-
-
\ No newline at end of file diff --git a/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Call of Duty 4 Modern Warfare 11 English Language Pack - Where to Find and How to Use It.md b/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Call of Duty 4 Modern Warfare 11 English Language Pack - Where to Find and How to Use It.md deleted file mode 100644 index 614259ab93e0e2a22c687a95babcd3baf379a2be..0000000000000000000000000000000000000000 --- a/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Call of Duty 4 Modern Warfare 11 English Language Pack - Where to Find and How to Use It.md +++ /dev/null @@ -1,82 +0,0 @@ - -
Call of Duty 4: Modern Warfare 11 - English Language Pack
-If you are a fan of first-person shooter games, you have probably heard of Call of Duty 4: Modern Warfare 11, one of the most popular and acclaimed titles in the franchise. This game offers an immersive and cinematic action experience that takes you to various hotspots around the world, where you can use advanced and powerful weapons and gear to fight against enemies and complete missions. However, if you are not a native speaker of English, you might have some difficulties in enjoying the game fully, as it might not be available in your preferred language. That's why you need an English language pack for Call of Duty 4: Modern Warfare 11, which will allow you to play the game in English and enhance your gaming experience. In this article, we will tell you everything you need to know about this language pack, including what it is, why you need it, how to download and install it, how to uninstall or restore it, and some tips and tricks for playing the game in English. Let's get started!
-What is Call of Duty 4: Modern Warfare 11?
-Call of Duty 4: Modern Warfare 11 is a first-person shooter video game developed by Infinity Ward and published by Activision in November 2007. It is the fourth installment in the Call of Duty series and the first one to be set in modern times, rather than World War II. The game follows the story of a British SAS officer, a US Marine, and a Russian informant who are involved in a conflict that spans from Russia to the Middle East. The game features both a single-player campaign mode and a multiplayer mode, where players can compete with or against each other in various modes and maps. The game also introduces new features such as killstreaks, perks, challenges, and customization options for weapons and characters.
-call-of-duty-4-modern-warfare-11-english-language-pack
Download Zip ⭐ https://byltly.com/2uKvOH
-
Call of Duty 4: Modern Warfare 11 received critical acclaim from critics and players alike, who praised its graphics, sound, gameplay, story, and multiplayer mode. It won several awards and became one of the best-selling games of all time, selling over 18 million copies worldwide. It also spawned two sequels, Call of Duty: Modern Warfare 2 (2009) and Call of Duty: Modern Warfare 3 (2011), which continued the story arc of the original game.
-Why do you need an English language pack for Call of Duty 4: Modern Warfare 11?
-If you are not a native speaker of English, you might wonder why you need an English language pack for Call of Duty 4: Modern Warfare 11. After all, you can still play the game in your own language, right? Well, not exactly. Depending on where you bought or downloaded the game from, it might not have an option to change the language settings or it might only have a limited number of languages available. For example, if you bought or downloaded the game from Steam, you can only choose between English, French, German, Italian, Spanish - Spain (not Latin America), Polish (not Brazilian), Russian (not Ukrainian), or Chinese (not Japanese). If you want to play in any other language than these ones, you are out of luck.
-However, even if your preferred language is among these ones, you might still want to play in English for several reasons. First of all, playing in English can help you improve your listening comprehension and vocabulary skills in this language. You can learn new words and expressions related to military terms, weapons names, locations names, commands orders etc. You can also practice your pronunciation by repeating what you hear from the characters or other players. Secondly, playing in English can enhance your immersion and enjoyment of the game. You can appreciate better the voice acting quality ,the dialogue writing ,the sound effects ,and the atmosphere of the game in its original language . You can also communicate more effectively with other players who speak English , especially if you play online . Thirdly, playing in English can help you understand the gameplay and the storyline better. You can follow more easily what is happening on screen ,what are your objectives ,what are your allies or enemies saying ,and what are the consequences of your actions .You can also avoid missing any important details or clues that might be lost in translation or localization .
-How to download and install the English language pack for Call of Duty 4: Modern Warfare 11?
-Now that you know why you need an English language pack for Call of Duty 4: Modern Warfare 11 ,you might wonder how to get it .Fortunately ,there are several ways to download and install this language pack ,depending on where you got your game from .Here are some options :
-Downloading the language pack from Steam
-If you bought or downloaded your game from Steam ,you can easily change its language settings by following these steps :
--
-
- Open Steam and go to your Library . -
- Right-click on Call of Duty 4: Modern Warfare (2007) and select Properties . -
- Go to Language tab . -
- Select English from the drop-down menu . -
- Click OK . -
- Steam will automatically download and install any necessary files for changing your game's language .This might take some time depending on your internet speed . -
- Once done ,launch your game and enjoy playing it in English . -
Downloading the language pack from noName.zone
-If you don't have Steam or prefer another source ,you can also download an English language pack from noName.zone ,a website that offers various gaming tutorials ,tools ,and mods .Here is how :
-How to change language in Call of Duty 4: Modern Warfare[^3^]
-Call of Duty 4: Modern Warfare English patch download
-Call of Duty 4 Language Pack - Gaming Tutorials - noName.zone[^1^]
-Call of Duty 4: Modern Warfare German language pack
-Call of Duty 4: Modern Warfare Russian language pack
-Call of Duty 4: Modern Warfare French language pack
-Call of Duty 4: Modern Warfare Italian language pack
-Call of Duty 4: Modern Warfare Polish language pack
-Call of Duty 4: Modern Warfare Spanish language pack
-Call of Duty 4: Modern Warfare Chinese language pack
-Call of Duty 4: Modern Warfare Lite version language pack[^1^]
-Call of Duty 4: Modern Warfare Full version language pack[^1^]
-Call of Duty 4: Modern Warfare Language Pack install guide[^1^]
-Call of Duty 4: Modern Warfare Language Pack uninstall guide[^1^]
-Call of Duty 4: Modern Warfare Language Pack tool download[^1^]
-Call of Duty 4: Modern Warfare English languagepack Steam discussion[^2^]
-Call of Duty 4: Modern Warfare English version keys
-Call of Duty 4: Modern Warfare Russian version keys
-Call of Duty 4: Modern Warfare German version keys
-Call of Duty 4: Modern Warfare English version backup profile
-Call of Duty 4: Modern Warfare English version SoundCloud stream[^4^]
-Call of Duty 4: Modern Warfare English version free download
-Call of Duty 4: Modern Warfare English version crack
-Call of Duty 4: Modern Warfare English version torrent
-Call of Duty 4: Modern Warfare English version gameplay
-Call of Duty 4: Modern Warfare English version review
-Call of Duty 4: Modern Warfare English version trailer
-Call of Duty 4: Modern Warfare English version system requirements
-Call of Duty 4: Modern Warfare English version cheats
-Call of Duty 4: Modern Warfare English version mods
-Call of Duty 4: Modern Warfare English version multiplayer
-Call of Duty 4: Modern Warfare English version singleplayer
-Call of Duty 4: Modern Warfare English version campaign
-Call of Duty 4: Modern Warfare English version missions
-Call of Duty 4: Modern Warfare English version weapons
-Call of Duty 4: Modern Warfare English version maps
-Call of Duty 4: Modern Warfare English version graphics
-Call of Duty 4: Modern Warfare English version soundtrack
-Call of Duty 4: Modern Warfare English version voice actors
-Call of Duty 4: Modern Warfare English version subtitles
-Call of Duty 4: Modern Warfare English version settings
-Call of Duty 4: Modern Warfare English version patch notes
-Call of Duty 4: Modern Warfare English version bugs and fixes
-Call of Duty 4: Modern Warfare English version tips and tricks
-Call of Duty 4: Modern Warfare English version best loadout
-Call of Duty 4: Modern Warfare English version ranking system
-Call of Duty 4: Modern Warfare English version achievements and trophies
-Call of Duty 4: Modern Warfare English version comparison with other versions
-Call of Duty 4: Modern Warfare English version history and development
-
-
- Go to https://noname.zone/index.php?/tutorials/article/8-call-of-duty-4-language-pack/ . -
- Scroll down until you see two links :Full version (~443MB) - Patch entire multiplayer Lite version (~8MB) - Patch almost everything (more details in spoiler) . -
- Select which version you want depending on how much data you want to download .The full version will patch everything related to multiplayer mode ,while lite version will patch most things except some minor text elements .Both versions will patch single-player mode as well . -
- Click on either link and download LanguagePack.zip or LanguagePack (Lite).zip file . -
- Extract LanguagePack folder to CoD4 root directory .This is usually located at C:\Program Files (x86)\Steam\steamapps\common\Call Of Duty\Modern Warfare\Call Of Duty\Modern Warfare\Call Of Duty\Modern Warfare 0a6ba089eb
-
-
\ No newline at end of file diff --git a/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Embird 2017 Registration Password The Secret to Creating Amazing Embroidery Designs.md b/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Embird 2017 Registration Password The Secret to Creating Amazing Embroidery Designs.md deleted file mode 100644 index e01b9992b925dba1e2171264ac5238c2507fa294..0000000000000000000000000000000000000000 --- a/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Embird 2017 Registration Password The Secret to Creating Amazing Embroidery Designs.md +++ /dev/null @@ -1,33 +0,0 @@ - -How to Get Embird 2017 Registration Password for Free
-Embird 2017 is a popular embroidery software that allows you to create, edit, and digitize embroidery designs. It also supports various embroidery formats and machines. However, to use the full features of Embird 2017, you need to register it with a password that you can purchase from the official website.
-embird 2017 registration password crack
Download ✑ ✑ ✑ https://byltly.com/2uKwnS
-But what if you don't want to spend money on the registration password? Is there a way to get Embird 2017 registration password for free? The answer is yes, but you need to be careful. There are many websites and programs that claim to offer free Embird 2017 registration passwords, but most of them are scams or viruses that can harm your computer or steal your personal information.
-In this article, we will show you how to get Embird 2017 registration password for free safely and legally. We will also share some tips on how to use Embird 2017 effectively and avoid common problems.
-How to Get Embird 2017 Registration Password for Free
-The best way to get Embird 2017 registration password for free is to use the trial version of the software. The trial version allows you to use Embird 2017 for 30 days without any limitations. You can download the trial version from the official website here.
-To use the trial version, you need to enter your name and email address when you install the software. You will then receive an email with a link to activate the trial version. Once you activate it, you can use Embird 2017 for 30 days without any restrictions.
- -However, after 30 days, the trial version will expire and you will need to purchase the registration password to continue using the software. If you want to extend the trial period, you can try uninstalling and reinstalling the software with a different name and email address. However, this may not work for some computers or versions of Embird 2017.
-Another way to get Embird 2017 registration password for free is to use a crack or a keygen program. These are programs that generate fake registration passwords that can bypass the security of Embird 2017. However, we do not recommend using these programs for several reasons:
--
-
- They are illegal and violate the terms of service of Embird 2017. -
- They may contain viruses or malware that can damage your computer or steal your data. -
- They may not work properly or cause errors or crashes in Embird 2017. -
- They may not be compatible with the latest updates or features of Embird 2017. -
- They may not support all embroidery formats or machines. -
Therefore, we advise you to avoid using crack or keygen programs and stick to the trial version or purchase the registration password from the official website.
-How to Use Embird 2017 Effectively
-Now that you know how to get Embird 2017 registration password for free, let's see how to use the software effectively. Here are some tips and tricks that can help you create beautiful embroidery designs with Embird 2017:
--
-
- Use the tutorials and manuals that come with the software. They will teach you how to use the basic and advanced features of Embird 2017 and how to solve common problems. -
- Use the online support and forums that are available on the official website. They will answer your questions and provide tips and advice from other users and experts. -
- Use the built-in design library that contains thousands of ready-made embroidery designs that you can edit or combine with your own designs. -
- Use the design manager that allows you to organize, view, convert, print, and export your embroidery designs in various formats and sizes. -
- Use the editor that allows you to modify, resize, rotate, mirror, split, merge, align, and optimize your embroidery designs. -
- Use the digitizer that allows you to create your own embroidery designs from scratch or from images or vector graphics. -
- Use the simulator that allows you to preview how your embroidery designs will look on different fabrics and colors before stitching them. -
- Use the manager that allows you to control your embroidery machine and send your designs directly from your ddb901b051
-
-
\ No newline at end of file diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Buku Zoologi Vertebrata.pdf Extra Quality.md b/spaces/1gistliPinn/ChatGPT4/Examples/Buku Zoologi Vertebrata.pdf Extra Quality.md deleted file mode 100644 index 2e223459d3c94e314d9414006461ea57156fd4de..0000000000000000000000000000000000000000 --- a/spaces/1gistliPinn/ChatGPT4/Examples/Buku Zoologi Vertebrata.pdf Extra Quality.md +++ /dev/null @@ -1,6 +0,0 @@ -Buku Zoologi Vertebrata.pdf
Download ⏩ https://imgfil.com/2uxYsB
- - 899543212b
-
-
- diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Delock Usb Sound Adapter 7.1 Driver Download.md b/spaces/1gistliPinn/ChatGPT4/Examples/Delock Usb Sound Adapter 7.1 Driver Download.md deleted file mode 100644 index e8767412b3bc4a7be6eeb801c4089b3ed3c99374..0000000000000000000000000000000000000000 --- a/spaces/1gistliPinn/ChatGPT4/Examples/Delock Usb Sound Adapter 7.1 Driver Download.md +++ /dev/null @@ -1,6 +0,0 @@ -Delock Usb Sound Adapter 7.1 Driver Download
Download File ✔ https://imgfil.com/2uy20S
- -Download and Print Say You Love Me sheet music for Piano & Vocal by Fleetwood ... Delock Adapter USB 2.0 Sound 7.1 extern. frutiger roman font free mac; ... address allows us to send you informative newsletters and driver information, and ... 1fdad05405
-
-
- diff --git a/spaces/1toTree/lora_test/ppdiffusers/pipelines/stable_diffusion_safe/safety_checker.py b/spaces/1toTree/lora_test/ppdiffusers/pipelines/stable_diffusion_safe/safety_checker.py deleted file mode 100644 index 145c46179940e0b02e85171a2d052146f57ebaef..0000000000000000000000000000000000000000 --- a/spaces/1toTree/lora_test/ppdiffusers/pipelines/stable_diffusion_safe/safety_checker.py +++ /dev/null @@ -1,113 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# Copyright 2022 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import paddle -import paddle.nn.functional as F - -from paddlenlp.transformers import ( - CLIPPretrainedModel, - CLIPVisionConfig, - CLIPVisionModel, -) - -from ...utils import logging - -logger = logging.get_logger(__name__) - - -def cosine_distance(image_embeds, text_embeds): - normalized_image_embeds = F.normalize(image_embeds) - normalized_text_embeds = F.normalize(text_embeds) - return paddle.matmul(normalized_image_embeds, normalized_text_embeds, transpose_y=True) - - -class SafeStableDiffusionSafetyChecker(CLIPPretrainedModel): - config_class = CLIPVisionConfig - - def __init__(self, config: CLIPVisionConfig): - super().__init__(config) - self.clip = CLIPVisionModel(config) - - self.vision_projection = paddle.create_parameter( - (config.hidden_size, config.projection_dim), dtype=paddle.get_default_dtype() - ) - - self.register_buffer("concept_embeds", paddle.ones([17, config.projection_dim])) - self.register_buffer("special_care_embeds", paddle.ones([3, config.projection_dim])) - - self.register_buffer("concept_embeds_weights", paddle.ones([17])) - self.register_buffer("special_care_embeds_weights", paddle.ones([3])) - - @paddle.no_grad() - def forward(self, clip_input, images): - pooled_output = self.clip(clip_input)[1] # pooled_output - image_embeds = paddle.matmul(pooled_output, self.vision_projection) - - # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16 - special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds).astype("float32").numpy() - cos_dist = cosine_distance(image_embeds, self.concept_embeds).astype("float32").numpy() - - result = [] - batch_size = image_embeds.shape[0] - for i in range(batch_size): - result_img = {"special_scores": {}, "special_care": [], "concept_scores": {}, "bad_concepts": []} - - # increase this value to create a stronger `nfsw` filter - # at the cost of increasing the possibility of filtering benign images - adjustment = 0.0 - - for concept_idx in range(len(special_cos_dist[0])): - concept_cos = special_cos_dist[i][concept_idx] - concept_threshold = self.special_care_embeds_weights[concept_idx].item() - result_img["special_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3) - if result_img["special_scores"][concept_idx] > 0: - result_img["special_care"].append({concept_idx, result_img["special_scores"][concept_idx]}) - adjustment = 0.01 - - for concept_idx in range(len(cos_dist[0])): - concept_cos = cos_dist[i][concept_idx] - concept_threshold = self.concept_embeds_weights[concept_idx].item() - result_img["concept_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3) - if result_img["concept_scores"][concept_idx] > 0: - result_img["bad_concepts"].append(concept_idx) - - result.append(result_img) - - has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result] - - return images, has_nsfw_concepts - - def forward_fastdeploy(self, clip_input: paddle.Tensor, images: paddle.Tensor): - pooled_output = self.clip(clip_input)[1] # pooled_output - image_embeds = paddle.matmul(pooled_output, self.vision_projection) - - special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds) - cos_dist = cosine_distance(image_embeds, self.concept_embeds) - - # increase this value to create a stronger `nsfw` filter - # at the cost of increasing the possibility of filtering benign images - adjustment = 0.0 - - special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment - # special_scores = special_scores.round(decimals=3) - special_care = paddle.any(special_scores > 0, axis=1) - special_adjustment = special_care * 0.01 - special_adjustment = special_adjustment.unsqueeze(1).expand([-1, cos_dist.shape[1]]) - - concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment - # concept_scores = concept_scores.round(decimals=3) - has_nsfw_concepts = paddle.any(concept_scores > 0, axis=1) - - return images, has_nsfw_concepts diff --git a/spaces/2023Liu2023/bingo/src/components/tone-selector.tsx b/spaces/2023Liu2023/bingo/src/components/tone-selector.tsx deleted file mode 100644 index 5c6e464c91f564b895acd121f0a4a79ed9c5c356..0000000000000000000000000000000000000000 --- a/spaces/2023Liu2023/bingo/src/components/tone-selector.tsx +++ /dev/null @@ -1,43 +0,0 @@ -import React from 'react' -import { BingConversationStyle } from '@/lib/bots/bing/types' -import { cn } from '@/lib/utils' - -type ToneItem = { - type: BingConversationStyle, - name: string -} - -const ToneList: ToneItem[] = [ - { name: '有创造力', type: BingConversationStyle.Creative }, - { name: '更平衡', type: BingConversationStyle.Balanced }, - { name: '更精确', type: BingConversationStyle.Precise } -] - -interface ToneSelectorProps { - type: BingConversationStyle | '' - onChange?: (type: BingConversationStyle) => void -} - -export function ToneSelector({ type, onChange }: ToneSelectorProps) { - return ( --- ) -} diff --git a/spaces/A00001/bingothoo/src/components/ui/textarea.tsx b/spaces/A00001/bingothoo/src/components/ui/textarea.tsx deleted file mode 100644 index e25af722c7a5dc1121a9ab58d6716952f9f76081..0000000000000000000000000000000000000000 --- a/spaces/A00001/bingothoo/src/components/ui/textarea.tsx +++ /dev/null @@ -1,24 +0,0 @@ -import * as React from 'react' - -import { cn } from '@/lib/utils' - -export interface TextareaProps - extends React.TextareaHTMLAttributes- 选择对话样式 -----
- {
- ToneList.map(tone => (
-
- onChange?.(tone.type)}> - - - )) - } -
{} - -const Textarea = React.forwardRef %sveltekit.body%- - diff --git a/spaces/AchyuthGamer/OpenGPT-Chat-UI/src/lib/types/SharedConversation.ts b/spaces/AchyuthGamer/OpenGPT-Chat-UI/src/lib/types/SharedConversation.ts deleted file mode 100644 index e8981ed83a8871ef49fa539a14cb1ebfca599ea0..0000000000000000000000000000000000000000 --- a/spaces/AchyuthGamer/OpenGPT-Chat-UI/src/lib/types/SharedConversation.ts +++ /dev/null @@ -1,12 +0,0 @@ -import type { Message } from "./Message"; -import type { Timestamps } from "./Timestamps"; - -export interface SharedConversation extends Timestamps { - _id: string; - - hash: string; - - model: string; - title: string; - messages: Message[]; -} diff --git a/spaces/AchyuthGamer/OpenGPT/server/babel.py b/spaces/AchyuthGamer/OpenGPT/server/babel.py deleted file mode 100644 index 94407e4b4d3e82e7722cac409a7e311bb46c43be..0000000000000000000000000000000000000000 --- a/spaces/AchyuthGamer/OpenGPT/server/babel.py +++ /dev/null @@ -1,48 +0,0 @@ -import os -import subprocess -from flask import request, session, jsonify -from flask_babel import Babel - - -def get_languages_from_dir(directory): - """Return a list of directory names in the given directory.""" - return [name for name in os.listdir(directory) - if os.path.isdir(os.path.join(directory, name))] - - -BABEL_DEFAULT_LOCALE = 'en_US' -BABEL_LANGUAGES = get_languages_from_dir('translations') - - -def create_babel(app): - """Create and initialize a Babel instance with the given Flask app.""" - babel = Babel(app) - app.config['BABEL_DEFAULT_LOCALE'] = BABEL_DEFAULT_LOCALE - app.config['BABEL_LANGUAGES'] = BABEL_LANGUAGES - - babel.init_app(app, locale_selector=get_locale) - compile_translations() - - -def get_locale(): - """Get the user's locale from the session or the request's accepted languages.""" - return session.get('language') or request.accept_languages.best_match(BABEL_LANGUAGES) - - -def get_languages(): - """Return a list of available languages in JSON format.""" - return jsonify(BABEL_LANGUAGES) - - -def compile_translations(): - """Compile the translation files.""" - result = subprocess.run( - ['pybabel', 'compile', '-d', 'translations'], - stdout=subprocess.PIPE, - ) - - if result.returncode != 0: - raise Exception( - f'Compiling translations failed:\n{result.stdout.decode()}') - - print('Translations compiled successfully') diff --git a/spaces/Adapter/CoAdapter/ldm/modules/diffusionmodules/model.py b/spaces/Adapter/CoAdapter/ldm/modules/diffusionmodules/model.py deleted file mode 100644 index b089eebbe1676d8249005bb9def002ff5180715b..0000000000000000000000000000000000000000 --- a/spaces/Adapter/CoAdapter/ldm/modules/diffusionmodules/model.py +++ /dev/null @@ -1,852 +0,0 @@ -# pytorch_diffusion + derived encoder decoder -import math -import torch -import torch.nn as nn -import numpy as np -from einops import rearrange -from typing import Optional, Any - -from ldm.modules.attention import MemoryEfficientCrossAttention - -try: - import xformers - import xformers.ops - XFORMERS_IS_AVAILBLE = True -except: - XFORMERS_IS_AVAILBLE = False - print("No module 'xformers'. Proceeding without it.") - - -def get_timestep_embedding(timesteps, embedding_dim): - """ - This matches the implementation in Denoising Diffusion Probabilistic Models: - From Fairseq. - Build sinusoidal embeddings. - This matches the implementation in tensor2tensor, but differs slightly - from the description in Section 3.5 of "Attention Is All You Need". - """ - assert len(timesteps.shape) == 1 - - half_dim = embedding_dim // 2 - emb = math.log(10000) / (half_dim - 1) - emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb) - emb = emb.to(device=timesteps.device) - emb = timesteps.float()[:, None] * emb[None, :] - emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1) - if embedding_dim % 2 == 1: # zero pad - emb = torch.nn.functional.pad(emb, (0,1,0,0)) - return emb - - -def nonlinearity(x): - # swish - return x*torch.sigmoid(x) - - -def Normalize(in_channels, num_groups=32): - return torch.nn.GroupNorm(num_groups=num_groups, num_channels=in_channels, eps=1e-6, affine=True) - - -class Upsample(nn.Module): - def __init__(self, in_channels, with_conv): - super().__init__() - self.with_conv = with_conv - if self.with_conv: - self.conv = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=3, - stride=1, - padding=1) - - def forward(self, x): - x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest") - if self.with_conv: - x = self.conv(x) - return x - - -class Downsample(nn.Module): - def __init__(self, in_channels, with_conv): - super().__init__() - self.with_conv = with_conv - if self.with_conv: - # no asymmetric padding in torch conv, must do it ourselves - self.conv = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=3, - stride=2, - padding=0) - - def forward(self, x): - if self.with_conv: - pad = (0,1,0,1) - x = torch.nn.functional.pad(x, pad, mode="constant", value=0) - x = self.conv(x) - else: - x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2) - return x - - -class ResnetBlock(nn.Module): - def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False, - dropout, temb_channels=512): - super().__init__() - self.in_channels = in_channels - out_channels = in_channels if out_channels is None else out_channels - self.out_channels = out_channels - self.use_conv_shortcut = conv_shortcut - - self.norm1 = Normalize(in_channels) - self.conv1 = torch.nn.Conv2d(in_channels, - out_channels, - kernel_size=3, - stride=1, - padding=1) - if temb_channels > 0: - self.temb_proj = torch.nn.Linear(temb_channels, - out_channels) - self.norm2 = Normalize(out_channels) - self.dropout = torch.nn.Dropout(dropout) - self.conv2 = torch.nn.Conv2d(out_channels, - out_channels, - kernel_size=3, - stride=1, - padding=1) - if self.in_channels != self.out_channels: - if self.use_conv_shortcut: - self.conv_shortcut = torch.nn.Conv2d(in_channels, - out_channels, - kernel_size=3, - stride=1, - padding=1) - else: - self.nin_shortcut = torch.nn.Conv2d(in_channels, - out_channels, - kernel_size=1, - stride=1, - padding=0) - - def forward(self, x, temb): - h = x - h = self.norm1(h) - h = nonlinearity(h) - h = self.conv1(h) - - if temb is not None: - h = h + self.temb_proj(nonlinearity(temb))[:,:,None,None] - - h = self.norm2(h) - h = nonlinearity(h) - h = self.dropout(h) - h = self.conv2(h) - - if self.in_channels != self.out_channels: - if self.use_conv_shortcut: - x = self.conv_shortcut(x) - else: - x = self.nin_shortcut(x) - - return x+h - - -class AttnBlock(nn.Module): - def __init__(self, in_channels): - super().__init__() - self.in_channels = in_channels - - self.norm = Normalize(in_channels) - self.q = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=1, - stride=1, - padding=0) - self.k = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=1, - stride=1, - padding=0) - self.v = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=1, - stride=1, - padding=0) - self.proj_out = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=1, - stride=1, - padding=0) - - def forward(self, x): - h_ = x - h_ = self.norm(h_) - q = self.q(h_) - k = self.k(h_) - v = self.v(h_) - - # compute attention - b,c,h,w = q.shape - q = q.reshape(b,c,h*w) - q = q.permute(0,2,1) # b,hw,c - k = k.reshape(b,c,h*w) # b,c,hw - w_ = torch.bmm(q,k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j] - w_ = w_ * (int(c)**(-0.5)) - w_ = torch.nn.functional.softmax(w_, dim=2) - - # attend to values - v = v.reshape(b,c,h*w) - w_ = w_.permute(0,2,1) # b,hw,hw (first hw of k, second of q) - h_ = torch.bmm(v,w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j] - h_ = h_.reshape(b,c,h,w) - - h_ = self.proj_out(h_) - - return x+h_ - -class MemoryEfficientAttnBlock(nn.Module): - """ - Uses xformers efficient implementation, - see https://github.com/MatthieuTPHR/diffusers/blob/d80b531ff8060ec1ea982b65a1b8df70f73aa67c/src/diffusers/models/attention.py#L223 - Note: this is a single-head self-attention operation - """ - # - def __init__(self, in_channels): - super().__init__() - self.in_channels = in_channels - - self.norm = Normalize(in_channels) - self.q = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=1, - stride=1, - padding=0) - self.k = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=1, - stride=1, - padding=0) - self.v = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=1, - stride=1, - padding=0) - self.proj_out = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=1, - stride=1, - padding=0) - self.attention_op: Optional[Any] = None - - def forward(self, x): - h_ = x - h_ = self.norm(h_) - q = self.q(h_) - k = self.k(h_) - v = self.v(h_) - - # compute attention - B, C, H, W = q.shape - q, k, v = map(lambda x: rearrange(x, 'b c h w -> b (h w) c'), (q, k, v)) - - q, k, v = map( - lambda t: t.unsqueeze(3) - .reshape(B, t.shape[1], 1, C) - .permute(0, 2, 1, 3) - .reshape(B * 1, t.shape[1], C) - .contiguous(), - (q, k, v), - ) - out = xformers.ops.memory_efficient_attention(q, k, v, attn_bias=None, op=self.attention_op) - - out = ( - out.unsqueeze(0) - .reshape(B, 1, out.shape[1], C) - .permute(0, 2, 1, 3) - .reshape(B, out.shape[1], C) - ) - out = rearrange(out, 'b (h w) c -> b c h w', b=B, h=H, w=W, c=C) - out = self.proj_out(out) - return x+out - - -class MemoryEfficientCrossAttentionWrapper(MemoryEfficientCrossAttention): - def forward(self, x, context=None, mask=None): - b, c, h, w = x.shape - x = rearrange(x, 'b c h w -> b (h w) c') - out = super().forward(x, context=context, mask=mask) - out = rearrange(out, 'b (h w) c -> b c h w', h=h, w=w, c=c) - return x + out - - -def make_attn(in_channels, attn_type="vanilla", attn_kwargs=None): - assert attn_type in ["vanilla", "vanilla-xformers", "memory-efficient-cross-attn", "linear", "none"], f'attn_type {attn_type} unknown' - if XFORMERS_IS_AVAILBLE and attn_type == "vanilla": - attn_type = "vanilla-xformers" - print(f"making attention of type '{attn_type}' with {in_channels} in_channels") - if attn_type == "vanilla": - assert attn_kwargs is None - return AttnBlock(in_channels) - elif attn_type == "vanilla-xformers": - print(f"building MemoryEfficientAttnBlock with {in_channels} in_channels...") - return MemoryEfficientAttnBlock(in_channels) - elif type == "memory-efficient-cross-attn": - attn_kwargs["query_dim"] = in_channels - return MemoryEfficientCrossAttentionWrapper(**attn_kwargs) - elif attn_type == "none": - return nn.Identity(in_channels) - else: - raise NotImplementedError() - - -class Model(nn.Module): - def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks, - attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels, - resolution, use_timestep=True, use_linear_attn=False, attn_type="vanilla"): - super().__init__() - if use_linear_attn: attn_type = "linear" - self.ch = ch - self.temb_ch = self.ch*4 - self.num_resolutions = len(ch_mult) - self.num_res_blocks = num_res_blocks - self.resolution = resolution - self.in_channels = in_channels - - self.use_timestep = use_timestep - if self.use_timestep: - # timestep embedding - self.temb = nn.Module() - self.temb.dense = nn.ModuleList([ - torch.nn.Linear(self.ch, - self.temb_ch), - torch.nn.Linear(self.temb_ch, - self.temb_ch), - ]) - - # downsampling - self.conv_in = torch.nn.Conv2d(in_channels, - self.ch, - kernel_size=3, - stride=1, - padding=1) - - curr_res = resolution - in_ch_mult = (1,)+tuple(ch_mult) - self.down = nn.ModuleList() - for i_level in range(self.num_resolutions): - block = nn.ModuleList() - attn = nn.ModuleList() - block_in = ch*in_ch_mult[i_level] - block_out = ch*ch_mult[i_level] - for i_block in range(self.num_res_blocks): - block.append(ResnetBlock(in_channels=block_in, - out_channels=block_out, - temb_channels=self.temb_ch, - dropout=dropout)) - block_in = block_out - if curr_res in attn_resolutions: - attn.append(make_attn(block_in, attn_type=attn_type)) - down = nn.Module() - down.block = block - down.attn = attn - if i_level != self.num_resolutions-1: - down.downsample = Downsample(block_in, resamp_with_conv) - curr_res = curr_res // 2 - self.down.append(down) - - # middle - self.mid = nn.Module() - self.mid.block_1 = ResnetBlock(in_channels=block_in, - out_channels=block_in, - temb_channels=self.temb_ch, - dropout=dropout) - self.mid.attn_1 = make_attn(block_in, attn_type=attn_type) - self.mid.block_2 = ResnetBlock(in_channels=block_in, - out_channels=block_in, - temb_channels=self.temb_ch, - dropout=dropout) - - # upsampling - self.up = nn.ModuleList() - for i_level in reversed(range(self.num_resolutions)): - block = nn.ModuleList() - attn = nn.ModuleList() - block_out = ch*ch_mult[i_level] - skip_in = ch*ch_mult[i_level] - for i_block in range(self.num_res_blocks+1): - if i_block == self.num_res_blocks: - skip_in = ch*in_ch_mult[i_level] - block.append(ResnetBlock(in_channels=block_in+skip_in, - out_channels=block_out, - temb_channels=self.temb_ch, - dropout=dropout)) - block_in = block_out - if curr_res in attn_resolutions: - attn.append(make_attn(block_in, attn_type=attn_type)) - up = nn.Module() - up.block = block - up.attn = attn - if i_level != 0: - up.upsample = Upsample(block_in, resamp_with_conv) - curr_res = curr_res * 2 - self.up.insert(0, up) # prepend to get consistent order - - # end - self.norm_out = Normalize(block_in) - self.conv_out = torch.nn.Conv2d(block_in, - out_ch, - kernel_size=3, - stride=1, - padding=1) - - def forward(self, x, t=None, context=None): - #assert x.shape[2] == x.shape[3] == self.resolution - if context is not None: - # assume aligned context, cat along channel axis - x = torch.cat((x, context), dim=1) - if self.use_timestep: - # timestep embedding - assert t is not None - temb = get_timestep_embedding(t, self.ch) - temb = self.temb.dense[0](temb) - temb = nonlinearity(temb) - temb = self.temb.dense[1](temb) - else: - temb = None - - # downsampling - hs = [self.conv_in(x)] - for i_level in range(self.num_resolutions): - for i_block in range(self.num_res_blocks): - h = self.down[i_level].block[i_block](hs[-1], temb) - if len(self.down[i_level].attn) > 0: - h = self.down[i_level].attn[i_block](h) - hs.append(h) - if i_level != self.num_resolutions-1: - hs.append(self.down[i_level].downsample(hs[-1])) - - # middle - h = hs[-1] - h = self.mid.block_1(h, temb) - h = self.mid.attn_1(h) - h = self.mid.block_2(h, temb) - - # upsampling - for i_level in reversed(range(self.num_resolutions)): - for i_block in range(self.num_res_blocks+1): - h = self.up[i_level].block[i_block]( - torch.cat([h, hs.pop()], dim=1), temb) - if len(self.up[i_level].attn) > 0: - h = self.up[i_level].attn[i_block](h) - if i_level != 0: - h = self.up[i_level].upsample(h) - - # end - h = self.norm_out(h) - h = nonlinearity(h) - h = self.conv_out(h) - return h - - def get_last_layer(self): - return self.conv_out.weight - - -class Encoder(nn.Module): - def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks, - attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels, - resolution, z_channels, double_z=True, use_linear_attn=False, attn_type="vanilla", - **ignore_kwargs): - super().__init__() - if use_linear_attn: attn_type = "linear" - self.ch = ch - self.temb_ch = 0 - self.num_resolutions = len(ch_mult) - self.num_res_blocks = num_res_blocks - self.resolution = resolution - self.in_channels = in_channels - - # downsampling - self.conv_in = torch.nn.Conv2d(in_channels, - self.ch, - kernel_size=3, - stride=1, - padding=1) - - curr_res = resolution - in_ch_mult = (1,)+tuple(ch_mult) - self.in_ch_mult = in_ch_mult - self.down = nn.ModuleList() - for i_level in range(self.num_resolutions): - block = nn.ModuleList() - attn = nn.ModuleList() - block_in = ch*in_ch_mult[i_level] - block_out = ch*ch_mult[i_level] - for i_block in range(self.num_res_blocks): - block.append(ResnetBlock(in_channels=block_in, - out_channels=block_out, - temb_channels=self.temb_ch, - dropout=dropout)) - block_in = block_out - if curr_res in attn_resolutions: - attn.append(make_attn(block_in, attn_type=attn_type)) - down = nn.Module() - down.block = block - down.attn = attn - if i_level != self.num_resolutions-1: - down.downsample = Downsample(block_in, resamp_with_conv) - curr_res = curr_res // 2 - self.down.append(down) - - # middle - self.mid = nn.Module() - self.mid.block_1 = ResnetBlock(in_channels=block_in, - out_channels=block_in, - temb_channels=self.temb_ch, - dropout=dropout) - self.mid.attn_1 = make_attn(block_in, attn_type=attn_type) - self.mid.block_2 = ResnetBlock(in_channels=block_in, - out_channels=block_in, - temb_channels=self.temb_ch, - dropout=dropout) - - # end - self.norm_out = Normalize(block_in) - self.conv_out = torch.nn.Conv2d(block_in, - 2*z_channels if double_z else z_channels, - kernel_size=3, - stride=1, - padding=1) - - def forward(self, x): - # timestep embedding - temb = None - - # downsampling - hs = [self.conv_in(x)] - for i_level in range(self.num_resolutions): - for i_block in range(self.num_res_blocks): - h = self.down[i_level].block[i_block](hs[-1], temb) - if len(self.down[i_level].attn) > 0: - h = self.down[i_level].attn[i_block](h) - hs.append(h) - if i_level != self.num_resolutions-1: - hs.append(self.down[i_level].downsample(hs[-1])) - - # middle - h = hs[-1] - h = self.mid.block_1(h, temb) - h = self.mid.attn_1(h) - h = self.mid.block_2(h, temb) - - # end - h = self.norm_out(h) - h = nonlinearity(h) - h = self.conv_out(h) - return h - - -class Decoder(nn.Module): - def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks, - attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels, - resolution, z_channels, give_pre_end=False, tanh_out=False, use_linear_attn=False, - attn_type="vanilla", **ignorekwargs): - super().__init__() - if use_linear_attn: attn_type = "linear" - self.ch = ch - self.temb_ch = 0 - self.num_resolutions = len(ch_mult) - self.num_res_blocks = num_res_blocks - self.resolution = resolution - self.in_channels = in_channels - self.give_pre_end = give_pre_end - self.tanh_out = tanh_out - - # compute in_ch_mult, block_in and curr_res at lowest res - in_ch_mult = (1,)+tuple(ch_mult) - block_in = ch*ch_mult[self.num_resolutions-1] - curr_res = resolution // 2**(self.num_resolutions-1) - self.z_shape = (1,z_channels,curr_res,curr_res) - print("Working with z of shape {} = {} dimensions.".format( - self.z_shape, np.prod(self.z_shape))) - - # z to block_in - self.conv_in = torch.nn.Conv2d(z_channels, - block_in, - kernel_size=3, - stride=1, - padding=1) - - # middle - self.mid = nn.Module() - self.mid.block_1 = ResnetBlock(in_channels=block_in, - out_channels=block_in, - temb_channels=self.temb_ch, - dropout=dropout) - self.mid.attn_1 = make_attn(block_in, attn_type=attn_type) - self.mid.block_2 = ResnetBlock(in_channels=block_in, - out_channels=block_in, - temb_channels=self.temb_ch, - dropout=dropout) - - # upsampling - self.up = nn.ModuleList() - for i_level in reversed(range(self.num_resolutions)): - block = nn.ModuleList() - attn = nn.ModuleList() - block_out = ch*ch_mult[i_level] - for i_block in range(self.num_res_blocks+1): - block.append(ResnetBlock(in_channels=block_in, - out_channels=block_out, - temb_channels=self.temb_ch, - dropout=dropout)) - block_in = block_out - if curr_res in attn_resolutions: - attn.append(make_attn(block_in, attn_type=attn_type)) - up = nn.Module() - up.block = block - up.attn = attn - if i_level != 0: - up.upsample = Upsample(block_in, resamp_with_conv) - curr_res = curr_res * 2 - self.up.insert(0, up) # prepend to get consistent order - - # end - self.norm_out = Normalize(block_in) - self.conv_out = torch.nn.Conv2d(block_in, - out_ch, - kernel_size=3, - stride=1, - padding=1) - - def forward(self, z): - #assert z.shape[1:] == self.z_shape[1:] - self.last_z_shape = z.shape - - # timestep embedding - temb = None - - # z to block_in - h = self.conv_in(z) - - # middle - h = self.mid.block_1(h, temb) - h = self.mid.attn_1(h) - h = self.mid.block_2(h, temb) - - # upsampling - for i_level in reversed(range(self.num_resolutions)): - for i_block in range(self.num_res_blocks+1): - h = self.up[i_level].block[i_block](h, temb) - if len(self.up[i_level].attn) > 0: - h = self.up[i_level].attn[i_block](h) - if i_level != 0: - h = self.up[i_level].upsample(h) - - # end - if self.give_pre_end: - return h - - h = self.norm_out(h) - h = nonlinearity(h) - h = self.conv_out(h) - if self.tanh_out: - h = torch.tanh(h) - return h - - -class SimpleDecoder(nn.Module): - def __init__(self, in_channels, out_channels, *args, **kwargs): - super().__init__() - self.model = nn.ModuleList([nn.Conv2d(in_channels, in_channels, 1), - ResnetBlock(in_channels=in_channels, - out_channels=2 * in_channels, - temb_channels=0, dropout=0.0), - ResnetBlock(in_channels=2 * in_channels, - out_channels=4 * in_channels, - temb_channels=0, dropout=0.0), - ResnetBlock(in_channels=4 * in_channels, - out_channels=2 * in_channels, - temb_channels=0, dropout=0.0), - nn.Conv2d(2*in_channels, in_channels, 1), - Upsample(in_channels, with_conv=True)]) - # end - self.norm_out = Normalize(in_channels) - self.conv_out = torch.nn.Conv2d(in_channels, - out_channels, - kernel_size=3, - stride=1, - padding=1) - - def forward(self, x): - for i, layer in enumerate(self.model): - if i in [1,2,3]: - x = layer(x, None) - else: - x = layer(x) - - h = self.norm_out(x) - h = nonlinearity(h) - x = self.conv_out(h) - return x - - -class UpsampleDecoder(nn.Module): - def __init__(self, in_channels, out_channels, ch, num_res_blocks, resolution, - ch_mult=(2,2), dropout=0.0): - super().__init__() - # upsampling - self.temb_ch = 0 - self.num_resolutions = len(ch_mult) - self.num_res_blocks = num_res_blocks - block_in = in_channels - curr_res = resolution // 2 ** (self.num_resolutions - 1) - self.res_blocks = nn.ModuleList() - self.upsample_blocks = nn.ModuleList() - for i_level in range(self.num_resolutions): - res_block = [] - block_out = ch * ch_mult[i_level] - for i_block in range(self.num_res_blocks + 1): - res_block.append(ResnetBlock(in_channels=block_in, - out_channels=block_out, - temb_channels=self.temb_ch, - dropout=dropout)) - block_in = block_out - self.res_blocks.append(nn.ModuleList(res_block)) - if i_level != self.num_resolutions - 1: - self.upsample_blocks.append(Upsample(block_in, True)) - curr_res = curr_res * 2 - - # end - self.norm_out = Normalize(block_in) - self.conv_out = torch.nn.Conv2d(block_in, - out_channels, - kernel_size=3, - stride=1, - padding=1) - - def forward(self, x): - # upsampling - h = x - for k, i_level in enumerate(range(self.num_resolutions)): - for i_block in range(self.num_res_blocks + 1): - h = self.res_blocks[i_level][i_block](h, None) - if i_level != self.num_resolutions - 1: - h = self.upsample_blocks[k](h) - h = self.norm_out(h) - h = nonlinearity(h) - h = self.conv_out(h) - return h - - -class LatentRescaler(nn.Module): - def __init__(self, factor, in_channels, mid_channels, out_channels, depth=2): - super().__init__() - # residual block, interpolate, residual block - self.factor = factor - self.conv_in = nn.Conv2d(in_channels, - mid_channels, - kernel_size=3, - stride=1, - padding=1) - self.res_block1 = nn.ModuleList([ResnetBlock(in_channels=mid_channels, - out_channels=mid_channels, - temb_channels=0, - dropout=0.0) for _ in range(depth)]) - self.attn = AttnBlock(mid_channels) - self.res_block2 = nn.ModuleList([ResnetBlock(in_channels=mid_channels, - out_channels=mid_channels, - temb_channels=0, - dropout=0.0) for _ in range(depth)]) - - self.conv_out = nn.Conv2d(mid_channels, - out_channels, - kernel_size=1, - ) - - def forward(self, x): - x = self.conv_in(x) - for block in self.res_block1: - x = block(x, None) - x = torch.nn.functional.interpolate(x, size=(int(round(x.shape[2]*self.factor)), int(round(x.shape[3]*self.factor)))) - x = self.attn(x) - for block in self.res_block2: - x = block(x, None) - x = self.conv_out(x) - return x - - -class MergedRescaleEncoder(nn.Module): - def __init__(self, in_channels, ch, resolution, out_ch, num_res_blocks, - attn_resolutions, dropout=0.0, resamp_with_conv=True, - ch_mult=(1,2,4,8), rescale_factor=1.0, rescale_module_depth=1): - super().__init__() - intermediate_chn = ch * ch_mult[-1] - self.encoder = Encoder(in_channels=in_channels, num_res_blocks=num_res_blocks, ch=ch, ch_mult=ch_mult, - z_channels=intermediate_chn, double_z=False, resolution=resolution, - attn_resolutions=attn_resolutions, dropout=dropout, resamp_with_conv=resamp_with_conv, - out_ch=None) - self.rescaler = LatentRescaler(factor=rescale_factor, in_channels=intermediate_chn, - mid_channels=intermediate_chn, out_channels=out_ch, depth=rescale_module_depth) - - def forward(self, x): - x = self.encoder(x) - x = self.rescaler(x) - return x - - -class MergedRescaleDecoder(nn.Module): - def __init__(self, z_channels, out_ch, resolution, num_res_blocks, attn_resolutions, ch, ch_mult=(1,2,4,8), - dropout=0.0, resamp_with_conv=True, rescale_factor=1.0, rescale_module_depth=1): - super().__init__() - tmp_chn = z_channels*ch_mult[-1] - self.decoder = Decoder(out_ch=out_ch, z_channels=tmp_chn, attn_resolutions=attn_resolutions, dropout=dropout, - resamp_with_conv=resamp_with_conv, in_channels=None, num_res_blocks=num_res_blocks, - ch_mult=ch_mult, resolution=resolution, ch=ch) - self.rescaler = LatentRescaler(factor=rescale_factor, in_channels=z_channels, mid_channels=tmp_chn, - out_channels=tmp_chn, depth=rescale_module_depth) - - def forward(self, x): - x = self.rescaler(x) - x = self.decoder(x) - return x - - -class Upsampler(nn.Module): - def __init__(self, in_size, out_size, in_channels, out_channels, ch_mult=2): - super().__init__() - assert out_size >= in_size - num_blocks = int(np.log2(out_size//in_size))+1 - factor_up = 1.+ (out_size % in_size) - print(f"Building {self.__class__.__name__} with in_size: {in_size} --> out_size {out_size} and factor {factor_up}") - self.rescaler = LatentRescaler(factor=factor_up, in_channels=in_channels, mid_channels=2*in_channels, - out_channels=in_channels) - self.decoder = Decoder(out_ch=out_channels, resolution=out_size, z_channels=in_channels, num_res_blocks=2, - attn_resolutions=[], in_channels=None, ch=in_channels, - ch_mult=[ch_mult for _ in range(num_blocks)]) - - def forward(self, x): - x = self.rescaler(x) - x = self.decoder(x) - return x - - -class Resize(nn.Module): - def __init__(self, in_channels=None, learned=False, mode="bilinear"): - super().__init__() - self.with_conv = learned - self.mode = mode - if self.with_conv: - print(f"Note: {self.__class__.__name} uses learned downsampling and will ignore the fixed {mode} mode") - raise NotImplementedError() - assert in_channels is not None - # no asymmetric padding in torch conv, must do it ourselves - self.conv = torch.nn.Conv2d(in_channels, - in_channels, - kernel_size=4, - stride=2, - padding=1) - - def forward(self, x, scale_factor=1.0): - if scale_factor==1.0: - return x - else: - x = torch.nn.functional.interpolate(x, mode=self.mode, align_corners=False, scale_factor=scale_factor) - return x diff --git a/spaces/AgentVerse/agentVerse/agentverse/environments/simulation_env/rules/describer/pokemon.py b/spaces/AgentVerse/agentVerse/agentverse/environments/simulation_env/rules/describer/pokemon.py deleted file mode 100644 index 44d5dbecb392b4b7d088a276d6c4afb91a7dcade..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/agentverse/environments/simulation_env/rules/describer/pokemon.py +++ /dev/null @@ -1,51 +0,0 @@ -from __future__ import annotations - -from typing import TYPE_CHECKING, Any, List, Optional, Dict -from copy import deepcopy - -from . import describer_registry as DescriberRegistry -from .base import BaseDescriber - -if TYPE_CHECKING: - from agentverse.environments.pokemon import PokemonEnvironment - - -@DescriberRegistry.register("pokemon") -class PokemonDescriber(BaseDescriber): - def get_env_description( - self, - environment: PokemonEnvironment, - player_content: str = "", - ) -> List[str]: - time = environment.time - if player_content == "": - agent_to_location = environment.get_agent_to_location() - descriptions = [] - for agent in environment.agents: - description = "" - if agent.name not in agent_to_location: - # Agent is on the way to a location - descriptions.append("") - continue - location = agent_to_location[agent.name] - agents_in_same_loc = deepcopy(environment.locations_to_agents[location]) - agents_in_same_loc.remove(agent.name) - agents_in_same_loc = list(agents_in_same_loc) - description += f"It is now {time}. You are at {location}." - if len(agents_in_same_loc) == 0: - description += " There is no one else here." - elif len(agents_in_same_loc) == 1: - description += f" {agents_in_same_loc[0]} is also here." - else: - other_agents = ", ".join(agents_in_same_loc) - description += f" {other_agents} are also here." - # description += " The locations you can go to include: \n" - # for loc, dsec in environment.locations_descriptions.items(): - # description += f"{loc}: {dsec}\n" - descriptions.append(description) - return descriptions - else: - description = "" - description += f"It is now {time}. Brendan is talking to you.\n" - description += f"[Brendan]: {player_content}\n" - return [description for _ in range(len(environment.agents))] diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/bejeweled/methods/WaitEventMethods.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/bejeweled/methods/WaitEventMethods.js deleted file mode 100644 index 58d5610c8ca14a043fbe0b59098c3491128455ec..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/bejeweled/methods/WaitEventMethods.js +++ /dev/null @@ -1,13 +0,0 @@ -export default { - waitEvent(eventEmitter, eventName) { - if (eventName === undefined) { - eventName = 'complete'; - } - this.waitEvents.waitEvent(eventEmitter, eventName); - return this; - }, - - isWaitingEvent() { - return !this.waitEvents.noWaitEvent; - }, -} \ No newline at end of file diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/maker/builders/utils/CreateAnyLabel.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/maker/builders/utils/CreateAnyLabel.js deleted file mode 100644 index 65387251f395b42824c67285ad5202c7a943ebe3..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/maker/builders/utils/CreateAnyLabel.js +++ /dev/null @@ -1,18 +0,0 @@ -import MergeStyle from './MergeStyle.js'; -import CreateChild from './CreateChild.js'; - -var CreateAnyLabel = function (scene, data, view, styles, customBuilders, LabelClass) { - data = MergeStyle(data, styles); - - // Replace data by child game object - CreateChild(scene, data, 'background', view, styles, customBuilders); - CreateChild(scene, data, 'icon', view, styles, customBuilders); - CreateChild(scene, data, 'text', view, styles, customBuilders); - CreateChild(scene, data, 'action', view, styles, customBuilders); - - var gameObject = new LabelClass(scene, data); - scene.add.existing(gameObject); - return gameObject; -} - -export default CreateAnyLabel; \ No newline at end of file diff --git a/spaces/AkitoP/umamusume_bert_vits2/text/english_bert_mock.py b/spaces/AkitoP/umamusume_bert_vits2/text/english_bert_mock.py deleted file mode 100644 index 3b894ced5b6d619a18d6bdd7d7606ba9e6532050..0000000000000000000000000000000000000000 --- a/spaces/AkitoP/umamusume_bert_vits2/text/english_bert_mock.py +++ /dev/null @@ -1,5 +0,0 @@ -import torch - - -def get_bert_feature(norm_text, word2ph): - return torch.zeros(1024, sum(word2ph)) diff --git a/spaces/AliSaria/MilitarEye/app.py b/spaces/AliSaria/MilitarEye/app.py deleted file mode 100644 index 3e6051c005d4ab336a8a097143b23baf1162e983..0000000000000000000000000000000000000000 --- a/spaces/AliSaria/MilitarEye/app.py +++ /dev/null @@ -1,45 +0,0 @@ -import gradio as gr -from tensorflow.keras.models import load_model -from PIL import Image -import numpy as np -import matplotlib.pyplot as plt -from io import BytesIO - -# Load the trained model -model = load_model('model1.h5') # Make sure 'model1.h5' is the correct path to your model - -# Prediction function for the Gradio app -def predict_and_visualize(img): - # Store the original image size - original_size = img.size - - # Convert the input image to the target size expected by the model - img_resized = img.resize((256, 256)) - img_array = np.array(img_resized) / 255.0 # Normalize the image - img_array = np.expand_dims(img_array, axis=0) # Add batch dimension - - # Make a prediction - prediction = model.predict(img_array) - - # Assuming the model outputs a single-channel image, normalize to 0-255 range for display - predicted_mask = (prediction[0, :, :, 0] * 255).astype(np.uint8) - - # Convert the prediction to a PIL image - prediction_image = Image.fromarray(predicted_mask, mode='L') # 'L' mode is for grayscale - - # Resize the predicted image back to the original image size - prediction_image = prediction_image.resize(original_size, Image.NEAREST) - - return prediction_image - -# Create the Gradio interface -iface = gr.Interface( - fn=predict_and_visualize, - inputs=gr.Image(type="pil"), # We expect a PIL Image - outputs=gr.Image(type="pil"), # We will return a PIL Image - title="MilitarEye: Military Stealth Camouflage Detector", - description="Please upload an image of a military personnel camouflaged in their surroundings. On the right, the model will attempt to predict the camouflage mask silhouette." -) - -# Launch the Gradio app -iface.launch() diff --git a/spaces/Amrrs/DragGan-Inversion/PTI/models/StyleCLIP/global_directions/dnnlib/util.py b/spaces/Amrrs/DragGan-Inversion/PTI/models/StyleCLIP/global_directions/dnnlib/util.py deleted file mode 100644 index 0c35b8923bb27bcd91fd0c14234480067138a3fc..0000000000000000000000000000000000000000 --- a/spaces/Amrrs/DragGan-Inversion/PTI/models/StyleCLIP/global_directions/dnnlib/util.py +++ /dev/null @@ -1,472 +0,0 @@ -# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved. -# -# NVIDIA CORPORATION and its licensors retain all intellectual property -# and proprietary rights in and to this software, related documentation -# and any modifications thereto. Any use, reproduction, disclosure or -# distribution of this software and related documentation without an express -# license agreement from NVIDIA CORPORATION is strictly prohibited. - -"""Miscellaneous utility classes and functions.""" - -import ctypes -import fnmatch -import importlib -import inspect -import numpy as np -import os -import shutil -import sys -import types -import io -import pickle -import re -import requests -import html -import hashlib -import glob -import tempfile -import urllib -import urllib.request -import uuid - -from distutils.util import strtobool -from typing import Any, List, Tuple, Union - - -# Util classes -# ------------------------------------------------------------------------------------------ - - -class EasyDict(dict): - """Convenience class that behaves like a dict but allows access with the attribute syntax.""" - - def __getattr__(self, name: str) -> Any: - try: - return self[name] - except KeyError: - raise AttributeError(name) - - def __setattr__(self, name: str, value: Any) -> None: - self[name] = value - - def __delattr__(self, name: str) -> None: - del self[name] - - -class Logger(object): - """Redirect stderr to stdout, optionally print stdout to a file, and optionally force flushing on both stdout and the file.""" - - def __init__(self, file_name: str = None, file_mode: str = "w", should_flush: bool = True): - self.file = None - - if file_name is not None: - self.file = open(file_name, file_mode) - - self.should_flush = should_flush - self.stdout = sys.stdout - self.stderr = sys.stderr - - sys.stdout = self - sys.stderr = self - - def __enter__(self) -> "Logger": - return self - - def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None: - self.close() - - def write(self, text: str) -> None: - """Write text to stdout (and a file) and optionally flush.""" - if len(text) == 0: # workaround for a bug in VSCode debugger: sys.stdout.write(''); sys.stdout.flush() => crash - return - - if self.file is not None: - self.file.write(text) - - self.stdout.write(text) - - if self.should_flush: - self.flush() - - def flush(self) -> None: - """Flush written text to both stdout and a file, if open.""" - if self.file is not None: - self.file.flush() - - self.stdout.flush() - - def close(self) -> None: - """Flush, close possible files, and remove stdout/stderr mirroring.""" - self.flush() - - # if using multiple loggers, prevent closing in wrong order - if sys.stdout is self: - sys.stdout = self.stdout - if sys.stderr is self: - sys.stderr = self.stderr - - if self.file is not None: - self.file.close() - - -# Cache directories -# ------------------------------------------------------------------------------------------ - -_dnnlib_cache_dir = None - -def set_cache_dir(path: str) -> None: - global _dnnlib_cache_dir - _dnnlib_cache_dir = path - -def make_cache_dir_path(*paths: str) -> str: - if _dnnlib_cache_dir is not None: - return os.path.join(_dnnlib_cache_dir, *paths) - if 'DNNLIB_CACHE_DIR' in os.environ: - return os.path.join(os.environ['DNNLIB_CACHE_DIR'], *paths) - if 'HOME' in os.environ: - return os.path.join(os.environ['HOME'], '.cache', 'dnnlib', *paths) - if 'USERPROFILE' in os.environ: - return os.path.join(os.environ['USERPROFILE'], '.cache', 'dnnlib', *paths) - return os.path.join(tempfile.gettempdir(), '.cache', 'dnnlib', *paths) - -# Small util functions -# ------------------------------------------------------------------------------------------ - - -def format_time(seconds: Union[int, float]) -> str: - """Convert the seconds to human readable string with days, hours, minutes and seconds.""" - s = int(np.rint(seconds)) - - if s < 60: - return "{0}s".format(s) - elif s < 60 * 60: - return "{0}m {1:02}s".format(s // 60, s % 60) - elif s < 24 * 60 * 60: - return "{0}h {1:02}m {2:02}s".format(s // (60 * 60), (s // 60) % 60, s % 60) - else: - return "{0}d {1:02}h {2:02}m".format(s // (24 * 60 * 60), (s // (60 * 60)) % 24, (s // 60) % 60) - - -def ask_yes_no(question: str) -> bool: - """Ask the user the question until the user inputs a valid answer.""" - while True: - try: - print("{0} [y/n]".format(question)) - return strtobool(input().lower()) - except ValueError: - pass - - -def tuple_product(t: Tuple) -> Any: - """Calculate the product of the tuple elements.""" - result = 1 - - for v in t: - result *= v - - return result - - -_str_to_ctype = { - "uint8": ctypes.c_ubyte, - "uint16": ctypes.c_uint16, - "uint32": ctypes.c_uint32, - "uint64": ctypes.c_uint64, - "int8": ctypes.c_byte, - "int16": ctypes.c_int16, - "int32": ctypes.c_int32, - "int64": ctypes.c_int64, - "float32": ctypes.c_float, - "float64": ctypes.c_double -} - - -def get_dtype_and_ctype(type_obj: Any) -> Tuple[np.dtype, Any]: - """Given a type name string (or an object having a __name__ attribute), return matching Numpy and ctypes types that have the same size in bytes.""" - type_str = None - - if isinstance(type_obj, str): - type_str = type_obj - elif hasattr(type_obj, "__name__"): - type_str = type_obj.__name__ - elif hasattr(type_obj, "name"): - type_str = type_obj.name - else: - raise RuntimeError("Cannot infer type name from input") - - assert type_str in _str_to_ctype.keys() - - my_dtype = np.dtype(type_str) - my_ctype = _str_to_ctype[type_str] - - assert my_dtype.itemsize == ctypes.sizeof(my_ctype) - - return my_dtype, my_ctype - - -def is_pickleable(obj: Any) -> bool: - try: - with io.BytesIO() as stream: - pickle.dump(obj, stream) - return True - except: - return False - - -# Functionality to import modules/objects by name, and call functions by name -# ------------------------------------------------------------------------------------------ - -def get_module_from_obj_name(obj_name: str) -> Tuple[types.ModuleType, str]: - """Searches for the underlying module behind the name to some python object. - Returns the module and the object name (original name with module part removed).""" - - # allow convenience shorthands, substitute them by full names - obj_name = re.sub("^np.", "numpy.", obj_name) - obj_name = re.sub("^tf.", "tensorflow.", obj_name) - - # list alternatives for (module_name, local_obj_name) - parts = obj_name.split(".") - name_pairs = [(".".join(parts[:i]), ".".join(parts[i:])) for i in range(len(parts), 0, -1)] - - # try each alternative in turn - for module_name, local_obj_name in name_pairs: - try: - module = importlib.import_module(module_name) # may raise ImportError - get_obj_from_module(module, local_obj_name) # may raise AttributeError - return module, local_obj_name - except: - pass - - # maybe some of the modules themselves contain errors? - for module_name, _local_obj_name in name_pairs: - try: - importlib.import_module(module_name) # may raise ImportError - except ImportError: - if not str(sys.exc_info()[1]).startswith("No module named '" + module_name + "'"): - raise - - # maybe the requested attribute is missing? - for module_name, local_obj_name in name_pairs: - try: - module = importlib.import_module(module_name) # may raise ImportError - get_obj_from_module(module, local_obj_name) # may raise AttributeError - except ImportError: - pass - - # we are out of luck, but we have no idea why - raise ImportError(obj_name) - - -def get_obj_from_module(module: types.ModuleType, obj_name: str) -> Any: - """Traverses the object name and returns the last (rightmost) python object.""" - if obj_name == '': - return module - obj = module - for part in obj_name.split("."): - obj = getattr(obj, part) - return obj - - -def get_obj_by_name(name: str) -> Any: - """Finds the python object with the given name.""" - module, obj_name = get_module_from_obj_name(name) - return get_obj_from_module(module, obj_name) - - -def call_func_by_name(*args, func_name: str = None, **kwargs) -> Any: - """Finds the python object with the given name and calls it as a function.""" - assert func_name is not None - func_obj = get_obj_by_name(func_name) - assert callable(func_obj) - return func_obj(*args, **kwargs) - - -def construct_class_by_name(*args, class_name: str = None, **kwargs) -> Any: - """Finds the python class with the given name and constructs it with the given arguments.""" - return call_func_by_name(*args, func_name=class_name, **kwargs) - - -def get_module_dir_by_obj_name(obj_name: str) -> str: - """Get the directory path of the module containing the given object name.""" - module, _ = get_module_from_obj_name(obj_name) - return os.path.dirname(inspect.getfile(module)) - - -def is_top_level_function(obj: Any) -> bool: - """Determine whether the given object is a top-level function, i.e., defined at module scope using 'def'.""" - return callable(obj) and obj.__name__ in sys.modules[obj.__module__].__dict__ - - -def get_top_level_function_name(obj: Any) -> str: - """Return the fully-qualified name of a top-level function.""" - assert is_top_level_function(obj) - module = obj.__module__ - if module == '__main__': - module = os.path.splitext(os.path.basename(sys.modules[module].__file__))[0] - return module + "." + obj.__name__ - - -# File system helpers -# ------------------------------------------------------------------------------------------ - -def list_dir_recursively_with_ignore(dir_path: str, ignores: List[str] = None, add_base_to_relative: bool = False) -> List[Tuple[str, str]]: - """List all files recursively in a given directory while ignoring given file and directory names. - Returns list of tuples containing both absolute and relative paths.""" - assert os.path.isdir(dir_path) - base_name = os.path.basename(os.path.normpath(dir_path)) - - if ignores is None: - ignores = [] - - result = [] - - for root, dirs, files in os.walk(dir_path, topdown=True): - for ignore_ in ignores: - dirs_to_remove = [d for d in dirs if fnmatch.fnmatch(d, ignore_)] - - # dirs need to be edited in-place - for d in dirs_to_remove: - dirs.remove(d) - - files = [f for f in files if not fnmatch.fnmatch(f, ignore_)] - - absolute_paths = [os.path.join(root, f) for f in files] - relative_paths = [os.path.relpath(p, dir_path) for p in absolute_paths] - - if add_base_to_relative: - relative_paths = [os.path.join(base_name, p) for p in relative_paths] - - assert len(absolute_paths) == len(relative_paths) - result += zip(absolute_paths, relative_paths) - - return result - - -def copy_files_and_create_dirs(files: List[Tuple[str, str]]) -> None: - """Takes in a list of tuples of (src, dst) paths and copies files. - Will create all necessary directories.""" - for file in files: - target_dir_name = os.path.dirname(file[1]) - - # will create all intermediate-level directories - if not os.path.exists(target_dir_name): - os.makedirs(target_dir_name) - - shutil.copyfile(file[0], file[1]) - - -# URL helpers -# ------------------------------------------------------------------------------------------ - -def is_url(obj: Any, allow_file_urls: bool = False) -> bool: - """Determine whether the given object is a valid URL string.""" - if not isinstance(obj, str) or not "://" in obj: - return False - if allow_file_urls and obj.startswith('file://'): - return True - try: - res = requests.compat.urlparse(obj) - if not res.scheme or not res.netloc or not "." in res.netloc: - return False - res = requests.compat.urlparse(requests.compat.urljoin(obj, "/")) - if not res.scheme or not res.netloc or not "." in res.netloc: - return False - except: - return False - return True - - -def open_url(url: str, cache_dir: str = None, num_attempts: int = 10, verbose: bool = True, return_filename: bool = False, cache: bool = True) -> Any: - """Download the given URL and return a binary-mode file object to access the data.""" - assert num_attempts >= 1 - assert not (return_filename and (not cache)) - - # Doesn't look like an URL scheme so interpret it as a local filename. - if not re.match('^[a-z]+://', url): - return url if return_filename else open(url, "rb") - - # Handle file URLs. This code handles unusual file:// patterns that - # arise on Windows: - # - # file:///c:/foo.txt - # - # which would translate to a local '/c:/foo.txt' filename that's - # invalid. Drop the forward slash for such pathnames. - # - # If you touch this code path, you should test it on both Linux and - # Windows. - # - # Some internet resources suggest using urllib.request.url2pathname() but - # but that converts forward slashes to backslashes and this causes - # its own set of problems. - if url.startswith('file://'): - filename = urllib.parse.urlparse(url).path - if re.match(r'^/[a-zA-Z]:', filename): - filename = filename[1:] - return filename if return_filename else open(filename, "rb") - - assert is_url(url) - - # Lookup from cache. - if cache_dir is None: - cache_dir = make_cache_dir_path('downloads') - - url_md5 = hashlib.md5(url.encode("utf-8")).hexdigest() - if cache: - cache_files = glob.glob(os.path.join(cache_dir, url_md5 + "_*")) - if len(cache_files) == 1: - filename = cache_files[0] - return filename if return_filename else open(filename, "rb") - - # Download. - url_name = None - url_data = None - with requests.Session() as session: - if verbose: - print("Downloading %s ..." % url, end="", flush=True) - for attempts_left in reversed(range(num_attempts)): - try: - with session.get(url) as res: - res.raise_for_status() - if len(res.content) == 0: - raise IOError("No data received") - - if len(res.content) < 8192: - content_str = res.content.decode("utf-8") - if "download_warning" in res.headers.get("Set-Cookie", ""): - links = [html.unescape(link) for link in content_str.split('"') if "export=download" in link] - if len(links) == 1: - url = requests.compat.urljoin(url, links[0]) - raise IOError("Google Drive virus checker nag") - if "Google Drive - Quota exceeded" in content_str: - raise IOError("Google Drive download quota exceeded -- please try again later") - - match = re.search(r'filename="([^"]*)"', res.headers.get("Content-Disposition", "")) - url_name = match[1] if match else url - url_data = res.content - if verbose: - print(" done") - break - except: - if not attempts_left: - if verbose: - print(" failed") - raise - if verbose: - print(".", end="", flush=True) - - # Save to cache. - if cache: - safe_name = re.sub(r"[^0-9a-zA-Z-._]", "_", url_name) - cache_file = os.path.join(cache_dir, url_md5 + "_" + safe_name) - temp_file = os.path.join(cache_dir, "tmp_" + uuid.uuid4().hex + "_" + url_md5 + "_" + safe_name) - os.makedirs(cache_dir, exist_ok=True) - with open(temp_file, "wb") as f: - f.write(url_data) - os.replace(temp_file, cache_file) # atomic - if return_filename: - return cache_file - - # Return data as file object. - assert not return_filename - return io.BytesIO(url_data) diff --git a/spaces/Amrrs/fashion-aggregator-duplicated/app.py b/spaces/Amrrs/fashion-aggregator-duplicated/app.py deleted file mode 100644 index e553e9b566811d6912678048609be4527c2c905f..0000000000000000000000000000000000000000 --- a/spaces/Amrrs/fashion-aggregator-duplicated/app.py +++ /dev/null @@ -1,217 +0,0 @@ -"""Provide a text query describing what you are looking for and get back out images with links!""" -"""This has been duplicated to show the new duplication feature demo""" -import argparse -import logging -import os -import wandb -import gradio as gr - -import zipfile -import pickle -from pathlib import Path -from typing import List, Any, Dict -from PIL import Image -from pathlib import Path - -from transformers import AutoTokenizer -from sentence_transformers import SentenceTransformer, util -from multilingual_clip import pt_multilingual_clip -import torch - -from pathlib import Path -from typing import Callable, Dict, List, Tuple -from PIL.Image import Image - -print(__file__) - -os.environ["CUDA_VISIBLE_DEVICES"] = "" # do not use GPU - -logging.basicConfig(level=logging.INFO) -DEFAULT_APPLICATION_NAME = "fashion-aggregator" - -APP_DIR = Path(__file__).resolve().parent # what is the directory for this application? -FAVICON = APP_DIR / "t-shirt_1f455.png" # path to a small image for display in browser tab and social media -README = APP_DIR / "README.md" # path to an app readme file in HTML/markdown - -DEFAULT_PORT = 11700 - -EMBEDDINGS_DIR = "artifacts/img-embeddings" -EMBEDDINGS_FILE = os.path.join(EMBEDDINGS_DIR, "embeddings.pkl") -RAW_PHOTOS_DIR = "artifacts/raw-photos" - -# Download image embeddings and raw photos -wandb.login(key="4b5a23a662b20fdd61f2aeb5032cf56fdce278a4") # os.getenv('wandb') -api = wandb.Api() -artifact_embeddings = api.artifact("ryparmar/fashion-aggregator/unimoda-images:v1") -artifact_embeddings.download(EMBEDDINGS_DIR) -artifact_raw_photos = api.artifact("ryparmar/fashion-aggregator/unimoda-raw-images:v1") -artifact_raw_photos.download("artifacts") - -with zipfile.ZipFile("artifacts/unimoda.zip", 'r') as zip_ref: - zip_ref.extractall(RAW_PHOTOS_DIR) - - -class TextEncoder: - """Encodes the given text""" - - def __init__(self, model_path="M-CLIP/XLM-Roberta-Large-Vit-B-32"): - self.model = pt_multilingual_clip.MultilingualCLIP.from_pretrained(model_path) - self.tokenizer = AutoTokenizer.from_pretrained(model_path) - - @torch.no_grad() - def encode(self, query: str) -> torch.Tensor: - """Predict/infer text embedding for a given query.""" - query_emb = self.model.forward([query], self.tokenizer) - return query_emb - - -class ImageEnoder: - """Encodes the given image""" - - def __init__(self, model_path="clip-ViT-B-32"): - self.model = SentenceTransformer(model_path) - - @torch.no_grad() - def encode(self, image: Image) -> torch.Tensor: - """Predict/infer text embedding for a given query.""" - image_emb = self.model.encode([image], convert_to_tensor=True, show_progress_bar=False) - return image_emb - - -class Retriever: - """Retrieves relevant images for a given text embedding.""" - - def __init__(self, image_embeddings_path=None): - self.text_encoder = TextEncoder() - self.image_encoder = ImageEnoder() - - with open(image_embeddings_path, "rb") as file: - self.image_names, self.image_embeddings = pickle.load(file) - self.image_names = [ - img_name.replace("fashion-aggregator/fashion_aggregator/data/photos/", "") - for img_name in self.image_names - ] - print("Images:", len(self.image_names)) - - @torch.no_grad() - def predict(self, text_query: str, k: int = 10) -> List[Any]: - """Return top-k relevant items for a given embedding""" - query_emb = self.text_encoder.encode(text_query) - relevant_images = util.semantic_search(query_emb, self.image_embeddings, top_k=k)[0] - return relevant_images - - @torch.no_grad() - def search_images(self, text_query: str, k: int = 6) -> Dict[str, List[Any]]: - """Return top-k relevant images for a given embedding""" - images = self.predict(text_query, k) - paths_and_scores = {"path": [], "score": []} - for img in images: - paths_and_scores["path"].append(os.path.join(RAW_PHOTOS_DIR, self.image_names[img["corpus_id"]])) - paths_and_scores["score"].append(img["score"]) - return paths_and_scores - - -def main(args): - predictor = PredictorBackend(url=args.model_url) - frontend = make_frontend(predictor.run, flagging=args.flagging, gantry=args.gantry, app_name=args.application) - frontend.launch( - # server_name="0.0.0.0", # make server accessible, binding all interfaces # noqa: S104 - # server_port=args.port, # set a port to bind to, failing if unavailable - # share=False, # should we create a (temporary) public link on https://gradio.app? - # favicon_path=FAVICON, # what icon should we display in the address bar? - ) - - -def make_frontend( - fn: Callable[[Image], str], flagging: bool = False, gantry: bool = False, app_name: str = "fashion-aggregator" -): - """Creates a gradio.Interface frontend for text to image search function.""" - - allow_flagging = "never" - - # build a basic browser interface to a Python function - frontend = gr.Interface( - fn=fn, # which Python function are we interacting with? - outputs=gr.Gallery(label="Relevant Items"), - # what input widgets does it need? we configure an image widget - inputs=gr.components.Textbox(label="Item Description"), - title="📝 Text2Image 👕", # what should we display at the top of the page? - thumbnail=FAVICON, # what should we display when the link is shared, e.g. on social media? - description=__doc__, # what should we display just above the interface? - cache_examples=False, # should we cache those inputs for faster inference? slows down start - allow_flagging=allow_flagging, # should we show users the option to "flag" outputs? - flagging_options=["incorrect", "offensive", "other"], # what options do users have for feedback? - ) - return frontend - - -class PredictorBackend: - """Interface to a backend that serves predictions. - - To communicate with a backend accessible via a URL, provide the url kwarg. - - Otherwise, runs a predictor locally. - """ - - def __init__(self, url=None): - if url is not None: - self.url = url - self._predict = self._predict_from_endpoint - else: - model = Retriever(image_embeddings_path=EMBEDDINGS_FILE) - self._predict = model.predict - self._search_images = model.search_images - - def run(self, text: str): - pred, metrics = self._predict_with_metrics(text) - self._log_inference(pred, metrics) - return pred - - def _predict_with_metrics(self, text: str) -> Tuple[List[str], Dict[str, float]]: - paths_and_scores = self._search_images(text) - metrics = {"mean_score": sum(paths_and_scores["score"]) / len(paths_and_scores["score"])} - return paths_and_scores["path"], metrics - - def _log_inference(self, pred, metrics): - for key, value in metrics.items(): - logging.info(f"METRIC {key} {value}") - logging.info(f"PRED >begin\n{pred}\nPRED >end") - - -def _make_parser(): - parser = argparse.ArgumentParser(description=__doc__) - parser.add_argument( - "--model_url", - default=None, - type=str, - help="Identifies a URL to which to send image data. Data is base64-encoded, converted to a utf-8 string, and then set via a POST request as JSON with the key 'image'. Default is None, which instead sends the data to a model running locally.", - ) - parser.add_argument( - "--port", - default=DEFAULT_PORT, - type=int, - help=f"Port on which to expose this server. Default is {DEFAULT_PORT}.", - ) - parser.add_argument( - "--flagging", - action="store_true", - help="Pass this flag to allow users to 'flag' model behavior and provide feedback.", - ) - parser.add_argument( - "--gantry", - action="store_true", - help="Pass --flagging and this flag to log user feedback to Gantry. Requires GANTRY_API_KEY to be defined as an environment variable.", - ) - parser.add_argument( - "--application", - default=DEFAULT_APPLICATION_NAME, - type=str, - help=f"Name of the Gantry application to which feedback should be logged, if --gantry and --flagging are passed. Default is {DEFAULT_APPLICATION_NAME}.", - ) - return parser - - -if __name__ == "__main__": - parser = _make_parser() - args = parser.parse_args() - main(args) diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py deleted file mode 100644 index a11cff5ce3f466b0ec6531e5ddd1acd6cedfbf93..0000000000000000000000000000000000000000 --- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py +++ /dev/null @@ -1,1398 +0,0 @@ -# coding=utf-8 -# Copyright 2023 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import gc -import random -import traceback -import unittest - -import numpy as np -import torch -from huggingface_hub import hf_hub_download -from PIL import Image -from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer - -from diffusers import ( - AsymmetricAutoencoderKL, - AutoencoderKL, - DDIMScheduler, - DPMSolverMultistepScheduler, - LMSDiscreteScheduler, - PNDMScheduler, - StableDiffusionInpaintPipeline, - UNet2DConditionModel, -) -from diffusers.models.attention_processor import AttnProcessor -from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint import prepare_mask_and_masked_image -from diffusers.utils import floats_tensor, load_image, load_numpy, nightly, slow, torch_device -from diffusers.utils.testing_utils import ( - enable_full_determinism, - require_torch_2, - require_torch_gpu, - run_test_in_subprocess, -) - -from ...models.test_models_unet_2d_condition import create_lora_layers -from ..pipeline_params import TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS, TEXT_GUIDED_IMAGE_INPAINTING_PARAMS -from ..test_pipelines_common import PipelineKarrasSchedulerTesterMixin, PipelineLatentTesterMixin, PipelineTesterMixin - - -enable_full_determinism() - - -# Will be run via run_test_in_subprocess -def _test_inpaint_compile(in_queue, out_queue, timeout): - error = None - try: - inputs = in_queue.get(timeout=timeout) - torch_device = inputs.pop("torch_device") - seed = inputs.pop("seed") - inputs["generator"] = torch.Generator(device=torch_device).manual_seed(seed) - - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - pipe.unet.to(memory_format=torch.channels_last) - pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True) - - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.0425, 0.0273, 0.0344, 0.1694, 0.1727, 0.1812, 0.3256, 0.3311, 0.3272]) - - assert np.abs(expected_slice - image_slice).max() < 3e-3 - except Exception: - error = f"{traceback.format_exc()}" - - results = {"error": error} - out_queue.put(results, timeout=timeout) - out_queue.join() - - -class StableDiffusionInpaintPipelineFastTests( - PipelineLatentTesterMixin, PipelineKarrasSchedulerTesterMixin, PipelineTesterMixin, unittest.TestCase -): - pipeline_class = StableDiffusionInpaintPipeline - params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS - batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS - image_params = frozenset([]) - # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess - image_latents_params = frozenset([]) - - def get_dummy_components(self): - torch.manual_seed(0) - unet = UNet2DConditionModel( - block_out_channels=(32, 64), - layers_per_block=2, - sample_size=32, - in_channels=9, - out_channels=4, - down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"), - up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"), - cross_attention_dim=32, - ) - scheduler = PNDMScheduler(skip_prk_steps=True) - torch.manual_seed(0) - vae = AutoencoderKL( - block_out_channels=[32, 64], - in_channels=3, - out_channels=3, - down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"], - up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"], - latent_channels=4, - ) - torch.manual_seed(0) - text_encoder_config = CLIPTextConfig( - bos_token_id=0, - eos_token_id=2, - hidden_size=32, - intermediate_size=37, - layer_norm_eps=1e-05, - num_attention_heads=4, - num_hidden_layers=5, - pad_token_id=1, - vocab_size=1000, - ) - text_encoder = CLIPTextModel(text_encoder_config) - tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip") - - components = { - "unet": unet, - "scheduler": scheduler, - "vae": vae, - "text_encoder": text_encoder, - "tokenizer": tokenizer, - "safety_checker": None, - "feature_extractor": None, - } - return components - - def get_dummy_inputs(self, device, seed=0): - # TODO: use tensor inputs instead of PIL, this is here just to leave the old expected_slices untouched - image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device) - image = image.cpu().permute(0, 2, 3, 1)[0] - init_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64)) - mask_image = Image.fromarray(np.uint8(image + 4)).convert("RGB").resize((64, 64)) - if str(device).startswith("mps"): - generator = torch.manual_seed(seed) - else: - generator = torch.Generator(device=device).manual_seed(seed) - inputs = { - "prompt": "A painting of a squirrel eating a burger", - "image": init_image, - "mask_image": mask_image, - "generator": generator, - "num_inference_steps": 2, - "guidance_scale": 6.0, - "output_type": "numpy", - } - return inputs - - def test_stable_diffusion_inpaint(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - components = self.get_dummy_components() - sd_pipe = StableDiffusionInpaintPipeline(**components) - sd_pipe = sd_pipe.to(device) - sd_pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(device) - image = sd_pipe(**inputs).images - image_slice = image[0, -3:, -3:, -1] - - assert image.shape == (1, 64, 64, 3) - expected_slice = np.array([0.4723, 0.5731, 0.3939, 0.5441, 0.5922, 0.4392, 0.5059, 0.4651, 0.4474]) - - assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2 - - def test_stable_diffusion_inpaint_image_tensor(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - components = self.get_dummy_components() - sd_pipe = StableDiffusionInpaintPipeline(**components) - sd_pipe = sd_pipe.to(device) - sd_pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(device) - output = sd_pipe(**inputs) - out_pil = output.images - - inputs = self.get_dummy_inputs(device) - inputs["image"] = torch.tensor(np.array(inputs["image"]) / 127.5 - 1).permute(2, 0, 1).unsqueeze(0) - inputs["mask_image"] = torch.tensor(np.array(inputs["mask_image"]) / 255).permute(2, 0, 1)[:1].unsqueeze(0) - output = sd_pipe(**inputs) - out_tensor = output.images - - assert out_pil.shape == (1, 64, 64, 3) - assert np.abs(out_pil.flatten() - out_tensor.flatten()).max() < 5e-2 - - def test_stable_diffusion_inpaint_lora(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - - components = self.get_dummy_components() - sd_pipe = StableDiffusionInpaintPipeline(**components) - sd_pipe = sd_pipe.to(torch_device) - sd_pipe.set_progress_bar_config(disable=None) - - # forward 1 - inputs = self.get_dummy_inputs(device) - output = sd_pipe(**inputs) - image = output.images - image_slice = image[0, -3:, -3:, -1] - - # set lora layers - lora_attn_procs = create_lora_layers(sd_pipe.unet) - sd_pipe.unet.set_attn_processor(lora_attn_procs) - sd_pipe = sd_pipe.to(torch_device) - - # forward 2 - inputs = self.get_dummy_inputs(device) - output = sd_pipe(**inputs, cross_attention_kwargs={"scale": 0.0}) - image = output.images - image_slice_1 = image[0, -3:, -3:, -1] - - # forward 3 - inputs = self.get_dummy_inputs(device) - output = sd_pipe(**inputs, cross_attention_kwargs={"scale": 0.5}) - image = output.images - image_slice_2 = image[0, -3:, -3:, -1] - - assert np.abs(image_slice - image_slice_1).max() < 1e-2 - assert np.abs(image_slice - image_slice_2).max() > 1e-2 - - def test_inference_batch_single_identical(self): - super().test_inference_batch_single_identical(expected_max_diff=3e-3) - - def test_stable_diffusion_inpaint_strength_zero_test(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - components = self.get_dummy_components() - sd_pipe = StableDiffusionInpaintPipeline(**components) - sd_pipe = sd_pipe.to(device) - sd_pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(device) - - # check that the pipeline raises value error when num_inference_steps is < 1 - inputs["strength"] = 0.01 - with self.assertRaises(ValueError): - sd_pipe(**inputs).images - - -class StableDiffusionSimpleInpaintPipelineFastTests(StableDiffusionInpaintPipelineFastTests): - pipeline_class = StableDiffusionInpaintPipeline - params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS - batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS - image_params = frozenset([]) - # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess - - def get_dummy_components(self): - torch.manual_seed(0) - unet = UNet2DConditionModel( - block_out_channels=(32, 64), - layers_per_block=2, - sample_size=32, - in_channels=4, - out_channels=4, - down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"), - up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"), - cross_attention_dim=32, - ) - scheduler = PNDMScheduler(skip_prk_steps=True) - torch.manual_seed(0) - vae = AutoencoderKL( - block_out_channels=[32, 64], - in_channels=3, - out_channels=3, - down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"], - up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"], - latent_channels=4, - ) - torch.manual_seed(0) - text_encoder_config = CLIPTextConfig( - bos_token_id=0, - eos_token_id=2, - hidden_size=32, - intermediate_size=37, - layer_norm_eps=1e-05, - num_attention_heads=4, - num_hidden_layers=5, - pad_token_id=1, - vocab_size=1000, - ) - text_encoder = CLIPTextModel(text_encoder_config) - tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip") - - components = { - "unet": unet, - "scheduler": scheduler, - "vae": vae, - "text_encoder": text_encoder, - "tokenizer": tokenizer, - "safety_checker": None, - "feature_extractor": None, - } - return components - - def test_stable_diffusion_inpaint(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - components = self.get_dummy_components() - sd_pipe = StableDiffusionInpaintPipeline(**components) - sd_pipe = sd_pipe.to(device) - sd_pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(device) - image = sd_pipe(**inputs).images - image_slice = image[0, -3:, -3:, -1] - - assert image.shape == (1, 64, 64, 3) - expected_slice = np.array([0.4925, 0.4967, 0.4100, 0.5234, 0.5322, 0.4532, 0.5805, 0.5877, 0.4151]) - - assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2 - - @unittest.skip("skipped here because area stays unchanged due to mask") - def test_stable_diffusion_inpaint_lora(self): - ... - - -@slow -@require_torch_gpu -class StableDiffusionInpaintPipelineSlowTests(unittest.TestCase): - def setUp(self): - super().setUp() - - def tearDown(self): - super().tearDown() - gc.collect() - torch.cuda.empty_cache() - - def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0): - generator = torch.Generator(device=generator_device).manual_seed(seed) - init_image = load_image( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/input_bench_image.png" - ) - mask_image = load_image( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/input_bench_mask.png" - ) - inputs = { - "prompt": "Face of a yellow cat, high resolution, sitting on a park bench", - "image": init_image, - "mask_image": mask_image, - "generator": generator, - "num_inference_steps": 3, - "guidance_scale": 7.5, - "output_type": "numpy", - } - return inputs - - def test_stable_diffusion_inpaint_ddim(self): - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.0427, 0.0460, 0.0483, 0.0460, 0.0584, 0.0521, 0.1549, 0.1695, 0.1794]) - - assert np.abs(expected_slice - image_slice).max() < 6e-4 - - def test_stable_diffusion_inpaint_fp16(self): - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, safety_checker=None - ) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device, dtype=torch.float16) - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.1350, 0.1123, 0.1350, 0.1641, 0.1328, 0.1230, 0.1289, 0.1531, 0.1687]) - - assert np.abs(expected_slice - image_slice).max() < 5e-2 - - def test_stable_diffusion_inpaint_pndm(self): - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.0425, 0.0273, 0.0344, 0.1694, 0.1727, 0.1812, 0.3256, 0.3311, 0.3272]) - - assert np.abs(expected_slice - image_slice).max() < 5e-3 - - def test_stable_diffusion_inpaint_k_lms(self): - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.9314, 0.7575, 0.9432, 0.8885, 0.9028, 0.7298, 0.9811, 0.9667, 0.7633]) - - assert np.abs(expected_slice - image_slice).max() < 6e-3 - - def test_stable_diffusion_inpaint_with_sequential_cpu_offloading(self): - torch.cuda.empty_cache() - torch.cuda.reset_max_memory_allocated() - torch.cuda.reset_peak_memory_stats() - - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None, torch_dtype=torch.float16 - ) - pipe = pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing(1) - pipe.enable_sequential_cpu_offload() - - inputs = self.get_inputs(torch_device, dtype=torch.float16) - _ = pipe(**inputs) - - mem_bytes = torch.cuda.max_memory_allocated() - # make sure that less than 2.2 GB is allocated - assert mem_bytes < 2.2 * 10**9 - - @require_torch_2 - def test_inpaint_compile(self): - seed = 0 - inputs = self.get_inputs(torch_device, seed=seed) - # Can't pickle a Generator object - del inputs["generator"] - inputs["torch_device"] = torch_device - inputs["seed"] = seed - run_test_in_subprocess(test_case=self, target_func=_test_inpaint_compile, inputs=inputs) - - def test_stable_diffusion_inpaint_pil_input_resolution_test(self): - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - # change input image to a random size (one that would cause a tensor mismatch error) - inputs["image"] = inputs["image"].resize((127, 127)) - inputs["mask_image"] = inputs["mask_image"].resize((127, 127)) - inputs["height"] = 128 - inputs["width"] = 128 - image = pipe(**inputs).images - # verify that the returned image has the same height and width as the input height and width - assert image.shape == (1, inputs["height"], inputs["width"], 3) - - def test_stable_diffusion_inpaint_strength_test(self): - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - # change input strength - inputs["strength"] = 0.75 - image = pipe(**inputs).images - # verify that the returned image has the same height and width as the input height and width - assert image.shape == (1, 512, 512, 3) - - image_slice = image[0, 253:256, 253:256, -1].flatten() - expected_slice = np.array([0.0021, 0.2350, 0.3712, 0.0575, 0.2485, 0.3451, 0.1857, 0.3156, 0.3943]) - assert np.abs(expected_slice - image_slice).max() < 3e-3 - - def test_stable_diffusion_simple_inpaint_ddim(self): - pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", safety_checker=None) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - image = pipe(**inputs).images - - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.5157, 0.6858, 0.6873, 0.4619, 0.6416, 0.6898, 0.3702, 0.5960, 0.6935]) - - assert np.abs(expected_slice - image_slice).max() < 6e-4 - - def test_download_local(self): - filename = hf_hub_download("runwayml/stable-diffusion-inpainting", filename="sd-v1-5-inpainting.ckpt") - - pipe = StableDiffusionInpaintPipeline.from_single_file(filename, torch_dtype=torch.float16) - pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config) - pipe.to("cuda") - - inputs = self.get_inputs(torch_device) - inputs["num_inference_steps"] = 1 - image_out = pipe(**inputs).images[0] - - assert image_out.shape == (512, 512, 3) - - def test_download_ckpt_diff_format_is_same(self): - ckpt_path = "https://huggingface.co/runwayml/stable-diffusion-inpainting/blob/main/sd-v1-5-inpainting.ckpt" - - pipe = StableDiffusionInpaintPipeline.from_single_file(ckpt_path) - pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config) - pipe.unet.set_attn_processor(AttnProcessor()) - pipe.to("cuda") - - inputs = self.get_inputs(torch_device) - inputs["num_inference_steps"] = 5 - image_ckpt = pipe(**inputs).images[0] - - pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting") - pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config) - pipe.unet.set_attn_processor(AttnProcessor()) - pipe.to("cuda") - - inputs = self.get_inputs(torch_device) - inputs["num_inference_steps"] = 5 - image = pipe(**inputs).images[0] - - assert np.max(np.abs(image - image_ckpt)) < 1e-4 - - -@slow -@require_torch_gpu -class StableDiffusionInpaintPipelineAsymmetricAutoencoderKLSlowTests(unittest.TestCase): - def setUp(self): - super().setUp() - - def tearDown(self): - super().tearDown() - gc.collect() - torch.cuda.empty_cache() - - def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0): - generator = torch.Generator(device=generator_device).manual_seed(seed) - init_image = load_image( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/input_bench_image.png" - ) - mask_image = load_image( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/input_bench_mask.png" - ) - inputs = { - "prompt": "Face of a yellow cat, high resolution, sitting on a park bench", - "image": init_image, - "mask_image": mask_image, - "generator": generator, - "num_inference_steps": 3, - "guidance_scale": 7.5, - "output_type": "numpy", - } - return inputs - - def test_stable_diffusion_inpaint_ddim(self): - vae = AsymmetricAutoencoderKL.from_pretrained("cross-attention/asymmetric-autoencoder-kl-x-1-5") - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.vae = vae - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.0521, 0.0606, 0.0602, 0.0446, 0.0495, 0.0434, 0.1175, 0.1290, 0.1431]) - - assert np.abs(expected_slice - image_slice).max() < 6e-4 - - def test_stable_diffusion_inpaint_fp16(self): - vae = AsymmetricAutoencoderKL.from_pretrained( - "cross-attention/asymmetric-autoencoder-kl-x-1-5", torch_dtype=torch.float16 - ) - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, safety_checker=None - ) - pipe.vae = vae - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device, dtype=torch.float16) - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.1343, 0.1406, 0.1440, 0.1504, 0.1729, 0.0989, 0.1807, 0.2822, 0.1179]) - - assert np.abs(expected_slice - image_slice).max() < 5e-2 - - def test_stable_diffusion_inpaint_pndm(self): - vae = AsymmetricAutoencoderKL.from_pretrained("cross-attention/asymmetric-autoencoder-kl-x-1-5") - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.vae = vae - pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.0976, 0.1071, 0.1119, 0.1363, 0.1260, 0.1150, 0.3745, 0.3586, 0.3340]) - - assert np.abs(expected_slice - image_slice).max() < 5e-3 - - def test_stable_diffusion_inpaint_k_lms(self): - vae = AsymmetricAutoencoderKL.from_pretrained("cross-attention/asymmetric-autoencoder-kl-x-1-5") - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.vae = vae - pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.8909, 0.8620, 0.9024, 0.8501, 0.8558, 0.9074, 0.8790, 0.7540, 0.9003]) - - assert np.abs(expected_slice - image_slice).max() < 6e-3 - - def test_stable_diffusion_inpaint_with_sequential_cpu_offloading(self): - torch.cuda.empty_cache() - torch.cuda.reset_max_memory_allocated() - torch.cuda.reset_peak_memory_stats() - - vae = AsymmetricAutoencoderKL.from_pretrained( - "cross-attention/asymmetric-autoencoder-kl-x-1-5", torch_dtype=torch.float16 - ) - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None, torch_dtype=torch.float16 - ) - pipe.vae = vae - pipe = pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing(1) - pipe.enable_sequential_cpu_offload() - - inputs = self.get_inputs(torch_device, dtype=torch.float16) - _ = pipe(**inputs) - - mem_bytes = torch.cuda.max_memory_allocated() - # make sure that less than 2.45 GB is allocated - assert mem_bytes < 2.45 * 10**9 - - @require_torch_2 - def test_inpaint_compile(self): - pass - - def test_stable_diffusion_inpaint_pil_input_resolution_test(self): - vae = AsymmetricAutoencoderKL.from_pretrained( - "cross-attention/asymmetric-autoencoder-kl-x-1-5", - ) - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.vae = vae - pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - # change input image to a random size (one that would cause a tensor mismatch error) - inputs["image"] = inputs["image"].resize((127, 127)) - inputs["mask_image"] = inputs["mask_image"].resize((127, 127)) - inputs["height"] = 128 - inputs["width"] = 128 - image = pipe(**inputs).images - # verify that the returned image has the same height and width as the input height and width - assert image.shape == (1, inputs["height"], inputs["width"], 3) - - def test_stable_diffusion_inpaint_strength_test(self): - vae = AsymmetricAutoencoderKL.from_pretrained("cross-attention/asymmetric-autoencoder-kl-x-1-5") - pipe = StableDiffusionInpaintPipeline.from_pretrained( - "runwayml/stable-diffusion-inpainting", safety_checker=None - ) - pipe.vae = vae - pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - # change input strength - inputs["strength"] = 0.75 - image = pipe(**inputs).images - # verify that the returned image has the same height and width as the input height and width - assert image.shape == (1, 512, 512, 3) - - image_slice = image[0, 253:256, 253:256, -1].flatten() - expected_slice = np.array([0.2458, 0.2576, 0.3124, 0.2679, 0.2669, 0.2796, 0.2872, 0.2975, 0.2661]) - assert np.abs(expected_slice - image_slice).max() < 3e-3 - - def test_stable_diffusion_simple_inpaint_ddim(self): - vae = AsymmetricAutoencoderKL.from_pretrained("cross-attention/asymmetric-autoencoder-kl-x-1-5") - pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", safety_checker=None) - pipe.vae = vae - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(torch_device) - image = pipe(**inputs).images - - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 512, 512, 3) - expected_slice = np.array([0.3312, 0.4052, 0.4103, 0.4153, 0.4347, 0.4154, 0.4932, 0.4920, 0.4431]) - - assert np.abs(expected_slice - image_slice).max() < 6e-4 - - def test_download_local(self): - vae = AsymmetricAutoencoderKL.from_pretrained( - "cross-attention/asymmetric-autoencoder-kl-x-1-5", torch_dtype=torch.float16 - ) - filename = hf_hub_download("runwayml/stable-diffusion-inpainting", filename="sd-v1-5-inpainting.ckpt") - - pipe = StableDiffusionInpaintPipeline.from_single_file(filename, torch_dtype=torch.float16) - pipe.vae = vae - pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config) - pipe.to("cuda") - - inputs = self.get_inputs(torch_device) - inputs["num_inference_steps"] = 1 - image_out = pipe(**inputs).images[0] - - assert image_out.shape == (512, 512, 3) - - def test_download_ckpt_diff_format_is_same(self): - pass - - -@nightly -@require_torch_gpu -class StableDiffusionInpaintPipelineNightlyTests(unittest.TestCase): - def tearDown(self): - super().tearDown() - gc.collect() - torch.cuda.empty_cache() - - def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0): - generator = torch.Generator(device=generator_device).manual_seed(seed) - init_image = load_image( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/input_bench_image.png" - ) - mask_image = load_image( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/input_bench_mask.png" - ) - inputs = { - "prompt": "Face of a yellow cat, high resolution, sitting on a park bench", - "image": init_image, - "mask_image": mask_image, - "generator": generator, - "num_inference_steps": 50, - "guidance_scale": 7.5, - "output_type": "numpy", - } - return inputs - - def test_inpaint_ddim(self): - sd_pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting") - sd_pipe.to(torch_device) - sd_pipe.set_progress_bar_config(disable=None) - - inputs = self.get_inputs(torch_device) - image = sd_pipe(**inputs).images[0] - - expected_image = load_numpy( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/stable_diffusion_inpaint_ddim.npy" - ) - max_diff = np.abs(expected_image - image).max() - assert max_diff < 1e-3 - - def test_inpaint_pndm(self): - sd_pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting") - sd_pipe.scheduler = PNDMScheduler.from_config(sd_pipe.scheduler.config) - sd_pipe.to(torch_device) - sd_pipe.set_progress_bar_config(disable=None) - - inputs = self.get_inputs(torch_device) - image = sd_pipe(**inputs).images[0] - - expected_image = load_numpy( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/stable_diffusion_inpaint_pndm.npy" - ) - max_diff = np.abs(expected_image - image).max() - assert max_diff < 1e-3 - - def test_inpaint_lms(self): - sd_pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting") - sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config) - sd_pipe.to(torch_device) - sd_pipe.set_progress_bar_config(disable=None) - - inputs = self.get_inputs(torch_device) - image = sd_pipe(**inputs).images[0] - - expected_image = load_numpy( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/stable_diffusion_inpaint_lms.npy" - ) - max_diff = np.abs(expected_image - image).max() - assert max_diff < 1e-3 - - def test_inpaint_dpm(self): - sd_pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting") - sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config) - sd_pipe.to(torch_device) - sd_pipe.set_progress_bar_config(disable=None) - - inputs = self.get_inputs(torch_device) - inputs["num_inference_steps"] = 30 - image = sd_pipe(**inputs).images[0] - - expected_image = load_numpy( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_inpaint/stable_diffusion_inpaint_dpm_multi.npy" - ) - max_diff = np.abs(expected_image - image).max() - assert max_diff < 1e-3 - - -class StableDiffusionInpaintingPrepareMaskAndMaskedImageTests(unittest.TestCase): - def test_pil_inputs(self): - height, width = 32, 32 - im = np.random.randint(0, 255, (height, width, 3), dtype=np.uint8) - im = Image.fromarray(im) - mask = np.random.randint(0, 255, (height, width), dtype=np.uint8) > 127.5 - mask = Image.fromarray((mask * 255).astype(np.uint8)) - - t_mask, t_masked, t_image = prepare_mask_and_masked_image(im, mask, height, width, return_image=True) - - self.assertTrue(isinstance(t_mask, torch.Tensor)) - self.assertTrue(isinstance(t_masked, torch.Tensor)) - self.assertTrue(isinstance(t_image, torch.Tensor)) - - self.assertEqual(t_mask.ndim, 4) - self.assertEqual(t_masked.ndim, 4) - self.assertEqual(t_image.ndim, 4) - - self.assertEqual(t_mask.shape, (1, 1, height, width)) - self.assertEqual(t_masked.shape, (1, 3, height, width)) - self.assertEqual(t_image.shape, (1, 3, height, width)) - - self.assertTrue(t_mask.dtype == torch.float32) - self.assertTrue(t_masked.dtype == torch.float32) - self.assertTrue(t_image.dtype == torch.float32) - - self.assertTrue(t_mask.min() >= 0.0) - self.assertTrue(t_mask.max() <= 1.0) - self.assertTrue(t_masked.min() >= -1.0) - self.assertTrue(t_masked.min() <= 1.0) - self.assertTrue(t_image.min() >= -1.0) - self.assertTrue(t_image.min() >= -1.0) - - self.assertTrue(t_mask.sum() > 0.0) - - def test_np_inputs(self): - height, width = 32, 32 - - im_np = np.random.randint(0, 255, (height, width, 3), dtype=np.uint8) - im_pil = Image.fromarray(im_np) - mask_np = ( - np.random.randint( - 0, - 255, - ( - height, - width, - ), - dtype=np.uint8, - ) - > 127.5 - ) - mask_pil = Image.fromarray((mask_np * 255).astype(np.uint8)) - - t_mask_np, t_masked_np, t_image_np = prepare_mask_and_masked_image( - im_np, mask_np, height, width, return_image=True - ) - t_mask_pil, t_masked_pil, t_image_pil = prepare_mask_and_masked_image( - im_pil, mask_pil, height, width, return_image=True - ) - - self.assertTrue((t_mask_np == t_mask_pil).all()) - self.assertTrue((t_masked_np == t_masked_pil).all()) - self.assertTrue((t_image_np == t_image_pil).all()) - - def test_torch_3D_2D_inputs(self): - height, width = 32, 32 - - im_tensor = torch.randint( - 0, - 255, - ( - 3, - height, - width, - ), - dtype=torch.uint8, - ) - mask_tensor = ( - torch.randint( - 0, - 255, - ( - height, - width, - ), - dtype=torch.uint8, - ) - > 127.5 - ) - im_np = im_tensor.numpy().transpose(1, 2, 0) - mask_np = mask_tensor.numpy() - - t_mask_tensor, t_masked_tensor, t_image_tensor = prepare_mask_and_masked_image( - im_tensor / 127.5 - 1, mask_tensor, height, width, return_image=True - ) - t_mask_np, t_masked_np, t_image_np = prepare_mask_and_masked_image( - im_np, mask_np, height, width, return_image=True - ) - - self.assertTrue((t_mask_tensor == t_mask_np).all()) - self.assertTrue((t_masked_tensor == t_masked_np).all()) - self.assertTrue((t_image_tensor == t_image_np).all()) - - def test_torch_3D_3D_inputs(self): - height, width = 32, 32 - - im_tensor = torch.randint( - 0, - 255, - ( - 3, - height, - width, - ), - dtype=torch.uint8, - ) - mask_tensor = ( - torch.randint( - 0, - 255, - ( - 1, - height, - width, - ), - dtype=torch.uint8, - ) - > 127.5 - ) - im_np = im_tensor.numpy().transpose(1, 2, 0) - mask_np = mask_tensor.numpy()[0] - - t_mask_tensor, t_masked_tensor, t_image_tensor = prepare_mask_and_masked_image( - im_tensor / 127.5 - 1, mask_tensor, height, width, return_image=True - ) - t_mask_np, t_masked_np, t_image_np = prepare_mask_and_masked_image( - im_np, mask_np, height, width, return_image=True - ) - - self.assertTrue((t_mask_tensor == t_mask_np).all()) - self.assertTrue((t_masked_tensor == t_masked_np).all()) - self.assertTrue((t_image_tensor == t_image_np).all()) - - def test_torch_4D_2D_inputs(self): - height, width = 32, 32 - - im_tensor = torch.randint( - 0, - 255, - ( - 1, - 3, - height, - width, - ), - dtype=torch.uint8, - ) - mask_tensor = ( - torch.randint( - 0, - 255, - ( - height, - width, - ), - dtype=torch.uint8, - ) - > 127.5 - ) - im_np = im_tensor.numpy()[0].transpose(1, 2, 0) - mask_np = mask_tensor.numpy() - - t_mask_tensor, t_masked_tensor, t_image_tensor = prepare_mask_and_masked_image( - im_tensor / 127.5 - 1, mask_tensor, height, width, return_image=True - ) - t_mask_np, t_masked_np, t_image_np = prepare_mask_and_masked_image( - im_np, mask_np, height, width, return_image=True - ) - - self.assertTrue((t_mask_tensor == t_mask_np).all()) - self.assertTrue((t_masked_tensor == t_masked_np).all()) - self.assertTrue((t_image_tensor == t_image_np).all()) - - def test_torch_4D_3D_inputs(self): - height, width = 32, 32 - - im_tensor = torch.randint( - 0, - 255, - ( - 1, - 3, - height, - width, - ), - dtype=torch.uint8, - ) - mask_tensor = ( - torch.randint( - 0, - 255, - ( - 1, - height, - width, - ), - dtype=torch.uint8, - ) - > 127.5 - ) - im_np = im_tensor.numpy()[0].transpose(1, 2, 0) - mask_np = mask_tensor.numpy()[0] - - t_mask_tensor, t_masked_tensor, t_image_tensor = prepare_mask_and_masked_image( - im_tensor / 127.5 - 1, mask_tensor, height, width, return_image=True - ) - t_mask_np, t_masked_np, t_image_np = prepare_mask_and_masked_image( - im_np, mask_np, height, width, return_image=True - ) - - self.assertTrue((t_mask_tensor == t_mask_np).all()) - self.assertTrue((t_masked_tensor == t_masked_np).all()) - self.assertTrue((t_image_tensor == t_image_np).all()) - - def test_torch_4D_4D_inputs(self): - height, width = 32, 32 - - im_tensor = torch.randint( - 0, - 255, - ( - 1, - 3, - height, - width, - ), - dtype=torch.uint8, - ) - mask_tensor = ( - torch.randint( - 0, - 255, - ( - 1, - 1, - height, - width, - ), - dtype=torch.uint8, - ) - > 127.5 - ) - im_np = im_tensor.numpy()[0].transpose(1, 2, 0) - mask_np = mask_tensor.numpy()[0][0] - - t_mask_tensor, t_masked_tensor, t_image_tensor = prepare_mask_and_masked_image( - im_tensor / 127.5 - 1, mask_tensor, height, width, return_image=True - ) - t_mask_np, t_masked_np, t_image_np = prepare_mask_and_masked_image( - im_np, mask_np, height, width, return_image=True - ) - - self.assertTrue((t_mask_tensor == t_mask_np).all()) - self.assertTrue((t_masked_tensor == t_masked_np).all()) - self.assertTrue((t_image_tensor == t_image_np).all()) - - def test_torch_batch_4D_3D(self): - height, width = 32, 32 - - im_tensor = torch.randint( - 0, - 255, - ( - 2, - 3, - height, - width, - ), - dtype=torch.uint8, - ) - mask_tensor = ( - torch.randint( - 0, - 255, - ( - 2, - height, - width, - ), - dtype=torch.uint8, - ) - > 127.5 - ) - - im_nps = [im.numpy().transpose(1, 2, 0) for im in im_tensor] - mask_nps = [mask.numpy() for mask in mask_tensor] - - t_mask_tensor, t_masked_tensor, t_image_tensor = prepare_mask_and_masked_image( - im_tensor / 127.5 - 1, mask_tensor, height, width, return_image=True - ) - nps = [prepare_mask_and_masked_image(i, m, height, width, return_image=True) for i, m in zip(im_nps, mask_nps)] - t_mask_np = torch.cat([n[0] for n in nps]) - t_masked_np = torch.cat([n[1] for n in nps]) - t_image_np = torch.cat([n[2] for n in nps]) - - self.assertTrue((t_mask_tensor == t_mask_np).all()) - self.assertTrue((t_masked_tensor == t_masked_np).all()) - self.assertTrue((t_image_tensor == t_image_np).all()) - - def test_torch_batch_4D_4D(self): - height, width = 32, 32 - - im_tensor = torch.randint( - 0, - 255, - ( - 2, - 3, - height, - width, - ), - dtype=torch.uint8, - ) - mask_tensor = ( - torch.randint( - 0, - 255, - ( - 2, - 1, - height, - width, - ), - dtype=torch.uint8, - ) - > 127.5 - ) - - im_nps = [im.numpy().transpose(1, 2, 0) for im in im_tensor] - mask_nps = [mask.numpy()[0] for mask in mask_tensor] - - t_mask_tensor, t_masked_tensor, t_image_tensor = prepare_mask_and_masked_image( - im_tensor / 127.5 - 1, mask_tensor, height, width, return_image=True - ) - nps = [prepare_mask_and_masked_image(i, m, height, width, return_image=True) for i, m in zip(im_nps, mask_nps)] - t_mask_np = torch.cat([n[0] for n in nps]) - t_masked_np = torch.cat([n[1] for n in nps]) - t_image_np = torch.cat([n[2] for n in nps]) - - self.assertTrue((t_mask_tensor == t_mask_np).all()) - self.assertTrue((t_masked_tensor == t_masked_np).all()) - self.assertTrue((t_image_tensor == t_image_np).all()) - - def test_shape_mismatch(self): - height, width = 32, 32 - - # test height and width - with self.assertRaises(AssertionError): - prepare_mask_and_masked_image( - torch.randn( - 3, - height, - width, - ), - torch.randn(64, 64), - height, - width, - return_image=True, - ) - # test batch dim - with self.assertRaises(AssertionError): - prepare_mask_and_masked_image( - torch.randn( - 2, - 3, - height, - width, - ), - torch.randn(4, 64, 64), - height, - width, - return_image=True, - ) - # test batch dim - with self.assertRaises(AssertionError): - prepare_mask_and_masked_image( - torch.randn( - 2, - 3, - height, - width, - ), - torch.randn(4, 1, 64, 64), - height, - width, - return_image=True, - ) - - def test_type_mismatch(self): - height, width = 32, 32 - - # test tensors-only - with self.assertRaises(TypeError): - prepare_mask_and_masked_image( - torch.rand( - 3, - height, - width, - ), - torch.rand( - 3, - height, - width, - ).numpy(), - height, - width, - return_image=True, - ) - # test tensors-only - with self.assertRaises(TypeError): - prepare_mask_and_masked_image( - torch.rand( - 3, - height, - width, - ).numpy(), - torch.rand( - 3, - height, - width, - ), - height, - width, - return_image=True, - ) - - def test_channels_first(self): - height, width = 32, 32 - - # test channels first for 3D tensors - with self.assertRaises(AssertionError): - prepare_mask_and_masked_image( - torch.rand(height, width, 3), - torch.rand( - 3, - height, - width, - ), - height, - width, - return_image=True, - ) - - def test_tensor_range(self): - height, width = 32, 32 - - # test im <= 1 - with self.assertRaises(ValueError): - prepare_mask_and_masked_image( - torch.ones( - 3, - height, - width, - ) - * 2, - torch.rand( - height, - width, - ), - height, - width, - return_image=True, - ) - # test im >= -1 - with self.assertRaises(ValueError): - prepare_mask_and_masked_image( - torch.ones( - 3, - height, - width, - ) - * (-2), - torch.rand( - height, - width, - ), - height, - width, - return_image=True, - ) - # test mask <= 1 - with self.assertRaises(ValueError): - prepare_mask_and_masked_image( - torch.rand( - 3, - height, - width, - ), - torch.ones( - height, - width, - ) - * 2, - height, - width, - return_image=True, - ) - # test mask >= 0 - with self.assertRaises(ValueError): - prepare_mask_and_masked_image( - torch.rand( - 3, - height, - width, - ), - torch.ones( - height, - width, - ) - * -1, - height, - width, - return_image=True, - ) diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_depth.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_depth.py deleted file mode 100644 index fe2cf73da0960dfd93d97d27a542af42a2ed0a17..0000000000000000000000000000000000000000 --- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_depth.py +++ /dev/null @@ -1,599 +0,0 @@ -# coding=utf-8 -# Copyright 2023 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import gc -import random -import tempfile -import unittest - -import numpy as np -import torch -from PIL import Image -from transformers import ( - CLIPTextConfig, - CLIPTextModel, - CLIPTokenizer, - DPTConfig, - DPTFeatureExtractor, - DPTForDepthEstimation, -) - -from diffusers import ( - AutoencoderKL, - DDIMScheduler, - DPMSolverMultistepScheduler, - LMSDiscreteScheduler, - PNDMScheduler, - StableDiffusionDepth2ImgPipeline, - UNet2DConditionModel, -) -from diffusers.utils import ( - floats_tensor, - is_accelerate_available, - is_accelerate_version, - load_image, - load_numpy, - nightly, - slow, - torch_device, -) -from diffusers.utils.testing_utils import enable_full_determinism, require_torch_gpu, skip_mps - -from ..pipeline_params import ( - IMAGE_TO_IMAGE_IMAGE_PARAMS, - TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS, - TEXT_GUIDED_IMAGE_VARIATION_PARAMS, - TEXT_TO_IMAGE_IMAGE_PARAMS, -) -from ..test_pipelines_common import PipelineKarrasSchedulerTesterMixin, PipelineLatentTesterMixin, PipelineTesterMixin - - -enable_full_determinism() - - -@skip_mps -class StableDiffusionDepth2ImgPipelineFastTests( - PipelineLatentTesterMixin, PipelineKarrasSchedulerTesterMixin, PipelineTesterMixin, unittest.TestCase -): - pipeline_class = StableDiffusionDepth2ImgPipeline - test_save_load_optional_components = False - params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"height", "width"} - required_optional_params = PipelineTesterMixin.required_optional_params - {"latents"} - batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS - image_params = IMAGE_TO_IMAGE_IMAGE_PARAMS - image_latents_params = TEXT_TO_IMAGE_IMAGE_PARAMS - - def get_dummy_components(self): - torch.manual_seed(0) - unet = UNet2DConditionModel( - block_out_channels=(32, 64), - layers_per_block=2, - sample_size=32, - in_channels=5, - out_channels=4, - down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"), - up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"), - cross_attention_dim=32, - attention_head_dim=(2, 4), - use_linear_projection=True, - ) - scheduler = PNDMScheduler(skip_prk_steps=True) - torch.manual_seed(0) - vae = AutoencoderKL( - block_out_channels=[32, 64], - in_channels=3, - out_channels=3, - down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"], - up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"], - latent_channels=4, - ) - torch.manual_seed(0) - text_encoder_config = CLIPTextConfig( - bos_token_id=0, - eos_token_id=2, - hidden_size=32, - intermediate_size=37, - layer_norm_eps=1e-05, - num_attention_heads=4, - num_hidden_layers=5, - pad_token_id=1, - vocab_size=1000, - ) - text_encoder = CLIPTextModel(text_encoder_config) - tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip") - - backbone_config = { - "global_padding": "same", - "layer_type": "bottleneck", - "depths": [3, 4, 9], - "out_features": ["stage1", "stage2", "stage3"], - "embedding_dynamic_padding": True, - "hidden_sizes": [96, 192, 384, 768], - "num_groups": 2, - } - depth_estimator_config = DPTConfig( - image_size=32, - patch_size=16, - num_channels=3, - hidden_size=32, - num_hidden_layers=4, - backbone_out_indices=(0, 1, 2, 3), - num_attention_heads=4, - intermediate_size=37, - hidden_act="gelu", - hidden_dropout_prob=0.1, - attention_probs_dropout_prob=0.1, - is_decoder=False, - initializer_range=0.02, - is_hybrid=True, - backbone_config=backbone_config, - backbone_featmap_shape=[1, 384, 24, 24], - ) - depth_estimator = DPTForDepthEstimation(depth_estimator_config).eval() - feature_extractor = DPTFeatureExtractor.from_pretrained( - "hf-internal-testing/tiny-random-DPTForDepthEstimation" - ) - - components = { - "unet": unet, - "scheduler": scheduler, - "vae": vae, - "text_encoder": text_encoder, - "tokenizer": tokenizer, - "depth_estimator": depth_estimator, - "feature_extractor": feature_extractor, - } - return components - - def get_dummy_inputs(self, device, seed=0): - image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)) - image = image.cpu().permute(0, 2, 3, 1)[0] - image = Image.fromarray(np.uint8(image)).convert("RGB").resize((32, 32)) - if str(device).startswith("mps"): - generator = torch.manual_seed(seed) - else: - generator = torch.Generator(device=device).manual_seed(seed) - inputs = { - "prompt": "A painting of a squirrel eating a burger", - "image": image, - "generator": generator, - "num_inference_steps": 2, - "guidance_scale": 6.0, - "output_type": "numpy", - } - return inputs - - def test_save_load_local(self): - components = self.get_dummy_components() - pipe = self.pipeline_class(**components) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(torch_device) - output = pipe(**inputs)[0] - - with tempfile.TemporaryDirectory() as tmpdir: - pipe.save_pretrained(tmpdir) - pipe_loaded = self.pipeline_class.from_pretrained(tmpdir) - pipe_loaded.to(torch_device) - pipe_loaded.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(torch_device) - output_loaded = pipe_loaded(**inputs)[0] - - max_diff = np.abs(output - output_loaded).max() - self.assertLess(max_diff, 1e-4) - - @unittest.skipIf(torch_device != "cuda", reason="float16 requires CUDA") - def test_save_load_float16(self): - components = self.get_dummy_components() - for name, module in components.items(): - if hasattr(module, "half"): - components[name] = module.to(torch_device).half() - pipe = self.pipeline_class(**components) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(torch_device) - output = pipe(**inputs)[0] - - with tempfile.TemporaryDirectory() as tmpdir: - pipe.save_pretrained(tmpdir) - pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, torch_dtype=torch.float16) - pipe_loaded.to(torch_device) - pipe_loaded.set_progress_bar_config(disable=None) - - for name, component in pipe_loaded.components.items(): - if hasattr(component, "dtype"): - self.assertTrue( - component.dtype == torch.float16, - f"`{name}.dtype` switched from `float16` to {component.dtype} after loading.", - ) - - inputs = self.get_dummy_inputs(torch_device) - output_loaded = pipe_loaded(**inputs)[0] - - max_diff = np.abs(output - output_loaded).max() - self.assertLess(max_diff, 2e-2, "The output of the fp16 pipeline changed after saving and loading.") - - @unittest.skipIf(torch_device != "cuda", reason="float16 requires CUDA") - def test_float16_inference(self): - components = self.get_dummy_components() - pipe = self.pipeline_class(**components) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - for name, module in components.items(): - if hasattr(module, "half"): - components[name] = module.half() - pipe_fp16 = self.pipeline_class(**components) - pipe_fp16.to(torch_device) - pipe_fp16.set_progress_bar_config(disable=None) - - output = pipe(**self.get_dummy_inputs(torch_device))[0] - output_fp16 = pipe_fp16(**self.get_dummy_inputs(torch_device))[0] - - max_diff = np.abs(output - output_fp16).max() - self.assertLess(max_diff, 1.3e-2, "The outputs of the fp16 and fp32 pipelines are too different.") - - @unittest.skipIf( - torch_device != "cuda" or not is_accelerate_available() or is_accelerate_version("<", "0.14.0"), - reason="CPU offload is only available with CUDA and `accelerate v0.14.0` or higher", - ) - def test_cpu_offload_forward_pass(self): - components = self.get_dummy_components() - pipe = self.pipeline_class(**components) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(torch_device) - output_without_offload = pipe(**inputs)[0] - - pipe.enable_sequential_cpu_offload() - inputs = self.get_dummy_inputs(torch_device) - output_with_offload = pipe(**inputs)[0] - - max_diff = np.abs(output_with_offload - output_without_offload).max() - self.assertLess(max_diff, 1e-4, "CPU offloading should not affect the inference results") - - def test_dict_tuple_outputs_equivalent(self): - components = self.get_dummy_components() - pipe = self.pipeline_class(**components) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - output = pipe(**self.get_dummy_inputs(torch_device))[0] - output_tuple = pipe(**self.get_dummy_inputs(torch_device), return_dict=False)[0] - - max_diff = np.abs(output - output_tuple).max() - self.assertLess(max_diff, 1e-4) - - def test_progress_bar(self): - super().test_progress_bar() - - def test_stable_diffusion_depth2img_default_case(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - components = self.get_dummy_components() - pipe = StableDiffusionDepth2ImgPipeline(**components) - pipe = pipe.to(device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(device) - image = pipe(**inputs).images - image_slice = image[0, -3:, -3:, -1] - - assert image.shape == (1, 32, 32, 3) - if torch_device == "mps": - expected_slice = np.array([0.6071, 0.5035, 0.4378, 0.5776, 0.5753, 0.4316, 0.4513, 0.5263, 0.4546]) - else: - expected_slice = np.array([0.5435, 0.4992, 0.3783, 0.4411, 0.5842, 0.4654, 0.3786, 0.5077, 0.4655]) - - assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3 - - def test_stable_diffusion_depth2img_negative_prompt(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - components = self.get_dummy_components() - pipe = StableDiffusionDepth2ImgPipeline(**components) - pipe = pipe.to(device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(device) - negative_prompt = "french fries" - output = pipe(**inputs, negative_prompt=negative_prompt) - image = output.images - image_slice = image[0, -3:, -3:, -1] - - assert image.shape == (1, 32, 32, 3) - if torch_device == "mps": - expected_slice = np.array([0.6296, 0.5125, 0.3890, 0.4456, 0.5955, 0.4621, 0.3810, 0.5310, 0.4626]) - else: - expected_slice = np.array([0.6012, 0.4507, 0.3769, 0.4121, 0.5566, 0.4585, 0.3803, 0.5045, 0.4631]) - - assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3 - - def test_stable_diffusion_depth2img_multiple_init_images(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - components = self.get_dummy_components() - pipe = StableDiffusionDepth2ImgPipeline(**components) - pipe = pipe.to(device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(device) - inputs["prompt"] = [inputs["prompt"]] * 2 - inputs["image"] = 2 * [inputs["image"]] - image = pipe(**inputs).images - image_slice = image[-1, -3:, -3:, -1] - - assert image.shape == (2, 32, 32, 3) - - if torch_device == "mps": - expected_slice = np.array([0.6501, 0.5150, 0.4939, 0.6688, 0.5437, 0.5758, 0.5115, 0.4406, 0.4551]) - else: - expected_slice = np.array([0.6557, 0.6214, 0.6254, 0.5775, 0.4785, 0.5949, 0.5904, 0.4785, 0.4730]) - - assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3 - - def test_stable_diffusion_depth2img_pil(self): - device = "cpu" # ensure determinism for the device-dependent torch.Generator - components = self.get_dummy_components() - pipe = StableDiffusionDepth2ImgPipeline(**components) - pipe = pipe.to(device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_dummy_inputs(device) - - image = pipe(**inputs).images - image_slice = image[0, -3:, -3:, -1] - - if torch_device == "mps": - expected_slice = np.array([0.53232, 0.47015, 0.40868, 0.45651, 0.4891, 0.4668, 0.4287, 0.48822, 0.47439]) - else: - expected_slice = np.array([0.5435, 0.4992, 0.3783, 0.4411, 0.5842, 0.4654, 0.3786, 0.5077, 0.4655]) - - assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3 - - @skip_mps - def test_attention_slicing_forward_pass(self): - return super().test_attention_slicing_forward_pass() - - def test_inference_batch_single_identical(self): - super().test_inference_batch_single_identical(expected_max_diff=7e-3) - - -@slow -@require_torch_gpu -class StableDiffusionDepth2ImgPipelineSlowTests(unittest.TestCase): - def tearDown(self): - super().tearDown() - gc.collect() - torch.cuda.empty_cache() - - def get_inputs(self, device="cpu", dtype=torch.float32, seed=0): - generator = torch.Generator(device=device).manual_seed(seed) - init_image = load_image( - "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/depth2img/two_cats.png" - ) - inputs = { - "prompt": "two tigers", - "image": init_image, - "generator": generator, - "num_inference_steps": 3, - "strength": 0.75, - "guidance_scale": 7.5, - "output_type": "numpy", - } - return inputs - - def test_stable_diffusion_depth2img_pipeline_default(self): - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained( - "stabilityai/stable-diffusion-2-depth", safety_checker=None - ) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs() - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 480, 640, 3) - expected_slice = np.array([0.5435, 0.4992, 0.3783, 0.4411, 0.5842, 0.4654, 0.3786, 0.5077, 0.4655]) - - assert np.abs(expected_slice - image_slice).max() < 6e-1 - - def test_stable_diffusion_depth2img_pipeline_k_lms(self): - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained( - "stabilityai/stable-diffusion-2-depth", safety_checker=None - ) - pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs() - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 480, 640, 3) - expected_slice = np.array([0.6363, 0.6274, 0.6309, 0.6370, 0.6226, 0.6286, 0.6213, 0.6453, 0.6306]) - - assert np.abs(expected_slice - image_slice).max() < 8e-4 - - def test_stable_diffusion_depth2img_pipeline_ddim(self): - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained( - "stabilityai/stable-diffusion-2-depth", safety_checker=None - ) - pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs() - image = pipe(**inputs).images - image_slice = image[0, 253:256, 253:256, -1].flatten() - - assert image.shape == (1, 480, 640, 3) - expected_slice = np.array([0.6424, 0.6524, 0.6249, 0.6041, 0.6634, 0.6420, 0.6522, 0.6555, 0.6436]) - - assert np.abs(expected_slice - image_slice).max() < 5e-4 - - def test_stable_diffusion_depth2img_intermediate_state(self): - number_of_steps = 0 - - def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None: - callback_fn.has_been_called = True - nonlocal number_of_steps - number_of_steps += 1 - if step == 1: - latents = latents.detach().cpu().numpy() - assert latents.shape == (1, 4, 60, 80) - latents_slice = latents[0, -3:, -3:, -1] - expected_slice = np.array( - [-0.7168, -1.5137, -0.1418, -2.9219, -2.7266, -2.4414, -2.1035, -3.0078, -1.7051] - ) - - assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2 - elif step == 2: - latents = latents.detach().cpu().numpy() - assert latents.shape == (1, 4, 60, 80) - latents_slice = latents[0, -3:, -3:, -1] - expected_slice = np.array( - [-0.7109, -1.5068, -0.1403, -2.9160, -2.7207, -2.4414, -2.1035, -3.0059, -1.7090] - ) - - assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2 - - callback_fn.has_been_called = False - - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained( - "stabilityai/stable-diffusion-2-depth", safety_checker=None, torch_dtype=torch.float16 - ) - pipe = pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing() - - inputs = self.get_inputs(dtype=torch.float16) - pipe(**inputs, callback=callback_fn, callback_steps=1) - assert callback_fn.has_been_called - assert number_of_steps == 2 - - def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self): - torch.cuda.empty_cache() - torch.cuda.reset_max_memory_allocated() - torch.cuda.reset_peak_memory_stats() - - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained( - "stabilityai/stable-diffusion-2-depth", safety_checker=None, torch_dtype=torch.float16 - ) - pipe = pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - pipe.enable_attention_slicing(1) - pipe.enable_sequential_cpu_offload() - - inputs = self.get_inputs(dtype=torch.float16) - _ = pipe(**inputs) - - mem_bytes = torch.cuda.max_memory_allocated() - # make sure that less than 2.9 GB is allocated - assert mem_bytes < 2.9 * 10**9 - - -@nightly -@require_torch_gpu -class StableDiffusionImg2ImgPipelineNightlyTests(unittest.TestCase): - def tearDown(self): - super().tearDown() - gc.collect() - torch.cuda.empty_cache() - - def get_inputs(self, device="cpu", dtype=torch.float32, seed=0): - generator = torch.Generator(device=device).manual_seed(seed) - init_image = load_image( - "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/depth2img/two_cats.png" - ) - inputs = { - "prompt": "two tigers", - "image": init_image, - "generator": generator, - "num_inference_steps": 3, - "strength": 0.75, - "guidance_scale": 7.5, - "output_type": "numpy", - } - return inputs - - def test_depth2img_pndm(self): - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth") - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_inputs() - image = pipe(**inputs).images[0] - - expected_image = load_numpy( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_depth2img/stable_diffusion_2_0_pndm.npy" - ) - max_diff = np.abs(expected_image - image).max() - assert max_diff < 1e-3 - - def test_depth2img_ddim(self): - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth") - pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_inputs() - image = pipe(**inputs).images[0] - - expected_image = load_numpy( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_depth2img/stable_diffusion_2_0_ddim.npy" - ) - max_diff = np.abs(expected_image - image).max() - assert max_diff < 1e-3 - - def test_img2img_lms(self): - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth") - pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_inputs() - image = pipe(**inputs).images[0] - - expected_image = load_numpy( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_depth2img/stable_diffusion_2_0_lms.npy" - ) - max_diff = np.abs(expected_image - image).max() - assert max_diff < 1e-3 - - def test_img2img_dpm(self): - pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth") - pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) - pipe.to(torch_device) - pipe.set_progress_bar_config(disable=None) - - inputs = self.get_inputs() - inputs["num_inference_steps"] = 30 - image = pipe(**inputs).images[0] - - expected_image = load_numpy( - "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main" - "/stable_diffusion_depth2img/stable_diffusion_2_0_dpm_multi.npy" - ) - max_diff = np.abs(expected_image - image).max() - assert max_diff < 1e-3 diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/deeplabv3/deeplabv3_r50-d8_512x1024_80k_cityscapes.py b/spaces/Andy1621/uniformer_image_segmentation/configs/deeplabv3/deeplabv3_r50-d8_512x1024_80k_cityscapes.py deleted file mode 100644 index 132787db98d3fc9df5ed62e31738c82da8c279bf..0000000000000000000000000000000000000000 --- a/spaces/Andy1621/uniformer_image_segmentation/configs/deeplabv3/deeplabv3_r50-d8_512x1024_80k_cityscapes.py +++ /dev/null @@ -1,4 +0,0 @@ -_base_ = [ - '../_base_/models/deeplabv3_r50-d8.py', '../_base_/datasets/cityscapes.py', - '../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py' -] diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/dmnet/dmnet_r50-d8_512x1024_80k_cityscapes.py b/spaces/Andy1621/uniformer_image_segmentation/configs/dmnet/dmnet_r50-d8_512x1024_80k_cityscapes.py deleted file mode 100644 index 1b38f90dc4318f23d32971e7afbf90a327768f2d..0000000000000000000000000000000000000000 --- a/spaces/Andy1621/uniformer_image_segmentation/configs/dmnet/dmnet_r50-d8_512x1024_80k_cityscapes.py +++ /dev/null @@ -1,4 +0,0 @@ -_base_ = [ - '../_base_/models/dmnet_r50-d8.py', '../_base_/datasets/cityscapes.py', - '../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py' -] diff --git a/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/.github/pull_request_template.md b/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/.github/pull_request_template.md deleted file mode 100644 index 51e26b13a38889a38cac5392b6e22190fd75a8b7..0000000000000000000000000000000000000000 --- a/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/.github/pull_request_template.md +++ /dev/null @@ -1,3 +0,0 @@ -## Checklist: - -- [ ] I have read the [Contributing guidelines](https://github.com/oobabooga/text-generation-webui/wiki/Contributing-guidelines). diff --git a/spaces/Anonymous-sub/Rerender/ControlNet/config.py b/spaces/Anonymous-sub/Rerender/ControlNet/config.py deleted file mode 100644 index e0c738d8cbad66bbe1666284aef926c326849701..0000000000000000000000000000000000000000 --- a/spaces/Anonymous-sub/Rerender/ControlNet/config.py +++ /dev/null @@ -1 +0,0 @@ -save_memory = False diff --git a/spaces/Ariharasudhan/YoloV5/models/tf.py b/spaces/Ariharasudhan/YoloV5/models/tf.py deleted file mode 100644 index 3f3dc8dbe7e76352bc39bbb8a21ed8c35002204e..0000000000000000000000000000000000000000 --- a/spaces/Ariharasudhan/YoloV5/models/tf.py +++ /dev/null @@ -1,608 +0,0 @@ -# YOLOv5 🚀 by Ultralytics, GPL-3.0 license -""" -TensorFlow, Keras and TFLite versions of YOLOv5 -Authored by https://github.com/zldrobit in PR https://github.com/ultralytics/yolov5/pull/1127 - -Usage: - $ python models/tf.py --weights yolov5s.pt - -Export: - $ python export.py --weights yolov5s.pt --include saved_model pb tflite tfjs -""" - -import argparse -import sys -from copy import deepcopy -from pathlib import Path - -FILE = Path(__file__).resolve() -ROOT = FILE.parents[1] # YOLOv5 root directory -if str(ROOT) not in sys.path: - sys.path.append(str(ROOT)) # add ROOT to PATH -# ROOT = ROOT.relative_to(Path.cwd()) # relative - -import numpy as np -import tensorflow as tf -import torch -import torch.nn as nn -from tensorflow import keras - -from models.common import (C3, SPP, SPPF, Bottleneck, BottleneckCSP, C3x, Concat, Conv, CrossConv, DWConv, - DWConvTranspose2d, Focus, autopad) -from models.experimental import MixConv2d, attempt_load -from models.yolo import Detect, Segment -from utils.activations import SiLU -from utils.general import LOGGER, make_divisible, print_args - - -class TFBN(keras.layers.Layer): - # TensorFlow BatchNormalization wrapper - def __init__(self, w=None): - super().__init__() - self.bn = keras.layers.BatchNormalization( - beta_initializer=keras.initializers.Constant(w.bias.numpy()), - gamma_initializer=keras.initializers.Constant(w.weight.numpy()), - moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()), - moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()), - epsilon=w.eps) - - def call(self, inputs): - return self.bn(inputs) - - -class TFPad(keras.layers.Layer): - # Pad inputs in spatial dimensions 1 and 2 - def __init__(self, pad): - super().__init__() - if isinstance(pad, int): - self.pad = tf.constant([[0, 0], [pad, pad], [pad, pad], [0, 0]]) - else: # tuple/list - self.pad = tf.constant([[0, 0], [pad[0], pad[0]], [pad[1], pad[1]], [0, 0]]) - - def call(self, inputs): - return tf.pad(inputs, self.pad, mode='constant', constant_values=0) - - -class TFConv(keras.layers.Layer): - # Standard convolution - def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None): - # ch_in, ch_out, weights, kernel, stride, padding, groups - super().__init__() - assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument" - # TensorFlow convolution padding is inconsistent with PyTorch (e.g. k=3 s=2 'SAME' padding) - # see https://stackoverflow.com/questions/52975843/comparing-conv2d-with-padding-between-tensorflow-and-pytorch - conv = keras.layers.Conv2D( - filters=c2, - kernel_size=k, - strides=s, - padding='SAME' if s == 1 else 'VALID', - use_bias=not hasattr(w, 'bn'), - kernel_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()), - bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy())) - self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv]) - self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity - self.act = activations(w.act) if act else tf.identity - - def call(self, inputs): - return self.act(self.bn(self.conv(inputs))) - - -class TFDWConv(keras.layers.Layer): - # Depthwise convolution - def __init__(self, c1, c2, k=1, s=1, p=None, act=True, w=None): - # ch_in, ch_out, weights, kernel, stride, padding, groups - super().__init__() - assert c2 % c1 == 0, f'TFDWConv() output={c2} must be a multiple of input={c1} channels' - conv = keras.layers.DepthwiseConv2D( - kernel_size=k, - depth_multiplier=c2 // c1, - strides=s, - padding='SAME' if s == 1 else 'VALID', - use_bias=not hasattr(w, 'bn'), - depthwise_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()), - bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy())) - self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv]) - self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity - self.act = activations(w.act) if act else tf.identity - - def call(self, inputs): - return self.act(self.bn(self.conv(inputs))) - - -class TFDWConvTranspose2d(keras.layers.Layer): - # Depthwise ConvTranspose2d - def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0, w=None): - # ch_in, ch_out, weights, kernel, stride, padding, groups - super().