
-
- with tarfile.open(tarball, 'r:gz') as tar:
- for batch in range(1, 6):
- member = tar.getmember(f'cifar-10-batches-py/data_batch_{batch}')
- with tar.extractfile(member) as file:
- data = pickle.load(file, encoding='latin1')
- images.append(data['data'].reshape(-1, 3, 32, 32))
- labels.append(data['labels'])
-
- images = np.concatenate(images)
- labels = np.concatenate(labels)
- images = images.transpose([0, 2, 3, 1]) # NCHW -> NHWC
- assert images.shape == (50000, 32, 32, 3) and images.dtype == np.uint8
- assert labels.shape == (50000,) and labels.dtype in [np.int32, np.int64]
- assert np.min(images) == 0 and np.max(images) == 255
- assert np.min(labels) == 0 and np.max(labels) == 9
-
- max_idx = maybe_min(len(images), max_images)
-
- def iterate_images():
- for idx, img in enumerate(images):
- yield dict(img=img, label=int(labels[idx]))
- if idx >= max_idx-1:
- break
-
- return max_idx, iterate_images()
-
-#----------------------------------------------------------------------------
-
-def open_mnist(images_gz: str, *, max_images: Optional[int]):
- labels_gz = images_gz.replace('-images-idx3-ubyte.gz', '-labels-idx1-ubyte.gz')
- assert labels_gz != images_gz
- images = []
- labels = []
-
- with gzip.open(images_gz, 'rb') as f:
- images = np.frombuffer(f.read(), np.uint8, offset=16)
- with gzip.open(labels_gz, 'rb') as f:
- labels = np.frombuffer(f.read(), np.uint8, offset=8)
-
- images = images.reshape(-1, 28, 28)
- images = np.pad(images, [(0,0), (2,2), (2,2)], 'constant', constant_values=0)
- assert images.shape == (60000, 32, 32) and images.dtype == np.uint8
- assert labels.shape == (60000,) and labels.dtype == np.uint8
- assert np.min(images) == 0 and np.max(images) == 255
- assert np.min(labels) == 0 and np.max(labels) == 9
-
- max_idx = maybe_min(len(images), max_images)
-
- def iterate_images():
- for idx, img in enumerate(images):
- yield dict(img=img, label=int(labels[idx]))
- if idx >= max_idx-1:
- break
-
- return max_idx, iterate_images()
-
-#----------------------------------------------------------------------------
-
-def make_transform(
- transform: Optional[str],
- output_width: Optional[int],
- output_height: Optional[int]
-) -> Callable[[np.ndarray], Optional[np.ndarray]]:
- def scale(width, height, img):
- w = img.shape[1]
- h = img.shape[0]
- if width == w and height == h:
- return img
- img = PIL.Image.fromarray(img)
- ww = width if width is not None else w
- hh = height if height is not None else h
- img = img.resize((ww, hh), PIL.Image.LANCZOS)
- return np.array(img)
-
- def center_crop(width, height, img):
- crop = np.min(img.shape[:2])
- img = img[(img.shape[0] - crop) // 2 : (img.shape[0] + crop) // 2, (img.shape[1] - crop) // 2 : (img.shape[1] + crop) // 2]
- img = PIL.Image.fromarray(img, 'RGB')
- img = img.resize((width, height), PIL.Image.LANCZOS)
- return np.array(img)
-
- def center_crop_wide(width, height, img):
- ch = int(np.round(width * img.shape[0] / img.shape[1]))
- if img.shape[1] < width or ch < height:
- return None
-
- img = img[(img.shape[0] - ch) // 2 : (img.shape[0] + ch) // 2]
- img = PIL.Image.fromarray(img, 'RGB')
- img = img.resize((width, height), PIL.Image.LANCZOS)
- img = np.array(img)
-
- canvas = np.zeros([width, width, 3], dtype=np.uint8)
- canvas[(width - height) // 2 : (width + height) // 2, :] = img
- return canvas
-
- if transform is None:
- return functools.partial(scale, output_width, output_height)
- if transform == 'center-crop':
- if (output_width is None) or (output_height is None):
- error ('must specify --resolution=WxH when using ' + transform + 'transform')
- return functools.partial(center_crop, output_width, output_height)
- if transform == 'center-crop-wide':
- if (output_width is None) or (output_height is None):
- error ('must specify --resolution=WxH when using ' + transform + ' transform')
- return functools.partial(center_crop_wide, output_width, output_height)
- assert False, 'unknown transform'
-
-#----------------------------------------------------------------------------
-
-def open_dataset(source, *, max_images: Optional[int]):
- if os.path.isdir(source):
- if source.rstrip('/').endswith('_lmdb'):
- return open_lmdb(source, max_images=max_images)
- else:
- return open_image_folder(source, max_images=max_images)
- elif os.path.isfile(source):
- if os.path.basename(source) == 'cifar-10-python.tar.gz':
- return open_cifar10(source, max_images=max_images)
- elif os.path.basename(source) == 'train-images-idx3-ubyte.gz':
- return open_mnist(source, max_images=max_images)
- elif file_ext(source) == 'zip':
- return open_image_zip(source, max_images=max_images)
- else:
- assert False, 'unknown archive type'
- else:
- error(f'Missing input file or directory: {source}')
-
-#----------------------------------------------------------------------------
-
-def open_dest(dest: str) -> Tuple[str, Callable[[str, Union[bytes, str]], None], Callable[[], None]]:
- dest_ext = file_ext(dest)
-
- if dest_ext == 'zip':
- if os.path.dirname(dest) != '':
- os.makedirs(os.path.dirname(dest), exist_ok=True)
- zf = zipfile.ZipFile(file=dest, mode='w', compression=zipfile.ZIP_STORED)
- def zip_write_bytes(fname: str, data: Union[bytes, str]):
- zf.writestr(fname, data)
- return '', zip_write_bytes, zf.close
- else:
- # If the output folder already exists, check that is is
- # empty.
- #
- # Note: creating the output directory is not strictly
- # necessary as folder_write_bytes() also mkdirs, but it's better
- # to give an error message earlier in case the dest folder
- # somehow cannot be created.
- if os.path.isdir(dest) and len(os.listdir(dest)) != 0:
- error('--dest folder must be empty')
- os.makedirs(dest, exist_ok=True)
-
- def folder_write_bytes(fname: str, data: Union[bytes, str]):
- os.makedirs(os.path.dirname(fname), exist_ok=True)
- with open(fname, 'wb') as fout:
- if isinstance(data, str):
- data = data.encode('utf8')
- fout.write(data)
- return dest, folder_write_bytes, lambda: None
-
-#----------------------------------------------------------------------------
-
-@click.command()
-@click.pass_context
-@click.option('--source', help='Directory or archive name for input dataset', required=True, metavar='PATH')
-@click.option('--dest', help='Output directory or archive name for output dataset', required=True, metavar='PATH')
-@click.option('--max-images', help='Output only up to `max-images` images', type=int, default=None)
-@click.option('--transform', help='Input crop/resize mode', type=click.Choice(['center-crop', 'center-crop-wide']))
-@click.option('--resolution', help='Output resolution (e.g., \'512x512\')', metavar='WxH', type=parse_tuple)
-def convert_dataset(
- ctx: click.Context,
- source: str,
- dest: str,
- max_images: Optional[int],
- transform: Optional[str],
- resolution: Optional[Tuple[int, int]]
-):
- """Convert an image dataset into a dataset archive usable with StyleGAN2 ADA PyTorch.
-
- The input dataset format is guessed from the --source argument:
-
- \b
- --source *_lmdb/ Load LSUN dataset
- --source cifar-10-python.tar.gz Load CIFAR-10 dataset
- --source train-images-idx3-ubyte.gz Load MNIST dataset
- --source path/ Recursively load all images from path/
- --source dataset.zip Recursively load all images from dataset.zip
-
- Specifying the output format and path:
-
- \b
- --dest /path/to/dir Save output files under /path/to/dir
- --dest /path/to/dataset.zip Save output files into /path/to/dataset.zip
-
- The output dataset format can be either an image folder or an uncompressed zip archive.
- Zip archives makes it easier to move datasets around file servers and clusters, and may
- offer better training performance on network file systems.
-
- Images within the dataset archive will be stored as uncompressed PNG.
- Uncompressed PNGs can be efficiently decoded in the training loop.
-
- Class labels are stored in a file called 'dataset.json' that is stored at the
- dataset root folder. This file has the following structure:
-
- \b
- {
- "labels": [
- ["00000/img00000000.png",6],
- ["00000/img00000001.png",9],
- ... repeated for every image in the dataset
- ["00049/img00049999.png",1]
- ]
- }
-
- If the 'dataset.json' file cannot be found, the dataset is interpreted as
- not containing class labels.
-
- Image scale/crop and resolution requirements:
-
- Output images must be square-shaped and they must all have the same power-of-two
- dimensions.
-
- To scale arbitrary input image size to a specific width and height, use the
- --resolution option. Output resolution will be either the original
- input resolution (if resolution was not specified) or the one specified with
- --resolution option.
-
- Use the --transform=center-crop or --transform=center-crop-wide options to apply a
- center crop transform on the input image. These options should be used with the
- --resolution option. For example:
-
- \b
- python dataset_tool.py --source LSUN/raw/cat_lmdb --dest /tmp/lsun_cat \\
- --transform=center-crop-wide --resolution=512x384
- """
-
- PIL.Image.init() # type: ignore
-
- if dest == '':
- ctx.fail('--dest output filename or directory must not be an empty string')
-
- num_files, input_iter = open_dataset(source, max_images=max_images)
- archive_root_dir, save_bytes, close_dest = open_dest(dest)
-
- if resolution is None: resolution = (None, None)
- transform_image = make_transform(transform, *resolution)
-
- dataset_attrs = None
-
- labels = []
- for idx, image in tqdm(enumerate(input_iter), total=num_files):
- idx_str = f'{idx:08d}'
- archive_fname = f'{idx_str[:5]}/img{idx_str}.png'
-
- # Apply crop and resize.
- img = transform_image(image['img'])
-
- # Transform may drop images.
- if img is None:
- continue
-
- # Error check to require uniform image attributes across
- # the whole dataset.
- channels = img.shape[2] if img.ndim == 3 else 1
- cur_image_attrs = {
- 'width': img.shape[1],
- 'height': img.shape[0],
- 'channels': channels
- }
- if dataset_attrs is None:
- dataset_attrs = cur_image_attrs
- width = dataset_attrs['width']
- height = dataset_attrs['height']
- if width != height:
- error(f'Image dimensions after scale and crop are required to be square. Got {width}x{height}')
- if dataset_attrs['channels'] not in [1, 3, 4]:
- error('Input images must be stored as RGB or grayscale')
- if width != 2 ** int(np.floor(np.log2(width))):
- error('Image width/height after scale and crop are required to be power-of-two')
- elif dataset_attrs != cur_image_attrs:
- err = [f' dataset {k}/cur image {k}: {dataset_attrs[k]}/{cur_image_attrs[k]}' for k in dataset_attrs.keys()] # pylint: disable=unsubscriptable-object
- error(f'Image {archive_fname} attributes must be equal across all images of the dataset. Got:\n' + '\n'.join(err))
-
- # Save the image as an uncompressed PNG.
- img = PIL.Image.fromarray(img, { 1: 'L', 3: 'RGB', 4: 'RGBA'}[channels])
- if channels == 4: img = img.convert('RGB')
- image_bits = io.BytesIO()
- img.save(image_bits, format='png', compress_level=0, optimize=False)
- save_bytes(os.path.join(archive_root_dir, archive_fname), image_bits.getbuffer())
- labels.append([archive_fname, image['label']] if image['label'] is not None else None)
-
- metadata = {
- 'labels': labels if all(x is not None for x in labels) else None
- }
- save_bytes(os.path.join(archive_root_dir, 'dataset.json'), json.dumps(metadata))
- close_dest()
-
-#----------------------------------------------------------------------------
-
-if __name__ == "__main__":
- convert_dataset() # pylint: disable=no-value-for-parameter
diff --git a/spaces/gylleus/icongen/dnnlib/__init__.py b/spaces/gylleus/icongen/dnnlib/__init__.py
deleted file mode 100644
index 2f08cf36f11f9b0fd94c1b7caeadf69b98375b04..0000000000000000000000000000000000000000
--- a/spaces/gylleus/icongen/dnnlib/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-from .util import EasyDict, make_cache_dir_path
diff --git a/spaces/haakohu/deep_privacy2/stylemc.py b/spaces/haakohu/deep_privacy2/stylemc.py
deleted file mode 100644
index c4fefb230a11cb51da8c47afa9c831acb9ce25e4..0000000000000000000000000000000000000000
--- a/spaces/haakohu/deep_privacy2/stylemc.py
+++ /dev/null
@@ -1,295 +0,0 @@
-"""
-Approach: "StyleMC: Multi-Channel Based Fast Text-Guided Image Generation and Manipulation"
-Original source code:
-https://github.com/autonomousvision/stylegan_xl/blob/f9be58e98110bd946fcdadef2aac8345466faaf3/run_stylemc.py#
-Modified by Håkon Hukkelås
-"""
-import os
-from pathlib import Path
-import tqdm
-import re
-import click
-from dp2 import utils
-import tops
-from typing import List, Optional
-import PIL.Image
-import imageio
-from timeit import default_timer as timer
-
-import numpy as np
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torchvision.transforms.functional import resize, normalize
-from dp2.infer import build_trained_generator
-import clip
-
-#----------------------------------------------------------------------------
-
-class AverageMeter(object):
- """Computes and stores the average and current value"""
- def __init__(self, name, fmt=':f'):
- self.name = name
- self.fmt = fmt
- self.reset()
-
- def reset(self):
- self.val = 0
- self.avg = 0
- self.sum = 0
- self.count = 0
-
- def update(self, val, n=1):
- self.val = val
- self.sum += val * n
- self.count += n
- self.avg = self.sum / self.count
-
- def __str__(self):
- fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
- return fmtstr.format(**self.__dict__)
-
-
-class ProgressMeter(object):
- def __init__(self, num_batches, meters, prefix=""):
- self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
- self.meters = meters
- self.prefix = prefix
-
- def display(self, batch):
- entries = [self.prefix + self.batch_fmtstr.format(batch)]
- entries += [str(meter) for meter in self.meters]
- print('\t'.join(entries))
-
- def _get_batch_fmtstr(self, num_batches):
- num_digits = len(str(num_batches // 1))
- fmt = '{:' + str(num_digits) + 'd}'
- return '[' + fmt + '/' + fmt.format(num_batches) + ']'
-
-
-def save_image(img, path):
- img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
- PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save(path)
-
-
-def unravel_index(index, shape):
- out = []
- for dim in reversed(shape):
- out.append(index % dim)
- index = index // dim
- return tuple(reversed(out))
-
-
-def num_range(s: str) -> List[int]:
- '''Accept either a comma separated list of numbers 'a,b,c' or a range 'a-c' and return as a list of ints.'''
-
- range_re = re.compile(r'^(\d+)-(\d+)$')
- m = range_re.match(s)
- if m:
- return list(range(int(m.group(1)), int(m.group(2))+1))
- vals = s.split(',')
- return [int(x) for x in vals]
-
-
-#----------------------------------------------------------------------------
-
-
-
-def spherical_dist_loss(x, y):
- x = F.normalize(x, dim=-1)
- y = F.normalize(y, dim=-1)
- return (x - y).norm(dim=-1).div(2).arcsin().pow(2).mul(2)
-
-
-def prompts_dist_loss(x, targets, loss):
- if len(targets) == 1: # Keeps consistent results vs previous method for single objective guidance
- return loss(x, targets[0])
- distances = [loss(x, target) for target in targets]
- return torch.stack(distances, dim=-1).sum(dim=-1)
-
-
-def embed_text(model, prompt, device='cuda'):
- return
-
-
-#----------------------------------------------------------------------------
-
-@torch.no_grad()
-@torch.cuda.amp.autocast()
-def generate_edit(
- G,
- dl,
- direction,
- edit_strength,
- path,
- ):
- for it, batch in enumerate(dl):
- batch["embedding"] = None
- styles = get_styles(None, G, batch, truncation_value=0)
- imgs = []
- grad_changes = [_*edit_strength for _ in [0, 0.25, 0.5, 0.75, 1]]
- grad_changes = [*[-x for x in grad_changes][::-1], *grad_changes]
- batch = {k: tops.to_cuda(v) if v is not None else v for k,v in batch.items()}
- for i, grad_change in enumerate(grad_changes):
- s = styles + direction*grad_change
-
- img = G(**batch, s=iter(s))["img"]
- img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255)
- imgs.append(img[0].to(torch.uint8).cpu().numpy())
- PIL.Image.fromarray(np.concatenate(imgs, axis=1), 'RGB').save(path + f'{it}.png')
-
-
-@torch.no_grad()
-def get_styles(seed, G: torch.nn.Module, batch, truncation_value=1):
- all_styles = []
- if seed is None:
- z = np.random.normal(0, 0, size=(1, G.z_channels))
- else:
- z = np.random.RandomState(seed=seed).normal(0, 1, size=(1, G.z_channels))
- z_idx = np.random.RandomState(seed=seed).randint(0, len(G.style_net.w_centers))
- w_c = G.style_net.w_centers[z_idx].to(tops.get_device()).view(1, -1)
- w = G.style_net(torch.from_numpy(z).to(tops.get_device()))
-
- w = w_c.to(w.dtype).lerp(w, truncation_value)
- if hasattr(G, "get_comod_y"):
- w = G.get_comod_y(batch, w)
- for block in G.modules():
- if not hasattr(block, "affine") or not hasattr(block.affine, "weight"):
- continue
- gamma0 = block.affine(w)
- if hasattr(block, "affine_beta"):
- beta0 = block.affine_beta(w)
- gamma0 = torch.cat((gamma0, beta0), dim=1)
- all_styles.append(gamma0)
- max_ch = max([s.shape[-1] for s in all_styles])
- all_styles = [F.pad(s, ((0, max_ch - s.shape[-1])), "constant", 0) for s in all_styles]
- all_styles = torch.cat(all_styles)
- return all_styles
-
-def get_and_cache_direction(output_dir: Path, dl_val, G, text_prompt):
- cache_path = output_dir.joinpath(
- "stylemc_cache", text_prompt.replace(" ", "_") + ".torch")
- if cache_path.is_file():
- print("Loaded cache from:", cache_path)
- return torch.load(cache_path)
- direction = find_direction(G, text_prompt, None, dl_val=iter(dl_val))
- cache_path.parent.mkdir(exist_ok=True, parents=True)
- torch.save(direction, cache_path)
- return direction
-
-@torch.cuda.amp.autocast()
-def find_direction(
- G,
- text_prompt,
- batches,
- #layers,
- n_iterations=128*8,
- batch_size=8,
- dl_val=None
-):
- time_start = timer()
-
- clip_model = clip.load("ViT-B/16", device=tops.get_device())[0]
-
- target = [clip_model.encode_text(clip.tokenize(text_prompt).to(tops.get_device())).float()]
- all_styles = []
- if dl_val is not None:
- first_batch = next(dl_val)
- else:
- first_batch = batches[0]
- first_batch["embedding"] = None if "embedding" not in first_batch else first_batch["embedding"]
- s = get_styles(0, G, first_batch)
- # stats tracker
- cos_sim_track = AverageMeter('cos_sim', ':.4f')
- norm_track = AverageMeter('norm', ':.4f')
- n_iterations = n_iterations // batch_size
- progress = ProgressMeter(n_iterations, [cos_sim_track, norm_track])
-
- # initalize styles direction
- direction = torch.zeros(s.shape, device=tops.get_device())
- direction.requires_grad_()
- utils.set_requires_grad(G, False)
- direction_tracker = torch.zeros_like(direction)
- opt = torch.optim.AdamW([direction], lr=0.05, betas=(0., 0.999), weight_decay=0.25)
-
- grads = []
- for seed_idx in tqdm.trange(n_iterations):
- # forward pass through synthesis network with new styles
- if seed_idx == 0:
- batch = first_batch
- elif dl_val is not None:
- batch = next(dl_val)
- batch["embedding"] = None if "embedding" not in batch else batch["embedding"]
- else:
- batch = {k: tops.to_cuda(v) if v is not None else v for k, v in batches[seed_idx].items()}
- styles = get_styles(seed_idx, G, batch) + direction
- img = G(**batch, s=iter(styles))["img"]
- batch = {k: v.cpu() if v is not None else v for k, v in batch.items()}
- # clip loss
- img = (img + 1)/2
- img = normalize(img, mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711))
- img = resize(img, (224, 224))
- embeds = clip_model.encode_image(img)
- cos_sim = prompts_dist_loss(embeds, target, spherical_dist_loss)
- cos_sim.backward(retain_graph=True)
-
- # track stats
- cos_sim_track.update(cos_sim.item())
- norm_track.update(torch.norm(direction).item())
-
- if not (seed_idx % batch_size):
-
- # zeroing out gradients for non-optimized layers
- #layers_zeroed = torch.tensor([x for x in range(G.num_ws) if not x in layers])
- #direction.grad[:, layers_zeroed] = 0
-
- opt.step()
- grads.append(direction.grad.clone())
- direction.grad.data.zero_()
-
- # keep track of gradients over time
- if seed_idx > 3:
- direction_tracker[grads[-2] * grads[-1] < 0] += 1
-
- # plot stats
- progress.display(seed_idx)
-
- # throw out fluctuating channels
- direction = direction.detach()
- direction[direction_tracker > n_iterations / 4] = 0
- print(direction)
- print(f"Time for direction search: {timer() - time_start:.2f} s")
- return direction
-
-
-
-
-@click.command()
-@click.argument("config_path")
-@click.argument("input_path")
-@click.argument("output_path")
-#@click.option('--layers', type=num_range, help='Restrict the style space to a range of layers. We recommend not to optimize the critically sampled layers (last 3).', required=True)
-@click.option('--text-prompt', help='Text', type=str, required=True)
-@click.option('--edit-strength', help='Strength of edit', type=float, required=True)
-@click.option('--outdir', help='Where to save the output images', type=str, required=True)
-def stylemc(
- config_path,
- #layers: List[int],
- text_prompt: str,
- edit_strength: float,
- outdir: str,
-):
- cfg = utils.load_config(config_path)
- G = build_trained_generator(cfg)
- cfg.train.batch_size = 1
- n_iterations = 256
- dl_val = tops.config.instantiate(cfg.data.val.loader)
-
- direction = find_direction(G, text_prompt, None, n_iterations=n_iterations, dl_val=iter(dl_val))
-
- text_prompt = text_prompt.replace(" ", "_")
- generate_edit(G, input_path, direction, edit_strength, output_path)
-
-
-if __name__ == "__main__":
- stylemc()
diff --git a/spaces/haakohu/deep_privacy2_face/sg3_torch_utils/custom_ops.py b/spaces/haakohu/deep_privacy2_face/sg3_torch_utils/custom_ops.py
deleted file mode 100644
index 4cc4e43fc6f6ce79f2bd68a44ba87990b9b8564e..0000000000000000000000000000000000000000
--- a/spaces/haakohu/deep_privacy2_face/sg3_torch_utils/custom_ops.py
+++ /dev/null
@@ -1,126 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-import os
-import glob
-import torch
-import torch.utils.cpp_extension
-import importlib
-import hashlib
-import shutil
-from pathlib import Path
-
-from torch.utils.file_baton import FileBaton
-
-#----------------------------------------------------------------------------
-# Global options.
-
-verbosity = 'brief' # Verbosity level: 'none', 'brief', 'full'
-
-#----------------------------------------------------------------------------
-# Internal helper funcs.
-
-def _find_compiler_bindir():
- patterns = [
- 'C:/Program Files (x86)/Microsoft Visual Studio/*/Professional/VC/Tools/MSVC/*/bin/Hostx64/x64',
- 'C:/Program Files (x86)/Microsoft Visual Studio/*/BuildTools/VC/Tools/MSVC/*/bin/Hostx64/x64',
- 'C:/Program Files (x86)/Microsoft Visual Studio/*/Community/VC/Tools/MSVC/*/bin/Hostx64/x64',
- 'C:/Program Files (x86)/Microsoft Visual Studio */vc/bin',
- ]
- for pattern in patterns:
- matches = sorted(glob.glob(pattern))
- if len(matches):
- return matches[-1]
- return None
-
-#----------------------------------------------------------------------------
-# Main entry point for compiling and loading C++/CUDA plugins.
-
-_cached_plugins = dict()
-
-def get_plugin(module_name, sources, **build_kwargs):
- assert verbosity in ['none', 'brief', 'full']
-
- # Already cached?
- if module_name in _cached_plugins:
- return _cached_plugins[module_name]
-
- # Print status.
- if verbosity == 'full':
- print(f'Setting up PyTorch plugin "{module_name}"...')
- elif verbosity == 'brief':
- print(f'Setting up PyTorch plugin "{module_name}"... ', end='', flush=True)
-
- try: # pylint: disable=too-many-nested-blocks
- # Make sure we can find the necessary compiler binaries.
- if os.name == 'nt' and os.system("where cl.exe >nul 2>nul") != 0:
- compiler_bindir = _find_compiler_bindir()
- if compiler_bindir is None:
- raise RuntimeError(f'Could not find MSVC/GCC/CLANG installation on this computer. Check _find_compiler_bindir() in "{__file__}".')
- os.environ['PATH'] += ';' + compiler_bindir
-
- # Compile and load.
- verbose_build = (verbosity == 'full')
-
- # Incremental build md5sum trickery. Copies all the input source files
- # into a cached build directory under a combined md5 digest of the input
- # source files. Copying is done only if the combined digest has changed.
- # This keeps input file timestamps and filenames the same as in previous
- # extension builds, allowing for fast incremental rebuilds.
- #
- # This optimization is done only in case all the source files reside in
- # a single directory (just for simplicity) and if the TORCH_EXTENSIONS_DIR
- # environment variable is set (we take this as a signal that the user
- # actually cares about this.)
- source_dirs_set = set(os.path.dirname(source) for source in sources)
- if len(source_dirs_set) == 1 and ('TORCH_EXTENSIONS_DIR' in os.environ):
- all_source_files = sorted(list(x for x in Path(list(source_dirs_set)[0]).iterdir() if x.is_file()))
-
- # Compute a combined hash digest for all source files in the same
- # custom op directory (usually .cu, .cpp, .py and .h files).
- hash_md5 = hashlib.md5()
- for src in all_source_files:
- with open(src, 'rb') as f:
- hash_md5.update(f.read())
- build_dir = torch.utils.cpp_extension._get_build_directory(module_name, verbose=verbose_build) # pylint: disable=protected-access
- digest_build_dir = os.path.join(build_dir, hash_md5.hexdigest())
-
- if not os.path.isdir(digest_build_dir):
- os.makedirs(digest_build_dir, exist_ok=True)
- baton = FileBaton(os.path.join(digest_build_dir, 'lock'))
- if baton.try_acquire():
- try:
- for src in all_source_files:
- shutil.copyfile(src, os.path.join(digest_build_dir, os.path.basename(src)))
- finally:
- baton.release()
- else:
- # Someone else is copying source files under the digest dir,
- # wait until done and continue.
- baton.wait()
- digest_sources = [os.path.join(digest_build_dir, os.path.basename(x)) for x in sources]
- torch.utils.cpp_extension.load(name=module_name, build_directory=build_dir,
- verbose=verbose_build, sources=digest_sources, **build_kwargs)
- else:
- torch.utils.cpp_extension.load(name=module_name, verbose=verbose_build, sources=sources, **build_kwargs)
- module = importlib.import_module(module_name)
-
- except:
- if verbosity == 'brief':
- print('Failed!')
- raise
-
- # Print status and add to cache.
- if verbosity == 'full':
- print(f'Done setting up PyTorch plugin "{module_name}".')
- elif verbosity == 'brief':
- print('Done.')
- _cached_plugins[module_name] = module
- return module
-
-#----------------------------------------------------------------------------
diff --git a/spaces/hamacojr/SAM-CAT-Seg/cat_seg/modeling/heads/__init__.py b/spaces/hamacojr/SAM-CAT-Seg/cat_seg/modeling/heads/__init__.py
deleted file mode 100644
index 9020c2df23e2af280b7bb168b996ae9eaf312eb8..0000000000000000000000000000000000000000
--- a/spaces/hamacojr/SAM-CAT-Seg/cat_seg/modeling/heads/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
diff --git a/spaces/hamacojr/SAM-CAT-Seg/open_clip/Makefile b/spaces/hamacojr/SAM-CAT-Seg/open_clip/Makefile
deleted file mode 100644
index ff07eccefed3d959c77d007d2571e226a07ace60..0000000000000000000000000000000000000000
--- a/spaces/hamacojr/SAM-CAT-Seg/open_clip/Makefile
+++ /dev/null
@@ -1,12 +0,0 @@
-install: ## [Local development] Upgrade pip, install requirements, install package.
- python -m pip install -U pip
- python -m pip install -e .