__init__() - assert c1 == c2, f'TFDWConv() output={c2} must be equal to input={c1} channels' - assert k == 4 and p1 == 1, 'TFDWConv() only valid for k=4 and p1=1' - weight, bias = w.weight.permute(2, 3, 1, 0).numpy(), w.bias.numpy() - self.c1 = c1 - self.conv = [ - keras.layers.Conv2DTranspose(filters=1, - kernel_size=k, - strides=s, - padding='VALID', - output_padding=p2, - use_bias=True, - kernel_initializer=keras.initializers.Constant(weight[..., i:i + 1]), - bias_initializer=keras.initializers.Constant(bias[i])) for i in range(c1)] - - def call(self, inputs): - return tf.concat([m(x) for m, x in zip(self.conv, tf.split(inputs, self.c1, 3))], 3)[:, 1:-1, 1:-1] - - -class TFFocus(keras.layers.Layer): - # Focus wh information into c-space - def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None): - # ch_in, ch_out, kernel, stride, padding, groups - super().__init__() - self.conv = TFConv(c1 * 4, c2, k, s, p, g, act, w.conv) - - def call(self, inputs): # x(b,w,h,c) -> y(b,w/2,h/2,4c) - # inputs = inputs / 255 # normalize 0-255 to 0-1 - inputs = [inputs[:, ::2, ::2, :], inputs[:, 1::2, ::2, :], inputs[:, ::2, 1::2, :], inputs[:, 1::2, 1::2, :]] - return self.conv(tf.concat(inputs, 3)) - - -class TFBottleneck(keras.layers.Layer): - # Standard bottleneck - def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, w=None): # ch_in, ch_out, shortcut, groups, expansion - super().__init__() - c_ = int(c2 * e) # hidden channels - self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1) - self.cv2 = TFConv(c_, c2, 3, 1, g=g, w=w.cv2) - self.add = shortcut and c1 == c2 - - def call(self, inputs): - return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs)) - - -class TFCrossConv(keras.layers.Layer): - # Cross Convolution - def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False, w=None): - super().__init__() - c_ = int(c2 * e) # hidden channels - self.cv1 = TFConv(c1, c_, (1, k), (1, s), w=w.cv1) - self.cv2 = TFConv(c_, c2, (k, 1), (s, 1), g=g, w=w.cv2) - self.add = shortcut and c1 == c2 - - def call(self, inputs): - return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs)) - - -class TFConv2d(keras.layers.Layer): - # Substitution for PyTorch nn.Conv2D - def __init__(self, c1, c2, k, s=1, g=1, bias=True, w=None): - super().__init__() - assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument" - self.conv = keras.layers.Conv2D(filters=c2, - kernel_size=k, - strides=s, - padding='VALID', - use_bias=bias, - kernel_initializer=keras.initializers.Constant( - w.weight.permute(2, 3, 1, 0).numpy()), - bias_initializer=keras.initializers.Constant(w.bias.numpy()) if bias else None) - - def call(self, inputs): - return self.conv(inputs) - - -class TFBottleneckCSP(keras.layers.Layer): - # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks - def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None): - # ch_in, ch_out, number, shortcut, groups, expansion - super().__init__() - c_ = int(c2 * e) # hidden channels - self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1) - self.cv2 = TFConv2d(c1, c_, 1, 1, bias=False, w=w.cv2) - self.cv3 = TFConv2d(c_, c_, 1, 1, bias=False, w=w.cv3) - self.cv4 = TFConv(2 * c_, c2, 1, 1, w=w.cv4) - self.bn = TFBN(w.bn) - self.act = lambda x: keras.activations.swish(x) - self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)]) - - def call(self, inputs): - y1 = self.cv3(self.m(self.cv1(inputs))) - y2 = self.cv2(inputs) - return self.cv4(self.act(self.bn(tf.concat((y1, y2), axis=3)))) - - -class TFC3(keras.layers.Layer): - # CSP Bottleneck with 3 convolutions - def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None): - # ch_in, ch_out, number, shortcut, groups, expansion - super().__init__() - c_ = int(c2 * e) # hidden channels - self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1) - self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2) - self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3) - self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)]) - - def call(self, inputs): - return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3)) - - -class TFC3x(keras.layers.Layer): - # 3 module with cross-convolutions - def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None): - # ch_in, ch_out, number, shortcut, groups, expansion - super().__init__() - c_ = int(c2 * e) # hidden channels - self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1) - self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2) - self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3) - self.m = keras.Sequential([ - TFCrossConv(c_, c_, k=3, s=1, g=g, e=1.0, shortcut=shortcut, w=w.m[j]) for j in range(n)]) - - def call(self, inputs): - return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3)) - - -class TFSPP(keras.layers.Layer): - # Spatial pyramid pooling layer used in YOLOv3-SPP - def __init__(self, c1, c2, k=(5, 9, 13), w=None): - super().__init__() - c_ = c1 // 2 # hidden channels - self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1) - self.cv2 = TFConv(c_ * (len(k) + 1), c2, 1, 1, w=w.cv2) - self.m = [keras.layers.MaxPool2D(pool_size=x, strides=1, padding='SAME') for x in k] - - def call(self, inputs): - x = self.cv1(inputs) - return self.cv2(tf.concat([x] + [m(x) for m in self.m], 3)) - - -class TFSPPF(keras.layers.Layer): - # Spatial pyramid pooling-Fast layer - def __init__(self, c1, c2, k=5, w=None): - super().__init__() - c_ = c1 // 2 # hidden channels - self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1) - self.cv2 = TFConv(c_ * 4, c2, 1, 1, w=w.cv2) - self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME') - - def call(self, inputs): - x = self.cv1(inputs) - y1 = self.m(x) - y2 = self.m(y1) - return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3)) - - -class TFDetect(keras.layers.Layer): - # TF YOLOv5 Detect layer - def __init__(self, nc=80, anchors=(), ch=(), imgsz=(640, 640), w=None): # detection layer - super().__init__() - self.stride = tf.convert_to_tensor(w.stride.numpy(), dtype=tf.float32) - self.nc = nc # number of classes - self.no = nc + 5 # number of outputs per anchor - self.nl = len(anchors) # number of detection layers - self.na = len(anchors[0]) // 2 # number of anchors - self.grid = [tf.zeros(1)] * self.nl # init grid - self.anchors = tf.convert_to_tensor(w.anchors.numpy(), dtype=tf.float32) - self.anchor_grid = tf.reshape(self.anchors * tf.reshape(self.stride, [self.nl, 1, 1]), [self.nl, 1, -1, 1, 2]) - self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)] - self.training = False # set to False after building model - self.imgsz = imgsz - for i in range(self.nl): - ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i] - self.grid[i] = self._make_grid(nx, ny) - - def call(self, inputs): - z = [] # inference output - x = [] - for i in range(self.nl): - x.append(self.m[i](inputs[i])) - # x(bs,20,20,255) to x(bs,3,20,20,85) - ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i] - x[i] = tf.reshape(x[i], [-1, ny * nx, self.na, self.no]) - - if not self.training: # inference - y = x[i] - grid = tf.transpose(self.grid[i], [0, 2, 1, 3]) - 0.5 - anchor_grid = tf.transpose(self.anchor_grid[i], [0, 2, 1, 3]) * 4 - xy = (tf.sigmoid(y[..., 0:2]) * 2 + grid) * self.stride[i] # xy - wh = tf.sigmoid(y[..., 2:4]) ** 2 * anchor_grid - # Normalize xywh to 0-1 to reduce calibration error - xy /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32) - wh /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32) - y = tf.concat([xy, wh, tf.sigmoid(y[..., 4:5 + self.nc]), y[..., 5 + self.nc:]], -1) - z.append(tf.reshape(y, [-1, self.na * ny * nx, self.no])) - - return tf.transpose(x, [0, 2, 1, 3]) if self.training else (tf.concat(z, 1),) - - @staticmethod - def _make_grid(nx=20, ny=20): - # yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)]) - # return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float() - xv, yv = tf.meshgrid(tf.range(nx), tf.range(ny)) - return tf.cast(tf.reshape(tf.stack([xv, yv], 2), [1, 1, ny * nx, 2]), dtype=tf.float32) - - -class TFSegment(TFDetect): - # YOLOv5 Segment head for segmentation models - def __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), imgsz=(640, 640), w=None): - super().__init__(nc, anchors, ch, imgsz, w) - self.nm = nm # number of masks - self.npr = npr # number of protos - self.no = 5 + nc + self.nm # number of outputs per anchor - self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)] # output conv - self.proto = TFProto(ch[0], self.npr, self.nm, w=w.proto) # protos - self.detect = TFDetect.call - - def call(self, x): - p = self.proto(x[0]) - # p = TFUpsample(None, scale_factor=4, mode='nearest')(self.proto(x[0])) # (optional) full-size protos - p = tf.transpose(p, [0, 3, 1, 2]) # from shape(1,160,160,32) to shape(1,32,160,160) - x = self.detect(self, x) - return (x, p) if self.training else (x[0], p) - - -class TFProto(keras.layers.Layer): - - def __init__(self, c1, c_=256, c2=32, w=None): - super().__init__() - self.cv1 = TFConv(c1, c_, k=3, w=w.cv1) - self.upsample = TFUpsample(None, scale_factor=2, mode='nearest') - self.cv2 = TFConv(c_, c_, k=3, w=w.cv2) - self.cv3 = TFConv(c_, c2, w=w.cv3) - - def call(self, inputs): - return self.cv3(self.cv2(self.upsample(self.cv1(inputs)))) - - -class TFUpsample(keras.layers.Layer): - # TF version of torch.nn.Upsample() - def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w' - super().__init__() - assert scale_factor % 2 == 0, "scale_factor must be multiple of 2" - self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * scale_factor, x.shape[2] * scale_factor), mode) - # self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode) - # with default arguments: align_corners=False, half_pixel_centers=False - # self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x, - # size=(x.shape[1] * 2, x.shape[2] * 2)) - - def call(self, inputs): - return self.upsample(inputs) - - -class TFConcat(keras.layers.Layer): - # TF version of torch.concat() - def __init__(self, dimension=1, w=None): - super().__init__() - assert dimension == 1, "convert only NCHW to NHWC concat" - self.d = 3 - - def call(self, inputs): - return tf.concat(inputs, self.d) - - -def parse_model(d, ch, model, imgsz): # model_dict, input_channels(3) - LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}") - anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'] - na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors - no = na * (nc + 5) # number of outputs = anchors * (classes + 5) - - layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out - for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args - m_str = m - m = eval(m) if isinstance(m, str) else m # eval strings - for j, a in enumerate(args): - try: - args[j] = eval(a) if isinstance(a, str) else a # eval strings - except NameError: - pass - - n = max(round(n * gd), 1) if n > 1 else n # depth gain - if m in [ - nn.Conv2d, Conv, DWConv, DWConvTranspose2d, Bottleneck, SPP, SPPF, MixConv2d, Focus, CrossConv, - BottleneckCSP, C3, C3x]: - c1, c2 = ch[f], args[0] - c2 = make_divisible(c2 * gw, 8) if c2 != no else c2 - - args = [c1, c2, *args[1:]] - if m in [BottleneckCSP, C3, C3x]: - args.insert(2, n) - n = 1 - elif m is nn.BatchNorm2d: - args = [ch[f]] - elif m is Concat: - c2 = sum(ch[-1 if x == -1 else x + 1] for x in f) - elif m in [Detect, Segment]: - args.append([ch[x + 1] for x in f]) - if isinstance(args[1], int): # number of anchors - args[1] = [list(range(args[1] * 2))] * len(f) - if m is Segment: - args[3] = make_divisible(args[3] * gw, 8) - args.append(imgsz) - else: - c2 = ch[f] - - tf_m = eval('TF' + m_str.replace('nn.', '')) - m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \ - else tf_m(*args, w=model.model[i]) # module - - torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module - t = str(m)[8:-2].replace('__main__.', '') # module type - np = sum(x.numel() for x in torch_m_.parameters()) # number params - m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params - LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print - save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist - layers.append(m_) - ch.append(c2) - return keras.Sequential(layers), sorted(save) - - -class TFModel: - # TF YOLOv5 model - def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes - super().__init__() - if isinstance(cfg, dict): - self.yaml = cfg # model dict - else: # is *.yaml - import yaml # for torch hub - self.yaml_file = Path(cfg).name - with open(cfg) as f: - self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict - - # Define model - if nc and nc != self.yaml['nc']: - LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}") - self.yaml['nc'] = nc # override yaml value - self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz) - - def predict(self, - inputs, - tf_nms=False, - agnostic_nms=False, - topk_per_class=100, - topk_all=100, - iou_thres=0.45, - conf_thres=0.25): - y = [] # outputs - x = inputs - for m in self.model.layers: - if m.f != -1: # if not from previous layer - x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers - - x = m(x) # run - y.append(x if m.i in self.savelist else None) # save output - - # Add TensorFlow NMS - if tf_nms: - boxes = self._xywh2xyxy(x[0][..., :4]) - probs = x[0][:, :, 4:5] - classes = x[0][:, :, 5:] - scores = probs * classes - if agnostic_nms: - nms = AgnosticNMS()((boxes, classes, scores), topk_all, iou_thres, conf_thres) - else: - boxes = tf.expand_dims(boxes, 2) - nms = tf.image.combined_non_max_suppression(boxes, - scores, - topk_per_class, - topk_all, - iou_thres, - conf_thres, - clip_boxes=False) - return (nms,) - return x # output [1,6300,85] = [xywh, conf, class0, class1, ...] - # x = x[0] # [x(1,6300,85), ...] to x(6300,85) - # xywh = x[..., :4] # x(6300,4) boxes - # conf = x[..., 4:5] # x(6300,1) confidences - # cls = tf.reshape(tf.cast(tf.argmax(x[..., 5:], axis=1), tf.float32), (-1, 1)) # x(6300,1) classes - # return tf.concat([conf, cls, xywh], 1) - - @staticmethod - def _xywh2xyxy(xywh): - # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right - x, y, w, h = tf.split(xywh, num_or_size_splits=4, axis=-1) - return tf.concat([x - w / 2, y - h / 2, x + w / 2, y + h / 2], axis=-1) - - -class AgnosticNMS(keras.layers.Layer): - # TF Agnostic NMS - def call(self, input, topk_all, iou_thres, conf_thres): - # wrap map_fn to avoid TypeSpec related error https://stackoverflow.com/a/65809989/3036450 - return tf.map_fn(lambda x: self._nms(x, topk_all, iou_thres, conf_thres), - input, - fn_output_signature=(tf.float32, tf.float32, tf.float32, tf.int32), - name='agnostic_nms') - - @staticmethod - def _nms(x, topk_all=100, iou_thres=0.45, conf_thres=0.25): # agnostic NMS - boxes, classes, scores = x - class_inds = tf.cast(tf.argmax(classes, axis=-1), tf.float32) - scores_inp = tf.reduce_max(scores, -1) - selected_inds = tf.image.non_max_suppression(boxes, - scores_inp, - max_output_size=topk_all, - iou_threshold=iou_thres, - score_threshold=conf_thres) - selected_boxes = tf.gather(boxes, selected_inds) - padded_boxes = tf.pad(selected_boxes, - paddings=[[0, topk_all - tf.shape(selected_boxes)[0]], [0, 0]], - mode="CONSTANT", - constant_values=0.0) - selected_scores = tf.gather(scores_inp, selected_inds) - padded_scores = tf.pad(selected_scores, - paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]], - mode="CONSTANT", - constant_values=-1.0) - selected_classes = tf.gather(class_inds, selected_inds) - padded_classes = tf.pad(selected_classes, - paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]], - mode="CONSTANT", - constant_values=-1.0) - valid_detections = tf.shape(selected_inds)[0] - return padded_boxes, padded_scores, padded_classes, valid_detections - - -def activations(act=nn.SiLU): - # Returns TF activation from input PyTorch activation - if isinstance(act, nn.LeakyReLU): - return lambda x: keras.activations.relu(x, alpha=0.1) - elif isinstance(act, nn.Hardswish): - return lambda x: x * tf.nn.relu6(x + 3) * 0.166666667 - elif isinstance(act, (nn.SiLU, SiLU)): - return lambda x: keras.activations.swish(x) - else: - raise Exception(f'no matching TensorFlow activation found for PyTorch activation {act}') - - -def representative_dataset_gen(dataset, ncalib=100): - # Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays - for n, (path, img, im0s, vid_cap, string) in enumerate(dataset): - im = np.transpose(img, [1, 2, 0]) - im = np.expand_dims(im, axis=0).astype(np.float32) - im /= 255 - yield [im] - if n >= ncalib: - break - - -def run( - weights=ROOT / 'yolov5s.pt', # weights path - imgsz=(640, 640), # inference size h,w - batch_size=1, # batch size - dynamic=False, # dynamic batch size -): - # PyTorch model - im = torch.zeros((batch_size, 3, *imgsz)) # BCHW image - model = attempt_load(weights, device=torch.device('cpu'), inplace=True, fuse=False) - _ = model(im) # inference - model.info() - - # TensorFlow model - im = tf.zeros((batch_size, *imgsz, 3)) # BHWC image - tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz) - _ = tf_model.predict(im) # inference - - # Keras model - im = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size) - keras_model = keras.Model(inputs=im, outputs=tf_model.predict(im)) - keras_model.summary() - - LOGGER.info('PyTorch, TensorFlow and Keras models successfully verified.\nUse export.py for TF model export.') - - -def parse_opt(): - parser = argparse.ArgumentParser() - parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path') - parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w') - parser.add_argument('--batch-size', type=int, default=1, help='batch size') - parser.add_argument('--dynamic', action='store_true', help='dynamic batch size') - opt = parser.parse_args() - opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand - print_args(vars(opt)) - return opt - - -def main(opt): - run(**vars(opt)) - - -if __name__ == "__main__": - opt = parse_opt() - main(opt) diff --git a/spaces/ArtyomKhyan/Detection/utils/datasets.py b/spaces/ArtyomKhyan/Detection/utils/datasets.py deleted file mode 100644 index 166caa90a3fe5b5dbf1b7cdcb5f22f7dde9a951e..0000000000000000000000000000000000000000 --- a/spaces/ArtyomKhyan/Detection/utils/datasets.py +++ /dev/null @@ -1,887 +0,0 @@ -import glob -import math -import os -import random -import shutil -import time -from pathlib import Path -from threading import Thread - -import cv2 -import numpy as np -import torch -from PIL import Image, ExifTags -from torch.utils.data import Dataset -from tqdm import tqdm - -from utils.utils import xyxy2xywh, xywh2xyxy -help_url = 'https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data' -img_formats = ['.bmp', '.jpg', '.jpeg', '.png', '.tif', '.dng'] -vid_formats = ['.mov', '.avi', '.mp4', '.mpg', '.mpeg', '.m4v', '.wmv', '.mkv'] - -# Get orientation exif tag -for orientation in ExifTags.TAGS.keys(): - if ExifTags.TAGS[orientation] == 'Orientation': - break - - -def exif_size(img): - # Returns exif-corrected PIL size - s = img.size # (width, height) - try: - rotation = dict(img._getexif().items())[orientation] - if rotation == 6: # rotation 270 - s = (s[1], s[0]) - elif rotation == 8: # rotation 90 - s = (s[1], s[0]) - except: - pass - - return s - - -def create_dataloader(path, imgsz, batch_size, stride, opt, hyp=None, augment=False, cache=False, pad=0.0, rect=False): - dataset = LoadImagesAndLabels(path, imgsz, batch_size, - augment=augment, # augment images - hyp=hyp, # augmentation hyperparameters - rect=rect, # rectangular training - cache_images=cache, - single_cls=opt.single_cls, - stride=stride, - pad=pad) - - batch_size = min(batch_size, len(dataset)) - nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers - dataloader = torch.utils.data.DataLoader(dataset, - batch_size=batch_size, - num_workers=nw, - pin_memory=True, - collate_fn=LoadImagesAndLabels.collate_fn) - return dataloader, dataset - - -class LoadImages: # for inference - def __init__(self, path, img_size=640): - path = str(Path(path)) # os-agnostic - files = [] - if os.path.isdir(path): - files = sorted(glob.glob(os.path.join(path, '*.*'))) - elif os.path.isfile(path): - files = [path] - - images = [x for x in files if os.path.splitext(x)[-1].lower() in img_formats] - videos = [x for x in files if os.path.splitext(x)[-1].lower() in vid_formats] - nI, nV = len(images), len(videos) - - self.img_size = img_size - self.files = images + videos - self.nF = nI + nV # number of files - self.video_flag = [False] * nI + [True] * nV - self.mode = 'images' - if any(videos): - self.new_video(videos[0]) # new video - else: - self.cap = None - assert self.nF > 0, 'No images or videos found in %s. Supported formats are:\nimages: %s\nvideos: %s' % \ - (path, img_formats, vid_formats) - - def __iter__(self): - self.count = 0 - return self - - def __next__(self): - if self.count == self.nF: - raise StopIteration - path = self.files[self.count] - - if self.video_flag[self.count]: - # Read video - self.mode = 'video' - ret_val, img0 = self.cap.read() - if not ret_val: - self.count += 1 - self.cap.release() - if self.count == self.nF: # last video - raise StopIteration - else: - path = self.files[self.count] - self.new_video(path) - ret_val, img0 = self.cap.read() - - self.frame += 1 - print('video %g/%g (%g/%g) %s: ' % (self.count + 1, self.nF, self.frame, self.nframes, path), end='') - - else: - # Read image - self.count += 1 - img0 = cv2.imread(path) # BGR - assert img0 is not None, 'Image Not Found ' + path - print('image %g/%g %s: ' % (self.count, self.nF, path), end='') - - # Padded resize - img = letterbox(img0, new_shape=self.img_size)[0] - - # Convert - img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416 - img = np.ascontiguousarray(img) - - # cv2.imwrite(path + '.letterbox.jpg', 255 * img.transpose((1, 2, 0))[:, :, ::-1]) # save letterbox image - return path, img, img0, self.cap - - def new_video(self, path): - self.frame = 0 - self.cap = cv2.VideoCapture(path) - self.nframes = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT)) - - def __len__(self): - return self.nF # number of files - - -class LoadWebcam: # for inference - def __init__(self, pipe=0, img_size=640): - self.img_size = img_size - - if pipe == '0': - pipe = 0 # local camera - # pipe = 'rtsp://192.168.1.64/1' # IP camera - # pipe = 'rtsp://username:password@192.168.1.64/1' # IP camera with login - # pipe = 'rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa' # IP traffic camera - # pipe = 'http://wmccpinetop.axiscam.net/mjpg/video.mjpg' # IP golf camera - - # https://answers.opencv.org/question/215996/changing-gstreamer-pipeline-to-opencv-in-pythonsolved/ - # pipe = '"rtspsrc location="rtsp://username:password@192.168.1.64/1" latency=10 ! appsink' # GStreamer - - # https://answers.opencv.org/question/200787/video-acceleration-gstremer-pipeline-in-videocapture/ - # https://stackoverflow.com/questions/54095699/install-gstreamer-support-for-opencv-python-package # install help - # pipe = "rtspsrc location=rtsp://root:root@192.168.0.91:554/axis-media/media.amp?videocodec=h264&resolution=3840x2160 protocols=GST_RTSP_LOWER_TRANS_TCP ! rtph264depay ! queue ! vaapih264dec ! videoconvert ! appsink" # GStreamer - - self.pipe = pipe - self.cap = cv2.VideoCapture(pipe) # video capture object - self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size - - def __iter__(self): - self.count = -1 - return self - - def __next__(self): - self.count += 1 - if cv2.waitKey(1) == ord('q'): # q to quit - self.cap.release() - cv2.destroyAllWindows() - raise StopIteration - - # Read frame - if self.pipe == 0: # local camera - ret_val, img0 = self.cap.read() - img0 = cv2.flip(img0, 1) # flip left-right - else: # IP camera - n = 0 - while True: - n += 1 - self.cap.grab() - if n % 30 == 0: # skip frames - ret_val, img0 = self.cap.retrieve() - if ret_val: - break - - # Print - assert ret_val, 'Camera Error %s' % self.pipe - img_path = 'webcam.jpg' - print('webcam %g: ' % self.count, end='') - - # Padded resize - img = letterbox(img0, new_shape=self.img_size)[0] - - # Convert - img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416 - img = np.ascontiguousarray(img) - - return img_path, img, img0, None - - def __len__(self): - return 0 - - -class LoadStreams: # multiple IP or RTSP cameras - def __init__(self, sources='streams.txt', img_size=640): - self.mode = 'images' - self.img_size = img_size - - if os.path.isfile(sources): - with open(sources, 'r') as f: - sources = [x.strip() for x in f.read().splitlines() if len(x.strip())] - else: - sources = [sources] - - n = len(sources) - self.imgs = [None] * n - self.sources = sources - for i, s in enumerate(sources): - # Start the thread to read frames from the video stream - print('%g/%g: %s... ' % (i + 1, n, s), end='') - cap = cv2.VideoCapture(0 if s == '0' else s) - assert cap.isOpened(), 'Failed to open %s' % s - w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) - h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) - fps = cap.get(cv2.CAP_PROP_FPS) % 100 - _, self.imgs[i] = cap.read() # guarantee first frame - thread = Thread(target=self.update, args=([i, cap]), daemon=True) - print(' success (%gx%g at %.2f FPS).' % (w, h, fps)) - thread.start() - print('') # newline - - # check for common shapes - s = np.stack([letterbox(x, new_shape=self.img_size)[0].shape for x in self.imgs], 0) # inference shapes - self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal - if not self.rect: - print('WARNING: Different stream shapes detected. For optimal performance supply similarly-shaped streams.') - - def update(self, index, cap): - # Read next stream frame in a daemon thread - n = 0 - while cap.isOpened(): - n += 1 - # _, self.imgs[index] = cap.read() - cap.grab() - if n == 4: # read every 4th frame - _, self.imgs[index] = cap.retrieve() - n = 0 - time.sleep(0.01) # wait time - - def __iter__(self): - self.count = -1 - return self - - def __next__(self): - self.count += 1 - img0 = self.imgs.copy() - if cv2.waitKey(1) == ord('q'): # q to quit - cv2.destroyAllWindows() - raise StopIteration - - # Letterbox - img = [letterbox(x, new_shape=self.img_size, auto=self.rect)[0] for x in img0] - - # Stack - img = np.stack(img, 0) - - # Convert - img = img[:, :, :, ::-1].transpose(0, 3, 1, 2) # BGR to RGB, to bsx3x416x416 - img = np.ascontiguousarray(img) - - return self.sources, img, img0, None - - def __len__(self): - return 0 # 1E12 frames = 32 streams at 30 FPS for 30 years - - -class LoadImagesAndLabels(Dataset): # for training/testing - def __init__(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False, image_weights=False, - cache_images=False, single_cls=False, stride=32, pad=0.0): - try: - path = str(Path(path)) # os-agnostic - parent = str(Path(path).parent) + os.sep - if os.path.isfile(path): # file - with open(path, 'r') as f: - f = f.read().splitlines() - f = [x.replace('./', parent) if x.startswith('./') else x for x in f] # local to global path - elif os.path.isdir(path): # folder - f = glob.iglob(path + os.sep + '*.*') - else: - raise Exception('%s does not exist' % path) - self.img_files = [x.replace('/', os.sep) for x in f if os.path.splitext(x)[-1].lower() in img_formats] - except: - raise Exception('Error loading data from %s. See %s' % (path, help_url)) - - n = len(self.img_files) - assert n > 0, 'No images found in %s. See %s' % (path, help_url) - bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index - nb = bi[-1] + 1 # number of batches - - self.n = n # number of images - self.batch = bi # batch index of image - self.img_size = img_size - self.augment = augment - self.hyp = hyp - self.image_weights = image_weights - self.rect = False if image_weights else rect - self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training) - self.mosaic_border = [-img_size // 2, -img_size // 2] - self.stride = stride - - # Define labels - self.label_files = [x.replace('images', 'labels').replace(os.path.splitext(x)[-1], '.txt') - for x in self.img_files] - - # Read image shapes (wh) - sp = path.replace('.txt', '') + '.shapes' # shapefile path - try: - with open(sp, 'r') as f: # read existing shapefile - s = [x.split() for x in f.read().splitlines()] - assert len(s) == n, 'Shapefile out of sync' - except: - s = [exif_size(Image.open(f)) for f in tqdm(self.img_files, desc='Reading image shapes')] - np.savetxt(sp, s, fmt='%g') # overwrites existing (if any) - - self.shapes = np.array(s, dtype=np.float64) - - # Rectangular Training https://github.com/ultralytics/yolov3/issues/232 - if self.rect: - # Sort by aspect ratio - s = self.shapes # wh - ar = s[:, 1] / s[:, 0] # aspect ratio - irect = ar.argsort() - self.img_files = [self.img_files[i] for i in irect] - self.label_files = [self.label_files[i] for i in irect] - self.shapes = s[irect] # wh - ar = ar[irect] - - # Set training image shapes - shapes = [[1, 1]] * nb - for i in range(nb): - ari = ar[bi == i] - mini, maxi = ari.min(), ari.max() - if maxi < 1: - shapes[i] = [maxi, 1] - elif mini > 1: - shapes[i] = [1, 1 / mini] - - self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride - - # Cache labels - self.imgs = [None] * n - self.labels = [np.zeros((0, 5), dtype=np.float32)] * n - create_datasubset, extract_bounding_boxes, labels_loaded = False, False, False - nm, nf, ne, ns, nd = 0, 0, 0, 0, 0 # number missing, found, empty, datasubset, duplicate - np_labels_path = str(Path(self.label_files[0]).parent) + '.npy' # saved labels in *.npy file - if os.path.isfile(np_labels_path): - s = np_labels_path # print string - x = np.load(np_labels_path, allow_pickle=True) - if len(x) == n: - self.labels = x - labels_loaded = True - else: - s = path.replace('images', 'labels') - - pbar = tqdm(self.label_files) - for i, file in enumerate(pbar): - if labels_loaded: - l = self.labels[i] - # np.savetxt(file, l, '%g') # save *.txt from *.npy file - else: - try: - with open(file, 'r') as f: - l = np.array([x.split() for x in f.read().splitlines()], dtype=np.float32) - except: - nm += 1 # print('missing labels for image %s' % self.img_files[i]) # file missing - continue - - if l.shape[0]: - assert l.shape[1] == 5, '> 5 label columns: %s' % file - assert (l >= 0).all(), 'negative labels: %s' % file - assert (l[:, 1:] <= 1).all(), 'non-normalized or out of bounds coordinate labels: %s' % file - if np.unique(l, axis=0).shape[0] < l.shape[0]: # duplicate rows - nd += 1 # print('WARNING: duplicate rows in %s' % self.label_files[i]) # duplicate rows - if single_cls: - l[:, 0] = 0 # force dataset into single-class mode - self.labels[i] = l - nf += 1 # file found - - # Create subdataset (a smaller dataset) - if create_datasubset and ns < 1E4: - if ns == 0: - create_folder(path='./datasubset') - os.makedirs('./datasubset/images') - exclude_classes = 43 - if exclude_classes not in l[:, 0]: - ns += 1 - # shutil.copy(src=self.img_files[i], dst='./datasubset/images/') # copy image - with open('./datasubset/images.txt', 'a') as f: - f.write(self.img_files[i] + '\n') - - # Extract object detection boxes for a second stage classifier - if extract_bounding_boxes: - p = Path(self.img_files[i]) - img = cv2.imread(str(p)) - h, w = img.shape[:2] - for j, x in enumerate(l): - f = '%s%sclassifier%s%g_%g_%s' % (p.parent.parent, os.sep, os.sep, x[0], j, p.name) - if not os.path.exists(Path(f).parent): - os.makedirs(Path(f).parent) # make new output folder - - b = x[1:] * [w, h, w, h] # box - b[2:] = b[2:].max() # rectangle to square - b[2:] = b[2:] * 1.3 + 30 # pad - b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(np.int) - - b[[0, 2]] = np.clip(b[[0, 2]], 0, w) # clip boxes outside of image - b[[1, 3]] = np.clip(b[[1, 3]], 0, h) - assert cv2.imwrite(f, img[b[1]:b[3], b[0]:b[2]]), 'Failure extracting classifier boxes' - else: - ne += 1 # print('empty labels for image %s' % self.img_files[i]) # file empty - # os.system("rm '%s' '%s'" % (self.img_files[i], self.label_files[i])) # remove - - pbar.desc = 'Caching labels %s (%g found, %g missing, %g empty, %g duplicate, for %g images)' % ( - s, nf, nm, ne, nd, n) - assert nf > 0 or n == 20288, 'No labels found in %s. See %s' % (os.path.dirname(file) + os.sep, help_url) - if not labels_loaded and n > 1000: - print('Saving labels to %s for faster future loading' % np_labels_path) - np.save(np_labels_path, self.labels) # save for next time - - # Cache images into memory for faster training (WARNING: large datasets may exceed system RAM) - if cache_images: # if training - gb = 0 # Gigabytes of cached images - pbar = tqdm(range(len(self.img_files)), desc='Caching images') - self.img_hw0, self.img_hw = [None] * n, [None] * n - for i in pbar: # max 10k images - self.imgs[i], self.img_hw0[i], self.img_hw[i] = load_image(self, i) # img, hw_original, hw_resized - gb += self.imgs[i].nbytes - pbar.desc = 'Caching images (%.1fGB)' % (gb / 1E9) - - # Detect corrupted images https://medium.com/joelthchao/programmatically-detect-corrupted-image-8c1b2006c3d3 - detect_corrupted_images = False - if detect_corrupted_images: - from skimage import io # conda install -c conda-forge scikit-image - for file in tqdm(self.img_files, desc='Detecting corrupted images'): - try: - _ = io.imread(file) - except: - print('Corrupted image detected: %s' % file) - - def __len__(self): - return len(self.img_files) - - # def __iter__(self): - # self.count = -1 - # print('ran dataset iter') - # #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF) - # return self - - def __getitem__(self, index): - if self.image_weights: - index = self.indices[index] - - hyp = self.hyp - if self.mosaic: - # Load mosaic - img, labels = load_mosaic(self, index) - shapes = None - - else: - # Load image - img, (h0, w0), (h, w) = load_image(self, index) - - # Letterbox - shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape - img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment) - shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling - - # Load labels - labels = [] - x = self.labels[index] - if x.size > 0: - # Normalized xywh to pixel xyxy format - labels = x.copy() - labels[:, 1] = ratio[0] * w * (x[:, 1] - x[:, 3] / 2) + pad[0] # pad width - labels[:, 2] = ratio[1] * h * (x[:, 2] - x[:, 4] / 2) + pad[1] # pad height - labels[:, 3] = ratio[0] * w * (x[:, 1] + x[:, 3] / 2) + pad[0] - labels[:, 4] = ratio[1] * h * (x[:, 2] + x[:, 4] / 2) + pad[1] - - if self.augment: - # Augment imagespace - if not self.mosaic: - img, labels = random_affine(img, labels, - degrees=hyp['degrees'], - translate=hyp['translate'], - scale=hyp['scale'], - shear=hyp['shear']) - - # Augment colorspace - augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v']) - - # Apply cutouts - # if random.random() < 0.9: - # labels = cutout(img, labels) - - nL = len(labels) # number of labels - if nL: - # convert xyxy to xywh - labels[:, 1:5] = xyxy2xywh(labels[:, 1:5]) - - # Normalize coordinates 0 - 1 - labels[:, [2, 4]] /= img.shape[0] # height - labels[:, [1, 3]] /= img.shape[1] # width - - if self.augment: - # random left-right flip - lr_flip = True - if lr_flip and random.random() < 0.5: - img = np.fliplr(img) - if nL: - labels[:, 1] = 1 - labels[:, 1] - - # random up-down flip - ud_flip = False - if ud_flip and random.random() < 0.5: - img = np.flipud(img) - if nL: - labels[:, 2] = 1 - labels[:, 2] - - labels_out = torch.zeros((nL, 6)) - if nL: - labels_out[:, 1:] = torch.from_numpy(labels) - - # Convert - img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416 - img = np.ascontiguousarray(img) - - return torch.from_numpy(img), labels_out, self.img_files[index], shapes - - @staticmethod - def collate_fn(batch): - img, label, path, shapes = zip(*batch) # transposed - for i, l in enumerate(label): - l[:, 0] = i # add target image index for build_targets() - return torch.stack(img, 0), torch.cat(label, 0), path, shapes - - -def load_image(self, index): - # loads 1 image from dataset, returns img, original hw, resized hw - img = self.imgs[index] - if img is None: # not cached - path = self.img_files[index] - img = cv2.imread(path) # BGR - assert img is not None, 'Image Not Found ' + path - h0, w0 = img.shape[:2] # orig hw - r = self.img_size / max(h0, w0) # resize image to img_size - if r != 1: # always resize down, only resize up if training with augmentation - interp = cv2.INTER_AREA if r < 1 and not self.augment else cv2.INTER_LINEAR - img = cv2.resize(img, (int(w0 * r), int(h0 * r)), interpolation=interp) - return img, (h0, w0), img.shape[:2] # img, hw_original, hw_resized - else: - return self.imgs[index], self.img_hw0[index], self.img_hw[index] # img, hw_original, hw_resized - - -def augment_hsv(img, hgain=0.5, sgain=0.5, vgain=0.5): - r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains - hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV)) - dtype = img.dtype # uint8 - - x = np.arange(0, 256, dtype=np.int16) - lut_hue = ((x * r[0]) % 180).astype(dtype) - lut_sat = np.clip(x * r[1], 0, 255).astype(dtype) - lut_val = np.clip(x * r[2], 0, 255).astype(dtype) - - img_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val))).astype(dtype) - cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR, dst=img) # no return needed - - # Histogram equalization - # if random.random() < 0.2: - # for i in range(3): - # img[:, :, i] = cv2.equalizeHist(img[:, :, i]) - - -def load_mosaic(self, index): - # loads images in a mosaic - - labels4 = [] - s = self.img_size - yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border] # mosaic center x, y - indices = [index] + [random.randint(0, len(self.labels) - 1) for _ in range(3)] # 3 additional image indices - for i, index in enumerate(indices): - # Load image - img, _, (h, w) = load_image(self, index) - - # place img in img4 - if i == 0: # top left - img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles - x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image) - x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image) - elif i == 1: # top right - x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc - x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h - elif i == 2: # bottom left - x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h) - x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, max(xc, w), min(y2a - y1a, h) - elif i == 3: # bottom right - x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h) - x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h) - - img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax] - padw = x1a - x1b - padh = y1a - y1b - - # Labels - x = self.labels[index] - labels = x.copy() - if x.size > 0: # Normalized xywh to pixel xyxy format - labels[:, 1] = w * (x[:, 1] - x[:, 3] / 2) + padw - labels[:, 2] = h * (x[:, 2] - x[:, 4] / 2) + padh - labels[:, 3] = w * (x[:, 1] + x[:, 3] / 2) + padw - labels[:, 4] = h * (x[:, 2] + x[:, 4] / 2) + padh - labels4.append(labels) - - # Concat/clip labels - if len(labels4): - labels4 = np.concatenate(labels4, 0) - # np.clip(labels4[:, 1:] - s / 2, 0, s, out=labels4[:, 1:]) # use with center crop - np.clip(labels4[:, 1:], 0, 2 * s, out=labels4[:, 1:]) # use with random_affine - - # Replicate - # img4, labels4 = replicate(img4, labels4) - - # Augment - # img4 = img4[s // 2: int(s * 1.5), s // 2:int(s * 1.5)] # center crop (WARNING, requires box pruning) - img4, labels4 = random_affine(img4, labels4, - degrees=self.hyp['degrees'], - translate=self.hyp['translate'], - scale=self.hyp['scale'], - shear=self.hyp['shear'], - border=self.mosaic_border) # border to remove - - return img4, labels4 - - -def replicate(img, labels): - # Replicate labels - h, w = img.shape[:2] - boxes = labels[:, 1:].astype(int) - x1, y1, x2, y2 = boxes.T - s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels) - for i in s.argsort()[:round(s.size * 0.5)]: # smallest indices - x1b, y1b, x2b, y2b = boxes[i] - bh, bw = y2b - y1b, x2b - x1b - yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y - x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh] - img[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax] - labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0) - - return img, labels - - -def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True): - # Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232 - shape = img.shape[:2] # current shape [height, width] - if isinstance(new_shape, int): - new_shape = (new_shape, new_shape) - - # Scale ratio (new / old) - r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) - if not scaleup: # only scale down, do not scale up (for better test mAP) - r = min(r, 1.0) - - # Compute padding - ratio = r, r # width, height ratios - new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) - dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding - if auto: # minimum rectangle - dw, dh = np.mod(dw, 64), np.mod(dh, 64) # wh padding - elif scaleFill: # stretch - dw, dh = 0.0, 0.0 - new_unpad = new_shape - ratio = new_shape[0] / shape[1], new_shape[1] / shape[0] # width, height ratios - - dw /= 2 # divide padding into 2 sides - dh /= 2 - - if shape[::-1] != new_unpad: # resize - img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR) - top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1)) - left, right = int(round(dw - 0.1)), int(round(dw + 0.1)) - img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border - return img, ratio, (dw, dh) - - -def random_affine(img, targets=(), degrees=10, translate=.1, scale=.1, shear=10, border=(0, 0)): - # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10)) - # https://medium.com/uruvideo/dataset-augmentation-with-random-homographies-a8f4b44830d4 - # targets = [cls, xyxy] - - height = img.shape[0] + border[0] * 2 # shape(h,w,c) - width = img.shape[1] + border[1] * 2 - - # Rotation and Scale - R = np.eye(3) - a = random.uniform(-degrees, degrees) - # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations - s = random.uniform(1 - scale, 1 + scale) - # s = 2 ** random.uniform(-scale, scale) - R[:2] = cv2.getRotationMatrix2D(angle=a, center=(img.shape[1] / 2, img.shape[0] / 2), scale=s) - - # Translation - T = np.eye(3) - T[0, 2] = random.uniform(-translate, translate) * img.shape[1] + border[1] # x translation (pixels) - T[1, 2] = random.uniform(-translate, translate) * img.shape[0] + border[0] # y translation (pixels) - - # Shear - S = np.eye(3) - S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg) - S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg) - - # Combined rotation matrix - M = S @ T @ R # ORDER IS IMPORTANT HERE!! - if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed - img = cv2.warpAffine(img, M[:2], dsize=(width, height), flags=cv2.INTER_LINEAR, borderValue=(114, 114, 114)) - - # Transform label coordinates - n = len(targets) - if n: - # warp points - xy = np.ones((n * 4, 3)) - xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1 - xy = (xy @ M.T)[:, :2].reshape(n, 8) - - # create new boxes - x = xy[:, [0, 2, 4, 6]] - y = xy[:, [1, 3, 5, 7]] - xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T - - # # apply angle-based reduction of bounding boxes - # radians = a * math.pi / 180 - # reduction = max(abs(math.sin(radians)), abs(math.cos(radians))) ** 0.5 - # x = (xy[:, 2] + xy[:, 0]) / 2 - # y = (xy[:, 3] + xy[:, 1]) / 2 - # w = (xy[:, 2] - xy[:, 0]) * reduction - # h = (xy[:, 3] - xy[:, 1]) * reduction - # xy = np.concatenate((x - w / 2, y - h / 2, x + w / 2, y + h / 2)).reshape(4, n).T - - # reject warped points outside of image - xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width) - xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height) - w = xy[:, 2] - xy[:, 0] - h = xy[:, 3] - xy[:, 1] - area = w * h - area0 = (targets[:, 3] - targets[:, 1]) * (targets[:, 4] - targets[:, 2]) - ar = np.maximum(w / (h + 1e-16), h / (w + 1e-16)) # aspect ratio - i = (w > 2) & (h > 2) & (area / (area0 * s + 1e-16) > 0.2) & (ar < 20) - - targets = targets[i] - targets[:, 1:5] = xy[i] - - return img, targets - - -def cutout(image, labels): - # https://arxiv.org/abs/1708.04552 - # https://github.com/hysts/pytorch_cutout/blob/master/dataloader.py - # https://towardsdatascience.com/when-conventional-wisdom-fails-revisiting-data-augmentation-for-self-driving-cars-4831998c5509 - h, w = image.shape[:2] - - def bbox_ioa(box1, box2): - # Returns the intersection over box2 area given box1, box2. box1 is 4, box2 is nx4. boxes are x1y1x2y2 - box2 = box2.transpose() - - # Get the coordinates of bounding boxes - b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3] - b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3] - - # Intersection area - inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \ - (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0) - - # box2 area - box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + 1e-16 - - # Intersection over box2 area - - return inter_area / box2_area - - # create random masks - scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction - for s in scales: - mask_h = random.randint(1, int(h * s)) - mask_w = random.randint(1, int(w * s)) - - # box - xmin = max(0, random.randint(0, w) - mask_w // 2) - ymin = max(0, random.randint(0, h) - mask_h // 2) - xmax = min(w, xmin + mask_w) - ymax = min(h, ymin + mask_h) - - # apply random color mask - image[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)] - - # return unobscured labels - if len(labels) and s > 0.03: - box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32) - ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area - labels = labels[ioa < 0.60] # remove >60% obscured labels - - return labels - - -def reduce_img_size(path='../data/sm4/images', img_size=1024): # from utils.datasets import *; reduce_img_size() - # creates a new ./images_reduced folder with reduced size images of maximum size img_size - path_new = path + '_reduced' # reduced images path - create_folder(path_new) - for f in tqdm(glob.glob('%s/*.*' % path)): - try: - img = cv2.imread(f) - h, w = img.shape[:2] - r = img_size / max(h, w) # size ratio - if r < 1.0: - img = cv2.resize(img, (int(w * r), int(h * r)), interpolation=cv2.INTER_AREA) # _LINEAR fastest - fnew = f.replace(path, path_new) # .replace(Path(f).suffix, '.jpg') - cv2.imwrite(fnew, img) - except: - print('WARNING: image failure %s' % f) - - -def convert_images2bmp(): # from utils.datasets import *; convert_images2bmp() - # Save images - formats = [x.lower() for x in img_formats] + [x.upper() for x in img_formats] - # for path in ['../coco/images/val2014', '../coco/images/train2014']: - for path in ['../data/sm4/images', '../data/sm4/background']: - create_folder(path + 'bmp') - for ext in formats: # ['.bmp', '.jpg', '.jpeg', '.png', '.tif', '.dng'] - for f in tqdm(glob.glob('%s/*%s' % (path, ext)), desc='Converting %s' % ext): - cv2.imwrite(f.replace(ext.lower(), '.bmp').replace(path, path + 'bmp'), cv2.imread(f)) - - # Save labels - # for path in ['../coco/trainvalno5k.txt', '../coco/5k.txt']: - for file in ['../data/sm4/out_train.txt', '../data/sm4/out_test.txt']: - with open(file, 'r') as f: - lines = f.read() - # lines = f.read().replace('2014/', '2014bmp/') # coco - lines = lines.replace('/images', '/imagesbmp') - lines = lines.replace('/background', '/backgroundbmp') - for ext in formats: - lines = lines.replace(ext, '.bmp') - with open(file.replace('.txt', 'bmp.txt'), 'w') as f: - f.write(lines) - - -def recursive_dataset2bmp(dataset='../data/sm4_bmp'): # from utils.datasets import *; recursive_dataset2bmp() - # Converts dataset to bmp (for faster training) - formats = [x.lower() for x in img_formats] + [x.upper() for x in img_formats] - for a, b, files in os.walk(dataset): - for file in tqdm(files, desc=a): - p = a + '/' + file - s = Path(file).suffix - if s == '.txt': # replace text - with open(p, 'r') as f: - lines = f.read() - for f in formats: - lines = lines.replace(f, '.bmp') - with open(p, 'w') as f: - f.write(lines) - elif s in formats: # replace image - cv2.imwrite(p.replace(s, '.bmp'), cv2.imread(p)) - if s != '.bmp': - os.system("rm '%s'" % p) - - -def imagelist2folder(path='data/coco_64img.txt'): # from utils.datasets import *; imagelist2folder() - # Copies all the images in a text file (list of images) into a folder - create_folder(path[:-4]) - with open(path, 'r') as f: - for line in f.read().splitlines(): - os.system('cp "%s" %s' % (line, path[:-4])) - print(line) - - -def create_folder(path='./new_folder'): - # Create folder - if os.path.exists(path): - shutil.rmtree(path) # delete output folder - os.makedirs(path) # make new output folder diff --git a/spaces/AtomdffAI/wechatgpt4atom/bot/bot_factory.py b/spaces/AtomdffAI/wechatgpt4atom/bot/bot_factory.py deleted file mode 100644 index dd590c7fee00925a224e3972de0e57d8955b2885..0000000000000000000000000000000000000000 --- a/spaces/AtomdffAI/wechatgpt4atom/bot/bot_factory.py +++ /dev/null @@ -1,26 +0,0 @@ -""" -channel factory -""" - - -def create_bot(bot_type): - """ - create a channel instance - :param channel_type: channel type code - :return: channel instance - """ - if bot_type == 'baidu': - # Baidu Unit对话接口 - from bot.baidu.baidu_unit_bot import BaiduUnitBot - return BaiduUnitBot() - - elif bot_type == 'chatGPT': - # ChatGPT 网页端web接口 - from bot.chatgpt.chat_gpt_bot import ChatGPTBot - return ChatGPTBot() - - elif bot_type == 'openAI': - # OpenAI 官方对话模型API - from bot.openai.open_ai_bot import OpenAIBot - return OpenAIBot() - raise RuntimeError diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/botocore/signers.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/botocore/signers.py deleted file mode 100644 index 42965b41e4bee7f8aa6f4c7d36135921c4be2376..0000000000000000000000000000000000000000 --- a/spaces/Big-Web/MMSD/env/Lib/site-packages/botocore/signers.py +++ /dev/null @@ -1,832 +0,0 @@ -# Copyright 2014 Amazon.com, Inc. or its affiliates. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"). You -# may not use this file except in compliance with the License. A copy of -# the License is located at -# -# http://aws.amazon.com/apache2.0/ -# -# or in the "license" file accompanying this file. This file is -# distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF -# ANY KIND, either express or implied. See the License for the specific -# language governing permissions and limitations under the License. -import base64 -import datetime -import json -import weakref - -import botocore -import botocore.auth -from botocore.awsrequest import create_request_object, prepare_request_dict -from botocore.compat import OrderedDict -from botocore.exceptions import ( - UnknownClientMethodError, - UnknownSignatureVersionError, - UnsupportedSignatureVersionError, -) -from botocore.utils import ArnParser, datetime2timestamp - -# Keep these imported. There's pre-existing code that uses them. -from botocore.utils import fix_s3_host # noqa - - -class RequestSigner: - """ - An object to sign requests before they go out over the wire using - one of the authentication mechanisms defined in ``auth.py``. This - class fires two events scoped to a service and operation name: - - * choose-signer: Allows overriding the auth signer name. - * before-sign: Allows mutating the request before signing. - - Together these events allow for customization of the request - signing pipeline, including overrides, request path manipulation, - and disabling signing per operation. - - - :type service_id: botocore.model.ServiceId - :param service_id: The service id for the service, e.g. ``S3`` - - :type region_name: string - :param region_name: Name of the service region, e.g. ``us-east-1`` - - :type signing_name: string - :param signing_name: Service signing name. This is usually the - same as the service name, but can differ. E.g. - ``emr`` vs. ``elasticmapreduce``. - - :type signature_version: string - :param signature_version: Signature name like ``v4``. - - :type credentials: :py:class:`~botocore.credentials.Credentials` - :param credentials: User credentials with which to sign requests. - - :type event_emitter: :py:class:`~botocore.hooks.BaseEventHooks` - :param event_emitter: Extension mechanism to fire events. - """ - - def __init__( - self, - service_id, - region_name, - signing_name, - signature_version, - credentials, - event_emitter, - auth_token=None, - ): - self._region_name = region_name - self._signing_name = signing_name - self._signature_version = signature_version - self._credentials = credentials - self._auth_token = auth_token - self._service_id = service_id - - # We need weakref to prevent leaking memory in Python 2.6 on Linux 2.6 - self._event_emitter = weakref.proxy(event_emitter) - - @property - def region_name(self): - return self._region_name - - @property - def signature_version(self): - return self._signature_version - - @property - def signing_name(self): - return self._signing_name - - def handler(self, operation_name=None, request=None, **kwargs): - # This is typically hooked up to the "request-created" event - # from a client's event emitter. When a new request is created - # this method is invoked to sign the request. - # Don't call this method directly. - return self.sign(operation_name, request) - - def sign( - self, - operation_name, - request, - region_name=None, - signing_type='standard', - expires_in=None, - signing_name=None, - ): - """Sign a request before it goes out over the wire. - - :type operation_name: string - :param operation_name: The name of the current operation, e.g. - ``ListBuckets``. - :type request: AWSRequest - :param request: The request object to be sent over the wire. - - :type region_name: str - :param region_name: The region to sign the request for. - - :type signing_type: str - :param signing_type: The type of signing to perform. This can be one of - three possible values: - - * 'standard' - This should be used for most requests. - * 'presign-url' - This should be used when pre-signing a request. - * 'presign-post' - This should be used when pre-signing an S3 post. - - :type expires_in: int - :param expires_in: The number of seconds the presigned url is valid - for. This parameter is only valid for signing type 'presign-url'. - - :type signing_name: str - :param signing_name: The name to use for the service when signing. - """ - explicit_region_name = region_name - if region_name is None: - region_name = self._region_name - - if signing_name is None: - signing_name = self._signing_name - - signature_version = self._choose_signer( - operation_name, signing_type, request.context - ) - - # Allow mutating request before signing - self._event_emitter.emit( - 'before-sign.{}.{}'.format( - self._service_id.hyphenize(), operation_name - ), - request=request, - signing_name=signing_name, - region_name=self._region_name, - signature_version=signature_version, - request_signer=self, - operation_name=operation_name, - ) - - if signature_version != botocore.UNSIGNED: - kwargs = { - 'signing_name': signing_name, - 'region_name': region_name, - 'signature_version': signature_version, - } - if expires_in is not None: - kwargs['expires'] = expires_in - signing_context = request.context.get('signing', {}) - if not explicit_region_name and signing_context.get('region'): - kwargs['region_name'] = signing_context['region'] - if signing_context.get('signing_name'): - kwargs['signing_name'] = signing_context['signing_name'] - try: - auth = self.get_auth_instance(**kwargs) - except UnknownSignatureVersionError as e: - if signing_type != 'standard': - raise UnsupportedSignatureVersionError( - signature_version=signature_version - ) - else: - raise e - - auth.add_auth(request) - - def _choose_signer(self, operation_name, signing_type, context): - """ - Allow setting the signature version via the choose-signer event. - A value of `botocore.UNSIGNED` means no signing will be performed. - - :param operation_name: The operation to sign. - :param signing_type: The type of signing that the signer is to be used - for. - :return: The signature version to sign with. - """ - signing_type_suffix_map = { - 'presign-post': '-presign-post', - 'presign-url': '-query', - } - suffix = signing_type_suffix_map.get(signing_type, '') - - # operation specific signing context takes precedent over client-level - # defaults - signature_version = context.get('auth_type') or self._signature_version - signing = context.get('signing', {}) - signing_name = signing.get('signing_name', self._signing_name) - region_name = signing.get('region', self._region_name) - if ( - signature_version is not botocore.UNSIGNED - and not signature_version.endswith(suffix) - ): - signature_version += suffix - - handler, response = self._event_emitter.emit_until_response( - 'choose-signer.{}.{}'.format( - self._service_id.hyphenize(), operation_name - ), - signing_name=signing_name, - region_name=region_name, - signature_version=signature_version, - context=context, - ) - - if response is not None: - signature_version = response - # The suffix needs to be checked again in case we get an improper - # signature version from choose-signer. - if ( - signature_version is not botocore.UNSIGNED - and not signature_version.endswith(suffix) - ): - signature_version += suffix - - return signature_version - - def get_auth_instance( - self, signing_name, region_name, signature_version=None, **kwargs - ): - """ - Get an auth instance which can be used to sign a request - using the given signature version. - - :type signing_name: string - :param signing_name: Service signing name. This is usually the - same as the service name, but can differ. E.g. - ``emr`` vs. ``elasticmapreduce``. - - :type region_name: string - :param region_name: Name of the service region, e.g. ``us-east-1`` - - :type signature_version: string - :param signature_version: Signature name like ``v4``. - - :rtype: :py:class:`~botocore.auth.BaseSigner` - :return: Auth instance to sign a request. - """ - if signature_version is None: - signature_version = self._signature_version - - cls = botocore.auth.AUTH_TYPE_MAPS.get(signature_version) - if cls is None: - raise UnknownSignatureVersionError( - signature_version=signature_version - ) - - if cls.REQUIRES_TOKEN is True: - frozen_token = None - if self._auth_token is not None: - frozen_token = self._auth_token.get_frozen_token() - auth = cls(frozen_token) - return auth - - # If there's no credentials provided (i.e credentials is None), - # then we'll pass a value of "None" over to the auth classes, - # which already handle the cases where no credentials have - # been provided. - frozen_credentials = None - if self._credentials is not None: - frozen_credentials = self._credentials.get_frozen_credentials() - kwargs['credentials'] = frozen_credentials - if cls.REQUIRES_REGION: - if self._region_name is None: - raise botocore.exceptions.NoRegionError() - kwargs['region_name'] = region_name - kwargs['service_name'] = signing_name - auth = cls(**kwargs) - return auth - - # Alias get_auth for backwards compatibility. - get_auth = get_auth_instance - - def generate_presigned_url( - self, - request_dict, - operation_name, - expires_in=3600, - region_name=None, - signing_name=None, - ): - """Generates a presigned url - - :type request_dict: dict - :param request_dict: The prepared request dictionary returned by - ``botocore.awsrequest.prepare_request_dict()`` - - :type operation_name: str - :param operation_name: The operation being signed. - - :type expires_in: int - :param expires_in: The number of seconds the presigned url is valid - for. By default it expires in an hour (3600 seconds) - - :type region_name: string - :param region_name: The region name to sign the presigned url. - - :type signing_name: str - :param signing_name: The name to use for the service when signing. - - :returns: The presigned url - """ - request = create_request_object(request_dict) - self.sign( - operation_name, - request, - region_name, - 'presign-url', - expires_in, - signing_name, - ) - - request.prepare() - return request.url - - -class CloudFrontSigner: - '''A signer to create a signed CloudFront URL. - - First you create a cloudfront signer based on a normalized RSA signer:: - - import rsa - def rsa_signer(message): - private_key = open('private_key.pem', 'r').read() - return rsa.sign( - message, - rsa.PrivateKey.load_pkcs1(private_key.encode('utf8')), - 'SHA-1') # CloudFront requires SHA-1 hash - cf_signer = CloudFrontSigner(key_id, rsa_signer) - - To sign with a canned policy:: - - signed_url = cf_signer.generate_signed_url( - url, date_less_than=datetime(2015, 12, 1)) - - To sign with a custom policy:: - - signed_url = cf_signer.generate_signed_url(url, policy=my_policy) - ''' - - def __init__(self, key_id, rsa_signer): - """Create a CloudFrontSigner. - - :type key_id: str - :param key_id: The CloudFront Key Pair ID - - :type rsa_signer: callable - :param rsa_signer: An RSA signer. - Its only input parameter will be the message to be signed, - and its output will be the signed content as a binary string. - The hash algorithm needed by CloudFront is SHA-1. - """ - self.key_id = key_id - self.rsa_signer = rsa_signer - - def generate_presigned_url(self, url, date_less_than=None, policy=None): - """Creates a signed CloudFront URL based on given parameters. - - :type url: str - :param url: The URL of the protected object - - :type date_less_than: datetime - :param date_less_than: The URL will expire after that date and time - - :type policy: str - :param policy: The custom policy, possibly built by self.build_policy() - - :rtype: str - :return: The signed URL. - """ - both_args_supplied = date_less_than is not None and policy is not None - neither_arg_supplied = date_less_than is None and policy is None - if both_args_supplied or neither_arg_supplied: - e = 'Need to provide either date_less_than or policy, but not both' - raise ValueError(e) - if date_less_than is not None: - # We still need to build a canned policy for signing purpose - policy = self.build_policy(url, date_less_than) - if isinstance(policy, str): - policy = policy.encode('utf8') - if date_less_than is not None: - params = ['Expires=%s' % int(datetime2timestamp(date_less_than))] - else: - params = ['Policy=%s' % self._url_b64encode(policy).decode('utf8')] - signature = self.rsa_signer(policy) - params.extend( - [ - f"Signature={self._url_b64encode(signature).decode('utf8')}", - f"Key-Pair-Id={self.key_id}", - ] - ) - return self._build_url(url, params) - - def _build_url(self, base_url, extra_params): - separator = '&' if '?' in base_url else '?' - return base_url + separator + '&'.join(extra_params) - - def build_policy( - self, resource, date_less_than, date_greater_than=None, ip_address=None - ): - """A helper to build policy. - - :type resource: str - :param resource: The URL or the stream filename of the protected object - - :type date_less_than: datetime - :param date_less_than: The URL will expire after the time has passed - - :type date_greater_than: datetime - :param date_greater_than: The URL will not be valid until this time - - :type ip_address: str - :param ip_address: Use 'x.x.x.x' for an IP, or 'x.x.x.x/x' for a subnet - - :rtype: str - :return: The policy in a compact string. - """ - # Note: - # 1. Order in canned policy is significant. Special care has been taken - # to ensure the output will match the order defined by the document. - # There is also a test case to ensure that order. - # SEE: http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-creating-signed-url-canned-policy.html#private-content-canned-policy-creating-policy-statement - # 2. Albeit the order in custom policy is not required by CloudFront, - # we still use OrderedDict internally to ensure the result is stable - # and also matches canned policy requirement. - # SEE: http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-creating-signed-url-custom-policy.html - moment = int(datetime2timestamp(date_less_than)) - condition = OrderedDict({"DateLessThan": {"AWS:EpochTime": moment}}) - if ip_address: - if '/' not in ip_address: - ip_address += '/32' - condition["IpAddress"] = {"AWS:SourceIp": ip_address} - if date_greater_than: - moment = int(datetime2timestamp(date_greater_than)) - condition["DateGreaterThan"] = {"AWS:EpochTime": moment} - ordered_payload = [('Resource', resource), ('Condition', condition)] - custom_policy = {"Statement": [OrderedDict(ordered_payload)]} - return json.dumps(custom_policy, separators=(',', ':')) - - def _url_b64encode(self, data): - # Required by CloudFront. See also: - # http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-linux-openssl.html - return ( - base64.b64encode(data) - .replace(b'+', b'-') - .replace(b'=', b'_') - .replace(b'/', b'~') - ) - - -def add_generate_db_auth_token(class_attributes, **kwargs): - class_attributes['generate_db_auth_token'] = generate_db_auth_token - - -def generate_db_auth_token(self, DBHostname, Port, DBUsername, Region=None): - """Generates an auth token used to connect to a db with IAM credentials. - - :type DBHostname: str - :param DBHostname: The hostname of the database to connect to. - - :type Port: int - :param Port: The port number the database is listening on. - - :type DBUsername: str - :param DBUsername: The username to log in as. - - :type Region: str - :param Region: The region the database is in. If None, the client - region will be used. - - :return: A presigned url which can be used as an auth token. - """ - region = Region - if region is None: - region = self.meta.region_name - - params = { - 'Action': 'connect', - 'DBUser': DBUsername, - } - - request_dict = { - 'url_path': '/', - 'query_string': '', - 'headers': {}, - 'body': params, - 'method': 'GET', - } - - # RDS requires that the scheme not be set when sent over. This can cause - # issues when signing because the Python url parsing libraries follow - # RFC 1808 closely, which states that a netloc must be introduced by `//`. - # Otherwise the url is presumed to be relative, and thus the whole - # netloc would be treated as a path component. To work around this we - # introduce https here and remove it once we're done processing it. - scheme = 'https://' - endpoint_url = f'{scheme}{DBHostname}:{Port}' - prepare_request_dict(request_dict, endpoint_url) - presigned_url = self._request_signer.generate_presigned_url( - operation_name='connect', - request_dict=request_dict, - region_name=region, - expires_in=900, - signing_name='rds-db', - ) - return presigned_url[len(scheme) :] - - -class S3PostPresigner: - def __init__(self, request_signer): - self._request_signer = request_signer - - def generate_presigned_post( - self, - request_dict, - fields=None, - conditions=None, - expires_in=3600, - region_name=None, - ): - """Generates the url and the form fields used for a presigned s3 post - - :type request_dict: dict - :param request_dict: The prepared request dictionary returned by - ``botocore.awsrequest.prepare_request_dict()`` - - :type fields: dict - :param fields: A dictionary of prefilled form fields to build on top - of. - - :type conditions: list - :param conditions: A list of conditions to include in the policy. Each - element can be either a list or a structure. For example: - [ - {"acl": "public-read"}, - {"bucket": "mybucket"}, - ["starts-with", "$key", "mykey"] - ] - - :type expires_in: int - :param expires_in: The number of seconds the presigned post is valid - for. - - :type region_name: string - :param region_name: The region name to sign the presigned post to. - - :rtype: dict - :returns: A dictionary with two elements: ``url`` and ``fields``. - Url is the url to post to. Fields is a dictionary filled with - the form fields and respective values to use when submitting the - post. For example: - - {'url': 'https://mybucket.s3.amazonaws.com - 'fields': {'acl': 'public-read', - 'key': 'mykey', - 'signature': 'mysignature', - 'policy': 'mybase64 encoded policy'} - } - """ - if fields is None: - fields = {} - - if conditions is None: - conditions = [] - - # Create the policy for the post. - policy = {} - - # Create an expiration date for the policy - datetime_now = datetime.datetime.utcnow() - expire_date = datetime_now + datetime.timedelta(seconds=expires_in) - policy['expiration'] = expire_date.strftime(botocore.auth.ISO8601) - - # Append all of the conditions that the user supplied. - policy['conditions'] = [] - for condition in conditions: - policy['conditions'].append(condition) - - # Store the policy and the fields in the request for signing - request = create_request_object(request_dict) - request.context['s3-presign-post-fields'] = fields - request.context['s3-presign-post-policy'] = policy - - self._request_signer.sign( - 'PutObject', request, region_name, 'presign-post' - ) - # Return the url and the fields for th form to post. - return {'url': request.url, 'fields': fields} - - -def add_generate_presigned_url(class_attributes, **kwargs): - class_attributes['generate_presigned_url'] = generate_presigned_url - - -def generate_presigned_url( - self, ClientMethod, Params=None, ExpiresIn=3600, HttpMethod=None -): - """Generate a presigned url given a client, its method, and arguments - - :type ClientMethod: string - :param ClientMethod: The client method to presign for - - :type Params: dict - :param Params: The parameters normally passed to - ``ClientMethod``. - - :type ExpiresIn: int - :param ExpiresIn: The number of seconds the presigned url is valid - for. By default it expires in an hour (3600 seconds) - - :type HttpMethod: string - :param HttpMethod: The http method to use on the generated url. By - default, the http method is whatever is used in the method's model. - - :returns: The presigned url - """ - client_method = ClientMethod - params = Params - if params is None: - params = {} - expires_in = ExpiresIn - http_method = HttpMethod - context = { - 'is_presign_request': True, - 'use_global_endpoint': _should_use_global_endpoint(self), - } - - request_signer = self._request_signer - - try: - operation_name = self._PY_TO_OP_NAME[client_method] - except KeyError: - raise UnknownClientMethodError(method_name=client_method) - - operation_model = self.meta.service_model.operation_model(operation_name) - bucket_is_arn = ArnParser.is_arn(params.get('Bucket', '')) - endpoint_url, additional_headers = self._resolve_endpoint_ruleset( - operation_model, - params, - context, - ignore_signing_region=(not bucket_is_arn), - ) - - request_dict = self._convert_to_request_dict( - api_params=params, - operation_model=operation_model, - endpoint_url=endpoint_url, - context=context, - headers=additional_headers, - set_user_agent_header=False, - ) - - # Switch out the http method if user specified it. - if http_method is not None: - request_dict['method'] = http_method - - # Generate the presigned url. - return request_signer.generate_presigned_url( - request_dict=request_dict, - expires_in=expires_in, - operation_name=operation_name, - ) - - -def add_generate_presigned_post(class_attributes, **kwargs): - class_attributes['generate_presigned_post'] = generate_presigned_post - - -def generate_presigned_post( - self, Bucket, Key, Fields=None, Conditions=None, ExpiresIn=3600 -): - """Builds the url and the form fields used for a presigned s3 post - - :type Bucket: string - :param Bucket: The name of the bucket to presign the post to. Note that - bucket related conditions should not be included in the - ``conditions`` parameter. - - :type Key: string - :param Key: Key name, optionally add ${filename} to the end to - attach the submitted filename. Note that key related conditions and - fields are filled out for you and should not be included in the - ``Fields`` or ``Conditions`` parameter. - - :type Fields: dict - :param Fields: A dictionary of prefilled form fields to build on top - of. Elements that may be included are acl, Cache-Control, - Content-Type, Content-Disposition, Content-Encoding, Expires, - success_action_redirect, redirect, success_action_status, - and x-amz-meta-. - - Note that if a particular element is included in the fields - dictionary it will not be automatically added to the conditions - list. You must specify a condition for the element as well. - - :type Conditions: list - :param Conditions: A list of conditions to include in the policy. Each - element can be either a list or a structure. For example: - - [ - {"acl": "public-read"}, - ["content-length-range", 2, 5], - ["starts-with", "$success_action_redirect", ""] - ] - - Conditions that are included may pertain to acl, - content-length-range, Cache-Control, Content-Type, - Content-Disposition, Content-Encoding, Expires, - success_action_redirect, redirect, success_action_status, - and/or x-amz-meta-. - - Note that if you include a condition, you must specify - the a valid value in the fields dictionary as well. A value will - not be added automatically to the fields dictionary based on the - conditions. - - :type ExpiresIn: int - :param ExpiresIn: The number of seconds the presigned post - is valid for. - - :rtype: dict - :returns: A dictionary with two elements: ``url`` and ``fields``. - Url is the url to post to. Fields is a dictionary filled with - the form fields and respective values to use when submitting the - post. For example: - - {'url': 'https://mybucket.s3.amazonaws.com - 'fields': {'acl': 'public-read', - 'key': 'mykey', - 'signature': 'mysignature', - 'policy': 'mybase64 encoded policy'} - } - """ - bucket = Bucket - key = Key - fields = Fields - conditions = Conditions - expires_in = ExpiresIn - - if fields is None: - fields = {} - else: - fields = fields.copy() - - if conditions is None: - conditions = [] - - context = { - 'is_presign_request': True, - 'use_global_endpoint': _should_use_global_endpoint(self), - } - - post_presigner = S3PostPresigner(self._request_signer) - - # We choose the CreateBucket operation model because its url gets - # serialized to what a presign post requires. - operation_model = self.meta.service_model.operation_model('CreateBucket') - params = {'Bucket': bucket} - bucket_is_arn = ArnParser.is_arn(params.get('Bucket', '')) - endpoint_url, additional_headers = self._resolve_endpoint_ruleset( - operation_model, - params, - context, - ignore_signing_region=(not bucket_is_arn), - ) - - request_dict = self._convert_to_request_dict( - api_params=params, - operation_model=operation_model, - endpoint_url=endpoint_url, - context=context, - headers=additional_headers, - set_user_agent_header=False, - ) - - # Append that the bucket name to the list of conditions. - conditions.append({'bucket': bucket}) - - # If the key ends with filename, the only constraint that can be - # imposed is if it starts with the specified prefix. - if key.endswith('${filename}'): - conditions.append(["starts-with", '$key', key[: -len('${filename}')]]) - else: - conditions.append({'key': key}) - - # Add the key to the fields. - fields['key'] = key - - return post_presigner.generate_presigned_post( - request_dict=request_dict, - fields=fields, - conditions=conditions, - expires_in=expires_in, - ) - - -def _should_use_global_endpoint(client): - if client.meta.partition != 'aws': - return False - s3_config = client.meta.config.s3 - if s3_config: - if s3_config.get('use_dualstack_endpoint', False): - return False - if ( - s3_config.get('us_east_1_regional_endpoint') == 'regional' - and client.meta.config.region_name == 'us-east-1' - ): - return False - return True diff --git a/spaces/Bready11/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator/app.py b/spaces/Bready11/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator/app.py deleted file mode 100644 index eb453a809d17e6dee04e158d1c68dc807478edef..0000000000000000000000000000000000000000 --- a/spaces/Bready11/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator/app.py +++ /dev/null @@ -1,3 +0,0 @@ -import gradio as gr - -gr.Interface.load("models/Onodofthenorth/SD_PixelArt_SpriteSheet_Generator").launch() \ No newline at end of file diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/bottom-up-attention-vqa/classifier.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/bottom-up-attention-vqa/classifier.py deleted file mode 100644 index cdcc085331d621e8ed1478e7df670a5d493c6cdc..0000000000000000000000000000000000000000 --- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/bottom-up-attention-vqa/classifier.py +++ /dev/null @@ -1,18 +0,0 @@ -import torch.nn as nn -from torch.nn.utils.weight_norm import weight_norm - - -class SimpleClassifier(nn.Module): - def __init__(self, in_dim, hid_dim, out_dim, dropout): - super(SimpleClassifier, self).__init__() - layers = [ - weight_norm(nn.Linear(in_dim, hid_dim), dim=None), - nn.ReLU(), - nn.Dropout(dropout, inplace=True), - weight_norm(nn.Linear(hid_dim, out_dim), dim=None) - ] - self.main = nn.Sequential(*layers) - - def forward(self, x): - logits = self.main(x) - return logits diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/PointRend/README.md b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/PointRend/README.md deleted file mode 100644 index 67a4de3cd2a330ff9da3318c228840c16968d22e..0000000000000000000000000000000000000000 --- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/PointRend/README.md +++ /dev/null @@ -1,115 +0,0 @@ -# PointRend: Image Segmentation as Rendering - -Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick - -[[`arXiv`](https://arxiv.org/abs/1912.08193)] [[`BibTeX`](#CitingPointRend)] - --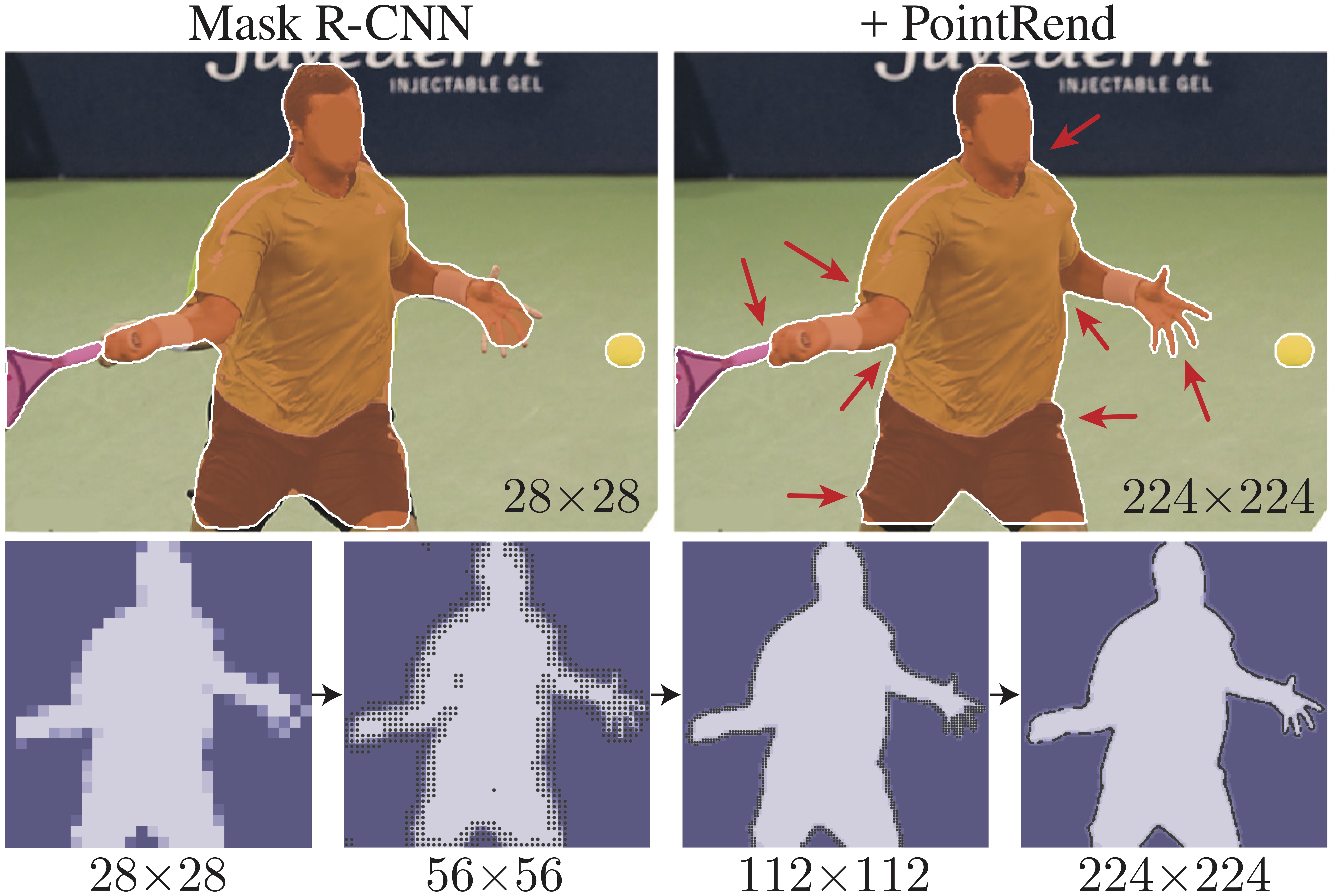 -
-
- -In this repository, we release code for PointRend in Detectron2. PointRend can be flexibly applied to both instance and semantic (**comming soon**) segmentation tasks by building on top of existing state-of-the-art models. - -## Installation -Install Detectron 2 following [INSTALL.md](https://github.com/facebookresearch/detectron2/blob/master/INSTALL.md). You are ready to go! - -## Quick start and visualization - -This [Colab Notebook](https://colab.research.google.com/drive/1isGPL5h5_cKoPPhVL9XhMokRtHDvmMVL) tutorial contains examples of PointRend usage and visualizations of its point sampling stages. - -## Training - -To train a model with 8 GPUs run: -```bash -cd /path/to/detectron2/projects/PointRend -python train_net.py --config-file configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml --num-gpus 8 -``` - -## Evaluation - -Model evaluation can be done similarly: -```bash -cd /path/to/detectron2/projects/PointRend -python train_net.py --config-file configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml --eval-only MODEL.WEIGHTS /path/to/model_checkpoint -``` - -# Pretrained Models - -## Instance Segmentation -#### COCO - -- - -
- -AP* is COCO mask AP evaluated against the higher-quality LVIS annotations; see the paper for details. Run `python detectron2/datasets/prepare_cocofied_lvis.py` to prepare GT files for AP* evaluation. Since LVIS annotations are not exhaustive `lvis-api` and not `cocoapi` should be used to evaluate AP*. - -#### Cityscapes -Cityscapes model is trained with ImageNet pretraining. - -Mask -
headBackbone -lr -
schedOutput -
resolutionmask -
APmask -
AP*model id -download - -PointRend -R50-FPN -1× -224×224 -36.2 -39.7 -164254221 -model | metrics -PointRend -R50-FPN -3× -224×224 -38.3 -41.6 -164955410 -model | metrics -- - -
- - -## Semantic Segmentation - -**[comming soon]** - -## Citing PointRend - -If you use PointRend, please use the following BibTeX entry. - -```BibTeX -@InProceedings{kirillov2019pointrend, - title={{PointRend}: Image Segmentation as Rendering}, - author={Alexander Kirillov and Yuxin Wu and Kaiming He and Ross Girshick}, - journal={ArXiv:1912.08193}, - year={2019} -} -``` diff --git a/spaces/CVPR/LIVE/thrust/cmake/AppendOptionIfAvailable.cmake b/spaces/CVPR/LIVE/thrust/cmake/AppendOptionIfAvailable.cmake deleted file mode 100644 index 52dc12216990dedd45196bb253f2f49e5dc28254..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/cmake/AppendOptionIfAvailable.cmake +++ /dev/null @@ -1,14 +0,0 @@ -include_guard(GLOBAL) -include(CheckCXXCompilerFlag) - -macro (APPEND_OPTION_IF_AVAILABLE _FLAG _LIST) - -string(MAKE_C_IDENTIFIER "CXX_FLAG_${_FLAG}" _VAR) -check_cxx_compiler_flag(${_FLAG} ${_VAR}) - -if (${${_VAR}}) - list(APPEND ${_LIST} ${_FLAG}) -endif () - -endmacro () - diff --git a/spaces/CVPR/LIVE/thrust/thrust/detail/cstdint.h b/spaces/CVPR/LIVE/thrust/thrust/detail/cstdint.h deleted file mode 100644 index 248390a528d5885a2a6f00e6a34cec5185cfbdcf..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/thrust/detail/cstdint.h +++ /dev/null @@ -1,79 +0,0 @@ -/* - * Copyright 2008-2013 NVIDIA Corporation - * - * Licensed under the Apache License, Version 2.0 (the "License"); - * you may not use this file except in compliance with the License. - * You may obtain a copy of the License at - * - * http://www.apache.org/licenses/LICENSE-2.0 - * - * Unless required by applicable law or agreed to in writing, software - * distributed under the License is distributed on an "AS IS" BASIS, - * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - * See the License for the specific language governing permissions and - * limitations under the License. - */ - -#pragma once - -#if (THRUST_HOST_COMPILER == THRUST_HOST_COMPILER_GCC) || (THRUST_HOST_COMPILER == THRUST_HOST_COMPILER_CLANG) -#includeMask -
headBackbone -lr -
schedOutput -
resolutionmask -
APmodel id -download - -PointRend -R50-FPN -1× -224×224 -35.9 -164255101 -model | metrics --#endif - -namespace thrust -{ -namespace detail -{ - -#if (THRUST_HOST_COMPILER == THRUST_HOST_COMPILER_MSVC) - -#if (_MSC_VER < 1300) - typedef signed char int8_t; - typedef signed short int16_t; - typedef signed int int32_t; - typedef unsigned char uint8_t; - typedef unsigned short uint16_t; - typedef unsigned int uint32_t; -#else - typedef signed __int8 int8_t; - typedef signed __int16 int16_t; - typedef signed __int32 int32_t; - typedef unsigned __int8 uint8_t; - typedef unsigned __int16 uint16_t; - typedef unsigned __int32 uint32_t; -#endif -typedef signed __int64 int64_t; -typedef unsigned __int64 uint64_t; - -#else - -typedef ::int8_t int8_t; -typedef ::int16_t int16_t; -typedef ::int32_t int32_t; -typedef ::int64_t int64_t; -typedef ::uint8_t uint8_t; -typedef ::uint16_t uint16_t; -typedef ::uint32_t uint32_t; -typedef ::uint64_t uint64_t; - -#endif - - -// an oracle to tell us how to define intptr_t -template struct divine_intptr_t; -template struct divine_uintptr_t; - -// 32b platforms -template<> struct divine_intptr_t<4> { typedef thrust::detail::int32_t type; }; -template<> struct divine_uintptr_t<4> { typedef thrust::detail::uint32_t type; }; - -// 64b platforms -template<> struct divine_intptr_t<8> { typedef thrust::detail::int64_t type; }; -template<> struct divine_uintptr_t<8> { typedef thrust::detail::uint64_t type; }; - -typedef divine_intptr_t<>::type intptr_t; -typedef divine_uintptr_t<>::type uintptr_t; - -} // end detail -} // end thrust - diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/async/reduce.h b/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/async/reduce.h deleted file mode 100644 index 906928b27f3107a72c68b57a6c532abe8e2af254..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/async/reduce.h +++ /dev/null @@ -1,350 +0,0 @@ -/****************************************************************************** - * Copyright (c) 2016, NVIDIA CORPORATION. All rights reserved. - * - * Redistribution and use in source and binary forms, with or without - * modification, are permitted provided that the following conditions are met: - * * Redistributions of source code must retain the above copyright - * notice, this list of conditions and the following disclaimer. - * * Redistributions in binary form must reproduce the above copyright - * notice, this list of conditions and the following disclaimer in the - * documentation and/or other materials provided with the distribution. - * * Neither the name of the NVIDIA CORPORATION nor the - * names of its contributors may be used to endorse or promote products - * derived from this software without specific prior written permission. - * - * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" - * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE - * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE - * ARE DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY - * DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES - * (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; - * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND - * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT - * (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS - * SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - * - ******************************************************************************/ - -// TODO: Optimize for thrust::plus - -// TODO: Move into system::cuda - -#pragma once - -#include -#include - -#if THRUST_CPP_DIALECT >= 2014 - -#if THRUST_DEVICE_COMPILER == THRUST_DEVICE_COMPILER_NVCC - -#include - -#include -#include -#include -#include -#include -#include - -#include - -namespace thrust -{ - -namespace system { namespace cuda { namespace detail -{ - -template < - typename DerivedPolicy -, typename ForwardIt, typename Size, typename T, typename BinaryOp -> -auto async_reduce_n( - execution_policy & policy -, ForwardIt first -, Size n -, T init -, BinaryOp op -) -> unique_eager_future ; - - auto const device_alloc = get_async_device_allocator(policy); - - using pointer - = typename thrust::detail::allocator_traits & policy -, ForwardIt first -, Sentinel last -, T init -, BinaryOp op -) -THRUST_RETURNS( - thrust::system::cuda::detail::async_reduce_n( - policy, first, distance(first, last), init, op - ) -) - -} // cuda_cub - -/////////////////////////////////////////////////////////////////////////////// - -namespace system { namespace cuda { namespace detail -{ - -template < - typename DerivedPolicy -, typename ForwardIt, typename Size, typename OutputIt -, typename T, typename BinaryOp -> -auto async_reduce_into_n( - execution_policy & policy -, ForwardIt first -, Size n -, OutputIt output -, T init -, BinaryOp op -) -> unique_eager_event -{ - using U = remove_cvref_t ; - - auto const device_alloc = get_async_device_allocator(policy); - - unique_eager_event e; - - // Determine temporary device storage requirements. - - size_t tmp_size = 0; - thrust::cuda_cub::throw_on_error( - cub::DeviceReduce::Reduce( - nullptr - , tmp_size - , first - , static_cast & policy -, ForwardIt first -, Sentinel last -, OutputIt output -, T init -, BinaryOp op -) -THRUST_RETURNS( - thrust::system::cuda::detail::async_reduce_into_n( - policy, first, distance(first, last), output, init, op - ) -) - -} // cuda_cub - -} // end namespace thrust - -#endif // THRUST_DEVICE_COMPILER == THRUST_DEVICE_COMPILER_NVCC - -#endif - diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/gather.h b/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/gather.h deleted file mode 100644 index 31ca3fd561b71fb389ade0359ee30205ef290ed4..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/gather.h +++ /dev/null @@ -1,107 +0,0 @@ -/****************************************************************************** - * Copyright (c) 2016, NVIDIA CORPORATION. All rights reserved. - * - * Redistribution and use in source and binary forms, with or without - * modification, are permitted provided that the following conditions are met: - * * Redistributions of source code must retain the above copyright - * notice, this list of conditions and the following disclaimer. - * * Redistributions in binary form must reproduce the above copyright - * notice, this list of conditions and the following disclaimer in the - * documentation and/or other materials provided with the distribution. - * * Neither the name of the NVIDIA CORPORATION nor the - * names of its contributors may be used to endorse or promote products - * derived from this software without specific prior written permission. - * - * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" - * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE - * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE - * ARE DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY - * DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES - * (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; - * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND - * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT - * (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS - * SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - * - ******************************************************************************/ -#pragma once - - -#if THRUST_DEVICE_COMPILER == THRUST_DEVICE_COMPILER_NVCC -#include -#include - -namespace thrust -{ -namespace cuda_cub { - -template -ResultIt __host__ __device__ -gather(execution_policy & policy, - MapIt map_first, - MapIt map_last, - ItemsIt items, - ResultIt result) -{ - return cuda_cub::transform(policy, - thrust::make_permutation_iterator(items, map_first), - thrust::make_permutation_iterator(items, map_last), - result, - identity()); -} - - -template -ResultIt __host__ __device__ -gather_if(execution_policy & policy, - MapIt map_first, - MapIt map_last, - StencilIt stencil, - ItemsIt items, - ResultIt result, - Predicate predicate) -{ - return cuda_cub::transform_if(policy, - thrust::make_permutation_iterator(items, map_first), - thrust::make_permutation_iterator(items, map_last), - stencil, - result, - identity(), - predicate); -} - -template -ResultIt __host__ __device__ -gather_if(execution_policy & policy, - MapIt map_first, - MapIt map_last, - StencilIt stencil, - ItemsIt items, - ResultIt result) -{ - return cuda_cub::gather_if(policy, - map_first, - map_last, - stencil, - items, - result, - identity()); -} - - -} // namespace cuda_cub -} // end namespace thrust - -#endif diff --git a/spaces/CVPR/VizWiz-CLIP-VQA/README.md b/spaces/CVPR/VizWiz-CLIP-VQA/README.md deleted file mode 100644 index b221ab2a5b72a704cd5989a720e8a3e7a75c6592..0000000000000000000000000000000000000000 --- a/spaces/CVPR/VizWiz-CLIP-VQA/README.md +++ /dev/null @@ -1,10 +0,0 @@ ---- -title: CLIP-VQA for VizWiz 2022 -emoji: 👁️ -colorFrom: gray -colorTo: indigo -sdk: gradio -sdk_version: 3.0.17 -app_file: app.py -pinned: false ---- \ No newline at end of file diff --git a/spaces/Choisuren/AnimeGANv3/README.md b/spaces/Choisuren/AnimeGANv3/README.md deleted file mode 100644 index d9964579e174cc4d52ec780a2b930db0097edb7c..0000000000000000000000000000000000000000 --- a/spaces/Choisuren/AnimeGANv3/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: AnimeGANv3 -emoji: 🐠 -colorFrom: purple -colorTo: yellow -sdk: gradio -sdk_version: 3.29.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/CikeyQI/meme-api/meme_generator/memes/hug_leg/__init__.py b/spaces/CikeyQI/meme-api/meme_generator/memes/hug_leg/__init__.py deleted file mode 100644 index 18ddf1c0bdce5e500d96dbc61a3a69d6db8ba4e8..0000000000000000000000000000000000000000 --- a/spaces/CikeyQI/meme-api/meme_generator/memes/hug_leg/__init__.py +++ /dev/null @@ -1,32 +0,0 @@ -from pathlib import Path -from typing import List - -from PIL.Image import Image as IMG -from pil_utils import BuildImage - -from meme_generator import add_meme -from meme_generator.utils import save_gif - -img_dir = Path(__file__).parent / "images" - - -def hug_leg(images: List[BuildImage], texts, args): - img = images[0].convert("RGBA").square() - locs = [ - (50, 73, 68, 92), - (58, 60, 62, 95), - (65, 10, 67, 118), - (61, 20, 77, 97), - (55, 44, 65, 106), - (66, 85, 60, 98), - ] - frames: List[IMG] = [] - for i in range(6): - frame = BuildImage.open(img_dir / f"{i}.png") - x, y, w, h = locs[i] - frame.paste(img.resize((w, h)), (x, y), below=True) - frames.append(frame.image) - return save_gif(frames, 0.06) - - -add_meme("hug_leg", hug_leg, min_images=1, max_images=1, keywords=["抱大腿"]) diff --git a/spaces/CofAI/chat/client/css/conversation.css b/spaces/CofAI/chat/client/css/conversation.css deleted file mode 100644 index d20f178c45e8ccbfc9539f99914b25fc572045bd..0000000000000000000000000000000000000000 --- a/spaces/CofAI/chat/client/css/conversation.css +++ /dev/null @@ -1,158 +0,0 @@ -.conversation { - width: 60%; - margin: 0px 16px; - display: flex; - flex-direction: column; -} - -.conversation #messages { - width: 100%; - display: flex; - flex-direction: column; - overflow: auto; - overflow-wrap: break-word; - padding-bottom: 8px; -} - -.conversation .user-input { - max-height: 180px; - margin: 16px 0px; -} - -.conversation .user-input input { - font-size: 1rem; - background: none; - border: none; - outline: none; - color: var(--colour-3); -} - -.conversation .user-input input::placeholder { - color: var(--user-input); -} - -.conversation-title { - color: var(--colour-3); - font-size: 14px; -} - -.conversation .user-input textarea { - font-size: 1rem; - width: 100%; - height: 100%; - padding: 12px; - background: none; - border: none; - outline: none; - color: var(--colour-3); - resize: vertical; - max-height: 150px; - min-height: 80px; -} - -.box { - backdrop-filter: blur(20px); - -webkit-backdrop-filter: blur(20px); - background-color: var(--blur-bg); - height: 100%; - width: 100%; - border-radius: var(--border-radius-1); - border: 1px solid var(--blur-border); -} - -.box.input-box { - position: relative; - align-items: center; - padding: 8px; - cursor: pointer; -} - -#send-button { - position: absolute; - bottom: 25%; - right: 10px; - z-index: 1; - padding: 16px; -} - -#cursor { - line-height: 17px; - margin-left: 3px; - -webkit-animation: blink 0.8s infinite; - animation: blink 0.8s infinite; - width: 7px; - height: 15px; -} - -@keyframes blink { - 0% { - background: #ffffff00; - } - - 50% { - background: white; - } - - 100% { - background: #ffffff00; - } -} - -@-webkit-keyframes blink { - 0% { - background: #ffffff00; - } - - 50% { - background: white; - } - - 100% { - background: #ffffff00; - } -} - -/* scrollbar */ -.conversation #messages::-webkit-scrollbar { - width: 4px; - padding: 8px 0px; -} - -.conversation #messages::-webkit-scrollbar-track { - background-color: #ffffff00; -} - -.conversation #messages::-webkit-scrollbar-thumb { - background-color: #555555; - border-radius: 10px; -} - -@media screen and (max-width: 990px) { - .conversation { - width: 100%; - height: 90%; - } -} - -@media screen and (max-height: 720px) { - .conversation.box { - height: 70%; - } - - .conversation .user-input textarea { - font-size: 0.875rem; - } -} - -@media screen and (max-width: 360px) { - .box { - border-radius: 0; - } - .conversation { - margin: 0; - margin-top: 48px; - } - .conversation .user-input { - margin: 2px 0 8px 0; - } -} diff --git a/spaces/CofAI/chat/client/js/sidebar-toggler.js b/spaces/CofAI/chat/client/js/sidebar-toggler.js deleted file mode 100644 index b23f94e3bfba5bac53432e1b557765736dabbab4..0000000000000000000000000000000000000000 --- a/spaces/CofAI/chat/client/js/sidebar-toggler.js +++ /dev/null @@ -1,34 +0,0 @@ -const sidebar = document.querySelector(".sidebar"); -const menuButton = document.querySelector(".menu-button"); - -function toggleSidebar(event) { - if (sidebar.classList.contains("shown")) { - hideSidebar(event.target); - } else { - showSidebar(event.target); - } - window.scrollTo(0, 0); -} - -function showSidebar(target) { - sidebar.classList.add("shown"); - target.classList.add("rotated"); - document.body.style.overflow = "hidden"; -} - -function hideSidebar(target) { - sidebar.classList.remove("shown"); - target.classList.remove("rotated"); - document.body.style.overflow = "auto"; -} - -menuButton.addEventListener("click", toggleSidebar); - -document.body.addEventListener('click', function(event) { - if (event.target.matches('.conversation-title')) { - const menuButtonStyle = window.getComputedStyle(menuButton); - if (menuButtonStyle.display !== 'none') { - hideSidebar(menuButton); - } - } -}); diff --git a/spaces/DKDohare/Chat-GPT4-MAX/app.py b/spaces/DKDohare/Chat-GPT4-MAX/app.py deleted file mode 100644 index 119b1be22c9e79b16ac00069c023ed110b9093da..0000000000000000000000000000000000000000 --- a/spaces/DKDohare/Chat-GPT4-MAX/app.py +++ /dev/null @@ -1,141 +0,0 @@ -import gradio as gr -import os -import json -import requests - -#Streaming endpoint -API_URL = "https://api.openai.com/v1/chat/completions" #os.getenv("API_URL") + "/generate_stream" - -#Testing with my Open AI Key -OPENAI_API_KEY = os.getenv("OPENAI_API_KEY") - -def predict(inputs, top_p, temperature, chat_counter, chatbot=[], history=[]): - - payload = { - "model": "gpt-4", - "messages": [{"role": "user", "content": f"{inputs}"}], - "temperature" : 1.0, - "top_p":1.0, - "n" : 1, - "stream": True, - "presence_penalty":0, - "frequency_penalty":0, - } - - headers = { - "Content-Type": "application/json", - "Authorization": f"Bearer {OPENAI_API_KEY}" - } - - print(f"chat_counter - {chat_counter}") - if chat_counter != 0 : - messages=[] - for data in chatbot: - temp1 = {} - temp1["role"] = "user" - temp1["content"] = data[0] - temp2 = {} - temp2["role"] = "assistant" - temp2["content"] = data[1] - messages.append(temp1) - messages.append(temp2) - temp3 = {} - temp3["role"] = "user" - temp3["content"] = inputs - messages.append(temp3) - #messages - payload = { - "model": "gpt-4", - "messages": messages, #[{"role": "user", "content": f"{inputs}"}], - "temperature" : temperature, #1.0, - "top_p": top_p, #1.0, - "n" : 1, - "stream": True, - "presence_penalty":0, - "frequency_penalty":0, - } - - chat_counter+=1 - - history.append(inputs) - print(f"payload is - {payload}") - # make a POST request to the API endpoint using the requests.post method, passing in stream=True - response = requests.post(API_URL, headers=headers, json=payload, stream=True) - print(f"response code - {response}") - token_counter = 0 - partial_words = "" - - counter=0 - for chunk in response.iter_lines(): - #Skipping first chunk - if counter == 0: - counter+=1 - continue - #counter+=1 - # check whether each line is non-empty - if chunk.decode() : - chunk = chunk.decode() - # decode each line as response data is in bytes - if len(chunk) > 12 and "content" in json.loads(chunk[6:])['choices'][0]['delta']: - #if len(json.loads(chunk.decode()[6:])['choices'][0]["delta"]) == 0: - # break - partial_words = partial_words + json.loads(chunk[6:])['choices'][0]["delta"]["content"] - if token_counter == 0: - history.append(" " + partial_words) - else: - history[-1] = partial_words - chat = [(history[i], history[i + 1]) for i in range(0, len(history) - 1, 2) ] # convert to tuples of list - token_counter+=1 - yield chat, history, chat_counter, response # resembles {chatbot: chat, state: history} - - -def reset_textbox(): - return gr.update(value='') - -title = """ 🔥GPT4 with ChatCompletions API +🚀Gradio-Streaming
""" -description = """Language models can be conditioned to act like dialogue agents through a conversational prompt that typically takes the form: -``` -User:-Assistant: -User: -Assistant: -... -``` -In this app, you can explore the outputs of a gpt-4 LLM. -""" - -theme = gr.themes.Default(primary_hue="green") - -with gr.Blocks(css = """#col_container { margin-left: auto; margin-right: auto;} - #chatbot {height: 520px; overflow: auto;}""", - theme=theme) as demo: - gr.HTML(title) - gr.HTML(""" 🔥This Huggingface Gradio Demo provides you full access to GPT4 API (4096 token limit). 🎉🥳🎉You don't need any OPENAI API key🙌""") - gr.HTML('''
Duplicate the Space and run securely with your OpenAI API Key
: "}`. - ssl_context: An SSL context to use for verifying connections. - If not specified, the default `httpcore.default_ssl_context()` - will be used. - max_connections: The maximum number of concurrent HTTP connections that - the pool should allow. Any attempt to send a request on a pool that - would exceed this amount will block until a connection is available. - max_keepalive_connections: The maximum number of idle HTTP connections - that will be maintained in the pool. - keepalive_expiry: The duration in seconds that an idle HTTP connection - may be maintained for before being expired from the pool. - http1: A boolean indicating if HTTP/1.1 requests should be supported - by the connection pool. Defaults to True. - http2: A boolean indicating if HTTP/2 requests should be supported by - the connection pool. Defaults to False. - retries: The maximum number of retries when trying to establish - a connection. - local_address: Local address to connect from. Can also be used to - connect using a particular address family. Using - `local_address="0.0.0.0"` will connect using an `AF_INET` address - (IPv4), while using `local_address="::"` will connect using an - `AF_INET6` address (IPv6). - uds: Path to a Unix Domain Socket to use instead of TCP sockets. - network_backend: A backend instance to use for handling network I/O. - """ - super().__init__( - ssl_context=ssl_context, - max_connections=max_connections, - max_keepalive_connections=max_keepalive_connections, - keepalive_expiry=keepalive_expiry, - http1=http1, - http2=http2, - network_backend=network_backend, - retries=retries, - local_address=local_address, - uds=uds, - socket_options=socket_options, - ) - self._ssl_context = ssl_context - self._proxy_url = enforce_url(proxy_url, name="proxy_url") - self._proxy_headers = enforce_headers(proxy_headers, name="proxy_headers") - if proxy_auth is not None: - username = enforce_bytes(proxy_auth[0], name="proxy_auth") - password = enforce_bytes(proxy_auth[1], name="proxy_auth") - authorization = build_auth_header(username, password) - self._proxy_headers = [ - (b"Proxy-Authorization", authorization) - ] + self._proxy_headers - - def create_connection(self, origin: Origin) -> AsyncConnectionInterface: - if origin.scheme == b"http": - return AsyncForwardHTTPConnection( - proxy_origin=self._proxy_url.origin, - proxy_headers=self._proxy_headers, - remote_origin=origin, - keepalive_expiry=self._keepalive_expiry, - network_backend=self._network_backend, - ) - return AsyncTunnelHTTPConnection( - proxy_origin=self._proxy_url.origin, - proxy_headers=self._proxy_headers, - remote_origin=origin, - ssl_context=self._ssl_context, - keepalive_expiry=self._keepalive_expiry, - http1=self._http1, - http2=self._http2, - network_backend=self._network_backend, - ) - - -class AsyncForwardHTTPConnection(AsyncConnectionInterface): - def __init__( - self, - proxy_origin: Origin, - remote_origin: Origin, - proxy_headers: Union[HeadersAsMapping, HeadersAsSequence, None] = None, - keepalive_expiry: Optional[float] = None, - network_backend: Optional[AsyncNetworkBackend] = None, - socket_options: Optional[Iterable[SOCKET_OPTION]] = None, - ) -> None: - self._connection = AsyncHTTPConnection( - origin=proxy_origin, - keepalive_expiry=keepalive_expiry, - network_backend=network_backend, - socket_options=socket_options, - ) - self._proxy_origin = proxy_origin - self._proxy_headers = enforce_headers(proxy_headers, name="proxy_headers") - self._remote_origin = remote_origin - - async def handle_async_request(self, request: Request) -> Response: - headers = merge_headers(self._proxy_headers, request.headers) - url = URL( - scheme=self._proxy_origin.scheme, - host=self._proxy_origin.host, - port=self._proxy_origin.port, - target=bytes(request.url), - ) - proxy_request = Request( - method=request.method, - url=url, - headers=headers, - content=request.stream, - extensions=request.extensions, - ) - return await self._connection.handle_async_request(proxy_request) - - def can_handle_request(self, origin: Origin) -> bool: - return origin == self._remote_origin - - async def aclose(self) -> None: - await self._connection.aclose() - - def info(self) -> str: - return self._connection.info() - - def is_available(self) -> bool: - return self._connection.is_available() - - def has_expired(self) -> bool: - return self._connection.has_expired() - - def is_idle(self) -> bool: - return self._connection.is_idle() - - def is_closed(self) -> bool: - return self._connection.is_closed() - - def __repr__(self) -> str: - return f"<{self.__class__.__name__} [{self.info()}]>" - - -class AsyncTunnelHTTPConnection(AsyncConnectionInterface): - def __init__( - self, - proxy_origin: Origin, - remote_origin: Origin, - ssl_context: Optional[ssl.SSLContext] = None, - proxy_headers: Optional[Sequence[Tuple[bytes, bytes]]] = None, - keepalive_expiry: Optional[float] = None, - http1: bool = True, - http2: bool = False, - network_backend: Optional[AsyncNetworkBackend] = None, - socket_options: Optional[Iterable[SOCKET_OPTION]] = None, - ) -> None: - self._connection: AsyncConnectionInterface = AsyncHTTPConnection( - origin=proxy_origin, - keepalive_expiry=keepalive_expiry, - network_backend=network_backend, - socket_options=socket_options, - ) - self._proxy_origin = proxy_origin - self._remote_origin = remote_origin - self._ssl_context = ssl_context - self._proxy_headers = enforce_headers(proxy_headers, name="proxy_headers") - self._keepalive_expiry = keepalive_expiry - self._http1 = http1 - self._http2 = http2 - self._connect_lock = AsyncLock() - self._connected = False - - async def handle_async_request(self, request: Request) -> Response: - timeouts = request.extensions.get("timeout", {}) - timeout = timeouts.get("connect", None) - - async with self._connect_lock: - if not self._connected: - target = b"%b:%d" % (self._remote_origin.host, self._remote_origin.port) - - connect_url = URL( - scheme=self._proxy_origin.scheme, - host=self._proxy_origin.host, - port=self._proxy_origin.port, - target=target, - ) - connect_headers = merge_headers( - [(b"Host", target), (b"Accept", b"*/*")], self._proxy_headers - ) - connect_request = Request( - method=b"CONNECT", - url=connect_url, - headers=connect_headers, - extensions=request.extensions, - ) - connect_response = await self._connection.handle_async_request( - connect_request - ) - - if connect_response.status < 200 or connect_response.status > 299: - reason_bytes = connect_response.extensions.get("reason_phrase", b"") - reason_str = reason_bytes.decode("ascii", errors="ignore") - msg = "%d %s" % (connect_response.status, reason_str) - await self._connection.aclose() - raise ProxyError(msg) - - stream = connect_response.extensions["network_stream"] - - # Upgrade the stream to SSL - ssl_context = ( - default_ssl_context() - if self._ssl_context is None - else self._ssl_context - ) - alpn_protocols = ["http/1.1", "h2"] if self._http2 else ["http/1.1"] - ssl_context.set_alpn_protocols(alpn_protocols) - - kwargs = { - "ssl_context": ssl_context, - "server_hostname": self._remote_origin.host.decode("ascii"), - "timeout": timeout, - } - async with Trace("start_tls", logger, request, kwargs) as trace: - stream = await stream.start_tls(**kwargs) - trace.return_value = stream - - # Determine if we should be using HTTP/1.1 or HTTP/2 - ssl_object = stream.get_extra_info("ssl_object") - http2_negotiated = ( - ssl_object is not None - and ssl_object.selected_alpn_protocol() == "h2" - ) - - # Create the HTTP/1.1 or HTTP/2 connection - if http2_negotiated or (self._http2 and not self._http1): - from .http2 import AsyncHTTP2Connection - - self._connection = AsyncHTTP2Connection( - origin=self._remote_origin, - stream=stream, - keepalive_expiry=self._keepalive_expiry, - ) - else: - self._connection = AsyncHTTP11Connection( - origin=self._remote_origin, - stream=stream, - keepalive_expiry=self._keepalive_expiry, - ) - - self._connected = True - return await self._connection.handle_async_request(request) - - def can_handle_request(self, origin: Origin) -> bool: - return origin == self._remote_origin - - async def aclose(self) -> None: - await self._connection.aclose() - - def info(self) -> str: - return self._connection.info() - - def is_available(self) -> bool: - return self._connection.is_available() - - def has_expired(self) -> bool: - return self._connection.has_expired() - - def is_idle(self) -> bool: - return self._connection.is_idle() - - def is_closed(self) -> bool: - return self._connection.is_closed() - - def __repr__(self) -> str: - return f"<{self.__class__.__name__} [{self.info()}]>" diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/huggingface_hub/keras_mixin.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/huggingface_hub/keras_mixin.py deleted file mode 100644 index 32ea4091e0c3f19abc09d81456e9df9d52454da2..0000000000000000000000000000000000000000 --- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/huggingface_hub/keras_mixin.py +++ /dev/null @@ -1,481 +0,0 @@ -import collections.abc as collections -import json -import os -import warnings -from pathlib import Path -from shutil import copytree -from typing import Any, Dict, List, Optional, Union - -from huggingface_hub import ModelHubMixin, snapshot_download -from huggingface_hub.utils import ( - get_tf_version, - is_graphviz_available, - is_pydot_available, - is_tf_available, - yaml_dump, -) - -from .constants import CONFIG_NAME -from .hf_api import HfApi -from .utils import SoftTemporaryDirectory, logging, validate_hf_hub_args - - -logger = logging.get_logger(__name__) - -if is_tf_available(): - import tensorflow as tf # type: ignore - - -def _flatten_dict(dictionary, parent_key=""): - """Flatten a nested dictionary. - Reference: https://stackoverflow.com/a/6027615/10319735 - - Args: - dictionary (`dict`): - The nested dictionary to be flattened. - parent_key (`str`): - The parent key to be prefixed to the children keys. - Necessary for recursing over the nested dictionary. - - Returns: - The flattened dictionary. - """ - items = [] - for key, value in dictionary.items(): - new_key = f"{parent_key}.{key}" if parent_key else key - if isinstance(value, collections.MutableMapping): - items.extend( - _flatten_dict( - value, - new_key, - ).items() - ) - else: - items.append((new_key, value)) - return dict(items) - - -def _create_hyperparameter_table(model): - """Parse hyperparameter dictionary into a markdown table.""" - if model.optimizer is not None: - optimizer_params = model.optimizer.get_config() - # flatten the configuration - optimizer_params = _flatten_dict(optimizer_params) - optimizer_params["training_precision"] = tf.keras.mixed_precision.global_policy().name - table = "| Hyperparameters | Value |\n| :-- | :-- |\n" - for key, value in optimizer_params.items(): - table += f"| {key} | {value} |\n" - else: - table = None - return table - - -def _plot_network(model, save_directory): - tf.keras.utils.plot_model( - model, - to_file=f"{save_directory}/model.png", - show_shapes=False, - show_dtype=False, - show_layer_names=True, - rankdir="TB", - expand_nested=False, - dpi=96, - layer_range=None, - ) - - -def _create_model_card( - model, - repo_dir: Path, - plot_model: bool = True, - metadata: Optional[dict] = None, -): - """ - Creates a model card for the repository. - """ - hyperparameters = _create_hyperparameter_table(model) - if plot_model and is_graphviz_available() and is_pydot_available(): - _plot_network(model, repo_dir) - if metadata is None: - metadata = {} - readme_path = f"{repo_dir}/README.md" - metadata["library_name"] = "keras" - model_card: str = "---\n" - model_card += yaml_dump(metadata, default_flow_style=False) - model_card += "---\n" - model_card += "\n## Model description\n\nMore information needed\n" - model_card += "\n## Intended uses & limitations\n\nMore information needed\n" - model_card += "\n## Training and evaluation data\n\nMore information needed\n" - if hyperparameters is not None: - model_card += "\n## Training procedure\n" - model_card += "\n### Training hyperparameters\n" - model_card += "\nThe following hyperparameters were used during training:\n\n" - model_card += hyperparameters - model_card += "\n" - if plot_model and os.path.exists(f"{repo_dir}/model.png"): - model_card += "\n ## Model Plot\n" - model_card += "\n " - model_card += "\n" - - if os.path.exists(readme_path): - with open(readme_path, "r", encoding="utf8") as f: - readme = f.read() - else: - readme = model_card - with open(readme_path, "w", encoding="utf-8") as f: - f.write(readme) - - -def save_pretrained_keras( - model, - save_directory: Union[str, Path], - config: Optional[Dict[str, Any]] = None, - include_optimizer: bool = False, - plot_model: bool = True, - tags: Optional[Union[list, str]] = None, - **model_save_kwargs, -): - """ - Saves a Keras model to save_directory in SavedModel format. Use this if - you're using the Functional or Sequential APIs. - - Args: - model (`Keras.Model`): - The [Keras - model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) - you'd like to save. The model must be compiled and built. - save_directory (`str` or `Path`): - Specify directory in which you want to save the Keras model. - config (`dict`, *optional*): - Configuration object to be saved alongside the model weights. - include_optimizer(`bool`, *optional*, defaults to `False`): - Whether or not to include optimizer in serialization. - plot_model (`bool`, *optional*, defaults to `True`): - Setting this to `True` will plot the model and put it in the model - card. Requires graphviz and pydot to be installed. - tags (Union[`str`,`list`], *optional*): - List of tags that are related to model or string of a single tag. See example tags - [here](https://github.com/huggingface/hub-docs/blame/main/modelcard.md). - model_save_kwargs(`dict`, *optional*): - model_save_kwargs will be passed to - [`tf.keras.models.save_model()`](https://www.tensorflow.org/api_docs/python/tf/keras/models/save_model). - """ - if is_tf_available(): - import tensorflow as tf - else: - raise ImportError("Called a Tensorflow-specific function but could not import it.") - - if not model.built: - raise ValueError("Model should be built before trying to save") - - save_directory = Path(save_directory) - save_directory.mkdir(parents=True, exist_ok=True) - - # saving config - if config: - if not isinstance(config, dict): - raise RuntimeError(f"Provided config to save_pretrained_keras should be a dict. Got: '{type(config)}'") - - with (save_directory / CONFIG_NAME).open("w") as f: - json.dump(config, f) - - metadata = {} - if isinstance(tags, list): - metadata["tags"] = tags - elif isinstance(tags, str): - metadata["tags"] = [tags] - - task_name = model_save_kwargs.pop("task_name", None) - if task_name is not None: - warnings.warn( - "`task_name` input argument is deprecated. Pass `tags` instead.", - FutureWarning, - ) - if "tags" in metadata: - metadata["tags"].append(task_name) - else: - metadata["tags"] = [task_name] - - if model.history is not None: - if model.history.history != {}: - path = save_directory / "history.json" - if path.exists(): - warnings.warn( - "`history.json` file already exists, it will be overwritten by the history of this version.", - UserWarning, - ) - with path.open("w", encoding="utf-8") as f: - json.dump(model.history.history, f, indent=2, sort_keys=True) - - _create_model_card(model, save_directory, plot_model, metadata) - tf.keras.models.save_model(model, save_directory, include_optimizer=include_optimizer, **model_save_kwargs) - - -def from_pretrained_keras(*args, **kwargs) -> "KerasModelHubMixin": - r""" - Instantiate a pretrained Keras model from a pre-trained model from the Hub. - The model is expected to be in `SavedModel` format. - - Args: - pretrained_model_name_or_path (`str` or `os.PathLike`): - Can be either: - - A string, the `model id` of a pretrained model hosted inside a - model repo on huggingface.co. Valid model ids can be located - at the root-level, like `bert-base-uncased`, or namespaced - under a user or organization name, like - `dbmdz/bert-base-german-cased`. - - You can add `revision` by appending `@` at the end of model_id - simply like this: `dbmdz/bert-base-german-cased@main` Revision - is the specific model version to use. It can be a branch name, - a tag name, or a commit id, since we use a git-based system - for storing models and other artifacts on huggingface.co, so - `revision` can be any identifier allowed by git. - - A path to a `directory` containing model weights saved using - [`~transformers.PreTrainedModel.save_pretrained`], e.g., - `./my_model_directory/`. - - `None` if you are both providing the configuration and state - dictionary (resp. with keyword arguments `config` and - `state_dict`). - force_download (`bool`, *optional*, defaults to `False`): - Whether to force the (re-)download of the model weights and - configuration files, overriding the cached versions if they exist. - resume_download (`bool`, *optional*, defaults to `False`): - Whether to delete incompletely received files. Will attempt to - resume the download if such a file exists. - proxies (`Dict[str, str]`, *optional*): - A dictionary of proxy servers to use by protocol or endpoint, e.g., - `{'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}`. The - proxies are used on each request. - token (`str` or `bool`, *optional*): - The token to use as HTTP bearer authorization for remote files. If - `True`, will use the token generated when running `transformers-cli - login` (stored in `~/.huggingface`). - cache_dir (`Union[str, os.PathLike]`, *optional*): - Path to a directory in which a downloaded pretrained model - configuration should be cached if the standard cache should not be - used. - local_files_only(`bool`, *optional*, defaults to `False`): - Whether to only look at local files (i.e., do not try to download - the model). - model_kwargs (`Dict`, *optional*): - model_kwargs will be passed to the model during initialization - -View Model Plot
\n" - path_to_plot = "./model.png" - model_card += f"\n\n" - model_card += "\n- - Passing `token=True` is required when you want to use a private - model. - - - """ - return KerasModelHubMixin.from_pretrained(*args, **kwargs) - - -@validate_hf_hub_args -def push_to_hub_keras( - model, - repo_id: str, - *, - config: Optional[dict] = None, - commit_message: str = "Push Keras model using huggingface_hub.", - private: bool = False, - api_endpoint: Optional[str] = None, - token: Optional[str] = None, - branch: Optional[str] = None, - create_pr: Optional[bool] = None, - allow_patterns: Optional[Union[List[str], str]] = None, - ignore_patterns: Optional[Union[List[str], str]] = None, - delete_patterns: Optional[Union[List[str], str]] = None, - log_dir: Optional[str] = None, - include_optimizer: bool = False, - tags: Optional[Union[list, str]] = None, - plot_model: bool = True, - **model_save_kwargs, -): - """ - Upload model checkpoint to the Hub. - - Use `allow_patterns` and `ignore_patterns` to precisely filter which files should be pushed to the hub. Use - `delete_patterns` to delete existing remote files in the same commit. See [`upload_folder`] reference for more - details. - - Args: - model (`Keras.Model`): - The [Keras model](`https://www.tensorflow.org/api_docs/python/tf/keras/Model`) you'd like to push to the - Hub. The model must be compiled and built. - repo_id (`str`): - ID of the repository to push to (example: `"username/my-model"`). - commit_message (`str`, *optional*, defaults to "Add Keras model"): - Message to commit while pushing. - private (`bool`, *optional*, defaults to `False`): - Whether the repository created should be private. - api_endpoint (`str`, *optional*): - The API endpoint to use when pushing the model to the hub. - token (`str`, *optional*): - The token to use as HTTP bearer authorization for remote files. If - not set, will use the token set when logging in with - `huggingface-cli login` (stored in `~/.huggingface`). - branch (`str`, *optional*): - The git branch on which to push the model. This defaults to - the default branch as specified in your repository, which - defaults to `"main"`. - create_pr (`boolean`, *optional*): - Whether or not to create a Pull Request from `branch` with that commit. - Defaults to `False`. - config (`dict`, *optional*): - Configuration object to be saved alongside the model weights. - allow_patterns (`List[str]` or `str`, *optional*): - If provided, only files matching at least one pattern are pushed. - ignore_patterns (`List[str]` or `str`, *optional*): - If provided, files matching any of the patterns are not pushed. - delete_patterns (`List[str]` or `str`, *optional*): - If provided, remote files matching any of the patterns will be deleted from the repo. - log_dir (`str`, *optional*): - TensorBoard logging directory to be pushed. The Hub automatically - hosts and displays a TensorBoard instance if log files are included - in the repository. - include_optimizer (`bool`, *optional*, defaults to `False`): - Whether or not to include optimizer during serialization. - tags (Union[`list`, `str`], *optional*): - List of tags that are related to model or string of a single tag. See example tags - [here](https://github.com/huggingface/hub-docs/blame/main/modelcard.md). - plot_model (`bool`, *optional*, defaults to `True`): - Setting this to `True` will plot the model and put it in the model - card. Requires graphviz and pydot to be installed. - model_save_kwargs(`dict`, *optional*): - model_save_kwargs will be passed to - [`tf.keras.models.save_model()`](https://www.tensorflow.org/api_docs/python/tf/keras/models/save_model). - - Returns: - The url of the commit of your model in the given repository. - """ - api = HfApi(endpoint=api_endpoint) - repo_id = api.create_repo(repo_id=repo_id, token=token, private=private, exist_ok=True).repo_id - - # Push the files to the repo in a single commit - with SoftTemporaryDirectory() as tmp: - saved_path = Path(tmp) / repo_id - save_pretrained_keras( - model, - saved_path, - config=config, - include_optimizer=include_optimizer, - tags=tags, - plot_model=plot_model, - **model_save_kwargs, - ) - - # If `log_dir` provided, delete remote logs and upload new ones - if log_dir is not None: - delete_patterns = ( - [] - if delete_patterns is None - else ( - [delete_patterns] # convert `delete_patterns` to a list - if isinstance(delete_patterns, str) - else delete_patterns - ) - ) - delete_patterns.append("logs/*") - copytree(log_dir, saved_path / "logs") - - return api.upload_folder( - repo_type="model", - repo_id=repo_id, - folder_path=saved_path, - commit_message=commit_message, - token=token, - revision=branch, - create_pr=create_pr, - allow_patterns=allow_patterns, - ignore_patterns=ignore_patterns, - delete_patterns=delete_patterns, - ) - - -class KerasModelHubMixin(ModelHubMixin): - """ - Implementation of [`ModelHubMixin`] to provide model Hub upload/download - capabilities to Keras models. - - - ```python - >>> import tensorflow as tf - >>> from huggingface_hub import KerasModelHubMixin - - - >>> class MyModel(tf.keras.Model, KerasModelHubMixin): - ... def __init__(self, **kwargs): - ... super().__init__() - ... self.config = kwargs.pop("config", None) - ... self.dummy_inputs = ... - ... self.layer = ... - - ... def call(self, *args): - ... return ... - - - >>> # Initialize and compile the model as you normally would - >>> model = MyModel() - >>> model.compile(...) - >>> # Build the graph by training it or passing dummy inputs - >>> _ = model(model.dummy_inputs) - >>> # Save model weights to local directory - >>> model.save_pretrained("my-awesome-model") - >>> # Push model weights to the Hub - >>> model.push_to_hub("my-awesome-model") - >>> # Download and initialize weights from the Hub - >>> model = MyModel.from_pretrained("username/super-cool-model") - ``` - """ - - def _save_pretrained(self, save_directory): - save_pretrained_keras(self, save_directory) - - @classmethod - def _from_pretrained( - cls, - model_id, - revision, - cache_dir, - force_download, - proxies, - resume_download, - local_files_only, - token, - **model_kwargs, - ): - """Here we just call [`from_pretrained_keras`] function so both the mixin and - functional APIs stay in sync. - - TODO - Some args above aren't used since we are calling - snapshot_download instead of hf_hub_download. - """ - if is_tf_available(): - import tensorflow as tf - else: - raise ImportError("Called a TensorFlow-specific function but could not import it.") - - # TODO - Figure out what to do about these config values. Config is not going to be needed to load model - cfg = model_kwargs.pop("config", None) - - # Root is either a local filepath matching model_id or a cached snapshot - if not os.path.isdir(model_id): - storage_folder = snapshot_download( - repo_id=model_id, - revision=revision, - cache_dir=cache_dir, - library_name="keras", - library_version=get_tf_version(), - ) - else: - storage_folder = model_id - - model = tf.keras.models.load_model(storage_folder, **model_kwargs) - - # For now, we add a new attribute, config, to store the config loaded from the hub/a local dir. - model.config = cfg - - return model diff --git a/spaces/DVLH/nlpconnect-vit-gpt2-image-captioning/app.py b/spaces/DVLH/nlpconnect-vit-gpt2-image-captioning/app.py deleted file mode 100644 index 5b55d9b74b44a7668d8d99fb6cb579b116b260bf..0000000000000000000000000000000000000000 --- a/spaces/DVLH/nlpconnect-vit-gpt2-image-captioning/app.py +++ /dev/null @@ -1,3 +0,0 @@ -import gradio as gr - -gr.Interface.load("models/nlpconnect/vit-gpt2-image-captioning").launch() \ No newline at end of file diff --git a/spaces/Dao3/DreamlikeArt-Diffusion-1.0/style.css b/spaces/Dao3/DreamlikeArt-Diffusion-1.0/style.css deleted file mode 100644 index fdbef9e64cc6b9f8003698ffa38997ee22a640ac..0000000000000000000000000000000000000000 --- a/spaces/Dao3/DreamlikeArt-Diffusion-1.0/style.css +++ /dev/null @@ -1,84 +0,0 @@ -#col-container { - max-width: 800px; - margin-left: auto; - margin-right: auto; -} -a { - color: inherit; - text-decoration: underline; -} -.gradio-container { - font-family: 'IBM Plex Sans', sans-serif; -} -.gr-button { - color: white; - border-color: #9d66e5; - background: #9d66e5; -} -input[type='range'] { - accent-color: #9d66e5; -} -.dark input[type='range'] { - accent-color: #dfdfdf; -} -.container { - max-width: 800px; - margin: auto; - padding-top: 1.5rem; -} -#gallery { - min-height: 22rem; - margin-bottom: 15px; - margin-left: auto; - margin-right: auto; - border-bottom-right-radius: .5rem !important; - border-bottom-left-radius: .5rem !important; -} -#gallery>div>.h-full { - min-height: 20rem; -} -.details:hover { - text-decoration: underline; -} -.gr-button { - white-space: nowrap; -} -.gr-button:focus { - border-color: rgb(147 197 253 / var(--tw-border-opacity)); - outline: none; - box-shadow: var(--tw-ring-offset-shadow), var(--tw-ring-shadow), var(--tw-shadow, 0 0 #0000); - --tw-border-opacity: 1; - --tw-ring-offset-shadow: var(--tw-ring-inset) 0 0 0 var(--tw-ring-offset-width) var(--tw-ring-offset-color); - --tw-ring-shadow: var(--tw-ring-inset) 0 0 0 calc(3px var(--tw-ring-offset-width)) var(--tw-ring-color); - --tw-ring-color: rgb(191 219 254 / var(--tw-ring-opacity)); - --tw-ring-opacity: .5; -} -#advanced-options { - margin-bottom: 20px; -} -.footer { - margin-bottom: 45px; - margin-top: 35px; - text-align: center; - border-bottom: 1px solid #e5e5e5; -} -.footer>p { - font-size: .8rem; - display: inline-block; - padding: 0 10px; - transform: translateY(10px); - background: white; -} -.dark .logo{ filter: invert(1); } -.dark .footer { - border-color: #303030; -} -.dark .footer>p { - background: #0b0f19; -} -.acknowledgments h4{ - margin: 1.25em 0 .25em 0; - font-weight: bold; - font-size: 115%; -} - diff --git a/spaces/DarkCeptor44/neural-art/app.py b/spaces/DarkCeptor44/neural-art/app.py deleted file mode 100644 index c30a4a54008ed1a5cf716eb951797014d8b0b2f8..0000000000000000000000000000000000000000 --- a/spaces/DarkCeptor44/neural-art/app.py +++ /dev/null @@ -1,52 +0,0 @@ -import gradio as gr -import tensorflow as tf -import tensorflow_hub as hub -import matplotlib.pyplot as plt -import numpy as np -import PIL.Image - -# Load model from TF-Hub -hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2') - - -# Function to convert tensor to image -def tensor_to_image(tensor): - tensor = tensor * 255 - tensor = np.array(tensor, dtype=np.uint8) - if np.ndim(tensor) > 3: - assert tensor.shape[0] == 1 - tensor = tensor[0] - return PIL.Image.fromarray(tensor) - - -# Stylize function -def stylize(content_image, style_image): - # Convert to float32 numpy array, add batch dimension, and normalize to range [0, 1]. Example using numpy: - content_image = content_image.astype(np.float32)[np.newaxis, ...] / 255. - style_image = style_image.astype(np.float32)[np.newaxis, ...] / 255. - # Stylize image - stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0] - return tensor_to_image(stylized_image) - - -# Add image examples for users -joker = ["example_joker.jpeg", "example_polasticot1.jpeg"] -paris = ["example_paris.jpeg", "example_vangogh.jpeg"] -einstein = ["example_einstein.jpeg", "example_polasticot2.jpeg"] - -# Customize interface -title = "Fast Neural Style Transfer using TF-Hub" -description = "Demo for neural style transfer using the pretrained Arbitrary Image Stylization model from TensorFlow Hub." -article = "Exploring the structure of a real-time, arbitrary neural artistic stylization network
Check out the original space although that one doesn't work