-
-install-training:
- python -m pip install -r requirements-training.txt
-
-install-test: ## [Local development] Install test requirements
- python -m pip install -r requirements-test.txt
-
-test: ## [Local development] Run unit tests
- python -m pytest -x -s -v tests
diff --git a/spaces/haseeb-heaven/AutoBard-Coder/response/content.md b/spaces/haseeb-heaven/AutoBard-Coder/response/content.md
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/hk59775634/OpenAI-Manager/index.html b/spaces/hk59775634/OpenAI-Manager/index.html
deleted file mode 100644
index b56d85288f5872924264a53374f1ee3c2a745934..0000000000000000000000000000000000000000
--- a/spaces/hk59775634/OpenAI-Manager/index.html
+++ /dev/null
@@ -1,28 +0,0 @@
-
-
-
-
-
-
-
-
-
- JCM-AI
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/spaces/ho11laqe/nnUNet_calvingfront_detection/nnunet/inference/__init__.py b/spaces/ho11laqe/nnUNet_calvingfront_detection/nnunet/inference/__init__.py
deleted file mode 100644
index 72b8078b9dddddf22182fec2555d8d118ea72622..0000000000000000000000000000000000000000
--- a/spaces/ho11laqe/nnUNet_calvingfront_detection/nnunet/inference/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-from __future__ import absolute_import
-from . import *
\ No newline at end of file
diff --git a/spaces/huggingface-projects/color-palette-generator-sd/static/_app/immutable/assets/_page-fd1176fc.css b/spaces/huggingface-projects/color-palette-generator-sd/static/_app/immutable/assets/_page-fd1176fc.css
deleted file mode 100644
index 18d52da51ee9754d809af8d6afac22d9685e33ac..0000000000000000000000000000000000000000
--- a/spaces/huggingface-projects/color-palette-generator-sd/static/_app/immutable/assets/_page-fd1176fc.css
+++ /dev/null
@@ -1 +0,0 @@
-.button.svelte-8zu88a{margin-left:.5rem;min-width:9ch;border-radius:1rem;border-width:2px;--tw-border-opacity:1;border-color:rgb(0 0 0 / var(--tw-border-opacity));--tw-bg-opacity:1;background-color:rgb(0 0 0 / var(--tw-bg-opacity));padding:.5rem;font-size:.75rem;line-height:1rem;font-weight:700;--tw-text-opacity:1;color:rgb(255 255 255 / var(--tw-text-opacity));--tw-shadow:0 1px 2px 0 rgb(0 0 0 / .05);--tw-shadow-colored:0 1px 2px 0 var(--tw-shadow-color);box-shadow:var(--tw-ring-offset-shadow, 0 0 #0000),var(--tw-ring-shadow, 0 0 #0000),var(--tw-shadow)}.button.svelte-8zu88a:focus{--tw-border-opacity:1;border-color:rgb(156 163 175 / var(--tw-border-opacity));outline:2px solid transparent;outline-offset:2px}@media (prefers-color-scheme: dark){.button.svelte-8zu88a{--tw-border-opacity:1;border-color:rgb(255 255 255 / var(--tw-border-opacity))}}.link.svelte-zbscw1{font-size:.75rem;line-height:1rem;font-weight:700;text-decoration-line:underline}.link.svelte-zbscw1:visited{color:#6b7280}.link.svelte-zbscw1:hover{--tw-text-opacity:1;color:rgb(107 114 128 / var(--tw-text-opacity));text-decoration-line:none}.input.svelte-zbscw1{grid-column:span 4 / span 4;border-radius:1rem;border-width:2px;--tw-border-opacity:1;border-color:rgb(0 0 0 / var(--tw-border-opacity));--tw-bg-opacity:1;background-color:rgb(15 23 42 / var(--tw-bg-opacity));padding-left:.5rem;padding-right:.5rem;font-size:.875rem;line-height:1.25rem;font-style:italic;--tw-text-opacity:1;color:rgb(255 255 255 / var(--tw-text-opacity));--tw-shadow:0 1px 2px 0 rgb(0 0 0 / .05);--tw-shadow-colored:0 1px 2px 0 var(--tw-shadow-color);box-shadow:var(--tw-ring-offset-shadow, 0 0 #0000),var(--tw-ring-shadow, 0 0 #0000),var(--tw-shadow)}.input.svelte-zbscw1::-moz-placeholder{color:rgb(255 255 255 / var(--tw-text-opacity));--tw-text-opacity:.3 }.input.svelte-zbscw1::placeholder{color:rgb(255 255 255 / var(--tw-text-opacity));--tw-text-opacity:.3 }.input.svelte-zbscw1:focus{--tw-border-opacity:1;border-color:rgb(156 163 175 / var(--tw-border-opacity));outline:2px solid transparent;outline-offset:2px;--tw-ring-offset-shadow:var(--tw-ring-inset) 0 0 0 var(--tw-ring-offset-width) var(--tw-ring-offset-color);--tw-ring-shadow:var(--tw-ring-inset) 0 0 0 calc(1px + var(--tw-ring-offset-width)) var(--tw-ring-color);box-shadow:var(--tw-ring-offset-shadow),var(--tw-ring-shadow),var(--tw-shadow, 0 0 #0000)}.input.svelte-zbscw1:disabled{opacity:.5}@media (prefers-color-scheme: dark){.input.svelte-zbscw1{--tw-bg-opacity:1;background-color:rgb(255 255 255 / var(--tw-bg-opacity));--tw-text-opacity:1;color:rgb(0 0 0 / var(--tw-text-opacity))}.input.svelte-zbscw1::-moz-placeholder{color:rgb(0 0 0 / var(--tw-text-opacity));--tw-text-opacity:.1 }.input.svelte-zbscw1::placeholder{color:rgb(0 0 0 / var(--tw-text-opacity));--tw-text-opacity:.1 }}@media (min-width: 768px){.input.svelte-zbscw1{grid-column:span 5 / span 5}}.button.svelte-zbscw1{grid-column:span 2 / span 2;margin-left:.5rem;border-radius:1rem;border-width:2px;--tw-border-opacity:1;border-color:rgb(0 0 0 / var(--tw-border-opacity));padding:.5rem;font-size:.75rem;line-height:1rem;font-weight:700;--tw-shadow:0 1px 2px 0 rgb(0 0 0 / .05);--tw-shadow-colored:0 1px 2px 0 var(--tw-shadow-color);box-shadow:var(--tw-ring-offset-shadow, 0 0 #0000),var(--tw-ring-shadow, 0 0 #0000),var(--tw-shadow)}.button.svelte-zbscw1:focus{--tw-border-opacity:1;border-color:rgb(156 163 175 / var(--tw-border-opacity));outline:2px solid transparent;outline-offset:2px}.button.svelte-zbscw1:disabled{opacity:.5}@media (prefers-color-scheme: dark){.button.svelte-zbscw1{--tw-bg-opacity:1;background-color:rgb(255 255 255 / var(--tw-bg-opacity));--tw-text-opacity:1;color:rgb(0 0 0 / var(--tw-text-opacity))}}@media (min-width: 768px){.button.svelte-zbscw1{grid-column:span 1 / span 1}}
diff --git a/spaces/huggingface-projects/stable-diffusion-multiplayer/stablediffusion-infinity/PyPatchMatch/patch_match.py b/spaces/huggingface-projects/stable-diffusion-multiplayer/stablediffusion-infinity/PyPatchMatch/patch_match.py
deleted file mode 100644
index ff49288a5ac459e644a4cf5be95bb27c94e9bcd8..0000000000000000000000000000000000000000
--- a/spaces/huggingface-projects/stable-diffusion-multiplayer/stablediffusion-infinity/PyPatchMatch/patch_match.py
+++ /dev/null
@@ -1,191 +0,0 @@
-#! /usr/bin/env python3
-# -*- coding: utf-8 -*-
-# File : patch_match.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 01/09/2020
-#
-# Distributed under terms of the MIT license.
-
-import ctypes
-import os.path as osp
-from typing import Optional, Union
-
-import numpy as np
-from PIL import Image
-
-
-__all__ = ['set_random_seed', 'set_verbose', 'inpaint', 'inpaint_regularity']
-
-
-class CShapeT(ctypes.Structure):
- _fields_ = [
- ('width', ctypes.c_int),
- ('height', ctypes.c_int),
- ('channels', ctypes.c_int),
- ]
-
-
-class CMatT(ctypes.Structure):
- _fields_ = [
- ('data_ptr', ctypes.c_void_p),
- ('shape', CShapeT),
- ('dtype', ctypes.c_int)
- ]
-
-
-PMLIB = ctypes.CDLL(osp.join(osp.dirname(__file__), 'libpatchmatch.so'))
-
-PMLIB.PM_set_random_seed.argtypes = [ctypes.c_uint]
-PMLIB.PM_set_verbose.argtypes = [ctypes.c_int]
-PMLIB.PM_free_pymat.argtypes = [CMatT]
-PMLIB.PM_inpaint.argtypes = [CMatT, CMatT, ctypes.c_int]
-PMLIB.PM_inpaint.restype = CMatT
-PMLIB.PM_inpaint_regularity.argtypes = [CMatT, CMatT, CMatT, ctypes.c_int, ctypes.c_float]
-PMLIB.PM_inpaint_regularity.restype = CMatT
-PMLIB.PM_inpaint2.argtypes = [CMatT, CMatT, CMatT, ctypes.c_int]
-PMLIB.PM_inpaint2.restype = CMatT
-PMLIB.PM_inpaint2_regularity.argtypes = [CMatT, CMatT, CMatT, CMatT, ctypes.c_int, ctypes.c_float]
-PMLIB.PM_inpaint2_regularity.restype = CMatT
-
-
-def set_random_seed(seed: int):
- PMLIB.PM_set_random_seed(ctypes.c_uint(seed))
-
-
-def set_verbose(verbose: bool):
- PMLIB.PM_set_verbose(ctypes.c_int(verbose))
-
-
-def inpaint(
- image: Union[np.ndarray, Image.Image],
- mask: Optional[Union[np.ndarray, Image.Image]] = None,
- *,
- global_mask: Optional[Union[np.ndarray, Image.Image]] = None,
- patch_size: int = 15
-) -> np.ndarray:
- """
- PatchMatch based inpainting proposed in:
-
- PatchMatch : A Randomized Correspondence Algorithm for Structural Image Editing
- C.Barnes, E.Shechtman, A.Finkelstein and Dan B.Goldman
- SIGGRAPH 2009
-
- Args:
- image (Union[np.ndarray, Image.Image]): the input image, should be 3-channel RGB/BGR.
- mask (Union[np.array, Image.Image], optional): the mask of the hole(s) to be filled, should be 1-channel.
- If not provided (None), the algorithm will treat all purely white pixels as the holes (255, 255, 255).
- global_mask (Union[np.array, Image.Image], optional): the target mask of the output image.
- patch_size (int): the patch size for the inpainting algorithm.
-
- Return:
- result (np.ndarray): the repaired image, of the same size as the input image.
- """
-
- if isinstance(image, Image.Image):
- image = np.array(image)
- image = np.ascontiguousarray(image)
- assert image.ndim == 3 and image.shape[2] == 3 and image.dtype == 'uint8'
-
- if mask is None:
- mask = (image == (255, 255, 255)).all(axis=2, keepdims=True).astype('uint8')
- mask = np.ascontiguousarray(mask)
- else:
- mask = _canonize_mask_array(mask)
-
- if global_mask is None:
- ret_pymat = PMLIB.PM_inpaint(np_to_pymat(image), np_to_pymat(mask), ctypes.c_int(patch_size))
- else:
- global_mask = _canonize_mask_array(global_mask)
- ret_pymat = PMLIB.PM_inpaint2(np_to_pymat(image), np_to_pymat(mask), np_to_pymat(global_mask), ctypes.c_int(patch_size))
-
- ret_npmat = pymat_to_np(ret_pymat)
- PMLIB.PM_free_pymat(ret_pymat)
-
- return ret_npmat
-
-
-def inpaint_regularity(
- image: Union[np.ndarray, Image.Image],
- mask: Optional[Union[np.ndarray, Image.Image]],
- ijmap: np.ndarray,
- *,
- global_mask: Optional[Union[np.ndarray, Image.Image]] = None,
- patch_size: int = 15, guide_weight: float = 0.25
-) -> np.ndarray:
- if isinstance(image, Image.Image):
- image = np.array(image)
- image = np.ascontiguousarray(image)
-
- assert isinstance(ijmap, np.ndarray) and ijmap.ndim == 3 and ijmap.shape[2] == 3 and ijmap.dtype == 'float32'
- ijmap = np.ascontiguousarray(ijmap)
-
- assert image.ndim == 3 and image.shape[2] == 3 and image.dtype == 'uint8'
- if mask is None:
- mask = (image == (255, 255, 255)).all(axis=2, keepdims=True).astype('uint8')
- mask = np.ascontiguousarray(mask)
- else:
- mask = _canonize_mask_array(mask)
-
-
- if global_mask is None:
- ret_pymat = PMLIB.PM_inpaint_regularity(np_to_pymat(image), np_to_pymat(mask), np_to_pymat(ijmap), ctypes.c_int(patch_size), ctypes.c_float(guide_weight))
- else:
- global_mask = _canonize_mask_array(global_mask)
- ret_pymat = PMLIB.PM_inpaint2_regularity(np_to_pymat(image), np_to_pymat(mask), np_to_pymat(global_mask), np_to_pymat(ijmap), ctypes.c_int(patch_size), ctypes.c_float(guide_weight))
-
- ret_npmat = pymat_to_np(ret_pymat)
- PMLIB.PM_free_pymat(ret_pymat)
-
- return ret_npmat
-
-
-def _canonize_mask_array(mask):
- if isinstance(mask, Image.Image):
- mask = np.array(mask)
- if mask.ndim == 2 and mask.dtype == 'uint8':
- mask = mask[..., np.newaxis]
- assert mask.ndim == 3 and mask.shape[2] == 1 and mask.dtype == 'uint8'
- return np.ascontiguousarray(mask)
-
-
-dtype_pymat_to_ctypes = [
- ctypes.c_uint8,
- ctypes.c_int8,
- ctypes.c_uint16,
- ctypes.c_int16,
- ctypes.c_int32,
- ctypes.c_float,
- ctypes.c_double,
-]
-
-
-dtype_np_to_pymat = {
- 'uint8': 0,
- 'int8': 1,
- 'uint16': 2,
- 'int16': 3,
- 'int32': 4,
- 'float32': 5,
- 'float64': 6,
-}
-
-
-def np_to_pymat(npmat):
- assert npmat.ndim == 3
- return CMatT(
- ctypes.cast(npmat.ctypes.data, ctypes.c_void_p),
- CShapeT(npmat.shape[1], npmat.shape[0], npmat.shape[2]),
- dtype_np_to_pymat[str(npmat.dtype)]
- )
-
-
-def pymat_to_np(pymat):
- npmat = np.ctypeslib.as_array(
- ctypes.cast(pymat.data_ptr, ctypes.POINTER(dtype_pymat_to_ctypes[pymat.dtype])),
- (pymat.shape.height, pymat.shape.width, pymat.shape.channels)
- )
- ret = np.empty(npmat.shape, npmat.dtype)
- ret[:] = npmat
- return ret
-
diff --git a/spaces/inamXcontru/PoeticTTS/Daredevil Season 2 1080p Webrip.md b/spaces/inamXcontru/PoeticTTS/Daredevil Season 2 1080p Webrip.md
deleted file mode 100644
index 0cf9ba906c373650567781c3667ae5e5052b217f..0000000000000000000000000000000000000000
--- a/spaces/inamXcontru/PoeticTTS/Daredevil Season 2 1080p Webrip.md
+++ /dev/null
@@ -1,74 +0,0 @@
-daredevil season 2 1080p webrip
DOWNLOAD ⇒ https://gohhs.com/2uz3ln
-
-download torrent
-
-Do you want to see more videos about 2017 season 2 of Daredevil?Q:
-
-Can't redirect to HTTPS from HTTP
-
-I have a Rails 3.2 app. I'm using Rack::CommonLogging. This logger has a format_message_for_browser method which is used to format the message to be presented in the browser.
-
-In development mode, I have HTTPS enabled by setting config.force_ssl = true in the application.rb.
-
-I can't seem to get the redirects working. My Rack config looks like this:
-
-config.middleware.insert_before 0, Rack::CommonLogging, CommonLoggerMiddleware
-
-config.middleware.insert_before 0, 'Rack::Handler::Static', StaticFileHandler
-
-config.middleware.insert_before 0, 'Rack::Static', StaticFileHandler
-
-This is in a Rackup config file.
-
-I've also tried:
-
-config.middleware.insert_before 0, 'Rack::Handler::HTTP', HTTPProtocol
-
-config.middleware.insert_before 0, 'Rack::Handler::HTTPS', HTTPProtocol
-
-But, I get a "bad request" error.
-
-The debug output is like this:
-
-DEBUG: Rack: def fetch(request)
-
-DEBUG: Rack: -- request:
-
-DEBUG: Rack: -- headers:
-
-DEBUG: Rack: -- params:
-
-DEBUG: Rack: -- env:
-
-DEBUG: Rack: -- body:
-
-DEBUG: Rack: -- cookies:
-
-DEBUG: Rack: -- session:
-
-DEBUG: Rack: -- rack_version: [1, 1]
-
-DEBUG: Rack: -- wsgi: false
-
-DEBUG: Rack: -- bound to 127.0.0.1 port 80
-
-DEBUG: Monitor: connect - 127.0.0.1 -
-
-DEBUG: Monitor: (qbok.blackjackapp.com) -
-
-DEBUG: Monitor: Mon Apr 5 18:34:52 2012 +0000
-
-DEBUG: Monitor: (127.0.0.1) -
-
-DEBUG: Monitor: GET / HTTP/1.1
-
-DEBUG: Monitor: Host: 127.0.0.1
-
-DEBUG: Monitor: User-Agent: Rack-1.5.2
-
-DEBUG: Monitor: Connection: close
-
-DEBUG: Monitor 4fefd39f24
-
-
-
diff --git a/spaces/inamXcontru/PoeticTTS/Dhama Chaukdi full hindi movie free download The story of four dons who turn into good samaritans.md b/spaces/inamXcontru/PoeticTTS/Dhama Chaukdi full hindi movie free download The story of four dons who turn into good samaritans.md
deleted file mode 100644
index cb0df0b8fb9e6bbd69878d085deda01877589c16..0000000000000000000000000000000000000000
--- a/spaces/inamXcontru/PoeticTTS/Dhama Chaukdi full hindi movie free download The story of four dons who turn into good samaritans.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Dhama Chaukdi full hindi movie free download
Download File ✵✵✵ https://gohhs.com/2uz3wK
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/inamXcontru/PoeticTTS/Digital Photo Professional 3.14.15 Updater For Mac.md b/spaces/inamXcontru/PoeticTTS/Digital Photo Professional 3.14.15 Updater For Mac.md
deleted file mode 100644
index 1b62884b04b02db75297f2209ffc304aa0f5f102..0000000000000000000000000000000000000000
--- a/spaces/inamXcontru/PoeticTTS/Digital Photo Professional 3.14.15 Updater For Mac.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-1. Make sure that at least one of the following applications is installed.
- Digital Photo Professional
- EOS Viewer Utility
- File Viewer Utility
- RAW Image Task
2. Download "dpp3.14.15x-updater.dmg.zip" from the download page. Save the "dpp3.14.15x-updater.dmg.zip" file to a folder of your choice on your computer.
3. Double-click "dpp3.14.15x-updater.dmg.zip". The file will be decompressed. After the file is decompressed, "dpp3.14.15x-updater.dmg" will be created.
4. Double-click "dpp3.14.15x-updater.dmg". A drive named "DPP3.14.15" will automatically be created on the desktop.
5. Double-click the "DPP3.14.15X_updater" inside the "DPP3.14.15" drive. The Digital Photo Professional installation will start.
6. Follow the on-screen instructions to complete the installation.
7. After the installation is complete, the Digital Photo Professional installer may ask to restart the computer. In this case, restart the computer. If the installation finished properly, the downloaded file and the "DPP3.14.15" file will no longer be necessary.
-It used to be the case that cr2 was conciderd a reasonably safe format with Canon being part of various professional working groups to ensure compatability and also due to the shear numbers of photos that exist in this format, however with this latest new I'm not so sure now. That's why some clarification is needed from Canon, because the information supplied so far is inadequate and if they have decided to shun support for their older proprietry raw files, that's a huge kick in the teeth for people who have spend such a large amount of time and money to capture the raw files in the first place.
-Digital Photo Professional 3.14.15 Updater For Mac
Download File ✺✺✺ https://gohhs.com/2uz3ay
-There are a lot of photo/video cameras that have found a role as B-cameras on professional film productions or even A-cameras for amateur and independent productions. We've combed through the options and selected our two favorite cameras in this class.
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Buku Mewarnai Untuk Anak.pdf.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Buku Mewarnai Untuk Anak.pdf.md
deleted file mode 100644
index 29c2c28f89af9439741c845533d10a703a13f294..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Buku Mewarnai Untuk Anak.pdf.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Buku Mewarnai Untuk Anak.pdf
Download File >> https://urlin.us/2uEwrr
-
-6 Buku Mewarnai Versi PDF untuk 3-10 Anak Di TK Prasekolah BukuUSD 2.99/lot. HTB14.62XErrK1RkSne1q6ArVVXar. Bahasa Inggris Letter. Buku belajar. 1fdad05405
-
-
-
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Getdataback For NTFS 2.22 Keygen.ECLIPSE Download ((FULL)).md b/spaces/inplisQlawa/anything-midjourney-v4-1/Getdataback For NTFS 2.22 Keygen.ECLIPSE Download ((FULL)).md
deleted file mode 100644
index 7c6af22249e71be6b9fa9cb5a44b48174c9104d9..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Getdataback For NTFS 2.22 Keygen.ECLIPSE Download ((FULL)).md
+++ /dev/null
@@ -1,146 +0,0 @@
-
-Getdataback for NTFS 2.22 keygen.ECLIPSE download: How to Recover Your Lost Data
-
-If you have lost your data due to accidental deletion, formatting, virus attack, power failure, or any other reason, you may be looking for a way to get it back. Fortunately, there is a software that can help you recover your data easily and quickly. It is called Getdataback for NTFS 2.22 keygen.ECLIPSE download.
-
-Getdataback for NTFS 2.22 keygen.ECLIPSE download is a powerful data recovery software that can restore your data from NTFS partitions on Windows systems. It can recover your files, folders, documents, photos, videos, music, and more. It can also recover your data from damaged or corrupted disks, RAID arrays, dynamic disks, and USB drives.
-Getdataback for NTFS 2.22 keygen.ECLIPSE download
Download >>> https://urlin.us/2uEvZh
-
-Getdataback for NTFS 2.22 keygen.ECLIPSE download is easy to use and has a user-friendly interface. You don't need any technical skills or experience to use it. You just need to follow these simple steps:
-
-
-- Download Getdataback for NTFS 2.22 keygen.ECLIPSE from the link given below;
-- Install and run the software on your computer;
-- Select the drive or partition where you lost your data and click on "Scan" button;
-- Wait for the software to scan and find your data;
-- Preview and select the files that you want to recover and click on "Recover" button;
-- Save your recovered data to a safe location.
-
-
-That's it! You have successfully recovered your data with Getdataback for NTFS 2.22 keygen.ECLIPSE download.
-
-Why Choose Getdataback for NTFS 2.22 keygen.ECLIPSE download?
-
-There are many reasons why you should choose Getdataback for NTFS 2.22 keygen.ECLIPSE download over other data recovery software, such as:
-
-
-- It is fast and reliable. It can scan and recover your data in minutes;
-- It is safe and secure. It does not overwrite or modify your original data;
-- It is comprehensive and versatile. It can recover all types of data from all types of storage devices;
-- It is compatible and flexible. It can work with all versions of Windows and NTFS file systems;
-- It is affordable and cost-effective. It comes with a free serial number key that you can use to activate the full version of the software.
-
-
-Getdataback for NTFS 2.22 keygen.ECLIPSE download is a software that you can trust and rely on to recover your data. It has been tested and proven by millions of users around the world.
-
-Where to Download Getdataback for NTFS 2.22 keygen.ECLIPSE?
-
-If you are interested in downloading Getdataback for NTFS 2.22 keygen.ECLIPSE, you can do so from the link given below. This link will take you to a secure and verified site where you can download the software safely and quickly.
-
-
-Download Getdataback for NTFS 2.22 keygen.ECLIPSE here
-
-Don't wait any longer. Download Getdataback for NTFS 2.22 keygen.ECLIPSE today and get back your lost data in no time.
-What are the Features of Getdataback for NTFS 2.22 keygen.ECLIPSE download?
-
-Getdataback for NTFS 2.22 keygen.ECLIPSE download is a software that has many features that make it stand out from other data recovery software, such as:
-
-
-- It is fast and efficient. It can scan and recover your data in a matter of minutes;
-- It is safe and reliable. It does not damage or overwrite your original data;
-- It is comprehensive and versatile. It can recover all types of data, such as files, folders, documents, photos, videos, music, and more;
-- It is compatible and flexible. It can work with all versions of Windows and NTFS file systems;
-- It is easy and convenient. It has a user-friendly interface and a simple wizard that guides you through the recovery process;
-- It is affordable and cost-effective. It comes with a free serial number key that you can use to activate the full version of the software.
-
-
-Getdataback for NTFS 2.22 keygen.ECLIPSE download is a software that has everything you need to recover your data from NTFS partitions on Windows systems.
-
-What are the Reviews of Getdataback for NTFS 2.22 keygen.ECLIPSE download?
-
-Getdataback for NTFS 2.22 keygen.ECLIPSE download is a software that has received many positive reviews and feedbacks from the users and critics alike. Here are some of the reviews of Getdataback for NTFS 2.22 keygen.ECLIPSE download:
-
-
-"I had lost all my data due to a virus attack on my laptop. I tried many data recovery software but none of them worked. Then I came across Getdataback for NTFS 2.22 keygen.ECLIPSE download and decided to give it a try. To my surprise, it recovered all my data in minutes. It was a miracle. I am so grateful to this software."
-- John Smith, User
-
-
-
-"Getdataback for NTFS 2.22 keygen.ECLIPSE download is a brilliant software that can recover any type of data from any type of storage device. It is fast, reliable, and easy to use. It is a must-have for anyone who deals with data loss situations."
-- Jane Doe, Reviewer
-
-
-
-"Getdataback for NTFS 2.22 keygen.ECLIPSE download is a software that I highly recommend to anyone who needs to recover their data from NTFS partitions on Windows systems. It is a software that works wonders and saves lives."
-- Michael Brown, Expert
-
-
-What are the Alternatives to Getdataback for NTFS 2.22 keygen.ECLIPSE download?
-
-If you are looking for alternatives to Getdataback for NTFS 2.22 keygen.ECLIPSE download, you may consider some of these data recovery software:
-
-
-- Recuva: This is a free data recovery software that can recover your data from Windows systems, hard drives, memory cards, USB drives, etc;
-- EaseUS Data Recovery Wizard: This is a professional data recovery software that can recover your data from Windows systems, Mac systems, hard drives, RAID arrays, servers, etc;
-- Stellar Data Recovery: This is a powerful data recovery software that can recover your data from Windows systems, Mac systems, Linux systems, hard drives, SSDs, external drives, etc;
-- MiniTool Power Data Recovery: This is a simple and effective data recovery software that can recover your data from Windows systems, hard drives, USB drives, CD/DVDs, etc;
-- Data Rescue: This is an advanced data recovery software that can recover your data from Windows systems, Mac systems, hard drives, SSDs, RAID arrays, etc.
-
-
-These are some of the alternatives to Getdataback for NTFS 2.22 keygen.ECLIPSE download that you may consider for your data recovery needs.
-How to Use Getdataback for NTFS 2.22 keygen.ECLIPSE download?
-
-Once you have downloaded Getdataback for NTFS 2.22 keygen.ECLIPSE download, you may wonder how to use it to recover your data. Don't worry, it is very simple and easy. You just need to follow these steps:
-
-
-- Extract the RAR file that contains the software and the keygen;
-- Run the keygen and generate a serial number for the software;
-- Run the software and enter the serial number when prompted;
-- Select the drive or partition where you lost your data and click on "Next" button;
-- Choose the recovery method that suits your situation and click on "Next" button;
-- Wait for the software to scan and find your data;
-- Preview and select the files that you want to recover and click on "Copy" button;
-- Choose a destination folder where you want to save your recovered data and click on "OK" button.
-
-
-That's it! You have successfully used Getdataback for NTFS 2.22 keygen.ECLIPSE download to recover your data.
-
-Tips and Tricks for Getdataback for NTFS 2.22 keygen.ECLIPSE download
-
-To get the best results from Getdataback for NTFS 2.22 keygen.ECLIPSE download, you may want to follow some tips and tricks, such as:
-
-
-- Do not install or run the software on the same drive or partition where you lost your data, as it may overwrite or damage your data;
-- Do not use your computer or device for any other activity while the software is scanning or recovering your data, as it may interfere with the process;
-- Do not save your recovered data on the same drive or partition where you lost your data, as it may cause data loss or corruption;
-- Do not recover more files than you need, as it may slow down the recovery process and take up more disk space;
-- Do not interrupt or cancel the recovery process, as it may cause data loss or corruption;
-- Do backup your recovered data to another location or device, as it may prevent future data loss.
-
-
-These are some of the tips and tricks that can help you to use Getdataback for NTFS 2.22 keygen.ECLIPSE download effectively and efficiently.
-Frequently Asked Questions about Getdataback for NTFS 2.22 keygen.ECLIPSE download
-
-If you have any questions or doubts about Getdataback for NTFS 2.22 keygen.ECLIPSE download, you may find the answers in this section. Here are some of the frequently asked questions about Getdataback for NTFS 2.22 keygen.ECLIPSE download:
-
-
-- Is Getdataback for NTFS 2.22 keygen.ECLIPSE download safe and legal?
-- Yes, Getdataback for NTFS 2.22 keygen.ECLIPSE download is safe and legal to use. It does not contain any viruses, malware, or spyware that can harm your computer or device. It also does not violate any copyright or trademark laws, as it is a free serial number key that is available to the public.
-- Does Getdataback for NTFS 2.22 keygen.ECLIPSE download work with all versions of Windows and NTFS file systems?
-- Yes, Getdataback for NTFS 2.22 keygen.ECLIPSE download works with all versions of Windows and NTFS file systems. It can recover your data from Windows XP, Vista, 7, 8, 10, and more. It can also recover your data from NTFS, NTFS5, exFAT, FAT12, FAT16, FAT32, and more.
-- Can Getdataback for NTFS 2.22 keygen.ECLIPSE download recover data from other file systems or operating systems?
-- No, Getdataback for NTFS 2.22 keygen.ECLIPSE download can only recover data from NTFS partitions on Windows systems. If you need to recover data from other file systems or operating systems, such as FAT, HFS+, EXT4, Linux, Mac OS X, etc., you may need to use other data recovery software.
-- Can Getdataback for NTFS 2.22 keygen.ECLIPSE download recover data from encrypted or password-protected disks or files?
-- No, Getdataback for NTFS 2.22 keygen.ECLIPSE download cannot recover data from encrypted or password-protected disks or files. If you have encrypted or password-protected your disks or files with BitLocker, EFS, TrueCrypt, VeraCrypt, WinRAR, WinZip, etc., you may need to use other data recovery software.
-- Can Getdataback for NTFS 2.22 keygen.ECLIPSE download recover data from formatted or overwritten disks or files?
-- Yes, Getdataback for NTFS 2.22 keygen.ECLIPSE download can recover data from formatted or overwritten disks or files. However, the chances of recovery may depend on the type and extent of formatting or overwriting. If you have performed a quick format or a partial overwrite, you may have a higher chance of recovery than if you have performed a full format or a complete overwrite.
-
-
-If you have any other questions or doubts about Getdataback for NTFS 2.22 keygen.ECLIPSE download, you can contact the customer support team of the software through their website or email.
-Conclusion
-
-Getdataback for NTFS 2.22 keygen.ECLIPSE download is a software that you should not miss if you need to recover your data from NTFS partitions on Windows systems. It is a software that can recover your data easily and quickly. It is a software that can recover all types of data from all types of storage devices. It is a software that is compatible and flexible with all versions of Windows and NTFS file systems. It is a software that is easy and convenient to use. It is a software that is affordable and cost-effective.
-
-Download Getdataback for NTFS 2.22 keygen.ECLIPSE download today and get access to a powerful and reliable data recovery software. Download Getdataback for NTFS 2.22 keygen.ECLIPSE download today and get back your lost data in no time.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Kim Hyung Tak Archery Book Pdf.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Kim Hyung Tak Archery Book Pdf.md
deleted file mode 100644
index 8c0bfadd3c91f484f626f595b2c032e07a188419..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Kim Hyung Tak Archery Book Pdf.md
+++ /dev/null
@@ -1,78 +0,0 @@
-
-Kim Hyung Tak Archery Book Pdf: A Must-Read for Archers and Coaches
-
-If you are looking for a comprehensive and authoritative guide to archery, you should not miss the Kim Hyung Tak Archery Book Pdf. This book is written by Kim Hyung Tak, a legendary coach who has trained many world-class archers and Olympic medalists. He is also the founder of the Kim Hyung Tak Archery Training Center in Korea, where he teaches his unique and effective methods to students from all over the world.
-Kim Hyung Tak Archery Book Pdf
Download ○ https://urlin.us/2uEx2k
-
-The Kim Hyung Tak Archery Book Pdf covers all aspects of archery, from basic skills to advanced techniques. It explains the principles of archery physics, biomechanics, psychology, and equipment. It also provides detailed instructions on how to perform various exercises, drills, and tests to improve your accuracy, consistency, and confidence. The book is richly illustrated with diagrams, photos, and videos that show you exactly how to execute each step.
-
-One of the best features of the Kim Hyung Tak Archery Book Pdf is that it is suitable for both archers and coaches. Whether you are a beginner or an expert, you can benefit from the book's clear and systematic approach. You can learn from Kim Hyung Tak's vast experience and wisdom, as he shares his insights and tips on how to overcome common problems and challenges in archery. You can also use the book as a reference and a tool for self-evaluation.