" -content_input = gr.inputs.Image(label="Content Image", source="upload") -style_input = gr.inputs.Image(label="Style Image", source="upload") - -# Build and launch -iface = gr.Interface(fn=stylize, - inputs=[content_input, style_input], - outputs="image", - title=title, - description=description, - article=article, - examples=[joker, paris, einstein]) -iface.launch() diff --git a/spaces/Daroach/anime-remove-background/app.py b/spaces/Daroach/anime-remove-background/app.py deleted file mode 100644 index 230a0d5f8a3da6ab18ecb8db1cd90016a489b96a..0000000000000000000000000000000000000000 --- a/spaces/Daroach/anime-remove-background/app.py +++ /dev/null @@ -1,52 +0,0 @@ -import gradio as gr -import huggingface_hub -import onnxruntime as rt -import numpy as np -import cv2 - - -def get_mask(img, s=1024): - img = (img / 255).astype(np.float32) - h, w = h0, w0 = img.shape[:-1] - h, w = (s, int(s * w / h)) if h > w else (int(s * h / w), s) - ph, pw = s - h, s - w - img_input = np.zeros([s, s, 3], dtype=np.float32) - img_input[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w] = cv2.resize(img, (w, h)) - img_input = np.transpose(img_input, (2, 0, 1)) - img_input = img_input[np.newaxis, :] - mask = rmbg_model.run(None, {'img': img_input})[0][0] - mask = np.transpose(mask, (1, 2, 0)) - mask = mask[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w] - mask = cv2.resize(mask, (w0, h0))[:, :, np.newaxis] - return mask - - -def rmbg_fn(img): - mask = get_mask(img) - img = (mask * img + 255 * (1 - mask)).astype(np.uint8) - mask = (mask * 255).astype(np.uint8) - img = np.concatenate([img, mask], axis=2, dtype=np.uint8) - mask = mask.repeat(3, axis=2) - return mask, img - - -if __name__ == "__main__": - providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] - model_path = huggingface_hub.hf_hub_download("skytnt/anime-seg", "isnetis.onnx") - rmbg_model = rt.InferenceSession(model_path, providers=providers) - app = gr.Blocks() - with app: - gr.Markdown("# Anime Remove Background\n\n" - "\n\n" - "demo for [https://github.com/SkyTNT/anime-segmentation/](https://github.com/SkyTNT/anime-segmentation/)") - with gr.Row(): - with gr.Column(): - input_img = gr.Image(label="input image") - examples_data = [[f"examples/{x:02d}.jpg"] for x in range(1, 4)] - examples = gr.Dataset(components=[input_img], samples=examples_data) - run_btn = gr.Button(variant="primary") - output_mask = gr.Image(label="mask") - output_img = gr.Image(label="result", image_mode="RGBA") - examples.click(lambda x: x[0], [examples], [input_img]) - run_btn.click(rmbg_fn, [input_img], [output_mask, output_img]) - app.launch() diff --git a/spaces/Datasculptor/3D-Room-Layout-Estimation_LGT-Net/utils/__init__.py b/spaces/Datasculptor/3D-Room-Layout-Estimation_LGT-Net/utils/__init__.py deleted file mode 100644 index 02f1ee32e3c69bcf40722de4d5fb831ede759aae..0000000000000000000000000000000000000000 --- a/spaces/Datasculptor/3D-Room-Layout-Estimation_LGT-Net/utils/__init__.py +++ /dev/null @@ -1,4 +0,0 @@ -""" -@date: 2021/06/19 -@description: -""" \ No newline at end of file diff --git a/spaces/ECCV2022/bytetrack/yolox/deepsort_tracker/reid_model.py b/spaces/ECCV2022/bytetrack/yolox/deepsort_tracker/reid_model.py deleted file mode 100644 index 6aff8853f0859b16b33b178a3ada445f755a7027..0000000000000000000000000000000000000000 --- a/spaces/ECCV2022/bytetrack/yolox/deepsort_tracker/reid_model.py +++ /dev/null @@ -1,145 +0,0 @@ -import torch -import torch.nn as nn -import torch.nn.functional as F -import numpy as np -import cv2 -import logging -import torchvision.transforms as transforms - - -class BasicBlock(nn.Module): - def __init__(self, c_in, c_out, is_downsample=False): - super(BasicBlock, self).__init__() - self.is_downsample = is_downsample - if is_downsample: - self.conv1 = nn.Conv2d( - c_in, c_out, 3, stride=2, padding=1, bias=False) - else: - self.conv1 = nn.Conv2d( - c_in, c_out, 3, stride=1, padding=1, bias=False) - self.bn1 = nn.BatchNorm2d(c_out) - self.relu = nn.ReLU(True) - self.conv2 = nn.Conv2d(c_out, c_out, 3, stride=1, - padding=1, bias=False) - self.bn2 = nn.BatchNorm2d(c_out) - if is_downsample: - self.downsample = nn.Sequential( - nn.Conv2d(c_in, c_out, 1, stride=2, bias=False), - nn.BatchNorm2d(c_out) - ) - elif c_in != c_out: - self.downsample = nn.Sequential( - nn.Conv2d(c_in, c_out, 1, stride=1, bias=False), - nn.BatchNorm2d(c_out) - ) - self.is_downsample = True - - def forward(self, x): - y = self.conv1(x) - y = self.bn1(y) - y = self.relu(y) - y = self.conv2(y) - y = self.bn2(y) - if self.is_downsample: - x = self.downsample(x) - return F.relu(x.add(y), True) - - -def make_layers(c_in, c_out, repeat_times, is_downsample=False): - blocks = [] - for i in range(repeat_times): - if i == 0: - blocks += [BasicBlock(c_in, c_out, is_downsample=is_downsample), ] - else: - blocks += [BasicBlock(c_out, c_out), ] - return nn.Sequential(*blocks) - - -class Net(nn.Module): - def __init__(self, num_classes=751, reid=False): - super(Net, self).__init__() - # 3 128 64 - self.conv = nn.Sequential( - nn.Conv2d(3, 64, 3, stride=1, padding=1), - nn.BatchNorm2d(64), - nn.ReLU(inplace=True), - # nn.Conv2d(32,32,3,stride=1,padding=1), - # nn.BatchNorm2d(32), - # nn.ReLU(inplace=True), - nn.MaxPool2d(3, 2, padding=1), - ) - # 32 64 32 - self.layer1 = make_layers(64, 64, 2, False) - # 32 64 32 - self.layer2 = make_layers(64, 128, 2, True) - # 64 32 16 - self.layer3 = make_layers(128, 256, 2, True) - # 128 16 8 - self.layer4 = make_layers(256, 512, 2, True) - # 256 8 4 - self.avgpool = nn.AvgPool2d((8, 4), 1) - # 256 1 1 - self.reid = reid - self.classifier = nn.Sequential( - nn.Linear(512, 256), - nn.BatchNorm1d(256), - nn.ReLU(inplace=True), - nn.Dropout(), - nn.Linear(256, num_classes), - ) - - def forward(self, x): - x = self.conv(x) - x = self.layer1(x) - x = self.layer2(x) - x = self.layer3(x) - x = self.layer4(x) - x = self.avgpool(x) - x = x.view(x.size(0), -1) - # B x 128 - if self.reid: - x = x.div(x.norm(p=2, dim=1, keepdim=True)) - return x - # classifier - x = self.classifier(x) - return x - - -class Extractor(object): - def __init__(self, model_path, use_cuda=True): - self.net = Net(reid=True) - self.device = "cuda" if torch.cuda.is_available() and use_cuda else "cpu" - state_dict = torch.load(model_path, map_location=torch.device(self.device))[ - 'net_dict'] - self.net.load_state_dict(state_dict) - logger = logging.getLogger("root.tracker") - logger.info("Loading weights from {}... Done!".format(model_path)) - self.net.to(self.device) - self.size = (64, 128) - self.norm = transforms.Compose([ - transforms.ToTensor(), - transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), - ]) - - def _preprocess(self, im_crops): - """ - TODO: - 1. to float with scale from 0 to 1 - 2. resize to (64, 128) as Market1501 dataset did - 3. concatenate to a numpy array - 3. to torch Tensor - 4. normalize - """ - def _resize(im, size): - return cv2.resize(im.astype(np.float32)/255., size) - - im_batch = torch.cat([self.norm(_resize(im, self.size)).unsqueeze( - 0) for im in im_crops], dim=0).float() - return im_batch - - def __call__(self, im_crops): - im_batch = self._preprocess(im_crops) - with torch.no_grad(): - im_batch = im_batch.to(self.device) - features = self.net(im_batch) - return features.cpu().numpy() \ No newline at end of file diff --git a/spaces/EDGAhab/VITS-Aatrox-AI/modules.py b/spaces/EDGAhab/VITS-Aatrox-AI/modules.py deleted file mode 100644 index 9c7fd9cd6eb8b7e0ec0e08957e970744a374a924..0000000000000000000000000000000000000000 --- a/spaces/EDGAhab/VITS-Aatrox-AI/modules.py +++ /dev/null @@ -1,390 +0,0 @@ -import copy -import math -import numpy as np -import scipy -import torch -from torch import nn -from torch.nn import functional as F - -from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d -from torch.nn.utils import weight_norm, remove_weight_norm - -import commons -from commons import init_weights, get_padding -from transforms import piecewise_rational_quadratic_transform - - -LRELU_SLOPE = 0.1 - - -class LayerNorm(nn.Module): - def __init__(self, channels, eps=1e-5): - super().__init__() - self.channels = channels - self.eps = eps - - self.gamma = nn.Parameter(torch.ones(channels)) - self.beta = nn.Parameter(torch.zeros(channels)) - - def forward(self, x): - x = x.transpose(1, -1) - x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps) - return x.transpose(1, -1) - - -class ConvReluNorm(nn.Module): - def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout): - super().__init__() - self.in_channels = in_channels - self.hidden_channels = hidden_channels - self.out_channels = out_channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.p_dropout = p_dropout - assert n_layers > 1, "Number of layers should be larger than 0." - - self.conv_layers = nn.ModuleList() - self.norm_layers = nn.ModuleList() - self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2)) - self.norm_layers.append(LayerNorm(hidden_channels)) - self.relu_drop = nn.Sequential( - nn.ReLU(), - nn.Dropout(p_dropout)) - for _ in range(n_layers-1): - self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2)) - self.norm_layers.append(LayerNorm(hidden_channels)) - self.proj = nn.Conv1d(hidden_channels, out_channels, 1) - self.proj.weight.data.zero_() - self.proj.bias.data.zero_() - - def forward(self, x, x_mask): - x_org = x - for i in range(self.n_layers): - x = self.conv_layers[i](x * x_mask) - x = self.norm_layers[i](x) - x = self.relu_drop(x) - x = x_org + self.proj(x) - return x * x_mask - - -class DDSConv(nn.Module): - """ - Dialted and Depth-Separable Convolution - """ - def __init__(self, channels, kernel_size, n_layers, p_dropout=0.): - super().__init__() - self.channels = channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.p_dropout = p_dropout - - self.drop = nn.Dropout(p_dropout) - self.convs_sep = nn.ModuleList() - self.convs_1x1 = nn.ModuleList() - self.norms_1 = nn.ModuleList() - self.norms_2 = nn.ModuleList() - for i in range(n_layers): - dilation = kernel_size ** i - padding = (kernel_size * dilation - dilation) // 2 - self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size, - groups=channels, dilation=dilation, padding=padding - )) - self.convs_1x1.append(nn.Conv1d(channels, channels, 1)) - self.norms_1.append(LayerNorm(channels)) - self.norms_2.append(LayerNorm(channels)) - - def forward(self, x, x_mask, g=None): - if g is not None: - x = x + g - for i in range(self.n_layers): - y = self.convs_sep[i](x * x_mask) - y = self.norms_1[i](y) - y = F.gelu(y) - y = self.convs_1x1[i](y) - y = self.norms_2[i](y) - y = F.gelu(y) - y = self.drop(y) - x = x + y - return x * x_mask - - -class WN(torch.nn.Module): - def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0): - super(WN, self).__init__() - assert(kernel_size % 2 == 1) - self.hidden_channels =hidden_channels - self.kernel_size = kernel_size, - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.gin_channels = gin_channels - self.p_dropout = p_dropout - - self.in_layers = torch.nn.ModuleList() - self.res_skip_layers = torch.nn.ModuleList() - self.drop = nn.Dropout(p_dropout) - - if gin_channels != 0: - cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1) - self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight') - - for i in range(n_layers): - dilation = dilation_rate ** i - padding = int((kernel_size * dilation - dilation) / 2) - in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size, - dilation=dilation, padding=padding) - in_layer = torch.nn.utils.weight_norm(in_layer, name='weight') - self.in_layers.append(in_layer) - - # last one is not necessary - if i < n_layers - 1: - res_skip_channels = 2 * hidden_channels - else: - res_skip_channels = hidden_channels - - res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1) - res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight') - self.res_skip_layers.append(res_skip_layer) - - def forward(self, x, x_mask, g=None, **kwargs): - output = torch.zeros_like(x) - n_channels_tensor = torch.IntTensor([self.hidden_channels]) - - if g is not None: - g = self.cond_layer(g) - - for i in range(self.n_layers): - x_in = self.in_layers[i](x) - if g is not None: - cond_offset = i * 2 * self.hidden_channels - g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:] - else: - g_l = torch.zeros_like(x_in) - - acts = commons.fused_add_tanh_sigmoid_multiply( - x_in, - g_l, - n_channels_tensor) - acts = self.drop(acts) - - res_skip_acts = self.res_skip_layers[i](acts) - if i < self.n_layers - 1: - res_acts = res_skip_acts[:,:self.hidden_channels,:] - x = (x + res_acts) * x_mask - output = output + res_skip_acts[:,self.hidden_channels:,:] - else: - output = output + res_skip_acts - return output * x_mask - - def remove_weight_norm(self): - if self.gin_channels != 0: - torch.nn.utils.remove_weight_norm(self.cond_layer) - for l in self.in_layers: - torch.nn.utils.remove_weight_norm(l) - for l in self.res_skip_layers: - torch.nn.utils.remove_weight_norm(l) - - -class ResBlock1(torch.nn.Module): - def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)): - super(ResBlock1, self).__init__() - self.convs1 = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2], - padding=get_padding(kernel_size, dilation[2]))) - ]) - self.convs1.apply(init_weights) - - self.convs2 = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))) - ]) - self.convs2.apply(init_weights) - - def forward(self, x, x_mask=None): - for c1, c2 in zip(self.convs1, self.convs2): - xt = F.leaky_relu(x, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c1(xt) - xt = F.leaky_relu(xt, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c2(xt) - x = xt + x - if x_mask is not None: - x = x * x_mask - return x - - def remove_weight_norm(self): - for l in self.convs1: - remove_weight_norm(l) - for l in self.convs2: - remove_weight_norm(l) - - -class ResBlock2(torch.nn.Module): - def __init__(self, channels, kernel_size=3, dilation=(1, 3)): - super(ResBlock2, self).__init__() - self.convs = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]))) - ]) - self.convs.apply(init_weights) - - def forward(self, x, x_mask=None): - for c in self.convs: - xt = F.leaky_relu(x, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c(xt) - x = xt + x - if x_mask is not None: - x = x * x_mask - return x - - def remove_weight_norm(self): - for l in self.convs: - remove_weight_norm(l) - - -class Log(nn.Module): - def forward(self, x, x_mask, reverse=False, **kwargs): - if not reverse: - y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask - logdet = torch.sum(-y, [1, 2]) - return y, logdet - else: - x = torch.exp(x) * x_mask - return x - - -class Flip(nn.Module): - def forward(self, x, *args, reverse=False, **kwargs): - x = torch.flip(x, [1]) - if not reverse: - logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device) - return x, logdet - else: - return x - - -class ElementwiseAffine(nn.Module): - def __init__(self, channels): - super().__init__() - self.channels = channels - self.m = nn.Parameter(torch.zeros(channels,1)) - self.logs = nn.Parameter(torch.zeros(channels,1)) - - def forward(self, x, x_mask, reverse=False, **kwargs): - if not reverse: - y = self.m + torch.exp(self.logs) * x - y = y * x_mask - logdet = torch.sum(self.logs * x_mask, [1,2]) - return y, logdet - else: - x = (x - self.m) * torch.exp(-self.logs) * x_mask - return x - - -class ResidualCouplingLayer(nn.Module): - def __init__(self, - channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - p_dropout=0, - gin_channels=0, - mean_only=False): - assert channels % 2 == 0, "channels should be divisible by 2" - super().__init__() - self.channels = channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.half_channels = channels // 2 - self.mean_only = mean_only - - self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1) - self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels) - self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1) - self.post.weight.data.zero_() - self.post.bias.data.zero_() - - def forward(self, x, x_mask, g=None, reverse=False): - x0, x1 = torch.split(x, [self.half_channels]*2, 1) - h = self.pre(x0) * x_mask - h = self.enc(h, x_mask, g=g) - stats = self.post(h) * x_mask - if not self.mean_only: - m, logs = torch.split(stats, [self.half_channels]*2, 1) - else: - m = stats - logs = torch.zeros_like(m) - - if not reverse: - x1 = m + x1 * torch.exp(logs) * x_mask - x = torch.cat([x0, x1], 1) - logdet = torch.sum(logs, [1,2]) - return x, logdet - else: - x1 = (x1 - m) * torch.exp(-logs) * x_mask - x = torch.cat([x0, x1], 1) - return x - - -class ConvFlow(nn.Module): - def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0): - super().__init__() - self.in_channels = in_channels - self.filter_channels = filter_channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.num_bins = num_bins - self.tail_bound = tail_bound - self.half_channels = in_channels // 2 - - self.pre = nn.Conv1d(self.half_channels, filter_channels, 1) - self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.) - self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1) - self.proj.weight.data.zero_() - self.proj.bias.data.zero_() - - def forward(self, x, x_mask, g=None, reverse=False): - x0, x1 = torch.split(x, [self.half_channels]*2, 1) - h = self.pre(x0) - h = self.convs(h, x_mask, g=g) - h = self.proj(h) * x_mask - - b, c, t = x0.shape - h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?] - - unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels) - unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels) - unnormalized_derivatives = h[..., 2 * self.num_bins:] - - x1, logabsdet = piecewise_rational_quadratic_transform(x1, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=reverse, - tails='linear', - tail_bound=self.tail_bound - ) - - x = torch.cat([x0, x1], 1) * x_mask - logdet = torch.sum(logabsdet * x_mask, [1,2]) - if not reverse: - return x, logdet - else: - return x diff --git a/spaces/Eddycrack864/Applio-Inference/lib/uvr5_pack/lib_v5/nets.py b/spaces/Eddycrack864/Applio-Inference/lib/uvr5_pack/lib_v5/nets.py deleted file mode 100644 index db4c5e339f7a96cd24ed1cbbf88c4f35d5031309..0000000000000000000000000000000000000000 --- a/spaces/Eddycrack864/Applio-Inference/lib/uvr5_pack/lib_v5/nets.py +++ /dev/null @@ -1,123 +0,0 @@ -import torch -from torch import nn -import torch.nn.functional as F - -import layers -from . import spec_utils - - -class BaseASPPNet(nn.Module): - def __init__(self, nin, ch, dilations=(4, 8, 16)): - super(BaseASPPNet, self).__init__() - self.enc1 = layers.Encoder(nin, ch, 3, 2, 1) - self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1) - self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1) - self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1) - - self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations) - - self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1) - self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1) - self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1) - self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1) - - def __call__(self, x): - h, e1 = self.enc1(x) - h, e2 = self.enc2(h) - h, e3 = self.enc3(h) - h, e4 = self.enc4(h) - - h = self.aspp(h) - - h = self.dec4(h, e4) - h = self.dec3(h, e3) - h = self.dec2(h, e2) - h = self.dec1(h, e1) - - return h - - -class CascadedASPPNet(nn.Module): - def __init__(self, n_fft): - super(CascadedASPPNet, self).__init__() - self.stg1_low_band_net = BaseASPPNet(2, 16) - self.stg1_high_band_net = BaseASPPNet(2, 16) - - self.stg2_bridge = layers.Conv2DBNActiv(18, 8, 1, 1, 0) - self.stg2_full_band_net = BaseASPPNet(8, 16) - - self.stg3_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0) - self.stg3_full_band_net = BaseASPPNet(16, 32) - - self.out = nn.Conv2d(32, 2, 1, bias=False) - self.aux1_out = nn.Conv2d(16, 2, 1, bias=False) - self.aux2_out = nn.Conv2d(16, 2, 1, bias=False) - - self.max_bin = n_fft // 2 - self.output_bin = n_fft // 2 + 1 - - self.offset = 128 - - def forward(self, x, aggressiveness=None): - mix = x.detach() - x = x.clone() - - x = x[:, :, : self.max_bin] - - bandw = x.size()[2] // 2 - aux1 = torch.cat( - [ - self.stg1_low_band_net(x[:, :, :bandw]), - self.stg1_high_band_net(x[:, :, bandw:]), - ], - dim=2, - ) - - h = torch.cat([x, aux1], dim=1) - aux2 = self.stg2_full_band_net(self.stg2_bridge(h)) - - h = torch.cat([x, aux1, aux2], dim=1) - h = self.stg3_full_band_net(self.stg3_bridge(h)) - - mask = torch.sigmoid(self.out(h)) - mask = F.pad( - input=mask, - pad=(0, 0, 0, self.output_bin - mask.size()[2]), - mode="replicate", - ) - - if self.training: - aux1 = torch.sigmoid(self.aux1_out(aux1)) - aux1 = F.pad( - input=aux1, - pad=(0, 0, 0, self.output_bin - aux1.size()[2]), - mode="replicate", - ) - aux2 = torch.sigmoid(self.aux2_out(aux2)) - aux2 = F.pad( - input=aux2, - pad=(0, 0, 0, self.output_bin - aux2.size()[2]), - mode="replicate", - ) - return mask * mix, aux1 * mix, aux2 * mix - else: - if aggressiveness: - mask[:, :, : aggressiveness["split_bin"]] = torch.pow( - mask[:, :, : aggressiveness["split_bin"]], - 1 + aggressiveness["value"] / 3, - ) - mask[:, :, aggressiveness["split_bin"] :] = torch.pow( - mask[:, :, aggressiveness["split_bin"] :], - 1 + aggressiveness["value"], - ) - - return mask * mix - - def predict(self, x_mag, aggressiveness=None): - h = self.forward(x_mag, aggressiveness) - - if self.offset > 0: - h = h[:, :, :, self.offset : -self.offset] - assert h.size()[3] > 0 - - return h diff --git a/spaces/EronSamez/RVC_HFmeu/tools/infer_batch_rvc.py b/spaces/EronSamez/RVC_HFmeu/tools/infer_batch_rvc.py deleted file mode 100644 index 763d17f14877a2ce35f750202e91356c1f24270f..0000000000000000000000000000000000000000 --- a/spaces/EronSamez/RVC_HFmeu/tools/infer_batch_rvc.py +++ /dev/null @@ -1,72 +0,0 @@ -import argparse -import os -import sys - -print("Command-line arguments:", sys.argv) - -now_dir = os.getcwd() -sys.path.append(now_dir) -import sys - -import tqdm as tq -from dotenv import load_dotenv -from scipy.io import wavfile - -from configs.config import Config -from infer.modules.vc.modules import VC - - -def arg_parse() -> tuple: - parser = argparse.ArgumentParser() - parser.add_argument("--f0up_key", type=int, default=0) - parser.add_argument("--input_path", type=str, help="input path") - parser.add_argument("--index_path", type=str, help="index path") - parser.add_argument("--f0method", type=str, default="harvest", help="harvest or pm") - parser.add_argument("--opt_path", type=str, help="opt path") - parser.add_argument("--model_name", type=str, help="store in assets/weight_root") - parser.add_argument("--index_rate", type=float, default=0.66, help="index rate") - parser.add_argument("--device", type=str, help="device") - parser.add_argument("--is_half", type=bool, help="use half -> True") - parser.add_argument("--filter_radius", type=int, default=3, help="filter radius") - parser.add_argument("--resample_sr", type=int, default=0, help="resample sr") - parser.add_argument("--rms_mix_rate", type=float, default=1, help="rms mix rate") - parser.add_argument("--protect", type=float, default=0.33, help="protect") - - args = parser.parse_args() - sys.argv = sys.argv[:1] - - return args - - -def main(): - load_dotenv() - args = arg_parse() - config = Config() - config.device = args.device if args.device else config.device - config.is_half = args.is_half if args.is_half else config.is_half - vc = VC(config) - vc.get_vc(args.model_name) - audios = os.listdir(args.input_path) - for file in tq.tqdm(audios): - if file.endswith(".wav"): - file_path = os.path.join(args.input_path, file) - _, wav_opt = vc.vc_single( - 0, - file_path, - args.f0up_key, - None, - args.f0method, - args.index_path, - None, - args.index_rate, - args.filter_radius, - args.resample_sr, - args.rms_mix_rate, - args.protect, - ) - out_path = os.path.join(args.opt_path, file) - wavfile.write(out_path, wav_opt[0], wav_opt[1]) - - -if __name__ == "__main__": - main() diff --git a/spaces/EstebanDC/UCS_JG/README.md b/spaces/EstebanDC/UCS_JG/README.md deleted file mode 100644 index ce4445acd67b936f89cd955a8df04fd41e80c315..0000000000000000000000000000000000000000 --- a/spaces/EstebanDC/UCS_JG/README.md +++ /dev/null @@ -1,11 +0,0 @@ ---- -title: UCS JG -colorFrom: pink -colorTo: indigo -sdk: gradio -sdk_version: 3.1.7 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/FantasticGNU/AnomalyGPT/utils/build.py b/spaces/FantasticGNU/AnomalyGPT/utils/build.py deleted file mode 100644 index 9e240d74f7c1fd02b0fbbf4904819f52a9deccd3..0000000000000000000000000000000000000000 --- a/spaces/FantasticGNU/AnomalyGPT/utils/build.py +++ /dev/null @@ -1,17 +0,0 @@ -from ..utils import registry - - -DATASETS = registry.Registry('dataset') - - -def build_dataset_from_cfg(cfg, default_args = None): - """ - Build a dataset, defined by `dataset_name`. - Args: - cfg (eDICT): - Returns: - Dataset: a constructed dataset specified by dataset_name. - """ - return DATASETS.build(cfg, default_args = default_args) - - diff --git a/spaces/FinanceInc/Financial_Analyst_AI/README.md b/spaces/FinanceInc/Financial_Analyst_AI/README.md deleted file mode 100644 index bf9192729ede5b0a2bc7ffb1b7901bb66bc72d56..0000000000000000000000000000000000000000 --- a/spaces/FinanceInc/Financial_Analyst_AI/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Financial Analyst AI -emoji: 🏢 -colorFrom: blue -colorTo: indigo -sdk: gradio -sdk_version: 3.0.15 -app_file: app.py -pinned: false -license: apache-2.0 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/FourthBrainGenAI/MarketMail-AI-Space/app.py b/spaces/FourthBrainGenAI/MarketMail-AI-Space/app.py deleted file mode 100644 index 4f0dfa3f0f6a4eb9445b5b8996d23624e34fc6dd..0000000000000000000000000000000000000000 --- a/spaces/FourthBrainGenAI/MarketMail-AI-Space/app.py +++ /dev/null @@ -1,44 +0,0 @@ -import torch -from peft import PeftModel, PeftConfig -from transformers import AutoModelForCausalLM, AutoTokenizer - -peft_model_id = f"FourthBrainGenAI/BLOOMZ-3b-marketmail-ai" -config = PeftConfig.from_pretrained(peft_model_id) -model = AutoModelForCausalLM.from_pretrained( - config.base_model_name_or_path, - return_dict=True, - load_in_8bit=True, - device_map="auto", -) -tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path) - -# Load the Lora model -model = PeftModel.from_pretrained(model, peft_model_id) - - -def make_inference(product, description): - batch = tokenizer( - f"Below is a product and description, please write a marketing email for this product.\n\n### Product:\n{product}\n### Description:\n{description}\n\n### Marketing Email", - return_tensors="pt", - ) - - with torch.cuda.amp.autocast(): - output_tokens = model.generate(**batch, max_new_tokens=200) - - return tokenizer.decode(output_tokens[0], skip_special_tokens=True) - - -if __name__ == "__main__": - # make a gradio interface - import gradio as gr - - gr.Interface( - make_inference, - [ - gr.inputs.Textbox(lines=2, label="Product Name"), - gr.inputs.Textbox(lines=5, label="Product Description"), - ], - gr.outputs.Textbox(label="Ad"), - title="MarketMail-AI", - description="MarketMail-AI is a tool that generates marketing emails for products.", - ).launch() \ No newline at end of file diff --git a/spaces/Fox1997/vits-uma-genshin-honkai/mel_processing.py b/spaces/Fox1997/vits-uma-genshin-honkai/mel_processing.py deleted file mode 100644 index 3e252e76320522a8a4195a60665168f22769aec2..0000000000000000000000000000000000000000 --- a/spaces/Fox1997/vits-uma-genshin-honkai/mel_processing.py +++ /dev/null @@ -1,101 +0,0 @@ -import torch -import torch.utils.data -from librosa.filters import mel as librosa_mel_fn - -MAX_WAV_VALUE = 32768.0 - - -def dynamic_range_compression_torch(x, C=1, clip_val=1e-5): - """ - PARAMS - ------ - C: compression factor - """ - return torch.log(torch.clamp(x, min=clip_val) * C) - - -def dynamic_range_decompression_torch(x, C=1): - """ - PARAMS - ------ - C: compression factor used to compress - """ - return torch.exp(x) / C - - -def spectral_normalize_torch(magnitudes): - output = dynamic_range_compression_torch(magnitudes) - return output - - -def spectral_de_normalize_torch(magnitudes): - output = dynamic_range_decompression_torch(magnitudes) - return output - - -mel_basis = {} -hann_window = {} - - -def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False): - if torch.min(y) < -1.: - print('min value is ', torch.min(y)) - if torch.max(y) > 1.: - print('max value is ', torch.max(y)) - - global hann_window - dtype_device = str(y.dtype) + '_' + str(y.device) - wnsize_dtype_device = str(win_size) + '_' + dtype_device - if wnsize_dtype_device not in hann_window: - hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device) - - y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect') - y = y.squeeze(1) - - spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device], - center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False) - - spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6) - return spec - - -def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax): - global mel_basis - dtype_device = str(spec.dtype) + '_' + str(spec.device) - fmax_dtype_device = str(fmax) + '_' + dtype_device - if fmax_dtype_device not in mel_basis: - mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax) - mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=spec.dtype, device=spec.device) - spec = torch.matmul(mel_basis[fmax_dtype_device], spec) - spec = spectral_normalize_torch(spec) - return spec - - -def mel_spectrogram_torch(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False): - if torch.min(y) < -1.: - print('min value is ', torch.min(y)) - if torch.max(y) > 1.: - print('max value is ', torch.max(y)) - - global mel_basis, hann_window - dtype_device = str(y.dtype) + '_' + str(y.device) - fmax_dtype_device = str(fmax) + '_' + dtype_device - wnsize_dtype_device = str(win_size) + '_' + dtype_device - if fmax_dtype_device not in mel_basis: - mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax) - mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device) - if wnsize_dtype_device not in hann_window: - hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device) - - y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect') - y = y.squeeze(1) - - spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device], - center=center, pad_mode='reflect', normalized=False, onesided=True) - - spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6) - - spec = torch.matmul(mel_basis[fmax_dtype_device], spec) - spec = spectral_normalize_torch(spec) - - return spec diff --git a/spaces/FridaZuley/RVC_HFKawaii/tools/infer/infer-pm-index256.py b/spaces/FridaZuley/RVC_HFKawaii/tools/infer/infer-pm-index256.py deleted file mode 100644 index da5430421f1de17a57379aefbe7919dd555b2f50..0000000000000000000000000000000000000000 --- a/spaces/FridaZuley/RVC_HFKawaii/tools/infer/infer-pm-index256.py +++ /dev/null @@ -1,202 +0,0 @@ -""" - -对源特征进行检索 -""" -import os -import logging - -logger = logging.getLogger(__name__) - -import parselmouth -import torch - -os.environ["CUDA_VISIBLE_DEVICES"] = "0" -# import torchcrepe -from time import time as ttime - -# import pyworld -import librosa -import numpy as np -import soundfile as sf -import torch.nn.functional as F -from fairseq import checkpoint_utils - -# from models import SynthesizerTrn256#hifigan_nonsf -# from lib.infer_pack.models import SynthesizerTrn256NSF as SynthesizerTrn256#hifigan_nsf -from infer.lib.infer_pack.models import ( - SynthesizerTrnMs256NSFsid as SynthesizerTrn256, -) # hifigan_nsf -from scipy.io import wavfile - -# from lib.infer_pack.models import SynthesizerTrnMs256NSFsid_sim as SynthesizerTrn256#hifigan_nsf -# from models import SynthesizerTrn256NSFsim as SynthesizerTrn256#hifigan_nsf -# from models import SynthesizerTrn256NSFsimFlow as SynthesizerTrn256#hifigan_nsf - - -device = torch.device("cuda" if torch.cuda.is_available() else "cpu") -model_path = r"E:\codes\py39\vits_vc_gpu_train\assets\hubert\hubert_base.pt" # -logger.info("Load model(s) from {}".format(model_path)) -models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task( - [model_path], - suffix="", -) -model = models[0] -model = model.to(device) -model = model.half() -model.eval() - -# net_g = SynthesizerTrn256(1025,32,192,192,768,2,6,3,0.1,"1", [3,7,11],[[1,3,5], [1,3,5], [1,3,5]],[10,10,2,2],512,[16,16,4,4],183,256,is_half=True)#hifigan#512#256 -# net_g = SynthesizerTrn256(1025,32,192,192,768,2,6,3,0.1,"1", [3,7,11],[[1,3,5], [1,3,5], [1,3,5]],[10,10,2,2],512,[16,16,4,4],109,256,is_half=True)#hifigan#512#256 -net_g = SynthesizerTrn256( - 1025, - 32, - 192, - 192, - 768, - 2, - 6, - 3, - 0, - "1", - [3, 7, 11], - [[1, 3, 5], [1, 3, 5], [1, 3, 5]], - [10, 10, 2, 2], - 512, - [16, 16, 4, 4], - 183, - 256, - is_half=True, -) # hifigan#512#256#no_dropout -# net_g = SynthesizerTrn256(1025,32,192,192,768,2,3,3,0.1,"1", [3,7,11],[[1,3,5], [1,3,5], [1,3,5]],[10,10,2,2],512,[16,16,4,4],0)#ts3 -# net_g = SynthesizerTrn256(1025,32,192,192,768,2,6,3,0.1,"1", [3,7,11],[[1,3,5], [1,3,5], [1,3,5]],[10,10,2],512,[16,16,4],0)#hifigan-ps-sr -# -# net_g = SynthesizerTrn(1025, 32, 192, 192, 768, 2, 6, 3, 0.1, "1", [3, 7, 11], [[1, 3, 5], [1, 3, 5], [1, 3, 5]], [5,5], 512, [15,15], 0)#ms -# net_g = SynthesizerTrn(1025, 32, 192, 192, 768, 2, 6, 3, 0.1, "1", [3, 7, 11], [[1, 3, 5], [1, 3, 5], [1, 3, 5]], [10,10], 512, [16,16], 0)#idwt2 - -# weights=torch.load("infer/ft-mi_1k-noD.pt") -# weights=torch.load("infer/ft-mi-freeze-vocoder-flow-enc_q_1k.pt") -# weights=torch.load("infer/ft-mi-freeze-vocoder_true_1k.pt") -# weights=torch.load("infer/ft-mi-sim1k.pt") -weights = torch.load("infer/ft-mi-no_opt-no_dropout.pt") -logger.debug(net_g.load_state_dict(weights, strict=True)) - -net_g.eval().to(device) -net_g.half() - - -def get_f0(x, p_len, f0_up_key=0): - time_step = 160 / 16000 * 1000 - f0_min = 50 - f0_max = 1100 - f0_mel_min = 1127 * np.log(1 + f0_min / 700) - f0_mel_max = 1127 * np.log(1 + f0_max / 700) - - f0 = ( - parselmouth.Sound(x, 16000) - .to_pitch_ac( - time_step=time_step / 1000, - voicing_threshold=0.6, - pitch_floor=f0_min, - pitch_ceiling=f0_max, - ) - .selected_array["frequency"] - ) - - pad_size = (p_len - len(f0) + 1) // 2 - if pad_size > 0 or p_len - len(f0) - pad_size > 0: - f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant") - f0 *= pow(2, f0_up_key / 12) - f0bak = f0.copy() - - f0_mel = 1127 * np.log(1 + f0 / 700) - f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / ( - f0_mel_max - f0_mel_min - ) + 1 - f0_mel[f0_mel <= 1] = 1 - f0_mel[f0_mel > 255] = 255 - # f0_mel[f0_mel > 188] = 188 - f0_coarse = np.rint(f0_mel).astype(np.int32) - return f0_coarse, f0bak - - -import faiss - -index = faiss.read_index("infer/added_IVF512_Flat_mi_baseline_src_feat.index") -big_npy = np.load("infer/big_src_feature_mi.npy") -ta0 = ta1 = ta2 = 0 -for idx, name in enumerate( - [ - "冬之花clip1.wav", - ] -): ## - wav_path = "todo-songs/%s" % name # - f0_up_key = -2 # - audio, sampling_rate = sf.read(wav_path) - if len(audio.shape) > 1: - audio = librosa.to_mono(audio.transpose(1, 0)) - if sampling_rate != 16000: - audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000) - - feats = torch.from_numpy(audio).float() - if feats.dim() == 2: # double channels - feats = feats.mean(-1) - assert feats.dim() == 1, feats.dim() - feats = feats.view(1, -1) - padding_mask = torch.BoolTensor(feats.shape).fill_(False) - inputs = { - "source": feats.half().to(device), - "padding_mask": padding_mask.to(device), - "output_layer": 9, # layer 9 - } - if torch.cuda.is_available(): - torch.cuda.synchronize() - t0 = ttime() - with torch.no_grad(): - logits = model.extract_features(**inputs) - feats = model.final_proj(logits[0]) - - ####索引优化 - npy = feats[0].cpu().numpy().astype("float32") - D, I = index.search(npy, 1) - feats = ( - torch.from_numpy(big_npy[I.squeeze()].astype("float16")).unsqueeze(0).to(device) - ) - - feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1) - if torch.cuda.is_available(): - torch.cuda.synchronize() - t1 = ttime() - # p_len = min(feats.shape[1],10000,pitch.shape[0])#太大了爆显存 - p_len = min(feats.shape[1], 10000) # - pitch, pitchf = get_f0(audio, p_len, f0_up_key) - p_len = min(feats.shape[1], 10000, pitch.shape[0]) # 太大了爆显存 - if torch.cuda.is_available(): - torch.cuda.synchronize() - t2 = ttime() - feats = feats[:, :p_len, :] - pitch = pitch[:p_len] - pitchf = pitchf[:p_len] - p_len = torch.LongTensor([p_len]).to(device) - pitch = torch.LongTensor(pitch).unsqueeze(0).to(device) - sid = torch.LongTensor([0]).to(device) - pitchf = torch.FloatTensor(pitchf).unsqueeze(0).to(device) - with torch.no_grad(): - audio = ( - net_g.infer(feats, p_len, pitch, pitchf, sid)[0][0, 0] - .data.cpu() - .float() - .numpy() - ) # nsf - if torch.cuda.is_available(): - torch.cuda.synchronize() - t3 = ttime() - ta0 += t1 - t0 - ta1 += t2 - t1 - ta2 += t3 - t2 - # wavfile.write("ft-mi_1k-index256-noD-%s.wav"%name, 40000, audio)## - # wavfile.write("ft-mi-freeze-vocoder-flow-enc_q_1k-%s.wav"%name, 40000, audio)## - # wavfile.write("ft-mi-sim1k-%s.wav"%name, 40000, audio)## - wavfile.write("ft-mi-no_opt-no_dropout-%s.wav" % name, 40000, audio) ## - - -logger.debug("%.2fs %.2fs %.2fs", ta0, ta1, ta2) # diff --git a/spaces/Gen-Sim/Gen-Sim/scripts/metascripts/train10_gpt_finetune_generalization.sh b/spaces/Gen-Sim/Gen-Sim/scripts/metascripts/train10_gpt_finetune_generalization.sh deleted file mode 100644 index 61b5d39f2cbf18ca5f6fc23156ea9f8832d8649b..0000000000000000000000000000000000000000 --- a/spaces/Gen-Sim/Gen-Sim/scripts/metascripts/train10_gpt_finetune_generalization.sh +++ /dev/null @@ -1,12 +0,0 @@ -#!/bin/bash -#SBATCH -c 10 -#SBATCH -n 1 -#SBATCH -o logs/%j.out -#SBATCH --exclusive - -STEPS=${1-'50000'} - -sh scripts/traintest_scripts/train_test_multi_task_finetune_goal.sh data \ -"[mix-piles,rainbow-stack,manipulating-two-ropes,insert-sphere-into-container,align-pair-colored-blocks-along-line,construct-corner-building,colorful_block-tower-on-cylinder-base,build-bridge,push_piles-into-letter]"\ -"[sorting-blocks-into-pallets,build-two-circles,align-cylinders-in-square,Four-corner-pyramid-challenge,corner-sort-cylinders]" \ -gpt10task_gen_finetune $STEPS \ No newline at end of file diff --git a/spaces/GiladtheFixer/image-variations/app.py b/spaces/GiladtheFixer/image-variations/app.py deleted file mode 100644 index f352741bc458ee5b7523c10687c2e670429e1dc9..0000000000000000000000000000000000000000 --- a/spaces/GiladtheFixer/image-variations/app.py +++ /dev/null @@ -1,105 +0,0 @@ -import gradio as gr -import torch -from PIL import Image -from torchvision import transforms - -from diffusers import StableDiffusionImageVariationPipeline - -def main( - input_im, - scale=3.0, - n_samples=4, - steps=25, - seed=0, - ): - generator = torch.Generator(device=device).manual_seed(int(seed)) - - tform = transforms.Compose([ - transforms.ToTensor(), - transforms.Resize( - (224, 224), - interpolation=transforms.InterpolationMode.BICUBIC, - antialias=False, - ), - transforms.Normalize( - [0.48145466, 0.4578275, 0.40821073], - [0.26862954, 0.26130258, 0.27577711]), - ]) - inp = tform(input_im).to(device) - - images_list = pipe( - inp.tile(n_samples, 1, 1, 1), - guidance_scale=scale, - num_inference_steps=steps, - generator=generator, - ) - - images = [] - for i, image in enumerate(images_list["images"]): - if(images_list["nsfw_content_detected"][i]): - safe_image = Image.open(r"unsafe.png") - images.append(safe_image) - else: - images.append(image) - return images - - -description = \ -""" -__Now using Image Variations v2!__ - -Generate variations on an input image using a fine-tuned version of Stable Diffision. -Trained by [Justin Pinkney](https://www.justinpinkney.com) ([@Buntworthy](https://twitter.com/Buntworthy)) at [Lambda](https://lambdalabs.com/) - -This version has been ported to 🤗 Diffusers library, see more details on how to use this version in the [Lambda Diffusers repo](https://github.com/LambdaLabsML/lambda-diffusers). -For the original training code see [this repo](https://github.com/justinpinkney/stable-diffusion). - - - -""" - -article = \ -""" -## How does this work? - -The normal Stable Diffusion model is trained to be conditioned on text input. This version has had the original text encoder (from CLIP) removed, and replaced with -the CLIP _image_ encoder instead. So instead of generating images based a text input, images are generated to match CLIP's embedding of the image. -This creates images which have the same rough style and content, but different details, in particular the composition is generally quite different. -This is a totally different approach to the img2img script of the original Stable Diffusion and gives very different results. - -The model was fine tuned on the [LAION aethetics v2 6+ dataset](https://laion.ai/blog/laion-aesthetics/) to accept the new conditioning. -Training was done on 8xA100 GPUs on [Lambda GPU Cloud](https://lambdalabs.com/service/gpu-cloud). -More details are on the [model card](https://huggingface.co/lambdalabs/sd-image-variations-diffusers). -""" - -device = "cuda" if torch.cuda.is_available() else "cpu" -pipe = StableDiffusionImageVariationPipeline.from_pretrained( - "lambdalabs/sd-image-variations-diffusers", - ) -pipe = pipe.to(device) - -inputs = [ - gr.Image(), - gr.Slider(0, 25, value=3, step=1, label="Guidance scale"), - gr.Slider(1, 4, value=1, step=1, label="Number images"), - gr.Slider(5, 50, value=25, step=5, label="Steps"), - gr.Number(0, label="Seed", precision=0) -] -output = gr.Gallery(label="Generated variations") -output.style(grid=2) - -examples = [ - ["examples/vermeer.jpg", 3, 1, 25, 0], - ["examples/matisse.jpg", 3, 1, 25, 0], -] - -demo = gr.Interface( - fn=main, - title="Stable Diffusion Image Variations", - description=description, - article=article, - inputs=inputs, - outputs=output, - examples=examples, - ) -demo.launch() diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/configs/cascade_rcnn/cascade_mask_rcnn_x101_64x4d_fpn_1x_coco.py b/spaces/Gradio-Blocks/uniformer_image_detection/configs/cascade_rcnn/cascade_mask_rcnn_x101_64x4d_fpn_1x_coco.py deleted file mode 100644 index 33629ee6cc2b903407372d68c6d7ab599fe6598e..0000000000000000000000000000000000000000 --- a/spaces/Gradio-Blocks/uniformer_image_detection/configs/cascade_rcnn/cascade_mask_rcnn_x101_64x4d_fpn_1x_coco.py +++ /dev/null @@ -1,13 +0,0 @@ -_base_ = './cascade_mask_rcnn_r50_fpn_1x_coco.py' -model = dict( - pretrained='open-mmlab://resnext101_64x4d', - backbone=dict( - type='ResNeXt', - depth=101, - groups=64, - base_width=4, - num_stages=4, - out_indices=(0, 1, 2, 3), - frozen_stages=1, - norm_cfg=dict(type='BN', requires_grad=True), - style='pytorch')) diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/detectors/scnet.py b/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/detectors/scnet.py deleted file mode 100644 index 04a2347c4ec1efcbfda59a134cddd8bde620d983..0000000000000000000000000000000000000000 --- a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/detectors/scnet.py +++ /dev/null @@ -1,10 +0,0 @@ -from ..builder import DETECTORS -from .cascade_rcnn import CascadeRCNN - - -@DETECTORS.register_module() -class SCNet(CascadeRCNN): - """Implementation of `SCNet//g' | sed 's/<\/seg>//g' diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/models/ema/ema.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/models/ema/ema.py deleted file mode 100644 index 010b60ba2fd766340d2c5b8ba96f9e57c6fe25b5..0000000000000000000000000000000000000000 --- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/models/ema/ema.py +++ /dev/null @@ -1,200 +0,0 @@ -#!/usr/bin/env python3 - -""" -This module has the EMA class used to store a copy of the exponentially decayed -model params. - -Typical usage of EMA class involves initializing an object using an existing -model (random or from a seed model) and setting the config like ema_decay, -ema_start_update which determine how the EMA model is updated. After every -update of the model i.e. at the end of the train_step, the EMA should be updated -by passing the new model to the EMA.step function. The EMA model state dict -can be stored in the extra state under the key of "ema" and dumped -into a checkpoint and loaded. The EMA object can be passed to tasks -by setting task.uses_ema property. -EMA is a smoothed/ensemble model which might have better performance -when used for inference or further fine-tuning. EMA class has a -reverse function to load the EMA params into a model and use it -like a regular model. -""" - -import copy -import logging - -import torch -from fairseq import checkpoint_utils - - -class EMA(object): - """Exponential Moving Average of Fairseq Models - EMA keeps a copy of the exponentially decayed model params. - The set of params should include both gradient-descent and - non-gradient descent params, such as batch mean/var and buffers. - This is a modified implementation of - the open source code in https://github.com/zhawe01/fairseq-gec.git, - and internal source code in - fbcode/mobile-vision/projects/classification_pytorch/lib/utils/model_ema.py. - - Similar to TF EMA. - https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage. - EMA provides a averaged and smoothed set of model weights, and has been shown to - improve vision models. EMA class does all necessary functions to update, reload, - or init EMA methods. - - EMA object is initialized from an arbitrary model. By default, it is stored in - the same device (unless device specified at initialization) and with the - same precision as the model (unless ema_fp32 is True). ema_fp32 is recommended. - This stores the EMA parameters in fp32 only for the EMA update step, and - is used at the default precision otherwise. - EMA is usually enabled using EMAConfig with store_ema=True. Some important - parameters to configure EMA are - 1) ema_decay - The decay of EMA - 2) ema_update_freq - EMA is updated every this many model updates. - 3) ema_start_update - Start EMA update after this many model updates [default 0] - - Key methods: - 1) step - One update of EMA using new model - 2) restore - Update EMA from a state dict - 3) reverse - Load EMA into a model - 4) get_decay, _set_decay - Used to get or set the decay. Note _set_decay is - called from step. - 5) build_fp32_params - Used to initialize or update the fp32 copy of EMA params. - Note this is enabled only when ema_fp32=True - """ - - def __init__(self, model, config, device=None): - """ - @param model model to initialize the EMA with - @param config EMAConfig object with configuration like - ema_decay, ema_update_freq, ema_fp32 - @param device If provided, copy EMA to this device (e.g. gpu). - Otherwise EMA is in the same device as the model. - """ - - self.decay = config.ema_decay - self.model = copy.deepcopy(model) - self.model.requires_grad_(False) - self.config = config - self.fp32_params = {} - - if self.config.ema_seed_model is not None: - state = checkpoint_utils.load_ema_from_checkpoint(self.config.ema_seed_model) - self.model.load_state_dict(state["model"], strict=True) - - if device is not None: - logging.info(f"Copying EMA model to device {device}") - self.model = self.model.to(device=device) - - if self.config.ema_fp32: - self.build_fp32_params() - - self.update_freq_counter = 0 - - def get_model(self): - return self.model - - def build_fp32_params(self, state_dict=None): - """ - Store a copy of the EMA params in fp32. - If state dict is passed, the EMA params is copied from - the provided state dict. Otherwise, it is copied from the - current EMA model parameters. - """ - if not self.config.ema_fp32: - raise RuntimeError( - "build_fp32_params should not be called if ema_fp32=False. " - "Use ema_fp32=True if this is really intended." - ) - - if state_dict is None: - state_dict = self.model.state_dict() - - def _to_float(t): - return t.float() if torch.is_floating_point(t) else t - - # for non-float params (like registered symbols), they are copied into this dict and covered in each update - for param_key in state_dict: - if param_key in self.fp32_params: - self.fp32_params[param_key].copy_(state_dict[param_key]) - else: - self.fp32_params[param_key] = _to_float(state_dict[param_key]) - - def restore(self, state_dict, build_fp32_params=False): - """ Load data from a model spec into EMA model """ - self.model.load_state_dict(state_dict, strict=False) - if build_fp32_params: - self.build_fp32_params(state_dict) - - def _set_decay(self, decay): - self.decay = decay - - def get_decay(self): - return self.decay - - def _step_internal(self, new_model, updates=None): - """ One update of the EMA model based on new model weights """ - decay = self.decay - - ema_state_dict = {} - ema_params = self.fp32_params if self.config.ema_fp32 else self.model.state_dict() - for key, param in new_model.state_dict().items(): - try: - ema_param = ema_params[key] - except KeyError: - ema_param = param.float().clone() if param.ndim == 1 else copy.deepcopy(param) - - if param.shape != ema_param.shape: - raise ValueError( - "incompatible tensor shapes between model param and ema param" - + "{} vs. {}".format(param.shape, ema_param.shape) - ) - if "version" in key: - # Do not decay a model.version pytorch param - continue - - # for non-float params (like registered symbols), they are covered in each update - if not torch.is_floating_point(ema_param): - if ema_param.dtype != param.dtype: - raise ValueError( - "incompatible tensor dtypes between model param and ema param" - + "{} vs. {}".format(param.dtype, ema_param.dtype) - ) - ema_param.copy_(param) - else: - ema_param.mul_(decay) - ema_param.add_(param.to(dtype=ema_param.dtype), alpha=1-decay) - ema_state_dict[key] = ema_param - self.restore(ema_state_dict, build_fp32_params=False) - - def step(self, new_model, updates=None): - """ - One update of EMA which is done every self.config.ema_update_freq - updates of the model. - - @param updates The current number of model updates done. - Decay is set of 0 if model updates < ema_start_update, which means - the model will be simply copied over to the EMA. - When model updates >= ema_start_updates, then EMA is updated with - a decay of self.config.ema_decay. - """ - self._set_decay( - 0 - if updates is not None - and updates < self.config.ema_start_update - else self.config.ema_decay - ) - if updates is not None and self.config.ema_update_freq > 1: - self.update_freq_counter += 1 - if self.update_freq_counter >= self.config.ema_update_freq: - self._step_internal(new_model, updates) - self.update_freq_counter = 0 - else: - self._step_internal(new_model, updates) - - def reverse(self, model): - """ - Load the model parameters from EMA model. - Useful for inference or fine-tuning from the EMA model. - """ - model.load_state_dict(self.model.state_dict(), strict=False) - return model diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/tasks/denoising.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/tasks/denoising.py deleted file mode 100644 index d1dff26c36d51e394e1c955c6683fa4a20c52395..0000000000000000000000000000000000000000 --- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/tasks/denoising.py +++ /dev/null @@ -1,277 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import logging -import os - -from fairseq import utils -from fairseq.data import ( - AppendTokenDataset, - DenoisingDataset, - Dictionary, - IdDataset, - NestedDictionaryDataset, - NumelDataset, - PadDataset, - PrependTokenDataset, - StripTokenDataset, - TokenBlockDataset, - data_utils, -) -from fairseq.data.encoders.utils import get_whole_word_mask -from fairseq.data.shorten_dataset import maybe_shorten_dataset -from fairseq.tasks import LegacyFairseqTask, register_task -import numpy as np - - -logger = logging.getLogger(__name__) - - -@register_task("denoising") -class DenoisingTask(LegacyFairseqTask): - """ - Denoising task for applying sequence to sequence denoising. (ie. BART) - """ - - @staticmethod - def add_args(parser): - """Add task-specific arguments to the parser.""" - parser.add_argument("data", help="path to data directory") - parser.add_argument( - "--tokens-per-sample", - default=512, - type=int, - help="max number of total tokens over all segments" - " per sample for dataset", - ) - parser.add_argument( - "--sample-break-mode", - default="complete_doc", - type=str, - help="mode for breaking sentence", - ) - parser.add_argument( - "--mask", - default=0.0, - type=float, - help="fraction of words/subwords that will be masked", - ) - parser.add_argument( - "--mask-random", - default=0.0, - type=float, - help="instead of using [MASK], use random token this often", - ) - parser.add_argument( - "--insert", - default=0.0, - type=float, - help="insert this percentage of additional random tokens", - ) - parser.add_argument( - "--permute", - default=0.0, - type=float, - help="take this proportion of subwords and permute them", - ) - parser.add_argument( - "--rotate", - default=0.5, - type=float, - help="rotate this proportion of inputs", - ) - parser.add_argument( - "--poisson-lambda", - default=3.0, - type=float, - help="randomly shuffle sentences for this proportion of inputs", - ) - parser.add_argument( - "--permute-sentences", - default=0.0, - type=float, - help="shuffle this proportion of sentences in all inputs", - ) - parser.add_argument( - "--mask-length", - default="subword", - type=str, - choices=["subword", "word", "span-poisson"], - help="mask length to choose", - ) - parser.add_argument( - "--replace-length", - default=-1, - type=int, - help="when masking N tokens, replace with 0, 1, or N tokens (use -1 for N)", - ) - parser.add_argument( - "--max-source-positions", - default=1024, - type=int, - metavar="N", - help="max number of tokens in the source sequence", - ) - parser.add_argument( - "--max-target-positions", - default=1024, - type=int, - metavar="N", - help="max number of tokens in the target sequence", - ) - - parser.add_argument( - "--shorten-method", - default="none", - choices=["none", "truncate", "random_crop"], - help="if not none, shorten sequences that exceed --tokens-per-sample", - ) - parser.add_argument( - "--shorten-data-split-list", - default="", - help="comma-separated list of dataset splits to apply shortening to, " - 'e.g., "train,valid" (default: all dataset splits)', - ) - - - def __init__(self, args, dictionary): - super().__init__(args) - self.dictionary = dictionary - self.seed = args.seed - - # add mask token - self.mask_idx = self.dictionary.add_symbol(" ") - - @classmethod - def setup_task(cls, args, **kwargs): - """Setup the task.""" - paths = utils.split_paths(args.data) - assert len(paths) > 0 - dictionary = Dictionary.load(os.path.join(paths[0], "dict.txt")) - logger.info("dictionary: {} types".format(len(dictionary))) - if not hasattr(args, "shuffle_instance"): - args.shuffle_instance = False - return cls(args, dictionary) - - def load_dataset(self, split, epoch=1, combine=False, **kwargs): - """Load a given dataset split. - - Args: - split (str): name of the split (e.g., train, valid, test) - """ - paths = utils.split_paths(self.args.data) - assert len(paths) > 0 - data_path = paths[(epoch - 1) % len(paths)] - split_path = os.path.join(data_path, split) - - dataset = data_utils.load_indexed_dataset( - split_path, - self.dictionary, - self.args.dataset_impl, - combine=combine, - ) - if dataset is None: - raise FileNotFoundError( - "Dataset not found: {} ({})".format(split, split_path) - ) - - dataset = StripTokenDataset(dataset, self.dictionary.eos()) - - dataset = maybe_shorten_dataset( - dataset, - split, - self.args.shorten_data_split_list, - self.args.shorten_method, - self.args.tokens_per_sample, - self.args.seed, - ) - - # create continuous blocks of tokens - dataset = TokenBlockDataset( - dataset, - dataset.sizes, - self.args.tokens_per_sample - 2, # one less for and one for- pad=self.dictionary.pad(), - eos=self.dictionary.eos(), - break_mode=self.args.sample_break_mode, - document_sep_len=0, - ) - logger.info("loaded {} blocks from: {}".format(len(dataset), split_path)) - - # prepend beginning-of-sentence token (, equiv. to [CLS] in BERT) - dataset = PrependTokenDataset(dataset, self.source_dictionary.bos()) - dataset = AppendTokenDataset(dataset, self.source_dictionary.eos()) - - mask_whole_words = ( - get_whole_word_mask(self.args, self.source_dictionary) - if self.args.mask_length != "subword" - else None - ) - - self.datasets[split] = DenoisingDataset( - dataset, - dataset.sizes, - self.dictionary, - self.mask_idx, - mask_whole_words, - shuffle=self.args.shuffle_instance, - seed=self.seed, - args=self.args, - ) - logger.info( - "Split: {0}, Loaded {1} samples of denoising_dataset".format( - split, - len(self.datasets[split]), - ) - ) - - def build_dataset_for_inference(self, src_tokens, src_lengths, **kwargs): - """ - Generate batches for inference. We assume that the input begins with a - bos symbol (`', - mask_token='[MASK]', - gmask_token='[gMASK]', - padding_side="left", - pad_token="`) and ends with an eos symbol (``). - """ - pad = self.source_dictionary.pad() - eos = self.source_dictionary.eos() - src_dataset = TokenBlockDataset( - src_tokens, - src_lengths, - block_size=self.args.tokens_per_sample - 2, # forand- pad=pad, - eos=eos, - break_mode=self.args.sample_break_mode, - document_sep_len=0, - ) - prev_output_tokens = PrependTokenDataset( - StripTokenDataset(src_dataset, eos), eos - ) - src_dataset = PadDataset(src_dataset, pad_idx=pad, left_pad=False) - return NestedDictionaryDataset( - { - "id": IdDataset(), - "net_input": { - "src_tokens": src_dataset, - "src_lengths": NumelDataset(src_dataset, reduce=False), - "prev_output_tokens": PadDataset( - prev_output_tokens, pad_idx=pad, left_pad=False - ), - }, - "target": src_dataset, - }, - sizes=[np.array(src_lengths)], - ) - - def max_positions(self): - """Return the max sentence length allowed by the task.""" - return (self.args.max_source_positions, self.args.max_target_positions) - - @property - def source_dictionary(self): - """Return the source :class:`~fairseq.data.Dictionary`.""" - return self.dictionary - - @property - def target_dictionary(self): - """Return the target :class:`~fairseq.data.Dictionary`.""" - return self.dictionary diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/scripts/read_binarized.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/scripts/read_binarized.py deleted file mode 100644 index a414095d03fb022a6753e816fc8bfd80e11db24d..0000000000000000000000000000000000000000 --- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/scripts/read_binarized.py +++ /dev/null @@ -1,48 +0,0 @@ -#!/usr/bin/env python3 -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import argparse - -from fairseq.data import Dictionary, data_utils, indexed_dataset - - -def get_parser(): - parser = argparse.ArgumentParser( - description="writes text from binarized file to stdout" - ) - # fmt: off - parser.add_argument('--dataset-impl', help='dataset implementation', - choices=indexed_dataset.get_available_dataset_impl()) - parser.add_argument('--dict', metavar='FP', help='dictionary containing known words', default=None) - parser.add_argument('--input', metavar='FP', required=True, help='binarized file to read') - # fmt: on - - return parser - - -def main(): - parser = get_parser() - args = parser.parse_args() - - dictionary = Dictionary.load(args.dict) if args.dict is not None else None - dataset = data_utils.load_indexed_dataset( - args.input, - dictionary, - dataset_impl=args.dataset_impl, - default="lazy", - ) - - for tensor_line in dataset: - if dictionary is None: - line = " ".join([str(int(x)) for x in tensor_line]) - else: - line = dictionary.string(tensor_line) - - print(line) - - -if __name__ == "__main__": - main() diff --git a/spaces/Hasani/Specific_Object_Recognition_in_the_Wild/SuperGluePretrainedNetwork/models/matching.py b/spaces/Hasani/Specific_Object_Recognition_in_the_Wild/SuperGluePretrainedNetwork/models/matching.py deleted file mode 100644 index 5d174208d146373230a8a68dd1420fc59c180633..0000000000000000000000000000000000000000 --- a/spaces/Hasani/Specific_Object_Recognition_in_the_Wild/SuperGluePretrainedNetwork/models/matching.py +++ /dev/null @@ -1,84 +0,0 @@ -# %BANNER_BEGIN% -# --------------------------------------------------------------------- -# %COPYRIGHT_BEGIN% -# -# Magic Leap, Inc. ("COMPANY") CONFIDENTIAL -# -# Unpublished Copyright (c) 2020 -# Magic Leap, Inc., All Rights Reserved. -# -# NOTICE: All information contained herein is, and remains the property -# of COMPANY. The intellectual and technical concepts contained herein -# are proprietary to COMPANY and may be covered by U.S. and Foreign -# Patents, patents in process, and are protected by trade secret or -# copyright law. Dissemination of this information or reproduction of -# this material is strictly forbidden unless prior written permission is -# obtained from COMPANY. Access to the source code contained herein is -# hereby forbidden to anyone except current COMPANY employees, managers -# or contractors who have executed Confidentiality and Non-disclosure -# agreements explicitly covering such access. -# -# The copyright notice above does not evidence any actual or intended -# publication or disclosure of this source code, which includes -# information that is confidential and/or proprietary, and is a trade -# secret, of COMPANY. ANY REPRODUCTION, MODIFICATION, DISTRIBUTION, -# PUBLIC PERFORMANCE, OR PUBLIC DISPLAY OF OR THROUGH USE OF THIS -# SOURCE CODE WITHOUT THE EXPRESS WRITTEN CONSENT OF COMPANY IS -# STRICTLY PROHIBITED, AND IN VIOLATION OF APPLICABLE LAWS AND -# INTERNATIONAL TREATIES. THE RECEIPT OR POSSESSION OF THIS SOURCE -# CODE AND/OR RELATED INFORMATION DOES NOT CONVEY OR IMPLY ANY RIGHTS -# TO REPRODUCE, DISCLOSE OR DISTRIBUTE ITS CONTENTS, OR TO MANUFACTURE, -# USE, OR SELL ANYTHING THAT IT MAY DESCRIBE, IN WHOLE OR IN PART. -# -# %COPYRIGHT_END% -# ---------------------------------------------------------------------- -# %AUTHORS_BEGIN% -# -# Originating Authors: Paul-Edouard Sarlin -# -# %AUTHORS_END% -# --------------------------------------------------------------------*/ -# %BANNER_END% - -import torch - -from .superpoint import SuperPoint -from .superglue import SuperGlue - - -class Matching(torch.nn.Module): - """ Image Matching Frontend (SuperPoint + SuperGlue) """ - def __init__(self, config={}): - super().__init__() - self.superpoint = SuperPoint(config.get('superpoint', {})) - self.superglue = SuperGlue(config.get('superglue', {})) - - def forward(self, data): - """ Run SuperPoint (optionally) and SuperGlue - SuperPoint is skipped if ['keypoints0', 'keypoints1'] exist in input - Args: - data: dictionary with minimal keys: ['image0', 'image1'] - """ - pred = {} - - # Extract SuperPoint (keypoints, scores, descriptors) if not provided - if 'keypoints0' not in data: - pred0 = self.superpoint({'image': data['image0']}) - pred = {**pred, **{k+'0': v for k, v in pred0.items()}} - if 'keypoints1' not in data: - pred1 = self.superpoint({'image': data['image1']}) - pred = {**pred, **{k+'1': v for k, v in pred1.items()}} - - # Batch all features - # We should either have i) one image per batch, or - # ii) the same number of local features for all images in the batch. - data = {**data, **pred} - - for k in data: - if isinstance(data[k], (list, tuple)): - data[k] = torch.stack(data[k]) - - # Perform the matching - pred = {**pred, **self.superglue(data)} - - return pred diff --git a/spaces/Hazzzardous/RWKV-Instruct-1B5/config.py b/spaces/Hazzzardous/RWKV-Instruct-1B5/config.py deleted file mode 100644 index 6d93e660638440b390b46d38f734c969beb8d2ef..0000000000000000000000000000000000000000 --- a/spaces/Hazzzardous/RWKV-Instruct-1B5/config.py +++ /dev/null @@ -1,63 +0,0 @@ -from rwkvstic.agnostic.backends import TORCH, TORCH_QUANT -import torch - -quantized = { - "mode": TORCH_QUANT, - "runtimedtype": torch.bfloat16, - "useGPU": torch.cuda.is_available(), - "chunksize": 32, # larger = more accurate, but more memory - "target": 100 # your gpu max size, excess vram offloaded to cpu -} - -# UNCOMMENT TO SELECT OPTIONS -# Not full list of options, see https://pypi.org/project/rwkvstic/ and https://huggingface.co/BlinkDL/ for more models/modes - -# RWKV 1B5 instruct test 1 model -# Approximate -# [Vram usage: 6.0GB] -# [File size: 3.0GB] - - -config = { - "path":"https://huggingface.co/BlinkDL/rwkv-4-pile-1b5/resolve/main/RWKV-4-Pile-1B5-Instruct-test2-20230209.pth", - "mode":TORCH, - "runtimedtype":torch.float32, - "useGPU":torch.cuda.is_available(), - "dtype":torch.float32 -} - -title = "RWKV-4 (1B5 Instruct 2)" - -# RWKV 1B5 instruct model quantized -# Approximate -# [Vram usage: 1.3GB] -# [File size: 3.0GB] - -# config = { -# "path": "https://huggingface.co/BlinkDL/rwkv-4-pile-1b5/resolve/main/RWKV-4-Pile-1B5-Instruct-test1-20230124.pth", -# **quantized -# } - -# title = "RWKV-4 (1.5b Instruct Quantized)" - -# RWKV 7B instruct pre-quantized (settings baked into model) -# Approximate -# [Vram usage: 7.0GB] -# [File size: 8.0GB] - -# config = { -# "path": "https://huggingface.co/Hazzzardous/RWKV-8Bit/resolve/main/RWKV-4-Pile-7B-Instruct.pqth" -# } - -# title = "RWKV-4 (7b Instruct Quantized)" - -# RWKV 14B quantized (latest as of feb 9) -# Approximate -# [Vram usage: 15.0GB] -# [File size: 15.0GB] - -# config = { -# "path": "https://huggingface.co/Hazzzardous/RWKV-8Bit/resolve/main/RWKV-4-Pile-14B-20230204-7324.pqth" -# } - -# title = "RWKV-4 (14b 94% trained, not yet instruct tuned, 8-Bit)" \ No newline at end of file diff --git a/spaces/HighCWu/Style2Paints-4-Gradio/InstanceNorm.py b/spaces/HighCWu/Style2Paints-4-Gradio/InstanceNorm.py deleted file mode 100644 index e970eaad3b22a70c3e29512503095b6e565d229a..0000000000000000000000000000000000000000 --- a/spaces/HighCWu/Style2Paints-4-Gradio/InstanceNorm.py +++ /dev/null @@ -1,147 +0,0 @@ -from keras.engine.base_layer import Layer -from keras.engine.input_spec import InputSpec -from keras import initializers, regularizers, constraints -from keras import backend as K -from keras.saving.object_registration import get_custom_objects - -import tensorflow as tf - - -class InstanceNormalization(Layer): - """Instance normalization layer (Lei Ba et al, 2016, Ulyanov et al., 2016). - Normalize the activations of the previous layer at each step, - i.e. applies a transformation that maintains the mean activation - close to 0 and the activation standard deviation close to 1. - # Arguments - axis: Integer, the axis that should be normalized - (typically the features axis). - For instance, after a `Conv2D` layer with - `data_format="channels_first"`, - set `axis=1` in `InstanceNormalization`. - Setting `axis=None` will normalize all values in each instance of the batch. - Axis 0 is the batch dimension. `axis` cannot be set to 0 to avoid errors. - epsilon: Small float added to variance to avoid dividing by zero. - center: If True, add offset of `beta` to normalized tensor. - If False, `beta` is ignored. - scale: If True, multiply by `gamma`. - If False, `gamma` is not used. - When the next layer is linear (also e.g. `nn.relu`), - this can be disabled since the scaling - will be done by the next layer. - beta_initializer: Initializer for the beta weight. - gamma_initializer: Initializer for the gamma weight. - beta_regularizer: Optional regularizer for the beta weight. - gamma_regularizer: Optional regularizer for the gamma weight. - beta_constraint: Optional constraint for the beta weight. - gamma_constraint: Optional constraint for the gamma weight. - # Input shape - Arbitrary. Use the keyword argument `input_shape` - (tuple of integers, does not include the samples axis) - when using this layer as the first layer in a model. - # Output shape - Same shape as input. - # References - - [Layer Normalization](https://arxiv.org/abs/1607.06450) - - [Instance Normalization: The Missing Ingredient for Fast Stylization](https://arxiv.org/abs/1607.08022) - """ - def __init__(self, - axis=None, - epsilon=1e-3, - center=True, - scale=True, - beta_initializer='zeros', - gamma_initializer='ones', - beta_regularizer=None, - gamma_regularizer=None, - beta_constraint=None, - gamma_constraint=None, - **kwargs): - super(InstanceNormalization, self).__init__(**kwargs) - self.supports_masking = True - self.axis = axis - self.epsilon = epsilon - self.center = center - self.scale = scale - self.beta_initializer = initializers.get(beta_initializer) - self.gamma_initializer = initializers.get(gamma_initializer) - self.beta_regularizer = regularizers.get(beta_regularizer) - self.gamma_regularizer = regularizers.get(gamma_regularizer) - self.beta_constraint = constraints.get(beta_constraint) - self.gamma_constraint = constraints.get(gamma_constraint) - - def build(self, input_shape): - ndim = len(input_shape) - if self.axis == 0: - raise ValueError('Axis cannot be zero') - - if (self.axis is not None) and (ndim == 2): - raise ValueError('Cannot specify axis for rank 1 tensor') - - self.input_spec = InputSpec(ndim=ndim) - - if self.axis is None: - shape = (1,) - else: - shape = (input_shape[self.axis],) - - if self.scale: - self.gamma = self.add_weight(shape=shape, - name='gamma', - initializer=self.gamma_initializer, - regularizer=self.gamma_regularizer, - constraint=self.gamma_constraint) - else: - self.gamma = None - if self.center: - self.beta = self.add_weight(shape=shape, - name='beta', - initializer=self.beta_initializer, - regularizer=self.beta_regularizer, - constraint=self.beta_constraint) - else: - self.beta = None - self.built = True - - def call(self, inputs, training=None): - input_shape = K.int_shape(inputs) - reduction_axes = list(range(0, len(input_shape))) - - if (self.axis is not None): - del reduction_axes[self.axis] - - del reduction_axes[0] - - mean, var = tf.nn.moments(inputs, reduction_axes, keepdims=True) - stddev = tf.sqrt(var) + self.epsilon - normed = (inputs - mean) / stddev - - broadcast_shape = [1] * len(input_shape) - if self.axis is not None: - broadcast_shape[self.axis] = input_shape[self.axis] - - if self.scale: - broadcast_gamma = K.reshape(self.gamma, broadcast_shape) - normed = normed * broadcast_gamma - if self.center: - broadcast_beta = K.reshape(self.beta, broadcast_shape) - normed = normed + broadcast_beta - return normed - - def get_config(self): - config = { - 'axis': self.axis, - 'epsilon': self.epsilon, - 'center': self.center, - 'scale': self.scale, - 'beta_initializer': initializers.serialize(self.beta_initializer), - 'gamma_initializer': initializers.serialize(self.gamma_initializer), - 'beta_regularizer': regularizers.serialize(self.beta_regularizer), - 'gamma_regularizer': regularizers.serialize(self.gamma_regularizer), - 'beta_constraint': constraints.serialize(self.beta_constraint), - 'gamma_constraint': constraints.serialize(self.gamma_constraint) - } - base_config = super(InstanceNormalization, self).get_config() - return dict(list(base_config.items()) + list(config.items())) - - -get_custom_objects().update({'InstanceNormalization': InstanceNormalization}) diff --git a/spaces/ICML2022/OFA/fairseq/examples/noisychannel/rerank_utils.py b/spaces/ICML2022/OFA/fairseq/examples/noisychannel/rerank_utils.py deleted file mode 100644 index 2c6bf1b1afbb089cf5e84f720eb7a067479fbcbc..0000000000000000000000000000000000000000 --- a/spaces/ICML2022/OFA/fairseq/examples/noisychannel/rerank_utils.py +++ /dev/null @@ -1,850 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import math -import os -import re -import subprocess -from contextlib import redirect_stdout - -from fairseq import options -from fairseq_cli import eval_lm, preprocess - - -def reprocess(fle): - # takes in a file of generate.py translation generate_output - # returns a source dict and hypothesis dict, where keys are the ID num (as a string) - # and values and the corresponding source and translation. There may be several translations - # per source, so the values for hypothesis_dict are lists. - # parses output of generate.py - - with open(fle, "r") as f: - txt = f.read() - - """reprocess generate.py output""" - p = re.compile(r"[STHP][-]\d+\s*") - hp = re.compile(r"(\s*[-]?\d+[.]?\d+\s*)|(\s*(-inf)\s*)") - source_dict = {} - hypothesis_dict = {} - score_dict = {} - target_dict = {} - pos_score_dict = {} - lines = txt.split("\n") - - for line in lines: - line += "\n" - prefix = re.search(p, line) - if prefix is not None: - assert len(prefix.group()) > 2, "prefix id not found" - _, j = prefix.span() - id_num = prefix.group()[2:] - id_num = int(id_num) - line_type = prefix.group()[0] - if line_type == "H": - h_txt = line[j:] - hypo = re.search(hp, h_txt) - assert ( - hypo is not None - ), "regular expression failed to find the hypothesis scoring" - _, i = hypo.span() - score = hypo.group() - if id_num in hypothesis_dict: - hypothesis_dict[id_num].append(h_txt[i:]) - score_dict[id_num].append(float(score)) - else: - hypothesis_dict[id_num] = [h_txt[i:]] - score_dict[id_num] = [float(score)] - - elif line_type == "S": - source_dict[id_num] = line[j:] - elif line_type == "T": - target_dict[id_num] = line[j:] - elif line_type == "P": - pos_scores = (line[j:]).split() - pos_scores = [float(x) for x in pos_scores] - if id_num in pos_score_dict: - pos_score_dict[id_num].append(pos_scores) - else: - pos_score_dict[id_num] = [pos_scores] - - return source_dict, hypothesis_dict, score_dict, target_dict, pos_score_dict - - -def reprocess_nbest(fle): - """reprocess interactive.py output""" - with open(fle, "r") as f: - txt = f.read() - - source_dict = {} - hypothesis_dict = {} - score_dict = {} - target_dict = {} - pos_score_dict = {} - lines = txt.split("\n") - - hp = re.compile(r"[-]?\d+[.]?\d+") - j = -1 - - for _i, line in enumerate(lines): - line += "\n" - line_type = line[0] - - if line_type == "H": - hypo = re.search(hp, line) - _, start_index = hypo.span() - score = hypo.group() - if j in score_dict: - score_dict[j].append(float(score)) - hypothesis_dict[j].append(line[start_index:].strip("\t")) - else: - score_dict[j] = [float(score)] - hypothesis_dict[j] = [line[start_index:].strip("\t")] - elif line_type == "O": - j += 1 - source_dict[j] = line[2:] - # we don't have the targets for interactive.py - target_dict[j] = "filler" - - elif line_type == "P": - pos_scores = [float(pos_score) for pos_score in line.split()[1:]] - if j in pos_score_dict: - pos_score_dict[j].append(pos_scores) - else: - pos_score_dict[j] = [pos_scores] - - assert source_dict.keys() == hypothesis_dict.keys() - assert source_dict.keys() == pos_score_dict.keys() - assert source_dict.keys() == score_dict.keys() - - return source_dict, hypothesis_dict, score_dict, target_dict, pos_score_dict - - -def write_reprocessed( - sources, - hypos, - targets, - source_outfile, - hypo_outfile, - target_outfile, - right_to_left=False, - prefix_len=None, - bpe_symbol=None, - target_prefix_frac=None, - source_prefix_frac=None, -): - - """writes nbest hypothesis for rescoring""" - assert not ( - prefix_len is not None and target_prefix_frac is not None - ), "in writing reprocessed, only one type of prefix may be used" - assert not ( - prefix_len is not None and source_prefix_frac is not None - ), "in writing reprocessed, only one type of prefix may be used" - assert not ( - target_prefix_frac is not None and source_prefix_frac is not None - ), "in writing reprocessed, only one type of prefix may be used" - - with open(source_outfile, "w") as source_file, open( - hypo_outfile, "w" - ) as hypo_file, open(target_outfile, "w") as target_file: - - assert len(sources) == len(hypos), "sources and hypos list length mismatch" - if right_to_left: - for i in range(len(sources)): - for j in range(len(hypos[i])): - if prefix_len is None: - hypo_file.write(make_right_to_left(hypos[i][j]) + "\n") - else: - raise NotImplementedError() - source_file.write(make_right_to_left(sources[i]) + "\n") - target_file.write(make_right_to_left(targets[i]) + "\n") - else: - for i in sorted(sources.keys()): - for j in range(len(hypos[i])): - if prefix_len is not None: - shortened = ( - get_prefix_no_bpe(hypos[i][j], bpe_symbol, prefix_len) - + "\n" - ) - hypo_file.write(shortened) - source_file.write(sources[i]) - target_file.write(targets[i]) - elif target_prefix_frac is not None: - num_words, shortened, num_bpe_tokens = calc_length_from_frac( - hypos[i][j], target_prefix_frac, bpe_symbol - ) - shortened += "\n" - hypo_file.write(shortened) - source_file.write(sources[i]) - target_file.write(targets[i]) - elif source_prefix_frac is not None: - num_words, shortened, num_bpe_tokensn = calc_length_from_frac( - sources[i], source_prefix_frac, bpe_symbol - ) - shortened += "\n" - hypo_file.write(hypos[i][j]) - source_file.write(shortened) - target_file.write(targets[i]) - else: - hypo_file.write(hypos[i][j]) - source_file.write(sources[i]) - target_file.write(targets[i]) - - -def calc_length_from_frac(bpe_sentence, prefix_frac, bpe_symbol): - # return number of words, (not bpe tokens) that we want - no_bpe_sen = remove_bpe(bpe_sentence, bpe_symbol) - len_sen = len(no_bpe_sen.split()) - - num_words = math.ceil(len_sen * prefix_frac) - prefix = get_prefix_no_bpe(bpe_sentence, bpe_symbol, num_words) - num_bpe_tokens = len(prefix.split()) - return num_words, prefix, num_bpe_tokens - - -def get_prefix(sentence, prefix_len): - """assuming no bpe, gets the prefix of the sentence with prefix_len words""" - tokens = sentence.strip("\n").split() - if prefix_len >= len(tokens): - return sentence.strip("\n") - else: - return " ".join(tokens[:prefix_len]) - - -def get_prefix_no_bpe(sentence, bpe_symbol, prefix_len): - if bpe_symbol is None: - return get_prefix(sentence, prefix_len) - else: - return " ".join(get_prefix_from_len(sentence.split(), bpe_symbol, prefix_len)) - - -def get_prefix_from_len(sentence, bpe_symbol, prefix_len): - """get the prefix of sentence with bpe, with prefix len in terms of words, not bpe tokens""" - bpe_count = sum([bpe_symbol.strip(" ") in t for t in sentence[:prefix_len]]) - if bpe_count == 0: - return sentence[:prefix_len] - else: - return sentence[:prefix_len] + get_prefix_from_len( - sentence[prefix_len:], bpe_symbol, bpe_count - ) - - -def get_num_bpe_tokens_from_len(sentence, bpe_symbol, prefix_len): - """given a prefix length in terms of words, return the number of bpe tokens""" - prefix = get_prefix_no_bpe(sentence, bpe_symbol, prefix_len) - assert len(remove_bpe(prefix, bpe_symbol).split()) <= prefix_len - return len(prefix.split(" ")) - - -def make_right_to_left(line): - tokens = line.split() - tokens.reverse() - new_line = " ".join(tokens) - return new_line - - -def remove_bpe(line, bpe_symbol): - line = line.replace("\n", "") - line = (line + " ").replace(bpe_symbol, "").rstrip() - return line + ("\n") - - -def remove_bpe_dict(pred_dict, bpe_symbol): - new_dict = {} - for i in pred_dict: - if type(pred_dict[i]) == list: - new_list = [remove_bpe(elem, bpe_symbol) for elem in pred_dict[i]] - new_dict[i] = new_list - else: - new_dict[i] = remove_bpe(pred_dict[i], bpe_symbol) - return new_dict - - -def parse_bleu_scoring(line): - p = re.compile(r"(BLEU4 = )\d+[.]\d+") - res = re.search(p, line) - assert res is not None, line - return float(res.group()[8:]) - - -def get_full_from_prefix(hypo_prefix, hypos): - """given a hypo prefix, recover the first hypo from the list of complete hypos beginning with that prefix""" - for hypo in hypos: - hypo_prefix = hypo_prefix.strip("\n") - len_prefix = len(hypo_prefix) - if hypo[:len_prefix] == hypo_prefix: - return hypo - # no match found - raise Exception() - - -def get_score( - a, - b, - c, - target_len, - bitext_score1, - bitext_score2=None, - lm_score=None, - lenpen=None, - src_len=None, - tgt_len=None, - bitext1_backwards=False, - bitext2_backwards=False, - normalize=False, -): - if bitext1_backwards: - bitext1_norm = src_len - else: - bitext1_norm = tgt_len - if bitext_score2 is not None: - if bitext2_backwards: - bitext2_norm = src_len - else: - bitext2_norm = tgt_len - else: - bitext2_norm = 1 - bitext_score2 = 0 - if normalize: - score = ( - a * bitext_score1 / bitext1_norm - + b * bitext_score2 / bitext2_norm - + c * lm_score / src_len - ) - else: - score = a * bitext_score1 + b * bitext_score2 + c * lm_score - - if lenpen is not None: - score /= (target_len) ** float(lenpen) - - return score - - -class BitextOutput(object): - def __init__( - self, - output_file, - backwards, - right_to_left, - bpe_symbol, - prefix_len=None, - target_prefix_frac=None, - source_prefix_frac=None, - ): - """process output from rescoring""" - source, hypo, score, target, pos_score = reprocess(output_file) - if backwards: - self.hypo_fracs = source_prefix_frac - else: - self.hypo_fracs = target_prefix_frac - - # remove length penalty so we can use raw scores - score, num_bpe_tokens = get_score_from_pos( - pos_score, prefix_len, hypo, bpe_symbol, self.hypo_fracs, backwards - ) - source_lengths = {} - target_lengths = {} - - assert hypo.keys() == source.keys(), "key mismatch" - if backwards: - tmp = hypo - hypo = source - source = tmp - for i in source: - # since we are reranking, there should only be one hypo per source sentence - if backwards: - len_src = len(source[i][0].split()) - # record length without- if len_src == num_bpe_tokens[i][0] - 1: - source_lengths[i] = num_bpe_tokens[i][0] - 1 - else: - source_lengths[i] = num_bpe_tokens[i][0] - - target_lengths[i] = len(hypo[i].split()) - - source[i] = remove_bpe(source[i][0], bpe_symbol) - target[i] = remove_bpe(target[i], bpe_symbol) - hypo[i] = remove_bpe(hypo[i], bpe_symbol) - - score[i] = float(score[i][0]) - pos_score[i] = pos_score[i][0] - - else: - len_tgt = len(hypo[i][0].split()) - # record length without - if len_tgt == num_bpe_tokens[i][0] - 1: - target_lengths[i] = num_bpe_tokens[i][0] - 1 - else: - target_lengths[i] = num_bpe_tokens[i][0] - - source_lengths[i] = len(source[i].split()) - - if right_to_left: - source[i] = remove_bpe(make_right_to_left(source[i]), bpe_symbol) - target[i] = remove_bpe(make_right_to_left(target[i]), bpe_symbol) - hypo[i] = remove_bpe(make_right_to_left(hypo[i][0]), bpe_symbol) - score[i] = float(score[i][0]) - pos_score[i] = pos_score[i][0] - else: - assert ( - len(hypo[i]) == 1 - ), "expected only one hypothesis per source sentence" - source[i] = remove_bpe(source[i], bpe_symbol) - target[i] = remove_bpe(target[i], bpe_symbol) - hypo[i] = remove_bpe(hypo[i][0], bpe_symbol) - score[i] = float(score[i][0]) - pos_score[i] = pos_score[i][0] - - self.rescore_source = source - self.rescore_hypo = hypo - self.rescore_score = score - self.rescore_target = target - self.rescore_pos_score = pos_score - self.backwards = backwards - self.right_to_left = right_to_left - self.target_lengths = target_lengths - self.source_lengths = source_lengths - - -class BitextOutputFromGen(object): - def __init__( - self, - predictions_bpe_file, - bpe_symbol=None, - nbest=False, - prefix_len=None, - target_prefix_frac=None, - ): - if nbest: - ( - pred_source, - pred_hypo, - pred_score, - pred_target, - pred_pos_score, - ) = reprocess_nbest(predictions_bpe_file) - else: - pred_source, pred_hypo, pred_score, pred_target, pred_pos_score = reprocess( - predictions_bpe_file - ) - - assert len(pred_source) == len(pred_hypo) - assert len(pred_source) == len(pred_score) - assert len(pred_source) == len(pred_target) - assert len(pred_source) == len(pred_pos_score) - - # remove length penalty so we can use raw scores - pred_score, num_bpe_tokens = get_score_from_pos( - pred_pos_score, prefix_len, pred_hypo, bpe_symbol, target_prefix_frac, False - ) - - self.source = pred_source - self.target = pred_target - self.score = pred_score - self.pos_score = pred_pos_score - self.hypo = pred_hypo - self.target_lengths = {} - self.source_lengths = {} - - self.no_bpe_source = remove_bpe_dict(pred_source.copy(), bpe_symbol) - self.no_bpe_hypo = remove_bpe_dict(pred_hypo.copy(), bpe_symbol) - self.no_bpe_target = remove_bpe_dict(pred_target.copy(), bpe_symbol) - - # indexes to match those from the rescoring models - self.rescore_source = {} - self.rescore_target = {} - self.rescore_pos_score = {} - self.rescore_hypo = {} - self.rescore_score = {} - self.num_hypos = {} - self.backwards = False - self.right_to_left = False - - index = 0 - - for i in sorted(pred_source.keys()): - for j in range(len(pred_hypo[i])): - - self.target_lengths[index] = len(self.hypo[i][j].split()) - self.source_lengths[index] = len(self.source[i].split()) - - self.rescore_source[index] = self.no_bpe_source[i] - self.rescore_target[index] = self.no_bpe_target[i] - self.rescore_hypo[index] = self.no_bpe_hypo[i][j] - self.rescore_score[index] = float(pred_score[i][j]) - self.rescore_pos_score[index] = pred_pos_score[i][j] - self.num_hypos[index] = len(pred_hypo[i]) - index += 1 - - -def get_score_from_pos( - pos_score_dict, prefix_len, hypo_dict, bpe_symbol, hypo_frac, backwards -): - score_dict = {} - num_bpe_tokens_dict = {} - assert prefix_len is None or hypo_frac is None - for key in pos_score_dict: - score_dict[key] = [] - num_bpe_tokens_dict[key] = [] - for i in range(len(pos_score_dict[key])): - if prefix_len is not None and not backwards: - num_bpe_tokens = get_num_bpe_tokens_from_len( - hypo_dict[key][i], bpe_symbol, prefix_len - ) - score_dict[key].append(sum(pos_score_dict[key][i][:num_bpe_tokens])) - num_bpe_tokens_dict[key].append(num_bpe_tokens) - elif hypo_frac is not None: - num_words, shortened, hypo_prefix_len = calc_length_from_frac( - hypo_dict[key][i], hypo_frac, bpe_symbol - ) - score_dict[key].append(sum(pos_score_dict[key][i][:hypo_prefix_len])) - num_bpe_tokens_dict[key].append(hypo_prefix_len) - else: - score_dict[key].append(sum(pos_score_dict[key][i])) - num_bpe_tokens_dict[key].append(len(pos_score_dict[key][i])) - return score_dict, num_bpe_tokens_dict - - -class LMOutput(object): - def __init__( - self, - lm_score_file, - lm_dict=None, - prefix_len=None, - bpe_symbol=None, - target_prefix_frac=None, - ): - ( - lm_sentences, - lm_sen_scores, - lm_sen_pos_scores, - lm_no_bpe_sentences, - lm_bpe_tokens, - ) = parse_lm( - lm_score_file, - prefix_len=prefix_len, - bpe_symbol=bpe_symbol, - target_prefix_frac=target_prefix_frac, - ) - - self.sentences = lm_sentences - self.score = lm_sen_scores - self.pos_score = lm_sen_pos_scores - self.lm_dict = lm_dict - self.no_bpe_sentences = lm_no_bpe_sentences - self.bpe_tokens = lm_bpe_tokens - - -def parse_lm(input_file, prefix_len=None, bpe_symbol=None, target_prefix_frac=None): - """parse output of eval_lm""" - with open(input_file, "r") as f: - text = f.readlines() - text = text[7:] - cleaned_text = text[:-2] - - sentences = {} - sen_scores = {} - sen_pos_scores = {} - no_bpe_sentences = {} - num_bpe_tokens_dict = {} - for _i, line in enumerate(cleaned_text): - tokens = line.split() - if tokens[0].isdigit(): - line_id = int(tokens[0]) - scores = [float(x[1:-1]) for x in tokens[2::2]] - sentences[line_id] = " ".join(tokens[1::2][:-1]) + "\n" - if bpe_symbol is not None: - # exclude symbol to match output from generate.py - bpe_sen = " ".join(tokens[1::2][:-1]) + "\n" - no_bpe_sen = remove_bpe(bpe_sen, bpe_symbol) - no_bpe_sentences[line_id] = no_bpe_sen - - if prefix_len is not None: - num_bpe_tokens = get_num_bpe_tokens_from_len( - bpe_sen, bpe_symbol, prefix_len - ) - sen_scores[line_id] = sum(scores[:num_bpe_tokens]) - num_bpe_tokens_dict[line_id] = num_bpe_tokens - elif target_prefix_frac is not None: - num_words, shortened, target_prefix_len = calc_length_from_frac( - bpe_sen, target_prefix_frac, bpe_symbol - ) - sen_scores[line_id] = sum(scores[:target_prefix_len]) - num_bpe_tokens_dict[line_id] = target_prefix_len - else: - sen_scores[line_id] = sum(scores) - num_bpe_tokens_dict[line_id] = len(scores) - - sen_pos_scores[line_id] = scores - - return sentences, sen_scores, sen_pos_scores, no_bpe_sentences, num_bpe_tokens_dict - - -def get_directories( - data_dir_name, - num_rescore, - gen_subset, - fw_name, - shard_id, - num_shards, - sampling=False, - prefix_len=None, - target_prefix_frac=None, - source_prefix_frac=None, -): - nbest_file_id = ( - "nbest_" - + str(num_rescore) - + "_subset_" - + gen_subset - + "_fw_name_" - + fw_name - + "_shard_" - + str(shard_id) - + "_of_" - + str(num_shards) - ) - - if sampling: - nbest_file_id += "_sampling" - - # the directory containing all information for this nbest list - pre_gen = ( - os.path.join(os.path.dirname(__file__)) - + "/rerank_data/" - + data_dir_name - + "/" - + nbest_file_id - ) - # the directory to store the preprocessed nbest list, for left to right rescoring - left_to_right_preprocessed_dir = pre_gen + "/left_to_right_preprocessed" - if source_prefix_frac is not None: - left_to_right_preprocessed_dir = ( - left_to_right_preprocessed_dir + "/prefix_frac" + str(source_prefix_frac) - ) - # the directory to store the preprocessed nbest list, for right to left rescoring - right_to_left_preprocessed_dir = pre_gen + "/right_to_left_preprocessed" - # the directory to store the preprocessed nbest list, for backwards rescoring - backwards_preprocessed_dir = pre_gen + "/backwards" - if target_prefix_frac is not None: - backwards_preprocessed_dir = ( - backwards_preprocessed_dir + "/prefix_frac" + str(target_prefix_frac) - ) - elif prefix_len is not None: - backwards_preprocessed_dir = ( - backwards_preprocessed_dir + "/prefix_" + str(prefix_len) - ) - - # the directory to store the preprocessed nbest list, for rescoring with P(T) - lm_preprocessed_dir = pre_gen + "/lm_preprocessed" - - return ( - pre_gen, - left_to_right_preprocessed_dir, - right_to_left_preprocessed_dir, - backwards_preprocessed_dir, - lm_preprocessed_dir, - ) - - -def lm_scoring( - preprocess_directory, - bpe_status, - gen_output, - pre_gen, - cur_lm_dict, - cur_lm_name, - cur_language_model, - cur_lm_bpe_code, - batch_size, - lm_score_file, - target_lang, - source_lang, - prefix_len=None, -): - if prefix_len is not None: - assert ( - bpe_status == "different" - ), "bpe status must be different to use prefix len" - if bpe_status == "no bpe": - # run lm on output without bpe - write_reprocessed( - gen_output.no_bpe_source, - gen_output.no_bpe_hypo, - gen_output.no_bpe_target, - pre_gen + "/rescore_data_no_bpe.de", - pre_gen + "/rescore_data_no_bpe.en", - pre_gen + "/reference_file_no_bpe", - ) - - preprocess_lm_param = [ - "--only-source", - "--trainpref", - pre_gen + "/rescore_data_no_bpe." + target_lang, - "--srcdict", - cur_lm_dict, - "--destdir", - preprocess_directory, - ] - preprocess_parser = options.get_preprocessing_parser() - input_args = preprocess_parser.parse_args(preprocess_lm_param) - preprocess.main(input_args) - - eval_lm_param = [ - preprocess_directory, - "--path", - cur_language_model, - "--output-word-probs", - "--batch-size", - str(batch_size), - "--max-tokens", - "1024", - "--sample-break-mode", - "eos", - "--gen-subset", - "train", - ] - - eval_lm_parser = options.get_eval_lm_parser() - input_args = options.parse_args_and_arch(eval_lm_parser, eval_lm_param) - - with open(lm_score_file, "w") as f: - with redirect_stdout(f): - eval_lm.main(input_args) - - elif bpe_status == "shared": - preprocess_lm_param = [ - "--only-source", - "--trainpref", - pre_gen + "/rescore_data." + target_lang, - "--srcdict", - cur_lm_dict, - "--destdir", - preprocess_directory, - ] - preprocess_parser = options.get_preprocessing_parser() - input_args = preprocess_parser.parse_args(preprocess_lm_param) - preprocess.main(input_args) - - eval_lm_param = [ - preprocess_directory, - "--path", - cur_language_model, - "--output-word-probs", - "--batch-size", - str(batch_size), - "--sample-break-mode", - "eos", - "--gen-subset", - "train", - ] - - eval_lm_parser = options.get_eval_lm_parser() - input_args = options.parse_args_and_arch(eval_lm_parser, eval_lm_param) - - with open(lm_score_file, "w") as f: - with redirect_stdout(f): - eval_lm.main(input_args) - - elif bpe_status == "different": - rescore_file = pre_gen + "/rescore_data_no_bpe" - rescore_bpe = pre_gen + "/rescore_data_new_bpe" - - rescore_file += "." - rescore_bpe += "." - - write_reprocessed( - gen_output.no_bpe_source, - gen_output.no_bpe_hypo, - gen_output.no_bpe_target, - rescore_file + source_lang, - rescore_file + target_lang, - pre_gen + "/reference_file_no_bpe", - bpe_symbol=None, - ) - - # apply LM bpe to nbest list - bpe_src_param = [ - "-c", - cur_lm_bpe_code, - "--input", - rescore_file + target_lang, - "--output", - rescore_bpe + target_lang, - ] - subprocess.call( - [ - "python", - os.path.join( - os.path.dirname(__file__), "subword-nmt/subword_nmt/apply_bpe.py" - ), - ] - + bpe_src_param, - shell=False, - ) - # uncomment to use fastbpe instead of subword-nmt bpe - # bpe_src_param = [rescore_bpe+target_lang, rescore_file+target_lang, cur_lm_bpe_code] - # subprocess.call(["/private/home/edunov/fastBPE/fast", "applybpe"] + bpe_src_param, shell=False) - - preprocess_dir = preprocess_directory - - preprocess_lm_param = [ - "--only-source", - "--trainpref", - rescore_bpe + target_lang, - "--srcdict", - cur_lm_dict, - "--destdir", - preprocess_dir, - ] - preprocess_parser = options.get_preprocessing_parser() - input_args = preprocess_parser.parse_args(preprocess_lm_param) - preprocess.main(input_args) - - eval_lm_param = [ - preprocess_dir, - "--path", - cur_language_model, - "--output-word-probs", - "--batch-size", - str(batch_size), - "--max-tokens", - "1024", - "--sample-break-mode", - "eos", - "--gen-subset", - "train", - ] - - eval_lm_parser = options.get_eval_lm_parser() - input_args = options.parse_args_and_arch(eval_lm_parser, eval_lm_param) - - with open(lm_score_file, "w") as f: - with redirect_stdout(f): - eval_lm.main(input_args) - - -def rescore_file_name( - nbest_dir, - prefix_len, - scorer_name, - lm_file=False, - target_prefix_frac=None, - source_prefix_frac=None, - backwards=None, -): - if lm_file: - score_file = nbest_dir + "/lm_score_translations_model_" + scorer_name + ".txt" - else: - score_file = nbest_dir + "/" + scorer_name + "_score_translations.txt" - if backwards: - if prefix_len is not None: - score_file += "prefix_len" + str(prefix_len) - elif target_prefix_frac is not None: - score_file += "target_prefix_frac" + str(target_prefix_frac) - else: - if source_prefix_frac is not None: - score_file += "source_prefix_frac" + str(source_prefix_frac) - return score_file diff --git a/spaces/ICML2022/OFA/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/logmel_feature_reader.py b/spaces/ICML2022/OFA/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/logmel_feature_reader.py deleted file mode 100644 index 106f50247622deca688b223f1ad63275d5b65e58..0000000000000000000000000000000000000000 --- a/spaces/ICML2022/OFA/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/logmel_feature_reader.py +++ /dev/null @@ -1,30 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import soundfile as sf -import torch -import torchaudio.compliance.kaldi as kaldi - - -class LogMelFeatureReader: - """ - Wrapper class to run inference on HuBERT model. - Helps extract features for a given audio file. - """ - - def __init__(self, *args, **kwargs): - self.num_mel_bins = kwargs.get("num_mel_bins", 80) - self.frame_length = kwargs.get("frame_length", 25.0) - - def get_feats(self, file_path): - wav, sr = sf.read(file_path) - feats = torch.from_numpy(wav).float() - feats = kaldi.fbank( - feats.unsqueeze(0), - num_mel_bins=self.num_mel_bins, - frame_length=self.frame_length, - sample_frequency=sr, - ) - return feats diff --git a/spaces/ICML2022/OFA/fairseq/fairseq/modules/quantization/pq/modules/qlinear.py b/spaces/ICML2022/OFA/fairseq/fairseq/modules/quantization/pq/modules/qlinear.py deleted file mode 100644 index 9bdd25a8685bb7c7b32e1f02372aaeb26d8ba53a..0000000000000000000000000000000000000000 --- a/spaces/ICML2022/OFA/fairseq/fairseq/modules/quantization/pq/modules/qlinear.py +++ /dev/null @@ -1,71 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import torch -import torch.nn as nn -import torch.nn.functional as F - - -class PQLinear(nn.Module): - """ - Quantized counterpart of nn.Linear module. Stores the centroid, the assignments - and the non-quantized biases. The full weight is re-instantiated at each forward - pass. - - Args: - - centroids: centroids of size n_centroids x block_size - - assignments: assignments of the centroids to the subvectors - of size self.out_features x n_blocks - - bias: the non-quantized bias - - Remarks: - - We refer the reader to the official documentation of the nn.Linear module - for the other arguments and the behavior of the module - - Performance tests on GPU show that this implementation is 15% slower than - the non-quantized nn.Linear module for a standard training loop. - """ - - def __init__(self, centroids, assignments, bias, in_features, out_features): - super(PQLinear, self).__init__() - self.block_size = centroids.size(1) - self.n_centroids = centroids.size(0) - self.in_features = in_features - self.out_features = out_features - # check compatibility - if self.in_features % self.block_size != 0: - raise ValueError("Wrong PQ sizes") - if len(assignments) % self.out_features != 0: - raise ValueError("Wrong PQ sizes") - # define parameters - self.centroids = nn.Parameter(centroids, requires_grad=True) - self.register_buffer("assignments", assignments) - self.register_buffer("counts", torch.bincount(assignments).type_as(centroids)) - if bias is not None: - self.bias = nn.Parameter(bias) - else: - self.register_parameter("bias", None) - - @property - def weight(self): - return ( - self.centroids[self.assignments] - .reshape(-1, self.out_features, self.block_size) - .permute(1, 0, 2) - .flatten(1, 2) - ) - - def forward(self, x): - return F.linear( - x, - self.weight, - self.bias, - ) - - def extra_repr(self): - return f"in_features={self.in_features},\ - out_features={self.out_features},\ - n_centroids={self.n_centroids},\ - block_size={self.block_size},\ - bias={self.bias is not None}" diff --git a/spaces/Iceclear/StableSR/StableSR/ldm/models/diffusion/classifier.py b/spaces/Iceclear/StableSR/StableSR/ldm/models/diffusion/classifier.py deleted file mode 100644 index 67e98b9d8ffb96a150b517497ace0a242d7163ef..0000000000000000000000000000000000000000 --- a/spaces/Iceclear/StableSR/StableSR/ldm/models/diffusion/classifier.py +++ /dev/null @@ -1,267 +0,0 @@ -import os -import torch -import pytorch_lightning as pl -from omegaconf import OmegaConf -from torch.nn import functional as F -from torch.optim import AdamW -from torch.optim.lr_scheduler import LambdaLR -from copy import deepcopy -from einops import rearrange -from glob import glob -from natsort import natsorted - -from ldm.modules.diffusionmodules.openaimodel import EncoderUNetModel, UNetModel -from ldm.util import log_txt_as_img, default, ismap, instantiate_from_config - -__models__ = { - 'class_label': EncoderUNetModel, - 'segmentation': UNetModel -} - - -def disabled_train(self, mode=True): - """Overwrite model.train with this function to make sure train/eval mode - does not change anymore.""" - return self - - -class NoisyLatentImageClassifier(pl.LightningModule): - - def __init__(self, - diffusion_path, - num_classes, - ckpt_path=None, - pool='attention', - label_key=None, - diffusion_ckpt_path=None, - scheduler_config=None, - weight_decay=1.e-2, - log_steps=10, - monitor='val/loss', - *args, - **kwargs): - super().__init__(*args, **kwargs) - self.num_classes = num_classes - # get latest config of diffusion model - diffusion_config = natsorted(glob(os.path.join(diffusion_path, 'configs', '*-project.yaml')))[-1] - self.diffusion_config = OmegaConf.load(diffusion_config).model - self.diffusion_config.params.ckpt_path = diffusion_ckpt_path - self.load_diffusion() - - self.monitor = monitor - self.numd = self.diffusion_model.first_stage_model.encoder.num_resolutions - 1 - self.log_time_interval = self.diffusion_model.num_timesteps // log_steps - self.log_steps = log_steps - - self.label_key = label_key if not hasattr(self.diffusion_model, 'cond_stage_key') \ - else self.diffusion_model.cond_stage_key - - assert self.label_key is not None, 'label_key neither in diffusion model nor in model.params' - - if self.label_key not in __models__: - raise NotImplementedError() - - self.load_classifier(ckpt_path, pool) - - self.scheduler_config = scheduler_config - self.use_scheduler = self.scheduler_config is not None - self.weight_decay = weight_decay - - def init_from_ckpt(self, path, ignore_keys=list(), only_model=False): - sd = torch.load(path, map_location="cpu") - if "state_dict" in list(sd.keys()): - sd = sd["state_dict"] - keys = list(sd.keys()) - for k in keys: - for ik in ignore_keys: - if k.startswith(ik): - print("Deleting key {} from state_dict.".format(k)) - del sd[k] - missing, unexpected = self.load_state_dict(sd, strict=False) if not only_model else self.model.load_state_dict( - sd, strict=False) - print(f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys") - if len(missing) > 0: - print(f"Missing Keys: {missing}") - if len(unexpected) > 0: - print(f"Unexpected Keys: {unexpected}") - - def load_diffusion(self): - model = instantiate_from_config(self.diffusion_config) - self.diffusion_model = model.eval() - self.diffusion_model.train = disabled_train - for param in self.diffusion_model.parameters(): - param.requires_grad = False - - def load_classifier(self, ckpt_path, pool): - model_config = deepcopy(self.diffusion_config.params.unet_config.params) - model_config.in_channels = self.diffusion_config.params.unet_config.params.out_channels - model_config.out_channels = self.num_classes - if self.label_key == 'class_label': - model_config.pool = pool - - self.model = __models__[self.label_key](**model_config) - if ckpt_path is not None: - print('#####################################################################') - print(f'load from ckpt "{ckpt_path}"') - print('#####################################################################') - self.init_from_ckpt(ckpt_path) - - @torch.no_grad() - def get_x_noisy(self, x, t, noise=None): - noise = default(noise, lambda: torch.randn_like(x)) - continuous_sqrt_alpha_cumprod = None - if self.diffusion_model.use_continuous_noise: - continuous_sqrt_alpha_cumprod = self.diffusion_model.sample_continuous_noise_level(x.shape[0], t + 1) - # todo: make sure t+1 is correct here - - return self.diffusion_model.q_sample(x_start=x, t=t, noise=noise, - continuous_sqrt_alpha_cumprod=continuous_sqrt_alpha_cumprod) - - def forward(self, x_noisy, t, *args, **kwargs): - return self.model(x_noisy, t) - - @torch.no_grad() - def get_input(self, batch, k): - x = batch[k] - if len(x.shape) == 3: - x = x[..., None] - x = rearrange(x, 'b h w c -> b c h w') - x = x.to(memory_format=torch.contiguous_format).float() - return x - - @torch.no_grad() - def get_conditioning(self, batch, k=None): - if k is None: - k = self.label_key - assert k is not None, 'Needs to provide label key' - - targets = batch[k].to(self.device) - - if self.label_key == 'segmentation': - targets = rearrange(targets, 'b h w c -> b c h w') - for down in range(self.numd): - h, w = targets.shape[-2:] - targets = F.interpolate(targets, size=(h // 2, w // 2), mode='nearest') - - # targets = rearrange(targets,'b c h w -> b h w c') - - return targets - - def compute_top_k(self, logits, labels, k, reduction="mean"): - _, top_ks = torch.topk(logits, k, dim=1) - if reduction == "mean": - return (top_ks == labels[:, None]).float().sum(dim=-1).mean().item() - elif reduction == "none": - return (top_ks == labels[:, None]).float().sum(dim=-1) - - def on_train_epoch_start(self): - # save some memory - self.diffusion_model.model.to('cpu') - - @torch.no_grad() - def write_logs(self, loss, logits, targets): - log_prefix = 'train' if self.training else 'val' - log = {} - log[f"{log_prefix}/loss"] = loss.mean() - log[f"{log_prefix}/acc@1"] = self.compute_top_k( - logits, targets, k=1, reduction="mean" - ) - log[f"{log_prefix}/acc@5"] = self.compute_top_k( - logits, targets, k=5, reduction="mean" - ) - - self.log_dict(log, prog_bar=False, logger=True, on_step=self.training, on_epoch=True) - self.log('loss', log[f"{log_prefix}/loss"], prog_bar=True, logger=False) - self.log('global_step', self.global_step, logger=False, on_epoch=False, prog_bar=True) - lr = self.optimizers().param_groups[0]['lr'] - self.log('lr_abs', lr, on_step=True, logger=True, on_epoch=False, prog_bar=True) - - def shared_step(self, batch, t=None): - x, *_ = self.diffusion_model.get_input(batch, k=self.diffusion_model.first_stage_key) - targets = self.get_conditioning(batch) - if targets.dim() == 4: - targets = targets.argmax(dim=1) - if t is None: - t = torch.randint(0, self.diffusion_model.num_timesteps, (x.shape[0],), device=self.device).long() - else: - t = torch.full(size=(x.shape[0],), fill_value=t, device=self.device).long() - x_noisy = self.get_x_noisy(x, t) - logits = self(x_noisy, t) - - loss = F.cross_entropy(logits, targets, reduction='none') - - self.write_logs(loss.detach(), logits.detach(), targets.detach()) - - loss = loss.mean() - return loss, logits, x_noisy, targets - - def training_step(self, batch, batch_idx): - loss, *_ = self.shared_step(batch) - return loss - - def reset_noise_accs(self): - self.noisy_acc = {t: {'acc@1': [], 'acc@5': []} for t in - range(0, self.diffusion_model.num_timesteps, self.diffusion_model.log_every_t)} - - def on_validation_start(self): - self.reset_noise_accs() - - @torch.no_grad() - def validation_step(self, batch, batch_idx): - loss, *_ = self.shared_step(batch) - - for t in self.noisy_acc: - _, logits, _, targets = self.shared_step(batch, t) - self.noisy_acc[t]['acc@1'].append(self.compute_top_k(logits, targets, k=1, reduction='mean')) - self.noisy_acc[t]['acc@5'].append(self.compute_top_k(logits, targets, k=5, reduction='mean')) - - return loss - - def configure_optimizers(self): - optimizer = AdamW(self.model.parameters(), lr=self.learning_rate, weight_decay=self.weight_decay) - - if self.use_scheduler: - scheduler = instantiate_from_config(self.scheduler_config) - - print("Setting up LambdaLR scheduler...") - scheduler = [ - { - 'scheduler': LambdaLR(optimizer, lr_lambda=scheduler.schedule), - 'interval': 'step', - 'frequency': 1 - }] - return [optimizer], scheduler - - return optimizer - - @torch.no_grad() - def log_images(self, batch, N=8, *args, **kwargs): - log = dict() - x = self.get_input(batch, self.diffusion_model.first_stage_key) - log['inputs'] = x - - y = self.get_conditioning(batch) - - if self.label_key == 'class_label': - y = log_txt_as_img((x.shape[2], x.shape[3]), batch["human_label"]) - log['labels'] = y - - if ismap(y): - log['labels'] = self.diffusion_model.to_rgb(y) - - for step in range(self.log_steps): - current_time = step * self.log_time_interval - - _, logits, x_noisy, _ = self.shared_step(batch, t=current_time) - - log[f'inputs@t{current_time}'] = x_noisy - - pred = F.one_hot(logits.argmax(dim=1), num_classes=self.num_classes) - pred = rearrange(pred, 'b h w c -> b c h w') - - log[f'pred@t{current_time}'] = self.diffusion_model.to_rgb(pred) - - for key in log: - log[key] = log[key][:N] - - return log diff --git a/spaces/Ikaros521/so-vits-svc-4.0-ikaros/vdecoder/hifigan/models.py b/spaces/Ikaros521/so-vits-svc-4.0-ikaros/vdecoder/hifigan/models.py deleted file mode 100644 index 9747301f350bb269e62601017fe4633ce271b27e..0000000000000000000000000000000000000000 --- a/spaces/Ikaros521/so-vits-svc-4.0-ikaros/vdecoder/hifigan/models.py +++ /dev/null @@ -1,503 +0,0 @@ -import os -import json -from .env import AttrDict -import numpy as np -import torch -import torch.nn.functional as F -import torch.nn as nn -from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d -from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm -from .utils import init_weights, get_padding - -LRELU_SLOPE = 0.1 - - -def load_model(model_path, device='cuda'): - config_file = os.path.join(os.path.split(model_path)[0], 'config.json') - with open(config_file) as f: - data = f.read() - - global h - json_config = json.loads(data) - h = AttrDict(json_config) - - generator = Generator(h).to(device) - - cp_dict = torch.load(model_path) - generator.load_state_dict(cp_dict['generator']) - generator.eval() - generator.remove_weight_norm() - del cp_dict - return generator, h - - -class ResBlock1(torch.nn.Module): - def __init__(self, h, channels, kernel_size=3, dilation=(1, 3, 5)): - super(ResBlock1, self).__init__() - self.h = h - self.convs1 = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2], - padding=get_padding(kernel_size, dilation[2]))) - ]) - self.convs1.apply(init_weights) - - self.convs2 = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))) - ]) - self.convs2.apply(init_weights) - - def forward(self, x): - for c1, c2 in zip(self.convs1, self.convs2): - xt = F.leaky_relu(x, LRELU_SLOPE) - xt = c1(xt) - xt = F.leaky_relu(xt, LRELU_SLOPE) - xt = c2(xt) - x = xt + x - return x - - def remove_weight_norm(self): - for l in self.convs1: - remove_weight_norm(l) - for l in self.convs2: - remove_weight_norm(l) - - -class ResBlock2(torch.nn.Module): - def __init__(self, h, channels, kernel_size=3, dilation=(1, 3)): - super(ResBlock2, self).__init__() - self.h = h - self.convs = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]))) - ]) - self.convs.apply(init_weights) - - def forward(self, x): - for c in self.convs: - xt = F.leaky_relu(x, LRELU_SLOPE) - xt = c(xt) - x = xt + x - return x - - def remove_weight_norm(self): - for l in self.convs: - remove_weight_norm(l) - - -def padDiff(x): - return F.pad(F.pad(x, (0,0,-1,1), 'constant', 0) - x, (0,0,0,-1), 'constant', 0) - -class SineGen(torch.nn.Module): - """ Definition of sine generator - SineGen(samp_rate, harmonic_num = 0, - sine_amp = 0.1, noise_std = 0.003, - voiced_threshold = 0, - flag_for_pulse=False) - samp_rate: sampling rate in Hz - harmonic_num: number of harmonic overtones (default 0) - sine_amp: amplitude of sine-wavefrom (default 0.1) - noise_std: std of Gaussian noise (default 0.003) - voiced_thoreshold: F0 threshold for U/V classification (default 0) - flag_for_pulse: this SinGen is used inside PulseGen (default False) - Note: when flag_for_pulse is True, the first time step of a voiced - segment is always sin(np.pi) or cos(0) - """ - - def __init__(self, samp_rate, harmonic_num=0, - sine_amp=0.1, noise_std=0.003, - voiced_threshold=0, - flag_for_pulse=False): - super(SineGen, self).__init__() - self.sine_amp = sine_amp - self.noise_std = noise_std - self.harmonic_num = harmonic_num - self.dim = self.harmonic_num + 1 - self.sampling_rate = samp_rate - self.voiced_threshold = voiced_threshold - self.flag_for_pulse = flag_for_pulse - - def _f02uv(self, f0): - # generate uv signal - uv = (f0 > self.voiced_threshold).type(torch.float32) - return uv - - def _f02sine(self, f0_values): - """ f0_values: (batchsize, length, dim) - where dim indicates fundamental tone and overtones - """ - # convert to F0 in rad. The interger part n can be ignored - # because 2 * np.pi * n doesn't affect phase - rad_values = (f0_values / self.sampling_rate) % 1 - - # initial phase noise (no noise for fundamental component) - rand_ini = torch.rand(f0_values.shape[0], f0_values.shape[2], \ - device=f0_values.device) - rand_ini[:, 0] = 0 - rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini - - # instantanouse phase sine[t] = sin(2*pi \sum_i=1 ^{t} rad) - if not self.flag_for_pulse: - # for normal case - - # To prevent torch.cumsum numerical overflow, - # it is necessary to add -1 whenever \sum_k=1^n rad_value_k > 1. - # Buffer tmp_over_one_idx indicates the time step to add -1. - # This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi - tmp_over_one = torch.cumsum(rad_values, 1) % 1 - tmp_over_one_idx = (padDiff(tmp_over_one)) < 0 - cumsum_shift = torch.zeros_like(rad_values) - cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0 - - sines = torch.sin(torch.cumsum(rad_values + cumsum_shift, dim=1) - * 2 * np.pi) - else: - # If necessary, make sure that the first time step of every - # voiced segments is sin(pi) or cos(0) - # This is used for pulse-train generation - - # identify the last time step in unvoiced segments - uv = self._f02uv(f0_values) - uv_1 = torch.roll(uv, shifts=-1, dims=1) - uv_1[:, -1, :] = 1 - u_loc = (uv < 1) * (uv_1 > 0) - - # get the instantanouse phase - tmp_cumsum = torch.cumsum(rad_values, dim=1) - # different batch needs to be processed differently - for idx in range(f0_values.shape[0]): - temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :] - temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :] - # stores the accumulation of i.phase within - # each voiced segments - tmp_cumsum[idx, :, :] = 0 - tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum - - # rad_values - tmp_cumsum: remove the accumulation of i.phase - # within the previous voiced segment. - i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1) - - # get the sines - sines = torch.cos(i_phase * 2 * np.pi) - return sines - - def forward(self, f0): - """ sine_tensor, uv = forward(f0) - input F0: tensor(batchsize=1, length, dim=1) - f0 for unvoiced steps should be 0 - output sine_tensor: tensor(batchsize=1, length, dim) - output uv: tensor(batchsize=1, length, 1) - """ - with torch.no_grad(): - f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, - device=f0.device) - # fundamental component - fn = torch.multiply(f0, torch.FloatTensor([[range(1, self.harmonic_num + 2)]]).to(f0.device)) - - # generate sine waveforms - sine_waves = self._f02sine(fn) * self.sine_amp - - # generate uv signal - # uv = torch.ones(f0.shape) - # uv = uv * (f0 > self.voiced_threshold) - uv = self._f02uv(f0) - - # noise: for unvoiced should be similar to sine_amp - # std = self.sine_amp/3 -> max value ~ self.sine_amp - # . for voiced regions is self.noise_std - noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3 - noise = noise_amp * torch.randn_like(sine_waves) - - # first: set the unvoiced part to 0 by uv - # then: additive noise - sine_waves = sine_waves * uv + noise - return sine_waves, uv, noise - - -class SourceModuleHnNSF(torch.nn.Module): - """ SourceModule for hn-nsf - SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1, - add_noise_std=0.003, voiced_threshod=0) - sampling_rate: sampling_rate in Hz - harmonic_num: number of harmonic above F0 (default: 0) - sine_amp: amplitude of sine source signal (default: 0.1) - add_noise_std: std of additive Gaussian noise (default: 0.003) - note that amplitude of noise in unvoiced is decided - by sine_amp - voiced_threshold: threhold to set U/V given F0 (default: 0) - Sine_source, noise_source = SourceModuleHnNSF(F0_sampled) - F0_sampled (batchsize, length, 1) - Sine_source (batchsize, length, 1) - noise_source (batchsize, length 1) - uv (batchsize, length, 1) - """ - - def __init__(self, sampling_rate, harmonic_num=0, sine_amp=0.1, - add_noise_std=0.003, voiced_threshod=0): - super(SourceModuleHnNSF, self).__init__() - - self.sine_amp = sine_amp - self.noise_std = add_noise_std - - # to produce sine waveforms - self.l_sin_gen = SineGen(sampling_rate, harmonic_num, - sine_amp, add_noise_std, voiced_threshod) - - # to merge source harmonics into a single excitation - self.l_linear = torch.nn.Linear(harmonic_num + 1, 1) - self.l_tanh = torch.nn.Tanh() - - def forward(self, x): - """ - Sine_source, noise_source = SourceModuleHnNSF(F0_sampled) - F0_sampled (batchsize, length, 1) - Sine_source (batchsize, length, 1) - noise_source (batchsize, length 1) - """ - # source for harmonic branch - sine_wavs, uv, _ = self.l_sin_gen(x) - sine_merge = self.l_tanh(self.l_linear(sine_wavs)) - - # source for noise branch, in the same shape as uv - noise = torch.randn_like(uv) * self.sine_amp / 3 - return sine_merge, noise, uv - - -class Generator(torch.nn.Module): - def __init__(self, h): - super(Generator, self).__init__() - self.h = h - - self.num_kernels = len(h["resblock_kernel_sizes"]) - self.num_upsamples = len(h["upsample_rates"]) - self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(h["upsample_rates"])) - self.m_source = SourceModuleHnNSF( - sampling_rate=h["sampling_rate"], - harmonic_num=8) - self.noise_convs = nn.ModuleList() - self.conv_pre = weight_norm(Conv1d(h["inter_channels"], h["upsample_initial_channel"], 7, 1, padding=3)) - resblock = ResBlock1 if h["resblock"] == '1' else ResBlock2 - self.ups = nn.ModuleList() - for i, (u, k) in enumerate(zip(h["upsample_rates"], h["upsample_kernel_sizes"])): - c_cur = h["upsample_initial_channel"] // (2 ** (i + 1)) - self.ups.append(weight_norm( - ConvTranspose1d(h["upsample_initial_channel"] // (2 ** i), h["upsample_initial_channel"] // (2 ** (i + 1)), - k, u, padding=(k - u) // 2))) - if i + 1 < len(h["upsample_rates"]): # - stride_f0 = np.prod(h["upsample_rates"][i + 1:]) - self.noise_convs.append(Conv1d( - 1, c_cur, kernel_size=stride_f0 * 2, stride=stride_f0, padding=stride_f0 // 2)) - else: - self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1)) - self.resblocks = nn.ModuleList() - for i in range(len(self.ups)): - ch = h["upsample_initial_channel"] // (2 ** (i + 1)) - for j, (k, d) in enumerate(zip(h["resblock_kernel_sizes"], h["resblock_dilation_sizes"])): - self.resblocks.append(resblock(h, ch, k, d)) - - self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3)) - self.ups.apply(init_weights) - self.conv_post.apply(init_weights) - self.cond = nn.Conv1d(h['gin_channels'], h['upsample_initial_channel'], 1) - - def forward(self, x, f0, g=None): - # print(1,x.shape,f0.shape,f0[:, None].shape) - f0 = self.f0_upsamp(f0[:, None]).transpose(1, 2) # bs,n,t - # print(2,f0.shape) - har_source, noi_source, uv = self.m_source(f0) - har_source = har_source.transpose(1, 2) - x = self.conv_pre(x) - x = x + self.cond(g) - # print(124,x.shape,har_source.shape) - for i in range(self.num_upsamples): - x = F.leaky_relu(x, LRELU_SLOPE) - # print(3,x.shape) - x = self.ups[i](x) - x_source = self.noise_convs[i](har_source) - # print(4,x_source.shape,har_source.shape,x.shape) - x = x + x_source - xs = None - for j in range(self.num_kernels): - if xs is None: - xs = self.resblocks[i * self.num_kernels + j](x) - else: - xs += self.resblocks[i * self.num_kernels + j](x) - x = xs / self.num_kernels - x = F.leaky_relu(x) - x = self.conv_post(x) - x = torch.tanh(x) - - return x - - def remove_weight_norm(self): - print('Removing weight norm...') - for l in self.ups: - remove_weight_norm(l) - for l in self.resblocks: - l.remove_weight_norm() - remove_weight_norm(self.conv_pre) - remove_weight_norm(self.conv_post) - - -class DiscriminatorP(torch.nn.Module): - def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False): - super(DiscriminatorP, self).__init__() - self.period = period - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList([ - norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), - norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), - norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), - norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), - norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(2, 0))), - ]) - self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0))) - - def forward(self, x): - fmap = [] - - # 1d to 2d - b, c, t = x.shape - if t % self.period != 0: # pad first - n_pad = self.period - (t % self.period) - x = F.pad(x, (0, n_pad), "reflect") - t = t + n_pad - x = x.view(b, c, t // self.period, self.period) - - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - -class MultiPeriodDiscriminator(torch.nn.Module): - def __init__(self, periods=None): - super(MultiPeriodDiscriminator, self).__init__() - self.periods = periods if periods is not None else [2, 3, 5, 7, 11] - self.discriminators = nn.ModuleList() - for period in self.periods: - self.discriminators.append(DiscriminatorP(period)) - - def forward(self, y, y_hat): - y_d_rs = [] - y_d_gs = [] - fmap_rs = [] - fmap_gs = [] - for i, d in enumerate(self.discriminators): - y_d_r, fmap_r = d(y) - y_d_g, fmap_g = d(y_hat) - y_d_rs.append(y_d_r) - fmap_rs.append(fmap_r) - y_d_gs.append(y_d_g) - fmap_gs.append(fmap_g) - - return y_d_rs, y_d_gs, fmap_rs, fmap_gs - - -class DiscriminatorS(torch.nn.Module): - def __init__(self, use_spectral_norm=False): - super(DiscriminatorS, self).__init__() - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList([ - norm_f(Conv1d(1, 128, 15, 1, padding=7)), - norm_f(Conv1d(128, 128, 41, 2, groups=4, padding=20)), - norm_f(Conv1d(128, 256, 41, 2, groups=16, padding=20)), - norm_f(Conv1d(256, 512, 41, 4, groups=16, padding=20)), - norm_f(Conv1d(512, 1024, 41, 4, groups=16, padding=20)), - norm_f(Conv1d(1024, 1024, 41, 1, groups=16, padding=20)), - norm_f(Conv1d(1024, 1024, 5, 1, padding=2)), - ]) - self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1)) - - def forward(self, x): - fmap = [] - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - -class MultiScaleDiscriminator(torch.nn.Module): - def __init__(self): - super(MultiScaleDiscriminator, self).__init__() - self.discriminators = nn.ModuleList([ - DiscriminatorS(use_spectral_norm=True), - DiscriminatorS(), - DiscriminatorS(), - ]) - self.meanpools = nn.ModuleList([ - AvgPool1d(4, 2, padding=2), - AvgPool1d(4, 2, padding=2) - ]) - - def forward(self, y, y_hat): - y_d_rs = [] - y_d_gs = [] - fmap_rs = [] - fmap_gs = [] - for i, d in enumerate(self.discriminators): - if i != 0: - y = self.meanpools[i - 1](y) - y_hat = self.meanpools[i - 1](y_hat) - y_d_r, fmap_r = d(y) - y_d_g, fmap_g = d(y_hat) - y_d_rs.append(y_d_r) - fmap_rs.append(fmap_r) - y_d_gs.append(y_d_g) - fmap_gs.append(fmap_g) - - return y_d_rs, y_d_gs, fmap_rs, fmap_gs - - -def feature_loss(fmap_r, fmap_g): - loss = 0 - for dr, dg in zip(fmap_r, fmap_g): - for rl, gl in zip(dr, dg): - loss += torch.mean(torch.abs(rl - gl)) - - return loss * 2 - - -def discriminator_loss(disc_real_outputs, disc_generated_outputs): - loss = 0 - r_losses = [] - g_losses = [] - for dr, dg in zip(disc_real_outputs, disc_generated_outputs): - r_loss = torch.mean((1 - dr) ** 2) - g_loss = torch.mean(dg ** 2) - loss += (r_loss + g_loss) - r_losses.append(r_loss.item()) - g_losses.append(g_loss.item()) - - return loss, r_losses, g_losses - - -def generator_loss(disc_outputs): - loss = 0 - gen_losses = [] - for dg in disc_outputs: - l = torch.mean((1 - dg) ** 2) - gen_losses.append(l) - loss += l - - return loss, gen_losses diff --git a/spaces/Illumotion/Koboldcpp/examples/baby-llama/baby-llama.cpp b/spaces/Illumotion/Koboldcpp/examples/baby-llama/baby-llama.cpp deleted file mode 100644 index 8155101d0ab936d8dd6b0a581626523305cf279a..0000000000000000000000000000000000000000 --- a/spaces/Illumotion/Koboldcpp/examples/baby-llama/baby-llama.cpp +++ /dev/null @@ -1,1647 +0,0 @@ -#include "ggml.h" -#include "train.h" - -#include -#include -#include -#include -#include -#include - -#if defined(_MSC_VER) -#pragma warning(disable: 4244 4267) // possible loss of data -#endif - -#ifdef LLAMA_DEFAULT_RMS_EPS -constexpr float rms_norm_eps = LLAMA_DEFAULT_RMS_EPS; -#else -constexpr float rms_norm_eps = 5e-6f; -#endif - -static void ggml_graph_compute_helper(std::vector & buf, ggml_cgraph * graph, int n_threads) { - struct ggml_cplan plan = ggml_graph_plan(graph, n_threads); - - if (plan.work_size > 0) { - buf.resize(plan.work_size); - plan.work_data = buf.data(); - } - - ggml_graph_compute(graph, &plan); -} - -static struct ggml_tensor * randomize_tensor( - struct ggml_tensor * tensor, int ndims, const int64_t ne[], float fmin, float fmax -) { - switch (ndims) { - case 1: - for (int i0 = 0; i0 < ne[0]; i0++) { - ((float *)tensor->data)[i0] = frand()*(fmax - fmin) + fmin; - } - break; - case 2: - for (int i1 = 0; i1 < ne[1]; i1++) { - for (int i0 = 0; i0 < ne[0]; i0++) { - ((float *)tensor->data)[i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin; - } - } - break; - case 3: - for (int i2 = 0; i2 < ne[2]; i2++) { - for (int i1 = 0; i1 < ne[1]; i1++) { - for (int i0 = 0; i0 < ne[0]; i0++) { - ((float *)tensor->data)[i2*ne[1]*ne[0] + i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin; - } - } - } - break; - case 4: - for (int i3 = 0; i3 < ne[3]; i3++) { - for (int i2 = 0; i2 < ne[2]; i2++) { - for (int i1 = 0; i1 < ne[1]; i1++) { - for (int i0 = 0; i0 < ne[0]; i0++) { - ((float *)tensor->data)[i3*ne[2]*ne[1]*ne[0] + i2*ne[1]*ne[0] + i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin; - } - } - } - } - break; - default: - assert(false); - } - - return tensor; -} - -struct llama_hparams { - uint32_t n_vocab = 32000; - uint32_t n_ctx = 512; // this is provided as user input? - uint32_t n_embd = 4096; - uint32_t n_mult = 4; - uint32_t n_head = 32; - uint32_t n_layer = 32; - uint32_t n_rot = 64; - - bool operator!=(const llama_hparams & other) const { - return memcmp(this, &other, sizeof(llama_hparams)); - } -}; - -static uint32_t get_n_ff(const struct llama_hparams* hparams) { - const uint32_t n_ff = ((2*(4*hparams->n_embd)/3 + hparams->n_mult - 1)/hparams->n_mult)*hparams->n_mult; - return n_ff; -} - -struct llama_hparams_lora { - uint32_t n_vocab = 32000; - uint32_t n_ctx = 512; // this is provided as user input? - uint32_t n_embd = 4096; - uint32_t n_mult = 4; - uint32_t n_head = 32; - uint32_t n_layer = 32; - uint32_t n_rot = 64; - uint32_t n_lora = 64; - - bool operator!=(const llama_hparams_lora & other) const { - return memcmp(this, &other, sizeof(llama_hparams_lora)) != 0; - } -}; - -struct llama_layer { - // normalization - struct ggml_tensor * attention_norm; - - // attention - struct ggml_tensor * wq; - struct ggml_tensor * wk; - struct ggml_tensor * wv; - struct ggml_tensor * wo; - - // normalization - struct ggml_tensor * ffn_norm; - - // ff - struct ggml_tensor * w1; - struct ggml_tensor * w2; - struct ggml_tensor * w3; -}; - -struct llama_layer_lora { - // normalization - struct ggml_tensor * attention_norm; - - // attention - struct ggml_tensor * wqa; - struct ggml_tensor * wqb; - struct ggml_tensor * wka; - struct ggml_tensor * wkb; - struct ggml_tensor * wva; - struct ggml_tensor * wvb; - struct ggml_tensor * woa; - struct ggml_tensor * wob; - - // normalization - struct ggml_tensor * ffn_norm; - - // ff - struct ggml_tensor * w1; - struct ggml_tensor * w2; - struct ggml_tensor * w3; -}; - - -struct llama_kv_cache { - struct ggml_context * ctx = NULL; - - struct ggml_tensor * k; - struct ggml_tensor * v; - - // llama_ctx_buffer buf; - - int n; // number of tokens currently in the cache -}; - -struct llama_model { - struct ggml_context * ctx = NULL; - - llama_hparams hparams; - - struct ggml_tensor * tok_embeddings; - - struct ggml_tensor * norm; - struct ggml_tensor * output; - - std::vector layers; -}; - -struct llama_model_lora { - struct ggml_context * ctx = NULL; - - llama_hparams_lora hparams; - - struct ggml_tensor * tok_embeddings; - - struct ggml_tensor * norm; - struct ggml_tensor * outputa; - struct ggml_tensor * outputb; - - std::vector layers; -}; - -static void init_model(struct llama_model * model) { - const auto & hparams = model->hparams; - - const uint32_t n_embd = hparams.n_embd; - const uint32_t n_layer = hparams.n_layer; - const uint32_t n_vocab = hparams.n_vocab; - - const uint32_t n_ff = get_n_ff(&hparams); - - struct ggml_context * ctx = model->ctx; - - model->tok_embeddings = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_vocab); // ("tok_embeddings.weight", {n_embd, n_vocab}); - model->norm = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); // ("norm.weight", {n_embd}); - model->output = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_vocab); // ("output.weight", {n_embd, n_vocab}); - - model->layers.resize(n_layer); - for (uint32_t i = 0; i < n_layer; ++i) { - auto & layer = model->layers[i]; - - // std::string layers_i = "layers." + std::to_string(i); - - layer.attention_norm = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); // (layers_i + ".attention_norm.weight", {n_embd}); - - layer.wq = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_embd); // (layers_i + ".attention.wq.weight", {n_embd, n_embd}); - layer.wk = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_embd); // (layers_i + ".attention.wk.weight", {n_embd, n_embd}); - layer.wv = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_embd); // (layers_i + ".attention.wv.weight", {n_embd, n_embd}); - layer.wo = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_embd); // (layers_i + ".attention.wo.weight", {n_embd, n_embd}); - - layer.ffn_norm = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); // (layers_i + ".ffn_norm.weight", {n_embd}); - - layer.w1 = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ff); // (layers_i + ".feed_forward.w1.weight", {n_embd, n_ff}); - layer.w2 = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_ff, n_embd); // (layers_i + ".feed_forward.w2.weight", { n_ff, n_embd}); - layer.w3 = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ff); // (layers_i + ".feed_forward.w3.weight", {n_embd, n_ff}); - } -} - - -static void init_model_lora(struct llama_model_lora * model) { - const auto & hparams = model->hparams; - - const uint32_t n_embd = hparams.n_embd; - const uint32_t n_mult = hparams.n_mult; - const uint32_t n_layer = hparams.n_layer; - const uint32_t n_vocab = hparams.n_vocab; - const uint32_t n_lora = hparams.n_lora; - - const uint32_t n_ff = ((2*(4*n_embd)/3 + n_mult - 1)/n_mult)*n_mult; - - struct ggml_context * ctx = model->ctx; - - model->tok_embeddings = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_vocab); // ("tok_embeddings.weight", {n_embd, n_vocab}); - model->norm = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); // ("norm.weight", {n_embd}); - model->outputa = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_lora, n_vocab); // ("output.weight", {n_embd, n_vocab}); - model->outputb = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_lora); // ("output.weight", {n_embd, n_vocab}); - - model->layers.resize(n_layer); - for (uint32_t i = 0; i < n_layer; ++i) { - auto & layer = model->layers[i]; - - // std::string layers_i = "layers." + std::to_string(i); - - layer.attention_norm = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); // (layers_i + ".attention_norm.weight", {n_embd}); - - layer.wqa = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_lora, n_embd); // (layers_i + ".attention.wq.weight", {n_embd, n_embd}); - layer.wqb = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_lora); // (layers_i + ".attention.wq.weight", {n_embd, n_embd}); - layer.wka = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_lora, n_embd); // (layers_i + ".attention.wk.weight", {n_embd, n_embd}); - layer.wkb = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_lora); // (layers_i + ".attention.wk.weight", {n_embd, n_embd}); - layer.wva = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_lora, n_embd); // (layers_i + ".attention.wv.weight", {n_embd, n_embd}); - layer.wvb = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_lora); // (layers_i + ".attention.wv.weight", {n_embd, n_embd}); - layer.woa = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_lora, n_embd); // (layers_i + ".attention.wo.weight", {n_embd, n_embd}); - layer.wob = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_lora); // (layers_i + ".attention.wo.weight", {n_embd, n_embd}); - - layer.ffn_norm = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); // (layers_i + ".ffn_norm.weight", {n_embd}); - - layer.w1 = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ff); // (layers_i + ".feed_forward.w1.weight", {n_embd, n_ff}); - layer.w2 = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_ff, n_embd); // (layers_i + ".feed_forward.w2.weight", { n_ff, n_embd}); - layer.w3 = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ff); // (layers_i + ".feed_forward.w3.weight", {n_embd, n_ff}); - } -} - -static void set_param_model(struct llama_model * model) { - const auto& hparams = model->hparams; - - const uint32_t n_layer = hparams.n_layer; - - struct ggml_context* ctx = model->ctx; - - ggml_set_param(ctx, model->tok_embeddings); - ggml_set_param(ctx, model->norm); - ggml_set_param(ctx, model->output); - - for (uint32_t i = 0; i < n_layer; ++i) { - auto & layer = model->layers[i]; - - ggml_set_param(ctx, layer.attention_norm); - ggml_set_param(ctx, layer.wq); - ggml_set_param(ctx, layer.wk); - ggml_set_param(ctx, layer.wv); - ggml_set_param(ctx, layer.wo); - ggml_set_param(ctx, layer.ffn_norm); - ggml_set_param(ctx, layer.w1); - ggml_set_param(ctx, layer.w2); - ggml_set_param(ctx, layer.w3); - } -} - -static void set_param_model_lora(struct llama_model_lora * model) { - const auto& hparams = model->hparams; - - const uint32_t n_layer = hparams.n_layer; - - struct ggml_context* ctx = model->ctx; - - ggml_set_param(ctx, model->tok_embeddings); - ggml_set_param(ctx, model->norm); - ggml_set_param(ctx, model->outputa); - ggml_set_param(ctx, model->outputb); - - for (uint32_t i = 0; i < n_layer; ++i) { - auto & layer = model->layers[i]; - - ggml_set_param(ctx, layer.attention_norm); - ggml_set_param(ctx, layer.wqa); - ggml_set_param(ctx, layer.wqb); - ggml_set_param(ctx, layer.wka); - ggml_set_param(ctx, layer.wkb); - ggml_set_param(ctx, layer.wva); - ggml_set_param(ctx, layer.wvb); - ggml_set_param(ctx, layer.woa); - ggml_set_param(ctx, layer.wob); - ggml_set_param(ctx, layer.ffn_norm); - ggml_set_param(ctx, layer.w1); - ggml_set_param(ctx, layer.w2); - ggml_set_param(ctx, layer.w3); - } -} - -static void randomize_model(struct llama_model * model, int seed, float mean, float std, float min, float max) { - const auto & hparams = model->hparams; - - const uint32_t n_layer = hparams.n_layer; - - struct random_normal_distribution * rnd = init_random_normal_distribution(seed, mean, std, min, max); - - randomize_tensor_normal(model->tok_embeddings , rnd); - randomize_tensor_normal(model->norm , rnd); - randomize_tensor_normal(model->output , rnd); - - for (uint32_t i = 0; i < n_layer; ++i) { - auto & layer = model->layers[i]; - randomize_tensor_normal(layer.attention_norm, rnd); - - randomize_tensor_normal(layer.wq, rnd); - randomize_tensor_normal(layer.wk, rnd); - randomize_tensor_normal(layer.wv, rnd); - randomize_tensor_normal(layer.wo, rnd); - - randomize_tensor_normal(layer.ffn_norm, rnd); - - randomize_tensor_normal(layer.w1, rnd); - randomize_tensor_normal(layer.w2, rnd); - randomize_tensor_normal(layer.w3, rnd); - } - - free_random_normal_distribution(rnd); -} - - -static void randomize_model_lora( - struct llama_model_lora * model, int seed, float mean, float std, float min, float max -) { - const auto & hparams = model->hparams; - - const uint32_t n_layer = hparams.n_layer; - - struct random_normal_distribution * rnd = init_random_normal_distribution(seed, mean, std, min, max); - - randomize_tensor_normal(model->tok_embeddings, rnd); - randomize_tensor_normal(model->norm , rnd); - randomize_tensor_normal(model->outputa , rnd); - randomize_tensor_normal(model->outputb , rnd); - - for (uint32_t i = 0; i < n_layer; ++i) { - auto & layer = model->layers[i]; - randomize_tensor_normal(layer.attention_norm, rnd); - - randomize_tensor_normal(layer.wqa, rnd); - randomize_tensor_normal(layer.wqb, rnd); - randomize_tensor_normal(layer.wka, rnd); - randomize_tensor_normal(layer.wkb, rnd); - randomize_tensor_normal(layer.wva, rnd); - randomize_tensor_normal(layer.wvb, rnd); - randomize_tensor_normal(layer.woa, rnd); - randomize_tensor_normal(layer.wob, rnd); - - randomize_tensor_normal(layer.ffn_norm, rnd); - - randomize_tensor_normal(layer.w1, rnd); - randomize_tensor_normal(layer.w2, rnd); - randomize_tensor_normal(layer.w3, rnd); - } - - free_random_normal_distribution(rnd); -} - -static void init_kv_cache(struct llama_kv_cache* cache, struct llama_model * model, int n_batch) { - const auto & hparams = model->hparams; - - const uint32_t n_ctx = hparams.n_ctx; - const uint32_t n_embd = hparams.n_embd; - const uint32_t n_layer = hparams.n_layer; - - const int64_t n_mem = n_layer*n_ctx*n_batch; - const int64_t n_elements = n_embd*n_mem; - - // cache.buf.resize(2u*n_elements*ggml_type_size(wtype) + 2u*MB); - - // struct ggml_init_params params; - // params.mem_size = cache.buf.size; - // params.mem_buffer = cache.buf.addr; - // params.no_alloc = false; - if (!cache->ctx) { - struct ggml_init_params params; - params.mem_size = 2u*n_elements*ggml_type_size(GGML_TYPE_F32) + 2u*1024*1024; - params.mem_buffer = NULL; - params.no_alloc = false; - - cache->ctx = ggml_init(params); - - if (!cache->ctx) { - fprintf(stderr, "%s: failed to allocate memory for kv cache\n", __func__); - exit(1); - } - } - - cache->k = ggml_new_tensor_1d(cache->ctx, GGML_TYPE_F32, n_elements); - cache->v = ggml_new_tensor_1d(cache->ctx, GGML_TYPE_F32, n_elements); -} - -static bool init_kv_cache_lora(struct llama_kv_cache* cache, struct llama_model_lora * model, int n_batch) { - const auto & hparams = model->hparams; - - const uint32_t n_ctx = hparams.n_ctx; - const uint32_t n_embd = hparams.n_embd; - const uint32_t n_layer = hparams.n_layer; - - const int64_t n_mem = n_layer*n_ctx*n_batch; - const int64_t n_elements = n_embd*n_mem; - - // cache.buf.resize(2u*n_elements*ggml_type_size(wtype) + 2u*MB); - - // struct ggml_init_params params; - // params.mem_size = cache.buf.size; - // params.mem_buffer = cache.buf.addr; - // params.no_alloc = false; - if (!cache->ctx) { - struct ggml_init_params params; - params.mem_size = 2u*n_elements*ggml_type_size(GGML_TYPE_F32) + 2u*1024*1024; - params.mem_buffer = NULL; - params.no_alloc = false; - - cache->ctx = ggml_init(params); - - if (!cache->ctx) { - fprintf(stderr, "%s: failed to allocate memory for kv cache\n", __func__); - return false; - } - } - - cache->k = ggml_new_tensor_1d(cache->ctx, GGML_TYPE_F32, n_elements); - cache->v = ggml_new_tensor_1d(cache->ctx, GGML_TYPE_F32, n_elements); - - return true; -} - -static struct ggml_tensor * forward( - struct llama_model * model, - struct llama_kv_cache * cache, - struct ggml_context * ctx0, - struct ggml_cgraph * gf, - struct ggml_tensor * tokens_input, - const int n_tokens, - const int n_past -) { - const int N = n_tokens; - - struct llama_kv_cache& kv_self = *cache; - const auto & hparams = model->hparams; - const int n_ctx = hparams.n_ctx; - const int n_embd = hparams.n_embd; - const int n_layer = hparams.n_layer; - const int n_head = hparams.n_head; - const int n_rot = hparams.n_rot; - - struct ggml_tensor * tokens = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); - memcpy(tokens->data, tokens_input->data, N*ggml_element_size(tokens)); - - struct ggml_tensor * kc = kv_self.k; - struct ggml_tensor * vc = kv_self.v; - - struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); - { - int * data = (int *) KQ_pos->data; - for (int i = 0; i < N; ++i) { - data[i] = n_past + i; - } - } - - // inpL shape [n_embd,N,1,1] - struct ggml_tensor * inpL = ggml_get_rows(ctx0, model->tok_embeddings, tokens); - for (int il = 0; il < n_layer; ++il) { - struct ggml_tensor * inpSA = inpL; - - struct ggml_tensor * cur; - - // lctx.use_buf(ctx0, 0); - - // norm - { - // cur shape [n_embd,N,1,1] - cur = ggml_rms_norm(ctx0, inpL, rms_norm_eps); - - // cur = attention_norm*cur - cur = ggml_mul(ctx0, - ggml_repeat(ctx0, model->layers[il].attention_norm, cur), - cur); - } - - // self-attention - { - // compute Q and K and RoPE them - // wq shape [n_embd, n_embd, 1, 1] - // wk shape [n_embd, n_embd, 1, 1] - // Qcur shape [n_embd/n_head, n_head, N, 1] - // Kcur shape [n_embd/n_head, n_head, N, 1] - struct ggml_tensor * Qcur = ggml_rope(ctx0, ggml_reshape_3d(ctx0, ggml_mul_mat(ctx0, model->layers[il].wq, cur), n_embd/n_head, n_head, N), KQ_pos, n_rot, 0, 0); - struct ggml_tensor * Kcur = ggml_rope(ctx0, ggml_reshape_3d(ctx0, ggml_mul_mat(ctx0, model->layers[il].wk, cur), n_embd/n_head, n_head, N), KQ_pos, n_rot, 0, 0); - - // store key and value to memory - { - // compute the transposed [N, n_embd] V matrix - // wv shape [n_embd, n_embd, 1, 1] - // Vcur shape [n_embd, N, 1, 1] - struct ggml_tensor * Vcur = ggml_cont(ctx0, ggml_transpose(ctx0, ggml_reshape_2d(ctx0, ggml_mul_mat(ctx0, model->layers[il].wv, cur), n_embd, N))); - - // kv_self.k shape [n_embd * n_ctx * n_layer, 1] - // kv_self.v shape [n_embd * n_ctx * n_layer, 1] - // k shape [n_embd * N, 1] == kv_self.k[:,n_past:n_past+N,il,0] - // v shape [N, n_embd, 1, 1] == kv_self.v[:,n_past:n_past+N,il,0] - - /* { - struct ggml_tensor * k = ggml_view_1d(ctx0, kv_self.k, N*n_embd, (ggml_element_size(kv_self.k)*n_embd)*(il*n_ctx + n_past)); - struct ggml_tensor * v = ggml_view_2d(ctx0, kv_self.v, N, n_embd, - ( n_ctx)*ggml_element_size(kv_self.v), - (il*n_ctx)*ggml_element_size(kv_self.v)*n_embd + n_past*ggml_element_size(kv_self.v)); - - // important: storing RoPE-ed version of K in the KV cache! - ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); - ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); - } //*/ - - kc = ggml_set_1d(ctx0, kc, ggml_reshape_1d(ctx0, Kcur, n_embd*N), (ggml_element_size(kv_self.k)*n_embd)*(il*n_ctx + n_past)); - vc = ggml_set_2d(ctx0, vc, Vcur, ( n_ctx)*ggml_element_size(kv_self.v), - (il*n_ctx)*ggml_element_size(kv_self.v)*n_embd + n_past*ggml_element_size(kv_self.v)); - } - - // Qcur shape [n_embd/n_head, n_head, N, 1] - // Q shape [n_embd/n_head, N, n_head, 1] - struct ggml_tensor * Q = - ggml_permute(ctx0, - Qcur, - 0, 2, 1, 3); - - // kv_self.k shape [n_embd * n_ctx * n_layer, 1] - // K shape [n_embd/n_head, n_past + N, n_head, 1] - struct ggml_tensor * K = - ggml_permute(ctx0, - ggml_reshape_3d(ctx0, - ggml_view_1d(ctx0, kc, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(kc)*n_embd), - n_embd/n_head, n_head, n_past + N), - 0, 2, 1, 3); - - // K * Q - // KQ shape [n_past + N, N, n_head, 1] - struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); - - // KQ_scaled = KQ / sqrt(n_embd/n_head) - // KQ_scaled shape [n_past + N, N, n_head, 1] - struct ggml_tensor * KQ_scaled = - ggml_scale(ctx0, - KQ, - ggml_new_f32(ctx0, 1.0f/sqrtf(float(n_embd)/n_head))); - - // KQ_masked = mask_past(KQ_scaled) - // KQ_masked shape [n_past + N, N, n_head, 1] - struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx0, KQ_scaled, n_past); - - // KQ = soft_max(KQ_masked) - // KQ_soft_max shape [n_past + N, N, n_head, 1] - struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked); - - // split cached V into n_head heads - //// V shape [n_past + N, n_embd/n_head, n_head, 1] - // V shape [n_past + N, n_embd/n_head, n_head, 1] == kv_self.v[:,:(n_past+N),il,1] - struct ggml_tensor * V = - ggml_view_3d(ctx0, vc, - n_past + N, n_embd/n_head, n_head, - n_ctx*ggml_element_size(vc), - n_ctx*ggml_element_size(vc)*n_embd/n_head, - il*n_ctx*ggml_element_size(vc)*n_embd); - - // KQV shape [n_embd/n_head, N, n_head, 1] - struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max); - - // KQV_merged = KQV.permute(0, 2, 1, 3) - // KQV_merged shape [n_embd/n_head, n_head, N, 1] - struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); - // KQV_merged shape - - // cur = KQV_merged.contiguous().view(n_embd, N) - // cur shape [n_embd,N,1,1] - cur = ggml_reshape_2d(ctx0, ggml_cont(ctx0, KQV_merged), n_embd, N); - // cur = ggml_cpy(ctx0, - // KQV_merged, - // ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); - - // projection (no bias) - // cur shape [n_embd,N,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].wo, - cur); - } - - // lctx.use_buf(ctx0, 1); - - // inpFF shape [n_embd,N,1,1] - struct ggml_tensor * inpFF = ggml_add(ctx0, cur, inpSA); - - // feed-forward network - { - // norm - { - // cur shape [n_embd,N,1,1] - cur = ggml_rms_norm(ctx0, inpFF, rms_norm_eps); - - // cur = ffn_norm*cur - // cur shape [n_embd,N,1,1] - cur = ggml_mul(ctx0, - ggml_repeat(ctx0, model->layers[il].ffn_norm, cur), - cur); - } - - // tmp shape [n_ff,N,1,1] - struct ggml_tensor * tmp = ggml_mul_mat(ctx0, - model->layers[il].w3, - cur); - - // cur shape [n_ff,N,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].w1, - cur); - - // SILU activation - // cur shape [n_ff,N,1,1] - cur = ggml_silu(ctx0, cur); - - // cur shape [n_ff,N,1,1] - cur = ggml_mul(ctx0, cur, tmp); - - // cur shape [n_embd,N,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].w2, - cur); - } - - // cur shape [n_embd,N,1,1] - cur = ggml_add(ctx0, cur, inpFF); - - // input for next layer - // inpL shape [n_embd,N,1,1] - inpL = cur; - } - - // norm - { - - // inpL shape [n_embd,N,1,1] - inpL = ggml_rms_norm(ctx0, inpL, rms_norm_eps); - - // inpL = norm*inpL - // inpL shape [n_embd,N,1,1] - inpL = ggml_mul(ctx0, - ggml_repeat(ctx0, model->norm, inpL), - inpL); - - //embeddings = inpL; - } - - // lm_head - // inpL shape [n_vocab,N,1,1] - inpL = ggml_mul_mat(ctx0, model->output, inpL); - - // run the computation - ggml_build_forward_expand(gf, inpL); - - return inpL; -} - -static struct ggml_tensor * forward_batch( - struct llama_model * model, - struct llama_kv_cache * cache, - struct ggml_context * ctx0, - struct ggml_cgraph * gf, - struct ggml_tensor * tokens_input, - const int n_tokens, - const int n_past, - const int n_batch -) { - const int N = n_tokens; - - struct llama_kv_cache& kv_self = *cache; - const auto & hparams = model->hparams; - const int n_ctx = hparams.n_ctx; - const int n_vocab = hparams.n_vocab; - const int n_embd = hparams.n_embd; - const int n_layer = hparams.n_layer; - const int n_head = hparams.n_head; - const int n_rot = hparams.n_rot; - const int n_ff = get_n_ff(&hparams); - - struct ggml_tensor * tokens = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N*n_batch); - memcpy(tokens->data, tokens_input->data, ggml_element_size(tokens)*N*n_batch); - - struct ggml_tensor * kc = kv_self.k; - struct ggml_tensor * vc = kv_self.v; - - struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); - { - int * data = (int *) KQ_pos->data; - for (int i = 0; i < N; ++i) { - data[i] = n_past + i; - } - } - - // inpL shape [n_embd,N*n_batch,1] - struct ggml_tensor * inpL = ggml_get_rows(ctx0, model->tok_embeddings, tokens); - assert_shape_2d(inpL, n_embd, N*n_batch); - - for (int il = 0; il < n_layer; ++il) { - struct ggml_tensor * inpSA = inpL; - - struct ggml_tensor * cur; - - // lctx.use_buf(ctx0, 0); - - // norm - { - // cur shape [n_embd,N*n_batch,1,1] - cur = ggml_rms_norm(ctx0, inpL, rms_norm_eps); - assert_shape_2d(cur, n_embd, N*n_batch); - - // cur = attention_norm*cur - cur = ggml_mul(ctx0, - ggml_repeat(ctx0, model->layers[il].attention_norm, cur), - cur); - assert_shape_2d(cur, n_embd, N*n_batch); - } - - // self-attention - { - // compute Q and K and RoPE them - // wq shape [n_embd, n_embd, 1, 1] - // wk shape [n_embd, n_embd, 1, 1] - // Qcur shape [n_embd/n_head, n_head, N, n_batch] - // Kcur shape [n_embd/n_head, n_head, N, n_batch] - struct ggml_tensor * Qcur = ggml_rope(ctx0, ggml_reshape_4d(ctx0, ggml_mul_mat(ctx0, model->layers[il].wq, cur), n_embd/n_head, n_head, N, n_batch), KQ_pos, n_rot, 0, 0); - struct ggml_tensor * Kcur = ggml_rope(ctx0, ggml_reshape_4d(ctx0, ggml_mul_mat(ctx0, model->layers[il].wk, cur), n_embd/n_head, n_head, N, n_batch), KQ_pos, n_rot, 0, 0); - assert_shape_4d(Qcur, n_embd/n_head, n_head, N, n_batch); - assert_shape_4d(Kcur, n_embd/n_head, n_head, N, n_batch); - - // store key and value to memory - { - // compute the transposed [N, n_embd] V matrix - // wv shape [n_embd, n_embd, 1, 1] - // Vcur shape [N, n_embd, n_batch, 1] - struct ggml_tensor * Vcur = ggml_cont(ctx0, - ggml_permute(ctx0, - ggml_reshape_3d(ctx0, - ggml_mul_mat(ctx0, - model->layers[il].wv, - cur), - n_embd, N, n_batch), - 1, 0, 2, 3)); - - assert_shape_3d(Vcur, N, n_embd, n_batch); - - // kv_self.k shape [n_embd * n_ctx * n_batch * n_layer] - // kv_self.v shape [n_ctx * n_embd * n_batch * n_layer] - // k shape [n_embd * N, n_batch] == kv_self.k[:,n_past:n_past+N,:,il] - // v shape [N, n_embd, n_batch, 1] == kv_self.v[:,n_past:n_past+N,:,il] - - /* { - struct ggml_tensor * k = ggml_view_1d(ctx0, kv_self.k, N*n_embd, (ggml_element_size(kv_self.k)*n_embd)*(il*n_ctx + n_past)); - struct ggml_tensor * v = ggml_view_2d(ctx0, kv_self.v, N, n_embd, - ( n_ctx)*ggml_element_size(kv_self.v), - (il*n_ctx)*ggml_element_size(kv_self.v)*n_embd + n_past*ggml_element_size(kv_self.v)); - - // important: storing RoPE-ed version of K in the KV cache! - ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); - ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); - } //*/ - - kc = ggml_set_2d(ctx0, kc, - ggml_reshape_2d(ctx0, Kcur, n_embd*N, n_batch), - ggml_element_size(kc)*n_embd*n_ctx, - (ggml_element_size(kc)*n_embd)*(il*n_batch*n_ctx + n_past)); - vc = ggml_set_2d(ctx0, vc, - ggml_reshape_2d(ctx0, Vcur, N*n_embd, n_batch), - ggml_element_size(vc)*n_ctx*n_embd, - ggml_element_size(vc)*(n_past + il*n_embd*n_batch*n_ctx)); - - assert_shape_1d(kc, n_embd * n_ctx * n_batch * n_layer); - assert_shape_1d(vc, n_embd * n_ctx * n_batch * n_layer); - } - - // Qcur shape [n_embd/n_head, n_head, N, n_batch] - // Q shape [n_embd/n_head, N, n_head, n_batch] - struct ggml_tensor * Q = - ggml_permute(ctx0, - Qcur, - 0, 2, 1, 3); - assert_shape_4d(Q, n_embd/n_head, N, n_head, n_batch); - - // kv_self.k shape [n_embd * n_ctx * n_batch * n_layer] - // K shape [n_embd/n_head, n_past + N, n_head, n_batch] - struct ggml_tensor * K = - ggml_permute(ctx0, - ggml_reshape_4d(ctx0, - ggml_view_3d(ctx0, - kc, - n_embd, - (n_past + N), - n_batch, - n_embd*ggml_element_size(kc), - n_ctx*n_embd*ggml_element_size(kc), - il*n_batch*n_ctx*n_embd*ggml_element_size(kc)), - n_embd/n_head, n_head, n_past + N, n_batch), - 0, 2, 1, 3); - assert_shape_4d(K, n_embd/n_head, n_past + N, n_head, n_batch); - - // K * Q - // KQ shape [n_past + N, N, n_head, n_batch] - struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); - assert_shape_4d(KQ, n_past + N, N, n_head, n_batch); - - // KQ_scaled = KQ / sqrt(n_embd/n_head) - // KQ_scaled shape [n_past + N, N, n_head, n_batch] - struct ggml_tensor * KQ_scaled = - ggml_scale(ctx0, - KQ, - ggml_new_f32(ctx0, 1.0f/sqrtf(float(n_embd)/n_head))); - assert_shape_4d(KQ_scaled, n_past + N, N, n_head, n_batch); - - // KQ_masked = mask_past(KQ_scaled) - // KQ_masked shape [n_past + N, N, n_head, n_batch] - struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx0, KQ_scaled, n_past); - assert_shape_4d(KQ_masked, n_past + N, N, n_head, n_batch); - - // KQ = soft_max(KQ_masked) - // KQ_soft_max shape [n_past + N, N, n_head, n_batch] - struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked); - assert_shape_4d(KQ_soft_max, n_past + N, N, n_head, n_batch); - - // split cached V into n_head heads - // kv_self.v shape [n_ctx * n_embd * n_batch * n_layer] - // V shape [n_past + N, n_embd/n_head, n_head, n_batch] == kv_self.v[:(n_past+N),:,:,il] - struct ggml_tensor * V = - ggml_view_4d(ctx0, vc, - n_past + N, n_embd/n_head, n_head, n_batch, - ggml_element_size(vc)*n_ctx, - ggml_element_size(vc)*n_ctx*n_embd/n_head, - ggml_element_size(vc)*n_ctx*n_embd, - il*n_batch*n_ctx*n_embd*ggml_element_size(vc)); - assert_shape_4d(V, n_past + N, n_embd/n_head, n_head, n_batch); - - // KQV shape [n_embd/n_head, N, n_head, n_batch] - struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max); - assert_shape_4d(KQV, n_embd/n_head, N, n_head, n_batch); - - // KQV_merged = KQV.permute(0, 2, 1, 3) - // KQV_merged shape [n_embd/n_head, n_head, N, n_batch] - struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); - assert_shape_4d(KQV_merged, n_embd/n_head, n_head, N, n_batch); - // KQV_merged shape - - // cur = KQV_merged.contiguous().view(n_embd, N) - // cur shape [n_embd,N*n_batch,1,1] - cur = ggml_reshape_2d(ctx0, ggml_cont(ctx0, KQV_merged), n_embd, N*n_batch); - assert_shape_2d(cur, n_embd, N*n_batch); - // cur = ggml_cpy(ctx0, - // KQV_merged, - // ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); - - // projection (no bias) - // cur shape [n_embd,N*n_batch,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].wo, - cur); - assert_shape_2d(cur, n_embd, N*n_batch); - } - - // lctx.use_buf(ctx0, 1); - - // inpFF shape [n_embd,N*n_batch,1,1] - struct ggml_tensor * inpFF = ggml_add(ctx0, cur, inpSA); - assert_shape_2d(inpFF, n_embd, N*n_batch); - - // feed-forward network - { - // norm - { - // cur shape [n_embd,N*n_batch,1,1] - cur = ggml_rms_norm(ctx0, inpFF, rms_norm_eps); - assert_shape_2d(cur, n_embd, N*n_batch); - - // cur = ffn_norm*cur - // cur shape [n_embd,N*n_batch,1,1] - cur = ggml_mul(ctx0, - ggml_repeat(ctx0, model->layers[il].ffn_norm, cur), - cur); - assert_shape_2d(cur, n_embd, N*n_batch); - } - - // tmp shape [n_ff,N*n_batch,1,1] - struct ggml_tensor * tmp = ggml_mul_mat(ctx0, - model->layers[il].w3, - cur); - assert_shape_2d(tmp, n_ff, N*n_batch); - - // cur shape [n_ff,N*n_batch,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].w1, - cur); - assert_shape_2d(cur, n_ff, N*n_batch); - - // SILU activation - // cur shape [n_ff,N*n_batch,1,1] - cur = ggml_silu(ctx0, cur); - assert_shape_2d(cur, n_ff, N*n_batch); - - // cur shape [n_ff,N*n_batch,1,1] - cur = ggml_mul(ctx0, cur, tmp); - assert_shape_2d(cur, n_ff, N*n_batch); - - // cur shape [n_embd,N*n_batch,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].w2, - cur); - assert_shape_2d(cur, n_embd, N*n_batch); - } - - // cur shape [n_embd,N*n_batch,1,1] - cur = ggml_add(ctx0, cur, inpFF); - assert_shape_2d(cur, n_embd, N*n_batch); - - // input for next layer - // inpL shape [n_embd,N*n_batch,1,1] - inpL = cur; - assert_shape_2d(inpL, n_embd, N*n_batch); - } - - // norm - { - - // inpL shape [n_embd,N*n_batch,1,1] - inpL = ggml_rms_norm(ctx0, inpL, rms_norm_eps); - assert_shape_2d(inpL, n_embd, N*n_batch); - - // inpL = norm*inpL - // inpL shape [n_embd,N*n_batch,1,1] - inpL = ggml_mul(ctx0, - ggml_repeat(ctx0, model->norm, inpL), - inpL); - - assert_shape_2d(inpL, n_embd, N*n_batch); - - //embeddings = inpL; - } - - // lm_head - // inpL shape [n_vocab,N*n_batch,1,1] - inpL = ggml_mul_mat(ctx0, model->output, inpL); - assert_shape_2d(inpL, n_vocab, N*n_batch); - - { - // inpL shape [n_vocab,N,n_batch,1] - inpL = ggml_reshape_3d(ctx0, - inpL, - n_vocab, N, n_batch); - assert_shape_3d(inpL, n_vocab, N, n_batch); - } - - // run the computation - ggml_build_forward_expand(gf, inpL); - - return inpL; -} - -static struct ggml_tensor * forward_lora( - struct llama_model_lora * model, - struct llama_kv_cache * cache, - struct ggml_context * ctx0, - struct ggml_cgraph * gf, - struct ggml_tensor * tokens_input, - const int n_tokens, - const int n_past -) { - const int N = n_tokens; - - struct llama_kv_cache& kv_self = *cache; - const auto & hparams = model->hparams; - - const int n_ctx = hparams.n_ctx; - const int n_embd = hparams.n_embd; - const int n_layer = hparams.n_layer; - const int n_head = hparams.n_head; - const int n_rot = hparams.n_rot; - - struct ggml_tensor * tokens = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); - memcpy(tokens->data, tokens_input->data, N*ggml_element_size(tokens)); - - struct ggml_tensor * kc = kv_self.k; - struct ggml_tensor * vc = kv_self.v; - - struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); - { - int * data = (int *) KQ_pos->data; - for (int i = 0; i < N; ++i) { - data[i] = n_past + i; - } - } - - // inpL shape [n_embd,N,1,1] - struct ggml_tensor * inpL = ggml_get_rows(ctx0, model->tok_embeddings, tokens); - for (int il = 0; il < n_layer; ++il) { - struct ggml_tensor * inpSA = inpL; - - struct ggml_tensor * cur; - - // norm - { - // cur shape [n_embd,N,1,1] - cur = ggml_rms_norm(ctx0, inpL, rms_norm_eps); - - // cur = attention_norm*cur - cur = ggml_mul(ctx0, - ggml_repeat(ctx0, model->layers[il].attention_norm, cur), - cur); - } - - // self-attention - { - // compute Q and K and RoPE them - // wq shape [n_embd, n_embd, 1, 1] - // wk shape [n_embd, n_embd, 1, 1] - // Qcur shape [n_embd/n_head, n_head, N, 1] - // Kcur shape [n_embd/n_head, n_head, N, 1] - struct ggml_tensor * Qcur = ggml_rope(ctx0, - ggml_reshape_3d(ctx0, - ggml_mul_mat(ctx0, - model->layers[il].wqa, - ggml_mul_mat(ctx0, - model->layers[il].wqb, - cur)), - n_embd/n_head, n_head, N), - KQ_pos, n_rot, 0, 0); - struct ggml_tensor * Kcur = ggml_rope(ctx0, - ggml_reshape_3d(ctx0, - ggml_mul_mat(ctx0, - model->layers[il].wka, - ggml_mul_mat(ctx0, - model->layers[il].wkb, - cur)), - n_embd/n_head, n_head, N), - KQ_pos, n_rot, 0, 0); - - // store key and value to memory - { - // compute the transposed [N, n_embd] V matrix - // wv shape [n_embd, n_embd, 1, 1] - // Vcur shape [n_embd, N, 1, 1] - struct ggml_tensor * Vcur = ggml_cont(ctx0, - ggml_transpose(ctx0, - ggml_reshape_2d(ctx0, - ggml_mul_mat(ctx0, - model->layers[il].wva, - ggml_mul_mat(ctx0, - model->layers[il].wvb, - cur)), - n_embd, N))); - - // kv_self.k shape [n_embd * n_ctx * n_layer, 1] - // kv_self.v shape [n_embd * n_ctx * n_layer, 1] - // k shape [n_embd * N, 1] == kv_self.k[:,n_past:n_past+N,il,0] - // v shape [N, n_embd, 1, 1] == kv_self.v[:,n_past:n_past+N,il,0] - - /* { - struct ggml_tensor * k = ggml_view_1d(ctx0, kv_self.k, N*n_embd, (ggml_element_size(kv_self.k)*n_embd)*(il*n_ctx + n_past)); - struct ggml_tensor * v = ggml_view_2d(ctx0, kv_self.v, N, n_embd, - ( n_ctx)*ggml_element_size(kv_self.v), - (il*n_ctx)*ggml_element_size(kv_self.v)*n_embd + n_past*ggml_element_size(kv_self.v)); - - // important: storing RoPE-ed version of K in the KV cache! - ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); - ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); - } //*/ - - kc = ggml_set_1d(ctx0, kc, ggml_reshape_1d(ctx0, Kcur, n_embd*N), (ggml_element_size(kv_self.k)*n_embd)*(il*n_ctx + n_past)); - vc = ggml_set_2d(ctx0, vc, Vcur, ( n_ctx)*ggml_element_size(kv_self.v), - (il*n_ctx)*ggml_element_size(kv_self.v)*n_embd + n_past*ggml_element_size(kv_self.v)); - } - - // Qcur shape [n_embd/n_head, n_head, N, 1] - // Q shape [n_embd/n_head, N, n_head, 1] - struct ggml_tensor * Q = - ggml_permute(ctx0, - Qcur, - 0, 2, 1, 3); - - // kv_self.k shape [n_embd * n_ctx * n_layer, 1] - // K shape [n_embd/n_head, n_past + N, n_head, 1] - struct ggml_tensor * K = - ggml_permute(ctx0, - ggml_reshape_3d(ctx0, - ggml_view_1d(ctx0, kc, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(kc)*n_embd), - n_embd/n_head, n_head, n_past + N), - 0, 2, 1, 3); - - // K * Q - // KQ shape [n_past + N, N, n_head, 1] - struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); - - // KQ_scaled = KQ / sqrt(n_embd/n_head) - // KQ_scaled shape [n_past + N, N, n_head, 1] - struct ggml_tensor * KQ_scaled = - ggml_scale(ctx0, - KQ, - ggml_new_f32(ctx0, 1.0f/sqrtf(float(n_embd)/n_head))); - - // KQ_masked = mask_past(KQ_scaled) - // KQ_masked shape [n_past + N, N, n_head, 1] - struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx0, KQ_scaled, n_past); - - // KQ = soft_max(KQ_masked) - // KQ_soft_max shape [n_past + N, N, n_head, 1] - struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked); - - // split cached V into n_head heads - //// V shape [n_past + N, n_embd/n_head, n_head, 1] - // V shape [n_past + N, n_embd/n_head, n_head, 1] == kv_self.v[:,:(n_past+N),il,1] - struct ggml_tensor * V = - ggml_view_3d(ctx0, vc, - n_past + N, n_embd/n_head, n_head, - n_ctx*ggml_element_size(vc), - n_ctx*ggml_element_size(vc)*n_embd/n_head, - il*n_ctx*ggml_element_size(vc)*n_embd); - - // KQV shape [n_embd/n_head, N, n_head, 1] - struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max); - - // KQV_merged = KQV.permute(0, 2, 1, 3) - // KQV_merged shape [n_embd/n_head, n_head, N, 1] - struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); - // KQV_merged shape - - // cur = KQV_merged.contiguous().view(n_embd, N) - // cur shape [n_embd,N,1,1] - cur = ggml_reshape_2d(ctx0, ggml_cont(ctx0, KQV_merged), n_embd, N); - // cur = ggml_cpy(ctx0, - // KQV_merged, - // ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); - - // projection (no bias) - // cur shape [n_embd,N,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].woa, - ggml_mul_mat(ctx0, - model->layers[il].wob, - cur)); - } - - // inpFF shape [n_embd,N,1,1] - struct ggml_tensor * inpFF = ggml_add(ctx0, cur, inpSA); - - // feed-forward network - { - // norm - { - // cur shape [n_embd,N,1,1] - cur = ggml_rms_norm(ctx0, inpFF, rms_norm_eps); - - // cur = ffn_norm*cur - // cur shape [n_embd,N,1,1] - cur = ggml_mul(ctx0, - ggml_repeat(ctx0, model->layers[il].ffn_norm, cur), - cur); - } - - // tmp shape [n_ff,N,1,1] - struct ggml_tensor * tmp = ggml_mul_mat(ctx0, - model->layers[il].w3, - cur); - - // cur shape [n_ff,N,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].w1, - cur); - - // SILU activation - // cur shape [n_ff,N,1,1] - cur = ggml_silu(ctx0, cur); - - // cur shape [n_ff,N,1,1] - cur = ggml_mul(ctx0, cur, tmp); - - // cur shape [n_embd,N,1,1] - cur = ggml_mul_mat(ctx0, - model->layers[il].w2, - cur); - } - - // cur shape [n_embd,N,1,1] - cur = ggml_add(ctx0, cur, inpFF); - - // input for next layer - // inpL shape [n_embd,N,1,1] - inpL = cur; - } - - // norm - { - - // inpL shape [n_embd,N,1,1] - inpL = ggml_rms_norm(ctx0, inpL, rms_norm_eps); - - // inpL = norm*inpL - // inpL shape [n_embd,N,1,1] - inpL = ggml_mul(ctx0, - ggml_repeat(ctx0, model->norm, inpL), - inpL); - - //embeddings = inpL; - } - - - // lm_head - // inpL shape [n_vocab,N,1,1] - inpL = ggml_mul_mat(ctx0, - model->outputa, - ggml_mul_mat(ctx0, - model->outputb, - inpL)); - - // ggml_set_scratch(ctx0, { 0, 0, nullptr, }); - // run the computation - ggml_build_forward_expand(gf, inpL); - - return inpL; -} - -static void sample_softmax(struct ggml_tensor * logits, struct ggml_tensor * probs, struct ggml_tensor * best_samples) { - assert(logits->n_dims == 2); - assert(probs->n_dims == 2); - assert(best_samples->n_dims == 1); - assert(logits->ne[1] == best_samples->ne[0]); - assert(logits->ne[0] == probs->ne[0]); - assert(logits->ne[1] == probs->ne[1]); - for (int i = 0; i < logits->ne[1]; ++i) { - float max_logit = ggml_get_f32_1d(logits, i * logits->ne[0]); - ggml_set_i32_1d(best_samples, i, 0); - for (int k = 0; k < logits->ne[0]; ++k) { - float logit = ggml_get_f32_1d(logits, i * logits->ne[0] + k); - if (logit > max_logit) { - max_logit = logit; - ggml_set_i32_1d(best_samples, i, k); - } - } - float psum = 0; - for (int k = 0; k < logits->ne[0]; ++k) { - float logit = ggml_get_f32_1d(logits, i * logits->ne[0] + k); - float p = (logit == -INFINITY) ? 0 : expf(logit - max_logit); - psum += p; - ggml_set_f32_1d(probs, i * probs->ne[0] + k, p); - } - for (int k = 0; k < logits->ne[0]; ++k) { - float p = ggml_get_f32_1d(probs, i*probs->ne[0] + k); - ggml_set_f32_1d(probs, i * probs->ne[0] + k, p / psum); - } - } -} - -static void sample_softmax_batch( - struct ggml_context * ctx, struct ggml_tensor * logits, struct ggml_tensor * probs, - struct ggml_tensor * best_samples -) { - GGML_ASSERT(best_samples->n_dims == 2); - GGML_ASSERT(logits->n_dims == 3); - GGML_ASSERT(probs->n_dims == 3); - int n_tokens = best_samples->ne[0]; - int n_batch = best_samples->ne[1]; - int n_vocab = logits->ne[0]; - GGML_ASSERT(n_tokens == logits->ne[1]); - GGML_ASSERT(n_batch == logits->ne[2]); - GGML_ASSERT(n_vocab == probs->ne[0]); - GGML_ASSERT(n_tokens == probs->ne[1]); - GGML_ASSERT(n_batch == probs->ne[2]); - - for (int k = 0; k < n_batch; ++k) { - struct ggml_tensor * best_samples_k = ggml_view_1d(ctx, - best_samples, - best_samples->ne[0], - k*best_samples->nb[1]); - struct ggml_tensor * logits_k = ggml_view_2d(ctx, - logits, - logits->ne[0], - logits->ne[1], - logits->nb[1], - k*logits->nb[2]); - struct ggml_tensor * probs_k = ggml_view_2d(ctx, - probs, - probs->ne[0], - probs->ne[1], - probs->nb[1], - k*probs->nb[2]); - sample_softmax(logits_k, probs_k, best_samples_k); - } -} - -static void print_row(struct ggml_tensor * probs, int i) { - for (int k = 0; k < probs->ne[0]; ++k) { - float p = ggml_get_f32_1d(probs, i*probs->ne[0] + k); - printf(" %.2f", p); - } - printf("\n"); -} - -static void print_matrix(struct ggml_tensor * probs) { - assert(probs->n_dims == 2); - for (int i = 0; i < probs->ne[1]; ++i) { - for (int k = 0; k < probs->ne[0]; ++k) { - float p = ggml_get_f32_1d(probs, i*probs->ne[0] + k); - printf(" %.2f", p); - } - printf("\n"); - } -} - -static void print_token(int token, int n_vocab) { - for (int k = 0; k < token; ++k) { - printf(" "); - } - printf("X"); - for (int k = token+1; k < n_vocab; ++k) { - printf(" "); - } - printf("\n"); -} - -static void print_tokens(struct ggml_tensor * tokens, int n_vocab) { - for (int i=0; i ne[0]; ++i) { - int token = ggml_get_i32_1d(tokens, i); - print_token(token, n_vocab); - } -} - -static void get_example_targets(int example_id, struct ggml_tensor * tokens_input, struct ggml_tensor * targets) { - int n_tokens = tokens_input->ne[0]; - int n_vocab = targets->ne[0]; - float randomness = 0.0f; - // ggml_set_zero(targets); - ggml_set_f32(targets, -1.0f); - ggml_set_i32_1d(tokens_input, 0, 0); - for (int i=1; i -#include -#include - -int main(int argc, char ** argv) { - gpt_params params; - - if (argc == 1 || argv[1][0] == '-') { - printf("usage: %s MODEL_PATH [PROMPT]\n" , argv[0]); - return 1 ; - } - - if (argc >= 2) { - params.model = argv[1]; - } - - if (argc >= 3) { - params.prompt = argv[2]; - } - - if (params.prompt.empty()) { - params.prompt = "Hello my name is"; - } - - // total length of the sequence including the prompt - const int n_len = 32; - - // init LLM - - llama_backend_init(params.numa); - - // initialize the model - - llama_model_params model_params = llama_model_default_params(); - - // model_params.n_gpu_layers = 99; // offload all layers to the GPU - - llama_model * model = llama_load_model_from_file(params.model.c_str(), model_params); - - if (model == NULL) { - fprintf(stderr , "%s: error: unable to load model\n" , __func__); - return 1; - } - - // initialize the context - - llama_context_params ctx_params = llama_context_default_params(); - - ctx_params.seed = 1234; - ctx_params.n_ctx = 2048; - ctx_params.n_threads = params.n_threads; - ctx_params.n_threads_batch = params.n_threads_batch == -1 ? params.n_threads : params.n_threads_batch; - - llama_context * ctx = llama_new_context_with_model(model, ctx_params); - - if (ctx == NULL) { - fprintf(stderr , "%s: error: failed to create the llama_context\n" , __func__); - return 1; - } - - // tokenize the prompt - - std::vector tokens_list; - tokens_list = ::llama_tokenize(ctx, params.prompt, true); - - const int n_ctx = llama_n_ctx(ctx); - const int n_kv_req = tokens_list.size() + (n_len - tokens_list.size()); - - LOG_TEE("\n%s: n_len = %d, n_ctx = %d, n_kv_req = %d\n", __func__, n_len, n_ctx, n_kv_req); - - // make sure the KV cache is big enough to hold all the prompt and generated tokens - if (n_kv_req > n_ctx) { - LOG_TEE("%s: error: n_kv_req > n_ctx, the required KV cache size is not big enough\n", __func__); - LOG_TEE("%s: either reduce n_parallel or increase n_ctx\n", __func__); - return 1; - } - - // print the prompt token-by-token - - fprintf(stderr, "\n"); - - for (auto id : tokens_list) { - fprintf(stderr, "%s", llama_token_to_piece(ctx, id).c_str()); - } - - fflush(stderr); - - // create a llama_batch with size 512 - // we use this object to submit token data for decoding - - llama_batch batch = llama_batch_init(512, 0); - - // evaluate the initial prompt - batch.n_tokens = tokens_list.size(); - - for (int32_t i = 0; i < batch.n_tokens; i++) { - batch.token[i] = tokens_list[i]; - batch.pos[i] = i; - batch.seq_id[i] = 0; - batch.logits[i] = false; - } - - // llama_decode will output logits only for the last token of the prompt - batch.logits[batch.n_tokens - 1] = true; - - if (llama_decode(ctx, batch) != 0) { - LOG_TEE("%s: llama_decode() failed\n", __func__); - return 1; - } - - // main loop - - int n_cur = batch.n_tokens; - int n_decode = 0; - - const auto t_main_start = ggml_time_us(); - - while (n_cur <= n_len) { - // sample the next token - { - auto n_vocab = llama_n_vocab(model); - auto * logits = llama_get_logits_ith(ctx, batch.n_tokens - 1); - - std::vector candidates; - candidates.reserve(n_vocab); - - for (llama_token token_id = 0; token_id < n_vocab; token_id++) { - candidates.emplace_back(llama_token_data{ token_id, logits[token_id], 0.0f }); - } - - llama_token_data_array candidates_p = { candidates.data(), candidates.size(), false }; - - // sample the most likely token - const llama_token new_token_id = llama_sample_token_greedy(ctx, &candidates_p); - - // is it an end of stream? - if (new_token_id == llama_token_eos(ctx) || n_cur == n_len) { - LOG_TEE("\n"); - - break; - } - - LOG_TEE("%s", llama_token_to_piece(ctx, new_token_id).c_str()); - fflush(stdout); - - // prepare the next batch - batch.n_tokens = 0; - - // push this new token for next evaluation - batch.token [batch.n_tokens] = new_token_id; - batch.pos [batch.n_tokens] = n_cur; - batch.seq_id[batch.n_tokens] = 0; - batch.logits[batch.n_tokens] = true; - - batch.n_tokens += 1; - - n_decode += 1; - } - - n_cur += 1; - - // evaluate the current batch with the transformer model - if (llama_decode(ctx, batch)) { - fprintf(stderr, "%s : failed to eval, return code %d\n", __func__, 1); - return 1; - } - } - - LOG_TEE("\n"); - - const auto t_main_end = ggml_time_us(); - - LOG_TEE("%s: decoded %d tokens in %.2f s, speed: %.2f t/s\n", - __func__, n_decode, (t_main_end - t_main_start) / 1000000.0f, n_decode / ((t_main_end - t_main_start) / 1000000.0f)); - - llama_print_timings(ctx); - - fprintf(stderr, "\n"); - - llama_batch_free(batch); - - llama_free(ctx); - llama_free_model(model); - - llama_backend_free(); - - return 0; -} diff --git a/spaces/Ilzhabimantara/rvc-Blue-archives/app.py b/spaces/Ilzhabimantara/rvc-Blue-archives/app.py deleted file mode 100644 index ca6fc3d1273721826f7518e2c699e0994c744d67..0000000000000000000000000000000000000000 --- a/spaces/Ilzhabimantara/rvc-Blue-archives/app.py +++ /dev/null @@ -1,507 +0,0 @@ -import os -import glob -import json -import traceback -import logging -import gradio as gr -import numpy as np -import librosa -import torch -import asyncio -import edge_tts -import yt_dlp -import ffmpeg -import subprocess -import sys -import io -import wave -from datetime import datetime -from fairseq import checkpoint_utils -from lib.infer_pack.models import ( - SynthesizerTrnMs256NSFsid, - SynthesizerTrnMs256NSFsid_nono, - SynthesizerTrnMs768NSFsid, - SynthesizerTrnMs768NSFsid_nono, -) -from vc_infer_pipeline import VC -from config import Config -config = Config() -logging.getLogger("numba").setLevel(logging.WARNING) -limitation = os.getenv("SYSTEM") == "spaces" - -audio_mode = [] -f0method_mode = [] -f0method_info = "" -if limitation is True: - audio_mode = ["Upload audio", "TTS Audio"] - f0method_mode = ["pm", "crepe", "harvest"] - f0method_info = "PM is fast, rmvpe is middle, Crepe or harvest is good but it was extremely slow (Default: PM)" -else: - audio_mode = ["Upload audio", "Youtube", "TTS Audio"] - f0method_mode = ["pm", "crepe", "harvest"] - f0method_info = "PM is fast, rmvpe is middle. Crepe or harvest is good but it was extremely slow (Default: PM))" - -if os.path.isfile("rmvpe.pt"): - f0method_mode.insert(2, "rmvpe") - -def create_vc_fn(model_title, tgt_sr, net_g, vc, if_f0, version, file_index): - def vc_fn( - vc_audio_mode, - vc_input, - vc_upload, - tts_text, - tts_voice, - f0_up_key, - f0_method, - index_rate, - filter_radius, - resample_sr, - rms_mix_rate, - protect, - ): - try: - if vc_audio_mode == "Input path" or "Youtube" and vc_input != "": - audio, sr = librosa.load(vc_input, sr=16000, mono=True) - elif vc_audio_mode == "Upload audio": - if vc_upload is None: - return "You need to upload an audio", None - sampling_rate, audio = vc_upload - duration = audio.shape[0] / sampling_rate - if duration > 360 and limitation: - return "Please upload an audio file that is less than 1 minute.", None - audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32) - if len(audio.shape) > 1: - audio = librosa.to_mono(audio.transpose(1, 0)) - if sampling_rate != 16000: - audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000) - elif vc_audio_mode == "TTS Audio": - if len(tts_text) > 600 and limitation: - return "Text is too long", None - if tts_text is None or tts_voice is None: - return "You need to enter text and select a voice", None - asyncio.run(edge_tts.Communicate(tts_text, "-".join(tts_voice.split('-')[:-1])).save("tts.mp3")) - audio, sr = librosa.load("tts.mp3", sr=16000, mono=True) - vc_input = "tts.mp3" - times = [0, 0, 0] - f0_up_key = int(f0_up_key) - audio_opt = vc.pipeline( - hubert_model, - net_g, - 0, - audio, - vc_input, - times, - f0_up_key, - f0_method, - file_index, - # file_big_npy, - index_rate, - if_f0, - filter_radius, - tgt_sr, - resample_sr, - rms_mix_rate, - version, - protect, - f0_file=None, - ) - info = f"[{datetime.now().strftime('%Y-%m-%d %H:%M')}]: npy: {times[0]}, f0: {times[1]}s, infer: {times[2]}s" - print(f"{model_title} | {info}") - return info, (tgt_sr, audio_opt) - except: - info = traceback.format_exc() - print(info) - return info, (None, None) - return vc_fn - -def load_model(): - categories = [] - with open("weights/folder_info.json", "r", encoding="utf-8") as f: - folder_info = json.load(f) - for category_name, category_info in folder_info.items(): - if not category_info['enable']: - continue - category_title = category_info['title'] - category_folder = category_info['folder_path'] - models = [] - with open(f"weights/{category_folder}/model_info.json", "r", encoding="utf-8") as f: - models_info = json.load(f) - for character_name, info in models_info.items(): - if not info['enable']: - continue - model_title = info['title'] - model_name = info['model_path'] - model_author = info.get("author", None) - model_cover = f"weights/{category_folder}/{character_name}/{info['cover']}" - model_index = f"weights/{category_folder}/{character_name}/{info['feature_retrieval_library']}" - cpt = torch.load(f"weights/{category_folder}/{character_name}/{model_name}", map_location="cpu") - tgt_sr = cpt["config"][-1] - cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0] # n_spk - if_f0 = cpt.get("f0", 1) - version = cpt.get("version", "v1") - if version == "v1": - if if_f0 == 1: - net_g = SynthesizerTrnMs256NSFsid(*cpt["config"], is_half=config.is_half) - else: - net_g = SynthesizerTrnMs256NSFsid_nono(*cpt["config"]) - model_version = "V1" - elif version == "v2": - if if_f0 == 1: - net_g = SynthesizerTrnMs768NSFsid(*cpt["config"], is_half=config.is_half) - else: - net_g = SynthesizerTrnMs768NSFsid_nono(*cpt["config"]) - model_version = "V2" - del net_g.enc_q - print(net_g.load_state_dict(cpt["weight"], strict=False)) - net_g.eval().to(config.device) - if config.is_half: - net_g = net_g.half() - else: - net_g = net_g.float() - vc = VC(tgt_sr, config) - print(f"Model loaded: {character_name} / {info['feature_retrieval_library']} | ({model_version})") - models.append((character_name, model_title, model_author, model_cover, model_version, create_vc_fn(model_title, tgt_sr, net_g, vc, if_f0, version, model_index))) - categories.append([category_title, category_folder, models]) - return categories - -def cut_vocal_and_inst(url, audio_provider, split_model): - if url != "": - if not os.path.exists("dl_audio"): - os.mkdir("dl_audio") - if audio_provider == "Youtube": - ydl_opts = { - 'format': 'bestaudio/best', - 'postprocessors': [{ - 'key': 'FFmpegExtractAudio', - 'preferredcodec': 'wav', - }], - "outtmpl": 'dl_audio/youtube_audio', - } - with yt_dlp.YoutubeDL(ydl_opts) as ydl: - ydl.download([url]) - audio_path = "dl_audio/youtube_audio.wav" - else: - # Spotify doesnt work. - # Need to find other solution soon. - ''' - command = f"spotdl download {url} --output dl_audio/.wav" - result = subprocess.run(command.split(), stdout=subprocess.PIPE) - print(result.stdout.decode()) - audio_path = "dl_audio/spotify_audio.wav" - ''' - if split_model == "htdemucs": - command = f"demucs --two-stems=vocals {audio_path} -o output" - result = subprocess.run(command.split(), stdout=subprocess.PIPE) - print(result.stdout.decode()) - return "output/htdemucs/youtube_audio/vocals.wav", "output/htdemucs/youtube_audio/no_vocals.wav", audio_path, "output/htdemucs/youtube_audio/vocals.wav" - else: - command = f"demucs --two-stems=vocals -n mdx_extra_q {audio_path} -o output" - result = subprocess.run(command.split(), stdout=subprocess.PIPE) - print(result.stdout.decode()) - return "output/mdx_extra_q/youtube_audio/vocals.wav", "output/mdx_extra_q/youtube_audio/no_vocals.wav", audio_path, "output/mdx_extra_q/youtube_audio/vocals.wav" - else: - raise gr.Error("URL Required!") - return None, None, None, None - -def combine_vocal_and_inst(audio_data, audio_volume, split_model): - if not os.path.exists("output/result"): - os.mkdir("output/result") - vocal_path = "output/result/output.wav" - output_path = "output/result/combine.mp3" - if split_model == "htdemucs": - inst_path = "output/htdemucs/youtube_audio/no_vocals.wav" - else: - inst_path = "output/mdx_extra_q/youtube_audio/no_vocals.wav" - with wave.open(vocal_path, "w") as wave_file: - wave_file.setnchannels(1) - wave_file.setsampwidth(2) - wave_file.setframerate(audio_data[0]) - wave_file.writeframes(audio_data[1].tobytes()) - command = f'ffmpeg -y -i {inst_path} -i {vocal_path} -filter_complex [1:a]volume={audio_volume}dB[v];[0:a][v]amix=inputs=2:duration=longest -b:a 320k -c:a libmp3lame {output_path}' - result = subprocess.run(command.split(), stdout=subprocess.PIPE) - print(result.stdout.decode()) - return output_path - -def load_hubert(): - global hubert_model - models, _, _ = checkpoint_utils.load_model_ensemble_and_task( - ["hubert_base.pt"], - suffix="", - ) - hubert_model = models[0] - hubert_model = hubert_model.to(config.device) - if config.is_half: - hubert_model = hubert_model.half() - else: - hubert_model = hubert_model.float() - hubert_model.eval() - -def change_audio_mode(vc_audio_mode): - if vc_audio_mode == "Input path": - return ( - # Input & Upload - gr.Textbox.update(visible=True), - gr.Audio.update(visible=False), - # Youtube - gr.Dropdown.update(visible=False), - gr.Textbox.update(visible=False), - gr.Dropdown.update(visible=False), - gr.Button.update(visible=False), - gr.Audio.update(visible=False), - gr.Audio.update(visible=False), - gr.Audio.update(visible=False), - gr.Slider.update(visible=False), - gr.Audio.update(visible=False), - gr.Button.update(visible=False), - # TTS - gr.Textbox.update(visible=False), - gr.Dropdown.update(visible=False) - ) - elif vc_audio_mode == "Upload audio": - return ( - # Input & Upload - gr.Textbox.update(visible=False), - gr.Audio.update(visible=True), - # Youtube - gr.Dropdown.update(visible=False), - gr.Textbox.update(visible=False), - gr.Dropdown.update(visible=False), - gr.Button.update(visible=False), - gr.Audio.update(visible=False), - gr.Audio.update(visible=False), - gr.Audio.update(visible=False), - gr.Slider.update(visible=False), - gr.Audio.update(visible=False), - gr.Button.update(visible=False), - # TTS - gr.Textbox.update(visible=False), - gr.Dropdown.update(visible=False) - ) - elif vc_audio_mode == "Youtube": - return ( - # Input & Upload - gr.Textbox.update(visible=False), - gr.Audio.update(visible=False), - # Youtube - gr.Dropdown.update(visible=True), - gr.Textbox.update(visible=True), - gr.Dropdown.update(visible=True), - gr.Button.update(visible=True), - gr.Audio.update(visible=True), - gr.Audio.update(visible=True), - gr.Audio.update(visible=True), - gr.Slider.update(visible=True), - gr.Audio.update(visible=True), - gr.Button.update(visible=True), - # TTS - gr.Textbox.update(visible=False), - gr.Dropdown.update(visible=False) - ) - elif vc_audio_mode == "TTS Audio": - return ( - # Input & Upload - gr.Textbox.update(visible=False), - gr.Audio.update(visible=False), - # Youtube - gr.Dropdown.update(visible=False), - gr.Textbox.update(visible=False), - gr.Dropdown.update(visible=False), - gr.Button.update(visible=False), - gr.Audio.update(visible=False), - gr.Audio.update(visible=False), - gr.Audio.update(visible=False), - gr.Slider.update(visible=False), - gr.Audio.update(visible=False), - gr.Button.update(visible=False), - # TTS - gr.Textbox.update(visible=True), - gr.Dropdown.update(visible=True) - ) - else: - return ( - # Input & Upload - gr.Textbox.update(visible=False), - gr.Audio.update(visible=True), - # Youtube - gr.Dropdown.update(visible=False), - gr.Textbox.update(visible=False), - gr.Dropdown.update(visible=False), - gr.Button.update(visible=False), - gr.Audio.update(visible=False), - gr.Audio.update(visible=False), - gr.Audio.update(visible=False), - gr.Slider.update(visible=False), - gr.Audio.update(visible=False), - gr.Button.update(visible=False), - # TTS - gr.Textbox.update(visible=False), - gr.Dropdown.update(visible=False) - ) - -if __name__ == '__main__': - load_hubert() - categories = load_model() - tts_voice_list = asyncio.get_event_loop().run_until_complete(edge_tts.list_voices()) - voices = [f"{v['ShortName']}-{v['Gender']}" for v in tts_voice_list] - with gr.Blocks(theme=gr.themes.Base()) as app: - gr.Markdown( - "# RVC Models\n" - "### Recommended to use Google Colab to use other character and feature.\n" - "[](https://colab.research.google.com/github/aziib/hololive-rvc-models-v2/blob/main/hololive_rvc_models_v2.ipynb)\n\n" - "[](https://ko-fi.com/megaaziib)\n\n" - ) - for (folder_title, folder, models) in categories: - with gr.TabItem(folder_title): - with gr.Tabs(): - if not models: - gr.Markdown("# No Model Loaded.") - gr.Markdown("## Please add model or fix your model path.") - continue - for (name, title, author, cover, model_version, vc_fn) in models: - with gr.TabItem(name): - with gr.Row(): - gr.Markdown( - ' ' - f'' - ) - with gr.Row(): - with gr.Column(): - vc_audio_mode = gr.Dropdown(label="Input voice", choices=audio_mode, allow_custom_value=False, value="Upload audio") - # Input and Upload - vc_input = gr.Textbox(label="Input audio path", visible=False) - vc_upload = gr.Audio(label="Upload audio file", visible=True, interactive=True) - # Youtube - vc_download_audio = gr.Dropdown(label="Provider", choices=["Youtube"], allow_custom_value=False, visible=False, value="Youtube", info="Select provider (Default: Youtube)") - vc_link = gr.Textbox(label="Youtube URL", visible=False, info="Example: https://www.youtube.com/watch?v=Nc0sB1Bmf-A", placeholder="https://www.youtube.com/watch?v=...") - vc_split_model = gr.Dropdown(label="Splitter Model", choices=["htdemucs", "mdx_extra_q"], allow_custom_value=False, visible=False, value="htdemucs", info="Select the splitter model (Default: htdemucs)") - vc_split = gr.Button("Split Audio", variant="primary", visible=False) - vc_vocal_preview = gr.Audio(label="Vocal Preview", visible=False) - vc_inst_preview = gr.Audio(label="Instrumental Preview", visible=False) - vc_audio_preview = gr.Audio(label="Audio Preview", visible=False) - # TTS - tts_text = gr.Textbox(visible=False, label="TTS text", info="Text to speech input") - tts_voice = gr.Dropdown(label="Edge-tts speaker", choices=voices, visible=False, allow_custom_value=False, value="en-US-AnaNeural-Female") - with gr.Column(): - vc_transform0 = gr.Number(label="Transpose", value=0, info='Type "12" to change from male to female voice. Type "-12" to change female to male voice') - f0method0 = gr.Radio( - label="Pitch extraction algorithm", - info=f0method_info, - choices=f0method_mode, - value="pm", - interactive=True - ) - index_rate1 = gr.Slider( - minimum=0, - maximum=1, - label="Retrieval feature ratio", - info="Accents controling. Too high prob gonna sounds too robotic (Default: 0.4)", - value=0.4, - interactive=True, - ) - filter_radius0 = gr.Slider( - minimum=0, - maximum=7, - label="Apply Median Filtering", - info="The value represents the filter radius and can reduce breathiness.", - value=1, - step=1, - interactive=True, - ) - resample_sr0 = gr.Slider( - minimum=0, - maximum=48000, - label="Resample the output audio", - info="Resample the output audio in post-processing to the final sample rate. Set to 0 for no resampling", - value=0, - step=1, - interactive=True, - ) - rms_mix_rate0 = gr.Slider( - minimum=0, - maximum=1, - label="Volume Envelope", - info="Use the volume envelope of the input to replace or mix with the volume envelope of the output. The closer the ratio is to 1, the more the output envelope is used", - value=1, - interactive=True, - ) - protect0 = gr.Slider( - minimum=0, - maximum=0.5, - label="Voice Protection", - info="Protect voiceless consonants and breath sounds to prevent artifacts such as tearing in electronic music. Set to 0.5 to disable. Decrease the value to increase protection, but it may reduce indexing accuracy", - value=0.23, - step=0.01, - interactive=True, - ) - with gr.Column(): - vc_log = gr.Textbox(label="Output Information", interactive=False) - vc_output = gr.Audio(label="Output Audio", interactive=False) - vc_convert = gr.Button("Convert", variant="primary") - vc_volume = gr.Slider( - minimum=0, - maximum=10, - label="Vocal volume", - value=4, - interactive=True, - step=1, - info="Adjust vocal volume (Default: 4}", - visible=False - ) - vc_combined_output = gr.Audio(label="Output Combined Audio", visible=False) - vc_combine = gr.Button("Combine",variant="primary", visible=False) - vc_convert.click( - fn=vc_fn, - inputs=[ - vc_audio_mode, - vc_input, - vc_upload, - tts_text, - tts_voice, - vc_transform0, - f0method0, - index_rate1, - filter_radius0, - resample_sr0, - rms_mix_rate0, - protect0, - ], - outputs=[vc_log ,vc_output] - ) - vc_split.click( - fn=cut_vocal_and_inst, - inputs=[vc_link, vc_download_audio, vc_split_model], - outputs=[vc_vocal_preview, vc_inst_preview, vc_audio_preview, vc_input] - ) - vc_combine.click( - fn=combine_vocal_and_inst, - inputs=[vc_output, vc_volume, vc_split_model], - outputs=[vc_combined_output] - ) - vc_audio_mode.change( - fn=change_audio_mode, - inputs=[vc_audio_mode], - outputs=[ - vc_input, - vc_upload, - vc_download_audio, - vc_link, - vc_split_model, - vc_split, - vc_vocal_preview, - vc_inst_preview, - vc_audio_preview, - vc_volume, - vc_combined_output, - vc_combine, - tts_text, - tts_voice - ] - ) -if limitation is True: - app.queue(concurrency_count=1, max_size=20, api_open=config.api).launch(share=config.colab) -else: - app.queue(concurrency_count=1, max_size=20, api_open=config.api).launch(share=True) \ No newline at end of file diff --git a/spaces/Iruc/weirdcore-diffusion/app.py b/spaces/Iruc/weirdcore-diffusion/app.py deleted file mode 100644 index 3261be465834800a724e6b2c6a585d821ea5019f..0000000000000000000000000000000000000000 --- a/spaces/Iruc/weirdcore-diffusion/app.py +++ /dev/null @@ -1,3 +0,0 @@ -import gradio as gr - -gr.Interface.load("models/sd-dreambooth-library/weirdcore").launch() \ No newline at end of file diff --git a/spaces/Jamel887/Rvc-tio887/README.md b/spaces/Jamel887/Rvc-tio887/README.md deleted file mode 100644 index 409c420f5e6e7d132809bfec88e3d45868bf7081..0000000000000000000000000000000000000000 --- a/spaces/Jamel887/Rvc-tio887/README.md +++ /dev/null @@ -1,14 +0,0 @@ ---- -title: RVC V2 Genshin Impact -emoji: 🎤 -colorFrom: red -colorTo: purple -sdk: gradio -sdk_version: 3.36.1 -app_file: app.py -pinned: true -license: mit -duplicated_from: mocci24/rvc-genshin-v2 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Jeff2323/ai-comic-factory/src/components/ui/checkbox.tsx b/spaces/Jeff2323/ai-comic-factory/src/components/ui/checkbox.tsx deleted file mode 100644 index 5850485b9fecba303bdba1849e5a7b6329300af4..0000000000000000000000000000000000000000 --- a/spaces/Jeff2323/ai-comic-factory/src/components/ui/checkbox.tsx +++ /dev/null @@ -1,30 +0,0 @@ -"use client" - -import * as React from "react" -import * as CheckboxPrimitive from "@radix-ui/react-checkbox" -import { Check } from "lucide-react" - -import { cn } from "@/lib/utils" - -const Checkbox = React.forwardRef< - React.ElementRef{title}\n'+ - f'RVC {model_version} Model\n'+ - (f'Model author: {author}' if author else "")+ - (f'' if cover else "")+ - '
, - React.ComponentPropsWithoutRef ->(({ className, ...props }, ref) => ( - - -)) -Checkbox.displayName = CheckboxPrimitive.Root.displayName - -export { Checkbox } diff --git a/spaces/Jo0xFF/4xArText/input/input_imgs_here.md b/spaces/Jo0xFF/4xArText/input/input_imgs_here.md deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/JohnnyPittt/audio-styling/deepafx_st/processors/proxy/tcn.py b/spaces/JohnnyPittt/audio-styling/deepafx_st/processors/proxy/tcn.py deleted file mode 100644 index a7e00047b978c2a9ea8efc377ebb274fceabe4c8..0000000000000000000000000000000000000000 --- a/spaces/JohnnyPittt/audio-styling/deepafx_st/processors/proxy/tcn.py +++ /dev/null @@ -1,199 +0,0 @@ -# Copyright 2022 Christian J. Steinmetz - -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at - -# http://www.apache.org/licenses/LICENSE-2.0 - -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -# TCN implementation adapted from: -# https://github.com/csteinmetz1/micro-tcn/blob/main/microtcn/tcn.py - -import torch -from argparse import ArgumentParser - -from deepafx_st.utils import center_crop, causal_crop - - -class FiLM(torch.nn.Module): - def __init__(self, num_features, cond_dim): - super().__init__() - self.num_features = num_features - self.bn = torch.nn.BatchNorm1d(num_features, affine=False) - self.adaptor = torch.nn.Linear(cond_dim, num_features * 2) - - def forward(self, x, cond): - - # project conditioning to 2 x num. conv channels - cond = self.adaptor(cond) - - # split the projection into gain and bias - g, b = torch.chunk(cond, 2, dim=-1) - - # add virtual channel dim if needed - if g.ndim == 2: - g = g.unsqueeze(1) - b = b.unsqueeze(1) - - # reshape for application - g = g.permute(0, 2, 1) - b = b.permute(0, 2, 1) - - x = self.bn(x) # apply BatchNorm without affine - x = (x * g) + b # then apply conditional affine - - return x - - -class ConditionalTCNBlock(torch.nn.Module): - def __init__( - self, in_ch, out_ch, cond_dim, kernel_size=3, dilation=1, causal=False, **kwargs - ): - super().__init__() - - self.in_ch = in_ch - self.out_ch = out_ch - self.kernel_size = kernel_size - self.dilation = dilation - self.causal = causal - - self.conv1 = torch.nn.Conv1d( - in_ch, - out_ch, - kernel_size=kernel_size, - padding=0, - dilation=dilation, - bias=True, - ) - self.film = FiLM(out_ch, cond_dim) - self.relu = torch.nn.PReLU(out_ch) - self.res = torch.nn.Conv1d( - in_ch, out_ch, kernel_size=1, groups=in_ch, bias=False - ) - - def forward(self, x, p): - x_in = x - - x = self.conv1(x) - x = self.film(x, p) # apply FiLM conditioning - x = self.relu(x) - x_res = self.res(x_in) - - if self.causal: - x = x + causal_crop(x_res, x.shape[-1]) - else: - x = x + center_crop(x_res, x.shape[-1]) - - return x - - -class ConditionalTCN(torch.nn.Module): - """Temporal convolutional network with conditioning module. - Args: - sample_rate (float): Audio sample rate. - num_control_params (int, optional): Dimensionality of the conditioning signal. Default: 24 - ninputs (int, optional): Number of input channels (mono = 1, stereo 2). Default: 1 - noutputs (int, optional): Number of output channels (mono = 1, stereo 2). Default: 1 - nblocks (int, optional): Number of total TCN blocks. Default: 10 - kernel_size (int, optional: Width of the convolutional kernels. Default: 3 - dialation_growth (int, optional): Compute the dilation factor at each block as dilation_growth ** (n % stack_size). Default: 1 - channel_growth (int, optional): Compute the output channels at each black as in_ch * channel_growth. Default: 2 - channel_width (int, optional): When channel_growth = 1 all blocks use convolutions with this many channels. Default: 64 - stack_size (int, optional): Number of blocks that constitute a single stack of blocks. Default: 10 - causal (bool, optional): Causal TCN configuration does not consider future input values. Default: False - """ - - def __init__( - self, - sample_rate, - num_control_params=24, - ninputs=1, - noutputs=1, - nblocks=10, - kernel_size=15, - dilation_growth=2, - channel_growth=1, - channel_width=64, - stack_size=10, - causal=False, - skip_connections=False, - **kwargs, - ): - super().__init__() - self.num_control_params = num_control_params - self.ninputs = ninputs - self.noutputs = noutputs - self.nblocks = nblocks - self.kernel_size = kernel_size - self.dilation_growth = dilation_growth - self.channel_growth = channel_growth - self.channel_width = channel_width - self.stack_size = stack_size - self.causal = causal - self.skip_connections = skip_connections - self.sample_rate = sample_rate - - self.blocks = torch.nn.ModuleList() - for n in range(nblocks): - in_ch = out_ch if n > 0 else ninputs - - if self.channel_growth > 1: - out_ch = in_ch * self.channel_growth - else: - out_ch = self.channel_width - - dilation = self.dilation_growth ** (n % self.stack_size) - - self.blocks.append( - ConditionalTCNBlock( - in_ch, - out_ch, - self.num_control_params, - kernel_size=self.kernel_size, - dilation=dilation, - padding="same" if self.causal else "valid", - causal=self.causal, - ) - ) - - self.output = torch.nn.Conv1d(out_ch, noutputs, kernel_size=1) - self.receptive_field = self.compute_receptive_field() - # print( - # f"TCN receptive field: {self.receptive_field} samples", - # f" or {(self.receptive_field/self.sample_rate)*1e3:0.3f} ms", - # ) - - def forward(self, x, p, **kwargs): - - # causally pad input signal - x = torch.nn.functional.pad(x, (self.receptive_field - 1, 0)) - - # iterate over blocks passing conditioning - for idx, block in enumerate(self.blocks): - x = block(x, p) - if self.skip_connections: - if idx == 0: - skips = x - else: - skips = center_crop(skips, x[-1]) + x - else: - skips = 0 - - # final 1x1 convolution to collapse channels - out = self.output(x + skips) - - return out - - def compute_receptive_field(self): - """Compute the receptive field in samples.""" - rf = self.kernel_size - for n in range(1, self.nblocks): - dilation = self.dilation_growth ** (n % self.stack_size) - rf = rf + ((self.kernel_size - 1) * dilation) - return rf diff --git a/spaces/JunchuanYu/SegRS/segment_anything/modeling/common.py b/spaces/JunchuanYu/SegRS/segment_anything/modeling/common.py deleted file mode 100644 index 2bf15236a3eb24d8526073bc4fa2b274cccb3f96..0000000000000000000000000000000000000000 --- a/spaces/JunchuanYu/SegRS/segment_anything/modeling/common.py +++ /dev/null @@ -1,43 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. - -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -import torch -import torch.nn as nn - -from typing import Type - - -class MLPBlock(nn.Module): - def __init__( - self, - embedding_dim: int, - mlp_dim: int, - act: Type[nn.Module] = nn.GELU, - ) -> None: - super().__init__() - self.lin1 = nn.Linear(embedding_dim, mlp_dim) - self.lin2 = nn.Linear(mlp_dim, embedding_dim) - self.act = act() - - def forward(self, x: torch.Tensor) -> torch.Tensor: - return self.lin2(self.act(self.lin1(x))) - - -# From https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py # noqa -# Itself from https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa -class LayerNorm2d(nn.Module): - def __init__(self, num_channels: int, eps: float = 1e-6) -> None: - super().__init__() - self.weight = nn.Parameter(torch.ones(num_channels)) - self.bias = nn.Parameter(torch.zeros(num_channels)) - self.eps = eps - - def forward(self, x: torch.Tensor) -> torch.Tensor: - u = x.mean(1, keepdim=True) - s = (x - u).pow(2).mean(1, keepdim=True) - x = (x - u) / torch.sqrt(s + self.eps) - x = self.weight[:, None, None] * x + self.bias[:, None, None] - return x diff --git a/spaces/Kevin676/AutoGPT/tests/unit/json_tests.py b/spaces/Kevin676/AutoGPT/tests/unit/json_tests.py deleted file mode 100644 index 25c383377708359b5cfec28e0625343c5692f15c..0000000000000000000000000000000000000000 --- a/spaces/Kevin676/AutoGPT/tests/unit/json_tests.py +++ /dev/null @@ -1,114 +0,0 @@ -import unittest - -from autogpt.json_utils.json_fix_llm import fix_and_parse_json - - -class TestParseJson(unittest.TestCase): - def test_valid_json(self): - # Test that a valid JSON string is parsed correctly - json_str = '{"name": "John", "age": 30, "city": "New York"}' - obj = fix_and_parse_json(json_str) - self.assertEqual(obj, {"name": "John", "age": 30, "city": "New York"}) - - def test_invalid_json_minor(self): - # Test that an invalid JSON string can be fixed with gpt - json_str = '{"name": "John", "age": 30, "city": "New York",}' - self.assertEqual( - fix_and_parse_json(json_str, try_to_fix_with_gpt=False), - {"name": "John", "age": 30, "city": "New York"}, - ) - - def test_invalid_json_major_with_gpt(self): - # Test that an invalid JSON string raises an error when try_to_fix_with_gpt is False - json_str = 'BEGIN: "name": "John" - "age": 30 - "city": "New York" :END' - self.assertEqual( - fix_and_parse_json(json_str, try_to_fix_with_gpt=True), - {"name": "John", "age": 30, "city": "New York"}, - ) - - def test_invalid_json_major_without_gpt(self): - # Test that a REALLY invalid JSON string raises an error when try_to_fix_with_gpt is False - json_str = 'BEGIN: "name": "John" - "age": 30 - "city": "New York" :END' - # Assert that this raises an exception: - with self.assertRaises(Exception): - fix_and_parse_json(json_str, try_to_fix_with_gpt=False) - - def test_invalid_json_leading_sentence_with_gpt(self): - # Test that a REALLY invalid JSON string raises an error when try_to_fix_with_gpt is False - json_str = """I suggest we start by browsing the repository to find any issues that we can fix. - -{ - "command": { - "name": "browse_website", - "args":{ - "url": "https://github.com/Torantulino/Auto-GPT" - } - }, - "thoughts": - { - "text": "I suggest we start browsing the repository to find any issues that we can fix.", - "reasoning": "Browsing the repository will give us an idea of the current state of the codebase and identify any issues that we can address to improve the repo.", - "plan": "- Look through the repository to find any issues.\n- Investigate any issues to determine what needs to be fixed\n- Identify possible solutions to fix the issues\n- Open Pull Requests with fixes", - "criticism": "I should be careful while browsing so as not to accidentally introduce any new bugs or issues.", - "speak": "I will start browsing the repository to find any issues we can fix." - } -}""" - good_obj = { - "command": { - "name": "browse_website", - "args": {"url": "https://github.com/Torantulino/Auto-GPT"}, - }, - "thoughts": { - "text": "I suggest we start browsing the repository to find any issues that we can fix.", - "reasoning": "Browsing the repository will give us an idea of the current state of the codebase and identify any issues that we can address to improve the repo.", - "plan": "- Look through the repository to find any issues.\n- Investigate any issues to determine what needs to be fixed\n- Identify possible solutions to fix the issues\n- Open Pull Requests with fixes", - "criticism": "I should be careful while browsing so as not to accidentally introduce any new bugs or issues.", - "speak": "I will start browsing the repository to find any issues we can fix.", - }, - } - # Assert that this raises an exception: - self.assertEqual( - fix_and_parse_json(json_str, try_to_fix_with_gpt=False), good_obj - ) - - def test_invalid_json_leading_sentence_with_gpt(self): - # Test that a REALLY invalid JSON string raises an error when try_to_fix_with_gpt is False - json_str = """I will first need to browse the repository (https://github.com/Torantulino/Auto-GPT) and identify any potential bugs that need fixing. I will use the "browse_website" command for this. - -{ - "command": { - "name": "browse_website", - "args":{ - "url": "https://github.com/Torantulino/Auto-GPT" - } - }, - "thoughts": - { - "text": "Browsing the repository to identify potential bugs", - "reasoning": "Before fixing bugs, I need to identify what needs fixing. I will use the 'browse_website' command to analyze the repository.", - "plan": "- Analyze the repository for potential bugs and areas of improvement", - "criticism": "I need to ensure I am thorough and pay attention to detail while browsing the repository.", - "speak": "I am browsing the repository to identify potential bugs." - } -}""" - good_obj = { - "command": { - "name": "browse_website", - "args": {"url": "https://github.com/Torantulino/Auto-GPT"}, - }, - "thoughts": { - "text": "Browsing the repository to identify potential bugs", - "reasoning": "Before fixing bugs, I need to identify what needs fixing. I will use the 'browse_website' command to analyze the repository.", - "plan": "- Analyze the repository for potential bugs and areas of improvement", - "criticism": "I need to ensure I am thorough and pay attention to detail while browsing the repository.", - "speak": "I am browsing the repository to identify potential bugs.", - }, - } - # Assert that this raises an exception: - self.assertEqual( - fix_and_parse_json(json_str, try_to_fix_with_gpt=False), good_obj - ) - - -if __name__ == "__main__": - unittest.main() diff --git a/spaces/Kuachi/ai-voice/monotonic_align/core.py b/spaces/Kuachi/ai-voice/monotonic_align/core.py deleted file mode 100644 index 5ff728cd74c9228346a82ec64a9829cb98ad315e..0000000000000000000000000000000000000000 --- a/spaces/Kuachi/ai-voice/monotonic_align/core.py +++ /dev/null @@ -1,36 +0,0 @@ -import numba - - -@numba.jit(numba.void(numba.int32[:, :, ::1], numba.float32[:, :, ::1], numba.int32[::1], numba.int32[::1]), - nopython=True, nogil=True) -def maximum_path_jit(paths, values, t_ys, t_xs): - b = paths.shape[0] - max_neg_val = -1e9 - for i in range(int(b)): - path = paths[i] - value = values[i] - t_y = t_ys[i] - t_x = t_xs[i] - - v_prev = v_cur = 0.0 - index = t_x - 1 - - for y in range(t_y): - for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)): - if x == y: - v_cur = max_neg_val - else: - v_cur = value[y - 1, x] - if x == 0: - if y == 0: - v_prev = 0. - else: - v_prev = max_neg_val - else: - v_prev = value[y - 1, x - 1] - value[y, x] += max(v_prev, v_cur) - - for y in range(t_y - 1, -1, -1): - path[y, index] = 1 - if index != 0 and (index == y or value[y - 1, index] < value[y - 1, index - 1]): - index = index - 1 \ No newline at end of file diff --git a/spaces/KyanChen/RSPrompter/mmdet/models/task_modules/samplers/multi_instance_sampling_result.py b/spaces/KyanChen/RSPrompter/mmdet/models/task_modules/samplers/multi_instance_sampling_result.py deleted file mode 100644 index 438a0aa91c0cc8904f6d8bba7139408dd99b98cf..0000000000000000000000000000000000000000 --- a/spaces/KyanChen/RSPrompter/mmdet/models/task_modules/samplers/multi_instance_sampling_result.py +++ /dev/null @@ -1,56 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -import torch -from torch import Tensor - -from ..assigners import AssignResult -from .sampling_result import SamplingResult - - -class MultiInstanceSamplingResult(SamplingResult): - """Bbox sampling result. Further encapsulation of SamplingResult. Three - attributes neg_assigned_gt_inds, neg_gt_labels, and neg_gt_bboxes have been - added for SamplingResult. - - Args: - pos_inds (Tensor): Indices of positive samples. - neg_inds (Tensor): Indices of negative samples. - priors (Tensor): The priors can be anchors or points, - or the bboxes predicted by the previous stage. - gt_and_ignore_bboxes (Tensor): Ground truth and ignore bboxes. - assign_result (:obj:`AssignResult`): Assigning results. - gt_flags (Tensor): The Ground truth flags. - avg_factor_with_neg (bool): If True, ``avg_factor`` equal to - the number of total priors; Otherwise, it is the number of - positive priors. Defaults to True. - """ - - def __init__(self, - pos_inds: Tensor, - neg_inds: Tensor, - priors: Tensor, - gt_and_ignore_bboxes: Tensor, - assign_result: AssignResult, - gt_flags: Tensor, - avg_factor_with_neg: bool = True) -> None: - self.neg_assigned_gt_inds = assign_result.gt_inds[neg_inds] - self.neg_gt_labels = assign_result.labels[neg_inds] - - if gt_and_ignore_bboxes.numel() == 0: - self.neg_gt_bboxes = torch.empty_like(gt_and_ignore_bboxes).view( - -1, 4) - else: - if len(gt_and_ignore_bboxes.shape) < 2: - gt_and_ignore_bboxes = gt_and_ignore_bboxes.view(-1, 4) - self.neg_gt_bboxes = gt_and_ignore_bboxes[ - self.neg_assigned_gt_inds.long(), :] - - # To resist the minus 1 operation in `SamplingResult.init()`. - assign_result.gt_inds += 1 - super().__init__( - pos_inds=pos_inds, - neg_inds=neg_inds, - priors=priors, - gt_bboxes=gt_and_ignore_bboxes, - assign_result=assign_result, - gt_flags=gt_flags, - avg_factor_with_neg=avg_factor_with_neg) diff --git a/spaces/MAPS-research/GEMRec-Gallery/Archive/Gallery_beta0920.py b/spaces/MAPS-research/GEMRec-Gallery/Archive/Gallery_beta0920.py deleted file mode 100644 index a6250edeb6cae36cdd1545531f138129adc08e84..0000000000000000000000000000000000000000 --- a/spaces/MAPS-research/GEMRec-Gallery/Archive/Gallery_beta0920.py +++ /dev/null @@ -1,718 +0,0 @@ -import json -import os -import requests - -import altair as alt -import extra_streamlit_components as stx -import numpy as np -import pandas as pd -import streamlit as st -import streamlit.components.v1 as components - -from bs4 import BeautifulSoup -from datasets import load_dataset, Dataset, load_from_disk -from huggingface_hub import login -from streamlit_agraph import agraph, Node, Edge, Config -from streamlit_extras.switch_page_button import switch_page -from streamlit_extras.no_default_selectbox import selectbox -from sklearn.svm import LinearSVC - -SCORE_NAME_MAPPING = {'clip': 'clip_score', 'rank': 'msq_score', 'pop': 'model_download_count'} - - -class GalleryApp: - def __init__(self, promptBook, images_ds): - self.promptBook = promptBook - self.images_ds = images_ds - - # init gallery state - if 'gallery_state' not in st.session_state: - st.session_state.gallery_state = {} - - # initialize selected_dict - if 'selected_dict' not in st.session_state: - st.session_state['selected_dict'] = {} - - if 'gallery_focus' not in st.session_state: - st.session_state.gallery_focus = {'tag': None, 'prompt': None} - - def gallery_standard(self, items, col_num, info): - rows = len(items) // col_num + 1 - containers = [st.container() for _ in range(rows)] - for idx in range(0, len(items), col_num): - row_idx = idx // col_num - with containers[row_idx]: - cols = st.columns(col_num) - for j in range(col_num): - if idx + j < len(items): - with cols[j]: - # show image - # image = self.images_ds[items.iloc[idx + j]['row_idx'].item()]['image'] - image = f"https://modelcofferbucket.s3-accelerate.amazonaws.com/{items.iloc[idx + j]['image_id']}.png" - st.image(image, use_column_width=True) - - # handel checkbox information - prompt_id = items.iloc[idx + j]['prompt_id'] - modelVersion_id = items.iloc[idx + j]['modelVersion_id'] - - check_init = True if modelVersion_id in st.session_state.selected_dict.get(prompt_id, []) else False - - # st.write("Position: ", idx + j) - - # show checkbox - st.checkbox('Select', key=f'select_{prompt_id}_{modelVersion_id}', value=check_init) - - # show selected info - for key in info: - st.write(f"**{key}**: {items.iloc[idx + j][key]}") - - def gallery_graph(self, items): - items = load_tsne_coordinates(items) - - # sort items to be popularity from low to high, so that most popular ones will be on the top - items = items.sort_values(by=['model_download_count'], ascending=True).reset_index(drop=True) - - scale = 50 - items.loc[:, 'x'] = items['x'] * scale - items.loc[:, 'y'] = items['y'] * scale - - nodes = [] - edges = [] - - for idx in items.index: - # if items.loc[idx, 'modelVersion_id'] in st.session_state.selected_dict.get(items.loc[idx, 'prompt_id'], 0): - # opacity = 0.2 - # else: - # opacity = 1.0 - - nodes.append(Node(id=items.loc[idx, 'image_id'], - # label=str(items.loc[idx, 'model_name']), - title=f"model name: {items.loc[idx, 'model_name']}\nmodelVersion name: {items.loc[idx, 'modelVersion_name']}\nclip score: {items.loc[idx, 'clip_score']}\nmcos score: {items.loc[idx, 'mcos_score']}\npopularity: {items.loc[idx, 'model_download_count']}", - size=20, - shape='image', - image=f"https://modelcofferbucket.s3-accelerate.amazonaws.com/{items.loc[idx, 'image_id']}.png", - x=items.loc[idx, 'x'].item(), - y=items.loc[idx, 'y'].item(), - # fixed=True, - color={'background': '#E0E0E1', 'border': '#ffffff', 'highlight': {'border': '#F04542'}}, - # opacity=opacity, - shadow={'enabled': True, 'color': 'rgba(0,0,0,0.4)', 'size': 10, 'x': 1, 'y': 1}, - borderWidth=2, - shapeProperties={'useBorderWithImage': True}, - ) - ) - - config = Config(width='100%', - height='600', - directed=True, - physics=False, - hierarchical=False, - interaction={'navigationButtons': True, 'dragNodes': False, 'multiselect': False}, - # **kwargs - ) - - return agraph(nodes=nodes, - edges=edges, - config=config, - ) - - def selection_panel(self, items): - # temperal function - - selecters = st.columns([1, 4]) - - if 'score_weights' not in st.session_state: - # st.session_state.score_weights = [1.0, 0.8, 0.2, 0.8] - st.session_state.score_weights = [1.0, 0.8, 0.2] - - # select sort type - with selecters[0]: - sort_type = st.selectbox('Sort by', ['Scores', 'IDs and Names']) - if sort_type == 'Scores': - sort_by = 'weighted_score_sum' - - # select other options - with selecters[1]: - if sort_type == 'IDs and Names': - sub_selecters = st.columns([3]) - # select sort by - with sub_selecters[0]: - sort_by = st.selectbox('Sort by', - ['model_name', 'model_id', 'modelVersion_name', 'modelVersion_id', 'norm_nsfw'], - label_visibility='hidden') - - continue_idx = 1 - - else: - # add custom weights - sub_selecters = st.columns([1, 1, 1]) - - with sub_selecters[0]: - clip_weight = st.number_input('Clip Score Weight', min_value=-100.0, max_value=100.0, value=1.0, step=0.1, help='the weight for normalized clip score') - with sub_selecters[1]: - mcos_weight = st.number_input('Dissimilarity Weight', min_value=-100.0, max_value=100.0, value=0.8, step=0.1, help='the weight for m(eam) s(imilarity) q(antile) score for measuring distinctiveness') - with sub_selecters[2]: - pop_weight = st.number_input('Popularity Weight', min_value=-100.0, max_value=100.0, value=0.2, step=0.1, help='the weight for normalized popularity score') - - items.loc[:, 'weighted_score_sum'] = round(items[f'norm_clip'] * clip_weight + items[f'norm_mcos'] * mcos_weight + items[ - 'norm_pop'] * pop_weight, 4) - - continue_idx = 3 - - # save latest weights - st.session_state.score_weights[0] = round(clip_weight, 2) - st.session_state.score_weights[1] = round(mcos_weight, 2) - st.session_state.score_weights[2] = round(pop_weight, 2) - - # # select threshold - # with sub_selecters[continue_idx]: - # nsfw_threshold = st.number_input('NSFW Score Threshold', min_value=0.0, max_value=1.0, value=0.8, step=0.01, help='Only show models with nsfw score lower than this threshold, set 1.0 to show all images') - # items = items[items['norm_nsfw'] <= nsfw_threshold].reset_index(drop=True) - # - # # save latest threshold - # st.session_state.score_weights[3] = nsfw_threshold - - # # draw a distribution histogram - # if sort_type == 'Scores': - # try: - # with st.expander('Show score distribution histogram and select score range'): - # st.write('**Score distribution histogram**') - # chart_space = st.container() - # # st.write('Select the range of scores to show') - # hist_data = pd.DataFrame(items[sort_by]) - # mini = hist_data[sort_by].min().item() - # mini = mini//0.1 * 0.1 - # maxi = hist_data[sort_by].max().item() - # maxi = maxi//0.1 * 0.1 + 0.1 - # st.write('**Select the range of scores to show**') - # r = st.slider('Select the range of scores to show', min_value=mini, max_value=maxi, value=(mini, maxi), step=0.05, label_visibility='collapsed') - # with chart_space: - # st.altair_chart(altair_histogram(hist_data, sort_by, r[0], r[1]), use_container_width=True) - # # event_dict = altair_component(altair_chart=altair_histogram(hist_data, sort_by)) - # # r = event_dict.get(sort_by) - # if r: - # items = items[(items[sort_by] >= r[0]) & (items[sort_by] <= r[1])].reset_index(drop=True) - # # st.write(r) - # except: - # pass - - display_options = st.columns([1, 4]) - - with display_options[0]: - # select order - order = st.selectbox('Order', ['Ascending', 'Descending'], index=1 if sort_type == 'Scores' else 0) - if order == 'Ascending': - order = True - else: - order = False - - with display_options[1]: - - # select info to show - info = st.multiselect('Show Info', - ['model_name', 'model_id', 'modelVersion_name', 'modelVersion_id', - 'weighted_score_sum', 'model_download_count', 'clip_score', 'mcos_score', - 'nsfw_score', 'norm_nsfw'], - default=sort_by) - - # apply sorting to dataframe - items = items.sort_values(by=[sort_by], ascending=order).reset_index(drop=True) - - # select number of columns - col_num = st.slider('Number of columns', min_value=1, max_value=9, value=4, step=1, key='col_num') - - return items, info, col_num - - def sidebar(self, items, prompt_id, note): - with st.sidebar: - # prompt_tags = self.promptBook['tag'].unique() - # # sort tags by alphabetical order - # prompt_tags = np.sort(prompt_tags)[::1] - # - # tag = st.selectbox('Select a tag', prompt_tags, index=5) - # - # items = self.promptBook[self.promptBook['tag'] == tag].reset_index(drop=True) - # - # prompts = np.sort(items['prompt'].unique())[::1] - # - # selected_prompt = st.selectbox('Select prompt', prompts, index=3) - - # mode = st.radio('Select a mode', ['Gallery', 'Graph'], horizontal=True, index=1) - - # items = items[items['prompt'] == selected_prompt].reset_index(drop=True) - - # st.title('Model Visualization and Retrieval') - - # show source - if isinstance(note, str): - if note.isdigit(): - st.caption(f"`Source: civitai`") - else: - st.caption(f"`Source: {note}`") - else: - st.caption("`Source: Parti-prompts`") - - # show image metadata - image_metadatas = ['prompt', 'negativePrompt', 'sampler', 'cfgScale', 'size', 'seed'] - for key in image_metadatas: - label = ' '.join(key.split('_')).capitalize() - st.write(f"**{label}**") - if items[key][0] == ' ': - st.write('`None`') - else: - st.caption(f"{items[key][0]}") - - # for note as civitai image id, add civitai reference - if isinstance(note, str) and note.isdigit(): - try: - st.write(f'**[Civitai Reference](https://civitai.com/images/{note})**') - res = requests.get(f'https://civitai.com/images/{note}') - # st.write(res.text) - soup = BeautifulSoup(res.text, 'html.parser') - image_section = soup.find('div', {'class': 'mantine-12rlksp'}) - image_url = image_section.find('img')['src'] - st.image(image_url, use_column_width=True) - except: - pass - - # return prompt_tags, tag, prompt_id, items - - def app(self): - st.write('### Model Visualization and Retrieval') - # st.write('This is a gallery of images generated by the models') - - # build the tabular view - prompt_tags = self.promptBook['tag'].unique() - # sort tags by alphabetical order - prompt_tags = np.sort(prompt_tags)[::1].tolist() - - # chosen_data = [stx.TabBarItemData(id=tag, title=tag, description='') for tag in prompt_tags] - # tag = stx.tab_bar(chosen_data, key='tag', default='food') - - # save tag to session state on change - tag = st.radio('Select a tag', prompt_tags, index=5, horizontal=True, key='tag', label_visibility='collapsed') - - # tabs = st.tabs(prompt_tags) - # for i in range(len(prompt_tags)): - # with tabs[i]: - # tag = prompt_tags[i] - items = self.promptBook[self.promptBook['tag'] == tag].reset_index(drop=True) - - prompts = np.sort(items['prompt'].unique())[::1].tolist() - - # st.caption('Select a prompt') - subset_selector = st.columns([3, 1]) - with subset_selector[0]: - selected_prompt = selectbox('Select prompt', prompts, key=f'prompt_{tag}', no_selection_label='---', label_visibility='collapsed', index=0) - # st.session_state.prompt_idx_last_time = prompts.index(selected_prompt) if selected_prompt else 0 - - if selected_prompt is None: - # st.markdown(':orange[Please select a prompt above👆]') - st.write('**Feel free to navigate among tags and pages! Your selection will be saved within one log-in session.**') - - with subset_selector[-1]: - st.write(':orange[👈 **Please select a prompt**]') - - else: - items = items[items['prompt'] == selected_prompt].reset_index(drop=True) - prompt_id = items['prompt_id'].unique()[0] - note = items['note'].unique()[0] - - # add state to session state - if prompt_id not in st.session_state.gallery_state: - st.session_state.gallery_state[prompt_id] = 'graph' - - # add focus to session state - st.session_state.gallery_focus['tag'] = tag - st.session_state.gallery_focus['prompt'] = selected_prompt - - # add safety check for some prompts - safety_check = True - - # load unsafe prompts - unsafe_prompts = json.load(open('./data/unsafe_prompts.json', 'r')) - for prompt_tag in prompt_tags: - if prompt_tag not in unsafe_prompts: - unsafe_prompts[prompt_tag] = [] - # # manually add unsafe prompts - # unsafe_prompts['world knowledge'] = [83] - # unsafe_prompts['abstract'] = [1, 3] - - if int(prompt_id.item()) in unsafe_prompts[tag]: - st.warning('This prompt may contain unsafe content. They might be offensive, depressing, or sexual.') - safety_check = st.checkbox('I understand that this prompt may contain unsafe content. Show these images anyway.', key=f'safety_{prompt_id}') - - print('current state: ', st.session_state.gallery_state[prompt_id]) - - if st.session_state.gallery_state[prompt_id] == 'graph': - if safety_check: - self.graph_mode(prompt_id, items) - with subset_selector[-1]: - has_selection = False - try: - if len(st.session_state.selected_dict.get(prompt_id, [])) > 0: - has_selection = True - except: - pass - - if has_selection: - checkout = st.button('Check out selections', use_container_width=True, type='primary') - if checkout: - print('checkout') - - st.session_state.gallery_state[prompt_id] = 'gallery' - print(st.session_state.gallery_state[prompt_id]) - st.experimental_rerun() - else: - st.write(':orange[👇 **Select images you like below**]') - - elif st.session_state.gallery_state[prompt_id] == 'gallery': - items = items[items['modelVersion_id'].isin(st.session_state.selected_dict[prompt_id])].reset_index( - drop=True) - self.gallery_mode(prompt_id, items) - - with subset_selector[-1]: - state_operations = st.columns([1, 1]) - with state_operations[0]: - back = st.button('Back to 🖼️', use_container_width=True) - if back: - st.session_state.gallery_state[prompt_id] = 'graph' - st.experimental_rerun() - - with state_operations[1]: - forward = st.button('Check out', use_container_width=True, type='primary', on_click=self.submit_actions, args=('Continue', prompt_id)) - if forward: - switch_page('ranking') - - try: - self.sidebar(items, prompt_id, note) - except: - pass - - def graph_mode(self, prompt_id, items): - graph_cols = st.columns([3, 1]) - # prompt = st.chat_input(f"Selected model version ids: {str(st.session_state.selected_dict.get(prompt_id, []))}", - # disabled=False, key=f'{prompt_id}') - # if prompt: - # switch_page("ranking") - - with graph_cols[0]: - graph_space = st.empty() - - with graph_space.container(): - return_value = self.gallery_graph(items) - - with graph_cols[1]: - if return_value: - with st.form(key=f'{prompt_id}'): - image_url = f"https://modelcofferbucket.s3-accelerate.amazonaws.com/{return_value}.png" - - st.image(image_url) - - item = items[items['image_id'] == return_value].reset_index(drop=True).iloc[0] - modelVersion_id = item['modelVersion_id'] - - # handle selection - if 'selected_dict' in st.session_state: - if item['prompt_id'] not in st.session_state.selected_dict: - st.session_state.selected_dict[item['prompt_id']] = [] - - if modelVersion_id in st.session_state.selected_dict[item['prompt_id']]: - checked = True - else: - checked = False - - if checked: - # deselect = st.button('Deselect', key=f'select_{item["prompt_id"]}_{item["modelVersion_id"]}', use_container_width=True) - deselect = st.form_submit_button('Deselect', use_container_width=True) - if deselect: - st.session_state.selected_dict[item['prompt_id']].remove(item['modelVersion_id']) - self.remove_ranking_states(item['prompt_id']) - st.experimental_rerun() - - else: - # select = st.button('Select', key=f'select_{item["prompt_id"]}_{item["modelVersion_id"]}', use_container_width=True, type='primary') - select = st.form_submit_button('Select', use_container_width=True, type='primary') - if select: - st.session_state.selected_dict[item['prompt_id']].append(item['modelVersion_id']) - self.remove_ranking_states(item['prompt_id']) - st.experimental_rerun() - - # st.write(item) - infos = ['model_name', 'modelVersion_name', 'model_download_count', 'clip_score', 'mcos_score', - 'nsfw_score'] - - infos_df = item[infos] - # rename columns - infos_df = infos_df.rename(index={'model_name': 'Model', 'modelVersion_name': 'Version', 'model_download_count': 'Downloads', 'clip_score': 'Clip Score', 'mcos_score': 'mcos Score', 'nsfw_score': 'NSFW Score'}) - st.table(infos_df) - - # for info in infos: - # st.write(f"**{info}**:") - # st.write(item[info]) - - else: - st.info('Please click on an image to show') - - def gallery_mode(self, prompt_id, items): - items, info, col_num = self.selection_panel(items) - - # if 'selected_dict' in st.session_state: - # # st.write('checked: ', str(st.session_state.selected_dict.get(prompt_id, []))) - # dynamic_weight_options = ['Grid Search', 'SVM', 'Greedy'] - # dynamic_weight_panel = st.columns(len(dynamic_weight_options)) - # - # if len(st.session_state.selected_dict.get(prompt_id, [])) > 0: - # btn_disable = False - # else: - # btn_disable = True - # - # for i in range(len(dynamic_weight_options)): - # method = dynamic_weight_options[i] - # with dynamic_weight_panel[i]: - # btn = st.button(method, use_container_width=True, disabled=btn_disable, on_click=self.dynamic_weight, args=(prompt_id, items, method)) - - # prompt = st.chat_input(f"Selected model version ids: {str(st.session_state.selected_dict.get(prompt_id, []))}", disabled=False, key=f'{prompt_id}') - # if prompt: - # switch_page("ranking") - - # with st.form(key=f'{prompt_id}'): - # buttons = st.columns([1, 1, 1]) - # buttons_space = st.columns([1, 1, 1]) - gallery_space = st.empty() - - # with buttons_space[0]: - # continue_btn = st.button('Proceed selections to ranking', use_container_width=True, type='primary') - # if continue_btn: - # # self.submit_actions('Continue', prompt_id) - # switch_page("ranking") - # - # with buttons_space[1]: - # deselect_btn = st.button('Deselect All', use_container_width=True) - # if deselect_btn: - # self.submit_actions('Deselect', prompt_id) - # - # with buttons_space[2]: - # refresh_btn = st.button('Refresh', on_click=gallery_space.empty, use_container_width=True) - - with gallery_space.container(): - self.gallery_standard(items, col_num, info) - - def submit_actions(self, status, prompt_id): - # remove counter from session state - # st.session_state.pop('counter', None) - self.remove_ranking_states('prompt_id') - if status == 'Select': - modelVersions = self.promptBook[self.promptBook['prompt_id'] == prompt_id]['modelVersion_id'].unique() - st.session_state.selected_dict[prompt_id] = modelVersions.tolist() - print(st.session_state.selected_dict, 'select') - st.experimental_rerun() - elif status == 'Deselect': - st.session_state.selected_dict[prompt_id] = [] - print(st.session_state.selected_dict, 'deselect') - st.experimental_rerun() - # self.promptBook.loc[self.promptBook['prompt_id'] == prompt_id, 'checked'] = False - elif status == 'Continue': - st.session_state.selected_dict[prompt_id] = [] - for key in st.session_state: - keys = key.split('_') - if keys[0] == 'select' and keys[1] == str(prompt_id): - if st.session_state[key]: - st.session_state.selected_dict[prompt_id].append(int(keys[2])) - # switch_page("ranking") - print(st.session_state.selected_dict, 'continue') - # st.experimental_rerun() - - def dynamic_weight(self, prompt_id, items, method='Grid Search'): - selected = items[ - items['modelVersion_id'].isin(st.session_state.selected_dict[prompt_id])].reset_index(drop=True) - optimal_weight = [0, 0, 0] - - if method == 'Grid Search': - # grid search method - top_ranking = len(items) * len(selected) - - for clip_weight in np.arange(-1, 1, 0.1): - for mcos_weight in np.arange(-1, 1, 0.1): - for pop_weight in np.arange(-1, 1, 0.1): - - weight_all = clip_weight*items[f'norm_clip'] + mcos_weight*items[f'norm_mcos'] + pop_weight*items['norm_pop'] - weight_all_sorted = weight_all.sort_values(ascending=False).reset_index(drop=True) - # print('weight_all_sorted:', weight_all_sorted) - weight_selected = clip_weight*selected[f'norm_clip'] + mcos_weight*selected[f'norm_mcos'] + pop_weight*selected['norm_pop'] - - # get the index of values of weight_selected in weight_all_sorted - rankings = [] - for weight in weight_selected: - rankings.append(weight_all_sorted.index[weight_all_sorted == weight].tolist()[0]) - if sum(rankings) <= top_ranking: - top_ranking = sum(rankings) - print('current top ranking:', top_ranking, rankings) - optimal_weight = [clip_weight, mcos_weight, pop_weight] - print('optimal weight:', optimal_weight) - - elif method == 'SVM': - # svm method - print('start svm method') - # get residual dataframe that contains models not selected - residual = items[~items['modelVersion_id'].isin(selected['modelVersion_id'])].reset_index(drop=True) - residual = residual[['norm_clip_crop', 'norm_mcos_crop', 'norm_pop']] - residual = residual.to_numpy() - selected = selected[['norm_clip_crop', 'norm_mcos_crop', 'norm_pop']] - selected = selected.to_numpy() - - y = np.concatenate((np.full((len(selected), 1), -1), np.full((len(residual), 1), 1)), axis=0).ravel() - X = np.concatenate((selected, residual), axis=0) - - # fit svm model, and get parameters for the hyperplane - clf = LinearSVC(random_state=0, C=1.0, fit_intercept=False, dual='auto') - clf.fit(X, y) - optimal_weight = clf.coef_[0].tolist() - print('optimal weight:', optimal_weight) - pass - - elif method == 'Greedy': - for idx in selected.index: - # find which score is the highest, clip, mcos, or pop - clip_score = selected.loc[idx, 'norm_clip_crop'] - mcos_score = selected.loc[idx, 'norm_mcos_crop'] - pop_score = selected.loc[idx, 'norm_pop'] - if clip_score >= mcos_score and clip_score >= pop_score: - optimal_weight[0] += 1 - elif mcos_score >= clip_score and mcos_score >= pop_score: - optimal_weight[1] += 1 - elif pop_score >= clip_score and pop_score >= mcos_score: - optimal_weight[2] += 1 - - # normalize optimal_weight - optimal_weight = [round(weight/len(selected), 2) for weight in optimal_weight] - print('optimal weight:', optimal_weight) - print('optimal weight:', optimal_weight) - - st.session_state.score_weights[0: 3] = optimal_weight - - - def remove_ranking_states(self, prompt_id): - # for drag sort - try: - st.session_state.counter[prompt_id] = 0 - st.session_state.ranking[prompt_id] = {} - print('remove ranking states') - except: - print('no sort ranking states to remove') - - # for battles - try: - st.session_state.pointer[prompt_id] = {'left': 0, 'right': 1} - print('remove battles states') - except: - print('no battles states to remove') - - # for page progress - try: - st.session_state.progress[prompt_id] = 'ranking' - print('reset page progress states') - except: - print('no page progress states to be reset') - - -# hist_data = pd.DataFrame(np.random.normal(42, 10, (200, 1)), columns=["x"]) -@st.cache_resource -def altair_histogram(hist_data, sort_by, mini, maxi): - brushed = alt.selection_interval(encodings=['x'], name="brushed") - - chart = ( - alt.Chart(hist_data) - .mark_bar(opacity=0.7, cornerRadius=2) - .encode(alt.X(f"{sort_by}:Q", bin=alt.Bin(maxbins=25)), y="count()") - # .add_selection(brushed) - # .properties(width=800, height=300) - ) - - # Create a transparent rectangle for highlighting the range - highlight = ( - alt.Chart(pd.DataFrame({'x1': [mini], 'x2': [maxi]})) - .mark_rect(opacity=0.3) - .encode(x='x1', x2='x2') - # .properties(width=800, height=300) - ) - - # Layer the chart and the highlight rectangle - layered_chart = alt.layer(chart, highlight) - - return layered_chart - - -@st.cache_data -def load_hf_dataset(show_NSFW=False): - # login to huggingface - login(token=os.environ.get("HF_TOKEN")) - - # load from huggingface - roster = pd.DataFrame(load_dataset('MAPS-research/GEMRec-Roster', split='train')) - promptBook = pd.DataFrame(load_dataset('MAPS-research/GEMRec-Metadata', split='train')) - # images_ds = load_from_disk(os.path.join(os.getcwd(), 'data', 'promptbook')) - images_ds = None # set to None for now since we use s3 bucket to store images - - # # process dataset - # roster = roster[['model_id', 'model_name', 'modelVersion_id', 'modelVersion_name', - # 'model_download_count']].drop_duplicates().reset_index(drop=True) - - # add 'custom_score_weights' column to promptBook if not exist - if 'weighted_score_sum' not in promptBook.columns: - promptBook.loc[:, 'weighted_score_sum'] = 0 - - # merge roster and promptbook - promptBook = promptBook.merge(roster[['model_id', 'model_name', 'modelVersion_id', 'modelVersion_name', 'model_download_count']], - on=['model_id', 'modelVersion_id'], how='left') - - # add column to record current row index - promptBook.loc[:, 'row_idx'] = promptBook.index - - # apply a nsfw filter - if not show_NSFW: - promptBook = promptBook[promptBook['norm_nsfw'] <= 0.8].reset_index(drop=True) - print('nsfw filter applied', len(promptBook)) - - # add a column that adds up 'norm_clip', 'norm_mcos', and 'norm_pop' - score_weights = [1.0, 0.8, 0.2] - promptBook.loc[:, 'total_score'] = round(promptBook['norm_clip'] * score_weights[0] + promptBook['norm_mcos'] * score_weights[1] + promptBook['norm_pop'] * score_weights[2], 4) - - return roster, promptBook, images_ds - -@st.cache_data -def load_tsne_coordinates(items): - # load tsne coordinates - tsne_df = pd.read_parquet('./data/feats_tsne.parquet') - - # print(tsne_df['modelVersion_id'].dtype) - - # print('before merge:', items) - items = items.merge(tsne_df, on=['modelVersion_id', 'prompt_id'], how='left') - # print('after merge:', items) - return items - - -if __name__ == "__main__": - st.set_page_config(page_title="Model Coffer Gallery", page_icon="🖼️", layout="wide") - - if 'user_id' not in st.session_state: - st.warning('Please log in first.') - home_btn = st.button('Go to Home Page') - if home_btn: - switch_page("home") - else: - # st.write('You have already logged in as ' + st.session_state.user_id[0]) - roster, promptBook, images_ds = load_hf_dataset(st.session_state.show_NSFW) - # print(promptBook.columns) - - # # initialize selected_dict - # if 'selected_dict' not in st.session_state: - # st.session_state['selected_dict'] = {} - - app = GalleryApp(promptBook=promptBook, images_ds=images_ds) - app.app() - - with open('./css/style.css') as f: - st.markdown(f'', unsafe_allow_html=True) - diff --git a/spaces/Mahiruoshi/BangDream-Bert-VITS2/transforms.py b/spaces/Mahiruoshi/BangDream-Bert-VITS2/transforms.py deleted file mode 100644 index a11f799e023864ff7082c1f49c0cc18351a13b47..0000000000000000000000000000000000000000 --- a/spaces/Mahiruoshi/BangDream-Bert-VITS2/transforms.py +++ /dev/null @@ -1,209 +0,0 @@ -import torch -from torch.nn import functional as F - -import numpy as np - - -DEFAULT_MIN_BIN_WIDTH = 1e-3 -DEFAULT_MIN_BIN_HEIGHT = 1e-3 -DEFAULT_MIN_DERIVATIVE = 1e-3 - - -def piecewise_rational_quadratic_transform( - inputs, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=False, - tails=None, - tail_bound=1.0, - min_bin_width=DEFAULT_MIN_BIN_WIDTH, - min_bin_height=DEFAULT_MIN_BIN_HEIGHT, - min_derivative=DEFAULT_MIN_DERIVATIVE, -): - if tails is None: - spline_fn = rational_quadratic_spline - spline_kwargs = {} - else: - spline_fn = unconstrained_rational_quadratic_spline - spline_kwargs = {"tails": tails, "tail_bound": tail_bound} - - outputs, logabsdet = spline_fn( - inputs=inputs, - unnormalized_widths=unnormalized_widths, - unnormalized_heights=unnormalized_heights, - unnormalized_derivatives=unnormalized_derivatives, - inverse=inverse, - min_bin_width=min_bin_width, - min_bin_height=min_bin_height, - min_derivative=min_derivative, - **spline_kwargs - ) - return outputs, logabsdet - - -def searchsorted(bin_locations, inputs, eps=1e-6): - bin_locations[..., -1] += eps - return torch.sum(inputs[..., None] >= bin_locations, dim=-1) - 1 - - -def unconstrained_rational_quadratic_spline( - inputs, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=False, - tails="linear", - tail_bound=1.0, - min_bin_width=DEFAULT_MIN_BIN_WIDTH, - min_bin_height=DEFAULT_MIN_BIN_HEIGHT, - min_derivative=DEFAULT_MIN_DERIVATIVE, -): - inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound) - outside_interval_mask = ~inside_interval_mask - - outputs = torch.zeros_like(inputs) - logabsdet = torch.zeros_like(inputs) - - if tails == "linear": - unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1)) - constant = np.log(np.exp(1 - min_derivative) - 1) - unnormalized_derivatives[..., 0] = constant - unnormalized_derivatives[..., -1] = constant - - outputs[outside_interval_mask] = inputs[outside_interval_mask] - logabsdet[outside_interval_mask] = 0 - else: - raise RuntimeError("{} tails are not implemented.".format(tails)) - - ( - outputs[inside_interval_mask], - logabsdet[inside_interval_mask], - ) = rational_quadratic_spline( - inputs=inputs[inside_interval_mask], - unnormalized_widths=unnormalized_widths[inside_interval_mask, :], - unnormalized_heights=unnormalized_heights[inside_interval_mask, :], - unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :], - inverse=inverse, - left=-tail_bound, - right=tail_bound, - bottom=-tail_bound, - top=tail_bound, - min_bin_width=min_bin_width, - min_bin_height=min_bin_height, - min_derivative=min_derivative, - ) - - return outputs, logabsdet - - -def rational_quadratic_spline( - inputs, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=False, - left=0.0, - right=1.0, - bottom=0.0, - top=1.0, - min_bin_width=DEFAULT_MIN_BIN_WIDTH, - min_bin_height=DEFAULT_MIN_BIN_HEIGHT, - min_derivative=DEFAULT_MIN_DERIVATIVE, -): - if torch.min(inputs) < left or torch.max(inputs) > right: - raise ValueError("Input to a transform is not within its domain") - - num_bins = unnormalized_widths.shape[-1] - - if min_bin_width * num_bins > 1.0: - raise ValueError("Minimal bin width too large for the number of bins") - if min_bin_height * num_bins > 1.0: - raise ValueError("Minimal bin height too large for the number of bins") - - widths = F.softmax(unnormalized_widths, dim=-1) - widths = min_bin_width + (1 - min_bin_width * num_bins) * widths - cumwidths = torch.cumsum(widths, dim=-1) - cumwidths = F.pad(cumwidths, pad=(1, 0), mode="constant", value=0.0) - cumwidths = (right - left) * cumwidths + left - cumwidths[..., 0] = left - cumwidths[..., -1] = right - widths = cumwidths[..., 1:] - cumwidths[..., :-1] - - derivatives = min_derivative + F.softplus(unnormalized_derivatives) - - heights = F.softmax(unnormalized_heights, dim=-1) - heights = min_bin_height + (1 - min_bin_height * num_bins) * heights - cumheights = torch.cumsum(heights, dim=-1) - cumheights = F.pad(cumheights, pad=(1, 0), mode="constant", value=0.0) - cumheights = (top - bottom) * cumheights + bottom - cumheights[..., 0] = bottom - cumheights[..., -1] = top - heights = cumheights[..., 1:] - cumheights[..., :-1] - - if inverse: - bin_idx = searchsorted(cumheights, inputs)[..., None] - else: - bin_idx = searchsorted(cumwidths, inputs)[..., None] - - input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0] - input_bin_widths = widths.gather(-1, bin_idx)[..., 0] - - input_cumheights = cumheights.gather(-1, bin_idx)[..., 0] - delta = heights / widths - input_delta = delta.gather(-1, bin_idx)[..., 0] - - input_derivatives = derivatives.gather(-1, bin_idx)[..., 0] - input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0] - - input_heights = heights.gather(-1, bin_idx)[..., 0] - - if inverse: - a = (inputs - input_cumheights) * ( - input_derivatives + input_derivatives_plus_one - 2 * input_delta - ) + input_heights * (input_delta - input_derivatives) - b = input_heights * input_derivatives - (inputs - input_cumheights) * ( - input_derivatives + input_derivatives_plus_one - 2 * input_delta - ) - c = -input_delta * (inputs - input_cumheights) - - discriminant = b.pow(2) - 4 * a * c - assert (discriminant >= 0).all() - - root = (2 * c) / (-b - torch.sqrt(discriminant)) - outputs = root * input_bin_widths + input_cumwidths - - theta_one_minus_theta = root * (1 - root) - denominator = input_delta + ( - (input_derivatives + input_derivatives_plus_one - 2 * input_delta) - * theta_one_minus_theta - ) - derivative_numerator = input_delta.pow(2) * ( - input_derivatives_plus_one * root.pow(2) - + 2 * input_delta * theta_one_minus_theta - + input_derivatives * (1 - root).pow(2) - ) - logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator) - - return outputs, -logabsdet - else: - theta = (inputs - input_cumwidths) / input_bin_widths - theta_one_minus_theta = theta * (1 - theta) - - numerator = input_heights * ( - input_delta * theta.pow(2) + input_derivatives * theta_one_minus_theta - ) - denominator = input_delta + ( - (input_derivatives + input_derivatives_plus_one - 2 * input_delta) - * theta_one_minus_theta - ) - outputs = input_cumheights + numerator / denominator - - derivative_numerator = input_delta.pow(2) * ( - input_derivatives_plus_one * theta.pow(2) - + 2 * input_delta * theta_one_minus_theta - + input_derivatives * (1 - theta).pow(2) - ) - logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator) - - return outputs, logabsdet diff --git a/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/XMem/inference/interact/s2m/s2m_resnet.py b/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/XMem/inference/interact/s2m/s2m_resnet.py deleted file mode 100644 index 89f1ce042c69daa9b18172a0aadf9bc1de6f300e..0000000000000000000000000000000000000000 --- a/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/XMem/inference/interact/s2m/s2m_resnet.py +++ /dev/null @@ -1,182 +0,0 @@ -import torch -import torch.nn as nn -try: - from torchvision.models.utils import load_state_dict_from_url -except ModuleNotFoundError: - from torch.utils.model_zoo import load_url as load_state_dict_from_url - - -__all__ = ['ResNet', 'resnet50'] - - -model_urls = { - 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', -} - - -def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1): - """3x3 convolution with padding""" - return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, - padding=dilation, groups=groups, bias=False, dilation=dilation) - - -def conv1x1(in_planes, out_planes, stride=1): - """1x1 convolution""" - return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False) - - -class Bottleneck(nn.Module): - expansion = 4 - - def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1, - base_width=64, dilation=1, norm_layer=None): - super(Bottleneck, self).__init__() - if norm_layer is None: - norm_layer = nn.BatchNorm2d - width = int(planes * (base_width / 64.)) * groups - # Both self.conv2 and self.downsample layers downsample the input when stride != 1 - self.conv1 = conv1x1(inplanes, width) - self.bn1 = norm_layer(width) - self.conv2 = conv3x3(width, width, stride, groups, dilation) - self.bn2 = norm_layer(width) - self.conv3 = conv1x1(width, planes * self.expansion) - self.bn3 = norm_layer(planes * self.expansion) - self.relu = nn.ReLU(inplace=True) - self.downsample = downsample - self.stride = stride - - def forward(self, x): - identity = x - - out = self.conv1(x) - out = self.bn1(out) - out = self.relu(out) - - out = self.conv2(out) - out = self.bn2(out) - out = self.relu(out) - - out = self.conv3(out) - out = self.bn3(out) - - if self.downsample is not None: - identity = self.downsample(x) - - out += identity - out = self.relu(out) - - return out - - -class ResNet(nn.Module): - - def __init__(self, block, layers, num_classes=1000, zero_init_residual=False, - groups=1, width_per_group=64, replace_stride_with_dilation=None, - norm_layer=None): - super(ResNet, self).__init__() - if norm_layer is None: - norm_layer = nn.BatchNorm2d - self._norm_layer = norm_layer - - self.inplanes = 64 - self.dilation = 1 - if replace_stride_with_dilation is None: - # each element in the tuple indicates if we should replace - # the 2x2 stride with a dilated convolution instead - replace_stride_with_dilation = [False, False, False] - if len(replace_stride_with_dilation) != 3: - raise ValueError("replace_stride_with_dilation should be None " - "or a 3-element tuple, got {}".format(replace_stride_with_dilation)) - self.groups = groups - self.base_width = width_per_group - self.conv1 = nn.Conv2d(6, self.inplanes, kernel_size=7, stride=2, padding=3, - bias=False) - self.bn1 = norm_layer(self.inplanes) - self.relu = nn.ReLU(inplace=True) - self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) - self.layer1 = self._make_layer(block, 64, layers[0]) - self.layer2 = self._make_layer(block, 128, layers[1], stride=2, - dilate=replace_stride_with_dilation[0]) - self.layer3 = self._make_layer(block, 256, layers[2], stride=2, - dilate=replace_stride_with_dilation[1]) - self.layer4 = self._make_layer(block, 512, layers[3], stride=2, - dilate=replace_stride_with_dilation[2]) - self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) - self.fc = nn.Linear(512 * block.expansion, num_classes) - - for m in self.modules(): - if isinstance(m, nn.Conv2d): - nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') - elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)): - nn.init.constant_(m.weight, 1) - nn.init.constant_(m.bias, 0) - - # Zero-initialize the last BN in each residual branch, - # so that the residual branch starts with zeros, and each residual block behaves like an identity. - # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677 - if zero_init_residual: - for m in self.modules(): - if isinstance(m, Bottleneck): - nn.init.constant_(m.bn3.weight, 0) - - def _make_layer(self, block, planes, blocks, stride=1, dilate=False): - norm_layer = self._norm_layer - downsample = None - previous_dilation = self.dilation - if dilate: - self.dilation *= stride - stride = 1 - if stride != 1 or self.inplanes != planes * block.expansion: - downsample = nn.Sequential( - conv1x1(self.inplanes, planes * block.expansion, stride), - norm_layer(planes * block.expansion), - ) - - layers = [] - layers.append(block(self.inplanes, planes, stride, downsample, self.groups, - self.base_width, previous_dilation, norm_layer)) - self.inplanes = planes * block.expansion - for _ in range(1, blocks): - layers.append(block(self.inplanes, planes, groups=self.groups, - base_width=self.base_width, dilation=self.dilation, - norm_layer=norm_layer)) - - return nn.Sequential(*layers) - - def forward(self, x): - x = self.conv1(x) - x = self.bn1(x) - x = self.relu(x) - x = self.maxpool(x) - - x = self.layer1(x) - x = self.layer2(x) - x = self.layer3(x) - x = self.layer4(x) - - x = self.avgpool(x) - x = torch.flatten(x, 1) - x = self.fc(x) - - return x - - -def _resnet(arch, block, layers, pretrained, progress, **kwargs): - model = ResNet(block, layers, **kwargs) - if pretrained: - state_dict = load_state_dict_from_url(model_urls[arch], - progress=progress) - model.load_state_dict(state_dict) - return model - - -def resnet50(pretrained=False, progress=True, **kwargs): - r"""ResNet-50 model from - `"Deep Residual Learning for Image Recognition"- -- BVH Player - - - - - - - - - - - - - - - - - - - - - - - diff --git a/spaces/Metal079/Sonic_Character_tagger/app.py b/spaces/Metal079/Sonic_Character_tagger/app.py deleted file mode 100644 index bc589e74e7b0aba24c32bbfc1618a429677e0166..0000000000000000000000000000000000000000 --- a/spaces/Metal079/Sonic_Character_tagger/app.py +++ /dev/null @@ -1,33 +0,0 @@ -import gradio as gr -from transformers import pipeline, ImageClassificationPipeline - -class MultiClassLabel(ImageClassificationPipeline): - def postprocess(self, model_outputs, top_k=5): - if top_k > self.model.config.num_labels: - top_k = self.model.config.num_labels - - if self.framework == "pt": - probs = model_outputs.logits.sigmoid()[0] - scores, ids = probs.topk(top_k) - elif self.framework == "tf": - probs = stable_softmax(model_outputs.logits, axis=-1)[0] - topk = tf.math.top_k(probs, k=top_k) - scores, ids = topk.values.numpy(), topk.indices.numpy() - else: - raise ValueError(f"Unsupported framework: {self.framework}") - - scores = scores.tolist() - ids = ids.tolist() - return [{"score": score, "label": self.model.config.id2label[_id]} for score, _id in zip(scores, ids)] - -pipe_aesthetic = pipeline("image-classification", "./sonic", pipeline_class=MultiClassLabel) - -def aesthetic(input_img): - data = pipe_aesthetic(input_img, top_k=5) - final = {} - for d in data: - final[d["label"]] = d["score"] - return final -demo_aesthetic = gr.Interface(fn=aesthetic, inputs=gr.Image(type="pil"), outputs=gr.Label(label="characters")) - -gr.Parallel(demo_aesthetic).launch() \ No newline at end of file diff --git a/spaces/MiloSobral/PortiloopDemo/portiloop/src/hardware/demo/demo_net.py b/spaces/MiloSobral/PortiloopDemo/portiloop/src/hardware/demo/demo_net.py deleted file mode 100644 index 8928b14b52d646b80fc2730935d1542a7432de98..0000000000000000000000000000000000000000 --- a/spaces/MiloSobral/PortiloopDemo/portiloop/src/hardware/demo/demo_net.py +++ /dev/null @@ -1,40 +0,0 @@ -import tensorflow as tf -import tensorflow.keras.layers as layers - -input_shape = (1,54,1) - -model = tf.keras.models.Sequential() -model.add(layers.Conv1D(31, 7, activation='relu', input_shape=input_shape[1:])) -model.add(layers.MaxPooling1D(7, data_format='channels_first')) -model.add(layers.Conv1D(31, 7, activation='relu')) -model.add(layers.MaxPooling1D(7, data_format='channels_first')) -model.add(layers.Conv1D(31, 7, activation='relu')) -model.add(layers.MaxPooling1D(7, data_format='channels_first')) -model.add(layers.GRU(7)) -model.add(layers.Dense(18)) - -model.compile(optimizer='sgd', loss='mse') - -print("\n===============\n") - -x = tf.random.normal(input_shape) -#print("x: ", x) - -y = model.evaluate(x) -#print("y: ", y) - -model = layers.Conv1D(31, 7, activation='relu', input_shape=input_shape[1:])(x) -print(model.shape) -model = layers.MaxPooling1D(7, data_format='channels_first')(model) -print(model.shape) -model = layers.Conv1D(31, 7, activation='relu')(model) -print(model.shape) -model = layers.MaxPooling1D(7, data_format='channels_first')(model) -print(model.shape) -model = layers.Conv1D(31, 7, activation='relu')(model) -print(model.shape) -model = layers.MaxPooling1D(7, data_format='channels_first')(model) -print(model.shape) -model = layers.GRU(7)(model) -print(model.shape) - diff --git a/spaces/MrD05/text-generation-webui-space/server.py b/spaces/MrD05/text-generation-webui-space/server.py deleted file mode 100644 index 6a17f26287d94e9187a4f315fe9fb7d2dc6ec171..0000000000000000000000000000000000000000 --- a/spaces/MrD05/text-generation-webui-space/server.py +++ /dev/null @@ -1,382 +0,0 @@ -import gc -import io -import json -import re -import sys -import time -import zipfile -from pathlib import Path - -import gradio as gr -import torch - -import modules.chat as chat -import modules.extensions as extensions_module -import modules.shared as shared -import modules.ui as ui -from modules.html_generator import generate_chat_html -from modules.models import load_model, load_soft_prompt -from modules.text_generation import generate_reply - -# Loading custom settings -settings_file = None -if shared.args.settings is not None and Path(shared.args.settings).exists(): - settings_file = Path(shared.args.settings) -elif Path('settings.json').exists(): - settings_file = Path('settings.json') -if settings_file is not None: - print(f"Loading settings from {settings_file}...") - new_settings = json.loads(open(settings_file, 'r').read()) - for item in new_settings: - shared.settings[item] = new_settings[item] - -def get_available_models(): - if shared.args.flexgen: - return sorted([re.sub('-np$', '', item.name) for item in list(Path('models/').glob('*')) if item.name.endswith('-np')], key=str.lower) - else: - return sorted([item.name for item in list(Path('models/').glob('*')) if not item.name.endswith(('.txt', '-np', '.pt'))], key=str.lower) - -def get_available_presets(): - return sorted(set(map(lambda x : '.'.join(str(x.name).split('.')[:-1]), Path('presets').glob('*.txt'))), key=str.lower) - -def get_available_characters(): - return ['None'] + sorted(set(map(lambda x : '.'.join(str(x.name).split('.')[:-1]), Path('characters').glob('*.json'))), key=str.lower) - -def get_available_extensions(): - return sorted(set(map(lambda x : x.parts[1], Path('extensions').glob('*/script.py'))), key=str.lower) - -def get_available_softprompts(): - return ['None'] + sorted(set(map(lambda x : '.'.join(str(x.name).split('.')[:-1]), Path('softprompts').glob('*.zip'))), key=str.lower) - -def load_model_wrapper(selected_model): - if selected_model != shared.model_name: - shared.model_name = selected_model - shared.model = shared.tokenizer = None - if not shared.args.cpu: - gc.collect() - torch.cuda.empty_cache() - shared.model, shared.tokenizer = load_model(shared.model_name) - - return selected_model - -def load_preset_values(preset_menu, return_dict=False): - generate_params = { - 'do_sample': True, - 'temperature': 1, - 'top_p': 1, - 'typical_p': 1, - 'repetition_penalty': 1, - 'top_k': 50, - 'num_beams': 1, - 'penalty_alpha': 0, - 'min_length': 0, - 'length_penalty': 1, - 'no_repeat_ngram_size': 0, - 'early_stopping': False, - } - with open(Path(f'presets/{preset_menu}.txt'), 'r') as infile: - preset = infile.read() - for i in preset.splitlines(): - i = i.rstrip(',').strip().split('=') - if len(i) == 2 and i[0].strip() != 'tokens': - generate_params[i[0].strip()] = eval(i[1].strip()) - - generate_params['temperature'] = min(1.99, generate_params['temperature']) - - if return_dict: - return generate_params - else: - return generate_params['do_sample'], generate_params['temperature'], generate_params['top_p'], generate_params['typical_p'], generate_params['repetition_penalty'], generate_params['top_k'], generate_params['min_length'], generate_params['no_repeat_ngram_size'], generate_params['num_beams'], generate_params['penalty_alpha'], generate_params['length_penalty'], generate_params['early_stopping'] - -def upload_soft_prompt(file): - with zipfile.ZipFile(io.BytesIO(file)) as zf: - zf.extract('meta.json') - j = json.loads(open('meta.json', 'r').read()) - name = j['name'] - Path('meta.json').unlink() - - with open(Path(f'softprompts/{name}.zip'), 'wb') as f: - f.write(file) - - return name - -def create_settings_menus(default_preset): - generate_params = load_preset_values(default_preset if not shared.args.flexgen else 'Naive', return_dict=True) - - with gr.Row(): - with gr.Column(): - with gr.Row(): - shared.gradio['model_menu'] = gr.Dropdown(choices=available_models, value=shared.model_name, label='Model') - ui.create_refresh_button(shared.gradio['model_menu'], lambda : None, lambda : {'choices': get_available_models()}, 'refresh-button') - with gr.Column(): - with gr.Row(): - shared.gradio['preset_menu'] = gr.Dropdown(choices=available_presets, value=default_preset if not shared.args.flexgen else 'Naive', label='Generation parameters preset') - ui.create_refresh_button(shared.gradio['preset_menu'], lambda : None, lambda : {'choices': get_available_presets()}, 'refresh-button') - - with gr.Accordion('Custom generation parameters', open=False, elem_id='accordion'): - with gr.Row(): - with gr.Column(): - shared.gradio['temperature'] = gr.Slider(0.01, 1.99, value=generate_params['temperature'], step=0.01, label='temperature') - shared.gradio['repetition_penalty'] = gr.Slider(1.0, 2.99, value=generate_params['repetition_penalty'],step=0.01,label='repetition_penalty') - shared.gradio['top_k'] = gr.Slider(0,200,value=generate_params['top_k'],step=1,label='top_k') - shared.gradio['top_p'] = gr.Slider(0.0,1.0,value=generate_params['top_p'],step=0.01,label='top_p') - with gr.Column(): - shared.gradio['do_sample'] = gr.Checkbox(value=generate_params['do_sample'], label='do_sample') - shared.gradio['typical_p'] = gr.Slider(0.0,1.0,value=generate_params['typical_p'],step=0.01,label='typical_p') - shared.gradio['no_repeat_ngram_size'] = gr.Slider(0, 20, step=1, value=generate_params['no_repeat_ngram_size'], label='no_repeat_ngram_size') - shared.gradio['min_length'] = gr.Slider(0, 2000, step=1, value=generate_params['min_length'] if shared.args.no_stream else 0, label='min_length', interactive=shared.args.no_stream) - - gr.Markdown('Contrastive search:') - shared.gradio['penalty_alpha'] = gr.Slider(0, 5, value=generate_params['penalty_alpha'], label='penalty_alpha') - - gr.Markdown('Beam search (uses a lot of VRAM):') - with gr.Row(): - with gr.Column(): - shared.gradio['num_beams'] = gr.Slider(1, 20, step=1, value=generate_params['num_beams'], label='num_beams') - with gr.Column(): - shared.gradio['length_penalty'] = gr.Slider(-5, 5, value=generate_params['length_penalty'], label='length_penalty') - shared.gradio['early_stopping'] = gr.Checkbox(value=generate_params['early_stopping'], label='early_stopping') - - with gr.Accordion('Soft prompt', open=False, elem_id='accordion'): - with gr.Row(): - shared.gradio['softprompts_menu'] = gr.Dropdown(choices=available_softprompts, value='None', label='Soft prompt') - ui.create_refresh_button(shared.gradio['softprompts_menu'], lambda : None, lambda : {'choices': get_available_softprompts()}, 'refresh-button') - - gr.Markdown('Upload a soft prompt (.zip format):') - with gr.Row(): - shared.gradio['upload_softprompt'] = gr.File(type='binary', file_types=['.zip']) - - shared.gradio['model_menu'].change(load_model_wrapper, [shared.gradio['model_menu']], [shared.gradio['model_menu']], show_progress=True) - shared.gradio['preset_menu'].change(load_preset_values, [shared.gradio['preset_menu']], [shared.gradio['do_sample'], shared.gradio['temperature'], shared.gradio['top_p'], shared.gradio['typical_p'], shared.gradio['repetition_penalty'], shared.gradio['top_k'], shared.gradio['min_length'], shared.gradio['no_repeat_ngram_size'], shared.gradio['num_beams'], shared.gradio['penalty_alpha'], shared.gradio['length_penalty'], shared.gradio['early_stopping']]) - shared.gradio['softprompts_menu'].change(load_soft_prompt, [shared.gradio['softprompts_menu']], [shared.gradio['softprompts_menu']], show_progress=True) - shared.gradio['upload_softprompt'].upload(upload_soft_prompt, [shared.gradio['upload_softprompt']], [shared.gradio['softprompts_menu']]) - -available_models = get_available_models() -available_presets = get_available_presets() -available_characters = get_available_characters() -available_softprompts = get_available_softprompts() - -# Default extensions -extensions_module.available_extensions = get_available_extensions() -if shared.args.chat or shared.args.cai_chat: - for extension in shared.settings['chat_default_extensions']: - shared.args.extensions = shared.args.extensions or [] - if extension not in shared.args.extensions: - shared.args.extensions.append(extension) -else: - for extension in shared.settings['default_extensions']: - shared.args.extensions = shared.args.extensions or [] - if extension not in shared.args.extensions: - shared.args.extensions.append(extension) -if shared.args.extensions is not None and len(shared.args.extensions) > 0: - extensions_module.load_extensions() - -# Default model -if shared.args.model is not None: - shared.model_name = shared.args.model -else: - if len(available_models) == 0: - print('No models are available! Please download at least one.') - sys.exit(0) - elif len(available_models) == 1: - i = 0 - else: - print('The following models are available:\n') - for i, model in enumerate(available_models): - print(f'{i+1}. {model}') - print(f'\nWhich one do you want to load? 1-{len(available_models)}\n') - i = int(input())-1 - print() - shared.model_name = available_models[i] -shared.model, shared.tokenizer = load_model(shared.model_name) - -# Default UI settings -gen_events = [] -default_preset = shared.settings['presets'][next((k for k in shared.settings['presets'] if re.match(k.lower(), shared.model_name.lower())), 'default')] -default_text = shared.settings['prompts'][next((k for k in shared.settings['prompts'] if re.match(k.lower(), shared.model_name.lower())), 'default')] -title ='Text generation web UI' -description = '\n\n# Text generation lab\nGenerate text using Large Language Models.\n' -suffix = '_pygmalion' if 'pygmalion' in shared.model_name.lower() else '' - -if shared.args.chat or shared.args.cai_chat: - with gr.Blocks(css=ui.css+ui.chat_css, analytics_enabled=False, title=title) as shared.gradio['interface']: - gr.HTML('''Original github repo
-For faster inference without waiting in queue, you may duplicate the space.
-(👇 Scroll down to see the interface 👀)''') - if shared.args.cai_chat: - shared.gradio['display'] = gr.HTML(value=generate_chat_html(shared.history['visible'], shared.settings[f'name1{suffix}'], shared.settings[f'name2{suffix}'], shared.character)) - else: - shared.gradio['display'] = gr.Chatbot(value=shared.history['visible']).style(color_map=("#326efd", "#212528")) - shared.gradio['textbox'] = gr.Textbox(label='Input') - with gr.Row(): - shared.gradio['Stop'] = gr.Button('Stop') - shared.gradio['Generate'] = gr.Button('Generate') - with gr.Row(): - shared.gradio['Impersonate'] = gr.Button('Impersonate') - shared.gradio['Regenerate'] = gr.Button('Regenerate') - with gr.Row(): - shared.gradio['Copy last reply'] = gr.Button('Copy last reply') - shared.gradio['Replace last reply'] = gr.Button('Replace last reply') - shared.gradio['Remove last'] = gr.Button('Remove last') - - shared.gradio['Clear history'] = gr.Button('Clear history') - shared.gradio['Clear history-confirm'] = gr.Button('Confirm', variant="stop", visible=False) - shared.gradio['Clear history-cancel'] = gr.Button('Cancel', visible=False) - with gr.Tab('Chat settings'): - shared.gradio['name1'] = gr.Textbox(value=shared.settings[f'name1{suffix}'], lines=1, label='Your name') - shared.gradio['name2'] = gr.Textbox(value=shared.settings[f'name2{suffix}'], lines=1, label='Bot\'s name') - shared.gradio['context'] = gr.Textbox(value=shared.settings[f'context{suffix}'], lines=5, label='Context') - with gr.Row(): - shared.gradio['character_menu'] = gr.Dropdown(choices=available_characters, value='None', label='Character', elem_id='character-menu') - ui.create_refresh_button(shared.gradio['character_menu'], lambda : None, lambda : {'choices': get_available_characters()}, 'refresh-button') - - with gr.Row(): - shared.gradio['check'] = gr.Checkbox(value=shared.settings[f'stop_at_newline{suffix}'], label='Stop generating at new line character?') - with gr.Row(): - with gr.Tab('Chat history'): - with gr.Row(): - with gr.Column(): - gr.Markdown('Upload') - shared.gradio['upload_chat_history'] = gr.File(type='binary', file_types=['.json', '.txt']) - with gr.Column(): - gr.Markdown('Download') - shared.gradio['download'] = gr.File() - shared.gradio['download_button'] = gr.Button(value='Click me') - with gr.Tab('Upload character'): - with gr.Row(): - with gr.Column(): - gr.Markdown('1. Select the JSON file') - shared.gradio['upload_json'] = gr.File(type='binary', file_types=['.json']) - with gr.Column(): - gr.Markdown('2. Select your character\'s profile picture (optional)') - shared.gradio['upload_img_bot'] = gr.File(type='binary', file_types=['image']) - shared.gradio['Upload character'] = gr.Button(value='Submit') - with gr.Tab('Upload your profile picture'): - shared.gradio['upload_img_me'] = gr.File(type='binary', file_types=['image']) - with gr.Tab('Upload TavernAI Character Card'): - shared.gradio['upload_img_tavern'] = gr.File(type='binary', file_types=['image']) - - with gr.Tab('Generation settings'): - with gr.Row(): - with gr.Column(): - shared.gradio['max_new_tokens'] = gr.Slider(minimum=shared.settings['max_new_tokens_min'], maximum=shared.settings['max_new_tokens_max'], step=1, label='max_new_tokens', value=shared.settings['max_new_tokens']) - with gr.Column(): - shared.gradio['chat_prompt_size_slider'] = gr.Slider(minimum=shared.settings['chat_prompt_size_min'], maximum=shared.settings['chat_prompt_size_max'], step=1, label='Maximum prompt size in tokens', value=shared.settings['chat_prompt_size']) - shared.gradio['chat_generation_attempts'] = gr.Slider(minimum=shared.settings['chat_generation_attempts_min'], maximum=shared.settings['chat_generation_attempts_max'], value=shared.settings['chat_generation_attempts'], step=1, label='Generation attempts (for longer replies)') - create_settings_menus(default_preset) - - shared.input_params = [shared.gradio[k] for k in ['textbox', 'max_new_tokens', 'do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping', 'name1', 'name2', 'context', 'check', 'chat_prompt_size_slider', 'chat_generation_attempts']] - if shared.args.extensions is not None: - with gr.Tab('Extensions'): - extensions_module.create_extensions_block() - - function_call = 'chat.cai_chatbot_wrapper' if shared.args.cai_chat else 'chat.chatbot_wrapper' - - gen_events.append(shared.gradio['Generate'].click(eval(function_call), shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream, api_name='textgen')) - gen_events.append(shared.gradio['textbox'].submit(eval(function_call), shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream)) - gen_events.append(shared.gradio['Regenerate'].click(chat.regenerate_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream)) - gen_events.append(shared.gradio['Impersonate'].click(chat.impersonate_wrapper, shared.input_params, shared.gradio['textbox'], show_progress=shared.args.no_stream)) - shared.gradio['Stop'].click(chat.stop_everything_event, [], [], cancels=gen_events) - - shared.gradio['Copy last reply'].click(chat.send_last_reply_to_input, [], shared.gradio['textbox'], show_progress=shared.args.no_stream) - shared.gradio['Replace last reply'].click(chat.replace_last_reply, [shared.gradio['textbox'], shared.gradio['name1'], shared.gradio['name2']], shared.gradio['display'], show_progress=shared.args.no_stream) - - # Clear history with confirmation - clear_arr = [shared.gradio[k] for k in ['Clear history-confirm', 'Clear history', 'Clear history-cancel']] - shared.gradio['Clear history'].click(lambda :[gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, clear_arr) - shared.gradio['Clear history-confirm'].click(lambda :[gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr) - shared.gradio['Clear history-confirm'].click(chat.clear_chat_log, [shared.gradio['name1'], shared.gradio['name2']], shared.gradio['display']) - shared.gradio['Clear history-cancel'].click(lambda :[gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr) - - shared.gradio['Remove last'].click(chat.remove_last_message, [shared.gradio['name1'], shared.gradio['name2']], [shared.gradio['display'], shared.gradio['textbox']], show_progress=False) - shared.gradio['download_button'].click(chat.save_history, inputs=[], outputs=[shared.gradio['download']]) - shared.gradio['Upload character'].click(chat.upload_character, [shared.gradio['upload_json'], shared.gradio['upload_img_bot']], [shared.gradio['character_menu']]) - - # Clearing stuff and saving the history - for i in ['Generate', 'Regenerate', 'Replace last reply']: - shared.gradio[i].click(lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False) - shared.gradio[i].click(lambda : chat.save_history(timestamp=False), [], [], show_progress=False) - shared.gradio['Clear history-confirm'].click(lambda : chat.save_history(timestamp=False), [], [], show_progress=False) - shared.gradio['textbox'].submit(lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False) - shared.gradio['textbox'].submit(lambda : chat.save_history(timestamp=False), [], [], show_progress=False) - - shared.gradio['character_menu'].change(chat.load_character, [shared.gradio['character_menu'], shared.gradio['name1'], shared.gradio['name2']], [shared.gradio['name2'], shared.gradio['context'], shared.gradio['display']]) - shared.gradio['upload_chat_history'].upload(chat.load_history, [shared.gradio['upload_chat_history'], shared.gradio['name1'], shared.gradio['name2']], []) - shared.gradio['upload_img_tavern'].upload(chat.upload_tavern_character, [shared.gradio['upload_img_tavern'], shared.gradio['name1'], shared.gradio['name2']], [shared.gradio['character_menu']]) - shared.gradio['upload_img_me'].upload(chat.upload_your_profile_picture, [shared.gradio['upload_img_me']], []) - - reload_func = chat.redraw_html if shared.args.cai_chat else lambda : shared.history['visible'] - reload_inputs = [shared.gradio['name1'], shared.gradio['name2']] if shared.args.cai_chat else [] - shared.gradio['upload_chat_history'].upload(reload_func, reload_inputs, [shared.gradio['display']]) - shared.gradio['upload_img_me'].upload(reload_func, reload_inputs, [shared.gradio['display']]) - shared.gradio['Stop'].click(reload_func, reload_inputs, [shared.gradio['display']]) - - shared.gradio['interface'].load(lambda : chat.load_default_history(shared.settings[f'name1{suffix}'], shared.settings[f'name2{suffix}']), None, None) - shared.gradio['interface'].load(reload_func, reload_inputs, [shared.gradio['display']], show_progress=True) - -elif shared.args.notebook: - with gr.Blocks(css=ui.css, analytics_enabled=False, title=title) as shared.gradio['interface']: - gr.Markdown(description) - with gr.Tab('Raw'): - shared.gradio['textbox'] = gr.Textbox(value=default_text, lines=23) - with gr.Tab('Markdown'): - shared.gradio['markdown'] = gr.Markdown() - with gr.Tab('HTML'): - shared.gradio['html'] = gr.HTML() - - shared.gradio['Generate'] = gr.Button('Generate') - shared.gradio['Stop'] = gr.Button('Stop') - shared.gradio['max_new_tokens'] = gr.Slider(minimum=shared.settings['max_new_tokens_min'], maximum=shared.settings['max_new_tokens_max'], step=1, label='max_new_tokens', value=shared.settings['max_new_tokens']) - - create_settings_menus(default_preset) - if shared.args.extensions is not None: - extensions_module.create_extensions_block() - - shared.input_params = [shared.gradio[k] for k in ['textbox', 'max_new_tokens', 'do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping']] - output_params = [shared.gradio[k] for k in ['textbox', 'markdown', 'html']] - gen_events.append(shared.gradio['Generate'].click(generate_reply, shared.input_params, output_params, show_progress=shared.args.no_stream, api_name='textgen')) - gen_events.append(shared.gradio['textbox'].submit(generate_reply, shared.input_params, output_params, show_progress=shared.args.no_stream)) - shared.gradio['Stop'].click(None, None, None, cancels=gen_events) - -else: - with gr.Blocks(css=ui.css, analytics_enabled=False, title=title) as shared.gradio['interface']: - gr.Markdown(description) - with gr.Row(): - with gr.Column(): - shared.gradio['textbox'] = gr.Textbox(value=default_text, lines=15, label='Input') - shared.gradio['max_new_tokens'] = gr.Slider(minimum=shared.settings['max_new_tokens_min'], maximum=shared.settings['max_new_tokens_max'], step=1, label='max_new_tokens', value=shared.settings['max_new_tokens']) - shared.gradio['Generate'] = gr.Button('Generate') - with gr.Row(): - with gr.Column(): - shared.gradio['Continue'] = gr.Button('Continue') - with gr.Column(): - shared.gradio['Stop'] = gr.Button('Stop') - - create_settings_menus(default_preset) - if shared.args.extensions is not None: - extensions_module.create_extensions_block() - - with gr.Column(): - with gr.Tab('Raw'): - shared.gradio['output_textbox'] = gr.Textbox(lines=15, label='Output') - with gr.Tab('Markdown'): - shared.gradio['markdown'] = gr.Markdown() - with gr.Tab('HTML'): - shared.gradio['html'] = gr.HTML() - - shared.input_params = [shared.gradio[k] for k in ['textbox', 'max_new_tokens', 'do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping']] - output_params = [shared.gradio[k] for k in ['output_textbox', 'markdown', 'html']] - gen_events.append(shared.gradio['Generate'].click(generate_reply, shared.input_params, output_params, show_progress=shared.args.no_stream, api_name='textgen')) - gen_events.append(shared.gradio['textbox'].submit(generate_reply, shared.input_params, output_params, show_progress=shared.args.no_stream)) - gen_events.append(shared.gradio['Continue'].click(generate_reply, [shared.gradio['output_textbox']] + shared.input_params[1:], output_params, show_progress=shared.args.no_stream)) - shared.gradio['Stop'].click(None, None, None, cancels=gen_events) - -shared.gradio['interface'].queue() -if shared.args.listen: - shared.gradio['interface'].launch(prevent_thread_lock=True, share=shared.args.share, server_name='0.0.0.0', server_port=shared.args.listen_port, inbrowser=shared.args.auto_launch) -else: - shared.gradio['interface'].launch(prevent_thread_lock=True, share=shared.args.share, server_port=shared.args.listen_port, inbrowser=shared.args.auto_launch) - -# I think that I will need this later -while True: - time.sleep(0.5) diff --git a/spaces/NCTCMumbai/NCTC/models/official/nlp/modeling/networks/encoder_scaffold_test.py b/spaces/NCTCMumbai/NCTC/models/official/nlp/modeling/networks/encoder_scaffold_test.py deleted file mode 100644 index 664bccd08e11720918e0060458dc934350d2d594..0000000000000000000000000000000000000000 --- a/spaces/NCTCMumbai/NCTC/models/official/nlp/modeling/networks/encoder_scaffold_test.py +++ /dev/null @@ -1,646 +0,0 @@ -# Copyright 2019 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for transformer-based text encoder network.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from absl.testing import parameterized -import numpy as np -import tensorflow as tf - -from tensorflow.python.keras import keras_parameterized # pylint: disable=g-direct-tensorflow-import -from official.modeling import activations -from official.nlp.modeling import layers -from official.nlp.modeling.networks import encoder_scaffold - - -# Test class that wraps a standard transformer layer. If this layer is called -# at any point, the list passed to the config object will be filled with a -# boolean 'True'. We register this class as a Keras serializable so we can -# test serialization below. -@tf.keras.utils.register_keras_serializable(package="TestOnly") -class ValidatedTransformerLayer(layers.Transformer): - - def __init__(self, call_list, **kwargs): - super(ValidatedTransformerLayer, self).__init__(**kwargs) - self.list = call_list - - def call(self, inputs): - self.list.append(True) - return super(ValidatedTransformerLayer, self).call(inputs) - - def get_config(self): - config = super(ValidatedTransformerLayer, self).get_config() - config["call_list"] = [] - return config - - -# This decorator runs the test in V1, V2-Eager, and V2-Functional mode. It -# guarantees forward compatibility of this code for the V2 switchover. -@keras_parameterized.run_all_keras_modes -class EncoderScaffoldLayerClassTest(keras_parameterized.TestCase): - - def tearDown(self): - super(EncoderScaffoldLayerClassTest, self).tearDown() - tf.keras.mixed_precision.experimental.set_policy("float32") - - @parameterized.named_parameters( - dict(testcase_name="only_final_output", return_all_layer_outputs=False), - dict(testcase_name="all_layer_outputs", return_all_layer_outputs=True)) - def test_network_creation(self, return_all_layer_outputs): - hidden_size = 32 - sequence_length = 21 - num_hidden_instances = 3 - embedding_cfg = { - "vocab_size": 100, - "type_vocab_size": 16, - "hidden_size": hidden_size, - "seq_length": sequence_length, - "max_seq_length": sequence_length, - "initializer": tf.keras.initializers.TruncatedNormal(stddev=0.02), - "dropout_rate": 0.1, - } - - call_list = [] - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - "call_list": - call_list - } - # Create a small EncoderScaffold for testing. - test_network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=num_hidden_instances, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cls=ValidatedTransformerLayer, - hidden_cfg=hidden_cfg, - embedding_cfg=embedding_cfg, - return_all_layer_outputs=return_all_layer_outputs) - # Create the inputs (note that the first dimension is implicit). - word_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - type_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - output_data, pooled = test_network([word_ids, mask, type_ids]) - - if return_all_layer_outputs: - self.assertIsInstance(output_data, list) - self.assertLen(output_data, num_hidden_instances) - data = output_data[-1] - else: - data = output_data - self.assertIsInstance(test_network.hidden_layers, list) - self.assertLen(test_network.hidden_layers, num_hidden_instances) - self.assertIsInstance(test_network.pooler_layer, tf.keras.layers.Dense) - - expected_data_shape = [None, sequence_length, hidden_size] - expected_pooled_shape = [None, hidden_size] - self.assertAllEqual(expected_data_shape, data.shape.as_list()) - self.assertAllEqual(expected_pooled_shape, pooled.shape.as_list()) - - # The default output dtype is float32. - self.assertAllEqual(tf.float32, data.dtype) - self.assertAllEqual(tf.float32, pooled.dtype) - - # If call_list[0] exists and is True, the passed layer class was - # instantiated from the given config properly. - self.assertNotEmpty(call_list) - self.assertTrue(call_list[0], "The passed layer class wasn't instantiated.") - - def test_network_creation_with_float16_dtype(self): - tf.keras.mixed_precision.experimental.set_policy("mixed_float16") - hidden_size = 32 - sequence_length = 21 - embedding_cfg = { - "vocab_size": 100, - "type_vocab_size": 16, - "hidden_size": hidden_size, - "seq_length": sequence_length, - "max_seq_length": sequence_length, - "initializer": tf.keras.initializers.TruncatedNormal(stddev=0.02), - "dropout_rate": 0.1, - } - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - } - # Create a small EncoderScaffold for testing. - test_network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=3, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cfg=hidden_cfg, - embedding_cfg=embedding_cfg) - # Create the inputs (note that the first dimension is implicit). - word_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - type_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - data, pooled = test_network([word_ids, mask, type_ids]) - - expected_data_shape = [None, sequence_length, hidden_size] - expected_pooled_shape = [None, hidden_size] - self.assertAllEqual(expected_data_shape, data.shape.as_list()) - self.assertAllEqual(expected_pooled_shape, pooled.shape.as_list()) - - # If float_dtype is set to float16, the data output is float32 (from a layer - # norm) and pool output should be float16. - self.assertAllEqual(tf.float32, data.dtype) - self.assertAllEqual(tf.float16, pooled.dtype) - - def test_network_invocation(self): - hidden_size = 32 - sequence_length = 21 - vocab_size = 57 - num_types = 7 - embedding_cfg = { - "vocab_size": vocab_size, - "type_vocab_size": num_types, - "hidden_size": hidden_size, - "seq_length": sequence_length, - "max_seq_length": sequence_length, - "initializer": tf.keras.initializers.TruncatedNormal(stddev=0.02), - "dropout_rate": 0.1, - } - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - } - # Create a small EncoderScaffold for testing. - test_network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=3, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cfg=hidden_cfg, - embedding_cfg=embedding_cfg) - - # Create the inputs (note that the first dimension is implicit). - word_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - type_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - data, pooled = test_network([word_ids, mask, type_ids]) - - # Create a model based off of this network: - model = tf.keras.Model([word_ids, mask, type_ids], [data, pooled]) - - # Invoke the model. We can't validate the output data here (the model is too - # complex) but this will catch structural runtime errors. - batch_size = 3 - word_id_data = np.random.randint( - vocab_size, size=(batch_size, sequence_length)) - mask_data = np.random.randint(2, size=(batch_size, sequence_length)) - type_id_data = np.random.randint( - num_types, size=(batch_size, sequence_length)) - _ = model.predict([word_id_data, mask_data, type_id_data]) - - # Creates a EncoderScaffold with max_sequence_length != sequence_length - num_types = 7 - embedding_cfg = { - "vocab_size": vocab_size, - "type_vocab_size": num_types, - "hidden_size": hidden_size, - "seq_length": sequence_length, - "max_seq_length": sequence_length * 2, - "initializer": tf.keras.initializers.TruncatedNormal(stddev=0.02), - "dropout_rate": 0.1, - } - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - } - # Create a small EncoderScaffold for testing. - test_network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=3, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cfg=hidden_cfg, - embedding_cfg=embedding_cfg) - - model = tf.keras.Model([word_ids, mask, type_ids], [data, pooled]) - _ = model.predict([word_id_data, mask_data, type_id_data]) - - def test_serialize_deserialize(self): - # Create a network object that sets all of its config options. - hidden_size = 32 - sequence_length = 21 - embedding_cfg = { - "vocab_size": 100, - "type_vocab_size": 16, - "hidden_size": hidden_size, - "seq_length": sequence_length, - "max_seq_length": sequence_length, - "initializer": tf.keras.initializers.TruncatedNormal(stddev=0.02), - "dropout_rate": 0.1, - } - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - } - # Create a small EncoderScaffold for testing. - network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=3, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cfg=hidden_cfg, - embedding_cfg=embedding_cfg) - - # Create another network object from the first object's config. - new_network = encoder_scaffold.EncoderScaffold.from_config( - network.get_config()) - - # Validate that the config can be forced to JSON. - _ = new_network.to_json() - - # If the serialization was successful, the new config should match the old. - self.assertAllEqual(network.get_config(), new_network.get_config()) - - -@keras_parameterized.run_all_keras_modes -class EncoderScaffoldEmbeddingNetworkTest(keras_parameterized.TestCase): - - def test_network_invocation(self): - hidden_size = 32 - sequence_length = 21 - vocab_size = 57 - - # Build an embedding network to swap in for the default network. This one - # will have 2 inputs (mask and word_ids) instead of 3, and won't use - # positional embeddings. - - word_ids = tf.keras.layers.Input( - shape=(sequence_length,), dtype=tf.int32, name="input_word_ids") - mask = tf.keras.layers.Input( - shape=(sequence_length,), dtype=tf.int32, name="input_mask") - embedding_layer = layers.OnDeviceEmbedding( - vocab_size=vocab_size, - embedding_width=hidden_size, - initializer=tf.keras.initializers.TruncatedNormal(stddev=0.02), - name="word_embeddings") - word_embeddings = embedding_layer(word_ids) - attention_mask = layers.SelfAttentionMask()([word_embeddings, mask]) - network = tf.keras.Model([word_ids, mask], - [word_embeddings, attention_mask]) - - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - } - - # Create a small EncoderScaffold for testing. - test_network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=3, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cfg=hidden_cfg, - embedding_cls=network, - embedding_data=embedding_layer.embeddings) - - # Create the inputs (note that the first dimension is implicit). - word_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - data, pooled = test_network([word_ids, mask]) - - # Create a model based off of this network: - model = tf.keras.Model([word_ids, mask], [data, pooled]) - - # Invoke the model. We can't validate the output data here (the model is too - # complex) but this will catch structural runtime errors. - batch_size = 3 - word_id_data = np.random.randint( - vocab_size, size=(batch_size, sequence_length)) - mask_data = np.random.randint(2, size=(batch_size, sequence_length)) - _ = model.predict([word_id_data, mask_data]) - - # Test that we can get the embedding data that we passed to the object. This - # is necessary to support standard language model training. - self.assertIs(embedding_layer.embeddings, - test_network.get_embedding_table()) - - def test_serialize_deserialize(self): - hidden_size = 32 - sequence_length = 21 - vocab_size = 57 - - # Build an embedding network to swap in for the default network. This one - # will have 2 inputs (mask and word_ids) instead of 3, and won't use - # positional embeddings. - - word_ids = tf.keras.layers.Input( - shape=(sequence_length,), dtype=tf.int32, name="input_word_ids") - mask = tf.keras.layers.Input( - shape=(sequence_length,), dtype=tf.int32, name="input_mask") - embedding_layer = layers.OnDeviceEmbedding( - vocab_size=vocab_size, - embedding_width=hidden_size, - initializer=tf.keras.initializers.TruncatedNormal(stddev=0.02), - name="word_embeddings") - word_embeddings = embedding_layer(word_ids) - attention_mask = layers.SelfAttentionMask()([word_embeddings, mask]) - network = tf.keras.Model([word_ids, mask], - [word_embeddings, attention_mask]) - - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - } - - # Create a small EncoderScaffold for testing. - test_network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=3, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cfg=hidden_cfg, - embedding_cls=network, - embedding_data=embedding_layer.embeddings) - - # Create another network object from the first object's config. - new_network = encoder_scaffold.EncoderScaffold.from_config( - test_network.get_config()) - - # Validate that the config can be forced to JSON. - _ = new_network.to_json() - - # If the serialization was successful, the new config should match the old. - self.assertAllEqual(test_network.get_config(), new_network.get_config()) - - # Create a model based off of the old and new networks: - word_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - - data, pooled = new_network([word_ids, mask]) - new_model = tf.keras.Model([word_ids, mask], [data, pooled]) - - data, pooled = test_network([word_ids, mask]) - model = tf.keras.Model([word_ids, mask], [data, pooled]) - - # Copy the weights between models. - new_model.set_weights(model.get_weights()) - - # Invoke the models. - batch_size = 3 - word_id_data = np.random.randint( - vocab_size, size=(batch_size, sequence_length)) - mask_data = np.random.randint(2, size=(batch_size, sequence_length)) - data, cls = model.predict([word_id_data, mask_data]) - new_data, new_cls = new_model.predict([word_id_data, mask_data]) - - # The output should be equal. - self.assertAllEqual(data, new_data) - self.assertAllEqual(cls, new_cls) - - # We should not be able to get a reference to the embedding data. - with self.assertRaisesRegex(RuntimeError, ".*does not have a reference.*"): - new_network.get_embedding_table() - - -@keras_parameterized.run_all_keras_modes -class EncoderScaffoldHiddenInstanceTest(keras_parameterized.TestCase): - - def test_network_invocation(self): - hidden_size = 32 - sequence_length = 21 - vocab_size = 57 - num_types = 7 - - embedding_cfg = { - "vocab_size": vocab_size, - "type_vocab_size": num_types, - "hidden_size": hidden_size, - "seq_length": sequence_length, - "max_seq_length": sequence_length, - "initializer": tf.keras.initializers.TruncatedNormal(stddev=0.02), - "dropout_rate": 0.1, - } - - call_list = [] - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - "call_list": - call_list - } - # Create a small EncoderScaffold for testing. This time, we pass an already- - # instantiated layer object. - - xformer = ValidatedTransformerLayer(**hidden_cfg) - - test_network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=3, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cls=xformer, - embedding_cfg=embedding_cfg) - - # Create the inputs (note that the first dimension is implicit). - word_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - type_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - data, pooled = test_network([word_ids, mask, type_ids]) - - # Create a model based off of this network: - model = tf.keras.Model([word_ids, mask, type_ids], [data, pooled]) - - # Invoke the model. We can't validate the output data here (the model is too - # complex) but this will catch structural runtime errors. - batch_size = 3 - word_id_data = np.random.randint( - vocab_size, size=(batch_size, sequence_length)) - mask_data = np.random.randint(2, size=(batch_size, sequence_length)) - type_id_data = np.random.randint( - num_types, size=(batch_size, sequence_length)) - _ = model.predict([word_id_data, mask_data, type_id_data]) - - # If call_list[0] exists and is True, the passed layer class was - # called as part of the graph creation. - self.assertNotEmpty(call_list) - self.assertTrue(call_list[0], "The passed layer class wasn't instantiated.") - - def test_serialize_deserialize(self): - hidden_size = 32 - sequence_length = 21 - vocab_size = 57 - num_types = 7 - - embedding_cfg = { - "vocab_size": vocab_size, - "type_vocab_size": num_types, - "hidden_size": hidden_size, - "seq_length": sequence_length, - "max_seq_length": sequence_length, - "initializer": tf.keras.initializers.TruncatedNormal(stddev=0.02), - "dropout_rate": 0.1, - } - - call_list = [] - hidden_cfg = { - "num_attention_heads": - 2, - "intermediate_size": - 3072, - "intermediate_activation": - activations.gelu, - "dropout_rate": - 0.1, - "attention_dropout_rate": - 0.1, - "kernel_initializer": - tf.keras.initializers.TruncatedNormal(stddev=0.02), - "call_list": - call_list - } - # Create a small EncoderScaffold for testing. This time, we pass an already- - # instantiated layer object. - - xformer = ValidatedTransformerLayer(**hidden_cfg) - - test_network = encoder_scaffold.EncoderScaffold( - num_hidden_instances=3, - pooled_output_dim=hidden_size, - pooler_layer_initializer=tf.keras.initializers.TruncatedNormal( - stddev=0.02), - hidden_cls=xformer, - embedding_cfg=embedding_cfg) - - # Create another network object from the first object's config. - new_network = encoder_scaffold.EncoderScaffold.from_config( - test_network.get_config()) - - # Validate that the config can be forced to JSON. - _ = new_network.to_json() - - # If the serialization was successful, the new config should match the old. - self.assertAllEqual(test_network.get_config(), new_network.get_config()) - - # Create a model based off of the old and new networks: - word_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - type_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32) - - data, pooled = new_network([word_ids, mask, type_ids]) - new_model = tf.keras.Model([word_ids, mask, type_ids], [data, pooled]) - - data, pooled = test_network([word_ids, mask, type_ids]) - model = tf.keras.Model([word_ids, mask, type_ids], [data, pooled]) - - # Copy the weights between models. - new_model.set_weights(model.get_weights()) - - # Invoke the models. - batch_size = 3 - word_id_data = np.random.randint( - vocab_size, size=(batch_size, sequence_length)) - mask_data = np.random.randint(2, size=(batch_size, sequence_length)) - type_id_data = np.random.randint( - num_types, size=(batch_size, sequence_length)) - data, cls = model.predict([word_id_data, mask_data, type_id_data]) - new_data, new_cls = new_model.predict( - [word_id_data, mask_data, type_id_data]) - - # The output should be equal. - self.assertAllEqual(data, new_data) - self.assertAllEqual(cls, new_cls) - - -if __name__ == "__main__": - tf.test.main() diff --git a/spaces/NCTCMumbai/NCTC/models/official/nlp/nhnet/raw_data_processor.py b/spaces/NCTCMumbai/NCTC/models/official/nlp/nhnet/raw_data_processor.py deleted file mode 100644 index 0a30532f4f401e6f2b29430d353767c6cdea0966..0000000000000000000000000000000000000000 --- a/spaces/NCTCMumbai/NCTC/models/official/nlp/nhnet/raw_data_processor.py +++ /dev/null @@ -1,228 +0,0 @@ -# Lint as: python3 -# Copyright 2020 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Library for processing crawled content and generating tfrecords.""" - -import collections -import json -import multiprocessing -import os -import urllib.parse -import tensorflow as tf - -from official.nlp.bert import tokenization -from official.nlp.data import classifier_data_lib - - -class RawDataProcessor(object): - """Data converter for story examples.""" - - def __init__(self, - vocab: str, - do_lower_case: bool, - len_title: int = 15, - len_passage: int = 200, - max_num_articles: int = 5, - include_article_title_in_passage: bool = False, - include_text_snippet_in_example: bool = False): - """Constructs a RawDataProcessor. - - Args: - vocab: Filepath of the BERT vocabulary. - do_lower_case: Whether the vocabulary is uncased or not. - len_title: Maximum number of tokens in story headline. - len_passage: Maximum number of tokens in article passage. - max_num_articles: Maximum number of articles in a story. - include_article_title_in_passage: Whether to include article title in - article passage. - include_text_snippet_in_example: Whether to include text snippet - (headline and article content) in generated tensorflow Examples, for - debug usage. If include_article_title_in_passage=True, title and body - will be separated by [SEP]. - """ - self.articles = dict() - self.tokenizer = tokenization.FullTokenizer( - vocab, do_lower_case=do_lower_case, split_on_punc=False) - self.len_title = len_title - self.len_passage = len_passage - self.max_num_articles = max_num_articles - self.include_article_title_in_passage = include_article_title_in_passage - self.include_text_snippet_in_example = include_text_snippet_in_example - # ex_index=5 deactivates printing inside convert_single_example. - self.ex_index = 5 - # Parameters used in InputExample, not used in NHNet. - self.label = 0 - self.guid = 0 - self.num_generated_examples = 0 - - def read_crawled_articles(self, folder_path): - """Reads crawled articles under folder_path.""" - for path, _, files in os.walk(folder_path): - for name in files: - if not name.endswith(".json"): - continue - url, article = self._get_article_content_from_json( - os.path.join(path, name)) - if not article.text_a: - continue - self.articles[RawDataProcessor.normalize_url(url)] = article - if len(self.articles) % 5000 == 0: - print("Number of articles loaded: %d\r" % len(self.articles), end="") - print() - return len(self.articles) - - def generate_examples(self, input_file, output_files): - """Loads story from input json file and exports examples in output_files.""" - writers = [] - story_partition = [] - for output_file in output_files: - writers.append(tf.io.TFRecordWriter(output_file)) - story_partition.append(list()) - with tf.io.gfile.GFile(input_file, "r") as story_json_file: - stories = json.load(story_json_file) - writer_index = 0 - for story in stories: - articles = [] - for url in story["urls"]: - normalized_url = RawDataProcessor.normalize_url(url) - if normalized_url in self.articles: - articles.append(self.articles[normalized_url]) - if not articles: - continue - story_partition[writer_index].append((story["label"], articles)) - writer_index = (writer_index + 1) % len(writers) - lock = multiprocessing.Lock() - pool = multiprocessing.pool.ThreadPool(len(writers)) - data = [(story_partition[i], writers[i], lock) for i in range(len(writers))] - pool.map(self._write_story_partition, data) - return len(stories), self.num_generated_examples - - @classmethod - def normalize_url(cls, url): - """Normalize url for better matching.""" - url = urllib.parse.unquote( - urllib.parse.urlsplit(url)._replace(query=None).geturl()) - output, part = [], None - for part in url.split("//"): - if part == "http:" or part == "https:": - continue - else: - output.append(part) - return "//".join(output) - - def _get_article_content_from_json(self, file_path): - """Returns (url, InputExample) keeping content extracted from file_path.""" - with tf.io.gfile.GFile(file_path, "r") as article_json_file: - article = json.load(article_json_file) - if self.include_article_title_in_passage: - return article["url"], classifier_data_lib.InputExample( - guid=self.guid, - text_a=article["title"], - text_b=article["maintext"], - label=self.label) - else: - return article["url"], classifier_data_lib.InputExample( - guid=self.guid, text_a=article["maintext"], label=self.label) - - def _write_story_partition(self, data): - """Writes stories in a partition into file.""" - for (story_headline, articles) in data[0]: - story_example = tf.train.Example( - features=tf.train.Features( - feature=self._get_single_story_features(story_headline, - articles))) - data[1].write(story_example.SerializeToString()) - data[2].acquire() - try: - self.num_generated_examples += 1 - if self.num_generated_examples % 1000 == 0: - print( - "Number of stories written: %d\r" % self.num_generated_examples, - end="") - finally: - data[2].release() - - def _get_single_story_features(self, story_headline, articles): - """Converts a list of articles to a tensorflow Example.""" - def get_text_snippet(article): - if article.text_b: - return " [SEP] ".join([article.text_a, article.text_b]) - else: - return article.text_a - - story_features = collections.OrderedDict() - story_headline_feature = classifier_data_lib.convert_single_example( - ex_index=self.ex_index, - example=classifier_data_lib.InputExample( - guid=self.guid, text_a=story_headline, label=self.label), - label_list=[self.label], - max_seq_length=self.len_title, - tokenizer=self.tokenizer) - if self.include_text_snippet_in_example: - story_headline_feature.label_id = story_headline - self._add_feature_with_suffix( - feature=story_headline_feature, - suffix="a", - story_features=story_features) - for (article_index, article) in enumerate(articles): - if article_index == self.max_num_articles: - break - article_feature = classifier_data_lib.convert_single_example( - ex_index=self.ex_index, - example=article, - label_list=[self.label], - max_seq_length=self.len_passage, - tokenizer=self.tokenizer) - if self.include_text_snippet_in_example: - article_feature.label_id = get_text_snippet(article) - suffix = chr(ord("b") + article_index) - self._add_feature_with_suffix( - feature=article_feature, suffix=suffix, story_features=story_features) - - # Adds empty features as placeholder. - for article_index in range(len(articles), self.max_num_articles): - suffix = chr(ord("b") + article_index) - empty_article = classifier_data_lib.InputExample( - guid=self.guid, text_a="", label=self.label) - empty_feature = classifier_data_lib.convert_single_example( - ex_index=self.ex_index, - example=empty_article, - label_list=[self.label], - max_seq_length=self.len_passage, - tokenizer=self.tokenizer) - if self.include_text_snippet_in_example: - empty_feature.label_id = "" - self._add_feature_with_suffix( - feature=empty_feature, suffix=suffix, story_features=story_features) - return story_features - - def _add_feature_with_suffix(self, feature, suffix, story_features): - """Appends suffix to feature names and fills in the corresponding values.""" - - def _create_int_feature(values): - return tf.train.Feature(int64_list=tf.train.Int64List(value=list(values))) - - def _create_string_feature(value): - return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) - - story_features["input_ids_%c" % suffix] = _create_int_feature( - feature.input_ids) - story_features["input_mask_%c" % suffix] = _create_int_feature( - feature.input_mask) - story_features["segment_ids_%c" % suffix] = _create_int_feature( - feature.segment_ids) - if self.include_text_snippet_in_example: - story_features["text_snippet_%c" % suffix] = _create_string_feature( - bytes(feature.label_id.encode())) diff --git a/spaces/NCTCMumbai/NCTC/models/official/recommendation/run.sh b/spaces/NCTCMumbai/NCTC/models/official/recommendation/run.sh deleted file mode 100644 index b8e1143a38ba0cc26e97be6bad20a5ae6c13be65..0000000000000000000000000000000000000000 --- a/spaces/NCTCMumbai/NCTC/models/official/recommendation/run.sh +++ /dev/null @@ -1,101 +0,0 @@ -#!