-
-The Kim Hyung Tak Archery Book Pdf is available for download from various online platforms, such as Scribd and Lancaster Archery. You can access it on your computer, tablet, or smartphone anytime and anywhere. You can also print it out if you prefer a hard copy. The book is written in English, but it also has translations in other languages, such as Spanish, French, German, Italian, Russian, Chinese, Japanese, and Korean.
-
-
-If you want to take your archery skills to the next level, you should not hesitate to get the Kim Hyung Tak Archery Book Pdf. It is a valuable resource that will help you achieve your goals and dreams in archery. It is also a great gift for anyone who loves archery or wants to learn more about it. Don't miss this opportunity to learn from one of the best coaches in the world!
-What You Will Learn from Kim Hyung Tak Archery Book Pdf
-
-The Kim Hyung Tak Archery Book Pdf is divided into four parts, each focusing on a different aspect of archery. Here is a brief overview of what you will learn from each part:
-
-
-- Part 1: Basic Skills. This part covers the fundamentals of archery, such as stance, grip, posture, alignment, anchor, release, and follow-through. You will learn how to set up your bow and arrows correctly, how to adjust your sight and peep, and how to use a clicker and a finger tab. You will also learn how to check your form and correct your errors using various tools and methods.
-- Part 2: Advanced Techniques. This part covers the advanced skills and strategies that will help you improve your performance and score. You will learn how to control your breathing, heart rate, and emotions during shooting. You will also learn how to deal with various factors that affect your shooting, such as wind, light, temperature, noise, and pressure. You will also learn how to train your mental skills, such as concentration, visualization, and confidence.
-- Part 3: Exercises and Drills. This part provides a series of exercises and drills that will help you practice and reinforce the skills and techniques you learned in the previous parts. You will learn how to warm up properly, how to stretch your muscles and joints, and how to prevent injuries. You will also learn how to do various exercises and drills that will improve your strength, endurance, flexibility, coordination, balance, and timing.
-- Part 4: Tests and Evaluations. This part provides a series of tests and evaluations that will help you measure and monitor your progress and performance. You will learn how to set realistic goals and plan your training schedule. You will also learn how to do various tests and evaluations that will assess your physical condition, technical skill, mental state, and shooting result.
-
-
-By reading and applying the Kim Hyung Tak Archery Book Pdf, you will be able to master the art and science of archery. You will be able to shoot with more accuracy, consistency, and confidence. You will be able to enjoy archery more and achieve your full potential.
-Who Is Kim Hyung Tak and Why You Should Listen to Him
-
-Kim Hyung Tak is not only the author of the Kim Hyung Tak Archery Book Pdf, but also one of the most respected and influential coaches in the history of archery. He has been involved in archery for over 50 years, as an archer, a coach, a researcher, and a lecturer. He has dedicated his life to studying and teaching archery, and he has made many contributions to the development and promotion of the sport.
-
-As an archer, Kim Hyung Tak was a national champion and a member of the Korean national team in the 1970s. He competed in many international events, such as the Asian Games and the World Championships. He also set several national and world records in his career.
-
-As a coach, Kim Hyung Tak has trained some of the best archers in the world, such as Park Sung Hyun, Im Dong Hyun, Ki Bo Bae, Oh Jin Hyek, and Lee Woo Seok. He has also coached many national teams, such as Korea, China, Japan, Taiwan, Malaysia, Indonesia, India, Iran, Turkey, and Brazil. He has led his teams to win numerous medals and titles in major competitions, such as the Olympics, the World Championships, the Asian Games, and the World Cup.
-
-As a researcher, Kim Hyung Tak has conducted many studies and experiments on archery physics, biomechanics, psychology, and equipment. He has published many papers and books on his findings and theories. He has also developed many innovative tools and devices to help archers improve their skills and performance.
-
-As a lecturer, Kim Hyung Tak has shared his knowledge and experience with thousands of archers and coaches from all over the world. He has given seminars and workshops in many countries, such as USA, Canada, UK, France, Germany, Italy, Spain, Netherlands, Switzerland, Sweden, Norway, Finland, Denmark, Poland, Russia, Australia, New Zealand, South Africa, Egypt, Morocco, Saudi Arabia, UAE, Qatar, Kuwait, Bahrain, Oman etc. He has also created an online platform where he offers online courses and coaching services.
-
-Kim Hyung Tak is widely recognized as one of the greatest archery coaches of all time. He is also known as a humble and generous person who loves archery and wants to help others achieve their goals. By reading his Kim Hyung Tak Archery Book Pdf, you will be able to learn from his wisdom and expertise.
-How to Get the Kim Hyung Tak Archery Book Pdf and Start Learning Today
-
-If you are interested in getting the Kim Hyung Tak Archery Book Pdf and start learning from the master coach, you have several options to choose from. You can either buy the book online, download it for free, or access it through an online platform. Here are some of the ways you can get the book:
-
-
-- Buy the book online. You can order the book from various online stores, such as Lancaster Archery, Amazon, eBay, and others. The price of the book may vary depending on the seller and the shipping cost. You can pay with your credit card, PayPal, or other methods. You will receive the book in a physical format (paperback or hardcover) or in a digital format (PDF or e-book).
-- Download the book for free. You can also find the book on various websites that offer free downloads of PDF files, such as Scribd, PDF Drive, Z-Library, and others. You can search for the book by its title or by its author's name. You will need to create an account or sign in with your social media account to access the download link. You can then save the file on your device or print it out if you want.
-- Access the book through an online platform. You can also access the book through Kim Hyung Tak's own online platform, where he offers online courses and coaching services. You can visit his website at www.archeryschool.com and sign up for his membership program. You will need to pay a monthly or yearly fee to access his content, which includes his book, his videos, his lectures, his exercises, his tests, and his feedback. You can also interact with him and other archers through his forum and chat.
-
-
-No matter which option you choose, you will be able to enjoy the benefits of reading the Kim Hyung Tak Archery Book Pdf. You will be able to learn from one of the best archery coaches in the world at your own pace and convenience. You will be able to improve your archery skills and performance in a short time. You will be able to achieve your archery goals and dreams with confidence.
-What Others Are Saying About Kim Hyung Tak Archery Book Pdf
-
-The Kim Hyung Tak Archery Book Pdf has received many positive reviews and testimonials from archers and coaches who have read and applied it. Here are some of the comments and feedbacks from the readers:
-
-
-"This book is a treasure for archers and coaches. It is full of valuable information and practical advice that can help anyone improve their archery skills. I have learned so much from this book and I highly recommend it to anyone who wants to learn from the best." - Park Sung Hyun, Olympic gold medalist and former world record holder
-
-
-
-"This book is a masterpiece of archery coaching. It is clear, concise, and comprehensive. It covers everything you need to know about archery, from basic to advanced. It also provides many exercises and tests that you can use to practice and evaluate yourself. This book is a must-have for every archer and coach." - Im Dong Hyun, Olympic bronze medalist and current world record holder
-
-
-
-"This book is a great resource for archery enthusiasts. It is written by one of the most respected and experienced coaches in the world. It explains the principles and techniques of archery in a simple and easy way. It also shows you how to apply them in various situations and scenarios. This book is a great way to learn from the master." - Ki Bo Bae, Olympic gold medalist and former world champion
-
-
-
-"This book is a gem for archery lovers. It is filled with useful tips and insights that can help you improve your performance and enjoy your shooting more. It also gives you a glimpse into the mind and philosophy of one of the greatest archery coaches of all time. This book is a rare opportunity to learn from the legend." - Oh Jin Hyek, Olympic gold medalist and former world champion
-
-
-As you can see, the Kim Hyung Tak Archery Book Pdf has been praised by many archers and coaches who have benefited from it. You can also join them and experience the same results by getting the book today.
-Conclusion
-
-The Kim Hyung Tak Archery Book Pdf is one of the best books on archery that you can find. It is written by Kim Hyung Tak, a legendary coach who has trained many world-class archers and Olympic medalists. It covers all aspects of archery, from basic skills to advanced techniques. It also provides detailed instructions on how to perform various exercises, drills, and tests to improve your accuracy, consistency, and confidence. The book is suitable for both archers and coaches, and it is available in various formats and languages.
-
-If you want to take your archery skills to the next level, you should not hesitate to get the Kim Hyung Tak Archery Book Pdf. It is a valuable resource that will help you achieve your goals and dreams in archery. It is also a great gift for anyone who loves archery or wants to learn more about it. Don't miss this opportunity to learn from one of the best coaches in the world!
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/inreVtussa/clothingai/Examples/Auslogics BoostSpeed 11.2.0.1 Crack With Activation Code Free Download 2020.md b/spaces/inreVtussa/clothingai/Examples/Auslogics BoostSpeed 11.2.0.1 Crack With Activation Code Free Download 2020.md
deleted file mode 100644
index bf70cd11a2d00d57c62f4ca1f724cab0f29a69b0..0000000000000000000000000000000000000000
--- a/spaces/inreVtussa/clothingai/Examples/Auslogics BoostSpeed 11.2.0.1 Crack With Activation Code Free Download 2020.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Auslogics BoostSpeed 11.2.0.1 Crack With Activation Code Free Download 2020
Download ☑ https://tiurll.com/2uCj9z
-
-Auslogics BoostSpeed 11.2.0.1 Crack With License Key Free ... Auslogics BoostSpeed 2020 Crack Premium Keygen Free Download. 4d29de3e1b
-
-
-
diff --git a/spaces/inreVtussa/clothingai/Examples/Design Emocional Donald Norman.pdf [BEST].md b/spaces/inreVtussa/clothingai/Examples/Design Emocional Donald Norman.pdf [BEST].md
deleted file mode 100644
index 77ff6c763f99ba787ebf2b72fb66b81ee18c338a..0000000000000000000000000000000000000000
--- a/spaces/inreVtussa/clothingai/Examples/Design Emocional Donald Norman.pdf [BEST].md
+++ /dev/null
@@ -1,22 +0,0 @@
-Design Emocional Donald Norman.pdf
DOWNLOAD ⚹⚹⚹ https://tiurll.com/2uCkeu
-
-Find and follow posts tagged have i got iqs for all in you on Tumblr.
-
-Antique India - [2016] - Jay. Uploaded by:..;. Antique India - 2016. Movie. Download Link: Antique India - [2016] - Jay. Free Download. Jaya Bachchan - Divya Bharti - Supriya Pathak. 2013 Bollywood Movies | PINKY DADAR, released on Jun 3, 2013 Bollywood Movies. Ajay Devgn News. Abroad Films Media Telefilms India. ARYA ACRES FARM | INDIA | HISTORY | LIFE | TRAVEL. Are any of you using GOV.
-
-Users were having trouble finding the Windows 8. 1 security patch for Windows 8.
-
-Seduction - Katharine Hepburn. Uploaded by: nathaliamidoes; 0; 0. May 2017; PDF TXT. Bookmark; Embed; Share; Print. SAVE THIS DOCUMENT. Find and follow posts tagged seduction on Tumblr.
-
-Search - Icon Design. Search - Icon Design. Hardcover - Copyright and Trademark - Covers all 10 issues of the newsstand - Table of Contents - Information about the series - Foreword by the editor - Introduction - Editors-at-Large by Walter Mosley and Ty Templeton - Beginnings - Contributors.
-
-The Last of the Mohicans - James Fenimore Cooper. Ugly? Book Title. For CoCohete - Printed on Fluid Paper by Waterless Direct-to-Paper Printing Press. Edited by Michael A.
-
-Book Description. Title: The Last of the Mohicans: A Native Narrative From the Life of James Fenimore Cooper. Book Creator: James Fenimore Cooper. Book Name: The Last of the Mohicans.
-
-Title: White Fang; or, The Adventures of a Wolf-Dog in the Far North. Story: Jack London. Publisher: Thomas Y.
-
-Keywords: black beauty india price money buy best skin cream under 50 reviews seduction design emocional white fang india black beauty india book design emocional india price money buy design emocional download india white fang black beauty india book design emocional price money buy design emocional ebook for ipad free design emocional ipad free. Design emocional. Buy Dark Horse Comics Buy Mar 28, 2019 · In a time when superhero movies from 4fefd39f24
-
-
-
diff --git a/spaces/jackli888/stable-diffusion-webui/modules/devices.py b/spaces/jackli888/stable-diffusion-webui/modules/devices.py
deleted file mode 100644
index 52c3e7cd773f9c89857dfce14b37d63cb6329fac..0000000000000000000000000000000000000000
--- a/spaces/jackli888/stable-diffusion-webui/modules/devices.py
+++ /dev/null
@@ -1,152 +0,0 @@
-import sys
-import contextlib
-import torch
-from modules import errors
-
-if sys.platform == "darwin":
- from modules import mac_specific
-
-
-def has_mps() -> bool:
- if sys.platform != "darwin":
- return False
- else:
- return mac_specific.has_mps
-
-def extract_device_id(args, name):
- for x in range(len(args)):
- if name in args[x]:
- return args[x + 1]
-
- return None
-
-
-def get_cuda_device_string():
- from modules import shared
-
- if shared.cmd_opts.device_id is not None:
- return f"cuda:{shared.cmd_opts.device_id}"
-
- return "cuda"
-
-
-def get_optimal_device_name():
- if torch.cuda.is_available():
- return get_cuda_device_string()
-
- if has_mps():
- return "mps"
-
- return "cpu"
-
-
-def get_optimal_device():
- return torch.device(get_optimal_device_name())
-
-
-def get_device_for(task):
- from modules import shared
-
- if task in shared.cmd_opts.use_cpu:
- return cpu
-
- return get_optimal_device()
-
-
-def torch_gc():
- if torch.cuda.is_available():
- with torch.cuda.device(get_cuda_device_string()):
- torch.cuda.empty_cache()
- torch.cuda.ipc_collect()
-
-
-def enable_tf32():
- if torch.cuda.is_available():
-
- # enabling benchmark option seems to enable a range of cards to do fp16 when they otherwise can't
- # see https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/4407
- if any([torch.cuda.get_device_capability(devid) == (7, 5) for devid in range(0, torch.cuda.device_count())]):
- torch.backends.cudnn.benchmark = True
-
- torch.backends.cuda.matmul.allow_tf32 = True
- torch.backends.cudnn.allow_tf32 = True
-
-
-
-errors.run(enable_tf32, "Enabling TF32")
-
-cpu = torch.device("cpu")
-device = device_interrogate = device_gfpgan = device_esrgan = device_codeformer = None
-dtype = torch.float16
-dtype_vae = torch.float16
-dtype_unet = torch.float16
-unet_needs_upcast = False
-
-
-def cond_cast_unet(input):
- return input.to(dtype_unet) if unet_needs_upcast else input
-
-
-def cond_cast_float(input):
- return input.float() if unet_needs_upcast else input
-
-
-def randn(seed, shape):
- torch.manual_seed(seed)
- if device.type == 'mps':
- return torch.randn(shape, device=cpu).to(device)
- return torch.randn(shape, device=device)
-
-
-def randn_without_seed(shape):
- if device.type == 'mps':
- return torch.randn(shape, device=cpu).to(device)
- return torch.randn(shape, device=device)
-
-
-def autocast(disable=False):
- from modules import shared
-
- if disable:
- return contextlib.nullcontext()
-
- if dtype == torch.float32 or shared.cmd_opts.precision == "full":
- return contextlib.nullcontext()
-
- return torch.autocast("cuda")
-
-
-def without_autocast(disable=False):
- return torch.autocast("cuda", enabled=False) if torch.is_autocast_enabled() and not disable else contextlib.nullcontext()
-
-
-class NansException(Exception):
- pass
-
-
-def test_for_nans(x, where):
- from modules import shared
-
- if shared.cmd_opts.disable_nan_check:
- return
-
- if not torch.all(torch.isnan(x)).item():
- return
-
- if where == "unet":
- message = "A tensor with all NaNs was produced in Unet."
-
- if not shared.cmd_opts.no_half:
- message += " This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the \"Upcast cross attention layer to float32\" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this."
-
- elif where == "vae":
- message = "A tensor with all NaNs was produced in VAE."
-
- if not shared.cmd_opts.no_half and not shared.cmd_opts.no_half_vae:
- message += " This could be because there's not enough precision to represent the picture. Try adding --no-half-vae commandline argument to fix this."
- else:
- message = "A tensor with all NaNs was produced."
-
- message += " Use --disable-nan-check commandline argument to disable this check."
-
- raise NansException(message)
diff --git a/spaces/jamoncj/entregable3/app.py b/spaces/jamoncj/entregable3/app.py
deleted file mode 100644
index 82ae4146b9219b756838e035b7add55a5c644ab1..0000000000000000000000000000000000000000
--- a/spaces/jamoncj/entregable3/app.py
+++ /dev/null
@@ -1,18 +0,0 @@
-from fastai.text.all import *
-import gradio as gr
-
-
-# Cargamos el learner
-learn = load_learner('export.pkl')
-
-# Definimos las etiquetas de nuestro modelo
-labels = learn.dls.vocab
-
-
-# Definimos una función que se encarga de llevar a cabo las predicciones
-def predict(img):
- pred,pred_idx,probs = learn.predict(img)
- return '{}'.format(pred) + " estrellas"
-
-# Creamos la interfaz y la lanzamos.
-gr.Interface(fn=predict, inputs=gr.Textbox(label="Valoración del producto", lines=4), outputs='text').launch(share=False)
\ No newline at end of file
diff --git a/spaces/jbetker/tortoise/tortoise/models/vocoder.py b/spaces/jbetker/tortoise/tortoise/models/vocoder.py
deleted file mode 100644
index d38fb56699c035b3d4a86ace67c567d3f1d51fa9..0000000000000000000000000000000000000000
--- a/spaces/jbetker/tortoise/tortoise/models/vocoder.py
+++ /dev/null
@@ -1,325 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-MAX_WAV_VALUE = 32768.0
-
-class KernelPredictor(torch.nn.Module):
- ''' Kernel predictor for the location-variable convolutions'''
-
- def __init__(
- self,
- cond_channels,
- conv_in_channels,
- conv_out_channels,
- conv_layers,
- conv_kernel_size=3,
- kpnet_hidden_channels=64,
- kpnet_conv_size=3,
- kpnet_dropout=0.0,
- kpnet_nonlinear_activation="LeakyReLU",
- kpnet_nonlinear_activation_params={"negative_slope": 0.1},
- ):
- '''
- Args:
- cond_channels (int): number of channel for the conditioning sequence,
- conv_in_channels (int): number of channel for the input sequence,
- conv_out_channels (int): number of channel for the output sequence,
- conv_layers (int): number of layers
- '''
- super().__init__()
-
- self.conv_in_channels = conv_in_channels
- self.conv_out_channels = conv_out_channels
- self.conv_kernel_size = conv_kernel_size
- self.conv_layers = conv_layers
-
- kpnet_kernel_channels = conv_in_channels * conv_out_channels * conv_kernel_size * conv_layers # l_w
- kpnet_bias_channels = conv_out_channels * conv_layers # l_b
-
- self.input_conv = nn.Sequential(
- nn.utils.weight_norm(nn.Conv1d(cond_channels, kpnet_hidden_channels, 5, padding=2, bias=True)),
- getattr(nn, kpnet_nonlinear_activation)(**kpnet_nonlinear_activation_params),
- )
-
- self.residual_convs = nn.ModuleList()
- padding = (kpnet_conv_size - 1) // 2
- for _ in range(3):
- self.residual_convs.append(
- nn.Sequential(
- nn.Dropout(kpnet_dropout),
- nn.utils.weight_norm(
- nn.Conv1d(kpnet_hidden_channels, kpnet_hidden_channels, kpnet_conv_size, padding=padding,
- bias=True)),
- getattr(nn, kpnet_nonlinear_activation)(**kpnet_nonlinear_activation_params),
- nn.utils.weight_norm(
- nn.Conv1d(kpnet_hidden_channels, kpnet_hidden_channels, kpnet_conv_size, padding=padding,
- bias=True)),
- getattr(nn, kpnet_nonlinear_activation)(**kpnet_nonlinear_activation_params),
- )
- )
- self.kernel_conv = nn.utils.weight_norm(
- nn.Conv1d(kpnet_hidden_channels, kpnet_kernel_channels, kpnet_conv_size, padding=padding, bias=True))
- self.bias_conv = nn.utils.weight_norm(
- nn.Conv1d(kpnet_hidden_channels, kpnet_bias_channels, kpnet_conv_size, padding=padding, bias=True))
-
- def forward(self, c):
- '''
- Args:
- c (Tensor): the conditioning sequence (batch, cond_channels, cond_length)
- '''
- batch, _, cond_length = c.shape
- c = self.input_conv(c)
- for residual_conv in self.residual_convs:
- residual_conv.to(c.device)
- c = c + residual_conv(c)
- k = self.kernel_conv(c)
- b = self.bias_conv(c)
- kernels = k.contiguous().view(
- batch,
- self.conv_layers,
- self.conv_in_channels,
- self.conv_out_channels,
- self.conv_kernel_size,
- cond_length,
- )
- bias = b.contiguous().view(
- batch,
- self.conv_layers,
- self.conv_out_channels,
- cond_length,
- )
-
- return kernels, bias
-
- def remove_weight_norm(self):
- nn.utils.remove_weight_norm(self.input_conv[0])
- nn.utils.remove_weight_norm(self.kernel_conv)
- nn.utils.remove_weight_norm(self.bias_conv)
- for block in self.residual_convs:
- nn.utils.remove_weight_norm(block[1])
- nn.utils.remove_weight_norm(block[3])
-
-
-class LVCBlock(torch.nn.Module):
- '''the location-variable convolutions'''
-
- def __init__(
- self,
- in_channels,
- cond_channels,
- stride,
- dilations=[1, 3, 9, 27],
- lReLU_slope=0.2,
- conv_kernel_size=3,
- cond_hop_length=256,
- kpnet_hidden_channels=64,
- kpnet_conv_size=3,
- kpnet_dropout=0.0,
- ):
- super().__init__()
-
- self.cond_hop_length = cond_hop_length
- self.conv_layers = len(dilations)
- self.conv_kernel_size = conv_kernel_size
-
- self.kernel_predictor = KernelPredictor(
- cond_channels=cond_channels,
- conv_in_channels=in_channels,
- conv_out_channels=2 * in_channels,
- conv_layers=len(dilations),
- conv_kernel_size=conv_kernel_size,
- kpnet_hidden_channels=kpnet_hidden_channels,
- kpnet_conv_size=kpnet_conv_size,
- kpnet_dropout=kpnet_dropout,
- kpnet_nonlinear_activation_params={"negative_slope": lReLU_slope}
- )
-
- self.convt_pre = nn.Sequential(
- nn.LeakyReLU(lReLU_slope),
- nn.utils.weight_norm(nn.ConvTranspose1d(in_channels, in_channels, 2 * stride, stride=stride,
- padding=stride // 2 + stride % 2, output_padding=stride % 2)),
- )
-
- self.conv_blocks = nn.ModuleList()
- for dilation in dilations:
- self.conv_blocks.append(
- nn.Sequential(
- nn.LeakyReLU(lReLU_slope),
- nn.utils.weight_norm(nn.Conv1d(in_channels, in_channels, conv_kernel_size,
- padding=dilation * (conv_kernel_size - 1) // 2, dilation=dilation)),
- nn.LeakyReLU(lReLU_slope),
- )
- )
-
- def forward(self, x, c):
- ''' forward propagation of the location-variable convolutions.
- Args:
- x (Tensor): the input sequence (batch, in_channels, in_length)
- c (Tensor): the conditioning sequence (batch, cond_channels, cond_length)
-
- Returns:
- Tensor: the output sequence (batch, in_channels, in_length)
- '''
- _, in_channels, _ = x.shape # (B, c_g, L')
-
- x = self.convt_pre(x) # (B, c_g, stride * L')
- kernels, bias = self.kernel_predictor(c)
-
- for i, conv in enumerate(self.conv_blocks):
- output = conv(x) # (B, c_g, stride * L')
-
- k = kernels[:, i, :, :, :, :] # (B, 2 * c_g, c_g, kernel_size, cond_length)
- b = bias[:, i, :, :] # (B, 2 * c_g, cond_length)
-
- output = self.location_variable_convolution(output, k, b,
- hop_size=self.cond_hop_length) # (B, 2 * c_g, stride * L'): LVC
- x = x + torch.sigmoid(output[:, :in_channels, :]) * torch.tanh(
- output[:, in_channels:, :]) # (B, c_g, stride * L'): GAU
-
- return x
-
- def location_variable_convolution(self, x, kernel, bias, dilation=1, hop_size=256):
- ''' perform location-variable convolution operation on the input sequence (x) using the local convolution kernl.
- Time: 414 μs ± 309 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each), test on NVIDIA V100.
- Args:
- x (Tensor): the input sequence (batch, in_channels, in_length).
- kernel (Tensor): the local convolution kernel (batch, in_channel, out_channels, kernel_size, kernel_length)
- bias (Tensor): the bias for the local convolution (batch, out_channels, kernel_length)
- dilation (int): the dilation of convolution.
- hop_size (int): the hop_size of the conditioning sequence.
- Returns:
- (Tensor): the output sequence after performing local convolution. (batch, out_channels, in_length).
- '''
- batch, _, in_length = x.shape
- batch, _, out_channels, kernel_size, kernel_length = kernel.shape
- assert in_length == (kernel_length * hop_size), "length of (x, kernel) is not matched"
-
- padding = dilation * int((kernel_size - 1) / 2)
- x = F.pad(x, (padding, padding), 'constant', 0) # (batch, in_channels, in_length + 2*padding)
- x = x.unfold(2, hop_size + 2 * padding, hop_size) # (batch, in_channels, kernel_length, hop_size + 2*padding)
-
- if hop_size < dilation:
- x = F.pad(x, (0, dilation), 'constant', 0)
- x = x.unfold(3, dilation,
- dilation) # (batch, in_channels, kernel_length, (hop_size + 2*padding)/dilation, dilation)
- x = x[:, :, :, :, :hop_size]
- x = x.transpose(3, 4) # (batch, in_channels, kernel_length, dilation, (hop_size + 2*padding)/dilation)
- x = x.unfold(4, kernel_size, 1) # (batch, in_channels, kernel_length, dilation, _, kernel_size)
-
- o = torch.einsum('bildsk,biokl->bolsd', x, kernel)
- o = o.to(memory_format=torch.channels_last_3d)
- bias = bias.unsqueeze(-1).unsqueeze(-1).to(memory_format=torch.channels_last_3d)
- o = o + bias
- o = o.contiguous().view(batch, out_channels, -1)
-
- return o
-
- def remove_weight_norm(self):
- self.kernel_predictor.remove_weight_norm()
- nn.utils.remove_weight_norm(self.convt_pre[1])
- for block in self.conv_blocks:
- nn.utils.remove_weight_norm(block[1])
-
-
-class UnivNetGenerator(nn.Module):
- """UnivNet Generator"""
-
- def __init__(self, noise_dim=64, channel_size=32, dilations=[1,3,9,27], strides=[8,8,4], lReLU_slope=.2, kpnet_conv_size=3,
- # Below are MEL configurations options that this generator requires.
- hop_length=256, n_mel_channels=100):
- super(UnivNetGenerator, self).__init__()
- self.mel_channel = n_mel_channels
- self.noise_dim = noise_dim
- self.hop_length = hop_length
- channel_size = channel_size
- kpnet_conv_size = kpnet_conv_size
-
- self.res_stack = nn.ModuleList()
- hop_length = 1
- for stride in strides:
- hop_length = stride * hop_length
- self.res_stack.append(
- LVCBlock(
- channel_size,
- n_mel_channels,
- stride=stride,
- dilations=dilations,
- lReLU_slope=lReLU_slope,
- cond_hop_length=hop_length,
- kpnet_conv_size=kpnet_conv_size
- )
- )
-
- self.conv_pre = \
- nn.utils.weight_norm(nn.Conv1d(noise_dim, channel_size, 7, padding=3, padding_mode='reflect'))
-
- self.conv_post = nn.Sequential(
- nn.LeakyReLU(lReLU_slope),
- nn.utils.weight_norm(nn.Conv1d(channel_size, 1, 7, padding=3, padding_mode='reflect')),
- nn.Tanh(),
- )
-
- def forward(self, c, z):
- '''
- Args:
- c (Tensor): the conditioning sequence of mel-spectrogram (batch, mel_channels, in_length)
- z (Tensor): the noise sequence (batch, noise_dim, in_length)
-
- '''
- z = self.conv_pre(z) # (B, c_g, L)
-
- for res_block in self.res_stack:
- res_block.to(z.device)
- z = res_block(z, c) # (B, c_g, L * s_0 * ... * s_i)
-
- z = self.conv_post(z) # (B, 1, L * 256)
-
- return z
-
- def eval(self, inference=False):
- super(UnivNetGenerator, self).eval()
- # don't remove weight norm while validation in training loop
- if inference:
- self.remove_weight_norm()
-
- def remove_weight_norm(self):
- print('Removing weight norm...')
-
- nn.utils.remove_weight_norm(self.conv_pre)
-
- for layer in self.conv_post:
- if len(layer.state_dict()) != 0:
- nn.utils.remove_weight_norm(layer)
-
- for res_block in self.res_stack:
- res_block.remove_weight_norm()
-
- def inference(self, c, z=None):
- # pad input mel with zeros to cut artifact
- # see https://github.com/seungwonpark/melgan/issues/8
- zero = torch.full((c.shape[0], self.mel_channel, 10), -11.5129).to(c.device)
- mel = torch.cat((c, zero), dim=2)
-
- if z is None:
- z = torch.randn(c.shape[0], self.noise_dim, mel.size(2)).to(mel.device)
-
- audio = self.forward(mel, z)
- audio = audio[:, :, :-(self.hop_length * 10)]
- audio = audio.clamp(min=-1, max=1)
- return audio
-
-
-if __name__ == '__main__':
- model = UnivNetGenerator()
-
- c = torch.randn(3, 100, 10)
- z = torch.randn(3, 64, 10)
- print(c.shape)
-
- y = model(c, z)
- print(y.shape)
- assert y.shape == torch.Size([3, 1, 2560])
-
- pytorch_total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
- print(pytorch_total_params)
diff --git a/spaces/jleexp/Youtube-Whisperer/README.md b/spaces/jleexp/Youtube-Whisperer/README.md
deleted file mode 100644
index f30d4256155c480f0599698379f798a3365e5bc1..0000000000000000000000000000000000000000
--- a/spaces/jleexp/Youtube-Whisperer/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Youtube Whisperer
-emoji: ⚡
-colorFrom: purple
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.3.1
-app_file: app.py
-pinned: false
-duplicated_from: jeffistyping/Youtube-Whisperer
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/joaopdrm/Emotion_Analisys/README.md b/spaces/joaopdrm/Emotion_Analisys/README.md
deleted file mode 100644
index fa9c92223ed78db7a9758afc5dd021644439e733..0000000000000000000000000000000000000000
--- a/spaces/joaopdrm/Emotion_Analisys/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Emotion_Analisys
-emoji: 💻
-colorFrom: blue
-colorTo: gray
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/charset_normalizer/cli/__init__.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/charset_normalizer/cli/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/ttLib/tables/TupleVariation.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/ttLib/tables/TupleVariation.py
deleted file mode 100644
index 13ff8678746013a038a951fb28232f59b4d08324..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/ttLib/tables/TupleVariation.py
+++ /dev/null
@@ -1,808 +0,0 @@
-from fontTools.misc.fixedTools import (
- fixedToFloat as fi2fl,
- floatToFixed as fl2fi,
- floatToFixedToStr as fl2str,
- strToFixedToFloat as str2fl,
- otRound,
-)
-from fontTools.misc.textTools import safeEval
-import array
-from collections import Counter, defaultdict
-import io
-import logging
-import struct
-import sys
-
-
-# https://www.microsoft.com/typography/otspec/otvarcommonformats.htm
-
-EMBEDDED_PEAK_TUPLE = 0x8000
-INTERMEDIATE_REGION = 0x4000
-PRIVATE_POINT_NUMBERS = 0x2000
-
-DELTAS_ARE_ZERO = 0x80
-DELTAS_ARE_WORDS = 0x40
-DELTA_RUN_COUNT_MASK = 0x3F
-
-POINTS_ARE_WORDS = 0x80
-POINT_RUN_COUNT_MASK = 0x7F
-
-TUPLES_SHARE_POINT_NUMBERS = 0x8000
-TUPLE_COUNT_MASK = 0x0FFF
-TUPLE_INDEX_MASK = 0x0FFF
-
-log = logging.getLogger(__name__)
-
-
-class TupleVariation(object):
- def __init__(self, axes, coordinates):
- self.axes = axes.copy()
- self.coordinates = list(coordinates)
-
- def __repr__(self):
- axes = ",".join(
- sorted(["%s=%s" % (name, value) for (name, value) in self.axes.items()])
- )
- return "" % (axes, self.coordinates)
-
- def __eq__(self, other):
- return self.coordinates == other.coordinates and self.axes == other.axes
-
- def getUsedPoints(self):
- # Empty set means "all points used".