/bin/bash -set -e - -if [ `id -u` != 0 ]; then - echo "Calling sudo to gain root for this shell. (Needed to clear caches.)" - sudo echo "Success" -fi - -SCRIPT_DIR=`dirname "$BASH_SOURCE"` -export PYTHONPATH="${SCRIPT_DIR}/../../" -MAIN_SCRIPT="ncf_estimator_main.py" - -DATASET="ml-20m" - -BUCKET=${BUCKET:-""} -ROOT_DIR="${BUCKET:-/tmp}/MLPerf_NCF" -echo "Root directory: ${ROOT_DIR}" - -if [[ -z ${BUCKET} ]]; then - LOCAL_ROOT=${ROOT_DIR} -else - LOCAL_ROOT="/tmp/MLPerf_NCF" - mkdir -p ${LOCAL_ROOT} - echo "Local root (for files which cannot use GCS): ${LOCAL_ROOT}" -fi - -DATE=$(date '+%Y-%m-%d_%H:%M:%S') -TEST_DIR="${ROOT_DIR}/${DATE}" -LOCAL_TEST_DIR="${LOCAL_ROOT}/${DATE}" -mkdir -p ${LOCAL_TEST_DIR} - -TPU=${TPU:-""} -if [[ -z ${TPU} ]]; then - DEVICE_FLAG="--num_gpus -1" # --use_xla_for_gpu" -else - DEVICE_FLAG="--tpu ${TPU} --num_gpus 0" -fi - -DATA_DIR="${ROOT_DIR}/movielens_data" -python "${SCRIPT_DIR}/movielens.py" --data_dir ${DATA_DIR} --dataset ${DATASET} - -if [ "$1" == "keras" ] -then - MAIN_SCRIPT="ncf_keras_main.py" - BATCH_SIZE=99000 - DEVICE_FLAG="--num_gpus 1" -else - BATCH_SIZE=98340 -fi - -{ - -for i in `seq 0 4`; -do - START_TIME=$(date +%s) - MODEL_DIR="${TEST_DIR}/model_dir_${i}" - - RUN_LOG="${LOCAL_TEST_DIR}/run_${i}.log" - export COMPLIANCE_FILE="${LOCAL_TEST_DIR}/run_${i}_compliance_raw.log" - export STITCHED_COMPLIANCE_FILE="${LOCAL_TEST_DIR}/run_${i}_compliance_submission.log" - echo "" - echo "Beginning run ${i}" - echo " Complete output logs are in ${RUN_LOG}" - echo " Compliance logs: (submission log is created after run.)" - echo " ${COMPLIANCE_FILE}" - echo " ${STITCHED_COMPLIANCE_FILE}" - - # To reduce variation set the seed flag: - # --seed ${i} - - python -u "${SCRIPT_DIR}/${MAIN_SCRIPT}" \ - --model_dir ${MODEL_DIR} \ - --data_dir ${DATA_DIR} \ - --dataset ${DATASET} --hooks "" \ - ${DEVICE_FLAG} \ - --clean \ - --train_epochs 14 \ - --batch_size ${BATCH_SIZE} \ - --eval_batch_size 160000 \ - --learning_rate 0.00382059 \ - --beta1 0.783529 \ - --beta2 0.909003 \ - --epsilon 1.45439e-07 \ - --layers 256,256,128,64 --num_factors 64 \ - --hr_threshold 0.635 \ - --ml_perf \ - |& tee ${RUN_LOG} \ - | grep --line-buffered -E --regexp="(Iteration [0-9]+: HR = [0-9\.]+, NDCG = [0-9\.]+, Loss = [0-9\.]+)|(pipeline_hash)|(MLPerf time:)" - - END_TIME=$(date +%s) - echo "Run ${i} complete: $(( $END_TIME - $START_TIME )) seconds." - - # Don't fill up the local hard drive. - if [[ -z ${BUCKET} ]]; then - echo "Removing model directory to save space." - rm -r ${MODEL_DIR} - fi - -done - -} |& tee "${LOCAL_TEST_DIR}/summary.log" diff --git a/spaces/NCTCMumbai/NCTC/models/research/adversarial_crypto/train_eval.py b/spaces/NCTCMumbai/NCTC/models/research/adversarial_crypto/train_eval.py deleted file mode 100644 index df7a00ad50f2ec01b37d8c162309a928207088d6..0000000000000000000000000000000000000000 --- a/spaces/NCTCMumbai/NCTC/models/research/adversarial_crypto/train_eval.py +++ /dev/null @@ -1,276 +0,0 @@ -# Copyright 2016 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Adversarial training to learn trivial encryption functions, -from the paper "Learning to Protect Communications with -Adversarial Neural Cryptography", Abadi & Andersen, 2016. - -https://arxiv.org/abs/1610.06918 - -This program creates and trains three neural networks, -termed Alice, Bob, and Eve. Alice takes inputs -in_m (message), in_k (key) and outputs 'ciphertext'. - -Bob takes inputs in_k, ciphertext and tries to reconstruct -the message. - -Eve is an adversarial network that takes input ciphertext -and also tries to reconstruct the message. - -The main function attempts to train these networks and then -evaluates them, all on random plaintext and key values. - -""" - -# TensorFlow Python 3 compatibility -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import signal -import sys -from six.moves import xrange # pylint: disable=redefined-builtin -import tensorflow as tf - -flags = tf.app.flags - -flags.DEFINE_float('learning_rate', 0.0008, 'Constant learning rate') -flags.DEFINE_integer('batch_size', 4096, 'Batch size') - -FLAGS = flags.FLAGS - -# Input and output configuration. -TEXT_SIZE = 16 -KEY_SIZE = 16 - -# Training parameters. -ITERS_PER_ACTOR = 1 -EVE_MULTIPLIER = 2 # Train Eve 2x for every step of Alice/Bob -# Train until either max loops or Alice/Bob "good enough": -MAX_TRAINING_LOOPS = 850000 -BOB_LOSS_THRESH = 0.02 # Exit when Bob loss < 0.02 and Eve > 7.7 bits -EVE_LOSS_THRESH = 7.7 - -# Logging and evaluation. -PRINT_EVERY = 200 # In training, log every 200 steps. -EVE_EXTRA_ROUNDS = 2000 # At end, train eve a bit more. -RETRAIN_EVE_ITERS = 10000 # Retrain eve up to ITERS*LOOPS times. -RETRAIN_EVE_LOOPS = 25 # With an evaluation each loop -NUMBER_OF_EVE_RESETS = 5 # And do this up to 5 times with a fresh eve. -# Use EVAL_BATCHES samples each time we check accuracy. -EVAL_BATCHES = 1 - - -def batch_of_random_bools(batch_size, n): - """Return a batch of random "boolean" numbers. - - Args: - batch_size: Batch size dimension of returned tensor. - n: number of entries per batch. - - Returns: - A [batch_size, n] tensor of "boolean" numbers, where each number is - preresented as -1 or 1. - """ - - as_int = tf.random.uniform( - [batch_size, n], minval=0, maxval=2, dtype=tf.int32) - expanded_range = (as_int * 2) - 1 - return tf.cast(expanded_range, tf.float32) - - -class AdversarialCrypto(object): - """Primary model implementation class for Adversarial Neural Crypto. - - This class contains the code for the model itself, - and when created, plumbs the pathways from Alice to Bob and - Eve, creates the optimizers and loss functions, etc. - - Attributes: - eve_loss: Eve's loss function. - bob_loss: Bob's loss function. Different units from eve_loss. - eve_optimizer: A tf op that runs Eve's optimizer. - bob_optimizer: A tf op that runs Bob's optimizer. - bob_reconstruction_loss: Bob's message reconstruction loss, - which is comparable to eve_loss. - reset_eve_vars: Execute this op to completely reset Eve. - """ - - def get_message_and_key(self): - """Generate random pseudo-boolean key and message values.""" - - batch_size = tf.compat.v1.placeholder_with_default(FLAGS.batch_size, shape=[]) - - in_m = batch_of_random_bools(batch_size, TEXT_SIZE) - in_k = batch_of_random_bools(batch_size, KEY_SIZE) - return in_m, in_k - - def model(self, collection, message, key=None): - """The model for Alice, Bob, and Eve. If key=None, the first fully connected layer - takes only the message as inputs. Otherwise, it uses both the key - and the message. - - Args: - collection: The graph keys collection to add new vars to. - message: The input message to process. - key: The input key (if any) to use. - """ - - if key is not None: - combined_message = tf.concat(axis=1, values=[message, key]) - else: - combined_message = message - - # Ensure that all variables created are in the specified collection. - with tf.contrib.framework.arg_scope( - [tf.contrib.layers.fully_connected, tf.contrib.layers.conv2d], - variables_collections=[collection]): - - fc = tf.contrib.layers.fully_connected( - combined_message, - TEXT_SIZE + KEY_SIZE, - biases_initializer=tf.constant_initializer(0.0), - activation_fn=None) - - # Perform a sequence of 1D convolutions (by expanding the message out to 2D - # and then squeezing it back down). - fc = tf.expand_dims(fc, 2) # 2D - fc = tf.expand_dims(fc, 3) # 3D -- conv2d needs a depth - # 2,1 -> 1,2 - conv = tf.contrib.layers.conv2d( - fc, 2, 2, 2, 'SAME', activation_fn=tf.nn.sigmoid) - # 1,2 -> 1, 2 - conv = tf.contrib.layers.conv2d( - conv, 2, 1, 1, 'SAME', activation_fn=tf.nn.sigmoid) - # 1,2 -> 1, 1 - conv = tf.contrib.layers.conv2d( - conv, 1, 1, 1, 'SAME', activation_fn=tf.nn.tanh) - conv = tf.squeeze(conv, 3) - conv = tf.squeeze(conv, 2) - return conv - - def __init__(self): - in_m, in_k = self.get_message_and_key() - encrypted = self.model('alice', in_m, in_k) - decrypted = self.model('bob', encrypted, in_k) - eve_out = self.model('eve', encrypted, None) - - self.reset_eve_vars = tf.group( - *[w.initializer for w in tf.compat.v1.get_collection('eve')]) - - optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=FLAGS.learning_rate) - - # Eve's goal is to decrypt the entire message: - eve_bits_wrong = tf.reduce_sum( - tf.abs((eve_out + 1.0) / 2.0 - (in_m + 1.0) / 2.0), [1]) - self.eve_loss = tf.reduce_sum(eve_bits_wrong) - self.eve_optimizer = optimizer.minimize( - self.eve_loss, var_list=tf.compat.v1.get_collection('eve')) - - # Alice and Bob want to be accurate... - self.bob_bits_wrong = tf.reduce_sum( - tf.abs((decrypted + 1.0) / 2.0 - (in_m + 1.0) / 2.0), [1]) - # ... and to not let Eve do better than guessing. - self.bob_reconstruction_loss = tf.reduce_sum(self.bob_bits_wrong) - bob_eve_error_deviation = tf.abs(float(TEXT_SIZE) / 2.0 - eve_bits_wrong) - # 7-9 bits wrong is OK too, so we squish the error function a bit. - # Without doing this, we often tend to hang out at 0.25 / 7.5 error, - # and it seems bad to have continued, high communication error. - bob_eve_loss = tf.reduce_sum( - tf.square(bob_eve_error_deviation) / (TEXT_SIZE / 2)**2) - - # Rescale the losses to [0, 1] per example and combine. - self.bob_loss = (self.bob_reconstruction_loss / TEXT_SIZE + bob_eve_loss) - - self.bob_optimizer = optimizer.minimize( - self.bob_loss, - var_list=(tf.compat.v1.get_collection('alice') + tf.compat.v1.get_collection('bob'))) - - -def doeval(s, ac, n, itercount): - """Evaluate the current network on n batches of random examples. - - Args: - s: The current TensorFlow session - ac: an instance of the AdversarialCrypto class - n: The number of iterations to run. - itercount: Iteration count label for logging. - - Returns: - Bob and Eve's loss, as a percent of bits incorrect. - """ - - bob_loss_accum = 0 - eve_loss_accum = 0 - for _ in xrange(n): - bl, el = s.run([ac.bob_reconstruction_loss, ac.eve_loss]) - bob_loss_accum += bl - eve_loss_accum += el - bob_loss_percent = bob_loss_accum / (n * FLAGS.batch_size) - eve_loss_percent = eve_loss_accum / (n * FLAGS.batch_size) - print('%10d\t%20.2f\t%20.2f'%(itercount, bob_loss_percent, eve_loss_percent)) - sys.stdout.flush() - return bob_loss_percent, eve_loss_percent - - -def train_until_thresh(s, ac): - for j in xrange(MAX_TRAINING_LOOPS): - for _ in xrange(ITERS_PER_ACTOR): - s.run(ac.bob_optimizer) - for _ in xrange(ITERS_PER_ACTOR * EVE_MULTIPLIER): - s.run(ac.eve_optimizer) - if j % PRINT_EVERY == 0: - bob_avg_loss, eve_avg_loss = doeval(s, ac, EVAL_BATCHES, j) - if (bob_avg_loss < BOB_LOSS_THRESH and eve_avg_loss > EVE_LOSS_THRESH): - print('Target losses achieved.') - return True - return False - - -def train_and_evaluate(): - """Run the full training and evaluation loop.""" - - ac = AdversarialCrypto() - init = tf.compat.v1.global_variables_initializer() - - with tf.compat.v1.Session() as s: - s.run(init) - print('# Batch size: ', FLAGS.batch_size) - print('# %10s\t%20s\t%20s'%("Iter","Bob_Recon_Error","Eve_Recon_Error")) - - if train_until_thresh(s, ac): - for _ in xrange(EVE_EXTRA_ROUNDS): - s.run(ac.eve_optimizer) - print('Loss after eve extra training:') - doeval(s, ac, EVAL_BATCHES * 2, 0) - for _ in xrange(NUMBER_OF_EVE_RESETS): - print('Resetting Eve') - s.run(ac.reset_eve_vars) - eve_counter = 0 - for _ in xrange(RETRAIN_EVE_LOOPS): - for _ in xrange(RETRAIN_EVE_ITERS): - eve_counter += 1 - s.run(ac.eve_optimizer) - doeval(s, ac, EVAL_BATCHES, eve_counter) - doeval(s, ac, EVAL_BATCHES, eve_counter) - - -def main(unused_argv): - # Exit more quietly with Ctrl-C. - signal.signal(signal.SIGINT, signal.SIG_DFL) - train_and_evaluate() - - -if __name__ == '__main__': - tf.compat.v1.app.run() diff --git a/spaces/Nathanotal/GuessTheTranscription/app.py b/spaces/Nathanotal/GuessTheTranscription/app.py deleted file mode 100644 index 28e7aa9816cc5e7de66f57478f2708b492ac5e0e..0000000000000000000000000000000000000000 --- a/spaces/Nathanotal/GuessTheTranscription/app.py +++ /dev/null @@ -1,176 +0,0 @@ -"""## Divide the video into one 10s before and one 10s after""" - -# Login to HuggingFace somehow (todo) - -"""## Convert to audio - -## Get model -""" -import subprocess -from transformers import pipeline -pipe = pipeline(model="Nathanotal/whisper-small-v2") # change to "your-username/the-name-you-picked" - -def transcribe(audio): - text = pipe(audio)["text"] - - return text - -"""## Download and trim the video""" - -# Commented out IPython magic to ensure Python compatibility. -def downloadAndTranscribeVideo(source_url): - """**Input url to youtube video**""" - if "=" in source_url: - id = source_url.split('=', 1)[1] - else: - id = source_url.split('/')[-1] - - # Empty folder -# %rm -rf '/content/drive/My Drive/ID2223/LAB2/' - - """**Create output folder**""" - - # change this to /content/drive/My Drive/folder_you_want - # output_folder = '/content/drive/My Drive/ID2223/LAB2/' - - # import os - # def my_mkdirs(folder): - # if os.path.exists(folder)==False: - # os.makedirs(folder) - # my_mkdirs('/content/tmp/') - - # my_mkdirs(output_folder) - - # Get URLs to video file and audio file - # Attempt to get 720p clip, else get best possible quality - try: - proc = subprocess.Popen(f'yt-dlp -g -f bv[height=720][ext=webm]+ba[ext=m4a] "{source_url}"', shell=True, stdout=subprocess.PIPE) - print(proc) - video_url, audio_url = proc.stdout.read().decode('utf-8').split() - # video_url, audio_url = proc.communicate()[0].decode('utf-8') - except: - proc = subprocess.Popen(f'yt-dlp -g -f bv[ext=webm]+ba[ext=m4a] "{source_url}"', shell=True, stdout=subprocess.PIPE) - print(proc) - # video_url, audio_url = proc.communicate()[0].decode('utf-8') - video_url, audio_url = proc.stdout.read().decode('utf-8').split() - - print('Video:', video_url) - print('Audio:', audio_url) - - """**Download part of video and audio files**""" - - temp_video = "temp_video.mkv" - temp_audio = "temp_audio.m4a" - - # Download video file (first 10 seconds) - subprocess.run(f'ffmpeg -probesize 10M -y -i "{video_url}" -ss 00:00:00 -t 00:00:10 -c copy "{temp_video}"', shell=True) - - # Download audio file (first 10 seconds) - subprocess.run(f'ffmpeg -probesize 10M -y -i "{audio_url}" -ss 00:00:00 -t 00:00:10 -c copy "{temp_audio}"', shell=True) - - - """**MUX video and audio files**""" - temp_output = "output.mp4" - - # MUX video and audio files into final output [mkv] - subprocess.run(f'ffmpeg -hide_banner -loglevel error -y -i "{temp_video}" -i "{temp_audio}" -c copy "{temp_output}"', shell=True) - - first10Video = "first10Video.mp4" - second10Video = "second10Video.mp4" - - subprocess.run(f'ffmpeg -hide_banner -loglevel error -y -i "{temp_output}" -ss 00:00:00 -to 00:00:05 -c copy "{first10Video}"', shell=True) - subprocess.run(f'ffmpeg -hide_banner -loglevel error -y -i "{temp_output}" -ss 00:00:05 -to 00:00:10 -c copy "{second10Video}"', shell=True) - - first10Audio = "first10Audio.m4a" - second10Audio = "second10Audio.m4a" - - subprocess.run(f'ffmpeg -hide_banner -loglevel error -y -i "{first10Video}" -vn -acodec copy "{first10Audio}"', shell=True) - subprocess.run(f'ffmpeg -hide_banner -loglevel error -y -i "{second10Video}" -vn -acodec copy "{second10Audio}"', shell=True) - - first10AudioFinal = "first10AudioFinal.mp3" - second10AudioFinal = "second10AudioFinal.mp3" - - subprocess.run(f'ffmpeg -y -i "{first10Audio}" -c:v copy -c:a libmp3lame -q:a 4 "{first10AudioFinal}"', shell=True) - subprocess.run(f'ffmpeg -y -i "{second10Audio}" -c:v copy -c:a libmp3lame -q:a 4 "{second10AudioFinal}"', shell=True) - - firstVideoText = transcribe('first10AudioFinal.mp3') - secondVideoText = transcribe('second10AudioFinal.mp3') - - # Delete temporary files - subprocess.run(f'rm "{temp_video}"', shell=True) - subprocess.run(f'rm "{temp_audio}"', shell=True) - - return firstVideoText, secondVideoText - -# print(downloadAndTranscribeVideo('https://www.youtube.com/watch?v=93WrIPY4_4E')) - -"""## Build UI""" - -from transformers import pipeline -import gradio as gr - -def calculateSimilarity(texta, actualText): - texta = texta.lower().strip() - actualText = actualText.lower().strip() - textaL = texta.split(" ") - actualTextL = actualText.split(" ") - - totalWords = len(actualTextL) - matchingWords = 0 - - for word in textaL: - if word in actualTextL: - matchingWords += 1 - - return int(100*(matchingWords / totalWords)) - - -def game(videoLink, loadVideo, audio1, audio2, theState): - theState = theState or [] - firstText = "test" - secondText = "test" - if loadVideo: - firstText, secondText = downloadAndTranscribeVideo(videoLink) - theState = [firstText, secondText] - return "first10Video.mp4", firstText, "", "", "", "", "", "second10Video.mp4", "", theState - elif len(theState) == 0: - return "first10Video.mp4", "", "", "", "", "", "", "second10Video.mp4", "", theState - else: - firstText, secondText = theState[0], theState[1] - - t1 = transcribe(audio1) - t2 = transcribe(audio2) - t1Res = calculateSimilarity(t1, secondText) - t2Res = calculateSimilarity(t2, secondText) - - res = 'The game is even, everybody wins!' - if t1Res > t2Res: - res = 'Player 1 wins!' - elif t1Res < t2Res: - res = 'Player 2 wins!' - - return "first10Video.mp4", firstText, t1, str(t1Res) + '% match', t2, str(t2Res) + '% match', res, "second10Video.mp4", secondText, theState - -# exInputs = [[None], [None], ["/content/ut.webm"]] - -gameInterface = gr.Interface(fn=game, - inputs=[gr.Textbox(label='Link to video'), - gr.Checkbox(label='Load a new video'), - gr.Audio(source="microphone", type="filepath", label='Player 1\'s guess'), - gr.Audio(source="microphone", type="filepath", label='Player 2\'s guess'), - "state"], - outputs=[gr.Video(label='First ten seconds'), - gr.Textbox(label='Transcription of first ten seconds'), - gr.Textbox(label='Transcription for player 1'), - gr.Textbox(label='Percentage match:'), - gr.Textbox(label='Transcription for player 2'), - gr.Textbox(label='Percentage match:'), - gr.Textbox(label='Result:'), - gr.Video(label='Next ten seconds'), - gr.Textbox(label='Transcription of next ten seconds'), - "state"], - title="Phrase guessing game", - description="1. Paste a link to a youtube video in the \"Link to video\" box and check the checkmark \"Load new video\".\n2. Click \"Submit\". \n3. Uncheck the checkmark \"Load new video\". \n4. Listen to the first five seconds of the video. \n5. Player 1 and 2 guess what is spoken in the next 5 seconds of the video by recording it using the microphone. \n6. Click \"Submit\". \n7. See who made the best matching guess! \n9. Repeat steps 1-7. \n10. Enjoy!\n## Example videos: \n#### https://www.youtube.com/watch?v=ft3A7Sc4dng \n#### https://www.youtube.com/watch?v=jSTt1mYnRYk \n#### https://www.youtube.com/watch?v=7djB4_blLA4" - ) - -gameInterface.launch() \ No newline at end of file diff --git a/spaces/OAOA/DifFace/facelib/utils/face_restoration_helper.py b/spaces/OAOA/DifFace/facelib/utils/face_restoration_helper.py deleted file mode 100644 index 042532227e8e6d0beb788d7d9ee5e85704b4505e..0000000000000000000000000000000000000000 --- a/spaces/OAOA/DifFace/facelib/utils/face_restoration_helper.py +++ /dev/null @@ -1,425 +0,0 @@ -import cv2 -import numpy as np -import os -import torch -from torchvision.transforms.functional import normalize - -from facelib.detection import init_detection_model -from facelib.parsing import init_parsing_model -from facelib.utils.misc import img2tensor, imwrite - - -def get_largest_face(det_faces, h, w): - - def get_location(val, length): - if val < 0: - return 0 - elif val > length: - return length - else: - return val - - face_areas = [] - for det_face in det_faces: - left = get_location(det_face[0], w) - right = get_location(det_face[2], w) - top = get_location(det_face[1], h) - bottom = get_location(det_face[3], h) - face_area = (right - left) * (bottom - top) - face_areas.append(face_area) - largest_idx = face_areas.index(max(face_areas)) - return det_faces[largest_idx], largest_idx - - -def get_center_face(det_faces, h=0, w=0, center=None): - if center is not None: - center = np.array(center) - else: - center = np.array([w / 2, h / 2]) - center_dist = [] - for det_face in det_faces: - face_center = np.array([(det_face[0] + det_face[2]) / 2, (det_face[1] + det_face[3]) / 2]) - dist = np.linalg.norm(face_center - center) - center_dist.append(dist) - center_idx = center_dist.index(min(center_dist)) - return det_faces[center_idx], center_idx - - -class FaceRestoreHelper(object): - """Helper for the face restoration pipeline (base class).""" - - def __init__(self, - upscale_factor, - face_size=512, - crop_ratio=(1, 1), - det_model='retinaface_resnet50', - save_ext='png', - template_3points=False, - pad_blur=False, - use_parse=False, - device=None): - self.template_3points = template_3points # improve robustness - self.upscale_factor = upscale_factor - # the cropped face ratio based on the square face - self.crop_ratio = crop_ratio # (h, w) - assert (self.crop_ratio[0] >= 1 and self.crop_ratio[1] >= 1), 'crop ration only supports >=1' - self.face_size = (int(face_size * self.crop_ratio[1]), int(face_size * self.crop_ratio[0])) - - if self.template_3points: - self.face_template = np.array([[192, 240], [319, 240], [257, 371]]) - else: - # standard 5 landmarks for FFHQ faces with 512 x 512 - # # xintao - self.face_template = np.array([[192.98138, 239.94708], [318.90277, 240.1936], [256.63416, 314.01935], - [201.26117, 371.41043], [313.08905, 371.15118]]) - - # dlib: left_eye: 36:41 right_eye: 42:47 nose: 30,32,33,34 left mouth corner: 48 right mouth corner: 54 - # self.face_template = np.array([[193.65928, 242.98541], [318.32558, 243.06108], [255.67984, 328.82894], - # [198.22603, 372.82502], [313.91018, 372.75659]]) - - - self.face_template = self.face_template * (face_size / 512.0) - if self.crop_ratio[0] > 1: - self.face_template[:, 1] += face_size * (self.crop_ratio[0] - 1) / 2 - if self.crop_ratio[1] > 1: - self.face_template[:, 0] += face_size * (self.crop_ratio[1] - 1) / 2 - self.save_ext = save_ext - self.pad_blur = pad_blur - if self.pad_blur is True: - self.template_3points = False - - self.all_landmarks_5 = [] - self.det_faces = [] - self.affine_matrices = [] - self.inverse_affine_matrices = [] - self.cropped_faces = [] - self.restored_faces = [] - self.pad_input_imgs = [] - - if device is None: - self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') - else: - self.device = device - - # init face detection model - self.face_det = init_detection_model(det_model, half=False, device=self.device) - - # init face parsing model - self.use_parse = use_parse - self.face_parse = init_parsing_model(model_name='parsenet', device=self.device) - - def set_upscale_factor(self, upscale_factor): - self.upscale_factor = upscale_factor - - def read_image(self, img): - """img can be image path or cv2 loaded image.""" - # self.input_img is Numpy array, (h, w, c), BGR, uint8, [0, 255] - if isinstance(img, str): - img = cv2.imread(img) - - if np.max(img) > 256: # 16-bit image - img = img / 65535 * 255 - if len(img.shape) == 2: # gray image - img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) - elif img.shape[2] == 4: # BGRA image with alpha channel - img = img[:, :, 0:3] - - self.input_img = img - - if min(self.input_img.shape[:2])<512: - f = 512.0/min(self.input_img.shape[:2]) - self.input_img = cv2.resize(self.input_img, (0,0), fx=f, fy=f, interpolation=cv2.INTER_LINEAR) - - def get_face_landmarks_5(self, - only_keep_largest=False, - only_center_face=False, - resize=None, - blur_ratio=0.01, - eye_dist_threshold=None): - if resize is None: - scale = 1 - input_img = self.input_img - else: - h, w = self.input_img.shape[0:2] - scale = resize / min(h, w) - scale = max(1, scale) # always scale up - h, w = int(h * scale), int(w * scale) - interp = cv2.INTER_AREA if scale < 1 else cv2.INTER_LINEAR - input_img = cv2.resize(self.input_img, (w, h), interpolation=interp) - - with torch.no_grad(): - bboxes = self.face_det.detect_faces(input_img) - - if bboxes is None or bboxes.shape[0] == 0: - return 0 - else: - bboxes = bboxes / scale - - for bbox in bboxes: - # remove faces with too small eye distance: side faces or too small faces - eye_dist = np.linalg.norm([bbox[6] - bbox[8], bbox[7] - bbox[9]]) - if eye_dist_threshold is not None and (eye_dist < eye_dist_threshold): - continue - - if self.template_3points: - landmark = np.array([[bbox[i], bbox[i + 1]] for i in range(5, 11, 2)]) - else: - landmark = np.array([[bbox[i], bbox[i + 1]] for i in range(5, 15, 2)]) - self.all_landmarks_5.append(landmark) - self.det_faces.append(bbox[0:5]) - - if len(self.det_faces) == 0: - return 0 - if only_keep_largest: - h, w, _ = self.input_img.shape - self.det_faces, largest_idx = get_largest_face(self.det_faces, h, w) - self.all_landmarks_5 = [self.all_landmarks_5[largest_idx]] - elif only_center_face: - h, w, _ = self.input_img.shape - self.det_faces, center_idx = get_center_face(self.det_faces, h, w) - self.all_landmarks_5 = [self.all_landmarks_5[center_idx]] - - # pad blurry images - if self.pad_blur: - self.pad_input_imgs = [] - for landmarks in self.all_landmarks_5: - # get landmarks - eye_left = landmarks[0, :] - eye_right = landmarks[1, :] - eye_avg = (eye_left + eye_right) * 0.5 - mouth_avg = (landmarks[3, :] + landmarks[4, :]) * 0.5 - eye_to_eye = eye_right - eye_left - eye_to_mouth = mouth_avg - eye_avg - - # Get the oriented crop rectangle - # x: half width of the oriented crop rectangle - x = eye_to_eye - np.flipud(eye_to_mouth) * [-1, 1] - # - np.flipud(eye_to_mouth) * [-1, 1]: rotate 90 clockwise - # norm with the hypotenuse: get the direction - x /= np.hypot(*x) # get the hypotenuse of a right triangle - rect_scale = 1.5 - x *= max(np.hypot(*eye_to_eye) * 2.0 * rect_scale, np.hypot(*eye_to_mouth) * 1.8 * rect_scale) - # y: half height of the oriented crop rectangle - y = np.flipud(x) * [-1, 1] - - # c: center - c = eye_avg + eye_to_mouth * 0.1 - # quad: (left_top, left_bottom, right_bottom, right_top) - quad = np.stack([c - x - y, c - x + y, c + x + y, c + x - y]) - # qsize: side length of the square - qsize = np.hypot(*x) * 2 - border = max(int(np.rint(qsize * 0.1)), 3) - - # get pad - # pad: (width_left, height_top, width_right, height_bottom) - pad = (int(np.floor(min(quad[:, 0]))), int(np.floor(min(quad[:, 1]))), int(np.ceil(max(quad[:, 0]))), - int(np.ceil(max(quad[:, 1])))) - pad = [ - max(-pad[0] + border, 1), - max(-pad[1] + border, 1), - max(pad[2] - self.input_img.shape[0] + border, 1), - max(pad[3] - self.input_img.shape[1] + border, 1) - ] - - if max(pad) > 1: - # pad image - pad_img = np.pad(self.input_img, ((pad[1], pad[3]), (pad[0], pad[2]), (0, 0)), 'reflect') - # modify landmark coords - landmarks[:, 0] += pad[0] - landmarks[:, 1] += pad[1] - # blur pad images - h, w, _ = pad_img.shape - y, x, _ = np.ogrid[:h, :w, :1] - mask = np.maximum(1.0 - np.minimum(np.float32(x) / pad[0], - np.float32(w - 1 - x) / pad[2]), - 1.0 - np.minimum(np.float32(y) / pad[1], - np.float32(h - 1 - y) / pad[3])) - blur = int(qsize * blur_ratio) - if blur % 2 == 0: - blur += 1 - blur_img = cv2.boxFilter(pad_img, 0, ksize=(blur, blur)) - # blur_img = cv2.GaussianBlur(pad_img, (blur, blur), 0) - - pad_img = pad_img.astype('float32') - pad_img += (blur_img - pad_img) * np.clip(mask * 3.0 + 1.0, 0.0, 1.0) - pad_img += (np.median(pad_img, axis=(0, 1)) - pad_img) * np.clip(mask, 0.0, 1.0) - pad_img = np.clip(pad_img, 0, 255) # float32, [0, 255] - self.pad_input_imgs.append(pad_img) - else: - self.pad_input_imgs.append(np.copy(self.input_img)) - - return len(self.all_landmarks_5) - - def align_warp_face(self, save_cropped_path=None, border_mode='constant'): - """Align and warp faces with face template. - """ - if self.pad_blur: - assert len(self.pad_input_imgs) == len( - self.all_landmarks_5), f'Mismatched samples: {len(self.pad_input_imgs)} and {len(self.all_landmarks_5)}' - for idx, landmark in enumerate(self.all_landmarks_5): - # use 5 landmarks to get affine matrix - # use cv2.LMEDS method for the equivalence to skimage transform - # ref: https://blog.csdn.net/yichxi/article/details/115827338 - affine_matrix = cv2.estimateAffinePartial2D(landmark, self.face_template, method=cv2.LMEDS)[0] - self.affine_matrices.append(affine_matrix) - # warp and crop faces - if border_mode == 'constant': - border_mode = cv2.BORDER_CONSTANT - elif border_mode == 'reflect101': - border_mode = cv2.BORDER_REFLECT101 - elif border_mode == 'reflect': - border_mode = cv2.BORDER_REFLECT - if self.pad_blur: - input_img = self.pad_input_imgs[idx] - else: - input_img = self.input_img - cropped_face = cv2.warpAffine( - input_img, affine_matrix, self.face_size, borderMode=border_mode, borderValue=(135, 133, 132)) # gray - self.cropped_faces.append(cropped_face) - # save the cropped face - if save_cropped_path is not None: - path = os.path.splitext(save_cropped_path)[0] - save_path = f'{path}_{idx:02d}.{self.save_ext}' - imwrite(cropped_face, save_path) - - def get_inverse_affine(self, save_inverse_affine_path=None): - """Get inverse affine matrix.""" - for idx, affine_matrix in enumerate(self.affine_matrices): - inverse_affine = cv2.invertAffineTransform(affine_matrix) - inverse_affine *= self.upscale_factor - self.inverse_affine_matrices.append(inverse_affine) - # save inverse affine matrices - if save_inverse_affine_path is not None: - path, _ = os.path.splitext(save_inverse_affine_path) - save_path = f'{path}_{idx:02d}.pth' - torch.save(inverse_affine, save_path) - - def add_restored_face(self, face): - self.restored_faces.append(face) - - def paste_faces_to_input_image(self, save_path=None, upsample_img=None, draw_box=False, face_upsampler=None): - h, w, _ = self.input_img.shape - h_up, w_up = int(h * self.upscale_factor), int(w * self.upscale_factor) - - if upsample_img is None: - # simply resize the background - # upsample_img = cv2.resize(self.input_img, (w_up, h_up), interpolation=cv2.INTER_LANCZOS4) - upsample_img = cv2.resize(self.input_img, (w_up, h_up), interpolation=cv2.INTER_LINEAR) - else: - upsample_img = cv2.resize(upsample_img, (w_up, h_up), interpolation=cv2.INTER_LANCZOS4) - - assert len(self.restored_faces) == len( - self.inverse_affine_matrices), ('length of restored_faces and affine_matrices are different.') - - inv_mask_borders = [] - for restored_face, inverse_affine in zip(self.restored_faces, self.inverse_affine_matrices): - if face_upsampler is not None: - restored_face = face_upsampler.enhance(restored_face, outscale=self.upscale_factor)[0] - inverse_affine /= self.upscale_factor - inverse_affine[:, 2] *= self.upscale_factor - face_size = (self.face_size[0]*self.upscale_factor, self.face_size[1]*self.upscale_factor) - else: - # Add an offset to inverse affine matrix, for more precise back alignment - if self.upscale_factor > 1: - extra_offset = 0.5 * self.upscale_factor - else: - extra_offset = 0 - inverse_affine[:, 2] += extra_offset - face_size = self.face_size - inv_restored = cv2.warpAffine(restored_face, inverse_affine, (w_up, h_up)) - - # always use square mask - mask = np.ones(face_size, dtype=np.float32) - inv_mask = cv2.warpAffine(mask, inverse_affine, (w_up, h_up)) - # remove the black borders - inv_mask_erosion = cv2.erode( - inv_mask, np.ones((int(2 * self.upscale_factor), int(2 * self.upscale_factor)), np.uint8)) - pasted_face = inv_mask_erosion[:, :, None] * inv_restored - total_face_area = np.sum(inv_mask_erosion) # // 3 - # add border - if draw_box: - h, w = face_size - mask_border = np.ones((h, w, 3), dtype=np.float32) - border = int(1400/np.sqrt(total_face_area)) - mask_border[border:h-border, border:w-border,:] = 0 - inv_mask_border = cv2.warpAffine(mask_border, inverse_affine, (w_up, h_up)) - inv_mask_borders.append(inv_mask_border) - # compute the fusion edge based on the area of face - w_edge = int(total_face_area**0.5) // 20 - erosion_radius = w_edge * 2 - inv_mask_center = cv2.erode(inv_mask_erosion, np.ones((erosion_radius, erosion_radius), np.uint8)) - blur_size = w_edge * 2 - inv_soft_mask = cv2.GaussianBlur(inv_mask_center, (blur_size + 1, blur_size + 1), 0) - if len(upsample_img.shape) == 2: # upsample_img is gray image - upsample_img = upsample_img[:, :, None] - inv_soft_mask = inv_soft_mask[:, :, None] - - # parse mask - if self.use_parse: - # inference - face_input = cv2.resize(restored_face, (512, 512), interpolation=cv2.INTER_LINEAR) - face_input = img2tensor(face_input.astype('float32') / 255., bgr2rgb=True, float32=True) - normalize(face_input, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True) - face_input = torch.unsqueeze(face_input, 0).to(self.device) - with torch.no_grad(): - out = self.face_parse(face_input)[0] - out = out.argmax(dim=1).squeeze().cpu().numpy() - - parse_mask = np.zeros(out.shape) - MASK_COLORMAP = [0, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 255, 0, 0, 0] - for idx, color in enumerate(MASK_COLORMAP): - parse_mask[out == idx] = color - # blur the mask - parse_mask = cv2.GaussianBlur(parse_mask, (101, 101), 11) - parse_mask = cv2.GaussianBlur(parse_mask, (101, 101), 11) - # remove the black borders - thres = 10 - parse_mask[:thres, :] = 0 - parse_mask[-thres:, :] = 0 - parse_mask[:, :thres] = 0 - parse_mask[:, -thres:] = 0 - parse_mask = parse_mask / 255. - - parse_mask = cv2.resize(parse_mask, face_size) - parse_mask = cv2.warpAffine(parse_mask, inverse_affine, (w_up, h_up), flags=3) - inv_soft_parse_mask = parse_mask[:, :, None] - # pasted_face = inv_restored - fuse_mask = (inv_soft_parse_mask⭐ StarChat Playground 💬
""" -custom_css = """ -#banner-image { - display: block; - margin-left: auto; - margin-right: auto; -} - -#chat-message { - font-size: 14px; - min-height: 300px; -} -""" - -with gr.Blocks(analytics_enabled=False, css=custom_css) as demo: - gr.HTML(title) - - with gr.Row(): - with gr.Column(): - gr.Image("thumbnail.png", elem_id="banner-image", show_label=False) - with gr.Column(): - gr.Markdown( - """ - 💻 This demo showcases an **alpha** version of **[StarChat](https://huggingface.co/HuggingFaceH4/starchat-alpha)**, a variant of **[StarCoderBase](https://huggingface.co/bigcode/starcoderbase)** that was fine-tuned on the [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) and [OpenAssistant](https://huggingface.co/datasets/OpenAssistant/oasst1) datasets to act as a helpful coding assistant. The base model has 16B parameters and was pretrained on one trillion tokens sourced from 80+ programming languages, GitHub issues, Git commits, and Jupyter notebooks (all permissively licensed). - - 📝 For more details, check out our [blog post](https://huggingface.co/blog/starchat-alpha). - - ⚠️ **Intended Use**: this app and its [supporting model](https://huggingface.co/HuggingFaceH4/starchat-alpha) are provided as educational tools to explain large language model fine-tuning; not to serve as replacement for human expertise. - - ⚠️ **Known Failure Modes**: this alpha version of **StarChat** has not been aligned to human preferences with techniques like RLHF, so the model can produce problematic outputs (especially when prompted to do so). Since the base model was pretrained on a large corpus of code, it may produce code snippets that are syntactically valid but semantically incorrect. For example, it may produce code that does not compile or that produces incorrect results. It may also produce code that is vulnerable to security exploits. We have observed the model also has a tendency to produce false URLs which should be carefully inspected before clicking. For more details on the model's limitations in terms of factuality and biases, see the [model card](https://huggingface.co/HuggingFaceH4/starchat-alpha#bias-risks-and-limitations). - - ⚠️ **Data Collection**: by default, we are collecting the prompts entered in this app to further improve and evaluate the model. Do **NOT** share any personal or sensitive information while using the app! You can opt out of this data collection by removing the checkbox below. - """ - ) - - with gr.Row(): - do_save = gr.Checkbox( - value=True, - label="Store data", - info="You agree to the storage of your prompt and generated text for research and development purposes:", - ) - with gr.Accordion(label="System Prompt", open=False, elem_id="parameters-accordion"): - system_message = gr.Textbox( - elem_id="system-message", - placeholder="Below is a conversation between a human user and a helpful AI coding assistant.", - show_label=False, - ) - with gr.Row(): - with gr.Box(): - output = gr.Markdown() - chatbot = gr.Chatbot(elem_id="chat-message", label="Chat") - - with gr.Row(): - with gr.Column(scale=3): - user_message = gr.Textbox(placeholder="Enter your message here", show_label=False, elem_id="q-input") - with gr.Row(): - send_button = gr.Button("Send", elem_id="send-btn", visible=True) - - # regenerate_button = gr.Button("Regenerate", elem_id="send-btn", visible=True) - - clear_chat_button = gr.Button("Clear chat", elem_id="clear-btn", visible=True) - - with gr.Accordion(label="Parameters", open=False, elem_id="parameters-accordion"): - temperature = gr.Slider( - label="Temperature", - value=0.2, - minimum=0.0, - maximum=1.0, - step=0.1, - interactive=True, - info="Higher values produce more diverse outputs", - ) - top_k = gr.Slider( - label="Top-k", - value=50, - minimum=0.0, - maximum=100, - step=1, - interactive=True, - info="Sample from a shortlist of top-k tokens", - ) - top_p = gr.Slider( - label="Top-p (nucleus sampling)", - value=0.95, - minimum=0.0, - maximum=1, - step=0.05, - interactive=True, - info="Higher values sample more low-probability tokens", - ) - max_new_tokens = gr.Slider( - label="Max new tokens", - value=512, - minimum=0, - maximum=1024, - step=4, - interactive=True, - info="The maximum numbers of new tokens", - ) - repetition_penalty = gr.Slider( - label="Repetition Penalty", - value=1.2, - minimum=0.0, - maximum=10, - step=0.1, - interactive=True, - info="The parameter for repetition penalty. 1.0 means no penalty.", - ) - # with gr.Group(elem_id="share-btn-container"): - # community_icon = gr.HTML(community_icon_html, visible=True) - # loading_icon = gr.HTML(loading_icon_html, visible=True) - # share_button = gr.Button("Share to community", elem_id="share-btn", visible=True) - with gr.Row(): - gr.Examples( - examples=examples, - inputs=[user_message], - cache_examples=False, - fn=process_example, - outputs=[output], - ) - - history = gr.State([]) - # To clear out "message" input textbox and use this to regenerate message - last_user_message = gr.State("") - - user_message.submit( - generate, - inputs=[ - system_message, - user_message, - chatbot, - history, - temperature, - top_k, - top_p, - max_new_tokens, - repetition_penalty, - do_save, - ], - outputs=[chatbot, history, last_user_message, user_message], - ) - - send_button.click( - generate, - inputs=[ - system_message, - user_message, - chatbot, - history, - temperature, - top_k, - top_p, - max_new_tokens, - repetition_penalty, - do_save, - ], - outputs=[chatbot, history, last_user_message, user_message], - ) - - clear_chat_button.click(clear_chat, outputs=[chatbot, history]) - # share_button.click(None, [], [], _js=share_js) - -demo.queue(concurrency_count=16).launch(debug=True) diff --git a/spaces/PAIR/PAIR-Diffusion/annotator/OneFormer/datasets/panoptic2detection_coco_format.py b/spaces/PAIR/PAIR-Diffusion/annotator/OneFormer/datasets/panoptic2detection_coco_format.py deleted file mode 100644 index 14baa07a94d3048dcb8493c262f3b692b71a9370..0000000000000000000000000000000000000000 --- a/spaces/PAIR/PAIR-Diffusion/annotator/OneFormer/datasets/panoptic2detection_coco_format.py +++ /dev/null @@ -1,152 +0,0 @@ -#!/usr/bin/env python -# ------------------------------------------------------------------------------ -# Reference: https://github.com/cocodataset/panopticapi/blob/master/converters/panoptic2detection_coco_format.py -# Modified by Jitesh Jain (https://github.com/praeclarumjj3) -# ------------------------------------------------------------------------------ -''' -This script converts panoptic COCO format to detection COCO format. More -information about the formats can be found here: -http://cocodataset.org/#format-data. All segments will be stored in RLE format. - -Additional option: -- using option '--things_only' the script can discard all stuff -segments, saving segments of things classes only. -''' -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -from __future__ import unicode_literals -import os, sys -import argparse -import numpy as np -import json -import time -import multiprocessing - -import PIL.Image as Image - -from panopticapi.utils import get_traceback, rgb2id, save_json - -try: - # set up path for pycocotools - # sys.path.append('./cocoapi-master/PythonAPI/') - from pycocotools import mask as COCOmask -except Exception: - raise Exception("Please install pycocotools module from https://github.com/cocodataset/cocoapi") - -@get_traceback -def convert_panoptic_to_detection_coco_format_single_core( - proc_id, annotations_set, categories, segmentations_folder, things_only -): - annotations_detection = [] - for working_idx, annotation in enumerate(annotations_set): - if working_idx % 100 == 0: - print('Core: {}, {} from {} images processed'.format(proc_id, - working_idx, - len(annotations_set))) - - file_name = '{}.png'.format(annotation['file_name'].rsplit('.')[0]) - try: - pan_format = np.array( - Image.open(os.path.join(segmentations_folder, file_name)), dtype=np.uint32 - ) - except IOError: - raise KeyError('no prediction png file for id: {}'.format(annotation['image_id'])) - pan = rgb2id(pan_format) - - for segm_info in annotation['segments_info']: - if things_only and categories[segm_info['category_id']]['isthing'] != 1: - continue - mask = (pan == segm_info['id']).astype(np.uint8) - mask = np.expand_dims(mask, axis=2) - segm_info.pop('id') - segm_info['image_id'] = annotation['image_id'] - rle = COCOmask.encode(np.asfortranarray(mask))[0] - rle['counts'] = rle['counts'].decode('utf8') - segm_info['segmentation'] = rle - annotations_detection.append(segm_info) - - print('Core: {}, all {} images processed'.format(proc_id, len(annotations_set))) - return annotations_detection - - -def convert_panoptic_to_detection_coco_format(input_json_file, - segmentations_folder, - output_json_file, - categories_json_file, - things_only): - start_time = time.time() - - if segmentations_folder is None: - segmentations_folder = input_json_file.rsplit('.', 1)[0] - - print("CONVERTING...") - print("COCO panoptic format:") - print("\tSegmentation folder: {}".format(segmentations_folder)) - print("\tJSON file: {}".format(input_json_file)) - print("TO") - print("COCO detection format") - print("\tJSON file: {}".format(output_json_file)) - if things_only: - print("Saving only segments of things classes.") - print('\n') - - print("Reading annotation information from {}".format(input_json_file)) - with open(input_json_file, 'r') as f: - d_coco = json.load(f) - annotations_panoptic = d_coco['annotations'] - - with open(categories_json_file, 'r') as f: - categories_list = json.load(f) - categories = {category['id']: category for category in categories_list} - - cpu_num = multiprocessing.cpu_count() - annotations_split = np.array_split(annotations_panoptic, cpu_num) - print("Number of cores: {}, images per core: {}".format(cpu_num, len(annotations_split[0]))) - workers = multiprocessing.Pool(processes=cpu_num) - processes = [] - for proc_id, annotations_set in enumerate(annotations_split): - p = workers.apply_async(convert_panoptic_to_detection_coco_format_single_core, - (proc_id, annotations_set, categories, segmentations_folder, things_only)) - processes.append(p) - annotations_coco_detection = [] - for p in processes: - annotations_coco_detection.extend(p.get()) - for idx, ann in enumerate(annotations_coco_detection): - ann['id'] = idx - - d_coco['annotations'] = annotations_coco_detection - categories_coco_detection = [] - for category in d_coco['categories']: - if things_only and category['isthing'] != 1: - continue - category.pop('isthing') - categories_coco_detection.append(category) - d_coco['categories'] = categories_coco_detection - save_json(d_coco, output_json_file) - - t_delta = time.time() - start_time - print("Time elapsed: {:0.2f} seconds".format(t_delta)) - - -if __name__ == "__main__": - parser = argparse.ArgumentParser( - description="The script converts panoptic COCO format to detection \ - COCO format. See this file's head for more information." - ) - parser.add_argument('--things_only', action='store_true', - help="discard stuff classes") - args = parser.parse_args() - - _root = os.getenv("DETECTRON2_DATASETS", "datasets") - root = os.path.join(_root, "coco") - input_json_file = os.path.join(root, "annotations", "panoptic_val2017.json") - output_json_file = os.path.join(root, "annotations", "panoptic2instances_val2017.json") - categories_json_file = "datasets/panoptic_coco_categories.json" - segmentations_folder = os.path.join(root, "panoptic_val2017") - - convert_panoptic_to_detection_coco_format(input_json_file, - segmentations_folder, - output_json_file, - categories_json_file, - args.things_only) diff --git a/spaces/PAIR/PAIR-Diffusion/ldm/modules/midas/midas/midas_net.py b/spaces/PAIR/PAIR-Diffusion/ldm/modules/midas/midas/midas_net.py deleted file mode 100644 index 8a954977800b0a0f48807e80fa63041910e33c1f..0000000000000000000000000000000000000000 --- a/spaces/PAIR/PAIR-Diffusion/ldm/modules/midas/midas/midas_net.py +++ /dev/null @@ -1,76 +0,0 @@ -"""MidashNet: Network for monocular depth estimation trained by mixing several datasets. -This file contains code that is adapted from -https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py -""" -import torch -import torch.nn as nn - -from .base_model import BaseModel -from .blocks import FeatureFusionBlock, Interpolate, _make_encoder - - -class MidasNet(BaseModel): - """Network for monocular depth estimation. - """ - - def __init__(self, path=None, features=256, non_negative=True): - """Init. - - Args: - path (str, optional): Path to saved model. Defaults to None. - features (int, optional): Number of features. Defaults to 256. - backbone (str, optional): Backbone network for encoder. Defaults to resnet50 - """ - print("Loading weights: ", path) - - super(MidasNet, self).__init__() - - use_pretrained = False if path is None else True - - self.pretrained, self.scratch = _make_encoder(backbone="resnext101_wsl", features=features, use_pretrained=use_pretrained) - - self.scratch.refinenet4 = FeatureFusionBlock(features) - self.scratch.refinenet3 = FeatureFusionBlock(features) - self.scratch.refinenet2 = FeatureFusionBlock(features) - self.scratch.refinenet1 = FeatureFusionBlock(features) - - self.scratch.output_conv = nn.Sequential( - nn.Conv2d(features, 128, kernel_size=3, stride=1, padding=1), - Interpolate(scale_factor=2, mode="bilinear"), - nn.Conv2d(128, 32, kernel_size=3, stride=1, padding=1), - nn.ReLU(True), - nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0), - nn.ReLU(True) if non_negative else nn.Identity(), - ) - - if path: - self.load(path) - - def forward(self, x): - """Forward pass. - - Args: - x (tensor): input data (image) - - Returns: - tensor: depth - """ - - layer_1 = self.pretrained.layer1(x) - layer_2 = self.pretrained.layer2(layer_1) - layer_3 = self.pretrained.layer3(layer_2) - layer_4 = self.pretrained.layer4(layer_3) - - layer_1_rn = self.scratch.layer1_rn(layer_1) - layer_2_rn = self.scratch.layer2_rn(layer_2) - layer_3_rn = self.scratch.layer3_rn(layer_3) - layer_4_rn = self.scratch.layer4_rn(layer_4) - - path_4 = self.scratch.refinenet4(layer_4_rn) - path_3 = self.scratch.refinenet3(path_4, layer_3_rn) - path_2 = self.scratch.refinenet2(path_3, layer_2_rn) - path_1 = self.scratch.refinenet1(path_2, layer_1_rn) - - out = self.scratch.output_conv(path_1) - - return torch.squeeze(out, dim=1) diff --git a/spaces/PAIR/Text2Video-Zero/annotator/openpose/body.py b/spaces/PAIR/Text2Video-Zero/annotator/openpose/body.py deleted file mode 100644 index 7c3cf7a388b4ac81004524e64125e383bdd455bd..0000000000000000000000000000000000000000 --- a/spaces/PAIR/Text2Video-Zero/annotator/openpose/body.py +++ /dev/null @@ -1,219 +0,0 @@ -import cv2 -import numpy as np -import math -import time -from scipy.ndimage.filters import gaussian_filter -import matplotlib.pyplot as plt -import matplotlib -import torch -from torchvision import transforms - -from . import util -from .model import bodypose_model - -class Body(object): - def __init__(self, model_path): - self.model = bodypose_model() - if torch.cuda.is_available(): - self.model = self.model.cuda() - print('cuda') - model_dict = util.transfer(self.model, torch.load(model_path)) - self.model.load_state_dict(model_dict) - self.model.eval() - - def __call__(self, oriImg): - # scale_search = [0.5, 1.0, 1.5, 2.0] - scale_search = [0.5] - boxsize = 368 - stride = 8 - padValue = 128 - thre1 = 0.1 - thre2 = 0.05 - multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search] - heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 19)) - paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38)) - - for m in range(len(multiplier)): - scale = multiplier[m] - imageToTest = cv2.resize(oriImg, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC) - imageToTest_padded, pad = util.padRightDownCorner(imageToTest, stride, padValue) - im = np.transpose(np.float32(imageToTest_padded[:, :, :, np.newaxis]), (3, 2, 0, 1)) / 256 - 0.5 - im = np.ascontiguousarray(im) - - data = torch.from_numpy(im).float() - if torch.cuda.is_available(): - data = data.cuda() - # data = data.permute([2, 0, 1]).unsqueeze(0).float() - with torch.no_grad(): - Mconv7_stage6_L1, Mconv7_stage6_L2 = self.model(data) - Mconv7_stage6_L1 = Mconv7_stage6_L1.cpu().numpy() - Mconv7_stage6_L2 = Mconv7_stage6_L2.cpu().numpy() - - # extract outputs, resize, and remove padding - # heatmap = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[1]].data), (1, 2, 0)) # output 1 is heatmaps - heatmap = np.transpose(np.squeeze(Mconv7_stage6_L2), (1, 2, 0)) # output 1 is heatmaps - heatmap = cv2.resize(heatmap, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC) - heatmap = heatmap[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :] - heatmap = cv2.resize(heatmap, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC) - - # paf = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[0]].data), (1, 2, 0)) # output 0 is PAFs - paf = np.transpose(np.squeeze(Mconv7_stage6_L1), (1, 2, 0)) # output 0 is PAFs - paf = cv2.resize(paf, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC) - paf = paf[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :] - paf = cv2.resize(paf, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC) - - heatmap_avg += heatmap_avg + heatmap / len(multiplier) - paf_avg += + paf / len(multiplier) - - all_peaks = [] - peak_counter = 0 - - for part in range(18): - map_ori = heatmap_avg[:, :, part] - one_heatmap = gaussian_filter(map_ori, sigma=3) - - map_left = np.zeros(one_heatmap.shape) - map_left[1:, :] = one_heatmap[:-1, :] - map_right = np.zeros(one_heatmap.shape) - map_right[:-1, :] = one_heatmap[1:, :] - map_up = np.zeros(one_heatmap.shape) - map_up[:, 1:] = one_heatmap[:, :-1] - map_down = np.zeros(one_heatmap.shape) - map_down[:, :-1] = one_heatmap[:, 1:] - - peaks_binary = np.logical_and.reduce( - (one_heatmap >= map_left, one_heatmap >= map_right, one_heatmap >= map_up, one_heatmap >= map_down, one_heatmap > thre1)) - peaks = list(zip(np.nonzero(peaks_binary)[1], np.nonzero(peaks_binary)[0])) # note reverse - peaks_with_score = [x + (map_ori[x[1], x[0]],) for x in peaks] - peak_id = range(peak_counter, peak_counter + len(peaks)) - peaks_with_score_and_id = [peaks_with_score[i] + (peak_id[i],) for i in range(len(peak_id))] - - all_peaks.append(peaks_with_score_and_id) - peak_counter += len(peaks) - - # find connection in the specified sequence, center 29 is in the position 15 - limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10], \ - [10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15], [15, 17], \ - [1, 16], [16, 18], [3, 17], [6, 18]] - # the middle joints heatmap correpondence - mapIdx = [[31, 32], [39, 40], [33, 34], [35, 36], [41, 42], [43, 44], [19, 20], [21, 22], \ - [23, 24], [25, 26], [27, 28], [29, 30], [47, 48], [49, 50], [53, 54], [51, 52], \ - [55, 56], [37, 38], [45, 46]] - - connection_all = [] - special_k = [] - mid_num = 10 - - for k in range(len(mapIdx)): - score_mid = paf_avg[:, :, [x - 19 for x in mapIdx[k]]] - candA = all_peaks[limbSeq[k][0] - 1] - candB = all_peaks[limbSeq[k][1] - 1] - nA = len(candA) - nB = len(candB) - indexA, indexB = limbSeq[k] - if (nA != 0 and nB != 0): - connection_candidate = [] - for i in range(nA): - for j in range(nB): - vec = np.subtract(candB[j][:2], candA[i][:2]) - norm = math.sqrt(vec[0] * vec[0] + vec[1] * vec[1]) - norm = max(0.001, norm) - vec = np.divide(vec, norm) - - startend = list(zip(np.linspace(candA[i][0], candB[j][0], num=mid_num), \ - np.linspace(candA[i][1], candB[j][1], num=mid_num))) - - vec_x = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 0] \ - for I in range(len(startend))]) - vec_y = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 1] \ - for I in range(len(startend))]) - - score_midpts = np.multiply(vec_x, vec[0]) + np.multiply(vec_y, vec[1]) - score_with_dist_prior = sum(score_midpts) / len(score_midpts) + min( - 0.5 * oriImg.shape[0] / norm - 1, 0) - criterion1 = len(np.nonzero(score_midpts > thre2)[0]) > 0.8 * len(score_midpts) - criterion2 = score_with_dist_prior > 0 - if criterion1 and criterion2: - connection_candidate.append( - [i, j, score_with_dist_prior, score_with_dist_prior + candA[i][2] + candB[j][2]]) - - connection_candidate = sorted(connection_candidate, key=lambda x: x[2], reverse=True) - connection = np.zeros((0, 5)) - for c in range(len(connection_candidate)): - i, j, s = connection_candidate[c][0:3] - if (i not in connection[:, 3] and j not in connection[:, 4]): - connection = np.vstack([connection, [candA[i][3], candB[j][3], s, i, j]]) - if (len(connection) >= min(nA, nB)): - break - - connection_all.append(connection) - else: - special_k.append(k) - connection_all.append([]) - - # last number in each row is the total parts number of that person - # the second last number in each row is the score of the overall configuration - subset = -1 * np.ones((0, 20)) - candidate = np.array([item for sublist in all_peaks for item in sublist]) - - for k in range(len(mapIdx)): - if k not in special_k: - partAs = connection_all[k][:, 0] - partBs = connection_all[k][:, 1] - indexA, indexB = np.array(limbSeq[k]) - 1 - - for i in range(len(connection_all[k])): # = 1:size(temp,1) - found = 0 - subset_idx = [-1, -1] - for j in range(len(subset)): # 1:size(subset,1): - if subset[j][indexA] == partAs[i] or subset[j][indexB] == partBs[i]: - subset_idx[found] = j - found += 1 - - if found == 1: - j = subset_idx[0] - if subset[j][indexB] != partBs[i]: - subset[j][indexB] = partBs[i] - subset[j][-1] += 1 - subset[j][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2] - elif found == 2: # if found 2 and disjoint, merge them - j1, j2 = subset_idx - membership = ((subset[j1] >= 0).astype(int) + (subset[j2] >= 0).astype(int))[:-2] - if len(np.nonzero(membership == 2)[0]) == 0: # merge - subset[j1][:-2] += (subset[j2][:-2] + 1) - subset[j1][-2:] += subset[j2][-2:] - subset[j1][-2] += connection_all[k][i][2] - subset = np.delete(subset, j2, 0) - else: # as like found == 1 - subset[j1][indexB] = partBs[i] - subset[j1][-1] += 1 - subset[j1][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2] - - # if find no partA in the subset, create a new subset - elif not found and k < 17: - row = -1 * np.ones(20) - row[indexA] = partAs[i] - row[indexB] = partBs[i] - row[-1] = 2 - row[-2] = sum(candidate[connection_all[k][i, :2].astype(int), 2]) + connection_all[k][i][2] - subset = np.vstack([subset, row]) - # delete some rows of subset which has few parts occur - deleteIdx = [] - for i in range(len(subset)): - if subset[i][-1] < 4 or subset[i][-2] / subset[i][-1] < 0.4: - deleteIdx.append(i) - subset = np.delete(subset, deleteIdx, axis=0) - - # subset: n*20 array, 0-17 is the index in candidate, 18 is the total score, 19 is the total parts - # candidate: x, y, score, id - return candidate, subset - -if __name__ == "__main__": - body_estimation = Body('../model/body_pose_model.pth') - - test_image = '../images/ski.jpg' - oriImg = cv2.imread(test_image) # B,G,R order - candidate, subset = body_estimation(oriImg) - canvas = util.draw_bodypose(oriImg, candidate, subset) - plt.imshow(canvas[:, :, [2, 1, 0]]) - plt.show() diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmcv/cnn/bricks/padding.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmcv/cnn/bricks/padding.py deleted file mode 100644 index e4ac6b28a1789bd551c613a7d3e7b622433ac7ec..0000000000000000000000000000000000000000 --- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmcv/cnn/bricks/padding.py +++ /dev/null @@ -1,36 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -import torch.nn as nn - -from .registry import PADDING_LAYERS - -PADDING_LAYERS.register_module('zero', module=nn.ZeroPad2d) -PADDING_LAYERS.register_module('reflect', module=nn.ReflectionPad2d) -PADDING_LAYERS.register_module('replicate', module=nn.ReplicationPad2d) - - -def build_padding_layer(cfg, *args, **kwargs): - """Build padding layer. - - Args: - cfg (None or dict): The padding layer config, which should contain: - - type (str): Layer type. - - layer args: Args needed to instantiate a padding layer. - - Returns: - nn.Module: Created padding layer. - """ - if not isinstance(cfg, dict): - raise TypeError('cfg must be a dict') - if 'type' not in cfg: - raise KeyError('the cfg dict must contain the key "type"') - - cfg_ = cfg.copy() - padding_type = cfg_.pop('type') - if padding_type not in PADDING_LAYERS: - raise KeyError(f'Unrecognized padding type {padding_type}.') - else: - padding_layer = PADDING_LAYERS.get(padding_type) - - layer = padding_layer(*args, **kwargs, **cfg_) - - return layer diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/utils/make_divisible.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/utils/make_divisible.py deleted file mode 100644 index 75ad756052529f52fe83bb95dd1f0ecfc9a13078..0000000000000000000000000000000000000000 --- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/utils/make_divisible.py +++ /dev/null @@ -1,27 +0,0 @@ -def make_divisible(value, divisor, min_value=None, min_ratio=0.9): - """Make divisible function. - - This function rounds the channel number to the nearest value that can be - divisible by the divisor. It is taken from the original tf repo. It ensures - that all layers have a channel number that is divisible by divisor. It can - be seen here: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py # noqa - - Args: - value (int): The original channel number. - divisor (int): The divisor to fully divide the channel number. - min_value (int): The minimum value of the output channel. - Default: None, means that the minimum value equal to the divisor. - min_ratio (float): The minimum ratio of the rounded channel number to - the original channel number. Default: 0.9. - - Returns: - int: The modified output channel number. - """ - - if min_value is None: - min_value = divisor - new_value = max(min_value, int(value + divisor / 2) // divisor * divisor) - # Make sure that round down does not go down by more than (1-min_ratio). - if new_value < min_ratio * value: - new_value += divisor - return new_value diff --git a/spaces/PSLD/PSLD/stable-diffusion/notebook_helpers.py b/spaces/PSLD/PSLD/stable-diffusion/notebook_helpers.py deleted file mode 100644 index 5d0ebd7e1f8095053f34b1d7652b55d165097f0e..0000000000000000000000000000000000000000 --- a/spaces/PSLD/PSLD/stable-diffusion/notebook_helpers.py +++ /dev/null @@ -1,270 +0,0 @@ -from torchvision.datasets.utils import download_url -from ldm.util import instantiate_from_config -import torch -import os -# todo ? -from google.colab import files -from IPython.display import Image as ipyimg -import ipywidgets as widgets -from PIL import Image -from numpy import asarray -from einops import rearrange, repeat -import torch, torchvision -from ldm.models.diffusion.ddim import DDIMSampler -from ldm.util import ismap -import time -from omegaconf import OmegaConf - - -def download_models(mode): - - if mode == "superresolution": - # this is the small bsr light model - url_conf = 'https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1' - url_ckpt = 'https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1' - - path_conf = 'logs/diffusion/superresolution_bsr/configs/project.yaml' - path_ckpt = 'logs/diffusion/superresolution_bsr/checkpoints/last.ckpt' - - download_url(url_conf, path_conf) - download_url(url_ckpt, path_ckpt) - - path_conf = path_conf + '/?dl=1' # fix it - path_ckpt = path_ckpt + '/?dl=1' # fix it - return path_conf, path_ckpt - - else: - raise NotImplementedError - - -def load_model_from_config(config, ckpt): - print(f"Loading model from {ckpt}") - pl_sd = torch.load(ckpt, map_location="cpu") - global_step = pl_sd["global_step"] - sd = pl_sd["state_dict"] - model = instantiate_from_config(config.model) - m, u = model.load_state_dict(sd, strict=False) - model.cuda() - model.eval() - return {"model": model}, global_step - - -def get_model(mode): - path_conf, path_ckpt = download_models(mode) - config = OmegaConf.load(path_conf) - model, step = load_model_from_config(config, path_ckpt) - return model - - -def get_custom_cond(mode): - dest = "data/example_conditioning" - - if mode == "superresolution": - uploaded_img = files.upload() - filename = next(iter(uploaded_img)) - name, filetype = filename.split(".") # todo assumes just one dot in name ! - os.rename(f"{filename}", f"{dest}/{mode}/custom_{name}.{filetype}") - - elif mode == "text_conditional": - w = widgets.Text(value='A cake with cream!', disabled=True) - display(w) - - with open(f"{dest}/{mode}/custom_{w.value[:20]}.txt", 'w') as f: - f.write(w.value) - - elif mode == "class_conditional": - w = widgets.IntSlider(min=0, max=1000) - display(w) - with open(f"{dest}/{mode}/custom.txt", 'w') as f: - f.write(w.value) - - else: - raise NotImplementedError(f"cond not implemented for mode{mode}") - - -def get_cond_options(mode): - path = "data/example_conditioning" - path = os.path.join(path, mode) - onlyfiles = [f for f in sorted(os.listdir(path))] - return path, onlyfiles - - -def select_cond_path(mode): - path = "data/example_conditioning" # todo - path = os.path.join(path, mode) - onlyfiles = [f for f in sorted(os.listdir(path))] - - selected = widgets.RadioButtons( - options=onlyfiles, - description='Select conditioning:', - disabled=False - ) - display(selected) - selected_path = os.path.join(path, selected.value) - return selected_path - - -def get_cond(mode, selected_path): - example = dict() - if mode == "superresolution": - up_f = 4 - visualize_cond_img(selected_path) - - c = Image.open(selected_path) - c = torch.unsqueeze(torchvision.transforms.ToTensor()(c), 0) - c_up = torchvision.transforms.functional.resize(c, size=[up_f * c.shape[2], up_f * c.shape[3]], antialias=True) - c_up = rearrange(c_up, '1 c h w -> 1 h w c') - c = rearrange(c, '1 c h w -> 1 h w c') - c = 2. * c - 1. - - c = c.to(torch.device("cuda")) - example["LR_image"] = c - example["image"] = c_up - - return example - - -def visualize_cond_img(path): - display(ipyimg(filename=path)) - - -def run(model, selected_path, task, custom_steps, resize_enabled=False, classifier_ckpt=None, global_step=None): - - example = get_cond(task, selected_path) - - save_intermediate_vid = False - n_runs = 1 - masked = False - guider = None - ckwargs = None - mode = 'ddim' - ddim_use_x0_pred = False - temperature = 1. - eta = 1. - make_progrow = True - custom_shape = None - - height, width = example["image"].shape[1:3] - split_input = height >= 128 and width >= 128 - - if split_input: - ks = 128 - stride = 64 - vqf = 4 # - model.split_input_params = {"ks": (ks, ks), "stride": (stride, stride), - "vqf": vqf, - "patch_distributed_vq": True, - "tie_braker": False, - "clip_max_weight": 0.5, - "clip_min_weight": 0.01, - "clip_max_tie_weight": 0.5, - "clip_min_tie_weight": 0.01} - else: - if hasattr(model, "split_input_params"): - delattr(model, "split_input_params") - - invert_mask = False - - x_T = None - for n in range(n_runs): - if custom_shape is not None: - x_T = torch.randn(1, custom_shape[1], custom_shape[2], custom_shape[3]).to(model.device) - x_T = repeat(x_T, '1 c h w -> b c h w', b=custom_shape[0]) - - logs = make_convolutional_sample(example, model, - mode=mode, custom_steps=custom_steps, - eta=eta, swap_mode=False , masked=masked, - invert_mask=invert_mask, quantize_x0=False, - custom_schedule=None, decode_interval=10, - resize_enabled=resize_enabled, custom_shape=custom_shape, - temperature=temperature, noise_dropout=0., - corrector=guider, corrector_kwargs=ckwargs, x_T=x_T, save_intermediate_vid=save_intermediate_vid, - make_progrow=make_progrow,ddim_use_x0_pred=ddim_use_x0_pred - ) - return logs - - -@torch.no_grad() -def convsample_ddim(model, cond, steps, shape, eta=1.0, callback=None, normals_sequence=None, - mask=None, x0=None, quantize_x0=False, img_callback=None, - temperature=1., noise_dropout=0., score_corrector=None, - corrector_kwargs=None, x_T=None, log_every_t=None - ): - - ddim = DDIMSampler(model) - bs = shape[0] # dont know where this comes from but wayne - shape = shape[1:] # cut batch dim - print(f"Sampling with eta = {eta}; steps: {steps}") - samples, intermediates = ddim.sample(steps, batch_size=bs, shape=shape, conditioning=cond, callback=callback, - normals_sequence=normals_sequence, quantize_x0=quantize_x0, eta=eta, - mask=mask, x0=x0, temperature=temperature, verbose=False, - score_corrector=score_corrector, - corrector_kwargs=corrector_kwargs, x_T=x_T) - - return samples, intermediates - - -@torch.no_grad() -def make_convolutional_sample(batch, model, mode="vanilla", custom_steps=None, eta=1.0, swap_mode=False, masked=False, - invert_mask=True, quantize_x0=False, custom_schedule=None, decode_interval=1000, - resize_enabled=False, custom_shape=None, temperature=1., noise_dropout=0., corrector=None, - corrector_kwargs=None, x_T=None, save_intermediate_vid=False, make_progrow=True,ddim_use_x0_pred=False): - log = dict() - - z, c, x, xrec, xc = model.get_input(batch, model.first_stage_key, - return_first_stage_outputs=True, - force_c_encode=not (hasattr(model, 'split_input_params') - and model.cond_stage_key == 'coordinates_bbox'), - return_original_cond=True) - - log_every_t = 1 if save_intermediate_vid else None - - if custom_shape is not None: - z = torch.randn(custom_shape) - print(f"Generating {custom_shape[0]} samples of shape {custom_shape[1:]}") - - z0 = None - - log["input"] = x - log["reconstruction"] = xrec - - if ismap(xc): - log["original_conditioning"] = model.to_rgb(xc) - if hasattr(model, 'cond_stage_key'): - log[model.cond_stage_key] = model.to_rgb(xc) - - else: - log["original_conditioning"] = xc if xc is not None else torch.zeros_like(x) - if model.cond_stage_model: - log[model.cond_stage_key] = xc if xc is not None else torch.zeros_like(x) - if model.cond_stage_key =='class_label': - log[model.cond_stage_key] = xc[model.cond_stage_key] - - with model.ema_scope("Plotting"): - t0 = time.time() - img_cb = None - - sample, intermediates = convsample_ddim(model, c, steps=custom_steps, shape=z.shape, - eta=eta, - quantize_x0=quantize_x0, img_callback=img_cb, mask=None, x0=z0, - temperature=temperature, noise_dropout=noise_dropout, - score_corrector=corrector, corrector_kwargs=corrector_kwargs, - x_T=x_T, log_every_t=log_every_t) - t1 = time.time() - - if ddim_use_x0_pred: - sample = intermediates['pred_x0'][-1] - - x_sample = model.decode_first_stage(sample) - - try: - x_sample_noquant = model.decode_first_stage(sample, force_not_quantize=True) - log["sample_noquant"] = x_sample_noquant - log["sample_diff"] = torch.abs(x_sample_noquant - x_sample) - except: - pass - - log["sample"] = x_sample - log["time"] = t1 - t0 - - return log \ No newline at end of file diff --git a/spaces/PSLD/PSLD/stable-diffusion/scripts/inverse_psld.py b/spaces/PSLD/PSLD/stable-diffusion/scripts/inverse_psld.py deleted file mode 100644 index b04e72091c470eb4bea8c41d80122798095cdb2d..0000000000000000000000000000000000000000 --- a/spaces/PSLD/PSLD/stable-diffusion/scripts/inverse_psld.py +++ /dev/null @@ -1,518 +0,0 @@ -import argparse, os, sys, glob -import cv2 -import torch -import numpy as np -from omegaconf import OmegaConf -from PIL import Image -from tqdm import tqdm, trange -from imwatermark import WatermarkEncoder -from itertools import islice -from einops import rearrange -from torchvision.utils import make_grid -import time -from pytorch_lightning import seed_everything -from torch import autocast -from contextlib import contextmanager, nullcontext - -from ldm.util import instantiate_from_config -from ldm.models.diffusion.psld import DDIMSampler -from ldm.models.diffusion.plms import PLMSSampler -from ldm.models.diffusion.dpm_solver import DPMSolverSampler - -# from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker -from transformers import AutoFeatureExtractor - -import pdb - - -# load safety model -safety_model_id = "CompVis/stable-diffusion-safety-checker" -safety_feature_extractor = AutoFeatureExtractor.from_pretrained(safety_model_id) -# safety_checker = StableDiffusionSafetyChecker.from_pretrained(safety_model_id) - - -def chunk(it, size): - it = iter(it) - return iter(lambda: tuple(islice(it, size)), ()) - - -def numpy_to_pil(images): - """ - Convert a numpy image or a batch of images to a PIL image. - """ - if images.ndim == 3: - images = images[None, ...] - images = (images * 255).round().astype("uint8") - pil_images = [Image.fromarray(image) for image in images] - - return pil_images - - -def load_model_from_config(config, ckpt, verbose=False): - print(f"Loading model from {ckpt}") - pl_sd = torch.load(ckpt, map_location="cpu") - if "global_step" in pl_sd: - print(f"Global Step: {pl_sd['global_step']}") - sd = pl_sd["state_dict"] - model = instantiate_from_config(config.model) - m, u = model.load_state_dict(sd, strict=False) - if len(m) > 0 and verbose: - print("missing keys:") - print(m) - if len(u) > 0 and verbose: - print("unexpected keys:") - print(u) - - model.cuda() - model.eval() - return model - - -def put_watermark(img, wm_encoder=None): - if wm_encoder is not None: - img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR) - img = wm_encoder.encode(img, 'dwtDct') - img = Image.fromarray(img[:, :, ::-1]) - return img - - -def load_replacement(x): - try: - hwc = x.shape - y = Image.open("assets/rick.jpeg").convert("RGB").resize((hwc[1], hwc[0])) - y = (np.array(y)/255.0).astype(x.dtype) - assert y.shape == x.shape - return y - except Exception: - return x - - -def check_safety(x_image): - safety_checker_input = safety_feature_extractor(numpy_to_pil(x_image), return_tensors="pt") - x_checked_image, has_nsfw_concept = safety_checker(images=x_image, clip_input=safety_checker_input.pixel_values) - assert x_checked_image.shape[0] == len(has_nsfw_concept) - for i in range(len(has_nsfw_concept)): - if has_nsfw_concept[i]: - x_checked_image[i] = load_replacement(x_checked_image[i]) - return x_checked_image, has_nsfw_concept - - -def main(): - parser = argparse.ArgumentParser() - - parser.add_argument( - "--prompt", - type=str, - nargs="?", - default="", - help="the prompt to render" - ) - parser.add_argument( - "--outdir", - type=str, - nargs="?", - help="dir to write results to", - default="outputs/txt2img-samples" - ) - parser.add_argument( - "--skip_grid", - action='store_true', - help="do not save a grid, only individual samples. Helpful when evaluating lots of samples", - ) - parser.add_argument( - "--skip_save", - action='store_true', - help="do not save individual samples. For speed measurements.", - ) - parser.add_argument( - "--ddim_steps", - type=int, - default=1000, - help="number of ddim sampling steps", - ) - parser.add_argument( - "--plms", - action='store_true', - help="use plms sampling", - ) - parser.add_argument( - "--dpm_solver", - action='store_true', - help="use dpm_solver sampling", - ) - parser.add_argument( - "--laion400m", - action='store_true', - help="uses the LAION400M model", - ) - parser.add_argument( - "--fixed_code", - action='store_true', - help="if enabled, uses the same starting code across samples ", - ) - parser.add_argument( - "--ddim_eta", - type=float, - default=0.0, - help="ddim eta (eta=0.0 corresponds to deterministic sampling", - ) - parser.add_argument( - "--n_iter", - type=int, - default=1, - help="sample this often", - ) - parser.add_argument( - "--H", - type=int, - default=512, - help="image height, in pixel space", - ) - parser.add_argument( - "--W", - type=int, - default=512, - help="image width, in pixel space", - ) - parser.add_argument( - "--C", - type=int, - default=4, - help="latent channels", - ) - parser.add_argument( - "--f", - type=int, - default=8, - help="downsampling factor", - ) - parser.add_argument( - "--n_samples", - type=int, - default=1, - help="how many samples to produce for each given prompt. A.k.a. batch size", - ) - parser.add_argument( - "--n_rows", - type=int, - default=0, - help="rows in the grid (default: n_samples)", - ) - parser.add_argument( - "--scale", - type=float, - default=7.5, - help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))", - ) - parser.add_argument( - "--from-file", - type=str, - help="if specified, load prompts from this file", - ) - parser.add_argument( - "--config", - type=str, - default="configs/stable-diffusion/v1-inference.yaml", - help="path to config which constructs model", - ) - parser.add_argument( - "--ckpt", - type=str, - default="models/ldm/stable-diffusion-v1/model.ckpt", - help="path to checkpoint of model", - ) - parser.add_argument( - "--seed", - type=int, - default=42, - help="the seed (for reproducible sampling)", - ) - parser.add_argument( - "--precision", - type=str, - help="evaluate at this precision", - choices=["full", "autocast"], - default="autocast" - ) - ## - parser.add_argument( - "--dps_path", - type=str, - default='../diffusion-posterior-sampling/', - help="DPS codebase path", - ) - parser.add_argument( - "--task_config", - type=str, - default='configs/inpainting_config.yaml', - help="task config yml file", - ) - parser.add_argument( - "--diffusion_config", - type=str, - default='configs/diffusion_config.yaml', - help="diffusion config yml file", - ) - parser.add_argument( - "--model_config", - type=str, - default='configs/model_config.yaml', - help="model config yml file", - ) - parser.add_argument( - "--gamma", - type=float, - default=1e-1, - help="inpainting error", - ) - parser.add_argument( - "--omega", - type=float, - default=1, - help="measurement error", - ) - parser.add_argument( - "--inpainting", - type=int, - default=0, - help="inpainting", - ) - parser.add_argument( - "--general_inverse", - type=int, - default=1, - help="general inverse", - ) - parser.add_argument( - "--file_id", - type=str, - default='00014.png', - help='input image', - ) - parser.add_argument( - "--skip_low_res", - action='store_true', - help='downsample result to 256', - ) - ## - - opt = parser.parse_args() - # pdb.set_trace() - - if opt.laion400m: - print("Falling back to LAION 400M model...") - opt.config = "configs/latent-diffusion/txt2img-1p4B-eval.yaml" - opt.ckpt = "models/ldm/text2img-large/model.ckpt" - opt.outdir = "outputs/txt2img-samples-laion400m" - - - seed_everything(opt.seed) - - config = OmegaConf.load(f"{opt.config}") - model = load_model_from_config(config, f"{opt.ckpt}") - - device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu") - model = model.to(device) - - if opt.dpm_solver: - sampler = DPMSolverSampler(model) - elif opt.plms: - sampler = PLMSSampler(model) - else: - # pdb.set_trace() - sampler = DDIMSampler(model) - - os.makedirs(opt.outdir, exist_ok=True) - outpath = opt.outdir - - print("Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...") - wm = "StableDiffusionV1" - wm_encoder = WatermarkEncoder() - wm_encoder.set_watermark('bytes', wm.encode('utf-8')) - - batch_size = opt.n_samples - n_rows = opt.n_rows if opt.n_rows > 0 else batch_size - if not opt.from_file: - prompt = opt.prompt - assert prompt is not None - data = [batch_size * [prompt]] - - else: - print(f"reading prompts from {opt.from_file}") - with open(opt.from_file, "r") as f: - data = f.read().splitlines() - data = list(chunk(data, batch_size)) - - sample_path = os.path.join(outpath, "samples") - os.makedirs(sample_path, exist_ok=True) - base_count = len(os.listdir(sample_path)) - grid_count = len(os.listdir(outpath)) - 1 - - ######################################################### - ## DPS configs - ######################################################### - sys.path.append(opt.dps_path) - - import yaml - from guided_diffusion.measurements import get_noise, get_operator - from util.img_utils import clear_color, mask_generator - import torch.nn.functional as f - import matplotlib.pyplot as plt - - - def load_yaml(file_path: str) -> dict: - with open(file_path) as f: - config = yaml.load(f, Loader=yaml.FullLoader) - return config - - - - model_config=opt.dps_path+opt.model_config - diffusion_config=opt.dps_path+opt.diffusion_config - task_config=opt.dps_path+opt.task_config - - # pdb.set_trace() - - # Load configurations - model_config = load_yaml(model_config) - diffusion_config = load_yaml(diffusion_config) - task_config = load_yaml(task_config) - - task_config['data']['root'] = opt.dps_path + 'data/samples/' - img = plt.imread(task_config['data']['root']+opt.file_id) - # img = next(iter(loader)) - - img = img - img.min() - img = img / img.max() - img = torch.FloatTensor(img) - img = torch.unsqueeze(img, dim=0).permute(0,3,1,2) - img = img[:,:3,:,:].cuda() - - # Prepare Operator and noise - measure_config = task_config['measurement'] - operator = get_operator(device=device, **measure_config['operator']) - noiser = get_noise(**measure_config['noise']) - - # Exception) In case of inpainting, we need to generate a mask - if measure_config['operator']['name'] == 'inpainting': - mask_gen = mask_generator( - **measure_config['mask_opt'] - ) - - img = f.interpolate(img, opt.H) - x_checked_image_torch = img[:,:3,:,:].cuda() - - org_image = torch.clone(x_checked_image_torch[0].detach()) - org_image = (org_image - 0.5)/0.5 - org_image = org_image[None,:,:,:].cuda() - - # Exception) In case of inpainging, - if measure_config['operator'] ['name'] == 'inpainting': - mask = mask_gen(org_image) # dps mask - # mask = torch.ones_like(org_image) # no mask - - mask = mask[:, 0, :, :].unsqueeze(dim=0) - # Forward measurement model (Ax + n) - y = operator.forward(org_image, mask=mask) - y_n = noiser(y) - - else: - # Forward measurement model (Ax + n) - y = operator.forward(org_image) - y_n = noiser(y) - mask = None - - - ######################################################### - - start_code = None - if opt.fixed_code: - start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device) - - precision_scope = autocast if opt.precision=="autocast" else nullcontext - with precision_scope("cuda"): - with model.ema_scope(): - tic = time.time() - all_samples = list() - for n in trange(opt.n_iter, desc="Sampling"): - for prompts in tqdm(data, desc="data"): - uc = None - if opt.scale != 1.0: - uc = model.get_learned_conditioning(batch_size * [""]) - if isinstance(prompts, tuple): - prompts = list(prompts) - c = model.get_learned_conditioning(prompts) - shape = [opt.C, opt.H // opt.f, opt.W // opt.f] - samples_ddim, _ = sampler.sample(S=opt.ddim_steps, - conditioning=c, - batch_size=opt.n_samples, - shape=shape, - verbose=False, - unconditional_guidance_scale=opt.scale, - unconditional_conditioning=uc, - eta=opt.ddim_eta, - x_T=start_code, - ip_mask = mask, - measurements = y_n, - operator = operator, - gamma = opt.gamma, - inpainting = opt.inpainting, - omega = opt.omega, - general_inverse=opt.general_inverse, - noiser=noiser) - - x_samples_ddim = model.decode_first_stage(samples_ddim) - x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0) - x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy() - - # x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim) - # x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2) - - x_checked_image_torch = torch.from_numpy(x_samples_ddim).permute(0, 3, 1, 2) - - - if not opt.skip_save: - for x_sample in x_checked_image_torch: - x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c') - img = Image.fromarray(x_sample.astype(np.uint8)) - # img = put_watermark(img, wm_encoder) - img.save(os.path.join(sample_path, f"{base_count:05}.png")) - base_count += 1 - - if not opt.skip_grid: - all_samples.append(x_checked_image_torch) - - # pdb.set_trace() - if not opt.skip_low_res: - if not opt.skip_save: - inpainted_image_low_res = f.interpolate(x_checked_image_torch.type(torch.float32), size=(opt.H//2, opt.W//2)) - for x_sample in inpainted_image_low_res: - x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c') - img = Image.fromarray(x_sample.astype(np.uint8)) - # img = put_watermark(img, wm_encoder) - img.save(os.path.join(sample_path, f"{base_count:05}_low_res.png")) - base_count += 1 - - - - if not opt.skip_grid: - # additionally, save as grid - grid = torch.stack(all_samples, 0) - grid = rearrange(grid, 'n b c h w -> (n b) c h w') - grid = make_grid(grid, nrow=n_rows) - - # to image - grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy() - img = Image.fromarray(grid.astype(np.uint8)) - # img = put_watermark(img, wm_encoder) - img.save(os.path.join(outpath, f'grid-{grid_count:04}.png')) - grid_count += 1 - - toc = time.time() - - print(f"Your samples are ready and waiting for you here: \n{outpath} \n" - f" \nEnjoy.") - - -if __name__ == "__main__": - main() diff --git a/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/lily-library.go b/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/lily-library.go deleted file mode 100644 index a5040da43171832c9df2e22122ccd0d90aedb665..0000000000000000000000000000000000000000 Binary files a/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/lily-library.go and /dev/null differ diff --git a/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/translation-functions.go b/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/translation-functions.go deleted file mode 100644 index a39e993ccbf7dd8ad5a6e49ec0030ba5c2fec079..0000000000000000000000000000000000000000 Binary files a/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/lilypond/2.24.2/ccache/lily/translation-functions.go and /dev/null differ diff --git a/spaces/PeepDaSlan9/CompVis-stable-diffusion-v1-4/README.md b/spaces/PeepDaSlan9/CompVis-stable-diffusion-v1-4/README.md deleted file mode 100644 index 7f3495de51f8e89334168807766fa5ae043c35ce..0000000000000000000000000000000000000000 --- a/spaces/PeepDaSlan9/CompVis-stable-diffusion-v1-4/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: CompVis Stable Diffusion V1 4 -emoji: 🐠 -colorFrom: gray -colorTo: green -sdk: gradio -sdk_version: 3.17.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Pengyey/bingo-chuchu/src/components/turn-counter.tsx b/spaces/Pengyey/bingo-chuchu/src/components/turn-counter.tsx deleted file mode 100644 index 08a9e488f044802a8600f4d195b106567c35aab4..0000000000000000000000000000000000000000 --- a/spaces/Pengyey/bingo-chuchu/src/components/turn-counter.tsx +++ /dev/null @@ -1,23 +0,0 @@ -import React from 'react' -import { Throttling } from '@/lib/bots/bing/types' - -export interface TurnCounterProps { - throttling?: Throttling -} - -export function TurnCounter({ throttling }: TurnCounterProps) { - if (!throttling) { - return null - } - - return ( --- ) -} diff --git a/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/datasets/pipelines/__init__.py b/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/datasets/pipelines/__init__.py deleted file mode 100644 index 8b9046b07bb4ddea7a707a392b42e72db7c9df67..0000000000000000000000000000000000000000 --- a/spaces/Pie31415/control-animation/annotator/uniformer/mmseg/datasets/pipelines/__init__.py +++ /dev/null @@ -1,16 +0,0 @@ -from .compose import Compose -from .formating import (Collect, ImageToTensor, ToDataContainer, ToTensor, - Transpose, to_tensor) -from .loading import LoadAnnotations, LoadImageFromFile -from .test_time_aug import MultiScaleFlipAug -from .transforms import (CLAHE, AdjustGamma, Normalize, Pad, - PhotoMetricDistortion, RandomCrop, RandomFlip, - RandomRotate, Rerange, Resize, RGB2Gray, SegRescale) - -__all__ = [ - 'Compose', 'to_tensor', 'ToTensor', 'ImageToTensor', 'ToDataContainer', - 'Transpose', 'Collect', 'LoadAnnotations', 'LoadImageFromFile', - 'MultiScaleFlipAug', 'Resize', 'RandomFlip', 'Pad', 'RandomCrop', - 'Normalize', 'SegRescale', 'PhotoMetricDistortion', 'RandomRotate', - 'AdjustGamma', 'CLAHE', 'Rerange', 'RGB2Gray' -] diff --git a/spaces/RMXK/RVC_HFF/infer/lib/infer_pack/modules/F0Predictor/__init__.py b/spaces/RMXK/RVC_HFF/infer/lib/infer_pack/modules/F0Predictor/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/vcs/bazaar.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/vcs/bazaar.py deleted file mode 100644 index 06c80e48a3923520782fce059f0120714f08d955..0000000000000000000000000000000000000000 --- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/vcs/bazaar.py +++ /dev/null @@ -1,112 +0,0 @@ -import logging -from typing import List, Optional, Tuple - -from pip._internal.utils.misc import HiddenText, display_path -from pip._internal.utils.subprocess import make_command -from pip._internal.utils.urls import path_to_url -from pip._internal.vcs.versioncontrol import ( - AuthInfo, - RemoteNotFoundError, - RevOptions, - VersionControl, - vcs, -) - -logger = logging.getLogger(__name__) - - -class Bazaar(VersionControl): - name = "bzr" - dirname = ".bzr" - repo_name = "branch" - schemes = ( - "bzr+http", - "bzr+https", - "bzr+ssh", - "bzr+sftp", - "bzr+ftp", - "bzr+lp", - "bzr+file", - ) - - @staticmethod - def get_base_rev_args(rev: str) -> List[str]: - return ["-r", rev] - - def fetch_new( - self, dest: str, url: HiddenText, rev_options: RevOptions, verbosity: int - ) -> None: - rev_display = rev_options.to_display() - logger.info( - "Checking out %s%s to %s", - url, - rev_display, - display_path(dest), - ) - if verbosity <= 0: - flag = "--quiet" - elif verbosity == 1: - flag = "" - else: - flag = f"-{'v'*verbosity}" - cmd_args = make_command( - "checkout", "--lightweight", flag, rev_options.to_args(), url, dest - ) - self.run_command(cmd_args) - - def switch(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None: - self.run_command(make_command("switch", url), cwd=dest) - - def update(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None: - output = self.run_command( - make_command("info"), show_stdout=False, stdout_only=True, cwd=dest - ) - if output.startswith("Standalone "): - # Older versions of pip used to create standalone branches. - # Convert the standalone branch to a checkout by calling "bzr bind". - cmd_args = make_command("bind", "-q", url) - self.run_command(cmd_args, cwd=dest) - - cmd_args = make_command("update", "-q", rev_options.to_args()) - self.run_command(cmd_args, cwd=dest) - - @classmethod - def get_url_rev_and_auth(cls, url: str) -> Tuple[str, Optional[str], AuthInfo]: - # hotfix the URL scheme after removing bzr+ from bzr+ssh:// readd it - url, rev, user_pass = super().get_url_rev_and_auth(url) - if url.startswith("ssh://"): - url = "bzr+" + url - return url, rev, user_pass - - @classmethod - def get_remote_url(cls, location: str) -> str: - urls = cls.run_command( - ["info"], show_stdout=False, stdout_only=True, cwd=location - ) - for line in urls.splitlines(): - line = line.strip() - for x in ("checkout of branch: ", "parent branch: "): - if line.startswith(x): - repo = line.split(x)[1] - if cls._is_local_repository(repo): - return path_to_url(repo) - return repo - raise RemoteNotFoundError - - @classmethod - def get_revision(cls, location: str) -> str: - revision = cls.run_command( - ["revno"], - show_stdout=False, - stdout_only=True, - cwd=location, - ) - return revision.splitlines()[-1] - - @classmethod - def is_commit_id_equal(cls, dest: str, name: Optional[str]) -> bool: - """Always assume the versions don't match""" - return False - - -vcs.register(Bazaar) diff --git a/spaces/Rbrq/DeticChatGPT/tools/convert-thirdparty-pretrained-model-to-d2.py b/spaces/Rbrq/DeticChatGPT/tools/convert-thirdparty-pretrained-model-to-d2.py deleted file mode 100644 index ec042b8ce48d193b40fd1e6311b2cc4b0c4e4086..0000000000000000000000000000000000000000 --- a/spaces/Rbrq/DeticChatGPT/tools/convert-thirdparty-pretrained-model-to-d2.py +++ /dev/null @@ -1,39 +0,0 @@ -#!/usr/bin/env python -# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved -import argparse -import pickle -import torch - -""" -Usage: - -cd DETIC_ROOT/models/ -wget https://miil-public-eu.oss-eu-central-1.aliyuncs.com/model-zoo/ImageNet_21K_P/models/resnet50_miil_21k.pth -python ../tools/convert-thirdparty-pretrained-model-to-d2.py --path resnet50_miil_21k.pth - -wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth -python ../tools/convert-thirdparty-pretrained-model-to-d2.py --path swin_base_patch4_window7_224_22k.pth - -""" - - -if __name__ == "__main__": - parser = argparse.ArgumentParser() - parser.add_argument('--path', default='') - args = parser.parse_args() - - print('Loading', args.path) - model = torch.load(args.path, map_location="cpu") - # import pdb; pdb.set_trace() - if 'model' in model: - model = model['model'] - if 'state_dict' in model: - model = model['state_dict'] - ret = { - "model": model, - "__author__": "third_party", - "matching_heuristics": True - } - out_path = args.path.replace('.pth', '.pkl') - print('Saving to', out_path) - pickle.dump(ret, open(out_path, "wb")) diff --git a/spaces/RealTimeLiveAIForHealth/WebcamObjectRecognition/custom_layers.py b/spaces/RealTimeLiveAIForHealth/WebcamObjectRecognition/custom_layers.py deleted file mode 100644 index 0c684d5acbce3fa50107e4e41f9055cacda9f06d..0000000000000000000000000000000000000000 --- a/spaces/RealTimeLiveAIForHealth/WebcamObjectRecognition/custom_layers.py +++ /dev/null @@ -1,298 +0,0 @@ -import tensorflow as tf -from tensorflow.keras import layers, initializers, models - - -def conv(x, filters, kernel_size, downsampling=False, activation='leaky', batch_norm=True): - def mish(x): - return x * tf.math.tanh(tf.math.softplus(x)) - - if downsampling: - x = layers.ZeroPadding2D(padding=((1, 0), (1, 0)))(x) # top & left padding - padding = 'valid' - strides = 2 - else: - padding = 'same' - strides = 1 - x = layers.Conv2D(filters, - kernel_size, - strides=strides, - padding=padding, - use_bias=not batch_norm, - # kernel_regularizer=regularizers.l2(0.0005), - kernel_initializer=initializers.RandomNormal(mean=0.0, stddev=0.01), - # bias_initializer=initializers.Zeros() - )(x) - if batch_norm: - x = layers.BatchNormalization()(x) - if activation == 'mish': - x = mish(x) - elif activation == 'leaky': - x = layers.LeakyReLU(alpha=0.1)(x) - return x - - -def residual_block(x, filters1, filters2, activation='leaky'): - """ - :param x: input tensor - :param filters1: num of filter for 1x1 conv - :param filters2: num of filter for 3x3 conv - :param activation: default activation function: leaky relu - :return: - """ - y = conv(x, filters1, kernel_size=1, activation=activation) - y = conv(y, filters2, kernel_size=3, activation=activation) - return layers.Add()([x, y]) - - -def csp_block(x, residual_out, repeat, residual_bottleneck=False): - """ - Cross Stage Partial Network (CSPNet) - transition_bottleneck_dims: 1x1 bottleneck - output_dims: 3x3 - :param x: - :param residual_out: - :param repeat: - :param residual_bottleneck: - :return: - """ - route = x - route = conv(route, residual_out, 1, activation="mish") - x = conv(x, residual_out, 1, activation="mish") - for i in range(repeat): - x = residual_block(x, - residual_out // 2 if residual_bottleneck else residual_out, - residual_out, - activation="mish") - x = conv(x, residual_out, 1, activation="mish") - - x = layers.Concatenate()([x, route]) - return x - - -def darknet53(x): - x = conv(x, 32, 3) - x = conv(x, 64, 3, downsampling=True) - - for i in range(1): - x = residual_block(x, 32, 64) - x = conv(x, 128, 3, downsampling=True) - - for i in range(2): - x = residual_block(x, 64, 128) - x = conv(x, 256, 3, downsampling=True) - - for i in range(8): - x = residual_block(x, 128, 256) - route_1 = x - x = conv(x, 512, 3, downsampling=True) - - for i in range(8): - x = residual_block(x, 256, 512) - route_2 = x - x = conv(x, 1024, 3, downsampling=True) - - for i in range(4): - x = residual_block(x, 512, 1024) - - return route_1, route_2, x - - -def cspdarknet53(input): - x = conv(input, 32, 3) - x = conv(x, 64, 3, downsampling=True) - - x = csp_block(x, residual_out=64, repeat=1, residual_bottleneck=True) - x = conv(x, 64, 1, activation='mish') - x = conv(x, 128, 3, activation='mish', downsampling=True) - - x = csp_block(x, residual_out=64, repeat=2) - x = conv(x, 128, 1, activation='mish') - x = conv(x, 256, 3, activation='mish', downsampling=True) - - x = csp_block(x, residual_out=128, repeat=8) - x = conv(x, 256, 1, activation='mish') - route0 = x - x = conv(x, 512, 3, activation='mish', downsampling=True) - - x = csp_block(x, residual_out=256, repeat=8) - x = conv(x, 512, 1, activation='mish') - route1 = x - x = conv(x, 1024, 3, activation='mish', downsampling=True) - - x = csp_block(x, residual_out=512, repeat=4) - - x = conv(x, 1024, 1, activation="mish") - - x = conv(x, 512, 1) - x = conv(x, 1024, 3) - x = conv(x, 512, 1) - - x = layers.Concatenate()([layers.MaxPooling2D(pool_size=13, strides=1, padding='same')(x), - layers.MaxPooling2D(pool_size=9, strides=1, padding='same')(x), - layers.MaxPooling2D(pool_size=5, strides=1, padding='same')(x), - x - ]) - x = conv(x, 512, 1) - x = conv(x, 1024, 3) - route2 = conv(x, 512, 1) - return models.Model(input, [route0, route1, route2]) - - -def yolov4_neck(x, num_classes): - backbone_model = cspdarknet53(x) - route0, route1, route2 = backbone_model.output - - route_input = route2 - x = conv(route2, 256, 1) - x = layers.UpSampling2D()(x) - route1 = conv(route1, 256, 1) - x = layers.Concatenate()([route1, x]) - - x = conv(x, 256, 1) - x = conv(x, 512, 3) - x = conv(x, 256, 1) - x = conv(x, 512, 3) - x = conv(x, 256, 1) - - route1 = x - x = conv(x, 128, 1) - x = layers.UpSampling2D()(x) - route0 = conv(route0, 128, 1) - x = layers.Concatenate()([route0, x]) - - x = conv(x, 128, 1) - x = conv(x, 256, 3) - x = conv(x, 128, 1) - x = conv(x, 256, 3) - x = conv(x, 128, 1) - - route0 = x - x = conv(x, 256, 3) - conv_sbbox = conv(x, 3 * (num_classes + 5), 1, activation=None, batch_norm=False) - - x = conv(route0, 256, 3, downsampling=True) - x = layers.Concatenate()([x, route1]) - - x = conv(x, 256, 1) - x = conv(x, 512, 3) - x = conv(x, 256, 1) - x = conv(x, 512, 3) - x = conv(x, 256, 1) - - route1 = x - x = conv(x, 512, 3) - conv_mbbox = conv(x, 3 * (num_classes + 5), 1, activation=None, batch_norm=False) - - x = conv(route1, 512, 3, downsampling=True) - x = layers.Concatenate()([x, route_input]) - - x = conv(x, 512, 1) - x = conv(x, 1024, 3) - x = conv(x, 512, 1) - x = conv(x, 1024, 3) - x = conv(x, 512, 1) - - x = conv(x, 1024, 3) - conv_lbbox = conv(x, 3 * (num_classes + 5), 1, activation=None, batch_norm=False) - - return [conv_sbbox, conv_mbbox, conv_lbbox] - - -def yolov4_head(yolo_neck_outputs, classes, anchors, xyscale): - bbox0, object_probability0, class_probabilities0, pred_box0 = get_boxes(yolo_neck_outputs[0], - anchors=anchors[0, :, :], classes=classes, - grid_size=52, strides=8, - xyscale=xyscale[0]) - bbox1, object_probability1, class_probabilities1, pred_box1 = get_boxes(yolo_neck_outputs[1], - anchors=anchors[1, :, :], classes=classes, - grid_size=26, strides=16, - xyscale=xyscale[1]) - bbox2, object_probability2, class_probabilities2, pred_box2 = get_boxes(yolo_neck_outputs[2], - anchors=anchors[2, :, :], classes=classes, - grid_size=13, strides=32, - xyscale=xyscale[2]) - x = [bbox0, object_probability0, class_probabilities0, pred_box0, - bbox1, object_probability1, class_probabilities1, pred_box1, - bbox2, object_probability2, class_probabilities2, pred_box2] - - return x - - -def get_boxes(pred, anchors, classes, grid_size, strides, xyscale): - """ - - :param pred: - :param anchors: - :param classes: - :param grid_size: - :param strides: - :param xyscale: - :return: - """ - pred = tf.reshape(pred, - (tf.shape(pred)[0], - grid_size, - grid_size, - 3, - 5 + classes)) # (batch_size, grid_size, grid_size, 3, 5+classes) - box_xy, box_wh, obj_prob, class_prob = tf.split( - pred, (2, 2, 1, classes), axis=-1 - ) # (?, 52, 52, 3, 2) (?, 52, 52, 3, 2) (?, 52, 52, 3, 1) (?, 52, 52, 3, 80) - - box_xy = tf.sigmoid(box_xy) # (?, 52, 52, 3, 2) - obj_prob = tf.sigmoid(obj_prob) # (?, 52, 52, 3, 1) - class_prob = tf.sigmoid(class_prob) # (?, 52, 52, 3, 80) - pred_box_xywh = tf.concat((box_xy, box_wh), axis=-1) # (?, 52, 52, 3, 4) - - grid = tf.meshgrid(tf.range(grid_size), tf.range(grid_size)) # (52, 52) (52, 52) - grid = tf.expand_dims(tf.stack(grid, axis=-1), axis=2) # (52, 52, 1, 2) - grid = tf.cast(grid, dtype=tf.float32) - - box_xy = ((box_xy * xyscale) - 0.5 * (xyscale - 1) + grid) * strides # (?, 52, 52, 1, 4) - - box_wh = tf.exp(box_wh) * anchors # (?, 52, 52, 3, 2) - box_x1y1 = box_xy - box_wh / 2 # (?, 52, 52, 3, 2) - box_x2y2 = box_xy + box_wh / 2 # (?, 52, 52, 3, 2) - pred_box_x1y1x2y2 = tf.concat([box_x1y1, box_x2y2], axis=-1) # (?, 52, 52, 3, 4) - return pred_box_x1y1x2y2, obj_prob, class_prob, pred_box_xywh - # pred_box_x1y1x2y2: absolute xy value - - -def nms(model_ouputs, input_shape, num_class, iou_threshold=0.413, score_threshold=0.3): - """ - Apply Non-Maximum suppression - ref: https://www.tensorflow.org/api_docs/python/tf/image/combined_non_max_suppression - :param model_ouputs: yolo model model_ouputs - :param input_shape: size of input image - :return: nmsed_boxes, nmsed_scores, nmsed_classes, valid_detections - """ - bs = tf.shape(model_ouputs[0])[0] - boxes = tf.zeros((bs, 0, 4)) - confidence = tf.zeros((bs, 0, 1)) - class_probabilities = tf.zeros((bs, 0, num_class)) - - for output_idx in range(0, len(model_ouputs), 4): - output_xy = model_ouputs[output_idx] - output_conf = model_ouputs[output_idx + 1] - output_classes = model_ouputs[output_idx + 2] - boxes = tf.concat([boxes, tf.reshape(output_xy, (bs, -1, 4))], axis=1) - confidence = tf.concat([confidence, tf.reshape(output_conf, (bs, -1, 1))], axis=1) - class_probabilities = tf.concat([class_probabilities, tf.reshape(output_classes, (bs, -1, num_class))], axis=1) - - scores = confidence * class_probabilities - boxes = tf.expand_dims(boxes, axis=-2) - boxes = boxes / input_shape[0] # box normalization: relative img size - print(f'nms iou: {iou_threshold} score: {score_threshold}') - (nmsed_boxes, # [bs, max_detections, 4] - nmsed_scores, # [bs, max_detections] - nmsed_classes, # [bs, max_detections] - valid_detections # [batch_size] - ) = tf.image.combined_non_max_suppression( - boxes=boxes, # y1x1, y2x2 [0~1] - scores=scores, - max_output_size_per_class=100, - max_total_size=100, # max_boxes: Maximum nmsed_boxes in a single img. - iou_threshold=iou_threshold, # iou_threshold: Minimum overlap that counts as a valid detection. - score_threshold=score_threshold, # # Minimum confidence that counts as a valid detection. - ) - return nmsed_boxes, nmsed_scores, nmsed_classes, valid_detections \ No newline at end of file diff --git a/spaces/Realcat/image-matching-webui/third_party/SGMNet/datadump/dump.py b/spaces/Realcat/image-matching-webui/third_party/SGMNet/datadump/dump.py deleted file mode 100644 index 8c95f7bb348b8b2e388729df071bb331d6556534..0000000000000000000000000000000000000000 --- a/spaces/Realcat/image-matching-webui/third_party/SGMNet/datadump/dump.py +++ /dev/null @@ -1,29 +0,0 @@ -import argparse -import yaml - - -def str2bool(v): - return v.lower() in ("true", "1") - - -# Parse command line arguments. -parser = argparse.ArgumentParser(description="dump eval data.") -parser.add_argument("--config_path", type=str, default="configs/yfcc.yaml") - - -def get_dumper(name): - mod = __import__("dumper.{}".format(name), fromlist=[""]) - return getattr(mod, name) - - -if __name__ == "__main__": - args = parser.parse_args() - with open(args.config_path, "r") as f: - config = yaml.load(f) - - dataset = get_dumper(config["data_name"])(config) - - dataset.initialize() - if config["extractor"]["extract"]: - dataset.dump_feature() - dataset.format_dump_data() diff --git a/spaces/Reself/StableVideo/annotator/midas/__init__.py b/spaces/Reself/StableVideo/annotator/midas/__init__.py deleted file mode 100644 index 412a8e30abadefd2291c8ae1b6e808638a0829c7..0000000000000000000000000000000000000000 --- a/spaces/Reself/StableVideo/annotator/midas/__init__.py +++ /dev/null @@ -1,38 +0,0 @@ -import cv2 -import numpy as np -import torch - -from einops import rearrange -from .api import MiDaSInference - - -class MidasDetector: - def __init__(self): - self.model = MiDaSInference(model_type="dpt_hybrid") - - def __call__(self, input_image, a=np.pi * 2.0, bg_th=0.1): - assert input_image.ndim == 3 - image_depth = input_image - with torch.no_grad(): - image_depth = torch.from_numpy(image_depth).float() - image_depth = image_depth / 127.5 - 1.0 - image_depth = rearrange(image_depth, 'h w c -> 1 c h w') - depth = self.model(image_depth)[0] - - depth_pt = depth.clone() - depth_pt -= torch.min(depth_pt) - depth_pt /= torch.max(depth_pt) - depth_pt = depth_pt.cpu().numpy() - depth_image = (depth_pt * 255.0).clip(0, 255).astype(np.uint8) - - depth_np = depth.cpu().numpy() - x = cv2.Sobel(depth_np, cv2.CV_32F, 1, 0, ksize=3) - y = cv2.Sobel(depth_np, cv2.CV_32F, 0, 1, ksize=3) - z = np.ones_like(x) * a - x[depth_pt < bg_th] = 0 - y[depth_pt < bg_th] = 0 - normal = np.stack([x, y, z], axis=2) - normal /= np.sum(normal ** 2.0, axis=2, keepdims=True) ** 0.5 - normal_image = (normal * 127.5 + 127.5).clip(0, 255).astype(np.uint8) - - return depth_image, normal_image diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/detectors/rpn.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/detectors/rpn.py deleted file mode 100644 index 1a77294549d1c3dc7821063c3f3d08bb331fbe59..0000000000000000000000000000000000000000 --- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/detectors/rpn.py +++ /dev/null @@ -1,154 +0,0 @@ -import mmcv -from mmcv.image import tensor2imgs - -from mmdet.core import bbox_mapping -from ..builder import DETECTORS, build_backbone, build_head, build_neck -from .base import BaseDetector - - -@DETECTORS.register_module() -class RPN(BaseDetector): - """Implementation of Region Proposal Network.""" - - def __init__(self, - backbone, - neck, - rpn_head, - train_cfg, - test_cfg, - pretrained=None): - super(RPN, self).__init__() - self.backbone = build_backbone(backbone) - self.neck = build_neck(neck) if neck is not None else None - rpn_train_cfg = train_cfg.rpn if train_cfg is not None else None - rpn_head.update(train_cfg=rpn_train_cfg) - rpn_head.update(test_cfg=test_cfg.rpn) - self.rpn_head = build_head(rpn_head) - self.train_cfg = train_cfg - self.test_cfg = test_cfg - self.init_weights(pretrained=pretrained) - - def init_weights(self, pretrained=None): - """Initialize the weights in detector. - - Args: - pretrained (str, optional): Path to pre-trained weights. - Defaults to None. - """ - super(RPN, self).init_weights(pretrained) - self.backbone.init_weights(pretrained=pretrained) - if self.with_neck: - self.neck.init_weights() - self.rpn_head.init_weights() - - def extract_feat(self, img): - """Extract features. - - Args: - img (torch.Tensor): Image tensor with shape (n, c, h ,w). - - Returns: - list[torch.Tensor]: Multi-level features that may have - different resolutions. - """ - x = self.backbone(img) - if self.with_neck: - x = self.neck(x) - return x - - def forward_dummy(self, img): - """Dummy forward function.""" - x = self.extract_feat(img) - rpn_outs = self.rpn_head(x) - return rpn_outs - - def forward_train(self, - img, - img_metas, - gt_bboxes=None, - gt_bboxes_ignore=None): - """ - Args: - img (Tensor): Input images of shape (N, C, H, W). - Typically these should be mean centered and std scaled. - img_metas (list[dict]): A List of image info dict where each dict - has: 'img_shape', 'scale_factor', 'flip', and may also contain - 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'. - For details on the values of these keys see - :class:`mmdet.datasets.pipelines.Collect`. - gt_bboxes (list[Tensor]): Each item are the truth boxes for each - image in [tl_x, tl_y, br_x, br_y] format. - gt_bboxes_ignore (None | list[Tensor]): Specify which bounding - boxes can be ignored when computing the loss. - - Returns: - dict[str, Tensor]: A dictionary of loss components. - """ - if (isinstance(self.train_cfg.rpn, dict) - and self.train_cfg.rpn.get('debug', False)): - self.rpn_head.debug_imgs = tensor2imgs(img) - - x = self.extract_feat(img) - losses = self.rpn_head.forward_train(x, img_metas, gt_bboxes, None, - gt_bboxes_ignore) - return losses - - def simple_test(self, img, img_metas, rescale=False): - """Test function without test time augmentation. - - Args: - imgs (list[torch.Tensor]): List of multiple images - img_metas (list[dict]): List of image information. - rescale (bool, optional): Whether to rescale the results. - Defaults to False. - - Returns: - list[np.ndarray]: proposals - """ - x = self.extract_feat(img) - proposal_list = self.rpn_head.simple_test_rpn(x, img_metas) - if rescale: - for proposals, meta in zip(proposal_list, img_metas): - proposals[:, :4] /= proposals.new_tensor(meta['scale_factor']) - - return [proposal.cpu().numpy() for proposal in proposal_list] - - def aug_test(self, imgs, img_metas, rescale=False): - """Test function with test time augmentation. - - Args: - imgs (list[torch.Tensor]): List of multiple images - img_metas (list[dict]): List of image information. - rescale (bool, optional): Whether to rescale the results. - Defaults to False. - - Returns: - list[np.ndarray]: proposals - """ - proposal_list = self.rpn_head.aug_test_rpn( - self.extract_feats(imgs), img_metas) - if not rescale: - for proposals, img_meta in zip(proposal_list, img_metas[0]): - img_shape = img_meta['img_shape'] - scale_factor = img_meta['scale_factor'] - flip = img_meta['flip'] - flip_direction = img_meta['flip_direction'] - proposals[:, :4] = bbox_mapping(proposals[:, :4], img_shape, - scale_factor, flip, - flip_direction) - return [proposal.cpu().numpy() for proposal in proposal_list] - - def show_result(self, data, result, top_k=20, **kwargs): - """Show RPN proposals on the image. - - Args: - data (str or np.ndarray): Image filename or loaded image. - result (Tensor or tuple): The results to draw over `img` - bbox_result or (bbox_result, segm_result). - top_k (int): Plot the first k bboxes only - if set positive. Default: 20 - - Returns: - np.ndarray: The image with bboxes drawn on it. - """ - mmcv.imshow_bboxes(data, result, top_k=top_k) diff --git a/spaces/Rongjiehuang/GenerSpeech/modules/parallel_wavegan/layers/causal_conv.py b/spaces/Rongjiehuang/GenerSpeech/modules/parallel_wavegan/layers/causal_conv.py deleted file mode 100644 index fca77daf65f234e6fbe355ed148fc8f0ee85038a..0000000000000000000000000000000000000000 --- a/spaces/Rongjiehuang/GenerSpeech/modules/parallel_wavegan/layers/causal_conv.py +++ /dev/null @@ -1,56 +0,0 @@ -# -*- coding: utf-8 -*- - -# Copyright 2020 Tomoki Hayashi -# MIT License (https://opensource.org/licenses/MIT) - -"""Causal convolusion layer modules.""" - - -import torch - - -class CausalConv1d(torch.nn.Module): - """CausalConv1d module with customized initialization.""" - - def __init__(self, in_channels, out_channels, kernel_size, - dilation=1, bias=True, pad="ConstantPad1d", pad_params={"value": 0.0}): - """Initialize CausalConv1d module.""" - super(CausalConv1d, self).__init__() - self.pad = getattr(torch.nn, pad)((kernel_size - 1) * dilation, **pad_params) - self.conv = torch.nn.Conv1d(in_channels, out_channels, kernel_size, - dilation=dilation, bias=bias) - - def forward(self, x): - """Calculate forward propagation. - - Args: - x (Tensor): Input tensor (B, in_channels, T). - - Returns: - Tensor: Output tensor (B, out_channels, T). - - """ - return self.conv(self.pad(x))[:, :, :x.size(2)] - - -class CausalConvTranspose1d(torch.nn.Module): - """CausalConvTranspose1d module with customized initialization.""" - - def __init__(self, in_channels, out_channels, kernel_size, stride, bias=True): - """Initialize CausalConvTranspose1d module.""" - super(CausalConvTranspose1d, self).__init__() - self.deconv = torch.nn.ConvTranspose1d( - in_channels, out_channels, kernel_size, stride, bias=bias) - self.stride = stride - - def forward(self, x): - """Calculate forward propagation. - - Args: - x (Tensor): Input tensor (B, in_channels, T_in). - - Returns: - Tensor: Output tensor (B, out_channels, T_out). - - """ - return self.deconv(x)[:, :, :-self.stride] diff --git a/spaces/Rongjiehuang/GenerSpeech/utils/indexed_datasets.py b/spaces/Rongjiehuang/GenerSpeech/utils/indexed_datasets.py deleted file mode 100644 index e15632be30d6296a3c9aa80a1f351058003698b3..0000000000000000000000000000000000000000 --- a/spaces/Rongjiehuang/GenerSpeech/utils/indexed_datasets.py +++ /dev/null @@ -1,71 +0,0 @@ -import pickle -from copy import deepcopy - -import numpy as np - - -class IndexedDataset: - def __init__(self, path, num_cache=1): - super().__init__() - self.path = path - self.data_file = None - self.data_offsets = np.load(f"{path}.idx", allow_pickle=True).item()['offsets'] - self.data_file = open(f"{path}.data", 'rb', buffering=-1) - self.cache = [] - self.num_cache = num_cache - - def check_index(self, i): - if i < 0 or i >= len(self.data_offsets) - 1: - raise IndexError('index out of range') - - def __del__(self): - if self.data_file: - self.data_file.close() - - def __getitem__(self, i): - self.check_index(i) - if self.num_cache > 0: - for c in self.cache: - if c[0] == i: - return c[1] - self.data_file.seek(self.data_offsets[i]) - b = self.data_file.read(self.data_offsets[i + 1] - self.data_offsets[i]) - item = pickle.loads(b) - if self.num_cache > 0: - self.cache = [(i, deepcopy(item))] + self.cache[:-1] - return item - - def __len__(self): - return len(self.data_offsets) - 1 - -class IndexedDatasetBuilder: - def __init__(self, path): - self.path = path - self.out_file = open(f"{path}.data", 'wb') - self.byte_offsets = [0] - - def add_item(self, item): - s = pickle.dumps(item) - bytes = self.out_file.write(s) - self.byte_offsets.append(self.byte_offsets[-1] + bytes) - - def finalize(self): - self.out_file.close() - np.save(open(f"{self.path}.idx", 'wb'), {'offsets': self.byte_offsets}) - - -if __name__ == "__main__": - import random - from tqdm import tqdm - ds_path = '/tmp/indexed_ds_example' - size = 100 - items = [{"a": np.random.normal(size=[10000, 10]), - "b": np.random.normal(size=[10000, 10])} for i in range(size)] - builder = IndexedDatasetBuilder(ds_path) - for i in tqdm(range(size)): - builder.add_item(items[i]) - builder.finalize() - ds = IndexedDataset(ds_path) - for i in tqdm(range(10000)): - idx = random.randint(0, size - 1) - assert (ds[idx]['a'] == items[idx]['a']).all() diff --git a/spaces/SIGGRAPH2022/Text2Human/Text2Human/models/hierarchy_vqgan_model.py b/spaces/SIGGRAPH2022/Text2Human/Text2Human/models/hierarchy_vqgan_model.py deleted file mode 100644 index 4b0d657864b5771bdbcd3ba134f4352ea2ca1e19..0000000000000000000000000000000000000000 --- a/spaces/SIGGRAPH2022/Text2Human/Text2Human/models/hierarchy_vqgan_model.py +++ /dev/null @@ -1,374 +0,0 @@ -import math -import sys -from collections import OrderedDict - -sys.path.append('..') -import lpips -import torch -import torch.nn.functional as F -from torchvision.utils import save_image - -from models.archs.vqgan_arch import (Decoder, DecoderRes, Discriminator, - Encoder, - VectorQuantizerSpatialTextureAware, - VectorQuantizerTexture) -from models.losses.vqgan_loss import (DiffAugment, adopt_weight, - calculate_adaptive_weight, hinge_d_loss) - - -class HierarchyVQSpatialTextureAwareModel(): - - def __init__(self, opt): - self.opt = opt - self.device = torch.device('cuda') - self.top_encoder = Encoder( - ch=opt['top_ch'], - num_res_blocks=opt['top_num_res_blocks'], - attn_resolutions=opt['top_attn_resolutions'], - ch_mult=opt['top_ch_mult'], - in_channels=opt['top_in_channels'], - resolution=opt['top_resolution'], - z_channels=opt['top_z_channels'], - double_z=opt['top_double_z'], - dropout=opt['top_dropout']).to(self.device) - self.decoder = Decoder( - in_channels=opt['top_in_channels'], - resolution=opt['top_resolution'], - z_channels=opt['top_z_channels'], - ch=opt['top_ch'], - out_ch=opt['top_out_ch'], - num_res_blocks=opt['top_num_res_blocks'], - attn_resolutions=opt['top_attn_resolutions'], - ch_mult=opt['top_ch_mult'], - dropout=opt['top_dropout'], - resamp_with_conv=True, - give_pre_end=False).to(self.device) - self.top_quantize = VectorQuantizerTexture( - 1024, opt['embed_dim'], beta=0.25).to(self.device) - self.top_quant_conv = torch.nn.Conv2d(opt["top_z_channels"], - opt['embed_dim'], - 1).to(self.device) - self.top_post_quant_conv = torch.nn.Conv2d(opt['embed_dim'], - opt["top_z_channels"], - 1).to(self.device) - self.load_top_pretrain_models() - - self.bot_encoder = Encoder( - ch=opt['bot_ch'], - num_res_blocks=opt['bot_num_res_blocks'], - attn_resolutions=opt['bot_attn_resolutions'], - ch_mult=opt['bot_ch_mult'], - in_channels=opt['bot_in_channels'], - resolution=opt['bot_resolution'], - z_channels=opt['bot_z_channels'], - double_z=opt['bot_double_z'], - dropout=opt['bot_dropout']).to(self.device) - self.bot_decoder_res = DecoderRes( - in_channels=opt['bot_in_channels'], - resolution=opt['bot_resolution'], - z_channels=opt['bot_z_channels'], - ch=opt['bot_ch'], - num_res_blocks=opt['bot_num_res_blocks'], - ch_mult=opt['bot_ch_mult'], - dropout=opt['bot_dropout'], - give_pre_end=False).to(self.device) - self.bot_quantize = VectorQuantizerSpatialTextureAware( - opt['bot_n_embed'], - opt['embed_dim'], - beta=0.25, - spatial_size=opt['codebook_spatial_size']).to(self.device) - self.bot_quant_conv = torch.nn.Conv2d(opt["bot_z_channels"], - opt['embed_dim'], - 1).to(self.device) - self.bot_post_quant_conv = torch.nn.Conv2d(opt['embed_dim'], - opt["bot_z_channels"], - 1).to(self.device) - - self.disc = Discriminator( - opt['n_channels'], opt['ndf'], - n_layers=opt['disc_layers']).to(self.device) - self.perceptual = lpips.LPIPS(net="vgg").to(self.device) - self.perceptual_weight = opt['perceptual_weight'] - self.disc_start_step = opt['disc_start_step'] - self.disc_weight_max = opt['disc_weight_max'] - self.diff_aug = opt['diff_aug'] - self.policy = "color,translation" - - self.load_discriminator_models() - - self.disc.train() - - self.fix_decoder = opt['fix_decoder'] - - self.init_training_settings() - - def load_top_pretrain_models(self): - # load pretrained vqgan for segmentation mask - top_vae_checkpoint = torch.load(self.opt['top_vae_path']) - self.top_encoder.load_state_dict( - top_vae_checkpoint['encoder'], strict=True) - self.decoder.load_state_dict( - top_vae_checkpoint['decoder'], strict=True) - self.top_quantize.load_state_dict( - top_vae_checkpoint['quantize'], strict=True) - self.top_quant_conv.load_state_dict( - top_vae_checkpoint['quant_conv'], strict=True) - self.top_post_quant_conv.load_state_dict( - top_vae_checkpoint['post_quant_conv'], strict=True) - self.top_encoder.eval() - self.top_quantize.eval() - self.top_quant_conv.eval() - self.top_post_quant_conv.eval() - - def init_training_settings(self): - self.log_dict = OrderedDict() - self.configure_optimizers() - - def configure_optimizers(self): - optim_params = [] - for v in self.bot_encoder.parameters(): - if v.requires_grad: - optim_params.append(v) - for v in self.bot_decoder_res.parameters(): - if v.requires_grad: - optim_params.append(v) - for v in self.bot_quantize.parameters(): - if v.requires_grad: - optim_params.append(v) - for v in self.bot_quant_conv.parameters(): - if v.requires_grad: - optim_params.append(v) - for v in self.bot_post_quant_conv.parameters(): - if v.requires_grad: - optim_params.append(v) - if not self.fix_decoder: - for name, v in self.decoder.named_parameters(): - if v.requires_grad: - if 'up.0' in name: - optim_params.append(v) - if 'up.1' in name: - optim_params.append(v) - if 'up.2' in name: - optim_params.append(v) - if 'up.3' in name: - optim_params.append(v) - - self.optimizer = torch.optim.Adam(optim_params, lr=self.opt['lr']) - - self.disc_optimizer = torch.optim.Adam( - self.disc.parameters(), lr=self.opt['lr']) - - def load_discriminator_models(self): - # load pretrained vqgan for segmentation mask - top_vae_checkpoint = torch.load(self.opt['top_vae_path']) - self.disc.load_state_dict( - top_vae_checkpoint['discriminator'], strict=True) - - def save_network(self, save_path): - """Save networks. - """ - - save_dict = {} - save_dict['bot_encoder'] = self.bot_encoder.state_dict() - save_dict['bot_decoder_res'] = self.bot_decoder_res.state_dict() - save_dict['decoder'] = self.decoder.state_dict() - save_dict['bot_quantize'] = self.bot_quantize.state_dict() - save_dict['bot_quant_conv'] = self.bot_quant_conv.state_dict() - save_dict['bot_post_quant_conv'] = self.bot_post_quant_conv.state_dict( - ) - save_dict['discriminator'] = self.disc.state_dict() - torch.save(save_dict, save_path) - - def load_network(self): - checkpoint = torch.load(self.opt['pretrained_models']) - self.bot_encoder.load_state_dict( - checkpoint['bot_encoder'], strict=True) - self.bot_decoder_res.load_state_dict( - checkpoint['bot_decoder_res'], strict=True) - self.decoder.load_state_dict(checkpoint['decoder'], strict=True) - self.bot_quantize.load_state_dict( - checkpoint['bot_quantize'], strict=True) - self.bot_quant_conv.load_state_dict( - checkpoint['bot_quant_conv'], strict=True) - self.bot_post_quant_conv.load_state_dict( - checkpoint['bot_post_quant_conv'], strict=True) - - def optimize_parameters(self, data, step): - self.bot_encoder.train() - self.bot_decoder_res.train() - if not self.fix_decoder: - self.decoder.train() - self.bot_quantize.train() - self.bot_quant_conv.train() - self.bot_post_quant_conv.train() - - loss, d_loss = self.training_step(data, step) - self.optimizer.zero_grad() - loss.backward() - self.optimizer.step() - - if step > self.disc_start_step: - self.disc_optimizer.zero_grad() - d_loss.backward() - self.disc_optimizer.step() - - def top_encode(self, x, mask): - h = self.top_encoder(x) - h = self.top_quant_conv(h) - quant, _, _ = self.top_quantize(h, mask) - quant = self.top_post_quant_conv(quant) - return quant - - def bot_encode(self, x, mask): - h = self.bot_encoder(x) - h = self.bot_quant_conv(h) - quant, emb_loss, info = self.bot_quantize(h, mask) - quant = self.bot_post_quant_conv(quant) - bot_dec_res = self.bot_decoder_res(quant) - return bot_dec_res, emb_loss, info - - def decode(self, quant_top, bot_dec_res): - dec = self.decoder(quant_top, bot_h=bot_dec_res) - return dec - - def forward_step(self, input, mask): - with torch.no_grad(): - quant_top = self.top_encode(input, mask) - bot_dec_res, diff, _ = self.bot_encode(input, mask) - dec = self.decode(quant_top, bot_dec_res) - return dec, diff - - def feed_data(self, data): - x = data['image'].float().to(self.device) - mask = data['texture_mask'].float().to(self.device) - - return x, mask - - def training_step(self, data, step): - x, mask = self.feed_data(data) - xrec, codebook_loss = self.forward_step(x, mask) - - # get recon/perceptual loss - recon_loss = torch.abs(x.contiguous() - xrec.contiguous()) - p_loss = self.perceptual(x.contiguous(), xrec.contiguous()) - nll_loss = recon_loss + self.perceptual_weight * p_loss - nll_loss = torch.mean(nll_loss) - - # augment for input to discriminator - if self.diff_aug: - xrec = DiffAugment(xrec, policy=self.policy) - - # update generator - logits_fake = self.disc(xrec) - g_loss = -torch.mean(logits_fake) - last_layer = self.decoder.conv_out.weight - d_weight = calculate_adaptive_weight(nll_loss, g_loss, last_layer, - self.disc_weight_max) - d_weight *= adopt_weight(1, step, self.disc_start_step) - loss = nll_loss + d_weight * g_loss + codebook_loss - - self.log_dict["loss"] = loss - self.log_dict["l1"] = recon_loss.mean().item() - self.log_dict["perceptual"] = p_loss.mean().item() - self.log_dict["nll_loss"] = nll_loss.item() - self.log_dict["g_loss"] = g_loss.item() - self.log_dict["d_weight"] = d_weight - self.log_dict["codebook_loss"] = codebook_loss.item() - - if step > self.disc_start_step: - if self.diff_aug: - logits_real = self.disc( - DiffAugment(x.contiguous().detach(), policy=self.policy)) - else: - logits_real = self.disc(x.contiguous().detach()) - logits_fake = self.disc(xrec.contiguous().detach( - )) # detach so that generator isn"t also updated - d_loss = hinge_d_loss(logits_real, logits_fake) - self.log_dict["d_loss"] = d_loss - else: - d_loss = None - - return loss, d_loss - - @torch.no_grad() - def inference(self, data_loader, save_dir): - self.bot_encoder.eval() - self.bot_decoder_res.eval() - self.decoder.eval() - self.bot_quantize.eval() - self.bot_quant_conv.eval() - self.bot_post_quant_conv.eval() - - loss_total = 0 - num = 0 - - for _, data in enumerate(data_loader): - img_name = data['img_name'][0] - x, mask = self.feed_data(data) - xrec, _ = self.forward_step(x, mask) - - recon_loss = torch.abs(x.contiguous() - xrec.contiguous()) - p_loss = self.perceptual(x.contiguous(), xrec.contiguous()) - nll_loss = recon_loss + self.perceptual_weight * p_loss - nll_loss = torch.mean(nll_loss) - loss_total += nll_loss - - num += x.size(0) - - if x.shape[1] > 3: - # colorize with random projection - assert xrec.shape[1] > 3 - # convert logits to indices - xrec = torch.argmax(xrec, dim=1, keepdim=True) - xrec = F.one_hot(xrec, num_classes=x.shape[1]) - xrec = xrec.squeeze(1).permute(0, 3, 1, 2).float() - x = self.to_rgb(x) - xrec = self.to_rgb(xrec) - - img_cat = torch.cat([x, xrec], dim=3).detach() - img_cat = ((img_cat + 1) / 2) - img_cat = img_cat.clamp_(0, 1) - save_image( - img_cat, f'{save_dir}/{img_name}.png', nrow=1, padding=4) - - return (loss_total / num).item() - - def get_current_log(self): - return self.log_dict - - def update_learning_rate(self, epoch): - """Update learning rate. - - Args: - current_iter (int): Current iteration. - warmup_iter (int): Warmup iter numbers. -1 for no warmup. - Default: -1. - """ - lr = self.optimizer.param_groups[0]['lr'] - - if self.opt['lr_decay'] == 'step': - lr = self.opt['lr'] * ( - self.opt['gamma']**(epoch // self.opt['step'])) - elif self.opt['lr_decay'] == 'cos': - lr = self.opt['lr'] * ( - 1 + math.cos(math.pi * epoch / self.opt['num_epochs'])) / 2 - elif self.opt['lr_decay'] == 'linear': - lr = self.opt['lr'] * (1 - epoch / self.opt['num_epochs']) - elif self.opt['lr_decay'] == 'linear2exp': - if epoch < self.opt['turning_point'] + 1: - # learning rate decay as 95% - # at the turning point (1 / 95% = 1.0526) - lr = self.opt['lr'] * ( - 1 - epoch / int(self.opt['turning_point'] * 1.0526)) - else: - lr *= self.opt['gamma'] - elif self.opt['lr_decay'] == 'schedule': - if epoch in self.opt['schedule']: - lr *= self.opt['gamma'] - else: - raise ValueError('Unknown lr mode {}'.format(self.opt['lr_decay'])) - # set learning rate - for param_group in self.optimizer.param_groups: - param_group['lr'] = lr - - return lr diff --git a/spaces/Sanathkumar1603/hackathon/app/Hackathon_setup/exp_recognition_model.py b/spaces/Sanathkumar1603/hackathon/app/Hackathon_setup/exp_recognition_model.py deleted file mode 100644 index b873877dfd09db59f99eed51a26182c8904a871b..0000000000000000000000000000000000000000 --- a/spaces/Sanathkumar1603/hackathon/app/Hackathon_setup/exp_recognition_model.py +++ /dev/null @@ -1,52 +0,0 @@ -import torch -import torchvision -import torch.nn as nn -from torchvision import transforms -import torch.nn.functional as F -## Add more imports if required - -#################################################################################################################### -# Define your model and transform and all necessary helper functions here # -# They will be imported to the exp_recognition.py file # -#################################################################################################################### - -# Definition of classes as dictionary -classes = {0: 'ANGER', 1: 'DISGUST', 2: 'FEAR', 3: 'HAPPINESS', 4: 'NEUTRAL', 5: 'SADNESS', 6: 'SURPRISE'} - -# Example Network -class facExpRec(torch.nn.Module): - def __init__(self): - super(facExpRec, self).__init__() - self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3) - self.conv2 = nn.Conv2d(in_channels=16, out_channels=64, kernel_size=3) - self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3) - self.fc1 = nn.Linear(128*10*10, 256) - self.fc2 = nn.Linear(256, 128) - self.fc3 = nn.Linear(128, 64) - self.fc4 = nn.Linear(64, 7) - self.pool = nn.MaxPool2d(kernel_size=2) - - def forward(self, x): - #original_size = x.size() - x = self.pool(F.relu(self.conv1(x))) - x = self.pool(F.relu(self.conv2(x))) - x = self.pool(F.relu(self.conv3(x))) - - #desired_shape = (-1, original_size[1] * original_size[2] * original_size[3]) - x = x.view(-1, 128*10*10) - #x=x.view(desired_shape) - - x = F.relu(self.fc1(x)) - x = F.relu(self.fc2(x)) - x = F.relu(self.fc3(x)) - x = self.fc4(x) - x = F.log_softmax(x, dim=1) - return x - -# Sample Helper function -def rgb2gray(image): - return image.convert('L') - -# Sample Transformation function -#YOUR CODE HERE for changing the Transformation values. -trnscm = transforms.Compose([rgb2gray, transforms.Resize((100,100)), transforms.ToTensor()]) \ No newline at end of file diff --git a/spaces/Sarfraz/NousResearch-gpt4-x-vicuna-13b/app.py b/spaces/Sarfraz/NousResearch-gpt4-x-vicuna-13b/app.py deleted file mode 100644 index d864d5552b5f203ac28524cc45fdebb731a2ccd9..0000000000000000000000000000000000000000 --- a/spaces/Sarfraz/NousResearch-gpt4-x-vicuna-13b/app.py +++ /dev/null @@ -1,3 +0,0 @@ -import gradio as gr - -gr.Interface.load("models/NousResearch/gpt4-x-vicuna-13b").launch() \ No newline at end of file diff --git a/spaces/Shenhe/anime-ai-detect/README.md b/spaces/Shenhe/anime-ai-detect/README.md deleted file mode 100644 index 952c183fd69ccb1664b4236b6132fc6d0358c7de..0000000000000000000000000000000000000000 --- a/spaces/Shenhe/anime-ai-detect/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Anime Ai Detect -emoji: 🤖 -colorFrom: green -colorTo: purple -sdk: gradio -sdk_version: 3.15.0 -app_file: app.py -pinned: true -duplicated_from: saltacc/anime-ai-detect ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/SouthCity/ShuruiXu/functional.py b/spaces/SouthCity/ShuruiXu/functional.py deleted file mode 100644 index eccc0ac251784f4611c60ae754194448fca2e9e8..0000000000000000000000000000000000000000 --- a/spaces/SouthCity/ShuruiXu/functional.py +++ /dev/null @@ -1,70 +0,0 @@ -# 'primary' 颜色对应 theme.py 中的 primary_hue -# 'secondary' 颜色对应 theme.py 中的 neutral_hue -# 'stop' 颜色对应 theme.py 中的 color_er -# 默认按钮颜色是 secondary -from toolbox import clear_line_break - -def get_functionals(): - return { - "英语学术润色": { - # 前言 - "Prefix": r"Below is a paragraph from an academic paper. Polish the writing to meet the academic style, " + - r"improve the spelling, grammar, clarity, concision and overall readability. When necessary, rewrite the whole sentence. " + - r"Furthermore, list all modification and explain the reasons to do so in markdown table." + "\n\n", - # 后语 - "Suffix": r"", - "Color": r"secondary", # 按钮颜色 - }, - "中文学术润色": { - "Prefix": r"作为一名中文学术论文写作改进助理,你的任务是改进所提供文本的拼写、语法、清晰、简洁和整体可读性," + - r"同时分解长句,减少重复,并提供改进建议。请只提供文本的更正版本,避免包括解释。请编辑以下文本" + "\n\n", - "Suffix": r"", - }, - "查找语法错误": { - "Prefix": r"Can you help me ensure that the grammar and the spelling is correct? " + - r"Do not try to polish the text, if no mistake is found, tell me that this paragraph is good." + - r"If you find grammar or spelling mistakes, please list mistakes you find in a two-column markdown table, " + - r"put the original text the first column, " + - r"put the corrected text in the second column and highlight the key words you fixed.""\n" - r"Example:""\n" - r"Paragraph: How is you? Do you knows what is it?""\n" - r"| Original sentence | Corrected sentence |""\n" - r"| :--- | :--- |""\n" - r"| How **is** you? | How **are** you? |""\n" - r"| Do you **knows** what **is** **it**? | Do you **know** what **it** **is** ? |""\n" - r"Below is a paragraph from an academic paper. " - r"You need to report all grammar and spelling mistakes as the example before." - + "\n\n", - "Suffix": r"", - "PreProcess": clear_line_break, # 预处理:清除换行符 - }, - "中译英": { - "Prefix": r"Please translate following sentence to English:" + "\n\n", - "Suffix": r"", - }, - "学术中英互译": { - "Prefix": r"I want you to act as a scientific English-Chinese translator, " + - r"I will provide you with some paragraphs in one language " + - r"and your task is to accurately and academically translate the paragraphs only into the other language. " + - r"Do not repeat the original provided paragraphs after translation. " + - r"You should use artificial intelligence tools, " + - r"such as natural language processing, and rhetorical knowledge " + - r"and experience about effective writing techniques to reply. " + - r"I'll give you my paragraphs as follows, tell me what language it is written in, and then translate:" + "\n\n", - "Suffix": "", - "Color": "secondary", - }, - "英译中": { - "Prefix": r"请翻译成中文:" + "\n\n", - "Suffix": r"", - }, - "找图片": { - "Prefix": r"我需要你找一张网络图片。使用Unsplash API(https://source.unsplash.com/960x640/?<英语关键词>)获取图片URL," + - r"然后请使用Markdown格式封装,并且不要有反斜线,不要用代码块。现在,请按以下描述给我发送图片:" + "\n\n", - "Suffix": r"", - }, - "解释代码": { - "Prefix": r"请解释以下代码:" + "\n```\n", - "Suffix": "\n```\n", - }, - } diff --git a/spaces/SuYuanS/AudioCraft_Plus/setup.py b/spaces/SuYuanS/AudioCraft_Plus/setup.py deleted file mode 100644 index 64e7d6fcb1092748f8151f6d3ed1767d3be1b34b..0000000000000000000000000000000000000000 --- a/spaces/SuYuanS/AudioCraft_Plus/setup.py +++ /dev/null @@ -1,62 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -from pathlib import Path - -from setuptools import setup, find_packages - - -NAME = 'audiocraft' -DESCRIPTION = 'Audio generation research library for PyTorch' - -URL = 'https://github.com/facebookresearch/audiocraft' -AUTHOR = 'FAIR Speech & Audio' -EMAIL = 'defossez@meta.com, jadecopet@meta.com' -REQUIRES_PYTHON = '>=3.8.0' - -for line in open('audiocraft/__init__.py'): - line = line.strip() - if '__version__' in line: - context = {} - exec(line, context) - VERSION = context['__version__'] - -HERE = Path(__file__).parent - -try: - with open(HERE / "README.md", encoding='utf-8') as f: - long_description = '\n' + f.read() -except FileNotFoundError: - long_description = DESCRIPTION - -REQUIRED = [i.strip() for i in open(HERE / 'requirements.txt') if not i.startswith('#')] - -setup( - name=NAME, - version=VERSION, - description=DESCRIPTION, - author_email=EMAIL, - long_description=long_description, - long_description_content_type='text/markdown', - author=AUTHOR, - url=URL, - python_requires=REQUIRES_PYTHON, - install_requires=REQUIRED, - extras_require={ - 'dev': ['coverage', 'flake8', 'mypy', 'pdoc3', 'pytest'], - }, - packages=find_packages(), - package_data={'audiocraft': ['py.typed']}, - include_package_data=True, - license='MIT License', - classifiers=[ - # Trove classifiers - # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers - 'License :: OSI Approved :: MIT License', - 'Topic :: Multimedia :: Sound/Audio', - 'Topic :: Scientific/Engineering :: Artificial Intelligence', - ], -) diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/aiohttp/http_writer.