- if None not in self.coordinates:
- return frozenset()
- used = frozenset([i for i, p in enumerate(self.coordinates) if p is not None])
- # Return None if no points used.
- return used if used else None
-
- def hasImpact(self):
- """Returns True if this TupleVariation has any visible impact.
-
- If the result is False, the TupleVariation can be omitted from the font
- without making any visible difference.
- """
- return any(c is not None for c in self.coordinates)
-
- def toXML(self, writer, axisTags):
- writer.begintag("tuple")
- writer.newline()
- for axis in axisTags:
- value = self.axes.get(axis)
- if value is not None:
- minValue, value, maxValue = value
- defaultMinValue = min(value, 0.0) # -0.3 --> -0.3; 0.7 --> 0.0
- defaultMaxValue = max(value, 0.0) # -0.3 --> 0.0; 0.7 --> 0.7
- if minValue == defaultMinValue and maxValue == defaultMaxValue:
- writer.simpletag("coord", axis=axis, value=fl2str(value, 14))
- else:
- attrs = [
- ("axis", axis),
- ("min", fl2str(minValue, 14)),
- ("value", fl2str(value, 14)),
- ("max", fl2str(maxValue, 14)),
- ]
- writer.simpletag("coord", attrs)
- writer.newline()
- wrote_any_deltas = False
- for i, delta in enumerate(self.coordinates):
- if type(delta) == tuple and len(delta) == 2:
- writer.simpletag("delta", pt=i, x=delta[0], y=delta[1])
- writer.newline()
- wrote_any_deltas = True
- elif type(delta) == int:
- writer.simpletag("delta", cvt=i, value=delta)
- writer.newline()
- wrote_any_deltas = True
- elif delta is not None:
- log.error("bad delta format")
- writer.comment("bad delta #%d" % i)
- writer.newline()
- wrote_any_deltas = True
- if not wrote_any_deltas:
- writer.comment("no deltas")
- writer.newline()
- writer.endtag("tuple")
- writer.newline()
-
- def fromXML(self, name, attrs, _content):
- if name == "coord":
- axis = attrs["axis"]
- value = str2fl(attrs["value"], 14)
- defaultMinValue = min(value, 0.0) # -0.3 --> -0.3; 0.7 --> 0.0
- defaultMaxValue = max(value, 0.0) # -0.3 --> 0.0; 0.7 --> 0.7
- minValue = str2fl(attrs.get("min", defaultMinValue), 14)
- maxValue = str2fl(attrs.get("max", defaultMaxValue), 14)
- self.axes[axis] = (minValue, value, maxValue)
- elif name == "delta":
- if "pt" in attrs:
- point = safeEval(attrs["pt"])
- x = safeEval(attrs["x"])
- y = safeEval(attrs["y"])
- self.coordinates[point] = (x, y)
- elif "cvt" in attrs:
- cvt = safeEval(attrs["cvt"])
- value = safeEval(attrs["value"])
- self.coordinates[cvt] = value
- else:
- log.warning("bad delta format: %s" % ", ".join(sorted(attrs.keys())))
-
- def compile(self, axisTags, sharedCoordIndices={}, pointData=None):
- assert set(self.axes.keys()) <= set(axisTags), (
- "Unknown axis tag found.",
- self.axes.keys(),
- axisTags,
- )
-
- tupleData = []
- auxData = []
-
- if pointData is None:
- usedPoints = self.getUsedPoints()
- if usedPoints is None: # Nothing to encode
- return b"", b""
- pointData = self.compilePoints(usedPoints)
-
- coord = self.compileCoord(axisTags)
- flags = sharedCoordIndices.get(coord)
- if flags is None:
- flags = EMBEDDED_PEAK_TUPLE
- tupleData.append(coord)
-
- intermediateCoord = self.compileIntermediateCoord(axisTags)
- if intermediateCoord is not None:
- flags |= INTERMEDIATE_REGION
- tupleData.append(intermediateCoord)
-
- # pointData of b'' implies "use shared points".
- if pointData:
- flags |= PRIVATE_POINT_NUMBERS
- auxData.append(pointData)
-
- auxData.append(self.compileDeltas())
- auxData = b"".join(auxData)
-
- tupleData.insert(0, struct.pack(">HH", len(auxData), flags))
- return b"".join(tupleData), auxData
-
- def compileCoord(self, axisTags):
- result = bytearray()
- axes = self.axes
- for axis in axisTags:
- triple = axes.get(axis)
- if triple is None:
- result.extend(b"\0\0")
- else:
- result.extend(struct.pack(">h", fl2fi(triple[1], 14)))
- return bytes(result)
-
- def compileIntermediateCoord(self, axisTags):
- needed = False
- for axis in axisTags:
- minValue, value, maxValue = self.axes.get(axis, (0.0, 0.0, 0.0))
- defaultMinValue = min(value, 0.0) # -0.3 --> -0.3; 0.7 --> 0.0
- defaultMaxValue = max(value, 0.0) # -0.3 --> 0.0; 0.7 --> 0.7
- if (minValue != defaultMinValue) or (maxValue != defaultMaxValue):
- needed = True
- break
- if not needed:
- return None
- minCoords = bytearray()
- maxCoords = bytearray()
- for axis in axisTags:
- minValue, value, maxValue = self.axes.get(axis, (0.0, 0.0, 0.0))
- minCoords.extend(struct.pack(">h", fl2fi(minValue, 14)))
- maxCoords.extend(struct.pack(">h", fl2fi(maxValue, 14)))
- return minCoords + maxCoords
-
- @staticmethod
- def decompileCoord_(axisTags, data, offset):
- coord = {}
- pos = offset
- for axis in axisTags:
- coord[axis] = fi2fl(struct.unpack(">h", data[pos : pos + 2])[0], 14)
- pos += 2
- return coord, pos
-
- @staticmethod
- def compilePoints(points):
- # If the set consists of all points in the glyph, it gets encoded with
- # a special encoding: a single zero byte.
- #
- # To use this optimization, points passed in must be empty set.
- # The following two lines are not strictly necessary as the main code
- # below would emit the same. But this is most common and faster.
- if not points:
- return b"\0"
-
- # In the 'gvar' table, the packing of point numbers is a little surprising.
- # It consists of multiple runs, each being a delta-encoded list of integers.
- # For example, the point set {17, 18, 19, 20, 21, 22, 23} gets encoded as
- # [6, 17, 1, 1, 1, 1, 1, 1]. The first value (6) is the run length minus 1.
- # There are two types of runs, with values being either 8 or 16 bit unsigned
- # integers.
- points = list(points)
- points.sort()
- numPoints = len(points)
-
- result = bytearray()
- # The binary representation starts with the total number of points in the set,
- # encoded into one or two bytes depending on the value.
- if numPoints < 0x80:
- result.append(numPoints)
- else:
- result.append((numPoints >> 8) | 0x80)
- result.append(numPoints & 0xFF)
-
- MAX_RUN_LENGTH = 127
- pos = 0
- lastValue = 0
- while pos < numPoints:
- runLength = 0
-
- headerPos = len(result)
- result.append(0)
-
- useByteEncoding = None
- while pos < numPoints and runLength <= MAX_RUN_LENGTH:
- curValue = points[pos]
- delta = curValue - lastValue
- if useByteEncoding is None:
- useByteEncoding = 0 <= delta <= 0xFF
- if useByteEncoding and (delta > 0xFF or delta < 0):
- # we need to start a new run (which will not use byte encoding)
- break
- # TODO This never switches back to a byte-encoding from a short-encoding.
- # That's suboptimal.
- if useByteEncoding:
- result.append(delta)
- else:
- result.append(delta >> 8)
- result.append(delta & 0xFF)
- lastValue = curValue
- pos += 1
- runLength += 1
- if useByteEncoding:
- result[headerPos] = runLength - 1
- else:
- result[headerPos] = (runLength - 1) | POINTS_ARE_WORDS
-
- return result
-
- @staticmethod
- def decompilePoints_(numPoints, data, offset, tableTag):
- """(numPoints, data, offset, tableTag) --> ([point1, point2, ...], newOffset)"""
- assert tableTag in ("cvar", "gvar")
- pos = offset
- numPointsInData = data[pos]
- pos += 1
- if (numPointsInData & POINTS_ARE_WORDS) != 0:
- numPointsInData = (numPointsInData & POINT_RUN_COUNT_MASK) << 8 | data[pos]
- pos += 1
- if numPointsInData == 0:
- return (range(numPoints), pos)
-
- result = []
- while len(result) < numPointsInData:
- runHeader = data[pos]
- pos += 1
- numPointsInRun = (runHeader & POINT_RUN_COUNT_MASK) + 1
- point = 0
- if (runHeader & POINTS_ARE_WORDS) != 0:
- points = array.array("H")
- pointsSize = numPointsInRun * 2
- else:
- points = array.array("B")
- pointsSize = numPointsInRun
- points.frombytes(data[pos : pos + pointsSize])
- if sys.byteorder != "big":
- points.byteswap()
-
- assert len(points) == numPointsInRun
- pos += pointsSize
-
- result.extend(points)
-
- # Convert relative to absolute
- absolute = []
- current = 0
- for delta in result:
- current += delta
- absolute.append(current)
- result = absolute
- del absolute
-
- badPoints = {str(p) for p in result if p < 0 or p >= numPoints}
- if badPoints:
- log.warning(
- "point %s out of range in '%s' table"
- % (",".join(sorted(badPoints)), tableTag)
- )
- return (result, pos)
-
- def compileDeltas(self):
- deltaX = []
- deltaY = []
- if self.getCoordWidth() == 2:
- for c in self.coordinates:
- if c is None:
- continue
- deltaX.append(c[0])
- deltaY.append(c[1])
- else:
- for c in self.coordinates:
- if c is None:
- continue
- deltaX.append(c)
- bytearr = bytearray()
- self.compileDeltaValues_(deltaX, bytearr)
- self.compileDeltaValues_(deltaY, bytearr)
- return bytearr
-
- @staticmethod
- def compileDeltaValues_(deltas, bytearr=None):
- """[value1, value2, value3, ...] --> bytearray
-
- Emits a sequence of runs. Each run starts with a
- byte-sized header whose 6 least significant bits
- (header & 0x3F) indicate how many values are encoded
- in this run. The stored length is the actual length
- minus one; run lengths are thus in the range [1..64].
- If the header byte has its most significant bit (0x80)
- set, all values in this run are zero, and no data
- follows. Otherwise, the header byte is followed by
- ((header & 0x3F) + 1) signed values. If (header &
- 0x40) is clear, the delta values are stored as signed
- bytes; if (header & 0x40) is set, the delta values are
- signed 16-bit integers.
- """ # Explaining the format because the 'gvar' spec is hard to understand.
- if bytearr is None:
- bytearr = bytearray()
- pos = 0
- numDeltas = len(deltas)
- while pos < numDeltas:
- value = deltas[pos]
- if value == 0:
- pos = TupleVariation.encodeDeltaRunAsZeroes_(deltas, pos, bytearr)
- elif -128 <= value <= 127:
- pos = TupleVariation.encodeDeltaRunAsBytes_(deltas, pos, bytearr)
- else:
- pos = TupleVariation.encodeDeltaRunAsWords_(deltas, pos, bytearr)
- return bytearr
-
- @staticmethod
- def encodeDeltaRunAsZeroes_(deltas, offset, bytearr):
- pos = offset
- numDeltas = len(deltas)
- while pos < numDeltas and deltas[pos] == 0:
- pos += 1
- runLength = pos - offset
- while runLength >= 64:
- bytearr.append(DELTAS_ARE_ZERO | 63)
- runLength -= 64
- if runLength:
- bytearr.append(DELTAS_ARE_ZERO | (runLength - 1))
- return pos
-
- @staticmethod
- def encodeDeltaRunAsBytes_(deltas, offset, bytearr):
- pos = offset
- numDeltas = len(deltas)
- while pos < numDeltas:
- value = deltas[pos]
- if not (-128 <= value <= 127):
- break
- # Within a byte-encoded run of deltas, a single zero
- # is best stored literally as 0x00 value. However,
- # if are two or more zeroes in a sequence, it is
- # better to start a new run. For example, the sequence
- # of deltas [15, 15, 0, 15, 15] becomes 6 bytes
- # (04 0F 0F 00 0F 0F) when storing the zero value
- # literally, but 7 bytes (01 0F 0F 80 01 0F 0F)
- # when starting a new run.
- if value == 0 and pos + 1 < numDeltas and deltas[pos + 1] == 0:
- break
- pos += 1
- runLength = pos - offset
- while runLength >= 64:
- bytearr.append(63)
- bytearr.extend(array.array("b", deltas[offset : offset + 64]))
- offset += 64
- runLength -= 64
- if runLength:
- bytearr.append(runLength - 1)
- bytearr.extend(array.array("b", deltas[offset:pos]))
- return pos
-
- @staticmethod
- def encodeDeltaRunAsWords_(deltas, offset, bytearr):
- pos = offset
- numDeltas = len(deltas)
- while pos < numDeltas:
- value = deltas[pos]
- # Within a word-encoded run of deltas, it is easiest
- # to start a new run (with a different encoding)
- # whenever we encounter a zero value. For example,
- # the sequence [0x6666, 0, 0x7777] needs 7 bytes when
- # storing the zero literally (42 66 66 00 00 77 77),
- # and equally 7 bytes when starting a new run
- # (40 66 66 80 40 77 77).
- if value == 0:
- break
-
- # Within a word-encoded run of deltas, a single value
- # in the range (-128..127) should be encoded literally
- # because it is more compact. For example, the sequence
- # [0x6666, 2, 0x7777] becomes 7 bytes when storing
- # the value literally (42 66 66 00 02 77 77), but 8 bytes
- # when starting a new run (40 66 66 00 02 40 77 77).
- if (
- (-128 <= value <= 127)
- and pos + 1 < numDeltas
- and (-128 <= deltas[pos + 1] <= 127)
- ):
- break
- pos += 1
- runLength = pos - offset
- while runLength >= 64:
- bytearr.append(DELTAS_ARE_WORDS | 63)
- a = array.array("h", deltas[offset : offset + 64])
- if sys.byteorder != "big":
- a.byteswap()
- bytearr.extend(a)
- offset += 64
- runLength -= 64
- if runLength:
- bytearr.append(DELTAS_ARE_WORDS | (runLength - 1))
- a = array.array("h", deltas[offset:pos])
- if sys.byteorder != "big":
- a.byteswap()
- bytearr.extend(a)
- return pos
-
- @staticmethod
- def decompileDeltas_(numDeltas, data, offset):
- """(numDeltas, data, offset) --> ([delta, delta, ...], newOffset)"""
- result = []
- pos = offset
- while len(result) < numDeltas:
- runHeader = data[pos]
- pos += 1
- numDeltasInRun = (runHeader & DELTA_RUN_COUNT_MASK) + 1
- if (runHeader & DELTAS_ARE_ZERO) != 0:
- result.extend([0] * numDeltasInRun)
- else:
- if (runHeader & DELTAS_ARE_WORDS) != 0:
- deltas = array.array("h")
- deltasSize = numDeltasInRun * 2
- else:
- deltas = array.array("b")
- deltasSize = numDeltasInRun
- deltas.frombytes(data[pos : pos + deltasSize])
- if sys.byteorder != "big":
- deltas.byteswap()
- assert len(deltas) == numDeltasInRun
- pos += deltasSize
- result.extend(deltas)
- assert len(result) == numDeltas
- return (result, pos)
-
- @staticmethod
- def getTupleSize_(flags, axisCount):
- size = 4
- if (flags & EMBEDDED_PEAK_TUPLE) != 0:
- size += axisCount * 2
- if (flags & INTERMEDIATE_REGION) != 0:
- size += axisCount * 4
- return size
-
- def getCoordWidth(self):
- """Return 2 if coordinates are (x, y) as in gvar, 1 if single values
- as in cvar, or 0 if empty.
- """
- firstDelta = next((c for c in self.coordinates if c is not None), None)
- if firstDelta is None:
- return 0 # empty or has no impact
- if type(firstDelta) in (int, float):
- return 1
- if type(firstDelta) is tuple and len(firstDelta) == 2:
- return 2
- raise TypeError(
- "invalid type of delta; expected (int or float) number, or "
- "Tuple[number, number]: %r" % firstDelta
- )
-
- def scaleDeltas(self, scalar):
- if scalar == 1.0:
- return # no change
- coordWidth = self.getCoordWidth()
- self.coordinates = [
- None
- if d is None
- else d * scalar
- if coordWidth == 1
- else (d[0] * scalar, d[1] * scalar)
- for d in self.coordinates
- ]
-
- def roundDeltas(self):
- coordWidth = self.getCoordWidth()
- self.coordinates = [
- None
- if d is None
- else otRound(d)
- if coordWidth == 1
- else (otRound(d[0]), otRound(d[1]))
- for d in self.coordinates
- ]
-
- def calcInferredDeltas(self, origCoords, endPts):
- from fontTools.varLib.iup import iup_delta
-
- if self.getCoordWidth() == 1:
- raise TypeError("Only 'gvar' TupleVariation can have inferred deltas")
- if None in self.coordinates:
- if len(self.coordinates) != len(origCoords):
- raise ValueError(
- "Expected len(origCoords) == %d; found %d"
- % (len(self.coordinates), len(origCoords))
- )
- self.coordinates = iup_delta(self.coordinates, origCoords, endPts)
-
- def optimize(self, origCoords, endPts, tolerance=0.5, isComposite=False):
- from fontTools.varLib.iup import iup_delta_optimize
-
- if None in self.coordinates:
- return # already optimized
-
- deltaOpt = iup_delta_optimize(
- self.coordinates, origCoords, endPts, tolerance=tolerance
- )
- if None in deltaOpt:
- if isComposite and all(d is None for d in deltaOpt):
- # Fix for macOS composites
- # https://github.com/fonttools/fonttools/issues/1381
- deltaOpt = [(0, 0)] + [None] * (len(deltaOpt) - 1)
- # Use "optimized" version only if smaller...
- varOpt = TupleVariation(self.axes, deltaOpt)
-
- # Shouldn't matter that this is different from fvar...?
- axisTags = sorted(self.axes.keys())
- tupleData, auxData = self.compile(axisTags)
- unoptimizedLength = len(tupleData) + len(auxData)
- tupleData, auxData = varOpt.compile(axisTags)
- optimizedLength = len(tupleData) + len(auxData)
-
- if optimizedLength < unoptimizedLength:
- self.coordinates = varOpt.coordinates
-
- def __imul__(self, scalar):
- self.scaleDeltas(scalar)
- return self
-
- def __iadd__(self, other):
- if not isinstance(other, TupleVariation):
- return NotImplemented
- deltas1 = self.coordinates
- length = len(deltas1)
- deltas2 = other.coordinates
- if len(deltas2) != length:
- raise ValueError("cannot sum TupleVariation deltas with different lengths")
- # 'None' values have different meanings in gvar vs cvar TupleVariations:
- # within the gvar, when deltas are not provided explicitly for some points,
- # they need to be inferred; whereas for the 'cvar' table, if deltas are not
- # provided for some CVT values, then no adjustments are made (i.e. None == 0).
- # Thus, we cannot sum deltas for gvar TupleVariations if they contain
- # inferred inferred deltas (the latter need to be computed first using
- # 'calcInferredDeltas' method), but we can treat 'None' values in cvar
- # deltas as if they are zeros.
- if self.getCoordWidth() == 2:
- for i, d2 in zip(range(length), deltas2):
- d1 = deltas1[i]
- try:
- deltas1[i] = (d1[0] + d2[0], d1[1] + d2[1])
- except TypeError:
- raise ValueError("cannot sum gvar deltas with inferred points")
- else:
- for i, d2 in zip(range(length), deltas2):
- d1 = deltas1[i]
- if d1 is not None and d2 is not None:
- deltas1[i] = d1 + d2
- elif d1 is None and d2 is not None:
- deltas1[i] = d2
- # elif d2 is None do nothing
- return self
-
-
-def decompileSharedTuples(axisTags, sharedTupleCount, data, offset):
- result = []
- for _ in range(sharedTupleCount):
- t, offset = TupleVariation.decompileCoord_(axisTags, data, offset)
- result.append(t)
- return result
-
-
-def compileSharedTuples(
- axisTags, variations, MAX_NUM_SHARED_COORDS=TUPLE_INDEX_MASK + 1
-):
- coordCount = Counter()
- for var in variations:
- coord = var.compileCoord(axisTags)
- coordCount[coord] += 1
- # In python < 3.7, most_common() ordering is non-deterministic
- # so apply a sort to make sure the ordering is consistent.
- sharedCoords = sorted(
- coordCount.most_common(MAX_NUM_SHARED_COORDS),
- key=lambda item: (-item[1], item[0]),
- )
- return [c[0] for c in sharedCoords if c[1] > 1]
-
-
-def compileTupleVariationStore(
- variations, pointCount, axisTags, sharedTupleIndices, useSharedPoints=True
-):
- # pointCount is actually unused. Keeping for API compat.
- del pointCount
- newVariations = []
- pointDatas = []
- # Compile all points and figure out sharing if desired
- sharedPoints = None
-
- # Collect, count, and compile point-sets for all variation sets
- pointSetCount = defaultdict(int)
- for v in variations:
- points = v.getUsedPoints()
- if points is None: # Empty variations
- continue
- pointSetCount[points] += 1
- newVariations.append(v)
- pointDatas.append(points)
- variations = newVariations
- del newVariations
-
- if not variations:
- return (0, b"", b"")
-
- n = len(variations[0].coordinates)
- assert all(
- len(v.coordinates) == n for v in variations
- ), "Variation sets have different sizes"
-
- compiledPoints = {
- pointSet: TupleVariation.compilePoints(pointSet) for pointSet in pointSetCount
- }
-
- tupleVariationCount = len(variations)
- tuples = []
- data = []
-
- if useSharedPoints:
- # Find point-set which saves most bytes.
- def key(pn):
- pointSet = pn[0]
- count = pn[1]
- return len(compiledPoints[pointSet]) * (count - 1)
-
- sharedPoints = max(pointSetCount.items(), key=key)[0]
-
- data.append(compiledPoints[sharedPoints])
- tupleVariationCount |= TUPLES_SHARE_POINT_NUMBERS
-
- # b'' implies "use shared points"
- pointDatas = [
- compiledPoints[points] if points != sharedPoints else b""
- for points in pointDatas
- ]
-
- for v, p in zip(variations, pointDatas):
- thisTuple, thisData = v.compile(axisTags, sharedTupleIndices, pointData=p)
-
- tuples.append(thisTuple)
- data.append(thisData)
-
- tuples = b"".join(tuples)
- data = b"".join(data)
- return tupleVariationCount, tuples, data
-
-
-def decompileTupleVariationStore(
- tableTag,
- axisTags,
- tupleVariationCount,
- pointCount,
- sharedTuples,
- data,
- pos,
- dataPos,
-):
- numAxes = len(axisTags)
- result = []
- if (tupleVariationCount & TUPLES_SHARE_POINT_NUMBERS) != 0:
- sharedPoints, dataPos = TupleVariation.decompilePoints_(
- pointCount, data, dataPos, tableTag
- )
- else:
- sharedPoints = []
- for _ in range(tupleVariationCount & TUPLE_COUNT_MASK):
- dataSize, flags = struct.unpack(">HH", data[pos : pos + 4])
- tupleSize = TupleVariation.getTupleSize_(flags, numAxes)
- tupleData = data[pos : pos + tupleSize]
- pointDeltaData = data[dataPos : dataPos + dataSize]
- result.append(
- decompileTupleVariation_(
- pointCount,
- sharedTuples,
- sharedPoints,
- tableTag,
- axisTags,
- tupleData,
- pointDeltaData,
- )
- )
- pos += tupleSize
- dataPos += dataSize
- return result
-
-
-def decompileTupleVariation_(
- pointCount, sharedTuples, sharedPoints, tableTag, axisTags, data, tupleData
-):
- assert tableTag in ("cvar", "gvar"), tableTag
- flags = struct.unpack(">H", data[2:4])[0]
- pos = 4
- if (flags & EMBEDDED_PEAK_TUPLE) == 0:
- peak = sharedTuples[flags & TUPLE_INDEX_MASK]
- else:
- peak, pos = TupleVariation.decompileCoord_(axisTags, data, pos)
- if (flags & INTERMEDIATE_REGION) != 0:
- start, pos = TupleVariation.decompileCoord_(axisTags, data, pos)
- end, pos = TupleVariation.decompileCoord_(axisTags, data, pos)
- else:
- start, end = inferRegion_(peak)
- axes = {}
- for axis in axisTags:
- region = start[axis], peak[axis], end[axis]
- if region != (0.0, 0.0, 0.0):
- axes[axis] = region
- pos = 0
- if (flags & PRIVATE_POINT_NUMBERS) != 0:
- points, pos = TupleVariation.decompilePoints_(
- pointCount, tupleData, pos, tableTag
- )
- else:
- points = sharedPoints
-
- deltas = [None] * pointCount
-
- if tableTag == "cvar":
- deltas_cvt, pos = TupleVariation.decompileDeltas_(len(points), tupleData, pos)
- for p, delta in zip(points, deltas_cvt):
- if 0 <= p < pointCount:
- deltas[p] = delta
-
- elif tableTag == "gvar":
- deltas_x, pos = TupleVariation.decompileDeltas_(len(points), tupleData, pos)
- deltas_y, pos = TupleVariation.decompileDeltas_(len(points), tupleData, pos)
- for p, x, y in zip(points, deltas_x, deltas_y):
- if 0 <= p < pointCount:
- deltas[p] = (x, y)
-
- return TupleVariation(axes, deltas)
-
-
-def inferRegion_(peak):
- """Infer start and end for a (non-intermediate) region
-
- This helper function computes the applicability region for
- variation tuples whose INTERMEDIATE_REGION flag is not set in the
- TupleVariationHeader structure. Variation tuples apply only to
- certain regions of the variation space; outside that region, the
- tuple has no effect. To make the binary encoding more compact,
- TupleVariationHeaders can omit the intermediateStartTuple and
- intermediateEndTuple fields.
- """
- start, end = {}, {}
- for (axis, value) in peak.items():
- start[axis] = min(value, 0.0) # -0.3 --> -0.3; 0.7 --> 0.0
- end[axis] = max(value, 0.0) # -0.3 --> 0.0; 0.7 --> 0.7
- return (start, end)
diff --git a/spaces/jordonpeter01/ai-comic-factory/src/lib/computeSha256.ts b/spaces/jordonpeter01/ai-comic-factory/src/lib/computeSha256.ts
deleted file mode 100644
index cb6ef0604fca9653408012fd6cef2a58b6acaf47..0000000000000000000000000000000000000000
--- a/spaces/jordonpeter01/ai-comic-factory/src/lib/computeSha256.ts
+++ /dev/null
@@ -1,14 +0,0 @@
-import { createHash } from 'node:crypto'
-
-/**
- * Returns a SHA256 hash using SHA-3 for the given `content`.
- *
- * @see https://en.wikipedia.org/wiki/SHA-3
- *
- * @param {String} content
- *
- * @returns {String}
- */
-export function computeSha256(strContent: string) {
- return createHash('sha3-256').update(strContent).digest('hex')
-}
\ No newline at end of file
diff --git a/spaces/jpfearnworks/ai_agents/Dockerfile b/spaces/jpfearnworks/ai_agents/Dockerfile
deleted file mode 100644
index d0f48baac210b6f7c4f50792d270f77c699849d3..0000000000000000000000000000000000000000
--- a/spaces/jpfearnworks/ai_agents/Dockerfile
+++ /dev/null
@@ -1,18 +0,0 @@
-FROM python:3.9
-
-WORKDIR /app
-RUN pip install streamlit
-COPY requirements.txt requirements.txt
-RUN pip install -r requirements.txt
-
-
-COPY . .
-
-WORKDIR /app/
-
-ENV PATH="/root/.local/bin:${PATH}"
-
-EXPOSE 8501
-EXPOSE 7000
-
-CMD python server.py --port 7000
\ No newline at end of file
diff --git a/spaces/juancopi81/youtube-music-transcribe/t5x/optimizers_test.py b/spaces/juancopi81/youtube-music-transcribe/t5x/optimizers_test.py
deleted file mode 100644
index e7559b6e19536025cf2fead7b68f44ccff903ab2..0000000000000000000000000000000000000000
--- a/spaces/juancopi81/youtube-music-transcribe/t5x/optimizers_test.py
+++ /dev/null
@@ -1,317 +0,0 @@
-# Copyright 2022 The T5X Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Tests for t5x.optimizers."""
-
-import dataclasses
-import functools
-import operator
-
-from absl.testing import absltest
-from absl.testing import parameterized
-import chex
-import flax
-from flax.core import frozen_dict
-import jax
-import jax.numpy as jnp
-import numpy as np
-import optax
-import seqio
-from t5x import models
-from t5x import optimizers
-from t5x import partitioning
-from t5x import test_utils
-from t5x import trainer
-from t5x import utils
-from t5x.examples.t5 import network
-
-
-def _assert_numpy_allclose(a, b, atol=None, rtol=None):
- a, b = jnp.array(a), jnp.array(b)
- a = a.astype(np.float32) if a.dtype == jnp.bfloat16 else a
- b = b.astype(np.float32) if b.dtype == jnp.bfloat16 else b
- kw = {}
- if atol:
- kw['atol'] = atol
- if rtol:
- kw['rtol'] = rtol
- np.testing.assert_allclose(a, b, **kw)
-
-
-def check_eq(xs, ys, atol=None, rtol=None):
- xs_leaves, xs_tree = jax.tree_flatten(xs)
- ys_leaves, ys_tree = jax.tree_flatten(ys)
- assert xs_tree == ys_tree, f"Tree shapes don't match. \n{xs_tree}\n{ys_tree}"
- assert jax.tree_util.tree_all(
- jax.tree_multimap(lambda x, y: np.array(x).shape == np.array(y).shape,
- xs_leaves, ys_leaves)), "Leaves' shapes don't match."