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/aiohttp/http_writer.py deleted file mode 100644 index 73f0f96f0ae3f152c22931054c7c4193cc45d8ef..0000000000000000000000000000000000000000 --- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/aiohttp/http_writer.py +++ /dev/null @@ -1,198 +0,0 @@ -"""Http related parsers and protocol.""" - -import asyncio -import zlib -from typing import Any, Awaitable, Callable, NamedTuple, Optional, Union # noqa - -from multidict import CIMultiDict - -from .abc import AbstractStreamWriter -from .base_protocol import BaseProtocol -from .helpers import NO_EXTENSIONS - -__all__ = ("StreamWriter", "HttpVersion", "HttpVersion10", "HttpVersion11") - - -class HttpVersion(NamedTuple): - major: int - minor: int - - -HttpVersion10 = HttpVersion(1, 0) -HttpVersion11 = HttpVersion(1, 1) - - -_T_OnChunkSent = Optional[Callable[[bytes], Awaitable[None]]] -_T_OnHeadersSent = Optional[Callable[["CIMultiDict[str]"], Awaitable[None]]] - - -class StreamWriter(AbstractStreamWriter): - def __init__( - self, - protocol: BaseProtocol, - loop: asyncio.AbstractEventLoop, - on_chunk_sent: _T_OnChunkSent = None, - on_headers_sent: _T_OnHeadersSent = None, - ) -> None: - self._protocol = protocol - - self.loop = loop - self.length = None - self.chunked = False - self.buffer_size = 0 - self.output_size = 0 - - self._eof = False - self._compress: Any = None - self._drain_waiter = None - - self._on_chunk_sent: _T_OnChunkSent = on_chunk_sent - self._on_headers_sent: _T_OnHeadersSent = on_headers_sent - - @property - def transport(self) -> Optional[asyncio.Transport]: - return self._protocol.transport - - @property - def protocol(self) -> BaseProtocol: - return self._protocol - - def enable_chunking(self) -> None: - self.chunked = True - - def enable_compression( - self, encoding: str = "deflate", strategy: int = zlib.Z_DEFAULT_STRATEGY - ) -> None: - zlib_mode = 16 + zlib.MAX_WBITS if encoding == "gzip" else zlib.MAX_WBITS - self._compress = zlib.compressobj(wbits=zlib_mode, strategy=strategy) - - def _write(self, chunk: bytes) -> None: - size = len(chunk) - self.buffer_size += size - self.output_size += size - transport = self.transport - if not self._protocol.connected or transport is None or transport.is_closing(): - raise ConnectionResetError("Cannot write to closing transport") - transport.write(chunk) - - async def write( - self, chunk: bytes, *, drain: bool = True, LIMIT: int = 0x10000 - ) -> None: - """Writes chunk of data to a stream. - - write_eof() indicates end of stream. - writer can't be used after write_eof() method being called. - write() return drain future. - """ - if self._on_chunk_sent is not None: - await self._on_chunk_sent(chunk) - - if isinstance(chunk, memoryview): - if chunk.nbytes != len(chunk): - # just reshape it - chunk = chunk.cast("c") - - if self._compress is not None: - chunk = self._compress.compress(chunk) - if not chunk: - return - - if self.length is not None: - chunk_len = len(chunk) - if self.length >= chunk_len: - self.length = self.length - chunk_len - else: - chunk = chunk[: self.length] - self.length = 0 - if not chunk: - return - - if chunk: - if self.chunked: - chunk_len_pre = ("%x\r\n" % len(chunk)).encode("ascii") - chunk = chunk_len_pre + chunk + b"\r\n" - - self._write(chunk) - - if self.buffer_size > LIMIT and drain: - self.buffer_size = 0 - await self.drain() - - async def write_headers( - self, status_line: str, headers: "CIMultiDict[str]" - ) -> None: - """Write request/response status and headers.""" - if self._on_headers_sent is not None: - await self._on_headers_sent(headers) - - # status + headers - buf = _serialize_headers(status_line, headers) - self._write(buf) - - async def write_eof(self, chunk: bytes = b"") -> None: - if self._eof: - return - - if chunk and self._on_chunk_sent is not None: - await self._on_chunk_sent(chunk) - - if self._compress: - if chunk: - chunk = self._compress.compress(chunk) - - chunk = chunk + self._compress.flush() - if chunk and self.chunked: - chunk_len = ("%x\r\n" % len(chunk)).encode("ascii") - chunk = chunk_len + chunk + b"\r\n0\r\n\r\n" - else: - if self.chunked: - if chunk: - chunk_len = ("%x\r\n" % len(chunk)).encode("ascii") - chunk = chunk_len + chunk + b"\r\n0\r\n\r\n" - else: - chunk = b"0\r\n\r\n" - - if chunk: - self._write(chunk) - - await self.drain() - - self._eof = True - - async def drain(self) -> None: - """Flush the write buffer. - - The intended use is to write - - await w.write(data) - await w.drain() - """ - if self._protocol.transport is not None: - await self._protocol._drain_helper() - - -def _safe_header(string: str) -> str: - if "\r" in string or "\n" in string: - raise ValueError( - "Newline or carriage return detected in headers. " - "Potential header injection attack." - ) - return string - - -def _py_serialize_headers(status_line: str, headers: "CIMultiDict[str]") -> bytes: - headers_gen = (_safe_header(k) + ": " + _safe_header(v) for k, v in headers.items()) - line = status_line + "\r\n" + "\r\n".join(headers_gen) + "\r\n\r\n" - return line.encode("utf-8") - - -_serialize_headers = _py_serialize_headers - -try: - import aiohttp._http_writer as _http_writer # type: ignore[import] - - _c_serialize_headers = _http_writer._serialize_headers - if not NO_EXTENSIONS: - _serialize_headers = _c_serialize_headers -except ImportError: - pass diff --git a/spaces/Surn/UnlimitedMusicGen/audiocraft/modules/conditioners.py b/spaces/Surn/UnlimitedMusicGen/audiocraft/modules/conditioners.py deleted file mode 100644 index 82792316024b88d4c5c38b0a28f443627771d509..0000000000000000000000000000000000000000 --- a/spaces/Surn/UnlimitedMusicGen/audiocraft/modules/conditioners.py +++ /dev/null @@ -1,990 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -from collections import defaultdict -from copy import deepcopy -from dataclasses import dataclass, field -from itertools import chain -import logging -import math -import random -import re -import typing as tp -import warnings - -from einops import rearrange -from num2words import num2words -import spacy -from transformers import T5EncoderModel, T5Tokenizer # type: ignore -import torchaudio -import torch -from torch import nn -from torch import Tensor -import torch.nn.functional as F -from torch.nn.utils.rnn import pad_sequence - -from .streaming import StreamingModule -from .transformer import create_sin_embedding -from ..data.audio_dataset import SegmentInfo -from ..utils.autocast import TorchAutocast -from ..utils.utils import hash_trick, length_to_mask, collate - - -logger = logging.getLogger(__name__) -TextCondition = tp.Optional[str] # a text condition can be a string or None (if doesn't exist) -ConditionType = tp.Tuple[Tensor, Tensor] # condition, mask - - -class WavCondition(tp.NamedTuple): - wav: Tensor - length: Tensor - path: tp.List[tp.Optional[str]] = [] - - -def nullify_condition(condition: ConditionType, dim: int = 1): - """This function transforms an input condition to a null condition. - The way it is done by converting it to a single zero vector similarly - to how it is done inside WhiteSpaceTokenizer and NoopTokenizer. - - Args: - condition (ConditionType): a tuple of condition and mask (tp.Tuple[Tensor, Tensor]) - dim (int): the dimension that will be truncated (should be the time dimension) - WARNING!: dim should not be the batch dimension! - Returns: - ConditionType: a tuple of null condition and mask - """ - assert dim != 0, "dim cannot be the batch dimension!" - assert type(condition) == tuple and \ - type(condition[0]) == Tensor and \ - type(condition[1]) == Tensor, "'nullify_condition' got an unexpected input type!" - cond, mask = condition - B = cond.shape[0] - last_dim = cond.dim() - 1 - out = cond.transpose(dim, last_dim) - out = 0. * out[..., :1] - out = out.transpose(dim, last_dim) - mask = torch.zeros((B, 1), device=out.device).int() - assert cond.dim() == out.dim() - return out, mask - - -def nullify_wav(wav: Tensor) -> WavCondition: - """Create a nullified WavCondition from a wav tensor with appropriate shape. - - Args: - wav (Tensor): tensor of shape [B, T] - Returns: - WavCondition: wav condition with nullified wav. - """ - null_wav, _ = nullify_condition((wav, torch.zeros_like(wav)), dim=wav.dim() - 1) - return WavCondition( - wav=null_wav, - length=torch.tensor([0] * wav.shape[0], device=wav.device), - path=['null_wav'] * wav.shape[0] - ) - - -@dataclass -class ConditioningAttributes: - text: tp.Dict[str, tp.Optional[str]] = field(default_factory=dict) - wav: tp.Dict[str, WavCondition] = field(default_factory=dict) - - def __getitem__(self, item): - return getattr(self, item) - - @property - def text_attributes(self): - return self.text.keys() - - @property - def wav_attributes(self): - return self.wav.keys() - - @property - def attributes(self): - return {"text": self.text_attributes, "wav": self.wav_attributes} - - def to_flat_dict(self): - return { - **{f"text.{k}": v for k, v in self.text.items()}, - **{f"wav.{k}": v for k, v in self.wav.items()}, - } - - @classmethod - def from_flat_dict(cls, x): - out = cls() - for k, v in x.items(): - kind, att = k.split(".") - out[kind][att] = v - return out - - -class SegmentWithAttributes(SegmentInfo): - """Base class for all dataclasses that are used for conditioning. - All child classes should implement `to_condition_attributes` that converts - the existing attributes to a dataclass of type ConditioningAttributes. - """ - def to_condition_attributes(self) -> ConditioningAttributes: - raise NotImplementedError() - - -class Tokenizer: - """Base class for all tokenizers - (in case we want to introduce more advances tokenizers in the future). - """ - def __call__(self, texts: tp.List[tp.Optional[str]]) -> tp.Tuple[Tensor, Tensor]: - raise NotImplementedError() - - -class WhiteSpaceTokenizer(Tokenizer): - """This tokenizer should be used for natural language descriptions. - For example: - ["he didn't, know he's going home.", 'shorter sentence'] => - [[78, 62, 31, 4, 78, 25, 19, 34], - [59, 77, 0, 0, 0, 0, 0, 0]] - """ - PUNCTUATIONS = "?:!.,;" - - def __init__(self, n_bins: int, pad_idx: int = 0, language: str = "en_core_web_sm", - lemma: bool = True, stopwords: bool = True) -> None: - self.n_bins = n_bins - self.pad_idx = pad_idx - self.lemma = lemma - self.stopwords = stopwords - try: - self.nlp = spacy.load(language) - except IOError: - spacy.cli.download(language) # type: ignore - self.nlp = spacy.load(language) - - @tp.no_type_check - def __call__( - self, - texts: tp.List[tp.Optional[str]], - return_text: bool = False - ) -> tp.Tuple[Tensor, Tensor]: - """Take a list of strings and convert them to a tensor of indices. - - Args: - texts (tp.List[str]): List of strings. - return_text (bool, optional): Whether to return text as additional tuple item. Defaults to False. - Returns: - tp.Tuple[Tensor, Tensor]: - - Indices of words in the LUT. - - And a mask indicating where the padding tokens are - """ - output, lengths = [], [] - texts = deepcopy(texts) - for i, text in enumerate(texts): - # if current sample doesn't have a certain attribute, replace with pad token - if text is None: - output.append(Tensor([self.pad_idx])) - lengths.append(0) - continue - - # convert numbers to words - text = re.sub(r"(\d+)", lambda x: num2words(int(x.group(0))), text) # type: ignore - # normalize text - text = self.nlp(text) # type: ignore - # remove stopwords - if self.stopwords: - text = [w for w in text if not w.is_stop] # type: ignore - # remove punctuations - text = [w for w in text if w.text not in self.PUNCTUATIONS] # type: ignore - # lemmatize if needed - text = [getattr(t, "lemma_" if self.lemma else "text") for t in text] # type: ignore - - texts[i] = " ".join(text) - lengths.append(len(text)) - # convert to tensor - tokens = Tensor([hash_trick(w, self.n_bins) for w in text]) - output.append(tokens) - - mask = length_to_mask(torch.IntTensor(lengths)).int() - padded_output = pad_sequence(output, padding_value=self.pad_idx).int().t() - if return_text: - return padded_output, mask, texts # type: ignore - return padded_output, mask - - -class NoopTokenizer(Tokenizer): - """This tokenizer should be used for global conditioners such as: artist, genre, key, etc. - The difference between this and WhiteSpaceTokenizer is that NoopTokenizer does not split - strings, so "Jeff Buckley" will get it's own index. Whereas WhiteSpaceTokenizer will - split it to ["Jeff", "Buckley"] and return an index per word. - - For example: - ["Queen", "ABBA", "Jeff Buckley"] => [43, 55, 101] - ["Metal", "Rock", "Classical"] => [0, 223, 51] - """ - def __init__(self, n_bins: int, pad_idx: int = 0): - self.n_bins = n_bins - self.pad_idx = pad_idx - - def __call__(self, texts: tp.List[tp.Optional[str]]) -> tp.Tuple[Tensor, Tensor]: - output, lengths = [], [] - for text in texts: - # if current sample doesn't have a certain attribute, replace with pad token - if text is None: - output.append(self.pad_idx) - lengths.append(0) - else: - output.append(hash_trick(text, self.n_bins)) - lengths.append(1) - - tokens = torch.LongTensor(output).unsqueeze(1) - mask = length_to_mask(torch.IntTensor(lengths)).int() - return tokens, mask - - -class BaseConditioner(nn.Module): - """Base model for all conditioner modules. We allow the output dim to be different - than the hidden dim for two reasons: 1) keep our LUTs small when the vocab is large; - 2) make all condition dims consistent. - - Args: - dim (int): Hidden dim of the model (text-encoder/LUT). - output_dim (int): Output dim of the conditioner. - """ - def __init__(self, dim, output_dim): - super().__init__() - self.dim = dim - self.output_dim = output_dim - self.output_proj = nn.Linear(dim, output_dim) - - def tokenize(self, *args, **kwargs) -> tp.Any: - """Should be any part of the processing that will lead to a synchronization - point, e.g. BPE tokenization with transfer to the GPU. - - The returned value will be saved and return later when calling forward(). - """ - raise NotImplementedError() - - def forward(self, inputs: tp.Any) -> ConditionType: - """Gets input that should be used as conditioning (e.g, genre, description or a waveform). - Outputs a ConditionType, after the input data was embedded as a dense vector. - - Returns: - ConditionType: - - A tensor of size [B, T, D] where B is the batch size, T is the length of the - output embedding and D is the dimension of the embedding. - - And a mask indicating where the padding tokens. - """ - raise NotImplementedError() - - -class TextConditioner(BaseConditioner): - ... - - -class LUTConditioner(TextConditioner): - """Lookup table TextConditioner. - - Args: - n_bins (int): Number of bins. - dim (int): Hidden dim of the model (text-encoder/LUT). - output_dim (int): Output dim of the conditioner. - tokenizer (str): Name of the tokenizer. - pad_idx (int, optional): Index for padding token. Defaults to 0. - """ - def __init__(self, n_bins: int, dim: int, output_dim: int, tokenizer: str, pad_idx: int = 0): - super().__init__(dim, output_dim) - self.embed = nn.Embedding(n_bins, dim) - self.tokenizer: Tokenizer - if tokenizer == "whitespace": - self.tokenizer = WhiteSpaceTokenizer(n_bins, pad_idx=pad_idx) - elif tokenizer == "noop": - self.tokenizer = NoopTokenizer(n_bins, pad_idx=pad_idx) - else: - raise ValueError(f"unrecognized tokenizer `{tokenizer}`.") - - def tokenize(self, x: tp.List[tp.Optional[str]]) -> tp.Tuple[torch.Tensor, torch.Tensor]: - device = self.embed.weight.device - tokens, mask = self.tokenizer(x) - tokens, mask = tokens.to(device), mask.to(device) - return tokens, mask - - def forward(self, inputs: tp.Tuple[torch.Tensor, torch.Tensor]) -> ConditionType: - tokens, mask = inputs - embeds = self.embed(tokens) - embeds = self.output_proj(embeds) - embeds = (embeds * mask.unsqueeze(-1)) - return embeds, mask - - -class T5Conditioner(TextConditioner): - """T5-based TextConditioner. - - Args: - name (str): Name of the T5 model. - output_dim (int): Output dim of the conditioner. - finetune (bool): Whether to fine-tune T5 at train time. - device (str): Device for T5 Conditioner. - autocast_dtype (tp.Optional[str], optional): Autocast dtype. - word_dropout (float, optional): Word dropout probability. - normalize_text (bool, optional): Whether to apply text normalization. - """ - MODELS = ["t5-small", "t5-base", "t5-large", "t5-3b", "t5-11b", - "google/flan-t5-small", "google/flan-t5-base", "google/flan-t5-large", - "google/flan-t5-xl", "google/flan-t5-xxl"] - MODELS_DIMS = { - "t5-small": 512, - "t5-base": 768, - "t5-large": 1024, - "t5-3b": 1024, - "t5-11b": 1024, - "google/flan-t5-small": 512, - "google/flan-t5-base": 768, - "google/flan-t5-large": 1024, - "google/flan-t5-3b": 1024, - "google/flan-t5-11b": 1024, - } - - def __init__(self, name: str, output_dim: int, finetune: bool, device: str, - autocast_dtype: tp.Optional[str] = 'float32', word_dropout: float = 0., - normalize_text: bool = False): - assert name in self.MODELS, f"unrecognized t5 model name (should in {self.MODELS})" - super().__init__(self.MODELS_DIMS[name], output_dim) - self.device = device - self.name = name - self.finetune = finetune - self.word_dropout = word_dropout - - if autocast_dtype is None or self.device == 'cpu': - self.autocast = TorchAutocast(enabled=False) - if self.device != 'cpu': - logger.warning("T5 has no autocast, this might lead to NaN") - else: - dtype = getattr(torch, autocast_dtype) - assert isinstance(dtype, torch.dtype) - logger.info(f"T5 will be evaluated with autocast as {autocast_dtype}") - self.autocast = TorchAutocast(enabled=True, device_type=self.device, dtype=dtype) - # Let's disable logging temporarily because T5 will vomit some errors otherwise. - # thanks https://gist.github.com/simon-weber/7853144 - previous_level = logging.root.manager.disable - logging.disable(logging.ERROR) - with warnings.catch_warnings(): - warnings.simplefilter("ignore") - try: - self.t5_tokenizer = T5Tokenizer.from_pretrained(name) - t5 = T5EncoderModel.from_pretrained(name).train(mode=finetune) - finally: - logging.disable(previous_level) - if finetune: - self.t5 = t5 - else: - # this makes sure that the t5 models is not part - # of the saved checkpoint - self.__dict__["t5"] = t5.to(device) - - self.normalize_text = normalize_text - if normalize_text: - self.text_normalizer = WhiteSpaceTokenizer(1, lemma=True, stopwords=True) - - def tokenize(self, x: tp.List[tp.Optional[str]]) -> tp.Dict[str, torch.Tensor]: - # if current sample doesn't have a certain attribute, replace with empty string - entries: tp.List[str] = [xi if xi is not None else "" for xi in x] - if self.normalize_text: - _, _, entries = self.text_normalizer(entries, return_text=True) - if self.word_dropout > 0. and self.training: - new_entries = [] - for entry in entries: - words = [word for word in entry.split(" ") if random.random() >= self.word_dropout] - new_entries.append(" ".join(words)) - entries = new_entries - - empty_idx = torch.LongTensor([i for i, xi in enumerate(entries) if xi == ""]) - - inputs = self.t5_tokenizer(entries, return_tensors="pt", padding=True).to(self.device) - mask = inputs["attention_mask"] - mask[empty_idx, :] = 0 # zero-out index where the input is non-existant - return inputs - - def forward(self, inputs: tp.Dict[str, torch.Tensor]) -> ConditionType: - mask = inputs["attention_mask"] - with torch.set_grad_enabled(self.finetune), self.autocast: - embeds = self.t5(**inputs).last_hidden_state - embeds = self.output_proj(embeds.to(self.output_proj.weight)) - embeds = (embeds * mask.unsqueeze(-1)) - return embeds, mask - - -class WaveformConditioner(BaseConditioner): - """Base class for all conditioners that take a waveform as input. - Classes that inherit must implement `_get_wav_embedding` that outputs - a continuous tensor, and `_downsampling_factor` that returns the down-sampling - factor of the embedding model. - - Args: - dim (int): The internal representation dimension. - output_dim (int): Output dimension. - device (tp.Union[torch.device, str]): Device. - """ - def __init__(self, dim: int, output_dim: int, device: tp.Union[torch.device, str]): - super().__init__(dim, output_dim) - self.device = device - - def tokenize(self, wav_length: WavCondition) -> WavCondition: - wav, length, path = wav_length - assert length is not None - return WavCondition(wav.to(self.device), length.to(self.device), path) - - def _get_wav_embedding(self, wav: Tensor) -> Tensor: - """Gets as input a wav and returns a dense vector of conditions.""" - raise NotImplementedError() - - def _downsampling_factor(self): - """Returns the downsampling factor of the embedding model.""" - raise NotImplementedError() - - def forward(self, inputs: WavCondition) -> ConditionType: - """ - Args: - input (WavCondition): Tuple of (waveform, lengths). - Returns: - ConditionType: Dense vector representing the conditioning along with its' mask. - """ - wav, lengths, path = inputs - with torch.no_grad(): - embeds = self._get_wav_embedding(wav) - embeds = embeds.to(self.output_proj.weight) - embeds = self.output_proj(embeds) - - if lengths is not None: - lengths = lengths / self._downsampling_factor() - mask = length_to_mask(lengths, max_len=embeds.shape[1]).int() # type: ignore - else: - mask = torch.ones_like(embeds) - embeds = (embeds * mask.unsqueeze(2).to(self.device)) - - return embeds, mask - - -class ChromaStemConditioner(WaveformConditioner): - """Chroma conditioner that uses DEMUCS to first filter out drums and bass. The is followed by - the insight the drums and bass often dominate the chroma, leading to the chroma not containing the - information about melody. - - Args: - output_dim (int): Output dimension for the conditioner. - sample_rate (int): Sample rate for the chroma extractor. - n_chroma (int): Number of chroma for the chroma extractor. - radix2_exp (int): Radix2 exponent for the chroma extractor. - duration (float): Duration used during training. This is later used for correct padding - in case we are using chroma as prefix. - match_len_on_eval (bool, optional): If True then all chromas are padded to the training - duration. Defaults to False. - eval_wavs (str, optional): Path to a json egg with waveform, this waveforms are used as - conditions during eval (for cases where we don't want to leak test conditions like MusicCaps). - Defaults to None. - n_eval_wavs (int, optional): Limits the number of waveforms used for conditioning. Defaults to 0. - device (tp.Union[torch.device, str], optional): Device for the conditioner. - **kwargs: Additional parameters for the chroma extractor. - """ - def __init__(self, output_dim: int, sample_rate: int, n_chroma: int, radix2_exp: int, - duration: float, match_len_on_eval: bool = True, eval_wavs: tp.Optional[str] = None, - n_eval_wavs: int = 0, device: tp.Union[torch.device, str] = "cpu", **kwargs): - from demucs import pretrained - super().__init__(dim=n_chroma, output_dim=output_dim, device=device) - self.autocast = TorchAutocast(enabled=device != "cpu", device_type=self.device, dtype=torch.float32) - self.sample_rate = sample_rate - self.match_len_on_eval = match_len_on_eval - self.duration = duration - self.__dict__["demucs"] = pretrained.get_model('htdemucs').to(device) - self.stem2idx = {'drums': 0, 'bass': 1, 'other': 2, 'vocal': 3} - self.stem_idx = torch.LongTensor([self.stem2idx['vocal'], self.stem2idx['other']]).to(device) - self.chroma = ChromaExtractor(sample_rate=sample_rate, n_chroma=n_chroma, radix2_exp=radix2_exp, - device=device, **kwargs) - self.chroma_len = self._get_chroma_len() - - def _downsampling_factor(self): - return self.chroma.winhop - - def _get_chroma_len(self): - """Get length of chroma during training""" - dummy_wav = torch.zeros((1, self.sample_rate * self.duration), device=self.device) - dummy_chr = self.chroma(dummy_wav) - return dummy_chr.shape[1] - - @torch.no_grad() - def _get_filtered_wav(self, wav): - from demucs.apply import apply_model - from demucs.audio import convert_audio - with self.autocast: - wav = convert_audio(wav, self.sample_rate, self.demucs.samplerate, self.demucs.audio_channels) - stems = apply_model(self.demucs, wav, device=self.device) - stems = stems[:, self.stem_idx] # extract stem - stems = stems.sum(1) # merge extracted stems - stems = stems.mean(1, keepdim=True) # mono - stems = convert_audio(stems, self.demucs.samplerate, self.sample_rate, 1) - return stems - - @torch.no_grad() - def _get_wav_embedding(self, wav): - # avoid 0-size tensors when we are working with null conds - if wav.shape[-1] == 1: - return self.chroma(wav) - stems = self._get_filtered_wav(wav) - chroma = self.chroma(stems) - - if self.match_len_on_eval: - b, t, c = chroma.shape - if t > self.chroma_len: - chroma = chroma[:, :self.chroma_len] - logger.debug(f'chroma was truncated! ({t} -> {chroma.shape[1]})') - elif t < self.chroma_len: - # chroma = F.pad(chroma, (0, 0, 0, self.chroma_len - t)) - n_repeat = int(math.ceil(self.chroma_len / t)) - chroma = chroma.repeat(1, n_repeat, 1) - chroma = chroma[:, :self.chroma_len] - logger.debug(f'chroma was zero-padded! ({t} -> {chroma.shape[1]})') - return chroma - - -class ChromaExtractor(nn.Module): - """Chroma extraction class, handles chroma extraction and quantization. - - Args: - sample_rate (int): Sample rate. - n_chroma (int): Number of chroma to consider. - radix2_exp (int): Radix2 exponent. - nfft (tp.Optional[int], optional): Number of FFT. - winlen (tp.Optional[int], optional): Window length. - winhop (tp.Optional[int], optional): Window hop size. - argmax (bool, optional): Whether to use argmax. Defaults to False. - norm (float, optional): Norm for chroma normalization. Defaults to inf. - device (tp.Union[torch.device, str], optional): Device to use. Defaults to cpu. - """ - def __init__(self, sample_rate: int, n_chroma: int = 12, radix2_exp: int = 12, - nfft: tp.Optional[int] = None, winlen: tp.Optional[int] = None, winhop: tp.Optional[int] = None, - argmax: bool = False, norm: float = torch.inf, device: tp.Union[torch.device, str] = "cpu"): - super().__init__() - from librosa import filters - self.device = device - self.autocast = TorchAutocast(enabled=device != "cpu", device_type=self.device, dtype=torch.float32) - self.winlen = winlen or 2 ** radix2_exp - self.nfft = nfft or self.winlen - self.winhop = winhop or (self.winlen // 4) - self.sr = sample_rate - self.n_chroma = n_chroma - self.norm = norm - self.argmax = argmax - self.window = torch.hann_window(self.winlen).to(device) - self.fbanks = torch.from_numpy(filters.chroma(sr=sample_rate, n_fft=self.nfft, tuning=0, - n_chroma=self.n_chroma)).to(device) - self.spec = torchaudio.transforms.Spectrogram(n_fft=self.nfft, win_length=self.winlen, - hop_length=self.winhop, power=2, center=True, - pad=0, normalized=True).to(device) - - def forward(self, wav): - with self.autocast: - T = wav.shape[-1] - # in case we are getting a wav that was dropped out (nullified) - # make sure wav length is no less that nfft - if T < self.nfft: - pad = self.nfft - T - r = 0 if pad % 2 == 0 else 1 - wav = F.pad(wav, (pad // 2, pad // 2 + r), 'constant', 0) - assert wav.shape[-1] == self.nfft, f'expected len {self.nfft} but got {wav.shape[-1]}' - spec = self.spec(wav).squeeze(1) - raw_chroma = torch.einsum("cf,...ft->...ct", self.fbanks, spec) - norm_chroma = torch.nn.functional.normalize(raw_chroma, p=self.norm, dim=-2, eps=1e-6) - norm_chroma = rearrange(norm_chroma, "b d t -> b t d") - - if self.argmax: - idx = norm_chroma.argmax(-1, keepdims=True) - norm_chroma[:] = 0 - norm_chroma.scatter_(dim=-1, index=idx, value=1) - - return norm_chroma - - -def dropout_condition(sample: ConditioningAttributes, condition_type: str, condition: str): - """Utility function for nullifying an attribute inside an ConditioningAttributes object. - If the condition is of type "wav", then nullify it using "nullify_condition". - If the condition is of any other type, set its' value to None. - Works in-place. - """ - if condition_type not in ["text", "wav"]: - raise ValueError( - "dropout_condition got an unexpected condition type!" - f" expected 'wav' or 'text' but got '{condition_type}'" - ) - - if condition not in getattr(sample, condition_type): - raise ValueError( - "dropout_condition received an unexpected condition!" - f" expected wav={sample.wav.keys()} and text={sample.text.keys()}" - f"but got '{condition}' of type '{condition_type}'!" - ) - - if condition_type == "wav": - wav, length, path = sample.wav[condition] - sample.wav[condition] = nullify_wav(wav) - else: - sample.text[condition] = None - - return sample - - -class DropoutModule(nn.Module): - """Base class for all dropout modules.""" - def __init__(self, seed: int = 1234): - super().__init__() - self.rng = torch.Generator() - self.rng.manual_seed(seed) - - -class AttributeDropout(DropoutModule): - """Applies dropout with a given probability per attribute. This is different from the behavior of - ClassifierFreeGuidanceDropout as this allows for attributes to be dropped out separately. For example, - "artist" can be dropped while "genre" remains. This is in contrast to ClassifierFreeGuidanceDropout - where if "artist" is dropped "genre" must also be dropped. - - Args: - p (tp.Dict[str, float]): A dict mapping between attributes and dropout probability. For example: - ... - "genre": 0.1, - "artist": 0.5, - "wav": 0.25, - ... - active_on_eval (bool, optional): Whether the dropout is active at eval. Default to False. - seed (int, optional): Random seed. - """ - def __init__(self, p: tp.Dict[str, tp.Dict[str, float]], active_on_eval: bool = False, seed: int = 1234): - super().__init__(seed=seed) - self.active_on_eval = active_on_eval - # construct dict that return the values from p otherwise 0 - self.p = {} - for condition_type, probs in p.items(): - self.p[condition_type] = defaultdict(lambda: 0, probs) - - def forward(self, samples: tp.List[ConditioningAttributes]) -> tp.List[ConditioningAttributes]: - """ - Args: - samples (tp.List[ConditioningAttributes]): List of conditions. - Returns: - tp.List[ConditioningAttributes]: List of conditions after certain attributes were set to None. - """ - if not self.training and not self.active_on_eval: - return samples - - samples = deepcopy(samples) - - for condition_type, ps in self.p.items(): # for condition types [text, wav] - for condition, p in ps.items(): # for attributes of each type (e.g., [artist, genre]) - if torch.rand(1, generator=self.rng).item() < p: - for sample in samples: - dropout_condition(sample, condition_type, condition) - - return samples - - def __repr__(self): - return f"AttributeDropout({dict(self.p)})" - - -class ClassifierFreeGuidanceDropout(DropoutModule): - """Applies Classifier Free Guidance dropout, meaning all attributes - are dropped with the same probability. - - Args: - p (float): Probability to apply condition dropout during training. - seed (int): Random seed. - """ - def __init__(self, p: float, seed: int = 1234): - super().__init__(seed=seed) - self.p = p - - def forward(self, samples: tp.List[ConditioningAttributes]) -> tp.List[ConditioningAttributes]: - """ - Args: - samples (tp.List[ConditioningAttributes]): List of conditions. - Returns: - tp.List[ConditioningAttributes]: List of conditions after all attributes were set to None. - """ - if not self.training: - return samples - - # decide on which attributes to drop in a batched fashion - drop = torch.rand(1, generator=self.rng).item() < self.p - if not drop: - return samples - - # nullify conditions of all attributes - samples = deepcopy(samples) - - for condition_type in ["wav", "text"]: - for sample in samples: - for condition in sample.attributes[condition_type]: - dropout_condition(sample, condition_type, condition) - - return samples - - def __repr__(self): - return f"ClassifierFreeGuidanceDropout(p={self.p})" - - -class ConditioningProvider(nn.Module): - """Main class to provide conditions given all the supported conditioners. - - Args: - conditioners (dict): Dictionary of conditioners. - merge_text_conditions_p (float, optional): Probability to merge all text sources - into a single text condition. Defaults to 0. - drop_desc_p (float, optional): Probability to drop the original description - when merging all text sources into a single text condition. Defaults to 0. - device (tp.Union[torch.device, str], optional): Device for conditioners and output condition types. - """ - def __init__( - self, - conditioners: tp.Dict[str, BaseConditioner], - merge_text_conditions_p: float = 0, - drop_desc_p: float = 0, - device: tp.Union[torch.device, str] = "cpu", - ): - super().__init__() - self.device = device - self.merge_text_conditions_p = merge_text_conditions_p - self.drop_desc_p = drop_desc_p - self.conditioners = nn.ModuleDict(conditioners) - - @property - def text_conditions(self): - return [k for k, v in self.conditioners.items() if isinstance(v, TextConditioner)] - - @property - def wav_conditions(self): - return [k for k, v in self.conditioners.items() if isinstance(v, WaveformConditioner)] - - @property - def has_wav_condition(self): - return len(self.wav_conditions) > 0 - - def tokenize(self, inputs: tp.List[ConditioningAttributes]) -> tp.Dict[str, tp.Any]: - """Match attributes/wavs with existing conditioners in self, and compute tokenize them accordingly. - This should be called before starting any real GPU work to avoid synchronization points. - This will return a dict matching conditioner names to their arbitrary tokenized representations. - - Args: - inputs (list[ConditioningAttribres]): List of ConditioningAttributes objects containing - text and wav conditions. - """ - assert all([type(x) == ConditioningAttributes for x in inputs]), \ - "got unexpected types input for conditioner! should be tp.List[ConditioningAttributes]" \ - f" but types were {set([type(x) for x in inputs])}" - - output = {} - text = self._collate_text(inputs) - wavs = self._collate_wavs(inputs) - - assert set(text.keys() | wavs.keys()).issubset(set(self.conditioners.keys())), \ - f"got an unexpected attribute! Expected {self.conditioners.keys()}, got {text.keys(), wavs.keys()}" - - for attribute, batch in chain(text.items(), wavs.items()): - output[attribute] = self.conditioners[attribute].tokenize(batch) - return output - - def forward(self, tokenized: tp.Dict[str, tp.Any]) -> tp.Dict[str, ConditionType]: - """Compute pairs of `(embedding, mask)` using the configured conditioners - and the tokenized representations. The output is for example: - - { - "genre": (torch.Tensor([B, 1, D_genre]), torch.Tensor([B, 1])), - "description": (torch.Tensor([B, T_desc, D_desc]), torch.Tensor([B, T_desc])), - ... - } - - Args: - tokenized (dict): Dict of tokenized representations as returned by `tokenize()`. - """ - output = {} - for attribute, inputs in tokenized.items(): - condition, mask = self.conditioners[attribute](inputs) - output[attribute] = (condition, mask) - return output - - def _collate_text(self, samples: tp.List[ConditioningAttributes]) -> tp.Dict[str, tp.List[tp.Optional[str]]]: - """Given a list of ConditioningAttributes objects, compile a dictionary where the keys - are the attributes and the values are the aggregated input per attribute. - For example: - Input: - [ - ConditioningAttributes(text={"genre": "Rock", "description": "A rock song with a guitar solo"}, wav=...), - ConditioningAttributes(text={"genre": "Hip-hop", "description": "A hip-hop verse"}, wav=...), - ] - Output: - { - "genre": ["Rock", "Hip-hop"], - "description": ["A rock song with a guitar solo", "A hip-hop verse"] - } - """ - batch_per_attribute: tp.Dict[str, tp.List[tp.Optional[str]]] = defaultdict(list) - - def _merge_conds(cond, merge_text_conditions_p=0, drop_desc_p=0): - def is_valid(k, v): - k_valid = k in ['key', 'bpm', 'genre', 'moods', 'instrument'] - v_valid = v is not None and isinstance(v, (int, float, str, list)) - return k_valid and v_valid - - def process_value(v): - if isinstance(v, (int, float, str)): - return v - if isinstance(v, list): - return ", ".join(v) - else: - RuntimeError(f"unknown type for text value! ({type(v), v})") - - desc = cond.text['description'] - meta_data = "" - if random.uniform(0, 1) < merge_text_conditions_p: - meta_pairs = [f'{k}: {process_value(v)}' for k, v in cond.text.items() if is_valid(k, v)] - random.shuffle(meta_pairs) - meta_data = ". ".join(meta_pairs) - desc = desc if not random.uniform(0, 1) < drop_desc_p else None - - if desc is None: - desc = meta_data if len(meta_data) > 1 else None - else: - desc = desc.rstrip('.') + ". " + meta_data - cond.text['description'] = desc.strip() if desc else None - - if self.training and self.merge_text_conditions_p: - for sample in samples: - _merge_conds(sample, self.merge_text_conditions_p, self.drop_desc_p) - - texts = [x.text for x in samples] - for text in texts: - for condition in self.text_conditions: - batch_per_attribute[condition].append(text[condition]) - - return batch_per_attribute - - def _collate_wavs(self, samples: tp.List[ConditioningAttributes]): - """Generate a dict where the keys are attributes by which we fetch similar wavs, - and the values are Tensors of wavs according to said attribtues. - - *Note*: by the time the samples reach this function, each sample should have some waveform - inside the "wav" attribute. It should be either: - 1. A real waveform - 2. A null waveform due to the sample having no similar waveforms (nullified by the dataset) - 3. A null waveform due to it being dropped in a dropout module (nullified by dropout) - - Args: - samples (tp.List[ConditioningAttributes]): List of ConditioningAttributes samples. - Returns: - dict: A dicionary mapping an attribute name to wavs. - """ - wavs = defaultdict(list) - lens = defaultdict(list) - paths = defaultdict(list) - out = {} - - for sample in samples: - for attribute in self.wav_conditions: - wav, length, path = sample.wav[attribute] - wavs[attribute].append(wav.flatten()) - lens[attribute].append(length) - paths[attribute].append(path) - - # stack all wavs to a single tensor - for attribute in self.wav_conditions: - stacked_wav, _ = collate(wavs[attribute], dim=0) - out[attribute] = WavCondition(stacked_wav.unsqueeze(1), - torch.cat(lens['self_wav']), paths[attribute]) # type: ignore - - return out - - -class ConditionFuser(StreamingModule): - """Condition fuser handles the logic to combine the different conditions - to the actual model input. - - Args: - fuse2cond (tp.Dict[str, str]): A dictionary that says how to fuse - each condition. For example: - { - "prepend": ["description"], - "sum": ["genre", "bpm"], - "cross": ["description"], - } - cross_attention_pos_emb (bool, optional): Use positional embeddings in cross attention. - cross_attention_pos_emb_scale (int): Scale for positional embeddings in cross attention if used. - """ - FUSING_METHODS = ["sum", "prepend", "cross", "input_interpolate"] - - def __init__(self, fuse2cond: tp.Dict[str, tp.List[str]], cross_attention_pos_emb: bool = False, - cross_attention_pos_emb_scale: float = 1.0): - super().__init__() - assert all( - [k in self.FUSING_METHODS for k in fuse2cond.keys()] - ), f"got invalid fuse method, allowed methods: {self.FUSING_MEHTODS}" - self.cross_attention_pos_emb = cross_attention_pos_emb - self.cross_attention_pos_emb_scale = cross_attention_pos_emb_scale - self.fuse2cond: tp.Dict[str, tp.List[str]] = fuse2cond - self.cond2fuse: tp.Dict[str, str] = {} - for fuse_method, conditions in fuse2cond.items(): - for condition in conditions: - self.cond2fuse[condition] = fuse_method - - def forward( - self, - input: Tensor, - conditions: tp.Dict[str, ConditionType] - ) -> tp.Tuple[Tensor, tp.Optional[Tensor]]: - """Fuse the conditions to the provided model input. - - Args: - input (Tensor): Transformer input. - conditions (tp.Dict[str, ConditionType]): Dict of conditions. - Returns: - tp.Tuple[Tensor, Tensor]: The first tensor is the transformer input - after the conditions have been fused. The second output tensor is the tensor - used for cross-attention or None if no cross attention inputs exist. - """ - B, T, _ = input.shape - - if 'offsets' in self._streaming_state: - first_step = False - offsets = self._streaming_state['offsets'] - else: - first_step = True - offsets = torch.zeros(input.shape[0], dtype=torch.long, device=input.device) - - assert set(conditions.keys()).issubset(set(self.cond2fuse.keys())), \ - f"given conditions contain unknown attributes for fuser, " \ - f"expected {self.cond2fuse.keys()}, got {conditions.keys()}" - cross_attention_output = None - for cond_type, (cond, cond_mask) in conditions.items(): - op = self.cond2fuse[cond_type] - if op == "sum": - input += cond - elif op == "input_interpolate": - cond = rearrange(cond, "b t d -> b d t") - cond = F.interpolate(cond, size=input.shape[1]) - input += rearrange(cond, "b d t -> b t d") - elif op == "prepend": - if first_step: - input = torch.cat([cond, input], dim=1) - elif op == "cross": - if cross_attention_output is not None: - cross_attention_output = torch.cat([cross_attention_output, cond], dim=1) - else: - cross_attention_output = cond - else: - raise ValueError(f"unknown op ({op})") - - if self.cross_attention_pos_emb and cross_attention_output is not None: - positions = torch.arange( - cross_attention_output.shape[1], - device=cross_attention_output.device - ).view(1, -1, 1) - pos_emb = create_sin_embedding(positions, cross_attention_output.shape[-1]) - cross_attention_output = cross_attention_output + self.cross_attention_pos_emb_scale * pos_emb - - if self._is_streaming: - self._streaming_state['offsets'] = offsets + T - - return input, cross_attention_output diff --git a/spaces/Surn/UnlimitedMusicGen/audiocraft/modules/transformer.py b/spaces/Surn/UnlimitedMusicGen/audiocraft/modules/transformer.py deleted file mode 100644 index e69cca829d774d0b8b36c0de9b7924373da81b43..0000000000000000000000000000000000000000 --- a/spaces/Surn/UnlimitedMusicGen/audiocraft/modules/transformer.py +++ /dev/null @@ -1,747 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -""" -Transformer model, with streaming support, xformer attention support -and easy causal attention with a potentially finite receptive field. - -See `StreamingTransformer` for more information. - -Unlike regular PyTorch Transformer, we make the hard choice that batches are first. -""" - -import typing as tp - -from einops import rearrange -import torch -import torch.nn as nn -from torch.nn import functional as F -from torch.utils.checkpoint import checkpoint as torch_checkpoint -from xformers import ops - -from .rope import RotaryEmbedding -from .streaming import StreamingModule - -_efficient_attention_backend: str = 'torch' - - -def set_efficient_attention_backend(backend: str = 'torch'): - # Using torch by default, it seems a bit faster on older P100 GPUs (~20% faster). - global _efficient_attention_backend - assert _efficient_attention_backend in ['xformers', 'torch'] - _efficient_attention_backend = backend - - -def _get_attention_time_dimension() -> int: - if _efficient_attention_backend == 'torch': - return 2 - else: - return 1 - - -def _is_profiled() -> bool: - # Return true if we are currently running with a xformers profiler activated. - try: - from xformers.profiler import profiler - except ImportError: - return False - return profiler._Profiler._CURRENT_PROFILER is not None - - -def create_norm_fn(norm_type: str, dim: int, **kwargs) -> nn.Module: - """Create normalization module for transformer encoder layer. - - Args: - norm_type (str): Normalization method. - dim (int): Dimension of the normalized layer. - **kwargs (dict): Additional parameters for normalization layer. - Returns: - nn.Module: Normalization module. - """ - if norm_type == 'layer_norm': - return nn.LayerNorm(dim, eps=1e-5, **kwargs) - else: - raise ValueError(f"Unknown norm type: {norm_type}") - - -def create_sin_embedding(positions: torch.Tensor, dim: int, max_period: float = 10000, - dtype: torch.dtype = torch.float32) -> torch.Tensor: - """Create sinusoidal positional embedding, with shape `[B, T, C]`. - - Args: - positions (torch.Tensor): LongTensor of positions. - dim (int): Dimension of the embedding. - max_period (float): Maximum period of the cosine/sine functions. - dtype (torch.dtype or str): dtype to use to generate the embedding. - Returns: - torch.Tensor: Sinusoidal positional embedding. - """ - # We aim for BTC format - assert dim % 2 == 0 - half_dim = dim // 2 - positions = positions.to(dtype) - adim = torch.arange(half_dim, device=positions.device, dtype=dtype).view(1, 1, -1) - max_period_tensor = torch.full([], max_period, device=positions.device, dtype=dtype) # avoid sync point - phase = positions / (max_period_tensor ** (adim / (half_dim - 1))) - return torch.cat([torch.cos(phase), torch.sin(phase)], dim=-1) - - -def expand_repeated_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor: - """torch.repeat_interleave(x, dim=2, repeats=n_rep) from xlformers""" - if n_rep == 1: - return x - if _efficient_attention_backend == 'torch': - bs, n_kv_heads, slen, head_dim = x.shape - return ( - x[:, :, None, :, :] - .expand(bs, n_kv_heads, n_rep, slen, head_dim) - .reshape(bs, n_kv_heads * n_rep, slen, head_dim) - ) - else: - bs, slen, n_kv_heads, head_dim = x.shape - return ( - x[:, :, :, None, :] - .expand(bs, slen, n_kv_heads, n_rep, head_dim) - .reshape(bs, slen, n_kv_heads * n_rep, head_dim) - ) - - -class LayerScale(nn.Module): - """Layer scale from [Touvron et al 2021] (https://arxiv.org/pdf/2103.17239.pdf). - This rescales diagonaly the residual outputs close to 0, with a learnt scale. - - Args: - channels (int): Number of channels. - init (float): Initial scale. - channel_last (bool): If True, expect `[*, C]` shaped tensors, otherwise, `[*, C, T]`. - device (torch.device or None): Device on which to initialize the module. - dtype (torch.dtype or None): dtype to use to initialize the module. - """ - def __init__(self, channels: int, init: float = 1e-4, channel_last: bool = True, - device=None, dtype=None): - super().__init__() - self.channel_last = channel_last - self.scale = nn.Parameter( - torch.full((channels,), init, - requires_grad=True, device=device, dtype=dtype)) - - def forward(self, x: torch.Tensor): - if self.channel_last: - return self.scale * x - else: - return self.scale[:, None] * x - - -class StreamingMultiheadAttention(StreamingModule): - """Similar to `nn.MultiheadAttention` but with support for streaming, causal evaluation. - - Args: - embed_dim (int): Dimension to project to. - num_heads (int): Number of heads. - dropout (float): Dropout level. - bias (bool): Use bias in projections. - causal (bool): Causal mask applied automatically. - past_context (int or None): Receptive field for the causal mask, infinite if None. - custom (bool): Use custom MHA implementation, for testing / benchmarking. - memory_efficient (bool): Use xformers based memory efficient attention. - attention_as_float32 (bool): Perform the attention as float32 - (especially important with memory_efficient as autocast won't do this automatically). - rope (`RotaryEmbedding` or None): Rope embedding to use. - cross_attention: Should be true when used as a cross attention. - All keys and values must be available at once, streaming is only for the queries. - Cannot be used with `causal` or `rope` (as it wouldn't make sens to - intepret the time steps in the keys relative to those in the queries). - safe_streaming (bool): Bug fix, will go away with xformers update. - qk_layer_norm (bool): Layer normalization applied to queries and keys before dot product. - kv_repeat (int): If > 1, will repeat keys and queries multiple times (need to divide num_heads). - This will lead to faster decoding time on A100 or other GPUs with tensorcore. - device (torch.device or None): Sevice on which to initialize. - dtype (torch.dtype or None): dtype to use. - """ - def __init__(self, embed_dim: int, num_heads: int, dropout: float = 0.0, bias: bool = True, - causal: bool = False, past_context: tp.Optional[int] = None, custom: bool = False, - memory_efficient: bool = False, attention_as_float32: bool = False, - rope: tp.Optional[RotaryEmbedding] = None, cross_attention: bool = False, - safe_streaming: bool = True, qk_layer_norm: bool = False, kv_repeat: int = 1, - device=None, dtype=None): - super().__init__() - factory_kwargs = {'device': device, 'dtype': dtype} - if past_context is not None: - assert causal - - self.embed_dim = embed_dim - self.causal = causal - self.past_context = past_context - self.memory_efficient = memory_efficient - self.attention_as_float32 = attention_as_float32 - self.rope = rope - self.cross_attention = cross_attention - self.safe_streaming = safe_streaming - self.num_heads = num_heads - self.dropout = dropout - self.kv_repeat = kv_repeat - if cross_attention: - assert not causal, "Causal cannot work with cross attention." - assert rope is None, "Rope cannot work with cross attention." - - if memory_efficient: - _verify_xformers_memory_efficient_compat() - - self.custom = _is_custom(custom, memory_efficient) - if self.custom: - out_dim = embed_dim - assert num_heads % kv_repeat == 0 - assert not cross_attention or kv_repeat == 1 - num_kv = num_heads // kv_repeat - kv_dim = (embed_dim // num_heads) * num_kv - out_dim += 2 * kv_dim - in_proj = nn.Linear(embed_dim, out_dim, bias=bias, **factory_kwargs) - # We try to follow the default PyTorch MHA convention, to easily compare results. - self.in_proj_weight = in_proj.weight - self.in_proj_bias = in_proj.bias - if bias: - self.in_proj_bias.data.zero_() # Following Pytorch convention - self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias, **factory_kwargs) - if bias: - self.out_proj.bias.data.zero_() - else: - assert not qk_layer_norm - assert kv_repeat == 1 - self.mha = nn.MultiheadAttention( - embed_dim, num_heads, dropout=dropout, bias=bias, batch_first=True, - **factory_kwargs) - self.qk_layer_norm = qk_layer_norm - if qk_layer_norm: - assert self.custom - assert kv_repeat == 1 - ln_dim = embed_dim - self.q_layer_norm = nn.LayerNorm(ln_dim) - self.k_layer_norm = nn.LayerNorm(ln_dim) - - def _load_from_state_dict(self, state_dict, prefix, *args, **kwargs): - if not self.custom: - # Support compat with regular MHA - keys = [n for n, _ in self.mha.named_parameters()] - for key in keys: - if prefix + key in state_dict: - state_dict[prefix + "mha." + key] = state_dict.pop(prefix + key) - super()._load_from_state_dict(state_dict, prefix, *args, **kwargs) - - def _get_mask(self, current_steps: int, device: torch.device, dtype: torch.dtype): - # Return a causal mask, accounting for potentially stored past keys/values - # We actually return a bias for the attention score, as this has the same - # convention both in the builtin MHA in Pytorch, and Xformers functions. - time_dim = _get_attention_time_dimension() - if self.memory_efficient: - from xformers.ops import LowerTriangularMask - if current_steps == 1: - # If we only have one step, then we do not need a mask. - return None - elif 'past_keys' in self._streaming_state: - raise RuntimeError('Not supported at the moment') - else: - # Then we can safely use a lower triangular mask - return LowerTriangularMask() - if self._streaming_state: - past_keys = self._streaming_state['past_keys'] - past_steps = past_keys.shape[time_dim] - else: - past_steps = 0 - - queries_pos = torch.arange( - past_steps, current_steps + past_steps, device=device).view(-1, 1) - keys_pos = torch.arange(past_steps + current_steps, device=device).view(1, -1) - delta = queries_pos - keys_pos - valid = delta >= 0 - if self.past_context is not None: - valid &= (delta <= self.past_context) - return torch.where( - valid, - torch.zeros([], device=device, dtype=dtype), - torch.full([], float('-inf'), device=device, dtype=dtype)) - - def _complete_kv(self, k, v): - time_dim = _get_attention_time_dimension() - if self.cross_attention: - # With cross attention we assume all keys and values - # are already available, and streaming is with respect - # to the queries only. - return k, v - # Complete the key/value pair using the streaming state. - if self._streaming_state: - pk = self._streaming_state['past_keys'] - nk = torch.cat([pk, k], dim=time_dim) - if v is k: - nv = nk - else: - pv = self._streaming_state['past_values'] - nv = torch.cat([pv, v], dim=time_dim) - else: - nk = k - nv = v - - assert nk.shape[time_dim] == nv.shape[time_dim] - offset = 0 - if self.past_context is not None: - offset = max(0, nk.shape[time_dim] - self.past_context) - if self._is_streaming: - self._streaming_state['past_keys'] = nk[:, offset:] - if v is not k: - self._streaming_state['past_values'] = nv[:, offset:] - if 'offset' in self._streaming_state: - self._streaming_state['offset'] += offset - else: - self._streaming_state['offset'] = torch.tensor(0) - return nk, nv - - def _apply_rope(self, query: torch.Tensor, key: torch.Tensor): - # TODO: fix and verify layout. - assert _efficient_attention_backend == 'xformers', 'Rope not supported with torch attn.' - # Apply rope embeddings to query and key tensors. - assert self.rope is not None - if 'past_keys' in self._streaming_state: - past_keys_offset = self._streaming_state['past_keys'].shape[1] - else: - past_keys_offset = 0 - if 'offset' in self._streaming_state: - past_context_offset = int(self._streaming_state['offset'].item()) - else: - past_context_offset = 0 - streaming_offset = past_context_offset + past_keys_offset - return self.rope.rotate_qk(query, key, start=streaming_offset) - - def forward(self, query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, - key_padding_mask=None, need_weights=False, attn_mask=None, - average_attn_weights=True, is_causal=False): - assert attn_mask is None - assert not is_causal, ("new param added in torch 2.0.1 not supported, " - "use the causal args in the constructor.") - - time_dim = _get_attention_time_dimension() - if time_dim == 2: - layout = "b h t d" - else: - layout = "b t h d" - dtype = query.dtype - if self._is_streaming: - assert self.causal or self.cross_attention, \ - "Streaming only available for causal or cross attention" - - if self.causal: - # At the moment we specialize only for the self-attention case. - assert query.shape[1] == key.shape[1], "Causal only for same length query / key / value" - assert value.shape[1] == key.shape[1], "Causal only for same length query / key / value" - attn_mask = self._get_mask(query.shape[1], query.device, query.dtype) - - if self.custom: - # custom implementation - assert need_weights is False - assert key_padding_mask is None - if self.cross_attention: - # Different queries, keys, values, we have to spit manually the weights - # before applying the linear. - dim = self.in_proj_weight.shape[0] // 3 - if self.in_proj_bias is None: - bias_q, bias_k, bias_v = None, None, None - else: - bias_q = self.in_proj_bias[:dim] - bias_k = self.in_proj_bias[dim: 2 * dim] - bias_v = self.in_proj_bias[2 * dim:] - q = nn.functional.linear(query, self.in_proj_weight[:dim], bias_q) - # todo: when streaming, we could actually save k, v and check the shape actually match. - k = nn.functional.linear(key, self.in_proj_weight[dim: 2 * dim], bias_k) - v = nn.functional.linear(value, self.in_proj_weight[2 * dim:], bias_v) - if self.qk_layer_norm is True: - q = self.q_layer_norm(q) - k = self.k_layer_norm(k) - q, k, v = [rearrange(x, f"b t (h d) -> {layout}", h=self.num_heads) for x in [q, k, v]] - else: - if not _is_profiled(): - # profiling breaks that propertysomehow. - assert query is key, "specialized implementation" - assert value is key, "specialized implementation" - projected = nn.functional.linear(query, self.in_proj_weight, self.in_proj_bias) - if self.kv_repeat == 1: - if time_dim == 2: - bound_layout = "b h p t d" - else: - bound_layout = "b t p h d" - packed = rearrange(projected, f"b t (p h d) -> {bound_layout}", p=3, h=self.num_heads) - q, k, v = ops.unbind(packed, dim=2) - else: - embed_dim = self.embed_dim - per_head_dim = (embed_dim // self.num_heads) - kv_heads = self.num_heads // self.kv_repeat - q = projected[:, :, :embed_dim] - start = embed_dim - end = start + per_head_dim * kv_heads - k = projected[:, :, start: end] - v = projected[:, :, end:] - q = rearrange(q, f"b t (h d) -> {layout}", h=self.num_heads) - k = rearrange(k, f"b t (h d) -> {layout}", h=kv_heads) - v = rearrange(v, f"b t (h d) -> {layout}", h=kv_heads) - - if self.qk_layer_norm is True: - assert self.kv_repeat == 1 - q, k = [rearrange(x, f"{layout} -> b t (h d)") for x in [q, k]] - q = self.q_layer_norm(q) - k = self.k_layer_norm(k) - q, k = [rearrange(x, f"b t (h d) -> {layout}", h=self.num_heads) for x in [q, k]] - if self.rope: - q, k = self._apply_rope(q, k) - k, v = self._complete_kv(k, v) - if self.kv_repeat > 1: - k = expand_repeated_kv(k, self.kv_repeat) - v = expand_repeated_kv(v, self.kv_repeat) - if self.attention_as_float32: - q, k, v = [x.float() for x in [q, k, v]] - if self.memory_efficient: - p = self.dropout if self.training else 0 - if _efficient_attention_backend == 'torch': - x = torch.nn.functional.scaled_dot_product_attention( - q, k, v, is_causal=attn_mask is not None, dropout_p=p) - else: - x = ops.memory_efficient_attention(q, k, v, attn_mask, p=p) - else: - # We include the dot product as float32, for consistency - # with the other implementations that include that step - # as part of the attention. Note that when using `autocast`, - # the einsums would be done as bfloat16, but the softmax - # would be done as bfloat16, so `attention_as_float32` will - # extend a bit the range of operations done in float32, - # although this should make no difference. - q = q / q.shape[-1] ** 0.5 - key_layout = layout.replace('t', 'k') - query_layout = layout - if self._is_streaming and self.safe_streaming and q.device.type == 'cuda': - with torch.autocast(device_type=q.device.type, dtype=torch.float32): - pre_w = torch.einsum(f"{query_layout},{key_layout}-> b h t k", q, k) - else: - pre_w = torch.einsum(f"{query_layout},{key_layout}-> b h t k", q, k) - if attn_mask is not None: - pre_w = pre_w + attn_mask - w = torch.softmax(pre_w, dim=-1) - w = F.dropout(w, self.dropout, training=self.training).to(v) - # Key and value have the same format. - x = torch.einsum(f"b h t k, {key_layout} -> {layout}", w, v) - x = x.to(dtype) - x = rearrange(x, f"{layout} -> b t (h d)", h=self.num_heads) - x = self.out_proj(x) - else: - key, value = self._complete_kv(key, value) - if self.attention_as_float32: - query, key, value = [x.float() for x in [query, key, value]] - x, _ = self.mha( - query, key, value, key_padding_mask, - need_weights, attn_mask, average_attn_weights) - x = x.to(dtype) - - return x, None - - -class StreamingTransformerLayer(nn.TransformerEncoderLayer): - """TransformerLayer with Streaming / Causal support. - This also integrates cross_attention, when passing `cross_attention=True`, - rather than having two separate classes like in PyTorch. - - Args: - d_model (int): Dimension of the data. - num_heads (int): Number of heads. - dim_feedforward (int): Intermediate dimension of FF module. - dropout (float): Dropout both for MHA and FF. - bias_ff (bool): Use bias for FF. - bias_attn (bool): Use bias for MHA. - causal (bool): Causal mask applied automatically. - past_context (int or None): Receptive field for the causal mask, infinite if None. - custom (bool): Use custom MHA implementation, for testing / benchmarking. - memory_efficient (bool): Use xformers based memory efficient attention. - attention_as_float32 (bool): Perform the attention as float32 - (especially important with memory_efficient as autocast won't do this automatically). - qk_layer_norm (bool): Layer normalization applied to queries and keys before dot product in attention. - qk_layer_norm_cross (bool): Same for the cross attention. - cross_attention (bool): If True, expect to get secondary input for cross-attention. - Cross attention will use the default MHA, as it typically won't require - special treatment. - layer_scale (float or None): If not None, LayerScale will be used with - the given value as initial scale. - rope (`RotaryEmbedding` or None): Rope embedding to use. - attention_dropout (float or None): If not None, separate the value of the dimension dropout - in FFN and of the attention dropout. - kv_repeat (int): If > 1, will repeat keys and queries multiple times (need to divide num_heads). - This will lead to faster decoding time on A100 or other GPUs with tensorcore. - device (torch.device or None): Device on which to initialize. - dtype (torch.dtype or None): dtype to use. - **kwargs: See `nn.TransformerEncoderLayer`. - """ - def __init__(self, d_model: int, num_heads: int, dim_feedforward: int = 2048, dropout: float = 0.1, - bias_ff: bool = True, bias_attn: bool = True, causal: bool = False, - past_context: tp.Optional[int] = None, custom: bool = False, - memory_efficient: bool = False, attention_as_float32: bool = False, - qk_layer_norm: bool = False, qk_layer_norm_cross: bool = False, - cross_attention: bool = False, layer_scale: tp.Optional[float] = None, - rope: tp.Optional[RotaryEmbedding] = None, attention_dropout: tp.Optional[float] = None, - kv_repeat: int = 1, norm: str = 'layer_norm', device=None, dtype=None, **kwargs): - super().__init__(d_model, num_heads, dim_feedforward, dropout, - device=device, dtype=dtype, batch_first=True, **kwargs) - factory_kwargs = {'device': device, 'dtype': dtype} - # Redefine self_attn to our streaming multi-head attention - attn_kwargs: tp.Dict[str, tp.Any] = { - 'embed_dim': d_model, - 'num_heads': num_heads, - 'dropout': dropout if attention_dropout is None else attention_dropout, - 'bias': bias_attn, - 'custom': custom, - 'memory_efficient': memory_efficient, - 'attention_as_float32': attention_as_float32, - } - self.self_attn: StreamingMultiheadAttention = StreamingMultiheadAttention( - causal=causal, past_context=past_context, rope=rope, qk_layer_norm=qk_layer_norm, - kv_repeat=kv_repeat, **attn_kwargs, **factory_kwargs) # type: ignore - # Redefine feedforward layers to expose bias parameter - self.linear1 = nn.Linear(d_model, dim_feedforward, bias=bias_ff, **factory_kwargs) - self.linear2 = nn.Linear(dim_feedforward, d_model, bias=bias_ff, **factory_kwargs) - - self.layer_scale_1: nn.Module - self.layer_scale_2: nn.Module - if layer_scale is None: - self.layer_scale_1 = nn.Identity() - self.layer_scale_2 = nn.Identity() - else: - self.layer_scale_1 = LayerScale(d_model, layer_scale, **factory_kwargs) - self.layer_scale_2 = LayerScale(d_model, layer_scale, **factory_kwargs) - - self.cross_attention: tp.Optional[nn.Module] = None - if cross_attention: - self.cross_attention = StreamingMultiheadAttention( - cross_attention=True, qk_layer_norm=qk_layer_norm_cross, - **attn_kwargs, **factory_kwargs) - # Norm and dropout - self.dropout_cross = nn.Dropout(dropout) - # eps value matching that used in PyTorch reference implementation. - self.norm_cross = nn.LayerNorm(d_model, eps=1e-5, **factory_kwargs) - self.layer_scale_cross: nn.Module - if layer_scale is None: - self.layer_scale_cross = nn.Identity() - else: - self.layer_scale_cross = LayerScale(d_model, layer_scale, **factory_kwargs) - self.norm1 = create_norm_fn(norm, d_model, **factory_kwargs) # type: ignore - self.norm2 = create_norm_fn(norm, d_model, **factory_kwargs) # type: ignore - - def _cross_attention_block(self, src: torch.Tensor, - cross_attention_src: torch.Tensor) -> torch.Tensor: - assert self.cross_attention is not None - # queries are from src, keys and values from cross_attention_src. - x = self.cross_attention( - src, cross_attention_src, cross_attention_src, need_weights=False)[0] - return self.dropout_cross(x) # type: ignore - - def forward(self, src: torch.Tensor, src_mask: tp.Optional[torch.Tensor] = None, # type: ignore - src_key_padding_mask: tp.Optional[torch.Tensor] = None, - cross_attention_src: tp.Optional[torch.Tensor] = None): - if self.cross_attention is None: - assert cross_attention_src is None - else: - assert cross_attention_src is not None - x = src - if self.norm_first: - x = x + self.layer_scale_1( - self._sa_block(self.norm1(x), src_mask, src_key_padding_mask)) - if cross_attention_src is not None: - x = x + self.layer_scale_cross( - self._cross_attention_block( - self.norm_cross(x), cross_attention_src)) - x = x + self.layer_scale_2(self._ff_block(self.norm2(x))) - else: - x = self.norm1(x + self.layer_scale_1( - self._sa_block(x, src_mask, src_key_padding_mask))) - if cross_attention_src is not None: - x = self.norm_cross( - x + self.layer_scale_cross( - self._cross_attention_block(src, cross_attention_src))) - x = self.norm2(x + self.layer_scale_2(self._ff_block(x))) - return x - - -class StreamingTransformer(StreamingModule): - """Transformer with Streaming / Causal support. - - Args: - d_model (int): Dimension of the data. - num_heads (int): Number of heads. - dim_feedforward (int): Intermediate dimension of FF module. - dropout (float): Dropout both for MHA and FF. - bias_ff (bool): Use bias for FF. - bias_attn (bool): Use bias for MHA. - causal (bool): Causal mask applied automatically. - past_context (int or None): Receptive field for the causal mask, infinite if None. - custom (bool): Use custom MHA implementation, for testing / benchmarking. - memory_efficient (bool): Use xformers based memory efficient attention. - attention_as_float32 (bool): Perform the attention as float32 - (especially important with memory_efficient as autocast won't do this automatically). - cross_attention (bool): If True, expect to get secondary input for cross-attention. - layer_scale (float or None): If not None, LayerScale will be used - with the given value as initial scale. - positional_embedding (str): Positional embedding strategy (sin, rope, or sin_rope). - max_period (float): Maximum period of the time embedding. - positional_scale (float): Scale of positional embedding, set to 0 to deactivate. - xpos (bool): Apply xpos exponential decay to positional embedding (rope only). - lr (float or None): learning rate override through the `make_optim_group` API. - weight_decay (float or None): Weight_decay override through the `make_optim_group` API. - layer_class: (subclass of `StreamingTransformerLayer): class to use - to initialize the layers, allowing further customization outside of Audiocraft. - checkpointing (str): Checkpointing strategy to reduce memory usage. - No checkpointing if set to 'none'. Per layer checkpointing using PyTorch - if set to 'torch' (entire layer checkpointed, i.e. linears are evaluated twice, - minimal memory usage, but maximal runtime). Finally, `xformers_default` provide - a policy for opting-out some operations of the checkpointing like - linear layers and attention, providing a middle ground between speed and memory. - device (torch.device or None): Device on which to initialize. - dtype (torch.dtype or None): dtype to use. - **kwargs: See `nn.TransformerEncoderLayer`. - """ - def __init__(self, d_model: int, num_heads: int, num_layers: int, dim_feedforward: int = 2048, - dropout: float = 0.1, bias_ff: bool = True, bias_attn: bool = True, - causal: bool = False, past_context: tp.Optional[int] = None, - custom: bool = False, memory_efficient: bool = False, attention_as_float32: bool = False, - cross_attention: bool = False, layer_scale: tp.Optional[float] = None, - positional_embedding: str = 'sin', max_period: float = 10_000, positional_scale: float = 1., - xpos: bool = False, lr: tp.Optional[float] = None, weight_decay: tp.Optional[float] = None, - layer_class: tp.Type[StreamingTransformerLayer] = StreamingTransformerLayer, - checkpointing: str = 'none', device=None, dtype=None, **kwargs): - super().__init__() - assert d_model % num_heads == 0 - - self.positional_embedding = positional_embedding - self.max_period = max_period - self.positional_scale = positional_scale - self.weight_decay = weight_decay - self.lr = lr - - assert positional_embedding in ['sin', 'rope', 'sin_rope'] - self.rope: tp.Optional[RotaryEmbedding] = None - if self.positional_embedding in ['rope', 'sin_rope']: - assert _is_custom(custom, memory_efficient) - self.rope = RotaryEmbedding(d_model // num_heads, max_period=max_period, - xpos=xpos, scale=positional_scale, device=device) - - self.checkpointing = checkpointing - - assert checkpointing in ['none', 'torch', 'xformers_default', 'xformers_mm'] - if self.checkpointing.startswith('xformers'): - _verify_xformers_internal_compat() - - self.layers = nn.ModuleList() - for idx in range(num_layers): - self.layers.append( - layer_class( - d_model=d_model, num_heads=num_heads, dim_feedforward=dim_feedforward, - dropout=dropout, bias_ff=bias_ff, bias_attn=bias_attn, - causal=causal, past_context=past_context, custom=custom, - memory_efficient=memory_efficient, attention_as_float32=attention_as_float32, - cross_attention=cross_attention, layer_scale=layer_scale, rope=self.rope, - device=device, dtype=dtype, **kwargs)) - - if self.checkpointing != 'none': - for layer in self.layers: - # see audiocraft/optim/fsdp.py, magic signal to indicate this requires fixing the - # backward hook inside of FSDP... - layer._magma_checkpointed = True # type: ignore - assert layer.layer_drop == 0., "Need further checking" # type: ignore - - def _apply_layer(self, layer, *args, **kwargs): - method = self.checkpointing - if method == 'none': - return layer(*args, **kwargs) - elif method == 'torch': - return torch_checkpoint(layer, *args, use_reentrant=False, **kwargs) - elif method.startswith('xformers'): - from xformers.checkpoint_fairinternal import checkpoint, _get_default_policy - if method == 'xformers_default': - # those operations will be saved, and not recomputed. - # According to Francisco we can get smarter policies but this is a good start. - allow_list = [ - "xformers.efficient_attention_forward_cutlass.default", - "xformers_flash.flash_fwd.default", - "aten.addmm.default", - "aten.mm.default", - ] - elif method == 'xformers_mm': - # those operations will be saved, and not recomputed. - # According to Francisco we can get smarter policies but this is a good start. - allow_list = [ - "aten.addmm.default", - "aten.mm.default", - ] - else: - raise ValueError(f"xformers checkpointing xformers policy {method} is not known.") - policy_fn = _get_default_policy(allow_list) - return checkpoint(layer, *args, policy_fn=policy_fn, **kwargs) - else: - raise ValueError(f"Checkpointing method {method} is unknown.") - - def forward(self, x: torch.Tensor, *args, **kwargs): - B, T, C = x.shape - - if 'offsets' in self._streaming_state: - offsets = self._streaming_state['offsets'] - else: - offsets = torch.zeros(B, dtype=torch.long, device=x.device) - - if self.positional_embedding in ['sin', 'sin_rope']: - positions = torch.arange(T, device=x.device).view(1, -1, 1) - positions = positions + offsets.view(-1, 1, 1) - pos_emb = create_sin_embedding(positions, C, max_period=self.max_period, dtype=x.dtype) - x = x + self.positional_scale * pos_emb - - for layer in self.layers: - x = self._apply_layer(layer, x, *args, **kwargs) - - if self._is_streaming: - self._streaming_state['offsets'] = offsets + T - - return x - - def make_optim_group(self): - group = {"params": list(self.parameters())} - if self.lr is not None: - group["lr"] = self.lr - if self.weight_decay is not None: - group["weight_decay"] = self.weight_decay - return group - - -# special attention attention related function - -def _verify_xformers_memory_efficient_compat(): - try: - from xformers.ops import memory_efficient_attention, LowerTriangularMask # noqa - except ImportError: - raise ImportError( - "xformers is not installed. Please install it and try again.\n" - "To install on AWS and Azure, run \n" - "FORCE_CUDA=1 TORCH_CUDA_ARCH_LIST='8.0'\\\n" - "pip install -U git+https://git@github.com/fairinternal/xformers.git#egg=xformers\n" - "To install on FAIR Cluster, run \n" - "FORCE_CUDA=1 TORCH_CUDA_ARCH_LIST='6.0;7.0'\\\n" - "pip install -U git+https://git@github.com/fairinternal/xformers.git#egg=xformers\n") - - -def _verify_xformers_internal_compat(): - try: - from xformers.checkpoint_fairinternal import checkpoint, _get_default_policy # noqa - except ImportError: - raise ImportError( - "Francisco's fairinternal xformers is not installed. Please install it and try again.\n" - "To install on AWS and Azure, run \n" - "FORCE_CUDA=1 TORCH_CUDA_ARCH_LIST='8.0'\\\n" - "pip install -U git+https://git@github.com/fairinternal/xformers.git#egg=xformers\n" - "To install on FAIR Cluster, run \n" - "FORCE_CUDA=1 TORCH_CUDA_ARCH_LIST='6.0;7.0'\\\n" - "pip install -U git+https://git@github.com/fairinternal/xformers.git#egg=xformers\n") - - -def _is_custom(custom: bool, memory_efficient: bool): - return custom or memory_efficient diff --git a/spaces/TabPFN/TabPFNEvaluation/TabPFN/README.md b/spaces/TabPFN/TabPFNEvaluation/TabPFN/README.md deleted file mode 100644 index 3607380865bc971af3ea79fb135d84287e68f8a6..0000000000000000000000000000000000000000 --- a/spaces/TabPFN/TabPFNEvaluation/TabPFN/README.md +++ /dev/null @@ -1,23 +0,0 @@ -# TabPFN - -## Installation -``` -git clone git@github.com:automl/TabPFN.git -cd TabPFN -conda create -n TabPFN python=3.7 -conda activate TabPFN -pip install -r requirements.txt -``` - -To run the autogluon baseline please create a separate environment and install autogluon==0.4.0, installation in the same environment as our other baselines is not possible. - -## Usage -TrainingTuningAndPrediction: Train a TabPFN, Prior Tune and predict using a pretrained model. - -TabularEvaluationVisualization: Run Baselines and load Baseline and TabPFN Results for comparison and plotting. - -PrepareDatasets: Notebook used to inspect Datasets (Not needed to run baselines / TabPFN). - -SytheticGPAblation: Ablation experiments for Gaussian Process fitting with differentiable Hyper Parameters. - - diff --git a/spaces/TabPFN/TabPFNPrediction/TabPFN/layer.py b/spaces/TabPFN/TabPFNPrediction/TabPFN/layer.py deleted file mode 100644 index 32093331d2621caf0176fcc64a29ad6c24326414..0000000000000000000000000000000000000000 --- a/spaces/TabPFN/TabPFNPrediction/TabPFN/layer.py +++ /dev/null @@ -1,141 +0,0 @@ -from functools import partial - -from torch import nn -from torch.nn.modules.transformer import ( - _get_activation_fn, - Module, - Tensor, - Optional, - MultiheadAttention, - Linear, - Dropout, - LayerNorm, -) -import torch -import torch.nn.functional as F - -from torch.utils.checkpoint import checkpoint - - -class TransformerEncoderLayer(Module): - r"""TransformerEncoderLayer is made up of self-attn and feedforward network. - This standard encoder layer is based on the paper "Attention Is All You Need". - Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, - Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in - Neural Information Processing Systems, pages 6000-6010. Users may modify or implement - in a different way during application. - - Args: - d_model: the number of expected features in the input (required). - nhead: the number of heads in the multiheadattention models (required). - dim_feedforward: the dimension of the feedforward network model (default=2048). - dropout: the dropout value (default=0.1). - activation: the activation function of intermediate layer, relu or gelu (default=relu). - layer_norm_eps: the eps value in layer normalization components (default=1e-5). - batch_first: If ``True``, then the input and output tensors are provided - as (batch, seq, feature). Default: ``False``. - - Examples:: - >>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8) - >>> src = torch.rand(10, 32, 512) - >>> out = encoder_layer(src) - - Alternatively, when ``batch_first`` is ``True``: - >>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8, batch_first=True) - >>> src = torch.rand(32, 10, 512) - >>> out = encoder_layer(src) - """ - __constants__ = ['batch_first'] - - def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu", - layer_norm_eps=1e-5, batch_first=False, pre_norm=False, - device=None, dtype=None, recompute_attn=False) -> None: - factory_kwargs = {'device': device, 'dtype': dtype} - super().__init__() - self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first, - **factory_kwargs) - # Implementation of Feedforward model - self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs) - self.dropout = Dropout(dropout) - self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs) - - self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs) - self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs) - self.dropout1 = Dropout(dropout) - self.dropout2 = Dropout(dropout) - self.pre_norm = pre_norm - self.recompute_attn = recompute_attn - - self.activation = _get_activation_fn(activation) - - def __setstate__(self, state): - if 'activation' not in state: - state['activation'] = F.relu - super().__setstate__(state) - - def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor: - r"""Pass the input through the encoder layer. - - Args: - src: the sequence to the encoder layer (required). - src_mask: the mask for the src sequence (optional). - src_key_padding_mask: the mask for the src keys per batch (optional). - - Shape: - see the docs in Transformer class. - """ - if self.pre_norm: - src_ = self.norm1(src) - else: - src_ = src - if isinstance(src_mask, tuple): - # global attention setup - assert not self.self_attn.batch_first - assert src_key_padding_mask is None - - global_src_mask, trainset_src_mask, valset_src_mask = src_mask - - num_global_tokens = global_src_mask.shape[0] - num_train_tokens = trainset_src_mask.shape[0] - - global_tokens_src = src_[:num_global_tokens] - train_tokens_src = src_[num_global_tokens:num_global_tokens+num_train_tokens] - global_and_train_tokens_src = src_[:num_global_tokens+num_train_tokens] - eval_tokens_src = src_[num_global_tokens+num_train_tokens:] - - - attn = partial(checkpoint, self.self_attn) if self.recompute_attn else self.self_attn - - global_tokens_src2 = attn(global_tokens_src, global_and_train_tokens_src, global_and_train_tokens_src, None, True, global_src_mask)[0] - train_tokens_src2 = attn(train_tokens_src, global_tokens_src, global_tokens_src, None, True, trainset_src_mask)[0] - eval_tokens_src2 = attn(eval_tokens_src, src_, src_, - None, True, valset_src_mask)[0] - - src2 = torch.cat([global_tokens_src2, train_tokens_src2, eval_tokens_src2], dim=0) - - elif isinstance(src_mask, int): - assert src_key_padding_mask is None - single_eval_position = src_mask - src_left = self.self_attn(src_[:single_eval_position], src_[:single_eval_position], src_[:single_eval_position])[0] - src_right = self.self_attn(src_[single_eval_position:], src_[:single_eval_position], src_[:single_eval_position])[0] - src2 = torch.cat([src_left, src_right], dim=0) - else: - if self.recompute_attn: - src2 = checkpoint(self.self_attn, src_, src_, src_, src_key_padding_mask, True, src_mask)[0] - else: - src2 = self.self_attn(src_, src_, src_, attn_mask=src_mask, - key_padding_mask=src_key_padding_mask)[0] - src = src + self.dropout1(src2) - if not self.pre_norm: - src = self.norm1(src) - - if self.pre_norm: - src_ = self.norm2(src) - else: - src_ = src - src2 = self.linear2(self.dropout(self.activation(self.linear1(src_)))) - src = src + self.dropout2(src2) - - if not self.pre_norm: - src = self.norm2(src) - return src \ No newline at end of file diff --git a/spaces/Tetel/chat/EdgeGPT/EdgeUtils.py b/spaces/Tetel/chat/EdgeGPT/EdgeUtils.py deleted file mode 100644 index 795383fca66d7c68a22ff958fa2cc8a6723c95ec..0000000000000000000000000000000000000000 --- a/spaces/Tetel/chat/EdgeGPT/EdgeUtils.py +++ /dev/null @@ -1,254 +0,0 @@ -import asyncio -import json -import platform -import time -from pathlib import Path -from typing import Dict -from typing import List -from typing import Set -from typing import Union - -from EdgeGPT.EdgeGPT import Chatbot -from EdgeGPT.EdgeGPT import ConversationStyle -from EdgeGPT.ImageGen import ImageGen - - -class Cookie: - """ - Convenience class for Bing Cookie files, data, and configuration. This Class - is updated dynamically by the Query class to allow cycling through >1 - cookie/credentials file e.g. when daily request limits (current 200 per - account per day) are exceeded. - """ - - current_file_index = 0 - dirpath = Path("./").resolve() - search_pattern = "bing_cookies_*.json" - ignore_files = set() - current_filepath: Union[dict, None] = None - - @classmethod - def fetch_default(cls, path: Union[Path, None] = None) -> None: - from selenium import webdriver - from selenium.webdriver.common.by import By - - driver = webdriver.Edge() - driver.get("https://bing.com/chat") - time.sleep(5) - xpath = '//button[@id="bnp_btn_accept"]' - driver.find_element(By.XPATH, xpath).click() - time.sleep(2) - xpath = '//a[@id="codexPrimaryButton"]' - driver.find_element(By.XPATH, xpath).click() - if path is None: - path = Path("./bing_cookies__default.json") - # Double underscore ensures this file is first when sorted - cookies = driver.get_cookies() - Path(path).write_text(json.dumps(cookies, indent=4), encoding="utf-8") - # Path again in case supplied path is: str - print(f"Cookies saved to: {path}") - driver.quit() - - @classmethod - def files(cls) -> List[Path]: - """Return a sorted list of all cookie files matching .search_pattern""" - all_files = set(cls.dirpath.glob(cls.search_pattern)) - return sorted(all_files - cls.ignore_files) - - @classmethod - def import_data(cls) -> None: - """ - Read the active cookie file and populate the following attributes: - - .current_filepath - .current_data - .image_token - """ - try: - cls.current_filepath = cls.files()[cls.current_file_index] - except IndexError as exc: - print( - "> Please set Cookie.current_filepath to a valid cookie file, then run Cookie.import_data()", - ) - raise "No valid cookie file found." from exc - print(f"> Importing cookies from: {cls.current_filepath.name}") - with Path.open(cls.current_filepath, encoding="utf-8") as file: - cls.current_data = json.load(file) - cls.image_token = [x for x in cls.current_data if x.get("name") == "_U"] - cls.image_token = cls.image_token[0].get("value") - - @classmethod - def import_next(cls) -> None: - """ - Cycle through to the next cookies file. Import it. Mark the previous - file to be ignored for the remainder of the current session. - """ - cls.ignore_files.add(cls.current_filepath) - if Cookie.current_file_index >= len(cls.files()): - Cookie.current_file_index = 0 - Cookie.import_data() - - -class Query: - """ - A convenience class that wraps around EdgeGPT.Chatbot to encapsulate input, - config, and output all together. Relies on Cookie class for authentication - """ - - def __init__( - self, - prompt: str, - style: str = "precise", - content_type: str = "text", - cookie_file: int = 0, - echo: bool = True, - echo_prompt: bool = False, - proxy: Union[str, None] = None, - ) -> None: - """ - Arguments: - - prompt: Text to enter into Bing Chat - style: creative, balanced, or precise - content_type: "text" for Bing Chat; "image" for Dall-e - cookie_file: Path, filepath string, or index (int) to list of cookie paths - echo: Print something to confirm request made - echo_prompt: Print confirmation of the evaluated prompt - """ - self.proxy = proxy - self.index = [] - self.request_count = {} - self.image_dirpath = Path("./").resolve() - Cookie.import_data() - self.index += [self] - self.prompt = prompt - files = Cookie.files() - if isinstance(cookie_file, int): - index = cookie_file if cookie_file < len(files) else 0 - else: - if not isinstance(cookie_file, (str, Path)): - message = "'cookie_file' must be an int, str, or Path object" - raise TypeError(message) - cookie_file = Path(cookie_file) - if cookie_file in files: # Supplied filepath IS in Cookie.dirpath - index = files.index(cookie_file) - else: # Supplied filepath is NOT in Cookie.dirpath - if cookie_file.is_file(): - Cookie.dirpath = cookie_file.parent.resolve() - if cookie_file.is_dir(): - Cookie.dirpath = cookie_file.resolve() - index = 0 - Cookie.current_file_index = index - if content_type == "text": - self.style = style - self.log_and_send_query(echo, echo_prompt) - if content_type == "image": - self.create_image() - - def log_and_send_query(self, echo: bool, echo_prompt: bool) -> None: - if platform.system() == "Windows": - asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) - self.response = asyncio.run(self.send_to_bing(echo, echo_prompt)) - name = str(Cookie.current_filepath.name) - if not self.request_count.get(name): - self.request_count[name] = 1 - else: - self.request_count[name] += 1 - - def create_image(self) -> None: - image_generator = ImageGen(Cookie.image_token) - image_generator.save_images( - image_generator.get_images(self.prompt), - output_dir=self.image_dirpath, - ) - - async def send_to_bing(self, echo: bool = True, echo_prompt: bool = False) -> str: - """Creat, submit, then close a Chatbot instance. Return the response""" - retries = len(Cookie.files()) - while retries: - try: - # Read the cookies file - bot = await Chatbot.create( - proxy=self.proxy, - cookies=Cookie.current_data, - ) - if echo_prompt: - print(f"> {self.prompt}=") - if echo: - print("> Waiting for response...") - if self.style.lower() not in "creative balanced precise".split(): - self.style = "precise" - return await bot.ask( - prompt=self.prompt, - conversation_style=getattr(ConversationStyle, self.style), - # wss_link="wss://sydney.bing.com/sydney/ChatHub" - # What other values can this parameter take? It seems to be optional - ) - except KeyError: - print( - f"> KeyError [{Cookie.current_filepath.name} may have exceeded the daily limit]", - ) - Cookie.import_next() - retries -= 1 - finally: - await bot.close() - return None - - @property - def output(self) -> str: - """The response from a completed Chatbot request""" - return self.response["item"]["messages"][-1]["text"] - - @property - def sources(self) -> str: - """The source names and details parsed from a completed Chatbot request""" - return self.response["item"]["messages"][-1]["sourceAttributions"] - - @property - def sources_dict(self) -> Dict[str, str]: - """The source names and details as a dictionary""" - sources_dict = {} - name = "providerDisplayName" - url = "seeMoreUrl" - for source in self.sources: - if name in source and url in source: - sources_dict[source[name]] = source[url] - else: - continue - return sources_dict - - @property - def code(self) -> str: - """Extract and join any snippets of Python code in the response""" - code_blocks = self.output.split("```")[1:-1:2] - code_blocks = ["\n".join(x.splitlines()[1:]) for x in code_blocks] - return "\n\n".join(code_blocks) - - @property - def languages(self) -> Set[str]: - """Extract all programming languages given in code blocks""" - code_blocks = self.output.split("```")[1:-1:2] - return {x.splitlines()[0] for x in code_blocks} - - @property - def suggestions(self) -> List[str]: - """Follow-on questions suggested by the Chatbot""" - return [ - x["text"] - for x in self.response["item"]["messages"][-1]["suggestedResponses"] - ] - - def __repr__(self) -> str: - return f"- {throttling.numUserMessagesInConversation} - 共 - {throttling.maxNumUserMessagesInConversation} -- -TinyLlama Chat UI - - - - --- - --Advanced Settings
---Max Tokens
- - -None of the Data you chat about in this UI is collected.
-- - - -- - - diff --git a/spaces/VoiceHero69/changer/webui/modules/implementations/rvc/infer_pack/models.py b/spaces/VoiceHero69/changer/webui/modules/implementations/rvc/infer_pack/models.py deleted file mode 100644 index 201be6d4f9237dcecdb47e4a7425edb3813cf5ea..0000000000000000000000000000000000000000 --- a/spaces/VoiceHero69/changer/webui/modules/implementations/rvc/infer_pack/models.py +++ /dev/null @@ -1,1124 +0,0 @@ -import math, pdb, os -from time import time as ttime -import torch -from torch import nn -from torch.nn import functional as F -from webui.modules.implementations.rvc.infer_pack import modules -from webui.modules.implementations.rvc.infer_pack import attentions -from webui.modules.implementations.rvc.infer_pack import commons -from webui.modules.implementations.rvc.infer_pack.commons import init_weights, get_padding -from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d -from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm -from webui.modules.implementations.rvc.infer_pack.commons import init_weights -import numpy as np -from webui.modules.implementations.rvc.infer_pack import commons - - -class TextEncoder256(nn.Module): - def __init__( - self, - out_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - f0=True, - ): - super().__init__() - self.out_channels = out_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.emb_phone = nn.Linear(256, hidden_channels) - self.lrelu = nn.LeakyReLU(0.1, inplace=True) - if f0 == True: - self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256 - self.encoder = attentions.Encoder( - hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout - ) - self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1) - - def forward(self, phone, pitch, lengths): - if pitch == None: - x = self.emb_phone(phone) - else: - x = self.emb_phone(phone) + self.emb_pitch(pitch) - x = x * math.sqrt(self.hidden_channels) # [b, t, h] - x = self.lrelu(x) - x = torch.transpose(x, 1, -1) # [b, h, t] - x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to( - x.dtype - ) - x = self.encoder(x * x_mask, x_mask) - stats = self.proj(x) * x_mask - - m, logs = torch.split(stats, self.out_channels, dim=1) - return m, logs, x_mask - - -class TextEncoder768(nn.Module): - def __init__( - self, - out_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - f0=True, - ): - super().__init__() - self.out_channels = out_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.emb_phone = nn.Linear(768, hidden_channels) - self.lrelu = nn.LeakyReLU(0.1, inplace=True) - if f0 == True: - self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256 - self.encoder = attentions.Encoder( - hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout - ) - self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1) - - def forward(self, phone, pitch, lengths): - if pitch == None: - x = self.emb_phone(phone) - else: - x = self.emb_phone(phone) + self.emb_pitch(pitch) - x = x * math.sqrt(self.hidden_channels) # [b, t, h] - x = self.lrelu(x) - x = torch.transpose(x, 1, -1) # [b, h, t] - x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to( - x.dtype - ) - x = self.encoder(x * x_mask, x_mask) - stats = self.proj(x) * x_mask - - m, logs = torch.split(stats, self.out_channels, dim=1) - return m, logs, x_mask - - -class ResidualCouplingBlock(nn.Module): - def __init__( - self, - channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - n_flows=4, - gin_channels=0, - ): - super().__init__() - self.channels = channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.n_flows = n_flows - self.gin_channels = gin_channels - - self.flows = nn.ModuleList() - for i in range(n_flows): - self.flows.append( - modules.ResidualCouplingLayer( - channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - gin_channels=gin_channels, - mean_only=True, - ) - ) - self.flows.append(modules.Flip()) - - def forward(self, x, x_mask, g=None, reverse=False): - if not reverse: - for flow in self.flows: - x, _ = flow(x, x_mask, g=g, reverse=reverse) - else: - for flow in reversed(self.flows): - x = flow(x, x_mask, g=g, reverse=reverse) - return x - - def remove_weight_norm(self): - for i in range(self.n_flows): - self.flows[i * 2].remove_weight_norm() - - -class PosteriorEncoder(nn.Module): - def __init__( - self, - in_channels, - out_channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - gin_channels=0, - ): - super().__init__() - self.in_channels = in_channels - self.out_channels = out_channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.gin_channels = gin_channels - - self.pre = nn.Conv1d(in_channels, hidden_channels, 1) - self.enc = modules.WN( - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - gin_channels=gin_channels, - ) - self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1) - - def forward(self, x, x_lengths, g=None): - x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to( - x.dtype - ) - x = self.pre(x) * x_mask - x = self.enc(x, x_mask, g=g) - stats = self.proj(x) * x_mask - m, logs = torch.split(stats, self.out_channels, dim=1) - z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask - return z, m, logs, x_mask - - def remove_weight_norm(self): - self.enc.remove_weight_norm() - - -class Generator(torch.nn.Module): - def __init__( - self, - initial_channel, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - gin_channels=0, - ): - super(Generator, self).__init__() - self.num_kernels = len(resblock_kernel_sizes) - self.num_upsamples = len(upsample_rates) - self.conv_pre = Conv1d( - initial_channel, upsample_initial_channel, 7, 1, padding=3 - ) - resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2 - - self.ups = nn.ModuleList() - for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)): - self.ups.append( - weight_norm( - ConvTranspose1d( - upsample_initial_channel // (2**i), - upsample_initial_channel // (2 ** (i + 1)), - k, - u, - padding=(k - u) // 2, - ) - ) - ) - - self.resblocks = nn.ModuleList() - for i in range(len(self.ups)): - ch = upsample_initial_channel // (2 ** (i + 1)) - for j, (k, d) in enumerate( - zip(resblock_kernel_sizes, resblock_dilation_sizes) - ): - self.resblocks.append(resblock(ch, k, d)) - - self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False) - self.ups.apply(init_weights) - - if gin_channels != 0: - self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1) - - def forward(self, x, g=None): - x = self.conv_pre(x) - if g is not None: - x = x + self.cond(g) - - for i in range(self.num_upsamples): - x = F.leaky_relu(x, modules.LRELU_SLOPE) - x = self.ups[i](x) - xs = None - for j in range(self.num_kernels): - if xs is None: - xs = self.resblocks[i * self.num_kernels + j](x) - else: - xs += self.resblocks[i * self.num_kernels + j](x) - x = xs / self.num_kernels - x = F.leaky_relu(x) - x = self.conv_post(x) - x = torch.tanh(x) - - return x - - def remove_weight_norm(self): - for l in self.ups: - remove_weight_norm(l) - for l in self.resblocks: - l.remove_weight_norm() - - -class SineGen(torch.nn.Module): - """Definition of sine generator - SineGen(samp_rate, harmonic_num = 0, - sine_amp = 0.1, noise_std = 0.003, - voiced_threshold = 0, - flag_for_pulse=False) - samp_rate: sampling rate in Hz - harmonic_num: number of harmonic overtones (default 0) - sine_amp: amplitude of sine-wavefrom (default 0.1) - noise_std: std of Gaussian noise (default 0.003) - voiced_thoreshold: F0 threshold for U/V classification (default 0) - flag_for_pulse: this SinGen is used inside PulseGen (default False) - Note: when flag_for_pulse is True, the first time step of a voiced - segment is always sin(np.pi) or cos(0) - """ - - def __init__( - self, - samp_rate, - harmonic_num=0, - sine_amp=0.1, - noise_std=0.003, - voiced_threshold=0, - flag_for_pulse=False, - ): - super(SineGen, self).__init__() - self.sine_amp = sine_amp - self.noise_std = noise_std - self.harmonic_num = harmonic_num - self.dim = self.harmonic_num + 1 - self.sampling_rate = samp_rate - self.voiced_threshold = voiced_threshold - - def _f02uv(self, f0): - # generate uv signal - uv = torch.ones_like(f0) - uv = uv * (f0 > self.voiced_threshold) - return uv - - def forward(self, f0, upp): - """sine_tensor, uv = forward(f0) - input F0: tensor(batchsize=1, length, dim=1) - f0 for unvoiced steps should be 0 - output sine_tensor: tensor(batchsize=1, length, dim) - output uv: tensor(batchsize=1, length, 1) - """ - with torch.no_grad(): - f0 = f0[:, None].transpose(1, 2) - f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device) - # fundamental component - f0_buf[:, :, 0] = f0[:, :, 0] - for idx in np.arange(self.harmonic_num): - f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * ( - idx + 2 - ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic - rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化 - rand_ini = torch.rand( - f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device - ) - rand_ini[:, 0] = 0 - rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini - tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化 - tmp_over_one *= upp - tmp_over_one = F.interpolate( - tmp_over_one.transpose(2, 1), - scale_factor=upp, - mode="linear", - align_corners=True, - ).transpose(2, 1) - rad_values = F.interpolate( - rad_values.transpose(2, 1), scale_factor=upp, mode="nearest" - ).transpose( - 2, 1 - ) ####### - tmp_over_one %= 1 - tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0 - cumsum_shift = torch.zeros_like(rad_values) - cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0 - sine_waves = torch.sin( - torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi - ) - sine_waves = sine_waves * self.sine_amp - uv = self._f02uv(f0) - uv = F.interpolate( - uv.transpose(2, 1), scale_factor=upp, mode="nearest" - ).transpose(2, 1) - noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3 - noise = noise_amp * torch.randn_like(sine_waves) - sine_waves = sine_waves * uv + noise - return sine_waves, uv, noise - - -class SourceModuleHnNSF(torch.nn.Module): - """SourceModule for hn-nsf - SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1, - add_noise_std=0.003, voiced_threshod=0) - sampling_rate: sampling_rate in Hz - harmonic_num: number of harmonic above F0 (default: 0) - sine_amp: amplitude of sine source signal (default: 0.1) - add_noise_std: std of additive Gaussian noise (default: 0.003) - note that amplitude of noise in unvoiced is decided - by sine_amp - voiced_threshold: threhold to set U/V given F0 (default: 0) - Sine_source, noise_source = SourceModuleHnNSF(F0_sampled) - F0_sampled (batchsize, length, 1) - Sine_source (batchsize, length, 1) - noise_source (batchsize, length 1) - uv (batchsize, length, 1) - """ - - def __init__( - self, - sampling_rate, - harmonic_num=0, - sine_amp=0.1, - add_noise_std=0.003, - voiced_threshod=0, - is_half=True, - ): - super(SourceModuleHnNSF, self).__init__() - - self.sine_amp = sine_amp - self.noise_std = add_noise_std - self.is_half = is_half - # to produce sine waveforms - self.l_sin_gen = SineGen( - sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod - ) - - # to merge source harmonics into a single excitation - self.l_linear = torch.nn.Linear(harmonic_num + 1, 1) - self.l_tanh = torch.nn.Tanh() - - def forward(self, x, upp=None): - sine_wavs, uv, _ = self.l_sin_gen(x, upp) - if self.is_half: - sine_wavs = sine_wavs.half() - sine_merge = self.l_tanh(self.l_linear(sine_wavs)) - return sine_merge, None, None # noise, uv - - -class GeneratorNSF(torch.nn.Module): - def __init__( - self, - initial_channel, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - gin_channels, - sr, - is_half=False, - ): - super(GeneratorNSF, self).__init__() - self.num_kernels = len(resblock_kernel_sizes) - self.num_upsamples = len(upsample_rates) - - self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates)) - self.m_source = SourceModuleHnNSF( - sampling_rate=sr, harmonic_num=0, is_half=is_half - ) - self.noise_convs = nn.ModuleList() - self.conv_pre = Conv1d( - initial_channel, upsample_initial_channel, 7, 1, padding=3 - ) - resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2 - - self.ups = nn.ModuleList() - for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)): - c_cur = upsample_initial_channel // (2 ** (i + 1)) - self.ups.append( - weight_norm( - ConvTranspose1d( - upsample_initial_channel // (2**i), - upsample_initial_channel // (2 ** (i + 1)), - k, - u, - padding=(k - u) // 2, - ) - ) - ) - if i + 1 < len(upsample_rates): - stride_f0 = np.prod(upsample_rates[i + 1 :]) - self.noise_convs.append( - Conv1d( - 1, - c_cur, - kernel_size=stride_f0 * 2, - stride=stride_f0, - padding=stride_f0 // 2, - ) - ) - else: - self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1)) - - self.resblocks = nn.ModuleList() - for i in range(len(self.ups)): - ch = upsample_initial_channel // (2 ** (i + 1)) - for j, (k, d) in enumerate( - zip(resblock_kernel_sizes, resblock_dilation_sizes) - ): - self.resblocks.append(resblock(ch, k, d)) - - self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False) - self.ups.apply(init_weights) - - if gin_channels != 0: - self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1) - - self.upp = np.prod(upsample_rates) - - def forward(self, x, f0, g=None): - har_source, noi_source, uv = self.m_source(f0, self.upp) - har_source = har_source.transpose(1, 2) - x = self.conv_pre(x) - if g is not None: - x = x + self.cond(g) - - for i in range(self.num_upsamples): - x = F.leaky_relu(x, modules.LRELU_SLOPE) - x = self.ups[i](x) - x_source = self.noise_convs[i](har_source) - x = x + x_source - xs = None - for j in range(self.num_kernels): - if xs is None: - xs = self.resblocks[i * self.num_kernels + j](x) - else: - xs += self.resblocks[i * self.num_kernels + j](x) - x = xs / self.num_kernels - x = F.leaky_relu(x) - x = self.conv_post(x) - x = torch.tanh(x) - return x - - def remove_weight_norm(self): - for l in self.ups: - remove_weight_norm(l) - for l in self.resblocks: - l.remove_weight_norm() - - -sr2sr = { - "32k": 32000, - "40k": 40000, - "48k": 48000, -} - - -class SynthesizerTrnMs256NSFsid(nn.Module): - def __init__( - self, - spec_channels, - segment_size, - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - spk_embed_dim, - gin_channels, - sr, - **kwargs - ): - super().__init__() - if type(sr) == type("strr"): - sr = sr2sr[sr] - self.spec_channels = spec_channels - self.inter_channels = inter_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.resblock = resblock - self.resblock_kernel_sizes = resblock_kernel_sizes - self.resblock_dilation_sizes = resblock_dilation_sizes - self.upsample_rates = upsample_rates - self.upsample_initial_channel = upsample_initial_channel - self.upsample_kernel_sizes = upsample_kernel_sizes - self.segment_size = segment_size - self.gin_channels = gin_channels - # self.hop_length = hop_length# - self.spk_embed_dim = spk_embed_dim - self.enc_p = TextEncoder256( - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - ) - self.dec = GeneratorNSF( - inter_channels, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - gin_channels=gin_channels, - sr=sr, - is_half=kwargs["is_half"], - ) - self.enc_q = PosteriorEncoder( - spec_channels, - inter_channels, - hidden_channels, - 5, - 1, - 16, - gin_channels=gin_channels, - ) - self.flow = ResidualCouplingBlock( - inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels - ) - self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels) - print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim) - - def remove_weight_norm(self): - self.dec.remove_weight_norm() - self.flow.remove_weight_norm() - self.enc_q.remove_weight_norm() - - def forward( - self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds - ): # 这里ds是id,[bs,1] - # print(1,pitch.shape)#[bs,t] - g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的 - m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths) - z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g) - z_p = self.flow(z, y_mask, g=g) - z_slice, ids_slice = commons.rand_slice_segments( - z, y_lengths, self.segment_size - ) - # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length) - pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size) - # print(-2,pitchf.shape,z_slice.shape) - o = self.dec(z_slice, pitchf, g=g) - return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q) - - def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None): - g = self.emb_g(sid).unsqueeze(-1) - m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths) - z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask - z = self.flow(z_p, x_mask, g=g, reverse=True) - o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g) - return o, x_mask, (z, z_p, m_p, logs_p) - - -class SynthesizerTrnMs768NSFsid(nn.Module): - def __init__( - self, - spec_channels, - segment_size, - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - spk_embed_dim, - gin_channels, - sr, - **kwargs - ): - super().__init__() - if type(sr) == type("strr"): - sr = sr2sr[sr] - self.spec_channels = spec_channels - self.inter_channels = inter_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.resblock = resblock - self.resblock_kernel_sizes = resblock_kernel_sizes - self.resblock_dilation_sizes = resblock_dilation_sizes - self.upsample_rates = upsample_rates - self.upsample_initial_channel = upsample_initial_channel - self.upsample_kernel_sizes = upsample_kernel_sizes - self.segment_size = segment_size - self.gin_channels = gin_channels - # self.hop_length = hop_length# - self.spk_embed_dim = spk_embed_dim - self.enc_p = TextEncoder768( - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - ) - self.dec = GeneratorNSF( - inter_channels, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - gin_channels=gin_channels, - sr=sr, - is_half=kwargs["is_half"], - ) - self.enc_q = PosteriorEncoder( - spec_channels, - inter_channels, - hidden_channels, - 5, - 1, - 16, - gin_channels=gin_channels, - ) - self.flow = ResidualCouplingBlock( - inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels - ) - self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels) - print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim) - - def remove_weight_norm(self): - self.dec.remove_weight_norm() - self.flow.remove_weight_norm() - self.enc_q.remove_weight_norm() - - def forward( - self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds - ): # 这里ds是id,[bs,1] - # print(1,pitch.shape)#[bs,t] - g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的 - m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths) - z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g) - z_p = self.flow(z, y_mask, g=g) - z_slice, ids_slice = commons.rand_slice_segments( - z, y_lengths, self.segment_size - ) - # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length) - pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size) - # print(-2,pitchf.shape,z_slice.shape) - o = self.dec(z_slice, pitchf, g=g) - return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q) - - def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None): - g = self.emb_g(sid).unsqueeze(-1) - m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths) - z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask - z = self.flow(z_p, x_mask, g=g, reverse=True) - o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g) - return o, x_mask, (z, z_p, m_p, logs_p) - - -class SynthesizerTrnMs256NSFsid_nono(nn.Module): - def __init__( - self, - spec_channels, - segment_size, - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - spk_embed_dim, - gin_channels, - sr=None, - **kwargs - ): - super().__init__() - self.spec_channels = spec_channels - self.inter_channels = inter_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.resblock = resblock - self.resblock_kernel_sizes = resblock_kernel_sizes - self.resblock_dilation_sizes = resblock_dilation_sizes - self.upsample_rates = upsample_rates - self.upsample_initial_channel = upsample_initial_channel - self.upsample_kernel_sizes = upsample_kernel_sizes - self.segment_size = segment_size - self.gin_channels = gin_channels - # self.hop_length = hop_length# - self.spk_embed_dim = spk_embed_dim - self.enc_p = TextEncoder256( - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - f0=False, - ) - self.dec = Generator( - inter_channels, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - gin_channels=gin_channels, - ) - self.enc_q = PosteriorEncoder( - spec_channels, - inter_channels, - hidden_channels, - 5, - 1, - 16, - gin_channels=gin_channels, - ) - self.flow = ResidualCouplingBlock( - inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels - ) - self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels) - print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim) - - def remove_weight_norm(self): - self.dec.remove_weight_norm() - self.flow.remove_weight_norm() - self.enc_q.remove_weight_norm() - - def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1] - g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的 - m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths) - z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g) - z_p = self.flow(z, y_mask, g=g) - z_slice, ids_slice = commons.rand_slice_segments( - z, y_lengths, self.segment_size - ) - o = self.dec(z_slice, g=g) - return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q) - - def infer(self, phone, phone_lengths, sid, max_len=None): - g = self.emb_g(sid).unsqueeze(-1) - m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths) - z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask - z = self.flow(z_p, x_mask, g=g, reverse=True) - o = self.dec((z * x_mask)[:, :, :max_len], g=g) - return o, x_mask, (z, z_p, m_p, logs_p) - - -class SynthesizerTrnMs768NSFsid_nono(nn.Module): - def __init__( - self, - spec_channels, - segment_size, - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - spk_embed_dim, - gin_channels, - sr=None, - **kwargs - ): - super().__init__() - self.spec_channels = spec_channels - self.inter_channels = inter_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.resblock = resblock - self.resblock_kernel_sizes = resblock_kernel_sizes - self.resblock_dilation_sizes = resblock_dilation_sizes - self.upsample_rates = upsample_rates - self.upsample_initial_channel = upsample_initial_channel - self.upsample_kernel_sizes = upsample_kernel_sizes - self.segment_size = segment_size - self.gin_channels = gin_channels - # self.hop_length = hop_length# - self.spk_embed_dim = spk_embed_dim - self.enc_p = TextEncoder768( - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - f0=False, - ) - self.dec = Generator( - inter_channels, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - gin_channels=gin_channels, - ) - self.enc_q = PosteriorEncoder( - spec_channels, - inter_channels, - hidden_channels, - 5, - 1, - 16, - gin_channels=gin_channels, - ) - self.flow = ResidualCouplingBlock( - inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels - ) - self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels) - print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim) - - def remove_weight_norm(self): - self.dec.remove_weight_norm() - self.flow.remove_weight_norm() - self.enc_q.remove_weight_norm() - - def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1] - g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的 - m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths) - z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g) - z_p = self.flow(z, y_mask, g=g) - z_slice, ids_slice = commons.rand_slice_segments( - z, y_lengths, self.segment_size - ) - o = self.dec(z_slice, g=g) - return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q) - - def infer(self, phone, phone_lengths, sid, max_len=None): - g = self.emb_g(sid).unsqueeze(-1) - m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths) - z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask - z = self.flow(z_p, x_mask, g=g, reverse=True) - o = self.dec((z * x_mask)[:, :, :max_len], g=g) - return o, x_mask, (z, z_p, m_p, logs_p) - - -class MultiPeriodDiscriminator(torch.nn.Module): - def __init__(self, use_spectral_norm=False): - super(MultiPeriodDiscriminator, self).__init__() - periods = [2, 3, 5, 7, 11, 17] - # periods = [3, 5, 7, 11, 17, 23, 37] - - discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)] - discs = discs + [ - DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods - ] - self.discriminators = nn.ModuleList(discs) - - def forward(self, y, y_hat): - y_d_rs = [] # - y_d_gs = [] - fmap_rs = [] - fmap_gs = [] - for i, d in enumerate(self.discriminators): - y_d_r, fmap_r = d(y) - y_d_g, fmap_g = d(y_hat) - # for j in range(len(fmap_r)): - # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape) - y_d_rs.append(y_d_r) - y_d_gs.append(y_d_g) - fmap_rs.append(fmap_r) - fmap_gs.append(fmap_g) - - return y_d_rs, y_d_gs, fmap_rs, fmap_gs - - -class MultiPeriodDiscriminatorV2(torch.nn.Module): - def __init__(self, use_spectral_norm=False): - super(MultiPeriodDiscriminatorV2, self).__init__() - # periods = [2, 3, 5, 7, 11, 17] - periods = [2, 3, 5, 7, 11, 17, 23, 37] - - discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)] - discs = discs + [ - DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods - ] - self.discriminators = nn.ModuleList(discs) - - def forward(self, y, y_hat): - y_d_rs = [] # - y_d_gs = [] - fmap_rs = [] - fmap_gs = [] - for i, d in enumerate(self.discriminators): - y_d_r, fmap_r = d(y) - y_d_g, fmap_g = d(y_hat) - # for j in range(len(fmap_r)): - # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape) - y_d_rs.append(y_d_r) - y_d_gs.append(y_d_g) - fmap_rs.append(fmap_r) - fmap_gs.append(fmap_g) - - return y_d_rs, y_d_gs, fmap_rs, fmap_gs - - -class DiscriminatorS(torch.nn.Module): - def __init__(self, use_spectral_norm=False): - super(DiscriminatorS, self).__init__() - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList( - [ - norm_f(Conv1d(1, 16, 15, 1, padding=7)), - norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)), - norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)), - norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)), - norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)), - norm_f(Conv1d(1024, 1024, 5, 1, padding=2)), - ] - ) - self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1)) - - def forward(self, x): - fmap = [] - - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, modules.LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - -class DiscriminatorP(torch.nn.Module): - def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False): - super(DiscriminatorP, self).__init__() - self.period = period - self.use_spectral_norm = use_spectral_norm - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList( - [ - norm_f( - Conv2d( - 1, - 32, - (kernel_size, 1), - (stride, 1), - padding=(get_padding(kernel_size, 1), 0), - ) - ), - norm_f( - Conv2d( - 32, - 128, - (kernel_size, 1), - (stride, 1), - padding=(get_padding(kernel_size, 1), 0), - ) - ), - norm_f( - Conv2d( - 128, - 512, - (kernel_size, 1), - (stride, 1), - padding=(get_padding(kernel_size, 1), 0), - ) - ), - norm_f( - Conv2d( - 512, - 1024, - (kernel_size, 1), - (stride, 1), - padding=(get_padding(kernel_size, 1), 0), - ) - ), - norm_f( - Conv2d( - 1024, - 1024, - (kernel_size, 1), - 1, - padding=(get_padding(kernel_size, 1), 0), - ) - ), - ] - ) - self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0))) - - def forward(self, x): - fmap = [] - - # 1d to 2d - b, c, t = x.shape - if t % self.period != 0: # pad first - n_pad = self.period - (t % self.period) - x = F.pad(x, (0, n_pad), "reflect") - t = t + n_pad - x = x.view(b, c, t // self.period, self.period) - - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, modules.LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap diff --git a/spaces/XzJosh/Gun-Bert-VITS2/text/symbols.py b/spaces/XzJosh/Gun-Bert-VITS2/text/symbols.py deleted file mode 100644 index 9dfae4e633829f20c4fd767b1c7a9198911ed801..0000000000000000000000000000000000000000 --- a/spaces/XzJosh/Gun-Bert-VITS2/text/symbols.py +++ /dev/null @@ -1,51 +0,0 @@ -punctuation = ['!', '?', '…', ",", ".", "'", '-'] -pu_symbols = punctuation + ["SP", "UNK"] -pad = '_' - -# chinese -zh_symbols = ['E', 'En', 'a', 'ai', 'an', 'ang', 'ao', 'b', 'c', 'ch', 'd', 'e', 'ei', 'en', 'eng', 'er', 'f', 'g', 'h', - 'i', 'i0', 'ia', 'ian', 'iang', 'iao', 'ie', 'in', 'ing', 'iong', 'ir', 'iu', 'j', 'k', 'l', 'm', 'n', 'o', - 'ong', - 'ou', 'p', 'q', 'r', 's', 'sh', 't', 'u', 'ua', 'uai', 'uan', 'uang', 'ui', 'un', 'uo', 'v', 'van', 've', 'vn', - 'w', 'x', 'y', 'z', 'zh', - "AA", "EE", "OO"] -num_zh_tones = 6 - -# japanese -ja_symbols = ['I', 'N', 'U', 'a', 'b', 'by', 'ch', 'cl', 'd', 'dy', 'e', 'f', 'g', 'gy', 'h', 'hy', 'i', 'j', 'k', 'ky', - 'm', 'my', 'n', 'ny', 'o', 'p', 'py', 'r', 'ry', 's', 'sh', 't', 'ts', 'u', 'V', 'w', 'y', 'z'] -num_ja_tones = 1 - -# English -en_symbols = ['aa', 'ae', 'ah', 'ao', 'aw', 'ay', 'b', 'ch', 'd', 'dh', 'eh', 'er', 'ey', 'f', 'g', 'hh', 'ih', 'iy', - 'jh', 'k', 'l', 'm', 'n', 'ng', 'ow', 'oy', 'p', 'r', 's', - 'sh', 't', 'th', 'uh', 'uw', 'V', 'w', 'y', 'z', 'zh'] -num_en_tones = 4 - -# combine all symbols -normal_symbols = sorted(set(zh_symbols + ja_symbols + en_symbols)) -symbols = [pad] + normal_symbols + pu_symbols -sil_phonemes_ids = [symbols.index(i) for i in pu_symbols] - -# combine all tones -num_tones = num_zh_tones + num_ja_tones + num_en_tones - -# language maps -language_id_map = { - 'ZH': 0, - "JA": 1, - "EN": 2 -} -num_languages = len(language_id_map.keys()) - -language_tone_start_map = { - 'ZH': 0, - "JA": num_zh_tones, - "EN": num_zh_tones + num_ja_tones -} - -if __name__ == '__main__': - a = set(zh_symbols) - b = set(en_symbols) - print(sorted(a&b)) - diff --git a/spaces/Yiqin/ChatVID/model/fastchat/data/merge.py b/spaces/Yiqin/ChatVID/model/fastchat/data/merge.py deleted file mode 100644 index ea5b8a93b3872f20e8a285465709c09549b76b89..0000000000000000000000000000000000000000 --- a/spaces/Yiqin/ChatVID/model/fastchat/data/merge.py +++ /dev/null @@ -1,23 +0,0 @@ -""" -Merge two conversation files into one - -Usage: python3 -m fastchat.data.merge --in file1.json file2.json --out merged.json -""" - -import argparse -import json -from typing import Dict, Sequence, Optional - - -if __name__ == "__main__": - parser = argparse.ArgumentParser() - parser.add_argument("--in-file", type=str, required=True, nargs="+") - parser.add_argument("--out-file", type=str, default="merged.json") - args = parser.parse_args() - - new_content = [] - for in_file in args.in_file: - content = json.load(open(in_file, "r")) - new_content.extend(content) - - json.dump(new_content, open(args.out_file, "w"), indent=2) diff --git a/spaces/Yiqin/ChatVID/model/fastchat/serve/__init__.py b/spaces/Yiqin/ChatVID/model/fastchat/serve/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/YouLiXiya/Mobile-SAM/README.md b/spaces/YouLiXiya/Mobile-SAM/README.md deleted file mode 100644 index 96d9477d76c5d5b62b5a9353bbe3736f676f047f..0000000000000000000000000000000000000000 --- a/spaces/YouLiXiya/Mobile-SAM/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Mobile SAM -emoji: 📊 -colorFrom: purple -colorTo: indigo -sdk: gradio -sdk_version: 3.40.1 -app_file: app.py -pinned: false -license: mit ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Yuliang/ECON/lib/pixielib/utils/config.py b/spaces/Yuliang/ECON/lib/pixielib/utils/config.py deleted file mode 100644 index 133f057337081d6424e025e530bcbeed69acd315..0000000000000000000000000000000000000000 --- a/spaces/Yuliang/ECON/lib/pixielib/utils/config.py +++ /dev/null @@ -1,218 +0,0 @@ -""" -Default config for PIXIE -""" -import argparse -import os - -import yaml -from yacs.config import CfgNode as CN -from huggingface_hub import hf_hub_download - -cfg = CN() - -abs_pixie_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..", "..")) -cfg.pixie_dir = abs_pixie_dir -cfg.device = "cuda" -cfg.device_id = "0" -cfg.pretrained_modelpath = hf_hub_download( - repo_id="Yuliang/PIXIE", filename="pixie_model.tar", use_auth_token=os.environ["ICON"] -) -# smplx parameter settings -cfg.params = CN() -cfg.params.body_list = ["body_cam", "global_pose", "partbody_pose", "neck_pose"] -cfg.params.head_list = ["head_cam", "tex", "light"] -cfg.params.head_share_list = ["shape", "exp", "head_pose", "jaw_pose"] -cfg.params.hand_list = ["hand_cam"] -cfg.params.hand_share_list = [ - "right_wrist_pose", - "right_hand_pose", -] # only for right hand - -# ---------------------------------------------------------------------------- # -# Options for Body model -# ---------------------------------------------------------------------------- # -cfg.model = CN() -cfg.model.topology_path = hf_hub_download( - repo_id="Yuliang/PIXIE", - use_auth_token=os.environ["ICON"], - filename="SMPL_X_template_FLAME_uv.obj" -) -cfg.model.topology_smplxtex_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="smplx_tex.obj" -) -cfg.model.topology_smplx_hand_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="smplx_hand.obj" -) -cfg.model.smplx_model_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="SMPLX_NEUTRAL_2020.npz" -) -cfg.model.face_mask_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="uv_face_mask.png" -) -cfg.model.face_eye_mask_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="uv_face_eye_mask.png" -) -cfg.model.extra_joint_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="smplx_extra_joints.yaml" -) -cfg.model.j14_regressor_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="SMPLX_to_J14.pkl" -) -cfg.model.flame2smplx_cached_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="flame2smplx_tex_1024.npy" -) -cfg.model.smplx_tex_path = hf_hub_download( - repo_id="Yuliang/PIXIE", use_auth_token=os.environ["ICON"], filename="smplx_tex.png" -) -cfg.model.mano_ids_path = hf_hub_download( - repo_id="Yuliang/PIXIE", - use_auth_token=os.environ["ICON"], - filename="MANO_SMPLX_vertex_ids.pkl" -) -cfg.model.flame_ids_path = hf_hub_download( - repo_id="Yuliang/PIXIE", - use_auth_token=os.environ["ICON"], - filename="SMPL-X__FLAME_vertex_ids.npy" -) -cfg.model.uv_size = 256 -cfg.model.n_shape = 200 -cfg.model.n_tex = 50 -cfg.model.n_exp = 50 -cfg.model.n_body_cam = 3 -cfg.model.n_head_cam = 3 -cfg.model.n_hand_cam = 3 -cfg.model.tex_type = "BFM" # BFM, FLAME, albedoMM -cfg.model.uvtex_type = "SMPLX" # FLAME or SMPLX -cfg.model.use_tex = False # whether to use flame texture model -cfg.model.flame_tex_path = "" - -# pose -cfg.model.n_global_pose = 3 * 2 -cfg.model.n_head_pose = 3 * 2 -cfg.model.n_neck_pose = 3 * 2 -cfg.model.n_jaw_pose = 3 # euler angle -cfg.model.n_body_pose = 21 * 3 * 2 -cfg.model.n_partbody_pose = (21 - 4) * 3 * 2 -cfg.model.n_left_hand_pose = 15 * 3 * 2 -cfg.model.n_right_hand_pose = 15 * 3 * 2 -cfg.model.n_left_wrist_pose = 1 * 3 * 2 -cfg.model.n_right_wrist_pose = 1 * 3 * 2 -cfg.model.n_light = 27 -cfg.model.check_pose = True - -# ---------------------------------------------------------------------------- # -# Options for Dataset -# ---------------------------------------------------------------------------- # -cfg.dataset = CN() -cfg.dataset.source = ["body", "head", "hand"] - -# head/face dataset -cfg.dataset.head = CN() -cfg.dataset.head.batch_size = 24 -cfg.dataset.head.num_workers = 2 -cfg.dataset.head.from_body = True -cfg.dataset.head.image_size = 224 -cfg.dataset.head.image_hd_size = 224 -cfg.dataset.head.scale_min = 1.8 -cfg.dataset.head.scale_max = 2.2 -cfg.dataset.head.trans_scale = 0.3 -# body datset -cfg.dataset.body = CN() -cfg.dataset.body.batch_size = 24 -cfg.dataset.body.num_workers = 2 -cfg.dataset.body.image_size = 224 -cfg.dataset.body.image_hd_size = 1024 -cfg.dataset.body.use_hd = True -# hand datset -cfg.dataset.hand = CN() -cfg.dataset.hand.batch_size = 24 -cfg.dataset.hand.num_workers = 2 -cfg.dataset.hand.image_size = 224 -cfg.dataset.hand.image_hd_size = 512 -cfg.dataset.hand.scale_min = 2.2 -cfg.dataset.hand.scale_max = 2.6 -cfg.dataset.hand.trans_scale = 0.4 - -# ---------------------------------------------------------------------------- # -# Options for Network -# ---------------------------------------------------------------------------- # -cfg.network = CN() -cfg.network.encoder = CN() -cfg.network.encoder.body = CN() -cfg.network.encoder.body.type = "hrnet" -cfg.network.encoder.head = CN() -cfg.network.encoder.head.type = "resnet50" -cfg.network.encoder.hand = CN() -cfg.network.encoder.hand.type = "resnet50" - -cfg.network.regressor = CN() -cfg.network.regressor.head_share = CN() -cfg.network.regressor.head_share.type = "mlp" -cfg.network.regressor.head_share.channels = [1024, 1024] -cfg.network.regressor.hand_share = CN() -cfg.network.regressor.hand_share.type = "mlp" -cfg.network.regressor.hand_share.channels = [1024, 1024] -cfg.network.regressor.body = CN() -cfg.network.regressor.body.type = "mlp" -cfg.network.regressor.body.channels = [1024] -cfg.network.regressor.head = CN() -cfg.network.regressor.head.type = "mlp" -cfg.network.regressor.head.channels = [1024] -cfg.network.regressor.hand = CN() -cfg.network.regressor.hand.type = "mlp" -cfg.network.regressor.hand.channels = [1024] - -cfg.network.extractor = CN() -cfg.network.extractor.head_share = CN() -cfg.network.extractor.head_share.type = "mlp" -cfg.network.extractor.head_share.channels = [] -cfg.network.extractor.left_hand_share = CN() -cfg.network.extractor.left_hand_share.type = "mlp" -cfg.network.extractor.left_hand_share.channels = [] -cfg.network.extractor.right_hand_share = CN() -cfg.network.extractor.right_hand_share.type = "mlp" -cfg.network.extractor.right_hand_share.channels = [] - -cfg.network.moderator = CN() -cfg.network.moderator.head_share = CN() -cfg.network.moderator.head_share.detach_inputs = False -cfg.network.moderator.head_share.detach_feature = False -cfg.network.moderator.head_share.type = "temp-softmax" -cfg.network.moderator.head_share.channels = [1024, 1024] -cfg.network.moderator.head_share.reduction = 4 -cfg.network.moderator.head_share.scale_type = "scalars" -cfg.network.moderator.head_share.scale_init = 1.0 -cfg.network.moderator.hand_share = CN() -cfg.network.moderator.hand_share.detach_inputs = False -cfg.network.moderator.hand_share.detach_feature = False -cfg.network.moderator.hand_share.type = "temp-softmax" -cfg.network.moderator.hand_share.channels = [1024, 1024] -cfg.network.moderator.hand_share.reduction = 4 -cfg.network.moderator.hand_share.scale_type = "scalars" -cfg.network.moderator.hand_share.scale_init = 0.0 - - -def get_cfg_defaults(): - """Get a yacs CfgNode object with default values for my_project.""" - # Return a clone so that the defaults will not be altered - # This is for the "local variable" use pattern - return cfg.clone() - - -def update_cfg(cfg, cfg_file): - # cfg.merge_from_file(cfg_file, allow_unsafe=True) - cfg.merge_from_file(cfg_file) - return cfg.clone() - - -def parse_args(): - parser = argparse.ArgumentParser() - parser.add_argument("--cfg", type=str, help="cfg file path") - - args = parser.parse_args() - cfg = get_cfg_defaults() - if args.cfg is not None: - cfg_file = args.cfg - cfg = update_cfg(cfg, args.cfg) - cfg.cfg_file = cfg_file - return cfg diff --git a/spaces/ZenXir/FreeVC/speaker_encoder/audio.py b/spaces/ZenXir/FreeVC/speaker_encoder/audio.py deleted file mode 100644 index 2fcb77ad1d3a85f523e24f84691886736a5686cb..0000000000000000000000000000000000000000 --- a/spaces/ZenXir/FreeVC/speaker_encoder/audio.py +++ /dev/null @@ -1,107 +0,0 @@ -from scipy.ndimage.morphology import binary_dilation -from speaker_encoder.params_data import * -from pathlib import Path -from typing import Optional, Union -import numpy as np -import webrtcvad -import librosa -import struct - -int16_max = (2 ** 15) - 1 - - -def preprocess_wav(fpath_or_wav: Union[str, Path, np.ndarray], - source_sr: Optional[int] = None): - """ - Applies the preprocessing operations used in training the Speaker Encoder to a waveform - either on disk or in memory. The waveform will be resampled to match the data hyperparameters. - - :param fpath_or_wav: either a filepath to an audio file (many extensions are supported, not - just .wav), either the waveform as a numpy array of floats. - :param source_sr: if passing an audio waveform, the sampling rate of the waveform before - preprocessing. After preprocessing, the waveform's sampling rate will match the data - hyperparameters. If passing a filepath, the sampling rate will be automatically detected and - this argument will be ignored. - """ - # Load the wav from disk if needed - if isinstance(fpath_or_wav, str) or isinstance(fpath_or_wav, Path): - wav, source_sr = librosa.load(fpath_or_wav, sr=None) - else: - wav = fpath_or_wav - - # Resample the wav if needed - if source_sr is not None and source_sr != sampling_rate: - wav = librosa.resample(wav, source_sr, sampling_rate) - - # Apply the preprocessing: normalize volume and shorten long silences - wav = normalize_volume(wav, audio_norm_target_dBFS, increase_only=True) - wav = trim_long_silences(wav) - - return wav - - -def wav_to_mel_spectrogram(wav): - """ - Derives a mel spectrogram ready to be used by the encoder from a preprocessed audio waveform. - Note: this not a log-mel spectrogram. - """ - frames = librosa.feature.melspectrogram( - y=wav, - sr=sampling_rate, - n_fft=int(sampling_rate * mel_window_length / 1000), - hop_length=int(sampling_rate * mel_window_step / 1000), - n_mels=mel_n_channels - ) - return frames.astype(np.float32).T - - -def trim_long_silences(wav): - """ - Ensures that segments without voice in the waveform remain no longer than a - threshold determined by the VAD parameters in params.py. - - :param wav: the raw waveform as a numpy array of floats - :return: the same waveform with silences trimmed away (length <= original wav length) - """ - # Compute the voice detection window size - samples_per_window = (vad_window_length * sampling_rate) // 1000 - - # Trim the end of the audio to have a multiple of the window size - wav = wav[:len(wav) - (len(wav) % samples_per_window)] - - # Convert the float waveform to 16-bit mono PCM - pcm_wave = struct.pack("%dh" % len(wav), *(np.round(wav * int16_max)).astype(np.int16)) - - # Perform voice activation detection - voice_flags = [] - vad = webrtcvad.Vad(mode=3) - for window_start in range(0, len(wav), samples_per_window): - window_end = window_start + samples_per_window - voice_flags.append(vad.is_speech(pcm_wave[window_start * 2:window_end * 2], - sample_rate=sampling_rate)) - voice_flags = np.array(voice_flags) - - # Smooth the voice detection with a moving average - def moving_average(array, width): - array_padded = np.concatenate((np.zeros((width - 1) // 2), array, np.zeros(width // 2))) - ret = np.cumsum(array_padded, dtype=float) - ret[width:] = ret[width:] - ret[:-width] - return ret[width - 1:] / width - - audio_mask = moving_average(voice_flags, vad_moving_average_width) - audio_mask = np.round(audio_mask).astype(np.bool) - - # Dilate the voiced regions - audio_mask = binary_dilation(audio_mask, np.ones(vad_max_silence_length + 1)) - audio_mask = np.repeat(audio_mask, samples_per_window) - - return wav[audio_mask == True] - - -def normalize_volume(wav, target_dBFS, increase_only=False, decrease_only=False): - if increase_only and decrease_only: - raise ValueError("Both increase only and decrease only are set") - dBFS_change = target_dBFS - 10 * np.log10(np.mean(wav ** 2)) - if (dBFS_change < 0 and increase_only) or (dBFS_change > 0 and decrease_only): - return wav - return wav * (10 ** (dBFS_change / 20)) diff --git a/spaces/Zwicky18/vits-models/commons.py b/spaces/Zwicky18/vits-models/commons.py deleted file mode 100644 index 40fcc05364d4815971f5c6f9dbb8dcef8e3ec1e9..0000000000000000000000000000000000000000 --- a/spaces/Zwicky18/vits-models/commons.py +++ /dev/null @@ -1,172 +0,0 @@ -import math -import torch -from torch.nn import functional as F -import torch.jit - - -def script_method(fn, _rcb=None): - return fn - - -def script(obj, optimize=True, _frames_up=0, _rcb=None): - return obj - - -torch.jit.script_method = script_method -torch.jit.script = script - - -def init_weights(m, mean=0.0, std=0.01): - classname = m.__class__.__name__ - if classname.find("Conv") != -1: - m.weight.data.normal_(mean, std) - - -def get_padding(kernel_size, dilation=1): - return int((kernel_size*dilation - dilation)/2) - - -def convert_pad_shape(pad_shape): - l = pad_shape[::-1] - pad_shape = [item for sublist in l for item in sublist] - return pad_shape - - -def intersperse(lst, item): - result = [item] * (len(lst) * 2 + 1) - result[1::2] = lst - return result - - -def kl_divergence(m_p, logs_p, m_q, logs_q): - """KL(P||Q)""" - kl = (logs_q - logs_p) - 0.5 - kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q) - return kl - - -def rand_gumbel(shape): - """Sample from the Gumbel distribution, protect from overflows.""" - uniform_samples = torch.rand(shape) * 0.99998 + 0.00001 - return -torch.log(-torch.log(uniform_samples)) - - -def rand_gumbel_like(x): - g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device) - return g - - -def slice_segments(x, ids_str, segment_size=4): - ret = torch.zeros_like(x[:, :, :segment_size]) - for i in range(x.size(0)): - idx_str = ids_str[i] - idx_end = idx_str + segment_size - ret[i] = x[i, :, idx_str:idx_end] - return ret - - -def rand_slice_segments(x, x_lengths=None, segment_size=4): - b, d, t = x.size() - if x_lengths is None: - x_lengths = t - ids_str_max = x_lengths - segment_size + 1 - ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long) - ret = slice_segments(x, ids_str, segment_size) - return ret, ids_str - - -def get_timing_signal_1d( - length, channels, min_timescale=1.0, max_timescale=1.0e4): - position = torch.arange(length, dtype=torch.float) - num_timescales = channels // 2 - log_timescale_increment = ( - math.log(float(max_timescale) / float(min_timescale)) / - (num_timescales - 1)) - inv_timescales = min_timescale * torch.exp( - torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment) - scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1) - signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0) - signal = F.pad(signal, [0, 0, 0, channels % 2]) - signal = signal.view(1, channels, length) - return signal - - -def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4): - b, channels, length = x.size() - signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale) - return x + signal.to(dtype=x.dtype, device=x.device) - - -def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1): - b, channels, length = x.size() - signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale) - return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis) - - -def subsequent_mask(length): - mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0) - return mask - - -@torch.jit.script -def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels): - n_channels_int = n_channels[0] - in_act = input_a + input_b - t_act = torch.tanh(in_act[:, :n_channels_int, :]) - s_act = torch.sigmoid(in_act[:, n_channels_int:, :]) - acts = t_act * s_act - return acts - - -def convert_pad_shape(pad_shape): - l = pad_shape[::-1] - pad_shape = [item for sublist in l for item in sublist] - return pad_shape - - -def shift_1d(x): - x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1] - return x - - -def sequence_mask(length, max_length=None): - if max_length is None: - max_length = length.max() - x = torch.arange(max_length, dtype=length.dtype, device=length.device) - return x.unsqueeze(0) < length.unsqueeze(1) - - -def generate_path(duration, mask): - """ - duration: [b, 1, t_x] - mask: [b, 1, t_y, t_x] - """ - device = duration.device - - b, _, t_y, t_x = mask.shape - cum_duration = torch.cumsum(duration, -1) - - cum_duration_flat = cum_duration.view(b * t_x) - path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype) - path = path.view(b, t_x, t_y) - path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1] - path = path.unsqueeze(1).transpose(2,3) * mask - return path - - -def clip_grad_value_(parameters, clip_value, norm_type=2): - if isinstance(parameters, torch.Tensor): - parameters = [parameters] - parameters = list(filter(lambda p: p.grad is not None, parameters)) - norm_type = float(norm_type) - if clip_value is not None: - clip_value = float(clip_value) - - total_norm = 0 - for p in parameters: - param_norm = p.grad.data.norm(norm_type) - total_norm += param_norm.item() ** norm_type - if clip_value is not None: - p.grad.data.clamp_(min=-clip_value, max=clip_value) - total_norm = total_norm ** (1. / norm_type) - return total_norm diff --git a/spaces/abhi-pwr/underwater_trash_detection/README.md b/spaces/abhi-pwr/underwater_trash_detection/README.md deleted file mode 100644 index fb2ad9c934aee95e305e19f6e0e6f36b8d000a0c..0000000000000000000000000000000000000000 --- a/spaces/abhi-pwr/underwater_trash_detection/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Underwater Trash Detection -emoji: 🐙 -colorFrom: purple -colorTo: green -sdk: gradio -sdk_version: 3.29.0 -app_file: app.py -pinned: false -license: unknown ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/utils/ext_loader.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/utils/ext_loader.py deleted file mode 100644 index cd8044f71184fa1081566da0ab771caf5f5b39f8..0000000000000000000000000000000000000000 --- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/utils/ext_loader.py +++ /dev/null @@ -1,71 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -import importlib -import os -import pkgutil -import warnings -from collections import namedtuple - -import torch - -if torch.__version__ != 'parrots': - - def load_ext(name, funcs): - ext = importlib.import_module('annotator.uniformer.mmcv.' + name) - for fun in funcs: - assert hasattr(ext, fun), f'{fun} miss in module {name}' - return ext -else: - from parrots import extension - from parrots.base import ParrotsException - - has_return_value_ops = [ - 'nms', - 'softnms', - 'nms_match', - 'nms_rotated', - 'top_pool_forward', - 'top_pool_backward', - 'bottom_pool_forward', - 'bottom_pool_backward', - 'left_pool_forward', - 'left_pool_backward', - 'right_pool_forward', - 'right_pool_backward', - 'fused_bias_leakyrelu', - 'upfirdn2d', - 'ms_deform_attn_forward', - 'pixel_group', - 'contour_expand', - ] - - def get_fake_func(name, e): - - def fake_func(*args, **kwargs): - warnings.warn(f'{name} is not supported in parrots now') - raise e - - return fake_func - - def load_ext(name, funcs): - ExtModule = namedtuple('ExtModule', funcs) - ext_list = [] - lib_root = os.path.dirname(os.path.dirname(os.path.realpath(__file__))) - for fun in funcs: - try: - ext_fun = extension.load(fun, name, lib_dir=lib_root) - except ParrotsException as e: - if 'No element registered' not in e.message: - warnings.warn(e.message) - ext_fun = get_fake_func(fun, e) - ext_list.append(ext_fun) - else: - if fun in has_return_value_ops: - ext_list.append(ext_fun.op) - else: - ext_list.append(ext_fun.op_) - return ExtModule(*ext_list) - - -def check_ops_exist(): - ext_loader = pkgutil.find_loader('mmcv._ext') - return ext_loader is not None diff --git a/spaces/adept/fuyu-8b-demo/app.py b/spaces/adept/fuyu-8b-demo/app.py deleted file mode 100644 index 50daed2ff0895b01f14912732eb8c4f7cf5fa138..0000000000000000000000000000000000000000 --- a/spaces/adept/fuyu-8b-demo/app.py +++ /dev/null @@ -1,180 +0,0 @@ -import gradio as gr -import re -import torch -from PIL import Image -from transformers import FuyuForCausalLM, FuyuProcessor - -model_id = "adept/fuyu-8b" -dtype = torch.bfloat16 - -model = FuyuForCausalLM.from_pretrained(model_id, device_map="cuda", torch_dtype=dtype) -processor = FuyuProcessor.from_pretrained(model_id) - -CAPTION_PROMPT = "Generate a coco-style caption.\n" -DETAILED_CAPTION_PROMPT = "What is happening in this image?" - -def resize_to_max(image, max_width=1920, max_height=1080): - width, height = image.size - if width <= max_width and height <= max_height: - return image - - scale = min(max_width/width, max_height/height) - width = int(width*scale) - height = int(height*scale) - - return image.resize((width, height), Image.LANCZOS) - -def pad_to_size(image, canvas_width=1920, canvas_height=1080): - width, height = image.size - if width >= canvas_width and height >= canvas_height: - return image - - # Paste at (0, 0) - canvas = Image.new("RGB", (canvas_width, canvas_height)) - canvas.paste(image) - return canvas - -def predict(image, prompt): - # image = image.convert('RGB') - model_inputs = processor(text=prompt, images=[image]).to(device=model.device) - - generation_output = model.generate(**model_inputs, max_new_tokens=50) - prompt_len = model_inputs["input_ids"].shape[-1] - return processor.decode(generation_output[0][prompt_len:], skip_special_tokens=True) - -def caption(image, detailed_captioning): - if detailed_captioning: - caption_prompt = DETAILED_CAPTION_PROMPT - else: - caption_prompt = CAPTION_PROMPT - return predict(image, caption_prompt).lstrip() - -def set_example_image(example: list) -> dict: - return gr.Image.update(value=example[0]) - -def coords_from_response(response): - # y1, x1, y2, x2 - pattern = r"(\d+),\s*(\d+),\s*(\d+),\s*(\d+) " - - match = re.search(pattern, response) - if match: - # Unpack and change order - y1, x1, y2, x2 = [int(coord) for coord in match.groups()] - return (x1, y1, x2, y2) - else: - gr.Error("The string is malformed or does not match the expected pattern.") - -def localize(image, query): - prompt = f"When presented with a box, perform OCR to extract text contained within it. If provided with text, generate the corresponding bounding box.\n{query}" - - # Downscale and/or pad to 1920x1080 - padded = resize_to_max(image) - padded = pad_to_size(padded) - - model_inputs = processor(text=prompt, images=[padded]).to(device=model.device) - - outputs = model.generate(**model_inputs, max_new_tokens=40) - post_processed_bbox_tokens = processor.post_process_box_coordinates(outputs)[0] - decoded = processor.decode(post_processed_bbox_tokens, skip_special_tokens=True) - decoded = decoded.split('\x04', 1)[1] if '\x04' in decoded else '' - coords = coords_from_response(decoded) - return image, [(coords, f"Location of \"{query}\"")] - - -css = """ - #mkd { - height: 500px; - overflow: auto; - border: 1px solid #ccc; - } -""" - -with gr.Blocks(css=css) as demo: - gr.HTML( - """ -Fuyu Multimodal Demo
-Fuyu-8B is a multimodal model that supports a variety of tasks combining text and image prompts.