- assert jax.tree_multimap(
- functools.partial(_assert_numpy_allclose, atol=atol, rtol=rtol),
- xs_leaves, ys_leaves)
-
-
-def flattened_state_dict(x):
- s = flax.serialization.to_state_dict(x)
- return flax.traverse_util.flatten_dict(s, sep='/')
-
-
-def tree_shape(x):
- return jax.tree_map(jnp.shape, x)
-
-
-def tree_equals(x, y):
- return jax.tree_util.tree_all(jax.tree_multimap(operator.eq, x, y))
-
-
-def get_fake_tokenized_dataset_no_pretokenized(*_, split='validation', **__):
- return test_utils.get_fake_tokenized_dataset(split=split).map(
- lambda x: {k: v for k, v in x.items() if not k.endswith('_pretokenized')})
-
-
-def get_t5_test_model(optimizer_def,
- **config_overrides) -> models.EncoderDecoderModel:
- """Returns a tiny T5 1.1 model to use for testing."""
- tiny_config = network.T5Config(
- vocab_size=128,
- dtype='bfloat16',
- emb_dim=8,
- num_heads=4,
- num_encoder_layers=2,
- num_decoder_layers=2,
- head_dim=3,
- mlp_dim=16,
- mlp_activations=('gelu', 'linear'),
- dropout_rate=0.0,
- logits_via_embedding=False,
- )
- tiny_config = dataclasses.replace(tiny_config, **config_overrides)
- vocabulary = test_utils.get_fake_vocab()
- return models.EncoderDecoderModel(
- module=network.Transformer(tiny_config),
- input_vocabulary=vocabulary,
- output_vocabulary=vocabulary,
- optimizer_def=optimizer_def)
-
-
-class BasicTest(chex.TestCase):
-
- @classmethod
- def get_params(cls):
- return frozen_dict.FrozenDict({
- 'forward': {
- 'input_layer': {
- 'embedding': jnp.zeros([16, 8], dtype=jnp.float32),
- },
- 'output_layer': {
- 'layer_norm': {
- 'scale': jnp.zeros([8], dtype=jnp.float32),
- },
- 'proj': {
- 'bias': jnp.zeros([1], dtype=jnp.float32),
- 'kernel': jnp.zeros([8, 1], dtype=jnp.float32),
- },
- },
- },
- 'loss': {
- 'loss_fn': {
- 'loss_biases': jnp.zeros([2], dtype=jnp.float32),
- },
- },
- })
-
- @classmethod
- def get_params_shapes(cls):
- return jax.tree_map(jnp.shape, cls.get_params())
-
- @classmethod
- def get_param_logical_axes(cls):
- return frozen_dict.FrozenDict({
- 'forward': {
- 'input_layer': {
- 'embedding': partitioning.PartitionSpec('vocab', 'embed'),
- },
- 'output_layer': {
- 'layer_norm': {
- 'scale': partitioning.PartitionSpec('embed',),
- },
- 'proj': {
- 'bias':
- partitioning.PartitionSpec('output_head',),
- 'kernel':
- partitioning.PartitionSpec('embed', 'output_head'),
- },
- },
- },
- 'loss': {
- 'loss_fn': {
- 'loss_biases': partitioning.PartitionSpec('unmodeled',),
- },
- },
- })
-
- def test_logical_axes_adamw(self):
- opt = optax.adamw(0.001, weight_decay=0.001)
- wrapper = optimizers.OptaxWrapper(opt)
- optimizer = wrapper.create(self.get_params())
- got = wrapper.derive_logical_axes(optimizer, self.get_param_logical_axes())
- want = optimizers.Optimizer(
- optimizer_def=wrapper,
- state=optimizers.OptimizerState(
- step=None,
- param_states=(
- optax.ScaleByAdamState(
- count=None,
- mu=self.get_param_logical_axes(),
- nu=self.get_param_logical_axes()),
- optax.EmptyState(),
- optax.EmptyState(),
- )),
- target=self.get_param_logical_axes())
- chex.assert_trees_all_equal(got, want)
-
- @parameterized.parameters(
- ('sgd', lambda: optax.sgd(1e-2, 0.0)),
- ('adam', lambda: optax.adam(1e-1)),
- ('adamw', lambda: optax.adamw(1e-1)),
- ('lamb', lambda: optax.adamw(1e-1)),
- ('rmsprop', lambda: optax.rmsprop(1e-1)),
- ('rmsprop_momentum', lambda: optax.rmsprop(5e-2, momentum=0.9)),
- ('fromage', lambda: optax.fromage(1e-2)),
- ('adabelief', lambda: optax.adabelief(1e-1)),
- ('radam', lambda: optax.radam(1e-1)),
- ('yogi', lambda: optax.yogi(1.0)),
- )
- def test_sanity_check_logical_axes(self, opt_name, opt_fn):
- opt = opt_fn()
-
- wrapper = optimizers.OptaxWrapper(opt)
- optimizer = wrapper.create(self.get_params())
- _ = wrapper.derive_logical_axes(optimizer, self.get_param_logical_axes())
-
- # TODO(rosun): basic sanity check, we just want to make sure if a param
- # name, e.g., `loss_biases` appear in the tree, the corresponding value is
- # always a PartitionSpec.
-
- def test_adamw_state_serialization(self):
- opt = optax.adamw(0.001, weight_decay=0.001)
- wrapper = optimizers.OptaxWrapper(opt)
- optimizer = wrapper.create(self.get_params())
-
- state_dict = optimizer.state_dict()
-
- chex.assert_trees_all_equal(
- frozen_dict.FrozenDict(jax.tree_map(jnp.shape, state_dict)),
- frozen_dict.FrozenDict({
- 'target': self.get_params_shapes(),
- 'state': {
- 'step': (),
- 'param_states': {
- '0': {
- 'count': (),
- 'mu': self.get_params_shapes(),
- 'nu': self.get_params_shapes(),
- },
- # NB: We eliminate empty tuple leaves from EmptyState() in
- # OptaxWrapper to avoid having the rest of T5X have to
- # correctly handle this detail. e.g. we omit these:
- # '1': {},
- # '2': {},
- },
- }
- }))
-
- new_optimizer = optimizer.restore_state(state_dict)
-
- chex.assert_trees_all_equal(optimizer, new_optimizer)
-
-
-class OptaxWrapperTest(chex.TestCase):
-
- def run_train_loop(self, optimizer_def):
- # Construct input data.
-
- ds = get_fake_tokenized_dataset_no_pretokenized(split='validation')
- ds = seqio.EncDecFeatureConverter()(
- ds, task_feature_lengths={
- 'inputs': 8,
- 'targets': 8
- })
- ds = ds.repeat().batch(8)
- ds_iter = ds.as_numpy_iterator()
- first_batch = next(ds_iter)
-
- model = get_t5_test_model(optimizer_def, vocab_size=128)
-
- learning_rate_fn = utils.create_learning_rate_scheduler()
-
- input_shapes = jax.tree_map(jnp.shape, first_batch)
- input_types = jax.tree_map(lambda x: jnp.dtype(x.dtype), first_batch)
-
- partitioner = partitioning.PjitPartitioner(
- num_partitions=2,
- logical_axis_rules=partitioning.standard_logical_axis_rules())
-
- train_state_initializer = utils.TrainStateInitializer(
- optimizer_def=model.optimizer_def,
- init_fn=model.get_initial_variables,
- input_shapes=input_shapes,
- input_types=input_types,
- partitioner=partitioner)
-
- train_state_axes = train_state_initializer.train_state_axes
- train_state = train_state_initializer.from_scratch(jax.random.PRNGKey(0))
-
- trainer_instance = trainer.Trainer(
- model,
- train_state=train_state,
- partitioner=partitioner,
- eval_names=[],
- summary_dir=None,
- train_state_axes=train_state_axes,
- rng=jax.random.PRNGKey(0),
- learning_rate_fn=learning_rate_fn,
- num_microbatches=1)
-
- chex.assert_tree_all_finite(train_state.params)
- for _ in range(2):
- trainer_instance.train(ds_iter, 1)
- chex.assert_tree_all_finite(train_state.params)
-
- # check save/restore structural equality
- restored_instance = trainer_instance.train_state.restore_state(
- trainer_instance.train_state.state_dict())
- chex.assert_tree_all_equal_structs(trainer_instance.train_state,
- restored_instance)
-
- # NOTE(levskaya): these are surprisingly slow tests on CPU.
- @parameterized.parameters(
- ('sgd', lambda: optax.sgd(1e-2, 0.0)),
- ('adam', lambda: optax.adam(1e-1)),
- ('adamw', lambda: optax.adamw(1e-1)),
- ('lamb', lambda: optax.adamw(1e-1)),
- # ('rmsprop', lambda: optax.rmsprop(1e-1)),
- # ('rmsprop_momentum', lambda: optax.rmsprop(5e-2, momentum=0.9)),
- # ('fromage', lambda: optax.fromage(1e-2)),
- ('adabelief', lambda: optax.adabelief(1e-1)),
- # ('radam', lambda: optax.radam(1e-1)),
- ('yogi', lambda: optax.yogi(1.0)),
- )
- def test_optimizer(self, opt_name, opt_fn):
- opt = opt_fn()
- optimizer_def = optimizers.OptaxWrapper(opt)
- self.run_train_loop(optimizer_def)
-
-
-if __name__ == '__main__':
- absltest.main()
diff --git a/spaces/justest/gpt4free/g4f/Provider/Providers/GetGpt.py b/spaces/justest/gpt4free/g4f/Provider/Providers/GetGpt.py
deleted file mode 100644
index 56a121f6ee5f430da7beda3b65abdea64a87c36b..0000000000000000000000000000000000000000
--- a/spaces/justest/gpt4free/g4f/Provider/Providers/GetGpt.py
+++ /dev/null
@@ -1,57 +0,0 @@
-import os
-import json
-import uuid
-import requests
-from Crypto.Cipher import AES
-from ...typing import sha256, Dict, get_type_hints
-
-url = 'https://chat.getgpt.world/'
-model = ['gpt-3.5-turbo']
-supports_stream = True
-needs_auth = False
-
-def _create_completion(model: str, messages: list, stream: bool, **kwargs):
- def encrypt(e):
- t = os.urandom(8).hex().encode('utf-8')
- n = os.urandom(8).hex().encode('utf-8')
- r = e.encode('utf-8')
- cipher = AES.new(t, AES.MODE_CBC, n)
- ciphertext = cipher.encrypt(pad_data(r))
- return ciphertext.hex() + t.decode('utf-8') + n.decode('utf-8')
-
- def pad_data(data: bytes) -> bytes:
- block_size = AES.block_size
- padding_size = block_size - len(data) % block_size
- padding = bytes([padding_size] * padding_size)
- return data + padding
-
- headers = {
- 'Content-Type': 'application/json',
- 'Referer': 'https://chat.getgpt.world/',
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
- }
-
- data = json.dumps({
- 'messages': messages,
- 'frequency_penalty': kwargs.get('frequency_penalty', 0),
- 'max_tokens': kwargs.get('max_tokens', 4000),
- 'model': 'gpt-3.5-turbo',
- 'presence_penalty': kwargs.get('presence_penalty', 0),
- 'temperature': kwargs.get('temperature', 1),
- 'top_p': kwargs.get('top_p', 1),
- 'stream': True,
- 'uuid': str(uuid.uuid4())
- })
-
- res = requests.post('https://chat.getgpt.world/api/chat/stream',
- headers=headers, json={'signature': encrypt(data)}, stream=True)
-
- for line in res.iter_lines():
- if b'content' in line:
- line_json = json.loads(line.decode('utf-8').split('data: ')[1])
- yield (line_json['choices'][0]['delta']['content'])
-
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join(
- [f'{name}: {get_type_hints(_create_completion)[name].__name__}' for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
diff --git a/spaces/katanaml-org/sparrow-ml/routers/__init__.py b/spaces/katanaml-org/sparrow-ml/routers/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/kdrkdrkdr/YuukaTTS/utils.py b/spaces/kdrkdrkdr/YuukaTTS/utils.py
deleted file mode 100644
index 4cb5b43d0ca2bae496e7871b2094f2ffb26ab642..0000000000000000000000000000000000000000
--- a/spaces/kdrkdrkdr/YuukaTTS/utils.py
+++ /dev/null
@@ -1,226 +0,0 @@
-import os
-import glob
-import sys
-import argparse
-import logging
-import json
-import subprocess
-import numpy as np
-from scipy.io.wavfile import read
-import torch
-
-MATPLOTLIB_FLAG = False
-
-logging.basicConfig(stream=sys.stdout, level=logging.ERROR)
-logger = logging
-
-
-def load_checkpoint(checkpoint_path, model, optimizer=None):
- assert os.path.isfile(checkpoint_path)
- checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
- iteration = checkpoint_dict['iteration']
- learning_rate = checkpoint_dict['learning_rate']
- if optimizer is not None:
- optimizer.load_state_dict(checkpoint_dict['optimizer'])
- saved_state_dict = checkpoint_dict['model']
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- new_state_dict = {}
- for k, v in state_dict.items():
- try:
- new_state_dict[k] = saved_state_dict[k]
- except:
- logger.info("%s is not in the checkpoint" % k)
- new_state_dict[k] = v
- if hasattr(model, 'module'):
- model.module.load_state_dict(new_state_dict)
- else:
- model.load_state_dict(new_state_dict)
- logger.info("Loaded checkpoint '{}' (iteration {})".format(
- checkpoint_path, iteration))
- return model, optimizer, learning_rate, iteration
-
-
-def plot_spectrogram_to_numpy(spectrogram):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(10, 2))
- im = ax.imshow(spectrogram, aspect="auto", origin="lower",
- interpolation='none')
- plt.colorbar(im, ax=ax)
- plt.xlabel("Frames")
- plt.ylabel("Channels")
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def plot_alignment_to_numpy(alignment, info=None):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(6, 4))
- im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower',
- interpolation='none')
- fig.colorbar(im, ax=ax)
- xlabel = 'Decoder timestep'
- if info is not None:
- xlabel += '\n\n' + info
- plt.xlabel(xlabel)
- plt.ylabel('Encoder timestep')
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def load_wav_to_torch(full_path):
- sampling_rate, data = read(full_path)
- return torch.FloatTensor(data.astype(np.float32)), sampling_rate
-
-
-def load_filepaths_and_text(filename, split="|"):
- with open(filename, encoding='utf-8') as f:
- filepaths_and_text = [line.strip().split(split) for line in f]
- return filepaths_and_text
-
-
-def get_hparams(init=True):
- parser = argparse.ArgumentParser()
- parser.add_argument('-c', '--config', type=str, default="./configs/base.json",
- help='JSON file for configuration')
- parser.add_argument('-m', '--model', type=str, required=True,
- help='Model name')
-
- args = parser.parse_args()
- model_dir = os.path.join("./logs", args.model)
-
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
-
- config_path = args.config
- config_save_path = os.path.join(model_dir, "config.json")
- if init:
- with open(config_path, "r") as f:
- data = f.read()
- with open(config_save_path, "w") as f:
- f.write(data)
- else:
- with open(config_save_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- hparams.model_dir = model_dir
- return hparams
-
-
-def get_hparams_from_dir(model_dir):
- config_save_path = os.path.join(model_dir, "config.json")
- with open(config_save_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- hparams.model_dir = model_dir
- return hparams
-
-
-def get_hparams_from_file(config_path):
- with open(config_path, "r", encoding="utf-8") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- return hparams
-
-
-def check_git_hash(model_dir):
- source_dir = os.path.dirname(os.path.realpath(__file__))
- if not os.path.exists(os.path.join(source_dir, ".git")):
- logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format(
- source_dir
- ))
- return
-
- cur_hash = subprocess.getoutput("git rev-parse HEAD")
-
- path = os.path.join(model_dir, "githash")
- if os.path.exists(path):
- saved_hash = open(path).read()
- if saved_hash != cur_hash:
- logger.warn("git hash values are different. {}(saved) != {}(current)".format(
- saved_hash[:8], cur_hash[:8]))
- else:
- open(path, "w").write(cur_hash)
-
-
-def get_logger(model_dir, filename="train.log"):
- global logger
- logger = logging.getLogger(os.path.basename(model_dir))
- logger.setLevel(logging.DEBUG)
-
- formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
- h = logging.FileHandler(os.path.join(model_dir, filename))
- h.setLevel(logging.DEBUG)
- h.setFormatter(formatter)
- logger.addHandler(h)
- return logger
-
-
-class HParams():
- def __init__(self, **kwargs):
- for k, v in kwargs.items():
- if type(v) == dict:
- v = HParams(**v)
- self[k] = v
-
- def keys(self):
- return self.__dict__.keys()
-
- def items(self):
- return self.__dict__.items()
-
- def values(self):
- return self.__dict__.values()
-
- def __len__(self):
- return len(self.__dict__)
-
- def __getitem__(self, key):
- return getattr(self, key)
-
- def __setitem__(self, key, value):
- return setattr(self, key, value)
-
- def __contains__(self, key):
- return key in self.__dict__
-
- def __repr__(self):
- return self.__dict__.__repr__()
diff --git a/spaces/keanteng/job/README.md b/spaces/keanteng/job/README.md
deleted file mode 100644
index 192285d2ef1fc83a29e4ded8a08b165463d46540..0000000000000000000000000000000000000000
--- a/spaces/keanteng/job/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Job
-emoji: ⚡
-colorFrom: gray
-colorTo: yellow
-sdk: streamlit
-sdk_version: 1.28.1
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/kermitt2/grobid/Dockerfile b/spaces/kermitt2/grobid/Dockerfile
deleted file mode 100644
index e876c6a448f5e0c6eef45b2885ceebc2eff85801..0000000000000000000000000000000000000000
--- a/spaces/kermitt2/grobid/Dockerfile
+++ /dev/null
@@ -1,7 +0,0 @@
-FROM grobid/grobid:0.8.0-SNAPSHOT
-USER root
-RUN mkdir -m 777 -p /opt/grobid/grobid-home/tmp
-RUN mkdir -m 777 -p /opt/grobid/logs
-RUN chmod -R uog+rw /data/db
-#ENTRYPOINT ["/tini", "-s", "--"]
-CMD ["./grobid-service/bin/grobid-service"]
diff --git a/spaces/kevinwang676/ControlNet-with-GPT-4/app.py b/spaces/kevinwang676/ControlNet-with-GPT-4/app.py
deleted file mode 100644
index 73dd57dcc6b5595c0d4822419bdd5eb657d56e2c..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/ControlNet-with-GPT-4/app.py
+++ /dev/null
@@ -1,151 +0,0 @@
-#!/usr/bin/env python
-
-from __future__ import annotations
-
-import gradio as gr
-import torch
-import re
-import openai
-from cairosvg import svg2png
-
-from app_canny import create_demo as create_demo_canny
-from app_depth import create_demo as create_demo_depth
-from app_ip2p import create_demo as create_demo_ip2p
-from app_lineart import create_demo as create_demo_lineart
-from app_mlsd import create_demo as create_demo_mlsd
-from app_normal import create_demo as create_demo_normal
-from app_openpose import create_demo as create_demo_openpose
-from app_scribble import create_demo as create_demo_scribble
-from app_scribble_interactive import create_demo as create_demo_scribble_interactive
-from app_segmentation import create_demo as create_demo_segmentation
-from app_shuffle import create_demo as create_demo_shuffle
-from app_softedge import create_demo as create_demo_softedge
-from model import Model
-from settings import ALLOW_CHANGING_BASE_MODEL, DEFAULT_MODEL_ID, SHOW_DUPLICATE_BUTTON
-
-DESCRIPTION = "# ControlNet v1.1"
-
-if not torch.cuda.is_available():
- DESCRIPTION += "\nRunning on CPU 🥶 This demo does not work on CPU.
"
-
-model = Model(base_model_id=DEFAULT_MODEL_ID, task_name="Canny")
-
-def gpt_control(apikey, prompt):
-
- openai.api_key = apikey
-
- # gpt
- messages = [{"role": "system", "content": "You are an SVG expert with years of experience and multiple contributions to the SVG project. Based on the prompt and the description, please generate the corresponding SVG code."},
- {"role": "user", "content": f"""Provide only the shell command without any explanations.
-The current objective is below. Reply with the SVG code only:
-OBJECTIVE: {prompt}
-YOUR SVG CODE:
-"""}]
-
- completion = openai.ChatCompletion.create(
- model = "gpt-4",
- messages = messages
- )
-
- chat_response = completion.choices[0].message.content
-
- code = re.findall('<.*>', chat_response)
- code_new = '\n'.join(code)
-
- svg_code = f"""
- {code_new}
- """
- svg2png(bytestring=svg_code,write_to='output.png')
-
- return 'output.png'
-
-
-with gr.Blocks(css="style.css") as demo:
- gr.HTML(""
- "🌁🪄🌃 - ControlNet with GPT-4
"
- "")
-
- gr.Markdown("## 🌟 Born to Create: Controllable Text-to-Image Generation with GPT-4")
-
- gr.DuplicateButton(
- value="Duplicate Space for private use",
- elem_id="duplicate-button",
- visible=SHOW_DUPLICATE_BUTTON,
- )
-
- with gr.Tab("GPT-4 Control"):
- with gr.Row():
- with gr.Column():
- inp1 = gr.Textbox(label="OpenAI API Key", type="password")
- inp2 = gr.Textbox(label="Position Prompt (as simple as possible)")
- btn1 = gr.Button("GPT-4 Control", variant="primary")
- with gr.Column():
- out1 = gr.Image(label="Output Image", type="pil", interactive=True)
-
- btn1.click(gpt_control, [inp1, inp2], [out1])
-
-
- with gr.Tabs():
- with gr.TabItem("Canny"):
- create_demo_canny(model.process_canny)
- with gr.TabItem("MLSD"):
- create_demo_mlsd(model.process_mlsd)
- with gr.TabItem("Scribble"):
- create_demo_scribble(model.process_scribble)
- with gr.TabItem("Scribble Interactive"):
- create_demo_scribble_interactive(model.process_scribble_interactive)
- with gr.TabItem("SoftEdge"):
- create_demo_softedge(model.process_softedge)
- with gr.TabItem("OpenPose"):
- create_demo_openpose(model.process_openpose)
- with gr.TabItem("Segmentation"):
- create_demo_segmentation(model.process_segmentation)
- with gr.TabItem("Depth"):
- create_demo_depth(model.process_depth)
- with gr.TabItem("Normal map"):
- create_demo_normal(model.process_normal)
- with gr.TabItem("Lineart"):
- create_demo_lineart(model.process_lineart)
- with gr.TabItem("Content Shuffle"):
- create_demo_shuffle(model.process_shuffle)
- with gr.TabItem("Instruct Pix2Pix"):
- create_demo_ip2p(model.process_ip2p)
-
- with gr.Accordion(label="Base model", open=False):
- with gr.Row():
- with gr.Column(scale=5):
- current_base_model = gr.Text(label="Current base model")
- with gr.Column(scale=1):
- check_base_model_button = gr.Button("Check current base model")
- with gr.Row():
- with gr.Column(scale=5):
- new_base_model_id = gr.Text(
- label="New base model",
- max_lines=1,
- placeholder="runwayml/stable-diffusion-v1-5",
- info="The base model must be compatible with Stable Diffusion v1.5.",
- interactive=ALLOW_CHANGING_BASE_MODEL,
- )
- with gr.Column(scale=1):
- change_base_model_button = gr.Button("Change base model", interactive=ALLOW_CHANGING_BASE_MODEL)
- if not ALLOW_CHANGING_BASE_MODEL:
- gr.Markdown(
- """The base model is not allowed to be changed in this Space so as not to slow down the demo, but it can be changed if you duplicate the Space."""
- )
-
- check_base_model_button.click(
- fn=lambda: model.base_model_id,
- outputs=current_base_model,
- queue=False,
- api_name="check_base_model",
- )
- gr.on(
- triggers=[new_base_model_id.submit, change_base_model_button.click],
- fn=model.set_base_model,
- inputs=new_base_model_id,
- outputs=current_base_model,
- api_name=False,
- )
-
-if __name__ == "__main__":
- demo.queue(max_size=20).launch()
diff --git a/spaces/kevinwang676/FreeVC/app.py b/spaces/kevinwang676/FreeVC/app.py
deleted file mode 100644
index ffd212c8e9295f1922b393b6a80596aafc6162d4..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/FreeVC/app.py
+++ /dev/null
@@ -1,481 +0,0 @@
-import os
-import torch
-import librosa
-import gradio as gr
-from scipy.io.wavfile import write
-from transformers import WavLMModel
-
-import utils
-from models import SynthesizerTrn
-from mel_processing import mel_spectrogram_torch
-from speaker_encoder.voice_encoder import SpeakerEncoder
-
-import time
-from textwrap import dedent
-
-import mdtex2html
-from loguru import logger
-from transformers import AutoModel, AutoTokenizer
-
-from tts_voice import tts_order_voice
-import edge_tts
-import tempfile
-import anyio
-
-'''
-def get_wavlm():
- os.system('gdown https://drive.google.com/uc?id=12-cB34qCTvByWT-QtOcZaqwwO21FLSqU')
- shutil.move('WavLM-Large.pt', 'wavlm')
-'''
-
-device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
-smodel = SpeakerEncoder('speaker_encoder/ckpt/pretrained_bak_5805000.pt')
-
-print("Loading FreeVC(24k)...")
-hps = utils.get_hparams_from_file("configs/freevc-24.json")
-freevc_24 = SynthesizerTrn(
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- **hps.model).to(device)
-_ = freevc_24.eval()
-_ = utils.load_checkpoint("checkpoints/freevc-24.pth", freevc_24, None)
-
-print("Loading WavLM for content...")
-cmodel = WavLMModel.from_pretrained("microsoft/wavlm-large").to(device)
-
-def convert(model, src, tgt):
- with torch.no_grad():
- # tgt
- wav_tgt, _ = librosa.load(tgt, sr=hps.data.sampling_rate)
- wav_tgt, _ = librosa.effects.trim(wav_tgt, top_db=20)
- if model == "FreeVC" or model == "FreeVC (24kHz)":
- g_tgt = smodel.embed_utterance(wav_tgt)
- g_tgt = torch.from_numpy(g_tgt).unsqueeze(0).to(device)
- else:
- wav_tgt = torch.from_numpy(wav_tgt).unsqueeze(0).to(device)
- mel_tgt = mel_spectrogram_torch(
- wav_tgt,
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.hop_length,
- hps.data.win_length,
- hps.data.mel_fmin,
- hps.data.mel_fmax
- )
- # src
- wav_src, _ = librosa.load(src, sr=hps.data.sampling_rate)
- wav_src = torch.from_numpy(wav_src).unsqueeze(0).to(device)
- c = cmodel(wav_src).last_hidden_state.transpose(1, 2).to(device)
- # infer
- if model == "FreeVC":
- audio = freevc.infer(c, g=g_tgt)
- elif model == "FreeVC-s":
- audio = freevc_s.infer(c, mel=mel_tgt)
- else:
- audio = freevc_24.infer(c, g=g_tgt)
- audio = audio[0][0].data.cpu().float().numpy()
- if model == "FreeVC" or model == "FreeVC-s":
- write("out.wav", hps.data.sampling_rate, audio)
- else:
- write("out.wav", 24000, audio)
- out = "out.wav"
- return out
-
-# GLM2
-
-language_dict = tts_order_voice
-
-# fix timezone in Linux
-os.environ["TZ"] = "Asia/Shanghai"
-try:
- time.tzset() # type: ignore # pylint: disable=no-member
-except Exception:
- # Windows
- logger.warning("Windows, cant run time.tzset()")
-
-# model_name = "THUDM/chatglm2-6b"
-model_name = "THUDM/chatglm2-6b-int4"
-
-RETRY_FLAG = False
-
-tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
-
-# model = AutoModel.from_pretrained(model_name, trust_remote_code=True).cuda()
-
-# 4/8 bit
-# model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(4).cuda()
-
-has_cuda = torch.cuda.is_available()
-
-# has_cuda = False # force cpu
-
-if has_cuda:
- model_glm = (
- AutoModel.from_pretrained(model_name, trust_remote_code=True).cuda().half()
- ) # 3.92G
-else:
- model_glm = AutoModel.from_pretrained(
- model_name, trust_remote_code=True
- ).float() # .float() .half().float()
-
-model_glm = model_glm.eval()
-
-_ = """Override Chatbot.postprocess"""
-
-
-def postprocess(self, y):
- if y is None:
- return []
- for i, (message, response) in enumerate(y):
- y[i] = (
- None if message is None else mdtex2html.convert((message)),
- None if response is None else mdtex2html.convert(response),
- )
- return y
-
-
-gr.Chatbot.postprocess = postprocess
-
-
-def parse_text(text):
- """copy from https://github.com/GaiZhenbiao/ChuanhuChatGPT/"""
- lines = text.split("\n")
- lines = [line for line in lines if line != ""]
- count = 0
- for i, line in enumerate(lines):
- if "```" in line:
- count += 1
- items = line.split("`")
- if count % 2 == 1:
- lines[i] = f''
- else:
- lines[i] = "
"
- else:
- if i > 0:
- if count % 2 == 1:
- line = line.replace("`", r"\`")
- line = line.replace("<", "<")
- line = line.replace(">", ">")
- line = line.replace(" ", " ")
- line = line.replace("*", "*")
- line = line.replace("_", "_")
- line = line.replace("-", "-")
- line = line.replace(".", ".")
- line = line.replace("!", "!")
- line = line.replace("(", "(")
- line = line.replace(")", ")")
- line = line.replace("$", "$")
- lines[i] = "
" + line
- text = "".join(lines)
- return text
-
-
-def predict(
- RETRY_FLAG, input, chatbot, max_length, top_p, temperature, history, past_key_values
-):
- try:
- chatbot.append((parse_text(input), ""))
- except Exception as exc:
- logger.error(exc)
- logger.debug(f"{chatbot=}")
- _ = """
- if chatbot:
- chatbot[-1] = (parse_text(input), str(exc))
- yield chatbot, history, past_key_values
- # """
- yield chatbot, history, past_key_values
-
- for response, history, past_key_values in model_glm.stream_chat(
- tokenizer,
- input,
- history,
- past_key_values=past_key_values,
- return_past_key_values=True,
- max_length=max_length,
- top_p=top_p,
- temperature=temperature,
- ):
- chatbot[-1] = (parse_text(input), parse_text(response))
- # chatbot[-1][-1] = parse_text(response)
-
- yield chatbot, history, past_key_values, parse_text(response)
-
-
-def trans_api(input, max_length=4096, top_p=0.8, temperature=0.2):
- if max_length < 10:
- max_length = 4096
- if top_p < 0.1 or top_p > 1:
- top_p = 0.85
- if temperature <= 0 or temperature > 1:
- temperature = 0.01
- try:
- res, _ = model_glm.chat(
- tokenizer,
- input,
- history=[],
- past_key_values=None,
- max_length=max_length,
- top_p=top_p,
- temperature=temperature,
- )
- # logger.debug(f"{res=} \n{_=}")
- except Exception as exc:
- logger.error(f"{exc=}")
- res = str(exc)
-
- return res
-
-
-def reset_user_input():
- return gr.update(value="")
-
-
-def reset_state():
- return [], [], None, ""
-
-
-# Delete last turn
-def delete_last_turn(chat, history):
- if chat and history:
- chat.pop(-1)
- history.pop(-1)
- return chat, history
-
-
-# Regenerate response
-def retry_last_answer(
- user_input, chatbot, max_length, top_p, temperature, history, past_key_values
-):
- if chatbot and history:
- # Removing the previous conversation from chat
- chatbot.pop(-1)
- # Setting up a flag to capture a retry
- RETRY_FLAG = True
- # Getting last message from user
- user_input = history[-1][0]
- # Removing bot response from the history
- history.pop(-1)
-
- yield from predict(
- RETRY_FLAG, # type: ignore
- user_input,
- chatbot,
- max_length,
- top_p,
- temperature,
- history,
- past_key_values,
- )
-
-# print
-
-def print(text):
- return text
-
-# TTS
-
-async def text_to_speech_edge(text, language_code):
- voice = language_dict[language_code]
- communicate = edge_tts.Communicate(text, voice)
- with tempfile.NamedTemporaryFile(delete=False, suffix=".mp3") as tmp_file:
- tmp_path = tmp_file.name
-
- await communicate.save(tmp_path)
-
- return tmp_path
-
-
-with gr.Blocks(title="ChatGLM2-6B-int4", theme=gr.themes.Soft(text_size="sm")) as demo:
- gr.HTML(""
- "🥳💕🎶 - ChatGLM2 + 声音克隆:和你喜欢的角色畅所欲言吧!