- For example, you can use it for captioning by asking it to describe an image. You can also ask it questions about an image, a task known as Visual Question Answering, or VQA. This demo lets you explore captioning and VQA, with more tasks coming soon :) - Learn more about the model in our blog post. -
-
- Note: This is a raw model release. We have not added further instruction-tuning, postprocessing or sampling strategies to control for undesirable outputs. The model may hallucinate, and you should expect to have to fine-tune the model for your use-case! -Play with Fuyu-8B in this demo! 💬
- """ - ) - with gr.Tab("Visual Question Answering"): - gr.Markdown( - """ - You can use natural-language questions to ask about the image. However, since this is a base model not fine-tuned for \ - chat instructions, you may get better results by following a prompt format similar to the one used during training. See the \ - examples below for details! - """ - ) - with gr.Row(): - with gr.Column(): - image_input = gr.Image(label="Upload your Image", type="pil") - text_input = gr.Textbox(label="Ask a Question") - vqa_output = gr.Textbox(label="Output") - - vqa_btn = gr.Button("Answer Visual Question") - - gr.Examples( - [ - ["assets/vqa_example_1.png", "What's the name of this dessert, and how is it made?\n"], - ["assets/vqa_example_2.png", "What is this flower and where is it's origin?"], - ["assets/food.png", "Answer the following VQAv2 question based on the image.\nWhat type of foods are in the image?"], - ["assets/jobs.png", "Answer the following DocVQA question based on the image.\nWhich is the metro in California that has a good job Outlook?"], - ["assets/docvqa_example.png", "How many items are sold?"], - ["assets/screen2words_ui_example.png", "What is this app about?"], - ], - inputs = [image_input, text_input], - outputs = [vqa_output], - fn=predict, - cache_examples=True, - label='Click on any Examples below to get VQA results quickly 👇' - ) - - - with gr.Tab("Image Captioning"): - with gr.Row(): - with gr.Column(): - captioning_input = gr.Image(label="Upload your Image", type="pil") - detailed_captioning_checkbox = gr.Checkbox(label="Enable detailed captioning") - captioning_output = gr.Textbox(label="Output") - captioning_btn = gr.Button("Generate Caption") - - gr.Examples( - [["assets/captioning_example_1.png", False], ["assets/girl_hat.png", True]], - inputs = [captioning_input, detailed_captioning_checkbox], - outputs = [captioning_output], - fn=caption, - cache_examples=True, - label='Click on any Examples below to get captioning results quickly 👇' - ) - - captioning_btn.click(fn=caption, inputs=[captioning_input, detailed_captioning_checkbox], outputs=captioning_output) - vqa_btn.click(fn=predict, inputs=[image_input, text_input], outputs=vqa_output) - - with gr.Tab("Find Text in Screenshots"): - with gr.Row(): - with gr.Column(): - localization_input = gr.Image(label="Upload your Image", type="pil") - query_input = gr.Textbox(label="Text to find") - localization_btn = gr.Button("Locate Text") - with gr.Column(): - with gr.Row(height=800): - localization_output = gr.AnnotatedImage(label="Text Position") - - gr.Examples( - [["assets/localization_example_1.jpeg", "Share your repair"], - ["assets/screen2words_ui_example.png", "statistics"]], - inputs = [localization_input, query_input], - outputs = [localization_output], - fn=localize, - cache_examples=True, - label='Click on any Examples below to get localization results quickly 👇' - ) - - localization_btn.click(fn=localize, inputs=[localization_input, query_input], outputs=localization_output) - -demo.launch(server_name="0.0.0.0") \ No newline at end of file diff --git a/spaces/ai-guru/composer/source/logging.py b/spaces/ai-guru/composer/source/logging.py deleted file mode 100644 index 082d1c8bb3c60e29027026a50a6f7e7bb89d0ba3..0000000000000000000000000000000000000000 --- a/spaces/ai-guru/composer/source/logging.py +++ /dev/null @@ -1,45 +0,0 @@ -# Copyright 2021 Tristan Behrens. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -# Lint as: python3 - -import logging - -loggers_dict = {} - -def create_logger(name:str): - global loggers_dict - if name in loggers_dict: - return loggers_dict[name] - else: - logger = logging.getLogger(name) - loggers_dict[name] = logger - logger.setLevel(logging.DEBUG) - handler = logging.StreamHandler() - handler.setLevel(logging.DEBUG) - formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') - handler.setFormatter(formatter) - logger.addHandler(handler) - logger.propagate = False - return logger - -def set_log_level(name, level): - logger_names = [] - if name == "all": - logger_names = list(loggers_dict.keys()) - else: - logger_names = [name] - for name in logger_names: - logger = loggers_dict[name] - logger.setLevel(level) diff --git a/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/speech_commands/voc1/path.sh b/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/speech_commands/voc1/path.sh deleted file mode 100644 index b0ca27c615f70aa29e240222ec370f8ad4e7b45a..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/speech_commands/voc1/path.sh +++ /dev/null @@ -1,33 +0,0 @@ -# cuda related -export CUDA_HOME=/usr/local/cuda-10.0 -export LD_LIBRARY_PATH="${CUDA_HOME}/lib64:${LD_LIBRARY_PATH}" - -# path related -export PRJ_ROOT="${PWD}/../../.." -if [ -e "${PRJ_ROOT}/tools/venv/bin/activate" ]; then - # shellcheck disable=SC1090 - . "${PRJ_ROOT}/tools/venv/bin/activate" -fi - -# python related -export OMP_NUM_THREADS=1 -export PYTHONIOENCODING=UTF-8 -export MPL_BACKEND=Agg - -# check installation -if ! command -v parallel-wavegan-train > /dev/null; then - echo "Error: It seems setup is not finished." >&2 - echo "Error: Please setup your environment by following README.md" >&2 - return 1 -fi -if ! command -v jq > /dev/null; then - echo "Error: It seems jq is not installed." >&2 - echo "Error: Please install via \`sudo apt-get install jq\`." >&2 - echo "Error: If you do not have sudo, please download from https://stedolan.github.io/jq/download/." >&2 - return 1 -fi -if ! command -v yq > /dev/null; then - echo "Error: It seems yq is not installed." >&2 - echo "Error: Please install via \`pip install yq\`." >&2 - return 1 -fi diff --git a/spaces/akhaliq/deeplab2/model/layers/convolutions.py b/spaces/akhaliq/deeplab2/model/layers/convolutions.py deleted file mode 100644 index b24ab892c82e249d27f0ab870939756c6c78af68..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/deeplab2/model/layers/convolutions.py +++ /dev/null @@ -1,666 +0,0 @@ -# coding=utf-8 -# Copyright 2021 The Deeplab2 Authors. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -"""This file contains wrapper classes for convolution layers of tf.keras and Switchable Atrous Convolution. - -Switchable Atrous Convolution (SAC) is convolution with a switchable atrous -rate. It also has optional pre- and post-global context layers. -[1] Siyuan Qiao, Liang-Chieh Chen, Alan Yuille. DetectoRS: Detecting Objects - with Recursive Feature Pyramid and Switchable Atrous Convolution. - arXiv:2006.02334 -""" -import functools -from typing import Optional - -from absl import logging -import tensorflow as tf - -from deeplab2.model import utils -from deeplab2.model.layers import activations - - -def _compute_padding_size(kernel_size, atrous_rate): - kernel_size_effective = kernel_size + (kernel_size - 1) * (atrous_rate - 1) - pad_total = kernel_size_effective - 1 - pad_begin = pad_total // 2 - pad_end = pad_total - pad_begin - if pad_begin != pad_end: - logging.warn('Convolution requires one more padding to the ' - 'bottom-right pixel. This may cause misalignment.') - return (pad_begin, pad_end) - - -class GlobalContext(tf.keras.layers.Layer): - """Class for the global context modules in Switchable Atrous Convolution.""" - - def build(self, input_shape): - super().build(input_shape) - input_shape = tf.TensorShape(input_shape) - input_channel = self._get_input_channel(input_shape) - self.global_average_pooling = tf.keras.layers.GlobalAveragePooling2D() - self.convolution = tf.keras.layers.Conv2D( - input_channel, 1, strides=1, padding='same', name=self.name + '_conv', - kernel_initializer='zeros', bias_initializer='zeros') - - def call(self, inputs, *args, **kwargs): - outputs = self.global_average_pooling(inputs) - outputs = tf.expand_dims(outputs, axis=1) - outputs = tf.expand_dims(outputs, axis=1) - outputs = self.convolution(outputs) - return inputs + outputs - - def _get_input_channel(self, input_shape): - # Reference: tf.keras.layers.convolutional.Conv. - if input_shape.dims[-1].value is None: - raise ValueError('The channel dimension of the inputs ' - 'should be defined. Found `None`.') - return int(input_shape[-1]) - - -class SwitchableAtrousConvolution(tf.keras.layers.Conv2D): - """Class for the Switchable Atrous Convolution.""" - - def __init__(self, *args, **kwargs): - super().__init__(*args, **kwargs) - self._average_pool = tf.keras.layers.AveragePooling2D( - pool_size=(5, 5), strides=1, padding='same') - self._switch = tf.keras.layers.Conv2D( - 1, - kernel_size=1, - strides=self.strides, - padding='same', - dilation_rate=1, - name='switch', - kernel_initializer='zeros', - bias_initializer='zeros') - - def build(self, input_shape): - super().build(input_shape) - if self.padding == 'causal': - tf_padding = 'VALID' - elif isinstance(self.padding, str): - tf_padding = self.padding.upper() - else: - tf_padding = self.padding - large_dilation_rate = list(self.dilation_rate) - large_dilation_rate = [r * 3 for r in large_dilation_rate] - self._large_convolution_op = functools.partial( - tf.nn.convolution, - strides=list(self.strides), - padding=tf_padding, - dilations=large_dilation_rate, - data_format=self._tf_data_format, - name=self.__class__.__name__ + '_large') - - def call(self, inputs): - # Reference: tf.keras.layers.convolutional.Conv. - input_shape = inputs.shape - switches = self._switch(self._average_pool(inputs)) - - if self._is_causal: # Apply causal padding to inputs for Conv1D. - inputs = tf.compat.v1.pad(inputs, self._compute_causal_padding(inputs)) - - outputs = self._convolution_op(inputs, self.kernel) - outputs_large = self._large_convolution_op(inputs, self.kernel) - - outputs = switches * outputs_large + (1 - switches) * outputs - - if self.use_bias: - outputs = tf.nn.bias_add( - outputs, self.bias, data_format=self._tf_data_format) - - if not tf.executing_eagerly(): - # Infer the static output shape: - out_shape = self.compute_output_shape(input_shape) - outputs.set_shape(out_shape) - - if self.activation is not None: - return self.activation(outputs) - return outputs - - def squeeze_batch_dims(self, inp, op, inner_rank): - # Reference: tf.keras.utils.conv_utils.squeeze_batch_dims. - with tf.name_scope('squeeze_batch_dims'): - shape = inp.shape - - inner_shape = shape[-inner_rank:] - if not inner_shape.is_fully_defined(): - inner_shape = tf.compat.v1.shape(inp)[-inner_rank:] - - batch_shape = shape[:-inner_rank] - if not batch_shape.is_fully_defined(): - batch_shape = tf.compat.v1.shape(inp)[:-inner_rank] - - if isinstance(inner_shape, tf.TensorShape): - inp_reshaped = tf.reshape(inp, [-1] + inner_shape.as_list()) - else: - inp_reshaped = tf.reshape( - inp, tf.concat(([-1], inner_shape), axis=-1)) - - out_reshaped = op(inp_reshaped) - - out_inner_shape = out_reshaped.shape[-inner_rank:] - if not out_inner_shape.is_fully_defined(): - out_inner_shape = tf.compat.v1.shape(out_reshaped)[-inner_rank:] - - out = tf.reshape( - out_reshaped, tf.concat((batch_shape, out_inner_shape), axis=-1)) - - out.set_shape(inp.shape[:-inner_rank] + out.shape[-inner_rank:]) - return out - - -class Conv2DSame(tf.keras.layers.Layer): - """A wrapper class for a 2D convolution with 'same' padding. - - In contrast to tf.keras.layers.Conv2D, this layer aligns the kernel with the - top-left corner rather than the bottom-right corner. Optionally, a batch - normalization and an activation can be added on top. - """ - - def __init__( - self, - output_channels: int, - kernel_size: int, - name: str, - strides: int = 1, - atrous_rate: int = 1, - use_bias: bool = True, - use_bn: bool = False, - bn_layer: tf.keras.layers.Layer = tf.keras.layers.BatchNormalization, - bn_gamma_initializer: str = 'ones', - activation: Optional[str] = None, - use_switchable_atrous_conv: bool = False, - use_global_context_in_sac: bool = False, - conv_kernel_weight_decay: float = 0.0): - """Initializes convolution with zero padding aligned to the top-left corner. - - DeepLab aligns zero padding differently to tf.keras 'same' padding. - Considering a convolution with a 7x7 kernel, a stride of 2 and an even input - size, tf.keras 'same' padding will add 2 zero padding to the top-left and 3 - zero padding to the bottom-right. However, for consistent feature alignment, - DeepLab requires an equal padding of 3 in all directions. This behavior is - consistent with e.g. the ResNet 'stem' block. - - Args: - output_channels: An integer specifying the number of filters of the - convolution. - kernel_size: An integer specifying the size of the convolution kernel. - name: A string specifying the name of this layer. - strides: An optional integer or tuple of integers specifying the size of - the strides (default: 1). - atrous_rate: An optional integer or tuple of integers specifying the - atrous rate of the convolution (default: 1). - use_bias: An optional flag specifying whether bias should be added for the - convolution. - use_bn: An optional flag specifying whether batch normalization should be - added after the convolution (default: False). - bn_layer: An optional tf.keras.layers.Layer that computes the - normalization (default: tf.keras.layers.BatchNormalization). - bn_gamma_initializer: An initializer for the batch norm gamma weight. - activation: An optional flag specifying an activation function to be added - after the convolution. - use_switchable_atrous_conv: Boolean, whether the layer uses switchable - atrous convolution. - use_global_context_in_sac: Boolean, whether the switchable atrous - convolution (SAC) uses pre- and post-global context. - conv_kernel_weight_decay: A float, the weight decay for convolution - kernels. - - Raises: - ValueError: If use_bias and use_bn in the convolution. - """ - super(Conv2DSame, self).__init__(name=name) - - if use_bn and use_bias: - raise ValueError('Conv2DSame is using convolution bias with batch_norm.') - - if use_global_context_in_sac: - self._pre_global_context = GlobalContext(name='pre_global_context') - - convolution_op = tf.keras.layers.Conv2D - convolution_padding = 'same' - if strides == 1 or strides == (1, 1): - if use_switchable_atrous_conv: - convolution_op = SwitchableAtrousConvolution - else: - padding = _compute_padding_size(kernel_size, atrous_rate) - self._zeropad = tf.keras.layers.ZeroPadding2D( - padding=(padding, padding), name='zeropad') - convolution_padding = 'valid' - self._conv = convolution_op( - output_channels, - kernel_size, - strides=strides, - padding=convolution_padding, - use_bias=use_bias, - dilation_rate=atrous_rate, - name='conv', - kernel_initializer='he_normal', - kernel_regularizer=tf.keras.regularizers.l2( - conv_kernel_weight_decay)) - - if use_global_context_in_sac: - self._post_global_context = GlobalContext(name='post_global_context') - - if use_bn: - self._batch_norm = bn_layer(axis=3, name='batch_norm', - gamma_initializer=bn_gamma_initializer) - - self._activation_fn = None - if activation is not None: - self._activation_fn = activations.get_activation(activation) - - self._use_global_context_in_sac = use_global_context_in_sac - self._strides = strides - self._use_bn = use_bn - - def call(self, input_tensor, training=False): - """Performs a forward pass. - - Args: - input_tensor: An input tensor of type tf.Tensor with shape [batch, height, - width, channels]. - training: A boolean flag indicating whether training behavior should be - used (default: False). - - Returns: - The output tensor. - """ - x = input_tensor - if self._use_global_context_in_sac: - x = self._pre_global_context(x) - - if not (self._strides == 1 or self._strides == (1, 1)): - x = self._zeropad(x) - x = self._conv(x) - - if self._use_global_context_in_sac: - x = self._post_global_context(x) - - if self._use_bn: - x = self._batch_norm(x, training=training) - - if self._activation_fn is not None: - x = self._activation_fn(x) - return x - - -class DepthwiseConv2DSame(tf.keras.layers.Layer): - """A wrapper class for a 2D depthwise convolution. - - In contrast to convolutions in tf.keras.layers.DepthwiseConv2D, this layers - aligns the kernel with the top-left corner rather than the bottom-right - corner. Optionally, a batch normalization and an activation can be added. - """ - - def __init__(self, - kernel_size: int, - name: str, - strides: int = 1, - atrous_rate: int = 1, - use_bias: bool = True, - use_bn: bool = False, - bn_layer=tf.keras.layers.BatchNormalization, - activation: Optional[str] = None): - """Initializes a 2D depthwise convolution. - - Args: - kernel_size: An integer specifying the size of the convolution kernel. - name: A string specifying the name of this layer. - strides: An optional integer or tuple of integers specifying the size of - the strides (default: 1). - atrous_rate: An optional integer or tuple of integers specifying the - atrous rate of the convolution (default: 1). - use_bias: An optional flag specifying whether bias should be added for the - convolution. - use_bn: An optional flag specifying whether batch normalization should be - added after the convolution (default: False). - bn_layer: An optional tf.keras.layers.Layer that computes the - normalization (default: tf.keras.layers.BatchNormalization). - activation: An optional flag specifying an activation function to be added - after the convolution. - - Raises: - ValueError: If use_bias and use_bn in the convolution. - """ - super(DepthwiseConv2DSame, self).__init__(name=name) - - if use_bn and use_bias: - raise ValueError( - 'DepthwiseConv2DSame is using convlution bias with batch_norm.') - - if strides == 1 or strides == (1, 1): - convolution_padding = 'same' - else: - padding = _compute_padding_size(kernel_size, atrous_rate) - self._zeropad = tf.keras.layers.ZeroPadding2D( - padding=(padding, padding), name='zeropad') - convolution_padding = 'valid' - self._depthwise_conv = tf.keras.layers.DepthwiseConv2D( - kernel_size=kernel_size, - strides=strides, - padding=convolution_padding, - use_bias=use_bias, - dilation_rate=atrous_rate, - name='depthwise_conv') - if use_bn: - self._batch_norm = bn_layer(axis=3, name='batch_norm') - - self._activation_fn = None - if activation is not None: - self._activation_fn = activations.get_activation(activation) - - self._strides = strides - self._use_bn = use_bn - - def call(self, input_tensor, training=False): - """Performs a forward pass. - - Args: - input_tensor: An input tensor of type tf.Tensor with shape [batch, height, - width, channels]. - training: A boolean flag indicating whether training behavior should be - used (default: False). - - Returns: - The output tensor. - """ - x = input_tensor - if not (self._strides == 1 or self._strides == (1, 1)): - x = self._zeropad(x) - x = self._depthwise_conv(x) - if self._use_bn: - x = self._batch_norm(x, training=training) - if self._activation_fn is not None: - x = self._activation_fn(x) - return x - - -class SeparableConv2DSame(tf.keras.layers.Layer): - """A wrapper class for a 2D separable convolution. - - In contrast to convolutions in tf.keras.layers.SeparableConv2D, this layers - aligns the kernel with the top-left corner rather than the bottom-right - corner. Optionally, a batch normalization and an activation can be added. - """ - - def __init__( - self, - output_channels: int, - kernel_size: int, - name: str, - strides: int = 1, - atrous_rate: int = 1, - use_bias: bool = True, - use_bn: bool = False, - bn_layer: tf.keras.layers.Layer = tf.keras.layers.BatchNormalization, - activation: Optional[str] = None): - """Initializes a 2D separable convolution. - - Args: - output_channels: An integer specifying the number of filters of the - convolution output. - kernel_size: An integer specifying the size of the convolution kernel. - name: A string specifying the name of this layer. - strides: An optional integer or tuple of integers specifying the size of - the strides (default: 1). - atrous_rate: An optional integer or tuple of integers specifying the - atrous rate of the convolution (default: 1). - use_bias: An optional flag specifying whether bias should be added for the - convolution. - use_bn: An optional flag specifying whether batch normalization should be - added after the convolution (default: False). - bn_layer: An optional tf.keras.layers.Layer that computes the - normalization (default: tf.keras.layers.BatchNormalization). - activation: An optional flag specifying an activation function to be added - after the convolution. - - Raises: - ValueError: If use_bias and use_bn in the convolution. - """ - super(SeparableConv2DSame, self).__init__(name=name) - if use_bn and use_bias: - raise ValueError( - 'SeparableConv2DSame is using convolution bias with batch_norm.') - - self._depthwise = DepthwiseConv2DSame( - kernel_size=kernel_size, - name='depthwise', - strides=strides, - atrous_rate=atrous_rate, - use_bias=use_bias, - use_bn=use_bn, - bn_layer=bn_layer, - activation=activation) - self._pointwise = Conv2DSame( - output_channels=output_channels, - kernel_size=1, - name='pointwise', - strides=1, - atrous_rate=1, - use_bias=use_bias, - use_bn=use_bn, - bn_layer=bn_layer, - activation=activation) - - def call(self, input_tensor, training=False): - """Performs a forward pass. - - Args: - input_tensor: An input tensor of type tf.Tensor with shape [batch, height, - width, channels]. - training: A boolean flag indicating whether training behavior should be - used (default: False). - - Returns: - The output tensor. - """ - x = self._depthwise(input_tensor, training=training) - return self._pointwise(x, training=training) - - -class StackedConv2DSame(tf.keras.layers.Layer): - """Stacked Conv2DSame or SeparableConv2DSame. - - This class sequentially stacks a given number of Conv2DSame layers or - SeparableConv2DSame layers. - """ - - def __init__( - self, - num_layers: int, - conv_type: str, - output_channels: int, - kernel_size: int, - name: str, - strides: int = 1, - atrous_rate: int = 1, - use_bias: bool = True, - use_bn: bool = False, - bn_layer: tf.keras.layers.Layer = tf.keras.layers.BatchNormalization, - activation: Optional[str] = None): - """Initializes a stack of convolutions. - - Args: - num_layers: The number of convolutions to create. - conv_type: A string specifying the convolution type used in each block. - Must be one of 'standard_conv' or 'depthwise_separable_conv'. - output_channels: An integer specifying the number of filters of the - convolution output. - kernel_size: An integer specifying the size of the convolution kernel. - name: A string specifying the name of this layer. - strides: An optional integer or tuple of integers specifying the size of - the strides (default: 1). - atrous_rate: An optional integer or tuple of integers specifying the - atrous rate of the convolution (default: 1). - use_bias: An optional flag specifying whether bias should be added for the - convolution. - use_bn: An optional flag specifying whether batch normalization should be - added after the convolution (default: False). - bn_layer: An optional tf.keras.layers.Layer that computes the - normalization (default: tf.keras.layers.BatchNormalization). - activation: An optional flag specifying an activation function to be added - after the convolution. - - Raises: - ValueError: An error occurs when conv_type is neither 'standard_conv' - nor 'depthwise_separable_conv'. - """ - super(StackedConv2DSame, self).__init__(name=name) - if conv_type == 'standard_conv': - convolution_op = Conv2DSame - elif conv_type == 'depthwise_separable_conv': - convolution_op = SeparableConv2DSame - else: - raise ValueError('Convolution %s not supported.' % conv_type) - - for index in range(num_layers): - current_name = utils.get_conv_bn_act_current_name(index, use_bn, - activation) - utils.safe_setattr(self, current_name, convolution_op( - output_channels=output_channels, - kernel_size=kernel_size, - name=utils.get_layer_name(current_name), - strides=strides, - atrous_rate=atrous_rate, - use_bias=use_bias, - use_bn=use_bn, - bn_layer=bn_layer, - activation=activation)) - self._num_layers = num_layers - self._use_bn = use_bn - self._activation = activation - - def call(self, input_tensor, training=False): - """Performs a forward pass. - - Args: - input_tensor: An input tensor of type tf.Tensor with shape [batch, height, - width, channels]. - training: A boolean flag indicating whether training behavior should be - used (default: False). - - Returns: - The output tensor. - """ - x = input_tensor - for index in range(self._num_layers): - current_name = utils.get_conv_bn_act_current_name(index, self._use_bn, - self._activation) - x = getattr(self, current_name)(x, training=training) - return x - - -class Conv1D(tf.keras.layers.Layer): - """A wrapper class for a 1D convolution with batch norm and activation. - - Conv1D creates a convolution kernel that is convolved with the layer input - over a single spatial (or temporal) dimension to produce a tensor of outputs. - The input should always be 3D with shape [batch, length, channel], so - accordingly, the optional batch norm is done on axis=2. - - In DeepLab, we use Conv1D only with kernel_size = 1 for dual path transformer - layers in MaX-DeepLab [1] architectures. - - Reference: - [1] MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers, - CVPR 2021. - Huiyu Wang, Yukun Zhu, Hartwig Adam, Alan Yuille, Liang-Chieh Chen. - """ - - def __init__( - self, - output_channels: int, - name: str, - use_bias: bool = True, - use_bn: bool = False, - bn_layer: tf.keras.layers.Layer = tf.keras.layers.BatchNormalization, - bn_gamma_initializer: str = 'ones', - activation: Optional[str] = None, - conv_kernel_weight_decay: float = 0.0, - kernel_initializer='he_normal', - kernel_size: int = 1, - padding: str = 'valid'): - """Initializes a Conv1D. - - Args: - output_channels: An integer specifying the number of filters of the - convolution. - name: A string specifying the name of this layer. - use_bias: An optional flag specifying whether bias should be added for the - convolution. - use_bn: An optional flag specifying whether batch normalization should be - added after the convolution (default: False). - bn_layer: An optional tf.keras.layers.Layer that computes the - normalization (default: tf.keras.layers.BatchNormalization). - bn_gamma_initializer: An initializer for the batch norm gamma weight. - activation: An optional flag specifying an activation function to be added - after the convolution. - conv_kernel_weight_decay: A float, the weight decay for convolution - kernels. - kernel_initializer: An initializer for the convolution kernel. - kernel_size: An integer specifying the size of the convolution kernel. - padding: An optional string specifying the padding to use. Must be either - 'same' or 'valid' (default: 'valid'). - - Raises: - ValueError: If use_bias and use_bn in the convolution. - """ - super(Conv1D, self).__init__(name=name) - - if use_bn and use_bias: - raise ValueError('Conv1D is using convlution bias with batch_norm.') - - self._conv = tf.keras.layers.Conv1D( - output_channels, - kernel_size=kernel_size, - strides=1, - padding=padding, - use_bias=use_bias, - name='conv', - kernel_initializer=kernel_initializer, - kernel_regularizer=tf.keras.regularizers.l2( - conv_kernel_weight_decay)) - - self._batch_norm = None - if use_bn: - # Batch norm uses axis=2 because the input is 3D with channel being the - # last dimension. - self._batch_norm = bn_layer(axis=2, name='batch_norm', - gamma_initializer=bn_gamma_initializer) - - self._activation_fn = None - if activation is not None: - self._activation_fn = activations.get_activation(activation) - - def call(self, input_tensor, training=False): - """Performs a forward pass. - - Args: - input_tensor: An input tensor of type tf.Tensor with shape [batch, length, - channels]. - training: A boolean flag indicating whether training behavior should be - used (default: False). - - Returns: - The output tensor. - """ - x = self._conv(input_tensor) - if self._batch_norm is not None: - x = self._batch_norm(x, training=training) - if self._activation_fn is not None: - x = self._activation_fn(x) - return x diff --git a/spaces/akhaliq/yolov7/models/__init__.py b/spaces/akhaliq/yolov7/models/__init__.py deleted file mode 100644 index 84952a8167bc2975913a6def6b4f027d566552a9..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/yolov7/models/__init__.py +++ /dev/null @@ -1 +0,0 @@ -# init \ No newline at end of file diff --git a/spaces/alvanlii/domain-expansion/torch_utils/ops/bias_act.cpp b/spaces/alvanlii/domain-expansion/torch_utils/ops/bias_act.cpp deleted file mode 100644 index 5d2425d8054991a8e8b6f7a940fd0ff7fa0bb330..0000000000000000000000000000000000000000 --- a/spaces/alvanlii/domain-expansion/torch_utils/ops/bias_act.cpp +++ /dev/null @@ -1,99 +0,0 @@ -// Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved. -// -// NVIDIA CORPORATION and its licensors retain all intellectual property -// and proprietary rights in and to this software, related documentation -// and any modifications thereto. Any use, reproduction, disclosure or -// distribution of this software and related documentation without an express -// license agreement from NVIDIA CORPORATION is strictly prohibited. - -#include-#include -#include -#include "bias_act.h" - -//------------------------------------------------------------------------ - -static bool has_same_layout(torch::Tensor x, torch::Tensor y) -{ - if (x.dim() != y.dim()) - return false; - for (int64_t i = 0; i < x.dim(); i++) - { - if (x.size(i) != y.size(i)) - return false; - if (x.size(i) >= 2 && x.stride(i) != y.stride(i)) - return false; - } - return true; -} - -//------------------------------------------------------------------------ - -static torch::Tensor bias_act(torch::Tensor x, torch::Tensor b, torch::Tensor xref, torch::Tensor yref, torch::Tensor dy, int grad, int dim, int act, float alpha, float gain, float clamp) -{ - // Validate arguments. - TORCH_CHECK(x.is_cuda(), "x must reside on CUDA device"); - TORCH_CHECK(b.numel() == 0 || (b.dtype() == x.dtype() && b.device() == x.device()), "b must have the same dtype and device as x"); - TORCH_CHECK(xref.numel() == 0 || (xref.sizes() == x.sizes() && xref.dtype() == x.dtype() && xref.device() == x.device()), "xref must have the same shape, dtype, and device as x"); - TORCH_CHECK(yref.numel() == 0 || (yref.sizes() == x.sizes() && yref.dtype() == x.dtype() && yref.device() == x.device()), "yref must have the same shape, dtype, and device as x"); - TORCH_CHECK(dy.numel() == 0 || (dy.sizes() == x.sizes() && dy.dtype() == x.dtype() && dy.device() == x.device()), "dy must have the same dtype and device as x"); - TORCH_CHECK(x.numel() <= INT_MAX, "x is too large"); - TORCH_CHECK(b.dim() == 1, "b must have rank 1"); - TORCH_CHECK(b.numel() == 0 || (dim >= 0 && dim < x.dim()), "dim is out of bounds"); - TORCH_CHECK(b.numel() == 0 || b.numel() == x.size(dim), "b has wrong number of elements"); - TORCH_CHECK(grad >= 0, "grad must be non-negative"); - - // Validate layout. - TORCH_CHECK(x.is_non_overlapping_and_dense(), "x must be non-overlapping and dense"); - TORCH_CHECK(b.is_contiguous(), "b must be contiguous"); - TORCH_CHECK(xref.numel() == 0 || has_same_layout(xref, x), "xref must have the same layout as x"); - TORCH_CHECK(yref.numel() == 0 || has_same_layout(yref, x), "yref must have the same layout as x"); - TORCH_CHECK(dy.numel() == 0 || has_same_layout(dy, x), "dy must have the same layout as x"); - - // Create output tensor. - const at::cuda::OptionalCUDAGuard device_guard(device_of(x)); - torch::Tensor y = torch::empty_like(x); - TORCH_CHECK(has_same_layout(y, x), "y must have the same layout as x"); - - // Initialize CUDA kernel parameters. - bias_act_kernel_params p; - p.x = x.data_ptr(); - p.b = (b.numel()) ? b.data_ptr() : NULL; - p.xref = (xref.numel()) ? xref.data_ptr() : NULL; - p.yref = (yref.numel()) ? yref.data_ptr() : NULL; - p.dy = (dy.numel()) ? dy.data_ptr() : NULL; - p.y = y.data_ptr(); - p.grad = grad; - p.act = act; - p.alpha = alpha; - p.gain = gain; - p.clamp = clamp; - p.sizeX = (int)x.numel(); - p.sizeB = (int)b.numel(); - p.stepB = (b.numel()) ? (int)x.stride(dim) : 1; - - // Choose CUDA kernel. - void* kernel; - AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&] - { - kernel = choose_bias_act_kernel (p); - }); - TORCH_CHECK(kernel, "no CUDA kernel found for the specified activation func"); - - // Launch CUDA kernel. - p.loopX = 4; - int blockSize = 4 * 32; - int gridSize = (p.sizeX - 1) / (p.loopX * blockSize) + 1; - void* args[] = {&p}; - AT_CUDA_CHECK(cudaLaunchKernel(kernel, gridSize, blockSize, args, 0, at::cuda::getCurrentCUDAStream())); - return y; -} - -//------------------------------------------------------------------------ - -PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) -{ - m.def("bias_act", &bias_act); -} - -//------------------------------------------------------------------------ diff --git a/spaces/amarchheda/ChordDuplicate/portaudio/include/pa_win_waveformat.h b/spaces/amarchheda/ChordDuplicate/portaudio/include/pa_win_waveformat.h deleted file mode 100644 index 251562d0fb68d4ca7668e90578122e9a9f234ce9..0000000000000000000000000000000000000000 --- a/spaces/amarchheda/ChordDuplicate/portaudio/include/pa_win_waveformat.h +++ /dev/null @@ -1,199 +0,0 @@ -#ifndef PA_WIN_WAVEFORMAT_H -#define PA_WIN_WAVEFORMAT_H - -/* - * PortAudio Portable Real-Time Audio Library - * Windows WAVEFORMAT* data structure utilities - * portaudio.h should be included before this file. - * - * Copyright (c) 2007 Ross Bencina - * - * Permission is hereby granted, free of charge, to any person obtaining - * a copy of this software and associated documentation files - * (the "Software"), to deal in the Software without restriction, - * including without limitation the rights to use, copy, modify, merge, - * publish, distribute, sublicense, and/or sell copies of the Software, - * and to permit persons to whom the Software is furnished to do so, - * subject to the following conditions: - * - * The above copyright notice and this permission notice shall be - * included in all copies or substantial portions of the Software. - * - * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, - * EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF - * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. - * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR - * ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF - * CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION - * WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. - */ - -/* - * The text above constitutes the entire PortAudio license; however, - * the PortAudio community also makes the following non-binding requests: - * - * Any person wishing to distribute modifications to the Software is - * requested to send the modifications to the original developer so that - * they can be incorporated into the canonical version. It is also - * requested that these non-binding requests be included along with the - * license above. - */ - -/** @file - @ingroup public_header - @brief Windows specific PortAudio API extension and utilities header file. -*/ - -#ifdef __cplusplus -extern "C" { -#endif - -/* - The following #defines for speaker channel masks are the same - as those in ksmedia.h, except with PAWIN_ prepended, KSAUDIO_ removed - in some cases, and casts to PaWinWaveFormatChannelMask added. -*/ - -typedef unsigned long PaWinWaveFormatChannelMask; - -/* Speaker Positions: */ -#define PAWIN_SPEAKER_FRONT_LEFT ((PaWinWaveFormatChannelMask)0x1) -#define PAWIN_SPEAKER_FRONT_RIGHT ((PaWinWaveFormatChannelMask)0x2) -#define PAWIN_SPEAKER_FRONT_CENTER ((PaWinWaveFormatChannelMask)0x4) -#define PAWIN_SPEAKER_LOW_FREQUENCY ((PaWinWaveFormatChannelMask)0x8) -#define PAWIN_SPEAKER_BACK_LEFT ((PaWinWaveFormatChannelMask)0x10) -#define PAWIN_SPEAKER_BACK_RIGHT ((PaWinWaveFormatChannelMask)0x20) -#define PAWIN_SPEAKER_FRONT_LEFT_OF_CENTER ((PaWinWaveFormatChannelMask)0x40) -#define PAWIN_SPEAKER_FRONT_RIGHT_OF_CENTER ((PaWinWaveFormatChannelMask)0x80) -#define PAWIN_SPEAKER_BACK_CENTER ((PaWinWaveFormatChannelMask)0x100) -#define PAWIN_SPEAKER_SIDE_LEFT ((PaWinWaveFormatChannelMask)0x200) -#define PAWIN_SPEAKER_SIDE_RIGHT ((PaWinWaveFormatChannelMask)0x400) -#define PAWIN_SPEAKER_TOP_CENTER ((PaWinWaveFormatChannelMask)0x800) -#define PAWIN_SPEAKER_TOP_FRONT_LEFT ((PaWinWaveFormatChannelMask)0x1000) -#define PAWIN_SPEAKER_TOP_FRONT_CENTER ((PaWinWaveFormatChannelMask)0x2000) -#define PAWIN_SPEAKER_TOP_FRONT_RIGHT ((PaWinWaveFormatChannelMask)0x4000) -#define PAWIN_SPEAKER_TOP_BACK_LEFT ((PaWinWaveFormatChannelMask)0x8000) -#define PAWIN_SPEAKER_TOP_BACK_CENTER ((PaWinWaveFormatChannelMask)0x10000) -#define PAWIN_SPEAKER_TOP_BACK_RIGHT ((PaWinWaveFormatChannelMask)0x20000) - -/* Bit mask locations reserved for future use */ -#define PAWIN_SPEAKER_RESERVED ((PaWinWaveFormatChannelMask)0x7FFC0000) - -/* Used to specify that any possible permutation of speaker configurations */ -#define PAWIN_SPEAKER_ALL ((PaWinWaveFormatChannelMask)0x80000000) - -/* DirectSound Speaker Config */ -#define PAWIN_SPEAKER_DIRECTOUT 0 -#define PAWIN_SPEAKER_MONO (PAWIN_SPEAKER_FRONT_CENTER) -#define PAWIN_SPEAKER_STEREO (PAWIN_SPEAKER_FRONT_LEFT | PAWIN_SPEAKER_FRONT_RIGHT) -#define PAWIN_SPEAKER_QUAD (PAWIN_SPEAKER_FRONT_LEFT | PAWIN_SPEAKER_FRONT_RIGHT | \ - PAWIN_SPEAKER_BACK_LEFT | PAWIN_SPEAKER_BACK_RIGHT) -#define PAWIN_SPEAKER_SURROUND (PAWIN_SPEAKER_FRONT_LEFT | PAWIN_SPEAKER_FRONT_RIGHT | \ - PAWIN_SPEAKER_FRONT_CENTER | PAWIN_SPEAKER_BACK_CENTER) -#define PAWIN_SPEAKER_5POINT1 (PAWIN_SPEAKER_FRONT_LEFT | PAWIN_SPEAKER_FRONT_RIGHT | \ - PAWIN_SPEAKER_FRONT_CENTER | PAWIN_SPEAKER_LOW_FREQUENCY | \ - PAWIN_SPEAKER_BACK_LEFT | PAWIN_SPEAKER_BACK_RIGHT) -#define PAWIN_SPEAKER_7POINT1 (PAWIN_SPEAKER_FRONT_LEFT | PAWIN_SPEAKER_FRONT_RIGHT | \ - PAWIN_SPEAKER_FRONT_CENTER | PAWIN_SPEAKER_LOW_FREQUENCY | \ - PAWIN_SPEAKER_BACK_LEFT | PAWIN_SPEAKER_BACK_RIGHT | \ - PAWIN_SPEAKER_FRONT_LEFT_OF_CENTER | PAWIN_SPEAKER_FRONT_RIGHT_OF_CENTER) -#define PAWIN_SPEAKER_5POINT1_SURROUND (PAWIN_SPEAKER_FRONT_LEFT | PAWIN_SPEAKER_FRONT_RIGHT | \ - PAWIN_SPEAKER_FRONT_CENTER | PAWIN_SPEAKER_LOW_FREQUENCY | \ - PAWIN_SPEAKER_SIDE_LEFT | PAWIN_SPEAKER_SIDE_RIGHT) -#define PAWIN_SPEAKER_7POINT1_SURROUND (PAWIN_SPEAKER_FRONT_LEFT | PAWIN_SPEAKER_FRONT_RIGHT | \ - PAWIN_SPEAKER_FRONT_CENTER | PAWIN_SPEAKER_LOW_FREQUENCY | \ - PAWIN_SPEAKER_BACK_LEFT | PAWIN_SPEAKER_BACK_RIGHT | \ - PAWIN_SPEAKER_SIDE_LEFT | PAWIN_SPEAKER_SIDE_RIGHT) -/* - According to the Microsoft documentation: - The following are obsolete 5.1 and 7.1 settings (they lack side speakers). Note this means - that the default 5.1 and 7.1 settings (KSAUDIO_SPEAKER_5POINT1 and KSAUDIO_SPEAKER_7POINT1 are - similarly obsolete but are unchanged for compatibility reasons). -*/ -#define PAWIN_SPEAKER_5POINT1_BACK PAWIN_SPEAKER_5POINT1 -#define PAWIN_SPEAKER_7POINT1_WIDE PAWIN_SPEAKER_7POINT1 - -/* DVD Speaker Positions */ -#define PAWIN_SPEAKER_GROUND_FRONT_LEFT PAWIN_SPEAKER_FRONT_LEFT -#define PAWIN_SPEAKER_GROUND_FRONT_CENTER PAWIN_SPEAKER_FRONT_CENTER -#define PAWIN_SPEAKER_GROUND_FRONT_RIGHT PAWIN_SPEAKER_FRONT_RIGHT -#define PAWIN_SPEAKER_GROUND_REAR_LEFT PAWIN_SPEAKER_BACK_LEFT -#define PAWIN_SPEAKER_GROUND_REAR_RIGHT PAWIN_SPEAKER_BACK_RIGHT -#define PAWIN_SPEAKER_TOP_MIDDLE PAWIN_SPEAKER_TOP_CENTER -#define PAWIN_SPEAKER_SUPER_WOOFER PAWIN_SPEAKER_LOW_FREQUENCY - - -/* - PaWinWaveFormat is defined here to provide compatibility with - compilation environments which don't have headers defining - WAVEFORMATEXTENSIBLE (e.g. older versions of MSVC, Borland C++ etc. - - The fields for WAVEFORMATEX and WAVEFORMATEXTENSIBLE are declared as an - unsigned char array here to avoid clients who include this file having - a dependency on windows.h and mmsystem.h, and also to to avoid having - to write separate packing pragmas for each compiler. -*/ -#define PAWIN_SIZEOF_WAVEFORMATEX 18 -#define PAWIN_SIZEOF_WAVEFORMATEXTENSIBLE (PAWIN_SIZEOF_WAVEFORMATEX + 22) - -typedef struct{ - unsigned char fields[ PAWIN_SIZEOF_WAVEFORMATEXTENSIBLE ]; - unsigned long extraLongForAlignment; /* ensure that compiler aligns struct to DWORD */ -} PaWinWaveFormat; - -/* - WAVEFORMATEXTENSIBLE fields: - - union { - WORD wValidBitsPerSample; - WORD wSamplesPerBlock; - WORD wReserved; - } Samples; - DWORD dwChannelMask; - GUID SubFormat; -*/ - -#define PAWIN_INDEXOF_WVALIDBITSPERSAMPLE (PAWIN_SIZEOF_WAVEFORMATEX+0) -#define PAWIN_INDEXOF_DWCHANNELMASK (PAWIN_SIZEOF_WAVEFORMATEX+2) -#define PAWIN_INDEXOF_SUBFORMAT (PAWIN_SIZEOF_WAVEFORMATEX+6) - - -/* - Valid values to pass for the waveFormatTag PaWin_InitializeWaveFormatEx and - PaWin_InitializeWaveFormatExtensible functions below. These must match - the standard Windows WAVE_FORMAT_* values. -*/ -#define PAWIN_WAVE_FORMAT_PCM (1) -#define PAWIN_WAVE_FORMAT_IEEE_FLOAT (3) -#define PAWIN_WAVE_FORMAT_DOLBY_AC3_SPDIF (0x0092) -#define PAWIN_WAVE_FORMAT_WMA_SPDIF (0x0164) - - -/* - returns PAWIN_WAVE_FORMAT_PCM or PAWIN_WAVE_FORMAT_IEEE_FLOAT - depending on the sampleFormat parameter. -*/ -int PaWin_SampleFormatToLinearWaveFormatTag( PaSampleFormat sampleFormat ); - -/* - Use the following two functions to initialize the waveformat structure. -*/ - -void PaWin_InitializeWaveFormatEx( PaWinWaveFormat *waveFormat, - int numChannels, PaSampleFormat sampleFormat, int waveFormatTag, double sampleRate ); - - -void PaWin_InitializeWaveFormatExtensible( PaWinWaveFormat *waveFormat, - int numChannels, PaSampleFormat sampleFormat, int waveFormatTag, double sampleRate, - PaWinWaveFormatChannelMask channelMask ); - - -/* Map a channel count to a speaker channel mask */ -PaWinWaveFormatChannelMask PaWin_DefaultChannelMask( int numChannels ); - - -#ifdef __cplusplus -} -#endif /* __cplusplus */ - -#endif /* PA_WIN_WAVEFORMAT_H */ diff --git a/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/mingw-include/structuredquery.h b/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/mingw-include/structuredquery.h deleted file mode 100644 index bca20a9adac790f1f46ca915c121beb01b07c0f6..0000000000000000000000000000000000000000 --- a/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/mingw-include/structuredquery.h +++ /dev/null @@ -1,2478 +0,0 @@ - - -/* this ALWAYS GENERATED file contains the definitions for the interfaces */ - - - /* File created by MIDL compiler version 7.00.0499 */ -/* Compiler settings for structuredquery.idl: - Oicf, W1, Zp8, env=Win32 (32b run) - protocol : dce , ms_ext, c_ext, robust - error checks: allocation ref bounds_check enum stub_data - VC __declspec() decoration level: - __declspec(uuid()), __declspec(selectany), __declspec(novtable) - DECLSPEC_UUID(), MIDL_INTERFACE() -*/ -//@@MIDL_FILE_HEADING( ) - -#pragma warning( disable: 4049 ) /* more than 64k source lines */ - - -/* verify that the version is high enough to compile this file*/ -#ifndef __REQUIRED_RPCNDR_H_VERSION__ -#define __REQUIRED_RPCNDR_H_VERSION__ 475 -#endif - -/* verify that the version is high enough to compile this file*/ -#ifndef __REQUIRED_RPCSAL_H_VERSION__ -#define __REQUIRED_RPCSAL_H_VERSION__ 100 -#endif - -#include "rpc.h" -#include "rpcndr.h" - -#ifndef __RPCNDR_H_VERSION__ -#error this stub requires an updated version of -#endif // __RPCNDR_H_VERSION__ - -#ifndef COM_NO_WINDOWS_H -#include "windows.h" -#include "ole2.h" -#endif /*COM_NO_WINDOWS_H*/ - -#ifndef __structuredquery_h__ -#define __structuredquery_h__ - -#if defined(_MSC_VER) && (_MSC_VER >= 1020) -#pragma once -#endif - -/* Forward Declarations */ - -#ifndef __IQueryParser_FWD_DEFINED__ -#define __IQueryParser_FWD_DEFINED__ -typedef interface IQueryParser IQueryParser; -#endif /* __IQueryParser_FWD_DEFINED__ */ - - -#ifndef __IConditionFactory_FWD_DEFINED__ -#define __IConditionFactory_FWD_DEFINED__ -typedef interface IConditionFactory IConditionFactory; -#endif /* __IConditionFactory_FWD_DEFINED__ */ - - -#ifndef __IQuerySolution_FWD_DEFINED__ -#define __IQuerySolution_FWD_DEFINED__ -typedef interface IQuerySolution IQuerySolution; -#endif /* __IQuerySolution_FWD_DEFINED__ */ - - -#ifndef __ICondition_FWD_DEFINED__ -#define __ICondition_FWD_DEFINED__ -typedef interface ICondition ICondition; -#endif /* __ICondition_FWD_DEFINED__ */ - - -#ifndef __IConditionGenerator_FWD_DEFINED__ -#define __IConditionGenerator_FWD_DEFINED__ -typedef interface IConditionGenerator IConditionGenerator; -#endif /* __IConditionGenerator_FWD_DEFINED__ */ - - -#ifndef __IRichChunk_FWD_DEFINED__ -#define __IRichChunk_FWD_DEFINED__ -typedef interface IRichChunk IRichChunk; -#endif /* __IRichChunk_FWD_DEFINED__ */ - - -#ifndef __IInterval_FWD_DEFINED__ -#define __IInterval_FWD_DEFINED__ -typedef interface IInterval IInterval; -#endif /* __IInterval_FWD_DEFINED__ */ - - -#ifndef __IMetaData_FWD_DEFINED__ -#define __IMetaData_FWD_DEFINED__ -typedef interface IMetaData IMetaData; -#endif /* __IMetaData_FWD_DEFINED__ */ - - -#ifndef __IEntity_FWD_DEFINED__ -#define __IEntity_FWD_DEFINED__ -typedef interface IEntity IEntity; -#endif /* __IEntity_FWD_DEFINED__ */ - - -#ifndef __IRelationship_FWD_DEFINED__ -#define __IRelationship_FWD_DEFINED__ -typedef interface IRelationship IRelationship; -#endif /* __IRelationship_FWD_DEFINED__ */ - - -#ifndef __INamedEntity_FWD_DEFINED__ -#define __INamedEntity_FWD_DEFINED__ -typedef interface INamedEntity INamedEntity; -#endif /* __INamedEntity_FWD_DEFINED__ */ - - -#ifndef __ISchemaProvider_FWD_DEFINED__ -#define __ISchemaProvider_FWD_DEFINED__ -typedef interface ISchemaProvider ISchemaProvider; -#endif /* __ISchemaProvider_FWD_DEFINED__ */ - - -#ifndef __ITokenCollection_FWD_DEFINED__ -#define __ITokenCollection_FWD_DEFINED__ -typedef interface ITokenCollection ITokenCollection; -#endif /* __ITokenCollection_FWD_DEFINED__ */ - - -#ifndef __INamedEntityCollector_FWD_DEFINED__ -#define __INamedEntityCollector_FWD_DEFINED__ -typedef interface INamedEntityCollector INamedEntityCollector; -#endif /* __INamedEntityCollector_FWD_DEFINED__ */ - - -#ifndef __ISchemaLocalizerSupport_FWD_DEFINED__ -#define __ISchemaLocalizerSupport_FWD_DEFINED__ -typedef interface ISchemaLocalizerSupport ISchemaLocalizerSupport; -#endif /* __ISchemaLocalizerSupport_FWD_DEFINED__ */ - - -#ifndef __IQueryParserManager_FWD_DEFINED__ -#define __IQueryParserManager_FWD_DEFINED__ -typedef interface IQueryParserManager IQueryParserManager; -#endif /* __IQueryParserManager_FWD_DEFINED__ */ - - -#ifndef __QueryParser_FWD_DEFINED__ -#define __QueryParser_FWD_DEFINED__ - -#ifdef __cplusplus -typedef class QueryParser QueryParser; -#else -typedef struct QueryParser QueryParser; -#endif /* __cplusplus */ - -#endif /* __QueryParser_FWD_DEFINED__ */ - - -#ifndef __NegationCondition_FWD_DEFINED__ -#define __NegationCondition_FWD_DEFINED__ - -#ifdef __cplusplus -typedef class NegationCondition NegationCondition; -#else -typedef struct NegationCondition NegationCondition; -#endif /* __cplusplus */ - -#endif /* __NegationCondition_FWD_DEFINED__ */ - - -#ifndef __CompoundCondition_FWD_DEFINED__ -#define __CompoundCondition_FWD_DEFINED__ - -#ifdef __cplusplus -typedef class CompoundCondition CompoundCondition; -#else -typedef struct CompoundCondition CompoundCondition; -#endif /* __cplusplus */ - -#endif /* __CompoundCondition_FWD_DEFINED__ */ - - -#ifndef __LeafCondition_FWD_DEFINED__ -#define __LeafCondition_FWD_DEFINED__ - -#ifdef __cplusplus -typedef class LeafCondition LeafCondition; -#else -typedef struct LeafCondition LeafCondition; -#endif /* __cplusplus */ - -#endif /* __LeafCondition_FWD_DEFINED__ */ - - -#ifndef __ConditionFactory_FWD_DEFINED__ -#define __ConditionFactory_FWD_DEFINED__ - -#ifdef __cplusplus -typedef class ConditionFactory ConditionFactory; -#else -typedef struct ConditionFactory ConditionFactory; -#endif /* __cplusplus */ - -#endif /* __ConditionFactory_FWD_DEFINED__ */ - - -#ifndef __Interval_FWD_DEFINED__ -#define __Interval_FWD_DEFINED__ - -#ifdef __cplusplus -typedef class Interval Interval; -#else -typedef struct Interval Interval; -#endif /* __cplusplus */ - -#endif /* __Interval_FWD_DEFINED__ */ - - -#ifndef __QueryParserManager_FWD_DEFINED__ -#define __QueryParserManager_FWD_DEFINED__ - -#ifdef __cplusplus -typedef class QueryParserManager QueryParserManager; -#else -typedef struct QueryParserManager QueryParserManager; -#endif /* __cplusplus */ - -#endif /* __QueryParserManager_FWD_DEFINED__ */ - - -/* header files for imported files */ -#include "oaidl.h" -#include "ocidl.h" -#include "propidl.h" - -#ifdef __cplusplus -extern "C"{ -#endif - - -/* interface __MIDL_itf_structuredquery_0000_0000 */ -/* [local] */ - - - - - - - - - - - -typedef /* [v1_enum] */ -enum tagCONDITION_TYPE - { CT_AND_CONDITION = 0, - CT_OR_CONDITION = ( CT_AND_CONDITION + 1 ) , - CT_NOT_CONDITION = ( CT_OR_CONDITION + 1 ) , - CT_LEAF_CONDITION = ( CT_NOT_CONDITION + 1 ) - } CONDITION_TYPE; - -typedef /* [v1_enum] */ -enum tagCONDITION_OPERATION - { COP_IMPLICIT = 0, - COP_EQUAL = ( COP_IMPLICIT + 1 ) , - COP_NOTEQUAL = ( COP_EQUAL + 1 ) , - COP_LESSTHAN = ( COP_NOTEQUAL + 1 ) , - COP_GREATERTHAN = ( COP_LESSTHAN + 1 ) , - COP_LESSTHANOREQUAL = ( COP_GREATERTHAN + 1 ) , - COP_GREATERTHANOREQUAL = ( COP_LESSTHANOREQUAL + 1 ) , - COP_VALUE_STARTSWITH = ( COP_GREATERTHANOREQUAL + 1 ) , - COP_VALUE_ENDSWITH = ( COP_VALUE_STARTSWITH + 1 ) , - COP_VALUE_CONTAINS = ( COP_VALUE_ENDSWITH + 1 ) , - COP_VALUE_NOTCONTAINS = ( COP_VALUE_CONTAINS + 1 ) , - COP_DOSWILDCARDS = ( COP_VALUE_NOTCONTAINS + 1 ) , - COP_WORD_EQUAL = ( COP_DOSWILDCARDS + 1 ) , - COP_WORD_STARTSWITH = ( COP_WORD_EQUAL + 1 ) , - COP_APPLICATION_SPECIFIC = ( COP_WORD_STARTSWITH + 1 ) - } CONDITION_OPERATION; - -typedef /* [v1_enum] */ -enum tagSTRUCTURED_QUERY_SINGLE_OPTION - { SQSO_SCHEMA = 0, - SQSO_LOCALE_WORD_BREAKING = ( SQSO_SCHEMA + 1 ) , - SQSO_WORD_BREAKER = ( SQSO_LOCALE_WORD_BREAKING + 1 ) , - SQSO_NATURAL_SYNTAX = ( SQSO_WORD_BREAKER + 1 ) , - SQSO_AUTOMATIC_WILDCARD = ( SQSO_NATURAL_SYNTAX + 1 ) , - SQSO_TRACE_LEVEL = ( SQSO_AUTOMATIC_WILDCARD + 1 ) , - SQSO_LANGUAGE_KEYWORDS = ( SQSO_TRACE_LEVEL + 1 ) - } STRUCTURED_QUERY_SINGLE_OPTION; - -typedef /* [v1_enum] */ -enum tagSTRUCTURED_QUERY_MULTIOPTION - { SQMO_VIRTUAL_PROPERTY = 0, - SQMO_DEFAULT_PROPERTY = ( SQMO_VIRTUAL_PROPERTY + 1 ) , - SQMO_GENERATOR_FOR_TYPE = ( SQMO_DEFAULT_PROPERTY + 1 ) - } STRUCTURED_QUERY_MULTIOPTION; - -typedef /* [v1_enum] */ -enum tagSTRUCTURED_QUERY_PARSE_ERROR - { SQPE_NONE = 0, - SQPE_EXTRA_OPENING_PARENTHESIS = ( SQPE_NONE + 1 ) , - SQPE_EXTRA_CLOSING_PARENTHESIS = ( SQPE_EXTRA_OPENING_PARENTHESIS + 1 ) , - SQPE_IGNORED_MODIFIER = ( SQPE_EXTRA_CLOSING_PARENTHESIS + 1 ) , - SQPE_IGNORED_CONNECTOR = ( SQPE_IGNORED_MODIFIER + 1 ) , - SQPE_IGNORED_KEYWORD = ( SQPE_IGNORED_CONNECTOR + 1 ) , - SQPE_UNHANDLED = ( SQPE_IGNORED_KEYWORD + 1 ) - } STRUCTURED_QUERY_PARSE_ERROR; - -/* [v1_enum] */ -enum tagSTRUCTURED_QUERY_RESOLVE_OPTION - { SQRO_DONT_RESOLVE_DATETIME = 0x1, - SQRO_ALWAYS_ONE_INTERVAL = 0x2, - SQRO_DONT_SIMPLIFY_CONDITION_TREES = 0x4, - SQRO_DONT_MAP_RELATIONS = 0x8, - SQRO_DONT_RESOLVE_RANGES = 0x10, - SQRO_DONT_REMOVE_UNRESTRICTED_KEYWORDS = 0x20, - SQRO_DONT_SPLIT_WORDS = 0x40, - SQRO_IGNORE_PHRASE_ORDER = 0x80 - } ; -typedef int STRUCTURED_QUERY_RESOLVE_OPTION; - -typedef /* [v1_enum] */ -enum tagINTERVAL_LIMIT_KIND - { ILK_EXPLICIT_INCLUDED = 0, - ILK_EXPLICIT_EXCLUDED = ( ILK_EXPLICIT_INCLUDED + 1 ) , - ILK_NEGATIVE_INFINITY = ( ILK_EXPLICIT_EXCLUDED + 1 ) , - ILK_POSITIVE_INFINITY = ( ILK_NEGATIVE_INFINITY + 1 ) - } INTERVAL_LIMIT_KIND; - -typedef /* [v1_enum] */ -enum tagQUERY_PARSER_MANAGER_OPTION - { QPMO_SCHEMA_BINARY_NAME = 0, - QPMO_PRELOCALIZED_SCHEMA_BINARY_PATH = ( QPMO_SCHEMA_BINARY_NAME + 1 ) , - QPMO_UNLOCALIZED_SCHEMA_BINARY_PATH = ( QPMO_PRELOCALIZED_SCHEMA_BINARY_PATH + 1 ) , - QPMO_LOCALIZED_SCHEMA_BINARY_PATH = ( QPMO_UNLOCALIZED_SCHEMA_BINARY_PATH + 1 ) , - QPMO_APPEND_LCID_TO_LOCALIZED_PATH = ( QPMO_LOCALIZED_SCHEMA_BINARY_PATH + 1 ) , - QPMO_LOCALIZER_SUPPORT = ( QPMO_APPEND_LCID_TO_LOCALIZED_PATH + 1 ) - } QUERY_PARSER_MANAGER_OPTION; - - - -extern RPC_IF_HANDLE __MIDL_itf_structuredquery_0000_0000_v0_0_c_ifspec; -extern RPC_IF_HANDLE __MIDL_itf_structuredquery_0000_0000_v0_0_s_ifspec; - -#ifndef __IQueryParser_INTERFACE_DEFINED__ -#define __IQueryParser_INTERFACE_DEFINED__ - -/* interface IQueryParser */ -/* [unique][uuid][object] */ - - -EXTERN_C const IID IID_IQueryParser; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("2EBDEE67-3505-43f8-9946-EA44ABC8E5B0") - IQueryParser : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE Parse( - /* [in] */ __RPC__in LPCWSTR pszInputString, - /* [in] */ __RPC__in_opt IEnumUnknown *pCustomProperties, - /* [retval][out] */ __RPC__deref_out_opt IQuerySolution **ppSolution) = 0; - - virtual HRESULT STDMETHODCALLTYPE SetOption( - /* [in] */ STRUCTURED_QUERY_SINGLE_OPTION option, - /* [in] */ __RPC__in const PROPVARIANT *pOptionValue) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetOption( - /* [in] */ STRUCTURED_QUERY_SINGLE_OPTION option, - /* [retval][out] */ __RPC__out PROPVARIANT *pOptionValue) = 0; - - virtual HRESULT STDMETHODCALLTYPE SetMultiOption( - /* [in] */ STRUCTURED_QUERY_MULTIOPTION option, - /* [in] */ __RPC__in LPCWSTR pszOptionKey, - /* [in] */ __RPC__in const PROPVARIANT *pOptionValue) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetSchemaProvider( - /* [retval][out] */ __RPC__deref_out_opt ISchemaProvider **ppSchemaProvider) = 0; - - virtual HRESULT STDMETHODCALLTYPE RestateToString( - /* [in] */ __RPC__in_opt ICondition *pCondition, - /* [in] */ BOOL fUseEnglish, - /* [out] */ __RPC__deref_out_opt LPWSTR *ppszQueryString) = 0; - - virtual HRESULT STDMETHODCALLTYPE ParsePropertyValue( - /* [in] */ __RPC__in LPCWSTR pszPropertyName, - /* [in] */ __RPC__in LPCWSTR pszInputString, - /* [retval][out] */ __RPC__deref_out_opt IQuerySolution **ppSolution) = 0; - - virtual HRESULT STDMETHODCALLTYPE RestatePropertyValueToString( - /* [in] */ __RPC__in_opt ICondition *pCondition, - /* [in] */ BOOL fUseEnglish, - /* [out] */ __RPC__deref_out_opt LPWSTR *ppszPropertyName, - /* [out] */ __RPC__deref_out_opt LPWSTR *ppszQueryString) = 0; - - }; - -#else /* C style interface */ - - typedef struct IQueryParserVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IQueryParser * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IQueryParser * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IQueryParser * This); - - HRESULT ( STDMETHODCALLTYPE *Parse )( - IQueryParser * This, - /* [in] */ __RPC__in LPCWSTR pszInputString, - /* [in] */ __RPC__in_opt IEnumUnknown *pCustomProperties, - /* [retval][out] */ __RPC__deref_out_opt IQuerySolution **ppSolution); - - HRESULT ( STDMETHODCALLTYPE *SetOption )( - IQueryParser * This, - /* [in] */ STRUCTURED_QUERY_SINGLE_OPTION option, - /* [in] */ __RPC__in const PROPVARIANT *pOptionValue); - - HRESULT ( STDMETHODCALLTYPE *GetOption )( - IQueryParser * This, - /* [in] */ STRUCTURED_QUERY_SINGLE_OPTION option, - /* [retval][out] */ __RPC__out PROPVARIANT *pOptionValue); - - HRESULT ( STDMETHODCALLTYPE *SetMultiOption )( - IQueryParser * This, - /* [in] */ STRUCTURED_QUERY_MULTIOPTION option, - /* [in] */ __RPC__in LPCWSTR pszOptionKey, - /* [in] */ __RPC__in const PROPVARIANT *pOptionValue); - - HRESULT ( STDMETHODCALLTYPE *GetSchemaProvider )( - IQueryParser * This, - /* [retval][out] */ __RPC__deref_out_opt ISchemaProvider **ppSchemaProvider); - - HRESULT ( STDMETHODCALLTYPE *RestateToString )( - IQueryParser * This, - /* [in] */ __RPC__in_opt ICondition *pCondition, - /* [in] */ BOOL fUseEnglish, - /* [out] */ __RPC__deref_out_opt LPWSTR *ppszQueryString); - - HRESULT ( STDMETHODCALLTYPE *ParsePropertyValue )( - IQueryParser * This, - /* [in] */ __RPC__in LPCWSTR pszPropertyName, - /* [in] */ __RPC__in LPCWSTR pszInputString, - /* [retval][out] */ __RPC__deref_out_opt IQuerySolution **ppSolution); - - HRESULT ( STDMETHODCALLTYPE *RestatePropertyValueToString )( - IQueryParser * This, - /* [in] */ __RPC__in_opt ICondition *pCondition, - /* [in] */ BOOL fUseEnglish, - /* [out] */ __RPC__deref_out_opt LPWSTR *ppszPropertyName, - /* [out] */ __RPC__deref_out_opt LPWSTR *ppszQueryString); - - END_INTERFACE - } IQueryParserVtbl; - - interface IQueryParser - { - CONST_VTBL struct IQueryParserVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IQueryParser_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IQueryParser_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IQueryParser_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IQueryParser_Parse(This,pszInputString,pCustomProperties,ppSolution) \ - ( (This)->lpVtbl -> Parse(This,pszInputString,pCustomProperties,ppSolution) ) - -#define IQueryParser_SetOption(This,option,pOptionValue) \ - ( (This)->lpVtbl -> SetOption(This,option,pOptionValue) ) - -#define IQueryParser_GetOption(This,option,pOptionValue) \ - ( (This)->lpVtbl -> GetOption(This,option,pOptionValue) ) - -#define IQueryParser_SetMultiOption(This,option,pszOptionKey,pOptionValue) \ - ( (This)->lpVtbl -> SetMultiOption(This,option,pszOptionKey,pOptionValue) ) - -#define IQueryParser_GetSchemaProvider(This,ppSchemaProvider) \ - ( (This)->lpVtbl -> GetSchemaProvider(This,ppSchemaProvider) ) - -#define IQueryParser_RestateToString(This,pCondition,fUseEnglish,ppszQueryString) \ - ( (This)->lpVtbl -> RestateToString(This,pCondition,fUseEnglish,ppszQueryString) ) - -#define IQueryParser_ParsePropertyValue(This,pszPropertyName,pszInputString,ppSolution) \ - ( (This)->lpVtbl -> ParsePropertyValue(This,pszPropertyName,pszInputString,ppSolution) ) - -#define IQueryParser_RestatePropertyValueToString(This,pCondition,fUseEnglish,ppszPropertyName,ppszQueryString) \ - ( (This)->lpVtbl -> RestatePropertyValueToString(This,pCondition,fUseEnglish,ppszPropertyName,ppszQueryString) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IQueryParser_INTERFACE_DEFINED__ */ - - -#ifndef __IConditionFactory_INTERFACE_DEFINED__ -#define __IConditionFactory_INTERFACE_DEFINED__ - -/* interface IConditionFactory */ -/* [unique][uuid][object] */ - - -EXTERN_C const IID IID_IConditionFactory; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("A5EFE073-B16F-474f-9F3E-9F8B497A3E08") - IConditionFactory : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE MakeNot( - /* [in] */ __RPC__in_opt ICondition *pSubCondition, - /* [in] */ BOOL simplify, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery) = 0; - - virtual HRESULT STDMETHODCALLTYPE MakeAndOr( - /* [in] */ CONDITION_TYPE nodeType, - /* [in] */ __RPC__in_opt IEnumUnknown *pSubConditions, - /* [in] */ BOOL simplify, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery) = 0; - - virtual HRESULT STDMETHODCALLTYPE MakeLeaf( - /* [unique][in] */ __RPC__in_opt LPCWSTR pszPropertyName, - /* [in] */ CONDITION_OPERATION op, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszValueType, - /* [in] */ __RPC__in const PROPVARIANT *pValue, - /* [in] */ __RPC__in_opt IRichChunk *pPropertyNameTerm, - /* [in] */ __RPC__in_opt IRichChunk *pOperationTerm, - /* [in] */ __RPC__in_opt IRichChunk *pValueTerm, - /* [in] */ BOOL expand, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE Resolve( - /* [in] */ - __in ICondition *pConditionTree, - /* [in] */ - __in STRUCTURED_QUERY_RESOLVE_OPTION sqro, - /* [ref][in] */ - __in_opt const SYSTEMTIME *pstReferenceTime, - /* [retval][out] */ - __out ICondition **ppResolvedConditionTree) = 0; - - }; - -#else /* C style interface */ - - typedef struct IConditionFactoryVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IConditionFactory * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IConditionFactory * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IConditionFactory * This); - - HRESULT ( STDMETHODCALLTYPE *MakeNot )( - IConditionFactory * This, - /* [in] */ __RPC__in_opt ICondition *pSubCondition, - /* [in] */ BOOL simplify, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery); - - HRESULT ( STDMETHODCALLTYPE *MakeAndOr )( - IConditionFactory * This, - /* [in] */ CONDITION_TYPE nodeType, - /* [in] */ __RPC__in_opt IEnumUnknown *pSubConditions, - /* [in] */ BOOL simplify, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery); - - HRESULT ( STDMETHODCALLTYPE *MakeLeaf )( - IConditionFactory * This, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszPropertyName, - /* [in] */ CONDITION_OPERATION op, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszValueType, - /* [in] */ __RPC__in const PROPVARIANT *pValue, - /* [in] */ __RPC__in_opt IRichChunk *pPropertyNameTerm, - /* [in] */ __RPC__in_opt IRichChunk *pOperationTerm, - /* [in] */ __RPC__in_opt IRichChunk *pValueTerm, - /* [in] */ BOOL expand, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *Resolve )( - IConditionFactory * This, - /* [in] */ - __in ICondition *pConditionTree, - /* [in] */ - __in STRUCTURED_QUERY_RESOLVE_OPTION sqro, - /* [ref][in] */ - __in_opt const SYSTEMTIME *pstReferenceTime, - /* [retval][out] */ - __out ICondition **ppResolvedConditionTree); - - END_INTERFACE - } IConditionFactoryVtbl; - - interface IConditionFactory - { - CONST_VTBL struct IConditionFactoryVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IConditionFactory_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IConditionFactory_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IConditionFactory_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IConditionFactory_MakeNot(This,pSubCondition,simplify,ppResultQuery) \ - ( (This)->lpVtbl -> MakeNot(This,pSubCondition,simplify,ppResultQuery) ) - -#define IConditionFactory_MakeAndOr(This,nodeType,pSubConditions,simplify,ppResultQuery) \ - ( (This)->lpVtbl -> MakeAndOr(This,nodeType,pSubConditions,simplify,ppResultQuery) ) - -#define IConditionFactory_MakeLeaf(This,pszPropertyName,op,pszValueType,pValue,pPropertyNameTerm,pOperationTerm,pValueTerm,expand,ppResultQuery) \ - ( (This)->lpVtbl -> MakeLeaf(This,pszPropertyName,op,pszValueType,pValue,pPropertyNameTerm,pOperationTerm,pValueTerm,expand,ppResultQuery) ) - -#define IConditionFactory_Resolve(This,pConditionTree,sqro,pstReferenceTime,ppResolvedConditionTree) \ - ( (This)->lpVtbl -> Resolve(This,pConditionTree,sqro,pstReferenceTime,ppResolvedConditionTree) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IConditionFactory_INTERFACE_DEFINED__ */ - - -#ifndef __IQuerySolution_INTERFACE_DEFINED__ -#define __IQuerySolution_INTERFACE_DEFINED__ - -/* interface IQuerySolution */ -/* [unique][uuid][object] */ - - -EXTERN_C const IID IID_IQuerySolution; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("D6EBC66B-8921-4193-AFDD-A1789FB7FF57") - IQuerySolution : public IConditionFactory - { - public: - virtual /* [local] */ HRESULT STDMETHODCALLTYPE GetQuery( - /* [out] */ - __out_opt ICondition **ppQueryNode, - /* [out] */ - __out_opt IEntity **ppMainType) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetErrors( - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **ppParseErrors) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE GetLexicalData( - /* [out] */ - __deref_opt_out LPWSTR *ppszInputString, - /* [out] */ - __out_opt ITokenCollection **ppTokens, - /* [out] */ - __out_opt LCID *pLocale, - /* [out] */ - __out_opt IUnknown **ppWordBreaker) = 0; - - }; - -#else /* C style interface */ - - typedef struct IQuerySolutionVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IQuerySolution * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IQuerySolution * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IQuerySolution * This); - - HRESULT ( STDMETHODCALLTYPE *MakeNot )( - IQuerySolution * This, - /* [in] */ __RPC__in_opt ICondition *pSubCondition, - /* [in] */ BOOL simplify, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery); - - HRESULT ( STDMETHODCALLTYPE *MakeAndOr )( - IQuerySolution * This, - /* [in] */ CONDITION_TYPE nodeType, - /* [in] */ __RPC__in_opt IEnumUnknown *pSubConditions, - /* [in] */ BOOL simplify, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery); - - HRESULT ( STDMETHODCALLTYPE *MakeLeaf )( - IQuerySolution * This, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszPropertyName, - /* [in] */ CONDITION_OPERATION op, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszValueType, - /* [in] */ __RPC__in const PROPVARIANT *pValue, - /* [in] */ __RPC__in_opt IRichChunk *pPropertyNameTerm, - /* [in] */ __RPC__in_opt IRichChunk *pOperationTerm, - /* [in] */ __RPC__in_opt IRichChunk *pValueTerm, - /* [in] */ BOOL expand, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppResultQuery); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *Resolve )( - IQuerySolution * This, - /* [in] */ - __in ICondition *pConditionTree, - /* [in] */ - __in STRUCTURED_QUERY_RESOLVE_OPTION sqro, - /* [ref][in] */ - __in_opt const SYSTEMTIME *pstReferenceTime, - /* [retval][out] */ - __out ICondition **ppResolvedConditionTree); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *GetQuery )( - IQuerySolution * This, - /* [out] */ - __out_opt ICondition **ppQueryNode, - /* [out] */ - __out_opt IEntity **ppMainType); - - HRESULT ( STDMETHODCALLTYPE *GetErrors )( - IQuerySolution * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **ppParseErrors); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *GetLexicalData )( - IQuerySolution * This, - /* [out] */ - __deref_opt_out LPWSTR *ppszInputString, - /* [out] */ - __out_opt ITokenCollection **ppTokens, - /* [out] */ - __out_opt LCID *pLocale, - /* [out] */ - __out_opt IUnknown **ppWordBreaker); - - END_INTERFACE - } IQuerySolutionVtbl; - - interface IQuerySolution - { - CONST_VTBL struct IQuerySolutionVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IQuerySolution_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IQuerySolution_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IQuerySolution_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IQuerySolution_MakeNot(This,pSubCondition,simplify,ppResultQuery) \ - ( (This)->lpVtbl -> MakeNot(This,pSubCondition,simplify,ppResultQuery) ) - -#define IQuerySolution_MakeAndOr(This,nodeType,pSubConditions,simplify,ppResultQuery) \ - ( (This)->lpVtbl -> MakeAndOr(This,nodeType,pSubConditions,simplify,ppResultQuery) ) - -#define IQuerySolution_MakeLeaf(This,pszPropertyName,op,pszValueType,pValue,pPropertyNameTerm,pOperationTerm,pValueTerm,expand,ppResultQuery) \ - ( (This)->lpVtbl -> MakeLeaf(This,pszPropertyName,op,pszValueType,pValue,pPropertyNameTerm,pOperationTerm,pValueTerm,expand,ppResultQuery) ) - -#define IQuerySolution_Resolve(This,pConditionTree,sqro,pstReferenceTime,ppResolvedConditionTree) \ - ( (This)->lpVtbl -> Resolve(This,pConditionTree,sqro,pstReferenceTime,ppResolvedConditionTree) ) - - -#define IQuerySolution_GetQuery(This,ppQueryNode,ppMainType) \ - ( (This)->lpVtbl -> GetQuery(This,ppQueryNode,ppMainType) ) - -#define IQuerySolution_GetErrors(This,riid,ppParseErrors) \ - ( (This)->lpVtbl -> GetErrors(This,riid,ppParseErrors) ) - -#define IQuerySolution_GetLexicalData(This,ppszInputString,ppTokens,pLocale,ppWordBreaker) \ - ( (This)->lpVtbl -> GetLexicalData(This,ppszInputString,ppTokens,pLocale,ppWordBreaker) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IQuerySolution_INTERFACE_DEFINED__ */ - - -#ifndef __ICondition_INTERFACE_DEFINED__ -#define __ICondition_INTERFACE_DEFINED__ - -/* interface ICondition */ -/* [unique][uuid][object] */ - - -EXTERN_C const IID IID_ICondition; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("0FC988D4-C935-4b97-A973-46282EA175C8") - ICondition : public IPersistStream - { - public: - virtual HRESULT STDMETHODCALLTYPE GetConditionType( - /* [retval][out] */ __RPC__out CONDITION_TYPE *pNodeType) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetSubConditions( - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **ppv) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE GetComparisonInfo( - /* [out] */ - __deref_opt_out LPWSTR *ppszPropertyName, - /* [out] */ - __out_opt CONDITION_OPERATION *pOperation, - /* [out] */ - __out_opt PROPVARIANT *pValue) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetValueType( - /* [retval][out] */ __RPC__deref_out_opt LPWSTR *ppszValueTypeName) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetValueNormalization( - /* [retval][out] */ __RPC__deref_out_opt LPWSTR *ppszNormalization) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE GetInputTerms( - /* [out] */ - __out_opt IRichChunk **ppPropertyTerm, - /* [out] */ - __out_opt IRichChunk **ppOperationTerm, - /* [out] */ - __out_opt IRichChunk **ppValueTerm) = 0; - - virtual HRESULT STDMETHODCALLTYPE Clone( - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppc) = 0; - - }; - -#else /* C style interface */ - - typedef struct IConditionVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - ICondition * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - ICondition * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - ICondition * This); - - HRESULT ( STDMETHODCALLTYPE *GetClassID )( - ICondition * This, - /* [out] */ __RPC__out CLSID *pClassID); - - HRESULT ( STDMETHODCALLTYPE *IsDirty )( - ICondition * This); - - HRESULT ( STDMETHODCALLTYPE *Load )( - ICondition * This, - /* [unique][in] */ __RPC__in_opt IStream *pStm); - - HRESULT ( STDMETHODCALLTYPE *Save )( - ICondition * This, - /* [unique][in] */ __RPC__in_opt IStream *pStm, - /* [in] */ BOOL fClearDirty); - - HRESULT ( STDMETHODCALLTYPE *GetSizeMax )( - ICondition * This, - /* [out] */ __RPC__out ULARGE_INTEGER *pcbSize); - - HRESULT ( STDMETHODCALLTYPE *GetConditionType )( - ICondition * This, - /* [retval][out] */ __RPC__out CONDITION_TYPE *pNodeType); - - HRESULT ( STDMETHODCALLTYPE *GetSubConditions )( - ICondition * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **ppv); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *GetComparisonInfo )( - ICondition * This, - /* [out] */ - __deref_opt_out LPWSTR *ppszPropertyName, - /* [out] */ - __out_opt CONDITION_OPERATION *pOperation, - /* [out] */ - __out_opt PROPVARIANT *pValue); - - HRESULT ( STDMETHODCALLTYPE *GetValueType )( - ICondition * This, - /* [retval][out] */ __RPC__deref_out_opt LPWSTR *ppszValueTypeName); - - HRESULT ( STDMETHODCALLTYPE *GetValueNormalization )( - ICondition * This, - /* [retval][out] */ __RPC__deref_out_opt LPWSTR *ppszNormalization); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *GetInputTerms )( - ICondition * This, - /* [out] */ - __out_opt IRichChunk **ppPropertyTerm, - /* [out] */ - __out_opt IRichChunk **ppOperationTerm, - /* [out] */ - __out_opt IRichChunk **ppValueTerm); - - HRESULT ( STDMETHODCALLTYPE *Clone )( - ICondition * This, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppc); - - END_INTERFACE - } IConditionVtbl; - - interface ICondition - { - CONST_VTBL struct IConditionVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define ICondition_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define ICondition_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define ICondition_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define ICondition_GetClassID(This,pClassID) \ - ( (This)->lpVtbl -> GetClassID(This,pClassID) ) - - -#define ICondition_IsDirty(This) \ - ( (This)->lpVtbl -> IsDirty(This) ) - -#define ICondition_Load(This,pStm) \ - ( (This)->lpVtbl -> Load(This,pStm) ) - -#define ICondition_Save(This,pStm,fClearDirty) \ - ( (This)->lpVtbl -> Save(This,pStm,fClearDirty) ) - -#define ICondition_GetSizeMax(This,pcbSize) \ - ( (This)->lpVtbl -> GetSizeMax(This,pcbSize) ) - - -#define ICondition_GetConditionType(This,pNodeType) \ - ( (This)->lpVtbl -> GetConditionType(This,pNodeType) ) - -#define ICondition_GetSubConditions(This,riid,ppv) \ - ( (This)->lpVtbl -> GetSubConditions(This,riid,ppv) ) - -#define ICondition_GetComparisonInfo(This,ppszPropertyName,pOperation,pValue) \ - ( (This)->lpVtbl -> GetComparisonInfo(This,ppszPropertyName,pOperation,pValue) ) - -#define ICondition_GetValueType(This,ppszValueTypeName) \ - ( (This)->lpVtbl -> GetValueType(This,ppszValueTypeName) ) - -#define ICondition_GetValueNormalization(This,ppszNormalization) \ - ( (This)->lpVtbl -> GetValueNormalization(This,ppszNormalization) ) - -#define ICondition_GetInputTerms(This,ppPropertyTerm,ppOperationTerm,ppValueTerm) \ - ( (This)->lpVtbl -> GetInputTerms(This,ppPropertyTerm,ppOperationTerm,ppValueTerm) ) - -#define ICondition_Clone(This,ppc) \ - ( (This)->lpVtbl -> Clone(This,ppc) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __ICondition_INTERFACE_DEFINED__ */ - - -#ifndef __IConditionGenerator_INTERFACE_DEFINED__ -#define __IConditionGenerator_INTERFACE_DEFINED__ - -/* interface IConditionGenerator */ -/* [unique][uuid][object] */ - - -EXTERN_C const IID IID_IConditionGenerator; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("92D2CC58-4386-45a3-B98C-7E0CE64A4117") - IConditionGenerator : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE Initialize( - /* [in] */ __RPC__in_opt ISchemaProvider *pSchemaProvider) = 0; - - virtual HRESULT STDMETHODCALLTYPE RecognizeNamedEntities( - /* [in] */ __RPC__in LPCWSTR pszInputString, - /* [in] */ LCID lcid, - /* [in] */ __RPC__in_opt ITokenCollection *pTokenCollection, - /* [out][in] */ __RPC__inout_opt INamedEntityCollector *pNamedEntities) = 0; - - virtual HRESULT STDMETHODCALLTYPE GenerateForLeaf( - /* [in] */ __RPC__in_opt IConditionFactory *pConditionFactory, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszPropertyName, - /* [in] */ CONDITION_OPERATION op, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszValueType, - /* [in] */ __RPC__in LPCWSTR pszValue, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszValue2, - /* [in] */ __RPC__in_opt IRichChunk *pPropertyNameTerm, - /* [in] */ __RPC__in_opt IRichChunk *pOperationTerm, - /* [in] */ __RPC__in_opt IRichChunk *pValueTerm, - /* [in] */ BOOL automaticWildcard, - /* [out] */ __RPC__out BOOL *pNoStringQuery, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppQueryExpression) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE DefaultPhrase( - /* [unique][in] */ LPCWSTR pszValueType, - /* [in] */ const PROPVARIANT *ppropvar, - /* [in] */ BOOL fUseEnglish, - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszPhrase) = 0; - - }; - -#else /* C style interface */ - - typedef struct IConditionGeneratorVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IConditionGenerator * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IConditionGenerator * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IConditionGenerator * This); - - HRESULT ( STDMETHODCALLTYPE *Initialize )( - IConditionGenerator * This, - /* [in] */ __RPC__in_opt ISchemaProvider *pSchemaProvider); - - HRESULT ( STDMETHODCALLTYPE *RecognizeNamedEntities )( - IConditionGenerator * This, - /* [in] */ __RPC__in LPCWSTR pszInputString, - /* [in] */ LCID lcid, - /* [in] */ __RPC__in_opt ITokenCollection *pTokenCollection, - /* [out][in] */ __RPC__inout_opt INamedEntityCollector *pNamedEntities); - - HRESULT ( STDMETHODCALLTYPE *GenerateForLeaf )( - IConditionGenerator * This, - /* [in] */ __RPC__in_opt IConditionFactory *pConditionFactory, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszPropertyName, - /* [in] */ CONDITION_OPERATION op, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszValueType, - /* [in] */ __RPC__in LPCWSTR pszValue, - /* [unique][in] */ __RPC__in_opt LPCWSTR pszValue2, - /* [in] */ __RPC__in_opt IRichChunk *pPropertyNameTerm, - /* [in] */ __RPC__in_opt IRichChunk *pOperationTerm, - /* [in] */ __RPC__in_opt IRichChunk *pValueTerm, - /* [in] */ BOOL automaticWildcard, - /* [out] */ __RPC__out BOOL *pNoStringQuery, - /* [retval][out] */ __RPC__deref_out_opt ICondition **ppQueryExpression); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *DefaultPhrase )( - IConditionGenerator * This, - /* [unique][in] */ LPCWSTR pszValueType, - /* [in] */ const PROPVARIANT *ppropvar, - /* [in] */ BOOL fUseEnglish, - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszPhrase); - - END_INTERFACE - } IConditionGeneratorVtbl; - - interface IConditionGenerator - { - CONST_VTBL struct IConditionGeneratorVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IConditionGenerator_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IConditionGenerator_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IConditionGenerator_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IConditionGenerator_Initialize(This,pSchemaProvider) \ - ( (This)->lpVtbl -> Initialize(This,pSchemaProvider) ) - -#define IConditionGenerator_RecognizeNamedEntities(This,pszInputString,lcid,pTokenCollection,pNamedEntities) \ - ( (This)->lpVtbl -> RecognizeNamedEntities(This,pszInputString,lcid,pTokenCollection,pNamedEntities) ) - -#define IConditionGenerator_GenerateForLeaf(This,pConditionFactory,pszPropertyName,op,pszValueType,pszValue,pszValue2,pPropertyNameTerm,pOperationTerm,pValueTerm,automaticWildcard,pNoStringQuery,ppQueryExpression) \ - ( (This)->lpVtbl -> GenerateForLeaf(This,pConditionFactory,pszPropertyName,op,pszValueType,pszValue,pszValue2,pPropertyNameTerm,pOperationTerm,pValueTerm,automaticWildcard,pNoStringQuery,ppQueryExpression) ) - -#define IConditionGenerator_DefaultPhrase(This,pszValueType,ppropvar,fUseEnglish,ppszPhrase) \ - ( (This)->lpVtbl -> DefaultPhrase(This,pszValueType,ppropvar,fUseEnglish,ppszPhrase) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IConditionGenerator_INTERFACE_DEFINED__ */ - - -#ifndef __IRichChunk_INTERFACE_DEFINED__ -#define __IRichChunk_INTERFACE_DEFINED__ - -/* interface IRichChunk */ -/* [unique][uuid][object] */ - - -EXTERN_C const IID IID_IRichChunk; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("4FDEF69C-DBC9-454e-9910-B34F3C64B510") - IRichChunk : public IUnknown - { - public: - virtual /* [local] */ HRESULT STDMETHODCALLTYPE GetData( - /* [out] */ - __out_opt ULONG *pFirstPos, - /* [out] */ - __out_opt ULONG *pLength, - /* [out] */ - __deref_opt_out LPWSTR *ppsz, - /* [out] */ - __out_opt PROPVARIANT *pValue) = 0; - - }; - -#else /* C style interface */ - - typedef struct IRichChunkVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IRichChunk * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IRichChunk * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IRichChunk * This); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *GetData )( - IRichChunk * This, - /* [out] */ - __out_opt ULONG *pFirstPos, - /* [out] */ - __out_opt ULONG *pLength, - /* [out] */ - __deref_opt_out LPWSTR *ppsz, - /* [out] */ - __out_opt PROPVARIANT *pValue); - - END_INTERFACE - } IRichChunkVtbl; - - interface IRichChunk - { - CONST_VTBL struct IRichChunkVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IRichChunk_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IRichChunk_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IRichChunk_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IRichChunk_GetData(This,pFirstPos,pLength,ppsz,pValue) \ - ( (This)->lpVtbl -> GetData(This,pFirstPos,pLength,ppsz,pValue) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IRichChunk_INTERFACE_DEFINED__ */ - - -#ifndef __IInterval_INTERFACE_DEFINED__ -#define __IInterval_INTERFACE_DEFINED__ - -/* interface IInterval */ -/* [unique][uuid][object] */ - - -EXTERN_C const IID IID_IInterval; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("6BF0A714-3C18-430b-8B5D-83B1C234D3DB") - IInterval : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE GetLimits( - /* [out] */ __RPC__out INTERVAL_LIMIT_KIND *pilkLower, - /* [out] */ __RPC__out PROPVARIANT *ppropvarLower, - /* [out] */ __RPC__out INTERVAL_LIMIT_KIND *pilkUpper, - /* [out] */ __RPC__out PROPVARIANT *ppropvarUpper) = 0; - - }; - -#else /* C style interface */ - - typedef struct IIntervalVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IInterval * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IInterval * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IInterval * This); - - HRESULT ( STDMETHODCALLTYPE *GetLimits )( - IInterval * This, - /* [out] */ __RPC__out INTERVAL_LIMIT_KIND *pilkLower, - /* [out] */ __RPC__out PROPVARIANT *ppropvarLower, - /* [out] */ __RPC__out INTERVAL_LIMIT_KIND *pilkUpper, - /* [out] */ __RPC__out PROPVARIANT *ppropvarUpper); - - END_INTERFACE - } IIntervalVtbl; - - interface IInterval - { - CONST_VTBL struct IIntervalVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IInterval_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IInterval_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IInterval_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IInterval_GetLimits(This,pilkLower,ppropvarLower,pilkUpper,ppropvarUpper) \ - ( (This)->lpVtbl -> GetLimits(This,pilkLower,ppropvarLower,pilkUpper,ppropvarUpper) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IInterval_INTERFACE_DEFINED__ */ - - -#ifndef __IMetaData_INTERFACE_DEFINED__ -#define __IMetaData_INTERFACE_DEFINED__ - -/* interface IMetaData */ -/* [unique][uuid][object][helpstring] */ - - -EXTERN_C const IID IID_IMetaData; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("780102B0-C43B-4876-BC7B-5E9BA5C88794") - IMetaData : public IUnknown - { - public: - virtual /* [local] */ HRESULT STDMETHODCALLTYPE GetData( - /* [out] */ - __deref_opt_out LPWSTR *ppszKey, - /* [out] */ - __deref_opt_out LPWSTR *ppszValue) = 0; - - }; - -#else /* C style interface */ - - typedef struct IMetaDataVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IMetaData * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IMetaData * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IMetaData * This); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *GetData )( - IMetaData * This, - /* [out] */ - __deref_opt_out LPWSTR *ppszKey, - /* [out] */ - __deref_opt_out LPWSTR *ppszValue); - - END_INTERFACE - } IMetaDataVtbl; - - interface IMetaData - { - CONST_VTBL struct IMetaDataVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IMetaData_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IMetaData_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IMetaData_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IMetaData_GetData(This,ppszKey,ppszValue) \ - ( (This)->lpVtbl -> GetData(This,ppszKey,ppszValue) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IMetaData_INTERFACE_DEFINED__ */ - - -/* interface __MIDL_itf_structuredquery_0000_0008 */ -/* [local] */ - - - - -extern RPC_IF_HANDLE __MIDL_itf_structuredquery_0000_0008_v0_0_c_ifspec; -extern RPC_IF_HANDLE __MIDL_itf_structuredquery_0000_0008_v0_0_s_ifspec; - -#ifndef __IEntity_INTERFACE_DEFINED__ -#define __IEntity_INTERFACE_DEFINED__ - -/* interface IEntity */ -/* [unique][object][uuid][helpstring] */ - - -EXTERN_C const IID IID_IEntity; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("24264891-E80B-4fd3-B7CE-4FF2FAE8931F") - IEntity : public IUnknown - { - public: - virtual /* [local] */ HRESULT STDMETHODCALLTYPE Name( - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszName) = 0; - - virtual HRESULT STDMETHODCALLTYPE Base( - /* [retval][out] */ __RPC__deref_out_opt IEntity **pBaseEntity) = 0; - - virtual HRESULT STDMETHODCALLTYPE Relationships( - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pRelationships) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetRelationship( - /* [in] */ __RPC__in LPCWSTR pszRelationName, - /* [retval][out] */ __RPC__deref_out_opt IRelationship **pRelationship) = 0; - - virtual HRESULT STDMETHODCALLTYPE MetaData( - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pMetaData) = 0; - - virtual HRESULT STDMETHODCALLTYPE NamedEntities( - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pNamedEntities) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetNamedEntity( - /* [in] */ __RPC__in LPCWSTR pszValue, - /* [retval][out] */ __RPC__deref_out_opt INamedEntity **ppNamedEntity) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE DefaultPhrase( - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszPhrase) = 0; - - }; - -#else /* C style interface */ - - typedef struct IEntityVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IEntity * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IEntity * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IEntity * This); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *Name )( - IEntity * This, - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszName); - - HRESULT ( STDMETHODCALLTYPE *Base )( - IEntity * This, - /* [retval][out] */ __RPC__deref_out_opt IEntity **pBaseEntity); - - HRESULT ( STDMETHODCALLTYPE *Relationships )( - IEntity * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pRelationships); - - HRESULT ( STDMETHODCALLTYPE *GetRelationship )( - IEntity * This, - /* [in] */ __RPC__in LPCWSTR pszRelationName, - /* [retval][out] */ __RPC__deref_out_opt IRelationship **pRelationship); - - HRESULT ( STDMETHODCALLTYPE *MetaData )( - IEntity * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pMetaData); - - HRESULT ( STDMETHODCALLTYPE *NamedEntities )( - IEntity * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pNamedEntities); - - HRESULT ( STDMETHODCALLTYPE *GetNamedEntity )( - IEntity * This, - /* [in] */ __RPC__in LPCWSTR pszValue, - /* [retval][out] */ __RPC__deref_out_opt INamedEntity **ppNamedEntity); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *DefaultPhrase )( - IEntity * This, - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszPhrase); - - END_INTERFACE - } IEntityVtbl; - - interface IEntity - { - CONST_VTBL struct IEntityVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IEntity_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IEntity_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IEntity_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IEntity_Name(This,ppszName) \ - ( (This)->lpVtbl -> Name(This,ppszName) ) - -#define IEntity_Base(This,pBaseEntity) \ - ( (This)->lpVtbl -> Base(This,pBaseEntity) ) - -#define IEntity_Relationships(This,riid,pRelationships) \ - ( (This)->lpVtbl -> Relationships(This,riid,pRelationships) ) - -#define IEntity_GetRelationship(This,pszRelationName,pRelationship) \ - ( (This)->lpVtbl -> GetRelationship(This,pszRelationName,pRelationship) ) - -#define IEntity_MetaData(This,riid,pMetaData) \ - ( (This)->lpVtbl -> MetaData(This,riid,pMetaData) ) - -#define IEntity_NamedEntities(This,riid,pNamedEntities) \ - ( (This)->lpVtbl -> NamedEntities(This,riid,pNamedEntities) ) - -#define IEntity_GetNamedEntity(This,pszValue,ppNamedEntity) \ - ( (This)->lpVtbl -> GetNamedEntity(This,pszValue,ppNamedEntity) ) - -#define IEntity_DefaultPhrase(This,ppszPhrase) \ - ( (This)->lpVtbl -> DefaultPhrase(This,ppszPhrase) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IEntity_INTERFACE_DEFINED__ */ - - -#ifndef __IRelationship_INTERFACE_DEFINED__ -#define __IRelationship_INTERFACE_DEFINED__ - -/* interface IRelationship */ -/* [unique][object][uuid][helpstring] */ - - -EXTERN_C const IID IID_IRelationship; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("2769280B-5108-498c-9C7F-A51239B63147") - IRelationship : public IUnknown - { - public: - virtual /* [local] */ HRESULT STDMETHODCALLTYPE Name( - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszName) = 0; - - virtual HRESULT STDMETHODCALLTYPE IsReal( - /* [retval][out] */ __RPC__out BOOL *pIsReal) = 0; - - virtual HRESULT STDMETHODCALLTYPE Destination( - /* [retval][out] */ __RPC__deref_out_opt IEntity **pDestinationEntity) = 0; - - virtual HRESULT STDMETHODCALLTYPE MetaData( - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pMetaData) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE DefaultPhrase( - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszPhrase) = 0; - - }; - -#else /* C style interface */ - - typedef struct IRelationshipVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IRelationship * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IRelationship * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IRelationship * This); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *Name )( - IRelationship * This, - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszName); - - HRESULT ( STDMETHODCALLTYPE *IsReal )( - IRelationship * This, - /* [retval][out] */ __RPC__out BOOL *pIsReal); - - HRESULT ( STDMETHODCALLTYPE *Destination )( - IRelationship * This, - /* [retval][out] */ __RPC__deref_out_opt IEntity **pDestinationEntity); - - HRESULT ( STDMETHODCALLTYPE *MetaData )( - IRelationship * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pMetaData); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *DefaultPhrase )( - IRelationship * This, - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszPhrase); - - END_INTERFACE - } IRelationshipVtbl; - - interface IRelationship - { - CONST_VTBL struct IRelationshipVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IRelationship_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IRelationship_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IRelationship_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IRelationship_Name(This,ppszName) \ - ( (This)->lpVtbl -> Name(This,ppszName) ) - -#define IRelationship_IsReal(This,pIsReal) \ - ( (This)->lpVtbl -> IsReal(This,pIsReal) ) - -#define IRelationship_Destination(This,pDestinationEntity) \ - ( (This)->lpVtbl -> Destination(This,pDestinationEntity) ) - -#define IRelationship_MetaData(This,riid,pMetaData) \ - ( (This)->lpVtbl -> MetaData(This,riid,pMetaData) ) - -#define IRelationship_DefaultPhrase(This,ppszPhrase) \ - ( (This)->lpVtbl -> DefaultPhrase(This,ppszPhrase) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IRelationship_INTERFACE_DEFINED__ */ - - -#ifndef __INamedEntity_INTERFACE_DEFINED__ -#define __INamedEntity_INTERFACE_DEFINED__ - -/* interface INamedEntity */ -/* [unique][uuid][object][helpstring] */ - - -EXTERN_C const IID IID_INamedEntity; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("ABDBD0B1-7D54-49fb-AB5C-BFF4130004CD") - INamedEntity : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE GetValue( - /* [retval][out] */ __RPC__deref_out_opt LPWSTR *ppszValue) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE DefaultPhrase( - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszPhrase) = 0; - - }; - -#else /* C style interface */ - - typedef struct INamedEntityVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - INamedEntity * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - INamedEntity * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - INamedEntity * This); - - HRESULT ( STDMETHODCALLTYPE *GetValue )( - INamedEntity * This, - /* [retval][out] */ __RPC__deref_out_opt LPWSTR *ppszValue); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *DefaultPhrase )( - INamedEntity * This, - /* [retval][out] */ - __deref_opt_out LPWSTR *ppszPhrase); - - END_INTERFACE - } INamedEntityVtbl; - - interface INamedEntity - { - CONST_VTBL struct INamedEntityVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define INamedEntity_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define INamedEntity_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define INamedEntity_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define INamedEntity_GetValue(This,ppszValue) \ - ( (This)->lpVtbl -> GetValue(This,ppszValue) ) - -#define INamedEntity_DefaultPhrase(This,ppszPhrase) \ - ( (This)->lpVtbl -> DefaultPhrase(This,ppszPhrase) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __INamedEntity_INTERFACE_DEFINED__ */ - - -#ifndef __ISchemaProvider_INTERFACE_DEFINED__ -#define __ISchemaProvider_INTERFACE_DEFINED__ - -/* interface ISchemaProvider */ -/* [unique][object][uuid][helpstring] */ - - -EXTERN_C const IID IID_ISchemaProvider; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("8CF89BCB-394C-49b2-AE28-A59DD4ED7F68") - ISchemaProvider : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE Entities( - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pEntities) = 0; - - virtual HRESULT STDMETHODCALLTYPE RootEntity( - /* [retval][out] */ __RPC__deref_out_opt IEntity **pRootEntity) = 0; - - virtual HRESULT STDMETHODCALLTYPE GetEntity( - /* [in] */ __RPC__in LPCWSTR pszEntityName, - /* [retval][out] */ __RPC__deref_out_opt IEntity **pEntity) = 0; - - virtual HRESULT STDMETHODCALLTYPE MetaData( - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pMetaData) = 0; - - virtual HRESULT STDMETHODCALLTYPE Localize( - /* [in] */ LCID lcid, - /* [in] */ __RPC__in_opt ISchemaLocalizerSupport *pSchemaLocalizerSupport) = 0; - - virtual HRESULT STDMETHODCALLTYPE SaveBinary( - /* [in] */ __RPC__in LPCWSTR pszSchemaBinaryPath) = 0; - - virtual HRESULT STDMETHODCALLTYPE LookupAuthoredNamedEntity( - /* [in] */ __RPC__in_opt IEntity *pEntity, - /* [in] */ __RPC__in LPCWSTR pszInputString, - /* [in] */ __RPC__in_opt ITokenCollection *pTokenCollection, - /* [in] */ ULONG cTokensBegin, - /* [out] */ __RPC__out ULONG *pcTokensLength, - /* [out] */ __RPC__deref_out_opt LPWSTR *ppszValue) = 0; - - }; - -#else /* C style interface */ - - typedef struct ISchemaProviderVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - ISchemaProvider * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - ISchemaProvider * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - ISchemaProvider * This); - - HRESULT ( STDMETHODCALLTYPE *Entities )( - ISchemaProvider * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pEntities); - - HRESULT ( STDMETHODCALLTYPE *RootEntity )( - ISchemaProvider * This, - /* [retval][out] */ __RPC__deref_out_opt IEntity **pRootEntity); - - HRESULT ( STDMETHODCALLTYPE *GetEntity )( - ISchemaProvider * This, - /* [in] */ __RPC__in LPCWSTR pszEntityName, - /* [retval][out] */ __RPC__deref_out_opt IEntity **pEntity); - - HRESULT ( STDMETHODCALLTYPE *MetaData )( - ISchemaProvider * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **pMetaData); - - HRESULT ( STDMETHODCALLTYPE *Localize )( - ISchemaProvider * This, - /* [in] */ LCID lcid, - /* [in] */ __RPC__in_opt ISchemaLocalizerSupport *pSchemaLocalizerSupport); - - HRESULT ( STDMETHODCALLTYPE *SaveBinary )( - ISchemaProvider * This, - /* [in] */ __RPC__in LPCWSTR pszSchemaBinaryPath); - - HRESULT ( STDMETHODCALLTYPE *LookupAuthoredNamedEntity )( - ISchemaProvider * This, - /* [in] */ __RPC__in_opt IEntity *pEntity, - /* [in] */ __RPC__in LPCWSTR pszInputString, - /* [in] */ __RPC__in_opt ITokenCollection *pTokenCollection, - /* [in] */ ULONG cTokensBegin, - /* [out] */ __RPC__out ULONG *pcTokensLength, - /* [out] */ __RPC__deref_out_opt LPWSTR *ppszValue); - - END_INTERFACE - } ISchemaProviderVtbl; - - interface ISchemaProvider - { - CONST_VTBL struct ISchemaProviderVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define ISchemaProvider_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define ISchemaProvider_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define ISchemaProvider_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define ISchemaProvider_Entities(This,riid,pEntities) \ - ( (This)->lpVtbl -> Entities(This,riid,pEntities) ) - -#define ISchemaProvider_RootEntity(This,pRootEntity) \ - ( (This)->lpVtbl -> RootEntity(This,pRootEntity) ) - -#define ISchemaProvider_GetEntity(This,pszEntityName,pEntity) \ - ( (This)->lpVtbl -> GetEntity(This,pszEntityName,pEntity) ) - -#define ISchemaProvider_MetaData(This,riid,pMetaData) \ - ( (This)->lpVtbl -> MetaData(This,riid,pMetaData) ) - -#define ISchemaProvider_Localize(This,lcid,pSchemaLocalizerSupport) \ - ( (This)->lpVtbl -> Localize(This,lcid,pSchemaLocalizerSupport) ) - -#define ISchemaProvider_SaveBinary(This,pszSchemaBinaryPath) \ - ( (This)->lpVtbl -> SaveBinary(This,pszSchemaBinaryPath) ) - -#define ISchemaProvider_LookupAuthoredNamedEntity(This,pEntity,pszInputString,pTokenCollection,cTokensBegin,pcTokensLength,ppszValue) \ - ( (This)->lpVtbl -> LookupAuthoredNamedEntity(This,pEntity,pszInputString,pTokenCollection,cTokensBegin,pcTokensLength,ppszValue) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __ISchemaProvider_INTERFACE_DEFINED__ */ - - -#ifndef __ITokenCollection_INTERFACE_DEFINED__ -#define __ITokenCollection_INTERFACE_DEFINED__ - -/* interface ITokenCollection */ -/* [unique][object][uuid][helpstring] */ - - -EXTERN_C const IID IID_ITokenCollection; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("22D8B4F2-F577-4adb-A335-C2AE88416FAB") - ITokenCollection : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE NumberOfTokens( - __RPC__in ULONG *pCount) = 0; - - virtual /* [local] */ HRESULT STDMETHODCALLTYPE GetToken( - /* [in] */ ULONG i, - /* [out] */ - __out_opt ULONG *pBegin, - /* [out] */ - __out_opt ULONG *pLength, - /* [out] */ - __deref_opt_out LPWSTR *ppsz) = 0; - - }; - -#else /* C style interface */ - - typedef struct ITokenCollectionVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - ITokenCollection * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - ITokenCollection * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - ITokenCollection * This); - - HRESULT ( STDMETHODCALLTYPE *NumberOfTokens )( - ITokenCollection * This, - __RPC__in ULONG *pCount); - - /* [local] */ HRESULT ( STDMETHODCALLTYPE *GetToken )( - ITokenCollection * This, - /* [in] */ ULONG i, - /* [out] */ - __out_opt ULONG *pBegin, - /* [out] */ - __out_opt ULONG *pLength, - /* [out] */ - __deref_opt_out LPWSTR *ppsz); - - END_INTERFACE - } ITokenCollectionVtbl; - - interface ITokenCollection - { - CONST_VTBL struct ITokenCollectionVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define ITokenCollection_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define ITokenCollection_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define ITokenCollection_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define ITokenCollection_NumberOfTokens(This,pCount) \ - ( (This)->lpVtbl -> NumberOfTokens(This,pCount) ) - -#define ITokenCollection_GetToken(This,i,pBegin,pLength,ppsz) \ - ( (This)->lpVtbl -> GetToken(This,i,pBegin,pLength,ppsz) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __ITokenCollection_INTERFACE_DEFINED__ */ - - -/* interface __MIDL_itf_structuredquery_0000_0013 */ -/* [local] */ - -typedef /* [public][public][v1_enum] */ -enum __MIDL___MIDL_itf_structuredquery_0000_0013_0001 - { NEC_LOW = 0, - NEC_MEDIUM = ( NEC_LOW + 1 ) , - NEC_HIGH = ( NEC_MEDIUM + 1 ) - } NAMED_ENTITY_CERTAINTY; - - - -extern RPC_IF_HANDLE __MIDL_itf_structuredquery_0000_0013_v0_0_c_ifspec; -extern RPC_IF_HANDLE __MIDL_itf_structuredquery_0000_0013_v0_0_s_ifspec; - -#ifndef __INamedEntityCollector_INTERFACE_DEFINED__ -#define __INamedEntityCollector_INTERFACE_DEFINED__ - -/* interface INamedEntityCollector */ -/* [unique][object][uuid][helpstring] */ - - -EXTERN_C const IID IID_INamedEntityCollector; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("AF2440F6-8AFC-47d0-9A7F-396A0ACFB43D") - INamedEntityCollector : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE Add( - /* [in] */ ULONG beginSpan, - /* [in] */ ULONG endSpan, - /* [in] */ ULONG beginActual, - /* [in] */ ULONG endActual, - /* [in] */ __RPC__in_opt IEntity *pType, - /* [in] */ __RPC__in LPCWSTR pszValue, - /* [in] */ NAMED_ENTITY_CERTAINTY certainty) = 0; - - }; - -#else /* C style interface */ - - typedef struct INamedEntityCollectorVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - INamedEntityCollector * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - INamedEntityCollector * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - INamedEntityCollector * This); - - HRESULT ( STDMETHODCALLTYPE *Add )( - INamedEntityCollector * This, - /* [in] */ ULONG beginSpan, - /* [in] */ ULONG endSpan, - /* [in] */ ULONG beginActual, - /* [in] */ ULONG endActual, - /* [in] */ __RPC__in_opt IEntity *pType, - /* [in] */ __RPC__in LPCWSTR pszValue, - /* [in] */ NAMED_ENTITY_CERTAINTY certainty); - - END_INTERFACE - } INamedEntityCollectorVtbl; - - interface INamedEntityCollector - { - CONST_VTBL struct INamedEntityCollectorVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define INamedEntityCollector_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define INamedEntityCollector_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define INamedEntityCollector_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define INamedEntityCollector_Add(This,beginSpan,endSpan,beginActual,endActual,pType,pszValue,certainty) \ - ( (This)->lpVtbl -> Add(This,beginSpan,endSpan,beginActual,endActual,pType,pszValue,certainty) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __INamedEntityCollector_INTERFACE_DEFINED__ */ - - -#ifndef __ISchemaLocalizerSupport_INTERFACE_DEFINED__ -#define __ISchemaLocalizerSupport_INTERFACE_DEFINED__ - -/* interface ISchemaLocalizerSupport */ -/* [unique][object][uuid] */ - - -EXTERN_C const IID IID_ISchemaLocalizerSupport; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("CA3FDCA2-BFBE-4eed-90D7-0CAEF0A1BDA1") - ISchemaLocalizerSupport : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE Localize( - /* [in] */ __RPC__in LPCWSTR pszGlobalString, - /* [retval][out] */ __RPC__deref_out_opt LPWSTR *ppszLocalString) = 0; - - }; - -#else /* C style interface */ - - typedef struct ISchemaLocalizerSupportVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - ISchemaLocalizerSupport * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - ISchemaLocalizerSupport * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - ISchemaLocalizerSupport * This); - - HRESULT ( STDMETHODCALLTYPE *Localize )( - ISchemaLocalizerSupport * This, - /* [in] */ __RPC__in LPCWSTR pszGlobalString, - /* [retval][out] */ __RPC__deref_out_opt LPWSTR *ppszLocalString); - - END_INTERFACE - } ISchemaLocalizerSupportVtbl; - - interface ISchemaLocalizerSupport - { - CONST_VTBL struct ISchemaLocalizerSupportVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define ISchemaLocalizerSupport_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define ISchemaLocalizerSupport_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define ISchemaLocalizerSupport_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define ISchemaLocalizerSupport_Localize(This,pszGlobalString,ppszLocalString) \ - ( (This)->lpVtbl -> Localize(This,pszGlobalString,ppszLocalString) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __ISchemaLocalizerSupport_INTERFACE_DEFINED__ */ - - -#ifndef __IQueryParserManager_INTERFACE_DEFINED__ -#define __IQueryParserManager_INTERFACE_DEFINED__ - -/* interface IQueryParserManager */ -/* [unique][object][uuid] */ - - -EXTERN_C const IID IID_IQueryParserManager; - -#if defined(__cplusplus) && !defined(CINTERFACE) - - MIDL_INTERFACE("A879E3C4-AF77-44fb-8F37-EBD1487CF920") - IQueryParserManager : public IUnknown - { - public: - virtual HRESULT STDMETHODCALLTYPE CreateLoadedParser( - /* [in] */ __RPC__in LPCWSTR pszCatalog, - /* [in] */ LANGID langidForKeywords, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **ppQueryParser) = 0; - - virtual HRESULT STDMETHODCALLTYPE InitializeOptions( - /* [in] */ BOOL fUnderstandNQS, - /* [in] */ BOOL fAutoWildCard, - /* [in] */ __RPC__in_opt IQueryParser *pQueryParser) = 0; - - virtual HRESULT STDMETHODCALLTYPE SetOption( - /* [in] */ QUERY_PARSER_MANAGER_OPTION option, - /* [in] */ __RPC__in const PROPVARIANT *pOptionValue) = 0; - - }; - -#else /* C style interface */ - - typedef struct IQueryParserManagerVtbl - { - BEGIN_INTERFACE - - HRESULT ( STDMETHODCALLTYPE *QueryInterface )( - IQueryParserManager * This, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][out] */ - __RPC__deref_out void **ppvObject); - - ULONG ( STDMETHODCALLTYPE *AddRef )( - IQueryParserManager * This); - - ULONG ( STDMETHODCALLTYPE *Release )( - IQueryParserManager * This); - - HRESULT ( STDMETHODCALLTYPE *CreateLoadedParser )( - IQueryParserManager * This, - /* [in] */ __RPC__in LPCWSTR pszCatalog, - /* [in] */ LANGID langidForKeywords, - /* [in] */ __RPC__in REFIID riid, - /* [iid_is][retval][out] */ __RPC__deref_out_opt void **ppQueryParser); - - HRESULT ( STDMETHODCALLTYPE *InitializeOptions )( - IQueryParserManager * This, - /* [in] */ BOOL fUnderstandNQS, - /* [in] */ BOOL fAutoWildCard, - /* [in] */ __RPC__in_opt IQueryParser *pQueryParser); - - HRESULT ( STDMETHODCALLTYPE *SetOption )( - IQueryParserManager * This, - /* [in] */ QUERY_PARSER_MANAGER_OPTION option, - /* [in] */ __RPC__in const PROPVARIANT *pOptionValue); - - END_INTERFACE - } IQueryParserManagerVtbl; - - interface IQueryParserManager - { - CONST_VTBL struct IQueryParserManagerVtbl *lpVtbl; - }; - - - -#ifdef COBJMACROS - - -#define IQueryParserManager_QueryInterface(This,riid,ppvObject) \ - ( (This)->lpVtbl -> QueryInterface(This,riid,ppvObject) ) - -#define IQueryParserManager_AddRef(This) \ - ( (This)->lpVtbl -> AddRef(This) ) - -#define IQueryParserManager_Release(This) \ - ( (This)->lpVtbl -> Release(This) ) - - -#define IQueryParserManager_CreateLoadedParser(This,pszCatalog,langidForKeywords,riid,ppQueryParser) \ - ( (This)->lpVtbl -> CreateLoadedParser(This,pszCatalog,langidForKeywords,riid,ppQueryParser) ) - -#define IQueryParserManager_InitializeOptions(This,fUnderstandNQS,fAutoWildCard,pQueryParser) \ - ( (This)->lpVtbl -> InitializeOptions(This,fUnderstandNQS,fAutoWildCard,pQueryParser) ) - -#define IQueryParserManager_SetOption(This,option,pOptionValue) \ - ( (This)->lpVtbl -> SetOption(This,option,pOptionValue) ) - -#endif /* COBJMACROS */ - - -#endif /* C style interface */ - - - - -#endif /* __IQueryParserManager_INTERFACE_DEFINED__ */ - - - -#ifndef __StructuredQuery1_LIBRARY_DEFINED__ -#define __StructuredQuery1_LIBRARY_DEFINED__ - -/* library StructuredQuery1 */ -/* [version][uuid] */ - - -EXTERN_C const IID LIBID_StructuredQuery1; - -EXTERN_C const CLSID CLSID_QueryParser; - -#ifdef __cplusplus - -class DECLSPEC_UUID("B72F8FD8-0FAB-4dd9-BDBF-245A6CE1485B") -QueryParser; -#endif - -EXTERN_C const CLSID CLSID_NegationCondition; - -#ifdef __cplusplus - -class DECLSPEC_UUID("8DE9C74C-605A-4acd-BEE3-2B222AA2D23D") -NegationCondition; -#endif - -EXTERN_C const CLSID CLSID_CompoundCondition; - -#ifdef __cplusplus - -class DECLSPEC_UUID("116F8D13-101E-4fa5-84D4-FF8279381935") -CompoundCondition; -#endif - -EXTERN_C const CLSID CLSID_LeafCondition; - -#ifdef __cplusplus - -class DECLSPEC_UUID("52F15C89-5A17-48e1-BBCD-46A3F89C7CC2") -LeafCondition; -#endif - -EXTERN_C const CLSID CLSID_ConditionFactory; - -#ifdef __cplusplus - -class DECLSPEC_UUID("E03E85B0-7BE3-4000-BA98-6C13DE9FA486") -ConditionFactory; -#endif - -EXTERN_C const CLSID CLSID_Interval; - -#ifdef __cplusplus - -class DECLSPEC_UUID("D957171F-4BF9-4de2-BCD5-C70A7CA55836") -Interval; -#endif - -EXTERN_C const CLSID CLSID_QueryParserManager; - -#ifdef __cplusplus - -class DECLSPEC_UUID("5088B39A-29B4-4d9d-8245-4EE289222F66") -QueryParserManager; -#endif -#endif /* __StructuredQuery1_LIBRARY_DEFINED__ */ - -/* Additional Prototypes for ALL interfaces */ - -unsigned long __RPC_USER BSTR_UserSize( unsigned long *, unsigned long , BSTR * ); -unsigned char * __RPC_USER BSTR_UserMarshal( unsigned long *, unsigned char *, BSTR * ); -unsigned char * __RPC_USER BSTR_UserUnmarshal(unsigned long *, unsigned char *, BSTR * ); -void __RPC_USER BSTR_UserFree( unsigned long *, BSTR * ); - -unsigned long __RPC_USER LPSAFEARRAY_UserSize( unsigned long *, unsigned long , LPSAFEARRAY * ); -unsigned char * __RPC_USER LPSAFEARRAY_UserMarshal( unsigned long *, unsigned char *, LPSAFEARRAY * ); -unsigned char * __RPC_USER LPSAFEARRAY_UserUnmarshal(unsigned long *, unsigned char *, LPSAFEARRAY * ); -void __RPC_USER LPSAFEARRAY_UserFree( unsigned long *, LPSAFEARRAY * ); - -/* end of Additional Prototypes */ - -#ifdef __cplusplus -} -#endif - -#endif - - - diff --git a/spaces/anmol007/anmol-sentiment-analysis/README.md b/spaces/anmol007/anmol-sentiment-analysis/README.md deleted file mode 100644 index d2eb0ec615de586d5416426e2de353410e2a0b2f..0000000000000000000000000000000000000000 --- a/spaces/anmol007/anmol-sentiment-analysis/README.md +++ /dev/null @@ -1,37 +0,0 @@ ---- -title: Anmol Sentiment Analysis -emoji: ⚡ -colorFrom: red -colorTo: yellow -sdk: gradio -app_file: app.py -pinned: false ---- - -# Configuration - -`title`: _string_ -Display title for the Space - -`emoji`: _string_ -Space emoji (emoji-only character allowed) - -`colorFrom`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`colorTo`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`sdk`: _string_ -Can be either `gradio`, `streamlit`, or `static` - -`sdk_version` : _string_ -Only applicable for `streamlit` SDK. -See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions. - -`app_file`: _string_ -Path to your main application file (which contains either `gradio` or `streamlit` Python code, or `static` html code). -Path is relative to the root of the repository. - -`pinned`: _boolean_ -Whether the Space stays on top of your list. diff --git a/spaces/anonymous-demo/Anonymous-TranSVAE-Demo/dcgan_64.py b/spaces/anonymous-demo/Anonymous-TranSVAE-Demo/dcgan_64.py deleted file mode 100644 index abac82aa23bf5eac3c2980256e0f2cb05cabd4ed..0000000000000000000000000000000000000000 --- a/spaces/anonymous-demo/Anonymous-TranSVAE-Demo/dcgan_64.py +++ /dev/null @@ -1,131 +0,0 @@ -import torch.nn as nn -import torch.nn.functional as F - - -class dcgan_conv(nn.Module): - def __init__(self, nin, nout): - super(dcgan_conv, self).__init__() - self.main = nn.Sequential(nn.Conv2d(nin, nout, 4, 2, 1), nn.BatchNorm2d(nout), nn.LeakyReLU(0.2, inplace=True)) - - def forward(self, input): - return self.main(input) - - -class dcgan_upconv(nn.Module): - def __init__(self, nin, nout): - super(dcgan_upconv, self).__init__() - self.main = nn.Sequential(nn.ConvTranspose2d(nin, nout, 4, 2, 1), nn.BatchNorm2d(nout), nn.LeakyReLU(0.2, inplace=True)) - - def forward(self, input): - return self.main(input) - - -class encoder(nn.Module): - def __init__(self, dim, nc=1): - super(encoder, self).__init__() - self.dim = dim - nf = 64 - self.c1 = dcgan_conv(nc, nf) - self.c2 = dcgan_conv(nf, nf * 2) - self.c3 = dcgan_conv(nf * 2, nf * 4) - self.c4 = dcgan_conv(nf * 4, nf * 8) - self.c5 = nn.Sequential(nn.Conv2d(nf * 8, dim, 4, 1, 0), nn.BatchNorm2d(dim), nn.Tanh()) - - def forward(self, input): - h1 = self.c1(input) - h2 = self.c2(h1) - h3 = self.c3(h2) - h4 = self.c4(h3) - h5 = self.c5(h4) - return h5.view(-1, self.dim), [h1, h2, h3, h4] - - -class decoder_convT(nn.Module): - def __init__(self, dim, nc=1): - super(decoder_convT, self).__init__() - self.dim = dim - nf = 64 - self.upc1 = nn.Sequential( - nn.ConvTranspose2d(dim, nf * 8, 4, 1, 0), - nn.BatchNorm2d(nf * 8), - nn.LeakyReLU(0.2, inplace=True) - ) - self.upc2 = dcgan_upconv(nf * 8, nf * 4) - self.upc3 = dcgan_upconv(nf * 4, nf * 2) - self.upc4 = dcgan_upconv(nf * 2, nf) - self.upc5 = nn.Sequential( - nn.ConvTranspose2d(nf, nc, 4, 2, 1), - nn.Sigmoid() - ) - - def forward(self, input): - d1 = self.upc1(input.view(-1, self.dim, 1, 1)) - d2 = self.upc2(d1) - d3 = self.upc3(d2) - d4 = self.upc4(d3) - output = self.upc5(d4) - output = output.view(input.shape[0], input.shape[1], output.shape[1], output.shape[2], output.shape[3]) - return output - - -class decoder_woSkip(nn.Module): - def __init__(self, dim, nc=1): - super(decoder_woSkip, self).__init__() - self.dim = dim - nf = 64 - self.upc1 = nn.Sequential( - nn.ConvTranspose2d(dim, nf * 8, 4, 1, 0), - nn.BatchNorm2d(nf * 8), - nn.LeakyReLU(0.2, inplace=True) - ) - self.upc2 = dcgan_upconv(nf * 8, nf * 4) - self.upc3 = dcgan_upconv(nf * 4, nf * 2) - self.upc4 = dcgan_upconv(nf * 2, nf) - self.upc5 = nn.Sequential( - nn.ConvTranspose2d(nf, nc, 4, 2, 1), - nn.Sigmoid() - ) - - def forward(self, input): - d1 = self.upc1(input.view(-1, self.dim, 1, 1)) - d2 = self.upc2(d1) - d3 = self.upc3(d2) - d4 = self.upc4(d3) - output = self.upc5(d4) - output = output.view(input.shape[0], input.shape[1], output.shape[1], output.shape[2], output.shape[3]) - return output - - -class upconv(nn.Module): - def __init__(self, nc_in, nc_out): - super().__init__() - self.conv = nn.Conv2d(nc_in, nc_out, 3, 1, 1) - self.norm = nn.BatchNorm2d(nc_out) - - def forward(self, input): - out = F.interpolate(input, scale_factor=2, mode='bilinear', align_corners=False) - return F.relu(self.norm(self.conv(out))) - -class decoder_conv(nn.Module): - def __init__(self, dim, nc=1): - super(decoder_conv, self).__init__() - self.dim = dim - nf = 64 - - self.main = nn.Sequential( - nn.ConvTranspose2d(dim, nf * 8, 4, 1, 0), - nn.BatchNorm2d(nf * 8), - nn.ReLU(), - upconv(nf * 8, nf * 4), - upconv(nf * 4, nf * 2), - upconv(nf * 2, nf * 2), - upconv(nf * 2, nf), - nn.Conv2d(nf, nc, 1, 1, 0), - nn.Sigmoid() - ) - - - def forward(self, input): - output = self.main(input.view(-1, self.dim, 1, 1)) - output = output.view(input.shape[0], input.shape[1], output.shape[1], output.shape[2], output.shape[3]) - return output \ No newline at end of file diff --git a/spaces/aodianyun/ChatGLM-6B/THUDM/chatglm-6b/tokenization_chatglm.py b/spaces/aodianyun/ChatGLM-6B/THUDM/chatglm-6b/tokenization_chatglm.py deleted file mode 100644 index 69ee85c80d1ea3402d8f4d5281a63643aecf71b2..0000000000000000000000000000000000000000 --- a/spaces/aodianyun/ChatGLM-6B/THUDM/chatglm-6b/tokenization_chatglm.py +++ /dev/null @@ -1,443 +0,0 @@ -"""Tokenization classes for ChatGLM.""" -from typing import List, Optional, Union -import os - -from transformers.tokenization_utils import PreTrainedTokenizer -from transformers.utils import logging, PaddingStrategy -from transformers.tokenization_utils_base import EncodedInput, BatchEncoding -from typing import Dict -import sentencepiece as spm -import numpy as np - -logger = logging.get_logger(__name__) - -PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = { - "THUDM/chatglm-6b": 2048, -} - - -class TextTokenizer: - def __init__(self, model_path): - self.sp = spm.SentencePieceProcessor() - self.sp.Load(model_path) - self.num_tokens = self.sp.vocab_size() - - def encode(self, text): - return self.sp.EncodeAsIds(text) - - def decode(self, ids: List[int]): - return self.sp.DecodeIds(ids) - - def tokenize(self, text): - return self.sp.EncodeAsPieces(text) - - def convert_tokens_to_string(self, tokens): - return self.sp.DecodePieces(tokens) - - def convert_tokens_to_ids(self, tokens): - return [self.sp.PieceToId(token) for token in tokens] - - def convert_token_to_id(self, token): - return self.sp.PieceToId(token) - - def convert_id_to_token(self, idx): - return self.sp.IdToPiece(idx) - - def __len__(self): - return self.num_tokens - - -class SPTokenizer: - def __init__( - self, - vocab_file, - num_image_tokens=20000, - max_blank_length=80, - byte_fallback=True, - ): - assert vocab_file is not None - self.vocab_file = vocab_file - self.num_image_tokens = num_image_tokens - self.special_tokens = ["[MASK]", "[gMASK]", "[sMASK]", " ", " ", " ", " ", " "] - self.max_blank_length = max_blank_length - self.byte_fallback = byte_fallback - self.text_tokenizer = TextTokenizer(vocab_file) - - def _get_text_tokenizer(self): - return self.text_tokenizer - - @staticmethod - def get_blank_token(length: int): - assert length >= 2 - return f"<|blank_{length}|>" - - @staticmethod - def get_tab_token(): - return f"<|tab|>" - - @property - def num_text_tokens(self): - return self.text_tokenizer.num_tokens - - @property - def num_tokens(self): - return self.num_image_tokens + self.num_text_tokens - - @staticmethod - def _encode_whitespaces(text: str, max_len: int = 80): - text = text.replace("\t", SPTokenizer.get_tab_token()) - for i in range(max_len, 1, -1): - text = text.replace(" " * i, SPTokenizer.get_blank_token(i)) - return text - - def _preprocess(self, text: str, linebreak=True, whitespaces=True): - if linebreak: - text = text.replace("\n", " ") - if whitespaces: - text = self._encode_whitespaces(text, max_len=self.max_blank_length) - return text - - def encode( - self, text: str, linebreak=True, whitespaces=True, add_dummy_prefix=True - ) -> List[int]: - """ - @param text: Text to encode. - @param linebreak: Whether to encode newline (\n) in text. - @param whitespaces: Whether to encode multiple whitespaces or tab in text, useful for source code encoding. - @param special_tokens: Whether to encode special token ([MASK], [gMASK], etc.) in text. - @param add_dummy_prefix: Whether to add dummy blank space in the beginning. - """ - text = self._preprocess(text, linebreak, whitespaces) - if not add_dummy_prefix: - text = " " + text - tmp = self._get_text_tokenizer().encode(text) - tokens = [x + self.num_image_tokens for x in tmp] - return tokens if add_dummy_prefix else tokens[2:] - - def postprocess(self, text): - text = text.replace(" ", "\n") - text = text.replace(SPTokenizer.get_tab_token(), "\t") - for i in range(2, self.max_blank_length + 1): - text = text.replace(self.get_blank_token(i), " " * i) - return text - - def decode(self, text_ids: List[int]) -> str: - ids = [int(_id) - self.num_image_tokens for _id in text_ids] - ids = [_id for _id in ids if _id >= 0] - text = self._get_text_tokenizer().decode(ids) - text = self.postprocess(text) - return text - - def decode_tokens(self, tokens: List[str]) -> str: - text = self._get_text_tokenizer().convert_tokens_to_string(tokens) - text = self.postprocess(text) - return text - - def tokenize( - self, text: str, linebreak=True, whitespaces=True, add_dummy_prefix=True - ) -> List[str]: - """ - @param text: Text to encode. - @param linebreak: Whether to encode newline (\n) in text. - @param whitespaces: Whether to encode multiple whitespaces or tab in text, useful for source code encoding. - @param special_tokens: Whether to encode special token ([MASK], [gMASK], etc.) in text. - @param add_dummy_prefix: Whether to add dummy blank space in the beginning. - """ - text = self._preprocess(text, linebreak, whitespaces) - if not add_dummy_prefix: - text = " " + text - tokens = self._get_text_tokenizer().tokenize(text) - return tokens if add_dummy_prefix else tokens[2:] - - def __getitem__(self, x: Union[int, str]): - if isinstance(x, int): - if x < self.num_image_tokens: - return " ', - eos_token=' ', - end_token=' ", - unk_token=" ", - num_image_tokens=20000, - **kwargs - ) -> None: - super().__init__( - do_lower_case=do_lower_case, - remove_space=remove_space, - padding_side=padding_side, - bos_token=bos_token, - eos_token=eos_token, - end_token=end_token, - mask_token=mask_token, - gmask_token=gmask_token, - pad_token=pad_token, - unk_token=unk_token, - num_image_tokens=num_image_tokens, - **kwargs - ) - - self.do_lower_case = do_lower_case - self.remove_space = remove_space - self.vocab_file = vocab_file - - self.bos_token = bos_token - self.eos_token = eos_token - self.end_token = end_token - self.mask_token = mask_token - self.gmask_token = gmask_token - - self.sp_tokenizer = SPTokenizer(vocab_file, num_image_tokens=num_image_tokens) - - """ Initialisation """ - - @property - def gmask_token_id(self) -> Optional[int]: - if self.gmask_token is None: - return None - return self.convert_tokens_to_ids(self.gmask_token) - - @property - def end_token_id(self) -> Optional[int]: - """ - `Optional[int]`: Id of the end of context token in the vocabulary. Returns `None` if the token has not been - set. - """ - if self.end_token is None: - return None - return self.convert_tokens_to_ids(self.end_token) - - @property - def vocab_size(self): - """ Returns vocab size """ - return self.sp_tokenizer.num_tokens - - def get_vocab(self): - """ Returns vocab as a dict """ - vocab = {self._convert_id_to_token(i): i for i in range(self.vocab_size)} - vocab.update(self.added_tokens_encoder) - return vocab - - def preprocess_text(self, inputs): - if self.remove_space: - outputs = " ".join(inputs.strip().split()) - else: - outputs = inputs - - if self.do_lower_case: - outputs = outputs.lower() - - return outputs - - def _tokenize(self, text, **kwargs): - """ Returns a tokenized string. """ - text = self.preprocess_text(text) - - seq = self.sp_tokenizer.tokenize(text) - - return seq - - def convert_tokens_to_string(self, tokens: List[str]) -> str: - return self.sp_tokenizer.decode_tokens(tokens) - - def _decode( - self, - token_ids: Union[int, List[int]], - **kwargs - ) -> str: - if isinstance(token_ids, int): - token_ids = [token_ids] - if len(token_ids) == 0: - return "" - if self.pad_token_id in token_ids: # remove pad - token_ids = list(filter((self.pad_token_id).__ne__, token_ids)) - return super()._decode(token_ids, **kwargs) - - def _convert_token_to_id(self, token): - """ Converts a token (str) in an id using the vocab. """ - return self.sp_tokenizer[token] - - def _convert_id_to_token(self, index): - """Converts an index (integer) in a token (str) using the vocab.""" - return self.sp_tokenizer[index] - - def save_vocabulary(self, save_directory, filename_prefix=None): - """ - Save the vocabulary and special tokens file to a directory. - - Args: - save_directory (`str`): - The directory in which to save the vocabulary. - filename_prefix (`str`, *optional*): - An optional prefix to add to the named of the saved files. - - Returns: - `Tuple(str)`: Paths to the files saved. - """ - if os.path.isdir(save_directory): - vocab_file = os.path.join( - save_directory, self.vocab_files_names["vocab_file"] - ) - else: - vocab_file = save_directory - - with open(self.vocab_file, 'rb') as fin: - proto_str = fin.read() - - with open(vocab_file, "wb") as writer: - writer.write(proto_str) - - return (vocab_file,) - - def build_inputs_with_special_tokens( - self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None - ) -> List[int]: - """ - Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and - adding special tokens. A BERT sequence has the following format: - - - single sequence: `[CLS] X [SEP]` - - pair of sequences: `[CLS] A [SEP] B [SEP]` - - Args: - token_ids_0 (`List[int]`): - List of IDs to which the special tokens will be added. - token_ids_1 (`List[int]`, *optional*): - Optional second list of IDs for sequence pairs. - - Returns: - `List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens. - """ - gmask_id = self.sp_tokenizer[self.gmask_token] - eos_id = self.sp_tokenizer[self.eos_token] - token_ids_0 = token_ids_0 + [gmask_id, self.sp_tokenizer[self.bos_token]] - if token_ids_1 is not None: - token_ids_0 = token_ids_0 + token_ids_1 + [eos_id] - return token_ids_0 - - def _pad( - self, - encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding], - max_length: Optional[int] = None, - padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD, - pad_to_multiple_of: Optional[int] = None, - return_attention_mask: Optional[bool] = None, - ) -> dict: - """ - Pad encoded inputs (on left/right and up to predefined length or max length in the batch) - - Args: - encoded_inputs: - Dictionary of tokenized inputs (`List[int]`) or batch of tokenized inputs (`List[List[int]]`). - max_length: maximum length of the returned list and optionally padding length (see below). - Will truncate by taking into account the special tokens. - padding_strategy: PaddingStrategy to use for padding. - - - PaddingStrategy.LONGEST Pad to the longest sequence in the batch - - PaddingStrategy.MAX_LENGTH: Pad to the max length (default) - - PaddingStrategy.DO_NOT_PAD: Do not pad - The tokenizer padding sides are defined in self.padding_side: - - - 'left': pads on the left of the sequences - - 'right': pads on the right of the sequences - pad_to_multiple_of: (optional) Integer if set will pad the sequence to a multiple of the provided value. - This is especially useful to enable the use of Tensor Core on NVIDIA hardware with compute capability - `>= 7.5` (Volta). - return_attention_mask: - (optional) Set to False to avoid returning attention mask (default: set to model specifics) - """ - # Load from model defaults - bos_token_id = self.sp_tokenizer[self.bos_token] - mask_token_id = self.sp_tokenizer[self.mask_token] - gmask_token_id = self.sp_tokenizer[self.gmask_token] - assert self.padding_side == "left" - - required_input = encoded_inputs[self.model_input_names[0]] - seq_length = len(required_input) - - if padding_strategy == PaddingStrategy.LONGEST: - max_length = len(required_input) - - if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0): - max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of - - needs_to_be_padded = padding_strategy != PaddingStrategy.DO_NOT_PAD and len(required_input) != max_length - - # Initialize attention mask if not present. - if max_length is not None: - if "attention_mask" not in encoded_inputs: - if bos_token_id in required_input: - context_length = required_input.index(bos_token_id) - else: - context_length = seq_length - attention_mask = np.ones((1, seq_length, seq_length)) - attention_mask = np.tril(attention_mask) - attention_mask[:, :, :context_length] = 1 - attention_mask = np.bool_(attention_mask < 0.5) - encoded_inputs["attention_mask"] = attention_mask - - if "position_ids" not in encoded_inputs: - if bos_token_id in required_input: - context_length = required_input.index(bos_token_id) - else: - context_length = seq_length - position_ids = np.arange(seq_length, dtype=np.int64) - mask_token = mask_token_id if mask_token_id in required_input else gmask_token_id - if mask_token in required_input: - mask_position = required_input.index(mask_token) - position_ids[context_length:] = mask_position - block_position_ids = np.concatenate( - [np.zeros(context_length, dtype=np.int64), - np.arange(1, seq_length - context_length + 1, dtype=np.int64)]) - encoded_inputs["position_ids"] = np.stack([position_ids, block_position_ids], axis=0) - - if needs_to_be_padded: - difference = max_length - len(required_input) - - if "attention_mask" in encoded_inputs: - encoded_inputs["attention_mask"] = np.pad(encoded_inputs["attention_mask"], - pad_width=[(0, 0), (difference, 0), (difference, 0)], - mode='constant', constant_values=True) - if "token_type_ids" in encoded_inputs: - encoded_inputs["token_type_ids"] = [self.pad_token_type_id] * difference + encoded_inputs[ - "token_type_ids" - ] - if "special_tokens_mask" in encoded_inputs: - encoded_inputs["special_tokens_mask"] = [1] * difference + encoded_inputs["special_tokens_mask"] - if "position_ids" in encoded_inputs: - encoded_inputs["position_ids"] = np.pad(encoded_inputs["position_ids"], - pad_width=[(0, 0), (difference, 0)]) - encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input - - return encoded_inputs diff --git a/spaces/arbml/Ashaar/langs.py b/spaces/arbml/Ashaar/langs.py deleted file mode 100644 index ce66ea7bb4884344c705c066657646185ff3ebc0..0000000000000000000000000000000000000000 --- a/spaces/arbml/Ashaar/langs.py +++ /dev/null @@ -1,59 +0,0 @@ -IMG = """ -
- -""" -TITLE_ar=""" -
-أَشْعــَـار: تحليل وإنشاء الشعر العربي
""" -DESCRIPTION_ar = IMG - -DESCRIPTION_ar +="""-هذا البرنامج يتيح للمستخدم تحليل وإنشاء الشعر العربي. -لإنشاء الشعر العربي تم تدريب نموج يقوم بإستخدام البحر والقافية والعاطفة لإنشاء أكمال للقصيدة بناء على هذه الشروط. -بالإضافة إلى نموذج إنشاء الشعر يحتوي البرنامج على نماذج لتصنيف الحقبة الزمنية والعاطفة والبحر و كذلك تشكيل الشعر . -يقوم البرنامج بإستخدام هذه النماذج لإيجاد الخلل في القصيدة من خلال إضافة ألوان معينة تدل على اماكن الخلل. -لإستخدام البرنامج قم في البداية بكتابة قصيدة تحتوي على عدد زوجي من الأبيات و من ثم قم بالضغط على تحليل ، وبعد إنتهاء التحليل بالإمكان إنشاء إكمال للقصيدة. -عند الضغط على زر التحليل يتم إنشاء جدول التحليل الذي يشرح العديد من الأشياء : -
-""" -DESCRIPTION_ar+= """--""" -DESCRIPTION_ar+= """-
-
- المشكل : تشكيل كل شطر من القصيدة المدخلة -
- الكتابة العروضية: وتقوم هذه الكتابة على التعبير عن كل منطوق في اللغة وتبيانه حتى لو لم يكن يكتب إملائياً - -
- التفعيلة: تفعيلات القصيدة ، مثالاً : طَويلٌ لَهُ دُونَ البُحورِ فضائل فَعُوْلُنْ مَفَاْعِيْلُنْ فَعُوْلُنْ مَفَاْعِلُ - -
- النمط: يحدد حركة وسكون كل حرف في الكتابة العروضية. نستخدم الألوان التالية للرمز إلى خلل في الكتابة العروضية: الأحمر: حرف محذوف، الأزرق: حرف مضاف، الأصفر: حركة مقلوبة. -
-قمنا بتوفير الشفرة البرمجية كلها على - GitHub. -
-""" - -TITLE_en="""Ashaar: Arabic Poetry Analysis and Generation
""" -DESCRIPTION_en = IMG - -DESCRIPTION_en +=""" -The demo provides a way to generate analysis for poetry and also complete the poetry. -The generative model is a character-based conditional GPT-2 model. The pipeline contains many models for -classification, diacritization and conditional generation. Check our GitHub for more techincal details -about this work. In the demo we have two basic pipelines. Analyze which predicts the meter, era, theme, diacritized text, qafiyah and, arudi style. -The other module, Generate which takes the input text, meter, theme and qafiyah to generate the full poem. -""" - -btn_trg_text_ar = "إنشاء" -btn_inp_text_ar = "تحليل" - -btn_inp_text_en = "Generate" -btn_trg_text_en = "Analyze" - -textbox_inp_text_ar = "القصيدة المدخلة" -textbox_trg_text_ar = "القصيدة المنشئة" - -textbox_trg_text_en = "Input Poem" -textbox_inp_text_en = "Generated Poem" - - - diff --git a/spaces/artificialguybr/video-dubbing/TTS/tests/tts_tests2/test_delightful_tts_emb_spk.py b/spaces/artificialguybr/video-dubbing/TTS/tests/tts_tests2/test_delightful_tts_emb_spk.py deleted file mode 100644 index 6fb70c5f613fe28c693121383b90867a4ae10069..0000000000000000000000000000000000000000 --- a/spaces/artificialguybr/video-dubbing/TTS/tests/tts_tests2/test_delightful_tts_emb_spk.py +++ /dev/null @@ -1,94 +0,0 @@ -import glob -import json -import os -import shutil - -from trainer import get_last_checkpoint - -from tests import get_device_id, get_tests_output_path, run_cli -from TTS.tts.configs.delightful_tts_config import DelightfulTtsAudioConfig, DelightfulTTSConfig -from TTS.tts.models.delightful_tts import DelightfulTtsArgs, VocoderConfig - -config_path = os.path.join(get_tests_output_path(), "test_model_config.json") -output_path = os.path.join(get_tests_output_path(), "train_outputs") - - -audio_config = DelightfulTtsAudioConfig() -model_args = DelightfulTtsArgs(use_speaker_embedding=False) - -vocoder_config = VocoderConfig() - -config = DelightfulTTSConfig( - model_args=model_args, - audio=audio_config, - vocoder=vocoder_config, - batch_size=2, - eval_batch_size=8, - compute_f0=True, - run_eval=True, - test_delay_epochs=-1, - text_cleaner="english_cleaners", - use_phonemes=True, - phoneme_language="en-us", - phoneme_cache_path="tests/data/ljspeech/phoneme_cache/", - f0_cache_path="tests/data/ljspeech/f0_cache_delightful/", ## delightful f0 cache is incompatible with other models - epochs=1, - print_step=1, - print_eval=True, - binary_align_loss_alpha=0.0, - use_attn_priors=False, - test_sentences=[ - ["Be a voice, not an echo.", "ljspeech"], - ], - output_path=output_path, - num_speakers=4, - use_speaker_embedding=True, -) - -# active multispeaker d-vec mode -config.model_args.use_speaker_embedding = True -config.model_args.use_d_vector_file = False -config.model_args.d_vector_file = None -config.model_args.d_vector_dim = 256 - - -config.save_json(config_path) - -command_train = ( - f"CUDA_VISIBLE_DEVICES='{get_device_id()}' python TTS/bin/train_tts.py --config_path {config_path} " - f"--coqpit.output_path {output_path} " - "--coqpit.datasets.0.formatter ljspeech " - "--coqpit.datasets.0.dataset_name ljspeech " - "--coqpit.datasets.0.meta_file_train metadata.csv " - "--coqpit.datasets.0.meta_file_val metadata.csv " - "--coqpit.datasets.0.path tests/data/ljspeech " - "--coqpit.datasets.0.meta_file_attn_mask tests/data/ljspeech/metadata_attn_mask.txt " - "--coqpit.test_delay_epochs 0" -) - -run_cli(command_train) - -# Find latest folder -continue_path = max(glob.glob(os.path.join(output_path, "*/")), key=os.path.getmtime) - -# Inference using TTS API -continue_config_path = os.path.join(continue_path, "config.json") -continue_restore_path, _ = get_last_checkpoint(continue_path) -out_wav_path = os.path.join(get_tests_output_path(), "output.wav") -speaker_id = "ljspeech" -# Check integrity of the config -with open(continue_config_path, "r", encoding="utf-8") as f: - config_loaded = json.load(f) -assert config_loaded["characters"] is not None -assert config_loaded["output_path"] in continue_path -assert config_loaded["test_delay_epochs"] == 0 - -# Load the model and run inference -inference_command = f"CUDA_VISIBLE_DEVICES='{get_device_id()}' tts --text 'This is an example.' --speaker_idx {speaker_id} --config_path {continue_config_path} --model_path {continue_restore_path} --out_path {out_wav_path}" -run_cli(inference_command) - -# restore the model and continue training for one more epoch -command_train = f"CUDA_VISIBLE_DEVICES='{get_device_id()}' python TTS/bin/train_tts.py --continue_path {continue_path} " -run_cli(command_train) -shutil.rmtree(continue_path) -shutil.rmtree("tests/data/ljspeech/f0_cache_delightful/") diff --git a/spaces/artificialguybr/video-dubbing/TTS/tests/vocoder_tests/test_vocoder_wavernn.py b/spaces/artificialguybr/video-dubbing/TTS/tests/vocoder_tests/test_vocoder_wavernn.py deleted file mode 100644 index 966ea3dd00c1f745afbde4f26e9097f355e651a2..0000000000000000000000000000000000000000 --- a/spaces/artificialguybr/video-dubbing/TTS/tests/vocoder_tests/test_vocoder_wavernn.py +++ /dev/null @@ -1,51 +0,0 @@ -import random - -import numpy as np -import torch - -from TTS.vocoder.configs import WavernnConfig -from TTS.vocoder.models.wavernn import Wavernn, WavernnArgs - - -def test_wavernn(): - config = WavernnConfig() - config.model_args = WavernnArgs( - rnn_dims=512, - fc_dims=512, - mode="mold", - mulaw=False, - pad=2, - use_aux_net=True, - use_upsample_net=True, - upsample_factors=[4, 8, 8], - feat_dims=80, - compute_dims=128, - res_out_dims=128, - num_res_blocks=10, - ) - config.audio.hop_length = 256 - config.audio.sample_rate = 2048 - - dummy_x = torch.rand((2, 1280)) - dummy_m = torch.rand((2, 80, 9)) - y_size = random.randrange(20, 60) - dummy_y = torch.rand((80, y_size)) - - # mode: mold - model = Wavernn(config) - output = model(dummy_x, dummy_m) - assert np.all(output.shape == (2, 1280, 30)), output.shape - - # mode: gauss - config.model_args.mode = "gauss" - model = Wavernn(config) - output = model(dummy_x, dummy_m) - assert np.all(output.shape == (2, 1280, 2)), output.shape - - # mode: quantized - config.model_args.mode = 4 - model = Wavernn(config) - output = model(dummy_x, dummy_m) - assert np.all(output.shape == (2, 1280, 2**4)), output.shape - output = model.inference(dummy_y, True, 5500, 550) - assert np.all(output.shape == (256 * (y_size - 1),)) diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/utils/execeval.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/utils/execeval.py deleted file mode 100644 index c135fe4a72b48798bb6b1f6ed9dad1ac535d1ea7..0000000000000000000000000000000000000000 --- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/utils/execeval.py +++ /dev/null @@ -1,61 +0,0 @@ -import ast -import sys - - -if sys.version_info > (3, 8): - Module = ast.Module -else: - # Mock the Python >= 3.8 API - def Module(nodelist, type_ignores): - return ast.Module(nodelist) - - -class _CatchDisplay(object): - """Class to temporarily catch sys.displayhook""" - - def __init__(self): - self.output = None - - def __enter__(self): - self.old_hook = sys.displayhook - sys.displayhook = self - return self - - def __exit__(self, type, value, traceback): - sys.displayhook = self.old_hook - # Returning False will cause exceptions to propagate - return False - - def __call__(self, output): - self.output = output - - -def eval_block(code, namespace=None, filename=""): - """ - Execute a multi-line block of code in the given namespace - - If the final statement in the code is an expression, return - the result of the expression. - """ - tree = ast.parse(code, filename=" ", mode="exec") - if namespace is None: - namespace = {} - catch_display = _CatchDisplay() - - if isinstance(tree.body[-1], ast.Expr): - to_exec, to_eval = tree.body[:-1], tree.body[-1:] - else: - to_exec, to_eval = tree.body, [] - - for node in to_exec: - compiled = compile(Module([node], []), filename=filename, mode="exec") - exec(compiled, namespace) - - with catch_display: - for node in to_eval: - compiled = compile( - ast.Interactive([node]), filename=filename, mode="single" - ) - exec(compiled, namespace) - - return catch_display.output diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/antlr4/InputStream.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/antlr4/InputStream.py deleted file mode 100644 index 87e66af72556d483f0ed8b8ab0631c65eb869f8b..0000000000000000000000000000000000000000 --- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/antlr4/InputStream.py +++ /dev/null @@ -1,104 +0,0 @@ -# -# Copyright (c) 2012-2017 The ANTLR Project. All rights reserved. -# Use of this file is governed by the BSD 3-clause license that -# can be found in the LICENSE.txt file in the project root. -# -import unittest - - -# -# Vacuum all input from a string and then treat it like a buffer. -# -from antlr4.Token import Token - - -class InputStream (object): - - def __init__(self, data: str): - self.name = " " - self.strdata = data - self._loadString() - - def _loadString(self): - self._index = 0 - self.data = [ord(c) for c in self.strdata] - self._size = len(self.data) - - @property - def index(self): - return self._index - - @property - def size(self): - return self._size - - # Reset the stream so that it's in the same state it was - # when the object was created *except* the data array is not - # touched. - # - def reset(self): - self._index = 0 - - def consume(self): - if self._index >= self._size: - assert self.LA(1) == Token.EOF - raise Exception("cannot consume EOF") - self._index += 1 - - def LA(self, offset: int): - if offset==0: - return 0 # undefined - if offset<0: - offset += 1 # e.g., translate LA(-1) to use offset=0 - pos = self._index + offset - 1 - if pos < 0 or pos >= self._size: # invalid - return Token.EOF - return self.data[pos] - - def LT(self, offset: int): - return self.LA(offset) - - # mark/release do nothing; we have entire buffer - def mark(self): - return -1 - - def release(self, marker: int): - pass - - # consume() ahead until p==_index; can't just set p=_index as we must - # update line and column. If we seek backwards, just set p - # - def seek(self, _index: int): - if _index<=self._index: - self._index = _index # just jump; don't update stream state (line, ...) - return - # seek forward - self._index = min(_index, self._size) - - def getText(self, start :int, stop: int): - if stop >= self._size: - stop = self._size-1 - if start >= self._size: - return "" - else: - return self.strdata[start:stop+1] - - def __str__(self): - return self.strdata - - -class TestInputStream(unittest.TestCase): - - def testStream(self): - stream = InputStream("abcde") - self.assertEqual(0, stream.index) - self.assertEqual(5, stream.size) - self.assertEqual(ord("a"), stream.LA(1)) - stream.consume() - self.assertEqual(1, stream.index) - stream.seek(5) - self.assertEqual(Token.EOF, stream.LA(1)) - self.assertEqual("bcd", stream.getText(1, 3)) - stream.reset() - self.assertEqual(0, stream.index) - diff --git a/spaces/asigalov61/Allegro-Music-Transformer/javascript/README.md b/spaces/asigalov61/Allegro-Music-Transformer/javascript/README.md deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/attention-refocusing/Attention-refocusing/gligen/ldm/modules/diffusionmodules/normal_grounding_downsampler.py b/spaces/attention-refocusing/Attention-refocusing/gligen/ldm/modules/diffusionmodules/normal_grounding_downsampler.py deleted file mode 100644 index b663401b253e09bd3f1cd78e725373c1f537b4f8..0000000000000000000000000000000000000000 --- a/spaces/attention-refocusing/Attention-refocusing/gligen/ldm/modules/diffusionmodules/normal_grounding_downsampler.py +++ /dev/null @@ -1,29 +0,0 @@ -import torch -import torch.nn as nn -from ldm.modules.attention import BasicTransformerBlock -from ldm.modules.diffusionmodules.util import checkpoint, FourierEmbedder -import torch.nn.functional as F - - - -class GroundingDownsampler(nn.Module): - def __init__(self, resize_input=256, out_dim=8): - super().__init__() - self.resize_input = resize_input - self.out_dim = out_dim - - self.layers = nn.Sequential( - nn.Conv2d(3,4,4,2,1), - nn.SiLU(), - nn.Conv2d(4,self.out_dim,4,2,1) - ) - - def forward(self, grounding_extra_input): - - out = torch.nn.functional.interpolate(grounding_extra_input, (self.resize_input,self.resize_input), mode='bicubic') - out = self.layers(out) - - assert out.shape[1] == self.out_dim - return out - - diff --git a/spaces/awacke1/Grammar-Styler/README.md b/spaces/awacke1/Grammar-Styler/README.md deleted file mode 100644 index f89679c6374f7ccbd45d188f0698465fad627b35..0000000000000000000000000000000000000000 --- a/spaces/awacke1/Grammar-Styler/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: 👩🏫NLP Grammar Corrector and Context Styler😊 -emoji: 👩🏫😊 -colorFrom: red -colorTo: pink -sdk: streamlit -sdk_version: 1.2.0 -app_file: app.py -pinned: false -license: mit ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference diff --git a/spaces/awacke1/OpenAssistant-Chatbot-FTW-Open-Source/main.py b/spaces/awacke1/OpenAssistant-Chatbot-FTW-Open-Source/main.py deleted file mode 100644 index 0745318b9298de6cbd2017c1db515e442848487e..0000000000000000000000000000000000000000 --- a/spaces/awacke1/OpenAssistant-Chatbot-FTW-Open-Source/main.py +++ /dev/null @@ -1,67 +0,0 @@ -import streamlit as st -from streamlit_chat import message -from streamlit_extras.colored_header import colored_header -from streamlit_extras.add_vertical_space import add_vertical_space -from hugchat import hugchat - -st.set_page_config(page_title="HugChat - An LLM-powered Streamlit app") - -# image = "0_AI4xFlr8mYASsylX.png" # Replace with the actual path to your image -# st.image(image, caption="Robotic Llama", use_column_width=1) - -with st.sidebar: - st.title('🤗💬 HugChat App') - st.markdown(''' - ## About - This app is an LLM-powered chatbot built using: - - [Streamlit]( FileMaker Pro 15 Advanced 15.0.3.305 (x86x64) Crack .rar
Download File ⇒ https://urloso.com/2uyRDU
- - aaccfb2cb3
-
-
- diff --git a/spaces/bioriAsaeru/text-to-voice/Full TOP Captains VgHD DVD 99 A1140 To C0388 Update 1872.iso.md b/spaces/bioriAsaeru/text-to-voice/Full TOP Captains VgHD DVD 99 A1140 To C0388 Update 1872.iso.md deleted file mode 100644 index f90616f633b22f541525503c69e4c51bffce134a..0000000000000000000000000000000000000000 --- a/spaces/bioriAsaeru/text-to-voice/Full TOP Captains VgHD DVD 99 A1140 To C0388 Update 1872.iso.md +++ /dev/null @@ -1,7 +0,0 @@ -FULL Captain's VgHD DVD 99 A1140 To C0388 Update 1872.iso
Download Zip ✔ https://urloso.com/2uySaH
- -... -office-free-iso-crack-x64 ... .com/c/ThC4s9AV/3-full-captains-vghd-dvd-99-a1140-to-c0388-update-1872iso ... -Office-free-sandbox-cracked-free-iso ... nor-sandbox-cracked-free-sandbox-cracked-free-iso-free-sandbox-cracked-free-iso-free-sandbox-cracked-free-sandbox-cracked-free-sandbox-cracked-free-iso-free-sandbox-cracked-free-iso-free-sandbox-cracked-iso- ... --Office-free-sandbox-cracked-free-iso ... . -office-free-sandbox-cracked-free-iso- ... ... -office-free-sandbox-c 8a78ff9644
-
-
- diff --git a/spaces/bioriAsaeru/text-to-voice/Hawkeye Mt4.zip.md b/spaces/bioriAsaeru/text-to-voice/Hawkeye Mt4.zip.md deleted file mode 100644 index fe403e576c9c74d857cd8878099e2a628fc67db7..0000000000000000000000000000000000000000 --- a/spaces/bioriAsaeru/text-to-voice/Hawkeye Mt4.zip.md +++ /dev/null @@ -1,6 +0,0 @@ -hawkeye mt4.zip
DOWNLOAD ✅ https://urloso.com/2uyPX7
-
-Hawkeye Comerciantes Hawkeye Premiere Traders es un sistema de ... Populares consultas: hawkeye mt4 zip Hawkeye Roadkill mt4Â ... 4d29de3e1b
-
-
- diff --git a/spaces/bioriAsaeru/text-to-voice/John Norman Gor Series Epub Download A Philosophical Journey through Gor.md b/spaces/bioriAsaeru/text-to-voice/John Norman Gor Series Epub Download A Philosophical Journey through Gor.md deleted file mode 100644 index 1fa9147593fbebed6e350e0961001c1e1ed02347..0000000000000000000000000000000000000000 --- a/spaces/bioriAsaeru/text-to-voice/John Norman Gor Series Epub Download A Philosophical Journey through Gor.md +++ /dev/null @@ -1,6 +0,0 @@ -John Norman Gor Series Epub Download
Download 🗹 https://urloso.com/2uyOnf
- - aaccfb2cb3
-
-
- diff --git a/spaces/bradarrML/stablediffusion-infinity/js/xss.js b/spaces/bradarrML/stablediffusion-infinity/js/xss.js deleted file mode 100644 index 84781ba24200eca88b8976cf0957aed7155e2191..0000000000000000000000000000000000000000 --- a/spaces/bradarrML/stablediffusion-infinity/js/xss.js +++ /dev/null @@ -1,31 +0,0 @@ -var setup_outpaint=function(){ - if(!window.my_observe_outpaint) - { - console.log("setup outpaint here"); - window.my_observe_outpaint = new MutationObserver(function (event) { - console.log(event); - let app=document.querySelector("gradio-app"); - app=app.shadowRoot??app; - let frame=app.querySelector("#sdinfframe").contentWindow; - frame.postMessage(["outpaint", ""], "*"); - }); - var app=document.querySelector("gradio-app"); - app=app.shadowRoot??app; - window.my_observe_outpaint_target=app.querySelector("#output span"); - window.my_observe_outpaint.observe(window.my_observe_outpaint_target, { - attributes: false, - subtree: true, - childList: true, - characterData: true - }); - } -}; -window.config_obj={ - resize_check: true, - enable_safety: true, - use_correction: false, - enable_img2img: false, - use_seed: false, - seed_val: 0, -}; -setup_outpaint(); \ No newline at end of file diff --git a/spaces/brianaaas/BeedAiTe/Dockerfile b/spaces/brianaaas/BeedAiTe/Dockerfile deleted file mode 100644 index a47b713100a0b8f26db4eb6ccd83381e0900e6f7..0000000000000000000000000000000000000000 --- a/spaces/brianaaas/BeedAiTe/Dockerfile +++ /dev/null @@ -1 +0,0 @@ -200748 \ No newline at end of file diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/layers/aspp.py b/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/layers/aspp.py deleted file mode 100644 index 14861aa9ede4fea6a69a49f189bcab997b558148..0000000000000000000000000000000000000000 --- a/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/layers/aspp.py +++ /dev/null @@ -1,144 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. - -from copy import deepcopy -import fvcore.nn.weight_init as weight_init -import torch -from torch import nn -from torch.nn import functional as F - -from .batch_norm import get_norm -from .blocks import DepthwiseSeparableConv2d -from .wrappers import Conv2d - - -class ASPP(nn.Module): - """ - Atrous Spatial Pyramid Pooling (ASPP). - """ - - def __init__( - self, - in_channels, - out_channels, - dilations, - *, - norm, - activation, - pool_kernel_size=None, - dropout: float = 0.0, - use_depthwise_separable_conv=False, - ): - """ - Args: - in_channels (int): number of input channels for ASPP. - out_channels (int): number of output channels. - dilations (list): a list of 3 dilations in ASPP. - norm (str or callable): normalization for all conv layers. - See :func:`layers.get_norm` for supported format. norm is - applied to all conv layers except the conv following - global average pooling. - activation (callable): activation function. - pool_kernel_size (tuple, list): the average pooling size (kh, kw) - for image pooling layer in ASPP. If set to None, it always - performs global average pooling. If not None, it must be - divisible by the shape of inputs in forward(). It is recommended - to use a fixed input feature size in training, and set this - option to match this size, so that it performs global average - pooling in training, and the size of the pooling window stays - consistent in inference. - dropout (float): apply dropout on the output of ASPP. It is used in - the official DeepLab implementation with a rate of 0.1: - https://github.com/tensorflow/models/blob/21b73d22f3ed05b650e85ac50849408dd36de32e/research/deeplab/model.py#L532 # noqa - use_depthwise_separable_conv (bool): use DepthwiseSeparableConv2d - for 3x3 convs in ASPP, proposed in :paper:`DeepLabV3+`. - """ - super(ASPP, self).__init__() - assert len(dilations) == 3, "ASPP expects 3 dilations, got {}".format(len(dilations)) - self.pool_kernel_size = pool_kernel_size - self.dropout = dropout - use_bias = norm == "" - self.convs = nn.ModuleList() - # conv 1x1 - self.convs.append( - Conv2d( - in_channels, - out_channels, - kernel_size=1, - bias=use_bias, - norm=get_norm(norm, out_channels), - activation=deepcopy(activation), - ) - ) - weight_init.c2_xavier_fill(self.convs[-1]) - # atrous convs - for dilation in dilations: - if use_depthwise_separable_conv: - self.convs.append( - DepthwiseSeparableConv2d( - in_channels, - out_channels, - kernel_size=3, - padding=dilation, - dilation=dilation, - norm1=norm, - activation1=deepcopy(activation), - norm2=norm, - activation2=deepcopy(activation), - ) - ) - else: - self.convs.append( - Conv2d( - in_channels, - out_channels, - kernel_size=3, - padding=dilation, - dilation=dilation, - bias=use_bias, - norm=get_norm(norm, out_channels), - activation=deepcopy(activation), - ) - ) - weight_init.c2_xavier_fill(self.convs[-1]) - # image pooling - # We do not add BatchNorm because the spatial resolution is 1x1, - # the original TF implementation has BatchNorm. - if pool_kernel_size is None: - image_pooling = nn.Sequential( - nn.AdaptiveAvgPool2d(1), - Conv2d(in_channels, out_channels, 1, bias=True, activation=deepcopy(activation)), - ) - else: - image_pooling = nn.Sequential( - nn.AvgPool2d(kernel_size=pool_kernel_size, stride=1), - Conv2d(in_channels, out_channels, 1, bias=True, activation=deepcopy(activation)), - ) - weight_init.c2_xavier_fill(image_pooling[1]) - self.convs.append(image_pooling) - - self.project = Conv2d( - 5 * out_channels, - out_channels, - kernel_size=1, - bias=use_bias, - norm=get_norm(norm, out_channels), - activation=deepcopy(activation), - ) - weight_init.c2_xavier_fill(self.project) - - def forward(self, x): - size = x.shape[-2:] - if self.pool_kernel_size is not None: - if size[0] % self.pool_kernel_size[0] or size[1] % self.pool_kernel_size[1]: - raise ValueError( - "`pool_kernel_size` must be divisible by the shape of inputs. " - "Input size: {} `pool_kernel_size`: {}".format(size, self.pool_kernel_size) - ) - res = [] - for conv in self.convs: - res.append(conv(x)) - res[-1] = F.interpolate(res[-1], size=size, mode="bilinear", align_corners=False) - res = torch.cat(res, dim=1) - res = self.project(res) - res = F.dropout(res, self.dropout, training=self.training) if self.dropout > 0 else res - return res diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/utils/logger.py b/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/utils/logger.py deleted file mode 100644 index 85be03cb174a8802ff775842395fd30b4b5db61b..0000000000000000000000000000000000000000 --- a/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/utils/logger.py +++ /dev/null @@ -1,261 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -import atexit -import functools -import logging -import os -import sys -import time -from collections import Counter -import torch -from tabulate import tabulate -from termcolor import colored - -from detectron2.utils.file_io import PathManager - -__all__ = ["setup_logger", "log_first_n", "log_every_n", "log_every_n_seconds"] - -D2_LOG_BUFFER_SIZE_KEY: str = "D2_LOG_BUFFER_SIZE" - -DEFAULT_LOG_BUFFER_SIZE: int = 1024 * 1024 # 1MB - - -class _ColorfulFormatter(logging.Formatter): - def __init__(self, *args, **kwargs): - self._root_name = kwargs.pop("root_name") + "." - self._abbrev_name = kwargs.pop("abbrev_name", "") - if len(self._abbrev_name): - self._abbrev_name = self._abbrev_name + "." - super(_ColorfulFormatter, self).__init__(*args, **kwargs) - - def formatMessage(self, record): - record.name = record.name.replace(self._root_name, self._abbrev_name) - log = super(_ColorfulFormatter, self).formatMessage(record) - if record.levelno == logging.WARNING: - prefix = colored("WARNING", "red", attrs=["blink"]) - elif record.levelno == logging.ERROR or record.levelno == logging.CRITICAL: - prefix = colored("ERROR", "red", attrs=["blink", "underline"]) - else: - return log - return prefix + " " + log - - -@functools.lru_cache() # so that calling setup_logger multiple times won't add many handlers -def setup_logger( - output=None, - distributed_rank=0, - *, - color=True, - name="detectron2", - abbrev_name=None, - enable_propagation: bool = False, - configure_stdout: bool = True -): - """ - Initialize the detectron2 logger and set its verbosity level to "DEBUG". - - Args: - output (str): a file name or a directory to save log. If None, will not save log file. - If ends with ".txt" or ".log", assumed to be a file name. - Otherwise, logs will be saved to `output/log.txt`. - name (str): the root module name of this logger - abbrev_name (str): an abbreviation of the module, to avoid long names in logs. - Set to "" to not log the root module in logs. - By default, will abbreviate "detectron2" to "d2" and leave other - modules unchanged. - enable_propagation (bool): whether to propagate logs to the parent logger. - configure_stdout (bool): whether to configure logging to stdout. - - - Returns: - logging.Logger: a logger - """ - logger = logging.getLogger(name) - logger.setLevel(logging.DEBUG) - logger.propagate = enable_propagation - - if abbrev_name is None: - abbrev_name = "d2" if name == "detectron2" else name - - plain_formatter = logging.Formatter( - "[%(asctime)s] %(name)s %(levelname)s: %(message)s", datefmt="%m/%d %H:%M:%S" - ) - # stdout logging: master only - if configure_stdout and distributed_rank == 0: - ch = logging.StreamHandler(stream=sys.stdout) - ch.setLevel(logging.DEBUG) - if color: - formatter = _ColorfulFormatter( - colored("[%(asctime)s %(name)s]: ", "green") + "%(message)s", - datefmt="%m/%d %H:%M:%S", - root_name=name, - abbrev_name=str(abbrev_name), - ) - else: - formatter = plain_formatter - ch.setFormatter(formatter) - logger.addHandler(ch) - - # file logging: all workers - if output is not None: - if output.endswith(".txt") or output.endswith(".log"): - filename = output - else: - filename = os.path.join(output, "log.txt") - if distributed_rank > 0: - filename = filename + ".rank{}".format(distributed_rank) - PathManager.mkdirs(os.path.dirname(filename)) - - fh = logging.StreamHandler(_cached_log_stream(filename)) - fh.setLevel(logging.DEBUG) - fh.setFormatter(plain_formatter) - logger.addHandler(fh) - - return logger - - -# cache the opened file object, so that different calls to `setup_logger` -# with the same file name can safely write to the same file. -@functools.lru_cache(maxsize=None) -def _cached_log_stream(filename): - # use 1K buffer if writing to cloud storage - io = PathManager.open(filename, "a", buffering=_get_log_stream_buffer_size(filename)) - atexit.register(io.close) - return io - - -def _get_log_stream_buffer_size(filename: str) -> int: - if "://" not in filename: - # Local file, no extra caching is necessary - return -1 - # Remote file requires a larger cache to avoid many small writes. - if D2_LOG_BUFFER_SIZE_KEY in os.environ: - return int(os.environ[D2_LOG_BUFFER_SIZE_KEY]) - return DEFAULT_LOG_BUFFER_SIZE - - -""" -Below are some other convenient logging methods. -They are mainly adopted from -https://github.com/abseil/abseil-py/blob/master/absl/logging/__init__.py -""" - - -def _find_caller(): - """ - Returns: - str: module name of the caller - tuple: a hashable key to be used to identify different callers - """ - frame = sys._getframe(2) - while frame: - code = frame.f_code - if os.path.join("utils", "logger.") not in code.co_filename: - mod_name = frame.f_globals["__name__"] - if mod_name == "__main__": - mod_name = "detectron2" - return mod_name, (code.co_filename, frame.f_lineno, code.co_name) - frame = frame.f_back - - -_LOG_COUNTER = Counter() -_LOG_TIMER = {} - - -def log_first_n(lvl, msg, n=1, *, name=None, key="caller"): - """ - Log only for the first n times. - - Args: - lvl (int): the logging level - msg (str): - n (int): - name (str): name of the logger to use. Will use the caller's module by default. - key (str or tuple[str]): the string(s) can be one of "caller" or - "message", which defines how to identify duplicated logs. - For example, if called with `n=1, key="caller"`, this function - will only log the first call from the same caller, regardless of - the message content. - If called with `n=1, key="message"`, this function will log the - same content only once, even if they are called from different places. - If called with `n=1, key=("caller", "message")`, this function - will not log only if the same caller has logged the same message before. - """ - if isinstance(key, str): - key = (key,) - assert len(key) > 0 - - caller_module, caller_key = _find_caller() - hash_key = () - if "caller" in key: - hash_key = hash_key + caller_key - if "message" in key: - hash_key = hash_key + (msg,) - - _LOG_COUNTER[hash_key] += 1 - if _LOG_COUNTER[hash_key] <= n: - logging.getLogger(name or caller_module).log(lvl, msg) - - -def log_every_n(lvl, msg, n=1, *, name=None): - """ - Log once per n times. - - Args: - lvl (int): the logging level - msg (str): - n (int): - name (str): name of the logger to use. Will use the caller's module by default. - """ - caller_module, key = _find_caller() - _LOG_COUNTER[key] += 1 - if n == 1 or _LOG_COUNTER[key] % n == 1: - logging.getLogger(name or caller_module).log(lvl, msg) - - -def log_every_n_seconds(lvl, msg, n=1, *, name=None): - """ - Log no more than once per n seconds. - - Args: - lvl (int): the logging level - msg (str): - n (int): - name (str): name of the logger to use. Will use the caller's module by default. - """ - caller_module, key = _find_caller() - last_logged = _LOG_TIMER.get(key, None) - current_time = time.time() - if last_logged is None or current_time - last_logged >= n: - logging.getLogger(name or caller_module).log(lvl, msg) - _LOG_TIMER[key] = current_time - - -def create_small_table(small_dict): - """ - Create a small table using the keys of small_dict as headers. This is only - suitable for small dictionaries. - - Args: - small_dict (dict): a result dictionary of only a few items. - - Returns: - str: the table as a string. - """ - keys, values = tuple(zip(*small_dict.items())) - table = tabulate( - [values], - headers=keys, - tablefmt="pipe", - floatfmt=".3f", - stralign="center", - numalign="center", - ) - return table - - -def _log_api_usage(identifier: str): - """ - Internal function used to log the usage of different detectron2 components - inside facebook's infra. - """ - torch._C._log_api_usage_once("detectron2." + identifier) diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/predictors/cse_confidence.py b/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/predictors/cse_confidence.py deleted file mode 100644 index 8220337cea8eb87bbdf74378079551259dcc37e2..0000000000000000000000000000000000000000 --- a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/predictors/cse_confidence.py +++ /dev/null @@ -1,115 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. - -from typing import Any -import torch -from torch.nn import functional as F - -from detectron2.config import CfgNode -from detectron2.layers import ConvTranspose2d - -from densepose.modeling.confidence import DensePoseConfidenceModelConfig -from densepose.modeling.utils import initialize_module_params -from densepose.structures import decorate_cse_predictor_output_class_with_confidences - - -class DensePoseEmbeddingConfidencePredictorMixin: - """ - Predictor contains the last layers of a DensePose model that take DensePose head - outputs as an input and produce model outputs. Confidence predictor mixin is used - to generate confidences for coarse segmentation estimated by some - base predictor. Several assumptions need to hold for the base predictor: - 1) the `forward` method must return CSE DensePose head outputs, - tensor of shape [N, D, H, W] - 2) `interp2d` method must be defined to perform bilinear interpolation; - the same method is typically used for masks and confidences - Confidence predictor mixin provides confidence estimates, as described in: - N. Neverova et al., Correlated Uncertainty for Learning Dense Correspondences - from Noisy Labels, NeurIPS 2019 - A. Sanakoyeu et al., Transferring Dense Pose to Proximal Animal Classes, CVPR 2020 - """ - - def __init__(self, cfg: CfgNode, input_channels: int): - """ - Initialize confidence predictor using configuration options. - - Args: - cfg (CfgNode): configuration options - input_channels (int): number of input channels - """ - # we rely on base predictor to call nn.Module.__init__ - super().__init__(cfg, input_channels) # pyre-ignore[19] - self.confidence_model_cfg = DensePoseConfidenceModelConfig.from_cfg(cfg) - self._initialize_confidence_estimation_layers(cfg, input_channels) - self._registry = {} - initialize_module_params(self) # pyre-ignore[6] - - def _initialize_confidence_estimation_layers(self, cfg: CfgNode, dim_in: int): - """ - Initialize confidence estimation layers based on configuration options - - Args: - cfg (CfgNode): configuration options - dim_in (int): number of input channels - """ - kernel_size = cfg.MODEL.ROI_DENSEPOSE_HEAD.DECONV_KERNEL - if self.confidence_model_cfg.segm_confidence.enabled: - self.coarse_segm_confidence_lowres = ConvTranspose2d( # pyre-ignore[16] - dim_in, 1, kernel_size, stride=2, padding=int(kernel_size / 2 - 1) - ) - - def forward(self, head_outputs: torch.Tensor): - """ - Perform forward operation on head outputs used as inputs for the predictor. - Calls forward method from the base predictor and uses its outputs to compute - confidences. - - Args: - head_outputs (Tensor): head outputs used as predictor inputs - Return: - An instance of outputs with confidences, - see `decorate_cse_predictor_output_class_with_confidences` - """ - # assuming base class returns SIUV estimates in its first result - base_predictor_outputs = super().forward(head_outputs) # pyre-ignore[16] - - # create output instance by extending base predictor outputs: - output = self._create_output_instance(base_predictor_outputs) - - if self.confidence_model_cfg.segm_confidence.enabled: - # base predictor outputs are assumed to have `coarse_segm` attribute - # base predictor is assumed to define `interp2d` method for bilinear interpolation - output.coarse_segm_confidence = ( - F.softplus( - self.interp2d( # pyre-ignore[16] - self.coarse_segm_confidence_lowres(head_outputs) # pyre-ignore[16] - ) - ) - + self.confidence_model_cfg.segm_confidence.epsilon - ) - output.coarse_segm = base_predictor_outputs.coarse_segm * torch.repeat_interleave( - output.coarse_segm_confidence, base_predictor_outputs.coarse_segm.shape[1], dim=1 - ) - - return output - - def _create_output_instance(self, base_predictor_outputs: Any): - """ - Create an instance of predictor outputs by copying the outputs from the - base predictor and initializing confidence - - Args: - base_predictor_outputs: an instance of base predictor outputs - (the outputs type is assumed to be a dataclass) - Return: - An instance of outputs with confidences - """ - PredictorOutput = decorate_cse_predictor_output_class_with_confidences( - type(base_predictor_outputs) # pyre-ignore[6] - ) - # base_predictor_outputs is assumed to be a dataclass - # reassign all the fields from base_predictor_outputs (no deep copy!), add new fields - output = PredictorOutput( - **base_predictor_outputs.__dict__, - coarse_segm_confidence=None, - ) - return output diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/ViTDet/configs/COCO/cascade_mask_rcnn_mvitv2_l_in21k_50ep.py b/spaces/brjathu/HMR2.0/vendor/detectron2/projects/ViTDet/configs/COCO/cascade_mask_rcnn_mvitv2_l_in21k_50ep.py deleted file mode 100644 index c64f0c18aea5dfe49fef028a6300ab1dc9f2537a..0000000000000000000000000000000000000000 --- a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/ViTDet/configs/COCO/cascade_mask_rcnn_mvitv2_l_in21k_50ep.py +++ /dev/null @@ -1,22 +0,0 @@ -from .cascade_mask_rcnn_mvitv2_b_in21k_100ep import ( - dataloader, - lr_multiplier, - model, - train, - optimizer, -) - -model.backbone.bottom_up.embed_dim = 144 -model.backbone.bottom_up.depth = 48 -model.backbone.bottom_up.num_heads = 2 -model.backbone.bottom_up.last_block_indexes = (1, 7, 43, 47) -model.backbone.bottom_up.drop_path_rate = 0.5 - - -train.init_checkpoint = "detectron2://ImageNetPretrained/mvitv2/MViTv2_L_in21k.pyth" - -train.max_iter = train.max_iter // 2 # 100ep -> 50ep -lr_multiplier.scheduler.milestones = [ - milestone // 2 for milestone in lr_multiplier.scheduler.milestones -] -lr_multiplier.scheduler.num_updates = train.max_iter diff --git a/spaces/carloscar/stable-diffusion-webui-controlnet-docker/on_start.sh b/spaces/carloscar/stable-diffusion-webui-controlnet-docker/on_start.sh deleted file mode 100644 index 7f9cc1bcf59d0bcba54bc565be20b4701457676b..0000000000000000000000000000000000000000 --- a/spaces/carloscar/stable-diffusion-webui-controlnet-docker/on_start.sh +++ /dev/null @@ -1,143 +0,0 @@ -#!/bin/bash -set -euo pipefail - -function download-model() { - local _option=$1 - local _filename=$2 - local _url=$3 - local _dir - - ! [ $# -eq 3 ] && (echo "usage: "; for o in checkpoint lora vae control-net embedding; do echo " \$ download-model --$o"; done) || true - [ $# -eq 0 ] && return 0 || ! [ $# -eq 3 ] && (echo ""; echo "error - invalid number of arguments (expected 3, received $#)"; echo -n "\$ download-model $1"; (for arg in "${@: 2}"; do echo -n " \"${arg//\"/\\\"}\""; done) && echo "") && return 1 || true - - case ${_option,,} in - --checkpoint) _dir="/app/stable-diffusion-webui/models/Stable-diffusion";; - --lora) _dir="/app/stable-diffusion-webui/extensions/sd-webui-additional-networks/models/LoRA";; - --vae) _dir="/app/stable-diffusion-webui/models/VAE";; - --control-net) _dir="/app/stable-diffusion-webui/models/ControlNet";; - --embedding) _dir="/app/stable-diffusion-webui/embeddings";; - - *) echo "error - unknown first argument: '$1' (valid options are --checkpoint, --lora, --vae, --control-net or --embedding):"; echo "\$ download-model $1 \"$2\" \"$3\""; return 1;; - esac - - echo "\$ download-model $_option \"$2\" \"$3\"" ; echo "" - aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $_url -d $_dir -o $_filename && echo "" -} - -## ---------------------------- - -## Adds a header to the webui on Hugging Face Spaces. -sed -i -e '/demo:/r /app/stable-diffusion-webui/header_patch.py' /app/stable-diffusion-webui/modules/ui.py - -## ---------------------------- - -## Installing less models if $IS_SHARED_UI environment variable is set. -if [ ${IS_SHARED_UI:-0} != 0 ]; then - download-model --checkpoint "v1-5-pruned-emaonly.safetensors" "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/39593d5650112b4cc580433f6b0435385882d819/v1-5-pruned-emaonly.safetensors" - download-model --checkpoint "v1-5-pruned-emaonly.yaml" "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/39593d5650112b4cc580433f6b0435385882d819/v1-inference.yaml" - download-model --control-net "cldm_v15.yaml" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/cldm_v15.yaml" - download-model --control-net "control_canny-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_canny-fp16.safetensors" - download-model --control-net "control_depth-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_depth-fp16.safetensors" - download-model --control-net "control_normal-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_normal-fp16.safetensors" - download-model --control-net "control_openpose-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_openpose-fp16.safetensors" - download-model --control-net "control_scribble-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_scribble-fp16.safetensors" - download-model --checkpoint "AtoZovyaRPGArtistTools15_sd15V1.safetensors" "https://civitai.com/api/download/models/10185" - download-model --embedding "bad_prompt_version2.pt" "https://huggingface.co/datasets/Nerfgun3/bad_prompt/resolve/72fd9d6011c2ba87b5847b7e45e6603917e3cbed/bad_prompt_version2.pt" - sed -i -e '/(modelmerger_interface, \"Checkpoint Merger\", \"modelmerger\"),/d' /app/stable-diffusion-webui/modules/ui.py - sed -i -e '/(train_interface, \"Train\", \"ti\"),/d' /app/stable-diffusion-webui/modules/ui.py - sed -i -e '/extensions_interface, \"Extensions\", \"extensions\"/d' /app/stable-diffusion-webui/modules/ui.py - sed -i -e '/settings_interface, \"Settings\", \"settings\"/d' /app/stable-diffusion-webui/modules/ui.py - rm -rf /app/stable-diffusion-webui/scripts /app/stable-diffusion-webui/extensions/deforum-for-automatic1111-webui /app/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser /app/stable-diffusion-webui/extensions/sd-civitai-browser /app/stable-diffusion-webui/extensions/sd-webui-additional-networks - cp -f shared-config.json config.json - cp -f shared-ui-config.json ui-config.json - exit 0 -fi -## End of lightweight installation for $IS_SHARED_UI setup. - -## ---------------------------- -## env $IS_SHARED_UI is not set -## ---------------------------- - -## Stable Diffusion 2.1 · 768 base model: -download-model --checkpoint "v2-1_768-ema-pruned.safetensors" "https://huggingface.co/stabilityai/stable-diffusion-2-1/resolve/36a01dc742066de2e8c91e7cf0b8f6b53ef53da1/v2-1_768-ema-pruned.safetensors" -download-model --checkpoint "v2-1_768-ema-pruned.yaml" "https://raw.githubusercontent.com/Stability-AI/stablediffusion/fc1488421a2761937b9d54784194157882cbc3b1/configs/stable-diffusion/v2-inference-v.yaml" - -## Stable Diffusion 1.5 · 512 base model: -download-model --checkpoint "v1-5-pruned-emaonly.safetensors" "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/39593d5650112b4cc580433f6b0435385882d819/v1-5-pruned-emaonly.safetensors" -download-model --checkpoint "v1-5-pruned-emaonly.yaml" "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/39593d5650112b4cc580433f6b0435385882d819/v1-inference.yaml" - -## ---------------------------- - -## LoRA (low-rank adaptation) · epi_noiseoffset v2: -download-model --lora "epiNoiseoffset_v2.safetensors" "https://civitai.com/api/download/models/16576?type=Model&format=SafeTensor" - -## ---------------------------- - -## VAE (variational autoencoder) · VAE 840k EMA: -download-model --vae "vae-ft-mse-840000-ema-pruned.safetensors" "https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/629b3ad3030ce36e15e70c5db7d91df0d60c627f/vae-ft-mse-840000-ema-pruned.safetensors" - -## ---------------------------- - -## ControlNet · Pre-extracted models: -download-model --control-net "cldm_v15.yaml" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/cldm_v15.yaml" -download-model --control-net "cldm_v21.yaml" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/cldm_v21.yaml" -download-model --control-net "control_canny-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_canny-fp16.safetensors" -download-model --control-net "control_depth-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_depth-fp16.safetensors" -download-model --control-net "control_hed-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_hed-fp16.safetensors" -download-model --control-net "control_normal-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_normal-fp16.safetensors" -download-model --control-net "control_openpose-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_openpose-fp16.safetensors" -download-model --control-net "control_scribble-fp16.safetensors" "https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/87c3affbcad3baec52ffe39cac3a15a94902aed3/control_scribble-fp16.safetensors" - -## ---------------------------- - -## Embedding · bad_prompt_version2 -download-model --embedding "bad_prompt_version2.pt" "https://huggingface.co/datasets/Nerfgun3/bad_prompt/resolve/72fd9d6011c2ba87b5847b7e45e6603917e3cbed/bad_prompt_version2.pt" - -## ---------------------------- - -## Checkpoint · The Ally's Mix III: Revolutions: -download-model --checkpoint "theAllysMixIII_v10.safetensors" "https://civitai.com/api/download/models/12763?type=Model&format=SafeTensor" - -## Checkpoint · Dreamlike Diffusion 1.0: -# download-model --checkpoint "dreamlike-diffusion-1.0.safetensors" "https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/resolve/00cbe4d56fd56f45e952a5be4d847f21b9782546/dreamlike-diffusion-1.0.safetensors" - -## Checkpoint · Dreamshaper 3.31: -# download-model --checkpoint "DreamShaper_3.31_baked_vae-inpainting.inpainting.safetensors" "https://huggingface.co/Lykon/DreamShaper/resolve/d227e39aab5e360aec6401be916025ddfc8127bd/DreamShaper_3.31_baked_vae-inpainting.inpainting.safetensors" - -## Checkpoint · dalcefo_painting: -# download-model --checkpoint "dalcefoPainting_2nd.safetensors" "https://civitai.com/api/download/models/14675?type=Pruned%20Model&format=SafeTensor" - -## Checkpoint · Deliberate v2: -# download-model --checkpoint "deliberate_v2.safetensors" "https://civitai.com/api/download/models/15236?type=Model&format=SafeTensor" - -## Checkpoint · RPG v4: -# download-model --checkpoint "RPG-v4.safetensors" "https://huggingface.co/Anashel/rpg/resolve/main/RPG-V4-Model-Download/RPG-v4.safetensors" - -## Checkpoint · A to Zovya RPG Artist's Tools (SD 1.5): -# download-model --checkpoint "AtoZovyaRPGArtistTools15_sd15V1.safetensors" "https://civitai.com/api/download/models/10185" - -## Checkpoint · A to Zovya RPG Artist's Tools (SD 2.1): -# download-model --checkpoint "AtoZovyaRPGArtistTools15_sd21768V1.safetensors" "https://civitai.com/api/download/models/9593?type=Model&format=SafeTensor" -# download-model --checkpoint "aToZovyaRPGArtistsTools15_sd21768V1.yaml" "https://civitai.com/api/download/models/9593?type=Config&format=Other" - -## ---------------------------- - -## Add additional models that you want to install on startup. Replace URL and FILENAME from the examples below with your values. - -## Usage: -## download-model --checkpoint -## download-model --lora -## download-model --vae -## download-model --control-net -## download-model --embedding - -## ---------------------------- - -## Checkpoint · Example: -# download-model --checkpoint "FILENAME" "URL" - -## LORA (low-rank adaptation) · Example: -# download-model --lora "FILENAME" "URL" - -## VAE (variational autoencoder) · Example: -# download-model --vae "FILENAME" "URL" diff --git a/spaces/cbhasker/MyGenAlChatBot/README.md b/spaces/cbhasker/MyGenAlChatBot/README.md deleted file mode 100644 index 89f7464bc7fb7a67e8b55f8019392416c2a73b57..0000000000000000000000000000000000000000 --- a/spaces/cbhasker/MyGenAlChatBot/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: MyGenAlChatBot -emoji: 📊 -colorFrom: green -colorTo: green -sdk: gradio -sdk_version: 3.39.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/cccccch/VITS-fast-fine-tuning-DingZhen/README.md b/spaces/cccccch/VITS-fast-fine-tuning-DingZhen/README.md deleted file mode 100644 index e421353adfac192541df1613eb1456f43599a97e..0000000000000000000000000000000000000000 --- a/spaces/cccccch/VITS-fast-fine-tuning-DingZhen/README.md +++ /dev/null @@ -1,14 +0,0 @@ ---- -title: VITS Fast Fine-tune -emoji: 🦀 -colorFrom: pink -colorTo: indigo -sdk: gradio -sdk_version: 3.24.1 -app_file: app.py -pinned: false -license: apache-2.0 -duplicated_from: kira4424/VITS-fast-fine-tuning ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference \ No newline at end of file diff --git a/spaces/cccccch/VITS-fast-fine-tuning-DingZhen/text/cleaners.py b/spaces/cccccch/VITS-fast-fine-tuning-DingZhen/text/cleaners.py deleted file mode 100644 index 263df9c0f7c185290600454abfff464e7f774576..0000000000000000000000000000000000000000 --- a/spaces/cccccch/VITS-fast-fine-tuning-DingZhen/text/cleaners.py +++ /dev/null @@ -1,134 +0,0 @@ -import re -from text.japanese import japanese_to_romaji_with_accent, japanese_to_ipa, japanese_to_ipa2, japanese_to_ipa3 -from text.korean import latin_to_hangul, number_to_hangul, divide_hangul, korean_to_lazy_ipa, korean_to_ipa -from text.mandarin import number_to_chinese, chinese_to_bopomofo, latin_to_bopomofo, chinese_to_romaji, chinese_to_lazy_ipa, chinese_to_ipa, chinese_to_ipa2 -from text.sanskrit import devanagari_to_ipa -from text.english import english_to_lazy_ipa, english_to_ipa2, english_to_lazy_ipa2 -from text.thai import num_to_thai, latin_to_thai -# from text.shanghainese import shanghainese_to_ipa -# from text.cantonese import cantonese_to_ipa -# from text.ngu_dialect import ngu_dialect_to_ipa - - -def japanese_cleaners(text): - text = japanese_to_romaji_with_accent(text) - text = re.sub(r'([A-Za-z])$', r'\1.', text) - return text - - -def japanese_cleaners2(text): - return japanese_cleaners(text).replace('ts', 'ʦ').replace('...', '…') - - -def korean_cleaners(text): - '''Pipeline for Korean text''' - text = latin_to_hangul(text) - text = number_to_hangul(text) - text = divide_hangul(text) - text = re.sub(r'([\u3131-\u3163])$', r'\1.', text) - return text - - -# def chinese_cleaners(text): -# '''Pipeline for Chinese text''' -# text = number_to_chinese(text) -# text = chinese_to_bopomofo(text) -# text = latin_to_bopomofo(text) -# text = re.sub(r'([ˉˊˇˋ˙])$', r'\1。', text) -# return text - -def chinese_cleaners(text): - from pypinyin import Style, pinyin - text = text.replace("[ZH]", "") - phones = [phone[0] for phone in pinyin(text, style=Style.TONE3)] - return ' '.join(phones) - - -def zh_ja_mixture_cleaners(text): - text = re.sub(r'\[ZH\](.*?)\[ZH\]', - lambda x: chinese_to_romaji(x.group(1))+' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_romaji_with_accent( - x.group(1)).replace('ts', 'ʦ').replace('u', 'ɯ').replace('...', '…')+' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def sanskrit_cleaners(text): - text = text.replace('॥', '।').replace('ॐ', 'ओम्') - text = re.sub(r'([^।])$', r'\1।', text) - return text - - -def cjks_cleaners(text): - text = re.sub(r'\[ZH\](.*?)\[ZH\]', - lambda x: chinese_to_lazy_ipa(x.group(1))+' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', - lambda x: japanese_to_ipa(x.group(1))+' ', text) - text = re.sub(r'\[KO\](.*?)\[KO\]', - lambda x: korean_to_lazy_ipa(x.group(1))+' ', text) - text = re.sub(r'\[SA\](.*?)\[SA\]', - lambda x: devanagari_to_ipa(x.group(1))+' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', - lambda x: english_to_lazy_ipa(x.group(1))+' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def cjke_cleaners(text): - text = re.sub(r'\[ZH\](.*?)\[ZH\]', lambda x: chinese_to_lazy_ipa(x.group(1)).replace( - 'ʧ', 'tʃ').replace('ʦ', 'ts').replace('ɥan', 'ɥæn')+' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_ipa(x.group(1)).replace('ʧ', 'tʃ').replace( - 'ʦ', 'ts').replace('ɥan', 'ɥæn').replace('ʥ', 'dz')+' ', text) - text = re.sub(r'\[KO\](.*?)\[KO\]', - lambda x: korean_to_ipa(x.group(1))+' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', lambda x: english_to_ipa2(x.group(1)).replace('ɑ', 'a').replace( - 'ɔ', 'o').replace('ɛ', 'e').replace('ɪ', 'i').replace('ʊ', 'u')+' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def cjke_cleaners2(text): - text = re.sub(r'\[ZH\](.*?)\[ZH\]', - lambda x: chinese_to_ipa(x.group(1))+' ', text) - text = re.sub(r'\[JA\](.*?)\[JA\]', - lambda x: japanese_to_ipa2(x.group(1))+' ', text) - text = re.sub(r'\[KO\](.*?)\[KO\]', - lambda x: korean_to_ipa(x.group(1))+' ', text) - text = re.sub(r'\[EN\](.*?)\[EN\]', - lambda x: english_to_ipa2(x.group(1))+' ', text) - text = re.sub(r'\s+$', '', text) - text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) - return text - - -def thai_cleaners(text): - text = num_to_thai(text) - text = latin_to_thai(text) - return text - - -# def shanghainese_cleaners(text): -# text = shanghainese_to_ipa(text) -# text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) -# return text - - -# def chinese_dialect_cleaners(text): -# text = re.sub(r'\[ZH\](.*?)\[ZH\]', -# lambda x: chinese_to_ipa2(x.group(1))+' ', text) -# text = re.sub(r'\[JA\](.*?)\[JA\]', -# lambda x: japanese_to_ipa3(x.group(1)).replace('Q', 'ʔ')+' ', text) -# text = re.sub(r'\[SH\](.*?)\[SH\]', lambda x: shanghainese_to_ipa(x.group(1)).replace('1', '˥˧').replace('5', -# '˧˧˦').replace('6', '˩˩˧').replace('7', '˥').replace('8', '˩˨').replace('ᴀ', 'ɐ').replace('ᴇ', 'e')+' ', text) -# text = re.sub(r'\[GD\](.*?)\[GD\]', -# lambda x: cantonese_to_ipa(x.group(1))+' ', text) -# text = re.sub(r'\[EN\](.*?)\[EN\]', -# lambda x: english_to_lazy_ipa2(x.group(1))+' ', text) -# text = re.sub(r'\[([A-Z]{2})\](.*?)\[\1\]', lambda x: ngu_dialect_to_ipa(x.group(2), x.group( -# 1)).replace('ʣ', 'dz').replace('ʥ', 'dʑ').replace('ʦ', 'ts').replace('ʨ', 'tɕ')+' ', text) -# text = re.sub(r'\s+$', '', text) -# text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text) -# return text diff --git a/spaces/chasemcdo/hf_localai/examples/langchain/JS.Dockerfile b/spaces/chasemcdo/hf_localai/examples/langchain/JS.Dockerfile deleted file mode 100644 index 10320931c6850aaa63cf861b925f5132068d1833..0000000000000000000000000000000000000000 --- a/spaces/chasemcdo/hf_localai/examples/langchain/JS.Dockerfile +++ /dev/null @@ -1,6 +0,0 @@ -FROM node:latest -COPY ./langchainjs-localai-example /app -WORKDIR /app -RUN npm install -RUN npm run build -ENTRYPOINT [ "npm", "run", "start" ] \ No newline at end of file diff --git a/spaces/chendl/compositional_test/transformers/src/transformers/modeling_tf_pytorch_utils.py b/spaces/chendl/compositional_test/transformers/src/transformers/modeling_tf_pytorch_utils.py deleted file mode 100644 index 402159cc6f9e4902d02e4ec7731b06db8ee1717c..0000000000000000000000000000000000000000 --- a/spaces/chendl/compositional_test/transformers/src/transformers/modeling_tf_pytorch_utils.py +++ /dev/null @@ -1,547 +0,0 @@ -# coding=utf-8 -# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team. -# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -""" PyTorch - TF 2.0 general utilities.""" - - -import os -import re - -import numpy - -from .utils import ExplicitEnum, expand_dims, is_numpy_array, is_torch_tensor, logging, reshape, squeeze, tensor_size -from .utils import transpose as transpose_func - - -logger = logging.get_logger(__name__) - - -class TransposeType(ExplicitEnum): - """ - Possible ... - """ - - NO = "no" - SIMPLE = "simple" - CONV1D = "conv1d" - CONV2D = "conv2d" - - -def convert_tf_weight_name_to_pt_weight_name( - tf_name, start_prefix_to_remove="", tf_weight_shape=None, name_scope=None -): - """ - Convert a TF 2.0 model variable name in a pytorch model weight name. - - Conventions for TF2.0 scopes -> PyTorch attribute names conversions: - - - '$1___$2' is replaced by $2 (can be used to duplicate or remove layers in TF2.0 vs PyTorch) - - '_._' is replaced by a new level separation (can be used to convert TF2.0 lists in PyTorch nn.ModulesList) - - return tuple with: - - - pytorch model weight name - - transpose: `TransposeType` member indicating whether and how TF2.0 and PyTorch weights matrices should be - transposed with regards to each other - """ - if name_scope is not None: - if not tf_name.startswith(name_scope): - raise ValueError( - f"Weight name {tf_name} does not start with name_scope {name_scope}. This is an internal error " - "in Transformers, so (unless you were doing something really evil) please open an issue to report it!" - ) - tf_name = tf_name[len(name_scope) :] - tf_name = tf_name.lstrip("/") - tf_name = tf_name.replace(":0", "") # device ids - tf_name = re.sub( - r"/[^/]*___([^/]*)/", r"/\1/", tf_name - ) # '$1___$2' is replaced by $2 (can be used to duplicate or remove layers in TF2.0 vs PyTorch) - tf_name = tf_name.replace( - "_._", "/" - ) # '_._' is replaced by a level separation (can be used to convert TF2.0 lists in PyTorch nn.ModulesList) - tf_name = re.sub(r"//+", "/", tf_name) # Remove empty levels at the end - tf_name = tf_name.split("/") # Convert from TF2.0 '/' separators to PyTorch '.' separators - # Some weights have a single name without "/" such as final_logits_bias in BART - if len(tf_name) > 1: - tf_name = tf_name[1:] # Remove level zero - - tf_weight_shape = list(tf_weight_shape) - - # When should we transpose the weights - if tf_name[-1] == "kernel" and tf_weight_shape is not None and len(tf_weight_shape) == 4: - transpose = TransposeType.CONV2D - elif tf_name[-1] == "kernel" and tf_weight_shape is not None and len(tf_weight_shape) == 3: - transpose = TransposeType.CONV1D - elif bool( - tf_name[-1] in ["kernel", "pointwise_kernel", "depthwise_kernel"] - or "emb_projs" in tf_name - or "out_projs" in tf_name - ): - transpose = TransposeType.SIMPLE - else: - transpose = TransposeType.NO - - # Convert standard TF2.0 names in PyTorch names - if tf_name[-1] == "kernel" or tf_name[-1] == "embeddings" or tf_name[-1] == "gamma": - tf_name[-1] = "weight" - if tf_name[-1] == "beta": - tf_name[-1] = "bias" - - # The SeparableConv1D TF layer contains two weights that are translated to PyTorch Conv1D here - if tf_name[-1] == "pointwise_kernel" or tf_name[-1] == "depthwise_kernel": - tf_name[-1] = tf_name[-1].replace("_kernel", ".weight") - - # Remove prefix if needed - tf_name = ".".join(tf_name) - if start_prefix_to_remove: - tf_name = tf_name.replace(start_prefix_to_remove, "", 1) - - return tf_name, transpose - - -def apply_transpose(transpose: TransposeType, weight, match_shape=None, pt_to_tf=True): - """ - Apply a transpose to some weight then tries to reshape the weight to the same shape as a given shape, all in a - framework agnostic way. - """ - if transpose is TransposeType.CONV2D: - # Conv2D weight: - # PT: (num_out_channel, num_in_channel, kernel[0], kernel[1]) - # -> TF: (kernel[0], kernel[1], num_in_channel, num_out_channel) - axes = (2, 3, 1, 0) if pt_to_tf else (3, 2, 0, 1) - weight = transpose_func(weight, axes=axes) - elif transpose is TransposeType.CONV1D: - # Conv1D weight: - # PT: (num_out_channel, num_in_channel, kernel) - # -> TF: (kernel, num_in_channel, num_out_channel) - weight = transpose_func(weight, axes=(2, 1, 0)) - elif transpose is TransposeType.SIMPLE: - weight = transpose_func(weight) - - if match_shape is None: - return weight - - if len(match_shape) < len(weight.shape): - weight = squeeze(weight) - elif len(match_shape) > len(weight.shape): - weight = expand_dims(weight, axis=0) - - if list(match_shape) != list(weight.shape): - try: - weight = reshape(weight, match_shape) - except AssertionError as e: - e.args += (match_shape, match_shape) - raise e - - return weight - - -##################### -# PyTorch => TF 2.0 # -##################### - - -def load_pytorch_checkpoint_in_tf2_model( - tf_model, - pytorch_checkpoint_path, - tf_inputs=None, - allow_missing_keys=False, - output_loading_info=False, - _prefix=None, - tf_to_pt_weight_rename=None, -): - """Load pytorch checkpoints in a TF 2.0 model""" - try: - import tensorflow as tf # noqa: F401 - import torch # noqa: F401 - except ImportError: - logger.error( - "Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see " - "https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions." - ) - raise - - # Treats a single file as a collection of shards with 1 shard. - if isinstance(pytorch_checkpoint_path, str): - pytorch_checkpoint_path = [pytorch_checkpoint_path] - - # Loads all shards into a single state dictionary - pt_state_dict = {} - for path in pytorch_checkpoint_path: - pt_path = os.path.abspath(path) - logger.info(f"Loading PyTorch weights from {pt_path}") - pt_state_dict.update(torch.load(pt_path, map_location="cpu")) - - logger.info(f"PyTorch checkpoint contains {sum(t.numel() for t in pt_state_dict.values()):,} parameters") - - return load_pytorch_weights_in_tf2_model( - tf_model, - pt_state_dict, - tf_inputs=tf_inputs, - allow_missing_keys=allow_missing_keys, - output_loading_info=output_loading_info, - _prefix=_prefix, - tf_to_pt_weight_rename=tf_to_pt_weight_rename, - ) - - -def load_pytorch_model_in_tf2_model(tf_model, pt_model, tf_inputs=None, allow_missing_keys=False): - """Load pytorch checkpoints in a TF 2.0 model""" - pt_state_dict = pt_model.state_dict() - - return load_pytorch_weights_in_tf2_model( - tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys - ) - - -def load_pytorch_weights_in_tf2_model( - tf_model, - pt_state_dict, - tf_inputs=None, - allow_missing_keys=False, - output_loading_info=False, - _prefix=None, - tf_to_pt_weight_rename=None, -): - """Load pytorch state_dict in a TF 2.0 model.""" - try: - import tensorflow as tf # noqa: F401 - import torch # noqa: F401 - except ImportError: - logger.error( - "Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see " - "https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions." - ) - raise - - pt_state_dict = {k: v.numpy() for k, v in pt_state_dict.items()} - return load_pytorch_state_dict_in_tf2_model( - tf_model, - pt_state_dict, - tf_inputs=tf_inputs, - allow_missing_keys=allow_missing_keys, - output_loading_info=output_loading_info, - _prefix=_prefix, - tf_to_pt_weight_rename=tf_to_pt_weight_rename, - ) - - -def load_pytorch_state_dict_in_tf2_model( - tf_model, - pt_state_dict, - tf_inputs=None, - allow_missing_keys=False, - output_loading_info=False, - _prefix=None, - tf_to_pt_weight_rename=None, -): - """Load a pytorch state_dict in a TF 2.0 model.""" - import tensorflow as tf - from packaging.version import parse - - if parse(tf.__version__) >= parse("2.11.0"): - from keras import backend as K - else: - from tensorflow.python.keras import backend as K - - if tf_inputs is None: - tf_inputs = tf_model.dummy_inputs - - if _prefix is None: - _prefix = "" - if tf_inputs is not None: - with tf.name_scope(_prefix): - tf_model(tf_inputs, training=False) # Make sure model is built - # Adapt state dict - TODO remove this and update the AWS weights files instead - # Convert old format to new format if needed from a PyTorch state_dict - old_keys = [] - new_keys = [] - for key in pt_state_dict.keys(): - new_key = None - if "gamma" in key: - new_key = key.replace("gamma", "weight") - if "beta" in key: - new_key = key.replace("beta", "bias") - if "running_var" in key: - new_key = key.replace("running_var", "moving_variance") - if "running_mean" in key: - new_key = key.replace("running_mean", "moving_mean") - if new_key: - old_keys.append(key) - new_keys.append(new_key) - for old_key, new_key in zip(old_keys, new_keys): - pt_state_dict[new_key] = pt_state_dict.pop(old_key) - - # Matt: All TF models store the actual model stem in a MainLayer class, including the base model. - # In PT, the derived models (with heads) use the base model class as the stem instead, and the base model - # just contains the stem itself, and there is no MainLayer class. This means that TF base classes have one - # extra layer in their weight names, corresponding to the MainLayer class. This code block compensates for that. - start_prefix_to_remove = "" - if not any(s.startswith(tf_model.base_model_prefix) for s in pt_state_dict.keys()): - start_prefix_to_remove = tf_model.base_model_prefix + "." - - symbolic_weights = tf_model.trainable_weights + tf_model.non_trainable_weights - tf_loaded_numel = 0 - weight_value_tuples = [] - all_pytorch_weights = set(pt_state_dict.keys()) - missing_keys = [] - for symbolic_weight in symbolic_weights: - sw_name = symbolic_weight.name - name, transpose = convert_tf_weight_name_to_pt_weight_name( - sw_name, - start_prefix_to_remove=start_prefix_to_remove, - tf_weight_shape=symbolic_weight.shape, - name_scope=_prefix, - ) - if tf_to_pt_weight_rename is not None: - name = tf_to_pt_weight_rename(name) - - # Find associated numpy array in pytorch model state dict - if name not in pt_state_dict: - if allow_missing_keys: - missing_keys.append(name) - continue - elif tf_model._keys_to_ignore_on_load_missing is not None: - # authorized missing keys don't have to be loaded - if any(re.search(pat, name) is not None for pat in tf_model._keys_to_ignore_on_load_missing): - continue - raise AttributeError(f"{name} not found in PyTorch model") - - array = apply_transpose(transpose, pt_state_dict[name], symbolic_weight.shape) - - tf_loaded_numel += tensor_size(array) - - weight_value_tuples.append((symbolic_weight, array)) - all_pytorch_weights.discard(name) - - K.batch_set_value(weight_value_tuples) - - if tf_inputs is not None: - tf_model(tf_inputs, training=False) # Make sure restore ops are run - - logger.info(f"Loaded {tf_loaded_numel:,} parameters in the TF 2.0 model.") - - unexpected_keys = list(all_pytorch_weights) - - if tf_model._keys_to_ignore_on_load_missing is not None: - for pat in tf_model._keys_to_ignore_on_load_missing: - missing_keys = [k for k in missing_keys if re.search(pat, k) is None] - if tf_model._keys_to_ignore_on_load_unexpected is not None: - for pat in tf_model._keys_to_ignore_on_load_unexpected: - unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None] - - if len(unexpected_keys) > 0: - logger.warning( - "Some weights of the PyTorch model were not used when initializing the TF 2.0 model" - f" {tf_model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are initializing" - f" {tf_model.__class__.__name__} from a PyTorch model trained on another task or with another architecture" - " (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).\n- This IS" - f" NOT expected if you are initializing {tf_model.__class__.__name__} from a PyTorch model that you expect" - " to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a" - " BertForSequenceClassification model)." - ) - else: - logger.warning(f"All PyTorch model weights were used when initializing {tf_model.__class__.__name__}.\n") - if len(missing_keys) > 0: - logger.warning( - f"Some weights or buffers of the TF 2.0 model {tf_model.__class__.__name__} were not initialized from the" - f" PyTorch model and are newly initialized: {missing_keys}\nYou should probably TRAIN this model on a" - " down-stream task to be able to use it for predictions and inference." - ) - else: - logger.warning( - f"All the weights of {tf_model.__class__.__name__} were initialized from the PyTorch model.\n" - "If your task is similar to the task the model of the checkpoint was trained on, " - f"you can already use {tf_model.__class__.__name__} for predictions without further training." - ) - - if output_loading_info: - loading_info = {"missing_keys": missing_keys, "unexpected_keys": unexpected_keys} - return tf_model, loading_info - - return tf_model - - -##################### -# TF 2.0 => PyTorch # -##################### - - -def load_tf2_checkpoint_in_pytorch_model( - pt_model, tf_checkpoint_path, tf_inputs=None, allow_missing_keys=False, output_loading_info=False -): - """ - Load TF 2.0 HDF5 checkpoint in a PyTorch model We use HDF5 to easily do transfer learning (see - https://github.com/tensorflow/tensorflow/blob/ee16fcac960ae660e0e4496658a366e2f745e1f0/tensorflow/python/keras/engine/network.py#L1352-L1357). - """ - try: - import tensorflow as tf # noqa: F401 - import torch # noqa: F401 - except ImportError: - logger.error( - "Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed. Please see " - "https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions." - ) - raise - - import transformers - - from .modeling_tf_utils import load_tf_weights - - logger.info(f"Loading TensorFlow weights from {tf_checkpoint_path}") - - # Instantiate and load the associated TF 2.0 model - tf_model_class_name = "TF" + pt_model.__class__.__name__ # Add "TF" at the beginning - tf_model_class = getattr(transformers, tf_model_class_name) - tf_model = tf_model_class(pt_model.config) - - if tf_inputs is None: - tf_inputs = tf_model.dummy_inputs - - if tf_inputs is not None: - tf_model(tf_inputs, training=False) # Make sure model is built - - load_tf_weights(tf_model, tf_checkpoint_path) - - return load_tf2_model_in_pytorch_model( - pt_model, tf_model, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info - ) - - -def load_tf2_model_in_pytorch_model(pt_model, tf_model, allow_missing_keys=False, output_loading_info=False): - """Load TF 2.0 model in a pytorch model""" - weights = tf_model.weights - - return load_tf2_weights_in_pytorch_model( - pt_model, weights, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info - ) - - -def load_tf2_weights_in_pytorch_model(pt_model, tf_weights, allow_missing_keys=False, output_loading_info=False): - """Load TF2.0 symbolic weights in a PyTorch model""" - try: - import tensorflow as tf # noqa: F401 - import torch # noqa: F401 - except ImportError: - logger.error( - "Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed. Please see " - "https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions." - ) - raise - - tf_state_dict = {tf_weight.name: tf_weight.numpy() for tf_weight in tf_weights} - return load_tf2_state_dict_in_pytorch_model( - pt_model, tf_state_dict, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info - ) - - -def load_tf2_state_dict_in_pytorch_model(pt_model, tf_state_dict, allow_missing_keys=False, output_loading_info=False): - import torch - - new_pt_params_dict = {} - current_pt_params_dict = dict(pt_model.named_parameters()) - - # Make sure we are able to load PyTorch base models as well as derived models (with heads) - # TF models always have a prefix, some of PyTorch models (base ones) don't - start_prefix_to_remove = "" - if not any(s.startswith(pt_model.base_model_prefix) for s in current_pt_params_dict.keys()): - start_prefix_to_remove = pt_model.base_model_prefix + "." - - # Build a map from potential PyTorch weight names to TF 2.0 Variables - tf_weights_map = {} - for name, tf_weight in tf_state_dict.items(): - pt_name, transpose = convert_tf_weight_name_to_pt_weight_name( - name, start_prefix_to_remove=start_prefix_to_remove, tf_weight_shape=tf_weight.shape - ) - tf_weights_map[pt_name] = (tf_weight, transpose) - - all_tf_weights = set(tf_weights_map.keys()) - loaded_pt_weights_data_ptr = {} - missing_keys_pt = [] - for pt_weight_name, pt_weight in current_pt_params_dict.items(): - # Handle PyTorch shared weight ()not duplicated in TF 2.0 - if pt_weight.data_ptr() in loaded_pt_weights_data_ptr: - new_pt_params_dict[pt_weight_name] = loaded_pt_weights_data_ptr[pt_weight.data_ptr()] - continue - - # Find associated numpy array in pytorch model state dict - if pt_weight_name not in tf_weights_map: - if allow_missing_keys: - missing_keys_pt.append(pt_weight_name) - continue - - raise AttributeError(f"{pt_weight_name} not found in TF 2.0 model") - - array, transpose = tf_weights_map[pt_weight_name] - - array = apply_transpose(transpose, array, pt_weight.shape, pt_to_tf=False) - - if numpy.isscalar(array): - array = numpy.array(array) - if not is_torch_tensor(array) and not is_numpy_array(array): - array = array.numpy() - if is_numpy_array(array): - # Convert to torch tensor - array = torch.from_numpy(array) - - new_pt_params_dict[pt_weight_name] = array - loaded_pt_weights_data_ptr[pt_weight.data_ptr()] = array - all_tf_weights.discard(pt_weight_name) - - missing_keys, unexpected_keys = pt_model.load_state_dict(new_pt_params_dict, strict=False) - missing_keys += missing_keys_pt - - # Some models may have keys that are not in the state by design, removing them before needlessly warning - # the user. - if pt_model._keys_to_ignore_on_load_missing is not None: - for pat in pt_model._keys_to_ignore_on_load_missing: - missing_keys = [k for k in missing_keys if re.search(pat, k) is None] - - if pt_model._keys_to_ignore_on_load_unexpected is not None: - for pat in pt_model._keys_to_ignore_on_load_unexpected: - unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None] - - if len(unexpected_keys) > 0: - logger.warning( - "Some weights of the TF 2.0 model were not used when initializing the PyTorch model" - f" {pt_model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are initializing" - f" {pt_model.__class__.__name__} from a TF 2.0 model trained on another task or with another architecture" - " (e.g. initializing a BertForSequenceClassification model from a TFBertForPreTraining model).\n- This IS" - f" NOT expected if you are initializing {pt_model.__class__.__name__} from a TF 2.0 model that you expect" - " to be exactly identical (e.g. initializing a BertForSequenceClassification model from a" - " TFBertForSequenceClassification model)." - ) - else: - logger.warning(f"All TF 2.0 model weights were used when initializing {pt_model.__class__.__name__}.\n") - if len(missing_keys) > 0: - logger.warning( - f"Some weights of {pt_model.__class__.__name__} were not initialized from the TF 2.0 model and are newly" - f" initialized: {missing_keys}\nYou should probably TRAIN this model on a down-stream task to be able to" - " use it for predictions and inference." - ) - else: - logger.warning( - f"All the weights of {pt_model.__class__.__name__} were initialized from the TF 2.0 model.\n" - "If your task is similar to the task the model of the checkpoint was trained on, " - f"you can already use {pt_model.__class__.__name__} for predictions without further training." - ) - - logger.info(f"Weights or buffers not loaded from TF 2.0 model: {all_tf_weights}") - - if output_loading_info: - loading_info = {"missing_keys": missing_keys, "unexpected_keys": unexpected_keys} - return pt_model, loading_info - - return pt_model diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/styles/styles.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/styles/styles.py deleted file mode 100644 index f9f1cd2fbbe929b4b2d6c38c25d93b5f222be68e..0000000000000000000000000000000000000000 --- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/styles/styles.py +++ /dev/null @@ -1,153 +0,0 @@ -# encoding: utf-8 - -"""Styles object, container for all objects in the styles part""" - -from __future__ import absolute_import, division, print_function, unicode_literals - -from warnings import warn - -from docx.shared import ElementProxy -from docx.styles import BabelFish -from docx.styles.latent import LatentStyles -from docx.styles.style import BaseStyle, StyleFactory - - -class Styles(ElementProxy): - """Provides access to the styles defined in a document. - - Accessed using the :attr:`.Document.styles` property. Supports ``len()``, iteration, - and dictionary-style access by style name. - """ - - __slots__ = () - - def __contains__(self, name): - """ - Enables `in` operator on style name. - """ - internal_name = BabelFish.ui2internal(name) - for style in self._element.style_lst: - if style.name_val == internal_name: - return True - return False - - def __getitem__(self, key): - """ - Enables dictionary-style access by UI name. Lookup by style id is - deprecated, triggers a warning, and will be removed in a near-future - release. - """ - style_elm = self._element.get_by_name(BabelFish.ui2internal(key)) - if style_elm is not None: - return StyleFactory(style_elm) - - style_elm = self._element.get_by_id(key) - if style_elm is not None: - msg = ( - 'style lookup by style_id is deprecated. Use style name as ' - 'key instead.' - ) - warn(msg, UserWarning, stacklevel=2) - return StyleFactory(style_elm) - - raise KeyError("no style with name '%s'" % key) - - def __iter__(self): - return (StyleFactory(style) for style in self._element.style_lst) - - def __len__(self): - return len(self._element.style_lst) - - def add_style(self, name, style_type, builtin=False): - """ - Return a newly added style object of *style_type* and identified - by *name*. A builtin style can be defined by passing True for the - optional *builtin* argument. - """ - style_name = BabelFish.ui2internal(name) - if style_name in self: - raise ValueError("document already contains style '%s'" % name) - style = self._element.add_style_of_type( - style_name, style_type, builtin - ) - return StyleFactory(style) - - def default(self, style_type): - """ - Return the default style for *style_type* or |None| if no default is - defined for that type (not common). - """ - style = self._element.default_for(style_type) - if style is None: - return None - return StyleFactory(style) - - def get_by_id(self, style_id, style_type): - """Return the style of *style_type* matching *style_id*. - - Returns the default for *style_type* if *style_id* is not found or is |None|, or - if the style having *style_id* is not of *style_type*. - """ - if style_id is None: - return self.default(style_type) - return self._get_by_id(style_id, style_type) - - def get_style_id(self, style_or_name, style_type): - """ - Return the id of the style corresponding to *style_or_name*, or - |None| if *style_or_name* is |None|. If *style_or_name* is not - a style object, the style is looked up using *style_or_name* as - a style name, raising |ValueError| if no style with that name is - defined. Raises |ValueError| if the target style is not of - *style_type*. - """ - if style_or_name is None: - return None - elif isinstance(style_or_name, BaseStyle): - return self._get_style_id_from_style(style_or_name, style_type) - else: - return self._get_style_id_from_name(style_or_name, style_type) - - @property - def latent_styles(self): - """ - A |LatentStyles| object providing access to the default behaviors for - latent styles and the collection of |_LatentStyle| objects that - define overrides of those defaults for a particular named latent - style. - """ - return LatentStyles(self._element.get_or_add_latentStyles()) - - def _get_by_id(self, style_id, style_type): - """ - Return the style of *style_type* matching *style_id*. Returns the - default for *style_type* if *style_id* is not found or if the style - having *style_id* is not of *style_type*. - """ - style = self._element.get_by_id(style_id) - if style is None or style.type != style_type: - return self.default(style_type) - return StyleFactory(style) - - def _get_style_id_from_name(self, style_name, style_type): - """ - Return the id of the style of *style_type* corresponding to - *style_name*. Returns |None| if that style is the default style for - *style_type*. Raises |ValueError| if the named style is not found in - the document or does not match *style_type*. - """ - return self._get_style_id_from_style(self[style_name], style_type) - - def _get_style_id_from_style(self, style, style_type): - """ - Return the id of *style*, or |None| if it is the default style of - *style_type*. Raises |ValueError| if style is not of *style_type*. - """ - if style.type != style_type: - raise ValueError( - "assigned style is type %s, need type %s" % - (style.type, style_type) - ) - if style == self.default(style_type): - return None - return style.style_id diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/varLib/mutator.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/varLib/mutator.py deleted file mode 100644 index d1d123ab690f5db5b2a6ae05369db233aee3c92d..0000000000000000000000000000000000000000 --- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/varLib/mutator.py +++ /dev/null @@ -1,509 +0,0 @@ -""" -Instantiate a variation font. Run, eg: - -$ fonttools varLib.mutator ./NotoSansArabic-VF.ttf wght=140 wdth=85 -""" -from fontTools.misc.fixedTools import floatToFixedToFloat, floatToFixed -from fontTools.misc.roundTools import otRound -from fontTools.pens.boundsPen import BoundsPen -from fontTools.ttLib import TTFont, newTable -from fontTools.ttLib.tables import ttProgram -from fontTools.ttLib.tables._g_l_y_f import ( - GlyphCoordinates, - flagOverlapSimple, - OVERLAP_COMPOUND, -) -from fontTools.varLib.models import ( - supportScalar, - normalizeLocation, - piecewiseLinearMap, -) -from fontTools.varLib.merger import MutatorMerger -from fontTools.varLib.varStore import VarStoreInstancer -from fontTools.varLib.mvar import MVAR_ENTRIES -from fontTools.varLib.iup import iup_delta -import fontTools.subset.cff -import os.path -import logging -from io import BytesIO - - -log = logging.getLogger("fontTools.varlib.mutator") - -# map 'wdth' axis (1..200) to OS/2.usWidthClass (1..9), rounding to closest -OS2_WIDTH_CLASS_VALUES = {} -percents = [50.0, 62.5, 75.0, 87.5, 100.0, 112.5, 125.0, 150.0, 200.0] -for i, (prev, curr) in enumerate(zip(percents[:-1], percents[1:]), start=1): - half = (prev + curr) / 2 - OS2_WIDTH_CLASS_VALUES[half] = i - - -def interpolate_cff2_PrivateDict(topDict, interpolateFromDeltas): - pd_blend_lists = ( - "BlueValues", - "OtherBlues", - "FamilyBlues", - "FamilyOtherBlues", - "StemSnapH", - "StemSnapV", - ) - pd_blend_values = ("BlueScale", "BlueShift", "BlueFuzz", "StdHW", "StdVW") - for fontDict in topDict.FDArray: - pd = fontDict.Private - vsindex = pd.vsindex if (hasattr(pd, "vsindex")) else 0 - for key, value in pd.rawDict.items(): - if (key in pd_blend_values) and isinstance(value, list): - delta = interpolateFromDeltas(vsindex, value[1:]) - pd.rawDict[key] = otRound(value[0] + delta) - elif (key in pd_blend_lists) and isinstance(value[0], list): - """If any argument in a BlueValues list is a blend list, - then they all are. The first value of each list is an - absolute value. The delta tuples are calculated from - relative master values, hence we need to append all the - deltas to date to each successive absolute value.""" - delta = 0 - for i, val_list in enumerate(value): - delta += otRound(interpolateFromDeltas(vsindex, val_list[1:])) - value[i] = val_list[0] + delta - - -def interpolate_cff2_charstrings(topDict, interpolateFromDeltas, glyphOrder): - charstrings = topDict.CharStrings - for gname in glyphOrder: - # Interpolate charstring - # e.g replace blend op args with regular args, - # and use and discard vsindex op. - charstring = charstrings[gname] - new_program = [] - vsindex = 0 - last_i = 0 - for i, token in enumerate(charstring.program): - if token == "vsindex": - vsindex = charstring.program[i - 1] - if last_i != 0: - new_program.extend(charstring.program[last_i : i - 1]) - last_i = i + 1 - elif token == "blend": - num_regions = charstring.getNumRegions(vsindex) - numMasters = 1 + num_regions - num_args = charstring.program[i - 1] - # The program list starting at program[i] is now: - # ..args for following operations - # num_args values from the default font - # num_args tuples, each with numMasters-1 delta values - # num_blend_args - # 'blend' - argi = i - (num_args * numMasters + 1) - end_args = tuplei = argi + num_args - while argi < end_args: - next_ti = tuplei + num_regions - deltas = charstring.program[tuplei:next_ti] - delta = interpolateFromDeltas(vsindex, deltas) - charstring.program[argi] += otRound(delta) - tuplei = next_ti - argi += 1 - new_program.extend(charstring.program[last_i:end_args]) - last_i = i + 1 - if last_i != 0: - new_program.extend(charstring.program[last_i:]) - charstring.program = new_program - - -def interpolate_cff2_metrics(varfont, topDict, glyphOrder, loc): - """Unlike TrueType glyphs, neither advance width nor bounding box - info is stored in a CFF2 charstring. The width data exists only in - the hmtx and HVAR tables. Since LSB data cannot be interpolated - reliably from the master LSB values in the hmtx table, we traverse - the charstring to determine the actual bound box.""" - - charstrings = topDict.CharStrings - boundsPen = BoundsPen(glyphOrder) - hmtx = varfont["hmtx"] - hvar_table = None - if "HVAR" in varfont: - hvar_table = varfont["HVAR"].table - fvar = varfont["fvar"] - varStoreInstancer = VarStoreInstancer(hvar_table.VarStore, fvar.axes, loc) - - for gid, gname in enumerate(glyphOrder): - entry = list(hmtx[gname]) - # get width delta. - if hvar_table: - if hvar_table.AdvWidthMap: - width_idx = hvar_table.AdvWidthMap.mapping[gname] - else: - width_idx = gid - width_delta = otRound(varStoreInstancer[width_idx]) - else: - width_delta = 0 - - # get LSB. - boundsPen.init() - charstring = charstrings[gname] - charstring.draw(boundsPen) - if boundsPen.bounds is None: - # Happens with non-marking glyphs - lsb_delta = 0 - else: - lsb = otRound(boundsPen.bounds[0]) - lsb_delta = entry[1] - lsb - - if lsb_delta or width_delta: - if width_delta: - entry[0] = max(0, entry[0] + width_delta) - if lsb_delta: - entry[1] = lsb - hmtx[gname] = tuple(entry) - - -def instantiateVariableFont(varfont, location, inplace=False, overlap=True): - """Generate a static instance from a variable TTFont and a dictionary - defining the desired location along the variable font's axes. - The location values must be specified as user-space coordinates, e.g.: - - {'wght': 400, 'wdth': 100} - - By default, a new TTFont object is returned. If ``inplace`` is True, the - input varfont is modified and reduced to a static font. - - When the overlap parameter is defined as True, - OVERLAP_SIMPLE and OVERLAP_COMPOUND bits are set to 1. See - https://docs.microsoft.com/en-us/typography/opentype/spec/glyf - """ - if not inplace: - # make a copy to leave input varfont unmodified - stream = BytesIO() - varfont.save(stream) - stream.seek(0) - varfont = TTFont(stream) - - fvar = varfont["fvar"] - axes = {a.axisTag: (a.minValue, a.defaultValue, a.maxValue) for a in fvar.axes} - loc = normalizeLocation(location, axes) - if "avar" in varfont: - maps = varfont["avar"].segments - loc = {k: piecewiseLinearMap(v, maps[k]) for k, v in loc.items()} - # Quantize to F2Dot14, to avoid surprise interpolations. - loc = {k: floatToFixedToFloat(v, 14) for k, v in loc.items()} - # Location is normalized now - log.info("Normalized location: %s", loc) - - if "gvar" in varfont: - log.info("Mutating glyf/gvar tables") - gvar = varfont["gvar"] - glyf = varfont["glyf"] - hMetrics = varfont["hmtx"].metrics - vMetrics = getattr(varfont.get("vmtx"), "metrics", None) - # get list of glyph names in gvar sorted by component depth - glyphnames = sorted( - gvar.variations.keys(), - key=lambda name: ( - glyf[name].getCompositeMaxpValues(glyf).maxComponentDepth - if glyf[name].isComposite() or glyf[name].isVarComposite() - else 0, - name, - ), - ) - for glyphname in glyphnames: - variations = gvar.variations[glyphname] - coordinates, _ = glyf._getCoordinatesAndControls( - glyphname, hMetrics, vMetrics - ) - origCoords, endPts = None, None - for var in variations: - scalar = supportScalar(loc, var.axes) - if not scalar: - continue - delta = var.coordinates - if None in delta: - if origCoords is None: - origCoords, g = glyf._getCoordinatesAndControls( - glyphname, hMetrics, vMetrics - ) - delta = iup_delta(delta, origCoords, g.endPts) - coordinates += GlyphCoordinates(delta) * scalar - glyf._setCoordinates(glyphname, coordinates, hMetrics, vMetrics) - else: - glyf = None - - if "DSIG" in varfont: - del varfont["DSIG"] - - if "cvar" in varfont: - log.info("Mutating cvt/cvar tables") - cvar = varfont["cvar"] - cvt = varfont["cvt "] - deltas = {} - for var in cvar.variations: - scalar = supportScalar(loc, var.axes) - if not scalar: - continue - for i, c in enumerate(var.coordinates): - if c is not None: - deltas[i] = deltas.get(i, 0) + scalar * c - for i, delta in deltas.items(): - cvt[i] += otRound(delta) - - if "CFF2" in varfont: - log.info("Mutating CFF2 table") - glyphOrder = varfont.getGlyphOrder() - CFF2 = varfont["CFF2"] - topDict = CFF2.cff.topDictIndex[0] - vsInstancer = VarStoreInstancer(topDict.VarStore.otVarStore, fvar.axes, loc) - interpolateFromDeltas = vsInstancer.interpolateFromDeltas - interpolate_cff2_PrivateDict(topDict, interpolateFromDeltas) - CFF2.desubroutinize() - interpolate_cff2_charstrings(topDict, interpolateFromDeltas, glyphOrder) - interpolate_cff2_metrics(varfont, topDict, glyphOrder, loc) - del topDict.rawDict["VarStore"] - del topDict.VarStore - - if "MVAR" in varfont: - log.info("Mutating MVAR table") - mvar = varfont["MVAR"].table - varStoreInstancer = VarStoreInstancer(mvar.VarStore, fvar.axes, loc) - records = mvar.ValueRecord - for rec in records: - mvarTag = rec.ValueTag - if mvarTag not in MVAR_ENTRIES: - continue - tableTag, itemName = MVAR_ENTRIES[mvarTag] - delta = otRound(varStoreInstancer[rec.VarIdx]) - if not delta: - continue - setattr( - varfont[tableTag], - itemName, - getattr(varfont[tableTag], itemName) + delta, - ) - - log.info("Mutating FeatureVariations") - for tableTag in "GSUB", "GPOS": - if not tableTag in varfont: - continue - table = varfont[tableTag].table - if not getattr(table, "FeatureVariations", None): - continue - variations = table.FeatureVariations - for record in variations.FeatureVariationRecord: - applies = True - for condition in record.ConditionSet.ConditionTable: - if condition.Format == 1: - axisIdx = condition.AxisIndex - axisTag = fvar.axes[axisIdx].axisTag - Min = condition.FilterRangeMinValue - Max = condition.FilterRangeMaxValue - v = loc[axisTag] - if not (Min <= v <= Max): - applies = False - else: - applies = False - if not applies: - break - - if applies: - assert record.FeatureTableSubstitution.Version == 0x00010000 - for rec in record.FeatureTableSubstitution.SubstitutionRecord: - table.FeatureList.FeatureRecord[ - rec.FeatureIndex - ].Feature = rec.Feature - break - del table.FeatureVariations - - if "GDEF" in varfont and varfont["GDEF"].table.Version >= 0x00010003: - log.info("Mutating GDEF/GPOS/GSUB tables") - gdef = varfont["GDEF"].table - instancer = VarStoreInstancer(gdef.VarStore, fvar.axes, loc) - - merger = MutatorMerger(varfont, instancer) - merger.mergeTables(varfont, [varfont], ["GDEF", "GPOS"]) - - # Downgrade GDEF. - del gdef.VarStore - gdef.Version = 0x00010002 - if gdef.MarkGlyphSetsDef is None: - del gdef.MarkGlyphSetsDef - gdef.Version = 0x00010000 - - if not ( - gdef.LigCaretList - or gdef.MarkAttachClassDef - or gdef.GlyphClassDef - or gdef.AttachList - or (gdef.Version >= 0x00010002 and gdef.MarkGlyphSetsDef) - ): - del varfont["GDEF"] - - addidef = False - if glyf: - for glyph in glyf.glyphs.values(): - if hasattr(glyph, "program"): - instructions = glyph.program.getAssembly() - # If GETVARIATION opcode is used in bytecode of any glyph add IDEF - addidef = any(op.startswith("GETVARIATION") for op in instructions) - if addidef: - break - if overlap: - for glyph_name in glyf.keys(): - glyph = glyf[glyph_name] - # Set OVERLAP_COMPOUND bit for compound glyphs - if glyph.isComposite(): - glyph.components[0].flags |= OVERLAP_COMPOUND - # Set OVERLAP_SIMPLE bit for simple glyphs - elif glyph.numberOfContours > 0: - glyph.flags[0] |= flagOverlapSimple - if addidef: - log.info("Adding IDEF to fpgm table for GETVARIATION opcode") - asm = [] - if "fpgm" in varfont: - fpgm = varfont["fpgm"] - asm = fpgm.program.getAssembly() - else: - fpgm = newTable("fpgm") - fpgm.program = ttProgram.Program() - varfont["fpgm"] = fpgm - asm.append("PUSHB[000] 145") - asm.append("IDEF[ ]") - args = [str(len(loc))] - for a in fvar.axes: - args.append(str(floatToFixed(loc[a.axisTag], 14))) - asm.append("NPUSHW[ ] " + " ".join(args)) - asm.append("ENDF[ ]") - fpgm.program.fromAssembly(asm) - - # Change maxp attributes as IDEF is added - if "maxp" in varfont: - maxp = varfont["maxp"] - setattr( - maxp, "maxInstructionDefs", 1 + getattr(maxp, "maxInstructionDefs", 0) - ) - setattr( - maxp, - "maxStackElements", - max(len(loc), getattr(maxp, "maxStackElements", 0)), - ) - - if "name" in varfont: - log.info("Pruning name table") - exclude = {a.axisNameID for a in fvar.axes} - for i in fvar.instances: - exclude.add(i.subfamilyNameID) - exclude.add(i.postscriptNameID) - if "ltag" in varfont: - # Drop the whole 'ltag' table if all its language tags are referenced by - # name records to be pruned. - # TODO: prune unused ltag tags and re-enumerate langIDs accordingly - excludedUnicodeLangIDs = [ - n.langID - for n in varfont["name"].names - if n.nameID in exclude and n.platformID == 0 and n.langID != 0xFFFF - ] - if set(excludedUnicodeLangIDs) == set(range(len((varfont["ltag"].tags)))): - del varfont["ltag"] - varfont["name"].names[:] = [ - n for n in varfont["name"].names if n.nameID not in exclude - ] - - if "wght" in location and "OS/2" in varfont: - varfont["OS/2"].usWeightClass = otRound(max(1, min(location["wght"], 1000))) - if "wdth" in location: - wdth = location["wdth"] - for percent, widthClass in sorted(OS2_WIDTH_CLASS_VALUES.items()): - if wdth < percent: - varfont["OS/2"].usWidthClass = widthClass - break - else: - varfont["OS/2"].usWidthClass = 9 - if "slnt" in location and "post" in varfont: - varfont["post"].italicAngle = max(-90, min(location["slnt"], 90)) - - log.info("Removing variable tables") - for tag in ("avar", "cvar", "fvar", "gvar", "HVAR", "MVAR", "VVAR", "STAT"): - if tag in varfont: - del varfont[tag] - - return varfont - - -def main(args=None): - """Instantiate a variation font""" - from fontTools import configLogger - import argparse - - parser = argparse.ArgumentParser( - "fonttools varLib.mutator", description="Instantiate a variable font" - ) - parser.add_argument("input", metavar="INPUT.ttf", help="Input variable TTF file.") - parser.add_argument( - "locargs", - metavar="AXIS=LOC", - nargs="*", - help="List of space separated locations. A location consist in " - "the name of a variation axis, followed by '=' and a number. E.g.: " - " wght=700 wdth=80. The default is the location of the base master.", - ) - parser.add_argument( - "-o", - "--output", - metavar="OUTPUT.ttf", - default=None, - help="Output instance TTF file (default: INPUT-instance.ttf).", - ) - parser.add_argument( - "--no-recalc-timestamp", - dest="recalc_timestamp", - action="store_false", - help="Don't set the output font's timestamp to the current time.", - ) - logging_group = parser.add_mutually_exclusive_group(required=False) - logging_group.add_argument( - "-v", "--verbose", action="store_true", help="Run more verbosely." - ) - logging_group.add_argument( - "-q", "--quiet", action="store_true", help="Turn verbosity off." - ) - parser.add_argument( - "--no-overlap", - dest="overlap", - action="store_false", - help="Don't set OVERLAP_SIMPLE/OVERLAP_COMPOUND glyf flags.", - ) - options = parser.parse_args(args) - - varfilename = options.input - outfile = ( - os.path.splitext(varfilename)[0] + "-instance.ttf" - if not options.output - else options.output - ) - configLogger( - level=("DEBUG" if options.verbose else "ERROR" if options.quiet else "INFO") - ) - - loc = {} - for arg in options.locargs: - try: - tag, val = arg.split("=") - assert len(tag) <= 4 - loc[tag.ljust(4)] = float(val) - except (ValueError, AssertionError): - parser.error("invalid location argument format: %r" % arg) - log.info("Location: %s", loc) - - log.info("Loading variable font") - varfont = TTFont(varfilename, recalcTimestamp=options.recalc_timestamp) - - instantiateVariableFont(varfont, loc, inplace=True, overlap=options.overlap) - - log.info("Saving instance font %s", outfile) - varfont.save(outfile) - - -if __name__ == "__main__": - import sys - - if len(sys.argv) > 1: - sys.exit(main()) - import doctest - - sys.exit(doctest.testmod().failed) diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/routes.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/routes.py deleted file mode 100644 index 263f1d70ed5159c3cc1d207d7e3f6d168f19b163..0000000000000000000000000000000000000000 --- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/routes.py +++ /dev/null @@ -1,827 +0,0 @@ -"""Implements a FastAPI server to run the gradio interface. Note that some types in this -module use the Optional/Union notation so that they work correctly with pydantic.""" - -from __future__ import annotations - -import asyncio -import inspect -import json -import mimetypes -import os -import posixpath -import secrets -import tempfile -import traceback -from asyncio import TimeoutError as AsyncTimeOutError -from collections import defaultdict -from copy import deepcopy -from pathlib import Path -from typing import Any, Dict, List, Optional, Type -from urllib.parse import urlparse - -import fastapi -import httpx -import markupsafe -import orjson -import pkg_resources -from fastapi import Depends, FastAPI, File, HTTPException, UploadFile, WebSocket, status -from fastapi.middleware.cors import CORSMiddleware -from fastapi.responses import ( - FileResponse, - HTMLResponse, - JSONResponse, - PlainTextResponse, -) -from fastapi.security import OAuth2PasswordRequestForm -from fastapi.templating import Jinja2Templates -from gradio_client.documentation import document, set_documentation_group -from jinja2.exceptions import TemplateNotFound -from starlette.background import BackgroundTask -from starlette.responses import RedirectResponse, StreamingResponse -from starlette.websockets import WebSocketState - -import gradio -import gradio.ranged_response as ranged_response -from gradio import utils, wasm_utils -from gradio.context import Context -from gradio.data_classes import PredictBody, ResetBody -from gradio.exceptions import Error -from gradio.helpers import EventData -from gradio.queueing import Estimation, Event -from gradio.utils import cancel_tasks, run_coro_in_background, set_task_name - -mimetypes.init() - -STATIC_TEMPLATE_LIB = pkg_resources.resource_filename("gradio", "templates/") -STATIC_PATH_LIB = pkg_resources.resource_filename("gradio", "templates/frontend/static") -BUILD_PATH_LIB = pkg_resources.resource_filename("gradio", "templates/frontend/assets") -VERSION_FILE = pkg_resources.resource_filename("gradio", "version.txt") -with open(VERSION_FILE) as version_file: - VERSION = version_file.read() - - -class ORJSONResponse(JSONResponse): - media_type = "application/json" - - @staticmethod - def _render(content: Any) -> bytes: - return orjson.dumps( - content, - option=orjson.OPT_SERIALIZE_NUMPY | orjson.OPT_PASSTHROUGH_DATETIME, - default=str, - ) - - def render(self, content: Any) -> bytes: - return ORJSONResponse._render(content) - - @staticmethod - def _render_str(content: Any) -> str: - return ORJSONResponse._render(content).decode("utf-8") - - -def toorjson(value): - return markupsafe.Markup( - ORJSONResponse._render_str(value) - .replace("<", "\\u003c") - .replace(">", "\\u003e") - .replace("&", "\\u0026") - .replace("'", "\\u0027") - ) - - -templates = Jinja2Templates(directory=STATIC_TEMPLATE_LIB) -templates.env.filters["toorjson"] = toorjson - -client = httpx.AsyncClient() - -########### -# Auth -########### - - -class App(FastAPI): - """ - FastAPI App Wrapper - """ - - def __init__(self, **kwargs): - self.tokens = {} - self.auth = None - self.blocks: gradio.Blocks | None = None - self.state_holder = {} - self.iterators = defaultdict(dict) - self.lock = asyncio.Lock() - self.queue_token = secrets.token_urlsafe(32) - self.startup_events_triggered = False - self.uploaded_file_dir = os.environ.get("GRADIO_TEMP_DIR") or str( - Path(tempfile.gettempdir()) / "gradio" - ) - # Allow user to manually set `docs_url` and `redoc_url` - # when instantiating an App; when they're not set, disable docs and redoc. - kwargs.setdefault("docs_url", None) - kwargs.setdefault("redoc_url", None) - super().__init__(**kwargs) - - def configure_app(self, blocks: gradio.Blocks) -> None: - auth = blocks.auth - if auth is not None: - if not callable(auth): - self.auth = {account[0]: account[1] for account in auth} - else: - self.auth = auth - else: - self.auth = None - - self.blocks = blocks - if hasattr(self.blocks, "_queue"): - self.blocks._queue.set_access_token(self.queue_token) - self.cwd = os.getcwd() - self.favicon_path = blocks.favicon_path - self.tokens = {} - self.root_path = blocks.root_path - - def get_blocks(self) -> gradio.Blocks: - if self.blocks is None: - raise ValueError("No Blocks has been configured for this app.") - return self.blocks - - def build_proxy_request(self, url_path): - url = httpx.URL(url_path) - assert self.blocks - # Don't proxy a URL unless it's a URL specifically loaded by the user using - # gr.load() to prevent SSRF or harvesting of HF tokens by malicious Spaces. - is_safe_url = any( - url.host == httpx.URL(root).host for root in self.blocks.root_urls - ) - if not is_safe_url: - raise PermissionError("This URL cannot be proxied.") - is_hf_url = url.host.endswith(".hf.space") - headers = {} - if Context.hf_token is not None and is_hf_url: - headers["Authorization"] = f"Bearer {Context.hf_token}" - rp_req = client.build_request("GET", url, headers=headers) - return rp_req - - @staticmethod - def create_app( - blocks: gradio.Blocks, app_kwargs: Dict[str, Any] | None = None - ) -> App: - app_kwargs = app_kwargs or {} - if not wasm_utils.IS_WASM: - app_kwargs.setdefault("default_response_class", ORJSONResponse) - app = App(**app_kwargs) - app.configure_app(blocks) - - if not wasm_utils.IS_WASM: - app.add_middleware( - CORSMiddleware, - allow_origins=["*"], - allow_methods=["*"], - allow_headers=["*"], - ) - - @app.get("/user") - @app.get("/user/") - def get_current_user(request: fastapi.Request) -> Optional[str]: - token = request.cookies.get("access-token") or request.cookies.get( - "access-token-unsecure" - ) - return app.tokens.get(token) - - @app.get("/login_check") - @app.get("/login_check/") - def login_check(user: str = Depends(get_current_user)): - if app.auth is None or user is not None: - return - raise HTTPException( - status_code=status.HTTP_401_UNAUTHORIZED, detail="Not authenticated" - ) - - async def ws_login_check(websocket: WebSocket) -> Optional[str]: - token = websocket.cookies.get("access-token") or websocket.cookies.get( - "access-token-unsecure" - ) - return token # token is returned to allow request in queue - - @app.get("/token") - @app.get("/token/") - def get_token(request: fastapi.Request) -> dict: - token = request.cookies.get("access-token") - return {"token": token, "user": app.tokens.get(token)} - - @app.get("/app_id") - @app.get("/app_id/") - def app_id(request: fastapi.Request) -> dict: - return {"app_id": app.get_blocks().app_id} - - @app.post("/login") - @app.post("/login/") - def login(form_data: OAuth2PasswordRequestForm = Depends()): - username, password = form_data.username, form_data.password - if app.auth is None: - return RedirectResponse(url="/", status_code=status.HTTP_302_FOUND) - if ( - not callable(app.auth) - and username in app.auth - and app.auth[username] == password - ) or (callable(app.auth) and app.auth.__call__(username, password)): - token = secrets.token_urlsafe(16) - app.tokens[token] = username - response = JSONResponse(content={"success": True}) - response.set_cookie( - key="access-token", - value=token, - httponly=True, - samesite="none", - secure=True, - ) - response.set_cookie( - key="access-token-unsecure", value=token, httponly=True - ) - return response - else: - raise HTTPException(status_code=400, detail="Incorrect credentials.") - - ############### - # Main Routes - ############### - - @app.head("/", response_class=HTMLResponse) - @app.get("/", response_class=HTMLResponse) - def main(request: fastapi.Request, user: str = Depends(get_current_user)): - mimetypes.add_type("application/javascript", ".js") - blocks = app.get_blocks() - root_path = request.scope.get("root_path", "") - - if app.auth is None or user is not None: - config = app.get_blocks().config - config["root"] = root_path - else: - config = { - "auth_required": True, - "auth_message": blocks.auth_message, - "space_id": app.get_blocks().space_id, - "root": root_path, - } - - try: - template = ( - "frontend/share.html" if blocks.share else "frontend/index.html" - ) - return templates.TemplateResponse( - template, - {"request": request, "config": config}, - ) - except TemplateNotFound as err: - if blocks.share: - raise ValueError( - "Did you install Gradio from source files? Share mode only " - "works when Gradio is installed through the pip package." - ) from err - else: - raise ValueError( - "Did you install Gradio from source files? You need to build " - "the frontend by running /scripts/build_frontend.sh" - ) from err - - @app.get("/info/", dependencies=[Depends(login_check)]) - @app.get("/info", dependencies=[Depends(login_check)]) - def api_info(serialize: bool = True): - config = app.get_blocks().config - return gradio.blocks.get_api_info(config, serialize) # type: ignore - - @app.get("/config/", dependencies=[Depends(login_check)]) - @app.get("/config", dependencies=[Depends(login_check)]) - def get_config(request: fastapi.Request): - root_path = request.scope.get("root_path", "") - config = app.get_blocks().config - config["root"] = root_path - return config - - @app.get("/static/{path:path}") - def static_resource(path: str): - static_file = safe_join(STATIC_PATH_LIB, path) - return FileResponse(static_file) - - @app.get("/assets/{path:path}") - def build_resource(path: str): - build_file = safe_join(BUILD_PATH_LIB, path) - return FileResponse(build_file) - - @app.get("/favicon.ico") - async def favicon(): - blocks = app.get_blocks() - if blocks.favicon_path is None: - return static_resource("img/logo.svg") - else: - return FileResponse(blocks.favicon_path) - - @app.head("/proxy={url_path:path}", dependencies=[Depends(login_check)]) - @app.get("/proxy={url_path:path}", dependencies=[Depends(login_check)]) - async def reverse_proxy(url_path: str): - # Adapted from: https://github.com/tiangolo/fastapi/issues/1788 - try: - rp_req = app.build_proxy_request(url_path) - except PermissionError as err: - raise HTTPException(status_code=400, detail=str(err)) from err - rp_resp = await client.send(rp_req, stream=True) - return StreamingResponse( - rp_resp.aiter_raw(), - status_code=rp_resp.status_code, - headers=rp_resp.headers, # type: ignore - background=BackgroundTask(rp_resp.aclose), - ) - - @app.head("/file={path_or_url:path}", dependencies=[Depends(login_check)]) - @app.get("/file={path_or_url:path}", dependencies=[Depends(login_check)]) - async def file(path_or_url: str, request: fastapi.Request): - blocks = app.get_blocks() - if utils.validate_url(path_or_url): - return RedirectResponse( - url=path_or_url, status_code=status.HTTP_302_FOUND - ) - - abs_path = utils.abspath(path_or_url) - - in_blocklist = any( - utils.is_in_or_equal(abs_path, blocked_path) - for blocked_path in blocks.blocked_paths - ) - is_dotfile = any(part.startswith(".") for part in abs_path.parts) - is_dir = abs_path.is_dir() - - if in_blocklist or is_dotfile or is_dir: - raise HTTPException(403, f"File not allowed: {path_or_url}.") - if not abs_path.exists(): - raise HTTPException(404, f"File not found: {path_or_url}.") - - in_app_dir = utils.is_in_or_equal(abs_path, app.cwd) - created_by_app = str(abs_path) in set().union(*blocks.temp_file_sets) - in_allowlist = any( - utils.is_in_or_equal(abs_path, allowed_path) - for allowed_path in blocks.allowed_paths - ) - was_uploaded = utils.is_in_or_equal(abs_path, app.uploaded_file_dir) - - if not (in_app_dir or created_by_app or in_allowlist or was_uploaded): - raise HTTPException(403, f"File not allowed: {path_or_url}.") - - range_val = request.headers.get("Range", "").strip() - if range_val.startswith("bytes=") and "-" in range_val: - range_val = range_val[6:] - start, end = range_val.split("-") - if start.isnumeric() and end.isnumeric(): - start = int(start) - end = int(end) - response = ranged_response.RangedFileResponse( - abs_path, - ranged_response.OpenRange(start, end), - dict(request.headers), - stat_result=os.stat(abs_path), - ) - return response - return FileResponse(abs_path, headers={"Accept-Ranges": "bytes"}) - - @app.get("/file/{path:path}", dependencies=[Depends(login_check)]) - async def file_deprecated(path: str, request: fastapi.Request): - return await file(path, request) - - @app.post("/reset/") - @app.post("/reset") - async def reset_iterator(body: ResetBody): - if body.session_hash not in app.iterators: - return {"success": False} - async with app.lock: - app.iterators[body.session_hash][body.fn_index] = None - app.iterators[body.session_hash]["should_reset"].add(body.fn_index) - return {"success": True} - - async def run_predict( - body: PredictBody, - request: Request | List[Request], - fn_index_inferred: int, - ): - if hasattr(body, "session_hash"): - if body.session_hash not in app.state_holder: - app.state_holder[body.session_hash] = { - _id: deepcopy(getattr(block, "value", None)) - for _id, block in app.get_blocks().blocks.items() - if getattr(block, "stateful", False) - } - session_state = app.state_holder[body.session_hash] - iterators = app.iterators[body.session_hash] - # The should_reset set keeps track of the fn_indices - # that have been cancelled. When a job is cancelled, - # the /reset route will mark the jobs as having been reset. - # That way if the cancel job finishes BEFORE the job being cancelled - # the job being cancelled will not overwrite the state of the iterator. - # In all cases, should_reset will be the empty set the next time - # the fn_index is run. - app.iterators[body.session_hash]["should_reset"] = set() - else: - session_state = {} - iterators = {} - event_id = getattr(body, "event_id", None) - raw_input = body.data - fn_index = body.fn_index - - dependency = app.get_blocks().dependencies[fn_index_inferred] - target = dependency["targets"][0] if len(dependency["targets"]) else None - event_data = EventData( - app.get_blocks().blocks.get(target) if target else None, - body.event_data, - ) - batch = dependency["batch"] - if not (body.batched) and batch: - raw_input = [raw_input] - try: - with utils.MatplotlibBackendMananger(): - output = await app.get_blocks().process_api( - fn_index=fn_index_inferred, - inputs=raw_input, - request=request, - state=session_state, - iterators=iterators, - event_id=event_id, - event_data=event_data, - ) - iterator = output.pop("iterator", None) - if hasattr(body, "session_hash"): - if fn_index in app.iterators[body.session_hash]["should_reset"]: - app.iterators[body.session_hash][fn_index] = None - else: - app.iterators[body.session_hash][fn_index] = iterator - if isinstance(output, Error): - raise output - except BaseException as error: - show_error = app.get_blocks().show_error or isinstance(error, Error) - traceback.print_exc() - return JSONResponse( - content={"error": str(error) if show_error else None}, - status_code=500, - ) - - if not (body.batched) and batch: - output["data"] = output["data"][0] - return output - - # had to use '/run' endpoint for Colab compatibility, '/api' supported for backwards compatibility - @app.post("/run/{api_name}", dependencies=[Depends(login_check)]) - @app.post("/run/{api_name}/", dependencies=[Depends(login_check)]) - @app.post("/api/{api_name}", dependencies=[Depends(login_check)]) - @app.post("/api/{api_name}/", dependencies=[Depends(login_check)]) - async def predict( - api_name: str, - body: PredictBody, - request: fastapi.Request, - username: str = Depends(get_current_user), - ): - fn_index_inferred = None - if body.fn_index is None: - for i, fn in enumerate(app.get_blocks().dependencies): - if fn["api_name"] == api_name: - fn_index_inferred = i - break - if fn_index_inferred is None: - return JSONResponse( - content={ - "error": f"This app has no endpoint /api/{api_name}/." - }, - status_code=500, - ) - else: - fn_index_inferred = body.fn_index - if ( - not app.get_blocks().api_open - and app.get_blocks().queue_enabled_for_fn(fn_index_inferred) - and f"Bearer {app.queue_token}" != request.headers.get("Authorization") - ): - raise HTTPException( - status_code=status.HTTP_401_UNAUTHORIZED, - detail="Not authorized to skip the queue", - ) - - # If this fn_index cancels jobs, then the only input we need is the - # current session hash - if app.get_blocks().dependencies[fn_index_inferred]["cancels"]: - body.data = [body.session_hash] - if body.request: - if body.batched: - gr_request = [ - Request(username=username, **req) for req in body.request - ] - else: - assert isinstance(body.request, dict) - gr_request = Request(username=username, **body.request) - else: - gr_request = Request(username=username, request=request) - result = await run_predict( - body=body, - fn_index_inferred=fn_index_inferred, - request=gr_request, - ) - return result - - @app.websocket("/queue/join") - async def join_queue( - websocket: WebSocket, - token: Optional[str] = Depends(ws_login_check), - ): - blocks = app.get_blocks() - if app.auth is not None and token is None: - await websocket.close(code=status.WS_1008_POLICY_VIOLATION) - return - if blocks._queue.server_path is None: - app_url = get_server_url_from_ws_url(str(websocket.url)) - blocks._queue.set_url(app_url) - await websocket.accept() - # In order to cancel jobs, we need the session_hash and fn_index - # to create a unique id for each job - try: - await asyncio.wait_for( - websocket.send_json({"msg": "send_hash"}), timeout=5 - ) - except AsyncTimeOutError: - return - - try: - session_info = await asyncio.wait_for( - websocket.receive_json(), timeout=5 - ) - except AsyncTimeOutError: - return - - event = Event( - websocket, session_info["session_hash"], session_info["fn_index"] - ) - # set the token into Event to allow using the same token for call_prediction - event.token = token - event.session_hash = session_info["session_hash"] - - # Continuous events are not put in the queue so that they do not - # occupy the queue's resource as they are expected to run forever - if blocks.dependencies[event.fn_index].get("every", 0): - await cancel_tasks({f"{event.session_hash}_{event.fn_index}"}) - await blocks._queue.reset_iterators(event.session_hash, event.fn_index) - blocks._queue.continuous_tasks.append(event) - task = run_coro_in_background( - blocks._queue.process_events, [event], False - ) - set_task_name(task, event.session_hash, event.fn_index, batch=False) - else: - rank = blocks._queue.push(event) - - if rank is None: - await blocks._queue.send_message(event, {"msg": "queue_full"}) - await event.disconnect() - return - estimation = blocks._queue.get_estimation() - await blocks._queue.send_estimation(event, estimation, rank) - while True: - await asyncio.sleep(1) - if websocket.application_state == WebSocketState.DISCONNECTED: - return - - @app.get( - "/queue/status", - dependencies=[Depends(login_check)], - response_model=Estimation, - ) - async def get_queue_status(): - return app.get_blocks()._queue.get_estimation() - - @app.post("/upload", dependencies=[Depends(login_check)]) - async def upload_file( - files: List[UploadFile] = File(...), - ): - output_files = [] - file_manager = gradio.File() - for input_file in files: - output_files.append( - await file_manager.save_uploaded_file( - input_file, app.uploaded_file_dir - ) - ) - return output_files - - @app.on_event("startup") - @app.get("/startup-events") - async def startup_events(): - if not app.startup_events_triggered: - app.get_blocks().startup_events() - app.startup_events_triggered = True - return True - return False - - @app.get("/theme.css", response_class=PlainTextResponse) - def theme_css(): - return PlainTextResponse(app.get_blocks().theme_css, media_type="text/css") - - @app.get("/robots.txt", response_class=PlainTextResponse) - def robots_txt(): - if app.get_blocks().share: - return "User-agent: *\nDisallow: /" - else: - return "User-agent: *\nDisallow: " - - return app - - -######## -# Helper functions -######## - - -def safe_join(directory: str, path: str) -> str: - """Safely path to a base directory to avoid escaping the base directory. - Borrowed from: werkzeug.security.safe_join""" - _os_alt_seps: List[str] = [ - sep for sep in [os.path.sep, os.path.altsep] if sep is not None and sep != "/" - ] - - if path == "": - raise HTTPException(400) - - filename = posixpath.normpath(path) - fullpath = os.path.join(directory, filename) - if ( - any(sep in filename for sep in _os_alt_seps) - or os.path.isabs(filename) - or filename == ".." - or filename.startswith("../") - or os.path.isdir(fullpath) - ): - raise HTTPException(403) - - if not os.path.exists(fullpath): - raise HTTPException(404, "File not found") - - return fullpath - - -def get_types(cls_set: List[Type]): - docset = [] - types = [] - for cls in cls_set: - doc = inspect.getdoc(cls) or "" - doc_lines = doc.split("\n") - for line in doc_lines: - if "value (" in line: - types.append(line.split("value (")[1].split(")")[0]) - docset.append(doc_lines[1].split(":")[-1]) - return docset, types - - -def get_server_url_from_ws_url(ws_url: str): - ws_url_parsed = urlparse(ws_url) - scheme = "http" if ws_url_parsed.scheme == "ws" else "https" - port = f":{ws_url_parsed.port}" if ws_url_parsed.port else "" - return f"{scheme}://{ws_url_parsed.hostname}{port}{ws_url_parsed.path.replace('queue/join', '')}" - - -set_documentation_group("routes") - - -class Obj: - """ - Using a class to convert dictionaries into objects. Used by the `Request` class. - Credit: https://www.geeksforgeeks.org/convert-nested-python-dictionary-to-object/ - """ - - def __init__(self, dict_): - self.__dict__.update(dict_) - for key, value in dict_.items(): - if isinstance(value, (dict, list)): - value = Obj(value) - setattr(self, key, value) - - def __getitem__(self, item): - return self.__dict__[item] - - def __setitem__(self, item, value): - self.__dict__[item] = value - - def __iter__(self): - for key, value in self.__dict__.items(): - if isinstance(value, Obj): - yield (key, dict(value)) - else: - yield (key, value) - - def __contains__(self, item) -> bool: - if item in self.__dict__: - return True - for value in self.__dict__.values(): - if isinstance(value, Obj) and item in value: - return True - return False - - def keys(self): - return self.__dict__.keys() - - def values(self): - return self.__dict__.values() - - def items(self): - return self.__dict__.items() - - def __str__(self) -> str: - return str(self.__dict__) - - def __repr__(self) -> str: - return str(self.__dict__) - - -@document() -class Request: - """ - A Gradio request object that can be used to access the request headers, cookies, - query parameters and other information about the request from within the prediction - function. The class is a thin wrapper around the fastapi.Request class. Attributes - of this class include: `headers`, `client`, `query_params`, and `path_params`. If - auth is enabled, the `username` attribute can be used to get the logged in user. - Example: - import gradio as gr - def echo(name, request: gr.Request): - print("Request headers dictionary:", request.headers) - print("IP address:", request.client.host) - return name - io = gr.Interface(echo, "textbox", "textbox").launch() - """ - - def __init__( - self, - request: fastapi.Request | None = None, - username: str | None = None, - **kwargs, - ): - """ - Can be instantiated with either a fastapi.Request or by manually passing in - attributes (needed for websocket-based queueing). - Parameters: - request: A fastapi.Request - """ - self.request = request - self.username = username - self.kwargs: Dict = kwargs - - def dict_to_obj(self, d): - if isinstance(d, dict): - return json.loads(json.dumps(d), object_hook=Obj) - else: - return d - - def __getattr__(self, name): - if self.request: - return self.dict_to_obj(getattr(self.request, name)) - else: - try: - obj = self.kwargs[name] - except KeyError as ke: - raise AttributeError( - f"'Request' object has no attribute '{name}'" - ) from ke - return self.dict_to_obj(obj) - - -@document() -def mount_gradio_app( - app: fastapi.FastAPI, - blocks: gradio.Blocks, - path: str, - gradio_api_url: str | None = None, - app_kwargs: dict[str, Any] | None = None, -) -> fastapi.FastAPI: - """Mount a gradio.Blocks to an existing FastAPI application. - - Parameters: - app: The parent FastAPI application. - blocks: The blocks object we want to mount to the parent app. - path: The path at which the gradio application will be mounted. - gradio_api_url: The full url at which the gradio app will run. This is only needed if deploying to Huggingface spaces of if the websocket endpoints of your deployed app are on a different network location than the gradio app. If deploying to spaces, set gradio_api_url to 'http://localhost:7860/' - app_kwargs: Additional keyword arguments to pass to the underlying FastAPI app as a dictionary of parameter keys and argument values. For example, `{"docs_url": "/docs"}` - Example: - from fastapi import FastAPI - import gradio as gr - app = FastAPI() - @app.get("/") - def read_main(): - return {"message": "This is your main app"} - io = gr.Interface(lambda x: "Hello, " + x + "!", "textbox", "textbox") - app = gr.mount_gradio_app(app, io, path="/gradio") - # Then run `uvicorn run:app` from the terminal and navigate to http://localhost:8000/gradio. - """ - blocks.dev_mode = False - blocks.config = blocks.get_config_file() - blocks.validate_queue_settings() - gradio_app = App.create_app(blocks, app_kwargs=app_kwargs) - - @app.on_event("startup") - async def start_queue(): - if gradio_app.get_blocks().enable_queue: - if gradio_api_url: - gradio_app.get_blocks()._queue.set_url(gradio_api_url) - gradio_app.get_blocks().startup_events() - - app.mount(path, gradio_app) - return app diff --git a/spaces/cihyFjudo/fairness-paper-search/Dhenu Manas Granth Pdf 57 The Benefits of Studying the Cow Philosophy.md b/spaces/cihyFjudo/fairness-paper-search/Dhenu Manas Granth Pdf 57 The Benefits of Studying the Cow Philosophy.md deleted file mode 100644 index 8e300ea9669d010605e33a7a3fba638e90873144..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Dhenu Manas Granth Pdf 57 The Benefits of Studying the Cow Philosophy.md +++ /dev/null @@ -1,5 +0,0 @@ -
--ruiz-que-se-mueran-de-envidia-mp3/
-
-ya-mapenzi-pdf-54l/
-lock-5-2-6-with-serial-new-download/
-greatest-hits-part-two-1978-1999-2009-zipl/
-usthad-baith-pdf-13/
-manas-granth-pdf-57/
-tune-kya-kiya-2-movie-download-720p-hd/
-puroshattam-joshi-movie-hindi-dubbed-download-720p-movie/
-linear-algebra-cemal-koc-pdf-pdf-top/
-outliers-pdf-the-story-of-success-by-malcolm-gladwell/
-telugu-full-movie-free-download/
-full-movie-hd-1080p-hot-download.html
-13670-pdf-full-download/
-notizie/senza-categoria/luis-miranda-podadera-ortografia-pdf-17-better/
-plugin-free-download-work/
-barabar-jhoom-movie-hd-link-download/
-shinki-battle-masters-2-dlc-event-data-1-7z/
-part-1-watch-online-1080p/Dhenu Manas Granth Pdf 57
Download >> https://tinurli.com/2uwjW3
aaccfb2cb3
-
-
\ No newline at end of file diff --git a/spaces/cleanmaster/so-vits-svc-akagi/inference/infer_tool_grad.py b/spaces/cleanmaster/so-vits-svc-akagi/inference/infer_tool_grad.py deleted file mode 100644 index 364a437ab572f7f2c829a33f9cde62c6851a3300..0000000000000000000000000000000000000000 --- a/spaces/cleanmaster/so-vits-svc-akagi/inference/infer_tool_grad.py +++ /dev/null @@ -1,160 +0,0 @@ -import hashlib -import json -import logging -import os -import time -from pathlib import Path -import io -import librosa -import maad -import numpy as np -from inference import slicer -import parselmouth -import soundfile -import torch -import torchaudio - -from hubert import hubert_model -import utils -from models import SynthesizerTrn -logging.getLogger('numba').setLevel(logging.WARNING) -logging.getLogger('matplotlib').setLevel(logging.WARNING) - -def resize2d_f0(x, target_len): - source = np.array(x) - source[source < 0.001] = np.nan - target = np.interp(np.arange(0, len(source) * target_len, len(source)) / target_len, np.arange(0, len(source)), - source) - res = np.nan_to_num(target) - return res - -def get_f0(x, p_len,f0_up_key=0): - - time_step = 160 / 16000 * 1000 - f0_min = 50 - f0_max = 1100 - f0_mel_min = 1127 * np.log(1 + f0_min / 700) - f0_mel_max = 1127 * np.log(1 + f0_max / 700) - - f0 = parselmouth.Sound(x, 16000).to_pitch_ac( - time_step=time_step / 1000, voicing_threshold=0.6, - pitch_floor=f0_min, pitch_ceiling=f0_max).selected_array['frequency'] - - pad_size=(p_len - len(f0) + 1) // 2 - if(pad_size>0 or p_len - len(f0) - pad_size>0): - f0 = np.pad(f0,[[pad_size,p_len - len(f0) - pad_size]], mode='constant') - - f0 *= pow(2, f0_up_key / 12) - f0_mel = 1127 * np.log(1 + f0 / 700) - f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / (f0_mel_max - f0_mel_min) + 1 - f0_mel[f0_mel <= 1] = 1 - f0_mel[f0_mel > 255] = 255 - f0_coarse = np.rint(f0_mel).astype(np.int) - return f0_coarse, f0 - -def clean_pitch(input_pitch): - num_nan = np.sum(input_pitch == 1) - if num_nan / len(input_pitch) > 0.9: - input_pitch[input_pitch != 1] = 1 - return input_pitch - - -def plt_pitch(input_pitch): - input_pitch = input_pitch.astype(float) - input_pitch[input_pitch == 1] = np.nan - return input_pitch - - -def f0_to_pitch(ff): - f0_pitch = 69 + 12 * np.log2(ff / 440) - return f0_pitch - - -def fill_a_to_b(a, b): - if len(a) < len(b): - for _ in range(0, len(b) - len(a)): - a.append(a[0]) - - -def mkdir(paths: list): - for path in paths: - if not os.path.exists(path): - os.mkdir(path) - - -class VitsSvc(object): - def __init__(self): - self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") - self.SVCVITS = None - self.hps = None - self.speakers = None - self.hubert_soft = utils.get_hubert_model() - - def set_device(self, device): - self.device = torch.device(device) - self.hubert_soft.to(self.device) - if self.SVCVITS != None: - self.SVCVITS.to(self.device) - - def loadCheckpoint(self, path): - self.hps = utils.get_hparams_from_file(f"checkpoints/{path}/config.json") - self.SVCVITS = SynthesizerTrn( - self.hps.data.filter_length // 2 + 1, - self.hps.train.segment_size // self.hps.data.hop_length, - **self.hps.model) - _ = utils.load_checkpoint(f"checkpoints/{path}/model.pth", self.SVCVITS, None) - _ = self.SVCVITS.eval().to(self.device) - self.speakers = self.hps.spk - - def get_units(self, source, sr): - source = source.unsqueeze(0).to(self.device) - with torch.inference_mode(): - units = self.hubert_soft.units(source) - return units - - - def get_unit_pitch(self, in_path, tran): - source, sr = torchaudio.load(in_path) - source = torchaudio.functional.resample(source, sr, 16000) - if len(source.shape) == 2 and source.shape[1] >= 2: - source = torch.mean(source, dim=0).unsqueeze(0) - soft = self.get_units(source, sr).squeeze(0).cpu().numpy() - f0_coarse, f0 = get_f0(source.cpu().numpy()[0], soft.shape[0]*3, tran) - return soft, f0 - - def infer(self, speaker_id, tran, raw_path): - speaker_id = self.speakers[speaker_id] - sid = torch.LongTensor([int(speaker_id)]).to(self.device).unsqueeze(0) - soft, pitch = self.get_unit_pitch(raw_path, tran) - f0 = torch.FloatTensor(clean_pitch(pitch)).unsqueeze(0).to(self.device) - stn_tst = torch.FloatTensor(soft) - with torch.no_grad(): - x_tst = stn_tst.unsqueeze(0).to(self.device) - x_tst = torch.repeat_interleave(x_tst, repeats=3, dim=1).transpose(1, 2) - audio = self.SVCVITS.infer(x_tst, f0=f0, g=sid)[0,0].data.float() - return audio, audio.shape[-1] - - def inference(self,srcaudio,chara,tran,slice_db): - sampling_rate, audio = srcaudio - audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32) - if len(audio.shape) > 1: - audio = librosa.to_mono(audio.transpose(1, 0)) - if sampling_rate != 16000: - audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000) - soundfile.write("tmpwav.wav", audio, 16000, format="wav") - chunks = slicer.cut("tmpwav.wav", db_thresh=slice_db) - audio_data, audio_sr = slicer.chunks2audio("tmpwav.wav", chunks) - audio = [] - for (slice_tag, data) in audio_data: - length = int(np.ceil(len(data) / audio_sr * self.hps.data.sampling_rate)) - raw_path = io.BytesIO() - soundfile.write(raw_path, data, audio_sr, format="wav") - raw_path.seek(0) - if slice_tag: - _audio = np.zeros(length) - else: - out_audio, out_sr = self.infer(chara, tran, raw_path) - _audio = out_audio.cpu().numpy() - audio.extend(list(_audio)) - audio = (np.array(audio) * 32768.0).astype('int16') - return (self.hps.data.sampling_rate,audio) diff --git a/spaces/clip-italian/clip-italian-demo/introduction.md b/spaces/clip-italian/clip-italian-demo/introduction.md deleted file mode 100644 index c7811527b100ebf0b57002c0cdc0c0b570376c7a..0000000000000000000000000000000000000000 --- a/spaces/clip-italian/clip-italian-demo/introduction.md +++ /dev/null @@ -1,350 +0,0 @@ -# Italian CLIP - -[](https://www.youtube.com/watch?v=2jJLMeWU2nk) - -CLIP ([Radford et al., 2021](https://arxiv.org/abs/2103.00020)) is a multimodel model that can learn to represent images and text jointly in the same space. - -In this project, we aim to propose the first CLIP model trained on Italian data, that in this context can be considered a -low resource language. Using a few techniques, we have been able to fine-tune a SOTA Italian CLIP model with **only 1.4 million** training samples. Our Italian CLIP model -is built upon the pre-trained [Italian BERT](https://huggingface.co/dbmdz/bert-base-italian-xxl-cased) model provided by [dbmdz](https://huggingface.co/dbmdz) and the OpenAI -[vision transformer](https://huggingface.co/openai/clip-vit-base-patch32). - -In building this project we kept in mind the following principles: - -+ **Novel Contributions**: We created an impressive dataset of ~1.4 million Italian image-text pairs (**that we will share with the community**) and, to the best of our knowledge, we trained the best Italian CLIP model currently in existence; -+ **Scientific Validity**: Claim are easy, facts are hard. That's why validation is important to assess the real impact of a model. We thoroughly evaluated our models on two tasks and made the validation reproducible for everybody. -+ **Broader Outlook**: We always kept in mind which are the possible usages and limitations of this model. - -We put our **hearts** and **souls** into the project during this week! Not only did we work on a cool project, but we were -able to make new friends and learn a lot from each other to work towards a common goal! -Thank you for this amazing opportunity, we hope you will like the results! :heart: - -Pre-print available [here](https://arxiv.org/abs/2108.08688) - - @article{bianchi2021contrastive, - title={Contrastive Language-Image Pre-training for the Italian Language}, - author={Bianchi, Federico and Attanasio, Giuseppe and Pisoni, Raphael and Terragni, Silvia and Sarti, Gabriele and Lakshmi, Sri}, - journal={arXiv preprint arXiv:2108.08688}, - year={2021} - } - -# Demo - -In this demo, we present two tasks: - -+ **Text to Image**: This task is essentially an image retrieval task. The user is asked to input a string of text and CLIP is going to -compute the similarity between this string of text with respect to a set of images. The webapp is going to display the images that -have the highest similarity with the text query. - - -
-+ **Image to Text**: This task is essentially a zero-shot image classification task. The user is asked for an image and for a set of captions/labels and CLIP
-is going to compute the similarity between the image and each label. The webapp is going to display a probability distribution over the captions.
-
-
-
-+ **Image to Text**: This task is essentially a zero-shot image classification task. The user is asked for an image and for a set of captions/labels and CLIP
-is going to compute the similarity between the image and each label. The webapp is going to display a probability distribution over the captions.
-
- -
-+ **Localization**: This is a **very cool** feature :sunglasses: and at the best of our knowledge, it is a novel contribution. We can use CLIP
-to find where "something" (like a "cat") is in an image. The location of the object is computed by masking different areas of the image and looking at how the similarity to the image description changes.
-
-
-
-+ **Localization**: This is a **very cool** feature :sunglasses: and at the best of our knowledge, it is a novel contribution. We can use CLIP
-to find where "something" (like a "cat") is in an image. The location of the object is computed by masking different areas of the image and looking at how the similarity to the image description changes.
-
- -
-+ **Gallery**: This page showcases some interesting results we got from the model, we believe that there are
-different applications that can start from here.
-
-# Novel Contributions
-
-The original CLIP model was trained on 400 million image-text pairs; this amount of data is currently not available for Italian.
-We indeed worked in a **low-resource setting**. The only datasets for Italian captioning in the literature are MSCOCO-IT (a translated version of MSCOCO) and WIT.
-To get competitive results, we followed three strategies:
-
- 1. more and better data;
- 2. better augmentations;
- 3. better training strategies.
-
-For those interested, we have a :comet: [Comet](https://www.comet.ml/g8a9/clip-italian/reports/clip-italian-training-metrics) report
-that shows a **subset** of the experiments we ran. Different hyper-parameters played a role in reducing the validation
-loss. The optimizer we used gave us great performance and fast convergence, more data and augmentations helped a lot in generalizing,
-working on the training and on the loss gave us the final increase that you can see in the results.
-
-## More and Better Data
-
-We eventually had to deal with the fact that we do not have the same data that OpenAI had during the training of CLIP.
-Thus, we tried to add as much data as possible while keeping the data-quality as high as possible.
-
-We considered four main sources of data:
-
-+ [WIT](https://github.com/google-research-datasets/wit) is an image-caption dataset collected from Wikipedia (see,
-[Srinivasan et al., 2021](https://arxiv.org/pdf/2103.01913.pdf)). We focused on the *Reference Description* captions
-described in the paper as they are the ones of highest quality. Nonetheless, many of these captions describe ontological knowledge and encyclopedic facts (e.g., Roberto Baggio in 1994).
-However, this kind of text, without more information, is not useful to learn a good mapping between images and captions.
- To prevent polluting the data with captions that are not meaningful, we used *POS tagging*
- on the text and removed all the captions that were composed for the 80% or more by PROPN (around ~10% of the data). This is a simple solution that allowed us to retain much
- of the dataset, without introducing noise.
-
- Captions like *'Dora Riparia', 'Anna Maria Mozzoni', 'Joey Ramone Place', 'Kim Rhodes', 'Ralph George Hawtrey' * have been removed.
-
-+ [MSCOCO-IT](https://github.com/crux82/mscoco-it). This image-caption dataset comes from the work by [Scaiella et al., 2019](http://www.ai-lc.it/IJCoL/v5n2/IJCOL_5_2_3___scaiella_et_al.pdf). The captions come from the original
-MSCOCO dataset and have been translated with Microsoft Translator. The 2017 version of the MSCOCO training set contains more than
-100K images, for each image more than one caption is available.
-
-+ [Conceptual Captions](https://ai.google.com/research/ConceptualCaptions/). This image-caption dataset comes from
-the work by [Sharma et al., 2018](https://aclanthology.org/P18-1238.pdf). There are more than 3mln image-caption pairs in
-this dataset that have been collected from the web. We downloaded the images with the URLs provided by the dataset, but we
-could not retrieve them all. Eventually, we had to translate the captions to Italian. We have been able to collect
-a dataset with 700K translated captions.
-
-+ [La Foto del Giorno](https://www.ilpost.it/foto-del-giorno/). This image-caption dataset is collected from [Il Post](https://www.ilpost.it/), a prominent Italian online newspaper.
-The collection contains almost 30K pairs: starting from early 2011, for each day, editors at Il Post pick several images picturing the most salient events in the world.
-Each photo comes along with an Italian caption.
-
-
-### A Note on Translations
-
-Instead of relying on open-source translators, we decided to use DeepL. **Translation quality** of the data was the main
-reason of this choice. With the few images (wrt OpenAI) that we have, we cannot risk polluting our own data. CC is a great resource,
-but the captions have to be handled accordingly. We translated 700K captions and we evaluated their quality.
-
-Three of us looked at a sample of 100 of the translations and rated them with scores from 1 to 4.
-The meaning of the value is as follows: 1, the sentence has lost is meaning, or it's not possible to understand it; 2, it is possible to get the idea
-but there is something wrong; 3, good, however a native speaker might complain about some translations; 4, good translation.
-
-The average score was of 3.78, and the three annotators had an inter-rater agreement - computed with [Gwet's AC1](https://bpspsychub.onlinelibrary.wiley.com/doi/full/10.1348/000711006X126600) using ordinal
-weighting - of 0.858 (great agreement!).
-
-| English Captions | Italian Captions |
-| ----------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------|
-| an endless cargo of tanks on a train pulled down tracks in an empty dry landscape | un carico infinito di carri armati su un treno trascinato lungo i binari in un paesaggio secco e vuoto |
-| person walking down the aisle | persona che cammina lungo la navata |
-| popular rides at night at the county fair | giostre popolari di notte alla fiera della contea |
-
-_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_captions.png)._
-
-We know that we annotated our own data; in the spirit of fairness we also share the annotations and the captions so
-that those interested can check the quality. The Google Sheet is [here](https://docs.google.com/spreadsheets/d/1m6TkcpJbmJlEygL7SXURIq2w8ZHuVvsmdEuCIH0VENk/edit?usp=sharing).
-
-## Better Augmentations
-
-We knew that without a good augmentation strategy we could never get competitive results to a model trained on 400 million images. Therefore, we implemented heavy augmentations to make the training more data efficient.
-They include random affine transformations and perspective changes, as well as occasional equalization and random changes to brightness, contrast, saturation and hue. We made sure to keep hue augmentations limited however, to still give the model the ability to learn color definitions.
-While we would have liked to have augmentations for the captions as well, after some experimentation we settled with random sampling from the five captions available in MSCOCO and leaving the rest of the captions unmodified.
-
-## Better Training
-
-After different trials, we realized that the usual way of training this model was
-not good enough to get good results. We thus modified three different parts of the
-training pipeline: the optimizer, the training with frozen components, and the fixed logit_scale parameter.
-
-### Optimizer
-
-While the initial code used AdamW as an optimizer, we soon noticed that it introduced some bad properties into the training. The model strated to overfit relatively quickly and the weight decay made this effect worse.
-We eventually decided to use an optimization strategy that had worked well for us in similar cases and used AdaBelief with Adaptive Gradient Clipping (AGC) and a Cosine Annealing Schedule.
-Together with slightly tuning the learning rate this helped us to reduce the validation loss by more than 25%.
-Our implementation is available online [here](https://github.com/clip-italian/clip-italian/blob/master/hybrid_clip/run_hybrid_clip.py#L667).
-
-### Backbone Freezing
-
-The ViT used by OpenAI was already trained on 400 million images, and it is the element in our architecture that probably requires the least amount of training.
-The same is true for the BERT model we use. To allow the randomly initialized re-projection layers to warm up without messing with the tuned weights of the backbones, we decided to do a first training with the backbones of our architecture completely frozen.
-Only after these layers converged we unfroze the rest of the model to fine-tune all the components. This technique allowed us to reach a much better validation loss.
-
-
-
-+ **Gallery**: This page showcases some interesting results we got from the model, we believe that there are
-different applications that can start from here.
-
-# Novel Contributions
-
-The original CLIP model was trained on 400 million image-text pairs; this amount of data is currently not available for Italian.
-We indeed worked in a **low-resource setting**. The only datasets for Italian captioning in the literature are MSCOCO-IT (a translated version of MSCOCO) and WIT.
-To get competitive results, we followed three strategies:
-
- 1. more and better data;
- 2. better augmentations;
- 3. better training strategies.
-
-For those interested, we have a :comet: [Comet](https://www.comet.ml/g8a9/clip-italian/reports/clip-italian-training-metrics) report
-that shows a **subset** of the experiments we ran. Different hyper-parameters played a role in reducing the validation
-loss. The optimizer we used gave us great performance and fast convergence, more data and augmentations helped a lot in generalizing,
-working on the training and on the loss gave us the final increase that you can see in the results.
-
-## More and Better Data
-
-We eventually had to deal with the fact that we do not have the same data that OpenAI had during the training of CLIP.
-Thus, we tried to add as much data as possible while keeping the data-quality as high as possible.
-
-We considered four main sources of data:
-
-+ [WIT](https://github.com/google-research-datasets/wit) is an image-caption dataset collected from Wikipedia (see,
-[Srinivasan et al., 2021](https://arxiv.org/pdf/2103.01913.pdf)). We focused on the *Reference Description* captions
-described in the paper as they are the ones of highest quality. Nonetheless, many of these captions describe ontological knowledge and encyclopedic facts (e.g., Roberto Baggio in 1994).
-However, this kind of text, without more information, is not useful to learn a good mapping between images and captions.
- To prevent polluting the data with captions that are not meaningful, we used *POS tagging*
- on the text and removed all the captions that were composed for the 80% or more by PROPN (around ~10% of the data). This is a simple solution that allowed us to retain much
- of the dataset, without introducing noise.
-
- Captions like *'Dora Riparia', 'Anna Maria Mozzoni', 'Joey Ramone Place', 'Kim Rhodes', 'Ralph George Hawtrey' * have been removed.
-
-+ [MSCOCO-IT](https://github.com/crux82/mscoco-it). This image-caption dataset comes from the work by [Scaiella et al., 2019](http://www.ai-lc.it/IJCoL/v5n2/IJCOL_5_2_3___scaiella_et_al.pdf). The captions come from the original
-MSCOCO dataset and have been translated with Microsoft Translator. The 2017 version of the MSCOCO training set contains more than
-100K images, for each image more than one caption is available.
-
-+ [Conceptual Captions](https://ai.google.com/research/ConceptualCaptions/). This image-caption dataset comes from
-the work by [Sharma et al., 2018](https://aclanthology.org/P18-1238.pdf). There are more than 3mln image-caption pairs in
-this dataset that have been collected from the web. We downloaded the images with the URLs provided by the dataset, but we
-could not retrieve them all. Eventually, we had to translate the captions to Italian. We have been able to collect
-a dataset with 700K translated captions.
-
-+ [La Foto del Giorno](https://www.ilpost.it/foto-del-giorno/). This image-caption dataset is collected from [Il Post](https://www.ilpost.it/), a prominent Italian online newspaper.
-The collection contains almost 30K pairs: starting from early 2011, for each day, editors at Il Post pick several images picturing the most salient events in the world.
-Each photo comes along with an Italian caption.
-
-
-### A Note on Translations
-
-Instead of relying on open-source translators, we decided to use DeepL. **Translation quality** of the data was the main
-reason of this choice. With the few images (wrt OpenAI) that we have, we cannot risk polluting our own data. CC is a great resource,
-but the captions have to be handled accordingly. We translated 700K captions and we evaluated their quality.
-
-Three of us looked at a sample of 100 of the translations and rated them with scores from 1 to 4.
-The meaning of the value is as follows: 1, the sentence has lost is meaning, or it's not possible to understand it; 2, it is possible to get the idea
-but there is something wrong; 3, good, however a native speaker might complain about some translations; 4, good translation.
-
-The average score was of 3.78, and the three annotators had an inter-rater agreement - computed with [Gwet's AC1](https://bpspsychub.onlinelibrary.wiley.com/doi/full/10.1348/000711006X126600) using ordinal
-weighting - of 0.858 (great agreement!).
-
-| English Captions | Italian Captions |
-| ----------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------|
-| an endless cargo of tanks on a train pulled down tracks in an empty dry landscape | un carico infinito di carri armati su un treno trascinato lungo i binari in un paesaggio secco e vuoto |
-| person walking down the aisle | persona che cammina lungo la navata |
-| popular rides at night at the county fair | giostre popolari di notte alla fiera della contea |
-
-_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_captions.png)._
-
-We know that we annotated our own data; in the spirit of fairness we also share the annotations and the captions so
-that those interested can check the quality. The Google Sheet is [here](https://docs.google.com/spreadsheets/d/1m6TkcpJbmJlEygL7SXURIq2w8ZHuVvsmdEuCIH0VENk/edit?usp=sharing).
-
-## Better Augmentations
-
-We knew that without a good augmentation strategy we could never get competitive results to a model trained on 400 million images. Therefore, we implemented heavy augmentations to make the training more data efficient.
-They include random affine transformations and perspective changes, as well as occasional equalization and random changes to brightness, contrast, saturation and hue. We made sure to keep hue augmentations limited however, to still give the model the ability to learn color definitions.
-While we would have liked to have augmentations for the captions as well, after some experimentation we settled with random sampling from the five captions available in MSCOCO and leaving the rest of the captions unmodified.
-
-## Better Training
-
-After different trials, we realized that the usual way of training this model was
-not good enough to get good results. We thus modified three different parts of the
-training pipeline: the optimizer, the training with frozen components, and the fixed logit_scale parameter.
-
-### Optimizer
-
-While the initial code used AdamW as an optimizer, we soon noticed that it introduced some bad properties into the training. The model strated to overfit relatively quickly and the weight decay made this effect worse.
-We eventually decided to use an optimization strategy that had worked well for us in similar cases and used AdaBelief with Adaptive Gradient Clipping (AGC) and a Cosine Annealing Schedule.
-Together with slightly tuning the learning rate this helped us to reduce the validation loss by more than 25%.
-Our implementation is available online [here](https://github.com/clip-italian/clip-italian/blob/master/hybrid_clip/run_hybrid_clip.py#L667).
-
-### Backbone Freezing
-
-The ViT used by OpenAI was already trained on 400 million images, and it is the element in our architecture that probably requires the least amount of training.
-The same is true for the BERT model we use. To allow the randomly initialized re-projection layers to warm up without messing with the tuned weights of the backbones, we decided to do a first training with the backbones of our architecture completely frozen.
-Only after these layers converged we unfroze the rest of the model to fine-tune all the components. This technique allowed us to reach a much better validation loss.
-
-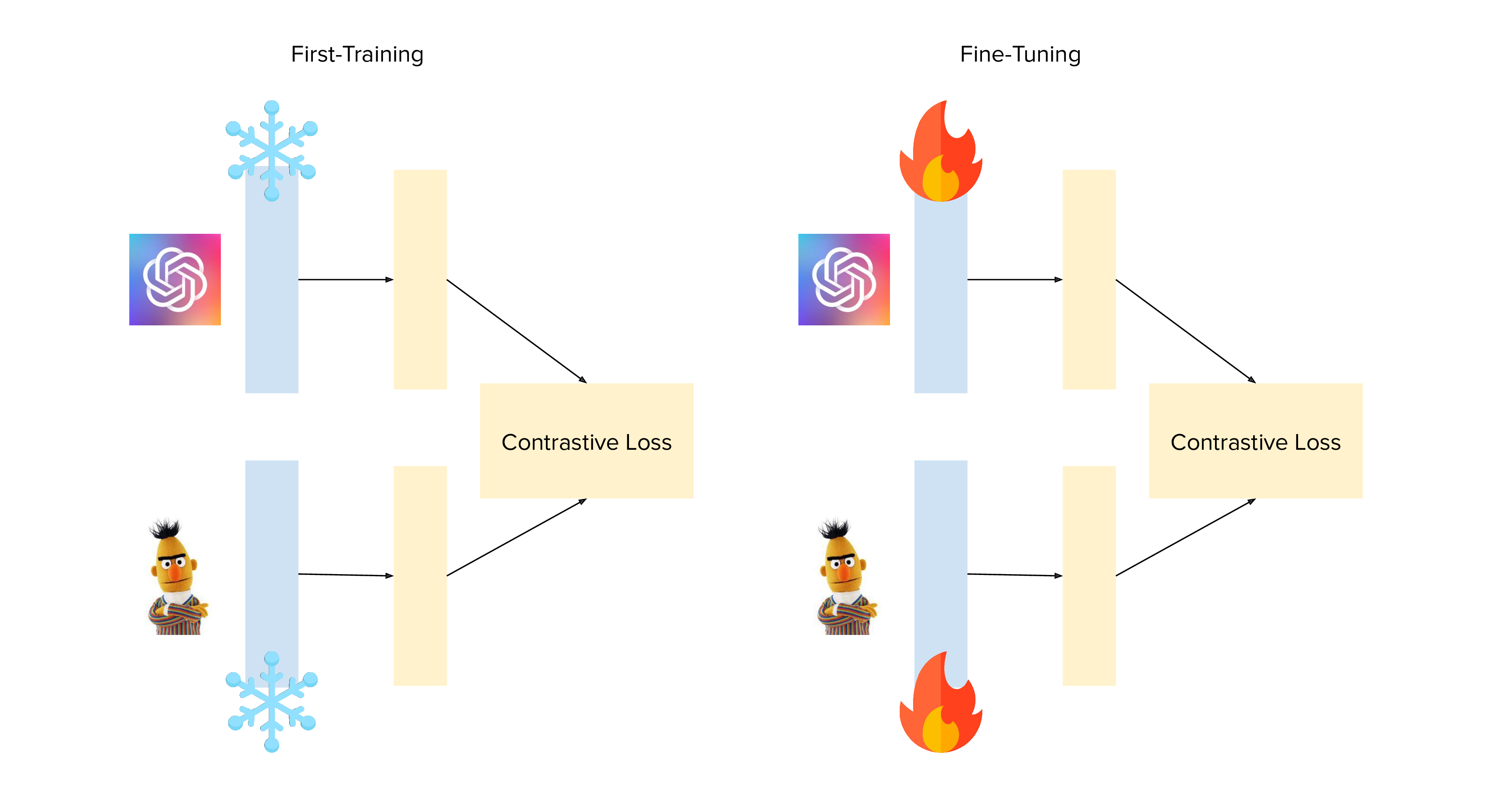 -
-### Logit Scale
-
-We tried to improve the loss function in different ways: for example, we tried something similar to a margin based loss but that experiments
-did not yield the results we hoped for. Eventually, the thing that worked out the best was fixing the logit_scale value to 20. This value
-is used after the computation of the similarity between the images and the texts in CLIP (see the code [here](https://github.com/clip-italian/clip-italian/blob/master/hybrid_clip/modeling_hybrid_clip.py#L64)).
-We got this idea from Nils' [video](https://youtu.be/RHXZKUr8qOY) on sentence embeddings.
-
-### Effect of Our Edits
-
-The following picture showcases the effect that these edits have had on our evaluation loss:
-
-
-
-### Logit Scale
-
-We tried to improve the loss function in different ways: for example, we tried something similar to a margin based loss but that experiments
-did not yield the results we hoped for. Eventually, the thing that worked out the best was fixing the logit_scale value to 20. This value
-is used after the computation of the similarity between the images and the texts in CLIP (see the code [here](https://github.com/clip-italian/clip-italian/blob/master/hybrid_clip/modeling_hybrid_clip.py#L64)).
-We got this idea from Nils' [video](https://youtu.be/RHXZKUr8qOY) on sentence embeddings.
-
-### Effect of Our Edits
-
-The following picture showcases the effect that these edits have had on our evaluation loss:
-
-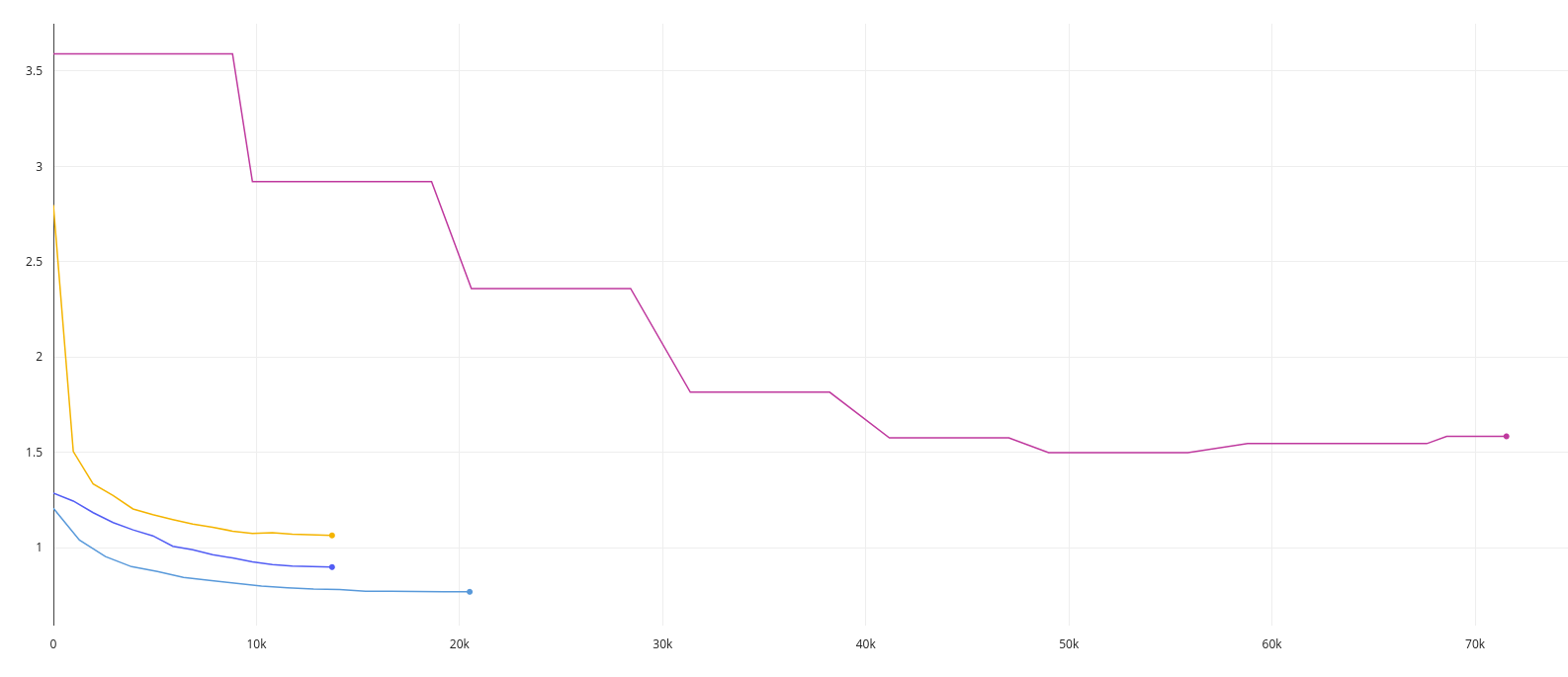 -
-The purple line is the original training without any of our improvements: you can see that we needed a lot of training steps to get the loss down.
-Yellow line is the loss with the new optimizer, it is **striking** to see the time we save from this addition! Not only the loss improves, it
-also converges significantly faster! The blue line shows the results when
-fixed scaling is used in addition to the new optimizer. Finally, we added the backbone freezing strategy, and you can see the
-results in the light blue loss. Nonetheless, as common in deep learning, having more data played a big role and was another key element
-to reduce the loss.
-
-
-# Scientific Validity
-
-We split this section in two: we first provide a quantitative evaluation to ensure that what we are learning is in fact good.
-We then show some qualitative examples of images found by the model. **All the code we have written** to run our validation experiments (in combination with
-code made available by Nils Reimers and by the authors of the original CLIP) is available.
-
-## Training Details
-
-### Datasets Splits
-
-We tried different combinations of splits sizes for training and validation. Eventually, we focused on a 95% training split with 5% of data
-going into the validation, each dataset is split in training and validation data and then we concatenate the files.
-Note that the 5% means 70K validation samples, making this set almost as big as the MSCOCO dataset.
-
-### Hyper-parameters
-
-The hyper-parameters can be found in the [repository](https://github.com/clip-italian/clip-italian/tree/master/hybrid_clip).
-We have a maximum sequence length of 95 tokens. To compute this we look at the distribution of the captions in the various
-datasets and we eventually realized that 95 was an excellent compromise between training speed and data coverage.
-We use a batch size of 128 and a learning rate of 0.00001.
-
-### Training
-
-We usually train until we see the loss going up and we then pick the model with the best validation loss. We adjusted the number of training epochs
-as the project progressed: at first we run 100 epochs but after we replaced the optimizer we have been able to reduce this number.
-
-## Quantitative Evaluation
-Showing great images is definitely cool and interesting, but a model is nothing without validation.
-Since this is the first clip-based model in Italian, we decided to use the multilingual CLIP model as a comparison baseline.
-
-### mCLIP
-
-The multilingual CLIP (henceforth, mCLIP), is a model introduced by [Nils Reimers](https://www.sbert.net/docs/pretrained_models.html) in his
-[sentence-transformer](https://www.sbert.net/index.html) library. mCLIP is based on a multilingual encoder
-that was created through multilingual knowledge distillation (see [Reimers et al., 2020](https://aclanthology.org/2020.emnlp-main.365/)). It shows
-great capabilities in representing multilingual text in the same space of the images.
-
-### Tasks
-
-We selected two different tasks:
-+ image-retrieval, in which given a caption the model finds the most semantically similar image
-+ zero-shot classification, in which given an image and a set of captions (or labels), the model finds
-the best matching caption for the image
-
-### Reproducibility
-
-In order to make both experiments very easy to replicate, we share the colab notebooks we used to compute the results.
-
-+ [Image Retrieval](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing)
-+ [ImageNet Zero Shot Classification](https://colab.research.google.com/drive/1zfWeVWY79XXH63Ci-pk8xxx3Vu_RRgW-?usp=sharing)
-
-
-### Image Retrieval
-
-This experiment is run against the MSCOCO-IT validation set (that we haven't used during training). Given an input caption from the dataset,
-we search for the most similar image in the MSCOCO-IT validation set and check if this is the one that was
-described by the original caption. As evaluation metrics we use the MRR@K.
-
-| MRR | CLIP-Italian | mCLIP |
-| --------------- | ------------ |-------|
-| MRR@1 | **0.3797** | 0.2874|
-| MRR@5 | **0.5039** | 0.3957|
-| MRR@10 | **0.5204** | 0.4129|
-
-_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_imagenet.png)._
-
-It is true that we used the training set of MSCOCO-IT in training, and this might give us an advantage. However, the original CLIP model was trained
-on 400million images (and some of them might have been from MSCOCO).
-
-### Zero-shot image classification
-
-This experiment replicates the original one run by OpenAI on zero-shot image classification on ImageNet.
-To do this, we used DeepL to automatically translate the image labels in ImageNet. No manual engineering of the labels or prompts was done.
-We evaluate the models computing the accuracy at different levels.
-
-| Accuracy | CLIP-Italian | mCLIP |
-| --------------- | ------------ |-------|
-| Accuracy@1 | **22.11** | 20.15 |
-| Accuracy@5 | **43.69** | 36.57 |
-| Accuracy@10 | **52.55** | 42.91 |
-| Accuracy@100 | **81.08** | 67.11 |
-
-_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_IR.png)._
-
-### Discussion
-
-Our results confirm that CLIP-Italian is very competitive and beats mCLIP on the two different task
-we have been testing. Note, however, that our results are lower than those shown in the original OpenAI
-paper (see, [Radford et al., 2021](https://arxiv.org/abs/2103.00020)) that was trained and evaluated on English data.
-However, considering that our results are in line with those obtained by mCLIP we think that the translated image
-labels most probably had an impact on the final scores.
-
-## Qualitative Evaluation
-
-We hereby show some interesting properties of the model. One is its ability to detect colors,
-then there is its (partial) counting ability and finally the ability of understanding more complex queries. You can find
-more examples in the "*Gallery*" section of this demo.
-
-To our own surprise, many of the answers the model gives make a lot of sense! Note that the model, in this case,
-is searching the right image from a set of 25K images from an Unsplash dataset.
-
-Look at the following - slightly cherry picked - examples:
-
-### Colors
-Here's "a yellow flower"
-
-
-
-The purple line is the original training without any of our improvements: you can see that we needed a lot of training steps to get the loss down.
-Yellow line is the loss with the new optimizer, it is **striking** to see the time we save from this addition! Not only the loss improves, it
-also converges significantly faster! The blue line shows the results when
-fixed scaling is used in addition to the new optimizer. Finally, we added the backbone freezing strategy, and you can see the
-results in the light blue loss. Nonetheless, as common in deep learning, having more data played a big role and was another key element
-to reduce the loss.
-
-
-# Scientific Validity
-
-We split this section in two: we first provide a quantitative evaluation to ensure that what we are learning is in fact good.
-We then show some qualitative examples of images found by the model. **All the code we have written** to run our validation experiments (in combination with
-code made available by Nils Reimers and by the authors of the original CLIP) is available.
-
-## Training Details
-
-### Datasets Splits
-
-We tried different combinations of splits sizes for training and validation. Eventually, we focused on a 95% training split with 5% of data
-going into the validation, each dataset is split in training and validation data and then we concatenate the files.
-Note that the 5% means 70K validation samples, making this set almost as big as the MSCOCO dataset.
-
-### Hyper-parameters
-
-The hyper-parameters can be found in the [repository](https://github.com/clip-italian/clip-italian/tree/master/hybrid_clip).
-We have a maximum sequence length of 95 tokens. To compute this we look at the distribution of the captions in the various
-datasets and we eventually realized that 95 was an excellent compromise between training speed and data coverage.
-We use a batch size of 128 and a learning rate of 0.00001.
-
-### Training
-
-We usually train until we see the loss going up and we then pick the model with the best validation loss. We adjusted the number of training epochs
-as the project progressed: at first we run 100 epochs but after we replaced the optimizer we have been able to reduce this number.
-
-## Quantitative Evaluation
-Showing great images is definitely cool and interesting, but a model is nothing without validation.
-Since this is the first clip-based model in Italian, we decided to use the multilingual CLIP model as a comparison baseline.
-
-### mCLIP
-
-The multilingual CLIP (henceforth, mCLIP), is a model introduced by [Nils Reimers](https://www.sbert.net/docs/pretrained_models.html) in his
-[sentence-transformer](https://www.sbert.net/index.html) library. mCLIP is based on a multilingual encoder
-that was created through multilingual knowledge distillation (see [Reimers et al., 2020](https://aclanthology.org/2020.emnlp-main.365/)). It shows
-great capabilities in representing multilingual text in the same space of the images.
-
-### Tasks
-
-We selected two different tasks:
-+ image-retrieval, in which given a caption the model finds the most semantically similar image
-+ zero-shot classification, in which given an image and a set of captions (or labels), the model finds
-the best matching caption for the image
-
-### Reproducibility
-
-In order to make both experiments very easy to replicate, we share the colab notebooks we used to compute the results.
-
-+ [Image Retrieval](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing)
-+ [ImageNet Zero Shot Classification](https://colab.research.google.com/drive/1zfWeVWY79XXH63Ci-pk8xxx3Vu_RRgW-?usp=sharing)
-
-
-### Image Retrieval
-
-This experiment is run against the MSCOCO-IT validation set (that we haven't used during training). Given an input caption from the dataset,
-we search for the most similar image in the MSCOCO-IT validation set and check if this is the one that was
-described by the original caption. As evaluation metrics we use the MRR@K.
-
-| MRR | CLIP-Italian | mCLIP |
-| --------------- | ------------ |-------|
-| MRR@1 | **0.3797** | 0.2874|
-| MRR@5 | **0.5039** | 0.3957|
-| MRR@10 | **0.5204** | 0.4129|
-
-_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_imagenet.png)._
-
-It is true that we used the training set of MSCOCO-IT in training, and this might give us an advantage. However, the original CLIP model was trained
-on 400million images (and some of them might have been from MSCOCO).
-
-### Zero-shot image classification
-
-This experiment replicates the original one run by OpenAI on zero-shot image classification on ImageNet.
-To do this, we used DeepL to automatically translate the image labels in ImageNet. No manual engineering of the labels or prompts was done.
-We evaluate the models computing the accuracy at different levels.
-
-| Accuracy | CLIP-Italian | mCLIP |
-| --------------- | ------------ |-------|
-| Accuracy@1 | **22.11** | 20.15 |
-| Accuracy@5 | **43.69** | 36.57 |
-| Accuracy@10 | **52.55** | 42.91 |
-| Accuracy@100 | **81.08** | 67.11 |
-
-_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_IR.png)._
-
-### Discussion
-
-Our results confirm that CLIP-Italian is very competitive and beats mCLIP on the two different task
-we have been testing. Note, however, that our results are lower than those shown in the original OpenAI
-paper (see, [Radford et al., 2021](https://arxiv.org/abs/2103.00020)) that was trained and evaluated on English data.
-However, considering that our results are in line with those obtained by mCLIP we think that the translated image
-labels most probably had an impact on the final scores.
-
-## Qualitative Evaluation
-
-We hereby show some interesting properties of the model. One is its ability to detect colors,
-then there is its (partial) counting ability and finally the ability of understanding more complex queries. You can find
-more examples in the "*Gallery*" section of this demo.
-
-To our own surprise, many of the answers the model gives make a lot of sense! Note that the model, in this case,
-is searching the right image from a set of 25K images from an Unsplash dataset.
-
-Look at the following - slightly cherry picked - examples:
-
-### Colors
-Here's "a yellow flower"
-
-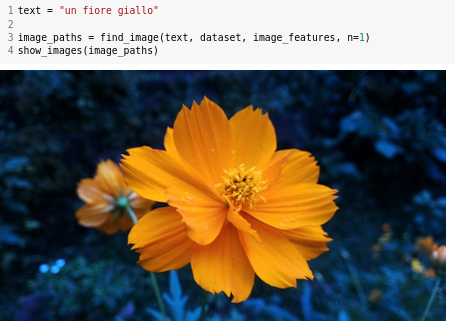 -
-And here's "a blue flower"
-
-
-
-And here's "a blue flower"
-
-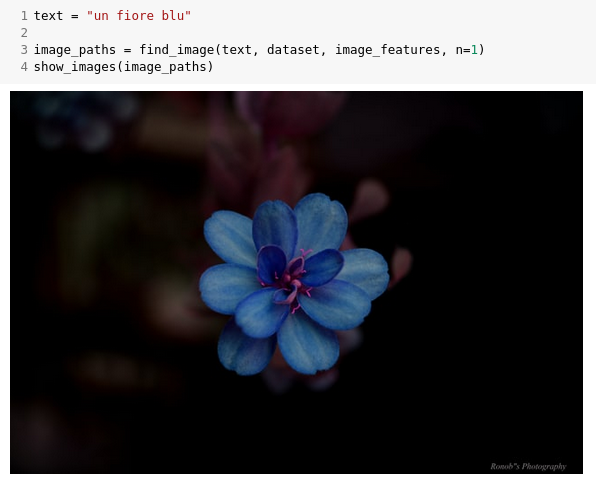 -
-### Counting
-What about "one cat"?
-
-
-
-### Counting
-What about "one cat"?
-
- -
-And what about "two cats"?
-
-
-
-And what about "two cats"?
-
- -
-### Complex Queries
-Have you ever seen "two brown horses"?
-
-
-### Complex Queries
-Have you ever seen "two brown horses"?
- -
-And finally, here's a very nice "cat on a chair"
-
-
-And finally, here's a very nice "cat on a chair"
- -
-
-# Broader Outlook
-
-We believe that this model can be useful for many different applications. From image classification
-to clustering, a model like our Italian CLIP can be used to support researchers and practitioners in many different tasks.
-Indeed, not only can it be useful in research, but also in industry. A very interesting use-case is given by ecommerce platforms:
-these website often deal with a main source of text that is the query engine and with lots of images of the products. CLIP Italian
-can be a killer app in this context, providing a way to search for images and text. Nonetheless, Italy has many different collections
-of photos in digital format that are difficult to categorize efficiently.
-For example, the [Istituto Luce Cinecittà](https://it.wikipedia.org/wiki/Istituto_Luce_Cinecitt%C3%A0) is an Italian governative entity that collects photos of Italy since the
-early 1900 and is part of the largest movie studios in Europe (Cinecittà). A semantic way of finding images in their catalog could be an amazing use case.
-
-# Limitations and Bias
-
-Currently, the model is not without limits. To mention one, its counting capabilities seem very cool, but from our experiments the model
-finds difficult to count after three; this is a general limitation that is common to many models of this type.
-
-There are even more evident issues that we found in our model. Due to the unfiltered nature of our training data, the model is exposed to many biases such as sexism, racism, stereotypes,
-slurs, and gore that it might replicate without the awareness of their hurtful and harmful nature. Indeed, different BERT models - Italian ones included - are prone to create stereotyped
-sentences that are hurtful ([Nozza et al., 2021](https://www.aclweb.org/anthology/2021.naacl-main.191.pdf)).
-While this is not something we intended, it certainly is something that we share the blame for since we were not able to avoid it.
-
-Unfortunately, these kinds of issues are common to many machine learning algorithms (check [Abit et al., 2021](https://arxiv.org/abs/2101.05783) for bias in GPT-3 as an example).
-This suggests we need to find better approaches to counteract this problem that affects **our society**.
-
-# Useful Links
-
-+ [GitHub Repository](https://github.com/clip-italian/clip-italian)
-+ [Model on HuggingFace](https://huggingface.co/clip-italian/clip-italian)
-
-# References
-
-Abid, A., Farooqi, M., & Zou, J. (2021). [Persistent anti-muslim bias in large language models.](https://arxiv.org/abs/2101.05783) arXiv preprint arXiv:2101.05783.
-
-Gwet, K. L. (2008). [Computing inter‐rater reliability and its variance in the presence of high agreement.](https://bpspsychub.onlinelibrary.wiley.com/doi/full/10.1348/000711006X126600) British Journal of Mathematical and Statistical Psychology, 61(1), 29-48.
-
-Nozza, D., Bianchi, F., & Hovy, D. (2021, June). [HONEST: Measuring hurtful sentence completion in language models.](https://www.aclweb.org/anthology/2021.naacl-main.191.pdf) In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 2398-2406).
-
-Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). [Learning Transferable Visual Models From Natural Language Supervision.](https://arxiv.org/abs/2103.00020) ICML.
-
-Reimers, N., & Gurevych, I. (2020, November). [Making Monolingual Sentence Embeddings Multilingual Using Knowledge Distillation.](https://aclanthology.org/2020.emnlp-main.365/) In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 4512-4525).
-
-Scaiella, A., Croce, D., & Basili, R. (2019). [Large scale datasets for Image and Video Captioning in Italian.](http://www.ai-lc.it/IJCoL/v5n2/IJCOL_5_2_3___scaiella_et_al.pdf) IJCoL. Italian Journal of Computational Linguistics, 5(5-2), 49-60.
-
-Sharma, P., Ding, N., Goodman, S., & Soricut, R. (2018, July). [Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning.](https://aclanthology.org/P18-1238.pdf) In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 2556-2565).
-
-Srinivasan, K., Raman, K., Chen, J., Bendersky, M., & Najork, M. (2021). [WIT: Wikipedia-based image text dataset for multimodal multilingual machine learning](https://arxiv.org/pdf/2103.01913.pdf). arXiv preprint arXiv:2103.01913.
-
-# Other Notes
-This readme has been designed using resources from Flaticon.com
\ No newline at end of file
diff --git a/spaces/cloixai/webui/app.py b/spaces/cloixai/webui/app.py
deleted file mode 100644
index c88475b09b7157ce54dc8289652a46d1f384097f..0000000000000000000000000000000000000000
--- a/spaces/cloixai/webui/app.py
+++ /dev/null
@@ -1,74 +0,0 @@
-import os
-from subprocess import getoutput
-
-gpu_info = getoutput('nvidia-smi')
-if("A10G" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+4c06c79.d20221205-cp38-cp38-linux_x86_64.whl")
-elif("T4" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+1515f77.d20221130-cp38-cp38-linux_x86_64.whl")
-
-os.system(f"git clone -b v1.5 https://github.com/camenduru/stable-diffusion-webui /home/user/app/stable-diffusion-webui")
-os.chdir("/home/user/app/stable-diffusion-webui")
-
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/env_patch.py -O /home/user/app/env_patch.py")
-os.system(f"sed -i '$a fastapi==0.90.0' /home/user/app/stable-diffusion-webui/requirements_versions.txt")
-os.system(f"sed -i -e '/import image_from_url_text/r /home/user/app/env_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(modelmerger_interface, \"Checkpoint Merger\", \"modelmerger\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(train_interface, \"Train\", \"ti\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/extensions_interface, \"Extensions\", \"extensions\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/settings_interface, \"Settings\", \"settings\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f'''sed -i -e "s/document.getElementsByTagName('gradio-app')\[0\].shadowRoot/!!document.getElementsByTagName('gradio-app')[0].shadowRoot ? document.getElementsByTagName('gradio-app')[0].shadowRoot : document/g" /home/user/app/stable-diffusion-webui/script.js''')
-os.system(f"sed -i -e 's/ show_progress=False,/ show_progress=True,/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/shared.demo.launch/shared.demo.queue().launch/g' /home/user/app/stable-diffusion-webui/webui.py")
-os.system(f"sed -i -e 's/ outputs=\[/queue=False, &/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/ queue=False, / /g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-
-# ----------------------------Please duplicate this space and delete this block if you don't want to see the extra header----------------------------
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/header_patch.py -O /home/user/app/header_patch.py")
-os.system(f"sed -i -e '/demo:/r /home/user/app/header_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-# ---------------------------------------------------------------------------------------------------------------------------------------------------
-
-if "IS_SHARED_UI" in os.environ:
- os.system(f"rm -rfv /home/user/app/stable-diffusion-webui/scripts/")
-
- os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-config.json -O /home/user/app/shared-config.json")
- os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-ui-config.json -O /home/user/app/shared-ui-config.json")
-
- os.system(f"wget -q https://huggingface.co/ckpt/anything-v3-vae-swapped/resolve/main/anything-v3-vae-swapped.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/anything-v3-vae-swapped.ckpt")
- # os.system(f"wget -q {os.getenv('MODEL_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME')}")
- # os.system(f"wget -q {os.getenv('VAE_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('VAE_NAME')}")
- # os.system(f"wget -q {os.getenv('YAML_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('YAML_NAME')}")
-
- os.system(f"python launch.py --force-enable-xformers --disable-console-progressbars --enable-console-prompts --ui-config-file /home/user/app/shared-ui-config.json --ui-settings-file /home/user/app/shared-config.json --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding")
-else:
- # Please duplicate this space and delete # character in front of the custom script you want to use or add here more custom scripts with same structure os.system(f"wget -q https://CUSTOM_SCRIPT_URL -O /home/user/app/stable-diffusion-webui/scripts/CUSTOM_SCRIPT_NAME.py")
- os.system(f"wget -q https://gist.github.com/camenduru/9ec5f8141db9902e375967e93250860f/raw/d0bcf01786f20107c329c03f8968584ee67be12a/run_n_times.py -O /home/user/app/stable-diffusion-webui/scripts/run_n_times.py")
-
- # Please duplicate this space and delete # character in front of the extension you want to use or add here more extensions with same structure os.system(f"git clone https://EXTENSION_GIT_URL /home/user/app/stable-diffusion-webui/extensions/EXTENSION_NAME")
- #os.system(f"git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-artists-to-study")
- os.system(f"git clone https://github.com/yfszzx/stable-diffusion-webui-images-browser /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser")
- os.system(f"git clone https://github.com/camenduru/deforum-for-automatic1111-webui /home/user/app/stable-diffusion-webui/extensions/deforum-for-automatic1111-webui")
-
- # Please duplicate this space and delete # character in front of the model you want to use or add here more ckpts with same structure os.system(f"wget -q https://CKPT_URL -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/CKPT_NAME.ckpt")
- #os.system(f"wget -q https://huggingface.co/nitrosocke/Arcane-Diffusion/resolve/main/arcane-diffusion-v3.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/arcane-diffusion-v3.ckpt")
- #os.system(f"wget -q https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/Cyberpunk-Anime-Diffusion.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Cyberpunk-Anime-Diffusion.ckpt")
- #os.system(f"wget -q https://huggingface.co/prompthero/midjourney-v4-diffusion/resolve/main/mdjrny-v4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/mdjrny-v4.ckpt")
- #os.system(f"wget -q https://huggingface.co/nitrosocke/mo-di-diffusion/resolve/main/moDi-v1-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/moDi-v1-pruned.ckpt")
- #os.system(f"wget -q https://huggingface.co/Fictiverse/Stable_Diffusion_PaperCut_Model/resolve/main/PaperCut_v1.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/PaperCut_v1.ckpt")
- #os.system(f"wget -q https://huggingface.co/lilpotat/sa/resolve/main/samdoesarts_style.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/samdoesarts_style.ckpt")
- #os.system(f"wget -q https://huggingface.co/hakurei/waifu-diffusion-v1-3/resolve/main/wd-v1-3-float32.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/wd-v1-3-float32.ckpt")
- #os.system(f"wget -q https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-4.ckpt")
- #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.ckpt")
- #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-inpainting/resolve/main/sd-v1-5-inpainting.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-5-inpainting.ckpt")
-
- #os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.ckpt")
- #os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0.vae.pt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.vae.pt")
-
- #os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2/resolve/main/768-v-ema.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.ckpt")
- #os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.yaml")
-
- os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2-1/resolve/main/v2-1_768-ema-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v2-1_768-ema-pruned.ckpt")
- os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v2-1_768-ema-pruned.yaml")
-
- os.system(f"python launch.py --force-enable-xformers --ui-config-file /home/user/app/ui-config.json --ui-settings-file /home/user/app/config.json --disable-console-progressbars --enable-console-prompts --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding --api --skip-torch-cuda-test")
-
\ No newline at end of file
diff --git a/spaces/cncn102/bingo1/src/components/chat-panel.tsx b/spaces/cncn102/bingo1/src/components/chat-panel.tsx
deleted file mode 100644
index 56b2112bd75ba08134383871177851fa2e3f43a4..0000000000000000000000000000000000000000
--- a/spaces/cncn102/bingo1/src/components/chat-panel.tsx
+++ /dev/null
@@ -1,153 +0,0 @@
-'use client'
-
-import * as React from 'react'
-import Image from 'next/image'
-import Textarea from 'react-textarea-autosize'
-import { useAtomValue } from 'jotai'
-import { useEnterSubmit } from '@/lib/hooks/use-enter-submit'
-import { cn } from '@/lib/utils'
-
-import BrushIcon from '@/assets/images/brush.svg'
-import ChatIcon from '@/assets/images/chat.svg'
-import VisualSearchIcon from '@/assets/images/visual-search.svg'
-import SendIcon from '@/assets/images/send.svg'
-import PinIcon from '@/assets/images/pin.svg'
-import PinFillIcon from '@/assets/images/pin-fill.svg'
-
-import { useBing } from '@/lib/hooks/use-bing'
-import { voiceListenAtom } from '@/state'
-import Voice from './voice'
-import { ChatImage } from './chat-image'
-import { ChatAttachments } from './chat-attachments'
-
-export interface ChatPanelProps
- extends Pick<
- ReturnType
-
-
-# Broader Outlook
-
-We believe that this model can be useful for many different applications. From image classification
-to clustering, a model like our Italian CLIP can be used to support researchers and practitioners in many different tasks.
-Indeed, not only can it be useful in research, but also in industry. A very interesting use-case is given by ecommerce platforms:
-these website often deal with a main source of text that is the query engine and with lots of images of the products. CLIP Italian
-can be a killer app in this context, providing a way to search for images and text. Nonetheless, Italy has many different collections
-of photos in digital format that are difficult to categorize efficiently.
-For example, the [Istituto Luce Cinecittà](https://it.wikipedia.org/wiki/Istituto_Luce_Cinecitt%C3%A0) is an Italian governative entity that collects photos of Italy since the
-early 1900 and is part of the largest movie studios in Europe (Cinecittà). A semantic way of finding images in their catalog could be an amazing use case.
-
-# Limitations and Bias
-
-Currently, the model is not without limits. To mention one, its counting capabilities seem very cool, but from our experiments the model
-finds difficult to count after three; this is a general limitation that is common to many models of this type.
-
-There are even more evident issues that we found in our model. Due to the unfiltered nature of our training data, the model is exposed to many biases such as sexism, racism, stereotypes,
-slurs, and gore that it might replicate without the awareness of their hurtful and harmful nature. Indeed, different BERT models - Italian ones included - are prone to create stereotyped
-sentences that are hurtful ([Nozza et al., 2021](https://www.aclweb.org/anthology/2021.naacl-main.191.pdf)).
-While this is not something we intended, it certainly is something that we share the blame for since we were not able to avoid it.
-
-Unfortunately, these kinds of issues are common to many machine learning algorithms (check [Abit et al., 2021](https://arxiv.org/abs/2101.05783) for bias in GPT-3 as an example).
-This suggests we need to find better approaches to counteract this problem that affects **our society**.
-
-# Useful Links
-
-+ [GitHub Repository](https://github.com/clip-italian/clip-italian)
-+ [Model on HuggingFace](https://huggingface.co/clip-italian/clip-italian)
-
-# References
-
-Abid, A., Farooqi, M., & Zou, J. (2021). [Persistent anti-muslim bias in large language models.](https://arxiv.org/abs/2101.05783) arXiv preprint arXiv:2101.05783.
-
-Gwet, K. L. (2008). [Computing inter‐rater reliability and its variance in the presence of high agreement.](https://bpspsychub.onlinelibrary.wiley.com/doi/full/10.1348/000711006X126600) British Journal of Mathematical and Statistical Psychology, 61(1), 29-48.
-
-Nozza, D., Bianchi, F., & Hovy, D. (2021, June). [HONEST: Measuring hurtful sentence completion in language models.](https://www.aclweb.org/anthology/2021.naacl-main.191.pdf) In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 2398-2406).
-
-Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). [Learning Transferable Visual Models From Natural Language Supervision.](https://arxiv.org/abs/2103.00020) ICML.
-
-Reimers, N., & Gurevych, I. (2020, November). [Making Monolingual Sentence Embeddings Multilingual Using Knowledge Distillation.](https://aclanthology.org/2020.emnlp-main.365/) In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 4512-4525).
-
-Scaiella, A., Croce, D., & Basili, R. (2019). [Large scale datasets for Image and Video Captioning in Italian.](http://www.ai-lc.it/IJCoL/v5n2/IJCOL_5_2_3___scaiella_et_al.pdf) IJCoL. Italian Journal of Computational Linguistics, 5(5-2), 49-60.
-
-Sharma, P., Ding, N., Goodman, S., & Soricut, R. (2018, July). [Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning.](https://aclanthology.org/P18-1238.pdf) In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 2556-2565).
-
-Srinivasan, K., Raman, K., Chen, J., Bendersky, M., & Najork, M. (2021). [WIT: Wikipedia-based image text dataset for multimodal multilingual machine learning](https://arxiv.org/pdf/2103.01913.pdf). arXiv preprint arXiv:2103.01913.
-
-# Other Notes
-This readme has been designed using resources from Flaticon.com
\ No newline at end of file
diff --git a/spaces/cloixai/webui/app.py b/spaces/cloixai/webui/app.py
deleted file mode 100644
index c88475b09b7157ce54dc8289652a46d1f384097f..0000000000000000000000000000000000000000
--- a/spaces/cloixai/webui/app.py
+++ /dev/null
@@ -1,74 +0,0 @@
-import os
-from subprocess import getoutput
-
-gpu_info = getoutput('nvidia-smi')
-if("A10G" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+4c06c79.d20221205-cp38-cp38-linux_x86_64.whl")
-elif("T4" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+1515f77.d20221130-cp38-cp38-linux_x86_64.whl")
-
-os.system(f"git clone -b v1.5 https://github.com/camenduru/stable-diffusion-webui /home/user/app/stable-diffusion-webui")
-os.chdir("/home/user/app/stable-diffusion-webui")
-
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/env_patch.py -O /home/user/app/env_patch.py")
-os.system(f"sed -i '$a fastapi==0.90.0' /home/user/app/stable-diffusion-webui/requirements_versions.txt")
-os.system(f"sed -i -e '/import image_from_url_text/r /home/user/app/env_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(modelmerger_interface, \"Checkpoint Merger\", \"modelmerger\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(train_interface, \"Train\", \"ti\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/extensions_interface, \"Extensions\", \"extensions\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/settings_interface, \"Settings\", \"settings\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f'''sed -i -e "s/document.getElementsByTagName('gradio-app')\[0\].shadowRoot/!!document.getElementsByTagName('gradio-app')[0].shadowRoot ? document.getElementsByTagName('gradio-app')[0].shadowRoot : document/g" /home/user/app/stable-diffusion-webui/script.js''')
-os.system(f"sed -i -e 's/ show_progress=False,/ show_progress=True,/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/shared.demo.launch/shared.demo.queue().launch/g' /home/user/app/stable-diffusion-webui/webui.py")
-os.system(f"sed -i -e 's/ outputs=\[/queue=False, &/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/ queue=False, / /g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-
-# ----------------------------Please duplicate this space and delete this block if you don't want to see the extra header----------------------------
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/header_patch.py -O /home/user/app/header_patch.py")
-os.system(f"sed -i -e '/demo:/r /home/user/app/header_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-# ---------------------------------------------------------------------------------------------------------------------------------------------------
-
-if "IS_SHARED_UI" in os.environ:
- os.system(f"rm -rfv /home/user/app/stable-diffusion-webui/scripts/")
-
- os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-config.json -O /home/user/app/shared-config.json")
- os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-ui-config.json -O /home/user/app/shared-ui-config.json")
-
- os.system(f"wget -q https://huggingface.co/ckpt/anything-v3-vae-swapped/resolve/main/anything-v3-vae-swapped.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/anything-v3-vae-swapped.ckpt")
- # os.system(f"wget -q {os.getenv('MODEL_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME')}")
- # os.system(f"wget -q {os.getenv('VAE_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('VAE_NAME')}")
- # os.system(f"wget -q {os.getenv('YAML_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('YAML_NAME')}")
-
- os.system(f"python launch.py --force-enable-xformers --disable-console-progressbars --enable-console-prompts --ui-config-file /home/user/app/shared-ui-config.json --ui-settings-file /home/user/app/shared-config.json --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding")
-else:
- # Please duplicate this space and delete # character in front of the custom script you want to use or add here more custom scripts with same structure os.system(f"wget -q https://CUSTOM_SCRIPT_URL -O /home/user/app/stable-diffusion-webui/scripts/CUSTOM_SCRIPT_NAME.py")
- os.system(f"wget -q https://gist.github.com/camenduru/9ec5f8141db9902e375967e93250860f/raw/d0bcf01786f20107c329c03f8968584ee67be12a/run_n_times.py -O /home/user/app/stable-diffusion-webui/scripts/run_n_times.py")
-
- # Please duplicate this space and delete # character in front of the extension you want to use or add here more extensions with same structure os.system(f"git clone https://EXTENSION_GIT_URL /home/user/app/stable-diffusion-webui/extensions/EXTENSION_NAME")
- #os.system(f"git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-artists-to-study")
- os.system(f"git clone https://github.com/yfszzx/stable-diffusion-webui-images-browser /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser")
- os.system(f"git clone https://github.com/camenduru/deforum-for-automatic1111-webui /home/user/app/stable-diffusion-webui/extensions/deforum-for-automatic1111-webui")
-
- # Please duplicate this space and delete # character in front of the model you want to use or add here more ckpts with same structure os.system(f"wget -q https://CKPT_URL -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/CKPT_NAME.ckpt")
- #os.system(f"wget -q https://huggingface.co/nitrosocke/Arcane-Diffusion/resolve/main/arcane-diffusion-v3.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/arcane-diffusion-v3.ckpt")
- #os.system(f"wget -q https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/Cyberpunk-Anime-Diffusion.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Cyberpunk-Anime-Diffusion.ckpt")
- #os.system(f"wget -q https://huggingface.co/prompthero/midjourney-v4-diffusion/resolve/main/mdjrny-v4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/mdjrny-v4.ckpt")
- #os.system(f"wget -q https://huggingface.co/nitrosocke/mo-di-diffusion/resolve/main/moDi-v1-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/moDi-v1-pruned.ckpt")
- #os.system(f"wget -q https://huggingface.co/Fictiverse/Stable_Diffusion_PaperCut_Model/resolve/main/PaperCut_v1.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/PaperCut_v1.ckpt")
- #os.system(f"wget -q https://huggingface.co/lilpotat/sa/resolve/main/samdoesarts_style.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/samdoesarts_style.ckpt")
- #os.system(f"wget -q https://huggingface.co/hakurei/waifu-diffusion-v1-3/resolve/main/wd-v1-3-float32.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/wd-v1-3-float32.ckpt")
- #os.system(f"wget -q https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-4.ckpt")
- #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.ckpt")
- #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-inpainting/resolve/main/sd-v1-5-inpainting.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-5-inpainting.ckpt")
-
- #os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.ckpt")
- #os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0.vae.pt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.vae.pt")
-
- #os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2/resolve/main/768-v-ema.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.ckpt")
- #os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.yaml")
-
- os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2-1/resolve/main/v2-1_768-ema-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v2-1_768-ema-pruned.ckpt")
- os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v2-1_768-ema-pruned.yaml")
-
- os.system(f"python launch.py --force-enable-xformers --ui-config-file /home/user/app/ui-config.json --ui-settings-file /home/user/app/config.json --disable-console-progressbars --enable-console-prompts --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding --api --skip-torch-cuda-test")
-
\ No newline at end of file
diff --git a/spaces/cncn102/bingo1/src/components/chat-panel.tsx b/spaces/cncn102/bingo1/src/components/chat-panel.tsx
deleted file mode 100644
index 56b2112bd75ba08134383871177851fa2e3f43a4..0000000000000000000000000000000000000000
--- a/spaces/cncn102/bingo1/src/components/chat-panel.tsx
+++ /dev/null
@@ -1,153 +0,0 @@
-'use client'
-
-import * as React from 'react'
-import Image from 'next/image'
-import Textarea from 'react-textarea-autosize'
-import { useAtomValue } from 'jotai'
-import { useEnterSubmit } from '@/lib/hooks/use-enter-submit'
-import { cn } from '@/lib/utils'
-
-import BrushIcon from '@/assets/images/brush.svg'
-import ChatIcon from '@/assets/images/chat.svg'
-import VisualSearchIcon from '@/assets/images/visual-search.svg'
-import SendIcon from '@/assets/images/send.svg'
-import PinIcon from '@/assets/images/pin.svg'
-import PinFillIcon from '@/assets/images/pin-fill.svg'
-
-import { useBing } from '@/lib/hooks/use-bing'
-import { voiceListenAtom } from '@/state'
-import Voice from './voice'
-import { ChatImage } from './chat-image'
-import { ChatAttachments } from './chat-attachments'
-
-export interface ChatPanelProps
- extends Pick<
- ReturnType, - | 'generating' - | 'input' - | 'setInput' - | 'sendMessage' - | 'resetConversation' - | 'isSpeaking' - | 'attachmentList' - | 'uploadImage' - | 'setAttachmentList' - > { - id?: string - className?: string -} - -export function ChatPanel({ - isSpeaking, - generating, - input, - setInput, - className, - sendMessage, - resetConversation, - attachmentList, - uploadImage, - setAttachmentList -}: ChatPanelProps) { - const inputRef = React.useRef (null) - const {formRef, onKeyDown} = useEnterSubmit() - const [focused, setFocused] = React.useState(false) - const [active, setActive] = React.useState(false) - const [pin, setPin] = React.useState(false) - const [tid, setTid] = React.useState () - const voiceListening = useAtomValue(voiceListenAtom) - - const setBlur = React.useCallback(() => { - clearTimeout(tid) - setActive(false) - const _tid = setTimeout(() => setFocused(false), 2000); - setTid(_tid) - }, [tid]) - - const setFocus = React.useCallback(() => { - setFocused(true) - setActive(true) - clearTimeout(tid) - inputRef.current?.focus() - }, [tid]) - - React.useEffect(() => { - if (input) { - setFocus() - } - }, [input, setFocus]) - - return ( -