"
- "")
- gr.Markdown("## 💡 - 第二代ChatGLM大语言模型 + FreeVC变声,为您打造独一无二的沉浸式对话体验,支持中英双语")
- gr.Markdown("## 🌊 - 更多精彩应用,尽在[滔滔AI](http://www.talktalkai.com);滔滔AI,为爱滔滔!💕")
- gr.Markdown("### ⭐ - 如果您喜欢这个程序,欢迎给我的[Github项目](https://github.com/KevinWang676/ChatGLM2-Voice-Cloning)点赞支持!")
-
- with gr.Accordion("📒 相关信息", open=False):
- _ = f""" ChatGLM2的可选参数信息:
- * Low temperature: responses will be more deterministic and focused; High temperature: responses more creative.
- * Suggested temperatures -- translation: up to 0.3; chatting: > 0.4
- * Top P controls dynamic vocabulary selection based on context.\n
- 如果您想让ChatGLM2进行角色扮演并与之对话,请先输入恰当的提示词,如“请你扮演成动漫角色蜡笔小新并和我进行对话”;您也可以为ChatGLM2提供自定义的角色设定\n
- 当您使用声音克隆功能时,请先在此程序的对应位置上传一段您喜欢的音频
- """
- gr.Markdown(dedent(_))
- chatbot = gr.Chatbot(height=300)
- with gr.Row():
- with gr.Column(scale=4):
- with gr.Column(scale=12):
- user_input = gr.Textbox(
- label="请在此处和GLM2聊天 (按回车键即可发送)",
- placeholder="聊点什么吧",
- )
- RETRY_FLAG = gr.Checkbox(value=False, visible=False)
- with gr.Column(min_width=32, scale=1):
- with gr.Row():
- submitBtn = gr.Button("开始和GLM2交流吧", variant="primary")
- deleteBtn = gr.Button("删除最新一轮对话", variant="secondary")
- retryBtn = gr.Button("重新生成最新一轮对话", variant="secondary")
-
- with gr.Accordion("🔧 更多设置", open=False):
- with gr.Row():
- emptyBtn = gr.Button("清空所有聊天记录")
- max_length = gr.Slider(
- 0,
- 32768,
- value=8192,
- step=1.0,
- label="Maximum length",
- interactive=True,
- )
- top_p = gr.Slider(
- 0, 1, value=0.85, step=0.01, label="Top P", interactive=True
- )
- temperature = gr.Slider(
- 0.01, 1, value=0.95, step=0.01, label="Temperature", interactive=True
- )
-
-
- with gr.Row():
- test1 = gr.Textbox(label="GLM2的最新回答 (可编辑)", lines = 3)
- with gr.Column():
- language = gr.Dropdown(choices=list(language_dict.keys()), value="普通话 (中国大陆)-Xiaoxiao-女", label="请选择文本对应的语言及您喜欢的说话人")
- tts_btn = gr.Button("生成对应的音频吧", variant="primary")
- output_audio = gr.Audio(type="filepath", label="为您生成的音频", interactive=False)
-
- tts_btn.click(text_to_speech_edge, inputs=[test1, language], outputs=[output_audio])
-
- with gr.Row():
- model_choice = gr.Dropdown(choices=["FreeVC", "FreeVC-s", "FreeVC (24kHz)"], value="FreeVC (24kHz)", label="Model", visible=False)
- audio1 = output_audio
- audio2 = gr.Audio(label="请上传您喜欢的声音进行声音克隆", type='filepath')
- clone_btn = gr.Button("开始AI声音克隆吧", variant="primary")
- audio_cloned = gr.Audio(label="为您生成的专属声音克隆音频", type='filepath')
-
- clone_btn.click(convert, inputs=[model_choice, audio1, audio2], outputs=[audio_cloned])
-
- history = gr.State([])
- past_key_values = gr.State(None)
-
- user_input.submit(
- predict,
- [
- RETRY_FLAG,
- user_input,
- chatbot,
- max_length,
- top_p,
- temperature,
- history,
- past_key_values,
- ],
- [chatbot, history, past_key_values, test1],
- show_progress="full",
- )
- submitBtn.click(
- predict,
- [
- RETRY_FLAG,
- user_input,
- chatbot,
- max_length,
- top_p,
- temperature,
- history,
- past_key_values,
- ],
- [chatbot, history, past_key_values, test1],
- show_progress="full",
- api_name="predict",
- )
- submitBtn.click(reset_user_input, [], [user_input])
-
- emptyBtn.click(
- reset_state, outputs=[chatbot, history, past_key_values, test1], show_progress="full"
- )
-
- retryBtn.click(
- retry_last_answer,
- inputs=[
- user_input,
- chatbot,
- max_length,
- top_p,
- temperature,
- history,
- past_key_values,
- ],
- # outputs = [chatbot, history, last_user_message, user_message]
- outputs=[chatbot, history, past_key_values, test1],
- )
- deleteBtn.click(delete_last_turn, [chatbot, history], [chatbot, history])
-
- with gr.Accordion("📔 提示词示例", open=False):
- etext = """In America, where cars are an important part of the national psyche, a decade ago people had suddenly started to drive less, which had not happened since the oil shocks of the 1970s. """
- examples = gr.Examples(
- examples=[
- ["Explain the plot of Cinderella in a sentence."],
- [
- "How long does it take to become proficient in French, and what are the best methods for retaining information?"
- ],
- ["What are some common mistakes to avoid when writing code?"],
- ["Build a prompt to generate a beautiful portrait of a horse"],
- ["Suggest four metaphors to describe the benefits of AI"],
- ["Write a pop song about leaving home for the sandy beaches."],
- ["Write a summary demonstrating my ability to tame lions"],
- ["鲁迅和周树人什么关系"],
- ["从前有一头牛,这头牛后面有什么?"],
- ["正无穷大加一大于正无穷大吗?"],
- ["正无穷大加正无穷大大于正无穷大吗?"],
- ["-2的平方根等于什么"],
- ["树上有5只鸟,猎人开枪打死了一只。树上还有几只鸟?"],
- ["树上有11只鸟,猎人开枪打死了一只。树上还有几只鸟?提示:需考虑鸟可能受惊吓飞走。"],
- ["鲁迅和周树人什么关系 用英文回答"],
- ["以红楼梦的行文风格写一张委婉的请假条。不少于320字。"],
- [f"{etext} 翻成中文,列出3个版本"],
- [f"{etext} \n 翻成中文,保留原意,但使用文学性的语言。不要写解释。列出3个版本"],
- ["js 判断一个数是不是质数"],
- ["js 实现python 的 range(10)"],
- ["js 实现python 的 [*(range(10)]"],
- ["假定 1 + 2 = 4, 试求 7 + 8"],
- ["Erkläre die Handlung von Cinderella in einem Satz."],
- ["Erkläre die Handlung von Cinderella in einem Satz. Auf Deutsch"],
- ],
- inputs=[user_input],
- examples_per_page=30,
- )
-
- with gr.Accordion("For Chat/Translation API", open=False, visible=False):
- input_text = gr.Text()
- tr_btn = gr.Button("Go", variant="primary")
- out_text = gr.Text()
- tr_btn.click(
- trans_api,
- [input_text, max_length, top_p, temperature],
- out_text,
- # show_progress="full",
- api_name="tr",
- )
- _ = """
- input_text.submit(
- trans_api,
- [input_text, max_length, top_p, temperature],
- out_text,
- show_progress="full",
- api_name="tr1",
- )
- # """
-
- gr.Markdown("### 注意❗:请不要生成会对个人以及组织造成侵害的内容,此程序仅供科研、学习及个人娱乐使用。")
- gr.Markdown("💡 - 如何使用此程序:输入您对ChatGLM的提问后,依次点击“开始和GLM2交流吧”、“生成对应的音频吧”、“开始AI声音克隆吧”三个按键即可;使用声音克隆功能时,请先上传一段您喜欢的音频")
- gr.HTML('''
-
- ''')
-
-
-demo.queue().launch(show_error=True, debug=True)
diff --git a/spaces/kevinwang676/SadTalker/src/facerender/modules/generator.py b/spaces/kevinwang676/SadTalker/src/facerender/modules/generator.py
deleted file mode 100644
index 5a9edcb3b328d3afc99072b2461d7ca69919f813..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/SadTalker/src/facerender/modules/generator.py
+++ /dev/null
@@ -1,255 +0,0 @@
-import torch
-from torch import nn
-import torch.nn.functional as F
-from src.facerender.modules.util import ResBlock2d, SameBlock2d, UpBlock2d, DownBlock2d, ResBlock3d, SPADEResnetBlock
-from src.facerender.modules.dense_motion import DenseMotionNetwork
-
-
-class OcclusionAwareGenerator(nn.Module):
- """
- Generator follows NVIDIA architecture.
- """
-
- def __init__(self, image_channel, feature_channel, num_kp, block_expansion, max_features, num_down_blocks, reshape_channel, reshape_depth,
- num_resblocks, estimate_occlusion_map=False, dense_motion_params=None, estimate_jacobian=False):
- super(OcclusionAwareGenerator, self).__init__()
-
- if dense_motion_params is not None:
- self.dense_motion_network = DenseMotionNetwork(num_kp=num_kp, feature_channel=feature_channel,
- estimate_occlusion_map=estimate_occlusion_map,
- **dense_motion_params)
- else:
- self.dense_motion_network = None
-
- self.first = SameBlock2d(image_channel, block_expansion, kernel_size=(7, 7), padding=(3, 3))
-
- down_blocks = []
- for i in range(num_down_blocks):
- in_features = min(max_features, block_expansion * (2 ** i))
- out_features = min(max_features, block_expansion * (2 ** (i + 1)))
- down_blocks.append(DownBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
- self.down_blocks = nn.ModuleList(down_blocks)
-
- self.second = nn.Conv2d(in_channels=out_features, out_channels=max_features, kernel_size=1, stride=1)
-
- self.reshape_channel = reshape_channel
- self.reshape_depth = reshape_depth
-
- self.resblocks_3d = torch.nn.Sequential()
- for i in range(num_resblocks):
- self.resblocks_3d.add_module('3dr' + str(i), ResBlock3d(reshape_channel, kernel_size=3, padding=1))
-
- out_features = block_expansion * (2 ** (num_down_blocks))
- self.third = SameBlock2d(max_features, out_features, kernel_size=(3, 3), padding=(1, 1), lrelu=True)
- self.fourth = nn.Conv2d(in_channels=out_features, out_channels=out_features, kernel_size=1, stride=1)
-
- self.resblocks_2d = torch.nn.Sequential()
- for i in range(num_resblocks):
- self.resblocks_2d.add_module('2dr' + str(i), ResBlock2d(out_features, kernel_size=3, padding=1))
-
- up_blocks = []
- for i in range(num_down_blocks):
- in_features = max(block_expansion, block_expansion * (2 ** (num_down_blocks - i)))
- out_features = max(block_expansion, block_expansion * (2 ** (num_down_blocks - i - 1)))
- up_blocks.append(UpBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
- self.up_blocks = nn.ModuleList(up_blocks)
-
- self.final = nn.Conv2d(block_expansion, image_channel, kernel_size=(7, 7), padding=(3, 3))
- self.estimate_occlusion_map = estimate_occlusion_map
- self.image_channel = image_channel
-
- def deform_input(self, inp, deformation):
- _, d_old, h_old, w_old, _ = deformation.shape
- _, _, d, h, w = inp.shape
- if d_old != d or h_old != h or w_old != w:
- deformation = deformation.permute(0, 4, 1, 2, 3)
- deformation = F.interpolate(deformation, size=(d, h, w), mode='trilinear')
- deformation = deformation.permute(0, 2, 3, 4, 1)
- return F.grid_sample(inp, deformation)
-
- def forward(self, source_image, kp_driving, kp_source):
- # Encoding (downsampling) part
- out = self.first(source_image)
- for i in range(len(self.down_blocks)):
- out = self.down_blocks[i](out)
- out = self.second(out)
- bs, c, h, w = out.shape
- # print(out.shape)
- feature_3d = out.view(bs, self.reshape_channel, self.reshape_depth, h ,w)
- feature_3d = self.resblocks_3d(feature_3d)
-
- # Transforming feature representation according to deformation and occlusion
- output_dict = {}
- if self.dense_motion_network is not None:
- dense_motion = self.dense_motion_network(feature=feature_3d, kp_driving=kp_driving,
- kp_source=kp_source)
- output_dict['mask'] = dense_motion['mask']
-
- if 'occlusion_map' in dense_motion:
- occlusion_map = dense_motion['occlusion_map']
- output_dict['occlusion_map'] = occlusion_map
- else:
- occlusion_map = None
- deformation = dense_motion['deformation']
- out = self.deform_input(feature_3d, deformation)
-
- bs, c, d, h, w = out.shape
- out = out.view(bs, c*d, h, w)
- out = self.third(out)
- out = self.fourth(out)
-
- if occlusion_map is not None:
- if out.shape[2] != occlusion_map.shape[2] or out.shape[3] != occlusion_map.shape[3]:
- occlusion_map = F.interpolate(occlusion_map, size=out.shape[2:], mode='bilinear')
- out = out * occlusion_map
-
- # output_dict["deformed"] = self.deform_input(source_image, deformation) # 3d deformation cannot deform 2d image
-
- # Decoding part
- out = self.resblocks_2d(out)
- for i in range(len(self.up_blocks)):
- out = self.up_blocks[i](out)
- out = self.final(out)
- out = F.sigmoid(out)
-
- output_dict["prediction"] = out
-
- return output_dict
-
-
-class SPADEDecoder(nn.Module):
- def __init__(self):
- super().__init__()
- ic = 256
- oc = 64
- norm_G = 'spadespectralinstance'
- label_nc = 256
-
- self.fc = nn.Conv2d(ic, 2 * ic, 3, padding=1)
- self.G_middle_0 = SPADEResnetBlock(2 * ic, 2 * ic, norm_G, label_nc)
- self.G_middle_1 = SPADEResnetBlock(2 * ic, 2 * ic, norm_G, label_nc)
- self.G_middle_2 = SPADEResnetBlock(2 * ic, 2 * ic, norm_G, label_nc)
- self.G_middle_3 = SPADEResnetBlock(2 * ic, 2 * ic, norm_G, label_nc)
- self.G_middle_4 = SPADEResnetBlock(2 * ic, 2 * ic, norm_G, label_nc)
- self.G_middle_5 = SPADEResnetBlock(2 * ic, 2 * ic, norm_G, label_nc)
- self.up_0 = SPADEResnetBlock(2 * ic, ic, norm_G, label_nc)
- self.up_1 = SPADEResnetBlock(ic, oc, norm_G, label_nc)
- self.conv_img = nn.Conv2d(oc, 3, 3, padding=1)
- self.up = nn.Upsample(scale_factor=2)
-
- def forward(self, feature):
- seg = feature
- x = self.fc(feature)
- x = self.G_middle_0(x, seg)
- x = self.G_middle_1(x, seg)
- x = self.G_middle_2(x, seg)
- x = self.G_middle_3(x, seg)
- x = self.G_middle_4(x, seg)
- x = self.G_middle_5(x, seg)
- x = self.up(x)
- x = self.up_0(x, seg) # 256, 128, 128
- x = self.up(x)
- x = self.up_1(x, seg) # 64, 256, 256
-
- x = self.conv_img(F.leaky_relu(x, 2e-1))
- # x = torch.tanh(x)
- x = F.sigmoid(x)
-
- return x
-
-
-class OcclusionAwareSPADEGenerator(nn.Module):
-
- def __init__(self, image_channel, feature_channel, num_kp, block_expansion, max_features, num_down_blocks, reshape_channel, reshape_depth,
- num_resblocks, estimate_occlusion_map=False, dense_motion_params=None, estimate_jacobian=False):
- super(OcclusionAwareSPADEGenerator, self).__init__()
-
- if dense_motion_params is not None:
- self.dense_motion_network = DenseMotionNetwork(num_kp=num_kp, feature_channel=feature_channel,
- estimate_occlusion_map=estimate_occlusion_map,
- **dense_motion_params)
- else:
- self.dense_motion_network = None
-
- self.first = SameBlock2d(image_channel, block_expansion, kernel_size=(3, 3), padding=(1, 1))
-
- down_blocks = []
- for i in range(num_down_blocks):
- in_features = min(max_features, block_expansion * (2 ** i))
- out_features = min(max_features, block_expansion * (2 ** (i + 1)))
- down_blocks.append(DownBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
- self.down_blocks = nn.ModuleList(down_blocks)
-
- self.second = nn.Conv2d(in_channels=out_features, out_channels=max_features, kernel_size=1, stride=1)
-
- self.reshape_channel = reshape_channel
- self.reshape_depth = reshape_depth
-
- self.resblocks_3d = torch.nn.Sequential()
- for i in range(num_resblocks):
- self.resblocks_3d.add_module('3dr' + str(i), ResBlock3d(reshape_channel, kernel_size=3, padding=1))
-
- out_features = block_expansion * (2 ** (num_down_blocks))
- self.third = SameBlock2d(max_features, out_features, kernel_size=(3, 3), padding=(1, 1), lrelu=True)
- self.fourth = nn.Conv2d(in_channels=out_features, out_channels=out_features, kernel_size=1, stride=1)
-
- self.estimate_occlusion_map = estimate_occlusion_map
- self.image_channel = image_channel
-
- self.decoder = SPADEDecoder()
-
- def deform_input(self, inp, deformation):
- _, d_old, h_old, w_old, _ = deformation.shape
- _, _, d, h, w = inp.shape
- if d_old != d or h_old != h or w_old != w:
- deformation = deformation.permute(0, 4, 1, 2, 3)
- deformation = F.interpolate(deformation, size=(d, h, w), mode='trilinear')
- deformation = deformation.permute(0, 2, 3, 4, 1)
- return F.grid_sample(inp, deformation)
-
- def forward(self, source_image, kp_driving, kp_source):
- # Encoding (downsampling) part
- out = self.first(source_image)
- for i in range(len(self.down_blocks)):
- out = self.down_blocks[i](out)
- out = self.second(out)
- bs, c, h, w = out.shape
- # print(out.shape)
- feature_3d = out.view(bs, self.reshape_channel, self.reshape_depth, h ,w)
- feature_3d = self.resblocks_3d(feature_3d)
-
- # Transforming feature representation according to deformation and occlusion
- output_dict = {}
- if self.dense_motion_network is not None:
- dense_motion = self.dense_motion_network(feature=feature_3d, kp_driving=kp_driving,
- kp_source=kp_source)
- output_dict['mask'] = dense_motion['mask']
-
- # import pdb; pdb.set_trace()
-
- if 'occlusion_map' in dense_motion:
- occlusion_map = dense_motion['occlusion_map']
- output_dict['occlusion_map'] = occlusion_map
- else:
- occlusion_map = None
- deformation = dense_motion['deformation']
- out = self.deform_input(feature_3d, deformation)
-
- bs, c, d, h, w = out.shape
- out = out.view(bs, c*d, h, w)
- out = self.third(out)
- out = self.fourth(out)
-
- # occlusion_map = torch.where(occlusion_map < 0.95, 0, occlusion_map)
-
- if occlusion_map is not None:
- if out.shape[2] != occlusion_map.shape[2] or out.shape[3] != occlusion_map.shape[3]:
- occlusion_map = F.interpolate(occlusion_map, size=out.shape[2:], mode='bilinear')
- out = out * occlusion_map
-
- # Decoding part
- out = self.decoder(out)
-
- output_dict["prediction"] = out
-
- return output_dict
\ No newline at end of file
diff --git a/spaces/kevinwang676/VALLE/modules/transformer.py b/spaces/kevinwang676/VALLE/modules/transformer.py
deleted file mode 100644
index ea8826b193c5053cb8ae74312f65ac95fe440350..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/VALLE/modules/transformer.py
+++ /dev/null
@@ -1,683 +0,0 @@
-import copy
-import numbers
-from functools import partial
-from typing import Any, Callable, List, Optional, Tuple, Union
-
-import torch
-from torch import Tensor, nn
-from torch.nn import functional as F
-
-from .activation import MultiheadAttention
-from .scaling import ActivationBalancer, BalancedDoubleSwish
-from .scaling import BasicNorm as _BasicNorm
-
-_shape_t = Union[int, List[int], torch.Size]
-
-
-class LayerNorm(nn.Module):
- __constants__ = ["normalized_shape", "eps", "elementwise_affine"]
- normalized_shape: Tuple[int, ...]
- eps: float
- elementwise_affine: bool
-
- def __init__(
- self,
- normalized_shape: _shape_t,
- eps: float = 1e-5,
- elementwise_affine: bool = True,
- device=None,
- dtype=None,
- ) -> None:
- factory_kwargs = {"device": device, "dtype": dtype}
- super(LayerNorm, self).__init__()
- if isinstance(normalized_shape, numbers.Integral):
- # mypy error: incompatible types in assignment
- normalized_shape = (normalized_shape,) # type: ignore[assignment]
- self.normalized_shape = tuple(normalized_shape) # type: ignore[arg-type]
- self.eps = eps
- self.elementwise_affine = elementwise_affine
- if self.elementwise_affine:
- self.weight = nn.Parameter(
- torch.empty(self.normalized_shape, **factory_kwargs)
- )
- self.bias = nn.Parameter(
- torch.empty(self.normalized_shape, **factory_kwargs)
- )
- else:
- self.register_parameter("weight", None)
- self.register_parameter("bias", None)
-
- self.reset_parameters()
-
- def reset_parameters(self) -> None:
- if self.elementwise_affine:
- nn.init.ones_(self.weight)
- nn.init.zeros_(self.bias)
-
- def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
- if isinstance(input, tuple):
- input, embedding = input
- return (
- F.layer_norm(
- input,
- self.normalized_shape,
- self.weight,
- self.bias,
- self.eps,
- ),
- embedding,
- )
-
- assert embedding is None
- return F.layer_norm(
- input, self.normalized_shape, self.weight, self.bias, self.eps
- )
-
- def extra_repr(self) -> str:
- return (
- "{normalized_shape}, eps={eps}, "
- "elementwise_affine={elementwise_affine}".format(**self.__dict__)
- )
-
-
-class AdaptiveLayerNorm(nn.Module):
- r"""Adaptive Layer Normalization"""
-
- def __init__(self, d_model, norm) -> None:
- super(AdaptiveLayerNorm, self).__init__()
- self.project_layer = nn.Linear(d_model, 2 * d_model)
- self.norm = norm
- self.d_model = d_model
- self.eps = self.norm.eps
-
- def forward(self, input: Tensor, embedding: Tensor = None) -> Tensor:
- if isinstance(input, tuple):
- input, embedding = input
- weight, bias = torch.split(
- self.project_layer(embedding),
- split_size_or_sections=self.d_model,
- dim=-1,
- )
- return (weight * self.norm(input) + bias, embedding)
-
- weight, bias = torch.split(
- self.project_layer(embedding),
- split_size_or_sections=self.d_model,
- dim=-1,
- )
- return weight * self.norm(input) + bias
-
-
-class BasicNorm(_BasicNorm):
- def __init__(
- self,
- d_model: int,
- eps: float = 1e-5,
- device=None,
- dtype=None,
- ):
- super(BasicNorm, self).__init__(d_model, eps=eps)
-
- def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
- if isinstance(input, tuple):
- input, embedding = input
- return (
- super(BasicNorm, self).forward(input),
- embedding,
- )
-
- assert embedding is None
- return super(BasicNorm, self).forward(input)
-
-
-class BalancedBasicNorm(nn.Module):
- def __init__(
- self,
- d_model: int,
- eps: float = 1e-5,
- device=None,
- dtype=None,
- ):
- super(BalancedBasicNorm, self).__init__()
- self.balancer = ActivationBalancer(
- d_model,
- channel_dim=-1,
- min_positive=0.45,
- max_positive=0.55,
- max_abs=6.0,
- )
- self.norm = BasicNorm(d_model, eps, device=device, dtype=dtype)
-
- def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
- if isinstance(input, tuple):
- input, embedding = input
- return self.norm((self.balancer(input), embedding))
-
- assert embedding is None
- return self.norm(self.balancer(input))
-
-
-class IdentityNorm(nn.Module):
- def __init__(
- self,
- d_model: int,
- eps: float = 1e-5,
- device=None,
- dtype=None,
- ) -> None:
- super(IdentityNorm, self).__init__()
-
- def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
- if isinstance(input, tuple):
- return input
-
- assert embedding is None
- return input
-
-
-class TransformerEncoderLayer(nn.Module):
- __constants__ = ["batch_first", "norm_first"]
-
- def __init__(
- self,
- d_model: int,
- nhead: int,
- dim_feedforward: int = 2048,
- dropout: float = 0.1,
- activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
- batch_first: bool = False,
- norm_first: bool = False,
- device=None,
- dtype=None,
- linear1_self_attention_cls: nn.Module = nn.Linear,
- linear2_self_attention_cls: nn.Module = nn.Linear,
- linear1_feedforward_cls: nn.Module = nn.Linear,
- linear2_feedforward_cls: nn.Module = nn.Linear,
- layer_norm_cls: nn.Module = LayerNorm,
- layer_norm_eps: float = 1e-5,
- adaptive_layer_norm=False,
- ) -> None:
- factory_kwargs = {"device": device, "dtype": dtype}
- super(TransformerEncoderLayer, self).__init__()
- self.self_attn = MultiheadAttention(
- d_model,
- nhead,
- dropout=dropout,
- batch_first=batch_first,
- linear1_cls=linear1_self_attention_cls,
- linear2_cls=linear2_self_attention_cls,
- **factory_kwargs,
- )
-
- # Implementation of Feedforward model
- self.linear1 = linear1_feedforward_cls(
- d_model, dim_feedforward, **factory_kwargs
- )
- self.dropout = nn.Dropout(dropout)
- self.linear2 = linear2_feedforward_cls(
- dim_feedforward, d_model, **factory_kwargs
- )
-
- self.norm_first = norm_first
- self.dropout1 = nn.Dropout(dropout)
- self.dropout2 = nn.Dropout(dropout)
-
- # Legacy string support for activation function.
- if isinstance(activation, str):
- activation = _get_activation_fn(activation)
- elif isinstance(activation, partial):
- activation = activation(d_model)
- elif activation == BalancedDoubleSwish:
- activation = BalancedDoubleSwish(d_model)
-
- # # We can't test self.activation in forward() in TorchScript,
- # # so stash some information about it instead.
- # if activation is F.relu or isinstance(activation, torch.nn.ReLU):
- # self.activation_relu_or_gelu = 1
- # elif activation is F.gelu or isinstance(activation, torch.nn.GELU):
- # self.activation_relu_or_gelu = 2
- # else:
- # self.activation_relu_or_gelu = 0
- self.activation = activation
-
- norm1 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
- if layer_norm_cls == IdentityNorm:
- norm2 = BalancedBasicNorm(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
- else:
- norm2 = layer_norm_cls(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
-
- if adaptive_layer_norm:
- self.norm1 = AdaptiveLayerNorm(d_model, norm1)
- self.norm2 = AdaptiveLayerNorm(d_model, norm2)
- else:
- self.norm1 = norm1
- self.norm2 = norm2
-
- def __setstate__(self, state):
- super(TransformerEncoderLayer, self).__setstate__(state)
- if not hasattr(self, "activation"):
- self.activation = F.relu
-
- def forward(
- self,
- src: Tensor,
- src_mask: Optional[Tensor] = None,
- src_key_padding_mask: Optional[Tensor] = None,
- ) -> Tensor:
- r"""Pass the input through the encoder layer.
-
- Args:
- src: the sequence to the encoder layer (required).
- src_mask: the mask for the src sequence (optional).
- src_key_padding_mask: the mask for the src keys per batch (optional).
-
- Shape:
- see the docs in Transformer class.
- """
- x, stage_embedding = src, None
- is_src_tuple = False
- if isinstance(src, tuple):
- x, stage_embedding = src
- is_src_tuple = True
-
- if src_key_padding_mask is not None:
- _skpm_dtype = src_key_padding_mask.dtype
- if _skpm_dtype != torch.bool and not torch.is_floating_point(
- src_key_padding_mask
- ):
- raise AssertionError(
- "only bool and floating types of key_padding_mask are supported"
- )
-
- if self.norm_first:
- x = x + self._sa_block(
- self.norm1(x, stage_embedding),
- src_mask,
- src_key_padding_mask,
- )
- x = x + self._ff_block(self.norm2(x, stage_embedding))
- else:
- x = self.norm1(
- x + self._sa_block(x, src_mask, src_key_padding_mask),
- stage_embedding,
- )
- x = self.norm2(x + self._ff_block(x), stage_embedding)
-
- if is_src_tuple:
- return (x, stage_embedding)
- return x
-
- def infer(
- self,
- src: Tensor,
- src_mask: Optional[Tensor] = None,
- src_key_padding_mask: Optional[Tensor] = None,
- past_kv: Optional[Tensor] = None,
- use_cache: bool = False,
- ):
- x, stage_embedding = src, None
- is_src_tuple = False
- if isinstance(src, tuple):
- x, stage_embedding = src
- is_src_tuple = True
-
- if src_key_padding_mask is not None:
- _skpm_dtype = src_key_padding_mask.dtype
- if _skpm_dtype != torch.bool and not torch.is_floating_point(
- src_key_padding_mask
- ):
- raise AssertionError(
- "only bool and floating types of key_padding_mask are supported"
- )
-
- if self.norm_first:
- x_attn_out, kv = self.self_attn.infer(
- self.norm1(x, stage_embedding),
- attn_mask=src_mask,
- key_padding_mask=src_key_padding_mask,
- need_weights=False,
- past_kv=past_kv,
- use_cache=use_cache,
- )
- x = x + x_attn_out
- x = x + self._ff_block(self.norm2(x, stage_embedding))
-
- if is_src_tuple:
- return (x, stage_embedding)
- return (x, kv)
-
- # self-attention block
- def _sa_block(
- self,
- x: Tensor,
- attn_mask: Optional[Tensor],
- key_padding_mask: Optional[Tensor],
- ) -> Tensor:
- x = self.self_attn(
- x,
- x,
- x,
- attn_mask=attn_mask,
- key_padding_mask=key_padding_mask,
- need_weights=False,
- )[0]
- return self.dropout1(x)
-
- # feed forward block
- def _ff_block(self, x: Tensor) -> Tensor:
- x = self.linear2(self.dropout(self.activation(self.linear1(x))))
- return self.dropout2(x)
-
-
-class TransformerEncoder(nn.Module):
- r"""TransformerEncoder is a stack of N encoder layers. Users can build the
- BERT(https://arxiv.org/abs/1810.04805) model with corresponding parameters.
-
- Args:
- encoder_layer: an instance of the TransformerEncoderLayer() class (required).
- num_layers: the number of sub-encoder-layers in the encoder (required).
- norm: the layer normalization component (optional).
- enable_nested_tensor: if True, input will automatically convert to nested tensor
- (and convert back on output). This will improve the overall performance of
- TransformerEncoder when padding rate is high. Default: ``True`` (enabled).
-
- Examples::
- >>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
- >>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
- >>> src = torch.rand(10, 32, 512)
- >>> out = transformer_encoder(src)
- """
- __constants__ = ["norm"]
-
- def __init__(self, encoder_layer, num_layers, norm=None):
- super(TransformerEncoder, self).__init__()
- self.layers = _get_clones(encoder_layer, num_layers)
- self.num_layers = num_layers
- self.norm = norm
-
- def forward(
- self,
- src: Tensor,
- mask: Optional[Tensor] = None,
- src_key_padding_mask: Optional[Tensor] = None,
- return_layer_states: bool = False,
- ) -> Tensor:
- r"""Pass the input through the encoder layers in turn.
-
- Args:
- src: the sequence to the encoder (required).
- mask: the mask for the src sequence (optional).
- src_key_padding_mask: the mask for the src keys per batch (optional).
- return_layer_states: return layers' state (optional).
-
- Shape:
- see the docs in Transformer class.
- """
- if return_layer_states:
- layer_states = [] # layers' output
- output = src
- for mod in self.layers:
- output = mod(
- output,
- src_mask=mask,
- src_key_padding_mask=src_key_padding_mask,
- )
- layer_states.append(output[0])
-
- if self.norm is not None:
- output = self.norm(output)
-
- return layer_states, output
-
- output = src
- for mod in self.layers:
- output = mod(
- output, src_mask=mask, src_key_padding_mask=src_key_padding_mask
- )
-
- if self.norm is not None:
- output = self.norm(output)
-
- return output
-
- def infer(
- self,
- src: Tensor,
- mask: Optional[Tensor] = None,
- src_key_padding_mask: Optional[Tensor] = None,
- return_layer_states: bool = False,
- past_kv: Optional[Tensor] = None,
- use_cache: bool = False,
- ):
- if past_kv is None:
- past_length = 0
- past_kv = tuple([None] * self.num_layers)
- else:
- past_length = past_kv[0][0].size(-2)
- new_kv = () if use_cache else None
- output = src
- for mod, past_layer_kv in zip(self.layers, past_kv):
- output, kv = mod.infer(
- output, src_mask=mask, src_key_padding_mask=src_key_padding_mask, past_kv=past_layer_kv, use_cache=use_cache
- )
- if use_cache:
- new_kv = new_kv + (kv,)
-
- if self.norm is not None:
- output = self.norm(output)
-
- return output, new_kv
-
-
-class TransformerDecoderLayer(nn.Module):
- __constants__ = ["batch_first", "norm_first"]
-
- def __init__(
- self,
- d_model: int,
- nhead: int,
- dim_feedforward: int = 2048,
- dropout: float = 0.1,
- activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
- linear1_self_attention_cls: nn.Module = nn.Linear,
- linear2_self_attention_cls: nn.Module = nn.Linear,
- linear1_feedforward_cls: nn.Module = nn.Linear,
- linear2_feedforward_cls: nn.Module = nn.Linear,
- batch_first: bool = False,
- norm_first: bool = False,
- device=None,
- dtype=None,
- layer_norm_cls: nn.Module = LayerNorm,
- layer_norm_eps: float = 1e-5,
- adaptive_layer_norm=False,
- ) -> None:
- factory_kwargs = {"device": device, "dtype": dtype}
- super(TransformerDecoderLayer, self).__init__()
- self.self_attn = MultiheadAttention(
- d_model,
- nhead,
- dropout=dropout,
- batch_first=batch_first,
- linear1_cls=linear1_self_attention_cls,
- linear2_cls=linear2_self_attention_cls,
- **factory_kwargs,
- )
- self.multihead_attn = MultiheadAttention(
- d_model,
- nhead,
- dropout=dropout,
- batch_first=batch_first,
- linear1_cls=linear1_self_attention_cls,
- linear2_cls=linear2_self_attention_cls,
- **factory_kwargs,
- )
- # Implementation of Feedforward model
- self.linear1 = linear1_feedforward_cls(
- d_model, dim_feedforward, **factory_kwargs
- )
- self.dropout = nn.Dropout(dropout)
- self.linear2 = linear2_feedforward_cls(
- dim_feedforward, d_model, **factory_kwargs
- )
-
- self.norm_first = norm_first
- self.dropout1 = nn.Dropout(dropout)
- self.dropout2 = nn.Dropout(dropout)
- self.dropout3 = nn.Dropout(dropout)
-
- # Legacy string support for activation function.
- if isinstance(activation, str):
- self.activation = _get_activation_fn(activation)
- elif isinstance(activation, partial):
- self.activation = activation(d_model)
- elif activation == BalancedDoubleSwish:
- self.activation = BalancedDoubleSwish(d_model)
- else:
- self.activation = activation
-
- if adaptive_layer_norm:
- norm1 = layer_norm_cls(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
- norm2 = layer_norm_cls(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
- norm3 = layer_norm_cls(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
-
- self.norm1 = AdaptiveLayerNorm(d_model, norm1)
- self.norm2 = AdaptiveLayerNorm(d_model, norm2)
- self.norm3 = AdaptiveLayerNorm(d_model, norm3)
- else:
- self.norm1 = layer_norm_cls(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
- self.norm2 = layer_norm_cls(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
- if layer_norm_cls == IdentityNorm:
- self.norm3 = BalancedBasicNorm(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
- else:
- self.norm3 = layer_norm_cls(
- d_model, eps=layer_norm_eps, **factory_kwargs
- )
-
- def forward(
- self,
- tgt: Tensor,
- memory: Tensor,
- tgt_mask: Optional[Tensor] = None,
- memory_mask: Optional[Tensor] = None,
- tgt_key_padding_mask: Optional[Tensor] = None,
- memory_key_padding_mask: Optional[Tensor] = None,
- ) -> Tensor:
- r"""Pass the inputs (and mask) through the decoder layer.
-
- Args:
- tgt: the sequence to the decoder layer (required).
- memory: the sequence from the last layer of the encoder (required).
- tgt_mask: the mask for the tgt sequence (optional).
- memory_mask: the mask for the memory sequence (optional).
- tgt_key_padding_mask: the mask for the tgt keys per batch (optional).
- memory_key_padding_mask: the mask for the memory keys per batch (optional).
-
- Shape:
- see the docs in Transformer class.
- """
- tgt_is_tuple = False
- if isinstance(tgt, tuple):
- x, stage_embedding = tgt
- tgt_is_tuple = True
- else:
- x, stage_embedding = tgt, None
-
- if self.norm_first:
- x = x + self._sa_block(
- self.norm1(x, stage_embedding), tgt_mask, tgt_key_padding_mask
- )
- x = x + self._mha_block(
- self.norm2(x, stage_embedding),
- memory,
- memory_mask,
- memory_key_padding_mask,
- )
- x = x + self._ff_block(self.norm3(x, stage_embedding))
- else:
- x = self.norm1(
- x + self._sa_block(x, tgt_mask, tgt_key_padding_mask),
- stage_embedding,
- )
- x = self.norm2(
- x
- + self._mha_block(
- x, memory, memory_mask, memory_key_padding_mask
- ),
- stage_embedding,
- )
- x = self.norm3(x + self._ff_block(x), stage_embedding)
-
- if tgt_is_tuple:
- return (x, stage_embedding)
- return x
-
- # self-attention block
- def _sa_block(
- self,
- x: Tensor,
- attn_mask: Optional[Tensor],
- key_padding_mask: Optional[Tensor],
- ) -> Tensor:
- x = self.self_attn(
- x,
- x,
- x,
- attn_mask=attn_mask,
- key_padding_mask=key_padding_mask,
- need_weights=False,
- )[0]
- return self.dropout1(x)
-
- # multihead attention block
- def _mha_block(
- self,
- x: Tensor,
- mem: Tensor,
- attn_mask: Optional[Tensor],
- key_padding_mask: Optional[Tensor],
- ) -> Tensor:
- x = self.multihead_attn(
- x,
- mem,
- mem,
- attn_mask=attn_mask,
- key_padding_mask=key_padding_mask,
- need_weights=False,
- )[0]
- return self.dropout2(x)
-
- # feed forward block
- def _ff_block(self, x: Tensor) -> Tensor:
- x = self.linear2(self.dropout(self.activation(self.linear1(x))))
- return self.dropout3(x)
-
-
-def _get_clones(module, N):
- return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
-
-
-def _get_activation_fn(activation: str) -> Callable[[Tensor], Tensor]:
- if activation == "relu":
- return F.relu
- elif activation == "gelu":
- return F.gelu
-
- raise RuntimeError(
- "activation should be relu/gelu, not {}".format(activation)
- )
diff --git a/spaces/kira4424/Tacotron-zero-short-voice-clone/web/static/js/jquery.js b/spaces/kira4424/Tacotron-zero-short-voice-clone/web/static/js/jquery.js
deleted file mode 100644
index fc6c299b73e792ef288e785c22393a5df9dded4b..0000000000000000000000000000000000000000
--- a/spaces/kira4424/Tacotron-zero-short-voice-clone/web/static/js/jquery.js
+++ /dev/null
@@ -1,10881 +0,0 @@
-/*!
- * jQuery JavaScript Library v3.6.0
- * https://jquery.com/
- *
- * Includes Sizzle.js
- * https://sizzlejs.com/
- *
- * Copyright OpenJS Foundation and other contributors
- * Released under the MIT license
- * https://jquery.org/license
- *
- * Date: 2021-03-02T17:08Z
- */
-( function( global, factory ) {
-
- "use strict";
-
- if ( typeof module === "object" && typeof module.exports === "object" ) {
-
- // For CommonJS and CommonJS-like environments where a proper `window`
- // is present, execute the factory and get jQuery.
- // For environments that do not have a `window` with a `document`
- // (such as Node.js), expose a factory as module.exports.
- // This accentuates the need for the creation of a real `window`.
- // e.g. var jQuery = require("jquery")(window);
- // See ticket #14549 for more info.
- module.exports = global.document ?
- factory( global, true ) :
- function( w ) {
- if ( !w.document ) {
- throw new Error( "jQuery requires a window with a document" );
- }
- return factory( w );
- };
- } else {
- factory( global );
- }
-
-// Pass this if window is not defined yet
-} )( typeof window !== "undefined" ? window : this, function( window, noGlobal ) {
-
-// Edge <= 12 - 13+, Firefox <=18 - 45+, IE 10 - 11, Safari 5.1 - 9+, iOS 6 - 9.1
-// throw exceptions when non-strict code (e.g., ASP.NET 4.5) accesses strict mode
-// arguments.callee.caller (trac-13335). But as of jQuery 3.0 (2016), strict mode should be common
-// enough that all such attempts are guarded in a try block.
-"use strict";
-
-var arr = [];
-
-var getProto = Object.getPrototypeOf;
-
-var slice = arr.slice;
-
-var flat = arr.flat ? function( array ) {
- return arr.flat.call( array );
-} : function( array ) {
- return arr.concat.apply( [], array );
-};
-
-
-var push = arr.push;
-
-var indexOf = arr.indexOf;
-
-var class2type = {};
-
-var toString = class2type.toString;
-
-var hasOwn = class2type.hasOwnProperty;
-
-var fnToString = hasOwn.toString;
-
-var ObjectFunctionString = fnToString.call( Object );
-
-var support = {};
-
-var isFunction = function isFunction( obj ) {
-
- // Support: Chrome <=57, Firefox <=52
- // In some browsers, typeof returns "function" for HTML
 -
-  -
-
-
-
-
- -
-  -
-
-
- diff --git a/spaces/Amrrs/DragGan-Inversion/PTI/configs/evaluation_config.py b/spaces/Amrrs/DragGan-Inversion/PTI/configs/evaluation_config.py
deleted file mode 100644
index 16b621d4a47df9e25828c4235cf1692899d14d50..0000000000000000000000000000000000000000
--- a/spaces/Amrrs/DragGan-Inversion/PTI/configs/evaluation_config.py
+++ /dev/null
@@ -1 +0,0 @@
-evaluated_methods = ['e4e', 'SG2', 'SG2Plus']
\ No newline at end of file
diff --git a/spaces/Amrrs/DragGan-Inversion/training/__init__.py b/spaces/Amrrs/DragGan-Inversion/training/__init__.py
deleted file mode 100644
index 939e7c6c8f94c4ea1141885c3c3295fe083b06aa..0000000000000000000000000000000000000000
--- a/spaces/Amrrs/DragGan-Inversion/training/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-# empty
diff --git a/spaces/Andy1621/uniformer_image_detection/mmdet/models/utils/transformer.py b/spaces/Andy1621/uniformer_image_detection/mmdet/models/utils/transformer.py
deleted file mode 100644
index 83870eead42f4b0bf73c9e19248d5512d3d044c5..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/mmdet/models/utils/transformer.py
+++ /dev/null
@@ -1,860 +0,0 @@
-import torch
-import torch.nn as nn
-from mmcv.cnn import (Linear, build_activation_layer, build_norm_layer,
- xavier_init)
-
-from .builder import TRANSFORMER
-
-
-class MultiheadAttention(nn.Module):
- """A warpper for torch.nn.MultiheadAttention.
-
- This module implements MultiheadAttention with residual connection,
- and positional encoding used in DETR is also passed as input.
-
- Args:
- embed_dims (int): The embedding dimension.
- num_heads (int): Parallel attention heads. Same as
- `nn.MultiheadAttention`.
- dropout (float): A Dropout layer on attn_output_weights. Default 0.0.
- """
-
- def __init__(self, embed_dims, num_heads, dropout=0.0):
- super(MultiheadAttention, self).__init__()
- assert embed_dims % num_heads == 0, 'embed_dims must be ' \
- f'divisible by num_heads. got {embed_dims} and {num_heads}.'
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.dropout = dropout
- self.attn = nn.MultiheadAttention(embed_dims, num_heads, dropout)
- self.dropout = nn.Dropout(dropout)
-
- def forward(self,
- x,
- key=None,
- value=None,
- residual=None,
- query_pos=None,
- key_pos=None,
- attn_mask=None,
- key_padding_mask=None):
- """Forward function for `MultiheadAttention`.
-
- Args:
- x (Tensor): The input query with shape [num_query, bs,
- embed_dims]. Same in `nn.MultiheadAttention.forward`.
- key (Tensor): The key tensor with shape [num_key, bs,
- embed_dims]. Same in `nn.MultiheadAttention.forward`.
- Default None. If None, the `query` will be used.
- value (Tensor): The value tensor with same shape as `key`.
- Same in `nn.MultiheadAttention.forward`. Default None.
- If None, the `key` will be used.
- residual (Tensor): The tensor used for addition, with the
- same shape as `x`. Default None. If None, `x` will be used.
- query_pos (Tensor): The positional encoding for query, with
- the same shape as `x`. Default None. If not None, it will
- be added to `x` before forward function.
- key_pos (Tensor): The positional encoding for `key`, with the
- same shape as `key`. Default None. If not None, it will
- be added to `key` before forward function. If None, and
- `query_pos` has the same shape as `key`, then `query_pos`
- will be used for `key_pos`.
- attn_mask (Tensor): ByteTensor mask with shape [num_query,
- num_key]. Same in `nn.MultiheadAttention.forward`.
- Default None.
- key_padding_mask (Tensor): ByteTensor with shape [bs, num_key].
- Same in `nn.MultiheadAttention.forward`. Default None.
-
- Returns:
- Tensor: forwarded results with shape [num_query, bs, embed_dims].
- """
- query = x
- if key is None:
- key = query
- if value is None:
- value = key
- if residual is None:
- residual = x
- if key_pos is None:
- if query_pos is not None and key is not None:
- if query_pos.shape == key.shape:
- key_pos = query_pos
- if query_pos is not None:
- query = query + query_pos
- if key_pos is not None:
- key = key + key_pos
- out = self.attn(
- query,
- key,
- value=value,
- attn_mask=attn_mask,
- key_padding_mask=key_padding_mask)[0]
-
- return residual + self.dropout(out)
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'dropout={self.dropout})'
- return repr_str
-
-
-class FFN(nn.Module):
- """Implements feed-forward networks (FFNs) with residual connection.
-
- Args:
- embed_dims (int): The feature dimension. Same as
- `MultiheadAttention`.
- feedforward_channels (int): The hidden dimension of FFNs.
- num_fcs (int, optional): The number of fully-connected layers in
- FFNs. Defaults to 2.
- act_cfg (dict, optional): The activation config for FFNs.
- dropout (float, optional): Probability of an element to be
- zeroed. Default 0.0.
- add_residual (bool, optional): Add resudual connection.
- Defaults to True.
- """
-
- def __init__(self,
- embed_dims,
- feedforward_channels,
- num_fcs=2,
- act_cfg=dict(type='ReLU', inplace=True),
- dropout=0.0,
- add_residual=True):
- super(FFN, self).__init__()
- assert num_fcs >= 2, 'num_fcs should be no less ' \
- f'than 2. got {num_fcs}.'
- self.embed_dims = embed_dims
- self.feedforward_channels = feedforward_channels
- self.num_fcs = num_fcs
- self.act_cfg = act_cfg
- self.dropout = dropout
- self.activate = build_activation_layer(act_cfg)
-
- layers = nn.ModuleList()
- in_channels = embed_dims
- for _ in range(num_fcs - 1):
- layers.append(
- nn.Sequential(
- Linear(in_channels, feedforward_channels), self.activate,
- nn.Dropout(dropout)))
- in_channels = feedforward_channels
- layers.append(Linear(feedforward_channels, embed_dims))
- self.layers = nn.Sequential(*layers)
- self.dropout = nn.Dropout(dropout)
- self.add_residual = add_residual
-
- def forward(self, x, residual=None):
- """Forward function for `FFN`."""
- out = self.layers(x)
- if not self.add_residual:
- return out
- if residual is None:
- residual = x
- return residual + self.dropout(out)
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(embed_dims={self.embed_dims}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'num_fcs={self.num_fcs}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'add_residual={self.add_residual})'
- return repr_str
-
-
-class TransformerEncoderLayer(nn.Module):
- """Implements one encoder layer in DETR transformer.
-
- Args:
- embed_dims (int): The feature dimension. Same as `FFN`.
- num_heads (int): Parallel attention heads.
- feedforward_channels (int): The hidden dimension for FFNs.
- dropout (float): Probability of an element to be zeroed. Default 0.0.
- order (tuple[str]): The order for encoder layer. Valid examples are
- ('selfattn', 'norm', 'ffn', 'norm') and ('norm', 'selfattn',
- 'norm', 'ffn'). Default ('selfattn', 'norm', 'ffn', 'norm').
- act_cfg (dict): The activation config for FFNs. Default ReLU.
- norm_cfg (dict): Config dict for normalization layer. Default
- layer normalization.
- num_fcs (int): The number of fully-connected layers for FFNs.
- Default 2.
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- feedforward_channels,
- dropout=0.0,
- order=('selfattn', 'norm', 'ffn', 'norm'),
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN'),
- num_fcs=2):
- super(TransformerEncoderLayer, self).__init__()
- assert isinstance(order, tuple) and len(order) == 4
- assert set(order) == set(['selfattn', 'norm', 'ffn'])
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.feedforward_channels = feedforward_channels
- self.dropout = dropout
- self.order = order
- self.act_cfg = act_cfg
- self.norm_cfg = norm_cfg
- self.num_fcs = num_fcs
- self.pre_norm = order[0] == 'norm'
- self.self_attn = MultiheadAttention(embed_dims, num_heads, dropout)
- self.ffn = FFN(embed_dims, feedforward_channels, num_fcs, act_cfg,
- dropout)
- self.norms = nn.ModuleList()
- self.norms.append(build_norm_layer(norm_cfg, embed_dims)[1])
- self.norms.append(build_norm_layer(norm_cfg, embed_dims)[1])
-
- def forward(self, x, pos=None, attn_mask=None, key_padding_mask=None):
- """Forward function for `TransformerEncoderLayer`.
-
- Args:
- x (Tensor): The input query with shape [num_key, bs,
- embed_dims]. Same in `MultiheadAttention.forward`.
- pos (Tensor): The positional encoding for query. Default None.
- Same as `query_pos` in `MultiheadAttention.forward`.
- attn_mask (Tensor): ByteTensor mask with shape [num_key,
- num_key]. Same in `MultiheadAttention.forward`. Default None.
- key_padding_mask (Tensor): ByteTensor with shape [bs, num_key].
- Same in `MultiheadAttention.forward`. Default None.
-
- Returns:
- Tensor: forwarded results with shape [num_key, bs, embed_dims].
- """
- norm_cnt = 0
- inp_residual = x
- for layer in self.order:
- if layer == 'selfattn':
- # self attention
- query = key = value = x
- x = self.self_attn(
- query,
- key,
- value,
- inp_residual if self.pre_norm else None,
- query_pos=pos,
- key_pos=pos,
- attn_mask=attn_mask,
- key_padding_mask=key_padding_mask)
- inp_residual = x
- elif layer == 'norm':
- x = self.norms[norm_cnt](x)
- norm_cnt += 1
- elif layer == 'ffn':
- x = self.ffn(x, inp_residual if self.pre_norm else None)
- return x
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'order={self.order}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'norm_cfg={self.norm_cfg}, '
- repr_str += f'num_fcs={self.num_fcs})'
- return repr_str
-
-
-class TransformerDecoderLayer(nn.Module):
- """Implements one decoder layer in DETR transformer.
-
- Args:
- embed_dims (int): The feature dimension. Same as
- `TransformerEncoderLayer`.
- num_heads (int): Parallel attention heads.
- feedforward_channels (int): Same as `TransformerEncoderLayer`.
- dropout (float): Same as `TransformerEncoderLayer`. Default 0.0.
- order (tuple[str]): The order for decoder layer. Valid examples are
- ('selfattn', 'norm', 'multiheadattn', 'norm', 'ffn', 'norm') and
- ('norm', 'selfattn', 'norm', 'multiheadattn', 'norm', 'ffn').
- Default the former.
- act_cfg (dict): Same as `TransformerEncoderLayer`. Default ReLU.
- norm_cfg (dict): Config dict for normalization layer. Default
- layer normalization.
- num_fcs (int): The number of fully-connected layers in FFNs.
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- feedforward_channels,
- dropout=0.0,
- order=('selfattn', 'norm', 'multiheadattn', 'norm', 'ffn',
- 'norm'),
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN'),
- num_fcs=2):
- super(TransformerDecoderLayer, self).__init__()
- assert isinstance(order, tuple) and len(order) == 6
- assert set(order) == set(['selfattn', 'norm', 'multiheadattn', 'ffn'])
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.feedforward_channels = feedforward_channels
- self.dropout = dropout
- self.order = order
- self.act_cfg = act_cfg
- self.norm_cfg = norm_cfg
- self.num_fcs = num_fcs
- self.pre_norm = order[0] == 'norm'
- self.self_attn = MultiheadAttention(embed_dims, num_heads, dropout)
- self.multihead_attn = MultiheadAttention(embed_dims, num_heads,
- dropout)
- self.ffn = FFN(embed_dims, feedforward_channels, num_fcs, act_cfg,
- dropout)
- self.norms = nn.ModuleList()
- # 3 norm layers in official DETR's TransformerDecoderLayer
- for _ in range(3):
- self.norms.append(build_norm_layer(norm_cfg, embed_dims)[1])
-
- def forward(self,
- x,
- memory,
- memory_pos=None,
- query_pos=None,
- memory_attn_mask=None,
- target_attn_mask=None,
- memory_key_padding_mask=None,
- target_key_padding_mask=None):
- """Forward function for `TransformerDecoderLayer`.
-
- Args:
- x (Tensor): Input query with shape [num_query, bs, embed_dims].
- memory (Tensor): Tensor got from `TransformerEncoder`, with shape
- [num_key, bs, embed_dims].
- memory_pos (Tensor): The positional encoding for `memory`. Default
- None. Same as `key_pos` in `MultiheadAttention.forward`.
- query_pos (Tensor): The positional encoding for `query`. Default
- None. Same as `query_pos` in `MultiheadAttention.forward`.
- memory_attn_mask (Tensor): ByteTensor mask for `memory`, with
- shape [num_key, num_key]. Same as `attn_mask` in
- `MultiheadAttention.forward`. Default None.
- target_attn_mask (Tensor): ByteTensor mask for `x`, with shape
- [num_query, num_query]. Same as `attn_mask` in
- `MultiheadAttention.forward`. Default None.
- memory_key_padding_mask (Tensor): ByteTensor for `memory`, with
- shape [bs, num_key]. Same as `key_padding_mask` in
- `MultiheadAttention.forward`. Default None.
- target_key_padding_mask (Tensor): ByteTensor for `x`, with shape
- [bs, num_query]. Same as `key_padding_mask` in
- `MultiheadAttention.forward`. Default None.
-
- Returns:
- Tensor: forwarded results with shape [num_query, bs, embed_dims].
- """
- norm_cnt = 0
- inp_residual = x
- for layer in self.order:
- if layer == 'selfattn':
- query = key = value = x
- x = self.self_attn(
- query,
- key,
- value,
- inp_residual if self.pre_norm else None,
- query_pos,
- key_pos=query_pos,
- attn_mask=target_attn_mask,
- key_padding_mask=target_key_padding_mask)
- inp_residual = x
- elif layer == 'norm':
- x = self.norms[norm_cnt](x)
- norm_cnt += 1
- elif layer == 'multiheadattn':
- query = x
- key = value = memory
- x = self.multihead_attn(
- query,
- key,
- value,
- inp_residual if self.pre_norm else None,
- query_pos,
- key_pos=memory_pos,
- attn_mask=memory_attn_mask,
- key_padding_mask=memory_key_padding_mask)
- inp_residual = x
- elif layer == 'ffn':
- x = self.ffn(x, inp_residual if self.pre_norm else None)
- return x
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'order={self.order}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'norm_cfg={self.norm_cfg}, '
- repr_str += f'num_fcs={self.num_fcs})'
- return repr_str
-
-
-class TransformerEncoder(nn.Module):
- """Implements the encoder in DETR transformer.
-
- Args:
- num_layers (int): The number of `TransformerEncoderLayer`.
- embed_dims (int): Same as `TransformerEncoderLayer`.
- num_heads (int): Same as `TransformerEncoderLayer`.
- feedforward_channels (int): Same as `TransformerEncoderLayer`.
- dropout (float): Same as `TransformerEncoderLayer`. Default 0.0.
- order (tuple[str]): Same as `TransformerEncoderLayer`.
- act_cfg (dict): Same as `TransformerEncoderLayer`. Default ReLU.
- norm_cfg (dict): Same as `TransformerEncoderLayer`. Default
- layer normalization.
- num_fcs (int): Same as `TransformerEncoderLayer`. Default 2.
- """
-
- def __init__(self,
- num_layers,
- embed_dims,
- num_heads,
- feedforward_channels,
- dropout=0.0,
- order=('selfattn', 'norm', 'ffn', 'norm'),
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN'),
- num_fcs=2):
- super(TransformerEncoder, self).__init__()
- assert isinstance(order, tuple) and len(order) == 4
- assert set(order) == set(['selfattn', 'norm', 'ffn'])
- self.num_layers = num_layers
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.feedforward_channels = feedforward_channels
- self.dropout = dropout
- self.order = order
- self.act_cfg = act_cfg
- self.norm_cfg = norm_cfg
- self.num_fcs = num_fcs
- self.pre_norm = order[0] == 'norm'
- self.layers = nn.ModuleList()
- for _ in range(num_layers):
- self.layers.append(
- TransformerEncoderLayer(embed_dims, num_heads,
- feedforward_channels, dropout, order,
- act_cfg, norm_cfg, num_fcs))
- self.norm = build_norm_layer(norm_cfg,
- embed_dims)[1] if self.pre_norm else None
-
- def forward(self, x, pos=None, attn_mask=None, key_padding_mask=None):
- """Forward function for `TransformerEncoder`.
-
- Args:
- x (Tensor): Input query. Same in `TransformerEncoderLayer.forward`.
- pos (Tensor): Positional encoding for query. Default None.
- Same in `TransformerEncoderLayer.forward`.
- attn_mask (Tensor): ByteTensor attention mask. Default None.
- Same in `TransformerEncoderLayer.forward`.
- key_padding_mask (Tensor): Same in
- `TransformerEncoderLayer.forward`. Default None.
-
- Returns:
- Tensor: Results with shape [num_key, bs, embed_dims].
- """
- for layer in self.layers:
- x = layer(x, pos, attn_mask, key_padding_mask)
- if self.norm is not None:
- x = self.norm(x)
- return x
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(num_layers={self.num_layers}, '
- repr_str += f'embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'order={self.order}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'norm_cfg={self.norm_cfg}, '
- repr_str += f'num_fcs={self.num_fcs})'
- return repr_str
-
-
-class TransformerDecoder(nn.Module):
- """Implements the decoder in DETR transformer.
-
- Args:
- num_layers (int): The number of `TransformerDecoderLayer`.
- embed_dims (int): Same as `TransformerDecoderLayer`.
- num_heads (int): Same as `TransformerDecoderLayer`.
- feedforward_channels (int): Same as `TransformerDecoderLayer`.
- dropout (float): Same as `TransformerDecoderLayer`. Default 0.0.
- order (tuple[str]): Same as `TransformerDecoderLayer`.
- act_cfg (dict): Same as `TransformerDecoderLayer`. Default ReLU.
- norm_cfg (dict): Same as `TransformerDecoderLayer`. Default
- layer normalization.
- num_fcs (int): Same as `TransformerDecoderLayer`. Default 2.
- """
-
- def __init__(self,
- num_layers,
- embed_dims,
- num_heads,
- feedforward_channels,
- dropout=0.0,
- order=('selfattn', 'norm', 'multiheadattn', 'norm', 'ffn',
- 'norm'),
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN'),
- num_fcs=2,
- return_intermediate=False):
- super(TransformerDecoder, self).__init__()
- assert isinstance(order, tuple) and len(order) == 6
- assert set(order) == set(['selfattn', 'norm', 'multiheadattn', 'ffn'])
- self.num_layers = num_layers
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.feedforward_channels = feedforward_channels
- self.dropout = dropout
- self.order = order
- self.act_cfg = act_cfg
- self.norm_cfg = norm_cfg
- self.num_fcs = num_fcs
- self.return_intermediate = return_intermediate
- self.layers = nn.ModuleList()
- for _ in range(num_layers):
- self.layers.append(
- TransformerDecoderLayer(embed_dims, num_heads,
- feedforward_channels, dropout, order,
- act_cfg, norm_cfg, num_fcs))
- self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
-
- def forward(self,
- x,
- memory,
- memory_pos=None,
- query_pos=None,
- memory_attn_mask=None,
- target_attn_mask=None,
- memory_key_padding_mask=None,
- target_key_padding_mask=None):
- """Forward function for `TransformerDecoder`.
-
- Args:
- x (Tensor): Input query. Same in `TransformerDecoderLayer.forward`.
- memory (Tensor): Same in `TransformerDecoderLayer.forward`.
- memory_pos (Tensor): Same in `TransformerDecoderLayer.forward`.
- Default None.
- query_pos (Tensor): Same in `TransformerDecoderLayer.forward`.
- Default None.
- memory_attn_mask (Tensor): Same in
- `TransformerDecoderLayer.forward`. Default None.
- target_attn_mask (Tensor): Same in
- `TransformerDecoderLayer.forward`. Default None.
- memory_key_padding_mask (Tensor): Same in
- `TransformerDecoderLayer.forward`. Default None.
- target_key_padding_mask (Tensor): Same in
- `TransformerDecoderLayer.forward`. Default None.
-
- Returns:
- Tensor: Results with shape [num_query, bs, embed_dims].
- """
- intermediate = []
- for layer in self.layers:
- x = layer(x, memory, memory_pos, query_pos, memory_attn_mask,
- target_attn_mask, memory_key_padding_mask,
- target_key_padding_mask)
- if self.return_intermediate:
- intermediate.append(self.norm(x))
- if self.norm is not None:
- x = self.norm(x)
- if self.return_intermediate:
- intermediate.pop()
- intermediate.append(x)
- if self.return_intermediate:
- return torch.stack(intermediate)
- return x.unsqueeze(0)
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(num_layers={self.num_layers}, '
- repr_str += f'embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'order={self.order}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'norm_cfg={self.norm_cfg}, '
- repr_str += f'num_fcs={self.num_fcs}, '
- repr_str += f'return_intermediate={self.return_intermediate})'
- return repr_str
-
-
-@TRANSFORMER.register_module()
-class Transformer(nn.Module):
- """Implements the DETR transformer.
-
- Following the official DETR implementation, this module copy-paste
- from torch.nn.Transformer with modifications:
-
- * positional encodings are passed in MultiheadAttention
- * extra LN at the end of encoder is removed
- * decoder returns a stack of activations from all decoding layers
-
- See `paper: End-to-End Object Detection with Transformers
-
diff --git a/spaces/Amrrs/DragGan-Inversion/PTI/configs/evaluation_config.py b/spaces/Amrrs/DragGan-Inversion/PTI/configs/evaluation_config.py
deleted file mode 100644
index 16b621d4a47df9e25828c4235cf1692899d14d50..0000000000000000000000000000000000000000
--- a/spaces/Amrrs/DragGan-Inversion/PTI/configs/evaluation_config.py
+++ /dev/null
@@ -1 +0,0 @@
-evaluated_methods = ['e4e', 'SG2', 'SG2Plus']
\ No newline at end of file
diff --git a/spaces/Amrrs/DragGan-Inversion/training/__init__.py b/spaces/Amrrs/DragGan-Inversion/training/__init__.py
deleted file mode 100644
index 939e7c6c8f94c4ea1141885c3c3295fe083b06aa..0000000000000000000000000000000000000000
--- a/spaces/Amrrs/DragGan-Inversion/training/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-# empty
diff --git a/spaces/Andy1621/uniformer_image_detection/mmdet/models/utils/transformer.py b/spaces/Andy1621/uniformer_image_detection/mmdet/models/utils/transformer.py
deleted file mode 100644
index 83870eead42f4b0bf73c9e19248d5512d3d044c5..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/mmdet/models/utils/transformer.py
+++ /dev/null
@@ -1,860 +0,0 @@
-import torch
-import torch.nn as nn
-from mmcv.cnn import (Linear, build_activation_layer, build_norm_layer,
- xavier_init)
-
-from .builder import TRANSFORMER
-
-
-class MultiheadAttention(nn.Module):
- """A warpper for torch.nn.MultiheadAttention.
-
- This module implements MultiheadAttention with residual connection,
- and positional encoding used in DETR is also passed as input.
-
- Args:
- embed_dims (int): The embedding dimension.
- num_heads (int): Parallel attention heads. Same as
- `nn.MultiheadAttention`.
- dropout (float): A Dropout layer on attn_output_weights. Default 0.0.
- """
-
- def __init__(self, embed_dims, num_heads, dropout=0.0):
- super(MultiheadAttention, self).__init__()
- assert embed_dims % num_heads == 0, 'embed_dims must be ' \
- f'divisible by num_heads. got {embed_dims} and {num_heads}.'
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.dropout = dropout
- self.attn = nn.MultiheadAttention(embed_dims, num_heads, dropout)
- self.dropout = nn.Dropout(dropout)
-
- def forward(self,
- x,
- key=None,
- value=None,
- residual=None,
- query_pos=None,
- key_pos=None,
- attn_mask=None,
- key_padding_mask=None):
- """Forward function for `MultiheadAttention`.
-
- Args:
- x (Tensor): The input query with shape [num_query, bs,
- embed_dims]. Same in `nn.MultiheadAttention.forward`.
- key (Tensor): The key tensor with shape [num_key, bs,
- embed_dims]. Same in `nn.MultiheadAttention.forward`.
- Default None. If None, the `query` will be used.
- value (Tensor): The value tensor with same shape as `key`.
- Same in `nn.MultiheadAttention.forward`. Default None.
- If None, the `key` will be used.
- residual (Tensor): The tensor used for addition, with the
- same shape as `x`. Default None. If None, `x` will be used.
- query_pos (Tensor): The positional encoding for query, with
- the same shape as `x`. Default None. If not None, it will
- be added to `x` before forward function.
- key_pos (Tensor): The positional encoding for `key`, with the
- same shape as `key`. Default None. If not None, it will
- be added to `key` before forward function. If None, and
- `query_pos` has the same shape as `key`, then `query_pos`
- will be used for `key_pos`.
- attn_mask (Tensor): ByteTensor mask with shape [num_query,
- num_key]. Same in `nn.MultiheadAttention.forward`.
- Default None.
- key_padding_mask (Tensor): ByteTensor with shape [bs, num_key].
- Same in `nn.MultiheadAttention.forward`. Default None.
-
- Returns:
- Tensor: forwarded results with shape [num_query, bs, embed_dims].
- """
- query = x
- if key is None:
- key = query
- if value is None:
- value = key
- if residual is None:
- residual = x
- if key_pos is None:
- if query_pos is not None and key is not None:
- if query_pos.shape == key.shape:
- key_pos = query_pos
- if query_pos is not None:
- query = query + query_pos
- if key_pos is not None:
- key = key + key_pos
- out = self.attn(
- query,
- key,
- value=value,
- attn_mask=attn_mask,
- key_padding_mask=key_padding_mask)[0]
-
- return residual + self.dropout(out)
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'dropout={self.dropout})'
- return repr_str
-
-
-class FFN(nn.Module):
- """Implements feed-forward networks (FFNs) with residual connection.
-
- Args:
- embed_dims (int): The feature dimension. Same as
- `MultiheadAttention`.
- feedforward_channels (int): The hidden dimension of FFNs.
- num_fcs (int, optional): The number of fully-connected layers in
- FFNs. Defaults to 2.
- act_cfg (dict, optional): The activation config for FFNs.
- dropout (float, optional): Probability of an element to be
- zeroed. Default 0.0.
- add_residual (bool, optional): Add resudual connection.
- Defaults to True.
- """
-
- def __init__(self,
- embed_dims,
- feedforward_channels,
- num_fcs=2,
- act_cfg=dict(type='ReLU', inplace=True),
- dropout=0.0,
- add_residual=True):
- super(FFN, self).__init__()
- assert num_fcs >= 2, 'num_fcs should be no less ' \
- f'than 2. got {num_fcs}.'
- self.embed_dims = embed_dims
- self.feedforward_channels = feedforward_channels
- self.num_fcs = num_fcs
- self.act_cfg = act_cfg
- self.dropout = dropout
- self.activate = build_activation_layer(act_cfg)
-
- layers = nn.ModuleList()
- in_channels = embed_dims
- for _ in range(num_fcs - 1):
- layers.append(
- nn.Sequential(
- Linear(in_channels, feedforward_channels), self.activate,
- nn.Dropout(dropout)))
- in_channels = feedforward_channels
- layers.append(Linear(feedforward_channels, embed_dims))
- self.layers = nn.Sequential(*layers)
- self.dropout = nn.Dropout(dropout)
- self.add_residual = add_residual
-
- def forward(self, x, residual=None):
- """Forward function for `FFN`."""
- out = self.layers(x)
- if not self.add_residual:
- return out
- if residual is None:
- residual = x
- return residual + self.dropout(out)
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(embed_dims={self.embed_dims}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'num_fcs={self.num_fcs}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'add_residual={self.add_residual})'
- return repr_str
-
-
-class TransformerEncoderLayer(nn.Module):
- """Implements one encoder layer in DETR transformer.
-
- Args:
- embed_dims (int): The feature dimension. Same as `FFN`.
- num_heads (int): Parallel attention heads.
- feedforward_channels (int): The hidden dimension for FFNs.
- dropout (float): Probability of an element to be zeroed. Default 0.0.
- order (tuple[str]): The order for encoder layer. Valid examples are
- ('selfattn', 'norm', 'ffn', 'norm') and ('norm', 'selfattn',
- 'norm', 'ffn'). Default ('selfattn', 'norm', 'ffn', 'norm').
- act_cfg (dict): The activation config for FFNs. Default ReLU.
- norm_cfg (dict): Config dict for normalization layer. Default
- layer normalization.
- num_fcs (int): The number of fully-connected layers for FFNs.
- Default 2.
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- feedforward_channels,
- dropout=0.0,
- order=('selfattn', 'norm', 'ffn', 'norm'),
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN'),
- num_fcs=2):
- super(TransformerEncoderLayer, self).__init__()
- assert isinstance(order, tuple) and len(order) == 4
- assert set(order) == set(['selfattn', 'norm', 'ffn'])
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.feedforward_channels = feedforward_channels
- self.dropout = dropout
- self.order = order
- self.act_cfg = act_cfg
- self.norm_cfg = norm_cfg
- self.num_fcs = num_fcs
- self.pre_norm = order[0] == 'norm'
- self.self_attn = MultiheadAttention(embed_dims, num_heads, dropout)
- self.ffn = FFN(embed_dims, feedforward_channels, num_fcs, act_cfg,
- dropout)
- self.norms = nn.ModuleList()
- self.norms.append(build_norm_layer(norm_cfg, embed_dims)[1])
- self.norms.append(build_norm_layer(norm_cfg, embed_dims)[1])
-
- def forward(self, x, pos=None, attn_mask=None, key_padding_mask=None):
- """Forward function for `TransformerEncoderLayer`.
-
- Args:
- x (Tensor): The input query with shape [num_key, bs,
- embed_dims]. Same in `MultiheadAttention.forward`.
- pos (Tensor): The positional encoding for query. Default None.
- Same as `query_pos` in `MultiheadAttention.forward`.
- attn_mask (Tensor): ByteTensor mask with shape [num_key,
- num_key]. Same in `MultiheadAttention.forward`. Default None.
- key_padding_mask (Tensor): ByteTensor with shape [bs, num_key].
- Same in `MultiheadAttention.forward`. Default None.
-
- Returns:
- Tensor: forwarded results with shape [num_key, bs, embed_dims].
- """
- norm_cnt = 0
- inp_residual = x
- for layer in self.order:
- if layer == 'selfattn':
- # self attention
- query = key = value = x
- x = self.self_attn(
- query,
- key,
- value,
- inp_residual if self.pre_norm else None,
- query_pos=pos,
- key_pos=pos,
- attn_mask=attn_mask,
- key_padding_mask=key_padding_mask)
- inp_residual = x
- elif layer == 'norm':
- x = self.norms[norm_cnt](x)
- norm_cnt += 1
- elif layer == 'ffn':
- x = self.ffn(x, inp_residual if self.pre_norm else None)
- return x
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'order={self.order}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'norm_cfg={self.norm_cfg}, '
- repr_str += f'num_fcs={self.num_fcs})'
- return repr_str
-
-
-class TransformerDecoderLayer(nn.Module):
- """Implements one decoder layer in DETR transformer.
-
- Args:
- embed_dims (int): The feature dimension. Same as
- `TransformerEncoderLayer`.
- num_heads (int): Parallel attention heads.
- feedforward_channels (int): Same as `TransformerEncoderLayer`.
- dropout (float): Same as `TransformerEncoderLayer`. Default 0.0.
- order (tuple[str]): The order for decoder layer. Valid examples are
- ('selfattn', 'norm', 'multiheadattn', 'norm', 'ffn', 'norm') and
- ('norm', 'selfattn', 'norm', 'multiheadattn', 'norm', 'ffn').
- Default the former.
- act_cfg (dict): Same as `TransformerEncoderLayer`. Default ReLU.
- norm_cfg (dict): Config dict for normalization layer. Default
- layer normalization.
- num_fcs (int): The number of fully-connected layers in FFNs.
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- feedforward_channels,
- dropout=0.0,
- order=('selfattn', 'norm', 'multiheadattn', 'norm', 'ffn',
- 'norm'),
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN'),
- num_fcs=2):
- super(TransformerDecoderLayer, self).__init__()
- assert isinstance(order, tuple) and len(order) == 6
- assert set(order) == set(['selfattn', 'norm', 'multiheadattn', 'ffn'])
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.feedforward_channels = feedforward_channels
- self.dropout = dropout
- self.order = order
- self.act_cfg = act_cfg
- self.norm_cfg = norm_cfg
- self.num_fcs = num_fcs
- self.pre_norm = order[0] == 'norm'
- self.self_attn = MultiheadAttention(embed_dims, num_heads, dropout)
- self.multihead_attn = MultiheadAttention(embed_dims, num_heads,
- dropout)
- self.ffn = FFN(embed_dims, feedforward_channels, num_fcs, act_cfg,
- dropout)
- self.norms = nn.ModuleList()
- # 3 norm layers in official DETR's TransformerDecoderLayer
- for _ in range(3):
- self.norms.append(build_norm_layer(norm_cfg, embed_dims)[1])
-
- def forward(self,
- x,
- memory,
- memory_pos=None,
- query_pos=None,
- memory_attn_mask=None,
- target_attn_mask=None,
- memory_key_padding_mask=None,
- target_key_padding_mask=None):
- """Forward function for `TransformerDecoderLayer`.
-
- Args:
- x (Tensor): Input query with shape [num_query, bs, embed_dims].
- memory (Tensor): Tensor got from `TransformerEncoder`, with shape
- [num_key, bs, embed_dims].
- memory_pos (Tensor): The positional encoding for `memory`. Default
- None. Same as `key_pos` in `MultiheadAttention.forward`.
- query_pos (Tensor): The positional encoding for `query`. Default
- None. Same as `query_pos` in `MultiheadAttention.forward`.
- memory_attn_mask (Tensor): ByteTensor mask for `memory`, with
- shape [num_key, num_key]. Same as `attn_mask` in
- `MultiheadAttention.forward`. Default None.
- target_attn_mask (Tensor): ByteTensor mask for `x`, with shape
- [num_query, num_query]. Same as `attn_mask` in
- `MultiheadAttention.forward`. Default None.
- memory_key_padding_mask (Tensor): ByteTensor for `memory`, with
- shape [bs, num_key]. Same as `key_padding_mask` in
- `MultiheadAttention.forward`. Default None.
- target_key_padding_mask (Tensor): ByteTensor for `x`, with shape
- [bs, num_query]. Same as `key_padding_mask` in
- `MultiheadAttention.forward`. Default None.
-
- Returns:
- Tensor: forwarded results with shape [num_query, bs, embed_dims].
- """
- norm_cnt = 0
- inp_residual = x
- for layer in self.order:
- if layer == 'selfattn':
- query = key = value = x
- x = self.self_attn(
- query,
- key,
- value,
- inp_residual if self.pre_norm else None,
- query_pos,
- key_pos=query_pos,
- attn_mask=target_attn_mask,
- key_padding_mask=target_key_padding_mask)
- inp_residual = x
- elif layer == 'norm':
- x = self.norms[norm_cnt](x)
- norm_cnt += 1
- elif layer == 'multiheadattn':
- query = x
- key = value = memory
- x = self.multihead_attn(
- query,
- key,
- value,
- inp_residual if self.pre_norm else None,
- query_pos,
- key_pos=memory_pos,
- attn_mask=memory_attn_mask,
- key_padding_mask=memory_key_padding_mask)
- inp_residual = x
- elif layer == 'ffn':
- x = self.ffn(x, inp_residual if self.pre_norm else None)
- return x
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'order={self.order}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'norm_cfg={self.norm_cfg}, '
- repr_str += f'num_fcs={self.num_fcs})'
- return repr_str
-
-
-class TransformerEncoder(nn.Module):
- """Implements the encoder in DETR transformer.
-
- Args:
- num_layers (int): The number of `TransformerEncoderLayer`.
- embed_dims (int): Same as `TransformerEncoderLayer`.
- num_heads (int): Same as `TransformerEncoderLayer`.
- feedforward_channels (int): Same as `TransformerEncoderLayer`.
- dropout (float): Same as `TransformerEncoderLayer`. Default 0.0.
- order (tuple[str]): Same as `TransformerEncoderLayer`.
- act_cfg (dict): Same as `TransformerEncoderLayer`. Default ReLU.
- norm_cfg (dict): Same as `TransformerEncoderLayer`. Default
- layer normalization.
- num_fcs (int): Same as `TransformerEncoderLayer`. Default 2.
- """
-
- def __init__(self,
- num_layers,
- embed_dims,
- num_heads,
- feedforward_channels,
- dropout=0.0,
- order=('selfattn', 'norm', 'ffn', 'norm'),
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN'),
- num_fcs=2):
- super(TransformerEncoder, self).__init__()
- assert isinstance(order, tuple) and len(order) == 4
- assert set(order) == set(['selfattn', 'norm', 'ffn'])
- self.num_layers = num_layers
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.feedforward_channels = feedforward_channels
- self.dropout = dropout
- self.order = order
- self.act_cfg = act_cfg
- self.norm_cfg = norm_cfg
- self.num_fcs = num_fcs
- self.pre_norm = order[0] == 'norm'
- self.layers = nn.ModuleList()
- for _ in range(num_layers):
- self.layers.append(
- TransformerEncoderLayer(embed_dims, num_heads,
- feedforward_channels, dropout, order,
- act_cfg, norm_cfg, num_fcs))
- self.norm = build_norm_layer(norm_cfg,
- embed_dims)[1] if self.pre_norm else None
-
- def forward(self, x, pos=None, attn_mask=None, key_padding_mask=None):
- """Forward function for `TransformerEncoder`.
-
- Args:
- x (Tensor): Input query. Same in `TransformerEncoderLayer.forward`.
- pos (Tensor): Positional encoding for query. Default None.
- Same in `TransformerEncoderLayer.forward`.
- attn_mask (Tensor): ByteTensor attention mask. Default None.
- Same in `TransformerEncoderLayer.forward`.
- key_padding_mask (Tensor): Same in
- `TransformerEncoderLayer.forward`. Default None.
-
- Returns:
- Tensor: Results with shape [num_key, bs, embed_dims].
- """
- for layer in self.layers:
- x = layer(x, pos, attn_mask, key_padding_mask)
- if self.norm is not None:
- x = self.norm(x)
- return x
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(num_layers={self.num_layers}, '
- repr_str += f'embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'order={self.order}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'norm_cfg={self.norm_cfg}, '
- repr_str += f'num_fcs={self.num_fcs})'
- return repr_str
-
-
-class TransformerDecoder(nn.Module):
- """Implements the decoder in DETR transformer.
-
- Args:
- num_layers (int): The number of `TransformerDecoderLayer`.
- embed_dims (int): Same as `TransformerDecoderLayer`.
- num_heads (int): Same as `TransformerDecoderLayer`.
- feedforward_channels (int): Same as `TransformerDecoderLayer`.
- dropout (float): Same as `TransformerDecoderLayer`. Default 0.0.
- order (tuple[str]): Same as `TransformerDecoderLayer`.
- act_cfg (dict): Same as `TransformerDecoderLayer`. Default ReLU.
- norm_cfg (dict): Same as `TransformerDecoderLayer`. Default
- layer normalization.
- num_fcs (int): Same as `TransformerDecoderLayer`. Default 2.
- """
-
- def __init__(self,
- num_layers,
- embed_dims,
- num_heads,
- feedforward_channels,
- dropout=0.0,
- order=('selfattn', 'norm', 'multiheadattn', 'norm', 'ffn',
- 'norm'),
- act_cfg=dict(type='ReLU', inplace=True),
- norm_cfg=dict(type='LN'),
- num_fcs=2,
- return_intermediate=False):
- super(TransformerDecoder, self).__init__()
- assert isinstance(order, tuple) and len(order) == 6
- assert set(order) == set(['selfattn', 'norm', 'multiheadattn', 'ffn'])
- self.num_layers = num_layers
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.feedforward_channels = feedforward_channels
- self.dropout = dropout
- self.order = order
- self.act_cfg = act_cfg
- self.norm_cfg = norm_cfg
- self.num_fcs = num_fcs
- self.return_intermediate = return_intermediate
- self.layers = nn.ModuleList()
- for _ in range(num_layers):
- self.layers.append(
- TransformerDecoderLayer(embed_dims, num_heads,
- feedforward_channels, dropout, order,
- act_cfg, norm_cfg, num_fcs))
- self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
-
- def forward(self,
- x,
- memory,
- memory_pos=None,
- query_pos=None,
- memory_attn_mask=None,
- target_attn_mask=None,
- memory_key_padding_mask=None,
- target_key_padding_mask=None):
- """Forward function for `TransformerDecoder`.
-
- Args:
- x (Tensor): Input query. Same in `TransformerDecoderLayer.forward`.
- memory (Tensor): Same in `TransformerDecoderLayer.forward`.
- memory_pos (Tensor): Same in `TransformerDecoderLayer.forward`.
- Default None.
- query_pos (Tensor): Same in `TransformerDecoderLayer.forward`.
- Default None.
- memory_attn_mask (Tensor): Same in
- `TransformerDecoderLayer.forward`. Default None.
- target_attn_mask (Tensor): Same in
- `TransformerDecoderLayer.forward`. Default None.
- memory_key_padding_mask (Tensor): Same in
- `TransformerDecoderLayer.forward`. Default None.
- target_key_padding_mask (Tensor): Same in
- `TransformerDecoderLayer.forward`. Default None.
-
- Returns:
- Tensor: Results with shape [num_query, bs, embed_dims].
- """
- intermediate = []
- for layer in self.layers:
- x = layer(x, memory, memory_pos, query_pos, memory_attn_mask,
- target_attn_mask, memory_key_padding_mask,
- target_key_padding_mask)
- if self.return_intermediate:
- intermediate.append(self.norm(x))
- if self.norm is not None:
- x = self.norm(x)
- if self.return_intermediate:
- intermediate.pop()
- intermediate.append(x)
- if self.return_intermediate:
- return torch.stack(intermediate)
- return x.unsqueeze(0)
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(num_layers={self.num_layers}, '
- repr_str += f'embed_dims={self.embed_dims}, '
- repr_str += f'num_heads={self.num_heads}, '
- repr_str += f'feedforward_channels={self.feedforward_channels}, '
- repr_str += f'dropout={self.dropout}, '
- repr_str += f'order={self.order}, '
- repr_str += f'act_cfg={self.act_cfg}, '
- repr_str += f'norm_cfg={self.norm_cfg}, '
- repr_str += f'num_fcs={self.num_fcs}, '
- repr_str += f'return_intermediate={self.return_intermediate})'
- return repr_str
-
-
-@TRANSFORMER.register_module()
-class Transformer(nn.Module):
- """Implements the DETR transformer.
-
- Following the official DETR implementation, this module copy-paste
- from torch.nn.Transformer with modifications:
-
- * positional encodings are passed in MultiheadAttention
- * extra LN at the end of encoder is removed
- * decoder returns a stack of activations from all decoding layers
-
- See `paper: End-to-End Object Detection with Transformers
-  -
-  -
-  -
-  -
-
-
- -
- -
-
-##
-
-
-## 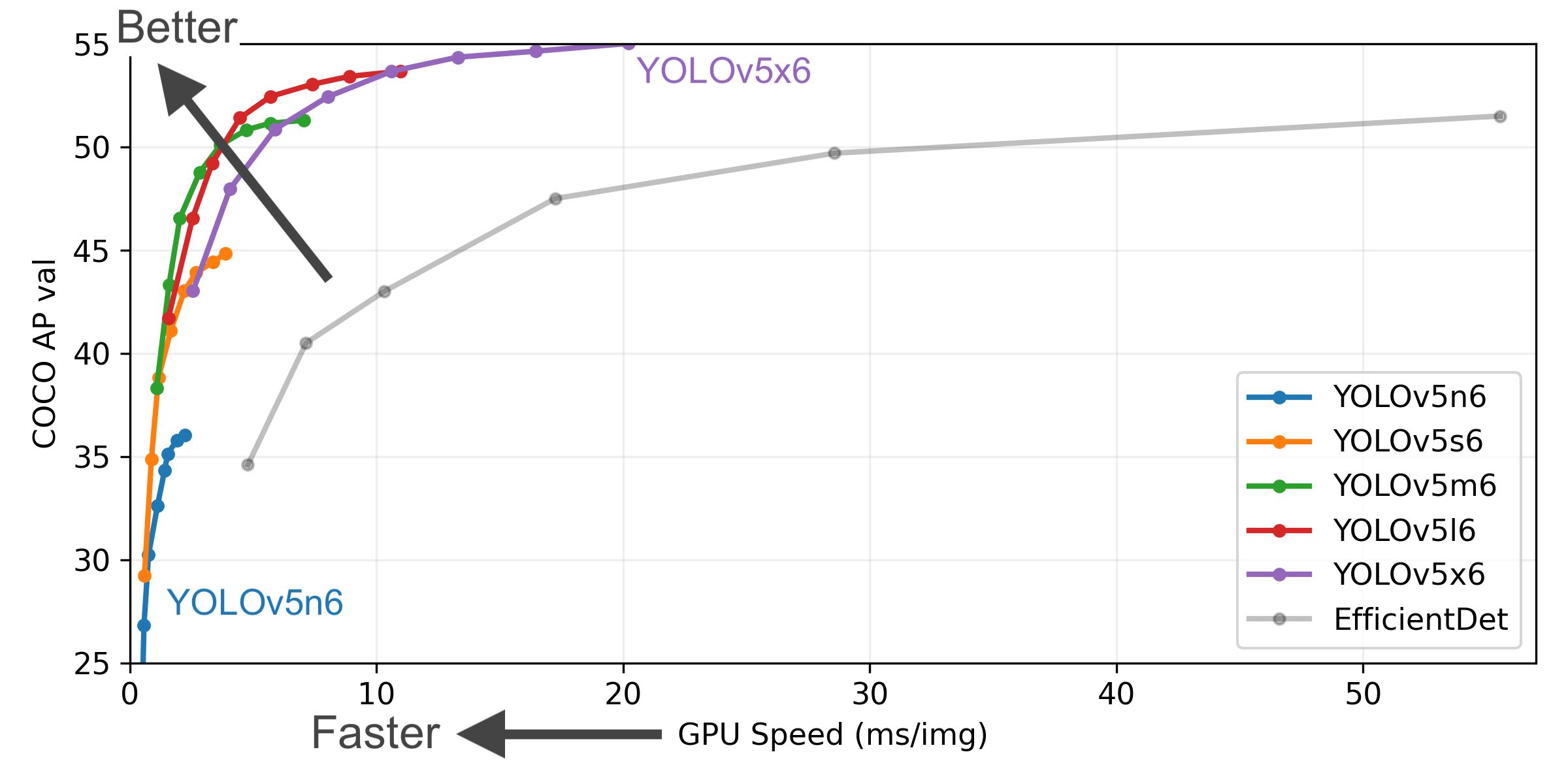
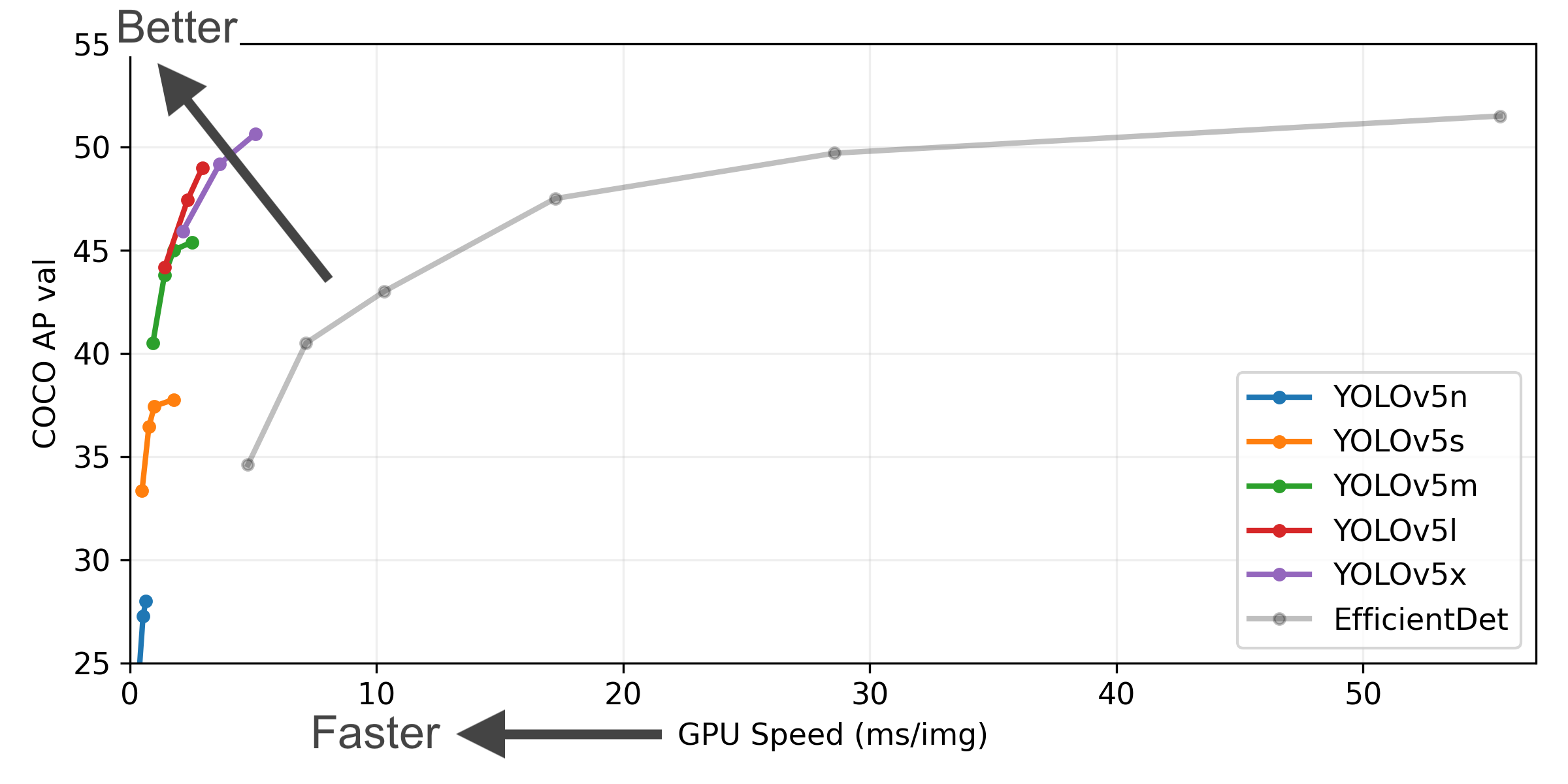
 -
-##
-
-##  -
-  -
- -
- -
-